mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-29 21:41:00 +08:00
commit
edf12b0459
@ -1,35 +1,36 @@
|
||||
Arch Linux 应用自动安装脚本
|
||||
ArchI0:Arch Linux 应用自动安装脚本
|
||||
======
|
||||
|
||||

|
||||
|
||||
Arch 用户你们好!今天,我偶然发现了一个叫做“**ArchI0**”的实用工具,它是基于命令行菜单的 Arch Linux 应用自动安装脚本。使用此脚本是安装基于 Arch 的发行版所有必要应用最简易的方式。请注意**此脚本仅适用于菜鸟级使用者**。中高级使用者可以轻松掌握[**如何使用 pacman **][1]来完成这件事。如果你想学习如何使用 Arch Linux,我建议你一个个手动安装所有的软件。对那些仍是菜鸟并且希望为自己基于 Arch 的系统快速安装所有必要应用的用户,可以使用此脚本。
|
||||
Arch 用户你们好!今天,我偶然发现了一个叫做 “**ArchI0**” 的实用工具,它是基于命令行菜单的 Arch Linux 应用自动安装脚本。使用此脚本是为基于 Arch 的发行版安装所有必要的应用最简易的方式。请注意**此脚本仅适用于菜鸟级使用者**。中高级使用者可以轻松掌握[如何使用 pacman][1]来完成这件事。如果你想学习如何使用 Arch Linux,我建议你一个个手动安装所有的软件。对那些仍是菜鸟并且希望为自己基于 Arch 的系统快速安装所有必要应用的用户,可以使用此脚本。
|
||||
|
||||
### ArchI0 – Arch Linux 应用自动安装脚本
|
||||
|
||||
此脚本的开发者已经制作了 **ArchI0live** 和 **ArchI0** 两个脚本。你可以通过 ArchI0live 测试,无需安装。这可能有助于在将脚本安装到系统之前了解其实际内容。
|
||||
此脚本的开发者已经制作了 **ArchI0live** 和 **ArchI0** 两个脚本。你可以通过 ArchI0live 测试应用,无需安装。这可能有助于在将脚本安装到系统之前了解其实际内容。
|
||||
|
||||
### 安装 ArchI0
|
||||
|
||||
要安装此脚本,使用如下命令通过 Git 克隆 ArchI0 脚本仓库:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/SifoHamlaoui/ArchI0.git
|
||||
|
||||
```
|
||||
|
||||
上面的命令会克隆 ArchI0 的 Github 仓库内容,在你当前目录的一个名为 ArchI0 的文件夹里。使用如下命令进入此目录:
|
||||
|
||||
```
|
||||
$ cd ArchI0/
|
||||
|
||||
```
|
||||
|
||||
使用如下命令赋予脚本可执行权限:
|
||||
|
||||
```
|
||||
$ chmod +x ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
使用如下命令执行脚本:
|
||||
|
||||
```
|
||||
$ sudo ./ArchI0live.sh
|
||||
|
||||
@ -37,9 +38,9 @@ $ sudo ./ArchI0live.sh
|
||||
|
||||
此脚本需要以 root 或 sudo 用户身份执行,因为安装应用需要 root 权限。
|
||||
|
||||
> **注意:** 有些人想知道此脚本中所有命令的开头部分,第一个命令是下载 **figlet**,因为此脚本的 logo 是使用 figlet 显示的。第二个命令是安装用来打开并查看许可协议文件的 **Leafpad**。第三个命令是安装从 sourceforge 下载文件的 **wget**。第四和第五个命令是下载许可协议文件并用 leafpad 打开。此外,最后的第6条命令是在阅读许可协议文件之后关闭它。
|
||||
> **注意:** 有些人想知道此脚本中开头的那些命令是做什么的,第一个命令是下载 **figlet**,因为此脚本的 logo 是使用 figlet 显示的。第二个命令是安装用来打开并查看许可协议文件的 **Leafpad**。第三个命令是安装用于从 sourceforge 下载文件的 **wget**。第四和第五个命令是下载许可协议文件并用 leafpad 打开。此外,最后的第 6 条命令是在阅读许可协议文件之后关闭它。
|
||||
|
||||
输入你的 Arch Linux 系统架构然后按回车键。当其请求安装此脚本时,键入 y 然后按回车键。
|
||||
输入你的 Arch Linux 系统架构然后按回车键。当其请求安装此脚本时,键入 `y` 然后按回车键。
|
||||
|
||||
![][3]
|
||||
|
||||
@ -47,25 +48,26 @@ $ sudo ./ArchI0live.sh
|
||||
|
||||
![][4]
|
||||
|
||||
正如前面的截图, ArchI0 有13个目录,包含90个容易安装的程序。这90个程序刚好足够配置一个完整的 Arch Linux 桌面,可执行日常活动。键入 **a** 可查看关于此脚本的信息,键入 **q** 可退出此脚本。
|
||||
正如前面的截图, ArchI0 包含有 13 类、90 个容易安装的程序。这 90 个程序刚好足够配置一个完整的 Arch Linux 桌面,可执行日常活动。键入 `a` 可查看关于此脚本的信息,键入 `q` 可退出此脚本。
|
||||
|
||||
安装后无需执行 ArchI0live 脚本。可以直接使用如下命令启动:
|
||||
|
||||
```
|
||||
$ sudo ArchI0
|
||||
|
||||
```
|
||||
|
||||
它会每次询问你选择 Arch Linux 发行版的架构。
|
||||
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
Preparing To Run Script
|
||||
Checking For ROOT: PASSED
|
||||
What Is Your OS Architecture? {32/64} 64
|
||||
|
||||
```
|
||||
|
||||
从现在开始,你可以从主菜单列出的类别选择要安装的程序。要查看特定类别下的可用程序列表,输入类别号即可。举个例子,要查看**文本编辑器**分类下的可用程序列表,输入 **1** 然后按回车键。
|
||||
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
@ -91,12 +93,12 @@ Make A Choice
|
||||
q) Leave ArchI0 Script
|
||||
|
||||
Choose An Option: 1
|
||||
|
||||
```
|
||||
|
||||
接下来,选择你想安装的程序。要返回至主菜单,输入 **q** 然后按回车键。
|
||||
接下来,选择你想安装的程序。要返回至主菜单,输入 `q` 然后按回车键。
|
||||
|
||||
我想安装 Emacs,所以我输入 `3`。
|
||||
|
||||
我想安装 Emacs,所以我输入 **3**。
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
@ -111,7 +113,6 @@ This script Is under GPLv3 License
|
||||
q) Return To Main Menu
|
||||
|
||||
Choose An Option: 3
|
||||
|
||||
```
|
||||
|
||||
现在,Emacs 将会安装至你的 Arch Linux 系统。
|
||||
@ -122,9 +123,9 @@ Choose An Option: 3
|
||||
|
||||
### 结论
|
||||
|
||||
毫无疑问,此脚本让 Arch Linux 用户使用起来更加容易,特别是刚开始使用的人。如果你正寻找快速简单无需 pacman 的安装应用的方法,此脚本是一个不错的选择。试用一下并在下面的评论区让我们知道你对此脚本的看法。
|
||||
毫无疑问,此脚本让 Arch Linux 用户使用起来更加容易,特别是刚开始使用的人。如果你正寻找快速简单无需使用 pacman 安装应用的方法,此脚本是一个不错的选择。试用一下并在下面的评论区让我们知道你对此脚本的看法。
|
||||
|
||||
就这些。希望这个工具能帮到你。我们每天都会推送实用的指南。如果你觉得我们的指南挺实用,请分享至你的社交网络,专业圈子并支持 OSTechNix。
|
||||
就这些。希望这个工具能帮到你。我们每天都会推送实用的指南。如果你觉得我们的指南挺实用,请分享至你的社交网络,专业圈子并支持我们。
|
||||
|
||||
干杯!
|
||||
|
||||
@ -137,7 +138,7 @@ via: https://www.ostechnix.com/archi0-arch-linux-applications-automatic-installa
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,154 @@
|
||||
如何在 Linux 中查看系统硬件制造商、型号和序列号
|
||||
======
|
||||
|
||||
对于 Linux 图形界面用户和 Windows 用户来说获取系统硬件信息都不算问题,但是对命令行用户来说想要获取这些细节时有点儿麻烦。
|
||||
|
||||
甚至我们中的大多数都不知道获取这些信息最好的命令是什么。Linux 中有许多可用的工具集来获取诸如制造商、型号和序列号等硬件信息。
|
||||
|
||||
在这里我尝试写下获取这些细节的可能的方式,你可以挑选一种最好用的。
|
||||
|
||||
你必须知道所有这些信息,因为当你向硬件制造商提交任何硬件问题时,你会需要它们。
|
||||
|
||||
这可以通过 6 种方法来实现,下面我来演示一下怎么做。
|
||||
|
||||
### 方法一:使用 dmidecode 命令
|
||||
|
||||
`dmidecode` 是一个读取电脑 DMI(<ruby>桌面管理接口<rt>Desktop Management Interface</rt></ruby>)表内容并且以人类可读的格式显示系统硬件信息的工具。(也有人说是读取 SMBIOS —— <ruby>系统管理 BIOS<rt>System Management BIOS</rt></ruby>)
|
||||
|
||||
这个表包含系统硬件组件的说明,也包含如序列号、制造商、发布日期以及 BIOS 修订版本号等其它有用的信息。
|
||||
|
||||
DMI 表不仅描述了当前的系统构成,还可以报告可能的升级信息(比如可以支持的最快的 CPU 或者最大的内存容量)。
|
||||
|
||||
这将有助于分析你的硬件兼容性,比如是否支持最新版本的程序。
|
||||
|
||||
```
|
||||
# dmidecode -t system
|
||||
|
||||
# dmidecode 2.12
|
||||
# SMBIOS entry point at 0x7e7bf000
|
||||
SMBIOS 2.7 present.
|
||||
|
||||
Handle 0x0024, DMI type 1, 27 bytes
|
||||
System Information
|
||||
Manufacturer: IBM
|
||||
Product Name: System x2530 M4: -[1214AC1]-
|
||||
Version: 0B
|
||||
Serial Number: MK2RL11
|
||||
UUID: 762A99BF-6916-450F-80A6-B2E9E78FC9A1
|
||||
Wake-up Type: Power Switch
|
||||
SKU Number: Not Specified
|
||||
Family: System X
|
||||
|
||||
Handle 0x004B, DMI type 12, 5 bytes
|
||||
System Configuration Options
|
||||
Option 1: JP20 pin1-2: TPM PP Disable, pin2-3: TPM PP Enable
|
||||
|
||||
Handle 0x004D, DMI type 32, 20 bytes
|
||||
System Boot Information
|
||||
Status: No errors detected
|
||||
```
|
||||
|
||||
**推荐阅读:** [Dmidecode –– 获取 Linux 系统硬件信息的简单方式][1]
|
||||
|
||||
### 方法二:使用 inxi 命令
|
||||
|
||||
`inxi` 是 Linux 上查看硬件信息的一个灵巧的小工具,它提供了大量的选项来获取所有硬件信息,这是我在现有的其它 Linux 工具集里所没见到过的。它是从 locsmif 编写的古老的但至今看来都异常灵活的 `infobash` fork 出来的。
|
||||
|
||||
`inxi` 是一个可以快速显示系统硬件、CPU、驱动、Xorg、桌面、内核、GCC 版本、进程、内存使用以及大量其它有用信息的脚本,也可以用来做技术支持和调试工具。
|
||||
|
||||
```
|
||||
# inxi -M
|
||||
Machine: Device: server System: IBM product: N/A v: 0B serial: MK2RL11
|
||||
Mobo: IBM model: 00Y8494 serial: 37M17D UEFI: IBM v: -[VVE134MUS-1.50]- date: 08/30/2013
|
||||
```
|
||||
|
||||
**推荐阅读:** [inxi —— 一个很棒的查看 Linux 硬件信息的工具][2]
|
||||
|
||||
### 方法三:使用 lshw 命令
|
||||
|
||||
`lshw`(指<ruby>硬件监听器<rt>Hardware Lister</rt></ruby>)是一个小巧灵活的工具,可以生成如内存配置、固件版本、主板配置、CPU 版本和速度、缓存配置、USB、网卡、显卡、多媒体、打印机以及总线速度等机器中各种硬件组件的详细报告。
|
||||
|
||||
它通过读取 `/proc` 目录下各种文件的内容和 DMI 表来生成硬件信息。
|
||||
|
||||
`lshw` 必须以超级用户的权限运行来检测完整的硬件信息,否则它只汇报部分信息。`lshw` 里有一个叫做 `class` 的特殊选项,它可以以详细的模式显示特定的硬件信息。
|
||||
|
||||
```
|
||||
# lshw -C system
|
||||
enal-dbo01t
|
||||
description: Blade
|
||||
product: System x2530 M4: -[1214AC1]-
|
||||
vendor: IBM
|
||||
version: 0B
|
||||
serial: MK2RL11
|
||||
width: 64 bits
|
||||
capabilities: smbios-2.7 dmi-2.7 vsyscall32
|
||||
configuration: boot=normal chassis=enclosure family=System X uuid=762A99BF-6916-450F-80A6-B2E9E78FC9A1
|
||||
```
|
||||
|
||||
**推荐阅读:** [LSHW (Hardware Lister) –– 获取 Linux 硬件信息的灵巧的小工具][3]
|
||||
|
||||
### 方法四:使用 /sys 文件系统
|
||||
|
||||
内核在 `/sys` 目录下的文件中公开了一些 DMI 信息。因此,我们可以通过如下方式运行 `grep` 命令来轻易地获取机器类型。
|
||||
|
||||
```
|
||||
# grep "" /sys/class/dmi/id/[pbs]*
|
||||
```
|
||||
|
||||
或者,可以使用 `cat` 命令仅打印出特定的详细信息。
|
||||
|
||||
```
|
||||
# cat /sys/class/dmi/id/board_vendor
|
||||
IBM
|
||||
|
||||
# cat /sys/class/dmi/id/product_name
|
||||
System x2530 M4: -[1214AC1]-
|
||||
|
||||
# cat /sys/class/dmi/id/product_serial
|
||||
MK2RL11
|
||||
|
||||
# cat /sys/class/dmi/id/bios_version
|
||||
-[VVE134MUS-1.50]-
|
||||
```
|
||||
|
||||
### 方法五:使用 dmesg 命令
|
||||
|
||||
`dmesg` 命令是在 Linux 上 `syslogd` 或 `klogd` 启动前用来记录内核消息(启动阶段的消息)的。它通过读取内核的环形缓冲区来获取数据。在排查问题或只是尝试获取系统硬件信息时,`dmesg` 非常有用。
|
||||
|
||||
```
|
||||
# dmesg | grep -i DMI
|
||||
DMI: System x2530 M4: -[1214AC1]-/00Y8494, BIOS -[VVE134MUS-1.50]- 08/30/2013
|
||||
```
|
||||
|
||||
### 方法六:使用 hwinfo 命令
|
||||
|
||||
`hwinfo`(<ruby>硬件信息<rt>hardware information</rt></ruby>)是另一个很棒的工具,用于检测当前系统存的硬件,并以人类可读的方式显示各种硬件模块的详细信息。
|
||||
|
||||
它报告关于 CPU、内存、键盘、鼠标、显卡、声卡、存储、网络接口、磁盘、分区、BIOS 以及桥接器等信息。它可以比其它像 `lshw`、`dmidecode` 或 `inxi` 等工具显示更为详细的信息。
|
||||
|
||||
`hwinfo` 使用 libhd 库 `libhd.so` 来收集系统上的硬件信息。该工具是为 openSuse 特别设计的,后来其它发行版也将它包含在其官方仓库中。
|
||||
|
||||
```
|
||||
# hwinfo | egrep "system.hardware.vendor|system.hardware.product"
|
||||
system.hardware.vendor = 'IBM'
|
||||
system.hardware.product = 'System x2530 M4: -[1214AC1]-'
|
||||
```
|
||||
|
||||
**推荐阅读:** [hwinfo (Hardware Info) –– 一款灵活的检测 Linux 系统硬件信息的工具][4]
|
||||
|
||||
---
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-system-hardware-manufacturer-model-and-serial-number-in-linux/
|
||||
|
||||
作者:[VINOTH KUMAR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[icecoobe](https://github.com/icecoobe)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/vinoth/
|
||||
[1]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[2]:https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
[3]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[4]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
630
published/20180726 The evolution of package managers.md
Normal file
630
published/20180726 The evolution of package managers.md
Normal file
@ -0,0 +1,630 @@
|
||||
包管理器的进化
|
||||
======
|
||||
|
||||
> 包管理器在 Linux 软件管理中扮演了重要角色。这里对一些主要的包管理器进行了对比。
|
||||
|
||||

|
||||
|
||||
今天,每个可计算设备都会使用某种软件来完成预定的任务。在软件开发的上古时期,为了找出软件中的“虫”和其它缺陷,软件会被严格的测试。在近十年间,软件被通过互联网来频繁分发,以试图通过持续不断的安装新版本的软件来解决软件的缺陷问题。在很多情况下,每个独立的应用软件都有其自带的更新器。而其它一些软件则让用户自己去搞明白如何获取和升级软件。
|
||||
|
||||
Linux 较早采用了维护一个中心化的软件仓库来发布软件更新这种做法,用户可以在这个软件仓库里查找并安装软件。在这篇文章里, 笔者将回顾在 Linux 上的如何进行软件安装的历史,以及现代操作系统如何保持更新以应对[软件安全漏洞(CVE)][1]不断的曝光。
|
||||
|
||||
### 那么在包管理器出现之前在 Linux 上是如何安装软件的呢?
|
||||
|
||||
曾几何时,软件都是通过 FTP 或邮件列表(LCTT 译注:即通过邮件列表发布源代码的补丁包)来分发的(最终这些发布方式在互联网的迅猛发展下都演化成为一个个现今常见的软件发布网站)。(一般在一个 tar 文件中)只有一个非常小的文件包含了创建二进制的说明。你需要做的是先解压这个包,然后仔细阅读当中的 `README` 文件, 如果你的系统上恰好有 GCC(LCTT 译注:GNU C Compiler)或者其它厂商的 C 编译器的话,你得首先运行 `./configure` 脚本,并在脚本后添加相应的参数,如库函数的路径、创建可执行文件的路径等等。除此之外,这个配置过程也会检查你操作系统上的软件依赖是否满足安装要求。如果缺失了任何主要的依赖,该配置脚本会退出不再继续安装,直到你满足了该依赖。如果该配置脚本正常执行完毕,将会创建一个 `Makefile` 文件。
|
||||
|
||||
当有了一个 `Makefile` 文件时, 你就可以接下去执行 `make` 命令(该命令由你所使用的编译器提供)。`make` 命令也有很多参数,被称为 `make` <ruby>标识<rt>flag</rt></ruby>,这些标识能为你的系统优化最终生成出来的二进制可执行文件。在计算机世界的早期,这些优化是非常重要的,因为彼时的计算机硬件正在为了跟上软件迅速的发展而疲于奔命。今日今时,编译标识变得更加通用而不是为了优化哪些具体的硬件型号,这得益于现代硬件和现代软件相比已经变得成本低廉,唾手可得。
|
||||
|
||||
最后,在 `make` 完成之后, 你需要运行 `make install` (或 `sudo make install`)(LCTT 译注:依赖于你的用户权限) 来“真正”将这个软件安装到你的系统上。可以想象,为你系统上的每一个软件都执行上述的流程将是多么无聊费时,更不用说如果更新一个已经安装的软件将会多复杂,多么需要精力投入。(LCTT 译注:上述流程也称 CMMI 安装, 即Configure、Make、Make Install)
|
||||
|
||||
### 那么软件包是什么?
|
||||
|
||||
<ruby>软件包<rt>package</rt></ruby>(LCTT 译注:下文简称“包”)这个概念是用来解决在软件安装、升级过程中的复杂性的。包将软件安装升级中需要的多个数据文件合并成一个单独的文件,这将便于传输和(通过压缩文件来)减小存储空间(LCTT 译注:减少存储空间这一点在现在已经不再重要),包中的二进制可执行文件已根据开发者所选择的编译标识预编译。包本身包括了所有需要的元数据,如软件的名字、软件的说明、版本号,以及要运行这个软件所需要的依赖包等等。
|
||||
|
||||
不同流派的 Linux 发行版都创造了它们自己的包格式,其中最常用的包格式有:
|
||||
|
||||
* .deb:这种包格式由 Debian、Ubuntu、Linux Mint 以及其它的变种使用。这是最早被发明的包类型。
|
||||
* .rpm:这种包格式最初被称作<ruby>红帽包管理器<rt>Red Hat Package Manager</rt></ruby>(LCTT 译注: 取自英文的首字母)。使用这种包的 Linux 发行版有 Red Hat、Fedora、SUSE 以及其它一些较小的发行版。
|
||||
* .tar.xz:这种包格式只是一个软件压缩包而已,这是 Arch Linux 所使用的格式。(LCTT 译注:这种格式无需特别的包管理器,解压即可)
|
||||
|
||||
尽管上述的包格式自身并不能直接管理软件的依赖问题,但是它们的出现将 Linux 软件包管理向前推进了一大步。
|
||||
|
||||
### 软件仓库到底是什么?
|
||||
|
||||
多年以前(当智能电话还没有像现在这样流行时),非 Linux 世界的用户是很难理解软件仓库的概念的。甚至今时今日,大多数完全工作在 Windows 下的用户还是习惯于打开浏览器,搜索要安装的软件(或升级包),下载然后安装。但是,智能电话传播了软件“商店”(LCTT 译注: 对应 Linux 里的软件仓库)这样一个概念。智能电话用户获取软件的方式和包管理器的工作方式已经非常相近了。些许不同的是,尽管大多数软件商店还在费力美化它的图形界面来吸引用户,大多数 Linux 用户还是愿意使用命令行来安装软件。总而言之,软件仓库是一个中心化的可安装软件列表,上面列举了在当前系统中预先配置好的软件仓库里所有可以安装的软件。下面我们举一些例子来说在各个不同的 Linux 发行版下如何在对应的软件仓库里搜寻某个特定的软件(输出有截断)。
|
||||
|
||||
在 Arch Linux 下使用 `aurman`:
|
||||
|
||||
```
|
||||
user@arch ~ $ aurman -Ss kate
|
||||
|
||||
extra/kate 18.04.2-2 (kde-applications kdebase)
|
||||
Advanced Text Editor
|
||||
aur/kate-root 18.04.0-1 (11, 1.139399)
|
||||
Advanced Text Editor, patched to be able to run as root
|
||||
aur/kate-git r15288.15d26a7-1 (1, 1e-06)
|
||||
An advanced editor component which is used in numerous KDE applications requiring a text editing component
|
||||
```
|
||||
|
||||
在 CentOS 7 下使用 `yum`:
|
||||
|
||||
```
|
||||
[user@centos ~]$ yum search kate
|
||||
|
||||
kate-devel.x86_64 : Development files for kate
|
||||
kate-libs.x86_64 : Runtime files for kate
|
||||
kate-part.x86_64 : Kate kpart plugin
|
||||
```
|
||||
|
||||
|
||||
在 Ubuntu 下使用 `apt`:
|
||||
|
||||
```
|
||||
user@ubuntu ~ $ apt search kate
|
||||
Sorting... Done
|
||||
Full Text Search... Done
|
||||
|
||||
kate/xenial 4:15.12.3-0ubuntu2 amd64
|
||||
powerful text editor
|
||||
|
||||
kate-data/xenial,xenial 4:4.14.3-0ubuntu4 all
|
||||
shared data files for Kate text editor
|
||||
|
||||
kate-dbg/xenial 4:15.12.3-0ubuntu2 amd64
|
||||
debugging symbols for Kate
|
||||
|
||||
kate5-data/xenial,xenial 4:15.12.3-0ubuntu2 all
|
||||
shared data files for Kate text editor
|
||||
```
|
||||
|
||||
### 最好用的包管理器有哪些?
|
||||
|
||||
如上示例的输出,包管理器用来和相应的软件仓库交互,获取软件的相应信息。下面对它们做一个简短介绍。
|
||||
|
||||
#### 基于 PRM 包格式的包管理器
|
||||
|
||||
更新基于 RPM 的系统,特别是那些基于 Red Hat 技术的系统,有着非常有趣而又详实的历史。实际上,现在的 [YUM][2] 版本(用于 企业级发行版)和 [DNF][3](用于社区版)就融合了好几个开源项目来提供它们现在的功能。
|
||||
|
||||
Red Hat 最初使用的包管理器,被称为 [RPM][4](<ruby>红帽包管理器<rt>Red Hat Package Manager</rt></ruby>),时至今日还在使用着。不过,它的主要作用是安装本地的 RPM 包,而不是去在软件仓库搜索软件。后来开发了一个叫 `up2date` 的包管理器,它被用来通知用户包的最新更新,还能让用户在远程仓库里搜索软件并便捷的安装软件的依赖。尽管这个包管理器尽职尽责,但一些社区成员还是感觉 `up2date` 有着明显的不足。
|
||||
|
||||
现在的 YUM 来自于好几个不同社区的努力。1999-2001 年一群在 Terra Soft Solution 的伙计们开发了<ruby>黄狗更新器<rt>Yellowdog Updater</rt></ruby>(YUP),将其作为 [Yellow Dog Linux][5] 图形安装器的后端。<ruby>杜克大学<rt>Duke University</rt></ruby>喜欢这个主意就决定去增强它的功能,它们开发了<ruby>[黄狗更新器--修改版][16]<rt>Yellowdog Updater, Modified</rt></ruby>(YUM),这最终被用来帮助管理杜克大学的 Red Hat 系统。Yum 壮大的很快,到 2005 年,它已经被超过一半的 Linux 市场所采用。今日,几乎所有的使用 RPM 的的 Linux 都会使用 YUM 来进行包管理(当然也有一些例外)。
|
||||
|
||||
##### 使用 YUM
|
||||
|
||||
为了能让 YUM 正常工作,比如从一个软件仓库里下载和安装包,仓库说明文件必须放在 `/etc/yum.repos.d/` 目录下且必须以 `.repo` 作为扩展名。如下是一个示例文件的内容:
|
||||
|
||||
```
|
||||
[local_base]
|
||||
name=Base CentOS (local)
|
||||
baseurl=http://7-repo.apps.home.local/yum-repo/7/
|
||||
enabled=1
|
||||
gpgcheck=0
|
||||
```
|
||||
|
||||
这是笔者本地仓库之一,这也是为什么 gpgcheck 值为 0 的原因。如果这个值为 1 的话,每个包都需要被密钥签名,相应的密钥(的公钥)也要导入到安装软件的系统上。因为这个软件仓库是笔者本人维护的且笔者信任这个仓库里的包,所以就不去对它们一一签名了。
|
||||
|
||||
当一个仓库文件准备好时,你就能开始从远程软件仓库开始安装文件了。最基本的命令是 `yum update`,这将会更新所有已安装的包。你也不需要用特殊的命令来更新仓库本身,所有这一切都已自动完成了。运行命令示例如下:
|
||||
|
||||
```
|
||||
[user@centos ~]$ sudo yum update
|
||||
Loaded plugins: fastestmirror, product-id, search-disabled-repos, subscription-manager
|
||||
local_base | 3.6 kB 00:00:00
|
||||
local_epel | 2.9 kB 00:00:00
|
||||
local_rpm_forge | 1.9 kB 00:00:00
|
||||
local_updates | 3.4 kB 00:00:00
|
||||
spideroak-one-stable | 2.9 kB 00:00:00
|
||||
zfs | 2.9 kB 00:00:00
|
||||
(1/6): local_base/group_gz | 166 kB 00:00:00
|
||||
(2/6): local_updates/primary_db | 2.7 MB 00:00:00
|
||||
(3/6): local_base/primary_db | 5.9 MB 00:00:00
|
||||
(4/6): spideroak-one-stable/primary_db | 12 kB 00:00:00
|
||||
(5/6): local_epel/primary_db | 6.3 MB 00:00:00
|
||||
(6/6): zfs/x86_64/primary_db | 78 kB 00:00:00
|
||||
local_rpm_forge/primary_db | 125 kB 00:00:00
|
||||
Determining fastest mirrors
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
```
|
||||
|
||||
如果你确定想让 YUM 在执行任何命令时不要停下来等待用户输入,你可以命令里放 `-y` 标志,如 `yum update -y`。
|
||||
|
||||
安装一个新包很简单。首先,用 `yum search` 搜索包的名字。
|
||||
|
||||
```
|
||||
[user@centos ~]$ yum search kate
|
||||
|
||||
artwiz-aleczapka-kates-fonts.noarch : Kates font in Artwiz family
|
||||
ghc-highlighting-kate-devel.x86_64 : Haskell highlighting-kate library development files
|
||||
kate-devel.i686 : Development files for kate
|
||||
kate-devel.x86_64 : Development files for kate
|
||||
kate-libs.i686 : Runtime files for kate
|
||||
kate-libs.x86_64 : Runtime files for kate
|
||||
kate-part.i686 : Kate kpart plugin
|
||||
```
|
||||
|
||||
当你找到你要安装的包后,你可以用 `sudo yum install kate-devel -y` 来安装。如果你安装了你不需要的软件,可以用 `sudo yum remove kdate-devel -y` 来从系统上删除它,默认情况下,YUM 会删除软件包以及它的依赖。
|
||||
|
||||
有些时候你甚至都不清楚要安装的包的名称,你只知道某个实用程序的名字。(LCTT 译注:可以理解实用程序是安装包的子集)。例如,你想找实用程序 `updatedb`(它是用来创建/更新由 `locate` 命令所使用的数据库的),直接试图安装 `updatedb` 会返回下面的结果:
|
||||
|
||||
```
|
||||
[user@centos ~]$ sudo yum install updatedb
|
||||
Loaded plugins: fastestmirror, langpacks
|
||||
Loading mirror speeds from cached hostfile
|
||||
No package updatedb available.
|
||||
Error: Nothing to do
|
||||
```
|
||||
|
||||
你可以搜索实用程序来自哪个包:
|
||||
|
||||
```
|
||||
[user@centos ~]$ yum whatprovides *updatedb
|
||||
Loaded plugins: fastestmirror, langpacks
|
||||
Loading mirror speeds from cached hostfile
|
||||
|
||||
bacula-director-5.2.13-23.1.el7.x86_64 : Bacula Director files
|
||||
Repo : local_base
|
||||
Matched from:
|
||||
Filename : /usr/share/doc/bacula-director-5.2.13/updatedb
|
||||
|
||||
mlocate-0.26-8.el7.x86_64 : An utility for finding files by name
|
||||
Repo : local_base
|
||||
Matched from:
|
||||
Filename : /usr/bin/updatedb
|
||||
```
|
||||
|
||||
笔者在前面使用星号的原因是 `yum whatprovides` 使用路径去匹配文件。笔者不确定文件在哪里,所以使用星号去指代任意路径。
|
||||
|
||||
当然 YUM 还有很多其它的可选项。这里笔者希望你能够自己查看 YUM 的手册来找到其它额外的可选项。
|
||||
|
||||
<ruby>[时髦的 Yum][7]<rt>Dandified Yum</rt></ruby>(DNF)是 YUM 的下一代接班人。从 Fedora 18 开始被作为包管理器引入系统,不过它并没有被企业版所采用,所以它只在 Fedora(以及变种)上占据了主导地位。DNF 的用法和 YUM 几乎一模一样,它主要是用来解决性能问题、晦涩无说明的API、缓慢/不可靠的依赖解析,以及偶尔的高内存占用。DNF 是作为 YUM 的直接替代品来开发的,因此这里笔者就不重复它的用法了,你只用简单的将 `yum` 替换为 `dnf` 就行了。
|
||||
|
||||
##### 使用 Zypper
|
||||
|
||||
[Zypper][8] 是用来管理 RPM 包的另外一个包管理器。这个包管理器主要用于 [SUSE][9](和 [openSUSE][10]),在[MeeGo][11]、[Sailfish OS][12]、[Tizen][13] 上也有使用。它最初开发于 2006 年,已经经过了多次迭代。除了作为系统管理工具 [YaST][14] 的后端和有些用户认为它比 YUM 要快之外也没有什么好多说的。
|
||||
|
||||
Zypper 使用与 YUM 非常相像。它被用来搜索、更新、安装和删除包,简单的使用命令如下:
|
||||
|
||||
```
|
||||
zypper search kate
|
||||
zypper update
|
||||
zypper install kate
|
||||
zypper remove kate
|
||||
```
|
||||
|
||||
主要的不同来自于使用 Zypper 的系统在添加软件仓库的做法上,Zypper 使用包管理器本身来添加软件仓库。最通用的方法是通过一个 URL,但是 Zypper 也支持从仓库文件里导入。
|
||||
|
||||
```
|
||||
suse:~ # zypper addrepo http://download.videolan.org/pub/vlc/SuSE/15.0 vlc
|
||||
Adding repository 'vlc' [done]
|
||||
Repository 'vlc' successfully added
|
||||
|
||||
Enabled : Yes
|
||||
Autorefresh : No
|
||||
GPG Check : Yes
|
||||
URI : http://download.videolan.org/pub/vlc/SuSE/15.0
|
||||
Priority : 99
|
||||
```
|
||||
|
||||
你也能用相似的手段来删除软件仓库:
|
||||
|
||||
```
|
||||
suse:~ # zypper removerepo vlc
|
||||
Removing repository 'vlc' ...................................[done]
|
||||
Repository 'vlc' has been removed.
|
||||
```
|
||||
|
||||
使用 `zypper repos` 命令来查看当前系统上的软件仓库的状态:
|
||||
|
||||
```
|
||||
suse:~ # zypper repos
|
||||
Repository priorities are without effect. All enabled repositories share the same priority.
|
||||
|
||||
# | Alias | Name | Enabled | GPG Check | Refresh
|
||||
---|---------------------------|-----------------------------------------|---------|-----------|--------
|
||||
1 | repo-debug | openSUSE-Leap-15.0-Debug | No | ---- | ----
|
||||
2 | repo-debug-non-oss | openSUSE-Leap-15.0-Debug-Non-Oss | No | ---- | ----
|
||||
3 | repo-debug-update | openSUSE-Leap-15.0-Update-Debug | No | ---- | ----
|
||||
4 | repo-debug-update-non-oss | openSUSE-Leap-15.0-Update-Debug-Non-Oss | No | ---- | ----
|
||||
5 | repo-non-oss | openSUSE-Leap-15.0-Non-Oss | Yes | ( p) Yes | Yes
|
||||
6 | repo-oss | openSUSE-Leap-15.0-Oss | Yes | ( p) Yes | Yes
|
||||
```
|
||||
|
||||
`zypper` 甚至还有和 YUM 相同的功能:搜索包含文件或二进制的包。和 YUM 有所不同的是,它在命令行里使用破折号(但是这个搜索方法现在被废除了……)
|
||||
|
||||
```
|
||||
localhost:~ # zypper what-provides kate
|
||||
Command 'what-provides' is replaced by 'search --provides --match-exact'.
|
||||
See 'help search' for all available options.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
S | Name | Summary | Type
|
||||
---|------|----------------------|------------
|
||||
i+ | Kate | Advanced Text Editor | application
|
||||
i | kate | Advanced Text Editor | package
|
||||
```
|
||||
|
||||
YUM、DNF 和 Zypper 三剑客拥有的功能比在这篇小文里讨论的要多得多,请查看官方文档来得到更深入的信息。
|
||||
|
||||
#### 基于 Debian 的包管理器
|
||||
|
||||
作为一个现今仍在被积极维护的最古老的 Linux 发行版之一,Debian 的包管理系统和基于 RPM 的系统的包管理系统非常类似。它使用扩展名为 “.deb” 的包,这种文件能被一个叫做 `dpkg` 的工具所管理。`dpgk` 同 `rpm` 非常相似,它被设计成用来管理在存在于本地(硬盘)的包。它不会去做包依赖关系解析(它会做依赖关系检查,不过仅此而已),而且在同远程软件仓库交互上也并无可靠的途径。为了提高用户体验并便于使用,Debian 项目开始了一个软件项目:Deity,最终这个代号被丢弃并改成了现在的 <ruby>[高级打包工具][15]<rt>Advanced Package Tool</rt></ruby>(APT)。
|
||||
|
||||
在 1998 年,APT 测试版本发布(甚至早于 1999 年的 Debian 2.1 发布),许多用户认为 APT 是基于 Debian 系统标配功能之一。APT 使用了和 RPM 一样的风格来管理仓库,不过和 YUM 使用单独的 .repo 文件不同,APT 曾经使用 `/etc/apt/sources.list` 文件来管理软件仓库,后来的变成也可以使用 `/etc/apt/sources.d` 目录来管理。如同基于 RPM 的系统一样,你也有很多很多选项配置来完成同样的事情。你可以编辑和创建前述的文件,或者使用图形界面来完成上述工作(如 Ubuntu 的“Software & Updates”),为了给所有的 Linux 发行版统一的待遇,笔者将会只介绍命令行的选项。
|
||||
要想不直接编辑文件内容而直接增加软件仓库的话,可以用如下命令:
|
||||
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-add-repository "deb http://APT.spideroak.com/ubuntu-spideroak-hardy/ release restricted"
|
||||
```
|
||||
|
||||
这个命令将会在 `/etc/apt/sources.list.d` 目录里创建一个 `spideroakone.list` 文件。显而易见,文件里的内容依赖于所添加的软件仓库,如果你想加一个<ruby>个人软件包存档<rt>Personal Package Archive</rt></ruby>(PPA)的话,你可以用如下的办法:
|
||||
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-add-repository ppa:gnome-desktop
|
||||
```
|
||||
|
||||
注意: Debian 原生并不支持本地 PPA 。
|
||||
|
||||
在添加了一个软件仓库后,需要通知基于 Debian 的系统有一个新的仓库可以用来搜索包,可以运行 `apt-get update` 来完成:
|
||||
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get update
|
||||
Get:1 http://security.ubuntu.com/ubuntu xenial-security InRelease [107 kB]
|
||||
Hit:2 http://APT.spideroak.com/ubuntu-spideroak-hardy release InRelease
|
||||
Hit:3 http://ca.archive.ubuntu.com/ubuntu xenial InRelease
|
||||
Get:4 http://ca.archive.ubuntu.com/ubuntu xenial-updates InRelease [109 kB]
|
||||
Get:5 http://security.ubuntu.com/ubuntu xenial-security/main amd64 Packages [517 kB]
|
||||
Get:6 http://security.ubuntu.com/ubuntu xenial-security/main i386 Packages [455 kB]
|
||||
Get:7 http://security.ubuntu.com/ubuntu xenial-security/main Translation-en [221 kB]
|
||||
...
