mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
commit
ef435396e9
@ -1,33 +1,33 @@
|
||||
中心化存储(iSCSI)- “初始器客户端” 在RHEL/CentOS/Fedora上的设置 - 第三部分
|
||||
================================================================================
|
||||
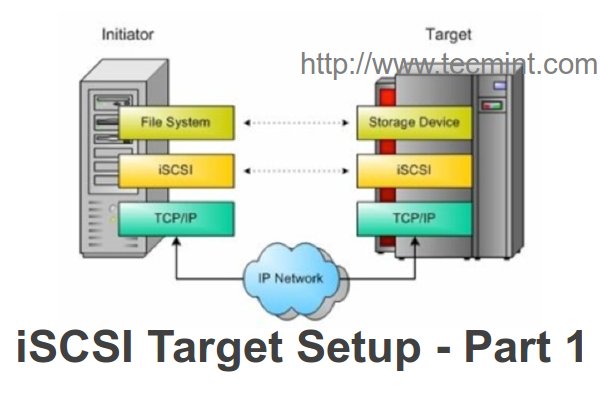
**iSCSI** 初始化器是一种用于与iSCSI target服务器认证并访问服务器上共享的的LUN的客户端。我们可以在本地挂载的硬盘上部署任何操作系统,只需要安装一个包来与target服务器验证。
|
||||
设置iSCSI的发起程序(客户端)(三)
|
||||
============================
|
||||
|
||||
**iSCSI** 发起程序是一种用于同 iSCSI 目标器认证并访问服务器上共享的LUN的客户端。我们可以在本地挂载的硬盘上部署任何操作系统,只需要安装一个包来与目标器验证。
|
||||
|
||||

|
||||
|
||||
初始器客户端设置
|
||||
*初始器客户端设置*
|
||||
|
||||
#### 功能 ####
|
||||
### 功能 ###
|
||||
|
||||
- 可以处理本地挂载磁盘上的任意文件系统
|
||||
- 在使用fdisk命令后不需要重启系统
|
||||
- 在使用fdisk命令分区后不需要重启系统
|
||||
|
||||
#### 要求 ####
|
||||
### 前置阅读 ###
|
||||
|
||||
- [使用iSCSI Target创建集中化安全存储- 第一部分][1]
|
||||
- [在Target服务器中使用LVM创建LUN - 第二部分][2]
|
||||
- [使用iSCSI Target创建集中式安全存储(一)][1]
|
||||
- [在 iSCSI Target 服务器中使用LVM创建和设置LUN(二)][2]
|
||||
|
||||
#### 我的客户端设置 ####
|
||||
|
||||
- 操作系统 – CentOS release 6.5 (最终版)
|
||||
- iSCSI Target IP – 192.168.0.50
|
||||
- 操作系统 – CentOS 6.5 (Final)
|
||||
- iSCSI 目标器 IP – 192.168.0.50
|
||||
- 使用的端口 : TCP 3260
|
||||
|
||||
**Warning**: Never stop the service while LUNs Mounted in Client machines (Initiator).
|
||||
**Warning**:永远不要在使用LUN的时候在客户端中(初始化器)停止服务。
|
||||
**警告**:永远不要在LUN还挂载在客户端(发起程序)时停止服务。
|
||||
|
||||
### 客户端设置 ###
|
||||
|
||||
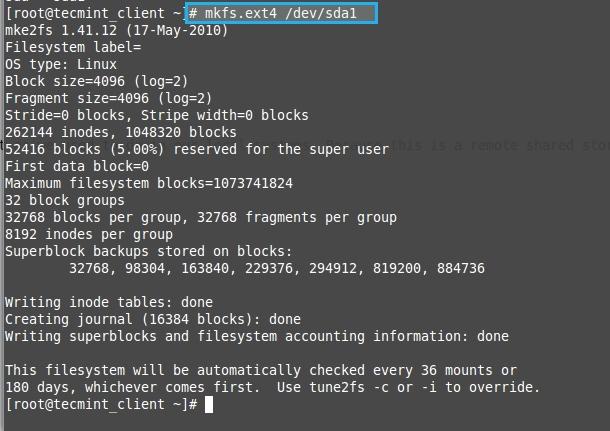
**1.** 在客户端,我们需要安装包‘**iSCSI-initiator-utils**‘,用下面的命令搜索包。
|
||||
**1.** 在客户端,我们需要安装包‘**iSCSI-initiator-utils**’,用下面的命令搜索包。
|
||||
|
||||
# yum search iscsi
|
||||
|
||||
@ -37,29 +37,29 @@
|
||||
iscsi-initiator-utils.x86_64 : iSCSI daemon and utility programs
|
||||
iscsi-initiator-utils-devel.x86_64 : Development files for iscsi-initiator-utils
|
||||
|
||||
**2.** 一旦定位了包,就用下面的yum命令安装初始化包。
|
||||
**2.** 找到了包,就用下面的yum命令安装初始化包。
|
||||
|
||||
# yum install iscsi-initiator-utils.x86_64
|
||||
|
||||
**3.** 安装完毕后,我们需要发现**Target 服务器**上的共享。客户端的命令有点难记,因此我们使用man来的到需要运行的命令列表
|
||||
**3.** 安装完毕后,我们需要发现**目标器**上的共享。客户端的命令有点难记,因此我们使用man找到需要运行的命令列表。
|
||||
|
||||
# man iscsiadm
|
||||
|
||||

|
||||
|
||||
man iscsiadm
|
||||
*man iscsiadm*
|
||||
|
||||
**4.** 按下**SHIFT+G** 进入man页的底部并且稍微向上滚动来的到登录的示例命令。下面的发现命令中,需要用我们的**服务器IP地址**来替换。
|
||||
**4.** 按下**SHIFT+G** 进入man页的底部并且稍微向上滚动找到示例的登录命令。下面的发现命令中,需要用我们的**服务器IP地址**来替换。
|
||||
|
||||
# iscsiadm --mode discoverydb --type sendtargets --portal 192.168.0.200 --discover
|
||||
|
||||
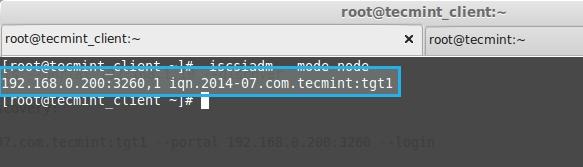
**5.** 这里我们从下面的命令中得到了iSCSIi限定名(iqn)。
|
||||
**5.** 这里我们从下面的命令输出中找到了iSCSI的限定名(iqn)。
|
||||
|
||||
192.168.0.200:3260,1 iqn.2014-07.com.tecmint:tgt1
|
||||
|
||||

|
||||
|
||||
发现服务器
|
||||
*发现服务器*
|
||||
|
||||
**6.** 要登录就用下面的命令来连接一台LUN到我们本地系统中,这会与服务器验证并允许我们登录LUN。
|
||||
|
||||
@ -67,7 +67,7 @@ man iscsiadm
|
||||
|
||||

|
||||
|
||||
登录到服务器
|
||||
*登录到服务器*
|
||||
|
||||
**注意**:登出使用登录命令并在命令的最后使用logout来替换。
|
||||
|
||||
@ -75,15 +75,15 @@ man iscsiadm
|
||||
|
||||

|
||||
|
||||
等出服务器
|
||||
*登出服务器*
|
||||
|
||||
**7.** 登录服务器后,使用下面的命令列出节点的记录。
|
||||
**7.** 登录服务器后,使用下面的命令列出节点的记录行。
|
||||
|
||||
# iscsiadm --mode node
|
||||
|
||||
|
||||
|
||||
列出节点
|
||||
*列出节点*
|
||||
|
||||
**8.** 显示特定节点的所有数据
|
||||
|
||||
@ -109,7 +109,7 @@ man iscsiadm
|
||||
iface.linklocal_autocfg = <empty>
|
||||
....
|
||||
|
||||
**9.** 接着列出使用的磁盘,fdisk会列出所有的认证过的磁盘。
|
||||
**9.** 接着列出使用的磁盘,fdisk会列出所有的登录认证过的磁盘。
|
||||
|
||||
# fdisk -l /dev/sda
|
||||
|
||||
@ -123,7 +123,7 @@ man iscsiadm
|
||||
|
||||

|
||||
|
||||
创建新分区
|
||||
*创建新分区*
|
||||
|
||||
**注意**:在使用fdisk创建新分区之后,我们无需重启,就像使用我们本地的文件系统一样就行。因为这个将远程共享存储挂载到本地了。
|
||||
|
||||
@ -133,7 +133,7 @@ man iscsiadm
|
||||
|
||||
|
||||
|
||||
格式化新分区
|
||||
*格式化新分区*
|
||||
|
||||
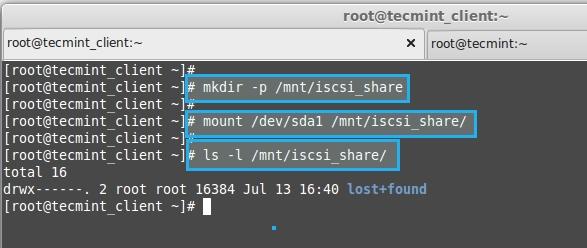
**12.** 创建一个目录来挂载新创建的分区
|
||||
|
||||
@ -143,20 +143,20 @@ man iscsiadm
|
||||
|
||||
|
||||
|
||||
挂载新分区
|
||||
*挂载新分区*
|
||||
|
||||
**13.** 列出挂载点
|
||||
|
||||
# df -Th
|
||||
|
||||
- **-T** – Prints files system types.
|
||||
- **-h** – Prints in human readable format eg : Megabyte or Gigabyte.
|
||||
- **-T** – 输出文件系统类型
|
||||
- **-h** – 以易读的方式显示大小
|
||||
|
||||

|
||||
|
||||
列出新分区
|
||||
*列出新分区*
|
||||
|
||||
**14.** 如果需要永久挂在使用fdtab文件
|
||||
**14.** 如果需要永久挂载,使用fdtab文件
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
@ -168,18 +168,18 @@ man iscsiadm
|
||||
|
||||

