mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-10 22:21:11 +08:00
commit
f1a7a9c15a
@ -0,0 +1,214 @@
|
|||||||
|
free:一个在 Linux 中检查内存使用情况的标准命令
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
我们都知道, IT 基础设施方面的大多数服务器(包括世界顶级的超级计算机)都运行在 Linux 平台上,因为和其他操作系统相比, Linux 更加灵活。有的操作系统对于一些微乎其微的改动和补丁更新都需要重启,但是 Linux 不需要,只有对于一些关键补丁的更新, Linux 才会需要重启。
|
||||||
|
|
||||||
|
Linux 系统管理员面临的一大挑战是如何在没有任何停机时间的情况下维护系统的良好运行。管理内存使用是 Linux 管理员又一个具有挑战性的任务。`free` 是 Linux 中一个标准的并且被广泛使用的命令,它被用来分析内存统计(空闲和已用)。今天,我们将要讨论 `free` 命令以及它的一些有用选项。
|
||||||
|
|
||||||
|
推荐文章:
|
||||||
|
|
||||||
|
* [smem - Linux 内存报告/统计工具][1]
|
||||||
|
* [vmstat - 一个报告虚拟内存统计的标准而又漂亮的工具][2]
|
||||||
|
|
||||||
|
### Free 命令是什么
|
||||||
|
|
||||||
|
free 命令能够显示系统中物理上的空闲(free)和已用(used)内存,还有交换(swap)内存,同时,也能显示被内核使用的缓冲(buffers)和缓存(caches)。这些信息是通过解析文件 `/proc/meninfo` 而收集到的。
|
||||||
|
|
||||||
|
### 显示系统内存
|
||||||
|
|
||||||
|
不带任何选项运行 `free` 命令会显示系统内存,包括空闲(free)、已用(used)、交换(swap)、缓冲(buffers)、缓存(caches)和交换(swap)的内存总数。
|
||||||
|
|
||||||
|
```
|
||||||
|
# free
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32869744 25434276 7435468 0 412032 23361716
|
||||||
|
-/+ buffers/cache: 1660528 31209216
|
||||||
|
Swap: 4095992 0 4095992
|
||||||
|
```
|
||||||
|
|
||||||
|
输出有三行:
|
||||||
|
|
||||||
|
* 第一行:表明全部内存、已用内存、空闲内存、共用内存(主要被 tmpfs(`/proc/meninfo` 中的 `Shmem` 项)使用)、用于缓冲的内存以及缓存内容大小。
|
||||||
|
* 全部:全部已安装内存(`/proc/meminfo` 中的 `MemTotal` 项)
|
||||||
|
* 已用:已用内存(全部计算 - 空间+缓冲+缓存)
|
||||||
|
* 空闲:未使用内存(`/proc/meminfo` 中的 `MemFree` 项)
|
||||||
|
* 共用:主要被 tmpfs 使用的内存(`/proc/meminfo` 中的 `Shmem` 项)
|
||||||
|
* 缓冲:被内核缓冲使用的内存(`/proc/meminfo` 中的 `Buffers` 项)
|
||||||
|
* 缓存:被页面缓存和 slab 使用的内存(`/proc/meminfo` 中的 `Cached` 和 `SSReclaimable` 项)
|
||||||
|
* 第二行:表明已用和空闲的缓冲/缓存
|
||||||
|
* 第三行:表明总交换内存(`/proc/meminfo` 中的 `SwapTotal` 项)、空闲内存(`/proc/meminfo` 中的 `SwapFree` 项)和已用交换内存。
|
||||||
|
|
||||||
|
### 以 MB 为单位显示系统内存
|
||||||
|
|
||||||
|
默认情况下, `free` 命令以 `KB - Kilobytes` 为单位输出系统内存,这对于绝大多数管理员来说会有一点迷糊(当系统内存很大的时候,我们中的许多人需要把输出转化为以 MB 为单位,从而才能够理解内存大小)。为了避免这个迷惑,我们在 ‘free’ 命令后面加上 `-m` 选项,就可以立即得到以 ‘MB - Megabytes’ 为单位的输出。
|
||||||
|
|
||||||
|
```
|
||||||
|
# free -m
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32099 24838 7261 0 402 22814
|
||||||
|
-/+ buffers/cache: 1621 30477
|
||||||
|
Swap: 3999 0 3999
|
||||||
|
```
|
||||||
|
|
||||||
|
如何从上面的输出中检查剩余多少空闲内存?主要基于已用(used)和空闲(free)两列。你可能在想,你只有很低的空闲内存,因为它只有 `10%`, 为什么?
|
||||||
|
|
||||||
|
- 全部实际可用内存 = (全部内存 - 第 2 行的已用内存)
|
||||||
|
- 全部内存 = 32099
|
||||||
|
- 实际已用内存 = 1621 ( = 全部内存 - 缓冲 - 缓存)
|
||||||
|
- 全部实际可用内存 = 30477
|
||||||
|
|
||||||
|
如果你的 Linux 版本是最新的,那么有一个查看实际空闲内存的选项,叫做可用(`available`) ,对于旧的版本,请看显示 `-/+ buffers/cache` 那一行对应的空闲(`free`)一列。
|
||||||
|
|
||||||
|
如何从上面的输出中检查有多少实际已用内存?基于已用(used)和空闲(free)一列。你可能想,你已经使用了超过 `95%` 的内存。
|
||||||
|
|
||||||
|
- 全部实际已用内存 = 第一列已用 - (第一列缓冲 + 第一列缓存)
|
||||||
|
- 已用内存 = 24838
|
||||||
|
- 已用缓冲 = 402
|
||||||
|
- 已用缓存 = 22814
|
||||||
|
- 全部实际已用内存 = 1621
|
||||||
|
|
||||||
|
### 以 GB 为单位显示内存
|
||||||
|
|
||||||
|
默认情况下, `free` 命令会以 `KB - kilobytes` 为单位显示输出,这对于大多数管理员来说会有一些迷惑,所以我们使用上面的选项来获得以 `MB - Megabytes` 为单位的输出。但是,当服务器的内存很大(超过 100 GB 或 200 GB)时,上面的选项也会让人很迷惑。所以,在这个时候,我们可以在 `free` 命令后面加上 `-g` 选项,从而立即得到以 `GB - Gigabytes` 为单位的输出。
|
||||||
|
|
||||||
|
```
|
||||||
|
# free -g
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 31 24 7 0 0 22
|
||||||
|
-/+ buffers/cache: 1 29
|
||||||
|
Swap: 3 0 3
|
||||||
|
```
|
||||||
|
|
||||||
|
### 显示全部内存行
|
||||||
|
|
||||||
|
默认情况下, `free` 命令的输出只有三行(内存、缓冲/缓存以及交换)。为了统一以单独一行显示(全部(内存+交换)、已用(内存+(已用-缓冲/缓存)+交换)以及空闲(内存+(已用-缓冲/缓存)+交换),在 ‘free’ 命令后面加上 `-t` 选项。
|
||||||
|
|
||||||
|
```
|
||||||
|
# free -t
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32869744 25434276 7435468 0 412032 23361716
|
||||||
|
-/+ buffers/cache: 1660528 31209216
|
||||||
|
Swap: 4095992 0 4095992
|
||||||
|
Total: 36965736 27094804 42740676
|
||||||
|
```
|
||||||
|
|
||||||
|
### 按延迟运行 free 命令以便更好的统计
|
||||||
|
|
||||||
|
默认情况下, free 命令只会显示一次统计输出,这是不足够进一步排除故障的,所以,可以通过添加延迟(延迟是指在几秒后再次更新)来定期统计内存活动。如果你想以两秒的延迟运行 free 命令,可以使用下面的命令(如果你想要更多的延迟,你可以按照你的意愿更改数值)。
|
||||||
|
|
||||||
|
下面的命令将会每 2 秒运行一次直到你退出:
|
||||||
|
|
||||||
|
```
|
||||||
|
# free -s 2
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32849392 25935844 6913548 188 182424 24632796
|
||||||
|
-/+ buffers/cache: 1120624 31728768
|
||||||
|
Swap: 20970492 0 20970492
|
||||||
|
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32849392 25935288 6914104 188 182424 24632796
|
||||||
|
-/+ buffers/cache: 1120068 31729324
|
||||||
|
Swap: 20970492 0 20970492
|
||||||
|
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32849392 25934968 6914424 188 182424 24632796
|
||||||
|
-/+ buffers/cache: 1119748 31729644
|
||||||
|
Swap: 20970492 0 20970492
|
||||||
|
```
|
||||||
|
|
||||||
|
### 按延迟和具体次数运行 free 命令
|
||||||
|
|
||||||
|
另外,你可以按延迟和具体次数运行 free 命令,一旦达到某个次数,便自动退出。
|
||||||
|
|
||||||
|
下面的命令将会每 2 秒运行一次 free 命令,计数 5 次以后自动退出。
|
||||||
|
|
||||||
|
```
|
||||||
|
# free -s 2 -c 5
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32849392 25931052 6918340 188 182424 24632796
|
||||||
|
-/+ buffers/cache: 1115832 31733560
|
||||||
|
Swap: 20970492 0 20970492
|
||||||
|
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32849392 25931192 6918200 188 182424 24632796
|
||||||
|
-/+ buffers/cache: 1115972 31733420
|
||||||
|
Swap: 20970492 0 20970492
|
||||||
|
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32849392 25931348 6918044 188 182424 24632796
|
||||||
|
-/+ buffers/cache: 1116128 31733264
|
||||||
|
Swap: 20970492 0 20970492
|
||||||
|
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32849392 25931316 6918076 188 182424 24632796
|
||||||
|
-/+ buffers/cache: 1116096 31733296
|
||||||
|
Swap: 20970492 0 20970492
|
||||||
|
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32849392 25931308 6918084 188 182424 24632796
|
||||||
|
-/+ buffers/cache: 1116088 31733304
|
||||||
|
Swap: 20970492 0 20970492
|
||||||
|
```
|
||||||
|
|
||||||
|
### 人类可读格式
|
||||||
|
|
||||||
|
为了以人类可读的格式输出,在 `free` 命令的后面加上 `-h` 选项,和其他选项比如 `-m` 和 `-g` 相比,这将会更人性化输出(自动使用 GB 和 MB 单位)。
|
||||||
|
|
||||||
|
```
|
||||||
|
# free -h
|
||||||
|
total used free shared buff/cache available
|
||||||
|
Mem: 2.0G 1.6G 138M 20M 188M 161M
|
||||||
|
Swap: 2.0G 1.8G 249M
|
||||||
|
```
|
||||||
|
|
||||||
|
### 取消缓冲区和缓存内存输出
|
||||||
|
|
||||||
|
默认情况下, `缓冲/缓存` 内存输出是同时输出的。为了取消缓冲和缓存内存的输出,可以在 `free` 命令后面加上 `-w` 选项。(该选项在版本 3.3.12 上可用)
|
||||||
|
|
||||||
|
注意比较上面有`缓冲/缓存`的输出。
|
||||||
|
|
||||||
|
```
|
||||||
|
# free -wh
|
||||||
|
total used free shared buffers cache available
|
||||||
|
Mem: 2.0G 1.6G 137M 20M 8.1M 183M 163M
|
||||||
|
Swap: 2.0G 1.8G 249M
|
||||||
|
```
|
||||||
|
|
||||||
|
### 显示最低和最高的内存统计
|
||||||
|
|
||||||
|
默认情况下, `free` 命令不会显示最低和最高的内存统计。为了显示最低和最高的内存统计,在 free 命令后面加上 `-l` 选项。
|
||||||
|
|
||||||
|
```
|
||||||
|
# free -l
|
||||||
|
total used free shared buffers cached
|
||||||
|
Mem: 32849392 25931336 6918056 188 182424 24632808
|
||||||
|
Low: 32849392 25931336 6918056
|
||||||
|
High: 0 0 0
|
||||||
|
-/+ buffers/cache: 1116104 31733288
|
||||||
|
Swap: 20970492 0 20970492
|
||||||
|
```
|
||||||
|
|
||||||
|
### 阅读关于 free 命令的更过信息
|
||||||
|
|
||||||
|
如果你想了解 free 命令的更多可用选项,只需查看其 man 手册。
|
||||||
|
|
||||||
|
```
|
||||||
|
# free --help
|
||||||
|
or
|
||||||
|
# man free
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/
|
||||||
|
|
||||||
|
作者:[MAGESH MARUTHAMUTHU][a]
|
||||||
|
译者:[ucasFL](https://github.com/ucasFL)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.2daygeek.com/author/magesh/
|
||||||
|
[1]:http://www.2daygeek.com/smem-linux-memory-usage-statistics-reporting-tool/
|
||||||
|
[2]:http://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/
|
||||||
|
[3]:http://www.2daygeek.com/author/magesh/
|
||||||
139
published/20170227 How to setup a Linux server on Amazon AWS.md
Normal file
139
published/20170227 How to setup a Linux server on Amazon AWS.md
Normal file
@ -0,0 +1,139 @@
|
|||||||
|
如何在 Amazon AWS 上设置一台 Linux 服务器
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
AWS(Amazon Web Services)是全球领先的云服务器提供商之一。你可以使用 AWS 平台在一分钟内设置完服务器。在 AWS 上,你可以微调服务器的许多技术细节,如 CPU 数量,内存和磁盘空间,磁盘类型(更快的 SSD 或者经典的 IDE)等。关于 AWS 最好的一点是,你只需要为你使用到的服务付费。在开始之前,AWS 提供了一个名为 “Free Tier” 的特殊帐户,你可以免费使用一年的 AWS 技术服务,但会有一些小限制,例如,你每个月使用服务器时长不能超过 750 小时,超过这个他们就会向你收费。你可以在 [aws 官网][3]上查看所有相关的规则。
|
||||||
|
|
||||||
|
因为我的这篇文章是关于在 AWS 上创建 Linux 服务器,因此拥有 “Free Tier” 帐户是先决条件。要注册帐户,你可以使用此[链接][4]。请注意,你需要在创建帐户时输入信用卡详细信息。
|
||||||
|
|
||||||
|
让我们假设你已经创建了 “Free Tier” 帐户。
|
||||||
|
|
||||||
|
在继续之前,你必须了解 AWS 中的一些术语以了解设置:
|
||||||
|
|
||||||
|
1. EC2(弹性计算云):此术语用于虚拟机。
|
||||||
|
2. AMI(Amazon 机器镜像):表示操作系统实例。
|
||||||
|
3. EBS(弹性块存储):AWS 中的一种存储环境类型。
|
||||||
|
|
||||||
|
通过以下链接登录 AWS 控制台:[https://console.aws.amazon.com/][5] 。
|
||||||
|
|
||||||
|
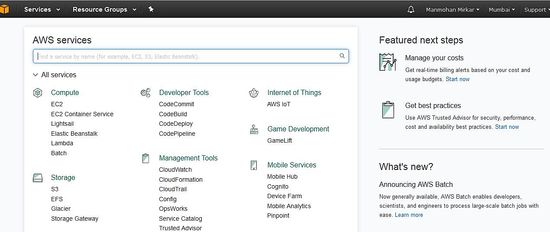
AWS 控制台将如下所示:
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][6]
|
||||||
|
|
||||||
|
### 在 AWS 中设置 Linux VM
|
||||||
|
|
||||||
|
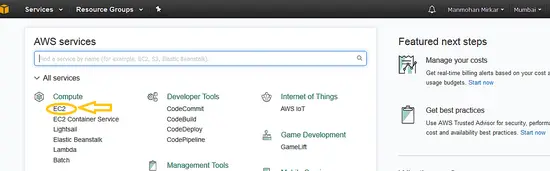
1、 创建一个 EC2(虚拟机)实例:在开始安装系统之前,你必须在 AWS 中创建一台虚拟机。要创建虚拟机,在“<ruby>计算<rt>compute</rt></ruby>”菜单下点击 EC2:
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][7]
|
||||||
|
|
||||||
|
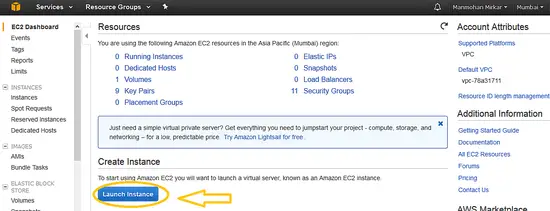
2、 现在在<ruby>创建实例<rt>Create instance</rt></ruby>下点击<ruby>“启动实例”<rt>Launch Instance</rt></ruby>按钮。
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][8]
|
||||||
|
|
||||||
|
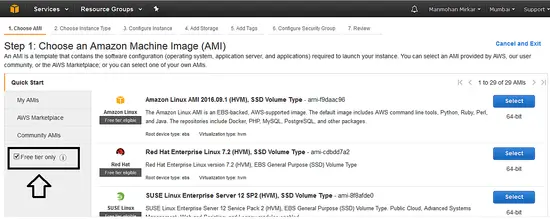
3、 现在,当你使用的是一个 “Free Tier” 帐号,接着最好选择 “Free Tier” 单选按钮以便 AWS 可以过滤出可以免费使用的实例。这可以让你不用为使用 AWS 的资源而付费。
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][9]
|
||||||
|
|
||||||
|
4、 要继续操作,请选择以下选项:
|
||||||
|
|
||||||
|
a、 在经典实例向导中选择一个 AMI(Amazon Machine Image),然后选择使用 **Red Hat Enterprise Linux 7.2(HVM),SSD 存储**
|
||||||
|
|
||||||
|
b、 选择 “**t2.micro**” 作为实例详细信息。
|
||||||
|
|
||||||
|
c、 **配置实例详细信息**:不要更改任何内容,只需单击下一步。
|
||||||
|
|
||||||
|
d、 **添加存储**:不要更改任何内容,只需点击下一步,因为此时我们将使用默认的 10(GiB)硬盘。
|
||||||
|
|
||||||
|
e、 **添加标签**:不要更改任何内容只需点击下一步。
|
||||||
|
|
||||||
|
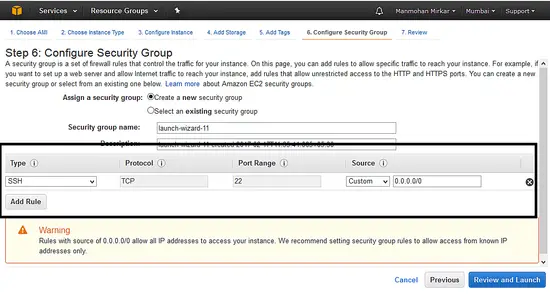
f、 **配置安全组**:现在选择用于 ssh 的 22 端口,以便你可以在任何地方访问此服务器。
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][10]
|
||||||
|
|
||||||
|
g、 选择“<ruby>查看并启动<rt>Review and Launch</rt></ruby>”按钮。
|
||||||
|
|
||||||
|
h、 如果所有的详情都无误,点击 “<ruby>启动<rt>Launch</rt></ruby>”按钮。
|
||||||
|
|
||||||
|
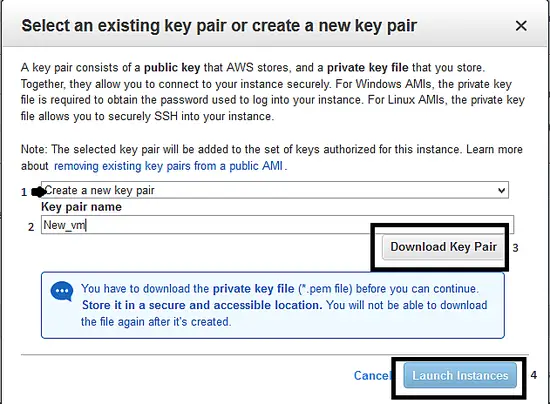
i、 单击“<ruby>启动<rt>Launch</rt></ruby>”按钮后,系统会像下面那样弹出一个窗口以创建“密钥对”:选择选项“<ruby>创建密钥对<rt>create a new key pair</rt></ruby>”,并给密钥对起个名字,然后下载下来。在使用 ssh 连接到服务器时,需要此密钥对。最后,单击“<ruby>启动实例<rt>Launch Instance</rt></ruby>”按钮。
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][11]
|
||||||
|
|
||||||
|
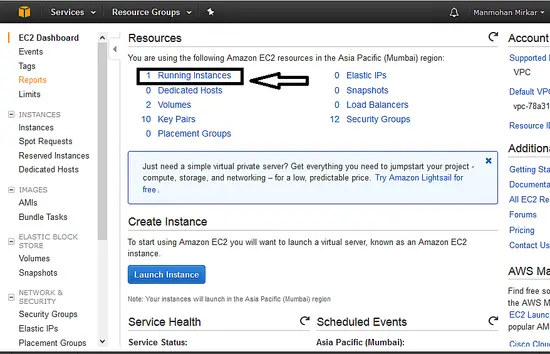
j、 点击“<ruby>启动实例<rt>Launch Instance</rt></ruby>”按钮后,转到左上角的服务。选择“<ruby>计算<rt>compute</rt></ruby>”--> “EC2”。现在点击“<ruby>运行实例<rt>Running Instances</rt></ruby>”:
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][12]
|
||||||
|
|
||||||
|
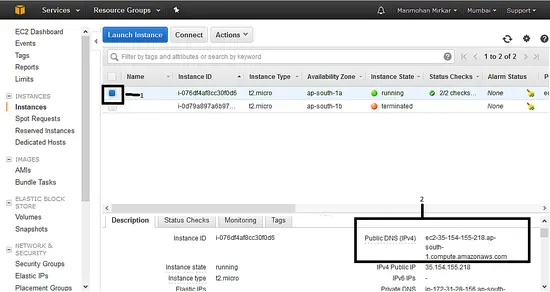
k、 现在你可以看到,你的新 VM 的状态是 “<ruby>运行中<rt>running</rt></ruby>”。选择实例,请记下登录到服务器所需的 “<ruby>公开 DNS 名称<rt>Public DNS</rt></ruby>”。
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][13]
|
||||||
|
|
||||||
|
现在你已完成创建一台运行 Linux 的 VM。要连接到服务器,请按照以下步骤操作。
|
||||||
|
|
||||||
|
### 从 Windows 中连接到 EC2 实例
|
||||||
|
|
||||||
|
1、 首先,你需要有 putty gen 和 Putty exe 用于从 Windows 连接到服务器(或 Linux 上的 SSH 命令)。你可以通过下面的[链接][14]下载 putty。
|
||||||
|
|
||||||
|
2、 现在打开 putty gen :`puttygen.exe`。
|
||||||
|
|
||||||
|
3、 你需要单击 “Load” 按钮,浏览并选择你从亚马逊上面下载的密钥对文件(pem 文件)。
|
||||||
|
|
||||||
|
4、 你需要选择 “ssh2-RSA” 选项,然后单击保存私钥按钮。请在下一个弹出窗口中选择 “yes”。
|
||||||
|
|
||||||
|
5、 将文件以扩展名 `.ppk` 保存。
|
||||||
|
|
||||||
|
6、 现在你需要打开 `putty.exe`。在左侧菜单中点击 “connect”,然后选择 “SSH”,然后选择 “Auth”。你需要单击浏览按钮来选择我们在步骤 4 中创建的 .ppk 文件。
|
||||||
|
|
||||||
|
7、 现在点击 “session” 菜单,并在“host name” 中粘贴在本教程中 “k” 步骤中的 DNS 值,然后点击 “open” 按钮。
|
||||||
|
|
||||||
|
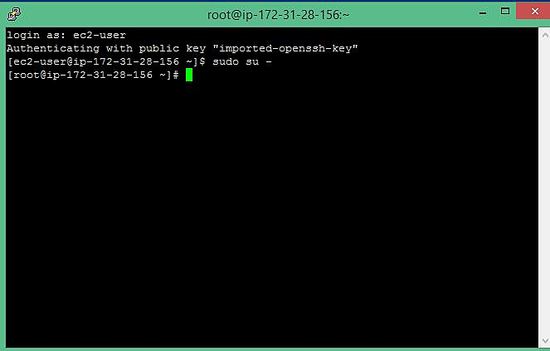
8、 在要求用户名和密码时,输入 `ec2-user` 和空白密码,然后输入下面的命令。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo su -
|
||||||
|
```
|
||||||
|
|
||||||
|
哈哈,你现在是在 AWS 云上托管的 Linux 服务器上的主人啦。
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][15]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/
|
||||||
|
|
||||||
|
作者:[MANMOHAN MIRKAR][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/
|
||||||
|
[1]:https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/#setup-a-linux-vm-in-aws
|
||||||
|
[2]:https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/#connect-to-an-ec-instance-from-windows
|
||||||
|
[3]:http://aws.amazon.com/free/
|
||||||
|
[4]:http://aws.amazon.com/ec2/
|
||||||
|
[5]:https://console.aws.amazon.com/
|
||||||
|
[6]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_console.JPG
|
||||||
|
[7]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_console_ec21.png
|
||||||
|
[8]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_launch_ec2.png
|
||||||
|
[9]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_free_tier_radio1.png
|
||||||
|
[10]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_ssh_port1.png
|
||||||
|
[11]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_key_pair.png
|
||||||
|
[12]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_running_instance.png
|
||||||
|
[13]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_dns_value.png
|
||||||
|
[14]:http://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
|
||||||
|
[15]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_putty1.JPG
|
||||||
@ -0,0 +1,111 @@
|
|||||||
|
如何在 Linux 中安装最新的 Python 3.6 版本
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
在这篇文章中,我将展示如何在 CentOS/RHEL 7、Debian 以及它的衍生版本比如 Ubuntu(最新的 Ubuntu 16.04 LTS 版本已经安装了最新的 Python 版本)或 Linux Mint 上安装和使用 Python 3.x 。我们的重点是安装可用于命令行的核心语言工具。
|
||||||
|
|
||||||
|
然后,我们也会阐述如何安装 Python IDLE - 一个基于 GUI 的工具,它允许我们运行 Python 代码和创建独立函数。
|
||||||
|
|
||||||
|
### 在 Linux 中安装 Python 3.6
|
||||||
|
|
||||||
|
在我写这篇文章的时候(2017 年三月中旬),在 CentOS 和 Debian 8 中可用的最新 Python 版本分别是 Python 3.4 和 Python 3.5 。
|
||||||
|
|
||||||
|
虽然我们可以使用 [yum][1] 和 [aptitude][2](或 [apt-get][3])安装核心安装包以及它们的依赖,但在这儿,我将阐述如何使用源代码进行安装。
|
||||||
|
|
||||||
|
为什么?理由很简单:这样我们能够获取语言的最新的稳定发行版(3.6),并且提供了一种和 Linux 版本无关的安装方法。
|
||||||
|
|
||||||
|
在 CentOS 7 中安装 Python 之前,请确保系统中已经有了所有必要的开发依赖:
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum -y groupinstall development
|
||||||
|
# yum -y install zlib-devel
|
||||||
|
```
|
||||||
|
|
||||||
|
在 Debian 中,我们需要安装 gcc、make 和 zlib 压缩/解压缩库:
|
||||||
|
|
||||||
|
```
|
||||||
|
# aptitude -y install gcc make zlib1g-dev
|
||||||
|
```
|
||||||
|
|
||||||
|
运行下面的命令来安装 Python 3.6:
|
||||||
|
|
||||||
|
```
|
||||||
|
# wget https://www.python.org/ftp/python/3.6.0/Python-3.6.0.tar.xz
|
||||||
|
# tar xJf Python-3.6.0.tar.xz
|
||||||
|
# cd Python-3.6.0
|
||||||
|
# ./configure
|
||||||
|
# make && make install
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,放松一下,或者饿的话去吃个三明治,因为这可能需要花费一些时间。安装完成以后,使用 `which` 命令来查看主要二进制代码的位置:
|
||||||
|
|
||||||
|
```
|
||||||
|
# which python3
|
||||||
|
# python3 -V
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的命令的输出应该和这相似:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][4]
|
||||||
|
|
||||||
|
*查看 Linux 系统中的 Python 版本*
|
||||||
|
|
||||||
|
要退出 Python 提示符,只需输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
quit()
|
||||||
|
或
|
||||||
|
exit()
|
||||||
|
```
|
||||||
|
|
||||||
|
然后按回车键。
|
||||||
|
|
||||||
|
恭喜!Python 3.6 已经安装在你的系统上了。
|
||||||
|
|
||||||
|
### 在 Linux 中安装 Python IDLE
|
||||||
|
|
||||||
|
Python IDLE 是一个基于 GUI 的 Python 工具。如果你想安装 Python IDLE,请安装叫做 idle(Debian)或 python-tools(CentOS)的包:
|
||||||
|
|
||||||
|
```
|
||||||
|
# apt-get install idle [On Debian]
|
||||||
|
# yum install python-tools [On CentOS]
|
||||||
|
```
|
||||||
|
|
||||||
|
输入下面的命令启动 Python IDLE:
|
||||||
|
|
||||||
|
```
|
||||||
|
# idle
|
||||||
|
```
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
在这篇文章中,我们阐述了如何从源代码安装最新的 Python 稳定版本。
|
||||||
|
|
||||||
|
最后但不是不重要,如果你之前使用 Python 2,那么你可能需要看一下 [从 Python 2 迁移到 Python 3 的官方文档][5]。这是一个可以读入 Python 2 代码,然后转化为有效的 Python 3 代码的程序。
|
||||||
|
|
||||||
|
你有任何关于这篇文章的问题或想法吗?请使用下面的评论栏与我们联系
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Gabriel Cánepa - 一位来自阿根廷圣路易斯梅塞德斯镇 (Villa Mercedes, San Luis, Argentina) 的 GNU/Linux 系统管理员,Web 开发者。就职于一家世界领先级的消费品公司,乐于在每天的工作中能使用 FOSS 工具来提高生产力。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/install-python-in-linux/
|
||||||
|
|
||||||
|
作者:[Gabriel Cánepa][a]
|
||||||
|
译者:[ucasFL](https://github.com/ucasFL)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/gacanepa/
|
||||||
|
|
||||||
|
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||||
|
[2]:http://www.tecmint.com/linux-package-management/
|
||||||
|
[3]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||||
|
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Python-Version-in-Linux.png
|
||||||
|
[5]:https://docs.python.org/3.6/library/2to3.html
|
||||||
@ -1,14 +0,0 @@
|
|||||||
Programmer Levels
|
|
||||||
=======
|
|
||||||

|
|
||||||
|
|
||||||
via: http://turnoff.us/geek/programmer-leves/
|
|
||||||
|
|
||||||
|
|
||||||
作者:[Daniel Stori][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: http://turnoff.us/about/
|
|
||||||
@ -1,277 +0,0 @@
|
|||||||
Index of turnoff.us
|
|
||||||
====================
|
|
||||||
|
|
||||||
* ### [Ode To My Family][1]
|
|
||||||
|
|
||||||
* ### [The Depressed Developer 11][2]
|
|
||||||
|
|
||||||
* ### [The Jealous Process][3]
|
|
||||||
|
|
||||||
* ### [#!S][4]
|
|
||||||
|
|
||||||
* ### [The Depressed Developer 10][5]
|
|
||||||
|
|
||||||
* ### [User Space Election][6]
|
|
||||||
|
|
||||||
* ### [The Depressed Developer 7][7]
|
|
||||||
|
|
||||||
* ### [The War for Port 80][8]
|
|
||||||
|
|
||||||
* ### [The Depressed Developer 6][9]
|
|
||||||
|
|
||||||
* ### [Adopt a good cause, DON'T SIGKILL][10]
|
|
||||||
|
|
||||||
* ### [Happy 0b11111100001][11]
|
|
||||||
|
|
||||||
* ### [Bash History][12]
|
|
||||||
|
|
||||||
* ### [My (Dev) Morning Routine][13]
|
|
||||||
|
|
||||||
* ### [The Depressed Developer 5][14]
|
|
||||||
|
|
||||||
* ### [The Real Reason Not To Share a Mutable State][15]
|
|
||||||
|
|
||||||
* ### [Any Given Day][16]
|
|
||||||
|
|
||||||
* ### [One Last Question][17]
|
|
||||||
|
|
||||||
* ### [The Depressed Developer 3][18]
|
|
||||||
|
|
||||||
* ### [The Depressed Developer 4][19]
|
|
||||||
|
|
||||||
* ### [The Depressed Developer 2][20]
|
|
||||||
|
|
||||||
* ### [The Depressed Developer][21]
|
|
||||||
|
|
||||||
* ### [Protocols][22]
|
|
||||||
|
|
||||||
* ### [The Lord of The Matrix][23]
|
|
||||||
|
|
||||||
* ### [Inheritance versus Composition][24]
|
|
||||||
|
|
||||||
* ### [Coding From Anthill][25]
|
|
||||||
|
|
||||||
* ### [Life of Embedded Processes][26]
|
|
||||||
|
|
||||||
* ### [Deadline][27]
|
|
||||||
|
|
||||||
* ### [Ubuntu Core][28]
|
|
||||||
|
|
||||||
* ### [The Truth About Google][29]
|
|
||||||
|
|
||||||
* ### [Inside the Linux Kernel][30]
|
|
||||||
|
|
||||||
* ### [Programmer Levels][31]
|
|
||||||
|
|
||||||
* ### [Microservices][32]
|
|
||||||
|
|
||||||
* ### [Binary Tree][33]
|
|
||||||
|
|
||||||
* ### [Annoying Software 4 - Checkbox vs Radio Button][34]
|
|
||||||
|
|
||||||
* ### [Zombie Processes][35]
|
|
||||||
|
|
||||||
* ### [Poprocks and Coke][36]
|
|
||||||
|
|
||||||
* ### [jhamlet][37]
|
|
||||||
|
|
||||||
* ### [Java Thread Life][38]
|
|
||||||
|
|
||||||
* ### [Stranger Things - In The SysAdmin's World][39]
|
|
||||||
|
|
||||||
* ### [Who Killed MySQL? - Epilogue][40]
|
|
||||||
|
|
||||||
* ### [Sometimes They Are][41]
|
|
||||||
|
|
||||||
* ### [Dotnet on Linux][42]
|
|
||||||
|
|
||||||
* ### [Who Killed MySQL?][43]
|
|
||||||
|
|
||||||
* ### [To VI Or Not To VI][44]
|
|
||||||
|
|
||||||
* ### [Brothers Conflict (at linux kernel)][45]
|
|
||||||
|
|
||||||
* ### [Big Numbers][46]
|
|
||||||
|
|
||||||
* ### [The Codeless Developer][47]
|
|
||||||
|
|
||||||
* ### [Introducing the OOM Killer][48]
|
|
||||||
|
|
||||||
* ### [Reactive and Boring][49]
|
|
||||||
|
|
||||||
* ### [Hype Detected][50]
|
|
||||||
|
|
||||||
* ### [3rd World Daily News][51]
|
|
||||||
|
|
||||||
* ### [Java Evolution Parade][52]
|
|
||||||
|
|
||||||
* ### [The Opposite of RIP][53]
|
|
||||||
|
|
||||||
* ### [How I Met Your Mother][54]
|
|
||||||
|
|
||||||
* ### [Schrödinger's Cat Last Declarations][55]
|
|
||||||
|
|
||||||
* ### [Bash on Windows][56]
|
|
||||||
|
|
||||||
* ### [Ubuntu Updates][57]
|
|
||||||
|
|
||||||
* ### [SQL Server on Linux Part 2][58]
|
|
||||||
|
|
||||||
* ### [About JavaScript Developers][59]
|
|
||||||
|
|
||||||
* ### [The Real Reason to Not Use SIGKILL][60]
|
|
||||||
|
|
||||||
* ### [Java 20 - Predictions][61]
|
|
||||||
|
|
||||||
* ### [Do the Evolution, Baby!][62]
|
|
||||||
|
|
||||||
* ### [SQL Server on Linux][63]
|
|
||||||
|
|
||||||
* ### [When Just-In-Time Is Justin Time][64]
|
|
||||||
|
|
||||||
* ### [The Agile Restaurant][65]
|
|
||||||
|
|
||||||
* ### [I Love Windows PowerShell][66]
|
|
||||||
|
|
||||||
* ### [Linux Master Hero][67]
|
|
||||||
|
|
||||||
* ### [Doing a Great Job Together][68]
|
|
||||||
|
|
||||||
* ### [Geek Rivalries][69]
|
|
||||||
|
|
||||||
* ### [A Java Nightmare][70]
|
|
||||||
|
|
||||||
* ### [Java Family Crisis][71]
|
|
||||||
|
|
||||||
* ### [Annoying Software 3 - The Date Situation][72]
|
|
||||||
|
|
||||||
* ### [The (Sometimes Hard) Cloud Journey][73]
|
|
||||||
|
|
||||||
* ### [Thread.Sleep Room][74]
|
|
||||||
|
|
||||||
* ### [Web Server Upgrade Training][75]
|
|
||||||
|
|
||||||
* ### [Life in a Web Server][76]
|
|
||||||
|
|
||||||
* ### [Mastering RegExp][77]
|
|
||||||
|
|
||||||
* ### [Java Collections in Duck Life][78]
|
|
||||||
|
|
||||||
* ### [Java Garbage Collection Explained][79]
|
|
||||||
|
|
||||||
* ### [Waze vs Battery][80]
|
|
||||||
|
|
||||||
* ### [Masks][81]
|
|
||||||
|
|
||||||
* ### [Big Data Marriage][82]
|
|
||||||
|
|
||||||
* ### [Annoying Software 2][83]
|
|
||||||
|
|
||||||
* ### [Annoying Software][84]
|
|
||||||
|
|
||||||
* ### [Advanced Species][85]
|
|
||||||
|
|
||||||
* ### [The Modern Evil][86]
|
|
||||||
|
|
||||||
* ### [Software Testing][87]
|
|
||||||
|
|
||||||
* ### [Arduino Project][88]
|
|
||||||
|
|
||||||
* ### [Tales of DOS][89]
|
|
||||||
|
|
||||||
* ### [Developers][90]
|
|
||||||
|
|
||||||
* ### [TCP Buddies][91]
|
|
||||||
|
|
||||||
|
|
||||||
[1]:https://turnoff.us/geek/ode-to-my-family
|
|
||||||
[2]:https://turnoff.us/geek/the-depressed-developer-11
|
|
||||||
[3]:https://turnoff.us/geek/the-jealous-process
|
|
||||||
[4]:https://turnoff.us/geek/shebang
|
|
||||||
[5]:https://turnoff.us/geek/the-depressed-developer-10
|
|
||||||
[6]:https://turnoff.us/geek/user-space-election
|
|
||||||
[7]:https://turnoff.us/geek/the-depressed-developer-7
|
|
||||||
[8]:https://turnoff.us/geek/apache-vs-nginx
|
|
||||||
[9]:https://turnoff.us/geek/the-depressed-developer-6
|
|
||||||
[10]:https://turnoff.us/geek/dont-sigkill-2
|
|
||||||
[11]:https://turnoff.us/geek/2016-2017
|
|
||||||
[12]:https://turnoff.us/geek/bash-history
|
|
||||||
[13]:https://turnoff.us/geek/my-morning-routine
|
|
||||||
[14]:https://turnoff.us/geek/the-depressed-developer-5
|
|
||||||
[15]:https://turnoff.us/geek/dont-share-mutable-state
|
|
||||||
[16]:https://turnoff.us/geek/sql-injection
|
|
||||||
[17]:https://turnoff.us/geek/one-last-question
|
|
||||||
[18]:https://turnoff.us/geek/the-depressed-developer-3
|
|
||||||
[19]:https://turnoff.us/geek/the-depressed-developer-4
|
|
||||||
[20]:https://turnoff.us/geek/the-depressed-developer-2
|
|
||||||
[21]:https://turnoff.us/geek/the-depressed-developer
|
|
||||||
[22]:https://turnoff.us/geek/protocols
|
|
||||||
[23]:https://turnoff.us/geek/the-lord-of-the-matrix
|
|
||||||
[24]:https://turnoff.us/geek/inheritance-versus-composition
|
|
||||||
[25]:https://turnoff.us/geek/ant
|
|
||||||
[26]:https://turnoff.us/geek/ubuntu-core-2
|
|
||||||
[27]:https://turnoff.us/geek/deadline
|
|
||||||
[28]:https://turnoff.us/geek/ubuntu-core
|
|
||||||
[29]:https://turnoff.us/geek/the-truth-about-google
|
|
||||||
[30]:https://turnoff.us/geek/inside-the-linux-kernel
|
|
||||||
[31]:https://turnoff.us/geek/programmer-leves
|
|
||||||
[32]:https://turnoff.us/geek/microservices
|
|
||||||
[33]:https://turnoff.us/geek/binary-tree
|
|
||||||
[34]:https://turnoff.us/geek/annoying-software-4
|
|
||||||
[35]:https://turnoff.us/geek/zombie-processes
|
|
||||||
[36]:https://turnoff.us/geek/poprocks-and-coke
|
|
||||||
[37]:https://turnoff.us/geek/jhamlet
|
|
||||||
[38]:https://turnoff.us/geek/java-thread-life
|
|
||||||
[39]:https://turnoff.us/geek/stranger-things-sysadmin-world
|
|
||||||
[40]:https://turnoff.us/geek/who-killed-mysql-epilogue
|
|
||||||
[41]:https://turnoff.us/geek/sad-robot
|
|
||||||
[42]:https://turnoff.us/geek/dotnet-on-linux
|
|
||||||
[43]:https://turnoff.us/geek/who-killed-mysql
|
|
||||||
[44]:https://turnoff.us/geek/to-vi-or-not-to-vi
|
|
||||||
[45]:https://turnoff.us/geek/brothers-conflict
|
|
||||||
[46]:https://turnoff.us/geek/big-numbers
|
|
||||||
[47]:https://turnoff.us/geek/codeless
|
|
||||||
[48]:https://turnoff.us/geek/oom-killer
|
|
||||||
[49]:https://turnoff.us/geek/reactive-and-boring
|
|
||||||
[50]:https://turnoff.us/geek/tech-adoption
|
|
||||||
[51]:https://turnoff.us/geek/3rd-world-news
|
|
||||||
[52]:https://turnoff.us/geek/java-evolution-parade
|
|
||||||
[53]:https://turnoff.us/geek/opposite-of-rip
|
|
||||||
[54]:https://turnoff.us/geek/how-i-met-your-mother
|
|
||||||
[55]:https://turnoff.us/geek/schrodinger-cat
|
|
||||||
[56]:https://turnoff.us/geek/bash-on-windows
|
|
||||||
[57]:https://turnoff.us/geek/ubuntu-updates
|
|
||||||
[58]:https://turnoff.us/geek/sql-server-on-linux-2
|
|
||||||
[59]:https://turnoff.us/geek/love-ecma6
|
|
||||||
[60]:https://turnoff.us/geek/dont-sigkill
|
|
||||||
[61]:https://turnoff.us/geek/java20-predictions
|
|
||||||
[62]:https://turnoff.us/geek/its-evolution-baby
|
|
||||||
[63]:https://turnoff.us/geek/sql-server-on-linux
|
|
||||||
[64]:https://turnoff.us/geek/lazy-justin-is-late-again
|
|
||||||
[65]:https://turnoff.us/geek/agile-restaurant
|
|
||||||
[66]:https://turnoff.us/geek/love-powershell
|
|
||||||
[67]:https://turnoff.us/geek/linux-master-hero
|
|
||||||
[68]:https://turnoff.us/geek/duke-tux
|
|
||||||
[69]:https://turnoff.us/geek/geek-rivalries
|
|
||||||
[70]:https://turnoff.us/geek/a-java-nightmare
|
|
||||||
[71]:https://turnoff.us/geek/java-family-crisis
|
|
||||||
[72]:https://turnoff.us/geek/annoying-software-3
|
|
||||||
[73]:https://turnoff.us/geek/cloud-sometimes-hard-journey
|
|
||||||
[74]:https://turnoff.us/geek/thread-sleep-room
|
|
||||||
[75]:https://turnoff.us/geek/webserver-upgrade-training
|
|
||||||
[76]:https://turnoff.us/geek/life-in-a-web-server
|
|
||||||
[77]:https://turnoff.us/geek/mastering-regexp
|
|
||||||
[78]:https://turnoff.us/geek/java-collections
|
|
||||||
[79]:https://turnoff.us/geek/java-gc-explained
|
|
||||||
[80]:https://turnoff.us/geek/waze-vs-battery
|
|
||||||
[81]:https://turnoff.us/geek/masks
|
|
||||||
[82]:https://turnoff.us/geek/bigdata-marriage
|
|
||||||
[83]:https://turnoff.us/geek/annoying-software-2
|
|
||||||
[84]:https://turnoff.us/geek/annoying-software
|
|
||||||
[85]:https://turnoff.us/geek/advanced-species
|
|
||||||
[86]:https://turnoff.us/geek/modern-evil
|
|
||||||
[87]:https://turnoff.us/geek/software-test
|
|
||||||
[88]:https://turnoff.us/geek/arduino-project
|
|
||||||
[89]:https://turnoff.us/geek/tales-of-dos
|
|
||||||
[90]:https://turnoff.us/geek/developers
|
|
||||||
[91]:https://turnoff.us/geek/tcp-buddies
|
|
||||||
@ -0,0 +1,97 @@
|
|||||||
|
Why do you use Linux and open source software?
