mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-31 23:30:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
f1db195cb2
74
sources/talk/20190123 Book Review- Fundamentals of Linux.md
Normal file
74
sources/talk/20190123 Book Review- Fundamentals of Linux.md
Normal file
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Book Review: Fundamentals of Linux)
|
||||
[#]: via: (https://itsfoss.com/fundamentals-of-linux-book-review)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
Book Review: Fundamentals of Linux
|
||||
======
|
||||
|
||||
There are many great books that cover the basics of what Linux is and how it works. Today, I will be taking a look at one such book. Today, the subject of our discussion is [Fundamentals of Linux][1] by Oliver Pelz and is published by [PacktPub][2].
|
||||
|
||||
[Oliver Pelz][3] has over ten years of experience as a software developer and a system administrator. He holds a degree in bioinformatics.
|
||||
|
||||
### What is the book ‘Fundamentals of Linux’ about?
|
||||
|
||||
![Fundamental of Linux books][4]
|
||||
|
||||
As can be guessed from the title, the goal of Fundamentals of Linux is to give the reader a strong foundation from which to learn about the Linux command line. The book is a little over two hundred pages long, so it only focuses on teaching the everyday tasks and problems that users commonly encounter. The book is designed for readers who want to become Linux administrators.
|
||||
|
||||
The first chapter starts out by giving an overview of virtualization. From there the author instructs how to create a virtual instance of [CentOS][5] in [VirtualBox][6], how to clone it, and how to use snapshots. You will also learn how to connect to the virtual machines via SSH.
|
||||
|
||||
The second chapter covers the basics of the Linux command line. This includes shell globbing, shell expansion, how to work with file names that contain spaces or special characters. It also explains how to interpret a command’s manual page, as well as, how to use `sed`, `awk`, and to navigate the Linux file system.
|
||||
|
||||
The third chapter takes a more in-depth look at the Linux file system. You will learn how files are linked in Linux and how to search for them. You will also be given an overview of users, groups and file permissions. Since the chapter focuses on interacting with files, it tells how to read text files from the command line, as well as, an overview of how to use the VIM editor.
|
||||
|
||||
Chapter four focuses on using the command line. It covers important commands, such as `cat`, `sort`, `awk`. `tee`, `tar`, `rsync`, `nmap`, `htop` and more. You will learn what processes are and how they communicate with each other. This chapter also includes an introduction to Bash shell scripting.
|
||||
|
||||
The fifth and final chapter covers networking on Linux and other advanced command line concepts. The author discusses how Linux handles networking and gives examples using multiple virtual machines. He also covers how to install new programs and how to set up a firewall.
|
||||
|
||||
### Thoughts on the book
|
||||
|
||||
Fundamentals of Linux might seem short at five chapters and a little over two hundred pages. However, quite a bit of information is covered. You are given everything that you need to get going on the command line.
|
||||
|
||||
The book’s sole focus on the command line is one thing to keep in mind. You won’t get any information on how to use a graphical user interface. That is partially because Linux has so many different desktop environments and so many similar system applications that it would be hard to write a book that could cover all of the variables. It is also partially because the book is aimed at potential Linux administrators.
|
||||
|
||||
I was kinda surprised to see that the author used [CentOS][7] to teach Linux. I would have expected him to use a more common Linux distro, like Ubuntu, Debian, or Fedora. However, because it is a distro designed for servers very little changes over time, so it is a very stable basis for a course on Linux basics.
|
||||
|
||||
I’ve used Linux for over half a decade. I spent most of that time using desktop Linux. I dove into the terminal when I needed to, but didn’t spend lots of time there. I have performed many of the actions covered in this book using a mouse. Now, I know how to do the same things via the terminal. It won’t change the way I do my tasks, but it will help me understand what goes on behind the curtain.
|
||||
|
||||
If you have either just started using Linux or are planning to do so in the future, I would not recommend this book. It might be a little overwhelming. If you have already spent some time with Linux or can quickly grasp the technical language, this book may very well be for you.
|
||||
|
||||
If you think this book is apt for your learning needs, you can get the book from the link below:
|
||||
|
||||
We will be trying to review more Linux books in coming months so stay tuned with us.
|
||||
|
||||
What is your favorite introductory book on Linux? Let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][8].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/fundamentals-of-linux-book-review
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.packtpub.com/networking-and-servers/fundamentals-linux
|
||||
[2]: https://www.packtpub.com/
|
||||
[3]: http://www.oliverpelz.de/index.html
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/fundamentals-of-linux-book-review.jpeg?resize=800%2C450&ssl=1
|
||||
[5]: https://centos.org/
|
||||
[6]: https://www.virtualbox.org/
|
||||
[7]: https://www.centos.org/
|
||||
[8]: http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,90 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Roland, a random selection tool for the command line)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tools-roland)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with Roland, a random selection tool for the command line
|
||||
======
|
||||
|
||||
Get help making hard choices with Roland, the seventh in our series on open source tools that will make you more productive in 2019.
|
||||
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the seventh of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Roland
|
||||
|
||||
By the time the workday has ended, often the only thing I want to think about is hitting the couch and playing the video game of the week. But even though my professional obligations stop at the end of the workday, I still have to manage my household. Laundry, pet care, making sure my teenager has what he needs, and most important: deciding what to make for dinner.
|
||||
|
||||
Like many people, I often suffer from [decision fatigue][1], and I make less-than-healthy choices for dinner based on speed, ease of preparation, and (quite frankly) whatever causes me the least stress.
|
||||
|
||||

|
||||
|
||||
[Roland][2] makes planning my meals much easier. Roland is a Perl application designed for tabletop role-playing games. It picks randomly from a list of items, such as monsters and hirelings. In essence, Roland does the same thing at the command line that a game master does when rolling physical dice to look up things in a table from the Game Master's Big Book of Bad Things to Do to Players.
|
||||
|
||||
With minor modifications, Roland can do so much more. For example, just by adding a table, I can enable Roland to help me choose what to cook for dinner.
|
||||
|
||||
The first step is installing Roland and all its dependencies.
|
||||
|
||||
```
|
||||
git clone git@github.com:rjbs/Roland.git
|
||||
cpan install Getopt::Long::Descriptive Moose \
|
||||
namespace::autoclean List:AllUtils Games::Dice \
|
||||
Sort::ByExample Data::Bucketeer Text::Autoformat \
|
||||
YAML::XS
|
||||
cd oland
|
||||
```
|
||||
|
||||
Next, I create a YAML document named **dinner** and enter all our meal options.
|
||||
|
||||
```
|
||||
type: list
|
||||
pick: 1
|
||||
items:
|
||||
- "frozen pizza"
|
||||
- "chipotle black beans"
|
||||
- "huevos rancheros"
|
||||
- "nachos"
|
||||
- "pork roast"
|
||||
- "15 bean soup"
|
||||
- "roast chicken"
|
||||
- "pot roast"
|
||||
- "grilled cheese sandwiches"
|
||||
```
|
||||
|
||||
Running the command **bin/roland dinner** will read the file and pick one of the options.
|
||||
|
||||
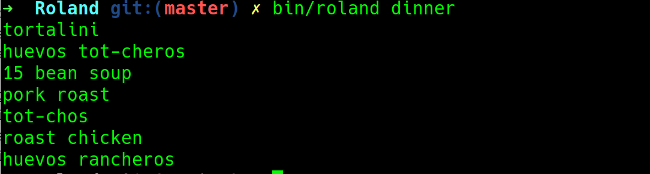
|
||||
|
||||
I like to plan for the week ahead so I can shop for all my ingredients in advance. The **pick** command determines how many items from the list to chose, and right now, the **pick** option is set to 1. If I want to plan a full week's dinner menu, I can just change **pick: 1** to **pick: 7** and it will give me a week's worth of dinners. You can also use the **-m** command line option to manually enter the choices.
|
||||
|
||||
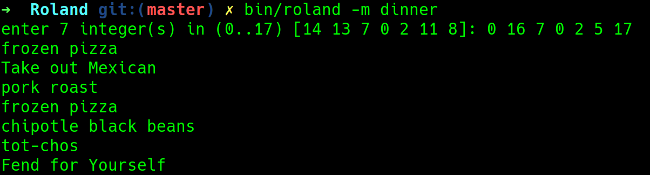
|
||||
|
||||
You can also do fun things with Roland, like adding a file named **8ball** with some classic phrases.
|
||||
|
||||

|
||||
|
||||
You can create all kinds of files to help with common decisions that seem so stressful after a long day of work. And even if you don't use it for that, you can still use it to decide which devious trap to set up for tonight's game.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tools-roland
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Decision_fatigue
|
||||
[2]: https://github.com/rjbs/Roland
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with TaskBoard, a lightweight kanban board)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-taskboard)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with TaskBoard, a lightweight kanban board
|
||||
======
|
||||
Check out the ninth tool in our series on open source tools that will make you more productive in 2019.
|
||||
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the ninth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### TaskBoard
|
||||
|
||||
As I wrote in the [second article][1] in this series, [kanban boards][2] are pretty popular these days. And not all kanban boards are created equal. [TaskBoard][3] is a PHP application that is easy to set up on an existing web server and has a set of functions that make it easy to use and manage.
|
||||
|
||||
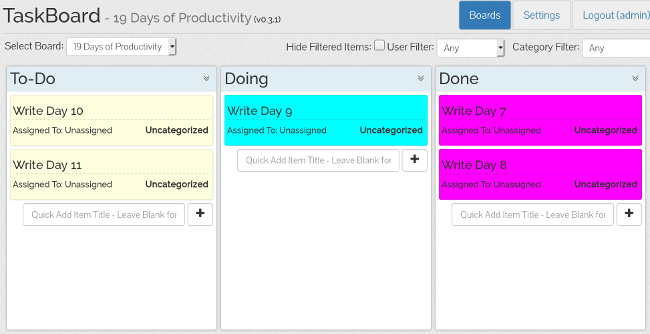
|
||||
|
||||
[Installation][4] is as simple as unzipping the files on your web server, running a script or two, and making sure the correct directories are accessible. The first time you start it up, you're presented with a login form, and then it's time to start adding users and making boards. Board creation options include adding the columns you want to use and setting the default color of the cards. You can also assign users to boards so everyone sees only the boards they need to see.
|
||||
|
||||
User management is lightweight, and all accounts are local to the server. You can set a default board for everyone on the server, and users can set their own default boards, too. These options can be useful when someone works on one board more than others.
|
||||
|
||||
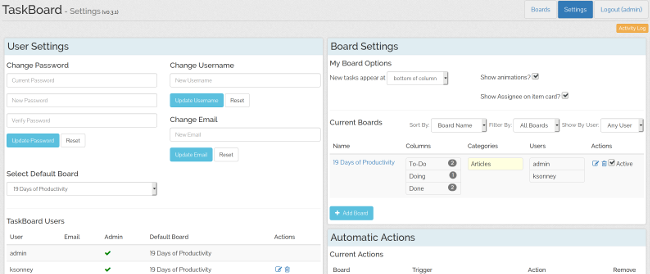
|
||||
|
||||
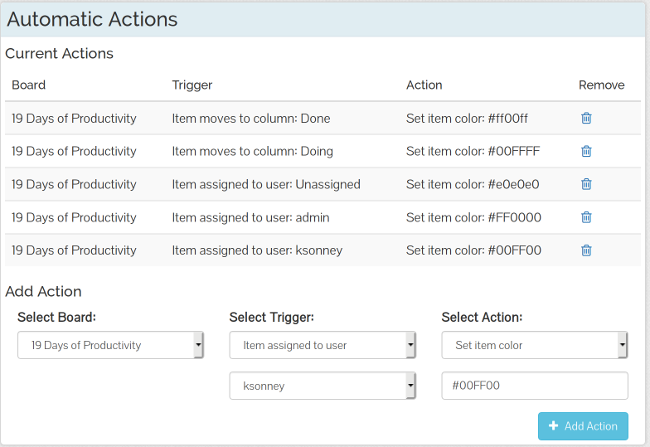
TaskBoard also allows you to create automatic actions, which are actions taken upon changes to user assignment, columns, or card categories. Although TaskBoard is not as powerful as some other kanban apps, you can set up automatic actions to make cards more visible for board users, clear due dates, and auto-assign new cards to people as needed. For example, in the screenshot below, if a card is assigned to the "admin" user, its color is changed to red, and when a card is assigned to my user, its color is changed to teal. I've also added an action to clear an item's due date if it's added to the "To-Do" column and to auto-assign cards to my user when that happens.
|
||||
|
||||
|
||||
|
||||
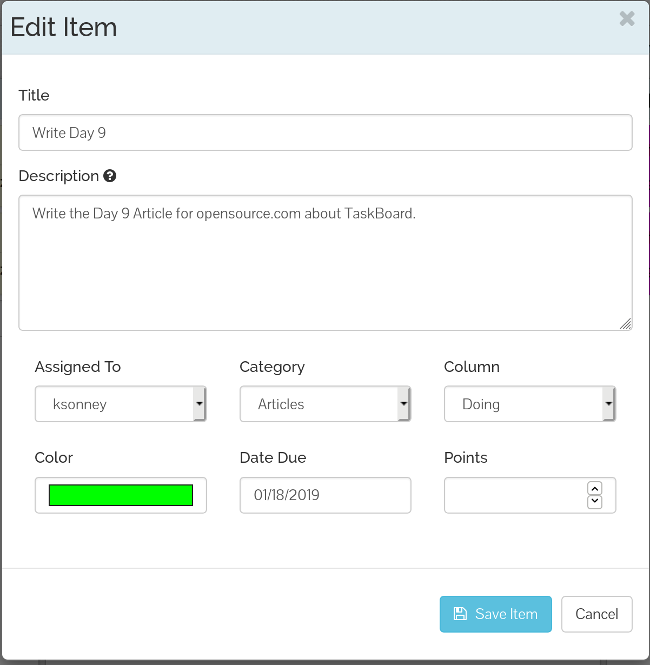
The cards are very straightforward. While they don't have a start date, they do have end dates and a points field. Points can be used for estimating the time needed, effort required, or just general priority. Using points is optional, but if you are using TaskBoard for scrum planning or other agile techniques, it is a really handy feature. You can also filter the view by users and categories. This can be helpful on a team with multiple work streams going on, as it allows a team lead or manager to get status information about progress or a person's workload.
|
||||
|
||||
|
||||
|
||||
If you need a reasonably lightweight kanban board, check out TaskBoard. It installs quickly, has some nice features, and is very, very easy to use. It's also flexible enough to be used for development teams, personal task tracking, and a whole lot more.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-taskboard
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/19/1/productivity-tool-wekan
|
||||
[2]: https://en.wikipedia.org/wiki/Kanban
|
||||
[3]: https://taskboard.matthewross.me/
|
||||
[4]: https://taskboard.matthewross.me/docs/
|
||||
@ -0,0 +1,149 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Resize OpenStack Instance (Virtual Machine) from Command line)
|
||||
[#]: via: (https://www.linuxtechi.com/resize-openstack-instance-command-line/)
|
||||
[#]: author: (Pradeep Kumar http://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
How to Resize OpenStack Instance (Virtual Machine) from Command line
|
||||
======
|
||||
|
||||
Being a Cloud administrator, resizing or changing resources of an instance or virtual machine is one of the most common tasks.