|
||||
|
||||
Fetched 6,399 kB in 3s (2,017 kB/s)
|
||||
Reading package lists... Done
|
||||
```
|
||||
|
||||
现在新的软件仓库已经在你的系统里安装并更新好了,你可以用 `apt-cache` 来搜索你想要的包了。
|
||||
|
||||
```
|
||||
user@ubuntu:~$ apt-cache search kate
|
||||
aterm-ml - Afterstep XVT - a VT102 emulator for the X window system
|
||||
frescobaldi - Qt4 LilyPond sheet music editor
|
||||
gitit - Wiki engine backed by a git or darcs filestore
|
||||
jedit - Plugin-based editor for programmers
|
||||
kate - powerful text editor
|
||||
kate-data - shared data files for Kate text editor
|
||||
kate-dbg - debugging symbols for Kate
|
||||
katepart - embeddable text editor component
|
||||
```
|
||||
|
||||
要安装 kate,简单的运行下面的命令:
|
||||
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get install kate
|
||||
```
|
||||
|
||||
要是删除一个包,使用 `apt-get remove`:
|
||||
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get remove kate
|
||||
```
|
||||
|
||||
要探索一个包的话,APT 并没有提供一个类似于 `yum whatprovides` 的功能,如果你想深入包内部去确定一个特定的文件的话,也有一些别的方法能帮你完成这个目标,
|
||||
|
||||
如: 用 `dpkg`
|
||||
|
||||
```
|
||||
user@ubuntu:~$ dpkg -S /bin/ls
|
||||
coreutils: /bin/ls
|
||||
```
|
||||
|
||||
或者: `apt-file`
|
||||
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get install apt-file -y
|
||||
user@ubuntu:~$ sudo apt-file update
|
||||
user@ubuntu:~$ apt-file search kate
|
||||
```
|
||||
|
||||
与 `yum whatprovides` 不同的是,`apt-file search` 的问题是因为自动添加了通配符搜索而输出过于详细(除非你知道确切的路径),最终在结果里包括了所有包含有 “kate” 的结果。
|
||||
|
||||
```
|
||||
kate: /usr/bin/kate
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katebacktracebrowserplugin.so
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katebuildplugin.so
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katecloseexceptplugin.so
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katectagsplugin.so
|
||||
```
|
||||
|
||||
上面这些例子大部分都使用了 `apt-get`。请注意现今大多数的 Ubuntu 教程里都径直使用了 `apt`。 单独一个 `apt` 设计用来实现那些最常用的 APT 命令的。`apt` 命令看上去是用来整合那些被分散在 `apt-get`、`apt-cache` 以及其它一些命令的的功能的。它还加上了一些额外的改进,如色彩、进度条以及其它一些小功能。上述的常用命令都能被 `apt` 替代,但是并不是所有的基于 Debian 的系统都能使用 `apt` 接受安全包补丁的,你有可能要安装额外的包的实现上述功能。
|
||||
|
||||
#### 基于 Arch 的包管理器
|
||||
|
||||
[Arch Linux][16] 使用称为 [packman][17] 的包管理器。和 .deb 以及 .rpm 不同,它使用更为传统的 LZMA2 压缩包形式 .tar.xz 。这可以使 Arch Linux 包能够比其它形式的压缩包(如 gzip)有更小的尺寸。自从 2002 年首次发布以来, `pacman` 一直在稳定发布和改善。使用它最大的好处之一是它支持 [Arch Build System][18],这是一个从源代码级别构建包的构建系统。该构建系统借助一个叫 `PKGBUILD` 的文件,这个文件包含了如版本号、发布号、依赖等等的元数据,以及一个为编译遵守 Arch Linux 需求的包所需要的带有必要的编译选项的脚本。而编译的结果就是前文所提的被 `pacman` 所使用的 .tar.xz 的文件。
|
||||
|
||||
上述的这套系统技术上导致了 <ruby>[Arch 用户仓库][19]<rt>Arch User Respository</rt></ruby>(AUR)的产生,这是一个社区驱动的软件仓库,仓库里包括有 `PKGBUILD` 文件以及支持补丁或脚本。这给 Arch Linux 带了无穷无尽的软件资源。最为明显的好处是如果一个用户(或开发者)希望他开发的软件能被广大公众所使用,他不必通过官方途径去在主流软件仓库获得许可。而不利之处则是它必须将依赖社区的流程,类似于 [Docker Hub][20]、
|
||||
Canonical 的 Snap Packages(LCTT 译注: Canonical 是 Ubuntu 的发行公司),或者其它类似的机制。有很多特定于 AUR 的包管理器能被用来从 AUR 里的 `PGKBUILD` 文件下载、编译、安装,下面我们来仔细看看怎么做。
|
||||
|
||||
##### 使用 pacman 和官方软件仓库
|
||||
|
||||
Arch 的主要包管理器:`pacman`,使用标识位而不是像 `yum` 或 `apt` 一样使用命令词。例如,要搜索一个包,你要用 `pacman -Ss` 。和 Linux 上别的命令一样,你可以找到 pacman 的手册页和在线帮助。`pacman` 大多数的命令都使用了同步(`-S`)这个标识位。例如:
|
||||
|
||||
```
|
||||
user@arch ~ $ pacman -Ss kate
|
||||
|
||||
extra/kate 18.04.2-2 (kde-applications kdebase)
|
||||
Advanced Text Editor
|
||||
extra/libkate 0.4.1-6 [installed]
|
||||
A karaoke and text codec for embedding in ogg
|
||||
extra/libtiger 0.3.4-5 [installed]
|
||||
A rendering library for Kate streams using Pango and Cairo
|
||||
extra/ttf-cheapskate 2.0-12
|
||||
TTFonts collection from dustimo.com
|
||||
community/haskell-cheapskate 0.1.1-100
|
||||
Experimental markdown processor.
|
||||
```
|
||||
|
||||
Arch 也使用和别的包管理器类似的软件仓库。在上面的输出中,搜索结果前面有标明它是从哪个仓库里搜索到的(这里是 `extra/` 和 `community/`)。同 Red Hat 和 Debian 系统一样,Arch 依靠用户将软件仓库的信息加入到一个特定的文件里:`/etc/pacman.conf`。下面的例子非常接近一个仓库系统。笔者还打开了 `[multilib]` 仓库来支持 Steam:
|
||||
|
||||
```
|
||||
[options]
|
||||
Architecture = auto
|
||||
|
||||
Color
|
||||
CheckSpace
|
||||
|
||||
SigLevel = Required DatabaseOptional
|
||||
LocalFileSigLevel = Optional
|
||||
|
||||
[core]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
|
||||
[extra]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
|
||||
[community]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
|
||||
[multilib]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
```
|
||||
|
||||
你也可以在 `pacman.conf` 里指定具体的 URL。这个功能可以用来确保在某一时刻所有的包来自一个确定的地方,比如,如果一个安装包存在严重的功能缺陷并且很不幸它恰好还有几个包依赖,你能及时回滚到一个安全点,如果你已经在 `pacman.conf` 里加入了具体的 URL 的话,你就用用这个命令降级你的系统。
|
||||
|
||||
```
|
||||
[core]
|
||||
Server=https://archive.archlinux.org/repos/2017/12/22/$repo/os/$arch
|
||||
```
|
||||
|
||||
和 Debian 系统一样,Arch 并不会自动更新它的本地仓库。你可以用下面的命令来刷新包管理器的数据库:
|
||||
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Sy
|
||||
|
||||
:: Synchronizing package databases...
|
||||
core 130.2 KiB 851K/s 00:00 [##########################################################] 100%
|
||||
extra 1645.3 KiB 2.69M/s 00:01 [##########################################################] 100%
|
||||
community 4.5 MiB 2.27M/s 00:02 [##########################################################] 100%
|
||||
multilib is up to date
|
||||
```
|
||||
|
||||
你可以看到在上述的输出中,`pacman` 认为 multilib 包数据库是更新到最新状态的。如果你认为这个结果不正确的话,你可以强制运行刷新:`pacman -Syy`。如果你想升级你的整个系统的话(不包括从 AUR 安装的包),你可以运行 `pacman -Syu`:
|
||||
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Syu
|
||||
|
||||
:: Synchronizing package databases...
|
||||
core is up to date
|
||||
extra is up to date
|
||||
community is up to date
|
||||
multilib is up to date
|
||||
:: Starting full system upgrade...
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (45) ceph-13.2.0-2 ceph-libs-13.2.0-2 debootstrap-1.0.105-1 guile-2.2.4-1 harfbuzz-1.8.2-1 harfbuzz-icu-1.8.2-1 haskell-aeson-1.3.1.1-20
|
||||
haskell-attoparsec-0.13.2.2-24 haskell-tagged-0.8.6-1 imagemagick-7.0.8.4-1 lib32-harfbuzz-1.8.2-1 lib32-libgusb-0.3.0-1 lib32-systemd-239.0-1
|
||||
libgit2-1:0.27.2-1 libinput-1.11.2-1 libmagick-7.0.8.4-1 libmagick6-6.9.10.4-1 libopenshot-0.2.0-1 libopenshot-audio-0.1.6-1 libosinfo-1.2.0-1
|
||||
libxfce4util-4.13.2-1 minetest-0.4.17.1-1 minetest-common-0.4.17.1-1 mlt-6.10.0-1 mlt-python-bindings-6.10.0-1 ndctl-61.1-1 netctl-1.17-1
|
||||
nodejs-10.6.0-1
|
||||
|
||||
Total Download Size: 2.66 MiB
|
||||
Total Installed Size: 879.15 MiB
|
||||
Net Upgrade Size: -365.27 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
```
|
||||
|
||||
在前面提到的降级系统的情景中,你可以运行 `pacman -Syyuu` 来强行降级系统。你必须重视这一点:虽然在大多数情况下这不会引起问题,但是这种可能性还是存在,即降级一个包或几个包将会引起级联传播的失败并会将你的系统处于不一致的状态(LCTT 译注:即系统进入无法正常使用的状态),请务必小心!
|
||||
|
||||
运行 `pacman -S kate` 来安装一个包。
|
||||
|
||||
```
|
||||
user@arch ~ $ sudo pacman -S kate
|
||||
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (7) editorconfig-core-c-0.12.2-1 kactivities-5.47.0-1 kparts-5.47.0-1 ktexteditor-5.47.0-2 syntax-highlighting-5.47.0-1 threadweaver-5.47.0-1
|
||||
kate-18.04.2-2
|
||||
|
||||
Total Download Size: 10.94 MiB
|
||||
Total Installed Size: 38.91 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
```
|
||||
|
||||
你可以运行 `pacman -R kate` 来删除一个包。这将会只删除这个包自身而不会去删除它的依赖包。
|
||||
|
||||
```
|
||||
user@arch ~ $ sudo pacman -S kate
|
||||
|
||||
checking dependencies...
|
||||
|
||||
Packages (1) kate-18.04.2-2
|
||||
|
||||
Total Removed Size: 20.30 MiB
|
||||
|
||||
:: Do you want to remove these packages? [Y/n]
|
||||
```
|
||||
|
||||
如果你想删除没有被其它包依赖的包,你可以运行 `pacman -Rs`:
|
||||
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Rs kate
|
||||
|
||||
checking dependencies...
|
||||
|
||||
Packages (7) editorconfig-core-c-0.12.2-1 kactivities-5.47.0-1 kparts-5.47.0-1 ktexteditor-5.47.0-2 syntax-highlighting-5.47.0-1 threadweaver-5.47.0-1
|
||||
kate-18.04.2-2
|
||||
|
||||
Total Removed Size: 38.91 MiB
|
||||
|
||||
:: Do you want to remove these packages? [Y/n]
|
||||
```
|
||||
|
||||
在笔者看来,Pacman 是搜索一个指定实用程序中的包名的最齐全的工具。如上所示,YUM 和 APT 都依赖于“路径”去搜索到有用的结果,而 Pacman 则做了一些智能的猜测,它会去猜测你最有可能想搜索的包。
|
||||
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Fs updatedb
|
||||
core/mlocate 0.26.git.20170220-1
|
||||
usr/bin/updatedb
|
||||
|
||||
user@arch ~ $ sudo pacman -Fs kate
|
||||
extra/kate 18.04.2-2
|
||||
usr/bin/kate
|
||||
```
|
||||
|
||||
##### 使用 AUR
|
||||
|
||||
有很多流行的 AUR 包管理器助手。其中 `yaourt` 和 `pacaur` 颇为流行。不过,这两个项目已经被 [Arch Wiki][21] 列为“不继续开发以及有已知的问题未解决”。因为这个原因,这里直接讨论 `aurman`,除了会搜索 AUR 以及包含几个有帮助的(其实很危险)的选项之外,它的工作机制和 `pacman` 极其类似。从 AUR 安装一个包将会初始化包维护者的构建脚本。你将会被要求输入几次授权以便让程序继续进行下去(为了简短起见,笔者截断了输出)。
|
||||
|
||||
```
|
||||
aurman -S telegram-desktop-bin
|
||||
~~ initializing aurman...
|
||||
~~ the following packages are neither in known repos nor in the aur
|
||||
...
|
||||
~~ calculating solutions...
|
||||
|
||||
:: The following 1 package(s) are getting updated:
|
||||
aur/telegram-desktop-bin 1.3.0-1 -> 1.3.9-1
|
||||
|
||||
?? Do you want to continue? Y/n: Y
|
||||
|
||||
~~ looking for new pkgbuilds and fetching them...
|
||||
Cloning into 'telegram-desktop-bin'...
|
||||
|
||||
remote: Counting objects: 301, done.
|
||||
remote: Compressing objects: 100% (152/152), done.
|
||||
remote: Total 301 (delta 161), reused 286 (delta 147)
|
||||
Receiving objects: 100% (301/301), 76.17 KiB | 639.00 KiB/s, done.
|
||||
Resolving deltas: 100% (161/161), done.
|
||||
?? Do you want to see the changes of telegram-desktop-bin? N/y: N
|
||||
|
||||
[sudo] password for user:
|
||||
|
||||
...
|
||||
==> Leaving fakeroot environment.
|
||||
==> Finished making: telegram-desktop-bin 1.3.9-1 (Thu 05 Jul 2018 11:22:02 AM EDT)
|
||||
==> Cleaning up...
|
||||
loading packages...
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (1) telegram-desktop-bin-1.3.9-1
|
||||
|
||||
Total Installed Size: 88.81 MiB
|
||||
Net Upgrade Size: 5.33 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
```
|
||||
|
||||
依照你所安装的包的复杂性程度的高低,有时你将会被要求给出进一步的输入,为了避免这些反复的输入,`aurman` 允许你使用 `--noconfirm` 和 `--noedit` 选项。这相当于说“接受所有的预定设置,并相信包管理器不会干坏事”。**使用这两个选项时请务必小心!!**,虽然这些选项本身不太会破坏你的系统,你也不能盲目的接受他人的脚本程序。
|
||||
|
||||
### 总结
|
||||
|
||||
这篇文章当然只能触及包管理器的皮毛。还有很多别的包管理器笔者没有在这篇文章里谈及。有些 Linux 发布版,如 Ubuntu 或 Elementary OS,已经在图形版的包管理器的开发上有了长远的进展。
|
||||
|
||||
如果你对包管理器的更高级功能有进一步的兴趣,请在评论区留言,笔者很乐意进一步的写一写相关的文章。
|
||||
|
||||
### 附录
|
||||
|
||||
```
|
||||
# search for packages
|
||||
yum search <package>
|
||||
dnf search <package>
|
||||
zypper search <package>
|
||||
apt-cache search <package>
|
||||
apt search <package>
|
||||
pacman -Ss <package>
|
||||
|
||||
# install packages
|
||||
yum install <package>
|
||||
dnf install <package>
|
||||
zypper install <package>
|
||||
apt-get install <package>
|
||||
apt install <package>
|
||||
pacman -Ss <package>
|
||||
|
||||
# update package database, not required by yum, dnf and zypper
|
||||
apt-get update
|
||||
apt update
|
||||
pacman -Sy
|
||||
|
||||
# update all system packages
|
||||
yum update
|
||||
dnf update
|
||||
zypper update
|
||||
apt-get upgrade
|
||||
apt upgrade
|
||||
pacman -Su
|
||||
|
||||
# remove an installed package
|
||||
yum remove <package>
|
||||
dnf remove <package>
|
||||
apt-get remove <package>
|
||||
apt remove <package>
|
||||
pacman -R <package>
|
||||
pacman -Rs <package>
|
||||
|
||||
# search for the package name containing specific file or folder
|
||||
yum whatprovides *<binary>
|
||||
dnf whatprovides *<binary>
|
||||
zypper what-provides <binary>
|
||||
zypper search --provides <binary>
|
||||
apt-file search <binary>
|
||||
pacman -Sf <binary>
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/evolution-package-managers
|
||||
|
||||
作者:[Steve Ovens][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/stratusss
|
||||
[1]:https://en.wikipedia.org/wiki/Common_Vulnerabilities_and_Exposures
|
||||
[2]:https://en.wikipedia.org/wiki/Yum_(software)
|
||||
[3]:https://fedoraproject.org/wiki/DNF
|
||||
[4]:https://en.wikipedia.org/wiki/Rpm_(software)
|
||||
[5]:https://en.wikipedia.org/wiki/Yellow_Dog_Linux
|
||||
[6]:https://searchdatacenter.techtarget.com/definition/Yellowdog-Updater-Modified-YUM
|
||||
[7]:https://en.wikipedia.org/wiki/DNF_(software)
|
||||
[8]:https://en.opensuse.org/Portal:Zypper
|
||||
[9]:https://www.suse.com/
|
||||
[10]:https://www.opensuse.org/
|
||||
[11]:https://en.wikipedia.org/wiki/MeeGo
|
||||
[12]:https://sailfishos.org/
|
||||
[13]:https://www.tizen.org/
|
||||
[14]:https://en.wikipedia.org/wiki/YaST
|
||||
[15]:https://en.wikipedia.org/wiki/APT_(Debian)
|
||||
[16]:https://www.archlinux.org/
|
||||
[17]:https://wiki.archlinux.org/index.php/pacman
|
||||
[18]:https://wiki.archlinux.org/index.php/Arch_Build_System
|
||||
[19]:https://aur.archlinux.org/
|
||||
[20]:https://hub.docker.com/
|
||||
[21]:https://wiki.archlinux.org/index.php/AUR_helpers#Discontinued_or_problematic
|
||||
102
published/20180803 UNIX curiosities.md
Normal file
102
published/20180803 UNIX curiosities.md
Normal file
@ -0,0 +1,102 @@
|
||||
UNIX 的怪东西
|
||||
======
|
||||
|
||||
最近我在用我编写的各种工具做更多 UNIX 下的事情,我遇到了两个有趣的问题。这些都不是 “bug”,而是我没想到的行为。
|
||||
|
||||
### 线程安全的 printf
|
||||
|
||||
我有一个 C 程序从磁盘读取一些图像,进行一些处理,并将有关这些图像的输出写入 STDOUT。伪代码:
|
||||
|
||||
```
|
||||
for(imagefilename in images)
|
||||
{
|
||||
results = process(imagefilename);
|
||||
printf(results);
|
||||
}
|
||||
```
|
||||
|
||||
对于每个图像都是独立处理的,因此我自然希望将处理任务分配在各个 CPU 之间以加快速度。我通常使用 `fork()`,所以我写了这个:
|
||||
|
||||
```
|
||||
for(child in children)
|
||||
{
|
||||
pipe = create_pipe();
|
||||
worker(pipe);
|
||||
}
|
||||
|
||||
// main parent process
|
||||
for(imagefilename in images)
|
||||
{
|
||||
write(pipe[i_image % N_children], imagefilename)
|
||||
}
|
||||
|
||||
worker()
|
||||
{
|
||||
while(1)
|
||||
{
|
||||
imagefilename = read(pipe);
|
||||
results = process(imagefilename);
|
||||
printf(results);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这是正常的做法:我为 IPC 创建管道,并通过这些管道给子进程 worker 发送图像名。每个 worker _能够_通过另一组管道将其结果写回主进程,但这很痛苦,所以每个 worker 都直接写入共享 STDOUT。这工作正常,但正如人们所预料的那样,对 STDOUT 的写入发生冲突,因此各种图像的结果最终会混杂在一起。那很糟糕。我不想自己设置个锁,但幸运的是 GNU libc 为它提供了函数:[flockfile()][1]。我把它们放进去了……但是没有用!为什么?因为 `flockfile()` 最终因为 `fork()` 的写时复制行为而被限制在单个子进程中。即 `fork()`提供的额外安全性(与线程相比),这实际上最终破坏了锁。
|
||||
|
||||
我没有尝试使用其他锁机制(例如 pthread 互斥锁),但我可以想象它们会遇到类似的问题。我想保持简单,所以将输出发送回父输出是不可能的:这给程序员和运行程序的计算机制造了更多的工作。
|
||||
|
||||
解决方案:使用线程而不是 `fork()`。这有制造冗余管道的好的副作用。最终的伪代码:
|
||||
|
||||
```
|
||||
for(children)
|
||||
{
|
||||
pthread_create(worker, child_index);
|
||||
}
|
||||
for(children)
|
||||
{
|
||||
pthread_join(child);
|
||||
}
|
||||
|
||||
worker(child_index)
|
||||
{
|
||||
for(i_image = child_index; i_image < N_images; i_image += N_children)
|
||||
{
|
||||
results = process(images[i_image]);
|
||||
flockfile(stdout);
|
||||
printf(results);
|
||||
funlockfile(stdout);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这更简单,如预期的那样工作。我猜有时线程更好。
|
||||
|
||||
### 将部分读取的文件传递给子进程
|
||||
|
||||
对于各种 [vnlog][2] 工具,我需要实现这个操作序列:
|
||||
|
||||
1. 进程打开一个关闭 `O_CLOEXEC` 标志的文件
|
||||
2. 进程读取此文件的一部分(在 vnlog 的情况下直到图例的末尾)
|
||||
3. 进程调用 `exec()` 以调用另一个程序来处理已经打开的文件的其余部分
|
||||
|
||||
第二个程序可能需要命令行中的文件名而不是已打开的文件描述符,因为第二个程序可能自己调用 `open()`。如果我传递文件名,这个新程序将重新打开文件,然后从头开始读取文件,而不是从原始程序停止的位置开始读取。在我的程序上不可以这样做,因此将文件名传递给第二个程序是行不通的。
|
||||
|
||||
所以我真的需要以某种方式传递已经打开的文件描述符。我在使用 Linux(其他操作系统可能在这里表现不同),所以我理论上可以通过传递 `/dev/fd/N` 而不是文件名来实现。但事实证明这也不起作用。在 Linux上(再说一次,也许是特定于 Linux)对于普通文件 `/dev/fd/N` 是原始文件的符号链接。所以这最终做的是与传递文件名完全相同的事情。
|
||||
|
||||
但有一个临时方案!如果我们正在读取管道而不是文件,那么没有什么可以符号链接,并且 `/dev/fd/N` 最终将原始管道传递给第二个进程,然后程序正常工作。我可以通过将上面的 `open("filename")` 更改为 `popen("cat filename")` 之类的东西来伪装。呸!这真的是我们所能做到最好的吗?这在 BSD 上看上去会怎么样?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://notes.secretsauce.net/notes/2018/08/03_unix-curiosities.html
|
||||
|
||||
作者:[Dima Kogan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://notes.secretsauce.net/
|
||||
[1]:https://www.gnu.org/software/libc/manual/html_node/Streams-and-Threads.html
|
||||
[2]:http://www.github.com/dkogan/vnlog
|
||||
91
sources/talk/20180719 Finding Jobs in Software.md
Normal file
91
sources/talk/20180719 Finding Jobs in Software.md
Normal file
@ -0,0 +1,91 @@
|
||||
translating by lujun9972
|
||||
Finding Jobs in Software
|
||||
======
|
||||
|
||||
A [PDF of this article][1] is available.
|
||||
|
||||
I was back home in Lancaster last week, chatting with a [friend from grad school][2] who’s remained in academia, and naturally we got to talking about what advice he could give his computer science students to better prepare them for their probable future careers.
|
||||
|
||||
In some later follow-up emails we got to talking about how engineers find jobs. I’ve fielded this question about a dozen times over the last couple years, so I thought it was about time to crystallize it into a blog post for future linking.
|
||||
|
||||
Here are some strategies for finding jobs, ordered roughly from most to least useful:
|
||||
|
||||
### Friend-of-a-friend networking
|
||||
|
||||
Many of the best jobs never make it to the open market at all, and it’s all about who you know. This makes sense for employers, since good engineers are hard to find and a reliable reference can be invaluable.
|
||||
|
||||
In the case of my current job at Iterable, for example, a mutual colleague from thoughtbot (a previous employer) suggested that I should talk to Iterable’s VP of engineering, since he’d worked with both of us and thought we’d get along well. We did, and I liked the team, so I went through the interview process and took the job.
|
||||
|
||||
Like many companies, thoughtbot has an alumni Slack group with a `#job-board` channel. Those sorts of semi-formal corporate alumni networks can definitely be useful, but you’ll probably find yourself relying more on individual connections.
|
||||
|
||||
“Networking” isn’t a dirty word, and it’s not about handing out business cards at a hotel bar. It’s about getting to know people in a friendly and sincere way, being interested in them, and helping them out (by, say, writing a lengthy blog post about how their students might find jobs). I’m not the type to throw around words like karma, but if I were, I would.
|
||||
|
||||
Go to (and speak at!) [meetups][3], offer help and advice when you can, and keep in touch with friends and ex-colleagues. In a couple of years you’ll have a healthy network. Easy-peasy.
|
||||
|
||||
This strategy doesn’t usually work at the beginning of a career, of course, but new grads and students should know that it’s eventually how things happen.
|
||||
|
||||
### Applying directly to specific companies
|
||||
|
||||
I keep a text file of companies where I might want to work. As I come across companies that catch my eye, I add ‘em to the list. When I’m on the hunt for a new job I just consult my list.
|
||||
|
||||
Lots of things might convince me to add a company to the list. They might have an especially appealing mission or product, use some particular technology, or employ some specific people that I’d like to work with and learn from.
|
||||
|
||||
One shockingly good heuristic that identifies a great workplace is whether a company sponsors or organizes meetups, and specifically if they sponsor groups related to minorities in tech. Plenty of great companies don’t do that, and they still may be terrific, but if they do it’s an extremely good sign.
|
||||
|
||||
### Job boards
|
||||
|
||||
I generally don’t use job boards, myself, because I find networking and targeted applications to be more valuable.
|
||||
|
||||
The big sites like Indeed and Dice are rarely useful. While some genuinely great companies do cross-post jobs there, there are so many atrocious jobs mixed in that I don’t bother with them.
|
||||
|
||||
However, smaller and more targeted job boards can be really handy. Someone has created a job site for any given technology (language, framework, database, whatever). If you’re really interested in working with a specific tool or in a particular market niche, it might be worthwhile for you to track down the appropriate board.
|
||||
|
||||
Similarly, if you’re interested in remote work, there are a few boards that cater specifically to that. [We Work Remotely][4] is a prominent and reputable one.
|
||||
|
||||
The enormously popular tech news site [Hacker News][5] posts a monthly “Who’s Hiring?” thread ([an example][6]). HN focuses mainly on startups and is almost adorably obsessed with trends, tech-wise, so it’s a thoroughly biased sample, but it’s still a huge selection of relatively high-quality jobs. Browsing it can also give you an idea of what technologies are currently in vogue. Some folks have also built [sites that make it easier to filter][7] those listings.
|
||||
|
||||
### Recruiters
|
||||
|
||||
These are the folks that message you on LinkedIn. Recruiters fall into two categories: internal and external.
|
||||
|
||||
An internal recruiter is an employee of a specific company and hires engineers to work for that company. They’re almost invariably non-technical, but they often have a fairly clear idea of what technical skills they’re looking for. They have no idea who you are, or what your goals are, but they’re encouraged to find a good fit for the company and are generally harmless.
|
||||
|
||||
It’s normal to work with an internal recruiter as part of the application process at a software company, especially a larger one.
|
||||
|
||||
An external recruiter works independently or for an agency. They’re market makers; they have a stable of companies who have contracted with them to find employees, and they get a placement fee for every person that one of those companies hires. As such, they have incentives to make as many matches as possible as quickly as possible, and they rarely have to deal with the fallout if the match isn’t a good one.
|
||||
|
||||
In my experience they add nothing to the job search process and, at best, just gum up the works as unnecessary middlemen. Less reputable ones may edit your resume without your approval, forward it along to companies that you’d never want to work with, and otherwise mangle your reputation. I avoid them.
|
||||
|
||||
Helpful and ethical external recruiters are a bit like UFOs. I’m prepared to acknowledge that they might, possibly, exist, but I’ve never seen one myself or spoken directly with anyone who’s encountered one, and I’ve only heard about them through confusing and doubtful chains of testimonials (and such testimonials usually make me question the testifier more than my assumptions).
|
||||
|
||||
### University career services
|
||||
|
||||
I’ve never found these to be of any use. The software job market is extraordinarily specialized, and it’s virtually impossible for a career services employee (who needs to be able to place every sort of student in every sort of job) to be familiar with it.
|
||||
|
||||
A recruiter, whose purview is limited to the software world, will often try to estimate good matches by looking at resume keywords like “Python” or “natural language processing.” A university career services employee needs to rely on even more amorphous keywords like “software” or “programming.” It’s hard for a non-technical person to distinguish a job engineering compilers from one hooking up printers.
|
||||
|
||||
Exceptions exist, of course (MIT and Stanford, for example, have predictably excellent software-specific career services), but they’re thoroughly exceptional.
|
||||
|
||||
There are plenty of other ways to find jobs, of course (job fairs at good industrial conferences—like [PyCon][8] or [Strange Loop][9]—aren’t bad, for example, though I’ve never taken a job through one). But the avenues above are the most common ways that job-finding happens. Good luck!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://harryrschwartz.com/2018/07/19/finding-jobs-in-software.html
|
||||
|
||||
作者:[Harry R. Schwartz][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://harryrschwartz.com/
|
||||
[1]:https://harryrschwartz.com/assets/documents/articles/finding-jobs-in-software.pdf
|
||||
[2]:https://www.fandm.edu/ed-novak
|
||||
[3]:https://meetup.com
|
||||
[4]:https://weworkremotely.com
|
||||
[5]:https://news.ycombinator.com
|
||||
[6]:https://news.ycombinator.com/item?id=13764728
|
||||
[7]:https://www.hnhiring.com
|
||||
[8]:https://us.pycon.org
|
||||
[9]:https://thestrangeloop.com
|
||||
@ -0,0 +1,116 @@
|
||||
Debian Turns 25! Here are Some Interesting Facts About Debian Linux
|
||||
======
|
||||
One of the oldest Linux distribution still in development, Debian has just turned 25. Let’s have a look at some interesting facts about this awesome FOSS project.
|
||||
|
||||
### 10 Interesting facts about Debian Linux
|
||||
|
||||
![Interesting facts about Debian Linux][1]
|
||||
|
||||
The facts presented here have been collected from various sources available from the internet. They are true to my knowledge, but in case of any error, please remind me to update the article.
|
||||
|
||||
#### 1\. One of the oldest Linux distributions still under active development
|
||||
|
||||
[Debian project][2] was announced on 16th August 1993 by Ian Murdock, Debian Founder. Like Linux creator [Linus Torvalds][3], Ian was a college student when he announced Debian project.
|
||||
|
||||

|
||||
|
||||
#### 2\. Some people get tattoo while some name their project after their girlfriend’s name
|
||||
|
||||
The project was named by combining the name of Ian and his then-girlfriend Debra Lynn. Ian and Debra got married and had three children. Debra and Ian got divorced in 2008.
|
||||
|
||||
#### 3\. Ian Murdock: The Maverick behind the creation of Debian project
|
||||
|
||||
![Debian Founder Ian Murdock][4]
|
||||
Ian Murdock
|
||||
|
||||
[Ian Murdock][5] led the Debian project from August 1993 until March 1996. He shaped Debian into a community project based on the principals of Free Software. The [Debian Manifesto][6] and the [Debian Social Contract][7] are still governing the project.
|
||||
|
||||
He founded a commercial Linux company called [Progeny Linux Systems][8] and worked for a number of Linux related companies such as Sun Microsystems, Linux Foundation and Docker.
|
||||
|
||||
Sadly, [Ian committed suicide in December 2015][9]. His contribution to Debian is certainly invaluable.
|
||||
|
||||
#### 4\. Debian is a community project in the true sense
|
||||
|
||||
Debian is a community based project in true sense. No one ‘owns’ Debian. Debian is being developed by volunteers from all over the world. It is not a commercial project, backed by corporates like many other Linux distributions.
|
||||
|
||||
Debian Linux distribution is composed of Free Software only. It’s one of the few Linux distributions that is true to the spirit of [Free Software][10] and takes proud in being called a GNU/Linux distribution.
|
||||
|
||||
Debian has its non-profit organization called [Software in Public Interest][11] (SPI). Along with Debian, SPI supports many other open source projects financially.
|
||||
|
||||
#### 5\. Debian and its 3 branches
|
||||
|
||||
Debian has three branches or versions: Debian Stable, Debian Unstable (Sid) and Debian Testing.
|
||||
|
||||
Debian Stable, as the name suggests, is the stable branch that has all the software and packages well tested to give you a rock solid stable system. Since it takes time before a well-tested software lands in the stable branch, Debian Stable often contains older versions of programs and hence people joke that Debian Stable means stale.
|
||||
|
||||
[Debian Unstable][12] codenamed Sid is the version where all the development of Debian takes place. This is where the new packages first land or developed. After that, these changes are propagated to the testing version.
|
||||
|
||||
[Debian Testing][13] is the next release after the current stable release. If the current stable release is N, Debian testing would be the N+1 release. The packages from Debian Unstable are tested in this version. After all the new changes are well tested, Debian Testing is then ‘promoted’ as the new Stable version.
|
||||
|
||||
There is no strict release schedule for Debian.
|
||||
|
||||
#### 7\. There was no Debian 1.0 release
|
||||
|
||||
Debian 1.0 was never released. The CD vendor, InfoMagic, accidentally shipped a development release of Debian and entitled it 1.0 in 1996. To prevent confusion between the CD version and the actual Debian release, the Debian Project renamed its next release to “Debian 1.1”.
|
||||
|
||||
#### 8\. Debian releases are codenamed after Toy Story characters
|
||||
|
||||
![Toy Story Characters][14]
|
||||
|
||||
Debian releases are codenamed after the characters from Pixar’s hit animation movie series [Toy Story][15].
|
||||
|
||||
Debian 1.1 was the first release with a codename. It was named Buzz after the Toy Story character Buzz Lightyear.
|
||||
|
||||
It was in 1996 and [Bruce Perens][16] had taken over leadership of the Project from Ian Murdock. Bruce was working at Pixar at the time.
|
||||
|
||||
This trend continued and all the subsequent releases had codenamed after Toy Story characters. For example, the current stable release is Stretch while the upcoming release has been codenamed Buster.
|
||||
|
||||
The unstable Debian version is codenamed Sid. This character in Toy Story is a kid with emotional problems and he enjoys breaking toys. This is symbolic in the sense that Debian Unstable might break your system with untested packages.
|
||||
|
||||
#### 9\. Debian also has a BSD ditribution
|
||||
|
||||
Debian is not limited to Linux. Debian also has a distribution based on FreeBSD kernel. It is called [Debian GNU/kFreeBSD][17].
|
||||
|
||||
#### 10\. Google uses Debian
|
||||
|
||||
[Google uses Debian][18] as its in-house development platform. Earlier, Google used a customized version of Ubuntu as its development platform. Recently they opted for Debian based gLinux.
|
||||
|
||||
#### Happy 25th birthday Debian
|
||||
|
||||
![Happy 25th birthday Debian][19]
|
||||
|
||||
I hope you liked these little facts about Debian. Stuff like these are reasons why people love Debian.
|
||||
|
||||
I wish a very happy 25th birthday to Debian. Please continue to be awesome. Cheers :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/debian-facts/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/Interesting-facts-about-debian.jpeg
|
||||
[2]:https://www.debian.org
|
||||
[3]:https://itsfoss.com/linus-torvalds-facts/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/ian-murdock.jpg
|
||||
[5]:https://en.wikipedia.org/wiki/Ian_Murdock
|
||||
[6]:https://www.debian.org/doc/manuals/project-history/ap-manifesto.en.html
|
||||
[7]:https://www.debian.org/social_contract
|
||||
[8]:https://en.wikipedia.org/wiki/Progeny_Linux_Systems
|
||||
[9]:https://itsfoss.com/ian-murdock-dies-mysteriously/
|
||||
[10]:https://www.fsf.org/
|
||||
[11]:https://www.spi-inc.org/
|
||||
[12]:https://www.debian.org/releases/sid/
|
||||
[13]:https://www.debian.org/releases/testing/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/toy-story-characters.jpeg
|
||||
[15]:https://en.wikipedia.org/wiki/Toy_Story_(franchise)
|
||||
[16]:https://perens.com/about-bruce-perens/
|
||||
[17]:https://wiki.debian.org/Debian_GNU/kFreeBSD
|
||||
[18]:https://itsfoss.com/goobuntu-glinux-google/
|
||||
[19]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/happy-25th-birthday-Debian.jpeg
|
||||
@ -0,0 +1,71 @@
|
||||
Mixing software development roles produces great results
|
||||
======
|
||||
|
||||

|
||||
|
||||
Most open source communities don’t have a lot of formal roles. There are certainly people who help with sysadmin tasks, testing, writing documentation, and translating or developing code. But people in open source communities typically move among different roles, often fulfilling several at once.
|
||||
|
||||
In contrast, team members at most traditional companies have defined roles, working on documentation, support, QA, and in other areas.
|
||||
|
||||
Why do open source communities take a shared-role approach, and more importantly, how does this way of collaborating affect products and customers?
|
||||
|
||||
[Nextcloud][1] has adopted this community-style practice of mixing roles, and we see large benefits for our customers and our users.
|
||||
|
||||
### 1\. Better product testing
|
||||
|
||||
Testing is a difficult job, as any tester can tell you. You need to understand the products engineers develop, and you need to devise test plans, execute them, and return the results to the developers. When that process is done, the developer makes changes, and you repeat the process, going back-and-forth as many times as necessary until the job is done.
|
||||
|
||||
In a community, contributors typically feel responsible for the projects they develop, so they test and document them extensively before handing them to users. Users close to the project often help test, translate, and write documentation in collaboration with developers. This creates a much tighter, faster feedback loop, speeding up development and improving quality.
|
||||
|
||||
When developers continuously confront the results of their work, it encourages them to write in a way that minimizes testing and debugging. Automated testing is an important element in development, and the feedback loop ensures that it is done right: Developers are organically motivated to automate what should be automated—no more and no less. Sure, they might _want_ others to do more testing or test automation, but when testing is the right thing to do, they do it. Moreover, they review each others' code because they know that issues tend to come back bite them later.
|
||||
|
||||
So, while I won't argue that it's better to forgo dedicated testers, certainly in a project without community volunteers who test, testers should be developers and closely embedded in the development team. The result? Customers get a product that was tested and developed by people who are 100% motivated to ensure that it is stable and reliable.
|
||||
|
||||
### 2\. Close alignment between development and customer needs
|
||||
|
||||
It is extraordinarily difficult to align product development with customer needs. Every customer has their own unique needs, there are long- and short-term factors to consider—and of course, as a company, you have ideas on where you want to go. How do you integrate all these ideas and visions?
|
||||
|
||||
Companies typically create roles like product management, support, QA, and others, which are separate from engineering and product development. The idea behind this is that people do best when they specialize, and engineers shouldn't be bothered with "simple" tasks like testing or support.
|
||||
|
||||
In effect, this role separation is a cost-cutting measure. It enables management to micromanage and feel more in control as they can simply order product management, for example, to prioritize items on the roadmap. (It also creates more meetings!)
|
||||
|
||||
In communities, on the other hand, "those who do the work decide." Developers are often also users (or are paid by users), so they align with users’ needs naturally. When users help with testing (as described above), developers work with them constantly, so both sides fully understand what is possible and what is needed.
|
||||
|
||||
This open way of working closely aligns users and projects. Without management interference and overhead, users' most pressing needs can be quickly met because engineers already intimately understand them.
|
||||
|
||||
At Nextcloud, customers never need to explain things twice or rely on a junior support team member to accurately communicate issues to an engineer. Our engineers continuously calibrate their priorities based on real customer needs. Meanwhile, long-term goals are set collaboratively, based on a deep knowledge of our customers.
|
||||
|
||||
### 3\. The best support
|
||||
|
||||
Unlike proprietary or [open core][2] vendors, open source vendors have a powerful incentive to offer the best possible support: It is a key differentiator from other companies in their ecosystem.
|
||||
|
||||
Why is the driving force behind a project—think [Collabora][3] behind [LibreOffice][4], [The Qt Company][5] behind [Qt][6], or [Red Hat][7] behind [RHEL][8]—the best source of customer support?
|
||||
|
||||
Direct access to engineers, of course. Rather than walling off support from engineering, many of these companies offer customers access to engineers' expertise. This helps ensure that customers always get the best answers as quickly as possible. While some engineers may spend more time than others on support, the entire engineering team plays a role in customer success. Proprietary vendors might provide customers a dedicated on-site engineer for a considerable cost, for example, but an open source company like [OpenNMS][9] offers that same level of service in your support contract—even if you’re not a Fortune 500 customer.
|
||||
|
||||
There's another benefit, which relates back to testing and customer alignment: Sharing roles ensures that engineers deal with customer issues and wishes daily, which motivates them to fix the most common problems quickly. They also tend to build extra tools and features to save customers from asking.
