mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
f110e6ec66
@ -1,200 +0,0 @@
|
||||
translating by ucasFL
|
||||
Building a Real-Time Recommendation Engine with Data Science
|
||||
======================
|
||||
|
||||
Editor’s Note: This presentation was given by Nicole White at GraphConnect Europe in April 2016. Here’s a quick review of what she covered:
|
||||
- [Basic graph-powered recommendations][1]
|
||||
- [Social recommendations][2]
|
||||
- [Similarity recommendations][3]
|
||||
- [Cluster recommendations][4]
|
||||
|
||||
What we’re going to be talking about today is data science and graph recommendations:
|
||||
|
||||
I’ve been with Neo4j for two years now, but have been working with Neo4j and Cypher for three. I discovered this particular graph database when I was a grad student at the University of Texas Austin studying for a masters in statistics with a focus on social networks.
|
||||
|
||||
[Real-time recommendation engines][5] are one of the most common use cases for Neo4j, and one of the things that makes it so powerful and easy to use. To explore this, I’ll explain how to incorporate statistical methods into these recommendations by using example datasets.
|
||||
|
||||
The first will be simple – entirely in Cypher with a focus on social recommendations. Next we’ll look at the similarity recommendation, which involves similarity metrics that can be calculated, and finally a clustering recommendation.
|
||||
|
||||
### Basic Graph-Powered Recommendations
|
||||
|
||||
The following dataset includes food and drink places in the Dallas Fort Worth International Airport, one of the major airport hubs in the United States:
|
||||
|
||||

|
||||
|
||||
We have place nodes in yellow and are modeling their location in terms of gate and terminal. And we are also categorizing the place in terms of major categories for food and drink. Some include Mexican food, sandwiches, bars and barbecue.
|
||||
|
||||
Let’s do a simple recommendation. We want to find a specific type of food in a certain location in the airport, and the curled brackets represent user inputs which are being entered into our hypothetical app:
|
||||
|
||||

|
||||
|
||||
This English sentence maps really well as a Cypher query:
|
||||
|
||||

|
||||
|
||||
This is going to pull all the places in the category, terminal and gate the user has requested. Then we get the absolute distance of the place to gate where the user is, and return the results in ascending order. Again, a very simple Cypher recommendation to a user based just on their location in the airport.
|
||||
|
||||
### Social Recommendations
|
||||
|
||||
Let’s look at a social recommendation. In our hypothetical app, we have users who can log in and “like” places in a way similar to Facebook and can also check into places:
|
||||
|
||||

|
||||
|
||||
Consider this data model on top of the first model that we explored, and now let’s find food and drink places in the following categories closest to some gate in whatever terminal that user’s friends like:
|
||||
|
||||

|
||||
|
||||
The MATCH clause is very similar to the MATCH clause of our first Cypher query, except now we are matching on likes and friends:
|
||||
|
||||

|
||||
|
||||
The first three lines are the same, but for the user in question – the user that’s “logged in” – we want to find their friends through the :FRIENDS_WITH relationship along with the places those friends liked. With just a few added lines of Cypher, we are now taking a social aspect into account for our recommendation engine.
|
||||
|
||||
Again, we’re only showing categories that the user explicitly asked for that are in the same terminals the user is in. And, of course, we want to filter this by the user who is logged in and making this request, and it returns the name of the place along with its location and category. We are also accounting for how many friends have liked that place and the absolute value of the distance of the place from the gate, all returned in the RETURN clause.
|
||||
|
||||
### Similarity Recommendation
|
||||
|
||||
Now let’s take a look at a similarity recommendation engine:
|
||||
|
||||

