mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
commit
ed13207568
published
20210625 Windows 11 Makes Your Hardware Obsolete, Use Linux Instead.md
202107
20180416 Cgo and Python.md20180713 What-s the difference between a fork and a distribution.md20190807 Trace code in Fedora with bpftrace.md20200210 Music composition with Python and Linux.md20200428 Learn Bash with this book of puzzles.md20200528 9 open source JavaScript frameworks for front-end web development.md20200807 An advanced guide to NLP analysis with Python and NLTK.md20200914 Use Python to solve a charity-s business problem.md20201012 My top 7 keywords in Rust.md20201105 6 evening rituals for working in tech.md20210129 Machine learning made easy with Python.md20210317 Programming 101- Input and output with Java.md20210418 F(r)iction- Or How I Learnt to Stop Worrying and Start Loving Vim.md20210508 My weird jobs before tech.md20210517 How to look at the stack with gdb.md20210529 Configuring Vim as a Writing Tool.md20210529 My family-s Linux story.md20210606 How Real-World Apps Lose Data.md20210612 How to get KDE Plasma 5.22 in Kubuntu 21.04 Hirsute Hippo.md20210614 What is a CI-CD pipeline.md20210616 Hash Linux- Arch Linux Preconfigured With Xmonad, Awesome, i3, and Bspwm Window Manager.md20210621 Jim Hall- How Do You Fedora.md20210621 Replace man pages with Tealdeer on Linux.md20210624 Copy files between Linux and FreeDOS.md20210624 View statistics about your code with Tokei.md20210625 How to Setup Internet in CentOS, RHEL, Rocky Linux Minimal Install.md20210625 Use Python to parse configuration files.md20210627 Using Git Version Control as a Writer.md20210628 Forgot Linux Password on WSL- Here-s How to Reset it Easily.md20210628 How to archive files on FreeDOS.md20210628 How to parse Bash program configuration files.md20210628 Query your Linux operating system like a database.md20210629 A brief history of FreeDOS.md20210629 Fotoxx- An Open Source App for Managing and Editing Large Photo Collection.md20210630 Parse JSON configuration files with Groovy.md20210703 Can Windows 11 Influence Linux Distributions.md20210703 Identify flowers and trees with this open source mobile app.md20210704 7 guides about open source to keep your brain busy this summer.md20210705 Enter invisible passwords using this Python module.md20210706 Edit PDFs on the Linux command line.md20210706 Send and receive Gmail from the Linux command line.md20210707 Generate passwords on the Linux command line.md20210708 Encrypt and decrypt files with a passphrase on Linux.md20210708 Linux Mint 20.2 is Now Available With New Features and Tools.md20210708 Write good examples by starting with real code.md20210709 How to Install Zlib on Ubuntu Linux.md20210712 Box64 Emulator Released for Arm64 Linux.md20210712 Converseen for Batch Processing Images on Linux.md20210712 What is XML.md20210713 Use XMLStarlet to parse XML in your the Linux terminal.md20210714 Getting Started with Podman on Fedora.md20210714 How different programming languages read and write data.md20210716 Apps for daily needs part 1- web browsers.md20210719 Linux package managers- dnf vs apt.md20210719 Run Python applications in virtual environments.md20210720 Meet Clapper- A Sleek Looking Linux Video Player for Minimalists.md20210720 Run a Linux virtual machine in Podman.md20210722 Top Android Emulators to Run and Test Android Apps on Linux.md20210722 Ubuntu 20.10 Reached End of Life, Time to Upgrade.md20210725 How to Install VLC on Fedora Linux.md
20210720 Install Shutter in Fedora 34 and Above.mdsources
news
20210625 Windows 11 Makes Your Hardware Obsolete, Use Linux Instead.md20210707 Nextcloud Hub 22 Makes It Easy to Collaborate and Manage Groups.md20210710 Linux Mint 20.2 -Uma- Released. This is What-s New.md
talk
20210418 F(r)iction- Or How I Learnt to Stop Worrying and Start Loving Vim.md20210730 What do we call post-modern system administrators.md20210731 Dealing with burnout in open source.md
tech
20210525 Pen testing with Linux security tools.md20210720 How to Upgrade to Debian 11 from Debian 10.md20210720 Install Shutter in Fedora 34 and Above.md20210726 How to use cron on Linux.md20210727 Analyze the Linux kernel with ftrace.md20210727 Check used disk space on Linux with du.md20210727 How to Change Lock and Login Screen Wallpaper in elementary OS.md20210728 Create your own custom Raspberry Pi image.md20210728 Getting started with Maxima in Fedora Linux.md20210728 Kernel tracing with trace-cmd.md20210729 5 reasons you should run your apps on WildFly.md20210730 4 cool new projects to try in Copr from July 2021.md20210730 Brave vs. Firefox- Your Ultimate Browser Choice for Private Web Experience.md
translated/tech
@ -0,0 +1,111 @@
|
||||
[#]: subject: (Windows 11 Makes Your Hardware Obsolete, Use Linux Instead!)
|
||||
[#]: via: (https://news.itsfoss.com/windows-11-linux/)
|
||||
[#]: author: (Ankush Das https://news.itsfoss.com/author/ankush/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zd200572)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13640-1.html)
|
||||
|
||||
Windows 11 让你的硬件过时,使用 Linux 代替吧!
|
||||
======
|
||||
|
||||
> 微软希望你为 Windows 11 买新的硬件。你是否应该为 Windows 11 升级你的电脑,或者只是,用 Linux 代替!?
|
||||
|
||||

|
||||
|
||||
Windows 11 终于来了,我们并不完全对此感到兴奋,它给许多电脑用户带来了困扰。
|
||||
|
||||
我甚至不是在讨论隐私方面或者它的设计选择,而是 Windows 11 要求更新的硬件才能工作,这在某种程度上让你的旧电脑变得过时,并迫使你毫无理由地升级新的硬件。
|
||||
|
||||
随着 Windows 11 的到来还有什么问题呢,它有什么不好的?
|
||||
|
||||
### 只有符合条件的设备才能获得 Windows 11 升级
|
||||
|
||||
首先,有意思的是,Windows 11 添加了一个最低系统需求,这表面上看起来还行:
|
||||
|
||||
* 1GHz 双核 64 位处理器
|
||||
* 4GB 内存
|
||||
* 64GB 存储空间
|
||||
* 支持 UEFI 安全启动
|
||||
* 受信任平台模块(TPM)版本 2.0
|
||||
* DirectX 12 兼容显卡
|
||||
* 720P 分辨率显示器
|
||||
|
||||
![][1]
|
||||
|
||||
你可以在 [微软官方网站][2] 下载“电脑健康状况检查”应用检查你的系统是否符合条件。
|
||||
|
||||
过去十年内的大多数电脑能达到这些标准 —— 但有一个陷阱。
|
||||
|
||||
硬件需要有一个 TPM 芯片,一些电脑和笔记本可能没有。幸运的是,你可能只需要从 BIOS 设置中启用它(包括安全引导支持),就可以使你的电脑符合条件。这里有一个 [PCGamer][3] 的向导可以帮你。
|
||||
|
||||
从技术上说,根据微软官方文档,Windows 11 不支持比 **Intel 第 8 代和 Ryzen 3000 系列**更老的处理器([AMD][4] | [Intel][5])。
|
||||
|
||||
可是,有相当数量的电脑不支持,你该怎么做?
|
||||
|
||||
很简单,在 Windows 10 不再收到更新之前,[都 2021 年了,换成 Linux 吧][6]。今年,在你的个人电脑上尝试 Linux 变得比任何时候更有意义!
|
||||
|
||||
### Windows 11 安装需要网络连接
|
||||
|
||||
![][7]
|
||||
|
||||
虽然我们不太清楚,但根据其系统要求规范,Windows 11 安装过程中将要求用户有可连通的互联网连接。
|
||||
|
||||
但是,Linux 不需要这样。
|
||||
|
||||
这只是其中一个 [使用 Linux 而不是 Windows][8] 的好处 —— 这是你可以完全掌控的操作系统。
|
||||
|
||||
### 没有 32 位支持
|
||||
|
||||
![][12]
|
||||
|
||||
Windows 10 确实是支持 32 位系统的,但是 Windows 11 终结了相关支持。
|
||||
|
||||
这又是 Linux 的优势了。
|
||||
|
||||
尽管对 32 位支持都在逐渐减少,我们依然有一系列 [支持 32 位系统的 Linux 发行版][9]。或许你的 32 位电脑还能与 Linux 一起工作 10 年。
|
||||
|
||||
### Windows 10 将在 2025 年结束支持
|
||||
|
||||
好吧,鉴于微软最初计划在 Windows 10 之后永远不会有升级,而是在可预见的未来一直支持它,这是个意外。
|
||||
|
||||
现在,Windows 10 将会在 2025 年被干掉……
|
||||
|
||||
那么,到时候你该怎么做呢?升级你的硬件,只因为它不支持 Windows 11?
|
||||
|
||||
除非有这个必要,否则 Linux 是你永远的朋友。
|
||||
|
||||
你可以尝试几个 [轻量级 Linux 发行版][10],它们将使你的任何一台被微软认为过时的电脑重新焕发生机。
|
||||
|
||||
### 结语
|
||||
|
||||
尽管 Windows 11 计划在未来几年内强迫用户升级他们的硬件,但 Linux 可以让你长时间继续使用你的硬件,并有一些额外的好处。
|
||||
|
||||
因此,如果你对 Windows 11 的发布不满意,你可能想开始使用 Linux 代替。不要烦恼,你可以参考我们的指南,来学习开始使用 Linux 的一切知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.itsfoss.com/windows-11-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zd200572](https://github.com/zd200572)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://news.itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/windows-11-requirements-new.png?w=1026&ssl=1
|
||||
[2]: https://www.microsoft.com/en-us/windows/windows-11
|
||||
[3]: https://www.pcgamer.com/Windows-11-PC-Health-Check/
|
||||
[4]: https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-amd-processors
|
||||
[5]: https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-intel-processors
|
||||
[6]: https://news.itsfoss.com/switch-to-linux-in-2021/
|
||||
[7]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/internet-connectivity-illustration.png?w=1200&ssl=1
|
||||
[8]: https://itsfoss.com/linux-better-than-windows/
|
||||
[9]: https://itsfoss.com/32-bit-linux-distributions/
|
||||
[10]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[11]: https://itsfoss.com
|
||||
[12]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/32-bit-support-illustration.png?w=1200&ssl=1
|
||||
200
published/202107/20190807 Trace code in Fedora with bpftrace.md
Normal file
200
published/202107/20190807 Trace code in Fedora with bpftrace.md
Normal file
@ -0,0 +1,200 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (YungeG)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13632-1.html)
|
||||
[#]: subject: (Trace code in Fedora with bpftrace)
|
||||
[#]: via: (https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/)
|
||||
[#]: author: (Augusto Caringi https://fedoramagazine.org/author/acaringi/)
|
||||
|
||||
在 Fedora 中用 bpftrace 追踪代码
|
||||
======
|
||||
|
||||

|
||||
|
||||
bpftrace 是一个 [基于 eBPF 的新型追踪工具][2],在 Fedora 28 第一次引入。Brendan Gregg、Alastair Robertson 和 Matheus Marchini 在网上的一个松散的黑客团队的帮助下开发了 bpftrace。它是一个允许你分析系统在幕后正在执行的操作的追踪工具,可以告诉你代码中正在被调用的函数、传递给函数的参数、函数的调用次数等。
|
||||
|
||||
这篇文章的内容涉及了 bpftrace 的一些基础,以及它是如何工作的,请继续阅读获取更多的信息和一些有用的实例。
|
||||
|
||||
### eBPF(<ruby>扩展的伯克利数据包过滤器<rt>extended Berkeley Packet Filter</rt></ruby>)
|
||||
|
||||
[eBPF][3] 是一个微型虚拟机,更确切的说是一个位于 Linux 内核中的虚拟 CPU。eBPF 可以在内核空间以一种安全可控的方式加载和运行小型程序,使得 eBPF 的使用更加安全,即使在生产环境系统中。eBPF 虚拟机有自己的指令集架构([ISA][4]),类似于现代处理器架构的一个子集。通过这个 ISA,可以很容易将 eBPF 程序转化为真实硬件上的代码。内核即时将程序转化为主流处理器架构上的本地代码,从而提升性能。
|
||||
|
||||
eBPF 虚拟机允许通过编程扩展内核,目前已经有一些内核子系统使用这一新型强大的 Linux 内核功能,比如网络、安全计算、追踪等。这些子系统的主要思想是添加 eBPF 程序到特定的代码点,从而扩展原生的内核行为。
|
||||
|
||||
虽然 eBPF 机器语言功能强大,由于是一种底层语言,直接用于编写代码很费力,bpftrace 就是为了解决这个问题而生的。eBPF 提供了一种编写 eBPF 追踪脚本的高级语言,然后在 clang / LLVM 库的帮助下将这些脚本转化为 eBPF,最终添加到特定的代码点。
|
||||
|
||||
### 安装和快速入门
|
||||
|
||||
在终端 [使用][5] [sudo][5] 执行下面的命令安装 bpftrace:
|
||||
|
||||
```
|
||||
$ sudo dnf install bpftrace
|
||||
```
|
||||
|
||||
使用“hello world”进行实验:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 'BEGIN { printf("hello world\n"); }'
|
||||
```
|
||||
|
||||
注意,出于特权级的需要,你必须使用 root 运行 `bpftrace`,使用 `-e` 选项指明一个程序,构建一个所谓的“单行程序”。这个例子只会打印 “hello world”,接着等待你按下 `Ctrl+C`。
|
||||
|
||||
`BEGIN` 是一个特殊的探针名,只在执行一开始生效一次;每次探针命中时,大括号 `{}` 内的操作(这个例子中只是一个 `printf`)都会执行。
|
||||
|
||||
现在让我们转向一个更有用的例子:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_enter_execve { printf("%s called %s\n", comm, str(args->filename)); }'
|
||||
```
|
||||
|
||||
这个例子打印了父进程的名字(`comm`)和系统中正在创建的每个新进程的名称。`t:syscalls:sys_enter_execve` 是一个内核追踪点,是 `tracepoint:syscalls:sys_enter_execve` 的简写,两种形式都可以使用。下一部分会向你展示如何列出所有可用的追踪点。
|
||||
|
||||
`comm` 是一个 bpftrace 内建指令,代表进程名;`filename` 是 `t:syscalls:sys_enter_execve` 追踪点的一个字段,这些字段可以通过 `args` 内建指令访问。
|
||||
|
||||
追踪点的所有可用字段可以通过这个命令列出:
|
||||
|
||||
```
|
||||
bpftrace -lv "t:syscalls:sys_enter_execve"
|
||||
```
|
||||
|
||||
### 示例用法
|
||||
|
||||
#### 列出探针
|
||||
|
||||
`bpftrace` 的一个核心概念是<ruby>探针点<rt>probe point</rt></ruby>,即 eBPF 程序可以连接到的(内核或用户空间的)代码中的测量点,可以分成以下几大类:
|
||||
|
||||
* `kprobe`——内核函数的开始处
|
||||
* `kretprobe`——内核函数的返回处
|
||||
* `uprobe`——用户级函数的开始处
|
||||
* `uretprobe`——用户级函数的返回处
|
||||
* `tracepoint`——内核静态追踪点
|
||||
* `usdt`——用户级静态追踪点
|
||||
* `profile`——基于时间的采样
|
||||
* `interval`——基于时间的输出
|
||||
* `software`——内核软件事件
|
||||
* `hardware`——处理器级事件
|
||||
|
||||
所有可用的 `kprobe` / `kretprobe`、`tracepoints`、`software` 和 `hardware` 探针可以通过这个命令列出:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -l
|
||||
```
|
||||
|
||||
`uprobe` / `uretprobe` 和 `usdt` 是用户空间探针,专用于某个可执行文件。要使用这些探针,通过下文中的特殊语法。
|
||||
|
||||
`profile` 和 `interval` 探针以固定的时间间隔触发;固定的时间间隔不在本文的范畴内。
|
||||
|
||||
#### 统计系统调用数
|
||||
|
||||
**映射** 是保存计数、统计数据和柱状图的特殊 BPF 数据类型,你可以使用映射统计每个系统调用正在被调用的次数:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_enter_* { @[probe] = count(); }'
|
||||
```
|
||||
|
||||
一些探针类型允许使用通配符匹配多个探针,你也可以使用一个逗号隔开的列表为一个操作块指明多个连接点。上面的例子中,操作块连接到了所有名称以 `t:syscalls:sysenter_` 开头的追踪点,即所有可用的系统调用。
|
||||
|
||||
`bpftrace` 的内建函数 `count()` 统计系统调用被调用的次数;`@[]` 代表一个映射(一个关联数组)。该映射的键 `probe` 是另一个内建指令,代表完整的探针名。
|
||||
|
||||
这个例子中,相同的操作块连接到了每个系统调用,之后每次有系统调用被调用时,映射就会被更新,映射中和系统调用对应的项就会增加。程序终止时,自动打印出所有声明的映射。
|
||||
|
||||
下面的例子统计所有的系统调用,然后通过 `bpftrace` 过滤语法使用 PID 过滤出某个特定进程调用的系统调用:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_enter_* / pid == 1234 / { @[probe] = count(); }'
|
||||
```
|
||||
|
||||
#### 进程写的字节数
|
||||
|
||||
让我们使用上面的概念分析每个进程正在写的字节数:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_exit_write /args->ret > 0/ { @[comm] = sum(args->ret); }'
|
||||
```
|
||||
|
||||
`bpftrace` 连接操作块到写系统调用的返回探针(`t:syscalls:sys_exit_write`),然后使用过滤器丢掉代表错误代码的负值(`/arg->ret > 0/`)。
|
||||
|
||||
映射的键 `comm` 代表调用系统调用的进程名;内建函数 `sum()` 累计每个映射项或进程写的字节数;`args` 是一个 `bpftrace` 内建指令,用于访问追踪点的参数和返回值。如果执行成功,`write` 系统调用返回写的字节数,`arg->ret` 用于访问这个字节数。
|
||||
|
||||
#### 进程的读取大小分布(柱状图):
|
||||
|
||||
`bpftrace` 支持创建柱状图。让我们分析一个创建进程的 `read` 大小分布的柱状图的例子:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
|
||||
```
|
||||
|
||||
柱状图是 BPF 映射,因此必须保存为一个映射(`@`),这个例子中映射键是 `comm`。
|
||||
|
||||
这个例子使 `bpftrace` 给每个调用 `read` 系统调用的进程生成一个柱状图。要生成一个全局柱状图,直接保存 `hist()` 函数到 `@`(不使用任何键)。
|
||||
|
||||
程序终止时,`bpftrace` 自动打印出声明的柱状图。创建柱状图的基准值是通过 _args->ret_ 获取到的读取的字节数。
|
||||
|
||||
#### 追踪用户空间程序
|
||||
|
||||
你也可以通过 `uprobes` / `uretprobes` 和 USDT(用户级静态定义的追踪)追踪用户空间程序。下一个例子使用探测用户级函数结尾处的 `uretprobe` ,获取系统中运行的每个 `bash` 发出的命令行:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 'uretprobe:/bin/bash:readline { printf("readline: \"%s\"\n", str(retval)); }'
|
||||
```
|
||||
|
||||
要列出可执行文件 `bash` 的所有可用 `uprobes` / `uretprobes`, 执行这个命令:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -l "uprobe:/bin/bash"
|
||||
```
|
||||
|
||||
`uprobe` 指向用户级函数执行的开始,`uretprobe` 指向执行的结束(返回处);`readline()` 是 `/bin/bash` 的一个函数,返回键入的命令行;`retval` 是被探测的指令的返回值,只能在 `uretprobe` 访问。
|
||||
|
||||
使用 `uprobes` 时,你可以用 `arg0..argN` 访问参数。需要调用 `str()` 将 `char *` 指针转化成一个字符串。
|
||||
|
||||
### 自带脚本
|
||||
|
||||
`bpftrace` 软件包附带了许多有用的脚本,可以在 `/usr/share/bpftrace/tools/` 目录找到。
|
||||
|
||||
这些脚本中,你可以找到:
|
||||
|
||||
* `killsnoop.bt`——追踪 `kill()` 系统调用发出的信号
|
||||
* `tcpconnect.bt`——追踪所有的 TCP 网络连接
|
||||
* `pidpersec.bt`——统计每秒钟(通过 `fork`)创建的新进程
|
||||
* `opensnoop.bt`——追踪 `open()` 系统调用
|
||||
* `bfsstat.bt`——追踪一些 VFS 调用,按秒统计
|
||||
|
||||
你可以直接使用这些脚本,比如:
|
||||
|
||||
```
|
||||
$ sudo /usr/share/bpftrace/tools/killsnoop.bt
|
||||
```
|
||||
|
||||
你也可以在创建新的工具时参考这些脚本。
|
||||
|
||||
### 链接
|
||||
|
||||
* bpftrace 参考指南——<https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md>
|
||||
* Linux 2018 `bpftrace`(DTrace 2.0)——<http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html>
|
||||
* BPF:通用的内核虚拟机——<https://lwn.net/Articles/599755/>
|
||||
* Linux Extended BPF(eBPF)Tracing Tools——<http://www.brendangregg.com/ebpf.html>
|
||||
* 深入 BPF:一个阅读材料列表—— [https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/
|
||||
|
||||
作者:[Augusto Caringi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[YungeG](https://github.com/YungeG)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/acaringi/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/bpftrace-816x345.jpg
|
||||
[2]: https://github.com/iovisor/bpftrace
|
||||
[3]: https://lwn.net/Articles/740157/
|
||||
[4]: https://github.com/iovisor/bpf-docs/blob/master/eBPF.md
|
||||
[5]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[6]: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
|
||||
[7]: https://unsplash.com/@wehavemegapixels?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]: https://unsplash.com/search/photos/trace?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -1,37 +1,37 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tanloong)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13628-1.html)
|
||||
[#]: subject: (Machine learning made easy with Python)
|
||||
[#]: via: (https://opensource.com/article/21/1/machine-learning-python)
|
||||
[#]: author: (Girish Managoli https://opensource.com/users/gammay)
|
||||
|
||||
用 Python 轻松实现机器学习
|
||||
======
|
||||
用朴素贝叶斯分类器解决现实世界里的机器学习问题
|
||||
![arrows cycle symbol for failing faster][1]
|
||||
|
||||
朴素贝叶斯是一种分类技术,它是许多分类器建模算法的基础。基于朴素贝叶斯的分类器是简单、快速和易用的机器学习技术之一,而且在现实世界的应用中很有效。
|
||||
> 用朴素贝叶斯分类器解决现实世界里的机器学习问题。
|
||||
|
||||
朴素贝叶斯是从 [贝叶斯定理][2] 发展来的。贝叶斯定理由 18 世纪的统计学家 [托马斯·贝叶斯][3] 提出,它根据与一个事件相关联的其他事件来计算该事件发生的概率。比如,[帕金森氏病][4] 患者通常嗓音会发生变化,因此嗓音变化就是与预测帕金森氏病相关联的症状。贝叶斯定理提供了计算目标事件发生概率的方法,而朴素贝叶斯是对该方法的推广和简化。
|
||||
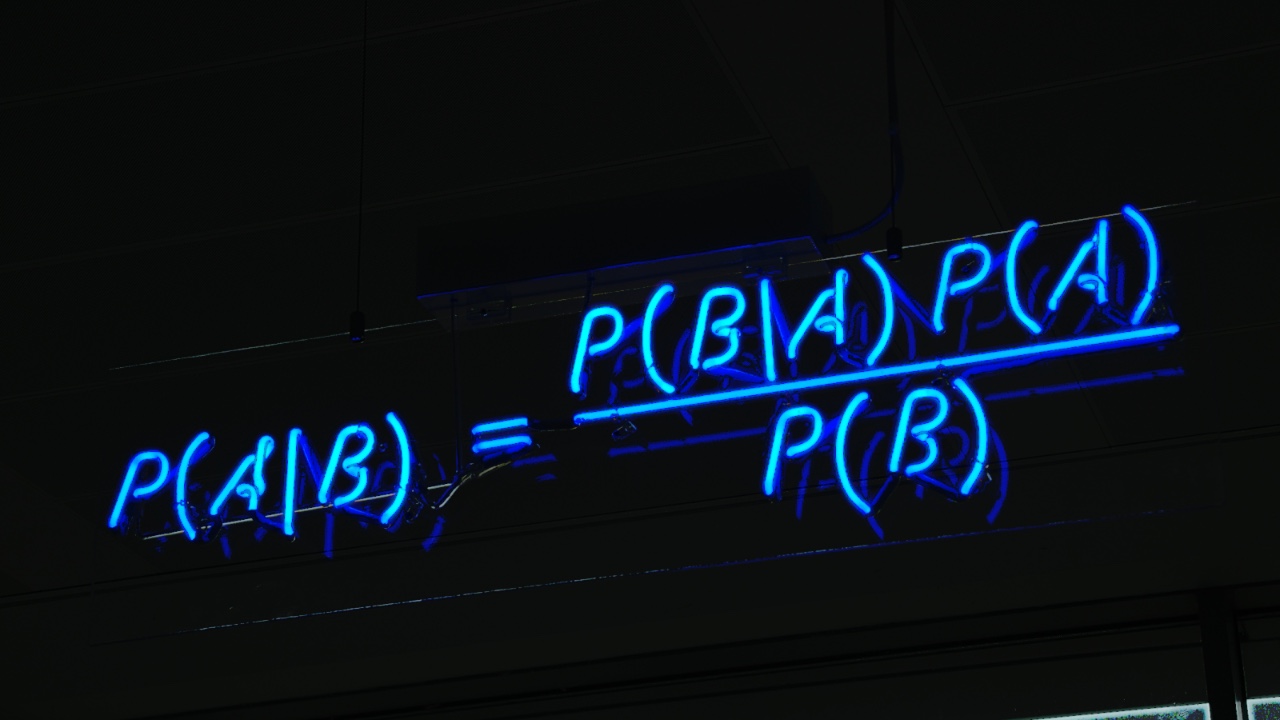
|
||||
|
||||
<ruby>朴素贝叶斯<rt>Naïve Bayes</rt></ruby>是一种分类技术,它是许多分类器建模算法的基础。基于朴素贝叶斯的分类器是简单、快速和易用的机器学习技术之一,而且在现实世界的应用中很有效。
|
||||
|
||||
朴素贝叶斯是从 <ruby>[贝叶斯定理][2]<rt>Bayes' theorem</rt></ruby> 发展来的。贝叶斯定理由 18 世纪的统计学家 [托马斯·贝叶斯][3] 提出,它根据与一个事件相关联的其他条件来计算该事件发生的概率。比如,[帕金森氏病][4] 患者通常嗓音会发生变化,因此嗓音变化就是与预测帕金森氏病相关联的症状。贝叶斯定理提供了计算目标事件发生概率的方法,而朴素贝叶斯是对该方法的推广和简化。
|
||||
|
||||
### 解决一个现实世界里的问题
|
||||
|
||||
这篇文章展示了朴素贝叶斯分类器解决现实世界问题 (与商业级应用相反) 的能力。我会假设你对机器学习有基本的了解,所以文章里会跳过一些与机器学习预测不大相关的步骤,比如 <ruby>数据打乱<rt>(date shuffling)</rt></ruby> 和 <ruby>数据切片<rt>(data splitting)</rt></ruby>。如果你是机器学习方面的新手或者需要一个进修课程,请查看 _[An introduction to machine learning today][5]_ 和 _[Getting started with open source machine learning][6]_。
|
||||
这篇文章展示了朴素贝叶斯分类器解决现实世界问题(相对于完整的商业级应用)的能力。我会假设你对机器学习有基本的了解,所以文章里会跳过一些与机器学习预测不大相关的步骤,比如 <ruby>数据打乱<rt>date shuffling</rt></ruby> 和 <ruby>数据切片<rt>data splitting</rt></ruby>。如果你是机器学习方面的新手或者需要一个进修课程,请查看 《[An introduction to machine learning today][5]》 和 《[Getting started with open source machine learning][6]》。
|
||||
|
||||
朴素贝叶斯分类器是 <ruby>[有监督的][7]<rt>(supervised)</rt></ruby>、属于 <ruby>[生成模型][8]<rt>(generative)</rt></ruby> 的、非线性的、属于 <ruby>[参数模型][9]<rt>(parametric)</rt></ruby> 的和 <ruby>[基于概率的][10]<rt>(probabilistic)</rt></ruby>。
|
||||
朴素贝叶斯分类器是 <ruby>[有监督的][7]<rt>supervised</rt></ruby>、属于 <ruby>[生成模型][8]<rt>generative</rt></ruby> 的、非线性的、属于 <ruby>[参数模型][9]<rt>parametric</rt></ruby> 的和 <ruby>[基于概率的][10]<rt>probabilistic</rt></ruby>。
|
||||
|
||||
在这篇文章里,我会演示如何用朴素贝叶斯预测帕金森氏病。需要用到的数据集来自 [UCI Machine Learning Repository][11]。这个数据集包含许多语音信号的指标,用于计算患帕金森氏病的可能性;在这个例子里我们将使用这些指标中的前 8 个:
|
||||
在这篇文章里,我会演示如何用朴素贝叶斯预测帕金森氏病。需要用到的数据集来自 [UCI 机器学习库][11]。这个数据集包含许多语音信号的指标,用于计算患帕金森氏病的可能性;在这个例子里我们将使用这些指标中的前 8 个:
|
||||
|
||||
* **MDVP:Fo(Hz):** 平均声带基频
|
||||
* **MDVP:Fhi(Hz):** 最高声带基频
|
||||
* **MDVP:Flo(Hz):** 最低声带基频
|
||||
* **MDVP:Jitter(%)**、**MDVP:Jitter(Abs)**、**MDVP:RAP**、**MDVP:PPQ** 和 **Jitter:DDP:** 5 个衡量声带基频变化的指标
|
||||
* **MDVP:Fo(Hz)**:平均声带基频
|
||||
* **MDVP:Fhi(Hz)**:最高声带基频
|
||||
* **MDVP:Flo(Hz)**:最低声带基频
|
||||
* **MDVP:Jitter(%)**、**MDVP:Jitter(Abs)**、**MDVP:RAP**、**MDVP:PPQ** 和 **Jitter:DDP**:5 个衡量声带基频变化的指标
|
||||
|
||||
|
||||
|
||||
这个例子里用到的数据集,可以在我的 [GitHub 仓库][12] 里找到。数据集已经事先做了打乱和分片。
|
||||
这个例子里用到的数据集,可以在我的 [GitHub 仓库][12] 里找到。数据集已经事先做了打乱和切片。
|
||||
|
||||
### 用 Python 实现机器学习
|
||||
|
||||
@ -41,23 +41,18 @@
|
||||
* Pandas 1.1.1
|
||||
* scikit-learn 0.22.2.post1
|
||||
|
||||
|
||||
|
||||
Python 有多个朴素贝叶斯分类器的实现,都是开源的,包括:
|
||||
|
||||
* **NLTK Naïve Bayes:** 基于标准的朴素贝叶斯算法,用于文本分类
|
||||
* **NLTK Positive Naïve Bayes:** NLTK Naïve Bayes 的变体,用于对只标注了一部分的训练集进行二分类
|
||||
* **Scikit-learn Gaussian Naïve Bayes:** 提供了 partial fit 方法来支持数据流或很大的数据集 (它们都可能无法一次性导入内存,用 partial fit 可以动态地增加数据)
|
||||
* **Scikit-learn Multinomial Naïve Bayes:** 针对离散型特征变量作了优化
|
||||
* **Scikit-learn Bernoulli Naïve Bayes:** 用于各个特征都是二元变量的情况
|
||||
|
||||
|
||||
* **NLTK Naïve Bayes**:基于标准的朴素贝叶斯算法,用于文本分类
|
||||
* **NLTK Positive Naïve Bayes**:NLTK Naïve Bayes 的变体,用于对只标注了一部分的训练集进行二分类
|
||||
* **Scikit-learn Gaussian Naïve Bayes**:提供了部分拟合方法来支持数据流或很大的数据集(LCTT 译注:它们可能无法一次性导入内存,用部分拟合可以动态地增加数据)
|
||||
* **Scikit-learn Multinomial Naïve Bayes**:针对离散型特征、实例计数、频率等作了优化
|
||||
* **Scikit-learn Bernoulli Naïve Bayes**:用于各个特征都是二元变量/布尔特征的情况
|
||||
|
||||
在这个例子里我将使用 [sklearn Gaussian Naive Bayes][13]。
|
||||
|
||||
我的 Python 实现在 `naive_bayes_parkinsons.py` 里,如下所示:
|
||||
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
|
||||
@ -108,7 +103,6 @@ print('Accuray score on test data:', accuracy_train)
|
||||
|
||||
运行这个 Python 脚本:
|
||||
|
||||
|
||||
```
|
||||
$ python naive_bayes_parkinsons.py
|
||||
|
||||
@ -146,21 +140,19 @@ Accuracy score on test data: 0.6666666666666666
|
||||
|
||||
### 背后原理
|
||||
|
||||
朴素贝叶斯分类器从贝叶斯定理发展来的。贝叶斯定理用于计算条件概率,或者说贝叶斯定理用于计算当与当与一个事件相关联的其他事件发生时,该事件发生的概率。简而言之,它解决了这个问题:_如果我们已经知道事件 x 发生在事件 y 之前的概率,那么当事件 x 再次发生时,事件 y 发生的概率是多少?_ 贝叶斯定理用一个先验的预测值来逐渐逼近一个最终的 [后验概率][14]。贝叶斯定理有一个基本假设,就是所有的参数重要性相同 (即相互独立)。
|
||||
朴素贝叶斯分类器从贝叶斯定理发展来的。贝叶斯定理用于计算条件概率,或者说贝叶斯定理用于计算当与一个事件相关联的其他事件发生时,该事件发生的概率。简而言之,它解决了这个问题:_如果我们已经知道事件 x 发生在事件 y 之前的概率,那么当事件 x 再次发生时,事件 y 发生的概率是多少?_ 贝叶斯定理用一个先验的预测值来逐渐逼近一个最终的 [后验概率][14]。贝叶斯定理有一个基本假设,就是所有的参数重要性相同(LCTT 译注:即相互独立)。
|
||||
|
||||
贝叶斯计算主要包括以下步骤:
|
||||
|
||||
1. 计算总的先验概率:
|
||||
$P(患病)$ 和 $P(不患病)$
|
||||
2. 计算 8 种指标各自是某个值时的后验概率 (value1,...,value8 分别是 MDVP:Fo(Hz),...,Jitter:DDP 的取值):
|
||||
2. 计算 8 种指标各自是某个值时的后验概率 (value1,...,value8 分别是 MDVP:Fo(Hz),...,Jitter:DDP 的取值):
|
||||
$P(value1,\ldots,value8\ |\ 患病)$
|
||||
$P(value1,\ldots,value8\ |\ 不患病)$
|
||||
3. 将第 1 步和第 2 步的结果相乘,最终得到患病和不患病的后验概率:
|
||||
$P(患病\ |\ value1,\ldots,value8) \propto P(患病) \times P(value1,\ldots,value8\ |\ 患病)$
|
||||
$P(不患病\ |\ value1,\ldots,value8) \propto P(不患病) \times P(value1,\ldots,value8\ |\ 不患病)$
|
||||
|
||||
|
||||
|
||||
上面第 2 步的计算非常复杂,朴素贝叶斯将它作了简化:
|
||||
|
||||
1. 计算总的先验概率:
|
||||
@ -172,18 +164,14 @@ Accuracy score on test data: 0.6666666666666666
|
||||
$P(患病\ |\ value1,\ldots,value8) \propto P(患病) \times P(value1\ |\ 患病) \times \ldots \times P(value8\ |\ 患病)$
|
||||
$P(不患病\ |\ value1,\ldots,value8) \propto P(不患病) \times P(value1\ |\ 不患病) \times \ldots \times P(value8\ |\ 不患病)$
|
||||
|
||||
|
||||
|
||||
这只是一个很初步的解释,还有很多其他因素需要考虑,比如数据类型的差异,如何解析数据,数据可能有缺失值等。
|
||||
这只是一个很初步的解释,还有很多其他因素需要考虑,比如数据类型的差异,稀疏数据,数据可能有缺失值等。
|
||||
|
||||
### 超参数
|
||||
|
||||
朴素贝叶斯作为一个简单直接的算法,不需要超参数。然而,有的版本的朴素贝叶斯实现可能提供一些高级特性 (比如超参数)。比如,[GaussianNB][13] 就有 2 个超参数:
|
||||
|
||||
* **priors:** 先验概率,可以事先指定,这样就不必让算法从数据中计算才能得出。
|
||||
* **var_smoothing:** 考虑数据的分布情况,当数据不满足标准的高斯分布时,这个超参数会发挥作用。
|
||||
|
||||
朴素贝叶斯作为一个简单直接的算法,不需要超参数。然而,有的版本的朴素贝叶斯实现可能提供一些高级特性(比如超参数)。比如,[GaussianNB][13] 就有 2 个超参数:
|
||||
|
||||
* **priors**:先验概率,可以事先指定,这样就不必让算法从数据中计算才能得出。
|
||||
* **var_smoothing**:考虑数据的分布情况,当数据不满足标准的高斯分布时,这个超参数会发挥作用。
|
||||
|
||||
### 损失函数
|
||||
|
||||
@ -191,10 +179,10 @@ Accuracy score on test data: 0.6666666666666666
|
||||
|
||||
### 优缺点
|
||||
|
||||
**优点:** 朴素贝叶斯是最简单最快速的算法之一。
|
||||
**优点:** 在数据量较少时,用朴素贝叶斯仍可作出可靠的预测。
|
||||
**缺点:** 朴素贝叶斯的预测只是估计值,并不准确。它胜在速度而不是准确度。
|
||||
**缺点:** 朴素贝叶斯有一个基本假设,就是所有特征相互独立,但现实情况并不总是如此。
|
||||
**优点**:朴素贝叶斯是最简单、最快速的算法之一。
|
||||
**优点**:在数据量较少时,用朴素贝叶斯仍可作出可靠的预测。
|
||||
**缺点**:朴素贝叶斯的预测只是估计值,并不准确。它胜在速度而不是准确度。
|
||||
**缺点**:朴素贝叶斯有一个基本假设,就是所有特征相互独立,但现实情况并不总是如此。
|
||||
|
||||
从本质上说,朴素贝叶斯是贝叶斯定理的推广。它是最简单最快速的机器学习算法之一,用来进行简单和快速的训练和预测。朴素贝叶斯提供了足够好、比较准确的预测。朴素贝叶斯假设预测特征之间是相互独立的。已经有许多朴素贝叶斯的开源的实现,它们的特性甚至超过了贝叶斯算法的实现。
|
||||
|
||||
@ -205,7 +193,7 @@ via: https://opensource.com/article/21/1/machine-learning-python
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tanloong](https://github.com/tanloong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,157 @@
|
||||
[#]: subject: (F\(r\)iction: Or How I Learnt to Stop Worrying and Start Loving Vim)
|
||||
[#]: via: (https://news.itsfoss.com/how-i-started-loving-vim/)
|
||||
[#]: author: (Theena https://news.itsfoss.com/author/theena/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (piaoshi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13634-1.html)
|
||||
|
||||
小说还是折磨:我如何学会克服焦虑并开始爱上 Vim
|
||||
======
|
||||
|
||||
> 非技术人员也可以使用 Linux 和开源软件进行非技术工作。这是我的故事。
|
||||
|
||||

|
||||
|
||||
(LCTT 译注:本文原文标题用 “F(r)iction” 一语双关的表示了<ruby>小说<rt>fiction</rt></ruby>写作过程中的<ruby>摩擦<rt>friction</rt></ruby>苦恼。)
|
||||
|
||||
时间:2009 年 12 月。我准备辞去工作。
|
||||
|
||||
我希望专心写我的第一本书;我的工作职责和技术环境都没办法让我完成这本书的写作。
|
||||
|
||||
写作是件苦差事。
|
||||
|
||||
在现代世界中,很少有工作像写作这样奇特或者说艰巨的追求 —— 面对一张白纸,坐下来,迫使你的大脑吐出文字,向读者传达一个想法。当然,我并不是说写作不能与他人合作完成,而只是想说明,对于作家来说,自己着手写一部新作品是多么令人生畏。小说还是非小说写作都是如此。但由于我是一名小说家,我在这篇文章中主要想关注是小说的写作。
|
||||
|
||||
![][1]
|
||||
|
||||
还记得 2009 年是什么样子吗?
