mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
commit
ef9cf944c8
@ -1,7 +1,5 @@
|
||||
<header class="post-header" style="text-rendering: optimizeLegibility; font-family: "Noto Serif", Georgia, Cambria, "Times New Roman", Times, serif; font-size: 20px; text-align: start; background-color: rgb(255, 255, 255);">[在 Go 中如何使用切片的容量和长度][14]
|
||||
============================================================</header>
|
||||
|
||||
<aside class="post-side" style="text-rendering: optimizeLegibility; position: fixed; top: 80px; left: 0px; width: 195px; padding-right: 5px; padding-left: 5px; text-align: right; z-index: 300; font-family: "Noto Serif", Georgia, Cambria, "Times New Roman", Times, serif; font-size: 20px;"></aside>
|
||||
在 Go 中如何使用切片的容量和长度
|
||||
============================================================
|
||||
|
||||
快速测试 - 下面的代码输出什么?
|
||||
|
||||
@ -19,15 +17,15 @@ _[在 Go Playground 运行一下][1]_
|
||||
|
||||
_等等,什么?_ 为什么不是 `[0 1 2 3 4]`?
|
||||
|
||||
如果你在测试中做错了,你也不用担心。这是在 Go 过渡的过程中相当常见的错误,在这篇文章中,我们将说明为什么输出不是你预期的,以及如何利用 Go 的细微差别来使你的代码更有效率。
|
||||
如果你在测试中做错了,你也不用担心。这是在过渡到 Go 语言的过程中相当常见的错误,在这篇文章中,我们将说明为什么输出不是你预期的,以及如何利用 Go 的细微差别来使你的代码更有效率。
|
||||
|
||||
### 切片 vs 数组
|
||||
|
||||
在 Go 中同时有数组和切片。这可能令人困惑,但一旦你习惯了,你会喜欢上它。请相信我
|
||||
在 Go 中同时有数组(array)和切片(slice)。这可能令人困惑,但一旦你习惯了,你会喜欢上它。请相信我。
|
||||
|
||||
切片和数组之间存在许多差异,但我们要在本文中重点介绍的内容是数组的大小是其类型的一部分,而切片可以具有动态大小,因为它们是围绕数组的包装。
|
||||
切片和数组之间存在许多差异,但我们要在本文中重点介绍的内容是数组的大小是其类型的一部分,而切片可以具有动态大小,因为它们是围绕数组的封装。
|
||||
|
||||
这在实践中意味着什么?那么假设我们有数组 `val a [10]int`。该数组具有固定大小,且无法更改。如果我们调用 “len(a)”,它总是返回 10,因为这个大小是类型的一部分。因此,如果你突然在数组中需要超过 10 个项,则必须创建一个完全不同类型的新对象,例如 `val b [11]int`,然后将所有值从 `a` 复制到 `b`。
|
||||
这在实践中意味着什么?那么假设我们有数组 `val a [10]int`。该数组具有固定大小,且无法更改。如果我们调用 `len(a)`,它总是返回 `10`,因为这个大小是类型的一部分。因此,如果你突然需要在数组中超过 10 个项,则必须创建一个完全不同类型的新对象,例如 `val b [11]int`,然后将所有值从 `a` 复制到 `b`。
|
||||
|
||||
在特定情况下,含有集合大小的数组是有价值的,但一般而言,这不是开发人员想要的。相反,他们希望在 Go 中使用类似于数组的东西,但是随着时间的推移,它们能够随时增长。一个粗略的方式是创建一个比它需要大得多的数组,然后将数组的一个子集视为数组。下面的代码是个例子。
|
||||
|
||||
@ -48,13 +46,13 @@ fmt.Println("The subset of our array has a length of:", subsetLen)
|
||||
|
||||
_[在 Go Playground 中运行][2]_
|
||||
|
||||
在代码中,我们有一个长度为 20 的数组,但是由于我们只使用一个子集,代码中我们可以假定数组的长度是 5,然后在我们向数组中添加一个新的项之后是 6。
|
||||
在代码中,我们有一个长度为 `20` 的数组,但是由于我们只使用一个子集,代码中我们可以假定数组的长度是 `5`,然后在我们向数组中添加一个新的项之后是 `6`。
|
||||
|
||||
这是(非常粗略地说)切片是如何工作的。它们包含一个具有设置大小的数组,就像我们前面的例子中的数组一样,它的大小为 20。
|
||||
这是(非常粗略地说)切片是如何工作的。它们包含一个具有设置大小的数组,就像我们前面的例子中的数组一样,它的大小为 `20`。
|
||||
|
||||
它们还跟踪程序中使用的数组的子集 - 这就是 `append` 属性,它类似于上一个例子中的 `subsetLen` 变量。
|
||||
|
||||
最后,一个 slice 还有一个 `capacity`,类似于前面例子中我们的数组(20)的总长度。这是很有用的, 因为它会告诉你的子集在无法容纳切片数组之前可以增长的大小。当发生这种情况时,需要分配一个新的数组,但所有这些逻辑都隐藏在 `append` 函数的后面。
|
||||
最后,一个切片还有一个 `capacity`,类似于前面例子中我们的数组的总长度(`20`)。这是很有用的,因为它会告诉你的子集在无法容纳切片数组之前可以增长的大小。当发生这种情况时,需要分配一个新的数组,但所有这些逻辑都隐藏在 `append` 函数的后面。
|
||||
|
||||