|
||||
|
||||
Put simply, folding QA, support, product management, and other engineering roles into one team ensures that the three famous virtues of great developers—[laziness, impatience, and hubris][10]—closely align with customers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/mixing-roles-engineering
|
||||
|
||||
作者:[Jos Poortvliet][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jospoortvliet
|
||||
[1]:https://nextcloud.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Open_core
|
||||
[3]:https://www.collaboraoffice.com/
|
||||
[4]:https://www.libreoffice.org/
|
||||
[5]:https://www.qt.io/
|
||||
[6]:https://www.qt.io/developers/
|
||||
[7]:https://www.redhat.com/en
|
||||
[8]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[9]:https://www.opennms.org/en
|
||||
[10]:http://threevirtues.com/
|
||||
@ -0,0 +1,60 @@
|
||||
OERu makes a college education affordable
|
||||
======
|
||||
|
||||

|
||||
|
||||
Open, higher education courses are a boon to adults who don’t have the time, money, or confidence to enroll in traditional college courses but want to further their education for work or personal satisfaction. [OERu][1] is a great option for these learners. It allows people to take courses assembled by accredited colleges and universities for free, using open textbooks, and pay for assessment only when (and if) they want to apply for formal academic credit.
|
||||
|
||||
I spoke with [Dave Lane][2], open source technologist at the [Open Education Resource Foundation][3], which is OERu’s parent organization, to learn more about the program. The OER Foundation is a nonprofit organization hosted by [Otago Polytechnic][4] in Dunedin, New Zealand. It partners with organizations around the globe to provide leadership, networking, and support to help advance [open education principles][5].
|
||||
|
||||
OERu is one of the foundation's flagship projects. (The other is [WikiEducator][6], a community of educators collaboratively developing open source materials.) OERu was conceived in 2011, two years after the foundation’s launch, with representatives from educational institutions around the world.
|
||||
|
||||
Its network "is made up of tertiary educational institutions in five continents working together to democratize tertiary education and its availability for those who cannot afford (or cannot find a seat in) tertiary education," Dave says. Some of OERu’s educational partners include UTaz (Australia), Thompson River University (Canada), North-West University or National Open University (ZA and Nigeria in Africa, respectively), and the University of the Highlands and Islands (Scotland in the UK). Funding is provided by the [William and Flora Hewlett Foundation][7]. These institutions have worked out the complexity associated with transferring academic credits within the network and across the different educational cultures, accreditation boards, and educational review committees.
|
||||
|
||||
### How it works
|
||||
|
||||
The primary requirements for taking OERu courses are fluency in English (which is the primary teaching language) and having a computer with internet access. To start learning, peruse the [list of courses][8], click the title of the course you want to take, and click “Start Learning” to complete any registration details (different courses have different requirements).
|
||||
|
||||
Once you complete a course, you can take an assessment that may qualify you for college-level course credit. While there’s no cost to take a course, each partner institution charges fees for administering assessments—but they are far less expensive than traditional college tuition and fees.
|
||||
|
||||
In March 2018, OERu launched a [Certificate Higher Education Business][9] (CertHE), a one-year program that the organization calls its [first year of study][10], which is "equivalent to the first year of a bachelor's degree." CertHE “is an introductory level qualification in business and management studies which provides a general overview for a possible career in business across a wide range of sectors and industries.” Although CertHE assessment costs vary, it’s likely that the first full year of study will be US$ 2,500, a significant cost savings for students.
|
||||
|
||||
OERu is adding courses and looking for ways to expand the model to eventually offer full baccalaureate degrees and possibly even graduate degrees at much lower cost than a traditional degree program.
|
||||
|
||||
### Open source technologist's background
|
||||
|
||||
Dave didn’t set out to work in IT or live and work in New Zealand. He grew up in the United States and earned his master’s degree in mechanical engineering from the University of Washington. Fresh out of graduate school, he moved to New Zealand to take a position as a research scientist at a government-funded [Crown Research Institute][11] to improve the efficiency of the country’s forest industry.
|
||||
|
||||
IT and open technologies were important parts of getting his job done. "The image processing and photogrammetry software I developed … was built on Linux, entirely using open source math (C/C++) and interface libraries (Qt)," he says. "The source material for my advanced photogrammetric algorithms was US Geological Survey scientist papers from the 1950s-60s, all publicly available."
|
||||
|
||||
His frustration with the low quality of IT systems in the outlying offices led him to assume the role of "ad hoc IT manager" using "100% open source software," he says, which delighted his colleagues but frustrated the fulltime IT staff in the main office.
|
||||
|
||||
After four years of working for the government, he founded a company called Egressive to build Linux-based server systems for small businesses in the Christchurch area. Egressive became a successful small business IT provider, specializing in free and open source software, web development and hosting, systems integration, and outsourced sysadmin services. After selling the business, he joined the OER Foundation’s staff in 2015. In addition to working on the WikiEducator.org and OERu projects, he develops [open source collaboration][12] and teaching tools for the foundation.
|
||||
|
||||
If you're interested in learning more about the OER Foundation, OERu, open source technology, and Dave's work, take a look at [his blog][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/oeru-courses
|
||||
|
||||
作者:[João Trindade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.flickr.com/photos/joao_trindade/4362409183
|
||||
[1]:https://oeru.org/
|
||||
[2]:https://www.linkedin.com/in/davelanenz/
|
||||
[3]:http://wikieducator.org/OERF:Home
|
||||
[4]:https://www.op.ac.nz/
|
||||
[5]:https://oeru.org/how-it-works/
|
||||
[6]:http://wikieducator.org/
|
||||
[7]:https://hewlett.org/
|
||||
[8]:https://oeru.org/courses/
|
||||
[9]:https://oeru.org/certhe-business/
|
||||
[10]:https://oeru.org/qualifications/
|
||||
[11]:https://en.wikipedia.org/wiki/Crown_Research_Institute
|
||||
[12]:https://tech.oeru.org/many-simple-tools-loosely-coupled
|
||||
[13]:https://tech.oeru.org/blog/1
|
||||
@ -0,0 +1,623 @@
|
||||
A Word from The Beegoist – Richard Kenneth Eng – Medium
|
||||
======
|
||||
I like the [Go programming language][22]. I sought to use Go to write web applications. To this end, I examined two of the “full stack” web frameworks available to Go developers (aka “Gophers”): [Beego][23] and [Revel][24].
|
||||
|
||||
The reason I looked for full stack was because of my prior experience with [web2py][25], a Python-based framework with extraordinary capability that was also [deliciously easy to get started and be highly productive in][26]. (I also cut my teeth on Smalltalk-based [Seaside][27], which has the same qualities.) In my opinion, full stack is the only way to go because developers should not waste time and effort on the minutiae of tool configuration and setup. The focus should be almost entirely on writing your application.
|
||||
|
||||
Between Beego and Revel, I chose the former. It seemed to be more mature and better documented. It also had a built-in [ORM][28].
|
||||
|
||||
To be sure, Beego isn’t as easy and productive as web2py, but I believe in Go, so it is worth the effort to give Beego my best shot. To get started with Beego, I needed a project, a useful exercise that covered all the bases, such as database management, CSS styling, email capability, form validation, etc., and also provided a useful end product.
|
||||
|
||||
The project I selected was a user account management component for web applications. All of my previous applications required user registration/login, and Beego did not appear to have anything like that available.
|
||||
|
||||
Now that I’ve completed the project, I believe it would be an excellent foundation for a Beego tutorial. I do not pretend that the code is optimal, nor do I pretend that it is bug-free, but if there are any bugs, it would be a good exercise for a novice to resolve them.
|
||||
|
||||
The inspiration for this tutorial arose from my failure to find good, thorough tutorials when I first started learning Beego. There is one 2-part tutorial that is often mentioned, but I found Part 2 sorely lacking. Throwing source code at you for you to figure out on your own is no way to teach. Thus, I wanted to offer my take on a tutorial. Only history will determine whether it was successful.
|
||||
|
||||
So, without further ado, let’s begin. The word is “Go!”
|
||||
|
||||
### Basic Assumptions
|
||||
|
||||
You have some familiarity with the Go language. I highly recommend you follow this [Go tutorial][1].
|
||||
|
||||
You’ve installed [Go][2] and [Beego][3] on your computer. There are plenty of good online resources to help you here (for [example][4]). It’s really quite easy.
|
||||
|
||||
You have basic knowledge of CSS, HTML, and databases. You have at least one database package installed on your computer such as [MySQL][5] (Community Edition) or [SQLite][6]. I have SQLite because it’s much easier to use.
|
||||
|
||||
You have some experience writing software; basic skills are assumed. If you studied computer programming in school, then you’re off to a good start.
|
||||
|
||||
You will be using your favourite programming editor in conjunction with the command line. I use [LiteIDE][7] (on the Mac), but I can suggest alternatives such as [TextMate][8] for the Mac, [Notepad++][9] for Windows, and [vim][10] for Linux.
|
||||
|
||||
These basic assumptions define the target audience for the tutorial. If you’re a programming veteran, though, you’ll breeze through it and hopefully gain much useful knowledge, as well.
|
||||
|
||||
### Creating the Project
|
||||
|
||||
First, we must create a Beego project. We’ll call it ‘[ACME][11]’. From the command line, change directory (cd) to $GOPATH/src and enter:
|
||||
```
|
||||
$ bee new acme
|
||||
|
||||
```
|
||||
|
||||
The following directory structure will be created:
|
||||
```
|
||||
acme
|
||||
....conf
|
||||
....controllers
|
||||
....models
|
||||
....routers
|
||||
....static
|
||||
........css
|
||||
........img
|
||||
........js
|
||||
....tests
|
||||
....views
|
||||
|
||||
```
|
||||
|
||||
Note that Beego is a MVC framework (Model/View/Controller), which means that your application will be separated into three general sections. Model refers to the internal database structure of your application. View is all about how your application looks on the computer screen; in our case, this includes HTML and CSS code. And Controller is where you have your business logic and user interactions.
|
||||
|
||||
You can immediately compile and run your application by changing directory (cd acme) and typing:
|
||||
```
|
||||
$ bee run
|
||||
|
||||
```
|
||||
|
||||
In your browser, go to <http://localhost:8080> to see the running application. It doesn’t do anything fancy right now; it simply greets you. But upon this foundation, we shall raise an impressive edifice.
|
||||
|
||||
### The Source Code
|
||||
|
||||
To follow along, you may [download the source code][12] for this tutorial. Cd to $GOPATH/src and unzip the file. [When you download the source, the filename that Github uses is ‘acme-master’. You must change it to ‘acme’.]
|
||||
|
||||
### Program Design
|
||||
|
||||
The user account management component provides the following functionality:
|
||||
|
||||
1. User registration (account creation)
|
||||
2. Account verification (via email)
|
||||
3. Login (create a session)
|
||||
4. Logout (delete the session)
|
||||
5. User profile (can change name, email, or password)
|
||||
6. Remove user account
|
||||
|
||||
|
||||
|
||||
The essence of a web application is the mapping of URLs (webpages) to the server functions that will process the HTTP requests. This mapping is what generates the work flow in the application. In Beego, the mapping is defined within the ‘router’. Here’s the code for our router (look at router.go in the ‘routers’ directory):
|
||||
```
|
||||
beego.Router("/home", &controllers.MainController{})
|
||||
beego.Router("/user/login/:back", &controllers.MainController{}, "get,post:Login")
|
||||
beego.Router("/user/logout", &controllers.MainController{}, "get:Logout")
|
||||
beego.Router("/user/register", &controllers.MainController{}, "get,post:Register")
|
||||
beego.Router("/user/profile", &controllers.MainController{}, "get,post:Profile")
|
||||
beego.Router("/user/verify/:uuid({[0-9A-F]{8}-[0-9A-F]{4}-4[0-9A-F]{3}-[89AB][0-9A-F]{3}-[0-9A-F]{12}})", &controllers.MainController{}, "get:Verify")
|
||||
beego.Router("/user/remove", &controllers.MainController{}, "get,post:Remove")
|
||||
beego.Router("/notice", &controllers.MainController{}, "get:Notice")
|
||||
|
||||
```
|
||||
|
||||
For example, in the line for ‘login’, “get,post:Login” says that both the GET and POST operations are handled by the ‘Login’ function. The ‘:back’ is a request parameter; in this case, it tells us what page to return to after successful login.
|
||||
|
||||
In the line for ‘verify’, the ‘:uuid’ is a request parameter that must match the [regular expression][13] for a Version 4 UUID. The GET operation is handled by the ‘Verify’ function.
|
||||
|
||||
More on this when we talk about controllers.
|
||||
|
||||
Note that I’ve added ‘/home’ to the first line in the router (it was originally ‘/’). This makes it convenient to go to the home page, which we often do in our application.
|
||||
|
||||
### Model
|
||||
|
||||
The database model for a user account is represented by the following struct:
|
||||
```
|
||||
package models
|
||||
|
||||
```
|
||||
```
|
||||
import (
|
||||
"github.com/astaxie/beego/orm"
|
||||
"time"
|
||||
)
|
||||
|
||||
```
|
||||
```
|
||||
type AuthUser struct {
|
||||
Id int
|
||||
First string
|
||||
Last string
|
||||
Email string `orm:"unique"`
|
||||
Password string
|
||||
Reg_key string
|
||||
Reg_date time.Time `orm:"auto_now_add;type(datetime)"`
|
||||
}
|
||||
|
||||
```
|
||||
```
|
||||
func init() {
|
||||
orm.RegisterModel(new(AuthUser))
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Place this in models.go in the ‘models’ directory. Ignore the init() for the time being.
|
||||
|
||||
‘Id’ is the primary key which is auto-incremented in the database. We also have ‘First’ and ‘Last’ names. ‘Password’ contains the hexadecimal representation of the [PBKDF2 hash][14] of the plaintext password.
|
||||
|
||||
‘Reg_key’ contains the [UUID][15] string that is used for account verification (via email). ‘Reg_date’ is the timestamp indicating the time of registration.
|
||||
|
||||
The funny-looking string literals associated with both ‘Email’ and ‘Reg_date’ are used to tell the database the special requirements of these fields. ‘Email’ must be a unique key. ‘Reg_date’ will be automatically assigned the date and time of database insertion.
|
||||
|
||||
By the way, don’t be scared of the PBKDF2 and UUID references. PBKDF2 is simply a way to securely store a user’s password in the database. A UUID is a unique identifier that can be used to ensure the identity of the user for verification purposes.
|
||||
|
||||
### View
|
||||
|
||||
For our CSS template design, I’ve chosen the [Stardust][16] theme (pictured at the start of this article). We will use its index.html as a basis for the view layout.
|
||||
|
||||
Place the appropriate files from the Stardust theme into the ‘css’ and ‘img’ directories of ‘static’ directory. The link statement in the header of index.html must be amended to:
|
||||
```
|
||||
<link href="/static/css/default.css" rel="stylesheet" type="text/css" />
|
||||
|
||||
```
|
||||
|
||||
And all references to image gifs and jpegs in index.html and default.css must point to ‘/static/img/’.
|
||||
|
||||
The view layout contains a header section, a footer section, a sidebar section, and the central section where most of the action will take place. We will be using Go’s templating facility which allows us to replace embedded codes, signified by ‘{{‘ and ‘}}’, with actual HTML. Here’s our basic-layout.tpl (.tpl for ‘template’):
|
||||
```
|
||||
{{.Header}}
|
||||
{{.LayoutContent}}
|
||||
{{.Sidebar}}
|
||||
{{.Footer}}
|
||||
|
||||
```
|
||||
|
||||
Since every webpage in our application will need to adhere to this basic layout, we need a common method to set it up (look at default.go):
|
||||
```
|
||||
func (this *MainController) activeContent(view string) {
|
||||
this.Layout = "basic-layout.tpl"
|
||||
this.LayoutSections = make(map[string]string)
|
||||
this.LayoutSections["Header"] = "header.tpl"
|
||||
this.LayoutSections["Sidebar"] = "sidebar.tpl"
|
||||
this.LayoutSections["Footer"] = "footer.tpl"
|
||||
this.TplNames = view + ".tpl"
|
||||
|
||||
```
|
||||
```
|
||||
sess := this.GetSession("acme")
|
||||
if sess != nil {
|
||||
this.Data["InSession"] = 1 // for login bar in header.tpl
|
||||
m := sess.(map[string]interface{})
|
||||
this.Data["First"] = m["first"]
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The template parameters, such as ‘.Sidebar’, correspond to the keys used in the LayoutSections map. ‘.LayoutContent’ is a special, implicit template parameter. We’ll get to the GetSession stuff further below.
|
||||
|
||||
Of course, we need to create the various template files (such as footer.tpl) in the ‘views’ directory. From index.html, we can carve out the header section for header.tpl:
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
|
||||
<title>StarDust by Free Css Templates</title>
|
||||
<meta name="keywords" content="" />
|
||||
<meta name="description" content="" />
|
||||
<link href="/static/css/default.css" rel="stylesheet" type="text/css" />
|
||||
</head>
|
||||
|
||||
```
|
||||
```
|
||||
<body>
|
||||
<!-- start header -->
|
||||
<div id="header-bg">
|
||||
<div id="header">
|
||||
<div align="right">{{if .InSession}}
|
||||
Welcome, {{.First}} [<a href="http://localhost:8080/logout">Logout</a>|<a href="http://localhost:8080/profile">Profile</a>]
|
||||
{{else}}
|
||||
[<a href="http://localhost:8080/login/home">Login</a>]
|
||||
{{end}}
|
||||
</div>
|
||||
<div id="logo">
|
||||
<h1><a href="#">StarDust<sup></sup></a></h1>
|
||||
<h2>Designed by FreeCSSTemplates</h2>
|
||||
</div>
|
||||
<div id="menu">
|
||||
<ul>
|
||||
<li class="active"><a href="http://localhost:8080/home">home</a></li>
|
||||
<li><a href="#">photos</a></li>
|
||||
<li><a href="#">about</a></li>
|
||||
<li><a href="#">links</a></li>
|
||||
<li><a href="#">contact </a></li>
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<!-- end header -->
|
||||
<!-- start page -->
|
||||
<div id="page">
|
||||
|
||||
```
|
||||
|
||||
I leave it as an exercise for you to carve out the sections for sidebar.tpl and footer.tpl.
|
||||
|
||||
Note the lines in bold. I added them to facilitate a “login bar” at the top of every webpage. Once you’ve logged into the application, you will see the bar as so:
|
||||
|
||||
![][17]
|
||||
|
||||
This login bar works in conjunction with the GetSession code snippet we saw in activeContent(). The logic is, if the user is logged in (ie, there is a non-nil session), then we set the InSession parameter to a value (any value), which tells the templating engine to use the “Welcome” bar instead of “Login”. We also extract the user’s first name from the session so that we can present the friendly affectation “Welcome, Richard”.
|
||||
|
||||
The home page, represented by index.tpl, uses the following snippet from index.html:
|
||||
```
|
||||
<!-- start content -->
|
||||
<div id="content">
|
||||
<div class="post">
|
||||
<h1 class="title">Welcome to StarDust</h1>
|
||||
// to save space, I won't enter the remainder
|
||||
// of the snippet
|
||||
</div>
|
||||
<!-- end content -->
|
||||
|
||||
```
|
||||
|
||||
#### Special Note
|
||||
|
||||
The template files for the user module reside in the ‘user’ directory within ‘views’, just to keep things tidy. So, for example, the call to activeContent() for login is:
|
||||
```
|
||||
this.activeContent("user/login")
|
||||
|
||||
```
|
||||
|
||||
### Controller
|
||||
|
||||
A controller handles requests by handing them off to the appropriate function or ‘method’. We only have one controller for our application and it’s defined in default.go. The default method Get() for handling a GET operation is associated with our home page:
|
||||
```
|
||||
func (this *MainController) Get() {
|
||||
this.activeContent("index")
|
||||
|
||||
```
|
||||
```
|
||||
//bin //boot //dev //etc //home //lib //lib64 //media //mnt //opt //proc //root //run //sbin //speedup //srv //sys //tmp //usr //var This page requires login
|
||||
sess := this.GetSession("acme")
|
||||
if sess == nil {
|
||||
this.Redirect("/user/login/home", 302)
|
||||
return
|
||||
}
|
||||
m := sess.(map[string]interface{})
|
||||
fmt.Println("username is", m["username"])
|
||||
fmt.Println("logged in at", m["timestamp"])
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
I’ve made login a requirement for accessing this page. Logging in means creating a session, which by default expires after 3600 seconds of inactivity. A session is typically maintained on the client side by a ‘cookie’.
|
||||
|
||||
In order to support sessions in the application, the ‘SessionOn’ flag must be set to true. There are two ways to do this:
|
||||
|
||||
1. Insert ‘beego.SessionOn = true’ in the main program, main.go.
|
||||
2. Insert ‘sessionon = true’ in the configuration file, app.conf, which can be found in the ‘conf’ directory.
|
||||
|
||||
|
||||
|
||||
I chose #1. (But note that I used the configuration file to set ‘EnableAdmin’ to true: ‘enableadmin = true’. EnableAdmin allows you to use the Supervisor Module in Beego that keeps track of CPU, memory, Garbage Collector, threads, etc., via port 8088: <http://localhost:8088>.)
|
||||
|
||||
#### The Main Program
|
||||
|
||||
The main program is also where we initialize the database to be used with the ORM (Object Relational Mapping) component. ORM makes it more convenient to perform database activities within our application. The main program’s init():
|
||||
```
|
||||
func init() {
|
||||
orm.RegisterDriver("sqlite", orm.DR_Sqlite)
|
||||
orm.RegisterDataBase("default", "sqlite3", "acme.db")
|
||||
name := "default"
|
||||
force := false
|
||||
verbose := false
|
||||
err := orm.RunSyncdb(name, force, verbose)
|
||||
if err != nil {
|
||||
fmt.Println(err)
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To use SQLite, we must import ‘go-sqlite3', which can be installed with the command:
|
||||
```
|
||||
$ go get github.com/mattn/go-sqlite3
|
||||
|
||||
```
|
||||
|
||||
As you can see in the code snippet, the SQLite driver must be registered and ‘acme.db’ must be registered as our SQLite database.
|
||||
|
||||
Recall in models.go, there was an init() function:
|
||||
```
|
||||
func init() {
|
||||
orm.RegisterModel(new(AuthUser))
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The database model has to be registered so that the appropriate table can be generated. To ensure that this init() function is executed, you must import ‘models’ without actually using it within the main program, as follows:
|
||||
```
|
||||
import _ "acme/models"
|
||||
|
||||
```
|
||||
|
||||
RunSyncdb() is used to autogenerate the tables when you start the program. (This is very handy for creating the database tables without having to **manually** do it in the database command line utility.) If you set ‘force’ to true, it will drop any existing tables and recreate them.
|
||||
|
||||
#### The User Module
|
||||
|
||||
User.go contains all the methods for handling login, registration, profile, etc. There are several third-party packages we need to import; they provide support for email, PBKDF2, and UUID. But first we must get them into our project…
|
||||
```
|
||||
$ go get github.com/alexcesaro/mail/gomail
|
||||
$ go get github.com/twinj/uuid
|
||||
|
||||
```
|
||||
|
||||
I originally got **github.com/gokyle/pbkdf2** , but this package was pulled from Github, so you can no longer get it. I’ve incorporated this package into my source under the ‘utilities’ folder, and the import is:
|
||||
```
|
||||
import pk "acme/utilities/pbkdf2"
|
||||
|
||||
```
|
||||
|
||||
The ‘pk’ is a convenient alias so that I don’t have to type the rather unwieldy ‘pbkdf2'.
|
||||
|
||||
#### ORM
|
||||
|
||||
It’s pretty straightforward to use ORM. The basic pattern is to create an ORM object, specify the ‘default’ database, and select which ORM operation you want, eg,
|
||||
```
|
||||
o := orm.NewOrm()
|
||||
o.Using("default")
|
||||
err := o.Insert(&user) // or
|
||||
err := o.Read(&user, "Email") // or
|
||||
err := o.Update(&user) // or
|
||||
err := o.Delete(&user)
|
||||
|
||||
```
|
||||
|
||||
#### Flash
|
||||
|
||||
By the way, Beego provides a way to present notifications on your webpage through the use of ‘flash’. Basically, you create a ‘flash’ object, give it your notification message, store the flash in the controller, and then retrieve the message in the template file, eg,
|
||||
```
|
||||
flash := beego.NewFlash()
|
||||
flash.Error("You've goofed!") // or
|
||||
flash.Notice("Well done!")
|
||||
flash.Store(&this.Controller)
|
||||
|
||||
```
|
||||
|
||||
And in your template file, reference the Error flash with:
|
||||
```
|
||||
{{if .flash.error}}
|
||||
<h3>{{.flash.error}}</h3>
|
||||
|
||||
{{end}}
|
||||
|
||||
```
|
||||
|
||||
#### Form Validation
|
||||
|
||||
Once the user posts a request (by pressing the Submit button, for example), our handler must extract and validate the form input. So, first, check that we have a POST operation:
|
||||
```
|
||||
if this.Ctx.Input.Method() == "POST" {
|
||||
|
||||
```
|
||||
|
||||
Let’s get a form element, say, email:
|
||||
```
|
||||
email := this.GetString("email")
|
||||
|
||||
```
|
||||
|
||||
The string “email” is the same as in the HTML form:
|
||||
```
|
||||
<input name="email" type="text" />
|
||||
|
||||
```
|
||||
|
||||
To validate it, we create a validation object, specify the type of validation, and then check to see if there are any errors:
|
||||
```
|
||||
valid := validation.Validation{}
|
||||
valid.Email(email, "email") // must be a proper email address
|
||||
if valid.HasErrors() {
|
||||
for _, err := range valid.Errors {
|
||||
|
||||
```
|
||||
|
||||
What you do with the errors is up to you. I like to present all of them at once to the user, so as I go through the range of valid.Errors, I add them to a map of errors that will eventually be used in the template file. Hence, the full snippet:
|
||||
```
|
||||
if this.Ctx.Input.Method() == "POST" {
|
||||
email := this.GetString("email")
|
||||
password := this.GetString("password")
|
||||
valid := validation.Validation{}
|
||||
valid.Email(email, "email")
|
||||
valid.Required(password, "password")
|
||||
if valid.HasErrors() {
|
||||
errormap := []string{}
|
||||
for _, err := range valid.Errors {
|
||||
errormap = append(errormap, "Validation failed on "+err.Key+": "+err.Message+"\n")
|
||||
}
|
||||
this.Data["Errors"] = errormap
|
||||
return
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### The User Management Methods
|
||||
|
||||
We’ve looked at the major pieces of the controller. Now, we get to the meat of the application, the user management methods:
|
||||
|
||||
* Login()
|
||||
* Logout()
|
||||
* Register()
|
||||
* Verify()
|
||||
* Profile()
|
||||
* Remove()
|
||||
|
||||
|
||||
|
||||
Recall that we saw references to these functions in the router. The router associates each URL (and HTTP request) with the corresponding controller method.
|
||||
|
||||
#### Login()
|
||||
|
||||
Let’s look at the pseudocode for this method:
|
||||
```
|
||||
if the HTTP request is "POST" then
|
||||
Validate the form (extract the email address and password).
|
||||
Read the password hash from the database, keying on email.
|
||||
Compare the submitted password with the one on record.
|
||||
Create a session for this user.
|
||||
endif
|
||||
|
||||
```
|
||||
|
||||
In order to compare passwords, we need to give pk.MatchPassword() a variable with members ‘Hash’ and ‘Salt’ that are **byte slices**. Hence,
|
||||
```
|
||||
var x pk.PasswordHash
|
||||
|
||||
```
|
||||
```
|
||||
x.Hash = make([]byte, 32)
|
||||
x.Salt = make([]byte, 16)
|
||||
// after x has the password from the database, then...
|
||||
|
||||
```
|
||||
```
|
||||
if !pk.MatchPassword(password, &x) {
|
||||
flash.Error("Bad password")
|
||||
flash.Store(&this.Controller)
|
||||
return
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Creating a session is trivial, but we want to store some useful information in the session, as well. So we make a map and store first name, email address, and the time of login:
|
||||
```
|
||||
m := make(map[string]interface{})
|
||||
m["first"] = user.First
|
||||
m["username"] = email
|
||||
m["timestamp"] = time.Now()
|
||||
this.SetSession("acme", m)
|
||||
this.Redirect("/"+back, 302) // go to previous page after login
|
||||
|
||||
```
|
||||
|
||||
Incidentally, the name “acme” passed to SetSession is completely arbitrary; you just need to reference the same name to get the same session.
|
||||
|
||||
#### Logout()
|
||||
|
||||
This one is trivially easy. We delete the session and redirect to the home page.
|
||||
|
||||
#### Register()
|
||||
```
|
||||
if the HTTP request is "POST" then
|
||||
Validate the form.
|
||||
Create the password hash for the submitted password.
|
||||
Prepare new user record.
|
||||
Convert the password hash to hexadecimal string.
|
||||
Generate a UUID and insert the user into database.
|
||||
Send a verification email.
|
||||
Flash a message on the notification page.
|
||||
endif
|
||||
|
||||
```
|
||||
|
||||
To send a verification email to the user, we use **gomail** …
|
||||
```
|
||||
link := "http://localhost:8080/user/verify/" + u // u is UUID
|
||||
host := "smtp.gmail.com"
|
||||
port := 587
|
||||
msg := gomail.NewMessage()
|
||||
msg.SetAddressHeader("From", "acmecorp@gmail.com", "ACME Corporation")
|
||||
msg.SetHeader("To", email)
|
||||
msg.SetHeader("Subject", "Account Verification for ACME Corporation")
|
||||
msg.SetBody("text/html", "To verify your account, please click on the link: <a href=\""+link+"\">"+link+"</a><br><br>Best Regards,<br>ACME Corporation")
|
||||
m := gomail.NewMailer(host, "youraccount@gmail.com", "YourPassword", port)
|
||||
if err := m.Send(msg); err != nil {
|
||||
return false
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
I chose Gmail as my email relay (you will need to open your own account). Note that Gmail ignores the “From” address (in our case, “[acmecorp@gmail.com][18]”) because Gmail does not permit you to alter the sender address in order to prevent phishing.
|
||||
|
||||
#### Notice()
|
||||
|
||||
This special router method is for displaying a flash message on a notification page. It’s not really a user module function; it’s general enough that you can use it in many other places.
|
||||
|
||||
#### Profile()
|
||||
|
||||
We’ve already discussed all the pieces in this function. The pseudocode is:
|
||||
```
|
||||
Login required; check for a session.
|
||||
Get user record from database, keyed on email (or username).
|
||||
if the HTTP request is "POST" then
|
||||
Validate the form.
|
||||
if there is a new password then
|
||||
Validate the new password.
|
||||
Create the password hash for the new password.
|
||||
Convert the password hash to hexadecimal string.
|
||||
endif
|
||||
Compare submitted current password with the one on record.
|
||||
Update the user record.
|
||||
- update the username stored in session
|
||||
endif
|
||||
|
||||
```
|
||||
|
||||
#### Verify()
|
||||
|
||||
The verification email contains a link which, when clicked by the recipient, causes Verify() to process the UUID. Verify() attempts to read the user record, keyed on the UUID or registration key, and if it’s found, then the registration key is removed from the database.
|
||||
|
||||
#### Remove()
|
||||
|
||||
Remove() is pretty much like Login(), except that instead of creating a session, you delete the user record from the database.
|
||||
|
||||
### Exercise
|
||||
|
||||
I left out one user management method: What if the user has forgotten his password? We should provide a way to reset the password. I leave this as an exercise for you. All the pieces you need are in this tutorial. (Hint: You’ll need to do it in a way similar to Registration verification. You should add a new Reset_key to the AuthUser table. And make sure the user email address exists in the database before you send the Reset email!)
|
||||
|
||||
[Okay, so I’ll give you the [exercise solution][19]. I’m not cruel.]
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Let’s review what we’ve learned. We covered the mapping of URLs to request handlers in the router. We showed how to incorporate a CSS template design into our views. We discussed the ORM package, and how it’s used to perform database operations. We examined a number of third-party utilities useful in writing our application. The end result is a component useful in many scenarios.
|
||||
|
||||
This is a great deal of material in a tutorial, but I believe it’s the best way to get started in writing a practical application.
|
||||
|
||||
[For further material, look at the [sequel][20] to this article, as well as the [final edition][21].]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@richardeng/a-word-from-the-beegoist-d562ff8589d7
|
||||
|
||||
作者:[Richard Kenneth Eng][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@richardeng?source=post_header_lockup
|
||||
[1]:http://tour.golang.org/
|
||||
[2]:http://golang.org/
|
||||
[3]:http://beego.me/
|
||||
[4]:https://medium.com/@richardeng/in-the-beginning-61c7e63a3ea6
|
||||
[5]:http://www.mysql.com/
|
||||
[6]:http://www.sqlite.org/
|
||||
[7]:https://code.google.com/p/liteide/
|
||||
[8]:http://macromates.com/
|
||||
[9]:http://notepad-plus-plus.org/
|
||||
[10]:https://medium.com/@richardeng/back-to-the-future-9db24d6bcee1
|
||||
[11]:http://en.wikipedia.org/wiki/Acme_Corporation
|
||||
[12]:https://github.com/horrido/acme
|
||||
[13]:http://en.wikipedia.org/wiki/Regular_expression
|
||||
[14]:http://en.wikipedia.org/wiki/PBKDF2
|
||||
[15]:http://en.wikipedia.org/wiki/Universally_unique_identifier
|
||||
[16]:http://www.freewebtemplates.com/download/free-website-template/stardust-141989295/
|
||||
[17]:https://cdn-images-1.medium.com/max/1600/1*1OpYy1ISYGUaBy0U_RJ75w.png
|
||||
[18]:mailto:acmecorp@gmail.com
|
||||
[19]:https://github.com/horrido/acme-exercise
|
||||
[20]:https://medium.com/@richardeng/a-word-from-the-beegoist-ii-9561351698eb
|
||||
[21]:https://medium.com/@richardeng/a-word-from-the-beegoist-iii-dbd6308b2594
|
||||
[22]: http://golang.org/
|
||||
[23]: http://beego.me/
|
||||
[24]: http://revel.github.io/
|
||||
[25]: http://www.web2py.com/
|
||||
[26]: https://medium.com/@richardeng/the-zen-of-web2py-ede59769d084
|
||||
[27]: http://www.seaside.st/
|
||||
[28]: http://en.wikipedia.org/wiki/Object-relational_mapping
|
||||
@ -1,157 +0,0 @@
|
||||
icecoobe translating
|
||||
|
||||
How To Check System Hardware Manufacturer, Model And Serial Number In Linux
|
||||
======
|
||||
Getting system hardware information is not a problem for Linux GUI and Windows users but CLI users facing trouble to get this details.
|
||||
|
||||
Even most of us don’t know what is the best command to get this. There are many utilities available in Linux to get system hardware information such as
|
||||
|
||||
System Hardware Manufacturer, Model And Serial Number.
|
||||
|
||||
We are trying to write possible ways to get this details but you can choose the best method for you.
|
||||
|
||||
It is mandatory to know all these information because it will be needed when you raise a case with hardware vendor for any kind of hardware issues.
|
||||
|
||||
This can be achieved in six methods, let me show you how to do that.
|
||||
|
||||
### Method-1 : Using Dmidecode Command
|
||||
|
||||
Dmidecode is a tool which reads a computer’s DMI (stands for Desktop Management Interface) (some say SMBIOS – stands for System Management BIOS) table contents and display system hardware information in a human-readable format.
|
||||
|
||||
This table contains a description of the system’s hardware components, as well as other useful information such as serial number, Manufacturer information, Release Date, and BIOS revision, etc,.,
|
||||
|
||||
The DMI table doesn’t only describe what the system is currently made of, it also can report the possible evolution (such as the fastest supported CPU or the maximal amount of memory supported).
|
||||
|
||||
This will help you to analyze your hardware capability like whether it’s support latest application version or not?
|
||||
```
|
||||
# dmidecode -t system
|
||||
|
||||
# dmidecode 2.12
|
||||
# SMBIOS entry point at 0x7e7bf000
|
||||
SMBIOS 2.7 present.
|
||||
|
||||
Handle 0x0024, DMI type 1, 27 bytes
|
||||
System Information
|
||||
Manufacturer: IBM
|
||||
Product Name: System x2530 M4: -[1214AC1]-
|
||||
Version: 0B
|
||||
Serial Number: MK2RL11
|
||||
UUID: 762A99BF-6916-450F-80A6-B2E9E78FC9A1
|
||||
Wake-up Type: Power Switch
|
||||
SKU Number: Not Specified
|
||||
Family: System X
|
||||
|
||||
Handle 0x004B, DMI type 12, 5 bytes
|
||||
System Configuration Options
|
||||
Option 1: JP20 pin1-2: TPM PP Disable, pin2-3: TPM PP Enable
|
||||
|
||||
Handle 0x004D, DMI type 32, 20 bytes
|
||||
System Boot Information
|
||||
Status: No errors detected
|
||||
|
||||
```
|
||||
|
||||
**Suggested Read :** [Dmidecode – Easy Way To Get Linux System Hardware Information][1]
|
||||
|
||||
### Method-2 : Using inxi Command
|
||||
|
||||
inxi is a nifty tool to check hardware information on Linux and offers wide range of option to get all the hardware information on Linux system that i never found in any other utility which are available in Linux. It was forked from the ancient and mindbendingly perverse yet ingenius infobash, by locsmif.
|
||||
|
||||
inxi is a script that quickly shows system hardware, CPU, drivers, Xorg, Desktop, Kernel, GCC version(s), Processes, RAM usage, and a wide variety of other useful information, also used for forum technical support & debugging tool.
|
||||
```
|
||||
# inxi -M
|
||||
Machine: Device: server System: IBM product: N/A v: 0B serial: MK2RL11
|
||||
Mobo: IBM model: 00Y8494 serial: 37M17D UEFI: IBM v: -[VVE134MUS-1.50]- date: 08/30/2013
|
||||
|
||||
```
|
||||
|
||||
**Suggested Read :** [inxi – A Great Tool to Check Hardware Information on Linux][2]
|
||||
|
||||
### Method-3 : Using lshw Command
|
||||
|
||||
lshw (stands for Hardware Lister) is a small nifty tool that generates detailed reports about various hardware components on the machine such as memory configuration, firmware version, mainboard configuration, CPU version and speed, cache configuration, usb, network card, graphics cards, multimedia, printers, bus speed, etc.
|
||||
|
||||
It’s generating hardware information by reading varies files under /proc directory and DMI table.
|
||||
|
||||
lshw must be run as super user to detect the maximum amount of information or it will only report partial information. Special option is available in lshw called class which will shows specific given hardware information in detailed manner.
|
||||
```
|
||||
# lshw -C system
|
||||
enal-dbo01t
|
||||
description: Blade
|
||||
product: System x2530 M4: -[1214AC1]-
|
||||
vendor: IBM
|
||||
version: 0B
|
||||
serial: MK2RL11
|
||||
width: 64 bits
|
||||
capabilities: smbios-2.7 dmi-2.7 vsyscall32
|
||||
configuration: boot=normal chassis=enclosure family=System X uuid=762A99BF-6916-450F-80A6-B2E9E78FC9A1
|
||||
|
||||
```
|
||||
|
||||
**Suggested Read :** [LSHW (Hardware Lister) – A Nifty Tool To Get A Hardware Information On Linux][3]
|
||||
|
||||
### Method-4 : Using /sys file system
|
||||
|
||||
The kernel expose some DMI information in the /sys virtual filesystem. So we can easily get the machine type by running grep command with following format.
|
||||
```
|
||||
# grep "" /sys/class/dmi/id/[pbs]*
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can print only specific details by using cat command.
|
||||
```
|
||||
# cat /sys/class/dmi/id/board_vendor
|
||||
IBM
|
||||
|
||||
# cat /sys/class/dmi/id/product_name
|
||||
System x2530 M4: -[1214AC1]-
|
||||
|
||||
# cat /sys/class/dmi/id/product_serial
|
||||
MK2RL11
|
||||
|
||||
# cat /sys/class/dmi/id/bios_version
|
||||
-[VVE134MUS-1.50]-
|
||||
|
||||
```
|
||||
|
||||
### Method-5 : Using dmesg Command
|
||||
|
||||
The dmesg command is used to write the kernel messages (boot-time messages) in Linux before syslogd or klogd start. It obtains its data by reading the kernel ring buffer. dmesg can be very useful when troubleshooting or just trying to obtain information about the hardware on a system.