|
||||
|
||||
智能手机已经诞生 3 年了 —— 而我还在使用功能机。笔记本电脑又大又笨重。同时,基于云的生产力 Web 应用还处于起步阶段,并不那么好用。从技术上讲,像我这样的作家们正在以 Gmail 账户(和一个非常年轻的基于云的存储服务 Dropbox)作为一个始终可用的选项来处理自己的草稿,即使我的个人电脑不在身边。虽然这与作家们必须要使用打字机(或,上帝保佑,使用笔和纸)工作时相比已经是一个很好的变化了,但并没有好多少。
|
||||
|
||||
首先,对手稿的版本控制是一场噩梦。此外,我为简化工作流程而在工具包中添加的工具越多,我转换写作环境(无论是用户界面还是用户体验)的次数就越多。
|
||||
|
||||
我是在 Windows 记事本上开始写草稿的,然后把它保存在家里电脑上的 MS Word 文档中,用电子邮件发给自己一份副本,同时在 Dropbox 上保留另一份副本(因为在上班时无法访问 Dropbox),在公司时对该文件的副本进行处理,在一天结束时用电子邮件发给自己,在家里的电脑上下载它,用一个新的名字和相应的日期保存它,这样我就能认出该文件是在公司(而不是家里)进行修改的……好吧,你知道这是怎样一个画面。如果你能感受到这种涉及 Windows 记事本、MS Word、Gmail 和 Dropbox 的工作流程有多么疯狂,那么现在你就知道我为什么辞职了。
|
||||
|
||||
让我更清醒的是,我仍然知道一些作家,其中竟然有些还是好作家,依然在使用我 2009 年遵循的工作流程的各种变体。
|
||||
|
||||
在接下来的三年里,我一直在写手稿,在 2012 年完成了初稿。在这三年里,技术环境发生了很大变化。智能手机确实相当给力,我在 2009 年遇到的一些复杂情况已经消失了。我仍然可以用手机处理我在家里外理的文件(不一定是新的写作,但由于手机上的 Dropbox,编辑变得相当容易)。我的主要写作工具仍然是微软的 Windows 记事本和 Word,我就是这样完成初稿的。
|
||||
|
||||
小说 [《第一声》][2] 于 2016 年出版,获得了评论界和商业界的好评。
|
||||
|
||||
结束了。
|
||||
|
||||
或许我是这么想的。
|
||||
|
||||
我一完成手稿发给了编辑,就已经开始着手第二部小说的写作。我不再为写作而辞职,而是采取了一种更务实的方法:我会在每年年底请两个星期的假,这样我就可以到山上的一个小木屋里去写作。
|
||||
|
||||
花了半天时间我才意识到,那些让我讨厌的 [写作工具][3] 和工作流程并没有消失,而是演变成了一个更复杂的野兽。作为一个作家,我并不像我想像的那样高产或高效。
|
||||
|
||||
### 新冠期间的 Linux
|
||||
|
||||
![][4]
|
||||
|
||||
时间:2020 年。世界正处于集体疯狂的边缘。
|
||||
|
||||
起初在中国分离出的一种新型病毒正在演变成 1911 年以来的第一次全球大流行疾病。3 月 20 日,斯里兰卡,跟随世界上大多数国家的脚步,封城了。
|
||||
|
||||
四月是斯里兰卡旱季的高峰。在像科伦坡这样的混凝土丛林中,温度可以达到三十多度,湿度高达九十多度。在最好的情况下,它也可以使大多数人精神错乱,更别说在全球大流行病正在进行的时候,被困在没有一直开着空调的家里?真是一个让人疯狂的好温床。
|
||||
|
||||
让我的疯狂是 Linux,或者说是“发行版跳跃”,像我们在开源社区中所说的。
|
||||
|
||||
我越在各种 *nix 发行版间蹿来蹿,我就对控制的想法越迷恋。当任何事情似乎都不在我们的控制之中时 —— 即使是与另一个人握手这样的简单行为 —— 我们自然会倾向于做那些我们感觉更有控制力的事。
|
||||
|
||||
在我的生活中,还有什么比计算机更容易被控制的呢?自然,这也延伸到我的写作工具和工作流程。
|
||||
|
||||
### 通往 Vim 之路
|
||||
|
||||
有一个关于 [Vim][5] 的笑话完美地描述了我对它的第一次体验:人们对 Vim 难以割舍是因为他们不知道怎么关掉它。
|
||||
|
||||
我试图编辑一个配置文件,而 [新安装的 Ubuntu 服务器][6] 只预装了 Vim 文本编辑器。第一次是恐慌 —— 以至于我重新启动了机器,以为操作系统没有识别出我的键盘。然而当它再次发生时,不可避免地,我谷歌搜索:“[我该如何关闭 Vim?][7]”
|
||||
|
||||
_哦。这真有趣_,我想。
|
||||
|
||||
_但为什么呢?_
|
||||
|
||||
要理解我为什么会对一个复杂到无法关闭的文本编辑器有点兴趣,你必须了解我是多么崇拜 Windows 记事本。
|
||||
|
||||
作为一个作家,我喜欢在它的没有废话、没有按钮、白纸一样的画布上写作。它没有拼写检查。它没有格式。但这些我并不关心。
|
||||
|
||||
对于我这个作家来说,记事本是有史以来最好的草稿写作板。不幸的是,它并不强大 —— 所以即使我会先用记事本写草稿,一旦超过 1000 字,我就会把它移到 MS Word 上 —— 记事本不是为散文而生的,当超过这个字数限制时,这些局限就会凸显出来。
|
||||
|
||||
因此,当我把我所有的计算机工作从 Windows 上迁移走时,我第一个要安装的就是一个好的文本编辑器。
|
||||
|
||||
[Kate][8] 是第一个让我感到比用 Windows 记事本更舒服的替代品 —— 它更强大(它有拼写检查功能!),而且,我可以在同一个环境中搞一些业余爱好式的编程。
|
||||
|
||||
当时它是我的爱。
|
||||
|
||||
但后来 Vim 出现了。
|
||||
|
||||
我对 Vim 了解得越多,看开发者在 Vim 上现场进行编码的次数越多,我就越发现自己在编辑文本时更想打开 Vim。我使用 Unix 传统意义上“文本编辑”这一短语:编辑配置文件中的文本块,或者有时编写基本的 Bash 脚本。
|
||||
|
||||
我仍然没有用 Vim 来满足我的散文写作需求。
|
||||
|
||||
在这方面我有 Libre Office。
|
||||
|
||||
算是吧。
|
||||
|
||||
虽然它是一个适当的 [MS Office 替代品][9],但我发现自己没有被它打动。它的用户界面可能比 MS Word 更让人分心,而且每个发行版都有不同的 Libre Office 软件包,我发现自己使用的是一个非常零散的工具包和工作流程,更不用说用户界面在不同的发行版和桌面环境中差异是多么大。
|
||||
|
||||
事情变得更加复杂了,因为我也开始读我的硕士学位了。这时,我要在 Kate 上做笔记,把它们转移到 Libre Office 上,然后保存到我的 Dropbox 上。
|
||||
|
||||
我每天都面临着情境转换。
|
||||
|
||||
生产力下降,因为我不得不打开和关闭一些不相关的应用程序。我需要一个写作工具来满足我所有的需求,无论是作为一个小说家,还是一个学生、亦或是一个业余的程序员。
|
||||
|
||||
这时我意识到,解决我场景切换噩梦的方法也同样摆在我的面前。
|
||||
|
||||
这时,我已经经常使用 Vim —— 甚至在我的安卓手机上利用 Termux 使用它。这使我对要把所有东西都搬到 Vim 上的想法感到相当舒服。由于它支持 Markdown 语法,记笔记也会变得更加容易。
|
||||
|
||||
这仅仅是大约两个月前的事。
|
||||
|
||||
现在怎么样了?
|
||||
|
||||
时间:2021 年 4 月。
|
||||
|
||||
坐在出租车上,我通过 Termux(借助蓝牙键盘)[用 Vim][10] 在手机上开始写这个草稿。我把文件推送到 GitHub 上我的用于写作使用的私人仓库,我从那里把文件拉到我的电脑上,又写了几行,然后再次出门。我把新版本的文件从 GitHub 拉到我的手机上,修改、推送,如此往复,直到我把最后的草稿用电子邮件发给编辑。
|
||||
|
||||
现在,场景切换的情景已经不复存在。
|
||||
|
||||
在文字处理器中写作所带来的分心问题也没有了。
|
||||
|
||||
编辑工作变得无比简单,而且更快了。
|
||||
|
||||
我的手腕不再疼痛,因为我不再需要鼠标了。
|
||||
|
||||
现在是 2021 年 4 月。
|
||||
|
||||
我是一名小说家。
|
||||
|
||||
而我在 Vim 上写作。
|
||||
|
||||
怎么做的?我将在本专栏系列的第二部分讨论这个工作流程的具体内容,即非技术人员如何使用免费和开源技术。敬请关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.itsfoss.com/how-i-started-loving-vim/
|
||||
|
||||
作者:[Theena][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[piaoshi](https://github.com/piaoshi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://news.itsfoss.com/author/theena/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/Cellphones-different-generations-set.png?w=800&ssl=1
|
||||
[2]: https://www.goodreads.com/book/show/29616237-first-utterance
|
||||
[3]: https://itsfoss.com/open-source-tools-writers/
|
||||
[4]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/quarantine.jpg?w=800&ssl=1
|
||||
[5]: https://www.vim.org/
|
||||
[6]: https://itsfoss.com/install-ubuntu-server-raspberry-pi/
|
||||
[7]: https://itsfoss.com/how-to-exit-vim/
|
||||
[8]: https://kate-editor.org/
|
||||
[9]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[10]: https://linuxhandbook.com/basic-vim-commands/
|
||||
@ -0,0 +1,232 @@
|
||||
[#]: subject: "Use XMLStarlet to parse XML in your the Linux terminal"
|
||||
[#]: via: "https://opensource.com/article/21/7/parse-xml-linux"
|
||||
[#]: author: "Seth Kenlon https://opensource.com/users/seth"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "zepoch"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-13627-1.html"
|
||||
|
||||
在命令行中使用 XMLStarlet 来解析 XML
|
||||
======
|
||||
|
||||
> 借助终端上的 XML 工具包 XMLStarlet,你就是 XML 之星。
|
||||
|
||||

|
||||
|
||||
学习解析 XML 通常被认为是一件复杂的事情,但它不一定是这样。[XML 是高度严格结构化的][2],所以也是相对来说可预测的。也有许多其他工具可以帮助你使这项工作易于管理。
|
||||
|
||||
我最喜欢的 XML 实用程序之一是 [XMLStarlet][3],这是一个用于终端的 XML 工具包,借助这个 XML 工具包,你可以验证、解析、编辑、格式化和转换 XML 数据。XMLStarLet 是个相对较小的命令,但浏览 XML 却充满潜力,因此本文演示了如何使用它来查询 XML 数据。
|
||||
|
||||
### 安装
|
||||
|
||||
XMLStarLet 默认安装在 CentOS、Fedora,和许多其他现代 Linux 发行版上,所以你可以打开终端,输入 `xmlstarlet` 来访问它。如果 XMLStarLet 还没有被安装,你的操作系统则会为你安装它。
|
||||
|
||||
或者,你可以用包管理器安装 `xmlstarlet`:
|
||||
|
||||
```
|
||||
$ sudo dnf install xmlstarlet
|
||||
```
|
||||
|
||||
在 macOS 上,可以使用 [MacPorts][4] 或 [Homebrew][5]。在 Windows 上,可以使用 [Chocolatey][6]。
|
||||
|
||||
如果都失败了,你可以从 [Sourceforge 上的源代码][7] 手动安装它。
|
||||
|
||||
### 用 XMLStarlet 解析 XML
|
||||
|
||||
有许多工具可以帮助解析和转换 XML 数据,包括允许你 [编写自己的解析器][8] 的软件库,和复杂的命令,如 `fop` 和 `xsltproc`。不过有时你不需要处理 XML 数据;你只需要一个方便的方法从 XML 数据中来提取、更新或验证重要数据。对于随手的 XML 交互,我使用 `xmlstarlet`,这是常见的处理 XML任务的一个典型的“瑞士军刀”式应用。通过运行 `--help` 命令,你可以看到它提供哪些选项:
|
||||
|
||||
```
|
||||
$ xmlstarlet --help
|
||||
Usage: xmlstarlet [<options>] <command> [<cmd-options>]
|
||||
where <command> is one of:
|
||||
ed (or edit) - Edit/Update XML document(s)
|
||||
sel (or select) - Select data or query XML document(s) (XPATH, etc)
|
||||
tr (or transform) - Transform XML document(s) using XSLT
|
||||
val (or validate) - Validate XML document(s) (well-formed/DTD/XSD/RelaxNG)
|
||||
fo (or format) - Format XML document(s)
|
||||
el (or elements) - Display element structure of XML document
|
||||
c14n (or canonic) - XML canonicalization
|
||||
ls (or list) - List directory as XML
|
||||
[...]
|
||||
```
|
||||
|
||||
你可以通过在这些子命令的末尾附加 `-help` 来获得进一步的帮助:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet sel --help
|
||||
-Q or --quiet - do not write anything to standard output.
|
||||
-C or --comp - display generated XSLT
|
||||
-R or --root - print root element <xsl-select>
|
||||
-T or --text - output is text (default is XML)
|
||||
-I or --indent - indent output
|
||||
[...]
|
||||
```
|
||||
|
||||
#### 用 sel 命令选择数据
|
||||
|
||||
可以使用 `xmlstarlet select`(简称 `sel`)命令查看 XML 格式的数据。下面是一个简单的 XML 文档:
|
||||
|
||||
```
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<xml>
|
||||
<os>
|
||||
<linux>
|
||||
<distribution>
|
||||
<name>Fedora</name>
|
||||
<release>7</release>
|
||||
<codename>Moonshine</codename>
|
||||
<spins>
|
||||
<name>Live</name>
|
||||
<name>Fedora</name>
|
||||
<name>Everything</name>
|
||||
</spins>
|
||||
</distribution>
|
||||
|
||||
<distribution>
|
||||
<name>Fedora Core</name>
|
||||
<release>6</release>
|
||||
<codename>Zod</codename>
|
||||
<spins></spins>
|
||||
</distribution>
|
||||
</linux>
|
||||
</os>
|
||||
</xml>
|
||||
```
|
||||
|
||||
在 XML 文件中查找数据时,你的第一个任务是关注要探索的节点。如果知道节点的路径,请使用 `-value of` 选项指定完整路径。你越早浏览 [文档对象模型][9](DOM)树,就可以看到更多信息:
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
--value-of /xml/os/linux/distribution \
|
||||
--nl myfile.xml
|
||||
Fedora
|
||||
7
|
||||
Moonshine
|
||||
|
||||
Live
|
||||
Fedora
|
||||
Everything
|
||||
|
||||
Fedora Core
|
||||
6
|
||||
Zod
|
||||
```
|
||||
|
||||
`--nl` 代表“新的一行”,它插入大量的空白,以确保在输入结果后,终端在新的一行显示。我已经删除了样本输出中的一些多余空间。
|
||||
|
||||
通过进一步深入 DOM 树来凝聚关注点:
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
--value-of /xml/os/linux/distribution/name \
|
||||
--nl myfile.xml
|
||||
Fedora
|
||||
Fedora Core
|
||||
```
|
||||
|
||||
#### 条件选择
|
||||
|
||||
用于导航和解析 XML 的最强大工具之一被称为 XPath。它规范了 XML 搜索中使用的语法,并从 XML 库调用函数。XMLStarlet 能够解析 XPath 表达式,因此可以使用 XPath 函数来有条件的进行选择。XPath 具有丰富的函数,[由 W3C 提供了详细文档][10],但我觉得 [Mozilla 的 XPath 文档][11] 更简洁。
|
||||
|
||||
可以使用方括号作为测试函数,将元素的内容与某个值进行比较。下面是对 `<name>` 元素的值的测试,它仅返回与特定匹配相关联的版本号。
|
||||
|
||||
想象一下,示例 XML 文件包含以 1 开头的所有 Fedora 版本。要查看与旧名称 “Fedora Core” 关联的所有版本号(该项目从版本 7 开始删除了名称中的 “Core”),请执行以下操作:
|
||||
|
||||
```
|
||||
$ xmlstarlet sel --template \
|
||||
--value-of '/xml/os/linux/distribution[name = "Fedora Core"]/release' \
|
||||
--nl myfile.xml
|
||||
6
|
||||
5
|
||||
4
|
||||
3
|
||||
2
|
||||
1
|
||||
```
|
||||
|
||||
通过将路径的 `--value-of` 更改为 `/xml/os/linux/distribution[name=“Fedora Core”]/codename`,你便可以查看这些版本的所有代号。
|
||||
|
||||
### 匹配路径和获取目标值
|
||||
|
||||
将 XML 标记视为节点的一个好处是,一旦找到节点,就可以将其视为当前的数据的“目录”。它不是一个真正的目录,至少不是文件系统意义上的目录,但它是一个可以查询的数据集合。为了帮助你将目标和“里面”的数据分开,XMLStarlet 把你试图用 `--match` 选项匹配的内容和用 `--value-of` 选项匹配的数据值进行了区分。
|
||||
|
||||
假设你知道 `<spin>` 节点包含几个元素。这就是你的目标节点。一旦到了这里,就可以使用 `--value-of` 指定想要哪个元素的值。要查看所有元素,可以使用点(`.`)来代表当前位置:
|
||||
|
||||
```
|
||||
$ xmlstarlet sel --template \
|
||||
--match '/xml/os/linux/distribution/spin' \
|
||||
--value-of '.' --nl myfile.xml \
|
||||
Live
|
||||
Fedora
|
||||
Everything
|
||||
```
|
||||
|
||||
与浏览 DOM 一样,可以使用 XPath 表达式来限制返回数据的范围。在本例中,我使用 `last()` 函数来检索 `spin` 节点中的最后一个元素:
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
--match '/xml/os/linux/distribution/spin' \
|
||||
--value-of '*[last()]' --nl myfile.xml
|
||||
Everything
|
||||
```
|
||||
|
||||
在本例中,我使用 `position()` 函数选择 `spin` 节点中的特定元素:
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
--match '/xml/os/linux/distribution/spin' \
|
||||
--value-of '*[position() = 2]' --nl myfile.xml
|
||||
Fedora
|
||||
```
|
||||
|
||||
`--match` 和 `--value` 选项可以重叠,因此如何将它们一起使用取决于你自己。对于示例 XML,这两个表达式执行的是相同的操作:
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
--match '/xml/os/linux/distribution/spin' \
|
||||
--value-of '.' \
|
||||
--nl myfile.xml
|
||||
Live
|
||||
Fedora
|
||||
Everything
|
||||
|
||||
$ xmlstarlet select --template \
|
||||
--match '/xml/os/linux/distribution' \
|
||||
--value-of 'spin' \
|
||||
--nl myfile.xml
|
||||
Live
|
||||
Fedora
|
||||
Everything
|
||||
```
|
||||
|
||||
### 熟悉 XML
|
||||
|
||||
XML 有时看起来过于冗长和笨拙,但为与之交互和构建的工具却总是让我吃惊。如果你想要好好使用 XML,那么 XMLStarlet 可能是一个很好的切入点。下次要打开 XML 文件查看其结构化数据时,请尝试使用 XMLStarlet,看看是否可以查询这些数据。当你对 XML 越熟悉时,它就越能作为一种健壮灵活的数据格式而为你服务。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/parse-xml-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zepoch](https://github.com/zepoch)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 "Penguin with green background"
|
||||
[2]: https://opensource.com/article/21/6/what-xml
|
||||
[3]: https://en.wikipedia.org/wiki/XMLStarlet
|
||||
[4]: https://opensource.com/article/20/11/macports
|
||||
[5]: https://opensource.com/article/20/6/homebrew-mac
|
||||
[6]: https://opensource.com/article/20/3/chocolatey
|
||||
[7]: http://xmlstar.sourceforge.net
|
||||
[8]: https://opensource.com/article/21/6/parsing-config-files-java
|
||||
[9]: https://opensource.com/article/21/6/what-xml#dom
|
||||
[10]: https://www.w3.org/TR/1999/REC-xpath-19991116
|
||||
[11]: https://developer.mozilla.org/en-US/docs/Web/XPath/Functions
|
||||
|
||||
@ -3,46 +3,45 @@
|
||||
[#]: author: (Sumantro Mukherjee https://opensource.com/users/sumantro)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13631-1.html)
|
||||
|
||||
在虚拟环境中运行 Python 应用
|
||||
pipx:在虚拟环境中运行 Python 应用
|
||||
======
|
||||
通过使用 pipx 隔离运行 Python 应用来避免版本冲突并提高安全性。
|
||||
![Digital creative of a browser on the internet][1]
|
||||
|
||||
> 通过使用 pipx 隔离运行 Python 应用来避免版本冲突并提高安全性。
|
||||
|
||||

|
||||
|
||||
如果你使用 Python,你可能会安装很多 Python 应用。有些是你只想尝试的工具。还有一些是你每天都在使用的久经考验的应用,所以你把它们安装在你使用的每一台计算机上。这两种情况下,在虚拟环境中运行你的 Python 应用是非常有用的,这可以使它们以及它们的依赖关系相互分离,以避免版本冲突,并使它们与你系统的其它部分隔离,以提高安全性。
|
||||
|
||||
这就是 [pipx][2] 出场的地方。
|
||||
|
||||
大多数 Python 应用可以使用 [pip][3] 进行安装,它只安装 Python 包。然而,Pipx 为你的 Python 应用创建并管理一个虚拟环境,并帮助你运行它们。
|
||||
大多数 Python 应用可以使用 [pip][3] 进行安装,它只安装 Python 包。然而,`pipx` 为你的 Python 应用创建并管理一个虚拟环境,并帮助你运行它们。
|
||||
|
||||
### 安装 pipx
|
||||
|
||||
Pipx 主要是一个 RPM 包,你可以在任何 Fedora、RHEL 或 CentOS 机器上安装它:
|
||||
|
||||
`pipx` 主要是一个 RPM 包,你可以在任何 Fedora、RHEL 或 CentOS 机器上安装它:
|
||||
|
||||
```
|
||||
`$ sudo dnf install pipx`
|
||||
$ sudo dnf install pipx
|
||||
```
|
||||
|
||||
### 使用 pipx
|
||||
|
||||
我将通过 Cowsay 以及 [Concentration][4] 工具演示如何使用 pipx。
|
||||
我将通过 Cowsay 以及 [Concentration][4] 工具演示如何使用 `pipx`。
|
||||
|
||||
#### 安装软件包
|
||||
|
||||
安装完 pipx 后,你可以用以下方法安装 Python 包:
|
||||
|
||||
安装完 `pipx` 后,你可以用以下方法安装 Python 包:
|
||||
|
||||
```
|
||||
`$ pipx install <python_package>`
|
||||
$ pipx install <python_package>
|
||||
```
|
||||
|
||||
要安装 Cowsay 包:
|
||||
|
||||
|
||||
```
|
||||
$ pipx install cowsay ✔ │ 20:13:41
|
||||
installed package cowsay 4.0, Python 3.9.5
|
||||
@ -55,28 +54,25 @@ done! ✨ 🌟 ✨
|
||||
|
||||
|
||||
```
|
||||
$ cowsay "I <3 OSDC"
|
||||
_________
|
||||
| I <3 OSDC |
|
||||
=========
|
||||
\
|
||||
\
|
||||
^__^
|
||||
(oo)\\_______
|
||||
(__)\ )\/\
|
||||
||----w |
|
||||
|| ||
|
||||
$ cowsay "I <3 OSDC"
|
||||
_________
|
||||
| I <3 OSDC |
|
||||
=========
|
||||
\
|
||||
\
|
||||
^__^
|
||||
(oo)\_______
|
||||
(__)\ )\/\
|
||||
||----w |
|
||||
|| ||
|
||||
```
|
||||
|
||||
![Cowsay][5]
|
||||
|
||||
(Sumantro Mukherjee, [CC BY-SA 4.0][6])
|
||||
|
||||
#### 以特殊权限进行安装
|
||||
|
||||
不是所有的应用都像 Cowsay 一样简单。例如,Concentration 会与你系统中的许多其他组件交互,所以它需要特殊的权限。用以下方式安装它:
|
||||
|
||||
|
||||
```
|
||||
$ pipx install concentration ✔ │ 10s │ │ 20:26:12
|
||||
installed package concentration 1.1.5, Python 3.9.5
|
||||
@ -85,8 +81,7 @@ $ pipx install concentration ✔ │ 10s
|
||||
done! ✨ 🌟 ✨
|
||||
```
|
||||
|
||||
Concentration 通过阻止 “distractors” 文件中列出的特定网站来帮助你集中注意力。要做到这点,它需要以 sudo 或 root 权限运行。你可以用 [OpenDoas][7] 来做到这点,这是 `doas` 命令的一个版本,可以用特定的用户权限运行任何命令。要使用 `doas` 以 sudo 权限来运行 Concentration:
|
||||
|
||||
Concentration 通过阻止 `distractors` 文件中列出的特定网站来帮助你集中注意力。要做到这点,它需要以 `sudo` 或 root 权限运行。你可以用 [OpenDoas][7] 来做到这点,这是 `doas` 命令的一个版本,可以用特定的用户权限运行任何命令。要使用 `doas` 以 `sudo` 权限来运行 Concentration:
|
||||
|
||||
```
|
||||
$ doas concentration improve ✔ │ │ 20:26:54
|
||||
@ -98,8 +93,7 @@ Concentration is now improved :D!