|
||||
|
||||

|
||||
|
||||
In Openstack environment, there are some scenarios where cloud user has spin a vm using some flavor( like m1.smalll) where root partition disk size is 20 GB, but at some point of time user wants to extends the root partition size to 40 GB. So resizing of vm’s root partition can be accomplished by using the resize option in nova command. During the resize, we need to specify the new flavor that will include disk size as 40 GB.
|
||||
|
||||
**Note:** Once you extend the instance resources like RAM, CPU and disk using resize option in openstack then you can’t reduce it.
|
||||
|
||||
**Read More on** : [**How to Create and Delete Virtual Machine(VM) from Command line in OpenStack**][1]
|
||||
|
||||
In this tutorial I will demonstrate how to resize an openstack instance from command line. Let’s assume I have an existing instance named “ **test_resize_vm** ” and it’s associated flavor is “m1.small” and root partition disk size is 20 GB.
|
||||
|
||||
Execute the below command from controller node to check on which compute host our vm “test_resize_vm” is provisioned and its flavor details
|
||||
|
||||
```
|
||||
:~# openstack server show test_resize_vm | grep -E "flavor|hypervisor"
|
||||
| OS-EXT-SRV-ATTR:hypervisor_hostname | compute-57 |
|
||||
| flavor | m1.small (2) |
|
||||
:~#
|
||||
```
|
||||
|
||||
Login to VM as well and check the root partition size,
|
||||
|
||||
```
|
||||
[[email protected] ~]# df -Th
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/vda1 xfs 20G 885M 20G 5% /
|
||||
devtmpfs devtmpfs 900M 0 900M 0% /dev
|
||||
tmpfs tmpfs 920M 0 920M 0% /dev/shm
|
||||
tmpfs tmpfs 920M 8.4M 912M 1% /run
|
||||
tmpfs tmpfs 920M 0 920M 0% /sys/fs/cgroup
|
||||
tmpfs tmpfs 184M 0 184M 0% /run/user/1000
|
||||
[[email protected] ~]# echo "test file for resize operation" > demofile
|
||||
[[email protected] ~]# cat demofile
|
||||
test file for resize operation
|
||||
[[email protected] ~]#
|
||||
```
|
||||
|
||||
Get the available flavor list using below command,
|
||||
|
||||
```
|
||||
:~# openstack flavor list
|
||||
+--------------------------------------|-----------------|-------|------|-----------|-------|-----------+
|
||||
| ID | Name | RAM | Disk | Ephemeral | VCPUs | Is Public |
|
||||
+--------------------------------------|-----------------|-------|------|-----------|-------|-----------+
|
||||
| 2 | m1.small | 2048 | 20 | 0 | 1 | True |
|
||||
| 3 | m1.medium | 4096 | 40 | 0 | 2 | True |
|
||||
| 4 | m1.large | 8192 | 80 | 0 | 4 | True |
|
||||
| 5 | m1.xlarge | 16384 | 160 | 0 | 8 | True |
|
||||
+--------------------------------------|-----------------|-------|------|-----------|-------|-----------+
|
||||
```
|
||||
|
||||
So we will be using the flavor “m1.medium” for resize operation, Run the beneath nova command to resize “test_resize_vm”,
|
||||
|
||||
Syntax: # nova resize {VM_Name} {flavor_id} —poll
|
||||
|
||||
```
|
||||
:~# nova resize test_resize_vm 3 --poll
|
||||
Server resizing... 100% complete
|
||||
Finished
|
||||
:~#
|
||||
```
|
||||
|
||||
Now confirm the resize operation using “ **openstack server –confirm”** command,
|
||||
|
||||
```
|
||||
~# openstack server list | grep -i test_resize_vm
|
||||
| 1d56f37f-94bd-4eef-9ff7-3dccb4682ce0 | test_resize_vm | VERIFY_RESIZE |private-net=10.20.10.51 |
|
||||
:~#
|
||||
```
|
||||
|
||||
As we can see in the above command output the current status of the vm is “ **verify_resize** “, execute below command to confirm resize,
|
||||
|
||||
```
|
||||
~# openstack server resize --confirm 1d56f37f-94bd-4eef-9ff7-3dccb4682ce0
|
||||
~#
|
||||
```
|
||||
|
||||
After the resize confirmation, status of VM will become active, now re-verify hypervisor and flavor details for the vm
|
||||
|
||||
```
|
||||
:~# openstack server show test_resize_vm | grep -E "flavor|hypervisor"
|
||||
| OS-EXT-SRV-ATTR:hypervisor_hostname | compute-58 |
|
||||
| flavor | m1.medium (3)|
|
||||
```
|
||||
|
||||
Login to your VM now and verify the root partition size
|
||||
|
||||
```
|
||||
[[email protected] ~]# df -Th
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/vda1 xfs 40G 887M 40G 3% /
|
||||
devtmpfs devtmpfs 1.9G 0 1.9G 0% /dev
|
||||
tmpfs tmpfs 1.9G 0 1.9G 0% /dev/shm
|
||||
tmpfs tmpfs 1.9G 8.4M 1.9G 1% /run
|
||||
tmpfs tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
|
||||
tmpfs tmpfs 380M 0 380M 0% /run/user/1000
|
||||
[[email protected] ~]# cat demofile
|
||||
test file for resize operation
|
||||
[[email protected] ~]#
|
||||
```
|
||||
|
||||
This confirm that VM root partition has been resized successfully.
|
||||
|
||||
**Note:** Due to some reason if resize operation was not successful and you want to revert the vm back to previous state, then run the following command,
|
||||
|
||||
```
|
||||
# openstack server resize --revert {instance_uuid}
|
||||
```
|
||||
|
||||
If have noticed “ **openstack server show** ” commands output, VM is migrated from compute-57 to compute-58 after resize. This is the default behavior of “nova resize” command ( i.e nova resize command will migrate the instance to another compute & then resize it based on the flavor details)
|
||||
|
||||
In case if you have only one compute node then nova resize will not work, but we can make it work by changing the below parameter in nova.conf file on compute node,
|
||||
|
||||
Login to compute node, verify the parameter value
|
||||
|
||||
If “ **allow_resize_to_same_host** ” is set as False then change it to True and restart the nova compute service.
|
||||
|
||||
**Read More on** [**OpenStack Deployment using Devstack on CentOS 7 / RHEL 7 System**][2]
|
||||
|
||||
That’s all from this tutorial, in case it helps you technically then please do share your feedback and comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/resize-openstack-instance-command-line/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linuxtechi.com/create-delete-virtual-machine-command-line-openstack/
|
||||
[2]: https://www.linuxtechi.com/openstack-deployment-devstack-centos-7-rhel-7/
|
||||
@ -0,0 +1,177 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Dcp (Dat Copy) – Easy And Secure Way To Transfer Files Between Linux Systems)
|
||||
[#]: via: (https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
Dcp (Dat Copy) – Easy And Secure Way To Transfer Files Between Linux Systems
|
||||
======
|
||||
|
||||
Linux has native command to perform this task nicely using scp and rsync. However, we need to try new things.
|
||||
|
||||
Also, we need to encourage the developers who is working new things with different concept and new technology.
|
||||
|
||||
We also written few articles about these kind of topic, you can navigate those by clicking the below appropriate links.
|
||||
|
||||
Those are **[OnionShare][1]** , **[Magic Wormhole][2]** , **[Transfer.sh][3]** and **ffsend**.
|
||||
|
||||
### What’s Dcp?
|
||||
|
||||
[dcp][4] copies files between hosts on a network using the peer-to-peer Dat network.
|
||||
|
||||
dcp can be seen as an alternative to tools like scp, removing the need to configure SSH access between hosts.
|
||||
|
||||
This lets you transfer files between two remote hosts, without you needing to worry about the specifics of how said hosts reach each other and regardless of whether hosts are behind NATs.
|
||||
|
||||
dcp requires zero configuration and is secure, fast, and peer-to-peer. Also, this is not production-ready software. Use at your own risk.
|
||||
|
||||
### What’s Dat Protocol?
|
||||
|
||||
Dat is a peer-to-peer protocol. A community-driven project powering a next-generation Web.
|
||||
|
||||
### How dcp works:
|
||||
|
||||
dcp will create a dat archive for a specified set of files or directories and, using the generated public key, lets you download said archive from a second host.
|
||||
|
||||
Any data shared over the network is encrypted using the public key of the archive, meaning data access is limited to those who have access to said key.
|
||||
|
||||
### dcp Use cases:
|
||||
|
||||
* Send files to multiple colleagues – just send the generated public key via chat and they can receive the files on their machine.
|
||||
* Sync files between two physical computers on your local network, without needing to set up SSH access.
|
||||
* Easily send files to a friend without needing to create a zip and upload it the cloud.
|
||||
* Copy files to a remote server when you have shell access but not SSH, for example on a kubernetes pod.
|
||||
* Share files between Linux/macOS and Windows, which isn’t exactly known for great SSH support.
|
||||
|
||||
|
||||
|
||||
### How To Install NodeJS & npm in Linux?
|
||||
|
||||
dcp package was written in JavaScript programming language so, we need to install NodeJS as a prerequisites to install dcp. Use the following command to install NodeJS in Linux.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][5]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo dnf install nodejs npm
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][6]** or **[APT Command][7]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo apt install nodejs npm
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][8]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo pacman -S nodejs npm
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][9]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum install nodejs npm
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][10]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo zypper nodejs6
|
||||
```
|
||||
|
||||
### How To Install dcp in Linux?
|
||||
|
||||
Once you have installed the NodeJS, use the following npm command to install dcp.
|
||||
|
||||
npm is a package manager for the JavaScript programming language. It is the default package manager for the JavaScript runtime environment Node.js.
|
||||
|
||||
```
|
||||
# npm i -g dat-cp
|
||||
```
|
||||
|
||||
### How to Send Files Through dcp?
|
||||
|
||||
Enter the files or folders which you want to transfer to remote server followed by the dcp command, And no need to mention the destination machine name.
|
||||
|
||||
```
|
||||
# dcp [File Name Which You Want To Transfer]
|
||||
```
|
||||
|
||||
It will generate a dat archive for the given file when you ran the dcp command. Once it’s done then it will geerate a public key at the bottom of the page.
|
||||
|
||||
### How To Receive Files Through dcp?
|
||||
|
||||
Enter the generated the public key on remote server to receive the files or folders.
|
||||
|
||||
```
|
||||
# dcp [Public Key]
|
||||
```
|
||||
|
||||
To recursively copy directories.
|
||||
|
||||
```
|
||||
# dcp [Folder Name Which You Want To Transfer] -r
|
||||
```
|
||||
|
||||
In the following example, we are going to transfer a single file.
|
||||
![][12]
|
||||
|
||||
Output for the above file transfer.
|
||||
![][13]
|
||||
|
||||
If you want to send more than one file, use the following format.
|
||||
![][14]
|
||||
|
||||
Output for the above file transfer.
|
||||
![][15]
|
||||
|
||||
To recursively copy directories.
|
||||
![][16]
|
||||
|
||||
Output for the above folder transfer.
|
||||
![][17]
|
||||
|
||||
It won’t allow you to download the files or folders in second time. It means once you downloaded the files or folders then immediately the link will be expired.
|
||||
![][18]
|
||||
|
||||
Navigate to man page to know about other options.
|
||||
|
||||
```
|
||||
# dcp --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/onionshare-secure-way-to-share-files-sharing-tool-linux/
|
||||
[2]: https://www.2daygeek.com/wormhole-securely-share-files-from-linux-command-line/
|
||||
[3]: https://www.2daygeek.com/transfer-sh-easy-fast-way-share-files-over-internet-from-command-line/
|
||||
[4]: https://github.com/tom-james-watson/dat-cp
|
||||
[5]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[6]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[7]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[9]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[11]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-1.png
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-2.png
|
||||
[14]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-3.jpg
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-4.jpg
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-6.jpg
|
||||
[17]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-7.jpg
|
||||
[18]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-5.jpg
|
||||
@ -0,0 +1,60 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Go For It, a flexible to-do list application)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-go-for-it)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with Go For It, a flexible to-do list application
|
||||
======
|
||||
Go For It, the tenth in our series on open source tools that will make you more productive in 2019, builds on the Todo.txt system to help you get more things done.
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the tenth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Go For It
|
||||
|
||||
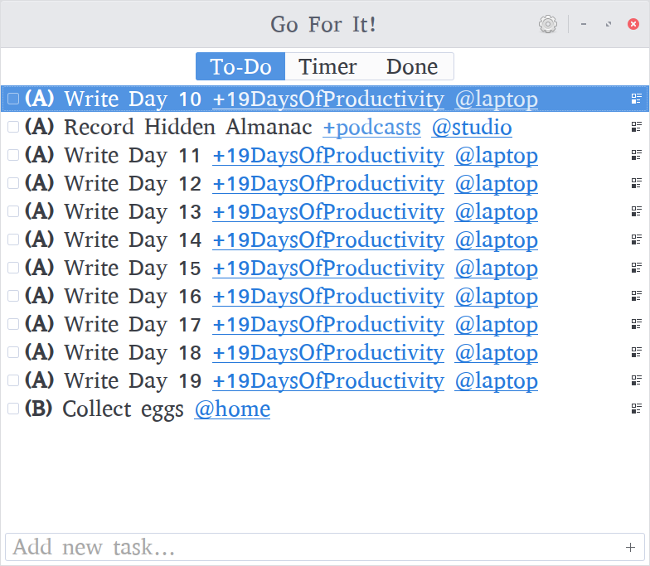
Sometimes what a person needs to be productive isn't a fancy kanban board or a set of notes, but a simple, straightforward to-do list. Something that is as basic as "add item to list, check it off when done." And for that, the [plain-text Todo.txt system][1] is possibly one of the easiest to use, and it's supported on almost every system out there.
|
||||
|
||||
|
||||
|
||||
[Go For It][2] is a simple, easy-to-use graphical interface for Todo.txt. It can be used with an existing file, if you are already using Todo.txt, and will create both a to-do and a done file if you aren't. It allows drag-and-drop ordering of tasks, allowing users to organize to-do items in the order they want to execute them. It also supports priorities, projects, and contexts, as outlined in the [Todo.txt format guidelines][3]. And, it can filter tasks by context or project simply by clicking on the project or context in the task list.