简而言之,使用 `append` 函数组合切片给我们一个非常类似于数组的类型,但随着时间的推移,它可以处理更多的元素。
|
||||
|
||||
@ -94,11 +92,11 @@ for i := 0; i < 5; i++ {
|
||||
fmt.Println(vals)
|
||||
```
|
||||
|
||||
当调用 `make` 时,我们允许最多传入 3 个参数。第一个是我们分配的类型,第二个是类型的 `长度`,第三个是类型的 `容量`(_这个参数是可选的_)。
|
||||
当调用 `make` 时,我们允许最多传入 3 个参数。第一个是我们分配的类型,第二个是类型的“长度”,第三个是类型的“容量”(_这个参数是可选的_)。
|
||||
|
||||
通过传递参数 `make([]int, 5)`,我们告诉程序我们要创建一个长度为 5 的切片,在这种情况下,默认的容量与长度相同 - 本例中是 5。
|
||||
|
||||
虽然这可能看起来像我们想要的那样,这里的重要区别是我们告诉我们的切片,我们要将 `长度` 和 `容量` 设置为 5,假设你想要在初始的 5 个元素_之后_添加新的元素,我们接着调用 `append` 函数,那么它会增加容量的大小,并且会在切片的最后添加新的元素。
|
||||
虽然这可能看起来像我们想要的那样,这里的重要区别是我们告诉我们的切片,我们要将“长度”和“容量”设置为 5,假设你想要在初始的 5 个元素_之后_添加新的元素,我们接着调用 `append` 函数,那么它会增加容量的大小,并且会在切片的最后添加新的元素。
|
||||
|
||||
如果在代码中添加一条 `Println()` 语句,你可以看到容量的变化。
|
||||
|
||||
@ -119,7 +117,7 @@ _[在 Go Playground 中运行][4]_
|
||||
|
||||
如何修复它呢?好的,这有几种方法,我们将讲解两种,你可以选取任何一种在你的场景中最有用的方法。
|
||||
|
||||
### 直接使用索引写入而不是 `append`
|
||||
#### 直接使用索引写入而不是 `append`
|
||||
|
||||
第一种修复是保留 `make` 调用不变,并且显式地使用索引来设置每个元素。这样,我们就得到如下的代码:
|
||||
|
||||
@ -164,13 +162,13 @@ _[在 Go Playground 中运行][6]_
|
||||
|
||||
这样做很好,因为我们知道我们返回的切片的长度将与 map 的长度相同,因此我们可以用该长度初始化我们的切片,然后将每个元素分配到适当的索引中。这种方法的缺点是我们必须跟踪 `i`,以便了解每个索引要设置的值。
|
||||
|
||||
这就让我们引出了第二种方法。。。
|
||||
这就让我们引出了第二种方法……
|
||||
|
||||
### 使用 `0` 作为你的长度并指定容量
|
||||
#### 使用 `0` 作为你的长度并指定容量
|
||||
|
||||
与其跟踪我们要添加的值的索引,我们可以更新我们的 `make` 调用,并在切片类型之后提供两个参数。第一个,我们的新切片的长度将被设置为 `0`,因为我们还没有添加任何新的元素到切片中。第二个,我们新切片的容量将被设置为 map 参数的长度,因为我们知道我们的切片最终会添加许多字符串。
|
||||
|
||||
这会如前面的例子那样仍旧会在背后构建相同的数组,但是现在当我们调用 `append` 时,它会将它们放在切片开始处,因为切片的长度是0。
|
||||
这会如前面的例子那样仍旧会在背后构建相同的数组,但是现在当我们调用 `append` 时,它会将它们放在切片开始处,因为切片的长度是 0。
|
||||
|
||||
```
|
||||
package main
|
||||
@ -197,11 +195,11 @@ _[在 Go Playground 中运行][7]_
|
||||
|
||||
### 如果 `append` 处理它,为什么我们还要担心容量呢?
|
||||
|
||||
接下来你可能会问:“如果 `append` 函数可以为我增加切片的容量,那我们为什么要告诉程序容量呢?
|
||||
接下来你可能会问:“如果 `append` 函数可以为我增加切片的容量,那我们为什么要告诉程序容量呢?”
|
||||
|
||||
事实是,在大多数情况下,你不必担心这太多。如果它使你的代码变得更复杂,只需用 `var vals []int` 初始化你的切片,然后让 `append` 函数处理接下来的事。
|
||||
|
||||
但这种情况是不同的。它并不是声明容量是困难的例子,实际上这很容易确定我们的切片的最后容量,因为我们知道它将直接映射到提供的 map 中。因此,当我们初始化它时,我们可以声明切片的容量,并免于让我们程序执行不必要的内存分配。
|
||||
但这种情况是不同的。它并不是声明容量困难的例子,实际上这很容易确定我们的切片的最后容量,因为我们知道它将直接映射到提供的 map 中。因此,当我们初始化它时,我们可以声明切片的容量,并免于让我们的程序执行不必要的内存分配。
|
||||
|
||||
如果要查看额外的内存分配情况,请在 Go Playground 上运行以下代码。每次增加容量,程序都需要做一次内存分配。
|
||||
|
||||
@ -233,7 +231,7 @@ func keys(m map[string]struct{}) []string {
|
||||
|
||||
_[在 Go Playground 中运行][8]_
|
||||
|
||||
现在将此与相同的代码进行比较, 但具有预定义的容量。
|
||||
现在将此与相同的代码进行比较,但具有预定义的容量。
|
||||
|
||||
```
|
||||
package main
|
||||
@ -269,7 +267,7 @@ _[在 Go Playground 中运行][9]_
|
||||
|
||||
### 不要过分优化
|
||||
|
||||
如前所述,我通常不鼓励任何人担心这样的小优化,但如果最后大小的效果真的很明显,那么我强烈建议你尝试为切片设置适当的容量或长度。
|
||||
如前所述,我通常不鼓励任何人做这样的小优化,但如果最后大小的效果真的很明显,那么我强烈建议你尝试为切片设置适当的容量或长度。
|
||||
|
||||
这不仅有助于提高程序的性能,还可以通过明确说明输入的大小和输出的大小之间的关系来帮助澄清你的代码。
|
||||
|
||||
@ -293,7 +291,8 @@ _[在 Go Playground 中运行][9]_