|
||||
|
||||
#### 列出已安装的应用
|
||||
|
||||
`pipx list` 命令显示所有用 pipx 安装的应用和它们的可执行路径:
|
||||
|
||||
`pipx list` 命令显示所有用 `pipx` 安装的应用和它们的可执行路径:
|
||||
|
||||
```
|
||||
$ pipx list
|
||||
@ -113,16 +107,14 @@ apps are exposed on your $PATH at /home/sumantrom/.local/bin
|
||||
|
||||
#### 卸载应用
|
||||
|
||||
当你使用完毕后,知道如何卸载它们是很重要的。Pipx 有一个非常简单的卸载命令:
|
||||
|
||||
当你使用完毕后,知道如何卸载它们是很重要的。`pipx` 有一个非常简单的卸载命令:
|
||||
|
||||
```
|
||||
`$ pipx uninstall <package name>`
|
||||
$ pipx uninstall <package name>
|
||||
```
|
||||
|
||||
或者你可以删除每个软件包:
|
||||
|
||||
|
||||
```
|
||||
$ pipx uninstall-all
|
||||
|
||||
@ -133,9 +125,9 @@ uninstalled concentration! ✨ 🌟 ✨
|
||||
|
||||
### 尝试 pipx
|
||||
|
||||
Pipx 是一个流行的 Python 应用的包管理器。它可以访问 [PyPi][8] 上的所有东西,但它也可以从包含有效 Python 包的本地目录、Python wheel 或网络位置安装应用。
|
||||
`pipx` 是一个流行的 Python 应用的包管理器。它可以访问 [PyPi][8] 上的所有东西,但它也可以从包含有效 Python 包的本地目录、Python wheel 或网络位置安装应用。
|
||||
|
||||
如果你安装了大量的 Python 应用,可以试试 pipx。
|
||||
如果你安装了大量的 Python 应用,可以试试 `pipx`。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -144,7 +136,7 @@ via: https://opensource.com/article/21/7/python-pipx
|
||||
作者:[Sumantro Mukherjee][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,57 +3,54 @@
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (turbokernel)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13638-1.html)
|
||||
|
||||
认识 Clapper:一款外观时尚的 Linux 视频播放器,适合极简主义者使用
|
||||
认识 Clapper:一款外观时尚的 Linux 视频播放器,极简主义者适用
|
||||
======
|
||||
|
||||
喜欢极简主义吗?你会喜欢 Clapper 的。
|
||||
|
||||
Clapper 是一个新的 [Linux 视频播放器][1]。实际上,它更多的是为 GNOME 而不是为 Linux。
|
||||
Clapper 是一个全新 [Linux 视频播放器][1]。实际上,它更多的是基于 GNOME 而不是 Linux。
|
||||
|
||||
它构建在 GNOME 的 JavaScript 库和 GTK4 工具包之上,自然地融合在 GNOME 的桌面环境中。它使用 [GStreamer][2] 作为媒体后端,使用 [OpenGL][3] 进行渲染。
|
||||
它基于 GNOME 的 JavaScript 库和 GTK4 工具包构建,自然地融合在 GNOME 的桌面环境中。它使用 [GStreamer][2] 作为媒体后端,使用 [OpenGL][3] 进行渲染。
|
||||
|
||||
我喜欢极简主义的应用。虽然 VLC 是媒体播放器中的瑞士刀,但我更喜欢 [MPV 播放器][4],因为它的界面时尚、简约。现在我想要坚持使用 Clapper 一段时间了。
|
||||
我喜欢极简主义的应用。虽然 VLC 是媒体播放器中的瑞士军刀,但我更喜欢 [MPV 播放器][4],因为它的界面时尚、简约。现在我想要坚持使用 Clapper 一段时间了。
|
||||
|
||||
### Clapper 视频播放器
|
||||
|
||||
![A screenshot of Clapper video player][5]
|
||||
|
||||
[Clapper 默认使用硬件加速][6]。它支持英特尔和 AMD 的 GPU,在 Xorg 和 Wayland 上都能工作。
|
||||
[Clapper 默认开启硬件加速][6]。它支持英特尔和 AMD 的 GPU,在 Xorg 和 Wayland 上都能工作。
|
||||
|
||||
[Clapper][7] 不使用传统的上部窗口栏。有自动隐藏的偏好菜单、模式切换器和窗口控制按钮供你访问一些功能。这给了它一个时尚、简约的外观。
|
||||
[Clapper][7] 不使用传统的上部窗口栏。为你提供自动隐藏的偏好菜单、模式切换器和窗口控制按钮供等功能。这给了它一个时尚、简约的外观。
|
||||
|
||||
它有三种模式:
|
||||
|
||||
* 窗口模式:默认模式显示进度条和窗口控制。
|
||||
* 浮动模式:进度条被隐藏,播放器漂浮在其他应用程序的顶部,就像“[总是在顶部][8]”或“画中画”模式。
|
||||
* 浮动模式:隐藏进度条,播放器浮于其他应用程序的顶部,就像“[总是在顶部][8]”或“画中画”模式。
|
||||
* 全屏模式:播放器进入全屏,进度条变大,但它们都会自动隐藏起来
|
||||
|
||||
|
||||
|
||||
![Interface of Clapper video player with preference control and window modes][9]
|
||||
|
||||
Clapper 也有一个自适应的用户界面,也可以在基于 Linux 的智能手机和平板电脑上使用。因此,如果你有自己的 Pine Phone 或 Librem5,你可以在它上面使用 Clapper。
|
||||
Clapper 也有一个自适应的用户界面,可基于 Linux 的智能手机和平板电脑上使用。因此,如果你有自己的 Pine Phone 或 Librem5,你可以在它上面使用 Clapper。
|
||||
|
||||
它支持字幕,并可选择改变字体。然而,在我的测试中,字幕并不可用。也没有选项可以明确地在播放的视频中添加字幕。这一点必须改进。
|
||||
它支持字幕,并可选择改变字体。然而,在我的测试中,字幕并不可用。也没有可以明确地在播放的视频中添加字幕的选项。这一点必须改进。
|
||||
|
||||
和 VLC 一样,如果你再次打开同一个视频文件,Clapper 也可以让你选择从最后一个点恢复播放。这是我喜欢的 VLC 中的一个[方便的功能][10]。
|
||||
和 VLC 一样,如果你再次打开同一个视频文件,Clapper 也可以让你选择从最后一个时间点恢复播放。这是我喜欢的 VLC 中的一个 [方便的功能][10]。
|
||||
|
||||
如果你提供 URL,Clapper 也支持从互联网上播放视频。
|
||||
如果你有 URL,Clapper 也支持从互联网上播放视频。
|
||||
|
||||
这里的截图中,我正在 Clapper 中播放一个 YouTube 视频。这是一首由一位美丽的歌手和演员唱的优美歌曲。你能猜到这是哪首歌或哪部电影吗?
|
||||
|
||||
|
||||
![Clapper playing a video from YouTube][11]
|
||||
|
||||
### 在 Linux 上安装 Clapper
|
||||
|
||||
对 Arch 和 Manjaro 用户而言,Clapper 可在 AUR 中找到。这不是对所有人的惊喜。AUR 有这世上的一切。
|
||||
对 Arch 和 Manjaro 用户而言,Clapper 可在 AUR 中找到。这很稀疏平常,因为 AUR 包罗万象。
|
||||
|
||||
对于其他发行版,Clapper 官方提供了 [Flatpak 包][12]。所以,请[为你的发行版启用 Flatpak 支持][13],然后使用下面的命令来安装它:
|
||||
对于其他发行版,Clapper 官方提供了 [Flatpak 包][12]。所以,请 [为你的发行版启用 Flatpak 支持][13],然后使用下面的命令来安装它:
|
||||
|
||||
```
|
||||
flatpak install flathub com.github.rafostar.Clapper
|
||||
@ -61,7 +58,7 @@ flatpak install flathub com.github.rafostar.Clapper
|
||||
|
||||
安装后,只需在应用菜单中搜索它,或右击视频文件,选择用 Clapper 打开它。
|
||||
|
||||
Clapper 远不是一个完美的视频播放器。然而,它有可能成为一个流行的 Linux 应用。
|
||||
Clapper 仍不是一个完美的视频播放器。然而,它有可能成为一个流行的 Linux 应用。
|
||||
|
||||
如果你使用它,请分享你的经验。如果你发现问题,请[通知开发者][14]。
|
||||
|
||||
@ -72,7 +69,7 @@ via: https://itsfoss.com/clapper-video-player/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[turbokernel](https://github.com/turbokernel)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,18 +3,20 @@
|
||||
[#]: author: (Sumantro Mukherjee https://opensource.com/users/sumantro)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13635-1.html)
|
||||
|
||||
在 Podman 中运行一个 Linux 虚拟机
|
||||
======
|
||||
使用 Podman Machine 创建一个基本的 Fedora CoreOS 虚拟机来使用容器和容器化工作负载。
|
||||
![woman on laptop sitting at the window][1]
|
||||
|
||||
Fedora CoreOS 是一个自动更新、基于最小 [rpm-ostree][2]的 操作系统,用于安全地、大规模地运行容器化工作负载。
|
||||
> 使用 Podman Machine 创建一个基本的 Fedora CoreOS 虚拟机来使用容器和容器化工作负载。
|
||||
|
||||
[Podman][3] “是一个用于管理容器和镜像、挂载到这些容器中的卷,以及由这些容器组组成的 pod 的工具。Podman 基于 libpod,它是一个容器生命周期管理库”。
|
||||

|
||||
|
||||
Fedora CoreOS 是一个自动更新、最小化的基于 [rpm-ostree][2] 的操作系统,用于安全地、大规模地运行容器化工作负载。
|
||||
|
||||
[Podman][3] “是一个用于管理容器和镜像、挂载到这些容器中的卷,以及由这些容器组组成的吊舱的工具。Podman 基于 libpod,它是一个容器生命周期管理库”。
|
||||
|
||||
当你使用 [Podman Machine][4] 时,神奇的事情发生了,它可以帮助你创建一个基本的 Fedora CoreOS 虚拟机(VM)来使用容器和容器化工作负载。
|
||||
|
||||
@ -22,9 +24,8 @@ Fedora CoreOS 是一个自动更新、基于最小 [rpm-ostree][2]的 操作系
|
||||
|
||||
第一步是安装 Podman。如果你已经安装了最新版本的 Podman,你可以跳过这个步骤。在我的 Fedora 34 机器上,我用以下方式安装 Podman:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf install podman`
|
||||
$ sudo dnf install podman
|
||||
```
|
||||
|
||||
我使用的是 podman-3.2.2-1.fc34.x86_64。
|
||||
@ -33,7 +34,6 @@ Fedora CoreOS 是一个自动更新、基于最小 [rpm-ostree][2]的 操作系
|
||||
|
||||
Podman 安装完成后,用以下方法初始化它:
|
||||
|
||||
|
||||
```
|
||||
❯ podman machine init vm2
|
||||
Downloading VM image: fedora-coreos-34.20210626.1.0-qemu.x86_64.qcow2.xz: done
|
||||
@ -46,7 +46,6 @@ Extracting compressed file
|
||||
|
||||
了解你的虚拟机和它们的状态是很重要的,`list` 命令可以帮助你做到这一点。下面的例子显示了我所有的虚拟机的名称,它们被创建的日期,以及它们最后一次启动的时间:
|
||||
|
||||
|
||||
```
|
||||
❯ podman machine list
|
||||
NAME VM TYPE CREATED LAST UP
|
||||
@ -58,24 +57,22 @@ vm2 qemu 11 minutes ago 11 minutes ago
|
||||
|
||||
要启动一个虚拟机,请运行:
|
||||
|
||||
|
||||
```
|
||||
❯ podman machine start
|
||||
Waiting for VM …
|
||||
Waiting for VM ...
|
||||
```
|
||||
|
||||
### SSH 到虚拟机
|
||||
|
||||
你可以使用 SSH 来访问你的虚拟机,并使用它来运行工作负载,而没有任何麻烦的设置:
|
||||
|
||||
|
||||
```
|
||||
❯ podman machine ssh
|
||||
❯ podman machine ssh
|
||||
Connecting to vm podman-machine-default. To close connection, use `~.` or `exit`
|
||||
Fedora CoreOS 34.20210611.1.0
|
||||
Tracker: <https://github.com/coreos/fedora-coreos-tracker>
|
||||
Discuss: <https://discussion.fedoraproject.org/c/server/coreos/>
|
||||
|
||||
Tracker: https://github.com/coreos/fedora-coreos-tracker
|
||||
Discuss: https://discussion.fedoraproject.org/c/server/coreos/
|
||||
|
||||
Last login: Wed Jun 23 13:23:36 2021 from 10.0.2.2
|
||||
[core@localhost ~]$ uname -a
|
||||
Linux localhost 5.12.9-300.fc34.x86_64 #1 SMP Thu Jun 3 13:51:40 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
|
||||
@ -88,7 +85,6 @@ Linux localhost 5.12.9-300.fc34.x86_64 #1 SMP Thu Jun 3 13:51:40 UTC 2021 x86_64
|
||||
|
||||
要停止运行中的虚拟机,请使用 `stop` 命令:
|
||||
|
||||
|
||||
```
|
||||
❯ podman machine stop
|
||||
|
||||
@ -106,7 +102,7 @@ via: https://opensource.com/article/21/7/linux-podman
|
||||
作者:[Sumantro Mukherjee][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,42 +3,46 @@
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13629-1.html)
|
||||
|
||||
在 Linux 上运行和测试 Android 应用的顶级 Android 模拟器
|
||||
Linux 上的顶级安卓模拟器
|
||||
======
|
||||
|
||||

|
||||
|
||||
安卓系统是建立在高度定制的 Linux 内核之上的。因此,使用安卓模拟器在 Linux 上运行移动应用是有意义的。
|
||||
|
||||
虽然这不是在 Linux 机器上你可以做的新事情,但在 Windows 于 2021 年推出运行安卓应用的能力后,它是一个更需要的功能。
|
||||
虽然这不是在 Linux 机器上你可以做的新鲜事,但在 Windows 于 2021 年推出运行安卓应用的能力后,它是一个更需要的功能。
|
||||
|
||||
不仅仅限于使用应用,一些安卓模拟器也可以在开发和测试中派上用场。
|
||||
|
||||
因此,我总结了一份最好的模拟器清单,你可以用它来测试或在 Linux 上运行 Android 应用/游戏。
|
||||
因此,我总结了一份最好的模拟器清单,你可以用它来测试或在 Linux 上运行安卓应用/游戏。
|
||||
|
||||
### 1\. Anbox
|
||||
### 1、Anbox
|
||||
|
||||
Anbox 是一个相当流行的让 Linux 用户运行 Android 应用的模拟器。可能 Deepin Linux 正是利用它使得开箱即可运行 Android 应用。
|
||||

|
||||
|
||||
Anbox 是一个相当流行的模拟器,可以让 Linux 用户运行 Android 应用。可能深度 Linux 正是利用它使得开箱即可运行安卓应用。
|
||||
|
||||
它使用一个容器将安卓操作系统与主机隔离,这也让它们可以使用最新的安卓版本。
|
||||
|
||||
运行的安卓应用将不能直接访问你的硬件,这是一个很好的安全决定。
|
||||
运行的安卓应用不能直接访问你的硬件,这是一个很好的安全决定。
|
||||
|
||||
与这里的其他一些选项不同,Anbox 在技术上不需要仿真层来使安卓系统工作。换句话说,它在你的 Linux 系统上最接近于原生的 Android 体验。
|
||||
与这里的其他一些选择不同,Anbox 在技术上不需要仿真层来使安卓系统工作。换句话说,它在你的 Linux 系统上最接近于原生的安卓体验。
|
||||
|
||||
由于这个原因,它可能不是最简单的选择。你不能只使用谷歌应用商店来安装应用,你需要使用安卓调试桥(ADB)。你只需要一个应用的 APK 文件就可以安装和使用它。
|
||||
|
||||
[Anbox][1]
|
||||
- [Anbox][1]
|
||||
|
||||
### 2\. Genymotion
|
||||
### 2、Genymotion
|
||||
|
||||
![][2]
|
||||
|
||||
Genymotion 是一个为测试和开发量身定做的令人印象深刻的解决方案。
|
||||
|
||||
它不是一个免费和开源的选择。它们通过云端或独立于 Android Studio 的桌面客户端,提供虚拟的 Android 体验作为服务。
|
||||
它不是一个自由开源的选择。它们通过云端或独立于 Android Studio 的桌面客户端,提供虚拟的安卓体验作为服务。
|
||||
|
||||
你可以模拟各种硬件配置和安卓版本,创建一个虚拟设备进行测试。它还让你有能力扩大规模,并有多个安卓虚拟设备运行,进行广泛的测试。
|
||||
|
||||
@ -46,63 +50,63 @@ Genymotion 是一个为测试和开发量身定做的令人印象深刻的解决
|
||||
|
||||
虽然它是一个主要针对专业人士的高级解决方案,但它确实支持最新的 Linux 发行版,包括 Ubuntu 20.04 LTS。
|
||||
|
||||
[Genymotion][3]
|
||||
- [Genymotion][3]
|
||||
|
||||
### 3\. Android-x86
|
||||
### 3、Android-x86
|
||||
|
||||
![][4]
|
||||
|
||||
Android x86 是一个开源项目,使得 Android 在 PC 上运行,并支持 32 位。
|
||||
Android x86 是一个开源项目,使得安卓可以在 PC 上运行,并支持 32 位。
|
||||
|
||||
你可以选择在你的 Linux 系统上使用虚拟机管理器来安装它,或者直接在你的 PC 上试用它。
|
||||
|
||||
如果你需要安装,可以查看官方的[安装说明][5]。
|
||||
如果你需要安装,可以查看官方的 [安装说明][5]。
|
||||
|
||||
与其他一些选项不同,它是一个简单的试图在 PC 上工作的模拟器,没有花哨的功能。
|
||||
与其他一些选择不同,它是一个简单的试图在 PC 上工作的模拟器,没有花哨的功能。
|
||||
|
||||
[Android x86][6]
|
||||
- [Android x86][6]
|
||||
|
||||
### 4\. Android Studio (虚拟设备)
|
||||
### 4、Android Studio (虚拟设备)
|
||||
|
||||
![][7]
|
||||
|
||||
Android Studio 是一个用于开发和测试的完整工具。幸运的是,由于对 Linux 的支持,如果你需要的话,你可以用它来模拟 Android 的体验进行实验。
|
||||
Android Studio 是一个用于开发和测试的完整工具。幸运的是,由于对 Linux 的支持,如果你需要的话,你可以用它来模拟安卓的体验进行实验。
|
||||
|
||||
你只需要创建一个安卓虚拟设备(AVD),你可以对其进行配置,然后作为模拟器进行模拟。
|
||||
|
||||
也有很大的机会找到对一些最新的智能手机、电视和智能手表的支持。
|
||||
也有很大的机会能找到对一些最新的智能手机、电视和智能手表的支持。
|
||||
|
||||
它需要一定的学习曲线才能上手,但它是免费的,而且是完全开源的。
|
||||
|
||||
[Android Studio][8]
|
||||
- [Android Studio][8]
|
||||
|
||||
### 5\. ARChon
|
||||
### 5、ARChon
|
||||
|
||||
![][9]
|
||||
|
||||
一个有趣的解决方案是一个你可以在 Linux 和任何其他平台上使用的 Android 模拟器。
|
||||
一个有趣的解决方案,这是一个你可以在 Linux 和任何其他平台上使用的安卓模拟器。
|
||||
|
||||
它有助于在 Chrome OS 上运行 Android 应用,或者在任何操作系统上使用 Chrome 浏览器。与其他一些不同的是,你可能不会得到完整的安卓体验,而只是能够运行安卓应用。
|
||||
它有助于在 Chrome OS 上运行安卓应用,或者在任何操作系统上使用 Chrome 浏览器。与其他一些不同的是,你可能不会得到完整的安卓体验,而只是能够运行安卓应用。
|
||||
|
||||
你只需解压运行时,并将其加载到 Chrome 扩展中。接下来,下载 APK 文件到上面来添加你想使用的应用。
|
||||
|
||||
[ARChon][10]
|
||||
- [ARChon][10]
|
||||
|
||||
### 6\. Bliss OS
|
||||
### 6、Bliss OS
|
||||
|
||||
![][11]
|
||||
|
||||
Bliss OS 是另一个开源项目,与 Android x86 类似,旨在使 Android 在 PC 上运行。
|
||||
Bliss OS 是另一个开源项目,与 Android x86 类似,旨在使安卓在 PC 上运行。
|
||||
|
||||
与 Android x86 不同的是,它通过支持 32 位和 64 位架构提供了更多的兼容性选择。此外,你可以根据你的处理器下载兼容文件。
|
||||
|
||||
它有积极的维护,支持市场上最新的安卓版本。
|
||||
|
||||
[Bliss OS][12]
|
||||
- [Bliss OS][12]
|
||||
|
||||
### 总结
|
||||
|
||||
虽然你会发现有几个可用于 Linux 的安卓模拟器,但它们可能无法取代全面的智能手机体验。
|
||||
虽然你会能找到几个可用于 Linux 的安卓模拟器,但它们可能无法取代全面的智能手机体验。
|
||||
|
||||
每个模拟器都有一系列的功能和特定目的。请选择你需要的那个!
|
||||
|
||||
@ -115,7 +119,7 @@ via: https://itsfoss.com/android-emulators-linux/
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,16 +3,18 @@
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13637-1.html)
|
||||
|
||||
如何在 Fedora Linux 上安装 VLC
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你刚刚安装了 Fedora,现在想在上面安装你最喜欢的视频播放器 VLC,你可能不会在软件中心找到它。至少不会立即找到。
|
||||
|
||||
由于开发者最清楚的原因,Fedora 既没有安装 [VLC][1],也不包括在 Fedora 官方仓库中。
|
||||
出于只有它的开发者知道的原因,Fedora 既没有安装 [VLC][1],也不包括在 Fedora 官方仓库中。
|
||||
|
||||
那么,你如何在 Fedora 上安装 VLC 呢?很简单。RPM Fusion 是你的朋友。让我告诉你详细的步骤。
|
||||
|
||||
@ -26,13 +28,13 @@
|
||||
sudo dnf install https://mirrors.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
|
||||
```
|
||||
|
||||
当被要求确认添加新仓库时按 Y。接下来,使用 DNF 命令安装 VLC:
|
||||
当被要求确认添加新仓库时按 `Y`。接下来,使用 DNF 命令安装 VLC:
|
||||
|
||||
```
|
||||
sudo dnf install vlc
|
||||
```
|
||||
|
||||
它将在 Fedora 中从RPM Fusion 仓库中安装 VLC,并从不同的仓库中安装一些额外的依赖项。
|
||||
它将在 Fedora 中从 RPM Fusion 仓库中安装 VLC,并从不同的仓库中安装一些额外的依赖项。
|
||||
|
||||
![Installing VLC in Fedora with DNF command][2]
|
||||
|
||||
@ -65,7 +67,7 @@ via: https://itsfoss.com/install-vlc-fedora/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
86
published/20210720 Install Shutter in Fedora 34 and Above.md
Normal file
86
published/20210720 Install Shutter in Fedora 34 and Above.md
Normal file
@ -0,0 +1,86 @@
|
||||
[#]: subject: (Install Shutter in Fedora 34 and Above)
|
||||
[#]: via: (https://www.debugpoint.com/2021/07/install-shutter-fedora/)
|
||||
[#]: author: (Arindam https://www.debugpoint.com/author/admin1/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-13641-1.html)
|
||||
|
||||
在 Fedora 34 及以上版本中安装 Shutter
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 这个快速指南解释了在 Fedora 34 及以上版本中安装 Shutter 所需的步骤。
|
||||
|
||||
截图工具有很多替代和选择。但在我个人看来,没有一个能接近 Shutter 的灵活性。不幸的是,由于各种依赖性问题,特别是它的设计方式,多年来,Linux 发行版,如 Ubuntu、Fedora,都面临着将这个应用打包到官方仓库的问题。
|
||||
|
||||
主要问题是它仍然基于 GTK2 和 Perl。当大多数应用转移到 GTK3 时,它仍然是 GTK2。这就造成了一个依赖性问题,因为 Debian/Ubuntu、Fedora 删除了某些包的依赖的 GTK2 版本。
|
||||
|
||||
在 Fedora 34 及以上版本中安装 [Shutter][1] 截图工具需要采用另一种方法。
|
||||
|
||||
现在,你只能通过个人包存档(PPA)来安装这个工具。下面是如何在 Fedora 34 及以上版本中安装它。
|
||||
|
||||
![Shutter in Fedora][2]
|
||||
|
||||
### 在 Fedora 34 及以上版本中安装 Shutter
|
||||
|
||||
在你的 Fedora 中打开一个终端,启用以下 [Shutter 的 copr 仓库][3]。这个包存档为 Fedora 的 Shutter 提供了一个单独的构建,其中包含了所有未满足的依赖项。
|
||||
|
||||
```
|
||||
sudo dnf copr enable geraldosimiao/shutter
|
||||
```
|
||||
|
||||
完成后,你就可以通过 `dnf` 在 Fedora 34 及以上版本中简单地安装 Shutter。
|
||||
|
||||
```
|
||||
sudo dnf install shutter
|
||||
```
|
||||
|
||||
尽管目前最新的版本是 v0.97。遗憾的是,该仓库目前包含旧的 v0.94.x。我希望版本库的所有者尽快包括最新的版本。
|
||||
|
||||
安装后,你可以通过应用菜单启动它。
|
||||
|
||||
#### 卸载 Shutter
|
||||
|
||||
如果你愿意,你可以通过命令轻松地删除这个第三方仓库:
|
||||
|
||||
```
|
||||
sudo dnf copr remove geraldosimiao/shutter
|
||||
```
|
||||
|
||||
然后按照下面的方法,完全删除 Shutter,包括依赖关系。
|
||||
|
||||
```
|
||||
sudo dnf autoremove shutter
|
||||
```
|
||||
|
||||
#### 在其他 Linux 发行版中安装 Shutter
|
||||
|
||||
如果你想在 Debian、Ubuntu 或相关发行版中安装它,请 [查看此指南][4]。
|
||||
|
||||
### Shutter 的开发
|
||||
|
||||
最近,这个项目 [转移到了 GitHub][6],以便更好地协作,并且正在进行 GTK3 移植。而且它相当活跃,最近还发布了一个版本。我们希望它能尽快被移植到 GTK3 上,并在各发行版的原生仓库中可用。
|
||||
|
||||
如果你在安装 Shutter 时遇到任何错误,请在评论栏告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.debugpoint.com/2021/07/install-shutter-fedora/
|
||||
|
||||
作者:[Arindam][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.debugpoint.com/author/admin1/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.debugpoint.com/tag/shutter
|
||||
[2]: https://www.debugpoint.com/blog/wp-content/uploads/2021/07/Shutter-in-Fedora.jpeg
|
||||
[3]: https://copr.fedorainfracloud.org/coprs/geraldosimiao/shutter/
|
||||
[4]: https://www.debugpoint.com/2020/04/shutter-install-ubuntu/
|
||||
[6]: https://github.com/shutter-project/shutter
|
||||
@ -1,114 +0,0 @@
|
||||
[#]: subject: (Windows 11 Makes Your Hardware Obsolete, Use Linux Instead!)
|
||||
[#]: via: (https://news.itsfoss.com/windows-11-linux/)
|
||||
[#]: author: (Ankush Das https://news.itsfoss.com/author/ankush/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Windows 11 Makes Your Hardware Obsolete, Use Linux Instead!
|
||||
======
|
||||
|
||||
Windows 11 is finally here. We’re not entirely thrilled by it – but it introduces problems for many computer users.
|
||||
|
||||
And I’m not even talking the privacy aspect or its design choice. But it seems that Windows 11 is demanding newer hardware to work, which makes your old computer obsolete in a way and forces you to upgrade your hardware for no good reason.
|
||||
|
||||
What else is a problem with the arrival of Windows 11? What’s so bad about it?
|
||||
|
||||
### Only Eligible Devices Can Get the Windows 11 Upgrade
|
||||
|
||||
To start with, Windows 11 has interestingly added a minimum system requirement which looks good on paper:
|
||||
|
||||
* 1 GHz dual-core 64-bit processor
|
||||
* 4 GB RAM
|
||||
* 64 GB storage
|
||||
* UEFI, Secure Boot support
|
||||
* Trusted Platform Module version 2.0
|
||||
* DirectX 12 compatible graphics
|
||||
* 720p resolution display
|
||||
|
||||
|
||||
|
||||
![][1]
|
||||
|
||||
You can check if your system is eligible by downloading the **PC Health Check** app from [Microsoft’s official site][2].
|
||||
|
||||
Most of the computers from the last decade should meet these criteria – but there’s a catch.
|
||||
|
||||
The hardware should have a TPM chip, which may not be the case for some PC builds or laptops. Fortunately, it is not all bad, you may just need to enable it from your BIOS settings including the Secure Boot support, to make your PC eligible. There’s a guide on [PCGamer][3] to help you with that.
|
||||
|
||||
Technically, processors older than **Intel 8th gen and Ryzen 3000 series** are not officially supported as per Microsoft’s official documentations ([AMD][4] | [Intel][5]).
|
||||
|
||||
However, there are a sound number of systems that may not have the support for it. So, what do you do?
|
||||
|
||||
Easy, [**switch to Linux in 2021**][6] before Windows 10 no longer receives updates. This year, it makes more sense than ever for you to try Linux for your personal computer!
|
||||
|
||||
### Windows 11 Installation Requires Internet Connectivity
|
||||
|
||||
![][7]
|
||||
|
||||
While we do not have enough clarity about this but as per its system requirement specifications, it will require users to have an active Internet connection for Windows 11 installation.
|
||||
|
||||
But, with Linux, you do not need that.
|
||||
|
||||
That’s just one of the [benefits of using Linux over Windows][8] – you get complete control of your operating system.
|
||||
|
||||
### No 32-Bit Support
|
||||
|
||||
![][7]
|
||||
|
||||
Windows 10 did support 32-bit systems, but Windows 11 ends that.
|
||||
|
||||
This is where Linux shines.
|
||||
|
||||
Even though the 32-bit support is dwindling everywhere, we still have a bunch of [**Linux distributions that support 32-bit systems**][9]. Your 32-bit system may still live for a decade with Linux.
|
||||
|
||||
### Windows 10 Support Ends in 2025
|
||||
|
||||
Well, this was unexpected considering Microsoft initially planned to never have an upgrade after Windows 10 but support it for the foreseeable future.
|
||||
|
||||
Now, Windows 10 will be killed in 2025…
|
||||
|
||||
So, what do you do then? Upgrade your hardware just because it does not support Windows 11?
|
||||
|
||||
Unless there’s a necessity, Linux is your friend forever.
|
||||
|
||||
You can try several [**lightweight Linux distributions**][10] that will revive any of your computers that Microsoft considers obsolete!
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
While Windows 11 plans to force users to upgrade their hardware in the next few years, Linux lets you keep your hardware for a long time along with several added benefits.
|
||||
|
||||
So, if you are not happy with Windows 11 release, you may want to start using Linux instead. Fret not, you can refer to our guides on our main web portal [It’s FOSS][11] to learn everything you need to get started using Linux!
|
||||
|
||||
#### Big Tech Websites Get Millions in Revenue, It's FOSS Got You!
|
||||
|
||||
If you like what we do here at It's FOSS, please consider making a donation to support our independent publication. Your support will help us keep publishing content focusing on desktop Linux and open source software.
|
||||
|
||||
I'm not interested
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.itsfoss.com/windows-11-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://news.itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9IjIyNSIgd2lkdGg9Ijc4MCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIiB2ZXJzaW9uPSIxLjEiLz4=
|
||||
[2]: https://www.microsoft.com/en-us/windows/windows-11
|
||||
[3]: https://www.pcgamer.com/Windows-11-PC-Health-Check/
|
||||
[4]: https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-amd-processors
|
||||
[5]: https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-intel-processors
|
||||
[6]: https://news.itsfoss.com/switch-to-linux-in-2021/
|
||||
[7]: data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9IjQzOSIgd2lkdGg9Ijc4MCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIiB2ZXJzaW9uPSIxLjEiLz4=
|
||||
[8]: https://itsfoss.com/linux-better-than-windows/
|
||||
[9]: https://itsfoss.com/32-bit-linux-distributions/
|
||||
[10]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[11]: https://itsfoss.com
|
||||
@ -1,101 +0,0 @@
|
||||
[#]: subject: (Nextcloud Hub 22 Makes It Easy to Collaborate and Manage Groups)
|
||||
[#]: via: (https://news.itsfoss.com/nextcloud-hub-22-release/)
|
||||
[#]: author: (Ankush Das https://news.itsfoss.com/author/ankush/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Nextcloud Hub 22 Makes It Easy to Collaborate and Manage Groups
|
||||
======
|
||||
|
||||
[Nextcloud][1] is one of the best open-source remote working tools available.
|
||||
|
||||
With every new release, it is just keeps getting better. The latest Nextcloud Hub 22 release introduces significant improvements to the workflow and a new app that should make it easier to collaborate and efficiently manage groups.
|
||||
|
||||
### Nextcloud Hub 22: What’s New?
|
||||
|
||||
Here, let me highlight the key changes involved in the release.
|
||||
|
||||
#### Collectives App to Manage and Share Knowledge
|
||||
|
||||
![][2]
|
||||
|
||||
Taking notes or managing information that you consume in an individual level is doable. But, how do you ease knowledge management and sharing for a group of individuals?
|
||||
|
||||
Collectives app comes to the rescue with Nextcloud 22 that lets you create pages/subpages to structure knowledge and cross-document links to interlink information.
|
||||
|
||||
You can manage access to the information using user-defined groups, which is also a new feature introduced with this release.
|
||||
|
||||
#### User-defined Groups
|
||||
|
||||
![][3]
|
||||
|
||||
Normally, the administrator manages groups/teams. But, with user-defined groups i.e. **Circles**, you can add anyone from your contacts to form a group without needing an administrator.
|
||||
|
||||
A circle is a custom group anyone can create. You can also choose to make it visible to other members or keep it private.
|
||||
|
||||
This lets you easily share tasks/files with a particular circle.
|
||||
|
||||
#### Integrated Chat and Task Management
|
||||
|
||||
As part of an improved workflow, Nextcloud 22 lets you turn a chat message to deck card to quickly assign a task.
|
||||
|
||||
![][4]
|
||||
|
||||
You will get the ability to tweak the due date and assign it to someone specific.
|
||||
|
||||
Also, you can easily share the deck card created in a chat room of your choice.
|
||||
|
||||
#### Document Signing & Approval
|
||||
|
||||
![][5]
|
||||
|
||||
Another major improvement to the workflow is the introduction of document signing capabilities within Nextcloud and the document approval option.
|
||||
|
||||
You get support for PDF signing tools like LibreSign and DocuSign. You can get a formal signature for any of your documents without leaving Nextcloud, make things more convenient.
|
||||
|
||||
The approval option also lets you share proposals or applications and get a response within Nextcloud.
|
||||
|
||||
#### Other Improvements
|
||||
|
||||
With Nextcloud 22, you can finally restore deleted calendar events. When deleted, the calendar events reside in a trash bin, which gives you the chance to look back for about a month.
|
||||
|
||||
In addition to the new features, there are performance and security upgrades as well.
|
||||
|
||||
If you are curious, you can check out the [official announcement post][6] about this release.
|
||||
|
||||
You should find the latest Nextcloud version available to download for desktop, mobile, and server in the official website.
|
||||
|
||||
[Download Nextcloud 22][7]
|
||||
|
||||
If you want help installing it in your server, go through our tutorial on [installing Nextcloud with Docker][8].
|
||||
|
||||
#### Big Tech Websites Get Millions in Revenue, It's FOSS Got You!
|
||||
|
||||
If you like what we do here at It's FOSS, please consider making a donation to support our independent publication. Your support will help us keep publishing content focusing on desktop Linux and open source software.