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
>LinuxQuestions.org readers share reasons they use Linux and open source technologies. How will Opensource.com readers respond?
|
||||||
|
|
||||||
|

|
||||||
|
>Image by : opensource.com
|
||||||
|
|
||||||
|
As I mentioned when [The Queue][4] launched, although typically I will answer questions from readers, sometimes I'll switch that around and ask readers a question. I haven't done so since that initial column, so it's overdue. I recently asked two related questions at LinuxQuestions.org and the response was overwhelming. Let's see how the Opensource.com community answers both questions, and how those responses compare and contrast to those on LQ.
|
||||||
|
|
||||||
|
### Why do you use Linux?
|
||||||
|
|
||||||
|
The first question I asked the LinuxQuestions.org community is: **[What are the reasons you use Linux?][1]**
|
||||||
|
|
||||||
|
### Answer highlights
|
||||||
|
|
||||||
|
_oldwierdal_ : I use Linux because it is fast, safe, and reliable. With contributors from all over the world, it has become, perhaps, the most advanced and innovative software available. And, here is the icing on the red-velvet cake; It is free!
|
||||||
|
|
||||||
|
_Timothy Miller_ : I started using it because it was free as in beer and I was poor so couldn't afford to keep buying new Windows licenses.
|
||||||
|
|
||||||
|
_ondoho_ : Because it's a global community effort, self-governed grassroot operating system. Because it's free in every sense. Because there's good reason to trust in it.
|
||||||
|
|
||||||
|
_joham34_ : Stable, free, safe, runs in low specs PCs, nice support community, little to no danger for viruses.
|
||||||
|
|
||||||
|
_Ook_ : I use Linux because it just works, something Windows never did well for me. I don't have to waste time and money getting it going and keeping it going.
|
||||||
|
|
||||||
|
_rhamel_ : I am very concerned about the loss of privacy as a whole on the internet. I recognize that compromises have to be made between privacy and convenience. I may be fooling myself but I think Linux gives me at least the possibility of some measure of privacy.
|
||||||
|
|
||||||
|
_educateme_ : I use Linux because of the open-minded, learning-hungry, passionately helpful community. And, it's free.
|
||||||
|
|
||||||
|
_colinetsegers_ : Why I use Linux? There's not only one reason. In short I would say:
|
||||||
|
|
||||||
|
1. The philosophy of free shared knowledge.
|
||||||
|
2. Feeling safe while surfing the web.
|
||||||
|
3. Lots of free and useful software.
|
||||||
|
|
||||||
|
_bamunds_ : Because I love freedom.
|
||||||
|
|
||||||
|
_cecilskinner1989_ : I use linux for two reasons: stability and privacy.
|
||||||
|
|
||||||
|
### Why do you use open source software?
|
||||||
|
|
||||||
|
The second questions is, more broadly: **[What are the reasons you use open source software?][2]** You'll notice that, although there is a fair amount of overlap here, the general tone is different, with some sentiments receiving more emphasis, and others less.
|
||||||
|
|
||||||
|
### Answer highlights
|
||||||
|
|
||||||
|
_robert leleu_ : Warm and cooperative atmosphere is the main reason of my addiction to open source.
|
||||||
|
|
||||||
|
_cjturner_ : Open Source is an answer to the Pareto Principle as applied to Applications; OOTB, a software package ends up meeting 80% of your requirements, and you have to get the other 20% done. Open Source gives you a mechanism and a community to share this burden, putting your own effort (if you have the skills) or money into your high-priority requirements.
|
||||||
|
|
||||||
|
_Timothy Miller_ : I like the knowledge that I _can_ examine the source code to verify that the software is secure if I so choose.
|
||||||
|
|
||||||
|
_teckk_ : There are no burdensome licensing requirements or DRM and it's available to everyone.
|
||||||
|
|
||||||
|
_rokytnji_ : Beer money. Motorcycle parts. Grandkids birthday presents.
|
||||||
|
|
||||||
|
_timl_ : Privacy is impossible without free software
|
||||||
|
|
||||||
|
_hazel_ : I like the philosophy of free software, but I wouldn't use it just for philosophical reasons if Linux was a bad OS. I use Linux because I love Linux, and because you can get it for free as in free beer. The fact that it's also free as in free speech is a bonus, because it makes me feel good about using it. But if I find that a piece of hardware on my machine needs proprietary firmware, I'll use proprietary firmware.
|
||||||
|
|
||||||
|
_lm8_ : I use open source software because I don't have to worry about it going obsolete when a company goes out of business or decides to stop supporting it. I can continue to update and maintain the software myself. I can also customize it if the software does almost everything I want, but it would be nice to have a few more features. I also like open source because I can share my favorite programs with friend and coworkers.
|
||||||
|
|
||||||
|
_donguitar_ : Because it empowers me and enables me to empower others.
|
||||||
|
|
||||||
|
### Your turn
|
||||||
|
|
||||||
|
So, what are the reasons _**you**_ use Linux? What are the reasons _**you**_ use open source software? Let us know in the comments.
|
||||||
|
|
||||||
|
### Fill The Queue
|
||||||
|
|
||||||
|
Lastly, what questions would you like to see answered in a future article? From questions on building and maintaining communities, to what you'd like to know about contributing to an open source project, to questions more technical in nature—[submit your Linux and open source questions][5].
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Jeremy Garcia - Jeremy Garcia is the founder of LinuxQuestions.org and an ardent but realistic open source advocate. Follow Jeremy on Twitter: @linuxquestions
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software
|
||||||
|
|
||||||
|
作者:[Jeremy Garcia ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/jeremy-garcia
|
||||||
|
[1]:http://www.linuxquestions.org/questions/linux-general-1/what-are-the-reasons-you-use-linux-4175600842/
|
||||||
|
[2]:http://www.linuxquestions.org/questions/linux-general-1/what-are-the-reasons-you-use-open-source-software-4175600843/
|
||||||
|
[3]:https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software?rate=lVazcbF6Oern5CpV86PgNrRNZltZ8aJZwrUp7SrZIAw
|
||||||
|
[4]:https://opensource.com/tags/queue-column
|
||||||
|
[5]:https://opensource.com/thequeue-submit-question
|
||||||
|
[6]:https://opensource.com/user/86816/feed
|
||||||
|
[7]:https://opensource.com/article/17/3/why-do-you-use-linux-and-open-source-software#comments
|
||||||
|
[8]:https://opensource.com/users/jeremy-garcia
|
||||||
@ -1,176 +0,0 @@
|
|||||||
translating by xiaow6
|
|
||||||
Your visual how-to guide for SELinux policy enforcement
|
|
||||||
============================================================
|
|
||||||
|
|
||||||

|
|
||||||
>Image by : opensource.com
|
|
||||||
|
|
||||||
We are celebrating the SELinux 10th year anversary this year. Hard to believe it. SELinux was first introduced in Fedora Core 3 and later in Red Hat Enterprise Linux 4. For those who have never used SELinux, or would like an explanation...
|
|
||||||
|
|
||||||
More Linux resources
|
|
||||||
|
|
||||||
* [What is Linux?][1]
|
|
||||||
* [What are Linux containers?][2]
|
|
||||||
* [Managing devices in Linux][3]
|
|
||||||
* [Download Now: Linux commands cheat sheet][4]
|
|
||||||
* [Our latest Linux articles][5]
|
|
||||||
|
|
||||||
SElinux is a labeling system. Every process has a label. Every file/directory object in the operating system has a label. Even network ports, devices, and potentially hostnames have labels assigned to them. We write rules to control the access of a process label to an a object label like a file. We call this _policy_ . The kernel enforces the rules. Sometimes this enforcement is called Mandatory Access Control (MAC).
|
|
||||||
|
|
||||||
The owner of an object does not have discretion over the security attributes of a object. Standard Linux access control, owner/group + permission flags like rwx, is often called Discretionary Access Control (DAC). SELinux has no concept of UID or ownership of files. Everything is controlled by the labels. Meaning an SELinux system can be setup without an all powerful root process.
|
|
||||||
|
|
||||||
**Note:** _SELinux does not let you side step DAC Controls. SELinux is a parallel enforcement model. An application has to be allowed by BOTH SELinux and DAC to do certain activities. This can lead to confusion for administrators because the process gets Permission Denied. Administrators see Permission Denied means something is wrong with DAC, not SELinux labels._
|
|
||||||
|
|
||||||
### Type enforcement
|
|
||||||
|
|
||||||
Lets look a little further into the labels. The SELinux primary model or enforcement is called _type enforcement_ . Basically this means we define the label on a process based on its type, and the label on a file system object based on its type.
|
|
||||||
|
|
||||||
_Analogy_
|
|
||||||
|
|
||||||
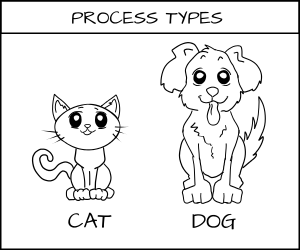
Imagine a system where we define types on objects like cats and dogs. A cat and dog are process types.
|
|
||||||
|
|
||||||
_*all cartoons by [Máirín Duffy][6]_
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
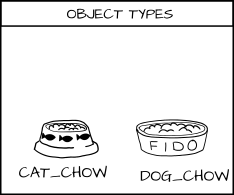
We have a class of objects that they want to interact with which we call food. And I want to add types to the food, _cat_food_ and _dog_food_ .
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
As a policy writer, I would say that a dog has permission to eat _dog_chow_ food and a cat has permission to eat _cat_chow_ food. In SELinux we would write this rule in policy.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
allow cat cat_chow:food eat;
|
|
||||||
|
|
||||||
allow dog dog_chow:food eat;
|
|
||||||
|
|
||||||
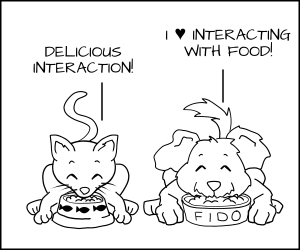
With these rules the kernel would allow the cat process to eat food labeled _cat_chow _ and the dog to eat food labeled _dog_chow_ .
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
But in an SELinux system everything is denied by default. This means that if the dog process tried to eat the _cat_chow_ , the kernel would prevent it.
|
|
||||||
|
|
||||||
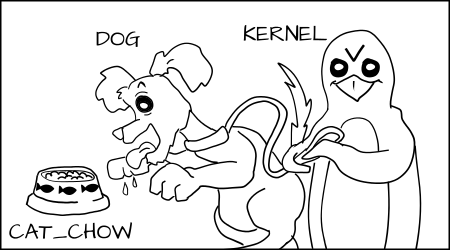
|
|
||||||
|
|
||||||
Likewise cats would not be allowed to touch dog food.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
_Real world_
|
|
||||||
|
|
||||||
We label Apache processes as _httpd_t_ and we label Apache content as _httpd_sys_content_t _ and _httpd_sys_content_rw_t_ . Imagine we have credit card data stored in a mySQL database which is labeled _msyqld_data_t_ . If an Apache process is hacked, the hacker could get control of the _httpd_t process_ and would be allowed to read _httpd_sys_content_t_ files and write to _httpd_sys_content_rw_t_ . But the hacker would not be allowed to read the credit card data ( _mysqld_data_t_ ) even if the process was running as root. In this case SELinux has mitigated the break in.
|
|
||||||
|
|
||||||
### MCS enforcement
|
|
||||||
|
|
||||||
_Analogy _
|
|
||||||
|
|
||||||
Above, we typed the dog process and cat process, but what happens if you have multiple dogs processes: Fido and Spot. You want to stop Fido from eating Spot's _dog_chow_ .
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
One solution would be to create lots of new types, like _Fido_dog_ and _Fido_dog_chow_ . But, this will quickly become unruly because all dogs have pretty much the same permissions.
|
|
||||||
|
|
||||||
To handle this we developed a new form of enforcement, which we call Multi Category Security (MCS). In MCS, we add another section of the label which we can apply to the dog process and to the dog_chow food. Now we label the dog process as _dog:random1 _ (Fido) and _dog:random2_ (Spot).
|
|
||||||
|
|
||||||
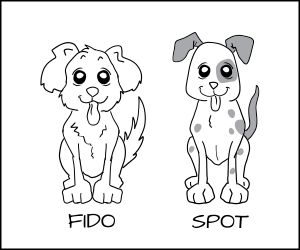
|
|
||||||
|
|
||||||
We label the dog chow as _dog_chow:random1 (Fido)_ and _dog_chow:random2_ (Spot).
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
MCS rules say that if the type enforcement rules are OK and the random MCS labels match exactly, then the access is allowed, if not it is denied.
|
|
||||||
|
|
||||||
Fido (dog:random1) trying to eat _cat_chow:food_ is denied by type enforcement.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Fido (dog:random1) is allowed to eat _dog_chow:random1._
|
|
||||||
|
|
||||||
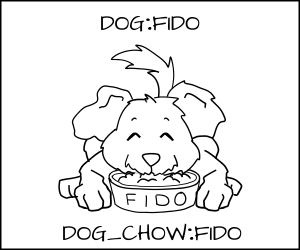
|
|
||||||
|
|
||||||
Fido (dog:random1) denied to eat spot's ( _dog_chow:random2_ ) food.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
_Real world_
|
|
||||||
|
|
||||||
In computer systems we often have lots of processes all with the same access, but we want them separated from each other. We sometimes call this a _multi-tenant environment_ . The best example of this is virtual machines. If I have a server running lots of virtual machines, and one of them gets hacked, I want to prevent it from attacking the other virtual machines and virtual machine images. But in a type enforcement system the KVM virtual machine is labeled _svirt_t_ and the image is labeled _svirt_image_t_ . We have rules that say _svirt_t_ can read/write/delete content labeled _svirt_image_t_ . With libvirt we implemented not only type enforcement separation, but also MCS separation. When libvirt is about to launch a virtual machine it picks out a random MCS label like _s0:c1,c2_ , it then assigns the _svirt_image_t:s0:c1,c2_ label to all of the content that the virtual machine is going to need to manage. Finally, it launches the virtual machine as _svirt_t:s0:c1,c2_ . Then, the SELinux kernel controls that _svirt_t:s0:c1,c2_ can not write to _svirt_image_t:s0:c3,c4_ , even if the virtual machine is controled by a hacker and takes it over. Even if it is running as root.
|
|
||||||
|
|
||||||
We use [similar separation][8] in OpenShift. Each gear (user/app process)runs with the same SELinux type (openshift_t). Policy defines the rules controlling the access of the gear type and a unique MCS label to make sure one gear can not interact with other gears.
|
|
||||||
|
|
||||||
Watch [this short video][9] on what would happen if an Openshift gear became root.
|
|
||||||
|
|
||||||
### MLS enforcement
|
|
||||||
|
|
||||||
Another form of SELinux enforcement, used much less frequently, is called Multi Level Security (MLS); it was developed back in the 60s and is used mainly in trusted operating systems like Trusted Solaris.
|
|
||||||
|
|
||||||
The main idea is to control processes based on the level of the data they will be using. A _secret _ process can not read _top secret_ data.
|
|
||||||
|
|
||||||
MLS is very similar to MCS, except it adds a concept of dominance to enforcement. Where MCS labels have to match exactly, one MLS label can dominate another MLS label and get access.
|
|
||||||
|
|
||||||
_Analogy_
|
|
||||||
|
|
||||||
Instead of talking about different dogs, we now look at different breeds. We might have a Greyhound and a Chihuahua.
|
|
||||||
|
|
||||||
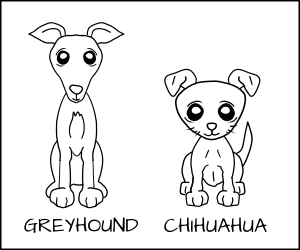
|
|
||||||
|
|
||||||
We might want to allow the Greyhound to eat any dog food, but a Chihuahua could choke if it tried to eat Greyhound dog food.
|
|
||||||
|
|
||||||
We want to label the Greyhound as _dog:Greyhound_ and his dog food as _dog_chow:Greyhound, _ and label the Chihuahua as _dog:Chihuahua_ and his food as _dog_chow:Chihuahua_ .
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
With the MLS policy, we would have the MLS Greyhound label dominate the Chihuahua label. This means _dog:Greyhound_ is allowed to eat _dog_chow:Greyhound _ and _dog_chow:Chihuahua_ .
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
But _dog:Chihuahua_ is not allowed to eat _dog_chow:Greyhound_ .
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Of course, _dog:Greyhound_ and _dog:Chihuahua_ are still prevented from eating _cat_chow:Siamese_ by type enforcement, even if the MLS type Greyhound dominates Siamese.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
_Real world_
|
|
||||||
|
|
||||||
I could have two Apache servers: one running as _httpd_t:TopSecret_ and another running as _httpd_t:Secret_ . If the Apache process _httpd_t:Secret_ were hacked, the hacker could read _httpd_sys_content_t:Secret_ but would be prevented from reading _httpd_sys_content_t:TopSecret_ .
|
|
||||||
|
|
||||||
However, if the Apache server running _httpd_t:TopSecret_ was hacked, it could read _httpd_sys_content_t:Secret data_ as well as _httpd_sys_content_t:TopSecret_ .
|
|
||||||
|
|
||||||
We use the MLS in military environments where a user might only be allowed to see _secret _ data, but another user on the same system could read _top secret_ data.
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
SELinux is a powerful labeling system, controlling access granted to individual processes by the kernel. The primary feature of this is type enforcement where rules define the access allowed to a process is allowed based on the labeled type of the process and the labeled type of the object. Two additional controls have been added to separate processes with the same type from each other called MCS, total separtion from each other, and MLS, allowing for process domination.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
Daniel J Walsh - Daniel Walsh has worked in the computer security field for almost 30 years. Dan joined Red Hat in August 2001.
|
|
||||||
|
|
||||||
-------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/business/13/11/selinux-policy-guide
|
|
||||||
|
|
||||||
作者:[Daniel J Walsh ][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/rhatdan
|
|
||||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
|
||||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
|
||||||
[3]:https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu
|
|
||||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
|
||||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
|
||||||
[6]:https://opensource.com/users/mairin
|
|
||||||
[7]:https://opensource.com/business/13/11/selinux-policy-guide?rate=XNCbBUJpG2rjpCoRumnDzQw-VsLWBEh-9G2hdHyB31I
|
|
||||||
[8]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
|
||||||
[9]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
|
||||||
[10]:https://opensource.com/user/16673/feed
|
|
||||||
[11]:https://opensource.com/business/13/11/selinux-policy-guide#comments
|
|
||||||
[12]:https://opensource.com/users/rhatdan
|
|
||||||
@ -1,4 +1,4 @@
|
|||||||
|
[kenxx](https://github.com/kenxx)
|
||||||
|
|
||||||
[Why (most) High Level Languages are Slow][7]
|
[Why (most) High Level Languages are Slow][7]
|
||||||
============================================================
|
============================================================
|
||||||
@ -98,7 +98,7 @@ I typically blog graphics, languages, performance, and such. Feel free to hit me
|
|||||||
via: https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow
|
via: https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow
|
||||||
|
|
||||||
作者:[Sebastian Sylvan ][a]
|
作者:[Sebastian Sylvan ][a]
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
译者:[kenxx](https://github.com/kenxx)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|||||||
@ -0,0 +1,255 @@
|
|||||||
|
5 ways to change GRUB background in Kali Linux
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
This is a simple guide on how to change GRUB background in Kali Linux (i.e. it’s actually Kali Linux GRUB splash image). Kali dev team did few things that seems almost too much work, so in this article I will explain one of two things about GRUB and somewhat make this post little unnecessarily long and boring cause I like to write! So here goes …
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][10]
|
||||||
|
|
||||||
|
### Finding GRUB settings
|
||||||
|
|
||||||
|
This is usually the first issue everyone faces, where do I look? There’s a many ways to find GRUB settings. Users might have their own opinion but I always found that `update-grub` is the easiest way. If you run `update-grub` in a VMWare/VirtualBox, you will see something like this:
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~# update-grub
|
||||||
|
Generating grub configuration file ...
|
||||||
|
Found background image: /usr/share/images/desktop-base/desktop-grub.png
|
||||||
|
Found linux image: /boot/vmlinuz-4.0.0-kali1-amd64
|
||||||
|
Found initrd image: /boot/initrd.img-4.0.0-kali1-amd64
|
||||||
|
No volume groups found
|
||||||
|
done
|
||||||
|
root@kali:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
If you’re using a Dual Boot, Triple Boot then you will see GRUB goes in and finds other OS’es as well. However, the part we’re interested is the background image part, in my case this is what I see (you will see exactly the same thing):
|
||||||
|
|
||||||
|
```
|
||||||
|
Found background image: /usr/share/images/desktop-base/desktop-grub.png
|
||||||
|
```
|
||||||
|
|
||||||
|
### GRUB splash image search order
|
||||||
|
|
||||||
|
In grub-2.02, it will search for the splash image in the following order for a Debian based system:
|
||||||
|
|
||||||
|
1. GRUB_BACKGROUND line in `/etc/default/grub`
|
||||||
|
2. First image found in `/boot/grub/` ( more images found, it will be taken alphanumerically )
|
||||||
|
3. The image specified in `/usr/share/desktop-base/grub_background.sh`
|
||||||
|
4. The file listed in the WALLPAPER line in `/etc/grub.d/05_debian_theme`
|
||||||
|
|
||||||
|
Now hang onto this info and we will soon revisit it.
|
||||||
|
|
||||||
|
### Kali Linux GRUB splash image
|
||||||
|
|
||||||
|
As I use Kali Linux (cause I like do stuff), we found that Kali is using a background image from here: `/usr/share/images/desktop-base/desktop-grub.png`
|
||||||
|
|
||||||
|
Just to be sure, let’s check that `.png` file and it’s properties.
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~#
|
||||||
|
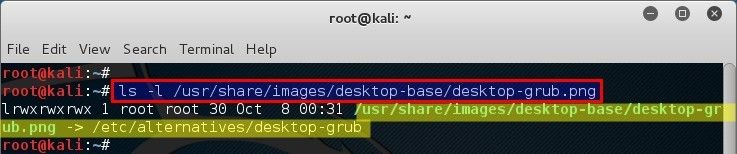
root@kali:~# ls -l /usr/share/images/desktop-base/desktop-grub.png
|
||||||
|
lrwxrwxrwx 1 root root 30 Oct 8 00:31 /usr/share/images/desktop-base/desktop-grub.png -> /etc/alternatives/desktop-grub
|
||||||
|
root@kali:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][11]
|
||||||
|
|
||||||
|
What? It’s just a symbolic link to `/etc/alternatives/desktop-grub` file? But `/etc/alternatives/desktop-grub` is not an image file. Looks like I need to check that file and it’s properties as well.
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~#
|
||||||
|
root@kali:~# ls -l /etc/alternatives/desktop-grub
|
||||||
|
lrwxrwxrwx 1 root root 44 Oct 8 00:27 /etc/alternatives/desktop-grub -> /usr/share/images/desktop-base/kali-grub.png
|
||||||
|
root@kali:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
[
|
||||||
|
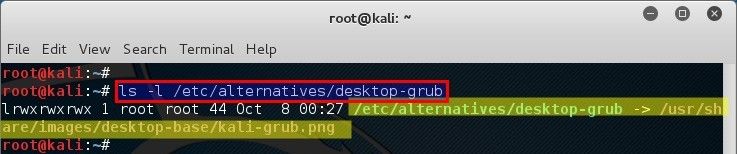
|
||||||
|
][12]
|
||||||
|
|
||||||
|
Alright, that’s confusing as! So `/etc/alternatives/desktop-grub` is another symbolic link which points back to
|
||||||
|
`/usr/share/images/desktop-base/kali-grub.png`
|
||||||
|
which is in the same folder we started from. doh! That’s all I can say. But at least now we can just replace that file and get it over with.
|
||||||
|
|
||||||
|
Before we do that we need to check the properties of this file `/usr/share/images/desktop-base/kali-grub.png` and ensure that we will download same type and dimension file.
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~#
|
||||||
|
root@kali:~# file /usr/share/images/desktop-base/kali-grub.png
|
||||||
|
/usr/share/images/desktop-base/kali-grub.png: PNG image data, 640 x 480, 8-bit/color RGB, non-interlaced
|
||||||
|
root@kali:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
So this file is DEFINITELY a PNG image data, 640 x 480 dimension.
|
||||||
|
|
||||||
|
### GRUB background image properties
|
||||||
|
|
||||||
|
GRUB 2 can use `PNG`, `JPG`/`JPEG` and `TGA` images for the background. The image must meet the following specifications:
|
||||||
|
|
||||||
|
* `JPG`/`JPEG` images must be `8-bit` (`256 color`)
|
||||||
|
* Images should be non-indexed, `RGB`
|
||||||
|
|
||||||
|
By default, if `desktop-base` package is installed, images conforming to the above specification will be located in `/usr/share/images/desktop-base/` directory. A quick Google search found similar files. Out of those, I picked one.
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~#
|
||||||
|
root@kali:~# file Downloads/wallpaper-1.png
|
||||||
|
Downloads/wallpaper-1.png: PNG image data, 640 x 480, 8-bit/color RGB, non-interlaced
|
||||||
|
root@kali:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][13]
|
||||||
|
|
||||||
|
### Option 1: replace the image
|
||||||
|
|
||||||
|
Now we simply need to replace this `/usr/share/images/desktop-base/kali-grub.png` file with our new file. Note that this is the easiest way without mucking around `grub-config` files. If you are familiar with GRUB, then go ahead and simpy modify GRUB default config and run `update-grub`.
|
||||||
|
|
||||||
|
As usual, I will make a backup of the original file by renaming it to `kali-grub.png.bkp`
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~#
|
||||||
|
root@kali:~# mv /usr/share/images/desktop-base/kali-grub.png /usr/share/images/desktop-base/kali-grub.png.bkp
|
||||||
|
root@kali:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][14]
|
||||||
|
|
||||||
|
Now let’s copy our downloaded file and rename that to `kali-grub.png.bkp`.
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~#
|
||||||
|
root@kali:~# cp Downloads/wallpaper-1.png /usr/share/images/desktop-base/kali-grub.png
|
||||||
|
root@kali:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][15]
|
||||||
|
|
||||||
|
And finally run `update-grub`
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~# update-grub
|
||||||
|
Generating grub configuration file ...
|
||||||
|
Found background image: /usr/share/images/desktop-base/desktop-grub.png
|
||||||
|
Found linux image: /boot/vmlinuz-4.0.0-kali1-amd64
|
||||||
|
Found initrd image: /boot/initrd.img-4.0.0-kali1-amd64
|
||||||
|
No volume groups found
|
||||||
|
done
|
||||||
|
root@kali:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
[
|
||||||
|
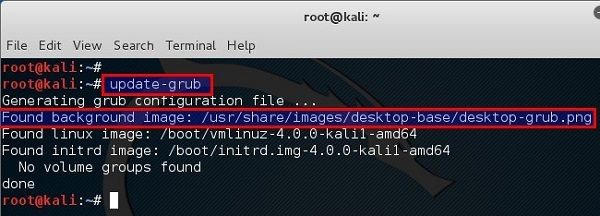
|
||||||
|
][16]
|
||||||
|
|
||||||
|
Next time you restart your Kali Linux, you will see your own image as the GRUB background. (GRUB splash image).
|
||||||
|
|
||||||
|
Following is what my new GRUB splash image looks like in Kali Linux now. What about you? Tried this method yet?
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][17]
|
||||||
|
|
||||||
|
This was the easiest and safest way, if you muck it up the worst, you will see a Blue background in GRUB but will still be able to login and fix things later. Now if you’re confident, lets move to better ways (bit complex) of changing GRUB settings. Next steps are more fun and works with any Linux using GRUB bootloader.
|
||||||
|
|
||||||
|
Now remember those 4 places GRUB looks for a background splash image? Here are those again:
|
||||||
|
|
||||||
|
1. GRUB_BACKGROUND line in `/etc/default/grub`
|
||||||
|
2. First image found in `/boot/grub/` ( more images found, it will be taken alphanumerically )
|
||||||
|
3. The image specified in `/usr/share/desktop-base/grub_background.sh`
|
||||||
|
4. The file listed in the `WALLPAPER` line in `/etc/grub.d/05_debian_theme`
|
||||||
|
|
||||||
|
So lets again try few of these options in Kali Linux (or any Linux using GRUB2).
|
||||||
|
|
||||||
|
### Option 2: Define an image path in GRUB_BACKGROUND
|
||||||
|
|
||||||
|
So you can use any of the above in the order of priority to make GRUB display your own images. The following is the content of `/etc/default/grub` file on my system.
