mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
f42776c4aa
@ -1,59 +1,64 @@
|
||||
使用 Showterm 录制和共享终端会话
|
||||
使用 Showterm 录制和分享终端会话
|
||||
======
|
||||
|
||||

|
||||
|
||||
你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话,上传,共享,并将它们嵌入到任何网页中。一个优点是,你不会有巨大的文件来处理。
|
||||
你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话、上传、分享,并将它们嵌入到任何网页中的工具。一个优点是,你不会有巨大的文件来处理。
|
||||
|
||||
Showterm 是开源的,该项目可以在这个[ GitHub 页面][1]上找到。
|
||||
Showterm 是开源的,该项目可以在这个 [GitHub 页面][1]上找到。
|
||||
|
||||
**相关**:[2 个简单的将你的终端会话录制为视频的 Linux 程序][2]
|
||||
|
||||
### 在 Linux 中安装 Showterm
|
||||
|
||||
Showterm 要求你在计算机上安装了 Ruby。以下是如何安装该程序。
|
||||
|
||||
```
|
||||
gem install showterm
|
||||
```
|
||||
|
||||
如果你没有在 Linux 上安装 Ruby:
|
||||
如果你没有在 Linux 上安装 Ruby,可以这样:
|
||||
|
||||
```
|
||||
sudo curl showterm.io/showterm > ~/bin/showterm
|
||||
sudo chmod +x ~/bin/showterm
|
||||
```
|
||||
|
||||
如果你只是想运行程序而不是安装:
|
||||
|
||||
```
|
||||
bash <(curl record.showterm.io)
|
||||
```
|
||||
|
||||
你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 showterm。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
|
||||
你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 `showterm`。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
|
||||
|
||||
**相关**:[如何在 Ubuntu 中录制终端会话][3]
|
||||
**相关**:[如何在 Ubuntu 中录制终端会话][3]
|
||||
|
||||
### 录制终端会话
|
||||
|
||||
![showterm terminal][4]
|
||||
|
||||
录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 Ctrl + D 或在命令行中输入`exit` 停止录制。
|
||||
录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 `Ctrl + D` 或在命令行中输入`exit` 停止录制。
|
||||
|
||||
Showterm 会上传你的视频并输出一个看起来像 http://showterm.io/<一长串字符> 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete <recording URL>` 删除任何已上传的视频。在上传视频之前,你可以通过在 showterm 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry <script> <times>` 强制重试。
|
||||
Showterm 会上传你的视频并输出一个看起来像 `http://showterm.io/<一长串字符>` 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete <recording URL>` 删除任何已上传的视频。在上传视频之前,你可以通过在 `showterm` 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry <script> <times>` 强制重试。
|
||||
|
||||
在查看录制内容时,还可以通过在 URL 中添加 “#slow”、“#fast” 或 “#stop” 来控制视频的计时。slow 让视频以正常速度播放、fast 是速度加倍、stop,如名称所示,停止播放视频。
|
||||
在查看录制内容时,还可以通过在 URL 中添加 `#slow`、`#fast` 或 `#stop` 来控制视频的计时。`#slow` 让视频以正常速度播放、`#fast` 是速度加倍、`#stop`,如名称所示,停止播放视频。
|
||||
|
||||
Showterm 终端录制视频可以通过 iframe 轻松嵌入到网页中。这可以通过将 iframe 源添加到 showterm 视频地址来实现,如下所示。
|
||||
|
||||
![showtermio][5]
|
||||
|
||||
作为开源工具,Showterm 允许进一步定制。例如,要运行你自己的 Showterm 服务器,你需要运行以下命令:
|
||||
|
||||
```
|
||||
export SHOWTERM_SERVER=https://showterm.myorg.local/
|
||||
```
|
||||
这样你的客户端可以和它通信。还有额外的功能只需很少的编程知识就可添加。Showterm 服务器项目可在此[ GitHub 页面][1]获得。
|
||||
|
||||
这样你的客户端可以和它通信。还有额外的功能只需很少的编程知识就可添加。Showterm 服务器项目可在此 [GitHub 页面][1]获得。
|
||||
|
||||
### 结论
|
||||
|
||||
如果你想与同事分享一些命令行教程,请务必记得 Showterm。Showterm 是基于文本的。因此,与其他屏幕录制机相比,它将产生相对较小的视频。该工具本身尺寸相当小 - 只有几千字节。
|
||||
如果你想与同事分享一些命令行教程,请务必记得 Showterm。Showterm 是基于文本的。因此,与其他屏幕录制机相比,它将产生相对较小的视频。该工具本身尺寸相当小 —— 只有几千字节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -61,7 +66,7 @@ via: https://www.maketecheasier.com/record-terminal-session-showterm/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
110
published/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
110
published/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
@ -0,0 +1,110 @@
|
||||
在 Linux 中自动配置 IPv6 地址
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 [KVM 中测试 IPv6 网络:第 1 部分][1] 一文中,我们学习了关于<ruby>唯一本地地址<rt>unique local addresses</rt></ruby>(ULA)的相关内容。在本文中,我们将学习如何为 ULA 自动配置 IP 地址。
|
||||
|
||||
### 何时使用唯一本地地址
|
||||
|
||||
<ruby>唯一本地地址<rt>unique local addresses</rt></ruby>(ULA)使用 `fd00::/8` 地址块,它类似于我们常用的 IPv4 的私有地址:`10.0.0.0/8`、`172.16.0.0/12`、以及 `192.168.0.0/16`。但它们并不能直接替换。IPv4 的私有地址分类和网络地址转换(NAT)功能是为了缓解 IPv4 地址短缺的问题,这是个明智的解决方案,它延缓了本该被替换的 IPv4 的生命周期。IPv6 也支持 NAT,但是我想不出使用它的理由。IPv6 的地址数量远远大于 IPv4;它是不一样的,因此需要做不一样的事情。
|
||||
|
||||
那么,ULA 存在的意义是什么呢?尤其是在我们已经有了<ruby>本地链路地址<rt>link-local addresses</rt></ruby>(`fe80::/10`)时,到底需不需要我们去配置它们呢?它们之间(LCTT 译注:指的是唯一本地地址和本地链路地址)有两个重要的区别。一是,本地链路地址是不可路由的,因此,你不能跨子网使用它。二是,ULA 是你自己管理的;你可以自己选择它用于子网的地址范围,并且它们是可路由的。
|
||||
|
||||
使用 ULA 的另一个好处是,如果你只是在局域网中“混日子”的话,你不需要为它们分配全局单播 IPv6 地址。当然了,如果你的 ISP 已经为你分配了 IPv6 的<ruby>全局单播地址<rt>global unicast addresses</rt></ruby>,就不需要使用 ULA 了。你也可以在同一个网络中混合使用全局单播地址和 ULA,但是,我想不出这样使用的一个好理由,并且要一定确保你不使用网络地址转换(NAT)以使 ULA 可公共访问。在我看来,这是很愚蠢的行为。
|
||||
|
||||
ULA 是仅为私有网络使用的,并且应该阻止其流出你的网络,不允许进入因特网。这很简单,在你的边界设备上只要阻止整个 `fd00::/8` 范围的 IPv6 地址即可实现。
|
||||
|
||||
### 地址自动配置
|
||||
|
||||
ULA 不像本地链路地址那样自动配置的,但是使用 radvd 设置自动配置是非常容易的,radva 是路由器公告守护程序。在你开始之前,运行 `ifconfig` 或者 `ip addr show` 去查看你现有的 IP 地址。
|
||||
|
||||
在生产系统上使用时,你应该将 radvd 安装在一台单独的路由器上,如果只是测试使用,你可以将它安装在你的网络中的任意 Linux PC 上。在我的小型 KVM 测试实验室中,我使用 `apt-get install radvd` 命令把它安装在 Ubuntu 上。安装完成之后,我先不启动它,因为它还没有配置文件:
|
||||
|
||||
```
|
||||
$ sudo systemctl status radvd
|
||||
● radvd.service - LSB: Router Advertising Daemon
|
||||
Loaded: loaded (/etc/init.d/radvd; bad; vendor preset: enabled)
|
||||
Active: active (exited) since Mon 2017-12-11 20:08:25 PST; 4min 59s ago
|
||||
Docs: man:systemd-sysv-generator(8)
|
||||
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Starting LSB: Router Advertising Daemon...
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: Starting radvd:
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * /etc/radvd.conf does not exist or is empty.
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * See /usr/share/doc/radvd/README.Debian
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * radvd will *not* be started.
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Started LSB: Router Advertising Daemon.
|
||||
```
|
||||
|
||||
这些所有的消息有点让人困惑,实际上 radvd 并没有运行,你可以使用经典命令 `ps | grep radvd` 来验证这一点。因此,我们现在需要去创建 `/etc/radvd.conf` 文件。拷贝这个示例,将第一行的网络接口名替换成你自己的接口名字:
|
||||
|
||||
```
|
||||
interface ens7 {
|
||||
AdvSendAdvert on;
|
||||
MinRtrAdvInterval 3;
|
||||
MaxRtrAdvInterval 10;
|
||||
prefix fd7d:844d:3e17:f3ae::/64
|
||||
{
|
||||
AdvOnLink on;
|
||||
AdvAutonomous on;
|
||||
};
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
前缀(`prefix`)定义了你的网络地址,它是地址的前 64 位。前两个字符必须是 `fd`,前缀接下来的剩余部分你自己定义它,最后的 64 位留空,因为 radvd 将去分配最后的 64 位。前缀后面的 16 位用来定义子网,剩余的地址定义为主机地址。你的子网必须总是 `/64`。RFC 4193 要求地址必须随机生成;查看 [在 KVM 中测试 IPv6 Networking:第 1 部分][1] 学习创建和管理 ULAs 的更多知识。
|
||||
|
||||
### IPv6 转发
|
||||
|
||||
IPv6 转发必须要启用。下面的命令去启用它,重启后生效:
|
||||
|
||||
```
|
||||
$ sudo sysctl -w net.ipv6.conf.all.forwarding=1
|
||||
```
|
||||
|
||||
取消注释或者添加如下的行到 `/etc/sysctl.conf` 文件中,以使它永久生效:
|
||||
|
||||
```
|
||||
net.ipv6.conf.all.forwarding = 1
|
||||
```
|
||||
|
||||
启动 radvd 守护程序:
|
||||
|
||||
```
|
||||
$ sudo systemctl stop radvd
|
||||
$ sudo systemctl start radvd
|
||||
```
|
||||
|
||||
这个示例在我的 Ubuntu 测试系统中遇到了一个怪事;radvd 总是停止,我查看它的状态却没有任何问题,做任何改变之后都需要重新启动 radvd。
|
||||
|
||||
启动成功后没有任何输出,并且失败也是如此,因此,需要运行 `sudo systemctl status radvd` 去查看它的运行状态。如果有错误,`systemctl` 会告诉你。一般常见的错误都是 `/etc/radvd.conf` 中的语法错误。
|
||||
|
||||
在 Twitter 上抱怨了上述问题之后,我学到了一件很酷的技巧:当你运行 ` journalctl -xe --no-pager` 去调试 `systemctl` 错误时,你的输出会被换行,然后,你就可以看到错误信息。
|
||||
|
||||
现在检查你的主机,查看它们自动分配的新地址:
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
ens7 Link encap:Ethernet HWaddr 52:54:00:57:71:50
|
||||
[...]
|
||||
inet6 addr: fd7d:844d:3e17:f3ae:9808:98d5:bea9:14d9/64 Scope:Global
|
||||
[...]
|
||||
```
|
||||
|
||||
本文到此为止,下周继续学习如何为 ULA 管理 DNS,这样你就可以使用一个合适的主机名来代替这些长长的 IPv6 地址。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的 [“Linux 入门”][2] 免费课程学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/ipv6-auto-configuration-linux
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
224
published/20180116 Analyzing the Linux boot process.md
Normal file
224
published/20180116 Analyzing the Linux boot process.md
Normal file
@ -0,0 +1,224 @@
|
||||
Linux 启动过程分析
|
||||
======
|
||||
|
||||
> 理解运转良好的系统对于处理不可避免的故障是最好的准备。
|
||||
|
||||

|
||||
|
||||
*图片由企鹅和靴子“赞助”,由 Opensource.com 修改。CC BY-SA 4.0。*
|
||||
|
||||
关于开源软件最古老的笑话是:“代码是<ruby>自具文档化的<rt>self-documenting</rt></ruby>”。经验表明,阅读源代码就像听天气预报一样:明智的人依然出门会看看室外的天气。本文讲述了如何运用调试工具来观察和分析 Linux 系统的启动。分析一个功能正常的系统启动过程,有助于用户和开发人员应对不可避免的故障。
|
||||
|
||||
从某些方面看,启动过程非常简单。内核在单核上以单线程和同步状态启动,似乎可以理解。但内核本身是如何启动的呢?[initrd(initial ramdisk)][1] 和<ruby>引导程序<rt>bootloader</rt></ruby>具有哪些功能?还有,为什么以太网端口上的 LED 灯是常亮的呢?
|
||||
|
||||
请继续阅读寻找答案。在 GitHub 上也提供了 [介绍演示和练习的代码][2]。
|
||||
|
||||
### 启动的开始:OFF 状态
|
||||
|
||||
#### <ruby>局域网唤醒<rt>Wake-on-LAN</rt></ruby>
|
||||
|
||||
OFF 状态表示系统没有上电,没错吧?表面简单,其实不然。例如,如果系统启用了局域网唤醒机制(WOL),以太网指示灯将亮起。通过以下命令来检查是否是这种情况:
|
||||
|
||||
```
|
||||
# sudo ethtool <interface name>
|
||||
```
|
||||
|
||||
其中 `<interface name>` 是网络接口的名字,比如 `eth0`。(`ethtool` 可以在同名的 Linux 软件包中找到。)如果输出中的 `Wake-on` 显示 `g`,则远程主机可以通过发送 [<ruby>魔法数据包<rt>MagicPacket</rt></ruby>][3] 来启动系统。如果您无意远程唤醒系统,也不希望其他人这样做,请在系统 BIOS 菜单中将 WOL 关闭,或者用以下方式:
|
||||
|
||||
```
|
||||
# sudo ethtool -s <interface name> wol d
|
||||
```
|
||||
|
||||
响应魔法数据包的处理器可能是网络接口的一部分,也可能是 [<ruby>底板管理控制器<rt>Baseboard Management Controller</rt></ruby>][4](BMC)。
|
||||
|
||||
#### 英特尔管理引擎、平台控制器单元和 Minix
|
||||
|
||||
BMC 不是唯一的在系统关闭时仍在监听的微控制器(MCU)。x86_64 系统还包含了用于远程管理系统的英特尔管理引擎(IME)软件套件。从服务器到笔记本电脑,各种各样的设备都包含了这项技术,它开启了如 KVM 远程控制和英特尔功能许可服务等 [功能][5]。根据 [Intel 自己的检测工具][7],[IME 存在尚未修补的漏洞][6]。坏消息是,要禁用 IME 很难。Trammell Hudson 发起了一个 [me_cleaner 项目][8],它可以清除一些相对恶劣的 IME 组件,比如嵌入式 Web 服务器,但也可能会影响运行它的系统。
|
||||
|
||||
IME 固件和<ruby>系统管理模式<rt>System Management Mode</rt></ruby>(SMM)软件是 [基于 Minix 操作系统][9] 的,并运行在单独的<ruby>平台控制器单元<rt>Platform Controller Hub</rt></ruby>上(LCTT 译注:即南桥芯片),而不是主 CPU 上。然后,SMM 启动位于主处理器上的<ruby>通用可扩展固件接口<rt>Universal Extensible Firmware Interface</rt></ruby>(UEFI)软件,相关内容 [已被提及多次][10]。Google 的 Coreboot 小组已经启动了一个雄心勃勃的 [<ruby>非扩展性缩减版固件<rt>Non-Extensible Reduced Firmware</rt></ruby>][11](NERF)项目,其目的不仅是要取代 UEFI,还要取代早期的 Linux 用户空间组件,如 systemd。在我们等待这些新成果的同时,Linux 用户现在就可以从 Purism、System76 或 Dell 等处购买 [禁用了 IME][12] 的笔记本电脑,另外 [带有 ARM 64 位处理器笔记本电脑][13] 还是值得期待的。
|
||||
|
||||
#### 引导程序
|
||||
|
||||
除了启动那些问题不断的间谍软件外,早期引导固件还有什么功能呢?引导程序的作用是为新上电的处理器提供通用操作系统(如 Linux)所需的资源。在开机时,不但没有虚拟内存,在控制器启动之前连 DRAM 也没有。然后,引导程序打开电源,并扫描总线和接口,以定位内核镜像和根文件系统的位置。U-Boot 和 GRUB 等常见的引导程序支持 USB、PCI 和 NFS 等接口,以及更多的嵌入式专用设备,如 NOR 闪存和 NAND 闪存。引导程序还与 [<ruby>可信平台模块<rt>Trusted Platform Module</rt></ruby>][14](TPM)等硬件安全设备进行交互,在启动最开始建立信任链。
|
||||
|
||||
![Running the U-boot bootloader][16]
|
||||
|
||||
*在构建主机上的沙盒中运行 U-boot 引导程序。*
|
||||
|
||||
包括树莓派、任天堂设备、汽车主板和 Chromebook 在内的系统都支持广泛使用的开源引导程序 [U-Boot][17]。它没有系统日志,当发生问题时,甚至没有任何控制台输出。为了便于调试,U-Boot 团队提供了一个沙盒,可以在构建主机甚至是夜间的持续集成(CI)系统上测试补丁程序。如果系统上安装了 Git 和 GNU Compiler Collection(GCC)等通用的开发工具,使用 U-Boot 沙盒会相对简单:
|
||||
|
||||
```
|
||||
# git clone git://git.denx.de/u-boot; cd u-boot
|
||||
# make ARCH=sandbox defconfig
|
||||
# make; ./u-boot
|
||||
=> printenv
|
||||
=> help
|
||||
```
|
||||
|
||||
在 x86_64 上运行 U-Boot,可以测试一些棘手的功能,如 [模拟存储设备][2] 的重新分区、基于 TPM 的密钥操作以及 USB 设备热插拔等。U-Boot 沙盒甚至可以在 GDB 调试器下单步执行。使用沙盒进行开发的速度比将引导程序刷新到电路板上的测试快 10 倍,并且可以使用 `Ctrl + C` 恢复一个“变砖”的沙盒。
|
||||
|
||||
### 启动内核
|
||||
|
||||
#### 配置引导内核
|
||||
|
||||
引导程序完成任务后将跳转到已加载到主内存中的内核代码,并开始执行,传递用户指定的任何命令行选项。内核是什么样的程序呢?用命令 `file /boot/vmlinuz` 可以看到它是一个 “bzImage”,意思是一个大的压缩的镜像。Linux 源代码树包含了一个可以解压缩这个文件的工具—— [extract-vmlinux][18]:
|
||||
|
||||
```
|
||||
# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
|
||||
# file vmlinux
|
||||
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
|
||||
linked, stripped
|
||||
```
|
||||
|
||||
内核是一个 [<ruby>可执行与可链接格式<rt> Executable and Linking Format</rt></ruby>][19](ELF)的二进制文件,就像 Linux 的用户空间程序一样。这意味着我们可以使用 `binutils` 包中的命令,如 `readelf` 来检查它。比较一下输出,例如:
|
||||
|
||||
```
|
||||
# readelf -S /bin/date
|
||||
# readelf -S vmlinux
|
||||
```
|
||||
|
||||
这两个二进制文件中的段内容大致相同。
|
||||
|
||||
所以内核必须像其他的 Linux ELF 文件一样启动,但用户空间程序是如何启动的呢?在 `main()` 函数中?并不确切。
|
||||
|
||||
在 `main()` 函数运行之前,程序需要一个执行上下文,包括堆栈内存以及 `stdio`、`stdout` 和 `stderr` 的文件描述符。用户空间程序从标准库(多数 Linux 系统在用 “glibc”)中获取这些资源。参照以下输出:
|
||||
|
||||
```
|
||||
# file /bin/date
|
||||
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
|
||||
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
|
||||
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
|
||||
stripped
|
||||
```
|
||||
|
||||
ELF 二进制文件有一个解释器,就像 Bash 和 Python 脚本一样,但是解释器不需要像脚本那样用 `#!` 指定,因为 ELF 是 Linux 的原生格式。ELF 解释器通过调用 `_start()` 函数来用所需资源 [配置一个二进制文件][20],这个函数可以从 glibc 源代码包中找到,可以 [用 GDB 查看][21]。内核显然没有解释器,必须自我配置,这是怎么做到的呢?
|
||||
|
||||
用 GDB 检查内核的启动给出了答案。首先安装内核的调试软件包,内核中包含一个<ruby>未剥离的<rt>unstripped</rt></ruby> vmlinux,例如 `apt-get install linux-image-amd64-dbg`,或者从源代码编译和安装你自己的内核,可以参照 [Debian Kernel Handbook][22] 中的指令。`gdb vmlinux` 后加 `info files` 可显示 ELF 段 `init.text`。在 `init.text` 中用 `l *(address)` 列出程序执行的开头,其中 `address` 是 `init.text` 的十六进制开头。用 GDB 可以看到 x86_64 内核从内核文件 [arch/x86/kernel/head_64.S][23] 开始启动,在这个文件中我们找到了汇编函数 `start_cpu0()`,以及一段明确的代码显示在调用 `x86_64 start_kernel()` 函数之前创建了堆栈并解压了 zImage。ARM 32 位内核也有类似的文件 [arch/arm/kernel/head.S][24]。`start_kernel()` 不针对特定的体系结构,所以这个函数驻留在内核的 [init/main.c][25] 中。`start_kernel()` 可以说是 Linux 真正的 `main()` 函数。
|
||||
|
||||
### 从 start_kernel() 到 PID 1
|
||||
|
||||
#### 内核的硬件清单:设备树和 ACPI 表
|
||||
|
||||
在引导时,内核需要硬件信息,不仅仅是已编译过的处理器类型。代码中的指令通过单独存储的配置数据进行扩充。有两种主要的数据存储方法:[<ruby>设备树<rt>device-tree</rt></ruby>][26] 和 [高级配置和电源接口(ACPI)表][27]。内核通过读取这些文件了解每次启动时需要运行的硬件。
|
||||
|
||||
对于嵌入式设备,设备树是已安装硬件的清单。设备树只是一个与内核源代码同时编译的文件,通常与 `vmlinux` 一样位于 `/boot` 目录中。要查看 ARM 设备上的设备树的内容,只需对名称与 `/boot/*.dtb` 匹配的文件执行 `binutils` 包中的 `strings` 命令即可,这里 `dtb` 是指<ruby>设备树二进制文件<rt>device-tree binary</rt></ruby>。显然,只需编辑构成它的类 JSON 的文件并重新运行随内核源代码提供的特殊 `dtc` 编译器即可修改设备树。虽然设备树是一个静态文件,其文件路径通常由命令行引导程序传递给内核,但近年来增加了一个 [设备树覆盖][28] 的功能,内核在启动后可以动态加载热插拔的附加设备。
|
||||
|
||||
x86 系列和许多企业级的 ARM64 设备使用 [ACPI][27] 机制。与设备树不同的是,ACPI 信息存储在内核在启动时通过访问板载 ROM 而创建的 `/sys/firmware/acpi/tables` 虚拟文件系统中。读取 ACPI 表的简单方法是使用 `acpica-tools` 包中的 `acpidump` 命令。例如:
|
||||
|
||||
![ACPI tables on Lenovo laptops][30]
|
||||
|
||||
*联想笔记本电脑的 ACPI 表都是为 Windows 2001 设置的。*
|
||||
|
||||
是的,你的 Linux 系统已经准备好用于 Windows 2001 了,你要考虑安装吗?与设备树不同,ACPI 具有方法和数据,而设备树更多地是一种硬件描述语言。ACPI 方法在启动后仍处于活动状态。例如,运行 `acpi_listen` 命令(在 `apcid` 包中),然后打开和关闭笔记本机盖会发现 ACPI 功能一直在运行。暂时地和动态地 [覆盖 ACPI 表][31] 是可能的,而永久地改变它需要在引导时与 BIOS 菜单交互或刷新 ROM。如果你遇到那么多麻烦,也许你应该 [安装 coreboot][32],这是开源固件的替代品。
|
||||
|
||||
#### 从 start_kernel() 到用户空间
|
||||
|
||||
[init/main.c][25] 中的代码竟然是可读的,而且有趣的是,它仍然在使用 1991 - 1992 年的 Linus Torvalds 的原始版权。在一个刚启动的系统上运行 `dmesg | head`,其输出主要来源于此文件。第一个 CPU 注册到系统中,全局数据结构被初始化,并且调度程序、中断处理程序(IRQ)、定时器和控制台按照严格的顺序逐一启动。在 `timekeeping_init()` 函数运行之前,所有的时间戳都是零。内核初始化的这部分是同步的,也就是说执行只发生在一个线程中,在最后一个完成并返回之前,没有任何函数会被执行。因此,即使在两个系统之间,`dmesg` 的输出也是完全可重复的,只要它们具有相同的设备树或 ACPI 表。Linux 的行为就像在 MCU 上运行的 RTOS(实时操作系统)一样,如 QNX 或 VxWorks。这种情况持续存在于函数 `rest_init()` 中,该函数在终止时由 `start_kernel()` 调用。
|
||||
|
||||
![Summary of early kernel boot process.][34]
|
||||
|
||||
*早期的内核启动流程。*
|
||||
|
||||
函数 `rest_init()` 产生了一个新进程以运行 `kernel_init()`,并调用了 `do_initcalls()`。用户可以通过将 `initcall_debug` 附加到内核命令行来监控 `initcalls`,这样每运行一次 `initcall` 函数就会产生 一个 `dmesg` 条目。`initcalls` 会历经七个连续的级别:early、core、postcore、arch、subsys、fs、device 和 late。`initcalls` 最为用户可见的部分是所有处理器外围设备的探测和设置:总线、网络、存储和显示器等等,同时加载其内核模块。`rest_init()` 也会在引导处理器上产生第二个线程,它首先运行 `cpu_idle()`,然后等待调度器分配工作。
|
||||
|
||||
`kernel_init()` 也可以 [设置对称多处理(SMP)结构][35]。在较新的内核中,如果 `dmesg` 的输出中出现 “Bringing up secondary CPUs...” 等字样,系统便使用了 SMP。SMP 通过“热插拔” CPU 来进行,这意味着它用状态机来管理其生命周期,这种状态机在概念上类似于热插拔的 U 盘一样。内核的电源管理系统经常会使某个<ruby>核<rt>core</rt></ruby>离线,然后根据需要将其唤醒,以便在不忙的机器上反复调用同一段的 CPU 热插拔代码。观察电源管理系统调用 CPU 热插拔代码的 [BCC 工具][36] 称为 `offcputime.py`。
|
||||
|
||||
请注意,`init/main.c` 中的代码在 `smp_init()` 运行时几乎已执行完毕:引导处理器已经完成了大部分一次性初始化操作,其它核无需重复。尽管如此,跨 CPU 的线程仍然要在每个核上生成,以管理每个核的中断(IRQ)、工作队列、定时器和电源事件。例如,通过 `ps -o psr` 命令可以查看服务每个 CPU 上的线程的 softirqs 和 workqueues。
|
||||
|
||||
```
|
||||
# ps -o pid,psr,comm $(pgrep ksoftirqd)
|
||||
PID PSR COMMAND
|
||||
7 0 ksoftirqd/0
|
||||
16 1 ksoftirqd/1
|
||||
22 2 ksoftirqd/2
|
||||
28 3 ksoftirqd/3
|
||||
|
||||
# ps -o pid,psr,comm $(pgrep kworker)
|
||||
PID PSR COMMAND
|
||||
4 0 kworker/0:0H
|
||||
18 1 kworker/1:0H
|
||||
24 2 kworker/2:0H
|
||||
30 3 kworker/3:0H
|
||||
[ . . . ]
|
||||
```
|
||||
|
||||
其中,PSR 字段代表“<ruby>处理器<rt>processor</rt></ruby>”。每个核还必须拥有自己的定时器和 `cpuhp` 热插拔处理程序。
|
||||
|
||||
那么用户空间是如何启动的呢?在最后,`kernel_init()` 寻找可以代表它执行 `init` 进程的 `initrd`。如果没有找到,内核直接执行 `init` 本身。那么为什么需要 `initrd` 呢?
|
||||
|
||||
#### 早期的用户空间:谁规定要用 initrd?
|
||||
|
||||
除了设备树之外,在启动时可以提供给内核的另一个文件路径是 `initrd` 的路径。`initrd` 通常位于 `/boot` 目录中,与 x86 系统中的 bzImage 文件 vmlinuz 一样,或是与 ARM 系统中的 uImage 和设备树相同。用 `initramfs-tools-core` 软件包中的 `lsinitramfs` 工具可以列出 `initrd` 的内容。发行版的 `initrd` 方案包含了最小化的 `/bin`、`/sbin` 和 `/etc` 目录以及内核模块,还有 `/scripts` 中的一些文件。所有这些看起来都很熟悉,因为 `initrd` 大致上是一个简单的最小化 Linux 根文件系统。看似相似,其实不然,因为位于虚拟内存盘中的 `/bin` 和 `/sbin` 目录下的所有可执行文件几乎都是指向 [BusyBox 二进制文件][38] 的符号链接,由此导致 `/bin` 和 `/sbin` 目录比 glibc 的小 10 倍。
|
||||
|
||||
如果要做的只是加载一些模块,然后在普通的根文件系统上启动 `init`,为什么还要创建一个 `initrd` 呢?想想一个加密的根文件系统,解密可能依赖于加载一个位于根文件系统 `/lib/modules` 的内核模块,当然还有 `initrd` 中的。加密模块可能被静态地编译到内核中,而不是从文件加载,但有多种原因不希望这样做。例如,用模块静态编译内核可能会使其太大而不能适应存储空间,或者静态编译可能会违反软件许可条款。不出所料,存储、网络和人类输入设备(HID)驱动程序也可能存在于 `initrd` 中。`initrd` 基本上包含了任何挂载根文件系统所必需的非内核代码。`initrd` 也是用户存放 [自定义ACPI][38] 表代码的地方。
|
||||
|
||||
![Rescue shell and a custom <code>initrd</code>.][40]
|
||||
|
||||
*救援模式的 shell 和自定义的 `initrd` 还是很有意思的。*
|
||||
|
||||
`initrd` 对测试文件系统和数据存储设备也很有用。将这些测试工具存放在 `initrd` 中,并从内存中运行测试,而不是从被测对象中运行。
|
||||
|
||||
最后,当 `init` 开始运行时,系统就启动啦!由于第二个处理器现在在运行,机器已经成为我们所熟知和喜爱的异步、可抢占、不可预测和高性能的生物。的确,`ps -o pid,psr,comm -p 1` 很容易显示用户空间的 `init` 进程已不在引导处理器上运行了。
|
||||
|
||||
### 总结
|
||||
|
||||
Linux 引导过程听起来或许令人生畏,即使是简单嵌入式设备上的软件数量也是如此。但换个角度来看,启动过程相当简单,因为启动中没有抢占、RCU 和竞争条件等扑朔迷离的复杂功能。只关注内核和 PID 1 会忽略了引导程序和辅助处理器为运行内核执行的大量准备工作。虽然内核在 Linux 程序中是独一无二的,但通过一些检查 ELF 文件的工具也可以了解其结构。学习一个正常的启动过程,可以帮助运维人员处理启动的故障。
|
||||
|
||||
要了解更多信息,请参阅 Alison Chaiken 的演讲——[Linux: The first second][41],已于 1 月 22 日至 26 日在悉尼举行。参见 [linux.conf.au][42]。
|
||||
|
||||
感谢 [Akkana Peck][43] 的提议和指正。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/analyzing-linux-boot-process
|
||||
|
||||
作者:[Alison Chaiken][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[2]:https://github.com/chaiken/LCA2018-Demo-Code
|
||||
[3]:https://en.wikipedia.org/wiki/Wake-on-LAN
|
||||
[4]:https://lwn.net/Articles/630778/
|
||||
[5]:https://www.youtube.com/watch?v=iffTJ1vPCSo&amp;amp;amp;amp;amp;index=65&amp;amp;amp;amp;amp;list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
|
||||
[6]:https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&amp;amp;amp;amp;amp;languageid=en-fr
|
||||
[7]:https://www.intel.com/content/www/us/en/support/articles/000025619/software.html
|
||||
[8]:https://github.com/corna/me_cleaner
|
||||
[9]:https://lwn.net/Articles/738649/
|
||||
[10]:https://lwn.net/Articles/699551/
|
||||
[11]:https://trmm.net/NERF
|
||||
[12]:https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled
|
||||
[13]:https://lwn.net/Articles/733837/
|
||||
[14]:https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639
|
||||
[15]:/file/383501
|
||||
[16]:https://opensource.com/sites/default/files/u128651/linuxboot_1.png "Running the U-boot bootloader"
|
||||
[17]:http://www.denx.de/wiki/DULG/Manual
|
||||
[18]:https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux
|
||||
[19]:http://man7.org/linux/man-pages/man5/elf.5.html
|
||||
[20]:https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html
|
||||
[21]:https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e
|
||||
[22]:http://kernel-handbook.alioth.debian.org/
|
||||
[23]:https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S
|
||||
[24]:https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S
|
||||
[25]:https://github.com/torvalds/linux/blob/master/init/main.c
|
||||
[26]:https://www.youtube.com/watch?v=m_NyYEBxfn8
|
||||
[27]:http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf
|
||||
[28]:http://lwn.net/Articles/616859/
|
||||
[29]:/file/383506
|
||||
[30]:https://opensource.com/sites/default/files/u128651/linuxboot_2.png "ACPI tables on Lenovo laptops"
|
||||
[31]:https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt
|
||||
[32]:https://www.coreboot.org/Supported_Motherboards
|
||||
[33]:/file/383511
|
||||
[34]:https://opensource.com/sites/default/files/u128651/linuxboot_3.png "Summary of early kernel boot process."
|
||||
[35]:http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc
|
||||
[36]:http://www.brendangregg.com/ebpf.html
|
||||
[37]:https://www.busybox.net/
|
||||
[38]:https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt
|
||||
[39]:/file/383516
|
||||
[40]:https://opensource.com/sites/default/files/u128651/linuxboot_4.png "Rescue shell and a custom <code>initrd</code>."
|
||||
[41]:https://rego.linux.conf.au/schedule/presentation/16/
|
||||
[42]:https://linux.conf.au/index.html
|
||||
[43]:http://shallowsky.com/
|
||||
@ -1,4 +1,4 @@
|
||||
SPARTA —— 用于网络渗透测试的 GUI 工具套件
|
||||
SPARTA:用于网络渗透测试的 GUI 工具套件
|
||||
======
|
||||
|
||||

