mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
ee81de8e63
@ -0,0 +1,136 @@
|
||||
在 Linux 中用 nmcli 命令绑定多块网卡
|
||||
================================================================================
|
||||
今天,我们来学习一下在 CentOS 7.x 中如何用 nmcli(Network Manager Command Line Interface:网络管理命令行接口)进行网卡绑定。
|
||||
|
||||
网卡(接口)绑定是将多块 **网卡** 逻辑地连接到一起从而允许故障转移或者提高吞吐率的方法。提高服务器网络可用性的一个方式是使用多个网卡。Linux 绑定驱动程序提供了一种将多个网卡聚合到一个逻辑的绑定接口的方法。这是个新的实现绑定的方法,并不影响 linux 内核中旧绑定驱动。
|
||||
|
||||
**网卡绑定为我们提供了两个主要的好处:**
|
||||
|
||||
1. **高带宽**
|
||||
1. **冗余/弹性**
|
||||
|
||||
现在让我们在 CentOS 7 上配置网卡绑定吧。我们需要决定选取哪些接口配置成一个组接口(Team interface)。
|
||||
|
||||
运行 **ip link** 命令查看系统中可用的接口。
|
||||
|
||||
$ ip link
|
||||
|
||||

|
||||
|
||||
这里我们使用 **eno16777736** 和 **eno33554960** 网卡在 “主动备份” 模式下创建一个组接口。(译者注:关于不同模式可以参考:<a href="http://support.huawei.com/ecommunity/bbs/10155553.html">多网卡的7种bond模式原理</a>)
|
||||
|
||||
按照下面的语法,用 **nmcli** 命令为网络组接口创建一个连接。
|
||||
|
||||
# nmcli con add type team con-name CNAME ifname INAME [config JSON]
|
||||
|
||||
**CNAME** 指代连接的名称,**INAME** 是接口名称,**JSON** (JavaScript Object Notation) 指定所使用的处理器(runner)。**JSON** 语法格式如下:
|
||||
|
||||
'{"runner":{"name":"METHOD"}}'
|
||||
|
||||
**METHOD** 是以下的其中一个:**broadcast、activebackup、roundrobin、loadbalance** 或者 **lacp**。
|
||||
|
||||
### 1. 创建组接口 ###
|
||||
|
||||
现在让我们来创建组接口。这是我们创建组接口所使用的命令。
|
||||
|
||||
# nmcli con add type team con-name team0 ifname team0 config '{"runner":{"name":"activebackup"}}'
|
||||
|
||||

|
||||
|
||||
运行 **# nmcli con show** 命令验证组接口配置。
|
||||
|
||||
# nmcli con show
|
||||
|
||||

|
||||
|
||||
### 2. 添加从设备 ###
|
||||
|
||||
现在让我们添加从设备到主设备 team0。这是添加从设备的语法:
|
||||
|
||||
# nmcli con add type team-slave con-name CNAME ifname INAME master TEAM
|
||||
|
||||
在这里我们添加 **eno16777736** 和 **eno33554960** 作为 **team0** 接口的从设备。
|
||||
|
||||
# nmcli con add type team-slave con-name team0-port1 ifname eno16777736 master team0
|
||||
|
||||
# nmcli con add type team-slave con-name team0-port2 ifname eno33554960 master team0
|
||||
|
||||

|
||||
|
||||
再次用命令 **#nmcli con show** 验证连接配置。现在我们可以看到从设备配置信息。
|
||||
|
||||
#nmcli con show
|
||||
|
||||

|
||||
|
||||
### 3. 分配 IP 地址 ###
|
||||
|
||||
上面的命令会在 **/etc/sysconfig/network-scripts/** 目录下创建需要的配置文件。
|
||||
|
||||
现在让我们为 team0 接口分配一个 IP 地址并启用这个连接。这是进行 IP 分配的命令。
|
||||
|
||||
# nmcli con mod team0 ipv4.addresses "192.168.1.24/24 192.168.1.1"
|
||||
# nmcli con mod team0 ipv4.method manual
|
||||
# nmcli con up team0
|
||||
|
||||

|
||||
|
||||
### 4. 验证绑定 ###
|
||||
|
||||
用 **#ip add show team0** 命令验证 IP 地址信息。
|
||||
|
||||
#ip add show team0
|
||||
|
||||

|
||||
|
||||
现在用 **teamdctl** 命令检查 **主动备份** 配置功能。
|
||||
|
||||
# teamdctl team0 state
|
||||
|
||||

|
||||
|
||||
现在让我们把激活的端口断开连接并再次检查状态来确认主动备份配置是否像希望的那样工作。
|
||||
|
||||
# nmcli dev dis eno33554960
|
||||
|
||||

|
||||
|
||||
断开激活端口后再次用命令 **#teamdctl team0 state** 检查状态。
|
||||
|
||||
# teamdctl team0 state
|
||||
|
||||

|
||||
|
||||
是的,它运行良好!!我们会使用下面的命令连接回到 team0 的断开的连接。
|
||||
|
||||
#nmcli dev con eno33554960
|
||||
|
||||

|
||||
|
||||
我们还有一个 **teamnl** 命令可以显示 **teamnl** 命令的一些选项。
|
||||
|
||||
用下面的命令检查在 team0 运行的端口。
|
||||
|
||||
# teamnl team0 ports
|
||||
|
||||

|
||||
|
||||
显示 **team0** 当前活动的端口。
|
||||
|
||||
# teamnl team0 getoption activeport
|
||||
|
||||

|
||||
|
||||
好了,我们已经成功地配置了网卡绑定 :-) ,如果有任何反馈,请告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/interface-nics-bonding-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,236 @@
|
||||
搭建一个私有的Docker registry
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] 这是系列的第二篇文章,这系列讲述了我的公司如何把基础服务从PaaS迁移到Docker上
|
||||
|
||||
- [第一篇文章][1]: 我谈到了接触Docker之前的经历;
|
||||
- [第三篇文章][2]: 我展示如何使创建镜像的过程自动化以及如何用Docker部署一个Rails应用。
|
||||
|
||||
----------
|
||||
|
||||
为什么需要搭建一个私有的registry呢?嗯,对于新手来说,Docker Hub(一个Docker公共仓库)只允许你拥有一个免费的私有版本库(repo)。其他的公司也开始提供类似服务,但是价格可不便宜。另外,如果你需要用Docker部署一个用于生产环境的应用,恐怕你不希望将这些镜像放在公开的Docker Hub上吧!
|
||||
|
||||
这篇文章提供了一个非常务实的方法来处理搭建私有Docker registry时出现的各种错综复杂的情况。我们将会使用一个运行于DigitalOcean(之后简称为DO)的非常小巧的512MB VPS 实例。并且我会假定你已经了解了Docker的基本概念,因为我必须集中精力在复杂的事情上!
|
||||
|
||||
###本地搭建###
|
||||
|
||||
首先你需要安装**boot2docker**以及docker CLI。如果你已经搭建好了基本的Docker环境,你可以直接跳过这一步。
|
||||
|
||||
从终端运行以下命令(我假设你使用OS X,使用 HomeBrew 来安装相关软件,你可以根据你的环境使用不同的包管理软件来安装):
|
||||
|
||||
brew install boot2docker docker
|
||||
|
||||
如果一切顺利(想要了解搭建docker环境的完整指南,请参阅 [http://boot2docker.io/][10]) ,你现在就能够通过如下命令启动一个 Docker 运行于其中的虚拟机:
|
||||
|
||||
boot2docker up
|
||||
|
||||
按照屏幕显示的说明,复制粘贴book2docker在终端输出的命令。如果你现在运行`docker ps`命令,终端将有以下显示。
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
|
||||
好了,Docker已经准备就绪,这就够了,我们回过头去搭建registry。
|
||||
|
||||
###创建服务器###
|
||||
|
||||
登录进你的DO账号,选择一个预安装了Docker的镜像文件,创建一个新的Drople。(本文写成时选择的是 Image > Applications > Docker 1.4.1 on 14.04)
|
||||
|
||||

|
||||
|
||||
你将会以邮件的方式收到一个根用户凭证。登录进去,然后运行`docker ps`命令来查看系统状态。
|
||||
|
||||
### 搭建AWS S3 ###
|
||||
|
||||
我们现在将使用Amazo Simple Storage Service(S3)作为我们registry/repository的存储层。我们将需要创建一个桶(bucket)以及用户凭证(user credentials)来允许我们的docker容器访问它。
|
||||
|
||||
登录到我们的AWS账号(如果没有,就申请一个[http://aws.amazon.com/][5]),在控制台选择S3(Simpole Storage Service)。
|
||||
|
||||

|
||||
|
||||
点击 **Create Bucket**,为你的桶输入一个名字(把它记下来,我们一会需要用到它),然后点击**Create**。
|
||||
|
||||

|
||||
|
||||
OK!我们已经搭建好存储部分了。
|
||||
|
||||
### 设置AWS访问凭证###
|
||||
|
||||
我们现在将要创建一个新的用户。退回到AWS控制台然后选择IAM(Identity & Access Management)。
|
||||
|
||||

|
||||
|
||||
在dashboard的左边,点击Users。然后选择 **Create New Users**。
|
||||
|
||||
如图所示:
|
||||
|
||||

|
||||
|
||||
输入一个用户名(例如 docker-registry)然后点击Create。写下(或者下载csv文件)你的Access Key以及Secret Access Key。回到你的用户列表然后选择你刚刚创建的用户。
|
||||
|
||||
在Permission section下面,点击Attach User Policy。之后在下一屏,选择Custom Policy。
|
||||
|
||||

|
||||
|
||||
custom policy的内容如下:
|
||||
|
||||
{
|
||||
"Version": "2012-10-17",
|
||||
"Statement": [
|
||||
{
|
||||
"Sid": "SomeStatement",
|
||||
"Effect": "Allow",
|
||||
"Action": [
|
||||
"s3:*"
|
||||
],
|
||||
"Resource": [
|
||||
"arn:aws:s3:::docker-registry-bucket-name/*",
|
||||
"arn:aws:s3:::docker-registry-bucket-name"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
这个配置将允许用户(也就是regitstry)来对桶上的内容进行操作(读/写)(确保使用你之前创建AWS S3时使用的桶名)。总结一下:当你想把你的Docker镜像从你的本机推送到仓库中时,服务器就会将他们上传到S3。
|
||||
|
||||
### 安装registry ###
|
||||
|
||||
现在回过头来看我们的DO服务器,SSH登录其上。我们将要[使用][11]一个[官方Docker registry镜像][6]。
|
||||
|
||||
输入如下命令,开启registry。
|
||||
|
||||
docker run \
|
||||
-e SETTINGS_FLAVOR=s3 \
|
||||
-e AWS_BUCKET=bucket-name \
|
||||
-e STORAGE_PATH=/registry \
|
||||
-e AWS_KEY=your_aws_key \
|
||||
-e AWS_SECRET=your_aws_secret \
|
||||
-e SEARCH_BACKEND=sqlalchemy \
|
||||
-p 5000:5000 \
|
||||
--name registry \
|
||||
-d \
|
||||
registry
|
||||
|
||||
Docker将会从Docker Hub上拉取所需的文件系统分层(fs layers)并启动守护容器(daemonised container)。
|
||||
|
||||
### 测试registry ###
|
||||
|
||||
如果上述操作奏效,你可以通过ping命令,或者查找它的内容来测试registry(虽然这个时候容器还是空的)。
|
||||
|
||||
我们的registry非常基础,而且没有提供任何“验明正身”的方式。因为添加身份验证可不是一件轻松事(至少我认为没有一种部署方法是简单的,像是为了证明你努力过似的),我觉得“查询/拉取/推送”仓库内容的最简单方法就是通过SSH通道的未加密连接(通过HTTP)。
|
||||
|
||||
打开SSH通道的操作非常简单:
|
||||
|
||||
ssh -N -L 5000:localhost:5000 root@your_registry.com
|
||||
|
||||
这条命令建立了一条从registry服务器(前面执行`docker run`命令的时候我们见过它)的5000号端口到本机的5000号端口之间的 SSH 管道连接。
|
||||
|
||||
如果你现在用浏览器访问 [http://localhost:5000/v1/_ping][7],将会看到下面这个非常简短的回复。
|
||||
|
||||
{}
|
||||
|
||||
这个意味着registry工作正常。你还可以通过登录 [http://localhost:5000/v1/search][8] 来查看registry内容,内容相似:
|
||||
|
||||
{
|
||||
"num_results": 2,
|
||||
"query": "",
|
||||
"results": [
|
||||
{
|
||||
"description": "",
|
||||
"name": "username/first-repo"
|
||||
},
|
||||
{
|
||||
"description": "",
|
||||
"name": "username/second-repo"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
### 创建一个镜像 ###
|
||||
|
||||
我们现在创建一个非常简单的Docker镜像,来检验我们新弄好的registry。在我们的本机上,用如下内容创建一个Dockerfile(这里只有一点代码,在下一篇文章里我将会展示给你如何将一个Rails应用绑定进Docker容器中。):
|
||||
|
||||
# ruby 2.2.0 的基础镜像
|
||||
FROM ruby:2.2.0
|
||||
|
||||
MAINTAINER Michelangelo Chasseur <michelangelo.chasseur@touchwa.re>
|
||||
|
||||
并创建它:
|
||||
|
||||
docker build -t localhost:5000/username/repo-name .
|
||||
|
||||
`localhost:5000`这个部分非常重要:Docker镜像名的最前面一个部分将告知`docker push`命令我们将要把我们的镜像推送到哪里。在我们这个例子当中,因为我们要通过SSH管道连接远程的私有registry,`localhost:5000`精确地指向了我们的registry。
|
||||
|
||||
如果一切顺利,当命令执行完成返回后,你可以输入`docker images`命令来列出新近创建的镜像。执行它看看会出现什么现象?
|
||||
|
||||
### 推送到仓库 ###
|
||||
|
||||
接下来是更好玩的部分。实现我所描述的东西着实花了我一点时间,所以如果你第一次读的话就耐心一点吧,跟着我一起操作。我知道接下来的东西会非常复杂(如果你不自动化这个过程就一定会这样),但是我保证到最后你一定都能明白。在下一篇文章里我将会使用到一大波shell脚本和Rake任务,通过它们实现自动化并且用简单的命令实现部署Rails应用。
|
||||
|
||||
你在终端上运行的docker命令实际上都是使用boot2docker虚拟机来运行容器及各种东西。所以当你执行像`docker push some_repo`这样的命令时,是boot2docker虚拟机在与registry交互,而不是我们自己的机器。
|
||||
|
||||
接下来是一个非常重要的点:为了将Docker镜像推送到远端的私有仓库,SSH管道需要在boot2docker虚拟机上配置好,而不是在你的本地机器上配置。
|
||||
|
||||
有许多种方法实现它。我给你展示最简短的一种(可能不是最容易理解的,但是能够帮助你实现自动化)
|
||||
|
||||
在这之前,我们需要对 SSH 做最后一点工作。
|
||||
|
||||
### 设置 SSH ###
|
||||
|
||||
让我们把boot2docker 的 SSH key添加到远端服务器的“已知主机”里面。我们可以使用ssh-copy-id工具完成,通过下面的命令就可以安装上它了:
|
||||
|
||||
brew install ssh-copy-id
|
||||
|
||||
然后运行:
|
||||
|
||||
ssh-copy-id -i /Users/username/.ssh/id_boot2docker root@your-registry.com
|
||||
|
||||
用你ssh key的真实路径代替`/Users/username/.ssh/id_boot2docker`。
|
||||
|
||||
这样做能够让我们免密码登录SSH。
|
||||
|
||||
现在我们来测试以下:
|
||||
|
||||
boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &" &
|
||||
|
||||
分开阐述:
|
||||
|
||||
- `boot2docker ssh`允许你以参数的形式传递给boot2docker虚拟机一条执行的命令;
|
||||
- 最后面那个`&`表明这条命令将在后台执行;
|
||||
- `ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &`是boot2docker虚拟机实际运行的命令;
|
||||
- `-o 'StrictHostKeyChecking no'`——不提示安全问题;
|
||||
- `-i /Users/michelangelo/.ssh/id_boot2docker`指出虚拟机使用哪个SSH key来进行身份验证。(注意这里的key应该是你前面添加到远程仓库的那个)
|
||||
- 最后我们将打开一条端口5000映射到localhost:5000的SSH通道。
|
||||
|
||||
### 从其他服务器上拉取 ###
|
||||
|
||||
你现在将可以通过下面的简单命令将你的镜像推送到远端仓库:
|
||||
|
||||
docker push localhost:5000/username/repo_name
|
||||
|
||||
在下一篇[文章][9]中,我们将会了解到如何自动化处理这些事务,并且真正地容器化一个Rails应用。请继续收听!
|
||||
|
||||
如有错误,请不吝指出。祝你Docker之路顺利!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-2/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:https://linux.cn/article-5339-1.html
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
[3]:http://cocoahunter.com/2015/01/23/docker-2/#fn:1
|
||||
[4]:http://cocoahunter.com/2015/01/23/docker-2/#fn:2
|
||||
[5]:http://aws.amazon.com/
|
||||
[6]:https://registry.hub.docker.com/_/registry/
|
||||
[7]:http://localhost:5000/v1/_ping
|
||||
[8]:http://localhost:5000/v1/search
|
||||
[9]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
[10]:http://boot2docker.io/
|
||||
[11]:https://github.com/docker/docker-registry/
|
||||
@ -0,0 +1,246 @@
|
||||
自动化部署基于Docker的Rails应用
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] 这是系列文章的第三篇,讲述了我的公司是如何将基础设施从PaaS移植到Docker上的。
|
||||
|
||||
- [第一部分][1]:谈论了我接触Docker之前的经历;
|
||||
- [第二部分][2]:一步步搭建一个安全而又私有的registry。
|
||||
|
||||
----------
|
||||
|
||||
在系列文章的最后一篇里,我们将用一个实例来学习如何自动化整个部署过程。
|
||||
|
||||
### 基本的Rails应用程序###
|
||||
|
||||
现在让我们启动一个基本的Rails应用。为了更好的展示,我使用Ruby 2.2.0和Rails 4.1.1
|
||||
|
||||
在终端运行:
|
||||
|
||||
$ rvm use 2.2.0
|
||||
$ rails new && cd docker-test
|
||||
|
||||
创建一个基本的控制器:
|
||||
|
||||
$ rails g controller welcome index
|
||||
|
||||
……,然后编辑 `routes.rb` ,以便让该项目的根指向我们新创建的welcome#index方法:
|
||||
|
||||
root 'welcome#index'
|
||||
|
||||
在终端运行 `rails s` ,然后打开浏览器,登录[http://localhost:3000][3],你会进入到索引界面当中。我们不准备给应用加上多么神奇的东西,这只是一个基础的实例,当我们将要创建并部署容器的时候,用它来验证一切是否运行正常。
|
||||
|
||||
### 安装webserver ###
|
||||
|
||||
我们打算使用Unicorn当做我们的webserver。在Gemfile中添加 `gem 'unicorn'`和 `gem 'foreman'`然后将它bundle起来(运行 `bundle install`命令)。
|
||||
|
||||
启动Rails应用时,需要先配置好Unicorn,所以我们将一个**unicorn.rb**文件放在**config**目录下。[这里有一个Unicorn配置文件的例子][4],你可以直接复制粘贴Gist的内容。
|
||||
|
||||
接下来,在项目的根目录下添加一个Procfile,以便可以使用foreman启动应用,内容为下:
|
||||
|
||||
web: bundle exec unicorn -p $PORT -c ./config/unicorn.rb
|
||||
|
||||
现在运行**foreman start**命令启动应用,一切都将正常运行,并且你将能够在[http://localhost:5000][5]上看到一个正在运行的应用。
|
||||
|
||||
### 构建一个Docker镜像 ###
|
||||
|
||||
现在我们构建一个镜像来运行我们的应用。在这个Rails项目的根目录下,创建一个名为**Dockerfile**的文件,然后粘贴进以下内容:
|
||||
|
||||
# 基于镜像 ruby 2.2.0
|
||||
FROM ruby:2.2.0
|
||||
|
||||
# 安装所需的库和依赖
|
||||
RUN apt-get update && apt-get install -qy nodejs postgresql-client sqlite3 --no-install-recommends && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# 设置 Rails 版本
|
||||
ENV RAILS_VERSION 4.1.1
|
||||
|
||||
# 安装 Rails
|
||||
RUN gem install rails --version "$RAILS_VERSION"
|
||||
|
||||
# 创建代码所运行的目录
|
||||
RUN mkdir -p /usr/src/app
|
||||
WORKDIR /usr/src/app
|
||||
|
||||
# 使 webserver 可以在容器外面访问
|
||||
EXPOSE 3000
|
||||
|
||||
# 设置环境变量
|
||||
ENV PORT=3000
|
||||
|
||||
# 启动 web 应用
|
||||
CMD ["foreman","start"]
|
||||
|
||||
# 安装所需的 gems
|
||||
ADD Gemfile /usr/src/app/Gemfile
|
||||
ADD Gemfile.lock /usr/src/app/Gemfile.lock
|
||||
RUN bundle install --without development test
|
||||
|
||||
# 将 rails 项目(和 Dockerfile 同一个目录)添加到项目目录
|
||||
ADD ./ /usr/src/app
|
||||
|
||||
# 运行 rake 任务
|
||||
RUN RAILS_ENV=production rake db:create db:migrate
|
||||
|
||||
使用上述Dockerfile,执行下列命令创建一个镜像(确保**boot2docker**已经启动并在运行当中):
|
||||
|
||||
$ docker build -t localhost:5000/your_username/docker-test .
|
||||
|
||||
然后,如果一切正常,长长的日志输出的最后一行应该类似于:
|
||||
|
||||
Successfully built 82e48769506c
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
localhost:5000/your_username/docker-test latest 82e48769506c About a minute ago 884.2 MB
|
||||
|
||||
让我们运行一下容器试试!
|
||||
|
||||
$ docker run -d -p 3000:3000 --name docker-test localhost:5000/your_username/docker-test
|
||||
|
||||
通过你的boot2docker虚拟机的3000号端口(我的是[http://192.168.59.103:3000][6]),你可以观察你的Rails应用。(如果不清楚你的boot2docker虚拟地址,输入` $ boot2docker ip`命令查看。)
|
||||
|
||||
### 使用shell脚本进行自动化部署 ###
|
||||
|
||||
前面的文章(指文章1和文章2)已经告诉了你如何将新创建的镜像推送到私有registry中,并将其部署在服务器上,所以我们跳过这一部分直接开始自动化进程。
|
||||
|
||||
我们将要定义3个shell脚本,然后最后使用rake将它们捆绑在一起。
|
||||
|
||||
### 清除 ###
|
||||
|
||||
每当我们创建镜像的时候,
|
||||
|
||||
- 停止并重启boot2docker;
|
||||
- 去除Docker孤儿镜像(那些没有标签,并且不再被容器所使用的镜像们)。
|
||||
|
||||
在你的工程根目录下的**clean.sh**文件中输入下列命令。
|
||||
|
||||
echo Restarting boot2docker...
|
||||
boot2docker down
|
||||
boot2docker up
|
||||
|
||||
echo Exporting Docker variables...
|
||||
sleep 1
|
||||
export DOCKER_HOST=tcp://192.168.59.103:2376
|
||||
export DOCKER_CERT_PATH=/Users/user/.boot2docker/certs/boot2docker-vm
|
||||
export DOCKER_TLS_VERIFY=1
|
||||
|
||||
sleep 1
|
||||
echo Removing orphaned images without tags...
|
||||
docker images | grep "<none>" | awk '{print $3}' | xargs docker rmi
|
||||
|
||||
给脚本加上执行权限:
|
||||
|
||||
$ chmod +x clean.sh
|
||||
|
||||
### 构建 ###
|
||||
|
||||
构建的过程基本上和之前我们所做的(docker build)内容相似。在工程的根目录下创建一个**build.sh**脚本,填写如下内容:
|
||||
|
||||
docker build -t localhost:5000/your_username/docker-test .
|
||||
|
||||
记得给脚本执行权限。
|
||||
|
||||
### 部署 ###
|
||||
|
||||
最后,创建一个**deploy.sh**脚本,在里面填进如下内容:
|
||||
|
||||
# 打开 boot2docker 到私有注册库的 SSH 连接
|
||||
boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/username/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@your-registry.com &" &
|
||||
|
||||
# 在推送前先确认该 SSH 通道是开放的。
|
||||
echo Waiting 5 seconds before pushing image.
|
||||
|
||||
echo 5...
|
||||
sleep 1
|
||||
echo 4...
|
||||
sleep 1
|
||||
echo 3...
|
||||
sleep 1
|
||||
echo 2...
|
||||
sleep 1
|
||||
echo 1...
|
||||
sleep 1
|
||||
|
||||
# Push image onto remote registry / repo
|
||||
echo Starting push!
|
||||
docker push localhost:5000/username/docker-test
|
||||
|
||||
如果你不理解这其中的含义,请先仔细阅读这部分[第二部分][2]。
|
||||
|
||||
给脚本加上执行权限。
|
||||
|
||||
### 使用rake将以上所有绑定 ###
|
||||
|
||||
现在的情况是,每次你想要部署你的应用时,你都需要单独运行这三个脚本。
|
||||
|
||||
1. clean
|
||||
1. build
|
||||
1. deploy / push
|
||||
|
||||
这一点都不费工夫,可是事实上开发者比你想象的要懒得多!那么咱们就索性再懒一点!
|
||||
|
||||
我们最后再把工作好好整理一番,我们现在要将三个脚本通过rake捆绑在一起。
|
||||
|
||||
为了更简单一点,你可以在工程根目录下已经存在的Rakefile中添加几行代码,打开Rakefile文件,把下列内容粘贴进去。
|
||||
|
||||
namespace :docker do
|
||||
desc "Remove docker container"
|
||||
task :clean do
|
||||
sh './clean.sh'
|
||||
end
|
||||
|
||||
desc "Build Docker image"
|
||||
task :build => [:clean] do
|
||||
sh './build.sh'
|
||||
end
|
||||
|
||||
desc "Deploy Docker image"
|
||||
task :deploy => [:build] do
|
||||
sh './deploy.sh'
|
||||
end
|
||||
end
|
||||
|
||||
即使你不清楚rake的语法(其实你真应该去了解一下,这玩意太酷了!),上面的内容也是很显然的吧。我们在一个命名空间(docker)里声明了三个任务。
|
||||
|
||||
三个任务是:
|
||||
|
||||
- rake docker:clean
|
||||
- rake docker:build
|
||||
- rake docker:deploy
|
||||
|
||||
Deploy独立于build,build独立于clean。所以每次我们输入命令运行的时候。
|
||||
|
||||
$ rake docker:deploy
|
||||
|
||||
所有的脚本都会按照顺序执行。
|
||||
|
||||
### 测试 ###
|
||||
|
||||
现在我们来看看是否一切正常,你只需要在app的代码里做一个小改动:
|
||||
|
||||
$ rake docker:deploy
|
||||
|
||||
接下来就是见证奇迹的时刻了。一旦镜像文件被上传(第一次可能花费较长的时间),你就可以ssh登录产品服务器,并且(通过SSH管道)把docker镜像拉取到服务器并运行了。多么简单!
|
||||
|
||||
也许你需要一段时间来习惯,但是一旦成功,它几乎与用Heroku部署一样简单。
|
||||
|
||||
备注:像往常一样,请让我了解到你的意见。我不敢保证这种方法是最好,最快,或者最安全的Docker开发的方法,但是这东西对我们确实奏效。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-3/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:https://linux.cn/article-5339-1.html
|
||||
[2]:https://linux.cn/article-5379-1.html
|
||||
[3]:http://localhost:3000/
|
||||
[4]:https://gist.github.com/chasseurmic/0dad4d692ff499761b20
|
||||
[5]:http://localhost:5000/
|
||||
[6]:http://192.168.59.103:3000/
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
25个给git熟手的技巧
|
||||
25个 Git 进阶技巧
|
||||
================================================================================
|
||||
我已经使用git差不多18个月了,觉得自己对它应该已经非常了解。然后来自GitHub的[Scott Chacon][1]过来给LVS做培训,[LVS是一个赌博软件供应商和开发商][2](从2013年开始的合同),而我在第一天里就学到了很多。
|
||||
我已经使用git差不多18个月了,觉得自己对它应该已经非常了解。然后来自GitHub的[Scott Chacon][1]过来给LVS做培训([LVS是一个赌博软件供应商和开发商][2],从2013年开始的合同),而我在第一天里就学到了很多。
|
||||
|
||||
作为一个对git感觉良好的人,我觉得分享从社区里掌握的一些有价值的信息,也许能帮某人解决问题而不用做太深入研究。
|
||||
|
||||
@ -15,21 +15,21 @@
|
||||
|
||||
#### 2. Git是基于指针的 ####
|
||||
|
||||
保存在git里的一切都是文件。当你创建一个提交的时候,会建立一个包含你的提交信息和相关数据(名字,邮件地址,日期/时间,前一个提交,等等)的文件,并把它链接到一个文件树中。文件树中包含了对象或其他树的列表。对象或容器是和本次提交相关的实际内容(也是一个文件,你想了解的话,尽管文件名并没有包含在对象里,而是在树中)。所有这些文件都使用对象的SHA-1哈希值作为文件名。
|
||||
保存在git里的一切都是文件。当你创建一个提交的时候,会建立一个包含你的提交信息和相关数据(名字,邮件地址,日期/时间,前一个提交,等等)的文件,并把它链接到一个树文件中。这个树文件中包含了对象或其他树的列表。这里的提到的对象(或二进制大对象)是和本次提交相关的实际内容(它也是一个文件,另外,尽管文件名并没有包含在对象里,但是存储在树中)。所有这些文件都使用对象的SHA-1哈希值作为文件名。
|
||||
|
||||
用这种方式,分支和标签就是简单的文件(基本上是这样),包含指向实际提交的SHA-1哈希值。使用这些索引会带来优秀的灵活性和速度,比如创建一个新分支就只要简单地创建一个包含分支名字和所分出的那个提交的SHA-1索引的文件。当然,你不需要自己做这些,而只要使用Git命令行工具(或者GUI),但是实际上就是这么简单。
|
||||
用这种方式,分支和标签就是简单的文件(基本上是这样),包含指向该提交的SHA-1哈希值。使用这些索引会带来优秀的灵活性和速度,比如创建一个新分支就是简单地用分支名字和所分出的那个提交的SHA-1索引来创建一个文件。当然,你不需要自己做这些,而只要使用Git命令行工具(或者GUI),但是实际上就是这么简单。
|
||||
|
||||
你也许听说过叫HEAD的索引。这只是简单的一个文件,包含了你当前指向的那个提交的SHA-1索引值。如果你正在解决一次合并冲突然后看到了HEAD,这并不是一个特别的分支或分值上一个必须的特殊点,只是标明你当前所在位置。
|
||||
你也许听说过叫HEAD的索引。这只是简单的一个文件,包含了你当前指向的那个提交的SHA-1索引值。如果你正在解决一次合并冲突然后看到了HEAD,这并不是一个特别的分支或分支上的一个必需的特殊位置,只是标明你当前所在位置。
|
||||
|
||||
所有的分支指针都保存在.git/refs/heads里,HEAD在.git/HEAD里,而标签保存在.git/refs/tags里 - 自己可以放心地进去看看。
|
||||
所有的分支指针都保存在.git/refs/heads里,HEAD在.git/HEAD里,而标签保存在.git/refs/tags里 - 自己可以随便进去看看。
|
||||
|
||||
#### 3. 两个父节点 - 当然! ####
|
||||
#### 3. 两个爸爸(父节点) - 你没看错! ####
|
||||
|
||||
在历史中查看一个合并提交的信息时,你将看到有两个父节点(相对于一般工作上的常规提交的情况)。第一个父节点是你所在的分支,第二个是你合并过来的分支。
|
||||
在历史中查看一个合并提交的信息时,你将看到有两个父节点(不同于工作副本上的常规提交的情况)。第一个父节点是你所在的分支,第二个是你合并过来的分支。
|
||||
|
||||
#### 4. 合并冲突 ####
|
||||
|
||||
目前我相信你碰到过合并冲突并且解决过。通常是编辑一下文件,去掉<<<<,====,>>>>标志,保留需要留下的代码。有时能够看到这两个修改之前的代码会很不错,比如,在这两个分支上有冲突的改动之前。下面是一种方式:
|
||||
目前我相信你碰到过合并冲突并且解决过。通常是编辑一下文件,去掉<<<<,====,>>>>标志,保留需要留下的代码。有时能够看到这两个修改之前的代码会很不错,比如,在这两个现在冲突的分支之前的改动。下面是一种方式:
|
||||
|
||||
$ git diff --merge
|
||||
diff --cc dummy.rb
|
||||
@ -45,14 +45,14 @@
|
||||
end
|
||||
end
|
||||
|
||||
如果是二进制文件,比较差异就没那么简单了...通常你要做的就是测试这个二进制文件的两个版本来决定保留哪个(或者在二进制文件编辑器里手工复制冲突部分)。从一个特定分支获取文件拷贝(比如说你在合并master和feature123):
|
||||
如果是二进制文件,比较差异就没那么简单了...通常你要做的就是测试这个二进制文件的两个版本来决定保留哪个(或者在二进制文件编辑器里手工复制冲突部分)。从一个特定分支获取文件拷贝(比如说你在合并master和feature123两个分支):
|
||||
|
||||
$ git checkout master flash/foo.fla # 或者...
|
||||
$ git checkout feature132 flash/foo.fla
|
||||
$ # 然后...
|
||||
$ git add flash/foo.fla
|
||||
|
||||
另一种方式是通过git输出文件 - 你可以输出到另外的文件名,然后再重命名正确的文件(当你决定了要用哪个)为正常的文件名:
|
||||
另一种方式是通过git输出文件 - 你可以输出到另外的文件名,然后当你决定了要用哪个后,再将选定的正确文件复制为正常的文件名:
|
||||
|
||||
$ git show master:flash/foo.fla > master-foo.fla
|
||||
$ git show feature132:flash/foo.fla > feature132-foo.fla
|
||||
@ -71,7 +71,7 @@
|
||||
|
||||
#### 5. 远端服务器 ####
|
||||
|
||||
git的一个超强大的功能就是可以有不止一个远端服务器(实际上你一直都在一个本地仓库上工作)。你并不是一定都要有写权限,你可以有多个可以读取的服务器(用来合并他们的工作)然后写入其他仓库。添加一个新的远端服务器很简单:
|
||||
git的一个超强大的功能就是可以有不止一个远端服务器(实际上你一直都在一个本地仓库上工作)。你并不是一定都要有这些服务器的写权限,你可以有多个可以读取的服务器(用来合并他们的工作)然后写入到另外一个仓库。添加一个新的远端服务器很简单:
|
||||
|
||||
$ git remote add john git@github.com:johnsomeone/someproject.git
|
||||
|
||||
@ -87,10 +87,10 @@ git的一个超强大的功能就是可以有不止一个远端服务器(实
|
||||
|
||||
$ git diff master..john/master
|
||||
|
||||
你也可以查看不在远端分支的HEAD的改动:
|
||||
你也可以查看没有在远端分支上的HEAD的改动:
|
||||
|
||||
$ git log remote/branch..
|
||||
# 注意:..后面没有结束的refspec
|
||||
# 注意:..后面没有结束的特定引用
|
||||
|
||||
#### 6. 标签 ####
|
||||
|
||||
@ -99,7 +99,7 @@ git的一个超强大的功能就是可以有不止一个远端服务器(实
|
||||
建立这两种类型的标签都很简单(只有一个命令行开关的差异)
|
||||
|
||||
$ git tag to-be-tested
|
||||
$ git tag -a v1.1.0 # 会提示输入标签信息
|
||||
$ git tag -a v1.1.0 # 会提示输入标签的信息
|
||||
|
||||
#### 7. 建立分支 ####
|
||||
|
||||
@ -108,7 +108,7 @@ git的一个超强大的功能就是可以有不止一个远端服务器(实
|
||||
$ git branch feature132
|
||||
$ git checkout feature132
|
||||
|
||||
当然,如果你确定自己要新建分支并直接切换过去,可以用一个命令实现:
|
||||
当然,如果你确定自己直接切换到新建的分支,可以用一个命令实现:
|
||||
|
||||
$ git checkout -b feature132
|
||||
|
||||
@ -117,20 +117,20 @@ git的一个超强大的功能就是可以有不止一个远端服务器(实
|
||||
$ git checkout -b twitter-experiment feature132
|
||||
$ git branch -d feature132
|
||||
|
||||
更新:你也可以(像Brian Palmer在原博客文章的评论里提出的)只用“git branch”的-m开关在一个命令里实现(像Mike提出的,如果你只有一个分支参数,就会重命名当前分支):
|
||||
更新:你也可以(像Brian Palmer在原博客文章的评论里提出的)只用“git branch”的-m开关在一个命令里实现(像Mike提出的,如果你只指定了一个分支参数,就会重命名当前分支):
|
||||
|
||||
$ git branch -m twitter-experiment
|
||||
$ git branch -m feature132 twitter-experiment
|
||||
|
||||
#### 8. 合并分支 ####
|
||||
|
||||
在将来什么时候,你希望合并改动。有两种方式:
|
||||
也许在将来的某个时候,你希望将改动合并。有两种方式:
|
||||
|
||||
$ git checkout master
|
||||
$ git merge feature83 # 或者...
|
||||
$ git rebase feature83
|
||||
|
||||
merge和rebase之间的差别是merge会尝试处理改动并建立一个新的混合了两者的提交。rebase会尝试把你从一个分支最后一次分离后的所有改动,一个个加到该分支的HEAD上。不过,在已经将分支推到远端服务器后不要再rebase了 - 这回引起冲突/问题。
|
||||
merge和rebase之间的差别是merge会尝试处理改动并建立一个新的混合了两者的提交。rebase会尝试把你从一个分支最后一次分离后的所有改动,一个个加到该分支的HEAD上。不过,在已经将分支推到远端服务器后不要再rebase了 - 这会引起冲突/问题。
|
||||
|
||||
如果你不确定在哪些分支上还有独有的工作 - 所以你也不知道哪些分支需要合并而哪些可以删除,git branch有两个开关可以帮你:
|
||||
|
||||
@ -147,7 +147,7 @@ merge和rebase之间的差别是merge会尝试处理改动并建立一个新的
|
||||
$ git push origin twitter-experiment:refs/heads/twitter-experiment
|
||||
# origin是我们服务器的名字,而twitter-experiment是分支名字
|
||||
|
||||
更新:感谢Erlend在原博客文章上的评论 - 这个实际上和`git push origin twitter-experiment`效果一样,不过使用完整的语法,你可以在两者之间使用不同的分知名(这样本地分支可以是`add-ssl-support`而远端是`issue-1723`)。
|
||||
更新:感谢Erlend在原博客文章上的评论 - 这个实际上和`git push origin twitter-experiment`效果一样,不过使用完整的语法,你可以在两者之间使用不同的分支名(这样本地分支可以是`add-ssl-support`而远端是`issue-1723`)。
|
||||
|
||||
如果你想在远端服务器上删除一个分支(注意分支名前面的冒号):
|
||||
|
||||
@ -210,7 +210,7 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
|
||||
这会让你进入一个基于菜单的交互式提示。你可以使用命令中的数字或高亮的字母(如果你在终端里打开了高亮的话)来进入相应的模式。然后就只是输入你希望操作的文件的数字了(你可以使用这样的格式,1或者1-4或2,4,7)。
|
||||
|
||||
如果你想进入补丁模式(交互式模式下的‘p’或‘5’),你也可以直接进入:
|
||||
如果你想进入补丁模式(交互式模式下按‘p’或‘5’),你也可以直接进入:
|
||||
|
||||
$ git add -p
|
||||
diff --git a/dummy.rb b/dummy.rb
|
||||
@ -226,11 +226,11 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
end
|
||||
Stage this hunk [y,n,q,a,d,/,e,?]?
|
||||
|
||||
你可以看到下方会有一些选项供选择用来添加该文件的这个改动,该文件的所有改动,等等。使用‘?’命令可以详细解释这些选项。
|
||||
你可以看到下方会有一些选项供选择用来添加该文件的这个改动、该文件的所有改动,等等。使用‘?’命令可以详细解释这些选项。
|
||||
|
||||
#### 12. 从文件系统里保存/取回改动 ####
|
||||
|
||||
有些项目(比如git项目本身)在git文件系统中直接保存额外文件而并没有将它们加入到版本控制中。
|
||||
有些项目(比如Git项目本身)在git文件系统中直接保存额外文件而并没有将它们加入到版本控制中。
|
||||
|
||||
让我们从在git中存储一个随机文件开始:
|
||||
|
||||
@ -251,7 +251,7 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
|
||||
#### 13. 查看日志 ####
|
||||
|
||||
如果不用‘git log’来查看最近的提交你git用不了多久。不过,有一些技巧来更好地应用。比如,你可以使用下面的命令来查看每次提交的具体改动:
|
||||
长时间使用 Git 的话,不会没用过‘git log’来查看最近的提交。不过,有一些技巧来更好地应用。比如,你可以使用下面的命令来查看每次提交的具体改动:
|
||||
|
||||
$ git log -p
|
||||
|
||||
@ -268,7 +268,7 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
|
||||
#### 14. 搜索日志 ####
|
||||
|
||||
如果你想找特定作者可以这样做:
|
||||
如果你想找特定提交者可以这样做:
|
||||
|
||||
$ git log --author=Andy
|
||||
|
||||
@ -278,7 +278,7 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
|
||||
$ git log --grep="Something in the message"
|
||||
|
||||
也有一个更强大的叫做pickaxe的命令用来查找删除或添加某个特定内容的提交(比如,该文件第一次出现或被删除)。这可以告诉你什么时候增加了一行(但这一行里的某个字符后面被改动过就不行了):
|
||||
也有一个更强大的叫做pickaxe的命令用来查找包含了删除或添加的某个特定内容的提交(比如,该内容第一次出现或被删除)。这可以告诉你什么时候增加了一行(但这一行里的某个字符后面被改动过就不行了):
|
||||
|
||||
$ git log -S "TODO: Check for admin status"
|
||||
|
||||
@ -294,7 +294,7 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
|
||||
$ git log --since=2.months.ago --until=1.day.ago
|
||||
|
||||
默认情况下会用OR来组合查询,但你可以轻易地改为AND(如果你有超过一条的标准)
|
||||
默认情况下会用OR来组合查询,但你可以轻易地改为AND(如果你有超过一条的查询标准)
|
||||
|
||||
$ git log --since=2.months.ago --until=1.day.ago --author=andy -S "something" --all-match
|
||||
|
||||
@ -310,7 +310,7 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
$ git show feature132@{yesterday} # 时间相关
|
||||
$ git show feature132@{2.hours.ago} # 时间相关
|
||||
|
||||
注意和之前部分有些不同,末尾的插入符号意思是该提交的父节点 - 开始位置的插入符号意思是不在这个分支。
|
||||
注意和之前部分有些不同,末尾的^的意思是该提交的父节点 - 开始位置的^的意思是不在这个分支。
|
||||
|
||||
#### 16. 选择范围 ####
|
||||
|
||||
@ -321,7 +321,7 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
|
||||
你也可以省略[new],将使用当前的HEAD。
|
||||
|
||||
### Rewinding Time & Fixing Mistakes ###
|
||||
### 时光回溯和后悔药 ###
|
||||
|
||||
#### 17. 重置改动 ####
|
||||
|
||||
@ -329,7 +329,7 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
|
||||
$ git reset HEAD lib/foo.rb
|
||||
|
||||
通常会使用‘unstage’的别名,因为看上去有些不直观。
|
||||
通常会使用‘unstage’的别名,因为上面的看上去有些不直观。
|
||||
|
||||
$ git config --global alias.unstage "reset HEAD"
|
||||
$ git unstage lib/foo.rb
|
||||
@ -369,11 +369,11 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
|
||||
#### 19. 交互式切换基础 ####
|
||||
|
||||
这是一个我之前看过展示却没真正理解过的很赞的功能,现在很简单。假如说你提交了3次但是你希望更改顺序或编辑(或者合并):
|
||||
这是一个我之前看过展示却没真正理解过的很赞的功能,现在觉得它就很简单了。假如说你提交了3次但是你希望更改顺序或编辑(或者合并):
|
||||
|
||||
$ git rebase -i master~3
|
||||
|
||||
然后会启动你的编辑器并带有一些指令。你所要做的就是修改这些指令来选择/插入/编辑(或者删除)提交和保存/退出。然后在编辑完后你可以用`git rebase --continue`命令来让每一条指令生效。
|
||||
然后这会启动你的编辑器并带有一些指令。你所要做的就是修改这些指令来选择/插入/编辑(或者删除)提交和保存/退出。然后在编辑完后你可以用`git rebase --continue`命令来让每一条指令生效。
|
||||
|
||||
如果你有修改,将会切换到你提交时所处的状态,之后你需要使用命令git commit --amend来编辑。
|
||||
|
||||
@ -446,7 +446,7 @@ git会基于当前的提交信息自动创建评论。如果你更希望有自
|
||||
|
||||
$ git branch experimental SHA1_OF_HASH
|
||||
|
||||
如果你访问过的话,你通常可以用git reflog来找到SHA1哈希值。
|
||||
如果你最近访问过的话,你通常可以用git reflog来找到SHA1哈希值。
|
||||
|
||||
另一种方式是使用`git fsck —lost-found`。其中一个dangling的提交就是丢失的HEAD(它只是已删除分支的HEAD,而HEAD^被引用为当前的HEAD所以它并不处于dangling状态)
|
||||
|
||||
@ -460,7 +460,7 @@ via: https://www.andyjeffries.co.uk/25-tips-for-intermediate-git-users/
|
||||
|
||||
作者:[Andy Jeffries][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
Linux有问必答时间--如何在Linux下禁用IPv6
|
||||
Linux有问必答:如何在Linux下禁用IPv6
|
||||
================================================================================
|
||||
> **问题**:我发现我的一个应用程序在尝试通过IPv6建立连接,但是由于我们本地网络不允许分配IPv6的流量,IPv6连接会超时,应用程序的连接会退回到IPv4,这样就会造成不必要的延迟。由于我目前对IPv6没有任何需求,所以我想在我的Linux主机上禁用IPv6。有什么比较合适的方法呢?
|
||||
> **问题**:我发现我的一个应用程序在尝试通过IPv6建立连接,但是由于我们本地网络不允许分配IPv6的流量,IPv6连接会超时,应用程序的连接会回退到IPv4,这样就会造成不必要的延迟。由于我目前对IPv6没有任何需求,所以我想在我的Linux主机上禁用IPv6。有什么比较合适的方法呢?
|
||||
|
||||
IPv6被认为是IPv4——互联网上的传统32位地址空间的替代产品,它为了解决现有IPv4地址空间即将耗尽的问题。然而,由于IPv4已经被每台主机或设备连接到了互联网上,所以想在一夜之间将它们全部切换到IPv6几乎是不可能的。许多IPv4到IPv6的转换机制(例如:双协议栈、网络隧道、代理) 已经被提出来用来促进IPv6能被采用,并且很多应用也正在进行重写,就像我们所说的,来增加对IPv6的支持。有一件事情能确定,就是在可预见的未来里IPv4和IPv6势必将共存。
|
||||
IPv6被认为是IPv4——互联网上的传统32位地址空间——的替代产品,它用来解决现有IPv4地址空间即将耗尽的问题。然而,由于已经有大量主机、设备用IPv4连接到了互联网上,所以想在一夜之间将它们全部切换到IPv6几乎是不可能的。许多IPv4到IPv6的转换机制(例如:双协议栈、网络隧道、代理) 已经被提出来用来促进IPv6能被采用,并且很多应用也正在进行重写,如我们所提倡的,来增加对IPv6的支持。有一件事情可以确定,就是在可预见的未来里IPv4和IPv6势必将共存。
|
||||
|
||||
理想情况下,[向IPv6过渡的进程][1]不应该被最终的用户所看见,但是IPv4/IPv6混合环境有时会让你碰到各种源于IPv4和IPv6之间不经意间的相互作用的问题。举个例子,你会碰到应用程序超时的问题比如apt-get或ssh尝试通过IPv6连接失败、DNS服务器意外清空了IPv6的AAAA记录、或者你支持IPv6的设备不兼容你的互联网服务提供商遗留下的IPv4网络等等等等。
|
||||
理想情况下,[向IPv6过渡的进程][1]不应该被最终的用户所看见,但是IPv4/IPv6混合环境有时会让你碰到各种源于IPv4和IPv6之间不经意间的相互碰撞的问题。举个例子,你会碰到应用程序超时的问题,比如apt-get或ssh尝试通过IPv6连接失败、DNS服务器意外清空了IPv6的AAAA记录、或者你支持IPv6的设备不兼容你的互联网服务提供商遗留下的IPv4网络,等等等等。
|
||||
|
||||
当然这不意味着你应该盲目地在你的Linux机器上禁用IPv6。鉴于IPv6许诺的种种好处,作为社会的一份子我们最终还是要充分拥抱它的,但是作为给最终用户进行故障排除过程的一部分,如果IPv6确实是罪魁祸首那你可以尝试去关闭它。
|
||||
当然这不意味着你应该盲目地在你的Linux机器上禁用IPv6。鉴于IPv6许诺的种种好处,作为社会的一份子我们最终还是要充分拥抱它的,但是作为给最终用户进行故障排除过程的一部分,如果IPv6确实是罪魁祸首,那你可以尝试去关闭它。
|
||||
|
||||
这里有一些让你在Linux中部分或全部禁用IPv6的小技巧(例如:为一个已经确定的网络接口)。这些小贴士应该适用于所有主流的Linux发行版包括Ubuntu、Debian、Linux Mint、CentOS、Fedora、RHEL以及Arch Linux。
|
||||
这里有一些让你在Linux中部分(例如:对于某个特定的网络接口)或全部禁用IPv6的小技巧。这些小贴士应该适用于所有主流的Linux发行版包括Ubuntu、Debian、Linux Mint、CentOS、Fedora、RHEL以及Arch Linux。
|
||||
|
||||
### 查看IPv6在Linux中是否被启用 ###
|
||||
|
||||
@ -24,7 +24,7 @@ IPv6被认为是IPv4——互联网上的传统32位地址空间的替代产品
|
||||
|
||||
### 临时禁用IPv6 ###
|
||||
|
||||
如果你想要在你的Linux系统上临时关闭IPv6,你可以用 /proc 文件系统。"临时",意思是我们所做的禁用IPv6的更改在系统重启后将不被保存。IPv6会在你的Linux机器重启后再次被启用。
|
||||
如果你想要在你的Linux系统上临时关闭IPv6,你可以用 /proc 文件系统。"临时"的意思是我们所做的禁用IPv6的更改在系统重启后将不被保存。IPv6会在你的Linux机器重启后再次被启用。
|
||||
|
||||
要将一个特定的网络接口禁用IPv6,使用以下命令:
|
||||
|
||||
@ -50,7 +50,7 @@ IPv6被认为是IPv4——互联网上的传统32位地址空间的替代产品
|
||||
|
||||
#### 方法一 ####
|
||||
|
||||
第一种方法是请求以上提到的 /proc 对 /etc/sysctl.conf 文件进行修改。
|
||||
第一种方法是通过 /etc/sysctl.conf 文件对 /proc 进行永久修改。
|
||||
|
||||
换句话说,就是用文本编辑器打开 /etc/sysctl.conf 然后添加以下内容:
|
||||
|
||||
@ -69,7 +69,7 @@ IPv6被认为是IPv4——互联网上的传统32位地址空间的替代产品
|
||||
|
||||
#### 方法二 ####
|
||||
|
||||
另一个永久禁用IPv6的方法是在开机的时候执行一个必要的内核参数。
|
||||
另一个永久禁用IPv6的方法是在开机的时候传递一个必要的内核参数。
|
||||
|
||||
用文本编辑器打开 /etc/default/grub 并给GRUB_CMDLINE_LINUX变量添加"ipv6.disable=1"。
|
||||
|
||||
@ -79,7 +79,7 @@ IPv6被认为是IPv4——互联网上的传统32位地址空间的替代产品
|
||||
|
||||
GRUB_CMDLINE_LINUX="xxxxx ipv6.disable=1"
|
||||
|
||||
上面的"xxxxx"代表任意存在着的内核参数,在它后面添加"ipv6.disable=1"。
|
||||
上面的"xxxxx"代表任何已有的内核参数,在它后面添加"ipv6.disable=1"。
|
||||
|
||||

