mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
ee4526a5c4
@ -1,6 +1,7 @@
|
||||
如何在 CentOS 7.x 上安装 Zephyr 测试管理工具
|
||||
================================================================================
|
||||
测试管理工具包括作为测试人员需要的任何东西。测试管理工具用来记录测试执行的结果、计划测试活动以及报告质量保证活动的情况。在这篇文章中我们会向你介绍如何配置 Zephyr 测试管理工具,它包括了管理测试活动需要的所有东西,不需要单独安装测试活动所需要的应用程序从而降低测试人员不必要的麻烦。一旦你安装完它,你就看可以用它跟踪 bug、缺陷,和你的团队成员协作项目任务,因为你可以轻松地共享和访问测试过程中多个项目团队的数据。
|
||||
|
||||
测试管理(Test Management)指测试人员所需要的任何的所有东西。测试管理工具用来记录测试执行的结果、计划测试活动以及汇报质量控制活动的情况。在这篇文章中我们会向你介绍如何配置 Zephyr 测试管理工具,它包括了管理测试活动需要的所有东西,不需要单独安装测试活动所需要的应用程序从而降低测试人员不必要的麻烦。一旦你安装完它,你就看可以用它跟踪 bug 和缺陷,和你的团队成员协作项目任务,因为你可以轻松地共享和访问测试过程中多个项目团队的数据。
|
||||
|
||||
### Zephyr 要求 ###
|
||||
|
||||
@ -19,21 +20,21 @@
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="140"><strong>Packages</strong></td>
|
||||
<td width="312">JDK 7 or above , Oracle JDK 6 update</td>
|
||||
<td width="209">No Prior Tomcat, MySQL installed</td>
|
||||
<td width="312">JDK 7 或更高 , Oracle JDK 6 update</td>
|
||||
<td width="209">没有事先安装的 Tomcat 和 MySQL</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="140"><strong>RAM</strong></td>
|
||||
<td width="312">4 GB</td>
|
||||
<td width="209">Preferred 8 GB</td>
|
||||
<td width="209">推荐 8 GB</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="140"><strong>CPU</strong></td>
|
||||
<td width="521" colspan="2">2.0 GHZ or Higher</td>
|
||||
<td width="521" colspan="2">2.0 GHZ 或更高</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="140"><strong>Hard Disk</strong></td>
|
||||
<td width="521" colspan="2">30 GB , Atleast 5GB must be free</td>
|
||||
<td width="521" colspan="2">30 GB , 至少 5GB </td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
@ -48,8 +49,6 @@
|
||||
|
||||
[root@centos-007 ~]# yum install java-1.7.0-openjdk-1.7.0.79-2.5.5.2.el7_1
|
||||
|
||||
----------
|
||||
|
||||
[root@centos-007 ~]# yum install java-1.7.0-openjdk-devel-1.7.0.85-2.6.1.2.el7_1.x86_64
|
||||
|
||||
安装完 java 和它的所有依赖后,运行下面的命令设置 JAVA_HOME 环境变量。
|
||||
@ -61,8 +60,6 @@
|
||||
|
||||
[root@centos-007 ~]# java –version
|
||||
|
||||
----------
|
||||
|
||||
java version "1.7.0_79"
|
||||
OpenJDK Runtime Environment (rhel-2.5.5.2.el7_1-x86_64 u79-b14)
|
||||
OpenJDK 64-Bit Server VM (build 24.79-b02, mixed mode)
|
||||
@ -71,7 +68,7 @@
|
||||
|
||||
### 安装 MySQL 5.6.x ###
|
||||
|
||||
如果的机器上有其它的 MySQL,建议你先卸载它们并安装这个版本,或者升级它们的模式到指定的版本。因为 Zephyr 前提要求这个指定的主要/最小 MySQL (5.6.x)版本要有 root 用户名。
|
||||
如果的机器上有其它的 MySQL,建议你先卸载它们并安装这个版本,或者升级它们的模式(schemas)到指定的版本。因为 Zephyr 前提要求这个指定的 5.6.x 版本的 MySQL ,要有 root 用户名。
|
||||
|
||||
可以按照下面的步骤在 CentOS-7.1 上安装 MySQL 5.6 :
|
||||
|
||||
@ -93,10 +90,7 @@
|
||||
[root@centos-007 ~]# service mysqld start
|
||||
[root@centos-007 ~]# service mysqld status
|
||||
|
||||
对于全新安装的 MySQL 服务器,MySQL root 用户的密码为空。
|
||||
为了安全起见,我们应该重置 MySQL root 用户的密码。
|
||||
|
||||
用自动生成的空密码连接到 MySQL 并更改 root 用户密码。
|
||||
对于全新安装的 MySQL 服务器,MySQL root 用户的密码为空。为了安全起见,我们应该重置 MySQL root 用户的密码。用自动生成的空密码连接到 MySQL 并更改 root 用户密码。
|
||||
|
||||
[root@centos-007 ~]# mysql
|
||||
mysql> SET PASSWORD FOR 'root'@'localhost' = PASSWORD('your_password');
|
||||
@ -224,7 +218,7 @@ via: http://linoxide.com/linux-how-to/setup-zephyr-tool-centos-7-x/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -8,45 +8,44 @@ Copyright (C) 2015 greenbytes GmbH
|
||||
|
||||
### 源码 ###
|
||||
|
||||
你可以从[这里][1]得到 Apache 发行版。Apache 2.4.17 及其更高版本都支持 HTTP/2。我不会再重复介绍如何构建服务器的指令。在很多地方有很好的指南,例如[这里][2]。
|
||||
你可以从[这里][1]得到 Apache 版本。Apache 2.4.17 及其更高版本都支持 HTTP/2。我不会再重复介绍如何构建该服务器的指令。在很多地方有很好的指南,例如[这里][2]。
|
||||
|
||||
(有任何试验的链接?在 Twitter 上告诉我吧 @icing)
|
||||
(有任何这个试验性软件包的相关链接?在 Twitter 上告诉我吧 @icing)
|
||||
|
||||
#### 编译支持 HTTP/2 ####
|
||||
#### 编译支持 HTTP/2 ####
|
||||
|
||||
在你编译发行版之前,你要进行一些**配置**。这里有成千上万的选项。和 HTTP/2 相关的是:
|
||||
在你编译版本之前,你要进行一些**配置**。这里有成千上万的选项。和 HTTP/2 相关的是:
|
||||
|
||||
- **--enable-http2**
|
||||
|
||||
启用在 Apache 服务器内部实现协议的 ‘http2’ 模块。
|
||||
启用在 Apache 服务器内部实现该协议的 ‘http2’ 模块。
|
||||
|
||||
- **--with-nghttp2=<dir>**
|
||||
- **--with-nghttp2=\<dir>**
|
||||
|
||||
指定 http2 模块需要的 libnghttp2 模块的非默认位置。如果 nghttp2 是在默认的位置,配置过程会自动采用。
|
||||
|
||||
- **--enable-nghttp2-staticlib-deps**
|
||||
|
||||
很少用到的选项,你可能用来静态链接 nghttp2 库到服务器。在大部分平台上,只有在找不到共享 nghttp2 库时才有效。
|
||||
很少用到的选项,你可能想将 nghttp2 库静态链接到服务器里。在大部分平台上,只有在找不到共享 nghttp2 库时才有用。
|
||||
|
||||
如果你想自己编译 nghttp2,你可以到 [nghttp2.org][3] 查看文档。最新的 Fedora 以及其它发行版已经附带了这个库。
|
||||
如果你想自己编译 nghttp2,你可以到 [nghttp2.org][3] 查看文档。最新的 Fedora 以及其它版本已经附带了这个库。
|
||||
|
||||
#### TLS 支持 ####
|
||||
|
||||
大部分人想在浏览器上使用 HTTP/2, 而浏览器只在 TLS 连接(**https:// 开头的 url)时支持它。你需要一些我下面介绍的配置。但首先你需要的是支持 ALPN 扩展的 TLS 库。
|
||||
大部分人想在浏览器上使用 HTTP/2, 而浏览器只在使用 TLS 连接(**https:// 开头的 url)时才支持 HTTP/2。你需要一些我下面介绍的配置。但首先你需要的是支持 ALPN 扩展的 TLS 库。
|
||||
|
||||
ALPN 用来协商(negotiate)服务器和客户端之间的协议。如果你服务器上 TLS 库还没有实现 ALPN,客户端只能通过 HTTP/1.1 通信。那么,可以和 Apache 链接并支持它的是什么库呢?
|
||||
|
||||
ALPN 用来屏蔽服务器和客户端之间的协议。如果你服务器上 TLS 库还没有实现 ALPN,客户端只能通过 HTTP/1.1 通信。那么,和 Apache 连接的到底是什么?又是什么支持它呢?
|
||||
- **OpenSSL 1.0.2** 及其以后。
|
||||
- ??? (别的我也不知道了)
|
||||
|
||||
- **OpenSSL 1.0.2** 即将到来。
|
||||
- ???
|
||||
|
||||
如果你的 OpenSSL 库是 Linux 发行版自带的,这里使用的版本号可能和官方 OpenSSL 发行版的不同。如果不确定的话检查一下你的 Linux 发行版吧。
|
||||
如果你的 OpenSSL 库是 Linux 版本自带的,这里使用的版本号可能和官方 OpenSSL 版本的不同。如果不确定的话检查一下你的 Linux 版本吧。
|
||||
|
||||
### 配置 ###
|
||||
|
||||
另一个给服务器的好建议是为 http2 模块设置合适的日志等级。添加下面的配置:
|
||||
|
||||
# 某个地方有这样一行
|
||||
# 放在某个地方的这样一行
|
||||
LoadModule http2_module modules/mod_http2.so
|
||||
|
||||
<IfModule http2_module>
|
||||
@ -62,38 +61,37 @@ ALPN 用来屏蔽服务器和客户端之间的协议。如果你服务器上 TL
|
||||
|
||||
那么,假设你已经编译部署好了服务器, TLS 库也是最新的,你启动了你的服务器,打开了浏览器。。。你怎么知道它在工作呢?
|
||||
|
||||
如果除此之外你没有添加其它到服务器配置,很可能它没有工作。
|
||||
如果除此之外你没有添加其它的服务器配置,很可能它没有工作。
|
||||
|
||||
你需要告诉服务器在哪里使用协议。默认情况下,你的服务器并没有启动 HTTP/2 协议。因为这是安全路由,你可能要有一套部署了才能继续。
|
||||
你需要告诉服务器在哪里使用该协议。默认情况下,你的服务器并没有启动 HTTP/2 协议。因为这样比较安全,也许才能让你已有的部署可以继续工作。
|
||||
|
||||
你用 **Protocols** 命令启用 HTTP/2 协议:
|
||||
你可以用新的 **Protocols** 指令启用 HTTP/2 协议:
|
||||
|
||||
# for a https server
|
||||
# 对于 https 服务器
|
||||
Protocols h2 http/1.1
|
||||
...
|
||||
|
||||
# for a http server
|
||||
# 对于 http 服务器
|
||||
Protocols h2c http/1.1
|
||||
|
||||
你可以给一般服务器或者指定的 **vhosts** 添加这个配置。
|
||||
你可以给整个服务器或者指定的 **vhosts** 添加这个配置。
|
||||
|
||||
#### SSL 参数 ####
|
||||
|
||||
对于 TLS (SSL),HTTP/2 有一些特殊的要求。阅读 [https:// 连接][4]了解更详细的信息。
|
||||
对于 TLS (SSL),HTTP/2 有一些特殊的要求。阅读下面的“ https:// 连接”一节了解更详细的信息。
|
||||
|
||||
### http:// 连接 (h2c) ###
|
||||
|
||||
尽管现在还没有浏览器支持 HTTP/2 协议, http:// 这样的 url 也能正常工作, 因为有 mod_h[ttp]2 的支持。启用它你只需要做的一件事是在 **httpd.conf** 配置 Protocols :
|
||||
尽管现在还没有浏览器支持,但是 HTTP/2 协议也工作在 http:// 这样的 url 上, 而且 mod_h[ttp]2 也支持。启用它你唯一所要做的是在 Protocols 配置中启用它:
|
||||
|
||||
# for a http server
|
||||
# 对于 http 服务器
|
||||
Protocols h2c http/1.1
|
||||
|
||||
|
||||
这里有一些支持 **h2c** 的客户端(和客户端库)。我会在下面介绍:
|
||||
|
||||
#### curl ####
|
||||
|
||||
Daniel Stenberg 维护的网络资源命令行客户端 curl 当然支持。如果你的系统上有 curl,有一个简单的方法检查它是否支持 http/2:
|
||||
Daniel Stenberg 维护的用于访问网络资源的命令行客户端 curl 当然支持。如果你的系统上有 curl,有一个简单的方法检查它是否支持 http/2:
|
||||
|
||||
sh> curl -V
|
||||
curl 7.43.0 (x86_64-apple-darwin15.0) libcurl/7.43.0 SecureTransport zlib/1.2.5
|
||||
@ -126,11 +124,11 @@ Daniel Stenberg 维护的网络资源命令行客户端 curl 当然支持。如
|
||||
|
||||
恭喜,如果看到了有 **...101 Switching...** 的行就表示它正在工作!