|
||||
|
||||
Similarly to our earlier data model, we have users who can like places, but this time they can also rate places with an integer between one and 10. This is easily modeled in Neo4j by adding a property to the relationship.
|
||||
|
||||
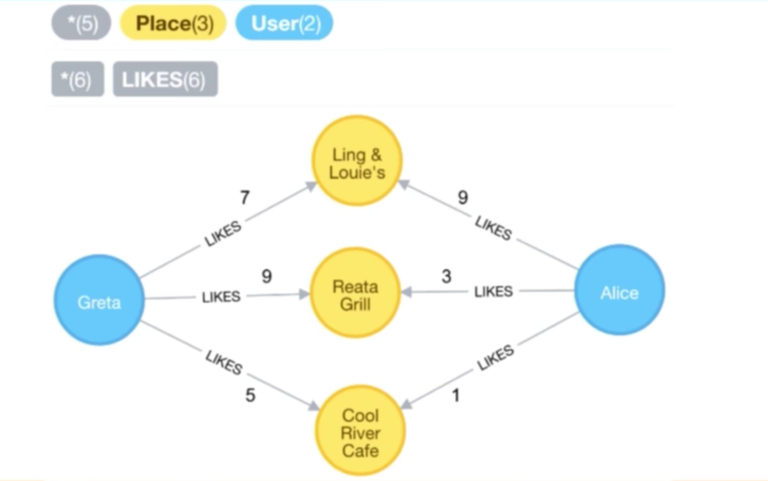
This allows us to find other similar users, like in the example of Greta and Alice. We’ve queried the places they’ve mutually liked, and for each of those places, we can see the weights they have assigned. Presumably, we can use these numbers to determine how similar they are to each other:
|
||||
|
||||
|
||||
|
||||
Now we have two vectors:
|
||||
|
||||

|
||||
|
||||
And now let’s apply Euclidean distance to find the distance between those two vectors:
|
||||
|
||||

|
||||
|
||||
And when we plug in all the numbers, we get the following similarity metric, which is really the distance metric between the two users:
|
||||
|
||||

|
||||
|
||||
You can do this between two specific users easily in Cypher, especially if they’ve only mutually liked a small subset of places. Again, here we’re matching on two users, Alice and Greta, and are trying to find places they’ve mutually liked:
|
||||
|
||||

|
||||
|
||||
They both have to have a :LIKES relationship to the place for it to be found in this result, and then we can easily calculate the Euclidean distance between them with the square root of the sum of their squared differences in Cypher.
|
||||
|
||||
While this may work in an example with two specific people, it doesn’t necessarily work in real time when you’re trying to infer similar users from another user on the fly, by comparing them against every other user in the database in real time. Needless to say, this doesn’t work very well.
|
||||
|
||||
To find a way around this, we pre-compute this calculation and store it in an actual relationship:
|
||||
|
||||

|
||||
|
||||
While in large datasets we would do this in batches, in this small example dataset, we can match on a Cartesian product of all the users and places they’ve mutually liked. When we use WHERE id(u1) < id(u2) as part of our Cypher query, this is just a trick to ensure we’re not finding the same pair twice on both the left and the right.
|
||||
|
||||
Then with their Euclidean distance and themselves, we’re going to create a relationship between them called :DISTANCE and set a Euclidean property called euclidean. In theory, we could also store other similarity metrics on some relationship between users to capture different similarity metrics, since some might be more useful than others in certain contexts.
|
||||
|
||||
And it’s really this ability to model properties on relationships in Neo4j that makes things like this incredibly easy. However, in practice you don’t want to store every single relationship that can possibly exist because you’ll only want to return the top few people of their neighbors.
|
||||
|
||||
So you can just store the top in according to some threshold so you don’t have this fully connected graph. This allows you to perform graph database queries like the below in real time, because we’ve pre-computed it and stored it on the relationship, and in Cypher we’ll be able to grab that very quickly:
|
||||
|
||||

|
||||
|
||||
In this query, we’re matching on places and categories:
|
||||
|
||||

