mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
commit
f065a1b9d4
@ -1,37 +1,39 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10850-1.html)
|
||||
[#]: subject: (Build a game framework with Python using the module Pygame)
|
||||
[#]: via: (https://opensource.com/article/17/12/game-framework-python)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 Python 和 Pygame 模块构建一个游戏框架
|
||||
======
|
||||
这系列的第一篇通过创建一个简单的骰子游戏来探究 Python。现在是来从零制作你自己的游戏的时间。
|
||||
|
||||
> 这系列的第一篇通过创建一个简单的骰子游戏来探究 Python。现在是来从零制作你自己的游戏的时间。
|
||||
|
||||

|
||||
|
||||
在我的 [这系列的第一篇文章][1] 中, 我已经讲解如何使用 Python 创建一个简单的,基于文本的骰子游戏。这次,我将展示如何使用 Python 和 Pygame 模块来创建一个图形化游戏。它将占用一些文章来得到一个确实完成一些东西的游戏,但是在这系列的结尾,你将有一个更好的理解,如何查找和学习新的 Python 模块和如何从其基础上构建一个应用程序。
|
||||
在我的[这系列的第一篇文章][1] 中, 我已经讲解如何使用 Python 创建一个简单的、基于文本的骰子游戏。这次,我将展示如何使用 Python 模块 Pygame 来创建一个图形化游戏。它将需要几篇文章才能来得到一个确实做成一些东西的游戏,但是到这系列的结尾,你将更好地理解如何查找和学习新的 Python 模块和如何从其基础上构建一个应用程序。
|
||||
|
||||
在开始前,你必须安装 [Pygame][2]。
|
||||
|
||||
### 安装新的 Python 模块
|
||||
|
||||
这里有一些方法来安装 Python 模块,但是最通用的两个是:
|
||||
有几种方法来安装 Python 模块,但是最通用的两个是:
|
||||
|
||||
* 从你的发行版的软件存储库
|
||||
* 使用 Python 的软件包管理器,pip
|
||||
* 使用 Python 的软件包管理器 `pip`
|
||||
|
||||
两个方法都工作很好,并且每一个都有它自己的一套优势。如果你是在 Linux 或 BSD 上开发,促使你的发行版的软件存储库确保自动及时更新。
|
||||
两个方法都工作的很好,并且每一个都有它自己的一套优势。如果你是在 Linux 或 BSD 上开发,可以利用你的发行版的软件存储库来自动和及时地更新。
|
||||
|
||||
然而,使用 Python 的内置软件包管理器给予你控制更新模块时间的能力。而且,它不是明确指定操作系统的,意味着,即使当你不是在你常用的开发机器上时,你也可以使用它。pip 的其它的优势是允许模块局部安装,如果你没有一台正在使用的计算机的权限,它是有用的。
|
||||
然而,使用 Python 的内置软件包管理器可以给予你控制更新模块时间的能力。而且,它不是特定于操作系统的,这意味着,即使当你不是在你常用的开发机器上时,你也可以使用它。`pip` 的其它的优势是允许本地安装模块,如果你没有正在使用的计算机的管理权限,这是有用的。
|
||||
|
||||
### 使用 pip
|
||||
|
||||
如果 Python 和 Python3 都安装在你的系统上,你想使用的命令很可能是 `pip3`,它区分来自Python 2.x 的 `pip` 的命令。如果你不确定,先尝试 `pip3`。
|
||||
如果 Python 和 Python3 都安装在你的系统上,你想使用的命令很可能是 `pip3`,它用来区分 Python 2.x 的 `pip` 的命令。如果你不确定,先尝试 `pip3`。
|
||||
|
||||
`pip` 命令有些像大多数 Linux 软件包管理器的工作。你可以使用 `search` 搜索 Pythin 模块,然后使用 `install` 安装它们。如果你没有你正在使用的计算机的权限来安装软件,你可以使用 `--user` 选项来仅仅安装模块到你的 home 目录。
|
||||
`pip` 命令有些像大多数 Linux 软件包管理器一样工作。你可以使用 `search` 搜索 Python 模块,然后使用 `install` 安装它们。如果你没有你正在使用的计算机的管理权限来安装软件,你可以使用 `--user` 选项来仅仅安装模块到你的家目录。
|
||||
|
||||
```
|
||||
$ pip3 search pygame
|
||||
@ -44,11 +46,11 @@ pygame_cffi (0.2.1) - A cffi-based SDL wrapper that copies the
|
||||
$ pip3 install Pygame --user
|
||||
```
|
||||
|
||||
Pygame 是一个 Python 模块,这意味着它仅仅是一套可以被使用在你的 Python 程序中库。换句话说,它不是一个你启动的程序,像 [IDLE][3] 或 [Ninja-IDE][4] 一样。
|
||||
Pygame 是一个 Python 模块,这意味着它仅仅是一套可以使用在你的 Python 程序中的库。换句话说,它不是一个像 [IDLE][3] 或 [Ninja-IDE][4] 一样可以让你启动的程序。
|
||||
|
||||
### Pygame 新手入门
|
||||
|
||||
一个电子游戏需要一个故事背景;一个发生的地点。在 Python 中,有两种不同的方法来创建你的故事背景:
|
||||
一个电子游戏需要一个背景设定:故事发生的地点。在 Python 中,有两种不同的方法来创建你的故事背景:
|
||||
|
||||
* 设置一种背景颜色
|
||||
* 设置一张背景图片
|
||||
@ -57,15 +59,15 @@ Pygame 是一个 Python 模块,这意味着它仅仅是一套可以被使用
|
||||
|
||||
### 设置你的 Pygame 脚本
|
||||
|
||||
为了开始一个新的 Pygame 脚本,在计算机上创建一个文件夹。游戏的全部文件被放在这个目录中。在工程文件夹内部保持所需要的所有的文件来运行游戏是极其重要的。
|
||||
要开始一个新的 Pygame 工程,先在计算机上创建一个文件夹。游戏的全部文件被放在这个目录中。在你的工程文件夹内部保持所需要的所有的文件来运行游戏是极其重要的。
|
||||
|
||||
|
||||
|
||||
一个 Python 脚本以文件类型,你的姓名,和你想使用的协议开始。使用一个开放源码协议,以便你的朋友可以改善你的游戏并与你一起分享他们的更改:
|
||||
一个 Python 脚本以文件类型、你的姓名,和你想使用的许可证开始。使用一个开放源码许可证,以便你的朋友可以改善你的游戏并与你一起分享他们的更改:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# Seth Kenlon 编写
|
||||
# by Seth Kenlon
|
||||
|
||||
## GPLv3
|
||||
# This program is free software: you can redistribute it and/or
|
||||
@ -75,14 +77,14 @@ Pygame 是一个 Python 模块,这意味着它仅仅是一套可以被使用
|
||||
#
|
||||
# This program is distributed in the hope that it will be useful, but
|
||||
# WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
# General Public License for more details.
|
||||
#
|
||||
# You should have received a copy of the GNU General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
```
|
||||
|
||||
然后,你告诉 Python 你想使用的模块。一些模块是常见的 Python 库,当然,你想包括一个你刚刚安装的,Pygame 。
|
||||
然后,你告诉 Python 你想使用的模块。一些模块是常见的 Python 库,当然,你想包括一个你刚刚安装的 Pygame 模块。
|
||||
|
||||
```
|
||||
import pygame # 加载 pygame 关键字
|
||||
@ -90,7 +92,7 @@ import sys # 让 python 使用你的文件系统
|
||||
import os # 帮助 python 识别你的操作系统
|
||||
```
|
||||
|
||||
由于你将用这个脚本文件工作很多,在文件中制作成段落是有帮助的,以便你知道在哪里放原料。使用语句块注释来做这些,这些注释仅在看你的源文件代码时是可见的。在你的代码中创建三个语句块。
|
||||
由于你将用这个脚本文件做很多工作,在文件中分成段落是有帮助的,以便你知道在哪里放代码。你可以使用块注释来做这些,这些注释仅在看你的源文件代码时是可见的。在你的代码中创建三个块。
|
||||
|
||||
```
|
||||
'''
|
||||
@ -114,7 +116,7 @@ Main Loop
|
||||
|
||||
接下来,为你的游戏设置窗口大小。注意,不是每一个人都有大计算机屏幕,所以,最好使用一个适合大多数人的计算机的屏幕大小。
|
||||
|
||||
这里有一个方法来切换全屏模式,很多现代电子游戏做的方法,但是,由于你刚刚开始,保存它简单和仅设置一个大小。
|
||||
这里有一个方法来切换全屏模式,很多现代电子游戏都会这样做,但是,由于你刚刚开始,简单起见仅设置一个大小即可。
|
||||
|
||||
```
|
||||
'''
|
||||
@ -124,7 +126,7 @@ worldx = 960
|
||||
worldy = 720
|
||||
```
|
||||
|
||||
在一个脚本中使用 Pygame 引擎前,你需要一些基本的设置。你必需设置帧频,启动它的内部时钟,然后开始 (`init`) Pygame 。
|
||||
在脚本中使用 Pygame 引擎前,你需要一些基本的设置。你必须设置帧频,启动它的内部时钟,然后开始 (`init`)Pygame 。
|
||||
|
||||
```
|
||||
fps = 40 # 帧频
|
||||
@ -137,17 +139,15 @@ pygame.init()
|
||||
|
||||
### 设置背景
|
||||
|
||||
在你继续前,打开一个图形应用程序,并为你的游戏世界创建一个背景。在你的工程目录中的 `images` 文件夹内部保存它为 `stage.png` 。
|
||||
在你继续前,打开一个图形应用程序,为你的游戏世界创建一个背景。在你的工程目录中的 `images` 文件夹内部保存它为 `stage.png` 。
|
||||
|
||||
这里有一些你可以使用的自由图形应用程序。
|
||||
|
||||
* [Krita][5] 是一个专业级绘图原料模拟器,它可以被用于创建漂亮的图片。如果你对电子游戏创建艺术作品非常感兴趣,你甚至可以购买一系列的[游戏艺术作品教程][6].
|
||||
* [Pinta][7] 是一个基本的,易于学习的绘图应用程序。
|
||||
* [Inkscape][8] 是一个矢量图形应用程序。使用它来绘制形状,线,样条曲线,和 Bézier 曲线。
|
||||
* [Krita][5] 是一个专业级绘图素材模拟器,它可以被用于创建漂亮的图片。如果你对创建电子游戏艺术作品非常感兴趣,你甚至可以购买一系列的[游戏艺术作品教程][6]。
|
||||
* [Pinta][7] 是一个基本的,易于学习的绘图应用程序。
|
||||
* [Inkscape][8] 是一个矢量图形应用程序。使用它来绘制形状、线、样条曲线和贝塞尔曲线。
|
||||
|
||||
|
||||
|
||||
你的图像不必很复杂,你可以以后回去更改它。一旦你有它,在你文件的 setup 部分添加这些代码:
|
||||
你的图像不必很复杂,你可以以后回去更改它。一旦有了它,在你文件的 Setup 部分添加这些代码:
|
||||
|
||||
```
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
@ -155,13 +155,13 @@ backdrop = pygame.image.load(os.path.join('images','stage.png').convert())
|
||||
backdropbox = world.get_rect()
|
||||
```
|
||||
|
||||
如果你仅仅用一种颜色来填充你的游戏的背景,你需要做的全部是:
|
||||
如果你仅仅用一种颜色来填充你的游戏的背景,你需要做的就是:
|
||||
|
||||
```
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
```
|
||||
|
||||
你也必需定义一个来使用的颜色。在你的 setup 部分,使用红,绿,蓝 (RGB) 的值来创建一些颜色的定义。
|
||||
你也必须定义颜色以使用。在你的 Setup 部分,使用红、绿、蓝 (RGB) 的值来创建一些颜色的定义。
|
||||
|
||||
```
|
||||
'''
|
||||
@ -173,13 +173,13 @@ BLACK = (23,23,23 )
|
||||
WHITE = (254,254,254)
|
||||
```
|
||||
|
||||
在这点上,你能理论上启动你的游戏。问题是,它可能仅持续一毫秒。
|
||||
至此,你理论上可以启动你的游戏了。问题是,它可能仅持续了一毫秒。
|
||||
|
||||
为证明这一点,保存你的文件为 `your-name_game.py` (用你真实的名称替换 `your-name` )。然后启动你的游戏。
|
||||
为证明这一点,保存你的文件为 `your-name_game.py`(用你真实的名称替换 `your-name`)。然后启动你的游戏。
|
||||
|
||||
如果你正在使用 IDLE ,通过选择来自 Run 菜单的 `Run Module` 来运行你的游戏。
|
||||
如果你正在使用 IDLE,通过选择来自 “Run” 菜单的 “Run Module” 来运行你的游戏。
|
||||
|
||||
如果你正在使用 Ninja ,在左侧按钮条中单击 `Run file` 按钮。
|
||||
如果你正在使用 Ninja,在左侧按钮条中单击 “Run file” 按钮。
|
||||
|
||||
|
||||
|
||||
@ -189,27 +189,27 @@ WHITE = (254,254,254)
|
||||
$ python3 ./your-name_game.py
|
||||
```
|
||||
|
||||
如果你正在使用 Windows ,使用这命令:
|
||||
如果你正在使用 Windows,使用这命令:
|
||||
|
||||
```
|
||||
py.exe your-name_game.py
|
||||
```
|
||||
|
||||
你启动它,不过不要期望很多,因为你的游戏现在仅仅持续几毫秒。你可以在下一部分中修复它。
|
||||
启动它,不过不要期望很多,因为你的游戏现在仅仅持续几毫秒。你可以在下一部分中修复它。
|
||||
|
||||
### 循环
|
||||
|
||||
除非另有说明,一个 Python 脚本运行一次并仅一次。近来计算机的运行速度是非常快的,所以你的 Python 脚本运行时间少于1秒钟。
|
||||
除非另有说明,一个 Python 脚本运行一次并仅一次。近来计算机的运行速度是非常快的,所以你的 Python 脚本运行时间会少于 1 秒钟。
|
||||
|
||||
为强制你的游戏来处于足够长的打开和活跃状态来让人看到它(更不要说玩它),使用一个 `while` 循环。为使你的游戏保存打开,你可以设置一个变量为一些值,然后告诉一个 `while` 循环只要变量保持未更改则一直保存循环。
|
||||
|
||||
这经常被称为一个"主循环",你可以使用术语 `main` 作为你的变量。在你的 setup 部分的任意位置添加这些代码:
|
||||
这经常被称为一个“主循环”,你可以使用术语 `main` 作为你的变量。在你的 Setup 部分的任意位置添加代码:
|
||||
|
||||
```
|
||||
main = True
|
||||
```
|
||||
|
||||
在主循环期间,使用 Pygame 关键字来检查是否在键盘上的按键已经被按下或释放。添加这些代码到你的主循环部分:
|
||||
在主循环期间,使用 Pygame 关键字来检查键盘上的按键是否已经被按下或释放。添加这些代码到你的主循环部分:
|
||||
|
||||
```
|
||||
'''
|
||||
@ -228,7 +228,7 @@ while main == True:
|
||||
main = False
|
||||
```
|
||||
|
||||
也在你的循环中,刷新你世界的背景。
|
||||
也是在你的循环中,刷新你世界的背景。
|
||||
|
||||
如果你使用一个图片作为背景:
|
||||
|
||||
@ -242,33 +242,33 @@ world.blit(backdrop, backdropbox)
|
||||
world.fill(BLUE)
|
||||
```
|
||||
|
||||
最后,告诉 Pygame 来刷新在屏幕上的所有内容并推进游戏的内部时钟。
|
||||
最后,告诉 Pygame 来重新刷新屏幕上的所有内容,并推进游戏的内部时钟。
|
||||
|
||||
```
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
保存你的文件,再次运行它来查看曾经创建的最无趣的游戏。
|
||||
保存你的文件,再次运行它来查看你曾经创建的最无趣的游戏。
|
||||
|
||||
退出游戏,在你的键盘上按 `q` 键。
|
||||
|
||||
在这系列的 [下一篇文章][9] 中,我将向你演示,如何加强你当前空的游戏世界,所以,继续学习并创建一些将要使用的图形!
|
||||
在这系列的 [下一篇文章][9] 中,我将向你演示,如何加强你当前空空如也的游戏世界,所以,继续学习并创建一些将要使用的图形!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
通过: https://opensource.com/article/17/12/game-framework-python
|
||||
via: https://opensource.com/article/17/12/game-framework-python
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/10/python-101
|
||||
[1]: https://linux.cn/article-9071-1.html
|
||||
[2]: http://www.pygame.org/wiki/about
|
||||
[3]: https://en.wikipedia.org/wiki/IDLE
|
||||
[4]: http://ninja-ide.org/
|
||||
163
published/20171215 How to add a player to your Python game.md
Normal file
163
published/20171215 How to add a player to your Python game.md
Normal file
@ -0,0 +1,163 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cycoe)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10858-1.html)
|
||||
[#]: subject: (How to add a player to your Python game)
|
||||
[#]: via: (https://opensource.com/article/17/12/game-python-add-a-player)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何在你的 Python 游戏中添加一个玩家
|
||||
======
|
||||
> 这是用 Python 从头开始构建游戏的系列文章的第三部分。
|
||||
|
||||

|
||||
|
||||
在 [这个系列的第一篇文章][1] 中,我解释了如何使用 Python 创建一个简单的基于文本的骰子游戏。在第二部分中,我向你们展示了如何从头开始构建游戏,即从 [创建游戏的环境][2] 开始。但是每个游戏都需要一名玩家,并且每个玩家都需要一个可操控的角色,这也就是我们接下来要在这个系列的第三部分中需要做的。
|
||||
|
||||
在 Pygame 中,玩家操控的图标或者化身被称作<ruby>妖精<rt>sprite</rt></ruby>。如果你现在还没有任何可用于玩家妖精的图像,你可以使用 [Krita][3] 或 [Inkscape][4] 来自己创建一些图像。如果你对自己的艺术细胞缺乏自信,你也可以在 [OpenClipArt.org][5] 或 [OpenGameArt.org][6] 搜索一些现成的图像。如果你还未按照上一篇文章所说的单独创建一个 `images` 文件夹,那么你需要在你的 Python 项目目录中创建它。将你想要在游戏中使用的图片都放 `images` 文件夹中。
|
||||
|
||||
为了使你的游戏真正的刺激,你应该为你的英雄使用一张动态的妖精图片。这意味着你需要绘制更多的素材,并且它们要大不相同。最常见的动画就是走路循环,通过一系列的图像让你的妖精看起来像是在走路。走路循环最快捷粗糙的版本需要四张图像。
|
||||
|
||||
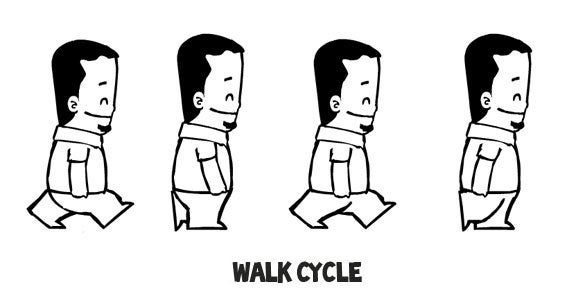
|
||||
|
||||
注意:这篇文章中的代码示例同时兼容静止的和动态的玩家妖精。
|
||||
|
||||
将你的玩家妖精命名为 `hero.png`。如果你正在创建一个动态的妖精,则需要在名字后面加上一个数字,从 `hero1.png` 开始。
|
||||
|
||||
### 创建一个 Python 类
|
||||
|
||||
在 Python 中,当你在创建一个你想要显示在屏幕上的对象时,你需要创建一个类。
|
||||
|
||||
在你的 Python 脚本靠近顶端的位置,加入如下代码来创建一个玩家。在以下的代码示例中,前三行已经在你正在处理的 Python 脚本中:
|
||||
|
||||
```
|
||||
import pygame
|
||||
import sys
|
||||
import os # 以下是新代码
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
生成一个玩家
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.images = []
|
||||
img = pygame.image.load(os.path.join('images','hero.png')).convert()
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
```
|
||||
|
||||
如果你的可操控角色拥有一个走路循环,在 `images` 文件夹中将对应图片保存为 `hero1.png` 到 `hero4.png` 的独立文件。
|
||||
|
||||
使用一个循环来告诉 Python 遍历每个文件。
|
||||
|
||||
```
|
||||
'''
|
||||
对象
|
||||
'''
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
生成一个玩家
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.images = []
|
||||
for i in range(1,5):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
```
|
||||
|
||||
### 将玩家带入游戏世界
|
||||
|
||||
现在已经创建好了一个 Player 类,你需要使用它在你的游戏世界中生成一个玩家妖精。如果你不调用 Player 类,那它永远不会起作用,(游戏世界中)也就不会有玩家。你可以通过立马运行你的游戏来验证一下。游戏会像上一篇文章末尾看到的那样运行,并得到明确的结果:一个空荡荡的游戏世界。
|
||||
|
||||
为了将一个玩家妖精带到你的游戏世界,你必须通过调用 Player 类来生成一个妖精,并将它加入到 Pygame 的妖精组中。在如下的代码示例中,前三行是已经存在的代码,你需要在其后添加代码:
|
||||
|
||||
```
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = screen.get_rect()
|
||||
|
||||
# 以下是新代码
|
||||
|
||||
player = Player() # 生成玩家
|
||||
player.rect.x = 0 # 移动 x 坐标
|
||||
player.rect.y = 0 # 移动 y 坐标
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
```
|
||||
|
||||
尝试启动你的游戏来看看发生了什么。高能预警:它不会像你预期的那样工作,当你启动你的项目,玩家妖精没有出现。事实上它生成了,只不过只出现了一毫秒。你要如何修复一个只出现了一毫秒的东西呢?你可能回想起上一篇文章中,你需要在主循环中添加一些东西。为了使玩家的存在时间超过一毫秒,你需要告诉 Python 在每次循环中都绘制一次。
|
||||
|
||||
将你的循环底部的语句更改如下:
|
||||
|
||||
```
|
||||
world.blit(backdrop, backdropbox)
|
||||
player_list.draw(screen) # 绘制玩家
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
现在启动你的游戏,你的玩家出现了!
|
||||
|
||||
### 设置 alpha 通道
|
||||
|
||||
根据你如何创建你的玩家妖精,在它周围可能会有一个色块。你所看到的是 alpha 通道应该占据的空间。它本来是不可见的“颜色”,但 Python 现在还不知道要使它不可见。那么你所看到的,是围绕在妖精周围的边界区(或现代游戏术语中的“<ruby>命中区<rt>hit box</rt></ruby>”)内的空间。
|
||||
|
||||

|
||||
|
||||
你可以通过设置一个 alpha 通道和 RGB 值来告诉 Python 使哪种颜色不可见。如果你不知道你使用 alpha 通道的图像的 RGB 值,你可以使用 Krita 或 Inkscape 打开它,并使用一种独特的颜色,比如 `#00ff00`(差不多是“绿屏绿”)来填充图像周围的空白区域。记下颜色对应的十六进制值(此处为 `#00ff00`,绿屏绿)并将其作为 alpha 通道用于你的 Python 脚本。
|
||||
|
||||
使用 alpha 通道需要在你的妖精生成相关代码中添加如下两行。类似第一行的代码已经存在于你的脚本中,你只需要添加另外两行:
|
||||
|
||||
```
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha() # 优化 alpha
|
||||
img.set_colorkey(ALPHA) # 设置 alpha
|
||||
```
|
||||
|
||||
除非你告诉它,否则 Python 不知道将哪种颜色作为 alpha 通道。在你代码的设置相关区域,添加一些颜色定义。将如下的变量定义添加于你的设置相关区域的任意位置:
|
||||
|
||||
```
|
||||
ALPHA = (0, 255, 0)
|
||||
```
|
||||
|
||||
在以上示例代码中,`0,255,0` 被我们使用,它在 RGB 中所代表的值与 `#00ff00` 在十六进制中所代表的值相同。你可以通过一个优秀的图像应用程序,如 [GIMP][7]、Krita 或 Inkscape,来获取所有这些颜色值。或者,你可以使用一个优秀的系统级颜色选择器,如 [KColorChooser][8],来检测颜色。
|
||||
|
||||
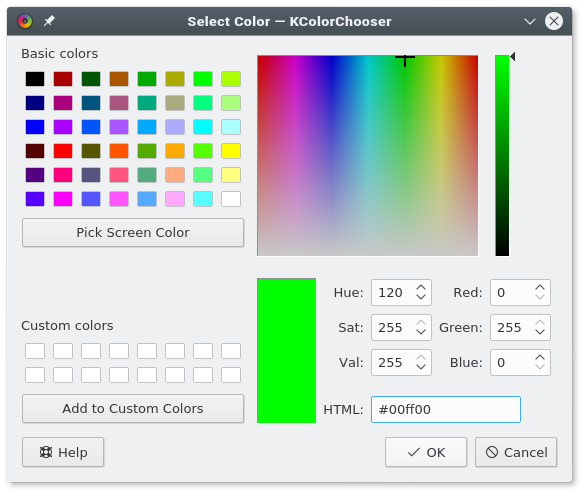
|
||||
|
||||
如果你的图像应用程序将你的妖精背景渲染成了其他的值,你可以按需调整 `ALPHA` 变量的值。不论你将 alpha 设为多少,最后它都将“不可见”。RGB 颜色值是非常严格的,因此如果你需要将 alpha 设为 000,但你又想将 000 用于你图像中的黑线,你只需要将图像中线的颜色设为 111。这样一来,(图像中的黑线)就足够接近黑色,但除了电脑以外没有人能看出区别。
|
||||
|
||||
运行你的游戏查看结果。
|
||||
|
||||

|
||||
|
||||
在 [这个系列的第四篇文章][9] 中,我会向你们展示如何使你的妖精动起来。多么的激动人心啊!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/game-python-add-a-player
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-9071-1.html
|
||||
[2]: https://linux.cn/article-10850-1.html
|
||||
[3]: http://krita.org
|
||||
[4]: http://inkscape.org
|
||||
[5]: http://openclipart.org
|
||||
[6]: https://opengameart.org/
|
||||
[7]: http://gimp.org
|
||||
[8]: https://github.com/KDE/kcolorchooser
|
||||
[9]: https://opensource.com/article/17/12/program-game-python-part-4-moving-your-sprite
|
||||
@ -1,21 +1,22 @@
|
||||
没有恶棍,英雄又将如何?如何向你的 Python 游戏中添加一个敌人
|
||||
如何向你的 Python 游戏中添加一个敌人
|
||||
======
|
||||
|
||||
> 在本系列的第五部分,学习如何增加一个坏蛋与你的好人战斗。
|
||||
|
||||

|
||||
|
||||
在本系列的前几篇文章中(参见 [第一部分][1]、[第二部分][2]、[第三部分][3] 以及 [第四部分][4]),你已经学习了如何使用 Pygame 和 Python 在一个空白的视频游戏世界中生成一个可玩的角色。但没有恶棍,英雄又将如何?
|
||||
|
||||
如果你没有敌人,那将会是一个非常无聊的游戏。所以在此篇文章中,你将为你的游戏添加一个敌人并构建一个用于创建关卡的框架。
|
||||
|
||||
在对玩家妖精实现全部功能仍有许多事情可做之前,跳向敌人似乎就很奇怪。但你已经学到了很多东西,创造恶棍与与创造玩家妖精非常相似。所以放轻松,使用你已经掌握的知识,看看能挑起怎样一些麻烦。
|
||||
在对玩家妖精实现全部功能之前,就来实现一个敌人似乎就很奇怪。但你已经学到了很多东西,创造恶棍与与创造玩家妖精非常相似。所以放轻松,使用你已经掌握的知识,看看能挑起怎样一些麻烦。
|
||||
|
||||
针对本次训练,你能够从 [Open Game Art][5] 下载一些预创建的素材。此处是我使用的一些素材:
|
||||
|
||||
|
||||
+ 印加花砖(译注:游戏中使用的花砖贴图)
|
||||
+ 印加花砖(LCTT 译注:游戏中使用的花砖贴图)
|
||||
+ 一些侵略者
|
||||
+ 妖精、角色、物体以及特效
|
||||
|
||||
|
||||
### 创造敌方妖精
|
||||
|
||||
是的,不管你意识到与否,你其实已经知道如何去实现敌人。这个过程与创造一个玩家妖精非常相似:
|
||||
@ -24,40 +25,27 @@
|
||||
2. 创建 `update` 方法使得敌人能够检测碰撞
|
||||
3. 创建 `move` 方法使得敌人能够四处游荡
|
||||
|
||||
|
||||
|
||||
从类入手。从概念上看,它与你的 Player 类大体相同。你设置一张或者一组图片,然后设置妖精的初始位置。
|
||||
从类入手。从概念上看,它与你的 `Player` 类大体相同。你设置一张或者一组图片,然后设置妖精的初始位置。
|
||||
|
||||
在继续下一步之前,确保你有一张你的敌人的图像,即使只是一张临时图像。将图像放在你的游戏项目的 `images` 目录(你放置你的玩家图像的相同目录)。
|
||||
|
||||
如果所有的活物都拥有动画,那么游戏看起来会好得多。为敌方妖精设置动画与为玩家妖精设置动画具有相同的方式。但现在,为了保持简单,我们使用一个没有动画的妖精。
|
||||
|
||||
在你代码 `objects` 节的顶部,使用以下代码创建一个叫做 `Enemy` 的类:
|
||||
|
||||
```
|
||||
class Enemy(pygame.sprite.Sprite):
|
||||
|
||||
'''
|
||||
|
||||
生成一个敌人
|
||||
|
||||
'''
|
||||
|
||||
def __init__(self,x,y,img):
|
||||
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
|
||||
self.image = pygame.image.load(os.path.join('images',img))
|
||||
|
||||
self.image.convert_alpha()
|
||||
|
||||
self.image.set_colorkey(ALPHA)
|
||||
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
self.rect.x = x
|
||||
|
||||
self.rect.y = y
|
||||
|
||||
```
|
||||
|
||||
如果你想让你的敌人动起来,使用让你的玩家拥有动画的 [相同方式][4]。
|
||||
@ -67,25 +55,21 @@ class Enemy(pygame.sprite.Sprite):
|
||||
你能够通过告诉类,妖精应使用哪张图像,应出现在世界上的什么地方,来生成不只一个敌人。这意味着,你能够使用相同的敌人类,在游戏世界的任意地方生成任意数量的敌方妖精。你需要做的仅仅是调用这个类,并告诉它应使用哪张图像,以及你期望生成点的 X 和 Y 坐标。
|
||||
|
||||
再次,这从原则上与生成一个玩家精灵相似。在你脚本的 `setup` 节添加如下代码:
|
||||
|
||||
```
|
||||
enemy = Enemy(20,200,'yeti.png') # 生成敌人
|
||||
|
||||
enemy_list = pygame.sprite.Group() # 创建敌人组
|
||||
|
||||
enemy_list.add(enemy) # 将敌人加入敌人组
|
||||
|
||||
```
|
||||
|
||||
在示例代码中,X 坐标为 20,Y 坐标为 200。你可能需要根据你的敌方妖精的大小,来调整这些数字,但尽量生成在一个地方,使得你的玩家妖精能够到它。`Yeti.png` 是用于敌人的图像。
|
||||
在示例代码中,X 坐标为 20,Y 坐标为 200。你可能需要根据你的敌方妖精的大小,来调整这些数字,但尽量生成在一个范围内,使得你的玩家妖精能够碰到它。`Yeti.png` 是用于敌人的图像。
|
||||
|
||||
接下来,将敌人组的所有敌人绘制在屏幕上。现在,你只有一个敌人,如果你想要更多你可以稍后添加。一但你将一个敌人加入敌人组,它就会在主循环中被绘制在屏幕上。中间这一行是你需要添加的新行:
|
||||
|
||||
```
|
||||
player_list.draw(world)
|
||||
|
||||
enemy_list.draw(world) # 刷新敌人
|
||||
|
||||
pygame.display.flip()
|
||||
|
||||
```
|
||||
|
||||
启动你的游戏,你的敌人会出现在游戏世界中你选择的 X 和 Y 坐标处。
|
||||
@ -96,42 +80,31 @@ enemy_list.add(enemy) # 将敌人加入敌人组
|
||||
|
||||
思考一下“关卡”是什么。你如何知道你是在游戏中的一个特定关卡中呢?
|
||||
|
||||
你可以把关卡想成一系列项目的集合。就像你刚刚创建的这个平台中,一个关卡,包含了平台、敌人放置、赃物等的一个特定排列。你可以创建一个类,用来在你的玩家附近创建关卡。最终,当你创建了超过一个关卡,你就可以在你的玩家达到特定目标时,使用这个类生成下一个关卡。
|
||||
你可以把关卡想成一系列项目的集合。就像你刚刚创建的这个平台中,一个关卡,包含了平台、敌人放置、战利品等的一个特定排列。你可以创建一个类,用来在你的玩家附近创建关卡。最终,当你创建了一个以上的关卡,你就可以在你的玩家达到特定目标时,使用这个类生成下一个关卡。
|
||||
|
||||
将你写的用于生成敌人及其群组的代码,移动到一个每次生成新关卡时都会被调用的新函数中。你需要做一些修改,使得每次你创建新关卡时,你都能够创建一些敌人。
|
||||
|
||||
```
|
||||
class Level():
|
||||
|
||||
def bad(lvl,eloc):
|
||||
|
||||
if lvl == 1:
|
||||
|
||||
enemy = Enemy(eloc[0],eloc[1],'yeti.png') # 生成敌人
|
||||
|
||||
enemy_list = pygame.sprite.Group() # 生成敌人组
|
||||
|
||||
enemy_list.add(enemy) # 将敌人加入敌人组
|
||||
|
||||
if lvl == 2:
|
||||
|
||||
print("Level " + str(lvl) )
|
||||
|
||||
|
||||
|
||||
return enemy_list
|
||||
|
||||
```
|
||||
|
||||
`return` 语句确保了当你调用 `Level.bad` 方法时,你将会得到一个 `enemy_list` 变量包含了所有你定义的敌人。
|
||||
|
||||
因为你现在将创造敌人作为每个关卡的一部分,你的 `setup` 部分也需要做些更改。不同于创造一个敌人,取而代之的是你必须去定义敌人在那里生成,以及敌人属于哪个关卡。
|
||||
|
||||
```
|
||||
eloc = []
|
||||
|
||||
eloc = [200,20]
|
||||
|
||||
enemy_list = Level.bad( 1, eloc )
|
||||
|
||||
```
|
||||
|
||||
再次运行游戏来确认你的关卡生成正确。与往常一样,你应该会看到你的玩家,并且能看到你在本章节中添加的敌人。
|
||||
@ -140,31 +113,27 @@ enemy_list = Level.bad( 1, eloc )
|
||||
|
||||
一个敌人如果对玩家没有效果,那么它不太算得上是一个敌人。当玩家与敌人发生碰撞时,他们通常会对玩家造成伤害。
|
||||
|
||||
因为你可能想要去跟踪玩家的生命值,因此碰撞检测发生在 Player 类,而不是 Enemy 类中。当然如果你想,你也可以跟踪敌人的生命值。它们之间的逻辑与代码大体相似,现在,我们只需要跟踪玩家的生命值。
|
||||
因为你可能想要去跟踪玩家的生命值,因此碰撞检测发生在 `Player` 类,而不是 `Enemy` 类中。当然如果你想,你也可以跟踪敌人的生命值。它们之间的逻辑与代码大体相似,现在,我们只需要跟踪玩家的生命值。
|
||||
|
||||
为了跟踪玩家的生命值,你必须为它确定一个变量。代码示例中的第一行是上下文提示,那么将第二行代码添加到你的 Player 类中:
|
||||
|
||||
```
|
||||
self.frame = 0
|
||||
|
||||
self.health = 10
|
||||
|
||||
```
|
||||
|
||||
在你 Player 类的 `update` 方法中,添加如下代码块:
|
||||
在你 `Player` 类的 `update` 方法中,添加如下代码块:
|
||||
|
||||
```
|
||||
hit_list = pygame.sprite.spritecollide(self, enemy_list, False)
|
||||
|
||||
for enemy in hit_list:
|
||||
|
||||
self.health -= 1
|
||||
|
||||
print(self.health)
|
||||
|
||||
```
|
||||
|
||||
这段代码使用 Pygame 的 `sprite.spritecollide` 方法,建立了一个碰撞检测器,称作 `enemy_hit`。每当它的父类妖精(生成检测器的玩家妖精)的碰撞区触碰到 `enemy_list` 中的任一妖精的碰撞区时,碰撞检测器都会发出一个信号。当这个信号被接收,`for` 循环就会被触发,同时扣除一点玩家生命值。
|
||||
|
||||
一旦这段代码出现在你 Player 类的 `update` 方法,并且 `update` 方法在你的主循环中被调用,Pygame 会在每个时钟 tick 检测一次碰撞。
|
||||
一旦这段代码出现在你 `Player` 类的 `update` 方法,并且 `update` 方法在你的主循环中被调用,Pygame 会在每个时钟滴答中检测一次碰撞。
|
||||
|
||||
### 移动敌人
|
||||
|
||||
@ -176,60 +145,41 @@ enemy_list = Level.bad( 1, eloc )
|
||||
|
||||
举个例子,你告诉你的敌方妖精向右移动 10 步,向左移动 10 步。但敌方妖精不会计数,因此你需要创建一个变量来跟踪你的敌人已经移动了多少步,并根据计数变量的值来向左或向右移动你的敌人。
|
||||
|
||||
首先,在你的 Enemy 类中创建计数变量。添加以下代码示例中的最后一行代码:
|
||||
首先,在你的 `Enemy` 类中创建计数变量。添加以下代码示例中的最后一行代码:
|
||||
|
||||
```
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
self.rect.x = x
|
||||
|
||||
self.rect.y = y
|
||||
|
||||
self.counter = 0 # 计数变量
|
||||
|
||||
```
|
||||
|
||||
然后,在你的 Enemy 类中创建一个 `move` 方法。使用 if-else 循环来创建一个所谓的死循环:
|
||||
然后,在你的 `Enemy` 类中创建一个 `move` 方法。使用 if-else 循环来创建一个所谓的死循环:
|
||||
|
||||
* 如果计数在 0 到 100 之间,向右移动;
|
||||
* 如果计数在 100 到 200 之间,向左移动;
|
||||
* 如果计数大于 200,则将计数重置为 0。
|
||||
|
||||
|
||||
|
||||
死循环没有终点,因为循环判断条件永远为真,所以它将永远循环下去。在此情况下,计数器总是介于 0 到 100 或 100 到 200 之间,因此敌人会永远地从左向右再从右向左移动。
|
||||
|
||||
你用于敌人在每个方向上移动距离的具体值,取决于你的屏幕尺寸,更确切地说,取决于你的敌人移动的平台大小。从较小的值开始,依据习惯逐步提高数值。首先进行如下尝试:
|
||||
|
||||
```
|
||||
def move(self):
|
||||
|
||||
'''
|
||||
|
||||
敌人移动
|
||||
|
||||
'''
|
||||
|
||||
distance = 80
|
||||
|
||||
speed = 8
|
||||
|
||||
|
||||
|
||||
if self.counter >= 0 and self.counter <= distance:
|
||||
|
||||
self.rect.x += speed
|
||||
|
||||
elif self.counter >= distance and self.counter <= distance*2:
|
||||
|
||||
self.rect.x -= speed
|
||||
|
||||
else:
|
||||
|
||||
self.counter = 0
|
||||
|
||||
|
||||
|
||||
self.counter += 1
|
||||
|
||||
```
|
||||
|
||||
你可以根据需要调整距离和速度。
|
||||
@ -237,13 +187,11 @@ enemy_list = Level.bad( 1, eloc )
|
||||
当你现在启动游戏,这段代码有效果吗?
|
||||
|
||||
当然不,你应该也知道原因。你必须在主循环中调用 `move` 方法。如下示例代码中的第一行是上下文提示,那么添加最后两行代码:
|
||||
|
||||
```
|
||||
enemy_list.draw(world) #refresh enemy
|
||||
|
||||
for e in enemy_list:
|
||||
|
||||
e.move()
|
||||
|
||||
```
|
||||
|
||||
启动你的游戏看看当你打击敌人时发生了什么。你可能需要调整妖精的生成地点,使得你的玩家和敌人能够碰撞。当他们发生碰撞时,查看 [IDLE][6] 或 [Ninja-IDE][7] 的控制台,你可以看到生命值正在被扣除。
|
||||
@ -261,15 +209,15 @@ via: https://opensource.com/article/18/5/pygame-enemy
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:https://opensource.com/article/17/10/python-101
|
||||
[2]:https://opensource.com/article/17/12/game-framework-python
|
||||
[3]:https://opensource.com/article/17/12/game-python-add-a-player
|
||||
[4]:https://opensource.com/article/17/12/game-python-moving-player
|
||||
[1]:https://linux.cn/article-9071-1.html
|
||||
[2]:https://linux.cn/article-10850-1.html
|
||||
[3]:https://linux.cn/article-10858-1.html
|
||||
[4]:https://linux.cn/article-10874-1.html
|
||||
[5]:https://opengameart.org
|
||||
[6]:https://docs.python.org/3/library/idle.html
|
||||
[7]:http://ninja-ide.org/
|
||||
@ -0,0 +1,596 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10848-1.html)
|
||||
[#]: subject: (TLP – An Advanced Power Management Tool That Improve Battery Life On Linux Laptop)
|
||||
[#]: via: (https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
TLP:一个可以延长 Linux 笔记本电池寿命的高级电源管理工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
笔记本电池是针对 Windows 操作系统进行了高度优化的,当我在笔记本电脑中使用 Windows 操作系统时,我已经意识到这一点,但对于 Linux 来说却不一样。
|
||||
|
||||
多年来,Linux 在电池优化方面取得了很大进步,但我们仍然需要做一些必要的事情来改善 Linux 中笔记本电脑的电池寿命。
|
||||
|
||||
当我考虑延长电池寿命时,我没有多少选择,但我觉得 TLP 对我来说是一个更好的解决方案,所以我会继续使用它。
|
||||
|
||||
在本教程中,我们将详细讨论 TLP 以延长电池寿命。
|
||||
|
||||
我们之前在我们的网站上写过三篇关于 Linux [笔记本电池节电工具][1] 的文章:[PowerTOP][2] 和 [电池充电状态][3]。
|
||||
|
||||
### TLP
|
||||
|
||||
[TLP][4] 是一款自由开源的高级电源管理工具,可在不进行任何配置更改的情况下延长电池寿命。
|
||||
|
||||
由于它的默认配置已针对电池寿命进行了优化,因此你可能只需要安装,然后就忘记它吧。
|
||||
|
||||
此外,它可以高度定制化,以满足你的特定要求。TLP 是一个具有自动后台任务的纯命令行工具。它不包含GUI。
|
||||
|
||||
TLP 适用于各种品牌的笔记本电脑。设置电池充电阈值仅适用于 IBM/Lenovo ThinkPad。
|
||||
|
||||
所有 TLP 设置都存储在 `/etc/default/tlp` 中。其默认配置提供了开箱即用的优化的节能设置。
|
||||
|
||||
以下 TLP 设置可用于自定义,如果需要,你可以相应地进行必要的更改。
|
||||
|
||||
### TLP 功能
|
||||
|
||||
* 内核笔记本电脑模式和脏缓冲区超时
|
||||
* 处理器频率调整,包括 “turbo boost”/“turbo core”
|
||||
* 限制最大/最小的 P 状态以控制 CPU 的功耗
|
||||
* HWP 能源性能提示
|
||||
* 用于多核/超线程的功率感知进程调度程序
|
||||
* 处理器性能与节能策略(`x86_energy_perf_policy`)
|
||||
* 硬盘高级电源管理级别(APM)和降速超时(按磁盘)
|
||||
* AHCI 链路电源管理(ALPM)与设备黑名单
|
||||
* PCIe 活动状态电源管理(PCIe ASPM)
|
||||
* PCI(e) 总线设备的运行时电源管理
|
||||
* Radeon 图形电源管理(KMS 和 DPM)
|
||||
* Wifi 省电模式
|
||||
* 关闭驱动器托架中的光盘驱动器
|
||||
* 音频省电模式
|
||||
* I/O 调度程序(按磁盘)
|
||||
* USB 自动暂停,支持设备黑名单/白名单(输入设备自动排除)
|
||||
* 在系统启动和关闭时启用或禁用集成的 wifi、蓝牙或 wwan 设备
|
||||
* 在系统启动时恢复无线电设备状态(从之前的关机时的状态)
|
||||
* 无线电设备向导:在网络连接/断开和停靠/取消停靠时切换无线电
|
||||
* 禁用 LAN 唤醒
|
||||
* 挂起/休眠后恢复集成的 WWAN 和蓝牙状态
|
||||
* 英特尔处理器的动态电源降低 —— 需要内核和 PHC-Patch 支持
|
||||
* 电池充电阈值 —— 仅限 ThinkPad
|
||||
* 重新校准电池 —— 仅限 ThinkPad
|
||||
|
||||
### 如何在 Linux 上安装 TLP
|
||||
|
||||
TLP 包在大多数发行版官方存储库中都可用,因此,使用发行版的 [包管理器][5] 来安装它。
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 命令][6] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo dnf install tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPad 需要一些附加软件包。
|
||||
|
||||
```
|
||||
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
|
||||
$ sudo dnf install http://repo.linrunner.de/fedora/tlp/repos/releases/tlp-release.fc$(rpm -E %fedora).noarch.rpm
|
||||
$ sudo dnf install akmod-tp_smapi akmod-acpi_call kernel-devel
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo dnf install smartmontools
|
||||
```
|
||||
|
||||
对于 Debian/Ubuntu 系统,使用 [APT-GET 命令][7] 或 [APT 命令][8] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo apt install tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPad 需要一些附加软件包。
|
||||
|
||||
```
|
||||
$ sudo apt-get install tp-smapi-dkms acpi-call-dkms
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo apt-get install smartmontools
|
||||
```
|
||||
|
||||
当基于 Ubuntu 的系统的官方软件包过时时,请使用以下 PPA 存储库,该存储库提供最新版本。运行以下命令以使用 PPA 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:linrunner/tlp
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install tlp
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,使用 [Pacman 命令][9] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo pacman -S tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPad 需要一些附加软件包。
|
||||
|
||||
```
|
||||
$ pacman -S tp_smapi acpi_call
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo pacman -S smartmontools
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,在启动时启用 TLP 和 TLP-Sleep 服务。
|
||||
|
||||
```
|
||||
$ sudo systemctl enable tlp.service
|
||||
$ sudo systemctl enable tlp-sleep.service
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统,你还应该屏蔽以下服务以避免冲突,并确保 TLP 的无线电设备切换选项的正确操作。
|
||||
|
||||
```
|
||||
$ sudo systemctl mask systemd-rfkill.service
|
||||
$ sudo systemctl mask systemd-rfkill.socket
|
||||
```
|
||||
|
||||
对于 RHEL/CentOS 系统,使用 [YUM 命令][10] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo yum install tlp tlp-rdw
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo yum install smartmontools
|
||||
```
|
||||
|
||||
对于 openSUSE Leap 系统,使用 [Zypper 命令][11] 安装 TLP。
|
||||
|
||||
```
|
||||
$ sudo zypper install TLP
|
||||
```
|
||||
|
||||
安装 smartmontool 以显示 tlp-stat 中 S.M.A.R.T. 数据。
|
||||
|
||||
```
|
||||
$ sudo zypper install smartmontools
|
||||
```
|
||||
|
||||
成功安装 TLP 后,使用以下命令启动服务。
|
||||
|
||||
```
|
||||
$ systemctl start tlp.service
|
||||
```
|
||||
|
||||
### 使用方法
|
||||
|
||||
#### 显示电池信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -b
|
||||
或
|
||||
$ sudo tlp-stat --battery
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Battery Status
|
||||
/sys/class/power_supply/BAT0/manufacturer = SMP
|
||||
/sys/class/power_supply/BAT0/model_name = L14M4P23
|
||||
/sys/class/power_supply/BAT0/cycle_count = (not supported)
|
||||
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_full = 48850 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_now = 48850 [mWh]
|
||||
/sys/class/power_supply/BAT0/power_now = 0 [mW]
|
||||
/sys/class/power_supply/BAT0/status = Full
|
||||
|
||||
Charge = 100.0 [%]
|
||||
Capacity = 81.4 [%]
|
||||
```
|
||||
|
||||
#### 显示磁盘信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -d
|
||||
或
|
||||
$ sudo tlp-stat --disk
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Storage Devices
|
||||
/dev/sda:
|
||||
Model = WDC WD10SPCX-24HWST1
|
||||
Firmware = 02.01A02
|
||||
APM Level = 128
|
||||
Status = active/idle
|
||||
Scheduler = mq-deadline
|
||||
|
||||
Runtime PM: control = on, autosuspend_delay = (not available)
|
||||
|
||||
SMART info:
|
||||
4 Start_Stop_Count = 18787
|
||||
5 Reallocated_Sector_Ct = 0
|
||||
9 Power_On_Hours = 606 [h]
|
||||
12 Power_Cycle_Count = 1792
|
||||
193 Load_Cycle_Count = 25775
|
||||
194 Temperature_Celsius = 31 [°C]
|
||||
|
||||
|
||||
+++ AHCI Link Power Management (ALPM)
|
||||
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
|
||||
|
||||
+++ AHCI Host Controller Runtime Power Management
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
|
||||
```
|
||||
|
||||
#### 显示 PCI 设备信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -e
|
||||
或
|
||||
$ sudo tlp-stat --pcie
|
||||
```
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -e
|
||||
or
|
||||
$ sudo tlp-stat --pcie
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Runtime Power Management
|
||||
Device blacklist = (not configured)
|
||||
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
|
||||
|
||||
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
|
||||
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
|
||||
/sys/bus/pci/devices/0000:00:14.0/power/control = auto (0x0c0330, USB controller, xhci_hcd)
|
||||
|
||||
......
|
||||
```
|
||||
|
||||
#### 显示图形卡信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -g
|
||||
或
|
||||
$ sudo tlp-stat --graphics
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Intel Graphics
|
||||
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
|
||||
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
|
||||
/sys/module/i915/parameters/enable_psr = 0 (disabled)
|
||||
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
|
||||
```
|
||||
|
||||
#### 显示处理器信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -p
|
||||
或
|
||||
$ sudo tlp-stat --processor
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Processor
|
||||
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
......
|
||||
|
||||
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
|
||||
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
|
||||
|
||||
x86_energy_perf_policy: program not installed.
|
||||
|
||||
/sys/module/workqueue/parameters/power_efficient = Y
|
||||
/proc/sys/kernel/nmi_watchdog = 0
|
||||
|
||||
+++ Undervolting
|
||||
PHC kernel not available.
|
||||
```
|
||||
|
||||
#### 显示系统数据信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -s
|
||||
或
|
||||
$ sudo tlp-stat --system
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ System Info
|
||||
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
|
||||
BIOS = CDCN35WW
|
||||
Release = "Manjaro Linux"
|
||||
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
|
||||
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
|
||||
Init system = systemd
|
||||
Boot mode = BIOS (CSM, Legacy)
|
||||
|
||||
+++ TLP Status
|
||||
State = enabled
|
||||
Last run = 11:04:00 IST, 596 sec(s) ago
|
||||
Mode = battery
|
||||
Power source = battery
|
||||
```
|
||||
|
||||
#### 显示温度和风扇速度信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -t
|
||||
或
|
||||
$ sudo tlp-stat --temp
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Temperatures
|
||||
CPU temp = 36 [°C]
|
||||
Fan speed = (not available)
|
||||
```
|
||||
|
||||
#### 显示 USB 设备数据信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -u
|
||||
或
|
||||
$ sudo tlp-stat --usb
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ USB
|
||||
Autosuspend = disabled
|
||||
Device whitelist = (not configured)
|
||||
Device blacklist = (not configured)
|
||||
Bluetooth blacklist = disabled
|
||||
Phone blacklist = disabled
|
||||
WWAN blacklist = enabled
|
||||
|
||||
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
|
||||
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
|
||||
|
||||
......
|
||||
```
|
||||
|
||||
#### 显示警告信息
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -w
|
||||
或
|
||||
$ sudo tlp-stat --warn
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
No warnings detected.
|
||||
```
|
||||
|
||||
#### 状态报告及配置和所有活动的设置
|
||||
|
||||
```
|
||||
$ sudo tlp-stat
|
||||
```
|
||||
|
||||
```
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Configured Settings: /etc/default/tlp
|
||||
TLP_ENABLE=1
|
||||
TLP_DEFAULT_MODE=AC
|
||||
TLP_PERSISTENT_DEFAULT=0
|
||||
DISK_IDLE_SECS_ON_AC=0
|
||||
DISK_IDLE_SECS_ON_BAT=2
|
||||
MAX_LOST_WORK_SECS_ON_AC=15
|
||||
MAX_LOST_WORK_SECS_ON_BAT=60
|
||||
|
||||
......
|
||||
|
||||
+++ System Info
|
||||
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
|
||||
BIOS = CDCN35WW
|
||||
Release = "Manjaro Linux"
|
||||
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
|
||||
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
|
||||
Init system = systemd
|
||||
Boot mode = BIOS (CSM, Legacy)
|
||||
|
||||
+++ TLP Status
|
||||
State = enabled
|
||||
Last run = 11:04:00 IST, 684 sec(s) ago
|
||||
Mode = battery
|
||||
Power source = battery
|
||||
|
||||
+++ Processor
|
||||
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
|
||||
|
||||
......
|
||||
|
||||
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
|
||||
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
|
||||
|
||||
x86_energy_perf_policy: program not installed.
|
||||
|
||||
/sys/module/workqueue/parameters/power_efficient = Y
|
||||
/proc/sys/kernel/nmi_watchdog = 0
|
||||
|
||||
+++ Undervolting
|
||||
PHC kernel not available.
|
||||
|
||||
+++ Temperatures
|
||||
CPU temp = 42 [°C]
|
||||
Fan speed = (not available)
|
||||
|
||||
+++ File System
|
||||
/proc/sys/vm/laptop_mode = 2
|
||||
/proc/sys/vm/dirty_writeback_centisecs = 6000
|
||||
/proc/sys/vm/dirty_expire_centisecs = 6000
|
||||
/proc/sys/vm/dirty_ratio = 20
|
||||
/proc/sys/vm/dirty_background_ratio = 10
|
||||
|
||||
+++ Storage Devices
|
||||
/dev/sda:
|
||||
Model = WDC WD10SPCX-24HWST1
|
||||
Firmware = 02.01A02
|
||||
APM Level = 128
|
||||
Status = active/idle
|
||||
Scheduler = mq-deadline
|
||||
|
||||
Runtime PM: control = on, autosuspend_delay = (not available)
|
||||
|
||||
SMART info:
|
||||
4 Start_Stop_Count = 18787
|
||||
5 Reallocated_Sector_Ct = 0
|
||||
9 Power_On_Hours = 606 [h]
|
||||
12 Power_Cycle_Count = 1792
|
||||
193 Load_Cycle_Count = 25777
|
||||
194 Temperature_Celsius = 31 [°C]
|
||||
|
||||
|
||||
+++ AHCI Link Power Management (ALPM)
|
||||
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
|
||||
|
||||
+++ AHCI Host Controller Runtime Power Management
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
|
||||
|
||||
+++ PCIe Active State Power Management
|
||||
/sys/module/pcie_aspm/parameters/policy = powersave
|
||||
|
||||
+++ Intel Graphics
|
||||
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
|
||||
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
|
||||
/sys/module/i915/parameters/enable_psr = 0 (disabled)
|
||||
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
|
||||
|
||||
+++ Wireless
|
||||
bluetooth = on
|
||||
wifi = on
|
||||
wwan = none (no device)
|
||||
|
||||
hci0(btusb) : bluetooth, not connected
|
||||
wlp8s0(iwlwifi) : wifi, connected, power management = on
|
||||
|
||||
+++ Audio
|
||||
/sys/module/snd_hda_intel/parameters/power_save = 1
|
||||
/sys/module/snd_hda_intel/parameters/power_save_controller = Y
|
||||
|
||||
+++ Runtime Power Management
|
||||
Device blacklist = (not configured)
|
||||
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
|
||||
|
||||
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
|
||||
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
|
||||
|
||||
......
|
||||
|
||||
+++ USB
|
||||
Autosuspend = disabled
|
||||
Device whitelist = (not configured)
|
||||
Device blacklist = (not configured)
|
||||
Bluetooth blacklist = disabled
|
||||
Phone blacklist = disabled
|
||||
WWAN blacklist = enabled
|
||||
|
||||
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
|
||||
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
|
||||
Bus 001 Device 002 ID 17ef:6053 control = on, autosuspend_delay_ms = 2000 -- Lenovo (usbhid)
|
||||
Bus 001 Device 004 ID 8087:0a2b control = auto, autosuspend_delay_ms = 2000 -- Intel Corp. (btusb)
|
||||
Bus 001 Device 001 ID 1d6b:0002 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 2.0 root hub (hub)
|
||||
|
||||
+++ Battery Status
|
||||
/sys/class/power_supply/BAT0/manufacturer = SMP
|
||||
/sys/class/power_supply/BAT0/model_name = L14M4P23
|
||||
/sys/class/power_supply/BAT0/cycle_count = (not supported)
|
||||
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_full = 51690 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_now = 50140 [mWh]
|
||||
/sys/class/power_supply/BAT0/power_now = 12185 [mW]
|
||||
/sys/class/power_supply/BAT0/status = Discharging
|
||||
|
||||
Charge = 97.0 [%]
|
||||
Capacity = 86.2 [%]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/check-laptop-battery-status-and-charging-state-in-linux-terminal/
|
||||
[2]: https://www.2daygeek.com/powertop-monitors-laptop-battery-usage-linux/
|
||||
[3]: https://www.2daygeek.com/monitor-laptop-battery-charging-state-linux/
|
||||
[4]: https://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html
|
||||
[5]: https://www.2daygeek.com/category/package-management/
|
||||
[6]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,354 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cycoe)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10874-1.html)
|
||||
[#]: subject: (Using Pygame to move your game character around)
|
||||
[#]: via: (https://opensource.com/article/17/12/game-python-moving-player)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Pygame 使你的游戏角色移动起来
|
||||
======
|
||||
> 在本系列的第四部分,学习如何编写移动游戏角色的控制代码。
|
||||
|
||||

|
||||
|
||||
在这个系列的第一篇文章中,我解释了如何使用 Python 创建一个简单的[基于文本的骰子游戏][1]。在第二部分中,我向你们展示了如何从头开始构建游戏,即从 [创建游戏的环境][2] 开始。然后在第三部分,我们[创建了一个玩家妖精][3],并且使它在你的(而不是空的)游戏世界内生成。你可能已经注意到,如果你不能移动你的角色,那么游戏不是那么有趣。在本篇文章中,我们将使用 Pygame 来添加键盘控制,如此一来你就可以控制你的角色的移动。
|
||||
|
||||
在 Pygame 中有许多函数可以用来添加(除键盘外的)其他控制,但如果你正在敲击 Python 代码,那么你一定是有一个键盘的,这将成为我们接下来会使用的控制方式。一旦你理解了键盘控制,你可以自己去探索其他选项。
|
||||
|
||||
在本系列的第二篇文章中,你已经为退出游戏创建了一个按键,移动角色的(按键)原则也是相同的。但是,使你的角色移动起来要稍微复杂一点。
|
||||
|
||||
让我们从简单的部分入手:设置控制器按键。
|
||||
|
||||
### 为控制你的玩家妖精设置按键
|
||||
|
||||
在 IDLE、Ninja-IDE 或文本编辑器中打开你的 Python 游戏脚本。
|
||||
|
||||
因为游戏需要时刻“监听”键盘事件,所以你写的代码需要连续运行。你知道应该把需要在游戏周期中持续运行的代码放在哪里吗?
|
||||
|
||||
如果你回答“放在主循环中”,那么你是正确的!记住除非代码在循环中,否则(大多数情况下)它只会运行仅一次。如果它被写在一个从未被使用的类或函数中,它可能根本不会运行。
|
||||
|
||||
要使 Python 监听传入的按键,将如下代码添加到主循环。目前的代码还不能产生任何的效果,所以使用 `print` 语句来表示成功的信号。这是一种常见的调试技术。
|
||||
|
||||
```
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
print('left')
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
print('right')
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
print('left stop')
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
print('right stop')
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
```
|
||||
|
||||
一些人偏好使用键盘字母 `W`、`A`、`S` 和 `D` 来控制玩家角色,而另一些偏好使用方向键。因此确保你包含了两种选项。
|
||||
|
||||
注意:当你在编程时,同时考虑所有用户是非常重要的。如果你写代码只是为了自己运行,那么很可能你会成为你写的程序的唯一用户。更重要的是,如果你想找一个通过写代码赚钱的工作,你写的代码就应该让所有人都能运行。给你的用户选择权,比如提供使用方向键或 WASD 的选项,是一个优秀程序员的标志。
|
||||
|
||||
使用 Python 启动你的游戏,并在你按下“上下左右”方向键或 `A`、`D` 和 `W` 键的时候查看控制台窗口的输出。
|
||||
|
||||
```
|
||||
$ python ./your-name_game.py
|
||||
left
|
||||
left stop
|
||||
right
|
||||
right stop
|
||||
jump
|
||||
```
|
||||
|
||||
这验证了 Pygame 可以正确地检测按键。现在是时候来完成使妖精移动的艰巨任务了。
|
||||
|
||||
### 编写玩家移动函数
|
||||
|
||||
为了使你的妖精移动起来,你必须为你的妖精创建一个属性代表移动。当你的妖精没有在移动时,这个变量被设为 `0`。
|
||||
|
||||
如果你正在为你的妖精设置动画,或者你决定在将来为它设置动画,你还必须跟踪帧来使走路循环保持在轨迹上。
|
||||
|
||||
在 `Player` 类中创建如下变量。开头两行作为上下文对照(如果你一直跟着做,你的代码中就已经有这两行),因此只需要添加最后三行:
|
||||
|
||||
```
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0 # 沿 X 方向移动
|
||||
self.movey = 0 # 沿 Y 方向移动
|
||||
self.frame = 0 # 帧计数
|
||||
```
|
||||
|
||||
设置好了这些变量,是时候去为妖精移动编写代码了。
|
||||
|
||||
玩家妖精不需要时刻响应控制,有时它并没有在移动。控制妖精的代码,仅仅只是玩家妖精所有能做的事情中的一小部分。在 Python 中,当你想要使一个对象做某件事并独立于剩余其他代码时,你可以将你的新代码放入一个函数。Python 的函数以关键词 `def` 开头,(该关键词)代表了定义函数。
|
||||
|
||||
在你的 `Player` 类中创建如下函数,来为你的妖精在屏幕上的位置增加几个像素。现在先不要担心你增加几个像素,这将在后续的代码中确定。
|
||||
|
||||
```
|
||||
def control(self,x,y):
|
||||
'''
|
||||
控制玩家移动
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
```
|
||||
|
||||
为了在 Pygame 中移动妖精,你需要告诉 Python 在新的位置重绘妖精,以及这个新位置在哪里。
|
||||
|
||||
因为玩家妖精并不总是在移动,所以更新只需要是 Player 类中的一个函数。将此函数添加前面创建的 `control` 函数之后。
|
||||
|
||||
要使妖精看起来像是在行走(或者飞行,或是你的妖精应该做的任何事),你需要在按下适当的键时改变它在屏幕上的位置。要让它在屏幕上移动,你需要将它的位置(由 `self.rect.x` 和 `self.rect.y` 属性指定)重新定义为当前位置加上已应用的任意 `movex` 或 `movey`。(移动的像素数量将在后续进行设置。)
|
||||
|
||||
```
|
||||
def update(self):
|
||||
'''
|
||||
更新妖精位置
|
||||
'''
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
```
|
||||
|
||||
对 Y 方向做同样的处理:
|
||||
|
||||
```
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
```
|
||||
|
||||
对于动画,在妖精移动时推进动画帧,并使用相应的动画帧作为玩家的图像:
|
||||
|
||||
```
|
||||
# 向左移动
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# 向右移动
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
```
|
||||
|
||||
通过设置一个变量来告诉代码为你的妖精位置增加多少像素,然后在触发你的玩家妖精的函数时使用这个变量。
|
||||
|
||||
首先,在你的设置部分创建这个变量。在如下代码中,开头两行是上下文对照,因此只需要在你的脚本中增加第三行代码:
|
||||
|
||||
```
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10 # 移动多少个像素
|
||||
```
|
||||
|
||||
现在你已经有了适当的函数和变量,使用你的按键来触发函数并将变量传递给你的妖精。
|
||||
|
||||
为此,将主循环中的 `print` 语句替换为玩家妖精的名字(`player`)、函数(`.control`)以及你希望玩家妖精在每个循环中沿 X 轴和 Y 轴移动的步数。
|
||||
|
||||
```
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
```
|
||||
|
||||
记住,`steps` 变量代表了当一个按键被按下时,你的妖精会移动多少个像素。如果当你按下 `D` 或右方向键时,你的妖精的位置增加了 10 个像素。那么当你停止按下这个键时,你必须(将 `step`)减 10(`-steps`)来使你的妖精的动量回到 0。
|
||||
|
||||
现在尝试你的游戏。注意:它不会像你预想的那样运行。
|
||||
|
||||
为什么你的妖精仍无法移动?因为主循环还没有调用 `update` 函数。
|
||||
|
||||
将如下代码加入到你的主循环中来告诉 Python 更新你的玩家妖精的位置。增加带注释的那行:
|
||||
|
||||
```
|
||||
player.update() # 更新玩家位置
|
||||
player_list.draw(world)
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
再次启动你的游戏来见证你的玩家妖精在你的命令下在屏幕上来回移动。现在还没有垂直方向的移动,因为这部分函数会被重力控制,不过这是另一篇文章中的课程了。
|
||||
|
||||
与此同时,如果你拥有一个摇杆,你可以尝试阅读 Pygame 中 [joystick][4] 模块相关的文档,看看你是否能通过这种方式让你的妖精移动起来。或者,看看你是否能通过[鼠标][5]与你的妖精互动。
|
||||
|
||||
最重要的是,玩的开心!
|
||||
|
||||
### 本教程中用到的所有代码
|
||||
|
||||
为了方便查阅,以下是目前本系列文章用到的所有代码。
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# 绘制世界
|
||||
# 添加玩家和玩家控制
|
||||
# 添加玩家移动控制
|
||||
|
||||
# GNU All-Permissive License
|
||||
# Copying and distribution of this file, with or without modification,
|
||||
# are permitted in any medium without royalty provided the copyright
|
||||
# notice and this notice are preserved. This file is offered as-is,
|
||||
# without any warranty.
|
||||
|
||||
import pygame
|
||||
import sys
|
||||
import os
|
||||
|
||||
'''
|
||||
Objects
|
||||
'''
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
生成玩家
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0
|
||||
self.movey = 0
|
||||
self.frame = 0
|
||||
self.images = []
|
||||
for i in range(1,5):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha()
|
||||
img.set_colorkey(ALPHA)
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
def control(self,x,y):
|
||||
'''
|
||||
控制玩家移动
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
更新妖精位置
|
||||
'''
|
||||
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
|
||||
# 向左移动
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# 向右移动
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
|
||||
|
||||
'''
|
||||
设置
|
||||
'''
|
||||
worldx = 960
|
||||
worldy = 720
|
||||
|
||||
fps = 40 # 帧刷新率
|
||||
ani = 4 # 动画循环
|
||||
clock = pygame.time.Clock()
|
||||
pygame.init()
|
||||
main = True
|
||||
|
||||
BLUE = (25,25,200)
|
||||
BLACK = (23,23,23 )
|
||||
WHITE = (254,254,254)
|
||||
ALPHA = (0,255,0)
|
||||
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = world.get_rect()
|
||||
player = Player() # 生成玩家
|
||||
player.rect.x = 0
|
||||
player.rect.y = 0
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10 # 移动速度
|
||||
|
||||
'''
|
||||
主循环
|
||||
'''
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
|
||||
# world.fill(BLACK)
|
||||
world.blit(backdrop, backdropbox)
|
||||
player.update()
|
||||
player_list.draw(world) # 更新玩家位置
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
你已经学了很多,但还仍有许多可以做。在接下来的几篇文章中,你将实现添加敌方妖精、模拟重力等等。与此同时,练习 Python 吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/game-python-moving-player
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-9071-1.html
|
||||
[2]: https://linux.cn/article-10850-1.html
|
||||
[3]: https://linux.cn/article-10858-1.html
|
||||
[4]: http://pygame.org/docs/ref/joystick.html
|
||||
[5]: http://pygame.org/docs/ref/mouse.html#module-pygame.mouse
|
||||
@ -0,0 +1,210 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10884-1.html)
|
||||
[#]: subject: (Virtual filesystems in Linux: Why we need them and how they work)
|
||||
[#]: via: (https://opensource.com/article/19/3/virtual-filesystems-linux)
|
||||
[#]: author: (Alison Chariken )
|
||||
|
||||
详解 Linux 中的虚拟文件系统
|
||||
======
|
||||
|
||||
> 虚拟文件系统是一种神奇的抽象,它使得 “一切皆文件” 哲学在 Linux 中成为了可能。
|
||||
|
||||

|
||||
|
||||
什么是文件系统?根据早期的 Linux 贡献者和作家 [Robert Love][1] 所说,“文件系统是一个遵循特定结构的数据的分层存储。” 不过,这种描述也同样适用于 VFAT(<ruby>虚拟文件分配表<rt>Virtual File Allocation Table</rt></ruby>)、Git 和[Cassandra][2](一种 [NoSQL 数据库][3])。那么如何区别文件系统呢?
|
||||
|
||||
### 文件系统基础概念
|
||||
|
||||
Linux 内核要求文件系统必须是实体,它还必须在持久对象上实现 `open()`、`read()` 和 `write()` 方法,并且这些实体需要有与之关联的名字。从 [面向对象编程][4] 的角度来看,内核将通用文件系统视为一个抽象接口,这三大函数是“虚拟”的,没有默认定义。因此,内核的默认文件系统实现被称为虚拟文件系统(VFS)。
|
||||
|
||||
![][5]
|
||||
|
||||
*如果我们能够 `open()`、`read()` 和 `write()`,它就是一个文件,如这个主控台会话所示。*
|
||||
|
||||
VFS 是著名的类 Unix 系统中 “一切皆文件” 概念的基础。让我们看一下它有多奇怪,上面的小小演示体现了字符设备 `/dev/console` 实际的工作。该图显示了一个在虚拟电传打字控制台(tty)上的交互式 Bash 会话。将一个字符串发送到虚拟控制台设备会使其显示在虚拟屏幕上。而 VFS 甚至还有其它更奇怪的属性。例如,它[可以在其中寻址][6]。
|
||||
|
||||
我们熟悉的文件系统如 ext4、NFS 和 /proc 都在名为 [file_operations] [7] 的 C 语言数据结构中提供了三大函数的定义。此外,个别的文件系统会以熟悉的面向对象的方式扩展和覆盖了 VFS 功能。正如 Robert Love 指出的那样,VFS 的抽象使 Linux 用户可以轻松地将文件复制到(或复制自)外部操作系统或抽象实体(如管道),而无需担心其内部数据格式。在用户空间这一侧,通过系统调用,进程可以使用文件系统方法之一 `read()` 从文件复制到内核的数据结构中,然后使用另一种文件系统的方法 `write()` 输出数据。
|
||||
|
||||
属于 VFS 基本类型的函数定义本身可以在内核源代码的 [fs/*.c 文件][8] 中找到,而 `fs/` 的子目录中包含了特定的文件系统。内核还包含了类似文件系统的实体,例如 cgroup、`/dev` 和 tmpfs,在引导过程的早期需要它们,因此定义在内核的 `init/` 子目录中。请注意,cgroup、`/dev` 和 tmpfs 不会调用 `file_operations` 的三大函数,而是直接读取和写入内存。
|
||||
|
||||
下图大致说明了用户空间如何访问通常挂载在 Linux 系统上的各种类型文件系统。像管道、dmesg 和 POSIX 时钟这样的结构在此图中未显示,它们也实现了 `struct file_operations`,而且其访问也要通过 VFS 层。
|
||||
|
||||
![How userspace accesses various types of filesystems][9]
|
||||
|
||||
VFS 是个“垫片层”,位于系统调用和特定 `file_operations` 的实现(如 ext4 和 procfs)之间。然后,`file_operations` 函数可以与特定于设备的驱动程序或内存访问器进行通信。tmpfs、devtmpfs 和 cgroup 不使用 `file_operations` 而是直接访问内存。
|
||||
|
||||
VFS 的存在促进了代码重用,因为与文件系统相关的基本方法不需要由每种文件系统类型重新实现。代码重用是一种被广泛接受的软件工程最佳实践!唉,但是如果重用的代码[引入了严重的错误][10],那么继承常用方法的所有实现都会受到影响。
|
||||
|
||||
### /tmp:一个小提示
|
||||
|
||||
找出系统中存在的 VFS 的简单方法是键入 `mount | grep -v sd | grep -v :/`,在大多数计算机上,它将列出所有未驻留在磁盘上,同时也不是 NFS 的已挂载文件系统。其中一个列出的 VFS 挂载肯定是 `/tmp`,对吧?
|
||||
|
||||
![Man with shocked expression][11]
|
||||
|
||||
*谁都知道把 /tmp 放在物理存储设备上简直是疯了!图片:<https://tinyurl.com/ybomxyfo>*
|
||||
|
||||
为什么把 `/tmp` 留在存储设备上是不可取的?因为 `/tmp` 中的文件是临时的(!),并且存储设备比内存慢,所以创建了 tmpfs 这种文件系统。此外,比起内存,物理设备频繁写入更容易磨损。最后,`/tmp` 中的文件可能包含敏感信息,因此在每次重新启动时让它们消失是一项功能。
|
||||
|
||||
不幸的是,默认情况下,某些 Linux 发行版的安装脚本仍会在存储设备上创建 /tmp。如果你的系统出现这种情况,请不要绝望。按照一直优秀的 [Arch Wiki][12] 上的简单说明来解决问题就行,记住分配给 tmpfs 的内存就不能用于其他目的了。换句话说,包含了大文件的庞大的 tmpfs 可能会让系统耗尽内存并崩溃。
|
||||
|
||||
另一个提示:编辑 `/etc/fstab` 文件时,请务必以换行符结束,否则系统将无法启动。(猜猜我怎么知道。)
|
||||
|
||||
### /proc 和 /sys
|
||||
|
||||
除了 `/tmp` 之外,大多数 Linux 用户最熟悉的 VFS 是 `/proc` 和 `/sys`。(`/dev` 依赖于共享内存,而没有 `file_operations` 结构)。为什么有两种呢?让我们来看看更多细节。
|
||||
|
||||
procfs 为用户空间提供了内核及其控制的进程的瞬时状态的快照。在 `/proc` 中,内核发布有关其提供的设施的信息,如中断、虚拟内存和调度程序。此外,`/proc/sys` 是存放可以通过 [sysctl 命令][13]配置的设置的地方,可供用户空间访问。单个进程的状态和统计信息在 `/proc/<PID>` 目录中报告。
|
||||
|
||||
![Console][14]
|
||||
|
||||
*/proc/meminfo 是一个空文件,但仍包含有价值的信息。*
|
||||
|
||||
`/proc` 文件的行为说明了 VFS 可以与磁盘上的文件系统不同。一方面,`/proc/meminfo` 包含了可由命令 `free` 展现出来的信息。另一方面,它还是空的!怎么会这样?这种情况让人联想起康奈尔大学物理学家 N. David Mermin 在 1985 年写的一篇名为《[没有人看见月亮的情况吗?][15]现实和量子理论》。事实是当进程从 `/proc` 请求数据时内核再收集有关内存的统计信息,而且当没有人查看它时,`/proc` 中的文件实际上没有任何内容。正如 [Mermin 所说][16],“这是一个基本的量子学说,一般来说,测量不会揭示被测属性的预先存在的价值。”(关于月球的问题的答案留作练习。)
|
||||
|
||||
![Full moon][17]
|
||||
|
||||
*当没有进程访问它们时,/proc 中的文件为空。([来源][18])*
|
||||
|
||||
procfs 的空文件是有道理的,因为那里可用的信息是动态的。sysfs 的情况则不同。让我们比较一下 `/proc` 与 `/sys` 中不为空的文件数量。
|
||||
|
||||