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~# vi /etc/default/grub
|
||||||
|
```
|
||||||
|
|
||||||
|
Add a line similar to this: GRUB_BACKGROUND=”/root/World-Map.jpg” where World-Map.jpg is the image file you want to use as GRUB background.
|
||||||
|
|
||||||
|
```
|
||||||
|
# If you change this file, run 'update-grub' afterwards to update
|
||||||
|
# /boot/grub/grub.cfg.
|
||||||
|
# For full documentation of the options in this file, see:
|
||||||
|
# info -f grub -n 'Simple configuration'
|
||||||
|
|
||||||
|
GRUB_DEFAULT=0
|
||||||
|
GRUB_TIMEOUT=15
|
||||||
|
GRUB_DISTRIBUTOR=`lsb_release -i -s 2> /dev/null || echo Debian`
|
||||||
|
GRUB_CMDLINE_LINUX_DEFAULT="quiet"
|
||||||
|
GRUB_CMDLINE_LINUX="initrd=/install/gtk/initrd.gz"
|
||||||
|
GRUB_BACKGROUND="/root/World-Map.jpg"
|
||||||
|
```
|
||||||
|
|
||||||
|
Once changes has been done using any of the above methods, make sure you execute `update-grub` command as shown below.
|
||||||
|
|
||||||
|
```
|
||||||
|
root@kali:~# update-grub
|
||||||
|
Generating grub configuration file ...
|
||||||
|
Found background: /root/World-Map.jpg
|
||||||
|
Found background image: /root/World-Map.jpg
|
||||||
|
Found linux image: /boot/vmlinuz-4.0.0-kali1-amd64
|
||||||
|
Found initrd image: /boot/initrd.img-4.0.0-kali1-amd64
|
||||||
|
No volume groups found
|
||||||
|
done
|
||||||
|
root@kali:~#
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, when you boot your machine, you will see the customized image in GRUB.
|
||||||
|
|
||||||
|
### Option 3: Put an image on /boot/grub/ folder
|
||||||
|
|
||||||
|
If nothing is specified in `GRUB_BACKGROUND` in `/etc/default/grub` file, GRUB ideally should pick first image found in `/boot/grub/` folder and use that a its background. If GRUB finds more than one image in /boot/grub/ folder, it will use the first alphanumerically image name.
|
||||||
|
|
||||||
|
### Option 4: Specify an image path in grub_background.sh
|
||||||
|
|
||||||
|
If nothing is specified in `GRUB_BACKGROUND` in `/etc/default/grub` file or there is no image in `/boot/grub/` folder, GRUB will start looking into `/usr/share/desktop-base/grub_background.sh` file and search for the image path specified. For Kali Linux, it was defined in here. Every Linux distro has it’s own take on it.
|
||||||
|
|
||||||
|
### Option 5: Define an image in WALLPAPER line in /etc/grub.d/05_debian_theme file
|
||||||
|
|
||||||
|
This would be that last part GRUB looking for a Background image. It will search here if everything else failed.
|
||||||
|
|
||||||
|
### Conclusion
|
||||||
|
|
||||||
|
This post was long, but I wanted to cover a few important basic things. If you’ve followed it carefully, you will understand how to follow symbolic links back and forth in Kali Linux. You will get a VERY good idea on exactly which places you need to search to find GRUB Background image in any Linux. Just read a bit more to understand how the colors in GRUB works and you’re all set.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/
|
||||||
|
|
||||||
|
作者:[https://www.blackmoreops.com/][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/
|
||||||
|
[1]:http://www.facebook.com/sharer.php?u=https://www.blackmoreops.com/?p=5958
|
||||||
|
[2]:https://twitter.com/intent/tweet?text=5+ways+to+change+GRUB+background+in+Kali+Linux%20via%20%40blackmoreops&url=https://www.blackmoreops.com/?p=5958
|
||||||
|
[3]:https://plusone.google.com/_/+1/confirm?hl=en&url=https://www.blackmoreops.com/?p=5958&name=5+ways+to+change+GRUB+background+in+Kali+Linux
|
||||||
|
[4]:https://www.blackmoreops.com/how-to/
|
||||||
|
[5]:https://www.blackmoreops.com/kali-linux/
|
||||||
|
[6]:https://www.blackmoreops.com/kali-linux-2-x-sana/
|
||||||
|
[7]:https://www.blackmoreops.com/administration/
|
||||||
|
[8]:https://www.blackmoreops.com/usability/
|
||||||
|
[9]:https://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/#comments
|
||||||
|
[10]:http://www.blackmoreops.com/wp-content/uploads/2015/11/Change-GRUB-background-in-Kali-Linux-blackMORE-OPs-10.jpg
|
||||||
|
[11]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-1/
|
||||||
|
[12]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-3/
|
||||||
|
[13]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-6/
|
||||||
|
[14]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-4/
|
||||||
|
[15]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-5/
|
||||||
|
[16]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-7/
|
||||||
|
[17]:http://www.blackmoreops.com/wp-content/uploads/2015/11/Change-GRUB-background-in-Kali-Linux-blackMORE-OPs-9.jpg
|
||||||
73
sources/tech/20160104 How to Change Linux IO Scheduler.md
Normal file
73
sources/tech/20160104 How to Change Linux IO Scheduler.md
Normal file
@ -0,0 +1,73 @@
|
|||||||
|
honpey is tranlating
|
||||||
|
|
||||||
|
How to Change Linux I/O Scheduler
|
||||||
|
==================================
|
||||||
|
|
||||||
|
|
||||||
|
Linux I/O Scheduler is a process of accessing the block I/O from storage volumes. I/O scheduling is sometimes called disk scheduling. Linux I/O scheduler works by managing a block device’s request queue. It selects the order of requests in the queue and at what time each request is sent to the block device. Linux I/O Scheduler manages the request queue with the goal of reducing seeks, which results in great extent for global throughput.
|
||||||
|
|
||||||
|
There are following I/O Scheduler present on Linux:
|
||||||
|
|
||||||
|
1. noop – is often the best choice for memory-backed block devices
|
||||||
|
2. cfq – A fairness-oriented scheduler. It tries to maintain system-wide fairness of I/O bandwidth.
|
||||||
|
3. Deadline – A latency-oriented I/O scheduler. Each I/O request has got a deadline assigned.
|
||||||
|
4. Anticipatory – conceptually similar to deadline, but with more heuristics to improve performance.
|
||||||
|
|
||||||
|
To View Current Disk scheduler:
|
||||||
|
|
||||||
|
```
|
||||||
|
# cat /sys/block/<Disk_Name>/queue/scheduler
|
||||||
|
```
|
||||||
|
|
||||||
|
Let’s assume that , disk name is /dev/sdc, type:
|
||||||
|
|
||||||
|
```
|
||||||
|
# cat /sys/block/sdc/queue/scheduler
|
||||||
|
noop anticipatory deadline [cfq]
|
||||||
|
```
|
||||||
|
|
||||||
|
### To change Linux I/O Scheduler For A Hard Disk:
|
||||||
|
|
||||||
|
To set a specific scheduler, simply type below command:
|
||||||
|
|
||||||
|
```
|
||||||
|
# echo {SCHEDULER-NAME} > /sys/block/<Disk_Name>/queue/scheduler
|
||||||
|
```
|
||||||
|
|
||||||
|
For example,to set noop scheduler, enter:
|
||||||
|
|
||||||
|
```
|
||||||
|
# echo noop > /sys/block/sdc/queue/scheduler
|
||||||
|
```
|
||||||
|
|
||||||
|
The above change is valid till reboot of the server , to make this change permanent across reboot follow below procedure:
|
||||||
|
|
||||||
|
Implement permanent setting by adding “elevator=noop” to the default para in the /boot/grub/menu.lst file
|
||||||
|
|
||||||
|
#### 1. Create backup of menu.lst file
|
||||||
|
|
||||||
|
```
|
||||||
|
cp -p /boot/grub/menu.lst /boot/grub/menu.lst-backup
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2. Update /boot/grub/menu.lst
|
||||||
|
|
||||||
|
Now add “elevator=noop” at the end of the line as below:
|
||||||
|
|
||||||
|
Example
|
||||||
|
|
||||||
|
```
|
||||||
|
kernel /vmlinuz-2.6.16.60-0.91.1-smp root=/dev/sysvg/root splash=silent splash=off showopts elevator=noop
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://linuxroutes.com/change-io-scheduler-linux/
|
||||||
|
|
||||||
|
作者:[UX Techno][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://linuxroutes.com/change-io-scheduler-linux/
|
||||||
@ -1,11 +1,12 @@
|
|||||||
|
|
||||||
|
|
||||||
|
tranlating by xiaow6
|
||||||
Git in 2016
|
Git in 2016
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
Git had a _huge_ year in 2016, with five feature releases[¹][57] ( _v2.7_ through _v2.11_ ) and sixteen patch releases[²][58]. 189 authors[³][59] contributed 3,676 commits[⁴][60] to `master`, which is up 15%[⁵][61] over 2015! In total, 1,545 files were changed with 276,799 lines added and 100,973 lines removed[⁶][62].
|
Git had a _huge_ year in 2016, with five feature releases[¹][57] ( _v2.7_ through _v2.11_ ) and sixteen patch releases[²][58]. 189 authors[³][59] contributed 3,676 commits[⁴][60] to `master`, which is up 15%[⁵][61] over 2015! In total, 1,545 files were changed with 276,799 lines added and 100,973 lines removed[⁶][62].
|
||||||
|
|
||||||
However, commit counts and LOC are pretty terrible ways to measure productivity. Until deep learning develops to the point where it can qualitatively grok code, we’re going to be stuck with human judgment as the arbiter of productivity.
|
However, commit counts and LOC are pretty terrible ways to measure productivity. Until deep learning develops to the point where it can qualitatively grok code, we’re going to be stuck with human judgment as the arbiter of productivity.
|
||||||
@ -632,7 +633,6 @@ Or if you can’t wait ’til then, head over to Atlassian’s excellent selecti
|
|||||||
|
|
||||||
_If you scrolled to the end looking for the footnotes from the first paragraph, please jump to the _ [ _[Citation needed]_ ][77] _ section for the commands used to generate the stats. Gratuitous cover image generated using _ [ _instaco.de_ ][78] _ ❤️_
|
_If you scrolled to the end looking for the footnotes from the first paragraph, please jump to the _ [ _[Citation needed]_ ][77] _ section for the commands used to generate the stats. Gratuitous cover image generated using _ [ _instaco.de_ ][78] _ ❤️_
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: https://hackernoon.com/git-in-2016-fad96ae22a15#.t5c5cm48f
|
via: https://hackernoon.com/git-in-2016-fad96ae22a15#.t5c5cm48f
|
||||||
|
|||||||
@ -1,95 +0,0 @@
|
|||||||
wcnnbdk1 translating
|
|
||||||
NMAP Common Scans – Part One
|
|
||||||
========================
|
|
||||||
|
|
||||||
In a previous article, ‘[NMAP Installation][1]’, a listing of ten different ZeNMAP Profiles were listed. Most of the Profiles used various parameters. Most of the parameters represented different scans which can be performed. This article will cover the common four scan types.
|
|
||||||
|
|
||||||
**The Common Four Scan Types**
|
|
||||||
|
|
||||||
The four main scan types which are used most often are the following:
|
|
||||||
|
|
||||||
1. PING Scan (-sP)
|
|
||||||
2. TCP SYN Scan (-sS)
|
|
||||||
3. TCP Connect() Scan (-sT)
|
|
||||||
4. UDP Scan (-sU)
|
|
||||||
|
|
||||||
When using NMAP to perform scans these four scans are the four to keep in mind. The main thing to keep in mind about them is what they do and how they do it. This article covers the PING and UDP scans. The next article will cover the TCP scans.
|
|
||||||
|
|
||||||
**PING Scan (-sP)**
|
|
||||||
|
|
||||||
Some scans can flood the network with packets, but the Ping Scan only puts, at most, two packets on the network. The two packets do not count DNS Lookup or ARP Requests if needed. A minimum of one packet is required per IP Address being scanned.
|
|
||||||
|
|
||||||
A typical PING operation is used to determine if a network host is on-line with the IP Address specified. For example, if I were on the Internet and found that I could not reach a specific Web Server I could PING the Server to determine if it were on-line. The PING would also verify that the route between my system and the Web Server was also functioning.
|
|
||||||
|
|
||||||
**NOTE:** When discussing TCP/IP the information is both useful for the Internet and a Local Area Network (LAN) using TCP/IP. The procedures work for both. The procedures would also work for a Wide Area Network (WAN) just as well.
|
|
||||||
|
|
||||||
If the Domain Name Service (DNS) Server is needed to find the IP Address (if a Domain Name is given) then extra packets are generated. For example, to ‘ping linuxforum.com’ would first require that the IP Address (98.124.199.63) be found for the Domain Name (linuxforum.com). If the command ‘ping 98.124.199.63’ was executed then the DNS Lookup is not needed. If the MAC Address is unknown, then an ARP Request is sent to find the MAC Address of the system with the specified IP Address.
|
|
||||||
|
|
||||||
The PING command sends an Internet Control Message Protocol (ICMP) packet to the given IP Address. The packet is an ICMP Echo Request which needs a response. A response will be sent back if the system is on-line. If a Firewall exists between the two systems a PING can be dropped by the Firewall. Some servers can be configured to ignore PING requests as well to prevent the possibility of a PING of Death.
|
|
||||||
|
|
||||||
**NOTE:** The PING of Death is a malformed PING packet which is sent to a system and causes it to leave a connection open to wait for the rest of the packet. Once a bunch of these are sent to the same system it will refuse any connections since it has all available connection opened. The system is then technically unavailable.
|
|
||||||
|
|
||||||
Once a system receives the ICMP Echo Request it will respond with an ICMP Echo Reply. Once the source system receives the ICMP Echo Reply then it knows the system is on-line.
|
|
||||||
|
|
||||||
Using NMAP you specify a single IP Address or a range of IP Addresses. A PING is then performed on each IP Address when a PING Scan (-sP) is specified.
|
|
||||||
|
|
||||||
In Figure 1 you can see I performed the command ‘nmap -sP 10.0.0.1-10’. The program will try to contact every system with an IP Address of 10.0.0.1 to 10.0.0.10\. An ARP is sent out, three for each IP Address given to the command. In this case thirty requests went out – two for each of the ten IP Addresses.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**FIGURE 1**
|
|
||||||
|
|
||||||
Figure 2 shows the Wireshark capture from another machine on the network – yes it is a Windows system. Line 1 shows the first request sent out to IP Address 10.0.0.2\. The IP Address 10.0.0.1 was skipped due to it being the local system on which NMAP was being run. Now we can say that there were only 27 ARP Requests since the local one was skipped. Line 2 shows the ARP Response from the system with the IP Address of 10.0.0.2\. Lines 3 through 10 are ARP Requests for the remaining IP Addresses. Line 11 is another response from the system at IP Address 10.0.0.2 since it has not heard back from the requesting system (10.0.0.1). Line 12 is a response from the source system to 10.0.0.2 responding with ‘SYN’ at Sequence 0\. Line 13 and 14 are the system at 10.0.0.2 responding twice with the Restart (RST) and Synchronize (SYN) response to close the two connections it had opened on Lines 2 and 11\. Notice the Sequence ID is ‘1’ - the source Sequence ID + 1\. Lines 15 on are a continuation of the same.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**FIGURE 2**
|
|
||||||
|
|
||||||
Looking back at Figure 1 we can see that there were two hosts found up and running. Of course the local system was found (10.0.0.1) and one other (10.0.0.2). The whole scan took a total time of 14.40 seconds.
|
|
||||||
|
|
||||||
The PING Scan is a fast scan used to find systems which are up and running. No other information is really found about the network or the systems from the scan. The scan is a good start to see what is available on a network so you can perform more complex scans on the on-line systems only. You may also be able to find systems on the network which should not exist. Rogue systems on a network can be dangerous because they can be gathering internal network and system information easily.
|
|
||||||
|
|
||||||
Once you have a list of on-line systems you can then detect what Ports may be open on each system with a UDP Scan.
|
|
||||||
|
|
||||||
**UDP Scan (-sU)**
|
|
||||||
|
|
||||||
Now that you know what systems are available to scan you can concentrate on these IP Addresses only. It is not a good idea to flood a network with a lot of scan activity. Administrators can have programs monitor network traffic and alert them when large amounts of suspicious activities occur.
|
|
||||||
|
|
||||||
The User Datagram Protocol (UDP) is useful to determine open Ports on an on-line system. Since UDP is a connectionless protocol, a response is not needed. This scan can send a UDP packet to a system with a specified Port number. If the target system does not respond then the Port is either closed or filtered. If the Port is open then a response should be made. In most cases a target system will send an ICMP message back that the Port is unreachable. The ICMP information lets NMAP know that the Port is closed. If a Port is open then the target system should respond with an ICMP message to let NMAP know it is an available Port.
|
|
||||||
|
|
||||||
**NOTE: **Only the top 1,000 most used Ports are scanned. A deeper scan will be covered in later articles.
|
|
||||||
|
|
||||||
In my scan I will only perform the scan on the system with the IP Address 10.0.0.2 since I know it is on-line. The scan sends and receives a total of 3,278 packets. The result of the NMAP command ‘sudo nmap -sU 10.0.0.2’ is shown in Figure 3.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**FIGURE 3**
|
|
||||||
|
|
||||||
Here you can see that one Port was found open – 137 (netbios-ns). The results from Wireshark are shown in Figure 4\. Not much to see but a bunch of UDP packets.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**FIGURE 4**
|
|
||||||
|
|
||||||
What would happen if I turned off the Firewall on the target system? My results are quite a bit different. The NMAP command and results are shown in Figure 5.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**FIGURE 5**
|
|
||||||
|
|
||||||
**NOTE:** When performing a UDP Scan you are required to have root permissions.
|
|
||||||
|
|
||||||
The high quantity of the number of packets is due to the fact that UDP is being used. Once the NMAP system sends a request it is not guaranteed that the packet was received. Because of the possible loss of packets the packets are sent multiple times.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.linuxforum.com/threads/nmap-common-scans-part-one.3637/
|
|
||||||
|
|
||||||
作者:[Jarret][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
|
||||||
[1]:https://www.linuxforum.com/threads/nmap-installation.3431/
|
|
||||||
@ -1 +1,159 @@
|
|||||||
|
ucasFL translating
|
||||||
|
# [10 Best Linux Terminal Emulators For Ubuntu And Fedora][12]
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][3]
|
||||||
|
|
||||||
|
One of the most important applications for Linux users is the terminal emulator. It allows every user to get access to the shell. Bash is the most common shell for Linux and UNIX distributions, it’s powerful and very necessary for newbies and advanced users. So, in this article, you are going to know the great alternatives that you have to use an excellent terminal emulator.
|
||||||
|
|
||||||
|
### 1\. Terminator
|
||||||
|
|
||||||
|
The goal of this project is to produce a useful tool for arranging terminals. It is inspired by programs such as gnome-multi-term, quadkonsole, etc. in that the main focus is arranging terminals in grids.
|
||||||
|
|
||||||
|
#### Features At A Glance
|
||||||
|
|
||||||
|
* Arrange terminals in a grid
|
||||||
|
* Tabs
|
||||||
|
* Drag and drop re-ordering of terminals
|
||||||
|
* Lots of keyboard shortcuts
|
||||||
|
* Save multiple layouts and profiles via GUI preferences editor
|
||||||
|
* Simultaneous typing to arbitrary groups of terminals
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][4]
|
||||||
|
|
||||||
|
You can install Terminator typing -
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-get install terminator
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2\. Tilda - a drop down terminal
|
||||||
|
|
||||||
|
The specialities of **Tilda** are that it does not behave like a normal window instead it can be pulled up and down from the top of the screen with a special hotkey. Additionally, Tilda is highly configurable. It is possible to configure the hotkeys for keybindings, change the appearance and many options that affect the behaviour of Tilda.
|
||||||
|
|
||||||
|
Tilda is available for Ubuntu and Fedora through the package manager, also you can check its GitHub repository: [https://github.com/lanoxx/tilda][14][
|
||||||
|
|
||||||
|

|
||||||
|
][5]Also read - [Terminator Emulator With Multiple Terminals In One Window][1]
|
||||||
|
|
||||||
|
### 3\. Guake
|
||||||
|
|
||||||
|
It’s another drop-down terminal emulator like Tilda or yakuake. You can add features to Guake, only you must have knowledge about Python, Git and GTK.
|
||||||
|
|
||||||
|
Guake is available for many distros, so if you want to install it, you should check the repositories of your distro.
|
||||||
|
|
||||||
|
#### Features At A Glance
|
||||||
|
|
||||||
|
* Lightweight
|
||||||
|
* Simple Easy and Elegant
|
||||||
|
* Smooth integration of terminal into GUI
|
||||||
|
* Appears when you call and disappears once you are done by pressing a predefined hotkey (F12 by default)
|
||||||
|
* Compiz transparency support
|
||||||
|
* Multi-tab
|
||||||
|
* Plenty of color palettes
|
||||||
|
* and more …
|
||||||
|
|
||||||
|
Homepage: [http://guake-project.org/][15]
|
||||||
|
|
||||||
|
### 4\. ROXTerm
|
||||||
|
|
||||||
|
If you’re looking for a lightweight and highly customizable terminal emulator ROXTerm is for you. It is a terminal emulator intended to provide similar features to gnome-terminal, based on the same VTE library. It was originally designed to have a smaller footprint and quicker start-up time, and it’s more configurable than gnome-terminal and aimed more at "power" users who make heavy use of terminals.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][6][http://roxterm.sourceforge.net/index.php?page=index&lang=en][16]
|
||||||
|
|
||||||
|
### 5\. XTerm
|
||||||
|
|
||||||
|
It’s the most popular terminal for Linux and UNIX systems because its the default terminal for the X Window System. It is very lightweight and simple.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][7]Also read - [Guake Another Linux Terminal Emulator][2]
|
||||||
|
|
||||||
|
### 6\. Eterm
|
||||||
|
|
||||||
|
If you’re looking for an awesome and powerful terminal emulator Eterm is your best choice. Eterm is a color vt102 terminal emulator intended as a replacement for XTerm. It is designed with a Freedom of Choice philosophy, leaving as much power, flexibility, and freedom as possible in the hands of the user.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][8]Official Website: [http://www.eterm.org/][17]
|
||||||
|
|
||||||
|
### 7\. Gnome Terminal
|
||||||
|
|
||||||
|
It’s one of the most popular terminal emulator used by many Linux users because it’s part of the Gnome Desktop environment and Gnome is very used. It has many features and support for a lot of themes.
|
||||||
|
|
||||||
|
It comes by default in several Linux distros but also you can install it using your package manager.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][9]
|
||||||
|
|
||||||
|
### 8\. Sakura
|
||||||
|
|
||||||
|
Sakura is a terminal emulator based just on GTK and VTE. It's a terminal emulator with few dependencies, so you don't need a full GNOME desktop installed to have a decent terminal emulator.
|
||||||
|
|
||||||
|
You can install it using your package manager because Sakura is available for most Linux distros.
|
||||||
|
|
||||||
|
### 9\. LilyTerm
|
||||||
|
|
||||||
|
LilyTerm is a terminal emulator based off of libvte that aims to be fast and lightweight, Licensed under GPLv3.
|
||||||
|
|
||||||
|
#### Features At A Glance
|
||||||
|
|
||||||
|
* Low resource consumption
|
||||||
|
* Multi Tab
|
||||||
|
* Color scheme
|
||||||
|
* Hyperlink support
|
||||||
|
* Fullscreen support
|
||||||
|
* and many others …
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][10]
|
||||||
|
|
||||||
|
### 10\. Konsole
|
||||||
|
|
||||||
|
If you’re a KDE or Plasma user, you must know Konsole. It’s the default terminal emulator for KDE and it’s one of my favorites because is comfortable and useful.
|
||||||
|
|
||||||
|
It’s available for Ubuntu and fedora, but if you’re using Ubuntu (Unity) you should choose another option or maybe you should think about use Kubuntu.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][11]
|
||||||
|
|
||||||
|
### Conclusion
|
||||||
|
|
||||||
|
We are Linux users and we’ve many options to choose the better applications for our purposes, so you can choose the **best terminal** for your needs although also you should check another shell for your needs, for example you can use fish shell. |
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||||
|
|
||||||
|
作者:[Mohd Sohail][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://disqus.com/by/MohdSohail1/
|
||||||
|
[1]:http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||||
|
[2]:http://www.linuxandubuntu.com/home/another-linux-terminal-app-guake
|
||||||
|
[3]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||||
|
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/terminator-linux-terminals_orig.png
|
||||||
|
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/tilda-linux-terminal_orig.png
|
||||||
|
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/roxterm-linux-terminal_orig.png
|
||||||
|
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/xterm-linux-terminal_orig.png
|
||||||
|
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/etern-linux-terminal_orig.jpg
|
||||||
|
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-terminal_orig.jpg
|
||||||
|
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/lilyterm-linux-terminal_orig.jpg
|
||||||
|
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/konsole-linux-terminal_orig.png
|
||||||
|
[12]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||||
|
[13]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora#comments
|
||||||
|
[14]:https://github.com/lanoxx/tilda
|
||||||
|
[15]:http://guake-project.org/
|
||||||
|
[16]:http://roxterm.sourceforge.net/index.php?page=index&lang=en
|
||||||
|
[17]:http://www.eterm.org/
|
||||||
|
|||||||
@ -1,82 +0,0 @@
|
|||||||
Yoo-4x translating
|
|
||||||
# [CentOS Vs. Ubuntu][5]
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][4]Linux options available are almost “limitless” because, everyone can build it, either by changing an already existing distro or a new [Linux From Scratch][7] (LFS).Our choices on getting a Linux Distributions include its user interfaces, file system, package distribution, new features options and even updates periods and maintenance.
|
|
||||||
|
|
||||||
On this article we will talk about the two big Linux Distributions, actually, it will be the difference between one another, where one is better than another and other features.
|
|
||||||
|
|
||||||
### What is CentOS?
|
|
||||||
|
|
||||||
CentOS ( _Community Enterprise Operating System_ ) is Linux cloned community-supported distribution derived from Red Hat Enterprise Linux (RHEL) and is compatible with it (RHEL), so we can say that CentOS is a free version of RHEL. Every Distribution is maintained for 10 years and each version released every 2 years. It was on January 14th that CentOS announced the official joining with Red Hat, while staying independent from RHEL under a new CentOS board.
|
|
||||||
|
|
||||||
Also Read - [How To Install CentOS?][1]
|
|
||||||
|
|
||||||
### History and first release of CentOS
|
|
||||||
|
|
||||||
[CentOS][8] was first released in 2004 as cAOs Linux which was an RPM-based distribution and was community maintained and managed.
|
|
||||||
|
|
||||||
It combined aspects of Debian, Red Hat Linux/Fedora and FreeBSD in a way that was stable enough for servers and clusters in a life cycle of 3 to 5 years. It was a part of a larger organization (the CAOS Foundation) with a group of open source developers[1].
|
|
||||||
|
|
||||||
In June 2006 TAO Linux, another RHEL clone developed by David Parsley announced the retirement of TAO Linux and it’s rolling into development of CentOS. His migration to CentOS didn’t affect his previous users (TAO users), as they were able to migrate just by upgrading their system using yum update.
|
|
||||||
|
|
||||||
In January 2014 Red Hat started sponsoring CentOS Project transferring the ownership and trademarks to it.
|
|
||||||
|
|
||||||
[[1\. Open Source Software][9]]
|
|
||||||
|
|
||||||
### CentOS Design
|
|
||||||
|
|
||||||
CentOS is exactly the clone of the paid Red Hat version RHEL (Red Had Enterprise Edition). RHEL provides its source code that is later changed (removed the brand and logos) and modified to be released as a final CentOS product.
|
|
||||||
|
|
||||||
### Ubuntu
|
|
||||||
|
|
||||||
Ubuntu is a Linux operating system that is based on Debian, currently used on desktops, servers, smartphones and tablets. Ubuntu is launched by a company called Canonical Ltd based in the UK founded and funded by South African Mark Shuttleworth.
|
|
||||||
|
|
||||||
Also Read - [10 Things To Do After Installing Ubuntu 16.10][2]
|
|
||||||
|
|
||||||
### Ubuntu Design
|
|
||||||
|
|
||||||
Ubuntu is an Open source distro with many contributions from developers around the world. Along the years it has evolved to a stated where its interface has become more intuitive and modern, the Whole system has become fast in response, more secure and with tons of applications to download.
|
|
||||||
|
|
||||||
Since is based on [Debian][10] it supports .deb packages and the post recent package system and more secure [snap package format (snappy)][11].
|
|
||||||
|
|
||||||
This new packaging system allows applications to be delivered with all dependencies satisfied.
|
|
||||||
|
|
||||||
Also Read - [LinuxAndUbuntu Review Of Unity 8 In Ubuntu 16.10][3]
|
|
||||||
|
|
||||||
### Differences between CentOS and Ubuntu
|
|
||||||
|
|
||||||
* While ubuntu is based on Debian, CentOS is based on RHEL;
|
|
||||||
* Ubuntu uses .deb and .snap packages and centOS uses .rpm and flatpak;
|
|
||||||
* Ubuntu uses apt for updates while centOS uses YUM;
|
|
||||||
* CentOS seems to be more stable because doesn’t have regular updates to their packages like ubuntu but, this doesn’t mean that ubuntu is less secure;
|
|
||||||
* Ubuntu has more documentation and free support for problem solving and information;
|
|
||||||
* Ubuntu Server version has more support for cloud and container deployments.
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
Regardless of your choice, **Ubuntu or CentOS**, both distros are very good distros and stable. If you want a distro with a short release cycle stick with ubuntu and if you want a distro that doesn't change it’s package so often go with CentOS. Leave your comments below and tell us which one you prefer. |
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
|
||||||
|
|
||||||
作者:[linuxandubuntu.com][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
|
||||||
[1]:http://www.linuxandubuntu.com/home/how-to-install-centos
|
|
||||||
[2]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-ubuntu-16-04-xenial-xerus
|
|
||||||
[3]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-unity-8-preview-in-ubuntu-1610
|
|
||||||
[4]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
|
||||||
[5]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
|
||||||
[6]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu#comments
|
|
||||||
[7]:http://www.linuxandubuntu.com/home/how-to-create-a-linux-distro
|
|
||||||
[8]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-centos
|
|
||||||
[9]:https://en.wikipedia.org/wiki/Open-source_software
|
|
||||||
[10]:https://www.debian.org/
|
|
||||||
[11]:https://en.wikipedia.org/wiki/Snappy_(package_manager)
|
|
||||||
@ -1,89 +0,0 @@
|
|||||||
ucasFL translating
|
|
||||||
How to Install Ubuntu with Separate Root and Home Hard Drives
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
When building a Linux installation, there are two options. The first option is to find a super-fast solid state drive. This will ensure very fast boot times and overall speed when accessing data. The second option is to go for a slower but beefier spinning disk hard drive – one with fast RPMs and a large amount of storage. This ensures a massive amount of storage for applications and data.
|
|
||||||
|
|
||||||
|
|
||||||
However, as some Linux users are aware, [solid state drives][10] are nice, but expensive, and spinning disk drives have a lot of storage but tend to be slow. What if I told you that it was possible to have both? A super-fast, modern solid state drive powering the core of your Linux and a large spinning disk drive for all the data.
|
|
||||||
|
|
||||||
In this article we’ll go over how to install Ubuntu Linux with separate root and home hard drives – with root folder in the SSD and home folder in the spinning disk hard drive.
|
|
||||||
|
|
||||||
### No extra hard drives? Try SD cards!
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Setting up a multi-drive Linux installation is great and something advanced users should get behind. However, there is another reason for users to do a setup like this – low-storage-capacity laptops. Maybe you have a cheap laptop that didn’t cost much, and Linux was installed on it. It’s not much, but the laptop has an SD card slot.
|
|
||||||
|
|
||||||
This guide is for those types of computers as well. Follow this guide, and instead of a second hard drive, maybe go out and buy a fast and speedy SD card for the laptop, and use that as a home folder. This tutorial will work for that use case too!
|
|
||||||
|
|
||||||
### Making the USB disk
|
|
||||||
|
|
||||||
Start out by heading over to [this website][11] to download the latest version of Ubuntu Linux. Then [download][12] the Etcher USB imaging tool. This is a very easy-to-use tool and supports all major operating systems. You will also need a USB drive of at least 2 GB in size.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Install Etcher, then launch it. Make an image by clicking the “Select Image” button. This will prompt the user to browse for the ISO image. Find the Ubuntu ISO file downloaded earlier and select it. From here, insert the USB drive. Etcher should automatically select it. Then, click the “Flash!” button. The Ubuntu live disk creation process will begin.
|
|
||||||
|
|
||||||
To boot into Ubuntu, configure the BIOS. This is needed so that the computer will boot the newly-created Ubuntu live USB. To get into the BIOS, reboot with the USB in, and press the correct key (Del, F2, or whatever the key is on your particular machine). Find where the option is to enable booting from USB and enable it.
|
|
||||||
|
|
||||||
If your PC does not support booting from USB, burn the Ubuntu image to a DVD.
|
|
||||||
|
|
||||||
### Installation
|
|
||||||
|
|
||||||
When Ubuntu first loads, the welcome screen appears with two options. Select the “Install Ubuntu” button to proceed. On the next page the Ubiquity installation tool asks the user to select some options. These options aren’t mandatory and can be ignored. However, it is recommended that both boxes be checked, as they save time after the installation, specifically with the installation of MP3 codecs and updating the system.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
After selecting both boxes in the “Preparing to install Ubuntu” page, it will be time to select the installation type. There are many. However, with this tutorial the option required is the custom one. To get to the custom installation page, select the “something else” box, then click continue.
|
|
||||||
|
|
||||||
This reveals Ubuntu’s custom installation partitioning tool. It will show any and all disks that can install Ubuntu. If two hard drives are available, they will appear. If an SD card is plugged in, it will appear.
|
|
||||||
|
|
||||||
Select the hard drive that you plan to use for the root file system. If there is already a partition table on it, the editor will show partitions. Delete all of them, using the tool. If the drive isn’t formatted and has no partitions, select the drive with the mouse, then click “new partition table.” Do this for all drives so that they both have partition tables.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Now that both drives have partition tables (and partitions deleted), the configuration can begin. Select the free space under drive one, then click the plus sign button to create a new partition. This will bring up the “Create partition window.” Allow the tool to use the entire hard drive, then go to the “Mount Point” drop-down menu. Select `/` as the mount point, then the OK button to confirm the settings.
|
|
||||||
|
|
||||||
Do the same with the second drive. This time select `/home` as the mount point. With both drives set up, select the correct drive the boot loader will go to, then click the “install now” button to start the installation process.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The installation process from here is the standard installation. Create a username, select the timezone, etc.
|
|
||||||
|
|
||||||
**Notes:** Are you installing in UEFI mode? A 512 MB, FAT32 partition will need to be created for boot. Do this before creating any other partitions. Be sure to select “/boot” as the mount point for this partition as well.
|
|
||||||
|
|
||||||
If you require Swap, create a partition on the first drive before making the partition used for `/`. This can be done by clicking the “+” (plus) button, entering the desired size, and selecting “swap area” in the drop-down.
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
The best thing about Linux is how configurable it is. How many other operating systems let you split up the file system onto separate hard drives? Not many, that’s for sure! I hope that with this guide you’ll realize the true power Ubuntu can offer!
|
|
||||||
|
|
||||||
Would you use multiple drives in your Ubuntu installation? Let us know below in the comments.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.maketecheasier.com/install-ubuntu-with-different-root-home-hard-drives/
|
|
||||||
|
|
||||||
作者:[Derrik Diener][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.maketecheasier.com/author/derrikdiener/
|
|
||||||
[1]:https://www.maketecheasier.com/author/derrikdiener/
|
|
||||||
[2]:https://www.maketecheasier.com/install-ubuntu-with-different-root-home-hard-drives/#respond
|
|
||||||
[3]:https://www.maketecheasier.com/category/linux-tips/
|
|
||||||
[4]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Finstall-ubuntu-with-different-root-home-hard-drives%2F
|
|
||||||
[5]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Finstall-ubuntu-with-different-root-home-hard-drives%2F&text=How+to+Install+Ubuntu+with+Separate+Root+and+Home+Hard+Drives
|
|
||||||
[6]:mailto:?subject=How%20to%20Install%20Ubuntu%20with%20Separate%20Root%20and%20Home%20Hard%20Drives&body=https%3A%2F%2Fwww.maketecheasier.com%2Finstall-ubuntu-with-different-root-home-hard-drives%2F
|
|
||||||
[7]:https://www.maketecheasier.com/byb-dimmable-eye-care-desk-lamp/
|
|
||||||
[8]:https://www.maketecheasier.com/download-appx-files-from-windows-store/
|
|
||||||
[9]:https://support.google.com/adsense/troubleshooter/1631343
|
|
||||||
[10]:http://www.maketecheasier.com/tag/ssd
|
|
||||||
[11]:http://ubuntu.com/download
|
|
||||||
[12]:https://etcher.io/
|
|
||||||
@ -1,159 +0,0 @@
|
|||||||
申请翻译
|
|
||||||
Understanding the difference between sudo and su
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### On this page
|
|
||||||
|
|
||||||
1. [The su command in Linux][7]
|
|
||||||
1. [su -][1]
|
|
||||||
2. [su -c][2]
|
|
||||||
2. [Sudo vs Su][8]
|
|
||||||
1. [Password][3]
|
|
||||||
2. [Default behavior][4]
|
|
||||||
3. [Logging][5]
|
|
||||||
4. [Flexibility][6]
|
|
||||||
3. [Sudo su][9]
|
|
||||||
|
|
||||||
In one of our[ earlier articles][11], we discussed the 'sudo' command in detail. Towards the ends of that tutorial, there was a mention of another similar command 'su' in a small note. Well, in this article, we will discuss in detail the 'su' command as well as how it differs from the 'sudo' command.
|
|
||||||
|
|
||||||
But before we do that, please note that all the instructions and examples mentioned in this tutorial have been tested on Ubuntu 14.04LTS.
|
|
||||||
|
|
||||||
### The su command in Linux
|
|
||||||
|
|
||||||
The main work of the su command is to let you switch to some other user during a login session. In other words, the tool lets you assume the identity of some other user without having to logout and then login (as that user).
|
|
||||||
|
|
||||||
The su command is mostly used to switch to the superuser/root account (as root privileges are frequently required while working on the command line), but - as already mentioned - you can use it to switch to any other, non-root user as well.
|
|
||||||
|
|
||||||
Here's how you can use this command to switch to the root user:
|
|
||||||
|
|
||||||
[
|
|
||||||
|
|
||||||
][12]
|
|
||||||
|
|
||||||
The password that this command requires is also of the root user. So in general, the su command requires you to enter the password of the target user. After the correct password is entered, the tool starts a sub-session inside the existing session on the terminal.
|
|
||||||
|
|
||||||
### su -
|
|
||||||
|
|
||||||
There's another way to switch to the root user: run the 'su -' command:
|
|
||||||
|
|
||||||
[
|
|
||||||
|
|
||||||
][13]
|
|
||||||
|
|
||||||
Now, what's the difference between 'su' and 'su -' ? Well, the former keeps the environment of the old/original user even after the switch to root has been made, while the latter creates a new environment (as dictated by the ~/.bashrc of the root user), similar to the case when you explicitly log in as root user from the log-in screen.
|
|
||||||
|
|
||||||
The man page of 'su' also makes it clear:
|
|
||||||
|
|
||||||
```
|
|
||||||
The optional argument - may be used to provide an environment similar to what the user would expect had the user logged in directly.
|
|
||||||
```
|
|
||||||
|
|
||||||
So, you'll agree that logging in with 'su -' makes more sense. But as the 'su' command also exists, one might wonder when that's useful. The following excerpt - taken from the [ArchLinux wiki website][14] - gives a good idea about the benefits and pitfalls of the 'su' command:
|
|
||||||
|
|
||||||
* It sometimes can be advantageous for a system administrator to use the shell account of an ordinary user rather than its own. In particular, occasionally the most efficient way to solve a user's problem is to log into that user's account in order to reproduce or debug the problem.
|
|
||||||
|
|
||||||
* However, in many situations it is not desirable, or it can even be dangerous, for the root user to be operating from an ordinary user's shell account and with that account's environmental variables rather than from its own. While inadvertently using an ordinary user's shell account, root could install a program or make other changes to the system that would not have the same result as if they were made while using the root account. For instance, a program could be installed that could give the ordinary user power to accidentally damage the system or gain unauthorized access to certain data.
|
|
||||||
|
|
||||||
Note: In case you want to pass more arguments after - in 'su -', then you should use the -l command line option that the command offers (instead of -). Here's the definition of - and the -l command line option:
|
|
||||||
|
|
||||||
```
|
|
||||||
-, -l, --login
|
|
||||||
Provide an environment similar to what the user would expect had the user logged in directly.
|
|
||||||
|
|
||||||
When - is used, it must be specified as the last su option. The other forms (-l and --login) do not have this restriction.
|
|
||||||
```
|
|
||||||
|
|
||||||
### su -c
|
|
||||||
|
|
||||||
There's another option of the 'su' command that's worth mentioning: -c. It lets you provide a command that you want to run after switching to the target user.