|
||||
|
||||
|
||||
|
||||
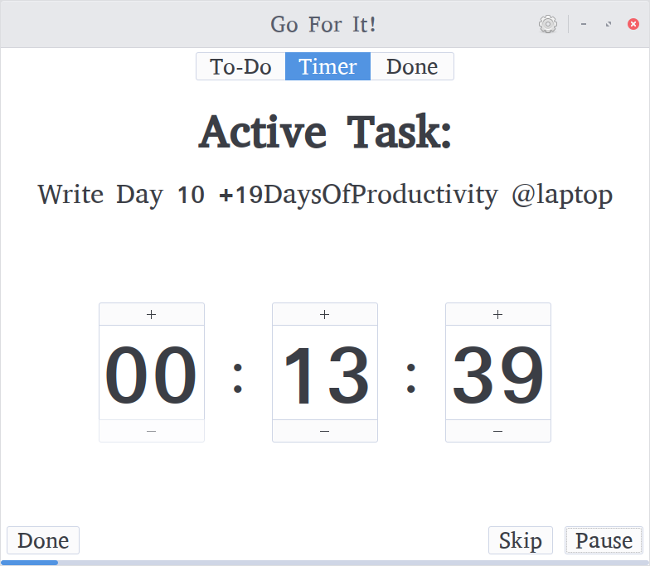
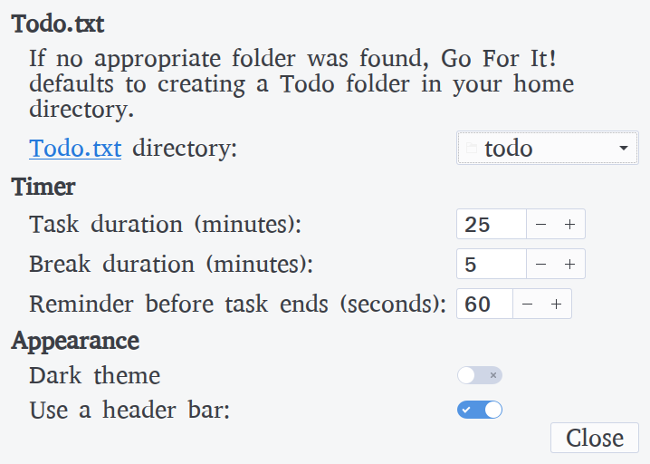
At first, Go For It may look the same as just about any other Todo.txt program, but looks can be deceiving. The real feature that sets Go For It apart is that it includes a built-in [Pomodoro Technique][4] timer. Select the task you want to complete, switch to the Timer tab, and click Start. When the task is done, simply click Done, and it will automatically reset the timer and pick the next task on the list. You can pause and restart the timer as well as click Skip to jump to the next task (or break). It provides a warning when 60 seconds are left for the current task. The default time for tasks is set at 25 minutes, and the default time for breaks is set at five minutes. You can adjust this in the Settings screen, as well as the location of the directory containing your Todo.txt and done.txt files.
|
||||
|
||||
|
||||
|
||||
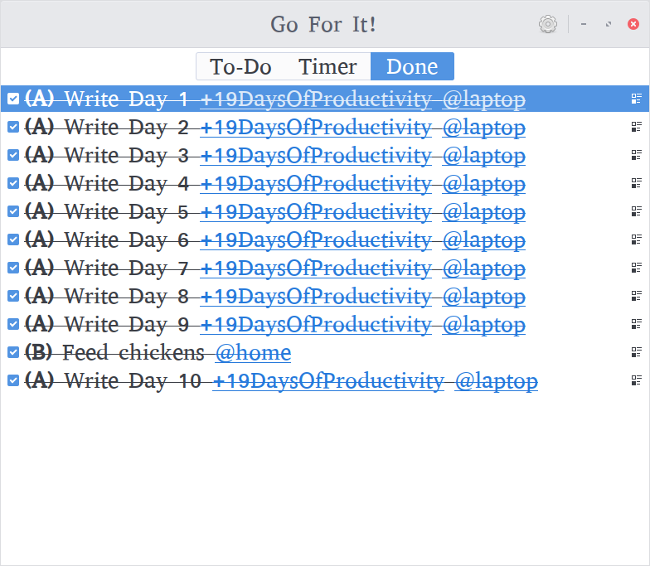
Go For It's third tab, Done, allows you to look at the tasks you've completed and clean them out when you want. Being able to look at what you've accomplished can be very motivating and a good way to get a feel for where you are in a longer process.
|
||||
|
||||
|
||||
|
||||
It also has all of Todo.txt's other advantages. Go For It's list is accessible by other programs that use the same format, including [Todo.txt's original command-line tool][5] and any [add-ons][6] you've installed.
|
||||
|
||||
Go For It seeks to be a simple tool to help manage your to-do list and get those items done. If you already use Todo.txt, Go For It is a fantastic addition to your toolkit, and if you don't, it's a really good way to start using one of the simplest and most flexible systems available.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-go-for-it
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://todotxt.org/
|
||||
[2]: http://manuel-kehl.de/projects/go-for-it/
|
||||
[3]: https://github.com/todotxt/todo.txt
|
||||
[4]: https://en.wikipedia.org/wiki/Pomodoro_Technique
|
||||
[5]: https://github.com/todotxt/todo.txt-cli
|
||||
[6]: https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory
|
||||
@ -0,0 +1,156 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Commands to help you monitor activity on your Linux server)
|
||||
[#]: via: (https://www.networkworld.com/article/3335200/linux/how-to-monitor-activity-on-your-linux-server.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Commands to help you monitor activity on your Linux server
|
||||
======
|
||||
The watch, top, and ac commands provide some effective ways to oversee what is happening on your Linux servers.
|
||||
|
||||

|
||||
|
||||
Linux systems provide a number of commands that make it easy to report on system activity. In this post, we're going to look at several commands that are especially helpful.
|
||||
|
||||
### The watch command
|
||||
|
||||
The **watch** command is one that makes it easy to repeatedly examine a variety of data on your system — user activities, running processes, logins, memory usage, etc. All the command really does is run the command that you specify repeatedly, each time overwriting the previously displayed output, but this lends itself to a very convenient way of monitoring what's happening on your system.
|
||||
|
||||
To start with a very basic and not particularly useful command, you could run **watch -n 5 date** and see a display with the current date and time that updates every 5 seconds. As you likely have guessed, the **-n 5** option specifies the number of seconds to wait between each run of the command. The default is 2 seconds. The command will run and update a display like this until you stop it with a ^c.
|
||||
|
||||
```
|
||||
Every 5.0s: date butterfly: Wed Jan 23 15:59:14 2019
|
||||
|
||||
Wed Jan 23 15:59:14 EST 2019
|
||||
```
|
||||
|
||||
As a more interesting command example, you can watch an updated list of whoever is logging into the server. As written, this command will update every 10 seconds. Users who log out will disappear from the current display and those who log in will come into view. If no one is logging in or out, the display will remain the same except for the time displayed.
|
||||
|
||||
```
|
||||
$ watch -n 10 who
|
||||
|
||||
Every 10.0s: who butterfly: Tue Jan 23 16:02:03 2019
|
||||
|
||||
shs :0 2019-01-23 09:45 (:0)
|
||||
dory pts/0 2019-01-23 15:50 (192.168.0.5)
|
||||
nemo pts/1 2019-01-23 16:01 (192.168.0.15)
|
||||
shark pts/3 2019-01-23 11:11 (192.168.0.27)
|
||||
```
|
||||
|
||||
If you just want to see how many users are logged in, you can get a user count along with load averages showing you how hard the system is working by having watch call the **uptime** command.
|
||||
|
||||
```
|
||||
$ watch uptime
|
||||
|
||||
Every 2.0s: uptime butterfly: Tue Jan 23 16:25:48 2019
|
||||
|
||||
16:25:48 up 22 days, 4:38, 3 users, load average: 1.15, 0.89, 1.02
|
||||
```
|
||||
|
||||
If you want to use watch to repeat a command that includes a pipe, you need to put the command between quote marks like this command that every 5 seconds shows you how many processes are running:
|
||||
|
||||
```
|
||||
$ watch -n 5 'ps -ef | wc -l'
|
||||
|
||||
Every 5.0s: ps -ef | wc -l butterfly: Tue Jan 23 16:11:54 2019
|
||||
|
||||
245
|
||||
```
|
||||
|
||||
To watch memory usage, you might try a command like this one:
|
||||
|
||||
```
|
||||
$ watch -n 5 free -m
|
||||
|
||||
Every 5.0s: free -m butterfly: Tue Jan 23 16:34:09 2019
|
||||
|
||||
total used free shared buff/cache available
|
||||
Mem: 5959 776 3276 12 1906 4878
|
||||
Swap: 2047 0 2047
|
||||
```
|
||||
|
||||
You could watch processes being run by one particular user with **watch,** but the **top** command provides a much better option.
|
||||
|
||||
### The top command
|
||||
|
||||
If you want to watch one particular user's processes, top has an ideal option for you — the -u option:
|
||||
|
||||
```
|
||||
$ top -u nemo
|
||||
top - 16:14:33 up 2 days, 4:27, 3 users, load average: 0.00, 0.01, 0.02
|
||||
Tasks: 199 total, 1 running, 198 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
MiB Mem : 5959.4 total, 3277.3 free, 776.4 used, 1905.8 buff/cache
|
||||
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 4878.4 avail Mem
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
23026 nemo 20 0 46340 7820 6504 S 0.0 0.1 0:00.05 systemd
|
||||
23033 nemo 20 0 149660 3140 72 S 0.0 0.1 0:00.00 (sd-pam)
|
||||
23125 nemo 20 0 63396 5100 4092 S 0.0 0.1 0:00.00 sshd
|
||||
23128 nemo 20 0 16836 5636 4284 S 0.0 0.1 0:00.03 zsh
|
||||
```
|
||||
|
||||
You not only see what processes the user is running, but the resources (CPU time and memory) that the process is consuming and how hard the system is working overall.
|
||||
|
||||
### The ac command
|
||||
|
||||
If you'd like to see how much time each of your users is spending logged in, you can make use of the **ac** command. This requires installation of the **acct** (Debian) or **psacct** (RHEL, Centos, etc.) package.
|
||||
|
||||
The **ac** command has a number of options, but it pulls its data from the current **wtmp** file. Here's an example showing the total number of hours users were logged in recently:
|
||||
|
||||
```
|
||||
$ ac
|
||||
total 1261.72
|
||||
```
|
||||
|
||||
This command shows total hours by user:
|
||||
|
||||
```
|
||||
$ ac -p
|
||||
shark 5.24
|
||||
nemo 5.52
|
||||
shs 1251.00
|
||||
total 1261.76
|
||||
```
|
||||
|
||||
This ac command shows daily counts of how many hours users were logged in:
|
||||
|
||||
```
|
||||
$ ac -d | tail -10
|
||||
|
||||
Jan 11 total 0.05
|
||||
Jan 12 total 1.36
|
||||
Jan 13 total 16.39
|
||||
Jan 15 total 55.33
|
||||
Jan 16 total 38.02
|
||||
Jan 17 total 28.51
|
||||
Jan 19 total 48.66
|
||||
Jan 20 total 1.37
|
||||
Jan 22 total 23.48
|
||||
Today total 9.83
|
||||
```
|
||||
|
||||
### Wrap-up
|
||||
|
||||
There are many commands for examining system activity. The **watch** command allows you to run just about any command in a repetitive way and watch how the output changes. The **top** command is a better option for focusing on user processes and also loops in a way that allows you to see the changes as they happen, while the **ac** command examines user connect time.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3335200/linux/how-to-monitor-activity-on-your-linux-server.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.facebook.com/NetworkWorld/
|
||||
[2]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Dockter: A container image builder for researchers)
|
||||
[#]: via: (https://opensource.com/article/19/1/dockter-image-builder-researchers)
|
||||
[#]: author: (Nokome Bentley https://opensource.com/users/nokome)
|
||||
|
||||
Dockter: A container image builder for researchers
|
||||
======
|
||||
Dockter supports the specific requirements of researchers doing data analysis, including those using R.
|
||||
|
||||

|
||||
|
||||
Dependency hell is ubiquitous in the world of software for research, and this affects research transparency and reproducibility. Containerization is one solution to this problem, but it creates new challenges for researchers. Docker is gaining popularity in the research community—but using it efficiently requires solid Dockerfile writing skills.
|
||||
|
||||
As a part of the [Stencila][1] project, which is a platform for creating, collaborating on, and sharing data-driven content, we are developing [Dockter][2], an open source tool that makes it easier for researchers to create Docker images for their projects. Dockter scans a research project's source code, generates a Dockerfile, and builds a Docker image. It has a range of features that allow flexibility and can help researchers learn more about working with Docker.
|
||||
|
||||
Dockter also generates a JSON file with information about the software environment (based on [CodeMeta][3] and [Schema.org][4]) to enable further processing and interoperability with other tools.
|
||||
|
||||
Several other projects create Docker images from source code and/or requirements files, including: [alibaba/derrick][5], [jupyter/repo2docker][6], [Gueils/whales][7], [o2r-project/containerit][8]; [openshift/source-to-image][9], and [ViDA-NYU/reprozip][10]. Dockter is similar to repo2docker, containerit, and ReproZip in that it is aimed at researchers doing data analysis (and supports R), whereas most other tools are aimed at software developers (and don't support R).
|
||||
|
||||
Dockter differs from these projects principally in that it:
|
||||
|
||||
* Performs static code analysis for multiple languages to determine package requirements
|
||||
* Uses package databases to determine package system dependencies and generate linked metadata (containerit does this for R)
|
||||
* Installs language package dependencies quicker (which can be useful during research projects where dependencies often change)
|
||||
* By default but optionally, installs Stencila packages so that Stencila client interfaces can execute code in the container
|
||||
|
||||
|
||||
|
||||
### Dockter's features
|
||||
|
||||
Following are some of the ways researchers can use Dockter.
|
||||
|
||||
#### Generating Docker images from code
|
||||
|
||||
Dockter scans a research project folder and builds a Docker image for it. If the folder already has a Dockerfile, Dockter will build the image from that. If not, Dockter will scan the source code files in the folder and generate one. Dockter currently handles R, Python, and Node.js source code. The .dockerfile (with the dot at the beginning) it generates is fully editable so users can take over from Dockter and carry on with editing the file as they see fit.
|
||||
|
||||
If the folder contains an R package [DESCRIPTION][11] file, Dockter will install the R packages listed under Imports into the image. If the folder does not contain a DESCRIPTION file, Dockter will scan all the R files in the folder for package import or usage statements and create a .DESCRIPTION file.
|
||||
|
||||
If the folder contains a [requirements.txt][12] file for Python, Dockter will copy it into the Docker image and use [pip][13] to install the specified packages. If the folder does not contain either of those files, Dockter will scan all the folder's .py files for import statements and create a .requirements.txt file.
|
||||
|
||||
If the folder contains a [package.json][14] file, Dockter will copy it into the Docker image and use npm to install the specified packages. If the folder does not contain a package.json file, Dockter will scan all the folder's .js files for require calls and create a .package.json file.
|
||||
|
||||
#### Capturing system requirements automatically
|
||||
|
||||
One of the headaches researchers face when hand-writing Dockerfiles is figuring out which system dependencies their project needs. Often this involves a lot of trial and error. Dockter automatically checks if any dependencies (or dependencies of dependencies, or dependencies of…) require system packages and installs those into the image. No more trial and error cycles of build, fail, add dependency, repeat…
|
||||
|
||||
#### Reinstalling language packages faster
|
||||
|
||||
If you have ever built a Docker image, you know it can be frustrating waiting for all your project's dependencies to reinstall when you add or remove just one.