|
||||
@ -7,12 +7,11 @@ SPARTA 是使用 Python 开发的 GUI 应用程序,它是 Kali Linux 内置的
|
||||
|
||||
SPARTA GUI 工具套件最擅长的事情是扫描和发现目标端口和运行的服务。
|
||||
|
||||
因此,作为枚举阶段的一部分功能,它提供对开放端口和服务的暴力攻击。
|
||||
|
||||
此外,作为枚举阶段的一部分功能,它提供对开放端口和服务的暴力攻击。
|
||||
|
||||
延伸阅读:[网络渗透检查清单][1]
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
请从 GitHub 上克隆最新版本的 SPARTA:
|
||||
|
||||
@ -21,64 +20,58 @@ git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
|
||||
或者,从 [这里][2] 下载最新版本的 Zip 文件。
|
||||
|
||||
```
|
||||
cd /usr/share/
|
||||
git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
将 "sparta" 文件放到 /usr/bin/ 目录下并赋于可运行权限。
|
||||
|
||||
将 `sparta` 文件放到 `/usr/bin/` 目录下并赋于可运行权限。
|
||||
|
||||
在任意终端中输入 'sparta' 来启动应用程序。
|
||||
|
||||
### 网络渗透测试的范围
|
||||
|
||||
## 网络渗透测试的范围:
|
||||
|
||||
* 添加一个目标主机或者目标主机的列表到范围中,来发现一个组织的网络基础设备在安全方面的薄弱环节。
|
||||
* 选择菜单条 - File > Add host(s) to scope
|
||||
|
||||
添加一个目标主机或者目标主机的列表到测试范围中,来发现一个组织的网络基础设备在安全方面的薄弱环节。
|
||||
|
||||
选择菜单条 - “File” -> “Add host(s) to scope”
|
||||
|
||||
[![Network Penetration Testing][3]][4]
|
||||
|
||||
[![Network Penetration Testing][5]][6]
|
||||
|
||||
* 上图展示了在扫描范围中添加 IP 地址。根据你网络的具体情况,你可以添加一个 IP 地址的范围去扫描。
|
||||
* 扫描范围添加之后,Nmap 将开始扫描,并很快得到结果,扫描阶段结束。
|
||||
|
||||
|
||||
|
||||
## 打开 Ports & Services:
|
||||
|
||||
* Nmap 扫描结果提供了目标上开放的端口和服务。
|
||||
上图展示了在扫描范围中添加 IP 地址。根据你网络的具体情况,你可以添加一个 IP 地址的范围去扫描。
|
||||
扫描范围添加之后,Nmap 将开始扫描,并很快得到结果,扫描阶段结束。
|
||||
|
||||
### 打开的端口及服务
|
||||
|
||||
Nmap 扫描结果提供了目标上开放的端口和服务。
|
||||
|
||||
[![Network Penetration Testing][7]][8]
|
||||
|
||||
* 上图展示了扫描发现的目标操作系统、开发的端口和服务。
|
||||
|
||||
|
||||
|
||||
## 在开放端口上实施暴力攻击:
|
||||
|
||||
* 我们来通过 445 端口的服务器消息块(SMB)协议来暴力获取用户列表和它们的有效密码。
|
||||
上图展示了扫描发现的目标操作系统、开发的端口和服务。
|
||||
|
||||
### 在开放端口上实施暴力攻击
|
||||
|
||||
我们来通过 445 端口的服务器消息块(SMB)协议来暴力获取用户列表和它们的有效密码。
|
||||
|
||||
[![Network Penetration Testing][9]][10]
|
||||
|
||||
* 右键并选择 “Send to Brute” 选项。也可以选择发现的目标上的开放端口和服务。
|
||||
* 浏览和在用户名密码框中添加字典文件。
|
||||
|
||||
右键并选择 “Send to Brute” 选项。也可以选择发现的目标上的开放端口和服务。
|
||||
|
||||
浏览和在用户名密码框中添加字典文件。
|
||||
|
||||
[![Network Penetration Testing][11]][12]
|
||||
|
||||
* 点击 “Run” 去启动对目标的暴力攻击。上图展示了对目标 IP 地址进行的暴力攻击取得成功,找到了有效的密码。
|
||||
* 在 Windows 中失败的登陆尝试总是被记录到事件日志中。
|
||||
* 密码每 15 到 30 天改变一次的策略是非常好的一个实践经验。
|
||||
* 强烈建议使用强密码策略。密码锁定策略是阻止这种暴力攻击的最佳方法之一( 5 次失败的登陆尝试之后将锁定帐户)
|
||||
* 将关键业务资产整合到 SIEM( 安全冲突 & 事件管理)中将尽可能快地检测到这类攻击行为。
|
||||
点击 “Run” 去启动对目标的暴力攻击。上图展示了对目标 IP 地址进行的暴力攻击取得成功,找到了有效的密码。
|
||||
|
||||
在 Windows 中失败的登陆尝试总是被记录到事件日志中。
|
||||
|
||||
密码每 15 到 30 天改变一次的策略是非常好的一个实践经验。
|
||||
|
||||
强烈建议使用强密码策略。密码锁定策略是阻止这种暴力攻击的最佳方法之一( 5 次失败的登录尝试之后将锁定帐户)。
|
||||
|
||||
将关键业务资产整合到 SIEM( 安全冲突 & 事件管理)中将尽可能快地检测到这类攻击行为。
|
||||
|
||||
SPARTA 对渗透测试的扫描和枚举阶段来说是一个非常省时的 GUI 工具套件。SPARTA 可以扫描和暴力破解各种协议。它有许多的功能!祝你测试顺利!
|
||||
|
||||
@ -88,7 +81,7 @@ via: https://gbhackers.com/sparta-network-penetration-testing-gui-toolkit/
|
||||
|
||||
作者:[Balaganesh][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,28 +1,28 @@
|
||||
为初学者介绍的 Linux tee 命令(6 个例子)
|
||||
======
|
||||
|
||||
有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 **tee** 的命令可以帮助你。
|
||||
有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 `tee` 的命令可以帮助你。
|
||||
|
||||
本教程中,我们将基于 tee 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
|
||||
本教程中,我们将基于 `tee` 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
|
||||
|
||||
### Linux tee 命令
|
||||
|
||||
tee 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
|
||||
`tee` 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
|
||||
|
||||
```
|
||||
tee [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
这里是帮助文档的说明:
|
||||
```
|
||||
从标准输入中复制到每一个文件,并输出到标准输出。
|
||||
```
|
||||
|
||||
> 从标准输入中复制到每一个文件,并输出到标准输出。
|
||||
|
||||
|
||||
让 Q&A(问&答)风格的实例给我们带来更多灵感,深入了解这个命令。
|
||||
|
||||
### Q1. 如何在 Linux 上使用这个命令?
|
||||
### Q1、 如何在 Linux 上使用这个命令?
|
||||
|
||||
假设因为某些原因,你正在使用 ping 命令。
|
||||
假设因为某些原因,你正在使用 `ping` 命令。
|
||||
|
||||
```
|
||||
ping google.com
|
||||
@ -30,29 +30,29 @@ ping google.com
|
||||
|
||||
[![如何在 Linux 上使用 tee 命令][1]][2]
|
||||
|
||||
然后同时,你想要输出的信息也同时能写入文件。这个时候,tee 命令就有其用武之地了。
|
||||
然后同时,你想要输出的信息也同时能写入文件。这个时候,`tee` 命令就有其用武之地了。
|
||||
|
||||
```
|
||||
ping google.com | tee output.txt
|
||||
```
|
||||
|
||||
下面的截图展示了这个输出内容不仅被写入 ‘output.txt’ 文件,也被显示在标准输出中。
|
||||
下面的截图展示了这个输出内容不仅被写入 `output.txt` 文件,也被显示在标准输出中。
|
||||
|
||||
[![tee command 输出][3]][4]
|
||||
|
||||
如此应当明确了 tee 的基础用法。
|
||||
如此应当明白了 `tee` 的基础用法。
|
||||
|
||||
### Q2. 如何确保 tee 命令追加信息到文件中?
|
||||
### Q2、 如何确保 tee 命令追加信息到文件中?
|
||||
|
||||
默认情况下,在同一个文件下再次使用 tee 命令会覆盖之前的信息。如果你想的话,可以通过 -a 命令选项改变默认设置。
|
||||
默认情况下,在同一个文件下再次使用 `tee` 命令会覆盖之前的信息。如果你想的话,可以通过 `-a` 命令选项改变默认设置。
|
||||
|
||||
```
|
||||
[command] | tee -a [file]
|
||||
```
|
||||
|
||||
基本上,-a 选项强制 tee 命令追加信息到文件。
|
||||
基本上,`-a` 选项强制 `tee` 命令追加信息到文件。
|
||||
|
||||
### Q3. 如何让 tee 写入多个文件?
|
||||
### Q3、 如何让 tee 写入多个文件?
|
||||
|
||||
这非常之简单。你仅仅只需要写明文件名即可。
|
||||
|
||||
@ -70,7 +70,7 @@ ping google.com | tee output1.txt output2.txt output3.txt
|
||||
|
||||
### Q4. 如何让 tee 命令的输出内容直接作为另一个命令的输入内容?
|
||||
|
||||
使用 tee 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入‘output.txt’文件中,还会通过 wc 命令让你知道输入到 output.txt 中的文件数目。
|
||||
使用 `tee` 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入 `output.txt` 文件中,还会通过 `wc` 命令让你知道输入到 `output.txt` 中的文件数目。
|
||||
|
||||
```
|
||||
ls file* | tee output.txt | wc -l
|
||||
@ -80,11 +80,11 @@ ls file* | tee output.txt | wc -l
|
||||
|
||||
### Q5. 如何使用 tee 命令提升文件写入权限?
|
||||
|
||||
假如你使用 [Vim editor][9] 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 sudo 权限保存修改。
|
||||
假如你使用 [Vim 编辑器][9] 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 `sudo` 权限保存修改。
|
||||
|
||||
[![如何使用 tee 命令提升文件写入权限][10]][11]
|
||||
|
||||
如此情况下,你可以使用 tee 命令来提高权限。
|
||||
如此情况下,你可以(在 Vim 内)使用 `tee` 命令来提高权限。
|
||||
|
||||
```
|
||||
:w !sudo tee %
|
||||
@ -94,17 +94,17 @@ ls file* | tee output.txt | wc -l
|
||||
|
||||
### Q6. 如何让 tee 命令忽视中断?
|
||||
|
||||
-i 命令行选项使 tee 命令忽视通常由 crl+c 组合键发起的中断信号(`SIGINT`)。
|
||||
`-i` 命令行选项使 `tee` 命令忽视通常由 `ctrl+c` 组合键发起的中断信号(`SIGINT`)。
|
||||
|
||||
```
|
||||
[command] | tee -i [file]
|
||||
```
|
||||
|
||||
当你想要使用 crl+c 中断命令的同时,让 tee 命令优雅的退出,这个选项尤为实用。
|
||||
当你想要使用 `ctrl+c` 中断该命令,同时让 `tee` 命令优雅的退出,这个选项尤为实用。
|
||||
|
||||
### 总结
|
||||
|
||||
现在你可能已经认同 tee 是一个非常实用的命令。基于 tee 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档][12].
|
||||
现在你可能已经认同 `tee` 是一个非常实用的命令。基于 `tee` 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档][12].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -113,7 +113,7 @@ via: https://www.howtoforge.com/linux-tee-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
简单介绍 ldd 命令
|
||||
=========================================
|
||||
|
||||
如果您的工作涉及到 Linux 中的可执行文件和共享库的知识,则需要了解几种命令行工具。其中之一是 `ldd` ,您可以使用它来访问共享对象依赖关系。在本教程中,我们将使用一些易于理解的示例来讨论此实用程序的基础知识。
|
||||
|
||||
请注意,这里提到的所有示例都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
|
||||
|
||||
### Linux ldd 命令
|
||||
|
||||
正如开头已经提到的,`ldd` 命令打印共享对象依赖关系。以下是该命令的语法:
|
||||
|
||||
```
|
||||
ldd [option]... file...
|
||||
```
|
||||
|
||||
下面是该工具的手册页对它作出的解释:
|
||||
|
||||
> ldd 会输出命令行指定的每个程序或共享对象所需的共享对象(共享库)。
|
||||
|
||||
以下使用问答的方式让您更好地了解ldd的工作原理。
|
||||
|
||||
### 问题一、 如何使用 ldd 命令?
|
||||
|
||||
`ldd` 的基本用法非常简单,只需运行 `ldd` 命令以及可执行文件或共享对象的文件名称作为输入。
|
||||
|
||||
```
|
||||
ldd [object-name]
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
ldd test
|
||||
```
|
||||
|
||||
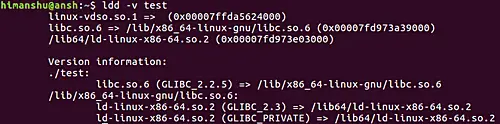
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-basic.png)
|
||||
|
||||
所以你可以看到所有的共享库依赖已经在输出中产生了。
|
||||
|
||||
### Q2、 如何使 ldd 在输出中生成详细的信息?
|
||||
|
||||
如果您想要 `ldd` 生成详细信息,包括符号版本控制数据,则可以使用 `-v` 命令行选项。例如,该命令
|
||||
|
||||
```
|
||||
ldd -v test
|
||||
```
|
||||
|
||||
当使用 `-v` 命令行选项时,在输出中产生以下内容:
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-v-option.png)
|
||||
|
||||
### Q3、 如何使 ldd 产生未使用的直接依赖关系?
|
||||
|
||||
对于这个信息,使用 `-u` 命令行选项。这是一个例子:
|
||||
|
||||
```
|
||||
ldd -u test
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-u-test.png)
|
||||
|
||||
### Q4、 如何让 ldd 执行重定位?
|
||||
|
||||
您可以在这里使用几个命令行选项:`-d` 和 `-r`。 前者告诉 `ldd` 执行数据重定位,后者则使 `ldd` 为数据对象和函数执行重定位。在这两种情况下,该工具都会报告丢失的 ELF 对象(如果有的话)。
|
||||
|
||||
```
|
||||
ldd -d
|
||||
ldd -r
|
||||
```
|
||||
|
||||
### Q5、 如何获得关于ldd的帮助?
|
||||
|
||||
`--help` 命令行选项使 `ldd` 为该工具生成有用的用法相关信息。
|
||||
|
||||
```
|
||||
ldd --help
|
||||
```
|
||||
|
||||
[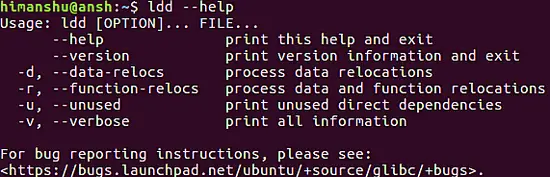](https://www.howtoforge.com/images/command-tutorial/big/ldd-help-option.png)
|
||||
|
||||
### 总结
|
||||
|
||||
`ldd` 不像 `cd`、`rm` 和 `mkdir` 这样的工具类别。这是因为它是为特定目的而构建的。该实用程序提供了有限的命令行选项,我们在这里介绍了其中的大部分。要了解更多信息,请前往 `ldd` 的[手册页](https://linux.die.net/man/1/ldd)。
|
||||
|
||||
---------
|
||||
|
||||
via: [https://www.howtoforge.com/linux-ldd-command/](https://www.howtoforge.com/linux-ldd-command/)
|
||||
|
||||
作者: [Himanshu Arora](https://www.howtoforge.com/)
|
||||
选题: [lujun9972](https://github.com/lujun9972)
|
||||
译者: [MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对: [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
69
published/20180219 How Linux became my job.md
Normal file
69
published/20180219 How Linux became my job.md
Normal file
@ -0,0 +1,69 @@
|
||||
Linux 如何成为我的工作
|
||||
======
|
||||
|
||||
> IBM 工程师 Phil Estes 分享了他的 Linux 爱好如何使他成为了一位开源领袖、贡献者和维护者。
|
||||
|
||||

|
||||
|
||||
从很早很早以前起,我就一直使用开源软件。那个时候,没有所谓的社交媒体。没有火狐,没有谷歌浏览器(甚至连谷歌也没有),没有亚马逊,甚至几乎没有互联网。事实上,那个时候最热门的是最新的 Linux 2.0 内核。当时的技术挑战是什么?嗯,是 Linux 发行版本中旧的 [a.out][2] 格式被 [ELF 格式][1]代替,导致升级一些 [Linux][3] 的安装可能有些棘手。
|
||||
|
||||
我如何将我自己对这个初出茅庐的年轻操作系统的兴趣转变为开源事业是一个有趣的故事。
|
||||
|
||||
### Linux 为乐趣为生,而非利益
|
||||
|
||||
1994 年我大学毕业时,计算机实验室是 UNIX 系统的小型网络;如果你幸运的话,它们会连接到这个叫做互联网的新东西上。我知道这难以置信!(那时,)“Web”(就是所知道的那个)大多是手写的 HTML,`cgi-bin` 目录是启用动态 Web 交互的一个新平台。我们许多人对这些新技术感到兴奋,我们还自学了 shell 脚本、[Perl][4]、HTML,以及所有我们在父母的 Windows 3.1 PC 上从没有见过的简短的 UNIX 命令。
|
||||
|
||||
毕业后,我加入 IBM,工作在一个不能访问 UNIX 系统的 PC 操作系统上,不久,我的大学切断了我通往工程实验室的远程通道。我该如何继续通过 [Pine][6] 使用 `vi` 和 `ls` 读我的电子邮件的呢?我一直听说开源 Linux,但我还没有时间去研究它。
|
||||
|
||||
1996 年,我在德克萨斯大学奥斯丁分校开始读硕士学位。我知道这将涉及编程和写论文,不知道还有什么,但我不想使用专有的编辑器,编译器或者文字处理器。我想要的是我的 UNIX 体验!
|
||||
|
||||
所以我拿了一个旧电脑,找到了一个 Linux 发行版本 Slackware 3.0,在我的 IBM 办公室下载了一张又一张的软盘。可以说我在第一次安装 Linux 后就没有回过头了。在最初的那些日子里,我学习了很多关于 Makefile 和 `make` 系统、构建软件、补丁还有源码控制的知识。虽然我开始使用 Linux 只是为了兴趣和个人知识,但它最终改变了我的职业生涯。
|
||||
|
||||
虽然我是一个愉快的 Linux 用户,但我认为开源开发仍然是其他人的工作;我觉得在线邮件列表都是神秘的 [UNIX][7] 极客的。我很感激像 Linux HOWTO 这样的项目,它们在我尝试添加软件包、升级 Linux 版本,或者安装新硬件和新 PC 的设备驱动程序撞得鼻青脸肿时帮助了我。但是要处理源代码并进行修改或提交到上游……那是别人的事,不是我。
|
||||
|
||||
### Linux 如何成为我的工作
|
||||
|
||||
1999 年,我终于有理由把我对 Linux 的个人兴趣与我在 IBM 的日常工作结合起来了。我接了一个研究项目,将 IBM 的 Java 虚拟机(JVM)移植到 Linux 上。为了确保我们在法律上是安全的,IBM 购买了一个塑封的盒装的 Red Hat Linux 6.1 副本来完成这项工作。在 IBM 东京研究实验室工作时,为了编写我们的 JVM 即时编译器(JIT),参考了 AIX JVM 源代码和 Windows 及 OS/2 的 JVM 源代码,我们在几周内就有了一个可以工作在 Linux 上的 JVM,击败了 SUN 公司官方宣告花了几个月才把 Java 移植到 Linux。既然我在 Linux 平台上做得了开发,我就更喜欢它了。
|
||||
|
||||
到 2000 年,IBM 使用 Linux 的频率迅速增加。由于 [Dan Frye][8] 的远见和坚持,IBM 在 Linux 上下了“[一亿美元的赌注][9]”,在 1999 年创建了 Linux 技术中心(LTC)。在 LTC 里面有内核开发者、开源贡献者、IBM 硬件设备的驱动程序编写者,以及各种各样的针对 Linux 的开源工作。比起留在与 LTC 联系不大的部门,我更想要成为这个令人兴奋的 IBM 新天地的一份子。
|
||||
|
||||
从 2003 年到 2013 年我深度参与了 IBM 的 Linux 战略和 Linux 发行版(在 IBM 内部)的使用,最终组成了一个团队成为大约 60 个产品的信息交换所,Linux 的使用涉及了 IBM 每个部门。我参与了收购,期望每个设备、管理系统和虚拟机或者基于物理设备的中间件都能运行 Linux。我开始熟悉 Linux 发行版的构建,包括打包、选择上游来源、开发发行版维护的补丁集、做定制,并通过我们的发行版合作伙伴提供支持。
|
||||
|
||||
由于我们的下游供应商,我很少提交补丁到上游,但我通过配合 [Ulrich Drepper][10] (将一个小补丁提交到 glibc)和改变[时区数据库][11]的工作贡献了自己的力量(Arthur David Olson 在 NIH 的 FTP 站点维护它的时候接受了这个改变)。但我仍然没有把开源项目的正式贡献者的工作来当做我的工作的一部分。是该改变这种情况的时候了。
|
||||
|
||||
在 2013 年末,我加入了 IBM 在开源社区的云组织,并正在寻找一个上游社区参与进来。我会在 Cloud Foundry 工作,还是会加入 IBM 为 OpenStack 贡献的大组中呢?都不是,因为在 2014 年 Docker 席卷了全球,IBM 要我们几个参与到这个热门的新技术。我在接下来的几个月里,经历了许多的第一次:使用 GitHub,比起只是 `git clone` [学习了关于 Git 的更多知识][12],做过 Pull Request 的审查,用 Go 语言写代码,等等。在接下来的一年中,我在 Docker 引擎项目上成为一个维护者,为 Dockr 创造下一版的镜像规范(支持多个架构),并在一个关于容器技术的会议上出席和讲话。
|
||||
|
||||
### 如今的我
|
||||
|
||||
一晃几年过去,我已经成为了包括 CNCF 的 [containerd][13] 项目在内的开源项目的维护者。我还创建了项目(如 [manifest-tool][14] 和 [bucketbench][15])。我也通过 OCI 参与了开源治理,我现在是技术监督委员会的成员;而在Moby 项目,我是技术指导委员会的成员。我乐于在世界各地的会议、沙龙、IBM 内部发表关于开源的演讲。
|
||||
|
||||
开源现在是我在 IBM 职业生涯的一部分。我与工程师、开发人员和行业领袖的联系可能比我在 IBM 内认识的人的联系还要多。虽然开源与专有开发团队和供应商合作伙伴有许多相同的挑战,但据我的经验,开源与全球各地的人们的关系和联系远远超过困难。随着不同的意见、观点和经验的不断优化,可以对软件和涉及的在其中的人产生一种不断学习和改进的文化。
|
||||
|
||||
这个旅程 —— 从我第一次使用 Linux 到今天成为一个领袖、贡献者,和现在云原生开源世界的维护者 —— 我获得了极大的收获。我期待着与全球各地的人们长久的进行开源协作和互动。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[ranchong](https://github.com/ranchong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://linux.cn/article-9319-1.html
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
@ -1,53 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
An old DOS BBS in a Docker container
|
||||
======
|
||||
Awhile back, I wrote about [my Debian Docker base images][1]. I decided to extend this concept a bit further: to running DOS applications in Docker.
|
||||
|
||||
But first, a screenshot:
|
||||
|
||||
![][2]
|
||||
|
||||
It turns out this is possible, but difficult. I went through all three major DOS emulators available (dosbox, qemu, and dosemu). I got them all running inside the Docker container, but had a number of, er, fun issues to resolve.
|
||||
|
||||
The general thing one has to do here is present a fake modem to the DOS environment. This needs to be exposed outside the container as a TCP port. That much is possible in various ways -- I wound up using tcpser. dosbox had a TCP modem interface, but it turned out to be too buggy for this purpose.
|
||||
|
||||
The challenge comes in where you want to be able to accept more than one incoming telnet (or TCP) connection at a time. DOS was not a multitasking operating system, so there were any number of hackish solutions back then. One might have had multiple physical computers, one for each incoming phone line. Or they might have run multiple pseudo-DOS instances under a multitasking layer like [DESQview][3], OS/2, or even Windows 3.1.
|
||||
|
||||
(Side note: I just learned of [DESQview/X][4], which integrated DESQview with X11R5 and [replaced the Windows 3 drivers][5] to allow running Windows as an X application).
|
||||
|
||||
For various reasons, I didn't want to try running one of those systems inside Docker. That left me with emulating the original multiple physical node setup. In theory, pretty easy -- spin up a bunch of DOS boxes, each using at most 1MB of emulated RAM, and go to town. But here came the challenge.
|
||||
|
||||
In a multiple-physical-node setup, you need some sort of file sharing, because your nodes have to access the shared message and file store. There were a myriad of clunky ways to do this in the old DOS days - [Netware][6], [LAN manager][7], even some PC NFS clients. I didn't have access to Netware. I tried the Microsoft LM client in DOS, talking to a Samba server running inside the Docker container. This I got working, but the LM client used so much RAM that, even with various high memory tricks, BBS software wasn't going to run. I couldn't just mount an underlying filesystem in multiple dosbox instances either, because dosbox did caching that wasn't going to be compatible.
|
||||
|
||||
This is why I wound up using dosemu. Besides being a more complete emulator than dosbox, it had a way of sharing the host's filesystems that was going to work.
|
||||
|
||||
So, all of this wound up with this: [jgoerzen/docker-bbs-renegade][8].
|
||||
|
||||
I also prepared building blocks for others that want to do something similar: [docker-dos-bbs][9] and the lower-level [docker-dosemu][10].
|
||||
|
||||
As a side bonus, I also attempted running this under Joyent's Triton (SmartOS, Solaris-based). I was pleasantly impressed that I got it all almost working there. So yes, a Renegade DOS BBS running under a Linux-based DOS emulator in a container on a Solaris machine.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9836-an-old-dos-bbs-in-a-docker-container
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://changelog.complete.org/archives/9794-fixing-the-problems-with-docker-images
|
||||
[2]:https://raw.githubusercontent.com/jgoerzen/docker-bbs-renegade/master/renegade-login.png
|
||||
[3]:https://en.wikipedia.org/wiki/DESQview
|
||||
[4]:http://toastytech.com/guis/dvx.html
|
||||
[5]:http://toastytech.com/guis/dvx3.html
|
||||
[6]:https://en.wikipedia.org/wiki/NetWare
|
||||
[7]:https://en.wikipedia.org/wiki/LAN_Manager
|
||||
[8]:https://github.com/jgoerzen/docker-bbs-renegade
|
||||
[9]:https://github.com/jgoerzen/docker-dos-bbs
|
||||
[10]:https://github.com/jgoerzen/docker-dosemu
|
||||
@ -0,0 +1,134 @@
|
||||
20 questions DevOps job candidates should be prepared to answer
|
||||
======
|
||||
|
||||

|
||||
Hiring the wrong person is [expensive][1]. Recruiting, hiring, and onboarding a new employee can cost a company as much as $240,000, according to Jörgen Sundberg, CEO of Link Humans. When you make the wrong hire:
|
||||
|
||||
* You lose what they know.
|
||||
* You lose who they know.
|
||||
* Your team could go into the [storming][2] phase of group development.
|
||||
* Your company risks disorganization.
|
||||
|
||||
|
||||
|
||||
When you lose an employee, you lose a piece of the fabric of the company. It's also worth mentioning the pain on the other end. The person hired into the wrong job may experience stress, feelings of overall dissatisfaction, and even health issues.
|
||||
|
||||
On the other hand, when you get it right, your new hire will:
|
||||
|
||||
* Enhance the existing culture, making your organization an even a better place to work. Studies show that a positive work culture helps [drive long-term financial performance][3] and that if you work in a happy environment, you’re more likely to do better in life.
|
||||
* Love working with your organization. When people love what they do, they tend to do it well.
|
||||
|
||||
|
||||
|
||||
Hiring to fit or enhance your existing culture is essential in DevOps and agile teams. That means hiring someone who can encourage effective collaboration so that individual contributors from varying backgrounds, and teams with different goals and working styles, can work together productively. Your new hire should help teams collaborate to maximize their value while also increasing employee satisfaction and balancing conflicting organizational goals. He or she should be able to choose tools and workflows wisely to complement your organization. Culture is everything.
|
||||
|
||||
As a follow-up to our November 2017 post, [20 questions DevOps hiring managers should be prepared to answer][4], this article will focus on how to hire for the best mutual fit.
|
||||
|
||||
### Why hiring goes wrong
|
||||
|
||||
The typical hiring strategy many companies use today is based on a talent surplus:
|
||||
|
||||
* Post on job boards.
|
||||
* Focus on candidates with the skills they need.
|
||||
* Find as many candidates as possible.
|
||||
* Interview to weed out the weak.
|
||||
* Conduct formal interviews to do more weeding.
|
||||
* Assess, vote, and select.
|
||||
* Close on compensation.
|
||||
|
||||

|
||||
|
||||
Job boards were invented during the Great Depression when millions of people were out of work and there was a talent surplus. There is no talent surplus in today's job market, yet we’re still using a hiring strategy that's based on one.
|
||||
|
||||