|
||||
|
||||
@ -97,7 +97,7 @@ Fedora、CentOS/RHEL系统:
|
||||
|
||||
### 禁用IPv6之后的其它可选步骤 ###
|
||||
|
||||
这里有一些可选步骤在你禁用IPv6后需要考虑,这是因为当你在内核里禁用IPv6后,其它程序仍然会尝试使用IPv6。在大多数情况下,例如应用程序的运转状态不太会遭到破坏,但是出于效率或安全方面的原因,你要为他们禁用IPv6。
|
||||
这里有一些在你禁用IPv6后需要考虑的可选步骤,这是因为当你在内核里禁用IPv6后,其它程序也许仍然会尝试使用IPv6。在大多数情况下,应用程序的这种行为不太会影响到什么,但是出于效率或安全方面的原因,你可以为他们禁用IPv6。
|
||||
|
||||
#### /etc/hosts ####
|
||||
|
||||
@ -124,7 +124,7 @@ Fedora、CentOS/RHEL系统:
|
||||
|
||||
默认情况下,OpenSSH服务(sshd)会去尝试捆绑IPv4和IPv6的地址。
|
||||
|
||||
要强制sshd只捆绑IPv4地址,用文本编辑器打开 /etc/ssh/sshd_config 并添加以下脚本行。inet只适用于IPv4,而inet6是适用于IPv6的。
|
||||
要强制sshd只捆绑IPv4地址,用文本编辑器打开 /etc/ssh/sshd_config 并添加以下行。inet只适用于IPv4,而inet6是适用于IPv6的。
|
||||
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
|
||||
@ -140,7 +140,7 @@ via: http://ask.xmodulo.com/disable-ipv6-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
如何修复:apt-get update无法添加新的CD-ROM
|
||||
如何修复 apt-get update 无法添加新的 CD-ROM 的错误
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -63,8 +63,8 @@
|
||||
via: http://itsfoss.com/fix-failed-fetch-cdrom-aptget-update-add-cdroms/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -53,11 +53,11 @@ Budgie是为Linux发行版定制的旗舰桌面,也是一个定制工程。为
|
||||
|
||||

|
||||
|
||||
**注意点**
|
||||
**注意**
|
||||
|
||||
这是一个活跃的开发版本,一些主要的特点可能还不是特别的完善,如:网络管理器,为数不多的控制组件,无通知系统斌并且无法将app锁定到任务栏。
|
||||
这是一个活跃的开发版本,一些主要的功能可能还不是特别的完善,如:没有网络管理器,没有音量控制组件(可以使用键盘控制),无通知系统并且无法将app锁定到任务栏。
|
||||
|
||||
作为工作区你能够禁用滚动栏,通过设置一个默认的主题并且通过下面的命令退出当前的会话
|
||||
有一个临时解决方案可以禁用叠加滚动栏:设置另外一个默认主题,然后从终端退出当前会话:
|
||||
|
||||
$ gnome-session-quit
|
||||
|
||||
@ -65,7 +65,7 @@ Budgie是为Linux发行版定制的旗舰桌面,也是一个定制工程。为
|
||||
|
||||
### 登录Budgie会话 ###
|
||||
|
||||
安装完成之后,我们能在登录时选择机进入budgie桌面。
|
||||
安装完成之后,我们能在登录时选择进入budgie桌面。
|
||||
|
||||

|
||||
|
||||
@ -79,8 +79,7 @@ Budgie是为Linux发行版定制的旗舰桌面,也是一个定制工程。为
|
||||
|
||||
### 结论 ###
|
||||
|
||||
Hurray! We have successfully installed our Lightweight Budgie Desktop Environment in our Ubuntu 14.04 LTS "Trusty" box. As we know, Budgie Desktop is still underdevelopment which makes it a lot of stuffs missing. Though it’s based on Gnome’s GTK3, it’s not a fork. The desktop is written completely from scratch, and the design is elegant and well thought out. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy Budgie Desktop 0.8 :-)
|
||||
Budgie桌面当前正在开发过程中,因此有目前有很多功能的缺失。虽然它是基于Gnome,但不是完全的复制。Budgie是完全从零开始实现,它的设计是优雅的并且正在不断的完善。
|
||||
嗨,现在我们已经成功的在 Ubuntu 14.04 LTS 上安装了轻量级 Budgie 桌面环境。Budgie桌面当前正在开发过程中,因此有目前有很多功能的缺失。虽然它是基于Gnome 的 GTK3,但不是完全的复制。Budgie是完全从零开始实现,它的设计是优雅的并且正在不断的完善。如果你有任何问题、评论,请在下面的评论框发表。愿你喜欢 Budgie 桌面 0.8 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -88,7 +87,7 @@ via: http://linoxide.com/ubuntu-how-to/install-lightweight-budgie-v8-desktop-ubu
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[johnhoow](https://github.com/johnhoow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Linux 基础:如何修复Ubuntu上“E: /var/cache/apt/archives/ subprocess new pre-removal script returned error exit status 1 ”的错误
|
||||
如何修复 Ubuntu 上“...script returned error exit status 1”的错误
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -6,11 +6,11 @@ Linux 基础:如何修复Ubuntu上“E: /var/cache/apt/archives/ subprocess ne
|
||||
|
||||
> E: /var/cache/apt/archives/ subprocess new pre-removal script returned error exit status 1
|
||||
|
||||

|
||||

|
||||
|
||||
### 解决: ###
|
||||
|
||||
我google了以下并找到了方法。下面是我解决的方法。
|
||||
我google了一下并找到了方法。下面是我解决的方法。
|
||||
|
||||
sudo apt-get clean
|
||||
sudo apt-get update && sudo apt-get upgrade
|
||||
@ -33,11 +33,11 @@ Linux 基础:如何修复Ubuntu上“E: /var/cache/apt/archives/ subprocess ne
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/linux-basics-how-to-fix-e-varcacheaptarchives-subprocess-new-pre-removal-script-returned-error-exit-status-1-in-ubuntu/
|
||||
via: http://www.unixmen.com/linux-basics-how-to-fix-e-varcacheaptarchives-subprocess-new-pre-removal-script-returned-error-exit-status-1-in-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -54,7 +54,7 @@ via: http://www.unixmen.com/install-mate-desktop-freebsd-10-1/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
Ubuntu中,使用Prey定位被盗的笔记本与手机
|
||||
使用Prey定位被盗的Ubuntu笔记本与智能电话
|
||||
===============================================================================
|
||||
Prey是一款跨平台的开源工具,可以帮助你找回被盗的笔记本,台式机,平板和智能手机。它已经获得了广泛的流行,声称帮助召回了成百上千台丢失的笔记本和智能手机。Prey的使用特别简单,首先安装在你的笔记本或者手机上,当你的设备不见了,用你的账号登入Prey网站,并且标记你的设备为“丢失”。只要小偷将设备接入网络,Prey就会马上发送设备的地理位置给你。如果你的笔记本有摄像头,它还会拍下小偷。
|
||||
Prey是一款跨平台的开源工具,可以帮助你找回被盗的笔记本,台式机,平板和智能手机。它已经获得了广泛的流行,声称帮助找回了成百上千台丢失的笔记本和智能手机。Prey的使用特别简单,首先安装在你的笔记本或者手机上,当你的设备不见了,用你的账号登入Prey网站,并且标记你的设备为“丢失”。只要小偷将设备接入网络,Prey就会马上发送设备的地理位置给你。如果你的笔记本有摄像头,它还会拍下该死的贼。
|
||||
|
||||
Prey占用很小的系统资源;你不会对你的设备运行有任何影响。你也可以配合其他你已经在设备上安装的防盗软件使用。Prey采用安全加密的通道,在你的设备与Prey服务器之间进行数据传输。
|
||||
Prey占用很小的系统资源;你不会对你的设备运行有任何影响。你也可以配合其他你已经在设备上安装的防盗软件使用。Prey在你的设备与Prey服务器之间采用安全加密的通道进行数据传输。
|
||||
|
||||
### 在Ubuntu上安装并配置Prey ###
|
||||
|
||||
让我们来看看如何在Ubuntu上安装和配置Prey,需要提醒的是,在配置过程中,我们必须到Prey官网进行账号注册。一旦完成上述工作,Prey将会开始监视的设备了。免费的账号最多可以监视三个设备,如果你需要添加更多的设备,你就需要购买合适的的套餐了。
|
||||
让我们来看看如何在Ubuntu上安装和配置Prey,需要提醒的是,在配置过程中,我们必须到Prey官网进行账号注册。一旦完成上述工作,Prey将会开始监视你的设备了。免费的账号最多可以监视三个设备,如果你需要添加更多的设备,你就需要购买合适的的套餐了。
|
||||
|
||||
想象一下Prey多么流行与被广泛使用,它现在已经被添加到了官方的软件库中了。这意味着你不要往软件包管理器添加任何PPA。很简单地,登录你的终端,运行以下的命令来安装它:
|
||||
可以想象Prey多么流行与被广泛使用,它现在已经被添加到了官方的软件库中了。这意味着你不要往软件包管理器添加任何PPA。很简单,登录你的终端,运行以下的命令来安装它:
|
||||
|
||||
sudo apt-get install prey
|
||||
|
||||
@ -54,7 +54,7 @@ Prey有一个明显的不足。它需要你的设备接入互联网才会发送
|
||||
|
||||
### 结论 ###
|
||||
|
||||
这是一款小巧,非常有用的安全保护应用,可以让你在一个地方追踪你所有的设备,尽管不完美,但是仍然提供了找回被盗设备的机会。它在Linux,Windows和Mac平台上无缝运行。以上就是Prey完整使用的所有细节。
|
||||
这是一款小巧,非常有用的安全保护应用,可以让你在一个地方追踪你所有的设备,尽管不完美,但是仍然提供了找回被盗设备的机会。它在Linux,Windows和Mac平台上无缝运行。以上就是[Prey][2]完整使用的所有细节。
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
@ -62,9 +62,10 @@ via: http://linoxide.com/ubuntu-how-to/anti-theft-application-prey-ubuntu/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
[1]:https://preyproject.com/
|
||||
[2]:https://preyproject.com/plans
|
||||
@ -1,4 +1,4 @@
|
||||
Moving to Docker
|
||||
走向 Docker
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -8,11 +8,11 @@ Moving to Docker
|
||||
|
||||
上个月,我一直在折腾开发环境。这是我个人故事和经验,关于尝试用Docker简化Rails应用的部署过程。
|
||||
|
||||
当我在2012年创建我的公司 – [Touchware][1]时,我还是一个独立开发者。很多事情很小,不复杂,不他们需要很多维护,他们也不需要不部署到很多机器上。经过过去一年的发展,我们成长了很多(我们现在是是拥有10个人团队)而且我们的服务端的程序和API无论在范围和规模方面都有增长。
|
||||
当我在2012年创建我的公司 – [Touchware][1]时,我还是一个独立开发者。很多事情很小,不复杂,他们不需要很多维护,他们也不需要部署到很多机器上。经过过去一年的发展,我们成长了很多(我们现在是是拥有10个人的团队)而且我们的服务端的程序和API无论在范围和规模方面都有增长。
|
||||
|
||||
### 第1步 - Heroku ###
|
||||
|
||||
我们还是个小公司,我们需要让事情运行地尽可能平稳。当我们寻找可行的解决方案时,我们打算坚持用那些可以帮助我们减轻对硬件依赖负担的工具。由于我们主要开发Rails应用,而Heroku对RoR,常用的数据库和缓存(Postgres/Mongo/Redis等)有很好的支持,最明智的选择就是用[Heroku][2] 。我们就是这样做的。
|
||||
我们还是个小公司,我们需要让事情运行地尽可能平稳。当我们寻找可行的解决方案时,我们打算坚持用那些可以帮助我们减轻对硬件依赖负担的工具。由于我们主要开发Rails应用,而Heroku对RoR、常用的数据库和缓存(Postgres/Mongo/Redis等)有很好的支持,最明智的选择就是用[Heroku][2] 。我们就是这样做的。
|
||||
|
||||
Heroku有很好的技术支持和文档,使得部署非常轻松。唯一的问题是,当你处于起步阶段,你需要很多开销。这不是最好的选择,真的。
|
||||
|
||||
@ -20,18 +20,18 @@ Heroku有很好的技术支持和文档,使得部署非常轻松。唯一的
|
||||
|
||||
为了尝试并降低成本,我们决定试试Dokku。[Dokku][3],引用GitHub上的一句话
|
||||
|
||||
> Docker powered mini-Heroku in around 100 lines of Bash
|
||||
> Docker 驱动的 mini-Heroku,只用了一百来行的 bash 脚本
|
||||
|
||||
我们启用的[DigitalOcean][4]上的很多台机器,都预装了Dokku。Dokku非常像Heroku,但是当你有复杂的项目需要调整配置参数或者是需要特殊的依赖时,它就不能胜任了。我们有一个应用,它需要对图片进行多次转换,我们无法安装一个适合版本的imagemagick到托管我们Rails应用的基于Dokku的Docker容器内。尽管我们还有很多应用运行在Dokku上,但我们还是不得不把一些迁移回Heroku。
|
||||
我们启用的[DigitalOcean][4]上的很多台机器,都预装了Dokku。Dokku非常像Heroku,但是当你有复杂的项目需要调整配置参数或者是需要特殊的依赖时,它就不能胜任了。我们有一个应用,它需要对图片进行多次转换,我们把我们Rails应用的托管到基于Dokku的Docker容器,但是无法安装一个适合版本的imagemagick到里面。尽管我们还有很多应用运行在Dokku上,但我们还是不得不把一些迁移回Heroku。
|
||||
|
||||
### 第3步 - Docker ###
|
||||
|
||||
几个月前,由于开发环境和生产环境的问题重新出现,我决定试试Docker。简单来说,Docker让开发者容器化应用,简化部署。由于一个Docker容器本质上已经包含项目运行所需要的所有依赖,只要它能在你的笔记本上运行地很好,你就能确保它将也能在任何一个别的远程服务器的生产环境上运行,包括Amazon的EC2和DigitalOcean上的VPS。
|
||||
几个月前,由于开发环境和生产环境的问题重新出现,我决定试试Docker。简单来说,Docker让开发者容器化应用、简化部署。由于一个Docker容器本质上已经包含项目运行所需要的所有依赖,只要它能在你的笔记本上运行地很好,你就能确保它将也能在任何一个别的远程服务器的生产环境上运行,包括Amazon的EC2和DigitalOcean上的VPS。
|
||||
|
||||
Docker IMHO特别有意思的原因是:
|
||||
就我个人的看法来说,Docker 特别有意思的原因是:
|
||||
|
||||
- 它促进了模块化和分离关注点:你只需要去考虑应用的逻辑部分(负载均衡:1个容器;数据库:1个容器;web服务器:1个容器);
|
||||
- 在部署的配置上非常灵活:容器可以被部署在大量的HW上,也可以容易地重新部署在不同的服务器或者提供商那;
|
||||
- 它促进了模块化和关注点分离:你只需要去考虑应用的逻辑部分(负载均衡:1个容器;数据库:1个容器;web服务器:1个容器);
|
||||
- 在部署的配置上非常灵活:容器可以被部署在各种硬件上,也可以容易地重新部署在不同的服务器和不同的提供商;
|
||||
- 它允许非常细粒度地优化应用的运行环境:你可以利用你的容器来创建镜像,所以你有很多选择来配置环境。
|
||||
|
||||
它也有一些缺点:
|
||||
@ -54,15 +54,15 @@ via: http://cocoahunter.com/2015/01/23/docker-1/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:http://www.touchwa.re/
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-1/www.heroku.com
|
||||
[2]:http://www.heroku.com
|
||||
[3]:https://github.com/progrium/dokku
|
||||
[4]:http://cocoahunter.com/2015/01/23/docker-1/www.digitalocean.com
|
||||
[4]:http://www.digitalocean.com
|
||||
[5]:http://www.docker.com/
|
||||
[6]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[7]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
@ -78,4 +78,3 @@ via: http://cocoahunter.com/2015/01/23/docker-1/
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -0,0 +1,144 @@
|
||||
在 Linux 中以交互方式实时查看Apache web访问统计
|
||||
================================================================================
|
||||
|
||||
无论你是在网站托管业务,还是在自己的VPS上运行几个网站,你总会有需要显示访客统计信息,例如前几的访客、访问请求的文件(无论动态或者静态)、所用的带宽、客户端的浏览器,和访问的来源网站,等等。
|
||||
|
||||
[GoAccess][1] 是一款用于Apache或者Nginx的命令行日志分析器和交互式查看器。使用这款工具,你不仅可以浏览到之前提及的相关数据,还可以通过分析网站服务器日志来进一步挖掘数据 - 而且**这一切都是在一个终端窗口实时输出的**。由于今天的[大多数web服务器][2]都使用Debian的衍生版或者基于RedHat的发行版来作为底层操作系统,所以本文中我告诉你如何在Debian和CentOS中安装和使用GoAccess。
|
||||
|
||||
### 在Linux系统安装GoAccess ###
|
||||
|
||||
在Debian,Ubuntu及其衍生版本,运行以下命令来安装GoAccess:
|
||||
|
||||
# aptitude install goaccess
|
||||
|
||||
在CentOS中,你将需要使你的[EPEL 仓库][3]可用然后执行以下命令:
|
||||
|
||||
# yum install goaccess
|
||||
|
||||
在Fedora,同样使用yum命令:
|
||||
|
||||
# yum install goaccess
|
||||
|
||||
|
||||
如果你想从源码安装GoAccess来使用更多功能(例如 GeoIP 定位功能),需要在你的操作系统安装[必需的依赖包][4],然后按以下步骤进行:
|
||||
|
||||
# wget http://tar.goaccess.io/goaccess-0.8.5.tar.gz
|
||||
# tar -xzvf goaccess-0.8.5.tar.gz
|
||||
# cd goaccess-0.8.5/
|
||||
# ./configure --enable-geoip
|
||||
# make
|
||||
# make install
|
||||
|
||||
以上安装的版本是 0.8.5,但是你也可以在该软件的网站[下载页][5]确认是否是最新版本。
|
||||
|
||||
由于GoAccess不需要后续的配置,一旦安装你就可以马上使用。
|
||||
|
||||
### 运行 GoAccess ###
|
||||
|
||||
开始使用GoAccess,只需要对它指定你的Apache访问日志。
|
||||
|
||||
对于Debian及其衍生版本:
|
||||
|
||||
# goaccess -f /var/log/apache2/access.log
|
||||
|
||||
基于红帽的发行版:
|
||||
|
||||
# goaccess -f /var/log/httpd/access_log
|
||||
|
||||
当你第一次启动GoAccess,你将会看到如下的屏幕中选择日期和日志格式。正如前面所述,你可以按空格键进行选择,并按F10确认。至于日期和日志格式,你可能需要参考[Apache 文档][6]来刷新你的记忆。
|
||||
|
||||
在这个例子中,选择常见日志格式(Common Log Format(CLF)):
|
||||
|
||||
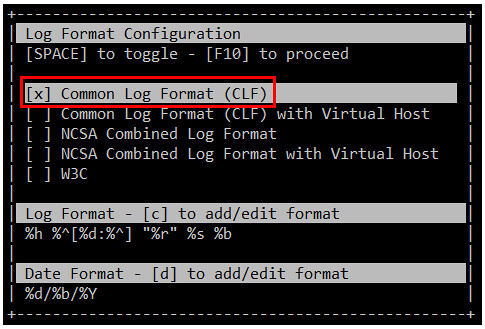
|
||||
|
||||
然后按F10 确认。你将会从屏幕上看到统计数据。为了简洁起见,这里只显示了首部,也就是日志文件的摘要,如下图所示:
|
||||
|
||||

|
||||
|
||||
### 通过 GoAccess来浏览网站服务器统计数据 ###
|
||||
|
||||
你可以按向下的箭头滚动页面,你会发现以下区域,它们是按请求排序的。这里提及的目录顺序可能会根据你的发行版或者你所选的安装方式(从源和库)不同而不同:
|
||||
|
||||
1. 每天唯一访客(来自同样IP、同一日期和同一浏览器的请求被认为是是唯一访问)
|
||||
|
||||
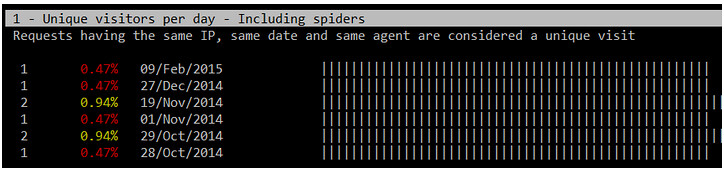
|
||||
|
||||
2. 请求的文件(网页URL)
|
||||
|
||||

|
||||
|
||||
3. 请求的静态文件(例如,.png文件,.js文件等等)
|
||||
|
||||
4. 来源的URLs(每一个URL请求的出处)
|
||||
|
||||
5. HTTP 404 未找到的响应代码
|
||||
|
||||

|
||||
|
||||
6. 操作系统
|
||||
|
||||
7. 浏览器
|
||||
|
||||
8. 主机地址(客户端IP地址)
|
||||
|
||||

|
||||
|
||||
9. HTTP 状态代码
|
||||
|
||||

|
||||
|
||||
10. 前几位的来源站点
|
||||
|
||||
11. 来自谷歌搜索引擎的前几位的关键字
|
||||
|
||||
如果你想要检查已经存档的日志,你可以通过管道将它们发送给GoAccess,如下:
|
||||
|
||||
在Debian及其衍生版本:
|
||||
|
||||
# zcat -f /var/log/apache2/access.log* | goaccess
|
||||
|
||||
在基于红帽的发行版:
|
||||
|
||||
# cat /var/log/httpd/access* | goaccess
|
||||
|
||||
如果你需要上述部分的详细报告(1至11项),直接按下其序号再按O(大写o),就可以显示出你需要的详细视图。下面的图像显示5-O的输出(先按5,再按O)
|
||||
|
||||

|
||||
|
||||
如果要显示GeoIP位置信息,打开主机部分的详细视图,如前面所述,你将会看到正在请求你的服务器的客户端IP地址所在的位置。
|
||||
|
||||

|
||||
|
||||
如果你的系统还不是很忙碌,以上提及的章节将不会显示大量的信息,但是这种情形可以通过在你网站服务器越来越多的请求发生改变。
|
||||
|
||||
### 保存用于离线分析的报告 ###
|
||||
|
||||
有时候你不想每次都实时去检查你的系统状态,可以保存一份在线的分析文件或打印出来。要生成一个HTML报告,只需要通过之前提到GoAccess命令,将输出来重定向到一个HTML文件即可。然后,用web浏览器来将这份报告打开即可。
|
||||
|
||||
# zcat -f /var/log/apache2/access.log* | goaccess > /var/www/webserverstats.html
|
||||
|
||||
一旦报告生成,你将需要点击展开的链接来显示每个类别详细的视图信息:
|
||||
|
||||

|
||||
|
||||
可以查看youtube视频:https://youtu.be/UVbLuaOpYdg 。
|
||||
|
||||
正如我们通过这篇文章讨论,GoAccess是一个非常有价值的工具,它能给系统管理员实时提供可视的HTTP 统计分析。虽然GoAccess的默认输出是标准输出,但是你也可以将他们保存到JSON,HTML或者CSV文件。这种转换可以让 GoAccess在监控和显示网站服务器的统计数据时更有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/interactive-apache-web-server-log-analyzer-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[disylee](https://github.com/disylee)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://goaccess.io/
|
||||
[2]:http://w3techs.com/technologies/details/os-linux/all/all
|
||||
[3]:http://linux.cn/article-2324-1.html
|
||||
[4]:http://goaccess.io/download#dependencies
|
||||
[5]:http://goaccess.io/download
|
||||
[6]:http://httpd.apache.org/docs/2.4/logs.html
|
||||
@ -1,154 +1,169 @@
|
||||
10个有用的‘ls’命令面试问题-第二部分
|
||||
10 个‘ls’命 令面试的问题(二)
|
||||
================================================================================
|
||||
这是关于文件列表命令的第二篇文章,继续探讨‘ls’命令的其他方面。该系列的第一篇文章收到了Tecmint社区的高度关注,如果你错过了该系列的第一部分,你可能会访问以下地址:
|
||||
这是关于文件列表命令的第二篇文章,继续探讨‘ls’命令的其他方面。该系列的第一篇文章受到了社区的高度关注,如果你错过了该系列的第一部分,可以访问以下地址:
|
||||
|
||||
- [15 Interview Questions on “ls” Command – Part 1][1]
|
||||
- [15 个‘ls’命令的面试问题(一)][1]
|
||||
|
||||
这篇文章通过样例来很好地展现‘ls’命令的深入应用,我们加倍小心地来写这篇文章来保持其简洁可理解性,同时又能提供最全面的服务。
|
||||
|
||||

|
||||
10 Interview Questions on ls Command
|
||||
|
||||
### 1. 假如你想要以长列表的形式列出目录中的内容,但是不打印文件创建者名称以及文件所属组。同时在输出中显示其不同之处。###
|
||||
*10 ‘ls’ 命令面试的问题*
|
||||
|
||||
### 16. 假如你想要以长列表的形式列出目录中的内容,但是不打印文件创建者名称以及文件所属组。看看输出有何不同之处。###
|
||||
|
||||
a. ls 命令在与‘-l’选项一起使用时会将文件以长列表格式输出。
|
||||
|
||||
# ls -l
|
||||
|
||||

|
||||
List Files in- Long List Format
|
||||
|
||||
*以长格式列出文件*
|
||||
|
||||
b. ls 命令在与‘-l’和‘--author’一起使用时,会将文件以长列表格式输出并带有文件创建者的名称信息。
|
||||
|
||||
# ls -l --author
|
||||
|
||||

|
||||
List Files By Author
|
||||
|
||||
*列出文件的创建者*
|
||||
|
||||
c. ls 命令在与‘-g’选项 一起将会列出文件名但是不带属主名称。
|
||||
|
||||
# ls -g
|
||||
|
||||

|
||||
List Files Without Printing Owner Name
|
||||
|
||||
d. ls 命令在与'-G'和‘-l’选项一起将会使用长列表格式列出文件名称带式不带文件所属组名称。
|
||||
*列出文件但不列出属主*
|
||||
|
||||
d. ls 命令在与'-G'和‘-l’选项一起将会使用长列表格式列出文件名称但是不带文件所属组名称。
|
||||
|
||||
# ls -Gl
|
||||
|
||||

|
||||
List Files Without Printing Group
|
||||
|
||||
### 2. 使用用户友好的格式打印出当前目录中的文件以及文件夹的大小,你会如何做?###
|
||||
*列出文件但是不列出所属组*
|
||||
|
||||
### 17. 使用易读格式打印出当前目录中的文件以及文件夹的大小,你会如何做?###
|
||||
|
||||
这里我们需要使用'-h'选项(人类可阅读的、易读的)同‘-l’或‘-s’选项与ls命令一起使用来得到想要的输出。
|
||||
|
||||
这里我们需要使用'-h'选项(人类可阅读的)同‘-l’或‘-s’选项与ls命令一起使用来得到想要的输出。
|
||||
# ls -hl
|
||||
|
||||

|
||||
List Files in Human Readable Format
|
||||
|
||||
*以易读格式的长列表列出文件*
|
||||
|
||||
# ls -hs
|
||||
|
||||

|
||||
List File Sizes in Long List Format
|
||||
|
||||
*以易读格式的短列表列出文件*
|
||||
|
||||
**注意**: ‘-h’选项使用1024(计算机中的标准)的幂,文件或文件夹的大小分别以K,M和G作为输出单位。
|
||||
|
||||
### 3. 既然‘-h’选项是使用1024的幂作为标准来输出大小,那么ls命令还支持其他的幂值呢?###
|
||||
### 18. 既然‘-h’选项是使用1024的幂作为标准来输出大小,那么ls命令是否还支持其他的幂值呢?###
|
||||
|
||||
存在一个选项 ‘-si’与选项‘-h’相似,不同之处在于前者以使用1000的幂,后者使用1024的幂。
|
||||
存在一个选项 ‘--si’与选项‘-h’相似,不同之处在于前者以使用1000的幂,后者使用1024的幂。
|
||||
|
||||
# ls -si
|
||||
# ls --si
|
||||
|
||||

|
||||
Supported Power Values of ls Command
|
||||
所以'--si'也可以与‘-l’选项一起使用来按照1000的幂来输出文件夹的大小,并且以长列表格式显示。
|
||||
|
||||
所以'-si'也可以与‘-l’选项一起使用来按照1000的幂来输出文件夹的大小,并且以长列表格式显示。
|
||||
# ls --si -l
|
||||
|
||||
# ls -si -l
|
||||
(LCTT 译注:此处原文参数有误,附图也不对,因此删除之)
|
||||
|
||||

|
||||
List Files by Power Values
|
||||
### 19. 假如要你使用逗号‘,’作为分隔符来打印一个目录中的内容,可以吗? 对于长列表形式也可行吗?###
|
||||
|
||||
### 4. 假如要你使用逗号‘,’作为分隔符来打印一个目录中的内容,可以吗? 对于长列表形式也可行吗?###
|
||||
|
||||
当然!linux的ls命令当与其选项‘-m’一起使用时可以在打印目录内容时以逗号‘,’分割。由于逗号分割的内容是水平填充的,ls命令不能在垂直列出内容时使用逗号来分割内容。
|
||||
当然!linux的ls命令当与其选项‘-m’一起使用时可以在打印目录内容时以逗号‘,’分割。由于逗号分割的内容是水平填充的,ls命令不能在垂直列出内容时使用逗号来分割内容。
|
||||
|
||||
# ls -m
|
||||
|
||||

|
||||
Print Contents of Directory by Comma
|
||||
|
||||
*以逗号分隔显示内容*
|
||||
|
||||
当使用长列表格式时,‘-m’选项就没有什么效果了。
|
||||
|
||||
# ls -ml
|
||||
|
||||

|
||||
Listing Content Horizontally
|
||||
|
||||
### 5. 有办法将目录的内容逆序打印出来吗?###
|
||||
*长列表不能使用逗号分隔列表*
|
||||
|
||||
### 20. 有办法将目录的内容逆序打印出来吗?###
|
||||
|
||||
可以!上面的情形可以轻松地通过'-r'选项搞定,该选项将输出顺序倒置。这个选项也可以与‘-l’选项一起使用。
|
||||
|
||||
# ls -r
|
||||
|
||||

|
||||
List Content in Reverse Order
|
||||
|
||||
*逆序列出*
|
||||
|
||||
# ls -rl
|
||||
|
||||

|
||||
Long List Content in Reverse Order
|
||||
|
||||
### 6. 如果你被分配一个任务,来递归地打印各个子目录,你会如何应付?注意哟,只针对子目录而不是文件哦。###
|
||||
*逆序长列表*
|
||||
|
||||
### 21. 如果你被分配一个任务,来递归地打印各个子目录,你会如何应付?注意,只针对子目录而不是文件哦。###
|
||||
|
||||
小意思!使用“-R”选项就可以轻轻松松拿下,它也可以更进一步地与其他选项如‘-l’和‘-m’选项等组合使用。
|
||||
|
||||
# ls -R
|
||||
|
||||

|
||||
Print Sub Directories in Recursively
|
||||
|
||||
### 7. 如何按照文件大小对其进行排序?###
|
||||
*递归列出子目录*
|
||||
|
||||
### 22. 如何按照文件大小对其进行排序?###
|
||||
|
||||
linux命令行选项'-S'赋予了ls命令这个超能力。按照文件大小从大到小的顺序排序:
|
||||
|
||||
# ls -S
|
||||
|
||||

|
||||
Sort Files with ls Command
|
||||
*按文件大小排序*
|
||||
|
||||
按照文件大小从小到大的顺序排序。
|
||||
|
||||
# ls -Sr
|
||||
|
||||

|
||||
Sort Files in Descending Order
|
||||
|
||||
### 8. 列出目录中的内容按照一行一个文件并且不带额外信息的方式 ###
|
||||
*从小到大的排序*
|
||||
|
||||
选项‘-l’在此可以解决这个问题,使用‘-l’选项来使用ls命令可以将目录中的内容按照一行一个文件并且不带额外信息的方式进行输出。
|
||||
### 23. 按照一行一个文件列出目录中的内容,并且不带额外信息的方式 ###
|
||||
|
||||
选项‘-1’在此可以解决这个问题,使用‘-1’选项来使用ls命令可以将目录中的内容按照一行一个文件并且不带额外信息的方式进行输出。
|
||||
|
||||
# ls -1
|
||||
|
||||

|
||||
List Files Without Information
|
||||
|
||||
### 9. 现在委派给你一个任务,你必须将目录中的内容输出到终端而且需要使用双引号引起来,你会如何做?###
|
||||
*不带其他信息,一行一个列出文件*
|
||||
|
||||
存在一个选项‘-Q’会将ls命令的输出内容用双引号引起来。
|
||||
### 24. 现在委派给你一个任务,你必须将目录中的内容输出到终端而且需要使用双引号引起来,你会如何做?###
|
||||
|
||||
有一个选项‘-Q’会将ls命令的输出内容用双引号引起来。
|
||||
|
||||
# ls -Q
|
||||
|
||||

|
||||
Print Files with Double Quotes
|
||||
|
||||
### 10. 想象一下你正在与一个包含有很多文件和文件夹的目录打交道,你需要使目录名显示在文件名之前,你如何做?###
|
||||
*输出的文件名用引号引起来*
|
||||
|
||||
### 25. 想象一下你正在与一个包含有很多文件和文件夹的目录打交道,你需要使目录名显示在文件名之前,你如何做?###
|
||||
|
||||
# ls --group-directories-first
|
||||
|
||||

|
||||
Print Directories First
|
||||
|
||||
先点到为止,我们会马上提供该系列文章的下一部分。别换频道,关注Tecmint。 另外别忘了在下面的评论中提出你们宝贵的反馈信息,喜欢就分享,帮助我们得到更好的传播吧!
|
||||
*目录优先显示*
|
||||
|
||||
先点到为止,我们会马上提供该系列文章的下一部分。别换频道,关注我们。 另外别忘了在下面的评论中提出你们宝贵的反馈信息,喜欢就分享,帮助我们得到更好的传播吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -156,9 +171,9 @@ via: http://www.tecmint.com/ls-interview-questions/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[theo-l](https://github.com/theo-l)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://www.tecmint.com/ls-command-interview-questions/
|
||||
[1]:http://linux.cn/article-5349-1.html
|
||||
@ -1,85 +1,91 @@
|
||||
关于linux中的“ls”命令的15个面试问题 - 第一部分
|
||||
15 个‘ls’命令的面试问题(一)
|
||||
================================================================================
|
||||
Unix或类Unix系统中的“文件列表”命令“ls”是最基础并且使用的最广泛的命令行中工具之一。
|
||||
它是一个在GNU基本工具集以及BSD各种变体上可用的与POSIX兼容的工具。
|
||||
“ls”命令可以通过与大量的选项一起使用来达到想要的结果。
|
||||
Unix或类Unix系统中的“文件列表”命令“ls”是最基础并且使用的最广泛的命令行中工具之一。它是一个POSIX兼容工具,在GNU基本工具集以及BSD各种变体上都可以使用。“ls”命令可以结合大量的选项来达到想要的结果。
|
||||
|
||||
这篇文章的目的在于通过相关的样例来深入讨论文件列表命令。
|
||||
|
||||

|
||||
15个“ls”命令问题。
|
||||
|
||||
### 1. 你会如何从目录中列出文件?###
|
||||
*15个“ls”命令问题。*
|
||||
|
||||
答:使用linux文件列表命令“ls”驾到拯救。
|
||||
### 1. 如何列出目录中的文件?###
|
||||
|
||||
答:linux文件列表命令“ls”就是干这个的。
|
||||
|
||||
# ls
|
||||
|
||||

|
||||
列出文件
|
||||
|
||||
同时,我们也可以使用“echo(打印)”命令与一个通配符(*)相关联的方式在目录中列出其中的所有文件。
|
||||
*列出文件*
|
||||
|
||||
同时,我们也可以使用“echo(回显)”命令与一个通配符(*)参数来雷锤目录中的所有文件。
|
||||
|
||||
# echo *
|
||||
|
||||

|
||||
列出所有的文件。
|
||||
|
||||
### 2. 你会如何只通过使用echo命令来列出目录中的所有文件?###
|
||||
*列出所有的文件。*
|
||||
|
||||
### 2. 如何只使用echo命令来只列出所有目录?###
|
||||
|
||||
# echo */
|
||||
|
||||

|
||||
列出所有的目录
|
||||
|
||||
### 3. 你会怎样列出一个目录中的所有文件, 包括隐藏的dot文件?###
|
||||
*列出所有的目录*
|
||||
|
||||
### 3. 怎样列出一个目录中的所有文件, 包括隐藏的以“.”开头的文件?###
|
||||
|
||||
答:我们需要将“-a”选项与“ls”命令一起使用。
|
||||
|
||||
# ls -a
|
||||
|
||||

|
||||
列出所有的隐藏文件。
|
||||
|
||||
### 4. 如何列出目录中除了 “当前目录暗喻(.)”和“父目录暗喻(..)”之外的所有文件,包括隐藏文件?###
|
||||
*列出所有的隐藏文件。*
|
||||
|
||||
### 4. 如何列出目录中除了 “当前目录 .”和“父目录 ..”之外的所有文件,包括隐藏文件?###
|
||||
|
||||
答: 我们需要将“-A”选项与“ls”命令一起使用
|
||||
|
||||
# ls -A
|
||||
|
||||

|
||||
别列出暗喻文件。
|
||||
|
||||
### 5. 如何将当前目录中的内容使用长格式打印列表?###
|
||||
*别列出指代当前目录和父目录的文件*
|
||||
|
||||
### 5. 如何使用长格式打印出当前目录内容?###
|
||||
|
||||
答: 我们需要将“-l”选项与“ls”命令一起使用。
|
||||
|
||||
# ls -l
|
||||
|
||||

|
||||
列出文件的长格式。
|
||||
|
||||
*列出文件的长格式。*
|
||||
|
||||
上面的样例中,其输出结果看起来向下面这样。
|
||||
|
||||
drwxr-xr-x 5 avi tecmint 4096 Sep 30 11:31 Binary
|
||||
|
||||
上面的drwxr-xr-x 是文件的权限,分别代表了文件所有者,组以及对整个世界。 所有者具有读(r),写(w)以及执行(x)等权限。 该文件所属组具有读(r)和执行(x)但是没有写的权限,相同的权限预示着
|
||||
对于整个世界的其他可以访问该文件的用户。
|
||||
上面的drwxr-xr-x 是文件的权限,分别代表了文件所有者,所属组以及“整个世界”。 所有者具有读(r),写(w)以及执行(x)等权限。 该文件所属组具有读(r)和执行(x)但是没有写的权限,整个世界的其他可以访问到该文件的人也具有相同权限。
|
||||
|
||||
- 开头的‘d’意味着这是一个目录
|
||||
- 数字'5'表示符号链接
|
||||
- 数字'5'表示符号链接(有5个符号链接)
|
||||
- 文件 Binary归属于用户 “avi”以及用户组 "tecmint"
|
||||
- Sep 30 11:31 表示文件最后一次的访问日期与时间。
|
||||
|
||||
### 6. 假如让你来将目录中的内容以长格式列表打印,并且显示出隐藏的“点文件”,你会如何实现?###
|
||||
|
||||
答: 我们需要同时将"-a"和"-l"选项与“ls”命令一起使用。
|
||||
答: 我们需要同时将"-a"和"-l"选项与“ls”命令一起使用(LCTT 译注:单字符选项可以合并写)。
|
||||
|
||||
# ls -la
|
||||
|
||||

|
||||
打印目录内容
|
||||
|
||||
同时,如果我们不想列出“当前目录暗喻”和"父目录暗喻",可以将“-A”和“-l”选项同“ls”命令一起使用。
|
||||
*打印目录内容*
|
||||
|
||||
此外,如果我们不想列出“当前目录”和"父目录",可以将“-A”和“-l”选项同“ls”命令一起使用。
|
||||
|
||||
# ls -lA
|
||||
|
||||
@ -90,9 +96,10 @@ Unix或类Unix系统中的“文件列表”命令“ls”是最基础并且使
|
||||
# ls --author -l
|
||||
|
||||

|
||||
列出文件创建者。
|
||||
|
||||
### 8. 如何对非显示字符进行转义打印?###
|
||||
*列出文件创建者。*
|
||||
|
||||
### 8. 如何对用转义字符打印出非显示字符?###
|
||||
|
||||
答:我们只需要使用“-b”选项来对非显示字符进行转义打印
|
||||
|
||||
@ -100,52 +107,58 @@ Unix或类Unix系统中的“文件列表”命令“ls”是最基础并且使
|
||||
|
||||
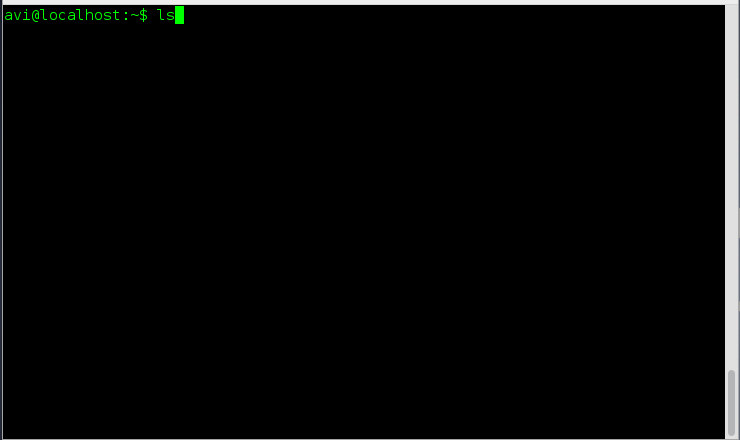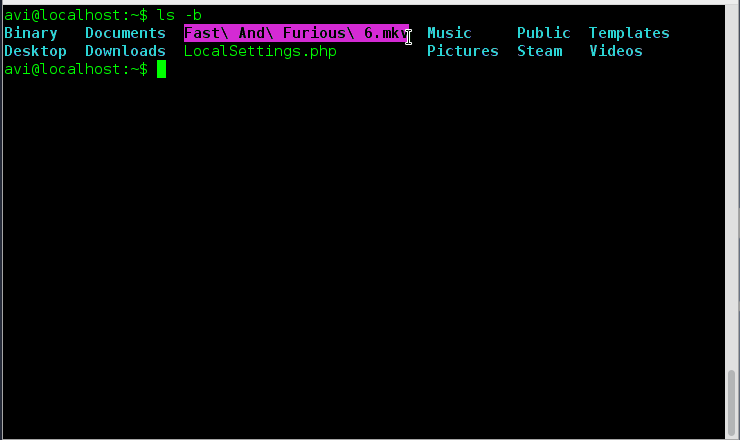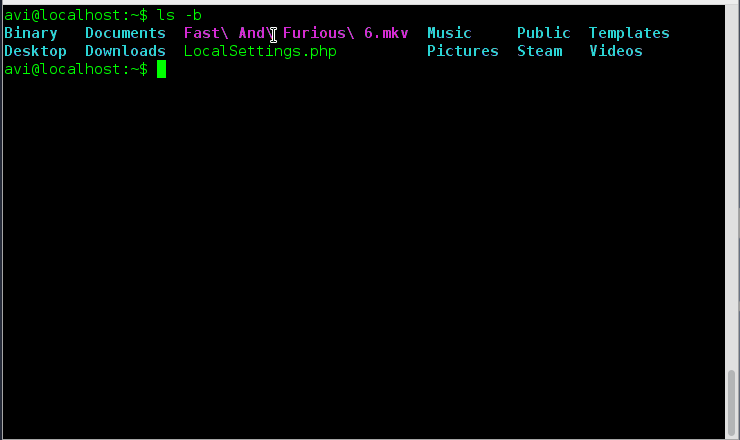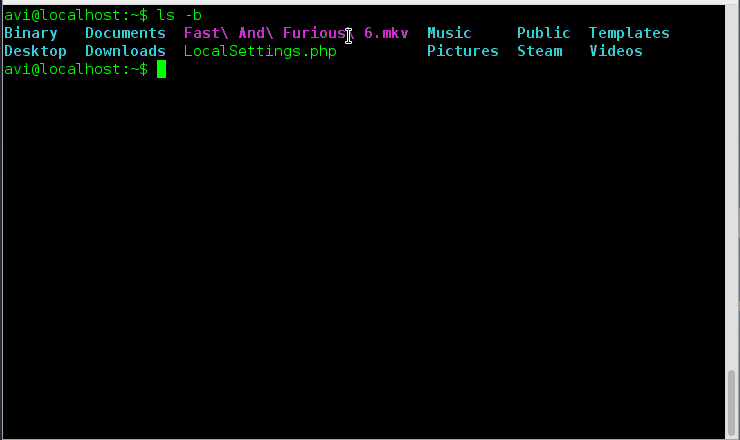
|
||||
|
||||
### 9. 指定特定的单位格式来列出文件和目录的大小,你会如何实现?###
|
||||
答: 在此可以同时使用选项“-block-size=scale”和“-l”,但是我们需要用特定的单位如M,K等来替换‘scale’。
|
||||
### 9. 用指定特定的单位格式来列出文件和目录的大小,你会如何实现?###
|
||||
|
||||
答: 在此可以同时使用选项“-block-size=scale”和“-l”,但是我们需要用特定的单位如M,K等来替换‘scale’参数。
|
||||
|
||||
# ls --block-size=M -l
|
||||
# ls --block-size=K -l
|
||||
|
||||
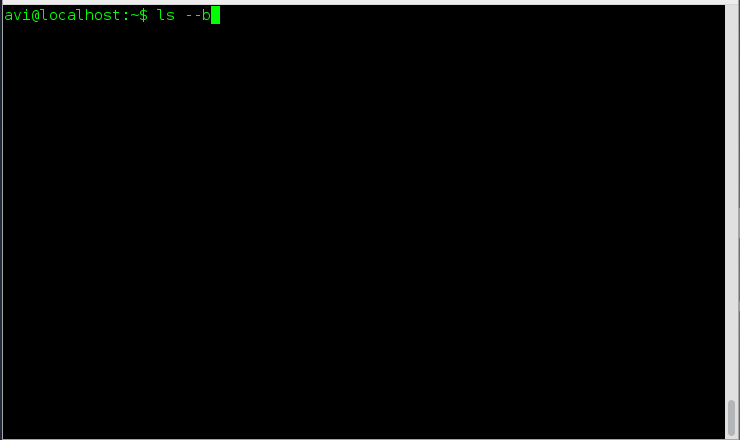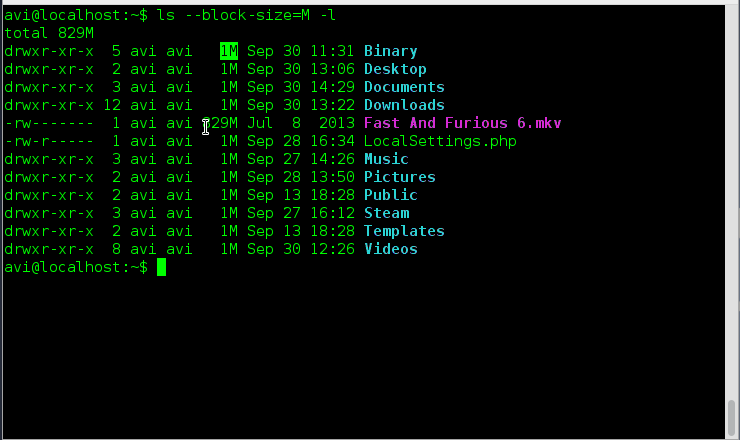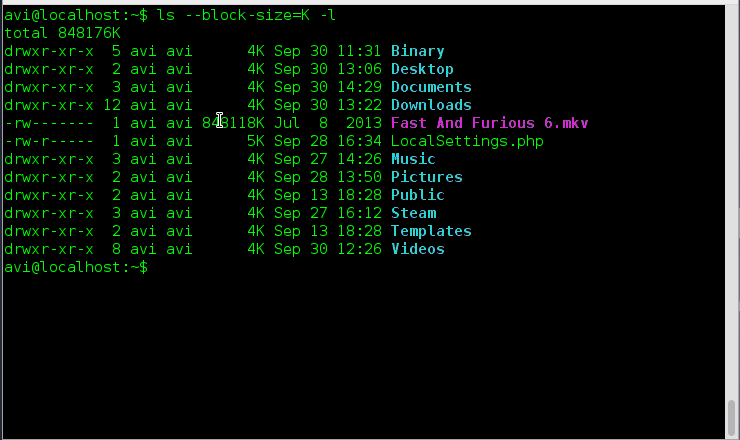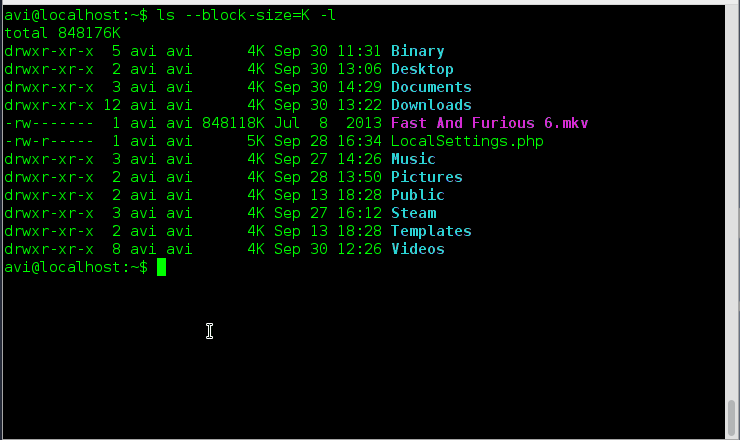
|
||||
列出文件大小单位格式。
|
||||
|
||||
### 10. 列出目录中的非备份文件,也就是那些文件名以‘~’结尾的文件###
|
||||
*列出文件大小单位格式。*
|
||||
|
||||
### 10. 列出目录中的文件,但是不显示备份文件,即那些文件名以‘~’结尾的文件###
|
||||
|
||||
答: 选项‘-B’赶来救驾。
|
||||
|
||||
# ls -B
|
||||
|
||||