|
||||
|
||||
I'm not interested
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.itsfoss.com/nextcloud-hub-22-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://news.itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/nextcloud/
|
||||
[2]: https://i0.wp.com/i.ytimg.com/vi/yeKRhD3GG3Y/hqdefault.jpg?w=780&ssl=1
|
||||
[3]: https://i0.wp.com/i.ytimg.com/vi/AD--RNtC89Y/hqdefault.jpg?w=780&ssl=1
|
||||
[4]: https://i2.wp.com/i.ytimg.com/vi/OOOTYMpXXvQ/hqdefault.jpg?w=780&ssl=1
|
||||
[5]: https://i1.wp.com/i.ytimg.com/vi/iqx3E1a3FfA/hqdefault.jpg?w=780&ssl=1
|
||||
[6]: https://nextcloud.com/blog/nextcloud-hub-22-introduces-approval-workflows-integrated-knowledge-management-and-decentralized-group-administration/
|
||||
[7]: https://nextcloud.com/install/
|
||||
[8]: https://linuxhandbook.com/install-nextcloud-docker/
|
||||
@ -1,119 +0,0 @@
|
||||
[#]: subject: (Linux Mint 20.2 “Uma” Released. This is What’s New)
|
||||
[#]: via: (https://www.debugpoint.com/2021/07/linux-mint-20-2-release-announcement/)
|
||||
[#]: author: (Arindam https://www.debugpoint.com/author/admin1/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Linux Mint 20.2 “Uma” Released. This is What’s New
|
||||
======
|
||||
Linux Mint 20.2 Uma is now available for download and to upgrade. We
|
||||
wrap up the release for you with download instructions.In
|
||||
Brief:Details:Bulky
|
||||
![Linux Mint 20.2 Cinnamon Desktop][1]
|
||||
|
||||
The latest installment of Linux Mint is [announced][2]. This second installment of Linux Mint 20 series code-named “Uma” brings some cool features alongside the usual package and application updates. This release contains 6 month worth of updates since the release of Linux Mint 20.1.
|
||||
|
||||
Here are the top new features.
|
||||
|
||||
### Linux Mint 20.2 – What’s New
|
||||
|
||||
Packages and Components summary in Linux Mint 20.2.
|
||||
|
||||
* Based on Ubuntu 20.04.2 LTS
|
||||
* Linux Kernel 5.4.0
|
||||
* Cinnamon Desktop 5.0.2
|
||||
* Xfce Desktop 4.16
|
||||
* MATE Desktop 1.24
|
||||
* Python 3.8.5
|
||||
* Firefox 89.0
|
||||
* LibreOffice 6.4.7.2
|
||||
* New XApp Bulky 1.3
|
||||
* Warpinator 1.2.2
|
||||
|
||||
|
||||
|
||||
#### Core
|
||||
|
||||
The Linux Mint 20.x entire series is based on Ubuntu 20.04 LTS. That means, the Kernel version, packages remain aligned to the Ubuntu LTS version. Hence with this release, you get Linux Kernel 5.4 and other stable core updates.
|
||||
|
||||
#### New App – Bulky
|
||||
|
||||
![New Bulky App \(Image Credit – Mint\)][3]
|
||||
|
||||
A new native application is introduced in the Uma release. Named “” – this desktop utility helps you to rename files and directories in batch. It has options like regular expression and other search features which help while remaining files and directories of similar patterns. It is primarily for MATE and Cinnamon flavor. The application is available as “File Renamer” in the application menu.
|
||||
|
||||
#### Warpinator Updates
|
||||
|
||||
Warpinator which is one of the best Linux Mint app used to transfer files across the Network (Wired and Wireless), brings more enhancement. In the next version, it gives you the ability to select the Network Interface which you want to use for file transfer. If you have both Wired and Wireless ethernet, you can select which one you want to use to share files to another device on the same selected network interface.
|
||||
|
||||
[][4]
|
||||
|
||||
SEE ALSO: How to Upgrade to Linux Mint 20.2 from 20.1
|
||||
|
||||
Not only that, but it also brings compression settings which enable “3 times faster” transfer across devices – provided both the machine have the compression enabled.
|
||||
|
||||
#### Nemo 5.0
|
||||
|
||||
![Search in File Contents in Nemo File Manager][5]
|
||||
|
||||
The Cinnamon file manager Nemo version 5.0.1 brings file content search which is part of the Cinnamon 5.0 release. Today, Nemo only searches in the file and directory names for matching search criteria. With this enhancement, Nemo can search inside the file contents for a keyword. The team says that Regular expressions and recursive folder searches are also supported. This feature will be very useful for many users who use Linux Mint as a daily driver and work with many files as part of their workflow.
|
||||
|
||||
#### Others
|
||||
|
||||
“Nvidia-prime-applet 1.2.7 was backported recently. It contains a fix for a regression in ubuntu-drivers-common which made the applet disappear.
|
||||
|
||||
It also contains support for computers with AMD/NVIDIA hybrids (i.e. systems with an integrated AMD GPU and a discrete NVIDIA GPU).”
|
||||
|
||||
### Linux Mint 20.2 Download
|
||||
|
||||
The .iso files can now be downloaded from the below torrents for respective desktop environment – Xfce, Cinnamon and MATE.
|
||||
|
||||
* [Cinnamon – Torrent – Download][6]
|
||||
* [MATE – Torrent – Download][7]
|
||||
* [Xfce – Torrent – Download][8]
|
||||
|
||||
|
||||
|
||||
If you are running [Linux Mint 20.1 Ulyssa][9], then wait for a day or two, you should get the updates via Linux Mint update manager.
|
||||
|
||||
### Upgrade Steps
|
||||
|
||||
The upgrade to Linux Mint 20.2 is pretty straight forward with a bit of caution. [Here is the detailed guide of the upgrade.][4]
|
||||
|
||||
> [How to Upgrade to Linux Mint 20.2 from 20.1][4]
|
||||
|
||||
Official Release notes are available in the below places.
|
||||
|
||||
* <https://www.linuxmint.com/rel_uma_cinnamon.php>
|
||||
* <https://www.linuxmint.com/rel_uma_mate.php>
|
||||
* <https://www.linuxmint.com/rel_uma_xfce.php>
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.debugpoint.com/2021/07/linux-mint-20-2-release-announcement/
|
||||
|
||||
作者:[Arindam][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.debugpoint.com/author/admin1/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.debugpoint.com/blog/wp-content/uploads/2021/07/Linux-Mint-20.2-Cinnamon-Desktop-1024x768.jpeg
|
||||
[2]: https://blog.linuxmint.com/?p=4102
|
||||
[3]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/New-Bulky-App-Image-Credit-Mint.png
|
||||
[4]: https://www.debugpoint.com/2021/07/upgrade-linux-mint-20-2/
|
||||
[5]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/Search-in-File-Contents-in-Nemo-File-Manager.jpg
|
||||
[6]: https://linuxmint.com/torrents/linuxmint-20.2-cinnamon-64bit.iso.torrent
|
||||
[7]: https://linuxmint.com/torrents/linuxmint-20.2-mate-64bit.iso.torrent
|
||||
[8]: https://linuxmint.com/torrents/linuxmint-20.2-xfce-64bit.iso.torrent
|
||||
[9]: https://www.debugpoint.com/2021/01/linux-mint-20-1-release-announcement/
|
||||
@ -1,179 +0,0 @@
|
||||
[#]: subject: (F(r)iction: Or How I Learnt to Stop Worrying and Start Loving Vim)
|
||||
[#]: via: (https://news.itsfoss.com/how-i-started-loving-vim/)
|
||||
[#]: author: (Theena https://news.itsfoss.com/author/theena/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (piaoshi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
F(r)iction: Or How I Learnt to Stop Worrying and Start Loving Vim
|
||||
======
|
||||
|
||||
It is Dec 2009, and I am ready to quit my job.
|
||||
|
||||
I wanted to focus on writing my first book; neither my commitments at work nor the state of technology was helping.
|
||||
|
||||
Writing is hard work.
|
||||
|
||||
Few tasks in the modern world can be as singular – or as daunting – a pursuit as sitting down in front of a blank piece of paper, and asking your brain to vomit out words that communicate an idea to readers. I am not suggesting that writing can’t be collaborative of course, but merely illustrating how daunting it can be for writers to set off on a new piece by themselves. This is true for fiction
|
||||
and non-fiction writing, but since I am a novelist I’d like to focus primarily on fiction in this article.
|
||||
|
||||
![][1]
|
||||
|
||||
Remember what 2009 was like?
|
||||
|
||||
Smart phones were 3 years old – I still hadn’t gone away from feature phones. Laptops were big and bulky. Meanwhile, cloud-based web applications for productivity was in their infancy, and just not good. Technologically speaking, writers like me were using their Gmail accounts (and a very young cloud-based storage called Dropbox) as an always-available option to work on their drafts, even while away from my personal computer. While this was a nice change from what writers had to go through when working with typewriters (or god forbid, pen and paper), it wasn’t much.
|
||||
|
||||
For one thing, version control of manuscripts was a nightmare. Further, the more tools I added to my tool kit to simplify the workflow, the more I had to switch context – both from a UI and a UX sense.
|
||||
|
||||
I would start writing drafts on Windows Notepad, save it on a MS Word Document on my PC at home, email myself a copy, keep another copy on Dropbox (since Dropbox wasn’t accessible at work), work on the copy of that file at work, email it back to myself at the end of the day, download it on the home computer, saving it under a new name and the respective date so that I would recognize the changes in the file were made at work (as opposed to home)…well you get the picture. If you think this workflow involving Windows Notepad, MS Word, Gmail, and Dropbox is insane, well now you know why I quit my job.
|
||||
|
||||
More soberingly, I still know writers, damn good writers too, who use variations of the workflow that I followed in 2009.
|
||||
|
||||
Over the next three years, I worked on the manuscript, completing the first draft in 2012. During the three years much had changed with the state of technology. Smart phones were actually pretty great, and some of the complications I had in 2009 had disappeared. I could still work on the same file that I had been working from at home, on my phone (not necessarily fresh writing, but editing had become considerably easier thanks to Dropbox on the phone.) My main writing tool remained Microsoft’s Windows Notepad and Word, which is how I completed the first draft.
|
||||
|
||||
The novel [**First Utterance**][2] was released in 2016 to critical and commercial acclaim.
|
||||
|
||||
The end.
|
||||
|
||||
Or so I thought.
|
||||
|
||||
As soon as I completed the manuscript and sent it to my editor, I had begun working on the second novel. I was no longer quitting my job to work on writing, but I had taken a more pragmatic approach: I’d take two weeks off at the end of ever year so that I could go to a little cabin in the mountains to write.
|
||||
|
||||
It took me half a day to realize that the things that annoyed me about my [writing tools][3] and workflow had not disappeared, but morphed into a more complex beast. As a writer, I wasn’t being productive or as efficient as I wanted.
|
||||
|
||||
### Linux in the time of Corona
|
||||
|
||||
![][4]
|
||||
|
||||
It is 2020 and the world is on the verge of mass hysteria.
|
||||
|
||||
What had started out as an isolated novel virus in China was morphing into the first global pandemic since 1911. On March 20th, Sri Lanka followed most of the rest of the world and shutdown.
|
||||
|
||||
April in Sri Lanka is the height of the dry season. Temperatures in concrete jungles like Colombo can reach the mid 30s, with humidity in the high 90s. It can drive most people to distraction at the best of times, but stuck at home with no always-on air conditioning while a global pandemic is underway? That is a good recipe for madness.
|
||||
|
||||
My madness was Linux or, as we in the open source community call it, ‘distro-hopping’.
|
||||
|
||||
The more I played around with *nix distros, the more enamoured I came to be with the idea of control. When nothing seems to be within our control – not even the simple act of shaking hands with another person – then it is only natural we lean towards things where we feel more in control.
|
||||
|
||||
Where better to get more control in my life than with my computing? Naturally, this extended to my writing tools and workflow too.
|
||||
|
||||
### The path to Vim
|
||||
|
||||
There’s a joke about [Vim][5] that describes perfectly my first experience with it. People are obsessive about Vim because they don’t know how to close it.
|
||||
|
||||
I was attempting to edit a configuration file, and the [fresh install of Ubuntu Server][6] had only Vim pre-installed. First there was panic – so much so I restarted the machine thinking the OS wasn’t picking up my keyboard. Then when it happened again, the inevitable Google search: ‘[How do I close vim?][7]‘
|
||||
|
||||
_Oh. That’s interesting_, I thought.
|
||||
|
||||
_But why?_
|
||||
|
||||
To understand why I was even remotely interested in a text editor that was too complex to close, you have to understand how much I adore Windows Notepad.
|
||||
|
||||
As a writer, I loved writing on its no-nonsense, no buttons, white-abyss like canvas. It had no spell check. It had no formatting. But I didn’t care.
|
||||
|
||||
For the writer in me, Notepad was the best writing scratch pad ever devised. Unfortunately, it isn’t powerful – so even if I start writing my drafts in Notepad, I would move it to MS Word once I had passed a 1000 words – Notepad wasn’t built for prose, and those limitations would be glaringly obvious when I passed that word limit.
|
||||
|
||||
So the first thing I installed I moved all my computing away from Windows, was a good text editor.
|
||||
|
||||
[Kate][8] was the first replacement where I felt more comfortable than I did on Windows Notepad – it was more powerful (it had spell-checker!), and hey, I could mess around with some hobbyist-type coding in the same environment.
|
||||
|
||||
It was love.
|
||||
|
||||
But then Vim happened.
|
||||
|
||||
The more I learnt about Vim, the more I watched developers live coding on Vim, the more I found myself opening Vim for my text editing needs. I use the phrase ‘text editing’ in the traditional Unix sense: editing blocks of text in configuration files, or sometimes writing basic Bash scripts.
|
||||
|
||||
I still hadn’t used Vim remotely for my prose writing needs.
|
||||
|
||||
For that I had LibreOffice.
|
||||
|
||||
Sort of.
|
||||
|
||||
While it is an adequate [replacement for MS Office][9], I found myself underwhelmed. The UI is perhaps even more distracting than MS Word, and with each distro having different packages of LibreOffice, I found myself using a hellishly fragmented tool kit and workflow, to say nothing about how different the UI can look in various distros and desktop environments.
|
||||
|
||||
Things had become even more complicated because I had also started my Masters. In this scenario, I was taking notes down on Kate, transferring them to LibreOffice, and then saving it on to my Dropbox.
|
||||
|
||||
Context switching was staring at me in the face every day.
|
||||
|
||||
Productivity dropped as I had to open and close a number of unrelated applications. I needed one writing tool to meet all my needs – as a novelist, as a student, and as a hobbyist coder.
|
||||
|
||||
And that’s when I realized that the solution to my context switching nightmare was also staring at me in the face at the same time.
|
||||
|
||||
By this point, I had used Vim often enough – even used it with Termux on my Android phone – to be pretty comfortable with the idea of moving everything to Vim. Since it supported markdown syntax, note-taking would also become even easier.
|
||||
|
||||
This was just about two months ago.
|
||||
|
||||
How am I doing?
|
||||
|
||||
It is April 2021.
|
||||
|
||||
I started this draft on my phone, [using Vim][10] via Termux (with the aid of a Bluetooth keyboard), while in a taxi. I pushed the file to a GitHub private repo for my writing, from which I pulled the file to my PC, wrote a few more lines, before heading out again. I pulled the new version of the file from GitHub to my phone, made changes, pushed it, repeat, until I emailed the final draft to the editor.
|
||||
|
||||
The context switching is now no more.
|
||||
|
||||
The distractions that come from writing in word processors is no more.
|
||||
|
||||
Editing is infinitely easier, and faster.
|
||||
|
||||
My wrists are no longer in pain because I hid my mouse from sight.
|
||||
|
||||
It is April 2021.
|
||||
|
||||
I am a novelist.
|
||||
|
||||
And I write on Vim.
|
||||
|
||||
How? I’ll discuss the specific of this workflow in the second part of this column series on how non-tech people are using free and open source technology. Stay tuned.
|
||||
|
||||
![][11]
|
||||
|
||||
I'm not interested
|
||||
|
||||
#### _Related_
|
||||
|
||||
* [Going Against Google Analytics With Plausible's Co-Founder [Interview]][12]
|
||||
* ![][13] ![Interview with Plausible founder Marco Saric][14]
|
||||
|
||||
|
||||
* [The Progress Linux has Made in Terms of Gaming is Simply Incredible: Lutris Creator][15]
|
||||
* ![][13] ![][16]
|
||||
|
||||
|
||||
* [Multi Monitor and HiDPI Setup is Looking Better on Ubuntu 21.04 [My Experience So Far]][17]
|
||||
* ![][13] ![Multimonitor setup with Ubuntu 21.04][18]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.itsfoss.com/how-i-started-loving-vim/
|
||||
|
||||
作者:[Theena][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://news.itsfoss.com/author/theena/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9JzM5MCcgd2lkdGg9Jzc4MCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB2ZXJzaW9uPScxLjEnLz4=
|
||||
[2]: https://www.goodreads.com/book/show/29616237-first-utterance
|
||||
[3]: https://itsfoss.com/open-source-tools-writers/
|
||||
[4]: data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9JzM5NScgd2lkdGg9Jzc4MCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB2ZXJzaW9uPScxLjEnLz4=
|
||||
[5]: https://www.vim.org/
|
||||
[6]: https://itsfoss.com/install-ubuntu-server-raspberry-pi/
|
||||
[7]: https://itsfoss.com/how-to-exit-vim/
|
||||
[8]: https://kate-editor.org/
|
||||
[9]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
[10]: https://linuxhandbook.com/basic-vim-commands/
|
||||
[11]: data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9JzI1MCcgd2lkdGg9Jzc1MCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB2ZXJzaW9uPScxLjEnLz4=
|
||||
[12]: https://news.itsfoss.com/marko-saric-plausible/
|
||||
[13]: data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9JzIwMCcgd2lkdGg9JzM1MCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB2ZXJzaW9uPScxLjEnLz4=
|
||||
[14]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/Interview-plausible.jpg?fit=1200%2C675&ssl=1&resize=350%2C200
|
||||
[15]: https://news.itsfoss.com/lutris-creator-interview/
|
||||
[16]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/03/lutris-interview-ft.png?fit=1200%2C675&ssl=1&resize=350%2C200
|
||||
[17]: https://news.itsfoss.com/ubuntu-21-04-multi-monitor-support/
|
||||
[18]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/03/multi-monitor-ubuntu-21-itsfoss.jpg?fit=1200%2C675&ssl=1&resize=350%2C200
|
||||
@ -0,0 +1,76 @@
|
||||
[#]: subject: (What do we call post-modern system administrators?)
|
||||
[#]: via: (https://opensource.com/article/21/7/system-administrators)
|
||||
[#]: author: (Joshua Allen Holm https://opensource.com/users/holmja)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
What do we call post-modern system administrators?
|
||||
======
|
||||
Our community discusses the responsibilities, possible titles, and
|
||||
potential skills of today's sysadmins.
|
||||
![Multi-colored and directional network computer cables][1]
|
||||
|
||||
For today's sysadmin, many companies expect you to have cross-platform knowledge, network knowledge, _and_ application knowledge. Add to that a dash of programming ability, a pinch of sysadmin experience, a heaping portion of social skills, and a fanatical commitment to reliability and automation.
|
||||
|
||||
What do we call this new, post-modern sysadmin? Do we use the same term and simply stretch the responsibilities? Or do we give this evolved role a new name?
|
||||
|
||||
We chatted with friends at [Enable Sysadmin][2] and in the Opensource.com Correspondent program to get their thoughts. Here's what we heard:
|
||||
|
||||
### Possible titles
|
||||
|
||||
* How about Enterprise Architect or Solutions Architect?
|
||||
* Or are we talking more of a DevOps Engineer or Site Reliability Engineer?
|
||||
* What level of experience and expertise are we looking at? Maybe an Applications Specialist or IT Helpdesk Administrator?
|
||||
* Overheard: Platform Engineer or System Engineer
|
||||
|
||||
|
||||
|
||||
### Potential skills
|
||||
|
||||
* setting up a new user account in Google Workplace or similar
|
||||
* configuring and ordering laptop, cell phone, service contracts
|
||||
* software training (teaching a new user how to use kanban boards, shared storage solutions, or similar)
|
||||
* preparing “procedures” manuals
|
||||
* monitoring and checking security settings and storage usage
|
||||
* keeping an eye on pooled storage
|
||||
* deactivating a user leaving us
|
||||
* arranging for pickup of equipment
|
||||
* working with a user and provider having personal equipment difficulties
|
||||
* keeping an eye on internet connection services, telephone services
|
||||
|
||||
|
||||
|
||||
### Lingering questions
|
||||
|
||||
Does today's sysadmin need to understand clustering, containers, FS sharding, unicast/multicast coms, and other similar topics?
|
||||
|
||||
Is there a dividing line between infrastructure and systems?
|
||||
|
||||
Could the title of systems administrator remain the same while the role changes?
|
||||
|
||||
Does the image of a sysadmin crawling under the desk to fix broken cupholders still apply?
|
||||
|
||||
Are most of today's sysadmins already using a PaaS approach in tandem with doing the basic administrative tasks of managing users, accounts, applications, and licenses?
|
||||
|
||||
Are they also a helpful resource for colleagues, acting as an interpersonal bridge between other departments and IT?
|
||||
|
||||
**Share your thoughts and experiences in the comments.**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/system-administrators
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/holmja
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/connections_wires_sysadmin_cable.png?itok=d5WqHmnJ (Multi-colored and directional network computer cables)
|
||||
[2]: https://www.redhat.com/sysadmin/
|
||||
105
sources/talk/20210731 Dealing with burnout in open source.md
Normal file
105
sources/talk/20210731 Dealing with burnout in open source.md
Normal file
@ -0,0 +1,105 @@
|
||||
[#]: subject: (Dealing with burnout in open source)
|
||||
[#]: via: (https://opensource.com/article/21/7/burnout-open-source)
|
||||
[#]: author: (Kiran Oliver https://opensource.com/users/kiranoliver-0)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Dealing with burnout in open source
|
||||
======
|
||||
What it is, why you should care, and how you can help prevent burnout.
|
||||
![Red heart with text "you are not alone"][1]
|
||||
|
||||
Burnout is something you don't expect to happen to you—until it does. The technology industry is one of the worst offenders; over [60% of industry professionals][2] report they've experienced burnout. Sixty percent! Chances are, you or someone you know has dealt with it. How can we tackle such a staggering burnout rate if those who make decisions about mental health barely know what burnout is, never mind how to prevent it?
|
||||
|
||||
The answer is to start simple. Ask the question "what is burnout?" and go from there.
|
||||
|
||||
![Definition of burnout][3]
|
||||
|
||||
(Kiran Oliver, [CC BY-SA 4.0][4])
|
||||
|
||||
### Autistic burnout, neurodivergence, and mental health
|
||||
|
||||
At [Upstream 2021][5], the Tidelift event that kicked off Maintainer Week celebrating open source maintainers, I gave [a talk about burnout in open source][6]. The individuals who attended my presentation shared their experiences with burnout and mental health as a whole, which are undeniably linked.
|
||||
|
||||
Burnout manifests in cognitive, emotional, and physical symptoms. It can take on different forms that are unique to the individual experiencing it.
|
||||
|
||||
Also, people who are [neurodivergent][7] (e.g., have autism, ADD/ADHD, dyslexia, dyspraxia, etc.) may have standard burnout symptoms, but it can also manifest as [autistic burnout][8], which is often harder to pin down. Crucially, burnout in neurodivergent employees can look like someone is slacking off, not doing their job, or missing important details, when none of these things are correct.
|
||||
|
||||
### How to help people experiencing burnout
|
||||
|
||||
When addressing burnout on a team, managers can do a few things to ensure the team has a psychologically safe environment:
|
||||
|
||||
1. Ask your human resources department if your insurance company offers mental health services.
|
||||
2. Make sure employees know about your company insurance plan's mental health benefits.
|
||||
3. Offer flexible time off.
|
||||
4. Be flexible with deadlines, if possible.
|
||||
5. Use asynchronous meetings.
|
||||
6. Embody best practices by taking time off and encouraging your team to do so.
|
||||
7. Learn to recognize the signs of burnout in yourself and others.
|
||||
|
||||
|
||||
|
||||
As an individual contributor, you might be wondering how you can help your teammates. Here are some things that you can do:
|
||||
|
||||
1. Assign someone to triage issues, or implement an auto-labeling process on your team's kanban and ticketing systems.
|
||||
2. Make use of integrations and [productivity tools][9].
|
||||
3. [Automate your business processes][10] wherever possible.
|
||||
4. Have a clearly defined process for code reviews.
|
||||
5. Encourage maintainers and contributors to take breaks.
|
||||
6. Understand and recognize the signs of burnout in yourself and others.
|
||||
|
||||
|
||||
|
||||
### Burnout in open source communities
|
||||
|
||||
In open source communities, burnout can lead to not responding to pull requests or leaving issues open for an extended period of time. It can look like missing meetings, roadmap deadlines, or general forgetfulness. It can also produce emotional fatigue, [anxiety][11], and stress, so someone might be more tired than usual or speak in a tone of voice different from their usual. They may also feel drained and lack the motivation to contribute to open source while struggling with burnout. For open source project maintainers, burnout can be a real challenge that the entire industry must continue to address.
|
||||
|
||||
![What's under the surface of burnout][12]
|
||||
|
||||
(Kiran Oliver, [CC BY-SA 4.0][4])
|
||||
|
||||
Recognizing burnout requires vulnerability on behalf of the person experiencing it as well as understanding and compassion from any person told about a team member feeling this way. If someone tells you they are burned out, respect and keep this information private. Do not broadcast it publicly, nor share it with anyone who does not need to know for official medical or legal reasons.
|
||||
|
||||
### Key takeaways
|
||||
|
||||
Burnout is a genuine issue that impacts many open source practitioners. Here are some tips for how to address it in open source organizations and communities:
|
||||
|
||||
* Be more accepting of neurodivergence in the workplace.
|
||||
* Create supportive policies and procedures for employees in your organization or open source community that may be experiencing burnout.
|
||||
* If you are a contributor to a large open source project, make sure you use automation and tools that allow people to step away and take a break with ease.
|
||||
* Lean on your community for support.
|
||||
* Learn to recognize the signs of burnout—not only in yourself but also in others.
|
||||
* Support your community, and remember that it's okay to admit to feeling burned out.
|
||||
|
||||
|
||||
|
||||
Do you have any other tips for dealing with burnout, either personally or with your open source colleagues? Please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/burnout-open-source
|
||||
|
||||
作者:[Kiran Oliver][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kiranoliver-0
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/red-love-heart-alone-stone-path.jpg?itok=O3q1nEVz (Red heart with text "you are not alone")
|
||||
[2]: https://usblog.teamblind.com/wp-content/uploads/2020/03/TheStateof-Burnout2020.pdf
|
||||
[3]: https://opensource.com/sites/default/files/uploads/burnoutdefinition.png (Definition of burnout)
|
||||
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[5]: https://upstream.live/
|
||||
[6]: https://www.youtube.com/watch?v=WlQmwAJc5n4&list=PLDlsR_qA-s0gbycSxXNQIF_LhsMThD3Zi&index=9
|
||||
[7]: https://neurocosmopolitanism.com/neurodiversity-some-basic-terms-definitions/
|
||||
[8]: https://www.autism.org.uk/advice-and-guidance/topics/mental-health/autistic-fatigue/autistic-adults
|
||||
[9]: https://opensource.com/article/21/1/open-source-productivity-apps
|
||||
[10]: https://camunda.com/solutions/human-workflow/
|
||||
[11]: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6424886/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/burnouticeburg.png (What's under the surface of burnout)
|
||||
@ -1,295 +0,0 @@
|
||||
[#]: subject: (Pen testing with Linux security tools)
|
||||
[#]: via: (https://opensource.com/article/21/5/linux-security-tools)
|
||||
[#]: author: (Peter Gervase https://opensource.com/users/pgervase)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Pen testing with Linux security tools
|
||||
======
|
||||
Use Kali Linux and other open source tools to uncover security gaps and
|
||||
weaknesses in your systems.
|
||||
![Magnifying glass on code][1]
|
||||
|
||||
The multitude of well-publicized breaches of large consumer corporations underscores the critical importance of system security management. Fortunately, there are many different applications that help secure computer systems. One is [Kali][2], a Linux distribution developed for security and penetration testing. This article demonstrates how to use Kali Linux to investigate your system to find weaknesses.
|
||||
|
||||
Kali installs a lot of tools, all of which are open source, and having them installed by default makes things easier.
|
||||
|
||||
![Kali's tools][3]
|
||||
|
||||
(Peter Gervase, [CC BY-SA 4.0][4])
|
||||
|
||||
The systems that I'll use in this tutorial are:
|
||||
|
||||
1. `kali.usersys.redhat.com`: This is the system where I'll launch the scans and attacks. It has 30GB of memory and six virtualized CPUs (vCPUs).
|
||||
2. `vulnerable.usersys.redhat.com`: This is a Red Hat Enterprise Linux 8 system that will be the target. It has 16GB of memory and six vCPUs. This is a relatively up-to-date system, but some packages might be out of date.
|
||||
3. This system also includes `httpd-2.4.37-30.module+el8.3.0+7001+0766b9e7.x86_64`, `mariadb-server-10.3.27-3.module+el8.3.0+8972+5e3224e9.x86_64`, `tigervnc-server-1.9.0-15.el8_1.x86_64`, `vsftpd-3.0.3-32.el8.x86_64`, and WordPress version 5.6.1.
|
||||
|
||||
|
||||
|
||||
I included the hardware specifications above because some of these tasks are pretty demanding, especially for the target system's CPU when running the WordPress Security Scanner ([WPScan][5]).
|
||||
|
||||
### Investigate your system
|
||||
|
||||
I started my investigation with a basic Nmap scan on my target system. (You can dive deeper into Nmap by reading [Using Nmap results to help harden Linux systems][6].) An Nmap scan is a quick way to get an overview of which ports and services are visible from the system initiating the Nmap scan.
|
||||
|
||||
![Nmap scan][7]
|
||||
|
||||
(Peter Gervase, [CC BY-SA 4.0][4])
|
||||
|
||||
This default scan shows that there are several possibly interesting open ports. In reality, any open port is possibly interesting because it could be a way for an attacker to breach your network. In this example, ports 21, 22, 80, and 443 are nice to scan because they are commonly used services. At this early stage, I'm simply doing reconnaissance work and trying to get as much information about the target system as I can.
|
||||
|
||||
I want to investigate port 80 with Nmap, so I use the `-p 80` argument to look at port 80 and `-A` to get information such as the operating system and application version.
|
||||
|
||||
![Nmap scan of port 80][8]
|
||||
|
||||
(Peter Gervase, [CC BY-SA 4.0][4])
|
||||
|
||||
Some of the key lines in this output are:
|
||||
|
||||
|
||||
```
|
||||
PORT STATE SERVICE VERSION
|
||||
80/tcp open http Apache httpd 2.4.37 ((Red Hat Enterprise Linux))
|
||||
|_http-generator: WordPress 5.6.1
|
||||
```
|
||||
|
||||
Since I now know this is a WordPress server, I can use WPScan to get information about potential weaknesses. A good investigation to run is to try to find some usernames. Using `--enumerate u` tells WPScan to look for users in the WordPress instance. For example:
|
||||
|
||||
|
||||
```
|
||||
┌──(root💀kali)-[~]
|
||||
└─# wpscan --url vulnerable.usersys.redhat.com --enumerate u
|
||||
_______________________________________________________________
|
||||
__ _______ _____
|
||||
\ \ / / __ \ / ____|
|
||||
\ \ /\ / /| |__) | (___ ___ __ _ _ __ ®
|
||||
\ \/ \/ / | ___/ \\___ \ / __|/ _` | '_ \
|
||||
\ /\ / | | ____) | (__| (_| | | | |
|
||||
\/ \/ |_| |_____/ \\___|\\__,_|_| |_|
|
||||
|
||||
WordPress Security Scanner by the WPScan Team
|
||||
Version 3.8.10
|
||||
Sponsored by Automattic - <https://automattic.com/>
|
||||
@_WPScan_, @ethicalhack3r, @erwan_lr, @firefart
|
||||
_______________________________________________________________
|
||||
|
||||
[+] URL: <http://vulnerable.usersys.redhat.com/> [10.19.47.242]
|
||||
[+] Started: Tue Feb 16 21:38:49 2021
|
||||
|
||||
Interesting Finding(s):
|
||||
...
|
||||
[i] User(s) Identified:
|
||||
|
||||
[+] admin
|
||||
| Found By: Author Posts - Display Name (Passive Detection)
|
||||
| Confirmed By:
|
||||
| Author Id Brute Forcing - Author Pattern (Aggressive Detection)
|
||||
| Login Error Messages (Aggressive Detection)
|
||||
|
||||
[+] pgervase
|
||||
| Found By: Author Posts - Display Name (Passive Detection)
|
||||
| Confirmed By:
|
||||
| Author Id Brute Forcing - Author Pattern (Aggressive Detection)
|
||||
| Login Error Messages (Aggressive Detection)
|
||||
```
|
||||
|
||||
This shows there are two users: `admin` and `pgervase`. I'll try to guess the password for `admin` by using a password dictionary, which is a text file with lots of possible passwords. The dictionary I used was 37G and had 3,543,076,137 lines.
|
||||
|
||||
Like there are multiple text editors, web browsers, and other applications you can choose from, there are multiple tools available to launch password attacks. Here are two example commands using Nmap and WPScan:
|
||||
|
||||
|
||||
```
|
||||
`# nmap -sV --script http-wordpress-brute --script-args userdb=users.txt,passdb=/path/to/passworddb,threads=6 vulnerable.usersys.redhat.com`[/code] [code]`# wpscan --url vulnerable.usersys.redhat.com --passwords /path/to/passworddb --usernames admin --max-threads 50 | tee nmap.txt`
|
||||
```
|
||||
|
||||
This Nmap script is one of many possible scripts I could have used, and scanning the URL with WPScan is just one of many possible tasks this tool can do. You can decide which you would prefer to use
|
||||
|
||||
This WPScan example shows the password at the end of the file:
|
||||
|
||||
|
||||
```
|
||||
┌──(root💀kali)-[~]
|
||||
└─# wpscan --url vulnerable.usersys.redhat.com --passwords passwords.txt --usernames admin
|
||||
_______________________________________________________________
|
||||
__ _______ _____
|
||||
\ \ / / __ \ / ____|
|
||||
\ \ /\ / /| |__) | (___ ___ __ _ _ __ ®
|
||||
\ \/ \/ / | ___/ \\___ \ / __|/ _` | '_ \
|
||||
\ /\ / | | ____) | (__| (_| | | | |
|
||||
\/ \/ |_| |_____/ \\___|\\__,_|_| |_|
|
||||
|
||||
WordPress Security Scanner by the WPScan Team
|
||||
Version 3.8.10
|
||||
Sponsored by Automattic - <https://automattic.com/>
|
||||
@_WPScan_, @ethicalhack3r, @erwan_lr, @firefart
|
||||
_______________________________________________________________
|
||||
|
||||
[+] URL: <http://vulnerable.usersys.redhat.com/> [10.19.47.242]
|
||||
[+] Started: Thu Feb 18 20:32:13 2021
|
||||
|
||||
Interesting Finding(s):
|
||||
|
||||
…..