|
|
||||||
|
|
||||||
The man page of 'su' explains it as:
|
|
||||||
|
|
||||||
```
|
|
||||||
-c, --command COMMAND
|
|
||||||
Specify a command that will be invoked by the shell using its -c.
|
|
||||||
|
|
||||||
The executed command will have no controlling terminal. This option cannot be used to execute interactive programs which need a controlling TTY.
|
|
||||||
```
|
|
||||||
|
|
||||||
Consider the following example template:
|
|
||||||
|
|
||||||
su [target-user] -c [command-to-run]
|
|
||||||
|
|
||||||
So in this case, the 'command-to-run' will be executed as:
|
|
||||||
|
|
||||||
[shell] -c [command-to-run]
|
|
||||||
|
|
||||||
Where 'shell' would be replaced by 'target-user' shell defined in the /etc/passwd file.
|
|
||||||
|
|
||||||
### Sudo vs Su
|
|
||||||
|
|
||||||
Now since we have discussed the basics of the 'su' command as well, it's time we discuss the differences between the 'sudo' and the 'su' commands.
|
|
||||||
|
|
||||||
### Password
|
|
||||||
|
|
||||||
The primary difference between the two is the password they require: while 'sudo' requires current user's password, 'su' requires you to enter the root user password.
|
|
||||||
|
|
||||||
Quite clearly, 'sudo' is a better alternative between the two as far as security is concerned. For example, consider the case of computer being used by multiple users who also require root access. Using 'su' in such a scenario means sharing the root password with all of them, which is not a good practice in general.
|
|
||||||
|
|
||||||
Moreover, in case you want to revoke the superuser/root access of a particular user, the only way is to change the root password and then redistribute the new root password among all the other users.
|
|
||||||
|
|
||||||
With Sudo, on the other hand, you can handle both these scenarios effortlessly. Given that 'sudo' requires users to enter their own password, you don't need to share the root password will all the users in the first place. And to stop a particular user from accessing root privileges, all you have to do is to tweak the corresponding entry in the 'sudoers' file.
|
|
||||||
|
|
||||||
### Default behavior
|
|
||||||
|
|
||||||
The other difference between the two commands is in their default behavior. While 'sudo' only allows you to run a single command with elevated privileges, the 'su' command launches a new shell, allowing you to run as many commands as you want with root privileges until you explicitly exit that sell.
|
|
||||||
|
|
||||||
So the default behavior of the 'su' command is potentially dangerous given the possibility that the user can forget the fact that they are working as root, and might inadvertently make some irrecoverable changes (such as run the 'rm -rf' command in wrong directory). For a detailed discussion on why it's not encouraged to always work as root, head [here][10].
|
|
||||||
|
|
||||||
### Logging
|
|
||||||
|
|
||||||
Although commands run through 'sudo' are executed as the target user (which is 'root' by default), they are tagged with the sudoer's user-name. But in case of 'su', it's not possible to directly trace what a user did after they su'd to the root account.
|
|
||||||
|
|
||||||
### Flexibility
|
|
||||||
|
|
||||||
The 'sudo' command is far more flexible in that you can even limit the commands that you want the sudo-ers to have access to. In other words, users with access to 'sudo' can only be given access to commands that are required for their job. However, with 'su' that's not possible - either you have the privilege to do everything or nothing.
|
|
||||||
|
|
||||||
### Sudo su
|
|
||||||
|
|
||||||
Presumably due to the potential risks involved with using 'su' or logging directly as root, some Linux distributions - like Ubuntu - disable the root user account by default. Users are encouraged to use 'sudo' whenever they need root privileges.
|
|
||||||
|
|
||||||
However, you can still do 'su' successfully, i.e, without entering the root password. All you need to do is to run the following command:
|
|
||||||
|
|
||||||
sudo su
|
|
||||||
|
|
||||||
Since you're running the command with 'sudo', you'll only be required to enter your password. So once that is done, the 'su' command will be run as root, meaning it won't ask for any passwords.
|
|
||||||
|
|
||||||
**PS**: In case you want to enable the root account on your system (although that's strongly discouraged because you can always use 'sudo' or 'sudo su'), you'll have to set the root password manually, which you can do that using the following command:
|
|
||||||
|
|
||||||
sudo passwd root
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
Both this as well as our previous tutorial (which focuses on 'sudo') should give you a good idea about the available tools that let you do tasks that require escalated (or a completely different set of) privileges. In case you have something to share about 'su' or 'sudo', or want to share your own experience, you are welcome to do that in comments below.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.howtoforge.com/tutorial/sudo-vs-su/
|
|
||||||
|
|
||||||
作者:[Himanshu Arora][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.howtoforge.com/tutorial/sudo-vs-su/
|
|
||||||
[1]:https://www.howtoforge.com/tutorial/sudo-vs-su/#su-
|
|
||||||
[2]:https://www.howtoforge.com/tutorial/sudo-vs-su/#su-c
|
|
||||||
[3]:https://www.howtoforge.com/tutorial/sudo-vs-su/#password
|
|
||||||
[4]:https://www.howtoforge.com/tutorial/sudo-vs-su/#default-behavior
|
|
||||||
[5]:https://www.howtoforge.com/tutorial/sudo-vs-su/#logging
|
|
||||||
[6]:https://www.howtoforge.com/tutorial/sudo-vs-su/#flexibility
|
|
||||||
[7]:https://www.howtoforge.com/tutorial/sudo-vs-su/#the-su-command-in-linux
|
|
||||||
[8]:https://www.howtoforge.com/tutorial/sudo-vs-su/#sudo-vs-su
|
|
||||||
[9]:https://www.howtoforge.com/tutorial/sudo-vs-su/#sudo-su
|
|
||||||
[10]:http://askubuntu.com/questions/16178/why-is-it-bad-to-login-as-root
|
|
||||||
[11]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/
|
|
||||||
[12]:https://www.howtoforge.com/images/sudo-vs-su/big/su-command.png
|
|
||||||
[13]:https://www.howtoforge.com/images/sudo-vs-su/big/su-hyphen-command.png
|
|
||||||
[14]:https://wiki.archlinux.org/index.php/Su
|
|
||||||
@ -1,144 +0,0 @@
|
|||||||
How to setup a Linux server on Amazon AWS
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### On this page
|
|
||||||
|
|
||||||
1. [Setup a Linux VM in AWS][1]
|
|
||||||
2. [Connect to an EC2 instance from Windows][2]
|
|
||||||
|
|
||||||
AWS (Amazon Web Services) is one of the leading cloud server providers worldwide. You can setup a server within a minute using the AWS platform. On AWS, you can fine tune many techncal details of your server like the number of CPU's, Memory and HDD space, type of HDD (SSD which is faster or a classic IDE) and so on. And the best thing about the AWS is that you need to pay only for the services that you have used. To get started, AWS provides a special account called "Free tier" where you can use the AWS technology free for one year with some minor restrictions like you can use the server only upto 750 Hours a month, when you cross this theshold they will charge you. You can check all the rules related this on [aws portal][3].
|
|
||||||
|
|
||||||
Since I am writing this post about creating a Linux server on AWS, having a "Free Tier" account is the main pre-requisite. To sign up for this account you can use this [link][4]. Kindly note that you need to enter your credit card details while creating the account.
|
|
||||||
|
|
||||||
So let's assume that you have created the "free tier" account.
|
|
||||||
|
|
||||||
Before we proceed, you must know some of the terminologies in AWS to understand the setup:
|
|
||||||
|
|
||||||
1. EC2 (Elastic compute cloud): This term used for the virtual machine.
|
|
||||||
2. AMI (Amazon machine image): Used for the OS instance.
|
|
||||||
3. EBS (Elastic block storage): one of the type Storage environment in AWS.
|
|
||||||
|
|
||||||
Now login to AWS console at below location:
|
|
||||||
|
|
||||||
[https://console.aws.amazon.com/][5]
|
|
||||||
|
|
||||||
The AWS console will look like this:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][6]
|
|
||||||
|
|
||||||
### Setup a Linux VM in AWS
|
|
||||||
|
|
||||||
1: Create an EC2 (virtual machine) instance: Before installing the OS on you must create a VM in AWS. To create this, click on EC2 under compute menu:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][7]
|
|
||||||
|
|
||||||
2\. Now click on "Launch Instance" Button under Create instance.
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][8]
|
|
||||||
|
|
||||||
3\. Now, when you are using a free tier account, then better select the Free Tier radio button so that AWS will filter the instances which are used for free usage. This will keep you aside from paying money to AWS for using billed resources under AWS.
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][9]
|
|
||||||
|
|
||||||
4\. To proceed further, select following options:
|
|
||||||
|
|
||||||
a. **Choose an AMI in the classic instance wizard: selection --> I'll use Red Hat Enterprise Linux 7.2 (HVM), SSD Volume Type here**
|
|
||||||
|
|
||||||
b. Select "**t2.micro**" for the instance details.
|
|
||||||
|
|
||||||
c. **Configure Instance Details**: Do not change anything simply click next.
|
|
||||||
|
|
||||||
d. **Add Storage: **Do not change anything simply click next as we will using default Size 10 (GiB) Hard disk in this case.
|
|
||||||
|
|
||||||
e. **Add Tags**: Do not change anything simply click next.
|
|
||||||
|
|
||||||
f. **Configure Security Group**: Now select port 22 which is used for ssh so that you can access this server from anywhere.
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][10]
|
|
||||||
|
|
||||||
g. **Select review and launch button**
|
|
||||||
|
|
||||||
h. If all the details are Ok now press the "**Launch**" button,
|
|
||||||
|
|
||||||
i. Once you clicked the Launch button, a popup window gets displayed to create a "Key pair" as shown below: Select the option "create a new key pair" and give a name to key pair. Then download the same. You require this key pair while connecting to the server using ssh. At the end, click the "Launch Instance" button.
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][11]
|
|
||||||
|
|
||||||
j. After clicking Launch instance Button, go to services at the left top side. Select Compute--> EC2\. Now click on running instance link as below:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][12]
|
|
||||||
|
|
||||||
k. Now you can see that your new VM is ready with status "running" as shown below. Select the Instance and Please note down the "Public DNS value" which is required for logging on to the server.
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][13]
|
|
||||||
|
|
||||||
Now you are done with creating a sample Linux installed VM. To connect to the server, follow below steps.
|
|
||||||
|
|
||||||
### Connect to an EC2 instance from Windows
|
|
||||||
|
|
||||||
1\. First of all, you need to have putty gen and Putty exe's for connecting to the server from Windows (or the SSH command on Linux). You can download putty by following this [Link][14].
|
|
||||||
|
|
||||||
2\. Now open the putty gen "puttygen.exe".
|
|
||||||
|
|
||||||
3\. You need to click on the "Load button", browse and select the keypair file (pem file) that you downloaded above from Amazon.
|
|
||||||
|
|
||||||
4\. You need to select the "ssh2-RSA" option and click on the save private key button. Kindly select yes on the next pop-up.
|
|
||||||
|
|
||||||
5\. Save the file with the file extension .ppk.
|
|
||||||
|
|
||||||
6\. Now you need to open Putty.exe. Go to connection at the left side menu then select "SSH" and then select "Auth". You need to click on the browse button to select the .ppk file that we created in the step 4.
|
|
||||||
|
|
||||||
7\. Now click on the "session" menu and paste the DNS value captured during the 'k' step of this tutorial in the "host name" box and hit the open button.
|
|
||||||
|
|
||||||
8\. Upon asking for username and password, enter "**ec2-user**" and blank password and then give below command.
|
|
||||||
|
|
||||||
$sudo su -
|
|
||||||
|
|
||||||
Hurray, you are now root on the Linux server which is hosted on AWS cloud.
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][15]
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/
|
|
||||||
|
|
||||||
作者:[MANMOHAN MIRKAR][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/
|
|
||||||
[1]:https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/#setup-a-linux-vm-in-aws
|
|
||||||
[2]:https://www.howtoforge.com/tutorial/how-to-setup-linux-server-with-aws/#connect-to-an-ec-instance-from-windows
|
|
||||||
[3]:http://aws.amazon.com/free/
|
|
||||||
[4]:http://aws.amazon.com/ec2/
|
|
||||||
[5]:https://console.aws.amazon.com/
|
|
||||||
[6]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_console.JPG
|
|
||||||
[7]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_console_ec21.png
|
|
||||||
[8]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_launch_ec2.png
|
|
||||||
[9]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_free_tier_radio1.png
|
|
||||||
[10]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_ssh_port1.png
|
|
||||||
[11]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_key_pair.png
|
|
||||||
[12]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_running_instance.png
|
|
||||||
[13]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_dns_value.png
|
|
||||||
[14]:http://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
|
|
||||||
[15]:https://www.howtoforge.com/images/how_to_setup_linux_server_with_aws/big/aws_putty1.JPG
|
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
申请翻译
|
||||||
|
|
||||||
Many SQL Performance Problems Stem from “Unnecessary, Mandatory Work”
|
Many SQL Performance Problems Stem from “Unnecessary, Mandatory Work”
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -1,98 +0,0 @@
|
|||||||
How to Change Root Password of MySQL or MariaDB in Linux
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
|
|
||||||
If you’re [installing MySQL or MariaDB in Linux][1] for the first time, chances are you will be executing mysql_secure_installation script to secure your MySQL installation with basic settings.
|
|
||||||
|
|
||||||
One of these settings is, database root password – which you must keep secret and use only when it is required. If you need to change it (for example, when a database administrator changes roles – or is laid off!).
|
|
||||||
|
|
||||||
**Suggested Read:** [Recover MySQL or MariaDB Root Password in Linux][2]
|
|
||||||
|
|
||||||
This article will come in handy. We will explain how to change a root password of MySQL or MariaDB database server in Linux.
|
|
||||||
|
|
||||||
Although we will use a MariaDB server in this article, the instructions should work for MySQL as well.
|
|
||||||
|
|
||||||
### Change MySQL or MariaDB Root Password
|
|
||||||
|
|
||||||
You know the root password and want to reset it, in this case, let’s make sure MariaDB is running:
|
|
||||||
|
|
||||||
```
|
|
||||||
------------- CentOS/RHEL 7 and Fedora 22+ -------------
|
|
||||||
# systemctl is-active mariadb
|
|
||||||
------------- CentOS/RHEL 6 and Fedora -------------
|
|
||||||
# /etc/init.d/mysqld status
|
|
||||||
```
|
|
||||||
[
|
|
||||||

|
|
||||||
][3]
|
|
||||||
|
|
||||||
Check MySQL Status
|
|
||||||
|
|
||||||
If the above command does not return the word `active` as output or its stopped, you will need to start the database service before proceeding:
|
|
||||||
|
|
||||||
```
|
|
||||||
------------- CentOS/RHEL 7 and Fedora 22+ -------------
|
|
||||||
# systemctl start mariadb
|
|
||||||
------------- CentOS/RHEL 6 and Fedora -------------
|
|
||||||
# /etc/init.d/mysqld start
|
|
||||||
```
|
|
||||||
|
|
||||||
Next, we will login to the database server as root:
|
|
||||||
|
|
||||||
```
|
|
||||||
# mysql -u root -p
|
|
||||||
```
|
|
||||||
|
|
||||||
For compatibility across versions, we will use the following statement to update the user table in the mysql database. Note that you need to replace `YourPasswordHere` with the new password you have chosen for root.
|
|
||||||
|
|
||||||
```
|
|
||||||
MariaDB [(none)]> USE mysql;
|
|
||||||
MariaDB [(none)]> UPDATE user SET password=PASSWORD('YourPasswordHere') WHERE User='root' AND Host = 'localhost';
|
|
||||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
|
||||||
```
|
|
||||||
|
|
||||||
To validate, exit your current MariaDB session by typing.
|
|
||||||
|
|
||||||
```
|
|
||||||
MariaDB [(none)]> exit;
|
|
||||||
```
|
|
||||||
|
|
||||||
and then press Enter. You should now be able to connect to the server using the new password.
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][4]
|
|
||||||
|
|
||||||
Change MySQL/MariaDB Root Password
|
|
||||||
|
|
||||||
##### Summary
|
|
||||||
|
|
||||||
In this article we have explained how to change the MariaDB / MySQL root password – whether you know the current one or not.
|
|
||||||
|
|
||||||
As always, feel free to drop us a note if you have any questions or feedback using our comment form below. We look forward to hearing from you!
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
Gabriel Cánepa is a GNU/Linux sysadmin and web developer from Villa Mercedes, San Luis, Argentina. He works for a worldwide leading consumer product company and takes great pleasure in using FOSS tools to increase productivity in all areas of his daily work.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.tecmint.com/change-mysql-mariadb-root-password/
|
|
||||||
|
|
||||||
作者:[Gabriel Cánepa][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.tecmint.com/author/gacanepa/
|
|
||||||
|
|
||||||
[1]:http://www.tecmint.com/install-mariadb-in-centos-7/
|
|
||||||
[2]:http://www.tecmint.com/reset-mysql-or-mariadb-root-password/
|
|
||||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-MySQL-Status.png
|
|
||||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Change-MySQL-Root-Password.png
|
|
||||||
[5]:http://www.tecmint.com/author/gacanepa/
|
|
||||||
[6]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
|
||||||
[7]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
|
||||||
@ -0,0 +1,83 @@
|
|||||||
|
How to open port on AWS EC2 Linux server
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_Small tutorial with screenshots which shows how to open port on AWS EC2 Linux server. This will help you to manage port specific services on EC2 server._
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
AWS i.e. Amazon Web Services is no new term for IT world. Its a cloud services platform offered by Amazon. Under its Free tier account it offers you limited services free of cost for one year. This is one of best place to try out new technologies without spending much on financial front.
|
||||||
|
|
||||||
|
AWS offers server computing as one of their services and they call them as EC (Elastic Computing). Under this we can build our Linux servers. We have already seen [how to setup Linux server on AWS free of cost][11].
|
||||||
|
|
||||||
|
By default, all Linux servers build under EC2 has post 22 i.e. SSH service port (inbound from all IP) is open only. So, if you are hosting any port specific service then relative port needs to be open on AWS firewall for your server.
|
||||||
|
|
||||||
|
Also it has port 1 to 65535 are open too (outbound for all traffic). If you want to change this you can use same below process for editing outbound rules too.
|
||||||
|
|
||||||
|
Setting up firewall rule on AWS for your server is easy job. You will be able to open ports in seconds for your server. I will walk you through procedure with screenshots to open port for EC2 server.
|
||||||
|
|
||||||
|
_Step 1 :_
|
||||||
|
|
||||||
|
Login to AWS account and navigate to EC2 management console. Goto Security Groups under Network & Security menu as highlighted below :
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Step 2 :_
|
||||||
|
|
||||||
|
On Security Groups screen select you r EC2 server and under Actions menu select Edit inbound rules
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
_Step 3:_
|
||||||
|
|
||||||
|
Now you will be presented with inbound rule window. You can add/edit/delete inbound rules here. There are several protocols like http, nfs etc listed in dropdown menu which auto-populate ports for you. If you have custom service and port you can define it too.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
For example if you want to open port 80 then you have to select :
|
||||||
|
|
||||||
|
* Type : http
|
||||||
|
* Protocol : TCP
|
||||||
|
* Port range : 80
|
||||||
|
* Source : Anywhere (Open port 80 for all incoming req from any IP (0.0.0.0/0), My IP : then it will auto populate your current public internet IP
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Step 4:_
|
||||||
|
|
||||||
|
Thats it. Once you save these settings your server inbound port 80 is open! you can check by telneting to port 80 ofor your EC2 server public DNS (can be found it EC2 server details)
|
||||||
|
|
||||||
|
You can also check it on websites like [ping.eu][12].
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/
|
||||||
|
|
||||||
|
作者:[Shrikant Lavhate ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/
|
||||||
|
[1]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||||
|
[2]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||||
|
[3]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||||
|
[4]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||||
|
[5]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||||
|
[6]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||||
|
[7]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||||
|
[8]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||||
|
[9]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||||
|
[10]:http://kerneltalks.com/author/shrikant/
|
||||||
|
[11]:http://kerneltalks.com/howto/install-ec2-linux-server-aws-with-screenshots/
|
||||||
|
[12]:http://ping.eu/port-chk/
|
||||||
@ -0,0 +1,137 @@
|
|||||||
|
An introduction to GRUB2 configuration for your Linux machine
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> Learn how the GRUB boot loader works to prepare your system and launch your operating system kernel.
|
||||||
|

|
||||||
|
>Image by : Internet Archive [Book][5] [Images][6]. Modified by Opensource.com. CC BY-SA 4.0
|
||||||
|
|
||||||
|
When researching my article from last month, _[An introduction to the Linux][1][ boot and startup process][2]_ , I became interested in learning more about GRUB2\. This article provides a quick introduction to configuring GRUB2, which I will mostly refer to as GRUB for simplicity.
|
||||||
|
|
||||||
|
### GRUB
|
||||||
|
|
||||||
|
GRUB stands for _GRand Unified Bootloader_ . Its function is to take over from BIOS at boot time, load itself, load the Linux kernel into memory, and then turn over execution to the kernel. Once the kernel takes over, GRUB has done its job and it is no longer needed.
|
||||||
|
|
||||||
|
GRUB supports multiple Linux kernels and allows the user to select between them at boot time using a menu. I have found this to be a very useful tool because there have been many instances that I have encountered problems with an application or system service that fails with a particular kernel version. Many times, booting to an older kernel can circumvent issues such as these. By default, three kernels are kept–the newest and two previous–when **yum** or **dnf** are used to perform upgrades. The number of kernels to be kept before the package manager erases them is configurable in the **/etc/dnf/dnf.conf** or **/etc/yum.conf** files. I usually change the **installonly_limit** value to 9 to retain a total of nine kernels. This has come in handy on a couple occasions when I had to revert to a kernel that was several versions down-level.
|
||||||
|
|
||||||
|
### GRUB menu
|
||||||
|
|
||||||
|
The function of the GRUB menu is to allow the user to select one of the installed kernels to boot in the case where the default kernel is not the desired one. Using the up and down arrow keys allows you to select the desired kernel and pressing the **Enter** key continues the boot process using the selected kernel.
|
||||||
|
|
||||||
|
The GRUB menu also provides a timeout so that, if the user does not make any other selection, GRUB will continue to boot with the default kernel without user intervention. Pressing any key on the keyboard except the **Enter** key terminates the countdown timer which is displayed on the console. Pressing the **Enter** key immediately continues the boot process with either the default kernel or an optionally selected one.
|
||||||
|
|
||||||
|
The GRUB menu also provides a "rescue" kernel, in for use when troubleshooting or when the regular kernels don't complete the boot process for some reason. Unfortunately, this rescue kernel does not boot to rescue mode. More on this later in this article.
|
||||||
|
|
||||||
|
### The grub.cfg file
|
||||||
|
|
||||||
|
The **grub.cfg** file is the GRUB configuration file. It is generated by the **grub2-mkconfig** program using a set of primary configuration files and the grub default file as a source for user configuration specifications. The **/****boot/grub2/****grub.cfg** file is first generated during Linux installation and regenerated when a new kernel is installed.
|
||||||
|
|
||||||
|
The **grub.cfg** file contains Bash-like code and a list of installed kernels in an array ordered by sequence of installation. For example, if you have four installed kernels, the most recent kernel will be at index 0, the previous kernel will be at index 1, and the oldest kernel will be index 3\. If you have access to a **grub.****cfg** file you should look at it to get a feel for what one looks like. The **grub.cfg** file is just too large to be included in this article.
|
||||||
|
|
||||||
|
### GRUB configuration files
|
||||||
|
|
||||||
|
The main set of configuration files for **grub.cfg** is located in the **/etc/grub.d **directory. Each of the files in that directory contains GRUB code that is collected into the final grub.cfg file. The numbering scheme used in the names of these configuration files is designed to provide ordering so that the final **grub.cfg** file is assembled into the correct sequence. Each of these files has a comment to denote the beginning and end of the section, and those comments are also part of the final grub.cfg file so that it is possible to see from which file each section is generated. The delimiting comments look like this:
|
||||||
|
|
||||||
|
```
|
||||||
|
### BEGIN /etc/grub.d/10_linux ###
|
||||||
|
|
||||||
|
### END /etc/grub.d/10_linux ###
|
||||||
|
```
|
||||||
|
|
||||||
|
These files should not be modified unless you are a GRUB expert and understand what the changes will do. Even then you should always keep a backup copy of the original, working **grub.****cfg** file. The specific files, **40_custom** and **41_custom** are intended to be used to generate user modifications to the GRUB configuration. You should still be aware of the consequences of any changes you make to these files and maintain a backup of the original **grub.****cfg** file.
|
||||||
|
|
||||||
|
You can also add your own files to the /etc/grub.d directory. One reason for doing that might be to add a menu line for a non-Linux operating system. Just be sure to follow the naming convention to ensure that the additional menu item is added either immediately before or after the **10_linux** entry in the configuration file.
|
||||||
|
|
||||||
|
### GRUB defaults file
|
||||||
|
|
||||||
|
Configuration of the original GRUB was fairly simple and straightforward. I would just modify **/boot/grub/grub.conf** and be good to go. I could still modify GRUB2 by changing **/boot/grub2/grub.****cfg**, but the new version is considerably more complex than the original GRUB. In addition, **grub.cfg** may be overwritten when a new kernel is installed, so any changes may disappear. However, the GNU.org GRUB Manual does discuss direct creation and modification of **/boot/grub2/grub.cfg**.
|
||||||
|
|
||||||
|
Changing the configuration for GRUB2 is fairly easy once you actually figure out how to do it. I only discovered this while researching GRUB2 for a previous article. The secret formula is in the **/etc/default **directory, with a file called, naturally enough, grub, which is then used in concert with a simple terminal command. The **/etc/default** directory contains configuration files for a few programs such as Google Chrome, useradd, and grub.
|
||||||
|
|
||||||
|
The **/etc/default/grub** file is very simple. The grub defaults file has a number of valid key/value pairs listed already. You can simply change the values of existing keys or add other keys that are not already in the file. Listing 1, below, shows an unmodified **/etc/default/gru**b file.
|
||||||
|
|
||||||
|
```
|
||||||
|
GRUB_TIMEOUT=5
|
||||||
|
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g'
|
||||||
|
/etc/system-release)"
|
||||||
|
GRUB_DEFAULT=saved
|
||||||
|
GRUB_DISABLE_SUBMENU=true
|
||||||
|
GRUB_TERMINAL_OUTPUT="console"
|
||||||
|
GRUB_CMDLINE_LINUX="rd.lvm.lv=fedora_fedora25vm/root
|
||||||
|
rd.lvm.lv=fedora_fedora25vm/swap
|
||||||
|
rd.lvm.lv=fedora_fedora25vm/usr rhgb quiet"
|
||||||
|
GRUB_DISABLE_RECOVERY="true"
|
||||||
|
```
|
||||||
|
|
||||||
|
_Listing 1: An original grub default file for Fedora 25._
|
||||||
|
|
||||||
|
[Section 5.1 of the GRUB Manual][7] contains information about all of the possible keys that can be included in the grub file. I have never had needed to do anything other than modifying the values of some of the keys that are already in the grub default file. Let's look at what each of these keys means as well as some that don't appear in the grub default file.
|
||||||
|
|
||||||
|
* **GRUB_TIMEOUT **The value of this key determines the length of time that the GRUB selection menu is displayed. GRUB offers the capability to keep multiple kernels installed simultaneously and choose between them at boot time using the GRUB menu. The default value for this key is 5 seconds, but I usually change that to 10 seconds to allow more time to view the choices and make a selection.
|
||||||
|
* **GRUB_DISTRIBUTOR **This key defines a [sed][3] expression that extracts the distribution release number from the /etc/system-release file. This information is used to generate the text names for each kernel release that appear in the GRUB menu, such as "Fedora". Due to variations in the structure of the data in the system-release file between distributions, this sed expression may be different on your system.
|
||||||
|
* **GRUB_DEFAULT **Determines which kernel is booted by default. That is the "saved" kernel which is the most recent kernel. Other options here are a number which represents the index of the list of kernels in **grub.cfg**. Using an index such as 3, however, to load the fourth kernel in the list will always load the fourth kernel in the list even after a new kernel is installed. So using an index will load a different kernel after a new kernel is installed. The only way to ensure that a specific kernel release is booted is to set the value of **GRUB_DEFAULT** to the name of the desired kernel, like 4.8.13-300.fc25.x86_64.
|
||||||
|
* **GRUB_SAVEDEFAULT **Normally, this option is not specified in the grub defaults file. Normal operation when a different kernel is selected for boot, that kernel is booted only that one time. The default kernel is not changed. When set to "true" and used with **GRUB_DEFAULT=saved** this option saves a different kernel as the default. This happens when a different kernel is selected for boot.
|
||||||
|
* **GRUB_DISABLE_SUBMENU **Some people may wish to create a hierarchical menu structure of kernels for the GRUB menu screen. This key, along with some additional configuration of the kernel stanzas in **grub.****cfg** allow creating such a hierarchy. For example, the one might have the main menu with "production" and "test" sub-menus where each sub-menu would contain the appropriate kernels. Setting this to "false" would enable the use of sub-menus.
|
||||||
|
* **GRUB_TERMINAL_OUTPUT **In some environments it may be desirable or necessary to redirect output to a different display console or terminal. The default is to send output to the default terminal, usually the "console" which equates to the standard display on an Intel class PC. Another useful option is to specify "serial" in a data center or lab environment in which serial terminals or Integrated Lights Out (ILO) terminal connections are in use.
|
||||||
|
* **GRUB_TERMINAL_INPUT **As with **GRUB_TERMINAL_OUTPUT**, it may be desirable or necessary to redirect input from a serial terminal or ILO device rather than the standard keyboard input.
|
||||||
|
* **GRUB_CMDLINE_LINUX **This key contains the command line arguments that will be passed to the kernel at boot time. Note that these arguments will be added to the kernel line of grub.cfg for all installed kernels. This means that all installed kernels will have the same arguments when booted. I usually remove the "rhgb" and "quiet" arguments so that I can see all of the very informative messages output by the kernel and systemd during the boot and startup.
|
||||||
|
* **GRUB_DISABLE_RECOVERY **When the value of this key is set to "false," a recovery entry is created in the GRUB menu for every installed kernel. When set to "true" no recovery entries are created. Regardless of this setting, the last kernel entry is always a "rescue" option. However, I encountered a problem with the rescue option, which I'll talk more about below.
|
||||||
|
|
||||||
|
There are other keys that I have not covered here that you might find useful. Their descriptions are located in Section 5.1 of the [GRUB Manual 2][8].
|
||||||
|
|
||||||
|
### Generate grub.cfg
|
||||||
|
|
||||||
|
After completing the desired configuration it is necessary to generate the **/boot/grub2/grub.****cfg** file. This is accomplished with the following command.
|
||||||
|
|
||||||
|
```
|
||||||
|
grub2-mkconfig > /boot/grub2/grub.cfg
|
||||||
|
```
|
||||||
|
|
||||||
|
This command takes the configuration files located in /etc/grub.d in sequence to build the **grub.****cfg** file, and uses the contents of the grub defaults file to modify the output to achieve the final desired configuration. The **grub2-mkconfig** command attempts to locate all of the installed kernels and creates an entry for each in the **10_Linux** section of the **grub.****cfg** file. It also creates a "rescue" entry to provide a method for recovering from significant problems that prevent Linux from booting.
|
||||||
|
|
||||||
|
It is strongly recommended that you do not edit the **grub.****cfg** file manually because any direct modifications to the file will be overwritten the next time a new kernel is installed or **grub2-mkconfig** is run manually.
|
||||||
|
|
||||||
|
### Issues
|
||||||
|
|
||||||
|
I encountered one problem with GRUB2 that could have serious consequences if you are not aware of it. The rescue kernel does not boot, instead, one of the other kernels boots. I found that to be the kernel at index 1 in the list, i.e., the second kernel in the list. Additional testing showed that this problem occurred whether using the original **grub.****cfg** configuration file or one that I generated. I have tried this on both virtual and real hardware and the problem is the same on each. I only tried this with Fedora 25 so it may not be an issue with other Fedora releases.
|
||||||
|
|
||||||
|
Note that the "recovery" kernel entry that is generated from the "rescue" kernel does work and boots to a maintenance mode login.
|
||||||
|
|
||||||
|
I recommend changing **GRUB_DISABLE_RECOVERY** to "false" in the grub defaults file, and generating your own **grub.cfg**. This will generate usable recovery entries in the GRUB menu for each of the installed kernels. These recovery configurations work as expected and boot to runlevel 1—according to the runlevel command—at a command line entry that requests a password to enter maintenance mode. You could also press **Ctrl-D** to continue a normal boot to the default runlevel.
|
||||||
|
|
||||||
|
### Conclusions
|
||||||
|
|
||||||
|
GRUB is the first step after BIOS in the sequence of events that boot a Linux computer to a usable state. Understanding how to configure GRUB is important to be able to recover from or to circumvent various types of problems.
|
||||||
|
|
||||||
|
I have had to boot to recovery or rescue mode many times over the years to resolve many types of problems. Some of those problems were actual boot problems due to things like improper entries in **/etc/fstab** or other configuration files, and others were due to problems with application or system software that was incompatible with the newest kernel. Hardware compatibility issues might also prevent a specific kernel from booting.
|
||||||
|
|
||||||
|
I hope this information will help you get started with GRUB configuration.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||||
|
|
||||||
|
|
||||||
|
----------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/3/introduction-grub2-configuration-linux
|
||||||
|
|
||||||
|
作者:[David Both ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/dboth
|
||||||
|
[1]:https://opensource.com/article/17/2/linux-boot-and-startup
|
||||||
|
[2]:https://opensource.com/article/17/2/linux-boot-and-startup
|
||||||
|
[3]:https://en.wikipedia.org/wiki/Sed
|
||||||
|
[4]:https://opensource.com/article/17/3/introduction-grub2-configuration-linux?rate=QrIzRpQ3YhewYlBD0AFp0JiF133SvhyAq783LOxjr4c
|
||||||
|
[5]:https://www.flickr.com/photos/internetarchivebookimages/14746482994/in/photolist-ot6zCN-odgbDq-orm48o-otifuv-otdyWa-ouDjnZ-otGT2L-odYVqY-otmff7-otGamG-otnmSg-rxnhoq-orTmKf-otUn6k-otBg1e-Gm6FEf-x4Fh64-otUcGR-wcXsxg-tLTN9R-otrWYV-otnyUE-iaaBKz-ovcPPi-ovokCg-ov4pwM-x8Tdf1-hT5mYr-otb75b-8Zk6XR-vtefQ7-vtehjQ-xhhN9r-vdXhWm-xFBgtQ-vdXdJU-vvTH6R-uyG5rH-vuZChC-xhhGii-vvU5Uv-vvTNpB-vvxqsV-xyN2Ai-vdXcFw-vdXuNC-wBMhes-xxYmxu-vdXxwS-vvU8Zt
|
||||||
|
[6]:https://www.flickr.com/photos/internetarchivebookimages/14774719031/in/photolist-ovAie2-otPK99-xtDX7p-tmxqWf-ow3i43-odd68o-xUPaxW-yHCtWi-wZVsrD-DExW5g-BrzB7b-CmMpC9-oy4hyF-x3UDWA-ow1m4A-x1ij7w-tBdz9a-tQMoRm-wn3tdw-oegTJz-owgrs2-rtpeX1-vNN6g9-owemNT-x3o3pX-wiJyEs-CGCC4W-owg22q-oeT71w-w6PRMn-Ds8gyR-x2Aodm-owoJQm-owtGp9-qVxppC-xM3Gw7-owgV5J-ou9WEs-wihHtF-CRmosE-uk9vB3-wiKdW6-oeGKq3-oeFS4f-x5AZtd-w6PNuv-xgkofr-wZx1gJ-EaYPED-oxCbFP
|
||||||
|
[7]:https://www.gnu.org/software/grub/manual/grub.html#Simple-configuration
|
||||||
|
[8]:https://www.gnu.org/software/grub/manual/grub.html#Simple-configuration
|
||||||
|
[9]:https://opensource.com/user/14106/feed
|
||||||
|
[10]:https://opensource.com/article/17/3/introduction-grub2-configuration-linux#comments
|
||||||
|
[11]:https://opensource.com/users/dboth
|
||||||
87
sources/tech/20170316 What is Linux VPS Hosting.md
Normal file
87
sources/tech/20170316 What is Linux VPS Hosting.md
Normal file
@ -0,0 +1,87 @@
|
|||||||
|
What is Linux VPS Hosting?