|
||||
列出非备份文件
|
||||
|
||||
### 11. 将目录中的所有文件按照名称进行排序并与最后修改时间信息进行关联显示###
|
||||
*列出非备份文件*
|
||||
|
||||
### 11. 将目录中的所有文件按照名称进行排序,并显示其最后修改时间信息?###
|
||||
|
||||
答: 为了实现这个需求,我们需要同时将“-c”和"-l"选项与命令一起使用。
|
||||
|
||||
# ls -cl
|
||||
|
||||
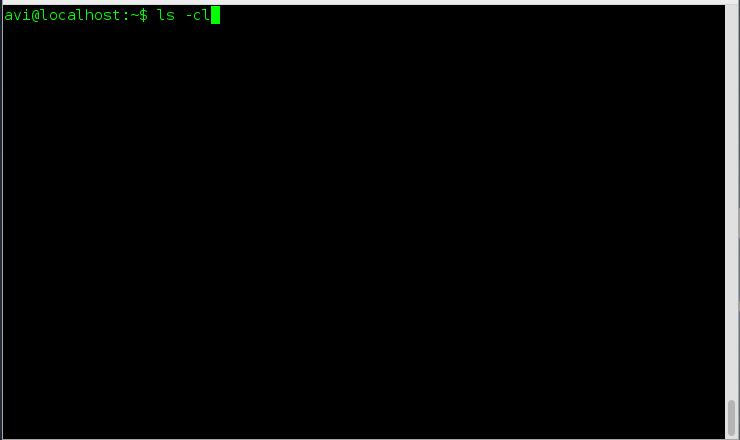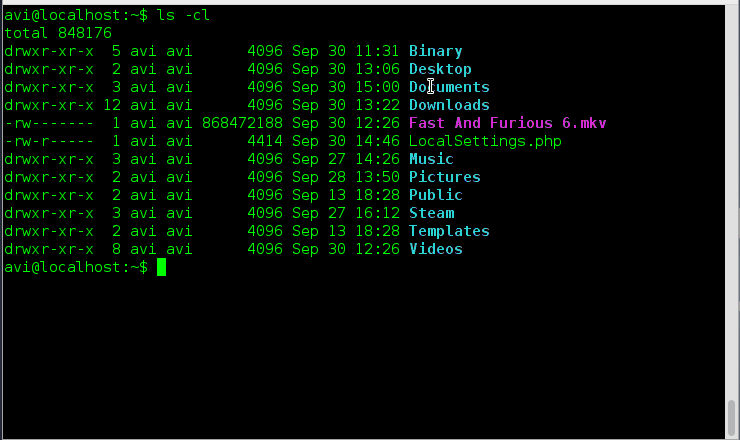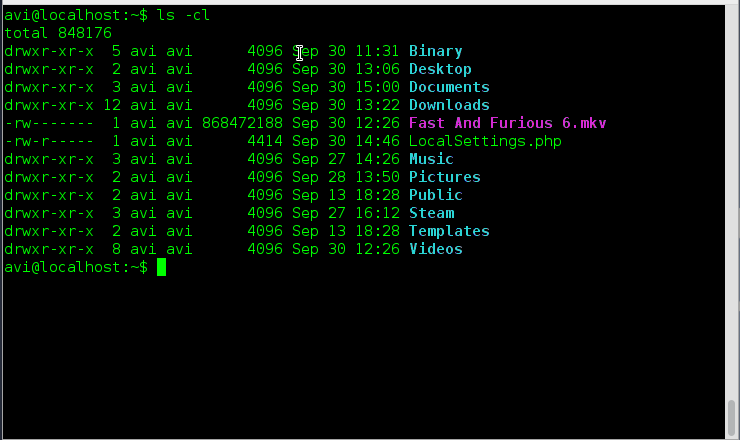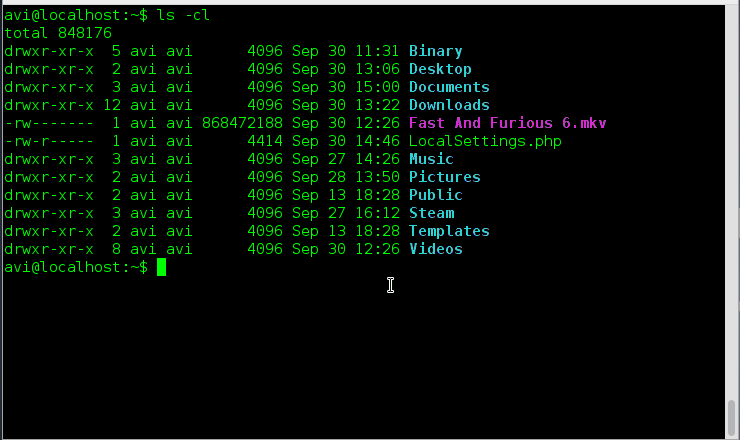
|
||||
文件排序
|
||||
|
||||
*文件排序*
|
||||
|
||||
### 12. 将目录中的文件按照修改时间进行排序,并显示相关联的信息。###
|
||||
|
||||
答: 我们需要同时使用3个选项--'-l','-t','-c'--与命令‘ls’一起使用来对文件使用修改时间排序,最新的修改时间排在最前。
|
||||
答: 我们需要同时使用3个选项:'-l','-t','-c' 来对文件使用修改时间排序,最新的修改时间排在最前。
|
||||
|
||||
# ls -ltc
|
||||
|
||||
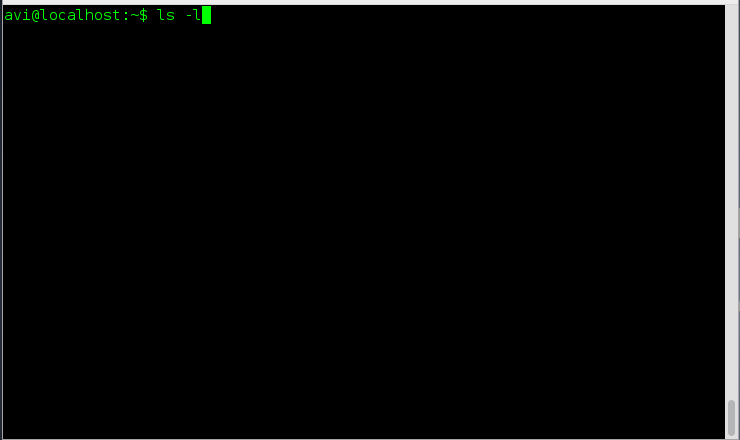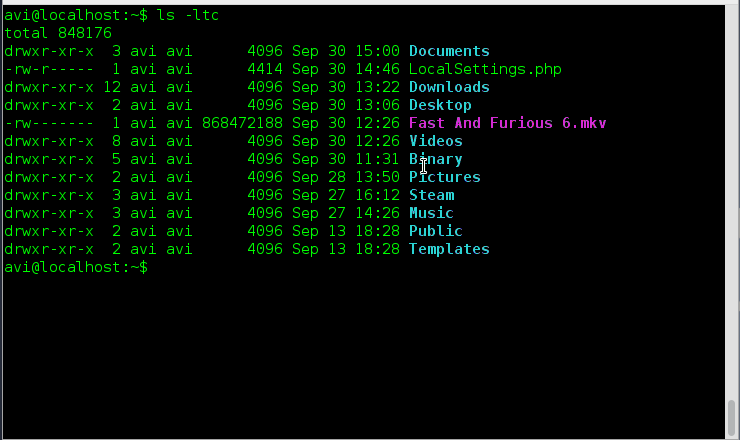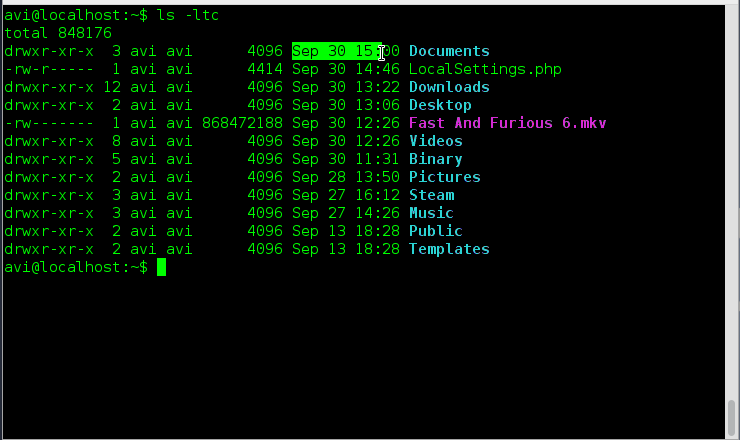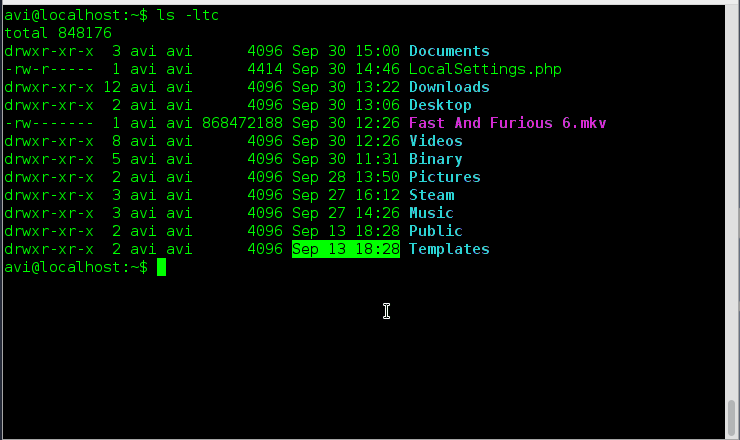
|
||||
按照修改时间对文件排序。
|
||||
|
||||
*按照修改时间对文件排序。*
|
||||
|
||||
### 13. 如何控制‘ls’命令的输出颜色的有无?###
|
||||
|
||||
答: 需要使用选项‘--color=parameter’,parameter参数值具有三种不同值,“auto(自动)”,“always(一直)”,“never(无色)”。
|
||||
答: 需要使用选项‘--color=parameter’,参数具有三种不同值,“auto(自动)”,“always(一直)”,“never(无色)”。
|
||||
|
||||
# ls --color=never
|
||||
# ls --color=auto
|
||||
# ls --color=always
|
||||
|
||||

|
||||
ls的输出颜色
|
||||
|
||||
*ls的输出颜色*
|
||||
|
||||
### 14. 假如只需要列出目录本身,而不是目录的内容,你会如何做?###
|
||||
|
||||
@ -154,9 +167,10 @@ ls的输出颜色
|
||||
# ls -d
|
||||
|
||||

|
||||
列出目录本身
|
||||
|
||||
### 15. 为长格式列表命令"ls -l"创建别名“ll”,并将其结果输出到一个文件而不是标准输出中。###
|
||||
*列出目录本身*
|
||||
|
||||
### 15. 为长格式列表命令"ls -l"创建一个别名“ll”,并将其结果输出到一个文件而不是标准输出中。###
|
||||
|
||||
答:在上述的这个场景中,我们需要将别名添加到.bashrc文件中,然后使用重定向操作符将输出写入到文件而不是标准输出中。我们将会使用编辑器nano。
|
||||
|
||||
@ -166,13 +180,14 @@ ls的输出颜色
|
||||
# nano ll.txt
|
||||
|
||||

|
||||
为ls命令创建别名。
|
||||
|
||||
*为ls命令创建别名。*
|
||||
|
||||
先到此为止,别忘了在下面的评论中提出你们的宝贵意见,我会再次带着另外的有趣的文章在此闪亮登场。
|
||||
|
||||
### 参考阅读:###
|
||||
|
||||
- [10 个‘ls’命令的面试问题-第二部分][1]
|
||||
- [10 个‘ls’命令的面试问题(二)][1]
|
||||
- [Linux中15个基础的'ls'命令][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -187,4 +202,4 @@ via: http://www.tecmint.com/ls-command-interview-questions/
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/ls-interview-questions/
|
||||
[2]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[2]:http://linux.cn/article-5109-1.html
|
||||
@ -0,0 +1,91 @@
|
||||
在Linux上安装使用‘Go for it!’备忘软件
|
||||
===============================================================================
|
||||

|
||||
|
||||
你在 Linux 桌面是如何管理任务和备忘的?我喜欢[用 Ubuntu 的粘帖便签][1]很久了。但是我要面对与其他设备同步的麻烦,特别是我的智能手机。这就是我为什么选择使用 [Google Keep][2] 的原因了。
|
||||
|
||||
Google Keep 是一款功能丰富的软件,我十分喜爱,而且喜欢到把它叫做 [Linux 的 Evernote ][3]地步。但是并不是每个人都喜欢一款功能丰富的备忘录软件。极简主义是目前的主流,很多人喜欢。如果你是极简主义的追求者之一,而且正在寻找一款开源的备忘录软件,那么你应该试一试 [Go For It!][4]。
|
||||
|
||||
### Go For It!高效的Linux桌面软件 ###
|
||||
|
||||
Go For It!是一款简洁的备忘软件,借助定时提醒帮助你专注于工作。所以,当你添加一个任务到列表后,可以附上一个定时器。到设定时间后,它就会提醒你去做任务。你可以看看其帅哥开发者 [Manuel Kehl][5] 制作的视频(youtube 视频) : https://www.youtube.com/watch?v=mnw556C9FZQ
|
||||
|
||||
### 安装 Go For It!###
|
||||
|
||||
要在 Ubuntu 15.04,14.04 和其他基于 Ubuntu 的Linux 发行版,如Linux Mint, elementary OS Freya 等上面安装 Go For It!请使用这款软件官方的 PPA:
|
||||
|
||||
sudo add-apt-repository ppa:mank319/go-for-it
|
||||
sudo apt-get update
|
||||
sudo apt-get install go-for-it
|
||||
|
||||
你也可以下载 .deb 包,Windows 安装包和源代码,链接如下:
|
||||
|
||||
- [Download source code][6]
|
||||
- [Download .deb binaries][7]
|
||||
- [Download for Windows][8]
|
||||
|
||||
### 在Linux桌面使用 Go For It!###
|
||||
|
||||
Go For It!使用真心方便。你只需添加任务到列表中,任务会自动存入 todo.txt 文件中。
|
||||
|
||||

|
||||
|
||||
每个任务默认定时25分钟。
|
||||
|
||||

|
||||
|
||||
任务一旦完成,就会被自动存档到 done.txt 文件中。根据设置,它会在规定的时间间隔或者任务过期前不久,发送桌面提醒:
|
||||
|
||||

|
||||
|
||||
你可以从配置里面修改所有的偏好。
|
||||
|
||||

|
||||
|
||||
目前一切都看着挺好。但是在智能手机上使用体验怎样呢?如果你不能使它在不同设备间同步,那这款高效软件就是不完整的。好消息是 Go For It!是基于 [todo.txt][9] 的,这意味着你可以用第三方软件和像 Dropbox 一样的云服务来使用它。
|
||||
|
||||
### 在安卓手机和平板上使用Go For It! ###
|
||||
|
||||
在这里你需要做一些工作。首先的首先,在 Linux 和你的安卓手机上安装 Dropbox,如果之前没有安装的话。下一步你要做的就是要配置 Go For It!和 **修改 todo.txt 的目录到 Dropbox 的路径下**。
|
||||
|
||||
然后,你得去下载 [Simpletask Andriod app][10]。这是免费的应用。安装它。当你第一次运行 Simletask 的时候,你会被要求关联你的账号到 Dropbox:
|
||||
|
||||

|
||||
|
||||
一旦你完成了 Simpletask 与 Dropbox 的关联,就可以打开应用了。如果你已经修改了 Go For It 的配置,将文件保存到Dropbox 上,你就应该可以在 Simpletask 里看到。而如果你没有看到,点击应用底部的设置,选择 Open Todo file 的选项:
|
||||
|
||||

|
||||
|
||||
现在,你应该可以看到 Simpletask 同步的任务了。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
对于 Simpletask,你就可以以类似[标记语言工具][11]的风格使用它。对于小巧和专注而言,Go For It!是一款不错的备忘软件。一个干净的界面是额外的加分点。如果拥有它自己的手机应用就更好了,但是我们也有临时替代方案了。
|
||||
|
||||
底层来讲,Go For It! 不会运行在后台。这就是说,你不得不让它一直保持运行。它甚至没有一个最小化的按钮,这有一点小小的烦扰。我想要看到的是有一个小的指示程序,运行在后台,并且快速进入主面板,这肯定会提升其可用性。
|
||||
|
||||
试试 Go For It!吧,分享一下你的使用体验。在 Linux 桌面上,你还使用了哪些其他的备忘软件?比起其他你最喜欢的同类应用,Go For It!怎么样?
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: http://itsfoss.com/go-for-it-to-do-app-in-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/indicator-stickynotes-windows-like-sticky-note-app-for-ubuntu/
|
||||
[2]:http://itsfoss.com/install-google-keep-ubuntu-1310/
|
||||
[3]:http://itsfoss.com/5-evernote-alternatives-linux/
|
||||
[4]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[5]:http://manuel-kehl.de/about-me/
|
||||
[6]:https://github.com/mank319/Go-For-It
|
||||
[7]:https://launchpad.net/~mank319/+archive/ubuntu/go-for-it
|
||||
[8]:http://manuel-kehl.de/projects/go-for-it/download-windows-version/
|
||||
[9]:http://todotxt.com/
|
||||
[10]:https://play.google.com/store/apps/details?id=nl.mpcjanssen.todotxtholo&hl=en
|
||||
[11]:http://itsfoss.com/install-latex-ubuntu-1404/
|
||||
@ -2,7 +2,7 @@ Linux存储的未来
|
||||
================================================================================
|
||||
> **摘要**:Linux系统的软件开发者们正致力于使Linux支持更多种类的文件和存储方案。
|
||||
|
||||
波士顿 - 在[Linux基金会][1]最近的[Vault][2]展示会上,全都是关于文件系统和存储方案的讨论。你可以会想关于这两个主题并没有什么展值得讨论的最新进展,但事实并非如此。
|
||||
波士顿 - 在[Linux基金会][1]最近的[Vault][2]展示会上,全都是关于文件系统和存储方案的讨论。你可以会觉得关于这两个主题并没有什么值得讨论的最新进展,但事实并非如此。
|
||||
|
||||

|
||||
|
||||
@ -14,17 +14,17 @@ Linux存储的未来
|
||||
|
||||
### Btrfs ###
|
||||
|
||||
例如,Chris Mason,一位来自Facebook的软件工程师,也是[Btrfs][6](对外宣称Butter FS)的维护者之一,说明了Facebook是如何使用这种文件系统。Btrfs拥有文件系统固有的许多优点,比如既能处理大量的小文件,也能处理大小可达16EB的单个文件;支持RAID的baked(烦请校正补充);内置的文件系统压缩,以及集成了对多种存储设备的支持。
|
||||
例如,Chris Mason,一位来自Facebook的软件工程师,也是[Btrfs][6](念做 Butter FS)的维护者之一,介绍了Facebook是如何使用这种文件系统。Btrfs拥有文件系统固有的许多优点,比如既能处理大量的小文件,也能处理大小可达16EB的单个文件;支持RAID ;内置的文件系统压缩,以及集成了对多种存储设备的支持。
|
||||
|
||||
当然,Facebook的服务器也运行在Linux上。更准确地讲,是运行在一个基于[CentOS][7]的内部发行版上,它是基于3.10和3.18版的内核。对Facebook来说,真正的收获是Btrfs在由Facebook持续的更新用户操作带来的巨大的IOPS(每秒钟输入输出的操作数)的负载下依旧保持稳定和快速。
|
||||
当然,Facebook的服务器也运行在Linux上。更准确地讲,是运行在一个基于[CentOS][7]的内部发行版上,它是基于3.10和3.18版的内核。对Facebook来说,真正的收获是Btrfs在Facebook持续更新的用户操作所带来的巨大的IOPS(每秒钟输入输出的操作数)的负载下依旧保持稳定和快速。
|
||||
|
||||
这就是好消息,但坏消息是对于像MySQL一样的传统DBMS(数据库管理系统)来说Btrfs还是太慢了。对此,Facebook采用了[XFS][8]。为了协同这两种文件系统,Facebook又用到了一种叫做[Gluster][9]的开源分布式文件系统。
|
||||
|
||||
Facebook,一直与上游的负责Btrfs的Linux内核开发者保持密切联系,致力于提高Btrfs在DBMS上的速度。Mason和他的同事在[RocksDB][10]数据库上使用Btrfs以达成目标,RocksDB是一种为提供快速存储开发的持久化键值存储系统,可以作为客户端服务器模式数据库的基础部分。
|
||||
Facebook,一直与上游的负责Btrfs的Linux内核开发者保持密切联系,致力于提高Btrfs在DBMS上的速度。Mason和他的同事的目标是在[RocksDB][10]数据库上使用Btrfs,RocksDB是一种为提供快速存储开发的持久化键值存储系统,可以作为客户端服务器模式数据库的基础部分。
|
||||
|
||||
当然Btrfs也还存在一些问题,比如,如果有用户傻到用数据把硬盘几乎要撑爆时,Btrfs会在硬盘被完全装满前阻止用户继续写入。对某些工程来说,比如[CoreOS][12],一款依赖容器化的企业版Linux系统,这种问题是致命的。[因此,CoreOS已经切换到使用xt4和overlayfs了][11]。
|
||||
|
||||
Btrfs的开发人员正致力于数据去重。在这一点上,当文件系统中拥有超过一个的相同文件时,会自动删除多余文件。正如Mason所说,“并非每个人都需要这个功能,但如果有人需要,那就是真的需要!”
|
||||
Btrfs的开发人员正致力于数据去重。在这一点上,当文件系统中拥有超过一个的相同文件时,会自动删除多余文件。正如Mason所说,“并非每个人都需要这个功能,但如果有人需要,那就是真的有用!”
|
||||
|
||||
在正在开展的重要性工作中,Btrfs并非是唯一的文件系统。John Spary,[Red Hat][13]的一位高级软件工程师,提到了另一款名为[Ceph][14]的分布式文件系统。
|
||||
|
||||
@ -38,7 +38,7 @@ Ceph提供了一种分布式对象存储方案和文件系统,反过来它依
|
||||
|
||||
但是,Ceph FS仍值得去做,正如Spray所说,“因为兼容POSIX的文件系统是操作系统通用的。”这并不是说Ceph FS就一无是处。“它并不是支离破碎的,相反它奏效了。所缺的是修复和监控工具。”
|
||||
|
||||
Red Hat目前正致力于获得[fsck][17]和日志修复工具、快照强化、更好客户端访问控制,以及云与容器的集成。尽管Ceph FS到目前为止只是一种有潜力或者没前景的文件系统,但仍然值得用在生产环境中。
|
||||
Red Hat目前正致力于完成[fsck][17]和日志修复工具开发、快照强化、更好客户端访问控制,以及云与容器的集成。尽管Ceph FS到目前为止只是一种有潜力或者没前景的文件系统,但仍然值得用在生产环境中。
|
||||
|
||||
### 文件与存储的差别与目标 ###
|
||||
|
||||
@ -56,7 +56,7 @@ via: http://www.zdnet.com/article/linux-storage-futures/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,27 +1,27 @@
|
||||
Papyrus:开源笔记管理工具
|
||||
Papyrus:开源笔记管理工具
|
||||
================================================================================
|
||||

|
||||
|
||||
在上一篇帖子中,我们介绍了[待办事项管理软件Go For It!][1]。今天我们将介绍一款名为**Papyrus的开源笔记软件**
|
||||
|
||||
[Papyrus][2] 是[Kaqaz笔记管理][3]的一个分支并使用QT5开发。它不仅有简洁、易用的界面,还具备了较好的安全性。由于强调简洁,我觉得Papyrus与OneNote比较相像。你可以将你的笔记像"纸张"一样分类整理,还可以给他们添加标签进行分组。够简单的吧!
|
||||
[Papyrus][2] 是[Kaqaz 笔记管理][3]的一个分支,使用 Qt5 开发。它不仅有简洁、易用的界面,(其宣称)还具备了较好的安全性。由于强调简洁,我觉得 Papyrus 与 OneNote 比较相像。你可以将你的笔记像"纸张"一样分类整理,还可以给他们添加标签进行分组。够简单的吧!
|
||||
|
||||
## Papyrus 的特性: ###
|
||||
|
||||
虽然Papyrus强调简洁,它依然有很多丰富的功能。他的一些主要功能如下:
|
||||
虽然 Papyrus 强调简洁,它依然有很多丰富的功能。它的一些主要功能如下:
|
||||
- 按类别和标签管理笔记
|
||||
- 高级搜索选项
|
||||
- 触屏模式
|
||||
- 全屏选项
|
||||
- 备份至Dropbox/硬盘
|
||||
- 某些页面允许加密
|
||||
- 备份至 Dropbox/硬盘/外部存储
|
||||
- 允许加密某些页面
|
||||
- 可与其他软件共享笔记
|
||||
- 与Dropbox加密同步
|
||||
- 除Linux外,还可在Android,Windows和OS X使用
|
||||
- 与 Dropbox 加密同步
|
||||
- 除 Linux 外,还可在 Android,Windows 和 OS X 使用
|
||||
|
||||
### 安装 Papyrus ###
|
||||
|
||||
Papyrus为Android用户提供了APK安装包。Windows和OS X也有安装文件。Linux用户还可以获取程序的源码。Ubuntu及其它基于Ubuntu的发行版可以使用.deb包进行安装。根据你的系统及习惯,你可以从Papyrus的下载页面中获取不同的文件:
|
||||
Papyrus 为 Android 用户提供了 APK 安装包。Windows 和 OS X 也有安装文件。Linux 用户还可以获取程序的源码。Ubuntu 及其它基于 Ubuntu 的发行版可以使用 .deb 包进行安装。根据你的系统及习惯,你可以从 Papyrus 的下载页面中获取不同的文件:
|
||||
|
||||
- [下载 Papyrus][4]
|
||||
|
||||
@ -40,7 +40,7 @@ Papyrus为Android用户提供了APK安装包。Windows和OS X也有安装文
|
||||
|
||||
试试Papyrus吧,你会喜欢上它的。在下方评论区和我们分享你的使用经验吧。
|
||||
|
||||
(译者注:此软件暂无中文版)
|
||||
(LCTT译注:此软件暂无中文版)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -53,7 +53,7 @@ via: http://itsfoss.com/papyrus-open-source-note-manager/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/go-for-it-to-do-app-in-linux/
|
||||
[1]:http://linux.cn/article-5337-1.html
|
||||
[2]:http://aseman.co/en/products/papyrus/
|
||||
[3]:https://github.com/sialan-labs/kaqaz/
|
||||
[4]:http://aseman.co/en/products/papyrus/
|
||||
@ -1,19 +1,17 @@
|
||||
Translated by H-mudcup
|
||||
|
||||
Picty:让图片管理变简单
|
||||
================================================================================
|
||||

|
||||
|
||||
### 关于Picty ###
|
||||
|
||||
**Picty**是个免费,简单,却强大的照片收藏管理器,它可以帮助你管理你的照片。它的设计围绕着管理**元数据**和**无损**的处理图像的方法。Picty目前同时支持在线(基于网页的)和离线(本地的)收藏集。在本地的收藏集中,图片将被保存在一个本地的文件夹和它的子文件夹中。为了加快用户主目录里图片的查询速度,它会维持一个数据库。在在线(基于网页的)收藏集中,你可以通过网页浏览器上传并分享图片。拥有适当权限的个人用户可以把图片分享给任何人,而且每个用户可以同时开放多个收藏集,收藏集也可以被多个用户分享。通过一个转载插件在收藏集间传递图片就有了个简单的交互界面。
|
||||
**Picty**是个免费,简单,却强大的照片收藏管理器,它可以帮助你管理你的照片。它是围绕着**元数据**管理和图像**无损**处理设计的。Picty目前同时支持在线(基于网页的)和离线(本地的)收藏集。在本地的收藏集中,图片将被保存在一个本地的文件夹及其子文件夹中。为了加快用户主目录里图片的查询速度,它会维持一个数据库。在在线(基于网页的)收藏集中,你可以通过网页浏览器上传并分享图片。拥有适当权限的个人用户可以把图片分享给任何人,而且用户可以同时打开多个收藏集,收藏集也可以分享给多个用户。有个简单的界面可以通过传输插件在收藏集之间传输图片。
|
||||
|
||||
你可以从你的相机或任何设备中下载任何数量的照片。除此之外,Picty允许你在下载前浏览在你相机里的图片集。Picty是个轻量级的应用,还有着清爽的界面。它支持Linux和Windows平台。
|
||||
你可以从你的相机或任何设备中下载任何数量的照片。除此之外,Picty允许你在下载前浏览在你相机里的图片集。Picty是个轻量级的应用,界面清爽。它支持Linux和Windows平台。
|
||||
|
||||
### 功能 ###
|
||||
|
||||
- 支持大相片集(20000张以上)。
|
||||
- 同时开放多个收藏集还可以在它们之间传照片。
|
||||
- 同时打开多个收藏集,还可以在它们之间传照片。
|
||||
- 收藏集包括:
|
||||
- 本地文件系统中保存图片的文件夹。
|
||||
- 相机、电话及其他媒体设备中的图片。
|
||||
@ -21,28 +19,28 @@ Picty:让图片管理变简单
|
||||
- Picty不是把相片“导入”到它的数据库中,它仅仅提供了一个界面来访问它们,不管它们保存在哪。为了保持迅速的反应以及能使你在离线时浏览图片的能力,Picty会保存缩略图和元数据的缓存。
|
||||
- 以业界标准格式Exif、IPTC和Xmp读写元数据。
|
||||
- 无损的方法:
|
||||
- Picty把所有改变包括图像编辑以元数据写入。例如,一个图片可以以任何方式剪切保存,原来的像素仍然保存在该文件里。
|
||||
- 修改会保存在Picty的收藏集缓存中直到你把你对元数据的修改保存到图片中。你能很容易撤销你不喜欢的未保存的修改。
|
||||
- 基本图片编辑:
|
||||
- Picty把所有改变包括图像编辑以元数据的方式写入。例如,一个图片可以以任何方式剪切保存,原来的图像仍然保存在该文件里。
|
||||
- 修改会保存在Picty的收藏集缓存中直到你把你对元数据的修改保存到图片中,所以你能很容易撤销你不喜欢的未保存的修改。
|
||||
- 基本图片编辑功能:
|
||||
- 目前支持基本的图像增强,如亮度、对比度、色彩、剪切以及矫正。
|
||||
- Improvements to those tools and other tools coming soon (red eye reduction, levels, curves, noise reduction)对这些工具的改善和其他的工具即将到来。(红眼消除、拉伸、弯曲、噪声消除)
|
||||
- 将要推出一些工具改进及更多工具。(红眼消除、拉伸、弯曲、噪声消除)
|
||||
- 图片标签:
|
||||
- 使用标准的IPTC和Xmp关键词为图片做标签。
|
||||
- 一个树状标签图让你能很容易的管理标签和对你的收藏集进行导航。
|
||||
- 一个树状标签图让你能很容易的管理标签和在收藏集内导航。
|
||||
- 文件夹视图:
|
||||
- 按照目录的结构对你的图片收藏进行导航
|
||||
- 按照目录的结构对你的图片收藏集进行导航
|
||||
- 支持多屏显示
|
||||
- Picty可以设置成让你在一个屏幕上浏览你的收藏集同时在另一个屏幕上全屏显示图片。
|
||||
- 可个性化
|
||||
- 可以为外部工具创建快捷方式
|
||||
- 支持插件——目前提供的功能中有许多(标签和文件夹视图以及所有的图片编辑工具)都可以通过插件提供。
|
||||
- 使用Python编写——自带batteries!(python的这个特点使它可在mac、Linux和windows上直接安装使用,无需复杂的设置。)
|
||||
- 使用Python编写——内置电池(batteries included)!
|
||||
|
||||
### 安装方法 ###
|
||||
|
||||
#### 1、从PPA安装 ####
|
||||
|
||||
Picty开发人员为基于Debian的发行版,如Ubuntu,创建了一个PPA,让安装更简单。
|
||||
Picty开发人员为Ubuntu这样的基于 Debian的发行版创建了一个PPA,让安装更简单。
|
||||
|
||||
要在Ubuntu和它的衍生版上安装,请运行以下命令:
|
||||
|
||||
@ -76,13 +74,13 @@ Picty开发人员为基于Debian的发行版,如Ubuntu,创建了一个PPA,
|
||||
|
||||

|
||||
|
||||
你可以选择已存在的收藏集、设备或目录。让我们创建一个**新收藏集** 。要这样做,得先点击新收藏集(New Collection)按钮。进入收藏集,然后浏览都你保存图片的地方。最后,点击**创建(Create)**按钮。
|
||||
你可以选择已存在的收藏集、设备或目录。这里让我们创建一个**新收藏集** ,请先点击新收藏集(New Collection)按钮。进入收藏集,然后浏览到你保存图片的地方。最后,点击**创建(Create)**按钮。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
你可以修改,旋转,添加/移除标签,设置每个图片的描述。要这么做,只需右击任何一个图片然后爱做什么做什么。
|
||||
你可以对每张图片进行修改,旋转,添加/移除标签,设置描述。只需右击任何一个图片然后爱做什么做什么。
|
||||
|
||||
访问下面这个Google组可以得到更多关于Picty相片管理器的信息和支持。
|
||||
|
||||
@ -96,7 +94,7 @@ via: http://www.unixmen.com/picty-managing-photos-made-easy/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -10,12 +10,14 @@
|
||||
|
||||
#### 在 64位 Ubuntu 15.04 ####
|
||||
|
||||
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.0-vivid/linux-image-4.0.0-040000-generic_4.0.0-040000.201504121935_amd64.deb
|
||||
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.0-vivid/linux-headers-4.0.0-040000-generic_4.0.0-040000.201504121935_amd64.deb
|
||||
|
||||
$ sudo dpkg -i linux-headers-4.0.0*.deb linux-image-4.0.0*.deb
|
||||
|
||||
#### 在 32位 Ubuntu 15.04 ####
|
||||
|
||||
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.0-vivid/linux-image-4.0.0-040000-generic_4.0.0-040000.201504121935_i386.deb
|
||||
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.0-vivid/linux-headers-4.0.0-040000-generic_4.0.0-040000.201504121935_i386.deb
|
||||
|
||||
$ sudo dpkg -i linux-headers-4.0.0*.deb linux-image-4.0.0*.deb
|
||||
@ -1,13 +1,13 @@
|
||||
安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情--1
|
||||
安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情(一)
|
||||
================================================================================
|
||||
CentOS 是一个工业标准的 Linux 发行版,是红帽企业版 Linux 的衍生版本。你安装完后马上就可以使用,但是为了更好地使用你的系统,你需要进行一些升级、软件包安装、配置特定服务和应用程序等操作。
|
||||
CentOS 是一个工业标准的 Linux 发行版,是红帽企业版 Linux 的衍生版本。你安装完后马上就可以使用,但是为了更好地使用你的系统,你需要进行一些升级、安装新的软件包、配置特定服务和应用程序等操作。
|
||||
|
||||
这篇文章介绍了 “安装完 RHEL/CentOS 7 后需要做的 30 件事情”。阅读帖子的时候请牢记已经完成了 RHEL/CentOS 最小化安装,这是首选的企业和生产环境,如果还没有,你可以按照下面的指南,它会告诉你两者的最小化安装方法。
|
||||
这篇文章介绍了 “安装完 RHEL/CentOS 7 后需要做的 30 件事情”。阅读帖子的时候请先完成 RHEL/CentOS 最小化安装,这是首选的企业和生产环境。如果还没有,你可以按照下面的指南,它会告诉你两者的最小化安装方法。
|
||||
|
||||
- [最小化安装 CentOS 7][1]
|
||||
- [最小化安装 RHEL 7][2]
|
||||
|
||||
下面是一些重要的事情列表,基于工业标准需求我们都会进行介绍。我们希望这些东西在你配置服务器的时候能有所帮助。
|
||||
我们会基于工业标准的需求来介绍以下列出的这些重要工作。我们希望这些东西在你配置服务器的时候能有所帮助。
|
||||
|
||||
1. 注册并启用红帽订阅
|
||||
2. 使用静态 IP 地址配置网络
|
||||
@ -42,50 +42,54 @@ CentOS 是一个工业标准的 Linux 发行版,是红帽企业版 Linux 的
|
||||
|
||||
### 1. 注册并启用红帽订阅 ###
|
||||
|
||||
RHEL 7 最小化安装完成后,是时候注册并启用系统红帽订阅库,以及执行一个完整的系统更新。这只当你有一个可用的红帽订阅时才能有效。你要注册才能启用官方红帽系统库并时不时进行操作系统更新。
|
||||
RHEL 7 最小化安装完成后,就应该注册并启用系统红帽订阅库, 并执行一个完整的系统更新。这只当你有一个可用的红帽订阅时才能有用。你要注册才能启用官方红帽系统库,并时不时进行操作系统更新。(LCTT 译注:订阅服务是收费的)
|
||||
|
||||
在下面的指南中我们已经包括了一个如何注册并激活红帽订阅的详细说明。
|
||||
|
||||
- [在 RHEL 7 中注册并启用红帽订阅][3]
|
||||
|
||||
**注意**: 这一步仅适用于有一个有效订阅的红帽企业版 Linux. 如果你用的是 CentOS 服务器,请查看后面的章节。
|
||||
**注意**: 这一步仅适用于有一个有效订阅的红帽企业版 Linux。如果你用的是 CentOS 服务器,请查看后面的章节。
|
||||
|
||||
### 2. 使用静态 IP 地址配置网络 ###
|
||||
|
||||
你第一件要做的事情就是为你的 CentOS 服务器配置静态 IP 地址,路由以及 DNS。我们会使用 ip 命令代替 ifconfig 命令。当然,ifconfig 命令对于大部分 Linux 发行版来说还是可用的,还能从默认库安装。
|
||||
你第一件要做的事情就是为你的 CentOS 服务器配置静态 IP 地址、路由以及 DNS。我们会使用 ip 命令代替 ifconfig 命令。当然,ifconfig 命令对于大部分 Linux 发行版来说还是可用的,还能从默认库安装。
|
||||
|
||||
# yum install net-tools [提供 ifconfig 工具]
|
||||
# yum install net-tools [它提供 ifconfig 工具,如果你不习惯 ip 命令,还可以使用它]
|
||||
|
||||
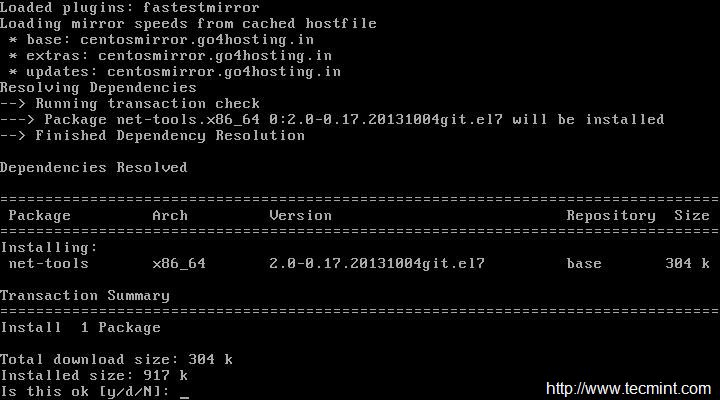
|
||||
|
||||
(LCTT 译注:关于 ip 命令的使用,请参照:http://www.linux.cn/article-3631-1.html )
|
||||
|
||||
但正如我之前说,我们会使用 ip 命令来配置静态 IP 地址。所以,确认你首先检查了当前的 IP 地址。
|
||||
|
||||
# ip addr show
|
||||
|
||||
|
||||
|
||||
现在用你的编辑器打开并编辑文件 /etc/sysconfig/network-scripts/ifcfg-enp0s3。这里,我使用 Vi 编辑器,另外你要确保你是 root 用户才能保存更改。
|
||||
现在用你的编辑器打开并编辑文件 /etc/sysconfig/network-scripts/ifcfg-enp0s3 (LCTT 译注:你的网卡名称可能不同,如果希望修改为老式网卡名称,参考:http://www.linux.cn/article-4045-1.html )。这里,我使用 vi 编辑器,另外你要确保你是 root 用户才能保存更改。
|
||||
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
|
||||
|
||||
我们会编辑文件中的四个地方。注意下面的四个地方并保证不碰任何其它的东西。也保留双引号,在它们中间输入你的数据。
|
||||
|
||||
IPADDR = “[在这里输入你的静态 IP]”
|
||||
GATEWAY = “[输入你的默认网关]”
|
||||
DNS1 = “[你的域名系统 1]”
|
||||
DNS2 = “[你的域名系统 2]”
|
||||
IPADDR = "[在这里输入你的静态 IP]"
|
||||
GATEWAY = "[输入你的默认网关]"
|
||||
DNS1 = "[你的DNS 1]"
|
||||
DNS2 = "[你的DNS 2]"
|
||||
|
||||
更改了 ‘ifcfg-enp0s3’ 之后,看起来像下面的图片。注意你的 IP,网关和 DNS 可能会变化,请和你的 ISP(译者注:互联网服务提供商商) 确认。保存并退出。
|
||||
更改了 ‘ifcfg-enp0s3’ 之后,它看起来像下面的图片。注意你的 IP,网关和 DNS 可能会变化,请和你的 ISP(译者注:互联网服务提供商,即给你提供接入的服务的电信或 IDC) 确认。保存并退出。
|
||||
|
||||
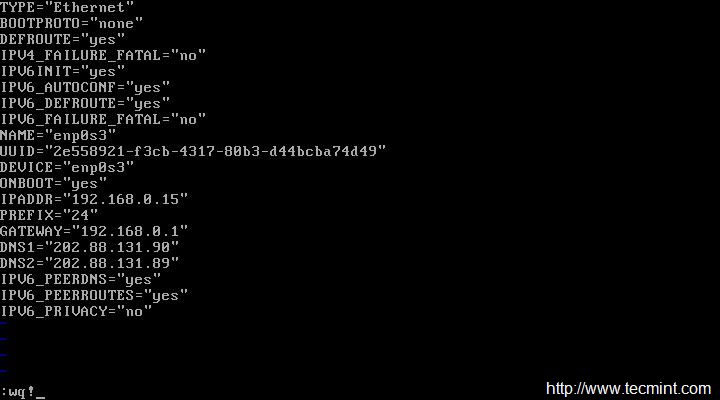
|
||||
网络详情
|
||||
|
||||
*网络详情*
|
||||
|
||||
重启网络服务并检查 IP 是否和分配的一样。如果一切都顺利,用 Ping 查看网络状态。
|
||||
|
||||
# service network restart
|
||||
|
||||
|
||||
重启网络服务
|
||||
|
||||
*重启网络服务*
|
||||
|
||||
重启网络后,确认检查了 IP 地址和网络状态。
|
||||
|
||||
@ -93,10 +97,14 @@ RHEL 7 最小化安装完成后,是时候注册并启用系统红帽订阅库
|
||||
# ping -c4 google.com
|
||||
|
||||
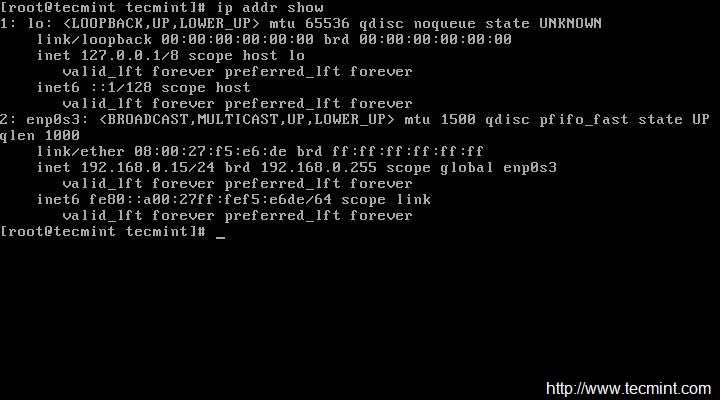
|
||||
验证 IP 地址
|
||||
|
||||
*验证 IP 地址*
|
||||
|
||||