|
||||
|
||||
自动挂载分区
|
||||
*自动挂载分区*
|
||||
|
||||
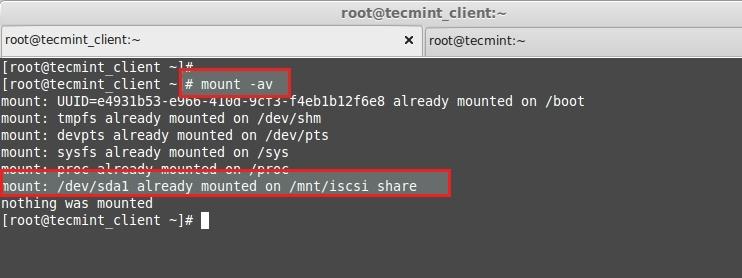
**16.** 最后检查我们fstab文件是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
- **-a** – 所有挂载点
|
||||
- **-v** – 繁琐模式
|
||||
- **-v** – 冗余模式
|
||||
|
||||
|
||||
|
||||
验证fstab文件
|
||||
*验证fstab文件*
|
||||
|
||||
我们已经成功完成了我们的客户端配置。现在让我们像本地磁盘一样使用它吧。
|
||||
|
||||
@ -189,10 +189,10 @@ via: http://www.tecmint.com/iscsi-initiator-client-setup/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/create-centralized-secure-storage-using-iscsi-targetin-linux/
|
||||
[2]:http://www.tecmint.com/create-luns-using-lvm-in-iscsi-target/
|
||||
[1]:http://linux.cn/article-4971-1.html
|
||||
[2]:http://linux.cn/article-4972-1.html
|
||||
@ -1,46 +1,47 @@
|
||||
在RHEL/CentOS/Fedora上使用iSCSI Target创建集中式安全存储 - 第一部分
|
||||
使用iSCSI Target创建集中式安全存储(一)
|
||||
================================================================================
|
||||
**iSCSI** 是一种就块级别协议,用于通过TCP/IP网络共享**原始存储设备**,可以用已经存在的IP和以太网如网卡、交换机、路由器等通过iSCSI协议共享和访问存储。iSCSI target是一种远程iSCSI服务器或者taget上的远程硬盘。
|
||||
**iSCSI** 是一种块级别的协议,用于通过TCP/IP网络共享**原始存储设备**,可以用已经存在的IP和以太网如网卡、交换机、路由器等通过iSCSI协议共享和访问存储。iSCSI target是一种由远程iSCSI服务器(target)提供的远程硬盘。
|
||||
|
||||
|
||||
在Linux中安装iSCSI Target
|
||||
|
||||
我们不需要在客户端为了稳定的连接和性能而占用很大的资源。iSCSI服务器称为Target,它共享存储。iSCSI客户端称为Initiator,它访问Target服务器行的存储。市场中有用于大型存储服务如SAN的iSCSI适配器。
|
||||
*在Linux中安装iSCSI Target*
|
||||
|
||||
我们不需要占用很大的资源就可以为客户端提供稳定的连接和性能。iSCSI服务器称为“Target(目标器)”,它提供服务器上的存储共享。iSCSI客户端称为“Initiator(发起程序)”,它访问目标器共享的存储。市场中有卖的用于大型存储服务如SAN的iSCSI适配器。
|
||||
|
||||
**我们为什么要在大型存储领域中使用iSCSI适配器**
|
||||
|
||||
以太网适配器(NIC)被设计用于在系统、服务器和存储设备如NAS间传输分组数据,它不适合在Internet中传输块级别数据。
|
||||
以太网适配器(NIC)被设计用于在系统、服务器和存储设备如NAS间传输分组数据,它不适合在Internet中传输块级数据。
|
||||
|
||||
### iSCSI Target的功能 ###
|
||||
|
||||
- 可以在一台机器上运行几个iSCSI target
|
||||
- 一台机器的多个iSCSI target可以在iSCSI中访问
|
||||
- 一个target就是一块存储,并且可以通过网络被初始化器(客户端)访问
|
||||
- 可以在一台机器上运行几个iSCSI 目标器
|
||||
- 一台机器可以提供多个iSCSI 目标器用于iSCSI SAN访问
|
||||
- 一个目标器就是一块存储,并且可以通过网络被发起程序(客户端)访问
|
||||
- 把这些存储汇聚在一起让它们在网络中可以访问的是iSCSI LUN(逻辑单元号)
|
||||
- iSCSI支持在同一个会话中含有多个连接
|
||||
- iSCSI初始化器在网络中发现目标接着用LUN验证并登录,这样就可以本地访问远程存储。
|
||||
- 我们了一在本地挂载的LUN上安装任何操作系统,就像我们安装我们本地的操作系统一样。
|
||||
- iSCSI支持在同一个会话中使用多个连接
|
||||
- iSCSI发起程序在网络中发现目标接着用LUN验证并登录,这样就可以本地访问远程存储。
|
||||
- 我们可以在本地挂载的LUN上安装任何操作系统,就像我们安装我们本地的操作系统一样。
|
||||
|
||||
### 为什么需要iSCSI? ###
|
||||
|
||||
在虚拟化中,我们需要存储拥有高度的冗余性、稳定性,iSCSI以低成本的方式提供了这些特性。与使用光纤通道的SAN比起来,我们可以使用已经存在的设备比如NIC、以太网交换机等建造一个低成本的SAN。
|
||||
|
||||
现在我开始使用iSCSI Target安装并配置安全存储。本篇中,我们遵循下面的步骤
|
||||
现在我开始使用iSCSI 目标器安装并配置安全存储。本篇中,我们遵循下面的步骤:
|
||||
|
||||
- 我们需要隔离一个系统来设置iSCSI Target服务器和初始化器(客户端)。
|
||||
- 可以在大型存储环境中添加多个硬盘,但是我们除了基本的安装盘之外只使用一个额外的驱动器。
|
||||
- 现在我们只使用2块硬盘,一个用于基本的服务器安装,另外一个用于存储(LUN),这个我们会在这个系列的第二篇描述。
|
||||
- 我们需要隔离一个系统来设置iSCSI Target服务器和发起程序(客户端)。
|
||||
- 在大型存储环境中可以添加多个硬盘,但是这里我们除了基本的安装盘之外只使用了一个额外的驱动器。
|
||||
- 这里我们只使用了2块硬盘,一个用于基本的服务器安装,另外一个用于存储(LUN),这个我们会在这个系列的第二篇描述。
|
||||
|
||||
#### 主服务器设置 ####
|
||||
|
||||
- 操作系统 – CentOS release 6.5 (最终版)
|
||||
- iSCSI Target IP – 192.168.0.200
|
||||
- 操作系统 – CentOS 6.5 (Final)
|
||||
- iSCSI 目标器 IP – 192.168.0.200
|
||||
- 使用的端口 : TCP 860, 3260
|
||||
- 配置文件 : /etc/tgt/targets.conf
|
||||
|
||||
## 安装 iSCSI Target ##
|
||||
### 安装 iSCSI Target ###
|
||||
|
||||
打开终端并使用yum命令来搜索我们需要在iscsi target上安装的包名。
|
||||
打开终端并使用yum命令来搜索需要在iscsi 目标器上安装的包名。
|
||||
|
||||
# yum search iscsi
|
||||
|
||||
@ -52,21 +53,21 @@
|
||||
lsscsi.x86_64 : List SCSI devices (or hosts) and associated information
|
||||
scsi-target-utils.x86_64 : The SCSI target daemon and utility programs
|
||||
|
||||
We got the search result as above, choose the **Target** package and install to play around.
|
||||
你会的到上面的那些结果,选择**Target**包来安装
|
||||
你会的到上面的那些结果,选择**Target**包来安装。
|
||||
|
||||
# yum install scsi-target-utils -y
|
||||
|
||||

|
||||
安装iSCSI工具
|
||||
|
||||
列出安装的包来了解默认的配置、服务和man页面的位置
|
||||
*安装iSCSI工具*
|
||||
|
||||
列出安装的包里面的内容来了解默认的配置、服务和man页面的位置。
|
||||
|
||||
# rpm -ql scsi-target-utils.x86_64
|
||||
|
||||

|
||||
|
||||
列出所有的iSCSI文件
|
||||
*列出所有的iSCSI包里面的文件*
|
||||
|
||||
让我们启动iSCSI服务,并检查服务运行的状态,iSCSI的服务名是**tgtd**。
|
||||
|
||||
@ -75,7 +76,7 @@ We got the search result as above, choose the **Target** package and install to
|
||||
|
||||

|
||||
|
||||
启动iSCSI服务
|
||||
*启动iSCSI服务*
|
||||
|
||||
现在我们需要配置开机自动启动。
|
||||
|
||||
@ -87,53 +88,53 @@ We got the search result as above, choose the **Target** package and install to
|
||||
|
||||

|
||||
|
||||
开机启动iSCSI
|
||||
*开机启动iSCSI*
|
||||
|
||||
现在使用**tgtadm**来列出在我们的服务器上已经配置了哪些target和LUN。
|
||||
现在使用**tgtadm**来列出在我们的服务器上已经配置了哪些目标器和LUN。
|
||||
|
||||
# tgtadm --mode target --op show
|
||||
|
||||
**tgtd**已经安装并在运行了,但是上面的命令没有**输出**因为我们还没有在Target服务器上定义LUN。要查看手册,运行‘**man**‘命令。
|
||||
**tgtd**已经安装并在运行了,但是上面的命令没有**输出**因为我们还没有在目标器上定义LUN。要查看手册,可以运行‘**man**‘命令。
|
||||
|
||||
# man tgtadm
|
||||
|
||||