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
If you have a site that gets a lot of traffic, or at least, is expected to generate a lot of traffic, then you might want to consider getting a [Linux VPS hosting][6] package. A Linux VPS hosting package is also one of your best options if you want more control over the things that are installed on the server where your website is hosted at. Here are some of the frequently asked questions about Linux VPS hosting, answered.
|
||||||
|
|
||||||
|
### What does Linux VPS stand for?
|
||||||
|
|
||||||
|
Basically, Linux VPS stands for a virtual private server running on a Linux system. A virtual private server is a virtual server hosted on a physical server. A server is virtual if it runs in a host computer’s memory. The host computer, in turn, can run a few other virtual servers.
|
||||||
|
|
||||||
|
### So I have to share a server with other users?
|
||||||
|
|
||||||
|
In most cases, yes. However, this does not mean that you will suffer from downtime or decreased performance. Each virtual server can run its own operating system, and each of these systems can be administered independently of each other. A virtual private server has its own operating system, data, and applications that are separated from all the other systems, applications, and data on the physical host server and the other virtual servers.
|
||||||
|
|
||||||
|
Despite sharing the physical server with other virtual private servers, you can still enjoy the benefits of a more expensive dedicated server without spending a lot of money for the service.
|
||||||
|
|
||||||
|
### What are the benefits of a Linux VPS hosting service?
|
||||||
|
|
||||||
|
There are many benefits when using a Linux VPS hosting service, including ease of use, increased security, and improved reliability at a lower total cost of ownership. However, for most webmasters, programmers, designers, and developers, the true benefit of a Linux VPS is the flexibility. Each virtual private server is isolated with its own operating environment, which means that you can easily and safely install the operating system that you prefer or need—in this case, Linux—as well as remove or add software and applications easily whenever you want to.
|
||||||
|
|
||||||
|
You can also modify the environment of your VPS to suit your performance needs, as well as improve the experience of your site’s users or visitors. Flexibility can be the advantage you need to set you apart from your competitors.
|
||||||
|
|
||||||
|
Note that some Linux VPS providers won’t give you full root access to your Linux VPS, in which case you’ll have limited functionality. Be sure to get a [Linux VPS where you’ll have full access to the VPS][7], so you can modify anything you want.
|
||||||
|
|
||||||
|
### Is Linux VPS hosting for everyone?
|
||||||
|
|
||||||
|
Yes! Even if you run a personal blog dedicated to your interests, you can surely benefit from a Linux VPS hosting package. If you are building and developing a website for a company, you would also enjoy the benefits. Basically, if you are expecting growth and heavy site traffic on your website, then a Linux VPS is for you.
|
||||||
|
|
||||||
|
Individuals and companies that want more flexibility in their customization and development options should definitely go for a Linux VPS, especially those who are looking to get great performance and service without paying for a dedicated server, which could eat up a huge chunk of the site’s operating costs.
|
||||||
|
|
||||||
|
### I don’t know how to work with Linux, can I still use a Linux VPS?
|
||||||
|
|
||||||
|
Of course! If you get a fully managed Linux VPS, your provider will manage the server for you, and most probably, will install and configure anything you want to run on your Linux VPS. If you get a VPS from us, we’ll take care of your server 24/7 and we’ll install, configure and optimize anything for you. All these services are included for free with all our [Managed Linux VPS hosting][8] packages.
|
||||||
|
|
||||||
|
So if you use our hosting services, it means that you get to enjoy the benefits of a Linux VPS, without any knowledge of working with Linux.
|
||||||
|
|
||||||
|
Another option to easy the use of a Linux VPS for beginners is to get a [VPS with cPanel][9], [DirectAdmin][10] or any [other hosting control panel][11]. If you use a control panel, you can manage your server via a GUI, which is a lot easier, especially for beginners. Although, [managing a Linux VPS from the command line][12] is fun and you can learn a lot by doing that.
|
||||||
|
|
||||||
|
### How different is a Linux VPS from a dedicated server?
|
||||||
|
|
||||||
|
As mentioned earlier, a virtual private server is just a virtual partition on a physical host computer. The physical server is divided into several virtual servers, which could diffuse the cost and overhead expenses between the users of the virtual partitions. This is why a Linux VPS is comparatively cheaper than a [dedicated server][13], which, as its name implies, is dedicated to only one user. For a more detailed overview of the differences, check our [Physical Server (dedicated) vs Virtual Server (VPS) comparison][14].
|
||||||
|
|
||||||
|
Aside from being more cost-efficient than dedicated servers, Linux virtual private servers often run on host computers that are more powerful than dedicated servers—performance and capacity are often greater than dedicated servers.
|
||||||
|
|
||||||
|
### I want to move from a shared hosting environment to a Linux VPS, can I do that?
|
||||||
|
|
||||||
|
If you currently use [shared hosting][15], you can easily move to a Linux VPS. One option is to [do it yourself][16], but the migration process can be a bit complicated and is definitely not recommended for beginners. Your best option is to find a host that offers [free website migrations][17] and let them do it for you. You can even move from shared hosting with a control panel to a Linux VPS without a control panel.
|
||||||
|
|
||||||
|
### Any more questions?
|
||||||
|
|
||||||
|
Feel free to leave a comment below.
|
||||||
|
|
||||||
|
If you get a VPS from us, our expert Linux admins will help you with anything you need with your Linux VPS and will answer any questions you have about working with your Linux VPS. Our admins are available 24/7 and will take care of your request immediately.
|
||||||
|
|
||||||
|
PS. If you liked this post please share it with your friends on the social networks using the buttons below or simply leave a reply in the comments section. Thanks.
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||||
|
|
||||||
|
作者:[https://www.rosehosting.com ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||||
|
[1]:https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||||
|
[2]:https://www.rosehosting.com/blog/what-is-linux-vps-hosting/#comments
|
||||||
|
[3]:https://www.rosehosting.com/blog/category/guides/
|
||||||
|
[4]:https://plus.google.com/share?url=https://www.rosehosting.com/blog/what-is-linux-vps-hosting/
|
||||||
|
[5]:http://www.linkedin.com/shareArticle?mini=true&url=https://www.rosehosting.com/blog/what-is-linux-vps-hosting/&title=What%20is%20Linux%20VPS%20Hosting%3F&summary=If%20you%20have%20a%20site%20that%20gets%20a%20lot%20of%20traffic,%20or%20at%20least,%20is%20expected%20to%20generate%20a%20lot%20of%20traffic,%20then%20you%20might%20want%20to%20consider%20getting%20a%20Linux%20VPS%20hosting%20package.%20A%20Linux%20VPS%20hosting%20package%20is%20also%20one%20of%20your%20best%20options%20if%20you%20want%20more%20...
|
||||||
|
[6]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||||
|
[7]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||||
|
[8]:https://www.rosehosting.com/linux-vps-hosting.html
|
||||||
|
[9]:https://www.rosehosting.com/cpanel-hosting.html
|
||||||
|
[10]:https://www.rosehosting.com/directadmin-hosting.html
|
||||||
|
[11]:https://www.rosehosting.com/control-panel-hosting.html
|
||||||
|
[12]:https://www.rosehosting.com/blog/basic-shell-commands-after-putty-ssh-logon/
|
||||||
|
[13]:https://www.rosehosting.com/dedicated-servers.html
|
||||||
|
[14]:https://www.rosehosting.com/blog/physical-server-vs-virtual-server-all-you-need-to-know/
|
||||||
|
[15]:https://www.rosehosting.com/linux-shared-hosting.html
|
||||||
|
[16]:https://www.rosehosting.com/blog/from-shared-to-vps-hosting/
|
||||||
|
[17]:https://www.rosehosting.com/website-migration.html
|
||||||
218
sources/tech/20170317 AWS cloud terminology.md
Normal file
218
sources/tech/20170317 AWS cloud terminology.md
Normal file
@ -0,0 +1,218 @@
|
|||||||
|
AWS cloud terminology
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_Understand AWS cloud terminology of 71 services! Get acquainted with terms used in AWS world to start with your AWS cloud career!_
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
AWS i.e. Amazon Web Services is cloud platform providing list of web services on pay per use basis. Its one of the famous cloud platform to date. Due to flexibility, availability, elasticity, scalability and no-maintenance many corporate are moving to cloud. Since many companies using these services its become necessary that sysadmin or devOps should be aware of AWS.
|
||||||
|
|
||||||
|
This article aims at listing services provided by AWS and explaining terminology used in AWS world.
|
||||||
|
|
||||||
|
As of today, AWS offers total of 71 services which are grouped together in 17 groups as below :
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Compute _
|
||||||
|
|
||||||
|
Its a cloud computing means virtual server provisioning. This group provides below services.
|
||||||
|
|
||||||
|
1. EC2 : EC2 stands for Elastic Compute Cloud. This service provides you scalable [virtual machines per your requirement.][11]
|
||||||
|
2. EC2 container service : Its high performance, high scalable which allows running services on EC2 clustered environment
|
||||||
|
3. Lightsail : This service enables user to launch and manage virtual servers (EC2) very easily.
|
||||||
|
4. Elastic Beanstalk : This service manages capacity provisioning, load balancing, scaling, health monitoring of your application automatically thus reducing your management load.
|
||||||
|
5. Lambda : It allows to run your code only when needed without managing servers for it.
|
||||||
|
6. Batch : It enables users to run computing workloads (batches) in customized managed way.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Storage_
|
||||||
|
|
||||||
|
Its a cloud storage i.e. cloud storage facility provided by Amazon. This group includes :
|
||||||
|
|
||||||
|
1. S3 : S3 stands for Simple Storage Service (3 times S). This provides you online storage to store/retrive any data at any time, from anywhere.
|
||||||
|
2. EFS : EFS stands for Elastic File System. Its a online storage which can be used with EC2 servers.
|
||||||
|
3. Glacier : Its a low cost/slow performance data storage solution mainly aimed at archives or long term backups.
|
||||||
|
4. Storage Gateway : Its interface which connects your on-premise applications (hosted outside AWS) with AWS storage.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Database_
|
||||||
|
|
||||||
|
AWS also offers to host databases on their Infra so that client can benefit with cutting edge tech Amazon have for faster/efficient/secured data processing. This group includes :
|
||||||
|
|
||||||
|
1. RDS : RDS stands for Relational Database Service. Helps to setup, operate, manage relational database on cloud.
|
||||||
|
2. DynamoDB : Its noSQL database providing fast processing and high scalability.
|
||||||
|
3. ElastiCache : Its a way to manage in-memory cache for your web application to run them faster!
|
||||||
|
4. Redshift : Its a huge (petabyte-size) fully scalable, data warehouse service in cloud.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Networking & Content Delivery_
|
||||||
|
|
||||||
|
As AWS provides cloud EC2 server, its corollary that networking will be in picture too. Content delivery is used to serve files to users from their geographically nearest location. This is pretty much famous for speeding up websites now a days.
|
||||||
|
|
||||||
|
1. VPC : VPC stands for Virtual Private Cloud. Its your very own virtual network dedicated to your AWS account.
|
||||||
|
2. CloudFront : Its content delivery network by AWS.
|
||||||
|
3. Direct Connect : Its a network way of connecting your datacenter/premises with AWS to increase throughput, reduce network cost and avoid connectivity issues which may arise due to internet-based connectivity.
|
||||||
|
4. Route 53 : Its a cloud domain name system DNS web service.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Migration_
|
||||||
|
|
||||||
|
Its a set of services to help you migrate from on-premises services to AWS. It includes :
|
||||||
|
|
||||||
|
1. Application Discovery Service : A service dedicated to analyse your servers, network, application to help/speed up migration.
|
||||||
|
2. DMS : DMS stands for Database Migration Service. It is used to migrate your data from on-premises DB to RDS or DB hosted on EC2.
|
||||||
|
3. Server Migration : Also called as SMS (Server Migration Service) is a agentless service which moves your workloads from on-premises to AWS.
|
||||||
|
4. Snowball : Intended to use when you want to transfer huge amount of data in/out of AWS using physical storage appliances (rather than internet/network based transfers)
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Developer Tools_
|
||||||
|
|
||||||
|
As name suggest, its a group of services helping developers to code easy/better way on cloud.
|
||||||
|
|
||||||
|
1. CodeCommit : Its a secure, scalable, managed source control service to host code repositories.
|
||||||
|
2. CodeBuild : Code builder on cloud. Executes, tests codes and build software packages for deployments.
|
||||||
|
3. CodeDeploy : Deployment service to automate application deployments on AWS servers or on-premises.
|
||||||
|
4. CodePipeline : This deployment service enables coders to visualize their application before release.
|
||||||
|
5. X-Ray : Analyse applications with event calls.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Management Tools_
|
||||||
|
|
||||||
|
Group of services which helps you manage your web services in AWS cloud.
|
||||||
|
|
||||||
|
1. CloudWatch : Monitoring service to monitor your AWS resources or applications.
|
||||||
|
2. CloudFormation : Infrastructure as a code! Its way of managing AWS relative infra in collective and orderly manner.
|
||||||
|
3. CloudTrail : Audit & compliance tool for AWS account.
|
||||||
|
4. Config : AWS resource inventory, configuration history, and configuration change notifications to enable security and governance.
|
||||||
|
5. OpsWorks : Automation to configure, deploy EC2 or on-premises compute
|
||||||
|
6. Service Catalog : Create and manage IT service catalogs which are approved to use in your/company account
|
||||||
|
7. Trusted Advisor : Its AWS AI helping you to have better, money saving AWS infra by inspecting your AWS Infra.
|
||||||
|
8. Managed Service : Provides ongoing infra management
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Security, Identity & compliance_
|
||||||
|
|
||||||
|
Important group of AWS services helping you secure your AWS space.
|
||||||
|
|
||||||
|
1. IAM : IAM stands for Identity and Access Management. Controls user access to your AWS resources and services.
|
||||||
|
2. Inspector : Automated security assessment helping you to secure and compliance your apps on AWS.
|
||||||
|
3. Certificate Manager : Provision, manage and deploy SSL/TLS certificates for AWS applications.
|
||||||
|
4. Directory Service : Its Microsoft Active Directory for AWS.
|
||||||
|
5. WAF & Shield : WAF stands for Web Application Firewall. Monitors and controls access to your content on CloudFront or Load balancer.
|
||||||
|
6. Compliance Reports : Compliance reporting of your AWS infra space to make sure your apps an dinfra are compliant to your policies.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Analytics_
|
||||||
|
|
||||||
|
Data analytics of your AWS space to help you see, plan, act on happenings in your account.
|
||||||
|
|
||||||
|
1. Athena : Its a SQL based query service to analyse S3 stored data.
|
||||||
|
2. EMR : EMR stands for Elastic Map Reduce. Service for big data processing and analysis.
|
||||||
|
3. CloudSearch : Search capability of AWS within application and services.
|
||||||
|
4. Elasticsearch Service : To create a domain and deploy, operate, and scale Elasticsearch clusters in the AWS Cloud
|
||||||
|
5. Kinesis : Streams large amount of data in real time.
|
||||||
|
6. Data Pipeline : Helps to move data between different AWS services.
|
||||||
|
7. QuickSight : Collect, analyse and present insight of business data on AWS.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Artificial Intelligence_
|
||||||
|
|
||||||
|
AI in AWS!
|
||||||
|
|
||||||
|
1. Lex : Helps to build conversational interfaces in application using voice and text.
|
||||||
|
2. Polly : Its a text to speech service.
|
||||||
|
3. Rekognition : Gives you ability to add image analysis to applications
|
||||||
|
4. Machine Learning : It has algorithms to learn patterns in your data.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Internet of Things_
|
||||||
|
|
||||||
|
This service enables AWS highly available on different devices.
|
||||||
|
|
||||||
|
1. AWS IoT : It lets connected hardware devices to interact with AWS applications.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Game Development_
|
||||||
|
|
||||||
|
As name suggest this services aims at Game Development.
|
||||||
|
|
||||||
|
1. Amazon GameLift : This service aims for deplyoing, managing dedicated gaming servers for session based multiplayer games.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Mobile Services_
|
||||||
|
|
||||||
|
Group of services mainly aimed at handheld devices
|
||||||
|
|
||||||
|
1. Mobile Hub : Helps you to create mobile app backend features and integrate them to mobile apps.
|
||||||
|
2. Cognito : Controls mobile user’s authentication and access to AWS on internet connected devices.
|
||||||
|
3. Device Farm : Mobile app testing service enables you to test apps across android, iOS on real phones hosted by AWS.
|
||||||
|
4. Mobile Analytics : Measure, track and analyze mobile app data on AWS.
|
||||||
|
5. Pinpoint : Targeted push notification and mobile engagements.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Application Services_
|
||||||
|
|
||||||
|
Its a group of services which can be used with your applications in AWS.
|
||||||
|
|
||||||
|
1. Step Functions : Define and use various functions in your applications
|
||||||
|
2. SWF : SWF stands for Simple Workflow Service. Its cloud workflow management helps developers to co-ordinate and contribute at different stages of application life cycle.
|
||||||
|
3. API Gateway : Helps developers to create, manage, host APIs
|
||||||
|
4. Elastic Transcoder : Helps developers to converts media files to play of various devices.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Messaging_
|
||||||
|
|
||||||
|
Notification and messaging services in AWS
|
||||||
|
|
||||||
|
1. SQS : SQS stands for Simple Queue Service. Fully managed messaging queue service to communicate between services and apps in AWS.
|
||||||
|
2. SNS : SNS stands for Simple Notification Service. Push notification service for AWS users to alert them about their services in AWS space.
|
||||||
|
3. SES : SES stands for Simple Email Service. Its cost effective email service from AWS for its own customers.
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Business Productivity_
|
||||||
|
|
||||||
|
Group of services to help boost your business productivity.
|
||||||
|
|
||||||
|
1. WorkDocs : Collaborative file sharing, storing and editing service.
|
||||||
|
2. WorkMail : Secured business mail, calendar service
|
||||||
|
3. Amazon Chime : Online business meetings!
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_Desktop & App Streaming_
|
||||||
|
|
||||||
|
Its desktop app streaming over cloud.
|
||||||
|
|
||||||
|
1. WorkSpaces : Fully managed, secured desktop computing service on cloud
|
||||||
|
2. AppStream 2.0 : Stream desktop applications from cloud.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://kerneltalks.com/virtualization/aws-cloud-terminology/
|
||||||
|
|
||||||
|
作者:[Shrikant Lavhate][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://kerneltalks.com/virtualization/aws-cloud-terminology/
|
||||||
@ -0,0 +1,410 @@
|
|||||||
|
How to control GPIO pins and operate relays with the Raspberry Pi
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> Learn how to operate relays and control GPIO pins with the Pi using PHP and a temperature sensor.
|
||||||
|
|
||||||
|

|
||||||
|
>Image by : opensource.com
|
||||||
|
|
||||||
|
Ever wondered how to control items like your fans, lights, and more using your phone or computer from anywhere?
|
||||||
|
|
||||||
|
I was looking to control my Christmas lights using any mobile phone, tablet, laptop... simply by using a Raspberry Pi. Let me show you how to operate relays and control GPIO pins with the Pi using PHP and a temperature sensor. I put them all together using AJAX.
|
||||||
|
|
||||||
|
### Hardware requirements
|
||||||
|
|
||||||
|
* Raspberry Pi
|
||||||
|
* SD Card with Raspbian installed (any SD card would work, but I prefer to use a 32GB class 10 card)
|
||||||
|
* Power adapter
|
||||||
|
* Jumper wires (female to female and male to female)
|
||||||
|
* Relay board (I use a 12V relay board with for relays)
|
||||||
|
* DS18B20 temperature probe
|
||||||
|
* Wi-Fi adapter for Raspberry Pi
|
||||||
|
* Router (for Internet access, you need to have a port-forwarding supported router)
|
||||||
|
* 10K-ohm resistor
|
||||||
|
|
||||||
|
### Software requirements
|
||||||
|
|
||||||
|
* Download and install Raspbian on your SD Card
|
||||||
|
* Working Internet connection
|
||||||
|
* Apache web server
|
||||||
|
* PHP
|
||||||
|
* WiringPi
|
||||||
|
* SSH client on a Mac or Windows client
|
||||||
|
|
||||||
|
### General configurations and setup
|
||||||
|
|
||||||
|
1\. Insert the SD card into Raspberry Pi and connect it to the router using an Ethernet cable
|
||||||
|
|
||||||
|
2\. Connect the Wi-Fi Adapter.
|
||||||
|
|
||||||
|
3\. Now SSH to Pi and edit the **interfaces** file using:
|
||||||
|
|
||||||
|
**sudo nano /etc/network/interfaces**
|
||||||
|
|
||||||
|
This will open the file in an editor called **nano**. It is a very simple text editor that is easy to approach and use. If you're not familiar to a Linux-based operating systems, just use the arrow keys.
|
||||||
|
|
||||||
|
After opening the file in **nano** you will see a screen like this:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
4\. To configure your wireless network, modify the file as follows:
|
||||||
|
|
||||||
|
**iface lo inet loopback**
|
||||||
|
|
||||||
|
**iface eth0 inet dhcp**
|
||||||
|
|
||||||
|
**allow-hotplug wlan0**
|
||||||
|
|
||||||
|
**auto wlan0**
|
||||||
|
|
||||||
|
**iface wlan0 inet dhcp**
|
||||||
|
|
||||||
|
** wpa-ssid "Your Network SSID"**
|
||||||
|
|
||||||
|
** wpa-psk "Your Password"**
|
||||||
|
|
||||||
|
5\. Press CTRL + O to save it, and then CTRL + X to exit the editor.
|
||||||
|
|
||||||
|
At this point, everything is configured and all you need to do is reload the network interfaces by running:
|
||||||
|
|
||||||
|
**sudo service networking reload**
|
||||||
|
|
||||||
|
(Warning: if you are connected using a remote connection it will disconnect now.)
|
||||||
|
|
||||||
|
### Software configurations
|
||||||
|
|
||||||
|
### Installing Apache Web Server
|
||||||
|
|
||||||
|
Apache is a popular web server application you can install on the Raspberry Pi to allow it to serve web pages. On its own, Apache can serve HTML files over HTTP, and with additional modules it can serve dynamic web pages using scripting languages such as PHP.
|
||||||
|
|
||||||
|
Install Apache by typing the following command on the command line:
|
||||||
|
|
||||||
|
**sudo apt-get install apache2 -y**
|
||||||
|
|
||||||
|
Once the installation is complete, type in the IP Address of your Pi to test the server. If you get the next image, then you have installed and set up your server successfully.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
To change this default page and add your own html file, go to **var/www/html**:
|
||||||
|
|
||||||
|
**cd /var/www/html**
|
||||||
|
|
||||||
|
To test this, add any file to this folder.
|
||||||
|
|
||||||
|
### Installing PHP
|
||||||
|
|
||||||
|
PHP is a preprocessor, meaning this is code that runs when the server receives a request for a web page. It runs, works out what needs to be shown on the page, then sends that page to the browser. Unlike static HTML, PHP can show different content under different circumstances. Other languages are capable of this, but since WordPress is written in PHP it's what you need to use this time. PHP is a very popular language on the web, with large projects like Facebook and Wikipedia written in it.
|
||||||
|
|
||||||
|
Install the PHP and Apache packages with the following command:
|
||||||
|
|
||||||
|
**sudo apt-get install php5 libapache2-mod-php5 -y**
|
||||||
|
|
||||||
|
### Testing PHP
|
||||||
|
|
||||||
|
Create the file **index.php**:
|
||||||
|
|
||||||
|
**sudo nano index.php**
|
||||||
|
|
||||||
|
Put some PHP content in it:
|
||||||
|
|
||||||
|
**<?php echo "hello world"; ?>**
|
||||||
|
|
||||||
|
Save the file. Next, delete "index.html" because it takes precedence over "index.php":
|
||||||
|
|
||||||
|
**sudo rm index.html**
|
||||||
|
|
||||||
|
Refresh your browser. You should see “hello world.” This is not dynamic, but it is still served by PHP. If you see the raw PHP above instead of “hello world,” reload and restart Apache with:
|
||||||
|
|
||||||
|
**sudo /etc/init.d/apache2 reload**
|
||||||
|
|
||||||
|
**sudo /etc/init.d/apache2 restart**
|
||||||
|
|
||||||
|
### Installing WiringPi
|
||||||
|
|
||||||
|
WiringPi is maintained under **git** for ease of change tracking; however, you have a plan B if you’re unable to use **git** for whatever reason. (Usually your firewall will be blocking you, so do check that first!)
|
||||||
|
|
||||||
|
If you do not have **git** installed, then under any of the Debian releases (e.g., Raspbian), you can install it with:
|
||||||
|
|
||||||
|
**sudo apt-get install git-core**
|
||||||
|
|
||||||
|
If you get any errors here, make sure your Pi is up to date with the latest version of Raspbian:
|
||||||
|
|
||||||
|
**sudo apt-get update sudo apt-get upgrade**
|
||||||
|
|
||||||
|
To obtain WiringPi using **git**:
|
||||||
|
|
||||||
|
**sudo git clone git://git.drogon.net/wiringPi**
|
||||||
|
|
||||||
|
If you have already used the clone operation for the first time, then:
|
||||||
|
|
||||||
|
**cd wiringPi git pull origin**
|
||||||
|
|
||||||
|
It will fetch an updated version, and then you can re-run the build script below.
|
||||||
|
|
||||||
|
To build/install there is a new simplified script:
|
||||||
|
|
||||||
|
**cd wiringPi ./build**
|
||||||
|
|
||||||
|
The new build script will compile and install it all for you. It does use the **sudo** command at one point, so you may wish to inspect the script before running it.
|
||||||
|
|
||||||
|
### Testing WiringPi
|
||||||
|
|
||||||
|
Run the **gpio** command to check the installation:
|
||||||
|
|
||||||
|
**gpio -v gpio readall**
|
||||||
|
|
||||||
|
This should give you some confidence that it’s working OK.
|
||||||
|
|
||||||
|
### Connecting DS18B20 To Raspberry Pi
|
||||||
|
|
||||||
|
* The Black wire on your probe is for GND
|
||||||
|
* The Red wire is for VCC
|
||||||
|
* The Yellow wire is the GPIO wire
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Connect:
|
||||||
|
|
||||||
|
* VCC to 3V Pin 1
|
||||||
|
* GPIO wire to Pin 7 (GPIO 04)
|
||||||
|
* Ground wire to any GND Pin 9
|
||||||
|
|
||||||
|
### Software Configuration
|
||||||
|
|
||||||
|
For using DS18B20 temperature sensor module with PHP, you need to activate the kernel module for the GPIO pins on the Raspberry Pi and the DS18B20 by executing the commands:
|
||||||
|
|
||||||
|
**sudo modprobe w1-gpio**
|
||||||
|
|
||||||
|
**sudo modprobe w1-therm**
|
||||||
|
|
||||||
|
You do not want to do that manually every time the Raspberry reboots, so you want to enable these modules on every boot. This is done by adding the following lines to the file **/etc/modules**:
|
||||||
|
|
||||||
|
**sudo nano /etc/modules/**
|
||||||
|
|
||||||
|
Add the following lines to it:
|
||||||
|
|
||||||
|
**w1-gpio**
|
||||||
|
|
||||||
|
**w1-therm**
|
||||||
|
|
||||||
|
To test this, type in:
|
||||||
|
|
||||||
|
**cd /sys/bus/w1/devices/**
|
||||||
|
|
||||||
|
Now type **ls. **
|
||||||
|
|
||||||
|
You should see your device information. In the device drivers, your DS18B20 sensor should be listed as a series of numbers and letters. In this case, the device is registered as 28-000005e2fdc3\. You then need to access the sensor with the cd command, replacing my serial number with your own: **cd 28-000005e2fdc3. **
|
||||||
|
|
||||||
|
The DS18B20 sensor periodically writes to the **w1_slave** file, so you simply use the cat command to read it**: cat w1_slave.**
|
||||||
|
|
||||||
|
This yields the following two lines of text, with the output **t=** showing the temperature in degrees Celsius. Place a decimal point after the first two digits (e.g., the temperature reading I received is 30.125 degrees Celsius).
|
||||||
|
|
||||||
|
### Connecting the relay
|
||||||
|
|
||||||
|
1\. Take two jumper wires and connect one of them to the GPIO 24 (Pin18) on the Pi and the other one to the GND Pin. You may refer the following diagram.
|
||||||
|
|
||||||
|
2\. Now connect the other ends of the wire to the relay board. Connect the GND to the GND on the relay and GPIO Output wire to the relay channel pin number, which depends on the relay that you are using. Remember theGNDgoes to GND on the relay and GPIO Output goes to the relay input pin.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Caution! Be very careful with the relay connections with Pi because if it causes a backflow of current, you with have a short circuit.
|
||||||
|
|
||||||
|
3\. Now connect the power supply to the relay, either using 12V power adapter or by connecting the VCC Pin to 3.3V or 5V on the Pi.
|
||||||
|
|
||||||
|
### Controlling the relay using PHP
|
||||||
|
|
||||||
|
Let's create a PHP script to control the GPIO pins on the Raspberry Pi, with the help of the WiringPi software.
|
||||||
|
|
||||||
|
1\. Create a file in the Apache server’s root web directory. Navigate using:
|
||||||
|
|
||||||
|
**cd ../../../**
|
||||||
|
|
||||||
|
**cd var/www/html/**
|
||||||
|
|
||||||
|
2\. Create a new folder called Home:
|
||||||
|
|
||||||
|
**sudo mkdir Home**
|
||||||
|
|
||||||
|
3\. Create a new PHP file called **on.php**:
|
||||||
|
|
||||||
|
**sudo nano on.php**
|
||||||
|
|
||||||
|
4\. Add the following code to it:
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
|
||||||
|
system(“ gpio-g mode 24 out “) ;
|
||||||
|
system(“ gpio-g write 24 1”) ;
|
||||||
|
|
||||||
|
?>
|
||||||
|
```
|
||||||
|
|
||||||
|
5\. Save the file using CTRL + O and exit using CTRL + X
|
||||||
|
|
||||||
|
In the code above, in the first line you've set the GPIO Pin 24 to output mode using the command:
|
||||||
|
|
||||||
|
```
|
||||||
|
system(“ gpio-g mode 24 out “) ;
|
||||||
|
```
|
||||||
|
|
||||||
|
In the second line, you’ve turned on the GPIO Pin 24, Using “1,” where “1” in binary refers to ON and “0” Means OFF.
|
||||||
|
|
||||||
|
6\. To turn off the relay, create another file called **off.php** and replace “1” with “0.”
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
|
||||||
|
system(“ gpio-g mode 24 out “) ;
|
||||||
|
system(“ gpio-g write 24 0”) ;
|
||||||
|
|
||||||
|
?>
|
||||||
|
```
|
||||||
|
|
||||||
|
7\. If you have your relay connected to the Pi, visit your web browser and type in the IP Address of your Pi followed by the directory name and file name:
|
||||||
|
|
||||||
|
**http://{IPADDRESS}/home/on.php**
|
||||||
|
|
||||||
|
This will turn ON the relay.
|
||||||
|
|
||||||
|
8\. To turn it OFF, open the page called **off.php**,
|
||||||
|
|
||||||
|
**http://{IPADDRESS}/home/off.php**
|
||||||
|
|
||||||
|
Now you need to control both these things from a single page without refreshing or visiting the pages individually. For that you'll use AJAX.
|
||||||
|
|
||||||
|
9\. Create a new HTML file and add this code to it.
|
||||||
|
|
||||||
|
```
|
||||||
|
[html + php + ajax codeblock]
|
||||||
|
|
||||||
|
<html>
|
||||||
|
|
||||||
|
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.11.3/jquery.min.js"></script>
|
||||||
|
|
||||||
|
<script type="text/javascript">// <![CDATA[
|
||||||
|
|
||||||
|
$(document).ready(function() {
|
||||||
|
|
||||||
|
$('#on').click(function(){
|
||||||
|
|
||||||
|
var a= new XMLHttpRequest();
|
||||||
|
|
||||||
|
a.open("GET", "on.php"); a.onreadystatechange=function(){
|
||||||
|
|
||||||
|
if(a.readyState==4){ if(a.status ==200){
|
||||||
|
|
||||||
|
} else alert ("http error"); } }
|
||||||
|
|
||||||
|
a.send();
|
||||||
|
|
||||||
|
});
|
||||||
|
|
||||||
|
});
|
||||||
|
|
||||||
|
$(document).ready(function()
|
||||||
|
|
||||||
|
{ $('#Off').click(function(){
|
||||||
|
|
||||||
|
var a= new XMLHttpRequest();
|
||||||
|
|
||||||
|
a.open("GET", "off.php");
|
||||||
|
|
||||||
|
a.onreadystatechange=function(){
|
||||||
|
|
||||||
|
if(a.readyState==4){
|
||||||
|
|
||||||
|
if(a.status ==200){
|
||||||
|
|
||||||
|
} else alert ("http error"); } }
|
||||||
|
|
||||||
|
a.send();
|
||||||
|
|
||||||
|
});
|
||||||
|
|
||||||
|
});
|
||||||
|
|
||||||
|
</script>
|
||||||
|
|
||||||
|
<button id="on" type="button"> Switch Lights On </button>
|
||||||
|
|
||||||
|
<button id="off" type="button"> Switch Lights Off </button>
|
||||||
|
```
|
||||||
|
|
||||||
|
10\. Save the file, go to your web browser, and open that page. You’ll see two buttons, which will turn lights on and off. Based on the same idea, you can create a beautiful web interface using bootstrap and CSS skills.
|
||||||
|
|
||||||
|
### Viewing temperature on this web page
|
||||||
|
|
||||||
|
1\. Create a file called **temperature.php**:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo nano temperature.php
|
||||||
|
```
|
||||||
|
|
||||||
|
2\. Add the following code to it, replace 10-000802292522 with your device ID:
|
||||||
|
|
||||||
|
```
|
||||||
|
<?php
|
||||||
|
//File to read
|
||||||
|
$file = '/sys/devices/w1_bus_master1/10-000802292522/w1_slave';
|
||||||
|
//Read the file line by line
|
||||||
|
$lines = file($file);
|
||||||
|
//Get the temp from second line
|
||||||
|
$temp = explode('=', $lines[1]);
|
||||||
|
//Setup some nice formatting (i.e., 21,3)
|
||||||
|
$temp = number_format($temp[1] / 1000, 1, ',', '');
|
||||||
|
//And echo that temp
|
||||||
|
echo $temp . " °C";
|
||||||
|
?>
|
||||||
|
```
|
||||||
|
|
||||||
|
3\. Go to the HTML file that you just created, and create a new **<div>** with the **id** “screen”: **<div id=“screen”></div>.**
|
||||||
|
|
||||||
|
4\. Add the following code after the **<body>** tag or at the end of the document:
|
||||||
|
|
||||||
|
```
|
||||||
|
<script>
|
||||||
|
$(document).ready(function(){
|
||||||
|
setInterval(function(){
|
||||||
|
$("#screen").load('temperature.php')
|
||||||
|
}, 1000);
|
||||||
|
});
|
||||||
|
</script>
|
||||||
|
```
|
||||||
|
|
||||||
|
In this, **#screen** is the **id** of **<div>** in which you want to display the temperature. It loads the **temperature.php** file every 1000 milliseconds.
|
||||||
|
|
||||||
|
I have used bootstrap to make a beautiful panel for displaying temperature. You can add multiple icons and glyphicons as well to make it more attractive.
|
||||||
|
|
||||||
|
This was just a basic system that controls a relay board and displays the temperature. You can develop it even further by creating event-based triggers based on timings, temperature readings from the thermostat, etc.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Abdul Hannan Mustajab - I'm 17 years old and live in India. I am pursuing an education in science, math, and computer science. I blog about my projects at spunkytechnology.com. I've been working on AI based IoT using different micro controllers and boards .
|
||||||
|
|
||||||
|
--------
|
||||||
|
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/3/operate-relays-control-gpio-pins-raspberry-pi
|
||||||
|
|
||||||
|
作者:[ Abdul Hannan Mustajab][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/mustajabhannan
|
||||||
|
[1]:http://www.php.net/system
|
||||||
|
[2]:http://www.php.net/system
|
||||||
|
[3]:http://www.php.net/system
|
||||||
|
[4]:http://www.php.net/system
|
||||||
|
[5]:http://www.php.net/system
|
||||||
|
[6]:http://www.php.net/file
|
||||||
|
[7]:http://www.php.net/explode
|
||||||
|
[8]:http://www.php.net/number_format
|
||||||
|
[9]:https://opensource.com/article/17/3/operate-relays-control-gpio-pins-raspberry-pi?rate=RX8QqLzmUb_wEeLw0Ee0UYdp1ehVokKZ-JbbJK_Cn5M
|
||||||
|
[10]:https://opensource.com/user/123336/feed
|
||||||
|
[11]:https://opensource.com/users/mustajabhannan
|
||||||
@ -0,0 +1,315 @@
|
|||||||
|
Join CentOS 7 Desktop to Samba4 AD as a Domain Member – Part 9
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
by [Matei Cezar][23] | Published: March 17, 2017 | Last Updated: March 17, 2017
|
||||||
|
|
||||||
|
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][24] | [4 Free Shell Scripting eBooks][25]
|
||||||
|
|
||||||
|
This guide will describe how you can integrate CentOS 7 Desktop to Samba4 Active Directory Domain Controller with Authconfig-gtk in order to authenticate users across your network infrastructure from a single centralized account database held by Samba.
|
||||||
|
|
||||||
|
#### Requirements
|
||||||
|
|
||||||
|
1. [Create an Active Directory Infrastructure with Samba4 on Ubuntu][1]
|
||||||
|
2. [CentOS 7.3 Installation Guide][2]
|
||||||
|
|
||||||
|
### Step 1: Configure CentOS Network for Samba4 AD DC
|
||||||
|
|
||||||
|
1. Before starting to join CentOS 7 Desktop to a Samba4 domain you need to assure that the network is properly setup to query domain via DNS service.
|
||||||
|
|
||||||
|
Open Network Settings and turn off the Wired network interface if enabled. Hit on the lower Settings button as illustrated in the below screenshots and manually edit your network settings, especially the DNS IPs that points to your Samba4 AD DC.
|
||||||
|
|
||||||
|
When you finish, Apply the configurations and turn on your Network Wired Card.