|
||||
```
|
||||
# dmesg | grep -i DMI
|
||||
DMI: System x2530 M4: -[1214AC1]-/00Y8494, BIOS -[VVE134MUS-1.50]- 08/30/2013
|
||||
|
||||
```
|
||||
|
||||
### Method-6 : Using hwinfo Command
|
||||
|
||||
hwinfo stands for hardware information tool is another great utility that used to probe for the hardware present in the system and display detailed information about varies hardware components in human readable format.
|
||||
|
||||
It reports information about CPU, RAM, keyboard, mouse, graphics card, sound, storage, network interface, disk, partition, bios, and bridge, etc,., This tool could display more detailed information among others like lshw, dmidecode, inxi, etc,.
|
||||
|
||||
hwinfo uses libhd library libhd.so to gather hardware information on the system. This tool especially designed for openSUSE system, later other distributions are included the tool into their official repository.
|
||||
```
|
||||
# hwinfo | egrep "system.hardware.vendor|system.hardware.product"
|
||||
system.hardware.vendor = 'IBM'
|
||||
system.hardware.product = 'System x2530 M4: -[1214AC1]-'
|
||||
|
||||
```
|
||||
|
||||
**Suggested Read :** [hwinfo (Hardware Info) – A Nifty Tool To Detect System Hardware Information On Linux][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-system-hardware-manufacturer-model-and-serial-number-in-linux/
|
||||
|
||||
作者:[VINOTH KUMAR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/vinoth/
|
||||
[1]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[2]:https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
[3]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[4]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
@ -1,285 +0,0 @@
|
||||
pinewall is translating
|
||||
|
||||
Anatomy of a Linux DNS Lookup – Part I
|
||||
============================================================
|
||||
|
||||
Since I [work][3] [a][4] [lot][5] [with][6] [clustered][7] [VMs][8], I’ve ended up spending a lot of time trying to figure out how [DNS lookups][9] work. I applied ‘fixes’ to my problems from StackOverflow without really understanding why they work (or don’t work) for some time.
|
||||
|
||||
Eventually I got fed up with this and decided to figure out how it all hangs together. I couldn’t find a complete guide for this anywhere online, and talking to colleagues they didn’t know of any (or really what happens in detail)
|
||||
|
||||
So I’m writing the guide myself.
|
||||
|
||||
_If you’re looking for Part II, click [here][1]_
|
||||
|
||||
Turns out there’s quite a bit in the phrase ‘Linux does a DNS lookup’…
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_“How hard can it be?”_
|
||||
|
||||
* * *
|
||||
|
||||
These posts are intended to break down how a program decides how it gets an IP address on a Linux host, and the components that can get involved. Without understanding how these pieces fit together, debugging and fixing problems with (for example) `dnsmasq`, `vagrant landrush`, or `resolvconf` can be utterly bewildering.
|
||||
|
||||
It’s also a valuable illustration of how something so simple can get so very complex over time. I’ve looked at over a dozen different technologies and their archaeologies so far while trying to grok what’s going on.
|
||||
|
||||
I even wrote some [automation code][10] to allow me to experiment in a VM. Contributions/corrections are welcome.
|
||||
|
||||
Note that this is not a post on ‘how DNS works’. This is about everything up to the call to the actual DNS server that’s configured on a linux host (assuming it even calls a DNS server – as you’ll see, it need not), and how it might find out which one to go to, or how it gets the IP some other way.
|
||||
|
||||
* * *
|
||||
|
||||
### 1) There is no such thing as a ‘DNS Lookup’ call
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_This is NOT how it works_
|
||||
|
||||
* * *
|
||||
|
||||
The first thing to grasp is that there is no single method of getting a DNS lookup done on Linux. It’s not a core system call with a clean interface.
|
||||
|
||||
There is, however, a standard C library call called which many programs use: `[getaddrinfo][2]`. But not all applications use this!
|
||||
|
||||
Let’s just take two simple standard programs: `ping` and `host`:
|
||||
|
||||
```
|
||||
root@linuxdns1:~# ping -c1 bbc.co.uk | head -1
|
||||
PING bbc.co.uk (151.101.192.81) 56(84) bytes of data.
|
||||
```
|
||||
|
||||
```
|
||||
root@linuxdns1:~# host bbc.co.uk | head -1
|
||||
bbc.co.uk has address 151.101.192.81
|
||||
```
|
||||
|
||||
They both get the same result, so they must be doing the same thing, right?
|
||||
|
||||
Wrong.
|
||||
|
||||
Here’s the files that `ping` looks at on my host that are relevant to DNS:
|
||||
|
||||
```
|
||||
root@linuxdns1:~# strace -e trace=open -f ping -c1 google.com
|
||||
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
|
||||
open("/lib/x86_64-linux-gnu/libcap.so.2", O_RDONLY|O_CLOEXEC) = 3
|
||||
open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
|
||||
open("/etc/resolv.conf", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/resolv.conf", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/lib/x86_64-linux-gnu/libnss_files.so.2", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/host.conf", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/lib/x86_64-linux-gnu/libnss_dns.so.2", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/lib/x86_64-linux-gnu/libresolv.so.2", O_RDONLY|O_CLOEXEC) = 4
|
||||
PING google.com (216.58.204.46) 56(84) bytes of data.
|
||||
open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 4
|
||||
64 bytes from lhr25s12-in-f14.1e100.net (216.58.204.46): icmp_seq=1 ttl=63 time=13.0 ms
|
||||
[...]
|
||||
```
|
||||
|
||||
and the same for `host`:
|
||||
|
||||
```
|
||||
$ strace -e trace=open -f host google.com
|
||||
[...]
|
||||
[pid 9869] open("/usr/share/locale/en_US.UTF-8/LC_MESSAGES/libdst.cat", O_RDONLY) = -1 ENOENT (No such file or directory)
|
||||
[pid 9869] open("/usr/share/locale/en/libdst.cat", O_RDONLY) = -1 ENOENT (No such file or directory)
|
||||
[pid 9869] open("/usr/share/locale/en/LC_MESSAGES/libdst.cat", O_RDONLY) = -1 ENOENT (No such file or directory)
|
||||
[pid 9869] open("/usr/lib/ssl/openssl.cnf", O_RDONLY) = 6
|
||||
[pid 9869] open("/usr/lib/x86_64-linux-gnu/openssl-1.0.0/engines/libgost.so", O_RDONLY|O_CLOEXEC) = 6[pid 9869] open("/etc/resolv.conf", O_RDONLY) = 6
|
||||
google.com has address 216.58.204.46
|
||||
[...]
|
||||
```
|
||||
|
||||
You can see that while my `ping` looks at `nsswitch.conf`, `host` does not. And they both look at `/etc/resolv.conf`.
|
||||
|
||||
We’re going to take these two `.conf` files in turn.
|
||||
|
||||
* * *
|
||||
|
||||
### 2) NSSwitch, and `/etc/nsswitch.conf`
|
||||
|
||||
We’ve established that applications can do what they like when they decide which DNS server to go to. Many apps (like `ping`) above can refer (depending on the implementation (*)) to NSSwitch via its config file `/etc/nsswitch.conf`.
|
||||
|
||||
###### (*) There’s a surprising degree of variation in
|
||||
ping implementations. That’s a rabbit-hole I
|
||||
_didn’t_ want to get lost in.
|
||||
|
||||
NSSwitch is not just for DNS lookups. It’s also used for passwords and user lookup information (for example).
|
||||
|
||||
NSSwitch was originally created as part of the Solaris OS to allow applications to not have to hard-code which file or service they look these things up on, but defer them to this other configurable centralised place they didn’t have to worry about.
|
||||
|
||||
Here’s my `nsswitch.conf`:
|
||||
|
||||
```
|
||||
passwd: compat
|
||||
group: compat
|
||||
shadow: compat
|
||||
gshadow: files
|
||||
hosts: files dns myhostname
|
||||
networks: files
|
||||
protocols: db files
|
||||
services: db files
|
||||
ethers: db files
|
||||
rpc: db files
|
||||
netgroup: nis
|
||||
```
|
||||
|
||||
The ‘hosts’ line is the one we’re interested in. We’ve shown that `ping` cares about `nsswitch.conf` so let’s fiddle with it and see how we can mess with `ping`.
|
||||
|
||||
* ### Set `nsswitch.conf` to only look at ‘files’
|
||||
|
||||
If you set the `hosts` line in `nsswitch.conf` to be ‘just’ `files`:
|
||||
|
||||
`hosts: files`
|
||||
|
||||
Then a `ping` to google.com will now fail:
|
||||
|
||||
```
|
||||
$ ping -c1 google.com
|
||||
ping: unknown host google.com
|
||||
```
|
||||
|
||||
but `localhost` still works:
|
||||
|
||||
```
|
||||
$ ping -c1 localhost
|
||||
PING localhost (127.0.0.1) 56(84) bytes of data.
|
||||
64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.039 ms
|
||||
```
|
||||
|
||||
and using `host` still works fine:
|
||||
|
||||
```
|
||||
$ host google.com
|
||||
google.com has address 216.58.206.110
|
||||
```
|
||||
|
||||
since, as we saw, it doesn’t care about `nsswitch.conf`
|
||||
|
||||
* ### Set `nsswitch.conf` to only look at ‘dns’
|
||||
|
||||
If you set the `hosts` line in `nsswitch.conf` to be ‘just’ dns:
|
||||
|
||||
`hosts: dns`
|
||||
|
||||
Then a `ping` to google.com will now succeed again:
|
||||
|
||||
```
|
||||
$ ping -c1 google.com
|
||||
PING google.com (216.58.198.174) 56(84) bytes of data.
|
||||
64 bytes from lhr25s10-in-f174.1e100.net (216.58.198.174): icmp_seq=1 ttl=63 time=8.01 ms
|
||||
```
|
||||
|
||||
But `localhost` is not found this time:
|
||||
|
||||
```
|
||||
$ ping -c1 localhost
|
||||
ping: unknown host localhost
|
||||
```
|
||||
|
||||
Here’s a diagram of what’s going on with NSSwitch by default wrt `hosts` lookup:
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_My default ‘`hosts:`‘ configuration in `nsswitch.conf`_
|
||||
|
||||
* * *
|
||||
|
||||
### 3) `/etc/resolv.conf`
|
||||
|
||||
We’ve seen now that `host` and `ping` both look at this `/etc/resolv.conf` file.
|
||||
|
||||
Here’s what my `/etc/resolv.conf` looks like:
|
||||
|
||||
```
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.3
|
||||
```
|
||||
|
||||
Ignore the first two lines – we’ll come back to those (they are significant, but you’re not ready for that ball of wool yet).
|
||||
|
||||
The `nameserver` lines specify the DNS servers to look up the host for.
|
||||
|
||||
If you hash out that line:
|
||||
|
||||
```
|
||||
#nameserver 10.0.2.3
|
||||
```
|
||||
|
||||
and run:
|
||||
|
||||
```
|
||||
$ ping -c1 google.com
|
||||
ping: unknown host google.com
|
||||
```
|
||||
|
||||
it fails, because there’s no nameserver to go to (*).
|
||||
|
||||
###### * Another rabbit hole: `host` appears to fall back to
|
||||
127.0.0.1:53 if there’s no nameserver specified.
|
||||
|
||||
This file takes other options too. For example, if you add this line to the `resolv.conf` file:
|
||||
|
||||
```
|
||||
search com
|
||||
```
|
||||
|
||||
and then `ping google` (sic)
|
||||
|
||||
```
|
||||
$ ping google
|
||||
PING google.com (216.58.204.14) 56(84) bytes of data.
|
||||
```
|
||||
|
||||
it will try the `.com` domain automatically for you.
|
||||
|
||||
### End of Part I
|
||||
|
||||
That’s the end of Part I. The next part will start by looking at how that resolv.conf gets created and updated.
|
||||
|
||||
Here’s what you covered above:
|
||||
|
||||
* There’s no ‘DNS lookup’ call in the OS
|
||||
|
||||
* Different programs figure out the IP of an address in different ways
|
||||
* For example, `ping` uses `nsswitch`, which in turn uses (or can use) `/etc/hosts`, `/etc/resolv.conf` and its own hostname to get the result
|
||||
|
||||
* `/etc/resolv.conf` helps decide:
|
||||
* which addresses get called
|
||||
|
||||
* which DNS server to look up
|
||||
|
||||
If you thought that was complicated, buckle up…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
|
||||
作者:[dmatech][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/dmatech2
|
||||
[1]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[2]:http://man7.org/linux/man-pages/man3/getaddrinfo.3.html
|
||||
[3]:https://zwischenzugs.com/2017/10/31/a-complete-chef-infrastructure-on-your-laptop/
|
||||
[4]:https://zwischenzugs.com/2017/03/04/a-complete-openshift-cluster-on-vagrant-step-by-step/
|
||||
[5]:https://zwischenzugs.com/2017/03/04/migrating-an-openshift-etcd-cluster/
|
||||
[6]:https://zwischenzugs.com/2017/03/04/1-minute-multi-node-vm-setup/
|
||||
[7]:https://zwischenzugs.com/2017/03/18/clustered-vm-testing-how-to/
|
||||
[8]:https://zwischenzugs.com/2017/10/27/ten-things-i-wish-id-known-before-using-vagrant/
|
||||
[9]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
|
||||
[10]:https://github.com/ianmiell/shutit-linux-dns/blob/master/linux_dns.py
|
||||
@ -0,0 +1,988 @@
|
||||
75 Most Used Essential Linux Applications of 2018
|
||||
======
|
||||
|
||||
**2018** has been an awesome year for a lot of applications, especially those that are both free and open source. And while various Linux distributions come with a number of default apps, users are free to take them out and use any of the free or paid alternatives of their choice.
|
||||
|
||||
Today, we bring you a [list of Linux applications][3] that have been able to make it to users’ Linux installations almost all the time despite the butt-load of other alternatives.
|
||||
|
||||
To simply put, any app on this list is among the most used in its category, and if you haven’t already tried it out you are probably missing out. Enjoy!
|
||||
|
||||
### Backup Tools
|
||||
|
||||
#### Rsync
|
||||
|
||||
[Rsync][4] is an open source bandwidth-friendly utility tool for performing swift incremental file transfers and it is available for free.
|
||||
```
|
||||
$ rsync [OPTION...] SRC... [DEST]
|
||||
|
||||
```
|
||||
|
||||
To know more examples and usage, read our article “[10 Practical Examples of Rsync Command][5]” to learn more about it.
|
||||
|
||||
#### Timeshift
|
||||
|
||||
[Timeshift][6] provides users with the ability to protect their system by taking incremental snapshots which can be reverted to at a different date – similar to the function of Time Machine in Mac OS and System restore in Windows.
|
||||
|
||||

|
||||
|
||||
### BitTorrent Client
|
||||
|
||||

|
||||
|
||||
#### Deluge
|
||||
|
||||
[Deluge][7] is a beautiful cross-platform BitTorrent client that aims to perfect the **μTorrent** experience and make it available to users for free.
|
||||
|
||||
Install **Deluge** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:deluge-team/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install deluge
|
||||
|
||||
```
|
||||
|
||||
#### qBittorent
|
||||
|
||||
[qBittorent][8] is an open source BitTorrent protocol client that aims to provide a free alternative to torrent apps like μTorrent.
|
||||
|
||||
Install **qBittorent** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:qbittorrent-team/qbittorrent-stable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install qbittorrent
|
||||
|
||||
```
|
||||
|
||||
#### Transmission
|
||||
|
||||
[Transmission][9] is also a BitTorrent client with awesome functionalities and a major focus on speed and ease of use. It comes preinstalled with many Linux distros.
|
||||
|
||||
Install **Transmission** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:transmissionbt/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install transmission-gtk transmission-cli transmission-common transmission-daemon
|
||||
|
||||
```
|
||||
|
||||
### Cloud Storage
|
||||
|
||||

|
||||
|
||||
#### Dropbox
|
||||
|
||||
The [Dropbox][10] team rebranded their cloud service earlier this year to provide an even better performance and app integration for their clients. It starts with 2GB of storage for free.
|
||||
|
||||
Install **Dropbox** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86" | tar xzf - [On 32-Bit]
|
||||
$ cd ~ && wget -O - "https://www.dropbox.com/download?plat=lnx.x86_64" | tar xzf - [On 64-Bit]
|
||||
$ ~/.dropbox-dist/dropboxd
|
||||
|
||||
```
|
||||
|
||||
#### Google Drive
|
||||
|
||||
[Google Drive][11] is Google’s cloud service solution and my guess is that it needs no introduction. Just like with **Dropbox** , you can sync files across all your connected devices. It starts with 15GB of storage for free and this includes Gmail, Google photos, Maps, etc.
|
||||
|
||||
Check out: [5 Google Drive Clients for Linux][12]
|
||||
|
||||
#### Mega
|
||||
|
||||
[Mega][13] stands out from the rest because apart from being extremely security-conscious, it gives free users 50GB to do as they wish! Its end-to-end encryption ensures that they can’t access your data, and if you forget your recovery key, you too wouldn’t be able to.
|
||||
|
||||
[**Download MEGA Cloud Storage for Ubuntu][14]
|
||||
|
||||
### Commandline Editors
|
||||
|
||||

|
||||
|
||||
#### Vim
|
||||
|
||||
[Vim][15] is an open source clone of vi text editor developed to be customizable and able to work with any type of text.
|
||||
|
||||
Install **Vim** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:jonathonf/vim
|
||||
$ sudo apt update
|
||||
$ sudo apt install vim
|
||||
|
||||
```
|
||||
|
||||
#### Emacs
|
||||
|
||||
[Emacs][16] refers to a set of highly configurable text editors. The most popular variant, GNU Emacs, is written in Lisp and C to be self-documenting, extensible, and customizable.
|
||||
|
||||
Install **Emacs** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:kelleyk/emacs
|
||||
$ sudo apt update
|
||||
$ sudo apt install emacs25
|
||||
|
||||
```
|
||||
|
||||
#### Nano
|
||||
|
||||
[Nano][17] is a feature-rich CLI text editor for power users and it has the ability to work with different terminals, among other functionalities.
|
||||
|
||||
Install **Nano** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:n-muench/programs-ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install nano
|
||||
|
||||
```
|
||||
|
||||
### Download Manager
|
||||
|
||||

|
||||
|
||||
#### Aria2
|
||||
|
||||
[Aria2][18] is an open source lightweight multi-source and multi-protocol command line-based downloader with support for Metalinks, torrents, HTTP/HTTPS, SFTP, etc.
|
||||
|
||||
Install **Aria2** on **Ubuntu** and **Debian** , using following command.
|
||||
```
|
||||
$ sudo apt-get install aria2
|
||||
|
||||
```
|
||||
|
||||
#### uGet
|
||||
|
||||
[uGet][19] has earned its title as the **#1** open source download manager for Linux distros and it features the ability to handle any downloading task you can throw at it including using multiple connections, using queues, categories, etc.
|
||||
|
||||
Install **uGet** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:plushuang-tw/uget-stable
|
||||
$ sudo apt update
|
||||
$ sudo apt install uget
|
||||
|
||||
```
|
||||
|
||||
#### XDM
|
||||
|
||||
[XDM][20], **Xtreme Download Manager** is an open source downloader written in Java. Like any good download manager, it can work with queues, torrents, browsers, and it also includes a video grabber and a smart scheduler.
|
||||
|
||||
Install **XDM** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:noobslab/apps
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install xdman
|
||||
|
||||
```
|
||||
|
||||
### Email Clients
|
||||
|
||||

|
||||
|
||||
#### Thunderbird
|
||||
|
||||
[Thunderbird][21] is among the most popular email applications. It is free, open source, customizable, feature-rich, and above all, easy to install.
|
||||
|
||||
Install **Thunderbird** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:ubuntu-mozilla-security/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install thunderbird
|
||||
|
||||
```
|
||||
|
||||
#### Geary
|
||||
|
||||
[Geary][22] is an open source email client based on WebKitGTK+. It is free, open-source, feature-rich, and adopted by the GNOME project.
|
||||
|
||||
Install **Geary** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:geary-team/releases
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install geary
|
||||
|
||||
```
|
||||
|
||||
#### Evolution
|
||||
|
||||
[Evolution][23] is a free and open source email client for managing emails, meeting schedules, reminders, and contacts.
|
||||
|
||||
Install **Evolution** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:gnome3-team/gnome3-staging
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install evolution
|
||||
|
||||
```
|
||||
|
||||
### Finance Software
|
||||
|
||||

|
||||
|
||||
#### GnuCash
|
||||
|
||||
[GnuCash][24] is a free, cross-platform, and open source software for financial accounting tasks for personal and small to mid-size businesses.
|
||||
|
||||
Install **GnuCash** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo sh -c 'echo "deb http://archive.getdeb.net/ubuntu $(lsb_release -sc)-getdeb apps" >> /etc/apt/sources.list.d/getdeb.list'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install gnucash
|
||||
|
||||
```
|
||||
|
||||
#### KMyMoney
|
||||
|
||||
[KMyMoney][25] is a finance manager software that provides all important features found in the commercially-available, personal finance managers.
|
||||
|
||||
Install **KMyMoney** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:claydoh/kmymoney2-kde4
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install kmymoney
|
||||
|
||||
```
|
||||
|
||||
### IDE Editors
|
||||
|
||||

|
||||
|
||||
#### Eclipse IDE
|
||||
|
||||
[Eclipse][26] is the most widely used Java IDE containing a base workspace and an impossible-to-overemphasize configurable plug-in system for personalizing its coding environment.
|
||||
|
||||
For installation, read our article “[How to Install Eclipse Oxygen IDE in Debian and Ubuntu][27]”
|
||||
|
||||
#### Netbeans IDE
|
||||
|
||||
A fan-favourite, [Netbeans][28] enables users to easily build applications for mobile, desktop, and web platforms using Java, PHP, HTML5, JavaScript, and C/C++, among other languages.
|
||||
|
||||
For installation, read our article “[How to Install Netbeans Oxygen IDE in Debian and Ubuntu][29]”
|
||||
|
||||
#### Brackets
|
||||
|
||||
[Brackets][30] is an advanced text editor developed by Adobe to feature visual tools, preprocessor support, and a design-focused user flow for web development. In the hands of an expert, it can serve as an IDE in its own right.
|
||||
|
||||
Install **Brackets** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:webupd8team/brackets
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install brackets
|
||||
|
||||
```
|
||||
|
||||
#### Atom IDE
|
||||
|
||||
[Atom IDE][31] is a more robust version of Atom text editor achieved by adding a number of extensions and libraries to boost its performance and functionalities. It is, in a sense, Atom on steroids.
|
||||
|
||||
Install **Atom** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install snapd
|
||||
$ sudo snap install atom --classic
|
||||
|
||||
```
|
||||
|
||||
#### Light Table
|
||||
|
||||
[Light Table][32] is a self-proclaimed next-generation IDE developed to offer awesome features like data value flow stats and coding collaboration.
|
||||
|
||||
Install **Light Table** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:dr-akulavich/lighttable
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install lighttable-installer
|
||||
|
||||
```
|
||||
|
||||
#### Visual Studio Code
|
||||
|
||||
[Visual Studio Code][33] is a source code editor created by Microsoft to offer users the best-advanced features in a text editor including syntax highlighting, code completion, debugging, performance statistics and graphs, etc.
|
||||
|
||||
[**Download Visual Studio Code for Ubuntu][34]
|
||||
|
||||
### Instant Messaging
|
||||
|
||||

|
||||
|
||||
#### Pidgin
|
||||
|
||||
[Pidgin][35] is an open source instant messaging app that supports virtually all chatting platforms and can have its abilities extended using extensions.
|
||||
|
||||
Install **Pidgin** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:jonathonf/backports
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install pidgin
|
||||
|
||||
```
|
||||
|
||||
#### Skype
|
||||
|
||||
[Skype][36] needs no introduction and its awesomeness is available for any interested Linux user.
|
||||
|
||||
Install **Skype** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt install snapd
|
||||
$ sudo snap install skype --classic
|
||||
|
||||
```
|
||||
|
||||
#### Empathy
|
||||
|
||||
[Empathy][37] is a messaging app with support for voice, video chat, text, and file transfers over multiple several protocols. It also allows you to add other service accounts to it and interface with all of them through it.
|
||||
|
||||
Install **Empathy** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install empathy
|
||||
|
||||
```
|
||||
|
||||
### Linux Antivirus
|
||||
|
||||
#### ClamAV/ClamTk
|
||||
|
||||
[ClamAV][38] is an open source and cross-platform command line antivirus app for detecting Trojans, viruses, and other malicious codes. [ClamTk][39] is its GUI front-end.
|
||||
|
||||
Install **ClamAV/ClamTk** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install clamav
|
||||
$ sudo apt-get install clamtk
|
||||
|
||||
```
|
||||
|
||||
### Linux Desktop Environments
|
||||
|
||||
#### Cinnamon
|
||||
|
||||
[Cinnamon][40] is a free and open-source derivative of **GNOME3** and it follows the traditional desktop metaphor conventions.
|
||||
|
||||
Install **Cinnamon** desktop on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:embrosyn/cinnamon
|
||||
$ sudo apt update
|
||||
$ sudo apt install cinnamon-desktop-environment lightdm
|
||||
|
||||
```
|
||||
|
||||
#### Mate
|
||||
|
||||
The [Mate][41] Desktop Environment is a derivative and continuation of **GNOME2** developed to offer an attractive UI on Linux using traditional metaphors.
|
||||
|
||||
Install **Mate** desktop on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt install tasksel
|
||||
$ sudo apt update
|
||||
$ sudo tasksel install ubuntu-mate-desktop
|
||||
|
||||
```
|
||||
|
||||
#### GNOME
|
||||
|
||||
[GNOME][42] is a Desktop Environment comprised of several free and open-source applications and can run on any Linux distro and on most BSD derivatives.
|
||||
|
||||
Install **Gnome** desktop on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt install tasksel
|
||||
$ sudo apt update
|
||||
$ sudo tasksel install ubuntu-desktop
|
||||
|
||||
```
|
||||
|
||||
#### KDE
|
||||
|
||||
[KDE][43] is developed by the KDE community to provide users with a graphical solution to interfacing with their system and performing several computing tasks.
|
||||
|
||||
Install **KDE** desktop on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt install tasksel
|
||||
$ sudo apt update
|
||||
$ sudo tasksel install kubuntu-desktop
|
||||
|
||||
```
|
||||
|
||||
### Linux Maintenance Tools
|
||||
|
||||
#### GNOME Tweak Tool
|
||||
|
||||
The [GNOME Tweak Tool][44] is the most popular tool for customizing and tweaking GNOME3 and GNOME Shell settings.
|
||||
|
||||
Install **GNOME Tweak Tool** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt install gnome-tweak-tool
|
||||
|
||||
```
|
||||
|
||||
#### Stacer
|
||||
|
||||
[Stacer][45] is a free, open-source app for monitoring and optimizing Linux systems.
|
||||
|
||||
Install **Stacer** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:oguzhaninan/stacer
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install stacer
|
||||
|
||||
```
|
||||
|
||||
#### BleachBit
|
||||
|
||||
[BleachBit][46] is a free disk space cleaner that also works as a privacy manager and system optimizer.
|
||||
|
||||
[**Download BleachBit for Ubuntu][47]
|
||||
|
||||
### Linux Terminals
|
||||
|
||||
#### GNOME Terminal
|
||||
|
||||
[GNOME Terminal][48] is GNOME’s default terminal emulator.
|
||||
|
||||
Install **Gnome Terminal** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install gnome-terminal
|
||||
|
||||
```
|
||||
|
||||
#### Konsole
|
||||
|
||||
[Konsole][49] is a terminal emulator for KDE.
|
||||
|
||||
Install **Konsole** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install konsole
|
||||
|
||||
```
|
||||
|
||||
#### Terminator
|
||||
|
||||
[Terminator][50] is a feature-rich GNOME Terminal-based terminal app built with a focus on arranging terminals, among other functions.
|
||||
|
||||
Install **Terminator** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install terminator
|
||||
|
||||
```
|
||||
|
||||
#### Guake
|
||||
|
||||
[Guake][51] is a lightweight drop-down terminal for the GNOME Desktop Environment.
|
||||
|
||||
Install **Guake** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install guake
|
||||
|
||||
```
|
||||
|
||||
### Multimedia Editors
|
||||
|
||||
#### Ardour
|
||||
|
||||
[Ardour][52] is a beautiful Digital Audio Workstation (DAW) for recording, editing, and mixing audio professionally.
|
||||
|
||||
Install **Ardour** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:dobey/audiotools
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install ardour
|
||||
|
||||
```
|
||||
|
||||
#### Audacity
|
||||
|
||||
[Audacity][53] is an easy-to-use cross-platform and open source multi-track audio editor and recorder; arguably the most famous of them all.
|
||||
|
||||
Install **Audacity** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:ubuntuhandbook1/audacity
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install audacity
|
||||
|
||||
```
|
||||
|
||||
#### GIMP
|
||||
|
||||
[GIMP][54] is the most popular open source Photoshop alternative and it is for a reason. It features various customization options, 3rd-party plugins, and a helpful user community.
|
||||
|
||||
Install **Gimp** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:otto-kesselgulasch/gimp
|
||||
$ sudo apt update
|
||||
$ sudo apt install gimp
|
||||
|
||||
```
|
||||
|
||||
#### Krita
|
||||
|
||||
[Krita][55] is an open source painting app that can also serve as an image manipulating tool and it features a beautiful UI with a reliable performance.
|
||||
|
||||
Install **Krita** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:kritalime/ppa
|
||||
$ sudo apt update
|
||||
$ sudo apt install krita
|
||||
|
||||
```
|
||||
|
||||
#### Lightworks
|
||||
|
||||
[Lightworks][56] is a powerful, flexible, and beautiful tool for editing videos professionally. It comes feature-packed with hundreds of amazing effects and presets that allow it to handle any editing task that you throw at it and it has 25 years of experience to back up its claims.
|
||||
|
||||
[**Download Lightworks for Ubuntu][57]
|
||||
|
||||
#### OpenShot
|
||||
|
||||
[OpenShot][58] is an award-winning free and open source video editor known for its excellent performance and powerful capabilities.
|
||||
|
||||
Install **Openshot** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:openshot.developers/ppa
|
||||
$ sudo apt update
|
||||
$ sudo apt install openshot-qt
|
||||
|
||||
```
|
||||
|
||||
#### PiTiV
|
||||
|
||||
[Pitivi][59] is a beautiful video editor that features a beautiful code base, awesome community, is easy to use, and allows for hassle-free collaboration.
|
||||
|
||||
Install **PiTiV** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ flatpak install --user https://flathub.org/repo/appstream/org.pitivi.Pitivi.flatpakref
|
||||
$ flatpak install --user http://flatpak.pitivi.org/pitivi.flatpakref
|
||||
$ flatpak run org.pitivi.Pitivi//stable
|
||||
|
||||
```
|
||||
|
||||
### Music Players
|
||||
|
||||
#### Rhythmbox
|
||||
|
||||
[Rhythmbox][60] posses the ability to perform all music tasks you throw at it and has so far proved to be a reliable music player that it ships with Ubuntu.
|
||||
|
||||
Install **Rhythmbox** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:fossfreedom/rhythmbox
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install rhythmbox
|
||||
|
||||
```
|
||||
|
||||
#### Lollypop
|
||||
|
||||
[Lollypop][61] is a beautiful, relatively new, open source music player featuring a number of advanced options like online radio, scrubbing support and party mode. Yet, it manages to keep everything simple and easy to manage.
|
||||
|
||||
Install **Lollypop** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:gnumdk/lollypop
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install lollypop
|
||||
|
||||
```
|
||||
|
||||
#### Amarok
|
||||
|
||||
[Amarok][62] is a robust music player with an intuitive UI and tons of advanced features bundled into a single unit. It also allows users to discover new music based on their genre preferences.
|
||||
|
||||
Install **Amarok** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install amarok
|
||||
|
||||
```
|
||||
|
||||
#### Clementine
|
||||
|
||||
[Clementine][63] is an Amarok-inspired music player that also features a straight-forward UI, advanced control features, and the ability to let users search for and discover new music.
|
||||
|
||||
Install **Clementine** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:me-davidsansome/clementine
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install clementine
|
||||
|
||||
```
|
||||
|
||||
#### Cmus
|
||||
|
||||
[Cmus][64] is arguably the most efficient CLI music player, Cmus is fast and reliable, and its functionality can be increased using extensions.
|
||||
|
||||
Install **Cmus** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:jmuc/cmus
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install cmus
|
||||
|
||||
```
|
||||
|
||||
### Office Suites
|
||||
|
||||
#### Calligra Suite
|
||||
|
||||
The [Calligra Suite][65] provides users with a set of 8 applications which cover working with office, management, and graphics tasks.
|
||||
|
||||
Install **Calligra Suite** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install calligra
|
||||
|
||||
```
|
||||
|
||||
#### LibreOffice
|
||||
|
||||
[LibreOffice][66] the most actively developed office suite in the open source community, LibreOffice is known for its reliability and its functions can be increased using extensions.
|
||||
|
||||
Install **LibreOffice** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:libreoffice/ppa
|
||||
$ sudo apt update
|
||||
$ sudo apt install libreoffice
|
||||
|
||||
```
|
||||
|
||||
#### WPS Office
|
||||
|
||||
[WPS Office][67] is a beautiful office suite alternative with a more modern UI.
|
||||
|
||||
[**Download WPS Office for Ubuntu][68]
|
||||
|
||||
### Screenshot Tools
|
||||
|
||||
#### Shutter
|
||||
|
||||
[Shutter][69] allows users to take screenshots of their desktop and then edit them using filters and other effects coupled with the option to upload and share them online.
|
||||
|
||||
Install **Shutter** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository -y ppa:shutter/ppa
|
||||
$ sudo apt update
|
||||
$ sudo apt install shutter
|
||||
|
||||
```
|
||||
|
||||
#### Kazam
|
||||
|
||||
[Kazam][70] screencaster captures screen content to output a video and audio file supported by any video player with VP8/WebM and PulseAudio support.
|
||||
|
||||
Install **Kazam** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:kazam-team/unstable-series
|
||||
$ sudo apt update
|
||||
$ sudo apt install kazam python3-cairo python3-xlib
|
||||
|
||||
```
|
||||
|
||||
#### Gnome Screenshot
|
||||
|
||||
[Gnome Screenshot][71] was once bundled with Gnome utilities but is now a standalone app. It can be used to take screencasts in a format that is easily shareable.
|
||||
|
||||
Install **Gnome Screenshot** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install gnome-screenshot
|
||||
|
||||
```
|
||||
|
||||
### Screen Recorders
|
||||
|
||||
#### SimpleScreenRecorder
|
||||
|
||||
[SimpleScreenRecorder][72] was created to be better than the screen-recording apps available at the time of its creation and has now turned into one of the most efficient and easy-to-use screen recorders for Linux distros.
|
||||
|
||||
Install **SimpleScreenRecorder** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:maarten-baert/simplescreenrecorder
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install simplescreenrecorder
|
||||
|
||||
```
|
||||
|
||||
#### recordMyDesktop
|
||||
|
||||
[recordMyDesktop][73] is an open source session recorder that is also capable of recording desktop session audio.
|
||||
|
||||
Install **recordMyDesktop** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install gtk-recordmydesktop
|
||||
|
||||
```
|
||||
|
||||
### Text Editors
|
||||
|
||||
#### Atom
|
||||
|
||||
[Atom][74] is a modern and customizable text editor created and maintained by GitHub. It is ready for use right out of the box and can have its functionality enhanced and its UI customized using extensions and themes.
|
||||
|
||||
Install **Atom** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install snapd
|
||||
$ sudo snap install atom --classic
|
||||
|
||||
```
|
||||
|
||||
#### Sublime Text
|
||||
|
||||
[Sublime Text][75] is easily among the most awesome text editors to date. It is customizable, lightweight (even when bulldozed with a lot of data files and extensions), flexible, and remains free to use forever.
|
||||
|
||||
Install **Sublime Text** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install snapd
|
||||
$ sudo snap install sublime-text
|
||||
|
||||
```
|
||||
|
||||
#### Geany
|
||||
|
||||
[Geany][76] is a memory-friendly text editor with basic IDE features designed to exhibit shot load times and extensible functions using libraries.
|
||||
|
||||
Install **Geany** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install geany
|
||||
|
||||
```
|
||||
|
||||
#### Gedit
|
||||
|
||||
[Gedit][77] is famous for its simplicity and it comes preinstalled with many Linux distros because of its function as an excellent general purpose text editor.
|
||||
|
||||
Install **Gedit** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install gedit
|
||||
|
||||
```
|
||||
|
||||
### To-Do List Apps
|
||||
|
||||
#### Evernote
|
||||
|
||||
[Evernote][78] is a cloud-based note-taking productivity app designed to work perfectly with different types of notes including to-do lists and reminders.
|
||||
|
||||
There is no any official evernote app for Linux, so check out other third party [6 Evernote Alternative Clients for Linux][79].
|
||||
|
||||
#### Everdo
|
||||
|
||||
[Everdo][78] is a beautiful, security-conscious, low-friction Getting-Things-Done app productivity app for handling to-dos and other note types. If Evernote comes off to you in an unpleasant way, Everdo is a perfect alternative.
|
||||
|
||||
[**Download Everdo for Ubuntu][80]
|
||||
|
||||
#### Taskwarrior
|
||||
|
||||
[Taskwarrior][81] is an open source and cross-platform command line app for managing tasks. It is famous for its speed and distraction-free environment.
|
||||
|
||||
Install **Taskwarrior** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install taskwarrior
|
||||
|
||||
```
|
||||
|
||||
### Video Players
|
||||
|
||||
#### Banshee
|
||||
|
||||
[Banshee][82] is an open source multi-format-supporting media player that was first developed in 2005 and has only been getting better since.
|
||||
|
||||
Install **Banshee** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:banshee-team/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install banshee
|
||||
|
||||
```
|
||||
|
||||
#### VLC
|
||||
|
||||
[VLC][83] is my favourite video player and it’s so awesome that it can play almost any audio and video format you throw at it. You can also use it to play internet radio, record desktop sessions, and stream movies online.
|
||||
|
||||
Install **VLC** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:videolan/stable-daily
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install vlc
|
||||
|
||||
```
|
||||
|
||||
#### Kodi
|
||||
|
||||
[Kodi][84] is among the world’s most famous media players and it comes as a full-fledged media centre app for playing all things media whether locally or remotely.
|
||||
|
||||
Install **Kodi** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo apt-get install software-properties-common
|
||||
$ sudo add-apt-repository ppa:team-xbmc/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install kodi
|
||||
|
||||
```
|
||||
|
||||
#### SMPlayer
|
||||
|
||||
[SMPlayer][85] is a GUI for the award-winning **MPlayer** and it is capable of handling all popular media formats; coupled with the ability to stream from YouTube, Chromcast, and download subtitles.
|
||||
|
||||
Install **SMPlayer** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:rvm/smplayer
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install smplayer
|
||||
|
||||
```
|
||||
|
||||
### Virtualization Tools
|
||||
|
||||
#### VirtualBox
|
||||
|
||||
[VirtualBox][86] is an open source app created for general-purpose OS virtualization and it can be run on servers, desktops, and embedded systems.
|
||||
|
||||
Install **VirtualBox** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
|
||||
$ wget -q https://www.virtualbox.org/download/oracle_vbox.asc -O- | sudo apt-key add -
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install virtualbox-5.2
|
||||
$ virtualbox
|
||||
|
||||
```
|
||||
|
||||
#### VMWare
|
||||
|
||||
[VMware][87] is a digital workspace that provides platform virtualization and cloud computing services to customers and is reportedly the first to successfully virtualize x86 architecture systems. One of its products, VMware workstations allows users to run multiple OSes in a virtual memory.
|
||||
|
||||
For installation, read our article “[How to Install VMware Workstation Pro on Ubuntu][88]“.
|
||||
|
||||
### Web Browsers
|
||||
|
||||
#### Chrome
|
||||
|
||||
[Google Chrome][89] is undoubtedly the most popular browser. Known for its speed, simplicity, security, and beauty following Google’s Material Design trend, Chrome is a browser that web developers cannot do without. It is also free to use and open source.