|
||||
检查网络状态
|
||||
|
||||
*检查网络状态*
|
||||
|
||||
(LCTT 译注:关于设置静态 IP 地址的更多信息,请参照:http://www.linux.cn/article-3977-1.html )
|
||||
|
||||
### 3. 设置服务器的主机名称 ###
|
||||
|
||||
@ -105,34 +113,40 @@ RHEL 7 最小化安装完成后,是时候注册并启用系统红帽订阅库
|
||||
# echo $HOSTNAME
|
||||
|
||||
|
||||
查看系统主机名称
|
||||
|
||||
*查看系统主机名称*
|
||||
|
||||
要设置新的主机名称,我们需要编辑 ‘/etc/hostsname’ 文件并用想要的名称替换旧的主机名称。
|
||||
|
||||
# vi /etc/hostname
|
||||
|
||||

|
||||
在 CentOS 中设置主机名称
|
||||
|
||||
*在 CentOS 中设置主机名称*
|
||||
|
||||
设置完了主机名称之后,务必注销后重新登录确认主机名称。登录后检查新的主机名称。
|
||||
|
||||
$ echo $HOSTNAME
|
||||
|
||||
|
||||
确认主机名称
|
||||
|
||||
*确认主机名称*
|
||||
|
||||
你也可以用 ‘hostname’ 命令查看你当前的主机名。
|
||||
|
||||
$ hostname
|
||||
|
||||
(LCTT 译注:关于设置静态、瞬态和灵活主机名的更多信息,请参考:http://www.linux.cn/article-3937-1.html )
|
||||
|
||||
### 4. 更新或升级最小化安装的 CentOS ###
|
||||
|
||||
除了更新和安装已经有的软件的最新版本以及安全升级,这不会安装任何新的软件。总的来说更新和升级是相同的,除了事实上 升级 = 更新 + 更新时进行废弃处理。
|
||||
这样做除了更新安装已有的软件最新版本以及安全升级,不会安装任何新的软件。总的来说更新(update)和升级(upgrade)是相同的,除了事实上 升级 = 更新 + 更新时进行废弃处理。
|
||||
|
||||
# yum update && yum upgrade
|
||||
|
||||
|
||||
更新最小化安装的 CentOS 服务器
|
||||
|
||||
*更新最小化安装的 CentOS 服务器*
|
||||
|
||||
**重要**: 你也可以运行下面的命令,这不会弹出软件更新的提示,你也就不需要输入 ‘y’ 接受更改。
|
||||
|
||||
@ -147,7 +161,8 @@ RHEL 7 最小化安装完成后,是时候注册并启用系统红帽订阅库
|
||||
# yum install links
|
||||
|
||||

|
||||
Links: 命令行 Web 浏览器
|
||||
|
||||
*Links: 命令行 Web 浏览器*
|
||||
|
||||
请查看我们的文章 [用 links 工具命令行浏览 Web][4] 了解用 links 工具浏览 web 的方法和例子。
|
||||
|
||||
@ -157,8 +172,9 @@ Links: 命令行 Web 浏览器
|
||||
|
||||
# yum install httpd
|
||||
|
||||
|
||||
安装 Apache 服务器
|
||||

|
||||
|
||||
*安装 Apache 服务器*
|
||||
|
||||
如果你想更改 Apache HTTP 服务器的默认端口号(80)为其它端口,你需要编辑配置文件 ‘/etc/httpd/conf/httpd.conf’ 并查找以下面开始的行:
|
||||
|
||||
@ -167,7 +183,8 @@ Links: 命令行 Web 浏览器
|
||||
把端口号 ‘80’ 改为其它任何端口(例如 3221),保存并退出。
|
||||
|
||||
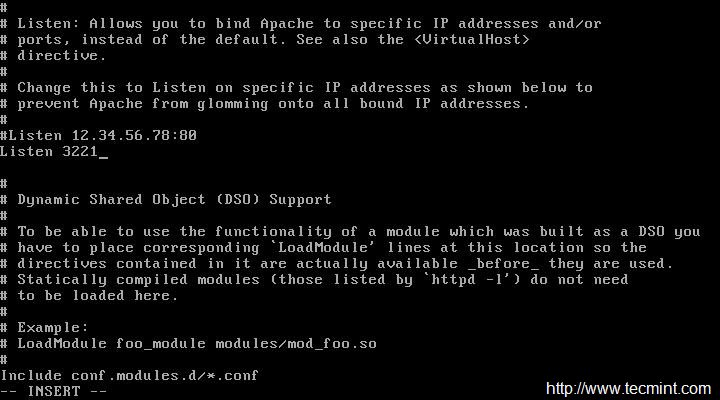
|
||||
更改 Apache 端口
|
||||
|
||||
*更改 Apache 端口*
|
||||
|
||||
增加刚才分配给 Apache 的端口通过防火墙,然后重新加载防火墙。
|
||||
|
||||
@ -183,6 +200,8 @@ Links: 命令行 Web 浏览器
|
||||
|
||||
# firewall-cmd –reload
|
||||
|
||||
(LCTT 译注:关于 firewall 的进一步使用,请参照:http://www.linux.cn/article-4425-1.html )
|
||||
|
||||
完成上面的所有事情之后,是时候重启 Apache HTTP 服务器了,然后新的端口号才能生效。
|
||||
|
||||
# systemctl restart httpd.service
|
||||
@ -192,12 +211,15 @@ Links: 命令行 Web 浏览器
|
||||
# systemctl start httpd.service
|
||||
# systemctl enable httpd.service
|
||||
|
||||
(LCTT 译注:关于 systemctl 的进一步使用,请参照:http://www.linux.cn/article-3719-1.html )
|
||||
|
||||
如下图所示,用 links 命令行工具 验证 Apache HTTP 服务器。
|
||||
|
||||
# links 127.0.0.1
|
||||
|
||||

|
||||
验证 Apache 状态
|
||||
|
||||
*验证 Apache 状态*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -205,7 +227,7 @@ via: http://www.tecmint.com/things-to-do-after-minimal-rhel-centos-7-installatio
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情--2
|
||||
安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情(二)
|
||||
================================================================================
|
||||
### 7. 安装 PHP ###
|
||||
|
||||
PHP 是用于 web 基础服务的服务器端脚本语言。它也经常被用作通用编程语言。在最小化安装的 CentOS 中安装 PHP。
|
||||
PHP 是用于 web 基础服务的服务器端脚本语言。它也经常被用作通用编程语言。在最小化安装的 CentOS 中安装 PHP:
|
||||
|
||||
# yum install php
|
||||
|
||||
@ -12,7 +12,7 @@ PHP 是用于 web 基础服务的服务器端脚本语言。它也经常被用
|
||||
|
||||
下一步,通过在 Apache 文档根目录下创建下面的 php 脚本验证 PHP。
|
||||
|
||||
# echo -e "<?php\nphpinfo();\n?>" > /var/ww/html/phpinfo.php
|
||||
# echo -e "<?php\nphpinfo();\n?>" > /var/www/html/phpinfo.php
|
||||
|
||||
现在在 Linux 命令行中查看我们刚才创建的 PHP 文件(phpinfo.php)。
|
||||
|
||||
@ -21,32 +21,35 @@ PHP 是用于 web 基础服务的服务器端脚本语言。它也经常被用
|
||||
# links http://127.0.0.1/phpinfo.php
|
||||
|
||||
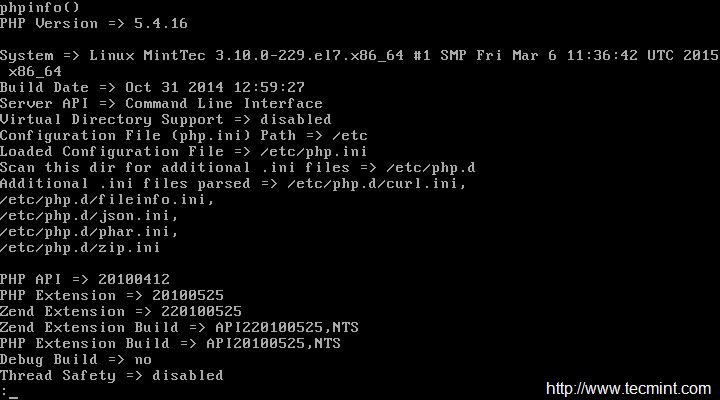
|
||||
验证 PHP
|
||||
|
||||
*验证 PHP*
|
||||
|
||||
### 8. 安装 MariaDB 数据库 ###
|
||||
|
||||
MariaDB 是 MySQL 的一个分支。红帽企业版 Linux 以及它的衍生版已经从 MySQL 迁移到 MariaDB。这是个主要的数据库管理系统。这又是一个你必须拥有的工具,不管你在配置怎样的服务器,或迟或早你都会需要它。在最小化安装的 CentOS 上安装 MariaDB,如下所示。
|
||||
MariaDB 是 MySQL 的一个分支。RHEL 以及它的衍生版已经从 MySQL 迁移到 MariaDB。这是一个主流的数据库管理系统,也是一个你必须拥有的工具。不管你在配置怎样的服务器,或迟或早你都会需要它。在最小化安装的 CentOS 上安装 MariaDB,如下所示:
|
||||
|
||||
# yum install mariadb-server mariadb
|
||||
|
||||

|
||||
安装 MariaDB 数据库
|
||||
|
||||
启动被配置 MariaDBs 随机启动。
|
||||
*安装 MariaDB 数据库*
|
||||
|
||||
启动 MariaDB 并配置它开机时自动启动。
|
||||
|
||||
# systemctl start mariadb.service
|
||||
# systemctl enable mariadb.service
|
||||
|
||||
允许 mysql(mariadb) 服务通过防火墙
|
||||
允许 mysql(mariadb) 服务通过防火墙(LCTT 译注:如果你的 MariaDB 只用在本机,则务必不要设置防火墙允许通过,使用 UNIX Socket 连接你的数据库;如果需要在别的服务器上连接数据库,则尽量使用内部网络,而不要将数据库服务暴露在公开的互联网上。)
|
||||
|
||||
# firewall-cmd –add-service=mysql
|
||||
|
||||
现在是时候确保 MariaDB 服务器安全了。
|
||||
现在是时候确保 MariaDB 服务器安全了(LCTT 译注:这个步骤主要是设置 mysql 管理密码)。
|
||||
|
||||
# /usr/bin/mysql_secure_installation
|
||||
|
||||
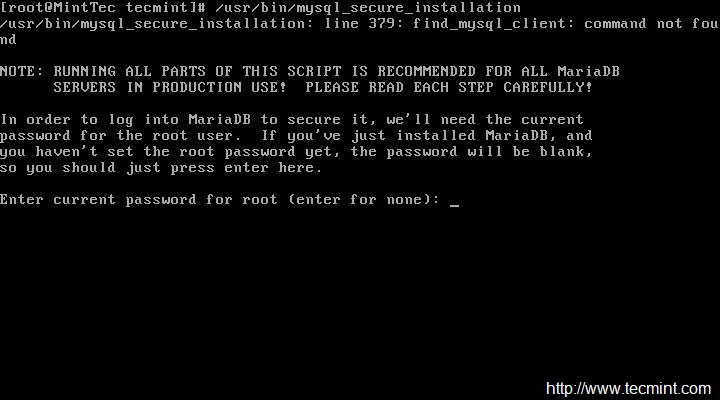
|
||||
保护 MariaDB 数据库
|
||||
|
||||
*保护 MariaDB 数据库*
|
||||
|
||||
请阅读:
|
||||
|
||||
@ -55,18 +58,19 @@ MariaDB 是 MySQL 的一个分支。红帽企业版 Linux 以及它的衍生版
|
||||
|
||||
### 9. 安装和配置 SSH 服务器 ###
|
||||
|
||||
SSH 表示 Secure Shell,是 Linux 远程管理的默认协议。 SSH 是随最小化 CentOS 服务器一起发布的最重要的软件之一。
|
||||
SSH 即 Secure Shell,是 Linux 远程管理的默认协议。 SSH 是随最小化 CentOS 服务器中安装运行的最重要的软件之一。
|
||||
|
||||
检查当前已安装的 SSH 版本。
|
||||
|
||||
# SSH -V
|
||||
|
||||

|
||||
检查 SSH 版本
|
||||
|
||||
在默认的 SSH 协议上使用安全协议,更改端口号进一步加强安全。编辑 SSH 的配置文件 ‘/etc/ssh/ssh_config’。
|
||||
*检查 SSH 版本*
|
||||
|
||||
去掉下面行的注释或者从协议行中删除 1,然后行看起来像这样:
|
||||
使用更安全的 SSH 协议,而不是默认的协议,并更改端口号进一步加强安全。编辑 SSH 的配置文件 ‘/etc/ssh/ssh_config’。
|
||||
|
||||
去掉下面行的注释或者从协议行中删除 1,然后行看起来像这样(LCTT 译注: SSH v1 是过期废弃的不安全协议):
|
||||
|
||||
# Protocol 2,1 (原来)
|
||||
Protocol 2 (现在)
|
||||
@ -74,15 +78,17 @@ SSH 表示 Secure Shell,是 Linux 远程管理的默认协议。 SSH 是随最
|
||||
这个改变强制 SSH 使用 协议 2,它被认为比协议 1 更安全,同时也确保在配置中更改端口号 22 为其它。
|
||||
|
||||
|
||||
保护 SSH 登录
|
||||
|
||||
取消 SSH ‘root login’ 然后允许只有当以普通用户账号登录后才能连接到 root 以进一步加强安全。为了做到这个,打开并编辑配置文件 ‘/etc/ssh/sshd_config’ 并更改 PermitRootLogin yes 为 PermitRootLogin no。
|
||||
*保护 SSH 登录*
|
||||
|
||||
取消 SSH 中的‘root login’, 只允许通过普通用户账号登录后才能使用 su 切换到 root,以进一步加强安全。请打开并编辑配置文件 ‘/etc/ssh/sshd_config’ 并更改 PermitRootLogin yes 为 PermitRootLogin no。
|
||||
|
||||
# PermitRootLogin yes (原来)
|
||||
PermitRootLogin no (现在)
|
||||
|
||||
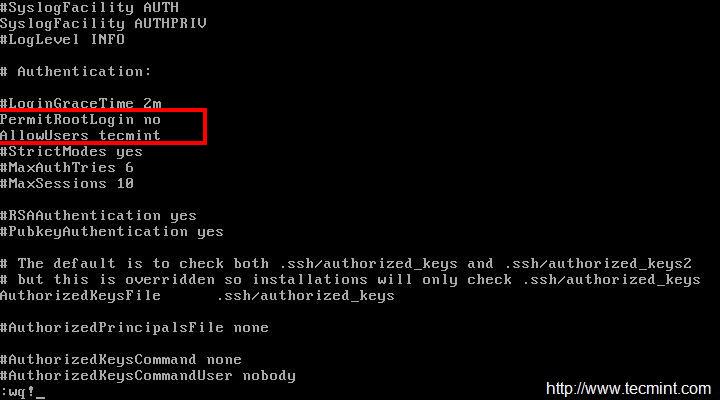
|
||||
取消 SSH Root 登录
|
||||
|
||||
*取消 SSH Root 直接登录*
|
||||
|
||||
最后,重启 SSH 服务启用更改。
|
||||
|
||||
@ -96,34 +102,39 @@ SSH 表示 Secure Shell,是 Linux 远程管理的默认协议。 SSH 是随最
|
||||
|
||||
### 10. 安装 GCC (GNU 编译器集) ###
|
||||
|
||||
GCC 表示 GNU 编译器集,是一个 GNU 项目开发的支持多种编程语言的编译系统。在最小化安装的 CentOS 没有默认安装。运行下面的命令安装 gcc 编译器。
|
||||
GCC 即 GNU 编译器集,是一个 GNU 项目开发的支持多种编程语言的编译系统(LCTT 译注:在你需要自己编译构建软件时需要它)。在最小化安装的 CentOS 没有默认安装。运行下面的命令安装 gcc 编译器。
|
||||
|
||||
# yum install gcc
|
||||
|
||||
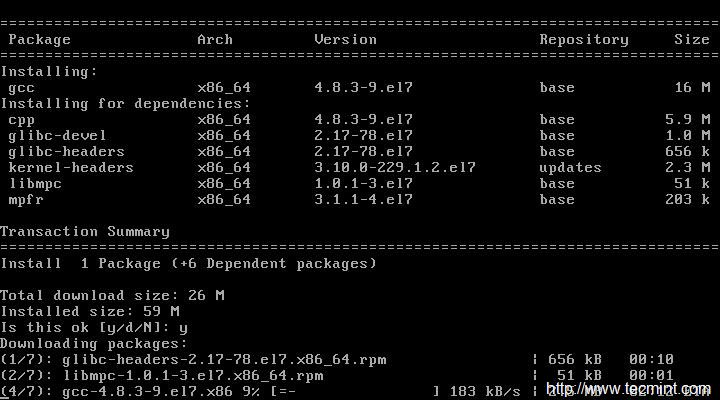
|
||||
在 CentOS 上安装 GCC
|
||||
|
||||
*在 CentOS 上安装 GCC*
|
||||
|
||||
检查安装的 gcc 版本。
|
||||
|
||||
# gcc --version
|
||||
|
||||
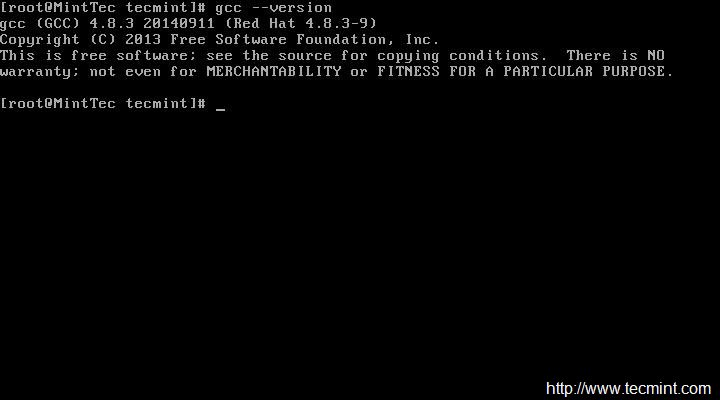
|
||||
检查 GCC 版本
|
||||
|
||||
*检查 GCC 版本*
|
||||
|
||||
### 11. 安装 Java ###
|
||||
|
||||
Java是一种通用的基于类的,面向对象的编程语言。在最小化 CentOS 服务器中没有默认安装。按照下面命令从库中安装 Java。
|
||||
Java是一种通用的基于类的,面向对象的编程语言。在最小化 CentOS 服务器中没有默认安装(LCTT 译注:如果你没有任何 Java 应用,可以不用装它)。按照下面命令从库中安装 Java。
|
||||
|
||||
# yum install java
|
||||
|
||||
|
||||
安装 Java
|
||||
|
||||
*安装 Java*
|
||||
|
||||
检查安装的 Java 版本。
|
||||
|
||||
# java -version
|
||||
|
||||

|
||||
检查 Java 版本
|
||||
|
||||
*检查 Java 版本*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -131,7 +142,7 @@ via: http://www.tecmint.com/things-to-do-after-minimal-rhel-centos-7-installatio
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,277 @@
|
||||
安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情(三)
|
||||
================================================================================
|
||||
### 12. 安装 Apache Tomcat ###
|
||||
|
||||
Tomcat 是由 Apache 设计的用来运行 Java HTTP web 服务器的 servlet 容器。按照下面的方法安装 tomcat,但需要指出的是安装 tomcat 之前必须先安装 Java。
|
||||
|
||||
# yum install tomcat
|
||||
|
||||
|
||||
|
||||
*安装 Apache Tomcat*
|
||||
|
||||
安装完 tomcat 之后,启动 tomcat 服务。
|
||||
|
||||
# systemctl start tomcat
|
||||
|
||||
查看 tomcat 版本。
|
||||
|
||||
# /usr/sbin/tomcat version
|
||||
|
||||
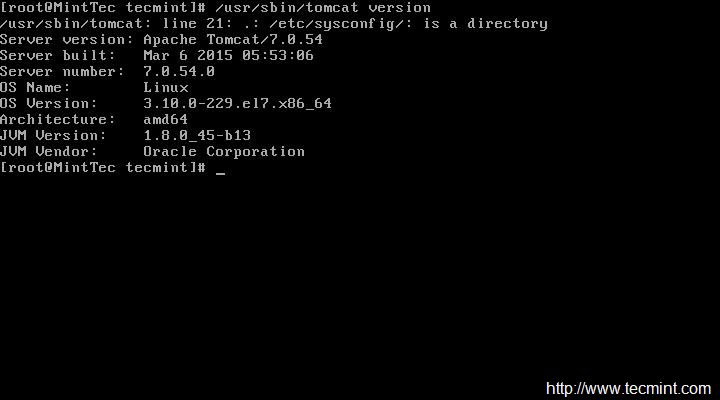
|
||||
|
||||
*查看 tomcat 版本*
|
||||
|
||||
允许 tomcat 服务和默认端口(8080) 通过防火墙并重新加载设置。
|
||||
|
||||
# firewall-cmd –zone=public –add-port=8080/tcp --permanent
|
||||
# firewall-cmd –reload
|
||||
|
||||
现在该保护 tomcat 服务器了,添加一个用于访问和管理的用户和密码。我们需要编辑文件 ‘/etc/tomcat/tomcat-users.xml’。查看类似下面的部分:
|
||||
|
||||
<tomcat-users>
|
||||
....
|
||||
</tomcat-users>
|
||||
|
||||
|
||||
<role rolename="manager-gui"/>
|
||||
<role rolename="manager-script"/>
|
||||
<role rolename="manager-jmx"/>
|
||||
<role rolename="manager-status"/>
|
||||
<role rolename="admin-gui"/>
|
||||
<role rolename="admin-script"/>
|
||||
<user username="tecmint" password="tecmint" roles="manager-gui,manager-script,manager-jmx,manager-status,admin-gui,admin-script"/>
|
||||
</tomcat-users>
|
||||
|
||||

|
||||
|
||||
*保护 Tomcat*
|
||||
|
||||
我们在这里添加用户 “tecmint” 到 tomcat 的管理员/管理组中,使用 “tecmint” 作为密码。先停止再启动 tomcat 服务以使更改生效,并添加 tomcat 服务到随系统启动。
|
||||
|
||||
# systemctl stop tomcat
|
||||
# systemctl start tomcat
|
||||
# systemctl enable tomcat.service
|
||||
|
||||
请阅读: [在 RHEL/CentOS 7.0/6.x 中安装和配置 Apache Tomcat 8.0.9][5]
|
||||
|
||||
### 13. 安装 Nmap 监视开放端口 ###
|
||||
|
||||
Nmap 网络映射器用来分析网络,通过运行它可以发现网络的映射关系。nmap 并没有默认安装,你需要从库中安装它。
|
||||
|
||||
# yum install nmap
|
||||
|
||||

|
||||
|
||||
*安装 Nmap 监视工具*
|
||||
|
||||
列出主机中所有的开放端口以及对应使用它们的服务。
|
||||
|
||||
# namp 127.0.01
|
||||
|
||||
!监视开放端口](http://www.tecmint.com/wp-content/uploads/2015/04/Monitor-Open-Ports.jpeg)
|
||||
|
||||
*监视开放端口*
|
||||
|
||||
你也可以使用 firewall-cmd 列出所有端口,但我发现 nmap 更有用。
|
||||
|
||||
# firewall-cmd –list-ports
|
||||
|
||||

|
||||
|
||||
*在防火墙中检查开放端口*
|
||||
|
||||
请阅读: [Nmap 监视开放端口的 29 个有用命令][1]
|
||||
|
||||
### 14. 配置 FirewallD ###
|
||||
|
||||
firewalld 是动态管理服务器的防火墙服务。在 CentOS 7 中 Firewalld 移除了 iptables 服务。在红帽企业版 Linux 和它的衍生版中默认安装了 Firewalld。如果有 iptables 的话为了使每个更改生效需要清空所有旧的规则然后创建新规则。
|
||||
|
||||
然而用firewalld,不需要清空并重新创建新规则就可以实现更改生效。
|
||||
|
||||
检查 Firewalld 是否运行。
|
||||
|
||||
# systemctl status firewalld
|
||||
或
|
||||
# firewall-cmd –state
|
||||
|
||||

|
||||
|
||||
*检查 Firewalld 状态*
|
||||
|
||||
获取所有的区域列表。
|
||||
|
||||
# firewall-cmd --get-zones
|
||||
|
||||

|
||||
|
||||
*检查 Firewalld 区域*
|
||||
|
||||
在切换之前先获取区域的详细信息。
|
||||
|
||||
# firewall-cmd --zone=work --list-all
|
||||
|
||||

|
||||
|
||||
*检查区域详情*
|
||||
|
||||
获取默认区域。
|
||||
|
||||
# firewall-cmd --get-default-zone
|
||||
|
||||

|
||||
|
||||
*Firewalld 默认区域*
|
||||
|
||||
切换到另一个区域,比如 ‘work’。
|
||||
|
||||
# firewall-cmd --set-default-zone=work
|
||||
|
||||

|
||||
|
||||
*切换 Firewalld 区域*
|
||||
|
||||
列出区域中的所有服务。
|
||||
|
||||
# firewall-cmd --list-services
|
||||
|
||||

|
||||
|
||||
*列出 Firewalld 区域的服务*
|
||||
|
||||
添加临时服务,比如 http,然后重载 firewalld。
|
||||
|
||||
# firewall-cmd --add-service=http
|
||||
# firewall-cmd –reload
|
||||
|
||||

|
||||
|
||||
*添加临时 http 服务*
|
||||
|
||||
添加永久服务,比如 http,然后重载 firewalld。
|
||||
|
||||
# firewall-cmd --add-service=http --permanent
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
*添加永久 http 服务*
|
||||
|
||||
删除临时服务,比如 http。
|
||||
|
||||
# firewall-cmd --remove-service=http
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
*删除临时 Firewalld 服务*
|
||||
|
||||
删除永久服务,比如 http
|
||||
|
||||
# firewall-cmd --zone=work --remove-service=http --permanent
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
*删除永久服务*
|
||||
|
||||
允许一个临时端口(比如 331)。
|
||||
|
||||
# firewall-cmd --add-port=331/tcp
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
*打开临时端口*
|
||||
|
||||
允许一个永久端口(比如 331)。
|
||||
|
||||
# firewall-cmd --add-port=331/tcp --permanent
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
*打开永久端口*
|
||||
|
||||
阻塞/移除临时端口(比如 331)。
|
||||
|
||||
# firewall-cmd --remove-port=331/tcp
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
*移除临时端口*
|
||||
|
||||
阻塞/移除永久端口(比如 331)。
|
||||
|
||||
# firewall-cmd --remove-port=331/tcp --permanent
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
*移除永久端口*
|
||||
|
||||
停用 firewalld。
|
||||
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
# firewall-cmd --state
|
||||
|
||||

|
||||
|
||||
*停用 Firewalld 服务*
|
||||
|
||||
启用 firewalld。
|
||||
|
||||
# systemctl enable firewalld
|
||||
# systemctl start firewalld
|
||||
# firewall-cmd --state
|
||||
|
||||

|
||||
|
||||
*启用 Firewalld*
|
||||
|
||||
- [如何在 RHEL/CentOS 7 中配置 ‘Firewalld’][2]
|
||||
- [配置和管理 Firewalld 的有用 ‘Firewalld’ 规则][3]
|
||||
|
||||
### 15. 安装 Wget ###
|
||||
|
||||
Wget 是从 web 服务器获取(下载)内容的命令行工具。它是你使用 wget 命令获取 web 内容或下载任何文件必须要有的重要工具。
|
||||
|
||||
# yum install wget
|
||||
|
||||

|
||||
|
||||
*安装 Wget 工具*
|
||||
|
||||
关于在终端中如何使用 wget 命令下载文件的方法和实际例子,请阅读[10 个 Wget 命令例子][4]。
|
||||
|
||||
### 16. 安装 Telnet 客户端###
|
||||
|
||||
Telnet 是通过 TCP/IP 允许用户登录到相同网络上的另一台计算机的网络协议。和远程计算机的连接建立后,它就成为了一个允许你在自己的计算机上用所有提供给你的权限和远程主机交互的虚拟终端。(LCTT 译注:除非你真的需要,不要安装 telnet 服务,也不要用 telnet 客户端连接另外一个 telnet 服务,因为 telnet 是明文传输的。不过如下用 telnet 客户端检测另外一个服务的端口是否工作是常用的操作。)
|
||||
|
||||
Telnet 对于检查远程计算机或主机的监听端口也非常有用。
|
||||
|
||||
# yum install telnet
|
||||
# telnet google.com 80
|
||||
|
||||

|
||||
|
||||
*Telnet 端口检查*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/things-to-do-after-minimal-rhel-centos-7-installation/3/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://linux.cn/article-2561-1.html
|
||||
[2]:http://linux.cn/article-4425-1.html
|
||||
[3]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
[4]:http://linux.cn/article-4129-1.html
|
||||
[5]:http://www.tecmint.com/install-apache-tomcat-in-centos/
|
||||
@ -0,0 +1,52 @@
|
||||
GNOME-Pie 0.6.1 应用启动器发布,酷炫新特性[多图+视频]
|
||||
=============================================
|
||||
|
||||
**Simon Schneegans 高兴地[宣布][1]他的 GNOME-Pie 0.6.1 已可供下载使用。GNOME-Pie 是一个可以在包括 GNOME 和 Unity 在内的多种桌面环境中作为应用启动器的小工具。**
|
||||
|
||||

|
||||
|
||||
GNOME-Pie 0.6.1 看起来是个主要版本更新,引入了许多新特性,比如支持半个或四分之一圆,可选择每个启动器想要的形状,也可以自动根据位置调整形状(圆形,半个或四分之一圆),以及多彩的动态图标。
|
||||
|
||||
此外,软件现在还适配若干类dock应用,包括elementary OS 的 Plank,Ubuntu 的 Unity,以及通用的 Docky。一些已有的 GNOME-Pie 主题也已更新,还引入了全新的为半圆启动器布局设计的主题 Simple,。
|
||||
|
||||
“Gnome-Pie 新版本已发布,实际上已经发布了两个版本:0.6.0和之后的0.6.1,修复了[issue #73][2],”Simon Schneegans 在发布声明上说道,“新版本修复了许多 bug,还带来了许多新特性!”
|
||||
|
||||
<iframe src="https://player.vimeo.com/video/125339537" width="500" height="281" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe>
|
||||
|
||||
### 现在就可在Ubuntu上安装GNOME-Pie ###
|
||||
|
||||
Ubuntu 及其衍生版用户现在就可通过 Simon Schneegans 的PPA源安装 GNOME-Pie。只需打开终端,运行下列命令即可。GNOME-Pie 适用于 Ubuntu 14.04 LTS,14.10和15.04。
|
||||
|
||||
sudo add-apt-repository ppa:simonschneegans/testing
|
||||
sudo apt-get update
|
||||
sudo apt-get install gnome-pie
|
||||
|
||||
|
||||
其他 GNU/Linux 发行版用户可以从官网下载 GNOME-Pie 0.6.1 的源代码,或者近期在系统的软件源中搜索新版GNOME-Pie。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/GNOME-Pie-0-6-Application-Launcher-Released-with-Many-New-Features-Video-478914.shtml
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://simmesimme.github.io/news/2015/04/18/gnome-pie-061/
|
||||
[2]:https://github.com/Simmesimme/Gnome-Pie/issues/73
|
||||
@ -1,9 +1,8 @@
|
||||
Translated by H-mudcup
|
||||
|
||||
适用于Ubuntu的环境音播放器播放让人放松的声音保持你的创造力
|
||||
环境音播放器:让人放松的声音,保持你的创造力
|
||||
================================================================================
|
||||