|
||||
|
||||
This happens because of Docker's layered filesystem: When you update a requirements file, Docker throws away all the subsequent layers—including the one where you previously installed your dependencies. That means all the packages have to be reinstalled.
|
||||
|
||||
Dockter takes a different approach. It leaves the installation of language packages to the language package managers: Python's pip, Node.js's npm, and R's install.packages. These package managers are good at the job they were designed for: checking which packages need to be updated and updating only them. The result is much faster rebuilds, especially for R packages, which often involve compilation.
|
||||
|
||||
Dockter does this by looking for a special **# dockter** comment in a Dockerfile. Instead of throwing away layers, it executes all instructions after this comment in the same layer—thereby reusing packages that were previously installed.
|
||||
|
||||
#### Generating structured metadata for a project
|
||||
|
||||
Dockter uses [JSON-LD][15] as its internal data structure. When it parses a project's source code, it generates a JSON-LD tree using vocabularies from schema.org and CodeMeta.
|
||||
|
||||
Dockter also fetches metadata on a project's dependencies, which could be used to generate a complete software citation for the project.
|
||||
|
||||
### Easy to pick up, easy to throw away
|
||||
|
||||
Dockter is designed to make it easier to get started creating Docker images for your project. But it's also designed to not get in your way or restrict you from using bare Docker. You can easily and individually override any of the steps Dockter takes to build an image.
|
||||
|
||||
* **Code analysis:** To stop Dockter from doing code analysis and specify your project's package dependencies, just remove the leading **.** (dot) from the .DESCRIPTION, .requirements.txt, or .package.json files.
|
||||
|
||||
* **Dockerfile generation:** Dockter aims to generate readable Dockerfiles that conform to best practices. They include comments on what each section does and are a good way to start learning how to write your own Dockerfiles. To stop Dockter from generating a .Dockerfile and start editing it yourself, just rename it Dockerfile (without the leading dot).
|
||||
|
||||
|
||||
|
||||
|
||||
### Install Dockter
|
||||
|
||||
[Dockter is available][16] as pre-compiled, standalone command line tool or as a Node.js package. Click [here][17] for a demo.
|
||||
|
||||
We welcome and encourage all [contributions][18]!
|
||||
|
||||
A longer version of this article is available on the project's [GitHub page][19].
|
||||
|
||||
Aleksandra Pawlik will present [Building reproducible computing environments: a workshop for non-experts][20] at [linux.conf.au][21], January 21-25 in Christchurch, New Zealand.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/dockter-image-builder-researchers
|
||||
|
||||
作者:[Nokome Bentley][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/nokome
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://stenci.la/
|
||||
[2]: https://stencila.github.io/dockter/
|
||||
[3]: https://codemeta.github.io/index.html
|
||||
[4]: http://Schema.org
|
||||
[5]: https://github.com/alibaba/derrick
|
||||
[6]: https://github.com/jupyter/repo2docker
|
||||
[7]: https://github.com/Gueils/whales
|
||||
[8]: https://github.com/o2r-project/containerit
|
||||
[9]: https://github.com/openshift/source-to-image
|
||||
[10]: https://github.com/ViDA-NYU/reprozip
|
||||
[11]: http://r-pkgs.had.co.nz/description.html
|
||||
[12]: https://pip.readthedocs.io/en/1.1/requirements.html
|
||||
[13]: https://pypi.org/project/pip/
|
||||
[14]: https://docs.npmjs.com/files/package.json
|
||||
[15]: https://json-ld.org/
|
||||
[16]: https://github.com/stencila/dockter/releases/
|
||||
[17]: https://asciinema.org/a/pOHpxUqIVkGdA1dqu7bENyxZk?size=medium&cols=120&autoplay=1
|
||||
[18]: https://github.com/stencila/dockter/blob/master/CONTRIBUTING.md
|
||||
[19]: https://github.com/stencila/dockter
|
||||
[20]: https://2019.linux.conf.au/schedule/presentation/185/
|
||||
[21]: https://linux.conf.au/
|
||||
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (GStreamer WebRTC: A flexible solution to web-based media)
|
||||
[#]: via: (https://opensource.com/article/19/1/gstreamer)
|
||||
[#]: author: (Nirbheek Chauhan https://opensource.com/users/nirbheek)
|
||||
|
||||
GStreamer WebRTC: A flexible solution to web-based media
|
||||
======
|
||||
GStreamer's WebRTC implementation eliminates some of the shortcomings of using WebRTC in native apps, server applications, and IoT devices.
|
||||
|
||||

|
||||
|
||||
Currently, [WebRTC.org][1] is the most popular and feature-rich WebRTC implementation. It is used in Chrome and Firefox and works well for browsers, but the Native API and implementation have several shortcomings that make it a less-than-ideal choice for uses outside of browsers, including native apps, server applications, and internet of things (IoT) devices.
|
||||
|
||||
Last year, our company ([Centricular][2]) made an independent implementation of a Native WebRTC API available in GStreamer 1.14. This implementation is much easier to use and more flexible than the WebRTC.org Native API, is transparently compatible with WebRTC.org, has been tested with all browsers, and is already in production use.
|
||||
|
||||
### What are GStreamer and WebRTC?
|
||||
|
||||
[GStreamer][3] is an open source, cross-platform multimedia framework and one of the easiest and most flexible ways to implement any application that needs to play, record, or transform media-like data across a diverse scale of devices and products, including embedded (IoT, in-vehicle infotainment, phones, TVs, etc.), desktop (video/music players, video recording, non-linear editing, video conferencing, [VoIP][4] clients, browsers, etc.), servers (encode/transcode farms, video/voice conferencing servers, etc.), and [more][5].
|
||||
|
||||
The main feature that makes GStreamer the go-to multimedia framework for many people is its pipeline-based model, which solves one of the hardest problems in API design: catering to applications of varying complexity; from the simplest one-liners and quick solutions to those that need several hundreds of thousands of lines of code to implement their full feature set. If you want to learn how to use GStreamer, [Jan Schmidt's tutorial][6] from [LCA 2018][7] is a good place to start.
|
||||
|
||||
[WebRTC][8] is a set of draft specifications that build upon existing [RTP][9], [RTCP][10], [SDP][11], [DTLS][12], [ICE][13], and other real-time communication (RTC) specifications and define an API for making them accessible using browser JavaScript (JS) APIs.
|
||||
|
||||
People have been doing real-time communication over [IP][14] for [decades][15] with the protocols WebRTC builds upon. WebRTC's real innovation was creating a bridge between native applications and web apps by defining a standard yet flexible API that browsers can expose to untrusted JavaScript code.
|
||||
|
||||
These specifications are [constantly being improved][16], which, combined with the ubiquitous nature of browsers, means WebRTC is fast becoming the standard choice for video conferencing on all platforms and for most applications.
|
||||
|
||||
### **Everything is great, let's build amazing apps!**
|
||||
|
||||
Not so fast, there's more to the story! For web apps, the [PeerConnection API][17] is [everywhere][18]. There are some browser-specific quirks, and the API keeps changing, but the [WebRTC JS adapter][19] handles most of that. Overall, the web app experience is mostly 👍.
|
||||
|
||||
Unfortunately, for native code or applications that need more flexibility than a sandboxed JavaScript app can achieve, there haven't been a lot of great options.
|
||||
|
||||
[Libwebrtc][20] (Google's implementation), [Janus][21], [Kurento][22], and [OpenWebRTC][23] have traditionally been the main contenders, but each implementation has its own inflexibilities, shortcomings, and constraints.
|
||||
|
||||
Libwebrtc is still the most mature implementation, but it is also the most difficult to work with. Since it's embedded inside Chrome, it's a moving target and the project [is quite difficult to build and integrate][24]. These are all obstacles for native or server app developers trying to quickly prototype and experiment with things.
|
||||
|
||||
Also, WebRTC was not built for multimedia, so the lower layers get in the way of non-browser use cases and applications. It is quite painful to do anything other than the default "set raw media, transmit" and "receive from remote, get raw media." This means if you want to use your own filters or hardware-specific codecs or sinks/sources, you end up having to fork libwebrtc.
|
||||
|
||||
[**OpenWebRTC**][23] by Ericsson was the first attempt to rectify this situation. It was built on top of GStreamer. Its target audience was app developers, and it fit the bill quite well as a proof of concept—even though it used a custom API and some of the architectural decisions made it quite inflexible for most other uses. However, after an initial flurry of activity around the project, momentum petered out, the project failed to gather a community, and it is now effectively dead. Full disclosure: Centricular worked with Ericsson to polish some of the rough edges around the project immediately prior to its public release.
|
||||
|
||||
### WebRTC in GStreamer
|
||||
|
||||
GStreamer's WebRTC implementation gives you full control, as it does with any other [GStreamer pipeline][25].
|
||||
|
||||
As we said, the WebRTC standards build upon existing standards and protocols that serve similar purposes. GStreamer has supported almost all of them for a while now because they were being used for real-time communication, live streaming, and many other IP-based applications. This led Ericsson to choose GStreamer as the base for its OpenWebRTC project.
|
||||
|
||||
Combined with the [SRTP][26] and DTLS plugins that were written during OpenWebRTC's development, it means that the implementation is built upon a solid and well-tested base, and implementing WebRTC features does not involve as much code-from-scratch work as one might presume. However, WebRTC is a large collection of standards, and reaching feature-parity with libwebrtc is an ongoing task.
|
||||
|
||||
Due to decisions made while architecting WebRTCbin's internals, the API follows the PeerConnection specification quite closely. Therefore, almost all its missing features involve writing code that would plug into clearly defined sockets. For instance, since the GStreamer 1.14 release, the following features have been added to the WebRTC implementation and will be available in the next release of the GStreamer WebRTC:
|
||||
|
||||
* Forward error correction
|
||||
* RTP retransmission (RTX)
|
||||
* RTP BUNDLE
|
||||
* Data channels over SCTP
|
||||
|
||||
|
||||
|
||||
We believe GStreamer's API is the most flexible, versatile, and easy to use WebRTC implementation out there, and it will only get better as time goes by. Bringing the power of pipeline-based multimedia manipulation to WebRTC opens new doors for interesting, unique, and highly efficient applications. If you'd like to demo the technology and play with the code, build and run [these demos][27], which include C, Rust, Python, and C# examples.
|
||||
|
||||
Matthew Waters will present [GStreamer WebRTC—The flexible solution to web-based media][28] at [linux.conf.au][29], January 21-25 in Christchurch, New Zealand.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/gstreamer
|
||||
|
||||
作者:[Nirbheek Chauhan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/nirbheek
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://webrtc.org/
|
||||
[2]: https://www.centricular.com/
|
||||
[3]: https://gstreamer.freedesktop.org/documentation/application-development/introduction/gstreamer.html
|
||||
[4]: https://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]: https://wiki.ligo.org/DASWG/GstLAL
|
||||
[6]: https://www.youtube.com/watch?v=ZphadMGufY8
|
||||
[7]: http://lca2018.linux.org.au/
|
||||
[8]: https://en.wikipedia.org/wiki/WebRTC
|
||||
[9]: https://en.wikipedia.org/wiki/Real-time_Transport_Protocol
|
||||
[10]: https://en.wikipedia.org/wiki/RTP_Control_Protocol
|
||||
[11]: https://en.wikipedia.org/wiki/Session_Description_Protocol
|
||||
[12]: https://en.wikipedia.org/wiki/Datagram_Transport_Layer_Security
|
||||
[13]: https://en.wikipedia.org/wiki/Interactive_Connectivity_Establishment
|
||||
[14]: https://en.wikipedia.org/wiki/Internet_Protocol
|
||||
[15]: https://en.wikipedia.org/wiki/Session_Initiation_Protocol
|
||||
[16]: https://datatracker.ietf.org/wg/rtcweb/documents/
|
||||
[17]: https://developer.mozilla.org/en-US/docs/Web/API/RTCPeerConnection
|
||||
[18]: https://caniuse.com/#feat=rtcpeerconnection
|
||||
[19]: https://github.com/webrtc/adapter
|
||||
[20]: https://github.com/aisouard/libwebrtc
|
||||
[21]: https://janus.conf.meetecho.com/
|
||||
[22]: https://www.kurento.org/kurento-architecture
|
||||
[23]: https://en.wikipedia.org/wiki/OpenWebRTC
|
||||
[24]: https://webrtchacks.com/building-webrtc-from-source/
|
||||
[25]: https://gstreamer.freedesktop.org/documentation/application-development/introduction/basics.html
|
||||
[26]: https://en.wikipedia.org/wiki/Secure_Real-time_Transport_Protocol
|
||||
[27]: https://github.com/centricular/gstwebrtc-demos/
|
||||
[28]: https://linux.conf.au/schedule/presentation/143/
|
||||
[29]: https://linux.conf.au/
|
||||
@ -0,0 +1,60 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Isotope, an open source webmail client)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-isotope)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Getting started with Isotope, an open source webmail client
|
||||
======
|
||||
Read rich-text emails with Isotope, a lightweight email client and the 11th in our series on open source tools that will make you more productive in 2019.