|
||||
|
||||
有一些情况不会发生到 HTTP/2 的 Upgrade 。如果你的第一个请求没有内容,例如你上传一个文件,就不会触发 Upgrade。[h2c 限制][5]部分有详细的解释。
|
||||
有一些情况不会发生 HTTP/2 的升级切换(Upgrade)。如果你的第一个请求有内容数据(body),例如你上传一个文件时,就不会触发升级切换。[h2c 限制][5]部分有详细的解释。
|
||||
|
||||
#### nghttp ####
|
||||
|
||||
nghttp2 有能一起编译的客户端和服务器。如果你的系统中有客户端,你可以简单地通过获取资源验证你的安装:
|
||||
nghttp2 可以一同编译它自己的客户端和服务器。如果你的系统中有该客户端,你可以简单地通过获取一个资源来验证你的安装:
|
||||
|
||||
sh> nghttp -uv http://<yourserver>/
|
||||
[ 0.001] Connected
|
||||
@ -151,7 +149,7 @@ nghttp2 有能一起编译的客户端和服务器。如果你的系统中有客
|
||||
|
||||
这和我们上面 **curl** 例子中看到的 Upgrade 输出很相似。
|
||||
|
||||
在命令行参数中隐藏着一种可以使用 **h2c**:的参数:**-u**。这会指示 **nghttp** 进行 HTTP/1 Upgrade 过程。但如果我们不使用呢?
|
||||
有另外一种在命令行参数中不用 **-u** 参数而使用 **h2c** 的方法。这个参数会指示 **nghttp** 进行 HTTP/1 升级切换过程。但如果我们不使用呢?
|
||||
|
||||
sh> nghttp -v http://<yourserver>/
|
||||
[ 0.002] Connected
|
||||
@ -166,36 +164,33 @@ nghttp2 有能一起编译的客户端和服务器。如果你的系统中有客
|
||||
:scheme: http
|
||||
...
|
||||
|
||||
连接马上显示出了 HTTP/2!这就是协议中所谓的直接模式,当客户端发送一些特殊的 24 字节到服务器时就会发生:
|
||||
连接马上使用了 HTTP/2!这就是协议中所谓的直接(direct)模式,当客户端发送一些特殊的 24 字节到服务器时就会发生:
|
||||
|
||||
0x505249202a20485454502f322e300d0a0d0a534d0d0a0d0a
|
||||
or in ASCII: PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
|
||||
|
||||
用 ASCII 表示是:
|
||||
|
||||
PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
|
||||
|
||||
支持 **h2c** 的服务器在一个新的连接中看到这些信息就会马上切换到 HTTP/2。HTTP/1.1 服务器则认为是一个可笑的请求,响应并关闭连接。
|
||||
|
||||
因此 **直接** 模式只适合于那些确定服务器支持 HTTP/2 的客户端。例如,前一个 Upgrade 过程是成功的。
|
||||
因此,**直接**模式只适合于那些确定服务器支持 HTTP/2 的客户端。例如,当前一个升级切换过程成功了的时候。
|
||||
|
||||
**直接** 模式的魅力是零开销,它支持所有请求,即使没有 body 部分(查看[h2c 限制][6])。任何支持 h2c 协议的服务器默认启用了直接模式。如果你想停用它,可以添加下面的配置指令到你的服务器:
|
||||
**直接**模式的魅力是零开销,它支持所有请求,即使带有请求数据部分(查看[h2c 限制][6])。
|
||||
|
||||
注:下面这行打删除线
|
||||
|
||||
H2Direct off
|
||||
|
||||
注:下面这行打删除线
|
||||
|
||||
对于 2.4.17 发行版,默认明文连接时启用 **H2Direct** 。但是有一些模块和这不兼容。因此,在下一发行版中,默认会设置为**off**,如果你希望你的服务器支持它,你需要设置它为:
|
||||
对于 2.4.17 版本,明文连接时默认启用 **H2Direct** 。但是有一些模块和这不兼容。因此,在下一版本中,默认会设置为**off**,如果你希望你的服务器支持它,你需要设置它为:
|
||||
|
||||
H2Direct on
|
||||
|
||||
### https:// 连接 (h2) ###
|
||||
|
||||
一旦你的 mod_h[ttp]2 支持 h2c 连接,就是时候一同启用 **h2**,因为现在的浏览器支持它和 **https:** 一同使用。
|
||||
当你的 mod_h[ttp]2 可以支持 h2c 连接时,那就可以一同启用 **h2** 兄弟了,现在的浏览器仅支持它和 **https:** 一同使用。
|
||||
|
||||
HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已经提到了 ALNP 扩展。另外的一个要求是不会使用特定[黑名单][7]中的密码。
|
||||
HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已经提到了 ALNP 扩展。另外的一个要求是不能使用特定[黑名单][7]中的加密算法。
|
||||
|
||||
尽管现在版本的 **mod_h[ttp]2** 不增强这些密码(以后可能会),大部分客户端会这么做。如果你用不切当的密码在浏览器中打开 **h2** 服务器,你会看到模糊警告**INADEQUATE_SECURITY**,浏览器会拒接连接。
|
||||
尽管现在版本的 **mod_h[ttp]2** 不增强这些算法(以后可能会),但大部分客户端会这么做。如果让你的浏览器使用不恰当的算法打开 **h2** 服务器,你会看到不明确的警告**INADEQUATE_SECURITY**,浏览器会拒接连接。
|
||||
|
||||
一个可接受的 Apache SSL 配置类似:
|
||||
一个可行的 Apache SSL 配置类似:
|
||||
|
||||
SSLCipherSuite ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!3DES:!MD5:!PSK
|
||||
SSLProtocol All -SSLv2 -SSLv3
|
||||
@ -203,11 +198,11 @@ HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已
|
||||
|
||||
(是的,这确实很长。)
|
||||
|
||||
这里还有一些应该调整的 SSL 配置参数,但不是必须:**SSLSessionCache**, **SSLUseStapling** 等,其它地方也有介绍这些。例如 Ilya Grigorik 写的一篇博客 [高性能浏览器网络][8]。
|
||||
这里还有一些应该调整,但不是必须调整的 SSL 配置参数:**SSLSessionCache**, **SSLUseStapling** 等,其它地方也有介绍这些。例如 Ilya Grigorik 写的一篇超赞的博客: [高性能浏览器网络][8]。
|
||||
|
||||
#### curl ####
|
||||
|
||||
再次回到 shell 并使用 curl(查看 [curl h2c 章节][9] 了解要求)你也可以通过 curl 用简单的命令检测你的服务器:
|
||||
再次回到 shell 使用 curl(查看上面的“curl h2c”章节了解要求),你也可以通过 curl 用简单的命令检测你的服务器:
|
||||
|
||||
sh> curl -v --http2 https://<yourserver>/
|
||||
...
|
||||
@ -220,9 +215,9 @@ HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已
|
||||
|
||||
恭喜你,能正常工作啦!如果还不能,可能原因是:
|
||||
|
||||
- 你的 curl 不支持 HTTP/2。查看[检测][10]。
|
||||
- 你的 curl 不支持 HTTP/2。查看上面的“检测 curl”一节。
|
||||
- 你的 openssl 版本太低不支持 ALPN。
|
||||
- 不能验证你的证书,或者不接受你的密码配置。尝试添加命令行选项 -k 停用 curl 中的检查。如果那能工作,还要重新配置你的 SSL 和证书。
|
||||
- 不能验证你的证书,或者不接受你的算法配置。尝试添加命令行选项 -k 停用 curl 中的这些检查。如果可以工作,就重新配置你的 SSL 和证书。
|
||||
|
||||
#### nghttp ####
|
||||
|
||||
@ -246,11 +241,11 @@ HTTP/2 标准对 https:(TLS)连接增加了一些额外的要求。上面已
|
||||
The negotiated protocol: http/1.1
|
||||
[ERROR] HTTP/2 protocol was not selected. (nghttp2 expects h2)
|
||||
|
||||
这表示 ALPN 能正常工作,但并没有用 h2 协议。你需要像上面介绍的那样在服务器上选中那个协议。如果一开始在 vhost 部分选中不能正常工作,试着在通用部分选中它。
|
||||
这表示 ALPN 能正常工作,但并没有用 h2 协议。你需要像上面介绍的那样检查你服务器上的 Protocols 配置。如果一开始在 vhost 部分设置不能正常工作,试着在通用部分设置它。
|
||||
|
||||
#### Firefox ####
|
||||
|
||||
Update: [Apache Lounge][11] 的 Steffen Land 告诉我 [Firefox HTTP/2 指示插件][12]。你可以看到有多少地方用到了 h2(提示:Apache Lounge 用 h2 已经有一段时间了。。。)
|
||||
更新: [Apache Lounge][11] 的 Steffen Land 告诉我 [Firefox 上有个 HTTP/2 指示插件][12]。你可以看到有多少地方用到了 h2(提示:Apache Lounge 用 h2 已经有一段时间了。。。)
|
||||
|
||||
你可以在 Firefox 浏览器中打开开发者工具,在那里的网络标签页查看 HTTP/2 连接。当你打开了 HTTP/2 并重新刷新 html 页面时,你会看到类似下面的东西:
|
||||
|
||||
@ -260,9 +255,9 @@ Update: [Apache Lounge][11] 的 Steffen Land 告诉我 [Firefox HTTP/2 指示
|
||||
|
||||
#### Google Chrome ####
|
||||
|
||||
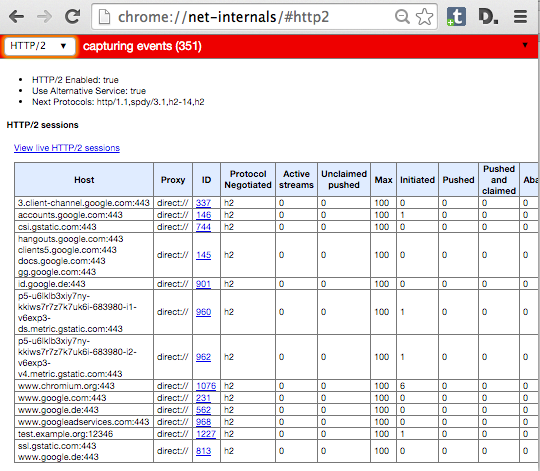
在 Google Chrome 中,你在开发者工具中看不到 HTTP/2 指示器。相反,Chrome 用特殊的地址 **chrome://net-internals/#http2** 给出了相关信息。
|
||||
在 Google Chrome 中,你在开发者工具中看不到 HTTP/2 指示器。相反,Chrome 用特殊的地址 **chrome://net-internals/#http2** 给出了相关信息。(LCTT 译注:Chrome 已经有一个 “HTTP/2 and SPDY indicator” 可以很好的在地址栏识别 HTTP/2 连接)
|
||||
|
||||
如果你在服务器中打开了一个页面并在 Chrome 那个页面查看,你可以看到类似下面这样:
|
||||
如果你打开了一个服务器的页面,可以在 Chrome 中查看那个 net-internals 页面,你可以看到类似下面这样:
|
||||
|
||||
|
||||
|
||||
@ -276,21 +271,21 @@ Windows 10 中 Internet Explorer 的继任者 Edge 也支持 HTTP/2。你也可
|
||||
|
||||
#### Safari ####
|
||||
|
||||
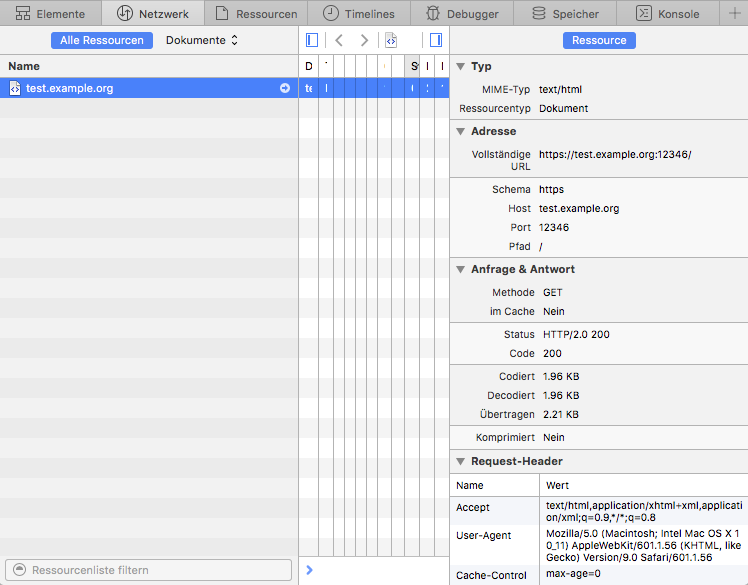
在 Apple 的 Safari 中,打开开发者工具,那里有个网络标签页。重新加载你的服务器页面并在开发者工具中选择显示了加载的行。如果你启用了在右边显示详细试图,看 **状态** 部分。那里显示了 **HTTP/2.0 200**,类似:
|
||||
在 Apple 的 Safari 中,打开开发者工具,那里有个网络标签页。重新加载你的服务器上的页面,并在开发者工具中选择显示了加载的那行。如果你启用了在右边显示详细视图,看 **Status** 部分。那里显示了 **HTTP/2.0 200**,像这样:
|
||||
|
||||
|
||||
|
||||
#### 重新协商 ####
|
||||
|
||||
https: 连接重新协商是指正在运行的连接中特定的 TLS 参数会发生变化。在 Apache httpd 中,你可以通过目录中的配置文件修改 TLS 参数。如果一个要获取特定位置资源的请求到来,配置的 TLS 参数会和当前的 TLS 参数进行对比。如果它们不相同,就会触发重新协商。
|
||||
https: 连接重新协商是指正在运行的连接中特定的 TLS 参数会发生变化。在 Apache httpd 中,你可以在 directory 配置中改变 TLS 参数。如果进来一个获取特定位置资源的请求,配置的 TLS 参数会和当前的 TLS 参数进行对比。如果它们不相同,就会触发重新协商。
|
||||
|
||||
这种最常见的情形是密码变化和客户端验证。你可以要求客户访问特定位置时需要通过验证,或者对于特定资源,你可以使用更安全的, CPU 敏感的密码。
|
||||
这种最常见的情形是算法变化和客户端证书。你可以要求客户访问特定位置时需要通过验证,或者对于特定资源,你可以使用更安全的、对 CPU 压力更大的算法。
|
||||
|
||||
不管你的想法有多么好,HTTP/2 中都**不可以**发生重新协商。如果有 100 多个请求到同一个地方,什么时候哪个会发生重新协商呢?