|
||||
|
||||
procfs 只有一个不为空的文件,即导出的内核配置,这是一个例外,因为每次启动只需要生成一次。另一方面,`/sys` 有许多更大一些的文件,其中大多数由一页内存组成。通常,sysfs 文件只包含一个数字或字符串,与通过读取 `/proc/meminfo` 等文件生成的信息表格形成鲜明对比。
|
||||
|
||||
sysfs 的目的是将内核称为 “kobject” 的可读写属性公开给用户空间。kobject 的唯一目的是引用计数:当删除对 kobject 的最后一个引用时,系统将回收与之关联的资源。然而,`/sys` 构成了内核著名的“[到用户空间的稳定 ABI][19]”,它的大部分内容[在任何情况下都没有人能“破坏”][20]。但这并不意味着 sysfs 中的文件是静态,这与易失性对象的引用计数相反。
|
||||
|
||||
内核的稳定 ABI 限制了 `/sys` 中可能出现的内容,而不是任何给定时刻实际存在的内容。列出 sysfs 中文件的权限可以了解如何设置或读取设备、模块、文件系统等的可配置、可调参数。逻辑上强调 procfs 也是内核稳定 ABI 的一部分的结论,尽管内核的[文档][19]没有明确说明。
|
||||
|
||||
![Console][21]
|
||||
|
||||
*sysfs 中的文件确切地描述了实体的每个属性,并且可以是可读的、可写的,或两者兼而有之。文件中的“0”表示 SSD 不可移动的存储设备。*
|
||||
|
||||
### 用 eBPF 和 bcc 工具一窥 VFS 内部
|
||||
|
||||
了解内核如何管理 sysfs 文件的最简单方法是观察它的运行情况,在 ARM64 或 x86_64 上观看的最简单方法是使用 eBPF。eBPF(<ruby>扩展的伯克利数据包过滤器<rt>extended Berkeley Packet Filter</rt></ruby>)由[在内核中运行的虚拟机][22]组成,特权用户可以从命令行进行查询。内核源代码告诉读者内核可以做什么;而在一个启动的系统上运行 eBPF 工具会显示内核实际上做了什么。
|
||||
|
||||
令人高兴的是,通过 [bcc][23] 工具入门使用 eBPF 非常容易,这些工具在[主要 Linux 发行版的软件包][24] 中都有,并且已经由 Brendan Gregg [给出了充分的文档说明][25]。bcc 工具是带有小段嵌入式 C 语言片段的 Python 脚本,这意味着任何对这两种语言熟悉的人都可以轻松修改它们。据当前统计,[bcc/tools 中有 80 个 Python 脚本][26],使得系统管理员或开发人员很有可能能够找到与她/他的需求相关的已有脚本。
|
||||
|
||||
要了解 VFS 在正在运行中的系统上的工作情况,请尝试使用简单的 [vfscount][27] 或 [vfsstat][28] 脚本,这可以看到每秒都会发生数十次对 `vfs_open()` 及其相关的调用。
|
||||
|
||||
![Console - vfsstat.py][29]
|
||||
|
||||
*vfsstat.py 是一个带有嵌入式 C 片段的 Python 脚本,它只是计数 VFS 函数调用。*
|
||||
|
||||
作为一个不太重要的例子,让我们看一下在运行的系统上插入 USB 记忆棒时 sysfs 中会发生什么。
|
||||
|
||||
![Console when USB is inserted][30]
|
||||
|
||||
*用 eBPF 观察插入 USB 记忆棒时 /sys 中会发生什么,简单的和复杂的例子。*
|
||||
|
||||
在上面的第一个简单示例中,只要 `sysfs_create_files()` 命令运行,[trace.py][31] bcc 工具脚本就会打印出一条消息。我们看到 `sysfs_create_files()` 由一个 kworker 线程启动,以响应 USB 棒的插入事件,但是它创建了什么文件?第二个例子说明了 eBPF 的强大能力。这里,`trace.py` 正在打印内核回溯(`-K` 选项)以及 `sysfs_create_files()` 创建的文件的名称。单引号内的代码段是一些 C 源代码,包括一个易于识别的格式字符串,所提供的 Python 脚本[引入 LLVM 即时编译器(JIT)][32] 来在内核虚拟机内编译和执行它。必须在第二个命令中重现完整的 `sysfs_create_files()` 函数签名,以便格式字符串可以引用其中一个参数。在此 C 片段中出错会导致可识别的 C 编译器错误。例如,如果省略 `-I` 参数,则结果为“无法编译 BPF 文本”。熟悉 C 或 Python 的开发人员会发现 bcc 工具易于扩展和修改。
|
||||
|
||||
插入 USB 记忆棒后,内核回溯显示 PID 7711 是一个 kworker 线程,它在 sysfs 中创建了一个名为 `events` 的文件。使用 `sysfs_remove_files()` 进行相应的调用表明,删除 USB 记忆棒会导致删除该 `events` 文件,这与引用计数的想法保持一致。在 USB 棒插入期间(未显示)在 eBPF 中观察 `sysfs_create_link()` 表明创建了不少于 48 个符号链接。
|
||||
|
||||
无论如何,`events` 文件的目的是什么?使用 [cscope][33] 查找函数 [`__device_add_disk()`][34] 显示它调用 `disk_add_events()`,并且可以将 “media_change” 或 “eject_request” 写入到该文件。这里,内核的块层通知用户空间该 “磁盘” 的出现和消失。考虑一下这种检查 USB 棒的插入的工作原理的方法与试图仅从源头中找出该过程的速度有多快。
|
||||
|
||||
### 只读根文件系统使得嵌入式设备成为可能
|
||||
|
||||
确实,没有人通过拔出电源插头来关闭服务器或桌面系统。为什么?因为物理存储设备上挂载的文件系统可能有挂起的(未完成的)写入,并且记录其状态的数据结构可能与写入存储器的内容不同步。当发生这种情况时,系统所有者将不得不在下次启动时等待 [fsck 文件系统恢复工具][35] 运行完成,在最坏的情况下,实际上会丢失数据。
|
||||
|
||||
然而,狂热爱好者会听说许多物联网和嵌入式设备,如路由器、恒温器和汽车现在都运行着 Linux。许多这些设备几乎完全没有用户界面,并且没有办法干净地让它们“解除启动”。想一想启动电池耗尽的汽车,其中[运行 Linux 的主机设备][36] 的电源会不断加电断电。当引擎最终开始运行时,系统如何在没有长时间 fsck 的情况下启动呢?答案是嵌入式设备依赖于[只读根文件系统][37](简称 ro-rootfs)。
|
||||
|
||||
![Photograph of a console][38]
|
||||
|
||||
*ro-rootfs 是嵌入式系统不经常需要 fsck 的原因。 来源:<https://tinyurl.com/yxoauoub>*
|
||||
|
||||
ro-rootfs 提供了许多优点,虽然这些优点不如耐用性那么显然。一个是,如果 Linux 进程不可以写入,那么恶意软件也无法写入 `/usr` 或 `/lib`。另一个是,基本上不可变的文件系统对于远程设备的现场支持至关重要,因为支持人员拥有理论上与现场相同的本地系统。也许最重要(但也是最微妙)的优势是 ro-rootfs 迫使开发人员在项目的设计阶段就决定好哪些系统对象是不可变的。处理 ro-rootfs 可能经常是不方便甚至是痛苦的,[编程语言中的常量变量][39]经常就是这样,但带来的好处很容易偿还这种额外的开销。
|
||||
|
||||
对于嵌入式开发人员,创建只读根文件系统确实需要做一些额外的工作,而这正是 VFS 的用武之地。Linux 需要 `/var` 中的文件可写,此外,嵌入式系统运行的许多流行应用程序会尝试在 `$HOME` 中创建配置的点文件。放在家目录中的配置文件的一种解决方案通常是预生成它们并将它们构建到 rootfs 中。对于 `/var`,一种方法是将其挂载在单独的可写分区上,而 `/` 本身以只读方式挂载。使用绑定或叠加挂载是另一种流行的替代方案。
|
||||
|
||||
### 绑定和叠加挂载以及在容器中的使用
|
||||
|
||||
运行 [man mount][40] 是了解<ruby>绑定挂载<rt>bind mount</rt></ruby>和<ruby>叠加挂载<rt>overlay mount</rt></ruby>的最好办法,这种方法使得嵌入式开发人员和系统管理员能够在一个路径位置创建文件系统,然后以另外一个路径将其提供给应用程序。对于嵌入式系统,这代表着可以将文件存储在 `/var` 中的不可写闪存设备上,但是在启动时将 tmpfs 中的路径叠加挂载或绑定挂载到 `/var` 路径上,这样应用程序就可以在那里随意写它们的内容了。下次加电时,`/var` 中的变化将会消失。叠加挂载为 tmpfs 和底层文件系统提供了联合,允许对 ro-rootfs 中的现有文件进行直接修改,而绑定挂载可以使新的空 tmpfs 目录在 ro-rootfs 路径中显示为可写。虽然叠加文件系统是一种适当的文件系统类型,而绑定挂载由 [VFS 命名空间工具][41] 实现的。
|
||||
|
||||
根据叠加挂载和绑定挂载的描述,没有人会对 [Linux 容器][42] 中大量使用它们感到惊讶。让我们通过运行 bcc 的 `mountsnoop` 工具监视当使用 [systemd-nspawn][43] 启动容器时会发生什么:
|
||||
|
||||
![Console - system-nspawn invocation][44]
|
||||
|
||||
*在 mountsnoop.py 运行的同时,system-nspawn 调用启动容器。*
|
||||
|
||||
让我们看看发生了什么:
|
||||
|
||||
![Console - Running mountsnoop][45]
|
||||
|
||||
*在容器 “启动” 期间运行 `mountsnoop` 可以看到容器运行时很大程度上依赖于绑定挂载。(仅显示冗长输出的开头)*
|
||||
|
||||
这里,`systemd-nspawn` 将主机的 procfs 和 sysfs 中的选定文件按其 rootfs 中的路径提供给容器。除了设置绑定挂载时的 `MS_BIND` 标志之外,`mount` 系统调用的一些其它标志用于确定主机命名空间和容器中的更改之间的关系。例如,绑定挂载可以将 `/proc` 和 `/sys` 中的更改传播到容器,也可以隐藏它们,具体取决于调用。
|
||||
|
||||
### 总结
|
||||
|
||||
理解 Linux 内部结构看似是一项不可能完成的任务,因为除了 Linux 用户空间应用程序和 glibc 这样的 C 库中的系统调用接口,内核本身也包含大量代码。取得进展的一种方法是阅读一个内核子系统的源代码,重点是理解面向用户空间的系统调用和头文件以及主要的内核内部接口,这里以 `file_operations` 表为例。`file_operations` 使得“一切都是文件”得以可以实际工作,因此掌握它们收获特别大。顶级 `fs/` 目录中的内核 C 源文件构成了虚拟文件系统的实现,虚拟文件系统是支持流行的文件系统和存储设备的广泛且相对简单的互操作性的垫片层。通过 Linux 命名空间进行绑定挂载和覆盖挂载是 VFS 魔术,它使容器和只读根文件系统成为可能。结合对源代码的研究,eBPF 内核工具及其 bcc 接口使得探测内核比以往任何时候都更简单。
|
||||
|
||||
非常感谢 [Akkana Peck][46] 和 [Michael Eager][47] 的评论和指正。
|
||||
|
||||
Alison Chaiken 也于 3 月 7 日至 10 日在加利福尼亚州帕萨迪纳举行的第 17 届南加州 Linux 博览会([SCaLE 17x][49])上演讲了[本主题][48]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/virtual-filesystems-linux
|
||||
|
||||
作者:[Alison Chariken][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/chaiken
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pearson.com/us/higher-education/program/Love-Linux-Kernel-Development-3rd-Edition/PGM202532.html
|
||||
[2]: http://cassandra.apache.org/
|
||||
[3]: https://en.wikipedia.org/wiki/NoSQL
|
||||
[4]: http://lwn.net/Articles/444910/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_1-console.png (Console)
|
||||
[6]: https://lwn.net/Articles/22355/
|
||||
[7]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/fs.h
|
||||
[8]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/fs
|
||||
[9]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_2-shim-layer.png (How userspace accesses various types of filesystems)
|
||||
[10]: https://lwn.net/Articles/774114/
|
||||
[11]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_3-crazy.jpg (Man with shocked expression)
|
||||
[12]: https://wiki.archlinux.org/index.php/Tmpfs
|
||||
[13]: http://man7.org/linux/man-pages/man8/sysctl.8.html
|
||||
[14]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_4-proc-meminfo.png (Console)
|
||||
[15]: http://www-f1.ijs.si/~ramsak/km1/mermin.moon.pdf
|
||||
[16]: https://en.wikiquote.org/wiki/David_Mermin
|
||||
[17]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_5-moon.jpg (Full moon)
|
||||
[18]: https://commons.wikimedia.org/wiki/Moon#/media/File:Full_Moon_Luc_Viatour.jpg
|
||||
[19]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/stable
|
||||
[20]: https://lkml.org/lkml/2012/12/23/75
|
||||
[21]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_7-sysfs.png (Console)
|
||||
[22]: https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[23]: https://github.com/iovisor/bcc
|
||||
[24]: https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[25]: http://brendangregg.com/ebpf.html
|
||||
[26]: https://github.com/iovisor/bcc/tree/master/tools
|
||||
[27]: https://github.com/iovisor/bcc/blob/master/tools/vfscount_example.txt
|
||||
[28]: https://github.com/iovisor/bcc/blob/master/tools/vfsstat.py
|
||||
[29]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_8-vfsstat.png (Console - vfsstat.py)
|
||||
[30]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_9-ebpf.png (Console when USB is inserted)
|
||||
[31]: https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt
|
||||
[32]: https://events.static.linuxfound.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[33]: http://northstar-www.dartmouth.edu/doc/solaris-forte/manuals/c/user_guide/cscope.html
|
||||
[34]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/block/genhd.c#n665
|
||||
[35]: http://www.man7.org/linux/man-pages/man8/fsck.8.html
|
||||
[36]: https://wiki.automotivelinux.org/_media/eg-rhsa/agl_referencehardwarespec_v0.1.0_20171018.pdf
|
||||
[37]: https://elinux.org/images/1/1f/Read-only_rootfs.pdf
|
||||
[38]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_10-code.jpg (Photograph of a console)
|
||||
[39]: https://www.meetup.com/ACCU-Bay-Area/events/drpmvfytlbqb/
|
||||
[40]: http://man7.org/linux/man-pages/man8/mount.8.html
|
||||
[41]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/filesystems/sharedsubtree.txt
|
||||
[42]: https://coreos.com/os/docs/latest/kernel-modules.html
|
||||
[43]: https://www.freedesktop.org/software/systemd/man/systemd-nspawn.html
|
||||
[44]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_11-system-nspawn.png (Console - system-nspawn invocation)
|
||||
[45]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_12-mountsnoop.png (Console - Running mountsnoop)
|
||||
[46]: http://shallowsky.com/
|
||||
[47]: http://eagercon.com/
|
||||
[48]: https://www.socallinuxexpo.org/scale/17x/presentations/virtual-filesystems-why-we-need-them-and-how-they-work
|
||||
[49]: https://www.socallinuxexpo.org/
|
||||
@ -62,47 +62,42 @@ producer-------->| disk file |<-------consumer
|
||||
#include <stdlib.h>
|
||||
#include <fcntl.h>
|
||||
#include <unistd.h>
|
||||
#include <string.h>
|
||||
|
||||
#define FileName "data.dat"
|
||||
#define DataString "Now is the winter of our discontent\nMade glorious summer by this sun of York\n"
|
||||
|
||||
void report_and_exit(const char* msg) {
|
||||
[perror][4](msg);
|
||||
[exit][5](-1); /* EXIT_FAILURE */
|
||||
perror(msg);
|
||||
exit(-1); /* EXIT_FAILURE */
|
||||
}
|
||||
|
||||
int main() {
|
||||
struct flock lock;
|
||||
lock.l_type = F_WRLCK; /* read/write (exclusive) lock */
|
||||
lock.l_type = F_WRLCK; /* read/write (exclusive versus shared) lock */
|
||||
lock.l_whence = SEEK_SET; /* base for seek offsets */
|
||||
lock.l_start = 0; /* 1st byte in file */
|
||||
lock.l_len = 0; /* 0 here means 'until EOF' */
|
||||
lock.l_pid = getpid(); /* process id */
|
||||
|
||||
int fd; /* file descriptor to identify a file within a process */
|
||||
if ((fd = open(FileName, O_RDONLY)) < 0) /* -1 signals an error */
|
||||
report_and_exit("open to read failed...");
|
||||
if ((fd = open(FileName, O_RDWR | O_CREAT, 0666)) < 0) /* -1 signals an error */
|
||||
report_and_exit("open failed...");
|
||||
|
||||
/* If the file is write-locked, we can't continue. */
|
||||
fcntl(fd, F_GETLK, &lock); /* sets lock.l_type to F_UNLCK if no write lock */
|
||||
if (lock.l_type != F_UNLCK)
|
||||
report_and_exit("file is still write locked...");
|
||||
if (fcntl(fd, F_SETLK, &lock) < 0) /** F_SETLK doesn't block, F_SETLKW does **/
|
||||
report_and_exit("fcntl failed to get lock...");
|
||||
else {
|
||||
write(fd, DataString, strlen(DataString)); /* populate data file */
|
||||
fprintf(stderr, "Process %d has written to data file...\n", lock.l_pid);
|
||||
}
|
||||
|
||||
lock.l_type = F_RDLCK; /* prevents any writing during the reading */
|
||||
if (fcntl(fd, F_SETLK, &lock) < 0)
|
||||
report_and_exit("can't get a read-only lock...");
|
||||
|
||||
/* Read the bytes (they happen to be ASCII codes) one at a time. */
|
||||
int c; /* buffer for read bytes */
|
||||
while (read(fd, &c, 1) > 0) /* 0 signals EOF */
|
||||
write(STDOUT_FILENO, &c, 1); /* write one byte to the standard output */
|
||||
|
||||
/* Release the lock explicitly. */
|
||||
/* Now release the lock explicitly. */
|
||||
lock.l_type = F_UNLCK;
|
||||
if (fcntl(fd, F_SETLK, &lock) < 0)
|
||||
report_and_exit("explicit unlocking failed...");
|
||||
|
||||
close(fd);
|
||||
return 0;
|
||||
close(fd); /* close the file: would unlock if needed */
|
||||
return 0; /* terminating the process would unlock as well */
|
||||
}
|
||||
```
|
||||
|
||||
@ -140,8 +135,8 @@ lock.l_type = F_UNLCK;
|
||||
#define FileName "data.dat"
|
||||
|
||||
void report_and_exit(const char* msg) {
|
||||
[perror][4](msg);
|
||||
[exit][5](-1); /* EXIT_FAILURE */
|
||||
perror(msg);
|
||||
exit(-1); /* EXIT_FAILURE */
|
||||
}
|
||||
|
||||
int main() {
|
||||
@ -240,37 +235,37 @@ This is the way the world ends...
|
||||
#include "shmem.h"
|
||||
|
||||
void report_and_exit(const char* msg) {
|
||||
[perror][4](msg);
|
||||
[exit][5](-1);
|
||||
perror(msg);
|
||||
exit(-1);
|
||||
}
|
||||
|
||||
int main() {
|
||||
int fd = shm_open(BackingFile, /* name from smem.h */
|
||||
O_RDWR | O_CREAT, /* read/write, create if needed */
|
||||
AccessPerms); /* access permissions (0644) */
|
||||
O_RDWR | O_CREAT, /* read/write, create if needed */
|
||||
AccessPerms); /* access permissions (0644) */
|
||||
if (fd < 0) report_and_exit("Can't open shared mem segment...");
|
||||
|
||||
ftruncate(fd, ByteSize); /* get the bytes */
|
||||
|
||||
caddr_t memptr = mmap(NULL, /* let system pick where to put segment */
|
||||
ByteSize, /* how many bytes */
|
||||
PROT_READ | PROT_WRITE, /* access protections */
|
||||
MAP_SHARED, /* mapping visible to other processes */
|
||||
fd, /* file descriptor */
|
||||
0); /* offset: start at 1st byte */
|
||||
ByteSize, /* how many bytes */
|
||||
PROT_READ | PROT_WRITE, /* access protections */
|
||||
MAP_SHARED, /* mapping visible to other processes */
|
||||
fd, /* file descriptor */
|
||||
0); /* offset: start at 1st byte */
|
||||
if ((caddr_t) -1 == memptr) report_and_exit("Can't get segment...");
|
||||
|
||||
[fprintf][7](stderr, "shared mem address: %p [0..%d]\n", memptr, ByteSize - 1);
|
||||
[fprintf][7](stderr, "backing file: /dev/shm%s\n", BackingFile );
|
||||
fprintf(stderr, "shared mem address: %p [0..%d]\n", memptr, ByteSize - 1);
|
||||
fprintf(stderr, "backing file: /dev/shm%s\n", BackingFile );
|
||||
|
||||
/* semahore code to lock the shared mem */
|
||||
/* semaphore code to lock the shared mem */
|
||||
sem_t* semptr = sem_open(SemaphoreName, /* name */
|
||||
O_CREAT, /* create the semaphore */
|
||||
AccessPerms, /* protection perms */
|
||||
0); /* initial value */
|
||||
O_CREAT, /* create the semaphore */
|
||||
AccessPerms, /* protection perms */
|
||||
0); /* initial value */
|
||||
if (semptr == (void*) -1) report_and_exit("sem_open");
|
||||
|
||||
[strcpy][8](memptr, MemContents); /* copy some ASCII bytes to the segment */
|
||||
strcpy(memptr, MemContents); /* copy some ASCII bytes to the segment */
|
||||
|
||||
/* increment the semaphore so that memreader can read */
|
||||
if (sem_post(semptr) < 0) report_and_exit("sem_post");
|
||||
@ -341,8 +336,8 @@ munmap(memptr, ByteSize); /* unmap the storage *
|
||||
#include "shmem.h"
|
||||
|
||||
void report_and_exit(const char* msg) {
|
||||
[perror][4](msg);
|
||||
[exit][5](-1);
|
||||
perror(msg);
|
||||
exit(-1);
|
||||
}
|
||||
|
||||
int main() {
|
||||
@ -351,24 +346,24 @@ int main() {
|
||||
|
||||
/* get a pointer to memory */
|
||||
caddr_t memptr = mmap(NULL, /* let system pick where to put segment */
|
||||
ByteSize, /* how many bytes */
|
||||
PROT_READ | PROT_WRITE, /* access protections */
|
||||
MAP_SHARED, /* mapping visible to other processes */
|
||||
fd, /* file descriptor */
|
||||
0); /* offset: start at 1st byte */
|
||||
ByteSize, /* how many bytes */
|
||||
PROT_READ | PROT_WRITE, /* access protections */
|
||||
MAP_SHARED, /* mapping visible to other processes */
|
||||
fd, /* file descriptor */
|
||||
0); /* offset: start at 1st byte */
|
||||
if ((caddr_t) -1 == memptr) report_and_exit("Can't access segment...");
|
||||
|
||||
/* create a semaphore for mutual exclusion */
|
||||
sem_t* semptr = sem_open(SemaphoreName, /* name */
|
||||
O_CREAT, /* create the semaphore */
|
||||
AccessPerms, /* protection perms */
|
||||
0); /* initial value */
|
||||
O_CREAT, /* create the semaphore */
|
||||
AccessPerms, /* protection perms */
|
||||
0); /* initial value */
|
||||
if (semptr == (void*) -1) report_and_exit("sem_open");
|
||||
|
||||
/* use semaphore as a mutex (lock) by waiting for writer to increment it */
|
||||
if (!sem_wait(semptr)) { /* wait until semaphore != 0 */
|
||||
int i;
|
||||
for (i = 0; i < [strlen][6](MemContents); i++)
|
||||
for (i = 0; i < strlen(MemContents); i++)
|
||||
write(STDOUT_FILENO, memptr + i, 1); /* one byte at a time */
|
||||
sem_post(semptr);
|
||||
}
|
||||
|
||||
@ -1,85 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10891-1.html)
|
||||
[#]: subject: (Detecting malaria with deep learning)
|
||||
[#]: via: (https://opensource.com/article/19/4/detecting-malaria-deep-learning)
|
||||
[#]: author: (Dipanjan Sarkar https://opensource.com/users/djsarkar)
|
||||
[#]: author: (Dipanjan Sarkar https://opensource.com/users/djsarkar)
|
||||
|
||||
使用深度学习检测疟疾
|
||||
==================
|
||||
人工智能结合开源硬件工具能够提升严重传染病疟疾的诊断。
|
||||
|
||||
> 人工智能结合开源硬件工具能够提升严重传染病疟疾的诊断。
|
||||
|
||||
![][1]
|
||||
|
||||
人工智能(AI)和开源工具,技术,和框架是促进社会进步的强有力的结合。_“健康就是财富”_可能有点陈词滥调,但它却是非常准确的!在本篇文章,我们将测试 AI 是如何与低花费,有效,精确的开源深度学习方法一起被利用来检测致死的传染病疟疾。
|
||||
人工智能(AI)和开源工具、技术和框架是促进社会进步的强有力的结合。“健康就是财富”可能有点陈词滥调,但它却是非常准确的!在本篇文章,我们将测试 AI 是如何与低成本、有效、精确的开源深度学习方法结合起来一起用来检测致死的传染病疟疾。
|
||||
|
||||
我既不是一个医生,也不是一个医疗保健研究者,我也绝不像他们那样合格,我只是对将 AI 应用到医疗保健研究感兴趣。在这片文章中我的想法是展示 AI 和开源解决方案如何帮助疟疾检测和减少人工劳动的方法。
|
||||
|
||||
![Python and TensorFlow][2]
|
||||
|
||||
Python and TensorFlow: 一个构建开源深度学习方法的很棒的结合
|
||||
*Python 和 TensorFlow: 一个构建开源深度学习方法的很棒的结合*
|
||||
|
||||
感谢 Python 的强大 和像 TensorFlow 这样的深度学习框架,我们能够构建鲁棒的,大规模的,有效的深度学习方法。因为这些工具是自由和开源的,我们能够构建低成本的能够轻易被任何人采纳和使用的解决方案。让我们开始吧!
|
||||
感谢 Python 的强大和像 TensorFlow 这样的深度学习框架,我们能够构建健壮的、大规模的、有效的深度学习方法。因为这些工具是自由和开源的,我们能够构建非常经济且易于被任何人采纳和使用的解决方案。让我们开始吧!
|
||||
|
||||
### 项目动机
|
||||
|
||||
疟疾是由_疟原虫_造成的致死的,有传染性的,蚊子传播的疾病,主要通过受感染的雌性按蚊叮咬传播。共有五种寄生虫能够造成疟疾,但是样例中的大多数是这两种类型- _恶性疟原虫_ 和 _间日疟原虫_ 造成的。
|
||||
疟疾是由*疟原虫*造成的致死的、有传染性的、蚊子传播的疾病,主要通过受感染的雌性按蚊叮咬传播。共有五种寄生虫能够引起疟疾,但是大多数病例是这两种类型造成的:恶性疟原虫和间日疟原虫。
|
||||
|
||||
![疟疾热图][3]
|
||||
|
||||
这个地图显示了疟疾在全球传播分布形势,尤其在热带地区,但疾病的性质和致命性是该项目的主要动机。
|
||||
|
||||
如果一个雌性蚊子咬了你,蚊子携带的寄生虫进入你的血液并且开始破坏携带氧气的红细胞(RBC)。通常,疟疾的最初症状类似于流感病毒,在蚊子叮咬后,他们通常在几天或几周内发作。然而,这些致死的寄生虫可以在你的身体里生存长达一年并且不会造成任何症状,延迟治疗可能造成并发症甚至死亡。因此,早期的检查能够挽救生命。
|
||||
如果一只受感染雌性蚊子叮咬了你,蚊子携带的寄生虫进入你的血液,并且开始破坏携带氧气的红细胞(RBC)。通常,疟疾的最初症状类似于流感病毒,在蚊子叮咬后,他们通常在几天或几周内发作。然而,这些致死的寄生虫可以在你的身体里生存长达一年并且不会造成任何症状,延迟治疗可能造成并发症甚至死亡。因此,早期的检查能够挽救生命。
|
||||
|
||||
世界健康组织(WHO)的[疟疾事件][4]暗示世界近乎一半的人口面临疟疾的风险,有超过 2 亿 的疟疾病例,每年由于疟疾造成的死亡近乎 40 万。这是使疟疾检测和诊断快速,简单和有效的一个动机。
|
||||
世界健康组织(WHO)的[疟疾实情][4]表明,世界近乎一半的人口面临疟疾的风险,有超过 2 亿的疟疾病例,每年由于疟疾造成的死亡将近 40 万。这是使疟疾检测和诊断快速、简单和有效的一个动机。
|
||||
|
||||
### 检测疟疾的方法
|
||||
|
||||
有几种方法能够用来检测和诊断疟疾。该文中的项目就是基于 Rajaraman,et al. 的论文:“[预先训练的卷积神经网络作为特征提取器,用于改善薄血涂片图像中的疟疾寄生虫检测][5]”,介绍了一些方法,包含聚合酶链反应(PCR)和快速诊断测试(RDT)。这两种测试通常在高质量的显微镜下使用,但这样的设备不是轻易能够获得的。
|
||||
有几种方法能够用来检测和诊断疟疾。该文中的项目就是基于 Rajaraman, et al. 的论文:“[预先训练的卷积神经网络作为特征提取器,用于改善薄血涂片图像中的疟疾寄生虫检测][5]”介绍的一些方法,包含聚合酶链反应(PCR)和快速诊断测试(RDT)。这两种测试通常用于无法提供高质量显微镜服务的地方。
|
||||
|
||||
标准的疟疾诊断通常使基于血液涂片工作流的,根据 Carlos Ariza 的文章“[Malaria Hero: 一个更快诊断疟原虫的网络应用][6]”,我从中了解到 Adrian Rosebrock 的“[使用 Keras 的深度学习和医学图像分析][7]”。我感激这些优秀的资源的作者,让我在疟原虫预防,诊断和治疗方面有了更多的想法。
|
||||
标准的疟疾诊断通常是基于血液涂片工作流程的,根据 Carlos Ariza 的文章“[Malaria Hero:一个更快诊断疟原虫的网络应用][6]”,我从中了解到 Adrian Rosebrock 的“[使用 Keras 的深度学习和医学图像分析][7]”。我感激这些优秀的资源的作者,让我在疟原虫预防、诊断和治疗方面有了更多的想法。
|
||||
|
||||
![疟原虫检测的血涂片工作流程][8]
|
||||
|
||||
一个疟原虫检测的血涂片工作流程
|
||||
*一个疟原虫检测的血涂片工作流程*
|
||||
|
||||
根据 WHO 草案,诊断通常包括对放大 100 倍的血涂片的集中检测。训练人们人工计数在 5000 个细胞中有多少红细胞中包含疟原虫。正如上述解释中引用的 Rajaraman, et al. 的论文:
|
||||
根据 WHO 方案,诊断通常包括对放大 100 倍的血涂片的集中检测。受过训练的人们手工计算在 5000 个细胞中有多少红细胞中包含疟原虫。正如上述解释中引用的 Rajaraman, et al. 的论文:
|
||||
|
||||
> 薄血涂片帮助检测疟原虫的存在性并且帮助识别造成传染(疾病控制和抑制中心,2012)的物种。诊断准确性在很大程度上取决于人类的专业知识,并且可能受到观察者间差异和疾病流行/资源受限区域大规模诊断所造成的不利影响(Mitiku, Mengistu, and Gelaw, 2003)。可替代的技术是使用聚合酶链反应(PCR)和快速诊断测试(RDT);然而,PCR 分析受限于它的性能(Hommelsheim, et al., 2014),RDT 在疾病流行的地区成本效益低(Hawkes,Katsuva, and Masumbuko, 2009)。
|
||||
> 厚血涂片有助于检测寄生虫的存在,而薄血涂片有助于识别引起感染的寄生虫种类(疾病控制和预防中心, 2012)。诊断准确性在很大程度上取决于诊断人的专业知识,并且可能受到观察者间差异和疾病流行/资源受限区域大规模诊断所造成的不利影响(Mitiku, Mengistu 和 Gelaw, 2003)。可替代的技术是使用聚合酶链反应(PCR)和快速诊断测试(RDT);然而,PCR 分析受限于它的性能(Hommelsheim, et al., 2014),RDT 在疾病流行的地区成本效益低(Hawkes, Katsuva 和 Masumbuko, 2009)。
|
||||
|
||||
因此,疟疾检测可能受益于使用机器学习的自动化。
|
||||
|
||||
### 疟原虫检测的深度学习
|
||||
### 疟疾检测的深度学习
|
||||
|
||||
人工诊断血涂片是一个加强的人工过程,需要专业知识来分类和计数被寄生虫感染的和未感染的细胞。这个过程可能不能很好的规模化,尤其在那些专业人士不足的地区。在利用最先进的图像处理和分析技术提取人工选取特征和构建基于机器学习的分类模型方面取得了一些进展。然而,这些模型不能大规模推广,因为没有更多的数据用来训练,并且人工选取特征需要花费很长时间。
|
||||
人工诊断血涂片是一个繁重的手工过程,需要专业知识来分类和计数被寄生虫感染的和未感染的细胞。这个过程可能不能很好的规模化,尤其在那些专业人士不足的地区。在利用最先进的图像处理和分析技术提取人工选取特征和构建基于机器学习的分类模型方面取得了一些进展。然而,这些模型不能大规模推广,因为没有更多的数据用来训练,并且人工选取特征需要花费很长时间。
|
||||
|
||||
深度学习模型,或者更具体地讲,卷积神经网络(CNNs),已经被证明在各种计算机视觉任务中非常有效。(如果你想有额外的关于 CNNs 的背景知识,我推荐你阅读[视觉识别的 CS2331n 卷积神经网络][9]。)简单地讲,CNN 模型的关键层包含卷积和池化层,正如下面图像显示。
|
||||
深度学习模型,或者更具体地讲,卷积神经网络(CNN),已经被证明在各种计算机视觉任务中非常有效。(如果你想更多的了解关于 CNN 的背景知识,我推荐你阅读[视觉识别的 CS2331n 卷积神经网络][9]。)简单地讲,CNN 模型的关键层包含卷积和池化层,正如下图所示。
|
||||
|
||||
![A typical CNN architecture][10]
|
||||
|
||||
一个典型的 CNN 架构
|
||||
*一个典型的 CNN 架构*
|
||||
|
||||
卷积层从数据中学习空间层级模式,它是平移不变的,因此它们能够学习不同方面的图像。例如,第一个卷积层将学习小的和本地图案,例如边缘和角落,第二个卷积层学习基于第一层的特征的更大的图案,等等。这允许 CNNs 自动化提取特征并且学习对于新数据点通用的有效的特征。池化层帮助下采样和降维。
|
||||
卷积层从数据中学习空间层级模式,它是平移不变的,因此它们能够学习图像的不同方面。例如,第一个卷积层将学习小的和局部图案,例如边缘和角落,第二个卷积层将基于第一层的特征学习更大的图案,等等。这允许 CNN 自动化提取特征并且学习对于新数据点通用的有效的特征。池化层有助于下采样和减少尺寸。
|
||||
|
||||
因此,CNNs 帮助自动化和规模化的特征工程。同样,在模型末尾加上密集层允许我们执行像图像分类这样的任务。使用像 CNNs 者的深度学习模型自动的疟疾检测可能非常有效,便宜和具有规模性,尤其是迁移学习和预训练模型效果非常好,甚至在少量数据的约束下。
|
||||
因此,CNN 有助于自动化和规模化的特征工程。同样,在模型末尾加上密集层允许我们执行像图像分类这样的任务。使用像 CNN 这样的深度学习模型自动的疟疾检测可能非常有效、便宜和具有规模性,尤其是迁移学习和预训练模型效果非常好,甚至在少量数据的约束下。
|
||||
|
||||
Rajaraman, et al. 的论文在一个数据集上利用六个预训练模型在检测疟疾 vs 无感染样本获取到令人吃惊的 95.9% 的准确率。我们的关注点是从头开始尝试一些简单的 CNN 模型和用一个预训练的训练模型使用迁移学习来查看我们能够从相同的数据集中得到什么。我们将使用开源工具和框架,包括 Python 和 TensorFlow,来构建我们的模型。
|
||||
Rajaraman, et al. 的论文在一个数据集上利用六个预训练模型在检测疟疾对比无感染样本获取到令人吃惊的 95.9% 的准确率。我们的重点是从头开始尝试一些简单的 CNN 模型和用一个预训练的训练模型使用迁移学习来查看我们能够从相同的数据集中得到什么。我们将使用开源工具和框架,包括 Python 和 TensorFlow,来构建我们的模型。
|
||||
|
||||
### 数据集
|
||||
|
||||
我们分析的数据来自 Lister Hill 国家生物医学交流中心(LHNCBC),国家医学图书馆(NLM)的一部分,他们细心收集和标记了健康和受感染的血涂片图像的[公众可获得的数据集][11]。这些研究者已经开发了一个运行在 Android 智能手机的移动[疟疾检测应用][12],连接到一个传统的光学显微镜。它们使用 吉姆萨染液 将 150 个受恶性疟原虫感染的和 50 个健康病人的薄血涂片染色,这些薄血涂片是在孟加拉的吉大港医学院附属医院收集和照相的。使用智能手机的内置相机获取每个显微镜视窗内的图像。这些图片由在泰国曼谷的马希多-牛津热带医学研究所的一个专家使用幻灯片阅读器标记的。
|
||||
我们分析的数据来自 Lister Hill 国家生物医学交流中心(LHNCBC)的研究人员,该中心是国家医学图书馆(NLM)的一部分,他们细心收集和标记了公开可用的健康和受感染的血涂片图像的[数据集][11]。这些研究者已经开发了一个运行在 Android 智能手机的[疟疾检测手机应用][12],连接到一个传统的光学显微镜。它们使用吉姆萨染液将 150 个受恶性疟原虫感染的和 50 个健康病人的薄血涂片染色,这些薄血涂片是在孟加拉的吉大港医学院附属医院收集和照相的。使用智能手机的内置相机获取每个显微镜视窗内的图像。这些图片由在泰国曼谷的马希多-牛津热带医学研究所的一个专家使用幻灯片阅读器标记的。
|
||||
|
||||
让我们简洁的查看数据集的结构。首先,我将安装一些基础的依赖(基于使用的操作系统)。
|
||||
让我们简要地查看一下数据集的结构。首先,我将安装一些基础的依赖(基于使用的操作系统)。
|
||||
|
||||
![Installing dependencies][13]
|
||||
|
||||
我使用的是云上的带有一个 GPU 的基于 Debian 的操作系统,这样我能更快的运行我的模型。为了查看目录结构,我们必须安装 tree 依赖(如果我们没有安装的话)使用 **sudo apt install tree**。
|
||||
我使用的是云上的带有一个 GPU 的基于 Debian 的操作系统,这样我能更快的运行我的模型。为了查看目录结构,我们必须使用 `sudo apt install tree` 安装 `tree` 及其依赖(如果我们没有安装的话)。
|
||||
|
||||
![Installing the tree dependency][14]
|
||||
|
||||
我们有两个文件夹包含血细胞的图像,包括受感染的和健康的。我们可以获取关于图像总数更多的细节通过输入:
|
||||
|
||||
我们有两个文件夹包含血细胞的图像,包括受感染的和健康的。我们通过输入可以获取关于图像总数更多的细节:
|
||||
|
||||
```
|
||||
import os
|
||||
@ -97,7 +98,7 @@ len(infected_files), len(healthy_files)
|
||||
(13779, 13779)
|
||||
```
|
||||
|
||||
看起来我们有一个平衡的 13,779 张疟疾的 和 13,779 张非疟疾的(健康的)血细胞图像。让我们根据这些构建数据帧,我们将用这些数据帧来构建我们的数据集。
|
||||
看起来我们有一个平衡的数据集,包含 13,779 张疟疾的和 13,779 张非疟疾的(健康的)血细胞图像。让我们根据这些构建数据帧,我们将用这些数据帧来构建我们的数据集。
|
||||
|
||||
|
||||
```
|
||||
@ -107,8 +108,8 @@ import pandas as pd
|
||||
np.random.seed(42)
|
||||
|
||||
files_df = pd.DataFrame({
|
||||
'filename': infected_files + healthy_files,
|
||||
'label': ['malaria'] * len(infected_files) + ['healthy'] * len(healthy_files)
|
||||
'filename': infected_files + healthy_files,
|
||||
'label': ['malaria'] * len(infected_files) + ['healthy'] * len(healthy_files)
|
||||
}).sample(frac=1, random_state=42).reset_index(drop=True)
|
||||
|
||||
files_df.head()
|
||||
@ -116,9 +117,9 @@ files_df.head()
|
||||
|
||||
![Datasets][15]
|
||||
|
||||
### 构建和参所图像数据集
|
||||
### 构建和了解图像数据集
|
||||
|
||||
为了构建深度学习模型,我们需要训练数据,但是我们还需要使用不可见的数据测试模型的性能。相应的,我们将使用 60:10:30 的划分用于训练,验证和测试数据集。我们将在训练期间应用训练和验证数据集并用测试数据集来检查模型的性能。
|
||||
为了构建深度学习模型,我们需要训练数据,但是我们还需要使用不可见的数据测试模型的性能。相应的,我们将使用 60:10:30 的比例来划分用于训练、验证和测试的数据集。我们将在训练期间应用训练和验证数据集,并用测试数据集来检查模型的性能。
|
||||
|
||||
|
||||
```
|
||||
@ -126,24 +127,23 @@ from sklearn.model_selection import train_test_split
|
||||
from collections import Counter
|
||||
|
||||
train_files, test_files, train_labels, test_labels = train_test_split(files_df['filename'].values,
|
||||
files_df['label'].values,
|
||||
test_size=0.3, random_state=42)
|
||||
files_df['label'].values,
|
||||
test_size=0.3, random_state=42)
|
||||
train_files, val_files, train_labels, val_labels = train_test_split(train_files,
|
||||
train_labels,
|
||||
test_size=0.1, random_state=42)
|
||||
train_labels,
|
||||
test_size=0.1, random_state=42)
|
||||
|
||||
print(train_files.shape, val_files.shape, test_files.shape)
|
||||
print('Train:', Counter(train_labels), '\nVal:', Counter(val_labels), '\nTest:', Counter(test_labels))
|
||||
|
||||
# Output
|
||||
(17361,) (1929,) (8268,)
|
||||
Train: Counter({'healthy': 8734, 'malaria': 8627})
|
||||
Val: Counter({'healthy': 970, 'malaria': 959})
|
||||
Train: Counter({'healthy': 8734, 'malaria': 8627})
|
||||
Val: Counter({'healthy': 970, 'malaria': 959})
|
||||
Test: Counter({'malaria': 4193, 'healthy': 4075})
|
||||
```
|
||||
|
||||
这些图片维度并不相同,因此血涂片和细胞图像是基于人类,测试方法,图片的朝向。让我们总结我们的训练数据集的统计信息来决定最佳的图像维度(牢记,我们根本不会碰测试数据集)。
|
||||
|
||||
这些图片尺寸并不相同,因为血涂片和细胞图像是基于人、测试方法、图片方向不同而不同的。让我们总结我们的训练数据集的统计信息来决定最佳的图像尺寸(牢记,我们根本不会碰测试数据集)。
|
||||
|
||||
```
|
||||
import cv2
|
||||
@ -151,24 +151,25 @@ from concurrent import futures
|
||||
import threading
|
||||
|
||||
def get_img_shape_parallel(idx, img, total_imgs):
|
||||
if idx % 5000 == 0 or idx == (total_imgs - 1):
|
||||
print('{}: working on img num: {}'.format(threading.current_thread().name,
|
||||
idx))
|
||||
return cv2.imread(img).shape
|
||||
|
||||
if idx % 5000 == 0 or idx == (total_imgs - 1):
|
||||
print('{}: working on img num: {}'.format(threading.current_thread().name,
|
||||
idx))
|
||||
return cv2.imread(img).shape
|
||||
|
||||
ex = futures.ThreadPoolExecutor(max_workers=None)
|
||||
data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
|
||||
print('Starting Img shape computation:')
|
||||
train_img_dims_map = ex.map(get_img_shape_parallel,
|
||||
[record[0] for record in data_inp],
|
||||
[record[1] for record in data_inp],
|
||||
[record[2] for record in data_inp])
|
||||
train_img_dims_map = ex.map(get_img_shape_parallel,
|
||||
[record[0] for record in data_inp],
|
||||
[record[1] for record in data_inp],
|
||||
[record[2] for record in data_inp])
|
||||
train_img_dims = list(train_img_dims_map)
|
||||
print('Min Dimensions:', np.min(train_img_dims, axis=0))
|
||||
print('Min Dimensions:', np.min(train_img_dims, axis=0))
|
||||
print('Avg Dimensions:', np.mean(train_img_dims, axis=0))
|
||||
print('Median Dimensions:', np.median(train_img_dims, axis=0))
|
||||
print('Max Dimensions:', np.max(train_img_dims, axis=0))
|
||||
|
||||
|
||||
# Output
|
||||
Starting Img shape computation:
|
||||
ThreadPoolExecutor-0_0: working on img num: 0
|
||||
@ -176,27 +177,26 @@ ThreadPoolExecutor-0_17: working on img num: 5000
|
||||
ThreadPoolExecutor-0_15: working on img num: 10000
|
||||
ThreadPoolExecutor-0_1: working on img num: 15000
|
||||
ThreadPoolExecutor-0_7: working on img num: 17360
|
||||
Min Dimensions: [46 46 3]
|
||||
Avg Dimensions: [132.77311215 132.45757733 3.]
|
||||
Median Dimensions: [130. 130. 3.]
|
||||
Max Dimensions: [385 394 3]
|
||||
Min Dimensions: [46 46 3]
|
||||
Avg Dimensions: [132.77311215 132.45757733 3.]
|
||||
Median Dimensions: [130. 130. 3.]
|
||||
Max Dimensions: [385 394 3]
|
||||
```
|
||||
|
||||
我们应用并行处理来加速图像读取,并且在总结统计时,我们将重新调整每幅图片到 125x125 像素。让我们载入我们所有的图像并重新调整它们为这些固定的大小。
|
||||
|
||||
我们应用并行处理来加速图像读取,并且基于汇总统计结果,我们将每幅图片的尺寸重新调整到 125x125 像素。让我们载入我们所有的图像并重新调整它们为这些固定尺寸。
|
||||
|
||||
```
|
||||
IMG_DIMS = (125, 125)
|
||||
|
||||
def get_img_data_parallel(idx, img, total_imgs):
|
||||
if idx % 5000 == 0 or idx == (total_imgs - 1):
|
||||
print('{}: working on img num: {}'.format(threading.current_thread().name,
|
||||
idx))
|
||||
img = cv2.imread(img)
|
||||
img = cv2.resize(img, dsize=IMG_DIMS,
|
||||
interpolation=cv2.INTER_CUBIC)
|
||||
img = np.array(img, dtype=np.float32)
|
||||
return img
|
||||
if idx % 5000 == 0 or idx == (total_imgs - 1):
|
||||
print('{}: working on img num: {}'.format(threading.current_thread().name,
|
||||
idx))
|
||||
img = cv2.imread(img)
|
||||
img = cv2.resize(img, dsize=IMG_DIMS,
|
||||
interpolation=cv2.INTER_CUBIC)
|
||||
img = np.array(img, dtype=np.float32)
|
||||
return img
|
||||
|
||||
ex = futures.ThreadPoolExecutor(max_workers=None)
|
||||
train_data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
|
||||
@ -204,27 +204,28 @@ val_data_inp = [(idx, img, len(val_files)) for idx, img in enumerate(val_files)]
|
||||
test_data_inp = [(idx, img, len(test_files)) for idx, img in enumerate(test_files)]
|
||||
|
||||
print('Loading Train Images:')
|
||||
train_data_map = ex.map(get_img_data_parallel,
|
||||
[record[0] for record in train_data_inp],
|
||||
[record[1] for record in train_data_inp],
|
||||
[record[2] for record in train_data_inp])
|
||||
train_data_map = ex.map(get_img_data_parallel,
|
||||
[record[0] for record in train_data_inp],
|
||||
[record[1] for record in train_data_inp],
|
||||
[record[2] for record in train_data_inp])
|
||||
train_data = np.array(list(train_data_map))
|
||||
|
||||
print('\nLoading Validation Images:')
|
||||
val_data_map = ex.map(get_img_data_parallel,
|
||||
[record[0] for record in val_data_inp],
|
||||
[record[1] for record in val_data_inp],
|
||||
[record[2] for record in val_data_inp])
|
||||
val_data_map = ex.map(get_img_data_parallel,
|
||||
[record[0] for record in val_data_inp],
|
||||
[record[1] for record in val_data_inp],
|
||||
[record[2] for record in val_data_inp])
|
||||
val_data = np.array(list(val_data_map))
|
||||
|
||||
print('\nLoading Test Images:')
|
||||
test_data_map = ex.map(get_img_data_parallel,
|
||||
[record[0] for record in test_data_inp],
|
||||
[record[1] for record in test_data_inp],
|
||||
[record[2] for record in test_data_inp])
|
||||
test_data_map = ex.map(get_img_data_parallel,
|
||||
[record[0] for record in test_data_inp],
|
||||
[record[1] for record in test_data_inp],
|
||||
[record[2] for record in test_data_inp])
|
||||
test_data = np.array(list(test_data_map))
|
||||
|
||||
train_data.shape, val_data.shape, test_data.shape
|
||||
train_data.shape, val_data.shape, test_data.shape
|
||||
|
||||
|
||||
# Output
|
||||
Loading Train Images:
|
||||
@ -245,23 +246,22 @@ ThreadPoolExecutor-1_8: working on img num: 8267
|
||||
((17361, 125, 125, 3), (1929, 125, 125, 3), (8268, 125, 125, 3))
|
||||
```
|
||||
|
||||
我们再次应用并行处理来加速有关图像载入和重新调整大小。最终,我们获得了想要的维度的图片张量,正如之前描述的。我们现在查看一些血细胞图像样本来对我们的数据什么样有个印象。
|
||||
|
||||
我们再次应用并行处理来加速有关图像载入和重新调整大小的计算。最终,我们获得了所需尺寸的图片张量,正如前面的输出所示。我们现在查看一些血细胞图像样本,以对我们的数据有个印象。
|
||||
|
||||
```
|
||||
import matplotlib.pyplot as plt
|
||||
%matplotlib inline
|
||||
|
||||
plt.figure(1 , figsize = (8 , 8))
|
||||
n = 0
|
||||
n = 0
|
||||
for i in range(16):
|
||||
n += 1
|
||||
r = np.random.randint(0 , train_data.shape[0] , 1)
|
||||
plt.subplot(4 , 4 , n)
|
||||
plt.subplots_adjust(hspace = 0.5 , wspace = 0.5)
|
||||
plt.imshow(train_data[r[0]]/255.)
|
||||
plt.title('{}'.format(train_labels[r[0]]))
|
||||
plt.xticks([]) , plt.yticks([])
|
||||
n += 1
|
||||
r = np.random.randint(0 , train_data.shape[0] , 1)
|
||||
plt.subplot(4 , 4 , n)
|
||||
plt.subplots_adjust(hspace = 0.5 , wspace = 0.5)
|
||||
plt.imshow(train_data[r[0]]/255.)
|
||||
plt.title('{}'.format(train_labels[r[0]]))
|
||||
plt.xticks([]) , plt.yticks([])
|
||||
```
|
||||
|
||||
![Malaria cell samples][16]
|
||||
@ -270,7 +270,6 @@ plt.xticks([]) , plt.yticks([])
|
||||
|
||||
开始我们的模型训练前,我们必须建立一些基础的配置设置。
|
||||
|
||||
|
||||
```
|
||||
BATCH_SIZE = 64
|
||||
NUM_CLASSES = 2
|
||||
@ -290,12 +289,12 @@ val_labels_enc = le.transform(val_labels)
|
||||
|
||||
print(train_labels[:6], train_labels_enc[:6])
|
||||
|
||||
|
||||
# Output
|
||||
['malaria' 'malaria' 'malaria' 'healthy' 'healthy' 'malaria'] [1 1 1 0 0 1]
|
||||
```
|
||||
|
||||
我们修复我们的图像维度,批大小,和历元并编码我们的分类类标签。TensorFlow 2.0 于 2019 年三月发布,这个练习是非常好的借口来试用它。
|
||||
|
||||
我们修复我们的图像尺寸、批量大小,和纪元,并编码我们的分类的类标签。TensorFlow 2.0 于 2019 年三月发布,这个练习是尝试它的完美理由。
|
||||
|
||||
```
|
||||
import tensorflow as tf
|
||||
@ -312,24 +311,23 @@ tf.__version__
|
||||
|
||||
### 深度学习训练
|
||||
|
||||
在模型训练阶段,我们将构建三个深度训练模型,使用我们的训练集训练,使用验证数据比较它们的性能。我们然后保存这些模型并在之后的模型评估阶段使用它们。
|
||||
在模型训练阶段,我们将构建三个深度训练模型,使用我们的训练集训练,使用验证数据比较它们的性能。然后,我们保存这些模型并在之后的模型评估阶段使用它们。
|
||||
|
||||
#### 模型 1:从头开始的 CNN
|
||||
|
||||
我们的第一个疟疾检测模型将从头开始构建和训练一个基础的 CNN。首先,让我们定义我们的模型架构,
|
||||
|
||||
|
||||
```
|
||||
inp = tf.keras.layers.Input(shape=INPUT_SHAPE)
|
||||
|
||||
conv1 = tf.keras.layers.Conv2D(32, kernel_size=(3, 3),
|
||||
activation='relu', padding='same')(inp)
|
||||
conv1 = tf.keras.layers.Conv2D(32, kernel_size=(3, 3),
|
||||
activation='relu', padding='same')(inp)
|
||||
pool1 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv1)
|
||||
conv2 = tf.keras.layers.Conv2D(64, kernel_size=(3, 3),
|
||||
activation='relu', padding='same')(pool1)
|
||||
conv2 = tf.keras.layers.Conv2D(64, kernel_size=(3, 3),
|
||||
activation='relu', padding='same')(pool1)
|
||||
pool2 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv2)
|
||||
conv3 = tf.keras.layers.Conv2D(128, kernel_size=(3, 3),
|
||||
activation='relu', padding='same')(pool2)
|
||||
conv3 = tf.keras.layers.Conv2D(128, kernel_size=(3, 3),
|
||||
activation='relu', padding='same')(pool2)
|
||||
pool3 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv3)
|
||||
|
||||
flat = tf.keras.layers.Flatten()(pool3)
|
||||
@ -343,31 +341,32 @@ out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
|
||||
|
||||
model = tf.keras.Model(inputs=inp, outputs=out)
|
||||
model.compile(optimizer='adam',
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy'])
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy'])
|
||||
model.summary()
|
||||
|
||||
|
||||
# Output
|
||||
Model: "model"
|
||||
_________________________________________________________________
|
||||
Layer (type) Output Shape Param #
|
||||
Layer (type) Output Shape Param #
|
||||
=================================================================
|
||||
input_1 (InputLayer) [(None, 125, 125, 3)] 0
|
||||
input_1 (InputLayer) [(None, 125, 125, 3)] 0
|
||||
_________________________________________________________________
|
||||
conv2d (Conv2D) (None, 125, 125, 32) 896
|
||||
conv2d (Conv2D) (None, 125, 125, 32) 896
|
||||
_________________________________________________________________
|
||||
max_pooling2d (MaxPooling2D) (None, 62, 62, 32) 0
|
||||
max_pooling2d (MaxPooling2D) (None, 62, 62, 32) 0
|
||||
_________________________________________________________________
|
||||
conv2d_1 (Conv2D) (None, 62, 62, 64) 18496
|
||||
conv2d_1 (Conv2D) (None, 62, 62, 64) 18496
|
||||
_________________________________________________________________
|
||||
...
|
||||
...
|
||||
_________________________________________________________________
|
||||
dense_1 (Dense) (None, 512) 262656
|
||||
dense_1 (Dense) (None, 512) 262656
|
||||
_________________________________________________________________
|
||||
dropout_1 (Dropout) (None, 512) 0
|
||||
dropout_1 (Dropout) (None, 512) 0
|
||||
_________________________________________________________________
|
||||
dense_2 (Dense) (None, 1) 513
|
||||
dense_2 (Dense) (None, 1) 513
|
||||
=================================================================
|
||||
Total params: 15,102,529
|
||||
Trainable params: 15,102,529
|
||||
@ -375,26 +374,26 @@ Non-trainable params: 0
|
||||
_________________________________________________________________
|
||||
```
|
||||
|
||||
基于这些代码的架构,我们的 CNN 模型有三个卷积和一个池化层,跟随两个致密层,以及用于正则化的丢失。让我们训练我们的模型。
|
||||
基于这些代码的架构,我们的 CNN 模型有三个卷积和一个池化层,其后是两个致密层,以及用于正则化的失活。让我们训练我们的模型。
|
||||
|
||||
|
||||
```
|
||||
import datetime
|
||||
|
||||
logdir = os.path.join('/home/dipanzan_sarkar/projects/tensorboard_logs',
|
||||
datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
|
||||
logdir = os.path.join('/home/dipanzan_sarkar/projects/tensorboard_logs',
|
||||
datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
|
||||
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
|
||||
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
|
||||
patience=2, min_lr=0.000001)
|
||||
patience=2, min_lr=0.000001)
|
||||
callbacks = [reduce_lr, tensorboard_callback]
|
||||
|
||||
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
|
||||
batch_size=BATCH_SIZE,
|
||||
epochs=EPOCHS,
|
||||
validation_data=(val_imgs_scaled, val_labels_enc),
|
||||
callbacks=callbacks,
|
||||
verbose=1)
|
||||
|
||||
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
|
||||
batch_size=BATCH_SIZE,
|
||||
epochs=EPOCHS,
|
||||
validation_data=(val_imgs_scaled, val_labels_enc),
|
||||
callbacks=callbacks,
|
||||
verbose=1)
|
||||
|
||||
|
||||
# Output
|
||||
Train on 17361 samples, validate on 1929 samples
|
||||
@ -439,57 +438,53 @@ l2 = ax2.legend(loc="best")
|
||||
|
||||
![Learning curves for basic CNN][17]
|
||||
|
||||
基础 CNN 学习曲线
|
||||
|
||||
我们可以看在在第五个历元,情况并没有改善很多。让我们保存这个模型用于将来的评估。
|
||||
*基础 CNN 学习曲线*
|
||||
|
||||
我们可以看在在第五个纪元,情况并没有改善很多。让我们保存这个模型用于将来的评估。
|
||||
|
||||
```
|
||||
`model.save('basic_cnn.h5')`
|
||||
model.save('basic_cnn.h5')
|
||||
```
|
||||
|
||||
#### 深度迁移学习
|
||||
|
||||
就像人类有与生俱来的能力在不同任务间传输知识,迁移学习允许我们利用从以前任务学到的知识用到新的任务,相关的任务,甚至在机器学习或深度学习的上下文中。如果想深入探究迁移学习,你应该看我的文章“[一个易于理解与现实应用一起学习深度学习中的迁移学习的指导实践][18]”和我的书[ Python 迁移学习实践][19]。
|
||||
就像人类有与生俱来在不同任务间传输知识的能力一样,迁移学习允许我们利用从以前任务学到的知识用到新的相关的任务,即使在机器学习或深度学习的情况下也是如此。如果想深入探究迁移学习,你应该看我的文章“[一个易于理解与现实应用一起学习深度学习中的迁移学习的指导实践][18]”和我的书《[Python 迁移学习实践][19]》。
|
||||
|
||||
![深度迁移学习的想法][20]
|
||||
|
||||
在这篇实践中我们想要探索的想法是:
|
||||
|
||||
> 在我们的问题上下文中,我们能够利用一个预训练深度学习模型(在大数据集上训练的,像 ImageNet)通过应用和迁移知识来解决疟疾检测的问题吗?
|
||||
> 在我们的问题背景下,我们能够利用一个预训练深度学习模型(在大数据集上训练的,像 ImageNet)通过应用和迁移知识来解决疟疾检测的问题吗?
|
||||
|
||||
我们将应用两个深度迁移学习的最流行的策略。
|
||||
我们将应用两个最流行的深度迁移学习策略。
|
||||
|
||||
* 预训练模型作为特征提取器
|
||||
* 微调的预训练模型
|
||||
|
||||
|
||||
|
||||
我们将使用预训练的 VGG-19 深度训练模型,由剑桥大学的视觉几何组(VGG)开发,作为我们的实验。一个像 VGG-19 的预训练模型在一个大的数据集上使用了很多不同的图像分类训练([Imagenet][21])。因此,这个模型应该已经学习到了鲁棒的特征层级结构,相对于你的 CNN 模型学到的特征,是空间不变的,转动不变的,平移不变的。因此,这个模型,已经从百万幅图片中学习到了一个好的特征显示,对于像疟疾检测这样的计算机视觉问题,可以作为一个好的合适新图像的特征提取器。在我们的问题中释放迁移学习的能力之前,让我们先讨论 VGG-19 模型。
|
||||
我们将使用预训练的 VGG-19 深度训练模型(由剑桥大学的视觉几何组(VGG)开发)进行我们的实验。像 VGG-19 这样的预训练模型是在一个大的数据集([Imagenet][21])上使用了很多不同的图像分类训练的。因此,这个模型应该已经学习到了健壮的特征层级结构,相对于你的 CNN 模型学到的特征,是空间不变的、转动不变的、平移不变的。因此,这个模型,已经从百万幅图片中学习到了一个好的特征显示,对于像疟疾检测这样的计算机视觉问题,可以作为一个好的合适新图像的特征提取器。在我们的问题中发挥迁移学习的能力之前,让我们先讨论 VGG-19 模型。
|
||||
|
||||
##### 理解 VGG-19 模型
|
||||
|
||||
VGG-19 模型是一个构建在 ImageNet 数据库之上的 19 层(卷积和全连接的)的深度学习网络,该数据库为了图像识别和分类的目的而开发。该模型由 Karen Simonyan 和 Andrew Zisserman 构建,在它们的论文”[大规模图像识别的非常深的卷积网络][22]“中描述。VGG-19 的架构模型是:
|
||||
VGG-19 模型是一个构建在 ImageNet 数据库之上的 19 层(卷积和全连接的)的深度学习网络,ImageNet 数据库为了图像识别和分类的目的而开发。该模型是由 Karen Simonyan 和 Andrew Zisserman 构建的,在他们的论文“[大规模图像识别的非常深的卷积网络][22]”中进行了描述。VGG-19 的架构模型是:
|
||||
|
||||
![VGG-19 模型架构][23]
|
||||
|
||||
你可以看到我们总共有 16 个使用 3x3 卷积过滤器的卷积层,与最大的池化层来下采样,和由 4096 个单元组成的两个全连接的隐藏层,每个隐藏层之后跟随一个由 1000 个单元组成的致密层,每个单元代表 ImageNet 数据库中的一个分类。我们不需要最后三层,因为我们将使用我们自己的全连接致密层来预测疟疾。我们更关心前五块,因此我们可以利用 VGG 模型作为一个有效的特征提取器。
|
||||
你可以看到我们总共有 16 个使用 3x3 卷积过滤器的卷积层,与最大的池化层来下采样,和由 4096 个单元组成的两个全连接的隐藏层,每个隐藏层之后跟随一个由 1000 个单元组成的致密层,每个单元代表 ImageNet 数据库中的一个分类。我们不需要最后三层,因为我们将使用我们自己的全连接致密层来预测疟疾。我们更关心前五个块,因此我们可以利用 VGG 模型作为一个有效的特征提取器。
|
||||
|
||||
我们将使用模型之一作为一个简单的特征提取器通过冻结五个卷积块的方式来确保它们的位权在每个时期后不会更新。对于最后一个模型,我们会应用微调到 VGG 模型,我们会解冻最后两个块(第 4 和第 5)因此当我们训练我们的模型时,它们的位权在每个时期(每批数据)被更新。
|
||||
我们将使用模型之一作为一个简单的特征提取器,通过冻结五个卷积块的方式来确保它们的位权在每个纪元后不会更新。对于最后一个模型,我们会对 VGG 模型进行微调,我们会解冻最后两个块(第 4 和第 5)因此当我们训练我们的模型时,它们的位权在每个时期(每批数据)被更新。
|
||||
|
||||
#### 模型 2:预训练的模型作为一个特征提取器
|
||||
|
||||
为了构建这个模型,我们将利用 TensorFlow 载入 VGG-19 模型并且冻结卷积块因此我们用够将他们用作特征提取器。我们插入我们自己的致密层在末尾来执行分类任务。
|
||||
|
||||
为了构建这个模型,我们将利用 TensorFlow 载入 VGG-19 模型并冻结卷积块,因此我们能够将它们用作特征提取器。我们在末尾插入我们自己的致密层来执行分类任务。
|
||||
|
||||
```
|
||||
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
|
||||
input_shape=INPUT_SHAPE)
|
||||
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
|
||||
input_shape=INPUT_SHAPE)
|
||||
vgg.trainable = False
|
||||
# Freeze the layers
|
||||
for layer in vgg.layers:
|
||||
layer.trainable = False
|
||||
|
||||
layer.trainable = False
|
||||
|
||||
base_vgg = vgg
|
||||
base_out = base_vgg.output
|
||||
pool_out = tf.keras.layers.Flatten()(base_out)
|
||||
@ -502,37 +497,38 @@ out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
|
||||
|
||||
model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
|
||||
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-4),
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy'])
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy'])
|
||||
model.summary()
|
||||
|
||||
|
||||
# Output
|
||||
Model: "model_1"
|
||||
_________________________________________________________________
|
||||
Layer (type) Output Shape Param #
|
||||
Layer (type) Output Shape Param #
|
||||
=================================================================
|
||||
input_2 (InputLayer) [(None, 125, 125, 3)] 0
|
||||
input_2 (InputLayer) [(None, 125, 125, 3)] 0
|
||||
_________________________________________________________________
|
||||
block1_conv1 (Conv2D) (None, 125, 125, 64) 1792
|
||||
block1_conv1 (Conv2D) (None, 125, 125, 64) 1792
|
||||
_________________________________________________________________
|
||||
block1_conv2 (Conv2D) (None, 125, 125, 64) 36928
|
||||
block1_conv2 (Conv2D) (None, 125, 125, 64) 36928
|
||||
_________________________________________________________________
|
||||
...
|
||||
...
|
||||
_________________________________________________________________
|
||||
block5_pool (MaxPooling2D) (None, 3, 3, 512) 0
|
||||
block5_pool (MaxPooling2D) (None, 3, 3, 512) 0
|
||||
_________________________________________________________________
|
||||
flatten_1 (Flatten) (None, 4608) 0
|
||||
flatten_1 (Flatten) (None, 4608) 0
|
||||
_________________________________________________________________
|
||||
dense_3 (Dense) (None, 512) 2359808
|
||||
dense_3 (Dense) (None, 512) 2359808
|
||||
_________________________________________________________________
|
||||
dropout_2 (Dropout) (None, 512) 0
|
||||
dropout_2 (Dropout) (None, 512) 0
|
||||
_________________________________________________________________
|
||||
dense_4 (Dense) (None, 512) 262656
|
||||
dense_4 (Dense) (None, 512) 262656
|
||||
_________________________________________________________________
|
||||
dropout_3 (Dropout) (None, 512) 0
|
||||
dropout_3 (Dropout) (None, 512) 0
|
||||
_________________________________________________________________
|
||||
dense_5 (Dense) (None, 1) 513
|
||||
dense_5 (Dense) (None, 1) 513
|
||||
=================================================================
|
||||
Total params: 22,647,361
|
||||
Trainable params: 2,622,977
|
||||
@ -540,45 +536,42 @@ Non-trainable params: 20,024,384
|
||||
_________________________________________________________________
|
||||
```
|
||||
|
||||
输出是很明白的,在我们的模型中我们有了很多层,我们将只利用 VGG-19 模型的冻结层作为特征提取器。你可以使用下列代码来验证我们的模型有多少层是实际训练的,我们的网络中总共存在多少层。
|
||||
|
||||
从整个输出可以明显看出,在我们的模型中我们有了很多层,我们将只利用 VGG-19 模型的冻结层作为特征提取器。你可以使用下列代码来验证我们的模型有多少层是实际可训练的,以及我们的网络中总共存在多少层。
|
||||
|
||||
```
|
||||
print("Total Layers:", len(model.layers))
|
||||
print("Total trainable layers:",
|
||||
sum([1 for l in model.layers if l.trainable]))
|
||||
print("Total trainable layers:",
|
||||
sum([1 for l in model.layers if l.trainable]))
|
||||
|
||||
# Output
|
||||
Total Layers: 28
|
||||
Total trainable layers: 6
|
||||
```
|
||||
|
||||
我们将使用和我们之前的模型相似的配置和回调来训练我们的模型。参考 [我的 GitHub 仓库][24] 获取训练模型的完整代码。我们观察下列显示模型精确度和损失曲线。
|
||||
我们将使用和我们之前的模型相似的配置和回调来训练我们的模型。参考[我的 GitHub 仓库][24]以获取训练模型的完整代码。我们观察下列图表,以显示模型精确度和损失曲线。
|
||||
|
||||
![Learning curves for frozen pre-trained CNN][25]
|
||||
|
||||
冻结的预训练的 CNN 的学习曲线
|
||||
|
||||
这显示了我们的模型没有像我们的基础 CNN 模型那样过拟合,但是性能有点不如我们的基础的 CNN 模型。让我们保存这个模型用户将来的评估。
|
||||
*冻结的预训练的 CNN 的学习曲线*
|
||||
|
||||
这表明我们的模型没有像我们的基础 CNN 模型那样过拟合,但是性能有点不如我们的基础的 CNN 模型。让我们保存这个模型,以备将来的评估。
|
||||
|
||||
```
|
||||
`model.save('vgg_frozen.h5')`
|
||||
model.save('vgg_frozen.h5')
|
||||
```
|
||||
|
||||
#### 模型 3:使用图像增强来微调预训练的模型
|
||||
|
||||
在我们的最后一个模型中,我们微调预定义好的 VGG-19 模型的最后两个块中层的位权。我们同样引入图像增强的概念。图像增强背后的想法和名字一样。我们从训练数据集中载入已存在的图像,并且应用转换操作,例如旋转,裁剪,转换,放大缩小,等等,来产生新的,改变的版本。由于这些随机的转换,我们每次获取到的图像不一样。我们将应用一个在 **tf.keras** 的优秀的工具叫做 **ImageDataGenerator** 来帮助构建图像增强器。
|
||||
|
||||
在我们的最后一个模型中,我们将在预定义好的 VGG-19 模型的最后两个块中微调层的位权。我们同样引入了图像增强的概念。图像增强背后的想法和其名字一样。我们从训练数据集中载入现有图像,并且应用转换操作,例如旋转、裁剪、转换、放大缩小等等,来产生新的、改变过的版本。由于这些随机转换,我们每次获取到的图像不一样。我们将应用 tf.keras 中的一个名为 ImageDataGenerator 的优秀工具来帮助构建图像增强器。
|
||||
|
||||
```
|
||||
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,
|
||||
zoom_range=0.05,
|
||||
rotation_range=25,
|
||||
width_shift_range=0.05,
|
||||
height_shift_range=0.05,
|
||||
shear_range=0.05, horizontal_flip=True,
|
||||
fill_mode='nearest')
|
||||
zoom_range=0.05,
|
||||
rotation_range=25,
|
||||
width_shift_range=0.05,
|
||||
height_shift_range=0.05,
|
||||
shear_range=0.05, horizontal_flip=True,
|
||||
fill_mode='nearest')
|
||||
|
||||
val_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
|
||||
|
||||
@ -587,13 +580,12 @@ train_generator = train_datagen.flow(train_data, train_labels_enc, batch_size=BA
|
||||
val_generator = val_datagen.flow(val_data, val_labels_enc, batch_size=BATCH_SIZE, shuffle=False)
|
||||
```
|
||||
|
||||
我们不会应用任何转换在我们的验证数据集上(除非是调整大小,它是强制性适应的)因为我们将在每个时期来评估我们的模型性能。对于在传输学习上下文中的图像增强的详细解释,请自由查看我们上述引用的[文章][18]。让我们从一批图像增强转换中查看一些样本结果。
|
||||
|
||||
我们不会对我们的验证数据集应用任何转换(除非是调整大小,因为这是必须的),因为我们将使用它评估每个纪元的模型性能。对于在传输学习环境中的图像增强的详细解释,请随时查看我上面引用的[文章][18]。让我们从一批图像增强转换中查看一些样本结果。
|
||||
|
||||
```
|
||||
img_id = 0
|
||||
sample_generator = train_datagen.flow(train_data[img_id:img_id+1], train_labels[img_id:img_id+1],
|
||||
batch_size=1)
|
||||
batch_size=1)
|
||||
sample = [next(sample_generator) for i in range(0,5)]
|
||||
fig, ax = plt.subplots(1,5, figsize=(16, 6))
|
||||
print('Labels:', [item[1][0] for item in sample])
|
||||
@ -602,24 +594,23 @@ l = [ax[i].imshow(sample[i][0][0]) for i in range(0,5)]
|
||||
|
||||
![Sample augmented images][26]
|
||||
|
||||
你可以清晰的看到与之前的输出中我们图像的轻微变化。我们现在构建我们的学习模型,确保 VGG-19 模型的最后两块是可以训练的。
|
||||
|
||||
你可以清晰的看到与之前的输出的我们图像的轻微变化。我们现在构建我们的学习模型,确保 VGG-19 模型的最后两块是可以训练的。
|
||||
|
||||
```
|
||||
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
|
||||
input_shape=INPUT_SHAPE)
|
||||
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
|
||||
input_shape=INPUT_SHAPE)
|
||||
# Freeze the layers
|
||||
vgg.trainable = True
|
||||
|
||||
set_trainable = False
|
||||
for layer in vgg.layers:
|
||||
if layer.name in ['block5_conv1', 'block4_conv1']:
|
||||
set_trainable = True
|
||||
if set_trainable:
|
||||
layer.trainable = True
|
||||
else:
|
||||
layer.trainable = False
|
||||
|
||||
if layer.name in ['block5_conv1', 'block4_conv1']:
|
||||
set_trainable = True
|
||||
if set_trainable:
|
||||
layer.trainable = True
|
||||
else:
|
||||
layer.trainable = False
|
||||
|
||||
base_vgg = vgg
|
||||
base_out = base_vgg.output
|
||||
pool_out = tf.keras.layers.Flatten()(base_out)
|
||||
@ -632,31 +623,32 @@ out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
|
||||
|
||||
model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
|
||||
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-5),
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy'])
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy'])
|
||||
|
||||
print("Total Layers:", len(model.layers))
|
||||
print("Total trainable layers:", sum([1 for l in model.layers if l.trainable]))
|
||||
|
||||
|
||||
# Output
|
||||
Total Layers: 28
|
||||
Total trainable layers: 16
|
||||
```
|
||||
|
||||
在我们的模型中我们降低了学习率,因为我们微调的时候不想在预训练的数据集上做大的位权更新。模型的训练过程可能有轻微的不同,因为我们使用了数据生成器,因此我们应用了 **fit_generator(...)** 函数。
|
||||
|
||||
在我们的模型中我们降低了学习率,因为我们不想在微调的时候对预训练的层做大的位权更新。模型的训练过程可能有轻微的不同,因为我们使用了数据生成器,因此我们将应用 `fit_generator(...)` 函数。
|
||||
|
||||
```
|
||||
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
|
||||
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
|
||||
patience=2, min_lr=0.000001)
|
||||
patience=2, min_lr=0.000001)
|
||||
|
||||
callbacks = [reduce_lr, tensorboard_callback]
|
||||
train_steps_per_epoch = train_generator.n // train_generator.batch_size
|
||||
val_steps_per_epoch = val_generator.n // val_generator.batch_size
|
||||
history = model.fit_generator(train_generator, steps_per_epoch=train_steps_per_epoch, epochs=EPOCHS,
|
||||
validation_data=val_generator, validation_steps=val_steps_per_epoch,
|
||||
verbose=1)
|
||||
validation_data=val_generator, validation_steps=val_steps_per_epoch,
|
||||
verbose=1)
|
||||
|
||||
|
||||
# Output
|
||||
Epoch 1/25
|
||||
@ -675,21 +667,20 @@ Epoch 25/25
|
||||
|
||||
![Learning curves for fine-tuned pre-trained CNN][27]
|
||||
|
||||
微调预训练的 CNN 的学习曲线
|
||||
*微调过的预训练 CNN 的学习曲线*
|
||||
|
||||
让我们保存这个模型,因此我们能够在测试集上使用。
|
||||
|
||||
|
||||
```
|
||||
`model.save('vgg_finetuned.h5')`
|
||||
model.save('vgg_finetuned.h5')
|
||||
```
|
||||
|
||||
这完成了我们的模型训练阶段。我们准备好在测试集上测试我们模型的性能。
|
||||
这就完成了我们的模型训练阶段。现在我们准备好了在测试集上测试我们模型的性能。
|
||||
|
||||
### 深度学习模型性能评估
|
||||
|
||||
我们将评估我们在训练阶段构建的三个模型,通过在我们的测试集上做预测,因为仅仅验证是不够的!我们同样构建了一个检测工具模块叫做 **model_evaluation_utils**,我们可以使用相关分类指标用来评估使用我们深度学习模型的性能。第一步是测量我们的数据集。
|
||||
|
||||
我们将通过在我们的测试集上做预测来评估我们在训练阶段构建的三个模型,因为仅仅验证是不够的!我们同样构建了一个检测工具模块叫做 `model_evaluation_utils`,我们可以使用相关分类指标用来评估使用我们深度学习模型的性能。第一步是扩展我们的数据集。
|
||||
|
||||
```
|
||||
test_imgs_scaled = test_data / 255.
|
||||
@ -701,7 +692,6 @@ test_imgs_scaled.shape, test_labels.shape
|
||||
|
||||
下一步包括载入我们保存的深度学习模型,在测试集上预测。
|
||||
|
||||
|
||||
```
|
||||
# Load Saved Deep Learning Models
|
||||
basic_cnn = tf.keras.models.load_model('./basic_cnn.h5')
|
||||
@ -713,16 +703,15 @@ basic_cnn_preds = basic_cnn.predict(test_imgs_scaled, batch_size=512)
|
||||
vgg_frz_preds = vgg_frz.predict(test_imgs_scaled, batch_size=512)
|
||||
vgg_ft_preds = vgg_ft.predict(test_imgs_scaled, batch_size=512)
|
||||
|
||||
basic_cnn_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
|
||||
for pred in basic_cnn_preds.ravel()])
|
||||
vgg_frz_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
|
||||
for pred in vgg_frz_preds.ravel()])
|
||||
vgg_ft_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
|
||||
for pred in vgg_ft_preds.ravel()])
|
||||
basic_cnn_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
|
||||
for pred in basic_cnn_preds.ravel()])
|
||||
vgg_frz_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
|
||||
for pred in vgg_frz_preds.ravel()])
|
||||
vgg_ft_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
|
||||
for pred in vgg_ft_preds.ravel()])
|
||||
```
|
||||
|
||||
下一步是应用我们的 **model_evaluation_utils** 模块根据相应分类指标来检查每个模块的性能。
|
||||
|
||||
下一步是应用我们的 `model_evaluation_utils` 模块根据相应分类指标来检查每个模块的性能。
|
||||
|
||||
```
|
||||
import model_evaluation_utils as meu
|
||||
@ -732,30 +721,30 @@ basic_cnn_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=ba
|
||||
vgg_frz_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_frz_pred_labels)
|
||||
vgg_ft_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_ft_pred_labels)
|
||||
|
||||
pd.DataFrame([basic_cnn_metrics, vgg_frz_metrics, vgg_ft_metrics],
|
||||
index=['Basic CNN', 'VGG-19 Frozen', 'VGG-19 Fine-tuned'])
|
||||
pd.DataFrame([basic_cnn_metrics, vgg_frz_metrics, vgg_ft_metrics],
|
||||
index=['Basic CNN', 'VGG-19 Frozen', 'VGG-19 Fine-tuned'])
|
||||
```
|
||||
|
||||
![Model accuracy][28]
|
||||
|
||||
看起来我们的第三个模型在我们的测试集上执行的最好,给出了一个模型精确性为 96% 的 F1得分,比起上述我们早期引用的研究论文和文章中提及的复杂的模型是相当好的。
|
||||
看起来我们的第三个模型在我们的测试集上执行的最好,给出了一个模型精确性为 96% 的 F1 得分,这非常好,与我们之前提到的研究论文和文章中的更复杂的模型相当。
|
||||
|
||||
### 总结
|
||||
|
||||
疟疾检测不是一个简单的程序,全球的合格的人员的可获得性在样例诊断和治疗当中是一个严重的问题。我们看到一个关于疟疾的有趣的真实世界的医学影像案例。易于构建的,开源的技术利用 AI 在检测疟疾方面可以给我们最先进的精确性,因此允许 AI 对社会是有益的。
|
||||
疟疾检测不是一个简单的过程,全球的合格人员的不足在病例诊断和治疗当中是一个严重的问题。我们研究了一个关于疟疾的有趣的真实世界的医学影像案例。利用 AI 的、易于构建的、开源的技术在检测疟疾方面可以为我们提供最先进的精确性,因此使 AI 具有社会效益。
|
||||
|
||||
我鼓励你检查这片文章中提到的文章和研究论文,没有它们,我就不能形成概念并写出来。如果你对运行和采纳这些技术感兴趣,本篇文章所有的代码都可以在[我的 GitHub 仓库][24]获得。记得从[官方网站][11]下载数据。
|
||||
我鼓励你查看这篇文章中提到的文章和研究论文,没有它们,我就不能形成概念并写出来。如果你对运行和采纳这些技术感兴趣,本篇文章所有的代码都可以在[我的 GitHub 仓库][24]获得。记得从[官方网站][11]下载数据。
|
||||
|
||||
让我们希望在健康医疗方面更多的采纳开源的 AI 能力,使它在世界范围内变得便宜些,易用些。
|
||||
让我们希望在健康医疗方面更多的采纳开源的 AI 能力,使它在世界范围内变得更便宜、更易用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/detecting-malaria-deep-learning
|
||||
|
||||
作者:[Dipanjan (DJ) Sarkar (Red Hat)][a]
|
||||
作者:[Dipanjan (DJ) Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -87,8 +87,8 @@ world
|
||||
#define WriteEnd 1
|
||||
|
||||
void report_and_exit(const char* msg) {
|
||||
[perror][6](msg);
|
||||
[exit][7](-1); /** failure **/
|
||||
perror(msg);
|
||||
exit(-1); /** failure **/
|
||||
}
|
||||
|
||||
int main() {
|
||||
@ -112,11 +112,11 @@ int main() {
|
||||
else { /*** parent ***/
|
||||
close(pipeFDs[ReadEnd]); /* parent writes, doesn't read */
|
||||
|
||||
write(pipeFDs[WriteEnd], msg, [strlen][8](msg)); /* write the bytes to the pipe */
|
||||
write(pipeFDs[WriteEnd], msg, strlen(msg)); /* write the bytes to the pipe */
|
||||
close(pipeFDs[WriteEnd]); /* done writing: generate eof */
|
||||
|
||||
wait(NULL); /* wait for child to exit */
|
||||
[exit][7](0); /* exit normally */
|
||||
exit(0); /* exit normally */
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
@ -249,7 +249,7 @@ bye, bye ## ditto
|
||||
```c
|
||||
#include <sys/types.h>
|
||||
#include <sys/stat.h>
|
||||
#include <fcntl.h>
|
||||
#include <fcntl.h>
|
||||
#include <unistd.h>
|
||||
#include <time.h>
|
||||
#include <stdlib.h>
|
||||
@ -264,24 +264,24 @@ int main() {
|
||||
const char* pipeName = "./fifoChannel";
|
||||
mkfifo(pipeName, 0666); /* read/write for user/group/others */
|
||||
int fd = open(pipeName, O_CREAT | O_WRONLY); /* open as write-only */
|
||||
if (fd < 0) return -1; /** error **/
|
||||
|
||||
if (fd < 0) return -1; /* can't go on */
|
||||
|
||||
int i;
|
||||
for (i = 0; i < MaxLoops; i++) { /* write MaxWrites times */
|
||||
int j;
|
||||
for (j = 0; j < ChunkSize; j++) { /* each time, write ChunkSize bytes */
|
||||
int k;
|
||||
int chunk[IntsPerChunk];
|
||||
for (k = 0; k < IntsPerChunk; k++)
|
||||
chunk[k] = [rand][9]();
|
||||
write(fd, chunk, sizeof(chunk));
|
||||
for (k = 0; k < IntsPerChunk; k++)
|
||||
chunk[k] = rand();
|
||||
write(fd, chunk, sizeof(chunk));
|
||||
}
|
||||
usleep(([rand][9]() % MaxZs) + 1); /* pause a bit for realism */
|
||||
usleep((rand() % MaxZs) + 1); /* pause a bit for realism */
|
||||
}
|
||||
|
||||
close(fd); /* close pipe: generates an end-of-file */
|
||||
unlink(pipeName); /* unlink from the implementing file */
|
||||
[printf][10]("%i ints sent to the pipe.\n", MaxLoops * ChunkSize * IntsPerChunk);
|
||||
close(fd); /* close pipe: generates an end-of-stream marker */
|
||||
unlink(pipeName); /* unlink from the implementing file */
|
||||
printf("%i ints sent to the pipe.\n", MaxLoops * ChunkSize * IntsPerChunk);
|
||||
|
||||
return 0;
|
||||
}
|
||||
@ -318,13 +318,12 @@ unlink(pipeName); /* unlink from the implementing file */
|
||||
#include <fcntl.h>
|
||||
#include <unistd.h>
|
||||
|
||||
|
||||
unsigned is_prime(unsigned n) { /* not pretty, but gets the job done efficiently */
|
||||
unsigned is_prime(unsigned n) { /* not pretty, but efficient */
|
||||
if (n <= 3) return n > 1;
|
||||
if (0 == (n % 2) || 0 == (n % 3)) return 0;
|
||||
|
||||
unsigned i;
|
||||
for (i = 5; (i * i) <= n; i += 6)
|
||||
for (i = 5; (i * i) <= n; i += 6)
|
||||
if (0 == (n % i) || 0 == (n % (i + 2))) return 0;
|
||||
|
||||
return 1; /* found a prime! */
|
||||
@ -332,25 +331,25 @@ unsigned is_prime(unsigned n) { /* not pretty, but gets the job done efficiently
|
||||
|
||||
int main() {
|
||||
const char* file = "./fifoChannel";
|
||||
int fd = open(file, O_RDONLY);
|
||||
int fd = open(file, O_RDONLY);
|
||||
if (fd < 0) return -1; /* no point in continuing */
|
||||
unsigned count = 0, total = 0, primes_count = 0;
|
||||
|
||||
while (1) {
|
||||
int next;
|
||||
int i;
|
||||
ssize_t count = read(fd, &next, sizeof(int));
|
||||
|
||||
ssize_t count = read(fd, &next, sizeof(int));
|
||||
if (0 == count) break; /* end of stream */
|
||||
else if (count == sizeof(int)) { /* read a 4-byte int value */
|
||||
total++;
|
||||
if (is_prime(next)) primes_count++;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
close(fd); /* close pipe from read end */
|
||||
unlink(file); /* unlink from the underlying file */
|
||||
[printf][10]("Received ints: %u, primes: %u\n", total, primes_count);
|
||||
printf("Received ints: %u, primes: %u\n", total, primes_count);
|
||||
|
||||
return 0;
|
||||
}
|
||||
@ -434,23 +433,23 @@ ID `qid` 在效果上是消息队列文件描述符的对应物。
|
||||
#### 示例 5. sender 程序
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <sys/ipc.h>
|
||||
#include <stdio.h>
|
||||
#include <sys/ipc.h>
|
||||
#include <sys/msg.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
#include "queue.h"
|
||||
|
||||
void report_and_exit(const char* msg) {
|
||||
[perror][6](msg);
|
||||
[exit][7](-1); /* EXIT_FAILURE */
|
||||
perror(msg);
|
||||
exit(-1); /* EXIT_FAILURE */
|
||||
}
|
||||
|
||||
int main() {
|
||||
key_t key = ftok(PathName, ProjectId);
|
||||
key_t key = ftok(PathName, ProjectId);
|
||||
if (key < 0) report_and_exit("couldn't get key...");
|
||||
|
||||
int qid = msgget(key, 0666 | IPC_CREAT);
|
||||
|
||||
int qid = msgget(key, 0666 | IPC_CREAT);
|
||||
if (qid < 0) report_and_exit("couldn't get queue id...");
|
||||
|
||||
char* payloads[] = {"msg1", "msg2", "msg3", "msg4", "msg5", "msg6"};
|
||||
@ -460,11 +459,11 @@ int main() {
|
||||
/* build the message */
|
||||
queuedMessage msg;
|
||||
msg.type = types[i];
|
||||
[strcpy][11](msg.payload, payloads[i]);
|
||||
strcpy(msg.payload, payloads[i]);
|
||||
|
||||
/* send the message */
|
||||
msgsnd(qid, &msg, sizeof(msg), IPC_NOWAIT); /* don't block */
|
||||
[printf][10]("%s sent as type %i\n", msg.payload, (int) msg.type);
|
||||
printf("%s sent as type %i\n", msg.payload, (int) msg.type);
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
@ -481,21 +480,21 @@ msgsnd(qid, &msg, sizeof(msg), IPC_NOWAIT);
|
||||
#### 示例 6. receiver 程序
|
||||
|
||||
```c
|
||||
#include <stdio.h>
|
||||
#include <sys/ipc.h>
|
||||
#include <stdio.h>
|
||||
#include <sys/ipc.h>
|
||||
#include <sys/msg.h>
|
||||
#include <stdlib.h>
|
||||
#include "queue.h"
|
||||
|
||||
void report_and_exit(const char* msg) {
|
||||
[perror][6](msg);
|
||||
[exit][7](-1); /* EXIT_FAILURE */
|
||||
perror(msg);
|
||||
exit(-1); /* EXIT_FAILURE */
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
int main() {
|
||||
key_t key= ftok(PathName, ProjectId); /* key to identify the queue */
|
||||
if (key < 0) report_and_exit("key not gotten...");
|
||||
|
||||
|
||||
int qid = msgget(key, 0666 | IPC_CREAT); /* access if created already */
|
||||
if (qid < 0) report_and_exit("no access to queue...");
|
||||
|
||||
@ -504,15 +503,15 @@ int main() {
|
||||
for (i = 0; i < MsgCount; i++) {
|
||||
queuedMessage msg; /* defined in queue.h */
|
||||
if (msgrcv(qid, &msg, sizeof(msg), types[i], MSG_NOERROR | IPC_NOWAIT) < 0)
|
||||
[puts][12]("msgrcv trouble...");
|
||||
[printf][10]("%s received as type %i\n", msg.payload, (int) msg.type);
|
||||
puts("msgrcv trouble...");
|
||||
printf("%s received as type %i\n", msg.payload, (int) msg.type);
|
||||
}
|
||||
|
||||
/** remove the queue **/
|
||||
if (msgctl(qid, IPC_RMID, NULL) < 0) /* NULL = 'no flags' */
|
||||
report_and_exit("trouble removing queue...");
|
||||
|
||||
return 0;
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -1,16 +1,18 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10867-1.html)
|
||||
[#]: subject: (Building scalable social media sentiment analysis services in Python)
|
||||
[#]: via: (https://opensource.com/article/19/4/social-media-sentiment-analysis-python-scalable)
|
||||
[#]: author: (Michael McCune https://opensource.com/users/elmiko/users/jschlessman)
|
||||
|
||||
使用 Python 构建可扩展的社交媒体情感分析服务
|
||||
======
|
||||
学习如何使用 spaCy、vaderSentiment、Flask 和 Python 来为你的工作添加情感分析能力。
|
||||
![Tall building with windows][1]
|
||||
|
||||
> 学习如何使用 spaCy、vaderSentiment、Flask 和 Python 来为你的作品添加情感分析能力。
|
||||
|
||||

|
||||
|
||||
本系列的[第一部分][2]提供了情感分析工作原理的一些背景知识,现在让我们研究如何将这些功能添加到你的设计中。
|
||||
|
||||
@ -20,7 +22,7 @@
|
||||
|
||||
* 一个终端 shell
|
||||
* shell 中的 Python 语言二进制文件(3.4+ 版本)
|
||||
* 用于安装 Python 包的 **pip** 命令
|
||||
* 用于安装 Python 包的 `pip` 命令
|
||||
* (可选)一个 [Python 虚拟环境][3]使你的工作与系统隔离开来
|
||||
|
||||
#### 配置环境
|
||||
@ -53,33 +55,44 @@ Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>>
|
||||
```
|
||||
|
||||
_(你的 Python 解释器版本打印可能与此不同。)_
|
||||
*(你的 Python 解释器版本打印可能与此不同。)*
|
||||
|
||||
1. 导入所需模块:
|
||||
```
|
||||
>>> import spacy
|
||||
>>> from vaderSentiment import vaderSentiment
|
||||
```
|
||||
2. 从 spaCy 加载英语语言模型:
|
||||
```
|
||||
>>> english = spacy.load("en_core_web_sm")
|
||||
```
|
||||
3. 处理一段文本。本例展示了一个非常简单的句子,我们希望它能给我们带来些许积极的情感:
|
||||
```
|
||||
>>> result = english("I like to eat applesauce with sugar and cinnamon.")
|
||||
```
|
||||
4. 从处理后的结果中收集句子。SpaCy 已识别并处理短语中的实体,这一步为每个句子生成情感(即时在本例中只有一个句子):
|
||||
```
|
||||
>>> sentences = [str(s) for s in result.sents]
|
||||
```
|
||||
5. 使用 vaderSentiments 创建一个分析器:
|
||||
```
|
||||
>>> analyzer = vaderSentiment.SentimentIntensityAnalyzer()
|
||||
```
|
||||
6. 对句子进行情感分析:
|
||||
```
|
||||
>>> sentiment = [analyzer.polarity_scores(str(s)) for s in sentences]
|
||||
```
|
||||
1、导入所需模块:
|
||||
|
||||
```
|
||||
>>> import spacy
|
||||
>>> from vaderSentiment import vaderSentiment
|
||||
```
|
||||
|
||||
2、从 spaCy 加载英语语言模型:
|
||||
|
||||
```
|
||||
>>> english = spacy.load("en_core_web_sm")
|
||||
```
|
||||
|
||||
3、处理一段文本。本例展示了一个非常简单的句子,我们希望它能给我们带来些许积极的情感:
|
||||
|
||||
```
|
||||
>>> result = english("I like to eat applesauce with sugar and cinnamon.")
|
||||
```
|
||||
|
||||
4、从处理后的结果中收集句子。SpaCy 已识别并处理短语中的实体,这一步为每个句子生成情感(即时在本例中只有一个句子):
|
||||
|
||||
```
|
||||
>>> sentences = [str(s) for s in result.sents]
|
||||
```
|
||||
|
||||
5、使用 vaderSentiments 创建一个分析器:
|
||||
|
||||
```
|
||||
>>> analyzer = vaderSentiment.SentimentIntensityAnalyzer()
|
||||
```
|
||||
|
||||
6、对句子进行情感分析:
|
||||
|
||||
```
|
||||
>>> sentiment = [analyzer.polarity_scores(str(s)) for s in sentences]
|
||||
```
|
||||
|
||||
`sentiment` 变量现在包含例句的极性分数。打印出这个值,看看它是如何分析这个句子的。
|
||||
|
||||
@ -90,7 +103,7 @@ _(你的 Python 解释器版本打印可能与此不同。)_
|
||||
|
||||
这个结构是什么意思?
|
||||
|
||||
表面上,这是一个只有一个字典对象的数组。如果有多个句子,那么每个句子都会对应一个字典对象。字典中有四个键对应不同类型的情感。**neg** 键表示负面情感,因为在本例中没有报告任何负面情感,**0.0** 值证明了这一点。**neu** 键表示中性情感,它的得分相当高,为**0.737**(最高为 **1.0**)。**pos** 键代表积极情感,得分适中,为 **0.263**。最后,**cmpound** 键代表文本的总体得分,它可以从负数到正数,**0.3612** 表示积极方面的情感多一点。
|
||||
表面上,这是一个只有一个字典对象的数组。如果有多个句子,那么每个句子都会对应一个字典对象。字典中有四个键对应不同类型的情感。`neg` 键表示负面情感,因为在本例中没有报告任何负面情感,`0.0` 值证明了这一点。`neu` 键表示中性情感,它的得分相当高,为 `0.737`(最高为 `1.0`)。`pos` 键代表积极情感,得分适中,为 `0.263`。最后,`cmpound` 键代表文本的总体得分,它可以从负数到正数,`0.3612` 表示积极方面的情感多一点。
|
||||
|
||||
要查看这些值可能如何变化,你可以使用已输入的代码做一个小实验。以下代码块显示了如何对类似句子的情感评分的评估。
|
||||
|
||||
@ -113,9 +126,9 @@ _(你的 Python 解释器版本打印可能与此不同。)_
|
||||
#### 前提条件
|
||||
|
||||
* 一个终端 shell
|
||||
* shell 中的 Python 语言二进制文件(3.4+版本)
|
||||
* 安装 Python 包的 **pip** 命令
|
||||
* **curl** 命令
|
||||
* shell 中的 Python 语言二进制文件(3.4+ 版本)
|
||||
* 安装 Python 包的 `pip` 命令
|
||||
* `curl` 命令
|
||||
* 一个文本编辑器
|
||||
* (可选) 一个 [Python 虚拟环境][3]使你的工作与系统隔离开来
|
||||
|
||||
@ -123,19 +136,21 @@ _(你的 Python 解释器版本打印可能与此不同。)_
|
||||
|
||||
这个环境几乎与上一节中的环境相同,唯一的区别是在 Python 环境中添加了 Flask 包。
|
||||
|
||||
1. 安装所需依赖项:
|
||||
```
|
||||
pip install spacy vaderSentiment flask
|
||||
```
|
||||
2. 安装 spaCy 的英语语言模型:
|
||||
```
|
||||
python -m spacy download en_core_web_sm
|
||||
```
|
||||
1、安装所需依赖项:
|
||||
|
||||
```
|
||||
pip install spacy vaderSentiment flask
|
||||
```
|
||||
|
||||
2、安装 spaCy 的英语语言模型:
|
||||
|
||||
```
|
||||
python -m spacy download en_core_web_sm
|
||||
```
|
||||
|
||||
#### 创建应用程序文件
|
||||
|
||||
打开编辑器,创建一个名为 **app.py** 的文件。添加以下内容 _(不用担心,我们将解释每一行)_ :
|
||||
打开编辑器,创建一个名为 `app.py` 的文件。添加以下内容 *(不用担心,我们将解释每一行)*:
|
||||
|
||||
|
||||
```
|
||||
@ -179,10 +194,9 @@ analyzer = vader.SentimentIntensityAnalyzer()
|
||||
english = spacy.load("en_core_web_sm")
|
||||
```
|
||||
|
||||
接下来的三行代码创建了一些全局变量。第一个变量 **app**,它是 Flask 用于创建 HTTP 路由的主要入口点。第二个变量 **analyzer** 与上一个示例中使用的类型相同,它将用于生成情感分数。最后一个变量 **english** 也与上一个示例中使用的类型相同,它将用于注释和标记初始文本输入。
|
||||
|
||||
你可能想知道为什么全局声明这些变量。对于 **app** 变量,这是许多 Flask 应用程序的标准过程。但是,对于 **analyzer** 和 **english** 变量,将它们设置为全局变量的决定是基于与所涉及的类关联的加载时间。虽然加载时间可能看起来很短,但是当它在 HTTP 服务器的上下文中运行时,这些延迟会对性能产生负面影响。
|
||||
接下来的三行代码创建了一些全局变量。第一个变量 `app`,它是 Flask 用于创建 HTTP 路由的主要入口点。第二个变量 `analyzer` 与上一个示例中使用的类型相同,它将用于生成情感分数。最后一个变量 `english` 也与上一个示例中使用的类型相同,它将用于注释和标记初始文本输入。
|
||||
|
||||
你可能想知道为什么全局声明这些变量。对于 `app` 变量,这是许多 Flask 应用程序的标准过程。但是,对于 `analyzer` 和 `english` 变量,将它们设置为全局变量的决定是基于与所涉及的类关联的加载时间。虽然加载时间可能看起来很短,但是当它在 HTTP 服务器的上下文中运行时,这些延迟会对性能产生负面影响。
|
||||
|
||||
```
|
||||
def get_sentiments(text):
|
||||
@ -192,8 +206,7 @@ def get_sentiments(text):
|
||||
return sentiments
|
||||
```
|
||||
|
||||
这部分是服务的核心 -- 一个用于从一串文本生成情感值的函数。你可以看到此函数中的操作对应于你之前在 Python 解释器中运行的命令。这里它们被封装在一个函数定义中,**text** 源作为文本变量传入,最后 **sentiments** 变量返回给调用者。
|
||||
|
||||
这部分是服务的核心 —— 一个用于从一串文本生成情感值的函数。你可以看到此函数中的操作对应于你之前在 Python 解释器中运行的命令。这里它们被封装在一个函数定义中,`text` 源作为文本变量传入,最后 `sentiments` 变量返回给调用者。
|
||||
|
||||
```
|
||||
@app.route("/", methods=["POST", "GET"])
|
||||
@ -206,11 +219,11 @@ def index():
|
||||
return flask.json.dumps(sentiments)
|
||||
```
|
||||
|
||||
源文件的最后一个函数包含了指导 Flask 如何为服务配置 HTTP 服务器的逻辑。它从一行开始,该行将 HTTP 路由 **/** 与请求方法 **POST** 和 **GET** 相关联。
|
||||
源文件的最后一个函数包含了指导 Flask 如何为服务配置 HTTP 服务器的逻辑。它从一行开始,该行将 HTTP 路由 `/` 与请求方法 `POST` 和 `GET` 相关联。
|
||||
|
||||
在函数定义行之后,**if** 子句将检测请求方法是否为 **GET**。如果用户向服务发送此请求,那么下面的行将返回一条指示如何访问服务器的文本消息。这主要是为了方便最终用户。
|
||||
在函数定义行之后,`if` 子句将检测请求方法是否为 `GET`。如果用户向服务发送此请求,那么下面的行将返回一条指示如何访问服务器的文本消息。这主要是为了方便最终用户。
|
||||
|
||||
下一行使用 **flask.request** 对象来获取请求的主体,该主体应包含要处理的文本字符串。**decode** 函数将字节数组转换为可用的格式化字符串。经过解码的文本消息被传递给 **get_sentiments** 函数以生成情感分数。最后,分数通过 HTTP 框架返回给用户。
|
||||
下一行使用 `flask.request` 对象来获取请求的主体,该主体应包含要处理的文本字符串。`decode` 函数将字节数组转换为可用的格式化字符串。经过解码的文本消息被传递给 `get_sentiments` 函数以生成情感分数。最后,分数通过 HTTP 框架返回给用户。
|
||||
|
||||
你现在应该保存文件,如果尚未保存,那么返回 shell。
|
||||
|
||||
@ -222,7 +235,7 @@ def index():
|
||||
FLASK_APP=app.py flask run
|
||||
```
|
||||
|
||||
现在,你将在 shell 中看到来自服务器的一些输出,并且服务器将处于运行状态。要测试服务器是否正在运行,你需要打开第二个 shell 并使用 **curl** 命令。
|
||||
现在,你将在 shell 中看到来自服务器的一些输出,并且服务器将处于运行状态。要测试服务器是否正在运行,你需要打开第二个 shell 并使用 `curl` 命令。
|
||||
|
||||
首先,输入以下命令检查是否打印了指令信息:
|
||||
|
||||
@ -252,11 +265,11 @@ curl http://localhost:5000 --header "Content-Type: application/json" --data "I l
|
||||
|
||||
### 继续探索
|
||||
|
||||
现在你已经了解了自然语言处理和情感分析背后的原理和机制,下面是进一步发现探索主题的一些方法。
|
||||
现在你已经了解了自然语言处理和情感分析背后的原理和机制,下面是进一步发现探索该主题的一些方法。
|
||||
|
||||
#### 在 OpenShift 上创建流式情感分析器
|
||||
|
||||
虽然创建本地应用程序来研究情绪分析很方便,但是接下来需要能够部署应用程序以实现更广泛的用途。按照[ Radnaalytics.io][11] 提供的指导和代码进行操作,你将学习如何创建一个情感分析仪,可以集装箱化并部署到 Kubernetes 平台。你还将了解如何将 APache Kafka 用作事件驱动消息传递的框架,以及如何将 Apache Spark 用作情绪分析的分布式计算平台。
|
||||
虽然创建本地应用程序来研究情绪分析很方便,但是接下来需要能够部署应用程序以实现更广泛的用途。按照[Radnaalytics.io][11] 提供的指导和代码进行操作,你将学习如何创建一个情感分析仪,可以容器化并部署到 Kubernetes 平台。你还将了解如何将 Apache Kafka 用作事件驱动消息传递的框架,以及如何将 Apache Spark 用作情绪分析的分布式计算平台。
|
||||
|
||||
#### 使用 Twitter API 发现实时数据
|
||||
|
||||
@ -266,17 +279,17 @@ curl http://localhost:5000 --header "Content-Type: application/json" --data "I l
|
||||
|
||||
via: https://opensource.com/article/19/4/social-media-sentiment-analysis-python-scalable
|
||||
|
||||
作者:[Michael McCune ][a]
|
||||
作者:[Michael McCune][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/elmiko/users/jschlessman
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/windows_building_sky_scale.jpg?itok=mH6CAX29 (Tall building with windows)
|
||||
[2]: https://opensource.com/article/19/4/social-media-sentiment-analysis-python-part-1
|
||||
[2]: https://linux.cn/article-10852-1.html
|
||||
[3]: https://virtualenv.pypa.io/en/stable/
|
||||
[4]: https://pypi.org/project/spacy/
|
||||
[5]: https://pypi.org/project/vaderSentiment/
|
||||
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10852-1.html)
|
||||
[#]: subject: (Getting started with social media sentiment analysis in Python)
|
||||
[#]: via: (https://opensource.com/article/19/4/social-media-sentiment-analysis-python)
|
||||
[#]: author: (Michael McCune https://opensource.com/users/elmiko/users/jschlessman)
|
||||
|
||||
使用 Python 进行社交媒体情感分析入门
|
||||
======
|
||||
|
||||
> 学习自然语言处理的基础知识并探索两个有用的 Python 包。
|
||||
|
||||

|
||||
|
||||
自然语言处理(NLP)是机器学习的一种,它解决了口语或书面语言和计算机辅助分析这些语言之间的相关性。日常生活中我们经历了无数的 NLP 创新,从写作帮助和建议到实时语音翻译,还有口译。
|
||||
|
||||
本文研究了 NLP 的一个特定领域:情感分析。重点是确定输入语言的积极、消极或中性性质。本部分将解释 NLP 和情感分析的背景,并探讨两个开源的 Python 包。[第 2 部分][2]将演示如何开始构建自己的可扩展情感分析服务。
|
||||
|
||||
在学习情感分析时,对 NLP 有一个大体了解是有帮助的。本文不会深入研究数学本质。相反,我们的目标是阐明 NLP 中的关键概念,这些概念对于将这些方法实际结合到你的解决方案中至关重要。
|
||||
|
||||
### 自然语言和文本数据
|
||||
|
||||
合理的起点是从定义开始:“什么是自然语言?”它是我们人类相互交流的方式,沟通的主要方式是口语和文字。我们可以更进一步,只关注文本交流。毕竟,生活在 Siri、Alexa 等无处不在的时代,我们知道语音是一组与文本无关的计算。
|
||||
|
||||
### 数据前景和挑战
|
||||
|
||||
我们只考虑使用文本数据,我们可以对语言和文本做什么呢?首先是语言,特别是英语,除了规则还有很多例外,含义的多样性和语境差异,这些都可能使人类口译员感到困惑,更不用说计算机翻译了。在小学,我们学习文章和标点符号,通过讲母语,我们获得了寻找直觉上表示唯一意义的词的能力。比如,出现诸如 “a”、“the” 和 “or” 之类的文章,它们在 NLP 中被称为*停止词*,因为传统上 NLP 算法是在一个序列中找到这些词时意味着搜索停止。
|
||||
|
||||
由于我们的目标是自动将文本分类为情感类,因此我们需要一种以计算方式处理文本数据的方法。因此,我们必须考虑如何向机器表示文本数据。众所周知,利用和解释语言的规则很复杂,输入文本的大小和结构可能会有很大差异。我们需要将文本数据转换为数字数据,这是机器和数学的首选方式。这种转变属于*特征提取*的范畴。
|
||||
|
||||
在提取输入文本数据的数字表示形式后,一个改进可能是:给定一个文本输入体,为上面列出的文章确定一组向量统计数据,并根据这些数据对文档进行分类。例如,过多的副词可能会使撰稿人感到愤怒,或者过度使用停止词可能有助于识别带有内容填充的学期论文。诚然,这可能与我们情感分析的目标没有太大关系。
|
||||
|
||||
### 词袋
|
||||
|
||||
当你评估一个文本陈述是积极还是消极的时候,你使用哪些上下文来评估它的极性?(例如,文本中是否具有积极的、消极的或中性的情感)一种方式是隐含形容词:被称为 “disgusting”(恶心) 的东西被认为是消极的,但如果同样的东西被称为 “beautiful”(漂亮),你会认为它是积极的。从定义上讲,俗语给人一种熟悉感,通常是积极的,而脏话可能是敌意的表现。文本数据也可以包括表情符号,它带有固定的情感。
|
||||
|
||||
理解单个单词的极性影响为文本的<ruby>[词袋][3]<rt>bag-of-words</rt></ruby>(BoW)模型提供了基础。它分析一组单词或词汇表,并提取关于这些单词在输入文本中是否存在的度量。词汇表是通过处理已知极性的文本形成称为*标记的训练数据*。从这组标记数据中提取特征,然后分析特征之间的关系,并将标记与数据关联起来。
|
||||
|
||||
“词袋”这个名称说明了它的用途:即不考虑空间位置或上下文的的单个词。词汇表通常是由训练集中出现的所有单词构建的,训练后往往会被修剪。如果在训练之前没有清理停止词,那么停止词会因为其高频率和低语境而被移除。很少使用的单词也可以删除,因为缺乏为一般输入实例提供的信息。
|
||||
|
||||
但是,重要的是要注意,你可以(并且应该)进一步考虑单词在单个训练数据实例之外的情形,这称为<ruby>[词频][4]<rt>term frequency</rt></ruby>(TF)。你还应该考虑输入数据在所有训练实例中的单词计数,通常,出现在所有文档中的低频词更重要,这被称为<ruby>[逆文本频率指数][5]<rt>inverse document frequency</rt></ruby>(IDF)。这些指标一定会在本主题系列的其他文章和软件包中提及,因此了解它们会有所帮助。
|
||||
|
||||
词袋在许多文档分类应用程序中很有用。然而,在情感分析中,当缺乏情境意识的问题被利用时,事情就可以解决。考虑以下句子:
|
||||
|
||||
* 我们不喜欢这场战争。
|
||||
* 我讨厌下雨天,好事是今天是晴天。
|
||||
* 这不是生死攸关的问题。
|
||||
|
||||
这些短语的情感对于人类口译员来说是有难度的,而且通过严格关注单个词汇的实例,对于机器翻译来说也是困难的。
|
||||
|
||||
在 NLP 中也可以使用称为 “n-grams” 的单词分组。一个二元组考虑两个相邻单词组成的组而不是(或除了)单个词袋。这应该可以缓解诸如上述“不喜欢”之类的情况,但由于缺乏语境意思,它仍然是个问题。此外,在上面的第二句中,下半句的情感语境可以被理解为否定前半部分。因此,这种方法中也会丢失上下文线索的空间局部性。从实用角度来看,使问题复杂化的是从给定输入文本中提取的特征的稀疏性。对于一个完整的大型词汇表,每个单词都有一个计数,可以将其视为一个整数向量。大多数文档的向量中都有大量的零计数向量,这给操作增加了不必要的空间和时间复杂度。虽然已经提出了许多用于降低这种复杂性的简便方法,但它仍然是一个问题。
|
||||
|
||||
### 词嵌入
|
||||
|
||||
<ruby>词嵌入<rt>Word embedding</rt></ruby>是一种分布式表示,它允许具有相似含义的单词具有相似的表示。这是基于使用实值向量来与它们周围相关联。重点在于使用单词的方式,而不仅仅是它们的存在与否。此外,词嵌入的一个巨大实用优势是它们关注于密集向量。通过摆脱具有相应数量的零值向量元素的单词计数模型,词嵌入在时间和存储方面提供了一个更有效的计算范例。
|
||||
|
||||
以下是两个优秀的词嵌入方法。
|
||||
|
||||
#### Word2vec
|
||||
|
||||
第一个是 [Word2vec][6],它是由 Google 开发的。随着你对 NLP 和情绪分析研究的深入,你可能会看到这种嵌入方法。它要么使用一个<ruby>连续的词袋<rt>continuous bag of words</rt></ruby>(CBOW),要么使用一个连续 skip-gram 模型。在 CBOW 中,一个单词的上下文是在训练中根据围绕它的单词来学习的。连续 skip-gram 学习倾向于围绕给定的单词学习单词。虽然这可能超出了你需要解决的问题,但是如果你曾经面对必须生成自己的词嵌入情况,那么 Word2vec 的作者就提倡使用 CBOW 方法来提高速度并评估频繁的单词,而 skip-gram 方法更适合嵌入稀有单词更重要的嵌入。
|
||||
|
||||
#### GloVe
|
||||
|
||||
第二个是<ruby>[用于词表示的全局向量][7]<rt>Global Vectors for Word Representation</rt></ruby>(GloVe),它是斯坦福大学开发的。它是 Word2vec 方法的扩展,试图通过将经典的全局文本统计特征提取获得的信息与 Word2vec 确定的本地上下文信息相结合。实际上,在一些应用程序中,GloVe 性能优于 Word2vec,而在另一些应用程序中则不如 Word2vec。最终,用于词嵌入的目标数据集将决定哪种方法最优。因此,最好了解它们的存在性和高级机制,因为你很可能会遇到它们。
|
||||
|
||||
#### 创建和使用词嵌入
|
||||
|
||||
最后,知道如何获得词嵌入是有用的。在第 2 部分中,你将看到我们通过利用社区中其他人的实质性工作,站到了巨人的肩膀上。这是获取词嵌入的一种方法:即使用现有的经过训练和验证的模型。实际上,有无数的模型适用于英语和其他语言,一定会有一种模型可以满足你的应用程序,让你开箱即用!
|
||||
|
||||
如果没有的话,就开发工作而言,另一个极端是培训你自己的独立模型,而不考虑你的应用程序。实质上,你将获得大量标记的训练数据,并可能使用上述方法之一来训练模型。即使这样,你仍然只是在理解你输入文本数据。然后,你需要为你应用程序开发一个特定的模型(例如,分析软件版本控制消息中的情感价值),这反过来又需要自己的时间和精力。
|
||||
|
||||
你还可以对针对你的应用程序的数据训练一个词嵌入,虽然这可以减少时间和精力,但这个词嵌入将是特定于应用程序的,这将会降低它的可重用性。
|
||||
|
||||
### 可用的工具选项
|
||||
|
||||
考虑到所需的大量时间和计算能力,你可能想知道如何才能找到解决问题的方法。的确,开发可靠模型的复杂性可能令人望而生畏。但是,有一个好消息:已经有许多经过验证的模型、工具和软件库可以为我们提供所需的大部分内容。我们将重点关注 [Python][8],因为它为这些应用程序提供了大量方便的工具。
|
||||
|
||||
#### SpaCy
|
||||
|
||||
[SpaCy][9] 提供了许多用于解析输入文本数据和提取特征的语言模型。它经过了高度优化,并被誉为同类中最快的库。最棒的是,它是开源的!SpaCy 会执行标识化、词性分类和依赖项注释。它包含了用于执行此功能的词嵌入模型,还有用于为超过 46 种语言的其他特征提取操作。在本系列的第二篇文章中,你将看到它如何用于文本分析和特征提取。
|
||||
|
||||
#### vaderSentiment
|
||||
|
||||
[vaderSentiment][10] 包提供了积极、消极和中性情绪的衡量标准。正如 [原论文][11] 的标题(《VADER:一个基于规则的社交媒体文本情感分析模型》)所示,这些模型是专门为社交媒体文本数据开发和调整的。VADER 接受了一组完整的人类标记过的数据的训练,包括常见的表情符号、UTF-8 编码的表情符号以及口语术语和缩写(例如 meh、lol、sux)。
|
||||
|
||||
对于给定的输入文本数据,vaderSentiment 返回一个极性分数百分比的三元组。它还提供了一个单个的评分标准,称为 *vaderSentiment 复合指标*。这是一个在 `[-1, 1]` 范围内的实值,其中对于分值大于 `0.05` 的情绪被认为是积极的,对于分值小于 `-0.05` 的被认为是消极的,否则为中性。
|
||||
|
||||
在[第 2 部分][2]中,你将学习如何使用这些工具为你的设计添加情感分析功能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/social-media-sentiment-analysis-python
|
||||
|
||||
作者:[Michael McCune][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/elmiko/users/jschlessman
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/getting_started_with_python.png?itok=MFEKm3gl (Raspberry Pi and Python)
|
||||
[2]: https://opensource.com/article/19/4/social-media-sentiment-analysis-python-part-2
|
||||
[3]: https://en.wikipedia.org/wiki/Bag-of-words_model
|
||||
[4]: https://en.wikipedia.org/wiki/Tf%E2%80%93idf#Term_frequency
|
||||
[5]: https://en.wikipedia.org/wiki/Tf%E2%80%93idf#Inverse_document_frequency
|
||||
[6]: https://en.wikipedia.org/wiki/Word2vec
|
||||
[7]: https://en.wikipedia.org/wiki/GloVe_(machine_learning)
|
||||
[8]: https://www.python.org/
|
||||
[9]: https://pypi.org/project/spacy/
|
||||
[10]: https://pypi.org/project/vaderSentiment/
|
||||
[11]: http://comp.social.gatech.edu/papers/icwsm14.vader.hutto.pdf
|
||||
132
published/20190425 Automate backups with restic and systemd.md
Normal file
132
published/20190425 Automate backups with restic and systemd.md
Normal file
@ -0,0 +1,132 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10875-1.html)
|
||||
[#]: subject: (Automate backups with restic and systemd)
|
||||
[#]: via: (https://fedoramagazine.org/automate-backups-with-restic-and-systemd/)
|
||||
[#]: author: (Link Dupont https://fedoramagazine.org/author/linkdupont/)
|
||||
|
||||
使用 restic 和 systemd 自动备份
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
及时备份很重要。即使在 [Fedora Magazine][3] 中,[备份软件][2] 也是一个常见的讨论话题。本文演示了如何仅使用 systemd 以及 `restic` 来自动备份。
|
||||
|
||||
有关 `restic` 的介绍,请查看我们的文章[在 Fedora 上使用 restic 进行加密备份][4]。然后继续阅读以了解更多详情。
|
||||
|
||||
为了自动创建快照以及清理数据,需要运行两个 systemd 服务。第一个运行*备份*命令的服务需要以常规频率运行。第二个服务负责数据清理。
|
||||
|
||||
如果你根本不熟悉 systemd,那么这是个很好的学习机会。查看 [Magazine 上关于 systemd 的系列文章] [5],从单元文件的这个入门开始:
|
||||
|
||||
- [systemd 单元文件基础][6]
|
||||
|
||||
如果你还没有安装 `restic`,请注意它在官方的 Fedora 仓库中。要安装它,请[带上 sudo][7] 运行此命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install restic
|
||||
```
|
||||
|
||||
### 备份
|
||||
|
||||
首先,创建 `~/.config/systemd/user/restic-backup.service`。将下面的文本复制并粘贴到文件中以获得最佳效果。
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Restic backup service
|
||||
[Service]
|
||||
Type=oneshot
|
||||
ExecStart=restic backup --verbose --one-file-system --tag systemd.timer $BACKUP_EXCLUDES $BACKUP_PATHS
|
||||
ExecStartPost=restic forget --verbose --tag systemd.timer --group-by "paths,tags" --keep-daily $RETENTION_DAYS --keep-weekly $RETENTION_WEEKS --keep-monthly $RETENTION_MONTHS --keep-yearly $RETENTION_YEARS
|
||||
EnvironmentFile=%h/.config/restic-backup.conf
|
||||
```
|
||||
|
||||
此服务引用环境文件来加载密钥(例如 `RESTIC_PASSWORD`)。创建 `~/.config/restic-backup.conf`。复制并粘贴以下内容以获得最佳效果。此示例使用 BackBlaze B2 存储。请相应地调整 ID、密钥、仓库和密码值。
|
||||
|
||||
```
|
||||
BACKUP_PATHS="/home/rupert"
|
||||
BACKUP_EXCLUDES="--exclude-file /home/rupert/.restic_excludes --exclude-if-present .exclude_from_backup"
|
||||
RETENTION_DAYS=7
|
||||
RETENTION_WEEKS=4
|
||||
RETENTION_MONTHS=6
|
||||
RETENTION_YEARS=3
|
||||
B2_ACCOUNT_ID=XXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
B2_ACCOUNT_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
RESTIC_REPOSITORY=b2:XXXXXXXXXXXXXXXXXX:/
|
||||
RESTIC_PASSWORD=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
```
|
||||
|
||||
现在已安装该服务,请重新加载 systemd:`systemctl -user daemon-reload`。尝试手动运行该服务以创建备份:`systemctl -user start restic-backup`。
|
||||
|
||||
因为该服务类型是*一次性*,它将运行一次并退出。验证服务运行并根据需要创建快照后,设置计时器以定期运行此服务。例如,要每天运行 `restic-backup.service`,请按如下所示创建 `~/.config/systemd/user/restic-backup.timer`。再次复制并粘贴此文本:
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Backup with restic daily
|
||||
[Timer]
|
||||
OnCalendar=daily
|
||||
Persistent=true
|
||||
[Install]
|
||||
WantedBy=timers.target
|
||||
```
|
||||
|
||||
运行以下命令启用:
|
||||
|
||||
```
|
||||
$ systemctl --user enable --now restic-backup.timer
|
||||
```
|
||||
|
||||
### 清理
|
||||
|
||||
虽然主服务运行 `forget` 命令仅保留保留策略中的快照,但实际上并未从 `restic` 仓库中删除数据。 `prune` 命令检查仓库和当前快照,并删除与快照无关的所有数据。由于 `prune` 可能是一个耗时的过程,因此无需在每次运行备份时运行。这是第二个服务和计时器的场景。首先,通过复制和粘贴此文本来创建文件 `~/.config/systemd/user/restic-prune.service`:
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Restic backup service (data pruning)
|
||||
[Service]
|
||||
Type=oneshot
|
||||
ExecStart=restic prune
|
||||
EnvironmentFile=%h/.config/restic-backup.conf
|
||||
```
|
||||
|
||||
与主 `restic-backup.service` 服务类似,`restic-prune` 也是一次性服务,并且可以手动运行。设置完服务后,创建 `~/.config/systemd/user/restic-prune.timer` 并启用相应的计时器:
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Prune data from the restic repository monthly
|
||||
[Timer]
|
||||
OnCalendar=monthly
|
||||
Persistent=true
|
||||
[Install]
|
||||
WantedBy=timers.target
|
||||
```
|
||||
|
||||
就是这些了!`restic` 将会每日运行并按月清理数据。
|
||||
|
||||
* * *
|
||||
|
||||
图片来自 [Unsplash][9] 由 [Samuel Zeller][8] 拍摄。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/automate-backups-with-restic-and-systemd/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/linkdupont/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/restic-systemd-816x345.jpg
|
||||
[2]: https://restic.net/
|
||||
[3]: https://fedoramagazine.org/?s=backup
|
||||
[4]: https://fedoramagazine.org/use-restic-encrypted-backups/
|
||||
[5]: https://fedoramagazine.org/series/systemd-series/
|
||||
[6]: https://fedoramagazine.org/systemd-getting-a-grip-on-units/
|
||||
[7]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[8]: https://unsplash.com/photos/JuFcQxgCXwA?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[9]: https://unsplash.com/search/photos/archive?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
96
published/20190430 Upgrading Fedora 29 to Fedora 30.md
Normal file
96
published/20190430 Upgrading Fedora 29 to Fedora 30.md
Normal file
@ -0,0 +1,96 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10854-1.html)
|
||||
[#]: subject: (Upgrading Fedora 29 to Fedora 30)
|
||||
[#]: via: (https://fedoramagazine.org/upgrading-fedora-29-to-fedora-30/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/author/ryanlerch/)
|
||||
|
||||
将 Fedora 29 升级到 Fedora 30
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 30 [已经发布了][2]。你可能希望将系统升级到最新版本的 Fedora。Fedora 工作站版本有图形化升级的方法。另外,Fedora 也提供了一个命令行方法,用于将 Fedora 29 升级到 Fedora 30。
|
||||
|
||||
### 将 Fedora 29 工作站版本升级到 Fedora 30
|
||||
|
||||
在发布不久后,桌面会显示一条通知告诉你可以升级。你可以单击通知启动 “GNOME 软件” 应用。或者你可以从 GNOME Shell 中选择“软件”。
|
||||
|
||||
在 “GNOME 软件” 中选择*更新*选项卡,你会看到一个页面通知你可以更新 Fedora 30。
|
||||
|
||||
如果你在屏幕上看不到任何内容,请尝试点击左上角的重新加载按钮。发布后,所有系统都可能需要一段时间才能看到可用的升级。
|
||||
|
||||
选择“下载”获取升级包。你可以继续做其他的事直到下载完成。然后使用 “GNOME 软件” 重启系统并应用升级。升级需要时间,因此你可以喝杯咖啡,稍后再回来。
|
||||
|
||||
### 使用命令行
|
||||
|
||||
如果你过去升级过 Fedora 版本,你可能熟悉 `dnf upgrade` 插件。这是从 Fedora 29 升级到 Fedora 30 的推荐和支持的方式。使用这个插件将使你的 Fedora 30 升级简单易行。
|
||||
|
||||
#### 1、更新软件并备份系统
|
||||
|
||||
在你执行任何操作之前,你需要确保在开始升级之前拥有 Fedora 29 的最新软件。要更新软件,请使用 “GNOME 软件” 或在终端中输入以下命令。
|
||||
|
||||
```
|
||||
sudo dnf upgrade --refresh
|
||||
```
|
||||
|
||||
此外,请确保在继续之前备份系统。关于备份的帮助,请参阅 Fedora Magazine 上的[备份系列][3]。
|
||||
|
||||
#### 2、安装 DNF 插件
|
||||
|
||||
接下来,打开终端并输入以下命令来安装插件:
|
||||
|
||||
```
|
||||
sudo dnf install dnf-plugin-system-upgrade
|
||||
```
|
||||
|
||||
#### 3、使用 DNF 开始更新
|
||||
|
||||
现在你的系统是最新的,完成了备份,并且已安装 DNF 插件,你可以在终端中使用以下命令开始升级:
|
||||
|
||||
```
|
||||
sudo dnf system-upgrade download --releasever=30
|
||||
```
|
||||
|
||||
此命令将开始在本地下载所有升级文件以准备升级。如果你因为没有更新包、错误的依赖,或过时的包在升级时遇到问题,请在输入上面的命令时添加 `-- allowerasing` 标志。这将允许 DNF 删除可能阻止系统升级的软件包。
|
||||
|
||||
#### 4、重启并升级
|
||||
|
||||
当前面的命令完成下载所有升级文件后,你的系统就可以重启了。要将系统引导至升级过程,请在终端中输入以下命令:
|
||||
|
||||
```
|
||||
sudo dnf system-upgrade reboot
|
||||
```
|
||||
|
||||
此后你的系统将重启。在许多版本之前,`fedup` 工具将在内核选择/引导页面上创建一个新选项。使用 `dnf-plugin-system-upgrade` 包,你的系统将使用当前 Fedora 29 安装的内核重启。这个是正常的。在内核选择页面后不久,系统开始升级过程。
|
||||
|
||||
现在可以休息一下了!完成后你的系统将重启,你就可以登录新升级的 Fedora 30 了。
|
||||
|
||||
![][4]
|
||||
|
||||
### 解决升级问题
|
||||
|
||||
升级系统时偶尔可能会出现意外问题。如果你遇到任何问题,请访问 [DNF 系统升级的维基页面][5],以获取有关出现问题时的故障排除的更多信息。
|
||||
|
||||
如果你在升级时遇到问题并在系统上安装了第三方仓库,那么可能需要在升级时禁用这些仓库。有关 Fedora 对未提供仓库的支持,请与仓库的提供商联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/upgrading-fedora-29-to-fedora-30/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/ryanlerch/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/29-30-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/announcing-fedora-30/
|
||||
[3]: https://fedoramagazine.org/taking-smart-backups-duplicity/
|
||||
[4]: https://cdn.fedoramagazine.org/wp-content/uploads/2016/06/Screenshot_f23-ws-upgrade-test_2016-06-10_110906-1024x768.png
|
||||
[5]: https://fedoraproject.org/wiki/DNF_system_upgrade#Resolving_post-upgrade_issues
|
||||
@ -0,0 +1,75 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10876-1.html)
|
||||
[#]: subject: (Cisco issues critical security warning for Nexus data-center switches)
|
||||
[#]: via: (https://www.networkworld.com/article/3392858/cisco-issues-critical-security-warning-for-nexus-data-center-switches.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
思科针对 Nexus 数据中心交换机发出危急安全预警
|
||||
======
|
||||
|
||||
> 思科围绕着 Nexus 的交换机、Firepower 防火墙和其他设备,发布了 40 个安全报告。
|
||||
|
||||
![Thinkstock][1]
|
||||
|
||||
日前,思科发布了 40 个左右的安全报告,但只有其中的一个被评定为“[危急][2]”:思科 Nexus 9000 系列应用中心基础设施(ACI)模式数据中心交换机中的一个漏洞,可能会让攻击者隐秘地访问到系统资源。
|
||||
|
||||
这个新发现的漏洞,被通用漏洞评分系统给到了 9.8 分(满分 10 分),思科表示,它是思科 Nexus 9000 系列的安全 shell (ssh)密钥管理方面的问题,这个漏洞允许远程攻击者以 root 用户的权限来连接到受影响的系统。
|
||||
|
||||
思科表示,“**这个漏洞是因为所有的设备都存在一对默认的 ssh 密钥对**,攻击者可以使用提取到的密钥材料,并通过 IPv6 来创建连接到目标设备的 SSH 连接。这个漏洞仅能通过 IPv6 来进行利用,IPv4 不会被攻击”。
|
||||
|
||||
型号为 Nexus 9000 系列且 NX-OS 软件版本在 14.1 之前的设备会受此漏洞的影响,该公司表示没有解决这个问题的变通办法。
|
||||
|
||||
然而,思科公司已经为解决这个漏洞[发布了免费的软件更新][4]。
|
||||
|
||||
该公司同样对 Nexus 9000 系列发布了一个“高危”级别的安全预警报告,报告中表示存在一种攻击,允许攻击者以 root 用户权限在受影响的设备上执行任意操作系统命令。思科表示,如果要用这种方式攻击成功,攻击者需要对应设备的有效的管理员用户凭证。
|
||||
|
||||
[思科表示][5],这个漏洞是由于过于宽泛的系统文件权限造成的。攻击者可以通过向受影响的设备进行认证,构造一个精心设计的命令字符串,并将这个字符串写入到特定位置的文件里。攻击者通过这种方式来利用这个漏洞。
|
||||
|
||||
思科发布了解决这个漏洞的软件更新。
|
||||
|
||||
另外两个被评为“高危”级别的漏洞的影响范围同样包括 Nexus 9000 系列:
|
||||
|
||||
- 思科 Nexus 9000 系列软件后台操作功能中的[漏洞][7],能够允许一个已认证的本地攻击者在受影响的设备上提权到 root 权限。这个漏洞是由于在受影响的设备上用户提供的文件验证不充分。思科表示,攻击者可以通过登录到受影响设备的命令行界面,并在文件系统的特定目录中构造一个精心设计过的文件,以此来利用这个漏洞。
|
||||
- 交换机软件后台操作功能中的[弱点][7]能够允许攻击者登录到受影响设备的命令行界面,并在文件系统的特定目录里创建一个精心构造过的文件。思科表示,这个漏洞是由于在受影响的设备上用户提供的文件验证不充分。
|
||||
|
||||
思科同样为这些漏洞[发布了软件更新][4]。
|
||||
|
||||
此外,这些安全警告中的一部分是针对思科 FirePower 防火墙系列中大量的“高危”漏洞警告。
|
||||
|
||||
例如,思科[写道][8],思科 Firepower 威胁防御软件的 SMB 协议预处理检测引擎中的多个漏洞能够允许未认证的相邻、远程攻击者造成拒绝服务攻击(DoS)的情况。
|
||||
|
||||
思科表示,思科 Firepower 2100 系列中思科 Firepower 软件里的内部数据包处理功能有[另一个漏洞][9],能够让未认证的远程攻击者造成受影响的设备停止处理流量,从而导致 DOS 的情况。
|
||||
|
||||
[软件补丁][4]可用于这些漏洞。
|
||||
|
||||
其他的产品,比如思科[自适应安全虚拟设备][10]和 [web 安全设备][11]同样也有高优先级的补丁。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3392858/cisco-issues-critical-security-warning-for-nexus-data-center-switches.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/02/lock_broken_unlocked_binary_code_security_circuits_protection_privacy_thinkstock_873916354-100750739-large.jpg
|
||||
[2]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-nexus9k-sshkey
|
||||
[3]: https://www.networkworld.com/article/3284352/data-center/how-to-plan-a-software-defined-data-center-network.html
|
||||
[4]: https://www.cisco.com/c/en/us/about/legal/cloud-and-software/end_user_license_agreement.html
|
||||
[5]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-nexus9k-rpe
|
||||
[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[7]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-aci-hw-clock-util
|
||||
[8]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-frpwr-smb-snort
|
||||
[9]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-frpwr-dos
|
||||
[10]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-asa-ipsec-dos
|
||||
[11]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-wsa-privesc
|
||||
[12]: https://www.facebook.com/NetworkWorld/
|
||||
[13]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10859-1.html)
|
||||
[#]: subject: (Write faster C extensions for Python with Cython)
|
||||
[#]: via: (https://opensource.com/article/19/5/python-cython)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez/users/moshez/users/foundjem/users/jugmac00)
|
||||
|
||||
使用 Cython 为 Python 编写更快的 C 扩展
|
||||
======
|
||||
|
||||
> 在我们这个包含了 7 个 PyPI 库的系列文章中学习解决常见的 Python 问题的方法。
|
||||
|
||||