|
||||
|
||||
iSCSI Man 页面
|
||||
*iSCSI Man 页面*
|
||||
|
||||
最终我们需要为iSCSI添加iptable规则,如果你的target服务器上存在iptable的话。首先使用netstat命令找出iscsi target的端口号,target总是监听TCP端口3260。
|
||||
如果你的target服务器上有iptable的话,那么我们需要为iSCSI添加iptable规则。首先使用netstat命令找出iscsi target的端口号,target总是监听TCP端口3260。
|
||||
|
||||
# netstat -tulnp | grep tgtd
|
||||
|
||||

|
||||
|
||||
找出iSCSI端口
|
||||
*找出iSCSI端口*
|
||||
|
||||
下面加入如下规则让iptable允许广播iSCSI target发现包。
|
||||
下面加入如下规则让iptable允许广播iSCSI 目标器发现包。
|
||||
|
||||
# iptables -A INPUT -i eth0 -p tcp --dport 860 -m state --state NEW,ESTABLISHED -j ACCEPT
|
||||
# iptables -A INPUT -i eth0 -p tcp --dport 3260 -m state --state NEW,ESTABLISHED -j ACCEPT
|
||||
|
||||

|
||||
|
||||
打开iSCSI端口
|
||||
*打开iSCSI端口*
|
||||
|
||||

|
||||
|
||||
添加iSCSI端口到iptable中
|
||||
*添加iSCSI端口到iptable中*
|
||||
|
||||
**注意**: 规则可能根据你的 **默认链策略**而不同。接着保存iptable并重启。
|
||||
**注意**: 规则可能根据你的 **默认链策略**而不同。接着保存iptable并重启该服务。
|
||||
|
||||
# iptables-save
|
||||
# /etc/init.d/iptables restart
|
||||
|
||||

|
||||
|
||||
重启iptable
|
||||
*重启iptable*
|
||||
|
||||
现在我们已经部署了一个target服务器来共享LUN给通过TCP/IP认证的初始化器。这也适用于从小到大规模的生产环境。
|
||||
现在我们已经部署了一个目标器来共享LUN给通过TCP/IP认证的发起程序。这也适用于从小到大规模的生产环境。
|
||||
|
||||
在我的下篇文章中,我会展示如何[在Target服务器中使用LVM创建LUN][1],并且如何在客户端中共享LUN,在此之前请继续关注TecMint获取更多的更新,并且不要忘记留下有价值的评论。
|
||||
在我的下篇文章中,我会展示如何[在目标器中使用LVM创建LUN][1],并且如何在客户端中共享LUN,不要忘记留下有价值的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -141,7 +142,7 @@ via: http://www.tecmint.com/create-centralized-secure-storage-using-iscsi-target
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,47 +1,47 @@
|
||||
如何在RHEL/CentOS/Fedora中使用LVM创建和设置LUN- 第二部分
|
||||
在 iSCSI Target 服务器中使用LVM创建和设置LUN(二)
|
||||
================================================================================
|
||||
LUN是逻辑单元号,它与iSCSI存储服务器共享。物理iSCSI target服务器共享它的驱动器来初始化TCP/IP网络。驱动器的集合称作LUN来幸存一个大型存储也就是SAN(Storage Area Network)。在真实环境中LUN在LVM中定义,因此它可以按需扩展。
|
||||
LUN是逻辑单元号,它与iSCSI存储服务器共享。iSCSI 目标器通过TCP/IP网络共享它的物理驱动器给发起程序(initiator)。这些来自一个大型存储(SAN:Storage Area Network)的驱动器集合称作LUN。在真实环境中LUN是在LVM中定义的,因为它可以按需扩展。
|
||||
|
||||

|
||||
Create LUNS using LVM in Target Server
|
||||
|
||||
*在目标器中使用 LVM 创建 LUN*
|
||||
|
||||
### 为什么使用LUN? ###
|
||||
|
||||
LUN用于存储,SAN存储大多数有LUN的集群来组成池,LUN由几块物理驱动器组成。我们可以使用LUN作为系统物理驱动器来安装操作系统,LUN在集群、虚拟服务器、SAN中使用。在虚拟服务器中使用LUN的目的是作为系统存储。LUN的性能和可靠性根据在创建目标存储服务器时所使用的驱动器决定。
|
||||
LUN用于存储,SAN存储大多数由LUN的集群来组成存储池,LUN由目标器的几块物理驱动器组成。我们可以使用LUN作为系统物理驱动器来安装操作系统,LUN可以用在集群、虚拟服务器、SAN中。在虚拟服务器中使用LUN的主要用途是作为操作系统的存储。LUN的性能和可靠性根据在创建目标存储服务器时所使用的驱动器决定。
|
||||
|
||||
### 需求 ###
|
||||
### 前置阅读 ###
|
||||
|
||||
要了解创建iSCSI target服务器点击下面的链接。
|
||||
要了解创建iSCSI 目标器,点击下面的链接。
|
||||
|
||||
- [使用iSCSI target创建爱你集中话安全存储][1]
|
||||
- [使用iSCSI Target创建集中式安全存储(一)][1]
|
||||
|
||||
#### 主服务器设置 ####
|
||||
|
||||
系统信息和网络设置部分与已经写的iSCSI Target服务相同 - 我们在相同的服务器上定义LUN。
|
||||
系统信息和网络设置部分与前文的iSCSI 目标器相同 - 我们在相同的服务器上定义LUN。
|
||||
|
||||
|
||||
- 操作系统 – CentOS release 6.5 (最终版)
|
||||
- iSCSI Target IP – 192.168.0.200
|
||||
- 操作系统 – CentOS 6.5 (Final)
|
||||
- iSCSI 目标器 IP – 192.168.0.200
|
||||
- 使用的端口 : TCP 860, 3260
|
||||
- 配置文件 : /etc/tgt/targets.conf
|
||||
|
||||
## 在iSCSI Target Server使用LVM创建LUN ##
|
||||
### 在iSCSI 目标器使用LVM创建LUN ###
|
||||
|
||||
首先,用**fdisk -l**命令找出驱动器的列表,这会列出系统中所有分区的列表。
|
||||
|
||||
# fdisk -l
|
||||
|
||||
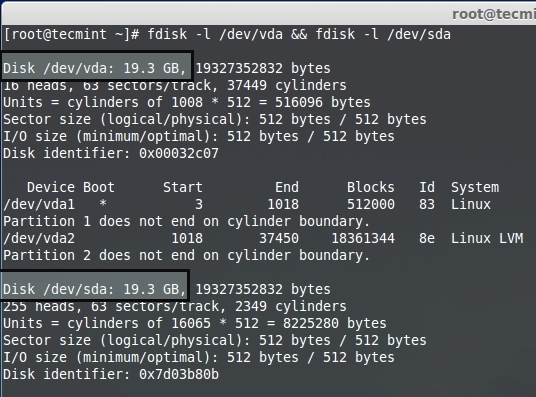
上面的命令只会给出基本系统的驱动器信息。为了个到存储设备的信息,使用下面的命令来的到存储设备的列表。
|
||||
上面的命令只会给出基本系统的驱动器信息。为了得到存储设备的信息,使用下面的命令来得到存储设备的列表。
|
||||
|
||||
# fdisk -l /dev/vda && fdisk -l /dev/sda
|
||||
|
||||
|
||||
|
||||
列出存储设备
|
||||
*列出存储设备*
|
||||
|
||||
**注意**:这里**vda**是虚拟机硬盘,因为我使用的是虚拟机来用于演示,**/dev/sda** 是额外加入的存储。
|
||||
|
||||
### 第一步: 创建用于LUN的LVM ###
|
||||
### 第一步: 创建用于LUN的LVM驱动器 ###
|
||||
|
||||
我们使用**/dev/sda**驱动器来创建LVM。
|
||||
|
||||
@ -49,14 +49,14 @@ LUN用于存储,SAN存储大多数有LUN的集群来组成池,LUN由几块
|
||||
|
||||

|
||||
|
||||
列出LVM驱动器
|
||||
*列出LVM驱动器*
|
||||
|
||||
现在让我们如下使用fdisk命令列出驱动器分区。
|
||||
现在让我们使用如下fdisk命令列出驱动器分区。
|
||||
|
||||
# fdisk -cu /dev/sda
|
||||
|
||||
- The option ‘**-c**‘ 关闭DOS兼容模式。
|
||||
- The option ‘**-u**‘ 用于列出分区表,给出扇区而不是柱面的大小。
|
||||
- 选项 ‘**-c**’ 关闭DOS兼容模式。
|
||||
- 选项 ‘**-u**’ 用于列出分区表时给出扇区而不是柱面的大小。
|
||||
|
||||
使用**n**创建新的分区。
|
||||
|
||||
@ -109,7 +109,7 @@ LUN用于存储,SAN存储大多数有LUN的集群来组成池,LUN由几块
|
||||
|
||||

|
||||
|
||||
创建LVM分区
|
||||
*创建LVM分区*
|
||||
|
||||
系统重启后,使用fdisk命令列出分区表。
|
||||
|
||||
@ -117,7 +117,7 @@ LUN用于存储,SAN存储大多数有LUN的集群来组成池,LUN由几块
|
||||
|
||||

|
||||
|
||||
验证LVM分区
|
||||
*验证LVM分区*
|
||||
|
||||
### 第二步: 为LUN创建逻辑卷 ###
|
||||
|
||||
@ -125,7 +125,7 @@ LUN用于存储,SAN存储大多数有LUN的集群来组成池,LUN由几块
|
||||
|
||||
# pvcreate /dev/sda1
|
||||
|
||||
用iSCSI的名字创建卷组来区分组。
|
||||
用iSCSI的名字创建卷组来区分这个卷组。
|
||||
|
||||
# vgcreate vg_iscsi /dev/sda1
|
||||
|
||||
@ -148,17 +148,17 @@ LUN用于存储,SAN存储大多数有LUN的集群来组成池,LUN由几块
|
||||
|
||||