|
||||
但不管你的想法有多么好,HTTP/2 中都**不可以**发生重新协商。在同一个连接上会有 100 多个请求,那么重新协商该什么时候做呢?
|
||||
|
||||
对于这种配置,现有的 **mod_h[ttp]2** 还不能保证你的安全。如果你有一个站点使用了 TLS 重新协商,别在上面启用 h2!
|
||||
对于这种配置,现有的 **mod_h[ttp]2** 还没有办法。如果你有一个站点使用了 TLS 重新协商,别在上面启用 h2!
|
||||
|
||||
当然,我们会在后面的发行版中解决这个问题然后你就可以安全地启用了。
|
||||
当然,我们会在后面的版本中解决这个问题,然后你就可以安全地启用了。
|
||||
|
||||
### 限制 ###
|
||||
|
||||
@ -298,45 +293,45 @@ https: 连接重新协商是指正在运行的连接中特定的 TLS 参数会
|
||||
|
||||
实现除 HTTP 之外协议的模块可能和 **mod_http2** 不兼容。这在其它协议要求服务器首先发送数据时无疑会发生。
|
||||
|
||||
**NNTP** 就是这种协议的一个例子。如果你在服务器中配置了 **mod_nntp_like_ssl**,甚至都不要加载 mod_http2。等待下一个发行版。
|
||||
**NNTP** 就是这种协议的一个例子。如果你在服务器中配置了 **mod\_nntp\_like\_ssl**,那么就不要加载 mod_http2。等待下一个版本。
|
||||
|
||||
#### h2c 限制 ####
|
||||
|
||||
**h2c** 的实现还有一些限制,你应该注意:
|
||||
|
||||
#### 在虚拟主机中拒绝 h2c ####
|
||||
##### 在虚拟主机中拒绝 h2c #####
|
||||
|
||||
你不能对指定的虚拟主机拒绝 **h2c 直连**。连接建立而没有看到请求时会触发**直连**,这使得不可能预先知道 Apache 需要查找哪个虚拟主机。
|
||||
|
||||
#### 升级请求体 ####
|
||||
##### 有请求数据时的升级切换 #####
|
||||
|
||||
对于有 body 部分的请求,**h2c** 升级不能正常工作。那些是 PUT 和 POST 请求(用于提交和上传)。如果你写了一个客户端,你可能会用一个简单的 GET 去处理请求或者用选项 * 去触发升级。
|
||||
对于有数据的请求,**h2c** 升级切换不能正常工作。那些是 PUT 和 POST 请求(用于提交和上传)。如果你写了一个客户端,你可能会用一个简单的 GET 或者 OPTIONS * 来处理那些请求以触发升级切换。
|
||||
|
||||
原因从技术层面来看显而易见,但如果你想知道:升级过程中,连接处于半疯状态。请求按照 HTTP/1.1 的格式,而响应使用 HTTP/2。如果请求有一个 body 部分,服务器在发送响应之前需要读取整个 body。因为响应可能需要从客户端处得到应答用于流控制。但如果仍在发送 HTTP/1.1 请求,客户端就还不能处理 HTTP/2 连接。
|
||||
原因从技术层面来看显而易见,但如果你想知道:在升级切换过程中,连接处于半疯状态。请求按照 HTTP/1.1 的格式,而响应使用 HTTP/2 帧。如果请求有一个数据部分,服务器在发送响应之前需要读取整个数据。因为响应可能需要从客户端处得到应答用于流控制及其它东西。但如果仍在发送 HTTP/1.1 请求,客户端就仍然不能以 HTTP/2 连接。
|
||||
|
||||
为了使行为可预测,几个服务器实现商决定不要在任何请求体中进行升级,即使 body 很小。
|
||||
为了使行为可预测,几个服务器在实现上决定不在任何带有请求数据的请求中进行升级切换,即使请求数据很小。
|
||||
|
||||
#### 升级 302s ####
|
||||
##### 302 时的升级切换 #####
|
||||
|
||||
有重定向发生时当前 h2c 升级也不能工作。看起来 mod_http2 之前的重写有可能发生。这当然不会导致断路,但你测试这样的站点也许会让你迷惑。
|
||||
有重定向发生时,当前的 h2c 升级切换也不能工作。看起来 mod_http2 之前的重写有可能发生。这当然不会导致断路,但你测试这样的站点也许会让你迷惑。
|
||||
|
||||
#### h2 限制 ####
|
||||
|
||||
这里有一些你应该意识到的 h2 实现限制:
|
||||
|
||||
#### 连接重用 ####
|
||||
##### 连接重用 #####
|
||||
|
||||
HTTP/2 协议允许在特定条件下重用 TLS 连接:如果你有带通配符的证书或者多个 AltSubject 名称,浏览器可能会重用现有的连接。例如:
|
||||
|
||||
你有一个 **a.example.org** 的证书,它还有另外一个名称 **b.example.org**。你在浏览器中打开 url **https://a.example.org/**,用另一个标签页加载 **https://b.example.org/**。
|
||||
你有一个 **a.example.org** 的证书,它还有另外一个名称 **b.example.org**。你在浏览器中打开 URL **https://a.example.org/**,用另一个标签页加载 **https://b.example.org/**。
|
||||
|
||||
在重新打开一个新的连接之前,浏览器看到它有一个到 **a.example.org** 的连接并且证书对于 **b.example.org** 也可用。因此,它在第一个连接上面向第二个标签页发送请求。
|
||||
在重新打开一个新的连接之前,浏览器看到它有一个到 **a.example.org** 的连接并且证书对于 **b.example.org** 也可用。因此,它在第一个连接上面发送第二个标签页的请求。
|
||||
|
||||
这种连接重用是刻意设计的,它使得致力于 HTTP/1 切分效率的站点能够不需要太多变化就能利用 HTTP/2。
|
||||
这种连接重用是刻意设计的,它使得使用了 HTTP/1 切分(sharding)来提高效率的站点能够不需要太多变化就能利用 HTTP/2。
|
||||
|
||||
Apache **mod_h[ttp]2** 还没有完全实现这点。如果 **a.example.org** 和 **b.example.org** 是不同的虚拟主机, Apache 不会允许这样的连接重用,并会告知浏览器状态码**421 错误请求**。浏览器会意识到它需要重新打开一个到 **b.example.org** 的连接。这仍然能工作,只是会降低一些效率。
|
||||
Apache **mod_h[ttp]2** 还没有完全实现这点。如果 **a.example.org** 和 **b.example.org** 是不同的虚拟主机, Apache 不会允许这样的连接重用,并会告知浏览器状态码 **421 Misdirected Request**。浏览器会意识到它需要重新打开一个到 **b.example.org** 的连接。这仍然能工作,只是会降低一些效率。
|
||||
|
||||
我们期望下一次的发布中能有切当的检查。
|
||||
我们期望下一次的发布中能有合适的检查。
|
||||
|
||||
Münster, 12.10.2015,
|
||||
|
||||
@ -355,7 +350,7 @@ via: https://icing.github.io/mod_h2/howto.html
|
||||
|
||||
作者:[icing][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
239
published/20151104 How to Install Redis Server on CentOS 7.md
Normal file
239
published/20151104 How to Install Redis Server on CentOS 7.md
Normal file
@ -0,0 +1,239 @@
|
||||
如何在 CentOS 7 上安装 Redis 服务器
|
||||
================================================================================
|
||||
|
||||
大家好,本文的主题是 Redis,我们将要在 CentOS 7 上安装它。编译源代码,安装二进制文件,创建、安装文件。在安装了它的组件之后,我们还会配置 redis ,就像配置操作系统参数一样,目标就是让 redis 运行的更加可靠和快速。
|
||||
|
||||

|
||||
|
||||
*Redis 服务器*
|
||||
|
||||
Redis 是一个开源的多平台数据存储软件,使用 ANSI C 编写,直接在内存使用数据集,这使得它得以实现非常高的效率。Redis 支持多种编程语言,包括 Lua, C, Java, Python, Perl, PHP 和其他很多语言。redis 的代码量很小,只有约3万行,它只做“很少”的事,但是做的很好。尽管是在内存里工作,但是数据持久化的保存还是有的,而redis 的可靠性就很高,同时也支持集群,这些可以很好的保证你的数据安全。
|
||||
|
||||
### 构建 Redis ###
|
||||
|
||||
redis 目前没有官方 RPM 安装包,我们需要从源代码编译,而为了要编译就需要安装 Make 和 GCC。
|
||||
|
||||
如果没有安装过 GCC 和 Make,那么就使用 yum 安装。
|
||||
|
||||
yum install gcc make
|
||||
|
||||
从[官网][1]下载 tar 压缩包。
|
||||
|
||||
curl http://download.redis.io/releases/redis-3.0.4.tar.gz -o redis-3.0.4.tar.gz
|
||||
|
||||
解压缩。
|
||||
|
||||
tar zxvf redis-3.0.4.tar.gz
|
||||
|
||||
进入解压后的目录。
|
||||
|
||||
cd redis-3.0.4
|
||||
|
||||
使用Make 编译源文件。
|
||||
|
||||
make
|
||||
|
||||
### 安装 ###
|
||||
|
||||
进入源文件的目录。
|
||||
|
||||
cd src
|
||||
|
||||
复制 Redis 的服务器和客户端到 /usr/local/bin。
|
||||
|
||||
cp redis-server redis-cli /usr/local/bin
|
||||
|
||||
最好也把 sentinel,benchmark 和 check 复制过去。
|
||||
|
||||
cp redis-sentinel redis-benchmark redis-check-aof redis-check-dump /usr/local/bin
|
||||
|
||||
创建redis 配置文件夹。
|
||||
|
||||
mkdir /etc/redis
|
||||
|
||||
在`/var/lib/redis` 下创建有效的保存数据的目录
|
||||
|
||||
mkdir -p /var/lib/redis/6379
|
||||
|
||||
#### 系统参数 ####
|
||||
|
||||
为了让 redis 正常工作需要配置一些内核参数。
|
||||
|
||||
配置 `vm.overcommit_memory` 为1,这可以避免数据被截断,详情[见此][2]。
|
||||
|
||||
sysctl -w vm.overcommit_memory=1
|
||||
|
||||
修改 backlog 连接数的最大值超过 redis.conf 中的 `tcp-backlog` 值,即默认值511。你可以在[kernel.org][3] 找到更多有关基于 sysctl 的 ip 网络隧道的信息。
|
||||
|
||||
sysctl -w net.core.somaxconn=512
|
||||
|
||||
取消对透明巨页内存(transparent huge pages)的支持,因为这会造成 redis 使用过程产生延时和内存访问问题。
|
||||
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### redis.conf ###
|
||||
|
||||
redis.conf 是 redis 的配置文件,然而你会看到这个文件的名字是 6379.conf ,而这个数字就是 redis 监听的网络端口。如果你想要运行超过一个的 redis 实例,推荐用这样的名字。
|
||||
|
||||
复制示例的 redis.conf 到 **/etc/redis/6379.conf**。
|
||||
|
||||
cp redis.conf /etc/redis/6379.conf
|
||||
|
||||
现在编辑这个文件并且配置参数。
|
||||
|
||||
vi /etc/redis/6379.conf
|
||||
|
||||
#### daemonize ####
|
||||
|
||||
设置 `daemonize` 为 no,systemd 需要它运行在前台,否则 redis 会突然挂掉。
|
||||
|
||||
daemonize no
|
||||
|
||||
#### pidfile ####
|
||||
|
||||
设置 `pidfile` 为 /var/run/redis_6379.pid。
|
||||
|
||||
pidfile /var/run/redis_6379.pid
|
||||
|
||||
#### port ####
|
||||
|
||||
如果不准备用默认端口,可以修改。
|
||||
|
||||
port 6379
|
||||
|
||||
#### loglevel ####
|
||||
|
||||
设置日志级别。
|
||||
|
||||
loglevel notice
|
||||
|
||||
#### logfile ####
|
||||
|
||||
修改日志文件路径。
|
||||
|
||||
logfile /var/log/redis_6379.log
|
||||
|
||||
#### dir ####
|
||||
|
||||
设置目录为 /var/lib/redis/6379
|
||||
|
||||
dir /var/lib/redis/6379
|
||||
|
||||
### 安全 ###
|
||||
|
||||
下面有几个可以提高安全性的操作。
|
||||
|
||||
#### Unix sockets ####
|
||||
|
||||
在很多情况下,客户端程序和服务器端程序运行在同一个机器上,所以不需要监听网络上的 socket。如果这和你的使用情况类似,你就可以使用 unix socket 替代网络 socket,为此你需要配置 `port` 为0,然后配置下面的选项来启用 unix socket。
|
||||
|
||||
设置 unix socket 的套接字文件。
|
||||
|
||||
unixsocket /tmp/redis.sock
|
||||
|
||||
限制 socket 文件的权限。
|
||||
|
||||
unixsocketperm 700
|
||||
|
||||
现在为了让 redis-cli 可以访问,应该使用 -s 参数指向该 socket 文件。
|
||||
|
||||
redis-cli -s /tmp/redis.sock
|
||||
|
||||
#### requirepass ####
|
||||
|
||||
你可能需要远程访问,如果是,那么你应该设置密码,这样子每次操作之前要求输入密码。
|
||||
|
||||
requirepass "bTFBx1NYYWRMTUEyNHhsCg"
|
||||
|
||||
#### rename-command ####
|
||||
|