|
||||
|
||||
Python 是当今使用最多的[流行编程语言][2]之一,因为:它是开源的,它有广泛的用途(例如 Web 编程、业务应用、游戏、科学编程等等),它有一个充满活力和专注的社区支持它。这个社区可以让我们在 [Python Package Index][3](PyPI)中有如此庞大、多样化的软件包,用以扩展和改进 Python 并解决不可避免的问题。
|
||||
|
||||
在本系列中,我们将介绍七个可以帮助你解决常见 Python 问题的 PyPI 库。首先是 [Cython][4],一个简化 Python 编写 C 扩展的语言。
|
||||
|
||||
### Cython
|
||||
|
||||
使用 Python 很有趣,但有时,用它编写的程序可能很慢。所有的运行时动态调度会带来很大的代价:有时它比用 C 或 Rust 等系统语言编写的等效代码慢 10 倍。
|
||||
|
||||
将代码迁移到一种全新的语言可能会在成本和可靠性方面付出巨大代价:所有的手工重写工作都将不可避免地引入错误。我们可以两者兼得么?
|
||||
|
||||
为了练习一下优化,我们需要一些慢代码。有什么比斐波那契数列的意外指数实现更慢?
|
||||
|
||||
```
|
||||
def fib(n):
|
||||
if n < 2:
|
||||
return 1
|
||||
return fib(n-1) + fib(n-2)
|
||||
```
|
||||
|
||||
由于对 `fib` 的调用会导致两次再次调用,因此这种效率极低的算法需要很长时间才能执行。例如,在我的新笔记本电脑上,`fib(36)` 需要大约 4.5 秒。这个 4.5 秒会成为我们探索 Python 的 Cython 扩展能提供的帮助的基准。
|
||||
|
||||
使用 Cython 的正确方法是将其集成到 `setup.py` 中。然而,使用 `pyximport` 可以快速地进行尝试。让我们将 `fib` 代码放在 `fib.pyx` 中并使用 Cython 运行它。
|
||||
|
||||
```
|
||||
>>> import pyximport; pyximport.install()
|
||||
>>> import fib
|
||||
>>> fib.fib(36)
|
||||
```
|
||||
|
||||
只使用 Cython 而不*修改*代码,这个算法在我笔记本上花费的时间减少到大约 2.5 秒。几乎无需任何努力,这几乎减少了 50% 的运行时间。当然,得到了一个不错的成果。
|
||||
|
||||
加把劲,我们可以让它变得更快。
|
||||
|
||||
```
|
||||
cpdef int fib(int n):
|
||||
if n < 2:
|
||||
return 1
|
||||
return fib(n - 1) + fib(n - 2)
|
||||
```
|
||||
|
||||
我们将 `fib` 中的代码变成用 `cpdef` 定义的函数,并添加了两个类型注释:它接受一个整数并返回一个整数。
|
||||
|
||||
这个变得快*多*了,大约只用了 0.05 秒。它是如此之快,以至于我可能开始怀疑我的测量方法包含噪声:之前,这种噪声在信号中丢失了。
|
||||
|
||||
当下次你的 Python 代码花费太多 CPU 时间时,也许会导致风扇狂转,为何不看看 Cython 是否可以解决问题呢?
|
||||
|
||||
在本系列的下一篇文章中,我们将看一下 Black,一个自动纠正代码格式错误的项目。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/python-cython
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez/users/moshez/users/foundjem/users/jugmac00
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_hand_draw.png?itok=dpAf--Db (Hand drawing out the word "code")
|
||||
[2]: https://opensource.com/article/18/5/numbers-python-community-trends
|
||||
[3]: https://pypi.org/
|
||||
[4]: https://pypi.org/project/Cython/
|
||||
@ -1,18 +1,18 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10864-1.html)
|
||||
[#]: subject: (Format Python however you like with Black)
|
||||
[#]: via: (https://opensource.com/article/19/5/python-black)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez/users/moshez/users/moshez)
|
||||
|
||||
使用 Black 随意格式化 Python
|
||||
使用 Black 自由格式化 Python
|
||||
======
|
||||
|
||||
> 在我们覆盖 7 个 PyPI 库的系列文章中了解解决 Python 问题的更多信息。
|
||||
|
||||
![OpenStack source code \(Python\) in VIM][1]
|
||||

|
||||
|
||||
Python 是当今使用最多的[流行编程语言][2]之一,因为:它是开源的,它有广泛的用途(例如 Web 编程、业务应用、游戏、科学编程等等),它有一个充满活力和专注的社区支持它。这个社区可以让我们在 [Python Package Index][3](PyPI)中有如此庞大、多样化的软件包,用以扩展和改进 Python 并解决不可避免的问题。
|
||||
|
||||
@ -83,10 +83,10 @@ $ echo $?
|
||||
|
||||
via: https://opensource.com/article/19/5/python-black
|
||||
|
||||
作者:[Moshe Zadka ][a]
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10880-1.html)
|
||||
[#]: subject: (Get started with Libki to manage public user computer access)
|
||||
[#]: via: (https://opensource.com/article/19/5/libki-computer-access)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins/users/tony-thomas)
|
||||
|
||||
使用 Libki 来管理公共用户访问计算机
|
||||
======
|
||||
> Libki 是一个跨平台的计算机预约和用时管理系统。
|
||||
|
||||

|
||||
|
||||
提供公共计算机的图书馆、学校、学院和其他组织需要一种管理用户访问权限的好方法 —— 否则,就无法阻止某些人独占机器并确保每个人都有公平的用时。这是 [Libki][2] 要解决的问题。
|
||||
|
||||
Libki 是一个面向 Windows 和 Linux PC 的开源、跨平台的计算机预约和用时管理系统。它提供了一个基于 Web 的服务器和一个基于 Web 的管理系统,员工可以使用它来管理计算机访问,包括创建和删除用户、设置帐户用时限制、登出和禁止用户以及设置访问限制。
|
||||
|
||||
根据其首席开发人员 [Kyle Hall][3] 所说,Libki 主要用于 PC 用时控制,作为 Envisionware 出品的专有计算机访问控制软件的开源替代品。当用户登录 Libki 管理的计算机时,他们会有一段使用计算机的时间。时间到了之后,他们就会被登出。时间默认设置为 45 分钟,但可以使用基于 Web 的管理系统轻松调整。一些组织在登出用户之前提供 24 小时访问权限,而有的组织则使用它来跟踪使用情况而不设置用时限制。
|
||||
|
||||
Kyle 目前是 [ByWater Solutions][4] 的首席开发人员,该公司为图书馆提供开源软件解决方案(包括 Libki)。在职业生涯早期,他在宾夕法尼亚州的[米德维尔公共图书馆][5]担任 IT 技术时开发了 Libki。在其他员工的午休期间,偶尔会要求他关注孩子们的房间。图书馆使用纸质注册表来管理对儿童房间计算机的访问,这意味着不断的监督和检查,以确保来到那里的人能够公平地使用。
|
||||
|
||||
Kyle 说,“我发现这很笨拙而不便的,我想找到一个解决方案。这个解决方案需要同时是 FOSS 和跨平台的。最后,没有现有的软件适合我们的特殊需求,那就是为什么我开发了 Libki。“
|
||||
|
||||
或者,正如 Libki 的网站所宣称的那样,“Libki 的诞生是为了避免与青少年打交道(的麻烦),现在允许图书馆员避免与世界各地的青少年打交道(的麻烦)!”
|
||||
|
||||
### 易于安装和使用
|
||||
|
||||
我最近决定在我经常在那里做志愿者的当地的公共图书馆尝试 Libki。我按照[文档][6]在 Ubuntu 18.04 Server 中自动进行了安装,它很快就启动起来了。
|
||||
|
||||
我计划在我们当地的图书馆支持 Libki,但我想知道在那些没有 IT 相关经验的人或者无法构建和部署服务器的图书馆是怎样的。Kyle 说:“ByWater Solutions 可以云端托管 Libki 服务器,这使得每个人的维护和管理变得更加简单。”
|
||||
|
||||
Kyle 表示,ByWater 并不打算将 Libki 与其最受欢迎的产品,开源集成图书馆系统 (ILS)Koha 或其支持的任何其他[项目][7]捆绑在一起。他说: “Libki 和 Koha 是不同[类型]的软件,满足不同的需求,但它们在图书馆中确实很好地协同工作。事实上,我很早就开发了 Libki 的 SIP2 集成,因此它可以支持使用 Koha 进行单点登录。“
|
||||
|
||||
### 如何贡献
|
||||
|
||||
Libki 客户端是 GPLv3 许可,Libki 服务器是 AGPLv3 许可。Kyle 说他希望 Libki 拥有一个更加活跃和强大的社区,项目一直在寻找新人加入其[贡献者][8]。如果你想参加,请访问 [Libki 社区页面][9]并加入邮件列表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/libki-computer-access
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins/users/tony-thomas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/desk_clock_job_work.jpg?itok=Nj4fuhl6
|
||||
[2]: https://libki.org/
|
||||
[3]: https://www.linkedin.com/in/kylemhallinfo/
|
||||
[4]: https://opensource.com/article/19/4/software-libraries
|
||||
[5]: https://meadvillelibrary.org/
|
||||
[6]: https://manual.libki.org/master/libki-manual.html#_automatic_installation
|
||||
[7]: https://bywatersolutions.com/projects
|
||||
[8]: https://github.com/Libki/libki-server/graphs/contributors
|
||||
[9]: https://libki.org/community/
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10895-1.html)
|
||||
[#]: subject: (Check your spelling at the command line with Ispell)
|
||||
[#]: via: (https://opensource.com/article/19/5/spelling-command-line-ispell)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
使用 Ispell 在命令行中检查拼写
|
||||
======
|
||||
|
||||
> Ispell 可以帮助你在纯文本中消除超过 50 种语言的拼写错误。
|
||||
|
||||

|
||||
|
||||
好的拼写是一种技巧。它是一项需要时间学习和掌握的技能。也就是说,有些人从来没有完全掌握这种技能,我知道有两三个出色的作家就无法完全掌握拼写。
|
||||
|
||||
即使你拼写得很好,偶尔也会输入错字。特别是在最后期限前如果你快速敲击键盘,那就更是如此。无论你的拼写的是什么,通过拼写检查器检查你所写的内容总是一个好主意。
|
||||
|
||||
我用[纯文本][2]完成了我的大部分写作,并经常使用名为 [Aspell][3] 的命令行拼写检查器来完成这项工作。Aspell 不是唯一的工具。你可能还想要看下不错的 [Ispell][4]。
|
||||
|
||||
### 入门
|
||||
|
||||
自 1971 年以来,Ispell 就以各种形式出现过。不要被它的年龄欺骗。Ispell 仍然是一个可以在 21 世纪高效使用的应用。
|
||||
|
||||
在开始之前,请打开终端窗口并输入 `which ispell` 来检查计算机上是否安装了 Ispell。如果未安装,请打开发行版的软件包管理器并从那里安装 Ispell。
|
||||
|
||||
不要忘记为你使用的语言安装词典。我唯一使用的语言是英语,所以我只需下载美国和英国英语字典。你可以不局限于我的(也是唯一的)母语。Ispell 有[超过 50 种语言的词典][5]。
|
||||
|
||||
![Installing Ispell dictionaries][6]
|
||||
|
||||
### 使用 Ispell
|
||||
|
||||
如果你还没有猜到,Ispell 只能用在文本文件。这包括用 HTML、LaTeX 和 [nroff 或 troff][7] 标记的文档。之后会有更多相关内容。
|
||||
|
||||
要开始使用,请打开终端窗口并进入包含要运行拼写检查的文件的目录。输入 `ispell` 后跟文件名,然后按回车键。
|
||||
|
||||
![Checking spelling with Ispell][8]
|
||||
|
||||
Ispell 高亮了它无法识别的第一个词。如果单词拼写错误,Ispell 通常会提供一个或多个备选方案。按下 `R`,然后按下正确选择旁边的数字。在上面的截图中,我按了 `R` 和 `0` 来修复错误。
|
||||
|
||||
另一方面,如果单词拼写正确,请按下 `A` 然后移动到下一个拼写错误的单词。
|
||||
|
||||
继续这样做直到到达文件的末尾。Ispell 会保存你的更改,创建你刚检查的文件的备份(扩展名为 `.bak`),然后关闭。
|
||||
|
||||
### 其他几个选项
|
||||
|
||||
此示例说明了 Ispell 的基本用法。这个程序有[很多选项][9],有些你*可能*会用到,而另一些你*可能永远*不会使用。让我们快速看下我经常使用的一些。
|
||||
|
||||
之前我提到过 Ispell 可以用于某些标记语言。你需要告诉它文件的格式。启动 Ispell 时,为 TeX 或 LaTeX 文件添加 `-t`,为 HTML 文件添加 `-H`,对于 groff 或 troff 文件添加 `-n`。例如,如果输入 `ispell -t myReport.tex`,Ispell 将忽略所有标记。
|
||||
|
||||
如果你不想在检查文件后创建备份文件,请将 `-x` 添加到命令行。例如,`ispell -x myFile.txt`。
|
||||
|
||||
如果 Ispell 遇到拼写正确但不在其字典中的单词,比如名字,会发生什么?你可以按 `I` 将该单词添加到个人单词列表中。这会将单词保存到 `/home` 目录下的 `.ispell_default` 的文件中。
|
||||
|
||||
这些是我在使用 Ispell 时最有用的选项,但请查看 [Ispell 的手册页][9]以了解其所有选项。
|
||||
|
||||
Ispell 比 Aspell 或其他命令行拼写检查器更好或者更快么?我会说它不比其他的差或者慢。Ispell 不是适合所有人。它也许也不适合你。但有更多选择也不错,不是么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/spelling-command-line-ispell
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/command_line_prompt.png?itok=wbGiJ_yg (Command line prompt)
|
||||
[2]: https://plaintextproject.online
|
||||
[3]: https://opensource.com/article/18/2/how-check-spelling-linux-command-line-aspell
|
||||
[4]: https://www.cs.hmc.edu/~geoff/ispell.html
|
||||
[5]: https://www.cs.hmc.edu/~geoff/ispell-dictionaries.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/ispell-install-dictionaries.png (Installing Ispell dictionaries)
|
||||
[7]: https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me
|
||||
[8]: https://opensource.com/sites/default/files/uploads/ispell-checking.png (Checking spelling with Ispell)
|
||||
[9]: https://www.cs.hmc.edu/~geoff/ispell-man.html
|
||||
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Say goodbye to boilerplate in Python with attrs)
|
||||
[#]: via: (https://opensource.com/article/19/5/python-attrs)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez/users/moshez)
|
||||
|
||||
使用 attrs 来告别 Python 中的样板
|
||||
======
|
||||
|
||||
> 在我们覆盖 7 个 PyPI 库的系列文章中了解更多解决 Python 问题的信息。
|
||||
|
||||

|
||||
|
||||
Python是当今使用最多[流行的编程语言][2]之一,因为:它是开源的,它具有广泛的用途(例如 Web 编程、业务应用、游戏、科学编程等等),它有一个充满活力和专注的社区支持它。这个社区是我们在 [Python Package Index][3](PyPI)中提供如此庞大、多样化的软件包的原因,用以扩展和改进 Python。并解决不可避免的问题。
|
||||
|
||||
在本系列中,我们将介绍七个可以帮助你解决常见 Python 问题的 PyPI 库。今天,我们将研究 [attrs][4],这是一个帮助你快速编写简洁、正确的代码的 Python 包。
|
||||
|
||||
### attrs
|
||||
|
||||
如果你已经写过一段时间的 Python,那么你可能习惯这样写代码:
|
||||
|
||||
```
|
||||
class Book(object):
|
||||
|
||||
def __init__(self, isbn, name, author):
|
||||
self.isbn = isbn
|
||||
self.name = name
|
||||
self.author = author
|
||||
```
|
||||
|
||||
接着写一个 `__repr__` 函数。否则,很难记录 `Book` 的实例:
|
||||
|
||||
|
||||
```
|
||||
def __repr__(self):
|
||||
return f"Book({self.isbn}, {self.name}, {self.author})"
|
||||
```
|
||||
|
||||
接下来你会写一个好看的 docstring 来记录期望的类型。但是你注意到你忘了添加 `edition` 和 `published_year` 属性,所以你必须在五个地方修改它们。
|
||||
|
||||
如果你不必这么做如何?
|
||||
|
||||
```
|
||||
@attr.s(auto_attribs=True)
|
||||
class Book(object):
|
||||
isbn: str
|
||||
name: str
|
||||
author: str
|
||||
published_year: int
|
||||
edition: int
|
||||
```
|
||||
|
||||
使用新的类型注释语法注释类型属性,`attrs` 会检测注释并创建一个类。
|
||||
|
||||
ISBN 有特定格式。如果我们想强行使用该格式怎么办?
|
||||
|
||||
```
|
||||
@attr.s(auto_attribs=True)
|
||||
class Book(object):
|
||||
isbn: str = attr.ib()
|
||||
@isbn.validator
|
||||
def pattern_match(self, attribute, value):
|
||||
m = re.match(r"^(\d{3}-)\d{1,3}-\d{2,3}-\d{1,7}-\d$", value)
|
||||
if not m:
|
||||
raise ValueError("incorrect format for isbn", value)
|
||||
name: str
|
||||
author: str
|
||||
published_year: int
|
||||
edition: int
|
||||
```
|
||||
|
||||
`attrs` 库也对[不可变式编程][5]支持良好。将第一行改成 `@attr.s(auto_attribs=True, frozen=True)` 意味着 `Book` 现在是不可变的:尝试修改一个属性将会引发一个异常。相反,比如,如果希望将发布日期向后一年,我们可以修改成 `attr.evolve(old_book, published_year=old_book.published_year+1)` 来得到一个*新的*实例。
|
||||
|
||||
本系列的下一篇文章我们将来看下 `singledispatch`,一个能让你向 Python 库添加方法的库。
|
||||
|
||||
#### 查看本系列先前的文章
|
||||
|
||||
* [Cython][6]
|
||||
* [Black][7]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/python-attrs
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_code_keyboard_orange_hands.png?itok=G6tJ_64Y (Programming at a browser, orange hands)
|
||||
[2]: https://opensource.com/article/18/5/numbers-python-community-trends
|
||||
[3]: https://pypi.org/
|
||||
[4]: https://pypi.org/project/attrs/
|
||||
[5]: https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures
|
||||
[6]: https://linux.cn/article-10859-1.html
|
||||
[7]: https://linux.cn/article-10864-1.html
|
||||
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10887-1.html)
|
||||
[#]: subject: (Add methods retroactively in Python with singledispatch)
|
||||
[#]: via: (https://opensource.com/article/19/5/python-singledispatch)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
使用 singledispatch 在 Python 中追溯地添加方法
|
||||
======
|
||||
|
||||
> 在我们覆盖 7 个 PyPI 库的系列文章中了解更多解决 Python 问题的信息。
|
||||
|
||||

|
||||
|
||||
Python 是当今使用最多[流行的编程语言][2]之一,因为:它是开源的,它具有广泛的用途(例如 Web 编程、业务应用、游戏、科学编程等等),它有一个充满活力和专注的社区支持它。这个社区是我们在 [Python Package Index][3](PyPI)中提供如此庞大、多样化的软件包的原因,用以扩展和改进 Python。并解决不可避免的问题。
|
||||
|
||||
在本系列中,我们将介绍七个可以帮助你解决常见 Python 问题的 PyPI 库。今天,我们将研究 [singledispatch][4],这是一个能让你追溯地向 Python 库添加方法的库。
|
||||
|
||||
### singledispatch
|
||||
|
||||
想象一下,你有一个有 Circle、Square 等类的“形状”库。
|
||||
|
||||
Circle 类有半径、Square 有边、Rectangle 有高和宽。我们的库已经存在,我们不想改变它。
|
||||
|
||||
然而,我们想给库添加一个面积计算。如果我们不会和其他人共享这个库,我们只需添加 `area` 方法,这样我们就能调用 `shape.area()` 而无需关心是什么形状。
|
||||
|
||||
虽然可以进入类并添加一个方法,但这是一个坏主意:没有人希望他们的类会被添加新的方法,程序会因奇怪的方式出错。
|
||||
|
||||
相反,functools 中的 `singledispatch` 函数可以帮助我们。
|
||||
|
||||
|
||||
```
|
||||
@singledispatch
|
||||
def get_area(shape):
|
||||
raise NotImplementedError("cannot calculate area for unknown shape",
|
||||
shape)
|
||||
```
|
||||
|
||||
`get_area` 函数的“基类”实现会报错。这保证了如果我们出现一个新的形状时,我们会明确地报错而不是返回一个无意义的结果。
|
||||
|
||||
|
||||
```
|
||||
@get_area.register(Square)
|
||||
def _get_area_square(shape):
|
||||
return shape.side ** 2
|
||||
@get_area.register(Circle)
|
||||
def _get_area_circle(shape):
|
||||
return math.pi * (shape.radius ** 2)
|
||||
```
|
||||
|
||||
这种方式的好处是如果某人写了一个匹配我们代码的*新*形状,它们可以自己实现 `get_area`。
|
||||
|
||||
|
||||
```
|
||||
from area_calculator import get_area
|
||||
|
||||
@attr.s(auto_attribs=True, frozen=True)
|
||||
class Ellipse:
|
||||
horizontal_axis: float
|
||||
vertical_axis: float
|
||||
|
||||
@get_area.register(Ellipse)
|
||||
def _get_area_ellipse(shape):
|
||||
return math.pi * shape.horizontal_axis * shape.vertical_axis
|
||||
```
|
||||
|
||||
*调用* `get_area` 很直接。
|
||||
|
||||
|
||||
```
|
||||
print(get_area(shape))
|
||||
```
|
||||
|
||||
这意味着我们可以将大量的 `if isintance()`/`elif isinstance()` 的代码以这种方式修改,而无需修改接口。下一次你要修改 if isinstance,你试试 `singledispatch!
|
||||
|
||||
在本系列的下一篇文章中,我们将介绍 tox,一个用于自动化 Python 代码测试的工具。
|
||||
|
||||
#### 回顾本系列的前几篇文章:
|
||||
|
||||
* [Cython][5]
|
||||
* [Black][6]
|
||||
* [attrs][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/python-singledispatch
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV
|
||||
[2]: https://opensource.com/article/18/5/numbers-python-community-trends
|
||||
[3]: https://pypi.org/
|
||||
[4]: https://pypi.org/project/singledispatch/
|
||||
[5]: https://linux.cn/article-10859-1.html
|
||||
[6]: https://linux.cn/article-10864-1.html
|
||||
[7]: https://linux.cn/article-10871-1.html
|
||||
219
published/20190504 Using the force at the Linux command line.md
Normal file
219
published/20190504 Using the force at the Linux command line.md
Normal file
@ -0,0 +1,219 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Moelf)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10881-1.html)
|
||||
[#]: subject: (Using the force at the Linux command line)
|
||||
[#]: via: (https://opensource.com/article/19/5/may-the-force-linux)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
在 Linux 命令行下使用“原力”
|
||||
======
|
||||
|
||||
> 和绝地武士的原力一样,`-f` 参数是很强大的,并伴随着潜在的毁灭性,在你能用好的时候又很便利。
|
||||
|
||||

|
||||
|
||||
近些年来,科幻发烧友开始在每年的 5 月 4 日庆祝[星战节][2],其口号是绝地武士的祝福语”愿<ruby>原力<rt>Force</rt></ruby>和你同在“。虽然大多数 Linux 用户可能不是绝地武士,但我们依然可以使用<ruby>原力<rt>Force</rt></ruby>。自然,如果尤达大师只是叫天行者卢克输入什么 “man X-Wing 战机“、“man 原力”,或者 RTFM(去读原力手册,肯定是这个意思对不对),那这电影肯定没啥意思。(LCTT 译注:RTFM 是 “Read The Fucking Manual” 的缩写 —— 读读该死的手册吧)。
|
||||
|
||||
很多 Linux 命令都有 `-f` 选项,意思你现在肯定也知道了,原力(LCTT 译注:force 选项原意是“强制”)!很多时候你先尝试执行命令然后失败了,或者提示你需要补充输入更多选项。通常这都是为了保护你试着改变的文件,或者告诉用户该设备正忙或文件已经存在之类的。
|
||||
|
||||
如果你不想被这些提醒打扰或者压根就不在乎,就使用原力吧!
|
||||
|
||||
不过要小心,通常使用原力选项是摧毁性的。所以用户一定要格外注意!并且确保你知道自己在做什么!用原力就要承担后果!
|
||||
|
||||
以下是一些常见 Linux 命令的原力选项和它们的效果,以及常见使用场景。
|
||||
|
||||
### cp
|
||||
|
||||
`cp` 是 “copy” 的缩写,这是个被用来复制文件或者目录的命令。其 [man 页面][3] 说:
|
||||
|
||||
> -f, --force
|
||||
>
|
||||
> 如果已经存在的目标文件无法被打开,删除它并重试
|
||||
|
||||
你可能会用它来处理只读状态的文件:
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ ls -l
|
||||
total 8
|
||||
-rw-rw---- 1 alan alan 13 May 1 12:24 Hoth
|
||||
-r--r----- 1 alan alan 14 May 1 12:23 Naboo
|
||||
[alan@workstation ~]$ cat Hoth Naboo
|
||||
Icy Planet
|
||||
|
||||
Green Planet
|
||||
```
|
||||
|
||||
如果你想要复制一个叫做 `Hoth` 的文件到 `Naboo`,但因为 `Naboo` 目前是只读状态,`cp` 命令不会执行:
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ cp Hoth Naboo
|
||||
cp: cannot create regular file 'Naboo': Permission denied
|
||||
```
|
||||
|
||||
但通过使用原力,`cp` 会强制执行。`Hoth` 的内容和文件权限会直接被复制到 `Naboo`:
|
||||
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ cp -f Hoth Naboo
|
||||
[alan@workstation ~]$ cat Hoth Naboo
|
||||
Icy Planet
|
||||
|
||||
Icy Planet
|
||||
|
||||
[alan@workstation ~]$ ls -l
|
||||
total 8
|
||||
-rw-rw---- 1 alan alan 12 May 1 12:32 Hoth
|
||||
-rw-rw---- 1 alan alan 12 May 1 12:38 Naboo
|
||||
```
|
||||
|
||||
### ln
|
||||
|
||||
`ln` 命令是用来在文件之间建立链接的,其 [man 页面][4] 描述的原力选项如下:
|
||||
|
||||
|
||||
> -f, --force
|
||||
>
|
||||
> 移除当前存在的文件
|
||||
|
||||
|
||||
假设莱娅公主在维护一个 Java 应用服务器,并且她又一个存放这所有 Java 版本的目录,比如:
|
||||
|
||||
```
|
||||
leia@workstation:/usr/lib/java$ ls -lt
|
||||
total 28
|
||||
lrwxrwxrwx 1 leia leia 12 Mar 5 2018 jdk -> jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
|
||||
```
|
||||
|
||||
正如你所看到的,这里有很多个版本的 JDK,并有一个符号链接指向最新版的 JDK。她接着用一个脚本来安装最新版本的 JDK。但是如果没有原力选项的话以下命令是不会成功的:
|
||||
|
||||
```
|
||||
tar xvzmf jdk1.8.0_181.tar.gz -C jdk1.8.0_181/
|
||||
ln -vs jdk1.8.0_181 jdk
|
||||
```
|
||||
|
||||
`tar` 命令会解压 .gz 文件到一个特定的目标目录,但 `ln` 命令会失败,因为这个链接已经存在了。这样的结果是该符号链接不会指向最新版本的 JDK:
|
||||
|
||||
```
|
||||
leia@workstation:/usr/lib/java$ ln -vs jdk1.8.0_181 jdk
|
||||
ln: failed to create symbolic link 'jdk/jdk1.8.0_181': File exists
|
||||
leia@workstation:/usr/lib/java$ ls -lt
|
||||
total 28
|
||||
drwxr-x--- 2 leia leia 4096 May 1 15:44 jdk1.8.0_181
|
||||
lrwxrwxrwx 1 leia leia 12 Mar 5 2018 jdk -> jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
|
||||
```
|
||||
|
||||
她可以通过使用原力选项强制 `ln` 更新链接,但这里她还需要使用 `-n`,`-n` 是因为这个情况下链接其实指向一个目录而非文件。这样的话,链接就会正确指向最新版本的JDK了。
|
||||
|
||||
```
|
||||
leia@workstation:/usr/lib/java$ ln -vsnf jdk1.8.0_181 jdk
|
||||
'jdk' -> 'jdk1.8.0_181'
|
||||
leia@workstation:/usr/lib/java$ ls -lt
|
||||
total 28
|
||||
lrwxrwxrwx 1 leia leia 12 May 1 16:13 jdk -> jdk1.8.0_181
|
||||
drwxr-x--- 2 leia leia 4096 May 1 15:44 jdk1.8.0_181
|
||||
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
|
||||
```
|
||||
|
||||
你可以配置 Java 应用使其一直使用在 `/usr/lib/java/jdk` 处的 JDK,而不用每次升级都更新。
|
||||
|
||||
### rm
|
||||
|
||||
`rm` 命令是 “remove” 的缩写(也叫做删除,因为某些系统 `del` 命令也干这事)。其 [man 页面][5] 对原力选项的描述如下:
|
||||
|
||||
|
||||
> -f, --force
|
||||
>
|
||||
> 无视不存在的文件或者参数,不向用户确认
|
||||
|
||||
如果你尝试删除一个只读的文件,`rm` 会寻求用户的确认:
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ ls -l
|
||||
total 4
|
||||
-r--r----- 1 alan alan 16 May 1 11:38 B-wing
|
||||
[alan@workstation ~]$ rm B-wing
|
||||
rm: remove write-protected regular file 'B-wing'?
|
||||
```
|
||||
|
||||
你一定要输入 `y` 或者 `n` 来回答确认才能让 `rm` 命令继续。如果你使用原力选项,`rm` 就不会寻求你的确认而直接删除文件:
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ rm -f B-wing
|
||||
[alan@workstation ~]$ ls -l
|
||||
total 0
|
||||
[alan@workstation ~]$
|
||||
```
|
||||
|
||||
最常见的 `rm` 原力选项用法是用来删除目录。 `-r`(递归)选项会让 `rm` 删除目录,当和原力选项结合起来,它会删除这个文件夹及其内容而无需用户确认。
|
||||
|
||||
`rm` 命令和一些选项结合起来是致命的,一直以来互联网上都有关于误用 `rm` 删除整个系统之类的玩笑和鬼故事。比如最出名的一不当心执行 `rm -rf .` 会直接删除目录和文件(没有用户确认)。(LCTT 译注:真的这么干过的校对飘过~~请按下回车前再三确认:我是谁,我在哪里,我在干什么)
|
||||
|
||||
### userdel
|
||||
|
||||
`userdel` 命令使用来删除用户的。其 [man 页面][6] 是这样描述它的原力选项的:
|
||||
|
||||
> -f, --force
|
||||
>
|
||||
> 这个选项会强制移除用户,即便用户当前处于登入状态。它同时还会强制
|
||||
删除用户的目录和邮件存储,即便这个用户目录被别人共享或者邮件存储并不
|
||||
属于这个用户。如果 `USERGROUPS_ENAB` 在 `/etc/login.defs` 里是 `yes`
|
||||
并且有一个组和此用户同名的话,这个组也会被移除,即便这个组还是别
|
||||
的用户的主要用户组也一样。
|
||||
>
|
||||
> 注意:这个选项有风险并可能让系统处于不稳定状态。
|
||||
|
||||
当欧比旺抵达穆斯塔法星的时候,他知道自己的使命。他需要删掉达斯·维达的用户账户——而达斯还在里面呢。
|
||||
|
||||
```
|
||||
[root@workstation ~]# ps -fu darth
|
||||
UID PID PPID C STIME TTY TIME CMD
|
||||
darth 7663 7655 0 13:28 pts/3 00:00:00 -bash
|
||||
[root@workstation ~]# userdel darth
|
||||
userdel: user darth is currently used by process 7663
|
||||
```
|
||||
|
||||
因为达斯还登在系统里,欧比旺需要使用原力选项操作 `userdel`。这能强制删除当前登入的用户。
|
||||
|
||||
```
|
||||
[root@workstation ~]# userdel -f darth
|
||||
userdel: user darth is currently used by process 7663
|
||||
[root@workstation ~]# finger darth
|
||||
finger: darth: no such user.
|
||||
[root@workstation ~]# ps -fu darth
|
||||
error: user name does not exist
|
||||
```
|
||||
|
||||
正如我们所见到的一样,`finger` 和 `ps` 命令让我们确认了达斯已经被删除了。
|
||||
|
||||
### 在 Shell 脚本里使用原力
|
||||
|
||||
很多命令都有原力选项,而在 shell 脚本里他们特别有用。因为我们经常使用脚本完成定期或者自动化的任务,避免用户输入至关重要,不然的话自动任务就无法完成了
|
||||
|
||||
我希望上面的几个例子能帮你理解一些需要使用原力的情况。你在命令行使用原力或把它们写入脚本之前应当完全理解它们的作用。误用原力会有毁灭性的后果——时常是对整个系统,甚至不仅限于一台设备。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/may-the-force-linux
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Jerry Ling](https://github.com/Moelf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fireworks_light_art_design.jpg?itok=hfx9i4By (Fireworks)
|
||||
[2]: https://www.starwars.com/star-wars-day
|
||||
[3]: http://man7.org/linux/man-pages/man1/cp.1.html
|
||||
[4]: http://man7.org/linux/man-pages/man1/ln.1.html
|
||||
[5]: http://man7.org/linux/man-pages/man1/rm.1.html
|
||||
[6]: http://man7.org/linux/man-pages/man8/userdel.8.html
|
||||
@ -0,0 +1,244 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10892-1.html)
|
||||
[#]: subject: (Duc – A Collection Of Tools To Inspect And Visualize Disk Usage)
|
||||
[#]: via: (https://www.ostechnix.com/duc-a-collection-of-tools-to-inspect-and-visualize-disk-usage/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Duc:一个能够可视化洞察硬盘使用情况的工具包
|
||||
======
|
||||
|
||||
![Duc:一个能够洞察并可视化硬盘使用情况的工具包][1]
|
||||
|
||||
Duc 是一个在类 Unix 操作系统上可以用来索引、洞察及可视化硬盘使用情况的工具包。别把它当成一个仅能用漂亮图表展现硬盘使用情况的 CLI 工具。它对巨大的文件系统也支持的很好。Duc 已在由超过五亿个文件和几 PB 的存储组成的系统上测试过,没有任何问题。
|
||||
|
||||
Duc 是一个快速而且灵活的工具。它将你的硬盘使用情况存在一个优化过的数据库里,这样你就可以在索引完成后迅速找到你的数据。此外,它自带不同的用户交互界面与后端以访问数据库并绘制图表。
|
||||
|
||||
以下列出的是目前支持的用户界面(UI):
|
||||
|
||||
1. 命令行界面(`duc ls`)
|
||||
2. Ncurses 控制台界面(`duc ui`)
|
||||
3. X11 GUI(`duc gui`)
|
||||
4. OpenGL GUI(`duc gui`)
|
||||
|
||||
支持的后端数据库:
|
||||
|
||||
* Tokyocabinet
|
||||
* Leveldb
|
||||
* Sqlite3
|
||||
|
||||
Duc 默认使用 Tokyocabinet 作为后端数据库。
|
||||
|
||||
### 安装 Duc
|
||||
|
||||
Duc 可以从 Debian 以及其衍生品例如 Ubuntu 的默认仓库中获取。因此在基于 DEB 的系统上安装 Duc 是小菜一碟。
|
||||
|
||||
```
|
||||
$ sudo apt-get install duc
|
||||
```
|
||||
|
||||
在其它 Linux 发行版上你需要像以下所展示的那样手动从源代码编译安装 Duc。
|
||||
|
||||
可以从 Github 上的[发行][2]页面下载最新的 Duc 源代码的 .tgz 文件。在写这篇教程的时候,最新的版本是1.4.4。
|
||||
|
||||
```
|
||||
$ wget https://github.com/zevv/duc/releases/download/1.4.4/duc-1.4.4.tar.gz
|
||||
```
|
||||
|
||||
然后一个接一个地运行以下命令来安装 DUC。
|
||||
|
||||
```
|
||||
$ tar -xzf duc-1.4.4.tar.gz
|
||||
$ cd duc-1.4.4
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
### 使用 Duc
|
||||
|
||||
`duc` 的典型用法是:
|
||||
|
||||
```
|
||||
$ duc <subcommand> <options>
|
||||
```
|
||||
|
||||
你可以通过运行以下命令来浏览总的选项列表以及子命令:
|
||||
|
||||
```
|
||||
$ duc help
|
||||
```
|
||||
|
||||
你也可以像下面这样了解一个特定子命令的用法。
|
||||
|
||||
```
|
||||
$ duc help <subcommand>
|
||||
```
|
||||
|
||||
要查看所有命令与其选项的列表,仅需运行:
|
||||
|
||||
```
|
||||
$ duc help --all
|
||||
```
|
||||
|
||||
让我们看看一些 `duc` 工具的特定用法。
|
||||
|
||||
### 创建索引(数据库)
|
||||
|
||||
首先,你需要创建一个你文件系统的索引文件(数据库)。使用 `duc index` 命令以创建索引文件。
|
||||
|
||||
比如说,要创建你的 `/home` 目录的索引,仅需运行:
|
||||
|
||||
```
|
||||
$ duc index /home
|
||||
```
|
||||
|
||||
上述命令将会创建你的 `/home` 目录的索引,并将其保存在 `$HOME/.duc.db` 文件中。如果你以后需要往 `/home` 目录添加新的文件或目录,只要在之后重新运行一下上面的命令来重建索引。
|
||||
|
||||
### 查询索引
|
||||
|
||||
Duc 有不同的子命令来查询并探索索引。
|
||||
|
||||
要查看可访问的索引列表,运行:
|
||||
|
||||
```
|
||||
$ duc info
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Date Time Files Dirs Size Path
|
||||
2019-04-09 15:45:55 3.5K 305 654.6M /home
|
||||
```
|
||||
|
||||
如你在上述输出所见,我已经索引好了 `/home` 目录。
|
||||
|
||||
要列出当前工作目录中所有的文件和目录,你可以这样做:
|
||||
|
||||
```
|
||||
$ duc ls
|
||||
```
|
||||
|
||||
要列出指定的目录,例如 `/home/sk/Downloads` 中的文件/目录,仅需像下面这样将路径作为参数传过去。
|
||||
|
||||
```
|
||||
$ duc ls /home/sk/Downloads
|
||||
```
|
||||
|
||||
类似的,运行 `duc ui` 命令来打开基于 ncurses 的控制台用户界面以探索文件系统使用情况,运行`duc gui` 以打开图形界面(X11)来探索文件系统。
|
||||
|
||||
要了解更多子命令的用法,仅需参考帮助部分。
|
||||
|
||||
```
|
||||
$ duc help ls
|
||||
```
|
||||
|
||||
上述命令将会展现 `ls` 子命令的帮助部分。
|
||||
|
||||
### 可视化硬盘使用状况
|
||||
|
||||
在之前的部分我们以及看到如何用 duc 子命令列出文件和目录。在此之外,你甚至可以用一张漂亮的图表展示文件大小。
|
||||
|
||||
要展示所提供目录的图表,像以下这样使用 `ls` 子命令。
|
||||
|
||||
```
|
||||
$ duc ls -Fg /home/sk
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![使用 “duc ls” 命令可视化硬盘使用情况][3]
|
||||
|
||||
如你在上述输出所见,`ls` 子命令查询 duc 数据库并列出了所提供目录包含的文件与目录的大小,在这里就是 `/home/sk/`。
|
||||
|
||||
这里 `-F` 选项是往条目中用来添加文件类型指示符(`/`),`-g` 选项是用来绘制每个条目相对大小的图表。
|
||||
|
||||
请注意如果未提供任何路径,就会使用当前工作目录。
|
||||
|
||||
你可以使用 `-R` 选项来用[树状结构][4]浏览硬盘使用情况。
|
||||
|
||||
```
|
||||
$ duc ls -R /home/sk
|
||||
```
|
||||
|
||||
![用树状结构可视化硬盘使用情况][5]
|
||||
|
||||
要查询 duc 数据库并打开基于 ncurses 的控制台以探索所提供的目录,像以下这样使用 `ui` 子命令。
|
||||
|
||||
```
|
||||
$ duc ui /home/sk
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
类似的,我们使用 `gui *` 子命令来查询 duc 数据库以及打开一个图形界面(X11)来了解指定路径的硬盘使用情况。
|
||||
|
||||
```
|
||||
$ duc gui /home/sk
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
像我之前所提到的,我们可以像下面这样了解更多关于特定子命令的用法。
|
||||
|
||||
```
|
||||
$ duc help <子命令名字>
|
||||
```
|
||||
|
||||
我仅仅覆盖了基本用法的部分,参考 man 页面了解关于 `duc` 工具的更多细节。
|
||||
|
||||
```
|
||||
$ man duc
|
||||
```
|
||||
|
||||
相关阅读:
|
||||
|
||||
* [Filelight – 在你的 Linux 系统上可视化硬盘使用情况][8]
|
||||
* [一些好的 du 命令的替代品][9]
|
||||
* [如何在 Linux 中用 Ncdu 检查硬盘使用情况][10]
|
||||
* [Agedu——发现 Linux 中被浪费的硬盘空间][11]
|
||||
* [如何在 Linux 中找到目录大小][12]
|
||||
* [为初学者打造的带有示例的 df 命令教程][13]
|
||||
|
||||
### 总结
|
||||
|
||||
Duc 是一款简单却有用的硬盘用量查看器。如果你想要快速简便地知道哪个文件/目录占用你的硬盘空间,Duc 可能是一个好的选择。你还等什么呢?获取这个工具,扫描你的文件系统,摆脱无用的文件/目录。
|
||||
|
||||
现在就到此为止了。希望这篇文章有用处。更多好东西马上就到。保持关注!
|
||||
|
||||
欢呼吧!
|
||||
|
||||
资源:
|
||||
|
||||
* [Duc 网站][14]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/duc-a-collection-of-tools-to-inspect-and-visualize-disk-usage/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/duc-720x340.png
|
||||
[2]: https://github.com/zevv/duc/releases
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/04/duc-1-1.png
|
||||
[4]: https://www.ostechnix.com/view-directory-tree-structure-linux/
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2019/04/duc-2.png
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2019/04/duc-3.png
|
||||
[7]: http://www.ostechnix.com/wp-content/uploads/2019/04/duc-4.png
|
||||
[8]: https://www.ostechnix.com/filelight-visualize-disk-usage-on-your-linux-system/
|
||||
[9]: https://www.ostechnix.com/some-good-alternatives-to-du-command/
|
||||
[10]: https://www.ostechnix.com/check-disk-space-usage-linux-using-ncdu/
|
||||
[11]: https://www.ostechnix.com/agedu-find-out-wasted-disk-space-in-linux/
|
||||
[12]: https://www.ostechnix.com/find-size-directory-linux/
|
||||
[13]: https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginners/
|
||||
[14]: https://duc.zevv.nl/
|
||||
197
published/20190505 How To Create SSH Alias In Linux.md
Normal file
197
published/20190505 How To Create SSH Alias In Linux.md
Normal file
@ -0,0 +1,197 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10851-1.html)
|
||||
[#]: subject: (How To Create SSH Alias In Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-create-ssh-alias-in-linux/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
如何在 Linux 中创建 SSH 别名
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你经常通过 SSH 访问许多不同的远程系统,这个技巧将为你节省一些时间。你可以通过 SSH 为频繁访问的系统创建 SSH 别名,这样你就不必记住所有不同的用户名、主机名、SSH 端口号和 IP 地址等。此外,它避免了在 SSH 到 Linux 服务器时重复输入相同的用户名、主机名、IP 地址、端口号。
|
||||
|
||||
### 在 Linux 中创建 SSH 别名
|
||||
|
||||
在我知道这个技巧之前,我通常使用以下任意一种方式通过 SSH 连接到远程系统。
|
||||
|
||||
使用 IP 地址:
|
||||
|
||||
```
|
||||
$ ssh 192.168.225.22
|
||||
```
|
||||
|
||||
或使用端口号、用户名和 IP 地址:
|
||||
|
||||
```
|
||||
$ ssh -p 22 sk@192.168.225.22
|
||||
```
|
||||
|
||||
或使用端口号、用户名和主机名:
|
||||
|
||||
```
|
||||
$ ssh -p 22 sk@server.example.com
|
||||
```
|
||||
|
||||
这里
|
||||
|
||||
* `22` 是端口号,
|
||||
* `sk` 是远程系统的用户名,
|
||||
* `192.168.225.22` 是我远程系统的 IP,
|
||||
* `server.example.com` 是远程系统的主机名。
|
||||
|
||||
我相信大多数 Linux 新手和(或一些)管理员都会以这种方式通过 SSH 连接到远程系统。但是,如果你通过 SSH 连接到多个不同的系统,记住所有主机名或 IP 地址,还有用户名是困难的,除非你将它们写在纸上或者将其保存在文本文件中。别担心!这可以通过为 SSH 连接创建别名(或快捷方式)轻松解决。
|
||||
|
||||
我们可以用两种方法为 SSH 命令创建别名。
|
||||
|
||||
#### 方法 1 – 使用 SSH 配置文件
|
||||
|
||||
这是我创建别名的首选方法。
|
||||
|
||||
我们可以使用 SSH 默认配置文件来创建 SSH 别名。为此,编辑 `~/.ssh/config` 文件(如果此文件不存在,只需创建一个):
|
||||
|
||||
```
|
||||
$ vi ~/.ssh/config
|
||||
```
|
||||
|
||||
添加所有远程主机的详细信息,如下所示:
|
||||
|
||||
```
|
||||
Host webserver
|
||||
HostName 192.168.225.22
|
||||
User sk
|
||||
|
||||
Host dns
|
||||
HostName server.example.com
|
||||
User root
|
||||
|
||||
Host dhcp
|
||||
HostName 192.168.225.25
|
||||
User ostechnix
|
||||
Port 2233
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
*使用 SSH 配置文件在 Linux 中创建 SSH 别名*
|
||||
|
||||
将 `Host`、`Hostname`、`User` 和 `Port` 配置的值替换为你自己的值。添加所有远程主机的详细信息后,保存并退出该文件。
|
||||
|
||||
现在你可以使用以下命令通过 SSH 进入系统:
|
||||
|
||||
```
|
||||
$ ssh webserver
|
||||
$ ssh dns
|
||||
$ ssh dhcp
|
||||
```
|
||||
|
||||
就是这么简单!
|
||||
|
||||
看看下面的截图。
|
||||
|
||||
![][3]
|
||||
|
||||
*使用 SSH 别名访问远程系统*
|
||||
|
||||
看到了吗?我只使用别名(例如 `webserver`)来访问 IP 地址为 `192.168.225.22` 的远程系统。
|
||||
|
||||
请注意,这只使用于当前用户。如果要为所有用户(系统范围内)提供别名,请在 `/etc/ssh/ssh_config` 文件中添加以上行。
|
||||
|
||||
你还可以在 SSH 配置文件中添加许多其他内容。例如,如果你[已配置基于 SSH 密钥的身份验证][4],说明 SSH 密钥文件的位置,如下所示:
|
||||
|
||||
```
|
||||
Host ubuntu
|
||||
HostName 192.168.225.50
|
||||
User senthil
|
||||
IdentityFIle ~/.ssh/id_rsa_remotesystem
|
||||
```
|
||||
|
||||
确保已使用你自己的值替换主机名、用户名和 SSH 密钥文件路径。
|
||||
|
||||
现在使用以下命令连接到远程服务器:
|
||||
|
||||
```
|
||||
$ ssh ubuntu
|
||||
```
|
||||
|
||||
这样,你可以添加希望通过 SSH 访问的任意多台远程主机,并使用别名快速访问它们。
|
||||
|
||||
#### 方法 2 – 使用 Bash 别名
|
||||
|
||||
这是创建 SSH 别名的一种应急变通的方法,可以加快通信的速度。你可以使用 [alias 命令][5]使这项任务更容易。
|
||||
|
||||
打开 `~/.bashrc` 或者 `~/.bash_profile` 文件:
|
||||
|
||||
```
|
||||
alias webserver='ssh sk@server.example.com'
|
||||
alias dns='ssh sk@server.example.com'
|
||||
alias dhcp='ssh sk@server.example.com -p 2233'
|
||||
alias ubuntu='ssh sk@server.example.com -i ~/.ssh/id_rsa_remotesystem'
|
||||
```
|
||||
|
||||
再次确保你已使用自己的值替换主机、主机名、端口号和 IP 地址。保存文件并退出。
|
||||
|
||||
然后,使用命令应用更改:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ source ~/.bash_profile
|
||||
```
|
||||
|
||||
在此方法中,你甚至不需要使用 `ssh 别名` 命令。相反,只需使用别名,如下所示。
|
||||
|
||||
```
|
||||
$ webserver
|
||||
$ dns
|
||||
$ dhcp
|
||||
$ ubuntu
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
这两种方法非常简单,但对于经常通过 SSH 连接到多个不同系统的人来说非常有用,而且非常方便。使用适合你的上述任何一种方法,通过 SSH 快速访问远程 Linux 系统。
|
||||
|
||||
建议阅读:
|
||||
|
||||
* [允许或拒绝 SSH 访问 Linux 中的特定用户或组][7]
|
||||
* [如何在 Linux 上 SSH 到特定目录][8]
|
||||
* [如何在 Linux 中断开 SSH 会话][9]
|
||||
* [4 种方式在退出 SSH 会话后保持命令运行][10]
|
||||
* [SSLH – 共享相同端口的 HTTPS 和 SSH][11]
|
||||
|
||||
目前这就是全部了,希望它对你有帮助。更多好东西要来了,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-create-ssh-alias-in-linux/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/ssh-alias-720x340.png
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2019/04/Create-SSH-Alias-In-Linux.png
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/04/create-ssh-alias.png
|
||||
[4]: https://www.ostechnix.com/configure-ssh-key-based-authentication-linux/
|
||||
[5]: https://www.ostechnix.com/the-alias-and-unalias-commands-explained-with-examples/
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2019/04/create-ssh-alias-1.png
|
||||
[7]: https://www.ostechnix.com/allow-deny-ssh-access-particular-user-group-linux/
|
||||
[8]: https://www.ostechnix.com/how-to-ssh-into-a-particular-directory-on-linux/
|
||||
[9]: https://www.ostechnix.com/how-to-stop-ssh-session-from-disconnecting-in-linux/
|
||||
[10]: https://www.ostechnix.com/4-ways-keep-command-running-log-ssh-session/
|
||||
[11]: https://www.ostechnix.com/sslh-share-port-https-ssh/
|
||||
142
published/20190505 Kindd - A Graphical Frontend To dd Command.md
Normal file
142
published/20190505 Kindd - A Graphical Frontend To dd Command.md
Normal file
@ -0,0 +1,142 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10847-1.html)
|
||||
[#]: subject: (Kindd – A Graphical Frontend To dd Command)
|
||||
[#]: via: (https://www.ostechnix.com/kindd-a-graphical-frontend-to-dd-command/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Kindd:一个图形化 dd 命令前端
|
||||
======
|
||||
|
||||
![Kindd - A Graphical Frontend To dd Command][1]
|
||||
|
||||
前不久,我们已经学习如何在类 Unix 系统中 [使用 dd 命令创建可启动的 ISO][2]。请记住,`dd` 命令是最具危险性和破坏性的命令之一。如果你不确定你实际在做什么,你可能会在几分钟内意外地擦除你的硬盘数据。`dd` 命令仅仅从 `if` 参数获取数据,并写入数据到 `of` 参数。它将不关心它正在覆盖什么,它也不关心是否在磁道上有一个分区表,或一个启动扇区,或者一个家文件夹,或者任何重要的东西。它将简单地做它被告诉去做的事。如果你是初学者,一般地尝试避免使用 `dd` 命令来做实验。幸好,这有一个支持 `dd` 命令的简单的 GUI 实用程序。向 “Kindd” 问好,一个属于 `dd` 命令的图形化前端。它是自由开源的、用 Qt Quick 所写的工具。总的来说,这个工具对那些对命令行不适应的初学者是非常有用的。
|
||||
|
||||
它的开发者创建这个工具主要是为了提供:
|
||||
|
||||
1. 一个用于 `dd` 命令的现代化的、简单而安全的图形化用户界面,
|
||||
2. 一种简单地创建可启动设备的图形化方法,而不必使用终端。
|
||||
|
||||
### 安装 Kindd
|
||||
|
||||
Kindd 在 [AUR][3] 中是可用的。所以,如果你是 Arch 用户,使用任一的 AUR 助手工具来安装它,例如 [Yay][4] 。
|
||||
|
||||
要安装其 Git 发布版,运行:
|
||||
|
||||
```
|
||||
$ yay -S kindd-git
|
||||
```
|
||||
|
||||
要安装正式发布版,运行:
|
||||
|
||||
```
|
||||
$ yay -S kindd
|
||||
```
|
||||
|
||||
在安装后,从菜单或应用程序启动器启动 Kindd。
|
||||
|
||||
对于其它的发行版,你需要从源文件手动编译和安装它,像下面所示。
|
||||
|
||||
确保你已经安装下面的必要条件。
|
||||
|
||||
* git
|
||||
* coreutils
|
||||
* polkit
|
||||
* qt5-base
|
||||
* qt5-quickcontrols
|
||||
* qt5-quickcontrols2
|
||||
* qt5-graphicaleffects
|
||||
|
||||
一旦所有必要条件安装,使用 `git` 克隆 Kindd 储存库:
|
||||
|
||||
```
|
||||
git clone https://github.com/LinArcX/Kindd/
|
||||
```
|
||||
|
||||
转到你刚刚克隆 Kindd 的目录,并编译和安装它:
|
||||
|
||||
```
|
||||
cd Kindd
|
||||
qmake
|
||||
make
|
||||
```
|
||||
|
||||
最后运行下面的命令来启动 Kindd 应用程序:
|
||||
|
||||
```
|
||||
./kindd
|
||||
```
|
||||
|
||||
Kindd 内部使用 pkexec。pkexec 代理被默认安装在大多数桌面环境中。但是,如果你使用 i3 (或者可能还有一些其它的桌面环境),你应该首先安装 polkit-gnome ,然后粘贴下面的行到 i3 配置文件:
|
||||
|
||||
```
|
||||
exec /usr/lib/polkit-gnome/polkit-gnome-authentication-agent-1 &
|
||||
```
|
||||
|
||||
### 使用 Kindd 创建可启动的 ISO
|
||||
|
||||
为从一个 ISO 创建一个可启动的 USB,插入 USB 驱动器。然后,从菜单或终端启动 Kindd 。
|
||||
|
||||
这是 Kindd 默认界面的外观:
|
||||
|
||||
![][5]
|
||||
|
||||
*Kindd 界面*
|
||||
|
||||
正如你所能看到的,Kindd 界面是非常简单的和明白易懂的。这里仅有两部分,即设备列表,它显示你的系统上的可用的设备(hdd 和 Usb),并创建可启动的 .iso 。默认情况下,你将在“创建可启动 .iso”部分。
|
||||
|
||||
在第一列中输入块大小,在第二列中选择 ISO 文件的路径,并在第三列中选择正确的设备(USB 驱动器路径)。单击“转换/复制”按钮来开始创建可启动的 ISO 。
|
||||
|
||||
![][6]
|
||||
|
||||
一旦进程被完成,你将看到成功的信息。
|
||||
|
||||
![][7]
|
||||
|
||||
现在,拔出 USB 驱动器,并用该 USB 启动器启动你的系统,来检查它是否真地工作。
|
||||
|
||||
如果你不知道真实的设备名称(目标路径),只需要在列出的设备上单击,并检查 USB 驱动器名称。
|
||||
|
||||
![][8]
|
||||
|
||||
Kindd 还处在早期开发阶段。因此,可能有错误。如果你找到一些错误,请在这篇的指南的结尾所给的 GitHub 页面报告它们。
|
||||
|
||||
这就是全部。希望这是有用的。更多的好东西将会来。敬请期待!
|
||||
|
||||
谢谢!
|
||||
|
||||
资源:
|
||||
|
||||
* [Kindd GitHub 储存库][11]
|
||||
|
||||
相关阅读:
|
||||
|
||||
* [Etcher:一个来创建可启动 SD 卡或 USB 驱动器的漂亮的应用程序][9]
|
||||
* [Bootiso 让你安全地创建可启动的 USB 驱动器][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/kindd-a-graphical-frontend-to-dd-command/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/kindd-720x340.png
|
||||
[2]: https://www.ostechnix.com/how-to-create-bootable-usb-drive-using-dd-command/
|
||||
[3]: https://aur.archlinux.org/packages/kindd-git/
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2019/04/kindd-interface.png
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2019/04/kindd-1.png
|
||||
[7]: http://www.ostechnix.com/wp-content/uploads/2019/04/kindd-2.png
|
||||
[8]: http://www.ostechnix.com/wp-content/uploads/2019/04/kindd-3.png
|
||||
[9]: https://www.ostechnix.com/etcher-beauitiful-app-create-bootable-sd-cards-usb-drives/
|
||||
[10]: https://www.ostechnix.com/bootiso-lets-you-safely-create-bootable-usb-drive/
|
||||
[11]: https://github.com/LinArcX/Kindd
|
||||
@ -0,0 +1,198 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10868-1.html)
|
||||
[#]: subject: (Linux Shell Script To Monitor Disk Space Usage And Send Email)
|
||||
[#]: via: (https://www.2daygeek.com/linux-shell-script-to-monitor-disk-space-usage-and-send-email/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
用 Linux Shell 脚本来监控磁盘使用情况并发送邮件
|
||||
============================================
|
||||
|
||||
市场上有很多用来监控 Linux 系统的监控工具,当系统到达阀值后它将发送一封邮件。它监控所有的东西例如 CPU 利用率、内存利用率、交换空间利用率、磁盘空间利用率等等。然而,它更适合小环境和大环境。
|
||||
|
||||
想一想如果你只有少量系统,那么什么是最好的方式来应对这种情况。
|
||||
|
||||
是的,我们想要写一个 [shell 脚本][1] 来实现。
|
||||
|
||||
在这篇指南中我们打算写一个 shell 脚本来监控系统的磁盘空间使用率。当系统到达给定的阀值,它将给对应的邮件地址发送一封邮件。在这篇文章中我们总共添加了四个 shell 脚本,每个用于不同的目的。之后,我们会想出其他 shell 脚本来监控 CPU,内存和交换空间利用率。
|
||||
|
||||
在此之前,我想澄清一件事,根据我观察的磁盘空间使用率 shell 脚本使用情况。
|
||||
|
||||
大多数用户在多篇博客中评论说,当他们运行磁盘空间使用率脚本时他们获得了以下错误。
|
||||
|
||||
```
|
||||
# sh /opt/script/disk-usage-alert-old.sh
|
||||
|
||||
/dev/mapper/vg_2g-lv_root
|
||||
test-script.sh: line 7: [: /dev/mapper/vg_2g-lv_root: integer expression expected
|
||||
/ 9.8G
|
||||
```
|
||||
|
||||
是的,这是对的。甚至,当我第一次运行这个脚本的时候我遇到了相同的问题。之后,我发现了根本原因。
|
||||
|
||||
当你在基于 RHEL 5 & RHEL 6 的系统上运行包含用于磁盘空间警告的 `df -h` 或 `df -H` 的 shell 脚本中时,你会发现上述错误信息,因为输出格式不对,查看下列输出。
|
||||
|
||||
为了解决这个问题,我们需要用 `df -Ph` (POSIX 输出格式),但是默认的 `df -h` 在基于 RHEL 7 的系统上运行的很好。
|
||||
|
||||
```
|
||||
# df -h
|
||||
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg_2g-lv_root
|
||||
10G 6.7G 3.4G 67% /
|
||||
tmpfs 7.8G 0 7.8G 0% /dev/shm
|
||||
/dev/sda1 976M 95M 830M 11% /boot
|
||||
/dev/mapper/vg_2g-lv_home
|
||||
5.0G 4.3G 784M 85% /home
|
||||
/dev/mapper/vg_2g-lv_tmp
|
||||
4.8G 14M 4.6G 1% /tmp
|
||||
```
|
||||
|
||||
### 方法一:Linux Shell 脚本来监控磁盘空间使用率和发送邮件
|
||||
|
||||
你可以使用下列 shell 脚本在 Linux 系统中来监控磁盘空间使用率。
|
||||
|
||||
当系统到达给定的阀值限制时,它将发送一封邮件。在这个例子中,我们设置阀值为 60% 用于测试目的,你可以改变这个限制来符合你的需求。
|
||||
|
||||
如果超过一个文件系统到达给定的阀值,它将发送多封邮件,因为这个脚本使用了循环。
|
||||
|
||||
同样,替换你的邮件地址来获取这份警告。
|
||||
|
||||
```
|
||||
# vi /opt/script/disk-usage-alert.sh
|
||||
|
||||
#!/bin/sh
|
||||
df -Ph | grep -vE '^Filesystem|tmpfs|cdrom' | awk '{ print $5,$1 }' | while read output;
|
||||
do
|
||||
echo $output
|
||||
used=$(echo $output | awk '{print $1}' | sed s/%//g)
|
||||
partition=$(echo $output | awk '{print $2}')
|
||||
if [ $used -ge 60 ]; then
|
||||
echo "The partition \"$partition\" on $(hostname) has used $used% at $(date)" | mail -s "Disk Space Alert: $used% Used On $(hostname)" [email protected]
|
||||
fi
|
||||
done
|
||||
```
|
||||
|
||||
输出:我获得了下列两封邮件警告。
|
||||
|
||||
```
|
||||
The partition "/dev/mapper/vg_2g-lv_home" on 2g.CentOS7 has used 85% at Mon Apr 29 06:16:14 IST 2019
|
||||
|
||||
The partition "/dev/mapper/vg_2g-lv_root" on 2g.CentOS7 has used 67% at Mon Apr 29 06:16:14 IST 2019
|
||||
```
|
||||
|
||||
最终添加了一个 [cronjob][2] 来自动完成。它会每 10 分钟运行一次。
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
*/10 * * * * /bin/bash /opt/script/disk-usage-alert.sh
|
||||
```
|
||||
|
||||
### 方法二:Linux Shell 脚本来监控磁盘空间使用率和发送邮件
|
||||
|
||||
作为代替,你可以使用下列的 shell 脚本。对比上面的脚本我们做了少量改变。
|
||||
|
||||
```
|
||||
# vi /opt/script/disk-usage-alert-1.sh
|
||||
|
||||
#!/bin/sh
|
||||
df -Ph | grep -vE '^Filesystem|tmpfs|cdrom' | awk '{ print $5,$1 }' | while read output;
|
||||
do
|
||||
max=60%
|
||||
echo $output
|
||||
used=$(echo $output | awk '{print $1}')
|
||||
partition=$(echo $output | awk '{print $2}')
|
||||
if [ ${used%?} -ge ${max%?} ]; then
|
||||
echo "The partition \"$partition\" on $(hostname) has used $used at $(date)" | mail -s "Disk Space Alert: $used Used On $(hostname)" [email protected]
|
||||
fi
|
||||
done
|
||||
```
|
||||
|
||||
输出:我获得了下列两封邮件警告。
|
||||
|
||||
|
||||
```
|
||||
The partition "/dev/mapper/vg_2g-lv_home" on 2g.CentOS7 has used 85% at Mon Apr 29 06:16:14 IST 2019
|
||||
|
||||
The partition "/dev/mapper/vg_2g-lv_root" on 2g.CentOS7 has used 67% at Mon Apr 29 06:16:14 IST 2019
|
||||
```
|
||||
|
||||
最终添加了一个 [cronjob][2] 来自动完成。它会每 10 分钟运行一次。
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
*/10 * * * * /bin/bash /opt/script/disk-usage-alert-1.sh
|
||||
```
|
||||
|
||||
### 方法三:Linux Shell 脚本来监控磁盘空间使用率和发送邮件
|
||||
|
||||
我更喜欢这种方法。因为,它工作起来很有魔力,你只会收到一封关于所有事的邮件。
|
||||
|
||||
这相当简单和直接。
|
||||
|
||||
```
|
||||
*/10 * * * * df -Ph | sed s/%//g | awk '{ if($5 > 60) print $0;}' | mail -s "Disk Space Alert On $(hostname)" [email protected]
|
||||
```
|
||||
|
||||
输出: 我获得了一封关于所有警告的邮件。
|
||||
|
||||
```
|
||||
Filesystem Size Used Avail Use Mounted on
|
||||
/dev/mapper/vg_2g-lv_root 10G 6.7G 3.4G 67 /
|
||||
/dev/mapper/vg_2g-lv_home 5.0G 4.3G 784M 85 /home
|
||||
```
|
||||
|
||||
### 方法四:Linux Shell 脚本来监控某个分区的磁盘空间使用情况和发送邮件
|
||||
|
||||
```
|
||||
# vi /opt/script/disk-usage-alert-2.sh
|
||||
|
||||
#!/bin/bash
|
||||
used=$(df -Ph | grep '/dev/mapper/vg_2g-lv_dbs' | awk {'print $5'})
|
||||
max=80%
|
||||
if [ ${used%?} -ge ${max%?} ]; then
|
||||
echo "The Mount Point "/DB" on $(hostname) has used $used at $(date)" | mail -s "Disk space alert on $(hostname): $used used" [email protected]
|
||||
fi
|
||||
```
|
||||
|
||||
输出: 我得到了下面的邮件警告。
|
||||
|
||||
```
|
||||
The partition /dev/mapper/vg_2g-lv_dbs on 2g.CentOS6 has used 82% at Mon Apr 29 06:16:14 IST 2019
|
||||
```
|
||||
|
||||
最终添加了一个 [cronjob][2] 来自动完成这些工作。它将每 10 分钟运行一次。
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
*/10 * * * * /bin/bash /opt/script/disk-usage-alert-2.sh
|
||||
```
|
||||
|
||||
注意: 你将在 10 分钟后收到一封邮件警告,因为这个脚本被计划为每 10 分钟运行一次(但也不是精确的 10 分钟,取决于时间)。
|
||||
|
||||
例如这个例子。如果你的系统在 8:25 到达了限制,你将在 5 分钟后收到邮件警告。希望现在讲清楚了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-shell-script-to-monitor-disk-space-usage-and-send-email/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/shell-script/
|
||||
[2]: https://www.2daygeek.com/crontab-cronjob-to-schedule-jobs-in-linux/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10872-1.html)
|
||||
[#]: subject: (How to Add Application Shortcuts on Ubuntu Desktop)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-desktop-shortcut/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 桌面手动添加应用快捷方式
|
||||
===============================
|
||||
|
||||
> 在这篇快速指南中,你将学到如何在 Ubuntu 桌面和其他使用 GNOME 桌面的发行版中添加应用图标。
|
||||
|
||||
一个经典的桌面操作系统在“桌面屏”上总是有图标的。这些桌面图标包括文件管理器、回收站和应用图标。
|
||||
|
||||
当在 Windows 中安装应用时,一些程序会询问你是否在桌面创建一个快捷方式。但在 Linux 系统中不是这样。
|
||||
|
||||
但是如果你热衷于这个特点,让我给你展示如何在 Ubuntu 桌面和其他使用 GNOME 桌面的发行版中创建应用的快捷方式。
|
||||
|
||||
![Application Shortcuts on Desktop in Ubuntu with GNOME desktop][2]
|
||||
|
||||
如果你想知道我的桌面外观,我正在使用 Ant 主题和 Tela 图标集。你可以获取一些 [GTK 主题][3] 和 [为 Ubuntu 准备的图标集][4]并换成你喜欢的。
|
||||
|
||||
### 在 Ubuntu 中添加桌面快捷方式
|
||||
|
||||
![][5]
|
||||
|
||||
个人来讲,我更喜欢为应用图标准备的 Ubuntu 启动器方式。如果我经常使用一个程序,我会添加到启动器。但是我知道不是每个人都有相同的偏好,可能少数人更喜欢桌面的快捷方式。
|
||||
|
||||
让我们看在桌面中创建应用快捷方式的最简单方式。
|
||||
|
||||
> 免责声明
|
||||
|
||||
> 这篇指南已经在 Ubuntu 18.04 LTS 的 GNOME 桌面上测试过了。它可能在其他发行版和桌面环境上也能发挥作用,但你必须自己尝试。一些 GNOME 特定步骤可能会变,所以请在[其他桌面环境][7]尝试时注意。
|
||||
|
||||
#### 准备
|
||||
|
||||
首先最重要的事是确保你有 GNOME 桌面的图标权限。
|
||||
|
||||
如果你跟随 Ubuntu 18.04 自定义提示,你会知道如何安装 GNOME Tweaks 工具。在这个工具中,确保你设置“Show Icons”选项为启用。
|
||||
|
||||
![Allow icons on desktop in GNOME][9]
|
||||
|
||||
一旦你确保已经设置,是时候在桌面添加应用快捷方式了。
|
||||
|
||||
#### 第一步:定位应用的 .desktop 文件
|
||||
|
||||
到 “Files -> Other Location -> Computer”。
|
||||
|
||||
![Go to Other Locations -> Computer][11]
|
||||
|
||||
从这里,到目录 “usr -> share -> applications”。你会在这里看到几个你已经安装的 [Ubuntu 应用][12]。即使你没有看到图标,你应该看到被命名为“应用名.desktop”形式的文件。
|
||||
|
||||
![Application Shortcuts][13]
|
||||
|
||||
#### 第二步:拷贝 .desktop 文件到桌面
|
||||
|
||||
现在你要做的只是查找应用图标(或者它的 desktop 文件)。当你找到后,拖文件到桌面或者拷贝文件(使用 `Ctrl+C` 快捷方式)并在桌面粘贴(使用 `Ctrl+V` 快捷方式)。
|
||||
|
||||
![Add .desktop file to the desktop][14]
|
||||
|
||||
#### 第三步:运行 desktop 文件
|
||||
|
||||
当你这么做,你应该在桌面上看到一个图标的文本文件而不是应用 logo。别担心,一会就不一样了。
|
||||
|
||||
你要做的就是双击桌面的那个文件。它将警告你它是一个“未信任的应用启动器’,点击“信任并启动”。
|
||||
|
||||
![Launch Desktop Shortcut][15]
|
||||
|
||||
这个应用像往常一样启动,好事是你会察觉到 .desktop 文件现在已经变成应用图标了。我相信你喜欢应用图标的方式,不是吗?
|
||||
|
||||
![Application shortcut on the desktop][16]
|
||||
|
||||
#### Ubuntu 19.04 或者 GNOME 3.32 用户的疑难杂症
|
||||
|
||||
如果你使用 Ubuntu 19.04 或者 GNOME 3.32,你的 .desktop 文件可能根本不会启动。你应该右击 .desktop 文件并选择 “允许启动”。
|
||||
|
||||
在这之后,你应该能够启动应用并且桌面上的应用快捷方式能够正常显示了。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你不喜欢桌面的某个应用启动器,选择删除就是了。它会删除应用快捷方式,但是应用仍安全的保留在你的系统中。
|
||||
|
||||
我希望你发现这篇快速指南有帮助并喜欢在 Ubuntu 桌面上的应用快捷方式。
|
||||
|
||||
如果你有问题或建议,请在下方评论让我知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-desktop-shortcut/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ubuntu.com/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/app-shortcut-on-ubuntu-desktop.jpeg?resize=800%2C450&ssl=1
|
||||
[3]: https://itsfoss.com/best-gtk-themes/
|
||||
[4]: https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/add-ubuntu-desktop-shortcut.jpeg?resize=800%2C450&ssl=1
|
||||
[6]: https://www.gnome.org/
|
||||
[7]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
[8]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/allow-icons-on-desktop-gnome.jpg?ssl=1
|
||||
[10]: https://itsfoss.com/replace-linux-from-dual-boot/
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/Adding-desktop-shortcut-Ubuntu-gnome-1.png?resize=800%2C436&ssl=1
|
||||
[12]: https://itsfoss.com/best-ubuntu-apps/
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/application-shortcuts-in-ubuntu.png?resize=800%2C422&ssl=1
|
||||
[14]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/add-desktop-file-to-desktop.jpeg?resize=800%2C458&ssl=1
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/launch-desktop-shortcut-.jpeg?resize=800%2C349&ssl=1
|
||||
[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/app-shortcut-on-desktop-ubuntu-gnome.jpeg?resize=800%2C375&ssl=1
|
||||
[17]: https://itsfoss.com/install-nemo-file-manager-ubuntu/
|
||||
@ -0,0 +1,139 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10865-1.html)
|
||||
[#]: subject: (How to use advanced rsync for large Linux backups)
|
||||
[#]: via: (https://opensource.com/article/19/5/advanced-rsync)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss/users/marcobravo)
|
||||
|
||||
如何使用 rsync 的高级用法进行大型备份
|
||||
=====================================
|
||||
|
||||
> 基础的 `rsync` 命令通常足够来管理你的 Linux 备份,但是额外的选项使大型备份集更快、更强大。
|
||||
|
||||
![Filing papers and documents][1]
|
||||
|
||||
很明显,备份一直是 Linux 世界的热门话题。回到 2017,David Both 为 [Opensource.com][2] 的读者在[使用 rsync 备份 Linux 系统][3]方面提了一些建议,在这年的更早时候,他发起了一项问卷调查询问大家,[在 Linux 中你的 /home 目录的主要备份策略是什么][4],在今年的另一个问卷调查中,Don Watkins 问到,[你使用哪种开源备份解决方案][5]。
|
||||
|
||||
我的回复是 [rsync][6]。我真的非常喜欢 rsync!市场上有大量大而复杂的工具,对于管理磁带机或者存储库设备,这些可能是必要的,但是可能你需要的只是一个简单的开源命令行工具。
|
||||
|
||||
### rsync 基础
|
||||
|
||||
我为一个大概拥有 35,000 开发者并有着几十 TB 文件的全球性机构管理二进制仓库。我经常一次移动或者归档上百 GB 的数据。使用的是 `rsync`。这种经历使我对这个简单的工具充满信心。(所以,是的,我在家使用它来备份我的 Linux 系统)
|
||||
|
||||
基础的 `rsync` 命令很简单。
|
||||
|
||||
|
||||
```
|
||||
rsync -av 源目录 目的地目录
|
||||
```
|
||||
|
||||
实际上,在各种指南中教的 `rsync` 命令在大多数通用情况下都运行的很好。然而,假设我们需要备份大量的数据。例如包含 2,000 个子目录的目录,每个包含 50GB 到 700GB 的数据。在这个目录运行 `rsync` 可能需要大量时间,尤其是当你使用校验选项时(我倾向使用)。
|
||||
|
||||
当我们试图同步大量数据或者通过慢的网络连接时,可能遇到性能问题。让我给你展示一些我使用的方法来确保好的性能和可靠性。
|
||||
|
||||
### rsync 高级用法
|
||||
|
||||
`rsync` 运行时出现的第一行是:“正在发送增量文件列表。” 如果你在网上搜索这一行,你将看到很多类似的问题:为什么它一直运行,或者为什么它似乎挂起了。
|
||||
|
||||
这里是一个基于这个场景的例子。假设我们有一个 `/storage` 的目录,我们想要备份到一个外部 USB 磁盘,我们可以使用下面的命令:
|
||||
|
||||
```
|
||||
rsync -cav /storage /media/WDPassport
|
||||
```
|
||||
|
||||
`-c` 选项告诉 `rsync` 使用文件校验和而不是时间戳来决定改变的文件,这通常消耗的时间更久。为了分解 `/storage` 目录,我通过子目录同步,使用 `find` 命令。这是一个例子:
|
||||
|
||||
|
||||
```
|
||||
find /storage -type d -exec rsync -cav {} /media/WDPassport \;
|
||||
```
|
||||
|
||||
这看起来可以,但是如果 `/storage` 目录有任何文件,它们将被跳过。因此,我们如何同步 `/storage` 目录中的文件呢?同样有一个细微的差别是这些选项将造成 `rsync` 会同步 `.` 目录,该目录是源目录自身;这意味着它会同步子目录两次,这并不是我们想要的。
|
||||
|
||||
长话短说,我的解决方案是一个 “双-递增”脚本。这允许我分解一个目录,例如,当你的家目录有多个大的目录,例如音乐或者家庭照片时,分解 `/home` 目录为单个的用户家目录。
|
||||
|
||||
这是我的脚本的一个例子:
|
||||
|
||||
```
|
||||
HOMES="alan"
|
||||
DRIVE="/media/WDPassport"
|
||||
|
||||
for HOME in $HOMES; do
|
||||
cd /home/$HOME
|
||||
rsync -cdlptgov --delete . /$DRIVE/$HOME
|
||||
find . -maxdepth 1 -type d -not -name "." -exec rsync -crlptgov --delete {} /$DRIVE/$HOME \;
|
||||
done
|
||||
```
|
||||
|
||||
第一个 `rsync` 命令拷贝它在源目录中发现的文件和目录。然而,它将目录留着不处理,因此我们能够通过 `find` 命令迭代它们。这通过传递 `-d` 参数来完成,它告诉 `rsync` 不要递归目录。
|
||||
|
||||
|
||||
```
|
||||
-d, --dirs 传输目录而不递归
|
||||
```
|
||||
|
||||
然后 `find` 命令传递每个目录来单独运行 `rsync`。之后 `rsync` 拷贝目录的内容。这通过传递 `-r` 参数来完成,它告诉 `rsync` 要递归目录。
|
||||
|
||||
|
||||
```
|
||||
-r, --recursive 递归进入目录
|
||||
```
|
||||
|
||||
这使得 `rsync` 使用的增量文件保持在一个合理的大小。
|
||||
|
||||
大多数 `rsync` 指南为了简便使用 `-a` (或者 `archive`) 参数。这实际是一个复合参数。
|
||||
|
||||
```
|
||||
-a, --archive 归档模式;等价于 -rlptgoD(没有 -H,-A,-X)
|
||||
```
|
||||
|
||||
我传递的其他参数包含在 `a` 中;这些是 `-l`、`-p`、`-t`、`-g`和 `-o`。
|
||||
|
||||
|
||||
```
|
||||
-l, --links 复制符号链接作为符号链接
|
||||
-p, --perms 保留权限
|
||||
-t, --times 保留修改时间
|
||||
-g, --group 保留组
|
||||
-o, --owner 保留拥有者(只适用于超级管理员)
|
||||
```
|
||||
|
||||
`--delete` 选项告诉 `rsync` 删除目的地目录中所有在源目录不存在的任意文件。这种方式,运行的结果仅仅是复制。你同样可以排除 `.Trash` 目录或者 MacOS 创建的 `.DS_Store` 文件。
|
||||
|
||||
|
||||
```
|
||||
-not -name ".Trash*" -not -name ".DS_Store"
|
||||
```
|
||||
|
||||
### 注意
|
||||
|
||||
最后一条建议: `rsync` 可以是破坏性的命令。幸运的是,它的睿智的创造者提供了 “空运行” 的能力。如果我们加入 `n` 选项,rsync 会显示预期的输出但不写任何数据。
|
||||
|
||||
|
||||
```
|
||||
`rsync -cdlptgovn --delete . /$DRIVE/$HOME`
|
||||
```
|
||||
|
||||
这个脚本适用于非常大的存储规模和高延迟或者慢链接的情况。一如既往,我确信仍有提升的空间。如果你有任何建议,请在下方评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/advanced-rsync
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/documents_papers_file_storage_work.png?itok=YlXpAqAJ (Filing papers and documents)
|
||||
[2]: http://Opensource.com
|
||||
[3]: https://linux.cn/article-8237-1.html
|
||||
[4]: https://opensource.com/poll/19/4/backup-strategy-home-directory-linux
|
||||
[5]: https://opensource.com/article/19/2/linux-backup-solutions
|
||||
[6]: https://en.wikipedia.org/wiki/Rsync
|
||||
@ -0,0 +1,263 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10860-1.html)
|
||||
[#]: subject: (21 Best Kali Linux Tools for Hacking and Penetration Testing)
|
||||
[#]: via: (https://itsfoss.com/best-kali-linux-tools/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
用于黑客渗透测试的 21 个最佳 Kali Linux 工具
|
||||
======
|
||||
|
||||
> 这里是最好的 Kali Linux 工具列表,它们可以让你评估 Web 服务器的安全性,并帮助你执行黑客渗透测试。
|
||||
|
||||
如果你读过 [Kali Linux 点评][1],你就知道为什么它被认为是[最好的黑客渗透测试的 Linux 发行版][2]之一,而且名副其实。它带有许多工具,使你可以更轻松地测试、破解以及进行与数字取证相关的任何其他工作。
|
||||
|
||||
它是<ruby>道德黑客<rt>ethical hacker</rt></ruby>最推荐的 Linux 发行版之一。即使你不是黑客而是网站管理员 —— 你仍然可以利用其中某些工具轻松地扫描你的网络服务器或网页。
|
||||
|
||||
在任何一种情况下,无论你的目的是什么 —— 让我们来看看你应该使用的一些最好的 Kali Linux 工具。
|
||||
|
||||
*注意:这里不是所提及的所有工具都是开源的。*
|
||||
|
||||
### 用于黑客渗透测试的 Kali Linux 工具
|
||||
|
||||

|
||||
|
||||
Kali Linux 预装了几种类型的工具。如果你发现有的工具没有安装,只需下载并进行设置即可。这很简单。
|
||||
|
||||
#### 1、Nmap
|
||||
|
||||
![Kali Linux Nmap][4]
|
||||
|
||||
[Nmap][5] (即 “<ruby>网络映射器<rt>Network Mapper</rt></ruby>”)是 Kali Linux 上最受欢迎的信息收集工具之一。换句话说,它可以获取有关主机的信息:其 IP 地址、操作系统检测以及网络安全的详细信息(如开放的端口数量及其含义)。
|
||||
|
||||
它还提供防火墙规避和欺骗功能。
|
||||
|
||||
#### 2、Lynis
|
||||
|
||||
![Lynis Kali Linux Tool][6]
|
||||
|
||||
[Lynis][7] 是安全审计、合规性测试和系统强化的强大工具。当然,你也可以将其用于漏洞检测和渗透测试。
|
||||
|
||||
它将根据检测到的组件扫描系统。例如,如果它检测到 Apache —— 它将针对入口信息运行与 Apache 相关的测试。
|
||||
|
||||
#### 3、WPScan
|
||||
|
||||
![][8]
|
||||
|
||||
WordPress 是[最好的开源 CMS][9]之一,而这个工具是最好的免费 WordpPress 安全审计工具。它是免费的,但不是开源的。
|
||||
|
||||
如果你想知道一个 WordPress 博客是否在某种程度上容易受到攻击,[WPScan][10] 就是你的朋友。
|
||||
|
||||
此外,它还为你提供了所用的插件的详细信息。当然,一个安全性很好的博客可能不会暴露给你很多细节,但它仍然是 WordPress 安全扫描找到潜在漏洞的最佳工具。
|
||||
|
||||
#### 4、Aircrack-ng
|
||||
|
||||
![][11]
|
||||
|
||||
[Aircrack-ng][12] 是评估 WiFi 网络安全性的工具集合。它不仅限于监控和获取信息 —— 还包括破坏网络(WEP、WPA 1 和 WPA 2)的能力。
|
||||
|
||||
如果你忘记了自己的 WiFi 网络的密码,可以尝试使用它来重新获得访问权限。它还包括各种无线攻击能力,你可以使用它们来定位和监控 WiFi 网络以增强其安全性。
|
||||
|
||||
#### 5、Hydra
|
||||
|
||||
![][13]
|
||||
|
||||
如果你正在寻找一个有趣的工具来破解登录密码,[Hydra][14] 将是 Kali Linux 预装的最好的工具之一。
|
||||
|
||||
它可能不再被积极维护,但它现在放在 [GitHub][15] 上,所以你也可以为它做贡献。
|
||||
|
||||
#### 6、Wireshark
|
||||
|
||||
![][17]
|
||||
|
||||
[Wireshark][18] 是 Kali Linux 上最受欢迎的网络分析仪。它也可以归类为用于网络嗅探的最佳 Kali Linux 工具之一。
|
||||
|
||||
它正在积极维护,所以我肯定会建议你试试它。
|
||||
|
||||
#### 7、Metasploit Framework
|
||||
|
||||
![][19]
|
||||
|
||||
[Metsploit Framework][20](MSF)是最常用的渗透测试框架。它提供两个版本:一个开源版,另外一个是其专业版。使用此工具,你可以验证漏洞、测试已知漏洞并执行完整的安全评估。
|
||||
|
||||
当然,免费版本不具备所有功能,所以如果你在意它们的区别,你应该在[这里][21]比较一下版本。
|
||||
|
||||
#### 8、Skipfish
|
||||
|
||||
![][22]
|
||||
|
||||
与 WPScan 类似,但它不仅仅专注于 WordPress。[Skipfish][23] 是一个 Web 应用扫描程序,可以为你提供几乎所有类型的 Web 应用程序的洞察信息。它快速且易于使用。此外,它的递归爬取方法使它更好用。
|
||||
|
||||
Skipfish 生成的报告可以用于专业的 Web 应用程序安全评估。
|
||||
|
||||
#### 9、Maltego
|
||||
|
||||
![][24]
|
||||
|
||||
[Maltego][25] 是一种令人印象深刻的数据挖掘工具,用于在线分析信息并连接信息点(如果有的话)。 根据这些信息,它创建了一个有向图,以帮助分析这些数据之间的链接。
|
||||
|
||||
请注意,这不是一个开源工具。
|
||||
|
||||
它已预装,但你必须注册才能选择要使用的版本。如果个人使用,社区版就足够了(只需要注册一个帐户),但如果想用于商业用途,则需要订阅 classic 或 XL 版本。
|
||||
|
||||
#### 10、Nessus
|
||||
|
||||
![Nessus][26]
|
||||
|
||||
如果你的计算机连接到了网络,Nessus 可以帮助你找到潜在攻击者可能利用的漏洞。当然,如果你是多台连接到网络的计算机的管理员,则可以使用它并保护这些计算机。
|
||||
|
||||
但是,它不再是免费的工具了,你可以从[官方网站][27]免费试用 7 天。
|
||||
|
||||
#### 11、Burp Suite Scanner
|
||||
|
||||
![][28]
|
||||
|
||||
[Burp Suite Scanner][29] 是一款出色的网络安全分析工具。与其它 Web 应用程序安全扫描程序不同,Burp 提供了 GUI 和一些高级工具。
|
||||
|
||||
社区版仅将功能限制为一些基本的手动工具。对于专业人士,你必须考虑升级。与前面的工具类似,这也不是开源的。
|
||||
|
||||
我使用过免费版本,但是如果你想了解更多细节,你应该查看他们[官方网站][29]上提供的功能。
|
||||
|
||||
#### 12、BeEF
|
||||
|
||||
![][30]
|
||||
|
||||
BeEF(<ruby>浏览器利用框架<rt>Browser Exploitation Framework</rt></ruby>)是另一个令人印象深刻的工具。它专为渗透测试人员量身定制,用于评估 Web 浏览器的安全性。
|
||||
|
||||
这是最好的 Kali Linux 工具之一,因为很多用户在谈论 Web 安全时希望了解并修复客户端的问题。
|
||||
|
||||
#### 13、Apktool
|
||||
|
||||
![][31]
|
||||
|
||||
[Apktool][32] 确实是 Kali Linux 上用于逆向工程 Android 应用程序的流行工具之一。当然,你应该正确利用它 —— 出于教育目的。
|
||||
|
||||
使用此工具,你可以自己尝试一下,并让原开发人员了解你的想法。你认为你会用它做什么?
|
||||
|
||||
#### 14、sqlmap
|
||||
|
||||
![][34]
|
||||
|
||||
如果你正在寻找一个开源渗透测试工具 —— [sqlmap][35] 是最好的之一。它可以自动化利用 SQL 注入漏洞的过程,并帮助你接管数据库服务器。
|
||||
|
||||
#### 15、John the Ripper
|
||||
|
||||
![John The Ripper][36]
|
||||
|
||||
[John the Ripper][37] 是 Kali Linux 上流行的密码破解工具。它也是自由开源的。但是,如果你对[社区增强版][37]不感兴趣,可以用于商业用途的[专业版][38]。
|
||||
|
||||
#### 16、Snort
|
||||
|
||||
想要实时流量分析和数据包记录功能吗?[Snort][39] 可以鼎力支持你。即使它是一个开源的入侵防御系统,也有很多东西可以提供。
|
||||
|
||||
如果你还没有安装它,[官方网站][40]提及了安装过程。
|
||||
|
||||
#### 17、Autopsy Forensic Browser
|
||||
|
||||
![][41]
|
||||
|
||||
[Autopsy][42] 是一个数字取证工具,用于调查计算机上发生的事情。那么,你也可以使用它从 SD 卡恢复图像。它也被执法官员使用。你可以阅读[文档][43]来探索可以用它做什么。
|
||||
|
||||
你还应该查看他们的 [GitHub 页面][44]。
|
||||
|
||||
#### 18、King Phisher
|
||||
|
||||
![King Phisher][45]
|
||||
|
||||
网络钓鱼攻击现在非常普遍。[King Phisher 工具][46]可以通过模拟真实的网络钓鱼攻击来帮助测试和提升用户意识。出于显而易见的原因,在模拟一个组织的服务器内容前,你需要获得许可。
|
||||
|
||||
#### 19、Nikto
|
||||
|
||||
![Nikto][47]
|
||||
|
||||
[Nikto][48] 是一款功能强大的 Web 服务器扫描程序 —— 这使其成为最好的 Kali Linux 工具之一。 它会检查存在潜在危险的文件/程序、过时的服务器版本等等。
|
||||
|
||||
#### 20、Yersinia
|
||||
|
||||
![][49]
|
||||
|
||||
[Yersinia][50] 是一个有趣的框架,用于在网络上执行第 2 层攻击(第 2 层是指 [OSI 模型][51]的数据链路层)。当然,如果你希望你的网络安全,则必须考虑所有七个层。但是,此工具侧重于第 2 层和各种网络协议,包括 STP、CDP,DTP 等。
|
||||
|
||||
#### 21、Social Engineering Toolkit (SET)
|
||||
|
||||
![][52]
|
||||
|
||||
如果你正在进行相当严格的渗透测试,那么这应该是你应该检查的最佳工具之一。社交工程是一个大问题,使用 [SET][53] 工具,你可以帮助防止此类攻击。
|
||||
|
||||
### 总结
|
||||
|
||||
实际上 Kali Linux 捆绑了很多工具。请参考 Kali Linux 的[官方工具列表页面][54]来查找所有内容。
|
||||
|
||||
你会发现其中一些是完全自由开源的,而有些则是专有解决方案(但是免费)。但是,出于商业目的,你应该始终选择高级版本。
|
||||
|
||||
我们可能错过了你最喜欢的某个 Kali Linux 工具。请在下面的评论部分告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-kali-linux-tools/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/kali-linux-review/
|
||||
[2]: https://itsfoss.com/linux-hacking-penetration-testing/
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/kali-linux-tools.jpg?resize=800%2C518&ssl=1
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/kali-linux-nmap.jpg?resize=800%2C559&ssl=1
|
||||
[5]: https://nmap.org/
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/lynis-kali-linux-tool.jpg?resize=800%2C525&ssl=1
|
||||
[7]: https://cisofy.com/lynis/
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/wpscan-kali-linux.jpg?resize=800%2C545&ssl=1
|
||||
[9]: https://itsfoss.com/open-source-cms/
|
||||
[10]: https://wpscan.org/
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/aircrack-ng-kali-linux-tool.jpg?resize=800%2C514&ssl=1
|
||||
[12]: https://www.aircrack-ng.org/
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/hydra-kali-linux.jpg?resize=800%2C529&ssl=1
|
||||
[14]: https://github.com/vanhauser-thc/thc-hydra
|
||||
[15]: https://github.com/vanhauser-thc/THC-Archive
|
||||
[16]: https://itsfoss.com/new-linux-distros-2013/
|
||||
[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/wireshark-network-analyzer.jpg?resize=800%2C556&ssl=1
|
||||
[18]: https://www.wireshark.org/
|
||||
[19]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/metasploit-framework.jpg?resize=800%2C561&ssl=1
|
||||
[20]: https://github.com/rapid7/metasploit-framework
|
||||
[21]: https://www.rapid7.com/products/metasploit/download/editions/
|
||||
[22]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/skipfish-kali-linux-tool.jpg?resize=800%2C515&ssl=1
|
||||
[23]: https://gitlab.com/kalilinux/packages/skipfish/
|
||||
[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/maltego.jpg?resize=800%2C403&ssl=1
|
||||
[25]: https://www.paterva.com/web7/buy/maltego-clients.php
|
||||
[26]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/nessus.jpg?resize=800%2C456&ssl=1
|
||||
[27]: https://www.tenable.com/try
|
||||
[28]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/burp-suite-community-edition-800x582.jpg?resize=800%2C582&ssl=1
|
||||
[29]: https://portswigger.net/burp
|
||||
[30]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/beef-framework.jpg?resize=800%2C339&ssl=1
|
||||
[31]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/apktool.jpg?resize=800%2C504&ssl=1
|
||||
[32]: https://github.com/iBotPeaches/Apktool
|
||||
[33]: https://itsfoss.com/format-factory-alternative-linux/
|
||||
[34]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/sqlmap.jpg?resize=800%2C528&ssl=1
|
||||
[35]: http://sqlmap.org/
|
||||
[36]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/john-the-ripper.jpg?ssl=1
|
||||
[37]: https://github.com/magnumripper/JohnTheRipper
|
||||
[38]: https://www.openwall.com/john/pro/
|
||||
[39]: https://www.snort.org/
|
||||
[40]: https://www.snort.org/#get-started
|
||||
[41]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/autopsy-forensic-browser.jpg?resize=800%2C319&ssl=1
|
||||
[42]: https://www.sleuthkit.org/autopsy/
|
||||
[43]: https://www.sleuthkit.org/autopsy/docs.php
|
||||
[44]: https://github.com/sleuthkit/autopsy
|
||||
[45]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/king-phisher.jpg?resize=800%2C626&ssl=1
|
||||
[46]: https://github.com/securestate/king-phisher
|
||||
[47]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/nikto.jpg?resize=800%2C511&ssl=1
|
||||
[48]: https://gitlab.com/kalilinux/packages/nikto/
|
||||
[49]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/yersinia.jpg?resize=800%2C516&ssl=1
|
||||
[50]: https://github.com/tomac/yersinia
|
||||
[51]: https://en.wikipedia.org/wiki/OSI_model
|
||||
[52]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/social-engineering-toolkit.jpg?resize=800%2C511&ssl=1
|
||||
[53]: https://www.trustedsec.com/social-engineer-toolkit-set/
|
||||
[54]: https://tools.kali.org/tools-listing
|
||||
@ -0,0 +1,109 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10855-1.html)
|
||||
[#]: subject: (How to Use 7Zip in Ubuntu and Other Linux [Quick Tip])
|
||||
[#]: via: (https://itsfoss.com/use-7zip-ubuntu-linux/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 和其他 Linux 发行版上使用 7Zip
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
> 不能在 Linux 中提取 .7z 文件?学习如何在 Ubuntu 和其他 Linux 发行版中安装和使用 7zip。
|
||||
|
||||
[7Zip][1](更适当的写法是 7-Zip)是一种在 Windows 用户中广泛流行的归档格式。一个 7Zip 归档文件通常以 .7z 扩展结尾。它大部分是开源的,除了包含一些少量解压 rar 文件的代码。
|
||||
|
||||
默认大多数 Linux 发行版不支持 7Zip。如果你试图提取它,你会看见这个错误:
|
||||
|
||||
> 不能打开这种文件类型
|
||||
|
||||
> 没有已安装的适用 7-zip 归档文件的命令。你想搜索一个命令来打开这个文件吗?
|
||||
|
||||
![][2]
|
||||
|
||||
不要担心,你可以轻松的在 Ubuntu 和其他 Linux 发行版中安装 7zip。
|
||||
|
||||
一个问题是你会注意到如果你试图用 [apt-get install 命令][3],你会发现没有以 7zip 开头的候选安装。因为在 Linux 中 7Zip 包的名字是 [p7zip][4]。以字母 “p” 开头而不是预期的数字 “7”。
|
||||
|
||||
让我们看一下如何在 Ubuntu 和其他 Linux 发行版中安装 7zip。
|
||||
|
||||
### 在 Ubuntu Linux 中安装 7Zip
|
||||
|
||||
你需要做的第一件事是安装 p7zip 包。你会在 Ubuntu 中发现 3 个包:p7zip、p7zip-full 和 pzip-rar。
|
||||
|
||||
pzip 和 p7zip-full 的不同是 pzip 是一个轻量级的版本,仅仅对 .7z 文件提供支持,而 p7zip-full 提供了更多的 7z 压缩算法(例如音频文件)。
|
||||
|
||||
p7zip-rar 包在 7z 中提供了对 [RAR 文件][6] 的支持
|
||||
|
||||
在大多数情况下安装 p7zip-full 就足够了,但是你可能想安装 p7zip-rar 来支持 rar 文件的解压。
|
||||
|
||||
p7zip 包在 [Ubuntu 的 universe 仓库][7] 因此保证你可以使用以下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository universe
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
在 Ubuntu 和基于 Debian 的发行版中使用以下命令。
|
||||
|
||||
```
|
||||
sudo apt install p7zip-full p7zip-rar
|
||||
```
|
||||
|
||||
这很好。现在在你的系统就有了 7zip 归档的支持。
|
||||
|
||||
### 在 Linux 中提取 7Zip 归档文件
|
||||
|
||||
安装了 7Zip 后,在 Linux 中,你可以在图形用户界面或者 命令行中提取 7zip 文件。
|
||||
|
||||
在图形用户界面,你可以像提取其他压缩文件一样提取 .7z 文件。右击文件来提取它。
|
||||
|
||||
在终端中,你可以使用下列命令提取 .7z 归档文件:
|
||||
|
||||
```
|
||||
7z e file.7z
|
||||
```
|
||||
|
||||
### 在 Linux 中压缩文件为 7zip 归档格式
|
||||
|
||||
你可以在图形界面压缩文件为 7zip 归档格式。简单的在文件或目录上右击,选择“压缩”。你应该看到几种类型的文件格式选项。选择 .7z。
|
||||
|
||||
![7zip Archive Ubuntu][9]
|
||||
|
||||
作为替换,你也可以在命令行中使用。这里是你可以用来压缩的命令:
|
||||
|
||||
```
|
||||
7z a 输出的文件名 要压缩的文件
|
||||
```
|
||||
|
||||
默认,归档文件有 .7z 扩展。你可以通过在指定输出文件扩展名为 .zip 以压缩为 zip 格式。
|
||||
|
||||
### 总结
|
||||
|
||||
就是这样。看,在 Linux 中使用 7zip 多简单?我希望你喜欢这个快速指南。如果你有问题或者建议,请随意在下方评论让我知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/use-7zip-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.7-zip.org/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2015/07/Install_7zip_ubuntu_1.png?ssl=1
|
||||
[3]: https://itsfoss.com/apt-get-linux-guide/
|
||||
[4]: https://sourceforge.net/projects/p7zip/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/7zip-linux.png?resize=800%2C450&ssl=1
|
||||
[6]: https://itsfoss.com/use-rar-ubuntu-linux/
|
||||
[7]: https://itsfoss.com/ubuntu-repositories/
|
||||
[8]: https://itsfoss.com/easily-share-files-linux-windows-mac-nitroshare/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/7zip-archive-ubuntu.png?resize=800%2C239&ssl=1
|
||||
169
published/20190510 PHP in 2019.md
Normal file
169
published/20190510 PHP in 2019.md
Normal file
@ -0,0 +1,169 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10870-1.html)
|
||||
[#]: subject: (PHP in 2019)
|
||||
[#]: via: (https://stitcher.io/blog/php-in-2019)
|
||||
[#]: author: (Brent https://stitcher.io/blog/php-in-2019)
|
||||
|
||||
9102 年的 PHP
|
||||
======
|
||||
|
||||
你还记得篇流行的博客文章《[PHP:设计糟糕的分形][3]》吗?我第一次读到它时,我在一个有很多遗留的 PHP 项目的糟糕地方工作。这篇文章让我觉得我是否应该放弃,并去做与编程完全不同的事情。
|
||||
|
||||
还好,我之后很快就换了工作,更重要的是,自从 5.x 版本以来,PHP 成功地进步了很多。今天,我在向那些不再使用 PHP 编程,或者陷入遗留项目的人们致意。
|
||||
|
||||
剧透:今天有些事情仍然很糟糕,就像几乎每种编程语言都有它的怪癖一样。许多核心功能仍然有不一致的调用方法,仍然有令人困惑的配置设置,仍然有许多开发人员在那里写蹩脚的代码 —— 因为他们必须如此,或是他们不知道更好的写法。
|
||||
|
||||
今天我想看看好的一面:让我们关注已经发生变化的事情,以及编写干净而可维护的 PHP 代码的方法。在此之前,我想请你暂时搁置任何偏见。
|
||||
|
||||
然后,你可以像以前一样对 PHP 自由吐槽。虽然,你可能会对 PHP 在过去的几年里的一些改进感到惊讶。(LCTT 译注:说实话,我是真的感到吃惊)
|
||||
|
||||
### 提前看结论
|
||||
|
||||
* PHP 在积极地开发,每年都有新版本
|
||||
* 自 PHP 5 时代以来的性能已经翻倍,如果不是三倍的话
|
||||
* 有一个非常活跃的框架、包和平台的生态系统
|
||||
* PHP 在过去几年中添加了许多新功能,并且这种语言在不断发展
|
||||
* 像静态分析这样的工具在过去几年中已经成熟,并且一直保持增长
|
||||
|
||||
更新:人们让我展示一些实际的代码。我觉得这没问题!这是我的一个业余项目的[源代码][4],用 PHP 和 Laravel 编写的;[这里][5]列出了我们在办公室维护的几百个自由开源软件包。这两者都是现代 PHP 项目的好例子。
|
||||
|
||||
那让我们开始吧。
|
||||
|
||||
### 历史总结
|
||||
|
||||
出于更好地衡量的目的,让我们快速回顾一下如今的 PHP 发布周期。我们现在的 PHP 为 7.3,预计在 2019 年底为 7.4。PHP 8.0 将是 7.4 之后的下一个版本。
|
||||
|
||||
自从 5.x 时代以来,核心团队试图保持每年发布一个版本的周期,并且他们在过去的四年中成功地做到了这一点。
|
||||
|
||||
一般来说,每个新版本都会在两年内得到积极支持,并再获得一年以上的“安全修复”。其目标是激励 PHP 开发人员尽可能保持最新:例如,每年进行小规模升级比在 5.4 到 7.0 之间跳转更容易。
|
||||
|
||||
可以在 [这里][6] 找到 PHP 时间轴的活动概述。
|
||||
|
||||
最后,PHP 5.6 是最新的 5.x 版本,而 8.0 是当前的下一个大版本。如果你想知道 PHP 6 发生了什么,你可以听听 [PHP Roundtable 播客][7]。
|
||||
|
||||
了解了这个,让我们揭穿一些关于现代 PHP 的常见误解。
|
||||
|
||||
### PHP 的性能
|
||||
|
||||
早在 5.x 时代,PHP 的表现就是……嗯,平均水平。但是在 7.0 版本中,PHP 从头开始重写了核心部分,导致其性能提升了两到三倍!
|
||||
|
||||
但光是嘴说是不够的。让我们来看看基准测试。幸运的是,人们花了很多时间对 PHP 性能进行了基准测试。 我发现 [Kinsta][8] 有一个很好的更新的测试列表。
|
||||
|
||||
自 7.0 升级以来,性能就一直在提升而没有回退。PHP Web 应用程序的性能可与其它语言中的 Web 框架相提并论,甚至在某些情况下更好。你可以看看这个[广泛的基准测试套件][9]。
|
||||
|
||||
当然 PHP 框架不会胜过 C 和 Rust,但它们比 Rails 或 Django 要好得多,并且与 ExpressJS 相当。
|
||||
|
||||
### 框架和生态系统
|
||||
|
||||
说到框架:PHP 可不仅仅是 WordPress。让我告诉你 —— 某些专业的 PHP 开发人员:WordPress 绝不代表当代的 PHP 生态系统。
|
||||
|
||||
一般来说,有两个主要的 Web 应用程序框架,[Symfony][10] 和 [Laravel][11],以及一些较小的应用程序框架。当然还有 Zend、Yii、Cake、Code Igniter 等等,但是如果你想知道现代 PHP 开发是怎么样的,这两者之一都是很好的选择。
|
||||
|
||||
这两个框架都有一个庞大的包和产品的生态系统。从管理面板和 CRM 到独立软件包,从 CI 到分析器,以及几个 Web 套接字服务器、队列管理器、支付集成等众多服务。老实说,要列出的内容太多了。
|
||||
|
||||
这些框架虽然适用于实际开发。如果你只是需要个内容管理系统(CMS),WordPress 和 CraftCMS 等平台就够了。
|
||||
|
||||
衡量 PHP 生态系统当前状态的一种方法是查看 Packagist,这是 PHP 主要的软件包存储库。它现在呈指数级增长。每天下载量达到了 2500 万次,可以说 PHP 生态系统已不再是以前的小型弱势群体了。
|
||||
|
||||
请查看此图表,它列出一段时间内的软件包和版本数量变化。它也可以在 [Packagist 网站][12]上找到它。
|
||||
|
||||
![][13]
|
||||
|
||||
除了应用程序框架和 CMS 之外,我们还看到过去几年里异步框架的兴起。
|
||||
|
||||
这些是用 PHP 或其他语言编写的框架和服务器,允许用户运行真正的异步 PHP,这些例子包括 [Swoole][14](创始人韩天峰),以及 [Amp][15] 和 [ReactPHP][16]。
|
||||
|
||||
我们已经进入了异步的世界,像 Web 套接字和具有大量 I/O 的应用程序之类的东西在 PHP 世界中已经变得非常重要。
|
||||
|
||||
在内部邮件列表里(PHP 核心开发人员讨论语言开发的地方)已经谈到了[将 libuv 添加到核心][17]。如果你还不知道 libuv:Node.js 全有赖它提供异步性。
|
||||
|
||||
### 语言本身
|
||||
|
||||
虽然尚未提供 `async` 和 `await`,但在过去几年中,PHP 语言本身已经有了很多改进。这是 PHP 中新功能的非详尽列表:
|
||||
|
||||
|
||||
+ [短闭包](https://stitcher.io/blog/short-closures-in-php)(箭头函数)
|
||||
+ [Null 合并操作符](https://stitcher.io/blog/shorthand-comparisons-in-php#null-coalescing-operator)(`??`)
|
||||
+ [Trait](https://www.php.net/manual/en/language.oop5.traits.php)(一种代码重用方式)
|
||||
+ [属性类型](https://stitcher.io/blog/new-in-php-74#typed-properties-rfc)
|
||||
+ [展开操作符](https://wiki.php.net/rfc/argument_unpacking)(参数解包 `...`)
|
||||
+ [JIT 编译器](https://wiki.php.net/rfc/jit)(即时编译器)
|
||||
+ [FFI](https://wiki.php.net/rfc/ffi)(外部函数接口)
|
||||
+ [匿名类](https://www.php.net/manual/en/language.oop5.anonymous.php)
|
||||
+ [返回类型声明](https://www.php.net/manual/en/functions.returning-values.php#functions.returning-values.type-declaration)
|
||||
+ [现代化的加密支持](https://wiki.php.net/rfc/libsodium)
|
||||
+ [生成器](https://wiki.php.net/rfc/generators)
|
||||
+ [等等](https://www.php.net/ChangeLog-7.php)
|
||||
|
||||
当我们讨论语言功能时,我们还要谈谈当今该语言的发展过程。虽然社区可以提出 RFC,但是得有一个活跃的志愿者核心团队才能推着它前进。
|
||||
|
||||
接下来,这些 RFC 将在“内部”邮件列表中进行讨论,这个邮件列表也可以[在线阅读][18]。在添加新的语言特性之前,必须进行投票。只有得到了至少 2/3 多数同意的 RFC 才能进入核心。
|
||||
|
||||
可能有大约 100 人能够投票,但不需要每个人对每个 RFC 进行投票。核心团队的成员当然可以投票,他们是维护代码库的人。除了他们之外,还有一群人从 PHP 社区中被单独挑选出来。这些人包括 PHP 文档的维护者,对 PHP 项目整体有贡献的人,以及 PHP 社区中的杰出开发人员。
|
||||
|
||||
虽然大多数核心开发都是在自愿的基础上完成的,但其中一位核心 PHP 开发人员 Nikita Popov 最近受雇于 [JetBrains][19] 全职从事于 PHP 语言的开发。另一个例子是 Linux 基金会最近决定[投资 Zend 框架][20]。像这样的雇佣和收购确保了 PHP 未来发展的稳定性。
|
||||
|
||||
### 工具
|
||||
|
||||
除了核心本身,我们看到过去几年中围绕它的工具有所增加。首先浮现于我脑海中的是静态分析器,比如由 Vimeo 创建 [Psalm][21],以及 [Phan][22] 和 [PHPStan][23]。
|
||||
|
||||
这些工具将静态分析你的 PHP 代码并报告任何类型错误和可能的错误等。在某种程度上,它们提供的功能可以与 TypeScript 进行比较,但是现在这种语言不能<ruby>转译<rt>transpiling</rt></ruby>,因此不支持使用自定义语法。
|
||||
|
||||
尽管这意味着我们需要依赖 docblocks,但是 PHP 之父 Rasmus Lerdorf 确实提到了[添加静态分析引擎][24]到核心的想法。虽然会有很多潜力,但这是一项艰巨的任务。
|
||||
|
||||
说到转译,以及受到 JavaScript 社区的启发;他们已经努力在用户领域中扩展 PHP 语法。一个名为 [Pre][25] 的项目正是如此:允许将新的 PHP 语法转译为普通的 PHP 代码。
|
||||
|
||||
虽然这个思路已经在 JavaScript 世界中被证明了,但如果提供了适当的 IDE 和静态分析支持,它就能在 PHP 中工作了。这是一个非常有趣的想法,但必须发展起来才能称之为“主流”。
|
||||
|
||||
### 结语
|
||||
|
||||
尽管如此,你仍然可以将 PHP 视为一种糟糕的语言。虽然这种语言肯定有它的缺点和背负了 20 年的遗产;但我可以放胆地说,我喜欢用它工作。
|
||||
|
||||
根据我的经验,我能够创建可靠、可维护和高质量的软件。我工作的客户对最终结果感到满意,“俺也一样”。
|
||||
|
||||
尽管仍然可以用 PHP 做很多乱七八糟的事情,但我认为如果明智和正确地使用的话,它是 Web 开发的绝佳选择。
|
||||
|
||||
你不同意吗?让我知道为什么!你可以通过 [Twitter][2] 或 [电子邮件][26] 与我联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://stitcher.io/blog/php-in-2019
|
||||
|
||||
作者:[Brent][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://stitcher.io/blog/php-in-2019
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://stitcher.io/
|
||||
[2]: https://twitter.com/brendt_gd
|
||||
[3]: https://eev.ee/blog/2012/04/09/php-a-fractal-of-bad-design/
|
||||
[4]: https://github.com/brendt/aggregate.stitcher.io
|
||||
[5]: https://spatie.be/open-source/packages
|
||||
[6]: https://www.php.net/supported-versions.php
|
||||
[7]: https://www.phproundtable.com/episode/what-happened-to-php-6
|
||||
[8]: https://kinsta.com/blog/php-benchmarks/
|
||||
[9]: https://github.com/the-benchmarker/web-frameworks
|
||||
[10]: https://symfony.com/
|
||||
[11]: https://laravel.com/
|
||||
[12]: https://packagist.org/statistics
|
||||
[13]: https://stitcher.io/resources/img/blog/php-in-2019/packagist.png
|
||||
[14]: https://www.swoole.co.uk/
|
||||
[15]: https://amphp.org/
|
||||
[16]: https://reactphp.org/
|
||||
[17]: https://externals.io/message/102415#102415
|
||||
[18]: https://externals.io/
|
||||
[19]: https://blog.jetbrains.com/phpstorm/2019/01/nikita-popov-joins-phpstorm-team/
|
||||
[20]: https://getlaminas.org/
|
||||
[21]: https://github.com/vimeo/psalm
|
||||
[22]: https://github.com/phan/phan
|
||||
[23]: https://github.com/phpstan/phpstan
|
||||
[24]: https://externals.io/message/101477#101592
|
||||
[25]: https://preprocess.io/
|
||||
[26]: mailto:brendt@stitcher.io
|
||||
@ -0,0 +1,120 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10888-1.html)
|
||||
[#]: subject: (How to SSH into a Raspberry Pi [Beginner’s Tip])
|
||||
[#]: via: (https://itsfoss.com/ssh-into-raspberry/)
|
||||
[#]: author: (Chinmay https://itsfoss.com/author/chinmay/)
|
||||
|
||||
新手教程:如何 SSH 进入树莓派
|
||||
======
|
||||
|
||||
> 在这篇树莓派文章中,你将学到如何在树莓派中启用 SSH 以及之后如何通过 SSH 进入树莓派。
|
||||
|
||||
在你可以用[树莓派][1]做的所有事情中,将其作为一个家庭网络的服务器是十分流行的做法。小体积与低功耗使它成为运行轻量级服务器的完美设备。
|
||||
|
||||
在这种情况下你做得到的事情之一是能够每次在树莓派上无须接上显示器、键盘、鼠标以及走到放置你的树莓派的地方就可以运行指令。
|
||||
|
||||
你可以从其它任意电脑、笔记本、台式机甚至你的手机通过 SSH([Secure Shell][2])登入你的树莓派来做到这一点。让我展示给你看:
|
||||
|
||||
### 如何 SSH 进入树莓派
|
||||
|
||||
![][3]
|
||||
|
||||
我假设你已经[在你的树莓派上运行 Raspbian][4] 并已经成功通过有线或者无线网连进网络了。你的树莓派接入网络这点是很重要的,否则你无法通过 SSH 连接树莓派(抱歉说出这种显而易见的事实)。
|
||||
|
||||
#### 步骤一:在树莓派上启用 SSH
|
||||
|
||||
SSH 在树莓派上是默认关闭的,因此在你安装好全新的 Raspbian 后打开树莓派时,你需要启用它。
|
||||
|
||||
首先通过菜单进入树莓派的配置界面。
|
||||
|
||||
![树莓派菜单,树莓派配置][5]
|
||||
|
||||
现在进入<ruby>接口<rt>interfaces</rt></ruby>标签,启动 SSH 并重启你的树莓派。
|
||||
|
||||
![在树莓派上启动 SSH][6]
|
||||
|
||||
你也可以通过终端直接启动 SSH。仅需输入命令 `sudo raspi-config` 然后进入高级设置以启用 SSH。
|
||||
|
||||
#### 步骤二: 找到树莓派的 IP 地址
|
||||
|
||||
在大多数情况下,你的树莓派会被分配一个看起来长得像 `192.168.x.x` 或者 `10.x.x.x` 的本地 IP 地址。你可以[使用多种 Linux 命令来找到 IP 地址][7]。
|
||||
|
||||
我在这使用古老而好用的 `ifconfig` 命令,但是你也可以使用 `ip address`。
|
||||
|
||||
```
|
||||
ifconfig
|
||||
```
|
||||
|
||||
![树莓派网络配置][9]
|
||||
|
||||
这行命令展现了所有活跃中的网络适配器以及其配置的列表。第一个条目(`eth0`)展示了例如`192.168.2.105` 的有效 IP 地址。我用有线网将我的树莓派连入网络,因此这里显示的是 `eth0`。如果你用无线网的话在叫做 `wlan0` 的条目下查看。
|
||||
|
||||
你也可以用其他方法例如查看你的路由器或者调制解调器的网络设备表以找到 IP 地址。
|
||||
|
||||
#### 步骤三:SSH 进你的树莓派
|
||||
|
||||
既然你已经启用了 SSH 功能并且找到了 IP 地址,你可以从任何电脑 SSH 进入你的树莓派。你同样需要树莓派的用户名和密码。
|
||||
|
||||
默认用户名和密码是:
|
||||
|
||||
* 用户名:`pi`
|
||||
* 密码:`raspberry`
|
||||
|
||||
如果你已改变了默认的密码,那就使用新的而不是以上的密码。理想状态下你必须改变默认的密码。在过去,有一款[恶意软件感染数千使用默认用户名和密码的树莓派设备][8]。
|
||||
|
||||
(在 Mac 或 Linux 上)从你想要 SSH 进树莓派的电脑上打开终端输入以下命令,在 Windows 上,你可以用类似 [Putty][10] 的 SSH 客户端。
|
||||
|
||||
这里,使用你在之前步骤中找到的 IP 地址。
|
||||
|
||||
```
|
||||
ssh [受保护的邮件]
|
||||
```
|
||||
|
||||
> 注意: 确保你的树莓派和你用来 SSH 进入树莓派的电脑接入了同一个网络。
|
||||
|
||||
![通过命令行 SSH][11]
|
||||
|
||||
第一次你会看到一个警告,输入 `yes` 并按下回车。
|
||||
|
||||
![输入密码 \(默认是 ‘raspberry‘\)][12]
|
||||
|
||||
现在,输入密码按下回车。
|
||||
|
||||
![成功通过 SSH 登入][13]
|
||||
|
||||
成功登入你将会看到树莓派的终端。现在你可以通过这个终端无需物理上访问你的树莓派就可以远程(在当前网络内)在它上面运行指令。
|
||||
|
||||
在此之上你也可以设置 SSH 密钥这样每次通过 SSH 登入时就可以无需输入密码,但那完全是另一个话题了。
|
||||
|
||||
我希望你通过跟着这个教程已能够 SSH 进入你的树莓派。在下方评论中让我知道你打算用你的树莓派做些什么!
|
||||
|
||||
--------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ssh-into-raspberry/
|
||||
|
||||
作者:[Chinmay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/chinmay/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/
|
||||
[2]: https://en.wikipedia.org/wiki/Secure_Shell
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/ssh-into-raspberry-pi.png?resize=800%2C450&ssl=1
|
||||
[4]: https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/Raspberry-pi-configuration.png?ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/enable-ssh-raspberry-pi.png?ssl=1
|
||||
[7]: https://linuxhandbook.com/find-ip-address/
|
||||
[8]: https://itsfoss.com/raspberry-pi-malware-threat/
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/ifconfig-rapberry-pi.png?ssl=1
|
||||
[10]: https://itsfoss.com/putty-linux/
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/SSH-into-pi-warning.png?fit=800%2C199&ssl=1
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/SSH-into-pi-password.png?fit=800%2C202&ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/SSH-into-Pi-successful-login.png?fit=800%2C306&ssl=1
|
||||
[14]: https://itsfoss.com/speed-up-ubuntu-unity-on-low-end-system/
|
||||
117
published/20190516 Building Smaller Container Images.md
Normal file
117
published/20190516 Building Smaller Container Images.md
Normal file
@ -0,0 +1,117 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10885-1.html)
|
||||
[#]: subject: (Building Smaller Container Images)
|
||||
[#]: via: (https://fedoramagazine.org/building-smaller-container-images/)
|
||||
[#]: author: (Muayyad Alsadi https://fedoramagazine.org/author/alsadi/)
|
||||
|
||||
构建更小的容器镜像的技巧
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Linux 容器已经成为一个热门话题,保证容器镜像较小被认为是一个好习惯。本文提供了有关如何构建较小 Fedora 容器镜像的一些技巧。
|
||||
|
||||
### microdnf
|
||||
|
||||
Fedora 的 DNF 是用 Python 编写的,因为它有各种各样的插件,因此它的设计是可扩展的。但是 有一个 Fedora 基本容器镜像替代品,它使用一个较小的名为 [microdnf][2] 的包管理器,使用 C 编写。要在 Dockerfile 中使用这个最小的镜像,`FROM` 行应该如下所示:
|
||||
|
||||
```
|
||||
FROM registry.fedoraproject.org/fedora-minimal:30
|
||||
```
|
||||
|
||||
如果你的镜像不需要像 Python 这样的典型 DNF 依赖项,例如,如果你在制作 NodeJS 镜像时,那么这是一个重要的节省项。
|
||||
|
||||
### 在一个层中安装和清理
|
||||
|
||||
为了节省空间,使用 `dnf clean all` 或其 microdnf 等效的 `microdnf clean all` 删除仓库元数据非常重要。但是你不应该分两步执行此操作,因为这实际上会将这些文件保存在容器镜像中,然后在另一层中将其标记为删除。要正确地执行此操作,你应该像这样一步完成安装和清理:
|
||||
|
||||
```
|
||||
FROM registry.fedoraproject.org/fedora-minimal:30
|
||||
RUN microdnf install nodejs && microdnf clean all
|
||||
```
|
||||
|
||||
### 使用 microdnf 进行模块化
|
||||
|
||||
模块化是一种给你选择不同堆栈版本的方法。例如,你可能需要在项目中用非 LTS 的 NodeJS v11,旧的 LTS NodeJS v8 用于另一个,最新的 LTS NodeJS v10 用于另一个。你可以使用冒号指定流。
|
||||
|
||||
```
|
||||
# dnf module list
|
||||
# dnf module install nodejs:8
|
||||
```
|
||||
|
||||
`dnf module install` 命令意味着两个命令,一个启用流,另一个是从它安装 nodejs。
|
||||
|
||||
```
|
||||
# dnf module enable nodejs:8
|
||||
# dnf install nodejs
|
||||
```
|
||||
|
||||
尽管 `microdnf` 不提供与模块化相关的任何命令,但是可以启用带有配置文件的模块,并且 libdnf(被 microdnf 使用)[似乎][3]支持模块化流。该文件看起来像这样:
|
||||
|
||||
```
|
||||
/etc/dnf/modules.d/nodejs.module
|
||||
[nodejs]
|
||||
name=nodejs
|
||||
stream=8
|
||||
profiles=
|
||||
state=enabled
|
||||
```
|
||||
|
||||
使用模块化的 `microdnf` 的完整 Dockerfile 如下所示:
|
||||
|
||||
```
|
||||
FROM registry.fedoraproject.org/fedora-minimal:30
|
||||
RUN \
|
||||
echo -e "[nodejs]\nname=nodejs\nstream=8\nprofiles=\nstate=enabled\n" > /etc/dnf/modules.d/nodejs.module && \
|
||||
microdnf install nodejs zopfli findutils busybox && \
|
||||
microdnf clean all
|
||||
```
|
||||
|
||||
### 多阶段构建
|
||||
|
||||
在许多情况下,你可能需要大量的无需用于运行软件的构建时依赖项,例如构建一个静态链接依赖项的 Go 二进制文件。多阶段构建是分离应用构建和应用运行时的有效方法。
|
||||
|
||||
例如,下面的 Dockerfile 构建了一个 Go 应用 [confd][4]。
|
||||
|
||||
```
|
||||
# building container
|
||||
FROM registry.fedoraproject.org/fedora-minimal AS build
|
||||
RUN mkdir /go && microdnf install golang && microdnf clean all
|
||||
WORKDIR /go
|
||||
RUN export GOPATH=/go; CGO_ENABLED=0 go get github.com/kelseyhightower/confd
|
||||
|
||||
FROM registry.fedoraproject.org/fedora-minimal
|
||||
WORKDIR /
|
||||
COPY --from=build /go/bin/confd /usr/local/bin
|
||||
CMD ["confd"]
|
||||
```
|
||||
|
||||
通过在 `FROM` 指令之后添加 `AS` 并从基本容器镜像中添加另一个 `FROM` 然后使用 `COPY --from=` 指令将内容从*构建*的容器复制到第二个容器来完成多阶段构建。
|
||||
|
||||
可以使用 `podman` 构建并运行此 Dockerfile:
|
||||
|
||||
```
|
||||
$ podman build -t myconfd .
|
||||
$ podman run -it myconfd
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/building-smaller-container-images/
|
||||
|
||||
作者:[Muayyad Alsadi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/alsadi/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/05/smaller-container-images-816x345.jpg
|
||||
[2]: https://github.com/rpm-software-management/microdnf
|
||||
[3]: https://bugzilla.redhat.com/show_bug.cgi?id=1575626
|
||||
[4]: https://github.com/kelseyhightower/confd
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10894-1.html)
|
||||
[#]: subject: (PiShrink – Make Raspberry Pi Images Smaller)
|
||||
[#]: via: (https://www.ostechnix.com/pishrink-make-raspberry-pi-images-smaller/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
PiShrink:使树莓派镜像更小
|
||||
======
|
||||
|
||||
![Make Raspberry Pi Images Smaller With PiShrink In Linux][1]
|
||||
|
||||
树莓派不需要过多介绍。它是一款小巧、价格实惠,只有信用卡大小的电脑,它可以连接到显示器或电视。我们可以连接一个标准的键盘和鼠标,并将其用作一台成熟的台式计算机来完成日常任务,如互联网浏览、播放视频/玩游戏、文字处理和电子表格制作等。它主要是为学校的计算机科学教学而开发的。如今,树莓派被广泛用于大学、中小型组织和研究所来教授编码。
|
||||
|
||||
如果你有一台树莓派,你可能需要了解一个名为 PiShrink 的 bash 脚本,该脚本可使树莓派镜像更小。PiShrink 将自动缩小镜像,然后在启动时将其调整为 SD 卡的最大大小。这能更快地将镜像复制到 SD 卡中,同时缩小的镜像将更好地压缩。这对于将大容量镜像放入 SD 卡非常有用。在这个简短的指南中,我们将学习如何在类 Unix 系统中将树莓派镜像缩小到更小。
|
||||
|
||||
### 安装 PiShrink
|
||||
|
||||
要在 Linux 机器上安装 PiShrink,请先使用以下命令下载最新版本:
|
||||
|
||||
```
|
||||
$ wget https://raw.githubusercontent.com/Drewsif/PiShrink/master/pishrink.sh
|
||||
```
|
||||
|
||||
接下来,将下载的 PiShrink 变成二进制可执行文件:
|
||||
|
||||
```
|
||||
$ chmod +x pishrink.sh
|
||||
```
|
||||
|
||||
最后,移动到目录:
|
||||
|
||||
```
|
||||
$ sudo mv pishrink.sh /usr/local/bin/
|
||||
```
|
||||
|
||||
### 使树莓派镜像更小
|
||||
|
||||
你可能已经知道,Raspbian 是所有树莓派型号的官方操作系统。树莓派基金会为 PC 和 Mac 开发了树莓派桌面版本。你可以创建一个 live CD,并在虚拟机中运行它,甚至也可以将其安装在桌面上。树莓派也有少量非官方操作系统镜像。为了测试,我从[官方下载页面][2]下载了官方的 Raspbian 系统。
|
||||
|
||||
解压下载的系统镜像:
|
||||
|
||||
```
|
||||
$ unzip 2019-04-08-raspbian-stretch-lite.zip
|
||||
```
|
||||
|
||||
上面的命令将提取当前目录中 `2019-04-08-raspbian-stretch-lite.zip` 文件的内容。
|
||||
|
||||
让我们看下提取文件的实际大小:
|
||||
|
||||
```
|
||||
$ du -h 2019-04-08-raspbian-stretch-lite.img
|
||||
1.7G 2019-04-08-raspbian-stretch-lite.img
|
||||
```
|
||||
|
||||
如你所见,提取的树莓派系统镜像大小为 1.7G。
|
||||
|
||||
现在,使用 PiShrink 缩小此文件的大小,如下所示:
|
||||
|
||||
```
|
||||
$ sudo pishrink.sh 2019-04-08-raspbian-stretch-lite.img
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Creating new /etc/rc.local
|
||||
rootfs: 39795/107072 files (0.1% non-contiguous), 239386/428032 blocks
|
||||
resize2fs 1.45.0 (6-Mar-2019)
|
||||
resize2fs 1.45.0 (6-Mar-2019)
|
||||
Resizing the filesystem on /dev/loop1 to 280763 (4k) blocks.
|
||||
Begin pass 3 (max = 14)
|
||||
Scanning inode table XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
Begin pass 4 (max = 3728)
|
||||
Updating inode references XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
The filesystem on /dev/loop1 is now 280763 (4k) blocks long.
|
||||
|
||||
Shrunk 2019-04-08-raspbian-stretch-lite.img from 1.7G to 1.2G
|
||||
```
|
||||
|
||||
正如你在上面的输出中看到的,树莓派镜像的大小已减少到 1.2G。
|
||||
|
||||
你还可以使用 `-s` 标志跳过该过程的自动扩展部分。
|
||||
|
||||
```
|
||||
$ sudo pishrink.sh -s 2019-04-08-raspbian-stretch-lite.img newpi.img
|
||||
```
|
||||
|
||||
这将创建一个源镜像文件(即 `2019-04-08-raspbian-stretch-lite.img`)的副本到一个新镜像文件(`newpi.img`)并进行处理。有关更多详细信息,请查看最后给出的官方 GitHub 页面。
|
||||
|
||||
就是这些了。希望本文有用。还有更多好东西,敬请期待!
|
||||
|
||||
|
||||
资源:
|
||||
|
||||
* [PiShrink 的 GitHub 仓库][4]
|
||||
* [树莓派网站][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/pishrink-make-raspberry-pi-images-smaller/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/05/pishrink-720x340.png
|
||||
[2]: https://www.raspberrypi.org/downloads/
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/05/pishrink-1.png
|
||||
[4]: https://github.com/Drewsif/PiShrink
|
||||
[5]: https://www.raspberrypi.org/
|
||||
396
published/20190520 xsos - A Tool To Read SOSReport In Linux.md
Normal file
396
published/20190520 xsos - A Tool To Read SOSReport In Linux.md
Normal file
@ -0,0 +1,396 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10889-1.html)
|
||||
[#]: subject: (xsos – A Tool To Read SOSReport In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/xsos-a-tool-to-read-sosreport-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
xsos:一个在 Linux 上阅读 SOSReport 的工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们都已经知道 [SOSReport][1]。它用来收集可用于诊断的系统信息。Redhat 的支持服务建议我们在提交案例时提供 SOSReport 来分析当前的系统状态。
|
||||
|
||||
它会收集全部类型的报告,以帮助用户找出问题的根本原因。我们可以轻松地提取和阅读 SOSReport,但它很难阅读。因为它的每个部分都是一个单独的文件。
|
||||
|
||||
那么,在 Linux 中使用语法高亮显示阅读所有这些内容的最佳方法是什么。是的,这可以通过 `xsos` 工具做到。
|
||||
|
||||
### sosreport
|
||||
|
||||
`sosreport` 命令是一个从运行中的系统(尤其是 RHEL 和 OEL 系统)收集大量配置细节、系统信息和诊断信息的工具。它可以帮助技术支持工程师在很多方面分析系统。
|
||||
|
||||
此报告包含有关系统的大量信息,例如引导信息、文件系统、内存、主机名、已安装的 RPM、系统 IP、网络详细信息、操作系统版本、已安装的内核、已加载的内核模块、打开的文件列表、PCI 设备列表、挂载点及其细节、运行中的进程信息、进程树输出、系统路由、位于 `/etc` 文件夹中的所有配置文件,以及位于 `/var` 文件夹中的所有日志文件。
|
||||
|
||||
这将需要一段时间来生成报告,这取决于你的系统安装和配置。
|
||||
|
||||
完成后,`sosreport` 将在 `/tmp` 目录下生成一个压缩的归档文件。
|
||||
|
||||
### xsos
|
||||
|
||||
[xsos][3] 是一个帮助用户轻松读取 Linux 系统上的 `sosreport` 的工具。另一方面,我们可以说它是 `sosreport` 考官。
|
||||
|
||||
它可以立即从 `sosreport` 或正在运行的系统中汇总系统信息。
|
||||
|
||||
`xsos` 将尝试简化、解析、计算并格式化来自数十个文件(和命令)的数据,以便为你提供有关系统的详细概述。
|
||||
|
||||
你可以通过运行以下命令立即汇总系统信息。
|
||||
|
||||
```
|
||||
# curl -Lo ./xsos bit.ly/xsos-direct; chmod +x ./xsos; ./xsos -ya
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
### 如何在 Linux 上安装 xsos
|
||||
|
||||
我们可以使用以下两种方法轻松安装 `xsos`。
|
||||
|
||||
如果你正在寻找最新的前沿版本。使用以下步骤:
|
||||
|
||||
```
|
||||
# curl -Lo /usr/local/bin/xsos bit.ly/xsos-direct
|
||||
# chmod +x /usr/local/bin/xsos
|
||||
```
|
||||
|
||||
下面是安装 `xsos` 的推荐方法。它将从 rpm 文件安装 `xsos`。
|
||||
|
||||
```
|
||||
# yum install http://people.redhat.com/rsawhill/rpms/latest-rsawaroha-release.rpm
|
||||
# yum install xsos
|
||||
```
|
||||
|
||||
### 如何在 Linux 上使用 xsos
|
||||
|
||||
一旦通过上述方法之一安装了 xsos。只需运行 `xsos` 命令,不带任何选项,它们会显示有关系统的基本信息。
|
||||
|
||||
```
|
||||
# xsos
|
||||
|
||||
OS
|
||||
Hostname: CentOS7.2daygeek.com
|
||||
Distro: [redhat-release] CentOS Linux release 7.6.1810 (Core)
|
||||
[centos-release] CentOS Linux release 7.6.1810 (Core)
|
||||
[os-release] CentOS Linux 7 (Core) 7 (Core)
|
||||
RHN: (missing)
|
||||
RHSM: (missing)
|
||||
YUM: 2 enabled plugins: fastestmirror, langpacks
|
||||
Runlevel: N 5 (default graphical)
|
||||
SELinux: enforcing (default enforcing)
|
||||
Arch: mach=x86_64 cpu=x86_64 platform=x86_64
|
||||
Kernel:
|
||||
Booted kernel: 3.10.0-957.el7.x86_64
|
||||
GRUB default: 3.10.0-957.el7.x86_64
|
||||
Build version:
|
||||
Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red
|
||||
Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018
|
||||
Booted kernel cmdline:
|
||||
root=/dev/mapper/centos-root ro crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
|
||||
LANG=en_US.UTF-8
|
||||
GRUB default kernel cmdline:
|
||||
root=/dev/mapper/centos-root ro crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
|
||||
LANG=en_US.UTF-8
|
||||
Taint-check: 0 (kernel untainted)
|
||||
- - - - - - - - - - - - - - - - - - -
|
||||
Sys time: Sun May 12 10:05:21 CDT 2019
|
||||
Boot time: Sun May 12 09:50:20 CDT 2019 (epoch: 1557672620)
|
||||
Time Zone: America/Chicago
|
||||
Uptime: 15 min, 1 user
|
||||
LoadAvg: [1 CPU] 0.00 (0%), 0.04 (4%), 0.09 (9%)
|
||||
/proc/stat:
|
||||
procs_running: 2 procs_blocked: 0 processes [Since boot]: 6423
|
||||
cpu [Utilization since boot]:
|
||||
us 1%, ni 0%, sys 1%, idle 99%, iowait 0%, irq 0%, sftirq 0%, steal 0%
|
||||
```
|
||||
|
||||
### 如何使用 xsos 命令在 Linux 中查看生成的 SOSReport 输出?
|
||||
|
||||
我们需要份 SOSReport 以使用 `xsos` 命令进一步阅读。
|
||||
|
||||
是的,我已经生成了一个 SOSReport,文件如下。
|
||||
|
||||
```
|
||||
# ls -lls -lh /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa.tar.xz
|
||||
9.8M -rw-------. 1 root root 9.8M May 12 10:13 /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa.tar.xz
|
||||
```
|
||||
|
||||
运行如下命令解开它。
|
||||
|
||||
```
|
||||
# tar xf sosreport-CentOS7-01-1005-2019-05-12-pomeqsa.tar.xz
|
||||
```
|
||||
|
||||
要查看全部信息,带上 `-a` 或 `--all` 开关运行 `xsos`:
|
||||
|
||||
```
|
||||
# xsos --all /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
```
|
||||
|
||||
要查看 BIOS 信息,带上 `-b` 或 `--bios` 开关运行 `xsos`。
|
||||
|
||||
```
|
||||
# xsos --bios /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
DMIDECODE
|
||||
BIOS:
|
||||
Vend: innotek GmbH
|
||||
Vers: VirtualBox
|
||||
Date: 12/01/2006
|
||||
BIOS Rev:
|
||||
FW Rev:
|
||||
System:
|
||||
Mfr: innotek GmbH
|
||||
Prod: VirtualBox
|
||||
Vers: 1.2
|
||||
Ser: 0
|
||||
UUID: 002f47b8-2af2-48f5-be1d-67b67e03514c
|
||||
CPU:
|
||||
0 of 0 CPU sockets populated, 0 cores/0 threads per CPU
|
||||
0 total cores, 0 total threads
|
||||
Mfr:
|
||||
Fam:
|
||||
Freq:
|
||||
Vers:
|
||||
Memory:
|
||||
Total: 0 MiB (0 GiB)
|
||||
DIMMs: 0 of 0 populated
|
||||
MaxCapacity: 0 MiB (0 GiB / 0.00 TiB)
|
||||
```
|
||||
|
||||
要查看系统基本信息,如主机名、发行版、SELinux、内核信息、正常运行时间等,请使用 `-o` 或 `--os` 开关运行 `xsos`。
|
||||
|
||||
```
|
||||
# xsos --os /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
OS
|
||||
Hostname: CentOS7.2daygeek.com
|
||||
Distro: [redhat-release] CentOS Linux release 7.6.1810 (Core)
|
||||
[centos-release] CentOS Linux release 7.6.1810 (Core)
|
||||
[os-release] CentOS Linux 7 (Core) 7 (Core)
|
||||
RHN: (missing)
|
||||
RHSM: (missing)
|
||||
YUM: 2 enabled plugins: fastestmirror, langpacks
|
||||
SELinux: enforcing (default enforcing)
|
||||
Arch: mach=x86_64 cpu=x86_64 platform=x86_64
|
||||
Kernel:
|
||||
Booted kernel: 3.10.0-957.el7.x86_64
|
||||
GRUB default: 3.10.0-957.el7.x86_64
|
||||
Build version:
|
||||
Linux version 3.10.0-957.el7.x86_64 ([email protected]) (gcc version 4.8.5 20150623 (Red
|
||||
Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 8 23:39:32 UTC 2018
|
||||
Booted kernel cmdline:
|
||||
root=/dev/mapper/centos-root ro crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
|
||||
LANG=en_US.UTF-8
|
||||
GRUB default kernel cmdline:
|
||||
root=/dev/mapper/centos-root ro crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
|
||||
LANG=en_US.UTF-8
|
||||
Taint-check: 536870912 (see https://access.redhat.com/solutions/40594)
|
||||
29 TECH_PREVIEW: Technology Preview code is loaded
|
||||
- - - - - - - - - - - - - - - - - - -
|
||||
Sys time: Sun May 12 10:12:22 CDT 2019
|
||||
Boot time: Sun May 12 09:50:20 CDT 2019 (epoch: 1557672620)
|
||||
Time Zone: America/Chicago
|
||||
Uptime: 22 min, 1 user
|
||||
LoadAvg: [1 CPU] 1.19 (119%), 0.27 (27%), 0.14 (14%)
|
||||
/proc/stat:
|
||||
procs_running: 8 procs_blocked: 2 processes [Since boot]: 9005
|
||||
cpu [Utilization since boot]:
|
||||
us 1%, ni 0%, sys 1%, idle 99%, iowait 0%, irq 0%, sftirq 0%, steal 0%
|
||||
```
|
||||
|
||||
要查看 kdump 配置,请使用 `-k` 或 `--kdump` 开关运行 `xsos`。
|
||||
|
||||
```
|
||||
# xsos --kdump /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
KDUMP CONFIG
|
||||
kexec-tools rpm version:
|
||||
kexec-tools-2.0.15-21.el7.x86_64
|
||||
Service enablement:
|
||||
UNIT STATE
|
||||
kdump.service enabled
|
||||
kdump initrd/initramfs:
|
||||
13585734 Feb 19 05:51 initramfs-3.10.0-957.el7.x86_64kdump.img
|
||||
Memory reservation config:
|
||||
/proc/cmdline { crashkernel=auto }
|
||||
GRUB default { crashkernel=auto }
|
||||
Actual memory reservation per /proc/iomem:
|
||||
2a000000-340fffff : Crash kernel
|
||||
kdump.conf:
|
||||
path /var/crash
|
||||
core_collector makedumpfile -l --message-level 1 -d 31
|
||||
kdump.conf "path" available space:
|
||||
System MemTotal (uncompressed core size) { 1.80 GiB }
|
||||
Available free space on target path's fs { 22.68 GiB } (fs=/)
|
||||
Panic sysctls:
|
||||
kernel.sysrq [bitmask] = "16" (see proc man page)
|
||||
kernel.panic [secs] = 0 (no autoreboot on panic)
|
||||
kernel.hung_task_panic = 0
|
||||
kernel.panic_on_oops = 1
|
||||
kernel.panic_on_io_nmi = 0
|
||||
kernel.panic_on_unrecovered_nmi = 0
|
||||
kernel.panic_on_stackoverflow = 0
|
||||
kernel.softlockup_panic = 0
|
||||
kernel.unknown_nmi_panic = 0
|
||||
kernel.nmi_watchdog = 1
|
||||
vm.panic_on_oom [0-2] = 0 (no panic)
|
||||
```
|
||||
|
||||
要查看有关 CPU 的信息,请使用 `-c` 或 `--cpu` 开关运行 `xsos`。
|
||||
|
||||
```
|
||||
# xsos --cpu /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
CPU
|
||||
1 logical processors
|
||||
1 Intel Core i7-6700HQ CPU @ 2.60GHz (flags: aes,constant_tsc,ht,lm,nx,pae,rdrand)
|
||||
```
|
||||
|
||||
要查看内存利用情况,请使用 `-m` 或 `--mem` 开关运行 `xsos`。
|
||||
|
||||
```
|
||||
# xsos --mem /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
MEMORY
|
||||
Stats graphed as percent of MemTotal:
|
||||
MemUsed ▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊..................... 58.8%
|
||||
Buffers .................................................. 0.6%
|
||||
Cached ▊▊▊▊▊▊▊▊▊▊▊▊▊▊▊................................... 29.9%
|
||||
HugePages .................................................. 0.0%
|
||||
Dirty .................................................. 0.7%
|
||||
RAM:
|
||||
1.8 GiB total ram
|
||||
1.1 GiB (59%) used
|
||||
0.5 GiB (28%) used excluding Buffers/Cached
|
||||
0.01 GiB (1%) dirty
|
||||
HugePages:
|
||||
No ram pre-allocated to HugePages
|
||||
LowMem/Slab/PageTables/Shmem:
|
||||
0.09 GiB (5%) of total ram used for Slab
|
||||
0.02 GiB (1%) of total ram used for PageTables
|
||||
0.01 GiB (1%) of total ram used for Shmem
|
||||
Swap:
|
||||
0 GiB (0%) used of 2 GiB total
|
||||
```
|
||||
|
||||
要查看添加的磁盘信息,请使用 `-d` 和 `-disks` 开关运行 `xsos`。
|
||||
|
||||
```
|
||||
# xsos --disks /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
STORAGE
|
||||
Whole Disks from /proc/partitions:
|
||||
2 disks, totaling 40 GiB (0.04 TiB)
|
||||
- - - - - - - - - - - - - - - - - - - - -
|
||||
Disk Size in GiB
|
||||
---- -----------
|
||||
sda 30
|
||||
sdb 10
|
||||
```
|
||||
|
||||
要查看网络接口配置,请使用 `-e` 或 `--ethtool` 开关运行 `xsos`。
|
||||
|
||||
```
|
||||
# xsos --ethtool /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
ETHTOOL
|
||||
Interface Status:
|
||||
enp0s10 0000:00:0a.0 link=up 1000Mb/s full (autoneg=Y) rx ring 256/4096 drv e1000 v7.3.21-k8-NAPI / fw UNKNOWN
|
||||
enp0s9 0000:00:09.0 link=up 1000Mb/s full (autoneg=Y) rx ring 256/4096 drv e1000 v7.3.21-k8-NAPI / fw UNKNOWN
|
||||
virbr0 N/A link=DOWN rx ring UNKNOWN drv bridge v2.3 / fw N/A
|
||||
virbr0-nic tap link=DOWN rx ring UNKNOWN drv tun v1.6 / fw UNKNOWN
|
||||
```
|
||||
|
||||
要查看有关 IP 地址的信息,请使用 `-i` 或 `--ip` 开关运行 `xsos`。
|
||||
|
||||
```
|
||||
# xsos --ip /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
IP4
|
||||
Interface Master IF MAC Address MTU State IPv4 Address
|
||||
========= ========= ================= ====== ===== ==================
|
||||
lo - - 65536 up 127.0.0.1/8
|
||||
enp0s9 - 08:00:27:0b:bc:e9 1500 up 192.168.1.8/24
|
||||
enp0s10 - 08:00:27:b2:08:91 1500 up 192.168.1.9/24
|
||||
virbr0 - 52:54:00:ae:01:94 1500 up 192.168.122.1/24
|
||||
virbr0-nic virbr0 52:54:00:ae:01:94 1500 DOWN -
|
||||
|
||||
IP6
|
||||
Interface Master IF MAC Address MTU State IPv6 Address Scope
|
||||
========= ========= ================= ====== ===== =========================================== =====
|
||||
lo - - 65536 up ::1/128 host
|
||||
enp0s9 - 08:00:27:0b:bc:e9 1500 up fe80::945b:8333:f4bc:9723/64 link
|
||||
enp0s10 - 08:00:27:b2:08:91 1500 up fe80::7ed4:1fab:23c3:3790/64 link
|
||||
virbr0 - 52:54:00:ae:01:94 1500 up - -
|
||||
virbr0-nic virbr0 52:54:00:ae:01:94 1500 DOWN - -
|
||||
```
|
||||
|
||||
要通过 `ps` 查看正在运行的进程,请使用 `-p` 或 `--ps` 开关运行 `xsos`。
|
||||
|
||||
```
|
||||
# xsos --ps /var/tmp/sosreport-CentOS7-01-1005-2019-05-12-pomeqsa
|
||||
PS CHECK
|
||||
Total number of threads/processes:
|
||||
501 / 171
|
||||
Top users of CPU & MEM:
|
||||
USER %CPU %MEM RSS
|
||||
root 20.6% 14.1% 0.30 GiB
|
||||
gdm 0.3% 16.8% 0.33 GiB
|
||||
postfix 0.0% 0.6% 0.01 GiB
|
||||
polkitd 0.0% 0.6% 0.01 GiB
|
||||
daygeek 0.0% 0.2% 0.00 GiB
|
||||
colord 0.0% 0.4% 0.01 GiB
|
||||
Uninteruptible sleep threads/processes (0/0):
|
||||
[None]
|
||||
Defunct zombie threads/processes (0/0):
|
||||
[None]
|
||||
Top CPU-using processes:
|
||||
USER PID %CPU %MEM VSZ-MiB RSS-MiB TTY STAT START TIME COMMAND
|
||||
root 6542 15.6 4.2 875 78 pts/0 Sl+ 10:11 0:07 /usr/bin/python /sbin/sosreport
|
||||
root 7582 3.0 0.1 10 2 pts/0 S 10:12 0:00 /bin/bash /usr/sbin/dracut --print-cmdline
|
||||
root 7969 0.7 0.1 95 4 ? Ss 10:12 0:00 /usr/sbin/certmonger -S -p
|
||||
root 7889 0.4 0.2 24 4 ? Ss 10:12 0:00 /usr/lib/systemd/systemd-hostnamed
|
||||
gdm 3866 0.3 7.1 2856 131 ? Sl 09:50 0:04 /usr/bin/gnome-shell
|
||||
root 8553 0.2 0.1 47 3 ? S 10:12 0:00 /usr/lib/systemd/systemd-udevd
|
||||
root 6971 0.2 0.4 342 9 ? Sl 10:12 0:00 /usr/sbin/abrt-dbus -t133
|
||||
root 3200 0.2 0.9 982 18 ? Ssl 09:50 0:02 /usr/sbin/libvirtd
|
||||
root 2855 0.1 0.1 88 3 ? Ss 09:50 0:01 /sbin/rngd -f
|
||||
rtkit 2826 0.0 0.0 194 2 ? SNsl 09:50 0:00 /usr/libexec/rtkit-daemon
|
||||
Top MEM-using processes:
|
||||
USER PID %CPU %MEM VSZ-MiB RSS-MiB TTY STAT START TIME COMMAND
|
||||
gdm 3866 0.3 7.1 2856 131 ? Sl 09:50 0:04 /usr/bin/gnome-shell
|
||||
root 6542 15.6 4.2 875 78 pts/0 Sl+ 10:11 0:07 /usr/bin/python /sbin/sosreport
|
||||
root 3264 0.0 1.2 271 23 tty1 Ssl+ 09:50 0:00 /usr/bin/X :0 -background
|
||||
root 3200 0.2 0.9 982 18 ? Ssl 09:50 0:02 /usr/sbin/libvirtd
|
||||
root 3189 0.0 0.9 560 17 ? Ssl 09:50 0:00 /usr/bin/python2 -Es /usr/sbin/tuned
|
||||
gdm 4072 0.0 0.9 988 17 ? Sl 09:50 0:00 /usr/libexec/gsd-media-keys
|
||||
gdm 4076 0.0 0.8 625 16 ? Sl 09:50 0:00 /usr/libexec/gsd-power
|
||||
gdm 4056 0.0 0.8 697 16 ? Sl 09:50 0:00 /usr/libexec/gsd-color
|
||||
root 2853 0.0 0.7 622 14 ? Ssl 09:50 0:00 /usr/sbin/NetworkManager --no-daemon
|
||||
gdm 4110 0.0 0.7 544 14 ? Sl 09:50 0:00 /usr/libexec/gsd-wacom
|
||||
Top thread-spawning processes:
|
||||
# USER PID %CPU %MEM VSZ-MiB RSS-MiB TTY STAT START TIME COMMAND
|
||||
17 root 3200 0.2 0.9 982 18 ? - 09:50 0:02 /usr/sbin/libvirtd
|
||||
12 root 6542 16.1 4.5 876 83 pts/0 - 10:11 0:07 /usr/bin/python /sbin/sosreport
|
||||
10 gdm 3866 0.3 7.1 2856 131 ? - 09:50 0:04 /usr/bin/gnome-shell
|
||||
7 polkitd 2864 0.0 0.6 602 13 ? - 09:50 0:01 /usr/lib/polkit-1/polkitd --no-debug
|
||||
6 root 2865 0.0 0.0 203 1 ? - 09:50 0:00 /usr/sbin/gssproxy -D
|
||||
5 root 3189 0.0 0.9 560 17 ? - 09:50 0:00 /usr/bin/python2 -Es /usr/sbin/tuned
|
||||
5 root 2823 0.0 0.3 443 6 ? - 09:50 0:00 /usr/libexec/udisks2/udisksd
|
||||
5 gdm 4102 0.0 0.2 461 5 ? - 09:50 0:00 /usr/libexec/gsd-smartcard
|
||||
4 root 3215 0.0 0.2 470 4 ? - 09:50 0:00 /usr/sbin/gdm
|
||||
4 gdm 4106 0.0 0.2 444 5 ? - 09:50 0:00 /usr/libexec/gsd-sound
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/xsos-a-tool-to-read-sosreport-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-create-collect-sosreport-in-linux/
|
||||
[2]: https://www.2daygeek.com/oswbb-how-to-install-and-configure-oswatcher-black-box-for-system-diagnostics/
|
||||
[3]: https://github.com/ryran/xsos
|
||||
[4]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]: https://www.2daygeek.com/wp-content/uploads/2019/05/xsos-a-tool-to-read-sosreport-in-linux-1.jpg
|
||||
@ -1,93 +1,94 @@
|
||||
10 principles of resilience for women in tech
|
||||
======
|
||||
|
||||