|
||||
|
||||
Again, the first three lines are the same, except that for the logged-in user, we’re getting users who have a :DISTANCE relationship to them. This is where what we went over earlier comes into play – in practice you should only store the top :DISTANCE relationships to users who are similar to them so you’re not grabbing a huge volume of users in this MATCH clause. Instead, we’re grabbing users who have a :DISTANCE relationship to them where those users like that place.
|
||||
|
||||
This has allowed us to express a somewhat complicated pattern in just a few lines. We’re also grabbing the :LIKES relationship and putting it on a variable because we’re going to use those weights later to apply a rating.
|
||||
|
||||
What’s important here is that we’re ordering those users by their distance ascending, because it is a distance metric, and we want the lowest distances because that indicates they are the most similar.
|
||||
|
||||
With those other users ordered by the Euclidean distance, we’re going to collect the top three users’ ratings and use those as our average score to recommend these places. In other words, we’ve taken an active user, found users who are most similar to them based on the places they’ve liked, and then averaged the scores those similar users have given to rank those places in a result set.
|
||||
|
||||
We’re essentially taking an average here by adding it up and dividing by the number of elements in the collection, and we’re ordering by that average ascending. Then secondarily, we’re ordering by the gate distance. Hypothetically, there could be ties I suppose, and then you order by the gate distance and then returning the name, category, gate and terminal.
|
||||
|
||||
### Cluster Recommendations
|
||||
|
||||
Our final example is going to be a cluster recommendation, which can be thought of as a workflow of offline computing that may be required as a workaround in Cypher. This may now be obsolete based on the new procedures announced at GraphConnect Europe, but sometimes you have to do certain algorithmic approaches that Cypher version 2.3 doesn’t expose.
|
||||
|
||||
This is where you can use some form of statistical software, pull data out of Neo4j into a software such as Apache Spark, R or Python. Below is an example of R code for pulling data out of Neo4j, running an algorithm, and then – if appropriate – writing the results of that algorithm back into Neo4j as either a property, node, relationship or a new label.
|
||||
|
||||
By persisting the results of that algorithm into the graph, you can use it in real-time with queries similar to the ones we just went over:
|
||||
|
||||

|
||||
|
||||
Below is some example code for how you do this in R, but you can easily do the same thing with whatever software you’re most comfortable with, such as Python or Spark. All you have to do is log in and connect to the graph.
|
||||
|
||||
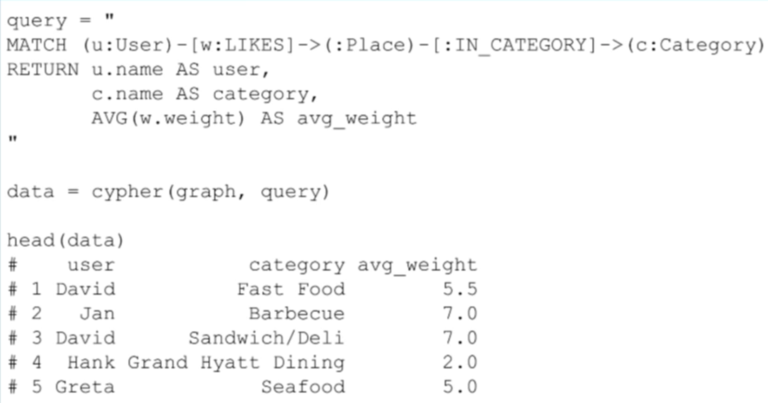
In the following example, I’ve clustered users together based on their similarities. Each user is represented as an observation, and I want to get the average rating that they’ve given each category:
|
||||
|
||||
|
||||
|
||||
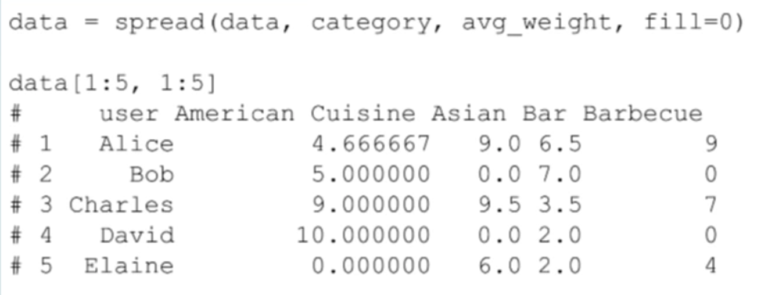
Presumably, users who rate the bar category in similar ways are similar in general. Here I’m grabbing the names of users who like places in the same category, the category name, and the average weight of the “likes” relationships, as average weight, and that’s going to give me a table like this:
|
||||
|
||||
|
||||
|
||||
Because we want each user to be an observation, we will have to manipulate the data where each feature is the average weight rating they’ve given restaurants within that category, per category. We’ll then use this to determine how similar they are, and I’m going to use a clustering algorithm to determine users being in different clusters.
|
||||
|
||||
In R this is very straightforward:
|
||||
|
||||