||||
想象一下如下指令的输出。是的,这会输出服务器的配置,所以你应该在任何可能的情况下拒绝这种访问。
|
||||
|
||||
CONFIG GET *
|
||||
|
||||
为了限制甚至禁止这条或者其他指令可以使用 `rename-command` 命令。你必须提供一个命令名和替代的名字。要禁止的话需要设置替代的名字为空字符串,这样禁止任何人猜测命令的名字会比较安全。
|
||||
|
||||
rename-command FLUSHDB "FLUSHDB_MY_SALT_G0ES_HERE09u09u"
|
||||
rename-command FLUSHALL ""
|
||||
rename-command CONFIG "CONFIG_MY_S4LT_GO3S_HERE09u09u"
|
||||
|
||||

|
||||
|
||||
*使用密码通过 unix socket 访问,和修改命令*
|
||||
|
||||
#### 快照 ####
|
||||
|
||||
默认情况下,redis 会周期性的将数据集转储到我们设置的目录下的 **dump.rdb** 文件。你可以使用 `save` 命令配置转储的频率,它的第一个参数是以秒为单位的时间帧,第二个参数是在数据文件上进行修改的数量。
|
||||
|
||||
每隔15分钟并且最少修改过一次键。
|
||||
|
||||
save 900 1
|
||||
|
||||
每隔5分钟并且最少修改过10次键。
|
||||
|
||||
save 300 10
|
||||
|
||||
每隔1分钟并且最少修改过10000次键。
|
||||
|
||||
save 60 10000
|
||||
|
||||
文件 `/var/lib/redis/6379/dump.rdb` 包含了从上次保存以来内存里数据集的转储数据。因为它先创建临时文件然后替换之前的转储文件,这里不存在数据破坏的问题,你不用担心,可以直接复制这个文件。
|
||||
|
||||
### 开机时启动 ###
|
||||
|
||||
你可以使用 systemd 将 redis 添加到系统开机启动列表。
|
||||
|
||||
复制示例的 init_script 文件到 `/etc/init.d`,注意脚本名所代表的端口号。
|
||||
|
||||
cp utils/redis_init_script /etc/init.d/redis_6379
|
||||
|
||||
现在我们要使用 systemd,所以在 `/etc/systems/system` 下创建一个单位文件名字为 `redis_6379.service`。
|
||||
|
||||
vi /etc/systemd/system/redis_6379.service
|
||||
|
||||
填写下面的内容,详情可见 systemd.service。
|
||||
|
||||
[Unit]
|
||||
Description=Redis on port 6379
|
||||
|
||||
[Service]
|
||||
Type=forking
|
||||
ExecStart=/etc/init.d/redis_6379 start
|
||||
ExecStop=/etc/init.d/redis_6379 stop
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
现在添加我之前在 `/etc/sysctl.conf` 里面修改过的内存过量使用和 backlog 最大值的选项。
|
||||
|
||||
vm.overcommit_memory = 1
|
||||
|
||||
net.core.somaxconn=512
|
||||
|
||||
对于透明巨页内存支持,并没有直接 sysctl 命令可以控制,所以需要将下面的命令放到 `/etc/rc.local` 的结尾。
|
||||
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### 总结 ###
|
||||
|
||||
这样就可以启动了,通过设置这些选项你就可以部署 redis 服务到很多简单的场景,然而在 redis.conf 还有很多为复杂环境准备的 redis 选项。在一些情况下,你可以使用 [replication][4] 和 [Sentinel][5] 来提高可用性,或者[将数据分散][6]在多个服务器上,创建服务器集群。
|
||||
|
||||
谢谢阅读。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/install-redis-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
[1]:http://redis.io/download
|
||||
[2]:https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
|
||||
[3]:https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
|
||||
[4]:http://redis.io/topics/replication
|
||||
[5]:http://redis.io/topics/sentinel
|
||||
[6]:http://redis.io/topics/partitioning
|
||||
@ -2,9 +2,9 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
Linus 最近(LCTT 译注:其实是11月份,没有及时翻译出来,看官轻喷Orz)骂了一个 Linux 开发者,原因是他向 kernel 提交了一份不安全的代码。
|
||||
Linus 上个月骂了一个 Linux 开发者,原因是他向 kernel 提交了一份不安全的代码。
|
||||
|
||||
Linus 是个 Linux 内核项目非官方的“仁慈的独裁者(LCTT译注:英国《卫报》曾将乔布斯评价为‘仁慈的独裁者’)”,这意味着他有权决定将哪些代码合入内核,哪些代码直接丢掉。
|
||||
Linus 是个 Linux 内核项目非官方的“仁慈的独裁者(benevolent dictator)”(LCTT译注:英国《卫报》曾将乔布斯评价为‘仁慈的独裁者’),这意味着他有权决定将哪些代码合入内核,哪些代码直接丢掉。
|
||||
|
||||
在10月28号,一个开源开发者提交的代码未能符合 Torvalds 的要求,于是遭来了[一顿臭骂][1]。Torvalds 在他提交的代码下评论道:“你提交的是什么东西。”
|
||||
|
||||
@ -14,7 +14,7 @@ Torvalds 为什么会这么生气?他觉得那段代码可以写得更有效
|
||||
|
||||
Torvalds 重新写了一版代码将原来的那份替换掉,并建议所有开发者应该像他那种风格来写代码。
|
||||
|
||||
Torvalds 一直在嘲讽那些不符合他观点的人。早在1991年他就攻击过[Andrew Tanenbaum][2]——那个 Minix 操作系统的作者,而那个 Minix 操作系统被 Torvalds 描述为“脑残”。
|
||||
Torvalds 一直在嘲讽那些不符合他观点的人。早在1991年他就攻击过 [Andrew Tanenbaum][2]——那个 Minix 操作系统的作者,而那个 Minix 操作系统被 Torvalds 描述为“脑残”。
|
||||
|
||||
但是 Torvalds 在这次嘲讽中表现得更有战略性了:“我想让*每个人*都知道,像他这种代码是完全不能被接收的。”他说他的目的是提醒每个 Linux 开发者,而不是针对那个开发者。
|
||||
|
||||
@ -26,7 +26,7 @@ via: http://thevarguy.com/open-source-application-software-companies/110415/linu
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
如何在CentOS 6/7 上移除被Fail2ban禁止的IP
|
||||
如何在 CentOS 6/7 上移除被 Fail2ban 禁止的 IP
|
||||
================================================================================
|
||||

|
||||
|
||||
[Fail2ban][1]是一款用于保护你的服务器免于暴力攻击的入侵保护软件。Fail2ban用python写成,并被广泛用户大多数服务器上。Fail2ban将扫描日志文件和IP黑名单来显示恶意软件、过多的密码失败、web服务器利用、Wordpress插件攻击和其他漏洞。如果你已经安装并使用了fail2ban来保护你的web服务器,你也许会想知道如何在CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7中找到被Fail2ban阻止的IP,或者你想将ip从fail2ban监狱中移除。
|
||||
[fail2ban][1] 是一款用于保护你的服务器免于暴力攻击的入侵保护软件。fail2ban 用 python 写成,并广泛用于很多服务器上。fail2ban 会扫描日志文件和 IP 黑名单来显示恶意软件、过多的密码失败尝试、web 服务器利用、wordpress 插件攻击和其他漏洞。如果你已经安装并使用了 fail2ban 来保护你的 web 服务器,你也许会想知道如何在 CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7 中找到被 fail2ban 阻止的 IP,或者你想将 ip 从 fail2ban 监狱中移除。
|
||||
|
||||
### 如何列出被禁止的IP ###
|
||||
### 如何列出被禁止的 IP ###
|
||||
|
||||
要查看所有被禁止的ip地址,运行下面的命令:
|
||||
要查看所有被禁止的 ip 地址,运行下面的命令:
|
||||
|
||||
# iptables -L
|
||||
Chain INPUT (policy ACCEPT)
|
||||
@ -40,19 +40,19 @@
|
||||
REJECT all -- 104.194.26.205 anywhere reject-with icmp-port-unreachable
|
||||
RETURN all -- anywhere anywhere
|
||||
|
||||
### 如何从Fail2ban中移除IP ###
|
||||
### 如何从 Fail2ban 中移除 IP ###
|
||||
|
||||
# iptables -D f2b-NoAuthFailures -s banned_ip -j REJECT
|
||||
|
||||
我希望这篇教程可以给你在CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7中移除被禁止的ip一些指导。
|
||||
我希望这篇教程可以给你在 CentOS 6、CentOS 7、RHEL 6、RHEL 7 和 Oracle Linux 6/7 中移除被禁止的 ip 一些指导。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ehowstuff.com/how-to-remove-banned-ip-from-fail2ban-on-centos/
|
||||
|
||||
作者:[skytech][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,44 +0,0 @@
|
||||
Let's Encrypt:Entering Public Beta
|
||||
================================================================================
|
||||
We’re happy to announce that Let’s Encrypt has entered Public Beta. Invitations are no longer needed in order to get free
|
||||
certificates from Let’s Encrypt.
|
||||
|
||||
It’s time for the Web to take a big step forward in terms of security and privacy. We want to see HTTPS become the default.
|
||||
Let’s Encrypt was built to enable that by making it as easy as possible to get and manage certificates.
|
||||
|
||||
We’d like to thank everyone who participated in the Limited Beta. Let’s Encrypt issued over 26,000 certificates during the
|
||||
Limited Beta period. This allowed us to gain valuable insight into how our systems perform, and to be confident about moving
|
||||
to Public Beta.
|
||||
|
||||
We’d also like to thank all of our [sponsors][1] for their support. We’re happy to have announced earlier today that
|
||||
[Facebook is our newest Gold sponsor][2]/
|
||||
|
||||
We have more work to do before we’re comfortable dropping the beta label entirely, particularly on the client experience.
|
||||
Automation is a cornerstone of our strategy, and we need to make sure that the client works smoothly and reliably on a
|
||||
wide range of platforms. We’ll be monitoring feedback from users closely, and making improvements as quickly as possible.
|
||||
|
||||
Instructions for getting a certificate with the [Let’s Encrypt client][3] can be found [here][4].
|
||||
|
||||
[Let’s Encrypt Community Support][5] is an invaluable resource for our community, we strongly recommend making use of the
|
||||
site if you have any questions about Let’s Encrypt.
|
||||
|
||||
Let’s Encrypt depends on support from a wide variety of individuals and organizations. Please consider [getting involved][6]
|
||||
, and if your company or organization would like to sponsor Let’s Encrypt please email us at [sponsor@letsencrypt.org][7].