|
||||
对于某些人来说雨声是个令人安心的声音
|
||||
|
||||
*对于某些人来说雨声是个令人安心的声音*
|
||||
|
||||
**如果我想变得非常有效率,我不能听‘正常’的音乐。它会使我分心,我会开始跟着唱或者让我想起另一首歌,结局就是我在自己的音乐库里到处戳并且……反正,你懂的。**
|
||||
|
||||
@ -23,11 +22,11 @@ Translated by H-mudcup
|
||||
|
||||
Google Play和苹果应用商店充满了环境音和白噪声的应用。现在,在Ubuntu里有同样的应用了。
|
||||
|
||||
‘[Ambient Noise][1]‘ ‘[环境音][1]’——人如其名——是一个专门被设计成播放这种声音的音频播放器。他甚至可以同Ubuntu声音菜单整合到一起,给你‘选择,点击即放松’的体验。
|
||||
‘[Ambient Noise (环境音)][1] ’——人如其名,这是一个专门被设计成播放这种声音的音频播放器。他甚至可以同Ubuntu声音菜单整合到一起,给你‘选择,点击即放松’的体验。
|
||||
|
||||
这个应用(又被称为‘ANoise播放器’,由Marcos Costales制作)带有**8个高品质声道**。
|
||||
这个应用(又被称为‘ANoise播放器’,由Marcos Costales制作)带有**8个高品质音频**。
|
||||
|
||||
这8个预设声道涵盖了多种环境,从下雨时有节奏的声音,到夜晚大自然静谧的旋律,还有下午熙熙攘攘的咖啡店的嗡嗡声。
|
||||
这8个预设音频涵盖了多种环境,从下雨时有节奏的声音,到夜晚大自然静谧的旋律,还有下午熙熙攘攘的咖啡店的嗡嗡声。
|
||||
|
||||
### 在Ubuntu上安装ANoise播放器 ###
|
||||
|
||||
@ -39,9 +38,9 @@ Google Play和苹果应用商店充满了环境音和白噪声的应用。现在
|
||||
|
||||
sudo apt-get update && sudo apt-get install anoise
|
||||
|
||||
安装好以后只需从Unity Dash(或DE里等价的地方)里打开它,通过声音菜单选择你喜欢的环境音然后……放松吧!这个应用甚至记得你上次用的环境音。
|
||||
安装好以后只需从Unity Dash(或桌面环境里类同的地方)里打开它,通过声音菜单选择你喜欢的环境音然后……放松吧!这个应用甚至记得你上次用的环境音。
|
||||
|
||||
Even so, give it a try out and see if it suits your needs. I would say let me know what you think, but I will be too focused to hear — and so might you!即便如此,你还是要试一试看它是否能满足你的需要。我要说的是让我直到你是怎么想的,但是我将会专心致志到听不到你的声音——你可能也会这样!
|
||||
即便如此,你还是要试一试看它是否能满足你的需要。我要说的是让我知道你是怎么想的,但是我将会专心致志到听不到你的声音——你可能也会这样!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -49,7 +48,7 @@ via: http://www.omgubuntu.co.uk/2015/04/ambient-noise-player-app-for-ubuntu-linu
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,41 @@
|
||||
EvilAP_Defender:可以警示和攻击 WIFI 热点陷阱的工具
|
||||
===============================================================================
|
||||
|
||||
**开发人员称,EvilAP_Defender甚至可以攻击流氓Wi-Fi接入点**
|
||||
|
||||
这是一个新的开源工具,可以定期扫描一个区域,以防出现恶意 Wi-Fi 接入点,同时如果发现情况会提醒网络管理员。
|
||||
|
||||
这个工具叫做 EvilAP_Defender,是为监测攻击者所配置的恶意接入点而专门设计的,这些接入点冒用合法的名字诱导用户连接上。
|
||||
|
||||
这类接入点被称做假面猎手(evil twin),使得黑客们可以从所接入的设备上监听互联网信息流。这可以被用来窃取证书、钓鱼网站等等。
|
||||
|
||||
大多数用户设置他们的计算机和设备可以自动连接一些无线网络,比如家里的或者工作地方的网络。通常,当面对两个同名的无线网络时,即SSID相同,有时候甚至连MAC地址(BSSID)也相同,这时候大多数设备会自动连接信号较强的一个。
|
||||
|
||||
这使得假面猎手攻击容易实现,因为SSID和BSSID都可以伪造。
|
||||
|
||||
[EvilAP_Defender][1]是一个叫Mohamed Idris的人用Python语言编写,公布在GitHub上面。它可以使用一个计算机的无线网卡来发现流氓接入点,这些坏蛋们复制了一个真实接入点的SSID,BSSID,甚至是其他的参数如通道,密码,隐私协议和认证信息等等。
|
||||
|
||||
该工具首先以学习模式运行,以便发现合法的接入点[AP],并且将其加入白名单。然后可以切换到正常模式,开始扫描未认证的接入点。
|
||||
|
||||
如果一个恶意[AP]被发现了,该工具会用电子邮件提醒网络管理员,但是开发者也打算在未来加入短信提醒功能。
|
||||
|
||||
该工具还有一个保护模式,在这种模式下,应用会发起一个denial-of-service [DoS]攻击反抗恶意接入点,为管理员采取防卫措施赢得一些时间。
|
||||
|
||||
“DoS 将仅仅针对有着相同SSID的而BSSID(AP的MAC地址)不同或者不同信道的流氓 AP,”Idris在这款工具的文档中说道。“这是为了避免攻击到你的正常网络。”
|
||||
|
||||
尽管如此,用户应该切记在许多国家,攻击别人的接入点很多时候都是非法的,甚至是一个看起来像是攻击者操控的恶意接入点。
|
||||
|
||||
要能够运行这款工具,需要Aircrack-ng无线网套装,一个支持Aircrack-ng的无线网卡,MySQL和Python运行环境。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2905725/security0/this-tool-can-alert-you-about-evil-twin-access-points-in-the-area.html
|
||||
|
||||
作者:[Lucian Constantin][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Lucian-Constantin/
|
||||
[1]:https://github.com/moha99sa/EvilAP_Defender/blob/master/README.TXT
|
||||
290
published/20150415 Strong SSL Security on nginx.md
Normal file
290
published/20150415 Strong SSL Security on nginx.md
Normal file
@ -0,0 +1,290 @@
|
||||
增强 nginx 的 SSL 安全性
|
||||
================================================================================
|
||||
[][1]
|
||||
|
||||
本文向你介绍如何在 nginx 服务器上设置健壮的 SSL 安全机制。我们通过禁用 SSL 压缩来降低 CRIME 攻击威胁;禁用协议上存在安全缺陷的 SSLv3 及更低版本,并设置更健壮的加密套件(cipher suite)来尽可能启用前向安全性(Forward Secrecy);此外,我们还启用了 HSTS 和 HPKP。这样我们就拥有了一个健壮而可经受考验的 SSL 配置,并可以在 Qually Labs 的 SSL 测试中得到 A 级评分。
|
||||
|
||||
如果不求甚解的话,可以从 [https://cipherli.st][2] 上找到 nginx 、Apache 和 Lighttpd 的安全设置,复制粘帖即可。
|
||||
|
||||
本教程在 Digital Ocean 的 VPS 上测试通过。如果你喜欢这篇教程,想要支持作者的站点的话,购买 Digital Ocean 的 VPS 时请使用如下链接:[https://www.digitalocean.com/?refcode=7435ae6b8212][3] 。
|
||||
|
||||
本教程可以通过[发布于 2014/1/21 的][4] SSL 实验室测试的严格要求(我之前就通过了测试,如果你按照本文操作就可以得到一个 A+ 评分)。
|
||||
|
||||
- [本教程也可用于 Apache ][5]
|
||||
- [本教程也可用于 Lighttpd ][6]
|
||||
- [本教程也可用于 FreeBSD, NetBSD 和 OpenBSD 上的 nginx ,放在 BSD Now 播客上][7]: [http://www.bsdnow.tv/tutorials/nginx][8]
|
||||
|
||||
你可以从下列链接中找到这方面的进一步内容:
|
||||
|
||||
- [野兽攻击(BEAST)][9]
|
||||
- [罪恶攻击(CRIME)][10]
|
||||
- [怪物攻击(FREAK )][11]
|
||||
- [心血漏洞(Heartbleed)][12]
|
||||
- [完备的前向安全性(Perfect Forward Secrecy)][13]
|
||||
- [RC4 和 BEAST 的处理][14]
|
||||
|
||||
我们需要编辑 nginx 的配置,在 Ubuntu/Debian 上是 `/etc/nginx/sited-enabled/yoursite.com`,在 RHEL/CentOS 上是 `/etc/nginx/conf.d/nginx.conf`。
|
||||
|
||||
本文中,我们需要编辑443端口(SSL)的 `server` 配置中的部分。在文末你可以看到完整的配置例子。
|
||||
|
||||
*在编辑之前切记备份一下配置文件!*
|
||||
|
||||
### 野兽攻击(BEAST)和 RC4 ###
|
||||
|
||||
简单的说,野兽攻击(BEAST)就是通过篡改一个加密算法的 CBC(密码块链)的模式,从而可以对部分编码流量悄悄解码。更多信息参照上面的链接。
|
||||
|
||||
针对野兽攻击(BEAST),较新的浏览器已经启用了客户端缓解方案。推荐方案是禁用 TLS 1.0 的所有加密算法,仅允许 RC4 算法。然而,[针对 RC4 算法的攻击也越来越多](http://www.isg.rhul.ac.uk/tls/) ,很多已经从理论上逐步发展为实际可行的攻击方式。此外,有理由相信 NSA 已经实现了他们所谓的“大突破”——攻破 RC4 。
|
||||
|
||||
禁用 RC4 会有几个后果。其一,当用户使用老旧的浏览器时,比如 Windows XP 上的 IE 会用 3DES 来替代 RC4。3DES 要比 RC4 更安全,但是它的计算成本更高,你的服务器就需要为这些用户付出更多的处理成本。其二,RC4 算法能减轻 野兽攻击(BEAST)的危害,如果禁用 RC4 会导致 TLS 1.0 用户会换到更容易受攻击的 AES-CBC 算法上(通常服务器端的对野兽攻击(BEAST)的“修复方法”是让 RC4 优先于其它算法)。我认为 RC4 的风险要高于野兽攻击(BEAST)的风险。事实上,有了客户端缓解方案(Chrome 和 Firefox 提供了缓解方案),野兽攻击(BEAST)就不是什么大问题了。而 RC4 的风险却在增长:随着时间推移,对加密算法的破解会越来越多。
|
||||
|
||||
### 怪物攻击(FREAK) ###
|
||||
|
||||
怪物攻击(FREAK)是一种中间人攻击,它是由来自 [INRIA、微软研究院和 IMDEA][15] 的密码学家们所发现的。怪物攻击(FREAK)的缩写来自“Factoring RSA-EXPORT Keys(RSA 出口密钥因子分解)”
|
||||
|
||||
这个漏洞可上溯到上世纪九十年代,当时美国政府禁止出口加密软件,除非其使用编码密钥长度不超过512位的出口加密套件。
|
||||
|
||||
这造成了一些现在的 TLS 客户端存在一个缺陷,这些客户端包括: 苹果的 SecureTransport 、OpenSSL。这个缺陷会导致它们会接受出口降级 RSA 密钥,即便客户端并没有要求使用出口降级 RSA 密钥。这个缺陷带来的影响很讨厌:在客户端存在缺陷,且服务器支持出口降级 RSA 密钥时,会发生中间人攻击,从而导致连接的强度降低。
|
||||
|
||||
攻击分为两个组成部分:首先是服务器必须接受“出口降级 RSA 密钥”。
|
||||
|
||||
中间人攻击可以按如下流程:
|
||||
|
||||
- 在客户端的 Hello 消息中,要求标准的 RSA 加密套件。
|
||||
- 中间人攻击者修改该消息为‘export RSA’(输出级 RSA 密钥)。
|
||||
- 服务器回应一个512位的输出级 RSA 密钥,并以其长期密钥签名。
|
||||
- 由于 OpenSSL/SecureTransport 的缺陷,客户端会接受这个弱密钥。
|
||||
- 攻击者根据 RSA 模数分解因子来恢复相应的 RSA 解密密钥。
|
||||
- 当客户端编码‘pre-master secret’(预主密码)给服务器时,攻击者现在就可以解码它并恢复 TLS 的‘master secret’(主密码)。
|
||||
- 从这里开始,攻击者就能看到了传输的明文并注入任何东西了。
|
||||
|
||||
本文所提供的加密套件不启用输出降级加密,请确认你的 OpenSSL 是最新的,也强烈建议你将客户端也升级到新的版本。
|
||||
|
||||
### 心血漏洞(Heartbleed) ###
|
||||
|
||||
心血漏洞(Heartbleed) 是一个于2014年4月公布的 OpenSSL 加密库的漏洞,它是一个被广泛使用的传输层安全(TLS)协议的实现。无论是服务器端还是客户端在 TLS 中使用了有缺陷的 OpenSSL,都可以被利用该缺陷。由于它是因 DTLS 心跳扩展(RFC 6520)中的输入验证不正确(缺少了边界检查)而导致的,所以该漏洞根据“心跳”而命名。这个漏洞是一种缓存区超读漏洞,它可以读取到本不应该读取的数据。
|
||||
|
||||
哪个版本的 OpenSSL 受到心血漏洞(Heartbleed)的影响?
|
||||
|
||||
各版本情况如下:
|
||||
|
||||
- OpenSSL 1.0.1 直到 1.0.1f (包括)**存在**该缺陷
|
||||
- OpenSSL 1.0.1g **没有**该缺陷
|
||||
- OpenSSL 1.0.0 分支**没有**该缺陷
|
||||
- OpenSSL 0.9.8 分支**没有**该缺陷
|
||||
|
||||
这个缺陷是2011年12月引入到 OpenSSL 中的,并随着 2012年3月14日 OpenSSL 发布的 1.0.1 而泛滥。2014年4月7日发布的 OpenSSL 1.0.1g 修复了该漏洞。
|
||||
|
||||
升级你的 OpenSSL 就可以避免该缺陷。
|
||||
|
||||
### SSL 压缩(罪恶攻击 CRIME) ###
|
||||
|
||||
罪恶攻击(CRIME)使用 SSL 压缩来完成它的魔法,SSL 压缩在下述版本是默认关闭的: nginx 1.1.6及更高/1.0.9及更高(如果使用了 OpenSSL 1.0.0及更高), nginx 1.3.2及更高/1.2.2及更高(如果使用较旧版本的 OpenSSL)。
|
||||
|
||||
如果你使用一个早期版本的 nginx 或 OpenSSL,而且你的发行版没有向后移植该选项,那么你需要重新编译没有一个 ZLIB 支持的 OpenSSL。这会禁止 OpenSSL 使用 DEFLATE 压缩方式。如果你禁用了这个,你仍然可以使用常规的 HTML DEFLATE 压缩。
|
||||
|
||||
### SSLv2 和 SSLv3 ###
|
||||
|
||||
SSLv2 是不安全的,所以我们需要禁用它。我们也禁用 SSLv3,因为 TLS 1.0 在遭受到降级攻击时,会允许攻击者强制连接使用 SSLv3,从而禁用了前向安全性(forward secrecy)。
|
||||
|
||||
如下编辑配置文件:
|
||||
|
||||
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
|
||||
|
||||
### 卷毛狗攻击(POODLE)和 TLS-FALLBACK-SCSV ###
|
||||
|
||||
SSLv3 会受到[卷毛狗漏洞(POODLE)][16]的攻击。这是禁用 SSLv3 的主要原因之一。
|
||||
|
||||
Google 提出了一个名为 [TLS\_FALLBACK\_SCSV][17] 的SSL/TLS 扩展,它用于防止强制 SSL 降级。如果你升级 到下述的 OpenSSL 版本会自动启用它。
|
||||
|
||||
- OpenSSL 1.0.1 带有 TLS\_FALLBACK\_SCSV 1.0.1j 及更高。
|
||||
- OpenSSL 1.0.0 带有 TLS\_FALLBACK\_SCSV 1.0.0o 及更高。
|
||||
- OpenSSL 0.9.8 带有 TLS\_FALLBACK\_SCSV 0.9.8zc 及更高。
|
||||
|
||||
[更多信息请参照 NGINX 文档][18]。
|
||||
|
||||
### 加密套件(cipher suite) ###
|
||||
|
||||
前向安全性(Forward Secrecy)用于在长期密钥被破解时确保会话密钥的完整性。PFS(完备的前向安全性)是指强制在每个/每次会话中推导新的密钥。
|
||||
|
||||
这就是说,泄露的私钥并不能用来解密(之前)记录下来的 SSL 通讯。
|
||||
|
||||
提供PFS(完备的前向安全性)功能的是那些使用了一种 Diffie-Hellman 密钥交换的短暂形式的加密套件。它们的缺点是系统开销较大,不过可以使用椭圆曲线的变体来改进。
|
||||
|
||||
以下两个加密套件是我推荐的,之后[Mozilla 基金会][19]也推荐了。
|
||||
|
||||
推荐的加密套件:
|
||||
|
||||
ssl_ciphers 'AES128+EECDH:AES128+EDH';
|
||||
|
||||
向后兼容的推荐的加密套件(IE6/WinXP):
|
||||
|
||||
ssl_ciphers "ECDHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA256:ECDHE-RSA-AES256-SHA:ECDHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES128-SHA256:DHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES256-GCM-SHA384:AES128-GCM-SHA256:AES256-SHA256:AES128-SHA256:AES256-SHA:AES128-SHA:DES-CBC3-SHA:HIGH:!aNULL:!eNULL:!EXPORT:!DES:!MD5:!PSK:!RC4";
|
||||
|
||||
如果你的 OpenSSL 版本比较旧,不可用的加密算法会自动丢弃。应该一直使用上述的完整套件,让 OpenSSL 选择一个它所支持的。
|
||||
|
||||
加密套件的顺序是非常重要的,因为其决定了优先选择哪个算法。上述优先推荐的算法中提供了PFS(完备的前向安全性)。
|
||||
|
||||
较旧版本的 OpenSSL 也许不能支持这个算法的完整列表,AES-GCM 和一些 ECDHE 算法是相当新的,在 Ubuntu 和 RHEL 中所带的绝大多数 OpenSSL 版本中不支持。
|
||||
|
||||
#### 优先顺序的逻辑 ####
|
||||
|
||||
- ECDHE+AESGCM 加密是首选的。它们是 TLS 1.2 加密算法,现在还没有广泛支持。当前还没有对它们的已知攻击。
|
||||
- PFS 加密套件好一些,首选 ECDHE,然后是 DHE。
|
||||
- AES 128 要好于 AES 256。有一个关于 AES256 带来的安全提升程度是否值回成本的[讨论][20],结果是显而易见的。目前,AES128 要更值一些,因为它提供了不错的安全水准,确实很快,而且看起来对时序攻击更有抵抗力。
|
||||
- 在向后兼容的加密套件里面,AES 要优于 3DES。在 TLS 1.1及其以上,减轻了针对 AES 的野兽攻击(BEAST)的威胁,而在 TLS 1.0上则难以实现该攻击。在非向后兼容的加密套件里面,不支持 3DES。
|
||||
- RC4 整个不支持了。3DES 用于向后兼容。参看 [#RC4\_weaknesses][21] 中的讨论。
|
||||
|
||||
#### 强制丢弃的算法 ####
|
||||
|
||||
- aNULL 包含了非验证的 Diffie-Hellman 密钥交换,这会受到中间人(MITM)攻击
|
||||
- eNULL 包含了无加密的算法(明文)
|
||||
- EXPORT 是老旧的弱加密算法,是被美国法律标示为可出口的
|
||||
- RC4 包含的加密算法使用了已弃用的 ARCFOUR 算法
|
||||
- DES 包含的加密算法使用了弃用的数据加密标准(DES)
|
||||
- SSLv2 包含了定义在旧版本 SSL 标准中的所有算法,现已弃用
|
||||
- MD5 包含了使用已弃用的 MD5 作为哈希算法的所有算法
|
||||
|
||||
### 更多设置 ###
|
||||
|
||||
确保你也添加了如下行:
|
||||
|
||||
ssl_prefer_server_ciphers on;
|
||||
ssl_session_cache shared:SSL:10m;
|
||||
|
||||
在一个 SSLv3 或 TLSv1 握手过程中选择一个加密算法时,一般使用客户端的首选算法。如果设置了上述配置,则会替代地使用服务器端的首选算法。
|
||||
|
||||
- [关于 ssl\_prefer\_server\_ciphers 的更多信息][22]
|
||||
- [关于 ssl\_ciphers 的更多信息][23]
|
||||
|
||||
### 前向安全性和 Diffie Hellman Ephemeral (DHE)参数 ###
|
||||
|
||||
前向安全性(Forward Secrecy)的概念很简单:客户端和服务器协商一个永不重用的密钥,并在会话结束时销毁它。服务器上的 RSA 私钥用于客户端和服务器之间的 Diffie-Hellman 密钥交换签名。从 Diffie-Hellman 握手中获取的预主密钥会用于之后的编码。因为预主密钥是特定于客户端和服务器之间建立的某个连接,并且只用在一个限定的时间内,所以称作短暂模式(Ephemeral)。
|
||||
|
||||
使用了前向安全性,如果一个攻击者取得了一个服务器的私钥,他是不能解码之前的通讯信息的。这个私钥仅用于 Diffie Hellman 握手签名,并不会泄露预主密钥。Diffie Hellman 算法会确保预主密钥绝不会离开客户端和服务器,而且不能被中间人攻击所拦截。
|
||||
|
||||
所有版本的 nginx(如1.4.4)都依赖于 OpenSSL 给 Diffie-Hellman (DH)的输入参数。不幸的是,这意味着 Diffie-Hellman Ephemeral(DHE)将使用 OpenSSL 的默认设置,包括一个用于密钥交换的1024位密钥。因为我们正在使用2048位证书,DHE 客户端就会使用一个要比非 DHE 客户端更弱的密钥交换。
|
||||
|
||||
我们需要生成一个更强壮的 DHE 参数:
|
||||
|
||||
cd /etc/ssl/certs
|
||||
openssl dhparam -out dhparam.pem 4096
|
||||
|
||||
然后告诉 nginx 将其用作 DHE 密钥交换:
|
||||
|
||||
ssl_dhparam /etc/ssl/certs/dhparam.pem;
|
||||
|
||||
### OCSP 装订(Stapling) ###
|
||||
|
||||
当连接到一个服务器时,客户端应该使用证书吊销列表(CRL)或在线证书状态协议(OCSP)记录来校验服务器证书的有效性。CRL 的问题是它已经增长的太大了,永远也下载不完了。
|
||||
|
||||
OCSP 更轻量级一些,因为我们每次只请求一条记录。但是副作用是当连接到一个服务器时必须对第三方 OCSP 响应器发起 OCSP 请求,这就增加了延迟和带来了潜在隐患。事实上,CA 所运营的 OCSP 响应器非常不可靠,浏览器如果不能及时收到答复,就会静默失败。攻击者通过 DoS 攻击一个 OCSP 响应器可以禁用其校验功能,这样就降低了安全性。
|
||||
|
||||
解决方法是允许服务器在 TLS 握手中发送缓存的 OCSP 记录,以绕开 OCSP 响应器。这个机制节省了客户端和 OCSP 响应器之间的通讯,称作 OCSP 装订。
|
||||
|
||||
客户端会在它的 CLIENT HELLO 中告知其支持 status\_request TLS 扩展,服务器仅在客户端请求它的时候才发送缓存的 OCSP 响应。
|
||||
|
||||
大多数服务器最多会缓存 OCSP 响应48小时。服务器会按照常规的间隔连接到 CA 的 OCSP 响应器来获取刷新的 OCSP 记录。OCSP 响应器的位置可以从签名的证书中的授权信息访问(Authority Information Access)字段中获得。
|
||||
|
||||
- [阅读我的教程:在 NGINX 中启用 OCSP 装订][24]
|
||||
|
||||
### HTTP 严格传输安全(HSTS) ###
|
||||
|
||||
如有可能,你应该启用 [HTTP 严格传输安全(HSTS)][25],它会引导浏览器和你的站点之间的通讯仅通过 HTTPS。
|
||||
|
||||
- [阅读我关于 HSTS 的文章,了解如何配置它][26]
|
||||
|
||||
### HTTP 公钥固定扩展(HPKP) ###
|
||||
|
||||
你也应该启用 [HTTP 公钥固定扩展(HPKP)][27]。
|
||||
|
||||
公钥固定的意思是一个证书链必须包括一个白名单中的公钥。它确保仅有白名单中的 CA 才能够为某个域名签署证书,而不是你的浏览器中存储的任何 CA。
|
||||
|
||||
我已经写了一篇[关于 HPKP 的背景理论及在 Apache、Lighttpd 和 NGINX 中配置例子的文章][28]。
|
||||
|
||||
### 配置范例 ###
|
||||
|
||||
server {
|
||||
|
||||
listen [::]:443 default_server;
|
||||
|
||||
ssl on;
|
||||
ssl_certificate_key /etc/ssl/cert/raymii_org.pem;
|
||||
ssl_certificate /etc/ssl/cert/ca-bundle.pem;
|
||||
|
||||
ssl_ciphers 'AES128+EECDH:AES128+EDH:!aNULL';
|
||||
|
||||
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
|
||||
ssl_session_cache shared:SSL:10m;
|
||||
|
||||
ssl_stapling on;
|
||||
ssl_stapling_verify on;
|
||||
resolver 8.8.4.4 8.8.8.8 valid=300s;
|
||||
resolver_timeout 10s;
|
||||
|
||||
ssl_prefer_server_ciphers on;
|
||||
ssl_dhparam /etc/ssl/certs/dhparam.pem;
|
||||
|
||||
add_header Strict-Transport-Security max-age=63072000;
|
||||
add_header X-Frame-Options DENY;
|
||||
add_header X-Content-Type-Options nosniff;
|
||||
|
||||
root /var/www/;
|
||||
index index.html index.htm;
|
||||
server_name raymii.org;
|
||||
|
||||
}
|
||||
|
||||
### 结尾 ###
|
||||
|
||||
如果你使用了上述配置,你需要重启 nginx:
|
||||
|
||||
# 首先检查配置文件是否正确
|
||||
/etc/init.d/nginx configtest
|
||||
# 然后重启
|
||||
/etc/init.d/nginx restart
|
||||
|
||||
现在使用 [SSL Labs 测试][29]来看看你是否能得到一个漂亮的“A”。当然了,你也得到了一个安全的、强壮的、经得起考验的 SSL 配置!
|
||||
|
||||
- [参考 Mozilla 关于这方面的内容][30]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://raymii.org/s/tutorials/Strong_SSL_Security_On_nginx.html
|
||||
|
||||
作者:[Remy van Elst][a]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://raymii.org/
|
||||
[1]:https://www.ssllabs.com/ssltest/analyze.html?d=raymii.org
|
||||
[2]:https://cipherli.st/
|
||||
[3]:https://www.digitalocean.com/?refcode=7435ae6b8212
|
||||
[4]:http://blog.ivanristic.com/2014/01/ssl-labs-stricter-security-requirements-for-2014.html
|
||||
[5]:https://raymii.org/s/tutorials/Strong_SSL_Security_On_Apache2.html
|
||||
[6]:https://raymii.org/s/tutorials/Pass_the_SSL_Labs_Test_on_Lighttpd_%28Mitigate_the_CRIME_and_BEAST_attack_-_Disable_SSLv2_-_Enable_PFS%29.html
|
||||
[7]:http://www.bsdnow.tv/episodes/2014_08_20-engineering_nginx
|
||||
[8]:http://www.bsdnow.tv/tutorials/nginx
|
||||
[9]:https://en.wikipedia.org/wiki/Transport_Layer_Security#BEAST_attack
|
||||
[10]:https://en.wikipedia.org/wiki/CRIME_%28security_exploit%29
|
||||
[11]:http://blog.cryptographyengineering.com/2015/03/attack-of-week-freak-or-factoring-nsa.html
|
||||
[12]:http://heartbleed.com/
|
||||
[13]:https://en.wikipedia.org/wiki/Perfect_forward_secrecy
|
||||
[14]:https://en.wikipedia.org/wiki/Transport_Layer_Security#Dealing_with_RC4_and_BEAST
|
||||
[15]:https://www.smacktls.com/
|
||||
[16]:https://raymii.org/s/articles/Check_servers_for_the_Poodle_bug.html
|
||||
[17]:https://tools.ietf.org/html/draft-ietf-tls-downgrade-scsv-00
|
||||
[18]:http://wiki.nginx.org/HttpSslModule#ssl_protocols
|
||||
[19]:https://wiki.mozilla.org/Security/Server_Side_TLS
|
||||
[20]:http://www.mail-archive.com/dev-tech-crypto@lists.mozilla.org/msg11247.html
|
||||
[21]:https://wiki.mozilla.org/Security/Server_Side_TLS#RC4_weaknesses
|
||||
[22]:http://wiki.nginx.org/HttpSslModule#ssl_prefer_server_ciphers
|
||||
[23]:http://wiki.nginx.org/HttpSslModule#ssl_ciphers
|
||||
[24]:https://raymii.org/s/tutorials/OCSP_Stapling_on_nginx.html
|
||||
[25]:https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security
|
||||
[26]:https://linux.cn/article-5266-1.html
|
||||
[27]:https://wiki.mozilla.org/SecurityEngineering/Public_Key_Pinning
|
||||
[28]:https://linux.cn/article-5282-1.html
|
||||
[29]:https://www.ssllabs.com/ssltest/
|
||||
[30]:https://wiki.mozilla.org/Security/Server_Side_TLS
|
||||
@ -1,24 +1,24 @@
|
||||
Linux ‘sort’命令的14个有用的范例 -- 第一部分
|
||||
Linux 的 ‘sort’命令的14个有用的范例(一)
|
||||
=============================================================
|
||||
Sort是用于对单个或多个文本文件内容进行排序的Linux程序。Sort命令以空格作为字段分隔符,将一行分割为多个关键字对文件进行排序。需要注意的是除非你将输出重定向到文件中,否则Sort命令并不对文件内容进行实际的排序(即文件内容没有修改),只是将文件内容按有序输出。
|
||||
|
||||
本文的目标是通过14个实际的范例让你更深刻的理解如何在Linux中使用sort命令。
|
||||
|
||||
###1. 首先我们将会创建一个用于执行‘sort’命令的文本文件(tecmint.txt)。工作路径是‘/home/$USER/Desktop/tecmint’。###
|
||||
1、 首先我们将会创建一个用于执行‘sort’命令的文本文件(tecmint.txt)。工作路径是‘/home/$USER/Desktop/tecmint’。
|
||||
|
||||
下面命令中的‘-e’选项将‘/’和‘/n’解析成一个新行
|
||||
下面命令中的‘-e’选项将启用‘\\’转义,将‘\n’解析成换行
|
||||
|
||||
$ echo -e "computer\nmouse\nLAPTOP\ndata\nRedHat\nlaptop\ndebian\nlaptop" > tecmint.txt
|
||||
|
||||
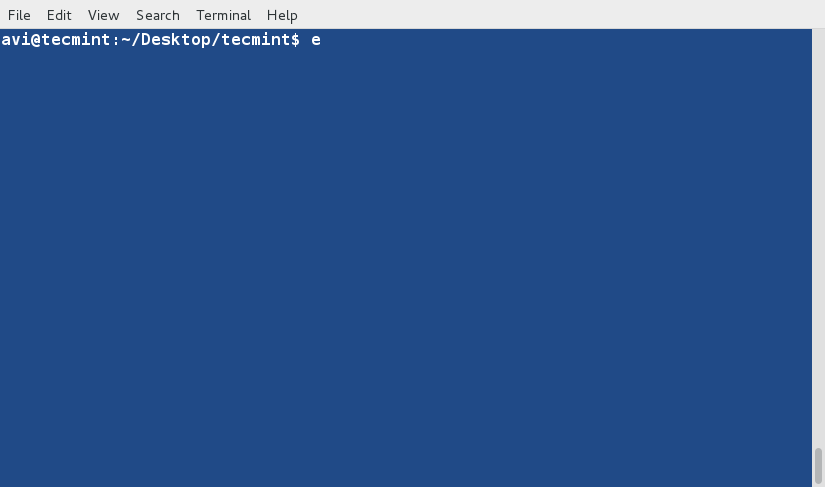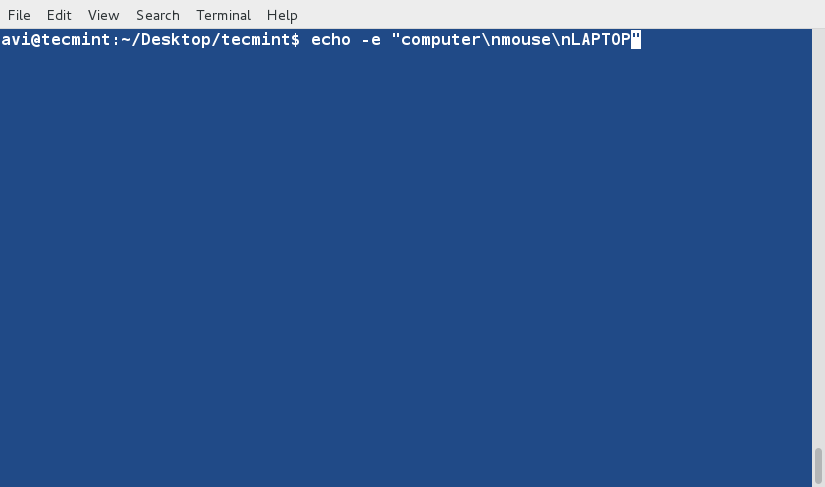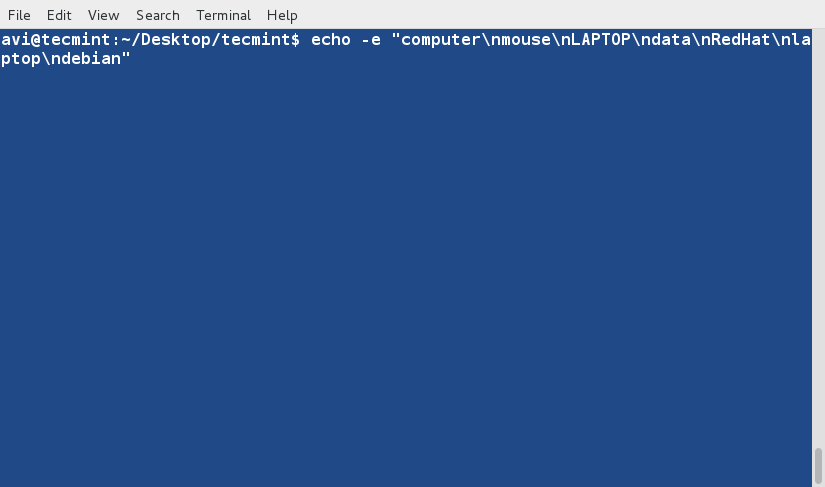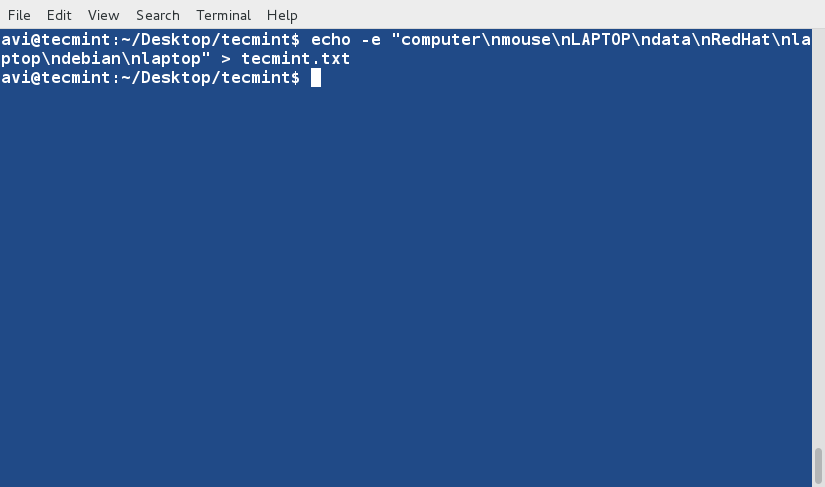
|
||||
|
||||
###2. 在开始学习‘sort’命令前,我们先看看文件的内容及其显示方式。###
|
||||
2、 在开始学习‘sort’命令前,我们先看看文件的内容及其显示方式。
|
||||
|
||||
$ cat tecmint.txt
|
||||
|
||||
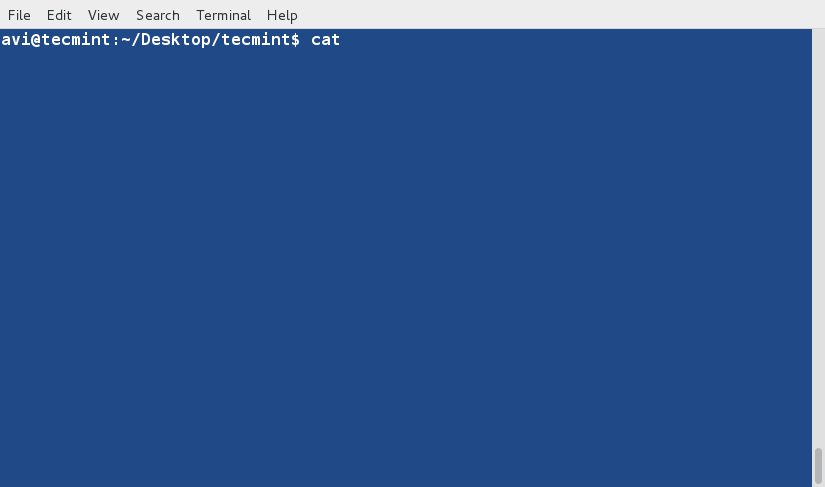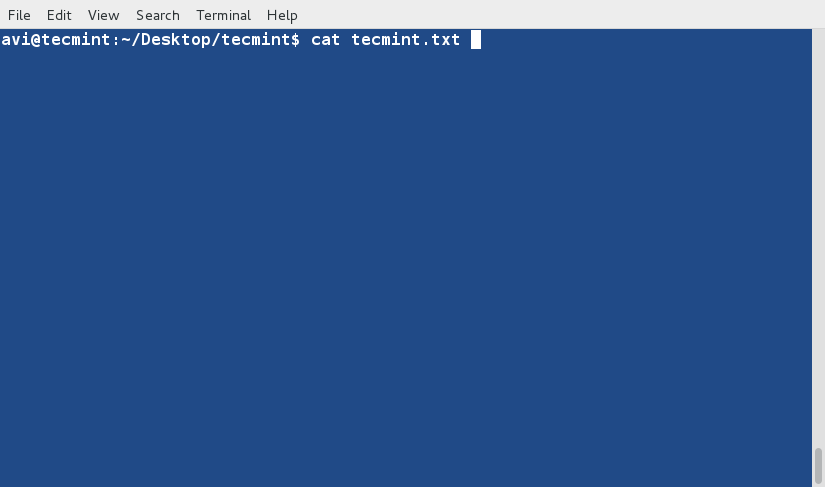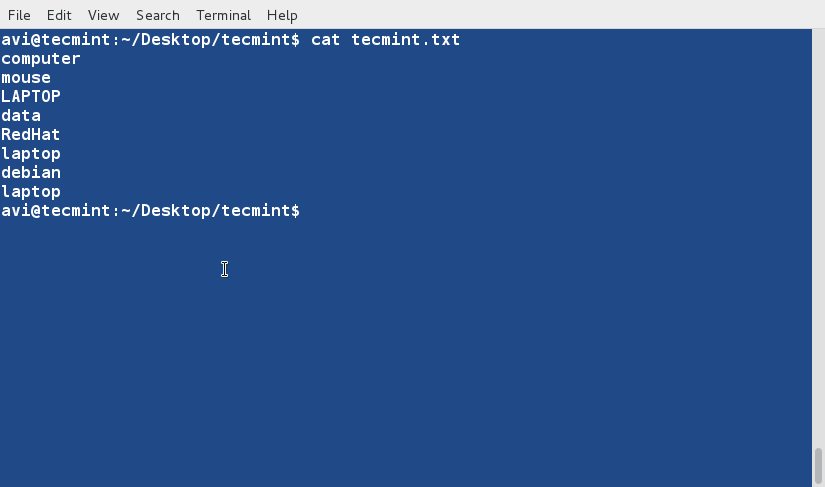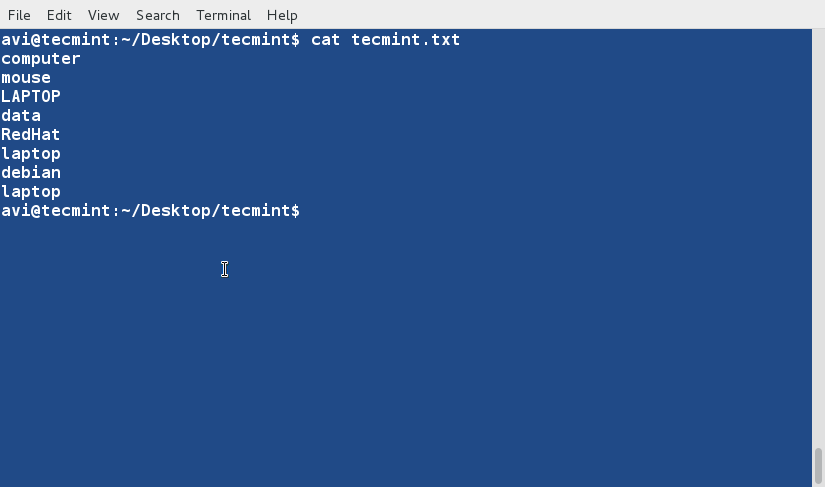
|
||||
|
||||
###3. 现在,使用如下命令对文件内容进行排序。###
|
||||
3、 现在,使用如下命令对文件内容进行排序。
|
||||
|
||||
$ sort tecmint.txt
|
||||
|
||||
@ -26,30 +26,30 @@ Sort是用于对单个或多个文本文件内容进行排序的Linux程序。So
|
||||
|
||||
**注意**:上面的命令并不对文件内容进行实际的排序,仅仅是将其内容按有序方式输出。
|
||||
|
||||
###4. 对文件‘tecmint.txt’文件内容排序,并将排序后的内容输出到名为sorted.txt的文件中,然后使用[cat][1]命令查看验证sorted.txt文件的内容。###
|
||||
4、 对文件‘tecmint.txt’文件内容排序,并将排序后的内容输出到名为sorted.txt的文件中,然后使用[cat][1]命令查看验证sorted.txt文件的内容。
|
||||
|
||||
$ sort tecmint.txt > sorted.txt
|
||||
$ cat sorted.txt
|
||||
|
||||
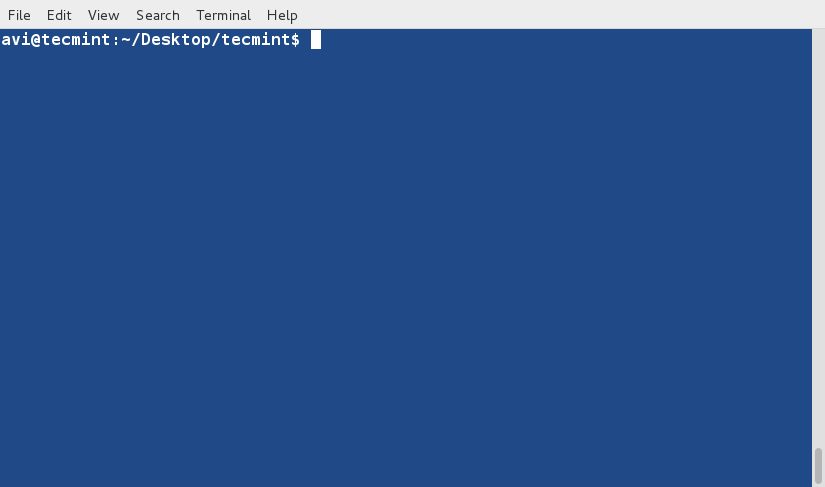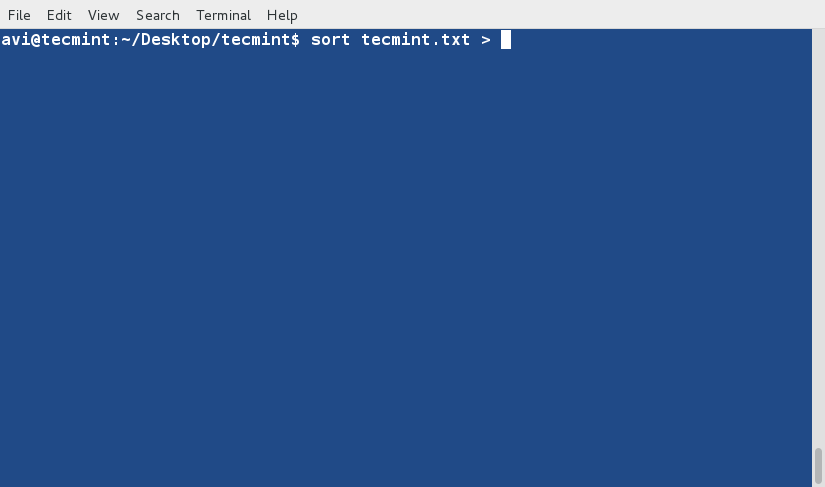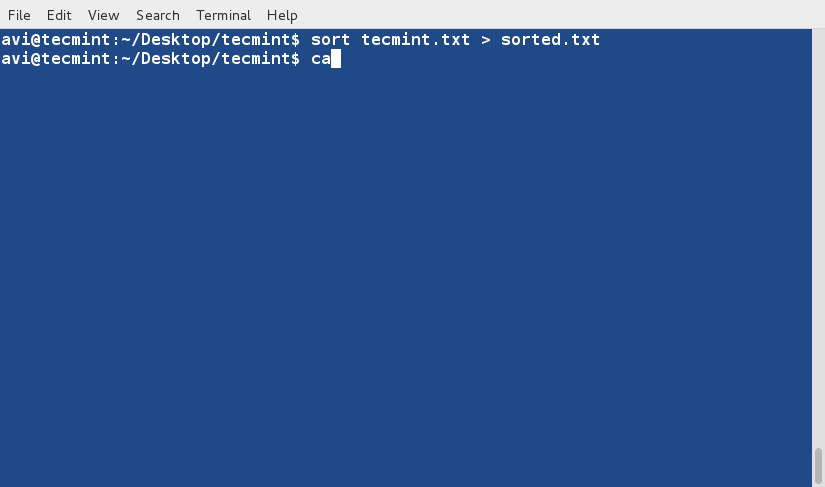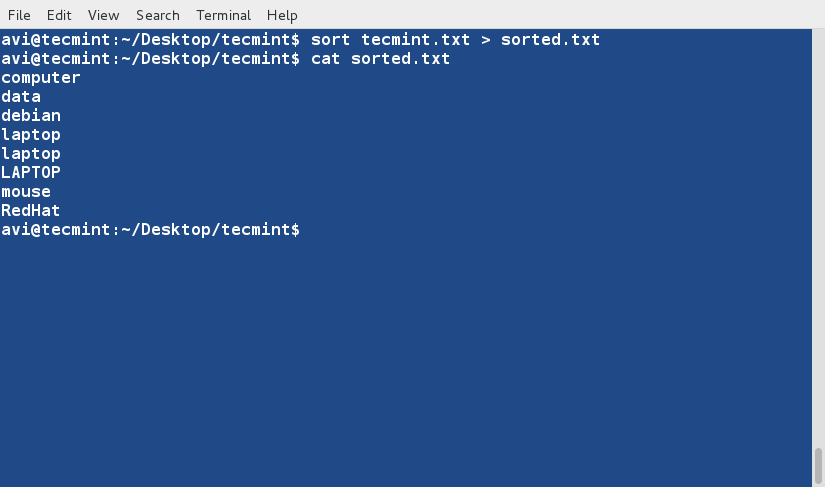
|
||||
|
||||
###5. 现在使用‘-r’参数对‘tecmint.txt’文件内容进行逆序排序,并将输出内容重定向到‘reversesorted.txt’文件中,并使用cat命令查看文件的内容。###
|
||||
5、 现在使用‘-r’参数对‘tecmint.txt’文件内容进行逆序排序,并将输出内容重定向到‘reversesorted.txt’文件中,并使用cat命令查看文件的内容。
|
||||
|
||||
$ sort -r tecmint.txt > reversesorted.txt
|
||||
$ cat reversesorted.txt
|
||||
|
||||
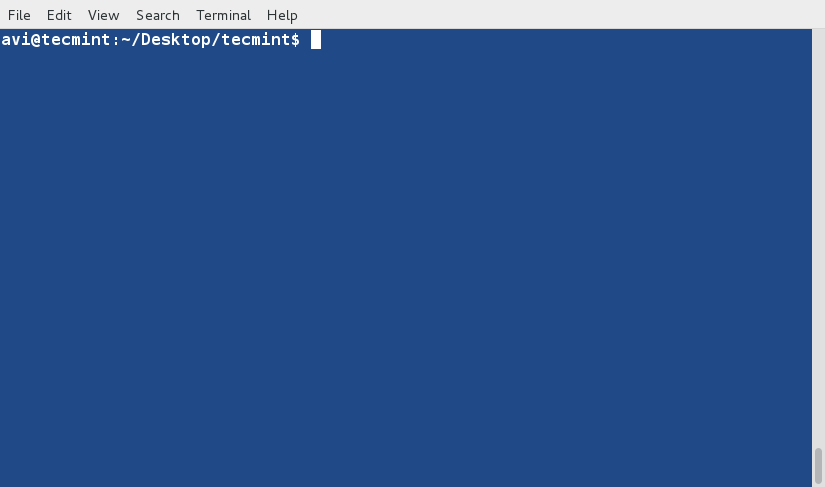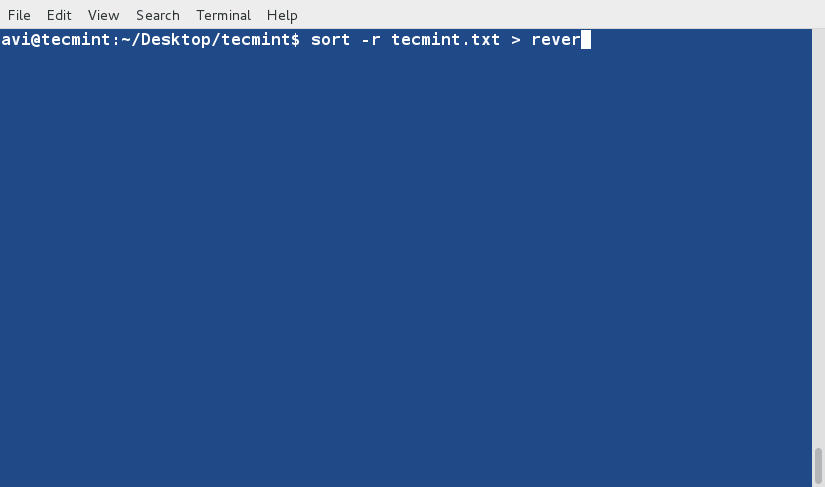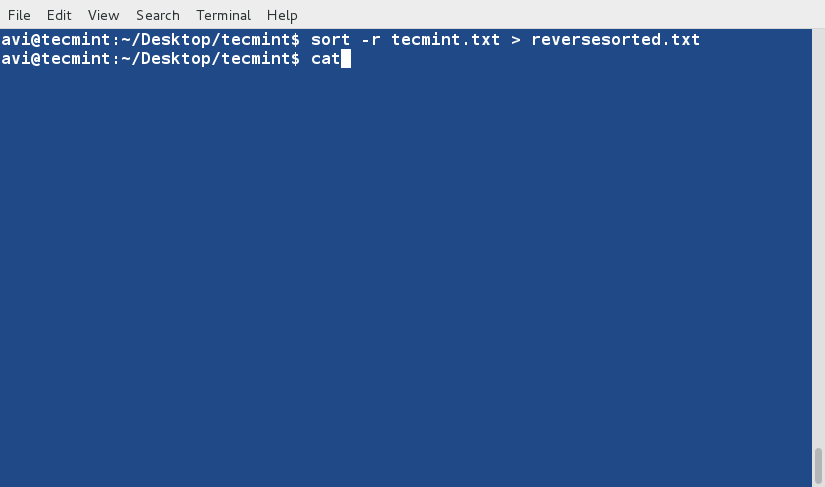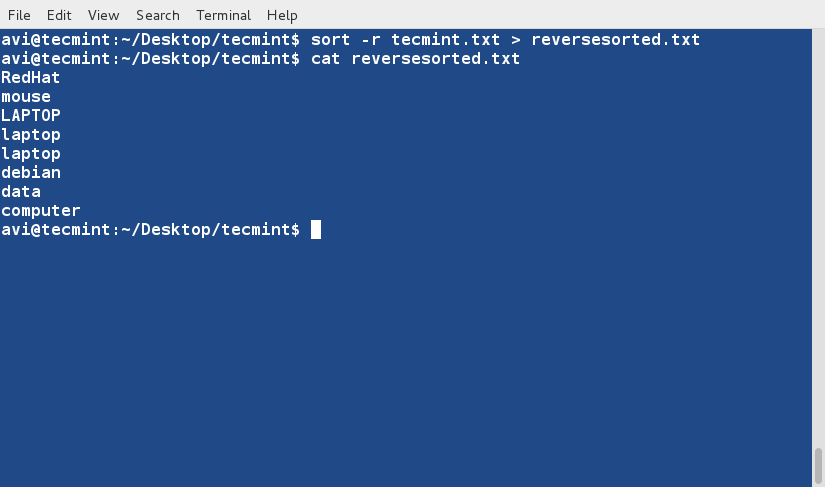
|
||||
|
||||
###6. 创建一个新文件(lsl.txt),文件内容为在home目录下执行‘ls -l’命令的输出。###
|
||||
6、 创建一个新文件(lsl.txt),文件内容为在home目录下执行‘ls -l’命令的输出。
|
||||
|
||||
$ ls -l /home/$USER > /home/$USER/Desktop/tecmint/lsl.txt
|
||||
$ cat lsl.txt
|
||||
|
||||
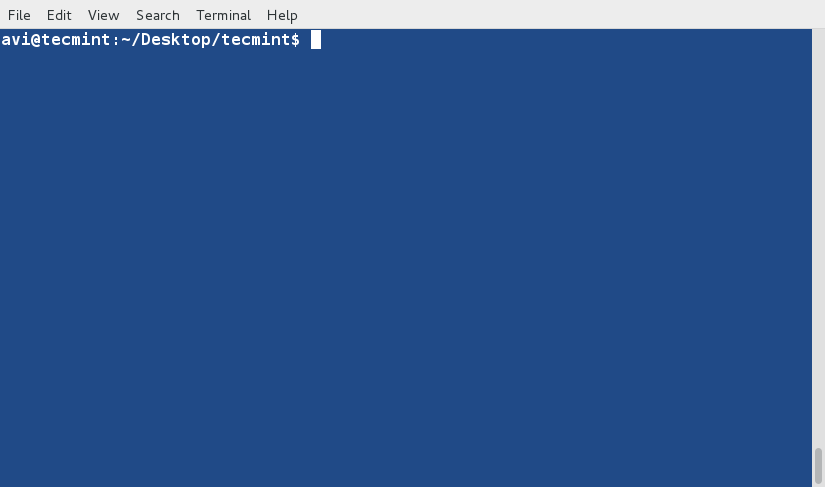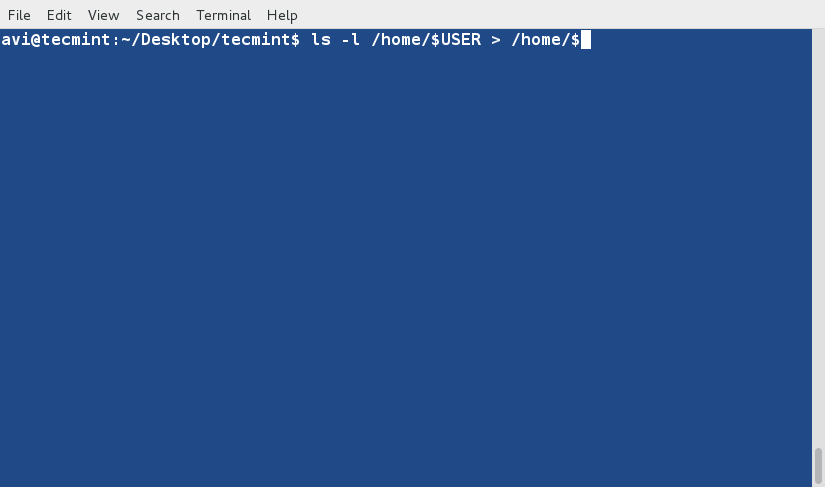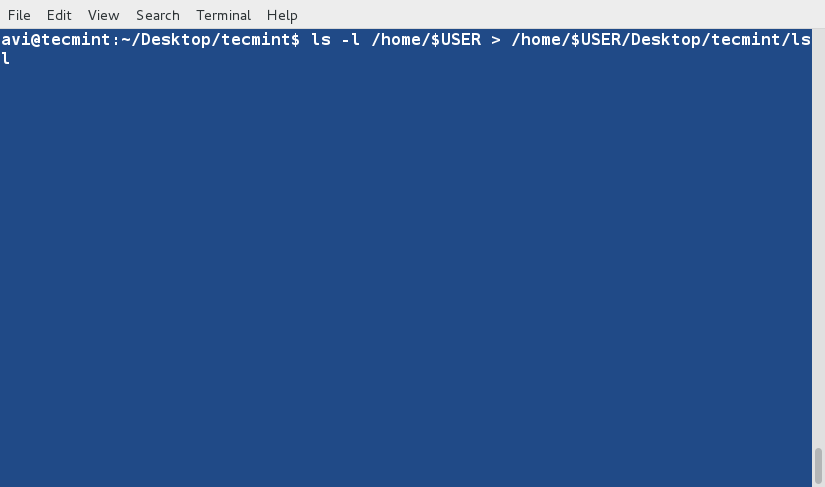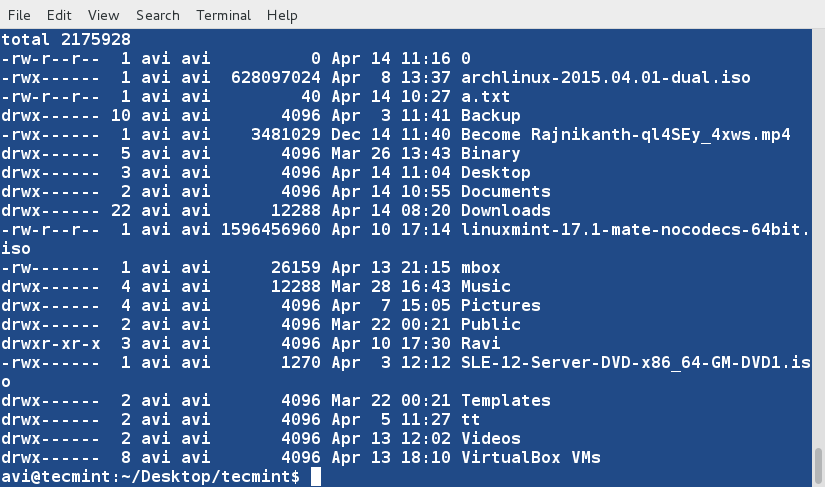
|
||||
|
||||
我们将会看到对其他基础字段进行排序的例子,而不是对默认的初始字符进行排序。
|
||||
我们将会看到对其他字段进行排序的例子,而不是对默认的开始字符进行排序。
|
||||
|
||||
###7. 基于第二列(符号连接的数量)对文件‘lsl.txt’进行排序。###
|
||||
7、 基于第二列(符号连接的数量)对文件‘lsl.txt’进行排序。
|
||||
|
||||
$ sort -nk2 lsl.txt
|
||||
|
||||
@ -57,19 +57,19 @@ Sort是用于对单个或多个文本文件内容进行排序的Linux程序。So
|
||||
|
||||