|
||||
|
||||
For this demonstration we are using k-means, which allows you to easily grab cluster assignments. In summary, I ran a clustering algorithm and now for each user I have a cluster assignment.
|
||||
|
||||
Bob and David are in the same cluster – they’re in cluster two – and now I’ll be able to see in real time which users have been determined to be in the same cluster.
|
||||
|
||||
Next we write it into a CSV, which we then load into the graph:
|
||||
|
||||

|
||||
|
||||
We have users and cluster assignments, so the CSV will only have two columns. LOAD CSV is a syntax that’s built into Cypher that allows you to call a CSV from some file path or URL and alias it as something. Then we’ll match on the users that already exist in the graph, grab the user column out of that CSV, and merge on the cluster.
|
||||
|
||||
Here we’re creating a new labeled node in the graph, the Cluster ID, which was given by k-means. Next we create relationships between the user and the cluster, which allows us to easily query when we get to the actual recommendation users who are in the same cluster.
|
||||
|
||||
Now we have a new label cluster where users who are in the same cluster have a relationship to that cluster. Below is what our new data model looks like, which is on top of the other data models we explored:
|
||||
|
||||

|
||||
|
||||
Now let’s consider the following query:
|
||||
|
||||

|
||||
|
||||
With this Cypher query, we’re going beyond similar users to users in the same cluster. At this point we’ve also deleted those distance relationships:
|
||||
|
||||

|
||||
|
||||
In this query, we’ve taken the user who’s logged in, finding their cluster based on the user-cluster relationship, and finding their neighbors who are in that same cluster.
|
||||
|
||||
We’ve assigned that to some variable cl, and we’re getting other users – which I’ve aliased as a neighbor variable – who have a user-cluster relationship to that same cluster, and then we’re getting the places that neighbor has liked. Again, we’re putting the “likes” on a variable, r, because we’re going want to grab weights off of the relationship to order our results.
|
||||
|
||||
All we’ve changed in the query is that instead of using the similarity distance, we’re grabbing users in the same cluster, asserting categories, asserting the terminal and asserting that we’re only grabbing the user who is logged in. We’re collecting all those weights of the :LIKES relationships from their neighbors liking places, getting the category, the absolute value of the distance, ordering that in descending order, and returning those results.
|
||||
|
||||
In these examples we’ve been able to take a pretty involved process and persist it in the graph, and then used the results of that algorithm – the results of the clustering algorithm and the clustering assignments – in real time.
|
||||
|
||||
Our preferred workflow is to update these clustering assignments however frequently you see fit — for example, nightly or hourly. And, of course, you can use intuition to figure out how often is acceptable to be updating these cluster assignments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Nicole White][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://neo4j.com/blog/contributor/nicole-white/
|
||||
[1]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#basic-graph-recommendations
|
||||
[2]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#social-recommendations
|
||||
[3]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#similarity-recommendations
|
||||
[4]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#cluster-recommendations
|
||||
[5]: https://neo4j.com/use-cases/real-time-recommendation-engine/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,199 @@
|
||||
用数据科学搭建一个实时推荐引擎
|
||||
======================
|
||||
|
||||
编者注:本文是 2016 年四月 Nicole Whilte 在欧洲 GraphConnect 时所作。这儿我们快速回顾一下她所涉及的内容:
|
||||
- 【基本图表动力推荐】【1】
|
||||
- 【社会推荐】【2】
|
||||
- 【相似性推荐】【3】
|
||||
- 【集群推荐】【4】
|
||||
|
||||
今天我们将要讨论的内容是数据科学和图表推荐:
|
||||
|
||||
Neo4j 已经伴随我两年了,但实际上我已经使用 Neo4j 和 Cypher 工作三年了。当我首次发现这个特别的图表数据库的时候,我还是一个研究生,那时候我在奥斯丁的德克萨斯大学攻读关于社会网络的统计学硕士学位。
|
||||
|
||||
【实时推荐引擎】【5】是 Neo4j 中广泛使用的一个实例,有一样东西使它如此强大并且容易使用。为了探索这个东西,我将通过使用示例数据集来阐述如何将统计学方法并入这些引擎中。
|
||||
|
||||
第一个很简单 - 仅仅在 Cypher 中关注社会推荐。接下来,我们将看一看相似性推荐,这涉及到可以被计算的相似性度量,最后探索的是集群推荐
|
||||
|
||||
### 基本图表动力推荐
|
||||
|
||||
下面的数据集包含所有达拉斯 Fort Worth 国际机场的餐饮场所,达拉斯 Fort Worth 国际机场是美国主要的机场枢纽之一:
|
||||
|
||||