|
||||
|
||||
创建LVM逻辑卷
|
||||
*创建LVM逻辑卷*
|
||||
|
||||

|
||||
|
||||
验证LVM逻辑卷
|
||||
*验证LVM逻辑卷*
|
||||
|
||||
### 第三步: 在Target Server中定义LUN ###
|
||||
### 第三步: 在目标器中定义LUN ###
|
||||
|
||||
我们已经创建了逻辑卷并准备使用LUN,现在我们在target配置中定义LUN,如果这样那么它只能用在客户机中(启动器)。
|
||||
我们已经创建了逻辑卷并准备使用LUN,现在我们在目标器配置中定义LUN,只有这样做它才能用在客户机中(发起程序)。
|
||||
|
||||
用你选择的编辑器打开位于‘/etc/tgt/targets.conf’的target配置文件。
|
||||
用你选择的编辑器打开位于‘/etc/tgt/targets.conf’的目标器配置文件。
|
||||
|
||||
# vim /etc/tgt/targets.conf
|
||||
|
||||
@ -179,20 +179,22 @@ LUN用于存储,SAN存储大多数有LUN的集群来组成池,LUN由几块
|
||||
|
||||
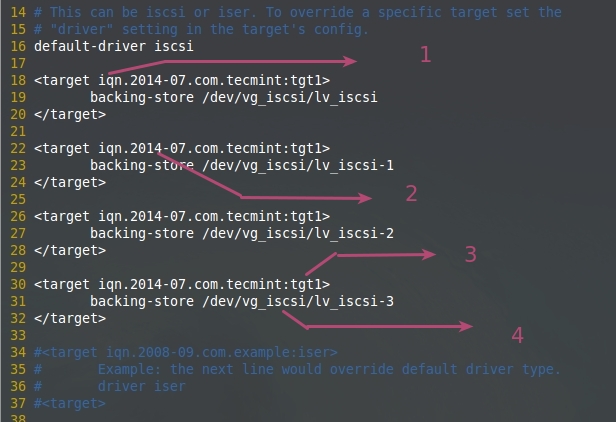
|
||||
|
||||
在target中配置LUN
|
||||
*在target中配置LUN*
|
||||
|
||||
- iSCSI 限定名 (iqn.2014-07.com.tecmint:tgt1).
|
||||
- 随你怎么使用
|
||||
- 确定使用目标, 这台服务器中的第一个目标
|
||||
- 4. LVM共享特定的LUN。
|
||||
上图的解释:
|
||||
|
||||
接下来使用下面命令重载**tgd**服务配置。
|
||||
1. iSCSI 采取限定名 (iqn.2014-07.com.tecmint:tgt1).
|
||||
2. 名称随便你
|
||||
3. 用于确定目标名, 这是这台服务器中的第一个目标
|
||||
4. LVM共享特定的LUN。
|
||||
|
||||
接下来使用下面的命令重载**tgd**服务配置。
|
||||
|
||||
# /etc/init.d/tgtd reload
|
||||
|
||||

|
||||
|
||||
重载配置
|
||||
*重载配置*
|
||||
|
||||
接下来使用下面的命令验证可用的LUN。
|
||||
|
||||
@ -200,23 +202,22 @@ LUN用于存储,SAN存储大多数有LUN的集群来组成池,LUN由几块
|
||||
|
||||

|
||||
|
||||
列出可用LUN
|
||||
*列出可用LUN*
|
||||
|
||||

|
||||
|
||||
LUN信息
|
||||
*LUN信息*
|
||||
|
||||
The above command will give long list of available LUNs with following information.
|
||||
上面的命令会列出可用LUN的下面这些信息
|
||||
|
||||
- iSCSI 限定名
|
||||
- iSCSI 准备使用
|
||||
- 默认LUN 0被控制器保留
|
||||
- LUN 1是我们定义的target服务器
|
||||
- 这里我为每个LUN都定义了4GB
|
||||
- 在线: 是的,这就是可以使用的LUN
|
||||
1. iSCSI 限定名
|
||||
2. iSCSI 已经准备好
|
||||
3. 默认LUN 0被控制器所保留
|
||||
4. LUN 1是我们定义的目标器
|
||||
5. 这里我为每个LUN都定义了4GB
|
||||
6. 在线: 是的,这就是可以使用的LUN
|
||||
|
||||
现在我们已经使用LVM为target服务器定义了LUN,这可扩展并且支持很多特性,如快照。我们将会在第三部分了解如何用target服务器授权,并且本地挂载远程存储。
|
||||
现在我们已经使用LVM为目标器定义了LUN,这可扩展并且支持很多特性,如快照。我们将会在第三部分了解如何用目标器授权,并且本地挂载远程存储。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -224,9 +225,9 @@ via: http://www.tecmint.com/create-luns-using-lvm-in-iscsi-target/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/create-centralized-secure-storage-using-iscsi-targetin-linux/
|
||||
[1]:http://linux.cn/article-4971-1.html
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
How to back up a Debian system using backupninja
|
||||
================================================================================
|
||||
Prudence or experience by disaster can teach every [sysadmin][1] the importance of taking frequent system backups. You can do so by writing good old shell scripts, or using one (or more) of the many backup tools available for the job. Thus the more tools you become acquainted with, the better informed decisions you will make when implementing a backup solution.
|
||||
@ -108,4 +110,4 @@ via: http://xmodulo.com/backup-debian-system-backupninja.html
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/recommend/sysadminbook
|
||||
[2]:https://labs.riseup.net/code/projects/backupninja
|
||||
[2]:https://labs.riseup.net/code/projects/backupninja
|
||||
|
||||
@ -1,187 +0,0 @@
|
||||
10 quick tar command examples to create/extract archives in Linux
|
||||
================================================================================
|
||||
### Tar command on Linux ###
|
||||
|
||||
The tar (tape archive) command is a frequently used command on linux that allows you to store files into an archive.
|
||||
|
||||
The commonly seen file extensions are .tar.gz and .tar.bz2 which is a tar archive further compressed using gzip or bzip algorithms respectively.
|
||||
|
||||
In this tutorial we shall take a look at simple examples of using the tar command to do daily jobs of creating and extracting archives on linux desktops or servers.
|
||||
|
||||
### Using the tar command ###
|
||||
|
||||
The tar command is available by default on most linux systems and you do not need to install it separately.
|
||||
|
||||
> With tar there are 2 compression formats, gzip and bzip. The "z" option specifies gzip and "j" option specifies bzip. It is also possible to create uncompressed archives.
|
||||
|
||||
#### 1. Extract a tar.gz archive ####
|
||||
|
||||
Well, the more common use is to extract tar archives. The following command shall extract the files out a tar.gz archive
|
||||
|
||||
$ tar -xvzf tarfile.tar.gz
|
||||
|
||||
Here is a quick explanation of the parameters used -
|
||||
|
||||
> x - Extract files
|
||||
>
|
||||
> v - verbose, print the file names as they are extracted one by one
|
||||
>
|
||||
> z - The file is a "gzipped" file
|
||||
>
|
||||
> f - Use the following tar archive for the operation
|
||||
|
||||
Those are some of the important options to memorise
|
||||
|
||||
**Extract tar.bz2/bzip archives**
|
||||
|
||||
Files with extension bz2 are compressed with the bzip algorithm and tar command can deal with them as well. Use the j option instead of the z option.
|
||||
|
||||
$ tar -xvjf archivefile.tar.bz2
|
||||
|
||||
#### 2. Extract files to a specific directory or path ####
|
||||
|
||||
To extract out the files to a specific directory, specify the path using the "-C" option. Note that its a capital C.
|
||||
|
||||
$ tar -xvzf abc.tar.gz -C /opt/folder/
|
||||
|
||||
However first make sure that the destination directory exists, since tar is not going to create the directory for you and will fail if it does not exist.
|
||||
|
||||
#### 3. Extract a single file ####
|
||||
|
||||
To extract a single file out of an archive just add the file name after the command like this
|
||||
|
||||
$ tar -xz -f abc.tar.gz "./new/abc.txt"
|
||||
|
||||
More than once file can be specified in the above command like this
|
||||
|
||||
$ tar -xv -f abc.tar.gz "./new/cde.txt" "./new/abc.txt"
|
||||
|
||||
#### 4. Extract multiple files using wildcards ####
|
||||
|
||||
Wildcards can be used to extract out a bunch of files matching the given wildcards. For example all files with ".txt" extension.
|
||||
|
||||
$ tar -xv -f abc.tar.gz --wildcards "*.txt"
|
||||
|
||||
#### 5. List and search contents of the tar archive ####
|
||||
|
||||
If you want to just list out the contents of the tar archive and not extract them, use the "-t" option. The following command prints the contents of a gzipped tar archive,
|
||||
|
||||
$ tar -tz -f abc.tar.gz
|
||||
./new/
|
||||
./new/cde.txt
|
||||
./new/subdir/
|
||||
./new/subdir/in.txt
|
||||
./new/abc.txt
|
||||
...
|
||||
|
||||
Pipe the output to grep to search a file or less command to browse the list. Using the "v" verbose option shall print additional details about each file.
|
||||
|
||||
For tar.bz2/bzip files use the "j" option
|
||||
|
||||
Use the above command in combination with the grep command to search the archive. Simple!
|
||||
|
||||
$ tar -tvz -f abc.tar.gz | grep abc.txt
|
||||
-rw-rw-r-- enlightened/enlightened 0 2015-01-13 11:40 ./new/abc.txt
|
||||
|
||||
#### 6. Create a tar/tar.gz archive ####
|
||||
|
||||
Now that we have learnt how to extract existing tar archives, its time to start creating new ones. The tar command can be told to put selected files in an archive or an entire directory. Here are some examples.
|
||||
|
||||
The following command creates a tar archive using a directory, adding all files in it and sub directories as well.
|
||||
|
||||
$ tar -cvf abc.tar ./new/
|
||||
./new/
|
||||
./new/cde.txt
|
||||
./new/abc.txt
|
||||
|
||||
The above example does not create a compressed archive. Just a plain archive, that puts multiple files together without any real compression.
|
||||
|
||||
In order to compress, use the "z" or "j" option for gzip or bzip respectively.
|
||||
|
||||
$ tar -cvzf abc.tar.gz ./new/
|
||||
|
||||
> The extension of the file name does not really matter. "tar.gz" and tgz are common extensions for files compressed with gzip. ".tar.bz2" and ".tbz" are commonly used extensions for bzip compressed files.
|
||||
|
||||
#### 7. Ask confirmation before adding files ####
|
||||
|
||||
A useful option is "w" which makes tar ask for confirmation for every file before adding it to the archive. This can be sometimes useful.
|
||||
|
||||
Only those files would be added which are given a yes answer. If you do not enter anything, the default answer would be a "No".
|
||||
|
||||
# Add specific files
|
||||
|
||||
$ tar -czw -f abc.tar.gz ./new/*
|
||||
add ‘./new/abc.txt’?y
|
||||
add ‘./new/cde.txt’?y
|
||||
add ‘./new/newfile.txt’?n
|
||||
add ‘./new/subdir’?y
|
||||
add ‘./new/subdir/in.txt’?n
|
||||
|
||||
# Now list the files added
|
||||
$ tar -t -f abc.tar.gz
|
||||
./new/abc.txt
|
||||
./new/cde.txt
|
||||
./new/subdir/
|
||||
|
||||
#### 8. Add files to existing archives ####
|
||||
|
||||
The r option can be used to add files to existing archives, without having to create new ones. Here is a quick example
|
||||
|
||||
$ tar -rv -f abc.tar abc.txt
|
||||
|
||||
> Files cannot be added to compressed archives (gz or bzip). Files can only be added to plain tar archives.
|
||||
|
||||
#### 9. Add files to compressed archives (tar.gz/tar.bz2) ####
|
||||
|
||||
Its already mentioned that its not possible to add files to compressed archives. However it can still be done with a simple trick. Use the gunzip command to uncompress the archive, add file to archive and compress it again.
|
||||
|
||||
$ gunzip archive.tar.gz
|
||||
$ tar -rf archive.tar ./path/to/file
|
||||
$ gzip archive.tar
|
||||
|
||||
For bzip files use the bzip2 and bunzip2 commands respectively.
|
||||
|
||||
#### 10. Backup with tar ####
|
||||
|
||||
A real scenario is to backup directories at regular intervals. The tar command can be scheduled to take such backups via cron. Here is an example -
|
||||
|
||||
$ tar -cvz -f archive-$(date +%Y%m%d).tar.gz ./new/
|
||||
|
||||
Run the above command via cron and it would keep creating backup files with names like -
|
||||
'archive-20150218.tar.gz'.
|
||||
|
||||
Ofcourse make sure that the disk space is not overflown with larger and larger archives.
|
||||
|
||||
#### 11. Verify archive files while creation ####
|
||||
|
||||
The "W" option can be used to verify the files after creating archives. Here is a quick example.
|
||||
|
||||
$ tar -cvW -f abc.tar ./new/
|
||||
./new/
|
||||
./new/cde.txt
|
||||
./new/subdir/
|
||||
./new/subdir/in.txt
|
||||
./new/newfile.txt
|
||||
./new/abc.txt
|
||||
Verify ./new/
|
||||
Verify ./new/cde.txt
|
||||
Verify ./new/subdir/
|
||||
Verify ./new/subdir/in.txt
|
||||
Verify ./new/newfile.txt
|
||||
Verify ./new/abc.txt
|
||||
|
||||
Note that the verification cannot be done on compressed archives. It works only with uncompressed tar archives.
|
||||
|
||||
Thats all for now. For more check out the man page for tar command, with "man tar".
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.binarytides.com/linux-tar-command/
|
||||
|
||||
作者:[Silver Moon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117145272367995638274/posts
|
||||
@ -0,0 +1,296 @@
|
||||
How to Limit the Network Bandwidth Used by Applications in a Linux System with Trickle
|
||||
================================================================================
|
||||
Have you ever encountered situations where one application dominated you all network bandwidth? If you have ever been in a situation where one application ate all your traffic, then you will value the role of the trickle bandwidth shaper application. Either you are a system admin or just a Linux user, you need to learn how to control the upload and download speeds for applications to make sure that your network bandwidth is not burned by a single application.
|
||||
|
||||