|
||||
|
||||
Install **Google Chrome** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
|
||||
$ sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-chrome-stable
|
||||
|
||||
```
|
||||
|
||||
#### Firefox
|
||||
|
||||
[Firefox Quantum][90] is a beautiful, speed, task-ready, and customizable browser capable of any browsing task that you throw at it. It is also free, open source, and packed with developer-friendly tools that are easy for even beginners to get up and running with.
|
||||
|
||||
Install **Firefox Quantum** on **Ubuntu** and **Debian** , using following commands.
|
||||
```
|
||||
$ sudo add-apt-repository ppa:mozillateam/firefox-next
|
||||
$ sudo apt update && sudo apt upgrade
|
||||
$ sudo apt install firefox
|
||||
|
||||
```
|
||||
|
||||
#### Vivaldi
|
||||
|
||||
[Vivaldi][91] is a free and open source Chrome-based project that aims to perfect Chrome’s features with a couple of more feature additions. It is known for its colourful panels, memory-friendly performance, and flexibility.
|
||||
|
||||
[**Download Vivaldi for Ubuntu][91]
|
||||
|
||||
That concludes our list for today. Did I skip a famous title? Tell me about it in the comments section below.
|
||||
|
||||
Don’t forget to share this post and to subscribe to our newsletter to get the latest publications from FossMint.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/most-used-linux-applications/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://plus.google.com/share?url=https://www.fossmint.com/most-used-linux-applications/ (Share on Google+)
|
||||
[2]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.fossmint.com/most-used-linux-applications/ (Share on LinkedIn)
|
||||
[3]:https://www.fossmint.com/awesome-linux-software/
|
||||
[4]:https://rsync.samba.org/
|
||||
[5]:https://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||
[6]:https://github.com/teejee2008/timeshift
|
||||
[7]:https://deluge-torrent.org/
|
||||
[8]:https://www.qbittorrent.org/
|
||||
[9]:https://transmissionbt.com/
|
||||
[10]:https://www.dropbox.com/
|
||||
[11]:https://www.google.com/drive/
|
||||
[12]:https://www.fossmint.com/best-google-drive-clients-for-linux/
|
||||
[13]:https://mega.nz/
|
||||
[14]:https://mega.nz/sync!linux
|
||||
[15]:https://www.vim.org/
|
||||
[16]:https://www.gnu.org/s/emacs/
|
||||
[17]:https://www.nano-editor.org/
|
||||
[18]:https://aria2.github.io/
|
||||
[19]:http://ugetdm.com/
|
||||
[20]:http://xdman.sourceforge.net/
|
||||
[21]:https://www.thunderbird.net/
|
||||
[22]:https://github.com/GNOME/geary
|
||||
[23]:https://github.com/GNOME/evolution
|
||||
[24]:https://www.gnucash.org/
|
||||
[25]:https://kmymoney.org/
|
||||
[26]:https://www.eclipse.org/ide/
|
||||
[27]:https://www.tecmint.com/install-eclipse-oxygen-ide-in-ubuntu-debian/
|
||||
[28]:https://netbeans.org/
|
||||
[29]:https://www.tecmint.com/install-netbeans-ide-in-ubuntu-debian-linux-mint/
|
||||
[30]:http://brackets.io/
|
||||
[31]:https://ide.atom.io/
|
||||
[32]:http://lighttable.com/
|
||||
[33]:https://code.visualstudio.com/
|
||||
[34]:https://code.visualstudio.com/download
|
||||
[35]:https://www.pidgin.im/
|
||||
[36]:https://www.skype.com/
|
||||
[37]:https://wiki.gnome.org/Apps/Empathy
|
||||
[38]:https://www.clamav.net/
|
||||
[39]:https://dave-theunsub.github.io/clamtk/
|
||||
[40]:https://github.com/linuxmint/cinnamon-desktop
|
||||
[41]:https://mate-desktop.org/
|
||||
[42]:https://www.gnome.org/
|
||||
[43]:https://www.kde.org/plasma-desktop
|
||||
[44]:https://github.com/nzjrs/gnome-tweak-tool
|
||||
[45]:https://github.com/oguzhaninan/Stacer
|
||||
[46]:https://www.bleachbit.org/
|
||||
[47]:https://www.bleachbit.org/download
|
||||
[48]:https://github.com/GNOME/gnome-terminal
|
||||
[49]:https://konsole.kde.org/
|
||||
[50]:https://gnometerminator.blogspot.com/p/introduction.html
|
||||
[51]:http://guake-project.org/
|
||||
[52]:https://ardour.org/
|
||||
[53]:https://www.audacityteam.org/
|
||||
[54]:https://www.gimp.org/
|
||||
[55]:https://krita.org/en/
|
||||
[56]:https://www.lwks.com/
|
||||
[57]:https://www.lwks.com/index.php?option=com_lwks&view=download&Itemid=206
|
||||
[58]:https://www.openshot.org/
|
||||
[59]:http://www.pitivi.org/
|
||||
[60]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[61]:https://gnumdk.github.io/lollypop-web/
|
||||
[62]:https://amarok.kde.org/en
|
||||
[63]:https://www.clementine-player.org/
|
||||
[64]:https://cmus.github.io/
|
||||
[65]:https://www.calligra.org/tour/calligra-suite/
|
||||
[66]:https://www.libreoffice.org/
|
||||
[67]:https://www.wps.com/
|
||||
[68]:http://wps-community.org/downloads
|
||||
[69]:http://shutter-project.org/
|
||||
[70]:https://launchpad.net/kazam
|
||||
[71]:https://gitlab.gnome.org/GNOME/gnome-screenshot
|
||||
[72]:http://www.maartenbaert.be/simplescreenrecorder/
|
||||
[73]:http://recordmydesktop.sourceforge.net/about.php
|
||||
[74]:https://atom.io/
|
||||
[75]:https://www.sublimetext.com/
|
||||
[76]:https://www.geany.org/
|
||||
[77]:https://wiki.gnome.org/Apps/Gedit
|
||||
[78]:https://everdo.net/
|
||||
[79]:https://www.fossmint.com/evernote-alternatives-for-linux/
|
||||
[80]:https://everdo.net/linux/
|
||||
[81]:https://taskwarrior.org/
|
||||
[82]:http://banshee.fm/
|
||||
[83]:https://www.videolan.org/
|
||||
[84]:https://kodi.tv/
|
||||
[85]:https://www.smplayer.info/
|
||||
[86]:https://www.virtualbox.org/wiki/VirtualBox
|
||||
[87]:https://www.vmware.com/
|
||||
[88]:https://www.tecmint.com/install-vmware-workstation-in-linux/
|
||||
[89]:https://www.google.com/chrome/
|
||||
[90]:https://www.mozilla.org/en-US/firefox/
|
||||
[91]:https://vivaldi.com/
|
||||
@ -1,601 +0,0 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
The evolution of package managers
|
||||
======
|
||||
|
||||

|
||||
|
||||
Every computerized device uses some form of software to perform its intended tasks. In the early days of software, products were stringently tested for bugs and other defects. For the last decade or so, software has been released via the internet with the intent that any bugs would be fixed by applying new versions of the software. In some cases, each individual application has its own updater. In others, it is left up to the user to figure out how to obtain and upgrade software.
|
||||
|
||||
Linux adopted early the practice of maintaining a centralized location where users could find and install software. In this article, I'll discuss the history of software installation on Linux and how modern operating systems are kept up to date against the never-ending torrent of [CVEs][1].
|
||||
|
||||
### How was software on Linux installed before package managers?
|
||||
|
||||
Historically, software was provided either via FTP or mailing lists (eventually this distribution would grow to include basic websites). Only a few small files contained the instructions to create a binary (normally in a tarfile). You would untar the files, read the readme, and as long as you had GCC or some other form of C compiler, you would then typically run a `./configure` script with some list of attributes, such as pathing to library files, location to create new binaries, etc. In addition, the `configure` process would check your system for application dependencies. If any major requirements were missing, the configure script would exit and you could not proceed with the installation until all the dependencies were met. If the configure script completed successfully, a `Makefile` would be created.
|
||||
|
||||
Once a `Makefile` existed, you would then proceed to run the `make` command (this command is provided by whichever compiler you were using). The `make` command has a number of options called make flags, which help optimize the resulting binaries for your system. In the earlier days of computing, this was very important because hardware struggled to keep up with modern software demands. Today, compilation options can be much more generic as most hardware is more than adequate for modern software.
|
||||
|
||||
Finally, after the `make` process had been completed, you would need to run `make install` (or `sudo make install`) in order to actually install the software. As you can imagine, doing this for every single piece of software was time-consuming and tedious—not to mention the fact that updating software was a complicated and potentially very involved process.
|
||||
|
||||
### What is a package?
|
||||
|
||||
Packages were invented to combat this complexity. Packages collect multiple data files together into a single archive file for easier portability and storage, or simply compress files to reduce storage space. The binaries included in a package are precompiled with according to the sane defaults the developer chosen. Packages also contain metadata, such as the software's name, a description of its purpose, a version number, and a list of dependencies necessary for the software to run properly.
|
||||
|
||||
Several flavors of Linux have created their own package formats. Some of the most commonly used package formats include:
|
||||
|
||||
* .deb: This package format is used by Debian, Ubuntu, Linux Mint, and several other derivatives. It was the first package type to be created.
|
||||
* .rpm: This package format was originally called Red Hat Package Manager. It is used by Red Hat, Fedora, SUSE, and several other smaller distributions.
|
||||
* .tar.xz: While it is just a compressed tarball, this is the format that Arch Linux uses.
|
||||
|
||||
|
||||
|
||||
While packages themselves don't manage dependencies directly, they represented a huge step forward in Linux software management.
|
||||
|
||||
### What is a software repository?
|
||||
|
||||
A few years ago, before the proliferation of smartphones, the idea of a software repository was difficult for many users to grasp if they were not involved in the Linux ecosystem. To this day, most Windows users still seem to be hardwired to open a web browser to search for and install new software. However, those with smartphones have gotten used to the idea of a software "store." The way smartphone users obtain software and the way package managers work are not dissimilar. While there have been several attempts at making an attractive UI for software repositories, the vast majority of Linux users still use the command line to install packages. Software repositories are a centralized listing of all of the available software for any repository the system has been configured to use. Below are some examples of searching a repository for a specifc package (note that these have been truncated for brevity):
|
||||
|
||||
Arch Linux with aurman
|
||||
```
|
||||
user@arch ~ $ aurman -Ss kate
|
||||
|
||||
extra/kate 18.04.2-2 (kde-applications kdebase)
|
||||
Advanced Text Editor
|
||||
aur/kate-root 18.04.0-1 (11, 1.139399)
|
||||
Advanced Text Editor, patched to be able to run as root
|
||||
aur/kate-git r15288.15d26a7-1 (1, 1e-06)
|
||||
An advanced editor component which is used in numerous KDE applications requiring a text editing component
|
||||
```
|
||||
|
||||
CentOS 7 using YUM
|
||||
```
|
||||
[user@centos ~]$ yum search kate
|
||||
|
||||
kate-devel.x86_64 : Development files for kate
|
||||
kate-libs.x86_64 : Runtime files for kate
|
||||
kate-part.x86_64 : Kate kpart plugin
|
||||
```
|
||||
|
||||
Ubuntu using APT
|
||||
```
|
||||
user@ubuntu ~ $ apt search kate
|
||||
Sorting... Done
|
||||
Full Text Search... Done
|
||||
|
||||
kate/xenial 4:15.12.3-0ubuntu2 amd64
|
||||
powerful text editor
|
||||
|
||||
kate-data/xenial,xenial 4:4.14.3-0ubuntu4 all
|
||||
shared data files for Kate text editor
|
||||
|
||||
kate-dbg/xenial 4:15.12.3-0ubuntu2 amd64
|
||||
debugging symbols for Kate
|
||||
|
||||
kate5-data/xenial,xenial 4:15.12.3-0ubuntu2 all
|
||||
shared data files for Kate text editor
|
||||
```
|
||||
|
||||
### What are the most prominent package managers?
|
||||
|
||||
As suggested in the above output, package managers are used to interact with software repositories. The following is a brief overview of some of the most prominent package managers.
|
||||
|
||||
#### RPM-based package managers
|
||||
|
||||
Updating RPM-based systems, particularly those based on Red Hat technologies, has a very interesting and detailed history. In fact, the current versions of [yum][2] (for enterprise distributions) and [DNF][3] (for community) combine several open source projects to provide their current functionality.
|
||||
|
||||
Initially, Red Hat used a package manager called [RPM][4] (Red Hat Package Manager), which is still in use today. However, its primary use is to install RPMs, which you have locally, not to search software repositories. The package manager named `up2date` was created to inform users of updates to packages and enable them to search remote repositories and easily install dependencies. While it served its purpose, some community members felt that `up2date` had some significant shortcomings.
|
||||
|
||||
The current incantation of yum came from several different community efforts. Yellowdog Updater (YUP) was developed in 1999-2001 by folks at Terra Soft Solutions as a back-end engine for a graphical installer of [Yellow Dog Linux][5]. Duke University liked the idea of YUP and decided to improve upon it. They created [Yellowdog Updater, Modified (yum)][6] which was eventually adapted to help manage the university's Red Hat Linux systems. Yum grew in popularity, and by 2005 it was estimated to be used by more than half of the Linux market. Today, almost every distribution of Linux that uses RPMs uses yum for package management (with a few notable exceptions).
|
||||
|
||||
#### Working with yum
|
||||
|
||||
In order for yum to download and install packages out of an internet repository, files must be located in `/etc/yum.repos.d/` and they must have the extension `.repo`. Here is an example repo file:
|
||||
```
|
||||
[local_base]
|
||||
name=Base CentOS (local)
|
||||
baseurl=http://7-repo.apps.home.local/yum-repo/7/
|
||||
enabled=1
|
||||
gpgcheck=0
|
||||
```
|
||||
|
||||
This is for one of my local repositories, which explains why the GPG check is off. If this check was on, each package would need to be signed with a cryptographic key and a corresponding key would need to be imported into the system receiving the updates. Because I maintain this repository myself, I trust the packages and do not bother signing them.
|
||||
|
||||
Once a repository file is in place, you can start installing packages from the remote repository. The most basic command is `yum update`, which will update every package currently installed. This does not require a specific step to refresh the information about repositories; this is done automatically. A sample of the command is shown below:
|
||||
```
|
||||
[user@centos ~]$ sudo yum update
|
||||
Loaded plugins: fastestmirror, product-id, search-disabled-repos, subscription-manager
|
||||
local_base | 3.6 kB 00:00:00
|
||||
local_epel | 2.9 kB 00:00:00
|
||||
local_rpm_forge | 1.9 kB 00:00:00
|
||||
local_updates | 3.4 kB 00:00:00
|
||||
spideroak-one-stable | 2.9 kB 00:00:00
|
||||
zfs | 2.9 kB 00:00:00
|
||||
(1/6): local_base/group_gz | 166 kB 00:00:00
|
||||
(2/6): local_updates/primary_db | 2.7 MB 00:00:00
|
||||
(3/6): local_base/primary_db | 5.9 MB 00:00:00
|
||||
(4/6): spideroak-one-stable/primary_db | 12 kB 00:00:00
|
||||
(5/6): local_epel/primary_db | 6.3 MB 00:00:00
|
||||
(6/6): zfs/x86_64/primary_db | 78 kB 00:00:00
|
||||
local_rpm_forge/primary_db | 125 kB 00:00:00
|
||||
Determining fastest mirrors
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
```
|
||||
|
||||
If you are sure you want yum to execute any command without stopping for input, you can put the `-y` flag in the command, such as `yum update -y`.
|
||||
|
||||
Installing a new package is just as easy. First, search for the name of the package with `yum search`:
|
||||
```
|
||||
[user@centos ~]$ yum search kate
|
||||
|
||||
artwiz-aleczapka-kates-fonts.noarch : Kates font in Artwiz family
|
||||
ghc-highlighting-kate-devel.x86_64 : Haskell highlighting-kate library development files
|
||||
kate-devel.i686 : Development files for kate
|
||||
kate-devel.x86_64 : Development files for kate
|
||||
kate-libs.i686 : Runtime files for kate
|
||||
kate-libs.x86_64 : Runtime files for kate
|
||||
kate-part.i686 : Kate kpart plugin
|
||||
```
|
||||
|
||||
Once you have the name of the package, you can simply install the package with `sudo yum install kate-devel -y`. If you installed a package you no longer need, you can remove it with `sudo yum remove kate-devel -y`. By default, yum will remove the package plus its dependencies.
|
||||
|
||||
There may be times when you do not know the name of the package, but you know the name of the utility. For example, suppose you are looking for the utility `updatedb`, which creates/updates the database used by the `locate` command. Attempting to install `updatedb` returns the following results:
|
||||
```
|
||||
[user@centos ~]$ sudo yum install updatedb
|
||||
Loaded plugins: fastestmirror, langpacks
|
||||
Loading mirror speeds from cached hostfile
|
||||
No package updatedb available.
|
||||
Error: Nothing to do
|
||||
```
|
||||
|
||||
You can find out what package the utility comes from by running:
|
||||
```
|
||||
[user@centos ~]$ yum whatprovides *updatedb
|
||||
Loaded plugins: fastestmirror, langpacks
|
||||
Loading mirror speeds from cached hostfile
|
||||
|
||||
bacula-director-5.2.13-23.1.el7.x86_64 : Bacula Director files
|
||||
Repo : local_base
|
||||
Matched from:
|
||||
Filename : /usr/share/doc/bacula-director-5.2.13/updatedb
|
||||
|
||||
mlocate-0.26-8.el7.x86_64 : An utility for finding files by name
|
||||
Repo : local_base
|
||||
Matched from:
|
||||
Filename : /usr/bin/updatedb
|
||||
```
|
||||
|
||||
The reason I have used an asterisk `*` in front of the command is because `yum whatprovides` uses the path to the file in order to make a match. Since I was not sure where the file was located, I used an asterisk to indicate any path.
|
||||
|
||||
There are, of course, many more options available to yum. I encourage you to view the man page for yum for additional options.
|
||||
|
||||
[Dandified Yum (DNF)][7] is a newer iteration on yum. Introduced in Fedora 18, it has not yet been adopted in the enterprise distributions, and as such is predominantly used in Fedora (and derivatives). Its usage is almost exactly the same as that of yum, but it was built to address poor performance, undocumented APIs, slow/broken dependency resolution, and occasional high memory usage. DNF is meant as a drop-in replacement for yum, and therefore I won't repeat the commands—wherever you would use `yum`, simply substitute `dnf`.
|
||||
|
||||
#### Working with Zypper
|
||||
|
||||
[Zypper][8] is another package manager meant to help manage RPMs. This package manager is most commonly associated with [SUSE][9] (and [openSUSE][10]) but has also seen adoption by [MeeGo][11], [Sailfish OS][12], and [Tizen][13]. It was originally introduced in 2006 and has been iterated upon ever since. There is not a whole lot to say other than Zypper is used as the back end for the system administration tool [YaST][14] and some users find it to be faster than yum.
|
||||
|
||||
Zypper's usage is very similar to that of yum. To search for, update, install or remove a package, simply use the following:
|
||||
```
|
||||
zypper search kate
|
||||
zypper update
|
||||
zypper install kate
|
||||
zypper remove kate
|
||||
```
|
||||
Some major differences come into play in how repositories are added to the system with `zypper`. Unlike the package managers discussed above, `zypper` adds repositories using the package manager itself. The most common way is via a URL, but `zypper` also supports importing from repo files.
|
||||
```
|
||||
suse:~ # zypper addrepo http://download.videolan.org/pub/vlc/SuSE/15.0 vlc
|
||||
Adding repository 'vlc' [done]
|
||||
Repository 'vlc' successfully added
|
||||
|
||||
Enabled : Yes
|
||||
Autorefresh : No
|
||||
GPG Check : Yes
|
||||
URI : http://download.videolan.org/pub/vlc/SuSE/15.0
|
||||
Priority : 99
|
||||
```
|
||||
|
||||
You remove repositories in a similar manner:
|
||||
```
|
||||
suse:~ # zypper removerepo vlc
|
||||
Removing repository 'vlc' ...................................[done]
|
||||
Repository 'vlc' has been removed.
|
||||
```
|
||||
|
||||
Use the `zypper repos` command to see what the status of repositories are on your system:
|
||||
```
|
||||
suse:~ # zypper repos
|
||||
Repository priorities are without effect. All enabled repositories share the same priority.
|
||||
|
||||
# | Alias | Name | Enabled | GPG Check | Refresh
|
||||
---|---------------------------|-----------------------------------------|---------|-----------|--------
|
||||
1 | repo-debug | openSUSE-Leap-15.0-Debug | No | ---- | ----
|
||||
2 | repo-debug-non-oss | openSUSE-Leap-15.0-Debug-Non-Oss | No | ---- | ----
|
||||
3 | repo-debug-update | openSUSE-Leap-15.0-Update-Debug | No | ---- | ----
|
||||
4 | repo-debug-update-non-oss | openSUSE-Leap-15.0-Update-Debug-Non-Oss | No | ---- | ----
|
||||
5 | repo-non-oss | openSUSE-Leap-15.0-Non-Oss | Yes | ( p) Yes | Yes
|
||||
6 | repo-oss | openSUSE-Leap-15.0-Oss | Yes | ( p) Yes | Yes
|
||||
```
|
||||
|
||||
`zypper` even has a similar ability to determine what package name contains files or binaries. Unlike YUM, it uses a hyphen in the command (although this method of searching is deprecated):
|
||||
```
|
||||
localhost:~ # zypper what-provides kate
|
||||
Command 'what-provides' is replaced by 'search --provides --match-exact'.
|
||||
See 'help search' for all available options.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
S | Name | Summary | Type
|
||||
---|------|----------------------|------------
|
||||
i+ | Kate | Advanced Text Editor | application
|
||||
i | kate | Advanced Text Editor | package
|
||||
```
|
||||
|
||||
As with YUM and DNF, Zypper has a much richer feature set than covered here. Please consult with the official documentation for more in-depth information.
|
||||
|
||||
#### Debian-based package managers
|
||||
|
||||
One of the oldest Linux distributions currently maintained, Debian's system is very similar to RPM-based systems. They use `.deb` packages, which can be managed by a tool called dpkg. dpkg is very similar to rpm in that it was designed to manage packages that are available locally. It does no dependency resolution (although it does dependency checking), and has no reliable way to interact with remote repositories. In order to improve the user experience and ease of use, the Debian project commissioned a project called Deity. This codename was eventually abandoned and changed to [Advanced Package Tool (APT)][15].
|
||||
|
||||
Released as test builds in 1998 (before making an appearance in Debian 2.1 in 1999), many users consider APT one of the defining features of Debian-based systems. It makes use of repositories in a similar fashion to RPM-based systems, but instead of individual `.repo` files that `yum` uses, `apt` has historically used `/etc/apt/sources.list` to manage repositories. More recently, it also ingests files from `/etc/apt/sources.d/`. Following the examples in the RPM-based package managers, to accomplish the same thing on Debian-based distributions you have a few options. You can edit/create the files manually in the aforementioned locations from the terminal, or in some cases, you can use a UI front end (such as `Software & Updates` provided by Ubuntu et al.). To provide the same treatment to all distributions, I will cover only the command-line options. To add a repository without directly editing a file, you can do something like this:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-add-repository "deb http://APT.spideroak.com/ubuntu-spideroak-hardy/ release restricted"
|
||||
|
||||
```
|
||||
|
||||
This will create a `spideroakone.list` file in `/etc/apt/sources.list.d`. Obviously, these lines change depending on the repository being added. If you are adding a Personal Package Archive (PPA), you can do this:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-add-repository ppa:gnome-desktop
|
||||
|
||||
```
|
||||
|
||||
NOTE: Debian does not support PPAs natively.
|
||||
|
||||
After a repository has been added, Debian-based systems need to be made aware that there is a new location to search for packages. This is done via the `apt-get update` command:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get update
|
||||
Get:1 http://security.ubuntu.com/ubuntu xenial-security InRelease [107 kB]
|
||||
Hit:2 http://APT.spideroak.com/ubuntu-spideroak-hardy release InRelease
|
||||
Hit:3 http://ca.archive.ubuntu.com/ubuntu xenial InRelease
|
||||
Get:4 http://ca.archive.ubuntu.com/ubuntu xenial-updates InRelease [109 kB]
|
||||
Get:5 http://security.ubuntu.com/ubuntu xenial-security/main amd64 Packages [517 kB]
|
||||
Get:6 http://security.ubuntu.com/ubuntu xenial-security/main i386 Packages [455 kB]
|
||||
Get:7 http://security.ubuntu.com/ubuntu xenial-security/main Translation-en [221 kB]
|
||||
...
|
||||
|
||||
Fetched 6,399 kB in 3s (2,017 kB/s)
|
||||
Reading package lists... Done
|
||||
```
|
||||
|
||||
Now that the new repository is added and updated, you can search for a package using the `apt-cache` command:
|
||||
```
|
||||
user@ubuntu:~$ apt-cache search kate
|
||||
aterm-ml - Afterstep XVT - a VT102 emulator for the X window system
|
||||
frescobaldi - Qt4 LilyPond sheet music editor
|
||||
gitit - Wiki engine backed by a git or darcs filestore
|
||||
jedit - Plugin-based editor for programmers
|
||||
kate - powerful text editor
|
||||
kate-data - shared data files for Kate text editor
|
||||
kate-dbg - debugging symbols for Kate
|
||||
katepart - embeddable text editor component
|
||||
```
|
||||
|
||||
To install `kate`, simply run the corresponding install command:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get install kate
|
||||
|
||||
```
|
||||
|
||||
To remove a package, use `apt-get remove`:
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get remove kate
|
||||
|
||||
```
|
||||
|
||||
When it comes to package discovery, APT does not provide any functionality that is similar to `yum whatprovides`. There are a few ways to get this information if you are trying to find where a specific file on disk has come from.
|
||||
|
||||
Using dpkg
|
||||
```
|
||||
user@ubuntu:~$ dpkg -S /bin/ls
|
||||
coreutils: /bin/ls
|
||||
```
|
||||
|
||||
Using apt-file
|
||||
```
|
||||
user@ubuntu:~$ sudo apt-get install apt-file -y
|
||||
|
||||
user@ubuntu:~$ sudo apt-file update
|
||||
|
||||
user@ubuntu:~$ apt-file search kate
|
||||
```
|
||||
|
||||
The problem with `apt-file search` is that it, unlike `yum whatprovides`, it is overly verbose unless you know the exact path, and it automatically adds a wildcard search so that you end up with results for anything with the word kate in it:
|
||||
```
|
||||
kate: /usr/bin/kate
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katebacktracebrowserplugin.so
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katebuildplugin.so
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katecloseexceptplugin.so
|
||||
kate: /usr/lib/x86_64-linux-gnu/qt5/plugins/ktexteditor/katectagsplugin.so
|
||||
```
|
||||
|
||||
Most of these examples have used `apt-get`. Note that most of the current tutorials for Ubuntu specifically have taken to simply using `apt`. The single `apt` command was designed to implement only the most commonly used commands in the APT arsenal. Since functionality is split between `apt-get`, `apt-cache`, and other commands, `apt` looks to unify these into a single command. It also adds some niceties such as colorization, progress bars, and other odds and ends. Most of the commands noted above can be replaced with `apt`, but not all Debian-based distributions currently receiving security patches support using `apt` by default, so you may need to install additional packages.
|
||||
|
||||
#### Arch-based package managers
|
||||
|
||||
[Arch Linux][16] uses a package manager called [pacman][17]. Unlike `.deb` or `.rpm` files, pacman uses a more traditional tarball with the LZMA2 compression (`.tar.xz`). This enables Arch Linux packages to be much smaller than other forms of compressed archives (such as gzip). Initially released in 2002, pacman has been steadily iterated and improved. One of the major benefits of pacman is that it supports the [Arch Build System][18], a system for building packages from source. The build system ingests a file called a PKGBUILD, which contains metadata (such as version numbers, revisions, dependencies, etc.) as well as a shell script with the required flags for compiling a package conforming to the Arch Linux requirements. The resulting binaries are then packaged into the aforementioned `.tar.xz` file for consumption by pacman.
|
||||
|
||||
This system led to the creation of the [Arch User Repository][19] (AUR) which is a community-driven repository containing PKGBUILD files and supporting patches or scripts. This allows for a virtually endless amount of software to be available in Arch. The obvious advantage of this system is that if a user (or maintainer) wishes to make software available to the public, they do not have to go through official channels to get it accepted in the main repositories. The downside is that it relies on community curation similar to [Docker Hub][20], Canonical's Snap packages, or other similar mechanisms. There are numerous AUR-specific package managers that can be used to download, compile, and install from the PKGBUILD files in the AUR (we will look at this later).
|
||||
|
||||
#### Working with pacman and official repositories
|
||||
|
||||
Arch's main package manager, pacman, uses flags instead of command words like `yum` and `apt`. For example, to search for a package, you would use `pacman -Ss`. As with most commands on Linux, you can find both a `manpage` and inline help. Most of the commands for `pacman `use the sync (-S) flag. For example:
|
||||
```
|
||||
user@arch ~ $ pacman -Ss kate
|
||||
|
||||
extra/kate 18.04.2-2 (kde-applications kdebase)
|
||||
Advanced Text Editor
|
||||
extra/libkate 0.4.1-6 [installed]
|
||||
A karaoke and text codec for embedding in ogg
|
||||
extra/libtiger 0.3.4-5 [installed]
|
||||
A rendering library for Kate streams using Pango and Cairo
|
||||
extra/ttf-cheapskate 2.0-12
|
||||
TTFonts collection from dustimo.com
|
||||
community/haskell-cheapskate 0.1.1-100
|
||||
Experimental markdown processor.
|
||||
```
|
||||
|
||||
Arch also uses repositories similar to other package managers. In the output above, search results are prefixed with the repository they are found in (`extra/` and `community/` in this case). Similar to both Red Hat and Debian-based systems, Arch relies on the user to add the repository information into a specific file. The location for these repositories is `/etc/pacman.conf`. The example below is fairly close to a stock system. I have enabled the `[multilib]` repository for Steam support:
|
||||
```
|
||||
[options]
|
||||
Architecture = auto
|
||||
|
||||
Color
|
||||
CheckSpace
|
||||
|
||||
SigLevel = Required DatabaseOptional
|
||||
LocalFileSigLevel = Optional
|
||||
|
||||
[core]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
|
||||
[extra]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
|
||||
[community]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
|
||||
[multilib]
|
||||
Include = /etc/pacman.d/mirrorlist
|
||||
```
|
||||
|
||||
It is possible to specify a specific URL in `pacman.conf`. This functionality can be used to make sure all packages come from a specific point in time. If, for example, a package has a bug that affects you severely and it has several dependencies, you can roll back to a specific point in time by adding a specific URL into your `pacman.conf` and then running the commands to downgrade the system:
|
||||
```
|
||||
[core]
|
||||
Server=https://archive.archlinux.org/repos/2017/12/22/$repo/os/$arch
|
||||
```
|
||||
|
||||
Like Debian-based systems, Arch does not update its local repository information until you tell it to do so. You can refresh the package database by issuing the following command:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Sy
|
||||
|
||||
:: Synchronizing package databases...
|
||||
core 130.2 KiB 851K/s 00:00 [##########################################################] 100%
|
||||
extra 1645.3 KiB 2.69M/s 00:01 [##########################################################] 100%
|
||||
community 4.5 MiB 2.27M/s 00:02 [##########################################################] 100%
|
||||
multilib is up to date
|
||||
```
|
||||
|
||||
As you can see in the above output, `pacman` thinks that the multilib package database is up to date. You can force a refresh if you think this is incorrect by running `pacman -Syy`. If you want to update your entire system (excluding packages installed from the AUR), you can run `pacman -Syu`:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Syu
|
||||
|
||||
:: Synchronizing package databases...
|
||||
core is up to date
|
||||
extra is up to date
|
||||
community is up to date
|
||||
multilib is up to date
|
||||
:: Starting full system upgrade...
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (45) ceph-13.2.0-2 ceph-libs-13.2.0-2 debootstrap-1.0.105-1 guile-2.2.4-1 harfbuzz-1.8.2-1 harfbuzz-icu-1.8.2-1 haskell-aeson-1.3.1.1-20
|
||||
haskell-attoparsec-0.13.2.2-24 haskell-tagged-0.8.6-1 imagemagick-7.0.8.4-1 lib32-harfbuzz-1.8.2-1 lib32-libgusb-0.3.0-1 lib32-systemd-239.0-1
|
||||
libgit2-1:0.27.2-1 libinput-1.11.2-1 libmagick-7.0.8.4-1 libmagick6-6.9.10.4-1 libopenshot-0.2.0-1 libopenshot-audio-0.1.6-1 libosinfo-1.2.0-1
|
||||
libxfce4util-4.13.2-1 minetest-0.4.17.1-1 minetest-common-0.4.17.1-1 mlt-6.10.0-1 mlt-python-bindings-6.10.0-1 ndctl-61.1-1 netctl-1.17-1
|
||||
nodejs-10.6.0-1
|
||||
|
||||
Total Download Size: 2.66 MiB
|
||||
Total Installed Size: 879.15 MiB
|
||||
Net Upgrade Size: -365.27 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
```
|
||||
|
||||
In the scenario mentioned earlier regarding downgrading a system, you can force a downgrade by issuing `pacman -Syyuu`. It is important to note that this should not be undertaken lightly. This should not cause a problem in most cases; however, there is a chance that downgrading of a package or several packages will cause a cascading failure and leave your system in an inconsistent state. USE WITH CAUTION!
|
||||
|
||||
To install a package, simply use `pacman -S kate`:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -S kate
|
||||
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (7) editorconfig-core-c-0.12.2-1 kactivities-5.47.0-1 kparts-5.47.0-1 ktexteditor-5.47.0-2 syntax-highlighting-5.47.0-1 threadweaver-5.47.0-1
|
||||
kate-18.04.2-2
|
||||
|
||||
Total Download Size: 10.94 MiB
|
||||
Total Installed Size: 38.91 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
```
|
||||
|
||||
To remove a package, you can run `pacman -R kate`. This removes only the package and not its dependencies:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -S kate
|
||||
|
||||
checking dependencies...
|
||||
|
||||
Packages (1) kate-18.04.2-2
|
||||
|
||||
Total Removed Size: 20.30 MiB
|
||||
|
||||
:: Do you want to remove these packages? [Y/n]
|
||||
```
|
||||
|
||||
If you want to remove the dependencies that are not required by other packages, you can run `pacman -Rs:`
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Rs kate
|
||||
|
||||
checking dependencies...
|
||||
|
||||
Packages (7) editorconfig-core-c-0.12.2-1 kactivities-5.47.0-1 kparts-5.47.0-1 ktexteditor-5.47.0-2 syntax-highlighting-5.47.0-1 threadweaver-5.47.0-1
|
||||
kate-18.04.2-2
|
||||
|
||||
Total Removed Size: 38.91 MiB
|
||||
|
||||
:: Do you want to remove these packages? [Y/n]
|
||||
```
|
||||
|
||||
Pacman, in my opinion, offers the most succinct way of searching for the name of a package for a given utility. As shown above, `yum` and `apt` both rely on pathing in order to find useful results. Pacman makes some intelligent guesses as to which package you are most likely looking for:
|
||||
```
|
||||
user@arch ~ $ sudo pacman -Fs updatedb
|
||||
core/mlocate 0.26.git.20170220-1
|
||||
usr/bin/updatedb
|
||||
|
||||
user@arch ~ $ sudo pacman -Fs kate
|
||||
extra/kate 18.04.2-2
|
||||
usr/bin/kate
|
||||
```
|
||||
|
||||
#### Working with the AUR
|
||||
|
||||
There are several popular AUR package manager helpers. Of these, `yaourt` and `pacaur` are fairly prolific. However, both projects are listed as discontinued or problematic on the [Arch Wiki][21]. For that reason, I will discuss `aurman`. It works almost exactly like `pacman,` except it searches the AUR and includes some helpful, albeit potentially dangerous, options. Installing a package from the AUR will initiate use of the package maintainer's build scripts. You will be prompted several times for permission to continue (I have truncated the output for brevity):
|
||||
```
|
||||
aurman -S telegram-desktop-bin
|
||||
~~ initializing aurman...
|
||||
~~ the following packages are neither in known repos nor in the aur
|
||||
...
|
||||
~~ calculating solutions...
|
||||
|
||||
:: The following 1 package(s) are getting updated:
|
||||
aur/telegram-desktop-bin 1.3.0-1 -> 1.3.9-1
|
||||
|
||||
?? Do you want to continue? Y/n: Y
|
||||
|
||||
~~ looking for new pkgbuilds and fetching them...
|
||||
Cloning into 'telegram-desktop-bin'...
|
||||
|
||||
remote: Counting objects: 301, done.
|
||||
remote: Compressing objects: 100% (152/152), done.
|
||||
remote: Total 301 (delta 161), reused 286 (delta 147)
|
||||
Receiving objects: 100% (301/301), 76.17 KiB | 639.00 KiB/s, done.
|
||||
Resolving deltas: 100% (161/161), done.
|
||||
?? Do you want to see the changes of telegram-desktop-bin? N/y: N
|
||||
|
||||
[sudo] password for user:
|
||||
|
||||
...
|
||||
==> Leaving fakeroot environment.
|
||||
==> Finished making: telegram-desktop-bin 1.3.9-1 (Thu 05 Jul 2018 11:22:02 AM EDT)
|
||||
==> Cleaning up...
|
||||
loading packages...
|
||||
resolving dependencies...
|
||||
looking for conflicting packages...
|
||||
|
||||
Packages (1) telegram-desktop-bin-1.3.9-1
|
||||
|
||||
Total Installed Size: 88.81 MiB
|
||||
Net Upgrade Size: 5.33 MiB
|
||||
|
||||
:: Proceed with installation? [Y/n]
|
||||
```
|
||||
|
||||
Sometimes you will be prompted for more input, depending on the complexity of the package you are installing. To avoid this tedium, `aurman` allows you to pass both the `--noconfirm` and `--noedit` options. This is equivalent to saying "accept all of the defaults, and trust that the package maintainers scripts will not be malicious." **USE THIS OPTION WITH EXTREME CAUTION!** While these options are unlikely to break your system on their own, you should never blindly accept someone else's scripts.
|
||||
|
||||
### Conclusion
|
||||
|
||||
This article, of course, only scratches the surface of what package managers can do. There are also many other package managers available that I could not cover in this space. Some distributions, such as Ubuntu or Elementary OS, have gone to great lengths to provide a graphical approach to package management.
|
||||
|
||||
If you are interested in some of the more advanced functions of package managers, please post your questions or comments below and I would be glad to write a follow-up article.