|
||||
|
||||
我们把节点标记成黄色并按照出入口和终点给它们的位置建模。同时我们也按照食物和饮料的主类别将地点分类,其中一些包括墨西哥食物,三明治,酒吧和烤肉。
|
||||
|
||||
让我们做一个简单的推荐。我们想要在机场的某一确定地点找到一种特定食物,大括号中的内容表示是的用户输入,它将进入我们假想的应用程序中。
|
||||
|
||||

|
||||
|
||||
这个英文句子很好地表示出了 Cypher 查询:
|
||||
|
||||

|
||||
|
||||
这将提取出目录中用户所请求的所有地点,终点和出入口。然后我们可以计算出用户所在位置到出入口的准确距离,并以升序返回结果。再次说明,一个非常简单的 Cypher 推荐仅仅依据用户在机场中的位置。
|
||||
### 社会推荐
|
||||
|
||||
让我们来看一下社会推荐。在我们的假想应用程序中,用户可以登录并且可以用和 Facebook 类似的方式标记自己“喜爱”的地点,也可以查询登记地点。
|
||||
|
||||

|
||||
|
||||
考虑位于我们所探索的第一个模型顶部的数据模型,现在让我们在下面的目录中找到离一些出入口最近的餐饮场所,不考虑用户的朋友想要去哪个终点:
|
||||
|
||||

|
||||
|
||||
匹配项目和我们第一次 Cypher 查询得到的匹配项目相似,只是现在我们依据喜好和朋友来匹配:
|
||||
|
||||

|
||||
|
||||
前三行是完全一样的,但是现在正在考虑的是关于那些登录的用户,我们想要通过喜欢相同的地点这一关系来找到他们的朋友。仅需通过在 Cypher 中增加一些行内容,我们现在已经把社会层面考虑到了我们的推荐引擎中。
|
||||
|
||||
在次说明,我们仅仅显示了用户明确请求的目录,并且这些目录中的地点与用户进入的地方有相同的终点。当然,我们希望通过登录用户做出请求来滤过这些目录,然后返回地点的名字、位置以及所在目录。我们也要显示出有多少朋友已经“喜爱”那个地点以及那个地点到出入口的确切距离,然后在返回项目中同时返回这些内容。
|
||||
|
||||
### 相似性推荐
|
||||
|
||||
现在,让我们看一看相似性推荐引擎:
|
||||
|
||||

|
||||
|
||||
和前面的数据模型相似,用户可以标记“喜爱”的地点,但是这一次他们可以用 1 到 10 的整数给地点评分。这是通过前期在 Neo4j 中增加一些属性到关系中建模实现的。
|
||||
|
||||
这将允许我们找到其他相似的用户,比如以 Greta 和 Alice 为例,我们已经查询了他们共同喜欢的地点,并且对于每一个地点,我们可以看到他们所设定的权重。大概地,我们可以通过他们的评分来确定他们之间的相似性大小。
|
||||
|
||||

|
||||
|
||||
现在我们有两个向量:
|
||||
|
||||

|
||||
|
||||
现在让我们按照欧几里得距离的定义来计算这两个向量之间的距离:
|
||||
|
||||

|
||||
|
||||
|
||||
我们把所有的数字带入公式中计算,然后得到下面的相似度,这就是两个用户之间的“距离”:
|
||||
|
||||

|
||||
|
||||
你可以提前在 Cypher 中计算两个特定用户的“距离”,特别是如果他们仅仅同时“喜爱”一个很小的地点子集。再次说明,这儿我们依据两个用户 Alice 和 Greta 来进行匹配,并尝试去找到他们同时“喜爱”的地点:
|
||||
|
||||

|
||||
|
||||
他们都有对最后找到的地点的“喜爱”关系,然后我们可以在 Cypher 中很容易的计算出他们之间的欧几里得距离,计算方法为他们对各个地点评分差的平方求和再开平方根。
|
||||
|
||||
在两个特定用户的例子中上面这个方法或许能够工作。但是,在实时情况下,当你想要通过和实时数据库中的其他用户比较,从而由一架飞机上的一个用户推断相似用户时,这个方法就不一定能够工作。不用说,至少它不能够很好的工作。
|
||||
|
||||
为了找到解决这个问题的好方法,我们可以预先计算好距离并存入实际关系中:
|
||||
|
||||