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://letsencrypt.org/2015/12/03/entering-public-beta.html
|
||||
|
||||
作者:[Josh Aas][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://letsencrypt.org/2015/12/03/entering-public-beta.html
|
||||
[1]:https://letsencrypt.org/sponsors/
|
||||
[2]:https://letsencrypt.org/2015/12/03/facebook-sponsorship.html
|
||||
[3]:https://github.com/letsencrypt/letsencrypt
|
||||
[4]:https://letsencrypt.readthedocs.org/en/latest/
|
||||
[5]:https://community.letsencrypt.org/
|
||||
[6]:https://letsencrypt.org/getinvolved/
|
||||
[7]:mailto:sponsor@letsencrypt.org
|
||||
@ -1,3 +1,4 @@
|
||||
translating。。
|
||||
eSpeak: Text To Speech Tool For Linux
|
||||
================================================================================
|
||||

|
||||
@ -61,4 +62,4 @@ via: http://itsfoss.com/espeak-text-speech-linux/
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://espeak.sourceforge.net/
|
||||
[2]:http://en.wikipedia.org/wiki/WAV
|
||||
[3]:http://en.wikipedia.org/wiki/Speech_Synthesis_Markup_Language
|
||||
[3]:http://en.wikipedia.org/wiki/Speech_Synthesis_Markup_Language
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating wi-cuckoo
|
||||
A Repository with 44 Years of Unix Evolution
|
||||
================================================================================
|
||||
### Abstract ###
|
||||
@ -199,4 +200,4 @@ via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.htm
|
||||
[50]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAI
|
||||
[51]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[52]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAJ
|
||||
[53]:https://github.com/dspinellis/unix-history-make
|
||||
[53]:https://github.com/dspinellis/unix-history-make
|
||||
|
||||
@ -1,259 +0,0 @@
|
||||
translating by Ezio
|
||||
|
||||
Data Structures in the Linux Kernel
|
||||
================================================================================
|
||||
|
||||
Doubly linked list
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
Linux kernel provides its own implementation of doubly linked list, which you can find in the [include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h). We will start `Data Structures in the Linux kernel` from the doubly linked list data structure. Why? Because it is very popular in the kernel, just try to [search](http://lxr.free-electrons.com/ident?i=list_head)
|
||||
|
||||
First of all, let's look on the main structure in the [include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h):
|
||||
|
||||
```C
|
||||
struct list_head {
|
||||
struct list_head *next, *prev;
|
||||
};
|
||||
```
|
||||
|
||||
You can note that it is different from many implementations of doubly linked list which you have seen. For example, this doubly linked list structure from the [glib](http://www.gnu.org/software/libc/) library looks like :
|
||||
|
||||
```C
|
||||
struct GList {
|
||||
gpointer data;
|
||||
GList *next;
|
||||
GList *prev;
|
||||
};
|
||||
```
|
||||
|
||||
Usually a linked list structure contains a pointer to the item. The implementation of linked list in Linux kernel does not. So the main question is - `where does the list store the data?`. The actual implementation of linked list in the kernel is - `Intrusive list`. An intrusive linked list does not contain data in its nodes - A node just contains pointers to the next and previous node and list nodes part of the data that are added to the list. This makes the data structure generic, so it does not care about entry data type anymore.
|
||||
|
||||
For example:
|
||||
|
||||
```C
|
||||
struct nmi_desc {
|
||||
spinlock_t lock;
|
||||
struct list_head head;
|
||||
};
|
||||
```
|
||||
|
||||
Let's look at some examples to understand how `list_head` is used in the kernel. As I already wrote about, there are many, really many different places where lists are used in the kernel. Let's look for an example in miscellaneous character drivers. Misc character drivers API from the [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) is used for writing small drivers for handling simple hardware or virtual devices. Those drivers share same major number:
|
||||
|
||||
```C
|
||||
#define MISC_MAJOR 10
|
||||
```
|
||||
|
||||
but have their own minor number. For example you can see it with:
|
||||
|
||||
```
|
||||
ls -l /dev | grep 10
|
||||
crw------- 1 root root 10, 235 Mar 21 12:01 autofs
|
||||
drwxr-xr-x 10 root root 200 Mar 21 12:01 cpu
|
||||
crw------- 1 root root 10, 62 Mar 21 12:01 cpu_dma_latency
|
||||
crw------- 1 root root 10, 203 Mar 21 12:01 cuse
|
||||
drwxr-xr-x 2 root root 100 Mar 21 12:01 dri
|
||||
crw-rw-rw- 1 root root 10, 229 Mar 21 12:01 fuse
|
||||
crw------- 1 root root 10, 228 Mar 21 12:01 hpet
|
||||
crw------- 1 root root 10, 183 Mar 21 12:01 hwrng
|
||||
crw-rw----+ 1 root kvm 10, 232 Mar 21 12:01 kvm
|
||||
crw-rw---- 1 root disk 10, 237 Mar 21 12:01 loop-control
|
||||
crw------- 1 root root 10, 227 Mar 21 12:01 mcelog
|
||||
crw------- 1 root root 10, 59 Mar 21 12:01 memory_bandwidth
|
||||
crw------- 1 root root 10, 61 Mar 21 12:01 network_latency
|
||||
crw------- 1 root root 10, 60 Mar 21 12:01 network_throughput
|
||||
crw-r----- 1 root kmem 10, 144 Mar 21 12:01 nvram
|
||||
brw-rw---- 1 root disk 1, 10 Mar 21 12:01 ram10
|
||||
crw--w---- 1 root tty 4, 10 Mar 21 12:01 tty10
|
||||
crw-rw---- 1 root dialout 4, 74 Mar 21 12:01 ttyS10
|
||||
crw------- 1 root root 10, 63 Mar 21 12:01 vga_arbiter
|
||||
crw------- 1 root root 10, 137 Mar 21 12:01 vhci
|
||||
```
|
||||
|
||||
Now let's have a close look at how lists are used in the misc device drivers. First of all, let's look on `miscdevice` structure:
|
||||
|
||||
```C
|
||||
struct miscdevice
|
||||
{
|
||||
int minor;
|
||||
const char *name;
|
||||
const struct file_operations *fops;
|
||||
struct list_head list;
|
||||
struct device *parent;
|
||||
struct device *this_device;
|
||||
const char *nodename;
|
||||
mode_t mode;
|
||||
};
|
||||
```
|
||||
|
||||
We can see the fourth field in the `miscdevice` structure - `list` which is a list of registered devices. In the beginning of the source code file we can see the definition of misc_list:
|
||||
|
||||
```C
|
||||
static LIST_HEAD(misc_list);
|
||||
```
|
||||
|
||||
which expands to the definition of variables with `list_head` type:
|
||||
|
||||
```C
|
||||
#define LIST_HEAD(name) \
|
||||
struct list_head name = LIST_HEAD_INIT(name)
|
||||
```
|
||||
|
||||
and initializes it with the `LIST_HEAD_INIT` macro, which sets previous and next entries with the address of variable - name:
|
||||
|
||||
```C
|
||||
#define LIST_HEAD_INIT(name) { &(name), &(name) }
|
||||
```
|
||||
|
||||
Now let's look on the `misc_register` function which registers a miscellaneous device. At the start it initializes `miscdevice->list` with the `INIT_LIST_HEAD` function:
|
||||
|
||||
```C
|
||||
INIT_LIST_HEAD(&misc->list);
|
||||
```
|
||||
|
||||
which does the same as the `LIST_HEAD_INIT` macro:
|
||||
|
||||
```C
|
||||
static inline void INIT_LIST_HEAD(struct list_head *list)
|
||||
{
|
||||
list->next = list;
|
||||
list->prev = list;
|
||||
}
|
||||
```
|
||||
|
||||
In the next step after a device is created by the `device_create` function, we add it to the miscellaneous devices list with:
|
||||
|
||||
```
|
||||
list_add(&misc->list, &misc_list);
|
||||
```
|
||||
|
||||
Kernel `list.h` provides this API for the addition of a new entry to the list. Let's look at its implementation:
|
||||
|
||||
```C
|
||||
static inline void list_add(struct list_head *new, struct list_head *head)
|
||||
{
|
||||
__list_add(new, head, head->next);
|
||||
}
|
||||
```
|
||||
|
||||
It just calls internal function `__list_add` with the 3 given parameters:
|
||||
|
||||
* new - new entry.
|
||||
* head - list head after which the new item will be inserted.
|
||||
* head->next - next item after list head.
|
||||
|
||||
Implementation of the `__list_add` is pretty simple:
|
||||
|
||||
```C
|
||||
static inline void __list_add(struct list_head *new,
|
||||
struct list_head *prev,
|
||||
struct list_head *next)
|
||||
{
|
||||
next->prev = new;
|
||||
new->next = next;
|
||||
new->prev = prev;
|
||||
prev->next = new;
|
||||
}
|
||||
```
|
||||
|
||||
Here we add a new item between `prev` and `next`. So `misc` list which we defined at the start with the `LIST_HEAD_INIT` macro will contain previous and next pointers to the `miscdevice->list`.
|
||||
|
||||
There is still one question: how to get list's entry. There is a special macro:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
which gets three parameters:
|
||||
|
||||
* ptr - the structure list_head pointer;
|
||||
* type - structure type;
|
||||
* member - the name of the list_head within the structure;
|
||||
|
||||
For example:
|
||||
|
||||
```C
|
||||
const struct miscdevice *p = list_entry(v, struct miscdevice, list)
|
||||
```
|
||||
|
||||
After this we can access to any `miscdevice` field with `p->minor` or `p->name` and etc... Let's look on the `list_entry` implementation:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
As we can see it just calls `container_of` macro with the same arguments. At first sight, the `container_of` looks strange:
|
||||
|
||||
```C
|
||||
#define container_of(ptr, type, member) ({ \
|
||||
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
|
||||
(type *)( (char *)__mptr - offsetof(type,member) );})
|
||||
```
|
||||
|
||||
First of all you can note that it consists of two expressions in curly brackets. The compiler will evaluate the whole block in the curly braces and use the value of the last expression.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
int i = 0;
|
||||
printf("i = %d\n", ({++i; ++i;}));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
will print `2`.
|
||||
|
||||
The next point is `typeof`, it's simple. As you can understand from its name, it just returns the type of the given variable. When I first saw the implementation of the `container_of` macro, the strangest thing I found was the zero in the `((type *)0)` expression. Actually this pointer magic calculates the offset of the given field from the address of the structure, but as we have `0` here, it will be just a zero offset along with the field width. Let's look at a simple example:
|
||||
|
||||
```C
|
||||
#include <stdio.h>
|
||||
|
||||
struct s {
|
||||
int field1;
|
||||
char field2;
|
||||
char field3;
|
||||
};
|
||||
|
||||
int main() {
|
||||
printf("%p\n", &((struct s*)0)->field3);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
will print `0x5`.
|
||||
|
||||
The next `offsetof` macro calculates offset from the beginning of the structure to the given structure's field. Its implementation is very similar to the previous code:
|
||||
|
||||
```C
|
||||
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
|
||||
```
|
||||
|
||||
Let's summarize all about `container_of` macro. The `container_of` macro returns the address of the structure by the given address of the structure's field with `list_head` type, the name of the structure field with `list_head` type and type of the container structure. At the first line this macro declares the `__mptr` pointer which points to the field of the structure that `ptr` points to and assigns `ptr` to it. Now `ptr` and `__mptr` point to the same address. Technically we don't need this line but it's useful for type checking. The first line ensures that the given structure (`type` parameter) has a member called `member`. In the second line it calculates offset of the field from the structure with the `offsetof` macro and subtracts it from the structure address. That's all.
|
||||
|
||||
Of course `list_add` and `list_entry` is not the only functions which `<linux/list.h>` provides. Implementation of the doubly linked list provides the following API:
|
||||
|
||||
* list_add
|
||||
* list_add_tail
|
||||
* list_del
|
||||
* list_replace
|
||||
* list_move
|
||||
* list_is_last
|
||||
* list_empty
|
||||
* list_cut_position
|
||||
* list_splice
|
||||
* list_for_each
|
||||
* list_for_each_entry
|
||||
|
||||
and many more.
|
||||
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,290 +0,0 @@
|
||||
(translating by runningwater)
|
||||
Regular Expressions In grep
|
||||
================================================================================
|
||||
How do I use the Grep command with regular expressions on a Linux and Unix-like operating systems?
|
||||
|
||||
Linux comes with GNU grep, which supports extended regular expressions. GNU grep is the default on all Linux systems. The grep command is used to locate information stored anywhere on your server or workstation.
|
||||
|
||||
### Regular Expressions ###
|
||||
|
||||
Regular Expressions is nothing but a pattern to match for each input line. A pattern is a sequence of characters. Following all are examples of pattern:
|
||||
|
||||
^w1
|
||||
w1|w2
|
||||
[^ ]
|
||||
|
||||
#### grep Regular Expressions Examples ####
|
||||
|
||||
Search for 'vivek' in /etc/passswd
|
||||
|
||||
grep vivek /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
gitevivek:x:1002:1002::/home/gitevivek:/bin/sh
|
||||
|
||||
Search vivek in any case (i.e. case insensitive search)
|
||||
|
||||
grep -i -w vivek /etc/passwd
|
||||
|
||||
Search vivek or raj in any case
|
||||
|
||||
grep -E -i -w 'vivek|raj' /etc/passwd
|
||||
|
||||
The PATTERN in last example, used as an extended regular expression.