|
||||
|
||||
### Hire for mutual fit: Use culture and emotions
|
||||
|
||||
The idea behind the talent surplus hiring strategy is to design jobs and then slot people into them.
|
||||
|
||||
Instead, do the opposite: Find talented people who will positively add to your business culture, then find the best fit for them in a job they’ll love. To do this, you must be open to creating jobs around their passions.
|
||||
|
||||
**Who is looking for a job?** According to a 2016 survey of more than 50,000 U.S. developers, [85.7% of respondents][5] were either not interested in new opportunities or were not actively looking for them. And of those who were looking, a whopping [28.3% of job discoveries][5] came from referrals by friends. If you’re searching only for people who are looking for jobs, you’re missing out on top talent.
|
||||
|
||||
**Use your team to find and vet potential recruits**. For example, if Diane is a developer on your team, chances are she has [been coding for years][6] and has met fellow developers along the way who also love what they do. Wouldn’t you think her chances of vetting potential recruits for skills, knowledge, and intelligence would be higher than having someone from HR find and vet potential recruits? And before asking Diane to share her knowledge of fellow recruits, inform her of the upcoming mission, explain your desire to hire a diverse team of passionate explorers, and describe some of the areas where help will be needed in the future.
|
||||
|
||||
**What do employees want?** A comprehensive study comparing the wants and needs of Millennials, GenX’ers, and Baby Boomers shows that within two percentage points, we all [want the same things][7]:
|
||||
|
||||
1. To make a positive impact on the organization
|
||||
2. To help solve social and/or environmental challenges
|
||||
3. To work with a diverse group of people
|
||||
|
||||
|
||||
|
||||
### The interview challenge
|
||||
|
||||
The interview should be a two-way conversation for finding a mutual fit between the person hiring and the person interviewing. Focus your interview on CQ ([Cultural Quotient][7]) and EQ ([Emotional Quotient][8]): Will this person reinforce and add to your culture and love working with you? Can you help make them successful at their job?
|
||||
|
||||
**For the hiring manager:** Every interview is an opportunity to learn how your organization could become more irresistible to prospective team members, and every positive interview can be your best opportunity to finding talent, even if you don’t hire that person. Everyone remembers being interviewed if it is a positive experience. Even if they don’t get hired, they will talk about the experience with their friends, and you may get a referral as a result. There is a big upside to this: If you’re not attracting this talent, you have the opportunity to learn the reason and fix it.
|
||||
|
||||
**For the interviewee** : Each interview experience is an opportunity to unlock your passions.
|
||||
|
||||
### 20 questions to help you unlock the passions of potential hires
|
||||
|
||||
1. What are you passionate about?
|
||||
|
||||
2. What makes you think, "I can't wait to get to work this morning!”
|
||||
|
||||
3. What is the most fun you’ve ever had?
|
||||
|
||||
4. What is your favorite example of a problem you’ve solved, and how did you solve it?
|
||||
|
||||
5. How do you feel about paired learning?
|
||||
|
||||
6. What’s at the top of your mind when you arrive at, and leave, the office?
|
||||
|
||||
7. If you could have changed one thing in your previous/current job, what would it be?
|
||||
|
||||
8. What are you excited to learn while working here?
|
||||
|
||||
9. What do you aspire to in life, and how are you pursuing it?
|
||||
|
||||
10. What do you want, or feel you need, to learn to achieve these aspirations?
|
||||
|
||||
11. What values do you hold?
|
||||
|
||||
12. How do you live those values?
|
||||
|
||||
13. What does balance mean in your life?
|
||||
|
||||
14. What work interactions are you are most proud of? Why?
|
||||
|
||||
15. What type of environment do you like to create?
|
||||
|
||||
16. How do you like to be treated?
|
||||
|
||||
17. What do you trust vs. verify?
|
||||
|
||||
18. Tell me about a recent learning you had when working on a project.
|
||||
|
||||
19. What else should we know about you?
|
||||
|
||||
20. If you were hiring me, what questions would you ask me?
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/questions-devops-employees-should-answer
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/catherinelouis
|
||||
[1]:https://www.shrm.org/resourcesandtools/hr-topics/employee-relations/pages/cost-of-bad-hires.aspx
|
||||
[2]:https://en.wikipedia.org/wiki/Tuckman%27s_stages_of_group_development
|
||||
[3]:http://www.forbes.com/sites/johnkotter/2011/02/10/does-corporate-culture-drive-financial-performance/
|
||||
[4]:https://opensource.com/article/17/11/inclusive-workforce-takes-work
|
||||
[5]:https://insights.stackoverflow.com/survey/2016#work-job-discovery
|
||||
[6]:https://research.hackerrank.com/developer-skills/2018/
|
||||
[7]:http://www-935.ibm.com/services/us/gbs/thoughtleadership/millennialworkplace/
|
||||
[8]:https://en.wikipedia.org/wiki/Emotional_intelligence
|
||||
95
sources/talk/20180308 What is open source programming.md
Normal file
95
sources/talk/20180308 What is open source programming.md
Normal file
@ -0,0 +1,95 @@
|
||||
What is open source programming?
|
||||
======
|
||||
|
||||

|
||||
|
||||
At the simplest level, open source programming is merely writing code that other people can freely use and modify. But you've heard the old chestnut about playing Go, right? "So simple it only takes a minute to learn the rules, but so complex it requires a lifetime to master." Writing open source code is a pretty similar experience. It's easy to chuck a few lines of code up on GitHub, Bitbucket, SourceForge, or your own blog or site. But doing it right requires some personal investment, effort, and forethought.
|
||||
|
||||

|
||||
|
||||
### What open source programming isn't
|
||||
|
||||
Let's be clear up front about something: Just being on GitHub in a public repo does not make your code open source. Copyright in nearly all countries attaches automatically when a work is fixed in a medium, without need for any action by the author. For any code that has not been licensed by the author, it is only the author who can exercise the rights associated with copyright ownership. Unlicensed code—no matter how publicly accessible—is a ticking time bomb for anyone who is unwise enough to use it.
|
||||
|
||||
A well-meaning author may think, "well, it's obvious this is free to use," and have no plans ever to sue anyone, but that doesn't mean the code is safe to use. No matter what you think someone will do, that author has the right to sue anyone who uses, modifies, or embeds that code anywhere else without an expressly granted license.
|
||||
|
||||
Clearly, you shouldn't put your own code out in public without a license and expect others to use or contribute to it. I would also recommend you avoid using (or even looking at) such code yourself. If you create a highly similar function or routine to a piece of unlicensed work you inspected at some point in the past, you could open yourself or your employer to infringement lawsuits.
|
||||
|
||||
Let's say that Jill Schmill writes AwesomeLib and puts it on GitHub without a license. Even if Jill never sues anybody, she might eventually sell all the rights to AwesomeLib to EvilCorp, who will. (Think of it as a lurking vulnerability, just waiting to be exploited.)
|
||||
|
||||
Unlicensed code is unsafe code, period.
|
||||
|
||||
### Choosing the right license
|
||||
|
||||
OK, you've decided you want to write a new program, and you want people to have open source rights to use it. The next step is figuring out which [license][1] best fits your needs. You can get started with the GitHub-curated [choosealicense.com][2], which is just what it says on the tin. The site is laid out a bit like a simple quiz, and most people should be one or two clicks at most from finding the right license for their project.
|
||||
|
||||
Unlicensed code is unsafe code, period.
|
||||
|
||||
A word of caution: Don't get overly fancy or self-important. If you choose a commonly used and well-known license like the
|
||||
|
||||
A word of caution: Don't get overly fancy or self-important. If you choose a commonly used and well-known license like the [Apache License][3] or the [GPLv3][4] , it's easy for people to understand what their rights are and what your rights are without needing a team of lawyers to look for pitfalls and problems. The further you stray from the beaten path, though, the more problems you open yourself and others up to.
|
||||
|
||||
Most importantly, do not write your own license! Making up your own license is an unnecessary source of confusion for everyone. Don't do it. If you absolutely must have your own special terms that you can't find in any existing license, write them as an addendum to an otherwise well-understood license... and keep the main license and your addendum clearly separated so everyone involved knows which parts they've got to be extra careful about.
|
||||
|
||||
I know some people stubborn up and say, "I don't care about licenses and don't want to think about them; it's public domain." The problem with that is that "public domain" isn't a universally understood term in a legal sense. It means different things from one country to the next, with different rights and terms attached. In some countries, you can't even place your own works in the public domain, because the government reserves control over that. Luckily, the [Unlicense][5] has you covered. The Unlicense uses as few words as possible to clearly describe what "just make it public domain!" means in a clear and universally enforceable way.
|
||||
|
||||
### How to apply the license
|
||||
|
||||
Once you've chosen a license, you need to clearly and unambiguously apply it. If you're publishing somewhere like GitHub or GitLab or BitBucket, you'll have what amounts to a folder structure for your project's files. In the root folder of your project, you should have a plaintext file called LICENSE.txt that contains the text of the license you selected.
|
||||
|
||||
Putting LICENSE.txt in the root folder of your project isn't quite the last step—you also need a comment block declaring the license at the header of each significant file in your project. This is one of those times where it comes in handy to be using a well-established license. A comment that says: `# this work (c)2018 myname, licensed GPLv3—see https://www.gnu.org/licenses/gpl-3.0.en.html` is much, much stronger and more useful than a comment block that merely makes a cryptic reference to a completely custom license.
|
||||
|
||||
If you're self-publishing your code on your own site, you'll want to follow basically the same process. Have a LICENSE.txt, put the full copy of your license in it, and link to your license in an abbreviated comment block at the head of each significant file.
|
||||
|
||||
### Open source code is different
|
||||
|
||||
A big difference between proprietary and open source code is that open source code is meant to be seen. As a 40-something sysadmin, I've written a lot of code. Most of it has been effectively proprietary—I started out writing code for myself to make my own jobs easier and scratch my own and/or my company's itches. The goal of such code is simple: All it has to do is work, in the exact way and under the exact circumstance its creator planned. As long as the thing you expected to happen when you invoked the program happens more frequently than not, it's a success.
|
||||
|
||||
A big difference between proprietary and open source code is that open source code is meant to be seen.
|
||||
|
||||
Open source code is very different. When you write open source code, you know that it not only has to work, it has to work in situations you never dreamed of and may not have planned for. Maybe you only had one very narrow use case for your code and invoked it in exactly the same way every time. The people you share it with, though... they'll expose use cases, mixtures of arguments, and just plain strange thought processes you never considered. Your code doesn't necessarily have to satisfy all of them—but it at least needs to handle their requests gracefully, and fail in predictable and logical ways when it can't service them. (For example: "Division by zero on line 583" is not an acceptable response to a failure to supply a command-line argument.)
|
||||
|
||||
Open source code is very different. When you write open source code, you know that it not only has to work, it has to work in situations you never dreamed of and may not have planned for. Maybe you only had one very narrow use case for your code and invoked it in exactly the same way every time. The people you share it with, though... they'll expose use cases, mixtures of arguments, and just plain strange thought processes you never considered. Your code doesn't necessarily have to satisfy all of them—but it at least needs to handle their requests gracefully, and fail in predictable and logical ways when it can't service them. (For example: "Division by zero on line 583" is not an acceptable response to a failure to supply a command-line argument.)
|
||||
|
||||
Your open source code also has to avoid unduly embarrassing you. That means that after you struggle and struggle to get a balky function or sub to finally produce the output you expected, you don't just sigh and move on to the next thing—you clean it up, because you don't want the rest of the world seeing your obvious house of cards. It means that you stop littering your code with variables like `$variable` and `$lol` and replace them with meaningful names like `$iterationcounter` or `$modelname`. And it means commenting things professionally (even if they're obvious to you in the heat of the moment) since you expect other people to be able to follow your code later.
|
||||
|
||||
This can be a little painful and frustrating at first—it's work you're not accustomed to doing. It makes you a better programmer, though, and it makes your code better as well. Just as important: Even if you're the only contributor your project ever has, it saves you work in the long run. Trust me, a year from now when you have to revisit your app, you're going to be very glad that `$modelname`, which gets parsed by several stunningly opaque regular expressions before getting socked into some other array somewhere, isn't named `$lol` anymore.
|
||||
|
||||
### You're not writing just for yourself
|
||||
|
||||
The true heart of open source isn't the code at all: it's the community. Projects with a strong community survive longer and are adopted much more heavily than those that don't. With that in mind, it's a good idea not only to embrace but actively plan for the community you hope to build around your project.
|
||||
|
||||
Batman might spend hundreds of hours in seclusion furiously building a project in secrecy, but you don't have to. Take to Twitter, Reddit, or mailing lists relevant to your project's scope, and announce that you're thinking of creating a new project. Talk about your design goals and how you plan to achieve them. Request input, listen to similar (but maybe not identical) use cases, and build that information into your process as you write code. You don't have to accept every suggestion or request—but if you know about them ahead of time, you can avoid pitfalls that require arduous major overhauls later.
|
||||
|
||||
This process doesn't end with the initial announcement. If you want your project to be adopted and used by other people, you need to develop it that way too. This isn't a barrier to entry; it's just a pattern to use. So don't just hunker down privately on your own machine with a text editor—start a real, publicly accessible project at one of the big foundries, and treat it as though the community was already there and watching.
|
||||
|
||||
### Ways to build a real public project
|
||||
|
||||
You can open accounts for open source projects at GitHub, GitLab, or BitBucket for free. Once you've opened your account and created a repository for your project, use it—create a README, assign a LICENSE, and push code incrementally as you develop it. This will build the habits you'll need to work with a real team later as you get accustomed to writing your code in measurable, documented commits with clear goals. The further you go, the more likely you'll start generating interest—usually in the form of end users first.
|
||||
|
||||
The users will start opening tickets, which will both delight and annoy you. You should take those tickets seriously and treat their owners courteously. Some of them will be based on tremendous misunderstandings of what your project is and what is or isn't within its scope—treat those courteously and professionally, also. In some cases, you'll guide those users into the fold of what you're doing. In others, however haltingly, they'll guide you into realizing the larger—or slightly differently centered—scope you probably should have planned for in the first place.
|
||||
|
||||
If you do a good job with the users, eventually fellow developers will show up and take an interest. This will also both delight and annoy you. At first, you'll probably just get trivial bugfixes. Eventually, you'll start to get pull requests that would either hardcode really, really niche special use-cases into your project (which would be a nightmare to maintain) or significantly alter the scope or even the focus of your project. You'll need to learn how to recognize which contributions are which and decide which ones you want to embrace and which you should politely reject.
|
||||
|
||||
### Why bother with all of this?
|
||||
|
||||
If all of this sounds like a lot of work, there's a good reason: it is. But it's rewarding work that you can cash in on in plenty of ways. Open source work sharpens your skills in ways you never realized were dull—from writing cleaner, more maintainable code to learning how to communicate well and work as a team. It's also the best possible resume builder for a working or aspiring professional developer; potential employers can hit your repository and see what you're capable of, and developers you've worked with on community projects may want to bring you in on paying gigs.
|
||||
|
||||
Ultimately, working on open source projects—yours or others'—means personal growth, because you're working on something larger than yourself.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/what-open-source-programming
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-salter
|
||||
[1]:https://opensource.com/tags/licensing
|
||||
[2]:https://choosealicense.com/
|
||||
[3]:https://choosealicense.com/licenses/apache-2.0/
|
||||
[4]:https://choosealicense.com/licenses/gpl-3.0/
|
||||
[5]:https://choosealicense.com/licenses/unlicense/
|
||||
@ -0,0 +1,82 @@
|
||||
Testing IPv6 Networking in KVM: Part 1
|
||||
======
|
||||
|
||||

|
||||
|
||||
Nothing beats hands-on playing with IPv6 addresses to get the hang of how they work, and setting up a little test lab in KVM is as easy as falling over — and more fun. In this two-part series, we will learn about IPv6 private addressing and configuring test networks in KVM.
|
||||
|
||||
### QEMU/KVM/Virtual Machine Manager
|
||||
|
||||
Let's start with understanding what KVM is. Here I use KVM as a convenient shorthand for the combination of QEMU, KVM, and the Virtual Machine Manager that is typically bundled together in Linux distributions. The simplified explanation is that QEMU emulates hardware, and KVM is a kernel module that creates the guest state on your CPU and manages access to memory and the CPU. Virtual Machine Manager is a lovely graphical overlay to all of this virtualization and hypervisor goodness.
|
||||
|
||||
But you're not stuck with pointy-clicky, no, for there are also fab command-line tools to use — such as virsh and virt-install.
|
||||
|
||||
If you're not experienced with KVM, you might want to start with [Creating Virtual Machines in KVM: Part 1][1] and [Creating Virtual Machines in KVM: Part 2 - Networking][2].
|
||||
|
||||
### IPv6 Unique Local Addresses
|
||||
|
||||
Configuring IPv6 networking in KVM is just like configuring IPv4 networks. The main difference is those weird long addresses. [Last time][3], we talked about the different types of IPv6 addresses. There is one more IPv6 unicast address class, and that is unique local addresses, fc00::/7 (see [RFC 4193][4]). This is analogous to the private address classes in IPv4, 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16.
|
||||
|
||||
This diagram illustrates the structure of the unique local address space. 48 bits define the prefix and global ID, 16 bits are for subnets, and the remaining 64 bits are the interface ID:
|
||||
```
|
||||
| 7 bits |1| 40 bits | 16 bits | 64 bits |
|
||||
+--------|-+------------|-----------|----------------------------+
|
||||
| Prefix |L| Global ID | Subnet ID | Interface ID |
|
||||
+--------|-+------------|-----------|----------------------------+
|
||||
|
||||
```
|
||||
|
||||
Here is another way to look at it, which is might be more helpful for understanding how to manipulate these addresses:
|
||||
```
|
||||
| Prefix | Global ID | Subnet ID | Interface ID |
|
||||
+--------|--------------|-------------|----------------------+
|
||||
| fd | 00:0000:0000 | 0000 | 0000:0000:0000:0000 |
|
||||
+--------|--------------|-------------|----------------------+
|
||||
|
||||
```
|
||||
|
||||
fc00::/7 is divided into two /8 blocks, fc00::/8 and fd00::/8. fc00::/8 is reserved for future use. So, unique local addresses always start with fd, and the rest is up to you. The L bit, which is the eighth bit, is always set to 1, which makes fd00::/8. Setting it to zero makes fc00::/8. You can see this with subnetcalc:
|
||||
```
|
||||
$ subnetcalc fd00::/8 -n
|
||||
Address = fd00::
|
||||
fd00 = 11111101 00000000
|
||||
|
||||
$ subnetcalc fc00::/8 -n
|
||||
Address = fc00::
|
||||
fc00 = 11111100 00000000
|
||||
|
||||
```
|
||||
|
||||
RFC 4193 requires that addresses be randomly generated. You can invent addresses any way you choose, as long as they start with fd, because the IPv6 cops aren't going to invade your home and give you a hard time. Still, it is a best practice to follow what RFCs say. The addresses must not be assigned sequentially or with well-known numbers. RFC 4193 includes an algorithm for building a pseudo-random address generator, or you can find any number of generators online.
|
||||
|
||||
Unique local addresses are not centrally managed like global unicast addresses (assigned to you by your Internet service provider), but even so the probability of address collisions is very low. This is a nice benefit when you need to merge some local networks or want to route between discrete private networks.
|
||||
|
||||
You can mix unique local addresses and global unicast addresses on the same subnets. Unique local addresses are routable and require no extra router tweaks. However, you should configure your border routers and firewalls to not allow them to leave your network except between private networks at different locations.
|
||||
|
||||
RFC 4193 advises against mingling AAAA and PTR records with your global unicast address records, because there is no guarantee that they will be unique, even though the odds of duplicates are low. Just like we do with IPv4 addresses, keep your private local name services and public name services separate. The tried-and-true combination of Dnsmasq for local name services and BIND for public name services works just as well for IPv6 as it does for IPv4.
|
||||
|
||||
### Pseudo-Random Address Generator
|
||||
|
||||
One example of an online address generator is [Local IPv6 Address Generator][5]. You can find many cool online tools like this. You can use it to create a new address for you, or use it with your existing global ID and play with creating subnets.
|
||||
|
||||
Come back next week to learn how to plug all of this IPv6 goodness into KVM and do live testing.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][6]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-1
|
||||
[2]:https://www.linux.com/learn/intro-to-linux/2017/5/creating-virtual-machines-kvm-part-2-networking
|
||||
[3]:https://www.linux.com/learn/intro-to-linux/2017/10/calculating-ipv6-subnets-linux
|
||||
[4]:https://tools.ietf.org/html/rfc4193
|
||||
[5]:https://www.ultratools.com/tools/rangeGenerator
|
||||
[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by MjSeven
|
||||
|
||||
How to Use GNOME Shell Extensions [Complete Guide]
|
||||
======
|
||||
**Brief: This is a detailed guide showing you how to install GNOME Shell Extensions manually or easily via a browser. **
|
||||
|
||||
@ -1,45 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to create better documentation with a kanban board
|
||||
======
|
||||

