mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
ee98cb4b60
.travis.yml
published
20180803 SDKMAN - A CLI Tool To Easily Manage Multiple Software Development Kits.md20180810 How To Quickly Serve Files And Folders Over HTTP In Linux.md20181019 Edit your videos with Pitivi on Fedora.md20181022 How to set up WordPress on a Raspberry Pi.md
scripts
sources
talk
tech
translated
@ -4,9 +4,9 @@ script:
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" = "false" ]; then sh ./scripts/badge.sh; fi'
|
||||
branches:
|
||||
only:
|
||||
- master
|
||||
- master
|
||||
except:
|
||||
- gh-pages
|
||||
- gh-pages
|
||||
git:
|
||||
submodules: false
|
||||
deploy:
|
||||
|
||||
@ -1,40 +1,41 @@
|
||||
SDKMAN – 轻松管理多个软件开发套件 (SDK) 的命令行工具
|
||||
SDKMAN:轻松管理多个软件开发套件 (SDK) 的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
你是否是一个经常在不同的 SDK 下安装和测试应用的开发者?我有一个好消息要告诉你!**SDKMAN**,一个可以帮你轻松管理多个 SDK 的命令行工具。它为安装、切换、列出和移除 SDK 提供了一个简便的方式。有了 SDKMAN,你可以在任何类 Unix 的操作系统上轻松地并行管理多个 SDK 的多个版本。它允许开发者为 JVM 安装不同的 SDK,例如 Java、Groovy、Scala、Kotlin 和 Ceylon、Ant、Gradle、Grails、Maven、SBT、Spark、Spring Boot、Vert.x,以及许多其他支持的 SDK。SDKMAN 是免费、轻量、开源、使用 **Bash** 编写的程序。
|
||||
你是否是一个经常在不同的 SDK 下安装和测试应用的开发者?我有一个好消息要告诉你!给你介绍一下 **SDKMAN**,一个可以帮你轻松管理多个 SDK 的命令行工具。它为安装、切换、列出和移除 SDK 提供了一个简便的方式。有了 SDKMAN,你可以在任何类 Unix 的操作系统上轻松地并行管理多个 SDK 的多个版本。它允许开发者为 JVM 安装不同的 SDK,例如 Java、Groovy、Scala、Kotlin 和 Ceylon、Ant、Gradle、Grails、Maven、SBT、Spark、Spring Boot、Vert.x,以及许多其他支持的 SDK。SDKMAN 是免费、轻量、开源、使用 **Bash** 编写的程序。
|
||||
|
||||
### 安装 SDKMAN
|
||||
|
||||
安装 SDKMAN 很简单。首先,确保你已经安装了 **zip** 和 **unzip** 这两个应用。它们在大多数的 Linux 发行版的默认仓库中。
|
||||
安装 SDKMAN 很简单。首先,确保你已经安装了 `zip` 和 `unzip` 这两个应用。它们在大多数的 Linux 发行版的默认仓库中。
|
||||
例如,在基于 Debian 的系统上安装 unzip,只需要运行:
|
||||
|
||||
```
|
||||
$ sudo apt-get install zip unzip
|
||||
|
||||
```
|
||||
|
||||
然后使用下面的命令安装 SDKMAN:
|
||||
|
||||
```
|
||||
$ curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
在安装完成之后,运行以下命令:
|
||||
|
||||
```
|
||||
$ source "$HOME/.sdkman/bin/sdkman-init.sh"
|
||||
|
||||
```
|
||||
|
||||
如果你希望自定义安装到其他位置,例如 **/usr/local/**,你可以这样做:
|
||||
如果你希望自定义安装到其他位置,例如 `/usr/local/`,你可以这样做:
|
||||
|
||||
```
|
||||
$ export SDKMAN_DIR="/usr/local/sdkman" && curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
确保你的用户有足够的权限访问这个目录。
|
||||
|
||||
最后,在安装完成后使用下面的命令检查一下:
|
||||
|
||||
```
|
||||
$ sdk version
|
||||
==== BROADCAST =================================================================
|
||||
@ -44,7 +45,6 @@ $ sdk version
|
||||
================================================================================
|
||||
|
||||
SDKMAN 5.7.2+323
|
||||
|
||||
```
|
||||
|
||||
恭喜你!SDKMAN 已经安装完成了。让我们接下来看如何安装和管理 SDKs 吧。
|
||||
@ -52,12 +52,13 @@ SDKMAN 5.7.2+323
|
||||
### 管理多个 SDK
|
||||
|
||||
查看可用的 SDK 清单,运行:
|
||||
|
||||
```
|
||||
$ sdk list
|
||||
|
||||
```
|
||||
|
||||
将会输出:
|
||||
|
||||
```
|
||||
================================================================================
|
||||
Available Candidates
|
||||
@ -79,18 +80,18 @@ used to pilot any type of process which can be described in terms of targets and
|
||||
tasks.
|
||||
|
||||
: $ sdk install ant
|
||||
|
||||
```
|
||||
|
||||
就像你看到的,SDK 每次列出众多 SDK 中的一个,以及该 SDK 的描述信息、官方网址和安装命令。按回车键继续下一个。
|
||||
|
||||
安装一个新的 SDK,例如 Java JDK,运行:
|
||||
|
||||
```
|
||||
$ sdk install java
|
||||
|
||||
```
|
||||
|
||||
将会输出:
|
||||
|
||||
```
|
||||
Downloading: java 8.0.172-zulu
|
||||
|
||||
@ -106,30 +107,30 @@ Installing: java 8.0.172-zulu
|
||||
Done installing!
|
||||
|
||||
Setting java 8.0.172-zulu as default.
|
||||
|
||||
```
|
||||
|
||||
如果你安装了多个 SDK,它将会提示你是否想要将当前安装的版本设置为 **默认版本**。回答 **Yes** 将会把当前版本设置为默认版本。
|
||||
如果你安装了多个 SDK,它将会提示你是否想要将当前安装的版本设置为 **默认版本**。回答 `Yes` 将会把当前版本设置为默认版本。
|
||||
|
||||
使用以下命令安装一个 SDK 的其他版本:
|
||||
|
||||
使用以下命令安装一个 SDK 的其他版本:
|
||||
```
|
||||
$ sdk install ant 1.10.1
|
||||
|
||||
```
|
||||
|
||||
如果你之前已经在本地安装了一个 SDK,你可以像下面这样设置它为本地版本。
|
||||
|
||||
```
|
||||
$ sdk install groovy 3.0.0-SNAPSHOT /path/to/groovy-3.0.0-SNAPSHOT
|
||||
|
||||
```
|
||||
|
||||
列出一个 SDK 的多个版本:
|
||||
|
||||
```
|
||||
$ sdk list ant
|
||||
|
||||
```
|
||||
|
||||
将会输出
|
||||
将会输出:
|
||||
|
||||
```
|
||||
================================================================================
|
||||
Available Ant Versions
|
||||
@ -145,32 +146,31 @@ Available Ant Versions
|
||||
* - installed
|
||||
> - currently in use
|
||||
================================================================================
|
||||
|
||||
```
|
||||
|
||||
像我之前说的,如果你安装了多个版本,SDKMAN 会提示你是否想要设置当前安装的版本为 **默认版本**。你可以回答 Yes 设置它为默认版本。当然,你也可以在稍后使用下面的命令设置:
|
||||
|
||||
```
|
||||
$ sdk default ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
上面的命令将会设置 Apache Ant 1.9.9 为默认版本。
|
||||
|
||||
你可以根据自己的需要选择使用任何已安装的 SDK 版本,仅需运行以下命令:
|
||||
你可以根据自己的需要选择使用任何已安装的 SDK 版本,仅需运行以下命令:
|
||||
|
||||
```
|
||||
$ sdk use ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
检查某个具体 SDK 当前的版本号,例如 Java,运行:
|
||||
|
||||
```
|
||||
$ sdk current java
|
||||
|
||||
Using java version 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
检查所有当下在使用的 SDK 版本号,运行:
|
||||
|
||||
```
|
||||
$ sdk current
|
||||
|
||||
@ -178,36 +178,35 @@ Using:
|
||||
|
||||
ant: 1.10.1
|
||||
java: 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
升级过时的 SDK,运行:
|
||||
|
||||
```
|
||||
$ sdk upgrade scala
|
||||
|
||||
```
|
||||
|
||||
你也可以检查所有的 SDKs 中还有哪些是过时的。
|
||||
你也可以检查所有的 SDK 中还有哪些是过时的。
|
||||
|
||||
```
|
||||
$ sdk upgrade
|
||||
|
||||
```
|
||||
|
||||
SDKMAN 有离线模式,可以让 SDKMAN 在离线时也正常运作。你可以使用下面的命令在任何时间开启或者关闭离线模式:
|
||||
|
||||
```
|
||||
$ sdk offline enable
|
||||
|
||||
$ sdk offline disable
|
||||
|
||||
```
|
||||
|
||||
要移除已安装的 SDK,运行:
|
||||
|
||||
```
|
||||
$ sdk uninstall ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
要了解更多的细节,参阅帮助章节。
|
||||
|
||||
```
|
||||
$ sdk help
|
||||
|
||||
@ -231,72 +230,68 @@ update
|
||||
flush <broadcast|archives|temp>
|
||||
|
||||
candidate : the SDK to install: groovy, scala, grails, gradle, kotlin, etc.
|
||||
use list command for comprehensive list of candidates
|
||||
eg: $ sdk list
|
||||
use list command for comprehensive list of candidates
|
||||
eg: $ sdk list
|
||||
|
||||
version : where optional, defaults to latest stable if not provided
|
||||
eg: $ sdk install groovy
|
||||
|
||||
eg: $ sdk install groovy
|
||||
```
|
||||
|
||||
### 更新 SDKMAN
|
||||
|
||||
如果有可用的新版本,可以使用下面的命令安装:
|
||||
|
||||
```
|
||||
$ sdk selfupdate
|
||||
|
||||
```
|
||||
|
||||
SDKMAN 会定期检查更新,以及让你了解如何更新的指令。
|
||||
SDKMAN 会定期检查更新,并给出让你了解如何更新的指令。
|
||||
|
||||
```
|
||||
WARNING: SDKMAN is out-of-date and requires an update.
|
||||
|
||||
$ sdk update
|
||||
Adding new candidates(s): scala
|
||||
|
||||
```
|
||||
|
||||
### 清除缓存
|
||||
|
||||
建议时不时的清理缓存(包括那些下载的 SDK 的二进制文件)。仅需运行下面的命令就可以了:
|
||||
建议时不时的清理缓存(包括那些下载的 SDK 的二进制文件)。仅需运行下面的命令就可以了:
|
||||
|
||||
```
|
||||
$ sdk flush archives
|
||||
|
||||
```
|
||||
|
||||
它也可以用于清理空的文件夹,节省一点空间:
|
||||
|
||||
```
|
||||
$ sdk flush temp
|
||||
|
||||
```
|
||||
|
||||
### 卸载 SDKMAN
|
||||
|
||||
如果你觉得不需要或者不喜欢 SDKMAN,可以使用下面的命令删除。
|
||||
|
||||
```
|
||||
$ tar zcvf ~/sdkman-backup_$(date +%F-%kh%M).tar.gz -C ~/ .sdkman
|
||||
$ rm -rf ~/.sdkman
|
||||
|
||||
```
|
||||
最后打开你的 **.bashrc**,**.bash_profile** 和/或者 **.profile**,找到并删除下面这几行。
|
||||
最后打开你的 `.bashrc`、`.bash_profile` 和/或者 `.profile`,找到并删除下面这几行。
|
||||
|
||||
```
|
||||
#THIS MUST BE AT THE END OF THE FILE FOR SDKMAN TO WORK!!!
|
||||
export SDKMAN_DIR="/home/sk/.sdkman"
|
||||
[[ -s "/home/sk/.sdkman/bin/sdkman-init.sh" ]] && source "/home/sk/.sdkman/bin/sdkman-init.sh"
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是 ZSH,就从 **.zshrc** 中删除上面这一行。
|
||||
如果你使用的是 ZSH,就从 `.zshrc` 中删除上面这一行。
|
||||
|
||||
这就是所有的内容了。我希望 SDKMAN 可以帮到你。还有更多的干货即将到来。敬请期待!
|
||||
|
||||
祝近祺!