|
||||
|
||||
### Anchors ###
|
||||
|
||||
You can use ^ and $ to force a regex to match only at the start or end of a line, respectively. The following example displays lines starting with the vivek only:
|
||||
|
||||
grep ^vivek /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
|
||||
You can display only lines starting with the word vivek only i.e. do not display vivekgite, vivekg etc:
|
||||
|
||||
grep -w ^vivek /etc/passwd
|
||||
|
||||
Find lines ending with word foo:
|
||||
grep 'foo$' filename
|
||||
|
||||
Match line only containing foo:
|
||||
|
||||
grep '^foo$' filename
|
||||
|
||||
You can search for blank lines with the following examples:
|
||||
|
||||
grep '^$' filename
|
||||
|
||||
### Character Class ###
|
||||
|
||||
Match Vivek or vivek:
|
||||
|
||||
grep '[vV]ivek' filename
|
||||
|
||||
OR
|
||||
|
||||
grep '[vV][iI][Vv][Ee][kK]' filename
|
||||
|
||||
You can also match digits (i.e match vivek1 or Vivek2 etc):
|
||||
|
||||
grep -w '[vV]ivek[0-9]' filename
|
||||
|
||||
You can match two numeric digits (i.e. match foo11, foo12 etc):
|
||||
|
||||
grep 'foo[0-9][0-9]' filename
|
||||
|
||||
You are not limited to digits, you can match at least one letter:
|
||||
|
||||
grep '[A-Za-z]' filename
|
||||
|
||||
Display all the lines containing either a "w" or "n" character:
|
||||
|
||||
grep [wn] filename
|
||||
|
||||
Within a bracket expression, the name of a character class enclosed in "[:" and ":]" stands for the list of all characters belonging to that class. Standard character class names are:
|
||||
|
||||
- [:alnum:] - Alphanumeric characters.
|
||||
- [:alpha:] - Alphabetic characters
|
||||
- [:blank:] - Blank characters: space and tab.
|
||||
- [:digit:] - Digits: '0 1 2 3 4 5 6 7 8 9'.
|
||||
- [:lower:] - Lower-case letters: 'a b c d e f g h i j k l m n o p q r s t u v w x y z'.
|
||||
- [:space:] - Space characters: tab, newline, vertical tab, form feed, carriage return, and space.
|
||||
- [:upper:] - Upper-case letters: 'A B C D E F G H I J K L M N O P Q R S T U V W X Y Z'.
|
||||
|
||||
In this example match all upper case letters:
|
||||
|
||||
grep '[:upper:]' filename
|
||||
|
||||
### Wildcards ###
|
||||
|
||||
You can use the "." for a single character match. In this example match all 3 character word starting with "b" and ending in "t":
|
||||
|
||||
grep '\<b.t\>' filename
|
||||
|
||||
Where,
|
||||
|
||||
- \< Match the empty string at the beginning of word
|
||||
- \> Match the empty string at the end of word.
|
||||
|
||||
Print all lines with exactly two characters:
|
||||
|
||||
grep '^..$' filename
|
||||
|
||||
Display any lines starting with a dot and digit:
|
||||
|
||||
grep '^\.[0-9]' filename
|
||||
|
||||
#### Escaping the dot ####
|
||||
|
||||
The following regex to find an IP address 192.168.1.254 will not work:
|
||||
|
||||
grep '192.168.1.254' /etc/hosts
|
||||
|
||||
All three dots need to be escaped:
|
||||
|
||||
grep '192\.168\.1\.254' /etc/hosts
|
||||
|
||||
The following example will only match an IP address:
|
||||
|
||||
egrep '[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}' filename
|
||||
|
||||
The following will match word Linux or UNIX in any case:
|
||||
|
||||
egrep -i '^(linux|unix)' filename
|
||||
|
||||
### How Do I Search a Pattern Which Has a Leading - Symbol? ###
|
||||
|
||||
Searches for all lines matching '--test--' using -e option Without -e, grep would attempt to parse '--test--' as a list of options:
|
||||
|
||||
grep -e '--test--' filename
|
||||
|
||||
### How Do I do OR with grep? ###
|
||||
|
||||
Use the following syntax:
|
||||
|
||||
grep 'word1|word2' filename
|
||||
|
||||
OR
|
||||
|
||||
grep 'word1\|word2' filename
|
||||
|
||||
### How Do I do AND with grep? ###
|
||||
|
||||
Use the following syntax to display all lines that contain both 'word1' and 'word2'
|
||||
|
||||
grep 'word1' filename | grep 'word2'
|
||||
|
||||
### How Do I Test Sequence? ###
|
||||
|
||||
You can test how often a character must be repeated in sequence using the following syntax:
|
||||
|
||||
{N}
|
||||
{N,}
|
||||
{min,max}
|
||||
|
||||
Match a character "v" two times:
|
||||
|
||||
egrep "v{2}" filename
|
||||
|
||||
The following will match both "col" and "cool":
|
||||
|
||||
egrep 'co{1,2}l' filename
|
||||
|
||||
The following will match any row of at least three letters 'c'.
|
||||
|
||||
egrep 'c{3,}' filename
|
||||
|
||||
The following example will match mobile number which is in the following format 91-1234567890 (i.e twodigit-tendigit)
|
||||
|
||||
grep "[[:digit:]]\{2\}[ -]\?[[:digit:]]\{10\}" filename
|
||||
|
||||
### How Do I Hightlight with grep? ###
|
||||
|
||||
Use the following syntax:
|
||||
|
||||
grep --color regex filename
|
||||
|
||||
How Do I Show Only The Matches, Not The Lines?
|
||||
|
||||
Use the following syntax:
|
||||
|
||||
grep -o regex filename
|
||||
|
||||
### Regular Expression Operator ###
|
||||
|
||||
注:表格
|
||||
<table border=1>
|
||||
<tr>
|
||||
<th>Regex operator</th>
|
||||
<th>Meaning</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>.</td>
|
||||
<td>Matches any single character.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>?</td>
|
||||
<td>The preceding item is optional and will be matched, at most, once.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>*</td>
|
||||
<td>The preceding item will be matched zero or more times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>+</td>
|
||||
<td>The preceding item will be matched one or more times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N}</td>
|
||||
<td>The preceding item is matched exactly N times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,}</td>
|
||||
<td>The preceding item is matched N or more times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,M}</td>
|
||||
<td>The preceding item is matched at least N times, but not more than M times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>-</td>
|
||||
<td>Represents the range if it's not first or last in a list or the ending point of a range in a list.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>^</td>
|
||||
<td>Matches the empty string at the beginning of a line; also represents the characters not in the range of a list.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>$</td>
|
||||
<td>Matches the empty string at the end of a line.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\b</td>
|
||||
<td>Matches the empty string at the edge of a word.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\B</td>
|
||||
<td>Matches the empty string provided it's not at the edge of a word.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\<</td>
|
||||
<td>Match the empty string at the beginning of word.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\></td>
|
||||
<td> Match the empty string at the end of word.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
#### grep vs egrep ####
|
||||
|
||||
egrep is the same as **grep -E**. It interpret PATTERN as an extended regular expression. From the grep man page:
|
||||
|
||||
In basic regular expressions the meta-characters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{,
|
||||
\|, \(, and \).
|
||||
Traditional egrep did not support the { meta-character, and some egrep implementations support \{ instead, so portable scripts should avoid { in
|
||||
grep -E patterns and should use [{] to match a literal {.
|
||||
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification.
|
||||
For example, the command grep -E '{1' searches for the two-character string {1 instead of reporting a syntax error in the regular expression.
|
||||
POSIX.2 allows this behavior as an extension, but portable scripts should avoid it.
|
||||
|
||||
References:
|
||||
|
||||
- man page grep and regex(7)
|
||||
- info page grep`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/grep-regular-expressions/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,4 +1,4 @@
|
||||
Search Multiple Words / String Pattern Using grep Command
|
||||
(翻译中 by runningwater)Search Multiple Words / String Pattern Using grep Command
|
||||
================================================================================
|
||||
How do I search multiple strings or words using the grep command? For example I'd like to search word1, word2, word3 and so on within /path/to/file. How do I force grep to search multiple words?
|
||||
|
||||
@ -33,7 +33,7 @@ Fig.01: Linux / Unix egrep Command Search Multiple Words Demo Output
|
||||
via: http://www.cyberciti.biz/faq/searching-multiple-words-string-using-grep/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,236 +0,0 @@
|
||||
How to Install Redis Server on CentOS 7.md
|
||||
|
||||
如何在CentOS 7上安装Redis 服务
|
||||
================================================================================
|
||||
|
||||
大家好, 本文的主题是Redis,我们将要在CentOS 7 上安装它。编译源代码,安装二进制文件,创建、安装文件。然后安装组建,我们还会配置redis ,就像配置操作系统参数一样,目标就是让redis 运行的更加可靠和快速。
|
||||
|
||||

|
||||
|
||||
Redis 服务器
|
||||
|
||||
Redis 是一个开源的多平台数据存储软件,使用ANSI C 编写,直接在内存使用数据集,这使得它得以实现非常高的效率。Redis 支持多种编程语言,包括Lua, C, Java, Python, Perl, PHP 和其他很多语言。redis 的代码量很小,只有约3万行,它只做很少的事,但是做的很好。尽管你在内存里工作,但是对数据持久化的需求还是存在的,而redis 的可靠性就很高,同时也支持集群,这儿些可以很好的保证你的数据安全。
|
||||
|
||||
### 构建 Redis ###
|
||||
|
||||
redis 目前没有官方RPM 安装包,我们需要从牙UN代码编译,而为了要编译就需要安装Make 和GCC。
|
||||
|
||||
如果没有安装过GCC 和Make,那么就使用yum 安装。
|
||||
|
||||
yum install gcc make
|
||||
|
||||
从[官网][1]下载tar 压缩包。
|
||||
|
||||
curl http://download.redis.io/releases/redis-3.0.4.tar.gz -o redis-3.0.4.tar.gz
|
||||
|
||||
解压缩。
|
||||
|
||||
tar zxvf redis-3.0.4.tar.gz
|
||||
|
||||
进入解压后的目录。
|
||||
|
||||
cd redis-3.0.4
|
||||
|
||||
使用Make 编译源文件。
|
||||
|
||||
make
|
||||
|
||||
### 安装 ###
|
||||
|
||||
进入源文件的目录。
|
||||
|
||||
cd src
|
||||
|
||||
复制 Redis server 和 client 到 /usr/local/bin
|
||||
|
||||
cp redis-server redis-cli /usr/local/bin
|
||||
|
||||
最好也把sentinel,benchmark 和check 复制过去。
|
||||
|
||||
cp redis-sentinel redis-benchmark redis-check-aof redis-check-dump /usr/local/bin
|
||||
|
||||
创建redis 配置文件夹。
|
||||
|
||||
mkdir /etc/redis
|
||||
|
||||
在`/var/lib/redis` 下创建有效的保存数据的目录
|
||||
|
||||
mkdir -p /var/lib/redis/6379
|
||||
|
||||
#### 系统参数 ####
|
||||
|
||||
为了让redis 正常工作需要配置一些内核参数。
|
||||
|
||||
配置vm.overcommit_memory 为1,它的意思是一直避免数据被截断,详情[见此][2].
|
||||
|
||||
sysctl -w vm.overcommit_memory=1
|
||||
|
||||
修改backlog 连接数的最大值超过redis.conf 中的tcp-backlog 值,即默认值511。你可以在[kernel.org][3] 找到更多有关基于sysctl 的ip 网络隧道的信息。
|
||||
|
||||
sysctl -w net.core.somaxconn=512.
|
||||
|
||||
禁止支持透明大页,,因为这会造成redis 使用过程产生延时和内存访问问题。
|
||||
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### redis.conf ###
|
||||
Redis.conf 是redis 的配置文件,然而你会看到这个文件的名字是6379.conf ,而这个数字就是redis 监听的网络端口。这个名字是告诉你可以运行超过一个redis 实例。
|
||||
|
||||
复制redis.conf 的示例到 **/etc/redis/6379.conf**.