|
||||
|
||||
Being a woman in tech is pretty damn cool. For every headline about [what Silicon Valley thinks of women][1], there are tens of thousands of women building, innovating, and managing technology teams around the world. Women are helping build the future despite the hurdles they face, and the community of women and allies growing to support each other is stronger than ever. From [BetterAllies][2] to organizations like [Girls Who Code][3] and communities like the one I met recently at [Red Hat Summit][4], there are more efforts than ever before to create an inclusive community for women in tech.
|
||||
|
||||
But the tech industry has not always been this welcoming, nor is the experience for women always aligned with the aspiration. And so we're feeling the pain. Women in technology roles have dropped from its peak in 1991 at 36% to 25% today, [according to a report by NCWIT][5]. [Harvard Business Review estimates][6] that more than half of the women in tech will eventually leave due to hostile work conditions. Meanwhile, Ernst & Young recently shared [a study][7] and found that merely 11% of high school girls are planning to pursue STEM careers.
|
||||
|
||||
We have much work to do, lest we build a future that is less inclusive than the one we live in today. We need everyone at the table, in the lab, at the conference and in the boardroom.
|
||||
|
||||
I've been interviewing both women and men for more than a year now about their experiences in tech, all as part of [The Chasing Grace Project][8], a documentary series about women in tech. The purpose of the series is to help recruit and retain female talent for the tech industry and to give women a platform to be seen, heard, and acknowledged for their experiences. We believe that compelling story can begin to transform culture.
|
||||
|
||||
### What Chasing Grace taught me
|
||||
|
||||
What I've learned is that no matter the dismal numbers, women want to keep building and they collectively possess a resilience unmatched by anything I've ever seen. And this is inspiring me. I've found a power, a strength, and a beauty in every story I've heard that is the result of resilience. I recently shared with the attendees at the Red Hat Summit Women’s Leadership Luncheon the top 10 principles of resilience I've heard from throughout my interviews so far. I hope that by sharing them here the ideas and concepts can support and inspire you, too.
|
||||
|
||||
#### 1\. Practice optimism
|
||||
|
||||
When taken too far, optimism can give you blind spots. But a healthy dose of optimism allows you to see the best in people and situations and that positive energy comes back to you 100-fold. I haven’t met a woman yet as part of this project who isn’t an optimist.
|
||||
|
||||
#### 2\. Build mental toughness
|
||||
|
||||
I haven’t met a woman yet as part of this project who isn’t an optimist.
|
||||
|
||||
When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said _mental toughness_. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
|
||||
|
||||
#### 3\. Recognize your power
|
||||
|
||||
When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
|
||||
|
||||
Most of the women I’ve interviewed don’t know their own power and so they give it away unknowingly. Too many women have told me that they willingly took on the housekeeping roles on their teams—picking up coffee, donuts, office supplies, and making the team dinner reservations. Usually the only woman on their teams, this put them in a position to be seen as less valuable than their male peers who didn’t readily volunteer for such tasks. All of us, men and women, have innate powers. Identify and know what your powers are and understand how to use them for good. You have so much more power than you realize. Know it, recognize it, use it strategically, and don’t give it away. It’s yours.
|
||||
|
||||
#### 4\. Know your strength
|
||||
|
||||
Not sure whether you can confront your boss about why you haven’t been promoted? You can. You don’t know your strength until you exercise it. Then, you’re unstoppable. Test your strength by pushing your fear aside and see what happens.
|
||||
|
||||
#### 5\. Celebrate vulnerability
|
||||
|
||||
Every single successful women I've interviewed isn't afraid to be vulnerable. She finds her strength in acknowledging where she is vulnerable and she looks to connect with others in that same place. Exposing, sharing, and celebrating each other’s vulnerabilities allows us to tap into something far greater than simply asserting strength; it actually builds strength—mental and emotional muscle. One women with whom we’ve talked shared how starting her own tech company made her feel like she was letting her husband down. She shared with us the details of that conversation with her husband. Honest conversations that share our doubts and our aspirations is what makes women uniquely suited to lead in many cases. Allow yourself to be seen and heard. It’s where we grow and learn.
|
||||
|
||||
#### 6\. Build community
|
||||
|
||||
If it doesn't exist, build it.
|
||||
|
||||
Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
|
||||
|
||||
#### 7\. Celebrate victories
|
||||
|
||||
Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
|
||||
|
||||
One of my favorite Facebook groups is [TechLadies][9] because of its recurring hashtag #YEPIDIDTHAT. It allows women to share their victories in a supportive community. No matter how big or small, don't let a victory go unrecognized. When you recognize your wins, you own them. They become a part of you and you build on top of each one.
|
||||
|
||||
#### 8\. Be curious
|
||||
|
||||
Being curious in the tech community often means asking questions: How does that work? What language is that written in? How can I make this do that? When I've managed teams over the years, my best employees have always been those who ask a lot of questions, those who are genuinely curious about things. But in this context, I mean be curious when your gut tells you something doesn't seem right. _The energy in the meeting was off. Did he/she just say what I think he said?_ Ask questions. Investigate. Communicate openly and clearly. It's the only way change happens.
|
||||
|
||||
#### 9\. Harness courage
|
||||
|
||||
One women told me a story about a meeting in which the women in the room kept being dismissed and talked over. During the debrief roundtable portion of the meeting, she called it out and asked if others noticed it, too. Being a 20-year tech veteran, she'd witnessed and experienced this many times but she had never summoned the courage to speak up about it. She told me she was incredibly nervous and was texting other women in the room to see if they agreed it should be addressed. She didn't want to be a "troublemaker." But this kind of courage results in an increased understanding by everyone in that room and can translate into other meetings, companies, and across the industry.
|
||||
|
||||
#### 10\. Share your story
|
||||
|
||||
When people connect to compelling story, they begin to change behaviors.
|
||||
|
||||
Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
|
||||
|
||||
Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
|
||||
|
||||
If you would like to support [The Chasing Grace Project][8], email Jennifer Cloer to learn more about how to get involved: [jennifer@wickedflicksproductions.com][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/being-woman-tech-10-principles-resilience
|
||||
|
||||
作者:[Jennifer Cloer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jennifer-cloer
|
||||
[1]:http://www.newsweek.com/2015/02/06/what-silicon-valley-thinks-women-302821.html%E2%80%9D
|
||||
[2]:https://opensource.com/article/17/6/male-allies-tech-industry-needs-you%E2%80%9D
|
||||
[3]:https://twitter.com/GirlsWhoCode%E2%80%9D
|
||||
[4]:http://opensource.com/tags/red-hat-summit%E2%80%9D
|
||||
[5]:https://www.ncwit.org/sites/default/files/resources/womenintech_facts_fullreport_05132016.pdf%E2%80%9D
|
||||
[6]:Dhttp://www.latimes.com/business/la-fi-women-tech-20150222-story.html%E2%80%9D
|
||||
[7]:http://www.ey.com/us/en/newsroom/news-releases/ey-news-new-research-reveals-the-differences-between-boys-and-girls-career-and-college-plans-and-an-ongoing-need-to-engage-girls-in-stem%E2%80%9D
|
||||
[8]:https://www.chasinggracefilm.com/
|
||||
[9]:https://www.facebook.com/therealTechLadies/%E2%80%9D
|
||||
[10]:mailto:jennifer@wickedflicksproductions.com
|
||||
XYenChi is translating
|
||||
10 principles of resilience for women in tech
|
||||
======
|
||||
|
||||