|
||||
|
||||
|
||||
:)
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/sdkman-a-cli-tool-to-easily-manage-multiple-software-development-kits/
|
||||
@ -304,7 +299,7 @@ via: https://www.ostechnix.com/sdkman-a-cli-tool-to-easily-manage-multiple-softw
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
如何在 Linux 中快速地通过 HTTP 访问文件和文件夹
|
||||
如何在 Linux 中快速地通过 HTTP 提供文件访问服务
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天,我有很多方法来通过网络浏览器为局域网中的其他系统提供单个文件或整个目录访问。我在我的 Ubuntu 测试机上测试了这些方法,它们和下面描述的那样运行正常。如果你想知道如何在类 Unix 操作系统中通过 HTTP 轻松快速地访问文件和文件夹,以下方法之一肯定会有所帮助。
|
||||
如今,我有很多方法来通过 Web 浏览器为局域网中的其他系统提供单个文件或整个目录的访问。我在我的 Ubuntu 测试机上测试了这些方法,它们如下面描述的那样运行正常。如果你想知道如何在类 Unix 操作系统中通过 HTTP 轻松快速地提供文件和文件夹的访问服务,以下方法之一肯定会有所帮助。
|
||||
|
||||
### 在 Linux 中通过 HTTP 访问文件和文件夹
|
||||
|
||||
@ -13,50 +13,59 @@
|
||||
|
||||
我们写了一篇简要的指南来设置一个简单的 http 服务器,以便在以下链接中即时共享文件和目录。如果你有一个安装了 Python 的系统,这个方法非常方便。
|
||||
|
||||
- [如何使用 simpleHTTPserver 设置一个简单的文件服务器](https://www.ostechnix.com/how-to-setup-a-file-server-in-minutes-using-python/)
|
||||
|
||||
#### 方法 2 - 使用 Quickserve(Python)
|
||||
|
||||
此方法针对 Arch Linux 及其衍生版。有关详细信息,请查看下面的链接。
|
||||
|
||||
- [如何在 Arch Linux 中即时共享文件和文件夹](https://www.ostechnix.com/instantly-share-files-folders-arch-linux/)
|
||||
|
||||
#### 方法 3 - 使用 Ruby
|
||||
|
||||
在此方法中,我们使用 Ruby 在类 Unix 系统中通过 HTTP 提供文件和文件夹访问。按照以下链接中的说明安装 Ruby 和 Rails。
|
||||
|
||||
- [在 CentOS 和 Ubuntu 中安装 Ruby on Rails](https://www.ostechnix.com/install-ruby-rails-ubuntu-16-04/)
|
||||
|
||||
安装 Ruby 后,进入要通过网络共享的目录,例如 ostechnix:
|
||||
|
||||
```
|
||||
$ cd ostechnix
|
||||
|
||||
```
|
||||
|
||||
并运行以下命令:
|
||||
|
||||
```
|
||||
$ ruby -run -ehttpd . -p8000
|
||||
[2018-08-10 16:02:55] INFO WEBrick 1.4.2
|
||||
[2018-08-10 16:02:55] INFO ruby 2.5.1 (2018-03-29) [x86_64-linux]
|
||||
[2018-08-10 16:02:55] INFO WEBrick::HTTPServer#start: pid=5859 port=8000
|
||||
|
||||
```
|
||||
|
||||
确保在路由器或防火墙中打开端口 8000。如果该端口已被其他一些服务使用,那么请使用不同的端口。
|
||||
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - **http:// <ip-address>:8000**。
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - `http:// <ip-address>:8000`。
|
||||
|
||||
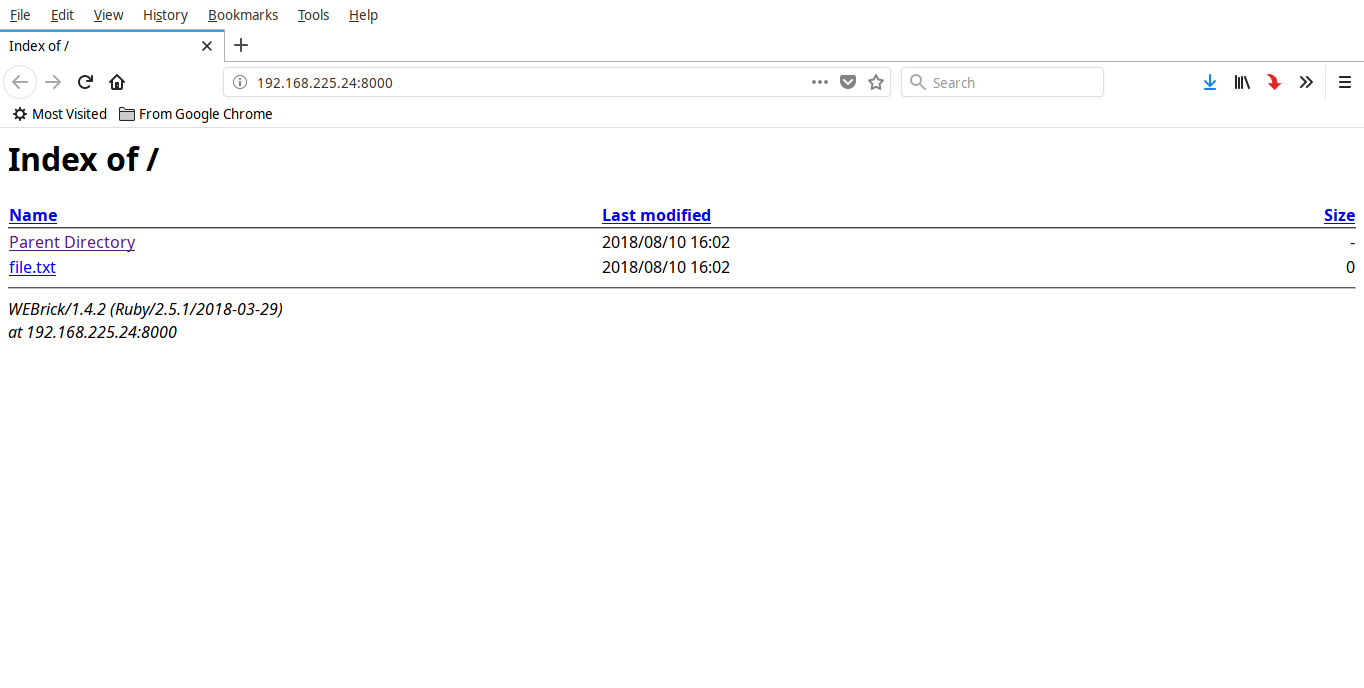
|
||||
|
||||
要停止共享,请按 **CTRL+C**。
|
||||
要停止共享,请按 `CTRL+C`。
|
||||
|
||||
#### 方法 4 - 使用 Http-server(NodeJS)
|
||||
|
||||
[**Http-server**][1] 是一个用 NodeJS 编写的简单的可用于生产的命令行 http-server。它不需要要配置,可用于通过 Web 浏览器即时共享文件和目录。
|
||||
[Http-server][1] 是一个用 NodeJS 编写的简单的可用于生产环境的命令行 http 服务器。它不需要配置,可用于通过 Web 浏览器即时共享文件和目录。
|
||||
|
||||
按如下所述安装 NodeJS。
|
||||
|
||||
- [如何在 Linux 上安装 NodeJS](https://www.ostechnix.com/install-node-js-linux/)
|
||||
|
||||
安装 NodeJS 后,运行以下命令安装 http-server。
|
||||
|
||||
```
|
||||
$ npm install -g http-server
|
||||
|
||||
```
|
||||
|
||||
现在进入任何目录并通过 HTTP 共享其内容,如下所示。
|
||||
|
||||
```
|
||||
$ cd ostechnix
|
||||
|
||||
@ -67,80 +76,81 @@ Available on:
|
||||
http://192.168.225.24:8000
|
||||
http://192.168.225.20:8000
|
||||
Hit CTRL-C to stop the server
|
||||
|
||||
```
|
||||
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - **http:// <ip-address>:8000**。
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - `http:// <ip-address>:8000`。
|
||||
|
||||

|
||||
|
||||
要停止共享,请按 **CTRL+C**。
|
||||
要停止共享,请按 `CTRL+C`。
|
||||
|
||||
#### 方法 5 - 使用 Miniserve(Rust)
|
||||
|
||||
[**Miniserve**][2] 是另一个命令行程序,它允许你通过 HTTP 快速访问文件。它是一个非常快速,易于使用的跨平台程序,它用 **Rust** 编程语言编写。与上面的程序/方法不同,它提供身份验证支持,因此你可以为共享设置用户名和密码。
|
||||
[**Miniserve**][2] 是另一个命令行程序,它允许你通过 HTTP 快速访问文件。它是一个非常快速、易于使用的跨平台程序,它用 Rust 编程语言编写。与上面的程序/方法不同,它提供身份验证支持,因此你可以为共享设置用户名和密码。
|
||||
|
||||
按下面的链接在 Linux 系统中安装 Rust。
|
||||
|
||||
- [在 Linux 上安装 Rust 编程语言](https://www.ostechnix.com/install-rust-programming-language-in-linux/)
|
||||
|
||||
安装 Rust 后,运行以下命令安装 miniserve:
|
||||
|
||||
```
|
||||
$ cargo install miniserve
|
||||
|
||||
```
|
||||
|
||||
或者,你可以在[**发布页**][3]下载二进制文件并使其可执行。
|
||||
或者,你可以在其[发布页][3]下载二进制文件并使其可执行。
|
||||
|
||||
```
|
||||
$ chmod +x miniserve-linux
|
||||
|
||||
```
|
||||
|
||||
然后,你可以使用命令运行它(假设 miniserve 二进制文件下载到当前的工作目录中):
|
||||
|
||||
```
|
||||
$ ./miniserve-linux <path-to-share>
|
||||
|
||||
```
|
||||
|
||||
**用法**
|
||||
|
||||
要提供目录访问:
|
||||
|
||||
```
|
||||
$ miniserve <path-to-directory>
|
||||
|
||||
```
|
||||
|
||||
**示例:**
|
||||
|
||||
```
|
||||
$ miniserve /home/sk/ostechnix/
|
||||
miniserve v0.2.0
|
||||
Serving path /home/sk/ostechnix at http://[::]:8080, http://localhost:8080
|
||||
Quit by pressing CTRL-C
|
||||
|
||||
```
|
||||
|
||||
现在,你可以在本地系统使用 URL – **<http://localhost:8080>** 访问共享,或者在远程系统使用 URL – **http:// <ip-address>:8080** 访问。
|
||||
现在,你可以在本地系统使用 URL – `http://localhost:8080` 访问共享,或者在远程系统使用 URL – `http://<ip-address>:8080` 访问。
|
||||
|
||||
要提供单个文件访问:
|
||||
|
||||
```
|
||||
$ miniserve <path-to-file>
|
||||
|
||||
```
|
||||
|
||||
**示例:**
|
||||
|
||||
```
|
||||
$ miniserve ostechnix/file.txt
|
||||
|
||||
```
|
||||
|
||||
带用户名和密码提供文件/文件夹访问:
|
||||
|
||||
```
|
||||
$ miniserve --auth joe:123 <path-to-share>
|
||||
|
||||
```
|
||||
|
||||
绑定到多个接口:
|
||||
|
||||
```
|
||||
$ miniserve -i 192.168.225.1 -i 10.10.0.1 -i ::1 -- <path-to-share>
|
||||
|
||||
```
|
||||
|
||||
如你所见,我只给出了 5 种方法。但是,本指南末尾附带的链接中还提供了几种方法。也去测试一下它们。此外,收藏并时不时重新访问它来检查将来是否有新的方法。
|
||||
@ -149,7 +159,9 @@ $ miniserve -i 192.168.225.1 -i 10.10.0.1 -i ::1 -- <path-to-share>
|
||||
|
||||
干杯!