|
||||
|
||||
### Appendix
|
||||
```
|
||||
# search for packages
|
||||
yum search <package>
|
||||
dnf search <package>
|
||||
zypper search <package>
|
||||
apt-cache search <package>
|
||||
apt search <package>
|
||||
pacman -Ss <package>
|
||||
|
||||
# install packages
|
||||
yum install <package>
|
||||
dnf install <package>
|
||||
zypper install <package>
|
||||
apt-get install <package>
|
||||
apt install <package>
|
||||
pacman -Ss <package>
|
||||
|
||||
# update package database, not required by yum, dnf and zypper
|
||||
apt-get update
|
||||
apt update
|
||||
pacman -Sy
|
||||
|
||||
# update all system packages
|
||||
yum update
|
||||
dnf update
|
||||
zypper update
|
||||
apt-get upgrade
|
||||
apt upgrade
|
||||
pacman -Su
|
||||
|
||||
# remove an installed package
|
||||
yum remove <package>
|
||||
dnf remove <package>
|
||||
apt-get remove <package>
|
||||
apt remove <package>
|
||||
pacman -R <package>
|
||||
pacman -Rs <package>
|
||||
|
||||
# search for the package name containing specific file or folder
|
||||
yum whatprovides *<binary>
|
||||
dnf whatprovides *<binary>
|
||||
zypper what-provides <binary>
|
||||
zypper search --provides <binary>
|
||||
apt-file search <binary>
|
||||
pacman -Sf <binary>
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/evolution-package-managers
|
||||
|
||||
作者:[Steve Ovens][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/stratusss
|
||||
[1]:https://en.wikipedia.org/wiki/Common_Vulnerabilities_and_Exposures
|
||||
[2]:https://en.wikipedia.org/wiki/Yum_(software)
|
||||
[3]:https://fedoraproject.org/wiki/DNF
|
||||
[4]:https://en.wikipedia.org/wiki/Rpm_(software)
|
||||
[5]:https://en.wikipedia.org/wiki/Yellow_Dog_Linux
|
||||
[6]:https://searchdatacenter.techtarget.com/definition/Yellowdog-Updater-Modified-YUM
|
||||
[7]:https://en.wikipedia.org/wiki/DNF_(software)
|
||||
[8]:https://en.opensuse.org/Portal:Zypper
|
||||
[9]:https://www.suse.com/
|
||||
[10]:https://www.opensuse.org/
|
||||
[11]:https://en.wikipedia.org/wiki/MeeGo
|
||||
[12]:https://sailfishos.org/
|
||||
[13]:https://www.tizen.org/
|
||||
[14]:https://en.wikipedia.org/wiki/YaST
|
||||
[15]:https://en.wikipedia.org/wiki/APT_(Debian)
|
||||
[16]:https://www.archlinux.org/
|
||||
[17]:https://wiki.archlinux.org/index.php/pacman
|
||||
[18]:https://wiki.archlinux.org/index.php/Arch_Build_System
|
||||
[19]:https://aur.archlinux.org/
|
||||
[20]:https://hub.docker.com/
|
||||
[21]:https://wiki.archlinux.org/index.php/AUR_helpers#Discontinued_or_problematic
|
||||
@ -0,0 +1,77 @@
|
||||
Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution
|
||||
======
|
||||

|
||||
Howdy Linux newbies! Today, I have come up with a good news for you!! You might wondering how to choose a suitable Linux distribution for you. Of course, you might already have consulted some Linux experts to help you to select a Linux distribution for your needs. And some of you might have googled and gone through various resources, Linux forums, websites and blogs in the pursuit of finding perfect distro. Well, you need not to do that anymore. Meet **Distrochooser** , a website that helps you to easily find out a Linux distribution.
|
||||
|
||||
### How Distrochooser will help Linux beginners choose a suitable Linux distribution?
|
||||
|
||||
The Distrochooser will ask you a series of questions and suggests you different suitable Linux distributions to try, based on your answers. Excited? Great! Let us go ahead and see how to find out a suitable Linux distribution. Click on the following link to get started.
|
||||
|
||||
![][2]
|
||||
|
||||
You will be now redirected to Distrochooser home page where a small test is awaiting for you to enroll.
|
||||
|
||||
|
||||
You need to answer a series of questions (16 questions to be precise). Both single choice and multiple choice questions are provided there. Here are the complete list of questions.
|
||||
|
||||
1. Software: Use case
|
||||
2. Computer knowledge
|
||||
3. Linux Knowledge
|
||||
4. Installation: Presets
|
||||
5. Installation: Live-Test needed?
|
||||
6. Installation: Hardware support
|
||||
7. Configuration: Help source
|
||||
8. Distributions: User experience concept
|
||||
9. Distributions: Price
|
||||
10. Distributions: Scope
|
||||
11. Distributions: Ideology
|
||||
12. Distributions: Privacy
|
||||
13. Distributions: Preset themes, icons and wallpapers
|
||||
14. Distribution: Special features
|
||||
15. Software: Administration
|
||||
16. Software: Updates
|
||||
|
||||
|
||||
|
||||
Carefully read the questions and choose the appropriate answer(s) below the respective questions. Distrochooser gives more options to choose a near-perfect distribution.
|
||||
|
||||
* You can always skip questions,
|
||||
* You can always click on ‘get result’,
|
||||
* You can answer in arbitrary order,
|
||||
* You can delete answers at any time,
|
||||
* You can weight properties at the end of the test to emphasize what is important to you.
|
||||
|
||||
|
||||
|
||||
After choosing the answer(s) for a question, click **Proceed** to move to the next question. Once you are done, click on **Get result** button. You can also clear the selection at any time by clicking on the **“Clear”** button below the answers.
|
||||
|
||||
### Results?
|
||||
|
||||
I didn’t believe Distrochooser will exactly find what I am looking for. Oh boy, I was wrong! To my surprise, it did indeed a good job. The results were almost accurate to me. I was expecting Arch Linux in the result and indeed it was my top recommendation, followed by 11 other recommendations such as NixOS, Void Linux, Qubes OS, Scientific Linux, Devuan, Gentoo Linux, Bedrock Linux, Slackware, CentOS, Linux from scratch and Redhat Enterprise Linux. Totally, I got 12 recommendations and each result is very detailed along with distribution’s description and home page link for each distribution.
|
||||
|
||||

|
||||
|
||||
I posted Distrochooser link on Reddit and 80% of the users could be able to find suitable Linux distribution for them. However, I won’t claim Distrochooser alone is enough to find good results for everyone. Some users disappointed about the survey result and the result wasn’t even close to what they use or want to use. So, I strongly recommend you to consult other Linux experts, websites, forums before trying any Linux. You can read the full Reddit discussion [**here**][3].
|
||||
|
||||
What are you waiting for? Go to the Distrochooser site and choose a suitable Linux distribution for you.
|
||||
|
||||
And, that’s all for now, folks. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/distrochooser-helps-linux-beginners-to-choose-a-suitable-linux-distribution/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:https://distrochooser.de/en
|
||||
[3]:https://www.reddit.com/r/linux/comments/93p6az/distrochooser_helps_linux_beginners_to_choose_a/
|
||||
@ -0,0 +1,143 @@
|
||||
Top 5 CAD Software Available for Linux in 2018
|
||||
======
|
||||
[Computer Aided Design (CAD)][1] is an essential part of many streams of engineering. CAD is professionally used is architecture, auto parts design, space shuttle research, aeronautics, bridge construction, interior design, and even clothing and jewelry.
|
||||
|
||||
A number of professional grade CAD software like SolidWorks and Autodesk AutoCAD are not natively supported on the Linux platform. So today we will be having a look at the top CAD software available for Linux. Let’s dive right in.
|
||||
|
||||
### Best CAD Software available for Linux
|
||||
|
||||
![CAD Software for Linux][2]
|
||||
|
||||
Before you see the list of CAD software for Linux, you should keep one thing in mind that not all the applications listed here are open source. We included some non-FOSS CAD software to help average Linux user.
|
||||
|
||||
Installation instructions of Ubuntu-based Linux distributions have been provided. You may check the respective websites to learn the installation procedure for other distributions.
|
||||
|
||||
The list is not any specific order. CAD application at number one should not be considered better than the one at number three and so on.
|
||||
|
||||
#### 1\. FreeCAD
|
||||
|
||||
For 3D Modelling, FreeCAD is an excellent option which is both free (beer and speech) and open source. FreeCAD is built with keeping mechanical engineering and product design as target purpose. FreeCAD is multiplatform and is available on Windows, Mac OS X+ along with Linux.
|
||||
|
||||
![freecad][3]
|
||||
|
||||
Although FreeCAD has been the choice of many Linux users, it should be noted that FreeCAD is still on version 0.17 and therefore, is not suitable for major deployment. But the development has picked up pace recently.
|
||||
|
||||
[FreeCAD][4]
|
||||
|
||||
FreeCAD does not focus on direct 2D drawings and animation of organic shapes but it’s great for design related to mechanical engineering. FreeCAD version 0.15 is available in the Ubuntu repositories. You can install it by running the below command.
|
||||
```
|
||||
sudo apt install freecad
|
||||
|
||||
```
|
||||
|
||||
To get newer daily builds (0.17 at the moment), open a terminal (ctrl+alt+t) and run the commands below one by one.
|
||||
```
|
||||
sudo add-apt-repository ppa:freecad-maintainers/freecad-daily
|
||||
|
||||
sudo apt update
|
||||
|
||||
sudo apt install freecad-daily
|
||||
|
||||
```
|
||||
|
||||
#### 2\. LibreCAD
|
||||
|
||||
LibreCAD is a free, opensource, 2D CAD solution. Generally, CAD tends to be a resource-intensive task, and if you have a rather modest hardware, then I’d suggest you go for LibreCAD as it is really lightweight in terms of resource usage. LibreCAD is a great candidate for geometric constructions.
|
||||
|
||||
![librecad][5]
|
||||
As a 2D tool, LibreCAD is good but it cannot work on 3D models and renderings. It might be unstable at times but it has a dependable autosave which won’t let your work go wasted.
|
||||
|
||||
[LibreCAD][6]
|
||||
|
||||
You can install LibreCAD by running the following command
|
||||
```
|
||||
sudo apt install librecad
|
||||
|
||||
```
|
||||
|
||||
#### 3\. OpenSCAD
|
||||
|
||||
OpenSCAD is a free 3D CAD software. OpenSCAD is very lightweight and flexible. OpenSCAD is not interactive. You need to ‘program’ the model and OpenSCAD interprets that code to render a visual model. It is a compiler in a sense. You cannot draw the model. You describe the model.
|
||||
|
||||
![openscad][7]
|
||||
|
||||
OpenSCAD is the most complicated tool on this list but once you get to know it, it provides an enjoyable work experience.
|
||||
|
||||
[OpenSCAD][8]
|
||||
|
||||
You can use the following commands to install OpenSCAD.
|
||||
```
|
||||
sudo apt-get install openscad
|
||||
|
||||
```
|
||||
|
||||
#### 4\. BRL-CAD
|
||||
|
||||
BRL-CAD is one of the oldest CAD tools out there. It also has been loved by Linux/UNIX users as it aligns itself with *nix philosophies of modularity and freedom.
|
||||
|
||||
![BRL-CAD rendering by Sean][9]
|
||||
|
||||
BRL-CAD was started in 1979, and it is still developed actively. Now, BRL-CAD is not AutoCAD but it is still a great choice for transport studies such as thermal and ballistic penetration. BRL-CAD underlies CSG instead of boundary representation. You might need to keep that in mind while opting for BRL-CAD. You can download BRL-CAD from its official website.
|
||||
|
||||
[BRL-CAD][10]
|
||||
|
||||
#### 5\. DraftSight (not open source)
|
||||
|
||||
If You’re used to working on AutoCAD, then DraftSight would be the perfect alternative for you.
|
||||
|
||||
DraftSight is a great CAD tool available on Linux. It has a rather similar workflow to AutoCAD, which makes migrating easier. It even provides a similar look and feel. DrafSight is also compatible with the .dwg file format of AutoCAD. But DrafSight is a 2D CAD software. It does not support 3D CAD as of yet.
|
||||
|
||||
![draftsight][11]
|
||||
|
||||
Although DrafSight is a commercial software with a starting price of $149. A free version is also made available on the[DraftSight website][12]. You can download the .deb package and install it on Ubuntu based distributions. need to register your free copy using your email ID to start using DraftSight.
|
||||
|
||||
[DraftSight][12]
|
||||
|
||||
#### Honorary mentions
|
||||
|
||||
* With a huge growth in cloud computing technologies, cloud CAD solutions like [OnShape][13] have been getting popular day by day.
|
||||
* [SolveSpace][14] is another open-source project worth mentioning. It supports 3D modeling.
|
||||
* Siemens NX is an industrial grade CAD solution available on Windows, Mac OS and Linux, but it is ridiculously expensive, so omitted in this list.
|
||||
* Then you have [LeoCAD][15], which is a CAD software where you use LEGO blocks to build stuff. What you do with this information is up to you.
|
||||
|
||||
|
||||
|
||||
#### CAD on Linux, in my opinion
|
||||
|
||||
Although gaming on Linux has picked up, I always tell my hardcore gaming friends to stick to Windows. Similarly, if You are an engineering student with CAD in your curriculum, I’d recommend that you use the software that your college prescribes (AutoCAD, SolidEdge, Catia), which generally tend to run on Windows only.
|
||||
|
||||
And for the advanced professionals, these tools are simply not up to the mark when we’re talking about industry standards.
|
||||
|
||||
For those of you thinking about running AutoCAD in WINE, although some older versions of AutoCAD can be installed on WINE, they simply do not perform, with glitches and crashes ruining the experience.
|
||||
|
||||
That being said, I highly respect the work that has been put by the developers of the above-listed software. They have enriched the FOSS world. And it’s great to see software like FreeCAD developing with an accelerated pace in the recent years.
|
||||
|
||||
Well, that’s it for today. Do share your thoughts with us using the comments section below and don’t forget to share this article. Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cad-software-linux/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://en.wikipedia.org/wiki/Computer-aided_design
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/cad-software-linux.jpeg
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freecad.jpg
|
||||
[4]:https://www.freecadweb.org/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/librecad.jpg
|
||||
[6]:https://librecad.org/
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/openscad.jpg
|
||||
[8]:http://www.openscad.org/
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/brlcad.jpg
|
||||
[10]:https://brlcad.org/
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/draftsight.jpg
|
||||
[12]:https://www.draftsight2018.com/
|
||||
[13]:https://www.onshape.com/
|
||||
[14]:http://solvespace.com/index.pl
|
||||
[15]:https://www.leocad.org/
|
||||
@ -1,3 +1,5 @@
|
||||
pinewall translating
|
||||
|
||||
How To Switch Between Different Versions Of Commands In Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,203 +0,0 @@
|
||||
translating by ypingcn
|
||||
|
||||
Tips for using the top command in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Trying to find out what's running on your machine—and which process is using up all your memory and making things slllooowwww—is a task served well by the utility `top`.
|
||||
|
||||
`top` is an extremely useful program that acts similar to Windows Task Manager or MacOS's Activity Monitor. Running `top` on your *nix machine will show you a live, running view of the process running on your system.
|
||||
```
|
||||
$ top
|
||||
|
||||
```
|
||||
|
||||
Depending on which version of `top` you're running, you'll get something that looks like this:
|
||||
```
|
||||
top - 08:31:32 up 1 day, 4:09, 0 users, load average: 0.20, 0.12, 0.10
|
||||
|
||||
Tasks: 3 total, 1 running, 2 sleeping, 0 stopped, 0 zombie
|
||||
|
||||
%Cpu(s): 0.5 us, 0.3 sy, 0.0 ni, 99.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
|
||||
KiB Mem: 4042284 total, 2523744 used, 1518540 free, 263776 buffers
|
||||
|
||||
KiB Swap: 1048572 total, 0 used, 1048572 free. 1804264 cached Mem
|
||||
|
||||
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
|
||||
1 root 20 0 21964 3632 3124 S 0.0 0.1 0:00.23 bash
|
||||
|
||||
193 root 20 0 123520 29636 8640 S 0.0 0.7 0:00.58 flask
|
||||
|
||||
195 root 20 0 23608 2724 2400 R 0.0 0.1 0:00.21 top
|
||||
|
||||
```
|
||||
|
||||
Your version of `top` may look different from this, particularly in the columns that are displayed.
|
||||
|
||||
### How to read the output
|
||||
|
||||
You can tell what you're running based on the output, but trying to interpret the results can be slightly confusing.
|
||||
|
||||
The first few lines contain a bunch of statistics (the details) followed by a table with a list of results (the list). Let's start with the latter.
|
||||
|
||||
#### The list
|
||||
|
||||
These are the processes that are running on the system. By default, they are ordered by CPU usage in descending order. This means the items at the top of the list are using more CPU resources and causing more load on your system. They are literally the "top" processes by resource usage. You have to admit, it's a clever name.
|
||||
|
||||
The `COMMAND` column on the far right reports the name of the process (the command you ran to start them). In this example, they are `bash` (a command interpreter we're running `top` in), `flask` (a web micro-framework written in Python), and `top` itself.
|
||||
|
||||
The other columns provide useful information about the processes:
|
||||
|
||||
* `PID`: the process id, a unique identifier for addressing the processes
|
||||
* `USER`: the user running the process
|
||||
* `PR`: the task's priority
|
||||
* `NI`: a nicer representation of the priority
|
||||
* `VIRT`: virtual memory size in KiB (kibibytes)*
|
||||
* `RES`: resident memory size in KiB* (the "physical memory" and a subset of VIRT)
|
||||
* `SHR`: shared memory size in KiB* (the "shared memory" and a subset of VIRT)
|
||||
* `S`: process state, usually **I** =idle, **R** =running, **S** =sleeping, **Z** =zombie, **T** or **t** =stopped (there are also other, less common options)
|
||||
* `%CPU`: Percentage of CPU usage since the last screen update
|
||||
* `%MEM`: percentage of `RES` memory usage since the last screen update
|
||||
* `TIME+`: total CPU time used since the process started
|
||||
* `COMMAND`: the command, as described above
|
||||
|
||||
|
||||
|
||||
*Knowing exactly what the `VIRT`, `RES`, and `SHR` values represent doesn't really matter in everyday operations. The important thing to know is that the process with the most `VIRT` is the process using the most memory. If you're in `top` because you're debugging why your computer feels like it's in a pool of molasses, the process with the largest `VIRT` number is the culprit. If you want to learn exactly what "shared" and "physical" memory mean, check out "Linux Memory Types" in the [top manual][1].
|
||||
|
||||
And, yes, I did mean to type kibibytes, not kilobytes. The 1,024 value that you normally call a kilobyte is actually a kibibyte. The Greek kilo ("χίλιοι") means thousand and means 1,000 of something (e.g., a kilometer is a thousand meters, a kilogram is a thousand grams). Kibi is a portmanteau of kilo and byte, and it means 1,024 bytes (or 210). But, because words are hard to say, many people say kilobyte when they mean 1,024 bytes. All this means is `top` is trying to use the proper terms here, so just go with it. #themoreyouknow 🌈.
|
||||
|
||||
#### A note on screen updates:
|
||||
|
||||
Live screen updates are one of the objectively **really cool things** Linux programs can do. This means they can update their own display in real time, so they appear animated. Even though they're using text. So cool! In our case, the time between updates is important, because some of our statistics (`%CPU` and `%MEM`) are based on the value since the last screen update.
|
||||
|
||||
And because we're running in a persistent application, we can press key commands to make live changes to settings or configurations (instead of, say, closing the application and running the application again with a different command-line flag).
|
||||
|
||||
Typing `h` invokes the "help" screen, which also shows the default delay (the time between screen updates). By default, this value is (around) three seconds, but you can change it by typing `d` (presumably for "delay") or `s` (probably for "screen" or "seconds").
|
||||
|
||||
#### The details
|
||||
|
||||
Above the list of processes, there's a whole bunch of other useful information. Some of these details may look strange and confusing, but once you take some time to step through each one, you'll see they're very useful stats to pull up in a pinch.
|
||||
|
||||
The first row contains general system information
|
||||
|
||||
* `top`: we're running `top`! Hi `top`!
|
||||
* `XX:YY:XX`: the time, updated every time the screen updates
|
||||
* `up` (then `X day, YY:ZZ`): the system's [uptime][2], or how much time has passed since the system turned on
|
||||
* `load average` (then three numbers): the [system load][3] over the last one, five, and 15 minutes, respectively
|
||||
|
||||
|
||||
|
||||
The second row (`Tasks`) shows information about the running tasks, and it's fairly self-explanatory. It shows the total number of processes and the number of running, sleeping, stopped, and zombie processes. This is literally a sum of the `S` (state) column described above.
|
||||
|
||||
The third row (`%Cpu(s)`) shows the CPU usage separated by types. The data are the values between screen refreshes. The values are:
|
||||
|
||||
* `us`: user processes
|
||||
* `sy`: system processes
|
||||
* `ni`: [nice][4] user processes
|
||||
* `id`: the CPU's idle time; a high idle time means there's not a lot going on otherwise
|
||||
* `wa`: wait time, or time spent waiting for I/O completion
|
||||
* `hi`: time spent waiting for hardware interrupts
|
||||
* `si`: time spent waiting for software interrupts
|
||||
* `st`: "time stolen from this VM by the hypervisor"
|
||||
|
||||
|
||||
|
||||
You can collapse the `Tasks` and `%Cpu(s)` rows by typing `t` (for "toggle").
|
||||
|
||||
The fourth (`KiB Mem`) and fifth rows (`KiB Swap`) provide information for memory and swap. These values are:
|
||||
|
||||
* `total`
|
||||
* `used`
|
||||
* `free`
|
||||
|
||||
|
||||
|
||||
But also:
|
||||
|
||||
* memory `buffers`
|
||||
* swap `cached Mem`
|
||||
|
||||
|
||||
|
||||
By default, they're listed in KiB, but pressing `E` (for "extend memory scaling") cycles through different values: kibibytes, mebibytes, gibibytes, tebibytes, pebibytes, and exbibytes. (That is, kilobytes, megabytes, gigabytes, terabytes, petabytes, and exabytes, but their "real names.")
|
||||
|
||||
The `top` user manual shows even more information about useful flags and configurations. To find the manual on your system, you can run `man top`. There are various websites that show an [HTML rendering of the manual][1], but note that these may be for a different version of top.
|
||||
|
||||
### Two top alternatives
|
||||
|
||||
You don't always have to use `top` to understand what's going on. Depending on your circumstances, other tools might help you diagnose issues, especially when you want a more graphical or specialized interface.
|
||||
|
||||
#### htop
|
||||
|
||||
`htop` is a lot like `top`, but it brings something extremely useful to the table: a graphical representation of CPU and memory use.
|
||||
|
||||
|
||||
|
||||
This is how the environment we examined in `top` looks in `htop`. The display is a lot simpler, but still rich in features.
|
||||
|
||||
Our task counts, load, uptime, and list of processes are still there, but we get a nifty, colorized, animated view of the CPU usage per core and a graph of memory usage.
|
||||
|
||||
Here's what the different colors mean (you can also get this information by pressing `h` for "help").
|
||||
|
||||
CPU task priorities or types:
|
||||
|
||||
* blue: low priority
|
||||
* green: normal priority
|
||||
* red: kernel tasks
|
||||
* blue: virtualized tasks
|
||||
* the value at end of the bar is the percentage of used CPU
|
||||
|
||||
|
||||
|
||||
Memory:
|
||||
|
||||
* green: used memory
|
||||
* blue: buffered memory
|
||||
* yellow: cached memory
|
||||
* the values at the end of the bar show the used and total memory
|
||||
|
||||
|
||||
|
||||
If colors aren't useful for you, you can run `htop -C` to disable them; instead `htop` will use different symbols to separate the CPU and memory types.
|
||||
|
||||
At the bottom, there's a useful display of active function keys that you can use to do things like filter results or change the sort order. Try out some of the commands to see what they do. Just be careful when trying out `F9`. This will bring up a list of signals that will kill (i.e., stop) a process. I would suggest exploring these options outside of a production environment.
|
||||
|
||||
The author of `htop`, Hisham Muhammad (and yes, it's called `htop` after Hisham) presented a [lightning talk][5] about `htop` at [FOSDEM 2018][6] in February. He explained how `htop` not only has neat graphics, but also surfaces more modern statistical information about processes that older monitoring utilities (like `top`) don't.
|
||||
|
||||
You can read more about `htop` on the [manual page][7] or the [htop website][8]. (Warning: the website contains an animated background of `htop`.)
|
||||
|
||||
#### docker stats
|
||||
|
||||
If you're working with Docker, you can run `docker stats` to generate a context-rich representation of what your containers are doing.
|
||||
|
||||
This can be more helpful than `top` because, instead of separating by processes, you are separating by container. This is especially useful when a container is slow, as seeing which container is using the most resources is quicker than running `top` and trying to map the process to the container.
|
||||
|
||||
The above explanations of acronyms and descriptors in `top` and `htop` should make it easy to understand the ones in `docker stats`. However, the [docker stats documentation][9] provides helpful descriptions of each column.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/top-tips-speed-up-computer
|
||||
|
||||
作者:[Katie McLaughlin][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/glasnt
|
||||
[1]:http://man7.org/linux/man-pages/man1/top.1.html
|
||||
[2]:https://en.wikipedia.org/wiki/Uptime
|
||||
[3]:https://en.wikipedia.org/wiki/Load_(computing)
|
||||
[4]:https://en.wikipedia.org/wiki/Nice_(Unix)#Etymology
|
||||
[5]:https://www.youtube.com/watch?v=L25waVhy78o
|
||||
[6]:https://fosdem.org/2018/schedule/event/htop/
|
||||
[7]:https://linux.die.net/man/1/htop
|
||||
[8]:https://hisham.hm/htop/index.php
|
||||
[9]:https://docs.docker.com/engine/reference/commandline/stats/
|
||||
@ -0,0 +1,95 @@
|
||||
Top Linux developers' recommended programming books
|
||||
======
|
||||
Without question, Linux was created by brilliant programmers who employed good computer science knowledge. Let the Linux programmers whose names you know share the books that got them started and the technology references they recommend for today's developers. How many of them have you read?
|
||||
|
||||
Linux is, arguably, the operating system of the 21st century. While Linus Torvalds made a lot of good business and community decisions in building the open source community, the primary reason networking professionals and developers adopted Linux is the quality of its code and its usefulness. While Torvalds is a programming genius, he has been assisted by many other brilliant developers.
|
||||
|
||||
I asked Torvalds and other top Linux developers which books helped them on their road to programming excellence. This is what they told me.
|
||||
|
||||
### By shining C
|
||||
|
||||
Linux was developed in the 1990s, as were other fundamental open source applications. As a result, the tools and languages the developers used reflected the times, which meant a lot of C programming language. While [C is no longer as popular][1], for many established developers it was their first serious language, which is reflected in their choice of influential books.
|
||||
|
||||
“You shouldn't start programming with the languages I started with or the way I did,” says Torvalds. He started with BASIC, moved on to machine code (“not even assembly language, actual ‘just numbers’ machine code,” he explains), then assembly language and C.
|
||||
|
||||
“None of those languages are what anybody should begin with anymore,” Torvalds says. “Some of them make no sense at all today (BASIC and machine code). And while C is still a major language, I don't think you should begin with it.”
|
||||
|
||||
It's not that he dislikes C. After all, Linux is written in [GNU C][2]. "I still think C is a great language with a pretty simple syntax and is very good for many things,” he says. But the effort to get started with it is much too high for it to be a good beginner language by today's standards. “I suspect you'd just get frustrated. Going from your first ‘Hello World’ program to something you might actually use is just too big of a step."
|
||||
|
||||
From that era, the only programming book that stood out for Torvalds is Brian W. Kernighan and Dennis M. Ritchie's [C Programming Language][3], known in serious programming circles as K&R. “It was small, clear, concise,” he explains. “But you need to already have a programming background to appreciate it."
|
||||
|
||||
Torvalds is not the only open source developer to recommend K&R. Several others cite their well-thumbed copies as influential references, among them Wim Coekaerts, senior vice president for Linux and virtualization development at Oracle; Linux developer Alan Cox; Google Cloud CTO Brian Stevens; and Pete Graner, Canonical's vice president of technical operations.
|
||||
|
||||
If you want to tackle C today, Jeremy Allison, co-founder of Samba, recommends [21st Century C][4]. Then, Allison suggests, follow it up with the older but still thorough [Expert C Programming][5] as well as the 20-year-old [Programming with POSIX Threads][6].
|
||||
|
||||
### If not C, what?
|
||||
|
||||
Linux developers’ recommendations for current programming books naturally are an offshoot of the tools and languages they think are most suitable for today’s development projects. They also reflect the developers’ personal preferences. For example, Allison thinks young developers would be well served by learning Go with the help of [The Go Programming Language][7] and Rust with [Programming Rust][8].
|
||||
|
||||
But it may make sense to think beyond programming languages (and thus books to teach you their techniques). To do something meaningful today, “start from some environment with a toolkit that does 99 percent of the obscure details for you, so that you can script things around it," Torvalds recommends.
|
||||
|
||||
"Honestly, the language itself isn't nearly as important as the infrastructure around it,” he continues. “Maybe you'd start with Java or Kotlin—not because of those languages per se, but because you want to write an app for your phone and the Android SDK ends up making those better choices. Or, maybe you're interested in games, so you start with one of the game engines, which often have some scripting language of their own."
|
||||
|
||||
That infrastructure includes programming books specific to the operating system itself. Graner followed K&R by reading W. Richard Stevens' [Unix Network Programming][10] books. In particular, Stevens' [TCP/IP Illustrated, Volume 1: The Protocols][11] is considered still relevant even though it's almost 30 years old. Because Linux development is largely [relevant to networking infrastructure][12], Graner also recommends the many O’Reilly books on [Sendmail][13], [Bash][14], [DNS][15], and [IMAP/POP][16].
|
||||
|
||||
Coekaerts is also fond of Maurice Bach's [The Design of the Unix Operating System][17]. So is James Bottomley, a Linux kernel developer who used Bach's tome to pull apart Linux when the OS was new.
|
||||
|
||||
### Design knowledge never goes stale
|
||||
|
||||
But even that may be too tech-specific. "All developers should start with design before syntax,” says Stevens. “[The Design of Everyday Things][18] is one of my favorites.”
|
||||
|
||||
Coekaerts likes Kernighan and Rob Pike's [The Practice of Programming][19]. The design-practice book wasn't around when Coekaerts was in school, “but I recommend it to everyone to read," he says.
|
||||
|
||||
Whenever you ask serious long-term developers about their favorite books, sooner or later someone's going to mention Donald Knuth’s [The Art of Computer Programming][20]. Dirk Hohndel, VMware's chief open source officer, considers it timeless though, admittedly, “not necessarily super-useful today."
|
||||
|
||||
### Read code. Lots of code
|
||||
|
||||
While programming books can teach you a lot, don’t miss another opportunity that is unique to the open source community: [reading the code][21]. There are untold megabytes of examples of how to solve a given programming problem—and how you can get in trouble, too. Stevens says his No. 1 “book” for honing programming skills is having access to the Unix source code.
|
||||
|
||||
Don’t overlook the opportunity to learn in person, too. “I learned BASIC by being in a computer club with other people all learning together,” says Cox. “In my opinion, that is still by far the best way to learn." He learned machine code from [Mastering Machine Code on Your ZX81][22] and the Honeywell L66 B compiler manuals, but working with other developers made a big difference.
|
||||
|
||||
“I still think the way to learn best remains to be with a group of people having fun and trying to solve a problem you care about together,” says Cox. “It doesn't matter if you are 5 or 55."
|
||||
|
||||
What struck me the most about these recommendations is how often the top Linux developers started at a low level—not just C or assembly language but machine language. Obviously, it’s been very useful in helping developers understand how computing works at a very basic level.
|
||||
|
||||
So, ready to give hard-core Linux development a try? Greg Kroah-Hartman, the Linux stable branch kernel maintainer, recommends Steve Oualline's [Practical C Programming][23] and Samuel Harbison and Guy Steele's [C: A Reference Manual][24]. Next, read "[HOWTO do Linux kernel development][25]." Then, says Kroah-Hartman, you'll be ready to start.
|
||||
|
||||
In the meantime, study hard, program lots, and best of luck to you in following the footsteps of Linux's top programmers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.hpe.com/us/en/insights/articles/top-linux-developers-recommended-programming-books-1808.html
|
||||
|
||||
作者:[Steven Vaughan-Nichols][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.hpe.com/us/en/insights/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:https://www.codingdojo.com/blog/7-most-in-demand-programming-languages-of-2018/
|
||||
[2]:https://www.gnu.org/software/gnu-c-manual/
|
||||
[3]:https://amzn.to/2nhyjEO
|
||||
[4]:https://amzn.to/2vsL8k9
|
||||
[5]:https://amzn.to/2KBbWn9
|
||||
[6]:https://amzn.to/2M0rfeR
|
||||
[7]:https://amzn.to/2nhyrnMe
|
||||
[8]:http://shop.oreilly.com/product/0636920040385.do
|
||||
[9]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_510384402_linuxbooks_containerebook0818
|
||||
[10]:https://amzn.to/2MfpbyC
|
||||
[11]:https://amzn.to/2MpgrTn
|
||||
[12]:https://www.hpe.com/us/en/insights/articles/how-to-see-whats-going-on-with-your-linux-system-right-now-1807.html
|
||||
[13]:http://shop.oreilly.com/product/9780596510299.do
|
||||
[14]:http://shop.oreilly.com/product/9780596009656.do
|
||||
[15]:http://shop.oreilly.com/product/9780596100575.do
|
||||
[16]:http://shop.oreilly.com/product/9780596000127.do
|
||||
[17]:https://amzn.to/2vsCJgF
|
||||
[18]:https://amzn.to/2APzt3Z
|
||||
[19]:https://www.amazon.com/Practice-Programming-Addison-Wesley-Professional-Computing/dp/020161586X/ref=as_li_ss_tl?ie=UTF8&linkCode=sl1&tag=thegroovycorpora&linkId=e6bbdb1ca2182487069bf9089fc8107e&language=en_US
|
||||
[20]:https://amzn.to/2OknFsJ
|
||||
[21]:https://amzn.to/2M4VVL3
|
||||
[22]:https://amzn.to/2OjccJA
|
||||
[23]:http://shop.oreilly.com/product/9781565923065.do
|
||||
[24]:https://amzn.to/2OjzgrT
|
||||
[25]:https://www.kernel.org/doc/html/v4.16/process/howto.html
|
||||
@ -0,0 +1,84 @@
|
||||
translating by lujun9972
|
||||
How to Create M3U Playlists in Linux [Quick Tip]
|
||||
======
|
||||
**Brief: A quick tip on how to create M3U playlists in Linux terminal from unordered files to play them in a sequence.**
|
||||
|
||||
![Create M3U playlists in Linux Terminal][1]
|
||||
|
||||
I am a fan of foreign tv series and it’s not always easy to get them on DVD or on streaming services like [Netflix][2]. Thankfully, you can find some of them on YouTube and [download them from YouTube][3].
|
||||
|
||||
Now there comes a problem. Your files might not be sorted in a particular order. In GNU/Linux files are not naturally sort ordered by number sequencing so I had to make a .m3u playlist so [MPV video player][4] would play the videos in sequence and not out of sequence.
|
||||
|
||||
Also sometimes the numbers are in the middle or the end like ‘My Web Series S01E01.mkv’ as an example. The episode information here is in the middle of the filename, the ‘S01E01’ which tells us, humans, which is the first episode and which needs to come in next.
|
||||
|
||||
So what I did was to generate an m3u playlist in the video directory and tell MPV to play the .m3u playlist and it would take care of playing them in the sequence.
|
||||
|
||||
### What is an M3U file?
|
||||
|
||||
[M3U][5] is basically a text file that contains filenames in a specific order. When a player like MPV or VLC opens an M3U file, it tries to play the specified files in the given sequence.
|
||||
|
||||
### Creating M3U to play audio/video files in a sequence
|
||||
|
||||
In my case, I used the following command:
|
||||
```
|
||||
$/home/shirish/Videos/web-series-video/$ ls -1v |grep .mkv > /tmp/1.m3u && mv /tmp/1.m3u .
|
||||
|
||||
```
|
||||
|
||||
Let’s break it down a bit and see each bit as to what it means –
|
||||
|
||||
**ls -1v** = This is using the plain ls or listing entries in the directory. The -1 means list one file per line. while -v natural sort of (version) numbers within text
|
||||
|
||||
**| grep .mkv** = It’s basically telling `ls` to look for files which are ending in .mkv . It could be .mp4 or any other media file format that you want.
|
||||
|
||||
It’s usually a good idea to do a dry run by running the command on the console:
|
||||
```
|
||||
ls -1v |grep .mkv
|
||||
My Web Series S01E01 [Episode 1 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E02 [Episode 2 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E03 [Episode 3 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E04 [Episode 4 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E05 [Episode 5 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E06 [Episode 6 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E07 [Episode 7 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
My Web Series S01E08 [Episode 8 Name] Multi 480p WEBRip x264 - xRG.mkv
|
||||
|
||||
```
|
||||
|
||||
This tells me that what I’m trying to do is correct. Now just have to make that the output is in the form of a .m3u playlist which is the next part.
|
||||
```
|
||||
ls -1v |grep .mkv > /tmp/web_playlist.m3u && mv /tmp/web_playlist.m3u .
|
||||
|
||||
```
|
||||
|
||||
This makes the .m3u generate in the current directory. The .m3u playlist is nothing but a .txt file with the same contents as above with the .m3u extension. You can edit it manually as well and add the exact filenames in an order you desire.
|
||||
|
||||
After that you just have to do something like this:
|
||||
```
|
||||
mpv web_playlist.m3u
|
||||
|
||||
```
|
||||
|
||||
The great thing about MPV and the playlists, in general, is that you don’t have to binge-watch. You can see however much you want to do in one sitting and see the rest in the next session or the session after that.
|
||||
|
||||
I hope to do articles featuring MPV as well as how to make mkv files embedding subtitles in a media file but that’s in the future.
|
||||
|
||||
Note: It’s FOSS doesn’t encourage piracy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/create-m3u-playlist-linux/
|
||||
|
||||
作者:[Shirsh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/shirish/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/Create-M3U-Playlists.jpeg
|
||||
[2]:https://itsfoss.com/netflix-open-source-ai/
|
||||
[3]:https://itsfoss.com/download-youtube-linux/
|
||||
[4]:https://itsfoss.com/mpv-video-player/
|
||||
[5]:https://en.wikipedia.org/wiki/M3U
|
||||
@ -0,0 +1,74 @@
|
||||
Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension)
|
||||
======
|
||||
A Unity feature that I miss (it only actually worked for a short while though) is automatically getting player controls in the Ubuntu Sound Indicator when visiting a website like YouTube in a web browser, so you could pause or stop the video directly from the top bar, as well as see the video / song information and a preview.
|
||||
|
||||
This Unity feature is long dead, but I was searching for something similar for Gnome Shell and I came across **[browser-mpris2][1], an extension that implements a MPRIS v2 interface for Google Chrome / Chromium, which currently only supports YouTube** , and I thought there might be some Linux Uprising readers who'll like this.
|
||||
|
||||
**The extension also works with Chromium-based web browsers like Opera and Vivaldi.**
|
||||
**
|
||||
** **browser-mpris2 also supports Firefox but since loading extensions via about:debugging is temporary, and this is needed for browser-mpris2, this article doesn't include Firefox instructions. The developer[intends][2] to submit the extension to the Firefox addons website in the future.**
|
||||
|
||||
**Using this Chrome extension you get YouTube media player controls (play, pause, stop and seeking) in MPRIS2-capable applets**. For example, if you use Gnome Shell, you get YouTube media player controls as a permanent notification or, you can use an extension like Media Player Indicator for this. In Cinnamon / Linux Mint with Cinnamon, it shows up in the Sound Applet.
|
||||
|
||||
**It didn't work for me on Unity** , I'm not sure why. I didn't try this extension with other MPRIS2-capable applets available in various desktop environments (KDE, Xfce, MATE, etc.). If you give it a try, let us know if it works with your desktop environment / MPRIS2 enabled applet.
|
||||
|
||||
Here is a screenshot with [Media Player Indicator][3] displaying information about the currently playing YouTube video, along with its controls (play/pause, stop and seeking), on Ubuntu 18.04 with Gnome Shell and Chromium browser:
|
||||
|
||||
|
||||
|
||||
And in Linux Mint 19 Cinnamon with its default sound applet and Chromium browser:
|
||||
|
||||
|
||||
|
||||
### How to install browser-mpris2 for Google Chrome / Chromium
|
||||
|
||||
**1\. Install Git if you haven't already.**
|
||||
|
||||
In Debian / Ubuntu / Linux Mint, use this command to install git:
|
||||
```
|
||||
sudo apt install git
|
||||
|
||||
```
|
||||
|
||||
**2\. Download and install the[browser-mpris2][1] required files.**
|
||||
|
||||
The commands below clone the browser-mpris2 Git repository and install the chrome-mpris2 file to `/usr/local/bin/` (run the "git clone..." command in a folder where you can continue to keep the browser-mpris2 folder because you can't remove it, as it will be used by Chrome / Chromium):
|
||||
```
|
||||
git clone https://github.com/otommod/browser-mpris2
|
||||
sudo install browser-mpris2/native/chrome-mpris2 /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
**3\. Load the extension in Chrome / Chromium-based web browsers.**
|
||||
|
||||
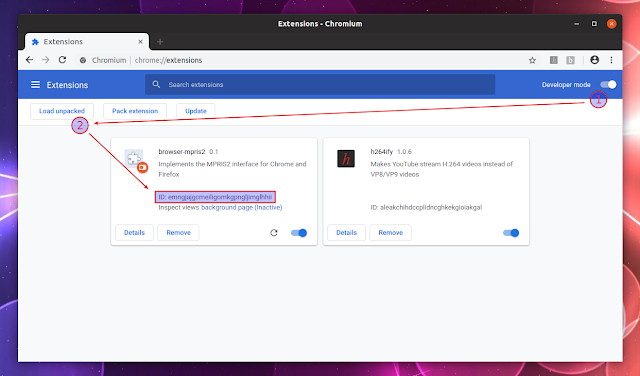
|
||||
|
||||
Open Google Chrome, Chromium, Opera or Vivaldi web browsers, go to the Extensions page (enter `chrome://extensions` in the URL bar), enable `Developer mode` using the toggle available in the top right-hand side of the screen, then select `Load Unpacked` and select the chrome-mpris2 directory (make sure to not select a subfolder).