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][3]
|
||||||
|
|
||||||
|
Network Settings
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][4]
|
||||||
|
|
||||||
|
Configure Network
|
||||||
|
|
||||||
|
2. Next, open your network interface configuration file and add a line at the end of file with the name of your domain. This line assures that the domain counterpart is automatically appended by DNS resolution (FQDN) when you use only a short name for a domain DNS record.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
|
||||||
|
```
|
||||||
|
|
||||||
|
Add the following line:
|
||||||
|
|
||||||
|
```
|
||||||
|
SEARCH="your_domain_name"
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][5]
|
||||||
|
|
||||||
|
Network Interface Configuration
|
||||||
|
|
||||||
|
3. Finally, restart the network services to reflect changes, verify if the resolver configuration file is correctly configured and issue a series of ping commands against your DCs short names and against your domain name in order to verify if DNS resolution is working.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo systemctl restart network
|
||||||
|
$ cat /etc/resolv.conf
|
||||||
|
$ ping -c1 adc1
|
||||||
|
$ ping -c1 adc2
|
||||||
|
$ ping tecmint.lan
|
||||||
|
```
|
||||||
|
[
|
||||||
|
|
||||||
|
][6]
|
||||||
|
|
||||||
|
Verify Network Configuration
|
||||||
|
|
||||||
|
4. Also, configure your machine hostname and reboot the machine to properly apply the settings by issuing the following commands:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo hostnamectl set-hostname your_hostname
|
||||||
|
$ sudo init 6
|
||||||
|
```
|
||||||
|
|
||||||
|
Verify if hostname was correctly applied with the below commands:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat /etc/hostname
|
||||||
|
$ hostname
|
||||||
|
```
|
||||||
|
|
||||||
|
5. The last setting will ensure that your system time is in sync with Samba4 AD DC by issuing the below commands:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo yum install ntpdate
|
||||||
|
$ sudo ntpdate -ud domain.tld
|
||||||
|
```
|
||||||
|
|
||||||
|
### Step 2: Install Required Software to Join Samba4 AD DC
|
||||||
|
|
||||||
|
6. In order to integrate CentOS 7 to an Active Directory domain install the following packages from command line:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo yum install samba samba samba-winbind krb5-workstation
|
||||||
|
```
|
||||||
|
|
||||||
|
7. Finally, install the graphical interface software used for domain integration provided by CentOS repos: Authconfig-gtk.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo yum install authconfig-gtk
|
||||||
|
```
|
||||||
|
|
||||||
|
### Step 3: Join CentOS 7 Desktop to Samba4 AD DC
|
||||||
|
|
||||||
|
8. The process of joining CentOS to a domain controller is very straightforward. From command line open Authconfig-gtk program with root privileges and make the following changes as described below:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo authconfig-gtk
|
||||||
|
```
|
||||||
|
|
||||||
|
On Identity & Authentication tab.
|
||||||
|
|
||||||
|
* User Account Database = select Winbind
|
||||||
|
* Winbind Domain = YOUR_DOMAIN
|
||||||
|
* Security Model = ADS
|
||||||
|
* Winbind ADS Realm = YOUR_DOMAIN.TLD
|
||||||
|
* Domain Controllers = domain machines FQDN
|
||||||
|
* Template Shell = /bin/bash
|
||||||
|
* Allow offline login = checked
|
||||||
|
|
||||||
|
[
|
||||||
|
|
||||||
|
][7]
|
||||||
|
|
||||||
|
Authentication Configuration
|
||||||
|
|
||||||
|
On Advanced Options tab.
|
||||||
|
|
||||||
|
* Local Authentication Options = check Enable fingerprint reader support
|
||||||
|
* Other Authentication Options = check Create home directories on the first login
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][8]
|
||||||
|
|
||||||
|
Authentication Advance Configuration
|
||||||
|
|
||||||
|
9. After you’ve added all required values, return to Identity & Authentication tab and hit on Join Domain button and the Save button from alert window to save settings.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][9]
|
||||||
|
|
||||||
|
Identity and Authentication
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][10]
|
||||||
|
|
||||||
|
Save Authentication Configuration
|
||||||
|
|
||||||
|
10. After the configuration has been saved you will be asked to provide a domain administrator account in order to join the domain. Supply the credentials for a domain administrator user and hit OK button to finally join the domain.
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][11]
|
||||||
|
|
||||||
|
Joining Winbind Domain
|
||||||
|
|
||||||
|
11. After your machine has been integrated into the realm, hit on Apply button to reflect changes, close all windows and reboot the machine.
|
||||||
|
|
||||||
|
[
|
||||||
|
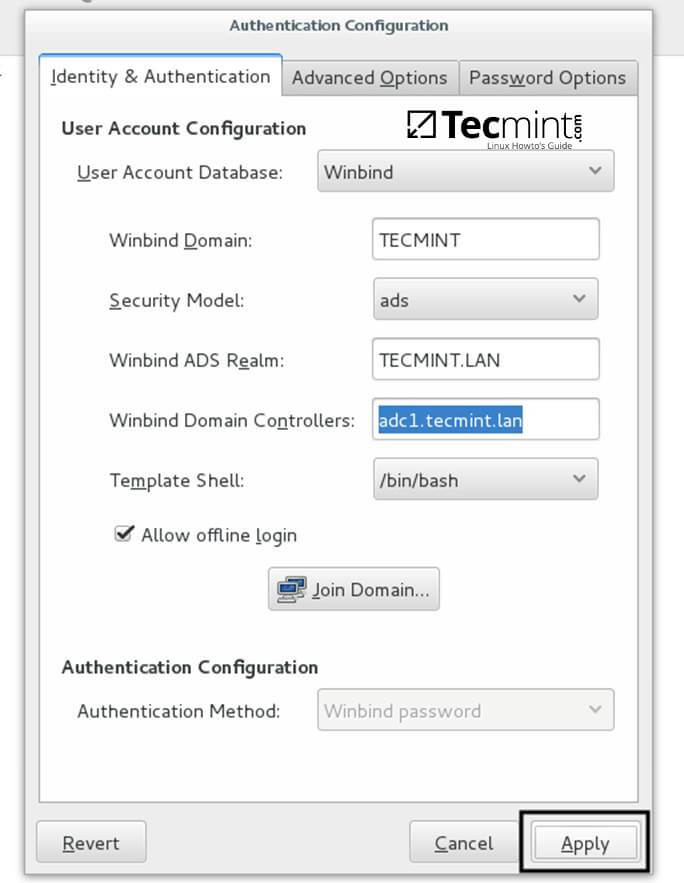
|
||||||
|
][12]
|
||||||
|
|
||||||
|
Apply Authentication Configuration
|
||||||
|
|
||||||
|
12. In order to verify if the system has been joined to Samba4 AD DC open AD Users and Computers from a Windows machine with [RSAT tools installed][13] and navigate to your domain Computers container.
|
||||||
|
|
||||||
|
The name of your CentOS machine should be listed on the right plane.
|
||||||
|
|
||||||
|
[
|
||||||
|
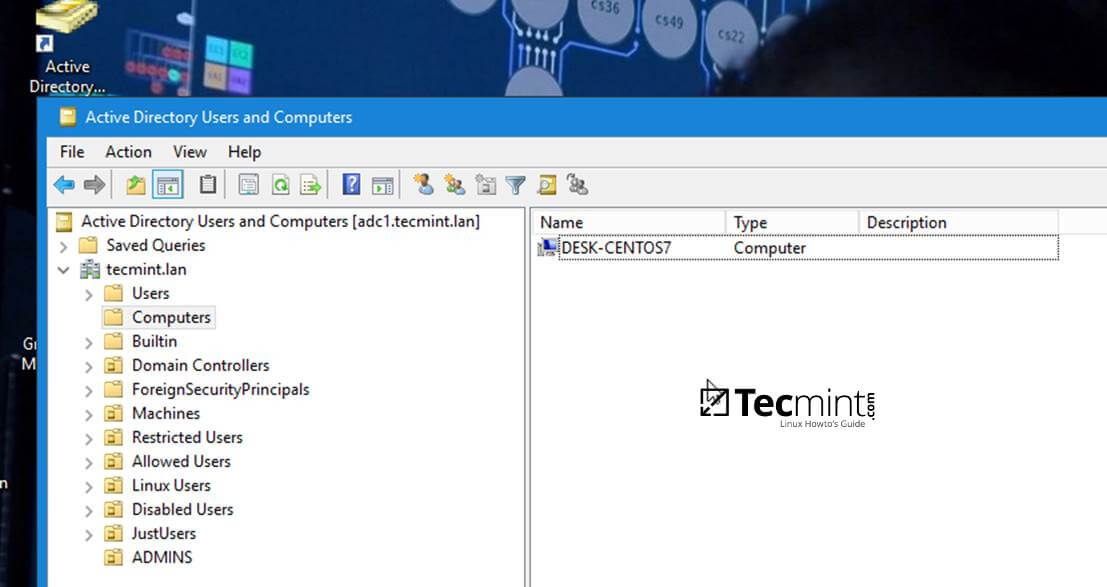
|
||||||
|
][14]
|
||||||
|
|
||||||
|
Active Directory Users and Computers
|
||||||
|
|
||||||
|
### Step 4: Login to CentOS Desktop with a Samba4 AD DC Account
|
||||||
|
|
||||||
|
13. In order to login to CentOS Desktop hit on Not listed? link and add the username of a domain account preceded by the domain counterpart as illustrated below.
|
||||||
|
|
||||||
|
```
|
||||||
|
Domain\domain_account
|
||||||
|
or
|
||||||
|
Domain_user@domain.tld
|
||||||
|
```
|
||||||
|
[
|
||||||
|
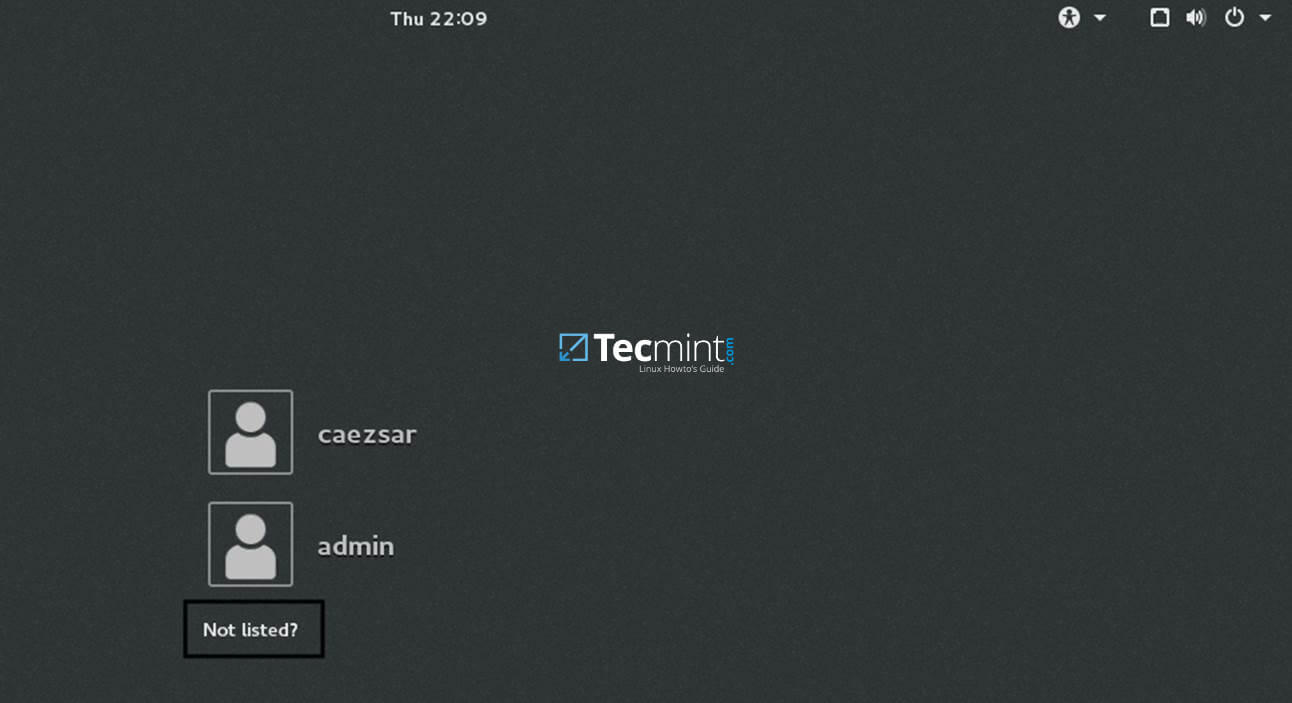
|
||||||
|
][15]
|
||||||
|
|
||||||
|
Not listed Users
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][16]
|
||||||
|
|
||||||
|
Enter Domain Username
|
||||||
|
|
||||||
|
14. To authenticate with a domain account from command line in CentOS use one of the following syntaxes:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ su - domain\domain_user
|
||||||
|
$ su - domain_user@domain.tld
|
||||||
|
```
|
||||||
|
[
|
||||||
|
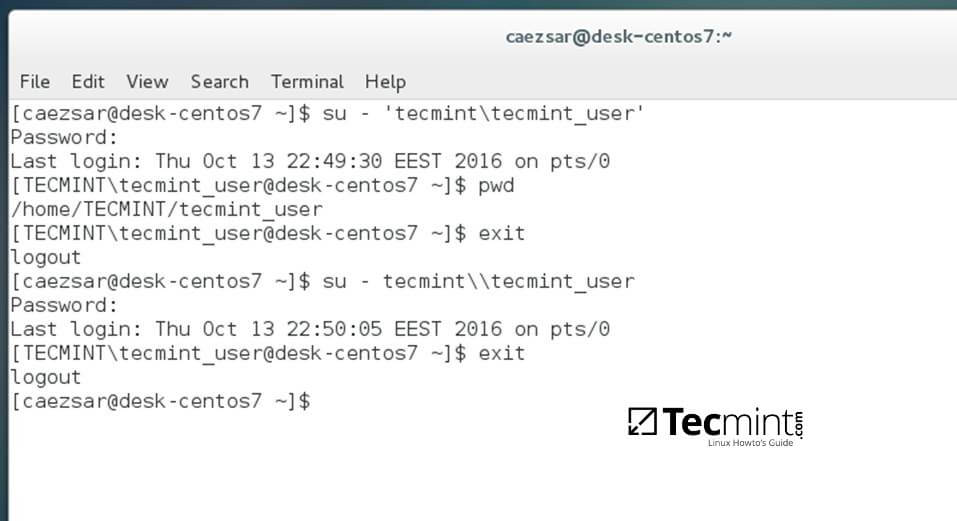
|
||||||
|
][17]
|
||||||
|
|
||||||
|
Authenticate Domain Username
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][18]
|
||||||
|
|
||||||
|
Authenticate Domain User Email
|
||||||
|
|
||||||
|
15. To add root privileges for a domain user or group, edit sudoers file using visudo command with root powers and add the following lines as illustrated on the below excerpt:
|
||||||
|
|
||||||
|
```
|
||||||
|
YOUR_DOMAIN\\domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||||
|
%YOUR_DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][19]
|
||||||
|
|
||||||
|
Assign Permission to User and Group
|
||||||
|
|
||||||
|
16. To display a summary about the domain controller use the following command:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo net ads info
|
||||||
|
```
|
||||||
|
[
|
||||||
|
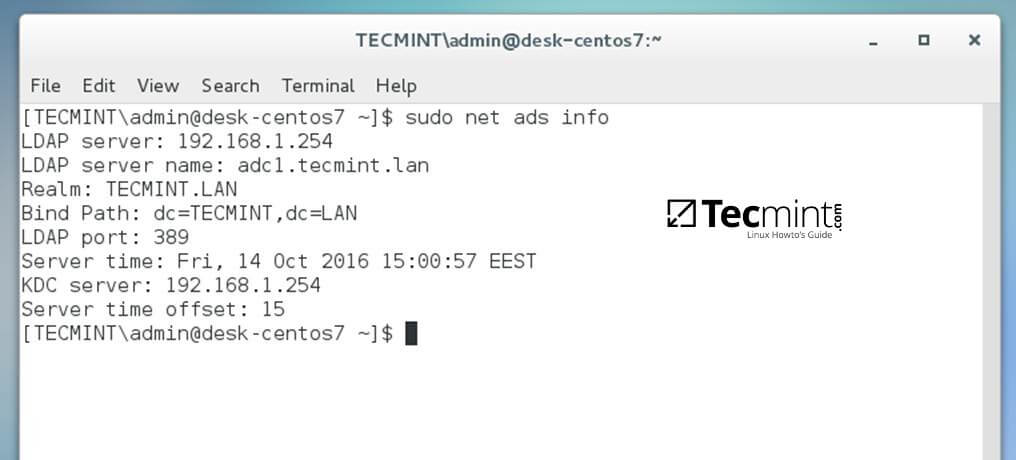
|
||||||
|
][20]
|
||||||
|
|
||||||
|
Check Domain Controller Info
|
||||||
|
|
||||||
|
17. In order to verify if the trust machine account created when CentOS was added to the Samba4 AD DC is functional and list domain accounts from command line install Winbind client by issuing the below command:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo yum install samba-winbind-clients
|
||||||
|
```
|
||||||
|
|
||||||
|
Then issue a series of checks against Samba4 AD DC by executing the following commands:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ wbinfo -p #Ping domain
|
||||||
|
$ wbinfo -t #Check trust relationship
|
||||||
|
$ wbinfo -u #List domain users
|
||||||
|
$ wbinfo -g #List domain groups
|
||||||
|
$ wbinfo -n domain_account #Get the SID of a domain account
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][21]
|
||||||
|
|
||||||
|
Get Samba4 AD DC Details
|
||||||
|
|
||||||
|
18. In case you want to leave the domain issue the following command against your domain name by using an domain account with administrator privileges:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo net ads leave your_domain -U domain_admin_username
|
||||||
|
```
|
||||||
|
[
|
||||||
|

|
||||||
|
][22]
|
||||||
|
|
||||||
|
Leave Domain from Samba4 AD
|
||||||
|
|
||||||
|
That’s all! Although this procedure is focused on joining CentOS 7 to a Samba4 AD DC, the same steps described in this documentation are also valid for integrating a CentOS 7 Desktop machine to a Microsoft Windows Server 2008 or 2012 domain.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/join-centos-7-to-samba4-active-directory/
|
||||||
|
|
||||||
|
作者:[Matei Cezar][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||||
|
|
||||||
|
[1]:http://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||||
|
[2]:http://www.tecmint.com/centos-7-3-installation-guide/
|
||||||
|
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Network-Settings.jpg
|
||||||
|
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Network.jpg
|
||||||
|
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Network-Interface-Configuration.jpg
|
||||||
|
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Verify-Network-Configuration.jpg
|
||||||
|
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Authentication-Configuration.jpg
|
||||||
|
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Authentication-Advance-Configuration.jpg
|
||||||
|
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Identity-and-Authentication.jpg
|
||||||
|
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Save-Authentication-Configuration.jpg
|
||||||
|
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Joining-Winbind-Domain.jpg
|
||||||
|
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Apply-Authentication-Configuration.jpg
|
||||||
|
[13]:http://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||||
|
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Active-Directory-Users-and-Computers.jpg
|
||||||
|
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/Not-listed-Users.jpg
|
||||||
|
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/Enter-Domain-Username.jpg
|
||||||
|
[17]:http://www.tecmint.com/wp-content/uploads/2017/03/Authenticate-Domain-User.jpg
|
||||||
|
[18]:http://www.tecmint.com/wp-content/uploads/2017/03/Authenticate-Domain-User-Email.jpg
|
||||||
|
[19]:http://www.tecmint.com/wp-content/uploads/2017/03/Assign-Permission-to-User-and-Group.jpg
|
||||||
|
[20]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Domain-Controller-Info.jpg
|
||||||
|
[21]:http://www.tecmint.com/wp-content/uploads/2017/03/Get-Samba4-AD-DC-Details.jpg
|
||||||
|
[22]:http://www.tecmint.com/wp-content/uploads/2017/03/Leave-Domain-from-Samba4-AD.jpg
|
||||||
|
[23]:http://www.tecmint.com/author/cezarmatei/
|
||||||
|
[24]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[25]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
@ -0,0 +1,153 @@
|
|||||||
|
Kgif – A Simple Shell Script to Create a Gif File from Active Window
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
[Kgif][2] is a simple shell script which create a Gif file from active window. I felt this app especially designed to capture the terminal activity. I personally used, very often for that purpose.
|
||||||
|
|
||||||
|
It captures activity as a series of PNG images, then combines all together to create a animated GIF. The script taking a screenshot of the active window at 0.5s intervals. If you feel, its not matching your requirement, straight away you can modify the script as per your need.
|
||||||
|
|
||||||
|
Originally it was created for capturing tty output and creating preview for github projects.
|
||||||
|
|
||||||
|
Make sure you have installed scrot and ImageMagick packages before running Kgif.
|
||||||
|
|
||||||
|
Suggested Read : [Peek – Create a Animated GIF Recorder in Linux][3]
|
||||||
|
|
||||||
|
What’s ImageMagick ImageMagick is a command line tool which used for image conversion and editing. It support all kind of image formats (over 200) such as PNG, JPEG, JPEG-2000, GIF, TIFF, DPX, EXR, WebP, Postscript, PDF, and SVG.
|
||||||
|
|
||||||
|
What’s Scrot Scrot stand for SCReenshOT is an open source, command line tool to capture a screen shots of your Desktop, Terminal or a Specific Window.
|
||||||
|
|
||||||
|
#### Install Dependencies
|
||||||
|
|
||||||
|
Kgif required scrot and ImageMagick to work.
|
||||||
|
|
||||||
|
For Debian based Systems
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt-get install scrot imagemagick
|
||||||
|
```
|
||||||
|
|
||||||
|
For RHEL/CentOS based Systems
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo yum install scrot ImageMagick
|
||||||
|
```
|
||||||
|
|
||||||
|
For Fedora Systems
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install scrot ImageMagick
|
||||||
|
```
|
||||||
|
|
||||||
|
For openSUSE Systems
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo zypper install scrot ImageMagick
|
||||||
|
```
|
||||||
|
|
||||||
|
For Arch Linux based Systems
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo pacman -S scrot ImageMagick
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Install Kgif & Usage
|
||||||
|
|
||||||
|
Installation of Kgif not a big deal because no installation required. Just clone the source file from developer github page wherever you want and run the `kgif.sh` file to capture the active window. By default, it’s sets delay to 1 sec, you can modify this by including `--delay` option with kgif. Finally press `Ctrl+c` to stop capturing.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone https://github.com/luminousmen/Kgif
|
||||||
|
$ cd Kgif
|
||||||
|
$ ./kgif.sh
|
||||||
|
Setting delay to 1 sec
|
||||||
|
|
||||||
|
Capturing...
|
||||||
|
^C
|
||||||
|
Stop capturing
|
||||||
|
Converting to gif...
|
||||||
|
Cleaning...
|
||||||
|
Done!
|
||||||
|
```
|
||||||
|
|
||||||
|
Check whether dependencies are presents in system.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./kgif.sh --check
|
||||||
|
OK: found scrot
|
||||||
|
OK: found imagemagick
|
||||||
|
```
|
||||||
|
|
||||||
|
Set delay in seconds with script to start capturing, after N seconds.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./kgif.sh --delay=5
|
||||||
|
|
||||||
|
Setting delay to 5 sec
|
||||||
|
|
||||||
|
Capturing...
|
||||||
|
^C
|
||||||
|
Stop capturing
|
||||||
|
Converting to gif...
|
||||||
|
Cleaning...
|
||||||
|
Done!
|
||||||
|
```
|
||||||
|
|
||||||
|
It save the gif file name as a `terminal.gif` and overwrite every time whenever get a new file. So, i advise you to add `--filename`option to save the file in a different name.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./kgif.sh --delay=5 --filename=2g-test.gif
|
||||||
|
|
||||||
|
Setting delay to 5 sec
|
||||||
|
|
||||||
|
Capturing...
|
||||||
|
^C
|
||||||
|
Stop capturing
|
||||||
|
Converting to gif...
|
||||||
|
Cleaning...
|
||||||
|
Done!
|
||||||
|
```
|
||||||
|
|
||||||
|
Set noclean with script to keep the source png screen shots.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./kgif.sh --delay=5 --noclean
|
||||||
|
```
|
||||||
|
|
||||||
|
To know more all the options.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./kgif.sh --help
|
||||||
|
|
||||||
|
usage: ./kgif.sh [--delay] [--filename ] [--gifdelay] [--noclean] [--check] [-h]
|
||||||
|
-h, --help Show this help, exit
|
||||||
|
--check Check if all dependencies are installed, exit
|
||||||
|
--delay= Set delay in seconds to specify how long script will wait until start capturing.
|
||||||
|
--gifdelay= Set delay in seconds to specify how fast images appears in gif.
|
||||||
|
--filename= Set file name for output gif.
|
||||||
|
--noclean Set if you don't want to delete source *.png screenshots.
|
||||||
|
```
|
||||||
|
|
||||||
|
Default capturing output.
|
||||||
|
[
|
||||||
|

|
||||||
|
][4]
|
||||||
|
|
||||||
|
I felt, the default capturing is very fast, then i made few changes and got the proper output.
|
||||||
|
[
|
||||||
|

|
||||||
|
][5]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
|
||||||
|
|
||||||
|
作者:[MAGESH MARUTHAMUTHU][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.2daygeek.com/author/magesh/
|
||||||
|
[1]:http://www.2daygeek.com/author/magesh/
|
||||||
|
[2]:https://github.com/luminousmen/Kgif
|
||||||
|
[3]:http://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
|
||||||
|
[4]:http://www.2daygeek.com/wp-content/uploads/2017/03/kgif-test.gif
|
||||||
|
[5]:http://www.2daygeek.com/wp-content/uploads/2017/03/kgif-test-delay-modified.gif
|
||||||
47
sources/tech/20170317 The End of the Line for EPEL-5.md
Normal file
47
sources/tech/20170317 The End of the Line for EPEL-5.md
Normal file
@ -0,0 +1,47 @@
|
|||||||
|
# [The End of the Line for EPEL-5][1]
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
For the last 10 years, the Fedora Project has been building packages for the same release of another operating system. **However on March 31st, 2017, that will come to an end** when Red Hat Enterprise Linux (RHEL) version 5 moves out of production.
|
||||||
|
|
||||||
|
### A Short History of EPEL
|
||||||
|
|
||||||
|
RHEL is a downstream rebuild of a subset of Fedora releases that Red Hat feels it can adequetely support over a multi-year lifetime. While these packages make for a full operating system, there have always been a need by system administrators for ‘more’ packages. Before RHEL-5, many of these packages would be built and supplied by various rebuilders. With Fedora Extras growing to include many of the packages, and several of the rebuilders having joined Fedora, there was an idea of combining forces and creating a dedicated sub-project who would rebuild Fedora packages with specific RHEL releases and then distribute them from Fedora’s centralized servers.
|
||||||
|
|
||||||
|
After much debate and a failure to come up with a catchy name, the Extra Packages for Enterprise Linux (or EPEL) sub-project of Fedora was created. While at first rebuilding packages for RHEL-4, the main goal was to have as many packages available for RHEL-5 when it arrived. It took a lot of hard work getting the plague builders in place, but most of the work was in crafting the rules and guidelines that EPEL would use for the next 10 years. [As anyone can see from the old mail archives][2], the debates were fierce from both various Fedora contributors feeling this took away focus from moving Fedora releases forward to outside contributors worried about conflicts with existing installed packages.
|
||||||
|
|
||||||
|
In the end, EPEL-5 went live sometime in April of 2007 and over the next 10 years grew to a repository of over 5000 source packages and 200,000 unique ip addresses checking in per day at its peak of 240,000 in early 2013\. While every package built for EPEL is done with the RHEL packages, all of these packages have been useful for the various community rebuilds (CentOS, Scientific Linux, Amazon Linux) of RHEL. This meant that growth in those eco-systems brought more users into using EPEL and helping on packaging as later RHEL releases came out. However as these newer releases and rebuilds grew in usage, the number of EPEL-5 users has gradually fallen to around 160,000 unique ip addresses per day. Also over that time, the number of packages supported by developers has fallen and the repository has shrunk in size to 2000 source packages.<>
|
||||||
|
|
||||||
|
Part of the shrinkage was due to the original rules put in place back in 2007\. At that time, Red Hat Enterprise Linux releases were only thought to have an active life time of 6 years before being end of lifed. It was thought that for such a ‘limited’ lifetime, packages could be ‘frozen’ in EPEL like they were in the RHEL release. This meant that whenever possible fixes should be backported and major changes would not be allowed. Time and packaging stands still for no human, and packages would be continually pruned from EPEL-5 as packagers no longer wanted to try and backport fixes. While various rules were loosened to allow for larger changes in packages, the packaging rules that Fedora used have continually moved and improved from 2007\. This has made trying to rebuild a package from newer releases harder and harder with the older operating systems.
|
||||||
|
|
||||||
|
### What Happens on March 31st 2017
|
||||||
|
|
||||||
|
As stated before, on March 31st Red Hat will end of life and no longer put updates out for RHEL-5 for regular customers. This means that
|
||||||
|
Fedora and the various rebuild distributors will start various archive processes. For the EPEL project this means that we will follow the steps that happen every year with Fedora releases.
|
||||||
|
|
||||||
|
1. On **March 27th**, no new builds will be allowed to be pushed for EPEL-5 so that the repository is essentially frozen. This will allow mirrors to have a clear tree of all files.
|
||||||
|
2. All packages in EPEL-5 will be hardlinked on the master mirror from `/pub/epel/5/` and `/pub/epel/testing/5/` to `/pub/archives/epel/`. **This will start happening on the 27th** so all mirrors of archives can populate their disks.
|
||||||
|
3. Because March 31st happens on a Friday, and system administrators do not like Friday surprises, there will be no change then. On **April 3rd**, mirrormanager will be updated to point to the archives.
|
||||||
|
4. On **April 6th**, the /pub/epel/5/ trees will be removed and mirrors will update accordingly.
|
||||||
|
|
||||||
|
For a system administrator who has cron jobs which do yum updates, there should be minimal hassle. The systems will continue to update and even install any packages which were in the archives at that time. There will be breakage for system administrators who have scripts which directly download files from mirrors. Those scripts will need to change to the new canonical location of /pub/archive/epel/5/.
|
||||||
|
|
||||||
|
While irksome, this is a blessing in disguise for many system administrators who will still be using an older Linux. Because packages have been regularly removed from EPEL-5, the various support mailing lists and irc channels have regular requests from system administrators wondering where some package they needed has gone. After the archive is done, this won’t be a problem because no more packages will be removed :).
|
||||||
|
|
||||||
|
For system administrators who have been hit by this problem, the older EPEL packages are still available though in a much slower method. All EPEL packages are built in the Fedora Koji system, and so older builds of packages can be found using [Koji search.][3]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/the-end-of-the-line-for-epel-5/
|
||||||
|
|
||||||
|
作者:[smooge][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://smooge.id.fedoraproject.org/
|
||||||
|
[1]:https://fedoramagazine.org/the-end-of-the-line-for-epel-5/
|
||||||
|
[2]:https://www.redhat.com/archives/epel-devel-list/2007-March/thread.html
|
||||||
|
[3]:https://koji.fedoraproject.org/koji/search
|
||||||
@ -1,88 +0,0 @@
|
|||||||
消沉的程序员系列漫画
|
|
||||||
=========================
|
|
||||||
### 消沉的程序员 1
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
很有意思吧,很多看到这样的漫画对话的程序员,应该感觉似曾相识吧。Bug 出现了?
|
|
||||||
|
|
||||||
### 消沉的程序员 2
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
有点疑惑,有好像有点眉目,好像是感觉到哪里错了,是不是要重构。
|
|
||||||
|
|
||||||
### 消沉的程序员 3
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
哎,终于发现错误了,感觉有点可笑,自己居然犯这样的错误,原来是那次急于提交代码造成的。
|
|
||||||
|
|
||||||
### 消沉的程序员 4
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
是啊,在编程里一生戎马,代码编写无数,各种平台、规范等等,到头来也是满身的错误啊。该是技术不行吧!
|
|
||||||
|
|
||||||
### 消沉的程序员 5
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
呀,快要消除错误了,可是,不对。相信事后的 Bug 和 Debug 会是程序员生活中的一个部分。
|
|
||||||
|
|
||||||
### 消沉的程序员 6
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
每个新建的工程都是有美好的设想吧,可后来为什么总是渐行渐远?大多时候的自言自语,总是是有人认为是在和代码对话吧?可没有身在其中,别人有这么懂得!
|
|
||||||
|
|
||||||
### 消沉的程序员 7
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
好吧,产品的上线,总是要经过无数次的创建分支,Bug 和 Debug 总还是程序员的永恒话题。其中,有些东西总免不了自己推翻自己,感觉要从头再来一样。
|
|
||||||
|
|
||||||
### 消沉的程序员 10
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
为了某项专门的研究,学习一门相关的语言,不知道是不是值得?是不是先要思考其必要性呢?最后发现自己并不喜欢这么语言,导致怀疑自己的专业技能,这样大概不好吧!
|
|
||||||
|
|
||||||
### 消沉的程序员 11
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
其实,本来是愉快的蹲个坑,却不自觉的陷入编码的思考。想想,不仅是程序员,很多人有都有类似此景的情况吧,明明在做着某事,却想着另外一件事。
|
|
||||||
|
|
||||||
### 后记
|
|
||||||
|
|
||||||
看至此处,各位朋友是不是感觉少了系列的第 8 和第 9 篇?起初,译者也这么想,后来问了作者 Daniel Stori 之后,才恍然,原来序号采用了八进制,按照作者说的,一个隐式的玩笑。明白了吗,朋友们?
|
|
||||||
|
|
||||||
大伙儿都习惯了日常的十进制。当常态处于优先级的时候,日常一些非常态就如同细枝末节,也就往往容易被人们忽略。大概就是这样吧。
|
|
||||||
|
|
||||||
-------------------------------
|
|
||||||
|
|
||||||
译者简介:
|
|
||||||
|
|
||||||
[GHLandy](http://GHLandy.com) —— 生活中所有欢乐与苦闷都应藏在心中,有些事儿注定无人知晓,自己也无从说起。
|
|
||||||
|
|
||||||
-------------------------------
|
|
||||||
|
|
||||||
via:
|
|
||||||
- http://turnoff.us/geek/the-depressed-developer/
|
|
||||||
- http://turnoff.us/geek/the-depressed-developer-2/
|
|
||||||
- http://turnoff.us/geek/the-depressed-developer-3/
|
|
||||||
- http://turnoff.us/geek/the-depressed-developer-4/
|
|
||||||
- http://turnoff.us/geek/the-depressed-developer-5/
|
|
||||||
- http://turnoff.us/geek/the-depressed-developer-6/
|
|
||||||
- http://turnoff.us/geek/the-depressed-developer-7/
|
|
||||||
- http://turnoff.us/geek/the-depressed-developer-10/
|
|
||||||
- http://turnoff.us/geek/the-depressed-developer-11/
|
|
||||||
|
|
||||||
作者:[Daniel Stori][a]
|
|
||||||
译者:[GHLandy](https://github.com/GHLandy)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://turnoff.us/about/
|
|
||||||
@ -0,0 +1,186 @@
|
|||||||
|
|
||||||
|
看漫画学 SELinux 强制策略
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
>图像来自: opensource.com
|
||||||
|
|
||||||
|
今年是我们一起庆祝 SELinux 纪念日的第十个年头了。真是太难以置信了!SELinux 最初在 Fedora Core 3 中被引入,随后加入了红帽企业版 Linux 4。从来没有使用过 SELinux 的家伙,你可要好好儿找个理由了……
|
||||||
|
|
||||||
|
更多的 Linux 资源
|
||||||
|
|
||||||
|
* [Linux 是什么?][1]
|
||||||
|
* [Linux 容器是什么?][2]
|
||||||
|
* [在 Linux 中操作设备][3]
|
||||||
|
* [立刻下载: Linux 命令小抄][4]
|
||||||
|
* [我们最新的 Linux 文章][5]
|
||||||
|
|
||||||
|
SElinux 是一个标签型系统。每一个进程都有一个标签。操作系统中的每一个文件/目录客体都有一个标签。甚至连网络端口、设备和潜在的主机名称都被分配了标签。我们把控制访问进程标签的规则写入一个类似文件的客体标签中。我们称之为_策略_。内核加强了这些规则。有时候这种加强被称为强制访问控制体系 (MAC)。
|
||||||
|
|
||||||
|
一个客体的拥有者在客体的安全属性下没有自主权。标准 Linux 访问控制体系,拥有者/分组 + 权限标志如 rwx,常常被称作自主访问控制(DAC)。SELinux 没有文件 UID 或 拥有权的概念。一切都被标签控制。意味着配置一个 SELinux 系统可以没有一个功能强大的根进程。
|
||||||
|
|
||||||
|
**注意:** _SELinux不允许你摒弃 DAC 控制。SELinux 是一个并行的强制模型。一个应用必须同时支持 SELinux 和 DAC 来完成特定的行为。这可能会导致管理员迷惑为什么进程返回拒绝访问。管理员看到拒绝访问是因为 DAC 出了问题,而不是 SELinux标签。
|
||||||
|
|
||||||
|
### 类型强制
|
||||||
|
|
||||||
|
让我们更深入的研究下标签。SELinux 最主要的模型或强制叫做_类型强制_。基本上这意味着我们通过一个进程的类型来定义它的标签,通过文件系统客体的类型来定义它的标签。
|
||||||
|
|
||||||
|
_打个比方_
|
||||||
|
|
||||||
|
想象一下在一个系统里定义客体的类型为猫和狗。猫(CAT)和狗(DOG)都是进程类型(PROCESS TYPES)。
|
||||||
|
|
||||||
|
_*所有的漫画都来自 [Máirín Duffy][6]_
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我们有一类客体希望能够和我们称之为食物的东西交互。而我希望能够为食物增加类型:_cat_food_ (猫粮)和 _dog_food_(狗粮)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
作为一个策略制定者,我可以说一只狗有权限去吃狗粮(DOG_CHOW),而一只猫有权限去吃猫粮(CAT_CHOW)。在 SELinux 中我可以将这条规则写入策略中。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
allow cat cat_chow:food eat;
|
||||||
|
|
||||||
|
允许 猫 猫粮 吃;
|
||||||
|
|
||||||
|
allow dog dog_chow:food eat;
|
||||||
|
|
||||||
|
允许 狗 狗粮 吃;
|
||||||
|
|
||||||
|
有了这些规则,内核会允许猫进程去吃打上猫粮标签 _cat_chow_ 的食物,允许狗去吃打上狗粮标签 _dog_chow_ 的食物。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
但是在 SELinux 系统中,一切都是默认被禁止的。这意味着,如果狗进程想要去吃猫粮 _cat_chow_,内核会阻止它。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
同理,猫也不允许去接触狗粮。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_现实例子_
|
||||||
|
|
||||||
|
我们将 Apache 进程标为 _httpd_t_,将 Apache 上下文标为 _httpd_sys_content_t_ 和 _httpdsys_content_rw_t_。想象一下我们把信用卡数据存储在 mySQL 数据库中,其标签为 _msyqld_data_t_。如果一个 Apache 进程被劫持,黑客可以获得 _httpd_t_ 进程的控制权而且允许去读取 _httpd_sys_content_t_ 文件并向 _httpd_sys_content_rw_t_ 执行写操作。但是黑客却不允许去读信用卡数据(_mysqld_data_t_),即使 Apache 进程是在 root 下运行。在这种情况下 SELinux 减轻了这次闯入的后果。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 多类别安全强制
|
||||||
|
|
||||||
|
_打个比方_
|
||||||
|
|
||||||
|
上面我们定义了狗进程和猫进程,但是如果你有多个狗进程:Fido 和 Spot,而你想要阻止 Fido 去吃 Spot 的狗粮 _dog_chow_ 怎么办呢?