|
||||
|
||||
### 资源
|
||||
|
||||
- [单行静态 http 服务器大全](https://gist.github.com/willurd/5720255)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -158,7 +170,7 @@ via: https://www.ostechnix.com/how-to-quickly-serve-files-and-folders-over-http-
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
在 Fedora 上使用 Pitivi 编辑你的视频
|
||||
在 Fedora 上使用 Pitivi 编辑视频
|
||||
======
|
||||
|
||||

|
||||
想制作一部你本周末冒险的视频吗?视频编辑有很多选择。但是,如果你在寻找一个容易上手的视频编辑器,并且也可以在官方 Fedora 仓库中找到,请尝试一下[Pitivi][1]。
|
||||
|
||||
Pitivi 是一个使用 GStreamer 框架的开源非线性视频编辑器。在 Fedora 下开箱即用,Pitivi 支持 OGG、WebM 和一系列其他格式。此外,通过 gstreamer 插件可以获得更多视频格式支持。Pitivi 也与 GNOME 桌面紧密集成,因此相比其他新的程序,它的 UI 在 Fedora Workstation 上会感觉很熟悉。
|
||||
想制作一部你本周末冒险的视频吗?视频编辑有很多选择。但是,如果你在寻找一个容易上手的视频编辑器,并且也可以在官方 Fedora 仓库中找到,请尝试一下 [Pitivi][1]。
|
||||
|
||||
Pitivi 是一个使用 GStreamer 框架的开源非线性视频编辑器。在 Fedora 下开箱即用,Pitivi 支持 OGG、WebM 和一系列其他格式。此外,通过 GStreamer 插件可以获得更多视频格式支持。Pitivi 也与 GNOME 桌面紧密集成,因此相比其他新的程序,它的 UI 在 Fedora Workstation 上会感觉很熟悉。
|
||||
|
||||
### 在 Fedora 上安装 Pitivi
|
||||
|
||||
@ -20,7 +21,7 @@ sudo dnf install pitivi
|
||||
|
||||
### 基本编辑
|
||||
|
||||
Pitivi 内置了多种工具,可以快速有效地编辑剪辑。只需将视频、音频和图像导入 Pitivi 媒体库,然后将它们拖到时间线上即可。此外,除了时间线上的简单淡入淡出过渡之外,pitivi 还允许你轻松地将剪辑的各个部分分割、修剪和分组。
|
||||
Pitivi 内置了多种工具,可以快速有效地编辑剪辑。只需将视频、音频和图像导入 Pitivi 媒体库,然后将它们拖到时间线上即可。此外,除了时间线上的简单淡入淡出过渡之外,Pitivi 还允许你轻松地将剪辑的各个部分分割、修剪和分组。
|
||||
|
||||
![][3]
|
||||
|
||||
@ -40,7 +41,7 @@ via: https://fedoramagazine.org/edit-your-videos-with-pitivi-on-fedora/
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,38 +1,39 @@
|
||||
如何在 Rasspberry Pi 上搭建 WordPress
|
||||
如何在树莓派上搭建 WordPress
|
||||
======
|
||||
|
||||
这篇简单的教程可以让你在 Rasspberry Pi 上运行你的 WordPress 网站。
|
||||
> 这篇简单的教程可以让你在树莓派上运行你的 WordPress 网站。
|
||||
|
||||

|
||||
|
||||
WordPress 是一个非常受欢迎的开源博客平台和内容管理平台(CMS)。它很容易搭建,而且还有一个活跃的开发者社区构建网站、创建主题和插件供其他人使用。
|
||||
|
||||
虽然通过一键式 WordPress 设置获得托管包很容易,但通过命令行就可以在 Linux 服务器上设置自己的托管包,而且 Raspberry Pi 是一种用来尝试它并顺便学习一些东西的相当好的途径。
|
||||
虽然通过一键式 WordPress 设置获得托管包很容易,但也可以简单地通过命令行在 Linux 服务器上设置自己的托管包,而且树莓派是一种用来尝试它并顺便学习一些东西的相当好的途径。
|
||||
|
||||
使用一个 web 堆栈的四个部分是 Linux、Apache、MySQL 和 PHP。这里是你对它们每一个需要了解的。
|
||||
一个经常使用的 Web 套件的四个部分是 Linux、Apache、MySQL 和 PHP。这里是你对它们每一个需要了解的。
|
||||
|
||||
### Linux
|
||||
|
||||
Raspberry Pi 上运行的系统是 Raspbian,这是一个基于 Debian,优化地可以很好的运行在 Raspberry Pi 硬件上的 Linux 发行版。你有两个选择:桌面版或是精简版。桌面版有一个熟悉的桌面还有很多教育软件和编程工具,像是 LibreOffice 套件、Mincraft,还有一个 web 浏览器。精简版本没有桌面环境,因此它只有命令行以及一些必要的软件。
|
||||
树莓派上运行的系统是 Raspbian,这是一个基于 Debian,为运行在树莓派硬件上而优化的很好的 Linux 发行版。你有两个选择:桌面版或是精简版。桌面版有一个熟悉的桌面还有很多教育软件和编程工具,像是 LibreOffice 套件、Mincraft,还有一个 web 浏览器。精简版本没有桌面环境,因此它只有命令行以及一些必要的软件。
|
||||
|
||||
这篇教程在两个版本上都可以使用,但是如果你使用的是精简版,你必须要有另外一台电脑去访问你的站点。
|
||||
|
||||
### Apache
|
||||
|
||||
Apache 是一个受欢迎的 web 服务器应用,你可以安装在你的 Raspberry Pi 上伺服你的 web 页面。就其自身而言,Apache 可以通过 HTTP 提供静态 HTML 文件。使用额外的模块,它也可以使用像是 PHP 的脚本语言提供动态网页。
|
||||
Apache 是一个受欢迎的 web 服务器应用,你可以安装在你的树莓派上伺服你的 web 页面。就其自身而言,Apache 可以通过 HTTP 提供静态 HTML 文件。使用额外的模块,它也可以使用像是 PHP 的脚本语言提供动态网页。
|
||||
|
||||
安装 Apache 非常简单。打开一个终端窗口,然后输入下面的命令:
|
||||
|
||||
```
|
||||
sudo apt install apache2 -y
|
||||
```
|
||||
Apache 默认放了一个测试文件在一个 web 目录中,你可以从你的电脑或是你网络中的其他计算机进行访问。只需要打开 web 浏览器,然后输入地址 **<http://localhost>**。或者(特别是你使用的是 Raspbian Lite 的话)输入你的 Pi 的 IP 地址代替 **localhost**。你应该会在你的浏览器窗口中看到这样的内容:
|
||||
|
||||
Apache 默认放了一个测试文件在一个 web 目录中,你可以从你的电脑或是你网络中的其他计算机进行访问。只需要打开 web 浏览器,然后输入地址 `<http://localhost>`。或者(特别是你使用的是 Raspbian Lite 的话)输入你的树莓派的 IP 地址代替 `localhost`。你应该会在你的浏览器窗口中看到这样的内容:
|
||||
|
||||
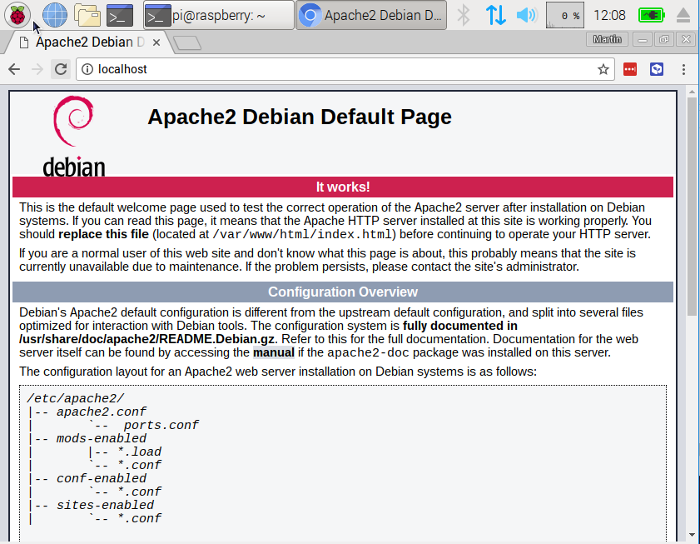
|
||||
|
||||
这意味着你的 Apache 已经开始工作了!
|
||||
|
||||
这个默认的网页仅仅是你文件系统里的一个文件。它在你本地的 **/var/www/html/index/html**。你可以使用 [Leafpad][2] 文本编辑器写一些 HTML 去替换这个文件的内容。
|
||||
这个默认的网页仅仅是你文件系统里的一个文件。它在你本地的 `/var/www/html/index/html`。你可以使用 [Leafpad][2] 文本编辑器写一些 HTML 去替换这个文件的内容。
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
@ -43,27 +44,27 @@ sudo leafpad index.html
|
||||
|
||||
### MySQL
|
||||
|
||||
MySQL (显然是 "my S-Q-L" 或者 "my sequel") 是一个很受欢迎的数据库引擎。就像 PHP,它被非常广泛的应用于网页服务,这也是为什么像 WordPress 一样的项目选择了它,以及这些项目是为何如此受欢迎。
|
||||
MySQL(读作 “my S-Q-L” 或者 “my sequel”)是一个很受欢迎的数据库引擎。就像 PHP,它被非常广泛的应用于网页服务,这也是为什么像 WordPress 一样的项目选择了它,以及这些项目是为何如此受欢迎。
|
||||
|
||||
在一个终端窗口中输入以下命令安装 MySQL 服务:
|
||||
在一个终端窗口中输入以下命令安装 MySQL 服务(LCTT 译注:实际上安装的是 MySQL 分支 MariaDB):
|
||||
|
||||
```
|
||||
sudo apt-get install mysql-server -y
|
||||
```
|
||||
|
||||
WordPress 使用 MySQL 存储文章、页面、用户数据、还有许多其他的内容。
|
||||
WordPress 使用 MySQL 存储文章、页面、用户数据、还有许多其他的内容。
|
||||
|
||||
### PHP
|
||||
|
||||
PHP 是一个预处理器:它是在服务器通过网络浏览器接受网页请求是运行的代码。它解决那些需要展示在网页上的内容,然后发送这些网页到浏览器上。,不像静态的 HTML,PHP 能在不同的情况下展示不同的内容。PHP 是一个在 web 上非常受欢迎的语言;很多像 Facebook 和 Wikipedia 的项目都使用 PHP 编写。
|
||||
PHP 是一个预处理器:它是在服务器通过网络浏览器接受网页请求是运行的代码。它解决那些需要展示在网页上的内容,然后发送这些网页到浏览器上。不像静态的 HTML,PHP 能在不同的情况下展示不同的内容。PHP 是一个在 web 上非常受欢迎的语言;很多像 Facebook 和 Wikipedia 的项目都使用 PHP 编写。
|
||||
|
||||
安装 PHP 和 MySQL 的插件:
|
||||
安装 PHP 和 MySQL 的插件:
|
||||
|
||||
```
|
||||
sudo apt-get install php php-mysql -y
|
||||
```
|
||||
|
||||
删除 **index.html**,然后创建 **index.php**:
|
||||
删除 `index.html`,然后创建 `index.php`:
|
||||
|
||||
```
|
||||
sudo rm index.html
|
||||
@ -82,16 +83,16 @@ sudo leafpad index.php
|
||||
|
||||
### WordPress
|
||||
|
||||
你可以使用 **wget** 命令从 [wordpress.org][3] 下载 WordPress。最新的 WordPress 总是使用 [wordpress.org/latest.tar.gz][4] 这个网址,所以你可以直接抓取这些文件,而无需到网页里面查看,现在的版本是 4.9.8。
|
||||
你可以使用 `wget` 命令从 [wordpress.org][3] 下载 WordPress。最新的 WordPress 总是使用 [wordpress.org/latest.tar.gz][4] 这个网址,所以你可以直接抓取这些文件,而无需到网页里面查看,现在的版本是 4.9.8。
|
||||
|
||||
确保你在 **/var/www/html** 目录中,然后删除里面的所有内容:
|
||||
确保你在 `/var/www/html` 目录中,然后删除里面的所有内容:
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
sudo rm *
|
||||
```
|
||||
|
||||
使用 **wget** 下载 WordPress,然后提取里面的内容,并移动提取的 WordPress 目录中的内容移动到 **html** 目录下:
|
||||
使用 `wget` 下载 WordPress,然后提取里面的内容,并移动提取的 WordPress 目录中的内容移动到 `html` 目录下:
|
||||
|
||||
```
|
||||
sudo wget http://wordpress.org/latest.tar.gz
|
||||
@ -99,13 +100,13 @@ sudo tar xzf latest.tar.gz
|
||||
sudo mv wordpress/* .
|
||||
```
|
||||
|
||||
现在可以删除压缩包和空的 **wordpress** 目录:
|
||||
现在可以删除压缩包和空的 `wordpress` 目录了:
|
||||
|
||||
```
|
||||
sudo rm -rf wordpress latest.tar.gz
|
||||
```
|
||||
|
||||
运行 **ls** 或者 **tree -L 1** 命令显示 WordPress 项目下包含的内容:
|
||||
运行 `ls` 或者 `tree -L 1` 命令显示 WordPress 项目下包含的内容:
|
||||
|
||||
```
|
||||
.
|
||||
@ -132,9 +133,9 @@ sudo rm -rf wordpress latest.tar.gz
|
||||
3 directories, 16 files
|
||||
```
|
||||
|
||||
这是 WordPress 的默认安装源。在 **wp-content** 目录中,你可以编辑你的自定义安装。
|
||||
这是 WordPress 的默认安装源。在 `wp-content` 目录中,你可以编辑你的自定义安装。
|
||||
|
||||
你现在应该把所有文件的所有权改为 Apache 用户:
|
||||
你现在应该把所有文件的所有权改为 Apache 的运行用户 `www-data`:
|
||||
|
||||
```
|
||||
sudo chown -R www-data: .