|
||||
|
||||
[+] Performing password attack on Wp Login against 1 user/s
|
||||
Trying admin / redhat Time: 00:01:57 <==================================================================================================================> (3231 / 3231) 100.00% Time: 00:01:57
|
||||
Trying admin / redhat Time: 00:01:57 <========================================================= > (3231 / 6462) 50.00% ETA: ??:??:??
|
||||
[SUCCESS] - admin / redhat
|
||||
|
||||
[!] Valid Combinations Found:
|
||||
| Username: admin, Password: redhat
|
||||
|
||||
[!] No WPVulnDB API Token given, as a result vulnerability data has not been output.
|
||||
[!] You can get a free API token with 50 daily requests by registering at <https://wpscan.com/register>
|
||||
|
||||
[+] Finished: Thu Feb 18 20:34:15 2021
|
||||
[+] Requests Done: 3255
|
||||
[+] Cached Requests: 34
|
||||
[+] Data Sent: 1.066 MB
|
||||
[+] Data Received: 24.513 MB
|
||||
[+] Memory used: 264.023 MB
|
||||
[+] Elapsed time: 00:02:02
|
||||
```
|
||||
|
||||
The Valid Combinations Found section near the end contains the admin username and password. It took only two minutes to go through 3,231 lines.
|
||||
|
||||
I have another dictionary file with 3,238,659,984 unique entries, which would take much longer and leave a lot more evidence.
|
||||
|
||||
Using Nmap produces a result much faster:
|
||||
|
||||
|
||||
```
|
||||
┌──(root💀kali)-[~]
|
||||
└─# nmap -sV --script http-wordpress-brute --script-args userdb=users.txt,passdb=password.txt,threads=6 vulnerable.usersys.redhat.com
|
||||
Starting Nmap 7.91 ( <https://nmap.org> ) at 2021-02-18 20:48 EST
|
||||
Nmap scan report for vulnerable.usersys.redhat.com (10.19.47.242)
|
||||
Host is up (0.00015s latency).
|
||||
Not shown: 995 closed ports
|
||||
PORT STATE SERVICE VERSION
|
||||
21/tcp open ftp vsftpd 3.0.3
|
||||
22/tcp open ssh OpenSSH 8.0 (protocol 2.0)
|
||||
80/tcp open http Apache httpd 2.4.37 ((Red Hat Enterprise Linux))
|
||||
|_http-server-header: Apache/2.4.37 (Red Hat Enterprise Linux)
|
||||
| http-wordpress-brute:
|
||||
| Accounts:
|
||||
| admin:redhat - Valid credentials <<<<<<<
|
||||
| pgervase:redhat - Valid credentials <<<<<<<
|
||||
|_ Statistics: Performed 6 guesses in 1 seconds, average tps: 6.0
|
||||
111/tcp open rpcbind 2-4 (RPC #100000)
|
||||
| rpcinfo:
|
||||
| program version port/proto service
|
||||
| 100000 2,3,4 111/tcp rpcbind
|
||||
| 100000 2,3,4 111/udp rpcbind
|
||||
| 100000 3,4 111/tcp6 rpcbind
|
||||
|_ 100000 3,4 111/udp6 rpcbind
|
||||
3306/tcp open mysql MySQL 5.5.5-10.3.27-MariaDB
|
||||
MAC Address: 52:54:00:8C:A1:C0 (QEMU virtual NIC)
|
||||
Service Info: OS: Unix
|
||||
|
||||
Service detection performed. Please report any incorrect results at <https://nmap.org/submit/> .
|
||||
Nmap done: 1 IP address (1 host up) scanned in 7.68 seconds
|
||||
```
|
||||
|
||||
However, running a scan like this can leave a flood of HTTPD logging messages on the target system:
|
||||
|
||||
|
||||
```
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:01 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
```
|
||||
|
||||
To get information about the HTTPS server found in my initial Nmap scan, I used the `sslscan` command:
|
||||
|
||||
|
||||
```
|
||||
┌──(root💀kali)-[~]
|
||||
└─# sslscan vulnerable.usersys.redhat.com
|
||||
Version: 2.0.6-static
|
||||
OpenSSL 1.1.1i-dev xx XXX xxxx
|
||||
|
||||
Connected to 10.19.47.242
|
||||
|
||||
Testing SSL server vulnerable.usersys.redhat.com on port 443 using SNI name vulnerable.usersys.redhat.com
|
||||
|
||||
SSL/TLS Protocols:
|
||||
SSLv2 disabled
|
||||
SSLv3 disabled
|
||||
TLSv1.0 disabled
|
||||
TLSv1.1 disabled
|
||||
TLSv1.2 enabled
|
||||
TLSv1.3 enabled
|
||||
<snip>
|
||||
```
|
||||
|
||||
This shows information about the enabled SSL protocols and, further down in the output, information about the Heartbleed vulnerability:
|
||||
|
||||
|
||||
```
|
||||
Heartbleed:
|
||||
TLSv1.3 not vulnerable to heartbleed
|
||||
TLSv1.2 not vulnerable to heartbleed
|
||||
```
|
||||
|
||||
### Tips for preventing or mitigating attackers
|
||||
|
||||
There are many ways to defend your systems against the multitude of attackers out there. A few key points are:
|
||||
|
||||
* **Know your systems:** This includes knowing which ports are open, what ports should be open, who should be able to see those open ports, and what is the expected traffic on those services. Nmap is a great tool to learn about systems on the network.
|
||||
* **Use current best practices:** What is considered a best practice today might not be a best practice down the road. As an admin, it's important to stay up to date on trends in the infosec realm.
|
||||
* **Know how to use your products:** For example, rather than letting an attacker continually hammer away at your WordPress system, block their IP address and limit the number of times they can try to log in before getting blocked. Blocking the IP address might not be as helpful in the real world because attackers are likely to use compromised systems to launch attacks. However, it's an easy setting to enable and could block some attacks.
|
||||
* **Maintain and verify good backups:** If an attacker comprises one or more of your systems, being able to rebuild from known good and clean backups could save lots of time and money.
|
||||
* **Check your logs:** As the examples above show, scanning and penetration commands may leave lots of logs indicating that an attacker is targeting the system. If you notice them, you can take preemptive action to mitigate the risk.
|
||||
* **Update your systems, their applications, and any extra modules:** As [NIST Special Publication 800-40r3][9] explains, "patches are usually the most effective way to mitigate software flaw vulnerabilities, and are often the only fully effective solution."
|
||||
* **Use the tools your vendors provide:** Vendors have different tools to help you maintain their systems, so make sure you take advantage of them. For example, [Red Hat Insights][10], included with Red Hat Enterprise Linux subscriptions, can help tune your systems and alert you to potential security threats.
|
||||
|
||||
|
||||
|
||||
### Learn more
|
||||
|
||||
This introduction to security tools and how to use them is just the tip of the iceberg. To dive deeper, you might want to look into the following resources:
|
||||
|
||||
* [Armitage][11], an open source attack management tool
|
||||
* [Red Hat Product Security Center][12]
|
||||
* [Red Hat Security Channel][13]
|
||||
* [NIST's Cybersecurity page][14]
|
||||
* [Using Nmap results to help harden Linux systems][6]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/5/linux-security-tools
|
||||
|
||||
作者:[Peter Gervase][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pgervase
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||
[2]: https://www.kali.org/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/kali-tools.png (Kali's tools)
|
||||
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[5]: https://wpscan.com/wordpress-security-scanner
|
||||
[6]: https://www.redhat.com/sysadmin/using-nmap-harden-systems
|
||||
[7]: https://opensource.com/sites/default/files/uploads/nmap-scan.png (Nmap scan)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/nmap-port80.png (Nmap scan of port 80)
|
||||
[9]: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-40r3.pdf%5D(https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-40r3.pdf
|
||||
[10]: https://www.redhat.com/sysadmin/how-red-hat-insights
|
||||
[11]: https://en.wikipedia.org/wiki/Armitage_(computing)
|
||||
[12]: https://access.redhat.com/security
|
||||
[13]: https://www.redhat.com/en/blog/channel/security
|
||||
[14]: https://www.nist.gov/cybersecurity
|
||||
@ -2,7 +2,7 @@
|
||||
[#]: via: (https://www.debugpoint.com/2021/07/upgrade-debian-11-from-debian-10/)
|
||||
[#]: author: (Arindam https://www.debugpoint.com/author/admin1/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,90 +0,0 @@
|
||||
[#]: subject: (Install Shutter in Fedora 34 and Above)
|
||||
[#]: via: (https://www.debugpoint.com/2021/07/install-shutter-fedora/)
|
||||
[#]: author: (Arindam https://www.debugpoint.com/author/admin1/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Install Shutter in Fedora 34 and Above
|
||||
======
|
||||
This quick guide explains the steps required to install shutter in
|
||||
Fedora 34 and above.
|
||||
There are many alternatives and options for screenshot tool. But in my personal opinion, there is none that come close to the flexibility of Shutter. Unfortunately over the years, Linux distributions such as Ubuntu, Fedora faced problem packaging this application in official repo for various dependency problem and specially how it is designed.
|
||||
|
||||
The primary problem is it still based on GTK2 and Perl. While most of the application moved to GTK3, it remained in GTK2. This created a dependency problem as Debian/Ubuntu, Fedora they removed the dependent GTK2 version of certain packages.
|
||||
|
||||
Installing [Shutter][1] screenshot tool in Fedora 34 and above requires an alternative approach.
|
||||
|
||||
Right now, you can only install this tool via personal package archive only. Here’s how to install it in Fedora 34 and above.
|
||||
|
||||
![Shutter in Fedora][2]
|
||||
|
||||
### Install Shutter in Fedora 34 and above
|
||||
|
||||
Open a terminal in your Fedora and enable the following [Copr repository for Shutter][3]. This package archive provides a separate build for Shutter for Fedora with all the unmet dependencies.
|
||||
|
||||
```
|
||||
sudo dnf copr enable geraldosimiao/shutter
|
||||
```
|
||||
|
||||
Once this is done, you can simply install shutter in Fedora 34 and above by dnf.
|
||||
|
||||
```
|
||||
sudo dnf install shutter
|
||||
```
|
||||
|
||||
Though the latest release is v0.97 at present. The repository sadly contains the old v0.94.x at the moment. I hope the repo owner soon include the latest version.
|
||||
|
||||
After installation, you can launch it via application menu.
|
||||
|
||||
#### Uninstall Shutter
|
||||
|
||||
If you want, you can easily remove this third-party repository via command:
|
||||
|
||||
```
|
||||
sudo dnf copr remove geraldosimiao/shutter
|
||||
```
|
||||
|
||||
And followed by below to remove Shutter completely including dependencies.
|
||||
|
||||
```
|
||||
sudo dnf autoremove shutter
|
||||
```
|
||||
|
||||
#### Install Shutter in Other Linux Distributions
|
||||
|
||||
If you want to install it in Debian, Ubuntu or related distribution – [check out this guide][4].
|
||||
|
||||
[][5]
|
||||
|
||||
SEE ALSO: How to fix disabled Edit Image Option in Shutter in Ubuntu 18.04 LTS
|
||||
|
||||
### Development of Shutter
|
||||
|
||||
Recently this project [moved to GitHub][6] for better collaboration and a GTK3 port is underway. And it is fairly active and recently had a release. We hope it gets ported to gtk3 soon and available in native repo of respective distributions.
|
||||
|
||||
Let me know using the comment box below if you face any error installing Shutter.
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.debugpoint.com/2021/07/install-shutter-fedora/
|
||||
|
||||
作者:[Arindam][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.debugpoint.com/author/admin1/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.debugpoint.com/tag/shutter
|
||||
[2]: https://www.debugpoint.com/blog/wp-content/uploads/2021/07/Shutter-in-Fedora.jpeg
|
||||
[3]: https://copr.fedorainfracloud.org/coprs/geraldosimiao/shutter/
|
||||
[4]: https://www.debugpoint.com/2020/04/shutter-install-ubuntu/
|
||||
[5]: https://www.debugpoint.com/2018/05/shutter-fix-disable-edit/
|
||||
[6]: https://github.com/shutter-project/shutter
|
||||
@ -1,116 +0,0 @@
|
||||
[#]: subject: (How to use cron on Linux)
|
||||
[#]: via: (https://opensource.com/article/21/7/cron-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (perfiffer)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
How to use cron on Linux
|
||||
======
|
||||
The cron system is a method to automatically run commands on a schedule.
|
||||
![Cron expression][1]
|
||||
|
||||
The cron system is a method to automatically run commands on a schedule. A scheduled job is called a _cronjob_, and it’s created in a file called a _crontab_. It’s the easiest and oldest way for a computer user to automate their computer.
|
||||
|
||||
### Writing a cronjob
|
||||
|
||||
To create a cronjob, you edit your `crontab` using the `-e` option:
|
||||
|
||||
|
||||
```
|
||||
`$ crontab -e`
|
||||
```
|
||||
|
||||
This opens your crontab your default text editor. To set the text editor explicitly, use the `EDITOR` [environment variable][2]:
|
||||
|
||||
|
||||
```
|
||||
`$ EDITOR=nano crontab -e`
|
||||
```
|
||||
|
||||
### Cron syntax
|
||||
|
||||
To schedule a cronjob, you provide the command you want your computer to execute, followed by a cron expression. The cron expression schedules when the command gets run:
|
||||
|
||||
* minute (0 to 59)
|
||||
|
||||
* hour (0 to 23, with 0 being midnight)
|
||||
|
||||
* day of month (1 to 31)
|
||||
|
||||
* month (1 to 12)
|
||||
|
||||
* day of week (0 to 6, with Sunday being 0)
|
||||
|
||||
|
||||
|
||||
|
||||
An asterisk (`*`) in a field translates to "every." For example, this expression runs a backup script at the 0th minute of _every_ hour on _every_ day of _every_ month:
|
||||
|
||||
|
||||
```
|
||||
`/opt/backup.sh 0 * * * *`
|
||||
```
|
||||
|
||||
This expression runs a backup script at 3:30 AM on Sunday:
|
||||
|
||||
|
||||
```
|
||||
`/opt/backup.sh 30 3 * * 0`
|
||||
```
|
||||
|
||||
### Simplified syntax
|
||||
|
||||
Modern cron implementations accept simplified macros instead of a cron expression:
|
||||
|
||||
* `@hourly` runs at the 0th minute of every hour of every day
|
||||
|
||||
* `@daily` runs at the 0th minute of the 0th hour of every day
|
||||
|
||||
* `@weekly` runs at the 0th minute of the 0th hour on Sunday
|
||||
|
||||
* `@monthly` runs at the 0th minute of the 0th hour on the first day of the month
|
||||
|
||||
|
||||
|
||||
|
||||
For example, this crontab line runs a backup script every day at midnight:
|
||||
|
||||
|
||||
```
|
||||
`/opt/backup.sh @daily`
|
||||
```
|
||||
|
||||
### How to stop a cronjob
|
||||
|
||||
Once you've started a cronjob, it's designed to run on schedule forever. To stop a cronjob once you've started it, you must edit your crontab, remove the line that triggers the job, and then save the file.
|
||||
|
||||
|
||||
```
|
||||
`$ EDITOR=nano crontab -e`
|
||||
```
|
||||
|
||||
To stop a job that's actively running, [use standard Linux process commands][3] to stop a running process.
|
||||
|
||||
### It’s automated
|
||||
|
||||
Once you’ve written your crontab, save the file and exit your editor. Your cronjob has been scheduled, so cron does the rest.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/cron-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/cron-splash.png?itok=AoBigzts (Cron expression)
|
||||
[2]: https://opensource.com/article/19/8/what-are-environment-variables
|
||||
[3]: https://opensource.com/article/18/5/how-kill-process-stop-program-linux
|
||||
@ -2,7 +2,7 @@
|
||||
[#]: via: (https://opensource.com/article/21/7/linux-kernel-ftrace)
|
||||
[#]: author: (Gaurav Kamathe https://opensource.com/users/gkamathe)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (mengxinayan)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -390,7 +390,7 @@ via: https://opensource.com/article/21/7/linux-kernel-ftrace
|
||||
|
||||
作者:[Gaurav Kamathe][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[萌新阿岩](https://github.com/mengxinayan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,110 +0,0 @@
|
||||
[#]: subject: (Check used disk space on Linux with du)
|
||||
[#]: via: (https://opensource.com/article/21/7/check-disk-space-linux-du)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Check used disk space on Linux with du
|
||||
======
|
||||
Find out how much disk space you're using with the Linux du command.
|
||||
![Check disk usage][1]
|
||||
|
||||
No matter how much storage space you have, there's always the possibility for it to fill up. On most personal devices, drives get filled up with photos and videos and music, but on servers, it's not unusual for space to diminish due to data in user accounts and log files. Whether you're in charge of managing a multi-user system or just your own laptop, you can check in on disk usage with the `du` command.
|
||||
|
||||
By default, `du` provides the amount of disk space used in your current directory, as well as the size of each subdirectory:
|
||||
|
||||
|
||||
```
|
||||
$ du
|
||||
12 ./.backups
|
||||
60 .
|
||||
```
|
||||
|
||||
In this example, my current directory takes up all of 60 KB, 12 KB of which is occupied by the subdirectory `.backups`.
|
||||
|
||||
If you find that confusing and would prefer to see all sizes separately, you can use the `--separate-dirs` (or `-S` for short) option:
|
||||
|
||||
|
||||
```
|
||||
$ du --separate-dirs
|
||||
12 ./.backups
|
||||
48 .
|
||||
```
|
||||
|
||||
It's the same information (48 and 12 is 60) but each directory is treated independently of one another.
|
||||
|
||||
To see even more detail, use the --all (or -a for short) option, which displays each file in each directory:
|
||||
|
||||
|
||||
```
|
||||
$ du --separate-dirs --all
|
||||
4 ./example.adoc
|
||||
28 ./graphic.png
|
||||
4 ./.backups/example.adoc~
|
||||
12 ./.backups
|
||||
4 ./index.html
|
||||
4 ./index.adoc
|
||||
48 .
|
||||
```
|
||||
|
||||
### See modification time of files
|
||||
|
||||
When looking through files to find out what's taking up space, it can be useful to see when a file was last modified. Something that hasn't been touched in a year is a likely candidate for archival, especially if you're running out of space.
|
||||
|
||||
To see modification times of files with du, use the `--time` option:
|
||||
|
||||
|
||||
```
|
||||
$ du --separate-dirs --all --time
|
||||
28 2021-07-21 11:12 ./graphic.png
|
||||
4 2021-07-03 10:43 ./example.adoc
|
||||
4 2021-07-13 13:03 ./index.html
|
||||
4 2021-07-23 14:18 ./index.adoc
|
||||
48 2021-07-23 14:19 .
|
||||
```
|
||||
|
||||
### Set a threshold for file size
|
||||
|
||||
When reviewing files in the interest of disk space, you may only care about files of nontrivial size. You set a threshold for the file sizes you want to see with the `--threshold` (or `-t` for short) option. For instance, to view only sizes larger than 1 GB:
|
||||
|
||||
|
||||
```
|
||||
$ \du --separate-dirs --all --time --threshold=1G ~/Footage/
|
||||
1839008 2021-07-14 13:55 /home/tux/Footage/snowfall.mp4
|
||||
1577980 2020-04-11 13:10 /home/tux/Footage/waterfall.mp4
|
||||
8588936 2021-07-14 13:55 /home/tux/Footage/
|
||||
```
|
||||
|
||||
When file sizes get particularly large, they can be difficult to read. Make file sizes easier with the `--human-readable` (or `-h` for short) option:
|
||||
|
||||
|
||||
```
|
||||
$ \du --separate-dirs --all --time \
|
||||
\--threshold=1G --human-readable ~/Footage/
|
||||
1.8G 2021-07-14 13:55 /home/tux/Footage/snowfall.mp4
|
||||
1.6G 2020-04-11 13:10 /home/tux/Footage/waterfall.mp4
|
||||
8.5G 2021-07-14 13:55 /home/tux/Footage/
|
||||
```
|
||||
|
||||
### See available disk space
|
||||
|
||||
To just get a summary of how much disk space remains on a drive, read our article about the [df command][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/check-disk-space-linux-du
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/du-splash.png?itok=nRLlI-5A (Check disk usage)
|
||||
[2]: https://opensource.com/article/21/7/use-df-check-free-disk-space-linux
|
||||
@ -2,7 +2,7 @@
|
||||
[#]: via: (https://www.debugpoint.com/2021/07/change-lock-login-screen-background-elementary-os/)
|
||||
[#]: author: (Arindam https://www.debugpoint.com/author/admin1/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,289 @@
|
||||
[#]: subject: (Create your own custom Raspberry Pi image)
|
||||
[#]: via: (https://opensource.com/article/21/7/custom-raspberry-pi-image)
|
||||
[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Create your own custom Raspberry Pi image
|
||||
======
|
||||
Build a Raspberry Pi image from scratch or convert your running,
|
||||
modified Raspberry Pi OS back to an image others can use.
|
||||
![Vector, generic Raspberry Pi board][1]
|
||||
|
||||
When I recently read [Alan Formy-Duval's][2] article [_Manage your Raspberry Pi with Cockpit_][3], I thought it would be a good idea to have an image with Cockpit already preinstalled. Luckily there are at least two ways to accomplish this task:
|
||||
|
||||
* Adapt the sources of the Raspberry Pi OS image building toolchain [pi-gen][4] which enables you to build a Raspberry Pi image from scratch
|
||||
* Convert your running, modified Raspberry Pi OS back to an image others can use
|
||||
|
||||
|
||||
|
||||
This article covers both methods. I'll highlight the pros and cons of each technique.
|
||||
|
||||
### Pi-gen
|
||||
|
||||
Let's begin with [pi-gen][4]. Before we start, there are a few prerequisites you'll need to consider.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
To successfully run the build process, it is recommended to use a 32bit version of Debian Buster or Ubuntu Xenial. It may work on other systems as well but to avoid unnecessary complications, I recommend to setup a virtual machine with one of the recommended systems. If you are not familiar with virtual machines, take a look at my article [Try Linux on any operating system with VirtualBox][5]. When you have everything up and running, also install the dependencies mentioned in the [repository description][6]. Also consider that you need internet access in the virtual machine and enough free disk space. I set up my virtual machine with a 40GB hard drive which seemed to be enough.
|
||||
|
||||
In order to follow the instructions in this article, make a clone of the [pi-gen][4] repository or fork it if you want to start developing you own image.
|
||||
|
||||
#### Repository Overview
|
||||
|
||||
The overall build process is separated into stages. Each stage is represented as an ordinary folder and represents a logical intermediate with regards to a full Raspberry Pi OS image.
|
||||
|
||||
* **Stage 0**: Bootstrap—Creates a usable filesystem
|
||||
* **Stage 1**: Minimal system—Creates an absolute minimal system
|
||||
* **Stage 2**: Lite system—Corresponds to Raspberry Pi OS Lite
|
||||
* **Stage 3**: Desktop system—Installs X11, LXDE, web browsers, and so on
|
||||
* **Stage 4**: Corresponds to an ordinary Raspberry Pi OS
|
||||
* **Stage 5**: Corresponds to Raspberry Pi OS Full
|
||||
|
||||
|
||||
|
||||
The stages build upon each other: It is not possible to build a higher stage without building the lower stages. You can't leave out a stage in the middle either. For example, to build a Raspberry Pi OS Lite, you have to build stages 0, 1, and 2. To build a Raspberry Pi OS with a desktop, you have to build stages 0, 1, 2, 3, 4, and 5.
|
||||
|
||||
#### Build process
|
||||
|
||||
The build process is controlled by the `build.sh`, which can be found in the root repository. If you already know how to read and write bash scripts, it won't be a hurdle to understand the process defined there. If not, reading the `build.sh` and trying to understand what is going on is a really good practice. But even without bash scripting skills, you will be able to create your own image with Cockpit preinstalled.
|
||||
|
||||
In general, the build process consists of several nested for-loops.
|
||||
|
||||
* **stage-loop:** Loop through all stage directories in ascending order
|
||||
* Skip further processing if a file named _SKIP_ is found
|
||||
* Run the script `prerun.sh`
|
||||
* **sub-loop:** Loop through each subdirectory in ascending order and process the following files if they are present:
|
||||
* * `00-run-sh`: Arbitrary instructions to run in advance
|
||||
* `00-run-chroot.sh`: Run this script in the chroot directory of the image
|
||||
* `00-debconfs`: Variables for the` debconf-set-selection`
|
||||
* `00-packages`: A list of packages to install
|
||||
* `00-packages-nr`: Similar to the _00-packages_, except that this will cause the installation with --no-install-recommends -y parameter to _apt-get_
|
||||
* `00-patches`: A directory containing patch files to be applied, using [quilt][7]
|
||||
|
||||
* Back in the stage-loop, if a file named `EXPORT_IMAGE` is found, generate an image for this stage
|
||||
|
||||
* If a file named `SKIP_IMAGE` is found, skip creating the image
|
||||
|
||||
|
||||
|
||||
|
||||
The `build.sh `also requires a file named `config` containing some specification which is read on startup.
|
||||
|
||||
#### Hands-On
|
||||
|
||||
First, we will create a basic Raspberry Pi OS Lite image. The Raspberry Pi OS Lite image will act as a base for our custom image. Create an empty file named _config_ and add the following two lines:
|
||||
|
||||
|
||||
```
|
||||
IMG_NAME='Cockpit'
|
||||
ENABLE_SSH=1
|
||||
```
|
||||
|
||||
Create an empty file named `SKIP` in the directories `stage3`, `stage4`, and `stage5`. `Stages 4` and `5` emit an image by default, therefore add an empty file named `SKIP_IMAGE` in `stage4` and `stage5`.
|
||||
|
||||
Now open a terminal and switch to the root user by typing `su`. Navigate to the root directory of the repository and start the build script by typing `./build.sh`.
|
||||
|
||||
The build process will take some time.
|
||||
|
||||
After the build process has finished, you will find two more directories in the root of the repository: `work `and `deploy`. The `work` folder contains some intermediate output. In the `deploy` folder you should find the zipped image file, ready for deployment.
|
||||
|
||||
If the overall build process was successful, we now can modify the process so that it installs Cockpit additionally.
|
||||
|
||||
#### Extending the build process
|
||||
|
||||
The Raspberry Pi OS Lite image acts as the base for our Cockpit installation. As the Raspberry Pi OS Lite image is complete with `stage2`, we will create our own `stage3` which will handle the Cockpit installation.
|
||||
|
||||
We remove the original `stage3` completely and create a new, empty `stage3`:
|
||||
|
||||
|
||||
```
|
||||
`rm -rf stage3 && mkdir stage3`
|
||||
```
|
||||
|
||||
Inside `stage3`, we create a substage for installing cockpit:
|
||||
|
||||
|
||||
```
|
||||
`mkdir stage3/00-cockpit`
|
||||
```
|
||||
|
||||
To install cockpit on the image, we simply need to add it to the package list:
|
||||
|
||||
|
||||
```
|
||||
`echo "cockpit" >> stage3/00-cockpit/00-packages`
|
||||
```
|
||||
|
||||
We also want to configure our new `stage3` to output an image, therefore we simply add this file in the `stage3` directory:
|
||||
|
||||
|
||||
```
|
||||
`touch stage3/EXPORT_IMAGE`
|
||||
```
|
||||
|
||||
As there are already intermediate images from the previous build process, we can prevent that the stages are built again by adding `skip-files` in the related directories:
|
||||
|
||||
Skip the build process for `stage0` and `stage1`:
|
||||
|
||||
|
||||
```
|
||||
`touch stage0/SKIP && touch stage1/SKIP`
|
||||
```
|
||||
|
||||
Skip the build process for `stage2` and also skip the image creation:
|
||||
|
||||
|
||||
```
|
||||
`touch stage2/SKIP && touch stage2/SKIP_IMAGE`
|
||||
```
|
||||
|
||||
Now run the build script again:
|
||||
|
||||
|
||||
```
|
||||
`./build.sh`
|
||||
```
|
||||
|
||||
In the folder `deployment` you now should find a zipped image `<date>-Cockpit-lite.zip`, which is ready for deployment.
|
||||
|
||||
#### Troubleshooting
|
||||
|
||||
If you try to apply more complex modifications, there is a lot of trial and error involved in building your own Raspberry Pi image with pi-gen. You will certainly face that the build process will stop in between for some reason. As there is no exception handling in the build process, we do have some cleanup manually in case the process stopped.
|
||||
|
||||
It is likely that the `chroot` file system is still mounted after the process stopped. You won't be able to start a new build process without unmounting it. In the case it is still mounted, unmount it manually by typing:
|
||||
|
||||
|
||||
```
|
||||
`umount work/<Build-date-&-image-name>/tmpimage/`
|
||||
```
|
||||
|
||||
Another issue I determined was that the script stopped when the `chroot` filesystem was about to be unmounted. In the file `scripts/qcow2_handling`, you can see that directly before the attempt to unmount `sync` is called. `Sync` forces the system to flush the write buffer. Running the build system as a virtual machine, the write process was not ready when `unmount` was called so the script stopped here.
|
||||
|
||||
To solve this, I just inserted a `sleep` between `sync` and `unmount` which solved the issue:
|
||||
|
||||
![Sleep in between sync and unmount - core dump example][8]
|
||||
|
||||
(I know that 30 seconds are overkill but as the whole build process takes > 20 minutes, 30 seconds are just a drop in the ocean)
|
||||
|
||||
### Modify existing image
|
||||
|
||||
In contrast to building an image with `pi-gen`, you could also directly apply the modification on a running Raspberry Pi OS. In our scenario, simply log in and install Cockpit with the following command:
|
||||
|
||||
|
||||
```
|
||||
`sudo apt install cockpit`
|
||||
```
|
||||
|
||||
Now shut down your Raspberry Pi, take out the SD card, and connect it to your PC. Check if your system has automatically mounted the partitions on the SD card by typing `lsblk -p`:
|
||||
|
||||
![Using lsblk -p to check mounting partitions][9]
|
||||
|
||||
In the screenshot above, the SD card is the device `/dev/sdc` and the `boot`\- and `rootfs`-partitions were automatically mounted at the mentioned mount points. Before you proceed, unmount them with :
|
||||
|
||||
|
||||
```
|
||||
`umount /dev/sdc1 && umount /dev/sdc2`
|
||||
```
|
||||
|
||||
Now we copy the contents of the SD card to our file system. Make sure you have enough disk space available as the image will have the same size as the SD card. Start the copy process with the following command:
|
||||
|
||||
|
||||
```
|
||||
`dd if=/dev/sdc of=~/MyImage.img bs=32M`
|
||||
```
|
||||
|
||||
![Copying image from the SD card][10]
|
||||
|
||||
Once the copy process is finished, we can shrink the image with the [PiShrink][11]. Follow the installation instructions mentioned in the repository which are:
|
||||
|
||||
|
||||
```
|
||||
wget <https://raw.githubusercontent.com/Drewsif/PiShrink/master/pishrink.sh>
|
||||
chmod +x pishrink.sh
|
||||
sudo mv pishrink.sh /usr/local/bin
|
||||
```
|
||||
|
||||
Now invoke the script by typing:
|
||||
|
||||
|
||||
```
|
||||
`sudo pishrink.sh ~/MyImage.img`
|
||||
```
|
||||
|
||||
![Invoking the pishrink.sh script][12]
|
||||
|
||||
PiShrink reduced the image size by almost a factor of ten: From the former 30GB to 3.5GB. You can still optimize the size by zipping it before you upload or share it.
|
||||
|
||||
That's it, you are now able to share and flash this image.
|
||||
|
||||
### Flashing the image
|
||||
|
||||
If you want to flash your own custom Raspberry Pi image back to the SD card using Linux, follow the steps below.
|
||||
|
||||
Put the SD card into your PC. Your system will likely automatically mount the filesystem on the SD card if there is already a previous installation. You can check this by opening a command line and typing `lsblk -p`:
|
||||
|
||||
![Checking automatic mounting with lsblk -p][13]
|
||||
|
||||
As you can see in the screenshot above, my system automatically mounted two filesystems, `boot` and `rootfs` as this SD card already contained a Raspberry Pi OS. Before we start flashing the SD card we have to unmount the file systems first by typing:
|
||||
|
||||
|
||||
```
|
||||
`umount /dev/sdc1 && umount /dev/sdc2`
|
||||
```
|
||||
|
||||
The output of `lsblk -p` should look like this in order to proceed:
|
||||
|
||||
![Output of lsblk -p][14]
|
||||
|
||||
Now you can flash the image to the SD card: Open a command line and type:
|
||||
|
||||
|
||||
```
|
||||
`dd if=/path/to/image.img of=/dev/sdc bs=32M, conv=fsync`
|
||||
```
|
||||
|
||||
With `bs=32M`, you specify that the SD card is written in 32-megabyte blocks, `conv=fsync` forces the process to physically write each block.
|
||||
|
||||
If successful, you should see this output:
|
||||
|
||||
![Successful output example][15]
|
||||
|
||||
Done! You can now put the SD card back into the Raspberry Pi and boot it.