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the 11th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Isotope
|
||||
|
||||
As we discussed in the [fourth article in this series][1] (about Cypht), we all spend a whole lot of time dealing with email. There are many options for dealing with it, and I've spent hours upon hours trying to find the best email client that works for me. I think that is an important distinction: What works for me doesn't always work for everyone else. And sometimes what works for me is a full client like [Thunderbird][2], sometimes it is a console client like [Mutt][3], and sometimes it's a web-based interface like [Gmail][4] or [RoundCube][5].
|
||||
|
||||

|
||||
|
||||
[Isotope][6] is a locally hosted, web-based email client. It is exceptionally lightweight, uses IMAP exclusively, and takes up very little disk space. Unlike Cypht, Isotope has full HTML mail support, which means there are no issues displaying rich-text only emails.
|
||||
|
||||
|
||||
|
||||
Installing Isotope is very easy if you have [Docker][7] installed. You only need to copy the commands from the documentation into a console and press Enter. Point a browser at **localhost** to get the Isotope login screen, and entering your IMAP server, login name, and password will open the inbox view.
|
||||
|
||||
|
||||
|
||||
At this point, Isotope functions pretty much as you'd expect. Click a message to view it, click the pencil icon to create a new message, etc. You will note that the user interface (UI) is very minimalistic and doesn't have the typical buttons for things like "move to folder," "copy to folder," and "archive." You move messages around with drag and drop, so you don't really miss the buttons anyway.
|
||||
|
||||
|
||||
|
||||
Overall, Isotope is clean, fast, and works exceptionally well. Even better, it is under active development (the most recent commit was two hours before I wrote this article), so it is constantly getting improvements. You can check out the code and contribute to it on [GitHub][8].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-isotope
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/19/1/productivity-tool-cypht-email
|
||||
[2]: https://www.thunderbird.net/
|
||||
[3]: http://www.mutt.org/
|
||||
[4]: https://mail.google.com/
|
||||
[5]: https://roundcube.net/
|
||||
[6]: https://blog.marcnuri.com/isotope-mail-client-introduction/
|
||||
[7]: https://www.docker.com/
|
||||
[8]: https://github.com/manusa/isotope-mail
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Mind map yourself using FreeMind and Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/)
|
||||
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
Mind map yourself using FreeMind and Fedora
|
||||
======
|
||||

|
||||
|
||||
A mind map of yourself sounds a little far-fetched at first. Is this process about neural pathways? Or telepathic communication? Not at all. Instead, a mind map of yourself is a way to describe yourself to others visually. It also shows connections among the characteristics you use to describe yourself. It’s a useful way to share information with others in a clever but also controllable way. You can use any mind map application for this purpose. This article shows you how to get started using [FreeMind][1], available in Fedora.
|
||||
|
||||
### Get the application
|
||||
|
||||
The FreeMind application has been around a while. While the UI is a bit dated and could use a refresh, it’s a powerful app that offers many options for building mind maps. And of course it’s 100% open source. There are other mind mapping apps available for Fedora and Linux users, as well. Check out [this previous article that covers several mind map options][2].
|
||||
|
||||
Install FreeMind from the Fedora repositories using the Software app if you’re running Fedora Workstation. Or use this [sudo][3] command in a terminal:
|
||||
|
||||
```
|
||||
$ sudo dnf install freemind
|
||||
```
|
||||
|
||||
You can launch the app from the GNOME Shell Overview in Fedora Workstation. Or use the application start service your desktop environment provides. FreeMind shows you a new, blank map by default:
|
||||
|
||||
![][4]
|
||||
FreeMind initial (blank) mind map
|
||||
|
||||
A map consists of linked items or descriptions — nodes. When you think of something related to a node you want to capture, simply create a new node connected to it.
|
||||
|
||||
### Mapping yourself
|
||||
|
||||
Click in the initial node. Replace it with your name by editing the text and hitting **Enter**. You’ve just started your mind map.
|
||||
|
||||
What would you think of if you had to fully describe yourself to someone? There are probably many things to cover. How do you spend your time? What do you enjoy? What do you dislike? What do you value? Do you have a family? All of this can be captured in nodes.
|
||||
|
||||
To add a node connection, select the existing node, and hit **Insert** , or use the “light bulb” icon for a new child node. To add another node at the same level as the new child, use **Enter**.
|
||||
|
||||
Don’t worry if you make a mistake. You can use the **Delete** key to remove an unwanted node. There’s no rules about content. Short nodes are best, though. They allow your mind to move quickly when creating the map. Concise nodes also let viewers scan and understand the map easily later.
|
||||
|
||||
This example uses nodes to explore each of these major categories:
|
||||
|
||||
![][5]
|
||||
Personal mind map, first level
|
||||
|
||||
You could do another round of iteration for each of these areas. Let your mind freely connect ideas to generate the map. Don’t worry about “getting it right.” It’s better to get everything out of your head and onto the display. Here’s what a next-level map might look like.
|
||||
|
||||
![][6]
|
||||
Personal mind map, second level
|
||||
|
||||
You could expand on any of these nodes in the same way. Notice how much information you can quickly understand about John Q. Public in the example.
|
||||
|
||||
### How to use your personal mind map
|
||||
|
||||
This is a great way to have team or project members introduce themselves to each other. You can apply all sorts of formatting and color to the map to give it personality. These are fun to do on paper, of course. But having one on your Fedora system means you can always fix mistakes, or even make changes as you change.
|
||||
|
||||
Have fun exploring your personal mind map!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://freemind.sourceforge.net/wiki/index.php/Main_Page
|
||||
[2]: https://fedoramagazine.org/three-mind-mapping-tools-fedora/
|
||||
[3]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-19-15-17-04-1024x736.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-19-15-32-38-1024x736.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-19-15-38-00-1024x736.png
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (ODrive (Open Drive) – Google Drive GUI Client For Linux)
|
||||
[#]: via: (https://www.2daygeek.com/odrive-open-drive-google-drive-gui-client-for-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
ODrive (Open Drive) – Google Drive GUI Client For Linux
|
||||
======
|
||||
|
||||
This we had discussed in so many times. However, i will give a small introduction about it.
|
||||
|
||||
As of now there is no official Google Drive Client for Linux and we need to use unofficial clients.
|
||||
|
||||
There are many applications available in Linux for Google Drive integration.
|
||||
|
||||
Each application has came out with set of features.
|
||||
|
||||
We had written few articles about this in our website in the past.
|
||||
|
||||
Those are **[DriveSync][1]** , **[Google Drive Ocamlfuse Client][2]** and **[Mount Google Drive in Linux Using Nautilus File Manager][3]**.
|
||||
|
||||
Today also we are going to discuss about the same topic and the utility name is ODrive.
|
||||
|
||||
### What’s ODrive?
|
||||
|
||||
ODrive stands for Open Drive. It’s a GUI client for Google Drive which was written in electron framework.
|
||||
|
||||
It’s simple GUI which allow users to integrate the Google Drive with few steps.
|
||||
|
||||
### How To Install & Setup ODrive on Linux?
|
||||
|
||||
Since the developer is offering the AppImage package and there is no difficulty for installing the ODrive on Linux.
|
||||
|
||||
Simple download the latest ODrive AppImage package from developer github page using **wget Command**.
|
||||
|
||||
```
|
||||
$ wget https://github.com/liberodark/ODrive/releases/download/0.1.3/odrive-0.1.3-x86_64.AppImage
|
||||
```
|
||||
|
||||
You have to set executable file permission to the ODrive AppImage file.
|
||||
|
||||
```
|
||||
$ chmod +x odrive-0.1.3-x86_64.AppImage
|
||||
```
|
||||
|
||||
Simple run the following ODrive AppImage file to launch the ODrive GUI for further setup.
|
||||
|
||||
```
|
||||
$ ./odrive-0.1.3-x86_64.AppImage
|
||||
```
|
||||
|
||||
You might get the same window like below when you ran the above command. Just hit the **`Next`** button for further setup.
|
||||
![][5]
|
||||
|
||||
Click **`Connect`** link to add a Google drive account.
|
||||
![][6]
|
||||
|
||||
Enter your email id which you want to setup a Google Drive account.
|
||||
![][7]
|
||||
|
||||
Enter your password for the given email id.
|
||||
![][8]
|
||||
|
||||
Allow ODrive (Open Drive) to access your Google account.
|
||||
![][9]
|
||||
|
||||
By default, it will choose the folder location. You can change if you want to use the specific one.
|
||||
![][10]
|
||||
|
||||
Finally hit **`Synchronize`** button to start download the files from Google Drive to your local system.
|
||||
![][11]
|
||||
|
||||
Synchronizing is in progress.
|
||||
![][12]
|
||||
|
||||
Once synchronizing is completed. It will show you all files downloaded.
|
||||
Once synchronizing is completed. It’s shows you that all the files has been downloaded.
|
||||
![][13]
|
||||
|
||||
I have seen all the files were downloaded in the mentioned directory.
|
||||
![][14]
|
||||
|
||||
If you want to sync any new files from local system to Google Drive. Just start the `ODrive` from the application menu but it won’t actual launch the application. But it will be running in the background that we can able to see by using the ps command.
|
||||
|
||||
```
|
||||
$ ps -df | grep odrive
|
||||
```
|
||||
|
||||
![][15]
|
||||
|
||||
It will automatically sync once you add a new file into the google drive folder. The same has been checked through notification menu. Yes, i can see one file was synced to Google Drive.
|
||||
![][16]
|
||||
|
||||
GUI is not loading after sync, and i’m not sure this functionality. I will check with developer and will add update based on his input.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/odrive-open-drive-google-drive-gui-client-for-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/drivesync-google-drive-sync-client-for-linux/
|
||||
[2]: https://www.2daygeek.com/mount-access-google-drive-on-linux-with-google-drive-ocamlfuse-client/
|
||||
[3]: https://www.2daygeek.com/mount-access-setup-google-drive-in-linux/
|
||||
[4]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-1.png
|
||||
[6]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-2.png
|
||||
[7]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-3.png
|
||||
[8]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-4.png
|
||||
[9]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-5.png
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-6.png
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-7.png
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-8a.png
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-9.png
|
||||
[14]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-11.png
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-9b.png
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-10.png
|
||||
@ -0,0 +1,128 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Orpie: A command-line reverse Polish notation calculator)
|
||||
[#]: via: (https://opensource.com/article/19/1/orpie)
|
||||
[#]: author: (Peter Faller https://opensource.com/users/peterfaller)
|
||||
|
||||
Orpie: A command-line reverse Polish notation calculator
|
||||
======
|
||||
Orpie is a scientific calculator that functions much like early, well-loved HP calculators.
|
||||

|
||||
Orpie is a text-mode [reverse Polish notation][1] (RPN) calculator for the Linux console. It works very much like the early, well-loved Hewlett-Packard calculators.
|
||||
|
||||
### Installing Orpie
|
||||
|
||||
RPM and DEB packages are available for most distributions, so installation is just a matter of using either:
|
||||
|
||||
```
|
||||
$ sudo apt install orpie
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```
|
||||
$ sudo yum install orpie
|
||||
```
|
||||
|
||||
Orpie has a comprehensive man page; new users may want to have it open in another terminal window as they get started. Orpie can be customized for each user by editing the **~/.orpierc** configuration file. The [orpierc(5)][2] man page describes the contents of this file, and **/etc/orpierc** describes the default configuration.
|
||||
|
||||
### Starting up
|
||||
|
||||
Start Orpie by typing **orpie** at the command line. The main screen shows context-sensitive help on the left and the stack on the right. The cursor, where you enter numbers you want to calculate, is at the bottom-right corner.
|
||||
|
||||
|
||||
|
||||
### Example calculation
|
||||
|
||||
For a simple example, let's calculate the factorial of **5 (2 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 3 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 4 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 5)**. First the long way:
|
||||
|
||||
| Keys | Result |
|
||||
| --------- | --------- |
|
||||
| 2 <enter> | Push 2 onto the stack |
|
||||
| 3 <enter> | Push 3 onto the stack |
|
||||
| * | Multiply to get 6 |
|
||||
| 4 <enter> | Push 4 onto the stack |
|
||||
| * | Multiply to get 24 |
|
||||
| 5 <enter> | Push 5 onto the stack |
|
||||
| * | Multiply to get 120 |
|
||||
|
||||
Note that the multiplication happens as soon as you type *****. If you hit **< enter>** after ***** , Orpie will duplicate the value at position 1 on the stack. (If this happens, you can drop the duplicate with **\**.)
|
||||
|
||||
Equivalent sequences are:
|
||||
|
||||
| Keys | Result |
|
||||
| ------------- | ------------- |
|
||||
| 2 <enter> 3 * 4 * 5 * | Faster! |
|
||||
| 2 <enter> 3 <enter> 4 <enter> 5 * * * | Same result |
|
||||
| 5 <enter> ' fact <enter> | Fastest: Use the built-in function |
|
||||
|
||||
Observe that when you enter **'** , the left pane changes to show matching functions as you type. In the example above, typing **fa** is enough to get the **fact** function. Orpie offers many functions—experiment by typing **'** and a few letters to see what's available.
|
||||
|
||||
|
||||
|
||||
Note that each operation replaces one or more values on the stack. If you want to store the value at position 1 in the stack, key in (for example) **@factot <enter>** and **S'**. To retrieve the value, key in (for example) **@factot <enter>** then **;** (if you want to see it; otherwise just leave **@factot** as the value for the next calculation).
|
||||
|
||||
### Constants and units
|
||||
|
||||
Orpie understands units and predefines many useful scientific constants. For example, to calculate the energy in a blue light photon at 400nm, calculate **E=hc/(400nm)**. The key sequences are:
|
||||
|
||||
| Keys | Result |
|
||||
| -------------- | -------------- |
|
||||
| C c <enter> | Get the speed of light in m/s |
|
||||
| C h <enter> | Get Planck's constant in Js |
|
||||
| * | Calculate h*c |
|
||||
| 400 <space> 9 n _ m | Input 4 _ 10^-9 m |
|
||||
| / | Do the division and get the result: 4.966 _ 10^-19 J |
|
||||
|
||||
Like choosing functions after typing **'** , typing **C** shows matching constants based on what you type.
|
||||
|
||||
|
||||
|
||||
### Matrices
|
||||
|
||||
Orpie can also do operations with matrices. For example, to multiply two 2x2 matrices:
|
||||
|
||||
| Keys | Result |
|
||||
| -------- | -------- |
|
||||
| [ 1 , 2 [ 3 , 4 <enter> | Stack contains the matrix [[ 1, 2 ][ 3, 4 ]] |
|
||||
| [ 1 , 0 [ 1 , 1 <enter> | Push the multiplier matrix onto the stack |
|
||||
| * | The result is: [[ 3, 2 ][ 7, 4 ]] |
|
||||
|
||||
Note that the **]** characters are automatically inserted—entering **[** starts a new row.
|
||||
|
||||
### Complex numbers
|
||||
|
||||
Orpie can also calculate with complex numbers. They can be entered or displayed in either polar or rectangular form. You can toggle between the polar and rectangular display using the **p** key, and between degrees and radians using the **r** key. For example, to multiply **3 + 4i** by **4 + 4i** :
|
||||
|
||||
| Keys | Result |
|
||||
| -------- | -------- |
|
||||
| ( 3 , 4 <enter> | The stack contains (3, 4) |
|
||||
| ( 4 , 4 <enter> | Push (4, 4) |
|
||||
| * | Get the result: (-4, 28) |
|
||||
|
||||
Note that as you go, the results are kept on the stack so you can observe intermediate results in a lengthy calculation.
|
||||
|
||||
|
||||
|
||||
### Quitting Orpie
|
||||
|
||||
You can exit from Orpie by typing **Q**. Your state is saved, so the next time you start Orpie, you'll find the stack as you left it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/orpie
|
||||
|
||||
作者:[Peter Faller][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/peterfaller
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Reverse_Polish_notation
|
||||
[2]: https://github.com/pelzlpj/orpie/blob/master/doc/orpierc.5
|
||||
154
sources/tech/20190124 Understanding Angle Brackets in Bash.md
Normal file
154
sources/tech/20190124 Understanding Angle Brackets in Bash.md
Normal file
@ -0,0 +1,154 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding Angle Brackets in Bash)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
|
||||
Understanding Angle Brackets in Bash
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Bash][1] provides many important built-in commands, like `ls`, `cd`, and `mv`, as well as regular tools such as `grep`, `awk,` and `sed`. But, it is equally important to know the punctuation marks -- [the glue in the shape of dots][2], commas, brackets. and quotes -- that allow you to transform and push data from one place to another. Take angle brackets (`< >`), for example.
|
||||
|
||||
### Pushing Around
|
||||
|
||||
If you are familiar with other programming and scripting languages, you may have used `<` and `>` as logical operators to check in a condition whether one value is larger or smaller than another. If you have ever written HTML, you have used angle brackets to enclose tags.
|
||||
|
||||
In shell scripting, you can also use brackets to push data from place to place, for example, to a file:
|
||||
|
||||
```
|
||||
ls > dir_content.txt
|
||||
```
|
||||
|
||||
In this example, instead of showing the contents of the directory on the command line, `>` tells the shell to copy it into a file called _dir_content.txt_. If _dir_content.txt_ doesn't exist, Bash will create it for you, but if _dir_content.txt_ already exists and is not empty, you will overwrite whatever it contained, so be careful!