|
||||
@ -152,24 +153,27 @@ sudo mysql_secure_installation
|
||||
|
||||
你将会被问到一系列的问题。这里原来没有设置密码,但是在下一步你应该设置一个。确保你记住了你输入的密码,后面你需要使用它去连接你的 WordPress。按回车确认下面的所有问题。
|
||||
|
||||
当它完成之后,你将会看到 "All done!" 和 "Thanks for using MariaDB!" 的信息。
|
||||
当它完成之后,你将会看到 “All done!” 和 “Thanks for using MariaDB!” 的信息。
|
||||
|
||||
在终端窗口运行 **mysql** 命令:
|
||||
在终端窗口运行 `mysql` 命令:
|
||||
|
||||
```
|
||||
sudo mysql -uroot -p
|
||||
```
|
||||
输入你创建的 root 密码。你将看到 “Welcome to the MariaDB monitor.” 的欢迎信息。在 **MariaDB [(none)] >** 提示处使用以下命令,为你 WordPress 的安装创建一个数据库:
|
||||
|
||||
输入你创建的 root 密码(LCTT 译注:不是 Linux 系统的 root 密码,是 MySQL 的 root 密码)。你将看到 “Welcome to the MariaDB monitor.” 的欢迎信息。在 “MariaDB [(none)] >” 提示处使用以下命令,为你 WordPress 的安装创建一个数据库:
|
||||
|
||||
```
|
||||
create database wordpress;
|
||||
```
|
||||
|
||||
注意声明最后的分号,如果命令执行成功,你将看到下面的提示:
|
||||
|
||||
```
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
```
|
||||
把 数据库权限交给 root 用户在声明的底部输入密码:
|
||||
|
||||
把数据库权限交给 root 用户在声明的底部输入密码:
|
||||
|
||||
```
|
||||
GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPASSWORD';
|
||||
@ -181,13 +185,13 @@ GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPAS
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
按 **Ctrl+D** 退出 MariaDB 提示,返回到 Bash shell。
|
||||
按 `Ctrl+D` 退出 MariaDB 提示符,返回到 Bash shell。
|
||||
|
||||
### WordPress 配置
|
||||
|
||||
在你的 Raspberry Pi 打开网页浏览器,地址栏输入 **<http://localhost>**。选择一个你想要在 WordPress 使用的语言,然后点击 **继续**。你将会看到 WordPress 的欢迎界面。点击 **让我们开始吧** 按钮。
|
||||
在你的 树莓派 打开网页浏览器,地址栏输入 `http://localhost`。选择一个你想要在 WordPress 使用的语言,然后点击“Continue”。你将会看到 WordPress 的欢迎界面。点击 “Let's go!” 按钮。
|
||||
|
||||
按照下面这样填写基本的站点信息:
|
||||
按照下面这样填写基本的站点信息:
|
||||
|
||||
```
|
||||
Database Name: wordpress
|
||||
@ -197,22 +201,23 @@ Database Host: localhost
|
||||
Table Prefix: wp_
|
||||
```
|
||||
|
||||
点击 **提交** 继续,然后点击 **运行安装**。
|
||||
点击 “Submit” 继续,然后点击 “Run the install”。
|
||||
|
||||
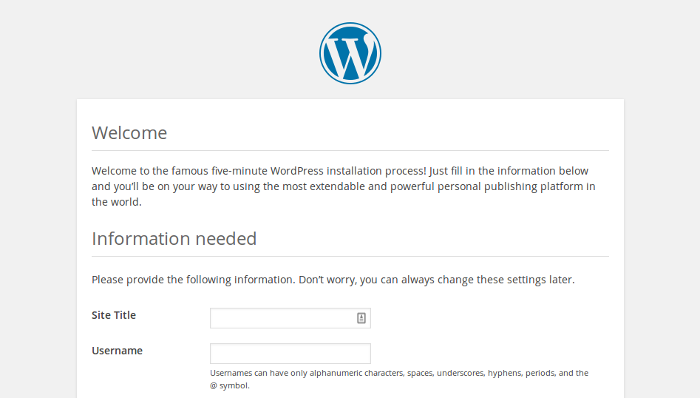
|
||||
|
||||
按下面的格式填写:为你的站点设置一个标题、创建一个用户名和密码、输入你的 email 地址。点击 **安装 WordPress** 按钮,然后使用你刚刚创建的账号登录,你现在已经登录,而且你的站点已经设置好了,你可以在浏览器地址栏输入 **<http://localhost/wp-admin>** 查看你的网站。
|
||||
按下面的格式填写:为你的站点设置一个标题、创建一个用户名和密码、输入你的 email 地址。点击 “Install WordPress” 按钮,然后使用你刚刚创建的账号登录,你现在已经登录,而且你的站点已经设置好了,你可以在浏览器地址栏输入 `http://localhost/wp-admin` 查看你的网站。
|
||||
|
||||
### 永久链接
|
||||
|
||||
更改你的永久链接,使得你的 URLs 更加友好是一个很好的想法。
|
||||
更改你的永久链接设置,使得你的 URL 更加友好是一个很好的想法。
|
||||
|
||||
要这样做,首先登录你的 WordPress ,进入仪表盘。进入 **设置**,**永久链接**。选择 **文章名** 选项,然后点击 **保存更改**。接着你需要开启 Apache 的 **改写** 模块。
|
||||
要这样做,首先登录你的 WordPress ,进入仪表盘。进入 “Settings”,“Permalinks”。选择 “Post name” 选项,然后点击 “Save Changes”。接着你需要开启 Apache 的 `rewrite` 模块。
|
||||
|
||||
```
|
||||
sudo a2enmod rewrite
|
||||
```
|
||||
你还需要告诉虚拟托管服务,站点允许改写请求。为你的虚拟主机编辑 Apache 配置文件
|
||||
|
||||
你还需要告诉虚拟托管服务,站点允许改写请求。为你的虚拟主机编辑 Apache 配置文件:
|
||||
|
||||
```
|
||||
sudo leafpad /etc/apache2/sites-available/000-default.conf
|
||||
@ -226,7 +231,7 @@ sudo leafpad /etc/apache2/sites-available/000-default.conf
|
||||
</Directory>
|
||||
```
|
||||
|
||||
确保其中有像这样的内容 **< VirtualHost \*:80>**
|
||||
确保其中有像这样的内容 `<VirtualHost *:80>`:
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
@ -244,17 +249,16 @@ sudo systemctl restart apache2
|
||||
|
||||
### 下一步?
|
||||
|
||||
WordPress 是可以高度自定义的。在网站顶部横幅处点击你的站点名,你就会进入仪表盘,。在这里你可以修改主题、添加页面和文章、编辑菜单、添加插件、以及许多其他的事情。
|
||||
WordPress 是可以高度自定义的。在网站顶部横幅处点击你的站点名,你就会进入仪表盘。在这里你可以修改主题、添加页面和文章、编辑菜单、添加插件、以及许多其他的事情。
|
||||
|
||||
这里有一些你可以在 Raspberry Pi 的网页服务上尝试的有趣的事情:
|
||||
这里有一些你可以在树莓派的网页服务上尝试的有趣的事情:
|
||||
|
||||
* 添加页面和文章到你的网站
|
||||
* 从外观菜单安装不同的主题
|
||||
* 自定义你的网站主题或是创建你自己的
|
||||
* 使用你的网站服务向你的网络上的其他人显示有用的信息
|
||||
|
||||
|
||||
不要忘记,Raspberry Pi 是一台 Linux 电脑。你也可以使用相同的结构在运行着 Debian 或者 Ubuntu 的服务器上安装 WordPress。
|
||||
不要忘记,树莓派是一台 Linux 电脑。你也可以使用相同的结构在运行着 Debian 或者 Ubuntu 的服务器上安装 WordPress。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -263,7 +267,7 @@ via: https://opensource.com/article/18/10/setting-wordpress-raspberry-pi
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# PR 检查脚本
|
||||
set -e
|
||||
|
||||
|
||||
@ -22,7 +22,12 @@ do_analyze() {
|
||||
# 统计每个类别的每个操作
|
||||
REGEX="$(get_operation_regex "$STAT" "$TYPE")"
|
||||
OTHER_REGEX="${OTHER_REGEX}|${REGEX}"
|
||||
eval "${TYPE}_${STAT}=\"\$(grep -Ec '$REGEX' /tmp/changes)\"" || true
|
||||
CHANGES_FILE="/tmp/changes_${TYPE}_${STAT}"
|
||||
eval "grep -E '$REGEX' /tmp/changes" \
|
||||
| sed 's/^[^\/]*\///g' \
|
||||
| sort > "$CHANGES_FILE" || true
|
||||
sed 's/^.*\///g' "$CHANGES_FILE" > "${CHANGES_FILE}_basename"
|
||||
eval "${TYPE}_${STAT}=$(wc -l < "$CHANGES_FILE")"
|
||||
eval echo "${TYPE}_${STAT}=\$${TYPE}_${STAT}"
|
||||
done
|
||||
done
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# 检查脚本状态
|
||||
set -e
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# PR 文件变更收集
|
||||
set -e
|
||||
|
||||
@ -31,7 +31,16 @@ git --no-pager show --summary "${MERGE_BASE}..HEAD"
|
||||
|
||||
echo "[收集] 写出文件变更列表……"
|
||||
|
||||
git diff "$MERGE_BASE" HEAD --no-renames --name-status > /tmp/changes
|
||||
RAW_CHANGES="$(git diff "$MERGE_BASE" HEAD --no-renames --name-status -z \
|
||||
| tr '\0' '\n')"
|
||||
[ -z "$RAW_CHANGES" ] && {
|
||||
echo "[收集] 无变更,退出……"
|
||||
exit 1
|
||||
}
|
||||
echo "$RAW_CHANGES" | while read -r STAT; do
|
||||
read -r NAME
|
||||
echo "${STAT} ${NAME}"
|
||||
done > /tmp/changes
|
||||
echo "[收集] 已写出文件变更列表:"
|
||||
cat /tmp/changes
|
||||
{ [ -z "$(cat /tmp/changes)" ] && echo "(无变更)"; } || true
|
||||
|
||||
@ -10,9 +10,10 @@ export TSL_DIR='translated' # 已翻译
|
||||
export PUB_DIR='published' # 已发布
|
||||
|
||||
# 定义匹配规则
|
||||
export CATE_PATTERN='(news|talk|tech)' # 类别
|
||||
export CATE_PATTERN='(talk|tech)' # 类别
|
||||
export FILE_PATTERN='[0-9]{8} [a-zA-Z0-9_.,() -]*\.md' # 文件名
|
||||
|
||||
# 获取用于匹配操作的正则表达式
|
||||
# 用法:get_operation_regex 状态 类型
|
||||
#
|
||||
# 状态为:
|
||||
@ -26,5 +27,50 @@ export FILE_PATTERN='[0-9]{8} [a-zA-Z0-9_.,() -]*\.md' # 文件名
|
||||
get_operation_regex() {
|
||||
STAT="$1"
|
||||
TYPE="$2"
|
||||
|
||||
echo "^${STAT}\\s+\"?$(eval echo "\$${TYPE}_DIR")/"
|
||||
}
|
||||
|
||||
# 确保两个变更文件一致
|
||||
# 用法:ensure_identical X类型 X状态 Y类型 Y状态 是否仅比较文件名
|
||||
#
|
||||
# 状态为:
|
||||
# - A:添加
|
||||
# - M:修改
|
||||
# - D:删除
|
||||
# 类型为:
|
||||
# - SRC:未翻译
|
||||
# - TSL:已翻译
|
||||
# - PUB:已发布
|
||||
ensure_identical() {
|
||||
TYPE_X="$1"
|
||||
STAT_X="$2"
|
||||
TYPE_Y="$3"
|
||||
STAT_Y="$4"
|
||||
NAME_ONLY="$5"
|
||||
SUFFIX=
|
||||
[ -n "$NAME_ONLY" ] && SUFFIX="_basename"
|
||||
|
||||
X_FILE="/tmp/changes_${TYPE_X}_${STAT_X}${SUFFIX}"
|
||||
Y_FILE="/tmp/changes_${TYPE_Y}_${STAT_Y}${SUFFIX}"
|
||||
|
||||
cmp "$X_FILE" "$Y_FILE" 2> /dev/null
|
||||
}
|
||||
|
||||
# 检查文章分类
|
||||
# 用法:check_category 类型 状态
|
||||
#
|
||||
# 状态为:
|
||||
# - A:添加
|
||||
# - M:修改
|
||||
# - D:删除
|
||||
# 类型为:
|
||||
# - SRC:未翻译
|
||||
# - TSL:已翻译
|
||||
check_category() {
|
||||
TYPE="$1"
|
||||
STAT="$2"
|
||||
|
||||
CHANGES="/tmp/changes_${TYPE}_${STAT}"
|
||||
! grep -Eqv "^${CATE_PATTERN}/" "$CHANGES"
|
||||
}
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# 匹配 PR 规则
|
||||
set -e
|
||||
|
||||
@ -27,31 +27,39 @@ rule_bypass_check() {
|
||||
# 添加原文:添加至少一篇原文
|
||||
rule_source_added() {
|
||||
[ "$SRC_A" -ge 1 ] \
|
||||
&& check_category SRC A \
|
||||
&& [ "$TOTAL" -eq "$SRC_A" ] && echo "匹配规则:添加原文 ${SRC_A} 篇"
|
||||
}
|
||||
|
||||
# 申领翻译:只能申领一篇原文
|
||||
rule_translation_requested() {
|
||||
[ "$SRC_M" -eq 1 ] \
|
||||
&& check_category SRC M \
|
||||
&& [ "$TOTAL" -eq 1 ] && echo "匹配规则:申领翻译"
|
||||
}
|
||||
|
||||
# 提交译文:只能提交一篇译文
|
||||
rule_translation_completed() {
|
||||
[ "$SRC_D" -eq 1 ] && [ "$TSL_A" -eq 1 ] \
|
||||
&& ensure_identical SRC D TSL A \
|
||||
&& check_category SRC D \
|
||||
&& check_category TSL A \
|
||||
&& [ "$TOTAL" -eq 2 ] && echo "匹配规则:提交译文"
|
||||
}
|
||||
|
||||
# 校对译文:只能校对一篇
|
||||
rule_translation_revised() {
|
||||
[ "$TSL_M" -eq 1 ] \
|
||||
&& check_category TSL M \
|
||||
&& [ "$TOTAL" -eq 1 ] && echo "匹配规则:校对译文"
|
||||
}
|
||||
|
||||
# 发布译文:发布多篇译文
|
||||
rule_translation_published() {
|
||||
[ "$TSL_D" -ge 1 ] && [ "$PUB_A" -ge 1 ] && [ "$TSL_D" -eq "$PUB_A" ] \
|
||||
&& [ "$TOTAL" -eq $(($TSL_D + $PUB_A)) ] \
|
||||
&& ensure_identical SRC D TSL A 1 \
|
||||
&& check_category TSL D \
|
||||
&& [ "$TOTAL" -eq $((TSL_D + PUB_A)) ] \
|
||||
&& echo "匹配规则:发布译文 ${PUB_A} 篇"
|
||||
}
|
||||
|
||||
|
||||
@ -1,107 +0,0 @@
|
||||
Translating by FelixYFZ
|
||||
5 steps to building a cloud that meets your users' needs
|
||||
======
|
||||
|
||||

|
||||
This article was co-written with [Ian Tewksbury][1].