|
||||
|
||||
cp redis.conf /etc/redis/6379.conf
|
||||
|
||||
现在编辑这个文件并且配置参数。
|
||||
|
||||
vi /etc/redis/6379.conf
|
||||
|
||||
#### 守护程序 ####
|
||||
|
||||
设置daemonize 为no,systemd 需要它运行在前台,否则redis 会突然挂掉。
|
||||
|
||||
daemonize no
|
||||
|
||||
#### pidfile ####
|
||||
|
||||
设置pidfile 为/var/run/redis_6379.pid。
|
||||
|
||||
pidfile /var/run/redis_6379.pid
|
||||
|
||||
#### port ####
|
||||
|
||||
如果不准备用默认端口,可以修改。
|
||||
|
||||
port 6379
|
||||
|
||||
#### loglevel ####
|
||||
|
||||
设置日志级别。
|
||||
|
||||
loglevel notice
|
||||
|
||||
#### logfile ####
|
||||
|
||||
修改日志文件路径。
|
||||
|
||||
logfile /var/log/redis_6379.log
|
||||
|
||||
#### dir ####
|
||||
|
||||
设置目录为 /var/lib/redis/6379
|
||||
|
||||
dir /var/lib/redis/6379
|
||||
|
||||
### 安全 ###
|
||||
|
||||
下面有几个操作可以提高安全性。
|
||||
|
||||
#### Unix sockets ####
|
||||
|
||||
在很多情况下,客户端程序和服务器端程序运行在同一个机器上,所以不需要监听网络上的socket。如果这和你的使用情况类似,你就可以使用unix socket 替代网络socket ,为此你需要配置**port** 为0,然后配置下面的选项来使能unix socket。
|
||||
|
||||
设置unix socket 的套接字文件。
|
||||
|
||||
unixsocket /tmp/redis.sock
|
||||
|
||||
限制socket 文件的权限。
|
||||
|
||||
unixsocketperm 700
|
||||
|
||||
现在为了获取redis-cli 的访问权限,应该使用-s 参数指向socket 文件。
|
||||
|
||||
redis-cli -s /tmp/redis.sock
|
||||
|
||||
#### 密码 ####
|
||||
|
||||
你可能需要远程访问,如果是,那么你应该设置密码,这样子每次操作之前要求输入密码。
|
||||
|
||||
requirepass "bTFBx1NYYWRMTUEyNHhsCg"
|
||||
|
||||
#### 重命名命令 ####
|
||||
|
||||
想象一下下面一条条指令的输出。使得,这回输出服务器的配置,所以你应该在任何可能的情况下拒绝这种信息。
|
||||
|
||||
CONFIG GET *
|
||||
|
||||
为了限制甚至禁止这条或者其他指令可以使用**rename-command** 命令。你必须提供一个命令名和替代的名字。要禁止的话需要设置replacement 为空字符串,这样子禁止任何人猜测命令的名字会比较安全。
|
||||
|
||||
rename-command FLUSHDB "FLUSHDB_MY_SALT_G0ES_HERE09u09u"
|
||||
rename-command FLUSHALL ""
|
||||
rename-command CONFIG "CONFIG_MY_S4LT_GO3S_HERE09u09u"
|
||||
|
||||

|
||||
|
||||
通过密码和修改命令来访问unix socket。
|
||||
|
||||
#### 快照 ####
|
||||
|
||||
默认情况下,redis 会周期性的将数据集转储到我们设置的目录下的文件**dump.rdb**。你可以使用save 命令配置转储的频率,他的第一个参数是以秒为单位的时间帧(译注:按照下文的意思单位应该是分钟),第二个参数是在数据文件上进行修改的数量。
|
||||
|
||||
每隔15小时并且最少修改过一次键。
|
||||
save 900 1
|
||||
|
||||
每隔5小时并且最少修改过10次键。
|
||||
|
||||
save 300 10
|
||||
|
||||
每隔1小时并且最少修改过10000次键。
|
||||
|
||||
save 60 10000
|
||||
|
||||
文件**/var/lib/redis/6379/dump.rdb** 包含了内存里经过上次保存命令的转储数据。因为他创建了临时文件并且替换了源文件,这里没有被破坏的问题,而且你不用担心直接复制这个文件。
|
||||
|
||||
### 开机时启动 ###
|
||||
|
||||
You may use systemd to add Redis to the system startup
|
||||
你可以使用systemd 将redis 添加到系统开机启动列表。
|
||||
|
||||
复制init_script 示例文件到/etc/init.d,注意脚本名所代表的端口号。
|
||||
|
||||
cp utils/redis_init_script /etc/init.d/redis_6379
|
||||
|
||||
现在我们来使用systemd,所以在**/etc/systems/system** 下创建一个单位文件名字为redis_6379.service。
|
||||
|
||||
vi /etc/systemd/system/redis_6379.service
|
||||
|
||||
填写下面的内容,详情可见systemd.service。
|
||||
|
||||
[Unit]
|
||||
Description=Redis on port 6379
|
||||
|
||||
[Service]
|
||||
Type=forking
|
||||
ExecStart=/etc/init.d/redis_6379 start
|
||||
ExecStop=/etc/init.d/redis_6379 stop
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
现在添加我之前在**/etc/sysctl.conf** 里面修改多的内存过分提交和backlog 最大值的选项。
|
||||
|
||||
vm.overcommit_memory = 1
|
||||
|
||||
net.core.somaxconn=512
|
||||
|
||||
对于透明大页支持,并没有直接sysctl 命令可以控制,所以需要将下面的命令放到/etc/rc.local 的结尾。
|
||||
echo never > /sys/kernel/mm/transparent_hugepage/enabled
|
||||
|
||||
### 总结 ###
|
||||
|
||||
这些足够启动了,通过设置这些选项你将足够部署redis 服务到很多简单的场景,然而在redis.conf 还有很多为复杂环境准备的redis 的选项。在一些情况下,你可以使用[replication][4] 和 [Sentinel][5] 来提高可用性,或者[将数据分散][6]在多个服务器上,创建服务器集群 。谢谢阅读。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/install-redis-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
[1]:http://redis.io/download
|
||||
[2]:https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
|
||||
[3]:https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
|
||||
[4]:http://redis.io/topics/replication
|
||||
[5]:http://redis.io/topics/sentinel
|
||||
[6]:http://redis.io/topics/partitioning
|
||||
@ -0,0 +1,258 @@
|
||||
Linux 内核里的数据结构——双向链表
|
||||
================================================================================
|
||||
|
||||
双向链表
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
Linux 内核自己实现了双向链表,可以在[include/linux/list.h](https://github.com/torvalds/linux/blob/master/include/linux/list.h)找到定义。我们将会从双向链表数据结构开始`内核的数据结构`。为什么?因为它在内核里使用的很广泛,你只需要在[free-electrons.com](http://lxr.free-electrons.com/ident?i=list_head) 检索一下就知道了。
|
||||
|
||||
首先让我们看一下在[include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) 里的主结构体:
|
||||
|
||||
```C
|
||||
struct list_head {
|
||||
struct list_head *next, *prev;
|
||||
};
|
||||
```
|
||||
|
||||
你可能注意到这和你以前见过的双向链表的实现方法是不同的。举个例子来说,在[glib](http://www.gnu.org/software/libc/) 库里是这样实现的:
|
||||
|
||||
```C
|
||||
struct GList {
|
||||
gpointer data;
|
||||
GList *next;
|
||||
GList *prev;
|
||||
};
|
||||
```
|
||||
|
||||
通常来说一个链表会包含一个指向某个项目的指针。但是内核的实现并没有这样做。所以问题来了:`链表在哪里保存数据呢?`。实际上内核里实现的链表实际上是`侵入式链表`。侵入式链表并不在节点内保存数据-节点仅仅包含指向前后节点的指针,然后把数据是附加到链表的。这就使得这个数据结构是通用的,使用起来就不需要考虑节点数据的类型了。
|
||||
|
||||
比如:
|
||||
|
||||
```C
|
||||
struct nmi_desc {
|
||||
spinlock_t lock;
|
||||
struct list_head head;
|
||||
};
|
||||
```
|
||||
|
||||
让我们看几个例子来理解一下在内核里是如何使用`list_head` 的。如上所述,在内核里有实在很多不同的地方用到了链表。我们来看一个在杂项字符驱动里面的使用的例子。在 [drivers/char/misc.c](https://github.com/torvalds/linux/blob/master/drivers/char/misc.c) 的杂项字符驱动API 被用来编写处理小型硬件和虚拟设备的小驱动。这些驱动共享相同的主设备号:
|
||||
|
||||
```C
|
||||
#define MISC_MAJOR 10
|
||||
```
|
||||
|
||||
但是都有各自不同的次设备号。比如:
|
||||
|
||||
```
|
||||
ls -l /dev | grep 10
|
||||
crw------- 1 root root 10, 235 Mar 21 12:01 autofs
|
||||
drwxr-xr-x 10 root root 200 Mar 21 12:01 cpu
|
||||
crw------- 1 root root 10, 62 Mar 21 12:01 cpu_dma_latency
|
||||
crw------- 1 root root 10, 203 Mar 21 12:01 cuse
|
||||
drwxr-xr-x 2 root root 100 Mar 21 12:01 dri
|
||||
crw-rw-rw- 1 root root 10, 229 Mar 21 12:01 fuse
|
||||
crw------- 1 root root 10, 228 Mar 21 12:01 hpet
|
||||
crw------- 1 root root 10, 183 Mar 21 12:01 hwrng
|
||||
crw-rw----+ 1 root kvm 10, 232 Mar 21 12:01 kvm
|
||||
crw-rw---- 1 root disk 10, 237 Mar 21 12:01 loop-control
|
||||
crw------- 1 root root 10, 227 Mar 21 12:01 mcelog
|
||||
crw------- 1 root root 10, 59 Mar 21 12:01 memory_bandwidth
|
||||
crw------- 1 root root 10, 61 Mar 21 12:01 network_latency
|
||||
crw------- 1 root root 10, 60 Mar 21 12:01 network_throughput
|
||||
crw-r----- 1 root kmem 10, 144 Mar 21 12:01 nvram
|
||||
brw-rw---- 1 root disk 1, 10 Mar 21 12:01 ram10
|
||||
crw--w---- 1 root tty 4, 10 Mar 21 12:01 tty10
|
||||
crw-rw---- 1 root dialout 4, 74 Mar 21 12:01 ttyS10
|
||||
crw------- 1 root root 10, 63 Mar 21 12:01 vga_arbiter
|
||||
crw------- 1 root root 10, 137 Mar 21 12:01 vhci
|
||||
```
|
||||
|
||||
现在让我们看看它是如何使用链表的。首先看一下结构体`miscdevice`:
|
||||
|
||||
```C
|
||||
struct miscdevice
|
||||
{
|
||||
int minor;
|
||||
const char *name;
|
||||
const struct file_operations *fops;
|
||||
struct list_head list;
|
||||
struct device *parent;
|
||||
struct device *this_device;
|
||||
const char *nodename;
|
||||
mode_t mode;
|
||||
};
|
||||
```
|
||||
|
||||
可以看到结构体的第四个变量`list` 是所有注册过的设备的链表。在源代码文件的开始可以看到这个链表的定义:
|
||||
|
||||
```C
|
||||
static LIST_HEAD(misc_list);
|
||||
```
|
||||
|
||||
它实际上是对用`list_head` 类型定义的变量的扩展。
|
||||
|
||||
```C
|
||||
#define LIST_HEAD(name) \
|
||||
struct list_head name = LIST_HEAD_INIT(name)
|
||||
```
|
||||
|
||||
然后使用宏`LIST_HEAD_INIT` 进行初始化,这会使用变量`name` 的地址来填充`prev`和`next` 结构体的两个变量。
|
||||
|
||||
```C
|
||||
#define LIST_HEAD_INIT(name) { &(name), &(name) }
|
||||
```
|
||||
|
||||
现在来看看注册杂项设备的函数`misc_register`。它在开始就用 `INIT_LIST_HEAD` 初始化了`miscdevice->list`。
|
||||
|
||||
```C
|
||||
INIT_LIST_HEAD(&misc->list);
|
||||
```
|
||||
|
||||
作用和宏`LIST_HEAD_INIT`一样。
|
||||
|
||||
```C
|
||||
static inline void INIT_LIST_HEAD(struct list_head *list)
|
||||
{
|
||||
list->next = list;
|
||||
list->prev = list;
|
||||
}
|
||||
```
|
||||
|
||||
在函数`device_create` 创建了设备后我们就用下面的语句将设备添加到设备链表:
|
||||
|
||||
```
|
||||
list_add(&misc->list, &misc_list);
|
||||
```
|
||||
|
||||
内核文件`list.h` 提供了项链表添加新项的API 接口。我们来看看它的实现:
|
||||
|
||||
|
||||
```C
|
||||
static inline void list_add(struct list_head *new, struct list_head *head)
|
||||
{
|
||||
__list_add(new, head, head->next);
|
||||
}
|
||||
```
|
||||
|
||||
实际上就是使用3个指定的参数来调用了内部函数`__list_add`:
|
||||
|
||||
* new - 新项。
|
||||
* head - 新项将会被添加到`head`之前.