|
||||
|
||||
当遇到一个很大的数据集时,我们需要成批处理这件事,在这个很小的示例数据集中,我们可以按照所有用户的迪卡尔乘积和他们共同“喜爱”的地点来进行匹配。当我们使用 WHERE id(u1) < id(u2) 作为 Cypher 询问的一部分时,它只是来确定我们在左边和右边没有找到相同的对的一个技巧。
|
||||
|
||||
通过用户之间的欧几里得距离,我们创建了他们之间的一种关系,叫做“距离”,并且设置了一个欧几里得属性,也叫做“欧几里得”。理论上,我们可以也通过用户间的一些关系来存储其他相似度从而获取不同的相似度,因为在确定的环境下一些相似度可能比其他相似度更有用。
|
||||
|
||||
在 Neo4j 中,的确是关于关系的模型性能力使得完成像这样的事情无比简单。然而,实际上,你不会希望存入每一个可能存在的单一关系,因为你仅仅希望返回离他们“最近”的一些人。
|
||||
|
||||
因此你可以根据一些临界值来存入顶端关系从而你不需要有完整的连通图。这允许你完成一些像下面这样的实时数据库查询,因为我们已经预先计算好了“距离”并存储在了关系中,在 Cypher 中,我们能够很快的攫取出数据。
|
||||
|
||||

|
||||
|
||||
在这个查询中,我们依据地点和目录来进行匹配:
|
||||
|
||||

|
||||
|
||||
再次说明,前三行是相同的,除了登录用户以外,我们找出了有距离关系的用户。这是我们前面查看的关系产生的作用 - 实际上,你只需要存储处于顶端的相似用户“距离”关系,因此你不需要在匹配项目中攫取大量用户。相反,我们只攫取和那些用户“喜爱”的地方有“距离”关系的用户。
|
||||
|
||||
这允许我们用少许几行内容表达较为复杂的模型。我们也可以攫取“喜爱”关系并把它放入到变量中,因为后面我们将使用这些权重来评分。
|
||||
|
||||
在这儿重要的是,我们可以依据“距离”大小将用户按照升序进行排序,因为这是一个距离测度。同时,我们想要找到用户间的最小距离因为距离越小表明他们的相似度最大。
|
||||
|
||||
通过其他按照欧几里得距离大小排序好的用户,我们得到用户评分最高的三个地点并按照用户的平均评分高低来推荐这些地点。用其他的话来说,我们先找出一个积极用户,然后依据其他用户“喜爱”的地点找出和他最相似的其他用户,接下来按照这些相似用户的平均评分把那些地点排序在结果的集合中。
|
||||
|
||||
本质上,我们通过把所有评分相加然后除以收集的用户数目来计算出平均分,然后按照平均评分的升序进行排序。其次,我们按照出入口距离排序。假想地,我猜测应该会有交接点,因此你可以按照出入口距离排序然后再返回名字、目录、出入口和终点。
|
||||
|
||||
### 集群推荐
|
||||
|
||||
我们最后要讲的一个例子是集群推荐,在 Cyphe 中,这可以被想像成一个作为工作区的离线工作流。这可能完全基于在欧洲 GraphConnect 上宣布的新程序,但是有时你必须进行一些 Cypher 2.3 版本没有显示的算法逼近。
|
||||
|
||||
在这儿你可以使用一些统计软件,把数据从 Neo4j 取出然后放入像 Apache Spark, R 或者 Python 这样的软件中。下面是一段把数据从 Neo4j 中取出的 R 代码,运行程序,如果正确,写下程序返回给 Neo4j 的结果,比如一个属性、节点、关系或者一个新的标签。
|
||||
|
||||
通过持续把程序运行结果放入到图表中,你可以在一个和我们刚刚看到的查询相似的实时查询中使用它:
|
||||
|
||||

|
||||
|
||||
下面是用 R 来完成这件事的一些示例代码,但是你可以使用任何你最喜欢的软件来做这件事,比如 Python 或 Spark。你需要做的只是登录并连接到图表。
|
||||
|
||||
在下面的例子中,我基于用户的相似性把他们集中起来。每个用户作为一个观察点,然后得到他们对每一个目录评分的平均值。
|
||||
|
||||