|
||||
|
||||
However you define it, a cloud is simply another tool for your users to perform their part of your organization's value stream. It can be easy when talking about any new paradigm or technology (the cloud is arguably both) to get distracted by the shiny newness of it. Conversations can quickly devolve into feature wish lists set off by a series of never-ending questions, all of which you probably have already considered:
|
||||
|
||||
* Will it be public, private, or hybrid?
|
||||
* Will it use virtual machines or containers, or both?
|
||||
* Will it be self-service?
|
||||
* Will it be fully automated from development to production, or will it have manual gates?
|
||||
* How fast can we make it?
|
||||
* What about tool X, Y, or Z?
|
||||
|
||||
|
||||
|
||||
The list goes on.
|
||||
|
||||
The usual approach to beginning IT modernization, or digital transformation, or whatever you call it is to start answering high-level questions in the higher-level echelons of management. The outcome of this approach is predictable: failure. After extensively researching and spending months, if not years, deploying the fanciest new technology, the new cloud is never used and falls into disrepair until it is eventually scrapped or forgotten in the dustier corners of the datacenter and budget.
|
||||
|
||||
That's because whatever was delivered was not the tool the users wanted or needed. Worse yet, it likely was a single tool when users really needed a collection of tools that could be swapped out over time as newer, shinier, upgraded tools come along that better meet their needs.
|
||||
|
||||
### Focus on what matters
|
||||
|
||||
The problem is focus, which has traditionally been on the tools. But the tools are not what add to your organization's value stream; end users making use of tools are what do that. You need to shift your focus from building your cloud—for example, the technology and the tools, to your people, your users.
|
||||
|
||||
Beyond the fact that users using tools (not the tools themselves) are what drive value, there are other reasons to focus attention on the users. The tools are for the users to use to solve their problems and allow them to create value, so it follows that if those tools don't meet those users' needs, then those tools won't be used. If you deliver tools that your users don't like, they won't use them. This is natural human behavior.
|
||||
|
||||
The IT industry got away with providing a single solution to users for decades because there were only one or two options, and the users had no power to change that. That is no longer the case. We now live in the world of technological choice. It is no longer acceptable to users to not be given a choice; they have choices in their personal technological lives, and they expect it in the workplace, too. Today's users are educated and know there are better options than the ones you've been providing.
|
||||
|
||||
As a result, outside the most physically secure locations, there is no way to stop them from just doing what they want, which we call "shadow IT." If your organization has such strict security and compliance polices that shadow IT is impossible, many of your best people will grow frustrated and leave for other organizations that offer them choices.
|
||||
|
||||
For all of these reasons, you must design your expensive and time-consuming cloud project with your end user foremost in mind.
|
||||
|
||||
### Five-step process to build a cloud for users' needs
|
||||
|
||||
Now that we know the why, let's talk about the how. How do you build a cloud for the end user? How do you start refocusing your attention from the technology to the people using that technology?
|
||||
|
||||
Through experience, we've learned that the best approach involves two things: getting constant feedback from your users, and building things iteratively.
|
||||
|
||||
Your cloud environment will continually evolve with your organization. The following five-step process will help you create a cloud that meets your users' needs.
|
||||
|
||||
#### 1\. Identify who your users will be.
|
||||
|
||||
Before you can start asking users questions, you first must identify who the users of your new cloud will be. They will likely include developers who build applications on the cloud; the operations team who will operate, maintain, and likely build the cloud; and the security team who protects your organization. For the first iteration, scope down your users to a smaller group so you're less overwhelmed by feedback. Ask each of your identified user groups to appoint two liaisons (a primary and a secondary) who will represent their team on this journey. This will also keep your first delivery small in both size and time.
|
||||
|
||||
#### 2\. Talk to your users face-to-face to get valuable input.
|
||||
|
||||
The best way to get users' feedback is through direct communication. Mass emails asking for input will self-select respondents—if you even get a response. Group discussions can be helpful, but people tend to be more candid when they have a private, attentive audience.
|
||||
|
||||
Schedule in-person, individual meetings with your first set of users to ask them questions like the following:
|
||||
|
||||
* What do you need in order to accomplish your tasks?
|
||||
* What do you want in order to accomplish your tasks?
|
||||
* What is your current, most annoying technological pain?
|
||||
* What is your current, most annoying policy or procedural pain?
|
||||
* What ideas do you have to address any of your needs, wants, or pains?
|
||||
|
||||
|
||||
|
||||
These questions are guidelines and not ideal for every organization. They should not be the only questions you ask, and they should lead to further discussion. Be sure to tell people that anything said or asked is taken as feedback, and all feedback is helpful, whether positive or negative. The outcome of these conversations will help set your development priorities.
|
||||
|
||||
Gathering this level of personalized feedback is another reason to keep your initial group of users small: It takes a lot of time to sit down with each user, but we have found it is absolutely worth the investment.
|
||||
|
||||
#### 3\. Design and deliver your first iteration of the solution.
|
||||
|
||||
Once you've collected feedback from your initial users, it is time to design and deliver a piece of functionality. We do not recommend trying to deliver the entire solution. The design and delivery phase should be short; this is to avoid making the huge mistake of spending a year building what you think is the correct solution, only to have your users reject it because it isn't beneficial to them. The specific tools you choose for building your cloud will depend on your organization and its specific needs. Just make sure that the solution you build is based on your users' feedback and that you deliver it in small chunks to solicit feedback from them as often as possible.
|
||||
|
||||
#### 4\. Ask users for feedback on the first iteration.
|
||||
|
||||
Great, now you've designed and delivered the first iteration of your fancy new cloud to your end users! You didn't spend a year doing it but instead tackled it in small pieces. Why is it important to do things in small chunks? It's because you're going back to your user groups and collecting feedback about your design and delivery. What do they like? What don't they like? Did you properly address their concerns? Is the technology great, but the process or policy side of the system still lacking?
|
||||
|
||||
Again, the questions you'll ask depend on your organization; the key here is to continue the discussions from the earlier phases. You're building this cloud for users after all, so make sure it's useful for them and a productive use of everyone's time.
|
||||
|
||||
#### 5\. Return to step 1.
|
||||
|
||||
This is an iterative process. Your first delivery should have been quick and small, and all future iterations should be, too. Don't expect to be able to follow this process once, twice, or even three times and be done. As you iterate, you will introduce more users and get better at the process. You will get more buy-in from users. You will be able to iterate faster and more reliably. And, finally, you will change your process to meet your users' needs.
|
||||
|
||||
Users are the most important part of this process, but the iteration is the second most important part because it allows you to keep going back to the users and getting more information. Throughout each phase, take note of what worked and what didn't. Be introspective and honest with yourself. Are we providing the most value possible for the time we spent? If not, try something different in the next phase. The great part about not spending too much time in each cycle is that, if something doesn't work this time, you can easily tweak it for next time, until you find an approach that works for your organization.
|
||||
|
||||
### This is just the beginning
|
||||
|
||||
Through many customer engagements, feedback gathered from users, and experiences from peers in the field, we've found time and time again that the most important thing you can do when building a cloud is to talk to your users. It seems obvious, but it is surprising how many organizations will go off and build something for months or years, then find out it isn't even useful to end users.
|
||||
|
||||
Now you know why you should keep your focus on the end users and have a process for building a cloud with them at the center. The remaining piece is the part that we all enjoy, the part where you go out and do it.
|
||||
|
||||
This article is based on "[Design your hybrid cloud for the end user—or fail][2]," a talk the authors will be giving at [Red Hat Summit 2018][3], which will be held May 8-10 in San Francisco.
|
||||
|
||||
[Register by May 7][3] to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly
|
||||
|
||||
作者:[Cameron Wyatt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cameronmwyatt
|
||||
[1]:https://opensource.com/users/itewk
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154225
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
@ -1,205 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to use a here documents to write data to a file in bash script
|
||||
======
|
||||
|
||||
A here document is nothing but I/O redirection that tells the bash shell to read input from the current source until a line containing only delimiter is seen.
|
||||
[![redirect output of here document to a text file][1]][1]
|
||||
This is useful for providing commands to ftp, cat, echo, ssh and many other useful Linux/Unix commands. This feature should work with bash or Bourne/Korn/POSIX shell too.
|
||||
|
||||
## heredoc syntax
|
||||
|
||||
How do I use a heredoc redirection feature (here documents) to write data to a file in my bash shell scripts? [A here document][2] is nothing but I/O redirection that tells the bash shell to read input from the current source until a line containing only delimiter is seen.This is useful for providing commands to ftp, cat, echo, ssh and many other useful Linux/Unix commands. This feature should work with bash or Bourne/Korn/POSIX shell too.
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
command <<EOF
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
EOF
|
||||
```
|
||||
|
||||
OR allow here-documents within shell scripts to be indented in a natural fashion using **EOF <**
|
||||
```
|
||||
command <<-EOF
|
||||
msg1
|
||||
msg2
|
||||
$var on line
|
||||
EOF
|
||||
```
|
||||
|
||||
OR
|
||||
```
|
||||
command <<'EOF'
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
$var won't expand as parameter substitution turned off
|
||||
by single quoting
|
||||
EOF
|
||||
```
|
||||
|
||||
OR **redirect and overwrite it** to a file named my_output_file.txt:
|
||||
```
|
||||
command << EOF > my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
OR **redirect and append it** to a file named my_output_file.txt:
|
||||
```
|
||||
command << EOF >> my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
## Examples
|
||||
|
||||
The following script will write the needed contents to a file named /tmp/output.txt:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
cat <<EOF >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
|
||||
You can view /tmp/output.txt with the [cat command][3]:
|
||||
`$ cat /tmp/output.txt`
|
||||
Sample outputs:
|
||||
```
|
||||
Status of backup as on Thu Nov 16 17:00:21 IST 2017
|
||||
Backing up files /home/vivek and /etc/
|
||||
|
||||
```
|
||||
|
||||
### Disabling pathname/parameter/variable expansion, command substitution, arithmetic expansion
|
||||
|
||||
Variable such as $HOME and command such as $(date) were interpreted substitution in script. To disable it use single quotes with 'EOF' as follows:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
# No parameter and variable expansion, command substitution, arithmetic expansion, or pathname expansion is performed on word.
|
||||
# If any part of word is quoted, the delimiter is the result of quote removal on word, and the lines in the here-document
|
||||
# are not expanded. So EOF is quoted as follows
|
||||
cat <<'EOF' >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
#!/bin/bash OUT=/tmp/output.txtecho "Starting my script..." echo "Doing something..." # No parameter and variable expansion, command substitution, arithmetic expansion, or pathname expansion is performed on word. # If any part of word is quoted, the delimiter is the result of quote removal on word, and the lines in the here-document # are not expanded. So EOF is quoted as follows cat <<'EOF' >$OUT Status of backup as on $(date) Backing up files $HOME and /etc/ EOFecho "Starting backup using rsync..."
|
||||
|
||||
You can view /tmp/output.txt with the [cat command][3]:
|
||||
`$ cat /tmp/output.txt`
|
||||
Sample outputs:
|
||||
```
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
|
||||
```
|
||||
|
||||
## A note about using tee command
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
tee /tmp/filename <<EOF >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
tee /tmp/filename <<EOF >/dev/null line 1 line 2 line 3 $(cmd) $var on $foo EOF
|
||||
|
||||
Or disable variable substitution/command substitution by quoting EOF in a single quote:
|
||||
```
|
||||
tee /tmp/filename <<'EOF' >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
tee /tmp/filename <<'EOF' >/dev/null line 1 line 2 line 3 $(cmd) $var on $foo EOF
|
||||
|
||||
Here is my updated script:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
tee $OUT <<EOF >/dev/null
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
#!/bin/bash OUT=/tmp/output.txtecho "Starting my script..." echo "Doing something..."tee $OUT <<EOF >/dev/null Status of backup as on $(date) Backing up files $HOME and /etc/ EOFecho "Starting backup using rsync..."
|
||||
|
||||
## A note about using in-memory here-docs
|
||||
|
||||
Here is my updated script:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
## in memory here docs
|
||||
## thanks https://twitter.com/freebsdfrau
|
||||
exec 9<<EOF
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
## continue
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
## do it
|
||||
cat <&9 >$OUT
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/using-heredoc-rediection-in-bash-shell-script-to-write-to-file/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2017/11/redirect-output-of-here-document-to-a-text-file.jpg
|
||||
[2]:https://bash.cyberciti.biz/guide/Here_documents
|
||||
[3]:https//www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ (See Linux/Unix cat command examples for more info)
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Create A Bootable Linux USB Drive From Windows OS 7,8 and 10?