|
||||
|
||||
###8. 基于第9列(文件和目录的名称,非数值)对文件‘lsl.txt’进行排序。###
|
||||
8、 基于第9列(文件和目录的名称,非数值)对文件‘lsl.txt’进行排序。
|
||||
|
||||
$ sort -k9 lsl.txt
|
||||
|
||||
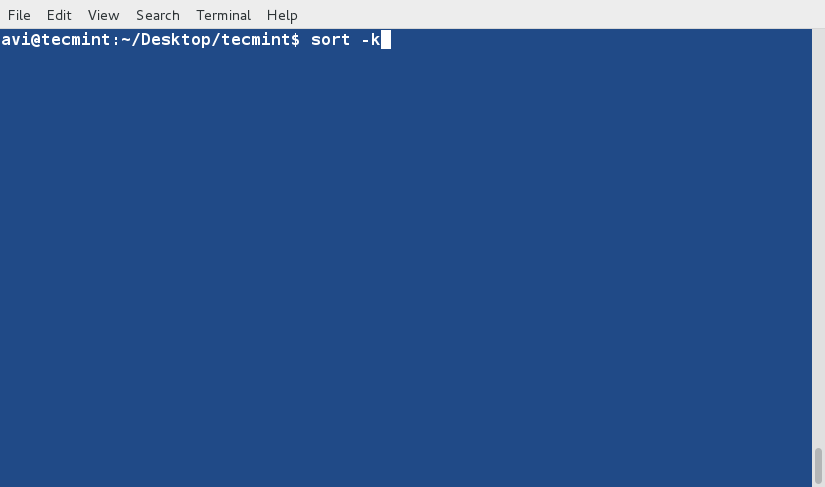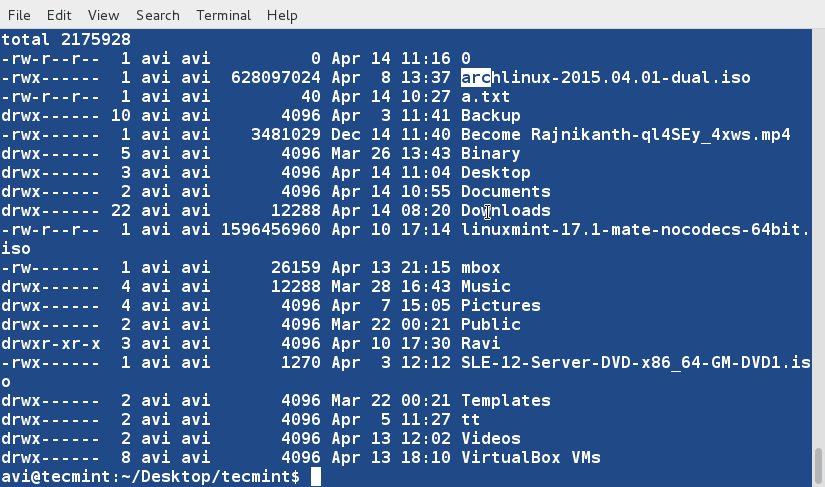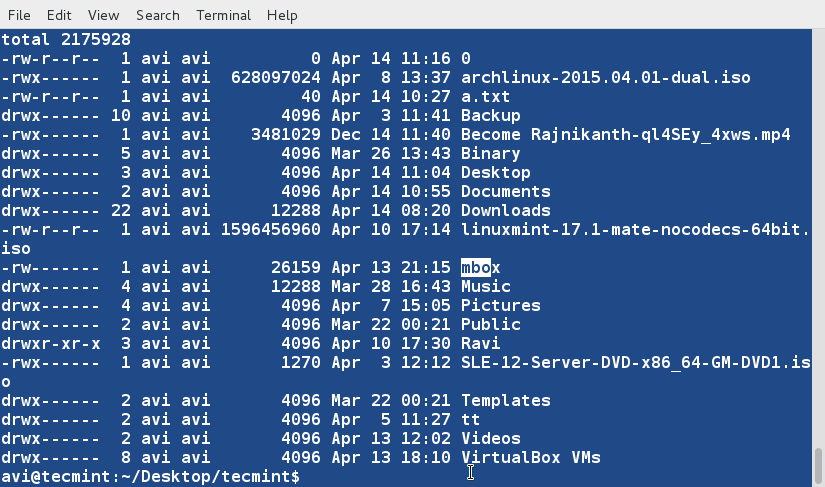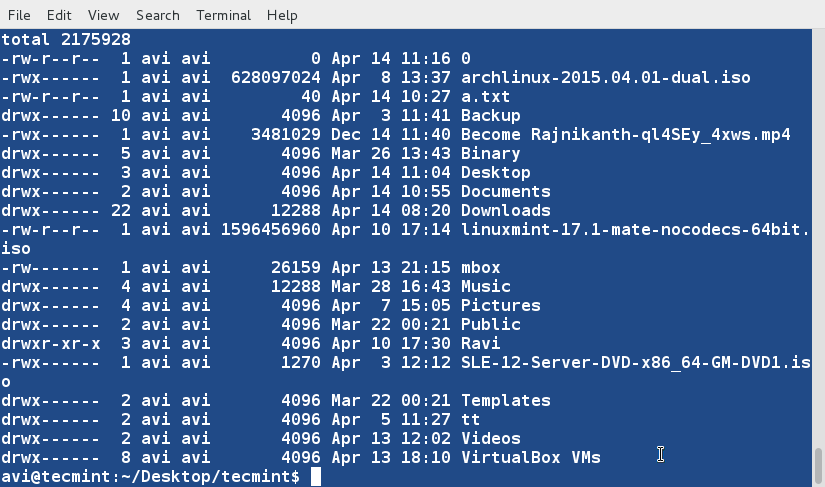
|
||||
|
||||
###9. sort命令并非仅能对文件进行排序,我们还可以通过管道将命令的输出内容重定向到sort命令中。###
|
||||
9、 sort命令并非仅能对文件进行排序,我们还可以通过管道将命令的输出内容重定向到sort命令中。
|
||||
|
||||
$ ls -l /home/$USER | sort -nk5
|
||||
|
||||
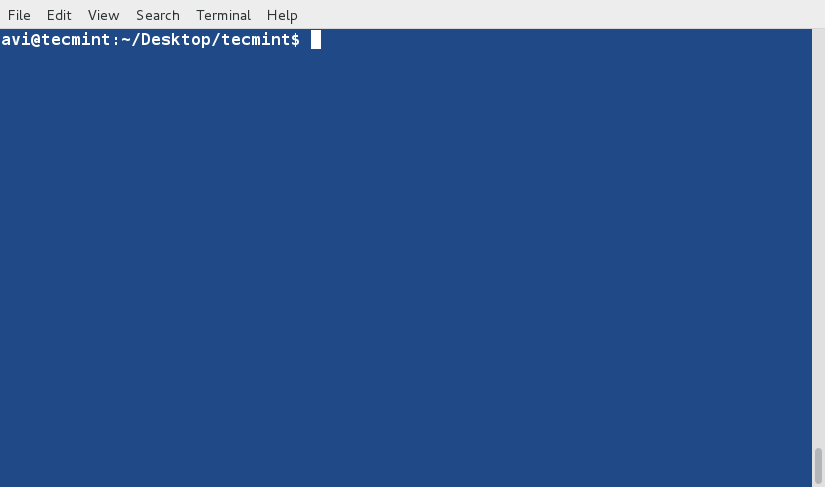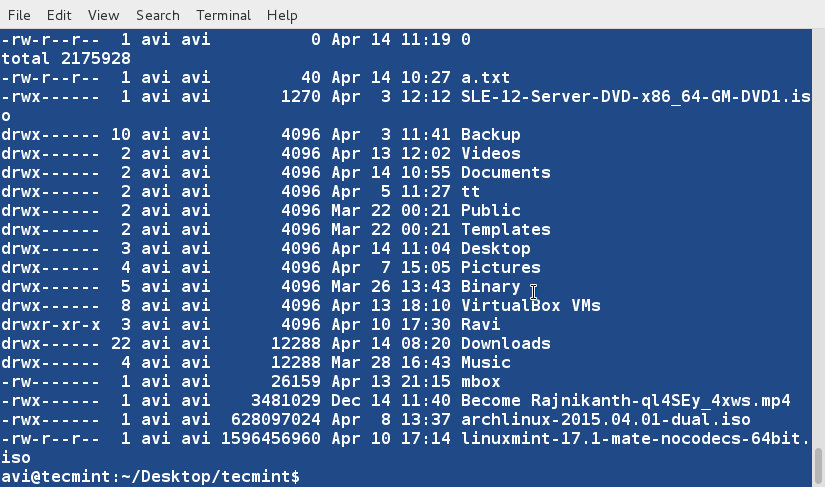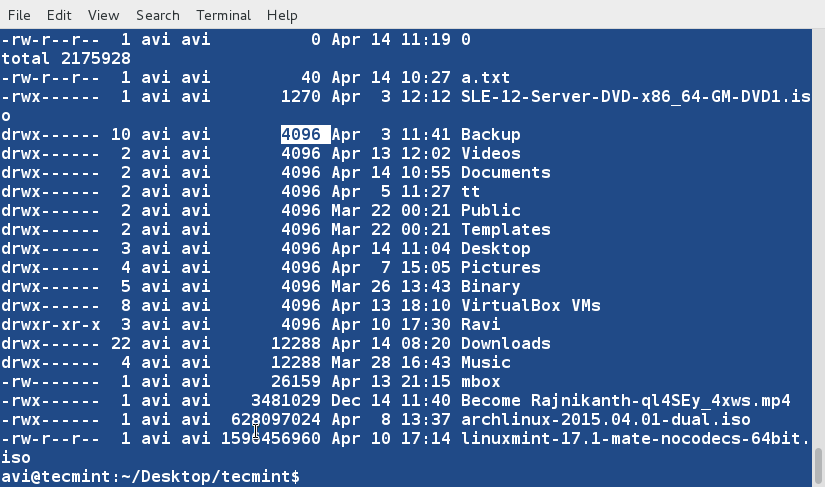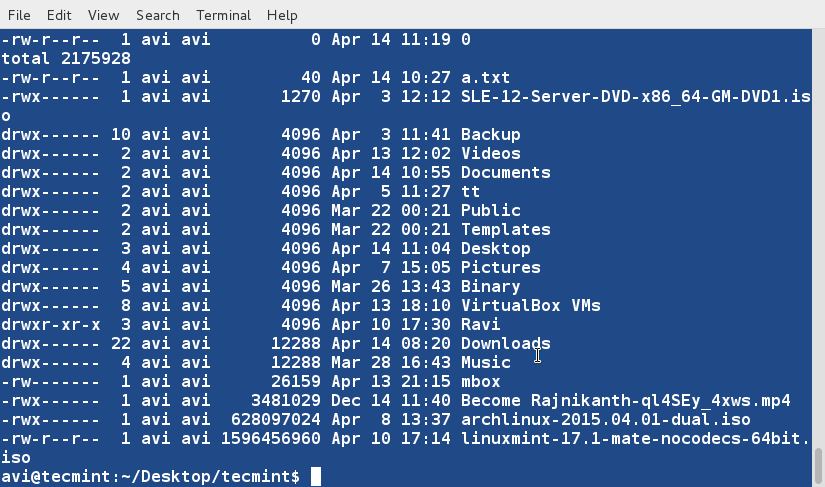
|
||||
|
||||
###10. 对文件tecmint.txt进行排序,并删除重复的行。然后检查重复的行是否已经删除了。###
|
||||
10、 对文件tecmint.txt进行排序,并删除重复的行。然后检查重复的行是否已经删除了。
|
||||
|
||||
$ cat tecmint.txt
|
||||
$ sort -u tecmint.txt
|
||||
@ -78,23 +78,23 @@ Sort是用于对单个或多个文本文件内容进行排序的Linux程序。So
|
||||
|
||||
目前我们发现的排序规则:
|
||||
|
||||
除非指定了‘-r’参数,否则排序的优先级按下面规则排序
|
||||
除非指定了‘-r’参数,否则排序的优先级按下面规则排序
|
||||
|
||||
- 以数字开头的行优先级最高
|
||||
- 以小写字母开头的行优先级次之
|
||||
- 待排序内容按字典序进行排序
|
||||
- 默认情况下,‘sort’命令将带排序内容的每行关键字当作一个字符串进行字典序排序(数字优先级最高,参看规则 - 1)
|
||||
- 默认情况下,‘sort’命令将带排序内容的每行关键字当作一个字符串进行字典序排序(数字优先级最高,参看规则 1)
|
||||
|
||||
|
||||
###11. 创建文件‘lsla.txt’,其内容用‘ls -la’命令的输出内容填充。###
|
||||
11、 在当前位置创建第三个文件‘lsla.txt’,其内容用‘ls -lA’命令的输出内容填充。
|
||||
|
||||
$ ls -lA /home/$USER > /home/$USER/Desktop/tecmint/lsla.txt
|
||||
$ cat lsla.txt
|
||||
|
||||
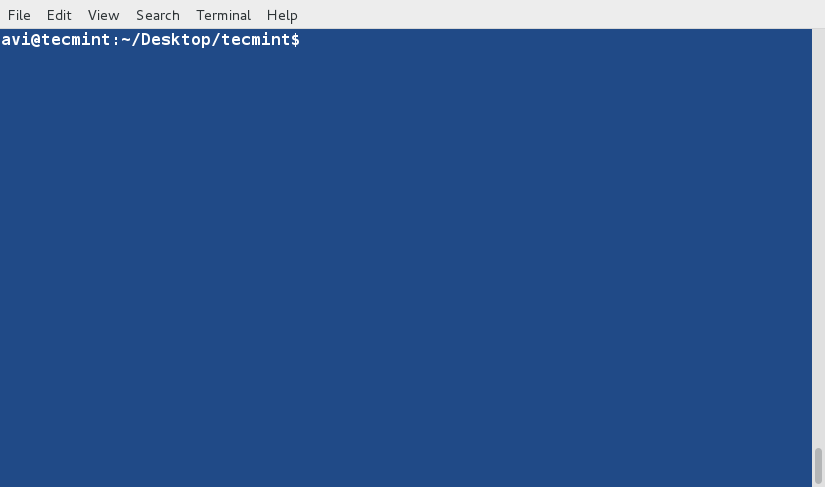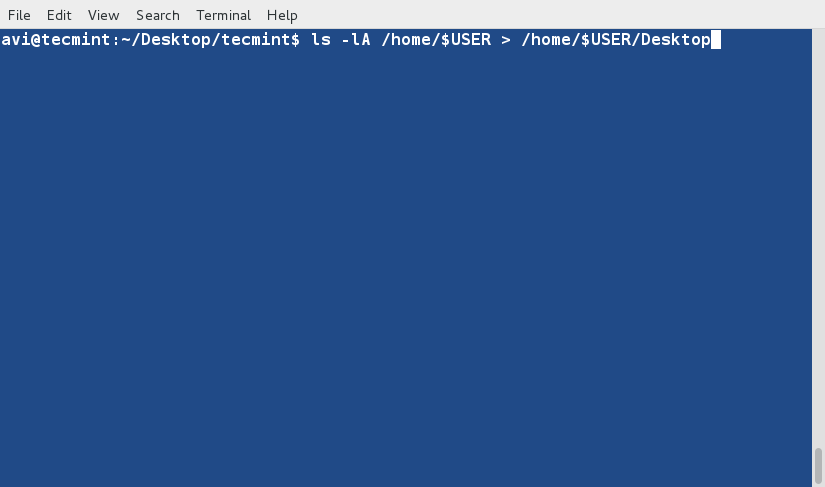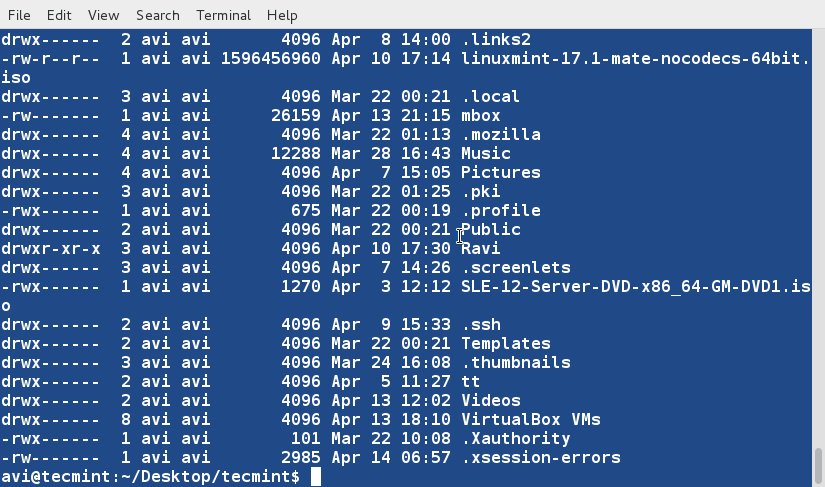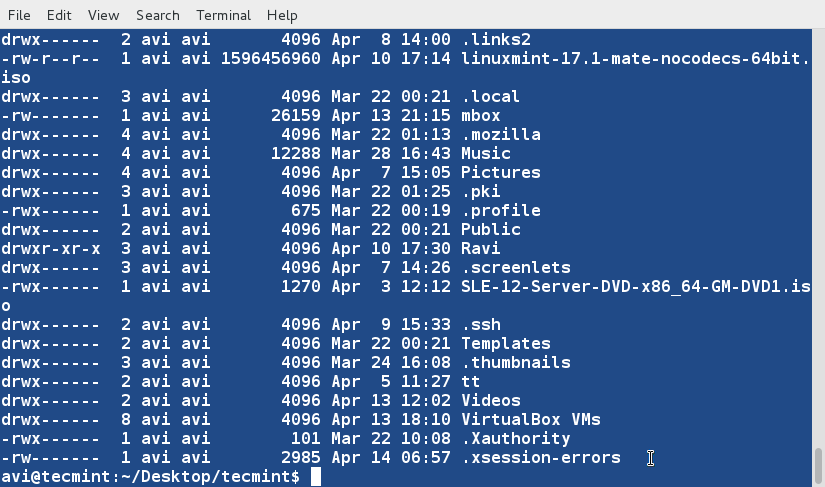
|
||||
|
||||
了解ls命令的读者都知道‘ls -la’=‘ls -l’ + 隐藏文件。因此这两个文件的大部分内容都是相同的。
|
||||
了解ls命令的读者都知道‘ls -lA’ 等于 ‘ls -l’ + 隐藏文件,所以这两个文件的大部分内容都是相同的。
|
||||
|
||||
###12. 对上面两个文件内容进行排序输出。###
|
||||
12、 对上面两个文件内容进行排序输出。
|
||||
|
||||
$ sort lsl.txt lsla.txt
|
||||
|
||||
@ -102,7 +102,7 @@ Sort是用于对单个或多个文本文件内容进行排序的Linux程序。So
|
||||
|
||||
注意文件和目录的重复
|
||||
|
||||
###13. 现在我们看看怎样对两个文件进行排序、合并,并且删除重复行。###
|
||||
13、 现在我们看看怎样对两个文件进行排序、合并,并且删除重复行。
|
||||
|
||||
$ sort -u lsl.txt lsla.txt
|
||||
|
||||
@ -110,13 +110,13 @@ Sort是用于对单个或多个文本文件内容进行排序的Linux程序。So
|
||||
|
||||
此时,我们注意到重复的行已经被删除了,我们可以将输出内容重定向到文件中。
|
||||
|
||||
###14. 我们同样可以基于多列对文件内容进行排序。基于第2,5(数值)和9(非数值)列对‘ls -l’命令的输出进行排序。###
|
||||
14、 我们同样可以基于多列对文件内容进行排序。基于第2,5(数值)和9(非数值)列对‘ls -l’命令的输出进行排序。
|
||||
|
||||
$ ls -l /home/$USER | sort -t "," -nk2,5 -k9
|
||||
|
||||
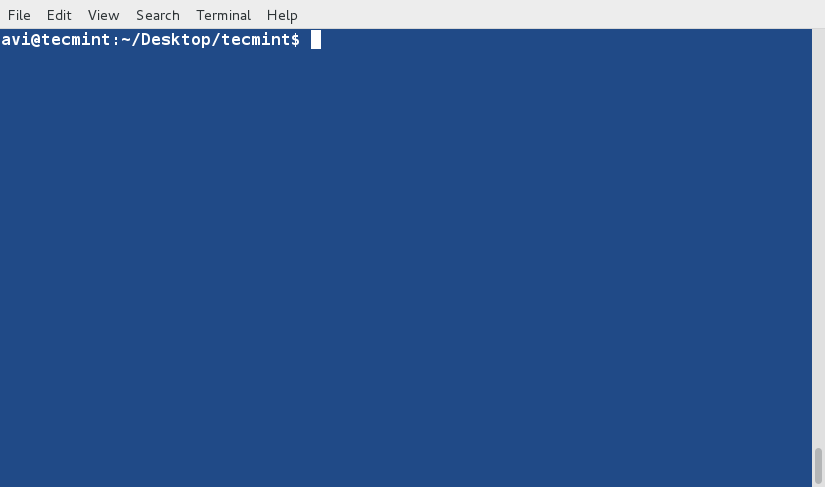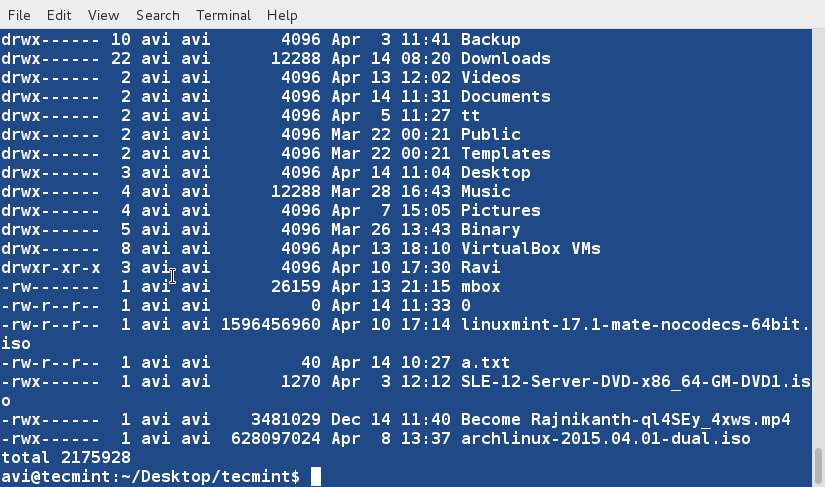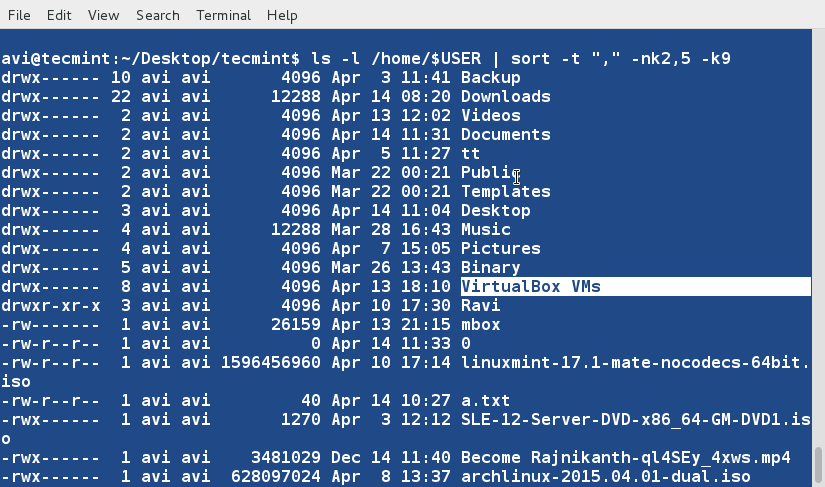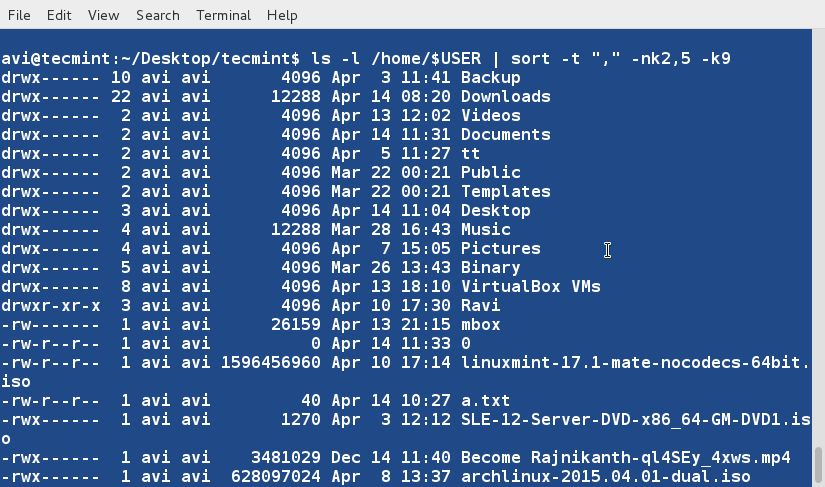
|
||||
|
||||
先到此为止了,在接下来的文章中我们将会学习到‘sort’命令更多的详细例子。届时敬请关注Tecmint。保持分享精神。若喜欢本文,敬请将本文分享给你的朋友。
|
||||
先到此为止了,在接下来的文章中我们将会学习到‘sort’命令更多的详细例子。届时敬请关注我们。保持分享精神。若喜欢本文,敬请将本文分享给你的朋友。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -124,7 +124,7 @@ via: http://www.tecmint.com/sort-command-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,10 @@
|
||||
|
||||
Linux 'sort'命令的七个有趣实例-第二部分
|
||||
Linux 的 'sort'命令的七个有趣实例(二)
|
||||
================================================================================
|
||||
在上一篇文章里,我们已经探讨了关于sort命令的多个例子,如果你错过了这篇文章,可以点击下面的链接进行阅读。今天的这篇文章作为上一篇文章的继续,将讨论关于sort命令的剩余用法,与上一篇一起作为Linux ‘sort’命令的完整指南。
|
||||
|
||||
注:前两天做过这个原文
|
||||
- [14 ‘sort’ Command Examples in Linux][1]
|
||||
-
|
||||
在[上一篇文章][1]里,我们已经探讨了关于sort命令的多个例子,如果你错过了这篇文章,可以点击下面的链接进行阅读。今天的这篇文章作为上一篇文章的继续,将讨论关于sort命令的剩余用法,与上一篇一起作为Linux ‘sort’命令的完整指南。
|
||||
|
||||
- [Linux 的 ‘sort’命令的14个有用的范例(一)][1]
|
||||
|
||||
在我们继续深入之前,先创建一个文本文档‘month.txt’,并且将上一次给出的数据填进去。
|
||||
|
||||
$ echo -e "mar\ndec\noct\nsep\nfeb\naug" > month.txt
|
||||
@ -13,7 +12,7 @@ Linux 'sort'命令的七个有趣实例-第二部分
|
||||
|
||||

|
||||
|
||||
### 15. 通过使用’M‘选项,对’month.txt‘文件按照月份顺序进行排序。###
|
||||
15、 通过使用’M‘选项,对’month.txt‘文件按照月份顺序进行排序。
|
||||
|
||||
$ sort -M month.txt
|
||||
|
||||
@ -21,14 +20,14 @@ Linux 'sort'命令的七个有趣实例-第二部分
|
||||
|
||||

|
||||
|
||||
### 16. 把数据整理成方便人们阅读的形式,比如1K、2M、3G、2T,这里面的K、G、M、T代表千、兆、吉、梯。
|
||||
(译者注:好像这个选项并不是所有Linu版本都有,而且也没有实现按KMGT显示。)
|
||||
16、 把数据整理成方便人们阅读的形式,比如1K、2M、3G、2T,这里面的K、G、M、T代表千、兆、吉、梯。
|
||||
(LCTT 译注:此处命令有误,ls 命令应该增加 -h 参数,径改之)
|
||||
|
||||
$ ls -l /home/$USER | sort -h -k5
|
||||
$ ls -lh /home/$USER | sort -h -k5
|
||||
|
||||

|
||||
|
||||
### 17. 在上一篇文章中,我们在例子4中创建了一个名为‘sorted.txt’的文件,在例子6中创建了一个‘lsl.txt’。‘sorted.txt'已经排好序了而’lsl.txt‘还没有。让我们使用sort命令来检查两个文件是否已经排好序。###
|
||||
17、 在上一篇文章中,我们在例子4中创建了一个名为‘sorted.txt’的文件,在例子6中创建了一个‘lsl.txt’。‘sorted.txt'已经排好序了而’lsl.txt‘还没有。让我们使用sort命令来检查两个文件是否已经排好序。
|
||||
|
||||
$ sort -c sorted.txt
|
||||
|
||||
@ -40,14 +39,14 @@ Linux 'sort'命令的七个有趣实例-第二部分
|
||||
|
||||

|
||||
|
||||
Reports Disorder. Conflict..
|
||||
报告无序。存在矛盾……
|
||||
|
||||
### 18. 如果文字之间的分隔符是空格,sort命令自动地将横向空格后的东西当做一个新文字单元,如果分隔符不是空格呢?###
|
||||
18、 如果文字之间的分隔符是空格,sort命令自动地将空格后的东西当做一个新文字单元,如果分隔符不是空格呢?
|
||||
|
||||
考虑这样一个文本文件,里面的内容可以由除了空格之外的任何符号分隔,比如‘|’,‘\’,‘+’,‘.’等……
|
||||
|
||||
创建一个分隔符为+的文本文件。使用‘cat‘命令查看文件内容。
|
||||
|
||||
$ echo -e "21+linux+server+production\n11+debian+RedHat+CentOS\n131+Apache+Mysql+PHP\n7+Shell Scripting+python+perl\n111+postfix+exim+sendmail" > delimiter.txt
|
||||
|
||||
----------
|
||||
@ -66,9 +65,9 @@ Reports Disorder. Conflict..
|
||||
|
||||

|
||||
|
||||
如果分隔符是Tab,你需要在’+‘的位置上用$’\t’代替,如上例所示。
|
||||
如果分隔符是制表符,你需要在’+‘的位置上用$’\t’代替,如上例所示。
|
||||
|
||||
### 19. 对主用户目录下使用‘ls -l’命令得到的结果基于第五列——‘数据的大小’进行一个乱序排列。
|
||||
19、 对主用户目录下使用‘ls -l’命令得到的结果基于第五列(‘文件大小’)进行一个乱序排列。
|
||||
|
||||
$ ls -l /home/avi/ | sort -k5 -R
|
||||
|
||||
@ -76,28 +75,30 @@ Reports Disorder. Conflict..
|
||||
|
||||
每一次你运行上面的脚本,你得到结果可能都不一样,因为结果是随机生成的。
|
||||
|
||||
正如我在上一篇文章中提到的规则2所说——相比于大写字母,sort命令更喜欢以小写字母开始的行。看一下上一篇文章的例3,字符串‘laptop’在‘LAPTOP’前出现。
|
||||
正如我在上一篇文章中提到的规则2所说——sort命令会将以小写字母开始的行排在大写字母开始的行前面。看一下上一篇文章的例3,字符串‘laptop’在‘LAPTOP’前出现。
|
||||
|
||||
### 20. 如何覆盖默认的排序优先权?在这之前我们需要先将环境变量LC_ALL的值设置为C。在命令行提示栏中运行下面的代码。###
|
||||
20、 如何覆盖默认的排序优先权?在这之前我们需要先将环境变量LC_ALL的值设置为C。在命令行提示栏中运行下面的代码。
|
||||
|
||||
$ export LC_ALL=C
|
||||
|
||||
然后以重写默认优先权的方式对‘tecmint.txt’文件重新排序。
|
||||
然后以非默认优先权的方式对‘tecmint.txt’文件重新排序。
|
||||
|
||||
$ sort tecmint.txt
|
||||
|
||||

|
||||
重写排序优先权
|
||||
|
||||
不要忘记与example 3中得到的输出结果做比较,并且你可以使用‘-f’选项,又叫‘-ignore-case’来获取非常有序的输出。
|
||||
*覆盖排序优先权*
|
||||
|
||||
不要忘记与example 3中得到的输出结果做比较,并且你可以使用‘-f’,又叫‘-ignore-case’(忽略大小写)的选项来获取更有序的输出。
|
||||
|
||||
$ sort -f tecmint.txt
|
||||
|
||||

|
||||
|
||||
### 21. 给两个输入文件进行‘sort‘,然后一口气把它们连接起来怎么样?###
|
||||
21、 给两个输入文件进行‘sort‘,然后把它们连接成一行!
|
||||
|
||||
我们创建两个文本文档’file1.txt‘以及’file2.txt‘,并用数据填充,如下所示,并用’cat‘命令查看文件的内容。
|
||||
|
||||
$ echo -e “5 Reliable\n2 Fast\n3 Secure\n1 open-source\n4 customizable” > file1.txt
|
||||
$ cat file1.txt
|
||||
|
||||
@ -117,7 +118,7 @@ Reports Disorder. Conflict..
|
||||

|
||||
|
||||
|
||||
我所要讲的全部内容就在这里了,希望与各位保持联系,也希望各位经常来Tecmint逛逛。有反馈就在下面评论吧。
|
||||
我所要讲的全部内容就在这里了,希望与各位保持联系,也希望各位经常来逛逛。有反馈就在下面评论吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -125,7 +126,7 @@ via: http://www.tecmint.com/linux-sort-command-examples/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,35 @@
|
||||
SuperTuxKart 0.9 已发行 —— Linux 中最好的竞速类游戏越来越棒了!
|
||||
================================================================================
|
||||
**热门竞速类游戏 SuperTuxKart 的新版本已经[打包发行][1]登陆下载服务器**
|
||||
|
||||

|
||||
|
||||
*Super Tux Kart 0.9 发行海报*
|
||||
|
||||
SuperTuxKart 0.9 相较前一版本做了巨大的升级,内部运行着刚出炉的新引擎(有个炫酷的名字叫‘Antarctica(南极洲)’),目的是要呈现更加炫酷的图形环境,从阴影到场景的纵深,外加卡丁车更好的物理效果。
|
||||
|
||||
突出的图形表现也增加了对显卡的要求。SuperTuxKart 开发人员给玩家的建议是,要有图像处理能力比得上(或者,想要完美的话,要超过) Intel HD Graphics 3000, NVIDIA GeForce 8600 或 AMD Radeon HD 3650 的显卡。
|
||||
|
||||
### 其他改变 ###
|
||||
|
||||
SuperTuxKart 0.9 中与图像的改善同样吸引人眼球的是一对**全新赛道**,新的卡丁车,新的在线账户可以记录和分享**全新推出的成就系统**里赢得的徽章,以及大量的改装和涂装的微调。
|
||||
|
||||
点击播放下面的官方发行视频,看看基于调色器的 STK 0.9 所散发的光辉吧。(youtube 视频:https://www.youtube.com/0FEwDH7XU9Q )
|
||||
|
||||
Ubuntu 用户可以从项目网站上下载新发行版已编译的二进制文件。
|
||||
|
||||
- [下载 SuperTuxKart 0.9][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/04/supertuxkart-0-9-released
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://supertuxkart.blogspot.co.uk/2015/04/supertuxkart-09-released.html
|
||||
[2]:http://supertuxkart.sourceforge.net/Downloads
|
||||
@ -0,0 +1,63 @@
|
||||
在Ubuntu中安装Visual Studio Code
|
||||
================================================================================
|
||||

|
||||
|
||||
微软令人意外地[发布了Visual Studio Code][1],并支持主要的桌面平台,当然包括linux。如果你是一名需要在ubuntu工作的web开发人员,你可以**非常轻松的安装Visual Studio Code**。
|
||||
|
||||
我将要使用[Ubuntu Make][2]来安装Visual Studio Code。Ubuntu Make,就是以前的Ubuntu开发者工具中心,是一个命令行工具,帮助用户快速安装各种开发工具、语言和IDE。也可以使用Ubuntu Make轻松[安装Android Studio][3] 和其他IDE,如Eclipse。本文将展示**如何在Ubuntu中使用Ubuntu Make安装Visual Studio Code**。(译注:也可以直接去微软官网下载安装包)
|
||||
|
||||
### 安装微软Visual Studio Code ###
|
||||
|
||||
开始之前,首先需要安装Ubuntu Make。虽然Ubuntu Make存在Ubuntu15.04官方库中,**但是需要Ubuntu Make 0.7以上版本才能安装Visual Studio**。所以,需要通过官方PPA更新到最新的Ubuntu Make。此PPA支持Ubuntu 14.04, 14.10 和 15.04。
|
||||
|
||||
注意,**仅支持64位版本**。
|
||||
|
||||
打开终端,使用下列命令,通过官方PPA来安装Ubuntu Make:
|
||||
|
||||
sudo add-apt-repository ppa:ubuntu-desktop/ubuntu-make
|
||||
sudo apt-get update
|
||||
sudo apt-get install ubuntu-make
|
||||
|
||||
安装Ubuntu Make完后,接着使用下列命令安装Visual Studio Code:
|
||||
|
||||
umake web visual-studio-code
|
||||
|
||||
安装过程中,将会询问安装路径,如下图:
|
||||
|
||||

|
||||
|
||||
在抛出一堆要求和条件后,它会询问你是否确认安装Visual Studio Code。输入‘a’来确定:
|
||||
|
||||

|
||||
|
||||
确定之后,安装程序会开始下载并安装。安装完成后,你可以发现Visual Studio Code 图标已经出现在了Unity启动器上。点击图标开始运行!下图是Ubuntu 15.04 Unity的截图:
|
||||
|
||||

|
||||
|
||||
### 卸载Visual Studio Code###
|
||||
|
||||
卸载Visual Studio Code,同样使用Ubuntu Make命令。如下:
|
||||
|
||||
umake web visual-studio-code --remove
|
||||
|
||||
如果你不打算使用Ubuntu Make,也可以通过微软官方下载安装文件。
|
||||
|
||||
- [下载Visual Studio Code Linux版][4]
|
||||
|
||||
怎样!是不是超级简单就可以安装Visual Studio Code,这都归功于Ubuntu Make。我希望这篇文章能帮助到你。如果您有任何问题或建议,欢迎给我留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://linux.cn/article-5376-1.html
|
||||
[2]:https://wiki.ubuntu.com/ubuntu-make
|
||||
[3]:http://itsfoss.com/install-android-studio-ubuntu-linux/
|
||||
[4]:https://code.visualstudio.com/Download
|
||||
@ -0,0 +1,164 @@
|
||||
如何使用Vault安全的存储密码和API密钥
|
||||
=======================================================================
|
||||
Vault是用来安全的获取秘密信息的工具,它可以保存密码、API密钥、证书等信息。Vault提供了一个统一的接口来访问秘密信息,其具有健壮的访问控制机制和丰富的事件日志。
|
||||
|
||||
对关键信息的授权访问是一个困难的问题,尤其是当有许多用户角色,并且用户请求不同的关键信息时,例如用不同权限登录数据库的登录配置,用于外部服务的API密钥,SOA通信的证书等。当保密信息由不同的平台进行管理,并使用一些自定义的配置时,情况变得更糟,因此,安全的存储、管理审计日志几乎是不可能的。但Vault为这种复杂情况提供了一个解决方案。
|
||||
|
||||
### 突出特点 ###
|
||||
|
||||
**数据加密**:Vault能够在不存储数据的情况下对数据进行加密、解密。开发者们便可以存储加密后的数据而无需开发自己的加密技术,Vault还允许安全团队自定义安全参数。
|
||||
|
||||
**安全密码存储**:Vault在将秘密信息(API密钥、密码、证书)存储到持久化存储之前对数据进行加密。因此,如果有人偶尔拿到了存储的数据,这也没有任何意义,除非加密后的信息能被解密。
|
||||
|
||||
**动态密码**:Vault可以随时为AWS、SQL数据库等类似的系统产生密码。比如,如果应用需要访问AWS S3 桶,它向Vault请求AWS密钥对,Vault将给出带有租期的所需秘密信息。一旦租用期过期,这个秘密信息就不再存储。
|
||||
|
||||
**租赁和更新**:Vault给出的秘密信息带有租期,一旦租用期过期,它便立刻收回秘密信息,如果应用仍需要该秘密信息,则可以通过API更新租用期。
|
||||
|
||||
**撤销**:在租用期到期之前,Vault可以撤销一个秘密信息或者一个秘密信息树。
|
||||
|
||||
### 安装Vault ###
|
||||
|
||||
有两种方式来安装使用Vault。
|
||||
|
||||
**1. 预编译的Vault二进制** 能用于所有的Linux发行版,下载地址如下,下载之后,解压并将它放在系统PATH路径下,以方便调用。
|
||||
|
||||
- [下载预编译的二进制 Vault (32-bit)][1]
|
||||
- [下载预编译的二进制 Vault (64-bit)][2]
|
||||
- [下载预编译的二进制 Vault (ARM)][3]
|
||||
|
||||

|
||||
|
||||
*下载相应的预编译的Vault二进制版本。*
|
||||
|
||||

|
||||
|
||||
*解压下载到本地的二进制版本。*
|
||||
|
||||
祝贺你!您现在可以使用Vault了。
|
||||
|
||||

|
||||
|
||||
**2. 从源代码编译**是另一种在系统中安装Vault的方式。在安装Vault之前需要安装GO和GIT。
|
||||
|
||||
在 **Redhat系统中安装GO** 使用下面的指令:
|
||||
|
||||
sudo yum install go
|
||||
|
||||
在 **Debin系统中安装GO** 使用下面的指令:
|
||||
|
||||
sudo apt-get install golang
|
||||
|
||||
或者
|
||||
|
||||
sudo add-apt-repository ppa:gophers/go
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install golang-stable
|
||||
|
||||
在 **Redhat系统中安装GIT** 使用下面的命令:
|
||||
|
||||
sudo yum install git
|
||||
|
||||
在 **Debian系统中安装GIT** 使用下面的命令:
|
||||
|
||||
sudo apt-get install git
|
||||
|
||||
一旦GO和GIT都已被安装好,我们便可以开始从源码编译安装Vault。
|
||||
|
||||
> 将下列的Vault仓库拷贝至GOPATH
|
||||
|
||||
https://github.com/hashicorp/vault
|
||||
|
||||
> 测试下面的文件是否存在,如果它不存在,那么Vault没有被克隆到合适的路径。
|
||||
|
||||
$GOPATH/src/github.com/hashicorp/vault/main.go
|
||||
|
||||
> 执行下面的指令来编译Vault,并将二进制文件放到系统bin目录下。
|
||||
|
||||
make dev
|
||||
|
||||

|
||||
|
||||
### 一份Vault入门教程 ###
|
||||
|
||||
我们已经编制了一份Vault的官方交互式教程,并带有它在SSH上的输出信息。
|
||||
|
||||
**概述**
|
||||
|
||||
这份教程包括下列步骤:
|
||||
|
||||
- 初始化并启封您的Vault
|
||||
- 在Vault中对您的请求授权
|
||||
- 读写秘密信息
|
||||
- 密封您的Vault
|
||||
|
||||
#### **初始化您的Vault**
|
||||
|
||||
首先,我们需要为您初始化一个Vault的工作实例。在初始化过程中,您可以配置Vault的密封行为。简单起见,现在使用一个启封密钥来初始化Vault,命令如下:
|
||||
|
||||
vault init -key-shares=1 -key-threshold=1
|
||||
|
||||
您会注意到Vault在这里输出了几个密钥。不要清除您的终端,这些密钥在后面的步骤中会使用到。
|
||||
|
||||

|
||||
|
||||
#### **启封您的Vault**
|
||||
|
||||
当一个Vault服务器启动时,它是密封的状态。在这种状态下,Vault被配置为知道物理存储在哪里及如何存取它,但不知道如何对其进行解密。Vault使用加密密钥来加密数据。这个密钥由"主密钥"加密,主密钥不保存。解密主密钥需要入口密钥。在这个例子中,我们使用了一个入口密钥来解密这个主密钥。
|
||||
|
||||
vault unseal <key 1>
|
||||
|
||||

|
||||
|
||||
####**为您的请求授权**
|
||||
|
||||
在执行任何操作之前,连接的客户端必须是被授权的。授权的过程是检验一个人或者机器是否如其所申明的那样具有正确的身份。这个身份用在向Vault发送请求时。为简单起见,我们将使用在步骤2中生成的root令牌,这个信息可以回滚终端屏幕看到。使用一个客户端令牌进行授权:
|
||||
|
||||
vault auth <root token>
|
||||
|
||||

|
||||
|
||||
####**读写保密信息**
|
||||
|
||||
现在Vault已经被设置妥当,我们可以开始读写默认挂载的秘密后端里面的秘密信息了。写在Vault中的秘密信息首先被加密,然后被写入后端存储中。后端存储机制绝不会看到未加密的信息,并且也没有在Vault之外解密的需要。
|
||||
|
||||
vault write secret/hello value=world
|
||||
|
||||
当然,您接下来便可以读这个保密信息了:
|
||||
|
||||
vault read secret/hello
|
||||
|
||||

|
||||
|
||||
####**密封您的Vault**
|
||||
|
||||
还有一个用I来密封Vault的API。它将丢掉现在的加密密钥并需要另一个启封过程来恢复它。密封仅需要一个拥有root权限的操作者。这是一种罕见的"打破玻璃过程"的典型部分。
|
||||
|
||||
这种方式中,如果检测到一个入侵,Vault数据将会立刻被锁住,以便最小化损失。如果不能访问到主密钥碎片的话,就不能再次获取数据。
|
||||
|
||||
vault seal
|
||||
|
||||

|
||||
|
||||
这便是入门教程的结尾。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Vault是一个非常有用的应用,它提供了一个可靠且安全的存储关键信息的方式。另外,它在存储前加密关键信息、审计日志维护、以租期的方式获取秘密信息,且一旦租用期过期它将立刻收回秘密信息。Vault是平台无关的,并且可以免费下载和安装。要发掘Vault的更多信息,请访问其[官方网站][4]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/secure-secret-store-vault/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
[1]:https://dl.bintray.com/mitchellh/vault/vault_0.1.0_linux_386.zip
|
||||
[2]:https://dl.bintray.com/mitchellh/vault/vault_0.1.0_linux_amd64.zip
|
||||
[3]:https://dl.bintray.com/mitchellh/vault/vault_0.1.0_linux_arm.zip
|
||||
[4]:https://vaultproject.io/
|
||||
@ -0,0 +1,190 @@
|
||||
安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情(四)
|
||||
================================================================================
|
||||
### 17. 安装 Webmin ###
|
||||
|
||||
Webmin 是基于 Web 的 Linux 配置工具。它像一个中央系统,用于配置各种系统设置,比如用户、磁盘分配、服务以及 HTTP 服务器、Apache、MySQL 等的配置。
|
||||
|
||||
# wget http://prdownloads.sourceforge.net/webadmin/webmin-1.740-1.noarch.rpm
|
||||
# rpm -ivh webmin-*.rpm
|
||||
|
||||

|
||||
|
||||
*安装 Webmin*
|
||||
|
||||
安装完 webmin 后,你会在终端上得到一个消息,提示你用 root 密码在端口 10000 登录你的主机 (http://ip-address:10000)。 如果运行的是无接口的服务器你可以转发端口然后从有接口的服务器上访问它。(LCTT 译注:无接口[headless]服务器指没有访问接口或界面的服务器,在此次场景,指的是是出于内网的服务器,可采用外网/路由器映射来访问该端口)
|
||||
|
||||
### 18. 启用第三方库 ###
|
||||
|
||||
添加不受信任的库并不是一个好主意,尤其是在生产环境中,这可能导致致命的问题。但仅作为例子在这里我们会添加一些社区证实可信任的库,以安装第三方工具和软件包。
|
||||
|
||||
为企业版 Linux(EPEL)库添加额外的软件包。
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
添加社区企业版 Linux (Community Enterprise Linux)库:
|
||||
|
||||
# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
|
||||
|
||||

|
||||
|
||||
*安装 Epel 库*
|
||||
|
||||
**注意!** 添加第三方库的时候尤其需要注意。
|
||||
|
||||
### 19. 安装 7-zip 工具 ###
|
||||
|
||||
在最小化安装 CentOS 时你并没有获得类似 unzip 或者 untar 的工具。我们可以选择根据需要来安装每个工具,或一个能处理所有格式的工具。7-zip 就是一个能压缩和解压所有已知类型文件的工具。
|
||||
|
||||
# yum install p7zip
|
||||
|
||||

|
||||
|
||||
*安装 7zip 工具*
|
||||
|
||||
**注意**: 该软件包从 Fedora EPEL 7 的库中下载和安装。
|
||||
|
||||
### 20. 安装 NTFS-3G 驱动 ###
|
||||
|
||||
NTFS-3G,一个很小但非常有用的 NTFS 驱动,在大部分类 UNIX 发行版上都可用。它对于挂载和访问 Windows NTFS 文件系统很有用。尽管也有其它可用的替代品,比如 Tuxera,但 NTFS-3G 是使用最广泛的。
|
||||
|
||||
# yum install ntfs-3g
|
||||
|
||||

|
||||
|
||||
*安装 NTFS-3G 用于挂载 Windows 分区*
|
||||
|
||||
ntfs-3g 安装完成之后,你可以使用以下命令挂载 Windows NTFS 分区(我的 Windows 分区是 /dev/sda5)。
|
||||
|
||||
# mount -ro ntfs-3g /dev/sda5 /mnt
|
||||
# cd /mnt
|
||||
# ls -l
|
||||
|
||||
### 21. 安装 Vsftpd FTP 服务器 ###
|
||||
|
||||
VSFTPD 表示 Very Secure File Transfer Protocol Daemon,是用于类 UNIX 系统的 FTP 服务器。它是现今最高效和安全的 FTP 服务器之一。
|
||||
|
||||
# yum install vsftpd
|
||||
|
||||

|
||||
|
||||
*安装 Vsftpd FTP*
|
||||
|
||||
编辑配置文件 ‘/etc/vsftpd/vsftpd.conf’ 用于保护 vsftpd。
|
||||
|
||||
# vi /etc/vsftpd/vsftpd.conf
|
||||
|
||||
编辑一些值并使其它行保留原样,除非你知道自己在做什么。
|
||||
|
||||
anonymous_enable=NO
|
||||
local_enable=YES
|
||||
write_enable=YES
|
||||
chroot_local_user=YES
|
||||
|
||||
你也可以更改端口号,记得让 vsftpd 端口通过防火墙。
|
||||
|
||||
# firewall-cmd --add-port=21/tcp
|
||||
# firewall-cmd --reload
|
||||
|
||||
下一步重启 vsftpd 并启用开机自动启动。
|
||||
|
||||
# systemctl restart vsftpd
|
||||
# systemctl enable vsftpd
|
||||
|
||||
### 22. 安装和配置 sudo ###
|
||||
|
||||
sudo 通常被称为 super do 或者 suitable user do,是一个类 UNIX 操作系统中用其它用户的安全权限执行程序的软件。让我们来看看怎样配置 sudo。
|
||||
|
||||
# visudo
|
||||
|
||||
这会打开 /etc/sudoers 并进行编辑
|
||||
|
||||

|
||||
|
||||
*sudoers 文件*
|
||||
|
||||
1. 给一个已经创建好的用户(比如 tecmint)赋予所有权限(等同于 root)。
|
||||
|
||||
tecmint ALL=(ALL) ALL
|
||||
|
||||
2. 如果给一个已经创建好的用户(比如 tecmint)赋予除了重启和关闭服务器以外的所有权限(等同于 root)。
|
||||
|
||||
首先,再一次打开文件并编辑如下内容:
|
||||
|
||||
cmnd_Alias nopermit = /sbin/shutdown, /sbin/reboot
|
||||
|
||||
然后,用逻辑操作符(!)添加该别名。
|
||||
|
||||
tecmint ALL=(ALL) ALL,!nopermit
|
||||
|
||||
3. 如果准许一个组(比如 debian)运行一些 root 权限命令,比如(增加或删除用户)。
|
||||
|
||||
cmnd_Alias permit = /usr/sbin/useradd, /usr/sbin/userdel
|
||||
|
||||
然后,给组 debian 增加权限。
|
||||
|
||||
debian ALL=(ALL) permit
|
||||
|
||||
### 23. 安装并启用 SELinux ###
|
||||
|
||||
SELinux 表示 Security-Enhanced Linux,是内核级别的安全模块。
|
||||
|
||||
# yum install selinux-policy
|
||||
|
||||

|
||||
|
||||
*安装 SElinux 策略*
|
||||
|
||||
查看 SELinux 当前模式。
|
||||
|
||||
# getenforce
|
||||
|
||||

|
||||
|
||||
*查看 SELinux 模式*
|
||||
|
||||
输出是 Enforcing,意味着 SELinux 策略已经生效。
|
||||
|
||||
如果需要调试,可以临时设置 selinux 模式为允许。不需要重启。
|
||||
|
||||
# setenforce 0
|
||||
|
||||
调试完了之后再次设置 selinux 为强制模式,无需重启。
|
||||
|
||||
# setenforce 1
|
||||
|
||||
(LCTT 译注:在生产环境中,SELinux 固然会提升安全,但是也确实会给应用部署和运行带来不少麻烦。具体是否部署,需要根据情况而定。)
|
||||
|
||||
### 24. 安装 Rootkit Hunter ###
|
||||
|
||||
Rootkit Hunter,简写为 RKhunter,是在 Linux 系统中扫描 rootkits 和其它可能有害攻击的程序。
|
||||
|
||||
# yum install rkhunter
|
||||
|
||||

|
||||
|
||||
*安装 Rootkit Hunter*
|
||||
|
||||
在 Linux 中,从脚本文件以计划作业的形式运行 rkhunter 或者手动扫描有害攻击。
|
||||
|
||||
# rkhunter --check
|
||||
|
||||

|
||||
|
||||
*扫描 rootkits*
|
||||
|
||||

|
||||
|
||||
*RootKit 扫描结果*
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/things-to-do-after-minimal-rhel-centos-7-installation/4/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
@ -0,0 +1,140 @@
|
||||
安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情(五)
|
||||
================================================================================
|
||||
### 25. 安装 Linux Malware Detect (LMD) ###
|
||||
|
||||
Linux Malware Detect (LMD) 是 GNU GPLv2 协议下发布的开源 Linux 恶意程序扫描器,它是特别为面临威胁的主机环境所设计的。LMD 完整的安装、配置以及使用方法可以查看:
|
||||
|
||||
- [安装 LMD 并和 ClamAV 一起使用作为反病毒引擎][1]
|
||||
|
||||
### 26. 用 Speedtest-cli 测试服务器带宽 ###
|
||||
|
||||
speedtest-cli 是用 python 写的用于测试网络下载和上传带宽的工具。关于 speedtest-cli 工具的完整安装和使用请阅读我们的文章[用命令行查看 Linux 服务器带宽][2]
|
||||
|
||||
### 27. 配置 Cron 任务 ###
|
||||
|
||||
这是最广泛使用的软件工具之一。它是一个任务调度器,比如,现在安排一个以后可以自动运行的作业。它用于未处理记录的日志和维护,以及其它日常工作,比如常规备份。所有的调度都写在文件 /etc/crontab 中。
|
||||
|
||||
crontab 文件包含下面的 6 个域:
|
||||
|
||||
分 时 日期 月份 星期 命令
|
||||
(0-59) (0-23) (1-31) (1/jan-12/dec) (0-6/sun-sat) Command/script
|
||||
|
||||