|
||||
|
||||
You can avoid overwriting existing content by tacking the new stuff onto the end of the old stuff. For that you use `>>` (instead of `>`):
|
||||
|
||||
```
|
||||
ls $HOME > dir_content.txt; wc -l dir_content.txt >> dir_content.txt
|
||||
```
|
||||
|
||||
This line stores the list of contents of your home directory into _dir_content.txt_. You then count the number of lines in _dir_content.txt_ (which gives you the number of items in the directory) with [`wc -l`][3] and you tack that value onto the end of the file.
|
||||
|
||||
After running the command line on my machine, this is what my _dir_content.txt_ file looks like:
|
||||
|
||||
```
|
||||
Applications
|
||||
bin
|
||||
cloud
|
||||
Desktop
|
||||
Documents
|
||||
Downloads
|
||||
Games
|
||||
ISOs
|
||||
lib
|
||||
logs
|
||||
Music
|
||||
OpenSCAD
|
||||
Pictures
|
||||
Public
|
||||
Templates
|
||||
test_dir
|
||||
Videos
|
||||
17 dir_content.txt
|
||||
```
|
||||
|
||||
The mnemonic here is to look at `>` and `>>` as arrows. In fact, the arrows can point the other way, too. Say you have a file called _CBActors_ containing some names of actors and the number of films by the Coen brothers they have been in. Something like this:
|
||||
|
||||
```
|
||||
John Goodman 5
|
||||
John Turturro 3
|
||||
George Clooney 2
|
||||
Frances McDormand 6
|
||||
Steve Buscemi 5
|
||||
Jon Polito 4
|
||||
Tony Shalhoub 3
|
||||
James Gandolfini 1
|
||||
```
|
||||
|
||||
Something like
|
||||
|
||||
```
|
||||
sort < CBActors # Do this
|
||||
Frances McDormand 6 # And you get this
|
||||
George Clooney 2
|
||||
James Gandolfini 1
|
||||
John Goodman 5
|
||||
John Turturro 3
|
||||
Jon Polito 4
|
||||
Steve Buscemi 5
|
||||
Tony Shalhoub 3
|
||||
```
|
||||
|
||||
Will [sort][4] the list alphabetically. But then again, you don't need `<` here since `sort` already expects a file anyway, so `sort CBActors` will work just as well.
|
||||
|
||||
However, if you need to see who is the Coens' favorite actor, you can check with :
|
||||
|
||||
```
|
||||
while read name surname films; do echo $films $name $surname > filmsfirst.txt; done < CBActors
|
||||
```
|
||||
|
||||
Or, to make that a bit more readable:
|
||||
|
||||
```
|
||||
while read name surname films;\
|
||||
do
|
||||
echo $films $name $surname >> filmsfirst;\
|
||||
done < CBActors
|
||||
```
|
||||
|
||||
Let's break this down, shall we?
|
||||
|
||||
* the [`while ...; do ... done`][5] structure is a loop. The instructions between `do` and `done` are repeatedly executed while a condition is met, in this case...
|
||||
* ... the [`read`][6] instruction has lines to read. `read` reads from the standard input and will continue reading until there is nothing more to read...
|
||||
* ... And as standard input is fed in via `<` and comes from _CBActors_ , that means the `while` loop will loop until the last line of _CBActors_ is piped into the loop.
|
||||
* Getting back to `read` for a sec, the tool is clever enough to see that there are three distinct fields separated by spaces on each line of the file. That allows you to put the first field from each line in the `name` variable, the second in `surname` and the third in `films`. This comes in handy later, on the line that says `echo $films $name $surname >> filmsfirst;\`, allowing you to reorder the fields and push them into a file called _filmsfirst_.
|
||||
|
||||
|
||||
|
||||
At the end of all that, you have a file called _filmsfirst_ that looks like this:
|
||||
|
||||
```
|
||||
5 John Goodman
|
||||
3 John Turturro
|
||||
2 George Clooney
|
||||
6 Frances McDormand
|
||||
5 Steve Buscemi
|
||||
4 Jon Polito
|
||||
3 Tony Shalhoub
|
||||
1 James Gandolfini
|
||||
```
|
||||
|
||||
which you can now use with `sort`:
|
||||
|
||||
```
|
||||
sort -r filmsfirst
|
||||
```
|
||||
|
||||
to see who is the Coens' favorite actor. Yes, it is Frances McDormand. (The [`-r`][4] option reverses the sort, so McDormand ends up on top).
|
||||
|
||||
We'll look at more angles on this topic next time!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/2019/1/bash-shell-utility-reaches-50-milestone
|
||||
[2]: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
|
||||
[3]: https://linux.die.net/man/1/wc
|
||||
[4]: https://linux.die.net/man/1/sort
|
||||
[5]: http://tldp.org/HOWTO/Bash-Prog-Intro-HOWTO-7.html
|
||||
[6]: https://linux.die.net/man/2/read
|
||||
@ -0,0 +1,330 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (ffsend – Easily And Securely Share Files From Linux Command Line Using Firefox Send Client)
|
||||
[#]: via: (https://www.2daygeek.com/ffsend-securely-share-files-folders-from-linux-command-line-using-firefox-send-client/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
ffsend – Easily And Securely Share Files From Linux Command Line Using Firefox Send Client
|
||||
======
|
||||
|
||||
Linux users were preferred to go with scp or rsync for files or folders copy.
|
||||
|
||||
However, so many new options are coming to Linux because it’s a opensource.
|
||||
|
||||
Anyone can develop a secure software for Linux.
|
||||
|
||||
We had written multiple articles in our site in the past about this topic.
|
||||
|
||||
Even, today we are going to discuss the same kind of topic called ffsend.
|
||||
|
||||
Those are **[OnionShare][1]** , **[Magic Wormhole][2]** , **[Transfer.sh][3]** and **[Dcp – Dat Copy][4]**.
|
||||
|
||||
### What’s ffsend?
|
||||
|
||||
[ffsend][5] is a command line Firefox Send client that allow users to transfer and receive files and folders through command line.
|
||||
|
||||
It allow us to easily and securely share files and directories from the command line through a safe, private and encrypted link using a single simple command.
|
||||
|
||||
Files are shared using the Send service and the allowed file size is up to 2GB.
|
||||
|
||||
Others are able to download these files with this tool, or through their web browser.
|
||||
|
||||
All files are always encrypted on the client, and secrets are never shared with the remote host.
|
||||
|
||||
Additionally you can add a password for the file upload.
|
||||
|
||||
The uploaded files will be removed after the download (default count is 1 up to 10) or after 24 hours. This will make sure that your files does not remain online forever.
|
||||
|
||||
This tool is currently in the alpha phase. Use at your own risk. Also, only limited installation options are available right now.
|
||||
|
||||
### ffsend Features:
|
||||
|
||||
* Fully featured and friendly command line tool
|
||||
* Upload and download files and directories securely
|
||||
* Always encrypted on the client
|
||||
* Additional password protection, generation and configurable download limits
|
||||
* Built-in file and directory archiving and extraction
|
||||
* History tracking your files for easy management
|
||||
* Ability to use your own Send host
|
||||
* Inspect or delete shared files
|
||||
* Accurate error reporting
|
||||
* Low memory footprint, due to encryption and download/upload streaming
|
||||
* Intended to be used in scripts without interaction
|
||||
|
||||
|
||||
|
||||
### How To Install ffsend in Linux?
|
||||
|
||||
There is no package for each distributions except Debian and Arch Linux systems. However, we can easily get this utility by downloading the prebuilt appropriate binaries file based on the operating system and architecture.
|
||||
|
||||
Run the below command to download the latest available version for your operating system.
|
||||
|
||||
```
|
||||
$ wget https://github.com/timvisee/ffsend/releases/download/v0.1.2/ffsend-v0.1.2-linux-x64.tar.gz
|
||||
```
|
||||
|
||||
Extract the tar archive using the following command.
|
||||
|
||||
```
|
||||
$ tar -xvf ffsend-v0.1.2-linux-x64.tar.gz
|
||||
```
|
||||
|
||||
Run the following command to identify your path variable.
|
||||
|
||||
```
|
||||
$ echo $PATH
|
||||
/home/daygeek/.cargo/bin:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/lib/jvm/default/bin:/usr/bin/site_perl:/usr/bin/vendor_perl:/usr/bin/core_perl
|
||||
```
|
||||
|
||||
As i told previously, just move the executable file to your path directory.
|
||||
|
||||
```
|
||||
$ sudo mv ffsend /usr/local/sbin
|
||||
```
|
||||
|
||||
Run the `ffsend` command alone to get the basic usage information.
|
||||
|
||||
```
|
||||
$ ffsend
|
||||
ffsend 0.1.2
|
||||
Usage: ffsend [FLAGS] ...
|
||||
|
||||
Easily and securely share files from the command line.
|
||||
A fully featured Firefox Send client.
|
||||
|
||||
Missing subcommand. Here are the most used:
|
||||
ffsend upload ...
|
||||
ffsend download ...
|
||||
|
||||
To show all subcommands, features and other help:
|
||||
ffsend help [SUBCOMMAND]
|
||||
```
|
||||
|
||||
For Arch Linux based users can easily install it with help of **[AUR Helper][6]** , as this package is available in AUR repository.
|
||||
|
||||
```
|
||||
$ yay -S ffsend
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[DPKG Command][7]** to install ffsend.
|
||||
|
||||
```
|
||||
$ wget https://github.com/timvisee/ffsend/releases/download/v0.1.2/ffsend_0.1.2_amd64.deb
|
||||
$ sudo dpkg -i ffsend_0.1.2_amd64.deb
|
||||
```
|
||||
|
||||
### How To Send A File Using ffsend?
|
||||
|
||||
It’s not complicated. We can easily send a file using simple syntax.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
```
|
||||
$ ffsend upload [/Path/to/the/file/name]
|
||||
```
|
||||
|
||||
In the following example, we are going to upload a file called `passwd-up1.sh`. Once you upload the file then you will be getting the unique URL.
|
||||
|
||||
```
|
||||
$ ffsend upload passwd-up1.sh --copy
|
||||
Upload complete
|
||||
Share link: https://send.firefox.com/download/a4062553f4/#yy2_VyPaUMG5HwXZzYRmpQ
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
Just download the above unique URL to get the file in any remote system.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
```
|
||||
$ ffsend download [Generated URL]
|
||||
```
|
||||
|
||||
Output for the above command.
|
||||
|
||||
```
|
||||
$ ffsend download https://send.firefox.com/download/a4062553f4/#yy2_VyPaUMG5HwXZzYRmpQ
|
||||
Download complete
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
Use the following syntax format for directory upload.
|
||||
|
||||
```
|
||||
$ ffsend upload [/Path/to/the/Directory] --copy
|
||||
```
|
||||
|
||||
In this example, we are going to upload `2g` directory.
|
||||
|
||||
```
|
||||
$ ffsend upload /home/daygeek/2g --copy
|
||||
You've selected a directory, only a single file may be uploaded.
|
||||
Archive the directory into a single file? [Y/n]: y
|
||||
Archiving...
|
||||
Upload complete
|
||||
Share link: https://send.firefox.com/download/90aa5cfe67/#hrwu6oXZRG2DNh8vOc3BGg
|
||||
```
|
||||
|
||||
Just download the above generated the unique URL to get a folder in any remote system.
|
||||
|
||||
```
|
||||
$ ffsend download https://send.firefox.com/download/90aa5cfe67/#hrwu6oXZRG2DNh8vOc3BGg
|
||||
You're downloading an archive, extract it into the selected directory? [Y/n]: y
|
||||
Extracting...
|
||||
Download complete
|
||||
```
|
||||
|
||||
As this already send files through a safe, private, and encrypted link. However, if you would like to add a additional security at your level. Yes, you can add a password for a file.
|
||||
|
||||
```
|
||||
$ ffsend upload file-copy-rsync.sh --copy --password
|
||||
Password:
|
||||
Upload complete
|
||||
Share link: https://send.firefox.com/download/0742d24515/#P7gcNiwZJ87vF8cumU71zA
|
||||
```
|
||||
|
||||
It will prompt you to update a password when you are trying to download a file in the remote system.
|
||||
|
||||
```
|
||||
$ ffsend download https://send.firefox.com/download/0742d24515/#P7gcNiwZJ87vF8cumU71zA
|
||||
This file is protected with a password.
|
||||
Password:
|
||||
Download complete
|
||||
```
|
||||
|
||||
Alternatively you can limit a download speed by providing the download speed while uploading a file.
|
||||
|
||||
```
|
||||
$ ffsend upload file-copy-scp.sh --copy --downloads 10
|
||||
Upload complete
|
||||
Share link: https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw
|
||||
```
|
||||
|
||||
Just download the above unique URL to get a file in any remote system.
|
||||
|
||||
```
|
||||
ffsend download https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw
|
||||
Download complete
|
||||
```
|
||||
|
||||
If you want to see more details about the file, use the following format. It will shows you the file name, file size, Download counts and when it will going to expire.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
```
|
||||
$ ffsend info [Generated URL]
|
||||
|
||||
$ ffsend info https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw
|
||||
ID: 23cb923c4e
|
||||
Name: file-copy-scp.sh
|
||||
Size: 115 B
|
||||
MIME: application/x-sh
|
||||
Downloads: 3 of 10
|
||||
Expiry: 23h58m (86280s)
|
||||
```
|
||||
|
||||
You can view your transaction history using the following format.
|
||||
|
||||
```
|
||||
$ ffsend history
|
||||
# LINK EXPIRY
|
||||
1 https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw 23h57m
|
||||
2 https://send.firefox.com/download/0742d24515/#P7gcNiwZJ87vF8cumU71zA 23h55m
|
||||
3 https://send.firefox.com/download/90aa5cfe67/#hrwu6oXZRG2DNh8vOc3BGg 23h52m
|
||||
4 https://send.firefox.com/download/a4062553f4/#yy2_VyPaUMG5HwXZzYRmpQ 23h46m
|
||||
5 https://send.firefox.com/download/74ff30e43e/#NYfDOUp_Ai-RKg5g0fCZXw 23h44m
|
||||
6 https://send.firefox.com/download/69afaab1f9/#5z51_94jtxcUCJNNvf6RcA 23h43m
|
||||
```
|
||||
|
||||
If you don’t want the link anymore then we can delete it.
|
||||
|
||||
**Syntax:**
|
||||
|
||||
```
|
||||
$ ffsend delete [Generated URL]
|
||||
|
||||
$ ffsend delete https://send.firefox.com/download/69afaab1f9/#5z51_94jtxcUCJNNvf6RcA
|
||||
File deleted
|
||||
```
|
||||
|
||||
Alternatively this can be done using firefox browser by opening the page <https://send.firefox.com/>.
|
||||
|
||||
Just drag and drop a file to upload it.
|
||||
![][11]
|
||||
|
||||
Once the file is downloaded, it will show you that 100% download completed.
|
||||
![][12]
|
||||
|
||||
To check other possible options, navigate to man page or help page.