|
||||
If you're working on documentation, a website, or other user-facing content, it's helpful to know what users expect to find--both the information they want and how the information is organized and structured. After all, great content isn't very useful if people can't find what they're looking for.
|
||||
|
||||
Card sorting is a simple and effective way to gather input from users about what they expect from menu interfaces and pages. The simplest implementation is to label a stack of index cards with the sections you plan to include in your website or documentation and ask users to sort the cards in the way they would look for the information. Variations include letting people write their own menu headers or content elements.
|
||||
|
||||
The goal is to learn what your users expect and where they expect to find it, rather than having to figure out your menu and layout on your own. This is relatively straightforward when you have users in the same physical location, but it's more challenging when you are trying to get feedback from people in many locations.
|
||||
|
||||
I've found [kanban][1] boards are a great tool for these situations. They allow people to easily drag virtual cards around to categorize and rank them, and they are multi-purpose, unlike dedicated card-sorting software.
|
||||
|
||||
I often use Trello for card sorting, but there are several [open source alternatives][2] that you might want to try.
|
||||
|
||||
### How it works
|
||||
|
||||
My most successful kanban experiment was when I was working on documentation for [Gluster][3], a free and open source scalable network-attached storage filesystem. I needed to take a large pile of documentation that had grown over time and break it into categories to create a navigation system. BEcause I didn't have the technical knowledge necessary to sort it, I turned to the Gluster team and developer community for guidance.
|
||||
|
||||
First, I created a shared Kanban board. I gave the columns general names that would enable sorting and created cards for all the topics I planned to cover in the documentation. I flagged some cards with different colors to indicate either a topic was missing and needed to be created, or it was present and needed to be removed. Then I put all the cards into an "unsorted" column and asked people to drag them where they thought the cards should be organized and send me a screen capture of what they thought was the ideal state.
|
||||
|
||||
Dealing with all the screen captures was the trickiest part. I wish there was a merge or consensus feature that would've helped me aggregate everyone's data, rather than having to examine a bunch of screen captures. Fortunately, after the first person sorted the cards, people more or less agreed on the structure and made only minor modifications. When opinions differed on a topic's placement, I set up flash meetings where people could explain their thinking and we could hash out the disagreements.
|
||||
|
||||
### Using the data
|
||||
|
||||
From here, it was easy to convert the information I captured into menus and refine it. If users thought items should become submenus, they usually told me in comments or when we talked on the phone. Perceptions of menu organization vary depending upon people's job tasks, so you never have complete agreement, but testing with users means you won't have as many blind spots about what people use and where they will look for it.
|
||||
|
||||
Pairing card sorting with analytics gives you even more insight on what people are looking for. Once, when I ran analytics on some training documentation I was working on, I was surprised that to learn that the most searched page was about title capitalization. So I surfaced that page at the top-menu level, even though my "logical" setting put it far down in a sub-menu.
|
||||
|
||||
I've found kanban card-sorting a great way to help me create content that users want to see and put it where they expect to find it. Have you found another great way to organize your content for users' benefit? Or another interesting use for kanban boards? If so, please share your thoughts in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/kanban-boards-card-sorting
|
||||
|
||||
作者:[Heidi Waterhouse][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hwaterhouse
|
||||
[1]:https://en.wikipedia.org/wiki/Kanban
|
||||
[2]:https://opensource.com/alternatives/trello
|
||||
[3]:https://www.gluster.org/
|
||||
@ -1,3 +1,4 @@
|
||||
@qhh0205 翻译中
|
||||
Running a Python application on Kubernetes
|
||||
============================================================
|
||||
|
||||
@ -277,4 +278,4 @@ via: https://opensource.com/article/18/1/running-python-application-kubernetes
|
||||
[14]:https://opensource.com/users/nanjekyejoannah
|
||||
[15]:https://opensource.com/users/nanjekyejoannah
|
||||
[16]:https://opensource.com/tags/python
|
||||
[17]:https://opensource.com/tags/kubernetes
|
||||
[17]:https://opensource.com/tags/kubernetes
|
||||
|
||||
@ -1,214 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Parsing HTML with Python
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image by : Jason Baker for Opensource.com.
|
||||
|
||||
As a long-time member of the documentation team at Scribus, I keep up-to-date with the latest updates of the source so I can help make updates and additions to the documentation. When I recently did a "checkout" using Subversion on a computer I had just upgraded to Fedora 27, I was amazed at how long it took to download the documentation, which consists of HTML pages and associated images. I became concerned that the project's documentation seemed much larger than it should be and suspected that some of the content was "zombie" documentation--HTML files that aren't used anymore and images that have lost all references in the currently used HTML.
|
||||
|
||||
I decided to create a project for myself to figure this out. One way to do this is to search for existing image files that aren't used. If I could scan through all the HTML files for image references, then compare that list to the actual image files, chances are I would see a mismatch.
|
||||
|
||||
Here is a typical image tag:
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
I'm interested in the part between the first set of quotation marks, after `src=`. After some searching for a solution, I found a Python module called [BeautifulSoup][1]. The tasty part of the script I wrote looks like this:
|
||||
```
|
||||
soup = BeautifulSoup(all_text, 'html.parser')
|
||||
match = soup.findAll("img")
|
||||
if len(match) > 0:
|
||||
for m in match:
|
||||
imagelist.append(str(m))
|
||||
```
|
||||
|
||||
We can use this `findAll` method to pluck out the image tags. Here is a tiny piece of the output:
|
||||
```
|
||||
|
||||
|
||||
<img src="images/pdf-form-ht3.png"/><img src="images/pdf-form-ht4.png"/><img src="images/pdf-form-ht5.png"/><img src="images/pdf-form-ht6.png"/><img align="middle" alt="GSview - Advanced Options Panel" src="images/gsadv1.png" title="GSview - Advanced Options Panel"/><img align="middle" alt="Scribus External Tools Preferences" src="images/gsadv2.png" title="Scribus External Tools Preferences"/>
|
||||
```
|
||||
|
||||
So far, so good. I thought that the next step might be to just carve this down, but when I tried some string methods in the script, it returned errors about this being tags and not strings. I saved the output to a file and went through the process of editing in [KWrite][2]. One nice thing about KWrite is that you can do a "find & replace" using regular expressions (regex), so I could replace `<img` with `\n<img`, which made it easier to see how to carve this down from there. Another nice thing with KWrite is that, if you make an injudicious choice with regex, you can undo it.
|
||||
|
||||
But I thought, surely there is something better than this, so I turned to regex, or more specifically the `re` module for Python. The relevant part of this new script looks like this:
|
||||
```
|
||||
match = re.findall(r'src="(.*)/>', all_text)
|
||||
if len(match)>0:
|
||||
for m in match:
|
||||
imagelist.append(m)
|
||||
```
|
||||
|
||||
And a tiny piece of its output looks like this:
|
||||
```
|
||||
images/cmcanvas.png" title="Context Menu for the document canvas" alt="Context Menu for the document canvas" /></td></tr></table><br images/eps-imp1.png" title="EPS preview in a file dialog" alt="EPS preview in a file dialog" images/eps-imp5.png" title="Colors imported from an EPS file" alt="Colors imported from an EPS file" images/eps-imp4.png" title="EPS font substitution" alt="EPS font substitution" images/eps-imp2.png" title="EPS import progress" alt="EPS import progress" images/eps-imp3.png" title="Bitmap conversion failure" alt="Bitmap conversion failure"
|
||||
```
|
||||
|
||||
At first glance, it looks similar to the output above, and has the nice feature of trimming out parts of the image tag, but there are puzzling inclusions of table tags and other content. I think this relates to this regex expression `src="(.*)/>`, which is termed greedy, meaning it doesn't necessarily stop at the first instance of `/>` it encounters. I should add that I also tried `src="(.*)"` which was really no better. Not being a regexpert (just made this up), my searching around for various ideas to improve this didn't help.
|
||||
|
||||
After a series of other things, even trying out `HTML::Parser` with Perl, I finally tried to compare this to the situation of some scripts that I wrote for Scribus that analyze the contents of a text frame, character by character, then take some action. For my purposes, what I finally came up with improves on all these methods and requires no regex or HTML parser at all. Let's go back to that example `img` tag I showed.
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
I decided to home in on the `src=` piece. One way would be to wait for an occurrence of `s`, then see if the next character is `r`, the next `c`, and the next `=`. If so, bingo! Then what follows between two sets of double quotation marks is what I need. The problem with this is the structure it takes to hang onto these. One way of looking at a string of characters representing a line of HTML text would be:
|
||||
```
|
||||
for c in all_text:
|
||||
```
|
||||
|
||||
But the logic was just too messy to hang onto the previous `c`, and the one before that, the one before that, and the one before that.
|
||||
|
||||
In the end, I decided to focus on the `=` and to use an indexing method whereby I could easily reference any prior or future character in the string. Here is the searching part:
|
||||
```
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and (all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
```
|
||||
|
||||
I start the search with the fourth character (indexing starts at 0), so I don't get an indexing error down below, and realistically, there will not be an equal sign before the fourth character of a line. The first test is to see if we find `=` as we're marching through the string, and if not, we march on. If we do see one, then we ask if the three previous characters were `s`, `r`, and `c`, in that order. If that happens, we call the function `imagefound`:
|
||||
```
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
```
|
||||
|
||||
We're sending the function the current index, which represents the `=`. We know the next character will be `"`, so we jump two characters and begin adding characters to a holding string named `newimage`, until we reach the following `"`, at which point we're done. We add the string plus a `newline` character to our list `imagelist` and `return`, keeping in mind there may be more image tags in this remaining string of HTML, so we're right back in the middle of our searching loop.
|
||||
|
||||
Here's what our output looks like now:
|
||||
```
|
||||
images/text-frame-link.png
|
||||
images/text-frame-unlink.png
|
||||
images/gimpoptions1.png
|
||||
images/gimpoptions3.png
|
||||
images/gimpoptions2.png
|
||||
images/fontpref3.png
|
||||
images/font-subst.png
|
||||
images/fontpref2.png
|
||||
images/fontpref1.png
|
||||
images/dtp-studio.png
|
||||
```
|
||||
|
||||
Ahhh, much cleaner, and this only took a few seconds to run. I could have jumped seven more index spots to cut out the `images/` part, but I like having it there to make sure I haven't chopped off the first letter of the image filename, and this is so easy to edit out with KWrite--you don't even need regex. After doing that and saving the file, the next step was to run another script I wrote called `sortlist.py`:
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# sortlist.py
|
||||
|
||||
import os
|
||||
|
||||
imagelist = []
|
||||
for line in open('/tmp/imagelist_parse4.txt').xreadlines():
|
||||
imagelist.append(line)
|
||||
|
||||
imagelist.sort()
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4_sorted.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
```
|
||||
|
||||
This pulls in the file contents as a list, sorts it, then saves it as another file. After that I could just do the following:
|
||||
```
|
||||
ls /home/gregp/development/Scribus15x/doc/en/images/*.png > '/tmp/actual_images.txt'
|
||||
```
|
||||
|
||||
Then I need to run `sortlist.py` on that file too, since the method `ls` uses to sort is different from Python. I could have run a comparison script on these files, but I preferred to do this visually. In the end, I ended up with 42 images that had no HTML reference from the documentation.
|
||||
|
||||
Here is my parsing script in its entirety:
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# parseimg4.py
|
||||
|
||||
import os
|
||||
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
|
||||
htmlnames = []
|
||||
imagelist = []
|
||||
tempstring = ''
|
||||
filenames = os.listdir('/home/gregp/development/Scribus15x/doc/en/')
|
||||
for name in filenames:
|
||||
if name.endswith('.html'):
|
||||
htmlnames.append(name)
|
||||
#print htmlnames
|
||||
for htmlfile in htmlnames:
|
||||
all_text = open('/home/gregp/development/Scribus15x/doc/en/' + htmlfile).read()
|
||||
linelength = len(all_text)
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and
|
||||
(all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
imageno = len(imagelist)
|
||||
print str(imageno) + " images were found and saved"
|
||||
```
|
||||
|
||||
Its name, `parseimg4.py`, doesn't really reflect the number of scripts I wrote along the way, with both minor and major rewrites, plus discards and starting over. Notice that I've hardcoded these directory and filenames, but it would be easy enough to generalize, asking for user input for these pieces of information. Also as they were working scripts, I sent the output to `/tmp`, so they disappear once I reboot my system.
|
||||
|
||||
This wasn't the end of the story, since the next question was: What about zombie HTML files? Any of these files that are not used might reference images not picked up by the previous method. We have a `menu.xml` file that serves as the table of contents for the online manual, but I also needed to consider that some files listed in the TOC might reference files not in the TOC, and yes, I did find some.
|
||||
|
||||
I'll conclude by saying that this was a simpler task than this image search, and it was greatly helped by the processes I had already developed.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][7] Greg Pittman - Greg is a retired neurologist in Louisville, Kentucky, with a long-standing interest in computers and programming, beginning with Fortran IV in the 1960s. When Linux and open source software came along, it kindled a commitment to learning more, and eventually contributing. He is a member of the Scribus Team.[More about me][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/parsing-html-python
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://www.crummy.com/software/BeautifulSoup/
|
||||
[2]:https://www.kde.org/applications/utilities/kwrite/
|
||||
[7]:https://opensource.com/users/greg-p
|
||||
[8]:https://opensource.com/users/greg-p
|
||||
@ -1,3 +1,5 @@
|
||||
translating----geekpi
|
||||
|
||||
Install AWFFull web server log analysis application on ubuntu 17.10
|
||||
======
|
||||
|
||||
|
||||
@ -1,536 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Manage printers and printing
|
||||
======
|
||||
|
||||
|
||||
### Printing in Linux
|
||||
|
||||
Although much of our communication today is electronic and paperless, we still have considerable need to print material from our computers. Bank statements, utility bills, financial and other reports, and benefits statements are just some of the items that we still print. This tutorial introduces you to printing in Linux using CUPS.
|
||||
|
||||
CUPS, formerly an acronym for Common UNIX Printing System, is the printer and print job manager for Linux. Early computer printers typically printed lines of text in a particular character set and font size. Today's graphical printers are capable of printing both graphics and text in a variety of sizes and fonts. Nevertheless, some of the commands you use today have their history in the older line printer daemon (LPD) technology.
|
||||
|
||||
This tutorial helps you prepare for Objective 108.4 in Topic 108 of the Linux Server Professional (LPIC-1) exam 102. The objective has a weight of 2.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
To get the most from the tutorials in this series, you need a basic knowledge of Linux and a working Linux system on which you can practice the commands covered in this tutorial. You should be familiar with GNU and UNIX® commands. Sometimes different versions of a program format output differently, so your results might not always look exactly like the listings shown here.
|
||||
|
||||
In this tutorial, I use Fedora 27 for examples.
|
||||
|
||||
### Some printing history
|
||||
|
||||
This small history is not part of the LPI objectives but may help you with context for this objective.
|
||||
|
||||
Early computers mostly used line printers. These were impact printers that printed a line of text at a time using fixed-pitch characters and a single font. To speed up overall system performance, early mainframe computers interleaved work for slow peripherals such as card readers, card punches, and line printers with other work. Thus was born Simultaneous Peripheral Operation On Line or spooling, a term that is still commonly used when talking about computer printing.
|
||||
|
||||
In UNIX and Linux systems, printing initially used the Berkeley Software Distribution (BSD) printing subsystem, consisting of a line printer daemon (lpd) running as a server, and client commands such as `lpr` to submit jobs for printing. This protocol was later standardized by the IETF as RFC 1179, **Line Printer Daemon Protocol**.
|
||||
|
||||
System also had a printing daemon. It was functionally similar to the Berkeley LPD, but had a different command set. You will frequently see two commands with different options that accomplish the same task. For example, `lpr` from the Berkeley implementation and `lp` from the System V implementation each print files.
|
||||
|
||||
Advances in printer technology made it possible to mix different fonts on a page and to print images as well as words. Variable pitch fonts, and more advanced printing techniques such as kerning and ligatures, are now standard. Several improvements to the basic lpd/lpr approach to printing were devised, such as LPRng, the next generation LPR, and CUPS.
|
||||
|
||||
Many printers capable of graphical printing initially used the Adobe PostScript language. A PostScript printer has an engine that interprets the commands in a print job and produces finished pages from these commands. PostScript is often used as an intermediate form between an original file, such as a text or an image file, and a final form suitable for a particular printer that does not have PostScript capability. Conversion of a print job, such as an ASCII text file or a JPEG image to PostScript, and conversion from PostScript to the final raster form required for a non-PostScript printer is done using filters.
|
||||
|
||||
Today, Portable Document Format (PDF), which is based on PostScript, has largely replaced raw PostScript. PDF is designed to be independent of hardware and software and to encapsulate a full description of the pages to be printed. You can view PDF files as well as print them.
|
||||
|
||||
### Manage print queues
|
||||
|
||||
Users direct print jobs to a logical entity called a print queue. In single-user systems, a print queue and a printer are usually equivalent. However, CUPS allows a system without an attached printer to queue print jobs for eventual printing on a remote system, and, through the use of classes to allow a print job directed to a class to be printed on the first available printer of that class.
|
||||
|
||||
You can inspect and manipulate print queues. Some of the commands to do so are new for CUPS. Others are compatibility commands that have their roots in LPD commands, although the current options are usually a limited subset of the original LPD printing system options.
|
||||
|
||||
You can check the queues known to the system using the CUPS `lpstat` command. Some common options are shown in Table 1.
|
||||
|
||||
###### Table 1. Options for lpstat
|
||||
| Option | Purpose |
|
||||
| -a | Display accepting status of printers. |
|
||||
| -c | Display print classes. |
|
||||
| -p | Display print status: enabled or disabled. |
|
||||
| -s | Display default printer, printers, and classes. Equivalent to -d -c -v. Note that multiple options must be separated as values can be specified for many. |
|
||||
| -s | Display printers and their devices. |
|
||||
|
||||
|
||||
You may also use the LPD `lpc` command, found in /usr/sbin, with the `status` option. If you do not specify a printer name, all queues are listed. Listing 1 shows some examples of both commands.
|
||||
|
||||
###### Listing 1. Displaying available print queues
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -d
|
||||
system default destination: HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -v HL-2280DW
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
[ian@atticf27 ~]$ lpstat -s
|
||||
system default destination: HL-2280DW
|
||||
members of class anyprint:
|
||||
HL-2280DW
|
||||
XP-610
|
||||
device for anyprint: ///dev/null
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
device for XP-610: dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
[ian@atticf27 ~]$ lpstat -a XP-610
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
[ian@atticf27 ~]$ /usr/sbin/lpc status HL-2280DW
|
||||
HL-2280DW:
|
||||
printer is on device 'dnssd' speed -1
|
||||
queuing is disabled
|
||||
printing is enabled
|
||||
no entries
|
||||
daemon present
|
||||
|
||||
```
|
||||
|
||||
This example shows two printers, HL-2280DW and XP-610, and a class, `anyprint`, which allows print jobs to be directed to the first available of these two printers.
|
||||
|
||||
In this example, queuing of print jobs to HL-2280DW is currently disabled, although printing is enabled, as might be done in order to drain the queue before taking the printer offline for maintenance. Whether queuing is enabled or disabled is controlled by the `cupsaccept` and `cupsreject` commands. Formerly, these were `accept` and `reject`, but you will probably find these commands in /usr/sbin are now just links to the newer commands. Similarly, whether printing is enabled or disabled is controlled by the `cupsenable` and `cupsdisable` commands. In earlier versions of CUPS, these were called `enable` and `disable`, which allowed confusion with the builtin bash shell `enable`. Listing 2 shows how to enable queuing on printer HL-2280DW while disabling printing. Several of the CUPS commands support a `-r` option to give a reason for the action. This reason is displayed when you use `lpstat`, but not if you use `lpc`.
|
||||
|
||||
###### Listing 2. Enabling queuing and disabling printing
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -a -p HL-2280DW
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW not accepting requests since Thu 27 Apr 2017 05:52:27 PM EDT -
|
||||
Maintenance scheduled
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
printer HL-2280DW is idle. enabled since Thu 27 Apr 2017 05:52:27 PM EDT
|
||||
Maintenance scheduled
|
||||
[ian@atticf27 ~]$ accept HL-2280DW
|
||||
[ian@atticf27 ~]$ cupsdisable -r "waiting for toner delivery" HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -p -a
|
||||
printer anyprint is idle. enabled since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
printer HL-2280DW disabled since Mon 29 Jan 2018 04:03:50 PM EST -
|
||||
waiting for toner delivery
|
||||
printer XP-610 is idle. enabled since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Mon 29 Jan 2018 04:03:50 PM EST
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
|
||||
```
|
||||
|
||||
Note that an authorized user must perform these tasks. This may be root or another authorized user. See the SystemGroup entry in /etc/cups/cups-files.conf and the man page for cups-files.conf for more information on authorizing user groups.
|
||||
|
||||
### Manage user print jobs
|
||||
|
||||
Now that you have seen a little of how to check on print queues and classes, I will show you how to manage jobs on printer queues. The first thing you might want to do is find out whether any jobs are queued for a particular printer or for all printers. You do this with the `lpq` command. If no option is specified, `lpq` displays the queue for the default printer. Use the `-P` option with a printer name to specify a particular printer or the `-a` option to specify all printers, as shown in Listing 3.
|
||||
|
||||
###### Listing 3. Checking print queues with lpq
|
||||
```
|
||||
[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st unknown 4 unknown 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th unknown 8 unknown 1024 bytes
|
||||
5th unknown 9 unknown 1024 bytes
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lpq -P xp-610
|
||||
xp-610 is ready
|
||||
no entries
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 8 .bashrc 1024 bytes
|
||||
5th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
In this example, five jobs, 4, 6, 7, 8, and 9, are queued for the printer named HL-2280DW and none for XP-610. Using the `-P` option in this case simply shows that the printer is ready but has no queued hobs. Note that CUPS printer names are not case-sensitive. Note also that user ian submitted a job twice, a common user action when a job does not print the first time.
|
||||
|
||||
In general, you can view or manipulate your own print jobs, but root or another authorized user is usually required to manipulate the jobs of others. Most CUPS commands also encrypted communication between the CUPS client command and CUPS server using a `-E` option
|
||||
|
||||
Use the `lprm` command to remove one of the .bashrc jobs from the queue. With no options, the current job is removed. With the `-` option, all jobs are removed. Otherwise, specify a list of jobs to be removed as shown in Listing 4.
|
||||
|
||||
###### Listing 4. Deleting print jobs with lprm
|
||||
```
|
||||
[[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lprm
|
||||
lprm: Forbidden
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lprm 8
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
Note that user pat was not able to remove the first job on the queue, because it was for user ian. However, ian was able to remove his own job number 8.
|
||||
|
||||
Another command that will help you manipulate jobs on print queues is the `lp` command. Use it to alter attributes of jobs, such as priority or number of copies. Let us assume user ian wants his job 9 to print before those of user pat, and he really did want two copies of it. The job priority ranges from a lowest priority of 1 to a highest priority of 100 with a default of 50. User ian could use the `-i`, `-n`, and `-q` options to specify a job to alter and a new number of copies and priority as shown in Listing 5. Note the use of the `-l` option of the `lpq` command, which provides more verbose output.
|
||||
|
||||
###### Listing 5. Changing the number of copies and priority with lp
|
||||
```
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
[ian@atticf27 ~]$ lp -i 9 -q 60 -n 2
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 9 .bashrc 1024 bytes
|
||||
2nd ian 4 permutation.C 6144 bytes
|
||||
3rd pat 6 bitlib.h 6144 bytes
|
||||
4th pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
Finally, the `lpmove` command allows jobs to be moved from one queue to another. For example, we might want to do this because printer HL-2280DW is not currently printing. You can specify just a hob number, such as 9, or you can qualify it with the queue name and a hyphen, such as HL-2280DW-0. The `lpmove` command requires an authorized user. Listing 6 shows how to move these jobs to another queue, specifying first by printer and job ID, then all jobs for a given printer. By the time we check the queues again, one of the jobs is already printing.
|
||||
|
||||
###### Listing 6. Moving jobs to another print queue with lpmove
|
||||
```
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW-9 anyprint
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW xp-610
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active ian 9 .bashrc 1024 bytes
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
[ian@atticf27 ~]$ # A few minutes later
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active pat 6 bitlib.h 6144 bytes
|
||||
1st pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
If you happen to use a print server that is not CUPS, such as LPD or LPRng, many of the queue administration functions are handled as subcommands of the `lpc` command. For example, you might use `lpc topq` to move a job to the top of a queue. Other `lpc` subcommands include `disable`, `down`, `enable`, `hold`, `move`, `redirect`, `release`, and `start`. These subcommands are not implemented in the CUPS `lpc` compatibility command.
|
||||
|
||||
#### Printing files
|
||||
|
||||
How are print jobs erected? Many graphical programs provide a method of printing, usually under the **File** menu option. These programs provide graphical tools for choosing a printer, margin sizes, color or black-and-white printing, number of copies, selecting 2-up printing (which is 2 pages per sheet, often used for handouts), and so on. Here I show you the command-line tools for controlling such features, and then a graphical implementation for comparison.
|
||||
|
||||
The simplest way to print any file is to use the `lpr` command and provide the file name. This prints the file on the default printer. The `lp` command can print files as well as modify print jobs. Listing 7 shows a simple example using both commands. Note that `lpr` quietly spools the job, but `lp` displays the job number of the spooled job.
|
||||
|
||||
###### Listing 7. Printing with lpr and lp
|
||||
```
|
||||
[ian@atticf27 ~]$ echo "Print this text" > printexample.txt
|
||||
[ian@atticf27 ~]$ lpr printexample.txt
|
||||
[ian@atticf27 ~]$ lp printexample.txt
|
||||
request id is HL-2280DW-12 (1 file(s))
|
||||
|
||||
```
|
||||
|
||||
Table 2 shows some options that you may use with `lpr`. Note that `lp` has similar options to `lpr`, but names may differ; for example, `-#` on `lpr` is equivalent to `-n` on `lp`. Check the man pages for more information.
|
||||
|
||||
###### Table 2. Options for lpr
|
||||
|
||||
| Option | Purpose |
|
||||
| -C, -J, or -T | Set a job name. |
|
||||
| -P | Select a particular printer. |
|
||||
| -# | Specify number of copies. Note this is different from the -n option you saw with the lp command. |
|
||||
| -m | Send email upon job completion. |
|
||||
| -l | Indicate that the print file is already formatted for printing. Equivalent to -o raw. |
|
||||
| -o | Set a job option. |
|
||||
| -p | Format a text file with a shaded header. Equivalent to -o prettyprint. |
|
||||
| -q | Hold (or queue) the job for later printing. |
|
||||
| -r | Remove the file after it has been spooled for printing. |
|
||||
|
||||
Listing 8 shows some of these options in action. I request an email confirmation after printing, that the job be held and that the file be deleted after printing.
|
||||
|
||||
###### Listing 8. Printing with lpr
|
||||
```
|
||||
[ian@atticf27 ~]$ lpr -P HL-2280DW -J "Ian's text file" -#2 -m -p -q -r printexample.txt
|
||||
[[ian@atticf27 ~]$ lpq -l
|
||||
HL-2280DW is ready
|
||||
|
||||
|
||||
ian: 1st [job 13 localhost]
|
||||
2 copies of Ian's text file 1024 bytes
|
||||
[ian@atticf27 ~]$ ls printexample.txt
|
||||
ls: cannot access 'printexample.txt': No such file or directory
|
||||
|
||||
```
|
||||
|
||||
I now have a held job in the HL-2280DW print queue. What to do? The `lp` command has options to hold and release jobs, using various values with the `-H` option. Listing 9 shows how to release the held job. Check the `lp` man page for information on other options.
|
||||
|
||||
###### Listing 9. Resuming printing of a held print job
|
||||
```
|
||||
[ian@atticf27 ~]$ lp -i 13 -H resume
|
||||
|
||||
```
|
||||
|
||||
Not all of the vast array of available printers support the same set of options. Use the `lpoptions` command to see the general options that are set for a printer. Add the `-l` option to display printer-specific options. Listing 10 shows two examples. Many common options relate to portrait/landscape printing, page dimensions, and placement of the output on the pages. See the man pages for details.
|
||||
|
||||
###### Listing 10. Checking printer options
|
||||
```
|
||||
[ian@atticf27 ~]$ lpoptions -p HL-2280DW
|
||||
copies=1 device-uri=dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
finishings=3 job-cancel-after=10800 job-hold-until=no-hold job-priority=50
|
||||
job-sheets=none,none marker-change-time=1517325288 marker-colors=#000000,#000000
|
||||
marker-levels=-1,92 marker-names='Black\ Toner\ Cartridge,Drum\ Unit'
|
||||
marker-types=toner,opc number-up=1 printer-commands=none
|
||||
printer-info='Brother HL-2280DW' printer-is-accepting-jobs=true
|
||||
printer-is-shared=true printer-is-temporary=false printer-location
|
||||
printer-make-and-model='Brother HL-2250DN - CUPS+Gutenprint v5.2.13 Simplified'
|
||||
printer-state=3 printer-state-change-time=1517325288 printer-state-reasons=none
|
||||
printer-type=135188 printer-uri-supported=ipp://localhost/printers/HL-2280DW
|
||||
sides=one-sided
|
||||
|
||||
[ian@atticf27 ~]$ lpoptions -l -p xp-610
|
||||
PageSize/Media Size: *Letter Legal Executive Statement A4
|
||||
ColorModel/Color Model: *Gray Black
|
||||
InputSlot/Media Source: *Standard ManualAdj Manual MultiPurposeAdj MultiPurpose
|
||||
UpperAdj Upper LowerAdj Lower LargeCapacityAdj LargeCapacity
|
||||
StpQuality/Print Quality: None Draft *Standard High
|
||||
Resolution/Resolution: *301x300dpi 150dpi 300dpi 600dpi
|
||||
Duplex/2-Sided Printing: *None DuplexNoTumble DuplexTumble
|
||||
StpiShrinkOutput/Shrink Page If Necessary to Fit Borders: *Shrink Crop Expand
|
||||
StpColorCorrection/Color Correction: *None Accurate Bright Hue Uncorrected
|
||||
Desaturated Threshold Density Raw Predithered
|
||||
StpBrightness/Brightness: 0 100 200 300 400 500 600 700 800 900 *None 1100
|
||||
1200 1300 1400 1500 1600 1700 1800 1900 2000 Custom.REAL
|
||||
StpContrast/Contrast: 0 100 200 300 400 500 600 700 800 900 *None 1100 1200
|
||||
1300 1400 1500 1600 1700 1800 1900 2000 2100 2200 2300 2400 2500 2600 2700
|
||||
2800 2900 3000 3100 3200 3300 3400 3500 3600 3700 3800 3900 4000 Custom.REAL
|
||||
StpImageType/Image Type: None Text Graphics *TextGraphics Photo LineArt
|
||||
|
||||
```
|
||||
|
||||
Most GUI applications have a print dialog, often using the **File >Print** menu choice. Figure 1 shows an example in GIMP, an image manipulation program.
|
||||
|
||||
###### Figure 1. Printing from the GIMP
|
||||
|
||||
![Printing from the GIMP][3]
|
||||
|
||||
So far, all our commands have been implicitly directed to the local CUPS print server. You can also direct most commands to the server on another system, by specifying the `-h` option along with a port number if it is not the CUPS default of 631.
|
||||
|
||||
### CUPS and the CUPS server
|
||||
|
||||
At the heart of the CUPS printing system is the `cupsd` print server which runs as a daemon process. The CUPS configuration file is normally located in /etc/cups/cupsd.conf. The /etc/cups directory also contains other configuration files related to CUPS. CUPS is usually started during system initialization, but may be controlled by the CUPS script located in /etc/rc.d/init.d or /etc/init.d, according to your distribution. For newer systems using systemd initialization, the CUPS service script is likely in /usr/lib/systemd/system/cups.service. As with most such scripts, you can stop, start, or restart the daemon. See our tutorial [Learn Linux, 101: Runlevels, boot targets, shutdown, and reboot][4] for more information on using initialization scripts.
|
||||
|
||||
The configuration file, /etc/cups/cupsd.conf, contains parameters that control things such as access to the printing system, whether remote printing is allowed, the location of spool files, and so on. On some systems, a second part describes individual print queues and is usually generated automatically by configuration tools. Listing 11 shows some entries for a default cupsd.conf file. Note that comments start with a # character. Defaults are usually shown as comments and entries that are changed from the default have the leading # character removed.
|
||||
|
||||
###### Listing 11. Parts of a default /etc/cups/cupsd.conf file
|
||||
```
|
||||
# Only listen for connections from the local machine.
|
||||
Listen localhost:631
|
||||
Listen /var/run/cups/cups.sock
|
||||
|
||||
# Show shared printers on the local network.
|
||||
Browsing On
|
||||
BrowseLocalProtocols dnssd
|
||||
|
||||
# Default authentication type, when authentication is required...
|
||||
DefaultAuthType Basic
|
||||
|
||||
# Web interface setting...
|
||||
WebInterface Yes
|
||||
|
||||
# Set the default printer/job policies...
|
||||
<Policy default>
|
||||
# Job/subscription privacy...
|
||||
JobPrivateAccess default
|
||||
JobPrivateValues default
|
||||
SubscriptionPrivateAccess default
|
||||
SubscriptionPrivateValues default
|
||||
|
||||
# Job-related operations must be done by the owner or an administrator...
|
||||
<Limit Create-Job Print-Job Print-URI Validate-Job>
|
||||
Order deny,allow
|
||||
</Limit>
|
||||
|
||||
```
|
||||
|
||||
File, directory, and user configuration directives that used to be allowed in cupsd.conf are now stored in cups-files.conf instead. This is to prevent certain types of privilege escalation attacks. Listing 12 shows some entries from cups-files.conf. Note that spool files are stored by default in the /var/spool file system as you would expect from the Filesystem Hierarchy Standard (FHS). See the man pages for cupsd.conf and cups-files.conf for more details on these configuration files.
|
||||
|
||||
###### Listing 12. Parts of a default /etc/cups/cups-files.conf
|
||||
```
|
||||
# Location of the file listing all of the local printers...
|
||||
#Printcap /etc/printcap
|
||||
|
||||
# Format of the Printcap file...
|
||||
#PrintcapFormat bsd
|
||||
#PrintcapFormat plist
|
||||
#PrintcapFormat solaris
|
||||
|
||||
# Location of all spool files...
|
||||
#RequestRoot /var/spool/cups
|
||||
|
||||
# Location of helper programs...
|
||||
#ServerBin /usr/lib/cups
|
||||
|
||||
# SSL/TLS keychain for the scheduler...
|
||||
#ServerKeychain ssl
|
||||
|
||||
# Location of other configuration files...
|
||||
#ServerRoot /etc/cups
|
||||
|
||||
```
|
||||
|
||||
Listing 12 refers to the /etc/printcap file. This was the name of the configuration file for LPD print servers, and some applications still use it to determine available printers and their properties. It is usually generated automatically in a CUPS system, so you will probably not modify it yourself. However, you may need to check it if you are diagnosing user printing problems. Listing 13 shows an example.
|
||||
|
||||
###### Listing 13. Automatically generated /etc/printcap
|
||||
```
|
||||
# This file was automatically generated by cupsd(8) from the
|
||||
# /etc/cups/printers.conf file. All changes to this file
|
||||
# will be lost.
|
||||
HL-2280DW|Brother HL-2280DW:rm=atticf27:rp=HL-2280DW:
|
||||
anyprint|Any available printer:rm=atticf27:rp=anyprint:
|
||||
XP-610|EPSON XP-610 Series:rm=atticf27:rp=XP-610:
|
||||
|
||||
```
|
||||
|
||||
Each line here has a printer name and printer description as well as the name of the remote machine (rm) and remote printer (rp) on that machine. Older /etc/printcap file also described the printer capabilities.
|
||||
|
||||
#### File conversion filters
|
||||
|
||||
You can print many types of files using CUPS, including plain text, PDF, PostScript, and a variety of image formats without needing to tell the `lpr` or `lp` command anything more than the file name. This magic feat is accomplished through the use of filters. Indeed, a popular filter for many years was named magicfilter.
|
||||
|
||||
CUPS uses Multipurpose Internet Mail Extensions (MIME) types to determine the appropriate conversion filter when printing a file. Other printing packages might use the magic number mechanism as used by the `file` command. See the man pages for `file` or `magic` for more details.
|
||||
|
||||
Input files are converted to an intermediate raster or PostScript format using filters. Job information such as number of copies is added. The data is finally sent through a beckend to the destination printer. There are some filters (such as `a2ps` or `dvips`) that you can use to manually filter input. You might do this to obtain special formatting results, or to handle a file format that CUPS does not support natively.
|
||||
|
||||
#### Adding printers
|
||||
|
||||
CUPS supports a variety of printers, including:
|
||||
|
||||
* Locally attached parallel and USB printers
|
||||
* Internet Printing Protocol (IPP) printers
|
||||
* Remote LPD printers
|
||||
* Microsoft® Windows® printers using SAMBA
|
||||
* Novell printers using NCP
|
||||
* HP Jetdirect attached printers
|
||||
|
||||
|
||||
|
||||
Most systems today attempt to autodetect and autoconfigure local hardware when the system starts or when the device is attached. Similarly, many network printers can be autodetected. Use the CUPS web administration tool ((<http://localhost:631> or <http://127.0.0.1:631>) to search for or add printers. Many distributions include their own configuration tools, for example YaST on SUSE systems. Figure 2 shows the CUPS interface using localhost:631 and Figure 3 shows the GNOME printer settings dialog on Fedora 27.
|
||||
|
||||
###### Figure 2. Using the CUPS web interface
|
||||
|
||||
|
||||
![Using the CUPS web interface][5]
|
||||
|
||||
###### Figure 3. Using printer settings on Fedora 27
|
||||
|
||||
|
||||
![Using printer settings on Fedora 27][6]
|
||||
|
||||
You can also configure printers from a command line. Before you configure a printer, you need some basic information about the printer and about how it is connected. If a remote system needs a user ID or password, you will also need that information.
|
||||
|
||||
You need to know what driver to use for your printer. Not all printers are fully supported on Linux and some may not work at all, or only with limitations. Check at OpenPrinting.org (see Related topics) to see if there is a driver for your particular printer. The `lpinfo` command can also help you identify the available device types and drivers. Use the `-v` option to list supported devices and the `-m` option to list drivers, as shown in Listing 14.
|
||||
|
||||
###### Listing 14. Available printer drivers
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i xp-610
|
||||
lsb/usr/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
EPSON XP-610 Series, Epson Inkjet Printer Driver (ESC/P-R) for Linux
|
||||
[ian@atticf27 ~]$ locate "Epson-XP-610_Series-epson-escpr-en.ppd.gz"
|
||||
/usr/share/ppd/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
[ian@atticf27 ~]$ lpinfo -v
|
||||
network socket
|
||||
network ipps
|
||||
network lpd
|
||||
network beh
|
||||
network ipp
|
||||
network http
|
||||
network https
|
||||
direct hp
|
||||
serial serial:/dev/ttyS0?baud=115200
|
||||
direct parallel:/dev/lp0
|
||||
network smb
|
||||
direct hpfax
|
||||
network dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
network dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
network lpd://BRN001BA98A1891/BINARY_P1
|
||||
network lpd://192.168.1.38:515/PASSTHRU
|
||||
|
||||
```
|
||||
|
||||
The Epson-XP-610_Series-epson-escpr-en.ppd.gz driver is located in the /usr/share/ppd/Epson/epson-inkjet-printer-escpr/ directory on my system.
|
||||
|
||||
Is you don't find a driver, check the printer manufacturer's website in case a proprietary driver is available. For example, at the time of writing Brother has a driver for my HL-2280DW printer, but this driver is not listed at OpenPrinting.org.
|
||||
|
||||
Once you have the basic information, you can configure a printer using the `lpadmin` command as shown in Listing 15. For this purpose, I will create another instance of my HL-2280DW printer for duplex printing.
|
||||
|
||||
###### Listing 15. Configuring a printer
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i "hl.*2280"
|
||||
HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
lsb/usr/HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW-duplex -E -m HL2280DW.ppd \
|
||||
> -v dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/ \
|
||||
> -D "Brother 1" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Tue 30 Jan 2018 10:56:10 AM EST
|
||||
HL-2280DW-duplex accepting requests since Wed 31 Jan 2018 11:41:16 AM EST
|
||||
HXP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
Rather than creating a copy of the printer for duplex printing, you can just create a new class for duplex printing using `lpadmin` with the `-c` option .
|
||||
|
||||
If you need to remove a printer, use `lpadmin` with the `-x` option.
|
||||
|
||||
Listing 16 shows how to remove the printer and create a class instead.
|
||||
|
||||
###### Listing 16. Removing a printer and creating a class
|
||||
```
|
||||
[ian@atticf27 ~]$ lpadmin -x HL-2280DW-duplex
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW -c duplex -E -D "Duplex printing" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ cupsenable duplex
|
||||
[ian@atticf27 ~]$ cupsaccept duplex
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
duplex accepting requests since Wed 31 Jan 2018 12:12:05 PM EST
|
||||
HL-2280DW accepting requests since Wed 31 Jan 2018 11:51:16 AM EST
|
||||
XP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
You can also set various printer options using the `lpadmin` or `lpoptions` commands. See the man pages for more details.
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
If you are having trouble printing, try these tips:
|
||||
|
||||
* Ensure that the CUPS server is running. You can use the `lpstat` command, which will report an error if it is unable to connect to the cupsd daemon. Alternatively, you might use the `ps -ef` command and check for cupsd in the output.
|
||||
* If you try to queue a job for printing and get an error message indicating that the printer is not accepting jobs results, use `lpstat -a` or `lpc status` to check that the printer is accepting jobs.
|
||||
* If a queued job does not print, use `lpstat -p` or `lpc status` to check that the printer is accepting jobs. You may need to move the job to another printer as discussed earlier.
|
||||
* If the printer is remote, check that it still exists on the remote system and that it is operational.
|
||||
* Check the configuration file to ensure that a particular user or remote system is allowed to print on the printer.
|
||||
* Ensure that your firewall allows remote printing requests, either from another system to your system, or from your system to another, as appropriate.
|
||||
* Verify that you have the right driver.
|
||||
|
||||
|
||||
|
||||
As you can see, printing involves the correct functioning of several components of your system and possibly network. In a tutorial of this length, we can only give you starting points for diagnosis. Most CUPS systems also have a graphical interface to the command-line functions that we discuss here. Generally, this interface is accessible from the local host using a browser pointed to port 631 (<http://localhost:631> or <http://127.0.0.1:631>), as shown earlier in Figure 2.
|
||||
|
||||
You can debug CUPS by running it in the foreground rather than as a daemon process. You can also test alternate configuration files if necessary. Run `cupsd -h` for more information, or see the man pages.
|
||||
|
||||
CUPS also maintains an access log and an error log. You can change the level of logging using the LogLevel statement in cupsd.conf. By default, logs are stored in the /var/log/cups directory. They may be viewed from the **Administration** tab on the browser interface (<http://localhost:631>). Use the `cupsctl` command without any options to display logging options. Either edit cupsd.conf, or use `cupsctl` to adjust various logging parameters. See the `cupsctl` man page for more details.
|
||||
|
||||
The Ubuntu Wiki also has a good page on [Debugging Printing Problems][7].
|
||||
|
||||
This concludes your introduction to printing and CUPS.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-4/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
[3]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/gimp-print.jpg
|
||||
[4]:https://www.ibm.com/developerworks/library/l-lpic1-101-3/
|
||||
[5]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-cups-web.jpg
|
||||
[6]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-settings.jpg
|
||||
[7]:https://wiki.ubuntu.com/DebuggingPrintingProblems
|
||||
@ -0,0 +1,78 @@
|
||||
3 open source tools for scientific publishing
|
||||
======
|
||||
|
||||
|
||||
One industry that lags behind others in the adoption of digital or open source tools is the competitive and lucrative world of scientific publishing. Worth over £19B ($26B) annually, according to figures published by Stephen Buranyi in [The Guardian][1] last year, the system for selecting, publishing, and sharing even the most important scientific research today still bears many of the constraints of print media. New digital-era technologies present a huge opportunity to accelerate discovery, make science collaborative instead of competitive, and redirect investments from infrastructure development into research that benefits society.
|
||||
|
||||
The non-profit [eLife initiative][2] was established by the funders of research, in part to encourage the use of these technologies to this end. In addition to publishing an open-access journal for important advances in life science and biomedical research, eLife has made itself into a platform for experimentation and showcasing innovation in research communication—with most of this experimentation based around the open source ethos.
|
||||
|
||||
Working on open publishing infrastructure projects gives us the opportunity to accelerate the reach and adoption of the types of technology and user experience (UX) best practices that we consider important to the advancement of the academic publishing industry. Speaking very generally, the UX of open source products is often left undeveloped, which can in some cases dissuade people from using it. As part of our investment in OSS development, we place a strong emphasis on UX in order to encourage users to adopt these products.
|
||||
|
||||
All of our code is open source, and we actively encourage community involvement in our projects, which to us means faster iteration, more experimentation, greater transparency, and increased reach for our work.
|
||||
|
||||
The projects that we are involved in, such as the development of Libero (formerly known as [eLife Continuum][3]) and the [Reproducible Document Stack][4], along with our recent collaboration with [Hypothesis][5], show how OSS can be used to bring about positive changes in the assessment, publication, and communication of new discoveries.
|
||||
|
||||
### Libero
|
||||
|
||||
Libero is a suite of services and applications available to publishers that includes a post-production publishing system, a full front-end user interface pattern suite, Libero's Lens Reader, an open API, and search and recommendation engines.
|
||||
|
||||
Last year, we took a user-driven approach to redesigning the front end of Libero, resulting in less distracting site “furniture” and a greater focus on research articles. We tested and iterated all the key functional areas of the site with members of the eLife community to ensure the best possible reading experience for everyone. The site’s new API also provides simpler access to content for machine readability, including text mining, machine learning, and online application development.
|
||||
|
||||
The content on our website and the patterns that drive the new design are all open source to encourage future product development for both eLife and other publishers that wish to use it.
|
||||
|
||||
### The Reproducible Document Stack
|
||||
|
||||
In collaboration with [Substance][6] and [Stencila][7], eLife is also engaged in a project to create a Reproducible Document Stack (RDS)—an open stack of tools for authoring, compiling, and publishing computationally reproducible manuscripts online.
|
||||
|
||||
Today, an increasing number of researchers are able to document their computational experiments through languages such as [R Markdown][8] and [Python][9]. These can serve as important parts of the experimental record, and while they can be shared independently from or alongside the resulting research article, traditional publishing workflows tend to relegate these assets as a secondary class of content. To publish papers, researchers using these languages often have little option but to submit their computational results as “flattened” outputs in the form of figures, losing much of the value and reusability of the code and data references used in the computation. And while electronic notebook solutions such as [Jupyter][10] can enable researchers to publish their code in an easily reusable and executable form, that’s still in addition to, rather than as an integral part of, the published manuscript.
|
||||
|
||||
The [Reproducible Document Stack][11] project aims to address these challenges through development and publication of a working prototype of a reproducible manuscript that treats code and data as integral parts of the document, demonstrating a complete end-to-end technology stack from authoring through to publication. It will ultimately allow authors to submit their manuscripts in a format that includes embedded code blocks and computed outputs (statistical results, tables, or graphs), and have those assets remain both visible and executable throughout the publication process. Publishers will then be able to preserve these assets directly as integral parts of the published online article.
|
||||
|
||||
### Open annotation with Hypothesis
|
||||
|
||||
Most recently, we introduced open annotation in collaboration with [Hypothesis][12] to enable users of our website to make comments, highlight important sections of articles, and engage with the reading public online.
|
||||
|
||||
Through this collaboration, the open source Hypothesis software was customized with new moderation features, single sign-on authentication, and user-interface customization options, giving publishers more control over its implementation on their sites. These enhancements are already driving higher-quality discussions around published scholarly content.
|
||||
|
||||
The tool can be integrated seamlessly into publishers’ websites, with the scholarly publishing platform [PubFactory][13] and content solutions provider [Ingenta][14] already taking advantage of its improved feature set. [HighWire][15] and [Silverchair][16] are also offering their publishers the opportunity to implement the service.
|
||||
|
||||
### Other industries and open source
|
||||
|
||||
Over time, we hope to see more publishers adopt Hypothesis, Libero, and other projects to help them foster the discovery and reuse of important scientific research. But the opportunities for innovation eLife has been able to leverage because of these and other OSS technologies are also prevalent in other industries.
|
||||
|
||||
The world of data science would be nowhere without the high-quality, well-supported open source software and the communities built around it; [TensorFlow][17] is a leading example of this. Thanks to OSS and its communities, all areas of AI and machine learning have seen rapid acceleration and advancement compared to other areas of computing. Similar is the explosion in usage of Linux as a cloud web host, followed by containerization with Docker, and now the growth of Kubernetes, one of the most popular open source projects on GitHub.
|
||||
|
||||
All of these technologies enable organizations to do more with less and focus on innovation instead of reinventing the wheel. And in the end, that’s the real benefit of OSS: It lets us all learn from each other’s failures while building on each other's successes.
|
||||
|
||||
We are always on the lookout for opportunities to engage with the best emerging talent and ideas at the interface of research and technology. Find out more about some of these engagements on [eLife Labs][18], or contact [innovation@elifesciences.org][19] for more information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/scientific-publishing-software
|
||||
|
||||
作者:[Paul Shanno][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pshannon
|
||||
[1]:https://www.theguardian.com/science/2017/jun/27/profitable-business-scientific-publishing-bad-for-science
|
||||
[2]:https://elifesciences.org/about
|
||||
[3]:https://elifesciences.org/inside-elife/33e4127f/elife-introduces-continuum-a-new-open-source-tool-for-publishing
|
||||
[4]:https://elifesciences.org/for-the-press/e6038800/elife-supports-development-of-open-technology-stack-for-publishing-reproducible-manuscripts-online
|
||||
[5]:https://elifesciences.org/for-the-press/81d42f7d/elife-enhances-open-annotation-with-hypothesis-to-promote-scientific-discussion-online
|
||||
[6]:https://github.com/substance
|
||||
[7]:https://github.com/stencila/stencila
|
||||
[8]:https://rmarkdown.rstudio.com/
|
||||
[9]:https://www.python.org/
|
||||
[10]:http://jupyter.org/
|
||||
[11]:https://elifesciences.org/labs/7dbeb390/reproducible-document-stack-supporting-the-next-generation-research-article
|
||||
[12]:https://github.com/hypothesis
|
||||
[13]:http://www.pubfactory.com/
|
||||
[14]:http://www.ingenta.com/
|
||||
[15]:https://github.com/highwire
|
||||
[16]:https://www.silverchair.com/community/silverchair-universe/hypothesis/
|
||||
[17]:https://www.tensorflow.org/
|
||||
[18]:https://elifesciences.org/labs
|
||||
[19]:mailto:innovation@elifesciences.org
|
||||
@ -0,0 +1,92 @@
|
||||
translating---geekpi
|
||||
|
||||
An Open Source Desktop YouTube Player For Privacy-minded People
|
||||
======
|
||||
|
||||