|
||||
Install Trickle Bandwidth Limit in Linux
|
||||
|
||||
### What is Trickle? ###
|
||||
|
||||
Trickle is a network bandwidth shaper tool that allows us to manage the upload and download speeds of applications in order to prevent any single one of them to hog all (or most) of the available bandwidth. In few words, trickle lets you control the network traffic rate on a per-application basis, as opposed to per-user control, which is the classic example of bandwidth shaping in a client-server environment, and is probably the setup we are more familiar with.
|
||||
|
||||
### How Trickle Works? ###
|
||||
|
||||
In addition, trickle can help us to define priorities on a per-application basis, so that when overall limits have been set for the entire system, priority apps will still get more bandwidth automatically. To accomplish this task, trickle sets traffic limits to the way in which data is sent to, and received from, sockets using TCP connections. We must note that, other than the data transfer rates, trickle does not modify in any way the behavior of the process it is shaping at any given moment.
|
||||
|
||||
### What Can’t Trickle do? ###
|
||||
|
||||
The only limitation, so to speak, is that trickle will not work with statically linked applications or binaries with the SUID or SGID bits set since it uses dynamic linking and loading to place itself between the shaped process and its associated network socket. Trickle then acts as a proxy between these two software components.
|
||||
|
||||
Since trickle does not require superuser privileges in order to run, users can set their own traffic limits. Since this may not be desirable, we will explore how to set overall limits that system users cannot exceed. In other words, users will still be able to manage their traffic rates, but always within the boundaries set by the system administrator.
|
||||
|
||||
In this article we will explain how to limit the network bandwidth used by applications in a Linux server with trickle. To generate the necessary traffic, we will use ncftpput and ncftpget (both tools are available by installing ncftp) on the client (CentOS 7 server – dev1: 192.168.0.17), and vsftpd on the server (Debian Wheezy 7.5 – dev2: 192.168.0.15) for demonstration purposes. The same instructions also works on RedHat, Fedora and Ubuntu based systems.
|
||||
|
||||
#### Prerequisites ####
|
||||
|
||||
1. For RHEL/CentOS 7/6, [enable the EPEL repository][1]. Extra Packages for Enterprise Linux (EPEL) is a repository of high-quality free and open-source software maintained by the Fedora project and is 100% compatible with its spinoffs, such as Red Hat Enterprise Linux and CentOS. Both trickle and ncftp are made available from this repository.
|
||||
|
||||
2. Install ncftp as follows:
|
||||
|
||||
# yum update && sudo yum install ncftp [On RedHat based systems]
|
||||
# aptitude update && aptitude install ncftp [On Debian based systems]
|
||||
|
||||
3. Set up a FTP server in a separate server. Please note that although FTP is inherently insecure, it is still widely used in cases when security in uploading or downloading files is not needed. We are using it in this article to illustrate the bounties of trickle and because it shows the transfer rates in stdout on the client, and we will leave the discussion of whether it should or should not be used for another date and time :).
|
||||
|
||||
# yum update && yum install vsftpd [On RedHat based systems]
|
||||
# aptitude update && aptitude install vsftpd [On Debian based systems]
|
||||
|
||||
Now, edit the /etc/vsftpd/vsftpd.conf file on the FTP server as follows:
|
||||
|
||||
anonymous_enable=NO
|
||||
local_enable=YES
|
||||
chroot_local_user=YES
|
||||
allow_writeable_chroot=YES
|
||||
|
||||
After that, make sure to start vsftpd for your current session and to enable it for automatic start on future boots:
|
||||
|
||||
# systemctl start vsftpd [For systemd-based systems]
|
||||
# systemctl enable vsftpd
|
||||
# service vsftpd start [For init-based systems]
|
||||
# chkconfig vsftpd on
|
||||
|
||||
4. If you chose to set up the FTP server in a CentOS/RHEL 7 droplet with SSH keys for remote access, you will need a password-protected user account with the appropriate directory and file permissions for uploading and downloading the desired content OUTSIDE root’s home directory.
|
||||
|
||||
You can then browse to your home directory by entering the following URL in your browser. A login window will pop up prompting you for a valid user account and password on the FTP server.
|
||||
|
||||
ftp://192.168.0.15
|
||||
|
||||
If the authentication succeeds, you will see the contents of your home directory. Later in this tutorial you will be able to refresh that page to display the files that have been uploaded during previous steps.
|
||||
|
||||