|
||||
|
||||
### Summary
|
||||
|
||||
Both of the techniques presented in this article have their advantages and disadvantages. Whereas using `pi-gen` to create your own custom Raspberry Pi images is more error-prone than simply modifying an existing image, it is the method of choice if you plan to set up a [CICD pipeline][16]. My personal favorite is clearly to modify an existing image as you are directly able to make sure that the changes you applied are working.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/custom-raspberry-pi-image
|
||||
|
||||
作者:[Stephan Avenwedde][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/hansic99
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/raspberrypi_board_vector_red.png?itok=yaqYjYqI (Vector, generic Raspberry Pi board)
|
||||
[2]: https://opensource.com/users/alanfdoss
|
||||
[3]: https://opensource.com/article/21/5/raspberry-pi-cockpit
|
||||
[4]: https://github.com/RPi-Distro/pi-gen
|
||||
[5]: https://opensource.com/article/21/6/try-linux-virtualbox
|
||||
[6]: https://github.com/RPi-Distro/pi-gen/blob/master/README.md#Dependencies
|
||||
[7]: https://man7.org/linux/man-pages/man1/quilt.1.html
|
||||
[8]: https://opensource.com/sites/default/files/uploads/1_pi_gen_sleep.png (Sleep in between sync and unmount - core dump example)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/pi_gen_lsblk_mounted.png (Using lsblk -p to check mounting partitions)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/rpi_image_copy.png (Copying image from the SD card)
|
||||
[11]: https://github.com/Drewsif/PiShrink
|
||||
[12]: https://opensource.com/sites/default/files/uploads/rpi_pishrink.png (Invoking the pishrink.sh script)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/pi_gen_lsblk_mounted_0.png (Checking automatic mounting with lsblk -p)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/pi_gen_lsblk_unmounted2.png (Output of lsblk -p)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/pi_gen_flash.png (Successful output example)
|
||||
[16]: https://en.wikipedia.org/wiki/CI/CD
|
||||
@ -0,0 +1,305 @@
|
||||
[#]: subject: (Getting started with Maxima in Fedora Linux)
|
||||
[#]: via: (https://fedoramagazine.org/getting-started-with-maxima-in-fedora-linux/)
|
||||
[#]: author: (Jagat Kafle https://fedoramagazine.org/author/jkafle/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Getting started with Maxima in Fedora Linux
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Photo by [Roman Mager][2] on [Unsplash][3]
|
||||
|
||||
[Maxima][4] is an open source computer algebra system (CAS) with powerful symbolic, numerical, and graphical capabilities. You can perform matrix operations, differentiation, integration, solve ordinary differential equations as well as plot functions and data in two and three dimensions. As such, it is helpful for anyone interested in science and math. This article goes through installing and using Maxima in Fedora Linux.
|
||||
|
||||
### Installing Maxima
|
||||
|
||||
Maxima is a command line system. You can install Maxima from the official Fedora repository using the following command:
|
||||
|
||||
```
|
||||
sudo dnf install maxima
|
||||
```
|
||||
|
||||
You can then use Maxima from the terminal by invoking the command _maxima_.
|
||||
|
||||
![Maxima session in gnome terminal in Fedora Linux 34][5]
|
||||
|
||||
### Installing wxMaxima
|
||||
|
||||
[wxMaxima][6] is a document based interface for Maxima. To install it in Fedora Linux, use the following command:
|
||||
|
||||
```
|
||||
sudo dnf install wxmaxima
|
||||
```
|
||||
|
||||
You can launch wxMaxima either by invoking the command _wxmaxima_ in the terminal or clicking its application icon from the app grid or menu.
|
||||
|
||||
![wxMaxima session in Fedora Linux 34][7]
|
||||
|
||||
### Basic Commands
|
||||
|
||||
After calling _maxima_, you should see terminal output as in the [figure above][8].
|
||||
|
||||
The _(%i1)_ is the input label where you enter the commands. Command in Maxima is an expression that can span over many lines and is closed with a semicolon (;). The _o_ labels denote the outputs. Comments are enclosed between _/*_ and _*/_. You can use the special symbol percent _(%)_ to refer to the immediately preceding result computed by Maxima. If you don’t want to print a result, you can finish your command with _$_ instead of _;_. Here are basic arithmetic commands in Maxima:
|
||||
|
||||
```
|
||||
(%i1) (19 + 7)/(52 - 2 * 13);
|
||||
(%o1) 1
|
||||
(%i2) 127 / 5;
|
||||
127
|
||||
(%o2) ---
|
||||
5
|
||||
(%i3) float (127 / 5);
|
||||
(%o3) 25.4
|
||||
(%i4) 127.0 / 5;
|
||||
(%o4) 25.4
|
||||
(%i5) sqrt(2.0);
|
||||
(%o5) 1.414213562373095
|
||||
(%i6) sin(%pi/2);
|
||||
(%o6) 1
|
||||
(%i7) abs(-12);
|
||||
(%o7) 12
|
||||
(%i8) 2+3%i + 5 - 4%i; /*complex arithmetic*/
|
||||
(%o8) 7 - %i
|
||||
```
|
||||
|
||||
To end the Maxima session, type the command:
|
||||
|
||||
```
|
||||
quit();
|
||||
```
|
||||
|
||||
### Algebra
|
||||
|
||||
Maxima can expand and factor polynomials:
|
||||
|
||||
```
|
||||
(%i1) (x+y)^3 + (x+y)^2 + (x+y);
|
||||
3 2
|
||||
(%o1) (y + x) + (y + x) + y + x
|
||||
(%i2) expand(%);
|
||||
3 2 2 2 3 2
|
||||
(%o2) y + 3 x y + y + 3 x y + 2 x y + y + x + x + x
|
||||
(%i3) factor(%);
|
||||
2 2
|
||||
(%o3) (y + x) (y + 2 x y + y + x + x + 1)
|
||||
```
|
||||
|
||||
To substitute _y_ with _z_ and _x_ with _5,_ refer the output label above and use the following command:
|
||||
|
||||
```
|
||||
(%i4) %o3, y=z, x=5;
|
||||
2
|
||||
(%o4) (z + 5) (z + 11 z + 31)
|
||||
```
|
||||
|
||||
You can easily manipulate trigonometric identities:
|
||||
|
||||
```
|
||||
(%i1) sin(x) * cos(x+y)^2;
|
||||
2
|
||||
(%o1) sin(x) cos (y + x)
|
||||
(%i2) trigexpand(%);
|
||||
2
|
||||
(%o2) sin(x) (cos(x) cos(y) - sin(x) sin(y))
|
||||
(%i3) trigreduce(%o1);
|
||||
sin(2 y + 3 x) - sin(2 y + x) sin(x)
|
||||
(%o3) ----------------------------- + ------
|
||||
4 2
|
||||
```
|
||||
|
||||
You can also solve algebraic equations in one or more variables:
|
||||
|
||||
```
|
||||
(%i1) solve(x^2+5*x+6);
|
||||
(%o1) [x = - 3, x = - 2]
|
||||
(%i2) solve(x^3 + 1);
|
||||
sqrt(3) %i - 1 sqrt(3) %i + 1
|
||||
(%o2) [x = - --------------, x = --------------, x = - 1]
|
||||
2 2
|
||||
(%i3) eqns: [x^2 + y^2 = 9, x + y = 3];
|
||||
2 2
|
||||
(%o3) [y + x = 9, y + x = 3]
|
||||
(%i4) solve(eqns, [x,y]);
|
||||
(%o4) [[x = 3, y = 0], [x = 0, y = 3]]
|
||||
```
|
||||
|
||||
### Calculus
|
||||
|
||||
Define _f_ to be a function of _x._ You can then find the limit, derivative and integral of the function:
|
||||
|
||||
```
|
||||
(%i1) f: x^2;
|
||||
2
|
||||
(%o1) x
|
||||
(%i2) limit(f,x,0);
|
||||
(%o2) 0
|
||||
(%i3) limit(1/f,x,0);
|
||||
(%o3) inf
|
||||
(%i4) diff(f, x);
|
||||
(%o4) 2 x
|
||||
(%i5) integrate(f, x);
|
||||
3
|
||||
x
|
||||
(%o5) --
|
||||
3
|
||||
```
|
||||
|
||||
To find definite integrals, slightly modify the syntax above.
|
||||
|
||||
```
|
||||
(%i6) integrate(f, x, 1, inf);
|
||||
defint: integral is divergent.
|
||||
-- an error. To debug this try: debugmode(true);
|
||||
(%i7) integrate(1/f, x, 1, inf);
|
||||
(%o7) 1
|
||||
```
|
||||
|
||||
Maxima can perform Taylor expansion. Here’s the Taylor expansion of sin(x) up to order 5 terms.
|
||||
|
||||
```
|
||||
(%i1) taylor(sin(x), x, 0, 5);
|
||||
3 5
|
||||
x x
|
||||
(%o1)/T/ x - -- + --- + . . .
|
||||
6 120
|
||||
```
|
||||
|
||||
To represent derivatives in unevaluated form, use the following syntax.
|
||||
|
||||
```
|
||||
(%i2) 'diff(y,x);
|
||||
dy
|
||||
(%o2) --
|
||||
dx
|
||||
```
|
||||
|
||||
The ode2 function can solve first and second order ordinary differential equations (ODEs).
|
||||
|
||||
```
|
||||
(%i1) 'diff(y,x,2) + y = 0;
|
||||
2
|
||||
d y
|
||||
(%o1) --- + y = 0
|
||||
2
|
||||
dx
|
||||
(%i2) ode2(%o1,y,x);
|
||||
(%o2) y = %k1 sin(x) + %k2 cos(x)
|
||||
```
|
||||
|
||||
### Matrix Operations
|
||||
|
||||
To enter a matrix, use the entermatrix function. Here’s an example of a general 2×2 matrix.
|
||||
|
||||
```
|
||||
(%i1) A: entermatrix(2,2);
|
||||
Is the matrix 1. Diagonal 2. Symmetric 3. Antisymmetric 4. General
|
||||
Answer 1, 2, 3 or 4 :
|
||||
4;
|
||||
Row 1 Column 1:
|
||||
1;
|
||||
Row 1 Column 2:
|
||||
2;
|
||||
Row 2 Column 1:
|
||||
3;
|
||||
Row 2 Column 2:
|
||||
4;
|
||||
Matrix entered.
|
||||
[ 1 2 ]
|
||||
(%o1) [ ]
|
||||
[ 3 4 ]
|
||||
```
|
||||
|
||||
You can then find the determinant, transpose, inverse, eigenvalues and eigenvectors of the matrix.
|
||||
|
||||
```
|
||||
(%i2) determinant(A);
|
||||
(%o2) - 2
|
||||
(%i3) transpose(A);
|
||||
[ 1 3 ]
|
||||
(%o3) [ ]
|
||||
[ 2 4 ]
|
||||
(%i4) invert(A);
|
||||
[ - 2 1 ]
|
||||
[ ]
|
||||
(%o4) [ 3 1 ]
|
||||
[ - - - ]
|
||||
[ 2 2 ]
|
||||
(%i5) eigenvectors(A);
|
||||
sqrt(33) - 5 sqrt(33) + 5
|
||||
(%o5) [[[- ------------, ------------], [1, 1]],
|
||||
2 2
|
||||
sqrt(33) - 3 sqrt(33) + 3
|
||||
[[[1, - ------------]], [[1, ------------]]]]
|
||||
4 4
|
||||
```
|
||||
|
||||
In the output label _(%o5)_ the first array gives the eigenvalues, the second array gives the multiplicity of the respective eigenvalues, and the next two arrays give the corresponding eigenvectors of the matrix A.
|
||||
|
||||
### Plotting
|
||||
|
||||
Maxima can use either [Gnuplot][9], [Xmaxima][10] or [Geomview][11] as graphics program. Maxima package in Fedora Linux comes with _gnuplot_ as a dependency, so Maxima uses _gnuplot_pipes_ as the plotting format. To check the plotting format, use the following command inside Maxima.
|
||||
|
||||
```
|
||||
get_plot_option(plot_format);
|
||||
```
|
||||
|
||||
Below are some plotting examples.
|
||||
|
||||
```
|
||||
(%i1) plot2d([sin(x), cos(x)], [x, -2%pi, 2%pi]);
|
||||
```
|
||||
|
||||
![2d plot using Maxima][12]
|
||||
|
||||
```
|
||||
(%i2) plot3d(sin(sqrt(x^2+y^2)), [x, -7, 7], [y, -7, 7]);
|
||||
```
|
||||
|
||||
![3d plot using Maxima][13]
|
||||
|
||||
```
|
||||
(%i3) mandelbrot ([iterations, 30], [x, -2, 1], [y, -1.2, 1.2],
|
||||
[grid,400,400]);
|
||||
```
|
||||
|
||||
![The Mandelbrot Set][14]
|
||||
|
||||
You can read more about Maxima and its capabilities in its [official website][15] and [documentation][16].
|
||||
|
||||
Fedora Linux has plethora of tools for scientific use. You can find the widely used ones in the [Fedora Scientific Guide][17].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/getting-started-with-maxima-in-fedora-linux/
|
||||
|
||||
作者:[Jagat Kafle][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/jkafle/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2021/07/Getting-started-with-Maxima-in-Fedora-Linux-816x345.png
|
||||
[2]: https://unsplash.com/@roman_lazygeek
|
||||
[3]: https://unsplash.com/s/photos/mathematics-tasks
|
||||
[4]: https://maxima.sourceforge.io/
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2021/07/maxima-terminal.png
|
||||
[6]: https://wxmaxima-developers.github.io/wxmaxima/index.html
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2021/07/wxmaxima.png
|
||||
[8]: tmp.LH5pctTy1x#maxima-terminal
|
||||
[9]: http://www.gnuplot.info/
|
||||
[10]: https://maxima.sourceforge.io/docs/xmaxima/xmaxima.html
|
||||
[11]: http://www.geomview.org/
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2021/07/2d-maxima.png
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2021/07/3d-maxima.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2021/07/mandelbrot-maxima.png
|
||||
[15]: https://maxima.sourceforge.io/index.html
|
||||
[16]: https://maxima.sourceforge.io/docs/manual/maxima_toc.html
|
||||
[17]: https://fedora-scientific.readthedocs.io/en/latest/index.html
|
||||
376
sources/tech/20210728 Kernel tracing with trace-cmd.md
Normal file
376
sources/tech/20210728 Kernel tracing with trace-cmd.md
Normal file
@ -0,0 +1,376 @@
|
||||
[#]: subject: (Kernel tracing with trace-cmd)
|
||||
[#]: via: (https://opensource.com/article/21/7/linux-kernel-trace-cmd)
|
||||
[#]: author: (Gaurav Kamathe https://opensource.com/users/gkamathe)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Kernel tracing with trace-cmd
|
||||
======
|
||||
trace-cmd is an easy-to-use, feature-rich utility for tracing Linux
|
||||
kernel functions.
|
||||
![Puzzle pieces coming together to form a computer screen][1]
|
||||
|
||||
In my [previous article][2], I explained how to use `ftrace` to trace kernel functions. Using `ftrace` by writing and reading from files can get tedious, so I used a wrapper around it to run commands with options to enable and disable tracing, set filters, view output, clear output, and more.
|
||||
|
||||
The [trace-cmd][3] command is a utility that helps you do just this. In this article, I use `trace-cmd` to perform the same tasks I did in my `ftrace` article. Since I refer back to that article frequently, I recommend you read it before you read this one.
|
||||
|
||||
### Install trace-cmd
|
||||
|
||||
I run the commands in this article as the root user.
|
||||
|
||||
The `ftrace` mechanism is built into the kernel, and you can verify it is enabled with:
|
||||
|
||||
|
||||
```
|
||||
# mount | grep tracefs
|
||||
none on /sys/kernel/tracing type tracefs (rw,relatime,seclabel)
|
||||
```
|
||||
|
||||
However, you need to install the `trace-cmd` utility manually.
|
||||
|
||||
|
||||
```
|
||||
`# dnf install trace-cmd -y`
|
||||
```
|
||||
|
||||
### List available tracers
|
||||
|
||||
When using `ftrace`, you must view a file's contents to see what tracers are available. But with `trace-cmd`, you can get this information with:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd list -t
|
||||
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
|
||||
```
|
||||
|
||||
### Enable the function tracer
|
||||
|
||||
In my [earlier article][2], I used two tracers, and I'll do the same here. Enable your first tracer, `function`, with:
|
||||
|
||||
|
||||
```
|
||||
$ trace-cmd start -p function
|
||||
plugin 'function'
|
||||
```
|
||||
|
||||
### View the trace output
|
||||
|
||||
Once the tracer is enabled, you can view the output by using the `show` arguments. This shows only the first 20 lines to keep the example short (see my earlier article for an explanation of the output):
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd show | head -20
|
||||
## tracer: function
|
||||
#
|
||||
# entries-in-buffer/entries-written: 410142/3380032 #P:8
|
||||
#
|
||||
# _-----=> irqs-off
|
||||
# / _----=> need-resched
|
||||
# | / _---=> hardirq/softirq
|
||||
# || / _--=> preempt-depth
|
||||
# ||| / delay
|
||||
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
|
||||
# | | | |||| | |
|
||||
gdbus-2606 [004] ..s. 10520.538759: __msecs_to_jiffies <-rebalance_domains
|
||||
gdbus-2606 [004] ..s. 10520.538760: load_balance <-rebalance_domains
|
||||
gdbus-2606 [004] ..s. 10520.538761: idle_cpu <-load_balance
|
||||
gdbus-2606 [004] ..s. 10520.538762: group_balance_cpu <-load_balance
|
||||
gdbus-2606 [004] ..s. 10520.538762: find_busiest_group <-load_balance
|
||||
gdbus-2606 [004] ..s. 10520.538763: update_group_capacity <-update_sd_lb_stats.constprop.0
|
||||
gdbus-2606 [004] ..s. 10520.538763: __msecs_to_jiffies <-update_group_capacity
|
||||
gdbus-2606 [004] ..s. 10520.538765: idle_cpu <-update_sd_lb_stats.constprop.0
|
||||
gdbus-2606 [004] ..s. 10520.538766: __msecs_to_jiffies <-rebalance_domains
|
||||
```
|
||||
|
||||
### Stop tracing and clear the buffer
|
||||
|
||||
Tracing continues to run in the background, and you can keep viewing the output using `show`.
|
||||
|
||||
To stop tracing, run `trace-cmd` with the `stop` argument:
|
||||
|
||||
|
||||
```
|
||||
`# trace-cmd stop`
|
||||
```
|
||||
|
||||
To clear the buffer, run it with the `clear` argument:
|
||||
|
||||
|
||||
```
|
||||
`# trace-cmd clear`
|
||||
```
|
||||
|
||||
### Enable the function_graph tracer
|
||||
|
||||
Enable the second tracer, `function_graph`, by running:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd start -p function_graph
|
||||
plugin 'function_graph'
|
||||
```
|
||||
|
||||
Once again, view the output using the `show` argument. As expected, the output is slightly different from the first trace output. This time it includes a `function calls` chain:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd show | head -20
|
||||
## tracer: function_graph
|
||||
#
|
||||
# CPU DURATION FUNCTION CALLS
|
||||
# | | | | | | |
|
||||
4) 0.079 us | } /* rcu_all_qs */
|
||||
4) 0.327 us | } /* __cond_resched */
|
||||
4) 0.081 us | rcu_read_unlock_strict();
|
||||
4) | __cond_resched() {
|
||||
4) 0.078 us | rcu_all_qs();
|
||||
4) 0.243 us | }
|
||||
4) 0.080 us | rcu_read_unlock_strict();
|
||||
4) | __cond_resched() {
|
||||
4) 0.078 us | rcu_all_qs();
|
||||
4) 0.241 us | }
|
||||
4) 0.080 us | rcu_read_unlock_strict();
|
||||
4) | __cond_resched() {
|
||||
4) 0.079 us | rcu_all_qs();
|
||||
4) 0.235 us | }
|
||||
4) 0.095 us | rcu_read_unlock_strict();
|
||||
4) | __cond_resched() {
|
||||
```
|
||||
|
||||
Use the `stop` and `clear` commands to stop tracing and clear the buffer:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd stop
|
||||
# trace-cmd clear
|
||||
```
|
||||
|
||||
### Tweak tracing to increase depth
|
||||
|
||||
If you want to see more depth in the function calls, you can tweak the tracer:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd start -p function_graph --max-graph-depth 5
|
||||
plugin 'function_graph'
|
||||
```
|
||||
|
||||
Now when you compare this output with what you saw before, you should see more nested function calls:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd show | head -20
|
||||
## tracer: function_graph
|
||||
#
|
||||
# CPU DURATION FUNCTION CALLS
|
||||
# | | | | | | |
|
||||
6) | __fget_light() {
|
||||
6) 0.804 us | __fget_files();
|
||||
6) 2.708 us | }
|
||||
6) 3.650 us | } /* __fdget */
|
||||
6) 0.547 us | eventfd_poll();
|
||||
6) 0.535 us | fput();
|
||||
6) | __fdget() {
|
||||
6) | __fget_light() {
|
||||
6) 0.946 us | __fget_files();
|
||||
6) 1.895 us | }
|
||||
6) 2.849 us | }
|
||||
6) | sock_poll() {
|
||||
6) 0.651 us | unix_poll();
|
||||
6) 1.905 us | }
|
||||
6) 0.475 us | fput();
|
||||
6) | __fdget() {
|
||||
```
|
||||
|
||||
### Learn available functions to trace
|
||||
|
||||
If you want to trace only certain functions and ignore the rest, you need to know the exact function names. You can get them with the `list` argument followed by `-f`. This example searches for the common kernel function `kmalloc`, which is used to allocate memory in the kernel:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd list -f | grep kmalloc
|
||||
bpf_map_kmalloc_node
|
||||
mempool_kmalloc
|
||||
__traceiter_kmalloc
|
||||
__traceiter_kmalloc_node
|
||||
kmalloc_slab
|
||||
kmalloc_order
|
||||
kmalloc_order_trace
|
||||
kmalloc_large_node
|
||||
__kmalloc
|
||||
__kmalloc_track_caller
|
||||
__kmalloc_node
|
||||
__kmalloc_node_track_caller
|
||||
[...]
|
||||
```
|
||||
|
||||
Here's the total count of functions available on my test system:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd list -f | wc -l
|
||||
63165
|
||||
```
|
||||
|
||||
### Trace kernel module-related functions
|
||||
|
||||
You can also trace functions related to a specific kernel module. Imagine you want to trace `kvm` kernel module-related functions. Ensure the module is loaded:
|
||||
|
||||
|
||||
```
|
||||
# lsmod | grep kvm_intel
|
||||
kvm_intel 335872 0
|
||||
kvm 987136 1 kvm_intel
|
||||
```
|
||||
|
||||
Run `trace-cmd` again with the `list` argument, and from the output, `grep` for lines that end in `]`. This will filter out the kernel modules. Then `grep` the kernel module `kvm_intel`, and you should see all the functions related to that kernel module:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd list -f | grep ]$ | grep kvm_intel
|
||||
vmx_can_emulate_instruction [kvm_intel]
|
||||
vmx_update_emulated_instruction [kvm_intel]
|
||||
vmx_setup_uret_msr [kvm_intel]
|
||||
vmx_set_identity_map_addr [kvm_intel]
|
||||
handle_machine_check [kvm_intel]
|
||||
handle_triple_fault [kvm_intel]
|
||||
vmx_patch_hypercall [kvm_intel]
|
||||
|
||||
[...]
|
||||
|
||||
vmx_dump_dtsel [kvm_intel]
|
||||
vmx_dump_sel [kvm_intel]
|
||||
```
|
||||
|
||||
### Trace specific functions
|
||||
|
||||
Now that you know how to find functions of interest, put that knowledge to work with an example. As in the earlier article, try to trace filesystem-related functions. The filesystem I had on my test system was `ext4`.
|
||||
|
||||
This procedure is slightly different; instead of `start`, you run the command with the `record` argument followed by the "pattern" of the functions you want to trace. You also need to specify the tracer you want; in this case, that's `function_graph`. The command continues recording the trace until you stop it with **Ctrl+C**. So after a few seconds, hit **Ctrl+C** to stop tracing:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd list -f | grep ^ext4_
|
||||
|
||||
# trace-cmd record -l ext4_* -p function_graph
|
||||
plugin 'function_graph'
|
||||
Hit Ctrl^C to stop recording
|
||||
^C
|
||||
CPU0 data recorded at offset=0x856000
|
||||
8192 bytes in size
|
||||
[...]
|
||||
```
|
||||
|
||||
### View the recorded trace
|
||||
|
||||
To view the trace you recorded earlier, run the command with the `report` argument. From the output, it's clear that the filter worked, and you see only the ext4-related function trace:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd report | head -20
|
||||
[...]
|
||||
cpus=8
|
||||
trace-cmd-12697 [000] 11303.928103: funcgraph_entry: | ext4_show_options() {
|
||||
trace-cmd-12697 [000] 11303.928104: funcgraph_entry: 0.187 us | ext4_get_dummy_policy();
|
||||
trace-cmd-12697 [000] 11303.928105: funcgraph_exit: 1.583 us | }
|
||||
trace-cmd-12697 [000] 11303.928122: funcgraph_entry: | ext4_create() {
|
||||
trace-cmd-12697 [000] 11303.928122: funcgraph_entry: | ext4_alloc_inode() {
|
||||
trace-cmd-12697 [000] 11303.928123: funcgraph_entry: 0.101 us | ext4_es_init_tree();
|
||||
trace-cmd-12697 [000] 11303.928123: funcgraph_entry: 0.083 us | ext4_init_pending_tree();
|
||||
trace-cmd-12697 [000] 11303.928123: funcgraph_entry: 0.141 us | ext4_fc_init_inode();
|
||||
trace-cmd-12697 [000] 11303.928123: funcgraph_exit: 0.931 us | }
|
||||
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.081 us | ext4_get_dummy_policy();
|
||||
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.133 us | ext4_get_group_desc();
|
||||
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.115 us | ext4_free_inodes_count();
|
||||
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.114 us | ext4_get_group_desc();
|
||||
```
|
||||
|
||||
### Trace a specific PID
|
||||
|
||||
Say you want to trace functions related to a specific persistent identifier (PID). Open another terminal and note the PID of the running shell:
|
||||
|
||||
|
||||
```
|
||||
# echo $$
|
||||
10885
|
||||
```
|
||||
|
||||
Run the `record` command again and pass the PID using the `-P` option. This time, let the terminal run (i.e., do not press **Ctrl+C** yet):
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd record -P 10885 -p function_graph
|
||||
plugin 'function_graph'
|
||||
Hit Ctrl^C to stop recording
|
||||
```
|
||||
|
||||
### Run some activity on the shell
|
||||
|
||||
Move back to the other terminal where you had a shell running with a specific PID and run any command, e.g., `ls` to list files:
|
||||
|
||||
|
||||
```
|
||||
# ls
|
||||
Temp-9b61f280-fdc1-4512-9211-5c60f764d702
|
||||
tracker-extract-3-files.1000
|
||||
v8-compile-cache-1000
|
||||
[...]
|
||||
```
|
||||
|
||||
Move back to the terminal where you enabled tracing and hit **Ctrl+C** to stop tracing:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd record -P 10885 -p function_graph
|
||||
plugin 'function_graph'
|
||||
Hit Ctrl^C to stop recording
|
||||
^C
|
||||
CPU1 data recorded at offset=0x856000
|
||||
618496 bytes in size
|
||||
[...]
|
||||
```
|
||||
|
||||
In the trace's output, you can see the PID and the Bash shell on the left and the function calls related to it on the right. This can be pretty handy to narrow down your tracing:
|
||||
|
||||
|
||||
```
|
||||
# trace-cmd report | head -20
|
||||
|
||||
cpus=8
|
||||
<idle>-0 [001] 11555.380581: funcgraph_entry: | switch_mm_irqs_off() {
|
||||
<idle>-0 [001] 11555.380583: funcgraph_entry: 1.703 us | load_new_mm_cr3();
|
||||
<idle>-0 [001] 11555.380586: funcgraph_entry: 0.493 us | switch_ldt();
|
||||
<idle>-0 [001] 11555.380587: funcgraph_exit: 7.235 us | }
|
||||
bash-10885 [001] 11555.380589: funcgraph_entry: 1.046 us | finish_task_switch.isra.0();
|
||||
bash-10885 [001] 11555.380591: funcgraph_entry: | __fdget() {
|
||||
bash-10885 [001] 11555.380592: funcgraph_entry: 2.036 us | __fget_light();
|
||||
bash-10885 [001] 11555.380594: funcgraph_exit: 3.256 us | }
|
||||
bash-10885 [001] 11555.380595: funcgraph_entry: | tty_poll() {
|
||||
bash-10885 [001] 11555.380597: funcgraph_entry: | tty_ldisc_ref_wait() {
|
||||
bash-10885 [001] 11555.380598: funcgraph_entry: | ldsem_down_read() {
|
||||
bash-10885 [001] 11555.380598: funcgraph_entry: | __cond_resched() {
|
||||
```
|
||||
|
||||
### Give it a try
|
||||
|
||||
These brief examples show how using `trace-cmd` instead of the underlying `ftrace` mechanism is both easy to use and rich in features, including many I didn't cover here. To learn more and get better at it, consult its man page and try out its other useful commands.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/linux-kernel-trace-cmd
|
||||
|
||||
作者:[Gaurav Kamathe][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gkamathe
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
|
||||
[2]: https://opensource.com/article/21/7/analyze-linux-kernel-ftrace
|
||||
[3]: https://lwn.net/Articles/410200/
|
||||
@ -0,0 +1,114 @@
|
||||
[#]: subject: (5 reasons you should run your apps on WildFly)
|
||||
[#]: via: (https://opensource.com/article/21/7/run-apps-wildfly)
|
||||
[#]: author: (Ranabir Chakraborty https://opensource.com/users/ranabir-chakraborty)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
5 reasons you should run your apps on WildFly
|
||||
======
|
||||
WildFly is a popular choice for users and developers worldwide who
|
||||
develop enterprise-capable applications.
|
||||
![Person drinking a hot drink at the computer][1]
|
||||
|
||||
WildFly, formerly known as JBoss Application Server, is an open source Java EE application server. Its primary goal is to provide a set of vital tools for enterprise Java applications.
|
||||
|
||||
According to the Jakarta EE 2020/2021 [survey][2], WildFly is head and shoulders above in the recent application servers and in the rating categories. Here are some of the reasons why:
|
||||
|
||||
### 1. Save time with faster development
|
||||
|
||||
WildFly supports the newest standards for REST-based data access, including JAX-RS 2 and JSON-P, and because it's building on Jakarta EE, which provides rich enterprise capabilities with ease of use of frameworks that eliminate boilerplate and reduce technical burden.
|
||||
|
||||
The quick boot feature of WildFly, integrated with the easy-to-use Arquillian framework, allows for test-driven development using the actual environment in which your code runs. This test code is separate and deployed alongside the application, where it has full access to server resources.
|
||||
|
||||
### 2\. Powerful but simple to use
|
||||
|
||||
WildFly configuration setup is centralized, simple, and user-focused.
|
||||
The configuration file—organized by subsystems—is easy to understand and has no internal server wiring that will be exposed. All management capabilities appear in a unified manner across all forms of access. These include a command-line interface, a web-based administration console, a native Java API, an HTTP/JSON-based REST API, and a JMX gateway. These options allow for custom automation using the tools and languages that best suit your needs.
|
||||
|
||||
### 3. Modular and lightweight
|
||||
|
||||
WildFly does classloading right. And it does it smoothly. It uses JBoss Modules to provide true application isolation while hiding server implementation classes from the application and only connects to JARs that your application needs. Appearance rules have sensible defaults but are usually customized. The dependency resolution algorithm means that classloading performance isn't affected by the number of versions of libraries you've got installed.
|
||||
|
||||
In WildFly base, they've developed runtime services to attenuate heap allocation using standard cached indexed metadata over duplicate full parses, which reduces heap and object churn. One hundred percent of the administration console is stateless and purely client-driven. It starts immediately and requires zero memory on the server. This integrated configuration enables WildFly to run with stock JVM settings—even on small devices while leaving more headroom for application data and supporting high-level scalability.
|
||||
|
||||
### 4\. Save resources with efficient management
|
||||
|
||||
WildFly takes a more aggressive approach to memory management and relies on pluggable subsystems, installed or removed as required. Subsystems use smart and intelligent defaults but can still be customized to best suit your needs. When working with domain mode, all participating servers' configuration is laid out in a well-organized, consistent manner within the same file.
|
||||
|
||||
### 5. Leverage open source
|
||||
|
||||
WildFly is an open source community project and is out there to be used and distributed using the LGPL v2.1 license, which means it's available for you to download and use for whatever you need. This allows organizations to develop unique new technologies and federates the world of technology to help successful startups to spring up anywhere.
|
||||
|
||||
## 8 ways to contribute to WildFly
|
||||
|
||||
Now that you know a bit about WildFly, Let’s try to understand the ways you can get involved with WildFly.
|
||||
|
||||
WildFly relies on contributions from people like you. I’ve joined Red Hat and contributed to WildFly for a year now, and it’s fun to work with great minds around you, and you’ll get to learn a lot. Here are some ways by which you can be a part of and assist the community.
|
||||
|
||||
### 1\. Check out the repository.
|
||||
|
||||
Here are the [WildFly][3] and [WildFly Core][4] (WildFly Core provides the core runtime used by the Wildfly application server). If you want to get more details, you can check out this [document][5].
|
||||
|
||||
### 2\. Raise a ticket or work on existing issues.
|
||||
|
||||
After checking out the WildFly repositories, if you feel some enhancements or fixes are needed, you can create issues for [WildFly][6] and [WildFly Core][7], or work on pre-existing issues.
|
||||
|
||||
### 3\. Edit the website
|
||||
|
||||
Like the WildFly project, the website is open source too. You can check out the [repository][8] and contribute here too, with some new and attractive modifications.
|
||||
|
||||
### 4\. Blog with us
|
||||
|
||||
You have a [blog][9], and all entries are maintained in a Git repository. If you have new ideas, you can share your experience and ideas in the form of an editorial. We use [markdown][10] and [AsciiDoc][11] so that you can submit your blog post as a pull request.