|
||||
======
|
||||
If you would like to learn about Linux, the first thing you have to do is install the Linux OS on your system.
|
||||
|
||||
@ -1,229 +0,0 @@
|
||||
translating by dianbanjiu Commandline quick tips: How to locate a file
|
||||
======
|
||||
|
||||

|
||||
|
||||
We all have files on our computers — documents, photos, source code, you name it. So many of them. Definitely more than I can remember. And if not challenging, it might be time consuming to find the right one you’re looking for. In this post, we’ll have a look at how to make sense of your files on the command line, and especially how to quickly find the ones you’re looking for.
|
||||
|
||||
Good news is there are few quite useful utilities in the Linux commandline designed specifically to look for files on your computer. We’ll have a look at three of those: ls, tree, and find.
|
||||
|
||||
### ls
|
||||
|
||||
If you know where your files are, and you just need to list them or see information about them, ls is here for you.
|
||||
|
||||
Just running ls lists all visible files and directories in the current directory:
|
||||
|
||||
```
|
||||
$ ls
|
||||
Documents Music Pictures Videos notes.txt
|
||||
```
|
||||
|
||||
Adding the **-l** option shows basic information about the files. And together with the **-h** option you’ll see file sizes in a human-readable format:
|
||||
|
||||
```
|
||||
$ ls -lh
|
||||
total 60K
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Documents
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Music
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:13 Pictures
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos
|
||||
-rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
|
||||
```
|
||||
|
||||
**Is** can also search a specific place:
|
||||
|
||||
```
|
||||
$ ls Pictures/
|
||||
trees.png wallpaper.png
|
||||
```
|
||||
|
||||
Or a specific file — even with just a part of the name:
|
||||
|
||||
```
|
||||
$ ls *.txt
|
||||
notes.txt
|
||||
```
|
||||
|
||||
Something missing? Looking for a hidden file? No problem, use the **-a** option:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
. .bash_logout .bashrc Documents Pictures notes.txt
|
||||
.. .bash_profile .vimrc Music Videos
|
||||
```
|
||||
|
||||
There are many other useful options for **ls** , and you can combine them together to achieve what you need. Learn about them by running:
|
||||
|
||||
```
|
||||
$ man ls
|
||||
```
|
||||
|
||||
### tree
|
||||
|
||||
If you want to see, well, a tree structure of your files, tree is a good choice. It’s probably not installed by default which you can do yourself using the package manager DNF:
|
||||
|
||||
```
|
||||
$ sudo dnf install tree
|
||||
```
|
||||
|
||||
Running tree without any options or parameters shows the whole tree starting at the current directory. Just a warning, this output might be huge, because it will include all files and directories:
|
||||
|
||||
```
|
||||
$ tree
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| | `-- christmas-presents.txt
|
||||
| `-- work
|
||||
| |-- project-abc
|
||||
| | |-- README.md
|
||||
| | |-- do-things.sh
|
||||
| | `-- project-notes.txt
|
||||
| `-- status-reports.txt
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
If that’s too much, I can limit the number of levels it goes using the -L option followed by a number specifying the number of levels I want to see:
|
||||
|
||||
```
|
||||
$ tree -L 2
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| `-- work
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
You can also display a tree of a specific path:
|
||||
|
||||
```
|
||||
$ tree Documents/work/
|
||||
Documents/work/
|
||||
|-- project-abc
|
||||
| |-- README.md
|
||||
| |-- do-things.sh
|
||||
| `-- project-notes.txt
|
||||
`-- status-reports.txt
|
||||
```
|
||||
|
||||
To browse and search a huge tree, you can use it together with less:
|
||||
|
||||
```
|
||||
$ tree | less
|
||||
```
|
||||
|
||||
Again, there are other options you can use with three, and you can combine them together for even more power. The manual page has them all:
|
||||
|
||||
```
|
||||
$ man tree
|
||||
```
|
||||
|
||||
### find
|
||||
|
||||
And what about files that live somewhere in the unknown? Let’s find them!
|
||||
|
||||
In case you don’t have find on your system, you can install it using DNF:
|
||||
|
||||
```
|
||||
$ sudo dnf install findutils
|
||||
```
|
||||
|
||||
Running find without any options or parameters recursively lists all files and directories in the current directory.
|
||||
|
||||
```
|
||||
$ find
|
||||
.
|
||||
./Documents
|
||||
./Documents/secret
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc
|
||||
./Documents/work/project-abc/README.md
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./.bash_logout
|
||||
./.bashrc
|
||||
./Videos
|
||||
./.bash_profile
|
||||
./.vimrc
|
||||
./Pictures
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
./notes.txt
|
||||
./Music
|
||||
```
|
||||
|
||||
But the true power of find is that you can search by name:
|
||||
|
||||
```
|
||||
$ find -name do-things.sh
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
```
|
||||
|
||||
Or just a part of a name — like the file extension. Let’s find all .txt files:
|
||||
|
||||
```
|
||||
$ find -name "*.txt"
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./notes.txt
|
||||
```
|
||||
|
||||
You can also look for files by size. That might be especially useful if you’re running out of space. Let’s list all files larger than 1 MB:
|
||||
|
||||
```
|
||||
$ find -size +1M
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
```
|
||||
|
||||
Searching a specific directory is also possible. Let’s say I want to find a file in my Documents directory, and I know it has the word “project” in its name:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*"
|
||||
Documents/work/project-abc
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
Ah! That also showed the directory. One thing I can do is to limit the search query to files only:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*" -type f
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
And again, find have many more options you can use, the man page might definitely help you:
|
||||
|
||||
```
|
||||
$ man find
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-locate-file/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,171 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
Introducing pydbgen: A random dataframe/database table generator
|
||||
======
|
||||
Simple tool generates large database files with multiple tables to practice SQL commands for data science.
|
||||
|
||||

|
||||
|
||||
When you start learning data science, often your biggest worry is not the algorithms or techniques but getting access to raw data. While there are many high-quality, real-life datasets available on the web for trying out cool machine learning techniques, I've found that the same is not true when it comes to learning SQL.
|
||||
|
||||
For data science, having a basic familiarity with SQL is almost as important as knowing how to write code in Python or R. But it's far easier to find toy datasets on Kaggle than it is to access a large enough database with real data (such as name, age, credit card, social security number, address, birthday, etc.) specifically designed or curated for machine learning tasks.
|
||||
|
||||
Wouldn't it be great to have a simple tool or library to generate a large database with multiple tables filled with data of your own choice?
|
||||
|
||||
Aside from beginners in data science, even seasoned software testers may find it useful to have a simple tool where, with a few lines of code, they can generate arbitrarily large data sets with random (fake), yet meaningful entries.
|
||||
|
||||
For this reason, I am glad to introduce a lightweight Python library called **[pydbgen][1]**. In this article, I'll briefly share some information about the package, and you can learn much more [by reading the docs][2].
|
||||
|
||||
### What is pydbgen?
|
||||
|
||||
Pydbgen is a lightweight, pure-Python library to generate random useful entries (e.g., name, address, credit card number, date, time, company name, job title, license plate number, etc.) and save them in a Pandas dataframe object, as an SQLite table in a database file, or in a Microsoft Excel file.
|
||||
|
||||
### How to install pydbgen
|
||||
|
||||
The current version (1.0.5) is hosted on PyPI (the Python Package Index repository). You need to have [Faker][3] installed to make this work. To install Pydbgen, enter:
|
||||
|
||||
```
|
||||
pip install pydbgen
|
||||
```
|
||||
|
||||
It has been tested on Python 3.6 and won't work on Python 2 installations.
|
||||
|
||||
### How to use it
|
||||
|
||||
To start using Pydbgen, initiate a **pydb** object.
|
||||
|
||||
```
|
||||
import pydbgen
|
||||
from pydbgen import pydbgen
|
||||
myDB=pydbgen.pydb()
|
||||
```
|
||||
|
||||
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
||||
|
||||
```
|
||||
myDB.city_real()
|
||||
>> 'Otterville'
|
||||
for _ in range(10):
|
||||
print(myDB.license_plate())
|
||||
>> 8NVX937
|
||||
6YZH485
|
||||
XBY-564
|
||||
SCG-2185
|
||||
XMR-158
|
||||
6OZZ231
|
||||
CJN-850
|
||||
SBL-4272
|
||||
TPY-658
|
||||
SZL-0934
|
||||
```
|
||||
|
||||
By the way, if you enter **city** instead of **city_real** , it will return fictitious city names.
|
||||
|
||||
```
|
||||
print(myDB.gen_data_series(num=8,data_type='city'))
|
||||
>>
|
||||
New Michelle
|
||||
Robinborough
|
||||
Leebury
|
||||
Kaylatown
|
||||
Hamiltonfort
|
||||
Lake Christopher
|
||||
Hannahstad
|
||||
West Adamborough
|
||||
```
|
||||
|
||||
### Generate a Pandas dataframe with random entries
|
||||
|
||||
You can choose how many and what data types will be generated. Note that everything returns as string/texts.
|
||||
|
||||
```
|
||||
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
|
||||
testdf
|
||||
```
|
||||
|
||||
The resulting dataframe looks like the following image.
|
||||
|
||||
|
||||
|
||||
### Generate a database table
|
||||
|
||||
You can choose how many and what data types will be generated. Everything is returned in the text/VARCHAR data type for the database. You can specify the database filename and the table name.
|
||||
|
||||
```
|
||||
myDB.gen_table(db_file='Testdb.DB',table_name='People',
|
||||
|
||||
fields=['name','city','street_address','email'])
|
||||
```
|
||||
|
||||
This generates a .db file which can be used with MySQL or the SQLite database server. The following image shows a database table opened in DB Browser for SQLite.
|
||||
|
||||
|
||||
### Generate an Excel file
|
||||
|
||||
Similar to the examples above, the following code will generate an Excel file with random data. Note that **phone_simple** is set to **False** so it can generate complex, long-form phone numbers. This can come in handy when you want to experiment with more involved data extraction codes.
|
||||
|
||||
```
|
||||
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
||||
phone_simple=False,filename='TestExcel.xlsx')
|
||||
```
|
||||
|
||||
The resulting file looks like this image:
|
||||
|
||||
|
||||
### Generate random email IDs for scrap use
|
||||
|
||||
A built-in method in pydbgen is **realistic_email** , which generates random email IDs from a seed name. This is helpful when you don't want to use your real email address on the web—but something close.
|
||||
|
||||
```
|
||||
for _ in range(10):
|
||||
print(myDB.realistic_email('Tirtha Sarkar'))
|
||||
>>
|
||||
Tirtha_Sarkar@gmail.com
|
||||
Sarkar.Tirtha@outlook.com
|
||||
Tirtha_S48@verizon.com
|
||||
Tirtha_Sarkar62@yahoo.com
|
||||
Tirtha.S46@yandex.com
|
||||
Tirtha.S@att.com
|
||||
Sarkar.Tirtha60@gmail.com
|
||||
TirthaSarkar@zoho.com
|
||||
Sarkar.Tirtha@protonmail.com
|
||||
Tirtha.S@comcast.net
|
||||
```
|
||||
|
||||
### Future improvements and user contributions
|
||||
|
||||
There may be many bugs in the current version—if you notice any and your program crashes during execution (except for a crash due to your incorrect entry), please let me know. Also, if you have a cool idea to contribute to the source code, the [GitHub repo][1] is open. Some questions readily come to mind:
|
||||
|
||||
* Can we integrate some machine learning/statistical modeling with this random data generator?
|
||||
* Should a visualization function be added to the generator?
|
||||
|
||||
|
||||
|
||||
The possibilities are endless and exciting!
|
||||
|
||||
If you have any questions or ideas to share, please contact me at [tirthajyoti[AT]gmail.com][4]. If you are, like me, passionate about machine learning and data science, please [add me on LinkedIn][5] or [follow me on Twitter][6]. Also, check my [GitHub repo][7] for other fun code snippets in Python, R, or MATLAB and some machine learning resources.
|
||||
|
||||
Originally published on [Towards Data Science][8]. Licensed under [CC BY-SA 4.0][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/pydbgen-random-database-table-generator
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tirthajyoti/pydbgen
|
||||
[2]: http://pydbgen.readthedocs.io/en/latest/
|
||||
[3]: https://faker.readthedocs.io/en/latest/index.html
|
||||
[4]: mailto:tirthajyoti@gmail.com
|
||||
[5]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[6]: https://twitter.com/tirthajyotiS
|
||||
[7]: https://github.com/tirthajyoti?tab=repositories
|
||||
[8]: https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5
|
||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
@ -0,0 +1,108 @@
|
||||
|
||||
构建满足客户需求的一套云环境的5个步骤
|
||||
======
|
||||
|
||||

|
||||
这篇文是和[Ian Teksbury][1]共同完成的。
|
||||
|
||||
无论你如何定义,云就是你的用户展现组织价值的另一个工具。当谈论新的范例或者技术的时候是很容易被,(云是两者兼有)它的新特性所分心。由一系列无止境的问题引发的对话能够很快的被发展为功能愿景清单,所有的这些都是你可能已经考虑到的。
|
||||
* 是公有云,私有云还是混合云?
|
||||
* 将会使用虚拟机还是容器,或者是两者?