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
一个解决方式是创建大量的新类型,如 _Fido_dog_ 和 _Fido_dog_chow_。但是这很快会变得难以驾驭因为所有的狗都有差不多相同的权限。
|
||||||
|
|
||||||
|
为了解决这个问题我们发明了一种新的强制形式,叫做多类别安全(MCS)。在 MCS 中,我们在狗进程和狗粮的标签上增加了另外一部分标签。现在我们将狗进程标记为 _dog:random1(Fido)_ 和 _dog:random2(Spot)_。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我们将狗粮标记为_dog_chow:random1(Fido)_ 和 _dog_chow:random2(Spot)_。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
MCS 规则声明如果类型强制规则被遵守而且随机 MCS 标签正确匹配,则访问是允许的,否则就会被拒绝。
|
||||||
|
|
||||||
|
Fido (dog:random1) 尝试去吃 _cat_chow:food_ 被类型强制拒绝了。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Fido (dog:random1) 允许去吃 _dog_chow:random1._
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Fido (dog:random1) 去吃 spot( _dog_chow:random2_ )的食物被拒绝.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_现实例子_
|
||||||
|
|
||||||
|
在计算机系统中我们经常有很多具有同样访问权限的进程,但是我们又希望它们各自独立。有时我们称之为_多租户环境_。最好的例子就是虚拟机。如果我有一个运行很多虚拟机的服务器,而其中一个被劫持,我希望能能够阻止它去攻击其它虚拟机和虚拟机镜像。但是在一个类型强制系统中 KVM 虚拟机被标记为 _svirt_t_ 而镜像被标记为 _svirt_image_t_。 我们有权限允许 _svirt_t_ 可以读/写/删除标记为 _svirt_image_t_ 的上下文。通过使用 libvirt 我们不仅实现了类型强制隔离,而且实现了 MCS 隔离。当 libvirt 将要启动一个虚拟机,它会挑选出一个随机 MCS 标签如 _s0:c1,c2_,接着它会将 _svirt_image_t:s0:c1,c2_ 标签分发给虚拟机需要去操作的所有上下文。最终,虚拟机以 _svirt_t:s0:c1,c2_ 为标签启动。因此,SELinux 内核控制 _svirt_t:s0:c1,c2_ 不允许写向 _svirt_image_t:s0:c3,c4_,即使虚拟机被一个黑客劫持并接管。即使它是运行在 root 下。
|
||||||
|
|
||||||
|
我们在 OpenShift 中使用[类似的隔离策略][8]。每一个 gear(user/app process)都有相同的 SELinux 类型(openshift_t)(译者注:gear 为 OpenShift 的计量单位)。策略定义的规则控制着 gear 类型的访问权限,而一个独一无二的 MCS 标签确保了一个 gear 不能影响其他 gear。
|
||||||
|
|
||||||
|
请观看[这个短视频][9]来看 OpenShift gear 切换到 root 会发生什么。
|
||||||
|
|
||||||
|
### MLS enforcement
|
||||||
|
|
||||||
|
多级别安全强制
|
||||||
|
|
||||||
|
另外一种不经常使用的 SELinux 强制形式叫做 多级别安全(MLS);它于 60 年代被开发并且主要使用在受信的操作系统上如 Trusted Solaris。
|
||||||
|
|
||||||
|
核心观点就是通过进程使用的数据等级来控制进程。一个 _secret_ 进程不能读取 _top secret_ 数据。
|
||||||
|
|
||||||
|
MLS 很像 MCS,除了它在强制策略中增加了支配概念。MCS 标签必须完全匹配,但 一个 MLS 标签可以支配另一个 MLS 标签并且获得访问。
|
||||||
|
|
||||||
|
_打个比方_
|
||||||
|
|
||||||
|
不讨论不同名字的狗,我们现在来看不同种类。我们现在有一只灰狗和一只吉娃娃。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我们可能想要允许灰狗去吃任何狗粮,但是吉娃娃如果尝试去吃灰狗的狗粮可能会被呛到。
|
||||||
|
|
||||||
|
我们把灰狗标记为 _dog:Greyhound_,把它的狗粮标记为 _dog_chow:Greyhound_,把吉娃娃标记为 _dog:Chihuahua_,把它的狗粮标记为 _dog_chow:Chihuahua_。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
使用 MLS 策略,我们可以使 MLS 灰狗标签支配吉娃娃标签。这意味着 _dog:Greyhound_ 允许去吃 _dog_chow:Greyhound_ 和 _dog_chow:Chihuahua_ 。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
但是 _dog:Chihuahua_ 不允许去吃 _dog_chow:Greyhound_。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
当然,由于类型强制, _dog:Greyhound_ 和 _dog:Chihuahua_ 仍然不允许去吃 _cat_chow:Siamese_,即使 MLS 类型 GreyHound 支配 Siamese。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_现实例子_
|
||||||
|
|
||||||
|
有两个 Apache 服务器:一个以 _httpd_t:TopSecret_ 运行,一个以 _httpd_t:Secret_ 运行。如果 Apache 进程 _httpd_t:Secret_ 被劫持,黑客可以读取 _httpd_sys_content_t:Secret_ 但会被禁止读取 _httpd_sys_content_t:TopSecret_。
|
||||||
|
|
||||||
|
但是如果运行 _httpd_t:TopSecret_ 的 Apache 进程被劫持,它可以读取 _httpd_sys_content_t:Secret_ 数据和 _httpd_sys_content_t:TopSecret_ 数据。
|
||||||
|
|
||||||
|
我们在军事系统上使用 MLS,一个用户可能被允许读取 _secret_ 数据,但是另一个用户在同一个系统上可以读取 _top secret_ 数据。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
SELinux 是一个功能强大的标签系统,控制内核授予每个进程的访问权限。最主要的特性是类型强制,策略规则定义的进程访问权限基于进程被标记的类型和客体被标记的类型。另外两个控制手段也被引入,来独立有着同样类型进程的叫做 MCS,可以完全独立每个进程,而MLS,允许进程间存在支配等级。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Daniel J Walsh - Daniel Walsh 已经在计算机安全领域工作了将近 30 年。Daniel 与 2001 年 8 月加入红帽。
|
||||||
|
|
||||||
|
-------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/business/13/11/selinux-policy-guide
|
||||||
|
|
||||||
|
作者:[Daniel J Walsh ][a]
|
||||||
|
译者:[xiaow6](https://github.com/xiaow6)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/rhatdan
|
||||||
|
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||||
|
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||||
|
[3]:https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu
|
||||||
|
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||||
|
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||||
|
[6]:https://opensource.com/users/mairin
|
||||||
|
[7]:https://opensource.com/business/13/11/selinux-policy-guide?rate=XNCbBUJpG2rjpCoRumnDzQw-VsLWBEh-9G2hdHyB31I
|
||||||
|
[8]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
||||||
|
[9]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
||||||
|
[10]:https://opensource.com/user/16673/feed
|
||||||
|
[11]:https://opensource.com/business/13/11/selinux-policy-guide#comments
|
||||||
|
[12]:https://opensource.com/users/rhatdan
|
||||||
@ -2,110 +2,110 @@
|
|||||||
============================================================
|
============================================================
|
||||||

|

|
||||||
|
|
||||||
[Min][1] 是一款具有最小设计的 web 浏览器,可以通过简单的功能提供快速操作。
|
[Min][1] 是一款精简设计的 web 浏览器,功能简便,响应迅速。
|
||||||
|
|
||||||
当涉及到软件设计时,“最小”并不意味着潜在的低级功能或未开发。如果你喜欢文本编辑器和笔记程序中的最小防干扰工具,那么你会在 Min 浏览器中有同样舒适的感觉。
|
在软件设计中,“简单”并不意味着功能低级、有待改进。你如果喜欢花哨工具比较少的文本编辑器和笔记程序,那么在 Min 浏览器中会有同样舒适的感觉。
|
||||||
|
|
||||||
我大多在我的台式机和笔记本电脑上使用 Google Chrome、Chromium和 Firefox。我研究了很多它们的附加功能,所以我可以在我的长期研究和工作中可以访问所有的专业服务。
|
我经常在台式机和笔记本电脑上使用 Google Chrome、Chromium和 Firefox。我研究了它们的很多附加功能,所以我在长期的研究和工作中可以享用它们的特色服务。
|
||||||
|
|
||||||
然而,我有时喜欢一个快速、整洁的替代品来上网。随着多个项目的进行,我可以很快打开一大批选项卡甚至是独立窗口的强大浏览器。
|
然而,有时我希望有个快速、整洁的替代品来上网。随着多个项目的进行,我需要很快打开一大批选项卡甚至是独立窗口的强大浏览器。
|
||||||
|
|
||||||
我试过其他浏览器选项但很少成功。替代品通常有自己的一套分散注意力的附件和功能,它们会让我开小差。
|
我试过其他浏览器但很少能令我满意。替代品通常有一套独特的花哨的附件和功能,它们会让我开小差。
|
||||||
|
|
||||||
Min 浏览器不这样做。它是一个易于使用并在 GitHub 开源的 web浏览器,它不会使我分心。
|
Min 浏览器就不这样。它是一个易于使用,并在 GitHub 开源的 web 浏览器,不会使我分心。
|
||||||
|
|
||||||
|

|
||||||
Min 浏览器是最小化浏览器,提供了简单的功能以及迅速的操作。只是不要指望马上上手
|
Min 浏览器是精简的浏览器,提供了简单的功能以及快速的响应。只是不要指望马上上手。
|
||||||
|
|
||||||
### 它做些什么
|
### 它做些什么
|
||||||
|
|
||||||
Min 浏览器提供了 Debian Linux 版本、Windows 和 Mac 机器的版本。它不能与主流跨平台 web 浏览器中的可用功能竞争。
|
Min 浏览器提供了 Debian Linux、Windows 和 Mac 机器的版本。它不能与功能众多的主流跨平台 web 浏览器竞争。
|
||||||
|
|
||||||
它不必竞争,但是它的声誉非常好,它可能是补充而不是取代它们。
|
但它不必竞争,它很有名的原因应该是补充而不是取代那些主流浏览器。
|
||||||
|
|
||||||
其中一个主要原因是其内置的广告拦截功能。开箱即用的 Min 浏览器不需要配置或寻找兼容的第三方应用程序来拦截广告。
|
其中一个主要原因是其内置的广告拦截功能。开箱即用的 Min 浏览器不需要配置或寻找兼容的第三方应用程序来拦截广告。
|
||||||
|
|
||||||
在 Edit/Preferences 中,关于内容阻止你有三个选项可以点击/取消点击。它很容易修改屏蔽策略来适应你的喜好。阻止跟踪器和广告选项使用 EasyList 和 EasyPrivacy。 如果没有其他原因,请保持此选项选中。
|
在 Edit/Preferences 中,你可以通过三个选项来设置阻止的内容。它很容易修改屏蔽策略来满足你的喜好。阻止跟踪器和广告选项使用 EasyList 和 EasyPrivacy。 如果没有其他原因,请保持此选项选中。
|
||||||
|
|
||||||
你还可以阻止脚本和图像。这样做可以最大限度地提高网站加载速度,并真正提高你对恶意代码的防御。
|
你还可以阻止脚本和图像。这样做可以最大限度地提高网站加载速度,并能有效防御恶意代码。
|
||||||
|
|
||||||
### 按你的方式搜索
|
### 按你的方式搜索
|
||||||
|
|
||||||
如果你花费大量时间在搜索上,你会喜欢 Min 处理搜索的方式。这是一个顶级的功能。
|
如果你在搜索上花费大量时间,你会喜欢 Min 处理搜索的方式。这是一个顶级的功能。
|
||||||
|
|
||||||
可以直接在浏览器的网址栏中访问搜索功能。Min 使用搜索引擎有 DuckDuckGo 和维基百科。你可以直接在 web 地址栏中输入搜索查询。
|
可以直接在浏览器的网址栏中使用搜索功能。Min 使用搜索引擎 DuckDuckGo 和维基百科的内容进行搜索。你可以直接在 web 地址栏中输入要搜索的东西。
|
||||||
|
|
||||||
这种方法很节省时间,因为你不必先进入搜索引擎窗口。 一个额外的好处是可以搜索你的书签。
|
这种方法很节省时间,因为你不必先进入搜索引擎窗口。 还有一个好处是可以搜索你的书签。
|
||||||
|
|
||||||
在 Edit/Preferences 菜单中,选择默认的搜索引擎。该列表包括 DuckDuckGo、Google、Bing、Yahoo、Baidu、Wikipedia 和 Yandex。
|
在 Edit/Preferences 菜单中,选择默认的搜索引擎。该列表包括 DuckDuckGo、Google、Bing、Yahoo、Baidu、Wikipedia 和 Yandex。
|
||||||
|
|
||||||
尝试将 DuckDuckGo 作为默认搜索引擎。 Min 默认使用这个选项,但它不会强加给你。
|
尝试将 DuckDuckGo 作为默认搜索引擎。 Min 默认使用这个引擎,但你也能更换。
|
||||||
|
|
||||||
|

|
||||||
Min 浏览器的搜索功能是 URL 栏的一部分。Min 使用 DuckDuckGo 和维基百科作为搜索引擎。你可以直接在 web 地址栏中输入搜索查询。
|
Min 浏览器的搜索功能是 URL 栏的一部分。Min 利用搜索引擎 DuckDuckGo 和维基百科的内容。你可以直接在 web 地址栏中输入要搜索的东西。
|
||||||
|
|
||||||
搜索栏会非常快速地显示你问题的答案。它会使用 DuckDuckGo 的信息,包括维基百科条目、计算器以及更多。
|
搜索栏会非常快速地显示问题的答案。它会使用 DuckDuckGo 的信息,包括维基百科条目、计算器和其它的内容。
|
||||||
|
|
||||||
它能提供快速片段、答案和网络建议。它是在基于 Google 环境的一个替代。
|
它能快速提供片段、答案和网络建议。它有点像不是基于 Goolge 环境的替代品。
|
||||||
|
|
||||||
### 导航辅助
|
### 导航辅助
|
||||||
|
|
||||||
Min 允许你使用模糊搜索快速跳转到任何网站。它几乎能立即向你抛出建议。
|
Min 允许你使用模糊搜索快速跳转到任何网站。它能立即向你提出建议。
|
||||||
|
|
||||||
我喜欢在当前标签旁边打开标签的方式。你不必设置此选项。它在默认情况下没有其他选择,但它是有道理的。
|
我喜欢在当前标签旁边打开标签的方式。你不必设置此选项。它在默认情况下没有其他选择,但这也有道理。
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
][2]
|
][2]
|
||||||
Min 的一个很酷的操作是将标签整理到任务中,这样你可以随时搜索。(点击图片放大)
|
Min 的一个很酷的功能是将标签整理到任务栏中,这样你随时都可以搜索。(点击图片放大)
|
||||||
|
|
||||||
你不用一直点击标签。这使你可以专注于当前的任务,而不会分心。
|
不点击标签,过一会儿它就会消失。这使你可以专注于当前的任务,而不会分心。
|
||||||
|
|
||||||
Min 不需要附加工具来控制多个标签。浏览器会显示标签列表,并允许你将它们分组。
|
Min 不需要附加工具来控制多个标签。浏览器会显示标签列表,并允许你将它们分组。
|
||||||
|
|
||||||
### 保持专注
|
### 保持专注
|
||||||
|
|
||||||
Min 在“视图”菜单中隐藏了一个可选的“聚焦模式”。启用后,除了你打开的选项卡外,它会隐藏所有选项卡。 你必须返回到菜单以关闭“聚焦模式”,然后才能打开新选项卡。
|
Min 在“视图”菜单中有一个可选的“聚焦模式”。启用后,除了你打开的选项卡外,它会隐藏其它所有选项卡。 你必须返回到菜单,关闭“聚焦模式”,才能打开新选项卡。
|
||||||
|
|
||||||
任务功能还可以帮助你保持专注。你可以从“文件”菜单或使用 Ctrl+Shift+N 创建任务。如果要打开新选项卡,可以在“文件”菜单中选择该选项,或使用 Control+T。
|
任务功能还可以帮助你保持专注。你可以在“文件(File)”菜单或使用 Ctrl+Shift+N 创建任务。如果要打开新选项卡,可以在“文件”菜单中选择该选项,或使用 Control+T。
|
||||||
|
|
||||||
调用符合你的风格的新任务。我喜欢能够组织与显示与工作项目或与我的研究的特定部分相关联的所有标签。我可以在任何时间召回整个列表,以轻松快速的方式找到我的浏览记录。
|
按照你的风格打开新任务。我喜欢按组来管理和显示标签,这组标签与工作项目或研究的某些部分相关。我可以在任何时间重新打开整个列表,从而轻松快速的方式找到我的浏览记录。
|
||||||
|
|
||||||
另一个整洁的功能是在 tab 区域可以找到段落对齐按钮。单击它启用阅读模式。此模式会保存文章以供将来参考,并删除页面上的一切,以便你可以专注于阅读任务。
|
另一个好用的功能是可以在 tab 区域找到段落对齐按钮。单击它启用阅读模式。此模式会保存文章以供将来参考,并删除页面上的一切,以便你可以专注于阅读任务。
|
||||||
|
|
||||||
### 并不完美
|
### 并不完美
|
||||||
|
|
||||||
Min 浏览器并不是强大的,功能丰富的完美替代品。它有一些明显的弱点,开发人员花了太长时间而不能改正。
|
Min 浏览器并不是强大的,功能丰富的完美替代品。它有一些明显的缺点,开发人员花了很多时间也没有修正。
|
||||||
|
|
||||||
例如,它缺乏一个支持论坛和详细用户指南的开发人员网站。可能部分原因是它的官网在 GitHub,而不是一个独立的开发人员网站。尽管如此,对新用户而言这是一个弱点。
|
例如,它缺乏一个支持论坛和详细用户指南的开发人员网站。可能部分原因是它的官网在 GitHub,而不是一个独立的开发人员网站。尽管如此,对新用户而言这是一个缺点。
|
||||||
|
|
||||||
没有网站支持,用户被迫在 GitHub 上寻找自述文件和各种目录列表。你也可以在 Min 浏览器的帮助菜单中访问它们 - 但这没有太多帮助。
|
没有网站支持,用户被迫在 GitHub 上寻找自述文件和各种目录列表。你也可以在 Min 浏览器的帮助菜单中访问它们 - 但这没有太多帮助。
|
||||||
|
|
||||||
一个例子是当你启动浏览器时,屏幕会显示欢迎界面。它会显示两个按钮,一个人是 “Start Browsing”,另一个是 “Take a Tour.”。但是没有一个按钮可以使用
|
一个例子是当你启动浏览器时,屏幕会显示欢迎界面。它会显示两个按钮,一个人是 “Start Browsing”,另一个是 “Take a Tour.”。但是没有一个按钮可以使用。
|
||||||
|
|
||||||
但是,你可以通过单击 Min 窗口顶部的菜单栏开始浏览。但是,缺少导览还没有解决办法。
|
但是,你可以通过单击 Min 窗口顶部的菜单栏开始浏览。但是,还没有解决缺少概览办法。
|
||||||
|
|
||||||
### 底线
|
### 底线
|
||||||
|
|
||||||
Min 并不是一个有完整功能的 web 浏览器。它不是为通常在成熟的 web 浏览器中有的插件和其他许多功能而设计的。然而,Min 通过提供速度和免打扰来达到它重要的目的。
|
Min 并不是一个功能完善、丰富的 web 浏览器。你在功能完善的主流浏览器中所用的插件和其它许多功能都不是 Min 的设计目标。然而,Min 在快速响应和免打扰方面很有用。
|
||||||
|
|
||||||
我越使用 Min 浏览器,它对我来说越有效率 - 但是当你第一次使用它时要小心。
|
我越使用 Min 浏览器,我越觉得它高效 - 但是当你第一次使用它时要小心。
|
||||||
|
|
||||||
Min 并不复杂或让人困惑 - 它只是有点古怪。你必须要玩弄一下才能明白它如何使用。
|
Min 并不复杂,也不难操作 - 它只是有点古怪。你必须要玩弄一下才能明白它如何使用。
|
||||||
|
|
||||||
### 想要提建议么?
|
### 想要提建议么?
|
||||||
|
|
||||||
有没有一个你想提议 Linux 程序或发行版?有没有你爱的或者想要了解的?
|
有没有你建议回顾的 Linux 程序或发行版?有没有你爱的或者想要了解的?
|
||||||
|
|
||||||
请[在电子邮件中给我发送你的想法][3],我会考虑将来在 Linux Picks and Pans 专栏上登出。
|
请[在电子邮件中给我发送你的想法][3],我会考虑将来在 “Linux Picks and Pans” 专栏上登出。
|
||||||
|
|
||||||
并使用下面的读者评论功能提出你的想法!
|
可以使用下方的读者评论功能说出你的想法!
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
作者简介:
|
作者简介:
|
||||||
|
|
||||||
Jack M. Germain 从苹果 II 和 PC 的早期起就一直在写关于计算机技术。他仍然有他原来的 IBM PC-Jr 和一些其他遗留的 DOS 和 Windows 盒子。他为 Linux 桌面的开源世界留下过共享软件。他运行几个版本的 Windows 和 Linux 操作系统,还通常不能决定是否用他的平板电脑、上网本或 Android 智能手机,而不是用他的台式机或笔记本电脑。你可以在 Google+ 上与他联系。
|
Jack M. Germain 从苹果 II 和 PC 的早期起就一直在写关于计算机技术。他仍然有他原来的 IBM PC-Jr 和一些其他遗留的 DOS 和 Windows 盒子。他为 Linux 桌面的开源世界留下过共享软件。他运行几个版本的 Windows 和 Linux 操作系统,还通常不能决定是否用他的平板电脑、上网本或 Android 智能手机,还是用他的台式机或笔记本电脑。你可以在 Google+ 上与他联系。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -113,7 +113,7 @@ via: http://www.linuxinsider.com/story/84212.html?rss=1
|
|||||||
|
|
||||||
作者:[Jack M. Germain][a]
|
作者:[Jack M. Germain][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[GitFuture](https://github.com/GitFuture)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
|||||||
94
translated/tech/20170111 NMAP Common Scans – Part One.md
Normal file
94
translated/tech/20170111 NMAP Common Scans – Part One.md
Normal file
@ -0,0 +1,94 @@
|
|||||||
|
NMAP 常用扫描简介 - 第一部分
|
||||||
|
========================
|
||||||
|
|
||||||
|
我们之前在‘[NMAP 的安装][1]’一文中,列出了 10 种不同的 ZeNMAP 扫描模式(这里将 Profiles 翻译成了模式,不知是否合适)。大多数的模式使用了各种参数。大多数的参数代表了执行不同的扫描模式。这篇文章将介绍其中的四种通用的扫描类型。
|
||||||
|
|
||||||
|
**四种通用扫描类型**
|
||||||
|
|
||||||
|
下面列出了最常使用的四种扫描类型:
|
||||||
|
|
||||||
|
1. PING 扫描 (-sP)
|
||||||
|
2. TCP SYN 扫描 (-sS)
|
||||||
|
3. TCP Connect() 扫描 (-sT)
|
||||||
|
4. UDP 扫描 (-sU)
|
||||||
|
|
||||||
|
当我们利用 NMAP 来执行扫描的时候,这四种扫描类型是我们需要熟练掌握的。更重要的是需要知道这些命令做了什么并且需要知道这些命令是怎么做的。本文将介绍 PING 扫描和 UDP 扫描。在之后的文中会介绍 TCP 扫描。
|
||||||
|
|
||||||
|
**PING 扫描 (-sP)**
|
||||||
|
|
||||||
|
某些扫描会造成网络拥塞,然而 Ping 扫描在网络中最多只会产生两个包。当然这两个包不包括可能需要的 DNS 搜索和 ARP 请求。每个被扫描的 IP 最少只需要一个包来完成 Ping 扫描。
|
||||||
|
|
||||||
|
通常 Ping 扫描是用来查看在指定的 IP 地址上是否有在线的主机存在。例如,当我拥有网络连接却联不上一台指定的网络服务器的时候,我就可以使用 PING 来判断这台服务器是否在线。PING 同样也可以用来验证我的当前设备与网络服务器之间的路由是否正常。
|
||||||
|
|
||||||
|
**注意:** 当我们讨论 TCP/IP 的时候,相关信息在使用 TCP/IP 协议的英特网与局域网(LAN)中都是相当有用的。这些程序都能工作。同样在广域网(WAN)也能工作得相当好。
|
||||||
|
|
||||||
|
当参数给出的是一个域名的时候,我们就需要域名解析服务来找到相对应的 IP 地址,这个时候将会生成一些额外的包。例如,当我们执行 ‘ping linuxforum.com’ 的时候,需要首先请求域名(linuxforum.com)的 IP 地址(98.124.199.63)。当我们执行 ‘ping 98.124.199.63’ 的时候 DNS 查询就不需要了。当 MAC 地址未知的时候,就需要发送 ARP 请求来获取指定 IP 地址的 MAC 地址了(这里的指定 IP 地址,未必是目的 IP)。
|
||||||
|
|
||||||
|
Ping 命令会向指定的 IP 地址发送一个英特网信息控制协议(ICMP)包。这个包是需要响应的 ICMP Echo 请求。当服务器系统在线的状态下我们会得到一个响应包。当两个系统之间存在防火墙的时候,PING 请求包可能会被防火墙丢弃。一些服务器也会被配置成不响应 PING 请求来避免可能发生的死亡之 PING。(现在的操作系统似乎不太可能)
|
||||||
|
|
||||||
|
**注意:** 死亡之 PING 是一种恶意构造的 PING 包当它被发送到系统的时候,会造成被打开的连接等待一个 rest 包。一旦有一堆这样的恶意请求被系统响应,由于所有的可用连接都已经被打开所以系统将会拒绝所有其它的连接。技术上来说这种状态下的系统就是不可达的。
|
||||||
|
|
||||||
|
当系统收到 ICMP Echo 请求后它将会返回一个 ICMP Echo 响应。当源系统收到 ICMP Echo 响应后我们就能知道目的系统是在线可达的。
|
||||||
|
|
||||||
|
使用 NMAP 的时候你可以指定单个 IP 地址也可以指定 某个 IP 地址段。当被指定为 PING 扫描(-sP)的时候,PING 命令将会对每一个 IP 地址执行。
|
||||||
|
|
||||||
|
在图 1 中你可以看到我执行‘nmap -sP 10.0.0.1-10’命令后的结果。An ARP is sent out, three for each IP Address given to the command. In this case thirty requests went out – two for each of the ten IP Addresses.(这两句话就没有读懂,不清楚具体指的是什么意思,从图2看的话第一句里的三指的是两个 ARP 包和一个 ICMP 包,按照下面一段话的描述的话就是每个 IP 地址会有三个 ARP 请求,但是自己试的时候 Centos6 它发了两个 ARP 请求没获取到 MAC 地址也就就结束了,这里不清楚究竟怎么理解)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**图 1**
|
||||||
|
|
||||||
|
图 2 中展示了利用 Wireshark 抓取的从网络上另一台计算机发出的请求-的确是在 Windows 系统下完成这次抓取的。第一行展示了发出的第一条请求,广播请求的是 10.0.0.2 IP 地址对应 MAC 地址。由于 NMAP 是在 10.0.0.1 这台机器上执行的,因此 10.0.0.1 被略过了。由于本机 IP 地址被略过,我们现在可以说总共只发出了 27 个 ARP 请求。第二行展示了 10.0.0.2 这台机器的 ARP 响应。第三行到第十行是其它八个 IP 地址的 ARP 请求。第十一行是由于没有收到请求系统(10.0.0.1)的反馈所以发送的另一个 ARP 响应。(自己试的话它发送一个请求收到一个响应就结束了,也没有搜到相关的重发响应是否存在的具体说明,不是十分清楚)第十二行是源系统向 10.0.0.2 响应的 ‘SYN’ 和 Sequence 0。(这行感觉更像是三次握手里的首包)第十三行和第十四行的两次 Restart(RST)和 Synchronize(SYN)响应是用来关闭第二行和第十一行所打开的连接的。(这个描述似乎有问题 ARP 请求怎么会需要 TCP 来关闭连接呢,感觉像是第十二行的响应)注意 Sequence ID 是 ‘1’ - 是源 Sequence ID + 1。(这个不理解,不是应该 ACK = seq + 1 的么)第十五行开始就是类似相同的内容。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**图 2**
|
||||||
|
|
||||||
|
回到图 1 中我们可以看到有两台主机在线。其中一台是本机(10.0.0.1)另一台是(10.0.0.2)。整个扫描花费了 14.40 秒。
|
||||||
|
|
||||||
|
PING 扫描是一种用来发现在线主机的快速扫描方式。扫描结果中没有关于网络、系统的其它信息。这是一种较好的初步发现网络上在线主机的方式,接着你就可以针对在线系统执行更加复杂的扫描了。你可能还会发现一些不应该出现在网络上的系统。出现在网络上的流氓软件是很危险的,他们可以很轻易的收集内网信息和相关的系统信息。
|
||||||
|
|
||||||
|
一旦你获得了在线系统的列表,你就可以使用 UDP 扫描来查看哪些端口是可能开启了的。
|
||||||
|
|
||||||
|
**UDP 扫描 (-sU)**
|
||||||
|
|
||||||
|
现在你已经知道了有那些系统是在线的,你的扫描就可以聚焦在这些 IP 地址之上。在整个网络上执行大量的没有针对性的扫描活动可不是一个好主意。系统管理员可以使用程序来监控网络流量当有大量可以活动发生的时候就会触发警报。
|
||||||
|
|
||||||
|
用户数据报协议(UDP)在发现在线系统的开放端口方面十分有用。由于 UDP 不是一个面向连接的协议,因此是不需要响应的。这种扫描方式可以向指定的端口发送一个 UDP 包。如果目标系统没有回应那么这个端口可能是关闭的也可能是被过滤了的。如果端口是开放状态的那么应该会有一个响应。在大多数的情况下目标系统会返回一个 ICMP 信息说端口不可达。ICMP 信息让 NMAP 知道端口是被关闭了。如果端口是开启的状态那么目标系统应该响应 ICMP 信息来告知 NMAP 端口可达。
|
||||||
|
|
||||||
|
**注意: **只有最前面的1024个常用端口会被扫描。(这里将 1000 改成了1024,因为手册中写的是默认扫描 1 到 1024 端口)在后面的文章中我们会介绍如何进行深度扫描。
|
||||||
|
|
||||||
|
由于我知道 10.0.0.2 这个主机是在线的,因此我只会针对这个 IP 地址来执行扫描。扫描过程中总共收发了 3278 个包。‘sudo nmap -sU 10.0.0.2’这个命令的输出结果在图 3 中展现。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**图 3**
|
||||||
|
|
||||||
|
在这副图中你可以看见端口 137(netbios-ns)被发现是开放的。在图 4 中展示了 Wireshark 抓包的结果。不能看到所有抓取的包,但是可以看到一长串的 UDP 包。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**图 4**
|
||||||
|
|
||||||
|
如果我把目标系统上的防火墙关闭之后会发生什么呢?我的结果有那么一点的不同。NMAP 命令的执行结果在图 5 中展示。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**图 5**
|
||||||
|
|
||||||
|
**注意:** 当你执行 UDP 扫描的时候是需要 root 权限的。
|
||||||
|
|
||||||
|
会产生大量的包是由于我们使用了 UDP。当 NMAP 发送 UDP 请求时它是不保证数据包会被收到的。因为数据包可能会在中途丢失因此它会多次发送请求。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxforum.com/threads/nmap-common-scans-part-one.3637/
|
||||||
|
|
||||||
|
作者:[Jarret][a]
|
||||||
|
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||||
|
[1]:https://www.linuxforum.com/threads/nmap-installation.3431/
|
||||||
@ -1,220 +0,0 @@
|
|||||||
free - 一个在 Linux 中检查内存使用统计(空闲和已用)的标准命令
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
我们都知道, IT 基础设施方面的大多数服务器(包括世界顶级超级计算机)都运行在 Linux 平台上,因为和其他操作系统相比, Linux 更加灵活。其他操作系统对于一些微乎其微的改动和补丁更新都需要重启,但是 Linux 不需要,只有对于一些关键补丁的更新, Linux 才会需要重启。
|
|
||||||
|
|
||||||
Linux 系统管理员面临的一大挑战是如何在没有任何停机时间的情况下维护系统的良好运行。管理内存使用是 Linux 管理员又一个具有挑战性的任务。`free` 是 Linux 中一个标准的并且被广泛使用的命令,它被用来分析内存统计(空闲和已用)。今天,我们将要讨论 `free` 命令以及它的一些有用选项。
|
|
||||||
|
|
||||||
推荐文章:
|
|
||||||
|
|
||||||
* [smem - Linux 内存报告/统计工具][1]
|
|
||||||
* [vmstat - 一个报告虚拟内存统计的标准而又漂亮的工具][2]
|
|
||||||
|
|
||||||
#### Free 命令是什么
|
|
||||||
|
|
||||||
free 命令能够显示系统中物理上的`空闲`和`已用`内存,还有`交换`内存,同时,也能显示被内核使用的`缓冲`和`缓存`。这些信息是通过解析文件 /proc/meninfo 而收集到的。
|
|
||||||
|
|
||||||
#### 显示系统内存
|
|
||||||
|
|
||||||
不带任何选项运行 `free` 命令会显示系统内存,包括`空闲`、`已用`、`缓冲`、`缓存`和`交换`的内存总数。
|
|
||||||
|
|
||||||
```
|
|
||||||
# free
|
|
||||||
总共 已用 空闲 共用 缓冲 缓存大小
|
|
||||||
内存: 32869744 25434276 7435468 0 412032 23361716
|
|
||||||
-/+ 缓冲/缓存: 1660528 31209216
|
|
||||||
交换: 4095992 0 4095992
|
|
||||||
```
|
|
||||||
|
|
||||||
输出有三行:
|
|
||||||
|
|
||||||
* 第一行:表明全部内存、已用内存、空闲内存、共用内存(主要被 tmpfs(/proc/meninfo 中的 Shmem 项)使用)、用于缓冲的内存以及缓存内容大小。
|
|
||||||
|
|
||||||
* 全部:全部已安装内存(/proc/meminfo 中的 MemTotal 项)
|
|
||||||
* 已用:已用内存(全部计算 - 空间+缓冲+缓存)
|
|
||||||
* 空闲:未使用内存(/proc/meminfo 中的 MemFree 项)
|
|
||||||
* 共用:主要被 tmpfs 使用的内存(/proc/meminfo 中的 Shmem 项)
|
|
||||||
* 缓冲:被内核缓冲使用的内存(/proc/meminfo 中的 Buffers 项)
|
|
||||||
* 缓存:被页面缓存使用的内存(/proc/meminfo 中的 Cached and SSReclaimable 项)
|
|
||||||
|
|
||||||
* 第二行:表明已用和空闲缓冲/缓存
|
|
||||||
* 第三行:表明总交换内存(/proc/meminfo 中的 SwapTotal 项)、空闲内存(/proc/meminfo 中的 SwapFree 项)和已用交换内存。
|
|
||||||
|
|
||||||
#### 以 MB 为单位显示系统内存
|
|
||||||
|
|
||||||
默认情况下, `free` 命令以 `KB - Kilobytes` 为单位输出系统内存,这对于绝大多数管理员来说会有一点迷糊(当系统内存很大的时候,我们中的许多人需要把输出转化为以 MB 为单位,从而才能够理解内存大小)。为了避免这个迷惑,我们在 ‘free’ 命令后面加上 `-m` 选项,就可以立即得到以 ‘MB - Megabytes’ 为单位的输出。
|
|
||||||
|
|
||||||
```
|
|
||||||
# free -m
|
|
||||||
全部 已用 空闲 公用 缓冲 缓存
|
|
||||||
内存: 32099 24838 7261 0 402 22814
|
|
||||||
-/+ 缓冲/缓存: 1621 30477
|
|
||||||
交换: 3999 0 3999
|
|
||||||
```
|
|
||||||
|
|
||||||
如何从上面的输出中检查剩余多少空闲内存?主要基于`已用`和`空闲`两列。你可能在想,你只有很低的空闲内存,因为它只有 `10%`, 为什么?