|
||||
|
||||
### 5\. Edit the Documentation
|
||||
|
||||
You can also help us to [make better documentation][12]. Let us know if you find a typo or an error, and feel free to send a pull request. Your input is valuable to us, and always welcome.
|
||||
|
||||
### 6\. Help somebody out
|
||||
|
||||
You can check out our [forums][13] and if you run into an issue, post your question and check the previous issues if you see some similarities. You can also share your knowledge and answer some of the queries because your knowledge can help others.
|
||||
|
||||
### 7\. Join our chatroom and follow the latest news
|
||||
|
||||
Our Project team has an open (and open source) and active [chatroom][14] where you can ask your questions and check out the [latest news][15] section to find what are the new things we are working on. Stop by, say hello, interact with the team members, but keep in mind that basic rules of civility apply.
|
||||
|
||||
### 8\. Spread the word
|
||||
|
||||
The simplest and easiest way to help the WildFly community is to act as a project ambassador by spreading the news, educating others about the usage of WildFly, and showing up to the community events in your area.
|
||||
|
||||
## **Final thoughts**
|
||||
|
||||
WildFly is a popular choice for users and developers worldwide who develop enterprise-capable applications. WildFly is an active project, so there are always new features in the works, and we're all delighted to be a part of it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/run-apps-wildfly
|
||||
|
||||
作者:[Ranabir Chakraborty][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ranabir-chakraborty
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_tea_laptop_computer_work_desk.png?itok=D5yMx_Dr (Person drinking a hot drink at the computer)
|
||||
[2]: https://arjan-tijms.omnifaces.org/2021/02/jakarta-ee-survey-20202021-results.html
|
||||
[3]: https://github.com/wildfly/wildfly
|
||||
[4]: https://github.com/wildfly/wildfly-core
|
||||
[5]: https://developer.jboss.org/docs/DOC-48381
|
||||
[6]: https://issues.redhat.com/browse/WFLY-14541?jql=project%20%3D%20WFLY%20AND%20resolution%20%3D%20Unresolved%20ORDER%20BY%20priority%20DESC%2C%20updated%20DESC
|
||||
[7]: https://issues.redhat.com/projects/WFCORE/issues/WFCORE-4827?filter=allopenissues
|
||||
[8]: https://github.com/wildfly/wildfly.org
|
||||
[9]: https://github.com/wildfly/wildfly.org/tree/master/_posts
|
||||
[10]: https://opensource.com/article/19/9/introduction-markdown
|
||||
[11]: https://asciidoc.org/
|
||||
[12]: https://github.com/wildfly/wildfly/tree/master/docs
|
||||
[13]: https://groups.google.com/g/wildfly
|
||||
[14]: https://wildfly.zulipchat.com/#recent_topics
|
||||
[15]: https://www.wildfly.org/news/
|
||||
@ -0,0 +1,155 @@
|
||||
[#]: subject: (4 cool new projects to try in Copr from July 2021)
|
||||
[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-july-2021/)
|
||||
[#]: author: (Jakub Kadlčík https://fedoramagazine.org/author/frostyx/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
4 cool new projects to try in Copr from July 2021
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Copr is a [collection][2] of personal repositories for software that isn’t carried in Fedora Linux. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora Linux standards, despite being free and open-source. Copr can offer these projects outside the Fedora Linux set of packages. Software in Copr isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
This article presents a few new and interesting projects in Copr. If you’re new to using Copr, see the [Copr User Documentation][3] for how to get started.
|
||||
|
||||
## [][4] Wike
|
||||
|
||||
[Wike][5] is a Wikipedia reader for the GNOME Desktop with search integration in the GNOME Shell. It provides distraction-free access to the [online encyclopedia][6]. The interface is minimalistic but it supports switching an article between multiple languages, bookmarks, article table of contents, dark mode, and more.
|
||||
|
||||
![][7]
|
||||
|
||||
### [][8] Installation instructions
|
||||
|
||||
The [repo][9] currently provides Wike for Fedora 33, 34, and Fedora Rawhide. To install it, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable xfgusta/wike
|
||||
sudo dnf install wike
|
||||
```
|
||||
|
||||
## [][10] DroidCam
|
||||
|
||||
We are living through confusing times, being isolated at our homes, and the majority of our interactions with friends and coworkers take place on some video conference platform. Don’t waste your money on an overpriced webcam if you carry one in your pocket already. [DroidCam][11] lets you pair your phone with a computer and use it as a dedicated webcam. The connection made through a USB cable or over WiFi. DroidCam provides remote control of the camera and allows zooming, using autofocus, toggling the LED light, and other convenient features.
|
||||
|
||||
![][12]
|
||||
|
||||
### [][13] Installation instructions
|
||||
|
||||
The [repo][14] currently provides DroidCam for Fedora 33 and 34. Before installing it, please update your system and reboot, or make sure you are running the latest kernel version and have an appropriate version of _kernel-headers_ installed.
|
||||
|
||||
```
|
||||
sudo dnf update
|
||||
sudo reboot
|
||||
```
|
||||
|
||||
Droidcam depends on _v4l2loopback_ which must be installed manually from the [RPM Fusion Free repository][15].
|
||||
|
||||
```
|
||||
sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
|
||||
sudo dnf install v4l2loopback
|
||||
sudo modprobe v4l2loopback
|
||||
```
|
||||
|
||||
Now install the _droidcam_ package:
|
||||
|
||||
```
|
||||
sudo dnf copr enable meeuw/droidcam
|
||||
sudo dnf install droidcam
|
||||
```
|
||||
|
||||
## [][16] Nyxt
|
||||
|
||||
[Nyxt][17] is a keyboard-oriented, infinitely extensible web browser designed for power users. It was heavily inspired by Emacs and as such is implemented and configured in Common Lisp providing familiar key-bindings ([Emacs][18], [vi][19], [CUA][20]).
|
||||
|
||||
Other killer features that cannot be missed are a built-in REPL, [tree history][21], [buffers instead of tabs][22], and [so much more][17].
|
||||
|
||||
Nyxt is web engine agnostic so don’t worry about pages rendering in unexpected ways.
|
||||
|
||||
![][23]
|
||||
|
||||
### [][24] Installation instructions
|
||||
|
||||
The [repo][25] currently provides Nyxt for Fedora 33, 34, and Fedora Rawhide. To install it, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable teervo/nyxt
|
||||
sudo dnf install nyxt
|
||||
```
|
||||
|
||||
## [][26] Bottom
|
||||
|
||||
[Bottom][27] is a system monitor with a customizable interface and multitude of features, It took inspiration from [gtop][28], [gotop][29], and [htop][30]. As such, it supports [processes][31] monitoring, [CPU][32], [RAM][33], and [network][34] usage monitoring. Besides those, it also provides more exotic widgets such as [disk capacity][35] usage, [temperature sensors][36], and [battery][37] usage.
|
||||
|
||||
Bottom utilizes the screen estate very efficiently thanks to the customizable layout of widgets as well as the [possibility to focus on just one widget and maximizing it][38].
|
||||
|
||||
![][39]
|
||||
|
||||
### [][40] Installation instructions
|
||||
|
||||
The [repo][41] currently provides Bottom for Fedora 33, 34, and Fedora Rawhide. It is also available for EPEL 7 and 8. To install it, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable opuk/bottom
|
||||
sudo dnf install bottom
|
||||
```
|
||||
|
||||
Use _btm_ command to run the program.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-july-2021/
|
||||
|
||||
作者:[Jakub Kadlčík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/frostyx/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2017/08/4-copr-945x400.jpg
|
||||
[2]: https://copr.fedorainfracloud.org/
|
||||
[3]: https://docs.pagure.org/copr.copr/user_documentation.html
|
||||
[4]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-july.md#wike
|
||||
[5]: https://github.com/hugolabe/Wike
|
||||
[6]: https://en.wikipedia.org/wiki/Main_Page
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2021/07/wike.png
|
||||
[8]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-july.md#installation-instructions
|
||||
[9]: https://copr.fedorainfracloud.org/coprs/xfgusta/wike/
|
||||
[10]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-july.md#droidcam
|
||||
[11]: https://www.dev47apps.com/
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2021/07/droidcam.png
|
||||
[13]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-july.md#installation-instructions-1
|
||||
[14]: https://copr.fedorainfracloud.org/coprs/meeuw/droidcam
|
||||
[15]: https://docs.fedoraproject.org/en-US/quick-docs/setup_rpmfusion/#proc_enabling-the-rpmfusion-repositories-using-command-line-utilities_enabling-the-rpmfusion-repositories
|
||||
[16]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-july.md#nyxt
|
||||
[17]: https://nyxt.atlas.engineer/
|
||||
[18]: https://en.wikipedia.org/wiki/Emacs
|
||||
[19]: https://en.wikipedia.org/wiki/Vim_(text_editor)
|
||||
[20]: https://en.wikipedia.org/wiki/IBM_Common_User_Access
|
||||
[21]: https://nyxt.atlas.engineer/#tree
|
||||
[22]: https://nyxt.atlas.engineer/#fuzzy
|
||||
[23]: https://fedoramagazine.org/wp-content/uploads/2021/07/nyxt.png
|
||||
[24]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-july.md#installation-instructions-2
|
||||
[25]: https://copr.fedorainfracloud.org/coprs/teervo/nyxt/
|
||||
[26]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-july.md#bottom
|
||||
[27]: https://github.com/ClementTsang/bottom
|
||||
[28]: https://github.com/aksakalli/gtop
|
||||
[29]: https://github.com/xxxserxxx/gotop
|
||||
[30]: https://github.com/htop-dev/htop/
|
||||
[31]: https://clementtsang.github.io/bottom/nightly/usage/widgets/process/
|
||||
[32]: https://clementtsang.github.io/bottom/nightly/usage/widgets/cpu/
|
||||
[33]: https://clementtsang.github.io/bottom/nightly/usage/widgets/memory/
|
||||
[34]: https://clementtsang.github.io/bottom/nightly/usage/widgets/network/
|
||||
[35]: https://clementtsang.github.io/bottom/nightly/usage/widgets/disk/
|
||||
[36]: https://clementtsang.github.io/bottom/nightly/usage/widgets/temperature/
|
||||
[37]: https://clementtsang.github.io/bottom/nightly/usage/widgets/battery/
|
||||
[38]: https://clementtsang.github.io/bottom/nightly/usage/general-usage/#expansion
|
||||
[39]: https://fedoramagazine.org/wp-content/uploads/2021/07/bottom.png
|
||||
[40]: https://github.com/FrostyX/fedora-magazine/blob/main/2021-july.md#installation-instructions-3
|
||||
[41]: https://copr.fedorainfracloud.org/coprs/opuk/bottom/
|
||||
@ -0,0 +1,247 @@
|
||||
[#]: subject: (Brave vs. Firefox: Your Ultimate Browser Choice for Private Web Experience)
|
||||
[#]: via: (https://itsfoss.com/brave-vs-firefox/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
Brave vs. Firefox: Your Ultimate Browser Choice for Private Web Experience
|
||||
======
|
||||
|
||||
Web browsers have evolved over the years. From downloading files to accessing a full-fledged web application, we have come a long way.
|
||||
|
||||
For a lot of users, the web browser is the only thing they need to get their work done these days.
|
||||
|
||||
Hence, choosing the right browser becomes an important task that could help improve your workflow over the years.
|
||||
|
||||
### Brave vs. Firefox Browser
|
||||
|
||||
Brave and Mozilla’s Firefox are two of the most popular web browsers for privacy-conscious users and open-source enthusiasts.
|
||||
|
||||
Considering that both focus heavily on privacy and security, let us look at what exactly they have to offer, to help you decide what you should go with.
|
||||
|
||||
Here are the comparison pointers that I’ve used, you can directly navigate to any of them:
|
||||
|
||||
* [User Interface][1]
|
||||
* [Performance][2]
|
||||
* [Browser Engine][3]
|
||||
* [Ad & Tracking Blocking Capabilities][4]
|
||||
* [Containers][5]
|
||||
* [Rewards][6]
|
||||
* [Cross-Platform Availability][7]
|
||||
* [Synchronization][8]
|
||||
* [Service Integrations][9]
|
||||
* [Customizability][10]
|
||||
* [Extension Support][11]
|
||||
|
||||
|
||||
|
||||
### User Interface
|
||||
|
||||
The user interface is what makes the biggest difference with the workflow and experience when using the browser.
|
||||
|
||||
Of course, you can have your personal preferences, but the easier, snappier, and cleaner it looks, the better it is.
|
||||
|
||||
![Brave browser][12]
|
||||
|
||||
To start with, Brave shares a similar look and feel to Chrome and Microsoft Edge. It offers a clean experience with minimal UI elements and all the essential options accessible through the browser menu.
|
||||
|
||||
It offers a black theme as well. The subtle animations make the interaction a pleasant experience.
|
||||
|
||||
To customize it, you can choose to use themes available from the chrome web store.
|
||||
|
||||
When it comes to Mozilla Firefox, it has had a couple of major redesigns over the years, and the latest user interface tries to offer a closer experience to Chrome.
|
||||
|
||||
![Firefox browser][13]
|
||||
|
||||
The Firefox design looks impressive and provides a clean user experience. It also lets you opt for a dark theme if needed and there are several theme options to download/apply as well.
|
||||
|
||||
Both web browsers offer a good user experience.
|
||||
|
||||
If you want a familiar experience, but with a pinch of uniqueness, Mozilla’s Firefox can be a good pick.
|
||||
|
||||
But, if you want a snappier experience with a better feel for the animations, Brave gets the edge.
|
||||
|
||||
### Performance
|
||||
|
||||
Practically, I find Brave loading web pages faster. Also, the overall user experience feels snappy.
|
||||
|
||||
Firefox is not terribly slow, but it definitely felt slower than Brave.
|
||||
|
||||
To give you some perspective, I also utilized [Basemark][14] to run a benchmark to see if that is true on paper.
|
||||
|
||||
You can check with other browser benchmark tools available, but Basemark performs a variety of tests, so we’ll go with that for this article.
|
||||
|
||||
![Firefox benchmark score][15]
|
||||
|
||||
![Brave benchmark score][16]
|
||||
|
||||
Firefox managed to score **630** and Brave pulled it off better with ~**792**.
|
||||
|
||||
Do note that these benchmarks were run with default browser settings without any browser extensions installed.
|
||||
|
||||
Of course, synthetic scores may vary depending on what you have going on in the background and the hardware configuration of your system.
|
||||
|
||||
This is what I got with **i5-7400, 16 GB RAM, and GTX 1050ti GPU** on my desktop.
|
||||
|
||||
In general, Brave browser is a fast browser compared to most of the popular options available.
|
||||
|
||||
Both utilize a decent chunk of system resources and that varies to a degree with the number of tabs, types of webpages accessed, and the kind of blocking extension used.
|
||||
|
||||
For instance, Brave blocks aggressively by default but Firefox does not block display advertisements by default. And, this affects the system resource usage.
|
||||
|
||||
### Browser Engine
|
||||
|
||||
Firefox utilizes its own Gecko engine as the foundation and is using components on top of that from [servo research project][17] to improve.
|
||||
|
||||
Currently, it is essentially an improved Gecko engine dubbed by a project name “Quantum” which was introduced with the release of Firefox Quantum.
|
||||
|
||||
On the other hand, Brave uses Chromium’s engine.
|
||||
|
||||
While both are capable enough to handle modern web experiences, Chromium-based engine is just more popular and web developers often tailor their sites for the best experience on Chrome-based browsers
|
||||
|
||||
Also, some services happen to exclusively support Chrome-based browsers.
|
||||
|
||||
### Ad & Tracker Blocking Capabilities
|
||||
|
||||
![][18]
|
||||
|
||||
As I have mentioned before, Brave is aggressive in blocking trackers and advertisements. By default, it comes with the blocking feature enabled.
|
||||
|
||||
Firefox also enables the enhanced privacy protection by default but does not block display advertisements.
|
||||
|
||||
You will have to opt for the “**Strict**” privacy protection mode with Firefox if you want to get rid of display advertisements.
|
||||
|
||||
With that being said, Firefox enforces some unique tracking protection technology that includes Total Cookie Protection which isolates cookies for each site and prevents cross-site cookie tracking.
|
||||
|
||||
![][19]
|
||||
|
||||
This was introduced with [Firefox 86][20] and to use it, you need to enable a strict privacy protection mode.
|
||||
|
||||
Overall, Brave might look like a better option out of the box, and Mozilla Firefox offers better privacy protection features.
|
||||
|
||||
### Containers
|
||||
|
||||
Firefox also offers a way to isolate site activity when you use Facebook with help of a container. In other words, it prevents Facebook from tracking your offsite activity.
|
||||
|
||||
You can also use containers to organize your tabs and separate sessions when needed.
|
||||
|
||||
Brave does not offer anything similar but it does block cross-site trackers and cookies out-of-the-box.
|
||||
|
||||
### Rewards
|
||||
|
||||
![][21]
|
||||
|
||||
Unlike Firefox, Brave offers its own advertising network by blocking other advertisements on the web.
|
||||
|
||||
When you opt in to display privacy-friendly ads by Brave, you get rewarded with tokens to a crypto wallet. And you can use these tokens to give back to your favorite websites.
|
||||
|
||||
While this is a good business strategy to get away from mainstream advertising, for users who do not want any kind of advertisements, it may not be useful.
|
||||
|
||||
So, Brave offers an alternative in the form of rewards to help websites even if you block advertisements. If it is something you appreciate, Brave will be a good pick for you.
|
||||
|
||||
### Cross-Platform Availability
|
||||
|
||||
You will find both Brave and Firefox available for Linux, Windows, and macOS. Mobile apps are also available for iOS and Android.
|
||||
|
||||
For Linux users, Firefox comes baked in with most of the Linux distributions. And, you can also find it available in the software center. In addition to that, there is also a [Flatpak][22] package available.
|
||||
|
||||
Brave is not available through default repositories and the software center. Hence, you need to follow the official instructions to add the private repository and then [get Brave installed in your Linux distro][23].
|
||||
|
||||
### Synchronization
|
||||
|
||||
With Mozilla Firefox, you get to create a Firefox account to sync all your data cross-platform.
|
||||
|
||||
![][24]
|
||||
|
||||
Brave also lets you sync cross-platform but you need access to one of the devices in order to successfully do it.
|
||||
|
||||
![][25]
|
||||
|
||||
Hence, Firefox sync is more convenient.
|
||||
|
||||
Also, you get access to Firefox’s VPN, data breach monitor, email relay, and password manager with the Firefox account.
|
||||
|
||||
### Service Integrations
|
||||
|
||||
Right off the bat, Firefox offers more service integrations that include Pocket, VPN, password manager, and also some of its new offerings like Firefox relay.
|
||||
|
||||
If you want access to these services through your browser, Firefox will be the convenient option for you.
|
||||
|
||||
While Brave does offer crypto wallets, it is not for everyone.
|
||||
|
||||
![][26]
|
||||
|
||||
Similarly, if you like using [Brave Search][27], you may have a seamless experience when using it with Brave browser because of the user experience.
|
||||
|
||||
### Customizability & Security
|
||||
|
||||
Firefox shines when it comes to customizability. You get more options to tweak the experience and also take control of the privacy/security of your browser.
|
||||
|
||||
The ability to customize lets you make Firefox more secure than the Brave browser.
|
||||
|
||||
While hardening Firefox is a separate topic which we’ll talk about. To give you an example, [Tor Browser][28] is just a customized Firefox browser.
|
||||
|
||||
However, that does not make Brave less secure. It is a secure browser overall but you do get more options with Firefox.
|
||||
|
||||
### Extension Support
|
||||
|
||||
There’s no doubt that the Chrome web store offers way more extensions.
|
||||
|
||||
So, Brave gets a clear edge over Firefox if you are someone who utilizes a lot of extensions (or constantly try new ones).
|
||||
|
||||
Firefox may not have the biggest catalog of extensions, it does support most of the extensions. For common use-cases, you will rarely find an extension that is not available as an addon for Firefox.
|
||||
|
||||
### What Should You Choose?
|
||||
|
||||
If you want the best compatibility with the modern web experience and want access to more extensions, Brave browser seems to make more sense.
|
||||
|
||||
On the other hand, Firefox is an excellent choice for everyday browsing with industry-first privacy features, and a convenient sync option for non-tech savvy users.
|
||||
|
||||
You will have a few trade-offs when selecting either of them. So, your will have to prioritize what you want the most.
|
||||
|
||||
Let me know about your final choice for your use case in the comments down below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/brave-vs-firefox/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: tmp.5yJseRG2rb#ui
|
||||
[2]: tmp.5yJseRG2rb#perf
|
||||
[3]: tmp.5yJseRG2rb#engine
|
||||
[4]: tmp.5yJseRG2rb#ad
|
||||
[5]: tmp.5yJseRG2rb#container
|
||||
[6]: tmp.5yJseRG2rb#reward
|
||||
[7]: tmp.5yJseRG2rb#cp
|
||||
[8]: tmp.5yJseRG2rb#sync
|
||||
[9]: tmp.5yJseRG2rb#service
|
||||
[10]: tmp.5yJseRG2rb#customise
|
||||
[11]: tmp.5yJseRG2rb#extensions
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/07/brave-ui-new.jpg?resize=800%2C450&ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/07/firefox-ui.jpg?resize=800%2C450&ssl=1
|
||||
[14]: https://web.basemark.com
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/07/firefox-basemark.png?resize=800%2C598&ssl=1
|
||||
[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/07/basemark-brave.png?resize=800%2C560&ssl=1
|
||||
[17]: https://servo.org
|
||||
[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/07/brave-blocker.png?resize=800%2C556&ssl=1
|
||||
[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/07/firefox-blocker.png?resize=800%2C564&ssl=1
|
||||
[20]: https://news.itsfoss.com/firefox-86-release/
|
||||
[21]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/07/brave-rewards.png?resize=800%2C560&ssl=1
|
||||
[22]: https://itsfoss.com/what-is-flatpak/
|
||||
[23]: https://itsfoss.com/brave-web-browser/
|
||||
[24]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/07/firefox-sync.png?resize=800%2C651&ssl=1
|
||||
[25]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/07/brave-sync.png?resize=800%2C383&ssl=1
|
||||
[26]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/07/brave-crypto-wallet.png?resize=800%2C531&ssl=1
|
||||
[27]: https://itsfoss.com/brave-search-features/
|
||||
[28]: https://itsfoss.com/install-tar-browser-linux/
|
||||
@ -1,210 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (YungeG)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Trace code in Fedora with bpftrace)
|
||||
[#]: via: (https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/)
|
||||
[#]: author: (Augusto Caringi https://fedoramagazine.org/author/acaringi/)
|
||||
|
||||
在 Fedora 中用 bpftrace 追踪代码
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
bpftrace 是一个[基于 eBPF 的新型追踪工具][2],在 Fedora 28 第一次引入。Brendan Gregg,Alastair Robertson 和 Matheus Marchini 在分散于全网络的黑客团队的帮助下开发了 bpftrace,一个允许你分析系统在幕后正在执行的操作的追踪工具,告诉你代码中正在被调用的函数、传递给函数的参数、函数的调用次数等。
|
||||
|
||||
这篇文章的内容涉及了 bpftrace 的一些基础,以及它是如何工作的,请继续阅读获取更多的信息和一些有用的实例。
|
||||
|
||||
### eBPF (extended Berkeley Packet Filter)
|
||||
|
||||
[eBPF][3] 是一个微型虚拟机,更确切的说是一个虚拟 CPU,位于 Linux 内核中。eBPF 可以在内核空间以一种安全可控的方式加载和运行体积较小的程序,保证 eBPF 的使用更加安全,即使在生产环境系统中。eBPF 虚拟机有自己的指令集([ISA][4]),类似于现代处理器架构的一个子集。通过这个 ISA,可以很容易将 eBPF 程序转化为真实硬件上的代码。内核即时将程序转化为主流处理器架构上的本地代码,从而提升性能。
|
||||
|
||||
eBPF 虚拟机允许通过编程扩展内核,目前已经有一些内核子系统使用这一新型强大的 Linux Kernel 功能,比如网络,安全计算、追踪等。这些子系统的主要思想是添加 eBPF 程序到特定的代码点,从而扩展原生的内核行为。
|
||||
|
||||
虽然 eBPF 机器语言功能强大,由于是一种底层语言,直接用于编写代码很费力,bpftrace 就是为了解决这个问题而生的。eBPF 提供了一种高级语言编写 eBPF 追踪脚本,然后在 clang / LLVM 库的帮助下将这些脚本转化为 eBPF,最终添加到特定的代码点。
|
||||
|
||||
## 安装和快速入门
|
||||
|
||||
在终端 [使用][5] _[sudo][5]_ 执行下面的命令安装 bpftrace:
|
||||
|
||||
```
|
||||
$ sudo dnf install bpftrace
|
||||
```
|
||||
|
||||
使用“hello world”进行实验:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 'BEGIN { printf("hello world\n"); }'
|
||||
```
|
||||
|
||||
注意,出于特权级的需要,你必须使用 _root_ 运行 _bpftrace_,使用 _-e_ 选项指明一个程序,构建一个所谓的“单行程序”。这个例子只会打印 _hello world_,接着等待你按下 **Ctrl+C**。
|
||||
|
||||
_BEGIN_ 是一个特殊的探针名,只在执行一开始生效一次;每次探针命中时,大括号 _{}_ 内的操作——这个例子中只是一个 _printf_——都会执行。
|
||||
|
||||
现在让我们转向一个更有用的例子:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_enter_execve { printf("%s called %s\n", comm, str(args->filename)); }'
|
||||
```
|
||||
|
||||
这个例子打印系统中正在创建的每个新进程的父进程名 _(comm)_。_t:syscalls:sys_enter_execve_ 是一个内核追踪点,是 _tracepoint:syscalls:sys_enter_execve_ 的简写,两种形式都可以使用。下一部分会向你展示如何列出所有可用的追踪点。
|
||||
|
||||
_comm_ 是一个 bpftrace 内建指令,代表进程名;_filename_ 是 _t:syscalls:sys_enter_execve_ 追踪点的一个域,这些域可以通过 _args_ 内建指令访问。
|
||||
|
||||
追踪点的所有可用域可以通过这个命令列出:
|
||||
|
||||
```
|
||||
bpftrace -lv "t:syscalls:sys_enter_execve"
|
||||
```
|
||||
|
||||
## 示例用法
|
||||
|
||||
### 列出探针
|
||||
|
||||
_bpftrace_ 的一个核心概念是 **探针点**,即 eBPF 程序可以连接到的(内核或用户空间)代码中的测量点,可以分成以下几大类:
|
||||
|
||||
* _kprobe_——内核函数的开始处
|
||||
* _uprobe_——内核函数的返回处
|
||||
* _uprobe_——用户级函数的开始处
|
||||
* _uretprobe_——用户级函数的返回处
|
||||
* _tracepoint_——内核静态追踪点
|
||||
* _usdt_——用户级静态追踪点
|
||||
* _profile_——基于时间的采样
|
||||
* _interval_——基于时间的输出
|
||||
* _software_——内核软件事件
|
||||
* _hardware_——用户级事件
|
||||
|
||||
所有可用的 _kprobe / kretprobe_、_tracepoints_、_software_ 和 _hardware_ 探针可以通过这个命令列出:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -l
|
||||
```
|
||||
|
||||
_uprobe / uretprobe_ 和 _usdt_ 是用户空间探针,专用于某个可执行文件。要使用这些探针,通过下文中的特殊语法。
|
||||
|
||||
_profile_ 和 _interval_ 探针以固定的时间间隔触发;固定的时间间隔不在本文的范畴内。
|
||||
|
||||
|
||||
### 统计系统调用数
|
||||
|
||||
### Counting system calls
|
||||
|
||||
**Maps** 是保存计数、统计数据和柱状图的特殊 BPF 数据类型,你可以使用映射统计每个系统调用正在被调用的次数:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_enter_* { @[probe] = count(); }'
|
||||
```
|
||||
|
||||
一些探针类型允许使用通配符匹配多个探针,你也可以使用一个逗号隔开的列表为一个操作块指明多个连接点。上面的例子中,操作块连接到了所有名称以 _t:syscalls:sysenter__ 开头的追踪点,即所有可用的系统调用。
|
||||
|
||||
bpftrace 的内建函数 _count()_ 统计系统调用被调用的次数;_@[]_ 代表一个映射(一个关联的数组)。映射的键是另一个内建指令 _probe_,代表完整的探针名。
|
||||
|
||||
这个例子中,相同的操作块连接到了每个系统调用,之后每次有系统调用被调用时,映射就会被更新,映射中和系统调用对应的项就会增加。程序终止时,自动打印出所有声明的映射。
|
||||
|
||||
下面的例子统计所有的系统调用,然后通过 bpftrace 过滤语法使用 _PID_ 过滤出某个特定进程调用的系统调用:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_enter_* / pid == 1234 / { @[probe] = count(); }'
|
||||
```
|
||||
|
||||
### 进程写的字节数
|
||||
|
||||
让我们使用上面的概念分析每个进程正在写的字节数:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_exit_write /args->ret > 0/ { @[comm] = sum(args->ret); }'
|
||||
```
|
||||
|
||||
_bpftrace_ 连接操作块到写系统调用的返回探针(_t:syscalls:sys_exit_write_),然后使用过滤器丢掉代表错误代码的负值(_/arg->ret > 0/_)。
|
||||
|
||||
映射的键 _comm_ 代表调用系统调用的进程名;内建函数 _sum()_ 累计每个映射项或进程写的字节数;_args_ 是一个 `bpftrace` 内建指令,用于访问追踪点的参数和返回值。如果执行成功,_write_ 系统调用返回写的字节数,_arg->ret_ 用于访问这个字节数。
|
||||
|
||||
### 进程的读取大小分布(柱状图):
|
||||
|
||||
_bpftrace_ 支持创建柱状图。让我们分析一个创建进程的 _read_ 大小分布的柱状图的例子:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 't:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
|
||||
```
|
||||
|
||||
柱状图是 BPF 映射,因此必须保存为一个映射(_@_),这个例子中映射键是 _comm_。
|
||||
|
||||
这个例子使 _bpftrace_ 给每个调用 _read_ 系统调用的进程生成一个柱状图。要生成一个全局柱状图,直接保存 _hist()_ 函数到 _'@'_(不使用任何键)。
|
||||
|
||||
程序终止时,bpftrace 自动打印出声明的柱状图。创建柱状图的基准值是通过 _args->ret_ 获取到的读取的字节数。
|
||||
|
||||
### 追踪用户空间程序
|
||||
|
||||
你也可以通过 _uprobes / uretprobes_ 和 _USDT_(用户级静态定义的追踪)追踪用户空间程序。下一个例子使用探测用户级函数结尾处的 _uretprobe_ ,获取系统中运行的每个 _bash_ 发出的命令行:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -e 'uretprobe:/bin/bash:readline { printf("readline: \"%s\"\n", str(retval)); }'
|
||||
```
|
||||
|
||||
要列出可执行文件 _bash_ 的所有可用 _uprobes / uretprobes_, 执行这个命令:
|
||||
|
||||
```
|
||||
$ sudo bpftrace -l "uprobe:/bin/bash"
|
||||
```
|
||||
|
||||
_uprobe_ 指向用户级函数执行的开始,_uretprobe_ 指向执行的结束(返回处);_readline()_ 是 _/bin/bash_ 的一个函数,返回键入的命令行;_retval_ 是被探测的指令的返回值,只能在 _uretprobe_ 访问。
|
||||
|
||||
使用 _uprobes_ 时,你可以用 _arg0..argN_ 访问参数。需要调用 _str()_ 将 _char *_ 指针转化成一个 _string_。
|
||||
|
||||
## 自带脚本
|
||||
|
||||
bpftrace 软件包附带了许多有用的脚本,可以在 _/usr/share/bpftrace/tools/_ 目录找到。
|
||||
|
||||
这些脚本中,你可以找到:
|
||||
|
||||
* _killsnoop.bt_——追踪 `kill()` 系统调用发出的信号
|
||||
* _tcpconnect.bt_——追踪所有的 TCP 网络连接
|
||||
* _pidpersec.bt_——统计每秒钟(通过 fork)创建的新进程
|
||||
* _opensnoop.bt_——追踪 `open()` 系统调用
|
||||
* _bfsstat.bt_——追踪一些 VFS 调用,按秒统计
|
||||
|
||||
你可以直接使用这些脚本,比如:
|
||||
|
||||
```
|
||||
$ sudo /usr/share/bpftrace/tools/killsnoop.bt
|
||||
```
|
||||
|
||||
你也可以在创建新的工具时参考这些脚本。
|
||||
|
||||
## 链接
|
||||
|
||||
* bpftrace 参考指南——<https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md>
|
||||
* Linux 2018 `bpftrace`(DTrace 2.0)——<http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html>
|
||||
* BPF:通用的内核虚拟机——<https://lwn.net/Articles/599755/>
|
||||
* Linux Extended BPF(eBPF)Tracing Tools——<http://www.brendangregg.com/ebpf.html>
|
||||
* 深入 BPF:一个阅读材料列表—— [https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf][6]
|
||||
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by _[_Roman Romashov_][7]_ on _[_Unsplash_][8]_._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/
|
||||
|
||||
作者:[Augusto Caringi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[YungeG](https://github.com/YungeG)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/acaringi/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/bpftrace-816x345.jpg
|
||||
[2]: https://github.com/iovisor/bpftrace
|
||||
[3]: https://lwn.net/Articles/740157/
|
||||
[4]: https://github.com/iovisor/bpf-docs/blob/master/eBPF.md
|
||||
[5]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[6]: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
|
||||
[7]: https://unsplash.com/@wehavemegapixels?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[8]: https://unsplash.com/search/photos/trace?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,296 @@
|
||||
[#]: subject: "Pen testing with Linux security tools"
|
||||
[#]: via: "https://opensource.com/article/21/5/linux-security-tools"
|
||||
[#]: author: "Peter Gervase https://opensource.com/users/pgervase"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "MjSeven"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
使用 Linux 安全工具进行渗透测试
|
||||
======
|
||||
使用 Kali Linux 和其他开源工具来发现系统中的安全漏洞和弱点。
|
||||
![Magnifying glass on code][1]
|
||||
|
||||
大量广泛报道的大型消费企业入侵事件凸显了系统安全管理的重要性。幸运的是,有许多不同的应用程序可以帮助保护计算机系统。其中一个是 [Kali][2],一个为安全和渗透测试而开发的 Linux 发行版。本文演示了如何使用 Kali Linux 来审视你的系统以发现威胁。
|
||||
|
||||
Kali 安装了很多工具,它们都是开源的,默认情况下安装它们会让事情变得更容易。
|
||||
|
||||
![Kali's tools][3]
|
||||
|
||||
(Peter Gervase, [CC BY-SA 4.0][4])
|
||||
|
||||
本文使用的系统是:
|
||||
|
||||
1. `kali.usersts.redhat.com`:我会启动扫描和攻击的系统。它拥有 30GB 内存和 6 个虚拟 CPU(vCPU)。
|
||||
2. `vulnerable.usersys.redhat.com`: Red Hat 企业版 Linux 8 系统,它也会成为目标。它拥有 16GB 内存和 6 个 vCPU。它是一个相对较新的系统,但有些软件包可能已经过时。
|
||||
3. 这个系统还将包括 `httpd-2.4.37-30.module+el8.3.0+7001+0766b9e7.x86_64`、 `mariadb-server-10.3.27-3.module+el8.3.0+8972+5e3224e9.x86_64`、 `tigervnc-server-1.9.0-15.el8_1.x86_64`、 `vsftpd-3.0.3-32.el8.x86_64` 和一个 5.6.1 版本的 WordPress。
|
||||
|
||||
我在上面列出了硬件规格,因为一些任务要求很高,尤其是在运行 WordPress 安全扫描程序([WPScan][5])时对目标系统 CPU 的要求。
|
||||
|
||||
### 探测你的系统
|
||||
|
||||
首先,我会在目标系统上进行基本的 Nmap 扫描(你可以阅读[使用 Nmap 结果帮助加固 Linux 系统][6]一文来更深入地了解 Nmap)。Nmap 扫描是一种快速的方法,可以大致了解被测系统中哪些端口和服务是暴露的。
|
||||
|
||||
![Nmap scan][7]
|
||||
|
||||
(Peter Gervase, [CC BY-SA 4.0][4])
|
||||
|
||||
默认扫描显示有几个你可能感兴趣的开放端口。实际上,任何开放端口都可能成为攻击者破坏你网络的一种方式。在本例中,端口 21、22、80 和 443 很容易扫描,因为它们是常用服务的端口。在这个早期阶段,我只是在做侦察工作,尽可能多地获取有关目标系统的信息。
|
||||
|
||||
我想用 Nmap 侦察 80 端口,所以我使用 `-p 80` 参数来查看端口 80,`-A` 参数来获取操作系统和应用程序版本等信息。
|
||||
|
||||
![Nmap scan of port 80][8]
|
||||
|
||||
(Peter Gervase, [CC BY-SA 4.0][4])
|
||||
|
||||
关键信息有:
|
||||
|
||||
|
||||
```bash
|
||||
PORT STATE SERVICE VERSION
|
||||
80/tcp open http Apache httpd 2.4.37 ((Red Hat Enterprise Linux))
|
||||
|_http-generator: WordPress 5.6.1
|
||||
```
|
||||
|
||||
现在我知道了这是一个 WordPress 服务器,我可以使用 WPScan 来获取有关潜在威胁的信息。一个很好的侦察方法是尝试找到一些用户名,使用 `--enumerate u` 告诉 WPScan 在 WordPress 实例中查找用户名。例如:
|
||||
|
||||
|
||||
```bash
|
||||
┌──(root💀kali)-[~]
|
||||
└─# wpscan --url vulnerable.usersys.redhat.com --enumerate u
|
||||
_______________________________________________________________
|
||||
__ _______ _____
|
||||
\ \ / / __ \ / ____|
|
||||
\ \ /\ / /| |__) | (___ ___ __ _ _ __ ®
|
||||
\ \/ \/ / | ___/ \\___ \ / __|/ _` | '_ \
|
||||
\ /\ / | | ____) | (__| (_| | | | |
|
||||
\/ \/ |_| |_____/ \\___|\\__,_|_| |_|
|
||||
|
||||
WordPress Security Scanner by the WPScan Team
|
||||
Version 3.8.10
|
||||
Sponsored by Automattic - <https://automattic.com/>
|
||||
@_WPScan_, @ethicalhack3r, @erwan_lr, @firefart
|
||||
_______________________________________________________________
|
||||
|
||||
[+] URL: <http://vulnerable.usersys.redhat.com/> [10.19.47.242]
|
||||
[+] Started: Tue Feb 16 21:38:49 2021
|
||||
|
||||
Interesting Finding(s):
|
||||
...