|
||||
|
||||
Copy the extension ID and save it because you'll need it later (it's something like: `emngjajgcmeiligomkgpngljimglhhii` but it's different for you so make sure to use the ID from your computer!) .
|
||||
|
||||
**4\. Run** `install-chrome.py` (from the `browser-mpris2/native` folder), specifying the extension id and chrome-mpris2 path.
|
||||
|
||||
Use this command in a terminal (replace `REPLACE-THIS-WITH-EXTENSION-ID` with the browser-mpris2 extension ID displayed under `chrome://extensions` from the previous step) to install this extension:
|
||||
```
|
||||
browser-mpris2/native/install-chrome.py REPLACE-THIS-WITH-EXTENSION-ID /usr/local/bin/chrome-mpris2
|
||||
|
||||
```
|
||||
|
||||
You only need to run this command once, there's no need to add it to startup or anything like that. Any YouTube video you play in Google Chrome or Chromium browsers should show up in whatever MPRISv2 applet you're using. There's no need to restart the web browser.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/add-youtube-player-controls-to-your.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://github.com/otommod/browser-mpris2
|
||||
[2]:https://github.com/otommod/browser-mpris2/issues/11
|
||||
[3]:https://extensions.gnome.org/extension/55/media-player-indicator/
|
||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,74 @@
|
||||
Designing your garden with Edraw Max – FOSS adventures
|
||||
======
|
||||
|
||||
I watch a lot of [BBC Gardeners World][1], which gives me a lot of inspiration for making changes to my own garden. I tried looking for a free and open source program for designing gardens in the openSUSE [package search][2]. The only application that I found was Rosegarden, a MIDI and Audio Sequencer and Notation Editor. Using google, I found [Edraw Max][3], an all-in-one diagram software. This included a Floor planner, including templates for garden design. And there are download options for various Linux distributions, including openSUSE.
|
||||
|
||||
### Installation
|
||||
|
||||
You can download a 14-day free trial from the Edraw Max [website][4].
|
||||
|
||||
![][5]
|
||||
|
||||
The next thing to do, is use Dolphin and browse to your Downloads folder. Find the zipped package and double click it. Ark will automatically load it. Then click on the Extract button.
|
||||
|
||||
![][6]
|
||||
|
||||
Now you can press F4 in Dolphin to open the integrated terminal. If you type in the commands as listed on the Edraw website, the application will install without an issue.
|
||||
|
||||
![][7]
|
||||
|
||||
### Experience
|
||||
|
||||
From the application launcher (start menu), you can now type Edraw Max and launch the application. Go to New and then Floor Plan and click on Garden Design.
|
||||
|
||||
![][8]
|
||||
|
||||
On the left side, there is a side pane with a lot of elements that you can use for drawing (see picture below). Start with measuring your garden and with the walls, you can ‘draw’ the borders of your garden. On the right side, there is a side pane where you can adjust the properties of these elements. For instance you can edit the fill (color) of the element, the border (color) of the element and adjust the properties. I didn’t need the other parts of this right side pane (which included shadow, insert picture, layer, hyperlink, attachment and comments).
|
||||
|
||||
![][9]
|
||||
|
||||
Now you can make various different garden designs! This is one of the 6 designs that I created for my own garden.
|
||||
|
||||
![][10]
|
||||
|
||||
The last feature that I like to mention is the export possibilities. There is a lot of export options here, including Jpeg, Tiff, PDF, PS, EPS, Word, PowerPoint, Excel, HTML, SVG and Visio. In the unlicensed version, all exports work except for the Visio export. In the PDF you will see a watermark “Created by Unlicensed Version”.
|
||||
|
||||
![][11]
|
||||
|
||||
### Conclusion
|
||||
|
||||
As this is proprietary software, you will have to pay for it after 14 days. Unfortunately, the price is quite high. As a Linux user, you can only select the [Lifetime license][12], which currently costs $ 245. It is a very complete package (280 different types of diagrams), but I find the pricing too high for my purposes. And there is no option to pay less. For professional users I can imagine that this price would not be a big issue, as the software will pay itself back when you get payed for making designs. For me personally, it was a very nice experience to use this limited trial and it helped me to think of different ways in which I can redesign my garden.
|
||||
|
||||
**Published on: 16 august 2018**
|
||||
|
||||
### A FOSS alternative found!
|
||||
|
||||
Thanks to reddit user compairelapin, I have found an open source alternative. It is called Sweet Home 3D and its available in the [openSUSE package search][13]. In a future post, I will take a look at this software and compare it to Edraw Max.
|
||||
|
||||
**Updated on: 17 august 2018**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossadventures.com/designing-your-garden-with-edraw-max/
|
||||
|
||||
作者:[Martin De Boer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossadventures.com/author/martin_de_boer/
|
||||
[1]:https://www.bbc.co.uk/programmes/b006mw1h
|
||||
[2]:https://software.opensuse.org/
|
||||
[3]:https://www.edrawsoft.com/edraw-max.php
|
||||
[4]:https://www.edrawsoft.com/download-edrawmax.php
|
||||
[5]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-01-1024x463.jpeg
|
||||
[6]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-03.jpeg
|
||||
[7]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-04.jpeg
|
||||
[8]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-05.jpeg
|
||||
[9]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-06.jpeg
|
||||
[10]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-07.jpeg
|
||||
[11]:https://www.fossadventures.com/wp-content/uploads/2018/08/Edraw-Max-08.jpeg
|
||||
[12]:https://www.edrawsoft.com/orderedrawmax.php
|
||||
[13]:https://software.opensuse.org/package/SweetHome3D
|
||||
121
sources/tech/20180816 Garbage collection in Perl 6.md
Normal file
121
sources/tech/20180816 Garbage collection in Perl 6.md
Normal file
@ -0,0 +1,121 @@
|
||||
Garbage collection in Perl 6
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the [first article][1] in this series on migrating Perl 5 code to Perl 6, we looked into some of the issues you might encounter when porting your code. In this second article, we’ll get into how garbage collection differs in Perl 6.
|
||||
|
||||
There is no timely destruction of objects in Perl 6. This revelation usually comes as quite a shock to people used to the semantics of object destruction in Perl 5. But worry not, there are other ways in Perl 6 to get the same behavior, albeit requiring a little more thought by the developer. Let’s first examine a little background on the situation in Perl 5.
|
||||
|
||||
### Reference counting
|
||||
|
||||
In Perl 5, timely destruction of objects “going out of scope” is achieved by [reference counting][2]. When something is created in Perl 5, it has a reference count of 1 or more, which keeps it alive. In its simplest case it looks like this:
|
||||
```
|
||||
{
|
||||
|
||||
my $a = 42; # reference count of $a = 1, because lives in lexical pad
|
||||
|
||||
}
|
||||
|
||||
# lexical pad is gone, reference count to 0
|
||||
|
||||
```
|
||||
|
||||
In Perl 5, if the value is an object (aka blessed), the `DESTROY` method will be called on it.
|
||||
```
|
||||
{
|
||||
|
||||
my $a = Foo->new;
|
||||
|
||||
}
|
||||
|
||||
# $a->DESTROY called
|
||||
|
||||
```
|
||||
|
||||
If no external resources are involved, timely destruction is just another way of managing memory used by a program. And you, as a programmer, shouldn’t need to care about how and when things get recycled. Having said that, timely destruction is a very nice feature to have if you need to deal with external resources, such as database handles (of which there are generally only a limited number provided by the database server). And reference counting can provide that.
|
||||
|
||||
However, reference counting has several drawbacks. It has taken Perl 5 core developers many years to get reference counting working correctly. And if you’re working in [XS][3], you always need to be aware of reference counting to prevent memory leakage or premature destruction.
|
||||
|
||||
Keeping things in sync gets more difficult in a multi-threaded environment, as you do not want to lose any updates to references made from multiple threads at the same time (as that would cause memory leakage and/or external resources to not be released). To circumvent that, some kind of locking or atomic updates would be needed, neither of which are cheap.
|
||||
|
||||
> Please note that Perl 5 ithreads are more like an in-memory fork with unshared memory between interpreters than threads in programming languages such as C. So, it still doesn’t need any locking for its reference counting.
|
||||
|
||||
Reference counting also has the basic drawback that if two objects contain references to each other, they will never be destroyed as they keep each other’s reference count above 0 (a circular reference). In practice, this often goes much deeper, more like `A -> B -> C -> A`, where A, B, and C are all keeping each other alive.
|
||||
|
||||
The concept of a weak reference was developed to circumvent these situations in Perl 5. Although this can fix the circular reference issue, it has performance implications and doesn’t fix the problem of having (and finding) circular references in the first place. You need to be able to find out where a weak reference can be used in the best way; otherwise, you might get unwanted premature object destruction.
|
||||
|
||||
### Reachability analysis
|
||||
|
||||
Since Perl 6 is multi-threaded in its core, it was decided at a very early stage that reference counting would be problematic performance-wise and maintenance-wise. Instead, objects are evicted from memory when more memory is needed and the object can be safely removed.
|
||||
|
||||
`DESTROY` method, just as you can in Perl 5. But you cannot be sure when (if ever) it will be called.
|
||||
|
||||
In Perl 6 you can create amethod, just as you can in Perl 5. But you cannot be sure when (if ever) it will be called.
|
||||
|
||||
Without getting into [too much detail][4], objects in Perl 6 are destroyed only when a garbage collection run is initiated, e.g., when a certain memory limit has been reached. Only then, if an object cannot be reached anymore by other objects in memory and it has a `DESTROY` method, will it be called just prior to the object being removed.
|
||||
|
||||
No garbage collection is done by Perl 6 when a program exits. Applicable [phasers][5] (such as `LEAVE` and `END`) will get called, but no garbage collection will be done other than what is (indirectly) initiated by the code run in the phasers.
|
||||
|
||||
If you always need an orderly shutdown of external resources used by your program (such as database handles), you can use a phaser to make sure the external resource is freed in a proper and timely manner.
|
||||
|
||||
For example, you can use the `END` phaser (known as an `END` block in Perl 5) to disconnect properly from a database when the program exits (for whatever reason):
|
||||
```
|
||||
my $dbh = DBIish.connect( ... ) or die "Couldn't connect";
|
||||
|
||||
END $dbh.disconnect;DBIishENDdisconnect
|
||||
|
||||
```
|
||||
|
||||
Note that the `END` phaser does not need to have a block (like `{ ... }`) in Perl 6. If it doesn’t, the code in the phaser shares the lexical pad (lexpad) with the surrounding code.
|
||||
|
||||
There is one flaw in the code above: If the program exits before the database connection is made or if the database connection failed for whatever reason, it will still attempt to call the `.disconnect` method on whatever is in `$dbh`, which will result in an execution error. There is however a simple idiom to circumvent this situation in Perl 6 [using with][6].
|
||||
```
|
||||
END .disconnect with $dbh;
|
||||
|
||||
```
|
||||
|
||||
The postfix `with` matches only if the given value is defined (generally, an instantiated object) and then topicalizes it to `$_`. The `.disconnect` is short for `$_.disconnect`.
|
||||
|
||||
If you would like to have an external resource clean up whenever a specific scope is exited, you can use the `LEAVE` phaser inside that scope.
|
||||
```
|
||||
if DBIish.connect( ... ) -> $dbh {
|
||||
|
||||
LEAVE $dbh.disconnect; # no need for `with` here
|
||||
|
||||
# do your stuff with the database
|
||||
|
||||
}
|
||||
|
||||
else {
|
||||
|
||||
say "Could not do the stuff that needed to be done";
|
||||
|
||||
}DBIishLEAVEdisconnectsay
|
||||
|
||||
```
|
||||
|
||||
Whenever the scope of the `if` is left, any `LEAVE` phaser will be executed. Thus the database resource will be freed whenever the code has run in that scope.
|
||||
|
||||
### Summary
|
||||
|
||||
Even though Perl 6 does not have the timely destruction of objects that Perl 5 users are used to, it does have easy-to-use alternative ways to ensure management of external resources, similar to those in Perl 5.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/garbage-collection-perl-6
|
||||
|
||||
作者:[Elizabeth Mattijsen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/lizmat
|
||||
[1]:https://opensource.com/article/18/7/migrating-perl-5-perl-6
|
||||
[2]:https://en.wikipedia.org/wiki/Reference_counting
|
||||
[3]:https://en.wikipedia.org/wiki/XS_%28Perl%29
|
||||
[4]:https://github.com/MoarVM/MoarVM/blob/master/docs/gc.markdown
|
||||
[5]:https://docs.perl6.org/language/phasers
|
||||
[6]:https://docs.perl6.org/syntax/with%20orwith%20without
|
||||
@ -0,0 +1,224 @@
|
||||
AryaLinux: A Distribution and a Platform
|
||||
======
|
||||
|
||||

|
||||
|
||||
Most Linux distributions are simply that: A distribution of Linux that offers a variation on an open source theme. You can download any of those distributions, install it, and use it. Simple. There’s very little mystery to using Linux these days, as the desktop is incredibly easy to use and server distributions are required in business.
|
||||
|
||||
But not every Linux distribution ends with that idea; some go one step further and create both a distribution and a platform. Such is the case with [AryaLinux][1]. What does that mean? Easy. AryaLinux doesn’t only offer an installable, open source operating system, they offer a platform with which users can build a complete GNU/Linux operating system. The provided scripts were created based on the instructions from [Linux From Scratch][2] and [Beyond Linux From Scratch][3].
|
||||
|
||||
If you’ve ever attempted to build you own Linux distribution, you probably know how challenging it can be. AryaLinux has made that process quite a bit less stressful. In fact, although the build can take quite a lot of time (up to 48 hours), the process of building the AryaLinux platform is quite easy.
|
||||
|
||||
But don’t think that’s the only way you can have this distribution. You can download a live version of AryaLinux and install as easily as if you were working with Ubuntu, Linux Mint, or Elementary OS.
|
||||
|
||||
Let’s get AryaLinux up and running from the live distribution and then walk through the process of building the platform, using the special builder image.
|
||||
|
||||
### The Live distribution
|
||||
|
||||
From the [AryaLinux download pag][4]e, you can get a version of the operating system that includes either [GNOME][5] or [Xfce][6]. I chose the GNOME route and found it to be configured to include Dash to dock and Applications menu extensions. Both of these will please most average GNOME users. Once you’ve downloaded the ISO image, burn it to either a DVD/CD or to a USB flash drive and boot up the live instance. Do note, you need to have at least 25GB of space on a drive to install AryaLinux. If you’re planning on testing this out as a virtual machine, create a 30-40 GB virtual drive, otherwise the installer will fail every time.
|
||||
|
||||
Once booted, you will be presented with a login screen, with the default user selected. Simply click the user and login (there is no password required).
|
||||
|
||||
To locate the installer, click the Applications menu, click Activities Overview, type “installer” and click on the resulting entry. This will launch the AryaLinux installer … one that looks very familiar to many Linux installers (Figure 1).
|
||||
|
||||
![AryaLinux installer][8]
|
||||
|
||||
Figure 1: The AryaLinux installer is quite easy to navigate.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
In the next window (Figure 2), you are required to define a root partition. To do this, type “/” (no quotes) in the Choose the root partition section.
|
||||
|
||||
![root partition][11]
|
||||
|
||||
Figure 2: Defining your root partition for the AryaLinux installation.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
If you don’t define a home partition, it will be created for you. If you don’t define a swap partition, none will be created. If you have a need to create a home partition outside of the standard /home, do it here. The next installation windows have you do the following:
|
||||
|
||||
* Create a standard user.
|
||||
|
||||
* Create an administrative password.
|
||||
|
||||
* Choose locale and keyboard.
|
||||
|
||||
* Choose your timezone.
|
||||
|
||||
|
||||
|
||||
|
||||
That’s all there is to the installation. Once it completes, reboot, remove the media (or delete the .iso from your Virtual Machine storage listing), and boot into your newly-installed AryaLinux operating system.
|
||||
|
||||
### What’s there?
|
||||
|
||||
Out of the box, you should find everything necessary to use AryaLinux as a full-functioning desktop distribution. Included is:
|
||||
|
||||
* LibreOffice
|
||||
|
||||
* Rhythmbox
|
||||
|
||||
* Files
|
||||
|
||||
* GNOME Maps
|
||||
|
||||
* GIMP
|
||||
|
||||
* Simple Scan
|
||||
|
||||
* Chromium
|
||||
|
||||
* Transmission
|
||||
|
||||
* Avahi SSH/VNC Server Browser
|
||||
|
||||
* Qt5 Assistant/Designer/Linguist/QDbusViewer
|
||||
|
||||
* Brasero
|
||||
|
||||
* Cheese
|
||||
|
||||
* Echomixer
|
||||
|
||||
* VLC
|
||||
|
||||
* Network Tools
|
||||
|
||||
* GParted
|
||||
|
||||
* dconf Editor
|
||||
|
||||
* Disks
|
||||
|
||||
* Disk Usage Analyzer
|
||||
|
||||
* Document Viewer
|
||||
|
||||
* And more
|
||||
|
||||
|
||||
|
||||
|
||||
### The caveats
|
||||
|
||||
It should be noted that this is the first official release of AryaLinux, so there will be issues. Right off the bat I realized that no matter what I tried, I could not get the terminal to open. Unfortunately, the terminal is a necessary tool for this distribution, as there is no GUI for updating or installing packages. In order to get to a bash prompt, I had to use a virtual screen. That’s when the next caveat came into play. The package manager for AryaLinux is alps, but its primary purpose is working in conjunction with the build scripts to install the platform. Unfortunately there is no included man page for alps on AryaLinux and the documentation is very scarce. Fortunately, the developers did think to roll in Flatpak support, so if you’re a fan of Flatpak, you can install anything you need (so long as it’s available as a flatpak package) using that system.
|
||||
|
||||
### Building the platform
|
||||
|
||||
Let’s talk about building the AryaLinux platform. This isn’t much harder than installing the standard distribution, only it’s done via the command line. Here’s what you do:
|
||||
|
||||
1. Download the [AryaLinux Builder Disk][12].
|
||||
|
||||
2. Burn the ISO to either DVD/CD or USB flash drive.
|
||||
|
||||
3. Boot the live image.
|
||||
|
||||
4. Once you reach the desktop, open a terminal window from the menu.
|
||||
|
||||
5. Change to the root user with the command sudo su.
|
||||
|
||||
6. Change directories with the command cd aryalinux/base-system
|
||||
|
||||
7. Run the build script with the command ./build-arya
|
||||
|
||||
|
||||
|
||||
|
||||
You will first be asked if you want to start a fresh build or resume a build (Figure 3). Remember, the AryaLinux build takes a LOT of time, so there might be an instance where you’ve started a build and need to resume.
|
||||
|
||||
![AryaLinux build][14]
|
||||
|
||||
Figure 3: Running the AryaLinux build script.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
To start a new build, type “1” and then hit Enter on your keyboard. You will now be asked to define a number of options (in order to fulfill the build script requirements). Those options are:
|
||||
|
||||
* Bootloader Device
|
||||
|
||||
* Root Partition
|
||||
|
||||
* Home Partition
|
||||
|
||||
* Locale
|
||||
|
||||
* OS Name
|
||||
|
||||
* OS Version
|
||||
|
||||
* OS Codename
|
||||
|
||||
* Domain Name
|
||||
|
||||
* Keyboard Layout
|
||||
|
||||
* Printer Paper Size
|
||||
|
||||
* Enter Full Name
|
||||
|
||||
* Username
|
||||
|
||||
* Computer Name
|
||||
|
||||
* Use multiple cores for build (y/n)
|
||||
|
||||
* Create backups (y/n)
|
||||
|
||||
* Install X Server (y/n)
|
||||
|
||||
* Install Desktop Environment (y/n)
|
||||
|
||||
* Choose Desktop Environment (XFCE, Mate, KDE, GNOME)
|
||||
|
||||
* Do you want to configure advanced options (y/n)
|
||||
|
||||
* Create admin password
|
||||
|
||||
* Create password for standard user
|
||||
|
||||
* Install bootloader (y/n)
|
||||
|
||||
* Create Live ISO (y/n)
|
||||
|
||||
* Select a timezone
|
||||
|
||||
|
||||
|
||||
|
||||
After you’ve completed the above, the build will start. Don’t bother watching it, as it will take a very long time to complete (depending upon your system and network connection). In fact, the build can take anywhere from 8-48 hours. After the build completes, reboot and log into your newly built AryaLinux platform.
|
||||
|
||||
### Who is AryaLinux for?
|
||||
|
||||
I’ll be honest, if you’re just a standard desktop user, AryaLinux is not for you. Although you can certainly get right to work on the desktop, if you need anything outside of the default applications, you might find it a bit too much trouble to bother with. If, on the other hand, you’re a developer, AryaLinux might be a great platform for you. Or, if you just want to see what it’s like to build a Linux distribution from scratch, AryaLinux is a pretty easy route.
|
||||
|
||||
Even with its quirks, AryaLinux holds a lot of promise as both a Linux distribution and platform. If the developers can see to it to build a GUI front-end for the alps package manager, AryaLinux could make some serious noise.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][15]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/8/aryalinux-distribution-and-platform
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:http://aryalinux.org
|
||||
[2]:http://www.linuxfromscratch.org/
|
||||
[3]:http://www.linuxfromscratch.org/blfs/
|
||||
[4]:http://aryalinux.org/downloads/
|
||||
[5]:https://sourceforge.net/projects/aryalinux/files/releases/1.0/aryalinux-gnome-1.0-x86_64-fixed.iso
|
||||
[6]:https://sourceforge.net/projects/aryalinux/files/releases/1.0/aryalinux-xfce-1.0-x86_64.iso
|
||||
[7]:/files/images/aryalinux1jpg
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/aryalinux_1.jpg?itok=vR11z5So (AryaLinux installer)
|
||||
[9]:/licenses/category/used-permission
|
||||
[10]:/files/images/aryalinux2jpg
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/aryalinux_2.jpg?itok=Lm50af-y (root partition)
|
||||
[12]:https://sourceforge.net/projects/aryalinux/files/releases/1.0/aryalinux-builder-1.0-x86_64.iso
|
||||
[13]:/files/images/aryalinux3jpg
|
||||
[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/aryalinux_3.jpg?itok=J-GUq99C (AryaLinux build)
|
||||
[15]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,282 @@
|
||||
Cloudgizer: An introduction to a new open source web development tool
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Cloudgizer][1] is a free open source tool for building web applications. It combines the ease of scripting languages with the performance of [C][2], helping manage the development effort and run-time resources for cloud applications.
|
||||
|
||||
Cloudgizer works on [Red Hat][3]/[CentOS][4] Linux with the [Apache web server][5] and [MariaDB database][6]. It is licensed under [Apache License version 2][7].
|
||||
|
||||
### Hello World
|
||||
|
||||
In this example, we output an [HTTP][8] header and Hello World, followed by a horizontal line:
|
||||
```
|
||||
#include "cld.h"
|
||||
|
||||
void home()
|
||||
{
|
||||
/*<
|
||||
output-http-header
|
||||
|
||||
Hello World!
|
||||
<hr/>
|
||||
>*/
|
||||
}
|
||||
```
|
||||
|
||||
Cloudgizer code is written as a C comment with `/*<` and `>*/` at the beginning and ending, respectively.
|
||||
|
||||
Writing output to the web client is as simple as directly writing [HTML][9] code in your source. There are no API calls or special markups for that—simplicity is good because HTML (or [JavaScript][10], [CSS][11], etc.) will probably comprise a good chunk of your code.
|
||||
|
||||
### How it works
|
||||
|
||||
Cloudgizer source files (with a `.v` extension) are translated into C code by the `cld` command-line tool. C code is then compiled and linked with the web server and your application is ready to be used. For instance, generated code for the source file named `home.v` would be `__home.c`, if you'd like to examine it.
|
||||
|
||||
Much of your code will be written as "markups," small snippets of intuitive and descriptive code that let you easily do things like the following:
|
||||
|
||||
* database queries
|
||||
* web programming
|
||||
* encoding and encryption
|
||||
* executing programs
|
||||
* safe string manipulation
|
||||
* file operations
|
||||
* sending emails
|
||||
|
||||
|
||||
|
||||
and other common tasks. For less common tasks, there is an API that covers broader functionality. And ultimately, you can write any C code and use any libraries you wish to complete your task.
|
||||
|
||||
The `main()` function is generated by Cloudgizer and is a part of the framework, which provides Apache and database integration and other services. One such service is tracing and debugging (including memory garbage collection, underwrite/overwrite detection, run-time HTML linting, etc.). A program crash produces a full stack, including the source code lines, and the crash report is emailed to you the moment it happens.
|
||||
|
||||
A Cloudgizer application is linked with the Apache server as an Apache module in a pre-fork configuration. This means the Apache web server will pre-fork a number of processes and direct incoming requests to them. The Apache module mechanism provides high-performance request handling for applications.
|
||||
|
||||
All Cloudgizer applications run under the same Linux user, with each application separated under its own application directory. This user is also the Apache user; i.e., the user running the web server.
|
||||
|
||||
Each application has its own database with the name matching that of the application. Cloudgizer establishes and maintains database connections across requests, increasing performance.
|
||||
|
||||
### Development process
|
||||
|
||||
The process of compiling your source code and building an installation file is automated. By using the `cldpackapp` script, you’ll transform your code into pure C code and create an installation file (a [.tar.gz file][12]). The end user will install this file with the help of a configuration file called `appinfo`, producing a working web application. This process is straightforward:
|
||||
|
||||
|
||||
|
||||
The deployment process is designed to be automated if needed, with configurable parameters.
|
||||
|
||||
### Getting started
|
||||
|
||||
The development starts with installing [the Example application][13]. This sets up the development environment; you start with a Hello World and build up your application from there.
|
||||
|
||||
The Example application also serves as a smoke test because it has a number of code snippets that test various Cloudgizer features. It also gives you a good amount of example code (hence the name).
|
||||
|
||||
There are two files to be aware of as you start:
|
||||
|
||||
* `cld_handle_request.v` is where incoming requests (such as `GET`, `POST`, or a command-line execution) are processed.
|
||||
* `sourcelist` lists all your source code so that Cloudgizer can make your application.
|
||||
|
||||
|
||||
|
||||
In addition to `cld_handle_request.v`, `oops.v` implements an error handler, and `file_too_large.v` implements a response to an upload that's too large. These are already implemented in the Example application, and you can keep them as they are or tweak them.
|
||||
|
||||
Use `cldbuild` to recompile source-file (`.v`) changes, and `cldpackapp` to create an installer file for testing or release delivery via `cldgoapp`:
|
||||
|
||||
|
||||
|
||||
Deployment via `cldgoapp` lets you install an application from scratch or update from one version to another.
|
||||
|
||||
### Example
|
||||
|
||||
Here's a stock-ticker application that updates and reports on ticker prices. It is included in the Example application.
|
||||
|
||||
#### The code
|
||||
|
||||
The request handler checks the URL query parameter page, and if it's `stock`, it calls `function stock()`:
|
||||
```
|
||||
#include "cld.h"
|
||||
|
||||
void cld_handle_request()
|
||||
{
|
||||
/*<
|
||||
input-param page
|
||||
|
||||
if-string page="stock"
|
||||
c stock ();
|
||||
else
|
||||
report-error "Unrecognized page %s", page
|
||||
end-if
|
||||
>*/
|
||||
}
|
||||
```
|
||||
|
||||
The implementation of function `stock()` would be in file `stock.v`. The code adds a stock ticker if the URL query parameter action is `add` or shows all stock tickers if it is `show`.
|
||||
```
|
||||
#include "cld.h"
|
||||
|
||||
void stock()
|
||||
{
|
||||
/*<
|
||||
|
||||
output-http-header
|
||||
|
||||
<html>
|
||||
<body>
|
||||
input-param action
|
||||
|
||||
if-string action="add"
|
||||
input-param stock_name
|
||||
input-param stock_price
|
||||
|
||||
run-query#add_data = "insert into stock \
|
||||
(stock_name, stock_price) values \
|
||||
(<?stock_name?>, <?stock_price?>) \
|
||||
on duplicate key update \
|
||||
stock_price=<?stock_price?>"
|
||||
|
||||
query-result#add_data, error as \
|
||||
define err
|
||||
|
||||
if atoi(err) != 0
|
||||
report-error "Cannot update \
|
||||
stock price, error [%s]",err
|
||||
end-if
|
||||
end-query
|
||||
|
||||
<div>
|
||||
Stock price updated!
|
||||
</div>
|
||||
else-if-string action="show"
|
||||
<table>
|
||||
<tr>
|
||||
<td>Stock name</td>
|
||||
<td>Stock price</td>
|
||||
</tr>
|
||||
run-query#show_data = "select stock_name, \
|
||||
stock_price from stock"
|
||||
|
||||
<tr>
|
||||
<td>
|
||||
query-result#show_data, stock_name
|
||||
</td>
|
||||
<td>
|
||||
query-result#show_data, stock_price
|
||||
</td>
|
||||
</tr>
|
||||
end-query
|
||||
</table>
|
||||
else
|
||||
<div>Unrecognized request!</div>
|
||||
end-if
|
||||
</body>
|
||||
</html>
|
||||
>*/
|
||||
}
|
||||
```
|
||||
|
||||
#### The database table
|
||||
|
||||
The SQL table used would be:
|
||||
```
|
||||
create table stock (stock_name varchar(100) primary key, stock_price bigint);
|
||||
```
|
||||
|
||||
#### Making and packaging
|
||||
|
||||
To include `stock.v` in your Cloudgizer application, simply add it to the sourcelist file:
|
||||
```
|
||||
SOURCE_FILES=stock.v ....
|
||||
...
|
||||
stock.o : stock.v $(CLDINCLUDE)/cld.h $(HEADER_FILES)
|
||||
...
|
||||
```
|
||||
|
||||
To recompile changes to your code, use:
|
||||
```
|
||||
cldbuild
|
||||
```
|
||||
|
||||
To package your application for deployment, use:
|
||||
```
|
||||
cldpackapp
|
||||
```
|
||||
|
||||
When packaging an application, all additional objects you create (other than source code files), should be included in the `create.sh` file. This file sets up anything that the Cloudgizer application installer doesn't do; in this case, create the above SQL table. For example, the following code in your `create.sh` might suffice:
|
||||
```
|
||||
echo -e "drop table if exists stock;\ncreate table stock (stock_name varchar(100) primary key, stock_price bigint);" | mysql -u root -p$CLD_DB_ROOT_PWD -D $CLD_APP_NAME
|
||||
```
|
||||
|
||||
In `create.sh`, you can use any variables from the `appinfo` file (an installation configuration file). Those variables always include `CLD_DB_ROOT_PWD` (the root password database, which is always automatically cleared after installation for security), `CLD_APP_NAME` (the application and database name), `CLD_SERVER` (the URL of the installation server), `CLD_EMAIL` (the administration and notification email address), and others. You also have `CLD_APP_HOME_DIR` (the application's home directory) and `CLD_APP_INSTALL_DIR` (the location where the installation .tar.gz file had been unzipped so you can copy files from it). You can include any other variables in the `appinfo` file that you find useful.
|
||||
|
||||
#### Using the application
|
||||
|
||||
If your application name is 'myapp' running on myserver.com, then the URL to update a stock ticker would be this:
|
||||
```
|
||||
https://myserver.com/go.myapp?page=stock&action=add&stock_name=RHT&stock_price=500
|
||||
```
|
||||
|
||||
and the URL to show all stock tickers would be this:
|
||||
```
|
||||
https://myserver.com/go.myapp?page=stock&action=show
|
||||
```
|
||||
|
||||
(The URL path for all Cloudgizer applications always starts with `go.`; in this case, `go.myapp`.)
|
||||
|
||||
### Download and more examples
|
||||
|
||||
For more examples or download and installation details, visit [Zigguro.org/cloudgizer][14]. You'll also find the above example included in the installation (see [the Example application source code][15]).
|
||||
|
||||
For a much larger real-world example, check out the [source code][16] for [Rentomy][17], a free open source cloud application for rental property managers, written entirely in Cloudgizer and consisting of over 32,000 lines of code.
|
||||
|
||||
### Why use Cloudgizer?
|
||||
|
||||
Here's why Rentomy is written in Cloudgizer:
|
||||
|
||||
Originally, the goal was to use one of the popular [scripting languages][18] or [process virtual machines][19] like [Java][20], and to host Rentomy as a [Software-as-a-Service][21] (Saas) free of charge.
|
||||
|
||||
Since there are nearly 50 million rental units in the US alone, a free service like this needs superior software performance.
|
||||
|
||||
So squeezing more power from CPUs and using less RAM became very important. And with [Moore's Law slowing down][22], the bloat of popular web languages is costing more computing resources—we're talking about process-virtual machines, interpreters, [p-code generators][23], etc.
|
||||
|
||||
Debugging can be a pain because more layers of abstraction exist between you and what's really going on. Not every library can be easily used, so some functional and interoperability limitations remain.
|
||||
|
||||
On the other hand, in terms of big performance and a small footprint, there is no match for C. Most libraries are written in C for the same reason, so virtually any library you need is available, and debugging is straightforward.
|
||||
|
||||
However, C has issues with memory and overall safety (overwrites, underwrites, garbage collection, etc.), usability (it is low-level), application packaging, etc. And equally important, much of the development cost lies in the ease of writing and debugging the code and in its accessibility to novices.
|
||||
|
||||
From this perspective, Cloudgizer was born. Greater performance and a smaller footprint mean cheaper computing power. Easy, stable coding brings Zen to the development process, as does the ability to manage it better.
|
||||
|
||||
In hindsight, using Cloudgizer to build Rentomy was like using a popular scripting language without the issues.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/cloudgizer-intro
|
||||
|
||||
作者:[Sergio Mijares][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sergio-mijares
|
||||
[1]:https://zigguro.org/cloudgizer/
|
||||
[2]:https://en.wikipedia.org/wiki/C_%28programming_language%29
|
||||
[3]:https://www.redhat.com/en
|
||||
[4]:https://www.centos.org/
|
||||
[5]:http://httpd.apache.org/
|
||||
[6]:https://mariadb.com/
|
||||
[7]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[8]:https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
|
||||
[9]:https://en.wikipedia.org/wiki/HTML
|
||||
[10]:https://en.wikipedia.org/wiki/JavaScript
|
||||
[11]:https://en.wikipedia.org/wiki/Cascading_Style_Sheets
|
||||
[12]:https://opensource.com/article/17/7/how-unzip-targz-file
|
||||
[13]:https://zigguro.org/cloudgizer/#install
|
||||
[14]:https://zigguro.org/cloudgizer
|
||||
[15]:https://bitbucket.org/zigguro/cloudgizer_example/src
|
||||
[16]:https://bitbucket.org/zigguro/rentomy/src
|
||||
[17]:https://zigguro.org/rentomy/
|
||||
[18]:https://en.wikipedia.org/wiki/Scripting_language
|
||||
[19]:https://en.wikipedia.org/wiki/Virtual_machine
|
||||
[20]:https://www.java.com/en/
|
||||
[21]:https://en.wikipedia.org/wiki/Software_as_a_service
|
||||
[22]:https://www.engineering.com/ElectronicsDesign/ElectronicsDesignArticles/ArticleID/17209/DARPAs-100-Million-Programs-for-a-Silicon-Compiler-and-a-New-Open-Hardware-Ecosystem.aspx
|
||||
[23]:https://en.wikipedia.org/wiki/P-code_machine
|
||||
@ -0,0 +1,279 @@
|
||||
Linux DNS 查询剖析 – 第一部分
|
||||
============================================================
|
||||
|
||||
我经常与虚拟机集群打交道([文1][3], [文2][4], [文3][5], [文4][6], [文5][7], [文6][8]),期间花费了大量时间试图掌握 [DNS 查询][9]的工作原理。遇到问题时,我有时只是不求甚解的使用 StackOverflow 上的“解决方案”;甚至那些“解决方案”有时并不工作。
|
||||
|
||||
最终我决定改变这种情况,决定一并找出所有问题的原因。我没有在网上找到完整手册或类似的其它东西,我问过一些同事,他们也是如此。
|
||||
|
||||
既然如此,我开始自己写这样的手册。
|
||||
|
||||
_如果你在找第二部分, 点击 [这里][1]_
|
||||
|
||||
结果发现,“Linux 执行一次 DNS 查询”的背后有相当多的工作。
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_“究竟有多难呢?”_
|
||||
|
||||
* * *
|
||||
|
||||
本系列文章试图将 Linux 主机上程序获取(域名对应的) IP 地址的过程及期间涉及的组件进行分块剖析。如果不理解这些块的协同工作方式,调试并解决 `dnsmasq`,`vagrant landrush` 和 `resolvconf` 等相关的问题会让人感到眼花缭乱。
|
||||
|
||||
同时这也是一份有价值的说明,指出原本很简单的东西可以如何随着时间的推移变得相当复杂。在弄清楚 DNS 查询的原理的过程中,我了解了大量不同的技术及其发展历程。
|
||||
|
||||
我甚至编写了一些[自动化脚本][10],可以让我在虚拟机中进行实验。欢迎读者参与贡献或勘误。
|
||||
|
||||
请注意,本系列主题并不是“DNS 工作原理”,而是与查询 Linux 主机配置的真实 DNS 服务器(这里假设查询了 DNS 服务器,但后面你会看到有时并不需要查询)相关的内容,以及如何确定使用哪个查询结果,或者何时使用其它方式确定 IP 地址。
|
||||
|
||||
* * *
|
||||
|
||||
### 1) 其实并没有名为“DNS 查询”的系统调用
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_工作方式并非如此_
|
||||
|
||||
* * *
|
||||
|
||||
首先要了解的一点是,Linux 上并没有一个单独的方法可以完成 DNS 查询工作;至少没有如此<ruby>明确接口<rt>clean interface</rt></ruby>的核心<ruby>系统调用<rt>system call</rt></ruby>。
|
||||
|
||||
有一个标准 C 库函数调用 `[getaddrinfo][2]`,不少程序使用了该调用;但不是所有程序或应用都使用该调用!
|
||||
|
||||
我们只考虑两个简单的标准程序:`ping` 和 `host`:
|
||||
|
||||
```
|
||||
root@linuxdns1:~# ping -c1 bbc.co.uk | head -1
|
||||
PING bbc.co.uk (151.101.192.81) 56(84) bytes of data.
|
||||
```
|
||||
|
||||
```
|
||||
root@linuxdns1:~# host bbc.co.uk | head -1
|
||||
bbc.co.uk has address 151.101.192.81
|
||||
```
|
||||
|
||||
对于同一个域名,两个程序得到的 IP 地址是相同的;那么它们是使用同样的方法得到结果的吧?
|
||||
|
||||
事实并非如此。
|
||||
|
||||
下面文件给出了我主机上 `ping` 对应的 DNS 相关的系统调用:
|
||||
|
||||
```
|
||||
root@linuxdns1:~# strace -e trace=open -f ping -c1 google.com
|
||||
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
|
||||
open("/lib/x86_64-linux-gnu/libcap.so.2", O_RDONLY|O_CLOEXEC) = 3
|
||||
open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
|
||||
open("/etc/resolv.conf", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/resolv.conf", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/lib/x86_64-linux-gnu/libnss_files.so.2", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/host.conf", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/lib/x86_64-linux-gnu/libnss_dns.so.2", O_RDONLY|O_CLOEXEC) = 4
|
||||
open("/lib/x86_64-linux-gnu/libresolv.so.2", O_RDONLY|O_CLOEXEC) = 4
|
||||
PING google.com (216.58.204.46) 56(84) bytes of data.
|
||||
open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 4
|
||||
64 bytes from lhr25s12-in-f14.1e100.net (216.58.204.46): icmp_seq=1 ttl=63 time=13.0 ms
|
||||
[...]