|
||||
|
||||
You already know that we need a Google account to subscribe channels and download videos from YouTube. If you don’t want Google track what you’re doing on YouTube, well, there is an open source YouTube player named **“FreeTube”**. It allows you to watch, search and download Youtube videos and subscribe your favorite channels without an account, which prevents Google from having your information. It gives you complete ad-free experience. Another notable advantage is it has a built-in basic HTML5 player to watch videos. Since we’re not using the built-in YouTube player, Google can’t track the “views” and the video analytics either. FreeTube only sends your IP details, but this also can be overcome by using a VPN. It is completely free, open source and available for GNU/Linux, Mac OS X, and Windows.
|
||||
|
||||
### Features
|
||||
|
||||
* Watch videos without ads.
|
||||
* Prevent Google from tracking what you watch using cookies or JavaScript.
|
||||
* Subscribe to channels without an account.
|
||||
* Store subscriptions, history, and saved videos locally.
|
||||
* Import / Backup subscriptions.
|
||||
* Mini Player.
|
||||
* Light / Dark Theme.
|
||||
* Free, Open Source.
|
||||
* Cross-platform.
|
||||
|
||||
|
||||
|
||||
### Installing FreeTube
|
||||
|
||||
Go to the [**releases page**][1] and grab the version depending upon the OS you use. For the purpose of this guide, I will be using **.tar.gz** file.
|
||||
```
|
||||
$ wget https://github.com/FreeTubeApp/FreeTube/releases/download/v0.1.3-beta/FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
Extract the downloaded archive:
|
||||
```
|
||||
$ tar xf FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
Go to the Freetube folder:
|
||||
```
|
||||
$ cd FreeTube-linux-x64/
|
||||
|
||||
```
|
||||
|
||||
Launch Freeube using command:
|
||||
```
|
||||
$ ./FreeTub
|
||||
|
||||
```
|
||||
|
||||
This is how FreeTube default interface looks like.
|
||||
|
||||
![][3]
|
||||
|
||||
### Usage
|
||||
|
||||
FreeTube currently uses **YouTube API** to search for videos. And then, It uses **Youtube-dl HTTP API** to grab the raw video files and play them in a basic HTML5 video player. Since subscriptions, history, and saved videos are stored locally on your system, your details will not be sent to Google or anyone else.
|
||||
|
||||
Enter the video name in the search box and hit ENTER key. FreeTube will list out the results based on your search query.
|
||||
|
||||
![][4]
|
||||
|
||||
You can click on any video to play it.
|
||||
|
||||
![][5]
|
||||
|
||||
If you want to change the theme or default API, import/export subscriptions, go to the **Settings** section.
|
||||
|
||||
![][6]
|
||||
|
||||
Please note that FreeTube is still in **beta** stage, so there will be bugs. If there are any bugs, please report them in the GitHub page given at the end of this guide.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/freetube-an-open-source-desktop-youtube-player-for-privacy-minded-people/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/FreeTubeApp/FreeTube/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-3.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-5-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-2.png
|
||||
@ -0,0 +1,167 @@
|
||||
Protecting Code Integrity with PGP — Part 4: Moving Your Master Key to Offline Storage
|
||||
======
|
||||
|
||||

|
||||
In this tutorial series, we're providing practical guidelines for using PGP. You can catch up on previous articles here:
|
||||
|
||||
[Part 1: Basic Concepts and Tools][1]
|
||||
|
||||
[Part 2: Generating Your Master Key][2]
|
||||
|
||||
[Part 3: Generating PGP Subkeys][3]
|
||||
|
||||
Here in part 4, we continue the series with a look at how and why to move your master key from your home directory to offline storage. Let's get started.
|
||||
|
||||
### Checklist
|
||||
|
||||
* Prepare encrypted detachable storage (ESSENTIAL)
|
||||
|
||||
* Back up your GnuPG directory (ESSENTIAL)
|
||||
|
||||
* Remove the master key from your home directory (NICE)
|
||||
|
||||
* Remove the revocation certificate from your home directory (NICE)
|
||||
|
||||
|
||||
|
||||
|
||||
#### Considerations
|
||||
|
||||
Why would you want to remove your master [C] key from your home directory? This is generally done to prevent your master key from being stolen or accidentally leaked. Private keys are tasty targets for malicious actors -- we know this from several successful malware attacks that scanned users' home directories and uploaded any private key content found there.
|
||||
|
||||
It would be very damaging for any developer to have their PGP keys stolen -- in the Free Software world, this is often tantamount to identity theft. Removing private keys from your home directory helps protect you from such events.
|
||||
|
||||
##### Back up your GnuPG directory
|
||||
|
||||
**!!!Do not skip this step!!!**
|
||||
|
||||
It is important to have a readily available backup of your PGP keys should you need to recover them (this is different from the disaster-level preparedness we did with paperkey).
|
||||
|
||||
##### Prepare detachable encrypted storage
|
||||
|
||||
Start by getting a small USB "thumb" drive (preferably two!) that you will use for backup purposes. You will first need to encrypt them:
|
||||
|
||||
For the encryption passphrase, you can use the same one as on your master key.
|
||||
|
||||
##### Back up your GnuPG directory
|
||||
|
||||
Once the encryption process is over, re-insert the USB drive and make sure it gets properly mounted. Find out the full mount point of the device, for example by running the mount command (under Linux, external media usually gets mounted under /media/disk, under Mac it's /Volumes).
|
||||
|
||||
Once you know the full mount path, copy your entire GnuPG directory there:
|
||||
```
|
||||
$ cp -rp ~/.gnupg [/media/disk/name]/gnupg-backup
|
||||
|
||||
```
|
||||
|
||||
(Note: If you get any Operation not supported on socket errors, those are benign and you can ignore them.)
|
||||
|
||||
You should now test to make sure everything still works:
|
||||
```
|
||||
$ gpg --homedir=[/media/disk/name]/gnupg-backup --list-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
If you don't get any errors, then you should be good to go. Unmount the USB drive and distinctly label it, so you don't blow it away next time you need to use a random USB drive. Then, put in a safe place -- but not too far away, because you'll need to use it every now and again for things like editing identities, adding or revoking subkeys, or signing other people's keys.
|
||||
|
||||
##### Remove the master key
|
||||
|
||||
The files in our home directory are not as well protected as we like to think. They can be leaked or stolen via many different means:
|
||||
|
||||
* By accident when making quick homedir copies to set up a new workstation
|
||||
|
||||
* By systems administrator negligence or malice
|
||||
|
||||
* Via poorly secured backups
|
||||
|
||||
* Via malware in desktop apps (browsers, pdf viewers, etc)
|
||||
|
||||
* Via coercion when crossing international borders
|
||||
|
||||
|
||||
|
||||
|
||||
Protecting your key with a good passphrase greatly helps reduce the risk of any of the above, but passphrases can be discovered via keyloggers, shoulder-surfing, or any number of other means. For this reason, the recommended setup is to remove your master key from your home directory and store it on offline storage.
|
||||
|
||||
###### Removing your master key
|
||||
|
||||
Please see the previous section and make sure you have backed up your GnuPG directory in its entirety. What we are about to do will render your key useless if you do not have a usable backup!
|
||||
|
||||
First, identify the keygrip of your master key:
|
||||
```
|
||||
$ gpg --with-keygrip --list-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
The output will be something like this:
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
Keygrip = AAAA999988887777666655554444333322221111
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
sub rsa2048 2017-12-06 [E]
|
||||
Keygrip = BBBB999988887777666655554444333322221111
|
||||
sub rsa2048 2017-12-06 [S]
|
||||
Keygrip = CCCC999988887777666655554444333322221111
|
||||
|
||||
```
|
||||
|
||||
Find the keygrip entry that is beneath the pub line (right under the master key fingerprint). This will correspond directly to a file in your home .gnupg directory:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ ls
|
||||
AAAA999988887777666655554444333322221111.key
|
||||
BBBB999988887777666655554444333322221111.key
|
||||
CCCC999988887777666655554444333322221111.key
|
||||
|
||||
```
|
||||
|
||||
All you have to do is simply remove the .key file that corresponds to the master keygrip:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ rm AAAA999988887777666655554444333322221111.key
|
||||
|
||||
```
|
||||
|
||||
Now, if you issue the --list-secret-keys command, it will show that the master key is missing (the # indicates it is not available):
|
||||
```
|
||||
$ gpg --list-secret-keys
|
||||
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
ssb rsa2048 2017-12-06 [E]
|
||||
ssb rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
##### Remove the revocation certificate
|
||||
|
||||
Another file you should remove (but keep in backups) is the revocation certificate that was automatically created with your master key. A revocation certificate allows someone to permanently mark your key as revoked, meaning it can no longer be used or trusted for any purpose. You would normally use it to revoke a key that, for some reason, you can no longer control -- for example, if you had lost the key passphrase.
|
||||
|
||||
Just as with the master key, if a revocation certificate leaks into malicious hands, it can be used to destroy your developer digital identity, so it's better to remove it from your home directory.
|
||||
```
|
||||
cd ~/.gnupg/openpgp-revocs.d
|
||||
rm [fpr].rev
|
||||
|
||||
```
|
||||
|
||||
Next time, you'll learn how to secure your subkeys as well. Stay tuned.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,87 @@
|
||||
How to set up a print server on a Raspberry Pi
|
||||
======
|
||||
|
||||

|
||||
|
||||
I like to work on small projects at home, so this year I picked up a [Raspberry Pi 3 Model B][1], a great model for home hobbyists like me. With built-in wireless on the Raspberry Pi 3 Model B, I can connect the Pi to my home network without a cable. This makes it really easy to put the Raspberry Pi to use right where it is needed.
|
||||
|
||||
At our house, my wife and I both have laptops, but we have just one printer: a slightly used HP Color LaserJet. Because our printer doesn't have a wireless card and can't connect to wireless networks, we usually leave the LaserJet connected to my laptop, since I do most of the printing. While that arrangement works most of the time, sometimes my wife would like to print something without having to go through me.
|
||||
|
||||
### Basic setup
|
||||
|
||||
I realized we really needed a solution to connect the printer to the wireless network so both of us could print to it whenever we wanted. I could buy a wireless print server to connect the USB printer to the wireless network, but I decided instead to use my Raspberry Pi to build a print server to make the LaserJet available to anyone in our house.
|
||||
|
||||
Setting up the Raspberry Pi is fairly straightforward. I downloaded the [Raspbian][2] image and wrote that to my microSD card. Then, I booted the Raspberry Pi with an HDMI display, a USB keyboard, and a USB mouse. With that, I was ready to go!
|
||||
|
||||
The Raspbian system automatically boots into a graphical desktop environment where I performed most of the basic setup: setting the keyboard language, connecting to my wireless network, setting the password for the regular user account (`pi`), and setting the password for the system administrator account (`root`).
|
||||
|
||||
I don't plan to use the Raspberry Pi as a desktop system. I only want to use it remotely from my regular Linux computer. So, I also used Raspbian's graphical administration tool to set the Raspberry Pi to boot into console mode, but not to automatically login as the `pi` user.
|
||||
|
||||
Once I rebooted the Raspberry Pi, I needed to make a few other system tweaks so I could use the Pi as a "server" on my network. I set the Dynamic Host Configuration Protocol (DHCP) client to use a static IP address; by default, the DHCP client might pick any available network address, which would make it tricky to know how to connect to the Raspberry Pi over the network. My home network uses a private class A network, so my router's IP address is `10.0.0.1` and all my IP addresses are `10.0.0.x`. In my case, IP addresses in the lower range are safe, so I set up a static IP address on the wireless network at `10.0.0.11` by adding these lines to the `/etc/dhcpcd.conf` file:
|
||||
```
|
||||
interface wlan0
|
||||
|
||||
static ip_address=10.0.0.11/24
|
||||
|
||||
static routers=10.0.0.1
|
||||
|
||||
static domain_name_servers=8.8.8.8 8.8.4.4
|
||||
|
||||
```
|
||||
|
||||
Before I rebooted again, I made sure that the secure shell daemon (SSHD) was running (you can set what services start at boot-up in Preferences). This allowed me to use a secure shell (SSH) client from my regular Linux system to connect to the Raspberry Pi over the network.
|
||||
|
||||
### Print setup
|
||||
|
||||
Now that my Raspberry Pi was on the network, I did the rest of the setup remotely, using SSH, from my regular Linux desktop machine. Make sure your printer is connected to the Raspberry Pi before taking the following steps.
|
||||
|
||||
Setting up printing is fairly easy. The modern print server is called CUPS, which stands for the Common Unix Printing System. Any recent Unix system should be able to print through a CUPS print server. To set up CUPS on Raspberry Pi, you just need to enter a few commands to install the CUPS software, allow printing by other systems, and restart the print server with the new configuration:
|
||||
```
|
||||
$ sudo apt-get install cups
|
||||
|
||||
$ sudo cupsctl --remote-any
|
||||
|
||||
$ sudo /etc/init.d/cups restart
|
||||
|
||||
```
|
||||
|
||||
Setting up a printer in CUPS is also straightforward and can be done through a web browser. CUPS listens on port 631, so just use your favorite web browser and surf to:
|
||||
```
|
||||
https://10.0.0.11:631/
|
||||
|
||||
```
|
||||
|
||||
Your web browser may complain that it doesn't recognize the web server's https certificate; just accept it, and login as the system administrator. You should see the standard CUPS panel:
|
||||
|
||||
|
||||
From there, navigate to the Administration tab, and select Add Printer.
|
||||
|
||||
|
||||
|
||||
If your printer is already connected via USB, you should be able to easily select the printer's make and model. Don't forget to tick the Share This Printer box so others can use it, too. And now your printer should be set up in CUPS:
|
||||
|
||||
|
||||
|
||||
### Client setup
|
||||
|
||||
Setting up a network printer from the Linux desktop should be quite simple. My desktop is GNOME, and you can add the network printer right from the GNOME Settings application. Just navigate to Devices and Printers and unlock the panel. Click on the Add button to add the printer.
|
||||
|
||||
On my system, GNOME Settings automatically discovered the network printer and added it. If that doesn't happen for you, you may need to add the IP address for your Raspberry Pi to manually add the printer.
|
||||
|
||||
|
||||
|
||||
And that's it! We are now able to print to the Color LaserJet over the wireless network from wherever we are in the house. I no longer need to be physically connected to the printer, and everyone in the family can print on their own.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/print-server-raspberry-pi
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
|
||||
[2]:https://www.raspberrypi.org/downloads/
|
||||
@ -0,0 +1,124 @@
|
||||
Test Your BASH Skills By Playing Command Line Games
|
||||
======
|
||||
|
||||

|
||||
We tend to learn and remember Linux commands more effectively if we use them regularly in a live scenario. You may forget the Linux commands over a period of time, unless you use them often. Whether you’re newbie, intermediate user, there are always some exciting methods to test your BASH skills. In this tutorial, I am going to explain how to test your BASH skills by playing command line games. Well, technically these are not actual games like Super TuxKart, NFS, or Counterstrike etc. These are just gamified versions of Linux command training lessons. You will be given a task to complete by follow certain instructions in the game itself.
|
||||
|
||||
Now, we will see few games that will help you to learn and practice Linux commands in real-time. These are not a time-passing or mind-boggling games. These games will help you to get a hands-on experience of terminal commands. Read on.
|
||||
|
||||
### Test BASH Skills with “Wargames”
|
||||
|
||||
It is an online game, so you must have an active Internet connection. These games helps you to learn and practice Linux commands in the form of fun-filled games. Wargames are collection of shell games and each game has many levels. You can access the next levels only by solving previous levels. Not to be worried! Each game provides clear and concise instructions about how to access the next levels.
|
||||
|
||||
To play the Wargames, go the following link:
|
||||
|
||||
![][2]
|
||||
|
||||
As you can see, there many shell games listed on the left side. Each shell game has its own SSH port. So, you will have to connect to the game via SSH from your local system. You can find the information about how to connect to each game using SSH in the top left corner of the Wargames website.
|
||||
|
||||
For instance, let us play the **Bandit** game. To do so, click on the Bandit link on the Wargames homepage. On the top left corner, you will see SSH information of the Bandit game.
|
||||
|
||||
![][3]
|
||||
|
||||
As you see in the above screenshot, there are many levels. To go to each level, click on the respective link on the left column. Also, there are instructions for the beginners on the right side. Read them if you have any questions about how to play this game.
|
||||
|
||||
Now, let us go to the level 0 by clicking on it. In the next screen, you will SSH information of this level.
|
||||
|
||||
![][4]
|
||||
|
||||
As you can see on the above screenshot, you need to connect is **bandit.labs.overthewire.org** , on port 2220 via SSH. The username is **bandit0** and the password is **bandit0**.
|
||||
|
||||
Let us connect to Bandit game level 0.
|
||||
|
||||
Enter the password i.e **bandit0**
|
||||
|
||||
Sample output will be:
|
||||
|
||||
![][5]
|
||||
|
||||
Once logged in, type **ls** command to see what’s in their or go to the **Level 1 page** to find out how to beat Level 1 and so on. The list of suggested command have been provided in every level. So, you can pick and use any suitable command to solve the each level.
|
||||
|
||||
I must admit that Wargames are addictive and really fun to solve each level. However some levels are really challenging, so you may need to google to know how to solve it. Give it a try, you will really like it.
|
||||
|
||||
### Test BASH Skills with “Terminus” game
|
||||
|
||||
This is a yet another browser-based online CLI game which can be used to improve or test your Linux command skills. To play this game, open up your web browser and navigate to the following URL.
|
||||
|
||||
Once you entered in the game, you see the instructions to learn how to play it. Unlike Wargames, you don’t need to connect to their game server to play the games. Terminus has a built-in CLI where you can find the instructions about how to play it.
|
||||
|
||||
You can look at your surroundings with the command **“ls”** , move to a new location with the command **“cd LOCATION”** , go back with the command **“cd ..”** , interact with things in the world with the command **“less ITEM”** and so on. To know your current location, just type **“pwd”**.
|
||||
|
||||
![][6]
|
||||
|
||||
### Test BASH Skills with “clmystery” game
|
||||
|
||||
Unlike the above games, you can play this game locally. You don’t need to be connected with any remote system. This is completely offline game.
|
||||
|
||||
Trust me, this is an interesting game folks. You are going to play a detective role to solve a mystery case by following the given instructions.
|
||||
|
||||
First, clone the repository:
|
||||
```
|
||||
$ git clone https://github.com/veltman/clmystery.git
|
||||
|
||||
```
|
||||
|
||||
Or, download it as a zip file from [**here**][7]. Extract it and go to the location where you have the files. Finally, solve the mystery case by reading the “instructions” file.
|
||||
```
|
||||
[sk@sk]: clmystery-master>$ ls
|
||||
cheatsheet.md cheatsheet.pdf encoded hint1 hint2 hint3 hint4 hint5 hint6 hint7 hint8 instructions LICENSE.md mystery README.md solution
|
||||
|
||||
```
|
||||
|
||||
Here is the instructions to play this game:
|
||||
|
||||
There’s been a murder in Terminal City, and TCPD needs your help. You need to help them to figure out who did the crime.
|
||||
|
||||
To find out who did it, you need to go to the **‘mystery’** subdirectory and start working from there. You might need to look into all clues at the crime scene (the **‘crimescene’** file). The officers on the scene are pretty meticulous, so they’ve written down EVERYTHING in their officer reports. Fortunately the sergeant went through and marked the real clues with the word “CLUE” in all caps.
|
||||
|
||||
If you get stuck at anywhere, open one of the hint files such as hint1, hint2 etc. You can open the hint files using cat command like below.
|
||||
```
|
||||
$ cat hint1
|
||||
|
||||
$ cat hint2
|
||||
|
||||
```
|
||||
|
||||
To check your answer or find out the solution, open the file ‘solution’ in the clmystery directory.
|
||||
```
|
||||
$ cat solution
|
||||
|
||||
```
|
||||
|
||||
To get started on how to use the command line, refer **cheatsheet.md** or **cheatsheet.pdf** (from the command line, you can type ‘nano cheatsheet.md’). Don’t use a text editor to view any files except these instructions, the cheatsheet, and hints.
|
||||
|
||||
For more details, refer the [**clmystery GitHub**][8] page.
|
||||
|
||||
**Recommended read:**
|
||||
|
||||
And, that’s all I can remember now. I will keep adding more games if I came across anything in future. Bookmark this link and do visit from time to time. If you know any other similar games, please let me know in the comment section below. I will test and update this guide.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/test-your-bash-skills-by-playing-command-line-games/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/Wargames-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-game.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0-ssh-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/Terminus.png
|
||||
[7]:https://github.com/veltman/clmystery/archive/master.zip
|
||||
[8]:https://github.com/veltman/clmystery
|
||||
128
sources/tech/20180309 A Comparison of Three Linux -App Stores.md
Normal file
128
sources/tech/20180309 A Comparison of Three Linux -App Stores.md
Normal file
@ -0,0 +1,128 @@
|
||||
A Comparison of Three Linux 'App Stores'
|
||||
======
|
||||

|
||||
|
||||
I remember, long, long ago, when installing apps in Linux required downloading and compiling source packages. If you were really lucky, some developer might have packaged the source code into a form that was more easily installable. Without those developers, installing packages could become a dependency nightmare.
|
||||
|
||||
But then, package managers like rpm and dpkg began to rise in popularity, followed quickly by the likes of yum and apt. This was an absolute boon to anyone looking to make Linux their operating system of choice. Although dependencies could still be an issue, they weren’t nearly as bad as they once were. In fact, many of these package managers made short shrift of picking up all the dependencies required for installation.
|
||||
|
||||
And the Linux world rejoiced! Hooray!
|
||||
|
||||
But, with those package managers came a continued requirement of the command line. That, of course, is all fine and good for old hat Linux users. However, there’s a new breed of Linux users who don’t necessarily want to work with the command line. For that user-base, the Linux “app store” was created.
|
||||
|
||||
This all started with the [Synaptic Package Manager][1]. This graphical front end for apt was first released in 2001 and was a breath of fresh air. Synaptic enabled user to easily search for a piece of software and install it with a few quick clicks. Dependencies would be picked up and everything worked. Even when something didn’t work, Synaptic included the means to fix broken packages—all from a drop-down menu.
|
||||
|
||||
Since then, a number of similar tools have arrived on the market, all of which improve on the usability of Synaptic. Although Synaptic is still around (and works quite well), new users demand more modern tools that are even easier to use. And Linux delivered.
|
||||
|
||||
I want to highlight three of the more popular “app stores” to be found on various Linux distributions. In the end, you’ll see that installing applications on Linux, regardless of your distribution, doesn’t have to be a nightmare.
|
||||
|
||||
### GNOME Software
|
||||
|
||||
GNOME’s take on the graphical package manager, [Software][2], hit the scene just in time for the Ubuntu Software Center to finally fade into the sunset (which was fortuitous, considering Canonical’s shift from Unity to GNOME). Any distribution that uses GNOME will include GNOME Software. Unlike the now-defunct Ubuntu Software Center, GNOME Software allows users to both install and update apps from within the same interface (Figure 1).
|
||||
|
||||
![GNOME Software][4]
|
||||
|
||||
Figure 1: The GNOME Software main window.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
To find a piece of software to install, click the Search button (top left, looking glass icon), type the name of the software you want to install, and wait for the results. When you find a title you want to install, click the Install button (Figure 2) and, when prompted, type your user (sudo) password.
|
||||
|
||||
![GNOME Software][7]
|
||||
|
||||
Figure 2: Installing Slack from GNOME Software.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
GNOME Software also includes easy to navigate categories, Editor’s Picks, and GNOME add-ons. As a bonus feature, GNOME Software also supports both snaps and flatpak software. Out of the box, GNOME Software on Ubuntu (and derivatives) support snaps. If you’re adventurous, you can add support for flatpak by opening a terminal window and issuing the command sudo apt install gnome-software-plugin-flatpak.
|
||||
|
||||
GNOME Software makes it so easy to install software on Linux, any user (regardless of experience level) can install and update apps with zero learning curve.
|
||||
|
||||
### KDE Discover
|
||||
|
||||
[Discover][8] is KDE’s answer to GNOME Software. Although the layout (Figure 3) is slightly different, Discover should feel immediately familiar.
|
||||
|
||||
![KDE Discover][10]
|
||||
|
||||
Figure 3: The KDE Discover main window is equally user friendly.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
One of the primary differences between Discover and Software is that Discover differentiates between Plasma (the KDE desktop) and application add-ons. Say, for example, you want to find an “extension” for the Kate text editor; click on Application Addons and search “kate” to see all available addons for the application.
|
||||
|
||||
The Plasma Addons feature makes it easy for users to search through the available desktop widgets and easily install them.
|
||||
|
||||
The one downfall of KDE Discover is that applications are listed in a reverse alphabetical order. Click on one of the given categories, from the main page, and you’ll be given a listing of available apps to scroll through, from Z to A (Figure 4).
|
||||
|
||||
![KDE Discover][12]
|
||||
|
||||
Figure 4: The KDE Discover app listing.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
You will also notice no apparent app rating system. With GNOME Software, it’s not only easy to rate a software title, it’s easy to decide if you want to pass on an app or not (based on a given rating). With KDE Discover, there is no rating system to be found.
|
||||
|
||||
One bonus that Discover adds, is the ability to quickly configure repositories. From the main window, click on Settings, and you can enable/disable any of the included sources (Figure 5). Click the drop-down in the upper right corner, and you can even add new sources.
|
||||
|
||||
![KDE Discover][14]
|
||||
|
||||
Figure 5: Enabling, disable, and add sources, all from within Discover.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
### Pamac
|
||||
|
||||
If you’re hoping to soon count yourself among the growing list of Arch Linux users, you’ll be glad to know that the Linux distribution often considered for the more “elite”, also includes a graphical package manager. [Pamac][15] does an outstanding job of making installing applications on Arch easy. Although Pamac isn’t quite on the design level of either GNOME Software or KDE Discover, it still does a great job of simplifying the installing and updating of applications. From the Pamac main window (Figure 6), you can either click on the search button, or click a Category or Group to find the software you’re looking to install.
|
||||
|
||||
![Pamac][17]
|
||||
|
||||
Figure 6: The Pamac main window.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
If you can’t find the software you’re looking for, you might need to enable one of the many repositories. Click on the Repository button and then search through the categories (Figure 7) to locate the repository to be added.
|
||||
|
||||
![Pamac][19]
|
||||
|
||||
Figure 7: Adding new repositories in Pamac.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Updates are smoothly handled with Pamac. Click on the Updates button (in the left navigation) and then, in the resulting window (Figure 8), click Apply. All of your Arch updates will be installed.
|
||||
|
||||
![Pamac][21]
|
||||
|
||||
Figure 8: Updating Arch via Pamac.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
### More where that came from
|
||||
|
||||
I’ve only listed three graphical package managers. That is not to say these three are the only options to be found. Other distributions have their own takes on the package manager GUI. However, these three do an outstanding job of representing just how far installing software on Linux has come, since those early days of only being able to install via source.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][22]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/comparison-three-linux-app-stores
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://code.launchpad.net/synaptic
|
||||
[2]:https://wiki.gnome.org/Apps/Software
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gnome_software.jpg?itok=MvRQRX3- (GNOME Software)
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gnome_software_2.jpg?itok=5nzpUQa7 (GNOME Software)
|
||||
[8]:https://userbase.kde.org/Discover
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_discover.jpg?itok=LDTmkkMV (KDE Discover)
|
||||
[12]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_discover_2.jpg?itok=f5P7elG_ (KDE Discover)
|
||||
[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kde_discover_3.jpg?itok=JvS3s6FB (KDE Discover)
|
||||
[15]:https://github.com/manjaro/pamac
|
||||
[17]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/pamac.jpg?itok=gZ9X-Z05 (Pamac)
|
||||
[19]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/pamac_1.jpg?itok=Ygt5_U8A (Pamac)
|
||||
[21]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/pamac_2.jpg?itok=cIjKM51m (Pamac)
|
||||
[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,100 @@
|
||||
How to check your network connections on Linux
|
||||
======
|
||||
|
||||