|
||||
|
||||
作者简介:
|
||||
|
||||
Jon 是一名软件顾问,也是 “Web Development with Go” 一书的作者。在此之前,他创立了 EasyPost,一家 Y Combinator 支持的创业公司,并在 Google 工作。
|
||||
Jon 是一名软件顾问,也是 《Web Development with Go》 一书的作者。在此之前,他创立了 EasyPost,一家 Y Combinator 支持的创业公司,并在 Google 工作。
|
||||
|
||||
https://www.usegolang.com
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -303,7 +302,7 @@ via: https://www.calhoun.io/how-to-use-slice-capacity-and-length-in-go
|
||||
|
||||
作者:[Jon Calhoun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,8 @@
|
||||
如何在 Ubuntu 16.04 上安装 OTRS (开源故障单系统)
|
||||
如何在 Ubuntu 16.04 上安装 OTRS (开源问题单系统)
|
||||
============================================================
|
||||
|
||||
|
||||
### 在本页中
|
||||
|
||||
1. [步骤 1 - 安装 Apache 和 PostgreSQL][1]
|
||||
2. [步骤 2 - 安装 Perl 模块][2]
|
||||
3. [步骤 3 - 为 OTRS 创建新用户][3]
|
||||
4. [步骤 4 - 创建和配置数据库][4]
|
||||
5. [步骤 5 - 下载和配置 OTRS][5]
|
||||
6. [步骤 6 - 导入样本数据库][6]
|
||||
7. [步骤 7 - 启动 OTRS][7]
|
||||
8. [步骤 8 - 配置 OTRS 计划任务][8]
|
||||
9. [步骤 9 - 测试 OTRS][9]
|
||||
10. [步骤 10 - 疑难排查][10]
|
||||
11. [参考][11]
|
||||
|
||||
OTRS 或者开源单据申请系统一个用于客户服务、帮助台和 IT 服务管理的开源单据软件。该软件是用 Perl 和 javascript 编写的。对于那些需要管理票据、投诉、支持请求或其他类型的报告的公司和组织,这是一个单据解决方案。OTRS 支持包括 MySQL、PostgreSQL、Oracle 和 SQL Server 在内的多个数据库系统,它是一个可以安装在 Windows 和 Linux 上的多平台软件。
|
||||
OTRS ,及开源问题单(ticket)申请系统是一个用于客户服务、帮助台和 IT 服务管理的开源问题单软件。该软件是用 Perl 和 javascript 编写的。对于那些需要管理票据、投诉、支持请求或其他类型的报告的公司和组织来说,这是一个问题单解决方案。OTRS 支持包括 MySQL、PostgreSQL、Oracle 和 SQL Server 在内的多个数据库系统,它是一个可以安装在 Windows 和 Linux 上的多平台软件。
|
||||
|
||||
在本教程中,我将介绍如何在 Ubuntu 16.04 上安装和配置 OTRS。我将使用 PostgreSQL 作为 OTRS 的数据库,将 Apache Web 服务器用作 Web 服务器。
|
||||
|
||||
@ -31,19 +18,27 @@ OTRS 或者开源单据申请系统一个用于客户服务、帮助台和 IT
|
||||
|
||||
使用 SSH 登录到你的 Ubuntu 服务器中:
|
||||
|
||||
`ssh root@192.168.33.14`
|
||||
```
|
||||
ssh root@192.168.33.14
|
||||
```
|
||||
|
||||
更新 Ubuntu 仓库。
|
||||
|
||||
`sudo apt-get update`
|
||||
```
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
使用 apt 安装 Apache2 以及 PostgreSQL:
|
||||
|
||||
`sudo apt-get install -y apache2 libapache2-mod-perl2 postgresql`
|
||||
```
|
||||
sudo apt-get install -y apache2 libapache2-mod-perl2 postgresql
|
||||
```
|
||||
|
||||
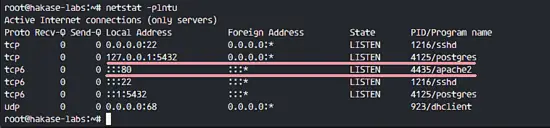
通过检查服务器端口确保 Apache 以及 PostgreSQL 运行了。
|
||||
|
||||
`netstat -plntu`
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -68,9 +63,11 @@ a2enmod perl
|
||||
systemctl restart apache2
|
||||
```
|
||||
|
||||
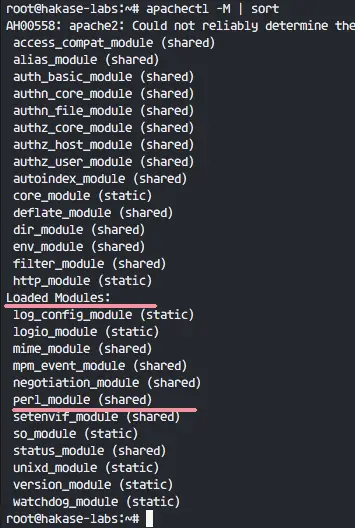
接下来,使用下面的命令检查模块已经加载了:
|
||||
接下来,使用下面的命令检查模块是否已经加载了:
|
||||
|
||||
`apachectl -M | sort`
|
||||
```
|
||||
apachectl -M | sort
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -82,21 +79,23 @@ systemctl restart apache2
|
||||
|
||||
OTRS 是一个基于 web 的程序并且运行与 apache web 服务器下。为了安全,我们需要以普通用户运行它,而不是 root 用户。
|
||||
|
||||
使用 useradd 命令创建一个 “otrs” 新用户:
|
||||
使用 useradd 命令创建一个 `otrs` 新用户:
|
||||
|
||||
```
|
||||
useradd -r -d /opt/otrs -c 'OTRS User' otrs
|
||||
|
||||
**-r**: make the user as a system account.
|
||||
**-d /opt/otrs**: define home directory for new user on '/opt/otrs'.
|
||||
**-c**: comment.
|
||||
```
|
||||
|
||||
接下来,将 otrs 用户加入到 “www-data” 用户组,因为 apache 运行于 “www-data” 用户以及用户组。
|
||||
* `-r`:将用户作为系统用户。
|
||||
* `-d /opt/otrs`:在 `/opt/otrs` 下放置新用户的主目录。
|
||||
* `-c`:备注。
|
||||
|
||||
`usermod -a -G www-data otrs`
|
||||
接下来,将 `otrs` 用户加入到 `www-data` 用户组,因为 apache 运行于 `www-data` 用户及用户组。
|
||||
|
||||
在 “/etc/passwd” 文件中已经有 otrs 用户了。
|
||||
```
|
||||
usermod -a -G www-data otrs
|
||||
```
|
||||
|
||||
在 `/etc/passwd` 文件中已经有 `otrs` 用户了。
|
||||
|
||||
```
|
||||
grep -rin otrs /etc/passwd
|
||||
@ -110,35 +109,35 @@ OTRS 的新用户已经创建了。
|
||||
|
||||
### 步骤 4 - 创建和配置数据库
|
||||
|
||||
在这节中,我们会为 OTRS 系统创建一个新 PostgreSQL 数据库并对 PostgreSQL 数据库的配置做一些小的更改。
|
||||
在这节中,我们会为 OTRS 系统创建一个新 PostgreSQL 数据库,并对 PostgreSQL 数据库的配置做一些小的更改。
|
||||
|
||||
登录到 **postgres** 用户并访问 PostgreSQL shell。
|
||||
登录到 `postgres` 用户并访问 PostgreSQL shell。
|
||||
|
||||
```
|
||||
su - postgres
|
||||
psql
|
||||
```
|
||||
|
||||
创建一个新的 “**otrs**” 角色,密码是 “**myotrspw**”,并且是非特权用户。
|
||||
创建一个新的角色 `otrs`,密码是 `myotrspw`,并且是非特权用户。
|
||||
|
||||
```
|
||||
create user otrs password 'myotrspw' nosuperuser;
|
||||
```
|
||||
|
||||
接着使用 “**otrs**” 用户权限创建一个新的 “**otrs**” 数据库:
|
||||
接着使用 `otrs` 用户权限创建一个新的 `otrs` 数据库:
|
||||
|
||||
```
|
||||
create database otrs owner otrs;
|
||||
\q
|
||||
```
|
||||
|
||||
接下来为 otrs 角色验证编辑 PostgreSQL 配置文件。
|
||||
接下来为 `otrs` 角色验证编辑 PostgreSQL 配置文件。
|
||||
|
||||
```
|
||||
vim /etc/postgresql/9.5/main/pg_hba.conf
|
||||
```
|
||||
|
||||
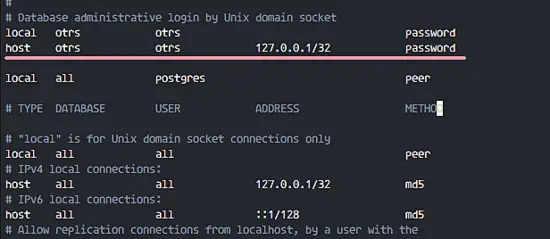
在 84 换行后粘贴下面的配置:
|
||||
在 84 行后粘贴下面的配置:
|
||||
|
||||
```
|
||||
local otrs otrs password
|
||||
@ -151,7 +150,7 @@ host otrs otrs 127.0.0.1/32
|
||||
|
||||
][20]
|
||||
|
||||
使用 “exit” 回到 root 权限并重启 PostgreSQL:
|
||||
使用 `exit` 回到 root 权限并重启 PostgreSQL:
|
||||
|
||||
```
|
||||
exit
|
||||
@ -168,14 +167,14 @@ PostgreSQL 已经为 OTRS 的安装准备好了。
|
||||
|
||||
在本教程中,我们会使用 OTRS 网站中最新的版本。
|
||||
|
||||
进入 “/opt” 目录并使用 wget 命令下载 OTRS 5.0:
|
||||
进入 `/opt` 目录并使用 `wget` 命令下载 OTRS 5.0:
|
||||
|
||||
```
|
||||
cd /opt/
|
||||
wget http://ftp.otrs.org/pub/otrs/otrs-5.0.16.tar.gz
|
||||
```
|
||||
|
||||
otrs 文件,重命名目录并更改所有 otrs 的文件和目录的所属人为 “otrs”。
|
||||
展开该 otrs 文件,重命名目录并更改所有 otrs 的文件和目录的所属人为 `otrs`。
|
||||
|
||||
```
|
||||
tar -xzvf otrs-5.0.16.tar.gz
|
||||
@ -206,7 +205,7 @@ cd /opt/otrs/
|
||||
cp Kernel/Config.pm.dist Kernel/Config.pm
|
||||
```
|
||||
|
||||
使用 vim 编辑 “Config.pm” 文件:
|
||||
使用 vim 编辑 `Config.pm` 文件:
|
||||
|
||||
```
|
||||
vim Kernel/Config.pm
|
||||
@ -220,7 +219,9 @@ $Self->{DatabasePw} = 'myotrspw';
|
||||
|
||||
注释 45 行的 MySQL 数据库支持:
|
||||
|
||||
```
|
||||
# $Self->{DatabaseDSN} = "DBI:mysql:database=$Self->{Database};host=$Self->{DatabaseHost};";
|
||||
```
|
||||
|
||||
取消注释 49 行的 PostgreSQL 数据库支持:
|