|
||||
FTP Directory Tree
|
||||
|
||||
### How to Install Trickle in Linux ###
|
||||
|
||||
1. Install trickle via yum or aptitude.
|
||||
|
||||
To ensure a successful installation, it is considered good practice to make sure the currently installed packages are up-to-date (using yum update) before installing the tool itself.
|
||||
|
||||
# yum -y update && yum install trickle [On RedHat based systems]
|
||||
# aptitude -y update && aptitude install trickle [On Debian based systems]
|
||||
|
||||
2. Verify whether trickle will work with the desired binary.
|
||||
|
||||
As we explained earlier, trickle will only work with binaries using dynamic, or shared, libraries. To verify whether we can use this tool with a certain application, we can use the well-known ldd utility, where ldd stands for list dynamic dependencies. Specifically, we will look for the presence of glibc (the GNU C library) in the list of dynamic dependencies of any given program because it is precisely that library which defines the system calls involved in communication through sockets.
|
||||
|
||||
Run the following command against a given binary to see if trickle can be used to shape its bandwidth:
|
||||
|
||||
# ldd $(which [binary]) | grep libc.so
|
||||
|
||||
For example,
|
||||
|
||||
# ldd $(which ncftp) | grep libc.so
|
||||
|
||||
whose output is:
|
||||
|
||||
# libc.so.6 => /lib64/libc.so.6 (0x00007efff2e6c000)
|
||||
|
||||
The string between brackets in the output may change from system to system and even between subsequent runs of the same command, since it represents the load address of the library in physical memory.
|
||||
|
||||
If the above command does not return any results, it means that the binary it was run against does not use libc and thus trickle cannot be used as bandwidth shaper in that case.
|
||||
|
||||
### Learn How to Use Trickle ###
|
||||
|
||||
The most basic usage of trickle is in standalone mode. Using this approach, trickle is used to explicitly define the download and upload speeds of a given application. As we explained earlier, for the sake of brevity, we will use the same application for download and upload tests.
|
||||
|
||||
#### Running Trickle in Standalone Mode ####
|
||||
|
||||
We will compare the download and upload speeds with and without using trickle. The -d option indicates the download speed in KB/s, while the -u flag tells trickle to limit the upload speed by the same unit. In addition, we will use the -s flag, which specifies that trickle should run in standalone mode.
|
||||
|
||||
The basic syntax to run trickle in standalone mode is as follows:
|
||||
|
||||
# trickle -s -d [download rate in KB/s] -u [upload rate in KB/s]
|
||||
|
||||
In order to perform the following examples on your own, make sure to have trickle and ncftp installed on the client machine (192.168.0.17 in my case).
|
||||
|
||||
**Example 1: Uploading a 2.8 MB PDF file with and without trickle.**
|
||||
|
||||
We are using the freely-distributable Linux Fundamentals PDF file (available from [here][2]) for the following tests.
|
||||
|
||||
You can initially download this file to your current working directory with the following command:
|
||||
|
||||
# wget http://linux-training.be/files/books/LinuxFun.pdf
|
||||
|
||||
The syntax to upload a file to our FTP server without trickle is as follows:
|
||||
|
||||
# ncftpput -u username -p password 192.168.0.15 /remote_directory local-filename
|
||||
|
||||
Where /remote_directory is the path of the upload directory relative to username’s home, and local-filename is a file in your current working directory.
|
||||
|
||||
Specifically, without trickle we get a peak upload speed of 52.02 MB/s (please note that this is not the real average upload speed, but an instant starting peak), and the file gets uploaded almost instantly:
|
||||
|
||||
# ncftpput -u username -p password 192.168.0.15 /testdir LinuxFun.pdf
|
||||
|
||||
Output:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 52.02 MB/s
|
||||
|
||||
With trickle, we will limit the upload transfer rate at 5 KB/s. Before uploading the file for the second time, we need to delete it from the destination directory; otherwise, ncftp will inform us that the file at the destination directory is the same that we are trying to upload, and will not perform the transfer:
|
||||
|
||||
# rm /absolute/path/to/destination/directory/LinuxFun.pdf
|
||||
|
||||
Then:
|
||||
|
||||
# trickle -s -u 5 ncftpput -u username -p password 111.111.111.111 /testdir LinuxFun.pdf
|
||||
|
||||
Output:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 4.94 kB/s
|
||||
|
||||
In the example above, we can see that the average upload speed dropped to ~5 KB/s.
|
||||
|
||||
**Example 2: Downloading the same 2.8 MB PDF file with and without trickle**
|
||||
|
||||
First, remember to delete the PDF from the original source directory:
|
||||
|
||||
# rm /absolute/path/to/source/directory/LinuxFun.pdf
|
||||
|
||||
Please note that the following cases will download the remote file to the current directory in the client machine. This fact is indicated by the period (‘.‘) that appears after the IP address of the FTP server.
|
||||
|
||||
Without trickle:
|
||||
|
||||
# ncftpget -u username -p password 111.111.111.111 . /testdir/LinuxFun.pdf
|
||||
|
||||
Output:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 260.53 MB/s
|
||||
|
||||
With trickle, limiting the download speed at 20 KB/s:
|
||||
|
||||
# trickle -s -d 30 ncftpget -u username -p password 111.111.111.111 . /testdir/LinuxFun.pdf
|
||||
|
||||
Output:
|
||||
|
||||
LinuxFun.pdf: 2.79 MB 17.76 kB/s
|
||||
|
||||
### Running Trickle in Supervised [unmanaged] Mode ###
|
||||
|
||||
Trickle can also run in unmanaged mode, following a series of parameters defined in /etc/trickled.conf. This file defines how trickled (the daemon) behaves and manages trickle.
|
||||
|
||||
In addition, if we want to set global settings to be used, overall, by all applications, we will need to use the trickled command. This command runs the daemon and allows us to define download and upload limits that will be shared by all the applications run through trickle without us needing to specify limits each time.
|
||||
|
||||
For example, running:
|
||||
|
||||
# trickled -d 50 -u 10
|
||||
|
||||
Will cause that the download and upload speeds of any application run through trickle be limited to 30 KB/s and 10 KB/s, respectively.
|
||||
|
||||
Please note that you can check at any time whether trickled is running and with what arguments:
|
||||
|
||||
# ps -ef | grep trickled | grep -v grep
|
||||
|
||||
Output:
|
||||
|
||||
root 16475 1 0 Dec24 ? 00:00:04 trickled -d 50 -u 10
|
||||
|
||||
**Example 3: Uploading a 19 MB mp4 file to our FTP server using with and without trickle.**
|
||||
|
||||
In this example we will use the freely-distributable “He is the gift” video, available for download from [this link][3].
|
||||
|
||||
We will initially download this file to your current working directory with the following command:
|
||||
|
||||
# wget http://media2.ldscdn.org/assets/missionary/our-people-2014/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
First off, we will start the trickled daemon with the command listed above:
|
||||
|
||||
# trickled -d 30 -u 10
|
||||
|
||||
Without trickle:
|
||||
|
||||
# ncftpput -u username -p password 192.168.0.15 /testdir 2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
Output:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 36.31 MB/s
|
||||
|
||||
With trickle:
|
||||
|
||||
# trickle ncftpput -u username -p password 192.168.0.15 /testdir 2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
Output:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 9.51 kB/s
|
||||
|
||||
As we can see in the output above, the upload transfer rate dropped to ~10 KB/s.
|
||||
|
||||
**Example 4: Downloading the same video with and without trickle**
|
||||
|
||||
As in Example 2, we will be downloading the file to the current working directory.
|
||||
|
||||
Without trickle:
|
||||
|
||||
# ncftpget -u username -p password 192.168.0.15 . /testdir/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
Output:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 108.34 MB/s
|
||||
|
||||
With trickle:
|
||||
|
||||
# trickle ncftpget -u username -p password 111.111.111.111 . /testdir/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
|
||||
Output:
|
||||
|
||||
2014-00-1460-he-is-the-gift-360p-eng.mp4: 18.53 MB 29.28 kB/s
|
||||
|
||||
Which is in accordance with the download limit set earlier (30 KB/s).
|
||||
|
||||
**Note:** That once the daemon has been started, there is no need to set individual limits for each application that uses trickle.
|
||||
|
||||
As we mentioned earlier, one can further customize trickle’s bandwidth shaping through trickled.conf. A typical section in this file consists of the following:
|
||||
|
||||
[service]
|
||||
Priority = <value>
|
||||
Time-Smoothing = <value>
|
||||
Length-Smoothing = <value>
|
||||
|
||||
Where,
|
||||
|
||||
- [service] indicates the name of the application whose bandwidth usage we intend to shape.
|
||||
- Priority allows us to specify a service to have a higher priority relative to another, thus not allowing a single application to hog all the bandwidth which the daemon is managing. The lower the number, the more bandwidth that is assigned to [service].
|
||||
- Time-Smoothing [in seconds]: defines with what time intervals trickled will try to let the application transfer and / or receive data. Smaller values (something between the range of 0.1 – 1s) are ideal for interactive applications and will result in a more continuous (smooth) session while slightly larger values (1 – 10 s) are better for applications that need bulk transfer. If no value is specified, the default (5 s) is used.
|
||||
- Length-Smoothing [in KB]: the idea is the same as in Time-Smoothing, but based on the length of an I/O operation. If no value is specified, the default (10 KB) is used.
|
||||
|
||||
Changing the smoothing values will translate into the application specified by [service] using transfer rates within an interval instead of a fixed value. Unfortunately, there is no formula to calculate the lower and upper limits of this interval as it mainly depends of each specific case scenario.
|
||||
|
||||
The following is a trickled.conf sample file in the CentOS 7 client (192.168.0.17):
|
||||
|
||||
[ssh]
|
||||
Priority = 1
|
||||
Time-Smoothing = 0.1
|
||||
Length-Smoothing = 2
|
||||
|
||||
[ftp]
|
||||
Priority = 2
|
||||
Time-Smoothing = 1
|
||||
Length-Smoothing = 3
|
||||
|
||||
Using this setup, trickled will prioritize SSH connections over FTP transfers. Note that an interactive process, such as SSH, uses smaller time-smoothing values, whereas a service that performs bulk data transfers (FTP) uses a greater value. The smoothing values are responsible for the download and upload speeds in our previous example not matching the exact value specified by the trickled daemon but moving in an interval close to it.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have explored how to limit the bandwidth used by applications using trickle on Fedora-based distributions and Debian / derivatives. Other possible use cases include, but are not limited to:
|
||||
|
||||
- Limiting the download speed via a system utility such as [wget][4], or a torrent client, for example.
|
||||
- Limiting the speed at which your system can be updated via `[yum][5]` (or `[aptitude][6]`, if you’re in a Debian-based system), the package management system.
|
||||
- If your server happens to be behind a proxy or firewall (or is the proxy or firewall itself), you can use trickle to set limits on both the download and upload, or communication speed with the clients or the outside.
|
||||
|
||||
Questions and comments are most welcome. Feel free to use the form below to send them our way.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-and-limit-downloadupload-bandwidth-with-trickle-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:http://linux-training.be/files/books/LinuxFun.pdf
|
||||
[3]:http://media2.ldscdn.org/assets/missionary/our-people-2014/2014-00-1460-he-is-the-gift-360p-eng.mp4
|
||||
[4]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[5]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[6]:http://www.tecmint.com/dpkg-command-examples/
|
||||
@ -0,0 +1,152 @@
|
||||
How to Manage KVM Virtual Environment using Commandline Tools in Linux
|
||||
================================================================================
|
||||
In this 4th part of our [KVM series][1], we are discussing KVM environment management using CLI. We use ‘virt-install’ CL tool to create and configure virtual machines, virsh CL tool to create and configure storage pools and qemu-img CL tool to create and manage disk images.
|
||||
|
||||