|
||||
The **ip** command has a lot to tell you about the configuration and state of your network connections, but what do all those words and numbers mean? Let’s take a deep dive in and see what all the displayed values are trying to tell you.
|
||||
|
||||
When you use the **ip a** (or **ip addr** ) command to get information on all the network interfaces on your system, you're going to see something like this:
|
||||
```
|
||||
$ ip a
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: enp0s25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
link/ether 00:1e:4f:c8:43:fc brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.0.24/24 brd 192.168.0.255 scope global dynamic enp0s25
|
||||
valid_lft 57295sec preferred_lft 57295sec
|
||||
inet6 fe80::2c8e:1de0:a862:14fd/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
```
|
||||
|
||||
The two interfaces on this system — the loopback (lo) and network (enp0s25) — are displayed along with a lot of stats. The "lo" interface is clearly the loopback. We can see the loopback IPv4 address (127.0.0.1) and the loopback IPv6 ( **::1** ) in the listing. The normal network interface is more interesting.
|
||||
|
||||
### Why enp0s25 and not eth0
|
||||
|
||||
If you're wondering why it's called **enp0s25** on this system instead of the likely more familiar **eth0** , a little explanation is in order.
|
||||
|
||||
The new naming scheme is referred to as the “Predictable Network Interface” naming. It’s been used on systemd-based Linux systems for some time. The interface name depends on the physical location of the hardware. The " **en** " simply means "ethernet" just like "eth" does for eth0. The " **p** " is the bus number of the ethernet card and the " **s** " is the slot number. So "enp0s25" tells us a lot about the hardware we're working with.
|
||||
|
||||
The <BROADCAST,MULTICAST,UP,LOWER_UP> string of settings tell us that ...
|
||||
```
|
||||
BROADCAST the interface supports broadcasting
|
||||
MULTICAST the interface supports multicasting
|
||||
UP the network interface is enabled
|
||||
LOWER_UP the network cable is plugged in and device connected to network
|
||||
mtu 1500 the maximum transfer unit (packet size) is 1,500 bytes
|
||||
|
||||
```
|
||||
|
||||
The other values listed also tell us a lot about the interface, but we need to know what words like "brd" and "qlen" represent. So, here's a translation of the rest of the **ip a** shown above.
|
||||
```
|
||||
mtu 1500 maximum transfer unit (packet size)
|
||||
qdisc pfifo_fast used for packet queueing
|
||||
state UP network interface is up
|
||||
group default interface group
|
||||
qlen 1000 transmission queue length
|
||||
link/ether 00:1e:4f:c8:43:fc MAC(hardware) address of the interface
|
||||
brd ff:ff:ff:ff:ff:ff broadcast address
|
||||
inet 192.168.0.24/24 IPv4 address
|
||||
brd 192.168.0.255 broadcast address
|
||||
scope global valid everywhere
|
||||
dynamic enp0s25 address is dynamically assigned
|
||||
valid_lft 80866sec valid lifetime for IPv4 address
|
||||
preferred_lft 80866sec preferred lifetime for IPv4 address
|
||||
inet6 fe80::2c8e:1de0:a862:14fd/64 IPv6 address
|
||||
scope link valid only on this device
|
||||
valid_lft forever valid lifetime for IPv6 address
|
||||
preferred_lft forever preferred lifetime for IPv6 address
|
||||
|
||||
```
|
||||
|
||||
You might have noticed that some of the information that the ifconfig command provides is not included in the **ip a** output — such as the stats on transmitted packets. If you want to see a list of the number of packets transmitted and received along with collisions, you can use this ip command:
|
||||
```
|
||||
$ ip -s link show enp0s25
|
||||
2: enp0s25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
|
||||
link/ether 00:1e:4f:c8:43:fc brd ff:ff:ff:ff:ff:ff
|
||||
RX: bytes packets errors dropped overrun mcast
|
||||
224258568 418718 0 0 0 84376
|
||||
TX: bytes packets errors dropped carrier collsns
|
||||
6131373 78152 0 0 0 0
|
||||
|
||||
```
|
||||
|
||||
Another **ip** command provides information on a system's routing table.
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.0.1 dev enp0s25 proto static metric 100
|
||||
169.254.0.0/16 dev enp0s25 scope link metric 1000
|
||||
192.168.0.0/24 dev enp0s25 proto kernel scope link src 192.168.0.24 metric 100
|
||||
|
||||
```
|
||||
|
||||
The **ip** command is extremely versatile. You can get a helpful cheat sheet on the **ip** command and its options from [Red Hat][1].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3262045/linux/checking-your-network-connections-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://access.redhat.com/sites/default/files/attachments/rh_ip_command_cheatsheet_1214_jcs_print.pdf
|
||||
@ -1,84 +0,0 @@
|
||||
简单介绍 ldd Linux 命令
|
||||
=========================================
|
||||
|
||||
如果您的工作涉及到 Linux 中的可执行文件和共享库的知识,则需要了解几种命令行工具。其中之一是 ldd ,您可以使用它来访问共享对象依赖关系。在本教程中,我们将使用一些易于理解的示例来讨论此实用程序的基础知识。
|
||||
|
||||
请注意,这里提到的所有示例都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
|
||||
|
||||
### Linux ldd 命令
|
||||
|
||||
正如开头已经提到的,ldd 命令打印共享对象依赖关系。以下是该命令的语法:
|
||||
|
||||
`ldd [option]... file...`
|
||||
|
||||
下面是该工具的手册页对它作出的解释:
|
||||
|
||||
```
|
||||
ldd prints the shared objects (shared libraries) required by each program or shared object
|
||||
|
||||
specified on the command line.
|
||||
|
||||
```
|
||||
|
||||
以下使用问答的方式让您更好地了解ldd的工作原理。
|
||||
|
||||
### 问题一. 如何使用 ldd 命令?
|
||||
|
||||
ldd 的基本用法非常简单,只需运行 'ldd' 命令以及可执行文件或共享对象文件名称作为输入。
|
||||
|
||||
`ldd [object-name]`
|
||||
|
||||
例如:
|
||||
|
||||
`ldd test`
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-basic.png)
|
||||
|
||||
所以你可以看到所有的共享库依赖已经在输出中产生了。
|
||||
|
||||
### Q2. 如何使 ldd 在输出中生成详细的信息?
|
||||
|
||||
如果您想要 ldd 生成详细信息,包括符号版本控制数据,则可以使用 **-v** 命令行选项。例如,该命令
|
||||
|
||||
`ldd -v test`
|
||||
|
||||
当使用-v命令行选项时,在输出中产生以下内容:
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-v-option.png)
|
||||
|
||||
### Q3. 如何使 ldd 产生未使用的直接依赖关系?
|
||||
|
||||
对于这个信息,使用 **-u** 命令行选项。这是一个例子:
|
||||
|
||||
`ldd -u test`
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-u-test.png)
|
||||
|
||||
### Q4. 如何让 ldd 执行重定位?
|
||||
|
||||
您可以在这里使用几个命令行选项:**-d** 和 **-r**。 前者告诉 ldd 执行数据重定位,后者则使 ldd 为数据对象和函数执行重定位。在这两种情况下,该工具都会报告丢失的 ELF 对象(如果有的话)。
|
||||
|
||||
`ldd -d`
|
||||
|
||||
`ldd -r`
|
||||
|
||||
### Q5. 如何获得关于ldd的帮助?
|
||||
|
||||
--help 命令行选项使 ldd 为该工具生成有用的用法相关信息。
|
||||
|
||||
`ldd --help`
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-help-option.png)
|
||||
|
||||
### 总结
|
||||
|
||||
ldd 不像 cd,rm 和 mkdir 这样的工具类别。这是因为它是为特定目的而构建的。该实用程序提供了有限的命令行选项,我们在这里介绍了其中的大部分。要了解更多信息,请前往 ldd 的[手册页](https://linux.die.net/man/1/ldd)。
|
||||
|
||||
* * *
|
||||
|
||||
via: [https://www.howtoforge.com/linux-ldd-command/](https://www.howtoforge.com/linux-ldd-command/)
|
||||
|
||||
作者: [Himanshu Arora](https://www.howtoforge.com/) 选题者: [@lujun9972](https://github.com/lujun9972) 译者: [MonkeyDEcho](https://github.com/MonkeyDEcho) 校对: [校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,65 +0,0 @@
|
||||
Linux 如何成为我的工作
|
||||
======
|
||||
|
||||

|
||||
|
||||
从很早很早以前起,我就一直使用开源软件。那个时候,没有所谓的社交媒体。没有搜狐,没有谷歌浏览器(甚至连谷歌也没有),没有亚马逊,几乎没有一个互联网。事实上,那个时候最热门的是最新的Linux 2.0内核。当时的技术挑战是什么?嗯,是 Linux 发行版本中旧的 a.out 格式被 ELF 格式代替,导致升级一些 linux 的安装可能有些棘手。
|
||||
我如何将我自己对这个初出茅庐的年轻操作系统的兴趣转变为开源事业是一个有趣的故事。
|
||||
### Linux 为乐趣,而非利润
|
||||
|
||||
1994 年我大学毕业时,计算机实验室是 UNIX 系统的小型网络;如果你幸运的话,他们会连接到这个叫做互联网的新东西。这难以置信,我知道!“网络”(正如我们所知道的)大多是手写的 HTML, `cgi-bin` 目录是启用动态 web 交互的一个新的平台。我们许多人对这些新技术感到兴奋,我们还自学了 shell 脚本, Per,HTML,以及所有我们在爸妈的 Windows3.1 上从没有见过的简介的 UNIX 命令。通过 `vi`,`ls`,和阅读我的邮件。
|
||||
|
||||
毕业后,我加入 IBM,在一个没有 UNIX 系统的 PC 操作系统上工作,不久,我的大学切断了我通往工程实验室的远程通道。我如何继续用 Pine(Pine是以显示导向为主的处理程序)读我的电子邮件?我一直听说开源 Linux,但我没有时间去研究它。
|
||||
|
||||
1996 年,我在德克萨斯大学奥斯丁分校开始读硕士学位。我知道这将涉及编程和写论文,不知道还有什么,但我不想使用专有的编辑器,编译器或者文字处理器。我想要的是我的 UNIX 经验!
|
||||
|
||||
所以我拿了一个旧电脑,找到并下载了一个 Slackware 3.0 的 Linux 发行版本,分配磁盘后,放在了我的 IBM 办公室。可以说我在第一次安装 Linux 后就没有回过头了。在最初的那些日子里,我学习了很多关于文件和 `make` 系统,关于建设软件和补丁还有源码控制的知识。虽然我只是开始使用 Linux 来获得乐趣和个人知识,但他最终改变了我的职业生涯。
|
||||
|
||||
虽然我是一个愉快的 Linux 用户,但我认为开源开发任然是其他人的工作;我想到了一个神秘的 UNIX 极客的在线邮件列表。我很感激 Linux HOWTO 项目,他帮助我尝试添加软件包,升级 Linux 版本,或者安装新硬件和新 PC 的设备驱动程序。但是要处理源代码并进行修改或提交到上游… …那是给别人的,不是我。
|
||||
|
||||
### Linux 如何成为我的工作
|
||||
|
||||
1999 年,我终于有理由把我个人对 Linux 的兴趣与我在 IBM 的日常工作结合起来了。我带了一个研究项目接到 JVM 虚拟机的 Linux 上。为了确保我们在法律上是安全的,IBM 购买了一个压缩包,创建 Red Hat Linux 6.1 副本来完成这项工作。在 IBM 东京研究实验室工作时,写下了我们的 JVM 即时(JIT)编辑器,AIX JAV 源代码,Windows 和 OS/2 的 JVM 参考源代码,我们有一个 JVM 的 Linux 工作在几周之内,击败了 SUN’S 公司官方 java 公告的 Linux 端口好几个月。既然我在 Linux 平台上做了开发,我得在上面服务。
|
||||
|
||||
到 2000 年,IBM 使用 Linux 的频率迅速增加。由于 Dan Frye 的远见和坚持,IBM 提出了“亿美元的赌注”在 Linux,在 1999 年创建 Linux 技术中心(LTC)。在 LTC 里面有内核开发者,开源贡献者,IBM 硬件设备驱动程序的编写者,以及各种各样的 Linux 开源代码的工作重点。比起剩下毫无相关的与 LTC 公司连接,我想去的是这个令人兴奋的 IBM 新天地。
|
||||
|
||||
从 2003 年到 2013 年我深入参与了 IBM 的 Linux 战略和深入使用了 Linux 发行版,最终组成一个团队,成为 IBM 每个部门大约 60 个产品的信息交换所。我参与了收购,期望每个设备,管理系统和虚拟机或者基于物理设备的中间器件都能运行 Linux。我开始熟悉 Linux 发行版的建设,包括打包资源,选择上游资源,发展原有发行版的补丁集,做定制,并通过我们的合作伙伴提供支持的发行版。
|
||||
|
||||
由于我们的下游供应商,我很少提交补丁到上游,但我通过配合 Ulrich Drepper (包括一个小补丁到glibc)去改变时区数据库的工作贡献自己的力量, Arthur David Olson 接受他在 NIH 的 FTP 站点的维护。但作为我工作的一部分,我还没有作为开源项目的正式贡献者工作过。是该改变这种情况的时候了。
|
||||
|
||||
在 2013 年末,我在开源集团加入了 IBM 的云组织,并正在寻找一个上游社区参与进来。这将是我们在云上工作,还是我会加入 IBM 的为 OpenStack 贡献的大组?都不是,是因为在 2014 年 Docker(开源的应用容器引擎)席卷了全球,IBM 邀请我们几个参与这个热门的新技术。我在接下来的几个月里,经历了许多的第一次:使用 GitHub,比起只是 git clone 学习了更多关于 Git,有 Pull requests 的复查,在 Go 上写代码,等等。在接下来的一年中,我在 Docker 引擎项目上成为一个维修者,以创造形象规范的下一版 Docker(支持多个架构),出席和讲话在一个关于封装技术的会议上。
|
||||
|
||||
### 现在我在哪里
|
||||
|
||||
一晃几年过去,我已经成为了一个开源项目的维护者,包括云端原生计算基础的(集中网络控制设备)containerd(一个控制 runC 的守护进程)项目。我还创建项目(如清单工具和比较容器运行时性能)。我已经通过 OCI(为创造开放的行业标准容器格式和runtime明确目的开放的治理结构)参与开源治理。我在世界会议,Meetuo 网站群,IBM 内部有过很高兴的关于开源的演讲。
|
||||
|
||||
开源现在是我在 IBM 职业生涯的一部分。我与工程师,开发人员和行业领导的联系可能比我在 IBM 内认识的人的联系还要多。虽然开源与专有开发团队和供应商合作伙伴有许多相同的挑战,但据我的经验,开源与全球各地的人们的关系和联系远远超过困难。随着不同的意见、观点和经验的不断优化,可以对软件和涉及的在其中的人产生一种不断学习和改进的文化。
|
||||
|
||||
这个旅程—从我第一次使用Linux到今天成为一个指导者,贡献者,和现在云本地开源世界的维护者—我获得了极大的收获。我期待着与全球各地的人们长久的进行开源协作和互动。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[译者ID](https://github.com/译者 ranchong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
@ -0,0 +1,44 @@
|
||||
如何使用看板创建更好的文档
|
||||
======
|
||||

|
||||
如果你正在处理文档、网站或其他面向用户的内容,那么了解用户希望找到的内容(包括他们想要的信息以及信息的组织和结构)很有帮助。毕竟,如果人们无法找到他们想要的东西,那么出色的内容就没有用。
|
||||
|
||||
|
||||
卡片分类是一种简单而有效的方式,可以从用户那里收集有关菜单界面和页面的内容。最简单的实现方式是在你计划在网站或文章分类标注一些索引卡,并要求用户按照查找信息的方式对卡进行分类。变体包括让人们编写自己的菜单标题或内容元素。
|
||||
|
||||
我们的目标是了解用户的期望以及他们希望在哪里找到它,而不是自己弄清楚菜单和布局。当与用户处于相同的物理位置时,这是相对简单的,但当莫尝试从多个位置的人员获得反馈时,这会更具挑战性。
|
||||
|
||||
我发现[看板][1]对于这些情况是一个很好的工具。它允许人们轻松拖动虚拟卡进行分类和排名,而且与专门卡片分类软件不同,它们是多用途的。
|
||||
|
||||
我经常使用 Trello 进行卡片分类,但有几种你可能想尝试的[开源替代品][2]。
|
||||
|
||||
### 怎么运行的
|
||||
|
||||
我最成功的 kanban 实验是在写 [Gluster][3] 文档的时候- 一个免费开源的可扩展网络存储文件系统。我需要携带大量随时间增长的文档,并将其分成若干类别以创建引导系统。由于我没有必要的技术知识来分类,我向 Gluster 团队和开发人员社区寻求指导。
|
||||
|
||||
首先,我创建了一个共享看板。我列出了一些通用名称,这些名称可以为我计划在文档中涵盖的所有主题排序和创建卡片。我标记了一些不同颜色的卡片,以表明某个主题缺失并需要创建,或者它存在并需要删除。然后,我把所有卡片放入“未排序”一列,并要求人们将它们拖到他们认为应该组织卡片的地方,然后给我一个他们认为是理想状态的截图。
|
||||
|
||||
处理所有截图是最棘手的部分。我希望有一个合并或共识功能可以帮助我汇总每个人的数据,而不必检查一堆截图。幸运的是,在第一个人对卡片进行分类之后,人们或多或少地对该结构达成一致,而只做了很小的修改。当对某个主题的位置有不同意见时,我发起一个快速会议,让人们可以解释他们的想法,并且可以排除分歧。
|
||||
|
||||
### 使用数据
|
||||
|
||||
在这里,很容易将捕捉到的信息转换为菜单并对其进行优化。如果用户认为项目应该成为子菜单,他们通常会在评论中或在电话聊天时告诉我。对菜单组织的看法因人们的工作任务而异,所以从来没有完全达成一致意见,但用户进行测试意味着你不会对人们使用什么以及在哪里查找有很多盲点。
|
||||
|
||||
将卡片分类与分析功能配对,可以让你更深入地了解人们在寻找什么。有一次,当我对一些我正在写培训文档进行分析时,我惊讶地发现搜索量最大的页面是关于资本的。所以我在顶层菜单层面上显示了该页面,即使我的“逻辑”设置将它放在了子菜单中。
|
||||
|
||||
我发现看板卡片分类是一种很好的方式,可以帮助我创建用户想要查看的内容,并将其放在希望被找到的位置。你是否发现了另一种对用户友好的组织内容的方法?或者看板的另一种有趣用途是什么?如果有的话,请在评论中分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/kanban-boards-card-sorting
|
||||
|
||||
作者:[Heidi Waterhouse][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hwaterhouse
|
||||
[1]:https://en.wikipedia.org/wiki/Kanban
|
||||
[2]:https://opensource.com/alternatives/trello
|
||||
[3]:https://www.gluster.org/
|
||||
@ -1,109 +0,0 @@
|
||||
在 Linux 中自动配置 IPv6 地址
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 [ KVM 中测试 IPv6 网络:第 1 部分][1] 一文中,我们学习了关于唯一本地地址(ULAs)的相关内容。在本文中,我们将学习如何为 ULAs 自动配置 IP 地址。
|
||||
|
||||
### 何时使用唯一本地地址
|
||||
|
||||
唯一本地地址使用 fd00::/8 地址块,它类似于我们常用的 IPv4 的私有地址:10.0.0.0/8、172.16.0.0/12、以及 192.168.0.0/16。但它们并不能直接替换。IPv4 的私有地址分类和网络地址转换(NAT)功能是为了缓解 IPv4 地址短缺的问题,这是个明智的解决方案,它延缓了本该被替换的 IPv4 的生命周期。IPv6 也支持 NAT,但是我想不出使用它的理由。IPv6 的地址数量远远大于 IPv4;它是不一样的,因此需要做不一样的事情。
|
||||
|
||||
那么,ULAs 存在的意义是什么呢?尤其是在我们已经有了本地链路地址(fe80::/10)时,到底需不需要我们去配置它们呢?它们之间(译者注:指的是唯一本地地址和本地链路地址)有两个重要的区别。一是,本地链路地址是不可路由的,因此,你不能跨子网使用它。二是,ULAs 是你自己管理的;你可以自己选择它用于子网的地址范围,并且它们是可路由的。
|
||||
|
||||
使用 ULAs 的另一个好处是,如果你只是在局域网中“混日子”的话,你不需要为它们分配全局单播 IPv6 地址。当然了,如果你的 ISP 已经为你分配了 IPv6 的全局单播地址,就不需要使用 ULAs 了。你也可以在同一个网络中混合使用全局单播地址和 ULAs,但是,我想不出这样使用的一个好理由,并且要一定确保你不使用网络地址转换以使 ULAs 可公共访问。在我看来,这是很愚蠢的行为。
|
||||
|
||||
ULAs 是仅为私有网络使用的,并且它会阻塞所有流出你的网络的数据包,不允许进入因特网。这很简单,在你的边界设备上只要阻止整个 fd00::/8 范围的 IPv6 地址即可实现。
|
||||
|
||||
### 地址自动配置
|
||||
|
||||
ULAs 不像本地链路地址那样自动配置的,但是使用 radvd 设置自动配置是非常容易的,radva 是路由器公告守护程序。在你开始之前,运行 `ifconfig` 或者 `ip addr show` 去查看你现有的 IP 地址。
|
||||
|
||||
在生产系统上使用时,你应该将 radvd 安装在一台单独的路由器上,如果只是测试使用,你可以将它安装在你的网络中的任意 Linux PC 上。在我的小型 KVM 测试实验室中,我使用 `apt-get install radvd` 命令把它安装在 Ubuntu 上。安装完成之后,我先不启动它,因为它还没有配置文件:
|
||||
```
|
||||
$ sudo systemctl status radvd
|
||||
● radvd.service - LSB: Router Advertising Daemon
|
||||
Loaded: loaded (/etc/init.d/radvd; bad; vendor preset: enabled)
|
||||
Active: active (exited) since Mon 2017-12-11 20:08:25 PST; 4min 59s ago
|
||||
Docs: man:systemd-sysv-generator(8)
|
||||
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Starting LSB: Router Advertising Daemon...
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: Starting radvd:
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * /etc/radvd.conf does not exist or is empty.
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * See /usr/share/doc/radvd/README.Debian
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * radvd will *not* be started.
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Started LSB: Router Advertising Daemon.
|
||||
|
||||
```
|
||||
|
||||
这些所有的消息有点让人困惑,实际上 radvd 并没有运行,你可以使用经典命令 `ps|grep radvd` 来验证这一点。因此,我们现在需要去创建 `/etc/radvd.conf` 文件。拷贝这个示例,将第一行的网络接口名替换成你自己的接口名字:
|
||||
```
|
||||
interface ens7 {
|
||||
AdvSendAdvert on;
|
||||
MinRtrAdvInterval 3;
|
||||
MaxRtrAdvInterval 10;
|
||||
prefix fd7d:844d:3e17:f3ae::/64
|
||||
{
|
||||
AdvOnLink on;
|
||||
AdvAutonomous on;
|
||||
};
|
||||
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
前缀定义了你的网络地址,它是地址的前 64 位。前两个字符必须是 `fd`,前缀接下来的剩余部分你自己定义它,最后的 64 位留空,因为 radvd 将去分配最后的 64 位。前缀后面的 16 位用来定义子网,剩余的地址定义为主机地址。你的子网必须总是 /64。RFC 4193 要求地址必须随机生成;查看 [在 KVM 中测试 IPv6 Networking:第 1 部分][1] 学习创建和管理 ULAs 的更多知识。
|
||||
|
||||
### IPv6 转发
|
||||
|
||||
IPv6 转发必须要启用。下面的命令去启用它,重启后生效:
|
||||
```
|
||||
$ sudo sysctl -w net.ipv6.conf.all.forwarding=1
|
||||
|
||||
```
|
||||
|
||||
取消注释或者添加如下的行到 `/etc/sysctl.conf` 文件中,以使它永久生效:
|
||||
```
|
||||
net.ipv6.conf.all.forwarding = 1
|
||||
```
|
||||
|
||||
启动 radvd 守护程序:
|
||||
```
|
||||
$ sudo systemctl stop radvd
|
||||
$ sudo systemctl start radvd
|
||||
|
||||
```
|
||||
|
||||
这个示例在我的 Ubuntu 测试系统中遇到了一个怪事;radvd 总是停止,我查看它的状态却没有任何问题,做任何改变之后都需要重新启动 radvd。
|
||||
|
||||
启动成功后没有任何输出,并且失败也是如此,因此,需要运行 `sudo systemctl radvd status` 去查看它的运行状态。如果有错误,systemctl 会告诉你。一般常见的错误都是 `/etc/radvd.conf` 中的语法错误。
|
||||
|
||||
在 Twitter 上抱怨了上述问题之后,我学到了一件很酷的技巧:当你运行 ` journalctl -xe --no-pager` 去调试 systemctl 错误时,你的输出将被封装打包,然后,你就可以看到错误信息。
|
||||
|
||||
现在检查你的主机,查看它们自动分配的新地址:
|
||||
```
|
||||
$ ifconfig
|
||||
ens7 Link encap:Ethernet HWaddr 52:54:00:57:71:50
|
||||
[...]
|
||||
inet6 addr: fd7d:844d:3e17:f3ae:9808:98d5:bea9:14d9/64 Scope:Global
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
本文到此为止,下周继续学习如何为 ULAs 管理 DNS,这样你就可以使用一个合适的主机名来代替这些长长的 IPv6 地址。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的 ["Linux 入门" ][2] 免费课程学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/ipv6-auto-configuration-linux
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,260 +0,0 @@
|
||||
Linux 启动过程分析
|
||||
======
|
||||
|
||||

|
||||
|
||||
图片由企鹅和靴子“赞助”,由 Opensource.com 修改。CC BY-SA 4.0。
|
||||
|
||||
关于开源软件最古老的笑话是:“代码是自文档化的(self-documenting)”。经验表明,阅读源代码就像听天气预报一样:明智的人依然出门会看看室外的天气。本文讲述了如何运用调试工具来观察和分析 Linux 系统的启动。分析一个正常的系统启动过程,有助于用户和开发人员应对不可避免的故障。
|
||||
|
||||
从某些方面看,启动过程非常简单。内核在单核上启动单线程和同步,似乎可以理解。但内核本身是如何启动的呢?[initrd(initial ramdisk)][1]和引导程序(bootloaders)具有哪些功能?还有,为什么以太网端口上的 LED 灯是常亮的呢?
|
||||
|
||||
请继续阅读寻找答案。GitHub 也提供了 [介绍演示和练习的代码][2]。
|
||||
|
||||
### 启动的开始:OFF 状态
|
||||
|
||||
#### 局域网唤醒(Wake-on-LAN)
|
||||
|
||||
OFF 状态表示系统没有上电,没错吧?表面简单,其实不然。例如,如果系统启用连局域网唤醒机制(WOL),以太网指示灯将亮起。通过以下命令来检查是否是这种情况:
|
||||
|
||||
```
|
||||
$# sudo ethtool <interface name>
|
||||
```
|
||||
|
||||
其中 `<interface name>` 是网络接口的名字,比如 `eth0`。(`ethtool` 可以在同名的 Linux 软件包中找到。)如果输出中的 “Wake-on” 显示 “g”,则远程主机可以通过发送 [魔法数据包(MagicPacket)][3] 来启动系统。如果您无意远程唤醒系统,也不希望其他人这样做,请在系统 BIOS 菜单中将 WOL 关闭,或者用以下方式:
|
||||
|
||||
```
|
||||
$# sudo ethtool -s <interface name> wol d
|
||||
```
|
||||
|
||||
响应魔法数据包的处理器可能是网络接口的一部分,也可能是 [底板管理控制器(Baseboard Management Controller,BMC)][4]。
|
||||
|
||||
#### 英特尔管理引擎、平台路径控制器和 Minix
|
||||
|
||||
BMC 不是唯一的在系统关闭时仍在监听的微控制器(MCU)。x86_64 系统还包含了用于远程管理系统的英特尔管理引擎(IME)软件套件。从服务器到笔记本电脑,各种各样的设备都包含了这项技术,开启了如 KVM 远程控制和英特尔功能许可服务等 [功能][5]。根据 [Intel 自己的检测工具][7],[IME 存在尚未修补的漏洞][6]。坏消息是,要禁用 IME 很难。Trammell Hudson 发起了一个 [me_cleaner 项目][8],它可以清除一些相对恶劣的 IME 组件,比如嵌入式 Web 服务器,但也可能会影响运行它的系统。
|
||||
|
||||
IME 固件和系统管理模式(SMM)软件是 [基于 Minix 操作系统][9] 的,并运行在单独的平台路径控制器上,而不是主 CPU 上。然后,SMM 启动位于主处理器上的通用可扩展固件接口(UEFI)软件,相关内容 [已被提及很多][10]。Google 的 Coreboot 小组已经启动了一个雄心勃勃的 [非扩展性缩减版固件][11](NERF)项目,其目的不仅是要取代 UEFI,还要取代早期的 Linux 用户空间组件,如 systemd。在我们等待这些新成果的同时,Linux 用户现在就可以从 Purism、System76 或 Dell 等处购买 [禁用了 IME][12] 的笔记本电脑,另外 [带有 ARM 64 位处理器笔记本电脑][13] 还是值得期待的。
|
||||
|
||||
####
|
||||
#### 引导程序
|
||||
|
||||
除了启动问题不断的间谍软件外,早期的引导固件还有什么功能呢?引导程序的作用是为新上电的处理器提供运行像 Linux 之类的通用操作系统所需的资源。在开机时,不但没有虚拟内存,在控制器启动之前连 DRAM 也没有。然后,引导程序打开电源,并扫描总线和接口,以定位到内核镜像和根文件系统的位置。U-Boot 和 GRUB 等常见的引导程序支持 USB、PCI 和 NFS 等接口,以及更多的嵌入式专用设备,如 NOR 和 NAND 闪存。引导程序还与 [可信平台模块][14](TPMs)等硬件安全设备进行交互,在启动最开始建立信任链。
|
||||
|
||||
![Running the U-boot bootloader][16]
|
||||
|
||||
在构建主机上的沙盒中运行 U-boot 引导程序。
|
||||
|
||||
包括树莓派、任天堂设备、汽车板和 Chromebook 在内的系统都支持广泛使用的开源引导程序 [U-Boot][17]。它没有系统日志,当发生问题时,甚至没有任何控制台输出。为了便于调试,U-Boot 团队提供了一个沙盒,可以在构建主机甚至是夜间的持续整合(Continuous Integration)系统上测试补丁程序。如果系统上安装了 Git 和 GNU Compiler Collection(GCC)等通用的开发工具,使用 U-Boot 沙盒会相对简单:
|
||||
|
||||
```
|
||||
|
||||
|
||||
$# git clone git://git.denx.de/u-boot; cd u-boot
|
||||
|
||||
$# make ARCH=sandbox defconfig
|
||||
|
||||
$# make; ./u-boot
|
||||
|
||||
=> printenv
|
||||
|
||||
=> help
|
||||
```
|
||||
|
||||
在 x86_64 上运行 U-Boot,可以测试一些棘手的功能,如 [模拟存储设备][2] 重新分区、基于 TPM 的密钥操作以及 USB 设备热插拔等。U-Boot 沙盒甚至可以在 GDB 调试器下单步执行。使用沙盒进行开发的速度比将引导程序刷新到电路板上的测试快 10 倍,并且可以使用 Ctrl + C 恢复一个“变砖”的沙盒。
|
||||
|
||||
### 启动内核
|
||||
|
||||
#### 配置引导内核
|
||||
|
||||
完成任务后,引导程序将跳转到已加载到主内存中的内核代码,并开始执行,传递用户指定的任何命令行选项。内核是什么样的程序呢?用命令 `file /boot/vmlinuz` 可以看到它是一个“bzImage”,意思是一个大的压缩的镜像。Linux 源代码树包含了一个可以解压缩这个文件的工具—— [extract-vmlinux][18]:
|
||||
|
||||
```
|
||||
|
||||
|
||||
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
|
||||
|
||||
$# file vmlinux
|
||||
|
||||
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
|
||||
|
||||
linked, stripped
|
||||
```
|
||||
|
||||
内核是一个 [可执行与可链接格式][19](ELF)的二进制文件,就像 Linux 的用户空间程序一样。这意味着我们可以使用 `binutils` 包中的命令,如 `readelf` 来检查它。比较一下输出,例如:
|
||||
|
||||
```
|
||||
|
||||
|
||||
$# readelf -S /bin/date
|
||||
|
||||
$# readelf -S vmlinux
|
||||
```
|
||||
|
||||
这两个文件中的段内容大致相同。
|
||||
|
||||
所以内核必须像其他的 Linux ELF 文件一样启动,但用户空间程序是如何启动的呢?在 `main()` 函数中?并不确切。
|
||||
|
||||
在 `main()` 函数运行之前,程序需要一个执行上下文,包括堆栈内存以及 `stdio`、`stdout` 和 `stderr` 的文件描述符。用户空间程序从标准库(多数 Linux 系统在用“glibc”)中获取这些资源。参照以下输出:
|
||||
|
||||
```
|
||||
|
||||
|