|
||||
|
||||
Being a woman in tech is pretty damn cool. For every headline about [what Silicon Valley thinks of women][1], there are tens of thousands of women building, innovating, and managing technology teams around the world. Women are helping build the future despite the hurdles they face, and the community of women and allies growing to support each other is stronger than ever. From [BetterAllies][2] to organizations like [Girls Who Code][3] and communities like the one I met recently at [Red Hat Summit][4], there are more efforts than ever before to create an inclusive community for women in tech.
|
||||
|
||||
But the tech industry has not always been this welcoming, nor is the experience for women always aligned with the aspiration. And so we're feeling the pain. Women in technology roles have dropped from its peak in 1991 at 36% to 25% today, [according to a report by NCWIT][5]. [Harvard Business Review estimates][6] that more than half of the women in tech will eventually leave due to hostile work conditions. Meanwhile, Ernst & Young recently shared [a study][7] and found that merely 11% of high school girls are planning to pursue STEM careers.
|
||||
|
||||
We have much work to do, lest we build a future that is less inclusive than the one we live in today. We need everyone at the table, in the lab, at the conference and in the boardroom.
|
||||
|
||||
I've been interviewing both women and men for more than a year now about their experiences in tech, all as part of [The Chasing Grace Project][8], a documentary series about women in tech. The purpose of the series is to help recruit and retain female talent for the tech industry and to give women a platform to be seen, heard, and acknowledged for their experiences. We believe that compelling story can begin to transform culture.
|
||||
|
||||
### What Chasing Grace taught me
|
||||
|
||||
What I've learned is that no matter the dismal numbers, women want to keep building and they collectively possess a resilience unmatched by anything I've ever seen. And this is inspiring me. I've found a power, a strength, and a beauty in every story I've heard that is the result of resilience. I recently shared with the attendees at the Red Hat Summit Women’s Leadership Luncheon the top 10 principles of resilience I've heard from throughout my interviews so far. I hope that by sharing them here the ideas and concepts can support and inspire you, too.
|
||||
|
||||
#### 1\. Practice optimism
|
||||
|
||||
When taken too far, optimism can give you blind spots. But a healthy dose of optimism allows you to see the best in people and situations and that positive energy comes back to you 100-fold. I haven’t met a woman yet as part of this project who isn’t an optimist.
|
||||
|
||||
#### 2\. Build mental toughness
|
||||
|
||||
I haven’t met a woman yet as part of this project who isn’t an optimist.
|
||||
|
||||
When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said _mental toughness_. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
|
||||
|
||||
#### 3\. Recognize your power
|
||||
|
||||
When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
|
||||
|
||||
Most of the women I’ve interviewed don’t know their own power and so they give it away unknowingly. Too many women have told me that they willingly took on the housekeeping roles on their teams—picking up coffee, donuts, office supplies, and making the team dinner reservations. Usually the only woman on their teams, this put them in a position to be seen as less valuable than their male peers who didn’t readily volunteer for such tasks. All of us, men and women, have innate powers. Identify and know what your powers are and understand how to use them for good. You have so much more power than you realize. Know it, recognize it, use it strategically, and don’t give it away. It’s yours.
|
||||
|
||||
#### 4\. Know your strength
|
||||
|
||||
Not sure whether you can confront your boss about why you haven’t been promoted? You can. You don’t know your strength until you exercise it. Then, you’re unstoppable. Test your strength by pushing your fear aside and see what happens.
|
||||
|
||||
#### 5\. Celebrate vulnerability
|
||||
|
||||
Every single successful women I've interviewed isn't afraid to be vulnerable. She finds her strength in acknowledging where she is vulnerable and she looks to connect with others in that same place. Exposing, sharing, and celebrating each other’s vulnerabilities allows us to tap into something far greater than simply asserting strength; it actually builds strength—mental and emotional muscle. One women with whom we’ve talked shared how starting her own tech company made her feel like she was letting her husband down. She shared with us the details of that conversation with her husband. Honest conversations that share our doubts and our aspirations is what makes women uniquely suited to lead in many cases. Allow yourself to be seen and heard. It’s where we grow and learn.
|
||||
|
||||
#### 6\. Build community
|
||||
|
||||
If it doesn't exist, build it.
|
||||
|
||||
Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
|
||||
|
||||
#### 7\. Celebrate victories
|
||||
|
||||
Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
|
||||
|
||||
One of my favorite Facebook groups is [TechLadies][9] because of its recurring hashtag #YEPIDIDTHAT. It allows women to share their victories in a supportive community. No matter how big or small, don't let a victory go unrecognized. When you recognize your wins, you own them. They become a part of you and you build on top of each one.
|
||||
|
||||
#### 8\. Be curious
|
||||
|
||||
Being curious in the tech community often means asking questions: How does that work? What language is that written in? How can I make this do that? When I've managed teams over the years, my best employees have always been those who ask a lot of questions, those who are genuinely curious about things. But in this context, I mean be curious when your gut tells you something doesn't seem right. _The energy in the meeting was off. Did he/she just say what I think he said?_ Ask questions. Investigate. Communicate openly and clearly. It's the only way change happens.
|
||||
|
||||
#### 9\. Harness courage
|
||||
|
||||
One women told me a story about a meeting in which the women in the room kept being dismissed and talked over. During the debrief roundtable portion of the meeting, she called it out and asked if others noticed it, too. Being a 20-year tech veteran, she'd witnessed and experienced this many times but she had never summoned the courage to speak up about it. She told me she was incredibly nervous and was texting other women in the room to see if they agreed it should be addressed. She didn't want to be a "troublemaker." But this kind of courage results in an increased understanding by everyone in that room and can translate into other meetings, companies, and across the industry.
|
||||
|
||||
#### 10\. Share your story
|
||||
|
||||
When people connect to compelling story, they begin to change behaviors.
|
||||
|
||||
Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
|
||||
|
||||
Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
|
||||
|
||||
If you would like to support [The Chasing Grace Project][8], email Jennifer Cloer to learn more about how to get involved: [jennifer@wickedflicksproductions.com][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/being-woman-tech-10-principles-resilience
|
||||
|
||||
作者:[Jennifer Cloer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jennifer-cloer
|
||||
[1]:http://www.newsweek.com/2015/02/06/what-silicon-valley-thinks-women-302821.html%E2%80%9D
|
||||
[2]:https://opensource.com/article/17/6/male-allies-tech-industry-needs-you%E2%80%9D
|
||||
[3]:https://twitter.com/GirlsWhoCode%E2%80%9D
|
||||
[4]:http://opensource.com/tags/red-hat-summit%E2%80%9D
|
||||
[5]:https://www.ncwit.org/sites/default/files/resources/womenintech_facts_fullreport_05132016.pdf%E2%80%9D
|
||||
[6]:Dhttp://www.latimes.com/business/la-fi-women-tech-20150222-story.html%E2%80%9D
|
||||
[7]:http://www.ey.com/us/en/newsroom/news-releases/ey-news-new-research-reveals-the-differences-between-boys-and-girls-career-and-college-plans-and-an-ongoing-need-to-engage-girls-in-stem%E2%80%9D
|
||||
[8]:https://www.chasinggracefilm.com/
|
||||
[9]:https://www.facebook.com/therealTechLadies/%E2%80%9D
|
||||
[10]:mailto:jennifer@wickedflicksproductions.com
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (ninifly )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,92 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to shop for enterprise firewalls)
|
||||
[#]: via: (https://www.networkworld.com/article/3390686/how-to-shop-for-enterprise-firewalls.html#tk.rss_all)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
How to shop for enterprise firewalls
|
||||
======
|
||||
Performance, form factors, and automation capabilities are key considerations when choosing a next-generation firewall (NGFW).
|
||||
Firewalls have been around for years, but the technology keeps evolving as the threat landscape changes. Here are some tips about what to look for in a next-generation firewall ([NGFW][1]) that will satisfy business needs today and into the future.
|
||||
|
||||
### Don't trust firewall performance stats
|
||||
|
||||
Understanding how a NGFW performs requires more than looking at a vendor’s specification or running a bit of traffic through it. Most [firewalls][2] will perform well when traffic loads are light. It’s important to see how a firewall responds at scale, particularly when [encryption][3] is turned on. Roughly 80% of traffic is encrypted today, and the ability to maintain performance levels with high volumes of encrypted traffic is critical.
|
||||
|
||||
**Learn more about network security**
|
||||
|
||||
* [How to boost collaboration between network and security teams][4]
|
||||
* [What is microsegmentation? How getting granular improves network security][5]
|
||||
* [What to consider when deploying a next-generation firewall][1]
|
||||
* [How firewalls fit into enterprise security][2]
|
||||
|
||||
|
||||
|
||||
Also, be sure to turn on all major functions – including application and user identification, IPS, anti-malware, URL filtering and logging – during testing to see how a firewall will hold up in a production setting. Firewall vendors often tout a single performance number that's achieved with core features turned off. Data from [ZK Research][6] shows many IT pros learn this lesson the hard way: 58% of security professionals polled said they were forced to turn off features to maintain performance.
|
||||
|
||||
Before committing to a vendor, be sure to run tests with as many different types of traffic as possible and with various types of applications. Important metrics to look at include application throughput, connections per second, maximum sessions for both IPv4 and [IPv6][7], and SSL performance.
|
||||
|
||||
### NGFW needs to fit into broader security platform
|
||||
|
||||
Is it better to have a best-of-breed strategy or go with a single vendor for security? The issue has been debated for years, but the fact is, neither approach works flawlessly. It’s important to understand that best-of-breed everywhere doesn’t ensure best-in-class security. In fact, the opposite is typically true; having too many vendors can lead to complexity that can't be managed, which puts a business at risk. A better approach is a security platform, which can be thought of as an open architecture, that third-party products can be plugged into.
|
||||
|
||||
Any NGFW must be able to plug into a platform so it can "see" everything from IoT endpoints to cloud traffic to end-user devices. Also, once the NGFW has aggregated the data, it should be able to perform analytics to provide insights. This will enable the NGFW to take action and enforce policies across the network.
|
||||
|
||||
### Multiple form factors, consistent security features
|
||||
|
||||
Firewalls used to be relegated to corporate data centers. Today, networks have opened up, and customers need a consistent feature set at every point in the network. NGFW vendors should have the following form factors available to optimize price/performance:
|
||||
|
||||
* Data center
|
||||
* Internet edge
|
||||
* Midsize branch office
|
||||
* Small branch office
|
||||
* Ruggedized for IoT environments
|
||||
* Cloud delivered
|
||||
* Virtual machines that can run in private and public clouds
|
||||
|
||||
|
||||
|
||||
Also, NGFW vendors should have a roadmap for a containerized form factor. This certainly isn’t a trivial task. Most vendors won’t have a [container][8]-ready product yet, but they should be able to talk to how they plan to address the problem.
|
||||
|
||||
### Single-pane-of-glass firewall management
|
||||
|
||||
Having a broad product line doesn’t matter if products need to be managed individually. This makes it hard to keep policies and rules up to date and leads to inconsistencies in features and functions. A firewall vendor must have a single management tool that provides end-to-end visibility and enables the administrator to make a change and push it out across the network at once. Visibility must extend everywhere, including the cloud, [IoT][9] edge, operational technology (OT) environments, and branch offices. A single dashboard is also the right place to implement and maintain software-based segmentation instead of having to configure each device.
|
||||
|
||||
### Firewall automation capabilities
|
||||
|
||||
The goal of [automation][10] is to help remove many of the manual steps that create "human latency" in the security process. Almost all vendors tout some automation capabilities as a way of saving on headcount, but automation goes well beyond that.
|
||||
|
||||
To continue reading this article register now
|
||||
|
||||
[Get Free Access][11]
|
||||
|
||||
[Learn More][12] Existing Users [Sign In][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3390686/how-to-shop-for-enterprise-firewalls.html#tk.rss_all
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3236448/what-to-consider-when-deploying-a-next-generation-firewall.html
|
||||
[2]: https://www.networkworld.com/article/3230457/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html
|
||||
[3]: https://www.networkworld.com/article/3098354/enterprise-encryption-adoption-up-but-the-devils-in-the-details.html
|
||||
[4]: https://www.networkworld.com/article/3328218/how-to-boost-collaboration-between-network-and-security-teams.html
|
||||
[5]: https://www.networkworld.com/article/3247672/what-is-microsegmentation-how-getting-granular-improves-network-security.html
|
||||
[6]: https://zkresearch.com/
|
||||
[7]: https://www.networkworld.com/article/3254575/what-is-ipv6-and-why-aren-t-we-there-yet.html
|
||||
[8]: https://www.networkworld.com/article/3159735/containers-what-are-containers.html
|
||||
[9]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
|
||||
[10]: https://www.networkworld.com/article/3184389/automation-rolls-on-what-are-you-doing-about-it.html
|
||||
[11]: javascript://
|
||||
[12]: /learn-about-insider/
|
||||
@ -1,54 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Must-know Linux Commands)
|
||||
[#]: via: (https://www.networkworld.com/article/3391029/must-know-linux-commands.html#tk.rss_all)
|
||||
[#]: author: (Tim Greene https://www.networkworld.com/author/Tim-Greene/)
|
||||
|
||||
Must-know Linux Commands
|
||||
======
|
||||
A compilation of essential commands for searching, monitoring and securing Linux systems - plus the Linux Command Line Cheat Sheet.
|
||||
It takes some time working with Linux commands before you know which one you need for the task at hand, how to format it and what result to expect, but it’s possible to speed up the process.
|
||||
|
||||
With that in mind, we’ve gathered together some of the essential Linux commands as explained by Network World's [Unix as a Second Language][1] blogger Sandra Henry-Stocker to give aspiring power users what they need to get started with Linux systems.
|
||||
|
||||
The breakdown starts with the rich options available for finding files on Linux – **find** , **locate** , **mlocate** , **which** , **whereis** , to name a few. Some overlap, but some are more efficient than others or zoom in on a narrow set of results. There’s even a command – **apropos** – to find the right command to do what you want to do. This section will demystify searches.
|
||||
|
||||
Henry-Stocker's article on memory provides a wealth of options for discovering the availability of physical and virtual memory and ways to have that information updated at intervals to constantly measure whether there’s enough memory to go around. It shows how it’s possible to tailor your requests so you get a concise presentation of the results you seek.
|
||||
|
||||
Two remaining articles in this package show how to monitor activity on Linux servers and how to set up security parameters on these systems.
|
||||
|
||||
The first of these shows how to run the same command repetitively in order to have regular updates about any designated activity. It also tells about a command that focuses on user processes and shows changes as they occur, and a command that examines the time that users are connected.
|
||||
|
||||
The final article is a deep dive into commands that help keep Linux systems secure. It describes 22 of them that are essential for day-to-day admin work. They can restrict privileges to keep individuals from having more capabilities than their jobs call for and report on who’s logged in, where from and how long they’ve been there.
|
||||
|
||||
Some of these commands can track recent logins for individuals, which can be useful in running down who made changes. Others find files with varying characteristics, such as having no owner or by their contents. There are commands to control firewalls and to display routing tables.
|
||||
|
||||
As a bonus, our bundle of commands includes **The Linux Command-Line Cheat Sheet,** a concise summary of important commands that are useful every single day. It’s suitable for printing out on two sides of a single sheet, laminating and keeping beside your keyboard.
|
||||
|
||||
Enjoy!
|
||||
|
||||
To continue reading this article register now
|
||||
|
||||
[Get Free Access][2]
|
||||
|
||||
[Learn More][3] Existing Users [Sign In][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3391029/must-know-linux-commands.html#tk.rss_all
|
||||
|
||||
作者:[Tim Greene][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Tim-Greene/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/blog/unix-as-a-second-language/?nsdr=true
|
||||
[2]: javascript://
|
||||
[3]: /learn-about-insider/
|
||||
@ -1,81 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco issues critical security warning for Nexus data-center switches)
|
||||
[#]: via: (https://www.networkworld.com/article/3392858/cisco-issues-critical-security-warning-for-nexus-data-center-switches.html#tk.rss_all)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco issues critical security warning for Nexus data-center switches
|
||||
======
|
||||
Cisco released 40 security advisories around Nexus switches, Firepower firewalls and more
|
||||
![Thinkstock][1]
|
||||
|
||||
Cisco issued some 40 security advisories today but only one of them was deemed “[critical][2]” – a vulnerability in the Cisco Nexus 9000 Series Application Centric Infrastructure (ACI) Mode data-center switch that could let an attacker secretly access system resources.
|
||||
|
||||
The exposure, which was given a Common Vulnerability Scoring System importance of 9.8 out of 10, is described as a problem with secure shell (SSH) key-management for the Cisco Nexus 9000 that lets a remote attacker to connect to the affected system with the privileges of a root user, Cisco said.
|
||||
|
||||
**[ Read also:[How to plan a software-defined data-center network][3] ]**
|
||||
|
||||
“The vulnerability is due to the presence of a default SSH key pair that is present in all devices. An attacker could exploit this vulnerability by opening an SSH connection via IPv6 to a targeted device using the extracted key materials. This vulnerability is only exploitable over IPv6; IPv4 is not vulnerable," Cisco wrote.
|
||||
|
||||
This vulnerability affects Nexus 9000s if they are running a Cisco NX-OS software release prior to 14.1, and the company said there were no workarounds to address the problem.
|
||||
|
||||
However, Cisco has [released free software updates][4] that address the vulnerability.
|
||||
|
||||
The company also issued a “high” security warning advisory for the Nexus 9000 that involves an exploit that would let attackers execute arbitrary operating-system commands as root on an affected device. To succeed, an attacker would need valid administrator credentials for the device, Cisco said.
|
||||
|
||||
The vulnerability is due to overly broad system-file permissions, [Cisco wrote][5]. An attacker could exploit this vulnerability by authenticating to an affected device, creating a crafted command string and writing this crafted string to a specific file location.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][6] ]**
|
||||
|
||||
Cisco has released software updates that address this vulnerability.
|
||||
|
||||
Two other vulneraries rated “high” also involved the Nexus 9000:
|
||||
|
||||
* [A vulnerability][7] in the background-operations functionality of Cisco Nexus 9000 software could allow an authenticated, local attacker to gain elevated privileges as root on an affected device. The vulnerability is due to insufficient validation of user-supplied files on an affected device. Cisco said an attacker could exploit this vulnerability by logging in to the CLI of the affected device and creating a crafted file in a specific directory on the filesystem.
|
||||
* A [weakness][7] in the background-operations functionality of the switch software could allow an attacker to login to the CLI of the affected device and create a crafted file in a specific directory on the filesystem. The vulnerability is due to insufficient validation of user-supplied files on an affected device, Cisco said.
|
||||
|
||||
|
||||
|
||||
Cisco has [released software][4] for these vulnerabilities as well.
|
||||
|
||||
Also part of these security alerts were a number of “high” rated warnings about vulneraries in Cisco’s FirePower firewall series.
|
||||
|
||||
For example Cisco [wrote][8] that multiple vulnerabilities in the Server Message Block Protocol preprocessor detection engine for Cisco Firepower Threat Defense Software could allow an unauthenticated, adjacent or remote attacker to cause a denial of service (DoS) condition.
|
||||
|
||||
Yet [another vulnerability][9] in the internal packet-processing functionality of Cisco Firepower software for the Cisco Firepower 2100 Series could let an unauthenticated, remote attacker cause an affected device to stop processing traffic, resulting in a DOS situation, Cisco said.
|
||||
|
||||
[Software patches][4] are available for these vulnerabilities.
|
||||
|
||||
Other products such as the Cisco [Adaptive Security Virtual Appliance][10], and [Web Security appliance][11] had high priority patches as well.
|
||||
|
||||
Join the Network World communities on [Facebook][12] and [LinkedIn][13] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3392858/cisco-issues-critical-security-warning-for-nexus-data-center-switches.html#tk.rss_all
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/02/lock_broken_unlocked_binary_code_security_circuits_protection_privacy_thinkstock_873916354-100750739-large.jpg
|
||||
[2]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-nexus9k-sshkey
|
||||
[3]: https://www.networkworld.com/article/3284352/data-center/how-to-plan-a-software-defined-data-center-network.html
|
||||
[4]: https://www.cisco.com/c/en/us/about/legal/cloud-and-software/end_user_license_agreement.html
|
||||
[5]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-nexus9k-rpe
|
||||
[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[7]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-aci-hw-clock-util
|
||||
[8]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-frpwr-smb-snort
|
||||
[9]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-frpwr-dos
|
||||
[10]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-asa-ipsec-dos
|
||||
[11]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190501-wsa-privesc
|
||||
[12]: https://www.facebook.com/NetworkWorld/
|
||||
[13]: https://www.linkedin.com/company/network-world
|
||||
@ -1,61 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Health care is still stitching together IoT systems)
|
||||
[#]: via: (https://www.networkworld.com/article/3392818/health-care-is-still-stitching-together-iot-systems.html#tk.rss_all)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
Health care is still stitching together IoT systems
|
||||
======
|
||||
The use of IoT technology in medicine is fraught with complications, but users are making it work.
|
||||
_Government regulations, safety and technical integration are all serious issues facing the use of IoT in medicine, but professionals in the field say that medical IoT is moving forward despite the obstacles. A vendor, a doctor, and an IT pro all spoke to Network World about the work involved._
|
||||
|
||||
### Vendor: It's tough to gain acceptance**
|
||||
|
||||
**
|
||||
|
||||
Josh Stein is the CEO and co-founder of Adheretech, a medical-IoT startup whose main product is a connected pill bottle. The idea is to help keep seriously ill patients current with their medications, by monitoring whether they’ve taken correct dosages or not.
|
||||
|
||||
The bottle – which patients get for free (Adheretech’s clients are hospitals and clinics) – uses a cellular modem to call home to the company’s servers and report on how much medication is left in the bottle, according to sensors that detect how many pills are touching the bottle’s sides and measuring its weight. There, the data is analyzed not just to determine whether patients are sticking to their doctor’s prescription, but to help identify possible side effects and whether they need additional help.
|
||||
|
||||
For example, a bottle that detects itself being moved to the bathroom too often might send up a flag that the patient is experiencing gastrointestinal side effects. The system can then contact patients or providers via phone or text to help them take the next steps.
|
||||
|
||||
The challenges to reach this point have been stiff, according to Stein. The company was founded in 2011 and spent the first four years of its existence simply designing and building its product.
|
||||
|
||||
“We had to go through many years of R&D to create a device that’s replicatible a million times over,” he said. “If you’re a healthcare company, you have to deal with HIPAA, the FDA, and then there’s lots of other things like medication bottles have their whole own set of regulatory certifications.”
|
||||
|
||||
Beyond the simple fact of regulatory compliance, Stein said that there’s resistance to this sort of new technology in the medical community.
|
||||
|
||||
“Healthcare is typically one of the last industries to adopt new technology,” he said.
|
||||
|
||||
### Doctor: Colleagues wonder if medical IoT plusses are worth the trouble
|
||||
|
||||
Dr. Rebecca Mishuris is the associate chief medical information officer at Boston Medical Center, a private non-profit hospital located in the South End. One of the institution’s chief missions is to act as a safety net for the population of the area – 57% of BMC’s patients come from under-served populations, and roughly a third don’t speak English as a primary language. That, in itself, can be a problem for IoT because many devices are designed to be used by native English speakers.
|
||||
|
||||
BMC’s adoption of IoT tech has taken place mostly at the individual-practice level – things like Bluetooth-enabled scales and diagnostic equipment for specific offices that want to use them – but there’s no hospital-wide IoT initiative happening, according to Mishuris.
|
||||
|
||||
That’s partially due to the fact that many practitioners aren’t convinced that connected healthcare devices are worth the trouble to purchase, install and manage, she said. HIPAA compliance and BMC’s own privacy regulations are a particular concern, given that many of the devices deal with patient-generated data.
|
||||
|
||||
To continue reading this article register now
|
||||
|
||||
[Get Free Access][1]
|
||||
|
||||
[Learn More][2] Existing Users [Sign In][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3392818/health-care-is-still-stitching-together-iot-systems.html#tk.rss_all
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: javascript://
|
||||
[2]: /learn-about-insider/
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco boosts SD-WAN with multicloud-to-branch access system)
|
||||
[#]: via: (https://www.networkworld.com/article/3393232/cisco-boosts-sd-wan-with-multicloud-to-branch-access-system.html#tk.rss_all)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco boosts SD-WAN with multicloud-to-branch access system
|
||||
======
|
||||
Cisco's SD-WAN Cloud onRamp for CoLocation can tie branch offices to private data centers in regional corporate headquarters via colocation facilities for shorter, faster, possibly more secure connections.
|
||||
![istock][1]
|
||||
|
||||
Cisco is looking to give traditional or legacy wide-area network users another reason to move to the [software-defined WAN world][2].
|
||||
|
||||
The company has rolled out an integrated hardware/software package called SD-WAN Cloud onRamp for CoLocation that lets customers tie distributed multicloud applications back to a local branch office or local private data center. The idea is that a cloud-to-branch link would be shorter, faster and possibly more secure that tying cloud-based applications directly all the way to the data center.
|
||||
|
||||
**More about SD-WAN**
|
||||
|
||||
* [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][3]
|
||||
* [How to pick an off-site data-backup method][4]
|
||||
* [SD-Branch: What it is and why you’ll need it][5]
|
||||
* [What are the options for security SD-WAN?][6]
|
||||
|
||||
|
||||
|
||||
“With Cisco SD-WAN Cloud onRamp for CoLocation operating regionally, connections from colocation facilities to branches are set up and configured according to traffic loads (such as video vs web browsing vs email) SLAs (requirements for low latency/jitter), and Quality of Experience for optimizing cloud application performance,” wrote Anand Oswal, senior vice president of engineering, in Cisco’s Enterprise Networking Business in a [blog about the new service][7].
|
||||
|
||||
According to Oswal, each branch or private data center is equipped with a network interface that provides a secure tunnel to the regional colocation facility. In turn, the Cloud onRamp for CoLocation establishes secure tunnels to SaaS application platforms, multi-cloud platform services, and enterprise data centers, he stated.
|
||||
|
||||
Traffic is securely routed through the Cloud onRamp for CoLocation stack which includes security features such as application-aware firewalls, URL-filtering, intrusion detection/prevention, DNS-layer security, and Advanced Malware Protection (AMP) Threat Grid, as well as other network services such as load-balancing and Wide Area Application Services, Oswal wrote.
|
||||
|
||||
A typical use case for the package is an enterprise that has dozens of distributed branch offices, clustered around major cities, spread over several countries. The goal is to tie each branch to enterprise data center databases, SaaS applications, and multi-cloud services while meeting service level agreements and application quality of experience, Oswal stated.
|
||||
|
||||
“With virtualized Cisco SD-WAN running on regional colocation centers, the branch workforce has access to applications and data residing in AWS, Azure, and Google cloud platforms as well as SaaS providers such as Microsoft 365 and Salesforce—transparently and securely,” Oswal said. “Distributing SD-WAN features over a regional architecture also brings processing power closer to where data is being generated—at the cloud edge.”
|
||||
|
||||
The idea is that paths to designated SaaS applications will be monitored continuously for performance, and the application traffic will be dynamically routed to the best-performing path, without requiring human intervention, Oswal stated.
|
||||
|
||||
For a typical configuration, a region covering a target city uses a colocation IaaS provider that hosts the Cisco Cloud onRamp for CoLocation, which includes:
|
||||
|
||||
* Cisco vManage software that lets customers manage applications and provision, monitor and troubleshooting the WAN.
|
||||
* [Cisco Cloud Services Platform (CSP) 5000][8] The systems are x86 Linux Kernel-based Virtual Machine (KVM) software and hardware platforms for the data center, regional hub, and colocation Network Functions Virtualization (NFV). The platforms let enterprise IT teams or service providers deploy any Cisco or third-party network virtual service with Cisco’s [Network Services Orchestrator (NSO)][9] or any other northbound management and orchestration system.
|
||||
* The Cisco [Catalyst 9500 Series][10] aggregation switches. Based on an x86 CPU, the Catalyst 9500 Series is Cisco’s lead purpose-built fixed core and aggregation enterprise switching platform, built for security, IoT, and cloud. The switches come with a 4-core x86, 2.4-GHz CPU, 16-GB DDR4 memory, and 16-GB internal storage.
|
||||
|
||||
|
||||
|
||||
If the features of the package sound familiar, that’s because the [Cloud onRamp for CoLocation][11] package is the second generation of a similar SD-WAN package offered by Viptela which Cisco [bought in 2017][12].
|
||||
|
||||
SD-WAN's driving principle is to simplify the way big companies turn up new links to branch offices, better manage the way those links are utilized – for data, voice or video – and potentially save money in the process.
|
||||
|
||||
It's a profoundly hot market with tons of players including [Cisco][13], VMware, Silver Peak, Riverbed, Aryaka, Fortinet, Nokia and Versa. IDC says the SD-WAN infrastructure market will hit $4.5 billion by 2022, growing at a more than 40% yearly clip between now and then.
|
||||
|
||||
[SD-WAN][14] lets networks route traffic based on centrally managed roles and rules, no matter what the entry and exit points of the traffic are, and with full security. For example, if a user in a branch office is working in Office365, SD-WAN can route their traffic directly to the closest cloud data center for that app, improving network responsiveness for the user and lowering bandwidth costs for the business.
|
||||
|
||||
"SD-WAN has been a promised technology for years, but in 2019 it will be a major driver in how networks are built and re-built," Oswal said a Network World [article][15] earlier this year.
|
||||
|
||||
Join the Network World communities on [Facebook][16] and [LinkedIn][17] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3393232/cisco-boosts-sd-wan-with-multicloud-to-branch-access-system.html#tk.rss_all
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/02/istock-578801262-100750453-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3209131/what-sdn-is-and-where-its-going.html
|
||||
[3]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
|
||||
[4]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
|
||||
[5]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[6]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html?nsdr=true
|
||||
[7]: https://blogs.cisco.com/enterprise/cisco-sd-wan-cloud-onramp-for-colocation-multicloud
|
||||
[8]: https://www.cisco.com/c/en/us/products/collateral/switches/cloud-services-platform-5000/nb-06-csp-5k-data-sheet-cte-en.html#ProductOverview
|
||||
[9]: https://www.cisco.com/go/nso
|
||||
[10]: https://www.cisco.com/c/en/us/products/collateral/switches/catalyst-9500-series-switches/data_sheet-c78-738978.html
|
||||
[11]: https://www.networkworld.com/article/3207751/viptela-cloud-onramp-optimizes-cloud-access.html
|
||||
[12]: https://www.networkworld.com/article/3193784/cisco-grabs-up-sd-wan-player-viptela-for-610m.html?nsdr=true
|
||||
[13]: https://www.networkworld.com/article/3322937/what-will-be-hot-for-cisco-in-2019.html
|
||||
[14]: https://www.networkworld.com/article/3031279/sd-wan/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[15]: https://www.networkworld.com/article/3332027/cisco-touts-5-technologies-that-will-change-networking-in-2019.html
|
||||
[16]: https://www.facebook.com/NetworkWorld/
|
||||
[17]: https://www.linkedin.com/company/network-world
|
||||
74
sources/talk/20190507 SD-WAN is Critical for IoT.md
Normal file
74
sources/talk/20190507 SD-WAN is Critical for IoT.md
Normal file
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (SD-WAN is Critical for IoT)
|
||||
[#]: via: (https://www.networkworld.com/article/3393445/sd-wan-is-critical-for-iot.html#tk.rss_all)
|
||||
[#]: author: (Rami Rammaha https://www.networkworld.com/author/Rami-Rammaha/)
|
||||
|
||||
SD-WAN is Critical for IoT
|
||||
======
|
||||
|
||||
![istock][1]
|
||||
|
||||
The Internet of Things (IoT) is everywhere and its use is growing fast. IoT is used by local governments to build smart cities. It’s used to build smart businesses. And, consumers are benefitting as it’s built into smart homes and smart cars. Industry analyst first estimates that over 20 billion IoT devices will be connected by 2020. That’s a 2.5x increase from the more than 8 billion connected devices in 2017*.
|
||||
|
||||
Manufacturing companies have the highest IoT spend to date of industries while the health care market is experiencing the highest IoT growth. By 2020, 50 percent of IoT spending will be driven by manufacturing, transportation and logistics, and utilities.
|
||||
|
||||
IoT growth is being fueled by the promise of analytical data insights that will ultimately yield greater efficiencies and enhanced customer satisfaction. The top use cases driving IoT growth are self-optimizing production, predictive maintenance and automated inventory management.
|
||||
|
||||
From a high-level view, the IoT architecture includes sensors that collect and transmit data (i.e. temperature, speed, humidity, video feed, pressure, IR, proximity, etc.) from “things” like cars, trucks, machines, etc. that are connected over the internet. Data collected is then analyzed, translating raw data into actionable information. Businesses can then act on this information. And at more advanced levels, machine learning and AI algorithms learn and adapt to this information and automatically respond at a system level.
|
||||
|
||||
IDC estimates that by 2025, over 75 billion IoT devices* will be connected. By that time, nearly a quarter of the world’s projected 163 zettabytes* (163 trillion gigabytes) of data will have been created in real-time, and the vast majority of that data will have been created by IoT devices. This massive amount of data will drive an exponential increase in traffic on the network infrastructure requiring massive scalability. Also, this increasing amount of data will require tremendous processing power to mine it and transform it into actionable intelligence. In parallel, security risks will continue to increase as there will be many more potential entry points onto the network. Lastly, management of the overall infrastructure will require better orchestration of policies as well as the means to streamline on-going operations.
|
||||
|
||||
### **How does SD-WAN enable IoT business initiatives?**
|
||||
|
||||
There are three key elements that an [SD-WAN][2] platform must include:
|
||||
|
||||
1. **Visibility** : Real-time visibility into the network is key. It takes the guesswork out of rapid problem resolution, enabling organizations to run more efficiently by accelerating troubleshooting and applying preventive measures. Furthermore, a CIO is able to pull metrics and see bandwidth consumed by any IoT application.
|
||||
2. **Security** : IoT traffic must be isolated from other application traffic. IT must prevent – or at least reduce – the possible attack surface that may be exposed to IoT device traffic. Also, the network must continue delivering other application traffic in the event of a melt down on a WAN link caused by a DDoS attack.
|
||||
3. **Agility** : With the increased number of connected devices, applications and users, a comprehensive, intelligent and centralized orchestration approach that continuously adapts to deliver the best experience to the business and users is critical to success.
|
||||
|
||||
|
||||
|
||||
### Key Silver Peak EdgeConnect SD-WAN capabilities for IoT
|
||||
|
||||
1\. Silver Peak has an [embedded real-time visibility engine][3] allowing IT to gain complete observability into the performance attributes of the network and applications in real-time. The [EdgeConnect][4] SD-WAN appliances deployed in branch offices send information to the centralized [Unity Orchestrator™][5]. Orchestrator collects the data and presents it in a comprehensive management dashboard via customizable widgets. These widgets provide a wealth of operational data including a health heatmap for every SD-WAN appliance deployed, flow counts, active tunnels, logical topologies, top talkers, alarms, bandwidth consumed by each application and location, latency and jitter and much more. Furthermore, the platform maintains weeks’ worth of data with context allowing IT to playback and see what has transpired at a specific time and location, similar to a DVR.
|
||||
|
||||
![Click to read Solution Brief][6]
|
||||
|
||||
2\. The second set of key capabilities center around security and end-to-end zone-based segmentation. An IoT traffic zone may be created on the LAN or branch side. IoT traffic is then mapped all the way across the WAN to the data center or cloud where the data will be processed. Zone-based segmentation is accomplished in a simplified and automated way within the Orchestrator GUI. In cases where further traffic inspection is required, IT can simply service chain to another security service. There are several key benefits realized by this approach. IT can easily and quickly apply segmentation policies; segmentation mitigates the attack surface; and IT can save on additional security investments.
|
||||
|
||||
![***Click to read Solution Brief ***][7]
|
||||
|
||||
3\. EdgeConnect employs machine learning at the global level where with internet sensors and third-party sensors feed into the cloud portal software. The software tracks the geolocation of all IP addresses and IP reputation, distributing signals down to the Unity Orchestrator running in each individual customer’s enterprise. In turn, it is speaking to the edge devices sitting in the branch offices. There, distributed learning is done by looking at the first packet, making an inference based on the first packet what the application is. So, if seeing that 100 times now, every time packets come from that particular IP address and turns out to be an IoT, we can make an inference that IP belongs to IoT application. In parallel, we’re using a mix of traditional techniques to validate the identification of the application. All this combined other multi-level intelligence enables simple and automated policy orchestration across a large number of devices and applications.
|
||||
|
||||
![***Click to read Solution Brief ***][8]
|
||||
|
||||
SD-WAN plays a foundational role as businesses continue to embrace IoT, but choosing the right SD-WAN platform is even more critical to ensuring businesses are ultimately able to fully optimize their operations.
|
||||
|
||||
* Source: [IDC][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3393445/sd-wan-is-critical-for-iot.html#tk.rss_all
|
||||
|
||||
作者:[Rami Rammaha][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Rami-Rammaha/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/istock-1019172426-100795551-large.jpg
|
||||
[2]: https://www.silver-peak.com/sd-wan/sd-wan-explained
|
||||
[3]: https://www.silver-peak.com/resource-center/simplify-sd-wan-operations-greater-visibility
|
||||
[4]: https://www.silver-peak.com/products/unity-edge-connect
|
||||
[5]: https://www.silver-peak.com/products/unity-orchestrator
|
||||
[6]: https://images.idgesg.net/images/article/2019/05/1_simplify-100795554-large.jpg
|
||||
[7]: https://images.idgesg.net/images/article/2019/05/2_centralize-100795555-large.jpg
|
||||
[8]: https://images.idgesg.net/images/article/2019/05/3_increase-100795558-large.jpg
|
||||
[9]: https://www.information-age.com/data-forecast-grow-10-fold-2025-123465538/
|
||||
@ -0,0 +1,56 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Server shipments to pick up in the second half of 2019)
|
||||
[#]: via: (https://www.networkworld.com/article/3393167/server-shipments-to-pick-up-in-the-second-half-of-2019.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Server shipments to pick up in the second half of 2019
|
||||
======
|
||||
Server sales slowed in anticipation of the new Intel Xeon processors, but they are expected to start up again before the end of the year.
|
||||
![Thinkstock][1]
|
||||
|
||||
Global server shipments are not expected to return to growth momentum until the third quarter or even the fourth quarter of 2019, according to Taiwan-based tech news site DigiTimes, which cited unnamed server supply chain sources. The one bright spot remains cloud providers like Amazon, Google, and Facebook, which continue their buying binge.
|
||||
|
||||
Normally I’d be reluctant to cite such a questionable source, but given most of the OEMs and ODMs are based in Taiwan and DigiTimes (the article is behind a paywall so I cannot link) has shown it has connections to them, I’m inclined to believe them.
|
||||
|
||||
Quanta Computer chairman Barry Lam told the publication that Quanta's shipments of cloud servers have risen steadily, compared to sharp declines in shipments of enterprise servers. Lam continued that enterprise servers command only 1-2% of the firm's total server shipments.
|
||||
|
||||
**[ Also read:[Gartner: IT spending to drop due to falling equipment prices][2] ]**
|
||||
|
||||
[Server shipments began to slow down in the first quarter][3] thanks in part to the impending arrival of second-generation Xeon Scalable processors from Intel. And since it takes a while to get parts and qualify them, this quarter won’t be much better.
|
||||
|
||||
In its latest quarterly earnings, Intel's data center group (DCG) said sales declined 6% year over year, the first decline of its kind since the first quarter of 2012 and reversing an average growth of over 20% in the past.
|
||||
|
||||
[The Osbourne Effect][4] wasn’t the sole reason. An economic slowdown in China and the trade war, which will add significant tariffs to Chinese-made products, are also hampering sales.
|
||||
|
||||
DigiTimes says Inventec, Intel's largest server motherboard supplier, expects shipments of enterprise server motherboards to further lose steams for the rest of the year, while sales of data center servers are expected to grow 10-15% on year in 2019.
|
||||
|
||||
**[[Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][5] ]**
|
||||
|
||||
It went on to say server shipments may concentrate in the second half or even the fourth quarter of the year, while cloud-based data center servers for the cloud giants will remain positive as demand for edge computing, new artificial intelligence (AI) applications, and the proliferation of 5G applications begin in 2020.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3393167/server-shipments-to-pick-up-in-the-second-half-of-2019.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2017/04/2_data_center_servers-100718306-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3391062/it-spending-to-drop-due-to-falling-equipment-prices-gartner-predicts.html
|
||||
[3]: https://www.networkworld.com/article/3332144/server-sales-projected-to-slow-while-memory-prices-drop.html
|
||||
[4]: https://en.wikipedia.org/wiki/Osborne_effect
|
||||
[5]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,66 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Some IT pros say they have too much data)
|
||||
[#]: via: (https://www.networkworld.com/article/3393205/some-it-pros-say-they-have-too-much-data.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Some IT pros say they have too much data
|
||||
======
|
||||
IT professionals have too many data sources to count, and they spend a huge amount of time wrestling that data into usable condition, a survey from Ivanti finds.
|
||||
![Getty Images][1]
|
||||
|
||||
A new survey has found that a growing number of IT professionals have too many data sources to even count, and they are spending more and more time just wrestling that data into usable condition.
|
||||
|
||||
Ivanti, an IT asset management firm, [surveyed 400 IT professionals on their data situation][2] and found IT faces numerous challenges when it comes to siloes, data, and implementation. The key takeaway is data overload is starting to overwhelm IT managers and data lakes are turning into data oceans.
|
||||
|
||||
**[ Read also:[Understanding mass data fragmentation][3] | Get daily insights [Sign up for Network World newsletters][4] ]**
|
||||
|
||||
Among the findings from Ivanti's survey:
|
||||
|
||||
* Fifteen percent of IT professionals say they have too many data sources to count, and 37% of professionals said they have about 11-25 different sources for data.
|
||||
* More than half of IT professionals (51%) report they have to work with their data for days, weeks or more before it's actionable.
|
||||
* Only 10% of respondents said the data they receive is actionable within minutes.
|
||||
* One in three respondents said they have the resources to act on their data, but more than half (52%) said they only sometimes have the resources.
|
||||
|
||||
|
||||
|
||||
“It’s clear from the results of this survey that IT professionals are in need of a more unified approach when working across organizational departments and resulting silos,” said Duane Newman, vice president of product management at Ivanti, in a statement.
|
||||
|
||||
### The problem with siloed data
|
||||
|
||||
The survey found siloed data represents a number of problems and challenges. Three key priorities suffer the most: automation (46%), user productivity and troubleshooting (42%), and customer experience (41%). The survey also found onboarding/offboarding suffers the least (20%) due to siloes, so apparently HR and IT are getting things right.
|
||||
|
||||
In terms of what they want from real-time insight, about 70% of IT professionals said their security status was the top priority over other issues. Respondents were least interested in real-time insights around warranty data.
|
||||
|
||||
### Data lake method a recipe for disaster
|
||||
|
||||
I’ve been immersed in this subject for other publications for some time now. Too many companies are hoovering up data for the sake of collecting it with little clue as to what they will do with it later. One thing you have to say about data warehouses, the schema on write at least forces you to think about what you are collecting and how you might use it because you have to store it away in a usable form.
|
||||
|
||||
The new data lake method is schema on read, meaning you filter/clean it when you read it into an application, and that’s just a recipe for disaster. If you are looking at data collected a month or a year ago, do you even know what it all is? Now you have to apply schema to data and may not even remember collecting it.
|
||||
|
||||
Too many people think more data is good when it isn’t. You just drown in it. When you reach a point of having too many data sources to count, you’ve gone too far and are not going to get insight. You’re going to get overwhelmed. Collect data you know you can use. Otherwise you are wasting petabytes of disk space.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3393205/some-it-pros-say-they-have-too-much-data.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/03/database_data-center_futuristic-technology-100752012-large.jpg
|
||||
[2]: https://www.ivanti.com/blog/survey-it-professionals-data-sources
|
||||
[3]: https://www.networkworld.com/article/3262145/lan-wan/customer-reviews-top-remote-access-tools.html#nww-fsb
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco adds AMP to SD-WAN for ISR/ASR routers)
|
||||
[#]: via: (https://www.networkworld.com/article/3394597/cisco-adds-amp-to-sd-wan-for-israsr-routers.html#tk.rss_all)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco adds AMP to SD-WAN for ISR/ASR routers
|
||||
======
|
||||
Cisco SD-WAN now sports Advanced Malware Protection on its popular edge routers, adding to their routing, segmentation, security, policy and orchestration capabilities.
|
||||
![vuk8691 / Getty Images][1]
|
||||
|
||||
Cisco has added support for Advanced Malware Protection (AMP) to its million-plus ISR/ASR edge routers, in an effort to [reinforce branch and core network malware protection][2] at across the SD-WAN.
|
||||
|
||||
Cisco last year added its Viptela SD-WAN technology to the IOS XE version 16.9.1 software that runs its core ISR/ASR routers such as the ISR models 1000, 4000 and ASR 5000, in use by organizations worldwide. Cisco bought Viptela in 2017.
|
||||
|
||||
**More about SD-WAN**
|
||||
|
||||
* [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][3]
|
||||
* [How to pick an off-site data-backup method][4]
|
||||
* [SD-Branch: What it is and why you’ll need it][5]
|
||||
* [What are the options for security SD-WAN?][6]
|
||||
|
||||
|
||||
|
||||
The release of Cisco IOS XE offered an instant upgrade path for creating cloud-controlled SD-WAN fabrics to connect distributed offices, people, devices and applications operating on the installed base, Cisco said. At the time Cisco said that Cisco SD-WAN on edge routers builds a secure virtual IP fabric by combining routing, segmentation, security, policy and orchestration.
|
||||
|
||||
With the recent release of [IOS-XE SD-WAN 16.11][7], Cisco has brought AMP and other enhancements to its SD-WAN.
|
||||
|
||||
“Together with Cisco Talos [Cisco’s security-intelligence arm], AMP imbues your SD-WAN branch, core and campuses locations with threat intelligence from millions of worldwide users, honeypots, sandboxes, and extensive industry partnerships,” wrote Cisco’s Patrick Vitalone a product marketing manager in a [blog][8] about the security portion of the new software. “In total, AMP identifies more than 1.1 million unique malware samples a day." When AMP in Cisco SD-WAN spots malicious behavior it automatically blocks it, he wrote.
|
||||
|
||||
The idea is to use integrated preventative engines, exploit prevention and intelligent signature-based antivirus to stop malicious attachments and fileless malware before they execute, Vitalone wrote.
|
||||
|
||||
AMP support is added to a menu of security features already included in the SD-WAN software including support for URL filtering, [Cisco Umbrella][9] DNS security, Snort Intrusion Prevention, the ability to segment users across the WAN and embedded platform security, including the [Cisco Trust Anchor][10] module.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][11] ]**
|
||||
|
||||
The software also supports [SD-WAN Cloud onRamp for CoLocation][12], which lets customers tie distributed multicloud applications back to a local branch office or local private data center. That way a cloud-to-branch link would be shorter, faster and possibly more secure that tying cloud-based applications directly to the data center.
|
||||
|
||||
“The idea that this kind of security technology is now integrated into Cisco’s SD-WAN offering is a critical for Cisco and customers looking to evaluate SD-WAN offerings,” said Lee Doyle, principal analyst at Doyle Research.
|
||||
|
||||
IOS-XE SD-WAN 16.11 is available now.
|
||||
|
||||
Join the Network World communities on [Facebook][13] and [LinkedIn][14] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3394597/cisco-adds-amp-to-sd-wan-for-israsr-routers.html#tk.rss_all
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/09/shimizu_island_el_nido_palawan_philippines_by_vuk8691_gettyimages-155385042_1200x800-100773533-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3285728/what-are-the-options-for-securing-sd-wan.html
|
||||
[3]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
|
||||
[4]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
|
||||
[5]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[6]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html?nsdr=true
|
||||
[7]: https://www.cisco.com/c/en/us/td/docs/routers/sdwan/release/notes/xe-16-11/sd-wan-rel-notes-19-1.html
|
||||
[8]: https://blogs.cisco.com/enterprise/enabling-amp-in-cisco-sd-wan
|
||||
[9]: https://www.networkworld.com/article/3167837/cisco-umbrella-cloud-service-shapes-security-for-cloud-mobile-resources.html
|
||||
[10]: https://www.cisco.com/c/dam/en_us/about/doing_business/trust-center/docs/trustworthy-technologies-datasheet.pdf
|
||||
[11]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[12]: https://www.networkworld.com/article/3393232/cisco-boosts-sd-wan-with-multicloud-to-branch-access-system.html
|
||||
[13]: https://www.facebook.com/NetworkWorld/
|
||||
[14]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,83 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (When it comes to uptime, not all cloud providers are created equal)
|
||||
[#]: via: (https://www.networkworld.com/article/3394341/when-it-comes-to-uptime-not-all-cloud-providers-are-created-equal.html#tk.rss_all)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
When it comes to uptime, not all cloud providers are created equal
|
||||
======
|
||||
Cloud uptime is critical today, but vendor-provided data can be confusing. Here's an analysis of how AWS, Google Cloud and Microsoft Azure compare.
|
||||
![Getty Images][1]
|
||||
|
||||
The cloud is not just important; it's mission-critical for many companies. More and more IT and business leaders I talk to look at public cloud as a core component of their digital transformation strategies — using it as part of their hybrid cloud or public cloud implementation.
|
||||
|
||||
That raises the bar on cloud reliability, as a cloud outage means important services are not available to the business. If this is a business-critical service, the company may not be able to operate while that key service is offline.
|
||||
|
||||
Because of the growing importance of the cloud, it’s critical that buyers have visibility into the reliability number for the cloud providers. The challenge is the cloud providers don't disclose the disruptions in a consistent manner. In fact, some are confusing to the point where it’s difficult to glean any kind of meaningful conclusion.
|
||||
|
||||
**[ RELATED:[What IT pros need to know about Azure Stack][2] and [Which cloud performs better, AWS, Azure or Google?][3] | Get regularly scheduled insights: [Sign up for Network World newsletters][4] ]**
|
||||
|
||||
### Reported cloud outage times don't always reflect actual downtime
|
||||
|
||||
Microsoft Azure and Google Cloud Platform (GCP) both typically provide information on date and time, but only high-level data on the services affected and sparse information on regional impact. The problem with that is it’s difficult to get a sense of overall reliability. For instance, if Azure reports a one-hour outage that impacts five services in three regions, the website might show just a single hour. In actuality, that’s 15 hours of total downtime.
|
||||
|
||||
Between Azure, GCP and Amazon Web Services (AWS), [Azure is the most obscure][5], as it provides the least amount of detail. [GCP does a better job of providing detail][6] at the service level but tends to be obscure with regional information. Sometimes it’s very clear as to what services are unavailable, and other times it’s not.
|
||||
|
||||
[AWS has the most granular reporting][7], as it shows every service in every region. If an incident occurs that impacts three services, all three of those services would light up red. If those were unavailable for one hour, AWS would record three hours of downtime.
|
||||
|
||||
Another inconsistency between the cloud providers is the amount of historical downtime data that is available. At one time, all three of the cloud vendors provided a one-year view into outages. GCP and AWS still do this, but Azure moved to only a [90-day view][5] sometime over the past year.
|
||||
|
||||
### Azure has significantly higher downtime than GCP and AWS
|
||||
|
||||
The next obvious question is who has the most downtime? To answer that, I worked with a third-party firm that has continually collected downtime information directly from the vendor websites. I have personally reviewed the information and can validate its accuracy. Based on the vendors own reported numbers, from the beginning of 2018 through May 3, 2019, AWS leads the pack with only 338 hours of downtime, followed by GCP closely at 361. Microsoft Azure has a whopping total of 1,934 hours of self-reported downtime.
|
||||
|
||||
![][8]
|
||||
|
||||
A few points on these numbers. First, this is an aggregation of the self-reported data from the vendors' websites, which isn’t the “true” number, as regional information or service granularity is sometimes obscured. If a service is unavailable for an hour and it’s reported for an hour on the website but it spanned five regions, correctly five hours should have been used. But for this calculation, we used only one hour because that is what was self-reported.
|
||||
|
||||
Because of this, the numbers are most favorable to Microsoft because they provide the least amount of regional information. The numbers are least favorable to AWS because they provide the most granularity. Also, I believe AWS has the most services in most regions, so they have more opportunities for an outage.
|
||||
|
||||
We had considered normalizing the data, but that would require a significant amount of work to destruct the downtime on a per service per region basis. I may choose to do that in the future, but for now, the vendor-reported view is a good indicator of relative performance.
|
||||
|
||||
Another important point is that only infrastructure as a service (IaaS) services were used to calculate downtime. If Google Street View or Bing Maps went down, most businesses would not care, so it would have been unfair to roll those number in.
|
||||
|
||||
### SLAs do not correlate to reliability
|
||||
|
||||
Given the importance of cloud services today, I would like to see every cloud provider post a 12-month running total of downtime somewhere on their website so customers can do an “apples to apples” comparison. This obviously isn’t the only factor used in determining which cloud provider to use, but it is one of the more critical ones.
|
||||
|
||||
Also, buyers should be aware that there is a big difference between service-level agreements (SLAs) and downtime. A cloud operator can promise anything they want, even provide a 100% SLA, but that just means they need to reimburse the business when a service isn’t available. Most IT leaders I have talked to say the few bucks they get back when a service is out is a mere fraction of what the outage actually cost them.
|
||||
|
||||
### Measure twice and cut once to minimize business disruption
|
||||
|
||||
If you’re reading this and you’re researching cloud services, it’s important to not just make the easy decision of buying for convenience. Many companies look at Azure because Microsoft gives away Azure credits as part of the Enterprise Agreement (EA). I’ve interviewed several companies that took the path of least resistance, but they wound up disappointed with availability and then switched to AWS or GCP later, which can have a disruptive effect.
|
||||
|
||||
I’m certainly not saying to not buy Microsoft Azure, but it is important to do your homework to understand the historical performance of the services you’re considering in the regions you need them. The information on the vendor websites may not tell the full picture, so it’s important to do the necessary due diligence to ensure you understand what you’re buying before you buy it.
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3394341/when-it-comes-to-uptime-not-all-cloud-providers-are-created-equal.html#tk.rss_all
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/cloud_comput_connect_blue-100787048-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3208029/azure-stack-microsoft-s-private-cloud-platform-and-what-it-pros-need-to-know-about-it
|
||||
[3]: https://www.networkworld.com/article/3319776/the-network-matters-for-public-cloud-performance.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://azure.microsoft.com/en-us/status/history/
|
||||
[6]: https://status.cloud.google.com/incident/appengine/19008
|
||||
[7]: https://status.aws.amazon.com/
|
||||
[8]: https://images.idgesg.net/images/article/2019/05/public-cloud-downtime-100795948-large.jpg
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,58 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Supermicro moves production from China)
|
||||
[#]: via: (https://www.networkworld.com/article/3394404/supermicro-moves-production-from-china.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Supermicro moves production from China
|
||||
======
|
||||
Supermicro was cleared of any activity related to the Chinese government and secret chips in its motherboards, but it is taking no chances and is moving its facilities.
|
||||
![Frank Schwichtenberg \(CC BY 4.0\)][1]
|
||||
|
||||
Server maker Supermicro, based in Fremont, California, is reportedly moving production out of China over customer concerns that the Chinese government had secretly inserted chips for spying into its motherboards.
|
||||
|
||||
The claims were made by Bloomberg late last year in a story that cited more than 100 sources in government and private industry, including Apple and Amazon Web Services (AWS). However, Apple CEO Tim Cook and AWS CEO Andy Jassy denied the claims and called for Bloomberg to retract the article. And a few months later, the third-party investigations firm Nardello & Co examined the claims and [cleared Supermicro][2] of any surreptitious activity.
|
||||
|
||||
At first it seemed like Supermicro was weathering the storm, but the story did have a negative impact. Server sales have fallen since the Bloomberg story, and the company is forecasting a near 10% decline in total revenues for the March quarter compared to the previous three months.
|
||||
|
||||
**[ Also read:[Who's developing quantum computers][3] ]**
|
||||
|
||||
And now, Nikkei Asian Review reports that despite the strong rebuttals, some customers remain cautious about the company's products. To address those concerns, Nikkei says Supermicro has told suppliers to [move production out of China][4], citing industry sources familiar with the matter.
|
||||
|
||||
It also has the side benefit of mitigating against the U.S.-China trade war, which is only getting worse. Since the tariffs are on the dollar amount of the product, that can quickly add up even for a low-end system, as Serve The Home noted in [this analysis][5].
|
||||
|
||||
Supermicro is the world's third-largest server maker by shipments, selling primarily to cloud providers like Amazon and Facebook. It does its own assembly in its Fremont facility but outsources motherboard production to numerous suppliers, mostly China and Taiwan.
|
||||
|
||||
"We have to be more self-reliant [to build in-house manufacturing] without depending only on those outsourcing partners whose production previously has mostly been in China," an executive told Nikkei.
|
||||
|
||||
Nikkei notes that roughly 90% of the motherboards shipped worldwide in 2017 were made in China, but that percentage dropped to less than 50% in 2018, according to Digitimes Research, a tech supply chain specialist based in Taiwan.
|
||||
|
||||
Supermicro just held a groundbreaking ceremony in Taiwan for a 800,000 square foot manufacturing plant in Taiwan and is expanding its San Jose, California, plant as well. So, they must be anxious to be free of China if they are willing to expand in one of the most expensive real estate markets in the world.
|
||||
|
||||
A Supermicro spokesperson said via email, “We have been expanding our manufacturing capacity for many years to meet increasing customer demand. We are currently constructing a new Green Computing Park building in Silicon Valley, where we are the only Tier 1 solutions vendor manufacturing in Silicon Valley, and we proudly broke ground this week on a new manufacturing facility in Taiwan. To support our continued global growth, we look forward to expanding in Europe as well.”
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3394404/supermicro-moves-production-from-china.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/supermicro_-_x11sae__cebit_2016_01-100796121-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3326828/investigator-finds-no-evidence-of-spy-chips-on-super-micro-motherboards.html
|
||||
[3]: https://www.networkworld.com/article/3275385/who-s-developing-quantum-computers.html
|
||||
[4]: https://asia.nikkei.com/Economy/Trade-war/Server-maker-Super-Micro-to-ditch-made-in-China-parts-on-spy-fears
|
||||
[5]: https://www.servethehome.com/how-tariffs-hurt-intel-xeon-d-atom-and-amd-epyc-3000/
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,162 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (HPE’s CEO lays out his technology vision)
|
||||
[#]: via: (https://www.networkworld.com/article/3394879/hpe-s-ceo-lays-out-his-technology-vision.html)
|
||||
[#]: author: (Eric Knorr )
|
||||
|
||||
HPE’s CEO lays out his technology vision
|
||||
======
|
||||
In an exclusive interview, HPE CEO Antonio Neri unpacks his portfolio of technology initiatives, from edge computing to tomorrow’s memory-driven architecture.
|
||||
![HPE][1]
|
||||
|
||||
Like Microsoft's Satya Nadella, HPE CEO Antonio Neri is a technologist with a long history of leading initiatives in his company. Meg Whitman, his former boss at HPE, showed her appreciation of Neri’s acumen by promoting him to HPE Executive Vice President in 2015 – and gave him the green light to acquire [Aruba][2], [SimpliVity][3], [Nimble Storage][4], and [Plexxi][5], all of which added key items to HPE’s portfolio.
|
||||
|
||||
Neri succeeded Whitman as CEO just 16 months ago. In a recent interview with Network World, Neri’s engineering background was on full display as he explained HPE’s technology roadmap. First and foremost, he sees a huge opportunity in [edge computing][6], into which HPE is investing $4 billion over four years to further develop edge “connectivity, security, and obviously cloud and analytics.”
|
||||
|
||||
**More about edge networking**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][7]
|
||||
* [Edge computing best practices][8]
|
||||
* [How edge computing can help secure the IoT][9]
|
||||
|
||||
|
||||
|
||||
Although his company abandoned its public cloud efforts in 2015, Neri is also bullish on the self-service “cloud experience,” which he asserts HPE is already implementing on-prem today in a software-defined, consumption-driven model. More fundamentally, he believes we are on the brink of a memory-driven computing revolution, where storage and memory become one and, depending on the use case, various compute engines are brought to bear on zettabytes of data.
|
||||
|
||||
This interview, conducted by Network World Editor-in-Chief Eric Knorr and edited for length and clarity, digs into Neri’s technology vision. [A companion interview on CIO][10] centers on Neri’s views of innovation, management, and company culture.
|
||||
|
||||
**Eric Knorr: ** Your biggest and highest profile investment so far has been in edge computing. My understanding of edge computing is that we’re really talking about mini-data centers, defined by IDC as less than 100 square feet in size. What’s the need for a $4 billion investment in that?
|
||||
|
||||
**Antonio Neri:** It’s twofold. We focus first on connectivity. Think about Aruba as a platform company, a cloud-enabled company. Now we offer branch solutions and edge data center solutions that include [wireless][11], LAN, [WAN][12] connectivity and soon [5G][13]. We give you a control plane so that that connectivity experience can be seen consistently the same way. All the policy management, the provisioning and the security aspects of it.
|
||||
|
||||
**Knorr:** Is 5G a big focus?
|
||||
|
||||
**[[Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][14] ]**
|
||||
|
||||
**Neri:** It’s a big focus for us. What customers are telling us is that it’s hard to get 5G inside the building. How you do hand off between 5G and Wi-Fi and give them the same experience? Because the problem is that we have LAN, wireless, and WAN already fully integrated into the control plane, but 5G sits over here. If you are an enterprise, you have to manage these two pipes independently.
|
||||
|
||||
With the new spectrum, though, they are kind of comingling anyway. [Customers ask] why don’t you give me [a unified] experience on top of that, with all this policy management and cloud-enablement, so I can provision the right connectivity for the right use case? A sensor can use a lower radio access or [Bluetooth][15] or other type of connectivity because you don’t need persistent connectivity and you don’t have the power to do it.
|
||||
|
||||
In some cases, you just put a SIM on it, and you have 5G, but in another one it’s just wireless connectivity. Wi-Fi connectivity is significantly lower cost than 5G. The use cases will dictate what type of connectivity you need, but the reality is they all want one experience. And we can do that because we have a great platform and a great partnership with MSPs, telcos, and providers.
|
||||
|
||||
**Knorr:** So it sounds like much of your investment is going into that integration.
|
||||
|
||||
**Neri:** The other part is how we provide the ability to provision the right cloud computing at the edge for the right use cases. Think about, for example, a manufacturing floor. We can converge the OT and IT worlds through a converged infrastructure aspect that digitizes the analog process into a digital process. We bring the cloud compute in there, which is fully virtualized and containerized, we integrate Wi-Fi connectivity or LAN connectivity, and we eliminate all these analog processes that are multi-failure touchpoints because you have multiple things that have to come together.
|
||||
|
||||
That’s a great example of a cloud at the edge. And maybe that small cloud is connected to a big cloud which could be in the large data center, which the customer owns – or it can be one of the largest public cloud providers.
|
||||
|
||||
**Knorr:** It’s difficult to talk about the software-defined data center and private cloud without talking about [VMware][16]. Where do your software-defined solutions leave off and where does VMware begin?
|
||||
|
||||
**Neri:** Where we stop is everything below the hypervisor, including the software-defined storage and things like SimpliVity. That has been the advantage we’ve had with [HPE OneView][17], so we can provision and manage the infrastructure-life-cycle and software-defined aspects at the infrastructure level. And let’s not forget security, because we’ve integrated [silicon root of trust][18] into our systems, which is a good advantage for us in the government space.
|
||||
|
||||
Then above that we continue to develop capabilities. Customers want choice. That’s why [the partnership with Nutanix][19] was important. We offer an alternative to vSphere and vCloud Foundation with Nutanix Prism and Acropolis.
|
||||
|
||||
**Knorr:** VMware has become the default for the private cloud, though.
|
||||
|
||||
**Neri:** Obviously, VMware owns 60 percent of the on-prem virtualized environment, but more and more, containers are becoming the way to go in a cloud-native approach. For us, we own the full container stack, because we base our solution on Kubernetes. We deploy that. That’s why the partnership with Nutanix is important. With Nutanix, we offer KVM and the Prism stack and then we’re fully integrated with HPE OneView for the rest of the infrastructure.
|
||||
|
||||
**Knorr:** You also offer GKE [Google [Kubernetes][20] Engine] on-prem.
|
||||
|
||||
**Neri:** Correct. We’re working with Google on the next version of that.
|
||||
|
||||
**Knorr:** How long do you think it will be before you start seeing Kubernetes and containers on bare metal?
|
||||
|
||||
**Neri:** It’s an interesting question. Many customers tell us it’s like going back to the future. It’s like we’re paying this tax on the virtualization layer.
|
||||
|
||||
**Knorr:** Exactly.
|
||||
|
||||
**Neri:** I can go bare metal and containers and be way more efficient. It is a little bit back to the future. But it’s a different future.
|
||||
|
||||
**Knorr:** And it makes the promise of [hybrid cloud][21] a little more real. I know HPE has been very bullish on hybrid.
|
||||
|
||||
**Neri:** We have been the one to say the world would be hybrid.
|
||||
|
||||
**Knorr:** But today, how hybrid is hybrid really? I mean, you have workloads in the public cloud, you have workloads in a [private cloud][22]. Can you really rope it all together into hybrid?
|
||||
|
||||
**Neri:** I think you have to have portability eventually.
|
||||
|
||||
**Knorr:** Eventually. It’s not really true now, though.
|
||||
|
||||
**Neri:** No, not true now. If you look at it from the software brokering perspective that makes hybrid very small. We know this eventually has to be all connected, but it’s not there yet. More and more of these workloads have to go back and forth.
|
||||
|
||||
If you ask me what the CIO role of the future will look like, it would be a service provider. I wake up in the morning, have a screen that says – oh, you know what? Today it’s cheaper to run that app here. I just slice it there and then it just moves. Whatever attributes on the data I want to manage and so forth – oh, today I have capacity here and by the way, why are you not using it? Slide it back here. That’s the hybrid world.
|
||||
|
||||
Many people, when they started with the cloud, thought, “I’ll just virtualize everything,” but that’s not the cloud. You’re [virtualizing][23], but you have to make it self-service. Obviously, cloud-native applications have developed that are different today. That’s why containers are definitely a much more efficient way, and that’s why I agree that the bare-metal piece of this is coming back.
|
||||
|
||||
**Knorr:** Do you worry about public cloud incursions into the [data center][24]?
|
||||
|
||||
**Neri:** It’s happening. Of course I’m worried. But what at least gives me comfort is twofold. One is that the customer wants choice. They don’t want to be locked in. Service is important. It’s one thing to say: Here’s the system. The other is: Who’s going to maintain it for me? Who is going to run it for me? And even though you have all the automation tools in the world, somebody has to watch this thing. Our job is to bring the public-cloud experience on prem, so that the customer has that choice.
|
||||
|
||||
**Knorr:** Part of that is economics.
|
||||
|
||||
**Neri:** When you look at economics it’s no longer just the cost of compute anymore. What we see more and more is the cost of the data bandwidth back and forth. That’s why the first question a customer asks is: Where should I put my data? And that dictates a lot of things, because today the data transfer bill is way higher than the cost of renting a VM.
|
||||
|
||||
The other thing is that when you go on the public cloud you can spin up a VM, but the problem is if you don’t shut it off, the bill keeps going. We brought, in the context of [composability][25], the ability to shut it off automatically. That’s why composability is important, because we can run, first of all, multi-workloads in the same infrastructure – whether it’s bare metal, virtualized or containerized. It’s called composable because the software layers of intelligence compose the right solutions from compute, storage, fabric and memory to that workload. When it doesn’t need it, it gives it back.
|
||||
|
||||
**Knorr:** Is there any opportunity left at the hardware level to innovate?
|
||||
|
||||
**Neri:** That’s why we think about memory-driven computing. Today we have a very CPU-centric approach. This is a limiting factor, and the reality is, if you believe data is the core of the architecture going forward, then the CPU can’t be the core of the architecture anymore.
|
||||
|
||||
You have a bunch of inefficiency by moving data back and forth across the system, which also creates energy waste and so forth. What we are doing is basically rearchitecting this for once in 70 years. We take memory and storage and collapse the two into one, so this becomes one central pool, which is nonvolatile and becomes the core. And then we bring the right computing capability to the data.
|
||||
|
||||
In an AI use case, you don’t move the data. You bring accelerators or GPUs to the data. For general purpose, you may use an X86, and maybe in video transcoding, you use an ARM-based architecture. The magic is this: You can do this on zettabytes of data and the benefit is there is no waste, very little power to keep it alive, and it’s persistent.
|
||||
|
||||
We call this the Generation Z fabric, which is based on a data fabric and silicon photonics. Now we go from copper, which is generating a lot of waste and a lot of heat and energy, to silicon photonics. So we not only scale this to zettabytes, we can do massive amounts of computation by bringing the right compute at the speed that’s needed to the data – and we solve a cost and scale problem too, because copper today costs a significant amount of money, and gold-plated connectors are hundreds of dollars.
|
||||
|
||||
We’re going to actually implement this capability in silicon photonics in our current architectures by the end of the year. In Synergy, for example, which is a composable blade system, at the back of the rack you can swap from Ethernet to silicon photonics. It was designed that way. We already prototyped this in a simple 2U chassis with 160 TB of memory and 2000 cores. We were able to process a billion-record database with 55 million combinations of algorithms in less than a minute.
|
||||
|
||||
**Knorr:** So you’re not just focusing on the edge, but the core, too.
|
||||
|
||||
**Neri:** As you go down from the cloud to the edge, that architecture actually scales to the smallest things. You can do it on a massive scale or you can do it on a small scale. We will deploy these technologies in our systems architectures now. Once the whole ecosystem is developed, because we also need an ISV ecosystem that can code applications in this new world or you’re not taking advantage of it. Also, the current Linux kernel can only handle so much memory, so you have to rewrite the kernel. We are working with two universities to do that.
|
||||
|
||||
The hardware will continue to evolve and develop, but there still is a lot of innovation that has to happen. What’s holding us back, honestly, is the software.
|
||||
|
||||
**Knorr:** And that’s where a lot of your investment is going?
|
||||
|
||||
**Neri:** Correct. Exactly right. Systems software, not application software. It’s the system software that makes this infrastructure solution-oriented, workload-optimized, autonomous and efficient.
|
||||
|
||||
Join the Network World communities on [Facebook][26] and [LinkedIn][27] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3394879/hpe-s-ceo-lays-out-his-technology-vision.html
|
||||
|
||||
作者:[Eric Knorr][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/antonio-neri_hpe_new-100796112-large.jpg
|
||||
[2]: https://www.networkworld.com/article/2891130/aruba-networks-is-different-than-hps-failed-wireless-acquisitions.html
|
||||
[3]: https://www.networkworld.com/article/3158784/hpe-buying-simplivity-for-650-million-to-boost-hyperconvergence.html
|
||||
[4]: https://www.networkworld.com/article/3177376/hpe-to-pay-1-billion-for-nimble-storage-after-cutting-emc-ties.html
|
||||
[5]: https://www.networkworld.com/article/3273113/hpe-snaps-up-hyperconverged-network-hcn-vendor-plexxi.html
|
||||
[6]: https://www.networkworld.com/article/3224893/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[7]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[8]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[9]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[10]: https://www.cio.com/article/3394598/hpe-ceo-antonio-neri-rearchitects-for-the-future.html
|
||||
[11]: https://www.networkworld.com/article/3238664/80211-wi-fi-standards-and-speeds-explained.html
|
||||
[12]: https://www.networkworld.com/article/3248989/what-is-a-wide-area-network-a-definition-examples-and-where-wans-are-headed.html
|
||||
[13]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
[14]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[15]: https://www.networkworld.com/article/3235124/internet-of-things-definitions-a-handy-guide-to-essential-iot-terms.html
|
||||
[16]: https://www.networkworld.com/article/3340259/vmware-s-transformation-takes-hold.html
|
||||
[17]: https://www.networkworld.com/article/2174203/hp-expands-oneview-into-vmware-environs.html
|
||||
[18]: https://www.networkworld.com/article/3199826/hpe-highlights-innovation-in-software-defined-it-security-at-discover.html
|
||||
[19]: https://www.networkworld.com/article/3388297/hpe-and-nutanix-partner-for-hyperconverged-private-cloud-systems.html
|
||||
[20]: https://www.infoworld.com/article/3268073/what-is-kubernetes-container-orchestration-explained.html
|
||||
[21]: https://www.networkworld.com/article/3268448/what-is-hybrid-cloud-really-and-whats-the-best-strategy.html
|
||||
[22]: https://www.networkworld.com/article/2159885/cloud-computing-gartner-5-things-a-private-cloud-is-not.html
|
||||
[23]: https://www.networkworld.com/article/3285906/whats-the-future-of-server-virtualization.html
|
||||
[24]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[25]: https://www.networkworld.com/article/3266106/what-is-composable-infrastructure.html
|
||||
[26]: https://www.facebook.com/NetworkWorld/
|
||||
[27]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,53 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top auto makers rely on cloud providers for IoT)
|
||||
[#]: via: (https://www.networkworld.com/article/3395137/top-auto-makers-rely-on-cloud-providers-for-iot.html)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
Top auto makers rely on cloud providers for IoT
|
||||
======
|
||||
|
||||
For the companies looking to implement the biggest and most complex [IoT][1] setups in the world, the idea of pairing up with [AWS][2], [Google Cloud][3] or [Azure][4] seems to be one whose time has come. Within the last two months, BMW and Volkswagen have both announced large-scale deals with Microsoft and Amazon, respectively, to help operate their extensive network of operational technology.
|
||||
|
||||
According to Alfonso Velosa, vice president and analyst at Gartner, part of the impetus behind those two deals is that the automotive sector fits in very well with the architecture of the public cloud. Public clouds are great at collecting and processing data from a diverse array of different sources, whether they’re in-vehicle sensors, dealerships, mechanics, production lines or anything else.
|
||||
|
||||
**[ RELATED:[What hybrid cloud means in practice][5]. | Get regularly scheduled insights by [signing up for Network World newsletters][6]. ]**
|
||||
|
||||
“What they’re trying to do is create a broader ecosystem. They think they can leverage the capabilities from these folks,” Velosa said.
|
||||
|
||||
### Cloud providers as IoT partners
|
||||
|
||||
The idea is automated analytics for service and reliability data, manufacturing and a host of other operational functions. And while the full realization of that type of service is still very much a work in progress, it has clear-cut advantages for big companies – a skilled partner handling tricky implementation work, built-in capability for sophisticated analytics and security, and, of course, the ability to scale up in a big way.
|
||||
|
||||
Hence, the structure of the biggest public clouds has upside for many large-scale IoT deployments, not just the ones taking place in the auto industry. The cloud giants have vast infrastructures, with multiple points of presence all over the world.
|
||||
|
||||
To continue reading this article register now
|
||||
|
||||
[Get Free Access][7]
|
||||
|
||||
[Learn More][8] Existing Users [Sign In][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3395137/top-auto-makers-rely-on-cloud-providers-for-iot.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
|
||||
[2]: https://www.networkworld.com/article/3324043/aws-does-hybrid-cloud-with-on-prem-hardware-vmware-help.html
|
||||
[3]: https://www.networkworld.com/article/3388218/cisco-google-reenergize-multicloudhybrid-cloud-joint-development.html
|
||||
[4]: https://www.networkworld.com/article/3385078/microsoft-introduces-azure-stack-for-hci.html
|
||||
[5]: https://www.networkworld.com/article/3249495/what-hybrid-cloud-mean-practice
|
||||
[6]: https://www.networkworld.com/newsletters/signup.html
|
||||
[7]: javascript://
|
||||
[8]: /learn-about-insider/
|
||||
@ -0,0 +1,56 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Brillio and Blue Planet Partner to Bring Network Automation to the Enterprise)
|
||||
[#]: via: (https://www.networkworld.com/article/3394687/brillio-and-blue-planet-partner-to-bring-network-automation-to-the-enterprise.html)
|
||||
[#]: author: (Rick Hamilton, Senior Vice President, Blue Planet Software )
|
||||
|
||||
Brillio and Blue Planet Partner to Bring Network Automation to the Enterprise
|
||||
======
|
||||
Rick Hamilton, senior vice president of Blue Planet, a division of Ciena, explains how partnering with Brillio brings the next generation of network capabilities to enterprises—just when they need it most.
|
||||
![Kritchanut][1]
|
||||
|
||||
![][2]
|
||||
|
||||
_Rick Hamilton, senior vice president of Blue Planet, a division of Ciena, explains how partnering with Brillio brings the next generation of network capabilities to enterprises—just when they need it most._
|
||||
|
||||
In February 2019, we announced that Blue Planet was evolving into a more independent division, helping us increase our focus on innovative intelligent automation solutions that help our enterprise and service provider customers accelerate and achieve their business transformation goals.
|
||||
|
||||
Today we’re excited to make another leap forward in delivering these benefits to enterprises of all types via our partnership with digital transformation services and solutions leader Brillio. Together, we are co-creating intelligent cloud and network management solutions that increase service visibility and improve service assurance by effectively leveraging the convergence of cloud, IoT, and AI.
|
||||
|
||||
**Accelerating digital transformation in the enterprise**
|
||||
|
||||
Enterprises continue to look toward cloud services to create new and incremental revenue streams based on innovative solution offerings and on-demand product/solution delivery models, and to optimize their infrastructure investments. In fact, Gartner predicts that enterprise IT spending for cloud-based offerings will continue to grow faster than non-cloud IT offerings, making up 28% of spending by 2022, up from 19% in 2018.
|
||||
|
||||
As enterprises adopt cloud, they realize there are many challenges associated with traditional approaches to operating and managing complex and hybrid multi-cloud environments. Our partnership with Brillio enables us to help these organizations across industries such as manufacturing, logistics, retail, and financial services meet their technical and business needs with high-impact solutions that improve customer experiences, drive operational efficiencies, and improve quality of service.
|
||||
|
||||
This is achieved by combining the Blue Planet intelligent automation platform and the Brillio CLIP™services delivery excellence platform and user-centered design (UCD) lead solution framework. Together, we offer end-to-end visibility of application and infrastructure assets in a hybrid multi-cloud environment and provide service assurance and self-healing capabilities that improve network and service availability.
|
||||
|
||||
**Partnering on research and development**
|
||||
|
||||
Brillio will also partner with Blue Planet on longer-term R&D efforts. As one of a preferred product engineering services providers, Brillio will work closely with our engineering team to develop and deliver network intelligence and automation solutions to help enterprises build dynamic, programmable infrastructure that leverage analytics and automation to realize the Adaptive Network vision.
|
||||
|
||||
Of course, a partnership like this is a two-way street, and we consider Brillio’s choice to work with us to be a testament to our expertise, vision, and execution. In the words of Brillio Chairman and CEO Raj Mamodia, “Blue Planet’s experience in end-to-end service orchestration coupled with Brillio’s expertise in cloudification, user-centered enterprise solutions design, and rapid software development delivers distinct advantages to the industry. Through integration of technologies like cloud, IoT, and AI into our combined solutions, our partnership spurs greater innovation and helps us address the large and growing enterprise networking automation market.”
|
||||
|
||||
Co-creating intelligent hybrid cloud and network management solutions with Brillio is key to advancing enterprise digital transformation initiatives. Partnering with Brillio helps us address the plethora of challenges facing enterprises today on their digital journey. Our partnership enables Blue Planet to achieve faster time-to-market and greater efficiency in developing new solutions to enable enterprises to continue to thrive and grow.
|
||||
|
||||
[Learn more about Blue Planet here][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3394687/brillio-and-blue-planet-partner-to-bring-network-automation-to-the-enterprise.html
|
||||
|
||||
作者:[Rick Hamilton, Senior Vice President, Blue Planet Software][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/istock-952625346-100796314-large.jpg
|
||||
[2]: https://images.idgesg.net/images/article/2019/05/rick-100796315-small.jpg
|
||||
[3]: https://www.blueplanet.com/?utm_campaign=X1058319&utm_source=NWW&utm_term=BPWeb_Brillio&utm_medium=sponsoredpost3Q19
|
||||
@ -0,0 +1,65 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Las Vegas targets transport, public safety with IoT deployments)
|
||||
[#]: via: (https://www.networkworld.com/article/3395536/las-vegas-targets-transport-public-safety-with-iot-deployments.html)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
Las Vegas targets transport, public safety with IoT deployments
|
||||
======
|
||||
|
||||
![Franck V. \(CC0\)][1]
|
||||
|
||||
The city of Las Vegas’ pilot program with NTT and Dell, designed to crack down on wrong-way driving on municipal roads, is just part of the big plans that Sin City has for leveraging IoT tech in the future, according to the city's director of technology Michael Sherwood, who sat down with Network World at the IoT World conference in Silicon Valley this week.
|
||||
|
||||
The system uses smart cameras and does most of its processing at the edge, according to Sherwood. The only information that gets sent back to the city’s private cloud is metadata – aggregated information about overall patterns, for decision-making and targeting purposes, not data about individual traffic incidents and wrong-way drivers.
|
||||
|
||||
**[ Also see[What is edge computing?][2] and [How edge networking and IoT will reshape data centers][3].]**
|
||||
|
||||
It’s an important public safety consideration, he said, but it’s a small part of the larger IoT-enabled framework that the city envisions for the future.
|
||||
|
||||
“Our goal is to make our data open to the public, not only for transparency purposes, but to help spur development and create new applications to make Vegas a better place to live,” said Sherwood.
|
||||
|
||||
[The city’s public data repository][4] already boasts a range of relevant data, some IoT-generated, some not. And efforts to make that data store more open have already begun to bear fruit, according to Sherwood. For example, one hackathon about a year ago resulted in an Alexa app that tells users how many traffic lights are out, by tracking energy usage data via the city’s portal, among other applications.
|
||||
|
||||
As with IoT in general, Sherwood said that the city’s efforts have been bolstered by an influx of operational talen. Rather than additional IT staff to run the new systems, they’ve brought in experts from the traffic department to help get the most out of the framework.
|
||||
|
||||
Another idea for leveraging the city’s traffic data involves tracking the status of the curb. Given the rise of Uber and Lyft and other on-demand transportation services, linking a piece of camera-generated information like “rideshares are parked along both sides of this street” directly into a navigation app could help truck drivers avoid gridlock.
|
||||
|
||||
“We’re really looking to make the roads a living source of information,” Sherwood said.
|
||||
|
||||
**Safer parks**
|
||||
|
||||
Las Vegas is also pursuing related public safety initiatives. One pilot project aims to make public parks safer by installing infrared cameras so authorities can tell whether people are in parks after hours without incurring undue privacy concerns, given that facial recognition is very tricky in infrared.
|
||||
|
||||
It’s the test-and-see method of IoT development, according to Sherwood.
|
||||
|
||||
“That’s a way of starting with an IoT project: start with one park. The cost to do something like this is not astronomical, and it allows you to gauge some other information from it,” he said.
|
||||
|
||||
The city has also worked to keep the costs of these projects low or even show a returnon investment, Sherwood added. Workforce development programs could train municipal workers to do simple maintenance on smart cameras in parks or along roadways, and the economic gains made from the successful use of the systems ought to outweigh deployment and operational outlay.
|
||||
|
||||
“If it’s doing it’s job, those efficiencies should cover the system’s cost,” he said.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3395536/las-vegas-targets-transport-public-safety-with-iot-deployments.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/07/pedestrian-walk-sign_go_start_begin_traffic-light_by-franck-v-unsplaash-100765089-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[3]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[4]: https://opendata.lasvegasnevada.gov/
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Mobility and SD-WAN, Part 1: SD-WAN with 4G LTE is a Reality)
|
||||
[#]: via: (https://www.networkworld.com/article/3394866/mobility-and-sd-wan-part-1-sd-wan-with-4g-lte-is-a-reality.html)
|
||||
[#]: author: (Francisca Segovia )
|
||||
|
||||
Mobility and SD-WAN, Part 1: SD-WAN with 4G LTE is a Reality
|
||||
======
|
||||
|
||||
![istock][1]
|
||||
|
||||
Without a doubt, 5G — the fifth generation of mobile wireless technology — is the hottest topic in wireless circles today. You can’t throw a stone without hitting 5G news. While telecommunications providers are in a heated competition to roll out 5G, it’s important to reflect on current 4G LTE (Long Term Evolution) business solutions as a preview of what we have learned and what’s possible.
|
||||
|
||||
This is part one of a two-part blog series that will explore the [SD-WAN][2] journey through the evolution of these wireless technologies.
|
||||
|
||||
### **Mobile SD-WAN is a reality**
|
||||
|
||||
4G LTE commercialization continues to expand. According to [the GSM (Groupe Spéciale Mobile) Association][3], 710 operators have rolled out 4G LTE in 217 countries, reaching 83 percent of the world’s population. The evolution of 4G is transforming the mobile industry and is setting the stage for the advent of 5G.
|
||||
|
||||
Mobile connectivity is increasingly integrated with SD-WAN, along with MPLS and broadband WAN services today. 4G LTE represents a very attractive transport alternative, as a backup or even an active member of the WAN transport mix to connect users to critical business applications. And in some cases, 4G LTE might be the only choice in locations where fixed lines aren’t available or reachable. Furthermore, an SD-WAN can optimize 4G LTE connectivity and bring new levels of performance and availability to mobile-based business use cases by selecting the best path available across several 4G LTE connections.
|
||||
|
||||
### **Increasing application performance and availability with 4G LTE**
|
||||
|
||||
Silver Peak has partnered with [BEC Technologies][4] to create a joint solution that enables customers to incorporate one or more low-cost 4G LTE services into any [Unity EdgeConnect™][5] SD-WAN edge platform deployment. All the capabilities of the EdgeConnect platform are supported across LTE links including packet-based link bonding, dynamic path control, path conditioning along with the optional [Unity Boost™ WAN Optimization][6] performance pack. This ensures always-consistent, always-available application performance even in the event of an outage or degraded service.
|
||||
|
||||
EdgeConnect also incorporates sophisticated NAT traversal technology that eliminates the requirement for provisioning the LTE service with extra-cost static IP addresses. The Silver Peak [Unity Orchestrator™][7] management software enables the prioritization of LTE bandwidth usage based on branch and application requirements – active-active or backup-only. This solution is ideal in retail point-of-sale and other deployment use cases where always-available WAN connectivity is critical for the business.
|
||||
|
||||
### **Automated SD-WAN enables innovative services**
|
||||
|
||||
An example of an innovative mobile SD-WAN service is [swyMed’s DOT Telemedicine Backpack][8] powered by the EdgeConnect [Ultra Small][9] hardware platform. This integrated telemedicine solution enables first responders to connect to doctors and communicate patient vital statistics and real-time video anywhere, any time, greatly improving and expediting care for emergency patients. Using a lifesaving backpack provisioned with two LTE services from different carriers, EdgeConnect continuously monitors the underlying 4G LTE services for packet loss, latency and jitter. In the case of transport failure or brownout, EdgeConnect automatically initiates a sub-second failover so that voice, video and data connections continue without interruption over the remaining active 4G service. By bonding the two LTE links together with the EdgeConnect SD-WAN, swyMed can achieve an aggregate signal quality in excess of 90 percent, bringing mobile telemedicine to areas that would have been impossible in the past due to poor signal strength.
|
||||
|
||||
To learn more about SD-WAN and the unique advantages that SD-WAN provides to enterprises across all industries, visit the [SD-WAN Explained][2] page on our website.
|
||||
|
||||
### **Prepare for the 5G future**
|
||||
|
||||
In summary, the adoption of 4G LTE is a reality. Service providers are taking advantage of the distinct benefits of SD-WAN to offer managed SD-WAN services that leverage 4G LTE.
|
||||
|
||||
As the race for the 5G gains momentum, service providers are sure to look for ways to drive new revenue streams to capitalize on their initial investments. Stay tuned for part 2 of this 2-blog series where I will discuss how SD-WAN is one of the technologies that can help service providers to transition from 4G to 5G and enable the monetization of a new wave of managed 5G services.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3394866/mobility-and-sd-wan-part-1-sd-wan-with-4g-lte-is-a-reality.html
|
||||
|
||||
作者:[Francisca Segovia][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/istock-952414660-100796279-large.jpg
|
||||
[2]: https://www.silver-peak.com/sd-wan/sd-wan-explained
|
||||
[3]: https://www.gsma.com/futurenetworks/resources/all-ip-statistics/
|
||||
[4]: https://www.silver-peak.com/resource-center/edgeconnect-4glte-solution-bec-technologies
|
||||
[5]: https://www.silver-peak.com/products/unity-edge-connect
|
||||
[6]: https://www.silver-peak.com/products/unity-boost
|
||||
[7]: https://www.silver-peak.com/products/unity-orchestrator
|
||||
[8]: https://www.silver-peak.com/resource-center/mobile-telemedicine-helps-save-lives-streaming-real-time-clinical-data-and-patient
|
||||
[9]: https://www.silver-peak.com/resource-center/edgeconnect-us-ec-us-specification-sheet
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Extreme addresses networked-IoT security)
|
||||
[#]: via: (https://www.networkworld.com/article/3395539/extreme-addresses-networked-iot-security.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Extreme addresses networked-IoT security
|
||||
======
|
||||
The ExtremeAI security app features machine learning that can understand typical behavior of IoT devices and alert when it finds anomalies.
|
||||
![Getty Images][1]
|
||||
|
||||
[Extreme Networks][2] has taken the wraps off a new security application it says will use machine learning and artificial intelligence to help customers effectively monitor, detect and automatically remediate security issues with networked IoT devices.
|
||||
|
||||
The application – ExtremeAI security—features machine-learning technology that can understand typical behavior of IoT devices and automatically trigger alerts when endpoints act in unusual or unexpected ways, Extreme said.
|
||||
|
||||
**More about edge networking**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][3]
|
||||
* [Edge computing best practices][4]
|
||||
* [How edge computing can help secure the IoT][5]
|
||||
|
||||
|
||||
|
||||
Extreme said that the ExtremeAI Security application can tie into all leading threat intelligence feeds, and had close integration with its existing [Extreme Workflow Composer][6] to enable automatic threat mitigation and remediation.
|
||||
|
||||
The application integrates the company’s ExtremeAnalytics application which lets customers view threats by severity, category, high-risk endpoints and geography. An automated ticketing feature integrates with variety of popular IT tools such as Slack, Jira, and ServiceNow, and the application interoperates with many popular security tools, including existing network taps, the vendor stated.
|
||||
|
||||
There has been an explosion of new endpoints ranging from million-dollar smart MRI machines to five-dollar sensors, which creates a complex and difficult job for network and security administrators, said Abby Strong, vice president of product marketing for Extreme. “We need smarter, secure and more self-healing networks especially where IT cybersecurity resources are stretched to the limit.”
|
||||
|
||||
Extreme is trying to address an issue that is important to enterprise-networking customers: how to get actionable, usable insights as close to real-time as possible, said Rohit Mehra, Vice President of Network Infrastructure at IDC. “Extreme is melding automation, analytics and security that can look at network traffic patterns and allow the system to take action when needed.”
|
||||
|
||||
The ExtremeAI application, which will be available in October, is but one layer of IoT security Extreme offers. Already on the market, its [Defender for IoT][7] package, which includes a Defender application and adapter, lets customers monitor, set policies and isolate IoT devices across an enterprise.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][8] ]**
|
||||
|
||||
The Extreme AI and Defender packages are now part of what the company calls Extreme Elements, which is a menu of its new and existing Smart OmniEdge, Automated Campus and Agile Data Center software, hardware and services that customers can order to build a manageable, secure system.
|
||||
|
||||
Aside from the applications, the Elements include Extreme Management Center, the company’s network management software; the company’s x86-based intelligent appliances, including the ExtremeCloud Appliance; and [ExtremeSwitching X465 premium][9], a stackable multi-rate gigabit Ethernet switch.
|
||||
|
||||
The switch and applications are just the beginning of a very busy time for Extreme. In its [3Q earnings cal][10]l this month company CEO Ed Meyercord noted Extreme was in the “early stages of refreshing 70 percent of our products” and seven different products will become generally available this quarter – a record for Extreme, he said.
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3395539/extreme-addresses-networked-iot-security.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/iot_security_tablet_conference_digital-100787102-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3289508/extreme-facing-challenges-girds-for-future-networking-battles.html
|
||||
[3]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[4]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[5]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[6]: https://www.extremenetworks.com/product/workflow-composer/
|
||||
[7]: https://www.extremenetworks.com/product/extreme-defender-for-iot/
|
||||
[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[9]: https://community.extremenetworks.com/extremeswitching-exos-223284/extremexos-30-2-and-smart-omniedge-premium-x465-switches-are-now-available-7823377
|
||||
[10]: https://seekingalpha.com/news/3457137-extreme-networks-minus-15-percent-quarterly-miss-light-guidance
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (IBM overhauls mainframe-software pricing, adds hybrid, private-cloud services)
|
||||
[#]: via: (https://www.networkworld.com/article/3395776/ibm-overhauls-mainframe-software-pricing-adds-hybrid-private-cloud-services.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
IBM overhauls mainframe-software pricing, adds hybrid, private-cloud services
|
||||
======
|
||||
IBM brings cloud consumption model to the mainframe, adds Docker container extensions
|
||||
![Thinkstock][1]
|
||||
|
||||
IBM continues to adopt new tools and practices for its mainframe customers to keep the Big Iron relevant in a cloud world.
|
||||
|
||||
First of all, the company switched-up its 20-year mainframe software pricing scheme to make it more palatable to hybrid and multicloud users who might be thinking of moving workloads off the mainframe and into the cloud.
|
||||
|
||||
**[ Check out[What is hybrid cloud computing][2] and learn [what you need to know about multi-cloud][3]. | Get regularly scheduled insights by [signing up for Network World newsletters][4]. ]**
|
||||
|
||||
Specifically IBM rolled out Tailored Fit Pricing for the IBM Z mainframe which offers two consumption-based pricing models that can help customers cope with ever-changing workload – and hence software – costs.
|
||||
|
||||
Tailored Fit Pricing removes the need for complex and restrictive capping, which typically weakens responsiveness and can impact service level availability, IBM said. IBM’s standard monthly mainframe licensing model calculates costs as a “rolling four-hour average” (R4HA) which would determine cost based on a customer’s peak usage during the month. Customers would many time cap usage to keep costs down, experts said
|
||||
|
||||
Systems can now be configured to support optimal response times and service level agreements, rather than artificially slowing down workloads to manage software licensing costs, IBM stated.
|
||||
|
||||
Predicting demand for IT services can be a major challenge and in the era of hybrid and multicloud, everything is connected and workload patterns constantly change, wrote IBM’s Ross Mauri, General Manager, IBM Z in a [blog][5] about the new pricing and services. “In this environment, managing demand for IT services can be a major challenge. As more customers shift to an enterprise IT model that incorporates on-premises, private cloud and public we’ve developed a simple cloud pricing model to drive the transformation forward.”
|
||||
|
||||
[Tailored Fit Pricing][6] for IBM Z comes in two flavors, the Enterprise Consumption Solution and the Enterprise Capacity Solution.
|
||||
|
||||
IBM said the Enterprise Consumption model is a tailored usage-based pricing model, where customers pay only for what they use, removing the need for complex and restrictive capping, IBM said.
|
||||
|
||||
The Enterprise Capacity model lets customers mix and match workloads to help maximize use of the full capacity of the platform. Charges are referenced to the overall size of the physical environment and are calculated based on the estimated mix of workloads running, while providing the flexibility to vary actual usage across workloads, IBM said.
|
||||
|
||||
The software pricing changes should be a welcome benefit to customers, experts said.
|
||||
|
||||
“By making access to Z mainframes more flexible and ‘cloud-like,’ IBM is making it less likely that customers will consider shifting Z workloads to other systems and environments. As cloud providers become increasingly able to support mission critical applications, that’s a big deal,” wrote Charles King, president and principal analyst for Pund-IT in a [blog][7] about the IBM changes.
|
||||
|
||||
“A notable point about both models is that discounted growth pricing is offered on all workloads – whether they be 40-year old Assembler programs or 4-day old JavaScript apps. This is in contrast to previous models which primarily rewarded only brand-new applications with growth pricing. By thinking outside the Big Iron box, the company has substantially eased the pain for its largest clients’ biggest mainframe-related headaches,” King wrote.
|
||||
|
||||
IBM’s Tailored Fit Pricing supports an increasing number of enterprises that want to continue to grow and build new services on top of this mission-critical platform, wrote [John McKenny][8] vice president of strategy for ZSolutions Optimization at BMC Software. “In not yet released results from the 2019 BMC State of the Mainframe Survey, 62% of the survey respondents reported that they are planning to expand MIPS/MSU consumption and are growing their mainframe workloads. For customers with no current plans for growth, the affordability and cost-competitiveness of the new pricing model will re-ignite interest in also using this platform as an integral part of their hybrid cloud strategies.”
|
||||
|
||||
In addition to the pricing, IBM announced some new services that bring the mainframe closer to cloud workloads.
|
||||
|
||||
First, IBM rolled out z/OS Container Extensions (zCX), which makes it possible to run Linux on Z applications that are packaged as Docker Container images on z/OS. Application developers can develop and data centers can operate popular open source packages, Linux applications, IBM software, and third-party software together with z/OS applications and data, IBM said. zCX will let customers use the latest open source tools, popular NoSQL databases, analytics frameworks, application servers, and so on within the z/OS environment.
|
||||
|
||||
“With z/OS Container Extensions, customers will be able to access the most recent development tools and processes available in Linux on the Z ecosystem, giving developers the flexibility to build new, cloud-native containerized apps and deploy them on z/OS without requiring Linux or a Linux partition,” IBM’s Mauri stated.
|
||||
|
||||
Big Blue also rolled out z/OS Cloud Broker which will let customers access and deploy z/OS resources and services on [IBM Cloud Private][9]. [IBM Cloud Private][10] is the company’s Kubernetes-based Platform as a Service (PaaS) environment for developing and managing containerized applications. IBM said z/OS Cloud Broker is designed to help cloud application developers more easily provision and deprovision apps in z/OS environments.
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3395776/ibm-overhauls-mainframe-software-pricing-adds-hybrid-private-cloud-services.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2015/08/thinkstockphotos-520137237-100610459-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3233132/cloud-computing/what-is-hybrid-cloud-computing.html
|
||||
[3]: https://www.networkworld.com/article/3252775/hybrid-cloud/multicloud-mania-what-to-know.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://www.ibm.com/blogs/systems/ibm-z-defines-the-future-of-hybrid-cloud/
|
||||
[6]: https://www-01.ibm.com/common/ssi/cgi-bin/ssialias?infotype=AN&subtype=CA&htmlfid=897/ENUS219-014&appname=USN
|
||||
[7]: https://www.pund-it.com/blog/ibm-reinvents-the-z-mainframe-again/
|
||||
[8]: https://www.bmc.com/blogs/bmc-supports-ibm-tailored-fit-pricing-ibm-z/
|
||||
[9]: https://www.ibm.com/marketplace/cloud-private-on-z-and-linuxone
|
||||
[10]: https://www.networkworld.com/article/3340043/ibm-marries-on-premises-private-and-public-cloud-data.html
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,88 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Will 5G be the first carbon-neutral network?)
|
||||
[#]: via: (https://www.networkworld.com/article/3395465/will-5g-be-the-first-carbon-neutral-network.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Will 5G be the first carbon-neutral network?
|
||||
======
|
||||
Increased energy consumption in new wireless networks could become ecologically unsustainable. Engineers think they have solutions that apply to 5G, but all is not certain.
|
||||
![Dushesina/Getty Images][1]
|
||||
|
||||
If wireless networks transfer 1,000 times more data, does that mean they will use 1,000 times more energy? It probably would with the old 4G LTE wireless technologies— LTE doesn’t have much of a sleep-standby. But with 5G, we might have a more energy-efficient option.
|
||||
|
||||
More customers want Earth-friendly options, and engineers are now working on how to achieve it — meaning 5G might introduce the first zero-carbon networks. It’s not all certain, though.
|
||||
|
||||
**[ Related:[What is 5G wireless? And how it will change networking as we know it][2] ]**
|
||||
|
||||
“When the 4G technology for wireless communication was developed, not many people thought about how much energy is consumed in transmitting bits of information,” says Emil Björnson, associate professor of communication systems at Linkoping University, [in an article on the school’s website][3].
|
||||
|
||||
Standby was never built into 4G, Björnson explains. Reasons include overbuilding — the architects wanted to ensure connections didn’t fail, so they just kept the power up. The downside to that redundancy was that almost the same amount of energy is used whether the system is transmitting data or not.
|
||||
|
||||
“We now know that this is not necessary,” Björnson says. 5G networks don’t use much power during periods of low traffic, and that reduces power consumption.
|
||||
|
||||
Björnson says he knows how to make future-networks — those 5G networks that one day may become the enterprise broadband replacement — super efficient even when there is heavy use. Massive-MIMO (multiple-in, multiple-out) antennas are the answer, he says. That’s hundreds of connected antennas taking advantage of multipath.
|
||||
|
||||
I’ve written before about some of Björnson's Massive-MIMO ideas. He thinks [Massive-MIMO will remove all capacity ceilings from wireless networks][4]. However, he now adds calculations to his research that he claims prove that the Massive-MIMO antenna technology will also reduce power use. He and his group are actively promoting their academic theories in a paper ([pdf][5]).
|
||||
|
||||
**[[Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][6] ]**
|
||||
|
||||
### Nokia's plan to reduce wireless networks' CO2 emissions
|
||||
|
||||
Björnson's isn’t the only 5G-aimed eco-concept out there. Nokia points out that it isn't just radios transmitting that use electricity. Cooling is actually the main electricity hog, says the telcommunications company, which is one of the world’s principal manufacturers of mobile network equipment.
|
||||
|
||||
Nokia says the global energy cost of Radio Access Networks (RANs) in 2016 (the last year numbers were available), which includes base transceiver stations (BTSs) needed by mobile networks, was around $80 billion. That figure increases with more users coming on stream, something that’s probable. Of the BTS’s electricity use, about 90% “converts to waste heat,” [Harry Kuosa, a marketing executive, writes on Nokia’s blog][7]. And base station sites account for about 80% of a mobile network’s entire energy use, Nokia expands on its website.
|
||||
|
||||
“A thousand-times more traffic that creates a thousand-times higher energy costs is unsustainable,” Nokia says in its [ebook][8] on the subject, “Turning the zero carbon vision into business opportunity,” and it’s why Nokia plans liquid-cooled 5G base stations among other things, including chip improvements. It says the liquid-cooling can reduce CO2 emissions by up to 80%.
|
||||
|
||||
### Will those ideas work?
|
||||
|
||||
Not all agree power consumption can be reduced when implementing 5G, though. Gabriel Brown of Heavy Reading, quotes [in a tweet][9] a China Mobile executive as saying that 5G BTSs will use three times as much power as 4G LTE ones because the higher frequencies used in 5G mean one needs more BTS units to provide the same geographic coverage: For physics reasons, higher frequencies equals shorter range.
|
||||
|
||||
If, as is projected, 5G develops into the new enterprise broadband for the internet of things (IoT), along with associated private networks covering everything else, then these eco- and cost-important questions are going to be salient — and they need answers quickly. 5G will soon be here, and [Gartner estimates that 60% of organizations will adopt it][10].
|
||||
|
||||
**More about 5G networks:**
|
||||
|
||||
* [How enterprises can prep for 5G networks][11]
|
||||
* [5G vs 4G: How speed, latency and apps support differ][12]
|
||||
* [Private 5G networks are coming][13]
|
||||
* [5G and 6G wireless have security issues][14]
|
||||
* [How millimeter-wave wireless could help support 5G and IoT][15]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][16] and [LinkedIn][17] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3395465/will-5g-be-the-first-carbon-neutral-network.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/01/4g-versus-5g_horizon_sunrise-100784230-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3203489/lan-wan/what-is-5g-wireless-networking-benefits-standards-availability-versus-lte.html
|
||||
[3]: https://liu.se/en/news-item/okningen-av-mobildata-kraver-energieffektivare-nat
|
||||
[4]: https://www.networkworld.com/article/3262991/future-wireless-networks-will-have-no-capacity-limits.html
|
||||
[5]: https://arxiv.org/pdf/1812.01688.pdf
|
||||
[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[7]: https://www.nokia.com/blog/nokia-has-ambitious-plans-reduce-network-power-consumption/
|
||||
[8]: https://pages.nokia.com/2364.Zero.Emissions.ebook.html?did=d000000001af&utm_campaign=5g_in_action_&utm_source=twitter&utm_medium=organic&utm_term=0dbf430c-1c94-47d7-8961-edc4f0ba3270
|
||||
[9]: https://twitter.com/Gabeuk/status/1099709788676636672?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1099709788676636672&ref_url=https%3A%2F%2Fwww.lightreading.com%2Fmobile%2F5g%2Fpower-consumption-5g-basestations-are-hungry-hungry-hippos%2Fd%2Fd-id%2F749979
|
||||
[10]: https://www.gartner.com/en/newsroom/press-releases/2018-12-18-gartner-survey-reveals-two-thirds-of-organizations-in
|
||||
[11]: https://www.networkworld.com/article/3306720/mobile-wireless/how-enterprises-can-prep-for-5g.html
|
||||
[12]: https://www.networkworld.com/article/3330603/mobile-wireless/5g-versus-4g-how-speed-latency-and-application-support-differ.html
|
||||
[13]: https://www.networkworld.com/article/3319176/mobile-wireless/private-5g-networks-are-coming.html
|
||||
[14]: https://www.networkworld.com/article/3315626/network-security/5g-and-6g-wireless-technologies-have-security-issues.html
|
||||
[15]: https://www.networkworld.com/article/3291323/mobile-wireless/millimeter-wave-wireless-could-help-support-5g-and-iot.html
|
||||
[16]: https://www.facebook.com/NetworkWorld/
|
||||
[17]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (HPE to buy Cray, offer HPC as a service)
|
||||
[#]: via: (https://www.networkworld.com/article/3396220/hpe-to-buy-cray-offer-hpc-as-a-service.html)
|
||||
[#]: author: (Tim Greene https://www.networkworld.com/author/Tim-Greene/)
|
||||
|
||||
HPE to buy Cray, offer HPC as a service
|
||||
======
|
||||
High-performance computing offerings from HPE plus Cray could enable things like AI, ML, high-speed financial trading, creation digital twins for entire enterprise networks.
|
||||
![Cray Inc.][1]
|
||||
|
||||
HPE has agreed to buy supercomputer-maker Cray for $1.3 billion, a deal that the companies say will bring their corporate customers high-performance computing as a service to help with analytics needed for artificial intelligence and machine learning, but also products supporting high-performance storage, compute and software.
|
||||
|
||||
In addition to bringing HPC capabilities that can blend with and expand HPE’s current products, Cray brings with it customers in government and academia that might be interested in HPE’s existing portfolio as well.
|
||||
|
||||
**[ Now read:[Who's developing quantum computers][2] ]**
|
||||
|
||||
The companies say they expect to close the cash deal by the end of next April.
|
||||
|
||||
The HPC-as-a-service would be offered through [HPE GreenLake][3], the company’s public-, private-, hybrid-cloud service. Such a service could address periodic enterprise need for fast computing that might otherwise be too expensive, says Tim Zimmerman, an analyst with Gartner.
|
||||
|
||||
Businesses could use the service, for example, to create [digital twins][4] of their entire networks and use them to test new code to see how it will impact the network before deploying it live, Zimmerman says.
|
||||
|
||||
Cray has HPC technology that HPE Labs might be exploring on its own, but that can be brought to market in a much quicker timeframe.
|
||||
|
||||
HPE says that overall, buying cray give it technologies needed for massively data-intensive workloads such as AI and ML that is used for engineering services, transaction-based trading by financial firms, pharmaceutical research and academic studies into weather and genomes, for instance, Zimmerman says.
|
||||
|
||||
As HPE puts it, Cray supercomputing platforms “have the ability to handle massive data sets, converged modelling, simulation, AI and analytics workloads.”
|
||||
|
||||
Cray is working on [what it says will be the world’s fastest supercomputer][5] when it’s finished in 2021, cranking out 1.5 exaflops. The current fastest supercomputer is 143.5 petaflops. [Click [here][6] to see the current top 10 fastest supercomputers.]
|
||||
|
||||
In general, HPE says it hopes to create a comprehensive line of products to support HPC infrastructure including “compute, high-performance storage, system interconnects, software and services.”
|
||||
|
||||
Together, the talent in the two companies and their combined technologies should be able to increase innovation, HPE says.
|
||||
|
||||
Earlier this month, HPE’s CEO Antonio Neri said in [an interview with _Network World_][7] that the company will be investing $4 billion over four years in a range of technology to boost “connectivity, security, and obviously cloud and analytics.” In laying out the company’s roadmap he made no specific mention of HPC.
|
||||
|
||||
HPE net revenues last fiscal year were $30.9 billion. Cray’s total revenue was $456 million, with a gross profit of $130 million.
|
||||
|
||||
The acquisition will pay $35 per share for Cray stock.
|
||||
|
||||
Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3396220/hpe-to-buy-cray-offer-hpc-as-a-service.html
|
||||
|
||||
作者:[Tim Greene][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Tim-Greene/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/06/the_cray_xc30_piz_daint_system_at_the_swiss_national_supercomputing_centre_via_cray_inc_3x2_978x652-100762113-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3275385/who-s-developing-quantum-computers.html
|
||||
[3]: https://www.networkworld.com/article/3280996/hpe-adds-greenlake-hybrid-cloud-to-enterprise-service-offerings.html
|
||||
[4]: https://www.networkworld.com/article/3280225/what-is-digital-twin-technology-and-why-it-matters.html
|
||||
[5]: https://www.networkworld.com/article/3373539/doe-plans-worlds-fastest-supercomputer.html
|
||||
[6]: https://www.networkworld.com/article/3236875/embargo-10-of-the-worlds-fastest-supercomputers.html
|
||||
[7]: https://www.networkworld.com/article/3394879/hpe-s-ceo-lays-out-his-technology-vision.html
|
||||
[8]: https://www.facebook.com/NetworkWorld/
|
||||
[9]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The modern data center and the rise in open-source IP routing suites)
|
||||
[#]: via: (https://www.networkworld.com/article/3396136/the-modern-data-center-and-the-rise-in-open-source-ip-routing-suites.html)
|
||||
[#]: author: (Matt Conran https://www.networkworld.com/author/Matt-Conran/)
|
||||
|
||||
The modern data center and the rise in open-source IP routing suites
|
||||
======
|
||||
Open source enables passionate people to come together and fabricate work of phenomenal quality. This is in contrast to a single vendor doing everything.
|
||||
![fdecomite \(CC BY 2.0\)][1]
|
||||
|
||||
As the cloud service providers and search engines started with the structuring process of their business, they quickly ran into the problems of managing the networking equipment. Ultimately, after a few rounds of getting the network vendors to understand their problems, these hyperscale network operators revolted.
|
||||
|
||||
Primarily, what the operators were looking for was a level of control in managing their network which the network vendors couldn’t offer. The revolution burned the path that introduced open networking, and network disaggregation to the work of networking. Let us first learn about disaggregation followed by open networking.
|
||||
|
||||
### Disaggregation
|
||||
|
||||
The concept of network disaggregation involves breaking-up of the vertical networking landscape into individual pieces, where each piece can be used in the best way possible. The hardware can be separated from the software, along with open or closed IP routing suites. This enables the network operators to use the best of breed for the hardware, software and the applications.
|
||||
|
||||
**[ Now see[7 free network tools you must have][2]. ]**
|
||||
|
||||
Networking has always been built as an appliance and not as a platform. The mindset is that the network vendor builds an appliance and as a specialized appliance, they will completely control what you can and cannot do on that box. In plain words, they will not enable anything that is not theirs. As a result, they act as gatekeepers and not gate-enablers.
|
||||
|
||||
Network disaggregation empowers the network operators with the ability to lay hands on the features they need when they need them. However, this is impossible in case of non-disaggregated hardware.
|
||||
|
||||
### Disaggregation leads to using best-of-breed
|
||||
|
||||
In the traditional vertically integrated networking market, you’re forced to live with the software because you like the hardware, or vice-versa. But network disaggregation drives different people to develop things that matter to them. This allows multiple groups of people to connect, with each one focused on doing what he or she does the best. Switching silicon manufacturers can provide the best merchant silicon. Routing suites can be provided by those who are the best at that. And the OS vendors can provide the glue that enables all of these to work well together.
|
||||
|
||||
With disaggregation, people are driven to do what they are good at. One company does the hardware, whereas another does the software and other company does the IP routing suites. Hence, today the networking world looks like more of the server world.
|
||||
|
||||
### Open source
|
||||
|
||||
Within this rise of the modern data center, there is another element that is driving network disaggregation; the notion of open source. Open source is “denoting software for which the original source code is made freely available, it may be redistributed and modified.” It enables passionate people to come together and fabricate work of phenomenal quality. This is in contrast to a single vendor doing everything.
|
||||
|
||||
As a matter of fact, the networking world has always been very vendor driven. However, the advent of open source gives the opportunity to like-minded people rather than the vendor controlling the features. This eliminates the element of vendor lock-in, thereby enabling interesting work. Open source allows more than one company to be involved.
|
||||
|
||||
### Open source in the data center
|
||||
|
||||
The traditional enterprise and data center networks were primarily designed by bridging and Spanning Tree Protocol (STP). However, the modern data center is driven by IP routing and the CLOS topology. As a result, you need a strong IP routing suite.
|
||||
|
||||
That was the point where the need for an open-source routing suite surfaced, the suite that can help drive the modern data center. The primary open-source routing suites are [FRRouting (FRR)][3], BIRD, GoBGP and ExaBGP.
|
||||
|
||||
Open-source IP routing protocol suites are slowly but steadily gaining acceptance and are used in data centers of various sizes. Why? It is because they allow a community of developers and users to work on finding solutions to common problems. Open-source IP routing protocol suites equip them to develop the specific features that they need. It also helps the network operators to create simple designs that make sense to them, as opposed to having everything controlled by the vendor. They also enable routing suites to run on compute nodes. Kubernetes among others uses this model of running a routing protocol on a compute node.
|
||||
|
||||
Today many startups are using FRR. Out of all of the IP routing suites, FRR is preferred in the data center as the primary open-source IP routing protocol suite. Some traditional network vendors have even demonstrated the use of FRR on their networking gear.
|
||||
|
||||
There are lots of new features currently being developed for FRR, not just by the developers but also by the network operators.
|
||||
|
||||
### Use cases for open-source routing suites
|
||||
|
||||
When it comes to use-cases, where do IP routing protocol suites sit? First and foremost, if you want to do any type of routing in the disaggregated network world, you need an IP routing suite.
|
||||
|
||||
Some operators are using FRR at the edge of the network as well, thereby receiving full BGP feeds. Many solutions which use Intel’s DPDK for packet forwarding use FRR as the control plane, receiving full BGP feeds. In addition, there are other vendors using FRR as the core IP routing suite for a full leaf and spine data center architecture. You can even get a version of FRR on pfSense which is a free and open source firewall.
|
||||
|
||||
We need to keep in mind that reference implementations are important. Open source allows you to test at scale. But vendors don’t allow you to do that. However, with FRR, we have the ability to spin up virtual machines (VMs) or even containers by using software like Vagrant to test your network. Some vendors do offer software versions, but they are not fully feature-compatible.
|
||||
|
||||
Also, with open source you do not need to wait. This empowers you with flexibility and speed which drives the modern data center.
|
||||
|
||||
### Deep dive on FRRouting (FRR)
|
||||
|
||||
FRR is a Linux foundation project. In a technical Linux sense, FRR is a group of daemons that work together, providing a complete routing suite that includes BGP, IS-IS, LDP, OSPF, BFD, PIM, and RIP.
|
||||
|
||||
Each one of these daemons communicate with the common routing information base (RIB) daemon called Zebra in order to interface with the OS and to resolve conflicts between the multiple routing protocols providing the same information. Interfacing with the OS is used to receive the link up/down events, to add and delete routes etc.
|
||||
|
||||
### FRRouting (FRR) components: Zebra
|
||||
|
||||
Zebra is the RIB of the routing systems. It knows everything about the state of the system relevant to routing and is able to pass and disseminate this information to all the interested parties.
|
||||
|
||||
The RIB in FRR acts just like a traditional RIB. When a route wins, it goes into the Linux kernel data plane where the forwarding occurs. All of the routing protocols run as separate processes and each of them have their source code in FRR.
|
||||
|
||||
For example, when BGP starts up, it needs to know, for instance, what kind of virtual routing and forwarding (VRF) and IP interfaces are available. Zebra collects and passes this information back to the interested daemons. It passes all the relevant information about state of the machine.
|
||||
|
||||
Furthermore, you can also register information with Zebra. For example, if a particular route changes, the daemon can be informed. This can also be used for reverse path forwarding (RPF). FRR doesn't need to do a pull when changes happen on the network.
|
||||
|
||||
There are a myriad of ways through which you can control Linux and the state. Sometimes you have to use options like the Netlink bus and sometimes you may need to read the state in proc file system of Linux. The goal of Zebra is to gather all this data for the upper level protocols.
|
||||
|
||||
### FRR supports remote data planes
|
||||
|
||||
FRR also has the ability to manage the remote data planes. So, what does this mean? Typically, the data forwarding plane and the routing protocols run on the same box. Another model, adopted by Openflow and SDN for example, is one in which the data forwarding plane can be on one box while FRR runs on a different box on behalf of the first box and pushes the computed routing state on the first box. In other words, the data plane and the control plane run on different boxes.
|
||||
|
||||
If you examine the traditional world, it’s like having one large chassis with different line cards with the ability to install routes in those different line cards. FRR operates with the same model which has one control plane and the capability to offer 3 boxes, if needed. It does this via the forwarding plane manager.
|
||||
|
||||
### Forwarding plane manager
|
||||
|
||||
Zebra can either install routes directly into the data plane of the box it is running on or use a forwarding plane manager to install routes on a remote box. When it installs a route, the forwarding plane manager abstracts the data which displays the route and the next hops. It then pushes the data to a remote system where the remote machine processes it and programs the ASIC appropriately.
|
||||
|
||||
After the data is abstracted, you can use whatever protocol you want in order to push the data to the remote machine. You can even include the data in an email.
|
||||
|
||||
### What is holding people back from open source?
|
||||
|
||||
Since last 30 years the networking world meant that you need to go to a vendor to solve a problem. But now with open-source routing suites, such as, FRR, there is a major drift in the mindset as to how you approach troubleshooting.
|
||||
|
||||
This causes the fear of not being able to use it properly because with open source you are the one who has to fix it. This at first can be scary and daunting. But it doesn’t necessarily have to be. Also, to switch to FRR on a traditional network gear, you need the vendor to enable it, but they may be reluctant as they are on competing platforms which can be another road blocker.
|
||||
|
||||
### The future of FRR
|
||||
|
||||
If we examine FRR from the use case perspective of the data center, FRR is feature-complete. Anyone building an IP based data center FRR has everything available. The latest 7.0 release of FRR adds Yang/NetConf, BGP Enhancements and OpenFabric.
|
||||
|
||||
FRR is not just about providing features, boosting the performance or being the same as or better than the traditional network vendor’s software, it is also about simplifying the process for the end user.
|
||||
|
||||
Since the modern data center is focused on automation and ease of use, FRR has made such progress that the vendors have not caught up with. FRR is very automation friendly. For example, FRR takes BGP and makes it automation-friendly without having to change the protocol. It supports BGP unnumbered that is unmatched by any other vendor suite. This is where the vendors are trying to catch up.
|
||||
|
||||
Also, while troubleshooting, FRR shows peer’s and host’s names and not just the IP addresses. This allows you to understand without having spent much time. However, vendors show the peer’s IP addresses which can be daunting when you need to troubleshoot.
|
||||
|
||||
FRR provides the features that you need to run an efficient network and data center. It makes easier to configure and manage the IP routing suite. Vendors just add keep adding features over features whether they are significant or not. Then you need to travel the certification paths that teach you how to twiddle 20 million nobs. How many of those networks are robust and stable?
|
||||
|
||||
FRR is about supporting features that matter and not every imaginable feature. FRR is an open source project that brings like-minded people together, good work that is offered isn’t turned away. As a case in point, FRR has an open source implementation of EIGRP.
|
||||
|
||||
The problem surfaces when you see a bunch of things, you think you need them. But in reality, you should try to keep the network as simple as possible. FRR is laser-focused on the ease of use and simplifying the use rather than implementing features that are mostly not needed to drive the modern data center.
|
||||
|
||||
For more information and to contribute, why not join the [FRR][4] [mailing list group][4].
|
||||
|
||||
**This article is published as part of the IDG Contributor Network.[Want to Join?][5]**
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3396136/the-modern-data-center-and-the-rise-in-open-source-ip-routing-suites.html
|
||||
|
||||
作者:[Matt Conran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Matt-Conran/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/12/modular_humanoid_polyhedra_connections_structure_building_networking_by_fdecomite_cc_by_2-0_via_flickr_1200x800-100782334-large.jpg
|
||||
[2]: https://www.networkworld.com/article/2825879/7-free-open-source-network-monitoring-tools.html
|
||||
[3]: https://frrouting.org/community/7.0-launch.html
|
||||
[4]: https://frrouting.org/#participate
|
||||
[5]: /contributor-network/signup.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -1,162 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to add a player to your Python game)
|
||||
[#]: via: (https://opensource.com/article/17/12/game-python-add-a-player)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
How to add a player to your Python game
|
||||
======
|
||||
Part three of a series on building a game from scratch with Python.
|
||||

|
||||
|
||||
In the [first article of this series][1], I explained how to use Python to create a simple, text-based dice game. In the second part, I showed you how to build a game from scratch, starting with [creating the game's environment][2]. But every game needs a player, and every player needs a playable character, so that's what we'll do next in the third part of the series.
|
||||
|
||||
In Pygame, the icon or avatar that a player controls is called a sprite. If you don't have any graphics to use for a player sprite yet, create something for yourself using [Krita][3] or [Inkscape][4]. If you lack confidence in your artistic skills, you can also search [OpenClipArt.org][5] or [OpenGameArt.org][6] for something pre-generated. Then, if you didn't already do so in the previous article, create a directory called `images` alongside your Python project directory. Put the images you want to use in your game into the `images` folder.
|
||||
|
||||
To make your game truly exciting, you ought to use an animated sprite for your hero. It means you have to draw more assets, but it makes a big difference. The most common animation is a walk cycle, a series of drawings that make it look like your sprite is walking. The quick and dirty version of a walk cycle requires four drawings.
|
||||
|
||||

|
||||
|
||||
Note: The code samples in this article allow for both a static player sprite and an animated one.
|
||||
|
||||
Name your player sprite `hero.png`. If you're creating an animated sprite, append a digit after the name, starting with `hero1.png`.
|
||||
|
||||
### Create a Python class
|
||||
|
||||
In Python, when you create an object that you want to appear on screen, you create a class.
|
||||
|
||||
Near the top of your Python script, add the code to create a player. In the code sample below, the first three lines are already in the Python script that you're working on:
|
||||
|
||||
```
|
||||
import pygame
|
||||
import sys
|
||||
import os # new code below
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
Spawn a player
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.images = []
|
||||
img = pygame.image.load(os.path.join('images','hero.png')).convert()
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
```
|
||||
|
||||
If you have a walk cycle for your playable character, save each drawing as an individual file called `hero1.png` to `hero4.png` in the `images` folder.
|
||||
|
||||
Use a loop to tell Python to cycle through each file.
|
||||
|
||||
```
|
||||
'''
|
||||
Objects
|
||||
'''
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
Spawn a player
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.images = []
|
||||
for i in range(1,5):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
```
|
||||
|
||||
### Bring the player into the game world
|
||||
|
||||
Now that a Player class exists, you must use it to spawn a player sprite in your game world. If you never call on the Player class, it never runs, and there will be no player. You can test this out by running your game now. The game will run just as well as it did at the end of the previous article, with the exact same results: an empty game world.
|
||||
|
||||
To bring a player sprite into your world, you must call the Player class to generate a sprite and then add it to a Pygame sprite group. In this code sample, the first three lines are existing code, so add the lines afterwards:
|
||||
|
||||
```
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = screen.get_rect()
|
||||
|
||||
# new code below
|
||||
|
||||
player = Player() # spawn player
|
||||
player.rect.x = 0 # go to x
|
||||
player.rect.y = 0 # go to y
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
```
|
||||
|
||||
Try launching your game to see what happens. Warning: it won't do what you expect. When you launch your project, the player sprite doesn't spawn. Actually, it spawns, but only for a millisecond. How do you fix something that only happens for a millisecond? You might recall from the previous article that you need to add something to the main loop. To make the player spawn for longer than a millisecond, tell Python to draw it once per loop.
|
||||
|
||||
Change the bottom clause of your loop to look like this:
|
||||
|
||||
```
|
||||
world.blit(backdrop, backdropbox)
|
||||
player_list.draw(screen) # draw player
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
Launch your game now. Your player spawns!
|
||||
|
||||
### Setting the alpha channel
|
||||
|
||||
Depending on how you created your player sprite, it may have a colored block around it. What you are seeing is the space that ought to be occupied by an alpha channel. It's meant to be the "color" of invisibility, but Python doesn't know to make it invisible yet. What you are seeing, then, is the space within the bounding box (or "hit box," in modern gaming terms) around the sprite.
|
||||
|
||||

|
||||
|
||||
You can tell Python what color to make invisible by setting an alpha channel and using RGB values. If you don't know the RGB values your drawing uses as alpha, open your drawing in Krita or Inkscape and fill the empty space around your drawing with a unique color, like #00ff00 (more or less a "greenscreen green"). Take note of the color's hex value (#00ff00, for greenscreen green) and use that in your Python script as the alpha channel.
|
||||
|
||||
Using alpha requires the addition of two lines in your Sprite creation code. Some version of the first line is already in your code. Add the other two lines:
|
||||
|
||||
```
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha() # optimise alpha
|
||||
img.set_colorkey(ALPHA) # set alpha
|
||||
```
|
||||
|
||||
Python doesn't know what to use as alpha unless you tell it. In the setup area of your code, add some more color definitions. Add this variable definition anywhere in your setup section:
|
||||
|
||||
```
|
||||
ALPHA = (0, 255, 0)
|
||||
```
|
||||
|
||||
In this example code, **0,255,0** is used, which is the same value in RGB as #00ff00 is in hex. You can get all of these color values from a good graphics application like [GIMP][7], Krita, or Inkscape. Alternately, you can also detect color values with a good system-wide color chooser, like [KColorChooser][8].
|
||||
|
||||

|
||||
|
||||
If your graphics application is rendering your sprite's background as some other value, adjust the values of your alpha variable as needed. No matter what you set your alpha value, it will be made "invisible." RGB values are very strict, so if you need to use 000 for alpha, but you need 000 for the black lines of your drawing, just change the lines of your drawing to 111, which is close enough to black that nobody but a computer can tell the difference.
|
||||
|
||||
Launch your game to see the results.
|
||||
|
||||

|
||||
|
||||
In the [fourth part of this series][9], I'll show you how to make your sprite move. How exciting!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/game-python-add-a-player
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/10/python-101
|
||||
[2]: https://opensource.com/article/17/12/program-game-python-part-2-creating-game-world
|
||||
[3]: http://krita.org
|
||||
[4]: http://inkscape.org
|
||||
[5]: http://openclipart.org
|
||||
[6]: https://opengameart.org/
|
||||
[7]: http://gimp.org
|
||||
[8]: https://github.com/KDE/kcolorchooser
|
||||
[9]: https://opensource.com/article/17/12/program-game-python-part-4-moving-your-sprite
|
||||
@ -1,170 +0,0 @@
|
||||
The Easiest PDO Tutorial (Basics)
|
||||
======
|
||||
|
||||

|
||||
|
||||
Approximately 80% of the web is powered by PHP. And similarly, high number goes for SQL as well. Up until PHP version 5.5, we had the **mysql_** commands for accessing mysql databases but they were eventually deprecated due to insufficient security.
|
||||
|
||||
This happened with PHP 5.5 in 2013 and as I write this article, the year is 2018 and we are on PHP 7.2. The deprecation of mysql**_** brought 2 major ways of accessing the database, the **mysqli** and the **PDO** libraries.
|
||||
|
||||
Now though the mysqli library was the official successor, PDO gained more fame due to a simple reason that mysqli could only support mysql databases whereas PDO could support 12 different types of database drivers. Also, PDO had several more features that made it the better choice for most developers. You can see some of the feature comparisons in the table below;
|
||||
|
||||
| | PDO | MySQLi |
|
||||
| Database support** | 12 drivers | Only MySQL |
|
||||
| Paradigm | OOP | Procedural + OOP |
|
||||
| Prepared Statements Client Side) | Yes | No |
|
||||
| Named Parameters | Yes | No |
|
||||
|
||||
Now I guess it is pretty clear why PDO is the choice for most developers, so let’s dig into it and hopefully we will try to cover most of the PDO you need in this article itself.
|
||||
|
||||
### Connection
|
||||
|
||||
The first step is connecting to the database and since PDO is completely Object Oriented, we will be using the instance of a PDO class.
|
||||
|
||||
The first thing we do is we define the host, database name, user, password and the database charset.
|
||||
|
||||
`$host = 'localhost';`
|
||||
|
||||
`$db = 'theitstuff';`
|
||||
|
||||
`$user = 'root';`
|
||||
|
||||
`$pass = 'root';`
|
||||
|
||||
`$charset = 'utf8mb4';`
|
||||
|
||||
`$dsn = "mysql:host=$host;dbname=$db;charset=$charset";`
|
||||
|
||||
`$conn = new PDO($dsn, $user, $pass);`
|
||||
|
||||
After that, as you can see in the code above we have created the **DSN** variable, the DSN variable is simply a variable that holds the information about the database. For some people running mysql on external servers, you could also adjust your port number by simply supplying a **port=$port_number**.
|
||||
|
||||
Finally, you can create an instance of the PDO class, I have used the **$conn** variable and I have supplied the **$dsn, $user, $pass** parameters. If you have followed this, you should now have an object named $conn that is an instance of the PDO connection class. Now it’s time to get into the database and run some queries.
|
||||
|
||||
### A simple SQL Query
|
||||
|
||||
Let us now run a simple SQL query.
|
||||
|
||||
`$tis = $conn->query('SELECT name, age FROM students');`
|
||||
|
||||
`while ($row = $tis->fetch())`
|
||||
|
||||
`{`
|
||||
|
||||
`echo $row['name']."\t";`
|
||||
|
||||
`echo $row['age'];`
|
||||
|
||||
`echo "<br>";`
|
||||
|
||||
`}`
|
||||
|
||||
This is the simplest form of running a query with PDO. We first created a variable called **tis( **short for TheITStuff** )** and then you can see the syntax as we used the query function from the $conn object that we had created.
|
||||
|
||||
We then ran a while loop and created a **$row** variable to fetch the contents from the **$tis** object and finally echoed out each row by calling out the column name.
|
||||
|
||||
Easy wasn’t it ?. Now let’s get to the prepared statement.
|
||||
|
||||
### Prepared Statements
|
||||
|
||||
Prepared statements were one of the major reasons people started using PDO as it had prepared statements that could prevent SQL injections.
|
||||
|
||||
There are 2 basic methods available, you could either use positional or named parameters.
|
||||
|
||||
#### Position parameters
|
||||
|
||||
Let us see an example of a query using positional parameters.
|
||||
|
||||
`$tis = $conn->prepare("INSERT INTO STUDENTS(name, age) values(?, ?)");`
|
||||
|
||||
`$tis->bindValue(1,'mike');`
|
||||
|
||||
`$tis->bindValue(2,22);`
|
||||
|
||||
`$tis->execute();`
|
||||
|
||||
In the above example, we have placed 2 question marks and later used the **bindValue()** function to map the values into the query. The values are bound to the position of the question mark in the statement.
|
||||
|
||||
I could also use variables instead of directly supplying values by using the **bindParam()** function and example for the same would be this.
|
||||
|
||||
`$name='Rishabh'; $age=20;`
|
||||
|
||||
`$tis = $conn->prepare("INSERT INTO STUDENTS(name, age) values(?, ?)");`
|
||||
|
||||
`$tis->bindParam(1,$name);`
|
||||
|
||||
`$tis->bindParam(2,$age);`
|
||||
|
||||
`$tis->execute();`
|
||||
|
||||
### Named Parameters
|
||||
|
||||
Named parameters are also prepared statements that map values/variables to a named position in the query. Since there is no positional binding, it is very efficient in queries that use the same variable multiple time.
|
||||
|
||||
`$name='Rishabh'; $age=20;`
|
||||
|
||||
`$tis = $conn->prepare("INSERT INTO STUDENTS(name, age) values(:name, :age)");`
|
||||
|
||||
`$tis->bindParam(':name', $name);`
|
||||
|
||||
`$tis->bindParam(':age', $age);`
|
||||
|
||||
`$tis->execute();`
|
||||
|
||||
The only change you can notice is that I used **:name** and **:age** as placeholders and then mapped variables to them. The colon is used before the parameter and it is of extreme importance to let PDO know that the position is for a variable.
|
||||
|
||||
You can similarly use **bindValue()** to directly map values using Named parameters as well.
|
||||
|
||||
### Fetching the Data
|
||||
|
||||
PDO is very rich when it comes to fetching data and it actually offers a number of formats in which you can get the data from your database.
|
||||
|
||||
You can use the **PDO::FETCH_ASSOC** to fetch associative arrays, **PDO::FETCH_NUM** to fetch numeric arrays and **PDO::FETCH_OBJ** to fetch object arrays.
|
||||
|
||||
`$tis = $conn->prepare("SELECT * FROM STUDENTS");`
|
||||
|
||||
`$tis->execute();`
|
||||
|
||||
`$result = $tis->fetchAll(PDO::FETCH_ASSOC);`
|
||||
|
||||
You can see that I have used **fetchAll** since I wanted all matching records. If only one row is expected or desired, you can simply use **fetch.**
|
||||
|
||||
Now that we have fetched the data it is time to loop through it and that is extremely easy.
|
||||
|
||||
`foreach($result as $lnu){`
|
||||
|
||||
`echo $lnu['name'];`
|
||||
|
||||
`echo $lnu['age']."<br>";`
|
||||
|
||||
`}`
|
||||
|
||||
You can see that since I had requested associative arrays, I am accessing individual members by their names.
|
||||
|
||||
Though there is absolutely no problem in defining how you want your data delivered, you could actually set one as default when defining the connection variable itself.
|
||||
|
||||
All you need to do is create an options array where you put in all your default configs and simply pass the array in the connection variable.
|
||||
|
||||
`$options = [`
|
||||
|
||||
` PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_ASSOC,`
|
||||
|
||||
`];`
|
||||
|
||||
`$conn = new PDO($dsn, $user, $pass, $options);`
|
||||
|
||||
This was a very brief and quick intro to PDO we will be making an advanced tutorial soon. If you had any difficulties understanding any part of the tutorial, do let me know in the comment section and I’ll be there for you.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/easiest-pdo-tutorial-basics
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
@ -1,4 +1,3 @@
|
||||
liujing97 is translating
|
||||
Working with data streams on the Linux command line
|
||||
======
|
||||
Learn to connect data streams from one utility to another using STDIO.
|
||||
|
||||
@ -1,745 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (TLP – An Advanced Power Management Tool That Improve Battery Life On Linux Laptop)
|
||||
[#]: via: (https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
TLP – An Advanced Power Management Tool That Improve Battery Life On Linux Laptop
|
||||
======
|
||||
|
||||
Laptop battery is highly optimized for Windows OS, that i had realized when i was using Windows OS in my laptop but it’s not same for Linux.
|
||||
|
||||
Over the years Linux has improved a lot for battery optimization but still we need make some necessary things to improve laptop battery life in Linux.
|
||||
|
||||
When i think about battery life, i got few options for that but i felt TLP is a better solutions for me so, i’m going with it.
|
||||
|
||||
In this tutorial we are going to discuss about TLP in details to improve battery life.
|
||||
|
||||
We had written three articles previously in our site about **[laptop battery saving utilities][1]** for Linux **[PowerTOP][2]** and **[Battery Charging State][3]**.
|
||||
|
||||
### What is TLP?
|
||||
|
||||
[TLP][4] is a free opensource advanced power management tool that improve your battery life without making any configuration change.
|
||||
|
||||
Since it comes with a default configuration already optimized for battery life, so you may just install and forget it.
|
||||
|
||||
Also, it is highly customizable to fulfill your specific requirements. TLP is a pure command line tool with automated background tasks. It does not contain a GUI.
|
||||
|
||||
TLP runs on every laptop brand. Setting the battery charge thresholds is available for IBM/Lenovo ThinkPads only.
|
||||
|
||||
All TLP settings are stored in `/etc/default/tlp`. The default configuration provides optimized power saving out of the box.
|
||||
|
||||
The following TLP settings is available for customization and you need to make the necessary changes accordingly if you want it.
|
||||
|
||||
### TLP Features
|
||||
|
||||
* Kernel laptop mode and dirty buffer timeouts
|
||||
* Processor frequency scaling including “turbo boost” / “turbo core”
|
||||
* Limit max/min P-state to control power dissipation of the CPU
|
||||
* HWP energy performance hints
|
||||
* Power aware process scheduler for multi-core/hyper-threading
|
||||
* Processor performance versus energy savings policy (x86_energy_perf_policy)
|
||||
* Hard disk advanced power magement level (APM) and spin down timeout (per disk)
|
||||
* AHCI link power management (ALPM) with device blacklist
|
||||
* PCIe active state power management (PCIe ASPM)
|
||||
* Runtime power management for PCI(e) bus devices
|
||||
* Radeon graphics power management (KMS and DPM)
|
||||
* Wifi power saving mode
|
||||
* Power off optical drive in drive bay
|
||||
* Audio power saving mode
|
||||
* I/O scheduler (per disk)
|
||||
* USB autosuspend with device blacklist/whitelist (input devices excluded automatically)
|
||||
* Enable or disable integrated wifi, bluetooth or wwan devices upon system startup and shutdown
|
||||
* Restore radio device state on system startup (from previous shutdown).
|
||||
* Radio device wizard: switch radios upon network connect/disconnect and dock/undock
|
||||
* Disable Wake On LAN
|
||||
* Integrated WWAN and bluetooth state is restored after suspend/hibernate
|
||||
* Untervolting of Intel processors – requires kernel with PHC-Patch
|
||||
* Battery charge thresholds – ThinkPads only
|
||||
* Recalibrate battery – ThinkPads only
|
||||
|
||||
|
||||
|
||||
### How to Install TLP in Linux
|
||||
|
||||
TLP package is available in most of the distributions official repository so, use the distributions **[Package Manager][5]** to install it.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][6]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo dnf install tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPads require an additional packages.
|
||||
|
||||
```
|
||||
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
|
||||
$ sudo dnf install http://repo.linrunner.de/fedora/tlp/repos/releases/tlp-release.fc$(rpm -E %fedora).noarch.rpm
|
||||
$ sudo dnf install akmod-tp_smapi akmod-acpi_call kernel-devel
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo dnf install smartmontools
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][7]** or **[APT Command][8]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo apt install tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPads require an additional packages.
|
||||
|
||||
```
|
||||
$ sudo apt-get install tp-smapi-dkms acpi-call-dkms
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo apt-get install smartmontools
|
||||
```
|
||||
|
||||
When the official package becomes outdated for Ubuntu based systems then use the following PPA repository which provides an up-to-date version. Run the following commands to install TLP using the PPA.
|
||||
|
||||
```
|
||||
$ sudo apt-get install tlp tlp-rdw
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][9]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo pacman -S tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPads require an additional packages.
|
||||
|
||||
```
|
||||
$ pacman -S tp_smapi acpi_call
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo pacman -S smartmontools
|
||||
```
|
||||
|
||||
Enable TLP & TLP-Sleep service on boot for Arch Linux based systems.
|
||||
|
||||
```
|
||||
$ sudo systemctl enable tlp.service
|
||||
$ sudo systemctl enable tlp-sleep.service
|
||||
```
|
||||
|
||||
You should also mask the following services to avoid conflicts and assure proper operation of TLP’s radio device switching options for Arch Linux based systems.
|
||||
|
||||
```
|
||||
$ sudo systemctl mask systemd-rfkill.service
|
||||
$ sudo systemctl mask systemd-rfkill.socket
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][10]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo yum install tlp tlp-rdw
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo yum install smartmontools
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][11]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo zypper install TLP
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo zypper install smartmontools
|
||||
```
|
||||
|
||||
After successfully TLP installed, use the following command to start the service.
|
||||
|
||||
```
|
||||
$ systemctl start tlp.service
|
||||
```
|
||||
|
||||
To show battery information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -b
|
||||
or
|
||||
$ sudo tlp-stat --battery
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Battery Status
|
||||
/sys/class/power_supply/BAT0/manufacturer = SMP
|
||||
/sys/class/power_supply/BAT0/model_name = L14M4P23
|
||||
/sys/class/power_supply/BAT0/cycle_count = (not supported)
|
||||
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_full = 48850 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_now = 48850 [mWh]
|
||||
/sys/class/power_supply/BAT0/power_now = 0 [mW]
|
||||
/sys/class/power_supply/BAT0/status = Full
|
||||
|
||||
Charge = 100.0 [%]
|
||||
Capacity = 81.4 [%]
|
||||
```
|
||||
|
||||
To show disk information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -d
|
||||
or
|
||||
$ sudo tlp-stat --disk
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Storage Devices
|
||||
/dev/sda:
|
||||
Model = WDC WD10SPCX-24HWST1
|
||||
Firmware = 02.01A02
|
||||
APM Level = 128
|
||||
Status = active/idle
|
||||
Scheduler = mq-deadline
|
||||
|
||||
Runtime PM: control = on, autosuspend_delay = (not available)
|
||||
|
||||
SMART info:
|
||||
4 Start_Stop_Count = 18787
|
||||
5 Reallocated_Sector_Ct = 0
|
||||
9 Power_On_Hours = 606 [h]
|
||||
12 Power_Cycle_Count = 1792
|
||||
193 Load_Cycle_Count = 25775
|
||||
194 Temperature_Celsius = 31 [°C]
|
||||
|
||||
|
||||
+++ AHCI Link Power Management (ALPM)
|
||||
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
|
||||
|
||||
+++ AHCI Host Controller Runtime Power Management
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
|
||||
```
|
||||
|
||||
To show PCI device information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -e
|
||||
or
|
||||
$ sudo tlp-stat --pcie
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Runtime Power Management
|
||||
Device blacklist = (not configured)
|
||||
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
|
||||
|
||||
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
|
||||
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
|
||||
/sys/bus/pci/devices/0000:00:14.0/power/control = auto (0x0c0330, USB controller, xhci_hcd)
|
||||
/sys/bus/pci/devices/0000:00:16.0/power/control = auto (0x078000, Communication controller, mei_me)
|
||||
/sys/bus/pci/devices/0000:00:17.0/power/control = auto (0x010601, SATA controller, ahci)
|
||||
/sys/bus/pci/devices/0000:00:1c.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1c.2/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1c.3/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1d.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1f.0/power/control = auto (0x060100, ISA bridge, no driver)
|
||||
/sys/bus/pci/devices/0000:00:1f.2/power/control = auto (0x058000, Memory controller, no driver)
|
||||
/sys/bus/pci/devices/0000:00:1f.3/power/control = auto (0x040300, Audio device, snd_hda_intel)
|
||||
/sys/bus/pci/devices/0000:00:1f.4/power/control = auto (0x0c0500, SMBus, i801_smbus)
|
||||
/sys/bus/pci/devices/0000:01:00.0/power/control = auto (0x030200, 3D controller, nouveau)
|
||||
/sys/bus/pci/devices/0000:07:00.0/power/control = auto (0x080501, SD Host controller, sdhci-pci)
|
||||
/sys/bus/pci/devices/0000:08:00.0/power/control = auto (0x028000, Network controller, iwlwifi)
|
||||
/sys/bus/pci/devices/0000:09:00.0/power/control = auto (0x020000, Ethernet controller, r8168)
|
||||
/sys/bus/pci/devices/0000:0a:00.0/power/control = auto (0x010802, Non-Volatile memory controller, nvme)
|
||||
```
|
||||
|
||||
To show graphics card information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -g
|
||||
or
|
||||
$ sudo tlp-stat --graphics
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Intel Graphics
|
||||
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
|
||||
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
|
||||
/sys/module/i915/parameters/enable_psr = 0 (disabled)
|
||||
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
|
||||
```
|
||||
|
||||
To show Processor information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -p
|
||||
or
|
||||
$ sudo tlp-stat --processor
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Processor
|
||||
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
|
||||
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
|
||||
|
||||
x86_energy_perf_policy: program not installed.
|
||||
|
||||
/sys/module/workqueue/parameters/power_efficient = Y
|
||||
/proc/sys/kernel/nmi_watchdog = 0
|
||||
|
||||
+++ Undervolting
|
||||
PHC kernel not available.
|
||||
```
|
||||
|
||||
To show system data information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -s
|
||||
or
|
||||
$ sudo tlp-stat --system
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ System Info
|
||||
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
|
||||
BIOS = CDCN35WW
|
||||
Release = "Manjaro Linux"
|
||||
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
|
||||
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
|
||||
Init system = systemd
|
||||
Boot mode = BIOS (CSM, Legacy)
|
||||
|
||||
+++ TLP Status
|
||||
State = enabled
|
||||
Last run = 11:04:00 IST, 596 sec(s) ago
|
||||
Mode = battery
|
||||
Power source = battery
|
||||
```
|
||||
|
||||
To show temperatures and fan speed information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -t
|
||||
or
|
||||
$ sudo tlp-stat --temp
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Temperatures
|
||||
CPU temp = 36 [°C]
|
||||
Fan speed = (not available)
|
||||
```
|
||||
|
||||
To show USB device data information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -u
|
||||
or
|
||||
$ sudo tlp-stat --usb
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ USB
|
||||
Autosuspend = disabled
|
||||
Device whitelist = (not configured)
|
||||
Device blacklist = (not configured)
|
||||
Bluetooth blacklist = disabled
|
||||
Phone blacklist = disabled
|
||||
WWAN blacklist = enabled
|
||||
|
||||
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
|
||||
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
|
||||
Bus 001 Device 002 ID 17ef:6053 control = on, autosuspend_delay_ms = 2000 -- Lenovo (usbhid)
|
||||
Bus 001 Device 004 ID 8087:0a2b control = auto, autosuspend_delay_ms = 2000 -- Intel Corp. (btusb)
|
||||
Bus 001 Device 001 ID 1d6b:0002 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 2.0 root hub (hub)
|
||||
```
|
||||
|
||||
To show warnings.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -w
|
||||
or
|
||||
$ sudo tlp-stat --warn
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
No warnings detected.
|
||||
```
|
||||
|
||||
Status report with configuration and all active settings.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Configured Settings: /etc/default/tlp
|
||||
TLP_ENABLE=1
|
||||
TLP_DEFAULT_MODE=AC
|
||||
TLP_PERSISTENT_DEFAULT=0
|
||||
DISK_IDLE_SECS_ON_AC=0
|
||||
DISK_IDLE_SECS_ON_BAT=2
|
||||
MAX_LOST_WORK_SECS_ON_AC=15
|
||||
MAX_LOST_WORK_SECS_ON_BAT=60
|
||||
CPU_HWP_ON_AC=balance_performance
|
||||
CPU_HWP_ON_BAT=balance_power
|
||||
SCHED_POWERSAVE_ON_AC=0
|
||||
SCHED_POWERSAVE_ON_BAT=1
|
||||
NMI_WATCHDOG=0
|
||||
ENERGY_PERF_POLICY_ON_AC=performance
|
||||
ENERGY_PERF_POLICY_ON_BAT=power
|
||||
DISK_DEVICES="sda sdb"
|
||||
DISK_APM_LEVEL_ON_AC="254 254"
|
||||
DISK_APM_LEVEL_ON_BAT="128 128"
|
||||
SATA_LINKPWR_ON_AC="med_power_with_dipm max_performance"
|
||||
SATA_LINKPWR_ON_BAT="med_power_with_dipm max_performance"
|
||||
AHCI_RUNTIME_PM_TIMEOUT=15
|
||||
PCIE_ASPM_ON_AC=performance
|
||||
PCIE_ASPM_ON_BAT=powersave
|
||||
RADEON_POWER_PROFILE_ON_AC=default
|
||||
RADEON_POWER_PROFILE_ON_BAT=low
|
||||
RADEON_DPM_STATE_ON_AC=performance
|
||||
RADEON_DPM_STATE_ON_BAT=battery
|
||||
RADEON_DPM_PERF_LEVEL_ON_AC=auto
|
||||
RADEON_DPM_PERF_LEVEL_ON_BAT=auto
|
||||
WIFI_PWR_ON_AC=off
|
||||
WIFI_PWR_ON_BAT=on
|
||||
WOL_DISABLE=Y
|
||||
SOUND_POWER_SAVE_ON_AC=0
|
||||
SOUND_POWER_SAVE_ON_BAT=1
|
||||
SOUND_POWER_SAVE_CONTROLLER=Y
|
||||
BAY_POWEROFF_ON_AC=0
|
||||
BAY_POWEROFF_ON_BAT=0
|
||||
BAY_DEVICE="sr0"
|
||||
RUNTIME_PM_ON_AC=on
|
||||
RUNTIME_PM_ON_BAT=auto
|
||||
RUNTIME_PM_DRIVER_BLACKLIST="amdgpu nouveau nvidia radeon pcieport"
|
||||
USB_AUTOSUSPEND=0
|
||||
USB_BLACKLIST_BTUSB=0
|
||||
USB_BLACKLIST_PHONE=0
|
||||
USB_BLACKLIST_PRINTER=1
|
||||
USB_BLACKLIST_WWAN=1
|
||||
RESTORE_DEVICE_STATE_ON_STARTUP=0
|
||||
|
||||
+++ System Info
|
||||
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
|
||||
BIOS = CDCN35WW
|
||||
Release = "Manjaro Linux"
|
||||
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
|
||||
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
|
||||
Init system = systemd
|
||||
Boot mode = BIOS (CSM, Legacy)
|
||||
|
||||
+++ TLP Status
|
||||
State = enabled
|
||||
Last run = 11:04:00 IST, 684 sec(s) ago
|
||||
Mode = battery
|
||||
Power source = battery
|
||||
|
||||
+++ Processor
|
||||
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
|
||||
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
|
||||
|
||||
x86_energy_perf_policy: program not installed.
|
||||
|
||||
/sys/module/workqueue/parameters/power_efficient = Y
|
||||
/proc/sys/kernel/nmi_watchdog = 0
|
||||
|
||||
+++ Undervolting
|
||||
PHC kernel not available.
|
||||
|
||||
+++ Temperatures
|
||||
CPU temp = 42 [°C]
|
||||
Fan speed = (not available)
|
||||
|
||||
+++ File System
|
||||
/proc/sys/vm/laptop_mode = 2
|
||||
/proc/sys/vm/dirty_writeback_centisecs = 6000
|
||||
/proc/sys/vm/dirty_expire_centisecs = 6000
|
||||
/proc/sys/vm/dirty_ratio = 20
|
||||
/proc/sys/vm/dirty_background_ratio = 10
|
||||
|
||||
+++ Storage Devices
|
||||
/dev/sda:
|
||||
Model = WDC WD10SPCX-24HWST1
|
||||
Firmware = 02.01A02
|
||||
APM Level = 128
|
||||
Status = active/idle
|
||||
Scheduler = mq-deadline
|
||||
|
||||
Runtime PM: control = on, autosuspend_delay = (not available)
|
||||
|
||||
SMART info:
|
||||
4 Start_Stop_Count = 18787
|
||||
5 Reallocated_Sector_Ct = 0
|
||||
9 Power_On_Hours = 606 [h]
|
||||
12 Power_Cycle_Count = 1792
|
||||
193 Load_Cycle_Count = 25777
|
||||
194 Temperature_Celsius = 31 [°C]
|
||||
|
||||
|
||||
+++ AHCI Link Power Management (ALPM)
|
||||
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
|
||||
|
||||
+++ AHCI Host Controller Runtime Power Management
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
|
||||
|
||||
+++ PCIe Active State Power Management
|
||||
/sys/module/pcie_aspm/parameters/policy = powersave
|
||||
|
||||
+++ Intel Graphics
|
||||
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
|
||||
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
|
||||
/sys/module/i915/parameters/enable_psr = 0 (disabled)
|
||||
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
|
||||
|
||||
+++ Wireless
|
||||
bluetooth = on
|
||||
wifi = on
|
||||
wwan = none (no device)
|
||||
|
||||
hci0(btusb) : bluetooth, not connected
|
||||
wlp8s0(iwlwifi) : wifi, connected, power management = on
|
||||
|
||||
+++ Audio
|
||||
/sys/module/snd_hda_intel/parameters/power_save = 1
|
||||
/sys/module/snd_hda_intel/parameters/power_save_controller = Y
|
||||
|
||||
+++ Runtime Power Management
|
||||
Device blacklist = (not configured)
|
||||
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
|
||||
|
||||
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
|
||||
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
|
||||
/sys/bus/pci/devices/0000:00:14.0/power/control = auto (0x0c0330, USB controller, xhci_hcd)
|
||||
/sys/bus/pci/devices/0000:00:16.0/power/control = auto (0x078000, Communication controller, mei_me)
|
||||
/sys/bus/pci/devices/0000:00:17.0/power/control = auto (0x010601, SATA controller, ahci)
|
||||
/sys/bus/pci/devices/0000:00:1c.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1c.2/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1c.3/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1d.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1f.0/power/control = auto (0x060100, ISA bridge, no driver)
|
||||
/sys/bus/pci/devices/0000:00:1f.2/power/control = auto (0x058000, Memory controller, no driver)
|
||||
/sys/bus/pci/devices/0000:00:1f.3/power/control = auto (0x040300, Audio device, snd_hda_intel)
|
||||
/sys/bus/pci/devices/0000:00:1f.4/power/control = auto (0x0c0500, SMBus, i801_smbus)
|
||||
/sys/bus/pci/devices/0000:01:00.0/power/control = auto (0x030200, 3D controller, nouveau)
|
||||
/sys/bus/pci/devices/0000:07:00.0/power/control = auto (0x080501, SD Host controller, sdhci-pci)
|
||||
/sys/bus/pci/devices/0000:08:00.0/power/control = auto (0x028000, Network controller, iwlwifi)
|
||||
/sys/bus/pci/devices/0000:09:00.0/power/control = auto (0x020000, Ethernet controller, r8168)
|
||||
/sys/bus/pci/devices/0000:0a:00.0/power/control = auto (0x010802, Non-Volatile memory controller, nvme)
|
||||
|
||||
+++ USB
|
||||
Autosuspend = disabled
|
||||
Device whitelist = (not configured)
|
||||
Device blacklist = (not configured)
|
||||
Bluetooth blacklist = disabled
|
||||
Phone blacklist = disabled
|
||||
WWAN blacklist = enabled
|
||||
|
||||
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
|
||||
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
|
||||
Bus 001 Device 002 ID 17ef:6053 control = on, autosuspend_delay_ms = 2000 -- Lenovo (usbhid)
|
||||
Bus 001 Device 004 ID 8087:0a2b control = auto, autosuspend_delay_ms = 2000 -- Intel Corp. (btusb)
|
||||
Bus 001 Device 001 ID 1d6b:0002 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 2.0 root hub (hub)
|
||||
|
||||
+++ Battery Status
|
||||
/sys/class/power_supply/BAT0/manufacturer = SMP
|
||||
/sys/class/power_supply/BAT0/model_name = L14M4P23
|
||||
/sys/class/power_supply/BAT0/cycle_count = (not supported)
|
||||
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_full = 51690 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_now = 50140 [mWh]
|
||||
/sys/class/power_supply/BAT0/power_now = 12185 [mW]
|
||||
/sys/class/power_supply/BAT0/status = Discharging
|
||||
|
||||
Charge = 97.0 [%]
|
||||
Capacity = 86.2 [%]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/check-laptop-battery-status-and-charging-state-in-linux-terminal/
|
||||
[2]: https://www.2daygeek.com/powertop-monitors-laptop-battery-usage-linux/
|
||||
[3]: https://www.2daygeek.com/monitor-laptop-battery-charging-state-linux/
|
||||
[4]: https://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html
|
||||
[5]: https://www.2daygeek.com/category/package-management/
|
||||
[6]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -1,353 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Pygame to move your game character around)
|
||||
[#]: via: (https://opensource.com/article/17/12/game-python-moving-player)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Using Pygame to move your game character around
|
||||
======
|
||||
In the fourth part of this series, learn how to code the controls needed to move a game character.
|
||||