|
||||
|
||||
*Crontab 域*
|
||||
|
||||
要在每天 04:30 运行一个 cron 任务(比如运行 /home/$USER/script.sh)。
|
||||
|
||||
分 时 日期 月份 星期 命令
|
||||
30 4 * * * speedtest-cli
|
||||
|
||||
就把下面的条目增加到 crontab 文件 ‘/etc/crontab/’。
|
||||
|
||||
30 4 * * * /home/$user/script.sh
|
||||
|
||||
把上面一行增加到 crontab 之后,它会在每天的 04:30 am 自动运行,输出取决于脚本文件的内容。另外脚本也可以用命令代替。关于更多 cron 任务的例子,可以阅读[Linux 上的 11 个 Cron 任务例子][3]
|
||||
|
||||
### 28. 安装 Owncloud ###
|
||||
|
||||
Owncloud 是一个基于 HTTP 的数据同步、文件共享和远程文件存储应用。更多关于安装 owncloud 的内容,你可以阅读这篇文章:[在 Linux 上创建个人/私有云存储][4]
|
||||
|
||||
### 29. 启用 Virtualbox 虚拟化 ###
|
||||
|
||||
虚拟化是创建虚拟操作系统、硬件和网络的过程,是当今最热门的技术之一。我们会详细地讨论如何安装和配置虚拟化。
|
||||
|
||||
我们的最小化 CentOS 服务器是一个无用户界面服务器(LCTT 译注:无用户界面[headless]服务器指没有监视器和鼠标键盘等外设的服务器)。我们通过安装下面的软件包,让它可以托管虚拟机,虚拟机可通过 HTTP 访问。
|
||||
|
||||
# yum groupinstall 'Development Tools' SDL kernel-devel kernel-headers dkms
|
||||
|
||||

|
||||
|
||||
*安装开发工具*
|
||||
|
||||
更改工作目录到 ‘/etc/yum.repos.d/’ 并下载 VirtualBox 库。
|
||||
|
||||
# wget -q http://download.virtualbox.org/virtualbox/debian/oracle_vbox.asc
|
||||
|
||||
安装刚下载的密钥。
|
||||
|
||||
# rpm --import oracle_vbox.asc
|
||||
|
||||
升级并安装 VirtualBox。
|
||||
|
||||
# yum update && yum install virtualbox-4.3
|
||||
|
||||
下一步,下载和安装 VirtualBox 扩展包。
|
||||
|
||||
# wget http://download.virtualbox.org/virtualbox/4.3.12/Oracle_VM_VirtualBox_Extension_Pack-4.3.12-93733.vbox-extpack
|
||||
# VBoxManage extpack install Oracle_VM_VirtualBox_Extension_Pack-4.3.12-93733.vbox-extpack
|
||||
|
||||

|
||||
|
||||
*安装 VirtualBox 扩展包*
|
||||
|
||||

|
||||
|
||||
*正在安装 VirtualBox 扩展包*
|
||||
|
||||
添加用户 ‘vbox’ 用于管理 VirtualBox 并把它添加到组 vboxusers 中。
|
||||
|
||||
# adduser vbox
|
||||
# passwd vobx
|
||||
# usermod -G vboxusers vbox
|
||||
|
||||
安装 HTTPD 服务器。
|
||||
|
||||
# yum install httpd
|
||||
|
||||
安装 PHP (支持 soap 扩展)。
|
||||
|
||||
# yum install php php-devel php-common php-soap php-gd
|
||||
|
||||
下载 phpVirtualBox(一个 PHP 写的开源的 VirtualBox 用户界面)。
|
||||
|
||||
# wget http://sourceforge.net/projects/phpvirtualbox/files/phpvirtualbox-4.3-1.zip
|
||||
|
||||
解压 zip 文件并把解压后的文件夹复制到 HTTP 工作目录。
|
||||
|
||||
# unzip phpvirtualbox-4.*.zip
|
||||
# cp phpvirtualbox-4.3-1 -R /var/www/html
|
||||
|
||||
下一步,重命名文件 /var/www/html/phpvirtualbox/config.php-example 为 var/www/html/phpvirtualbox/config.php。
|
||||
|
||||
# mv config.php.example config.php
|
||||
|
||||
打开配置文件并添加我们上一步创建的 ‘username ’ 和 ‘password’。
|
||||
|
||||
# vi config.php
|
||||
|
||||
最后,重启 VirtualBox 和 HTTP 服务器。
|
||||
|
||||
# service vbox-service restart
|
||||
# service httpd restart
|
||||
|
||||
转发端口并从一个有用户界面的服务器上访问它。
|
||||
|
||||
http://192.168.0.15/phpvirtualbox-4.3-1/
|
||||
|
||||

|
||||
|
||||
*登录 PHP Virtualbox*
|
||||
|
||||

|
||||
|
||||
*PHP Virtualbox 面板*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/things-to-do-after-minimal-rhel-centos-7-installation/5/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://linux.cn/article-5156-1.html
|
||||
[2]:https://linux.cn/article-3796-1.html
|
||||
[3]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[4]:https://linux.cn/article-2494-1.html
|
||||
@ -0,0 +1,86 @@
|
||||
安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情(六)
|
||||
================================================================================
|
||||
### 30. 用密码保护 GRUB ###
|
||||
|
||||
用密码保护你的 boot 引导程序这样你就可以在启动时获得额外的安全保障。同时你也可以在实物层面获得保护。通过在引导时给 GRUB 加锁防止任何无授权访问来保护你的服务器。
|
||||
|
||||
首先备份两个文件,这样如果有任何错误出现,你可以有回滚的选择。备份 ‘/etc/grub2/grub.cfg’ 为 ‘/etc/grub2/grub.cfg.old’。
|
||||
|
||||
# cp /boot/grub2/grub.cfg /boot/grub2/grub.cfg.old
|
||||
|
||||
同样,备份 ‘/etc/grub.d/10\_linux’ 为 ‘/etc/grub.d/10\_linux.old’。
|
||||
|
||||
# cp /etc/grub.d/10_linux /etc/grub.d/10_linux.old
|
||||
|
||||
打开文件 ‘/etc/grub.d/10\_linux’ 并在文件末尾添加下列行。
|
||||
|
||||
cat <<EOF
|
||||
set superusers="tecmint"
|
||||
Password tecmint avi@123
|
||||
EOF
|
||||
|
||||

|
||||
|
||||
*密码保护 Grub*
|
||||
|
||||
注意在上面的文件中,用你自己的用户名和密码代替 “tecmint” 和 “avi@123”。
|
||||
|
||||
现在通过运行下面的命令生成新的 grub.cfg 文件。
|
||||
|
||||
# grub2-mkconfig --output=/boot/grub2/grub.cfg
|
||||
|
||||
|
||||
|
||||
*生成 Grub 文件*
|
||||
|
||||
创建 grub.cfg 文件之后,重启机器并敲击 ‘e’ 进入编辑。你会发现它会要求你输入 “有效验证” 来编辑 boot 菜单。
|
||||
|
||||

|
||||
|
||||
*有密码保护的 Boot 菜单*
|
||||
|
||||
输入登录验证之后,你就可以编辑 grub boot 菜单。
|
||||
|
||||

|
||||
|
||||
*Grub 菜单文件*
|
||||
|
||||
你也可以用加密的密码代替上一步的明文密码。首先按照下面推荐的生成加密密码。
|
||||
|
||||
# grub2-mkpasswd-pbkdf2
|
||||
|
||||
[两次输入密码]
|
||||
|
||||

|
||||
|
||||
*生成加密的 Grub 密码*
|
||||
|
||||
打开 ‘/etc/grub.d/10_linux’ 文件并在文件末尾添加下列行。
|
||||
|
||||
cat <<EOF
|
||||
set superusers=”tecmint”
|
||||
Password_pbkdf2 tecmint
|
||||
grub.pbkdf2.sha512....你的加密密码....
|
||||
EOF
|
||||
|
||||
|
||||
|
||||
*加密 Grub 密码*
|
||||
|
||||
用你系统上生成的密码代替原来的密码,别忘了交叉检查密码。
|
||||
|
||||
同样注意在这种情况下你也需要像上面那样生成 grub.cfg。重启并敲击 ‘e’ 进入编辑,会提示你输入用户名和密码。
|
||||
|
||||
我们已经介绍了大部分工业标准发行版 RHEL 7 和 CentOS 7 安装后必要的操作。如果你发现我们缺少了一些点或者你有新的东西可以扩充这篇文章,你可以和我们一起分享,我们会通过扩充在这篇文章中包括你的分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/things-to-do-after-minimal-rhel-centos-7-installation/6/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
@ -1,8 +1,8 @@
|
||||
在 RedHat/CentOS 7.x 中使用 cmcli 命令管理网络
|
||||
在 RedHat/CentOS 7.x 中使用 nmcli 命令管理网络
|
||||
===============
|
||||
[**Red Hat Enterprise Linux 7** 与 **CentOS 7**][1] 中默认的网络服务由 **NetworkManager** 提供,这是动态控制及配置网络的守护进程,它用于保持当前网络设备及连接处于工作状态,同时也支持传统的 ifcfg 类型的配置文件。
|
||||
NetworkManager 可以用于以下类型的连接:
|
||||
Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移动3G)以及 IP-over-InfiniBand。针对与这些网络类型,NetworkManager 可以配置他们的网络别名,IP 地址,静态路由,DNS,VPN连接以及很多其它的特殊参数。
|
||||
|
||||
NetworkManager 可以用于以下类型的连接:Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移动3G)以及 IP-over-InfiniBand。针对与这些网络类型,NetworkManager 可以配置他们的网络别名,IP 地址,静态路由,DNS,VPN连接以及很多其它的特殊参数。
|
||||
|
||||
可以用命令行工具 nmcli 来控制 NetworkManager。
|
||||
|
||||
@ -24,19 +24,21 @@ Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移
|
||||
|
||||
显示所有连接。
|
||||
|
||||
# nmcli connection show -a
|
||||
# nmcli connection show -a
|
||||
|
||||
仅显示当前活动的连接。
|
||||
|
||||
# nmcli device status
|
||||
|
||||
列出通过 NetworkManager 验证的设备列表及他们的状态。
|
||||
列出 NetworkManager 识别出的设备列表及他们的状态。
|
||||
|
||||

|
||||
|
||||
### 启动/停止 网络接口###
|
||||
|
||||
使用 nmcli 工具启动或停止网络接口,与 ifconfig 的 up/down 是一样的。使用下列命令停止某个接口:
|
||||
使用 nmcli 工具启动或停止网络接口,与 ifconfig 的 up/down 是一样的。
|
||||
|
||||
使用下列命令停止某个接口:
|
||||
|
||||
# nmcli device disconnect eno16777736
|
||||
|
||||
@ -50,7 +52,7 @@ Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移
|
||||
|
||||
# nmcli connection add type ethernet con-name NAME_OF_CONNECTION ifname interface-name ip4 IP_ADDRESS gw4 GW_ADDRESS
|
||||
|
||||
根据你需要的配置更改 NAME_OF_CONNECTION,IP_ADDRESS, GW_ADDRESS参数(如果不需要网关的话可以省略最后一部分)。
|
||||
根据你需要的配置更改 NAME\_OF\_CONNECTION,IP\_ADDRESS, GW\_ADDRESS参数(如果不需要网关的话可以省略最后一部分)。
|
||||
|
||||
# nmcli connection add type ethernet con-name NEW ifname eno16777736 ip4 192.168.1.141 gw4 192.168.1.1
|
||||
|
||||
@ -68,9 +70,11 @@ Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移
|
||||
|
||||

|
||||
|
||||
###增加一个使用 DHCP 的新连接
|
||||
|
||||
增加新的连接,使用DHCP自动分配IP地址,网关,DNS等,你要做的就是将命令行后 ip/gw 地址部分去掉就行了,DHCP会自动分配这些参数。
|
||||
|
||||
例,在 eno 16777736 设备上配置一个 名为 NEW_DHCP 的 DHCP 连接
|
||||
例,在 eno 16777736 设备上配置一个 名为 NEW\_DHCP 的 DHCP 连接
|
||||
|
||||
# nmcli connection add type ethernet con-name NEW_DHCP ifname eno16777736
|
||||
|
||||
@ -79,8 +83,8 @@ Ethernet,VLANS,Bridges,Bonds,Teams,Wi-Fi,mobile boradband(如移
|
||||
via: http://linoxide.com/linux-command/nmcli-tool-red-hat-centos-7/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
(translating by runningwater)
|
||||
wyangsun翻译中
|
||||
Compact Text Editors Great for Remote Editing and Much More
|
||||
================================================================================
|
||||
A text editor is software used for editing plain text files. This type of software has many different uses including modifying configuration files, writing programming language source code, jotting down thoughts, or even making a grocery list. Given that editors can be used for such a diverse range of activities, it is worth spending the time finding an editor that best suites your preferences.
|
||||
@ -217,4 +217,4 @@ via: http://www.linuxlinks.com/article/20141011073917230/TextEditors.html
|
||||
[2]:http://www.vim.org/
|
||||
[3]:http://ne.di.unimi.it/
|
||||
[4]:http://www.gnu.org/software/zile/
|
||||
[5]:http://nano-editor.org/
|
||||
[5]:http://nano-editor.org/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
KevinSJ translating
|
||||
10 Truly Amusing Easter Eggs in Linux
|
||||
================================================================================
|
||||

|
||||
@ -151,4 +152,4 @@ via: http://www.linux.com/news/software/applications/820944-10-truly-amusing-lin
|
||||
[13]:http://nmap.org/book/output-formats-script-kiddie.html
|
||||
[14]:http://nmap.org/book/output-formats-script-kiddie.html
|
||||
[15]:https://www.youtube.com/watch?v=Ql1uLyuWra8
|
||||
[16]:http://en.wikipedia.org/wiki/Neko_%28computer_program%29
|
||||
[16]:http://en.wikipedia.org/wiki/Neko_%28computer_program%29
|
||||
|
||||
@ -1,37 +0,0 @@
|
||||
uperTuxKart 0.9 Released — The Best Racing Game on Linux Just Got Even Better
|
||||
================================================================================
|
||||
**A brand new version of the hugely popular racing game SuperTuxKart has [zipped past the release line][1] to land on download servers. **
|
||||
|
||||

|
||||
Super Tux Kart 0.9 Release Poster
|
||||
|
||||
SuperTuxKart 0.9 is a huge update over earlier versions, running a hot new engine (awesomely named ‘Antarctica’) under the hood that aims to deliver richer graphical environments , shading and depth of field plus better kart physics.
|
||||
|
||||
The bump in graphics performance necessitates a bump in graphics card requirements, too. SuperTuxKart developers advise would-be racers to will need a device with graphics comparable to (or, ideally, better than) Intel HD Graphics 3000, NVIDIA GeForce 8600 or AMD Radeon HD 3650.
|
||||
|
||||
### Other Changes ###
|
||||
|
||||
Keeping pace alongside the headline visual improvements in SuperTuxKart 0.9 is pair **brand new tracks**, new Karts, new online accounts for keeping track of and sharing badges earned through the **newly introduced achievements system**, and oodles of fixes and artwork tweaks.
|
||||
|
||||
Check out STK 0.9 in all its shader-based glory by hitting play on the official release video below.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/0FEwDH7XU9Q?feature=oembed"></iframe>
|
||||
|
||||
Ubuntu users can grab pre-compiled binaries for the new release from the project website.
|
||||
|
||||
- [Download SuperTuxKart 0.9][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/04/supertuxkart-0-9-released
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://supertuxkart.blogspot.co.uk/2015/04/supertuxkart-09-released.html
|
||||
[2]:http://supertuxkart.sourceforge.net/Downloads
|
||||
@ -0,0 +1,41 @@
|
||||
Synfig Studio 1.0 — Open Source Animation Gets Serious
|
||||
================================================================================
|
||||

|
||||
|
||||
**A brand new version of the free, open-source 2D animation software Synfig Studio is now available to download. **
|
||||
|
||||
The first release of the cross-platform software in well over a year, Synfig Studio 1.0 builds on its claim of offering “industrial-strength solution for creating film-quality animation” with a suite of new and improved features.
|
||||
|
||||
Among them is an improved user interface that the project developers say is ‘easier’ and ‘more intuitive’ to use. The client adds a new **single-window mode** for tidy working and has been **reworked to use the latest GTK3 libraries**.
|
||||
|
||||
On the features front there are several notable changes, including the addition of a fully-featured bone system.
|
||||
|
||||
This **joint-and-pivot ‘skeleton’ framework** is well suited to 2D cut-out animation and should prove super efficient when coupled with the complex deformations new to this release, or used with Synfig’s popular ‘automatic interpolated keyframes’ (read: frame-to-frame morphing).
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/M8zW1qCq8ng?feature=oembed"></iframe>
|
||||
|
||||
New non-destructive cutout tools, friction effects and initial support for full frame-by-frame bitmap animation, may help unlock the creativity of open-source animators, as might the addition of a sound layer for syncing the animation timeline with a soundtrack!
|
||||
|
||||
### Download Synfig Studio 1.0 ###
|
||||
|
||||
Synfig Studio is not a tool suited for everyone, though the latest batch of improvements in this latest release should help persuade some animators to give the free animation software a try.
|
||||
|
||||
If you want to find out what open-source animation software is like for yourself, you can grab an installer for Ubuntu for the latest release direct from the project’s Sourceforge page using the links below.
|
||||
|
||||
- [Download Synfig 1.0 (64bit) .deb Installer][1]
|
||||
- [Download Synfig 1.0 (32bit) .deb Installer][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/04/synfig-studio-new-release-features
|
||||
|
||||
作者:[oey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_amd64.deb/download
|
||||
[2]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_x86.deb/download
|
||||
@ -1,4 +1,3 @@
|
||||
[raywang]
|
||||
Open source all over the world
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,12 +1,8 @@
|
||||
theol-l translating
|
||||
|
||||
The Curious Case of the Disappearing Distros
|
||||
关于消失的发行版的古怪情形。
|
||||
================================================================================
|
||||

|
||||
|
||||
"Linux is a big game now, with billions of dollars of profit, and it's the best thing since sliced bread, but corporations are taking control, and slowly but systematically, community distros are being killed," said Google+ blogger Alessandro Ebersol. "Linux is slowly becoming just like BSD, where companies use and abuse it and give very little in return."
|
||||
"Linux现在成为了一个大型的游戏,同时具有巨额的利润,这是有史以来最好的事情。但是公司企业进行了控制,于是缓慢而系统的社区发行版就逐渐被干掉了,",Google+的一个博主 Alessandro Ebersol说到。"Linux开始变得像BSD--一些公司使用和滥用但是没有任何回报--一样缓慢。"
|
||||
|
||||
Well the holidays are pretty much upon us at last here in the Linux blogosphere, and there's nowhere left to hide. The next two weeks or so promise little more than a blur of forced social occasions and too-large meals, punctuated only -- for the luckier ones among us -- by occasional respite down at the Broken Windows Lounge.
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by weychen
|
||||
10 Top Distributions in Demand to Get Your Dream Job
|
||||
================================================================================
|
||||
We are coming up with a series of five articles which aims at making you aware of the top skills which will help you in getting yours dream job. In this competitive world you can not rely on one skill. You need to have balanced set of skills. There is no measure of a balanced skill set except a few conventions and statistics which changes from time-to-time.
|
||||
|
||||
@ -1,84 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
### Voice Actions—a supercomputer in your pocket ###
|
||||
|
||||
In August 2010, a new feature “[Voice Actions][1]" launched in the Android Market as part of the Voice Search app. Voice Actions allowed users to issue voice commands to their phone, and Android would try to interpret them and do something smart. Something like "Navigate to [address]" would fire up Google Maps and start turn-by-turn navigation to your stated destination. You could also send texts or e-mails, make a call, open a Website, get directions, or view a location on a map—all just by speaking.
|
||||
|
||||
注:youtube视频地址
|
||||
<iframe width="500" height="281" frameborder="0" src="http://www.youtube-nocookie.com/embed/gGbYVvU0Z5s?start=0&wmode=transparent" type="text/html" style="display:block"></iframe>
|
||||
|
||||
Voice Actions was the culmination of a new app design philosophy for Google. Voice Actions was the most advanced voice control software for its time, and the secret was that Google wasn’t doing any computing on the device. In general, voice recognition was very CPU intensive. In fact, many voice recognition programs still have a “speed versus accuracy" setting, where users can choose how long they are willing to wait for the voice recognition algorithms to work—more CPU power means better accuracy.
|
||||
|
||||
Google’s innovation was not bothering to do the voice recognition computing on the phone’s limited processor. When a command was spoken, the user’s voice was packaged up and shipped out over the Internet to Google’s cloud servers. There, Google’s farm of supercomputers pored over the message, interpreted it, and shipped it back to the phone. It was a long journey, but the Internet was finally fast enough to accomplish something like this in a second or two.
|
||||
|
||||
Many people throw the phrase “cloud computing" around to mean “anything that is stored on a server," but this was actual cloud computing. Google was doing hardcore compute operations in the cloud, and because it is throwing a ridiculous amount of CPU power at the problem, the only limit to the voice recognition accuracy is the algorithms themselves. The software didn't need to be individually “trained" by each user, because everyone who used Voice Actions was training it all the time. Using the power of the Internet, Android put a supercomputer in your pocket, and, compared to existing solutions, moving the voice recognition workload from a pocket-sized computer to a room-sized computer greatly increased accuracy.
|
||||
|
||||
Voice recognition had been a project of Google’s for some time, and it all started with an 800 number. [1-800-GOOG-411][1] was a free phone information service that Google launched in April 2007. It worked just like 411 information services had for years—users could call the number and ask for a phone book lookup—but Google offered it for free. No humans were involved in the lookup process, the 411 service was powered by voice recognition and a text-to-speech engine. Voice Actions was only possible after three years of the public teaching Google how to hear.
|
||||
|
||||
Voice recognition was a great example of Google’s extremely long-term thinking—the company wasn't afraid to invest in a project that wouldn’t become a commercial product for several years. Today, voice recognition powers products all across Google. It’s used for voice input in the Google Search app, Android’s voice typing, and on Google.com. It’s also the primary input interface for Google Glass and [Android Wear][2].
|
||||
|
||||
The company even uses it beyond input. Google's voice recognition technology is used to transcribe YouTube videos, which powers automatic closed captioning for the hearing impaired. The transcription is even indexed by Google, so you can search for words that were said in the video. Voice is the future of many products, and this long-term planning has led Google to be one of the few major tech companies with an in-house voice recognition service. Most other voice recognition products, like Apple’s Siri and Samsung devices, are forced to use—and pay a license fee for—voice recognition from Nuance.
|
||||
|
||||
With the computer hearing system up and running, Google is applying this strategy to computer vision next. That's why things like Google Goggles, Google Image Search, and [Project Tango][3] exist. Just like the days of GOOG-411, these projects are in the early stages. When [Google's robot division][4] gets off the ground with a real robot, it will need to see and hear, and Google's computer vision and hearing projects will likely give the company a head start.
|
||||
|
||||

|
||||
The Nexus S, the first Nexus phone made by Samsung.
|
||||
|
||||
### Android 2.3 Gingerbread—the first major UI overhaul ###
|
||||
|
||||
Gingerbread was released in December 2010, a whopping seven months after the release of 2.2. The wait was worth it, though, as Android 2.3 changed just about every screen in the OS. It was the first major overhaul since the initial formation of Android in version 0.9. 2.3 would kick off a series of continual revamps in an attempt to turn Android from an ugly duckling into something that was capable of holding its own—aesthetically—against the iPhone.
|
||||
|
||||
And speaking of Apple, six months earlier, the company released the iPhone 4 and iOS 4, which added multitasking and Facetime video chat. Microsoft was finally back in the game, too. The company jumped into the modern smartphone era with the launch of Windows Phone 7 in November 2010.
|
||||
|
||||
Android 2.3 focused a lot on the interface design, but with no direction or design documents, many apps ended up getting a new bespoke theme. Some apps went with a flatter, darker theme, some used a gradient-filled, bubbly dark theme, and others went with a high-contrast white and green look. While it wasn't cohesive, Gingerbread accomplished the goal of modernizing nearly every part of the OS. It was a good thing, too, because the next phone version of Android wouldn’t arrive until nearly a year later.
|
||||
|
||||
Gingerbread’s launch device was the Nexus S, Google’s second flagship device and the first Nexus manufactured by Samsung. While today we are used to new CPU models every year, back then that wasn't the case. The Nexus S had a 1GHz Cortex A8 processor, just like the Nexus One. The GPU was slightly faster, and that was it in the speed department. It was a little bigger than the Nexus One, with a 4-inch, 800×480 AMOLED display.
|
||||
|
||||
Spec wise, the Nexus S might seem like a tame upgrade, but it was actually home to a lot of firsts for Android. The Nexus S was Google’s first flagship to shun a MicroSD slot, shipping with 16GB on-board memory. The Nexus One had only 512MB of storage, but it had a MicroSD slot. Removing the SD slot simplified storage management for users—there was just one pool now—but hurt expandability for power users. It was also Google's first phone to have NFC, a special chip in the back of the phone that could transfer information when touched to another NFC chip. For now, the Nexus S could only read NFC tags—it couldn't send data.
|
||||
|
||||
Thanks to some upgrades in Gingerbread, the Nexus S was one of the first Android phones to ship without a hardware D-Pad or trackball. The Nexus S was now down to just the power, volume, and the four navigation buttons. The Nexus S was also a precursor to the [crazy curved-screen phones][6] of today, as Samsung outfitted the Nexus S with a piece of slightly curved glass.
|
||||
|
||||

|
||||
Gingerbread changed the status bar and wallpaper, and it added a bunch of new icons.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
An upgraded "Nexus" live wallpaper was released as an exclusive addition to the Nexus S. It was basically the same idea as the Nexus One version, with its animated streaks of light. On the Nexus S, the "grid" design was removed and replaced with a wavy blue/gray background. The dock at the bottom was given square corners and colored icons.
|
||||
|
||||
|
||||
The new notification panel and menu.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The status bar was finally overhauled from the version that first debuted in 0.9. The bar was changed from a white gradient to flat black, and all the icons were redrawn in gray and green. Just about everything looked crisper and more modern thanks to the sharp-angled icon design and higher resolution. The strangest decisions were probably the removal of the time period from the status bar clock and the confusing shade of gray that was used for the signal bars. Despite gray being used for many status bar icons, and there being four gray bars in the above screenshot, Android was actually indicating no cellular signal. Green bars would indicate a signal, gray bars indicated “empty" signal slots.
|
||||
|
||||
The green status bar icons in Gingerbread also doubled as a status indicator of network connectivity. If you had a working connection to Google's servers, the icons would be green, if there was no connection to Google, the icons turned white. This let you easily identify the connectivity status of your connection while you were out and about.
|
||||
|
||||
The notification panel was changed from the aging Android 1.5 design. Again, we saw a UI piece that changed from a light theme to a dark theme, getting a dark gray header, black background, and black-on-gray text.
|
||||
|
||||
The menu was darkened too, changing from a white background to a black one with a slight transparency. The contrast between the menu icons and the background wasn’t as strong as it should be, because the gray icons are the same color as they were on the white background. Requiring a color change would mean every developer would have to make new icons, so Google went with the preexisting gray color on black. This was a change at the system level, so this new menu would show up in every app.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/14/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2010/08/google-beefs-up-voice-search-mobile-sync/
|
||||
[2]:http://arstechnica.com/business/2007/04/google-rolls-out-free-411-service/
|
||||
[3]:http://arstechnica.com/gadgets/2014/03/in-depth-with-android-wear-googles-quantum-leap-of-a-smartwatch-os/
|
||||
[4]:http://arstechnica.com/gadgets/2014/02/googles-project-tango-is-a-smartphone-with-kinect-style-computer-vision/
|
||||
[5]:http://arstechnica.com/gadgets/2013/12/google-robots-former-android-chief-will-lead-google-robotics-division/
|
||||
[6]:http://arstechnica.com/gadgets/2013/12/lg-g-flex-review-form-over-even-basic-function/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
|
||||
@ -83,4 +85,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -1,8 +1,7 @@
|
||||
Translating by ly0
|
||||
|
||||
Linux下一些蛮不错的音频编辑软件
|
||||
What is good audio editing software on Linux
|
||||
================================================================================
|
||||
无论你是一个业余的音乐家或者仅仅是一个上课撸教授音的学,你总是需要和录音打交道。如果你有很长的时间仅仅用Mac干这种事情,那么可以和这个过程说拜拜了,现在Linux也可以干同样的事情。简而言之,这里有一个简单但是不错的音频编辑软件列表,来满足你对不同任务和需求。
|
||||
|
||||
Whether you are an amateur musician or just a student recording his professor, you need to edit and work with audio recordings. If for a long time such task was exclusively attributed to Macintosh, this time is over, and Linux now has what it takes to do the job. In short, here is a non-exhaustive list of good audio editing software, fit for different tasks and needs.
|
||||
|
||||
### 1. Audacity ###
|
||||
|
||||
|
||||
@ -0,0 +1,444 @@
|
||||
Web Caching Basics: Terminology, HTTP Headers, and Caching Strategies
|
||||
=====================================================================
|
||||
|
||||
### Introduction
|
||||
|
||||
Intelligent content caching is one of the most effective ways to improve
|
||||
the experience for your site's visitors. Caching, or temporarily storing
|
||||
content from previous requests, is part of the core content delivery
|
||||
strategy implemented within the HTTP protocol. Components throughout the
|
||||
delivery path can all cache items to speed up subsequent requests,
|
||||
subject to the caching policies declared for the content.
|
||||
|
||||
In this guide, we will discuss some of the basic concepts of web content
|
||||
caching. This will mainly cover how to select caching policies to ensure
|
||||
that caches throughout the internet can correctly process your content.
|
||||
We will talk about the benefits that caching affords, the side effects
|
||||
to be aware of, and the different strategies to employ to provide the
|
||||
best mixture of performance and flexibility.
|
||||
|
||||
What Is Caching?
|
||||
----------------
|
||||
|
||||
Caching is the term for storing reusable responses in order to make
|
||||
subsequent requests faster. There are many different types of caching
|
||||
available, each of which has its own characteristics. Application caches
|
||||
and memory caches are both popular for their ability to speed up certain
|
||||
responses.
|
||||
|
||||
Web caching, the focus of this guide, is a different type of cache. Web
|
||||
caching is a core design feature of the HTTP protocol meant to minimize
|
||||
network traffic while improving the perceived responsiveness of the
|
||||
system as a whole. Caches are found at every level of a content's
|
||||
journey from the original server to the browser.
|
||||
|
||||
Web caching works by caching the HTTP responses for requests according
|
||||
to certain rules. Subsequent requests for cached content can then be
|
||||
fulfilled from a cache closer to the user instead of sending the request
|
||||
all the way back to the web server.
|
||||
|
||||
Benefits
|
||||
--------
|
||||
|
||||
Effective caching aids both content consumers and content providers.
|
||||
Some of the benefits that caching brings to content delivery are:
|
||||
|
||||
- **Decreased network costs**: Content can be cached at various points
|
||||
in the network path between the content consumer and content origin.
|
||||
When the content is cached closer to the consumer, requests will not
|
||||
cause much additional network activity beyond the cache.
|
||||
- **Improved responsiveness**: Caching enables content to be retrieved
|
||||
faster because an entire network round trip is not necessary. Caches
|
||||
maintained close to the user, like the browser cache, can make this
|
||||
retrieval nearly instantaneous.
|
||||
- **Increased performance on the same hardware**: For the server where
|
||||
the content originated, more performance can be squeezed from the
|
||||
same hardware by allowing aggressive caching. The content owner can
|
||||
leverage the powerful servers along the delivery path to take the
|
||||
brunt of certain content loads.
|
||||
- **Availability of content during network interruptions**: With
|
||||
certain policies, caching can be used to serve content to end users
|
||||
even when it may be unavailable for short periods of time from the
|
||||
origin servers.
|
||||
|
||||
Terminology
|
||||
-----------
|
||||
|
||||
When dealing with caching, there are a few terms that you are likely to
|
||||
come across that might be unfamiliar. Some of the more common ones are
|
||||
below:
|
||||
|
||||
- **Origin server**: The origin server is the original location of the
|
||||
content. If you are acting as the web server administrator, this is
|
||||
the machine that you control. It is responsible for serving any
|
||||
content that could not be retrieved from a cache along the request
|
||||
route and for setting the caching policy for all content.
|
||||
- **Cache hit ratio**: A cache's effectiveness is measured in terms of
|
||||
its cache hit ratio or hit rate. This is a ratio of the requests
|
||||
able to be retrieved from a cache to the total requests made. A high
|
||||
cache hit ratio means that a high percentage of the content was able
|
||||
to be retrieved from the cache. This is usually the desired outcome
|
||||
for most administrators.
|
||||
- **Freshness**: Freshness is a term used to describe whether an item
|
||||
within a cache is still considered a candidate to serve to a client.
|
||||
Content in a cache will only be used to respond if it is within the
|
||||
freshness time frame specified by the caching policy.
|
||||
- **Stale content**: Items in the cache expire according to the cache
|
||||
freshness settings in the caching policy. Expired content is
|
||||
"stale". In general, expired content cannot be used to respond to
|
||||
client requests. The origin server must be re-contacted to retrieve
|
||||
the new content or at least verify that the cached content is still
|
||||
accurate.
|
||||
- **Validation**: Stale items in the cache can be validated in order
|
||||
to refresh their expiration time. Validation involves checking in
|
||||
with the origin server to see if the cached content still represents
|
||||
the most recent version of item.
|
||||
- **Invalidation**: Invalidation is the process of removing content
|
||||
from the cache before its specified expiration date. This is
|
||||
necessary if the item has been changed on the origin server and
|
||||
having an outdated item in cache would cause significant issues for
|
||||
the client.
|
||||
|
||||
There are plenty of other caching terms, but the ones above should help
|
||||
you get started.
|
||||
|
||||
What Can be Cached?
|
||||
-------------------
|
||||
|
||||
Certain content lends itself more readily to caching than others. Some
|
||||
very cache-friendly content for most sites are:
|
||||
|
||||
- Logos and brand images
|
||||
- Non-rotating images in general (navigation icons, for example)
|
||||
- Style sheets
|
||||
- General Javascript files
|
||||
- Downloadable Content
|
||||
- Media Files
|
||||
|
||||
These tend to change infrequently, so they can benefit from being cached
|
||||
for longer periods of time.
|
||||
|
||||
Some items that you have to be careful in caching are:
|
||||
|
||||
- HTML pages
|
||||
- Rotating images
|
||||
- Frequently modified Javascript and CSS
|
||||
- Content requested with authentication cookies
|
||||
|
||||
Some items that should almost never be cached are:
|
||||
|
||||
- Assets related to sensitive data (banking info, etc.)
|
||||
- Content that is user-specific and frequently changed
|
||||
|
||||
In addition to the above general rules, it's possible to specify
|
||||
policies that allow you to cache different types of content
|
||||
appropriately. For instance, if authenticated users all see the same
|
||||
view of your site, it may be possible to cache that view anywhere. If
|
||||
authenticated users see a user-sensitive view of the site that will be
|
||||
valid for some time, you may tell the user's browser to cache, but tell
|
||||
any intermediary caches not to store the view.
|
||||
|
||||
Locations Where Web Content Is Cached
|
||||
-------------------------------------
|
||||
|
||||
Content can be cached at many different points throughout the delivery
|
||||
chain:
|
||||
|
||||
- **Browser cache**: Web browsers themselves maintain a small cache.
|
||||
Typically, the browser sets a policy that dictates the most
|
||||
important items to cache. This may be user-specific content or
|
||||
content deemed expensive to download and likely to be requested
|
||||
again.
|
||||
- **Intermediary caching proxies**: Any server in between the client
|
||||
and your infrastructure can cache certain content as desired. These
|
||||
caches may be maintained by ISPs or other independent parties.
|
||||
- **Reverse Cache**: Your server infrastructure can implement its own
|
||||
cache for backend services. This way, content can be served from the
|
||||
point-of-contact instead of hitting backend servers on each request.
|
||||
|
||||
Each of these locations can and often do cache items according to their
|
||||
own caching policies and the policies set at the content origin.
|
||||
|
||||
Caching Headers
|
||||
---------------
|
||||
|
||||
Caching policy is dependent upon two different factors. The caching
|
||||
entity itself gets to decide whether or not to cache acceptable content.
|
||||
It can decide to cache less than it is allowed to cache, but never more.
|
||||
|
||||
The majority of caching behavior is determined by the caching policy,
|
||||
which is set by the content owner. These policies are mainly articulated
|
||||
through the use of specific HTTP headers.
|
||||
|
||||
Through various iterations of the HTTP protocol, a few different
|
||||
cache-focused headers have arisen with varying levels of sophistication.
|
||||
The ones you probably still need to pay attention to are below:
|
||||
|
||||
- **`Expires`**: The `Expires` header is very straight-forward,
|
||||
although fairly limited in scope. Basically, it sets a time in the
|
||||
future when the content will expire. At this point, any requests for
|
||||
the same content will have to go back to the origin server. This
|
||||
header is probably best used only as a fall back.
|
||||
- **`Cache-Control`**: This is the more modern replacement for the
|
||||
`Expires` header. It is well supported and implements a much more
|
||||
flexible design. In almost all cases, this is preferable to
|
||||
`Expires`, but it may not hurt to set both values. We will discuss
|
||||
the specifics of the options you can set with `Cache-Control` a bit
|
||||
later.
|
||||
- **`Etag`**: The `Etag` header is used with cache validation. The
|
||||
origin can provide a unique `Etag` for an item when it initially
|
||||
serves the content. When a cache needs to validate the content it
|
||||
has on-hand upon expiration, it can send back the `Etag` it has for
|
||||
the content. The origin will either tell the cache that the content
|
||||
is the same, or send the updated content (with the new `Etag`).
|
||||
- **`Last-Modified`**: This header specifies the last time that the
|
||||
item was modified. This may be used as part of the validation
|
||||
strategy to ensure fresh content.
|
||||
- **`Content-Length`**: While not specifically involved in caching,
|
||||
the `Content-Length` header is important to set when defining
|
||||
caching policies. Certain software will refuse to cache content if
|
||||
it does not know in advanced the size of the content it will need to
|
||||
reserve space for.
|
||||
- **`Vary`**: A cache typically uses the requested host and the path
|
||||
to the resource as the key with which to store the cache item. The
|
||||
`Vary` header can be used to tell caches to pay attention to an
|
||||
additional header when deciding whether a request is for the same
|
||||
item. This is most commonly used to tell caches to key by the
|
||||
`Accept-Encoding` header as well, so that the cache will know to
|
||||
differentiate between compressed and uncompressed content.
|
||||
|
||||
### An Aside about the Vary Header
|
||||
|
||||
The `Vary` header provides you with the ability to store different
|
||||
versions of the same content at the expense of diluting the entries in
|
||||
the cache.
|
||||
|
||||
In the case of `Accept-Encoding`, setting the `Vary` header allows for a
|
||||
critical distinction to take place between compressed and uncompressed
|
||||
content. This is needed to correctly serve these items to browsers that
|
||||
cannot handle compressed content and is necessary in order to provide
|
||||
basic usability. One characteristic that tells you that
|
||||
`Accept-Encoding` may be a good candidate for `Vary` is that it only has
|
||||
two or three possible values.
|
||||
|
||||
Items like `User-Agent` might at first glance seem to be a good way to
|
||||
differentiate between mobile and desktop browsers to serve different
|
||||
versions of your site. However, since `User-Agent` strings are
|
||||
non-standard, the result will likely be many versions of the same
|
||||
content on intermediary caches, with a very low cache hit ratio. The
|
||||
`Vary` header should be used sparingly, especially if you do not have
|
||||
the ability to normalize the requests in intermediate caches that you
|
||||
control (which may be possible, for instance, if you leverage a content
|
||||
delivery network).
|
||||
|
||||
How Cache-Control Flags Impact Caching
|
||||
--------------------------------------
|
||||
|
||||
Above, we mentioned how the `Cache-Control` header is used for modern
|
||||
cache policy specification. A number of different policy instructions
|
||||
can be set using this header, with multiple instructions being separated
|
||||
by commas.
|
||||
|
||||
Some of the `Cache-Control` options you can use to dictate your
|
||||
content's caching policy are:
|
||||
|
||||
- **`no-cache`**: This instruction specifies that any cached content
|
||||
must be re-validated on each request before being served to a
|
||||
client. This, in effect, marks the content as stale immediately, but
|
||||
allows it to use revalidation techniques to avoid re-downloading the
|
||||
entire item again.
|
||||
- **`no-store`**: This instruction indicates that the content cannot
|
||||
be cached in any way. This is appropriate to set if the response
|
||||
represents sensitive data.
|
||||
- **`public`**: This marks the content as public, which means that it
|
||||
can be cached by the browser and any intermediate caches. For
|
||||
requests that utilized HTTP authentication, responses are marked
|
||||
`private` by default. This header overrides that setting.
|
||||
- **`private`**: This marks the content as `private`. Private content
|
||||
may be stored by the user's browser, but must *not* be cached by any
|
||||
intermediate parties. This is often used for user-specific data.
|
||||
- **`max-age`**: This setting configures the maximum age that the
|
||||
content may be cached before it must revalidate or re-download the
|
||||
content from the origin server. In essence, this replaces the
|
||||
`Expires` header for modern browsing and is the basis for
|
||||
determining a piece of content's freshness. This option takes its
|
||||
value in seconds with a maximum valid freshness time of one year
|
||||
(31536000 seconds).
|
||||
- **`s-maxage`**: This is very similar to the `max-age` setting, in
|
||||
that it indicates the amount of time that the content can be cached.
|
||||
The difference is that this option is applied only to intermediary
|
||||
caches. Combining this with the above allows for more flexible
|
||||
policy construction.
|
||||
- **`must-revalidate`**: This indicates that the freshness information
|
||||
indicated by `max-age`, `s-maxage` or the `Expires` header must be
|
||||
obeyed strictly. Stale content cannot be served under any
|
||||
circumstance. This prevents cached content from being used in case
|
||||
of network interruptions and similar scenarios.
|
||||
- **`proxy-revalidate`**: This operates the same as the above setting,
|
||||
but only applies to intermediary proxies. In this case, the user's
|
||||
browser can potentially be used to serve stale content in the event
|
||||
of a network interruption, but intermediate caches cannot be used
|
||||
for this purpose.
|
||||
- **`no-transform`**: This option tells caches that they are not
|
||||
allowed to modify the received content for performance reasons under
|
||||
any circumstances. This means, for instance, that the cache is not
|
||||
able to send compressed versions of content it did not receive from
|
||||
the origin server compressed and is not allowed.
|
||||
|
||||
These can be combined in different ways to achieve various caching
|
||||
behavior. Some mutually exclusive values are:
|
||||
|
||||
- `no-cache`, `no-store`, and the regular caching behavior indicated
|
||||
by absence of either
|
||||
- `public` and `private`
|
||||
|
||||
The `no-store` option supersedes the `no-cache` if both are present. For
|
||||
responses to unauthenticated requests, `public` is implied. For
|
||||
responses to authenticated requests, `private` is implied. These can be
|
||||
overridden by including the opposite option in the `Cache-Control`
|
||||
header.
|
||||
|
||||
Developing a Caching Strategy
|
||||
-----------------------------
|
||||
|
||||
In a perfect world, everything could be cached aggressively and your
|
||||
servers would only be contacted to validate content occasionally. This
|
||||
doesn't often happen in practice though, so you should try to set some
|
||||
sane caching policies that aim to balance between implementing long-term
|
||||
caching and responding to the demands of a changing site.
|
||||
|
||||
### Common Issues
|
||||
|
||||
There are many situations where caching cannot or should not be
|
||||
implemented due to how the content is produced (dynamically generated
|
||||
per user) or the nature of the content (sensitive banking information,
|
||||
for example). Another problem that many administrators face when setting
|
||||
up caching is the situation where older versions of your content are out
|
||||
in the wild, not yet stale, even though new versions have been
|
||||
published.
|
||||
|
||||
These are both frequently encountered issues that can have serious
|
||||
impacts on cache performance and the accuracy of content you are
|
||||
serving. However, we can mitigate these issues by developing caching
|
||||
policies that anticipate these problems.
|
||||
|
||||
### General Recommendations
|
||||
|
||||
While your situation will dictate the caching strategy you use, the
|
||||
following recommendations can help guide you towards some reasonable
|
||||
decisions.
|
||||
|
||||
There are certain steps that you can take to increase your cache hit
|
||||
ratio before worrying about the specific headers you use. Some ideas
|
||||
are:
|
||||
|
||||
- **Establish specific directories for images, css, and shared
|
||||
content**: Placing content into dedicated directories will allow you
|
||||
to easily refer to them from any page on your site.
|
||||
- **Use the same URL to refer to the same items**: Since caches key
|
||||
off of both the host and the path to the content requested, ensure
|
||||
that you refer to your content in the same way on all of your pages.
|
||||
The previous recommendation makes this significantly easier.
|
||||
- **Use CSS image sprites where possible**: CSS image sprites for
|
||||
items like icons and navigation decrease the number of round trips
|
||||
needed to render your site and allow your site to cache that single
|
||||
sprite for a long time.
|
||||
- **Host scripts and external resources locally where possible**: If
|
||||
you utilize javascript scripts and other external resources,
|
||||
consider hosting those resources on your own servers if the correct
|
||||
headers are not being provided upstream. Note that you will have to
|
||||
be aware of any updates made to the resource upstream so that you
|
||||
can update your local copy.
|
||||
- **Fingerprint cache items**: For static content like CSS and
|
||||
Javascript files, it may be appropriate to fingerprint each item.
|
||||
This means adding a unique identifier to the filename (often a hash
|
||||
of the file) so that if the resource is modified, the new resource
|
||||
name can be requested, causing the requests to correctly bypass the
|
||||
cache. There are a variety of tools that can assist in creating
|
||||
fingerprints and modifying the references to them within HTML
|
||||
documents.
|
||||
|
||||
In terms of selecting the correct headers for different items, the
|
||||
following can serve as a general reference:
|
||||
|
||||
- **Allow all caches to store generic assets**: Static content and
|
||||
content that is not user-specific can and should be cached at all
|
||||
points in the delivery chain. This will allow intermediary caches to
|
||||
respond with the content for multiple users.
|
||||
- **Allow browsers to cache user-specific assets**: For per-user
|
||||
content, it is often acceptable and useful to allow caching within
|
||||
the user's browser. While this content would not be appropriate to
|
||||
cache on any intermediary caching proxies, caching in the browser
|
||||
will allow for instant retrieval for users during subsequent visits.
|
||||
- **Make exceptions for essential time-sensitive content**: If you
|
||||
have content that is time-sensitive, make an exception to the above
|
||||
rules so that the out-dated content is not served in critical
|
||||
situations. For instance, if your site has a shopping cart, it
|
||||
should reflect the items in the cart immediately. Depending on the
|
||||
nature of the content, the `no-cache` or `no-store` options can be
|
||||
set in the `Cache-Control` header to achieve this.
|
||||
- **Always provide validators**: Validators allow stale content to be
|
||||
refreshed without having to download the entire resource again.
|
||||
Setting the `Etag` and the `Last-Modified` headers allow caches to
|
||||
validate their content and re-serve it if it has not been modified
|
||||
at the origin, further reducing load.
|
||||
- **Set long freshness times for supporting content**: In order to
|
||||
leverage caching effectively, elements that are requested as
|
||||
supporting content to fulfill a request should often have a long
|
||||
freshness setting. This is generally appropriate for items like
|
||||
images and CSS that are pulled in to render the HTML page requested
|
||||
by the user. Setting extended freshness times, combined with
|
||||
fingerprinting, allows caches to store these resources for long
|
||||
periods of time. If the assets change, the modified fingerprint will
|
||||
invalidate the cached item and will trigger a download of the new
|
||||
content. Until then, the supporting items can be cached far into the
|
||||
future.
|
||||
- **Set short freshness times for parent content**: In order to make
|
||||
the above scheme work, the containing item must have relatively
|
||||
short freshness times or may not be cached at all. This is typically
|
||||
the HTML page that calls in the other assisting content. The HTML
|
||||
itself will be downloaded frequently, allowing it to respond to
|
||||
changes rapidly. The supporting content can then be cached
|
||||
aggressively.
|
||||
|
||||
The key is to strike a balance that favors aggressive caching where
|
||||
possible while leaving opportunities to invalidate entries in the future
|
||||
when changes are made. Your site will likely have a combination of:
|
||||
|
||||
- Aggressively cached items
|
||||
- Cached items with a short freshness time and the ability to
|
||||
re-validate
|
||||
- Items that should not be cached at all
|
||||
|
||||
The goal is to move content into the first categories when possible
|
||||
while maintaining an acceptable level of accuracy.
|
||||
|
||||
Conclusion
|
||||
----------
|
||||
|
||||
Taking the time to ensure that your site has proper caching policies in
|
||||
place can have a significant impact on your site. Caching allows you to
|
||||
cut down on the bandwidth costs associated with serving the same content
|
||||
repeatedly. Your server will also be able to handle a greater amount of
|
||||
traffic with the same hardware. Perhaps most importantly, clients will
|
||||
have a faster experience on your site, which may lead them to return
|
||||
more frequently. While effective web caching is not a silver bullet,
|
||||
setting up appropriate caching policies can give you measurable gains
|
||||
with minimal work.
|
||||
|
||||
|
||||
---
|
||||
|
||||
作者: [Justin Ellingwood](https://www.digitalocean.com/community/users/jellingwood)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
推荐:[royaso](https://github.com/royaso)
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/web-caching-basics-terminology-http-headers-and-caching-strategies
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,136 +0,0 @@
|
||||
Interface (NICs) Bonding in Linux using nmcli
|
||||
================================================================================
|
||||
Today, we'll learn how to perform Interface (NICs) bonding in our CentOS 7.x using nmcli (Network Manager Command Line Interface).
|
||||
|
||||
NICs (Interfaces) bonding is a method for linking **NICs** together logically to allow fail-over or higher throughput. One of the ways to increase the network availability of a server is by using multiple network interfaces. The Linux bonding driver provides a method for aggregating multiple network interfaces into a single logical bonded interface. It is a new implementation that does not affect the older bonding driver in linux kernel; it offers an alternate implementation.
|
||||
|
||||
**NIC bonding is done to provide two main benefits for us:**
|
||||
|
||||
1. **High bandwidth**
|
||||
1. **Redundancy/resilience**
|
||||
|
||||
Now lets configure NICs bonding in CentOS 7. We'll need to decide which interfaces that we would like to configure a Team interface.
|
||||
|
||||
run **ip link** command to check the available interface in the system.
|
||||
|
||||
$ ip link
|
||||
|
||||