||||
$# file /bin/date
|
||||
|
||||
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
|
||||
|
||||
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
|
||||
|
||||
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
|
||||
|
||||
stripped
|
||||
```
|
||||
|
||||
ELF 二进制文件有一个解释器,就像 Bash 和 Python 脚本一样,但是解释器不需要像脚本那样用 `#!` 指定,因为 ELF 是 Linux 的原生格式。ELF 解释器通过调用 `_start()` 函数来用所需资源 [配置一个二进制文件][20],这个函数可以从 glibc 源代码包中找到,可以 [用 GDB 查看][21]。内核显然没有解释器,必须自我配置,这是怎么做到的呢?
|
||||
|
||||
用 GDB 检查内核的启动给出了答案。首先安装内核的调试软件包,内核中包含一个未剥离的(unstripped)vmlinux,例如 `apt-get install linux-image-amd64-dbg`,或者从源代码编译和安装你自己的内核,可以参照 [Debian Kernel Handbook][22] 中的指令。`gdb vmlinux` 后加 `info files` 可显示 ELF 段 `init.text`。在 `init.text` 中用 `l *(address)` 列出程序执行的开头,其中 `address` 是 `init.text` 的十六进制开头。用 GDB 可以看到 x86_64 内核从内核文件 [arch/x86/kernel/head_64.S][23] 开始启动,在这个文件中我们找到了汇编函数 `start_cpu0()`,以及一段明确的代码显示在调用 `x86_64 start_kernel()` 函数之前创建了堆栈并解压了 zImage。ARM 32 位内核也有类似的文件 [arch/arm/kernel/head.S][24]。`start_kernel()` 不针对特定的体系结构,所以这个函数驻留在内核的 [init/main.c][25] 中。`start_kernel()` 可以说是 Linux 真正的 `main()` 函数。
|
||||
|
||||
### 从 start_kernel() 到 PID 1
|
||||
|
||||
#### 内核的硬件清单:设备树和 ACPI 表
|
||||
|
||||
在引导时,内核需要硬件信息,不仅仅是已编译过的处理器类型。代码中的指令通过单独存储的配置数据进行扩充。有两种主要的数据存储方法:[设备树][26] 和 [高级配置和电源接口(ACPI)表][27]。内核通过读取这些文件了解每次启动时需要运行的硬件。
|
||||
|
||||
对于嵌入式设备,设备树是已安装硬件的清单。设备树只是一个与内核源代码同时编译的文件,通常与 `vmlinux` 一样位于 `/boot` 目录中。要查看 ARM 设备上的设备树的内容,只需对名称与 `/boot/*.dtb` 匹配的文件执行 `binutils` 包中的 `strings` 命令即可,`dtb` 是指一个设备树二进制文件。显然,只需编辑构成它的类 JSON 文件并重新运行随内核源代码提供的特殊 `dtc` 编译器即可修改设备树。虽然设备树是一个静态文件,其文件路径通常由命令行引导程序传递给内核,但近年来增加了一个 [设备树覆盖][28] 的功能,内核在启动后可以动态加载热插拔的附加设备。
|
||||
|
||||
x86 系列和许多企业级的 ARM64 设备使用 [ACPI][27] 机制。与设备树不同的是,ACPI 信息存储在内核在启动时通过访问板载 ROM 而创建的 `/sys/firmware/acpi/tables` 虚拟文件系统中。读取 ACPI 表的简单方法是使用 `acpica-tools` 包中的 `acpidump` 命令。例如:
|
||||
|
||||
![ACPI tables on Lenovo laptops][30]
|
||||
|
||||
|
||||
联想笔记本电脑的 ACPI 表都是为 Windows 2001 设置的。
|
||||
|
||||
是的,你的 Linux 系统已经准备好用于 Windows 2001 了,你要考虑安装吗?与设备树不同,ACPI 具有方法和数据,而设备树更多地是一种硬件描述语言。ACPI 方法在启动后仍处于活动状态。例如,运行 `acpi_listen` 命令(在 `apcid` 包中),然后打开和关闭笔记本机盖会发现 ACPI 功能一直在运行。暂时地和动态地 [覆盖 ACPI 表][31] 是可能的,而永久地改变它需要在引导时与 BIOS 菜单交互或刷新 ROM。如果你遇到那么多麻烦,也许你应该 [安装 coreboot][32],这是开源固件的替代品。
|
||||
|
||||
#### 从 start_kernel() 到用户空间
|
||||
|
||||
[init/main.c][25] 中的代码竟然是可读的,而且有趣的是,它仍然在使用 1991 - 1992 年的 Linus Torvalds 的原始版权。在一个刚启动的系统上运行 `dmesg | head`,其输出主要来源于此文件。第一个 CPU 注册到系统中,全局数据结构被初始化,并且调度程序、中断处理程序(IRQ)、定时器和控制台按照严格的顺序逐一启动。在 `timekeeping_init()` 函数运行之前,所有的时间戳都是零。内核初始化的这部分是同步的,也就是说执行只发生在一个线程中,在最后一个完成并返回之前,没有任何函数会被执行。因此,即使在两个系统之间,`dmesg` 的输出也是完全可重复的,只要它们具有相同的设备树或 ACPI 表。Linux 的行为就像在 MCU 上运行的 RTOS(实时操作系统)一样,如 QNX 或 VxWorks。这种情况持续存在于函数 `rest_init()` 中,该函数在终止时由 `start_kernel()` 调用。
|
||||
|
||||
![Summary of early kernel boot process.][34]
|
||||
|
||||
早期的内核启动流程
|
||||
|
||||
函数 `rest_init()` 产生了一个新进程以运行 `kernel_init()`,并调用了 `do_initcalls()`。用户可以通过将 `initcall_debug` 附加到内核命令行来监控 `initcalls`,这样每运行一次 `initcall` 函数就会产生 `dmesg` 条目。`initcalls` 会历经七个连续的级别:early、core、postcore、arch、subsys、fs、device 和 late。`initcalls` 最为用户可见的部分是所有处理器外围设备的探测和设置:总线、网络、存储和显示器等等,同时加载其内核模块。`rest_init()` 也会在引导处理器上产生第二个线程,它首先运行 `cpu_idle()`,然后等待调度器分配工作。
|
||||
|
||||
`kernel_init()` 也可以 [设置对称多处理(SMP)结构][35]。在较新的内核中,如果 `dmesg` 的输出中出现“启动第二个 CPU...”等字样,系统便使用了 SMP。SMP 通过“热插拔”CPU 来进行,这意味着它用状态机来管理其生命周期,这种状态机在概念上类似于热插拔的 U 盘一样。内核的电源管理系统经常会使某个核(core)离线,然后根据需要将其唤醒,以便在不忙的机器上反复调用同一段的 CPU 热插拔代码。观察电源管理系统调用 CPU 热插拔代码的 [BCC 工具][36] 称为 `offcputime.py`。
|
||||
|
||||
请注意,`init/main.c` 中的代码在 `smp_init()` 运行时几乎已执行完毕:引导处理器已经完成了大部分其他核无需重复的一次性初始化操作。尽管如此,跨 CPU 的线程仍然要在每个核上生成,以管理每个核的中断(IRQ)、工作队列、定时器和电源事件。例如,通过 `ps -o psr` 命令可以查看服务 softirqs 和 workqueues 在每个 CPU 上的线程。
|
||||
|
||||
```
|
||||
|
||||
|
||||
$\# ps -o pid,psr,comm $(pgrep ksoftirqd)
|
||||
|
||||
PID PSR COMMAND
|
||||
|
||||
7 0 ksoftirqd/0
|
||||
|
||||
16 1 ksoftirqd/1
|
||||
|
||||
22 2 ksoftirqd/2
|
||||
|
||||
28 3 ksoftirqd/3
|
||||
|
||||
|
||||
|
||||
$\# ps -o pid,psr,comm $(pgrep kworker)
|
||||
|
||||
PID PSR COMMAND
|
||||
|
||||
4 0 kworker/0:0H
|
||||
|
||||
18 1 kworker/1:0H
|
||||
|
||||
24 2 kworker/2:0H
|
||||
|
||||
30 3 kworker/3:0H
|
||||
|
||||
[ . . . ]
|
||||
```
|
||||
|
||||
其中,PSR 字段代表“处理器”。每个核还必须拥有自己的定时器和 `cpuhp` 热插拔处理程序。
|
||||
|
||||
那么用户空间是如何启动的呢?在最后,`kernel_init()` 寻找可以代表它执行 `init` 进程的 `initrd`。如果没有找到,内核直接执行 `init` 本身。那么为什么需要 `initrd` 呢?
|
||||
|
||||
#### 早期的用户空间:谁规定要用 initrd?
|
||||
|
||||
除了设备树之外,在启动时可以提供给内核的另一个文件路径是 `initrd` 的路径。`initrd` 通常位于 `/boot` 目录中,与 x86 系统中的 bzImage 文件 vmlinuz 一样,或是与 ARM 系统中的 uImage 和设备树相同。用 `initramfs-tools-core` 软件包中的 `lsinitramfs` 工具可以列出 `initrd` 的内容。发行版的 `initrd` 方案包含了最小化的 `/bin`、`/sbin` 和 `/etc` 目录以及内核模块,还有 `/scripts` 中的一些文件。所有这些看起来都很熟悉,因为 `initrd` 大致上是一个简单的最小化 Linux 根文件系统。看似相似,其实不然,因为位于虚拟内存盘中的 `/bin` 和 `/sbin` 目录下的所有可执行文件几乎都是指向 [BusyBox binary][38] 的符号链接,由此导致 `/bin` 和 `/sbin` 目录比 glibc 的小 10 倍。
|
||||
|
||||
如果要做的只是加载一些模块,然后在普通的根文件系统上启动 `init`,为什么还要创建一个 `initrd` 呢?想想一个加密的根文件系统,解密可能依赖于加载一个位于根文件系统 `/lib/modules` 的内核模块,当然还有 `initrd` 中的。加密模块可能被静态地编译到内核中,而不是从文件加载,但有多种原因不希望这样做。例如,用模块静态编译内核可能会使其太大而不能适应存储空间,或者静态编译可能会违反软件许可条款。不出所料,存储、网络和人类输入设备(HID)驱动程序也可能存在于 `initrd` 中。`initrd` 基本上包含了任何挂载根文件系统所必需的非内核代码。`initrd` 也是用户存放 [自定义ACPI][38] 表代码的地方。
|
||||
|
||||
![Rescue shell and a custom <code>initrd</code>.][40]
|
||||
|
||||
救援模式的 shell 和自定义的 `initrd` 还是很有意思的。
|
||||
|
||||
`initrd` 对测试文件系统和数据存储设备也很有用。将这些测试工具存放在 `initrd` 中,并从内存中运行测试,而不是从被测对象中运行。
|
||||
|
||||
最后,当 `init` 开始运行时,系统就启动啦!由于辅助处理器正在运行,机器已经成为我们所熟知和喜爱的异步、可抢占、不可预测和高性能的生物。的确,`ps -o pid,psr,comm -p 1` 很容易显示已不在引导处理器上运行的用户空间的 `init` 进程。
|
||||
|
||||
### Summary
|
||||
### 总结
|
||||
|
||||
Linux 引导过程听起来或许令人生畏,即使考虑到简单嵌入式设备上的软件数量。换个角度来看,启动过程相当简单,因为启动中没有抢占、RCU 和竞争条件等扑朔迷离的复杂功能。只关注内核和 PID 1 会忽略了引导程序和辅助处理器为运行内核执行的大量准备工作。虽然内核在 Linux 程序中是独一无二的,但通过一些检查 ELF 文件的工具也可以了解其结构。学习一个正常的启动过程,可以帮助运维人员处理启动的故障。
|
||||
|
||||
要了解更多信息,请参阅 Alison Chaiken 的演讲——[Linux: The first second][41],将在 1 月 22 日至 26 日在悉尼举行。参见 [linux.conf.au][42]。
|
||||
|
||||
感谢 [Akkana Peck][43] 的提议和指正。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/analyzing-linux-boot-process
|
||||
|
||||
作者:[Alison Chaiken][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[2]:https://github.com/chaiken/LCA2018-Demo-Code
|
||||
[3]:https://en.wikipedia.org/wiki/Wake-on-LAN
|
||||
[4]:https://lwn.net/Articles/630778/
|
||||
[5]:https://www.youtube.com/watch?v=iffTJ1vPCSo&amp;amp;amp;amp;amp;index=65&amp;amp;amp;amp;amp;list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
|
||||
[6]:https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&amp;amp;amp;amp;amp;languageid=en-fr
|
||||
[7]:https://www.intel.com/content/www/us/en/support/articles/000025619/software.html
|
||||
[8]:https://github.com/corna/me_cleaner
|
||||
[9]:https://lwn.net/Articles/738649/
|
||||
[10]:https://lwn.net/Articles/699551/
|
||||
[11]:https://trmm.net/NERF
|
||||
[12]:https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled
|
||||
[13]:https://lwn.net/Articles/733837/
|
||||
[14]:https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639
|
||||
[15]:/file/383501
|
||||
[16]:https://opensource.com/sites/default/files/u128651/linuxboot_1.png "Running the U-boot bootloader"
|
||||
[17]:http://www.denx.de/wiki/DULG/Manual
|
||||
[18]:https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux
|
||||
[19]:http://man7.org/linux/man-pages/man5/elf.5.html
|
||||
[20]:https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html
|
||||
[21]:https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e
|
||||
[22]:http://kernel-handbook.alioth.debian.org/
|
||||
[23]:https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S
|
||||
[24]:https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S
|
||||
[25]:https://github.com/torvalds/linux/blob/master/init/main.c
|
||||
[26]:https://www.youtube.com/watch?v=m_NyYEBxfn8
|
||||
[27]:http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf
|
||||
[28]:http://lwn.net/Articles/616859/
|
||||
[29]:/file/383506
|
||||
[30]:https://opensource.com/sites/default/files/u128651/linuxboot_2.png "ACPI tables on Lenovo laptops"
|
||||
[31]:https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt
|
||||
[32]:https://www.coreboot.org/Supported_Motherboards
|
||||
[33]:/file/383511
|
||||
[34]:https://opensource.com/sites/default/files/u128651/linuxboot_3.png "Summary of early kernel boot process."
|
||||
[35]:http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc
|
||||
[36]:http://www.brendangregg.com/ebpf.html
|
||||
[37]:https://www.busybox.net/
|
||||
[38]:https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt
|
||||
[39]:/file/383516
|
||||
[40]:https://opensource.com/sites/default/files/u128651/linuxboot_4.png "Rescue shell and a custom <code>initrd</code>."
|
||||
[41]:https://rego.linux.conf.au/schedule/presentation/16/
|
||||
[42]:https://linux.conf.au/index.html
|
||||
[43]:http://shallowsky.com/
|
||||
219
translated/tech/20180129 Parsing HTML with Python.md
Normal file
219
translated/tech/20180129 Parsing HTML with Python.md
Normal file
@ -0,0 +1,219 @@
|
||||
用Python解析HTML
|
||||
======
|
||||
|
||||

|
||||
|
||||
图片由Jason Baker为Opensource.com所作。
|
||||
|
||||
作为Scribus文档团队的长期成员,我随时了解最新的源代码更新,以便对文档进行更新和补充。 我最近在刚升级到Fedora 27系统的计算机上使用Subversion进行“checkout”操作时,对于文档下载所需要的时间我感到很惊讶,文档由HTML页面和相关图像组成。 我担心该项目的文档看起来比项目本身大得多,并且怀疑其中的一些内容是“僵尸”文档——不会再使用的HTML文件以及HTML中无法访问到的图像。
|
||||
|
||||
我决定为自己创建一个项目来解决这个问题。 一种方法是搜索未使用的现有图像文件。 如果我可以扫描所有HTML文件中的图像引用,然后将该列表与实际图像文件进行比较,那么我可能会看到不匹配的文件。
|
||||
|
||||
这是一个典型的图像标签:
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我对第一组引号之间的部分很感兴趣,在src =之后。 寻找解决方案后,我找到一个名为[BeautifulSoup][1]的Python模块。 脚本的核心部分如下所示:
|
||||
|
||||
```
|
||||
soup = BeautifulSoup(all_text, 'html.parser')
|
||||
match = soup.findAll("img")
|
||||
if len(match) > 0:
|
||||
for m in match:
|
||||
imagelist.append(str(m))
|
||||
```
|
||||
|
||||
我们可以使用这个`findAll` 方法来挖出图片标签。 这是一小部分输出:
|
||||
|
||||
```
|
||||
<img src="images/pdf-form-ht3.png"/><img src="images/pdf-form-ht4.png"/><img src="images/pdf-form-ht5.png"/><img src="images/pdf-form-ht6.png"/><img align="middle" alt="GSview - Advanced Options Panel" src="images/gsadv1.png" title="GSview - Advanced Options Panel"/><img align="middle" alt="Scribus External Tools Preferences" src="images/gsadv2.png" title="Scribus External Tools Preferences"/>
|
||||
```
|
||||
|
||||
到现在为止还挺好。我原以为下一步就可以搞定了,但是当我在脚本中尝试了一些字符串方法时,它返回了有关标记的错误而不是字符串的错误。 我将输出保存到一个文件中,并在[KWrite][2]中进行编辑。 KWrite的一个好处是你可以使用正则表达式(regex)来做“查找和替换”操作,所以我可以用`\n<img` 替换 `<img`,这样可以看得更清楚。 KWrite的另一个好处是,如果你用正则表达式做了一个不明智的选择,你还可以撤消。
|
||||
|
||||
但我认为,肯定有比这更好的东西,所以我转而使用正则表达式,或者更具体地说Python的 `re` 模块。 这个新脚本的相关部分如下所示:
|
||||
|
||||
```
|
||||
match = re.findall(r'src="(.*)/>', all_text)
|
||||
if len(match)>0:
|
||||
for m in match:
|
||||
imagelist.append(m)
|
||||
```
|
||||
|
||||
它的一小部分输出如下所示:
|
||||
```
|
||||
images/cmcanvas.png" title="Context Menu for the document canvas" alt="Context Menu for the document canvas" /></td></tr></table><br images/eps-imp1.png" title="EPS preview in a file dialog" alt="EPS preview in a file dialog" images/eps-imp5.png" title="Colors imported from an EPS file" alt="Colors imported from an EPS file" images/eps-imp4.png" title="EPS font substitution" alt="EPS font substitution" images/eps-imp2.png" title="EPS import progress" alt="EPS import progress" images/eps-imp3.png" title="Bitmap conversion failure" alt="Bitmap conversion failure"
|
||||
```
|
||||
|
||||
乍一看,它看起来与上面的输出类似,并且附带有修剪部分图像标签的好处,但是有令人费解的是还夹杂着表格标签和其他内容。 我认为这涉及到这个正则表达式`src="(.*)/>`,这被称为贪婪,意味着它不一定停止在遇到`/>`的第一个实例。我应该补充一点,我也尝试过`src="(.*)"`,这真的没有什么更好的效果,不是一个正则表达式专家(只是做了这个),我找了各种方法来改进这一点但是并没什么用。
|
||||
|
||||
做了一系列的事情之后,甚至尝试了Perl的`HTML::Parser`模块,最终我试图将这与我为Scribus编写的一些脚本进行比较,这些脚本逐个字符的分析文本内容,然后采取一些行动。 为了最终目的,我终于想出了所有这些方法,并且完全不需要正则表达式或HTML解析器。 让我们回到展示的那个`img`标签的例子。
|
||||
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我决定回到`src=`这一块。 一种方法是等待`s`出现,然后看下一个字符是否是`r`,下一个是`c`,下一个是否`=`。 如果是这样,那就匹配上了! 那么两个双引号之间的内容就是我所需要的。 这种方法的问题在于需要连续识别上面这样的结构。 一种查看代表一行HTML文本的字符串的方法是:
|
||||
|
||||
```
|
||||
for c in all_text:
|
||||
```
|
||||
|
||||
但是这个逻辑太乱了,以至于不能持续匹配到前面的`c`,还有之前的字符,更之前的字符,更更之前的字符。
|
||||
|
||||
最后,我决定专注于`=`并使用索引方法,以便我可以轻松地引用字符串中的任何先前或将来的字符。 这里是搜索部分:
|
||||
|
||||
```
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and (all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
```
|
||||
|
||||
我用第四个字符开始搜索(索引从0开始),所以我在下面没有出现索引错误,并且实际上,在每一行的第四个字符之前不会有等号。 第一个测试是看字符串中是否出现了`=`,如果没有,我们就会前进。 如果我们确实看到一个等号,那么我们会看前三个字符是否是`s`,`r`和`c`。 如果全都匹配了,就调用函数`imagefound`:
|
||||
|
||||
```
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
```
|
||||
|
||||
我们正在给函数发送当前索引,它代表着`=`。 我们知道下一个字符将会是`"`,所以我们跳过两个字符,并开始向名为`newimage`的控制字符串添加字符,直到我们发现下一个`"`,此时我们完成了一次匹配。 我们将字符串加一个`换行`符添加到列表`imagelist`中并`返回`,请记住,在剩余的这个HTML字符串中可能会有更多图片标签,所以我们马上回到搜索循环的中间。
|
||||
|
||||
以下是我们的输出现在的样子:
|
||||
```
|
||||
images/text-frame-link.png
|
||||
images/text-frame-unlink.png
|
||||
images/gimpoptions1.png
|
||||
images/gimpoptions3.png
|
||||
images/gimpoptions2.png
|
||||
images/fontpref3.png
|
||||
images/font-subst.png
|
||||
images/fontpref2.png
|
||||
images/fontpref1.png
|
||||
images/dtp-studio.png
|
||||
```
|
||||
|
||||
啊,干净多了,而这只花费几秒钟的时间。 我本可以将索引前移7步来剪切`images/`部分,但我更愿意把这个部分保存下来,确保我没有切片掉图像文件名的第一个字母,这很容易用KWrite编辑成功- - 你甚至不需要正则表达式。 做完这些并保存文件后,下一步就是运行我编写的另一个脚本`sortlist.py`:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# sortlist.py
|
||||
|
||||
import os
|
||||
|
||||
imagelist = []
|
||||
for line in open('/tmp/imagelist_parse4.txt').xreadlines():
|
||||
imagelist.append(line)
|
||||
|
||||
imagelist.sort()
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4_sorted.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
```
|
||||
|
||||
这会读取文件内容,并存储为列表,对其排序,然后另存为另一个文件。 之后,我可以做到以下几点:
|
||||
|
||||
```
|
||||
ls /home/gregp/development/Scribus15x/doc/en/images/*.png > '/tmp/actual_images.txt'
|
||||
```
|
||||
|
||||
然后我需要在该文件上运行`sortlist.py`,因为`ls`方法的排序与Python不同。 我原本可以在这些文件上运行比较脚本,但我更愿意以可视方式进行操作。 最后,我成功找到了42个图像,这些图像没有来自文档的HTML引用。
|
||||
|
||||
这是我的完整解析脚本:
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# parseimg4.py
|
||||
|
||||
import os
|
||||
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
|
||||
htmlnames = []
|
||||
imagelist = []
|
||||
tempstring = ''
|
||||
filenames = os.listdir('/home/gregp/development/Scribus15x/doc/en/')
|
||||
for name in filenames:
|
||||
if name.endswith('.html'):
|
||||
htmlnames.append(name)
|
||||
#print htmlnames
|
||||
for htmlfile in htmlnames:
|
||||
all_text = open('/home/gregp/development/Scribus15x/doc/en/' + htmlfile).read()
|
||||
linelength = len(all_text)
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and
|
||||
(all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
imageno = len(imagelist)
|
||||
print str(imageno) + " images were found and saved"
|
||||
```
|
||||
|
||||
脚本名称为`parseimg4.py`,这并不能真实反映我陆续编写的脚本数量,包括微调的和大改的以及丢弃并重新开始写的。 请注意,我已经对这些目录和文件名进行了硬编码,但是总结起来很容易,要求用户输入这些信息。 同样,因为它们是工作脚本,所以我将输出发送到 `/tmp`目录,所以一旦重新启动系统,它们就会消失。
|
||||
|
||||
这不是故事的结尾,因为下一个问题是:僵尸HTML文件怎么办? 任何未使用的文件都可能会引用到前面比对方法没有提取到的图像。 我们有一个`menu.xml`文件作为联机手册的目录,但我还需要考虑TOC(译者注:TOC是table of contents的缩写)中列出的某些文件可能引用了不在TOC中的文件,是的,我确实找到了一些这样的文件。
|
||||
|
||||
最后我可以说,这是一个比图像搜索更简单的任务,而且开发的过程对我有很大的帮助。
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][7] Greg Pittman - Greg是Kentucky州Louisville市的一名退休的神经学家,从二十世纪六十年代的Fortran IV语言开始长期以来对计算机和编程有着浓厚的兴趣。 当Linux和开源软件出现的时候,Greg深受启发,去学习更多只是,并实现最终贡献的承诺。 他是Scribus团队的成员。[更多关于我][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/parsing-html-python
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://www.crummy.com/software/BeautifulSoup/
|
||||
[2]:https://www.kde.org/applications/utilities/kwrite/
|
||||
[7]:https://opensource.com/users/greg-p
|
||||
[8]:https://opensource.com/users/greg-p
|
||||
@ -0,0 +1,51 @@
|
||||
Docker 容器中的老式 DOS BBS
|
||||
======
|
||||
不久前,我写了一篇[我的 Debian Docker 基本映像][1]。我决定进一步扩展这个概念:在 Docker 中运行 DOS 程序。
|
||||
|
||||
但首先,一张截图:
|
||||
|
||||
![][2]
|
||||
|
||||
事实证明这是可能的,但很难。我使用了所有三种主要的 DOS 模拟器(dosbox、qemu 和 dosemu)。我让它们都能在 Docker 容器中运行,但有很多有趣的问题需要解决。
|
||||
|
||||
普遍要做的事是在 DOS 环境下提供一个伪造的调制解调器。这需要作为 TCP 端口暴露在容器外部。这有很多方法可以做到 - 我使用的是 tcpser结。dosbox 有一个 TCP 调制解调器接口,但事实证明,这样做太问题太多了。
|
||||
|
||||
挑战来自你希望能够一次接受多个传入 telnet(或 TCP)连接。DOS 不是一个多任务操作系统,所以当时有很多 hack 的方法。一种是有多台物理机,每个有一根传入电话线。或者它们可能会在 [DESQview][3]、OS/2 甚至 Windows 3.1 等多任务层下运行多个伪 DOS 实例。
|
||||
|
||||
(注意:我刚刚了解到 [DESQview/X][4],它将 DESQview 与 X11R5 集成在一起,并[取代了 Windows 3 驱动程序][5]来使 Windows 作为 X 应用程序运行。)
|
||||
|
||||
出于各种原因,我不想尝试在 Docker 中运行其中一个系统。这让我模拟了原来的多物理节点设置。从理论上讲,非常简单 - 运行一组 DOS 实例,每个实例最多使用 1MB 的模拟 RAM,这就行了。但是这里面临挑战。
|
||||
|
||||
在多物理节点设置中,你需要某种文件共享,因为你的节点需要访问共享消息和文件存储。在老式的 DOS 时代,有很多笨重的方法可以做到这一点 - [Netware][6]、[LAN manager][7],甚至一些 PC NFS 客户端。我没有访问 Netware。我尝试了 DOS 中的 Microsoft LM 客户端,与在 Docker 容器内运行的 Samba 服务器交互。这样可以使用,但 LM 客户端即使有各种高内存技巧还是占用了很多内存,BBS 软件也无法运行。我无法在多个 dosbox 实例中挂载底层文件系统,因为 dosbox 缓存不兼容。
|
||||
|
||||
这就是为什么我使用 dosemu 的原因。除了有比 dosbox 更完整的模拟器之外,它还有一种共享主机文件系统的方式。
|
||||
|
||||
|
||||
所以, 所有这一切都在此:[jgoerzen/docker-bbs-renegade][8]。
|
||||
|
||||
我还为其他想做类似事情的人准备了构建块:[docker-dos-bbs][9] 和底层 [docker-dosemu][10]。
|
||||
|
||||
意外的收获是,我也试图在 Joyent 的 Triton(基于 Solaris 的 SmartOS)下运行它。让我感到高兴的印象是,这几乎可以在这下工作。是的,在 Solaris 机器上在一个基于 Linux 的 DOS 模拟器的容器中运行 Renegade DOS BBS。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9836-an-old-dos-bbs-in-a-docker-container
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://changelog.complete.org/archives/9794-fixing-the-problems-with-docker-images
|
||||
[2]:https://raw.githubusercontent.com/jgoerzen/docker-bbs-renegade/master/renegade-login.png
|
||||
[3]:https://en.wikipedia.org/wiki/DESQview
|
||||
[4]:http://toastytech.com/guis/dvx.html
|
||||
[5]:http://toastytech.com/guis/dvx3.html
|
||||
[6]:https://en.wikipedia.org/wiki/NetWare
|
||||
[7]:https://en.wikipedia.org/wiki/LAN_Manager
|
||||
[8]:https://github.com/jgoerzen/docker-bbs-renegade
|
||||
[9]:https://github.com/jgoerzen/docker-dos-bbs
|
||||
[10]:https://github.com/jgoerzen/docker-dosemu
|
||||
534
translated/tech/20180206 Manage printers and printing.md
Normal file
534
translated/tech/20180206 Manage printers and printing.md
Normal file
@ -0,0 +1,534 @@
|
||||
Linux 中如何打印和管理打印机
|
||||
======
|
||||
|
||||
|
||||
### Linux 中的打印
|
||||
|
||||
虽然现在大量的沟通都是电子化和无纸化的,但是在我们的公司中还有大量的材料需要打印。银行结算单、公用事业帐单、财务和其它报告、以及收益结算单等一些东西还是需要打印的。本教程将介绍在 Linux 中如何使用 CUPS 去打印。
|
||||
|
||||
CUPS,是通用 Unix 打印系统(Common UNIX Printing System)的首字母缩写,它是 Linux 中的打印机和打印任务的管理者。早期计算机上的打印机一般是在特定的字符集和字体大小下打印文本文件行。现在的图形打印机可以打印各种字体和大小的文本和图形。尽管如此,现在你所使用的一些命令,在它们以前的历史上仍旧使用的是古老的行打印守护进程(LPD)技术。
|
||||
|
||||
本教程将帮你了解 Linux 服务器专业考试(LPIC-1)的第 108 号主题的 108.4 目标。这个目标的权重为 2。
|
||||
|
||||
#### 前提条件
|
||||
|
||||
为了更好地学习本系列教程,你需要具备基本的 Linux 知识,和使用 Linux 系统实践本教程中的命令的能力,你应该熟悉 GNU 和 UNIX® 命令的使用。有时不同版本的程序输出可能会不同,因此,你的结果可能与本教程中的示例有所不同。
|
||||
|
||||
本教程中的示例使用的是 Fedora 27 的系统。
|
||||
|
||||
### 有关打印的一些历史
|
||||
|
||||
这一小部分历史并不是 LPI 目标的,但它有助于你理解这个目标的相关环境。
|
||||
|
||||
早期的计算机大都使用行打印机。这些都是击打式打印机,一段时间以来,它们使用固定间距的字符和单一的字体来打印文本行。为提升整个系统性能,早期的主机都对慢速的外围设备如读卡器、卡片穿孔机、和运行其它工作的行打印进行交叉工作。因此就产生了在行上或者假脱机上的同步外围操作,这一术语目前在谈到计算机打印时仍然在使用。
|
||||
|
||||
在 UNIX 和 Linux 系统上,打印初始化使用的是 BSD(Berkeley Software Distribution)打印子系统,它是由一个作为服务器运行的行打印守护程序(LPD)组成,而客户端命令如 `lpr` 是用于提交打印作业。这个协议后来被 IETF 标准化为 RFC 1179 —— **行打印机守护协议**。
|
||||
|
||||
系统也有一个打印守护程序。它的功能与BSD 的 LPD 守护程序类似,但是它们的命令集不一样。你在后面会经常看到完成相同的任务使用不同选项的两个命令。例如,对于打印文件的命令,`lpr` 是伯克利实现的,而 `lp` 是 System V 实现的。
|
||||
|
||||
随着打印机技术的进步,在一个页面上混合出现不同字体成为可能,并且可以将图片像文字一样打印。可变间距字体,以及更多先进的打印技术,比如 kerning 和 ligatures,现在都已经标准化。它们对基本的 lpd/lpr 方法进行了改进设计,比如 LPRng,下一代的 LPR、以及 CUPS。
|
||||
|
||||
许多可以打印图形的打印机,使用 Adobe PostScript 语言进行初始化。一个 PostScript 打印机有一个解释器引擎,它可以解释打印任务中的命令并从这些命令中生成最终的页面。PostScript 经常被用做原始文件和打印机之间的中间层,比如一个文本文件或者一个图像文件,以及没有适合 PostScript 功能的特定打印机的最终格式。转换这些特定的打印任务,比如一个 ASCII 文本文件或者一个 JPEG 图像转换为 PostScript,然后再使用过滤器转换 PostScript 到非 PostScript 打印机所需要的最终光栅格式。
|
||||
|
||||
现在的便携式文档格式(PDF),它就是基于 PostScript 的,已经替换了传统的原始 PostScript。PDF 设计为与硬件和软件无关,它封装了要打印的页面的完整描述。你可以查看 PDF 文件,同时也可以打印它们。