|
||||
|
||||
In the first article in this series, I explained how to use Python to create a simple, [text-based dice game][1]. In the second part, we began building a game from scratch, starting with [creating the game's environment][2]. And, in the third installment, we [created a player sprite][3] and made it spawn in your (rather empty) game world. As you've probably noticed, a game isn't much fun if you can't move your character around. In this article, we'll use Pygame to add keyboard controls so you can direct your character's movement.
|
||||
|
||||
There are functions in Pygame to add other kinds of controls, but since you certainly have a keyboard if you're typing out Python code, that's what we'll use. Once you understand keyboard controls, you can explore other options on your own.
|
||||
|
||||
You created a key to quit your game in the second article in this series, and the principle is the same for movement. However, getting your character to move is a little more complex.
|
||||
|
||||
Let's start with the easy part: setting up the controller keys.
|
||||
|
||||
### Setting up keys for controlling your player sprite
|
||||
|
||||
Open your Python game script in IDLE, Ninja-IDE, or a text editor.
|
||||
|
||||
Since the game must constantly "listen" for keyboard events, you'll be writing code that needs to run continuously. Can you figure out where to put code that needs to run constantly for the duration of the game?
|
||||
|
||||
If you answered "in the main loop," you're correct! Remember that unless code is in a loop, it will run (at most) only once—and it may not run at all if it's hidden away in a class or function that never gets used.
|
||||
|
||||
To make Python monitor for incoming key presses, add this code to the main loop. There's no code to make anything happen yet, so use `print` statements to signal success. This is a common debugging technique.
|
||||
|
||||
```
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
print('left')
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
print('right')
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
print('left stop')
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
print('right stop')
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
```
|
||||
|
||||
Some people prefer to control player characters with the keyboard characters W, A, S, and D, and others prefer to use arrow keys. Be sure to include both options.
|
||||
|
||||
**Note: **It's vital that you consider all of your users when programming. If you write code that works only for you, it's very likely that you'll be the only one who uses your application. More importantly, if you seek out a job writing code for money, you are expected to write code that works for everyone. Giving your users choices, such as the option to use either arrow keys or WASD, is a sign of a good programmer.
|
||||
|
||||
Launch your game using Python, and watch the console window for output as you press the right, left, and up arrows, or the A, D, and W keys.
|
||||
|
||||
```
|
||||
$ python ./your-name_game.py
|
||||
left
|
||||
left stop
|
||||
right
|
||||
right stop
|
||||
jump
|
||||
```
|
||||
|
||||
This confirms that Pygame detects key presses correctly. Now it's time to do the hard work of making the sprite move.
|
||||
|
||||
### Coding the player movement function
|
||||
|
||||
To make your sprite move, you must create a property for your sprite that represents movement. When your sprite is not moving, this variable is set to `0`.
|
||||
|
||||
If you are animating your sprite, or should you decide to animate it in the future, you also must track frames to enable the walk cycle to stay on track.
|
||||
|
||||
Create the variables in the Player class. The first two lines are for context (you already have them in your code, if you've been following along), so add only the last three:
|
||||
|
||||
```
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0 # move along X
|
||||
self.movey = 0 # move along Y
|
||||
self.frame = 0 # count frames
|
||||
```
|
||||
|
||||
With those variables set, it's time to code the sprite's movement.
|
||||
|
||||
The player sprite doesn't need to respond to control all the time; sometimes it will not be moving. The code that controls the sprite, therefore, is only one small part of all the things the player sprite will do. When you want to make an object in Python do something independent of the rest of its code, you place your new code in a function. Python functions start with the keyword `def`, which stands for define.
|
||||
|
||||
Make a function in your Player class to add some number of pixels to your sprite's position on screen. Don't worry about how many pixels you add yet; that will be decided in later code.
|
||||
|
||||
```
|
||||
def control(self,x,y):
|
||||
'''
|
||||
control player movement
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
```
|
||||
|
||||
To move a sprite in Pygame, you have to tell Python to redraw the sprite in its new location—and where that new location is.
|
||||
|
||||
Since the Player sprite isn't always moving, the updates need to be only one function within the Player class. Add this function after the `control` function you created earlier.
|
||||
|
||||
To make it appear that the sprite is walking (or flying, or whatever it is your sprite is supposed to do), you need to change its position on screen when the appropriate key is pressed. To get it to move across the screen, you redefine its position, designated by the `self.rect.x` and `self.rect.y` properties, to its current position plus whatever amount of `movex` or `movey` is applied. (The number of pixels the move requires is set later.)
|
||||
|
||||
```
|
||||
def update(self):
|
||||
'''
|
||||
Update sprite position
|
||||
'''
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
```
|
||||
|
||||
Do the same thing for the Y position:
|
||||
|
||||
```
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
```
|
||||
|
||||
For animation, advance the animation frames whenever your sprite is moving, and use the corresponding animation frame as the player image:
|
||||
|
||||
```
|
||||
# moving left
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# moving right
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
```
|
||||
|
||||
Tell the code how many pixels to add to your sprite's position by setting a variable, then use that variable when triggering the functions of your Player sprite.
|
||||
|
||||
First, create the variable in your setup section. In this code, the first two lines are for context, so just add the third line to your script:
|
||||
|
||||
```
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10 # how many pixels to move
|
||||
```
|
||||
|
||||
Now that you have the appropriate function and variable, use your key presses to trigger the function and send the variable to your sprite.
|
||||
|
||||
Do this by replacing the `print` statements in your main loop with the Player sprite's name (player), the function (.control), and how many steps along the X axis and Y axis you want the player sprite to move with each loop.
|
||||
|
||||
```
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
```
|
||||
|
||||
Remember, `steps` is a variable representing how many pixels your sprite moves when a key is pressed. If you add 10 pixels to the location of your player sprite when you press D or the right arrow, then when you stop pressing that key you must subtract 10 (`-steps`) to return your sprite's momentum back to 0.
|
||||
|
||||
Try your game now. Warning: it won't do what you expect.
|
||||
|
||||
Why doesn't your sprite move yet? Because the main loop doesn't call the `update` function.
|
||||
|
||||
Add code to your main loop to tell Python to update the position of your player sprite. Add the line with the comment:
|
||||
|
||||
```
|
||||
player.update() # update player position
|
||||
player_list.draw(world)
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
Launch your game again to witness your player sprite move across the screen at your bidding. There's no vertical movement yet because those functions will be controlled by gravity, but that's another lesson for another article.
|
||||
|
||||
In the meantime, if you have access to a joystick, try reading Pygame's documentation for its [joystick][4] module and see if you can make your sprite move that way. Alternately, see if you can get the [mouse][5] to interact with your sprite.
|
||||
|
||||
Most importantly, have fun!
|
||||
|
||||
### All the code used in this tutorial
|
||||
|
||||
For your reference, here is all the code used in this series of articles so far.
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
# draw a world
|
||||
# add a player and player control
|
||||
# add player movement
|
||||
|
||||
# GNU All-Permissive License
|
||||
# Copying and distribution of this file, with or without modification,
|
||||
# are permitted in any medium without royalty provided the copyright
|
||||
# notice and this notice are preserved. This file is offered as-is,
|
||||
# without any warranty.
|
||||
|
||||
import pygame
|
||||
import sys
|
||||
import os
|
||||
|
||||
'''
|
||||
Objects
|
||||
'''
|
||||
|
||||
class Player(pygame.sprite.Sprite):
|
||||
'''
|
||||
Spawn a player
|
||||
'''
|
||||
def __init__(self):
|
||||
pygame.sprite.Sprite.__init__(self)
|
||||
self.movex = 0
|
||||
self.movey = 0
|
||||
self.frame = 0
|
||||
self.images = []
|
||||
for i in range(1,5):
|
||||
img = pygame.image.load(os.path.join('images','hero' + str(i) + '.png')).convert()
|
||||
img.convert_alpha()
|
||||
img.set_colorkey(ALPHA)
|
||||
self.images.append(img)
|
||||
self.image = self.images[0]
|
||||
self.rect = self.image.get_rect()
|
||||
|
||||
def control(self,x,y):
|
||||
'''
|
||||
control player movement
|
||||
'''
|
||||
self.movex += x
|
||||
self.movey += y
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
Update sprite position
|
||||
'''
|
||||
|
||||
self.rect.x = self.rect.x + self.movex
|
||||
self.rect.y = self.rect.y + self.movey
|
||||
|
||||
# moving left
|
||||
if self.movex < 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[self.frame//ani]
|
||||
|
||||
# moving right
|
||||
if self.movex > 0:
|
||||
self.frame += 1
|
||||
if self.frame > 3*ani:
|
||||
self.frame = 0
|
||||
self.image = self.images[(self.frame//ani)+4]
|
||||
|
||||
|
||||
'''
|
||||
Setup
|
||||
'''
|
||||
worldx = 960
|
||||
worldy = 720
|
||||
|
||||
fps = 40 # frame rate
|
||||
ani = 4 # animation cycles
|
||||
clock = pygame.time.Clock()
|
||||
pygame.init()
|
||||
main = True
|
||||
|
||||
BLUE = (25,25,200)
|
||||
BLACK = (23,23,23 )
|
||||
WHITE = (254,254,254)
|
||||
ALPHA = (0,255,0)
|
||||
|
||||
world = pygame.display.set_mode([worldx,worldy])
|
||||
backdrop = pygame.image.load(os.path.join('images','stage.png')).convert()
|
||||
backdropbox = world.get_rect()
|
||||
player = Player() # spawn player
|
||||
player.rect.x = 0
|
||||
player.rect.y = 0
|
||||
player_list = pygame.sprite.Group()
|
||||
player_list.add(player)
|
||||
steps = 10 # how fast to move
|
||||
|
||||
'''
|
||||
Main loop
|
||||
'''
|
||||
while main == True:
|
||||
for event in pygame.event.get():
|
||||
if event.type == pygame.QUIT:
|
||||
pygame.quit(); sys.exit()
|
||||
main = False
|
||||
|
||||
if event.type == pygame.KEYDOWN:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(-steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_UP or event.key == ord('w'):
|
||||
print('jump')
|
||||
|
||||
if event.type == pygame.KEYUP:
|
||||
if event.key == pygame.K_LEFT or event.key == ord('a'):
|
||||
player.control(steps,0)
|
||||
if event.key == pygame.K_RIGHT or event.key == ord('d'):
|
||||
player.control(-steps,0)
|
||||
if event.key == ord('q'):
|
||||
pygame.quit()
|
||||
sys.exit()
|
||||
main = False
|
||||
|
||||
# world.fill(BLACK)
|
||||
world.blit(backdrop, backdropbox)
|
||||
player.update()
|
||||
player_list.draw(world) #refresh player position
|
||||
pygame.display.flip()
|
||||
clock.tick(fps)
|
||||
```
|
||||
|
||||
You've come far and learned much, but there's a lot more to do. In the next few articles, you'll add enemy sprites, emulated gravity, and lots more. In the mean time, practice with Python!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/game-python-moving-player
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/10/python-101
|
||||
[2]: https://opensource.com/article/17/12/program-game-python-part-2-creating-game-world
|
||||
[3]: https://opensource.com/article/17/12/program-game-python-part-3-spawning-player
|
||||
[4]: http://pygame.org/docs/ref/joystick.html
|
||||
[5]: http://pygame.org/docs/ref/mouse.html#module-pygame.mouse
|
||||
@ -1,196 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Virtual filesystems in Linux: Why we need them and how they work)
|
||||
[#]: via: (https://opensource.com/article/19/3/virtual-filesystems-linux)
|
||||
[#]: author: (Alison Chariken )
|
||||
|
||||
Virtual filesystems in Linux: Why we need them and how they work
|
||||
======
|
||||
Virtual filesystems are the magic abstraction that makes the "everything is a file" philosophy of Linux possible.
|
||||

|
||||
|
||||
What is a filesystem? According to early Linux contributor and author [Robert Love][1], "A filesystem is a hierarchical storage of data adhering to a specific structure." However, this description applies equally well to VFAT (Virtual File Allocation Table), Git, and [Cassandra][2] (a [NoSQL database][3]). So what distinguishes a filesystem?
|
||||
|
||||
### Filesystem basics
|
||||
|
||||
The Linux kernel requires that for an entity to be a filesystem, it must also implement the **open()** , **read()** , and **write()** methods on persistent objects that have names associated with them. From the point of view of [object-oriented programming][4], the kernel treats the generic filesystem as an abstract interface, and these big-three functions are "virtual," with no default definition. Accordingly, the kernel's default filesystem implementation is called a virtual filesystem (VFS).
|
||||
|
||||
|
||||
![][5]
|
||||
If we can open(), read(), and write(), it is a file as this console session shows.
|
||||
|
||||
VFS underlies the famous observation that in Unix-like systems "everything is a file." Consider how weird it is that the tiny demo above featuring the character device /dev/console actually works. The image shows an interactive Bash session on a virtual teletype (tty). Sending a string into the virtual console device makes it appear on the virtual screen. VFS has other, even odder properties. For example, it's [possible to seek in them][6].
|
||||
|
||||
The familiar filesystems like ext4, NFS, and /proc all provide definitions of the big-three functions in a C-language data structure called [file_operations][7] . In addition, particular filesystems extend and override the VFS functions in the familiar object-oriented way. As Robert Love points out, the abstraction of VFS enables Linux users to blithely copy files to and from foreign operating systems or abstract entities like pipes without worrying about their internal data format. On behalf of userspace, via a system call, a process can copy from a file into the kernel's data structures with the read() method of one filesystem, then use the write() method of another kind of filesystem to output the data.
|
||||
|
||||
The function definitions that belong to the VFS base type itself are found in the [fs/*.c files][8] in kernel source, while the subdirectories of fs/ contain the specific filesystems. The kernel also contains filesystem-like entities such as cgroups, /dev, and tmpfs, which are needed early in the boot process and are therefore defined in the kernel's init/ subdirectory. Note that cgroups, /dev, and tmpfs do not call the file_operations big-three functions, but directly read from and write to memory instead.
|
||||
|
||||
The diagram below roughly illustrates how userspace accesses various types of filesystems commonly mounted on Linux systems. Not shown are constructs like pipes, dmesg, and POSIX clocks that also implement struct file_operations and whose accesses therefore pass through the VFS layer.
|
||||
|
||||
![How userspace accesses various types of filesystems][9]
|
||||
VFS are a "shim layer" between system calls and implementors of specific file_operations like ext4 and procfs. The file_operations functions can then communicate either with device-specific drivers or with memory accessors. tmpfs, devtmpfs and cgroups don't make use of file_operations but access memory directly.
|
||||
|
||||
VFS's existence promotes code reuse, as the basic methods associated with filesystems need not be re-implemented by every filesystem type. Code reuse is a widely accepted software engineering best practice! Alas, if the reused code [introduces serious bugs][10], then all the implementations that inherit the common methods suffer from them.
|
||||
|
||||
### /tmp: A simple tip
|
||||
|
||||
An easy way to find out what VFSes are present on a system is to type **mount | grep -v sd | grep -v :/** , which will list all mounted filesystems that are not resident on a disk and not NFS on most computers. One of the listed VFS mounts will assuredly be /tmp, right?
|
||||
|
||||
![Man with shocked expression][11]
|
||||
Everyone knows that keeping /tmp on a physical storage device is crazy! credit: <https://tinyurl.com/ybomxyfo>
|
||||
|
||||
Why is keeping /tmp on storage inadvisable? Because the files in /tmp are temporary(!), and storage devices are slower than memory, where tmpfs are created. Further, physical devices are more subject to wear from frequent writing than memory is. Last, files in /tmp may contain sensitive information, so having them disappear at every reboot is a feature.
|
||||
|
||||
Unfortunately, installation scripts for some Linux distros still create /tmp on a storage device by default. Do not despair should this be the case with your system. Follow simple instructions on the always excellent [Arch Wiki][12] to fix the problem, keeping in mind that memory allocated to tmpfs is not available for other purposes. In other words, a system with a gigantic tmpfs with large files in it can run out of memory and crash. Another tip: when editing the /etc/fstab file, be sure to end it with a newline, as your system will not boot otherwise. (Guess how I know.)
|
||||
|
||||
### /proc and /sys
|
||||
|
||||
Besides /tmp, the VFSes with which most Linux users are most familiar are /proc and /sys. (/dev relies on shared memory and has no file_operations). Why two flavors? Let's have a look in more detail.
|
||||
|
||||
The procfs offers a snapshot into the instantaneous state of the kernel and the processes that it controls for userspace. In /proc, the kernel publishes information about the facilities it provides, like interrupts, virtual memory, and the scheduler. In addition, /proc/sys is where the settings that are configurable via the [sysctl command][13] are accessible to userspace. Status and statistics on individual processes are reported in /proc/<PID> directories.
|
||||
|
||||
![Console][14]
|
||||
/proc/meminfo is an empty file that nonetheless contains valuable information.
|
||||
|
||||
The behavior of /proc files illustrates how unlike on-disk filesystems VFS can be. On the one hand, /proc/meminfo contains the information presented by the command **free**. On the other hand, it's also empty! How can this be? The situation is reminiscent of a famous article written by Cornell University physicist N. David Mermin in 1985 called "[Is the moon there when nobody looks?][15] Reality and the quantum theory." The truth is that the kernel gathers statistics about memory when a process requests them from /proc, and there actually is nothing in the files in /proc when no one is looking. As [Mermin said][16], "It is a fundamental quantum doctrine that a measurement does not, in general, reveal a preexisting value of the measured property." (The answer to the question about the moon is left as an exercise.)
|
||||
|
||||
![Full moon][17]
|
||||
The files in /proc are empty when no process accesses them. ([Source][18])
|
||||
|
||||
The apparent emptiness of procfs makes sense, as the information available there is dynamic. The situation with sysfs is different. Let's compare how many files of at least one byte in size there are in /proc versus /sys.
|
||||
|
||||