|
||||
|
||||
```
|
||||
$ ffsend --help
|
||||
ffsend 0.1.2
|
||||
Tim Visee
|
||||
Easily and securely share files from the command line.
|
||||
A fully featured Firefox Send client.
|
||||
|
||||
USAGE:
|
||||
ffsend [FLAGS] [OPTIONS] [SUBCOMMAND]
|
||||
|
||||
FLAGS:
|
||||
-f, --force Force the action, ignore warnings
|
||||
-h, --help Prints help information
|
||||
-i, --incognito Don't update local history for actions
|
||||
-I, --no-interact Not interactive, do not prompt
|
||||
-q, --quiet Produce output suitable for logging and automation
|
||||
-V, --version Prints version information
|
||||
-v, --verbose Enable verbose information and logging
|
||||
-y, --yes Assume yes for prompts
|
||||
|
||||
OPTIONS:
|
||||
-H, --history Use the specified history file [env: FFSEND_HISTORY]
|
||||
-t, --timeout Request timeout (0 to disable) [env: FFSEND_TIMEOUT]
|
||||
-T, --transfer-timeout Transfer timeout (0 to disable) [env: FFSEND_TRANSFER_TIMEOUT]
|
||||
|
||||
SUBCOMMANDS:
|
||||
upload Upload files [aliases: u, up]
|
||||
download Download files [aliases: d, down]
|
||||
debug View debug information [aliases: dbg]
|
||||
delete Delete a shared file [aliases: del]
|
||||
exists Check whether a remote file exists [aliases: e]
|
||||
help Prints this message or the help of the given subcommand(s)
|
||||
history View file history [aliases: h]
|
||||
info Fetch info about a shared file [aliases: i]
|
||||
parameters Change parameters of a shared file [aliases: params]
|
||||
password Change the password of a shared file [aliases: pass, p]
|
||||
|
||||
The public Send service that is used as default host is provided by Mozilla.
|
||||
This application is not affiliated with Mozilla, Firefox or Firefox Send.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/ffsend-securely-share-files-folders-from-linux-command-line-using-firefox-send-client/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/onionshare-secure-way-to-share-files-sharing-tool-linux/
|
||||
[2]: https://www.2daygeek.com/wormhole-securely-share-files-from-linux-command-line/
|
||||
[3]: https://www.2daygeek.com/transfer-sh-easy-fast-way-share-files-over-internet-from-command-line/
|
||||
[4]: https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/
|
||||
[5]: https://github.com/timvisee/ffsend
|
||||
[6]: https://www.2daygeek.com/category/aur-helper/
|
||||
[7]: https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/
|
||||
[8]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[9]: https://www.2daygeek.com/wp-content/uploads/2019/01/ffsend-easily-and-securely-share-files-from-linux-command-line-using-firefox-send-client-1.png
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2019/01/ffsend-easily-and-securely-share-files-from-linux-command-line-using-firefox-send-client-2.png
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2019/01/ffsend-easily-and-securely-share-files-from-linux-command-line-using-firefox-send-client-3.png
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/ffsend-easily-and-securely-share-files-from-linux-command-line-using-firefox-send-client-4.png
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (PyGame Zero: Games without boilerplate)
|
||||
[#]: via: (https://opensource.com/article/19/1/pygame-zero)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
PyGame Zero: Games without boilerplate
|
||||
======
|
||||
Say goodbye to boring boilerplate in your game development with PyGame Zero.
|
||||

|
||||
|
||||
Python is a good beginner programming language. And games are a good beginner project: they are visual, self-motivating, and fun to show off to friends and family. However, the most common library to write games in Python, [PyGame][1], can be frustrating for beginners because forgetting seemingly small details can easily lead to nothing rendering.
|
||||
|
||||
Until people understand why all the parts are there, they treat many of them as "mindless boilerplate"—magic paragraphs that need to be copied and pasted into their program to make it work.
|
||||
|
||||
[PyGame Zero][2] is intended to bridge that gap by putting a layer of abstraction over PyGame so it requires literally no boilerplate.
|
||||
|
||||
When we say literally, we mean it.
|
||||
|
||||
This is a valid PyGame Zero file:
|
||||
|
||||
```
|
||||
# This comment is here for clarity reasons
|
||||
```
|
||||
|
||||
We can run put it in a **game.py** file and run:
|
||||
|
||||
```
|
||||
$ pgzrun game.py
|
||||
```
|
||||
|
||||
This will show a window and run a game loop that can be shut down by closing the window or interrupting the program with **CTRL-C**.
|
||||
|
||||
This will, sadly, be a boring game. Nothing happens.
|
||||
|
||||
To make it slightly more interesting, we can draw a different background:
|
||||
|
||||
```
|
||||
def draw():
|
||||
screen.fill((255, 0, 0))
|
||||
```
|
||||
|
||||
This will make the background red instead of black. But it is still a boring game. Nothing is happening. We can make it slightly more interesting:
|
||||
|
||||
```
|
||||
colors = [0, 0, 0]
|
||||
|
||||
def draw():
|
||||
screen.fill(tuple(colors))
|
||||
|
||||
def update():
|
||||
colors[0] = (colors[0] + 1) % 256
|
||||
```
|
||||
|
||||
This will make a window that starts black, becomes brighter and brighter red, then goes back to black, over and over again.
|
||||
|
||||
The **update** function updates parameters, while the **draw** function renders the game based on these parameters.
|
||||
|
||||
However, there is no way for the player to interact with the game! Let's try something else:
|
||||
|
||||
```
|
||||
colors = [0, 0, 0]
|
||||
|
||||
def draw():
|
||||
screen.fill(tuple(colors))
|
||||
|
||||
def update():
|
||||
colors[0] = (colors[0] + 1) % 256
|
||||
|
||||
def on_key_down(key, mod, unicode):
|
||||
colors[1] = (colors[1] + 1) % 256
|
||||
```
|
||||
|
||||
Now pressing keys on the keyboard will increase the "greenness."
|
||||
|
||||
These comprise the three important parts of a game loop: respond to user input, update parameters, and re-render the screen.
|
||||
|
||||
PyGame Zero offers much more, including functions for drawing sprites and playing sound clips.
|
||||
|
||||
Try it out and see what type of game you can come up with!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/pygame-zero
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pygame.org/news
|
||||
[2]: https://pygame-zero.readthedocs.io/en/stable/
|
||||
@ -0,0 +1,161 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top 5 Linux Distributions for Development in 2019)
|
||||
[#]: via: (https://www.linux.com/blog/2019/1/top-5-linux-distributions-development-2019)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
|
||||
Top 5 Linux Distributions for Development in 2019
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of the most popular tasks undertaken on Linux is development. With good reason: Businesses rely on Linux. Without Linux, technology simply wouldn’t meet the demands of today’s ever-evolving world. Because of that, developers are constantly working to improve the environments with which they work. One way to manage such improvements is to have the right platform to start with. Thankfully, this is Linux, so you always have a plethora of choices.
|
||||
|
||||
But sometimes, too many choices can be a problem in and of itself. Which distribution is right for your development needs? That, of course, depends on what you’re developing, but certain distributions that just make sense to use as a foundation for your task. I’ll highlight five distributions I consider the best for developers in 2019.
|
||||
|
||||
### Ubuntu
|
||||
|
||||
Let’s not mince words here. Although the Linux Mint faithful are an incredibly loyal group (with good reason, their distro of choice is fantastic), Ubuntu Linux gets the nod here. Why? Because, thanks to the likes of [AWS][1], Ubuntu is one of the most deployed server operating systems. That means developing on a Ubuntu desktop distribution makes for a much easier translation to Ubuntu Server. And because Ubuntu makes it incredibly easy to develop for, work with, and deploy containers, it makes perfect sense that you’d want to work with this platform. Couple that with Ubuntu’s inclusion of Snap Packages, and Canonical's operating system gets yet another boost in popularity.
|
||||
|
||||
But it’s not just about what you can do with Ubuntu, it’s how easily you can do it. For nearly every task, Ubuntu is an incredibly easy distribution to use. And because Ubuntu is so popular, chances are every tool and IDE you want to work with can be easily installed from the Ubuntu Software GUI (Figure 1).
|
||||
|
||||
![Ubuntu][3]
|
||||
|
||||
Figure 1: Developer tools found in the Ubuntu Software tool.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
If you’re looking for ease of use, simplicity of migration, and plenty of available tools, you cannot go wrong with Ubuntu as a development platform.
|
||||
|
||||
### openSUSE
|
||||
|
||||
There’s a very specific reason why I add openSUSE to this list. Not only is it an outstanding desktop distribution, it’s also one of the best rolling releases you’ll find on the market. So if you’re wanting to develop with and release for the most recent software available, [openSUSE Tumbleweed][5] should be one of your top choices. If you want to leverage the latest releases of your favorite IDEs, if you always want to make sure you’re developing with the most recent libraries and toolkits, Tumbleweed is your platform.
|
||||
|
||||
But openSUSE doesn’t just offer a rolling release distribution. If you’d rather make use of a standard release platform, [openSUSE Leap][6] is what you want.
|
||||
|
||||
Of course, it’s not just about standard or rolling releases. The openSUSE platform also has a Kubernetes-specific release, called [Kubic][7], which is based on Kubernetes atop openSUSE MicroOS. But even if you aren’t developing for Kubernetes, you’ll find plenty of software and tools to work with.
|
||||
|
||||
And openSUSE also offers the ability to select your desktop environment, or (should you chose) a generic desktop or server (Figure 2).
|
||||
|
||||
![openSUSE][9]
|
||||
|
||||
Figure 2: The openSUSE Tumbleweed installation in action.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
### Fedora
|
||||
|
||||
Using Fedora as a development platform just makes sense. Why? The distribution itself seems geared toward developers. With a regular, six month release cycle, developers can be sure they won’t be working with out of date software for long. This can be important, when you need the most recent tools and libraries. And if you’re developing for enterprise-level businesses, Fedora makes for an ideal platform, as it is the upstream for Red Hat Enterprise Linux. What that means is the transition to RHEL should be painless. That’s important, especially if you hope to bring your project to a much larger market (one with deeper pockets than a desktop-centric target).
|
||||
|
||||
Fedora also offers one of the best GNOME experiences you’ll come across (Figure 3). This translates to a very stable and fast desktops.
|
||||
|
||||
![GNOME][11]
|
||||
|
||||
Figure 3: The GNOME desktop on Fedora.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
But if GNOME isn’t your jam, you can opt to install one of the [Fedora spins][12] (which includes KDE, XFCE, LXQT, Mate-Compiz, Cinnamon, LXDE, and SOAS).
|
||||
|
||||
### Pop!_OS
|
||||
|
||||
I’d be remiss if I didn’t include [System76][13]’s platform, customized specifically for their hardware (although it does work fine on other hardware). Why would I include such a distribution, especially one that doesn’t really venture far away from the Ubuntu platform for which is is based? Primarily because this is the distribution you want if you plan on purchasing a desktop or laptop from System76. But why would you do that (especially given that Linux works on nearly all off-the-shelf hardware)? Because System76 sells outstanding hardware. With the release of their Thelio desktop, you have available one of the most powerful desktop computers on the market. If you’re developing seriously large applications (especially ones that lean heavily on very large databases or require a lot of processing power for compilation), why not go for the best? And since Pop!_OS is perfectly tuned for System76 hardware, this is a no-brainer.
|
||||
Since Pop!_OS is based on Ubuntu, you’ll have all the tools available to the base platform at your fingertips (Figure 4).
|
||||
|
||||
![Pop!_OS][15]
|
||||
|
||||
Figure 4: The Anjunta IDE running on Pop!_OS.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Pop!_OS also defaults to encrypted drives, so you can trust your work will be safe from prying eyes (should your hardware fall into the wrong hands).
|
||||
|
||||
### Manjaro
|
||||
|
||||
For anyone that likes the idea of developing on Arch Linux, but doesn’t want to have to jump through all the hoops of installing and working with Arch Linux, there’s Manjaro. Manjaro makes it easy to have an Arch Linux-based distribution up and running (as easily as installing and using, say, Ubuntu).
|
||||
|
||||
But what makes Manjaro developer-friendly (besides enjoying that Arch-y goodness at the base) is how many different flavors you’ll find available for download. From the [Manjaro download page][16], you can grab the following flavors:
|
||||
|
||||
* GNOME
|
||||
|
||||
* XFCE
|
||||
|
||||
* KDE
|
||||
|
||||
* OpenBox
|
||||
|
||||
* Cinnamon
|
||||
|
||||
* I3
|
||||
|
||||
* Awesome
|
||||
|
||||
* Budgie
|
||||
|
||||
* Mate
|
||||
|
||||
* Xfce Developer Preview
|
||||
|
||||
* KDE Developer Preview
|
||||
|
||||
* GNOME Developer Preview
|
||||
|
||||
* Architect
|
||||
|
||||
* Deepin
|
||||
|
||||
|
||||
|
||||
|
||||
Of note are the developer editions (which are geared toward testers and developers), the Architect edition (which is for users who want to build Manjaro from the ground up), and the Awesome edition (Figure 5 - which is for developers dealing with everyday tasks). The one caveat to using Manjaro is that, like any rolling release, the code you develop today may not work tomorrow. Because of this, you need to think with a certain level of agility. Of course, if you’re not developing for Manjaro (or Arch), and you’re doing more generic (or web) development, that will only affect you if the tools you use are updated and no longer work for you. Chances of that happening, however, are slim. And like with most Linux distributions, you’ll find a ton of developer tools available for Manjaro.
|
||||
|
||||
![Manjaro][18]
|
||||
|
||||
Figure 5: The Manjaro Awesome Edition is great for developers.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Manjaro also supports the Arch User Repository (a community-driven repository for Arch users), which includes cutting edge software and libraries, as well as proprietary applications like [Unity Editor][19] or yEd. A word of warning, however, about the Arch User Repository: It was discovered that the AUR contained software considered to be malicious. So, if you opt to work with that repository, do so carefully and at your own risk.
|
||||
|
||||
### Any Linux Will Do
|
||||
|
||||
Truth be told, if you’re a developer, just about any Linux distribution will work. This is especially true if you do most of your development from the command line. But if you prefer a good GUI running on top of a reliable desktop, give one of these distributions a try, they will not disappoint.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][20]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2019/1/top-5-linux-distributions-development-2019
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://aws.amazon.com/
|
||||
[2]: https://www.linux.com/files/images/dev1jpg
|
||||
[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_1.jpg?itok=7QJQWBKi (Ubuntu)
|
||||
[4]: https://www.linux.com/licenses/category/used-permission
|
||||
[5]: https://en.opensuse.org/Portal:Tumbleweed
|
||||
[6]: https://en.opensuse.org/Portal:Leap
|
||||
[7]: https://software.opensuse.org/distributions/tumbleweed
|
||||
[8]: /files/images/dev2jpg
|
||||
[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_2.jpg?itok=1GJmpr1t (openSUSE)
|
||||
[10]: /files/images/dev3jpg
|
||||
[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_3.jpg?itok=_6Ki4EOo (GNOME)
|
||||
[12]: https://spins.fedoraproject.org/
|
||||
[13]: https://system76.com/
|
||||
[14]: /files/images/dev4jpg
|
||||
[15]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_4.jpg?itok=nNG2Ax24 (Pop!_OS)
|
||||
[16]: https://manjaro.org/download/
|
||||
[17]: /files/images/dev5jpg
|
||||
[18]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/dev_5.jpg?itok=RGfF2UEi (Manjaro)
|
||||
[19]: https://unity3d.com/unity/editor
|
||||
[20]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,208 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Antora for your open source documentation)
|
||||
[#]: via: (https://fedoramagazine.org/using-antora-for-your-open-source-documentation/)
|
||||
[#]: author: (Adam Šamalík https://fedoramagazine.org/author/asamalik/)
|
||||
|
||||
Using Antora for your open source documentation
|
||||
======
|
||||

|
||||
|
||||
Are you looking for an easy way to write and publish technical documentation? Let me introduce [Antora][1] — an open source documentation site generator. Simple enough for a tiny project, but also complex enough to cover large documentation sites such as [Fedora Docs][2].