|
||||
|
||||
### 管理打印队列
|
||||
|
||||
用户直接打印作业到一个名为打印队列的逻辑实体。在单用户系统中,一个打印队列和一个打印机通常是几乎相同的意思。但是,CUPS 允许系统对最终在一个远程系统上的打印,并不附属打印机到一个队列打印作业上,而是通过使用类,允许将打印作业重定向到该类第一个可用的打印机上。
|
||||
|
||||
你可以检查和管理打印队列。对于 CUPS 来说,其中一些命令还是很新的。另外的一些是源于 LPD 的兼容命令,不过现在的一些选项通常是原始 LPD 打印系统选项的有限子集。
|
||||
|
||||
你可以使用 CUPS 的 `lpstat` 命令去检查队列,以了解打印系统。一些常见命令如下表 1。
|
||||
|
||||
###### 表 1. lpstat 命令的选项
|
||||
| 选项 | 作用 |
|
||||
| -a | 显示打印机状态 |
|
||||
| -c | 显示打印类 |
|
||||
| -p | 显示打印状态:enabled 或者 disabled. |
|
||||
| -s | 显示默认打印机、打印机和类。相当于 -d -c -v。**注意:为指定多个选项,这些选项必须像值一样分隔开。**|
|
||||
| -s | 显示打印机和它们的设备。 |
|
||||
|
||||
|
||||
你也可以使用 LPD 的 `lpc` 命令,它可以在 /usr/sbin 中找到,使用它的 `status` 选项。如果你不想指定打印机名字,将列出所有的队列。列表 1 展示了命令的一些示例。
|
||||
|
||||
###### 列表 1. 显示可用打印队列
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -d
|
||||
system default destination: HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -v HL-2280DW
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
[ian@atticf27 ~]$ lpstat -s
|
||||
system default destination: HL-2280DW
|
||||
members of class anyprint:
|
||||
HL-2280DW
|
||||
XP-610
|
||||
device for anyprint: ///dev/null
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
device for XP-610: dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
[ian@atticf27 ~]$ lpstat -a XP-610
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
[ian@atticf27 ~]$ /usr/sbin/lpc status HL-2280DW
|
||||
HL-2280DW:
|
||||
printer is on device 'dnssd' speed -1
|
||||
queuing is disabled
|
||||
printing is enabled
|
||||
no entries
|
||||
daemon present
|
||||
|
||||
```
|
||||
|
||||
这个示例展示了两台打印机 —— HL-2280DW 和 XP-610,和一个类 `anyprint`,它允许打印作业定向到这两台打印机中的第一个可用打印机。
|
||||
|
||||
在这个示例中,已经禁用了打印到 HL-2280DW 队列,但是打印是启用的,这样便于打印机脱机维护之前可以完成打印队列中的任务。无论队列是启用还是禁用,都可以使用 `cupsaccept` 和 `cupsreject` 命令来管理它们。你或许可能在 /usr/sbin 中找到这些命令,它们现在都是链接到新的命令上。同样,无论打印是启用还是禁用,你都可以使用 `cupsenable` 和 `cupsdisable` 命令来管理它们。在早期版本的 CUPS 中,这些被称为 `enable` 和 `disable`,它也许会与 bash shell 内置的 `enable` 混淆。列表 2 展示了如何去启用打印机 HL-2280DW 上的队列,不过它的打印还是禁止的。CUPS 的几个命令支持使用一个 `-r` 选项去提供一个动作的理由。这个理由会在你使用 `lpstat` 时显示,但是如果你使用的是 `lpc` 命令则不会显示它。
|
||||
|
||||
###### 列表 2. 启用队列和禁用打印
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -a -p HL-2280DW
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW not accepting requests since Thu 27 Apr 2017 05:52:27 PM EDT -
|
||||
Maintenance scheduled
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
printer HL-2280DW is idle. enabled since Thu 27 Apr 2017 05:52:27 PM EDT
|
||||
Maintenance scheduled
|
||||
[ian@atticf27 ~]$ accept HL-2280DW
|
||||
[ian@atticf27 ~]$ cupsdisable -r "waiting for toner delivery" HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -p -a
|
||||
printer anyprint is idle. enabled since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
printer HL-2280DW disabled since Mon 29 Jan 2018 04:03:50 PM EST -
|
||||
waiting for toner delivery
|
||||
printer XP-610 is idle. enabled since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Mon 29 Jan 2018 04:03:50 PM EST
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
|
||||
```
|
||||
|
||||
注意:用户执行这些任务必须经过授权。它可能要求是 root 用户或者其它的授权用户。在 /etc/cups/cups-files.conf 中可以看到 SystemGroup 的条目,cups-files.conf 的 man 页面有更多授权用户组的信息。
|
||||
|
||||
### 管理用户打印作业
|
||||
|
||||
现在,你已经知道了一些如何去检查打印队列和类的方法,我将给你展示如何管理打印队列上的作业。你要做的第一件事是,如何找到一个特定打印机或者全部打印机上排队的任意作业。完成上述工作要使用 `lpq` 命令。如果没有指定任何选项,`lpq` 将显示默认打印机上的队列。使用 `-P` 选项和一个打印机名字将指定打印机,或者使用 `-a` 选项去指定所有的打印机,如下面的列表 3 所示。
|
||||
|
||||
###### 列表 3. 使用 lpq 检查打印队列
|
||||
```
|
||||
[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st unknown 4 unknown 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th unknown 8 unknown 1024 bytes
|
||||
5th unknown 9 unknown 1024 bytes
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lpq -P xp-610
|
||||
xp-610 is ready
|
||||
no entries
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 8 .bashrc 1024 bytes
|
||||
5th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
在这个示例中,共有五个作业,它们是 4、6、7、8、和 9,并且它是名为 HL-2280DW 的打印机的队列,而不是 XP-610 的。在这个示例中使用 `-P` 选项,可简单地显示那个打印机已经准备好,但是没有队列任务。注意,CUPS 的打印机命名,大小写是不敏感的。还要注意的是,用户 ian 提交了同样的作业两次,当一个作业第一次没有打印时,经常能看到用户的这种动作。
|
||||
|
||||
一般情况下,你可能查看或者维护你自己的打印作业,但是,root 用户或者其它授权的用户通常会去管理其它打印作业。大多数 CUPS 命令都可以使用一个 `-E` 选项,对 CUPS 服务器与客户端之间的通讯进行加密。
|
||||
|
||||
使用 `lprm` 命令从队列中去删除 .bashrc 作业。如果不使用选项,将删除当前的作业。使用 `-` 选项,将删除全部的作业。要么就如列表 4 那样,指定一个要删除的作业列表。
|
||||
|
||||
###### 列表 4. 使用 lprm 删除打印作业
|
||||
```
|
||||
[[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lprm
|
||||
lprm: Forbidden
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lprm 8
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
注意,用户 pat 不能删除队列中的第一个作业,因为它是用户 ian 的。但是,ian 可以删除他自己的 8 号作业。
|
||||
|
||||
另外的可以帮你操作打印队列中的作业的命令是 `lp`。使用它可以去修改作业属性,比如打印数量或者优先级。我们假设用户 ian 希望他的作业 9 在用户 pat 的作业之前打印,并且希望打印两份。作业优先级的默认值是 50,它的优先级范围从最低的 1 到最高的 100 之间。用户 ian 可以使用 `-i`、`-n`、以及 `-q` 选项去指定一个要修改的作业,而新的打印数量和优先级可以如下面的列表 5 所示的那样去修改。注意,使用 `-l` 选项的 `lpq` 命令可以提供更详细的输出。
|
||||
|
||||
###### 列表 5. 使用 lp 去改变打印数量和优先级
|
||||
```
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
[ian@atticf27 ~]$ lp -i 9 -q 60 -n 2
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 9 .bashrc 1024 bytes
|
||||
2nd ian 4 permutation.C 6144 bytes
|
||||
3rd pat 6 bitlib.h 6144 bytes
|
||||
4th pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
最后,`lpmove` 命令可以允许一个作业从一个队列移动到另一个队列。例如,我们可能因为打印机 HL-2280DW 现在不能使用,而想去移动一个作业到另外的队列上。你可以指定一个作业编号,比如 9,或者你可以用一个队列名加一个连字符去限定它,比如,HL-2280DW-0。`lpmove` 命令的操作要求一个授权用户。列表 6 展示了如何去从一个队列移动作业到另外的队列,通过打印机和作业 ID 指定第一个,然后指定打印机的所有作业都移动到第二个队列。稍后我们可以去再次检查队列,其中一个作业已经在打印中了。
|
||||
|
||||
###### 列表 6. 使用 lpmove 移动作业到另外一个打印队列
|
||||
```
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW-9 anyprint
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW xp-610
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active ian 9 .bashrc 1024 bytes
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
[ian@atticf27 ~]$ # A few minutes later
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active pat 6 bitlib.h 6144 bytes
|
||||
1st pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是打印服务器而不是 CUPS,比如 LPD 或者 LPRng,大多数的队列管理功能是由 `lpc` 命令的子命令来处理的。例如,你可以使用 `lpc topq` 去移动一个作业到队列的顶端。其它的 `lpc` 子命令包括 `disable`、`down`、`enable`、`hold`、`move`、`redirect`、`release`、和 `start`。这些子命令在 CUPS 的兼容命令中没有实现。
|
||||
|
||||
#### 打印文件
|
||||
|
||||
如何去打印创建的作业?大多数图形界面程序都提供了一个打印方法,通常是 **文件** 菜单下面的选项。这些程序为选择打印机、设置页边距、彩色或者黑白打印、打印数量、选择每张纸打印的页面数(每张纸打印两个页面,通常用于讲义)等等,都提供了图形化的工具。现在,我将为你展示如何使用命令行工具去管理这些功能,然后和图形化实现进行比较。
|
||||
|
||||
打印文件最简单的方法是使用 `lpr` 命令,然后提供一个文件名字。这将在默认打印机上打印这个文件。`lp` 命令不仅可以打印文件,也可以修改打印作业。列表 7 展示了使用这个命令的一个简单示例。注意,`lpr` 会静默处理这个作业,但是 `lp` 会显示处理后的作业的 ID。
|
||||
|
||||
###### 列表 7. 使用 lpr 和 lp 打印
|
||||
```
|
||||
[ian@atticf27 ~]$ echo "Print this text" > printexample.txt
|
||||
[ian@atticf27 ~]$ lpr printexample.txt
|
||||
[ian@atticf27 ~]$ lp printexample.txt
|
||||
request id is HL-2280DW-12 (1 file(s))
|
||||
|
||||
```
|
||||
|
||||
表 2 展示了 `lpr` 上你可以使用的一些选项。注意, `lp` 的选项和 `lpr` 的很类似,但是名字可能不一样;例如,`-#` 在 `lpr` 上是相当于 `lp` 的 `-n` 选项。查看 man 页面了解更多的信息。
|
||||
|
||||
###### 表 2. lpr 的选项
|
||||
|
||||
| 选项 | 作用 |
|
||||
| -C, -J, or -T | 设置一个作业名字。 |
|
||||
| -P | 选择一个指定的打印机。 |
|
||||
| -# | 指定打印数量。注意它与 lp 命令的 -n 有点差别。|
|
||||
| -m | 在作业完成时发送电子邮件。 |
|
||||
| -l | 表示打印文件已经为打印做好格式准备。相当于 -o raw。 |
|
||||
| -o | 设置一个作业选项。 |
|
||||
| -p | 格式化一个带有阴影标题的文本文件。相关于 -o prettyprint。 |
|
||||
| -q | 暂缓(或排队)最后的打印作业。 |
|
||||
| -r | 在文件进入打印池之后,删除文件。 |
|
||||
|
||||
列表 8 展示了一些选项。我要求打印之后给我发确认电子邮件,那个作业被暂缓执行,并且在打印之后删除文件。
|
||||
|
||||
###### 列表 8. 使用 lpr 打印
|
||||
```
|
||||
[ian@atticf27 ~]$ lpr -P HL-2280DW -J "Ian's text file" -#2 -m -p -q -r printexample.txt
|
||||
[[ian@atticf27 ~]$ lpq -l
|
||||
HL-2280DW is ready
|
||||
|
||||
|
||||
ian: 1st [job 13 localhost]
|
||||
2 copies of Ian's text file 1024 bytes
|
||||
[ian@atticf27 ~]$ ls printexample.txt
|
||||
ls: cannot access 'printexample.txt': No such file or directory
|
||||
|
||||
```
|
||||
|
||||
我现在有一个在 HL-2280DW 打印队列上暂缓执行的作业。怎么做到这样?`lp` 命令有一个选项可以暂缓或者投放作业,使用 `-H` 选项是使用各种值。列表 9 展示了如何投放被暂缓的作业。检查 `lp` 命令的 man 页面了解其它选项的信息。
|
||||
|
||||
###### 列表 9. 重启一个暂缓的打印作业
|
||||
```
|
||||
[ian@atticf27 ~]$ lp -i 13 -H resume
|
||||
|
||||
```
|
||||
|
||||
并不是所有的可用打印机都支持相同的选项集。使用 `lpoptions` 命令去查看一个打印机的常用选项。添加 `-l` 选项去显示打印机专用的选项。列表 10 展示了两个示例。许多常见的选项涉及到人像/风景打印、页面大小和输出在纸张上的布局。详细信息查看 man 页面。
|
||||
|
||||
###### 列表 10. 检查打印机选项
|
||||
```
|
||||
[ian@atticf27 ~]$ lpoptions -p HL-2280DW
|
||||
copies=1 device-uri=dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
finishings=3 job-cancel-after=10800 job-hold-until=no-hold job-priority=50
|
||||
job-sheets=none,none marker-change-time=1517325288 marker-colors=#000000,#000000
|
||||
marker-levels=-1,92 marker-names='Black\ Toner\ Cartridge,Drum\ Unit'
|
||||
marker-types=toner,opc number-up=1 printer-commands=none
|
||||
printer-info='Brother HL-2280DW' printer-is-accepting-jobs=true
|
||||
printer-is-shared=true printer-is-temporary=false printer-location
|
||||
printer-make-and-model='Brother HL-2250DN - CUPS+Gutenprint v5.2.13 Simplified'
|
||||
printer-state=3 printer-state-change-time=1517325288 printer-state-reasons=none
|
||||
printer-type=135188 printer-uri-supported=ipp://localhost/printers/HL-2280DW
|
||||
sides=one-sided
|
||||
|
||||
[ian@atticf27 ~]$ lpoptions -l -p xp-610
|
||||
PageSize/Media Size: *Letter Legal Executive Statement A4
|
||||
ColorModel/Color Model: *Gray Black
|
||||
InputSlot/Media Source: *Standard ManualAdj Manual MultiPurposeAdj MultiPurpose
|
||||
UpperAdj Upper LowerAdj Lower LargeCapacityAdj LargeCapacity
|
||||
StpQuality/Print Quality: None Draft *Standard High
|
||||
Resolution/Resolution: *301x300dpi 150dpi 300dpi 600dpi
|
||||
Duplex/2-Sided Printing: *None DuplexNoTumble DuplexTumble
|
||||
StpiShrinkOutput/Shrink Page If Necessary to Fit Borders: *Shrink Crop Expand
|
||||
StpColorCorrection/Color Correction: *None Accurate Bright Hue Uncorrected
|
||||
Desaturated Threshold Density Raw Predithered
|
||||
StpBrightness/Brightness: 0 100 200 300 400 500 600 700 800 900 *None 1100
|
||||
1200 1300 1400 1500 1600 1700 1800 1900 2000 Custom.REAL
|
||||
StpContrast/Contrast: 0 100 200 300 400 500 600 700 800 900 *None 1100 1200
|
||||
1300 1400 1500 1600 1700 1800 1900 2000 2100 2200 2300 2400 2500 2600 2700
|
||||
2800 2900 3000 3100 3200 3300 3400 3500 3600 3700 3800 3900 4000 Custom.REAL
|
||||
StpImageType/Image Type: None Text Graphics *TextGraphics Photo LineArt
|
||||
|
||||
```
|
||||
|
||||
大多数的 GUI 应用程序有一个打印对话框,通常你可以使用 **文件 >打印** 菜单去选择它。图 1 展示了在 GIMP 中的一个示例,GIMP 是一个图像处理程序。
|
||||
|
||||
###### 图 1. 在 GIMP 中打印
|
||||
|
||||
![Printing from the GIMP][3]
|
||||
|
||||
到目前为止,我们所有的命令都是隐式指向到本地的 CUPS 打印服务器上。你也可以通过指定 `-h` 选项和一个端口号(如果不是 CUPS 的默认端口号 631的话)将打印转向到另外一个系统上的服务器。
|
||||
|
||||
### CUPS 和 CUPS 服务器
|
||||
|
||||
CUPS 打印系统的核心是 `cupsd` 打印服务器,它是一个运行的守护进程。CUPS 配置文件一般位于 /etc/cups/cupsd.conf。/etc/cups 目录也有与 CUPS 相关的其它的配置文件。CUPS 一般在系统初始化期间启动,根据你的发行版不同,它也可能通过位于 /etc/rc.d/init.d 或者 /etc/init.d 目录中的 CUPS 脚本来控制。对于 最新使用 systemd 来初始化的系统,CUPS 服务脚本可能在 /usr/lib/systemd/system/cups.service 中。和大多数使用脚本的服务一样,你可以停止、启动、或者重启守护程序。查看我们的教程:[学习 Linux,101:运行级别、引导目标、关闭、和重启动][4],了解使用初始化脚本的更多信息。
|
||||
|
||||
配置文件 /etc/cups/cupsd.conf 包含管理一些事情的参数,比如访问打印系统、是否允许远程打印、本地打印池文件等等。在一些系统上,一个辅助的部分单独描述打印队列,它一般是由配置工具自动生成的。列表 11 展示了一个默认的 cupsd.conf 文件中的一些条目。注意,注释是以 # 字符开头的。默认值通常以注释的方式显示,并且可以通过删除前面的 # 字符去改变默认值。
|
||||
|
||||
###### Listing 11. 默认的 /etc/cups/cupsd.conf 文件的部分内容
|
||||
```
|
||||
# Only listen for connections from the local machine.
|
||||
Listen localhost:631
|
||||
Listen /var/run/cups/cups.sock
|
||||
|
||||
# Show shared printers on the local network.
|
||||
Browsing On
|
||||
BrowseLocalProtocols dnssd
|
||||
|
||||
# Default authentication type, when authentication is required...
|
||||
DefaultAuthType Basic
|
||||
|
||||
# Web interface setting...
|
||||
WebInterface Yes
|
||||
|
||||
# Set the default printer/job policies...
|
||||
<Policy default>
|
||||
# Job/subscription privacy...
|
||||
JobPrivateAccess default
|
||||
JobPrivateValues default
|
||||
SubscriptionPrivateAccess default
|
||||
SubscriptionPrivateValues default
|
||||
|
||||
# Job-related operations must be done by the owner or an administrator...
|
||||
<Limit Create-Job Print-Job Print-URI Validate-Job>
|
||||
Order deny,allow
|
||||
</Limit>
|
||||
|
||||
```
|
||||
|
||||
能够允许在 cupsd.conf 中使用的文件、目录、和用户配置命令,现在都存储在作为替代的 cups-files.conf 中。这是为了防范某些类型的提权攻击。列表 12 展示了 cups-files.conf 文件中的一些条目。注意,正如在文件层次结构标准(FHS)中所期望的那样,打印池文件默认保存在文件系统的 /var/spool 目录中。查看 man 页面了解 cupsd.conf 和 cups-files.conf 配置文件的更多信息。
|
||||
|
||||
###### 列表 12. 默认的 /etc/cups/cups-files.conf 配置文件的部分内容
|
||||
```
|
||||
# Location of the file listing all of the local printers...
|
||||
#Printcap /etc/printcap
|
||||
|
||||
# Format of the Printcap file...
|
||||
#PrintcapFormat bsd
|
||||
#PrintcapFormat plist
|
||||
#PrintcapFormat solaris
|
||||
|
||||
# Location of all spool files...
|
||||
#RequestRoot /var/spool/cups
|
||||
|
||||
# Location of helper programs...
|
||||
#ServerBin /usr/lib/cups
|
||||
|
||||
# SSL/TLS keychain for the scheduler...
|
||||
#ServerKeychain ssl
|
||||
|
||||
# Location of other configuration files...
|
||||
#ServerRoot /etc/cups
|
||||
|
||||
```
|
||||
|
||||
列表 12 引用了 /etc/printcap 文件。这是 LPD 打印服务器的配置文件的名字,并且一些应用程序仍然使用它去确定可用的打印机和它们的属性。它通常是在 CUPS 系统上自动生成的,因此,你可能没有必要去修改它。但是,如果你在诊断用户打印问题,你可能需要去检查它。列表 13 展示了一个示例。
|
||||
|
||||
###### 列表 13. 自动生成的 /etc/printcap
|
||||
```
|
||||
# This file was automatically generated by cupsd(8) from the
|
||||
# /etc/cups/printers.conf file. All changes to this file
|
||||
# will be lost.
|
||||
HL-2280DW|Brother HL-2280DW:rm=atticf27:rp=HL-2280DW:
|
||||
anyprint|Any available printer:rm=atticf27:rp=anyprint:
|
||||
XP-610|EPSON XP-610 Series:rm=atticf27:rp=XP-610:
|
||||
|
||||
```
|
||||
|
||||
这个文件中的每一行都有一个打印机名字、打印机描述,远程机器(rm)的名字、以及那个远程机器上的远程打印机(rp)。老的 /etc/printcap 文件也描述了打印机的能力。
|
||||
|
||||
#### 文件转换过滤器
|
||||
|
||||
你可以使用 CUPS 打印许多类型的文件,包括明文的文本文件、PDF、PostScript、和各种格式的图像文件,你只需要提供要打印的文件名,除此之外你再无需向 `lpr` 或 `lp` 命令提供更多的信息。这个神奇的壮举是通过使用过滤器来实现的。实际上,这些年来最流行的过滤器就命名为 magicfilter。
|
||||
|
||||
当打印一个文件时,CUPS 使用多用途因特网邮件扩展(MIME)类型去决定合适的转换过滤器。其它的打印包可能使用由 `file` 命令使用的神奇数字机制。关于 `file` 或者 `magic` 的更多信息可以查看它们的 man 页面。
|
||||
|
||||
输入文件被过滤器转换成中间层的光栅格式或者 PostScript 格式。一些作业信息,比如打印数量也会被添加进去。数据最终通过一个 bechend 发送到目标打印机。还有一些可以用手动过滤的输入文件的过滤器。你可以通过这些过滤器获得特殊格式的结果,或者去处理一些 CUPS 原生并不支持的文件格式。
|
||||
|
||||
#### 添加打印机
|
||||
|
||||
CUPS 支持多种打印机,包括:
|
||||
|
||||
* 本地连接的并行口和 USB 口打印机
|
||||
* 因特网打印协议(IPP)打印机
|
||||
* 远程 LPD 打印机
|
||||
* 使用 SAMBA 的 Microsoft® Windows® 打印机
|
||||
* 使用 NCP 的 Novell 打印机
|
||||
* HP Jetdirect 打印机
|
||||
|
||||
|
||||
|
||||
当系统启动或者设备连接时,现在的大多数系统都会尝试自动检测和自动配置本地硬件。同样,许多网络打印机也可以被自动检测到。使用 CUPS 的 web 管理工具(<http://localhost:631> 或者 <http://127.0.0.1:631>)去搜索或添加打印机。许多发行版都包含它们自己的配置工具,比如,在 SUSE 系统上的 YaST。图 2 展示了使用 localhost:631 的 CUPS 界面,图 3 展示了 Fedora 27 上的 GNOME 打印机设置对话框。
|
||||
|
||||
###### 图 2. 使用 CUPS 的 web 界面
|
||||
|
||||
|
||||
![Using the CUPS web interface][5]
|
||||
|
||||
###### 图 3. Fedora 27 上的打印机设置
|
||||
|
||||
|
||||
![Using printer settings on Fedora 27][6]
|
||||
|
||||
你也可以从命令行配置打印机。在配置打印机之前,你需要一些关于打印机和它的连接方式的基本信息。如果是一个远程系统,你还需要一个用户 ID 和密码。
|
||||
|
||||
你需要去知道你的打印机使用什么样的驱动程序。不是所有的打印机都支持 Linux,有些打印机在 Linux 上压根就不能使用,或者功能受限。你可以去 OpenPrinting.org(查看相关主题)去查看是否有你的特定的打印机的驱动程序。`lpinfo` 命令也可以帮你识别有效的设备类型和驱动程序。使用 `-v` 选项去列出支持的设备,使用 `-m` 选项去列出驱动程序,如列表 14 所示。
|
||||
|
||||
###### 列表 14. 可用的打印机驱动程序
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i xp-610
|
||||
lsb/usr/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
EPSON XP-610 Series, Epson Inkjet Printer Driver (ESC/P-R) for Linux
|
||||
[ian@atticf27 ~]$ locate "Epson-XP-610_Series-epson-escpr-en.ppd.gz"
|
||||
/usr/share/ppd/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
[ian@atticf27 ~]$ lpinfo -v
|
||||
network socket
|
||||
network ipps
|
||||
network lpd
|
||||
network beh
|
||||
network ipp
|
||||
network http
|
||||
network https
|
||||
direct hp
|
||||
serial serial:/dev/ttyS0?baud=115200
|
||||
direct parallel:/dev/lp0
|
||||
network smb
|
||||
direct hpfax
|
||||
network dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
network dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
network lpd://BRN001BA98A1891/BINARY_P1
|
||||
network lpd://192.168.1.38:515/PASSTHRU
|
||||
|
||||
```
|
||||
|
||||
Epson-XP-610_Series-epson-escpr-en.ppd.gz 驱动程序在我的系统上位于 /usr/share/ppd/Epson/epson-inkjet-printer-escpr/ 目录中。
|
||||
|
||||
如果你找不到驱动程序,你可以到打印机生产商的网站看看,说不上会有专用的驱动程序。例如,在写这篇文章的时候,Brother 就有一个我的 HL-2280DW 打印机的驱动程序,但是,这个驱动程序在 OpenPrinting.org 上还没有列出来。
|
||||
|
||||
如果你收集齐了基本信息,你可以如列表 15 所示的那样,使用 `lpadmin` 命令去配置打印机。为此,我将为我的 HL-2280DW 打印机创建另外一个实例,以便于双面打印。
|
||||
|
||||
###### 列表 15. 配置一台打印机
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i "hl.*2280"
|
||||
HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
lsb/usr/HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW-duplex -E -m HL2280DW.ppd \
|
||||
> -v dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/ \
|
||||
> -D "Brother 1" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Tue 30 Jan 2018 10:56:10 AM EST
|
||||
HL-2280DW-duplex accepting requests since Wed 31 Jan 2018 11:41:16 AM EST
|
||||
HXP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
你可以使用带 `-c` 选项的 `lpadmin` 命令去创建一个仅用于双面打印的新类,而不用为了双面打印去创建一个打印机的副本。
|
||||
|
||||
如果你需要删除一台打印机,使用带 `-x` 选项的 `lpadmin` 命令。
|
||||
|
||||
列表 16 展示了如何去删除打印机和创建一个替代类。
|
||||
|
||||
###### 列表 16. 删除一个打印机和创建一个类
|
||||
```
|
||||
[ian@atticf27 ~]$ lpadmin -x HL-2280DW-duplex
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW -c duplex -E -D "Duplex printing" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ cupsenable duplex
|
||||
[ian@atticf27 ~]$ cupsaccept duplex
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
duplex accepting requests since Wed 31 Jan 2018 12:12:05 PM EST
|
||||
HL-2280DW accepting requests since Wed 31 Jan 2018 11:51:16 AM EST
|
||||
XP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
你也可以使用 `lpadmin` 或者 `lpoptions` 命令去设置各种打印机选项。详细信息请查看 man 页面。
|
||||
|
||||
### 排错
|
||||
|
||||
如果你有一个打印问题,尝试下列的提示:
|
||||
|
||||
* 确保 CUPS 服务器正在运行。你可以使用 `lpstat` 命令,如果它不能连接到 cupsd 守护程序,它将会报告一个错误。或者,你可以使用 `ps -ef` 命令在输出中去检查是否有 cupsd。
|
||||
* 如果你尝试为打印去排队一个作业,而得到一个错误信息,指示打印机不接受这个作业,你可以使用 `lpstat -a` 或者 `lpc status` 去检查那个打印机可接受的作业。
|
||||
* 如果一个队列中的作业没有打印,使用 `lpstat -p` 或 `lpc status` 去检查那个打印机是否接受作业。如前面所讨论的那样,你可能需要将这个作业移动到其它的打印机。
|
||||
* 如果这个打印机是远程的,检查它在远程系统上是否存在,并且是可操作的。
|
||||
* 检查配置文件,确保特定的用户或者远程系统允许在这个打印机上打印。
|
||||
* 确保防火墙允许远程打印请求,是否允许从其它系统到你的系统,或者从你的系统到其它系统的数据包通讯。
|
||||
* 验证是否有正确的驱动程序。
|
||||
|
||||
|
||||
|
||||
正如你所见,打印涉及到你的系统中的几个组件,甚至还有网络。在本教程中,基于篇幅的考虑,我们仅为诊断给你提供了几个着手点。大多数的 CUPS 系统也有实现我们所讨论的命令行功能的图形界面。一般情况下,这个界面是从本地主机使用浏览器指向 631 端口(<http://localhost:631> 或 <http://127.0.0.1:631>)来访问的,如前面的图 2 所示。
|
||||
|
||||
你可以通过将 CUPS 运行在前台而不是做为一个守护进程来诊断它的问题。如果有需要,你也可以通过这种方式去测试替代的配置文件。运行 `cupsd -h` 获得更多信息,或者查看 man 页面。
|
||||
|
||||
CUPS 也管理一个访问日志和错误日志。你可以在 cupsd.conf 中使用 LogLevel 语句来改变日志级别。默认情况下,日志是保存在 /var/log/cups 目录。它们可以在浏览器界面(<http://localhost:631>)下,从 **Administration** 选项卡中查看。使用不带任何选项的 `cupsctl` 命令可以显示日志选项。也可以编辑 cupsd.conf 或者使用 `cupsctl` 去调整各种日志参数。查看 `cupsctl` 命令的 man 页面了解更多信息。
|
||||
|
||||
在 Ubuntu 的 Wiki 页面上的 [调试打印问题][7] 页面也是一个非常好的学习的地方。
|
||||
|
||||
它包含了打印和 CUPS 的介绍。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-4/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
[3]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/gimp-print.jpg
|
||||
[4]:https://www.ibm.com/developerworks/library/l-lpic1-101-3/
|
||||
[5]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-cups-web.jpg
|
||||
[6]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-settings.jpg
|
||||
[7]:https://wiki.ubuntu.com/DebuggingPrintingProblems
|
||||
Loading…
Reference in New Issue
Block a user