|
||||
|
||||
Procfs has precisely one, namely the exported kernel configuration, which is an exception since it needs to be generated only once per boot. On the other hand, /sys has lots of larger files, most of which comprise one page of memory. Typically, sysfs files contain exactly one number or string, in contrast to the tables of information produced by reading files like /proc/meminfo.
|
||||
|
||||
The purpose of sysfs is to expose the readable and writable properties of what the kernel calls "kobjects" to userspace. The only purpose of kobjects is reference-counting: when the last reference to a kobject is deleted, the system will reclaim the resources associated with it. Yet, /sys constitutes most of the kernel's famous "[stable ABI to userspace][19]" which [no one may ever, under any circumstances, "break."][20] That doesn't mean the files in sysfs are static, which would be contrary to reference-counting of volatile objects.
|
||||
|
||||
The kernel's stable ABI instead constrains what can appear in /sys, not what is actually present at any given instant. Listing the permissions on files in sysfs gives an idea of how the configurable, tunable parameters of devices, modules, filesystems, etc. can be set or read. Logic compels the conclusion that procfs is also part of the kernel's stable ABI, although the kernel's [documentation][19] doesn't state so explicitly.
|
||||
|
||||
![Console][21]
|
||||
Files in sysfs describe exactly one property each for an entity and may be readable, writable or both. The "0" in the file reveals that the SSD is not removable.
|
||||
|
||||
### Snooping on VFS with eBPF and bcc tools
|
||||
|
||||
The easiest way to learn how the kernel manages sysfs files is to watch it in action, and the simplest way to watch on ARM64 or x86_64 is to use eBPF. eBPF (extended Berkeley Packet Filter) consists of a [virtual machine running inside the kernel][22] that privileged users can query from the command line. Kernel source tells the reader what the kernel can do; running eBPF tools on a booted system shows instead what the kernel actually does.
|
||||
|
||||
Happily, getting started with eBPF is pretty easy via the [bcc][23] tools, which are available as [packages from major Linux distros][24] and have been [amply documented][25] by Brendan Gregg. The bcc tools are Python scripts with small embedded snippets of C, meaning anyone who is comfortable with either language can readily modify them. At this count, [there are 80 Python scripts in bcc/tools][26], making it highly likely that a system administrator or developer will find an existing one relevant to her/his needs.
|
||||
|
||||
To get a very crude idea about what work VFSes are performing on a running system, try the simple [vfscount][27] or [vfsstat][28], which show that dozens of calls to vfs_open() and its friends occur every second.
|
||||
|
||||
![Console - vfsstat.py][29]
|
||||
vfsstat.py is a Python script with an embedded C snippet that simply counts VFS function calls.
|
||||
|
||||
For a less trivial example, let's watch what happens in sysfs when a USB stick is inserted on a running system.
|
||||
|
||||
![Console when USB is inserted][30]
|
||||
Watch with eBPF what happens in /sys when a USB stick is inserted, with simple and complex examples.
|
||||
|
||||
In the first simple example above, the [trace.py][31] bcc tools script prints out a message whenever the sysfs_create_files() command runs. We see that sysfs_create_files() was started by a kworker thread in response to the USB stick insertion, but what file was created? The second example illustrates the full power of eBPF. Here, trace.py is printing the kernel backtrace (-K option) plus the name of the file created by sysfs_create_files(). The snippet inside the single quotes is some C source code, including an easily recognizable format string, that the provided Python script [induces a LLVM just-in-time compiler][32] to compile and execute inside an in-kernel virtual machine. The full sysfs_create_files() function signature must be reproduced in the second command so that the format string can refer to one of the parameters. Making mistakes in this C snippet results in recognizable C-compiler errors. For example, if the **-I** parameter is omitted, the result is "Failed to compile BPF text." Developers who are conversant with either C or Python will find the bcc tools easy to extend and modify.
|
||||
|
||||
When the USB stick is inserted, the kernel backtrace appears showing that PID 7711 is a kworker thread that created a file called "events" in sysfs. A corresponding invocation with sysfs_remove_files() shows that removal of the USB stick results in removal of the events file, in keeping with the idea of reference counting. Watching sysfs_create_link() with eBPF during USB stick insertion (not shown) reveals that no fewer than 48 symbolic links are created.
|
||||
|
||||
What is the purpose of the events file anyway? Using [cscope][33] to find the function [__device_add_disk()][34] reveals that it calls disk_add_events(), and either "media_change" or "eject_request" may be written to the events file. Here, the kernel's block layer is informing userspace about the appearance and disappearance of the "disk." Consider how quickly informative this method of investigating how USB stick insertion works is compared to trying to figure out the process solely from the source.
|
||||
|
||||
### Read-only root filesystems make embedded devices possible
|
||||
|
||||
Assuredly, no one shuts down a server or desktop system by pulling out the power plug. Why? Because mounted filesystems on the physical storage devices may have pending writes, and the data structures that record their state may become out of sync with what is written on the storage. When that happens, system owners will have to wait at next boot for the [fsck filesystem-recovery tool][35] to run and, in the worst case, will actually lose data.
|
||||
|
||||
Yet, aficionados will have heard that many IoT and embedded devices like routers, thermostats, and automobiles now run Linux. Many of these devices almost entirely lack a user interface, and there's no way to "unboot" them cleanly. Consider jump-starting a car with a dead battery where the power to the [Linux-running head unit][36] goes up and down repeatedly. How is it that the system boots without a long fsck when the engine finally starts running? The answer is that embedded devices rely on [a read-only root fileystem][37] (ro-rootfs for short).
|
||||
|
||||
![Photograph of a console][38]
|
||||
ro-rootfs are why embedded systems don't frequently need to fsck. Credit (with permission): <https://tinyurl.com/yxoauoub>
|
||||
|
||||
A ro-rootfs offers many advantages that are less obvious than incorruptibility. One is that malware cannot write to /usr or /lib if no Linux process can write there. Another is that a largely immutable filesystem is critical for field support of remote devices, as support personnel possess local systems that are nominally identical to those in the field. Perhaps the most important (but also most subtle) advantage is that ro-rootfs forces developers to decide during a project's design phase which system objects will be immutable. Dealing with ro-rootfs may often be inconvenient or even painful, as [const variables in programming languages][39] often are, but the benefits easily repay the extra overhead.
|
||||
|
||||
Creating a read-only rootfs does require some additional amount of effort for embedded developers, and that's where VFS comes in. Linux needs files in /var to be writable, and in addition, many popular applications that embedded systems run will try to create configuration dot-files in $HOME. One solution for configuration files in the home directory is typically to pregenerate them and build them into the rootfs. For /var, one approach is to mount it on a separate writable partition while / itself is mounted as read-only. Using bind or overlay mounts is another popular alternative.
|
||||
|
||||
### Bind and overlay mounts and their use by containers
|
||||
|
||||
Running **[man mount][40]** is the best place to learn about bind and overlay mounts, which give embedded developers and system administrators the power to create a filesystem in one path location and then provide it to applications at a second one. For embedded systems, the implication is that it's possible to store the files in /var on an unwritable flash device but overlay- or bind-mount a path in a tmpfs onto the /var path at boot so that applications can scrawl there to their heart's delight. At next power-on, the changes in /var will be gone. Overlay mounts provide a union between the tmpfs and the underlying filesystem and allow apparent modification to an existing file in a ro-rootfs, while bind mounts can make new empty tmpfs directories show up as writable at ro-rootfs paths. While overlayfs is a proper filesystem type, bind mounts are implemented by the [VFS namespace facility][41].
|
||||
|
||||
Based on the description of overlay and bind mounts, no one will be surprised that [Linux containers][42] make heavy use of them. Let's spy on what happens when we employ [systemd-nspawn][43] to start up a container by running bcc's mountsnoop tool:
|
||||
|
||||
![Console - system-nspawn invocation][44]
|
||||
The system-nspawn invocation fires up the container while mountsnoop.py runs.
|
||||
|
||||
And let's see what happened:
|
||||
|
||||
![Console - Running mountsnoop][45]
|
||||
Running mountsnoop during the container "boot" reveals that the container runtime relies heavily on bind mounts. (Only the beginning of the lengthy output is displayed)
|
||||
|
||||
Here, systemd-nspawn is providing selected files in the host's procfs and sysfs to the container at paths in its rootfs. Besides the MS_BIND flag that sets bind-mounting, some of the other flags that the "mount" system call invokes determine the relationship between changes in the host namespace and in the container. For example, the bind-mount can either propagate changes in /proc and /sys to the container, or hide them, depending on the invocation.
|
||||
|
||||
### Summary
|
||||
|
||||
Understanding Linux internals can seem an impossible task, as the kernel itself contains a gigantic amount of code, leaving aside Linux userspace applications and the system-call interface in C libraries like glibc. One way to make progress is to read the source code of one kernel subsystem with an emphasis on understanding the userspace-facing system calls and headers plus major kernel internal interfaces, exemplified here by the file_operations table. The file operations are what makes "everything is a file" actually work, so getting a handle on them is particularly satisfying. The kernel C source files in the top-level fs/ directory constitute its implementation of virtual filesystems, which are the shim layer that enables broad and relatively straightforward interoperability of popular filesystems and storage devices. Bind and overlay mounts via Linux namespaces are the VFS magic that makes containers and read-only root filesystems possible. In combination with a study of source code, the eBPF kernel facility and its bcc interface makes probing the kernel simpler than ever before.
|
||||
|
||||
Much thanks to [Akkana Peck][46] and [Michael Eager][47] for comments and corrections.
|
||||
|
||||
Alison Chaiken will present [Virtual filesystems: why we need them and how they work][48] at the 17th annual Southern California Linux Expo ([SCaLE 17x][49]) March 7-10 in Pasadena, Calif.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/virtual-filesystems-linux
|
||||
|
||||
作者:[Alison Chariken][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pearson.com/us/higher-education/program/Love-Linux-Kernel-Development-3rd-Edition/PGM202532.html
|
||||
[2]: http://cassandra.apache.org/
|
||||
[3]: https://en.wikipedia.org/wiki/NoSQL
|
||||
[4]: http://lwn.net/Articles/444910/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_1-console.png (Console)
|
||||
[6]: https://lwn.net/Articles/22355/
|
||||
[7]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/fs.h
|
||||
[8]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/fs
|
||||
[9]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_2-shim-layer.png (How userspace accesses various types of filesystems)
|
||||
[10]: https://lwn.net/Articles/774114/
|
||||
[11]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_3-crazy.jpg (Man with shocked expression)
|
||||
[12]: https://wiki.archlinux.org/index.php/Tmpfs
|
||||
[13]: http://man7.org/linux/man-pages/man8/sysctl.8.html
|
||||
[14]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_4-proc-meminfo.png (Console)
|
||||
[15]: http://www-f1.ijs.si/~ramsak/km1/mermin.moon.pdf
|
||||
[16]: https://en.wikiquote.org/wiki/David_Mermin
|
||||
[17]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_5-moon.jpg (Full moon)
|
||||
[18]: https://commons.wikimedia.org/wiki/Moon#/media/File:Full_Moon_Luc_Viatour.jpg
|
||||
[19]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/stable
|
||||
[20]: https://lkml.org/lkml/2012/12/23/75
|
||||
[21]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_7-sysfs.png (Console)
|
||||
[22]: https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[23]: https://github.com/iovisor/bcc
|
||||
[24]: https://github.com/iovisor/bcc/blob/master/INSTALL.md
|
||||
[25]: http://brendangregg.com/ebpf.html
|
||||
[26]: https://github.com/iovisor/bcc/tree/master/tools
|
||||
[27]: https://github.com/iovisor/bcc/blob/master/tools/vfscount_example.txt
|
||||
[28]: https://github.com/iovisor/bcc/blob/master/tools/vfsstat.py
|
||||
[29]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_8-vfsstat.png (Console - vfsstat.py)
|
||||
[30]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_9-ebpf.png (Console when USB is inserted)
|
||||
[31]: https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt
|
||||
[32]: https://events.static.linuxfound.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf
|
||||
[33]: http://northstar-www.dartmouth.edu/doc/solaris-forte/manuals/c/user_guide/cscope.html
|
||||
[34]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/block/genhd.c#n665
|
||||
[35]: http://www.man7.org/linux/man-pages/man8/fsck.8.html
|
||||
[36]: https://wiki.automotivelinux.org/_media/eg-rhsa/agl_referencehardwarespec_v0.1.0_20171018.pdf
|
||||
[37]: https://elinux.org/images/1/1f/Read-only_rootfs.pdf
|
||||
[38]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_10-code.jpg (Photograph of a console)
|
||||
[39]: https://www.meetup.com/ACCU-Bay-Area/events/drpmvfytlbqb/
|
||||
[40]: http://man7.org/linux/man-pages/man8/mount.8.html
|
||||
[41]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/filesystems/sharedsubtree.txt
|
||||
[42]: https://coreos.com/os/docs/latest/kernel-modules.html
|
||||
[43]: https://www.freedesktop.org/software/systemd/man/systemd-nspawn.html
|
||||
[44]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_11-system-nspawn.png (Console - system-nspawn invocation)
|
||||
[45]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_12-mountsnoop.png (Console - Running mountsnoop)
|
||||
[46]: http://shallowsky.com/
|
||||
[47]: http://eagercon.com/
|
||||
[48]: https://www.socallinuxexpo.org/scale/17x/presentations/virtual-filesystems-why-we-need-them-and-how-they-work
|
||||
[49]: https://www.socallinuxexpo.org/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (sanfusu)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -109,7 +109,7 @@ via: https://opensource.com/article/19/3/mobile-particulate-matter-sensor
|
||||
|
||||
作者:[Stephan Tetzel][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,70 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5G: A deep dive into fast, new wireless)
|
||||
[#]: via: (https://www.networkworld.com/article/3385030/5g-a-deep-dive-into-fast-new-wireless.html#tk.rss_all)
|
||||
[#]: author: (Craig Mathias https://www.networkworld.com/author/Craig-Mathias/)
|
||||
|
||||
5G: A deep dive into fast, new wireless
|
||||
======
|
||||
|
||||
### 5G wireless networks are just about ready for prime time, overcoming backhaul and backward-compatibility issues, and promising the possibility of all-mobile networking through enhanced throughput.
|
||||
|
||||
The next step in the evolution of wireless WAN communications - [5G networks][1] \- is about to hit the front pages, and for good reason: it will complete the evolution of cellular from wireline augmentation to wireline replacement, and strategically from mobile-first to mobile-only.
|
||||
|
||||
So it’s not too early to start least basic planning to understanding how 5G will fit into and benefit IT plans across organizations of all sizes, industries and missions.
|
||||
|
||||
**[ From Mobile World Congress:[The time of 5G is almost here][2] ]**
|
||||
|
||||
5G will of course provide end-users with the additional throughput, capacity, and other elements to address the continuing and dramatic growth in geographic availability, user base, range of subscriber devices, demand for capacity, and application requirements, but will also enable service providers to benefit from new opportunities in overall strategy, service offerings and broadened marketplace presence.
|
||||
|
||||
A look at the key features you can expect in 5G wireless. (Click for larger image.)
|
||||
|
||||
![A look at the key features you can expect in 5G wireless.][3]
|
||||
|
||||
This article explores the technologies and market drivers behind 5G, with an emphasis on what 5G means to enterprise and organizational IT.
|
||||
|
||||
While 5G remains an imprecise term today, key objectives for the development of the advances required have become clear. These are as follows:
|
||||
|
||||
## 5G speeds
|
||||
|
||||
As is the case with Wi-Fi, major advances in cellular are first and foremost defined by new upper-bound _throughput_ numbers. The magic number here for 5G is in fact a _floor_ of 1 Gbps, with numbers as high as 10 Gbps mentioned by some. However, and again as is the case with Wi-Fi, it’s important to think more in terms of overall individual-cell and system-wide _capacity_. We believe, then, that per-user throughput of 50 Mbps is a more reasonable – but clearly still remarkable – working assumption, with up to 300 Mbps peak throughput realized in some deployments over the next five years. The possibility of reaching higher throughput than that exceeds our planning horizon, but such is, well, possible.
|
||||
|
||||
## Reduced latency
|
||||
|
||||
Perhaps even more important than throughput, though, is a reduction in the round-trip time for each packet. Reducing latency is important for voice, which will most certainly be all-IP in 5G implementations, video, and, again, in improving overall capacity. The over-the-air latency goal for 5G is less than 10ms, with 1ms possible in some defined classes of service.
|
||||
|
||||
## 5G network management and OSS
|
||||
|
||||
Operators are always seeking to reduce overhead and operating expense, so enhancements to both system management and operational support systems (OSS) yielding improvements in reliability, availability, serviceability, resilience, consistency, analytics capabilities, and operational efficiency, are all expected. The benefits of these will, in most cases, however, be transparent to end-users.
|
||||
|
||||
## Mobility and 5G technology
|
||||
|
||||
Very-high-speed user mobility, to as much as hundreds of kilometers per hour, will be supported, thus serving users on all modes of transportation. Regulatory and situation-dependent restrictions – most notably, on aircraft – however, will still apply.
|
||||
|
||||
To continue reading this article register now
|
||||
|
||||
[Get Free Access][4]
|
||||
|
||||
[Learn More][5] Existing Users [Sign In][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3385030/5g-a-deep-dive-into-fast-new-wireless.html#tk.rss_all
|
||||
|
||||
作者:[Craig Mathias][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Craig-Mathias/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
[2]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||
[3]: https://images.idgesg.net/images/article/2017/06/2017_nw_5g_wireless_key_features-100727485-large.jpg
|
||||
[4]: javascript://
|
||||
[5]: /learn-about-insider/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,211 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Kubernetes on Fedora IoT with k3s)
|
||||
[#]: via: (https://fedoramagazine.org/kubernetes-on-fedora-iot-with-k3s/)
|
||||
[#]: author: (Lennart Jern https://fedoramagazine.org/author/lennartj/)
|
||||
|
||||
Kubernetes on Fedora IoT with k3s
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora IoT is an upcoming Fedora edition targeted at the Internet of Things. It was introduced last year on Fedora Magazine in the article [How to turn on an LED with Fedora IoT][2]. Since then, it has continued to improve together with Fedora Silverblue to provide an immutable base operating system aimed at container-focused workflows.
|
||||
|
||||
Kubernetes is an immensely popular container orchestration system. It is perhaps most commonly used on powerful hardware handling huge workloads. However, it can also be used on lightweight devices such as the Raspberry Pi 3. Read on to find out how.
|
||||
|
||||
### Why Kubernetes?
|
||||
|
||||
While Kubernetes is all the rage in the cloud, it may not be immediately obvious to run it on a small single board computer. But there are certainly reasons for doing it. First of all it is a great way to learn and get familiar with Kubernetes without the need for expensive hardware. Second, because of its popularity, there are [tons of applications][3] that comes pre-packaged for running in Kubernetes clusters. Not to mention the large community to provide help if you ever get stuck.
|
||||
|
||||
Last but not least, container orchestration may actually make things easier, even at the small scale in a home lab. This may not be apparent when tackling the the learning curve, but these skills will help when dealing with any cluster in the future. It doesn’t matter if it’s a single node Raspberry Pi cluster or a large scale machine learning farm.
|
||||
|
||||
#### K3s – a lightweight Kubernetes
|
||||
|
||||
A “normal” installation of Kubernetes (if such a thing can be said to exist) is a bit on the heavy side for IoT. The recommendation is a minimum of 2 GB RAM per machine! However, there are plenty of alternatives, and one of the newcomers is [k3s][4] – a lightweight Kubernetes distribution.
|
||||
|
||||
K3s is quite special in that it has replaced etcd with SQLite for its key-value storage needs. Another thing to note is that k3s ships as a single binary instead of one per component. This diminishes the memory footprint and simplifies the installation. Thanks to the above, k3s should be able to run k3s with just 512 MB of RAM, perfect for a small single board computer!
|
||||
|
||||
### What you will need
|
||||
|
||||
1. Fedora IoT in a virtual machine or on a physical device. See the excellent getting started guide [here][5]. One machine is enough but two will allow you to test adding more nodes to the cluster.
|
||||
2. [Configure the firewall][6] to allow traffic on ports 6443 and 8472. Or simply disable it for this experiment by running “systemctl stop firewalld”.
|
||||
|
||||
|
||||
|
||||
### Install k3s
|
||||
|
||||
Installing k3s is very easy. Simply run the installation script:
|
||||
|
||||
```
|
||||
curl -sfL https://get.k3s.io | sh -
|
||||
```
|
||||
|
||||
This will download, install and start up k3s. After installation, get a list of nodes from the server by running the following command:
|
||||
|
||||
```
|
||||
kubectl get nodes
|
||||
```
|
||||
|
||||
Note that there are several options that can be passed to the installation script through environment variables. These can be found in the [documentation][7]. And of course, there is nothing stopping you from installing k3s manually by downloading the binary directly.
|
||||
|
||||
While great for experimenting and learning, a single node cluster is not much of a cluster. Luckily, adding another node is no harder than setting up the first one. Just pass two environment variables to the installation script to make it find the first node and avoid running the server part of k3s
|
||||
|
||||
```
|
||||
curl -sfL https://get.k3s.io | K3S_URL=https://example-url:6443 \
|
||||
K3S_TOKEN=XXX sh -
|
||||
```
|
||||
|
||||
The example-url above should be replaced by the IP address or fully qualified domain name of the first node. On that node the token (represented by XXX) is found in the file /var/lib/rancher/k3s/server/node-token.
|
||||
|
||||
### Deploy some containers
|
||||
|
||||
Now that we have a Kubernetes cluster, what can we actually do with it? Let’s start by deploying a simple web server.
|
||||
|
||||
```
|
||||
kubectl create deployment my-server --image nginx
|
||||
```
|
||||
|
||||
This will create a [Deployment][8] named “my-server” from the container image “nginx” (defaulting to docker hub as registry and the latest tag). You can see the Pod created by running the following command.
|
||||
|
||||
```
|
||||
kubectl get pods
|
||||
```
|
||||
|
||||
In order to access the nginx server running in the pod, first expose the Deployment through a [Service][9]. The following command will create a Service with the same name as the deployment.
|
||||
|
||||
```
|
||||
kubectl expose deployment my-server --port 80
|
||||
```
|
||||
|
||||
The Service works as a kind of load balancer and DNS record for the Pods. For instance, when running a second Pod, we will be able to _curl_ the nginx server just by specifying _my-server_ (the name of the Service). See the example below for how to do this.
|
||||
|
||||
```
|
||||
# Start a pod and run bash interactively in it
|
||||
kubectl run debug --generator=run-pod/v1 --image=fedora -it -- bash
|
||||
# Wait for the bash prompt to appear
|
||||
curl my-server
|
||||
# You should get the "Welcome to nginx!" page as output
|
||||
```
|
||||
|
||||
### Ingress controller and external IP
|
||||
|
||||
By default, a Service only get a ClusterIP (only accessible inside the cluster), but you can also request an external IP for the service by setting its type to [LoadBalancer][10]. However, not all applications require their own IP address. Instead, it is often possible to share one IP address among many services by routing requests based on the host header or path. You can accomplish this in Kubernetes with an [Ingress][11], and this is what we will do. Ingresses also provide additional features such as TLS encryption of the traffic without having to modify your application.
|
||||
|
||||
Kubernetes needs an ingress controller to make the Ingress resources work and k3s includes [Traefik][12] for this purpose. It also includes a simple service load balancer that makes it possible to get an external IP for a Service in the cluster. The [documentation][13] describes the service like this:
|
||||
|
||||
> k3s includes a basic service load balancer that uses available host ports. If you try to create a load balancer that listens on port 80, for example, it will try to find a free host in the cluster for port 80. If no port is available the load balancer will stay in Pending.
|
||||
>
|
||||
> k3s README
|
||||
|
||||
The ingress controller is already exposed with this load balancer service. You can find the IP address that it is using with the following command.
|
||||
|
||||
```
|
||||
$ kubectl get svc --all-namespaces
|
||||
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
default kubernetes ClusterIP 10.43.0.1 443/TCP 33d
|
||||
default my-server ClusterIP 10.43.174.38 80/TCP 30m
|
||||
kube-system kube-dns ClusterIP 10.43.0.10 53/UDP,53/TCP,9153/TCP 33d
|
||||
kube-system traefik LoadBalancer 10.43.145.104 10.0.0.8 80:31596/TCP,443:31539/TCP 33d
|
||||
```
|
||||
|
||||
Look for the Service named traefik. In the above example the IP we are interested in is 10.0.0.8.
|
||||
|
||||
### Route incoming requests
|
||||
|
||||
Let’s create an Ingress that routes requests to our web server based on the host header. This example uses [xip.io][14] to avoid having to set up DNS records. It works by including the IP adress as a subdomain, to use any subdomain of 10.0.0.8.xip.io to reach the IP 10.0.0.8. In other words, my-server.10.0.0.8.xip.io is used to reach the ingress controller in the cluster. You can try this right now (with your own IP instead of 10.0.0.8). Without an ingress in place you should reach the “default backend” which is just a page showing “404 page not found”.
|
||||
|
||||
We can tell the ingress controller to route requests to our web server Service with the following Ingress.
|
||||
|
||||
```
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Ingress
|
||||
metadata:
|
||||
name: my-server
|
||||
spec:
|
||||
rules:
|
||||
- host: my-server.10.0.0.8.xip.io
|
||||
http:
|
||||
paths:
|
||||
- path: /
|
||||
backend:
|
||||
serviceName: my-server
|
||||
servicePort: 80
|
||||
```
|
||||
|
||||
Save the above snippet in a file named _my-ingress.yaml_ and add it to the cluster by running this command:
|
||||
|
||||
```
|
||||
kubectl apply -f my-ingress.yaml
|
||||
```
|
||||
|
||||
You should now be able to reach the default nginx welcoming page on the fully qualified domain name you chose. In my example this would be my-server.10.0.0.8.xip.io. The ingress controller is routing the requests based on the information in the Ingress. A request to my-server.10.0.0.8.xip.io will be routed to the Service and port defined as backend in the Ingress (my-server and 80 in this case).
|
||||
|
||||
### What about IoT then?
|
||||
|
||||
Imagine the following scenario. You have dozens of devices spread out around your home or farm. It is a heterogeneous collection of IoT devices with various hardware capabilities, sensors and actuators. Maybe some of them have cameras, weather or light sensors. Others may be hooked up to control the ventilation, lights, blinds or blink LEDs.
|
||||
|
||||
In this scenario, you want to gather data from all the sensors, maybe process and analyze it before you finally use it to make decisions and control the actuators. In addition to this, you may want to visualize what’s going on by setting up a dashboard. So how can Kubernetes help us manage something like this? How can we make sure that Pods run on suitable devices?
|
||||
|
||||
The simple answer is labels. You can label the nodes according to capabilities, like this:
|
||||
|
||||
```
|
||||
kubectl label nodes <node-name> <label-key>=<label-value>
|
||||
# Example
|
||||
kubectl label nodes node2 camera=available
|
||||
```
|
||||
|
||||
Once they are labeled, it is easy to select suitable nodes for your workload with [nodeSelectors][15]. The final piece to the puzzle, if you want to run your Pods on _all_ suitable nodes is to use [DaemonSets][16] instead of Deployments. In other words, create one DaemonSet for each data collecting application that uses some unique sensor and use nodeSelectors to make sure they only run on nodes with the proper hardware.
|
||||
|
||||
The service discovery feature that allows Pods to find each other simply by Service name makes it quite easy to handle these kinds of distributed systems. You don’t need to know or configure IP addresses or custom ports for the applications. Instead, they can easily find each other through named Services in the cluster.
|
||||
|
||||
#### Utilize spare resources
|
||||
|
||||
With the cluster up and running, collecting data and controlling your lights and climate control you may feel that you are finished. However, there are still plenty of compute resources in the cluster that could be used for other projects. This is where Kubernetes really shines.
|
||||
|
||||
You shouldn’t have to worry about where exactly those resources are or calculate if there is enough memory to fit an extra application here or there. This is exactly what orchestration solves! You can easily deploy more applications in the cluster and let Kubernetes figure out where (or if) they will fit.
|
||||
|
||||
Why not run your own [NextCloud][17] instance? Or maybe [gitea][18]? You could also set up a CI/CD pipeline for all those IoT containers. After all, why would you build and cross compile them on your main computer if you can do it natively in the cluster?
|
||||
|
||||
The point here is that Kubernetes makes it easier to make use of the “hidden” resources that you often end up with otherwise. Kubernetes handles scheduling of Pods in the cluster based on available resources and fault tolerance so that you don’t have to. However, in order to help Kubernetes make reasonable decisions you should definitely add [resource requests][19] to your workloads.
|
||||
|
||||
### Summary
|
||||
|
||||
While Kubernetes, or container orchestration in general, may not usually be associated with IoT, it certainly makes a lot of sense to have an orchestrator when you are dealing with distributed systems. Not only does is allow you to handle a diverse and heterogeneous fleet of devices in a unified way, but it also simplifies communication between them. In addition, Kubernetes makes it easier to utilize spare resources.
|
||||
|
||||
Container technology made it possible to build applications that could “run anywhere”. Now Kubernetes makes it easier to manage the “anywhere” part. And as an immutable base to build it all on, we have Fedora IoT.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/kubernetes-on-fedora-iot-with-k3s/
|
||||
|
||||
作者:[Lennart Jern][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/lennartj/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/k3s-1-816x345.png
|
||||
[2]: https://fedoramagazine.org/turnon-led-fedora-iot/
|
||||
[3]: https://hub.helm.sh/
|
||||
[4]: https://k3s.io
|
||||
[5]: https://docs.fedoraproject.org/en-US/iot/getting-started/
|
||||
[6]: https://github.com/rancher/k3s#open-ports--network-security
|
||||
[7]: https://github.com/rancher/k3s#systemd
|
||||
[8]: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
|
||||
[9]: https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[10]: https://kubernetes.io/docs/concepts/services-networking/service/#loadbalancer
|
||||
[11]: https://kubernetes.io/docs/concepts/services-networking/ingress/
|
||||
[12]: https://traefik.io/
|
||||
[13]: https://github.com/rancher/k3s/blob/master/README.md#service-load-balancer
|
||||
[14]: http://xip.io/
|
||||
[15]: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
|
||||
[16]: https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/
|
||||
[17]: https://nextcloud.com/
|
||||
[18]: https://gitea.io/en-us/
|
||||
[19]: https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
|
||||
@ -1,117 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with social media sentiment analysis in Python)
|
||||
[#]: via: (https://opensource.com/article/19/4/social-media-sentiment-analysis-python)
|
||||
[#]: author: (Michael McCune https://opensource.com/users/elmiko/users/jschlessman)
|
||||
|
||||
Getting started with social media sentiment analysis in Python
|
||||
======
|
||||
Learn the basics of natural language processing and explore two useful
|
||||
Python packages.
|
||||
![Raspberry Pi and Python][1]
|
||||
|
||||
Natural language processing (NLP) is a type of machine learning that addresses the correlation between spoken/written languages and computer-aided analysis of those languages. We experience numerous innovations from NLP in our daily lives, from writing assistance and suggestions to real-time speech translation and interpretation.
|
||||
|
||||
This article examines one specific area of NLP: sentiment analysis, with an emphasis on determining the positive, negative, or neutral nature of the input language. This part will explain the background behind NLP and sentiment analysis and explore two open source Python packages. [Part 2][2] will demonstrate how to begin building your own scalable sentiment analysis services.
|
||||
|
||||
When learning sentiment analysis, it is helpful to have an understanding of NLP in general. This article won't dig into the mathematical guts, rather our goal is to clarify key concepts in NLP that are crucial to incorporating these methods into your solutions in practical ways.
|
||||
|
||||
### Natural language and text data
|
||||
|
||||
A reasonable place to begin is defining: "What is natural language?" It is the means by which we, as humans, communicate with one another. The primary modalities for communication are verbal and text. We can take this a step further and focus solely on text communication; after all, living in an age of pervasive Siri, Alexa, etc., we know speech is a group of computations away from text.
|
||||
|
||||
### Data landscape and challenges
|
||||
|
||||
Limiting ourselves to textual data, what can we say about language and text? First, language, particularly English, is fraught with exceptions to rules, plurality of meanings, and contextual differences that can confuse even a human interpreter, let alone a computational one. In elementary school, we learn articles of speech and punctuation, and from speaking our native language, we acquire intuition about which words have less significance when searching for meaning. Examples of the latter would be articles of speech such as "a," "the," and "or," which in NLP are referred to as _stop words_ , since traditionally an NLP algorithm's search for meaning stops when reaching one of these words in a sequence.
|
||||
|
||||
Since our goal is to automate the classification of text as belonging to a sentiment class, we need a way to work with text data in a computational fashion. Therefore, we must consider how to represent text data to a machine. As we know, the rules for utilizing and interpreting language are complicated, and the size and structure of input text can vary greatly. We'll need to transform the text data into numeric data, the form of choice for machines and math. This transformation falls under the area of _feature extraction_.
|
||||
|
||||
Upon extracting numeric representations of input text data, one refinement might be, given an input body of text, to determine a set of quantitative statistics for the articles of speech listed above and perhaps classify documents based on them. For example, a glut of adverbs might make a copywriter bristle, or excessive use of stop words might be helpful in identifying term papers with content padding. Admittedly, this may not have much bearing on our goal of sentiment analysis.
|
||||
|
||||
### Bag of words
|
||||
|
||||
When you assess a text statement as positive or negative, what are some contextual clues you use to assess its polarity (i.e., whether the text has positive, negative, or neutral sentiment)? One way is connotative adjectives: something called "disgusting" is viewed as negative, but if the same thing were called "beautiful," you would judge it as positive. Colloquialisms, by definition, give a sense of familiarity and often positivity, whereas curse words could be a sign of hostility. Text data can also include emojis, which carry inherent sentiments.
|
||||
|
||||
Understanding the polarity influence of individual words provides a basis for the [_bag-of-words_][3] (BoW) model of text. It considers a set of words or vocabulary and extracts measures about the presence of those words in the input text. The vocabulary is formed by considering text where the polarity is known, referred to as _labeled training data_. Features are extracted from this set of labeled data, then the relationships between the features are analyzed and labels are associated with the data.
|
||||
|
||||
The name "bag of words" illustrates what it utilizes: namely, individual words without consideration of spatial locality or context. A vocabulary typically is built from all words appearing in the training set, which tends to be pruned afterward. Stop words, if not cleaned prior to training, are removed due to their high frequency and low contextual utility. Rarely used words can also be removed, given the lack of information they provide for general input cases.
|
||||
|
||||
It is important to note, however, that you can (and should) go further and consider the appearance of words beyond their use in an individual instance of training data, or what is called [_term frequency_][4] (TF). You should also consider the counts of a word through all instances of input data; typically the infrequency of words among all documents is notable, which is called the [_inverse document frequency_][5] (IDF). These metrics are bound to be mentioned in other articles and software packages on this subject, so having an awareness of them can only help.
|
||||
|
||||
BoW is useful in a number of document classification applications; however, in the case of sentiment analysis, things can be gamed when the lack of contextual awareness is leveraged. Consider the following sentences:
|
||||
|
||||
* We are not enjoying this war.
|
||||
* I loathe rainy days, good thing today is sunny.
|
||||
* This is not a matter of life and death.
|
||||
|
||||
|
||||
|
||||
The sentiment of these phrases is questionable for human interpreters, and by strictly focusing on instances of individual vocabulary words, it's difficult for a machine interpreter as well.
|
||||
|
||||
Groupings of words, called _n-grams_ , can also be considered in NLP. A bigram considers groups of two adjacent words instead of (or in addition to) the single BoW. This should alleviate situations such as "not enjoying" above, but it will remain open to gaming due to its loss of contextual awareness. Furthermore, in the second sentence above, the sentiment context of the second half of the sentence could be perceived as negating the first half. Thus, spatial locality of contextual clues also can be lost in this approach. Complicating matters from a pragmatic perspective is the sparsity of features extracted from a given input text. For a thorough and large vocabulary, a count is maintained for each word, which can be considered an integer vector. Most documents will have a large number of zero counts in their vectors, which adds unnecessary space and time complexity to operations. While a number of clever approaches have been proposed for reducing this complexity, it remains an issue.
|
||||
|
||||
### Word embeddings
|
||||
|
||||
Word embeddings are a distributed representation that allows words with a similar meaning to have a similar representation. This is based on using a real-valued vector to represent words in connection with the company they keep, as it were. The focus is on the manner that words are used, as opposed to simply their existence. In addition, a huge pragmatic benefit of word embeddings is their focus on dense vectors; by moving away from a word-counting model with commensurate amounts of zero-valued vector elements, word embeddings provide a more efficient computational paradigm with respect to both time and storage.
|
||||
|
||||
Following are two prominent word embedding approaches.
|
||||
|
||||
#### Word2vec
|
||||
|
||||
The first of these word embeddings, [Word2vec][6], was developed at Google. You'll probably see this embedding method mentioned as you go deeper in your study of NLP and sentiment analysis. It utilizes either a _continuous bag of words_ (CBOW) or a _continuous skip-gram_ model. In CBOW, a word's context is learned during training based on the words surrounding it. Continuous skip-gram learns the words that tend to surround a given word. Although this is more than what you'll probably need to tackle, if you're ever faced with having to generate your own word embeddings, the author of Word2vec advocates the CBOW method for speed and assessment of frequent words, while the skip-gram approach is better suited for embeddings where rare words are more important.
|
||||
|
||||
#### GloVe
|
||||
|
||||
The second word embedding, [_Global Vectors for Word Representation_][7] (GloVe), was developed at Stanford. It's an extension to the Word2vec method that attempts to combine the information gained through classical global text statistical feature extraction with the local contextual information determined by Word2vec. In practice, GloVe has outperformed Word2vec for some applications, while falling short of Word2vec's performance in others. Ultimately, the targeted dataset for your word embedding will dictate which method is optimal; as such, it's good to know the existence and high-level mechanics of each, as you'll likely come across them.
|
||||
|
||||
#### Creating and using word embeddings
|
||||
|
||||
Finally, it's useful to know how to obtain word embeddings; in part 2, you'll see that we are standing on the shoulders of giants, as it were, by leveraging the substantial work of others in the community. This is one method of acquiring a word embedding: namely, using an existing trained and proven model. Indeed, myriad models exist for English and other languages, and it's possible that one does what your application needs out of the box!
|
||||
|
||||
If not, the opposite end of the spectrum in terms of development effort is training your own standalone model without consideration of your application. In essence, you would acquire substantial amounts of labeled training data and likely use one of the approaches above to train a model. Even then, you are still only at the point of acquiring understanding of your input-text data; you then need to develop a model specific for your application (e.g., analyzing sentiment valence in software version-control messages) which, in turn, requires its own time and effort.
|
||||
|
||||
You also could train a word embedding on data specific to your application; while this could reduce time and effort, the word embedding would be application-specific, which would reduce reusability.
|
||||
|
||||
### Available tooling options
|
||||
|
||||
You may wonder how you'll ever get to a point of having a solution for your problem, given the intensive time and computing power needed. Indeed, the complexities of developing solid models can be daunting; however, there is good news: there are already many proven models, tools, and software libraries available that may provide much of what you need. We will focus on [Python][8], which conveniently has a plethora of tooling in place for these applications.
|
||||
|
||||
#### SpaCy
|
||||
|
||||
[SpaCy][9] provides a number of language models for parsing input text data and extracting features. It is highly optimized and touted as the fastest library of its kind. Best of all, it's open source! SpaCy performs tokenization, parts-of-speech classification, and dependency annotation. It contains word embedding models for performing this and other feature extraction operations for over 46 languages. You will see how it can be used for text analysis and feature extraction in the second article in this series.
|
||||
|
||||
#### vaderSentiment
|
||||
|
||||
The [vaderSentiment][10] package provides a measure of positive, negative, and neutral sentiment. As the [original paper][11]'s title ("VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text") indicates, the models were developed and tuned specifically for social media text data. VADER was trained on a thorough set of human-labeled data, which included common emoticons, UTF-8 encoded emojis, and colloquial terms and abbreviations (e.g., meh, lol, sux).
|
||||
|
||||
For given input text data, vaderSentiment returns a 3-tuple of polarity score percentages. It also provides a single scoring measure, referred to as _vaderSentiment's compound metric_. This is a real-valued measurement within the range **[-1, 1]** wherein sentiment is considered positive for values greater than **0.05** , negative for values less than **-0.05** , and neutral otherwise.
|
||||
|
||||
In [part 2][2], you will learn how to use these tools to add sentiment analysis capabilities to your designs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/social-media-sentiment-analysis-python
|
||||
|
||||
作者:[Michael McCune ][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/elmiko/users/jschlessman
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/getting_started_with_python.png?itok=MFEKm3gl (Raspberry Pi and Python)
|
||||
[2]: https://opensource.com/article/19/4/social-media-sentiment-analysis-python-part-2
|
||||
[3]: https://en.wikipedia.org/wiki/Bag-of-words_model
|
||||
[4]: https://en.wikipedia.org/wiki/Tf%E2%80%93idf#Term_frequency
|
||||
[5]: https://en.wikipedia.org/wiki/Tf%E2%80%93idf#Inverse_document_frequency
|
||||
[6]: https://en.wikipedia.org/wiki/Word2vec
|
||||
[7]: https://en.wikipedia.org/wiki/GloVe_(machine_learning)
|
||||
[8]: https://www.python.org/
|
||||
[9]: https://pypi.org/project/spacy/
|
||||
[10]: https://pypi.org/project/vaderSentiment/
|
||||
[11]: http://comp.social.gatech.edu/papers/icwsm14.vader.hutto.pdf
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -106,7 +106,7 @@ via: https://itsfoss.com/epic-games-lutris-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[Modrisco](https://github.com/Modrisco)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,132 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Automate backups with restic and systemd)
|
||||
[#]: via: (https://fedoramagazine.org/automate-backups-with-restic-and-systemd/)
|
||||
[#]: author: (Link Dupont https://fedoramagazine.org/author/linkdupont/)
|
||||
|
||||
Automate backups with restic and systemd
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Timely backups are important. So much so that [backing up software][2] is a common topic of discussion, even [here on the Fedora Magazine][3]. This article demonstrates how to automate backups with **restic** using only systemd unit files.
|
||||
|
||||
For an introduction to restic, be sure to check out our article [Use restic on Fedora for encrypted backups][4]. Then read on for more details.
|
||||
|
||||
Two systemd services are required to run in order to automate taking snapshots and keeping data pruned. The first service runs the _backup_ command needs to be run on a regular frequency. The second service takes care of data pruning.
|
||||
|
||||
If you’re not familiar with systemd at all, there’s never been a better time to learn. Check out [the series on systemd here at the Magazine][5], starting with this primer on unit files:
|
||||
|
||||
> [systemd unit file basics][6]
|
||||
|
||||
If you haven’t installed restic already, note it’s in the official Fedora repositories. To install use this command [with sudo][7]:
|
||||
|
||||
```
|
||||
$ sudo dnf install restic
|
||||
```
|
||||
|
||||
### Backup
|
||||
|
||||
First, create the _~/.config/systemd/user/restic-backup.service_ file. Copy and paste the text below into the file for best results.
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Restic backup service
|
||||
[Service]
|
||||
Type=oneshot
|
||||
ExecStart=restic backup --verbose --one-file-system --tag systemd.timer $BACKUP_EXCLUDES $BACKUP_PATHS
|
||||
ExecStartPost=restic forget --verbose --tag systemd.timer --group-by "paths,tags" --keep-daily $RETENTION_DAYS --keep-weekly $RETENTION_WEEKS --keep-monthly $RETENTION_MONTHS --keep-yearly $RETENTION_YEARS
|
||||
EnvironmentFile=%h/.config/restic-backup.conf
|
||||
```
|
||||
|
||||
This service references an environment file in order to load secrets (such as _RESTIC_PASSWORD_ ). Create the _~/.config/restic-backup.conf_ file. Copy and paste the content below for best results. This example uses BackBlaze B2 buckets. Adjust the ID, key, repository, and password values accordingly.
|
||||
|
||||
```
|
||||
BACKUP_PATHS="/home/rupert"
|
||||
BACKUP_EXCLUDES="--exclude-file /home/rupert/.restic_excludes --exclude-if-present .exclude_from_backup"
|
||||
RETENTION_DAYS=7
|
||||
RETENTION_WEEKS=4
|
||||
RETENTION_MONTHS=6
|
||||
RETENTION_YEARS=3
|
||||
B2_ACCOUNT_ID=XXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
B2_ACCOUNT_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
RESTIC_REPOSITORY=b2:XXXXXXXXXXXXXXXXXX:/
|
||||
RESTIC_PASSWORD=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
```
|
||||
|
||||
Now that the service is installed, reload systemd: _systemctl –user daemon-reload_. Try running the service manually to create a backup: _systemctl –user start restic-backup_.
|
||||
|
||||
Because the service is a _oneshot_ , it will run once and exit. After verifying that the service runs and creates snapshots as desired, set up a timer to run this service regularly. For example, to run the _restic-backup.service_ daily, create _~/.config/systemd/user/restic-backup.timer_ as follows. Again, copy and paste this text:
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Backup with restic daily
|
||||
[Timer]
|
||||
OnCalendar=daily
|
||||
Persistent=true
|
||||
[Install]
|
||||
WantedBy=timers.target
|
||||
```
|
||||
|
||||
Enable it by running this command:
|
||||
|
||||
```
|
||||
$ systemctl --user enable --now restic-backup.timer
|
||||
```
|
||||
|
||||
### Prune
|
||||
|
||||
While the main service runs the _forget_ command to only keep snapshots within the keep policy, the data is not actually removed from the restic repository. The _prune_ command inspects the repository and current snapshots, and deletes any data not associated with a snapshot. Because _prune_ can be a time-consuming process, it is not necessary to run every time a backup is run. This is the perfect scenario for a second service and timer. First, create the file _~/.config/systemd/user/restic-prune.service_ by copying and pasting this text:
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Restic backup service (data pruning)
|
||||
[Service]
|
||||
Type=oneshot
|
||||
ExecStart=restic prune
|
||||
EnvironmentFile=%h/.config/restic-backup.conf
|
||||
```
|
||||
|
||||
Similarly to the main _restic-backup.service_ , _restic-prune_ is a oneshot service and can be run manually. Once the service has been set up, create and enable a corresponding timer at _~/.config/systemd/user/restic-prune.timer_ :
|
||||
|
||||
```
|
||||
[Unit]
|
||||
Description=Prune data from the restic repository monthly
|
||||
[Timer]
|
||||
OnCalendar=monthly
|
||||
Persistent=true
|
||||
[Install]
|
||||
WantedBy=timers.target
|
||||
```
|
||||
|
||||
That’s it! Restic will now run daily and prune data monthly.
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[ _Samuel Zeller_][8]_ on _[_Unsplash_][9]_._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/automate-backups-with-restic-and-systemd/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/linkdupont/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/restic-systemd-816x345.jpg
|
||||
[2]: https://restic.net/
|
||||
[3]: https://fedoramagazine.org/?s=backup
|
||||
[4]: https://fedoramagazine.org/use-restic-encrypted-backups/
|
||||
[5]: https://fedoramagazine.org/series/systemd-series/
|
||||
[6]: https://fedoramagazine.org/systemd-getting-a-grip-on-units/
|
||||
[7]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[8]: https://unsplash.com/photos/JuFcQxgCXwA?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[9]: https://unsplash.com/search/photos/archive?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -1,96 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Upgrading Fedora 29 to Fedora 30)
|
||||
[#]: via: (https://fedoramagazine.org/upgrading-fedora-29-to-fedora-30/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/author/ryanlerch/)
|
||||
|
||||
Upgrading Fedora 29 to Fedora 30
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Fedora 30 i[s available now][2]. You’ll likely want to upgrade your system to the latest version of Fedora. Fedora Workstation has a graphical upgrade method. Alternatively, Fedora offers a command-line method for upgrading Fedora 29 to Fedora 30.
|
||||
|
||||
### Upgrading Fedora 29 Workstation to Fedora 30
|
||||
|
||||
Soon after release time, a notification appears to tell you an upgrade is available. You can click the notification to launch the **GNOME Software** app. Or you can choose Software from GNOME Shell.
|
||||
|
||||
Choose the _Updates_ tab in GNOME Software and you should see a screen informing you that Fedora 30 is Now Available.
|
||||
|
||||
If you don’t see anything on this screen, try using the reload button at the top left. It may take some time after release for all systems to be able to see an upgrade available.
|
||||
|
||||
Choose _Download_ to fetch the upgrade packages. You can continue working until you reach a stopping point, and the download is complete. Then use GNOME Software to restart your system and apply the upgrade. Upgrading takes time, so you may want to grab a coffee and come back to the system later.
|
||||
|
||||
### Using the command line
|
||||
|
||||
If you’ve upgraded from past Fedora releases, you are likely familiar with the _dnf upgrade_ plugin. This method is the recommended and supported way to upgrade from Fedora 29 to Fedora 30. Using this plugin will make your upgrade to Fedora 30 simple and easy.
|
||||
|
||||
##### 1\. Update software and back up your system
|
||||
|
||||
Before you do anything, you will want to make sure you have the latest software for Fedora 29 before beginning the upgrade process. To update your software, use _GNOME Software_ or enter the following command in a terminal.
|
||||
|
||||
```
|
||||
sudo dnf upgrade --refresh
|
||||
```
|
||||
|
||||
Additionally, make sure you back up your system before proceeding. For help with taking a backup, see [the backup series][3] on the Fedora Magazine.
|
||||
|
||||
##### 2\. Install the DNF plugin
|
||||
|
||||
Next, open a terminal and type the following command to install the plugin:
|
||||
|
||||
```
|
||||
sudo dnf install dnf-plugin-system-upgrade
|
||||
```
|
||||
|
||||
##### 3\. Start the update with DNF
|
||||
|
||||
Now that your system is up-to-date, backed up, and you have the DNF plugin installed, you can begin the upgrade by using the following command in a terminal:
|
||||
|
||||
```
|
||||
sudo dnf system-upgrade download --releasever=30
|
||||
```
|
||||
|
||||
This command will begin downloading all of the upgrades for your machine locally to prepare for the upgrade. If you have issues when upgrading because of packages without updates, broken dependencies, or retired packages, add the _‐‐allowerasing_ flag when typing the above command. This will allow DNF to remove packages that may be blocking your system upgrade.
|
||||
|
||||
##### 4\. Reboot and upgrade
|
||||
|
||||
Once the previous command finishes downloading all of the upgrades, your system will be ready for rebooting. To boot your system into the upgrade process, type the following command in a terminal:
|
||||
|
||||
```
|
||||
sudo dnf system-upgrade reboot
|
||||
```
|
||||
|
||||
Your system will restart after this. Many releases ago, the _fedup_ tool would create a new option on the kernel selection / boot screen. With the _dnf-plugin-system-upgrade_ package, your system reboots into the current kernel installed for Fedora 29; this is normal. Shortly after the kernel selection screen, your system begins the upgrade process.
|
||||
|
||||
Now might be a good time for a coffee break! Once it finishes, your system will restart and you’ll be able to log in to your newly upgraded Fedora 30 system.
|
||||
|
||||
![][4]
|
||||
|
||||
### Resolving upgrade problems
|
||||
|
||||
On occasion, there may be unexpected issues when you upgrade your system. If you experience any issues, please visit the [DNF system upgrade wiki page][5] for more information on troubleshooting in the event of a problem.
|
||||
|
||||
If you are having issues upgrading and have third-party repositories installed on your system, you may need to disable these repositories while you are upgrading. For support with repositories not provided by Fedora, please contact the providers of the repositories.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/upgrading-fedora-29-to-fedora-30/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/ryanlerch/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/29-30-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/announcing-fedora-30/
|
||||
[3]: https://fedoramagazine.org/taking-smart-backups-duplicity/
|
||||
[4]: https://cdn.fedoramagazine.org/wp-content/uploads/2016/06/Screenshot_f23-ws-upgrade-test_2016-06-10_110906-1024x768.png
|
||||
[5]: https://fedoraproject.org/wiki/DNF_system_upgrade#Resolving_post-upgrade_issues
|
||||
@ -1,73 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 apps to manage personal finances in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/3-apps-to-manage-personal-finances-in-fedora/)
|
||||
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
3 apps to manage personal finances in Fedora
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
There are numerous services available on the web for managing your personal finances. Although they may be convenient, they also often mean leaving your most valuable personal data with a company you can’t monitor. Some people are comfortable with this level of trust.
|
||||
|
||||
Whether you are or not, you might be interested in an app you can maintain on your own system. This means your data never has to leave your own computer if you don’t want. One of these three apps might be what you’re looking for.
|
||||
|
||||
### HomeBank
|
||||
|
||||
HomeBank is a fully featured way to manage multiple accounts. It’s easy to set up and keep updated. It has multiple ways to categorize and graph income and liabilities so you can see where your money goes. It’s available through the official Fedora repositories.
|
||||
|
||||
![A simple account set up in HomeBank with a few transactions.][2]
|
||||
|
||||
To install HomeBank, open the _Software_ app, search for _HomeBank_ , and select the app. Then click _Install_ to add it to your system. HomeBank is also available via a Flatpak.
|
||||
|
||||
### KMyMoney
|
||||
|
||||
The KMyMoney app is a mature app that has been around for a long while. It has a robust set of features to help you manage multiple accounts, including assets, liabilities, taxes, and more. KMyMoney includes a full set of tools for managing investments and making forecasts. It also sports a huge set of reports for seeing how your money is doing.
|
||||
|
||||
![A subset of the many reports available in KMyMoney.][3]
|
||||
|
||||
To install, use a software center app, or use the command line:
|
||||
|
||||
```
|
||||
$ sudo dnf install kmymoney
|
||||
```
|
||||
|
||||
### GnuCash
|
||||
|
||||
One of the most venerable free GUI apps for personal finance is GnuCash. GnuCash is not just for personal finances. It also has functions for managing income, assets, and liabilities for a business. That doesn’t mean you can’t use it for managing just your own accounts. Check out [the online tutorial and guide][4] to get started.
|
||||
|
||||
![Checking account records shown in GnuCash.][5]
|
||||
|
||||
Open the _Software_ app, search for _GnuCash_ , and select the app. Then click _Install_ to add it to your system. Or use _dnf install_ as above to install the _gnucash_ package.
|
||||
|
||||
It’s now available via Flathub which makes installation easy. If you don’t have Flathub support, check out [this article on the Fedora Magazine][6] for how to use it. Then you can also use the _flatpak install GnuCash_ command with a terminal.
|
||||
|
||||
* * *
|
||||
|
||||
*Photo by _[_Fabian Blank_][7]_ on *[ _Unsplash_][8].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/3-apps-to-manage-personal-finances-in-fedora/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/personal-finance-3-apps-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/wp-content/uploads/2019/04/Screenshot-from-2019-04-28-16-16-16-1024x637.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/04/Screenshot-from-2019-04-28-16-27-10-1-1024x649.png
|
||||
[4]: https://www.gnucash.org/viewdoc.phtml?rev=3&lang=C&doc=guide
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/04/Screenshot-from-2019-04-28-16-41-27-1024x631.png
|
||||
[6]: https://fedoramagazine.org/install-flathub-apps-fedora/
|
||||
[7]: https://unsplash.com/photos/pElSkGRA2NU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]: https://unsplash.com/search/photos/money?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (bodhix)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,61 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Libki to manage public user computer access)
|
||||
[#]: via: (https://opensource.com/article/19/5/libki-computer-access)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins/users/tony-thomas)
|
||||
|
||||
Get started with Libki to manage public user computer access
|
||||
======
|
||||
Libki is a cross-platform, computer reservation and time management
|
||||
system.
|
||||
![][1]
|
||||
|
||||
Libraries, schools, colleges, and other organizations that provide public computers need a good way to manage users' access—otherwise, there's no way to prevent some people from monopolizing the machines and ensure everyone has a fair amount of time. This is the problem that [Libki][2] was designed to solve.
|
||||
|
||||
Libki is an open source, cross-platform, computer reservation and time management system for Windows and Linux PCs. It provides a web-based server and a web-based administration system that staff can use to manage computer access, including creating and deleting users, setting time limits on accounts, logging out and banning users, and setting access restrictions.
|
||||
|
||||
According to lead developer [Kyle Hall][3], Libki is mainly used for PC time control as an open source alternative to Envisionware's proprietary computer access control software. When users log into a Libki-managed computer, they get a block of time to use the computer; once that time is up, they are logged off. The default setting is 45 minutes, but that can easily be adjusted using the web-based administration system. Some organizations offer 24 hours of access before logging users off, and others use it to track usage without setting time limits.
|
||||
|
||||
Kyle is currently lead developer at [ByWater Solutions][4], which provides open source software solutions (including Libki) to libraries. He developed Libki early in his career when he was the IT tech at the [Meadville Public Library][5] in Pennsylvania. He was occasionally asked to cover the children's room during lunch breaks for other employees. The library used a paper sign-up sheet to manage access to the computers in the children's room, which meant constant supervision and checking to ensure equitable access for the people who came there.
|
||||
|
||||
Kyle said, "I found this system to be cumbersome and awkward, and I wanted to find a solution. That solution needed to be both FOSS and cross-platform. In the end, no existing software package suited our particular needs, and that is why I developed Libki."
|
||||
|
||||
Or, as Libki's website proclaims, "Libki was born of the need to avoid interacting with teenagers and now allows librarians to avoid interacting with teenagers around the world!"
|
||||
|
||||
### Easy to set up and use
|
||||
|
||||
I recently decided to try Libki in our local public library, where I frequently volunteer. I followed the [documentation][6] for the automatic installation, using Ubuntu 18.04 Server, and very quickly had it up and running.
|
||||
|
||||
I am planning to support Libki in our local library, but I wondered about libraries that don't have someone with IT experience or the ability to build and deploy a server. Kyle says, "ByWater Solutions can cloud-host a Libki server, which makes maintenance and management much simpler for everyone."
|
||||
|
||||
Kyle says ByWater is not planning to bundle Libki with its most popular offering, open source integrated library system (ILS) Koha, or any of the other [projects][7] it supports. "Libki and Koha are different [types of] software serving different needs, but they definitely work well together in a library setting. In fact, it was quite early on that I developed Libki's SIP2 integration so it could support single sign-on using Koha," he says.
|
||||
|
||||
### How you can contribute
|
||||
|
||||
Libki client is licensed under the GPLv3 and Libki server is licensed under the AGPLv3. Kyle says he would love Libki to have a more active and robust community, and the project is always looking for new people to join its [contributors][8]. If you would like to participate, visit [Libki's Community page][9] and join the mailing list.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/libki-computer-access
|
||||
|
||||
作者:[Don Watkins ][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins/users/tony-thomas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/desk_clock_job_work.jpg?itok=Nj4fuhl6
|
||||
[2]: https://libki.org/
|
||||
[3]: https://www.linkedin.com/in/kylemhallinfo/
|
||||
[4]: https://opensource.com/article/19/4/software-libraries
|
||||
[5]: https://meadvillelibrary.org/
|
||||
[6]: https://manual.libki.org/master/libki-manual.html#_automatic_installation
|
||||
[7]: https://bywatersolutions.com/projects
|
||||
[8]: https://github.com/Libki/libki-server/graphs/contributors
|
||||
[9]: https://libki.org/community/
|
||||
@ -1,735 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (API evolution the right way)
|
||||
[#]: via: (https://opensource.com/article/19/5/api-evolution-right-way)
|
||||
[#]: author: (A. Jesse https://opensource.com/users/emptysquare)
|
||||
|
||||
API evolution the right way
|
||||
======
|
||||
Ten covenants that responsible library authors keep with their users.
|
||||
![Browser of things][1]
|
||||
|
||||
Imagine you are a creator deity, designing a body for a creature. In your benevolence, you wish for the creature to evolve over time: first, because it must respond to changes in its environment, and second, because your wisdom grows and you think of better designs for the beast. It shouldn't remain in the same body forever!
|
||||
|
||||
![Serpents][2]
|
||||
|
||||
The creature, however, might be relying on features of its present anatomy. You can't add wings or change its scales without warning. It needs an orderly process to adapt its lifestyle to its new body. How can you, as a responsible designer in charge of this creature's natural history, gently coax it toward ever greater improvements?
|
||||
|
||||
It's the same for responsible library maintainers. We keep our promises to the people who depend on our code: we release bugfixes and useful new features. We sometimes delete features if that's beneficial for the library's future. We continue to innovate, but we don't break the code of people who use our library. How can we fulfill all those goals at once?
|
||||
|
||||
### Add useful features
|
||||
|
||||
Your library shouldn't stay the same for eternity: you should add features that make your library better for your users. For example, if you have a Reptile class and it would be useful to have wings for flying, go for it.
|
||||
|
||||
|
||||
```
|
||||
class Reptile:
|
||||
@property
|
||||
def teeth(self):
|
||||
return 'sharp fangs'
|
||||
|
||||
# If wings are useful, add them!
|
||||
@property
|
||||
def wings(self):
|
||||
return 'majestic wings'
|
||||
```
|
||||
|
||||
But beware, features come with risk. Consider the following feature in the Python standard library, and see what went wrong with it.
|
||||
|
||||
|
||||
```
|
||||
bool(datetime.time(9, 30)) == True
|
||||
bool(datetime.time(0, 0)) == False
|
||||
```
|
||||
|
||||
This is peculiar: converting any time object to a boolean yields True, except for midnight. (Worse, the rules for timezone-aware times are even stranger.)
|
||||
|
||||
I've been writing Python for more than a decade but I didn't discover this rule until last week. What kind of bugs can this odd behavior cause in users' code?
|
||||
|
||||
Consider a calendar application with a function that creates events. If an event has an end time, the function requires it to also have a start time.
|
||||
|
||||
|
||||
```
|
||||
def create_event(day,
|
||||
start_time=None,
|
||||
end_time=None):
|
||||
if end_time and not start_time:
|
||||
raise ValueError("Can't pass end_time without start_time")
|
||||
|
||||
# The coven meets from midnight until 4am.
|
||||
create_event(datetime.date.today(),
|
||||
datetime.time(0, 0),
|
||||
datetime.time(4, 0))
|
||||
```
|
||||
|
||||
Unfortunately for witches, an event starting at midnight fails this validation. A careful programmer who knows about the quirk at midnight can write this function correctly, of course.
|
||||
|
||||
|
||||
```
|
||||
def create_event(day,
|
||||
start_time=None,
|
||||
end_time=None):
|
||||
if end_time is not None and start_time is None:
|
||||
raise ValueError("Can't pass end_time without start_time")
|
||||
```
|
||||
|
||||
But this subtlety is worrisome. If a library creator wanted to make an API that bites users, a "feature" like the boolean conversion of midnight works nicely.
|
||||
|
||||
![Man being chased by an alligator][3]
|
||||
|
||||
The responsible creator's goal, however, is to make your library easy to use correctly.
|
||||
|
||||
This feature was written by Tim Peters when he first made the datetime module in 2002. Even founding Pythonistas like Tim make mistakes. [The quirk was removed][4], and all times are True now.
|
||||
|
||||
|
||||
```
|
||||
# Python 3.5 and later.
|
||||
|
||||
bool(datetime.time(9, 30)) == True
|
||||
bool(datetime.time(0, 0)) == True
|
||||
```
|
||||
|
||||
Programmers who didn't know about the oddity of midnight are saved from obscure bugs, but it makes me nervous to think about any code that relies on the weird old behavior and didn't notice the change. It would have been better if this bad feature were never implemented at all. This leads us to the first promise of any library maintainer:
|
||||
|
||||
#### First covenant: Avoid bad features
|
||||
|
||||
The most painful change to make is when you have to delete a feature. One way to avoid bad features is to add few features in general! Make no public method, class, function, or property without a good reason. Thus:
|
||||
|
||||
#### Second covenant: Minimize features
|
||||
|
||||
Features are like children: conceived in a moment of passion, they must be supported for years. Don't do anything silly just because you can. Don't add feathers to a snake!
|
||||
|
||||
![Serpents with and without feathers][5]
|
||||
|
||||
But of course, there are plenty of occasions when users need something from your library that it does not yet offer. How do you choose the right feature to give them? Here's another cautionary tale.
|
||||
|
||||
### A cautionary tale from asyncio
|
||||
|
||||
As you may know, when you call a coroutine function, it returns a coroutine object:
|
||||
|
||||
|
||||
```
|
||||
async def my_coroutine():
|
||||
pass
|
||||
|
||||
print(my_coroutine())
|
||||
|
||||
[/code] [code]`<coroutine object my_coroutine at 0x10bfcbac8>`
|
||||
```
|
||||
|
||||
Your code must "await" this object to run the coroutine. It's easy to forget this, so asyncio's developers wanted a "debug mode" that catches this mistake. Whenever a coroutine is destroyed without being awaited, the debug mode prints a warning with a traceback to the line where it was created.
|
||||
|
||||
When Yury Selivanov implemented the debug mode, he added as its foundation a "coroutine wrapper" feature. The wrapper is a function that takes in a coroutine and returns anything at all. Yury used it to install the warning logic on each coroutine, but someone else could use it to turn coroutines into the string "hi!"
|
||||
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
def my_wrapper(coro):
|
||||
return 'hi!'
|
||||
|
||||
sys.set_coroutine_wrapper(my_wrapper)
|
||||
|
||||
async def my_coroutine():
|
||||
pass
|
||||
|
||||
print(my_coroutine())
|
||||
|
||||
[/code] [code]`hi!`
|
||||
```
|
||||
|
||||
That is one hell of a customization. It changes the very meaning of "async." Calling set_coroutine_wrapper once will globally and permanently change all coroutine functions. It is, [as Nathaniel Smith wrote][6], "a problematic API" that is prone to misuse and had to be removed. The asyncio developers could have avoided the pain of deleting the feature if they'd better shaped it to its purpose. Responsible creators must keep this in mind:
|
||||
|
||||
#### Third covenant: Keep features narrow
|
||||
|
||||
Luckily, Yury had the good judgment to mark this feature provisional, so asyncio users knew not to rely on it. Nathaniel was free to replace **set_coroutine_wrapper** with a narrower feature that only customized the traceback depth.
|
||||
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
sys.set_coroutine_origin_tracking_depth(2)
|
||||
|
||||
async def my_coroutine():
|
||||
pass
|
||||
|
||||
print(my_coroutine())
|
||||
|
||||
[/code] [code]
|
||||
|
||||
<coroutine object my_coroutine at 0x10bfcbac8>
|
||||
|
||||
RuntimeWarning:'my_coroutine' was never awaited
|
||||
|
||||
Coroutine created at (most recent call last)
|
||||
File "script.py", line 8, in <module>
|
||||
print(my_coroutine())
|
||||
```
|
||||
|
||||
This is much better. There's no more global setting that can change coroutines' type, so asyncio users need not code as defensively. Deities should all be as farsighted as Yury.
|
||||
|
||||
#### Fourth covenant: Mark experimental features "provisional"
|
||||
|
||||
If you have merely a hunch that your creature wants horns and a quadruple-forked tongue, introduce the features but mark them "provisional."
|
||||
|
||||
![Serpent with horns][7]
|
||||
|
||||
You might discover that the horns are extraneous but the quadruple-forked tongue is useful after all. In the next release of your library, you can delete the former and mark the latter official.
|
||||
|
||||
### Deleting features
|
||||
|
||||
No matter how wisely we guide our creature's evolution, there may come a time when it's best to delete an official feature. For example, you might have created a lizard, and now you choose to delete its legs. Perhaps you want to transform this awkward creature into a sleek and modern python.
|
||||
|
||||
![Lizard transformed to snake][8]
|
||||
|
||||
There are two main reasons to delete features. First, you might discover a feature was a bad idea, through user feedback or your own growing wisdom. That was the case with the quirky behavior of midnight. Or, the feature might have been well-adapted to your library's environment at first, but the ecology changes. Perhaps another deity invents mammals. Your creature wants to squeeze into the mammals' little burrows and eat the tasty mammal filling, so it has to lose its legs.
|
||||
|
||||
![A mouse][9]
|
||||
|
||||
Similarly, the Python standard library deletes features in response to changes in the language itself. Consider asyncio's Lock. It has been awaitable ever since "await" was added as a keyword:
|
||||
|
||||
|
||||
```
|
||||
lock = asyncio.Lock()
|
||||
|
||||
async def critical_section():
|
||||
await lock
|
||||
try:
|
||||
print('holding lock')
|
||||
finally:
|
||||
lock.release()
|
||||
```
|
||||
|
||||
But now, we can do "async with lock."
|
||||
|
||||
|
||||
```
|
||||
lock = asyncio.Lock()
|
||||
|
||||
async def critical_section():
|
||||
async with lock:
|
||||
print('holding lock')
|
||||
```
|
||||
|
||||
The new style is much better! It's short and less prone to mistakes in a big function with other try-except blocks. Since "there should be one and preferably only one obvious way to do it," [the old syntax is deprecated in Python 3.7][10] and it will be banned soon.
|
||||
|
||||
It's inevitable that ecological change will have this effect on your code, too, so learn to delete features gently. Before you do so, consider the cost or benefit of deleting it. Responsible maintainers are reluctant to make their users change a large amount of their code or change their logic. (Remember how painful it was when Python 3 removed the "u" string prefix, before it was added back.) If the code changes are mechanical, however, like a simple search-and-replace, or if the feature is dangerous, it may be worth deleting.
|
||||
|
||||
#### Whether to delete a feature
|
||||
|
||||
![Balance scales][11]
|
||||
|
||||
Con | Pro
|
||||
---|---
|
||||
Code must change | Change is mechanical
|
||||
Logic must change | Feature is dangerous
|
||||
|
||||
In the case of our hungry lizard, we decide to delete its legs so it can slither into a mouse's hole and eat it. How do we go about this? We could just delete the **walk** method, changing code from this:
|
||||
|
||||
|
||||
```
|
||||
class Reptile:
|
||||
def walk(self):
|
||||
print('step step step')
|
||||
```
|
||||
|
||||
to this:
|
||||
|
||||
|
||||
```
|
||||
class Reptile:
|
||||
def slither(self):
|
||||
print('slide slide slide')
|
||||
```
|
||||
|
||||
That's not a good idea; the creature is accustomed to walking! Or, in terms of a library, your users have code that relies on the existing method. When they upgrade to the latest version of your library, their code will break.
|
||||
|
||||
|
||||
```
|
||||
# User's code. Oops!
|
||||
Reptile.walk()
|
||||
```
|
||||
|
||||
Therefore, responsible creators make this promise:
|
||||
|
||||
#### Fifth covenant: Delete features gently
|
||||
|
||||
There are a few steps involved in deleting a feature gently. Starting with a lizard that walks with its legs, you first add the new method, "slither." Next, deprecate the old method.
|
||||
|
||||
|
||||
```
|
||||
import warnings
|
||||
|
||||
class Reptile:
|
||||
def walk(self):
|
||||
warnings.warn(
|
||||
"walk is deprecated, use slither",
|
||||
DeprecationWarning, stacklevel=2)
|
||||
print('step step step')
|
||||
|
||||
def slither(self):
|
||||
print('slide slide slide')
|
||||
```
|
||||
|
||||
The Python warnings module is quite powerful. By default it prints warnings to stderr, only once per code location, but you can silence warnings or turn them into exceptions, among other options.
|
||||
|
||||
As soon as you add this warning to your library, PyCharm and other IDEs render the deprecated method with a strikethrough. Users know right away that the method is due for deletion.
|
||||
|
||||
`Reptile().walk()`
|
||||
|
||||
What happens when they run their code with the upgraded library?
|
||||
|
||||
|
||||
```
|
||||
$ python3 script.py
|
||||
|
||||
DeprecationWarning: walk is deprecated, use slither
|
||||
script.py:14: Reptile().walk()
|
||||
|
||||
step step step
|
||||
```
|
||||
|
||||
By default, they see a warning on stderr, but the script succeeds and prints "step step step." The warning's traceback shows what line of the user's code must be fixed. (That's what the "stacklevel" argument does: it shows the call site that users need to change, not the line in your library where the warning is generated.) Notice that the error message is instructive, it describes what a library user must do to migrate to the new version.
|
||||
|
||||
Your users will want to test their code and prove they call no deprecated library methods. Warnings alone won't make unit tests fail, but exceptions will. Python has a command-line option to turn deprecation warnings into exceptions.
|
||||
|
||||
|
||||
```
|
||||
> python3 -Werror::DeprecationWarning script.py
|
||||
|
||||
Traceback (most recent call last):
|
||||
File "script.py", line 14, in <module>
|
||||
Reptile().walk()
|
||||
File "script.py", line 8, in walk
|
||||
DeprecationWarning, stacklevel=2)
|
||||
DeprecationWarning: walk is deprecated, use slither
|
||||
```
|
||||
|
||||
Now, "step step step" is not printed, because the script terminates with an error.
|
||||
|
||||
So, once you've released a version of your library that warns about the deprecated "walk" method, you can delete it safely in the next release. Right?
|
||||
|
||||
Consider what your library's users might have in their projects' requirements.
|
||||
|
||||
|
||||
```
|
||||
# User's requirements.txt has a dependency on the reptile package.
|
||||
reptile
|
||||
```
|
||||
|
||||
The next time they deploy their code, they'll install the latest version of your library. If they haven't yet handled all deprecations, then their code will break, because it still depends on "walk." You need to be gentler than this. There are three more promises you must keep to your users: maintain a changelog, choose a version scheme, and write an upgrade guide.
|
||||
|
||||
#### Sixth covenant: Maintain a changelog
|
||||
|
||||
Your library must have a changelog; its main purpose is to announce when a feature that your users rely on is deprecated or deleted.
|
||||
|
||||
#### Changes in Version 1.1
|
||||
|
||||
**New features**
|
||||
|
||||
* New function Reptile.slither()
|
||||
|
||||
|
||||
|
||||
**Deprecations**
|
||||
|
||||
* Reptile.walk() is deprecated and will be removed in version 2.0, use slither()
|
||||
|
||||
|
||||
---
|
||||
|
||||
Responsible creators use version numbers to express how a library has changed so users can make informed decisions about upgrading. A "version scheme" is a language for communicating the pace of change.
|
||||
|
||||
#### Seventh covenant: Choose a version scheme
|
||||
|
||||
There are two schemes in widespread use, [semantic versioning][12] and time-based versioning. I recommend semantic versioning for nearly any library. The Python flavor thereof is defined in [PEP 440][13], and tools like **pip** understand semantic version numbers.
|
||||
|
||||
If you choose semantic versioning for your library, you can delete its legs gently with version numbers like:
|
||||
|
||||
> 1.0: First "stable" release, with walk()
|
||||
> 1.1: Add slither(), deprecate walk()
|
||||
> 2.0: Delete walk()
|
||||
|
||||
Your users should depend on a range of your library's versions, like so:
|
||||
|
||||
|
||||
```
|
||||
# User's requirements.txt.
|
||||
reptile>=1,<2
|
||||
```
|
||||
|
||||
This allows them to upgrade automatically within a major release, receiving bugfixes and potentially raising some deprecation warnings, but not upgrading to the _next_ major release and risking a change that breaks their code.
|
||||
|
||||
If you follow time-based versioning, your releases might be numbered thus:
|
||||
|
||||
> 2017.06.0: A release in June 2017
|
||||
> 2018.11.0: Add slither(), deprecate walk()
|
||||
> 2019.04.0: Delete walk()
|
||||
|
||||
And users can depend on your library like:
|
||||
|
||||
|
||||
```
|
||||
# User's requirements.txt for time-based version.
|
||||
reptile==2018.11.*
|
||||
```
|
||||
|
||||
This is terrific, but how do your users know your versioning scheme and how to test their code for deprecations? You have to advise them how to upgrade.
|
||||
|
||||
#### Eighth covenant: Write an upgrade guide
|
||||
|
||||
Here's how a responsible library creator might guide users:
|
||||
|
||||
#### Upgrading to 2.0
|
||||
|
||||
**Migrate from Deprecated APIs**
|
||||
|
||||
See the changelog for deprecated features.
|
||||
|
||||
**Enable Deprecation Warnings**
|
||||
|
||||
Upgrade to 1.1 and test your code with:
|
||||
|
||||
`python -Werror::DeprecationWarning`
|
||||
|
||||
Now it's safe to upgrade.
|
||||
|
||||
---
|
||||
|
||||
You must teach users how to handle deprecation warnings by showing them the command line options. Not all Python programmers know this—I certainly have to look up the syntax each time. And take note, you must _release_ a version that prints warnings from each deprecated API so users can test with that version before upgrading again. In this example, version 1.1 is the bridge release. It allows your users to rewrite their code incrementally, fixing each deprecation warning separately until they have entirely migrated to the latest API. They can test changes to their code and changes in your library, independently from each other, and isolate the cause of bugs.
|
||||
|
||||
If you chose semantic versioning, this transitional period lasts until the next major release, from 1.x to 2.0, or from 2.x to 3.0, and so on. The gentle way to delete a creature's legs is to give it at least one version in which to adjust its lifestyle. Don't remove the legs all at once!
|
||||
|
||||
![A skink][14]
|
||||
|
||||
Version numbers, deprecation warnings, the changelog, and the upgrade guide work together to gently evolve your library without breaking the covenant with your users. The [Twisted project's Compatibility Policy][15] explains this beautifully:
|
||||
|
||||
> "The First One's Always Free"
|
||||
>
|
||||
> Any application which runs without warnings may be upgraded one minor version of Twisted.
|
||||
>
|
||||
> In other words, any application which runs its tests without triggering any warnings from Twisted should be able to have its Twisted version upgraded at least once with no ill effects except the possible production of new warnings.
|
||||
|
||||
Now, we creator deities have gained the wisdom and power to add features by adding methods and to delete them gently. We can also add features by adding parameters, but this brings a new level of difficulty. Are you ready?
|
||||
|
||||
### Adding parameters
|
||||
|
||||
Imagine that you just gave your snake-like creature a pair of wings. Now you must allow it the choice whether to move by slithering or flying. Currently its "move" function takes one parameter.
|
||||
|
||||
|
||||
```
|
||||
# Your library code.
|
||||
def move(direction):
|
||||
print(f'slither {direction}')
|
||||
|
||||
# A user's application.
|
||||
move('north')
|
||||
```
|
||||
|
||||
You want to add a "mode" parameter, but this breaks your users' code if they upgrade, because they pass only one argument.
|
||||
|
||||
|
||||
```
|
||||
# Your library code.
|
||||
def move(direction, mode):
|
||||
assert mode in ('slither', 'fly')
|
||||
print(f'{mode} {direction}')
|
||||
|
||||
# A user's application. Error!
|
||||
move('north')
|
||||
```
|
||||
|
||||
A truly wise creator promises not to break users' code this way.
|
||||
|
||||
#### Ninth covenant: Add parameters compatibly
|
||||
|
||||
To keep this covenant, add each new parameter with a default value that preserves the original behavior.
|
||||
|
||||
|
||||
```
|
||||
# Your library code.
|
||||
def move(direction, mode='slither'):
|
||||
assert mode in ('slither', 'fly')
|
||||
print(f'{mode} {direction}')
|
||||
|
||||
# A user's application.
|
||||
move('north')
|
||||
```
|
||||
|
||||
Over time, parameters are the natural history of your function's evolution. They're listed oldest first, each with a default value. Library users can pass keyword arguments to opt into specific new behaviors and accept the defaults for all others.
|
||||
|
||||
|
||||
```
|
||||
# Your library code.
|
||||
def move(direction,
|
||||
mode='slither',
|
||||
turbo=False,
|
||||
extra_sinuous=False,
|
||||
hail_lyft=False):
|
||||
# ...
|
||||
|
||||
# A user's application.
|
||||
move('north', extra_sinuous=True)
|
||||
```
|
||||
|
||||
There is a danger, however, that a user might write code like this:
|
||||
|
||||
|
||||
```
|
||||
# A user's application, poorly-written.
|
||||
move('north', 'slither', False, True)
|
||||
```
|
||||
|
||||
What happens if, in the next major version of your library, you get rid of one of the parameters, like "turbo"?
|
||||
|
||||
|
||||
```
|
||||
# Your library code, next major version. "turbo" is deleted.
|
||||
def move(direction,
|
||||
mode='slither',
|
||||
extra_sinuous=False,
|
||||
hail_lyft=False):
|
||||
# ...
|
||||
|
||||
# A user's application, poorly-written.
|
||||
move('north', 'slither', False, True)
|
||||
```
|
||||
|
||||
The user's code still compiles, and this is a bad thing. The code stopped moving extra-sinuously and started hailing a Lyft, which was not the intention. I trust that you can predict what I'll say next: Deleting a parameter requires several steps. First, of course, deprecate the "turbo" parameter. I like a technique like this one, which detects whether any user's code relies on this parameter.
|
||||
|
||||
|
||||
```
|
||||
# Your library code.
|
||||
_turbo_default = object()
|
||||
|
||||
def move(direction,
|
||||
mode='slither',
|
||||
turbo=_turbo_default,
|
||||
extra_sinuous=False,
|
||||
hail_lyft=False):
|
||||
if turbo is not _turbo_default:
|
||||
warnings.warn(
|
||||
"'turbo' is deprecated",
|
||||
DeprecationWarning,
|
||||
stacklevel=2)
|
||||
else:
|
||||
# The old default.
|
||||
turbo = False
|
||||
```
|
||||
|
||||
But your users might not notice the warning. Warnings are not very loud: they can be suppressed or lost in log files. Users might heedlessly upgrade to the next major version of your library, the version that deletes "turbo." Their code will run without error and silently do the wrong thing! As the Zen of Python says, "Errors should never pass silently." Indeed, reptiles hear poorly, so you must correct them very loudly when they make mistakes.
|
||||
|
||||
![Woman riding an alligator][16]
|
||||
|
||||
The best way to protect your users is with Python 3's star syntax, which requires callers to pass keyword arguments.
|
||||
|
||||
|
||||
```
|
||||
# Your library code.
|
||||
# All arguments after "*" must be passed by keyword.
|
||||
def move(direction,
|
||||
*,
|
||||
mode='slither',
|
||||
turbo=False,
|
||||
extra_sinuous=False,
|
||||
hail_lyft=False):
|
||||
# ...
|
||||
|
||||
# A user's application, poorly-written.
|
||||
# Error! Can't use positional args, keyword args required.
|
||||
move('north', 'slither', False, True)
|
||||
```
|
||||
|
||||
With the star in place, this is the only syntax allowed:
|
||||
|
||||
|
||||
```
|
||||
# A user's application.
|
||||
move('north', extra_sinuous=True)
|
||||
```
|
||||
|
||||
Now when you delete "turbo," you can be certain any user code that relies on it will fail loudly. If your library also supports Python 2, there's no shame in that; you can simulate the star syntax thus ([credit to Brett Slatkin][17]):
|
||||
|
||||
|
||||
```
|
||||
# Your library code, Python 2 compatible.
|
||||
def move(direction, **kwargs):
|
||||
mode = kwargs.pop('mode', 'slither')
|
||||
turbo = kwargs.pop('turbo', False)
|
||||
sinuous = kwargs.pop('extra_sinuous', False)
|
||||
lyft = kwargs.pop('hail_lyft', False)
|
||||
|
||||
if kwargs:
|
||||
raise TypeError('Unexpected kwargs: %r'
|
||||
% kwargs)
|
||||
|
||||
# ...
|
||||
```
|
||||
|
||||
Requiring keyword arguments is a wise choice, but it requires foresight. If you allow an argument to be passed positionally, you cannot convert it to keyword-only in a later release. So, add the star now. You can observe in the asyncio API that it uses the star pervasively in constructors, methods, and functions. Even though "Lock" only takes one optional parameter so far, the asyncio developers added the star right away. This is providential.
|
||||
|
||||
|
||||
```
|
||||
# In asyncio.
|
||||
class Lock:
|
||||
def __init__(self, *, loop=None):
|
||||
# ...
|
||||
```
|
||||
|
||||
Now we've gained the wisdom to change methods and parameters while keeping our covenant with users. The time has come to try the most challenging kind of evolution: changing behavior without changing either methods or parameters.
|
||||
|
||||
### Changing behavior
|
||||
|
||||
Let's say your creature is a rattlesnake, and you want to teach it a new behavior.
|
||||
|
||||
![Rattlesnake][18]
|
||||
|
||||
Sidewinding! The creature's body will appear the same, but its behavior will change. How can we prepare it for this step of its evolution?
|
||||
|
||||
![][19]
|
||||
|
||||
Image by HCA [[CC BY-SA 4.0][20]], [via Wikimedia Commons][21], modified by Opensource.com
|
||||
|
||||
A responsible creator can learn from the following example in the Python standard library, when behavior changed without a new function or parameters. Once upon a time, the os.stat function was introduced to get file statistics, like the creation time. At first, times were always integers.
|
||||
|
||||
|
||||
```
|
||||
>>> os.stat('file.txt').st_ctime
|
||||
1540817862
|
||||
```
|
||||
|
||||
One day, the core developers decided to use floats for os.stat times to give sub-second precision. But they worried that existing user code wasn't ready for the change. They created a setting in Python 2.3, "stat_float_times," that was false by default. A user could set it to True to opt into floating-point timestamps.
|
||||
|
||||
|
||||
```
|
||||
>>> # Python 2.3.
|
||||
>>> os.stat_float_times(True)
|
||||
>>> os.stat('file.txt').st_ctime
|
||||
1540817862.598021
|
||||
```
|
||||
|
||||
Starting in Python 2.5, float times became the default, so any new code written for 2.5 and later could ignore the setting and expect floats. Of course, you could set it to False to keep the old behavior or set it to True to ensure the new behavior in all Python versions, and prepare your code for the day when stat_float_times is deleted.
|
||||
|
||||
Ages passed. In Python 3.1, the setting was deprecated to prepare people for the distant future and finally, after its decades-long journey, [the setting was removed][22]. Float times are now the only option. It's a long road, but responsible deities are patient because we know this gradual process has a good chance of saving users from unexpected behavior changes.
|
||||
|
||||
#### Tenth covenant: Change behavior gradually
|
||||
|
||||
Here are the steps:
|
||||
|
||||
* Add a flag to opt into the new behavior, default False, warn if it's False
|
||||
* Change default to True, deprecate flag entirely
|
||||
* Remove the flag
|
||||
|
||||
|
||||
|
||||
If you follow semantic versioning, the versions might be like so:
|
||||
|
||||
Library version | Library API | User code
|
||||
---|---|---
|
||||
| |
|
||||
1.0 | No flag | Expect old behavior
|
||||
1.1 | Add flag, default False,
|
||||
warn if it's False | Set flag True,
|
||||
handle new behavior
|
||||
2.0 | Change default to True,
|
||||
deprecate flag entirely | Handle new behavior
|
||||
3.0 | Remove flag | Handle new behavior
|
||||
|
||||
You need _two_ major releases to complete the maneuver. If you had gone straight from "Add flag, default False, warn if it's False" to "Remove flag" without the intervening release, your users' code would be unable to upgrade. User code written correctly for 1.1, which sets the flag to True and handles the new behavior, must be able to upgrade to the next release with no ill effect except new warnings, but if the flag were deleted in the next release, that code would break. A responsible deity never violates the Twisted policy: "The First One's Always Free."
|
||||
|
||||
### The responsible creator
|
||||
|
||||
![Demeter][23]
|
||||
|
||||
Our 10 covenants belong loosely in three categories:
|
||||
|
||||
**Evolve cautiously**
|
||||
|
||||
1. Avoid bad features
|
||||
2. Minimize features
|
||||
3. Keep features narrow
|
||||
4. Mark experimental features "provisional"
|
||||
5. Delete features gently
|
||||
|
||||
|
||||
|
||||
**Record history rigorously**
|
||||
|
||||
1. Maintain a changelog
|
||||
2. Choose a version scheme
|
||||
3. Write an upgrade guide
|
||||
|
||||
|
||||
|
||||
**Change slowly and loudly**
|
||||
|
||||
1. Add parameters compatibly
|
||||
2. Change behavior gradually
|
||||
|
||||
|
||||
|
||||
If you keep these covenants with your creature, you'll be a responsible creator deity. Your creature's body can evolve over time, forever improving and adapting to changes in its environment but without sudden changes the creature isn't prepared for. If you maintain a library, keep these promises to your users and you can innovate your library without breaking the code of the people who rely on you.
|
||||
|
||||
* * *
|
||||
|
||||
_This article originally appeared on[A. Jesse Jiryu Davis's blog][24] and is republished with permission._
|
||||
|
||||
Illustration credits:
|
||||
|
||||
* [The World's Progress, The Delphian Society, 1913][25]
|
||||
* [Essay Towards a Natural History of Serpents, Charles Owen, 1742][26]
|
||||
* [On the batrachia and reptilia of Costa Rica: With notes on the herpetology and ichthyology of Nicaragua and Peru, Edward Drinker Cope, 1875][27]
|
||||
* [Natural History, Richard Lydekker et. al., 1897][28]
|
||||
* [Mes Prisons, Silvio Pellico, 1843][29]
|
||||
* [Tierfotoagentur / m.blue-shadow][30]
|
||||
* [Los Angeles Public Library, 1930][31]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/api-evolution-right-way
|
||||
|
||||
作者:[A. Jesse][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/emptysquare
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_desktop_website_checklist_metrics.png?itok=OKKbl1UR (Browser of things)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/praise-the-creator.jpg (Serpents)
|
||||
[3]: https://opensource.com/sites/default/files/uploads/bite.jpg (Man being chased by an alligator)
|
||||
[4]: https://bugs.python.org/issue13936
|
||||
[5]: https://opensource.com/sites/default/files/uploads/feathers.jpg (Serpents with and without feathers)
|
||||
[6]: https://bugs.python.org/issue32591
|
||||
[7]: https://opensource.com/sites/default/files/uploads/horns.jpg (Serpent with horns)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/lizard-to-snake.jpg (Lizard transformed to snake)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/mammal.jpg (A mouse)
|
||||
[10]: https://bugs.python.org/issue32253
|
||||
[11]: https://opensource.com/sites/default/files/uploads/scale.jpg (Balance scales)
|
||||
[12]: https://semver.org
|
||||
[13]: https://www.python.org/dev/peps/pep-0440/
|
||||
[14]: https://opensource.com/sites/default/files/uploads/skink.jpg (A skink)
|
||||
[15]: https://twistedmatrix.com/documents/current/core/development/policy/compatibility-policy.html
|
||||
[16]: https://opensource.com/sites/default/files/uploads/loudly.jpg (Woman riding an alligator)
|
||||
[17]: http://www.informit.com/articles/article.aspx?p=2314818
|
||||
[18]: https://opensource.com/sites/default/files/uploads/rattlesnake.jpg (Rattlesnake)
|
||||
[19]: https://opensource.com/sites/default/files/articles/neonate_sidewinder_sidewinding_with_tracks_unlabeled.png
|
||||
[20]: https://creativecommons.org/licenses/by-sa/4.0
|
||||
[21]: https://commons.wikimedia.org/wiki/File:Neonate_sidewinder_sidewinding_with_tracks_unlabeled.jpg
|
||||
[22]: https://bugs.python.org/issue31827
|
||||
[23]: https://opensource.com/sites/default/files/uploads/demeter.jpg (Demeter)
|
||||
[24]: https://emptysqua.re/blog/api-evolution-the-right-way/
|
||||
[25]: https://www.gutenberg.org/files/42224/42224-h/42224-h.htm
|
||||
[26]: https://publicdomainreview.org/product-att/artist/charles-owen/
|
||||
[27]: https://archive.org/details/onbatrachiarepti00cope/page/n3
|
||||
[28]: https://www.flickr.com/photos/internetarchivebookimages/20556001490
|
||||
[29]: https://www.oldbookillustrations.com/illustrations/stationery/
|
||||
[30]: https://www.alamy.com/mediacomp/ImageDetails.aspx?ref=D7Y61W
|
||||
[31]: https://www.vintag.es/2013/06/riding-alligator-c-1930s.html
|
||||
@ -1,81 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Check your spelling at the command line with Ispell)
|
||||
[#]: via: (https://opensource.com/article/19/5/spelling-command-line-ispell)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
Check your spelling at the command line with Ispell
|
||||
======
|
||||
Ispell helps you stamp out typos in plain text files written in more
|
||||
than 50 languages.
|
||||
![Command line prompt][1]
|
||||
|
||||
Good spelling is a skill. A skill that takes time to learn and to master. That said, there are people who never quite pick that skill up—I know a couple or three outstanding writers who can't spell to save their lives.
|
||||
|
||||
Even if you spell well, the occasional typo creeps in. That's especially true if you're quickly banging on your keyboard to meet a deadline. Regardless of your spelling chops, it's always a good idea to run what you've written through a spelling checker.
|
||||
|
||||
I do most of my writing in [plain text][2] and often use a command line spelling checker called [Aspell][3] to do the deed. Aspell isn't the only game in town. You might also want to check out the venerable [Ispell][4].
|
||||
|
||||
### Getting started
|
||||
|
||||
Ispell's been around, in various forms, since 1971. Don't let its age fool you. Ispell is still a peppy application that you can use effectively in the 21st century.
|
||||
|
||||
Before doing anything else, check whether or not Ispell is installed on your computer by cracking open a terminal window and typing **which ispell**. If it isn't installed, fire up your distribution's package manager and install Ispell from there.
|
||||
|
||||
Don't forget to install dictionaries for the languages you work in, too. My only language is English, so I just need to worry about grabbing the US and British English dictionaries. You're not limited to my mother (and only) tongue. Ispell has [dictionaries for over 50 languages][5].
|
||||
|
||||
![Installing Ispell dictionaries][6]
|
||||
|
||||
### Using Ispell
|
||||
|
||||
If you haven't guessed already, Ispell only works with text files. That includes ones marked up with HTML, LaTeX, and [nroff or troff][7]. More on this in a few moments.
|
||||
|
||||
To get to work, open a terminal window and navigate to the directory containing the file where you want to run a spelling check. Type **ispell** followed by the file's name and then press Enter.
|
||||
|
||||
![Checking spelling with Ispell][8]
|
||||
|
||||
Ispell highlights the first word it doesn't recognize. If the word is misspelled, Ispell usually offers one or more alternatives. Press **R** and then the number beside the correct choice. In the screen capture above, I'd press **R** and **0** to fix the error.
|
||||
|
||||
If, on the other hand, the word is correctly spelled, press **A** to move to the next misspelled word.
|
||||
|
||||
Keep doing that until you reach the end of the file. Ispell saves your changes, creates a backup of the file you just checked (with the extension _.bak_ ), and shuts down.
|
||||
|
||||
### A few other options
|
||||
|
||||
This example illustrates basic Ispell usage. The program has a [number of options][9], some of which you _might_ use and others you _might never_ use. Let's take a quick peek at some of the ones I regularly use.
|
||||
|
||||
A few paragraphs ago, I mentioned that Ispell works with certain markup languages. You need to tell it a file's format. When starting Ispell, add **-t** for a TeX or LaTeX file, **-H** for an HTML file, or **-n** for a groff or troff file. For example, if you enter **ispell -t myReport.tex** , Ispell ignores all markup.
|
||||
|
||||
If you don't want the backup file that Ispell creates after checking a file, add **-x** to the command line—for example, **ispell -x myFile.txt**.
|
||||
|
||||
What happens if Ispell runs into a word that's spelled correctly but isn't in its dictionary, like a proper name? You can add that word to a personal word list by pressing **I**. This saves the word to a file called _.ispell_default_ in the root of your _/home_ directory.
|
||||
|
||||
Those are the options I find most useful when working with Ispell, but check out [Ispell's man page][9] for descriptions of all its options.
|
||||
|
||||
Is Ispell any better or faster than Aspell or any other command line spelling checker? I have to say it's no worse than any of them, nor is it any slower. Ispell's not for everyone. It might not be for you. But it is good to have options, isn't it?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/spelling-command-line-ispell
|
||||
|
||||
作者:[Scott Nesbitt ][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/command_line_prompt.png?itok=wbGiJ_yg (Command line prompt)
|
||||
[2]: https://plaintextproject.online
|
||||
[3]: https://opensource.com/article/18/2/how-check-spelling-linux-command-line-aspell
|
||||
[4]: https://www.cs.hmc.edu/~geoff/ispell.html
|
||||
[5]: https://www.cs.hmc.edu/~geoff/ispell-dictionaries.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/ispell-install-dictionaries.png (Installing Ispell dictionaries)
|
||||
[7]: https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me
|
||||
[8]: https://opensource.com/sites/default/files/uploads/ispell-checking.png (Checking spelling with Ispell)
|
||||
[9]: https://www.cs.hmc.edu/~geoff/ispell-man.html
|
||||
@ -1,107 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Say goodbye to boilerplate in Python with attrs)
|
||||
[#]: via: (https://opensource.com/article/19/5/python-attrs)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez/users/moshez)
|
||||
|
||||
Say goodbye to boilerplate in Python with attrs
|
||||
======
|
||||
Learn more about solving common Python problems in our series covering
|
||||
seven PyPI libraries.
|
||||
![Programming at a browser, orange hands][1]
|
||||
|
||||
Python is one of the most [popular programming languages][2] in use today—and for good reasons: it's open source, it has a wide range of uses (such as web programming, business applications, games, scientific programming, and much more), and it has a vibrant and dedicated community supporting it. This community is the reason we have such a large, diverse range of software packages available in the [Python Package Index][3] (PyPI) to extend and improve Python and solve the inevitable glitches that crop up.
|
||||
|
||||
In this series, we'll look at seven PyPI libraries that can help you solve common Python problems. Today, we'll examine [**attrs**][4], a Python package that helps you write concise, correct code quickly.
|
||||
|
||||
### attrs
|
||||
|
||||
If you have been using Python for any length of time, you are probably used to writing code like:
|
||||
|
||||
|
||||
```
|
||||
class Book(object):
|
||||
|
||||
def __init__(self, isbn, name, author):
|
||||
self.isbn = isbn
|
||||
self.name = name
|
||||
self.author = author
|
||||
```
|
||||
|
||||
Then you write a **__repr__** function; otherwise, it would be hard to log instances of **Book** :
|
||||
|
||||
|
||||
```
|
||||
def __repr__(self):
|
||||
return f"Book({self.isbn}, {self.name}, {self.author})"
|
||||
```
|
||||
|
||||
Next, you write a nice docstring documenting the expected types. But you notice you forgot to add the **edition** and **published_year** attributes, so you have to modify them in five places.
|
||||
|
||||
What if you didn't have to?
|
||||
|
||||
|
||||
```
|
||||
@attr.s(auto_attribs=True)
|
||||
class Book(object):
|
||||
isbn: str
|
||||
name: str
|
||||
author: str
|
||||
published_year: int
|
||||
edition: int
|
||||
```
|
||||
|
||||
Annotating the attributes with types using the new type annotation syntax, **attrs** detects the annotations and creates a class.
|
||||
|
||||
ISBNs have a specific format. What if we want to enforce that format?
|
||||
|
||||
|
||||
```
|
||||
@attr.s(auto_attribs=True)
|
||||
class Book(object):
|
||||
isbn: str = attr.ib()
|
||||
@isbn.validator
|
||||
def pattern_match(self, attribute, value):
|
||||
m = re.match(r"^(\d{3}-)\d{1,3}-\d{2,3}-\d{1,7}-\d$", value)
|
||||
if not m:
|
||||
raise ValueError("incorrect format for isbn", value)
|
||||
name: str
|
||||
author: str
|
||||
published_year: int
|
||||
edition: int
|
||||
```
|
||||
|
||||
The **attrs** library also has great support for [immutability-style programming][5]. Changing the first line to **@attr.s(auto_attribs=True, frozen=True)** means that **Book** is now immutable: trying to modify an attribute will raise an exception. Instead, we can get a _new_ instance with modification using **attr.evolve(old_book, published_year=old_book.published_year+1)** , for example, if we need to push publication forward by a year.
|
||||
|
||||
In the next article in this series, we'll look at **singledispatch** , a library that allows you to add methods to Python libraries retroactively.
|
||||
|
||||
#### Review the previous articles in this series
|
||||
|
||||
* [Cython][6]
|
||||
* [Black][7]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/python-attrs
|
||||
|
||||
作者:[Moshe Zadka ][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_code_keyboard_orange_hands.png?itok=G6tJ_64Y (Programming at a browser, orange hands)
|
||||
[2]: https://opensource.com/article/18/5/numbers-python-community-trends
|
||||
[3]: https://pypi.org/
|
||||
[4]: https://pypi.org/project/attrs/
|
||||
[5]: https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures
|
||||
[6]: https://opensource.com/article/19/4/7-python-problems-solved-cython
|
||||
[7]: https://opensource.com/article/19/4/python-problems-solved-black
|
||||
@ -1,106 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Add methods retroactively in Python with singledispatch)
|
||||
[#]: via: (https://opensource.com/article/19/5/python-singledispatch)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
Add methods retroactively in Python with singledispatch
|
||||
======
|
||||
Learn more about solving common Python problems in our series covering
|
||||
seven PyPI libraries.
|
||||
![][1]
|
||||
|
||||
Python is one of the most [popular programming languages][2] in use today—and for good reasons: it's open source, it has a wide range of uses (such as web programming, business applications, games, scientific programming, and much more), and it has a vibrant and dedicated community supporting it. This community is the reason we have such a large, diverse range of software packages available in the [Python Package Index][3] (PyPI) to extend and improve Python and solve the inevitable glitches that crop up.
|
||||
|
||||
In this series, we'll look at seven PyPI libraries that can help you solve common Python problems. Today, we'll examine [**singledispatch**][4], a library that allows you to add methods to Python libraries retroactively.
|
||||
|
||||
### singledispatch
|
||||
|
||||
Imagine you have a "shapes" library with a **Circle** class, a **Square** class, etc.
|
||||
|
||||
A **Circle** has a **radius** , a **Square** has a **side** , and a **Rectangle** has **height** and **width**. Our library already exists; we do not want to change it.
|
||||
|
||||
However, we do want to add an **area** calculation to our library. If we didn't share this library with anyone else, we could just add an **area** method so we could call **shape.area()** and not worry about what the shape is.
|
||||
|
||||
While it is possible to reach into a class and add a method, this is a bad idea: nobody expects their class to grow new methods, and things might break in weird ways.
|
||||
|
||||
Instead, the **singledispatch** function in **functools** can come to our rescue.
|
||||
|
||||
|
||||
```
|
||||
@singledispatch
|
||||
def get_area(shape):
|
||||
raise NotImplementedError("cannot calculate area for unknown shape",
|
||||
shape)
|
||||
```
|
||||
|
||||
The "base" implementation for the **get_area** function fails. This makes sure that if we get a new shape, we will fail cleanly instead of returning a nonsense result.
|
||||
|
||||
|
||||
```
|
||||
@get_area.register(Square)
|
||||
def _get_area_square(shape):
|
||||
return shape.side ** 2
|
||||
@get_area.register(Circle)
|
||||
def _get_area_circle(shape):
|
||||
return math.pi * (shape.radius ** 2)
|
||||
```
|
||||
|
||||
One nice thing about doing things this way is that if someone writes a _new_ shape that is intended to play well with our code, they can implement **get_area** themselves.
|
||||
|
||||
|
||||
```
|
||||
from area_calculator import get_area
|
||||
|
||||
@attr.s(auto_attribs=True, frozen=True)
|
||||
class Ellipse:
|
||||
horizontal_axis: float
|
||||
vertical_axis: float
|
||||
|
||||
@get_area.register(Ellipse)
|
||||
def _get_area_ellipse(shape):
|
||||
return math.pi * shape.horizontal_axis * shape.vertical_axis
|
||||
```
|
||||
|
||||
_Calling_ **get_area** is straightforward.
|
||||
|
||||
|
||||
```
|
||||
`print(get_area(shape))`
|
||||
```
|
||||
|
||||
This means we can change a function that has a long **if isintance()/elif isinstance()** chain to work this way, without changing the interface. The next time you are tempted to check **if isinstance** , try using **singledispatch**!
|
||||
|
||||
In the next article in this series, we'll look at **tox** , a tool for automating tests on Python code.
|
||||
|
||||
#### Review the previous articles in this series:
|
||||
|
||||
* [Cython][5]
|
||||
* [Black][6]
|
||||
* [attrs][7]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/python-singledispatch
|
||||
|
||||
作者:[Moshe Zadka ][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV
|
||||
[2]: https://opensource.com/article/18/5/numbers-python-community-trends
|
||||
[3]: https://pypi.org/
|
||||
[4]: https://pypi.org/project/singledispatch/
|
||||
[5]: https://opensource.com/article/19/4/7-python-problems-solved-cython
|
||||
[6]: https://opensource.com/article/19/4/python-problems-solved-black
|
||||
[7]: https://opensource.com/article/19/4/python-problems-solved-attrs
|
||||
@ -1,240 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Moelf)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using the force at the Linux command line)
|
||||
[#]: via: (https://opensource.com/article/19/5/may-the-force-linux)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
Using the force at the Linux command line
|
||||
======
|
||||
Like the Jedi Force, -f is powerful, potentially destructive, and very
|
||||
helpful when you know how to use it.
|
||||
![Fireworks][1]
|
||||
|
||||
Sometime in recent history, sci-fi nerds began an annual celebration of everything [_Star Wars_ on May the 4th][2], a pun on the Jedi blessing, "May the Force be with you." Although most Linux users are probably not Jedi, they still have ways to use the force. Of course, the movie might not have been quite as exciting if Yoda simply told Luke to type **man X-Wing fighter** or **man force**. Or if he'd said, "RTFM" (Read the Force Manual, of course).
|
||||
|
||||
Many Linux commands have an **-f** option, which stands for, you guessed it, force! Sometimes when you execute a command, it fails or prompts you for additional input. This may be an effort to protect the files you are trying to change or inform the user that a device is busy or a file already exists.
|
||||
|
||||
If you don't want to be bothered by prompts or don't care about errors, use the force!
|
||||
|
||||
Be aware that using a command's force option to override these protections is, generally, destructive. Therefore, the user needs to pay close attention and be sure that they know what they are doing. Using the force can have consequences!
|
||||
|
||||
Following are four Linux commands with a force option and a brief description of how and why you might want to use it.
|
||||
|
||||
### cp
|
||||
|
||||
The **cp** command is short for copy—it's used to copy (or duplicate) a file or directory. The [man page][3] describes the force option for **cp** as:
|
||||
|
||||
|
||||
```
|
||||
-f, --force
|
||||
if an existing destination file cannot be opened, remove it
|
||||
and try again
|
||||
```
|
||||
|
||||
This example is for when you are working with read-only files:
|
||||
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ ls -l
|
||||
total 8
|
||||
-rw-rw---- 1 alan alan 13 May 1 12:24 Hoth
|
||||
-r--r----- 1 alan alan 14 May 1 12:23 Naboo
|
||||
[alan@workstation ~]$ cat Hoth Naboo
|
||||
Icy Planet
|
||||
|
||||
Green Planet
|
||||
```
|
||||
|
||||
If you want to copy a file called _Hoth_ to _Naboo_ , the **cp** command will not allow it since _Naboo_ is read-only:
|
||||
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ cp Hoth Naboo
|
||||
cp: cannot create regular file 'Naboo': Permission denied
|
||||
```
|
||||
|
||||
But by using the force, **cp** will not prompt. The contents and permissions of _Hoth_ will immediately be copied to _Naboo_ :
|
||||
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ cp -f Hoth Naboo
|
||||
[alan@workstation ~]$ cat Hoth Naboo
|
||||
Icy Planet
|
||||
|
||||
Icy Planet
|
||||
|
||||
[alan@workstation ~]$ ls -l
|
||||
total 8
|
||||
-rw-rw---- 1 alan alan 12 May 1 12:32 Hoth
|
||||
-rw-rw---- 1 alan alan 12 May 1 12:38 Naboo
|
||||
```
|
||||
|
||||
Oh no! I hope they have winter gear on Naboo.
|
||||
|
||||
### ln
|
||||
|
||||
The **ln** command is used to make links between files. The [man page][4] describes the force option for **ln** as:
|
||||
|
||||
|
||||
```
|
||||
-f, --force
|
||||
remove existing destination files
|
||||
```
|
||||
|
||||
Suppose Princess Leia is maintaining a Java application server and she has a directory where all Java versions are stored. Here is an example:
|
||||
|
||||
|
||||
```
|
||||
leia@workstation:/usr/lib/java$ ls -lt
|
||||
total 28
|
||||
lrwxrwxrwx 1 leia leia 12 Mar 5 2018 jdk -> jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
|
||||
```
|
||||
|
||||
As you can see, there are several versions of the Java Development Kit (JDK) and a symbolic link pointing to the latest one. She uses a script with the following commands to install new JDK versions. However, it won't work without a force option or unless the root user runs it:
|
||||
|
||||
|
||||
```
|
||||
tar xvzmf jdk1.8.0_181.tar.gz -C jdk1.8.0_181/
|
||||
ln -vs jdk1.8.0_181 jdk
|
||||
```
|
||||
|
||||
The **tar** command will extract the .gz file to the specified directory, but the **ln** command will fail to upgrade the link because one already exists. The result will be that the link no longer points to the latest JDK:
|
||||
|
||||
|
||||
```
|
||||
leia@workstation:/usr/lib/java$ ln -vs jdk1.8.0_181 jdk
|
||||
ln: failed to create symbolic link 'jdk/jdk1.8.0_181': File exists
|
||||
leia@workstation:/usr/lib/java$ ls -lt
|
||||
total 28
|
||||
drwxr-x--- 2 leia leia 4096 May 1 15:44 jdk1.8.0_181
|
||||
lrwxrwxrwx 1 leia leia 12 Mar 5 2018 jdk -> jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
|
||||
```
|
||||
|
||||
She can force **ln** to update the link correctly by passing the force option and one other, **-n**. The **-n** is needed because the link points to a directory. Now, the link again points to the latest JDK:
|
||||
|
||||
|
||||
```
|
||||
leia@workstation:/usr/lib/java$ ln -vsnf jdk1.8.0_181 jdk
|
||||
'jdk' -> 'jdk1.8.0_181'
|
||||
leia@workstation:/usr/lib/java$ ls -lt
|
||||
total 28
|
||||
lrwxrwxrwx 1 leia leia 12 May 1 16:13 jdk -> jdk1.8.0_181
|
||||
drwxr-x--- 2 leia leia 4096 May 1 15:44 jdk1.8.0_181
|
||||
drwxr-xr-x 8 leia leia 4096 Mar 5 2018 jdk1.8.0_162
|
||||
drwxr-xr-x 8 leia leia 4096 Aug 28 2017 jdk1.8.0_144
|
||||
```
|
||||
|
||||
A Java application can be configured to find the JDK with the path **/usr/lib/java/jdk** instead of having to change it every time Java is updated.
|
||||
|
||||
### rm
|
||||
|
||||
The **rm** command is short for "remove" (which we often call delete, since some other operating systems have a **del** command for this action). The [man page][5] describes the force option for **rm** as:
|
||||
|
||||
|
||||
```
|
||||
-f, --force
|
||||
ignore nonexistent files and arguments, never prompt
|
||||
```
|
||||
|
||||
If you try to delete a read-only file, you will be prompted by **rm** :
|
||||
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ ls -l
|
||||
total 4
|
||||
-r--r----- 1 alan alan 16 May 1 11:38 B-wing
|
||||
[alan@workstation ~]$ rm B-wing
|
||||
rm: remove write-protected regular file 'B-wing'?
|
||||
```
|
||||
|
||||
You must type either **y** or **n** to answer the prompt and allow the **rm** command to proceed. If you use the force option, **rm** will not prompt you and will immediately delete the file:
|
||||
|
||||
|
||||
```
|
||||
[alan@workstation ~]$ rm -f B-wing
|
||||
[alan@workstation ~]$ ls -l
|
||||
total 0
|
||||
[alan@workstation ~]$
|
||||
```
|
||||
|
||||
The most common use of force with **rm** is to delete a directory. The **-r** (recursive) option tells **rm** to remove a directory. When combined with the force option, it will remove the directory and all its contents without prompting.
|
||||
|
||||
The **rm** command with certain options can be disastrous. Over the years, online forums have filled with jokes and horror stories of users completely wiping their systems. This notorious usage is **rm -rf ***. This will immediately delete all files and directories without any prompt wherever it is used.
|
||||
|
||||
### userdel
|
||||
|
||||
The **userdel** command is short for user delete, which will delete a user. The [man page][6] describes the force option for **userdel** as:
|
||||
|
||||
|
||||
```
|
||||
-f, --force
|
||||
This option forces the removal of the user account, even if the
|
||||
user is still logged in. It also forces userdel to remove the
|
||||
user's home directory and mail spool, even if another user uses
|
||||
the same home directory or if the mail spool is not owned by the
|
||||
specified user. If USERGROUPS_ENAB is defined to yes in
|
||||
/etc/login.defs and if a group exists with the same name as the
|
||||
deleted user, then this group will be removed, even if it is
|
||||
still the primary group of another user.
|
||||
|
||||
Note: This option is dangerous and may leave your system in an
|
||||
inconsistent state.
|
||||
```
|
||||
|
||||
When Obi-Wan reached the castle on Mustafar, he knew what had to be done. He had to delete Darth's user account—but Darth was still logged in.
|
||||
|
||||
|
||||
```
|
||||
[root@workstation ~]# ps -fu darth
|
||||
UID PID PPID C STIME TTY TIME CMD
|
||||
darth 7663 7655 0 13:28 pts/3 00:00:00 -bash
|
||||
[root@workstation ~]# userdel darth
|
||||
userdel: user darth is currently used by process 7663
|
||||
```
|
||||
|
||||
Since Darth is currently logged in, Obi-Wan has to use the force option to **userdel**. This will delete the user account even though it's logged in.
|
||||
|
||||
|
||||
```
|
||||
[root@workstation ~]# userdel -f darth
|
||||
userdel: user darth is currently used by process 7663
|
||||
[root@workstation ~]# finger darth
|
||||
finger: darth: no such user.
|
||||
[root@workstation ~]# ps -fu darth
|
||||
error: user name does not exist
|
||||
```
|
||||
|
||||
As you can see, the **finger** and **ps** commands confirm the user Darth has been deleted.
|
||||
|
||||
### Using force in shell scripts
|
||||
|
||||
Many other commands have a force option. One place force is very useful is in shell scripts. Since we use scripts in cron jobs and other automated operations, avoiding any prompts is crucial, or else these automated processes will not complete.
|
||||
|
||||
I hope the four examples I shared above help you understand how certain circumstances may require the use of force. You should have a strong understanding of the force option when used at the command line or in creating automation scripts. It's misuse can have devastating effects—sometimes across your infrastructure, and not only on a single machine.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/may-the-force-linux
|
||||
|
||||
作者:[Alan Formy-Duval ][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fireworks_light_art_design.jpg?itok=hfx9i4By (Fireworks)
|
||||
[2]: https://www.starwars.com/star-wars-day
|
||||
[3]: http://man7.org/linux/man-pages/man1/cp.1.html
|
||||
[4]: http://man7.org/linux/man-pages/man1/ln.1.html
|
||||
[5]: http://man7.org/linux/man-pages/man1/rm.1.html
|
||||
[6]: http://man7.org/linux/man-pages/man8/userdel.8.html
|
||||
136
sources/tech/20190505 -Review- Void Linux, a Linux BSD Hybrid.md
Normal file
136
sources/tech/20190505 -Review- Void Linux, a Linux BSD Hybrid.md
Normal file
@ -0,0 +1,136 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: ([Review] Void Linux, a Linux BSD Hybrid)
|
||||
[#]: via: (https://itsfoss.com/void-linux/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
[Review] Void Linux, a Linux BSD Hybrid
|
||||
======
|
||||
|
||||
There are distros that follow the crowd and there are others that try to make their own path through the tall weed. Today, we’ll be looking at a small distro that looks to challenge how a distro should work. We’ll be looking at Void Linux.
|
||||
|
||||
### What is Void Linux?
|
||||
|
||||
[Void Linux][1] is a “general purpose operating system, based on the monolithic Linux kernel. Its package system allows you to quickly install, update and remove software; software is provided in binary packages or can be built directly from sources with the help of the XBPS source packages collection.”
|
||||
|
||||
![Void Linux Neofetch][2]
|
||||
|
||||
Like Solus, Void Linux is written from scratch and does not depend on any other operating system. It is a rolling release. Unlike the majority of Linux distros, Void does not use [systemd][3]. Instead, it uses [runit][4]. Another thing that separates Void from the rest of Linux distros is the fact that they use LibreSSL instead of OpenSSL. Void also offers support for the [musl C library][5]. In fact, when you download a .iso file, you can choose between `glibc` and `musl`.
|
||||
|
||||
The homegrown package manager that Void uses is named X Binary Package System (or xbps). According to the [Void wiki][6], xbps has the following features:
|
||||
|
||||
* Supports multiple local and remote repositories (HTTP/HTTPS/FTP).
|
||||
* RSA signed remote repositories
|
||||
* SHA256 hashes for package metadata, files, and binary packages
|
||||
* Supports package states (ala dpkg) to mitigate broken package * installs/updates
|
||||
* Ability to resume partial package install/updates
|
||||
* Ability to unpack only files that have been modified in * package updates
|
||||
* Ability to use virtual packages
|
||||
* Ability to check for incompatible shared libraries in reverse dependencies
|
||||
* Ability to replace packages
|
||||
* Ability to put packages on hold (to never update them)
|
||||
* Ability to preserve/update configuration files
|
||||
* Ability to force reinstallation of any installed package
|
||||
* Ability to downgrade any installed package
|
||||
* Ability to execute pre/post install/remove/update scriptlets
|
||||
* Ability to check package integrity: missing files, hashes, missing or unresolved (reverse)dependencies, dangling or modified symlinks, etc.
|
||||
|
||||
|
||||
|
||||
#### System Requirements
|
||||
|
||||
According to the [Void Linux download page][7], the system requirements differ based on the architecture you choose. 64-bit images require “EM64T CPU, 96MB RAM, 350MB disk, Ethernet/WiFi for network installation”. 32-bit images require “Pentium 4 CPU (SSE2), 96MB RAM, 350MB disk, Ethernet / WiFi for network installation”. The [Void Linux handbook][8] recommends 700 MB for storage and also notes that “Flavor installations require more resources. How much more depends on the flavor.”
|
||||
|
||||
Void also supports ARM devices. You can download [ready to boot images][9] for Raspberry Pi and several other [Raspberry Pi alternatives][10].
|
||||
|
||||
[][11]
|
||||
|
||||
Suggested read NomadBSD, a BSD for the Road
|
||||
|
||||
### Void Linux Installation
|
||||
|
||||
NOTE: you can either install [Void Linux download page][7] via a live image or use a net installer. I used a live image.
|
||||
|
||||
I was able to successfully install Void Linux on my Dell Latitude D630. This laptop has an Intel Centrino Duo Core processor running at 2.00 GHz, NVIDIA Quadro NVS 135M graphics chip, and 4 GB of RAM.
|
||||
|
||||
![Void Linux Mate][12]
|
||||
|
||||
After I `dd`ed the 800 MB Void Linux MATE image to my thumb drive and inserted it, I booted my computer. I was very quickly presented with a vanilla MATE desktop. To start installing Void, I opened up a terminal and typed `sudo void-installer`. After using the default password `voidlinux`, the installer started. The installer reminded me a little bit of the terminal Debian installer, but it was laid out more like FreeBSD. It was divided into keyboard, network, source, hostname, locale, timezone, root password, user account, bootloader, partition, and filesystems sections.
|
||||
|
||||
Most of the sections where self-explanatory. In the source section, you could choose whether to install the packages from the local image or grab them from the web. I chose local because I did not want to eat up bandwidth or take longer than I had to. The partition and filesystems sections are usually handled automatically by most installers, but not on Void. In this case, the first section allows you to use `cfdisk` to create partitions and the second allows to specify what filesystems will be used in those partitions. I followed the partition layout on [this page][13].
|
||||
|
||||
If you install Void Linux from the local image, you definitely need to update your system. The [Void wiki][14] recommends running `xbps-install -Suv` until there are no more updates to install. It would probably be a good idea to reboot between batches of updates.
|
||||
|
||||
### Experience with Void Linux
|
||||
|
||||
So far in my Linux journey, Void Linux has been by far the most difficult. It feels more like I’m [using a BSD than a Linux distro][15]. (I guess that should not be surprising since Void was created by a former [NetBSD][16] developer who wanted to experiment with his own package manager.) The steps in the command line installer are closer to that of [FreeBSD][17] than Debian.
|
||||
|
||||
Once Void was installed and updated, I went to work installing apps. Unfortunately, I ran into an issue with missing applications. Most of these applications come preinstalled on other distros. I had to install wget, unzip, git, nano, LibreOffice to name just a few.
|
||||
|
||||
Void does not come with a graphical package manager. There are three unofficial frontends for the xbps package manager and [one is based on qt][18]. I ran into issues getting one of the Bash-based tools to work. It hadn’t been updated in 4-5 years.
|
||||
|
||||
![Octoxbps][19]
|
||||
|
||||
The xbps package manager is kinda interesting. It downloads the package and its signature to verify it. You can see the [terminal print out][20] from when I installed Mcomix. Xbps does not use the normal naming convention used in most package managers (ie `apt install` or `pacman -R`), instead, it uses `xbps-install`, `xbps-query`, `xbps-remove`. Luckily, the Void wiki had a [page][21] to show what xbps command relates to apt or dnf commands.
|
||||
|
||||
[][22]
|
||||
|
||||
Suggested read How To Solve: error: no such partition grub rescue in Ubuntu Linux
|
||||
|
||||
The main repo for Void is located in Germany, so I decided to switch to a more local server to ease the burden on that server and to download packages quicker. Switching to a local mirror took a couple of tries because the documentation was not very clear. Documentation for Void is located in two different places: the [wiki][23] and the [handbook][24]. For me, the wiki’s [explanation][25] was confusing and I ran into issues. So, I searched for an answer on DuckDuckGo. From there I stumbled upon the [handbook’s instructions][26], which were much clearer. (The handbook is not linked on the Void Linux website and I had to stumble across it via search.)
|
||||
|
||||
One of the nice things about Void is the speed of the system once everything was installed. It had the quickest boot time I have ever encountered. Overall, the system was very responsive. I did not run into any system crashes.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
Void Linux took more work to get to a useable state than any other distro I have tried. Even the BSDs I tried felt more polished than Void. I think the tagline “General purpose Linux” is misleading. It should be “Linux with hackers and tinkerers in mind”. Personally, I prefer using distros that are ready for me to use after installing. While it is an interesting combination of Linux and BSD ideas, I don’t think I’ll add Void to my short list of go-to distros.
|
||||
|
||||
If you like tinkering with your Linux system or like building it from scratch, give [Void Linux][7] a try.
|
||||
|
||||
Have you ever used Void Linux? What is your favorite Debian-based distro? Please let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][27].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/void-linux/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://voidlinux.org/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/04/Void-Linux-Neofetch.png?resize=800%2C562&ssl=1
|
||||
[3]: https://en.wikipedia.org/wiki/Systemd
|
||||
[4]: http://smarden.org/runit/
|
||||
[5]: https://www.musl-libc.org/
|
||||
[6]: https://wiki.voidlinux.org/XBPS
|
||||
[7]: https://voidlinux.org/download/
|
||||
[8]: https://docs.voidlinux.org/installation/base-requirements.html
|
||||
[9]: https://voidlinux.org/download/#download-ready-to-boot-images-for-arm
|
||||
[10]: https://itsfoss.com/raspberry-pi-alternatives/
|
||||
[11]: https://itsfoss.com/nomadbsd/
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/04/Void-Linux-Mate.png?resize=800%2C640&ssl=1
|
||||
[13]: https://wiki.voidlinux.org/Disks#Filesystems
|
||||
[14]: https://wiki.voidlinux.org/Post_Installation#Updates
|
||||
[15]: https://itsfoss.com/why-use-bsd/
|
||||
[16]: https://itsfoss.com/netbsd-8-release/
|
||||
[17]: https://www.freebsd.org/
|
||||
[18]: https://github.com/aarnt/octoxbps
|
||||
[19]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/04/OctoXBPS.jpg?resize=800%2C534&ssl=1
|
||||
[20]: https://pastebin.com/g31n1bFT
|
||||
[21]: https://wiki.voidlinux.org/Rosetta_stone
|
||||
[22]: https://itsfoss.com/solve-error-partition-grub-rescue-ubuntu-linux/
|
||||
[23]: https://wiki.voidlinux.org/
|
||||
[24]: https://docs.voidlinux.org/
|
||||
[25]: https://wiki.voidlinux.org/XBPS#Official_Repositories
|
||||
[26]: https://docs.voidlinux.org/xbps/repositories/mirrors/changing.html
|
||||
[27]: http://reddit.com/r/linuxusersgroup
|
||||
@ -1,261 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Duc – A Collection Of Tools To Inspect And Visualize Disk Usage)
|
||||
[#]: via: (https://www.ostechnix.com/duc-a-collection-of-tools-to-inspect-and-visualize-disk-usage/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Duc – A Collection Of Tools To Inspect And Visualize Disk Usage
|
||||
======
|
||||
|
||||
![Duc - A Collection Of Tools To Inspect And Visualize Disk Usage][1]
|
||||
|
||||
**Duc** is a collection of tools that can be used to index, inspect and visualize disk usage on Unix-like operating systems. Don’t think of it as a simple CLI tool that merely displays a fancy graph of your disk usage. It is built to scale quite well on huge filesystems. Duc has been tested on systems that consisted of more than 500 million files and several petabytes of storage without any problems.
|
||||
|
||||
Duc is quite fast and versatile tool. It stores your disk usage in an optimized database, so you can quickly find where your bytes are as soon as the index is completed. In addition, it comes with various user interfaces and back-ends to access the database and draw the graphs.
|
||||
|
||||
Here is the list of currently supported user interfaces (UI):
|
||||
|
||||
1. Command line interface (ls),
|
||||
2. Ncurses console interface (ui),
|
||||
3. X11 GUI (duc gui),
|
||||
4. OpenGL GUI (duc gui).
|
||||
|
||||
|
||||
|
||||
List of supported database back-ends:
|
||||
|
||||
* Tokyocabinet,
|
||||
* Leveldb,
|
||||
* Sqlite3.
|
||||
|
||||
|
||||
|
||||
Duc uses **Tokyocabinet** as default database backend.
|
||||
|
||||
### Install Duc
|
||||
|
||||
Duc is available in the default repositories of Debian and its derivatives such as Ubuntu. So installing Duc on DEB-based systems is a piece of cake.
|
||||
|
||||
```
|
||||
$ sudo apt-get install duc
|
||||
```
|
||||
|
||||
On other Linux distributions, you may need to manually compile and install Duc from source as shown below.
|
||||
|
||||
Download latest duc source .tgz file from the [**releases**][2] page on github. As of writing this guide, the latest version was **1.4.4**.
|
||||
|
||||
```
|
||||
$ wget https://github.com/zevv/duc/releases/download/1.4.4/duc-1.4.4.tar.gz
|
||||
```
|
||||
|
||||
Then run the following commands one by one to install DUC.
|
||||
|
||||
```
|
||||
$ tar -xzf duc-1.4.4.tar.gz
|
||||
$ cd duc-1.4.4
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
### Duc Usage
|
||||
|
||||
The typical usage of duc is:
|
||||
|
||||
```
|
||||
$ duc <subcommand> <options>
|
||||
```
|
||||
|
||||
You can view the list of general options and sub-commands by running the following command:
|
||||
|
||||
```
|
||||
$ duc help
|
||||
```
|
||||
|
||||
You can also know the the usage of a specific subcommand as below.
|
||||
|
||||
```
|
||||
$ duc help <subcommand>
|
||||
```
|
||||
|
||||
To view the extensive list of all commands and their options, simply run:
|
||||
|
||||
```
|
||||
$ duc help --all
|
||||
```
|
||||
|
||||
Let us now se some practical use cases of duc utility.
|
||||
|
||||
### Create Index (database)
|
||||
|
||||
First of all, you need to create an index file (database) of your filesystem. To create an index file, use “duc index” command.
|
||||
|
||||
For example, to create an index of your **/home** directory, simply run:
|
||||
|
||||
```
|
||||
$ duc index /home
|
||||
```
|
||||
|
||||
The above command will create the index of your /home/ directory and save it in **$HOME/.duc.db** file. If you have added new files/directories in the /home directory in future, just re-run the above command at any time later to rebuild the index.
|
||||
|
||||
### Query Index
|
||||
|
||||
Duc has various sub-commands to query and explore the index.
|
||||
|
||||
To view the list of available indexes, run:
|
||||
|
||||
```
|
||||
$ duc info
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
Date Time Files Dirs Size Path
|
||||
2019-04-09 15:45:55 3.5K 305 654.6M /home
|
||||
```
|
||||
|
||||
As you see in the above output, I have already indexed the /home directory.
|
||||
|
||||
To list all files and directories in the current working directory, you can do:
|
||||
|
||||
```
|
||||
$ duc ls
|
||||
```
|
||||
|
||||
To list files/directories in a specific directory, for example **/home/sk/Downloads** , just pass the path as argument like below.
|
||||
|
||||
```
|
||||
$ duc ls /home/sk/Downloads
|
||||
```
|
||||
|
||||
Similarly, run **“duc ui”** command to open a **ncurses** based console user interface for exploring the file system usage and run **“duc gui”** to start a **graphical (X11)** interface to explore the file system.
|
||||
|
||||
To know more about a sub-command usage, simply refer the help section.
|
||||
|
||||
```
|
||||
$ duc help ls
|
||||
```
|
||||
|
||||
The above command will display the help section of “ls” subcommand.
|
||||
|
||||
### Visualize Disk Usage
|
||||
|
||||
In the previous section, we have seen how to list files and directories using duc subcommands. In addition, you can even show the file sizes in a fancy graph.
|
||||
|
||||
To show the graph of a given path, use “ls” subcommand like below.
|
||||
|
||||
```
|
||||
$ duc ls -Fg /home/sk
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
![][3]
|
||||
|
||||
Visualize disk usage using “duc ls” command
|
||||
|
||||
As you see in the above output, the “ls” subcommand queries the duc database and lists the inclusive size of all
|
||||
files and directories of the given path i.e **/home/sk/** in this case.
|
||||
|
||||
Here, the **“-F”** option is used to append file type indicator (one of */) to entries and the **“-g”** option is used to draw graph with relative size for each entry.
|
||||
|
||||
Please note that if no path is given, the current working directory is explored.
|
||||
|
||||
You can use **-R** option to view the disk usage result in [**tree**][4] structure.
|
||||
|
||||
```
|
||||
$ duc ls -R /home/sk
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
Visualize disk usage in tree structure
|
||||
|
||||
To query the duc database and open a **ncurses** based console user interface for exploring the disk usage of given path, use **“ui”** subcommand like below.
|
||||
|
||||
```
|
||||
$ duc ui /home/sk
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
Similarly, we use **“gui”** subcommand to query the duc database and start a **graphical (X11)** interface to explore the disk usage of the given path:
|
||||
|
||||
```
|
||||
$ duc gui /home/sk
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
Like I already mentioned earlier, we can learn more about a subcommand usage like below.
|
||||
|
||||
```
|
||||
$ duc help <subcommand-name>
|
||||
```
|
||||
|
||||
I covered the basic usage part only. Refer man pages for more details about “duc” tool.
|
||||
|
||||
```
|
||||
$ man duc
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
**Related read:**
|
||||
|
||||
* [**Filelight – Visualize Disk Usage On Your Linux System**][8]
|
||||
* [**Some Good Alternatives To ‘du’ Command**][9]
|
||||
* [**How To Check Disk Space Usage In Linux Using Ncdu**][10]
|
||||
* [**Agedu – Find Out Wasted Disk Space In Linux**][11]
|
||||
* [**How To Find The Size Of A Directory In Linux**][12]
|
||||
* [**The df Command Tutorial With Examples For Beginners**][13]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
### Conclusion
|
||||
|
||||
Duc is simple yet useful disk usage viewer. If you want to quickly and easily know which files/directories are eating up your disk space, Duc might be a good choice. What are you waiting for? Go get this tool already, scan your filesystem and get rid of unused files/directories.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
**Resource:**
|
||||
|
||||
* [**Duc website**][14]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/duc-a-collection-of-tools-to-inspect-and-visualize-disk-usage/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/duc-720x340.png
|
||||
[2]: https://github.com/zevv/duc/releases
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/04/duc-1-1.png
|
||||
[4]: https://www.ostechnix.com/view-directory-tree-structure-linux/
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2019/04/duc-2.png
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2019/04/duc-3.png
|
||||
[7]: http://www.ostechnix.com/wp-content/uploads/2019/04/duc-4.png
|
||||
[8]: https://www.ostechnix.com/filelight-visualize-disk-usage-on-your-linux-system/
|
||||
[9]: https://www.ostechnix.com/some-good-alternatives-to-du-command/
|
||||
[10]: https://www.ostechnix.com/check-disk-space-usage-linux-using-ncdu/
|
||||
[11]: https://www.ostechnix.com/agedu-find-out-wasted-disk-space-in-linux/
|
||||
[12]: https://www.ostechnix.com/find-size-directory-linux/
|
||||
[13]: https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginners/
|
||||
[14]: https://duc.zevv.nl/
|
||||
@ -1,209 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Create SSH Alias In Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-create-ssh-alias-in-linux/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Create SSH Alias In Linux
|
||||
======
|
||||
|
||||
![How To Create SSH Alias In Linux][1]
|
||||
|
||||
If you frequently access a lot of different remote systems via SSH, this trick will save you some time. You can create SSH alias to frequently-accessed systems via SSH. This way you need not to remember all the different usernames, hostnames, ssh port numbers and IP addresses etc. Additionally, It avoids the need to repetitively type the same username/hostname, ip address, port no whenever you SSH into a Linux server(s).
|
||||
|
||||
### Create SSH Alias In Linux
|
||||
|
||||
Before I know this trick, usually, I connect to a remote system over SSH using anyone of the following ways.
|
||||
|
||||
Using IP address:
|
||||
|
||||
```
|
||||
$ ssh 192.168.225.22
|
||||
```
|
||||
|
||||
Or using port number, username and IP address:
|
||||
|
||||
```
|
||||
$ ssh -p 22 sk@server.example.com
|
||||
```
|
||||
|
||||
Or using port number, username and hostname:
|
||||
|
||||
```
|
||||
$ ssh -p 22 sk@server.example.com
|
||||
```
|
||||
|
||||
Here,
|
||||
|
||||
* **22** is the port number,
|
||||
* **sk** is the username of the remote system,
|
||||
* **192.168.225.22** is the IP of my remote system,
|
||||
* **server.example.com** is the hostname of remote system.
|
||||
|
||||
|
||||
|
||||
I believe most of the newbie Linux users and/or admins would SSH into a remote system this way. However, If you SSH into multiple different systems, remembering all hostnames/ip addresses, usernames is bit difficult unless you write them down in a paper or save them in a text file. No worries! This can be easily solved by creating an alias(or shortcut) for SSH connections.
|
||||
|
||||
We can create an alias for SSH commands in two methods.
|
||||
|
||||
##### Method 1 – Using SSH Config File
|
||||
|
||||
This is my preferred way of creating aliases.
|
||||
|
||||
We can use SSH default configuration file to create SSH alias. To do so, edit **~/.ssh/config** file (If this file doesn’t exist, just create one):
|
||||
|
||||
```
|
||||
$ vi ~/.ssh/config
|
||||
```
|
||||
|
||||
Add all of your remote hosts details like below:
|
||||
|
||||
```
|
||||
Host webserver
|
||||
HostName 192.168.225.22
|
||||
User sk
|
||||
|
||||
Host dns
|
||||
HostName server.example.com
|
||||
User root
|
||||
|
||||
Host dhcp
|
||||
HostName 192.168.225.25
|
||||
User ostechnix
|
||||
Port 2233
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
Create SSH Alias In Linux Using SSH Config File
|
||||
|
||||
Replace the values of **Host** , **Hostname** , **User** and **Port** with your own. Once you added the details of all remote hosts, save and exit the file.
|
||||
|
||||
Now you can SSH into the systems with commands:
|
||||
|
||||
```
|
||||
$ ssh webserver
|
||||
|
||||
$ ssh dns
|
||||
|
||||
$ ssh dhcp
|
||||
```
|
||||
|
||||
It is simple as that.
|
||||
|
||||
Have a look at the following screenshot.
|
||||
|
||||
![][3]
|
||||
|
||||
Access remote system using SSH alias
|
||||
|
||||
See? I only used the alias name (i.e **webserver** ) to access my remote system that has IP address **192.168.225.22**.
|
||||
|
||||
Please note that this applies for current user only. If you want to make the aliases available for all users (system wide), add the above lines in **/etc/ssh/ssh_config** file.
|
||||
|
||||
You can also add plenty of other things in the SSH config file. For example, if you have [**configured SSH Key-based authentication**][4], mention the SSH keyfile location as below.
|
||||
|
||||
```
|
||||
Host ubuntu
|
||||
HostName 192.168.225.50
|
||||
User senthil
|
||||
IdentityFIle ~/.ssh/id_rsa_remotesystem
|
||||
```
|
||||
|
||||
Make sure you have replace the hostname, username and SSH keyfile path with your own.
|
||||
|
||||
Now connect to the remote server with command:
|
||||
|
||||
```
|
||||
$ ssh ubuntu
|
||||
```
|
||||
|
||||
This way you can add as many as remote hosts you want to access over SSH and quickly access them using their alias name.
|
||||
|
||||
##### Method 2 – Using Bash aliases
|
||||
|
||||
This is quick and dirty way to create SSH aliases for faster communication. You can use the [**alias command**][5] to make this task much easier.
|
||||
|
||||
Open **~/.bashrc** or **~/.bash_profile** file:
|
||||
|
||||
Add aliases for each SSH connections one by one like below.
|
||||
|
||||
```
|
||||
alias webserver='ssh sk@server.example.com'
|
||||
alias dns='ssh sk@server.example.com'
|
||||
alias dhcp='ssh sk@server.example.com -p 2233'
|
||||
alias ubuntu='ssh sk@server.example.com -i ~/.ssh/id_rsa_remotesystem'
|
||||
```
|
||||
|
||||
Again make sure you have replaced the host, hostname, port number and ip address with your own. Save the file and exit.
|
||||
|
||||
Then, apply the changes using command:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
Or,
|
||||
|
||||
```
|
||||
$ source ~/.bash_profile
|
||||
```
|
||||
|
||||
In this method, you don’t even need to use “ssh alias-name” command. Instead, just use alias name only like below.
|
||||
|
||||
```
|
||||
$ webserver
|
||||
$ dns
|
||||
$ dhcp
|
||||
$ ubuntu
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
These two methods are very simple, yet useful and much more convenient for those who often SSH into multiple different systems. Use any one of the aforementioned methods that suits for you to quickly access your remote Linux systems over SSH.
|
||||
|
||||
* * *
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
* [**Allow Or Deny SSH Access To A Particular User Or Group In Linux**][7]
|
||||
* [**How To SSH Into A Particular Directory On Linux**][8]
|
||||
* [**How To Stop SSH Session From Disconnecting In Linux**][9]
|
||||
* [**4 Ways To Keep A Command Running After You Log Out Of The SSH Session**][10]
|
||||
* [**SSLH – Share A Same Port For HTTPS And SSH**][11]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-create-ssh-alias-in-linux/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/ssh-alias-720x340.png
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2019/04/Create-SSH-Alias-In-Linux.png
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2019/04/create-ssh-alias.png
|
||||
[4]: https://www.ostechnix.com/configure-ssh-key-based-authentication-linux/
|
||||
[5]: https://www.ostechnix.com/the-alias-and-unalias-commands-explained-with-examples/
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2019/04/create-ssh-alias-1.png
|
||||
[7]: https://www.ostechnix.com/allow-deny-ssh-access-particular-user-group-linux/
|
||||
[8]: https://www.ostechnix.com/how-to-ssh-into-a-particular-directory-on-linux/
|
||||
[9]: https://www.ostechnix.com/how-to-stop-ssh-session-from-disconnecting-in-linux/
|
||||
[10]: https://www.ostechnix.com/4-ways-keep-command-running-log-ssh-session/
|
||||
[11]: https://www.ostechnix.com/sslh-share-port-https-ssh/
|
||||
@ -1,202 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux Shell Script To Monitor Disk Space Usage And Send Email)
|
||||
[#]: via: (https://www.2daygeek.com/linux-shell-script-to-monitor-disk-space-usage-and-send-email/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Linux Shell Script To Monitor Disk Space Usage And Send Email
|
||||
======
|
||||
|
||||
There are numerous monitoring tools are available in market to monitor Linux systems and it will send an email when the system reaches the threshold limit.
|
||||
|
||||
It monitors everything such as CPU utilization, Memory utilization, swap utilization, disk space utilization and much more.
|
||||
|
||||
However, it’s suitable for small and big environment.
|
||||
|
||||
Think about if you have only few systems then what will be the best approach on this.
|
||||
|
||||
Yup, we want to write a **[shell script][1]** to achieve this.
|
||||
|
||||
In this tutorial we are going to write a shell script to monitor disk space usage on system.
|
||||
|
||||
When the system reaches the given threshold then it will trigger a mail to corresponding email id.
|
||||
|
||||
We have added totally four shell scripts in this article and each has been used for different purpose.
|
||||
|
||||
Later, we will come up with other shell scripts to monitor CPU, Memory and Swap utilization.
|
||||
|
||||
Before step into that, i would like to clarify one thing which i noticed regarding the disk space usage shell script.
|
||||
|
||||
Most of the users were commented in multiple blogs saying they were getting the following error message when they are running the disk space usage script.
|
||||
|
||||
```
|
||||
# sh /opt/script/disk-usage-alert-old.sh
|
||||
|
||||
/dev/mapper/vg_2g-lv_root
|
||||
test-script.sh: line 7: [: /dev/mapper/vg_2g-lv_root: integer expression expected
|
||||
/ 9.8G
|
||||
```
|
||||
|
||||
Yes that’s right. Even, i had faced the same issue when i ran the script first time. Later, i had found the root causes.
|
||||
|
||||
When you use “df -h” or “df -H” in shell script for disk space alert on RHEL 5 & RHEL 6 based system, you will be end up with the above error message because the output is not in the proper format, see the below output.
|
||||
|
||||
To overcome this issue, we need to use “df -Ph” (POSIX output format) but by default “df -h” is working fine on RHEL 7 based systems.
|
||||
|
||||
```
|
||||
# df -h
|
||||
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg_2g-lv_root
|
||||
10G 6.7G 3.4G 67% /
|
||||
tmpfs 7.8G 0 7.8G 0% /dev/shm
|
||||
/dev/sda1 976M 95M 830M 11% /boot
|
||||
/dev/mapper/vg_2g-lv_home
|
||||
5.0G 4.3G 784M 85% /home
|
||||
/dev/mapper/vg_2g-lv_tmp
|
||||
4.8G 14M 4.6G 1% /tmp
|
||||
```
|
||||
|
||||
### Method-1 : Linux Shell Script To Monitor Disk Space Usage And Send Email
|
||||
|
||||
You can use the following shell script to monitor disk space usage on Linux system.
|
||||
|
||||
It will send an email when the system reaches the given threshold limit. In this example, we set threshold limit at 60% for testing purpose and you can change this limit as per your requirements.
|
||||
|
||||
It will send multiple mails if more than one file systems get reached the given threshold limit because the script is using loop.
|
||||
|
||||
Also, replace your email id instead of us to get this alert.
|
||||
|
||||
```
|
||||
# vi /opt/script/disk-usage-alert.sh
|
||||
|
||||
#!/bin/sh
|
||||
df -Ph | grep -vE '^Filesystem|tmpfs|cdrom' | awk '{ print $5,$1 }' | while read output;
|
||||
do
|
||||
echo $output
|
||||
used=$(echo $output | awk '{print $1}' | sed s/%//g)
|
||||
partition=$(echo $output | awk '{print $2}')
|
||||
if [ $used -ge 60 ]; then
|
||||
echo "The partition \"$partition\" on $(hostname) has used $used% at $(date)" | mail -s "Disk Space Alert: $used% Used On $(hostname)" [email protected]
|
||||
fi
|
||||
done
|
||||
```
|
||||
|
||||
**Output:** I got the following two email alerts.
|
||||
|
||||
```
|
||||
The partition "/dev/mapper/vg_2g-lv_home" on 2g.CentOS7 has used 85% at Mon Apr 29 06:16:14 IST 2019
|
||||
|
||||
The partition "/dev/mapper/vg_2g-lv_root" on 2g.CentOS7 has used 67% at Mon Apr 29 06:16:14 IST 2019
|
||||
```
|
||||
|
||||
Finally add a **[cronjob][2]** to automate this. It will run every 10 minutes.
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
*/10 * * * * /bin/bash /opt/script/disk-usage-alert.sh
|
||||
```
|
||||
|
||||
### Method-2 : Linux Shell Script To Monitor Disk Space Usage And Send Email
|
||||
|
||||
Alternatively, you can use the following shell script. We have made few changes in this compared with above script.
|
||||
|
||||
```
|
||||
# vi /opt/script/disk-usage-alert-1.sh
|
||||
|
||||
#!/bin/sh
|
||||
df -Ph | grep -vE '^Filesystem|tmpfs|cdrom' | awk '{ print $5,$1 }' | while read output;
|
||||
do
|
||||
max=60%
|
||||
echo $output
|
||||
used=$(echo $output | awk '{print $1}')
|
||||
partition=$(echo $output | awk '{print $2}')
|
||||
if [ ${used%?} -ge ${max%?} ]; then
|
||||
echo "The partition \"$partition\" on $(hostname) has used $used at $(date)" | mail -s "Disk Space Alert: $used Used On $(hostname)" [email protected]
|
||||
fi
|
||||
done
|
||||
```
|
||||
|
||||
**Output:** I got the following two email alerts.
|
||||
|
||||
```
|
||||
The partition "/dev/mapper/vg_2g-lv_home" on 2g.CentOS7 has used 85% at Mon Apr 29 06:16:14 IST 2019
|
||||
|
||||
The partition "/dev/mapper/vg_2g-lv_root" on 2g.CentOS7 has used 67% at Mon Apr 29 06:16:14 IST 2019
|
||||
```
|
||||
|
||||
Finally add a **[cronjob][2]** to automate this. It will run every 10 minutes.
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
*/10 * * * * /bin/bash /opt/script/disk-usage-alert-1.sh
|
||||
```
|
||||
|
||||
### Method-3 : Linux Shell Script To Monitor Disk Space Usage And Send Email
|
||||
|
||||
I would like to go with this method. Since, it work like a charm and you will be getting single email for everything.
|
||||
|
||||
This is very simple and straightforward.
|
||||
|
||||
```
|
||||
*/10 * * * * df -Ph | sed s/%//g | awk '{ if($5 > 60) print $0;}' | mail -s "Disk Space Alert On $(hostname)" [email protected]
|
||||
```
|
||||
|
||||
**Output:** I got a single mail for all alerts.
|
||||
|
||||
```
|
||||
Filesystem Size Used Avail Use Mounted on
|
||||
/dev/mapper/vg_2g-lv_root 10G 6.7G 3.4G 67 /
|
||||
/dev/mapper/vg_2g-lv_home 5.0G 4.3G 784M 85 /home
|
||||
```
|
||||
|
||||
### Method-4 : Linux Shell Script To Monitor Disk Space Usage Of Particular Partition And Send Email
|
||||
|
||||
If anybody wants to monitor the particular partition then you can use the following shell script. Simply replace your filesystem name instead of us.
|
||||
|
||||
```
|
||||
# vi /opt/script/disk-usage-alert-2.sh
|
||||
|
||||
#!/bin/bash
|
||||
used=$(df -Ph | grep '/dev/mapper/vg_2g-lv_dbs' | awk {'print $5'})
|
||||
max=80%
|
||||
if [ ${used%?} -ge ${max%?} ]; then
|
||||
echo "The Mount Point "/DB" on $(hostname) has used $used at $(date)" | mail -s "Disk space alert on $(hostname): $used used" [email protected]
|
||||
fi
|
||||
```
|
||||
|
||||
**Output:** I got the following email alerts.
|
||||
|
||||
```
|
||||
The partition /dev/mapper/vg_2g-lv_dbs on 2g.CentOS6 has used 82% at Mon Apr 29 06:16:14 IST 2019
|
||||
```
|
||||
|
||||
Finally add a **[cronjob][2]** to automate this. It will run every 10 minutes.
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
*/10 * * * * /bin/bash /opt/script/disk-usage-alert-2.sh
|
||||
```
|
||||
|
||||
**Note:** You will be getting an email alert 10 mins later since the script has scheduled to run every 10 minutes (But it’s not exactly 10 mins and it depends the timing).
|
||||
|
||||