|
||||
|
||||
With sources stored in git, written in a simple yet powerful markup language AsciiDoc, and a static HTML as an output, Antora makes writing, collaborating on, and publishing your documentation a no-brainer.
|
||||
|
||||
### The basic concepts
|
||||
|
||||
Before we build a simple site, let’s have a look at some of the core concepts Antora uses to make the world a happier place. Or, at least, to build a documentation website.
|
||||
|
||||
#### Organizing the content
|
||||
|
||||
All sources that are used to build your documentation site are stored in a **git repository**. Or multiple ones — potentially owned by different people. For example, at the time of writing, the Fedora Docs had its sources stored in 24 different repositories owned by different groups having their own rules around contributions.
|
||||
|
||||
The content in Antora is organized into **components** , usually representing different areas of your project, or, well, different components of the software you’re documenting — such as the backend, the UI, etc. Components can be independently versioned, and each component gets a separate space on the docs site with its own menu.
|
||||
|
||||
Components can be optionally broken down into so-called **modules**. Modules are mostly invisible on the site, but they allow you to organize your sources into logical groups, and even store each in different git repository if that’s something you need to do. We use this in Fedora Docs to separate [the Release Notes, the Installation Guide, and the System Administrator Guide][3] into three different source repositories with their own rules, while preserving a single view in the UI.
|
||||
|
||||
What’s great about this approach is that, to some extent, the way your sources are physically structured is not reflected on the site.
|
||||
|
||||
#### Virtual catalog
|
||||
|
||||
When assembling the site, Antora builds a **virtual catalog** of all pages, assigning a [unique ID][4] to each one based on its name and the component, the version, and module it belongs to. The page ID is then used to generate URLs for each page, and for internal links as well. So, to some extent, the source repository structure doesn’t really matter as far as the site is concerned.
|
||||
|
||||
As an example, if we’d for some reason decided to merge all the 24 repositories of Fedora Docs into one, nothing on the site would change. Well, except the “Edit this page” link on every page that would suddenly point to this one repository.
|
||||
|
||||
#### Independent UI
|
||||
|
||||
We’ve covered the content, but how it’s going to look like?
|
||||
|
||||
Documentation sites generated with Antora use a so-called [UI bundle][5] that defines the look and feel of your site. The UI bundle holds all graphical assets such as CSS, images, etc. to make your site look beautiful.
|
||||
|
||||
It is expected that the UI will be developed independently of the documentation content, and that’s exactly what Antora supports.
|
||||
|
||||
#### Putting it all together
|
||||
|
||||
Having sources distributed in multiple repositories might raise a question: How do you build the site? The answer is: [Antora Playbook][6].
|
||||
|
||||
Antora Playbook is a file that points to all the source repositories and the UI bundle. It also defines additional metadata such as the name of your site.
|
||||
|
||||
The Playbook is the only file you need to have locally available in order to build the site. Everything else gets fetched automatically as a part of the build process.
|
||||
|
||||
### Building a site with Antora
|
||||
|
||||
Demo time! To build a minimal site, you need three things:
|
||||
|
||||
1. At least one component holding your AsciiDoc sources.
|
||||
2. An Antora Playbook.
|
||||
3. A UI bundle
|
||||
|
||||
|
||||
|
||||
Good news is the nice people behind Antora provide [example Antora sources][7] we can try right away.
|
||||
|
||||
#### The Playbook
|
||||
|
||||
Let’s first have a look at [the Playbook][8]:
|
||||
|
||||
```
|
||||
site:
|
||||
title: Antora Demo Site
|
||||
# the 404 page and sitemap files only get generated when the url property is set
|
||||
url: https://example.org/docs
|
||||
start_page: component-b::index.adoc
|
||||
content:
|
||||
sources:
|
||||
- url: https://gitlab.com/antora/demo/demo-component-a.git
|
||||
branches: master
|
||||
- url: https://gitlab.com/antora/demo/demo-component-b.git
|
||||
branches: [v2.0, v1.0]
|
||||
start_path: docs
|
||||
ui:
|
||||
bundle:
|
||||
url: https://gitlab.com/antora/antora-ui-default/-/jobs/artifacts/master/raw/build/ui-bundle.zip?job=bundle-stable
|
||||
snapshot: true
|
||||
```
|
||||
|
||||
As we can see, the Playbook defines some information about the site, lists the content repositories, and points to the UI bundle.
|
||||
|
||||
There are two repositories. The [demo-component-a][9] with a single branch, and the [demo-component-b][10] having two branches, each representing a different version.
|
||||
|
||||
#### Components
|
||||
|
||||
The minimal source repository structure is nicely demonstrated in the [demo-component-a][9] repository:
|
||||
|
||||
```
|
||||
antora.yml <- component metadata
|
||||
modules/
|
||||
ROOT/ <- the default module
|
||||
nav.adoc <- menu definition
|
||||
pages/ <- a directory with all the .adoc sources
|
||||
source1.adoc
|
||||
source2.adoc
|
||||
...
|
||||
```
|
||||
|
||||
The following
|
||||
|
||||
```
|
||||
antora.yml
|
||||
```
|
||||
|
||||
```
|
||||
name: component-a
|
||||
title: Component A
|
||||
version: 1.5.6
|
||||
start_page: ROOT:inline-text-formatting.adoc
|
||||
nav:
|
||||
- modules/ROOT/nav.adoc
|
||||
```
|
||||
|
||||
contains metadata for this component such as the name and the version of the component, the starting page, and it also points to a menu definition file.
|
||||
|
||||
The menu definition file is a simple list that defines the structure of the menu and the content. It uses the [page ID][4] to identify each page.
|
||||
|
||||
```
|
||||
* xref:inline-text-formatting.adoc[Basic Inline Text Formatting]
|
||||
* xref:special-characters.adoc[Special Characters & Symbols]
|
||||
* xref:admonition.adoc[Admonition]
|
||||
* xref:sidebar.adoc[Sidebar]
|
||||
* xref:ui-macros.adoc[UI Macros]
|
||||
* Lists
|
||||
** xref:lists/ordered-list.adoc[Ordered List]
|
||||
** xref:lists/unordered-list.adoc[Unordered List]
|
||||
|
||||
And finally, there's the actual content under modules/ROOT/pages/ — you can see the repository for examples, or the AsciiDoc syntax reference
|
||||
```
|
||||
|
||||
#### The UI bundle
|
||||
|
||||
For the UI, we’ll be using the example UI provided by the project.
|
||||
|
||||
Going into the details of Antora UI would be above the scope of this article, but if you’re interested, please see the [Antora UI documentation][5] for more info.
|
||||
|
||||
#### Building the site
|
||||
|
||||
Note: We’ll be using Podman to run Antora in a container. You can [learn about Podman on the Fedora Magazine][11].
|
||||
|
||||
To build the site, we only need to call Antora on the Playbook file.
|
||||
|
||||
The easiest way to get antora at the moment is to use the container image provided by the project. You can get it by running:
|
||||
|
||||
```
|
||||
$ podman pull antora/antora
|
||||
```
|
||||
|
||||
Let’s get the playbook repository:
|
||||
|
||||
```
|
||||
$ git clone https://gitlab.com/antora/demo/demo-site.git
|
||||
$ cd demo-site
|
||||
```
|
||||
|
||||
And run Antora using the following command:
|
||||
|
||||
```
|
||||
$ podman run --rm -it -v $(pwd):/antora:z antora/antora site.yml
|
||||
```
|
||||
|
||||
The site will be available in the
|
||||
|
||||
public
|
||||
|
||||
```
|
||||
$ cd public
|
||||
$ python3 -m http.server 8080
|
||||
```
|
||||
|
||||
directory. You can either open it in your web browser directly, or start a local web server using:
|
||||
|
||||
Your site will be available on <http://localhost:8080>.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-antora-for-your-open-source-documentation/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://antora.org/
|
||||
[2]: http://docs.fedoraproject.org/
|
||||
[3]: https://docs.fedoraproject.org/en-US/fedora/f29/
|
||||
[4]: https://docs.antora.org/antora/2.0/page/page-id/#structure
|
||||
[5]: https://docs.antora.org/antora-ui-default/
|
||||
[6]: https://docs.antora.org/antora/2.0/playbook/
|
||||
[7]: https://gitlab.com/antora/demo
|
||||
[8]: https://gitlab.com/antora/demo/demo-site/blob/master/site.yml
|
||||
[9]: https://gitlab.com/antora/demo/demo-component-a
|
||||
[10]: https://gitlab.com/antora/demo/demo-component-b
|
||||
[11]: https://fedoramagazine.org/running-containers-with-podman/
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Tint2, an open source taskbar for Linux)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-tint2)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with Tint2, an open source taskbar for Linux
|
||||
======
|
||||
|
||||
Tint2, the 14th in our series on open source tools that will make you more productive in 2019, offers a consistent user experience with any window manager.
|
||||
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the 14th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Tint2
|
||||
|
||||
One of the best ways for me to be more productive is to use a clean interface with as little distraction as possible. As a Linux user, this means using a minimal window manager like [Openbox][1], [i3][2], or [Awesome][3]. Each has customization options that make me more efficient. The one thing that slows me down is that none has a consistent configuration, so I have to tweak and re-tune my window manager constantly.
|
||||
|
||||

|
||||
|
||||
[Tint2][4] is a lightweight panel and taskbar that provides a consistent experience with any window manager. It is included with most distributions, so it is as easy to install as any other package.
|
||||
|
||||
It includes two programs, Tint2 and Tint2conf. At first launch, Tint2 starts with its default layout and theme. The default configuration includes multiple web browsers, the tint2conf program, a taskbar, and a system tray.
|
||||
|
||||
|
||||
|
||||
Launching the configuration tool allows you to select from the included themes and customize the top, bottom, and sides of the screen. I recommend starting with the theme that is closest to what you want and customizing from there.
|
||||
|
||||
|
||||
|
||||
Within the themes, you can customize where panel items are placed as well as background and font options for every item on the panel. You can also add and remove items from the launcher.
|
||||
|
||||

|
||||
|
||||
Tint2 is a lightweight taskbar that helps you get to the tools you need quickly and efficiently. It is highly customizable, unobtrusive (unless the user wants it not to be), and compatible with almost any window manager on a Linux desktop.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://openbox.org/wiki/Main_Page
|
||||
[2]: https://i3wm.org/
|
||||
[3]: https://awesomewm.org/
|
||||
[4]: https://gitlab.com/o9000/tint2
|
||||
@ -0,0 +1,55 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with eDEX-UI, a Tron-influenced terminal program for tablets and desktops)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-edex-ui)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with eDEX-UI, a Tron-influenced terminal program for tablets and desktops
|
||||
======
|
||||
Make work more fun with eDEX-UI, the 15th in our series on open source tools that will make you more productive in 2019.
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the 15th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### eDEX-UI
|
||||
|
||||
I was 11 years old when [Tron][1] was in movie theaters. I cannot deny that, despite the fantastical nature of the film, it had an impact on my career choice later in life.
|
||||
|
||||
|
||||
|
||||
[eDEX-UI][2] is a cross-platform terminal program designed for tablets and desktops that was inspired by the user interface in Tron. It has five terminals in a tabbed interface, so it is easy to switch between tasks, as well as useful displays of system information.
|
||||
|
||||
At launch, eDEX-UI goes through a boot sequence with information about the ElectronJS system it is based on. After the boot, eDEX-UI shows system information, a file browser, a keyboard (for tablets), and the main terminal tab. The other four tabs (labeled EMPTY) don't have anything loaded and will start a shell when you click on one. The default shell in eDEX-UI is Bash (if you are on Windows, you will likely have to change it to either PowerShell or cmd.exe).
|
||||
|
||||
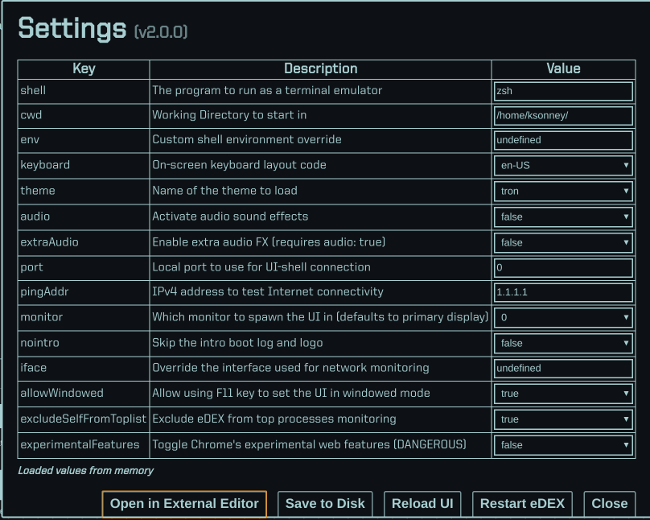
|
||||
|
||||
Changing directories in the file browser will change directories in the active terminal and vice-versa. The file browser does everything you'd expect, including opening associated applications when you click on a file. The one exception is eDEX-UI's settings.json file (in .config/eDEX-UI by default), which opens the configuration editor instead. This allows you to set the shell command for the terminals, change the theme, and modify several other settings for the user interface. Themes are also stored in the configuration directory and, since they are also JSON files, creating a custom theme is pretty straightforward.
|
||||
|
||||
|
||||
|
||||
eDEX-UI allows you to run five terminals with full emulation. The default terminal type is xterm-color, meaning it has full-color support. One thing to be aware of is that the keys light up on the keyboard while you type, so if you're using eDEX-UI on a tablet, the keyboard could present a security risk in environments where people can see the screen. It is better to use a theme without the keyboard on those devices, although it does look pretty cool when you are typing.
|
||||
|
||||
|
||||
|
||||
While eDEX-UI supports only five terminal windows, that has been more than enough for me. On a tablet, eDEX-UI gives me that cyberspace feel without impacting my productivity. On a desktop, eDEX-UI allows all of that and lets me look cool in front of my co-workers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-edex-ui
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Tron
|
||||
[2]: https://github.com/GitSquared/edex-ui
|
||||
Loading…
Reference in New Issue
Block a user