||||
|
||||
@ -264,13 +265,13 @@ perl -cw /opt/otrs/bin/otrs.Console.pl
|
||||
|
||||
在本教程中,我们会使用样本数据库,这可以在脚本目录中找到。因此我们只需要将所有的样本数据库以及表结构导入到第 4 步创建的数据库中。
|
||||
|
||||
登录到 postgres 用户并进入 otrs 目录中。
|
||||
登录到 `postgres` 用户并进入 otrs 目录中。
|
||||
|
||||
```
|
||||
su - postgres
|
||||
cd /opt/otrs/
|
||||
```
|
||||
作为 otrs 用户使用 psql 命令插入数据库以及表结构。
|
||||
作为 otrs 用户使用 `psql` 命令插入数据库以及表结构。
|
||||
|
||||
```
|
||||
psql -U otrs -W -f scripts/database/otrs-schema.postgresql.sql otrs
|
||||
@ -278,7 +279,7 @@ psql -U otrs -W -f scripts/database/otrs-initial_insert.postgresql.sql otrs
|
||||
psql -U otrs -W -f scripts/database/otrs-schema-post.postgresql.sql otrs
|
||||
```
|
||||
|
||||
在需要的时候输入数据库密码 “**myotrspw**”。
|
||||
在需要的时候输入数据库密码 `myotrspw`。
|
||||
|
||||
[
|
||||

|
||||
@ -288,7 +289,7 @@ psql -U otrs -W -f scripts/database/otrs-schema-post.postgresql.sql otrs
|
||||
|
||||
数据库以及 OTRS 已经配置了,现在我们可以启动 OTRS。
|
||||
|
||||
将 otrs 的文件及目录权限设置为 www-data 用户和用户组。
|
||||
将 otrs 的文件及目录权限设置为 `www-data` 用户和用户组。
|
||||
|
||||
```
|
||||
/opt/otrs/bin/otrs.SetPermissions.pl --otrs-user=www-data --web-group=www-data
|
||||
@ -307,7 +308,7 @@ a2ensite otrs
|
||||
systemctl restart apache2
|
||||
```
|
||||
|
||||
确保 apache 没有错误。
|
||||
确保 apache 启动没有错误。
|
||||
|
||||
[
|
||||

|
||||
@ -317,7 +318,7 @@ systemctl restart apache2
|
||||
|
||||
OTRS 已经安装并运行在 Apache Web 服务器中了,但是我们仍然需要配置 OTRS 计划任务。
|
||||
|
||||
登录到 “otrs” 用户,接着以 otrs 用户进入 “var/cron” 目录。
|
||||
登录到 `otrs` 用户,接着以 otrs 用户进入 `var/cron` 目录。
|
||||
|
||||
```
|
||||
su - otrs
|
||||
@ -325,13 +326,13 @@ cd var/cron/
|
||||
pwd
|
||||
```
|
||||
|
||||
使用下面的命令复制所有 .dist 计划任务脚本:
|
||||
使用下面的命令复制所有 `.dist` 计划任务脚本:
|
||||
|
||||
```
|
||||
for foo in *.dist; do cp $foo `basename $foo .dist`; done
|
||||
```
|
||||
|
||||
使用 exit 回到 root 权限,并使用 otrs 用户启动计划任务脚本。
|
||||
使用 `exit` 回到 root 权限,并使用 otrs 用户启动计划任务脚本。
|
||||
|
||||
```
|
||||
exit
|
||||
@ -372,11 +373,9 @@ OTRS 安装以及配置完成了。
|
||||
|
||||
### 步骤 9 - 测试 OTRS
|
||||
|
||||
打开你的 web 浏览器并输入你的服务器 IP 地址:
|
||||
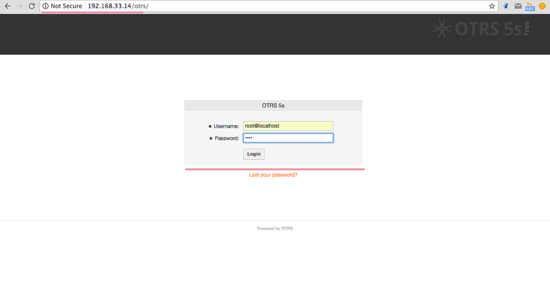
打开你的 web 浏览器并输入你的服务器 IP 地址: [http://192.168.33.14/otrs/][28]
|
||||
|
||||
[http://192.168.33.14/otrs/][28]
|
||||
|
||||
使用默认的用户 “**root@localhost**'” 以及密码 “**root**” 登录。
|
||||
使用默认的用户 `root@localhost` 以及密码 `root` 登录。
|
||||
|
||||
[
|
||||
|
||||
@ -390,9 +389,7 @@ OTRS 安装以及配置完成了。
|
||||
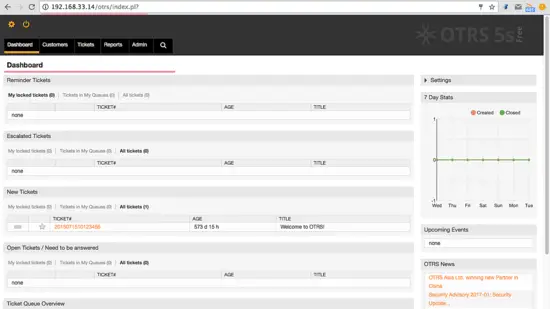
|
||||
][30]
|
||||
|
||||
如果你想作为客户登录,你可以使用 “customer.pl”。
|
||||
|
||||
[http://192.168.33.14/otrs/customer.pl][31]
|
||||
如果你想作为客户登录,你可以使用 `customer.pl` :[http://192.168.33.14/otrs/customer.pl][31]
|
||||
|
||||
你会看到客户登录界面,输入客户的用户名和密码。
|
||||
|
||||
@ -422,7 +419,7 @@ cd /opt/otrs/
|
||||
bin/otrs.Daemon.pl stop
|
||||
```
|
||||
|
||||
使用 --debug 选项启动 OTRS 守护进程。
|
||||
使用 `--debug` 选项启动 OTRS 守护进程。
|
||||
|
||||
```
|
||||
bin/otrs.Daemon.pl start --debug
|
||||
@ -440,7 +437,7 @@ via: https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,88 +0,0 @@