|
|
||||||
|
|
||||||
全部实际可用内存 = (全部内存 - 第 2 行已用内存)
|
|
||||||
全部内存 = 32099
|
|
||||||
实际已用内存 = -1621
|
|
||||||
|
|
||||||
全部实际可用内存 = 30477
|
|
||||||
|
|
||||||
如果你的 Linux 版本是最新的,那么有一个查看实际空闲内存的选项,叫做 `available` ,对于旧的版本,请看显示 `-/+ buffers/cache` 那一行对应的‘空闲’一列。
|
|
||||||
|
|
||||||
如何从上面的输出中检查有多少实际已用内存?基于`已用`和`空闲`一列。你可能想,你已经使用了超过 `95%` 的内存。
|
|
||||||
|
|
||||||
全部实际已用内存 = 第一列‘已用’ - (第一列‘缓冲’ + ‘第一列缓存’)
|
|
||||||
已用内存 = 24838
|
|
||||||
已用缓冲 = 402
|
|
||||||
已用缓存 = 22814
|
|
||||||
|
|
||||||
全部实际已用内存 = 1621
|
|
||||||
|
|
||||||
#### 以 GB 为单位显示内存
|
|
||||||
|
|
||||||
默认情况下, `free` 命令会以 `KB - kilobytes` 为单位显示输出,这对于大多数管理员来说会有一些迷惑,所以我们使用上面的选项来获得以 `MB - Megabytes` 为单位的输出。但是,当服务器的内存很大(超过 100 GB 或 200 GB)时,上面的选项也会让人很迷惑。所以,在这个时候,我们可以在 `free` 命令后面加上 `-g` 选项,从而立即得到以 `GB - Gigabytes` 为单位的输出。
|
|
||||||
|
|
||||||
```
|
|
||||||
# free -g
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 31 24 7 0 0 22
|
|
||||||
-/+ 缓冲/缓存: 1 29
|
|
||||||
交换: 3 0 3
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 显示全部内存线
|
|
||||||
|
|
||||||
默认情况下, `free` 命令的输出只有三列(内存、缓冲/缓存以及交换)。为了统一以分割线显示(全部(内存+交换)、已用(内存+(已用-缓冲/缓存)+交换)以及空闲(内存+(已用-缓冲/缓存)+交换),在 ‘free’ 命令后面加上 `-t` 选项
|
|
||||||
|
|
||||||
```
|
|
||||||
# free -t
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32869744 25434276 7435468 0 412032 23361716
|
|
||||||
-/+ 缓冲/缓存: 1660528 31209216
|
|
||||||
交换: 4095992 0 4095992
|
|
||||||
交换: 36965736 27094804 42740676
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 伴有延迟运行 free 命令从而更好的统计
|
|
||||||
|
|
||||||
默认情况下, free 命令只会显示单一的统计输出,这是不足够进一步排除故障的,所以,可以通过添加延迟(在几秒内更新的延迟)来定期统计内存活动。如果你想以两秒的延迟运行 free 命令,可以使用下面的命令(如果你想要更多的延迟,你可以按照你的意愿更改数值)。
|
|
||||||
|
|
||||||
下面的命令将会每 2 秒运行一次直到你退出:
|
|
||||||
|
|
||||||
```
|
|
||||||
# free -s 2
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32849392 25935844 6913548 188 182424 24632796
|
|
||||||
-/+ 缓冲/缓存: 1120624 31728768
|
|
||||||
交换: 20970492 0 20970492
|
|
||||||
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32849392 25935288 6914104 188 182424 24632796
|
|
||||||
-/+ 缓冲/缓存: 1120068 31729324
|
|
||||||
交换: 20970492 0 20970492
|
|
||||||
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32849392 25934968 6914424 188 182424 24632796
|
|
||||||
-/+ 缓冲/缓存: 1119748 31729644
|
|
||||||
交换: 20970492 0 20970492
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 伴有延迟和计数运行 free 命令
|
|
||||||
|
|
||||||
另外,你可以伴随延迟和具体计数运行 free 命令,一旦达到具体计数,便自动退出
|
|
||||||
|
|
||||||
下面的命令将会每 2 秒运行一次 free 命令,计数 5 次以后自动退出
|
|
||||||
|
|
||||||
```
|
|
||||||
# free -s 2 -c 5
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32849392 25931052 6918340 188 182424 24632796
|
|
||||||
-/+ 缓冲/缓存: 1115832 31733560
|
|
||||||
交换: 20970492 0 20970492
|
|
||||||
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32849392 25931192 6918200 188 182424 24632796
|
|
||||||
-/+ 缓冲/缓存: 1115972 31733420
|
|
||||||
Swap: 20970492 0 20970492
|
|
||||||
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32849392 25931348 6918044 188 182424 24632796
|
|
||||||
-/+ 缓冲/缓存: 1116128 31733264
|
|
||||||
交换: 20970492 0 20970492
|
|
||||||
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32849392 25931316 6918076 188 182424 24632796
|
|
||||||
-/+ 缓冲/缓存: 1116096 31733296
|
|
||||||
交换: 20970492 0 20970492
|
|
||||||
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32849392 25931308 6918084 188 182424 24632796
|
|
||||||
-/+ 缓冲/缓存: 1116088 31733304
|
|
||||||
交换: 20970492 0 20970492
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 人类可读格式
|
|
||||||
|
|
||||||
为了以人类可读的格式输出,在 `free` 命令的后面加上 `-h` 选项,和其他选项比如 `-m` 和 `-g` 相比,这将会打印出更多的细节输出。
|
|
||||||
|
|
||||||
```
|
|
||||||
# free -h
|
|
||||||
全部 已用 空闲 共用
|
|
||||||
缓冲/缓存 可用
|
|
||||||
内存: 2.0G 1.6G 138M 20M 188M 161M
|
|
||||||
交换: 2.0G 1.8G 249M
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 分离缓冲区和缓存内存输出
|
|
||||||
|
|
||||||
默认情况下, `缓冲/缓存` 内存输出是在一起的。为了分离缓冲和缓存内存输出,可以在 free 命令后面加上 `-w` 选项。(该选项在版本 3.3.12 上可用)
|
|
||||||
|
|
||||||
注意:看上面的输出,`缓冲/缓存`是在一起的。
|
|
||||||
|
|
||||||
```
|
|
||||||
# free -wh
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存 可用
|
|
||||||
内存: 2.0G 1.6G 137M 20M 8.1M 183M 163M
|
|
||||||
交换: 2.0G 1.8G 249M
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 显示最低和最高的内存统计
|
|
||||||
|
|
||||||
默认情况下, `free` 命令不会显示最低和最高的内存统计。为了显示最低和最高的内存统计,在 free 命令后面加上 `-l` 选项。
|
|
||||||
|
|
||||||
```
|
|
||||||
# free -l
|
|
||||||
全部 已用 空闲 共用 缓冲 缓存
|
|
||||||
内存: 32849392 25931336 6918056 188 182424 24632808
|
|
||||||
底: 32849392 25931336 6918056
|
|
||||||
高: 0 0 0
|
|
||||||
-/+ 缓冲/缓存: 1116104 31733288
|
|
||||||
交换: 20970492 0 20970492
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 阅读关于 free 命令的更过信息
|
|
||||||
|
|
||||||
如果你想了解 free 命令的更多可用选项,只需查看 man 手册。
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
# free --help
|
|
||||||
or
|
|
||||||
# man free
|
|
||||||
```
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/
|
|
||||||
|
|
||||||
作者:[MAGESH MARUTHAMUTHU][a]
|
|
||||||
译者:[ucasFL](https://github.com/ucasFL)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.2daygeek.com/author/magesh/
|
|
||||||
[1]:http://www.2daygeek.com/smem-linux-memory-usage-statistics-reporting-tool/
|
|
||||||
[2]:http://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/
|
|
||||||
[3]:http://www.2daygeek.com/author/magesh/
|
|
||||||
@ -4,27 +4,23 @@
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
FirewallD 是 CentOS 7 服务器上的一个默认可用的防火墙管理工具。基本上,它是 iptables 的封装,有图形配置工具 firewall-config 和命令行工具 firewall-cmd。使用 iptables 服务,每次改动都要求刷新旧规则,并且从 `/etc/sysconfig/iptables` 读取新规则,然而 firewalld 仅仅会应用改动了的不同部分。
|
||||||
|
|
||||||
FirewallD 是 CentOS 7 服务器上的一个默认可用的防火墙管理工具。基本上,它是 iptables 的封装,有图形配置工具 firewall-config 和命令行工具 firewall-cmd。使用 iptables 服务每次改动都要求刷新旧规则,并且从 `/etc/sysconfig/iptables` 读取新规则,然而 firewalld 仅仅会应用改动了的不同部分。
|
|
||||||
|
|
||||||
### FirewallD zones
|
### FirewallD zones
|
||||||
|
|
||||||
|
|
||||||
FirewallD 使用 services 和 zones 代替 iptables 的 rules 和 chains 。
|
FirewallD 使用 services 和 zones 代替 iptables 的 rules 和 chains 。
|
||||||
|
|
||||||
默认情况下,有以下的 zones 可用:
|
默认情况下,有以下的 zones 可用:
|
||||||
|
|
||||||
|
* **drop** – 丢弃所有传入的网络数据包并且无回应,只有传出网络连接可用。
|
||||||
* drop – 丢弃所有传入的网络数据包并且无回应,只有传出网络连接可用。
|
* **block** — 拒绝所有传入网络数据包并回应一条主机禁止 ICMP 的消息,只有传出网络连接可用。
|
||||||
* block — 拒绝所有传入网络数据包并回应一条主机禁止 ICMP 的消息,只有传出网络连接可用。
|
* **public** — 只接受被选择的传入网络连接,用于公共区域。
|
||||||
* public — 只接受被选择的传入网络连接,用于公共区域。
|
* **external** — 用于启用伪装的外部网络,只接受被选择的传入网络连接。
|
||||||
* external — 用于启用伪装的外部网络,只接受被选择的传入网络连接。
|
* **dmz** — DMZ 隔离区,外部受限地访问内部网络,只接受被选择的传入网络连接。
|
||||||
* dmz — DMZ 隔离区,外部受限地访问内部网络,只接受被选择的传入网络连接。
|
* **work** — 对于处在你家庭区域内的计算机,只接受被选择的传入网络连接。
|
||||||
* work — 对于处在你家庭区域内的计算机,只接受被选择的传入网络连接。
|
* **home** — 对于处在你家庭区域内的计算机,只接受被选择的传入网络连接。
|
||||||
* home — 对于处在你家庭区域内的计算机,只接受被选择的传入网络连接。
|
* **internal** — 对于处在你内部网络的计算机,只接受被选择的传入网络连接。
|
||||||
* internal — 对于处在你内部网络的计算机,只接受被选择的传入网络连接。
|
* **trusted** — 所有网络连接都接受。
|
||||||
* trusted — 所有网络连接都接受。
|
|
||||||
|
|
||||||
列出所有可用的 zones :
|
列出所有可用的 zones :
|
||||||
```
|
```
|
||||||
@ -145,7 +141,7 @@ via: https://www.rosehosting.com/blog/set-up-and-configure-a-firewall-with-firew
|
|||||||
|
|
||||||
作者:[rosehosting.com][a]
|
作者:[rosehosting.com][a]
|
||||||
译者:[Locez](https://github.com/locez)
|
译者:[Locez](https://github.com/locez)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
|||||||
@ -0,0 +1,88 @@
|
|||||||
|
|
||||||
|
如何通过分离 Root 目录和 Home 目录安装 Ubuntu
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
当我们在安装 Linux 系统时,可以有两种不同的方式。第一种方式是在一个超快的固态硬盘上进行安装,这样可以保证迅速开机和高速访问数据。第二种方式是在一个较慢但很强大的普通硬盘驱动上安装,这样的硬盘转速很快并且存储容量很大,从而可以存储大量的应用程序和数据。
|
||||||
|
|
||||||
|
然而,一些 Linux 用户都知道,[固态硬盘][10]很棒,但是又很贵,而普通硬盘容量很大但速度较慢。如果我告诉你,可以同时利用两种硬盘来安装 Linux 系统,会怎么样?一个超快、现代化的固态硬盘驱动 Linux 内核,一个容量很大的普通硬盘来存储其他数据。
|
||||||
|
|
||||||
|
在这篇文章中,我将阐述如何通过分离 Root 目录和 Home 目录安装 Ubuntu 系统 — Root 目录存于 SSD(固态硬盘)中,Home 目录存于普通硬盘中。
|
||||||
|
|
||||||
|
### 没有多余的硬盘驱动?尝试一下 SD 卡(内存卡)!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
进行多驱动 Linux 系统安装是很不错的,并且每一个高级用户都应该学会这样做。然而,还有一种情况使得用户应该这样安装 Linux 系统 - 在低存储容量的笔记本电脑上安装系统。可能你有一台很便宜、没有花费太多的笔记本电脑,上面安装了 Linux 系统,电脑上没有多余的硬盘驱动,但有一个 SD 卡插槽。
|
||||||
|
|
||||||
|
这篇教程也是针对这种类型的电脑的。跟随这篇教程,为笔记本电脑买一个高速的 SD 卡来存储 Home 目录,而不是使用另一个硬盘驱动。本教程也适用于使用另一个硬盘驱动来存储 Home 目录的情况。
|
||||||
|
|
||||||
|
### 制作 USB 启动盘
|
||||||
|
|
||||||
|
首先去[网站][11]下载最新的 Ubuntu Linux 版本。然后下载 [Etcher][12]- USB 镜像制作工具。这是一个使用起来很简单的工具,并且支持所有的主流操作系统。你还需要一个至少有 2GB 大小的 USB 驱动。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
安装好 Etcher 以后,直接打开。点击 “Select Image” 按钮来制作镜像。这将提示用户浏览、寻找 ISO 镜像,找到前面下载的 Ubuntu ISO 文件并选择。然后,插入 USB 驱动,Etcher 应该会自动选择驱动。之后,点击 “Flash!” 按钮,Ubuntu 启动盘的制作过程就开始了。
|
||||||
|
|
||||||
|
为了能够启动 Ubuntu 系统,需要配置 BIOS。这是必需的,这样计算机才能启动新创建的 Ubuntu 启动盘。为了进入 BIOS,在插入 USB 的情况下重启电脑,然后按正确的键(Del、F2 或者任何和你的特定电脑匹配的键)。找到 ‘从 USB 启动’ 选项,然后启用这个选项。
|
||||||
|
|
||||||
|
如果你的个人电脑不支持 USB 启动,那么把 Ubuntu 镜像刻入 DVD 中。
|
||||||
|
|
||||||
|
### 安装
|
||||||
|
|
||||||
|
第一次加载 Ubuntu 时,欢迎界面会出现两个选项。请选择 “安装 Ubuntu” 选项。在下一页中,强大的安装工具会请求用户选择一些选项。这些选项不是强制性的,可以忽略。然而,建议勾选这两个选项,因为这样可以节省安装系统以后的时间,特别是安装 MP3 解码器和更新系统。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
勾选了“准备安装 Ubuntu” 页面中的两个选项以后,需要选择安装类型了。有许多种安装类型。然而,这个教程需要选择自定义安装类型。为了进入自定义安装页面,勾选“其他”选项,然后点击“继续”。
|
||||||
|
|
||||||
|
这儿将用到 Ubuntu 自定义安装分区工具。它将显示任何/所有能够安装 Ubuntu 系统的磁盘。如果两个硬盘均可用,那么它们都会显示。如果插有 SD 卡,那么它也会显示。
|
||||||
|
|
||||||
|
选择用于 Root 文件系统的硬盘驱动。如果上面已经有分区表,请使用分区工具把它们全部删除。如果驱动没有格式化也没有分区,那么使用鼠标选择驱动,然后点击“新分区表”。对所有驱动执行这个操作,从而使它们都有分区表。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
现在所有分区都有了分区表(和已删除分区),可以开始进行配置了。在第一个驱动下选择空闲空间,然后点击加号按钮来创建新分区。然后将会出现一个“创建分区窗口”。允许工具使用整个硬盘。然后转到“挂载点”下拉菜单。选择 ‘/’ 作为挂载点,之后点击 OK 按钮确认设置。
|
||||||
|
|
||||||
|
对第二个驱动做相同的事,这次选择 ‘/home’ 作为挂载点。两个驱动都设置好以后,选择引导装载器将进入的正确驱动,然后点击 “install now”,安装进程就开始了。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
从这以后的安装进程是标准安装。创建用户名、选择时区等。
|
||||||
|
|
||||||
|
**注:**你是以 UEFI 模式进行安装吗?如果是,那么需要给 boot 创建一个 512 MB 大小的 FAT32 分区。在创建其他任何分区前做这件事。确保选择 “/boot” 作为这个分区的挂载点。
|
||||||
|
|
||||||
|
如果你需要一个交换分区,那么,在创建用于 ‘/’ 的分区前,在第一个驱动上进行创建。可以通过点击 ‘+’ 按钮,然后输入所需大小,选择下拉菜单中的“交换区域”来创建交换分区。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
Linux 最好的地方就是可以自己按需配置。有多少其他操作系统可以让你把文件系统分割在不同的硬盘驱动上?并不多,这是肯定的。我希望有了这个指南,你将意识到 Ubuntu 能够提供的真正力量。
|
||||||
|
|
||||||
|
你是否使用了多重驱动安装 Ubuntu 系统?请在下面的评论中让我们知道。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.maketecheasier.com/install-ubuntu-with-different-root-home-hard-drives/
|
||||||
|
|
||||||
|
作者:[Derrik Diener][a]
|
||||||
|
译者:[ucasFL](https://github.com/ucasFL)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.maketecheasier.com/author/derrikdiener/
|
||||||
|
[1]:https://www.maketecheasier.com/author/derrikdiener/
|
||||||
|
[2]:https://www.maketecheasier.com/install-ubuntu-with-different-root-home-hard-drives/#respond
|
||||||
|
[3]:https://www.maketecheasier.com/category/linux-tips/
|
||||||
|
[4]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Finstall-ubuntu-with-different-root-home-hard-drives%2F
|
||||||
|
[5]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Finstall-ubuntu-with-different-root-home-hard-drives%2F&text=How+to+Install+Ubuntu+with+Separate+Root+and+Home+Hard+Drives
|
||||||
|
[6]:mailto:?subject=How%20to%20Install%20Ubuntu%20with%20Separate%20Root%20and%20Home%20Hard%20Drives&body=https%3A%2F%2Fwww.maketecheasier.com%2Finstall-ubuntu-with-different-root-home-hard-drives%2F
|
||||||
|
[7]:https://www.maketecheasier.com/byb-dimmable-eye-care-desk-lamp/
|
||||||
|
[8]:https://www.maketecheasier.com/download-appx-files-from-windows-store/
|
||||||
|
[9]:https://support.google.com/adsense/troubleshooter/1631343
|
||||||
|
[10]:http://www.maketecheasier.com/tag/ssd
|
||||||
|
[11]:http://ubuntu.com/download
|
||||||
|
[12]:https://etcher.io/
|
||||||
@ -0,0 +1,168 @@
|
|||||||
|
理解 sudo 与 su 之间的区别
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
### 本文导航
|
||||||
|
|
||||||
|
1. [Linux su 命令][7]
|
||||||
|
1. [su -][1]
|
||||||
|
2. [su -c][2]
|
||||||
|
2. [Sudo vs Su][8]
|
||||||
|
2. [Sudo vs Su][8]
|
||||||
|
1. [关于密码][3]
|
||||||
|
2. [默认行为][4]
|
||||||
|
3. [日志记录][5]
|
||||||
|
4. [灵活性][6]
|
||||||
|
3. [Sudo su][9]
|
||||||
|
|
||||||
|
在[早前的一篇文章][11]中,我们深入讨论了 `sudo` 命令的相关内容。同时,在该文章的末尾有提到相关的命令 `su` 的部分内容。本文,我们将详细讨论关于 su 命令与 sudo 命令之间的区别。
|
||||||
|
|
||||||
|
在开始之前有必要说明一下,文中所涉及到的示例教程都已经在 Ubuntu 14.04 LTS 上测试通过。
|
||||||
|
|
||||||
|
### Linux su 命令
|
||||||
|
|
||||||
|
su 命令的主要作用是让你可以在已登录的会话中切换到另外一个用户。换句话说,这个工具可以让你在不登出当前用户的情况下登录另外一个用户(以该用户的身份)。
|
||||||
|
|
||||||
|
su 命令经常被用于切换到超级用户或 root 用户(因为在命令行下工作,经常需要 root 权限),但是 - 正如前面所提到的 - su 命令也可以用于切换到任意非 root 用户。
|
||||||
|
|
||||||
|
如何使用 su 命令切换到 root 用户,如下:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][12]
|
||||||
|
|
||||||
|
如上,su 命令要求输入的密码是 root 用户密码。所以,一般 su 命令需要输入目标用户的密码。在输入正确的密码之后,su 命令会在终端的当前会话中打开一个子会话。
|
||||||
|
|
||||||
|
### su -
|
||||||
|
|
||||||
|
还有一种方法可以切换到 root 用户:运行 `su -` 命令,如下:
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][13]
|
||||||
|
|
||||||
|
那么,`su` 命令与 `su -` 命令之间有什么区别呢?前者在切换到 root 用户之后仍然保持旧的或原始用户的环境,而后者则是创建一个新的环境(由 root 用户 ~/.bashrc 文件所设置的环境),相当于使用 root 用户正常登录(从登录屏幕显示登录)。
|
||||||
|
|
||||||
|
`su` 命令手册页很清楚地说明了这一点:
|
||||||
|
|
||||||
|
```
|
||||||
|
可选参数 `-` 可提供的环境为用户在直接登录时的环境。
|
||||||
|
```
|
||||||
|
|
||||||
|
因此,你会觉得使用 `su -` 登录更有意义。但是,同时存在 `su` 命令,那么大家可能会想知道它在什么时候用到。以下内容摘自[ArchLinux wiki website][14] - 关于 `su` 命令的好处和坏处:
|
||||||
|
|
||||||
|
* 有的时候,对于系统管理员来讲,使用其他普通用户的 Shell 账户而不是自己的 Shell 账户更会好一些。尤其是在处理用户问题时,最有效的方法就是是:登录目标用户以便重现以及调试问题。
|
||||||
|
|
||||||
|
* 然而,在多数情况下,当从普通用户切换到 root 用户进行操作时,如果还使用普通用户的环境变量的话,那是不可取甚至是危险的操作。因为是在无意间切换使用普通用户的环境,所以当使用 root 用户进行程序安装或系统更改时,会产生与正常使用 root 用户进行操作时不相符的结果。例如,可以给普通用户安装电源意外损坏系统的程序或获取对某些数据的未授权访问的程序。
|
||||||
|
|
||||||
|
注意:如果你想在 `su -` 命令后面传递更多的参数,那么你必须使用 `su -l` 来实现。以下是 `-` 和 `-l` 命令行选项的说明:
|
||||||
|
|
||||||
|
```
|
||||||
|
-, -l, --login
|
||||||
|
提供相当于用户在直接登录时所期望的环境。
|
||||||
|
|
||||||
|
当使用 - 时,必须放在 su 命令的最后一个选项。其他选项(-l 和 --login)无此限制。
|
||||||
|
```
|
||||||
|
|
||||||
|
### su -c
|
||||||
|
|
||||||
|
还有一个值得一提的 `su` 命令行选项为:`-c`。该选项允许你提供在切换到目标用户之后要运行的命令。
|
||||||
|
|
||||||
|
`su` 命令手册页是这样说明:
|
||||||
|
|
||||||
|
```
|
||||||
|
-c, --command COMMAND
|
||||||
|
使用 -c 选项指定由 Shell 调用的命令。
|
||||||
|
|
||||||
|
被执行的命令无法控制终端。所以,此选项不能用于执行需要控制 TTY 的交互式程序。
|
||||||
|
```
|
||||||
|
|
||||||
|
参考示例:
|
||||||
|
|
||||||
|
```
|
||||||
|
su [target-user] -c [command-to-run]
|
||||||
|
```
|
||||||
|
|
||||||
|
示例中,`command-to-run` 将会被这样执行:
|
||||||
|
|
||||||
|
```
|
||||||
|
[shell] -c [command-to-run]
|
||||||
|
```
|
||||||
|
|
||||||
|
示例中的 `shell` 类型将会被目标用户在 `/etc/passwd` 文件中定义的登录 shell 类型所替代。
|
||||||
|
|
||||||
|
### Sudo vs Su
|
||||||
|
|
||||||
|
现在,我们已经讨论了关于 `su` 命令的基础知识,是时候来探讨一下 `sudo` 和 `su` 命令之间的区别了。
|
||||||
|
|
||||||
|
### 关于密码
|
||||||
|
|
||||||
|
两个命令的最大区别是:`sudo` 命令需要输入当前用户的密码,`su` 命令需要输入 root 用户的密码。
|
||||||
|
|
||||||
|
很明显,就安全而言,`sudo` 命令更好。例如,考虑到需要 root 访问权限的多用户使用的计算机。在这种情况下,使用 `su` 意味着需要与其他用户共享 root 用户密码,这显然不是一种好习惯。
|
||||||
|
|
||||||
|
此外,如果要撤销特定用户的超级用户/root 用户的访问权限,唯一的办法就是更改 root 密码,然后再告知所有其他用户新的 root 密码。
|
||||||
|
|
||||||
|
而使用 `sudo` 命令就不一样了,你可以很好的处理以上的两种情况。鉴于 `sudo` 命令要求输入的是其他用户的密码,所以,不需要共享 root 密码。同时,想要阻止特定用户访问 root 权限,只需要调整 `sudoers` 文件中的相应配置即可。
|
||||||
|
|
||||||
|
### 默认行为
|
||||||
|
|
||||||
|
两个命令之间的另外一个区别是默认行为。`sudo` 命令只允许使用提升的权限运行单个命令,而 `su` 命令会启动一个新的 shell,同时允许使用 root 权限运行尽可能多的命令,直到显示退出登录。
|
||||||
|
|
||||||
|
因此,`su` 命令的默认行为是有风险的,因为用户很有可能会忘记他们正在以 root 用户身份进行工作,于是,无意中做出了一些不可恢复的更改(例如:对错误的目录运行 `rm -rf` 命令)。关于为什么不鼓励以 root 用户身份进行工作的详细内容,请参考[这里][10]
|
||||||
|
|
||||||
|
### 日志记录
|
||||||
|
|
||||||
|
尽管 `sudo` 命令是以目标用户(默认情况下是 root 用户)的身份执行命令,但是他们会使用 sudoer 所配置的用户名来记录是谁执行命令。而 `su` 命令是无法直接跟踪记录用户切换到 root 用户之后执行了什么操作。
|
||||||
|
|
||||||
|
### 灵活性
|
||||||
|
|
||||||
|
`sudo` 命令会比 `su` 命令灵活很多,因为你甚至可以限制 sudo 用户可以访问哪些命令。换句话说,用户通过 `sudo` 命令只能访问他们工作需要的命令。而 `su` 命令让用户有权限做任何事情。
|
||||||
|
|
||||||
|
### Sudo su
|
||||||
|
|
||||||
|
大概是因为使用 `su` 命令或直接以 root 用户身份登录有风险,所以,一些 Linux 发行版(如 Ubuntu)默认禁用 root 用户帐户。鼓励用户在需要 root 权限时使用 `sudo` 命令。
|
||||||
|
|
||||||
|
However, you can still do 'su' successfully, i.e, without entering the root password. All you need to do is to run the following command:
|
||||||
|
然而,您还是可以成功执行 `su` 命令,即不用输入 root 用户的密码。运行以下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo su
|
||||||
|
```
|
||||||
|
|
||||||
|
由于你使用 `sudo` 运行命令,你只需要输入当前用户的密码。所以,一旦完成操作,`su` 命令将会以 root 用户身份运行,这意味着它不会再要求输入任何密码。
|
||||||
|
|
||||||
|
** PS **:如果你想在系统中启用 root 用户帐户(虽然强烈反对,但你还是可以使用 `sudo` 命令或 `sudo su` 命令),你必须手动设置 root 用户密码 可以使用以下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo passwd root
|
||||||
|
```
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
这篇文章以及之前的教程(其中侧重于 `sudo` 命令)应该能给你一个比较好的建议,当你需要可用的工具来提升(或一组完全不同的)权限来执行任务时。 如果您也想分享关于 `su` 或 `sudo` 的相关内容或者经验,欢迎您在下方进行评论。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.howtoforge.com/tutorial/sudo-vs-su/
|
||||||
|
|
||||||
|
作者:[Himanshu Arora][a]
|
||||||
|
译者:[zhb127](https://github.com/zhb127)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.howtoforge.com/tutorial/sudo-vs-su/
|
||||||
|
[1]:https://www.howtoforge.com/tutorial/sudo-vs-su/#su-
|
||||||
|
[2]:https://www.howtoforge.com/tutorial/sudo-vs-su/#su-c
|
||||||
|
[3]:https://www.howtoforge.com/tutorial/sudo-vs-su/#password
|
||||||
|
[4]:https://www.howtoforge.com/tutorial/sudo-vs-su/#default-behavior
|
||||||
|
[5]:https://www.howtoforge.com/tutorial/sudo-vs-su/#logging
|
||||||
|
[6]:https://www.howtoforge.com/tutorial/sudo-vs-su/#flexibility
|
||||||
|
[7]:https://www.howtoforge.com/tutorial/sudo-vs-su/#the-su-command-in-linux
|
||||||
|
[8]:https://www.howtoforge.com/tutorial/sudo-vs-su/#sudo-vs-su
|
||||||
|
[9]:https://www.howtoforge.com/tutorial/sudo-vs-su/#sudo-su
|
||||||
|
[10]:http://askubuntu.com/questions/16178/why-is-it-bad-to-login-as-root
|
||||||
|
[11]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/
|
||||||
|
[12]:https://www.howtoforge.com/images/sudo-vs-su/big/su-command.png
|
||||||
|
[13]:https://www.howtoforge.com/images/sudo-vs-su/big/su-hyphen-command.png
|
||||||
|
[14]:https://wiki.archlinux.org/index.php/Su
|
||||||
@ -0,0 +1,99 @@
|
|||||||
|
在 Linux 中修改 MySQL 或 MariaDB 的 Root 密码
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
如果你是第一次[安装 MySQL 或 MariaDB][1],你可以执行 `mysql_secure_installation` 脚本来实现基本的安全设置。
|
||||||
|
|
||||||
|
其中的一个设置是数据库的 root 密码 —— 该密码必须保密,并且只在必要的时候使用。如果你需要修改它(例如,当数据库管理员换了人 —— 或者被解雇了!)。
|
||||||
|
|
||||||
|
**建议阅读:**[在 Linux 中恢复 MySQL 或 MariaDB 的 Root 密码][2]
|
||||||
|
|
||||||
|
这篇文章迟早会派上用场的。我们讲说明怎样来在 Linux 中修改 MySQL 或 MariaDB 数据库服务器的 root 密码。
|
||||||
|
|
||||||
|
尽管我们会在本文中使用 MariaDB 服务器,但本文中的用法说明对 MySQL 也有效。
|
||||||
|
|
||||||
|
### 修改 MySQL 或 MariaDB 的 root 密码
|
||||||
|
|
||||||
|
你知道 root 密码,但是想要重置它,对于这样的情况,让我们首先确定 MariaDB 正在运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
------------- CentOS/RHEL 7 and Fedora 22+ -------------
|
||||||
|
# systemctl is-active mariadb
|
||||||
|
------------- CentOS/RHEL 6 and Fedora -------------
|
||||||
|
# /etc/init.d/mysqld status
|
||||||
|
```
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][3]
|
||||||
|
|
||||||
|
*检查 MysQL 状态*
|
||||||
|
|
||||||
|
如果上面的命令返回中没有 `active` 这个关键词,那么该服务就是停止状态,你需要在进行下一步之前先启动数据库服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
------------- CentOS/RHEL 7 and Fedora 22+ -------------
|
||||||
|
# systemctl start mariadb
|
||||||
|
------------- CentOS/RHEL 6 and Fedora -------------
|
||||||
|
# /etc/init.d/mysqld start
|
||||||
|
```
|
||||||
|
|
||||||
|
接下来,我们将以 root 登录进数据库服务器:
|
||||||
|
|
||||||
|
```
|
||||||
|
# mysql -u root -p
|
||||||
|
```
|
||||||
|
|
||||||
|
为了兼容不同版本,我们将使用下面的声明来更新 mysql 数据库的用户表。注意,你需要将 `YourPasswordHere` 替换为你为 root 选择的新密码。
|
||||||
|
|
||||||
|
```
|
||||||
|
MariaDB [(none)]> USE mysql;
|
||||||
|
MariaDB [(none)]> UPDATE user SET password=PASSWORD('YourPasswordHere') WHERE User='root' AND Host = 'localhost';
|
||||||
|
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||||
|
```
|
||||||
|
|
||||||
|
要验证是否操作成功,请输入以下命令退出当前 MariaDB 会话。
|
||||||
|
|
||||||
|
```
|
||||||
|
MariaDB [(none)]> exit;
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,敲回车。你现在应该可以使用新密码连接到服务器了。
|
||||||
|
|
||||||
|
[
|
||||||
|

|
||||||
|
][4]
|
||||||
|
|
||||||
|
*修改 MysQL/MariaDB Root 密码*
|
||||||
|
|
||||||
|
|
||||||
|
##### 小结
|
||||||
|
|
||||||
|
在本文中,我们说明了如何修改 MariaDB / MySQL 的 root 密码 —— 或许你知道当前所讲的这个方法,也可能不知道。
|
||||||
|
|
||||||
|
像往常一样,如果你有任何问题或者反馈,请尽管使用下面的评论框来留下你宝贵的意见或建议,我们期待着您的留言。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Gabriel Cánepa是一位来自阿根廷圣路易斯的 Villa Mercedes 的 GNU/Linux 系统管理员和 web 开发者。他为世界范围内的主要的消费产品公司工作,也很钟情于在他日常工作的方方面面中使用 FOSS 工具来提高生产效率。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/change-mysql-mariadb-root-password/
|
||||||
|
|
||||||
|
作者:[Gabriel Cánepa][a]
|
||||||
|
译者:[GOLinux](https://github.com/GOLinux)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/gacanepa/
|
||||||
|
|
||||||
|
[1]:http://www.tecmint.com/install-mariadb-in-centos-7/
|
||||||
|
[2]:http://www.tecmint.com/reset-mysql-or-mariadb-root-password/
|
||||||
|
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-MySQL-Status.png
|
||||||
|
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Change-MySQL-Root-Password.png
|
||||||
|
[5]:http://www.tecmint.com/author/gacanepa/
|
||||||
|
[6]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[7]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
82
translated/tech/CentOS-vs-Ubuntu.md
Normal file
82
translated/tech/CentOS-vs-Ubuntu.md
Normal file
@ -0,0 +1,82 @@
|
|||||||
|
# CentOS vs. Ubuntu
|
||||||
|
|
||||||
|
[
|
||||||
|
][4]
|
||||||
|
Linux 的可选项似乎“无穷无尽”,因为每个人都可以通过修改一个已经发行的版本或者新的 [白手起家的版本] [7] (LFS) 来组建 Linux。关于 Linux 发行版的选择,我们关注的因素包括用户接口、文件系统、包分配、新的特征选项以及更新周期和可维护性等。
|
||||||
|
|
||||||
|
在这篇文章中,我们会讲到两个较为熟知的 Linux 发行版,实际山,更多的是介绍两者之间的不同,以及在哪些角度一方比另一方更好。
|
||||||
|
|
||||||
|
### 什么是 CentOS?
|
||||||
|
|
||||||
|
CentOS ( _Community Enterprise Operating System_ ) 是脱胎于
|
||||||
|
红帽企业 Linux (RHEL) 并与之兼容的 Linux 克隆社区支持的发行版,所以我们可以认为 CentOS 是 RHEL 的一个免费版。CentOS 的没一套发行版都有 10 年的维护期,每个新版本的释出周期为 2 年。在 1 月 14 日,CentOS 声明正式加入红帽,为新的 CentOS 董事会所管理,但仍然保持与 RHEL 的独立性。
|
||||||
|
|
||||||
|
扩展阅读——[如何安装 CentOS?][1]
|
||||||
|
|
||||||
|
### CentOS 的历史和第一次释出
|
||||||
|
|
||||||
|
[CentOS][8] 第一次释出是在 2004 年,当时名叫 cAOs Linux;它是由社区维护和管理的一套基于 RPM 的发行版。
|
||||||
|
|
||||||
|
CentOS 结合了包括 Debian、Red Hat Linux/Fedora 和 FreeBSD等在内的许多方面,使其能够令服务器和集群稳定工作 3 到 5 年的时间。它有一群开源软件开发者作为拥趸,但只是一个大型组织(CAO 组织)的一部分[1]。
|
||||||
|
|
||||||
|
在 2006 年 6 月,David Parsley宣布由他开发的 TAO Linux,另一个 RHEL 克隆版本,退出历史舞台并全力转入 CentOS 的开发工作。不过,他的领域转移并不会影响之前的 TAO 用户, 因为他们可以通过使用 yum update 来更新他们的系统。
|
||||||
|
|
||||||
|
2014 年 1 月,红帽开始赞助 CentOS 项目,并移交了所有权和商标。
|
||||||
|
|
||||||
|
[[1\. 开源软件][9]]
|
||||||
|
|
||||||
|
### CentOS 设计
|
||||||
|
确切地说,CentOS 是付费 RHEL (Red Had Enterprise Edition) 版本的克隆。RHEL 提供源码以供之后为 CentOS 修改和变更(移除商标和logo)并完善为最终的成品。
|
||||||
|
|
||||||
|
### Ubuntu
|
||||||
|
Ubuntu 是一个 基于 Debian 的 Linux 操作系统,应用于桌面、服务器、智能手机和平板电脑等多个领域。Ubuntu 是由一个叫做 Canonical Ltd 的公司发行的,南非的 Mark Shuttleworth 给予赞助。
|
||||||
|
|
||||||
|
扩展阅读—— [安装完 Ubuntu 16.10 必须做的 10 件事][2]
|
||||||
|
|
||||||
|
### Ubuntu Design
|
||||||
|
|
||||||
|
### Ubuntu 设计
|
||||||
|
|
||||||
|
Ubuntu 是一个在全世界的开发者共同努力下生成的开源发行版。在这些年的悉心经营下,Ubuntu 变得越来越现代化和人性化,整个系统运行也更加流畅、安全,并且有成千上万的应用可供下载。
|
||||||
|
|
||||||
|
由于它是基于 [Debian][10] 的,因此它也支持 .deb 包、最近 post 包系统和更为安全的 [snap 包格式 (snappy)][11].
|
||||||
|
|
||||||
|
这种新的打包系统允许应用能够满足所有的依赖性进而传送。
|
||||||
|
|
||||||
|
扩展阅读——[Ubuntu 16.10 中的 Linux 及 Ubuntu 回顾][3]
|
||||||
|
|
||||||
|
## CentOS 与 Ubuntu 的区别
|
||||||
|
|
||||||
|
* Ubuntu 基于 Debian, CentOS 基于 RHEL;
|
||||||
|
* Ubuntu 使用 .deb and .snap 的包,CentOS 使用 .rpm 和 flatpak 包;
|
||||||
|
* Ubuntu 使用 apt 来更新,CentOS 使用 yum;
|
||||||
|
* CentOS 看起来会更稳定,因为它不会像 Ubuntu 那样对包做常规性更新,但这并不意味着 Ubuntu 就不比 CentOS 安全;
|
||||||
|
* Ubuntu 有更多的文档和免费的问题、信息支持;
|
||||||
|
* Ubuntu 服务器版本有更多的云服务和容器部署上的支持。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
不论你的选择如何,**是 Ubuntu 还是 CentOS**,两者都是非常优秀稳定的发行版。如果你想要一个释出周期更短的版本,那么就选 Ubuntu;如果你想要一个不经常变更包的版本,那么就选 CentOS。在下方留下的评论,说出你更钟爱哪一个吧!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||||
|
|
||||||
|
作者:[linuxandubuntu.com][a]
|
||||||
|
译者:[Meditator-hkx](http://www.kaixinhuang.com)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||||
|
[1]:http://www.linuxandubuntu.com/home/how-to-install-centos
|
||||||
|
[2]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-ubuntu-16-04-xenial-xerus
|
||||||
|
[3]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-unity-8-preview-in-ubuntu-1610
|
||||||
|
[4]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||||
|
[5]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||||
|
[6]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu#comments
|
||||||
|
[7]:http://www.linuxandubuntu.com/home/how-to-create-a-linux-distro
|
||||||
|
[8]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-centos
|
||||||
|
[9]:https:]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-unity-8-preview-in-ubuntu-1610
|
||||||
|
[10]:https://www.debian.org/
|
||||||
|
[11]:https://en.wikipedia.org/wiki/Snappy_(package_manager)
|
||||||
Loading…
Reference in New Issue
Block a user