|
||||
* head->next - `head` 之后的项。
|
||||
|
||||
`__list_add`的实现非常简单:
|
||||
|
||||
```C
|
||||
static inline void __list_add(struct list_head *new,
|
||||
struct list_head *prev,
|
||||
struct list_head *next)
|
||||
{
|
||||
next->prev = new;
|
||||
new->next = next;
|
||||
new->prev = prev;
|
||||
prev->next = new;
|
||||
}
|
||||
```
|
||||
|
||||
我们会在`prev`和`next` 之间添加一个新项。所以我们用宏`LIST_HEAD_INIT`定义的`misc` 链表会包含指向`miscdevice->list` 的向前指针和向后指针。
|
||||
|
||||
这里有一个问题:如何得到列表的内容呢?这里有一个特殊的宏:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
使用了三个参数:
|
||||
|
||||
* ptr - 指向链表头的指针;
|
||||
* type - 结构体类型;
|
||||
* member - 在结构体内类型为`list_head` 的变量的名字;
|
||||
|
||||
比如说:
|
||||
|
||||
```C
|
||||
const struct miscdevice *p = list_entry(v, struct miscdevice, list)
|
||||
```
|
||||
|
||||
然后我们就可以使用`p->minor` 或者 `p->name`来访问`miscdevice`。让我们来看看`list_entry` 的实现:
|
||||
|
||||
```C
|
||||
#define list_entry(ptr, type, member) \
|
||||
container_of(ptr, type, member)
|
||||
```
|
||||
|
||||
如我们所见,它仅仅使用相同的参数调用了宏`container_of`。初看这个宏挺奇怪的:
|
||||
|
||||
```C
|
||||
#define container_of(ptr, type, member) ({ \
|
||||
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
|
||||
(type *)( (char *)__mptr - offsetof(type,member) );})
|
||||
```
|
||||
|
||||
首先你可以注意到花括号内包含两个表达式。编译器会执行花括号内的全部语句,然后返回最后的表达式的值。
|
||||
|
||||
举个例子来说:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main() {
|
||||
int i = 0;
|
||||
printf("i = %d\n", ({++i; ++i;}));
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
最终会打印`2`
|
||||
|
||||
下一点就是`typeof`,它也很简单。就如你从名字所理解的,它仅仅返回了给定变量的类型。当我第一次看到宏`container_of`的实现时,让我觉得最奇怪的就是`container_of`中的0.实际上这个指针巧妙的计算了从结构体特定变量的偏移,这里的`0`刚好就是位宽里的零偏移。让我们看一个简单的例子:
|
||||
|
||||
```C
|
||||
#include <stdio.h>
|
||||
|
||||
struct s {
|
||||
int field1;
|
||||
char field2;
|
||||
char field3;
|
||||
};
|
||||
|
||||
int main() {
|
||||
printf("%p\n", &((struct s*)0)->field3);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
结果显示`0x5`。
|
||||
|
||||
下一个宏`offsetof` 会计算从结构体的某个变量的相对于结构体起始地址的偏移。它的实现和上面类似:
|
||||
|
||||
```C
|
||||
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
|
||||
```
|
||||
|
||||
现在我们来总结一下宏`container_of`。只需要知道结构体里面类型为`list_head` 的变量的名字和结构体容器的类型,它可以通过结构体的变量`list_head`获得结构体的起始地址。在宏定义的第一行,声明了一个指向结构体成员变量`ptr`的指针`__mptr`,并且把`ptr` 的地址赋给它。现在`ptr` 和`__mptr` 指向了同一个地址。从技术上讲我们并不需要这一行,但是它可以方便的进行类型检查。第一行保证了特定的结构体(参数`type`)包含成员变量`member`。第二行代码会用宏`offsetof`计算成员变量相对于结构体起始地址的偏移,然后从结构体的地址减去这个偏移,最后就得到了结构体。
|
||||
|
||||
当然了`list_add` 和 `list_entry`不是`<linux/list.h>`提供的唯一功能。双向链表的实现还提供了如下API:
|
||||
|
||||
* list_add
|
||||
* list_add_tail
|
||||
* list_del
|
||||
* list_replace
|
||||
* list_move
|
||||
* list_is_last
|
||||
* list_empty
|
||||
* list_cut_position
|
||||
* list_splice
|
||||
* list_for_each
|
||||
* list_for_each_entry
|
||||
|
||||
等等很多其它API。
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/dlist.md
|
||||
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,288 @@
|
||||
## grep 中的正则表达式
|
||||
================================================================================
|
||||
在 Linux 、类 Unix 系统中我该如何使用 Grep 命令的正则表达式呢?
|
||||
|
||||
Linux 附带有 GNU grep 命令工具,它支持正则表达式,而且 GNU grep 在所有的 Linux 系统中都是默认有的。Grep 命令被用于搜索定位存储在您服务器或工作站的信息。
|
||||
|
||||
### 正则表达式 ###
|
||||
|
||||
正则表达式仅仅是对每个输入行的匹配的一种模式,即对字符序列的匹配模式。下面是范例:
|
||||
|
||||
^w1
|
||||
w1|w2
|
||||
[^ ]
|
||||
|
||||
#### grep 正则表达式示例 ####
|
||||
|
||||
在 /etc/passswd 目录中搜索 'vivek'
|
||||
|
||||
grep vivek /etc/passwd
|
||||
|
||||
输出例子:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
gitevivek:x:1002:1002::/home/gitevivek:/bin/sh
|
||||
|
||||
摸索任何情况下的 vivek(即不区分大小写的搜索)
|
||||
|
||||
grep -i -w vivek /etc/passwd
|
||||
|
||||
摸索任何情况下的 vivek 或 raj
|
||||
|
||||
grep -E -i -w 'vivek|raj' /etc/passwd
|
||||
|
||||
上面最后的例子显示的,就是一个正则表达式扩展的模式。
|
||||
|
||||
### 锚 ###
|
||||
|
||||
你可以分别使用 ^ 和 $ 符号来正则匹配输入行的开始或结尾。下面的例子搜索显示仅仅以 vivek 开始的输入行:
|
||||
|
||||
grep ^vivek /etc/passwd
|
||||
|
||||
输出例子:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
|
||||
你可以仅仅只搜索出以单词 vivek 开始的行,即不显示 vivekgit、vivekg 等
|
||||
|
||||
grep -w ^vivek /etc/passwd
|
||||
|
||||
找出以单词 word 结尾的行:
|
||||
|
||||
grep 'foo$' 文件名
|
||||
|
||||
匹配仅仅只包含 foo 的行:
|
||||
|
||||
grep '^foo$' 文件名
|
||||
|
||||
如下所示的例子可以搜索空行:
|
||||
|
||||
grep '^$' 文件名
|
||||
|
||||
### 字符类 ###
|
||||
|
||||
匹配 Vivek 或 vivek:
|
||||
|
||||
grep '[vV]ivek' 文件名
|
||||
|
||||
或者
|
||||
|
||||
grep '[vV][iI][Vv][Ee][kK]' 文件名
|
||||
|
||||
也可以匹配数字 (即匹配 vivek1 或 Vivek2 等等):
|
||||
|
||||
grep -w '[vV]ivek[0-9]' 文件名
|
||||
|
||||
可以匹配两个数字字符(即 foo11、foo12 等):
|
||||
|
||||
grep 'foo[0-9][0-9]' 文件名
|
||||
|
||||
不仅仅局限于数字,也能匹配至少一个字母的:
|
||||
|
||||
grep '[A-Za-z]' 文件名
|
||||
|
||||
显示含有"w" 或 "n" 字符的所有行:
|
||||
|
||||
grep [wn] 文件名
|
||||
|
||||
在括号内的表达式,即包在"[:" 和 ":]" 之间的字符类的名字,它表示的是属于此类的所有字符列表。标准的字符类名称如下:
|
||||
|
||||
- [:alnum:] - 字母数字字符.
|
||||
- [:alpha:] - 字母字符
|
||||
- [:blank:] - 空字符: 空格键符 和 制表符.
|
||||
- [:digit:] - 数字: '0 1 2 3 4 5 6 7 8 9'.
|
||||
- [:lower:] - 小写字母: 'a b c d e f g h i j k l m n o p q r s t u v w x y z'.
|
||||
- [:space:] - 空格字符: 制表符、换行符、垂直制表符、换页符、回车符和空格键符.
|
||||
- [:upper:] - 大写字母: 'A B C D E F G H I J K L M N O P Q R S T U V W X Y Z'.
|
||||
|
||||
例子所示的是匹配所有大写字母:
|
||||
|
||||
grep '[:upper:]' 文件名
|
||||
|
||||
### 通配符 ###
|
||||
|
||||
你可以使用 "." 来匹配单个字符。例子中匹配以"b"开头以"t"结尾的3个字符的单词:
|
||||
|
||||
grep '\<b.t\>' 文件名
|
||||
|
||||
在这儿,
|
||||
|
||||
- \< 匹配单词前面的空字符串
|
||||
- \> 匹配单词后面的空字符串
|
||||
|
||||
打印出只有两个字符的所有行:
|
||||
|
||||
grep '^..$' 文件名
|
||||
|
||||
显示以一个点和一个数字开头的行:
|
||||
|
||||
grep '^\.[0-9]' 文件名
|
||||
|
||||
#### 点号转义 ####
|
||||
|
||||
下面要匹配到 IP 地址为 192.168.1.254 的正则式是不会工作的:
|
||||
|
||||
egrep '192.168.1.254' /etc/hosts
|
||||
|
||||
三个点符号都需要转义:
|
||||
|
||||
grep '192\.168\.1\.254' /etc/hosts
|
||||
|
||||
下面的例子仅仅匹配出 IP 地址:
|
||||
|
||||
egrep '[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}' 文件名
|
||||
|
||||
下面的例子会匹配任意大小写的 Linux 或 UNIX 这两个单词:
|
||||
|
||||
egrep -i '^(linux|unix)' 文件名
|
||||
|
||||
### 怎么样搜索以 - 符号开头的匹配模式? ###
|
||||
|
||||
要使用 -e 选项来搜索匹配 '--test--' 字符串,如果不使用 -e 选项,grep 命令会试图把 '--test--' 当作自己的选项参数来解析:
|
||||
|
||||
grep -e '--test--' 文件名
|
||||
|
||||
### 怎么使用 grep 的 OR 匹配? ###
|
||||
|
||||
使用如下的语法:
|
||||
|
||||
grep 'word1|word2' 文件名
|
||||
|
||||
或者是
|
||||
|
||||
grep 'word1\|word2' 文件名
|
||||
|
||||
### 怎么使用 grep 的 AND 匹配? ###
|
||||
|
||||
使用下面的语法来显示既包含 'word1' 又包含 'word2' 的所有行
|
||||
|
||||
grep 'word1' 文件名 | grep 'word2'
|
||||
|
||||
### 怎么样使用序列检测? ###
|
||||
|
||||
使用如下的语法,您可以检测一个字符在序列中重复出现次数:
|
||||
|
||||
{N}
|
||||
{N,}
|
||||
{min,max}
|
||||
|
||||
要匹配字符 “v" 出现两次:
|
||||
|
||||
egrep "v{2}" 文件名
|
||||
|
||||
下面的命令能匹配到 "col" 和 "cool" :
|
||||
|
||||
egrep 'co{1,2}l' 文件名
|
||||
|
||||
下面的命令将会匹配出至少有三个 'c' 字符的所有行。
|
||||
|
||||
egrep 'c{3,}' 文件名
|
||||
|
||||
下面的例子会匹配 91-1234567890(即二个数字-十个数字) 这种格式的手机号。
|
||||
|
||||
grep "[[:digit:]]\{2\}[ -]\?[[:digit:]]\{10\}" 文件名
|
||||
|
||||
### 怎么样使 grep 命令突出显示?###
|
||||
|
||||
使用如下的语法:
|
||||
|
||||
grep --color regex 文件名
|
||||
|
||||
### 怎么样仅仅只显示匹配出的字符,而不是匹配出的行? ###
|
||||
|
||||
使用如下语法:
|
||||
|
||||
grep -o regex 文件名
|
||||
|
||||
### 正则表达式限定符###
|
||||
|
||||
注:表格
|
||||
<table border=1>
|
||||
<tr>
|
||||
<th>限定符</th>
|
||||
<th>描述</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>.</td>
|
||||
<td>匹配任意的一个字符.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>?</td>
|
||||
<td>匹配前面的子表达式,最多一次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>*</td>
|
||||
<td>匹配前面的子表达式零次或多次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>+</td>
|
||||
<td>匹配前面的子表达式一次或多次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N}</td>
|
||||
<td>匹配前面的子表达式 N 次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,}</td>
|
||||
<td>匹配前面的子表达式 N 次到多次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,M}</td>
|
||||
<td>匹配前面的子表达式 N 到 M 次,至少 N 次至多 M 次。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>-</td>
|
||||
<td>只要不是在序列开始、结尾或者序列的结束点上,表示序列范围</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>^</td>
|
||||
<td>匹配一行开始的空字符串;也表示字符不在要匹配的列表中。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>$</td>
|
||||
<td>匹配一行末尾的空字符串。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\b</td>
|
||||
<td>匹配一个单词前后的空字符串。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\B</td>
|
||||
<td>匹配一个单词中间的空字符串</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\<</td>
|
||||
<td>匹配单词前面的空字符串。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\></td>
|
||||
<td> 匹配单词后面的空字符串。</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
#### grep 和 egrep ####
|
||||
|
||||
egrep 跟 **grep -E** 是一样的。他会以正则表达式的模式来解释。下面是 grep 的帮助页(man):
|
||||
|
||||
基本的正则表达式元字符 ?、+、 {、 |、 ( 和 ) 已经失去了他们特殊的意义,要使用的话用反斜线的版本 \?、\+、\{、\|、\( 和 \) 来代替。
|
||||
传统的 egrep 不支持 { 元字符,一些 egrep 的实现是以 \{ 替代的,所以有 grep -E 的通用脚本应该避免使用 { 符号,要匹配字面的 { 应该使用 [}]。
|
||||
GNU grep -E 试图支持传统的用法,如果 { 出在在无效的间隔规范字符串这前,它就会假定 { 不是特殊字符。
|
||||
例如,grep -E '{1' 命令搜索包含 {1 两个字符的串,而不会报出正则表达式语法错误。
|
||||
POSIX.2 标准允许对这种操作的扩展,但在可移植脚本文件里应该避免这样使用。
|
||||
|
||||
引用:
|
||||
|
||||
- grep 和 regex 帮助手册页(7)
|
||||
- grep 的 info 页`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/grep-regular-expressions/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user