|
||||
Much ado about communication
|
||||
============================================================
|
||||
|
||||
### One of an open source project's first challenges is determining the best way for contributors to collaborate.
|
||||
|
||||
|
||||

|
||||
>Image by : Opensource.com
|
||||
|
||||
One of the first challenges an open source project faces is how to communicate among contributors. There are a plethora of options: forums, chat channels, issues, mailing lists, pull requests, and more. How do we choose which is the right medium to use and how do we do it right?
|
||||
|
||||
Sadly and all too often, projects shy away from making a disciplined decision and instead opt for "all of the above." This results in a fragmented community: Some people sit in Slack/Mattermost/IRC, some use the forum, some use mailing lists, some live in issues, and few read all of them.
|
||||
|
||||
This is a common issue I see in organizations I'm [working with to build their internal and external communities][2]. Which of these channels do we choose and for which purposes? Also, when is it OK to say no to one of them?
|
||||
|
||||
This is what I want to dig into here.
|
||||
|
||||
### Structured and unstructured
|
||||
|
||||
I have a tiny, peanut-sized brain in my head. Because of this, I tend to break problems down into smaller pieces so I can better understand them. Likewise, I tend to break different options in a scenario down into smaller thematic pieces to better understand their purpose. I take this approach with communication channels too.
|
||||
|
||||
I believe there are two broad categories of communication channels: structured and unstructured.
|
||||
|
||||
Structured channels have a very specific focus in each individual unit of communication. An example here is a GitHub/GitLab/Jira issue. An issue is a very specific piece of information that relates to a bug or feature. The discussion that cascades after the initial issue post is typically very focused on that specific topic and finding an outcome (such as a bugfix or a final plan for a feature). The outcome is then typically reflected in a status (e.g. "FIXED," "WONTFIX," or "INVALID"). This means you can understand the beginning and end of the communication without reading the pieces in between.
|
||||
|
||||
Likewise, pull/merge requests are structured. They are focused on a specific type (typically code) of contribution. After the initial pull/merge request, the discussion is very focused on an outcome: getting the contribution in shape to merge into the wider codebase.
|
||||
|
||||
Another example here is a StackOverflow/AskBot style Q&A post. These posts start with a question and are then edited and responded to in order to provide a concise answer to the question.
|
||||
|
||||
With each of these structured mechanisms there usually is little deviation from the structure. You never see people asking others how their kids/cats/dogs/family are doing in an issue, pull request, or Q&A topic. It is socially unacceptable to veer off topic, and that is part of the power of a structured medium: It is focused and (usually) efficient.
|
||||
|
||||
The inverse, unstructured media, include chat channels and forums. In these environments there is typically a theme (such as the topic of a channel or sub-forum), but conversations are much less tied to a specific outcome or conclusion and can often be more general in nature. As an example, in a developer mailing list you will get a mix of discussions including general questions, ideas for new features, architectural challenges, and discussions that relate to the operational running of the community itself. With each of these discussions it is imperative on the participants to keep the conversation focused, on topic, and productive. As you can imagine, this is often not the case, and these kinds of discussions can veer away from a productive outcome.
|
||||
|
||||
### The impact of recording
|
||||
|
||||
Aside from the subtle differences between structured and unstructured communication, the impact of what is recorded and how it can be searched plays a large role too.
|
||||
|
||||
Typically, all structured channels are recorded. People reference old bugs, questions from StackOverflow are reused over and over again. You can search for something, and even if there is lots of discussion, the issue, pull request, or question is usually updated to reflect the ultimate conclusion.
|
||||
|
||||
This is part of the point: We want to be able to quickly and easily dig up old issues/questions/pull requests/etc., link to them, and reference them. A key component here is that we convert this content into referenceable material that can be used to educate and inform people about previous knowledge. As our community grows, our structured communication becomes a corpus of knowledge that can inform the future from lessons in the past.
|
||||
|
||||
This gets murkier with unstructured communication. On one hand, forums are generally simple and effective to search, but they are of course filled with unstructured conversation, so the thing you are looking for might be buried inside a discussion. As an example, many communities use a forum as a support tool. While this is a more than capable platform, the problem is that the answer to a question may be response #16 or response #340 in a discussion. As we are bombarded with more and more sources of information (and in smaller pieces, such as Twitter), we have become increasingly impatient to reading through large swaths of material, and this can be problematic with an unstructured medium.
|
||||
|
||||
A particularly interesting case is real-time chat. Historically, IRC has paved the way for real-time chat for many years, and for most IRC users there was little (if any) notion of recording those discussions. Sure, some projects (such as Ubuntu) record IRC logs, but this is generally not a useful resource. As my pal Jeff Atwood said to me once: "If you have to search chat for something, you have already lost."
|
||||
|
||||
While IRC is limited in recording, Slack and Mattermost are better. Conversations are archived, but the point still typically stands: Why would you want to search through large bodies of conversation to find a point that someone made? Other channels are far better for referencing previous discussions.