|
||||
* 将会提供自助服务吗?
|
||||
* 将会完全自动的从开发转移到生产,还是它将需要手动操作?
|
||||
* 我们能以多块的速度创建?
|
||||
* 关于工具X,Y,还有Z?
|
||||
|
||||
这样的清单还可以列举很多。
|
||||
|
||||
开始现代化,或者数字转型,无论你是如何称呼的,通常方法是开始回答高级管理层的一些高层次问题,这种方法的结果是可以预想到的:失败。经过大范围的调研并且花费了数月的时间,如果不是几年,部署这个最炫的新技术,新的云技术从未被使用过而且陷入了荒废直到它最终被丢弃或者遗忘在数据中心的一角和预算中。
|
||||
|
||||
因为无论你交付的是什么工具都不是用户所想要或者需要的。更加糟糕的是,当用户真正需要的是一个单独的工具时,一系列其他的工具就会被用户抛弃因为新的,闪光的
|
||||
升级的工具能够更好的满足他们的需求。
|
||||
|
||||
### 议题聚焦
|
||||
|
||||
问题是关注,传统一直是关注工具。但工具并不是要增加到组织价值中的东西;终端用户利用它做什么。你需要将你的注意力从创建云(列入技术和工具)转移到你的人员和用户身上。
|
||||
|
||||
事实上,使用工具的用户(而不是工具本身)是驱动价值的因素,聚焦注意力在用户身上也是由其他原因的。工具是给用户使用去解决他们的问题并允许他们创造价值的,
|
||||
所有这就导致了如果那些工具不能满足那些用户的需求,那么那些工具将不会被使用。如果你交付给你的用户的工具并不是他们喜欢的,他们将不会使用,这就是人类的
|
||||
人性行为。
|
||||
|
||||
数十年来,IT产业只为用户提供一种解决方案,因为仅有一个或两个选项,用户是没有权力去改变的。现在情况已经不同了。我们现在生活在一个技术选择的世界中。
|
||||
不给用户一个选择的机会的情况将不会被接受的;他们在个人的科技生活中有选择,同时希望在工作中也有选择。现在的用户都是受过教育的并且知道将会有比你提供的机会更好的选择。
|
||||
|
||||
因此,在物理上的最安全的地点之外,没有能够阻止他们只做他们自己想要的东西的方法,我们称之为“影子IT。”如果你的组织由如此严格的安全策略和承诺策略,许多员工将会感到灰心丧气并且会离职去其他能提供更好机会的公司。
|
||||
|
||||
基于以上所有的原因,你必须牢记要首先和你的终端用户设计你的昂贵又费时的云项目。
|
||||
|
||||
### 创建满足用户需求的云五个步骤的过程
|
||||
|
||||
既然我们已经知道了为什么,接下来我们来讨论一下怎么做。你如何去为终端用户创建一个云?你怎样重新将你的注意力从技术转移到使用技术的用户身上?
|
||||
根据以往的经验,我们知道最好的方法中包含两件重要的事情:从你的用户中得到及时的反馈,创建中和用户进行更多的互动。
|
||||
|
||||
你的云环境将继续随着你的组织不段发展。下面的五个步骤将会帮助你创建满足用户需求的云环境。
|
||||
|
||||
### 1\. 识别谁将是你的用户
|
||||
|
||||
在你开始询问用户问题之前,你首先必须识别谁将是你的新的云环境的用户。他们可能包括将在云上创建开发应用的开发者。也可能是运营,维护或者或者创建云的运维团队;还可能是保护组织的安全团队。在第一次迭代时,将你的用户数量缩小至人数较少的小组防止你被大量的反馈所淹没,让你识别的每个小组指派两个代表(一个主要的一个辅助的)。这将使你的第一次交付在大小和时间上都很小。
|
||||
|
||||
#### 2\. 和你的用户面对面的交谈来收获有价值的输入。
|
||||
|
||||
The best way to get users' feedback is through direct communication. Mass emails asking for input will self-select respondents—if you even get a response. Group discussions can be helpful, but people tend to be more candid when they have a private, attentive audience.
|
||||
获得反馈的最佳途径是和用户直接交谈。如果你收到回复,大量的邮件要求你输入信息,你会选择自动回复。小组讨论会很有帮助的,但是当人们有私密的,吸引人注意的观众,他们会比较的坦诚。
|
||||
|
||||
和你的第一批用户安排面对面的个人的会谈并且向他们询问以下的问题:
|
||||
|
||||
* 为了完成你的任务,你需要什么?
|
||||
* 为了完成你的任务,你想要什么?
|
||||
* 你现在最头疼的技术点是什么?
|
||||
* 你现在最头疼的政策或者程序是哪个?
|
||||
* 为了满足你的需求你有什么想法,欲望还是疼痛?
|
||||
|
||||
这些问题只是指导性的并不一定适合每个组。你不应该只询问这些问题,他们应该导向更深层次的讨论。确保告诉用户任何所说的和被问的都会被反馈的。所有的反馈都是有帮助的,无论是消极的还是积极的。这些对话将会帮助你设置你的开发优先级。
|
||||
|
||||
收集这种个性化的反馈是保持初始用户群较小的另一个原因:将会花费你大量的时间来和每个用户交流,但是我们已经发现这是相当值得付出的投入。
|
||||
|
||||
#### 3\. 设计并交付你的解决方案的第一个版本
|
||||
|
||||
一旦你收到初始用户的反馈,就是时候开始去设计并交付一部分的功能了。我们不推荐尝试一次性交付整个解决方案。设计和交付的时期要短;这是为了避免犯一个需要你花费一年的时间去寻找解决方案的错误,只会让你的用户拒绝它,因为对他们来说毫无用处。创建你的云所需要的工具取决于你的组织和它的特殊需求。只需确保你的解决方案是建立在用户的反馈的基础上的,你将功能小块化的交付并且要经常的去征求用户的反馈。
|
||||
|
||||
#### 4\. 询问用户对第一个版本的反馈
|
||||
|
||||
太棒了,现在你已经设计并向你的用户交付了你的炫酷的新的云环境的第一个版本!你并不是花费一整年去完成它而是将它处理成小的模块。为什么将其分为小的模块如此重要呢?因为你要回归你的用户并且向他们收集关于你的设计和交付的功能。他们喜欢什么?不喜欢什么?你正确的处理了他们所关注的吗?是技术功能上很厉害,但系统进程或者策略方面仍然欠缺?
|
||||
|
||||
再重申一次,你要问的问题取决于你的组织;这里的关键是继续前一个阶段的讨论。毕竟你正在为用户创建云环境,所以确保它对用户来说是有用的并且能够有效利用每个人的时间。
|
||||
|
||||
#### 5\. 回到第一步。
|
||||
|
||||
这是一个互动的过程。你的第一次交付应该是快速而小规模的,而且以后的迭代也应该是这样的。不要期待仅仅按照这个流程完成了一次,两次即使是三次就能完成。
|
||||
一旦你持续的迭代,你将会吸引更多的用户从而能够在这个过程中得到更好的回报。你将会从用户那里得到更多的支持。你能狗迭代的更迅速并且更可靠。到最后,你
|
||||
将会通过改变你的进程来满足用户的需求。
|
||||
|
||||
用户是这个过程中最重要的一部分,但迭代是第二重要的因为它让你能够回到用户中进行持续沟通从而得到更多有用的信息。在每个阶段,记录那些是有效的哪些没有起到应有的效果。要自省,要对自己诚实。我们所花费的时间提供了最有价值的了吗?如果不是,在下一个阶段尝试些不同的。在每次循环中不要花费太多时间的重要部分是,如果某部分在这次不起作用,你能够很容易的在写一次中调整它,知道你找到能够在你组织中起作用的方法。
|
||||
|
||||
### 这仅仅是开始
|
||||
|
||||
通过许多客户的约定,从他们那里收集反馈,以及在这个领域的同行的经验,我们一次次的发现在你创建云的时候最重要事就是和你的用户交谈。这看起来是很明显的,
|
||||
但很让人惊讶的是很多组织却偏离了这个方向去花费数月或者数年的时间去创建,然后最终发现它对终端用户甚至一点用处都没有。
|
||||
|
||||
现在你已经知道为什么你需要将你的注意力集中到终端用户身上并且在中心节点和用户有一个一起创建云的互动过程。剩下的是我们所喜欢的部分,你出去做的部分。
|
||||
|
||||
这篇文章是基于"[为终端用户设计混合云或者失败],"一篇作者将在[Red Hat Summit 2018][3]上发表的文章,并且将于5月8日至10日在旧金山举行
|
||||
|
||||
[在5月7号前注册][3]将会节省US$500。在支付页面使用折扣码**OPEN18**将会享受到折扣。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly
|
||||
|
||||
作者:[Cameron Wyatt][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cameronmwyatt
|
||||
[1]:https://opensource.com/users/itewk
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154225
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
@ -0,0 +1,207 @@
|
||||
Bash脚本中如何使用 here 文档将数据写入文件
|
||||
======
|
||||
|
||||
<ruby>here 文档<rt>here document</rt></ruby> (LCTT译注:here文档又称作 heredoc )不是什么特殊的东西,只是一种 I/O 重定向方式,它告诉bash shell从当前源读取输入,直到读取到只有分隔符的行。
|
||||
![redirect output of here document to a text file][1]
|
||||
这对于向 ftp,cat,echo,ssh 和许多其他有用的 Linux/Unix 命令提供指令很有用。 此功能适用于 bash也适用于 Bourne,Korn,POSIX 这三种 shell。
|
||||
|
||||
## here 文档语法
|
||||
|
||||
语法是:
|
||||
```
|
||||
command <<EOF
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
EOF
|
||||
```
|
||||
|
||||
或者允许shell脚本中的 here 文档使用 **EOF<<-** 以自然的方式缩进
|
||||
|
||||
```
|
||||
command <<-EOF
|
||||
msg1
|
||||
msg2
|
||||
$var on line
|
||||
EOF
|
||||
```
|
||||
|
||||
或者
|
||||
```
|
||||
command <<'EOF'
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
$var won't expand as parameter substitution turned off
|
||||
by single quoting
|
||||
EOF
|
||||
```
|
||||
|
||||
或者 **重定向并将其覆盖** 到名为my_output_file.txt的文件中:
|
||||
```
|
||||
command << EOF > my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
或**重定向并将其追加**到名为my_output_file.txt的文件中:
|
||||
|
||||
```
|
||||
command << EOF >> my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
## 示例
|
||||
|
||||
以下脚本将所需内容写入名为/tmp/output.txt的文件中:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
cat <<EOF >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
你可以使用[cat命令][3]查看/tmp/output.txt文件:
|
||||
|
||||
```
|
||||
$ cat /tmp/output.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Status of backup as on Thu Nov 16 17:00:21 IST 2017
|
||||
Backing up files /home/vivek and /etc/
|
||||
|
||||
```
|
||||
|
||||
### 禁用路径名/参数/变量扩展,命令替换,算术扩展
|
||||
|
||||
像 $HOME 这类变量和像 $(date) 这类命令在脚本中会被解释为替换。 要禁用它,请使用带有 'EOF' 这样带有单引号的形式,如下所示:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
# No parameter and variable expansion, command substitution, arithmetic expansion, or pathname expansion is performed on word.