|
||||
|
||||
Here we are using **eno16777736** and **eno33554960** NICs to create a team interface in **activebackup** mode.
|
||||
|
||||
Use **nmcli** command to create a connection for the network team interface,with the following syntax.
|
||||
|
||||
# nmcli con add type team con-name CNAME ifname INAME [config JSON]
|
||||
|
||||
Where **CNAME** will be the name used to refer the connection ,**INAME** will be the interface name and **JSON** (JavaScript Object Notation) specifies the runner to be used.**JSON** has the following syntax:
|
||||
|
||||
'{"runner":{"name":"METHOD"}}'
|
||||
|
||||
where **METHOD** is one of the following: **broadcast, activebackup, roundrobin, loadbalance** or **lacp**.
|
||||
|
||||
### 1. Creating Team Interface ###
|
||||
|
||||
Now let us create the team interface. here is the command we used to create the team interface.
|
||||
|
||||
# nmcli con add type team con-name team0 ifname team0 config '{"runner":{"name":"activebackup"}}'
|
||||
|
||||

|
||||
|
||||
run **# nmcli con show** command to verify the team configuration.
|
||||
|
||||
# nmcli con show
|
||||
|
||||

|
||||
|
||||
### 2. Adding Slave Devices ###
|
||||
|
||||
Now lets add the slave devices to the master team0. here is the syntax for adding the slave devices.
|
||||
|
||||
# nmcli con add type team-slave con-name CNAME ifname INAME master TEAM
|
||||
|
||||
Here we are adding **eno16777736** and **eno33554960** as slave devices for **team0** interface.
|
||||
|
||||
# nmcli con add type team-slave con-name team0-port1 ifname eno16777736 master team0
|
||||
|
||||
# nmcli con add type team-slave con-name team0-port2 ifname eno33554960 master team0
|
||||
|
||||

|
||||
|
||||
Verify the connection configuration using **#nmcli con show** again. now we could see the slave configuration.
|
||||
|
||||
#nmcli con show
|
||||
|
||||

|
||||
|
||||
### 3. Assigning IP Address ###
|
||||
|
||||
All the above command will create the required configuration files under **/etc/sysconfig/network-scripts/**.
|
||||
|
||||
Lets assign an IP address to this team0 interface and enable the connection now. Here is the command to perform the IP assignment.
|
||||
|
||||
# nmcli con mod team0 ipv4.addresses "192.168.1.24/24 192.168.1.1"
|
||||
# nmcli con mod team0 ipv4.method manual
|
||||
# nmcli con up team0
|
||||
|
||||

|
||||
|
||||
### 4. Verifying the Bonding ###
|
||||
|
||||
Verify the IP address information in **#ip add show team0** command.
|
||||
|
||||
#ip add show team0
|
||||
|
||||

|
||||
|
||||
Now lets check the **activebackup** configuration functionality using the **teamdctl** command.
|
||||
|
||||
# teamdctl team0 state
|
||||
|
||||

|
||||
|
||||
Now lets disconnect the active port and check the state again. to confirm whether the active backup configuration is working as expected.
|
||||
|
||||
# nmcli dev dis eno33554960
|
||||
|
||||

|
||||
|
||||
disconnected the active port and now check the state again using **#teamdctl team0 state**.
|
||||
|
||||
# teamdctl team0 state
|
||||
|
||||

|
||||
|
||||
Yes its working cool !! we will connect the disconnected connection back to team0 using the following command.
|
||||
|
||||
#nmcli dev con eno33554960
|
||||
|
||||

|
||||
|
||||
We have one more command called **teamnl** let us show some options with **teamnl** command.
|
||||
|
||||
to check the ports in team0 run the following command.
|
||||
|
||||
# teamnl team0 ports
|
||||
|
||||

|
||||
|
||||
Display currently active port of **team0**.
|
||||
|
||||
# teamnl team0 getoption activeport
|
||||
|
||||

|
||||
|
||||
Hurray, we have successfully configured NICs bonding :-) Please share feedback if any.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/interface-nics-bonding-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,136 +0,0 @@
|
||||
translating by coloka
|
||||
What are useful command-line network monitors on Linux
|
||||
================================================================================
|
||||
Network monitoring is a critical IT function for businesses of all sizes. The goal of network monitoring can vary. For example, the monitoring activity can be part of long-term network provisioning, security protection, performance troubleshooting, network usage accounting, and so on. Depending on its goal, network monitoring is done in many different ways, such as performing packet-level sniffing, collecting flow-level statistics, actively injecting probes into the network, parsing server logs, etc.
|
||||
|
||||
While there are many dedicated network monitoring systems capable of 24/7/365 monitoring, you can also leverage command-line network monitors in certain situations, where a dedicated monitor is an overkill. If you are a system admin, you are expected to have hands-on experience with some of well known CLI network monitors. Here is a list of **popular and useful command-line network monitors on Linux**.
|
||||
|
||||
### Packet-Level Sniffing ###
|
||||
|
||||
In this category, monitoring tools capture individual packets on the wire, dissect their content, and display decoded packet content or packet-level statistics. These tools conduct network monitoring from the lowest level, and as such, can possibly do the most fine-grained monitoring at the cost of network I/O and analysis efforts.
|
||||
|
||||
1. **dhcpdump**: a comman-line DHCP traffic sniffer capturing DHCP request/response traffic, and displays dissected DHCP protocol messages in a human-friendly format. It is useful when you are troubleshooting DHCP related issues.
|
||||
|
||||
2. **[dsniff][1]**: a collection of command-line based sniffing, spoofing and hijacking tools designed for network auditing and penetration testing. They can sniff various information such as passwords, NSF traffic, email messages, website URLs, and so on.
|
||||
|
||||
3. **[httpry][2]**: an HTTP packet sniffer which captures and decode HTTP requests and response packets, and display them in a human-readable format.
|
||||
|
||||
4. **IPTraf**: a console-based network statistics viewer. It displays packet-level, connection-level, interface-level, protocol-level packet/byte counters in real-time. Packet capturing can be controlled by protocol filters, and its operation is full menu-driven.
|
||||
|
||||
|
||||
|
||||
5. **[mysql-sniffer][3]**: a packet sniffer which captures and decodes packets associated with MySQL queries. It displays the most frequent or all queries in a human-readable format.
|
||||
|
||||
6. **[ngrep][4]**: grep over network packets. It can capture live packets, and match (filtered) packets against regular expressions or hexadecimal expressions. It is useful for detecting and storing any anomalous traffic, or for sniffing particular patterns of information from live traffic.
|
||||
|
||||
7. **[p0f][5]**: a passive fingerprinting tool which, based on packet sniffing, reliably identifies operating systems, NAT or proxy settings, network link types and various other properites associated with an active TCP connection.
|
||||
|
||||
8. **pktstat**: a command-line tool which analyzes live packets to display connection-level bandwidth usages as well as descriptive information of protocols involved (e.g., HTTP GET/POST, FTP, X11).
|
||||
|
||||
|
||||
|
||||
9. **Snort**: an intrusion detection and prevention tool which can detect/prevent a variety of backdoor, botnets, phishing, spyware attacks from live traffic based on rule-driven protocol analysis and content matching.
|
||||
|
||||
10. **tcpdump**: a command-line packet sniffer which is capable of capturing nework packets on the wire based on filter expressions, dissect the packets, and dump the packet content for packet-level analysis. It is widely used for any kinds of networking related troubleshooting, network application debugging, or [security][6] monitoring.
|
||||
|
||||
11. **tshark**: a command-line packet sniffing tool that comes with Wireshark GUI program. It can capture and decode live packets on the wire, and show decoded packet content in a human-friendly fashion.
|
||||
|
||||
### Flow-/Process-/Interface-Level Monitoring ###
|
||||
|
||||
In this category, network monitoring is done by classifying network traffic into flows, associated processes or interfaces, and collecting per-flow, per-process or per-interface statistics. Source of information can be libpcap packet capture library or sysfs kernel virtual filesystem. Monitoring overhead of these tools is low, but packet-level inspection capabilities are missing.
|
||||
|
||||
12. **bmon**: a console-based bandwidth monitoring tool which shows various per-interface information, including not-only aggregate/average RX/TX statistics, but also a historical view of bandwidth usage.
|
||||
|
||||
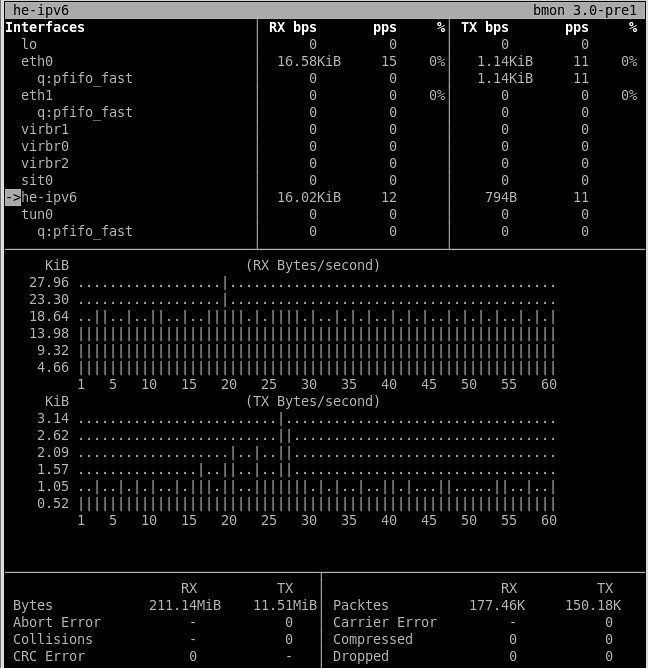
|
||||
|
||||
13. **[iftop][7]**: a bandwidth usage monitoring tool that can shows bandwidth usage for individual network connections in real time. It comes with ncurses-based interface to visualize bandwidth usage of all connections in a sorted order. It is useful for monitoring which connections are consuming the most bandwidth.
|
||||
|
||||
14. **nethogs**: a process monitoring tool which offers a real-time view of upload/download bandwidth usage of individual processes or programs in an ncurses-based interface. This is useful for detecting bandwidth hogging processes.
|
||||
|
||||
15. **netstat**: a command-line tool that shows various statistics and properties of the networking stack, such as open TCP/UDP connections, network interface RX/TX statistics, routing tables, protocol/socket statistics. It is useful when you diagnose performance and resource usage related problems of the networking stack.
|
||||
|
||||
16. **[speedometer][8]**: a console-based traffic monitor which visualizes the historical trend of an interface's RX/TX bandwidth usage with ncurses-drawn bar charts.
|
||||
|
||||
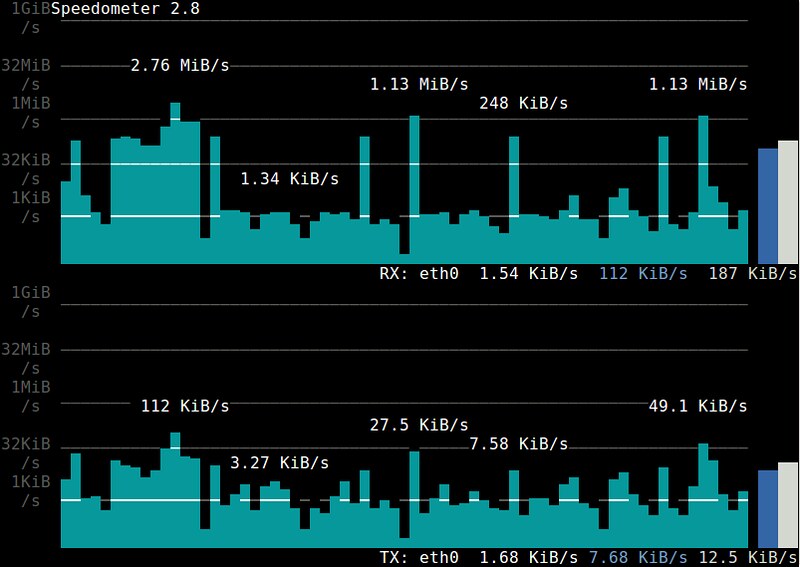
|
||||
|
||||
17. **[sysdig][9]**: a comprehensive system-level debugging tool with a unified interface for investigating different Linux subsystems. Its network monitoring module is capable of monitoring, either online or offline, various per-process/per-host networking statistics such as bandwidth usage, number of connections/requests, etc.
|
||||
|
||||
18. **tcptrack**: a TCP connection monitoring tool which displays information of active TCP connections, including source/destination IP addresses/ports, TCP state, and bandwidth usage.
|
||||
|
||||
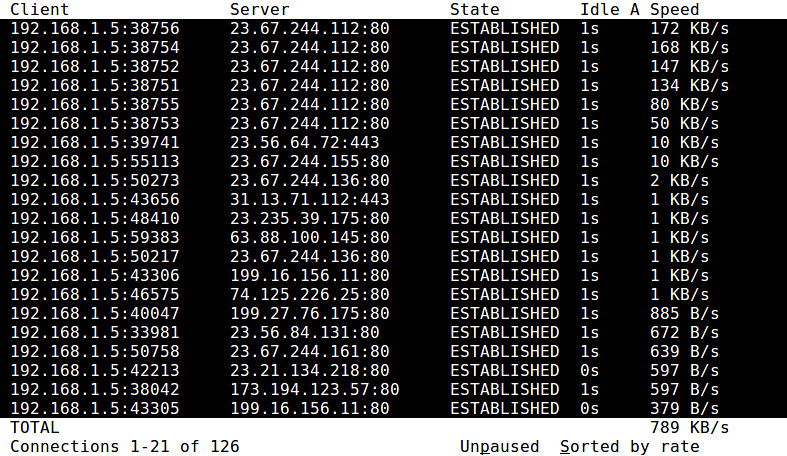
|
||||
|
||||
19. **vnStat**: a command-line traffic monitor which maintains a historical view of RX/TX bandwidh usage (e.g., current, daily, monthly) on a per-interface basis. Running as a background daemon, it collects and stores interface statistics on bandwidth rate and total bytes transferred.
|
||||
|
||||
### Active Network Monitoring ###
|
||||
|
||||
Unlike passive monitoring tools presented so far, tools in this category perform network monitoring by actively "injecting" probes into the network and collecting corresponding responses. Monitoring targets include routing path, available bandwidth, loss rates, delay, jitter, system settings or vulnerabilities, and so on.
|
||||
|
||||
20. **[dnsyo][10]**: a DNS monitoring tool which can conduct DNS lookup from open resolvers scattered across more than 1,500 different networks. It is useful when you check DNS propagation or troubleshoot DNS configuration.
|
||||
|
||||
21. **[iperf][11]**: a TCP/UDP bandwidth measurement utility which can measure maximum available bandwidth between two end points. It measures available bandwidth by having two hosts pump out TCP/UDP probe traffic between them either unidirectionally or bi-directionally. It is useful when you test the network capacity, or tune the parameters of network stack. A variant called [netperf][12] exists with more features and better statistics.
|
||||
|
||||
22. **[netcat][13]/socat**: versatile network debugging tools capable of reading from, writing to, or listen on TCP/UDP sockets. They are often used alongside with other programs or scripts for backend network transfer or port listening.
|
||||
|
||||
23. **nmap**: a command-line port scanning and network discovery utility. It relies on a number of TCP/UDP based scanning techniques to detect open ports, live hosts, or existing operating systems on the local network. It is useful when you audit local hosts for vulnerabilities or build a host map for maintenance purpose. [zmap][14] is an alernative scanning tool with Internet-wide scanning capability.
|
||||
|
||||
24. ping: a network testing tool which works by exchaning ICMP echo and reply packets with a remote host. It is useful when you measure round-trip-time (RTT) delay and loss rate of a routing path, as well as test the status or firewall rules of a remote system. Variations of ping exist with fancier interface (e.g., [noping][15]), multi-protocol support (e.g., [hping][16]) or parallel probing capability (e.g., [fping][17]).
|
||||
|
||||
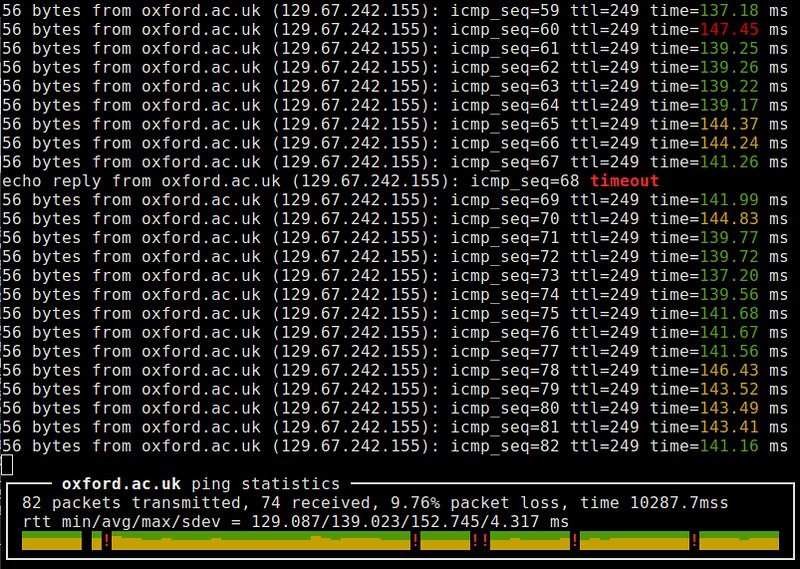
|
||||
|
||||
25. **[sprobe][18]**: a command-line tool that heuristically infers the bottleneck bandwidth between a local host and any arbitrary remote IP address. It uses TCP three-way handshake tricks to estimate the bottleneck bandwidth. It is useful when troubleshooting wide-area network performance and routing related problems.
|
||||
|
||||
26. **traceroute**: a network discovery tool which reveals a layer-3 routing/forwarding path from a local host to a remote host. It works by sending TTL-limited probe packets and collecting ICMP responses from intermediate routers. It is useful when troubleshooting slow network connections or routing related problems. Variations of traceroute exist with better RTT statistics (e.g., [mtr][19]).
|
||||
|
||||
### Application Log Parsing ###
|
||||
|
||||
In this category, network monitoring is targeted at a specific server application (e.g., web server or database server). Network traffic generated or consumed by a server application is monitored by analyzing its log file. Unlike network-level monitors presented in earlier categories, tools in this category can analyze and monitor network traffic from application-level.
|
||||
|
||||
27. **[GoAccess][20]**: a console-based interactive viewer for Apache and Nginx web server traffic. Based on access log analysis, it presents a real-time statistics of a number of metrics including daily visits, top requests, client operating systems, client locations, client browsers, in a scrollable view.
|
||||
|
||||
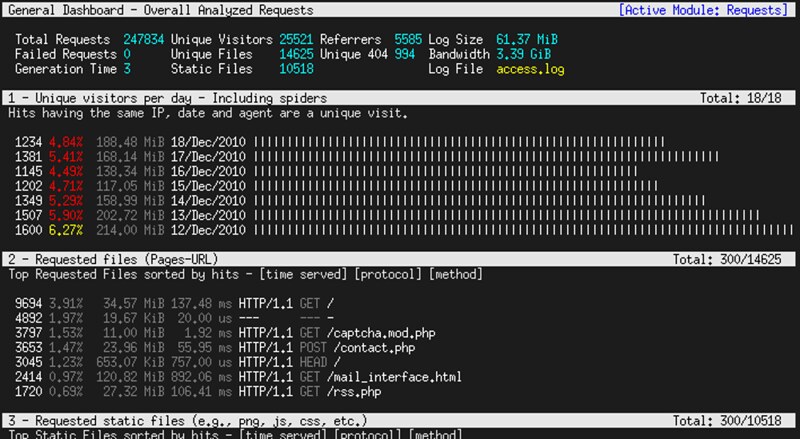
|
||||
|
||||
28. **[mtop][21]**: a command-line MySQL/MariaDB server moniter which visualizes the most expensive queries and current database server load. It is useful when you optimize MySQL server performance and tune server configurations.
|
||||
|
||||
|
||||
|
||||
29. **[ngxtop][22]**: a traffic monitoring tool for Nginx and Apache web server, which visualizes web server traffic in a top-like interface. It works by parsing a web server's access log file and collecting traffic statistics for individual destinations or requests.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, I presented a wide variety of command-line network monitoring tools, ranging from the lowest packet-level monitors to the highest application-level network monitors. Knowing which tool does what is one thing, and choosing which tool to use is another, as any single tool cannot be a universal solution for your every need. A good system admin should be able to decide which tool is right for the circumstance at hand. Hopefully the list helps with that.
|
||||
|
||||
You are always welcome to improve the list with your comment!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/useful-command-line-network-monitors-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://www.monkey.org/~dugsong/dsniff/
|
||||
[2]:http://xmodulo.com/monitor-http-traffic-command-line-linux.html
|
||||
[3]:https://github.com/zorkian/mysql-sniffer
|
||||
[4]:http://ngrep.sourceforge.net/
|
||||
[5]:http://lcamtuf.coredump.cx/p0f3/
|
||||
[6]:http://xmodulo.com/recommend/firewallbook
|
||||
[7]:http://xmodulo.com/how-to-install-iftop-on-linux.html
|
||||
[8]:https://excess.org/speedometer/
|
||||
[9]:http://xmodulo.com/monitor-troubleshoot-linux-server-sysdig.html
|
||||
[10]:http://xmodulo.com/check-dns-propagation-linux.html
|
||||
[11]:https://iperf.fr/
|
||||
[12]:http://www.netperf.org/netperf/
|
||||
[13]:http://xmodulo.com/useful-netcat-examples-linux.html
|
||||
[14]:https://zmap.io/
|
||||
[15]:http://noping.cc/
|
||||
[16]:http://www.hping.org/
|
||||
[17]:http://fping.org/
|
||||
[18]:http://sprobe.cs.washington.edu/
|
||||
[19]:http://xmodulo.com/better-alternatives-basic-command-line-utilities.html#mtr_link
|
||||
[20]:http://goaccess.io/
|
||||
[21]:http://mtop.sourceforge.net/
|
||||
[22]:http://xmodulo.com/monitor-nginx-web-server-command-line-real-time.html
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by Medusar
|
||||
|
||||
How to make a file immutable on Linux
|
||||
================================================================================
|
||||
Suppose you want to write-protect some important files on Linux, so that they cannot be deleted or tampered with by accident or otherwise. In other cases, you may want to prevent certain configuration files from being overwritten automatically by software. While changing their ownership or permission bits on the files by using chown or chmod is one way to deal with this situation, this is not a perfect solution as it cannot prevent any action done with root privilege. That is when chattr comes in handy.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
[Translating by DongShuaike]
|
||||
|
||||
Installing Cisco Packet tracer in Linux
|
||||
================================================================================
|
||||

|
||||
@ -194,4 +196,4 @@ via: http://www.unixmen.com/installing-cisco-packet-tracer-linux/
|
||||
[1]:https://www.netacad.com/
|
||||
[2]:https://www.dropbox.com/s/5evz8gyqqvq3o3v/Cisco%20Packet%20Tracer%206.1.1%20Linux.tar.gz?dl=0
|
||||
[3]:http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
|
||||
[4]:https://www.netacad.com/
|
||||
[4]:https://www.netacad.com/
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Ping -- Translating
|
||||
[Trnslating by DongShuaike]
|
||||
|
||||
iptraf: A TCP/UDP Network Monitoring Utility
|
||||
================================================================================
|
||||
|
||||
@ -1,241 +0,0 @@
|
||||
Setting up a private Docker registry
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] This is the second post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment.
|
||||
|
||||
- [First part][1]: where I talk about the process we went thru before approaching Docker;
|
||||
- [Third pard][2]: where I show how to automate the entire process of building images and deploying a Rails app with Docker.
|
||||
|
||||
----------
|
||||
|
||||
Why would ouy want ot set up a provate registry? Well, for starters, Docker Hub only allows you to have one free private repo. Other companies are beginning to offer similar services, but they are all not very cheap. In addition, if you need to deploy production ready applications built with Docker, you might not want to publish those images on the public Docker Hub.
|
||||
|
||||
This is a very pragmatic approach to dealing with the intricacies of setting up a private Docker registry. For the tutorial we will be using a small 512MB instance on DigitalOcean (from now on DO). I also assume you already know the basics of Docker since I will be concentrating on some more complicated stuff.
|
||||
|
||||
### Local set up ###
|
||||
|
||||
First of all you need to install **boot2docker** and docker CLI. If you already have your basic Docker environment up and running, you can just skip to the next section.
|
||||
|
||||
From the terminal run the following command[1][3]:
|
||||
|
||||
brew install boot2docker docker
|
||||
|
||||
If everything is ok[2][4], you will now be able to start the VM inside which Docker will run with the following command:
|
||||
|
||||
boot2docker up
|
||||
|
||||
Follow the instructions, copy and paste the export commands that boot2docker will print in the terminal. If you now run `docker ps` you should be greeted by the following line
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
|
||||
Ok, Docker is ready to go. This will be enough for the moment. Let's go back to setting up the registry.
|
||||
|
||||
### Creating the server ###
|
||||
|
||||
Log into you DO account and create a new Droplet by selecting an image with Docker pre-installed[^n].
|
||||
|
||||

|
||||
|
||||
You should receive your root credentials via email. Log into your instance and run `docker ps` to see if eveything is ok.
|
||||
|
||||
### Setting up AWS S3 ###
|
||||
|
||||
We are going to use Amazon Simple Storage Service (S3) as the storage layer for our registry / repository. We will need to create a bucket and user credentials to allow our docker container accessoing it.
|
||||
|
||||
Login into your AWS account (if you don't have one you can set one up at [http://aws.amazon.com/][5]) and from the console select S3 (Simple Storage Service).
|
||||
|
||||

|
||||
|
||||
Click on **Create Bucket**, enter a unique name for your bucket (and write it down, we're gonna need it later), then click on **Create**.
|
||||
|
||||

|
||||
|
||||
That's it! We're done setting up the storage part.
|
||||
|
||||
### Setup AWS access credentials ###
|
||||
|
||||
We are now going to create a new user. Go back to your AWS console and select IAM (Identity & Access Management).
|
||||
|
||||

|
||||
|
||||
In the dashboard, on the left side of the webpage, you should click on Users. Then select **Create New Users**.
|
||||
|
||||
You should be presented with the following screen:
|
||||
|
||||

|
||||
|
||||
Enter a name for your user (e.g. docker-registry) and click on Create. Write down (or download the csv file with) your Access Key and Secret Access Key that we'll need when running the Docker container. Go back to your users list and select the one you just created.
|
||||
|
||||
Under the Permission section, click on Attach User Policy. In the next screen, you will be presented with multiple choices: select Custom Policy.
|
||||
|
||||

|
||||
|
||||
Here's the content of the custom policy:
|
||||
|
||||
{
|
||||
"Version": "2012-10-17",
|
||||
"Statement": [
|
||||
{
|
||||
"Sid": "SomeStatement",
|
||||
"Effect": "Allow",
|
||||
"Action": [
|
||||
"s3:*"
|
||||
],
|
||||
"Resource": [
|
||||
"arn:aws:s3:::docker-registry-bucket-name/*",
|
||||
"arn:aws:s3:::docker-registry-bucket-name"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
This will allow the user (i.e. the registry) to manage (read/write) content on the bucket (make sure to use the bucket name you previously defined when setting up AWS S3). To sum it up: when you'll be pushing Docker images from your local machine to your repository, the server will be able to upload them to S3.
|
||||
|
||||
### Installing the registry ###
|
||||
|
||||
Now let's head back to our DO server and SSH into it. We are going to use[^n] one of the [official Docker registry images][6].
|
||||
|
||||
Let's start our registry with the following command:
|
||||
|
||||
docker run \
|
||||
-e SETTINGS_FLAVOR=s3 \
|
||||
-e AWS_BUCKET=bucket-name \
|
||||
-e STORAGE_PATH=/registry \
|
||||
-e AWS_KEY=your_aws_key \
|
||||
-e AWS_SECRET=your_aws_secret \
|
||||
-e SEARCH_BACKEND=sqlalchemy \
|
||||
-p 5000:5000 \
|
||||
--name registry \
|
||||
-d \
|
||||
registry
|
||||
|
||||
Docker should pull the required fs layers from the Docker Hub and eventually start the daemonised container.
|
||||
|
||||
### Testing the registry ###
|
||||
|
||||
If everything worked out, you should now be able to test the registry by pinging it and by searching its content (though for the time being it's still empty).
|
||||
|
||||
Our registry is very basic and it does not provide any means of authentication. Since there are no easy ways of adding authentication (at least none that I'm aware of that are easy enough to implment in order to justify the effort), I've decided that the easiest way of querying / pulling / pushing the registry is an unsecure (over HTTP) connection tunneled thru SSH.
|
||||
|
||||
Opening an SSH tunnel from your local machine is straightforward:
|
||||
|
||||
ssh -N -L 5000:localhost:5000 root@your_registry.com
|
||||
|
||||
The command is tunnelling connections over SSH from port 5000 of the registry server (which is the one we exposed with the `docker run` command in the previous paragraph) to port 5000 on the localhost.
|
||||
|
||||
If you now browse to the following address [http://localhost:5000/v1/_ping][7] you should get the following very simple response
|
||||
|
||||
{}
|
||||
|
||||
This just means that the registry is working correctly. You can also list the whole content of the registry by browsing to [http://localhost:5000/v1/search][8] that will get you a similar response:
|
||||
|
||||
{
|
||||
"num_results": 2,
|
||||
"query": "",
|
||||
"results": [
|
||||
{
|
||||
"description": "",
|
||||
"name": "username/first-repo"
|
||||
},
|
||||
{
|
||||
"description": "",
|
||||
"name": "username/second-repo"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
### Building an image ###
|
||||
|
||||
Let's now try and build a very simple Docker image to test our newly installed registry. On your local machine, create a Dockerfile with the following content[^n]:
|
||||
|
||||
# Base image with ruby 2.2.0
|
||||
FROM ruby:2.2.0
|
||||
|
||||
MAINTAINER Michelangelo Chasseur <michelangelo.chasseur@touchwa.re>
|
||||
|
||||
...and build it:
|
||||
|
||||
docker build -t localhost:5000/username/repo-name .
|
||||
|
||||
The `localhost:5000` part is especially important: the first part of the name of a Docker image will tell the `docker push` command the endpoint towards which we are trying to push our image. In our case, since we are connecting to our remote private registry via an SSH tunnel, `localhost:5000` represents exactly the reference to our registry.
|
||||
|
||||
If everything works as expected, when the command returns, you should be able to list your newly created image with the `docker images` command. Run it and see it for yourself.
|
||||
|
||||
### Pushing to the registry ###
|
||||
|
||||
Now comes the trickier part. It took a me a while to realize what I'm about to describe, so just be patient if you don't get it the first time you read and try to follow along. I know that all this stuff will seem pretty complicated (and it would be if you didn't automate the process), but I promise in the end it will all make sense. In the next post I will show a couple of shell scripts and Rake tasks that will automate the whole process and will let you deploy a Rails to your registry app with a single easy command.
|
||||
|
||||
The docker command you are running from your terminal is actually using the boot2docker VM to run the containers and do all the magic stuff. So when we run a command like `docker push some_repo` what is actually happening is that it's the boot2docker VM that is reacing out for the registry, not our localhost.
|
||||
|
||||
This is an extremely important point to understand: in order to push the Docker image to the remote private registry, the SSH tunnel needs to be established from the boot2docker VM and not from your local machine.
|
||||
|
||||
There are a couple of ways to go with it. I will show you the shortest one (which is not probably the easiest to understand, but it's the one that will let us automate the process with shell scripts).
|
||||
|
||||
First of all though we need to sort one last thing with SSH.
|
||||
|
||||
### Setting up SSH ###
|
||||
|
||||
Let's add our boot2docker SSH key to our remote server (registry) known hosts. We can do so using the ssh-copy-id utility that you can install with the following command shouldn't you already have it:
|
||||
|
||||
brew install ssh-copy-id
|
||||
|
||||
Then run:
|
||||
|
||||
ssh-copy-id -i /Users/username/.ssh/id_boot2docker root@your-registry.com
|
||||
|
||||
Make sure to substitute `/Users/username/.ssh/id_boot2docker` with the correct path of your ssh key.
|
||||
|
||||
This will allow us to connect via SSH to our remote registry without being prompted for the password.
|
||||
|
||||
Finally let's test it out:
|
||||
|
||||
boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &" &
|
||||
|
||||
To break things out a little bit:
|
||||
|
||||
- `boot2docker ssh` lets you pass a command as a parameter that will be executed by the boot2docker VM;
|
||||
- the final `&` indicates that we want our command to be executed in the background;
|
||||
- `ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &` is the actual command our boot2docker VM will run;
|
||||
- the `-o 'StrictHostKeyChecking no'` will make sure that we are not prompted with security questions;
|
||||
- the `-i /Users/michelangelo/.ssh/id_boot2docker` indicates which SSH key we want our VM to use for authentication purposes (note that this should be the key you added to your remote registry in the previous step);
|
||||
- finally we are opening a tunnel on mapping port 5000 to localhost:5000.
|
||||
|
||||
### Pulling from another server ###
|
||||
|
||||
You should now be able to push your image to the remote registry by simply issuing the following command:
|
||||
|
||||
docker push localhost:5000/username/repo_name
|
||||
|
||||
In the [next post][9] we'll se how to automate some of this stuff and we'll containerize a real Rails application. Stay tuned!
|
||||
|
||||
P.S. Please use the comments to let me know of any inconsistencies or fallacies in my tutorial. Hope you enjoyed it!
|
||||
|
||||
1. I'm also assuming you are running on OS X.
|
||||
1. For a complete list of instructions to set up your docker environment and requirements, please visit [http://boot2docker.io/][10]
|
||||
1. Select Image > Applications > Docker 1.4.1 on 14.04 at the time of this writing.
|
||||
1. [https://github.com/docker/docker-registry/][11]
|
||||
1. This is just a stub, in the next post I will show you how to bundle a Rails application into a Docker container.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-2/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:http://cocoahunter.com/2015/01/23/docker-1/
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
[3]:http://cocoahunter.com/2015/01/23/docker-2/#fn:1
|
||||
[4]:http://cocoahunter.com/2015/01/23/docker-2/#fn:2
|
||||
[5]:http://aws.amazon.com/
|
||||
[6]:https://registry.hub.docker.com/_/registry/
|
||||
[7]:http://localhost:5000/v1/_ping
|
||||
[8]:http://localhost:5000/v1/search
|
||||
[9]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
[10]:http://boot2docker.io/
|
||||
[11]:https://github.com/docker/docker-registry/
|
||||
@ -1,253 +0,0 @@
|
||||
Automated Docker-based Rails deployments
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] This is the third post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment.
|
||||
|
||||
- [First part][1]: where I talk about the process we went thru before approaching Docker;
|
||||
- [Second part][2]: where I explain how setting up a private registry for in house secure deployments.
|
||||
|
||||
----------
|
||||
|
||||
In this final part we will see how to automate the whole deployment process with a real world (though very basic) example.
|
||||
|
||||
### Basic Rails app ###
|
||||
|
||||
Let's dive into the topic right away and bootstrap a basic Rails app. For the purpose of this demonstration I'm going to use Ruby 2.2.0 and Rails 4.1.1
|
||||
|
||||
From the terminal run:
|
||||
|
||||
$ rvm use 2.2.0
|
||||
$ rails new && cd docker-test
|
||||
|
||||
Let's create a basic controller:
|
||||
|
||||
$ rails g controller welcome index
|
||||
|
||||
...and edit `routes.rb` so that the root of the project will point to our newly created welcome#index method:
|
||||
|
||||
root 'welcome#index'
|
||||
|
||||
Running `rails s` from the terminal and browsing to [http://localhost:3000][3] should bring you to the index page. We're not going to make anything fancier to the app, it's just a basic example to prove that when we'll build and deploy the container everything is working.
|
||||
|
||||
### Setup the webserver ###
|
||||
|
||||
We are going to use Unicorn as our webserver. Add `gem 'unicorn'` and `gem 'foreman'` to the Gemfile and bundle it up (run `bundle install` from the command line).
|
||||
|
||||
Unicorn needs to be configured when the Rails app launches, so let's put a **unicorn.rb** file inside the **config** directory. [Here is an example][4] of a Unicorn configuration file. You can just copy & paste the content of the Gist.
|
||||
|
||||
Let's also add a Procfile with the following content inside the root of the project so that we will be able to start the app with foreman:
|
||||
|
||||
web: bundle exec unicorn -p $PORT -c ./config/unicorn.rb
|
||||
|
||||
If you now try to run the app with **foreman start** everything should work as expected and you should have a running app on [http://localhost:5000][5]
|
||||
|
||||
### Building a Docker image ###
|
||||
|
||||
Now let's build the image inside which our app is going to live. In the root of our Rails project, create a file named **Dockerfile** and paste in it the following:
|
||||
|
||||
# Base image with ruby 2.2.0
|
||||
FROM ruby:2.2.0
|
||||
|
||||
# Install required libraries and dependencies
|
||||
RUN apt-get update && apt-get install -qy nodejs postgresql-client sqlite3 --no-install-recommends && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Set Rails version
|
||||
ENV RAILS_VERSION 4.1.1
|
||||
|
||||
# Install Rails
|
||||
RUN gem install rails --version "$RAILS_VERSION"
|
||||
|
||||
# Create directory from where the code will run
|
||||
RUN mkdir -p /usr/src/app
|
||||
WORKDIR /usr/src/app
|
||||
|
||||
# Make webserver reachable to the outside world
|
||||
EXPOSE 3000
|
||||
|
||||
# Set ENV variables
|
||||
ENV PORT=3000
|
||||
|
||||
# Start the web app
|
||||
CMD ["foreman","start"]
|
||||
|
||||
# Install the necessary gems
|
||||
ADD Gemfile /usr/src/app/Gemfile
|
||||
ADD Gemfile.lock /usr/src/app/Gemfile.lock
|
||||
RUN bundle install --without development test
|
||||
|
||||
# Add rails project (from same dir as Dockerfile) to project directory
|
||||
ADD ./ /usr/src/app
|
||||
|
||||
# Run rake tasks
|
||||
RUN RAILS_ENV=production rake db:create db:migrate
|
||||
|
||||
Using the provided Dockerfile, let's try and build an image with the following command[1][7]:
|
||||
|
||||
$ docker build -t localhost:5000/your_username/docker-test .
|
||||
|
||||
And again, if everything worked out correctly, the last line of the long log output should read something like:
|
||||
|
||||
Successfully built 82e48769506c
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
localhost:5000/your_username/docker-test latest 82e48769506c About a minute ago 884.2 MB
|
||||
|
||||
Let's try and run the container!
|
||||
|
||||
$ docker run -d -p 3000:3000 --name docker-test localhost:5000/your_username/docker-test
|
||||
|
||||
You should be able to reach your Rails app running inside the Docker container at port 3000 of your boot2docker VM[2][8] (in my case [http://192.168.59.103:3000][6]).
|
||||
|
||||
### Automating with shell scripts ###
|
||||
|
||||
Since you should already know from the previous post3 how to push your newly created image to a private regisitry and deploy it on a server, let's skip this part and go straight to automating the process.
|
||||
|
||||
We are going to define 3 shell scripts and finally tie it all together with rake.
|
||||
|
||||
### Clean ###
|
||||
|
||||
Every time we build our image and deploy we are better off always clean everything. That means the following:
|
||||
|
||||
- stop (if running) and restart boot2docker;
|
||||
- remove orphaned Docker images (images that are without tags and that are no longer used by your containers).
|
||||
|
||||
Put the following into a **clean.sh** file in the root of your project.
|
||||
|
||||
echo Restarting boot2docker...
|
||||
boot2docker down
|
||||
boot2docker up
|
||||
|
||||
echo Exporting Docker variables...
|
||||
sleep 1
|
||||
export DOCKER_HOST=tcp://192.168.59.103:2376
|
||||
export DOCKER_CERT_PATH=/Users/user/.boot2docker/certs/boot2docker-vm
|
||||
export DOCKER_TLS_VERIFY=1
|
||||
|
||||
sleep 1
|
||||
echo Removing orphaned images without tags...
|
||||
docker images | grep "<none>" | awk '{print $3}' | xargs docker rmi
|
||||
|
||||
Also make sure to make the script executable:
|
||||
|
||||
$ chmod +x clean.sh
|
||||
|
||||
### Build ###
|
||||
|
||||
The build process basically consists in reproducing what we just did before (docker build). Create a **build.sh** script at the root of your project with the following content:
|
||||
|
||||
docker build -t localhost:5000/your_username/docker-test .
|
||||
|
||||
Make the script executable.
|
||||
|
||||
### Deploy ###
|
||||
|
||||
Finally, create a **deploy.sh** script with this content:
|
||||
|
||||
# Open SSH connection from boot2docker to private registry
|
||||
boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/username/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@your-registry.com &" &
|
||||
|
||||
# Wait to make sure the SSH tunnel is open before pushing...
|
||||
echo Waiting 5 seconds before pushing image.
|
||||
|
||||
echo 5...
|
||||
sleep 1
|
||||
echo 4...
|
||||
sleep 1
|
||||
echo 3...
|
||||
sleep 1
|
||||
echo 2...
|
||||
sleep 1
|
||||
echo 1...
|
||||
sleep 1
|
||||
|
||||
# Push image onto remote registry / repo
|
||||
echo Starting push!
|
||||
docker push localhost:5000/username/docker-test
|
||||
|
||||
If you don't understand what's going on here, please make sure you've read thoroughfully [part 2][9] of this series of posts.
|
||||
|
||||
Make the script executable.
|
||||
|
||||
### Tying it all together with rake ###
|
||||
|
||||
Having 3 scripts would now require you to run them individually each time you decide to deploy your app:
|
||||
|
||||
1. clean
|
||||
1. build
|
||||
1. deploy / push
|
||||
|
||||
That wouldn't be much of an effort, if it weren't for the fact that developers are lazy! And lazy be it, then!
|
||||
|
||||
The final step to wrap things up, is tying the 3 parts together with rake.
|
||||
|
||||
To make things even simpler you can just append a bunch of lines of code to the end of the already present Rakefile in the root of your project. Open the Rakefile file - pun intended :) - and paste the following:
|
||||
|
||||
namespace :docker do
|
||||
desc "Remove docker container"
|
||||
task :clean do
|
||||
sh './clean.sh'
|
||||
end
|
||||
|
||||
desc "Build Docker image"
|
||||
task :build => [:clean] do
|
||||
sh './build.sh'
|
||||
end
|
||||
|
||||
desc "Deploy Docker image"
|
||||
task :deploy => [:build] do
|
||||
sh './deploy.sh'
|
||||
end
|
||||
end
|
||||
|
||||
Even if you don't know rake syntax (which you should, because it's pretty awesome!), it's pretty obvious what we are doing. We have declared 3 tasks inside a namespace (docker).
|
||||
|
||||
This will create the following 3 tasks:
|
||||
|
||||
- rake docker:clean
|
||||
- rake docker:build
|
||||
- rake docker:deploy
|
||||
|
||||
Deploy is dependent on build, build is dependent on clean. So every time we run from the command line
|
||||
|
||||
$ rake docker:deploy
|
||||
|
||||
All the script will be executed in the required order.
|
||||
|
||||
### Test it ###
|
||||
|
||||
To see if everything is working, you just need to make a small change in the code of your app and run
|
||||
|
||||
$ rake docker:deploy
|
||||
|
||||
and see the magic happening. Once the image has been uploaded (and the first time it could take quite a while), you can ssh into your production server and pull (thru an SSH tunnel) the docker image onto the server and run. It's that easy!
|
||||
|
||||
Well, maybe it takes a while to get accustomed to how everything works, but once it does, it's almost (almost) as easy as deploying with Heroku.
|
||||
|
||||
P.S. As always, please let me have your ideas. I'm not sure this is the best, or the fastest, or the safest way of doing devops with Docker, but it certainly worked out for us.
|
||||
|
||||
- make sure to have **boot2docker** up and running.
|
||||
- If you don't know your boot2docker VM address, just run `$ boot2docker ip`
|
||||
- if you don't, you can read it [here][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-3/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:http://cocoahunter.com/docker-1
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[3]:http://localhost:3000/
|
||||
[4]:https://gist.github.com/chasseurmic/0dad4d692ff499761b20
|
||||
[5]:http://localhost:5000/
|
||||
[6]:http://192.168.59.103:3000/
|
||||
[7]:http://cocoahunter.com/2015/01/23/docker-3/#fn:1
|
||||
[8]:http://cocoahunter.com/2015/01/23/docker-3/#fn:2
|
||||
[9]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[10]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
@ -1,5 +1,6 @@
|
||||
Install Linux-Dash (Web Based Monitoring tool) on Ubntu 14.10
|
||||
================================================================================
|
||||
|
||||
A low-overhead monitoring web dashboard for a GNU/Linux machine. Simply drop-in the app and go!.Linux Dash's interface provides a detailed overview of all vital aspects of your server, including RAM and disk usage, network, installed software, users, and running processes. All information is organized into sections, and you can jump to a specific section using the buttons in the main toolbar. Linux Dash is not the most advanced monitoring tool out there, but it might be a good fit for users looking for a slick, lightweight, and easy to deploy application.
|
||||
|
||||
### Linux-Dash Features ###
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
translating by KayGuoWhu
|
||||
[translating by KayGuoWhu]
|
||||
Enjoy Android Apps on Ubuntu using ARChon Runtime
|
||||
================================================================================
|
||||
Before, we gave try to many android app emulating tools like Genymotion, Virtualbox, Android SDK, etc to try to run android apps on it. But, with this new Chrome Android Runtime, we are able to run Android Apps on our Chrome Browser. So, here are the steps we'll need to follow to install Android Apps on Ubuntu using ARChon Runtime.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by createyuan
|
||||
|
||||
How to Test Your Internet Speed Bidirectionally from Command Line Using ‘Speedtest-CLI’ Tool
|
||||
================================================================================
|
||||
We always need to check the speed of the Internet connection at home and office. What we do for this? Go to websites like Speedtest.net and begin test. It loads JavaScript in the web browser and then select best server based upon ping and output the result. It also uses a Flash player to produce graphical results.
|
||||
@ -129,4 +131,4 @@ via: http://www.tecmint.com/check-internet-speed-from-command-line-in-linux/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/speedtest-mini-server-to-test-bandwidth-speed/
|
||||
[1]:http://www.tecmint.com/speedtest-mini-server-to-test-bandwidth-speed/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by runningwater
|
||||
How to Manage and Use LVM (Logical Volume Management) in Ubuntu
|
||||
================================================================================
|
||||

|
||||
@ -258,7 +259,7 @@ That should cover most of what you need to know to use LVM. If you’ve got some
|
||||
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,3 @@
|
||||
|
||||
tranlating by haimingfg
|
||||
|
||||
Sleuth Kit - Open Source Forensic Tool to Analyze Disk Images and Recover Files
|
||||
================================================================================
|
||||
SIFT is a Ubuntu based forensics distribution provided by SANS Inc. It consist of many forensics tools such as Sleuth kit / Autopsy etc . However, Sleuth kit/Autopsy tools can be installed on Ubuntu/Fedora distribution instead of downloading complete distribution of SIFT.
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user