|
||||
|
||||
This does create an interesting opportunity though. One consistent benefit that chat exhibits over all other media is how human it is. Structured channels, and even unstructured channels such as forums and mailing lists, rarely encourage off-the-cuff social discussion. Chat does. Chat is where you ask: "How was your weekend?" "Did you see the game?" and "Are you going to see Testament, Sepultura, and Prong next week?" (OK, maybe the last one is just me.)
|
||||
|
||||
So, while real-time discussion may be less effective in our corpus of previous collaboration, it does provide a vital glue in shaping relationships.
|
||||
|
||||
### Choose your poison
|
||||
|
||||
So, back to our original question for open source communities: Which of these do we pick?
|
||||
|
||||
While this answer will vary from project to project, I tend to think of this on two levels.
|
||||
|
||||
First, you should generally prioritize structured communication. This is where tangible work gets done: in bugs/issues, pull requests, in support Q&A discussions, etc. If you are tight on resources, focus your efforts on these channels: You can more easily draw a dotted line between the investment of time and money there and productive output in the community.
|
||||
|
||||
Second, if you are passionate about building a broader community that can focus on engineering, advocacy, translations, documentation, and more, explore whether bringing in unstructured channels makes sense. Community is not just about getting stuff done, it is also about building relationships and friendships, providing support to each other in our work, and helping people grow and flourish in our communities. Unstructured communication is a helpful tool in this.
|
||||
|
||||
Of course, I am merely scratching the surface of a large topic here, but I hope this provides a little clarity in how to assess and choose the value of communication channels. Remember, less is more here: Don't be tempted to defer the decision and provide all of the above; you will get a fragmented community that's just about as inviting as an empty restaurant.
|
||||
|
||||
May the force be with you, and be sure to let me know how you get on. I am always available through my [website][3] and at [jono@jonobacon.com][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jono Bacon - Jono Bacon is a leading community manager, speaker, author, and podcaster. He is the founder of Jono Bacon Consulting which provides community strategy/execution, developer workflow, and other services. He also previously served as director of community at GitHub, Canonical, XPRIZE, OpenAdvantage, and consulted and advised a range of organizations.
|
||||
|
||||
--------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/much-ado-about-communication
|
||||
|
||||
作者:[ Jono Bacon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jonobacon
|
||||
[1]:https://opensource.com/article/17/5/much-ado-about-communication?rate=fBsUIx1TCGIXAFnRdYGTUqSG1pMmMCpdhYlyrFtRLS8
|
||||
[2]:http://www.jonobaconconsulting.com/
|
||||
[3]:http://www.jonobacon.com/
|
||||
[4]:mailto:jono@jonobacon.com
|
||||
[5]:https://opensource.com/user/26312/feed
|
||||
[6]:https://opensource.com/users/jonobacon
|
||||
88
translated/tech/20170509 Much ado about communication.md
Normal file
88
translated/tech/20170509 Much ado about communication.md
Normal file
@ -0,0 +1,88 @@
|
||||
关于沟通的很多纷扰
|
||||
============================================================
|
||||
|
||||
### 开源项目的首要挑战是找出最佳的贡献者协作方式
|
||||
|
||||
|
||||

|
||||
>图片提供: Opensource.com
|
||||
|
||||
开源项目要面对的首要挑战之一是如何在贡献者之间沟通。这里有很多的选择:论坛、聊天频道、问题列表、邮件列表、pull request 等等。我们该选择哪个合适的来使用,我们又该如何做呢?
|
||||
|
||||