|
||||
|
||||
假定用户对酒吧目录评分的方式和一般的评分方式相似。然后我攫取出喜欢相同目录中的地点的用户名,目录名,“喜爱”关系的平均权重,比如平均权重这些信息,从而我可以得到下面这样一个表格:
|
||||
|
||||

|
||||
|
||||
因为我们把每一个用户都作为一个观察点,所以我们必须巧妙的处理每一个目录中的数据,这些数据的每一个特性都是用户对目录中餐厅评分的平均权重。接下来,我们将使用这些数据来确定用户的相似性,然后我将使用聚类算法来确定在不同集群中的用户。
|
||||
|
||||
在 R 中这很直接:
|
||||
|
||||

|
||||
|
||||
在这个示例中我们使用 K - 均值聚类算法,这将使你很容易攫取集群分配。总之,我通过运行聚类算法然后分别得到每一个用户的集群分配。
|
||||
|
||||
Bob 和 David 在一个相同的集群中 - 他们在集群二中 - 现在我可以实时查看哪些用户被放在了相同的集群中。
|
||||
|
||||
接下来我把集群分配写入 CSV 文件中,然后存入图表:
|
||||
|
||||

|
||||
|
||||
我们只有用户和集群分配,因此 CSV 文件只有两列。 LOAD CSV 是 Cypher 中的内建语法,它允许你从一些其他文件路径或者 URL 和别名调用 CSV 。接下来,我们将匹配图表中存在的用户,从 CSV 文件中攫取用户列然后合并到集群中。
|
||||
|
||||
我们在图表中创建了一个新的标签节点:集群 ID, 这是由 K - 平均聚类算法给出的。接下来我们创建用户和集群间的关系,通过创建这个关系,当我们想要找到在相同集群中的实际推荐用户时,就会很容易进行查询。
|
||||
|
||||
我们现在有了一个新的标签集群,在相同集群中的用户和那个集群存在关系。新的数据模型看起来像下面这样,它比我们前面探索的其他数据模型要更好:
|
||||
|
||||

|
||||
|
||||
现在让我们考虑下面的查询:
|
||||
|
||||

|
||||
|
||||
通过这个 Cypher 查询,我们在更远处找到了在同一个集群中的相似用户。由于这个原因,我们删除了“距离”关系:
|
||||
|
||||

|
||||
|
||||
在这个查询中,我们取出已经登录的用户,根据用户-集群关系找到他们所在的集群,找到他们附近和他们在相同集群中的用户。
|
||||
|
||||
我们把这些用户分配到变量 c1 中,然后我们得到其他被我取别名为附近变量的用户,这些用户和那个相同集群存在用户-集群关系,最后我们得到这些附近用户“喜爱”的地点。再次说明,我把“喜爱”放入了变量 r 中,因为我们需要从关系中攫取权重来对结果进行排序。
|
||||
|
||||
在这个查询中,我们所做的改变是,不使用相似性距离,而是攫取在相同集群中的用户,然后对目录、终点以及我们所攫取的登录用户进行声明。我们收集所有的权重:来自附近用户“喜爱”地点的“喜爱”关系,得到的目录,确定的距离值,然后把它们按升序进行排序并返回结果。
|
||||
|
||||
在这些例子中,我们可以进行一个相当复杂的进程并且在图表中实现进程,然后我们就可以使用实时算法结果-聚类算法和集群分配的结果。
|
||||
|
||||
我们更喜欢的工作流程是更新这些集群分配,更新频率适合你自己就可以,比如每晚一次或每小时一次。当然,你可以根据直觉来决定多久更新一次这些集群分配是可接受的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Nicole White][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://neo4j.com/blog/contributor/nicole-white/
|
||||
[1]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#basic-graph-recommendations
|
||||
[2]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#social-recommendations
|
||||
[3]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#similarity-recommendations
|
||||
[4]: https://neo4j.com/blog/real-time-recommendation-engine-data-science/?utm_source=dbweekly&utm_medium=email#cluster-recommendations
|
||||
[5]: https://neo4j.com/use-cases/real-time-recommendation-engine/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user