|
||||
```
|
||||
|
||||
下面是 `host` 对应的系统调用:
|
||||
|
||||
```
|
||||
$ strace -e trace=open -f host google.com
|
||||
[...]
|
||||
[pid 9869] open("/usr/share/locale/en_US.UTF-8/LC_MESSAGES/libdst.cat", O_RDONLY) = -1 ENOENT (No such file or directory)
|
||||
[pid 9869] open("/usr/share/locale/en/libdst.cat", O_RDONLY) = -1 ENOENT (No such file or directory)
|
||||
[pid 9869] open("/usr/share/locale/en/LC_MESSAGES/libdst.cat", O_RDONLY) = -1 ENOENT (No such file or directory)
|
||||
[pid 9869] open("/usr/lib/ssl/openssl.cnf", O_RDONLY) = 6
|
||||
[pid 9869] open("/usr/lib/x86_64-linux-gnu/openssl-1.0.0/engines/libgost.so", O_RDONLY|O_CLOEXEC) = 6[pid 9869] open("/etc/resolv.conf", O_RDONLY) = 6
|
||||
google.com has address 216.58.204.46
|
||||
[...]
|
||||
```
|
||||
|
||||
可以看出 `ping` 打开了 `nsswitch.conf` 文件,但 `host` 没有;但两个程序都打开了 `/etc/resolv.conf` 文件。
|
||||
|
||||
下面我们依次查看这两个 `.conf` 扩展名的文件。
|
||||
|
||||
* * *
|
||||
|
||||
### 2) NSSwitch 与 `/etc/nsswitch.conf`
|
||||
|
||||
我们已经确认应用可以自主决定选用哪个 DNS 服务器。很多应用(例如 `ping`)通过配置文件 `/etc/nsswitch.conf` (根据具体实现 (*))参考 NSSwitch 完成选择。
|
||||
|
||||
###### (*) ping 实现的变种之多令人惊叹。我 _不_ 希望在这里讨论过多。
|
||||
|
||||
NSSwitch 不仅用于 DNS 查询,例如,还用于密码与用户信息查询。
|
||||
|
||||
NSSwitch 最初是 Solaris OS 的一部分,可以让应用无需将查询所需的文件或服务硬编码,而是在其它集中式的、无需应用开发人员管理的配置文件中找到。
|
||||
|
||||
下面是我的 `nsswitch.conf`:
|
||||
|
||||
```
|
||||
passwd: compat
|
||||
group: compat
|
||||
shadow: compat
|
||||
gshadow: files
|
||||
hosts: files dns myhostname
|
||||
networks: files
|
||||
protocols: db files
|
||||
services: db files
|
||||
ethers: db files
|
||||
rpc: db files
|
||||
netgroup: nis
|
||||
```
|
||||
|
||||
我们需要关注的是 `hosts` 行。我们知道 `ping` 用到 `nsswitch.conf` 文件,那么我们修改这个文件(的 `hosts` 行),看看能够如何影响 `ping`。
|
||||
|
||||
|
||||
* ### 修改 `nsswitch.conf`, `hosts` 行仅保留 `files`
|
||||
|
||||
如果你修改 `nsswitch.conf`,将 `hosts` 行仅保留 `files`:
|
||||
|
||||
`hosts: files`
|
||||
|
||||
此时, `ping` 无法获取 google.com 对应的 IP 地址:
|
||||
|
||||
```
|
||||
$ ping -c1 google.com
|
||||
ping: unknown host google.com
|
||||
```
|
||||
|
||||
但 `localhost` 的解析不受影响:
|
||||
|
||||
```
|
||||
$ ping -c1 localhost
|
||||
PING localhost (127.0.0.1) 56(84) bytes of data.
|
||||
64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.039 ms
|
||||
```
|
||||
|
||||
此外,`host` 命令正常返回:
|
||||
|
||||
```
|
||||
$ host google.com
|
||||
google.com has address 216.58.206.110
|
||||
```
|
||||
|
||||
毕竟如我们之前看到的那样,`host` 不受 `nsswitch.conf` 影响。
|
||||
|
||||
* ### 修改 `nsswitch.conf`, `hosts` 行仅保留 `dns`
|
||||
|
||||
如果你修改 `nsswitch.conf`,将 `hosts` 行仅保留 `dns`:
|
||||
|
||||
`hosts: dns`
|
||||
|
||||
此时,google.com 的解析恢复正常:
|
||||
|
||||
```
|
||||
$ ping -c1 google.com
|
||||
PING google.com (216.58.198.174) 56(84) bytes of data.
|
||||
64 bytes from lhr25s10-in-f174.1e100.net (216.58.198.174): icmp_seq=1 ttl=63 time=8.01 ms
|
||||
```
|
||||
|
||||
但 `localhost` 无法解析:
|
||||
|
||||
```
|
||||
$ ping -c1 localhost
|
||||
ping: unknown host localhost
|
||||
```
|
||||
|
||||
下图给出默认 NSSwitch 中 `hosts` 行对应的查询逻辑:
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_我的 `hosts:` 配置是 `nsswitch.conf` 给出的默认值_
|
||||
|
||||
* * *
|
||||
|
||||
### 3) `/etc/resolv.conf`
|
||||
|
||||
我们已经知道 `host` 和 `ping` 都使用 `/etc/resolv.conf` 文件。
|
||||
|
||||
下面给出我主机的 `/etc/resolv.conf` 文件内容:
|
||||
|
||||
```
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.3
|
||||
```
|
||||
|
||||
先忽略前两行,后面我们会回过头来看这部分(它们很重要,但你还需要一些知识储备)。
|
||||
|
||||
其中 `nameserver` 行指定了查询用到的 DNS 服务器。
|
||||
|
||||
如果将该行注释掉:
|
||||
|
||||
```
|
||||
#nameserver 10.0.2.3
|
||||
```
|
||||
|
||||
再次运行:
|
||||
|
||||
```
|
||||
$ ping -c1 google.com
|
||||
ping: unknown host google.com
|
||||
```
|
||||
|
||||
解析失败了,这是因为没有可用的 nameserver (*)。
|
||||
|
||||
|
||||
###### * 另一个需要注意的地方: `host` 在没有指定 nameserver 的情况下会尝试 127.0.0.1:53。
|
||||
|
||||
该文件中还可以使用其它选项。例如,你可以在 `resolv.conf` 文件中增加如下行:
|
||||
|
||||
```
|
||||
search com
|
||||
```
|
||||
然后执行 `ping google` (不写 `.com`)
|
||||
|
||||
```
|
||||
$ ping google
|
||||
PING google.com (216.58.204.14) 56(84) bytes of data.
|
||||
```
|
||||
|
||||
程序会自动为你尝试 `.com` 域。
|
||||
|
||||
### 第一部分总结
|
||||
|
||||
第一部分到此结束,下一部分我们会了解 `resolv.conf` 文件是如何创建和更新的。
|
||||
|
||||
下面总结第一部分涵盖的内容:
|
||||
|
||||
* 操作系统中并不存在“DNS 查询”这个系统调用
|
||||
* 不同程序可能采用不同的策略获取名字对应的 IP 地址
|
||||
* 例如, `ping` 使用 `nsswitch`,后者进而使用(或可以使用) `/etc/hosts`,`/etc/resolv.conf` 以及主机名得到解析结果
|
||||
|
||||
* `/etc/resolv.conf` 用于决定:
|
||||
* 查询什么地址(LCTT 译注:这里可能指 search 带来的影响)
|
||||
* 使用什么 DNS 服务器执行查询
|
||||
|
||||
如果你曾认为 DNS 查询很复杂,请跟随这个系列学习吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
|
||||
作者:[dmatech][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/dmatech2
|
||||
[1]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[2]:http://man7.org/linux/man-pages/man3/getaddrinfo.3.html
|
||||
[3]:https://zwischenzugs.com/2017/10/31/a-complete-chef-infrastructure-on-your-laptop/
|
||||
[4]:https://zwischenzugs.com/2017/03/04/a-complete-openshift-cluster-on-vagrant-step-by-step/
|
||||
[5]:https://zwischenzugs.com/2017/03/04/migrating-an-openshift-etcd-cluster/
|
||||
[6]:https://zwischenzugs.com/2017/03/04/1-minute-multi-node-vm-setup/
|
||||
[7]:https://zwischenzugs.com/2017/03/18/clustered-vm-testing-how-to/
|
||||
[8]:https://zwischenzugs.com/2017/10/27/ten-things-i-wish-id-known-before-using-vagrant/
|
||||
[9]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
|
||||
[10]:https://github.com/ianmiell/shutit-linux-dns/blob/master/linux_dns.py
|
||||
@ -1,15 +1,15 @@
|
||||
Slices from the ground up
|
||||
============================================================
|
||||
从零开始学习切片
|
||||
======
|
||||
|
||||
这篇文章最初的灵感来源于我与一个使用切片作栈的同事的一次聊天。那次聊天,话题最后拓展到了 Go 语言中的切片是如何工作的。我认为把这些知识记录下来会帮到别人。
|
||||
这篇文章受到了我与同事讨论使用<ruby>切片<rt>slice</rt></ruby>作为<ruby>栈<rt>stack</rt></ruby>的一次聊天的启发。后来话题聊到了 Go 语言中的切片是如何工作的。我认为这些信息对别人也有用,所以就把它记录了下来。
|
||||
|
||||
### 数组
|
||||
|
||||
任何关于 Go 语言的切片的讨论都要从另一个数据结构,也就是 Go 语言的数组开始。Go 语言的数组有两个特性:
|
||||
任何关于 Go 语言切片的讨论都要从另一个数据结构也就是<ruby>数组<rt>array</rt></ruby>开始。Go 的数组有两个特性:
|
||||
|
||||
1. 数组的长度是固定的;`[5]int` 是由 5 个 `unt` 构成的数组,和`[3]int` 不同。
|
||||
1. 数组的长度是固定的;`[5]int` 是由 5 个 `int` 构成的数组,和 `[3]int` 不同。
|
||||
2. 数组是值类型。看下面这个示例:
|
||||
|
||||
2. 数组是值类型。考虑如下示例:
|
||||
```
|
||||
package main
|
||||
|
||||
@ -23,19 +23,19 @@ Slices from the ground up
|
||||
}
|
||||
```
|
||||
|
||||
语句 `b := a` 定义了一个新的变量 `b`,类型是 `[5]int`,然后把 `a` 中的内容_复制_到 `b` 中。改变 `b` 中的值对 `a` 中的内容没有影响,因为 `a` 和 `b` 是相互独立的值。 [1][1]
|
||||
语句 `b := a` 定义了一个类型是 `[5]int` 的新变量 `b`,然后把 `a` 中的内容 _复制_ 到 `b` 中。改变 `b` 对 `a` 中的内容没有影响,因为 `a` 和 `b` 是相互独立的值。[^1]
|
||||
|
||||
### 切片
|
||||
|
||||
Go 语言的切片和数组的主要有如下两个区别:
|
||||
|
||||
1. 切片没有一个固定的长度。切片的长度不是它类型定义的一部分,而是由切片内部自己维护的。我们可以使用内置的 `len` 函数知道他的长度。
|
||||
1. 切片没有一个固定的长度。切片的长度不是它类型定义的一部分,而是由切片内部自己维护的。我们可以使用内置的 `len` 函数知道它的长度。[^2]
|
||||
2. 将一个切片赋值给另一个切片时 _不会_ 对切片进行复制操作。这是因为切片没有直接保存它的内部数据,而是保留了一个指向 _底层数组_ [^3] 的指针。数据都保留在底层数组里。
|
||||
|
||||
2. 将一个切片赋值给另一个切片时 _不会_ 将切片进行复制操作。这是因为切片没有直接保存它的内部数据,而是保留了一个指向 _底层数组_ [3][3]的指针。数据都保留在底层数组里。
|
||||
|
||||
基于第二个特性,两个切片可以享有共同的底层数组。考虑如下示例:
|
||||
基于第二个特性,两个切片可以享有共同的底层数组。看下面的示例:
|
||||
|
||||
1. 对切片取切片
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
@ -49,9 +49,10 @@ Go 语言的切片和数组的主要有如下两个区别:
|
||||
}
|
||||
```
|
||||
|
||||
在这个例子里,`a` 和 `b` 享有共同的底层数组 —— 尽管 `b` 的起始值在数组里的偏移不同,两者的长度也不同。通过 `b` 修改底层数组的值也会导致 `a` 里的值的改变。
|
||||
在这个例子里,`a` 和 `b` 享有共同的底层数组 —— 尽管 `b` 在数组里的起始偏移量不同,两者的长度也不同。通过 `b` 修改底层数组的值也会导致 `a` 里的值的改变。
|
||||
|
||||
2. 将切片传进函数
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
@ -72,7 +73,7 @@ Go 语言的切片和数组的主要有如下两个区别:
|
||||
|
||||
在这个例子里,`a` 作为形参 `s` 的实参传进了 `negate` 函数,这个函数遍历 `s` 内的元素并改变其符号。尽管 `nagate` 没有返回值,且没有接触到 `main` 函数里的 `a`。但是当将之传进 `negate` 函数内时,`a` 里面的值却被改变了。
|
||||
|
||||
大多数程序员都能直观地了解 Go 语言切片的底层数组是如何工作的,因为它与其他语言中类似数组的工作方式类似。比如下面就是使用 Python 重写的这一小节的第一个示例:
|
||||
大多数程序员都能直观地了解 Go 语言切片的底层数组是如何工作的,因为它与其它语言中类似数组的工作方式类似。比如下面就是使用 Python 重写的这一小节的第一个示例:
|
||||
|
||||
```
|
||||
Python 2.7.10 (default, Feb 7 2017, 00:08:15)
|
||||
@ -98,11 +99,11 @@ irb(main):004:0> a
|
||||
=> [1, 2, 0, 4, 5]
|
||||
```
|
||||
|
||||
在大多数将数组视为对象或者是引用类型的语言也是如此。[4][8]
|
||||
在大多数将数组视为对象或者是引用类型的语言也是如此。[^4]
|
||||
|
||||
### 切片头
|
||||
|
||||
让切片得以同时拥有值和指针的特性的魔法来源于切片实际上是一个结构体类型。这个结构体通常叫做 _切片头_,这里是 [反射包内的相关定义][20]。且片头的定义大致如下:
|
||||
切片同时拥有值和指针特性的神奇之处在于理解切片实际上是一个<ruby>结构体<rt>struct</rt></ruby>类型。这个结构体通常叫做 _切片头_,这里是[<ruby>反射<rt>reflect</rt></ruby>包内的相关定义][7]。切片头的定义大致如下:
|
||||
|
||||
|
||||
|
||||
@ -116,9 +117,9 @@ type slice struct {
|
||||
}
|
||||
```
|
||||
|
||||
这个头很重要,因为和[ `map` 以及 `chan` 这两个类型不同][21],切片是值类型,当被赋值或者被作为函数的参数时候会被复制过去。
|
||||
这很重要,因为和 [`map` 以及 `chan` 这两个类型不同][7],切片是值类型,当被赋值或者被作为参数传入函数时候会被复制过去。
|
||||
|
||||
程序员们都能理解 `square` 的形参 `v` 和 `main` 中声明的 `v` 的是相互独立的,我们一次为例。
|
||||
程序员们都能理解 `square` 的形参 `v` 和 `main` 中声明的 `v` 的是相互独立的。请看下面的例子:
|
||||
|
||||
```
|
||||
package main
|
||||
@ -154,13 +155,13 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
Go 语言的切片是作为值传递的这一点很是不寻常。当你在 Go 语言内定义一个结构体时,90% 的时间里传递的都是这个结构体的指针。[5][9] 切片的传递方式真的很不寻常,我能想到的唯一与之相同的例子只有 `time.Time`。
|
||||
Go 的切片是作为值传递的这一点很是不寻常。当你在 Go 内定义一个结构体时,90% 的时间里传递的都是这个结构体的指针[^5]。切片的传递方式真的很不寻常,我能想到的唯一与之相同的例子只有 `time.Time`。
|
||||
|
||||
切片作为值传递而不是作为指针传递这一点会让很多想要理解切片的工作原理的 Go 程序员感到困惑,这是可以理解的。你只需要记住,当你对切片进行赋值,取切片,传参或者作为返回值等操作时,你是在复制结构体内的三个位域:指针,长度,以及容量。
|
||||
切片作为值传递而不是作为指针传递这一特殊行为会让很多想要理解切片的工作原理的 Go 程序员感到困惑,这是可以理解的。你只需要记住,当你对切片进行赋值,取切片,传参或者作为返回值等操作时,你是在复制切片头结构的三个字段:指向底层数组的指针,长度,以及容量。
|
||||
|
||||
### 总结
|
||||
|
||||
我们来用我们引出这一话题的切片作为栈的例子来总结下本文的内容:
|
||||
我们来用引出这一话题的切片作为栈的例子来总结下本文的内容:
|
||||
|
||||
```
|
||||
package main
|
||||
@ -181,7 +182,7 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
在 `main` 函数的最开始我们把一个 `nil` 切片以及 `level` 0传给了函数 `f`。在函数 `f` 里我们把当前的 `level` 添加到切片的后面,之后增加 `level` 的值并进行递归。一旦 `level` 大于 5,函数返回,打印出当前的 `level` 以及他们复制到的 `s` 的内容。
|
||||
在 `main` 函数的最开始我们把一个 `nil` 切片以及 `level` 的值 0 传给了函数 `f`。在函数 `f` 里我们把当前的 `level` 添加到切片的后面,之后增加 `level` 的值并进行递归。一旦 `level` 大于 5,函数返回,打印出当前的 `level` 以及它们复制到的 `s` 的内容。
|
||||
|
||||
```
|
||||
level: 5 slice: [0 1 2 3 4 5]
|
||||
@ -192,69 +193,46 @@ level: 1 slice: [0 1]
|
||||
level: 0 slice: [0]
|
||||
```
|
||||
|
||||
你可以注意到在每一个 `level` 内 `s` 的值没有被别的 `f` 的调用影响,尽管当计算更高阶的 `level` 时作为 `append` 的副产品,调用栈内的四个 `f` 函数创建了四个底层数组,但是没有影响到当前各自的切片。
|
||||
你可以注意到在每一个 `level` 内 `s` 的值没有被别的 `f` 的调用影响,尽管当计算更高的 `level` 时作为 `append` 的副产品,调用栈内的四个 `f` 函数创建了四个底层数组[^6],但是没有影响到当前各自的切片。
|
||||
|
||||
### 了解更多
|
||||
### 扩展阅读
|
||||
|
||||
如果你想要了解更多 Go 语言内切片运行的原理,我建议看看 Go 博客里的这些文章:
|
||||
|
||||
* [Go Slices: usage and internals][11] (blog.golang.org)
|
||||
|
||||
* [Arrays, slices (and strings): The mechanics of ‘append’][12] (blog.golang.org)
|
||||
* [Go Slices: usage and internals][5] (blog.golang.org)
|
||||
* [Arrays, slices (and strings): The mechanics of 'append'][6] (blog.golang.org)
|
||||
|
||||
### 注释
|
||||
|
||||
1. 这不是数组才有的特性,在 Go 语言里,_一切_ 赋值都是复制过去的,
|
||||
|
||||
2. 你可以在对数组使用 `len` 函数,但是得到的结果是多少人尽皆知。[][14]
|
||||
|
||||
3. 也叫做后台数组,以及更不严谨的说法是后台切片。[][15]
|
||||
|
||||
4. Go 语言里我们倾向于说值类型以及指针类型,因为 C++ 的引用会使使用引用类型这个词产生误会。但是在这里我说引用类型是没有问题的。[][16]
|
||||
|
||||
5. 如果你的结构体有[定义在其上的方法或者实现了什么接口][17],那么这个比率可以飙升到接近 100%。[][18]
|
||||
|
||||
6. 证明留做习题。
|
||||
[^1]: 这不是数组才有的特性,在 Go 语言里中 _一切_ 赋值都是复制过去的。
|
||||
[^2]: 你也可以在对数组使用 `len` 函数,但是得到的结果是多少人尽皆知。
|
||||
[^3]: 有时也叫做<ruby>后台数组<rt>backing array</rt></ruby>,以及更不严谨的说法是后台切片。
|
||||
[^4]: Go 语言里我们倾向于说值类型以及指针类型,因为 C++ 的<ruby>引用<rt>reference</rt></ruby>类型这个词产生误会。但在这里我认为调用数组作为引用类型是没有问题的。
|
||||
[^5]: 如果你的结构体有[定义在其上的方法或者用于满足某个接口][7],那么你传入结构体指针的比率可以飙升到接近 100%。
|
||||
[^6]: 证明留做习题。
|
||||
|
||||
### 相关文章:
|
||||
|
||||
1. [If a map isn’t a reference variable, what is it?][4]
|
||||
1. [If a map isn't a reference variable, what is it?][1]
|
||||
2. [What is the zero value, and why is it useful?][2]
|
||||
3. [The empty struct][3]
|
||||
4. [Should methods be declared on T or *T][4]
|
||||
|
||||
2. [What is the zero value, and why is it useful ?][5]
|
||||
|
||||
3. [The empty struct][6]
|
||||
|
||||
4. [Should methods be declared on T or *T][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
---
|
||||
|
||||
via: https://dave.cheney.net/2018/07/12/slices-from-the-ground-up
|
||||
|
||||
作者:[Dave Cheney][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://dave.cheney.net/
|
||||
[1]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-1-3265
|
||||
[2]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-2-3265
|
||||
[3]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-3-3265
|
||||
[4]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
[5]:https://dave.cheney.net/2013/01/19/what-is-the-zero-value-and-why-is-it-useful
|
||||
[6]:https://dave.cheney.net/2014/03/25/the-empty-struct
|
||||
[7]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
|
||||
[8]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-4-3265
|
||||
[9]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-5-3265
|
||||
[10]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-bottom-6-3265
|
||||
[11]:https://blog.golang.org/go-slices-usage-and-internals
|
||||
[12]:https://blog.golang.org/slices
|
||||
[13]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-1-3265
|
||||
[14]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-2-3265
|
||||
[15]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-3-3265
|
||||
[16]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-4-3265
|
||||
[17]:https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
|
||||
[18]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-5-3265
|
||||
[19]:https://dave.cheney.net/2018/07/12/slices-from-the-ground-up#easy-footnote-6-3265
|
||||
[20]:https://golang.org/pkg/reflect/#SliceHeader
|
||||
[21]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
[1]: https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
[2]: https://dave.cheney.net/2013/01/19/what-is-the-zero-value-and-why-is-it-useful
|
||||
[3]: https://dave.cheney.net/2014/03/25/the-empty-struct
|
||||
[4]: https://dave.cheney.net/2016/03/19/should-methods-be-declared-on-t-or-t
|
||||
[5]: https://blog.golang.org/go-slices-usage-and-internals
|
||||
[6]: https://blog.golang.org/slices
|
||||
[7]: https://golang.org/pkg/reflect/#SliceHeader
|
||||
|
||||
@ -1,102 +0,0 @@
|
||||
UNIX 的好奇
|
||||
======
|
||||
最近我在用我编写的各种工具做更多 UNIX 下的事情,我遇到了两个有趣的问题。这些都不是 “bug”,而是我没想到的行为。
|
||||
|
||||
### 线程安全的 printf
|
||||
|
||||
我有一个 C 程序从磁盘读取一些图像,进行一些处理,并将有关这些图像的输出写入 STDOUT。伪代码:
|
||||
```
|
||||
for(imagefilename in images)
|
||||
{
|
||||
results = process(imagefilename);
|
||||
printf(results);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
处理对于每个图像是独立的,因此我自然希望在各个 CPU 之间分配处理以加快速度。我通常使用 `fork()`,所以我写了这个:
|
||||
```
|
||||
for(child in children)
|
||||
{
|
||||
pipe = create_pipe();
|
||||
worker(pipe);
|
||||
}
|
||||
|
||||
// main parent process
|
||||
for(imagefilename in images)
|
||||
{
|
||||
write(pipe[i_image % N_children], imagefilename)
|
||||
}
|
||||
|
||||
worker()
|
||||
{
|
||||
while(1)
|
||||
{
|
||||
imagefilename = read(pipe);
|
||||
results = process(imagefilename);
|
||||
printf(results);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这是正常的事情:我为 IPC 创建管道,并通过这些管道发送子 worker 的图像名。每个 worker _能够_通过另一组管道将其结果写回主进程,但这很痛苦,所以每个 worker 都直接写入共享 STDOUT。这工作正常,但正如人们所预料的那样,对 STDOUT 的写入发生冲突,因此各种图像的结果最终会分散。这那很糟。我不想设置我自己的锁,但幸运的是 GNU libc 为它提供了函数:[`flockfile()`][1]。我把它们放进去了......但是没有用!为什么?因为 `flockfile()` 的内部最终因为 `fork()` 的写时复制行为而限制在单个子进程中。即 `fork()`提供的额外安全性(与线程相比),这实际上最终破坏了锁。
|
||||
|
||||
我没有尝试使用其他锁机制(例如 pthread 互斥锁),但我可以想象它们会遇到类似的问题。我想保持简单,所以将输出发送回父输出是不可能的:这给程序员和运行程序的计算机制造了更多的工作。
|
||||
|
||||
解决方案:使用线程而不是 fork。这有制造冗余管道的好的副作用。最终的伪代码:
|
||||
```
|
||||
for(children)
|
||||
{
|
||||
pthread_create(worker, child_index);
|
||||
}
|
||||
for(children)
|
||||
{
|
||||
pthread_join(child);
|
||||
}
|
||||
|
||||
worker(child_index)
|
||||
{
|
||||
for(i_image = child_index; i_image < N_images; i_image += N_children)
|
||||
{
|
||||
results = process(images[i_image]);
|
||||
flockfile(stdout);
|
||||
printf(results);
|
||||
funlockfile(stdout);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Much simpler, and actually works as desired. I guess sometimes threads are better.
|
||||
这更简单,实际按照需要的那样工作。我猜有时线程更好。
|
||||
|
||||
### 将部分读取的文件传递给子进程
|
||||
|
||||
对于各种 [vnlog][2] 工具,我需要实现这个次序:
|
||||
|
||||
1. 进程打开一个关闭 O_CLOEXEC 标志的文件
|
||||
2. 进程读取此文件的一部分(在 vnlog 的情况下直到图例的末尾)
|
||||
3. 进程调用 exec 以调用另一个程序来处理已经打开的文件的其余部分
|
||||
|
||||
第二个程序可能需要命令行中的文件名而不是已打开的文件描述符,因为第二个程序可能自己调用 open()。如果我传递文件名,这个新程序将重新打开文件,然后从头开始读取文件,而不是从原始程序停止的位置开始读取。这个不会在我的程序上发生很重要,因此将文件名传递给第二个程序是行不通的。
|
||||
|
||||
所以我真的需要以某种方式传递已经打开的文件描述符。我在使用 Linux(其他操作系统可能在这里表现不同),所以我理论上可以通过传递 /dev/fd/N 而不是文件名来实现。但事实证明这也不起作用。在 Linux上(再说一次,也许是特定于 Linux)对于普通文件 /dev/fd/N 是原始文件的符号链接。所以这最终完成了与传递文件名完全相同的事情。
|
||||
|
||||
但有一个临时方案!如果我们正在读取管道而不是文件,那么没有什么可以符号链接,并且 /dev/fd/N 最终将原始管道传递给第二个进程,然后程序正常工作。我可以通过将上面的 open(“filename”)更改为 popen(“cat filename”)之类的东西来伪装。呸!这真的是我们能做的最好的吗?这在 BSD 上看上去会怎么样?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://notes.secretsauce.net/notes/2018/08/03_unix-curiosities.html
|
||||
|
||||
作者:[Dima Kogan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://notes.secretsauce.net/
|
||||
[1]:https://www.gnu.org/software/libc/manual/html_node/Streams-and-Threads.html
|
||||
[2]:http://www.github.com/dkogan/vnlog
|
||||
@ -0,0 +1,178 @@
|
||||
在 Linux 中使用 top 命令的建议
|
||||
======
|
||||
|
||||

|
||||
|
||||
尝试找出你的机器正在运行的是什么程序,以及哪个进程耗尽了内存导致运行非常非常慢——这些都是 `top` 命令所能胜任的任务。
|
||||
|
||||
`top` 是一个非常有用的程序,其作用类似于 Windows 任务管理器或 MacOS 的活动监视器。在 *nix 机器上运行 `top` 将显示系统上运行的进程的实时运行视图。
|
||||
|
||||
```
|
||||
$ top
|
||||
```
|
||||
|
||||
取决于你正在运行的 `top` 版本,你将获得如下所示的内容:
|
||||
|
||||
```
|
||||
top - 08:31:32 up 1 day, 4:09, 0 users, load average: 0.20, 0.12, 0.10
|
||||
Tasks: 3 total, 1 running, 2 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.5 us, 0.3 sy, 0.0 ni, 99.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
KiB Mem: 4042284 total, 2523744 used, 1518540 free, 263776 buffers
|
||||
KiB Swap: 1048572 total, 0 used, 1048572 free. 1804264 cached Mem
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
1 root 20 0 21964 3632 3124 S 0.0 0.1 0:00.23 bash
|
||||
193 root 20 0 123520 29636 8640 S 0.0 0.7 0:00.58 flask
|
||||
195 root 20 0 23608 2724 2400 R 0.0 0.1 0:00.21 top
|
||||
```
|
||||
|
||||
你所用的 `top` 版本可能跟这个看起来不一样,特别是在显示的列上。
|
||||
|
||||
### 如何阅读输出的内容
|
||||
|
||||
你可以根据输出判断您正在运行的内容,但尝试去解释结果你可能会有些困惑。
|
||||
|
||||
前几行包含一堆统计信息(详细信息),后跟一个包含结果列表的表(列表)。 让我们从后者开始吧。
|
||||
|
||||
### 列表
|
||||
|
||||
这些是正运行在系统上的进程。默认按 CPU 使用率降序排序。这意味着在列表顶部的程序正使用更多的 CPU 资源和对你的系统造成更重的负担。对于资源使用而言,这些程序是字面上的消耗最多(top)进程。你必须承认,`top` 程序名字起得很妙。
|
||||
|
||||
最右边的`COMMAND`一列报告进程名(你用来启动它们的命令)。在这个例子里,进程名是`bash` (一个我们正在运行 `top` 的命令解释器)、`flask`(一个 Python 写的 web 框架) 和 `top` 自身。
|
||||
|
||||
其他列提供了关于进程的有效信息。
|
||||
|
||||
* `PID`: 进程 ID,一个用来定位进程的唯一标识符
|
||||
* `USER`:运行进程的用户
|
||||
* `PR`: 任务的优先度
|
||||
* `NI`: 优先度的一个更好的表现形式
|
||||
* `VIRT`: 虚拟内存的大小 单位是 Kib(kibibytes)
|
||||
* `RES`: 常驻内存大小 单位是 KiB (物理内存和虚拟内存的一部分)
|
||||
* `SHR`: 共享内存大小 单位是 KiB(共享内存和虚拟内存的一部分)
|
||||
* `S`: 进程状态, 一般 **I** 代表空闲,**R** 代表运行,**S** 代表休眠,, **Z** 代表僵尸进程,, **T** or **t** 代表停止(还有其他更少见的选项)
|
||||
* `%CPU`: 自从上次屏幕结果更新后的 CPU 使用率
|
||||
* `%MEM`: 自从上次屏幕更新后的`RES`常驻内存使用率
|
||||
* `TIME+`: 自从程序开始后总的 CPU 使用时间
|
||||
* `COMMAND`: 启动命令,如之前描述那样
|
||||
|
||||
确切知道 `VIRT` , `RES` 和 `SHR` 值代表什么在日常操作中并不重要。重要的事情是知道`VIRT` 值最高的那个进程是那个使用最多内存的进程。如果你在用 `top` 找为什么你的电脑运行慢得就像行走在糖蜜池时,那个`VIRT` 数值最大的进程就是元凶。如果你想要知道共享内存和物理内存的确切意思,请查阅[ top 手册][1]的 Linux 内存类型。
|
||||
|
||||
是的,我说的是 kibibytes 而不是 kilobytes。通常称为 kilobyte 的1024值实际上是 kibibyte 。 希腊语的 kilo ("χίλιοι") 意思是一千或者千(例如一千米是 1000 米,一千克是 1000 克)。Kibi 是 kilo 和 byte 的合成词,意思是 1024 字节(或者 210 )。但是,因为这个词很难说,所以很多人在说 1024 字节的时候会说 kilobyte。所有这些意味着 `top` 试图在这里使用恰当的术语,所以随它去吧。
|
||||
|
||||
#### 屏幕更新说明
|
||||
|
||||
实时屏幕更新是 Linux 程序可以做的 ** 非常酷 ** 的事情之一。这意味着程序能实时更新它们显示的内容,所以看起来很生动,即使它们使用的是文本。非常酷!在我们的例子里,更新之间的时间是重要的,因为我们的一些数据(`%CPU` 和 `%MEM`)是基于上次屏幕更新的数值的。
|
||||
|
||||
因为我们正在运行一个持续的应用,我们能按下按键命令对设置或者配置进行实时的修改(也就是说,关闭应用,然后用一个不同的命令行标志位来再次运行该应用)。
|
||||
|
||||
按下 `h` 调用帮助界面,界面也显示默认延迟(屏幕更新的时间间隔)。这个值默认(大约)是3秒,但是你能输入 `d` (大概是延迟 delay 的意思) 或者 `s` (可能是屏幕 screen 或者秒 seconds 的意识) 来修改这个默认值。
|
||||
|
||||
#### 细节
|
||||
|
||||
在上面的进程列表里有一大堆有用的信息。有些细节看起来奇怪,令人感到困惑。但是一旦你花一些时间来逐个过一遍,你会发现,在紧要关头,这些是非常有用的数据。
|
||||
|
||||
第一行包含系统的大致信息
|
||||
|
||||
* `top`:我们正在运行 `top`!你好! `top`!
|
||||
* `XX:YY:XX`: 当前时间,每次屏幕更新的时候更新
|
||||
* `up` (接下去是`X day, YY:ZZ`): 系统的 [正常运行时间][2],或者自从系统启动后已经过去了多长时间
|
||||
* `load average` (接下去是三个数字): 分别是过去 一分钟、五分钟、15分钟的 [系统负载][3]
|
||||
|
||||
第二行 (`Task`)显示了正在运行的任务的信息,不用解释。它显示了进程总数和正在运行的、休眠中的、停止的进程数和僵尸进程数。这实际上是上述 `S` (状态)列的总和。
|
||||
|
||||
第三行(`%Cpu(s)`)显示了按类型划分的 CPU 使用情况。数据是屏幕刷新之间的值。这些值是:
|
||||
|
||||
* `us`: 用户进程
|
||||
* `sy`: 系统进程
|
||||
* `ni`: [nice][4] 用户进程
|
||||
* `id`: CPU 的闲置时间, 高闲置时间意味着除此之外不会有太多事情发生
|
||||
* `wa`: 等待时间,或者花在等待 I/O 完成的时间
|
||||
* `hi`: 花在硬件中断的时间
|
||||
* `si`: 花在软件中断的时间
|
||||
* `st`: “虚拟机管理程序从该虚拟机窃取的时间”
|
||||
|
||||
你能通过点击`t` (触发 toggle 的意思)来展开 `Task` 和`%Cpu(s)` 列。
|
||||
|
||||
第四行(`Kib Mem`)和第五行(`KiB Swap`)提供了内存和交换空间的信息。这些数值是:
|
||||
|
||||
* `total`
|
||||
* `used`
|
||||
* `free`
|
||||
|
||||
还有:
|
||||
|
||||
* 内存的缓冲值
|
||||
* 交换空间的缓存值
|
||||
|
||||
默认它们是用 KiB 为单位展示的,但是按下 `E` (扩展内存缩放 extend memory scaling 的意思)能在不同的数值轮换:KiB 、MiB、 GiB、 TiB、 PiB、 EiB (kilobytes, megabytes, gigabytes, terabytes, petabytes, 和 exabytes,它们真正的名字)
|
||||
|
||||
`top` 用户手册甚至显示了关于有效标志位和配置的更多信息。 你能运行 `man top` 来找到你系统上的文档。有不同的网页显示 [HTML 版的手册][1],但是请留意,这些手册可能是给不同 top 版本看的。
|
||||
|
||||
### 两个 top 的替代品
|
||||
|
||||
你不必总是用 `top` 来理解发生了什么。根据您的情况,其他工具可能会帮助您诊断问题,尤其是当您想要更图形化或专业的界面时。
|
||||
|
||||
#### htop
|
||||
|
||||
`htop` 很像 `top` ,但是它给表格带来了一些非常有用的东西: CPU 和内存使用的图形表示。
|
||||
|
||||

|
||||
|
||||
这就是我们在 `top` 中考察的环境在`htop` 中的样子。显示要简单得多,但仍有丰富的功能。
|
||||
|
||||
我们的任务计数、负载、正常运行时间和进程列表仍然存在,但是我们获得了每个内核CPU使用情况的漂亮、彩色、动画视图和内存使用情况图表。
|
||||
|
||||
以下是不同颜色的含义(你也可以通过按“h”来获得这些信息,以获得“帮助”)。
|
||||
|
||||
CPU任务优先级或类型:
|
||||
|
||||
* 蓝色:低优先级
|
||||
* 绿色:正常优先级
|
||||
* 红色:核心任务
|
||||
* 蓝色:虚拟化任务
|
||||
* 条形末尾的值是已用CPU的百分比
|
||||
|
||||
内存:
|
||||
|
||||
* 绿色:已经使用的内存
|
||||
* 蓝色:缓冲的内存
|
||||
* 黄色:缓存内存
|
||||
* 条形图末尾的值显示已用内存和总内存
|
||||
|
||||
如果颜色对你没用,你可以运行 `htop - C` 来禁用它们;否则,`htop` 将使用不同的符号来分隔CPU和内存类型。
|
||||
|
||||
在底部,有一个有效功能键的提示,你可以用它来过滤结果或改变排序顺序。 尝试一些命令,看看它们能做什么。只是尝试 `F9` 时要小心。 这将会产生一个信号列表,这些信号会杀死(即停止)一个过程。 我建议在生产环境之外探索这些选项。
|
||||
|
||||
`htop` 的作者,Hisham Muhammad (是的,用 Hisham 命名的 `htop`)在二月份 的 [FOSDEM 2018][6] 就 [lightning talk][5] 做了一个展示。他解释 `htop` 是如何不仅有清晰的图形,还用更现代化的统计信息展示进程信息,这都是之前的工具 `top` 所不具备的。
|
||||
|
||||
你可以在 [手册页面][7] 或 [htop 网站][8] 阅读更多关于 `htop` 的信息。(警告:网站包含动画背景`htop`。)
|
||||
|
||||
#### docker stats
|
||||
|
||||
如果你正在用 Docker工作,你可以运行 `docker stats`来生成一个丰富的上下文来表示你的容器在做什么。
|
||||
|
||||
这可能比 `top` 更有帮助,因为您不是按进程分类,而是按容器分类。当容器运行缓慢时,这一点特别有用,因为查看哪个容器使用的资源最多比运行 `top` 和试图将进程映射到容器要快。
|
||||
|
||||
上面对 `top` 和 `htop` 中首字母缩略词和描述符的解释应该会让你更容易理解 `docker stats` 中的那些。然而,[docker stats 文档] [9]对每一栏都提供了有用的描述。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/top-tips-speed-up-computer
|
||||
|
||||
作者:[Katie McLaughlin][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/glasnt
|
||||
[1]:http://man7.org/linux/man-pages/man1/top.1.html
|
||||
[2]:https://en.wikipedia.org/wiki/Uptime
|
||||
[3]:https://en.wikipedia.org/wiki/Load_(computing)
|
||||
[4]:https://en.wikipedia.org/wiki/Nice_(Unix)#Etymology
|
||||
[5]:https://www.youtube.com/watch?v=L25waVhy78o
|
||||
[6]:https://fosdem.org/2018/schedule/event/htop/
|
||||
[7]:https://linux.die.net/man/1/htop
|
||||
[8]:https://hisham.hm/htop/index.php
|
||||
[9]:https://docs.docker.com/engine/reference/commandline/stats/
|
||||
Loading…
Reference in New Issue
Block a user