|
||||
KVM Management in Linux
|
||||
|
||||
There is nothing new concepts in this article, we just do the previous tasks using command line tools. There is no new prerequisite, just the same procedure, we have discussed in previous parts.
|
||||
|
||||
### Step 1: Configure Storage Pool ###
|
||||
|
||||
Virsh CLI tool is a management user interface for managing virsh guest domains. The virsh program can be used either to run one command by giving the command and its arguments on the shell command line.
|
||||
|
||||
In this section, we will use it to create storage pool for our KVM environment. For more information about the tool, use the following command.
|
||||
|
||||
# man virsh
|
||||
|
||||
**1. Using the command pool-define-as with virsh to define new storage pool, you need also to specify name, type and type’s arguments.**
|
||||
|
||||
In our case, name will be Spool1, type will be dir. By default you could provide five arguments for the type:
|
||||
|
||||
- source-host
|
||||
- source-path
|
||||
- source-dev
|
||||
- source-name
|
||||
- target
|
||||
|
||||
For (Dir) type, we need the last argumet “target” to specify the path of storage pool, for the other arguments we could use “-” to unspecific them.
|
||||
|
||||
# virsh pool-define-as Spool1 dir - - - - "/mnt/personal-data/SPool1/"
|
||||
|
||||

|
||||
Create New Storage Pool
|
||||
|
||||
**2. To check the all storage pools you have in the environment, use the following command.**
|
||||
|
||||
# virsh pool-list --all
|
||||
|
||||

|
||||
List All Storage Pools
|
||||
|
||||
**3. Now it’s time to build the storage pool, which we have defined above with the following command.**
|
||||
|
||||
# virsh pool-build Spool1
|
||||
|
||||

|
||||
Build Storage Pool
|
||||
|
||||
**4. Using the virsh command pool-start to active/enable the storage pool we have just created/built above.**
|
||||
|
||||
# virsh pool-start Spool1
|
||||
|
||||

|
||||
Active Storage Pool
|
||||
|
||||
**5. Check the status of environment storage pools using the following command.**
|
||||
|
||||
# virsh pool-list --all
|
||||
|
||||

|
||||
Check Storage Pool Status
|
||||
|
||||
You will notice that the status of Spool1 converted to active.
|
||||
|
||||
**6. Configure Spool1 to start by libvirtd service every time automaticlly.**
|
||||
|
||||
# virsh pool-autostart Spool1
|
||||
|
||||

|
||||
Configure KVM Storage Pool
|
||||
|
||||
**7. Finally lets display information about our new storage pool.**
|
||||
|
||||
# virsh pool-info Spool1
|
||||
|
||||

|
||||
Check KVM Storage Pool Information
|
||||
|
||||
Congratulations, Spool1 is ready to be used lets try to create storage volumes using it.
|
||||
|
||||
### Step 2: Configure Storage Volumes/Disk Images ###
|
||||
|
||||
Now it is disk image’s turn, using qemu-img to create new disk image from Spool1. For more details about qemy-img, use the man page.
|
||||
|
||||
# man qemu-img
|
||||
|
||||
**8. We should specify the qemu-img command “create, check,….etc”, disk image format, the path of disk image you want to create and the size.**
|
||||
|
||||
# qemu-img create -f raw /mnt/personal-data/SPool1/SVol1.img 10G
|
||||
|
||||

|
||||
Create Storage Volume
|
||||
|
||||
**9. By using qemu-img command info, you could get information about your new disk image.**
|
||||
|
||||

|
||||
Check Storage Volume Information
|
||||
|
||||
**Warning**: Never use qemu-img to modify images in use by a running virtual machine or any other process; this may destroy the image.
|
||||
|
||||
Now its time to create virtual machines in the next step.
|
||||
|
||||
### Step 3: Create Virtual Machines ###
|
||||
|
||||
10. Now with the last and latest part, we will create virtual machines using virt-istall. The virt-install is a command line tool for creating new KVM virtual machines using the “libvirt” hypervisor management library. For more details about it, use:
|
||||
|
||||
# man virt-install
|
||||
|
||||
To create new KVM virtual machine, you need to use the following command with all the details like shown in the below.
|
||||
|
||||
- Name: Virtual Machine’s name.
|
||||
- Disk Location: Location of disk image.
|
||||
- Graphics : How to connect to VM “Usually be SPICE”.
|
||||
- vcpu : Number of virtual CPU’s.
|
||||
- ram : Amount of allocated memory in megabytes.
|
||||
- Location : Specify the installation source path.
|
||||
- Network : Specify the virtual network “Usually be vibr00 bridge”.
|
||||
|
||||
# virt-install --name=rhel7 --disk path=/mnt/personal-data/SPool1/SVol1.img --graphics spice --vcpu=1 --ram=1024 --location=/run/media/dos/9e6f605a-f502-4e98-826e-e6376caea288/rhel-server-7.0-x86_64-dvd.iso --network bridge=virbr0
|
||||
|
||||

|
||||
Create New Virtual Machine
|
||||
|
||||
**11. You will find also a pop-up virt-vierwer window appears to communicate with virtual machine through it.**
|
||||
|
||||

|
||||
Booting Virtual Machine
|
||||
|
||||

|
||||
Installation of Virtual Machine
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
This is the latest part of our KVM tutorial, we haven’t covered everything of course. It a shot to scratch the KVM environment so its your turn to search and keep hands dirty using this nice resources.
|
||||
|
||||
- [KVM Getting Started Guide][2]
|
||||
- [KVM Virtualization Deployment and Administration Guide][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/kvm-management-tools-to-manage-virtual-machines/
|
||||
|
||||
作者:[Mohammad Dosoukey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/dos2009/
|
||||
[1]:http://www.tecmint.com/install-and-configure-kvm-in-linux/
|
||||
[2]:https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Getting_Started_Guide/index.html
|
||||
[3]:https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Virtualization_Deployment_and_Administration_Guide/index.html
|
||||
@ -0,0 +1,85 @@
|
||||
How to Setup Passwordless SSH Logon to Ubuntu 14.04
|
||||
================================================================================
|
||||
Hi all, today we'll gonna learn how we can setup Passwordless SSH Logon to Ubuntu 14.04 "Trusty". Only the workstations having the correct matching key pair (private and public) will be allowed to logon to the SSH server, without the key paring, access will not be allowed.
|
||||
|
||||
Usually, we need to enter username and password combination to connect to an SSH console. If the combination is correct to that of the system's then, we get access to the server else we are denied from the access. But, there is something more secure than Password logon, we have passwordless SSH logon using the encrypted keys.
|
||||
|
||||
If you want to enable this secured option, we can simply disable password-logon and only allow logon using an encryption key. When using encryption keys option, the client computer generates a private and public key pair. The client then must upload the public key to the SSH server authorized_key file. Before access is granted, the server and client computer validate the key pair. If the public key on the server matches the private key submitted via the client then access will be granted else will be denied.
|
||||
|
||||
This is a very secure way authenticating to a SSH server and it’s a recommended method if you wish to implement secure logon with single user SSH logon. Here's a quick step-wise process on how to enable Passwordless SSH logon.
|
||||
|
||||
### 1. Installing Openssh Server ###
|
||||
|
||||
First off all, we'll need to update our local repository index. To do so, we'll first need to run apt-get update as shown below.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||

|
||||
|
||||
Now, we can install openssh-server by running following command.
|
||||
|
||||
$ sudo apt-get install openssh-server
|
||||
|
||||

|
||||
|
||||
### 2. Enabling Openssh Server ###
|
||||
|
||||
Now, we'll want to enable OpenSSH server after we successfully installed it on our Ubuntu 14.04 Operating System. The command to enable/start the server is given as follows.
|
||||
|
||||
$ sudo service ssh start
|
||||
|
||||
OR
|
||||
|
||||
$ sudo /etc/init.d/ssh start
|
||||
|
||||
### 3. Configuring Key Pair ###
|
||||
|
||||
After we have installed our OpenSSH Server and enabled it. We'll now finally wanna go for generating our Public and Private Key Pair. To do that, run the following command in a terminal or console.
|
||||
|
||||
$ ssh-keygen -t rsa
|
||||
|
||||
After running the above command, we'll be prompted to complete a series of tasks. The first will be where to save the keys, press Enter to choose the default location which is in a hidden .ssh folder in the home directory. The next prompt will be to enter the Paraphrase. I personally leave this blank (just press enter) to continue. It will then create the key pair and we’re done.
|
||||
|
||||

|
||||
|
||||
After generation of the key pair, we will need to **copy the client’s public key to the SSH server** or host inorder to create trusted relationship with it. We'll need to run the commands below to copy the client public key to the server.
|
||||
|
||||
$ ssh-copy-id user@ip_address
|
||||
|
||||
After the public key is copied to the server, we can now go and disable password logon via SSH. To do that, we'll need to open **/etc/ssh/ssh_config** via a text editor by run the commands below.
|
||||
|
||||
$ sudo nano /etc/ssh/sshd_config
|
||||
|
||||
Now, we'll need to uncomment the lines and set the values as shown below.
|
||||
|
||||

|
||||
|
||||
### 4. Restarting the SSH Server ###
|
||||
|
||||
Finally, after we are done configuring SSH Server, we'll want to restart our SSH Server so that all the changes will take affect. To restart one can run the following command in a terminal or the console.
|
||||
|
||||
$ sudo service ssh restart
|
||||
|
||||
OR
|
||||
|
||||
$ sudo /etc/init.d/ssh restart
|
||||
|
||||