Say for example. If your system reaches the limit at 8.25 then you will get an email alert in another 5 mins. Hope it’s clear now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-shell-script-to-monitor-disk-space-usage-and-send-email/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/shell-script/
|
||||
[2]: https://www.2daygeek.com/crontab-cronjob-to-schedule-jobs-in-linux/
|
||||
@ -0,0 +1,199 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use udica to build SELinux policy for containers)
|
||||
[#]: via: (https://fedoramagazine.org/use-udica-to-build-selinux-policy-for-containers/)
|
||||
[#]: author: (Lukas Vrabec https://fedoramagazine.org/author/lvrabec/)
|
||||
|
||||
Use udica to build SELinux policy for containers
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
While modern IT environments move towards Linux containers, the need to secure these environments is as relevant as ever. Containers are a process isolation technology. While containers can be a defense mechanism, they only excel when combined with SELinux.
|
||||
|
||||
Fedora SELinux engineering built a new standalone tool, **udica** , to generate SELinux policy profiles for containers by automatically inspecting them. This article focuses on why _udica_ is needed in the container world, and how it makes SELinux and containers work better together. You’ll find examples of SELinux separation for containers that let you avoid turning protection off because the generic SELinux type _container_t_ is too tight. With _udica_ you can easily customize the policy with limited SELinux policy writing skills.
|
||||
|
||||
### SELinux technology
|
||||
|
||||
SELinux is a security technology that brings proactive security to Linux systems. It’s a labeling system that assigns a label to all _subjects_ (processes and users) and _objects_ (files, directories, sockets, etc.). These labels are then used in a security policy that controls access throughout the system. It’s important to mention that what’s not allowed in an SELinux security policy is denied by default. The policy rules are enforced by the kernel. This security technology has been in use on Fedora for several years. A real example of such a rule is:
|
||||
|
||||
```
|
||||
allow httpd_t httpd_log_t: file { append create getattr ioctl lock open read setattr };
|
||||
```
|
||||
|
||||
The rule allows any process labeled as _httpd_t_ ****to create, append, read and lock files labeled as _httpd_log_t_. Using the _ps_ command, you can list all processes with their labels:
|
||||
|
||||
```
|
||||
$ ps -efZ | grep httpd
|
||||
system_u:system_r:httpd_t:s0 root 13911 1 0 Apr14 ? 00:05:14 /usr/sbin/httpd -DFOREGROUND
|
||||
...
|
||||
```
|
||||
|
||||
To see which objects are labeled as httpd_log_t, use _semanage_ :
|
||||
|
||||
```
|
||||
# semanage fcontext -l | grep httpd_log_t
|
||||
/var/log/httpd(/.)? all files system_u:object_r:httpd_log_t:s0
|
||||
/var/log/nginx(/.)? all files system_u:object_r:httpd_log_t:s0
|
||||
...
|
||||
```
|
||||
|
||||
The SELinux security policy for Fedora is shipped in the _selinux-policy_ RPM package.
|
||||
|
||||
### SELinux vs. containers
|
||||
|
||||
In Fedora, the _container-selinux_ RPM package provides a generic SELinux policy for all containers started by engines like _podman_ or _docker_. Its main purposes are to protect the host system against a container process, and to separate containers from each other. For instance, containers confined by SELinux with the process type _container_t_ can only read/execute files in _/usr_ and write to _container_file_t_ ****files type on host file system. To prevent attacks by containers on each other, Multi-Category Security (MCS) is used.
|
||||
|
||||
Using only one generic policy for containers is problematic, because of the huge variety of container usage. On one hand, the default container type ( _container_t_ ) is often too strict. For example:
|
||||
|
||||
* [Fedora SilverBlue][2] needs containers to read/write a user’s home directory
|
||||
* [Fluentd][3] project needs containers to be able to read logs in the _/var/log_ directory
|
||||
|
||||
|
||||
|
||||
On the other hand, the default container type could be too loose for certain use cases:
|
||||
|
||||
* It has no SELinux network controls — all container processes can bind to any network port
|
||||
* It has no SELinux control on [Linux capabilities][4] — all container processes can use all capabilities
|
||||
|
||||
|
||||
|
||||
There is one solution to handle both use cases: write a custom SELinux security policy for the container. This can be tricky, because SELinux expertise is required. For this purpose, the _udica_ tool was created.
|
||||
|
||||
### Introducing udica
|
||||
|
||||
Udica generates SELinux security profiles for containers. Its concept is based on the “block inheritance” feature inside the [common intermediate language][5] (CIL) supported by SELinux userspace. The tool creates a policy that combines:
|
||||
|
||||
* Rules inherited from specified CIL blocks (templates), and
|
||||
* Rules discovered by inspection of container JSON file, which contains mountpoints and ports definitions
|
||||
|
||||
|
||||
|
||||
You can load the final policy immediately, or move it to another system to load into the kernel. Here’s an example, using a container that:
|
||||
|
||||
* Mounts _/home_ as read only
|
||||
* Mounts _/var/spool_ as read/write
|
||||
* Exposes port _tcp/21_
|
||||
|
||||
|
||||
|
||||
The container starts with this command:
|
||||
|
||||
```
|
||||
# podman run -v /home:/home:ro -v /var/spool:/var/spool:rw -p 21:21 -it fedora bash
|
||||
```
|
||||
|
||||
The default container type ( _container_t_ ) doesn’t allow any of these three actions. To prove it, you could use the _sesearch_ tool to query that the _allow_ rules are present on system:
|
||||
|
||||
```
|
||||
# sesearch -A -s container_t -t home_root_t -c dir -p read
|
||||
```
|
||||
|
||||
There’s no _allow_ rule present that lets a process labeled as _container_t_ access a directory labeled _home_root_t_ (like the _/home_ directory). The same situation occurs with _/var/spool_ , which is labeled _var_spool_t:_
|
||||
|
||||
```
|
||||
# sesearch -A -s container_t -t var_spool_t -c dir -p read
|
||||
```
|
||||
|
||||
On the other hand, the default policy completely allows network access.
|
||||
|
||||
```
|
||||
# sesearch -A -s container_t -t port_type -c tcp_socket
|
||||
allow container_net_domain port_type:tcp_socket { name_bind name_connect recv_msg send_msg };
|
||||
allow sandbox_net_domain port_type:tcp_socket { name_bind name_connect recv_msg send_msg };
|
||||
```
|
||||
|
||||
### Securing the container
|
||||
|
||||
It would be great to restrict this access and allow the container to bind just on TCP port _21_ or with the same label. Imagine you find an example container using _podman ps_ whose ID is _37a3635afb8f_ :
|
||||
|
||||
```
|
||||
# podman ps -q
|
||||
37a3635afb8f
|
||||
```
|
||||
|
||||
You can now inspect the container and pass the inspection file to the _udica_ tool. The name for the new policy is _my_container_.
|
||||
|
||||
```
|
||||
# podman inspect 37a3635afb8f > container.json
|
||||
# udica -j container.json my_container
|
||||
Policy my_container with container id 37a3635afb8f created!
|
||||
|
||||
Please load these modules using:
|
||||
# semodule -i my_container.cil /usr/share/udica/templates/{base_container.cil,net_container.cil,home_container.cil}
|
||||
|
||||
Restart the container with: "--security-opt label=type:my_container.process" parameter
|
||||
```
|
||||
|
||||
That’s it! You just created a custom SELinux security policy for the example container. Now you can load this policy into the kernel and make it active. The _udica_ output above even tells you the command to use:
|
||||
|
||||
```
|
||||
# semodule -i my_container.cil /usr/share/udica/templates/{base_container.cil,net_container.cil,home_container.cil}
|
||||
```
|
||||
|
||||
Now you must restart the container to allow the container engine to use the new custom policy:
|
||||
|
||||
```
|
||||
# podman run --security-opt label=type:my_container.process -v /home:/home:ro -v /var/spool:/var/spool:rw -p 21:21 -it fedora bash
|
||||
```
|
||||
|
||||
The example container is now running in the newly created _my_container.process_ SELinux process type:
|
||||
|
||||
```
|
||||
# ps -efZ | grep my_container.process
|
||||
unconfined_u:system_r:container_runtime_t:s0-s0:c0.c1023 root 2275 434 1 13:49 pts/1 00:00:00 podman run --security-opt label=type:my_container.process -v /home:/home:ro -v /var/spool:/var/spool:rw -p 21:21 -it fedora bash
|
||||
system_u:system_r:my_container.process:s0:c270,c963 root 2317 2305 0 13:49 pts/0 00:00:00 bash
|
||||
```
|
||||
|
||||
### Seeing the results
|
||||
|
||||
The command _sesearch_ now shows _allow_ rules for accessing _/home_ and _/var/spool:_
|
||||
|
||||
```
|
||||
# sesearch -A -s my_container.process -t home_root_t -c dir -p read
|
||||
allow my_container.process home_root_t:dir { getattr ioctl lock open read search };
|
||||
# sesearch -A -s my_container.process -t var_spool_t -c dir -p read
|
||||
allow my_container.process var_spool_t:dir { add_name getattr ioctl lock open read remove_name search write }
|
||||
```
|
||||
|
||||
The new custom SELinux policy also allows _my_container.process_ to bind only to TCP/UDP ports labeled the same as TCP port 21:
|
||||
|
||||
```
|
||||
# semanage port -l | grep 21 | grep ftp
|
||||
ftp_port_t tcp 21, 989, 990
|
||||
# sesearch -A -s my_container.process -c tcp_socket -p name_bind
|
||||
allow my_container.process ftp_port_t:tcp_socket name_bind;
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
The _udica_ tool helps you create SELinux policies for containers based on an inspection file without any SELinux expertise required. Now you can increase the security of containerized environments. Sources are available on [GitHub][6], and an RPM package is available in Fedora repositories for Fedora 28 and later.
|
||||
|
||||
* * *
|
||||
|
||||
*Photo by _[_Samuel Zeller_][7]_ on *[ _Unsplash_.][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/use-udica-to-build-selinux-policy-for-containers/
|
||||
|
||||
作者:[Lukas Vrabec][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/lvrabec/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/05/udica-816x345.jpg
|
||||
[2]: https://silverblue.fedoraproject.org
|
||||
[3]: https://www.fluentd.org
|
||||
[4]: http://man7.org/linux/man-pages/man7/capabilities.7.html
|
||||
[5]: https://en.wikipedia.org/wiki/Common_Intermediate_Language
|
||||
[6]: https://github.com/containers/udica
|
||||
[7]: https://unsplash.com/photos/KVG-XMOs6tw?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]: https://unsplash.com/search/photos/lockers?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Innovations on the Linux desktop: A look at Fedora 30's new features)
|
||||
[#]: via: (https://opensource.com/article/19/5/fedora-30-features)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva/users/marcobravo/users/alanfdoss/users/ansilva)
|
||||
|
||||
Innovations on the Linux desktop: A look at Fedora 30's new features
|
||||
======
|
||||
Learn about some of the highlights in the latest version of Fedora
|
||||
Linux.
|
||||
![Fedora Linux distro on laptop][1]
|
||||
|
||||
The latest version of Fedora Linux was released at the end of April. As a full-time Fedora user since its original release back in 2003 and an active contributor since 2007, I always find it satisfying to see new features and advancements in the community.
|
||||
|
||||
If you want a TL;DR version of what's has changed in [Fedora 30][2], feel free to ignore this article and jump straight to Fedora's [ChangeSet][3] wiki page. Otherwise, keep on reading to learn about some of the highlights in the new version.
|
||||
|
||||
### Upgrade vs. fresh install
|
||||
|
||||
I upgraded my Lenovo ThinkPad T series from Fedora 29 to 30 using the [DNF system upgrade instructions][4], and so far it is working great!
|
||||
|
||||
I also had the chance to do a fresh install on another ThinkPad, and it was a nice surprise to see a new boot screen on Fedora 30—it even picked up the Lenovo logo. I did not see this new and improved boot screen on the upgrade above; it was only on the fresh install.
|
||||
|
||||
![Fedora 30 boot screen][5]
|
||||
|
||||
### Desktop changes
|
||||
|
||||
If you are a GNOME user, you'll be happy to know that Fedora 30 comes with the latest version, [GNOME 3.32][6]. It has an improved on-screen keyboard (handy for touch-screen laptops), brand new icons for core applications, and a new "Applications" panel under Settings that allows users to gain a bit more control on GNOME default handlers, access permissions, and notifications. Version 3.32 also improves Google Drive performance so that Google files and calendar appointments will be integrated with GNOME.
|
||||
|
||||
![Applications panel in GNOME Settings][7]
|
||||
|
||||
The new Applications panel in GNOME Settings
|
||||
|
||||
Fedora 30 also introduces two new Desktop environments: Pantheon and Deepin. Pantheon is [ElementaryOS][8]'s default desktop environment and can be installed with a simple:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf groupinstall "Pantheon Desktop"`
|
||||
```
|
||||
|
||||
I haven't used Pantheon yet, but I do use [Deepin][9]. Installation is simple; just run:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf install deepin-desktop`
|
||||
```
|
||||
|
||||
then log out of GNOME and log back in, choosing "Deepin" by clicking on the gear icon on the login screen.
|
||||
|
||||
![Deepin desktop on Fedora 30][10]
|
||||
|
||||
Deepin desktop on Fedora 30
|
||||
|
||||
Deepin appears as a very polished, user-friendly desktop environment that allows you to control many aspects of your environment with a click of a button. So far, the only issue I've had is that it can take a few extra seconds to complete login and return control to your mouse pointer. Other than that, it is brilliant! It is the first desktop environment I've used that seems to do high dots per inch (HiDPI) properly—or at least close to correctly.
|
||||
|
||||
### Command line
|
||||
|
||||
Fedora 30 upgrades the Bourne Again Shell (aka Bash) to version 5.0.x. If you want to find out about every change since its last stable version (4.4), read this [description][11]. I do want to mention that three new environments have been introduced in Bash 5:
|
||||
|
||||
|
||||
```
|
||||
$ echo $EPOCHSECONDS
|
||||
1556636959
|
||||
$ echo $EPOCHREALTIME
|
||||
1556636968.012369
|
||||
$ echo $BASH_ARGV0
|
||||
bash
|
||||
```
|
||||
|
||||
Fedora 30 also updates the [Fish shell][12], a colorful shell with auto-suggestion, which can be very helpful for beginners. Fedora 30 comes with [Fish version 3][13], and you can even [try it out in a browser][14] without having to install it on your machine.
|
||||
|
||||
(Note that Fish shell is not the same as guestfish for mounting virtual machine images, which comes with the libguestfs-tools package.)
|
||||
|
||||
### Development
|
||||
|
||||
Fedora 30 brings updates to the following languages: [C][15], [Boost (C++)][16], [Erlang][17], [Go][18], [Haskell][19], [Python][20], [Ruby][21], and [PHP][22].
|
||||
|
||||
Regarding these updates, the most important thing to know is that Python 2 is deprecated in Fedora 30. The community and Fedora leadership are requesting that all package maintainers that still depend on Python 2 port their packages to Python 3 as soon as possible, as the plan is to remove virtually all Python 2 packages in Fedora 31.
|
||||
|
||||
### Containers
|
||||
|
||||
If you would like to run Fedora as an immutable OS for a container, kiosk, or appliance-like environment, check out [Fedora Silverblue][23]. It brings you all of Fedora's technology managed by [rpm-ostree][24], which is a hybrid image/package system that allows automatic updates and easy rollbacks for developers. It is a great option for anyone who wants to learn more and play around with [Flatpak deployments][25].
|
||||
|
||||
Fedora Atomic is no longer available under Fedora 30, but you can still [download it][26]. If your jam is containers, don't despair: even though Fedora Atomic is gone, a brand new [Fedora CoreOS][27] is under development and should be going live soon!
|
||||
|
||||
### What else is new?
|
||||
|
||||
As of Fedora 30, **/usr/bin/gpg** points to [GnuPG][28] v2 by default, and [NFS][29] server configuration is now located at **/etc/nfs.conf** instead of **/etc/sysconfig/nfs**.
|
||||
|
||||
There have also been a [few changes][30] for installation and boot time.
|
||||
|
||||
Last but not least, check out [Fedora Spins][31] for a spin of Fedora that defaults to your favorite Window manager and [Fedora Labs][32] for functionally curated software bundles built on Fedora 30 (i.e. astronomy, security, and gaming).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/fedora-30-features
|
||||
|
||||
作者:[Anderson Silva ][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva/users/marcobravo/users/alanfdoss/users/ansilva
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fedora_on_laptop_lead.jpg?itok=XMc5wo_e (Fedora Linux distro on laptop)
|
||||
[2]: https://getfedora.org/
|
||||
[3]: https://fedoraproject.org/wiki/Releases/30/ChangeSet
|
||||
[4]: https://fedoraproject.org/wiki/DNF_system_upgrade#How_do_I_use_it.3F
|
||||
[5]: https://opensource.com/sites/default/files/uploads/fedora30_fresh-boot.jpg (Fedora 30 boot screen)
|
||||
[6]: https://help.gnome.org/misc/release-notes/3.32/
|
||||
[7]: https://opensource.com/sites/default/files/uploads/fedora10_gnome.png (Applications panel in GNOME Settings)
|
||||
[8]: https://elementary.io/
|
||||
[9]: https://www.deepin.org/en/dde/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/fedora10_deepin.png (Deepin desktop on Fedora 30)
|
||||
[11]: https://git.savannah.gnu.org/cgit/bash.git/tree/NEWS
|
||||
[12]: https://fishshell.com/
|
||||
[13]: https://fishshell.com/release_notes.html
|
||||
[14]: https://rootnroll.com/d/fish-shell/
|
||||
[15]: https://docs.fedoraproject.org/en-US/fedora/f30/release-notes/developers/Development_C/
|
||||
[16]: https://docs.fedoraproject.org/en-US/fedora/f30/release-notes/developers/Development_Boost/
|
||||
[17]: https://docs.fedoraproject.org/en-US/fedora/f30/release-notes/developers/Development_Erlang/
|
||||
[18]: https://docs.fedoraproject.org/en-US/fedora/f30/release-notes/developers/Development_Go/
|
||||
[19]: https://docs.fedoraproject.org/en-US/fedora/f30/release-notes/developers/Development_Haskell/
|
||||
[20]: https://docs.fedoraproject.org/en-US/fedora/f30/release-notes/developers/Development_Python/
|
||||
[21]: https://docs.fedoraproject.org/en-US/fedora/f30/release-notes/developers/Development_Ruby/
|
||||
[22]: https://docs.fedoraproject.org/en-US/fedora/f30/release-notes/developers/Development_Web/
|
||||
[23]: https://silverblue.fedoraproject.org/
|
||||
[24]: https://rpm-ostree.readthedocs.io/en/latest/
|
||||
[25]: https://flatpak.org/setup/Fedora/
|
||||
[26]: https://getfedora.org/en/atomic/
|
||||
[27]: https://coreos.fedoraproject.org/
|
||||
[28]: https://gnupg.org/index.html
|
||||
[29]: https://en.wikipedia.org/wiki/Network_File_System
|
||||
[30]: https://docs.fedoraproject.org/en-US/fedora/f30/release-notes/sysadmin/Installation/
|
||||
[31]: https://spins.fedoraproject.org
|
||||
[32]: https://labs.fedoraproject.org/
|
||||
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why startups should release their code as open source)
|
||||
[#]: via: (https://opensource.com/article/19/5/startups-release-code)
|
||||
[#]: author: (Clément Flipo https://opensource.com/users/cl%C3%A9ment-flipo)
|
||||
|
||||
Why startups should release their code as open source
|
||||
======
|
||||
Dokit wondered whether giving away its knowledge as open source was a
|
||||
bad business decision, but that choice has been the foundation of its
|
||||
success.
|
||||
![open source button on keyboard][1]
|
||||
|
||||
It's always hard to recall exactly how a project started, but sometimes that can help you understand that project more clearly. When I think about it, our platform for creating user guides and documentation, [Dokit][2], came straight out of my childhood. Growing up in a house where my toys were Meccano and model airplane kits, the idea of making things, taking individual pieces and putting them together to create a new whole, was always a fundamental part of what it meant to play. My father worked for a DIY company, so there were always signs of building, repair, and instruction manuals around the house. When I was young, my parents sent me to join the Boy Scouts, where we made tables, tents and mud ovens, which helped foster my enjoyment of shared learning that I later found in the open source movement.
|
||||
|
||||
The art of repairing things and recycling products that I learned in childhood became part of what I did for a job. Then it became my ambition to take the reassuring feel of learning how to make and do and repair at home or in a group—but put it online. That inspired Dokit's creation.
|
||||
|
||||
### The first months
|
||||
|
||||
It hasn't always been easy, but since founding our company in 2017, I've realized that the biggest and most worthwhile goals are generally always difficult. If we were to achieve our plan to revolutionize the way [old-fashioned manuals and user guides are created and published][3], and maximize our impact in what we knew all along would be a niche market, we knew that a guiding mission was crucial to how we organized everything else. It was from there that we reached our first big decision: to [quickly launch a proof of concept using an existing open source framework][4], MediaWiki, and from there to release all of our code as open source.
|
||||
|
||||
In retrospect, this decision was made easier by the fact that [MediaWiki][5] was already up and running. With 15,000 developers already active around the world and on a platform that included 90% of the features we needed to meet our minimum viable product (MVP), things would have no doubt been harder without support from the engine that made its name by powering Wikipedia. Confluence, a documentation platform in use by many enterprises, offers some good features, but in the end, it was an easy choice between the two.
|
||||
|
||||
Placing our faith in the community, we put the first version of our platform straight onto GitHub. The excitement of watching the world's makers start using our platform, even before we'd done any real advertising, felt like an early indication that we were on the right track. Although the [maker and Fablab movements][6] encourage users to share instructions, and even sets out this expectation in the [Fablab charter][7] (as stated by MIT), in reality, there is a lack of real documentation.
|
||||
|
||||
The first and most significant reason people like using our platform is that it responds to the very real problem of poor documentation inside an otherwise great movement—one that we knew could be even better. To us, it felt a bit like we were repairing a gap in the community of makers and DIY. Within a year of our launch, Fablabs, [Wikifab][8], [Open Source Ecology][9], [Les Petits Debrouillards][10], [Ademe][11], and [Low-Tech Lab][12] had installed our tool on their servers for creating step-by-step tutorials.
|
||||
|
||||
Before even putting out a press release, one of our users, Wikifab, began to get praise in national media as "[the Wikipedia of DIY][13]." In just two years, we've seen hundreds of communities launched on their own Dokits, ranging from the fun to the funny to the more formal product guides. Again, the power of the community is the force we want to harness, and it's constantly amazing to see projects—ranging from wind turbines to pet feeders—develop engaging product manuals using the platform we started.
|
||||
|
||||
### Opening up open source
|
||||
|
||||
Looking back at such a successful first two years, it's clear to us that our choice to use open source was fundamental to how we got where we are as fast as we did. The ability to gather feedback in open source is second-to-none. If a piece of code didn't work, [someone could tell us right away][14]. Why wait on appointments with consultants if you can learn along with those who are already using the service you created?
|
||||
|
||||
The level of engagement from the community also revealed the potential (including the potential interest) in our market. [Paris has a good and growing community of developers][15], but open source took us from a pool of a few thousand locally, and brought us to millions of developers all around the world who could become a part of what we were trying to make happen. The open availability of our code also proved reassuring to our users and customers who felt safe that, even if our company went away, the code wouldn't.
|
||||
|
||||
If that was most of what we thought might happen as a result of using open source, there were also surprises along the way. By adopting an open method, we found ourselves gaining customers, reputation, and perfectly targeted advertising that we didn't have to pay for out of our limited startup budget. We found that the availability of our code helped improve our recruitment process because we were able to test candidates using our code before we made hires, and this also helped simplify the onboarding journey for those we did hire.
|
||||
|
||||
In what we see as a mixture of embarrassment and solidarity, the totally public nature of developers creating code in an open setting also helped drive up quality. People can share feedback with one another, but the public nature of the work also seems to encourage people to do their best. In the spirit of constant improvement and of continually building and rebuilding how Dokit works, supporting the community is something that we know we'd like to do more of and get better at in future.
|
||||
|
||||
### Where to next?
|
||||
|
||||
Even with the faith we've always had in what we were doing, and seeing the great product manuals that have been developed using our software, it never stops being exciting to see our project grow, and we're certain that the future has good things in store.
|
||||
|
||||
In the early days, we found ourselves living a lot under the fear of distributing our knowledge for free. In reality, it was the opposite—open source gave us the ability to very rapidly build a startup that was sustainable from the beginning. Dokit is a platform designed to give its users the confidence to build, assemble, repair, and create entirely new inventions with the support of a community. In hindsight, we found we were doing the same thing by using open source to build a platform.
|
||||
|
||||
Just like when doing a repair or assembling a physical product, it's only when you have confidence in your methods that things truly begin to feel right. Now, at the beginning of our third year, we're starting to see growing global interest as the industry responds to [new generations of customers who want to use, reuse, and assemble products][16] that respond to changing homes and lifestyles. By providing the support of an online community, we think we're helping to create circumstances in which people feel more confident in doing things for themselves.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/startups-release-code
|
||||
|
||||
作者:[Clément Flipo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cl%C3%A9ment-flipo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/button_push_open_keyboard_file_organize.png?itok=KlAsk1gx (open source button on keyboard)
|
||||
[2]: https://dokit.io/
|
||||
[3]: https://dokit.io/9-reasons-to-stop-writing-your-user-manuals-or-work-instructions-with-word-processors/
|
||||
[4]: https://medium.com/@gofloaters/5-cheap-ways-to-build-your-mvp-71d6170d5250
|
||||
[5]: https://en.wikipedia.org/wiki/MediaWiki
|
||||
[6]: https://en.wikipedia.org/wiki/Maker_culture
|
||||
[7]: http://fab.cba.mit.edu/about/charter/
|
||||
[8]: https://wikifab.org/
|
||||
[9]: https://www.opensourceecology.org/
|
||||
[10]: http://www.lespetitsdebrouillards.org/
|
||||
[11]: https://www.ademe.fr/en
|
||||
[12]: http://lowtechlab.org/
|
||||
[13]: https://www.20minutes.fr/magazine/economie-collaborative-mag/2428995-20160919-pour-construire-leurs-meubles-eux-memes-ils-creent-le-wikipedia-du-bricolage
|
||||
[14]: https://opensource.guide/how-to-contribute/
|
||||
[15]: https://www.rudebaguette.com/2013/03/here-are-the-details-on-the-new-developer-school-that-xavier-niel-is-launching-tomorrow/?lang=en
|
||||
[16]: https://www.inc.com/ari-zoldan/why-now-is-the-best-time-to-start-a-diy-home-based.html
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 essential values for the DevOps mindset)
|
||||
[#]: via: (https://opensource.com/article/19/5/values-devops-mindset)
|
||||
[#]: author: (Brent Aaron Reed https://opensource.com/users/brentaaronreed/users/wpschaub/users/wpschaub/users/wpschaub/users/cobiacomm/users/marcobravo/users/brentaaronreed)
|
||||
|
||||
5 essential values for the DevOps mindset
|
||||
======
|
||||
People and process take more time but are more important than any
|
||||
technology "silver bullet" in solving business problems.
|
||||
![human head, brain outlined with computer hardware background][1]
|
||||
|
||||
Many IT professionals today struggle with adapting to change and disruption. Are you struggling with just trying to keep the lights on, so to speak? Do you feel overwhelmed? This is not uncommon. Today, the status quo is not enough, so IT constantly tries to re-invent itself.
|
||||
|
||||
With over 30 years of combined IT experience, we have witnessed how important people and relationships are to IT's ability to be effective and help the business thrive. However, most of the time, our conversations about IT solutions start with technology rather than people and process. The propensity to look for a "silver bullet" to address business and IT challenges is far too common. But you can't just buy innovation, DevOps, or effective teams and ways of working; they need to be nurtured, supported, and guided.
|
||||
|
||||
With disruption so prevalent and there being such a critical demand for speed of change, we need both discipline and guardrails. The five essential values for the DevOps mindset, described below, will support the practices that will get us there. These values are not new ideas; they are refactored as we've learned from our experience. Some of the values may be interchangeable, they are flexible, and they guide overall principles that support (like a pillar) these five values.
|
||||
|
||||
![5 essential values for the DevOps mindset][2]
|
||||
|
||||
### 1\. Feedback from stakeholders is essential
|
||||
|
||||
How do we know if we are creating more value for us than for our stakeholders? We need persistent quality data to analyze, inform, and drive better decisions. Relevant information from trusted sources is vital for any business to thrive. We need to listen to and understand what our stakeholders are saying—and not saying—and we need to implement changes in a way that enables us to adjust our thinking—and our processes and technologies—and adapt them as needed to delight our stakeholders. Too often, we see little change, or lots of change for the wrong reasons, because of incorrect information (data). Therefore, aligning change to our stakeholders' feedback is an essential value and helps us focus on what is most important to making our company successful.
|
||||
|
||||
> Focus on our stakeholders and their feedback rather than simply changing for the sake of change.
|
||||
|
||||
### 2\. Improve beyond the limits of today's processes
|
||||
|
||||
We want our products and services to continuously delight our customers—our most important stakeholders—therefore, we need to improve continually. This is not only about quality; it could also mean costs, availability, relevance, and many other goals and factors. Creating repeatable processes or utilizing a common framework is great—they can improve governance and a host of other issues—however, that should not be our end goal. As we look for ways to improve, we must adjust our processes, complemented by the right tech and tools. There may be reasons to throw out a "so-called" framework because not doing so could add waste—or worse, simply "cargo culting" (doing something with of no value or purpose).
|
||||
|
||||
> Strive to always innovate and improve beyond repeatable processes and frameworks.
|
||||
|
||||
### 3\. No new silos to break down silos
|
||||
|
||||
Silos and DevOps are incompatible. We see this all the time: an IT director brings in so-called "experts" to implement agile and DevOps, and what do they do? These "experts" create a new problem on top of the existing problem, which is another silo added to an IT department and a business riddled with silos. Creating "DevOps" titles goes against the very principles of agile and DevOps, which are based on the concept of breaking down silos. In both agile and DevOps, teamwork is essential, and if you don't work in a self-organizing team, you're doing neither of them.
|
||||
|
||||
> Inspire and share collaboratively instead of becoming a hero or creating a silo.
|
||||
|
||||
### 4\. Knowing your customer means cross-organization collaboration
|
||||
|
||||
No part of the business is an independent entity because they all have stakeholders, and the primary stakeholder is always the customer. "The customer is always right" (or the king, as I like to say). The point is, without the customer, there really is no business, and to stay in business today, we need to "differentiate" from our competitors. We also need to know how our customers feel about us and what they want from us. Knowing what the customer wants is imperative and requires timely feedback to ensure the business addresses these primary stakeholders' needs and concerns quickly and responsibly.
|
||||
|
||||
![Minimize time spent with build-measure-learn process][3]
|
||||
|
||||
Whether it comes from an idea, a concept, an assumption, or direct stakeholder feedback, we need to identify and measure the feature or service our product delivers by using the explore, build, test, deliver lifecycle. Fundamentally, this means that we need to be "plugged into" our organization across the organization. There are no borders in continuous innovation, learning, and DevOps. Thus when we measure across the enterprise, we can understand the whole and take actionable, meaningful steps to improve.
|
||||
|
||||
> Measure performance across the organization, not just in a line of business.
|
||||
|
||||
### 5\. Inspire adoption through enthusiasm
|
||||
|
||||
Not everyone is driven to learn, adapt, and change; however, just like smiles can be infectious, so can learning and wanting to be part of a culture of change. Adapting and evolving within a culture of learning provides a natural mechanism for a group of people to learn and pass on information (i.e., cultural transmission). Learning styles, attitudes, methods, and processes continually evolve so we can improve upon them. The next step is to apply what was learned and improved and share the information with colleagues. Learning does not happen automatically; it takes effort, evaluation, discipline, awareness, and especially communication; unfortunately these are things that tools and automation alone will not provide. Review your processes, automation, tool strategies, and implementation work, make it transparent, and collaborate with your colleagues on reuse and improvement.
|
||||
|
||||
> Promote a culture of learning through lean quality deliverables, not just tools and automation.
|
||||
|
||||
### Summary
|
||||
|
||||
![Continuous goals of DevOps mindset][4]
|
||||
|
||||
As our companies adopt DevOps, we continue to champion these five values over any book, website, or automation software. It takes time to adopt this mindset, and this is very different than what we used to do as sysadmins. It's a wholly new way of working that will take many years to mature. Do these principles align with your own? Share them in the comments or on our website, [Agents of chaos][5].
|
||||
|
||||
* * *
|
||||
|
||||
Can you really do DevOps without sharing scripts or code? DevOps manifesto proponents value cross-...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/values-devops-mindset
|
||||
|
||||
作者:[Brent Aaron Reed][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brentaaronreed/users/wpschaub/users/wpschaub/users/wpschaub/users/cobiacomm/users/marcobravo/users/brentaaronreed
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/brain_data.png?itok=RH6NA32X (human head, brain outlined with computer hardware background)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/devops_mindset_values.png (5 essential values for the DevOps mindset)
|
||||
[3]: https://opensource.com/sites/default/files/uploads/devops_mindset_minimze-time.jpg (Minimize time spent with build-measure-learn process)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/devops_mindset_continuous.png (Continuous goals of DevOps mindset)
|
||||
[5]: http://agents-of-chaos.org
|
||||
@ -0,0 +1,138 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A day in the life of an open source performance engineering team)
|
||||
[#]: via: (https://opensource.com/article/19/5/life-performance-engineer)
|
||||
[#]: author: (Aakarsh Gopi https://opensource.com/users/aakarsh/users/portante/users/anaga/users/gameloid)
|
||||
|
||||
A day in the life of an open source performance engineering team
|
||||
======
|
||||
Collaborating with the community enables performance engineering to
|
||||
address the confusion and complexity that come with working on a broad
|
||||
spectrum of products.
|
||||
![Team checklist and to dos][1]
|
||||
|
||||
In today's world, open source software solutions are a collaborative effort of the community. Can a performance engineering team operate the same way, by collaborating with the community to address the confusion and complexity that come with working on a broad spectrum of products?
|
||||
|
||||
To answer that question, we need to explore some basic questions:
|
||||
|
||||
* What does a performance engineering team do?
|
||||
* How does a performance engineering team fulfill its responsibilities?
|
||||
* How are open source tools developed or leveraged for performance analysis?
|
||||
|
||||
|
||||
|
||||
The term "performance engineering" has different meanings, which causes difficulty in figuring out a performance engineering team's responsibilities. Adding to the confusion, a team may be charged with working on a broad spectrum of products, ranging from an operating system like RHEL, whose performance can be significantly impacted by hardware components (CPU caches, network interface controllers, disk technologies, etc.), to something much higher up in the stack like Kubernetes, which comes with the added challenges of operating at scale without compromising on performance.
|
||||
|
||||
Performance engineering has progressed a lot since the days of running manual A/B testing and single-system benchmarks. Now, these teams test cloud infrastructures and add machine learning classifiers as a component in the CI/CD pipeline for identifying performance regression in releases of products.
|
||||
|
||||
### What does a performance engineering team do?
|
||||
|
||||
A performance engineering team is generally responsible for the following (among other things):
|
||||
|
||||
* Identifying potential performance issues
|
||||
* Identifying any scale issues that could occur
|
||||
* Developing tuning guides and/or tools that would enable the user to achieve the most out of a product
|
||||
* Developing guides and/or working with customers to help with capacity planning
|
||||
* Providing customers with performance expectations for different use cases of the product
|
||||
|
||||
|
||||
|
||||
The mission of our specific team is to:
|
||||
|
||||
* Establish performance and scale leadership of the Red Hat portfolio; the scope includes component level, system, and solution analysis
|
||||
* Collaborate with engineering, product management, product marketing, and Customer Experience and Engagement (CEE), as well as hardware and software partners
|
||||
* Deliver public-facing guidance, internal enablement, and continuous integration tests
|
||||
|
||||
|
||||
|
||||
Our team fulfills our mission in the following ways:
|
||||
|
||||
* We work with product teams to set performance goals and develop performance tests to run against those products deployed to see how they measure up to those goals.
|
||||
* We also work to re-run performance tests to ensure there are no regressions in behaviors.
|
||||
* We develop open source tooling to achieve our product performance goals, making them available to the communities where the products are derived to re-create what we do.
|
||||
* We work to be transparent and open about how we do performance engineering; sharing these methods and approaches benefits communities, allowing them to reuse our work, and benefits us by leveraging the work they contribute with these tools.
|
||||
|
||||
|
||||
|
||||
### How does a performance engineering team fulfill its responsibilities?
|
||||
|
||||
Meeting these responsibilities requires collaboration with other teams, such as product management, development, QA/QE, documentation, and consulting, and with the communities.
|
||||
|
||||
_Collaboration_ allows a team to be successful by pulling together team members' diverse knowledge and experience. A performance engineering team builds tools to share their knowledge both within the team and with the community, furthering the value of collaboration.
|
||||
|
||||
Our performance engineering team achieves success through:
|
||||
|
||||
* **Collaboration:** _Intra_ -team collaboration is as important as _inter_ -team collaboration for our performance engineering team
|
||||
* Most performance engineers tend to create a niche for themselves in one or more sub-disciplines of performance engineering via tooling, performance analysis, systems knowledge, systems configuration, and such. Our team is composed of engineers with knowledge of setting up/configuring systems across the product stack, those who know how a configuration option would affect the system's performance, and so on. Our team's success is heavily reliant on effective collaboration between performance engineers on the team.
|
||||
* Our team works closely with other organizations at various levels within Red Hat and the communities where our products are derived.
|
||||
* **Knowledge:** To understand the performance implications of configuration and/or system changes, deep knowledge of the product alone is not sufficient.
|
||||
* Our team has the knowledge to cover performance across all levels of the stack:
|
||||
* Hardware setup and configuration
|
||||
* Networking and scale considerations
|
||||
* Operating system setup and configuration (Linux kernel, userspace stack)
|
||||
* Storage sub-systems (Ceph)
|
||||
* Cloud infrastructure (OpenStack, RHV)
|
||||
* Cloud deployments (OpenShift/Kubernetes)
|
||||
* Product architectures
|
||||
* Software technologies (databases like Postgres; software-defined networking and storage)
|
||||
* Product interactions with the underlying hardware
|
||||
* Tooling to monitor and accomplish repeatable benchmarking
|
||||
* **Tooling:** The differentiator for our performance engineering team is the data collected through its tools to help tackle performance analysis complexity in the environments where our products are deployed.
|
||||
|
||||
|
||||
|
||||
### How are open source tools developed or leveraged for performance analysis?
|
||||
|
||||
Tooling is no longer a luxury but a need for today's performance engineering teams. With today's product solutions being so complex (and increasing in complexity as more solutions are composed to solve ever-larger problems), we need tools to help us run performance test suites in a repeatable manner, collect data about those runs, and help us distill that data so it becomes understandable and usable.
|
||||
|
||||
Yet, no performance engineering team is judged on how performance analysis is done, but rather on the results achieved from this analysis.
|
||||
|
||||
This tension can be resolved by collaboratively developing tools. A performance engineering team can't spend all its time developing tools, since that would prevent it from effectively collecting data. By developing its tools in a collaborative manner, a team can leverage work from the community to make further progress while still generating the result by which they will be measured.
|
||||
|
||||
Tooling is the backbone of our performance engineering team, and we strive to use the tools already available upstream. When no tools are available in the community that fit our needs, we've built tools that help us achieve our goals and made them available to the community. Open sourcing our tools has helped us immensely because we receive contributions from our competitors and partners, allowing us to solve problems collectively through collaboration.
|
||||
|
||||
![Performance Engineering Tools][2]
|
||||
|
||||
Following are some of the tools our team has contributed to and rely upon for our work:
|
||||
|
||||
* **[Perf-c2c][3]:** Is your performance impacted by false sharing in CPU caches? The perf-c2c tool can help you tackle this problem by helping you inspect the cache lines where false sharing is detected and understand the readers/writers accessing those cache lines along with the offsets where those accesses occurred. You can read more about this tool on [Joe Mario's blog][4].
|
||||
* **[Pbench][5]:** Do you repeat the same steps when collecting data about performance, but fail to do it consistently? Or do you find it difficult to compare results with others because you're collecting different configuration data? Pbench is a tool that attempts to standardize the way data is collected for performance so comparisons and historical reviews are much easier. Pbench is at the heart of our tooling efforts, as most of the other tools consume it in some form. Pbench is a Swiss Army Knife, as it allows the user to run benchmarks such as fio, uperf, or custom, user-defined tests while gathering metrics through tools such as sar, iostat, and pidstat, standardizing the methods of collecting configuration data about the environment. Pbench provides a dashboard UI to help review and analyze the data collected.
|
||||
* **[Browbeat][6]:** Do you want to monitor a complex environment such as an OpenStack cluster while running tests? Browbeat is the solution, and its power lies in its ability to collect comprehensive data, ranging from logs to system metrics, about an OpenStack cluster while it orchestrates workloads. Browbeat can also monitor the OpenStack cluster while users run test/workloads of their choice either manually or through their own automation.
|
||||
* **[Ripsaw][7]:** Do you want to compare the performance of different Kubernetes distros against the same platform? Do you want to compare the performance of the same Kubernetes distros deployed on different platforms? Ripsaw is a relatively new tool created to run workloads through Kubernetes native calls using the Ansible operator framework to provide solutions to the above questions. Ripsaw's unique selling point is that it can run against any kind of Kubernetes distribution, thus it would run the same against a Kubernetes cluster, on Minikube, or on an OpenShift cluster deployed on OpenStack or bare metal.
|
||||
* **[ClusterLoader][8]:** Ever wondered how an OpenShift component would perform under different cluster states? If you are looking for an answer that can stress the cluster, ClusterLoader will help. The team has generalized the tool so it can be used with any Kubernetes distro. It is currently hosted in the [perf-tests repository][9].
|
||||
|
||||
|
||||
|
||||
### Bottom line
|
||||
|
||||
Given the scale at which products are evolving rapidly, performance engineering teams need to build tooling to help them keep up with products' evolution and diversification.
|
||||
|
||||
Open source-based software solutions are a collaborative effort of the community. Our performance engineering team operates in the same way, collaborating with the community to address the confusion and complexity that comes with working on a broad spectrum of products. By developing our tools in a collaborative manner and using tools from the community, we are leveraging the community's work to make progress, while still generating the results we are measured on.
|
||||
|
||||
_Collaboration_ is our key to accomplish our goals and ensure the success of our team.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/life-performance-engineer
|
||||
|
||||
作者:[Aakarsh Gopi ][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/aakarsh/users/portante/users/anaga/users/gameloid
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/todo_checklist_team_metrics_report.png?itok=oB5uQbzf (Team checklist and to dos)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/performanceengineeringtools.png (Performance Engineering Tools)
|
||||
[3]: http://man7.org/linux/man-pages/man1/perf-c2c.1.html
|
||||
[4]: https://joemario.github.io/blog/2016/09/01/c2c-blog/
|
||||
[5]: https://github.com/distributed-system-analysis/pbench
|
||||
[6]: https://github.com/openstack/browbeat
|
||||
[7]: https://github.com/cloud-bulldozer/ripsaw
|
||||
[8]: https://github.com/openshift/origin/tree/master/test/extended/cluster
|
||||
[9]: https://github.com/kubernetes/perf-tests/tree/master/clusterloader
|
||||
@ -0,0 +1,162 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Query freely available exchange rate data with ExchangeRate-API)
|
||||
[#]: via: (https://opensource.com/article/19/5/exchange-rate-data)
|
||||
[#]: author: (Chris Hermansen https://opensource.com/users/clhermansen)
|
||||
|
||||
Query freely available exchange rate data with ExchangeRate-API
|
||||
======
|
||||
In this interview, ExchangeRate-API's founder explains why exchange rate
|
||||
data should be freely accessible to developers who want to build useful
|
||||
stuff.
|
||||
![scientific calculator][1]
|
||||
|
||||
Last year, [I wrote about][2] using the Groovy programming language to access foreign exchange rate data from an API to simplify my expense records. I showed how two exchange rate sites, [fixer.io][3] and apilayer.net (now [apilayer.com][4]), could provide the data I needed, allowing me to convert between Indian rupees (INR) and Canadian dollars (CAD) using the former, and Chilean pesos (CLP) and Canadian dollars using the latter.
|
||||
|
||||
Recently, David over at [ExchangeRate-API.com][5] reached out to me to say, "the free API you mentioned (Fixer) has been bought by CurrencyLayer and had its no-signup/unlimited access deprecated." He also told me, "I run a free API called ExchangeRate-API.com that has the same JSON format as the original Fixer, doesn't require any signup, and allows unlimited requests."
|
||||
|
||||
After exchanging a few emails, we decided to turn our conversation into an interview. Below the interview, you can find scripts and usage instructions. (The interview has been edited slightly for clarity.)
|
||||
|
||||
### About ExchangeRate-API
|
||||
|
||||
_**Chris:** How is ExchangeRate-API different from other online exchange-rate services? What motivates you to provide this service?_
|
||||
|
||||
**David:** When I started ExchangeRate-API with a friend in 2010, we built and released it for free because we really needed this service for another project and couldn't find one despite extensive googling. There are now around 20 such APIs offering quite a few different approaches. Over the years, I've tried a number of different approaches, but offering quality data for free has always proven the most popular. I'm also motivated by the thought that this data should be freely accessible to developers who want to build useful stuff even if they don't have a budget.
|
||||
|
||||
Thus, the main difference with our currency conversion API is that it's unlimited and requires no signup. This also makes starting to use it really fast—you literally just copy the endpoint URL and you're good to go.
|
||||
|
||||
There are one or two other free and unlimited APIs, but these typically just serve the daily reference rates provided by the European Central Bank. ExchangeRate-API collects the public reference rates from a number of central banks and then blends them to reduce the risk of outlying values. It also does acceptance checking to ensure the rates aren't wildly wrong (for instance an inverted data capture recording US dollars to CLP instead of CLP to USD) and weights different sources based on their historical accuracy. This makes the service quite reliable. I'm currently working on a transparency project to compare and show the accuracy of this public reference rate blend against a proprietary data source so potential users can make more informed decisions on what type of currency data service is right for them.
|
||||
|
||||
_**Chris:** I'm delighted that you've included Canadian dollars and Indian rupees, as that is one problem I need to solve. I'm sad to see that you don't have Chilean pesos (another problem I need to solve). Can you tell us how you select the list of currencies? Do you anticipate adding other currencies to your list?_
|
||||
|
||||
**David:** Since my main aim for this service is to offer stable and reliable exchange rate data, I only include currencies when there is more than one data source for that currency code. For instance, after you mentioned that you're looking for CLP data, I added the daily reference rates published by the Central Bank of Chile to our system. If I can find another source that includes CLP, it would be included in our list of supported currencies, but until then, unfortunately not. The goal is to support as many currencies as possible.
|
||||
|
||||
One thing to note is that, for some currencies, the service has the minimum two sources, but a few currency pairs (for instance USD/EUR) are included in almost every set of public reference rates. The transparent accuracy project I mentioned will hopefully make this difference clear so that users can understand why our USD/EUR rate might be more accurate than less common pairs like CLP/INR and also the degree of variance in accuracy between the pairs. It will take some work to make showing this information quick and easy to understand.
|
||||
|
||||
### The API's architecture
|
||||
|
||||
_**Chris:** Can you tell us a bit about your API's architecture? Do you use open source components to deliver your service?_
|
||||
|
||||
**David:** I exclusively use open source software to run ExchangeRate-API. I'm definitely an open source enthusiast and am always getting friends to switch to open source, explaining licenses, and donating when I can to the projects I use most. I also try to email maintainers of projects I use to say thanks, but I don't do this enough.
|
||||
|
||||
The stack is currently Ubuntu LTS, MariaDB, Nginx, PHP 7, and Memcached. I also use Bootstrap and Picnic open source CSS frameworks. I use Let's Encrypt for HTTPS certificates via the Electronic Frontier Foundation's open source ACME client, [Certbot][6]. The service makes extensive use of classic tools like UFW/iptables, cURL, OpenSSH, and Git.
|
||||
|
||||
My approach is typically to keep everything as simple as possible while using the tried-and-tested open source building blocks. For a project that aims to _always_ be available for users to convert currencies, this feels like the best route to reliability. I love reading about innovative new projects that could be useful for a project like this (for example, CockroachDB), but I wouldn't use them until they are considered really bulletproof. Obviously, things like [Heartbleed][7] show that there are risks with "boring" projects too—but I think these are easier to manage than the potential for unknown risks with newer, cutting-edge projects.
|
||||
|
||||
In terms of the infrastructure setup, I've steadily built and improved the system over the last nine years, and it now comprises roughly three tiers. The main cluster runs on Amazon Web Services (AWS) and consists of Ubuntu EC2 servers and a high-availability MariaDB relational database service (RDS) instance. The EC2 instances are spread across multiple AWS Availability Zones and fronted by the managed AWS Elastic Load Balancing (ELB) service. Between the RDS database instance with automated cross-zone failover and the ELB-fronted EC2 instances spread across availability zones, this setup is exceptionally available. It is, however, only in one locale. So I've set up a second tier of virtual private server (VPS) instances in different geographic locations to reduce latency and distribute the load away from the more expensive AWS infrastructure. These are currently with Linode, but I have also used DigitalOcean and Vultr recently.
|
||||
|
||||
Finally, this is all protected behind Cloudflare. With a free service, it's inevitable that some users will choose to abuse the system, and Cloudflare is an amazing product that's vital to ExchangeRate-API. Our servers can be protected and our users get low-latency, in-region caches. Cloudflare is set up with both the load balancing and traffic steering products to reduce latency and instantly shift traffic from unhealthy parts of the infrastructure to available origins.
|
||||
|
||||
With this very redundant approach, there hasn't been downtime as a result of infrastructure problems or user load for around three years. The few periods of degraded service experienced in this time are all due to issues with code, deployment strategy, or config mistakes. The setup currently handles hundreds of millions of requests per month with low load levels and manageable costs, so there's plenty of room for growth.
|
||||
|
||||
The actual application code is PHP with heavy use of Memcached. Memcached is an amazing open source project started by Brad Fitzpatrick in 2003. It's not particularly glamorous, but it is an incredibly reliable and performant distributed in-memory key value store.
|
||||
|
||||
### Engaging with the open source community
|
||||
|
||||
_**Chris:** There is an impressive amount of open source in your configuration. How do you engage with the broader community of users in these projects?_
|
||||
|
||||
**David:** I really struggle with the best way to be a good open source citizen while running a side project SaaS. I've considered building an open source library of some sort and releasing it, but I haven't thought of something that hasn't already been done and that I would be able to make the time commitment to reliably maintain. I'd only start a project like this if I could be confident I'd have the time to ensure users who choose the project wouldn't suddenly find themselves depending on abandonware. I've also looked into contributing to the projects that ExchangeRate-API depends on, but since I only use the biggest, most established options, I lack the expertise to make a meaningful contribution to such serious projects.
|
||||
|
||||
I'm currently working on a new "Pro" plan for the service and I'm going to set a percentage of this income to donate to my open source dependencies. This still feels like a bandage though—answering this question makes me realize I need to put more time into starting an open source project that calls ExchangeRate-API home!
|
||||
|
||||
### Looking ahead
|
||||
|
||||
_**Chris:** We can only query the latest exchange rate, but it appears that you may be offering historical rates sometime later this year. Can you tell us more about the technical challenges with serving up historical data?_
|
||||
|
||||
**David:** There is a dataset of historical rates blended using our same algorithm from multiple central bank reference sets. However, I stopped new signups for it due to some issues with the data quality. The dataset reaches back to 1990, and there were a few earlier periods that need better data validation. As such, I'm building a better system for checking and comparing the data as it's ingested as well as adding an additional data source. The plan is to have a clean and more comprehensively verified-as-accurate dataset available later this year.
|
||||
|
||||
In terms of the technical side of things, historical data is slightly more complex than live data. Compared to the live dataset (which is just a few bytes) the historical data is millions of database rows. This data was originally served from the database infrastructure with a long time-to-live (TTL) intermediary-caching layer. This was largely performant but struggled in situations where users wanted to dump the entire dataset as fast as the network could handle it. If the cache was sufficiently warm, this was fine, but if reboots, new server deployments, etc. had taken place recently, these big request sets would "miss" enough on the cache that the database would have problematic load spikes.
|
||||
|
||||
Obviously, the goal is an infrastructure that can handle even aggressive use cases with normal performance, so the new historical rates dataset will be accompanied by a preemptive in-memory cache rather than a request-driven one. Thankfully, RAM is cheap these days, and putting a couple hundred megabytes of data entirely into RAM is a plausible approach even for a small project like ExchangeRate-API.com.
|
||||
|
||||
_**Chris:** It sounds like you've been through quite a few iterations of this service to get to where it is today! Where do you see it going in the next few years?_
|
||||
|
||||
**David:** I'd aim for it to have reached coverage of every world currency so that anyone looking for this sort of software can easily and programmatically get the exchange rates they need for free.
|
||||
|
||||
I'd also definitely like to have an affordable Pro plan that really resonates with users. Getting this right would mean better infrastructure and lower latency for free users as well.
|
||||
|
||||
Finally, I'd like to have some sort of useful open source library under the ExchangeRate-API banner. Starting a small project that finds an enthusiastic community would be really rewarding. It's great to run something that's free-as-in-beer, but it would be even better if part of it was free-as-in-speech, as well.
|
||||
|
||||
### How to use the service
|
||||
|
||||
It's easy enough to test out the service using **wget** , as follows:
|
||||
|
||||
|
||||
```
|
||||
clh@marseille:~$ wget -O - <https://api.exchangerate-api.com/v4/latest/INR>
|
||||
\--2019-04-26 13:48:23-- <https://api.exchangerate-api.com/v4/latest/INR>
|
||||
Resolving api.exchangerate-api.com (api.exchangerate-api.com)... 2606:4700:20::681a:c80, 2606:4700:20::681a:d80, 104.26.13.128, ...
|
||||
Connecting to api.exchangerate-api.com (api.exchangerate-api.com)|2606:4700:20::681a:c80|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: unspecified [application/json]
|
||||
Saving to: ‘STDOUT’
|
||||
|
||||
\- [<=>
|
||||
] 0 --.-KB/s {"base":"INR","date":"2019-04-26","time_last_updated":1556236800,"rates":{"INR":1,"AUD":0.020343,"BRL":0.056786,"CAD":0.019248,"CHF":0.014554,"CNY":0.096099,"CZK":0.329222,"DKK":0.095497,"EUR":0.012789,"GBP":0.011052,"HKD":0.111898,"HUF":4.118615,"IDR":199.61769,"ILS":0.051749,"ISK":1.741659,"JPY":1.595527,"KRW":16.553091,"MXN":0.272383,"MYR":0.058964,"NOK":0.123365,"NZD":0.02161,"PEN":0.047497,"PHP":0.744974,"PLN":0.054927,"RON":0.060923,"RUB":0.921808,"SAR":0.053562,"SEK":0.135226,"SGD":0.019442,"THB":0.457501,"TRY":0- [ <=> ] 579 --.-KB/s in 0s
|
||||
|
||||
2019-04-26 13:48:23 (15.5 MB/s) - written to stdout [579]
|
||||
|
||||
clh@marseille:~$
|
||||
```
|
||||
|
||||
The result is returned as a JSON payload, giving conversion rates from Indian rupees (the currency I requested in the URL) to all the currencies handled by ExchangeRate-API.
|
||||
|
||||
The Groovy shell can access the API:
|
||||
|
||||
|
||||
```
|
||||
clh@marseille:~$ groovysh
|
||||
Groovy Shell (2.5.3, JVM: 1.8.0_212)
|
||||
Type ':help' or ':h' for help.
|
||||
\----------------------------------------------------------------------------------------------------------------------------------
|
||||
groovy:000> import groovy.json.JsonSlurper
|
||||
===> groovy.json.JsonSlurper
|
||||
groovy:000> result = (new JsonSlurper()).parse(
|
||||
groovy:001> new InputStreamReader((new URL('<https://api.exchangerate-api.com/v4/latest/INR')).newInputStream(>))
|
||||
groovy:002> )
|
||||
===> [base:INR, date:2019-04-26, time_last_updated:1556236800, rates:[INR:1, AUD:0.020343, BRL:0.056786, CAD:0.019248, CHF:0.014554, CNY:0.096099, CZK:0.329222, DKK:0.095497, EUR:0.012789, GBP:0.011052, HKD:0.111898, HUF:4.118615, IDR:199.61769, ILS:0.051749, ISK:1.741659, JPY:1.595527, KRW:16.553091, MXN:0.272383, MYR:0.058964, NOK:0.123365, NZD:0.02161, PEN:0.047497, PHP:0.744974, PLN:0.054927, RON:0.060923, RUB:0.921808, SAR:0.053562, SEK:0.135226, SGD:0.019442, THB:0.457501, TRY:0.084362, TWD:0.441385, USD:0.014255, ZAR:0.206271]]
|
||||
groovy:000>
|
||||
```
|
||||
|
||||
The same JSON payload is returned as a result of the Groovy JSON slurper operating on the URL. Of course, since this is Groovy, the JSON is converted into a Map, so you can do stuff like this:
|
||||
|
||||
|
||||
```
|
||||
groovy:000> println result.base
|
||||
INR
|
||||
===> null
|
||||
groovy:000> println result.date
|
||||
2019-04-26
|
||||
===> null
|
||||
groovy:000> println result.rates.CAD
|
||||
0.019248
|
||||
===> null
|
||||
```
|
||||
|
||||
And that's it!
|
||||
|
||||
Do you use ExchangeRate-API or a similar service? Share how you use exchange rate data in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/exchange-rate-data
|
||||
|
||||
作者:[Chris Hermansen ][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calculator_money_currency_financial_tool.jpg?itok=2QMa1y8c (scientific calculator)
|
||||
[2]: https://opensource.com/article/18/3/groovy-calculate-foreign-exchange
|
||||
[3]: https://fixer.io/
|
||||
[4]: https://apilayer.com/
|
||||
[5]: https://www.exchangerate-api.com/
|
||||
[6]: https://certbot.eff.org/
|
||||
[7]: https://en.wikipedia.org/wiki/Heartbleed
|
||||
@ -0,0 +1,96 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 open source hardware products for the great outdoors)
|
||||
[#]: via: (https://opensource.com/article/19/5/hardware-outdoors)
|
||||
[#]: author: (Michael Weinberg https://opensource.com/users/mweinberg/users/aliciagibb)
|
||||
|
||||
5 open source hardware products for the great outdoors
|
||||
======
|
||||
Here's some equipment you can buy or make yourself for hitting the great
|
||||
outdoors, no generators or batteries required.
|
||||
![Tree clouds][1]
|
||||
|
||||
When people think about open source hardware, they often think about the general category of electronics that can be soldered and needs batteries. While there are [many][2] fantastic open source pieces of electronics, the overall category of open source hardware is much broader. This month we take a look at open source hardware that you can take out into the world, no power outlet or batteries required.
|
||||
|
||||
### Hummingbird Hammocks
|
||||
|
||||
[Hummingbird Hammocks][3] offers an entire line of open source camping gear. You can set up an open source [rain tarp][4]...
|
||||
|
||||
![An open source rain tarp from Hummingbird Hammocks][5]
|
||||
|
||||
...with open source [friction adjusters][6]
|
||||
|
||||
![Open source friction adjusters from Hummingbird Hammocks.][7]
|
||||
|
||||
Open source friction adjusters from Hummingbird Hammocks.
|
||||
|
||||
...over your open source [hammock][8]
|
||||
|
||||
![An open source hammock from Hummingbird Hammocks.][9]
|
||||
|
||||
An open source hammock from Hummingbird Hammocks.
|
||||
|
||||
...hung with open source [tree straps][10].
|
||||
|
||||
![Open source tree straps from Hummingbird Hammocks.][11]
|
||||
|
||||
Open source tree straps from Hummingbird Hammocks.
|
||||
|
||||
The design for each of these items is fully documented, so you can even use them as a starting point for making your own outdoor gear (if you are willing to trust friction adjusters you design yourself).
|
||||
|
||||
### Openfoil
|
||||
|
||||
[Openfoil][12] is an open source hydrofoil for kitesurfing. Hydrofoils are attached to the bottom of kiteboards and allow the rider to rise out of the water. This aspect of the design makes riding in low wind situations and with smaller kites easier. It can also reduce the amount of noise the board makes on the water, making for a quieter experience. Because this hydrofoil is open source you can customize it to your needs and adventure tolerance.
|
||||
|
||||
![Openfoil, an open source hydrofoil for kitesurfing.][13]
|
||||
|
||||
Openfoil, an open source hydrofoil for kitesurfing.
|
||||
|
||||
### Solar water heater
|
||||
|
||||
If you prefer your outdoors-ing a bit closer to home, you could build this open source [solar water heater][14] created by the [Anisa Foundation][15]. This appliance focuses energy from the sun to heat water that can then be used in your home, letting you reduce your carbon footprint without having to give up long, hot showers. Of course, you can also [monitor its temperature ][16]over the internet if you need to feel connected.
|
||||
|
||||
![An open source solar water heater from the Anisa Foundation.][17]
|
||||
|
||||
An open source solar water heater from the Anisa Foundation.
|
||||
|
||||
## Wrapping up
|
||||
|
||||
As these projects make clear, open source hardware is more than just electronics. You can take it with you to the woods, to the beach, or just to your roof. Next month we’ll talk about open source instruments and musical gear. Until then, [certify][18] your open source hardware!
|
||||
|
||||
Learn how and why you may want to start using the Open Source Hardware Certification logo on an...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/hardware-outdoors
|
||||
|
||||
作者:[Michael Weinberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mweinberg/users/aliciagibb
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life_tree_clouds.png?itok=b_ftihhP (Tree clouds)
|
||||
[2]: https://certification.oshwa.org/list.html
|
||||
[3]: https://hummingbirdhammocks.com/
|
||||
[4]: https://certification.oshwa.org/us000102.html
|
||||
[5]: https://opensource.com/sites/default/files/uploads/01-hummingbird_hammocks_rain_tarp.png (An open source rain tarp from Hummingbird Hammocks)
|
||||
[6]: https://certification.oshwa.org/us000105.html
|
||||
[7]: https://opensource.com/sites/default/files/uploads/02-hummingbird_hammocks_friction_adjusters_400_px.png (Open source friction adjusters from Hummingbird Hammocks.)
|
||||
[8]: https://certification.oshwa.org/us000095.html
|
||||
[9]: https://opensource.com/sites/default/files/uploads/03-hummingbird_hammocks_hammock_400_px.png (An open source hammock from Hummingbird Hammocks.)
|
||||
[10]: https://certification.oshwa.org/us000098.html
|
||||
[11]: https://opensource.com/sites/default/files/uploads/04-hummingbird_hammocks_tree_straps_400_px_0.png (Open source tree straps from Hummingbird Hammocks.)
|
||||
[12]: https://certification.oshwa.org/fr000004.html
|
||||
[13]: https://opensource.com/sites/default/files/uploads/05-openfoil-original_size.png (Openfoil, an open source hydrofoil for kitesurfing.)
|
||||
[14]: https://certification.oshwa.org/mx000002.html
|
||||
[15]: http://www.fundacionanisa.org/index.php?lang=en
|
||||
[16]: https://thingspeak.com/channels/72565
|
||||
[17]: https://opensource.com/sites/default/files/uploads/06-solar_water_heater_500_px.png (An open source solar water heater from the Anisa Foundation.)
|
||||
[18]: https://certification.oshwa.org/
|
||||
432
sources/tech/20190510 Check storage performance with dd.md
Normal file
432
sources/tech/20190510 Check storage performance with dd.md
Normal file
@ -0,0 +1,432 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Check storage performance with dd)
|
||||
[#]: via: (https://fedoramagazine.org/check-storage-performance-with-dd/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
Check storage performance with dd
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
This article includes some example commands to show you how to get a _rough_ estimate of hard drive and RAID array performance using the _dd_ command. Accurate measurements would have to take into account things like [write amplification][2] and [system call overhead][3], which this guide does not. For a tool that might give more accurate results, you might want to consider using [hdparm][4].
|
||||
|
||||
To factor out performance issues related to the file system, these examples show how to test the performance of your drives and arrays at the block level by reading and writing directly to/from their block devices. **WARNING** : The _write_ tests will destroy any data on the block devices against which they are run. **Do not run them against any device that contains data you want to keep!**
|
||||
|
||||
### Four tests
|
||||
|
||||
Below are four example dd commands that can be used to test the performance of a block device:
|
||||
|
||||
1. One process reading from $MY_DISK:
|
||||
|
||||
```
|
||||
# dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache
|
||||
```
|
||||
|
||||
2. One process writing to $MY_DISK:
|
||||
|
||||
```
|
||||
# dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct
|
||||
```
|
||||
|
||||
3. Two processes reading concurrently from $MY_DISK:
|
||||
|
||||
```
|
||||
# (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache &); (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache skip=200 &)
|
||||
```
|
||||
|
||||
4. Two processes writing concurrently to $MY_DISK:
|
||||
|
||||
```
|
||||
# (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct &); (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct skip=200 &)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
– The _iflag=nocache_ and _oflag=direct_ parameters are important when performing the read and write tests (respectively) because without them the dd command will sometimes show the resulting speed of transferring the data to/from [RAM][5] rather than the hard drive.
|
||||
|
||||
– The values for the _bs_ and _count_ parameters are somewhat arbitrary and what I have chosen should be large enough to provide a decent average in most cases for current hardware.
|
||||
|
||||
– The _null_ and _zero_ devices are used for the destination and source (respectively) in the read and write tests because they are fast enough that they will not be the limiting factor in the performance tests.
|
||||
|
||||
– The _skip=200_ parameter on the second dd command in the concurrent read and write tests is to ensure that the two copies of dd are operating on different areas of the hard drive.
|
||||
|
||||
### 16 examples
|
||||
|
||||
Below are demonstrations showing the results of running each of the above four tests against each of the following four block devices:
|
||||
|
||||
1. MY_DISK=/dev/sda2 (used in examples 1-X)
|
||||
2. MY_DISK=/dev/sdb2 (used in examples 2-X)
|
||||
3. MY_DISK=/dev/md/stripped (used in examples 3-X)
|
||||
4. MY_DISK=/dev/md/mirrored (used in examples 4-X)
|
||||
|
||||
|
||||
|
||||
A video demonstration of the these tests being run on a PC is provided at the end of this guide.
|
||||
|
||||
Begin by putting your computer into _rescue_ mode to reduce the chances that disk I/O from background services might randomly affect your test results. **WARNING** : This will shutdown all non-essential programs and services. Be sure to save your work before running these commands. You will need to know your _root_ password to get into rescue mode. The _passwd_ command, when run as the root user, will prompt you to (re)set your root account password.
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
# passwd
|
||||
# setenforce 0
|
||||
# systemctl rescue
|
||||
```
|
||||
|
||||
You might also want to temporarily disable logging to disk:
|
||||
|
||||
```
|
||||
# sed -r -i.bak 's/^#?Storage=.*/Storage=none/' /etc/systemd/journald.conf
|
||||
# systemctl restart systemd-journald.service
|
||||
```
|
||||
|
||||
If you have a swap device, it can be temporarily disabled and used to perform the following tests:
|
||||
|
||||
```
|
||||
# swapoff -a
|
||||
# MY_DEVS=$(mdadm --detail /dev/md/swap | grep active | grep -o "/dev/sd.*")
|
||||
# mdadm --stop /dev/md/swap
|
||||
# mdadm --zero-superblock $MY_DEVS
|
||||
```
|
||||
|
||||
#### Example 1-1 (reading from sda)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||
# dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.7003 s, 123 MB/s
|
||||
```
|
||||
|
||||
#### Example 1-2 (writing to sda)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||
# dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67117 s, 125 MB/s
|
||||
```
|
||||
|
||||
#### Example 1-3 (reading concurrently from sda)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||
# (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache &); (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache skip=200 &)
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.42875 s, 61.2 MB/s
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.52614 s, 59.5 MB/s
|
||||
```
|
||||
|
||||
#### Example 1-4 (writing concurrently to sda)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 1)
|
||||
# (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct &); (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct skip=200 &)
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.2435 s, 64.7 MB/s
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.60872 s, 58.1 MB/s
|
||||
```
|
||||
|
||||
#### Example 2-1 (reading from sdb)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||
# dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67285 s, 125 MB/s
|
||||
```
|
||||
|
||||
#### Example 2-2 (writing to sdb)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||
# dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67198 s, 125 MB/s
|
||||
```
|
||||
|
||||
#### Example 2-3 (reading concurrently from sdb)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||
# (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache &); (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache skip=200 &)
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.52808 s, 59.4 MB/s
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.57736 s, 58.6 MB/s
|
||||
```
|
||||
|
||||
#### Example 2-4 (writing concurrently to sdb)
|
||||
|
||||
```
|
||||
# MY_DISK=$(echo $MY_DEVS | cut -d ' ' -f 2)
|
||||
# (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct &); (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct skip=200 &)
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.7841 s, 55.4 MB/s
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 3.81475 s, 55.0 MB/s
|
||||
```
|
||||
|
||||
#### Example 3-1 (reading from RAID0)
|
||||
|
||||
```
|
||||
# mdadm --create /dev/md/stripped --homehost=any --metadata=1.0 --level=0 --raid-devices=2 $MY_DEVS
|
||||
# MY_DISK=/dev/md/stripped
|
||||
# dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 0.837419 s, 250 MB/s
|
||||
```
|
||||
|
||||
#### Example 3-2 (writing to RAID0)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/stripped
|
||||
# dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 0.823648 s, 255 MB/s
|
||||
```
|
||||
|
||||
#### Example 3-3 (reading concurrently from RAID0)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/stripped
|
||||
# (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache &); (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache skip=200 &)
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.31025 s, 160 MB/s
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.80016 s, 116 MB/s
|
||||
```
|
||||
|
||||
#### Example 3-4 (writing concurrently to RAID0)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/stripped
|
||||
# (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct &); (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct skip=200 &)
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.65026 s, 127 MB/s
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.81323 s, 116 MB/s
|
||||
```
|
||||
|
||||
#### Example 4-1 (reading from RAID1)
|
||||
|
||||
```
|
||||
# mdadm --stop /dev/md/stripped
|
||||
# mdadm --create /dev/md/mirrored --homehost=any --metadata=1.0 --level=1 --raid-devices=2 --assume-clean $MY_DEVS
|
||||
# MY_DISK=/dev/md/mirrored
|
||||
# dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.74963 s, 120 MB/s
|
||||
```
|
||||
|
||||
#### Example 4-2 (writing to RAID1)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/mirrored
|
||||
# dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.74625 s, 120 MB/s
|
||||
```
|
||||
|
||||
#### Example 4-3 (reading concurrently from RAID1)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/mirrored
|
||||
# (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache &); (dd if=$MY_DISK of=/dev/null bs=1MiB count=200 iflag=nocache skip=200 &)
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67171 s, 125 MB/s
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 1.67685 s, 125 MB/s
|
||||
```
|
||||
|
||||
#### Example 4-4 (writing concurrently to RAID1)
|
||||
|
||||
```
|
||||
# MY_DISK=/dev/md/mirrored
|
||||
# (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct &); (dd if=/dev/zero of=$MY_DISK bs=1MiB count=200 oflag=direct skip=200 &)
|
||||
```
|
||||
|
||||
```
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 4.09666 s, 51.2 MB/s
|
||||
200+0 records in
|
||||
200+0 records out
|
||||
209715200 bytes (210 MB, 200 MiB) copied, 4.1067 s, 51.1 MB/s
|
||||
```
|
||||
|
||||
#### Restore your swap device and journald configuration
|
||||
|
||||
```
|
||||
# mdadm --stop /dev/md/stripped /dev/md/mirrored
|
||||
# mdadm --create /dev/md/swap --homehost=any --metadata=1.0 --level=1 --raid-devices=2 $MY_DEVS
|
||||
# mkswap /dev/md/swap
|
||||
# swapon -a
|
||||
# mv /etc/systemd/journald.conf.bak /etc/systemd/journald.conf
|
||||
# systemctl restart systemd-journald.service
|
||||
# reboot
|
||||
```
|
||||
|
||||
### Interpreting the results
|
||||
|
||||
Examples 1-1, 1-2, 2-1, and 2-2 show that each of my drives read and write at about 125 MB/s.
|
||||
|
||||
Examples 1-3, 1-4, 2-3, and 2-4 show that when two reads or two writes are done in parallel on the same drive, each process gets at about half the drive’s bandwidth (60 MB/s).
|
||||
|
||||
The 3-x examples show the performance benefit of putting the two drives together in a RAID0 (data stripping) array. The numbers, in all cases, show that the RAID0 array performs about twice as fast as either drive is able to perform on its own. The trade-off is that you are twice as likely to lose everything because each drive only contains half the data. A three-drive array would perform three times as fast as a single drive (all drives being equal) but it would be thrice as likely to suffer a [catastrophic failure][6].
|
||||
|
||||
The 4-x examples show that the performance of the RAID1 (data mirroring) array is similar to that of a single disk except for the case where multiple processes are concurrently reading (example 4-3). In the case of multiple processes reading, the performance of the RAID1 array is similar to that of the RAID0 array. This means that you will see a performance benefit with RAID1, but only when processes are reading concurrently. For example, if a process tries to access a large number of files in the background while you are trying to use a web browser or email client in the foreground. The main benefit of RAID1 is that your data is unlikely to be lost [if a drive fails][7].
|
||||
|
||||
### Video demo
|
||||
|
||||
Testing storage throughput using dd
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
If the above tests aren’t performing as you expect, you might have a bad or failing drive. Most modern hard drives have built-in Self-Monitoring, Analysis and Reporting Technology ([SMART][8]). If your drive supports it, the _smartctl_ command can be used to query your hard drive for its internal statistics:
|
||||
|
||||
```
|
||||
# smartctl --health /dev/sda
|
||||
# smartctl --log=error /dev/sda
|
||||
# smartctl -x /dev/sda
|
||||
```
|
||||
|
||||
Another way that you might be able to tune your PC for better performance is by changing your [I/O scheduler][9]. Linux systems support several I/O schedulers and the current default for Fedora systems is the [multiqueue][10] variant of the [deadline][11] scheduler. The default performs very well overall and scales extremely well for large servers with many processors and large disk arrays. There are, however, a few more specialized schedulers that might perform better under certain conditions.
|
||||
|
||||
To view which I/O scheduler your drives are using, issue the following command:
|
||||
|
||||
```
|
||||
$ for i in /sys/block/sd?/queue/scheduler; do echo "$i: $(<$i)"; done
|
||||
```
|
||||
|
||||
You can change the scheduler for a drive by writing the name of the desired scheduler to the /sys/block/<device name>/queue/scheduler file:
|
||||
|
||||
```
|
||||
# echo bfq > /sys/block/sda/queue/scheduler
|
||||
```
|
||||
|
||||
You can make your changes permanent by creating a [udev rule][12] for your drive. The following example shows how to create a udev rule that will set all [rotational drives][13] to use the [BFQ][14] I/O scheduler:
|
||||
|
||||
```
|
||||
# cat << END > /etc/udev/rules.d/60-ioscheduler-rotational.rules
|
||||
ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="1", ATTR{queue/scheduler}="bfq"
|
||||
END
|
||||
```
|
||||
|
||||
Here is another example that sets all [solid-state drives][15] to use the [NOOP][16] I/O scheduler:
|
||||
|
||||
```
|
||||
# cat << END > /etc/udev/rules.d/60-ioscheduler-solid-state.rules
|
||||
ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="none"
|
||||
END
|
||||
```
|
||||
|
||||
Changing your I/O scheduler won’t affect the raw throughput of your devices, but it might make your PC seem more responsive by prioritizing the bandwidth for the foreground tasks over the background tasks or by eliminating unnecessary block reordering.
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[ _James Donovan_][17]_ on _[_Unsplash_][18]_._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/check-storage-performance-with-dd/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/glb/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/04/dd-performance-816x345.jpg
|
||||
[2]: https://www.ibm.com/developerworks/community/blogs/ibmnas/entry/misalignment_can_be_twice_the_cost1?lang=en
|
||||
[3]: https://eklitzke.org/efficient-file-copying-on-linux
|
||||
[4]: https://en.wikipedia.org/wiki/Hdparm
|
||||
[5]: https://en.wikipedia.org/wiki/Random-access_memory
|
||||
[6]: https://blog.elcomsoft.com/2019/01/why-ssds-die-a-sudden-death-and-how-to-deal-with-it/
|
||||
[7]: https://www.computerworld.com/article/2484998/ssds-do-die--as-linus-torvalds-just-discovered.html
|
||||
[8]: https://en.wikipedia.org/wiki/S.M.A.R.T.
|
||||
[9]: https://en.wikipedia.org/wiki/I/O_scheduling
|
||||
[10]: https://lwn.net/Articles/552904/
|
||||
[11]: https://en.wikipedia.org/wiki/Deadline_scheduler
|
||||
[12]: http://www.reactivated.net/writing_udev_rules.html
|
||||
[13]: https://en.wikipedia.org/wiki/Hard_disk_drive_performance_characteristics
|
||||
[14]: http://algo.ing.unimo.it/people/paolo/disk_sched/
|
||||
[15]: https://en.wikipedia.org/wiki/Solid-state_drive
|
||||
[16]: https://en.wikipedia.org/wiki/Noop_scheduler
|
||||
[17]: https://unsplash.com/photos/0ZBRKEG_5no?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[18]: https://unsplash.com/search/photos/speed?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,180 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Keeping an open source project alive when people leave)
|
||||
[#]: via: (https://opensource.com/article/19/5/code-missing-community-management)
|
||||
[#]: author: (Rodrigo Duarte Sousa https://opensource.com/users/rodrigods/users/tellesnobrega)
|
||||
|
||||
Keeping an open source project alive when people leave
|
||||
======
|
||||
How to find out what's done, what's not, and what's missing.
|
||||
![][1]
|
||||
|
||||
Suppose you wake up one day and decide to finally use that recipe video you keep watching all over social media. You get the ingredients, organize the necessary utensils, and start to follow the recipe steps. You cut this, cut that, then start heating the oven at the same time you put butter and onions in a pan. Then, your phone reminds you: you have a dinner appointment with your boss, and you're already late! You turn off everything and leave immediately, stopping the cooking process somewhere near the end.
|
||||
|
||||
Some minutes later, your roommate arrives at home ready to have dinner and finds only the _ongoing work_ in the kitchen. They have the following options:
|
||||
|
||||
1. Clean up the mess and start cooking something from scratch.
|
||||
2. Order dinner and don’t bother to cook and/or fix the mess you left.
|
||||
3. Start cooking “around” the mess you left, which will probably take more time since most of the utensils are dirty and there isn’t much space left in the kitchen.
|
||||
|
||||
|
||||
|
||||
If you left the printed version of the recipe somewhere, your roommate also has a fourth option. They could finish what you started! The problem is that they have no idea what's missing. It is not like you crossed out each completed step. Their best bet is either to call you or to examine all of your _changes_ to infer what is missing.
|
||||
|
||||
In this example, the kitchen is like a software project, the utensils are the code, and the recipe is a new feature being implemented. Leaving something behind is not usually doable in a company's private project since you're accountable for your work and—in a scenario where you need to leave—it's almost certain that there is someone tracking/following the project, so they avoid having a "single point of failure." With open source projects, though, this continuity rarely happens. So how can we in the open source community deal with legacy, unfinished code, or code that is completed but no one dares touch it?
|
||||
|
||||
### Knowledge legacy in open source projects
|
||||
|
||||
We have always felt that open source is one of the best ways for an inexperienced software engineer to improve her skills. For many, open source projects offer their first hands-on experience with particular tools. [Version control systems][2], [unit][3] and [integration][4] tests, [continuous delivery][5], [code reviews][6], [features planning][7], [bug reporting/fixing][8], and more.
|
||||
|
||||
In addition to learning opportunities, we can also view open source projects as a career opportunity—many senior engineers in the community get paid to be there, and you can add your contributions to your resume. That’s pretty cool. There's nothing like learning while improving your resume and getting potential employers' attention so you can pay your rent.
|
||||
|
||||
Is this whole situation an infinite loop where everyone wins? The answer is obviously no. This post focuses on one of the main issues that arise in any project: the [bus/truck factor][9]. In the open source context, specifically, when people experience major changes such as a new job or other more personal factors, they tend to leave the community. We will first describe the problems that can arise from people leaving their _recipes_ unfinished by using [OpenStack][10] as an example. Then, we'll try to discuss some ideas to try to mitigate the issues.
|
||||
|
||||
### Common problems
|
||||
|
||||
In the past few years, we've seen a lot of changes in the [OpenStack][11] community, where some projects lost some portion of their active contributors team. These losses led to incomplete work and even finished modules without clear maintainers. Below are other examples of what happens when people suddenly leave. While this article uses OpenStack terms, such as “specs,” these issues easily apply to software development in general:
|
||||
|
||||
* **Broken documentation:** A new API or setting either wasn't documented, or it was documented but not implemented.
|
||||
* **Hard to resolve knowledge deficits:** For example, a new requirement and/or feature requires part of the code to be refactored but no one has the necessary expertise.
|
||||
* **Incomplete features:** What are the missing tasks required for each feature? Which tasks were completed?
|
||||
* **Debugging drama:** If the person who wrote the code isn't there, meaning that it takes a lot of engineering hours just to decrypt—so to speak—the code path that needs to be fixed.
|
||||
|
||||
|
||||
|
||||
To illustrate, we will use the [Project Tree Deletion][12] feature. Project Tree Deletion is a tiny feature that one of us proposed more than three years ago and couldn’t complete. Basically, the main goal was to enable an OpenStack user/operator to erase a whole branch of projects without having to manually disable/delete every single of them starting from the leaves. Very straightforward, right? The PTD spec has been merged and has the following _work items_ :
|
||||
|
||||
* Update API spec documentation.
|
||||
* Add new rules to the file **policy.json**.
|
||||
* Add new endpoints to mirror the new features.
|
||||
* Implement the new deletion/disabling behavior for the project’s hierarchy.
|
||||
|
||||
|
||||
|
||||
What about the sequence of steps (roadmap) to get these work items done? How do we know where to start and when what to tackle next? Are there any logical dependencies between the work items? How do we know where to start, and with what?
|
||||
|
||||
Also, how do we know which work has been completed (if any)? One of the things that we do is look in the [blueprint][13] and/or the new [bug tracker][14], for example:
|
||||
|
||||
* Recursive deletion and project disabling: <https://review.openstack.org/148730>(merged)
|
||||
* API changes for Reseller: <https://review.openstack.org/153007>(merged)
|
||||
* Add parent_id to GET /projects: <https://review.openstack.org/166326>(merged)
|
||||
* Manager support for project cascade update: <https://review.openstack.org/243584>(merged)
|
||||
* API support for cascade update: <https://review.openstack.org/243585>(abandoned)
|
||||
* Manager support for project delete cascade: <https://review.openstack.org/244149>(merged)
|
||||
* API support for project cascade delete: <https://review.openstack.org/244248>(abandoned)
|
||||
* Add backend support for deleting a projects list: <https://review.openstack.org/245916>(merged)
|
||||
* Test list project hierarchy is correct for a large tree: <https://review.openstack.org/277512>(merged)
|
||||
* Fix cascade operations documentation: <https://review.openstack.org/274836>(merged)
|
||||
* Revert “Fix cascade operations documentation”: <https://review.openstack.org/286716>(merged)
|
||||
* Remove the APIs from the doc that aren't supported yet: <https://review.openstack.org/368570>(merged)
|
||||
|
||||
|
||||
|
||||
Here we can see a lot of merged patches, but also that some were abandoned, and that some include the words Revert and Remove in their titles. Now we have strong evidence that this work is not completed, but at least some work was started to clean it up and avoid exposing something incomplete in the service API. Let’s dig a little bit deeper and look at the [_current_ delete project code][15].
|
||||
|
||||
There, we can see an added **cascade** argument (“cascade” resembles deleting related things together, so this argument must be somehow related to the proposed feature), and that it has a special block to treat the cases for the possible values of **cascade** :
|
||||
|
||||
|
||||
```
|
||||
`def _delete_project(self, project, initiator=None, cascade=False):`[/code] [code]
|
||||
|
||||
if cascade:
|
||||
# Getting reversed project's subtrees list, i.e. from the leaves
|
||||
# to the root, so we do not break parent_id FK.
|
||||
subtree_list = self.list_projects_in_subtree(project_id)
|
||||
subtree_list.reverse()
|
||||
if not self._check_whole_subtree_is_disabled(
|
||||
project_id, subtree_list=subtree_list):
|
||||
raise exception.ForbiddenNotSecurity(
|
||||
_('Cannot delete project %(project_id)s since its subtree '
|
||||
'contains enabled projects.')
|
||||
% {'project_id': project_id})
|
||||
|
||||
project_list = subtree_list + [project]
|
||||
projects_ids = [x['id'] for x in project_list]
|
||||
|
||||
ret = self.driver.delete_projects_from_ids(projects_ids)
|
||||
for prj in project_list:
|
||||
self._post_delete_cleanup_project(prj['id'], prj, initiator)
|
||||
else:
|
||||
ret = self.driver.delete_project(project_id)
|
||||
self._post_delete_cleanup_project(project_id, project, initiator)
|
||||
```
|
||||
|
||||
What about the callers of this function? Do they use **cascade** at all? If we search for it, we only find occurrences in the backend tests:
|
||||
|
||||
|
||||
```
|
||||
$ git grep "delete_project" | grep "cascade" | grep -v "def"
|
||||
keystone/tests/unit/resource/test_backends.py: PROVIDERS.resource_api.delete_project(root_project['id'], cascade=True)
|
||||
keystone/tests/unit/resource/test_backends.py: PROVIDERS.resource_api.delete_project(p1['id'], cascade=True)
|
||||
```
|
||||
|
||||
We can also confirm this finding by looking at the [delete projects API implementation][16].
|
||||
|
||||
So it seems that we have a problem here, something simple that I started was left behind a very long time ago. How could the community or I have prevented this from happening?
|
||||
|
||||
From the example above, one of the most apparent problems is the lack of a clear roadmap and list of completed tasks somewhere. To follow the actual implementation status, we had to dig into the blueprint/bug comments and the code.
|
||||
|
||||
Based on this issue, we can sketch an idea: for each new feature, we need a roadmap stored somewhere to reflect the implementation status. Once the roadmap is defined within a spec, we can track each step as a [Launchpad][17] entry, for example, and have a better view of the progress status of that spec.
|
||||
|
||||
Of course, these steps won’t prevent unfinished projects and they add a little bit of process, but following them can give a better view of what's missing so someone else from the community could finish or even revert what's there.
|
||||
|
||||
### That’s not all
|
||||
|
||||
What about other aspects of the project besides feature completion? We shouldn’t expect that every person on the core team is an expert in every single project module. This issue highlights another very important aspect of any open source community: mentoring.
|
||||
|
||||
New people come to the community all the time and many have an incentive to continuing coming back as we discussed earlier. However, are our current community members willing to mentor them? How many times have you participated as a mentor in a program such as [Outreachy ][18]or [Google Summer of Code][19], or taken time to answer questions in the project’s chat?
|
||||
|
||||
We also know that people eventually move on to other open source communities, so we have the chance of not leaving what we learned behind. We can always transmit that knowledge directly to those who are currently interested and actively asking questions, or indirectly, by writing documentation, blog posts, giving talks, and so forth.
|
||||
|
||||
In order to have a healthy open source community, knowledge can’t be dominated by few people. We need to make an effort to have as many people capable of moving the project forward as possible. Also, a key aspect of mentoring is not only related to coding, but also to leadership skills. Preparing people to take roles like Project Team Lead, joining the Technical Committee, and so on is crucial if we intend to see the community grow even when we're not around anymore.
|
||||
|
||||
Needless to say, mentoring is also an important skill for climbing the engineering ladder in most companies. Consider that another motivation.
|
||||
|
||||
### To conclude
|
||||
|
||||
Open source should not be treated as only the means to an end. Collaboration is a crucial part of these projects, and alongside mentoring, should always be treated as a first citizen in any open source community. And, of course, we will fix the unfinished spec used as this article's example.
|
||||
|
||||
If you are part of an open source community, it is your responsibility to be focusing on sharing your knowledge while you are still around. Chances are that no one is going to tell you to do so, it should be part of the routine of any open source collaborator.
|
||||
|
||||
What are other ways of sharing knowledge? What are your thoughts and ideas about the issue?
|
||||
|
||||
_This original article was posted on[rodrigods][20]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/code-missing-community-management
|
||||
|
||||
作者:[Rodrigo Duarte Sousa][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rodrigods/users/tellesnobrega
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BIZ_question_B.png?itok=f88cyt00
|
||||
[2]: https://en.wikipedia.org/wiki/Version_control
|
||||
[3]: https://en.wikipedia.org/wiki/Unit_testing
|
||||
[4]: https://en.wikipedia.org/wiki/Integration_testing
|
||||
[5]: https://en.wikipedia.org/wiki/Continuous_delivery
|
||||
[6]: https://en.wikipedia.org/wiki/Code_review
|
||||
[7]: https://www.agilealliance.org/glossary/sprint-planning/
|
||||
[8]: https://www.softwaretestinghelp.com/how-to-write-good-bug-report/
|
||||
[9]: https://en.wikipedia.org/wiki/Bus_factor
|
||||
[10]: https://www.openstack.org/
|
||||
[11]: /resources/what-is-openstack
|
||||
[12]: https://review.opendev.org/#/c/148730/35
|
||||
[13]: https://blueprints.launchpad.net/keystone/+spec/project-tree-deletion
|
||||
[14]: https://bugs.launchpad.net/keystone/+bug/1816105
|
||||
[15]: https://github.com/openstack/keystone/blob/master/keystone/resource/core.py#L475-L519
|
||||
[16]: https://github.com/openstack/keystone/blob/master/keystone/api/projects.py#L202-L214
|
||||
[17]: https://launchpad.net
|
||||
[18]: https://www.outreachy.org/
|
||||
[19]: https://summerofcode.withgoogle.com/
|
||||
[20]: https://blog.rodrigods.com/knowledge-legacy-the-issue-of-passing-the-baton/
|
||||
594
sources/tech/20190510 Learn to change history with git rebase.md
Normal file
594
sources/tech/20190510 Learn to change history with git rebase.md
Normal file
@ -0,0 +1,594 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Learn to change history with git rebase!)
|
||||
[#]: via: (https://git-rebase.io/)
|
||||
[#]: author: (git-rebase https://git-rebase.io/)
|
||||
|
||||
Learn to change history with git rebase!
|
||||
======
|
||||
One of Git 's core value-adds is the ability to edit history. Unlike version control systems that treat the history as a sacred record, in git we can change history to suit our needs. This gives us a lot of powerful tools and allows us to curate a good commit history in the same way we use refactoring to uphold good software design practices. These tools can be a little bit intimidating to the novice or even intermediate git user, but this guide will help to demystify the powerful git-rebase .
|
||||
|
||||
```
|
||||
A word of caution : changing the history of public, shared, or stable branches is generally advised against. Editing the history of feature branches and personal forks is fine, and editing commits that you haven't pushed yet is always okay. Use git push -f to force push your changes to a personal fork or feature branch after editing your commits.
|
||||
```
|
||||
|
||||
Despite the scary warning, it's worth mentioning that everything mentioned in this guide is a non-destructive operation. It's actually pretty difficult to permanently lose data in git. Fixing things when you make mistakes is covered at the end of this guide.
|
||||
|
||||
### Setting up a sandbox
|
||||
|
||||
We don't want to mess up any of your actual repositories, so throughout this guide we'll be working with a sandbox repo. Run these commands to get started:
|
||||
|
||||
```
|
||||
git init /tmp/rebase-sandbox
|
||||
cd /tmp/rebase-sandbox
|
||||
git commit --allow-empty -m"Initial commit"
|
||||
```
|
||||
|
||||
If you run into trouble, just run rm -rf /tmp/rebase-sandbox and run these steps again to start over. Each step of this guide can be run on a fresh sandbox, so it's not necessary to re-do every task.
|
||||
|
||||
|
||||
### Amending your last commit
|
||||
|
||||
Let's start with something simple: fixing your most recent commit. Let's add a file to our sandbox - and make a mistake:
|
||||
|
||||
```
|
||||
echo "Hello wrold!" >greeting.txt
|
||||
git add greeting.txt
|
||||
git commit -m"Add greeting.txt"
|
||||
```
|
||||
|
||||
Fixing this mistake is pretty easy. We can just edit the file and commit with `--amend`, like so:
|
||||
|
||||
```
|
||||
echo "Hello world!" >greeting.txt
|
||||
git commit -a --amend
|
||||
```
|
||||
|
||||
Specifying `-a` automatically stages (i.e. `git add`'s) all files that git already knows about, and `--amend` will squash the changes into the most recent commit. Save and quit your editor (you have a chance to change the commit message now if you'd like). You can see the fixed commit by running `git show`:
|
||||
|
||||
```
|
||||
commit f5f19fbf6d35b2db37dcac3a55289ff9602e4d00 (HEAD -> master)
|
||||
Author: Drew DeVault
|
||||
Date: Sun Apr 28 11:09:47 2019 -0400
|
||||
|
||||
Add greeting.txt
|
||||
|
||||
diff --git a/greeting.txt b/greeting.txt
|
||||
new file mode 100644
|
||||
index 0000000..cd08755
|
||||
--- /dev/null
|
||||
+++ b/greeting.txt
|
||||
@@ -0,0 +1 @@
|
||||
+Hello world!
|
||||
```
|
||||
|
||||
### Fixing up older commits
|
||||
|
||||
Amending only works for the most recent commit. What happens if you need to correct an older commit? Let's start by setting up our sandbox accordingly:
|
||||
|
||||
```
|
||||
echo "Hello!" >greeting.txt
|
||||
git add greeting.txt
|
||||
git commit -m"Add greeting.txt"
|
||||
|
||||
echo "Goodbye world!" >farewell.txt
|
||||
git add farewell.txt
|
||||
git commit -m"Add farewell.txt"
|
||||
```
|
||||
|
||||
Looks like `greeting.txt` is missing "world". Let's write a commit normally which fixes that:
|
||||
|
||||
```
|
||||
echo "Hello world!" >greeting.txt
|
||||
git commit -a -m"fixup greeting.txt"
|
||||
```
|
||||
|
||||
So now the files look correct, but our history could be better - let's use the new commit to "fixup" the last one. For this, we need to introduce a new tool: the interactive rebase. We're going to edit the last three commits this way, so we'll run `git rebase -i HEAD~3` (`-i` for interactive). This'll open your text editor with something like this:
|
||||
|
||||
```
|
||||
pick 8d3fc77 Add greeting.txt
|
||||
pick 2a73a77 Add farewell.txt
|
||||
pick 0b9d0bb fixup greeting.txt
|
||||
|
||||
# Rebase f5f19fb..0b9d0bb onto f5f19fb (3 commands)
|
||||
#
|
||||
# Commands:
|
||||
# p, pick <commit> = use commit
|
||||
# f, fixup <commit> = like "squash", but discard this commit's log message
|
||||
```
|
||||
|
||||
This is the rebase plan, and by editing this file you can instruct git on how to edit history. I've trimmed the summary to just the details relevant to this part of the rebase guide, but feel free to skim the full summary in your text editor.
|
||||
|
||||
When we save and close our editor, git is going to remove all of these commits from its history, then execute each line one at a time. By default, it's going to pick each commit, summoning it from the heap and adding it to the branch. If we don't edit this file at all, we'll end up right back where we started, picking every commit as-is. We're going to use one of my favorite features now: fixup. Edit the third line to change the operation from "pick" to "fixup" and move it to immediately after the commit we want to "fix up":
|
||||
|
||||
```
|
||||
pick 8d3fc77 Add greeting.txt
|
||||
fixup 0b9d0bb fixup greeting.txt
|
||||
pick 2a73a77 Add farewell.txt
|
||||
```
|
||||
|
||||
**Tip** : We can also abbreviate this with just "f" to speed things up next time.
|
||||
|
||||
Save and quit your editor - git will run these commands. We can check the log to verify the result:
|
||||
|
||||
```
|
||||
$ git log -2 --oneline
|
||||
fcff6ae (HEAD -> master) Add farewell.txt
|
||||
a479e94 Add greeting.txt
|
||||
```
|
||||
|
||||
### Squashing several commits into one
|
||||
|
||||
As you work, you may find it useful to write lots of commits as you reach small milestones or fix bugs in previous commits. However, it may be useful to "squash" these commits together, to make a cleaner history before merging your work into master. For this, we'll use the "squash" operation. Let's start by writing a bunch of commits - just copy and paste this if you want to speed it up:
|
||||
|
||||
```
|
||||
git checkout -b squash
|
||||
for c in H e l l o , ' ' w o r l d; do
|
||||
echo "$c" >>squash.txt
|
||||
git add squash.txt
|
||||
git commit -m"Add '$c' to squash.txt"
|
||||
done
|
||||
```
|
||||
|
||||
That's a lot of commits to make a file that says "Hello, world"! Let's start another interactive rebase to squash them together. Note that we checked out a branch to try this on, first. Because of that, we can quickly rebase all of the commits since we branched by using `git rebase -i master`. The result:
|
||||
|
||||
```
|
||||
pick 1e85199 Add 'H' to squash.txt
|
||||
pick fff6631 Add 'e' to squash.txt
|
||||
pick b354c74 Add 'l' to squash.txt
|
||||
pick 04aaf74 Add 'l' to squash.txt
|
||||
pick 9b0f720 Add 'o' to squash.txt
|
||||
pick 66b114d Add ',' to squash.txt
|
||||
pick dc158cd Add ' ' to squash.txt
|
||||
pick dfcf9d6 Add 'w' to squash.txt
|
||||
pick 7a85f34 Add 'o' to squash.txt
|
||||
pick c275c27 Add 'r' to squash.txt
|
||||
pick a513fd1 Add 'l' to squash.txt
|
||||
pick 6b608ae Add 'd' to squash.txt
|
||||
|
||||
# Rebase 1af1b46..6b608ae onto 1af1b46 (12 commands)
|
||||
#
|
||||
# Commands:
|
||||
# p, pick <commit> = use commit
|
||||
# s, squash <commit> = use commit, but meld into previous commit
|
||||
```
|
||||
|
||||
**Tip** : your local master branch evolves independently of the remote master branch, and git stores the remote branch as `origin/master`. Combined with this trick, `git rebase -i origin/master` is often a very convenient way to rebase all of the commits which haven't been merged upstream yet!
|
||||
|
||||
We're going to squash all of these changes into the first commit. To do this, change every "pick" operation to "squash", except for the first line, like so:
|
||||
|
||||
```
|
||||
pick 1e85199 Add 'H' to squash.txt
|
||||
squash fff6631 Add 'e' to squash.txt
|
||||
squash b354c74 Add 'l' to squash.txt
|
||||
squash 04aaf74 Add 'l' to squash.txt
|
||||
squash 9b0f720 Add 'o' to squash.txt
|
||||
squash 66b114d Add ',' to squash.txt
|
||||
squash dc158cd Add ' ' to squash.txt
|
||||
squash dfcf9d6 Add 'w' to squash.txt
|
||||
squash 7a85f34 Add 'o' to squash.txt
|
||||
squash c275c27 Add 'r' to squash.txt
|
||||
squash a513fd1 Add 'l' to squash.txt
|
||||
squash 6b608ae Add 'd' to squash.txt
|
||||
```
|
||||
|
||||
When you save and close your editor, git will think about this for a moment, then open your editor again to revise the final commit message. You'll see something like this:
|
||||
|
||||
```
|
||||
# This is a combination of 12 commits.
|
||||
# This is the 1st commit message:
|
||||
|
||||
Add 'H' to squash.txt
|
||||
|
||||
# This is the commit message #2:
|
||||
|
||||
Add 'e' to squash.txt
|
||||
|
||||
# This is the commit message #3:
|
||||
|
||||
Add 'l' to squash.txt
|
||||
|
||||
# This is the commit message #4:
|
||||
|
||||
Add 'l' to squash.txt
|
||||
|
||||
# This is the commit message #5:
|
||||
|
||||
Add 'o' to squash.txt
|
||||
|
||||
# This is the commit message #6:
|
||||
|
||||
Add ',' to squash.txt
|
||||
|
||||
# This is the commit message #7:
|
||||
|
||||
Add ' ' to squash.txt
|
||||
|
||||
# This is the commit message #8:
|
||||
|
||||
Add 'w' to squash.txt
|
||||
|
||||
# This is the commit message #9:
|
||||
|
||||
Add 'o' to squash.txt
|
||||
|
||||
# This is the commit message #10:
|
||||
|
||||
Add 'r' to squash.txt
|
||||
|
||||
# This is the commit message #11:
|
||||
|
||||
Add 'l' to squash.txt
|
||||
|
||||
# This is the commit message #12:
|
||||
|
||||
Add 'd' to squash.txt
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with '#' will be ignored, and an empty message aborts the commit.
|
||||
#
|
||||
# Date: Sun Apr 28 14:21:56 2019 -0400
|
||||
#
|
||||
# interactive rebase in progress; onto 1af1b46
|
||||
# Last commands done (12 commands done):
|
||||
# squash a513fd1 Add 'l' to squash.txt
|
||||
# squash 6b608ae Add 'd' to squash.txt
|
||||
# No commands remaining.
|
||||
# You are currently rebasing branch 'squash' on '1af1b46'.
|
||||
#
|
||||
# Changes to be committed:
|
||||
# new file: squash.txt
|
||||
#
|
||||
```
|
||||
|
||||
This defaults to a combination of all of the commit messages which were squashed, but leaving it like this is almost always not what you want. The old commit messages may be useful for reference when writing the new one, though.
|
||||
|
||||
**Tip** : the "fixup" command you learned about in the previous section can be used for this purpose, too - but it discards the messages of the squashed commits.
|
||||
|
||||
Let's delete everything and replace it with a better commit message, like this:
|
||||
|
||||
```
|
||||
Add squash.txt with contents "Hello, world"
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with '#' will be ignored, and an empty message aborts the commit.
|
||||
#
|
||||
# Date: Sun Apr 28 14:21:56 2019 -0400
|
||||
#
|
||||
# interactive rebase in progress; onto 1af1b46
|
||||
# Last commands done (12 commands done):
|
||||
# squash a513fd1 Add 'l' to squash.txt
|
||||
# squash 6b608ae Add 'd' to squash.txt
|
||||
# No commands remaining.
|
||||
# You are currently rebasing branch 'squash' on '1af1b46'.
|
||||
#
|
||||
# Changes to be committed:
|
||||
# new file: squash.txt
|
||||
#
|
||||
```
|
||||
|
||||
Save and quit your editor, then examine your git log - success!
|
||||
|
||||
```
|
||||
commit c785f476c7dff76f21ce2cad7c51cf2af00a44b6 (HEAD -> squash)
|
||||
Author: Drew DeVault
|
||||
Date: Sun Apr 28 14:21:56 2019 -0400
|
||||
|
||||
Add squash.txt with contents "Hello, world"
|
||||
```
|
||||
|
||||
Before we move on, let's pull our changes into the master branch and get rid of this scratch one. We can use `git rebase` like we use `git merge`, but it avoids making a merge commit:
|
||||
|
||||
```
|
||||
git checkout master
|
||||
git rebase squash
|
||||
git branch -D squash
|
||||
```
|
||||
|
||||
We generally prefer to avoid using git merge unless we're actually merging unrelated histories. If you have two divergent branches, a git merge is useful to have a record of when they were... merged. In the course of your normal work, rebase is often more appropriate.
|
||||
|
||||
### Splitting one commit into several
|
||||
|
||||
Sometimes the opposite problem happens - one commit is just too big. Let's look into splitting it up. This time, let's write some actual code. Start with a simple C program2 (you can still copy+paste this snippet into your shell to do this quickly):
|
||||
|
||||
```
|
||||
cat <<EOF >main.c
|
||||
int main(int argc, char *argv[]) {
|
||||
return 0;
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
We'll commit this first.
|
||||
|
||||
```
|
||||
git add main.c
|
||||
git commit -m"Add C program skeleton"
|
||||
```
|
||||
|
||||
Next, let's extend the program a bit:
|
||||
|
||||
```
|
||||
cat <<EOF >main.c
|
||||
#include <stdio.h>
|
||||
|
||||
const char *get_name() {
|
||||
static char buf[128];
|
||||
scanf("%s", buf);
|
||||
return buf;
|
||||
}
|
||||
|
||||
int main(int argc, char *argv[]) {
|
||||
printf("What's your name? ");
|
||||
const char *name = get_name();
|
||||
printf("Hello, %s!\n", name);
|
||||
return 0;
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
After we commit this, we'll be ready to learn how to split it up.
|
||||
|
||||
```
|
||||
git commit -a -m"Flesh out C program"
|
||||
```
|
||||
|
||||
The first step is to start an interactive rebase. Let's rebase both commits with `git rebase -i HEAD~2`, giving us this rebase plan:
|
||||
|
||||
```
|
||||
pick 237b246 Add C program skeleton
|
||||
pick b3f188b Flesh out C program
|
||||
|
||||
# Rebase c785f47..b3f188b onto c785f47 (2 commands)
|
||||
#
|
||||
# Commands:
|
||||
# p, pick <commit> = use commit
|
||||
# e, edit <commit> = use commit, but stop for amending
|
||||
```
|
||||
|
||||
Change the second commit's command from "pick" to "edit", then save and close your editor. Git will think about this for a second, then present you with this:
|
||||
|
||||
```
|
||||
Stopped at b3f188b... Flesh out C program
|
||||
You can amend the commit now, with
|
||||
|
||||
git commit --amend
|
||||
|
||||
Once you are satisfied with your changes, run
|
||||
|
||||
git rebase --continue
|
||||
```
|
||||
|
||||
We could follow these instructions to add new changes to the commit, but instead let's do a "soft reset"3 by running `git reset HEAD^`. If you run `git status` after this, you'll see that it un-commits the latest commit and adds its changes to the working tree:
|
||||
|
||||
```
|
||||
Last commands done (2 commands done):
|
||||
pick 237b246 Add C program skeleton
|
||||
edit b3f188b Flesh out C program
|
||||
No commands remaining.
|
||||
You are currently splitting a commit while rebasing branch 'master' on 'c785f47'.
|
||||
(Once your working directory is clean, run "git rebase --continue")
|
||||
|
||||
Changes not staged for commit:
|
||||
(use "git add ..." to update what will be committed)
|
||||
(use "git checkout -- ..." to discard changes in working directory)
|
||||
|
||||
modified: main.c
|
||||
|
||||
no changes added to commit (use "git add" and/or "git commit -a")
|
||||
```
|
||||
|
||||
To split this up, we're going to do an interactive commit. This allows us to selectively commit only specific changes from the working tree. Run `git commit -p` to start this process, and you'll be presented with the following prompt:
|
||||
|
||||
```
|
||||
diff --git a/main.c b/main.c
|
||||
index b1d9c2c..3463610 100644
|
||||
--- a/main.c
|
||||
+++ b/main.c
|
||||
@@ -1,3 +1,14 @@
|
||||
+#include <stdio.h>
|
||||
+
|
||||
+const char *get_name() {
|
||||
+ static char buf[128];
|
||||
+ scanf("%s", buf);
|
||||
+ return buf;
|
||||
+}
|
||||
+
|
||||
int main(int argc, char *argv[]) {
|
||||
+ printf("What's your name? ");
|
||||
+ const char *name = get_name();
|
||||
+ printf("Hello, %s!\n", name);
|
||||
return 0;
|
||||
}
|
||||
Stage this hunk [y,n,q,a,d,s,e,?]?
|
||||
```
|
||||
|
||||
Git has presented you with just one "hunk" (i.e. a single change) to consider committing. This one is too big, though - let's use the "s" command to "split" up the hunk into smaller parts.
|
||||
|
||||
```
|
||||
Split into 2 hunks.
|
||||
@@ -1 +1,9 @@
|
||||
+#include <stdio.h>
|
||||
+
|
||||
+const char *get_name() {
|
||||
+ static char buf[128];
|
||||
+ scanf("%s", buf);
|
||||
+ return buf;
|
||||
+}
|
||||
+
|
||||
int main(int argc, char *argv[]) {
|
||||
Stage this hunk [y,n,q,a,d,j,J,g,/,e,?]?
|
||||
```
|
||||
|
||||
**Tip** : If you're curious about the other options, press "?" to summarize them.
|
||||
|
||||
This hunk looks better - a single, self-contained change. Let's hit "y" to answer the question (and stage that "hunk"), then "q" to "quit" the interactive session and proceed with the commit. Your editor will pop up to ask you to enter a suitable commit message.
|
||||
|
||||
```
|
||||
Add get_name function to C program
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with '#' will be ignored, and an empty message aborts the commit.
|
||||
#
|
||||
# interactive rebase in progress; onto c785f47
|
||||
# Last commands done (2 commands done):
|
||||
# pick 237b246 Add C program skeleton
|
||||
# edit b3f188b Flesh out C program
|
||||
# No commands remaining.
|
||||
# You are currently splitting a commit while rebasing branch 'master' on 'c785f47'.
|
||||
#
|
||||
# Changes to be committed:
|
||||
# modified: main.c
|
||||
#
|
||||
# Changes not staged for commit:
|
||||
# modified: main.c
|
||||
#
|
||||
```
|
||||
|
||||
Save and close your editor, then we'll make the second commit. We could do another interactive commit, but since we just want to include the rest of the changes in this commit we'll just do this:
|
||||
|
||||
```
|
||||
git commit -a -m"Prompt user for their name"
|
||||
git rebase --continue
|
||||
```
|
||||
|
||||
That last command tells git that we're done editing this commit, and to continue to the next rebase command. That's it! Run `git log` to see the fruits of your labor:
|
||||
|
||||
```
|
||||
$ git log -3 --oneline
|
||||
fe19cc3 (HEAD -> master) Prompt user for their name
|
||||
659a489 Add get_name function to C program
|
||||
237b246 Add C program skeleton
|
||||
```
|
||||
|
||||
### Reordering commits
|
||||
|
||||
This one is pretty easy. Let's start by setting up our sandbox:
|
||||
|
||||
```
|
||||
echo "Goodbye now!" >farewell.txt
|
||||
git add farewell.txt
|
||||
git commit -m"Add farewell.txt"
|
||||
|
||||
echo "Hello there!" >greeting.txt
|
||||
git add greeting.txt
|
||||
git commit -m"Add greeting.txt"
|
||||
|
||||
echo "How're you doing?" >inquiry.txt
|
||||
git add inquiry.txt
|
||||
git commit -m"Add inquiry.txt"
|
||||
```
|
||||
|
||||
The git log should now look like this:
|
||||
|
||||
```
|
||||
f03baa5 (HEAD -> master) Add inquiry.txt
|
||||
a4cebf7 Add greeting.txt
|
||||
90bb015 Add farewell.txt
|
||||
```
|
||||
|
||||
Clearly, this is all out of order. Let's do an interactive rebase of the past 3 commits to resolve this. Run `git rebase -i HEAD~3` and this rebase plan will appear:
|
||||
|
||||
```
|
||||
pick 90bb015 Add farewell.txt
|
||||
pick a4cebf7 Add greeting.txt
|
||||
pick f03baa5 Add inquiry.txt
|
||||
|
||||
# Rebase fe19cc3..f03baa5 onto fe19cc3 (3 commands)
|
||||
#
|
||||
# Commands:
|
||||
# p, pick <commit> = use commit
|
||||
#
|
||||
# These lines can be re-ordered; they are executed from top to bottom.
|
||||
```
|
||||
|
||||
The fix is now straightforward: just reorder these lines in the order you wish for the commits to appear. Should look something like this:
|
||||
|
||||
```
|
||||
pick a4cebf7 Add greeting.txt
|
||||
pick f03baa5 Add inquiry.txt
|
||||
pick 90bb015 Add farewell.txt
|
||||
```
|
||||
|
||||
Save and close your editor and git will do the rest for you. Note that it's possible to end up with conflicts when you do this in practice - click here for help resolving conflicts.
|
||||
|
||||
### git pull --rebase
|
||||
|
||||
If you've been writing some commits on a branch which has been updated upstream, normally `git pull` will create a merge commit. In this respect, `git pull`'s behavior by default is equivalent to:
|
||||
|
||||
```
|
||||
git fetch origin
|
||||
git merge origin/master
|
||||
```
|
||||
|
||||
There's another option, which is often more useful and leads to a much cleaner history: `git pull --rebase`. Unlike the merge approach, this is equivalent to the following:
|
||||
|
||||
```
|
||||
git fetch origin
|
||||
git rebase origin/master
|
||||
```
|
||||
|
||||
The merge approach is simpler and easier to understand, but the rebase approach is almost always what you want to do if you understand how to use git rebase. If you like, you can set it as the default behavior like so:
|
||||
|
||||
```
|
||||
git config --global pull.rebase true
|
||||
```
|
||||
|
||||
When you do this, technically you're applying the procedure we discuss in the next section... so let's explain what it means to do that deliberately, too.
|
||||
|
||||
### Using git rebase to... rebase
|
||||
|
||||
Ironically, the feature of git rebase that I use the least is the one it's named for: rebasing branches. Say you have the following branches:
|
||||
|
||||
```
|
||||
o--o--o--o--> master
|
||||
\--o--o--> feature-1
|
||||
\--o--> feature-2
|
||||
```
|
||||
|
||||
It turns out feature-2 doesn't depend on any of the changes in feature-1, so you can just base it off of master. The fix is thus:
|
||||
|
||||
```
|
||||
git checkout feature-2
|
||||
git rebase master
|
||||
```
|
||||
|
||||
The non-interactive rebase does the default operation for all implicated commits ("pick")4, which simply rolls your history back to the last common anscestor and replays the commits from both branches. Your history now looks like this:
|
||||
|
||||
```
|
||||
o--o--o--o--> master
|
||||
| \--o--> feature-2
|
||||
\--o--o--> feature-1
|
||||
```
|
||||
|
||||
### Resolving conflicts
|
||||
|
||||
The details on resolving merge conflicts are beyond the scope of this guide - keep your eye out for another guide for this in the future. Assuming you're familiar with resolving conflicts in general, here are the specifics that apply to rebasing.
|
||||
|
||||
The details on resolving merge conflicts are beyond the scope of this guide - keep your eye out for another guide for this in the future. Assuming you're familiar with resolving conflicts in general, here are the specifics that apply to rebasing.
|
||||
|
||||
Sometimes you'll get a merge conflict when doing a rebase, which you can handle just like any other merge conflict. Git will set up the conflict markers in the affected files, `git status` will show you what you need to resolve, and you can mark files as resolved with `git add` or `git rm`. However, in the context of a git rebase, there are two options you should be aware of.
|
||||
|
||||
The first is how you complete the conflict resolution. Rather than `git commit` like you'll use when addressing conflicts that arise from `git merge`, the appropriate command for rebasing is `git rebase --continue`. However, there's another option available to you: `git rebase --skip`. This will skip the commit you're working on, and it won't be included in the rebase. This is most common when doing a non-interactive rebase, when git doesn't realize that a commit it's pulled from the "other" branch is an updated version of the commit that it conflicts with on "our" branch.
|
||||
|
||||
### Help! I broke it!
|
||||
|
||||
No doubt about it - rebasing can be hard sometimes. If you've made a mistake and in so doing lost commits which you needed, then `git reflog` is here to save the day. Running this command will show you every operation which changed a ref, or reference - that is, branches and tags. Each line shows you what the old reference pointed to, and you can `git cherry-pick`, `git checkout`, `git show`, or use any other operation on git commits once thought lost.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://git-rebase.io/
|
||||
|
||||
作者:[git-rebase][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://git-rebase.io/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Blockchain 2.0 – Introduction To Hyperledger Fabric [Part 10])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Blockchain 2.0 – Introduction To Hyperledger Fabric [Part 10]
|
||||
======
|
||||
|
||||
![Hyperledger Fabric][1]
|
||||
|
||||
### Hyperledger Fabric
|
||||
|
||||
The [**Hyperledger project**][2] is an umbrella organization of sorts featuring many different modules and systems under development. Among the most popular among these individual sub-projects is the **Hyperledger Fabric**. This post will explore the features that would make the Fabric almost indispensable in the near future once blockchain systems start proliferating into main stream use. Towards the end we will also take a quick look at what developers and enthusiasts need to know regarding the technicalities of the Hyperledger Fabric.
|
||||
|
||||
### Inception
|
||||
|
||||
In the usual fashion for the Hyperledger project, Fabric was “donated” to the organization by one of its core members, **IBM** , who was previously the principle developer of the same. The technology platform shared by IBM was put to joint development at the Hyperledger project with contributions from over a 100 member companies and institutions.
|
||||
|
||||
Currently running on **v1.4** of the LTS version, Fabric has come a long way and is currently seen as the go to enterprise solution for managing business data. The core vision that surrounds the Hyperledger project inevitably permeates into the Fabric as well. The Hyperledger Fabric system carries forward all the enterprise ready and scalable features that are hard coded into all projects under the Hyperledger organization.
|
||||
|
||||
### Highlights Of Hyperledger Fabric
|
||||
|
||||
Hyperledger Fabric offers a wide variety of features and standards that are built around the mission of supporting fast development and modular architectures. Furthermore, compared to its competitors (primarily **Ripple** and [**Ethereum**][3]), Fabric takes an explicit stance toward closed and [**permissioned blockchains**][4]. Their core objective here is to develop a set of tools which will aid blockchain developers in creating customized solutions and not to create a standalone ecosystem or a product.
|
||||
|
||||
Some of the highlights of the Hyperledger Fabric are given below:
|
||||
|
||||
* **Permissioned blockchain systems**
|
||||
|
||||
|
||||
|
||||
This is a category where other platforms such as Ethereum and Ripple differ quite a lot with Hyperledger Fabric. The Fabric by default is a tool designed to implement a private permissioned blockchain. Such blockchains cannot be accessed by everyone and the nodes working to offer consensus or to verify transactions are chosen by a central authority. This might be important for some applications such as banking and insurance, where transactions have to be verified by the central authority rather than participants.
|
||||
|
||||
* **Confidential and controlled information flow**
|
||||
|
||||
|
||||
|
||||
The Fabric has built in permission systems that will restrict information flow within a specific group or certain individuals as the case may be. Unlike a public blockchain where anyone and everyone who runs a node will have a copy and selective access to data stored in the blockchain, the admin of the system can choose how to and who to share access to the information. There are also subsystems which will encrypt the stored data at better security standards compared to existing competition.
|
||||
|
||||
* **Plug and play architecture**
|
||||
|
||||
|
||||
|
||||
Hyperledger Fabric has a plug and play type architecture. Individual components of the system may be chosen to be implemented and components of the system that developers don’t see a use for maybe discarded. The Fabric takes a highly modular and customizable route to development rather than a one size fits all approach taken by its competitors. This is especially attractive for firms and companies looking to build a lean system fast. This combined with the interoperability of the Fabric with other Hyperledger components implies that developers and designers now have access to a diverse set of standardized tools instead of having to pull code from different sources and integrate them afterwards. It also presents a rather fail-safe way to build robust modular systems.
|
||||
|
||||
* **Smart contracts and chaincode**
|
||||
|
||||
|
||||
|
||||
A distributed application running on a blockchain is called a [**Smart contract**][5]. While the smart contract term is more or less associated with the Ethereum platform, chaincode is the name given to the same in the Hyperledger camp. Apart from possessing all the benefits of **DApps** being present in chaincode applications, what sets Hyperledger apart is the fact that the code for the same may be written in multiple high-level programming language. It supports [**Go**][6] and **JavaScript** out of the box and supports many other after integration with appropriate compiler modules as well. Though this fact might not mean much at this point, the fact remains that if existing talent can be used for ongoing projects involving blockchain that has the potential to save companies billions of dollars in personnel training and management in the long run. Developers can code in languages they’re comfortable in to start building applications on the Hyperledger Fabric and need not learn nor train in platform specific languages and syntax. This presents flexibility which current competitors of the Hyperledger Fabric do not offer.
|
||||
|
||||
* The Hyperledger Fabric is a back-end driver platform and is mainly aimed at integration projects where a blockchain or another distributed ledger technology is required. As such it does not provide any user facing services except for minor scripting capabilities. (Think of it to be more like a scripting language.)
|
||||
* Hyperledger Fabric supports building sidechains for specific use-cases. In case, the developer wishes to isolate a set of users or participants to a specific part or functionality of the application, they may do so by implementing side-chains. Side-chains are blockchains that derive from a main parent, but form a different chain after their initial block. This block which gives rise to the new chain will stay immune to further changes in the new chain and the new chain remains immutable even if new information is added to the original chain. This functionality will aid in scaling the platform being developed and usher in user specific and case specific processing capabilities.
|
||||
* The previous feature also means that not all users will have an “exact” copy of all the data in the blockchain as is expected usually from public chains. Participating nodes will have a copy of data that is only relevant to them. For instance, consider an application similar to PayTM in India. The app has wallet functionality as well as an e-commerce end. However, not all its wallet users use PayTM to shop online. In this scenario, only active shoppers will have the corresponding chain of transactions on the PayTM e-commerce site, whereas the wallet users will just have a copy of the chain that stores wallet transactions. This flexible architecture for data storage and retrieval is important while scaling, since massive singular blockchains have been shown to increase lead times for processing transactions. The chain can be kept lean and well categorised this way.
|
||||
|
||||
|
||||
|
||||
We will look at other modules under the Hyperledger Project in detail in upcoming posts.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
|
||||
[3]: https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/
|
||||
[4]: https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/
|
||||
[5]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
|
||||
[6]: https://www.ostechnix.com/install-go-language-linux/
|
||||
@ -0,0 +1,141 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Check Whether The Given Package Is Installed Or Not On Debian/Ubuntu System?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-check-whether-the-given-package-is-installed-or-not-on-ubuntu-debian-system/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Check Whether The Given Package Is Installed Or Not On Debian/Ubuntu System?
|
||||
======
|
||||
|
||||
We have recently published an article about bulk package installation.
|
||||
|
||||
While doing that, i was struggled to get the installed package information and did a small google search and found few methods about it.
|
||||
|
||||
I would like to share it in our website so, that it will be helpful for others too.
|
||||
|
||||
There are numerous ways we can achieve this.
|
||||
|
||||
I have add seven ways to achieve this. However, you can choose the preferred method for you.
|
||||
|
||||
Those methods are listed below.
|
||||
|
||||
* **`apt-cache Command:`** apt-cache command is used to query the APT cache or package metadata.
|
||||
* **`apt Command:`** APT is a powerful command-line tool for installing, downloading, removing, searching and managing packages on Debian based systems.
|
||||
* **`dpkg-query Command:`** dpkg-query is a tool to query the dpkg database.
|
||||
* **`dpkg Command:`** dpkg is a package manager for Debian based systems.
|
||||
* **`which Command:`** The which command returns the full path of the executable that would have been executed when the command had been entered in terminal.
|
||||
* **`whereis Command:`** The whereis command used to search the binary, source, and man page files for a given command.
|
||||
* **`locate Command:`** locate command works faster than the find command because it uses updatedb database, whereas the find command searches in the real system.
|
||||
|
||||
|
||||
|
||||
### Method-1 : How To Check Whether The Given Package Is Installed Or Not On Ubuntu System Using apt-cache Command?
|
||||
|
||||
apt-cache command is used to query the APT cache or package metadata from APT’s internal database.
|
||||
|
||||
It will search and display an information about the given package. It shows whether the package is installed or not, installed package version, source repository information.
|
||||
|
||||
The below output clearly showing that `nano` package has already installed in the system. Since installed part is showing the installed version of nano package.
|
||||
|
||||
```
|
||||
# apt-cache policy nano
|
||||
nano:
|
||||
Installed: 2.9.3-2
|
||||
Candidate: 2.9.3-2
|
||||
Version table:
|
||||
*** 2.9.3-2 500
|
||||
500 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 Packages
|
||||
100 /var/lib/dpkg/status
|
||||
```
|
||||
|
||||
### Method-2 : How To Check Whether The Given Package Is Installed Or Not On Ubuntu System Using apt Command?
|
||||
|
||||
APT is a powerful command-line tool for installing, downloading, removing, searching and managing as well as querying information about packages as a low-level access to all features of the libapt-pkg library. It’s contains some less used command-line utilities related to package management.
|
||||
|
||||
```
|
||||
# apt -qq list nano
|
||||
nano/bionic,now 2.9.3-2 amd64 [installed]
|
||||
```
|
||||
|
||||
### Method-3 : How To Check Whether The Given Package Is Installed Or Not On Ubuntu System Using dpkg-query Command?
|
||||
|
||||
dpkg-query is a tool to show information about packages listed in the dpkg database.
|
||||
|
||||
In the below output first column showing `ii`. It means, the given package has already installed in the system.
|
||||
|
||||
```
|
||||
# dpkg-query --list | grep -i nano
|
||||
ii nano 2.9.3-2 amd64 small, friendly text editor inspired by Pico
|
||||
```
|
||||
|
||||
### Method-4 : How To Check Whether The Given Package Is Installed Or Not On Ubuntu System Using dpkg Command?
|
||||
|
||||
DPKG stands for Debian Package is a tool to install, build, remove and manage Debian packages, but unlike other package management systems, it cannot automatically download and install packages or their dependencies.
|
||||
|
||||
In the below output first column showing `ii`. It means, the given package has already installed in the system.
|
||||
|
||||
```
|
||||
# dpkg -l | grep -i nano
|
||||
ii nano 2.9.3-2 amd64 small, friendly text editor inspired by Pico
|
||||
```
|
||||
|
||||
### Method-5 : How To Check Whether The Given Package Is Installed Or Not On Ubuntu System Using which Command?
|
||||
|
||||
The which command returns the full path of the executable that would have been executed when the command had been entered in terminal.
|
||||
|
||||
It’s very useful when you want to create a desktop shortcut or symbolic link for executable files.
|
||||
|
||||
Which command searches the directories listed in the current user’s PATH environment variable not for all the users. I mean, when you are logged in your own account and you can’t able to search for root user file or directory.
|
||||
|
||||
If the following output shows the given package binary or executable file location then the given package has already installed in the system. If not, the package is not installed in system.
|
||||
|
||||
```
|
||||
# which nano
|
||||
/bin/nano
|
||||
```
|
||||
|
||||
### Method-6 : How To Check Whether The Given Package Is Installed Or Not On Ubuntu System Using whereis Command?
|
||||
|
||||
The whereis command used to search the binary, source, and man page files for a given command.
|
||||
|
||||
If the following output shows the given package binary or executable file location then the given package has already installed in the system. If not, the package is not installed in system.
|
||||
|
||||
```
|
||||
# whereis nano
|
||||
nano: /bin/nano /usr/share/nano /usr/share/man/man1/nano.1.gz /usr/share/info/nano.info.gz
|
||||
```
|
||||
|
||||
### Method-7 : How To Check Whether The Given Package Is Installed Or Not On Ubuntu System Using locate Command?
|
||||
|
||||
locate command works faster than the find command because it uses updatedb database, whereas the find command searches in the real system.
|
||||
|
||||
It uses a database rather than hunting individual directory paths to get a given file.
|
||||
|
||||
locate command doesn’t pre-installed in most of the distributions so, use your distribution package manager to install it.
|
||||
|
||||
The database is updated regularly through cron. Even, we can update it manually.
|
||||
|
||||
If the following output shows the given package binary or executable file location then the given package has already installed in the system. If not, the package is not installed in system.
|
||||
|
||||
```
|
||||
# locate --basename '\nano'
|
||||
/usr/bin/nano
|
||||
/usr/share/nano
|
||||
/usr/share/doc/nano
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-whether-the-given-package-is-installed-or-not-on-ubuntu-debian-system/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
243
sources/tech/20190513 How To Set Password Complexity On Linux.md
Normal file
243
sources/tech/20190513 How To Set Password Complexity On Linux.md
Normal file
@ -0,0 +1,243 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Set Password Complexity On Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-set-password-complexity-policy-on-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Set Password Complexity On Linux?
|
||||
======
|
||||
|
||||
User management is one of the important task of Linux system administration.
|
||||
|
||||
There are many aspect is involved in this and implementing the strong password policy is one of them.
|
||||
|
||||
Navigate to the following URL, if you would like to **[generate a strong password on Linux][1]**.
|
||||
|
||||
It will Restrict unauthorized access to systems.
|
||||
|
||||
By default Linux is secure that everybody know. however, we need to make necessary tweak on this to make it more secure.
|
||||
|
||||
Insecure password will leads to breach security. So, take additional care on this.
|
||||
|
||||
Navigate to the following URL, if you would like to see the **[password strength and score][2]** of the generated strong password.
|
||||
|
||||
In this article, we will teach you, how to implement the best security policy on Linux.
|
||||
|
||||
We can use PAM (the “pluggable authentication module”) to enforce password policy On most Linux systems.
|
||||
|
||||
The file can be found in the following location.
|
||||
|
||||
For Redhat based systems @ `/etc/pam.d/system-auth` and Debian based systems @ `/etc/pam.d/common-password`.
|
||||
|
||||
The default password aging details can be found in the `/etc/login.defs` file.
|
||||
|
||||
I have trimmed this file for better understanding.
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MAX_DAYS 99999
|
||||
PASS_MIN_DAYS 0
|
||||
PASS_MIN_LEN 5
|
||||
PASS_WARN_AGE 7
|
||||
```
|
||||
|
||||
**Details:**
|
||||
|
||||
* **`PASS_MAX_DAYS:`**` ` Maximum number of days a password may be used.
|
||||
* **`PASS_MIN_DAYS:`**` ` Minimum number of days allowed between password changes.
|
||||
* **`PASS_MIN_LEN:`**` ` Minimum acceptable password length.
|
||||
* **`PASS_WARN_AGE:`**` ` Number of days warning given before a password expires.
|
||||
|
||||
|
||||
|
||||
We will show you, how to implement the below eleven password policies in Linux.
|
||||
|
||||
* Password Max days
|
||||
* Password Min days
|
||||
* Password warning days
|
||||
* Password history or Deny Re-Used Passwords
|
||||
* Password minimum length
|
||||
* Minimum upper case characters
|
||||
* Minimum lower case characters
|
||||
* Minimum digits in password
|
||||
* Minimum other characters (Symbols)
|
||||
* Account lock – retries
|
||||
* Account unlock time
|
||||
|
||||
|
||||
|
||||
### What Is Password Max days?
|
||||
|
||||
This parameter limits the maximum number of days a password can be used. It’s mandatory for user to change his/her account password before expiry.
|
||||
|
||||
If they forget to change, they are not allowed to login into the system. They need to work with admin team to get rid of it.
|
||||
|
||||
It can be set in `/etc/login.defs` file. I’m going to set `90 days`.
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MAX_DAYS 90
|
||||
```
|
||||
|
||||
### What Is Password Min days?
|
||||
|
||||
This parameter limits the minimum number of days after password can be changed.
|
||||
|
||||
Say for example, if this parameter is set to 15 and user changed password today. Then he won’t be able to change the password again before 15 days from now.
|
||||
|
||||
It can be set in `/etc/login.defs` file. I’m going to set `15 days`.
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_MIN_DAYS 15
|
||||
```
|
||||
|
||||
### What Is Password Warning Days?
|
||||
|
||||
This parameter controls the password warning days and it will warn the user when the password is going to expires.
|
||||
|
||||
A warning will be given to the user regularly until the warning days ends. This can helps user to change their password before expiry. Otherwise we need to work with admin team for unlock the password.
|
||||
|
||||
It can be set in `/etc/login.defs` file. I’m going to set `10 days`.
|
||||
|
||||
```
|
||||
# vi /etc/login.defs
|
||||
|
||||
PASS_WARN_AGE 10
|
||||
```
|
||||
|
||||
**Note:** All the above parameters only applicable for new accounts and not for existing accounts.
|
||||
|
||||
### What Is Password History Or Deny Re-Used Passwords?
|
||||
|
||||
This parameter keep controls of the password history. Keep history of passwords used (the number of previous passwords which cannot be reused).
|
||||
|
||||
When the users try to set a new password, it will check the password history and warn the user when they set the same old password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `5` for history of password.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password sufficient pam_unix.so md5 shadow nullok try_first_pass use_authtok remember=5
|
||||
```
|
||||
|
||||
### What Is Password Minimum Length?
|
||||
|
||||
This parameter keeps the minimum password length. When the users set a new password, it will check against this parameter and warn the user if they try to set the password length less than that.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `12` character for minimum password length.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12
|
||||
```
|
||||
|
||||
**try_first_pass retry=3** : Allow users to set a good password before the passwd command aborts.
|
||||
|
||||
### Set Minimum Upper Case Characters?
|
||||
|
||||
This parameter keeps, how many upper case characters should be added in the password. These are password strengthening parameters ,which increase the password strength.
|
||||
|
||||
When the users set a new password, it will check against this parameter and warn the user if they are not including any upper case characters in the password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `1` character for minimum password length.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 ucredit=-1
|
||||
```
|
||||
|
||||
### Set Minimum Lower Case Characters?
|
||||
|
||||
This parameter keeps, how many lower case characters should be added in the password. These are password strengthening parameters ,which increase the password strength.
|
||||
|
||||
When the users set a new password, it will check against this parameter and warn the user if they are not including any lower case characters in the password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `1` character.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 lcredit=-1
|
||||
```
|
||||
|
||||
### Set Minimum Digits In Password?
|
||||
|
||||
This parameter keeps, how many digits should be added in the password. These are password strengthening parameters ,which increase the password strength.
|
||||
|
||||
When the users set a new password, it will check against this parameter and warn the user if they are not including any digits in the password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `1` character.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 dcredit=-1
|
||||
```
|
||||
|
||||
### Set Minimum Other Characters (Symbols) In Password?
|
||||
|
||||
This parameter keeps, how many Symbols should be added in the password. These are password strengthening parameters ,which increase the password strength.
|
||||
|
||||
When the users set a new password, it will check against this parameter and warn the user if they are not including any Symbol in the password.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file. I’m going to set `1` character.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
password requisite pam_cracklib.so try_first_pass retry=3 minlen=12 ocredit=-1
|
||||
```
|
||||
|
||||
### Set Account Lock?
|
||||
|
||||
This parameter controls users failed attempts. It locks user account after reaches the given number of failed login attempts.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
auth required pam_tally2.so onerr=fail audit silent deny=5
|
||||
account required pam_tally2.so
|
||||
```
|
||||
|
||||
### Set Account Unlock Time?
|
||||
|
||||
This parameter keeps users unlock time. If the user account is locked after consecutive failed authentications.
|
||||
|
||||
It’s unlock the locked user account after reaches the given time. Sets the time (900 seconds = 15 minutes) for which the account should remain locked.
|
||||
|
||||
It can be set in `/etc/pam.d/system-auth` file.
|
||||
|
||||
```
|
||||
# vi /etc/pam.d/system-auth
|
||||
|
||||
auth required pam_tally2.so onerr=fail audit silent deny=5 unlock_time=900
|
||||
account required pam_tally2.so
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-set-password-complexity-policy-on-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/5-ways-to-generate-a-random-strong-password-in-linux-terminal/
|
||||
[2]: https://www.2daygeek.com/how-to-check-password-complexity-strength-and-score-in-linux/
|
||||
@ -0,0 +1,153 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Manage business documents with OpenAS2 on Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/manage-business-documents-with-openas2-on-fedora/)
|
||||
[#]: author: (Stuart D Gathman https://fedoramagazine.org/author/sdgathman/)
|
||||
|
||||
Manage business documents with OpenAS2 on Fedora
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Business documents often require special handling. Enter Electronic Document Interchange, or **EDI**. EDI is more than simply transferring files using email or http (or ftp), because these are documents like orders and invoices. When you send an invoice, you want to be sure that:
|
||||
|
||||
1\. It goes to the right destination, and is not intercepted by competitors.
|
||||
2\. Your invoice cannot be forged by a 3rd party.
|
||||
3\. Your customer can’t claim in court that they never got the invoice.
|
||||
|
||||
The first two goals can be accomplished by HTTPS or email with S/MIME, and in some situations, a simple HTTPS POST to a web API is sufficient. What EDI adds is the last part.
|
||||
|
||||
This article does not cover the messy topic of formats for the files exchanged. Even when using a standardized format like ANSI or EDIFACT, it is ultimately up to the business partners. It is not uncommon for business partners to use an ad-hoc CSV file format. This article shows you how to configure Fedora to send and receive in an EDI setup.
|
||||
|
||||
### Centralized EDI
|
||||
|
||||
The traditional solution is to use a Value Added Network, or **VAN**. The VAN is a central hub that transfers documents between their customers. Most importantly, it keeps a secure record of the documents exchanged that can be used as evidence in disputes. The VAN can use different transfer protocols for each of its customers
|
||||
|
||||
### AS Protocols and MDN
|
||||
|
||||
The AS protocols are a specification for adding a digital signature with optional encryption to an electronic document. What it adds over HTTPS or S/MIME is the Message Disposition Notification, or **MDN**. The MDN is a signed and dated response that says, in essence, “We got your invoice.” It uses a secure hash to identify the specific document received. This addresses point #3 without involving a third party.
|
||||
|
||||
The [AS2 protocol][2] uses HTTP or HTTPS for transport. Other AS protocols target [FTP][3] and [SMTP][4]. AS2 is used by companies big and small to avoid depending on (and paying) a VAN.
|
||||
|
||||
### OpenAS2
|
||||
|
||||
OpenAS2 is an open source Java implemention of the AS2 protocol. It is available in Fedora since 28, and installed with:
|
||||
|
||||
```
|
||||
$ sudo dnf install openas2
|
||||
$ cd /etc/openas2
|
||||
```
|
||||
|
||||
Configuration is done with a text editor, and the config files are in XML. The first order of business before starting OpenAS2 is to change the factory passwords.
|
||||
|
||||
Edit _/etc/openas2/config.xml_ and search for _ChangeMe_. Change those passwords. The default password on the certificate store is _testas2_ , but that doesn’t matter much as anyone who can read the certificate store can read _config.xml_ and get the password.
|
||||
|
||||
### What to share with AS2 partners
|
||||
|
||||
There are 3 things you will exchange with an AS2 peer.
|
||||
|
||||
#### AS2 ID
|
||||
|
||||
Don’t bother looking up the official AS2 standard for legal AS2 IDs. While OpenAS2 implements the standard, your partners will likely be using a proprietary product which doesn’t. While AS2 allows much longer IDs, many implementations break with more than 16 characters. Using otherwise legal AS2 ID chars like ‘:’ that can appear as path separators on a proprietary OS is also a problem. Restrict your AS2 ID to upper and lower case alpha, digits, and ‘_’ with no more than 16 characters.
|
||||
|
||||
#### SSL certificate
|
||||
|
||||
For real use, you will want to generate a certificate with SHA256 and RSA. OpenAS2 ships with two factory certs to play with. Don’t use these for anything real, obviously. The certificate file is in PKCS12 format. Java ships with _keytool_ which can maintain your PKCS12 “keystore,” as Java calls it. This article skips using _openssl_ to generate keys and certificates. Simply note that _sudo keytool -list -keystore as2_certs.p12_ will list the two factory practice certs.
|
||||
|
||||
#### AS2 URL
|
||||
|
||||
This is an HTTP URL that will access your OpenAS2 instance. HTTPS is also supported, but is redundant. To use it you have to uncomment the https module configuration in _config.xml_ , and supply a certificate signed by a public CA. This requires another article and is entirely unnecessary here.
|
||||
|
||||
By default, OpenAS2 listens on 10080 for HTTP and 10443 for HTTPS. OpenAS2 can talk to itself, so it ships with two partnerships using _<http://localhost:10080>_ as the AS2 URL. If you don’t find this a convincing demo, and can install a second instance (on a VM, for instance), you can use private IPs for the AS2 URLs. Or install [Cjdns][5] to get IPv6 mesh addresses that can be used anywhere, resulting in AS2 URLs like _http://[fcbf:fc54:e597:7354:8250:2b2e:95e6:d6ba]:10080_.
|
||||
|
||||
Most businesses will also want a list of IPs to add to their firewall. This is actually [bad practice][6]. An AS2 server has the same security risk as a web server, meaning you should isolate it in a VM or container. Also, the difficulty of keeping mutual lists of IPs up to date grows with the list of partners. The AS2 server rejects requests not signed by a configured partner.
|
||||
|
||||
### OpenAS2 Partners
|
||||
|
||||
With that in mind, open _partnerships.xml_ in your editor. At the top is a list of “partners.” Each partner has a name (referenced by the partnerships below as “sender” or “receiver”), AS2 ID, certificate, and email. You need a partner definition for yourself and those you exchange documents with. You can define multiple partners for yourself. OpenAS2 ships with two partners, OpenAS2A and OpenAS2B, which you’ll use to send a test document.
|
||||
|
||||
### OpenAS2 Partnerships
|
||||
|
||||
Next is a list of “partnerships,” one for each direction. Each partnership configuration includes the sender, receiver, and the AS2 URL used to send the documents. By default, partnerships use synchronous MDN. The MDN is returned on the same HTTP transaction. You could uncomment the _as2_receipt_option_ for asynchronous MDN, which is sent some time later. Use synchronous MDN whenever possible, as tracking pending MDNs adds complexity to your application.
|
||||
|
||||
The other partnership options select encryption, signature hash, and other protocol options. A fully implemented AS2 receiver can handle any combination of options, but AS2 partners may have incomplete implementations or policy requirements. For example, DES3 is a comparatively weak encryption algorithm, and may not be acceptable. It is the default because it is almost universally implemented.
|
||||
|
||||
If you went to the trouble to set up a second physical or virtual machine for this test, designate one as OpenAS2A and the other as OpenAS2B. Modify the _as2_url_ on the OpenAS2A-to-OpenAS2B partnership to use the IP (or hostname) of OpenAS2B, and vice versa for the OpenAS2B-to-OpenAS2A partnership. Unless they are using the FedoraWorkstation firewall profile, on both machines you’ll need:
|
||||
|
||||
```
|
||||
# sudo firewall-cmd --zone=public --add-port=10080/tcp
|
||||
```
|
||||
|
||||
Now start the _openas2_ service (on both machines if needed):
|
||||
|
||||
```
|
||||
# sudo systemctl start openas2
|
||||
```
|
||||
|
||||
### Resetting the MDN password
|
||||
|
||||
This initializes the MDN log database with the factory password, not the one you changed it to. This is a packaging bug to be fixed in the next release. To avoid frustration, here’s how to change the h2 database password:
|
||||
|
||||
```
|
||||
$ sudo systemctl stop openas2
|
||||
$ cat >h2passwd <<'DONE'
|
||||
#!/bin/bash
|
||||
AS2DIR="/var/lib/openas2"
|
||||
java -cp "$AS2DIR"/lib/h2* org.h2.tools.Shell \
|
||||
-url jdbc:h2:"$AS2DIR"/db/openas2 \
|
||||
-user sa -password "$1" <<EOF
|
||||
alter user sa set password '$2';
|
||||
exit
|
||||
EOF
|
||||
DONE
|
||||
$ sudo sh h2passwd ChangeMe yournewpasswordsetabove
|
||||
$ sudo systemctl start openas2
|
||||
```
|
||||
|
||||
### Testing the setup
|
||||
|
||||
With that out of the way, let’s send a document. Assuming you are on OpenAS2A machine:
|
||||
|
||||
```
|
||||
$ cat >testdoc <<'DONE'
|
||||
This is not a real EDI format, but is nevertheless a document.
|
||||
DONE
|
||||
$ sudo chown openas2 testdoc
|
||||
$ sudo mv testdoc /var/spool/openas2/toOpenAS2B
|
||||
$ sudo journalctl -f -u openas2
|
||||
... log output of sending file, Control-C to stop following log
|
||||
^C
|
||||
```
|
||||
|
||||
OpenAS2 does not send a document until it is writable by the _openas2_ user or group. As a consequence, your actual business application will copy, or generate in place, the document. Then it changes the group or permissions to send it on its way, to avoid sending a partial document.
|
||||
|
||||
Now, on the OpenAS2B machine, _/var/spool/openas2/OpenAS2A_OID-OpenAS2B_OID/inbox_ shows the message received. That should get you started!
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[ _Beatriz Pérez Moya_][7]_ on _[_Unsplash_][8]_._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/manage-business-documents-with-openas2-on-fedora/
|
||||
|
||||
作者:[Stuart D Gathman][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/sdgathman/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/05/openas2-816x345.jpg
|
||||
[2]: https://en.wikipedia.org/wiki/AS2
|
||||
[3]: https://en.wikipedia.org/wiki/AS3_(networking)
|
||||
[4]: https://en.wikipedia.org/wiki/AS1_(networking)
|
||||
[5]: https://fedoramagazine.org/decentralize-common-fedora-apps-cjdns/
|
||||
[6]: https://www.ld.com/as2-part-2-best-practices/
|
||||
[7]: https://unsplash.com/photos/XN4T2PVUUgk?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]: https://unsplash.com/search/photos/documents?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user