令人遗憾的是,项目往往不愿作出有纪律的决定,而是选择“上述所有”。这就导致了一个支离破碎的社区:有些人使用 Slack/Mattermost/IRC,而有些人使用论坛,有些使用邮件列表,有些使用问题列表,很少有人都用这些。
|
||||
|
||||
我在组织中常见到的一个问题是。我[正在努力建立它们的内部和外部社区][2]。我们会选择哪个渠道,以及出于什么目的?另外,何时可以对它们之一说不呢?
|
||||
|
||||
这就是我想在此处深挖的。
|
||||
|
||||
### 结构化和非结构化
|
||||
|
||||
我只有一个很小的如花生大小的头脑。因此,我倾向于将问题分成小的部分,这样我可以更好地理解它们。类似地,我倾向于将一个情景中不同困难的选择变成更小的题目来更好地理解它们的目的。我在沟通渠道的选择上也使用这种方法。
|
||||
|
||||
我相信有两大沟通渠道的分类:结构化和非结构化
|
||||
|
||||
结构化渠道在每个单独的沟通单位中都有非常具体的重点。例子如:GitHub/GitLab /Jira issue。一个问题是与 bug 或功能有关的一个非常具体的信息。在帖子发布之后的的讨论中都通常非常集中在该特定主题上并会有一个结果(比如 bugfix 或者一个功能的最终计划)。结果通常都反映在状态(例如 “FIXED”、“WONTFIX” 或 “INVALID”)中。这意味着你可以了解沟通的开始和结束,而无需阅读中间的内容。
|
||||
|
||||
类似的,pull/merge 请求也是结构化的。它们集中在特定类型(通常是代码)的贡献上。在最初的 pull/merge 请求后,讨论会会非常集中在一个结果上:让贡献符合要求来合并进入代码库中。
|
||||
|
||||
另一个例子是 StackOverflow/AskBot 这类的问答帖子。这些帖子以一个问题开始,接着被编辑以及回复来提供对这个问题的精确答案。
|
||||
|
||||
通过这些结构化机制,通常几乎不会偏离本来结构。你不会在问题列表,pull request 或问答主题上看到有人问别人他们的孩子/猫/狗/家人在做什么。偏离主题是社区上不可接受的,这是结构化媒体的力量的一部分:它是集中和(通常)高效的。
|
||||
|
||||
反之,非结构化媒体包括聊天频道和论坛。在这些环境中,通常会有一个主题(例如频道或分论坛的主题),但是会话与特定结果或结论的关系要小得多,而且通常情况下可能会更普遍。例如,在开发者邮件列表中,你会看到一系列讨论,包括一般问题、新功能的想法、架构挑战以及与社区自身运营相关的讨论。每一个讨论都必须让参与者保持对话的焦点、主题和工作效率。你可以想象,情况往往不是这样的, 这种讨论可能会偏离一个富有成效的结果。
|
||||
|
||||
### 记录的影响
|
||||
|
||||
除了结构化和非结构化沟通的微妙不同外,记录了什么的影响以及如何可以被搜索也扮演了一个很大的角色。
|
||||
|
||||
典型滴,所有的结构化渠道都是记录的。人们可以参考以前的 bug,来自 StackOverflow 的问题可以被反复地重用。你可以搜索一些东西,即使有很多讨论,问题,pull request 或者提问通常都会被更新以反映最终结论。
|
||||
|
||||
这是一个重点:我们希望能够快速,轻松地挖掘旧问题/提问/pull request 等,并链接到它们、引用它们。这里的一个关键部分是我们把这个内容转换成可以引用的材料,可以用来教育和告知人们以前的知识。随着社区的发展,我们的结构化沟通成为一种知识全集,可以通过以往的经验来告知未来。
|
||||
|
||||
这使得非结构化沟通变得越来越糟。一方面,论坛的搜索通常都简单高效,但是它们当然充满了非结构化的对话,所以你正在寻找的东西可能被埋在讨论之中。例如,许多社区使用论坛作为支持工具。虽然这是一个更强大的平台,但是问题在于,一个问题的答案可能是在 16 楼或者 340 楼中有响应。随着越来越多的信息来源(比如 Twitter)的轰炸,我们越来越不耐烦地阅读大量的材料,这对于非结构化媒体来说可能是一个问题。
|
||||
|
||||
一个专门的有趣案例是实时聊天。历史上,IRC 很多年来为实时聊天铺平了道路,对于大多数 IRC 用户而言很少有(如果有)记录这些讨论的念头。的确,一些项目(比如 Ubuntu)记录了 IRC 日志,但是这通常不是有用的资源。如我的伙伴 Atwood 有一次跟我说的:“如果你不得不在聊天中搜索一些东西时,你已经输了。”
|
||||
|
||||
虽然 IRC 在记录上有限制,但是 Slack 和 Mattermost 会好点。交流会被归档,但是问题仍旧存在:你为什么会想在海量的聊天信息中找出一个人提出的观点呢?其他的渠道能更好地引用先前的讨论。
|
||||
|
||||
不过,这的确创造了一个有趣的机会。聊天相比其他媒体的一个一贯的好处是能体现这是个怎样的人。结构化的渠道,甚至非结构化的渠道,如论坛和邮件列表,很少鼓励袖手旁观的社交讨论。但聊天是的。聊天时你会问:“你周末怎么样?”、 “你见过这个游戏吗?”还有“你下周会看 Testament,Sepultura 和 Prong 吗?” (好吧,也许最后一个只是我。)
|
||||
|
||||
因此,虽然实时聊天相比前面的那些方式也许更低效一些,但是它的确增进了人们的关系。
|
||||
|
||||
### 选择你的毒药
|
||||
|
||||
因此,回到我们最初的对于开源社区的提问:我们要选择哪个?
|
||||
|
||||
虽然这个答案对于不同的项目会不同,但我想在两个层面思考。
|
||||
|
||||
首先,你应该通常有限考虑结构化沟通。这有有形的工作可以完成:在 bug/问题 上、pull request、在支持问答讨论上等等。如果你资源有限,那么专注在这些渠道上:你可以更轻松地在时间和金钱的支出以及在社区的高效产出上画一条虚线。
|
||||
|
||||
再者,如果你热衷于建立一个可以专注于工程、宣传、翻译、文档等方面的更广泛的社区,那么探究是否引入非结构化渠道就有意义了。 社区不仅仅是为了完成工作,而且也是建立关系和友谊,在工作中相互支持,帮助人们在社区中发展壮大。非结构化通信是一个有用的工具。
|
||||
|
||||
当然,我这里只是抓住了庞大问题的表面,但是希望这对于如何评估和选择沟通渠道的价值提供一些清晰的想法。记住,少即是多:不要被引诱推迟决定并提供所有的渠道。否则你会得到一个支离破碎社区,就像一个空荡荡的餐厅一样。
|
||||
|
||||
愿原力与你同在,请确保让我知道你进行的如何另外。你可以通过我的[网站][3]和邮箱 [jono@jonobacon.com][4] 联系到我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jono Bacon - Jono Bacon 是一名领先的社区管理者、演讲者、作者和播客。他是 Jono Bacon Consulting 的创始人,提供社区策略/执行、开发者工作流程和其他服务。他以前曾担任 GitHub、Canonical、XPRIZE、OpenAdvantage 的社区总监,并为很多组织曾经提供建议和咨询。
|
||||
|
||||
--------------------
|
||||
|
||||
via: https://opensource.com/article/17/5/much-ado-about-communication
|
||||
|
||||
作者:[ Jono Bacon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jonobacon
|
||||
[1]:https://opensource.com/article/17/5/much-ado-about-communication?rate=fBsUIx1TCGIXAFnRdYGTUqSG1pMmMCpdhYlyrFtRLS8
|
||||
[2]:http://www.jonobaconconsulting.com/
|
||||
[3]:http://www.jonobacon.com/
|
||||
[4]:mailto:jono@jonobacon.com
|
||||
[5]:https://opensource.com/user/26312/feed
|
||||
[6]:https://opensource.com/users/jonobacon
|
||||
Loading…
Reference in New Issue
Block a user