|
||||
# If any part of word is quoted, the delimiter is the result of quote removal on word, and the lines in the here-document
|
||||
# are not expanded. So EOF is quoted as follows
|
||||
cat <<'EOF' >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
你可以使用[cat命令][3]查看/tmp/output.txt文件:
|
||||
|
||||
```
|
||||
$ cat /tmp/output.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
|
||||
```
|
||||
|
||||
## 关于 tee 命令的使用
|
||||
|
||||
语法是:
|
||||
```
|
||||
tee /tmp/filename <<EOF >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
或者通过在单引号中引用EOF来禁用变量替换和命令替换:
|
||||
|
||||
```
|
||||
tee /tmp/filename <<'EOF' >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
这是我更新的脚本:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
tee $OUT <<EOF >/dev/null
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
## 关于内存 here 文档的使用
|
||||
|
||||
这是我更新的脚本:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
## in memory here docs
|
||||
## thanks https://twitter.com/freebsdfrau
|
||||
exec 9<<EOF
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
## continue
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
## do it
|
||||
cat <&9 >$OUT
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/using-heredoc-rediection-in-bash-shell-script-to-write-to-file/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cyberciti.biz
|
||||
[1]: https://www.cyberciti.biz/media/new/faq/2017/11/redirect-output-of-here-document-to-a-text-file.jpg
|
||||
[2]: https://bash.cyberciti.biz/guide/Here_documents
|
||||
[3]: https//www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ "See Linux/Unix cat command examples for more info"
|
||||
@ -0,0 +1,228 @@
|
||||
命令行快捷提示:如何定位一个文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们都会有文件存储在电脑里 —— 目录,相片,源代码等等。它们是如此之多。也无疑超出了我的记忆范围。要是毫无目标,找到正确的那一个可能会很费时间。在这篇文章里我们来看一下如何在命令行里找到需要的文件,特别是快速找到你想要的那一个。
|
||||
|
||||
好消息是 Linux 命令行专门设计了很多非常有用的命令行工具在你的电脑上查找文件。下面我们看一下它们其中三个:ls、tree 和 tree。
|
||||
|
||||
### ls
|
||||
|
||||
如果你知道文件在哪里,你只需要列出它们或者查看有关它们的信息,ls 就是为此而生的。
|
||||
|
||||
只需运行 ls 就可以列出当下目录中所有可见的文件和目录:
|
||||
|
||||
```
|
||||
$ ls
|
||||
Documents Music Pictures Videos notes.txt
|
||||
```
|
||||
|
||||
添加 **-l** 选项可以查看文件的相关信息。同时再加上 **-h** 选项,就可以用一种人们易读的格式查看文件的大小:
|
||||
|
||||
```
|
||||
$ ls -lh
|
||||
total 60K
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Documents
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Music
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:13 Pictures
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos
|
||||
-rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
|
||||
```
|
||||
|
||||
**ls** 也可以搜索一个指定位置:
|
||||
|
||||
```
|
||||
$ ls Pictures/
|
||||
trees.png wallpaper.png
|
||||
```
|
||||
|
||||
或者一个指定文件 —— 即便只跟着名字的一部分:
|
||||
|
||||
```
|
||||
$ ls *.txt
|
||||
notes.txt
|
||||
```
|
||||
|
||||
少了点什么?想要查看一个隐藏文件?没问题,使用 **-a** 选项:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
. .bash_logout .bashrc Documents Pictures notes.txt
|
||||
.. .bash_profile .vimrc Music Videos
|
||||
```
|
||||
|
||||
**ls** 还有很多其他有用的选项,你可以把它们组合在一起获得你想要的效果。可以使用以下命令了解更多:
|
||||
|
||||
```
|
||||
$ man ls
|
||||
```
|
||||
|
||||
### tree
|
||||
|
||||
如果你想查看你的文件的树状结构,tree 是一个不错的选择。可能你的系统上没有默认安装它,你可以使用包管理 DNF 手动安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install tree
|
||||
```
|
||||
|
||||
如果不带任何选项或者参数地运行 tree,将会以当前目录开始,显示出包含其下所有目录和文件的一个树状图。提醒一下,这个输出可能会非常大,因为它包含了这个目录下的所有目录和文件:
|
||||
|
||||
```
|
||||
$ tree
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| | `-- christmas-presents.txt
|
||||
| `-- work
|
||||
| |-- project-abc
|
||||
| | |-- README.md
|
||||
| | |-- do-things.sh
|
||||
| | `-- project-notes.txt
|
||||
| `-- status-reports.txt
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
如果列出的太多了,使用 -L 选项,并在其后加上你想查看的层级数,可以限制列出文件的层级:
|
||||
|
||||
```
|
||||
$ tree -L 2
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| `-- work
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
你也可以显示一个指定目录的树状图:
|
||||
|
||||
```
|
||||
$ tree Documents/work/
|
||||
Documents/work/
|
||||
|-- project-abc
|
||||
| |-- README.md
|
||||
| |-- do-things.sh
|
||||
| `-- project-notes.txt
|
||||
`-- status-reports.txt
|
||||
```
|
||||
|
||||
如果使用 tree 列出的是一个很大的树状图,你可以把它跟 less 组合使用:
|
||||
|
||||
```
|
||||
$ tree | less
|
||||
```
|
||||
|
||||
再一次,tree 有很多其他的选项可以使用,你可以把他们组合在一起发挥更强大的作用。man 手册页有所有这些选项:
|
||||
|
||||
```
|
||||
$ man tree
|
||||
```
|
||||
|
||||
### find
|
||||
|
||||
那么如果不知道文件在哪里呢?就让我们来找到它们吧!
|
||||
|
||||
要是你的系统中没有 find,你可以使用 DNF 安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install findutils
|
||||
```
|
||||
|
||||
运行 find 时如果没有添加任何选项或者参数,它将会递归列出当前目录下的所有文件和目录。
|
||||
|
||||
```
|
||||
$ find
|
||||
.
|
||||
./Documents
|
||||
./Documents/secret
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc
|
||||
./Documents/work/project-abc/README.md
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./.bash_logout
|
||||
./.bashrc
|
||||
./Videos
|
||||
./.bash_profile
|
||||
./.vimrc
|
||||
./Pictures
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
./notes.txt
|
||||
./Music
|
||||
```
|
||||
|
||||
但是 find 真正强大的是你可以使用文件名进行搜索:
|
||||
|
||||
```
|
||||
$ find -name do-things.sh
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
```
|
||||
|
||||
或者仅仅是名字的一部分 —— 像是文件后缀。我们来找一下所有的 .txt 文件:
|
||||
|
||||
```
|
||||
$ find -name "*.txt"
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./notes.txt
|
||||
```
|
||||
你也可以根据大小寻找文件。如果你的空间不足的时候,这种方法也许特别有用。现在来列出所有大于 1 MB 的文件:
|
||||
|
||||
```
|
||||
$ find -size +1M
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
```
|
||||
|
||||
当然也可以搜索一个具体的目录。假如我想在我的 Documents 文件夹下找一个文件,而且我知道它的名字里有 “project” 这个词:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*"
|
||||
Documents/work/project-abc
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
除了文件它还显示目录。你可以限制仅搜索查询文件:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*" -type f
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
最后再一次,find 还有很多供你使用的选项,要是你想使用它们,man 手册页绝对可以帮到你:
|
||||
|
||||
```
|
||||
$ man find
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-locate-file/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,169 @@
|
||||
pydbgen:一个数据库随机生成器
|
||||
======
|
||||
> 用这个简单的工具生成大型数据库,让你更好地研究数据科学。
|
||||
|
||||

|
||||
|
||||
在研究数据科学的过程中,最麻烦的往往不是算法或者技术,而是如何获取到一批原始数据。尽管网上有很多真实优质的数据集可以用于机器学习,然而在学习 SQL 时却不是如此。
|
||||
|
||||
对于数据科学来说,熟悉 SQL 的重要性不亚于了解 Python 或 R 编程。如果想收集诸如姓名、年龄、信用卡信息、地址这些信息用于机器学习任务,在 Kaggle 上查找专门的数据集比使用足够大的真实数据库要容易得多。
|
||||
|
||||
如果有一个简单的工具或库来帮助你生成一个大型数据库,表里还存放着大量你需要的数据,岂不美哉?
|
||||
|
||||
不仅仅是数据科学的入门者,即使是经验丰富的软件测试人员也会需要这样一个简单的工具,只需编写几行代码,就可以通过随机(但是是假随机)生成任意数量但有意义的数据集。
|
||||
|
||||
因此,我要推荐这个名为 [pydbgen][1] 的轻量级 Python 库。在后文中,我会简要说明这个库的相关内容,你也可以[阅读它的文档][2]详细了解更多信息。
|
||||
|
||||
### pydbgen 是什么
|
||||
|
||||
`pydbgen` 是一个轻量的纯 Python 库,它可以用于生成随机但有意义的数据记录(包括姓名、地址、信用卡号、日期、时间、公司名称、职位、车牌号等等),存放在 Pandas Dataframe 对象中,并保存到 SQLite 数据库或 Excel 文件。
|
||||
|
||||
### 如何安装 pydbgen
|
||||
|
||||
目前 1.0.5 版本的 pydbgen 托管在 PyPI(<ruby>Python 包索引存储库<rt>Python Package Index repository</rt></ruby>)上,并且对 [Faker][3] 有依赖关系。安装 pydbgen 只需要执行命令:
|
||||
|
||||
```
|
||||
pip install pydbgen
|
||||
```
|
||||
|
||||
已经在 Python 3.6 环境下测试安装成功,但在 Python 2 环境下无法正常安装。
|
||||
|
||||
### 如何使用 pydbgen
|
||||
|
||||
在使用 `pydbgen` 之前,首先要初始化 `pydb` 对象。
|
||||
|
||||
```
|
||||
import pydbgen
|
||||
from pydbgen import pydbgen
|
||||
myDB=pydbgen.pydb()
|
||||
```
|
||||
|
||||
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
||||
随后就可以调用 `pydb` 对象公开的各种内部函数了。可以按照下面的例子,输出随机的美国城市和车牌号码:
|
||||
|
||||
```
|
||||
myDB.city_real()
|
||||
>> 'Otterville'
|
||||
for _ in range(10):
|
||||
print(myDB.license_plate())
|
||||
>> 8NVX937
|
||||
6YZH485
|
||||
XBY-564
|
||||
SCG-2185
|
||||
XMR-158
|
||||
6OZZ231
|
||||
CJN-850
|
||||
SBL-4272
|
||||
TPY-658
|
||||
SZL-0934
|
||||
```
|
||||
|
||||
另外,如果你输入的是 city 而不是 city_real,返回的将会是虚构的城市名。
|
||||
|
||||
```
|
||||
print(myDB.gen_data_series(num=8,data_type='city'))
|
||||
>>
|
||||
New Michelle
|
||||
Robinborough
|
||||
Leebury
|
||||
Kaylatown
|
||||
Hamiltonfort
|
||||
Lake Christopher
|
||||
Hannahstad
|
||||
West Adamborough
|
||||
```
|
||||
|
||||
### 生成随机的 Pandas Dataframe
|
||||
|
||||
你可以指定生成数据的数量和种类,但需要注意的是,返回结果均为字符串或文本类型。
|
||||
|
||||
```
|
||||
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
|
||||
testdf
|
||||
```
|
||||
|
||||
最终产生的 Dataframe 类似下图所示。
|
||||
|
||||

|
||||
|
||||
### 生成数据库表
|
||||
|
||||
你也可以指定生成数据的数量和种类,而返回结果是数据库中的文本或者变长字符串类型。在生成过程中,你可以指定对应的数据库文件名和表名。
|
||||
|
||||
```
|
||||
myDB.gen_table(db_file='Testdb.DB',table_name='People',
|
||||
|
||||
fields=['name','city','street_address','email'])
|
||||
```
|
||||
|
||||
上面的例子种生成了一个能被 MySQL 和 SQLite 支持的 `.db` 文件。下图则显示了这个文件中的数据表在 SQLite 可视化客户端中打开的画面。
|
||||

|
||||
|
||||
### 生成 Excel 文件
|
||||
|
||||
和上面的其它示例类似,下面的代码可以生成一个具有随机数据的 Excel 文件。值得一提的是,通过将`phone_simple` 参数设为 `False` ,可以生成较长较复杂的电话号码。如果你想要提高自己在数据提取方面的能力,不妨尝试一下这个功能。
|
||||
|
||||
```
|
||||
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
||||
phone_simple=False,filename='TestExcel.xlsx')
|
||||
```
|
||||
|
||||
最终的结果类似下图所示:
|
||||

|
||||
|
||||
### 生成随机电子邮箱地址
|
||||
|
||||
`pydbgen` 内置了一个 `realistic_email` 方法,它基于种子来生成随机的电子邮箱地址。如果你不想在网络上使用真实的电子邮箱地址时,这个功能可以派上用场。
|
||||
|
||||
```
|
||||
for _ in range(10):
|
||||
print(myDB.realistic_email('Tirtha Sarkar'))
|
||||
>>
|
||||
Tirtha_Sarkar@gmail.com
|
||||
Sarkar.Tirtha@outlook.com
|
||||
Tirtha_S48@verizon.com
|
||||
Tirtha_Sarkar62@yahoo.com
|
||||
Tirtha.S46@yandex.com
|
||||
Tirtha.S@att.com
|
||||
Sarkar.Tirtha60@gmail.com
|
||||
TirthaSarkar@zoho.com
|
||||
Sarkar.Tirtha@protonmail.com
|
||||
Tirtha.S@comcast.net
|
||||
```
|
||||
|
||||
### 未来的改进和用户贡献
|
||||
|
||||
目前的版本中并不完美。如果你发现了 pydbgen 的 bug 导致 pydbgen 在运行期间发生崩溃,请向我反馈。如果你打算对这个项目贡献代码,[也随时欢迎你][1]。当然现在也还有很多改进的方向:
|
||||
|
||||
* pydbgen 作为随机数据生成器,可以集成一些机器学习或统计建模的功能吗?
|
||||
* pydbgen 是否会添加可视化功能?
|
||||
|
||||
一切皆有可能!
|
||||
|
||||
如果你有任何问题或想法想要分享,都可以通过 [tirthajyoti@gmail.com][4] 与我联系。如果你像我一样对机器学习和数据科学感兴趣,也可以添加我的 [LinkedIn][5] 或在 [Twitter][6] 上关注我。另外,还可以在我的 [GitHub][7] 上找到更多 Python、R 或 MATLAB 的有趣代码和机器学习资源。
|
||||
|
||||
本文以 [CC BY-SA 4.0][9] 许可在 [Towards Data Science][8] 首发。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/pydbgen-random-database-table-generator
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tirthajyoti/pydbgen
|
||||
[2]: http://pydbgen.readthedocs.io/en/latest/
|
||||
[3]: https://faker.readthedocs.io/en/latest/index.html
|
||||
[4]: mailto:tirthajyoti@gmail.com
|
||||
[5]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[6]: https://twitter.com/tirthajyotiS
|
||||
[7]: https://github.com/tirthajyoti?tab=repositories
|
||||
[8]: https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5
|
||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user