|
||||
|
||||
Finally, we can now ssh in to the server without a password and only from the client having the same key pair not the password.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Hurray! We have successfully enabled Passwordless SSH logon. It is a lot secure to enable Encrypted Key Pair SSH logon . This is a very secure way authenticating to a SSH server and it’s a recommended method if you wish to implement secure logon with single user SSH logon. So, if you have any questions, suggestions, feedback please write them in the comment box below. Thank you ! Enjoy Encrypted Secure SSH Login :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-passwordless-ssh-logon-ubuntu-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,191 @@
|
||||
linux中创建和解压文档的10个快速tar命令样例
|
||||
================================================================================
|
||||
### linux中的tar命令###
|
||||
|
||||
tar(磁带归档)命令是linux系统中被经常用来将文件存入到一个归档文件中的命令。
|
||||
|
||||
常见的文件扩展包括:.tar.gz 和 .tar.bz2, 分别表示通过gzip或bzip算法进一步压缩的磁带归档文件扩展。
|
||||
|
||||
|
||||
在该教程中我们会窥探一下在linux桌面或服务器版本中使用tar命令来处理一些日常创建和解压归档文件的工作样例。
|
||||
### 使用tar命令###
|
||||
|
||||
tar命令在大部分linux系统默认情况下都是可用的,所以你不用单独安装该软件。
|
||||
|
||||
> tar命令具有两个压缩格式,gzip和bzip,该命令的“z”选项用来指定gzip,“j”选项用来指定bzip。同时也可哟用来创建非压缩归档文件。
|
||||
|
||||
#### 1.解压一个tar.gz归档 ####
|
||||
|
||||
一般常见的用法是用来解压归档文件,下面的命令将会把文件从一个tar.gz归档文件中解压出来。
|
||||
|
||||
|
||||
$ tar -xvzf tarfile.tar.gz
|
||||
|
||||
这里对这些参数做一个简单解释-
|
||||
|
||||
> x - 解压文件
|
||||
|
||||
> v - 繁琐,在解压每个文件时打印出文件的名称。
|
||||
|
||||
> z - 该文件是一个使用 gzip压缩的文件。
|
||||
|
||||
> f - 使用接下来的tar归档来进行操作。
|
||||
|
||||
这些就是一些需要记住的重要选项。
|
||||
|
||||
**解压 tar.bz2/bzip 归档文件 **
|
||||
|
||||
具有bz2扩展名的文件是使用bzip算法进行压缩的,但是tar命令也可以对其进行处理,但是是通过使用“j”选项来替换“z”选项。
|
||||
|
||||
$ tar -xvjf archivefile.tar.bz2
|
||||
|
||||
#### 2.将文件解压到一个指定的目录或路径 ####
|
||||
|
||||
为了将文件解压到一个指定的目录中,使用“-C”选项来指定路径,此处的“C”是大写“C”。
|
||||
|
||||
$ tar -xvzf abc.tar.gz -C /opt/folder/
|
||||
|
||||
然后,首先需要确认目标目录是否存在,毕竟tar命令并不会为你创建目录,所以如果目标目录不存在的情况下该命令会失败。
|
||||
|
||||
####3. 解压出单个文件 ####
|
||||
|
||||
为了从一个归档文件中解压出单个文件,只需要将文件名按照以下方式将其放置在命令后面。
|
||||
|
||||
$ tar -xz -f abc.tar.gz "./new/abc.txt"
|
||||
|
||||
在上述命令中,可以按照以下方式来指定多个文件。
|
||||
|
||||
$ tar -xv -f abc.tar.gz "./new/cde.txt" "./new/abc.txt"
|
||||
|
||||
#### 4.使用通配符来解压多个文件 ####
|
||||
|
||||
通配符可以用来解压于给定通配符匹配的一批文件,例如所有以".txt"作为扩展名的文件。
|
||||
|
||||
$ tar -xv -f abc.tar.gz --wildcards "*.txt"
|
||||
|
||||
#### 5. 列出并检索tar归档文件中的内容 ####
|
||||
|
||||
如果你仅仅想要列出而不是解压tar归档文件的中的内容,使用“-t”选项, 下面的命令用来打印一个使用gzip压缩过的tar归档文件中的内容。
|
||||
|
||||
$ tar -tz -f abc.tar.gz
|
||||
./new/
|
||||
./new/cde.txt
|
||||
./new/subdir/
|
||||
./new/subdir/in.txt
|
||||
./new/abc.txt
|
||||
...
|
||||
|
||||
将输出通过管道定向到grep来搜索一个文件或者定向到less命令来浏览内容列表。 使用"v"繁琐选项将会打印出每个文件的额外详细信息。
|
||||
|
||||
对于 tar.bz2/bzip文件,需要使用"j"选项。
|
||||
|
||||
结合上述的命令和grep命令来检索归档文件,如下所示。简单吧!
|
||||
|
||||
$ tar -tvz -f abc.tar.gz | grep abc.txt
|
||||
-rw-rw-r-- enlightened/enlightened 0 2015-01-13 11:40 ./new/abc.txt
|
||||
|
||||
#### 6.创建一个tar/tar.gz归档文件 ####
|
||||
|
||||
现在我们已经学过了如何解压一个tar归档文件,是时候开始创建一个新的tar归档文件了。tar命令可以用来将所选的文件或整个目录放入到一个归档文件中,以下是相应的样例。
|
||||
|
||||
|
||||
下面的命令使用一个目录来创建一个tar归档文件,它会将该目录中所有的文件和子目录都加入到归档文件中。
|
||||
|
||||
$ tar -cvf abc.tar ./new/
|
||||
./new/
|
||||
./new/cde.txt
|
||||
./new/abc.txt
|
||||
|
||||
上述命令不会创建一个压缩的的归档文件,只是一个普通的归档文件,只是将多个文件放入到一个归档文件中并没有真正地压缩每个文件。
|
||||
|
||||
为了使用压缩,可以分别使用“z”或“j”选项进行gzip或bzip压缩算法。
|
||||
|
||||
$ tar -cvzf abc.tar.gz ./new/
|
||||
|
||||
> 文件的扩展名其实并不真正有什么影响。“tar.gz” 和tgz是gzip压缩算法压缩文件的常见扩展名。 “tar.bz2”和“tbz”是bzip压缩算法压缩文件的常见扩展名。
|
||||
|
||||
|
||||
#### 7. 在添加文件之前进行确认 ####
|
||||
|
||||
一个有用的选项是“w”,该选项使得tar命令在添加每个文件到归档文件之前来让用户进行确认,有时候这会很有用。
|
||||
|
||||
使用该选项时,只有用户输入yes时的文件才会被加入到归档文件中,如果你输入任何东西,默认的回答是一个“No”。
|
||||
|
||||
# 添加指定文件
|
||||
|
||||
$ tar -czw -f abc.tar.gz ./new/*
|
||||
add ‘./new/abc.txt’?y
|
||||
add ‘./new/cde.txt’?y
|
||||
add ‘./new/newfile.txt’?n
|
||||
add ‘./new/subdir’?y
|
||||
add ‘./new/subdir/in.txt’?n
|
||||
|
||||
#现在列出所有被加入的文件
|
||||
|
||||
$ tar -t -f abc.tar.gz
|
||||
./new/abc.txt
|
||||
./new/cde.txt
|
||||
./new/subdir/
|
||||
|
||||
#### 8. 加入文件到存在的归档文件中 ####
|
||||
|
||||
“r”选项可以被用来将文件加入到已存在的归档文件中,而不用创建一个新的归档文件,下面是一个简单的样例:
|
||||
|
||||
$ tar -rv -f abc.tar abc.txt
|
||||
|
||||
> 文件并不能加入到已压缩的归档文件中(gz 或 bzip)。文件只能被加入到普通的归档文件中。
|
||||
|
||||
#### 9. 将文件加入到压缩的归档文件中(tar.gz/tar.bz2) ####
|
||||
|
||||
之前已经提到了不可能将文件加入到已压缩的归档文件中,然和依然可以通过简单的一些把戏来完成。使用gunzip命令来解压缩归档文件,然后将文件加入到归档文件中后重新进行压缩。
|
||||
|
||||
$ gunzip archive.tar.gz
|
||||
$ tar -rf archive.tar ./path/to/file
|
||||
$ gzip archive.tar
|
||||
|
||||
对于bzip文件分别使用bzip2和bunzip2。
|
||||
|
||||
#### 10.通过tar来进行备份 ####
|
||||
|
||||
一个真实的场景是在规则的间隔内来备份目录,tar命令可以通过cron调度来实现这样的一个备份,以下是一个样例 -
|
||||
|
||||
$ tar -cvz -f archive-$(date +%Y%m%d).tar.gz ./new/
|
||||
|
||||
使用cron来运行上述的命令会保持创建类似以下名称的备份文件 -
|
||||
'archive-20150218.tar.gz'.
|
||||
|
||||
当然,需要确保日益增长的归档文件不会导致磁盘空间的溢出。
|
||||
|
||||
#### 11. 在创建归档文件是进行验证 ####
|
||||
|
||||
"W"选项可以用来在创建归档文件之后进行验证,以下是一个简单例子。
|
||||
|
||||
$ tar -cvW -f abc.tar ./new/
|
||||
./new/
|
||||
./new/cde.txt
|
||||
./new/subdir/
|
||||
./new/subdir/in.txt
|
||||
./new/newfile.txt
|
||||
./new/abc.txt
|
||||
Verify ./new/
|
||||
Verify ./new/cde.txt
|
||||
Verify ./new/subdir/
|
||||
Verify ./new/subdir/in.txt
|
||||
Verify ./new/newfile.txt
|
||||
Verify ./new/abc.txt
|
||||
|
||||
需要注意的是验证动作不能呢该在压缩过的归档文件上进行,只能在非压缩的tar归档文件上执行。
|
||||
|
||||
现在就先到此为止,可以通过“man tar”命令来查看tar命令的的手册。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.binarytides.com/linux-tar-command/
|
||||
|
||||
作者:[Silver Moon][a]
|
||||
译者:[theo-l](https://github.com/theo-l)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117145272367995638274/posts
|
||||
Loading…
Reference in New Issue
Block a user