|
||||
[i] User(s) Identified:
|
||||
|
||||
[+] admin
|
||||
| Found By: Author Posts - Display Name (Passive Detection)
|
||||
| Confirmed By:
|
||||
| Author Id Brute Forcing - Author Pattern (Aggressive Detection)
|
||||
| Login Error Messages (Aggressive Detection)
|
||||
|
||||
[+] pgervase
|
||||
| Found By: Author Posts - Display Name (Passive Detection)
|
||||
| Confirmed By:
|
||||
| Author Id Brute Forcing - Author Pattern (Aggressive Detection)
|
||||
| Login Error Messages (Aggressive Detection)
|
||||
```
|
||||
|
||||
显示有两个用户:`admin` 和 `pgervase`。我将尝试使用密码字典来猜测 `admin` 的密码。密码字典是一个包含很多密码的文本文件。我使用的字典大小有 37G,有 3,543,076,137 行。
|
||||
|
||||
就像你可以选择不同的文本编辑器、Web 浏览器和其他应用程序 一样,也有很多工具可以启动密码攻击。下面是两个使用 Nmap 和 WPScan 的示例命令:
|
||||
|
||||
|
||||
```shell
|
||||
# nmap -sV --script http-wordpress-brute --script-args userdb=users.txt,passdb=/path/to/passworddb,threads=6 vulnerable.usersys.redhat.com
|
||||
```
|
||||
|
||||
```bash
|
||||
# wpscan --url vulnerable.usersys.redhat.com --passwords /path/to/passworddb --usernames admin --max-threads 50 | tee nmap.txt
|
||||
```
|
||||
|
||||
这个 Nmap 脚本是我使用的许多脚本之一,使用 WPScan 扫描 URL 只是这个工具可以完成的许多任务之一。你可以决定你喜欢的那一个。
|
||||
|
||||
WPScan 示例在文件末尾显示了密码:
|
||||
|
||||
|
||||
```bash
|
||||
┌──(root💀kali)-[~]
|
||||
└─# wpscan --url vulnerable.usersys.redhat.com --passwords passwords.txt --usernames admin
|
||||
_______________________________________________________________
|
||||
__ _______ _____
|
||||
\ \ / / __ \ / ____|
|
||||
\ \ /\ / /| |__) | (___ ___ __ _ _ __ ®
|
||||
\ \/ \/ / | ___/ \___ \ / __|/ _` | '_ \
|
||||
\ /\ / | | ____) | (__| (_| | | | |
|
||||
\/ \/ |_| |_____/ \___|\__,_|_| |_|
|
||||
|
||||
WordPress Security Scanner by the WPScan Team
|
||||
Version 3.8.10
|
||||
Sponsored by Automattic - https://automattic.com/
|
||||
@_WPScan_, @ethicalhack3r, @erwan_lr, @firefart
|
||||
_______________________________________________________________
|
||||
|
||||
[+] URL: http://vulnerable.usersys.redhat.com/ [10.19.47.242]
|
||||
[+] Started: Thu Feb 18 20:32:13 2021
|
||||
|
||||
Interesting Finding(s):
|
||||
|
||||
…..
|
||||
|
||||
[+] Performing password attack on Wp Login against 1 user/s
|
||||
Trying admin / redhat Time: 00:01:57 <==================================================================================================================> (3231 / 3231) 100.00% Time: 00:01:57
|
||||
Trying admin / redhat Time: 00:01:57 <========================================================= > (3231 / 6462) 50.00% ETA: ??:??:??
|
||||
[SUCCESS] - admin / redhat
|
||||
|
||||
[!] Valid Combinations Found:
|
||||
| Username: admin, Password: redhat
|
||||
|
||||
[!] No WPVulnDB API Token given, as a result vulnerability data has not been output.
|
||||
[!] You can get a free API token with 50 daily requests by registering at https://wpscan.com/register
|
||||
|
||||
[+] Finished: Thu Feb 18 20:34:15 2021
|
||||
[+] Requests Done: 3255
|
||||
[+] Cached Requests: 34
|
||||
[+] Data Sent: 1.066 MB
|
||||
[+] Data Received: 24.513 MB
|
||||
[+] Memory used: 264.023 MB
|
||||
[+] Elapsed time: 00:02:02
|
||||
```
|
||||
|
||||
在末尾的有效组合部分包含管理员用户名和密码,3231 行只用了两分钟。
|
||||
|
||||
我还有另一个字典文件,其中包含 3,238,659,984 行,使用它花费的时间更长并且会留下更多的证据。
|
||||
|
||||
使用 Nmap 可以更快地产生结果:
|
||||
|
||||
|
||||
```
|
||||
┌──(root💀kali)-[~]
|
||||
└─# nmap -sV --script http-wordpress-brute --script-args userdb=users.txt,passdb=password.txt,threads=6 vulnerable.usersys.redhat.com
|
||||
Starting Nmap 7.91 ( https://nmap.org ) at 2021-02-18 20:48 EST
|
||||
Nmap scan report for vulnerable.usersys.redhat.com (10.19.47.242)
|
||||
Host is up (0.00015s latency).
|
||||
Not shown: 995 closed ports
|
||||
PORT STATE SERVICE VERSION
|
||||
21/tcp open ftp vsftpd 3.0.3
|
||||
22/tcp open ssh OpenSSH 8.0 (protocol 2.0)
|
||||
80/tcp open http Apache httpd 2.4.37 ((Red Hat Enterprise Linux))
|
||||
|_http-server-header: Apache/2.4.37 (Red Hat Enterprise Linux)
|
||||
| http-wordpress-brute:
|
||||
| Accounts:
|
||||
| admin:redhat - Valid credentials <<<<<<<
|
||||
| pgervase:redhat - Valid credentials <<<<<<<
|
||||
|_ Statistics: Performed 6 guesses in 1 seconds, average tps: 6.0
|
||||
111/tcp open rpcbind 2-4 (RPC #100000)
|
||||
| rpcinfo:
|
||||
| program version port/proto service
|
||||
| 100000 2,3,4 111/tcp rpcbind
|
||||
| 100000 2,3,4 111/udp rpcbind
|
||||
| 100000 3,4 111/tcp6 rpcbind
|
||||
|_ 100000 3,4 111/udp6 rpcbind
|
||||
3306/tcp open mysql MySQL 5.5.5-10.3.27-MariaDB
|
||||
MAC Address: 52:54:00:8C:A1:C0 (QEMU virtual NIC)
|
||||
Service Info: OS: Unix
|
||||
|
||||
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
|
||||
Nmap done: 1 IP address (1 host up) scanned in 7.68 seconds
|
||||
```
|
||||
|
||||
然而,运行这样的扫描可能会在目标系统上留下大量的 HTTPD 日志消息:
|
||||
|
||||
|
||||
```shell
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:01 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "<http://vulnerable.usersys.redhat.com/>" "WPScan v3.8.10 (<https://wpscan.org/>)"
|
||||
```
|
||||
|
||||
为了获得关于在最初的 Nmap 扫描中发现的 HTTPS 服务器的信息,我使用了 `sslscan` 命令:
|
||||
|
||||
|
||||
```bash
|
||||
┌──(root💀kali)-[~]
|
||||
└─# sslscan vulnerable.usersys.redhat.com
|
||||
Version: 2.0.6-static
|
||||
OpenSSL 1.1.1i-dev xx XXX xxxx
|
||||
|
||||
Connected to 10.19.47.242
|
||||
|
||||
Testing SSL server vulnerable.usersys.redhat.com on port 443 using SNI name vulnerable.usersys.redhat.com
|
||||
|
||||
SSL/TLS Protocols:
|
||||
SSLv2 disabled
|
||||
SSLv3 disabled
|
||||
TLSv1.0 disabled
|
||||
TLSv1.1 disabled
|
||||
TLSv1.2 enabled
|
||||
TLSv1.3 enabled
|
||||
<snip>
|
||||
```
|
||||
|
||||
它显示了有关启用的 SSL 协议的信息,在最下方,是关于 Heartbleed 漏洞的信息:
|
||||
|
||||
|
||||
```bash
|
||||
Heartbleed:
|
||||
TLSv1.3 not vulnerable to heartbleed
|
||||
TLSv1.2 not vulnerable to heartbleed
|
||||
```
|
||||
|
||||
### 防御或减轻攻击的技巧
|
||||
|
||||
有很多方法可以保护你的系统免受大量攻击。几个关键点是:
|
||||
|
||||
* **了解你的系统:**包括了解哪些端口是开放的,哪些端口应该开放,谁应该能够看到这些开放的端口,以及使用这些端口服务的预期流量是多少。Nmap 是了解网络系统的一个绝佳工具。
|
||||
* **使用最新的最佳实践:** 现在的最佳实践可能不是未来的最佳实践。作为管理员,了解信息安全领域的最新趋势非常重要。
|
||||
* **知道如何使用你的产品:** 例如,与其让攻击者不断攻击你的 WordPress 系统,不如阻止他们的 IP 地址并限制尝试登录的次数。在现实世界中,阻止 IP 地址可能没有那么有用,因为攻击者可能会使用受感染的系统来发起攻击。但是,这是一个很容易启用的设置,可以阻止一些攻击。
|
||||
* **维护和验证良好的备份:** 如果攻击者攻击了一个或多个系统,能从已知的良好和干净的备份中重新构建可以节省大量时间和金钱。
|
||||
* **检查日志:** 如上所示,扫描和渗透命令可能会留下大量日志,这表明攻击者正在攻击系统。如果你注意到它们,可以采取先发制人的行动来降低风险。
|
||||
* **更新系统、应用程序和任何额外的模块:** 正如 [NIST Special Publication 800-40r3][9] 所解释的那样,“补丁通常是减轻软件缺陷漏洞最有效的方法,而且通常是唯一完全有效的解决方案。”
|
||||
* **使用供应商提供的工具:** 供应商有不同的工具来帮助你维护他们的系统,因此一定要充分利用它们。例如,红帽企业 Linux 订阅中包含的 [Red Hat Insights][10] 可以帮助你优化系统并提醒你注意潜在的安全威胁。
|
||||
|
||||
|
||||
|
||||
### 了解更多
|
||||
|
||||
本文对安全工具及其使用方法的介绍只是冰山一角。深入了解的话,你可能需要查看以下资源:
|
||||
|
||||
* [Armitage][11],一个开源的攻击管理工具
|
||||
* [Red Hat 产品安全中心][12]
|
||||
* [Red Hat 安全频道][13]
|
||||
* [NIST 网络安全页面][14]
|
||||
* [使用 Nmap 结果来帮助加固 Linux 系统][6]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/5/linux-security-tools
|
||||
|
||||
作者:[Peter Gervase][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pgervase
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 "Magnifying glass on code"
|
||||
[2]: https://www.kali.org/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/kali-tools.png "Kali's tools"
|
||||
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[5]: https://wpscan.com/wordpress-security-scanner
|
||||
[6]: https://www.redhat.com/sysadmin/using-nmap-harden-systems
|
||||
[7]: https://opensource.com/sites/default/files/uploads/nmap-scan.png "Nmap scan"
|
||||
[8]: https://opensource.com/sites/default/files/uploads/nmap-port80.png "Nmap scan of port 80"
|
||||
[9]: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-40r3.pdf%5D(https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-40r3.pdf
|
||||
[10]: https://www.redhat.com/sysadmin/how-red-hat-insights
|
||||
[11]: https://en.wikipedia.org/wiki/Armitage_(computing)
|
||||
[12]: https://access.redhat.com/security
|
||||
[13]: https://www.redhat.com/en/blog/channel/security
|
||||
[14]: https://www.nist.gov/cybersecurity
|
||||
@ -1,243 +0,0 @@
|
||||
[#]: subject: "Use XMLStarlet to parse XML in your the Linux terminal"
|
||||
[#]: via: "https://opensource.com/article/21/7/parse-xml-linux"
|
||||
[#]: author: "Seth Kenlon https://opensource.com/users/seth"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "zepoch"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
在你的 Linux 终端中使用 XMLStarlet 来解析 XML
|
||||
======
|
||||
|
||||
借助 XMLStarlet,一个终端上的 XML 工具包,你就是 XML 之星。
|
||||
![Penguin with green background][1]
|
||||
|
||||
学习解析 XML 通常被认为是一件复杂的事情,但其实大可不必。[XML 是高度严格结构化的][2],所以也是相对来说可预测的。也有许多其他工具可以帮助你管理工作。
|
||||
|
||||
我最喜欢的 XML 实用程序之一是 [XMLStarlet][3], 用于终端的 XML 工具包,借助 XML 工具包,你可以验证、解析、编辑、格式化和转换 XML 数据。XMLStarLet 是个相对最小的命令,但指导 XML 却充满潜力,因此本文演示了如何使用它来查询 XML 数据。
|
||||
|
||||
### 安装
|
||||
|
||||
XMLStarLet 默认安装在 CentOS,Fedora,和许多其他现代 Linux 发行版上,所以你可以打开终端,输入 `xmlstarlet` 来访问它。如果 XMLStarLet 还没有被安装,你的操作系统则会为你安装它。
|
||||
|
||||
或者,你可以用包管理器安装 `xmlstarlet`:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf install xmlstarlet`
|
||||
```
|
||||
|
||||
在 macOS 上,使用 [MacPorts][4] 或 [Homebrew][5]。在 Windows 上,使用 [Chocolatey][6]。
|
||||
|
||||
如果都失败了,您可以从 [Sourceforge 上的源代码][7]手动安装它。
|
||||
|
||||
### 用 XMLStarlet 解析 XML
|
||||
|
||||
有许多工具可以帮助解析和转换XML数据,包括允许您[编写自己的解析器][8]和复杂命令的软件库,如 `fop` 和 `xsltproc`。尽管有时您不需要处理XML数据;您可以很方便的从 XML 数据中来提取、更新或验证重要数据。对于自发的XML交互,我使用 `xmlstarlet`,这是常见的处理 XML任务的一个典型的“瑞士军刀”式应用。通过运行 `--help` 命令,您可以看到它提供哪些选项:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet --help
|
||||
Usage: xmlstarlet [<options>] <command> [<cmd-options>]
|
||||
where <command> is one of:
|
||||
ed (or edit) - Edit/Update XML document(s)
|
||||
sel (or select) - Select data or query XML document(s) (XPATH, etc)
|
||||
tr (or transform) - Transform XML document(s) using XSLT
|
||||
val (or validate) - Validate XML document(s) (well-formed/DTD/XSD/RelaxNG)
|
||||
fo (or format) - Format XML document(s)
|
||||
el (or elements) - Display element structure of XML document
|
||||
c14n (or canonic) - XML canonicalization
|
||||
ls (or list) - List directory as XML
|
||||
[...]
|
||||
```
|
||||
|
||||
您可以通过在这些子命令的末尾附加 `-help` 来获得进一步的帮助:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet sel --help
|
||||
-Q or --quiet - do not write anything to standard output.
|
||||
-C or --comp - display generated XSLT
|
||||
-R or --root - print root element <xsl-select>
|
||||
-T or --text - output is text (default is XML)
|
||||
-I or --indent - indent output
|
||||
[...]
|
||||
```
|
||||
|
||||
#### 用 sel 命令选择数据
|
||||
|
||||
可以使用 `xmlstarlet select`(简称 `sel`)命令查看XML格式的数据。下面是一个简单的XML文档:
|
||||
|
||||
|
||||
```
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
|
||||
<xml>
|
||||
<os>
|
||||
<linux>
|
||||
<distribution>
|
||||
<name>Fedora</name>
|
||||
<release>7</release>
|
||||
<codename>Moonshine</codename>
|
||||
<spins>
|
||||
<name>Live</name>
|
||||
<name>Fedora</name>
|
||||
<name>Everything</name>
|
||||
</spins>
|
||||
</distribution>
|
||||
|
||||
<distribution>
|
||||
<name>Fedora Core</name>
|
||||
<release>6</release>
|
||||
<codename>Zod</codename>
|
||||
<spins></spins>
|
||||
</distribution>
|
||||
</linux>
|
||||
</os>
|
||||
</xml>
|
||||
```
|
||||
|
||||
在 XML 文件中查找数据时,您的第一个任务是关注要探索的节点。如果知道节点的路径,请使用 `-value of` 选项指定完整路径。您越早浏览 [Document Object Model][9](DOM)树,就可以看到更多信息:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
\--value-of /xml/os/linux/distribution \
|
||||
\--nl myfile.xml
|
||||
Fedora
|
||||
7
|
||||
Moonshine
|
||||
|
||||
Live
|
||||
Fedora
|
||||
Everything
|
||||
|
||||
Fedora Core
|
||||
6
|
||||
Zod
|
||||
```
|
||||
|
||||
`--nl` 代表“新的一行”,它插入大量的空白,以确保在输入结果后,终端在新的一行显示。我已经删除了样本输出中的一些多余空间。
|
||||
|
||||
通过进一步深入 DOM 树来凝聚焦点:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
\--value-of /xml/os/linux/distribution/name \
|
||||
\--nl myfile.xml
|
||||
Fedora
|
||||
Fedora Core
|
||||
```
|
||||
|
||||
#### 条件选择
|
||||
|
||||
用于导航和解析 XML 的最强大工具之一被称为 XPath。它控制 XML 搜索中使用的语法,并从 XML 库调用函数。XMLStarlet 能够解析 XPath 表达式,因此可以使用 XPath 函数来有条件的进行选择。XPath 具有丰富的函数,[由 W3C 详细记录][10],但我觉得 [Mozilla 的 XPath 文档][11]更简洁。
|
||||
|
||||
可以使用方括号作为测试函数,将元素的内容与某个值进行比较。下面是对 `<name>` 元素的值的测试,它仅返回与特定匹配相关联的版本号。
|
||||
|
||||
想象一下,示例 XML 文件包含以 1 开头的所有 Fedora 版本。要查看与旧名称 “Fedora Core” 关联的所有版本号(项目从版本 7 开始名称中的 “Core” 被删除掉了),请执行以下操作:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet sel --template \
|
||||
\--value-of '/xml/os/linux/distribution[name = "Fedora Core"]/release' \
|
||||
\--nl myfile.xml
|
||||
6
|
||||
5
|
||||
4
|
||||
3
|
||||
2
|
||||
1
|
||||
```
|
||||
|
||||
通过将 `--path 的值`更改为 `/xml/os/linux/distribution[name=“Fedora Core”]/codename`,您便可以查看这些版本的所有代号。
|
||||
|
||||
### 匹配路径和获取目标值
|
||||
|
||||
将 XML 标记视为节点的一个优点是,一旦找到节点,就可以将其视为当前的数据“目录”。它不是一个真正的目录,至少不是文件系统意义上的目录,但它是一个可以查询的数据集合。为了帮助您将目标和“其他”的数据分开,XMLStarlet 把您试图用 `--match` 选项匹配的内容和用 `--value` 选项匹配的数据值进行了区分。
|
||||
|
||||
假设你知道 `<spin>` 节点包含几个元素。这就是你的目的节点了。一旦到了这一步,就可以使用 `-value of` 指定要为哪个元素赋值。要查看所有元素,可以使用点(`.`)展示当前位置的所有元素:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet sel --template \
|
||||
\--match '/xml/os/linux/distribution/spin' \
|
||||
\--value-of '.' --nl myfile.xml \
|
||||
Live
|
||||
Fedora
|
||||
Everything
|
||||
```
|
||||
|
||||
与导航 DOM 一样,可以使用 XPath 表达式来限制返回数据的范围。在本例中,我使用 `last()` 函数来检索 `spin` 节点中的最后一个元素:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
\--match '/xml/os/linux/distribution/spin' \
|
||||
\--value-of '*[last()]' --nl myfile.xml
|
||||
Everything
|
||||
```
|
||||
|
||||
在本例中,我使用 `position()` 函数选择 `spin` 节点中的特定元素:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
\--match '/xml/os/linux/distribution/spin' \
|
||||
\--value-of '*[position() = 2]' --nl myfile.xml
|
||||
Fedora
|
||||
```
|
||||
|
||||
The `--match` and `--value-of` options can overlap, so it's up to you how you want to use them together. These two expressions, in the case of the sample XML, do the same thing:
|
||||
|
||||
`--match` 和 `--value` 选项可以重叠,因此如何将它们一起使用取决于您自己。对于示例 XML,这两个表达式执行的是相同的操作:
|
||||
|
||||
|
||||
```
|
||||
$ xmlstarlet select --template \
|
||||
\--match '/xml/os/linux/distribution/spin' \
|
||||
\--value-of '.' \
|
||||
\--nl myfile.xml
|
||||
Live
|
||||
Fedora
|
||||
Everything
|
||||
|
||||
$ xmlstarlet select --template \
|
||||
\--match '/xml/os/linux/distribution' \
|
||||
\--value-of 'spin' \
|
||||
\--nl myfile.xml
|
||||
Live
|
||||
Fedora
|
||||
Everything
|
||||
```
|
||||
|
||||
### 熟悉XML
|
||||
|
||||
XML 有时看起来过于冗长和笨拙,但为与之交互和构建的工具却总是让我吃惊。如果您想要好好使用 XML,那么XMLStarlet 可能是一个很好的切入点。下次要打开 XML 文件查看结构化数据时,请尝试使用 XMLStarlet,看看是否可以改为查询该数据。当 XML 越适合你时,它就越能作为一种健壮灵活的数据格式而存在。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/parse-xml-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zepoch](https://github.com/zepoch)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 "Penguin with green background"
|
||||
[2]: https://opensource.com/article/21/6/what-xml
|
||||
[3]: https://en.wikipedia.org/wiki/XMLStarlet
|
||||
[4]: https://opensource.com/article/20/11/macports
|
||||
[5]: https://opensource.com/article/20/6/homebrew-mac
|
||||
[6]: https://opensource.com/article/20/3/chocolatey
|
||||
[7]: http://xmlstar.sourceforge.net
|
||||
[8]: https://opensource.com/article/21/6/parsing-config-files-java
|
||||
[9]: https://opensource.com/article/21/6/what-xml#dom
|
||||
[10]: https://www.w3.org/TR/1999/REC-xpath-19991116
|
||||
[11]: https://developer.mozilla.org/en-US/docs/Web/XPath/Functions
|
||||
|
||||
108
translated/tech/20210726 How to use cron on Linux.md
Normal file
108
translated/tech/20210726 How to use cron on Linux.md
Normal file
@ -0,0 +1,108 @@
|
||||
[#]: subject: (How to use cron on Linux)
|
||||
[#]: via: (https://opensource.com/article/21/7/cron-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (perfiffer)
|
||||
[#]: reviewer: (turbokernel)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
如何在 Linux 上使用 cron 定时器
|
||||
======
|
||||
cron 定时器是一个可以按照计划自动运行命令的工具。
|
||||
![Cron 表达式][1]
|
||||
|
||||
cron 定时器是一个可以按照计划自动运行命令的工具。定时器作业称为 cronjob,创建于 crontab 文件中。这是用户自动操作电脑的最简单也是最古老的方法。
|
||||
|
||||
### 创建一个 cronjob
|
||||
|
||||
要创建一个 cronjob,你可以使用 crontab 命令,并添加 `-e` 选项:
|
||||
|
||||
```
|
||||
`$ crontab -e`
|
||||
```
|
||||
|
||||
这将使用默认的文本编辑器打开 crontab。如需指定文本编辑器,请使用 `EDITOR` [环境变量][1]:
|
||||
|
||||
```
|
||||
`$ EDITOR=nano crontab -e`
|
||||
```
|
||||
|
||||
### Cron 语法
|
||||
|
||||
如需调度一个 cronjob,你需要提供给计算机你想要执行的命令,然后提供一个 cron 表达式。cron 表达式在命令调度时运行:
|
||||
|
||||
* minute (0 到 59)
|
||||
|
||||
* hour (0 到 23, 0 代表午夜执行)
|
||||
|
||||
* day of month (1 到 31)
|
||||
|
||||
* month (1 到 12)
|
||||
|
||||
* day of week (0 到 6, 星期天是 0)
|
||||
|
||||
|
||||
|
||||
星号 (`*`) 代表的是“每一个”。例如,下面的表达式在每月每日每小时的 0 分钟运行备份脚本:
|
||||
|
||||
```
|
||||
`/opt/backup.sh 0 * * * *`
|
||||
```
|
||||
|
||||
下面的表达式在周日的凌晨 3:30 运行备份脚本:
|
||||
|
||||
```
|
||||
`/opt/backup.sh 30 3 * * 0`
|
||||
```
|
||||
|
||||
### 简写语法
|
||||
|
||||
现代的 cron 支持简化的宏,而不是 cron 表达式:
|
||||
|
||||
* `@hourly` 在每天的每小时的 0 分运行
|
||||
|
||||
* `@daily` 在每天的 0 时 0 分运行
|
||||
|
||||
* `@weekly` 在周日的 0 时 0 分运行
|
||||
|
||||
* `@monthly` 在每月的第一天的 0 时 0 分运行
|
||||
|
||||
|
||||
|
||||
例如,下面的 crontab 命令在每天的 0 时运行备份脚本:
|
||||
|
||||
```
|
||||
`/opt/backup.sh @daily`
|
||||
```
|
||||
|
||||
### 如何停止一个 cronjob
|
||||
|
||||
一旦你开始了一个 cronjob,它就会永远按照计划运行。想要在启动后停止 cronjob,你必须编辑 crontab,删除触发该作业的命令行,然后保存文件。
|
||||
|
||||
```
|
||||
`$ EDITOR=nano crontab -e`
|
||||
```
|
||||
|
||||
如需停止一个正在运行的作业,可以[使用标准的Linux进程命令][3]来停止一个正在运行的进程。
|
||||
|
||||
### 它是自动的
|
||||
|
||||
一旦你编写完 crontab,保存了文件并且退出了编辑器。你的 cronjob 就已经被调度了,剩下的工作都交给 cron 完成。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/cron-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[perfiffer](https://github.com/perfiffer)
|
||||
校对:[turbokernel](https://github.com/turbokernel)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/cron-splash.png?itok=AoBigzts (Cron expression)
|
||||
[2]: https://opensource.com/article/19/8/what-are-environment-variables
|
||||
[3]: https://opensource.com/article/18/5/how-kill-process-stop-program-linux
|
||||
@ -0,0 +1,110 @@
|
||||
[#]: subject: (Check used disk space on Linux with du)
|
||||
[#]: via: (https://opensource.com/article/21/7/check-disk-space-linux-du)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
用 du 检查 Linux 上已使用的磁盘空间
|
||||
======
|
||||
用 Linux 的 du 命令了解你正在使用多少磁盘空间。
|
||||
![Check disk usage][1]
|
||||
|
||||
无论你有多少存储空间,它总是有可能被填满。在大多数个人设备上,驱动器被照片、视频和音乐填满,但在服务器上,由于用户账户和日志文件中的数据,空间减少是很正常的。无论你是负责管理一个多用户系统,还是只负责自己的笔记本电脑,你都可以用 `du` 命令检查磁盘的使用情况。
|
||||
|
||||
默认情况下,`du` 提供了你当前目录中使用的磁盘空间,以及每个子目录的大小。
|
||||
|
||||
|
||||
```
|
||||
$ du
|
||||
12 ./.backups
|
||||
60 .
|
||||
```
|
||||
|
||||
在这个例子中,我的当前目录总共占用了 60KB,其中 12KB 被子目录 `.backups` 占用。
|
||||
|
||||
如果你觉得这很混乱,并希望分别看到所有的大小,你可以使用 `--separate-dirs`(或简写 `S`)选项:
|
||||
|
||||
|
||||
```
|
||||
$ du --separate-dirs
|
||||
12 ./.backups
|
||||
48 .
|
||||
```
|
||||
|
||||
这是相同的信息(48 加 12 是 60),但每个目录被独立处理。
|
||||
|
||||
要想看到更多的细节,可以使用 --all(简写 -a)选项,它显示每个目录中的每个文件:
|
||||
|
||||
|
||||
```
|
||||
$ du --separate-dirs --all
|
||||
4 ./example.adoc
|
||||
28 ./graphic.png
|
||||
4 ./.backups/example.adoc~
|
||||
12 ./.backups
|
||||
4 ./index.html
|
||||
4 ./index.adoc
|
||||
48 .
|
||||
```
|
||||
|
||||
### 查看文件的修改时间
|
||||
|
||||
当查看文件以找出占用空间的内容时,查看文件最后一次被修改的时间是很有用的。一年内没有使用的文件很可能是归档的候选文件,特别是当你的空间快用完时。
|
||||
|
||||
用 du 查看文件的修改时间,使用 `--time` 选项:
|
||||
|
||||
|
||||
```
|
||||
$ du --separate-dirs --all --time
|
||||
28 2021-07-21 11:12 ./graphic.png
|
||||
4 2021-07-03 10:43 ./example.adoc
|
||||
4 2021-07-13 13:03 ./index.html
|
||||
4 2021-07-23 14:18 ./index.adoc
|
||||
48 2021-07-23 14:19 .
|
||||
```
|
||||
|
||||
### 为文件大小设置一个阈值
|
||||
|
||||
当为了磁盘空间而查看文件时,你可能只关心较大的文件。你可以用 `--threshold`(简写 `-t`)选项为你想看的文件大小设置一个阈值。例如,只查看大于 1GB 的文件:
|
||||
|
||||
|
||||
```
|
||||
$ \du --separate-dirs --all --time --threshold=1G ~/Footage/
|
||||
1839008 2021-07-14 13:55 /home/tux/Footage/snowfall.mp4
|
||||
1577980 2020-04-11 13:10 /home/tux/Footage/waterfall.mp4
|
||||
8588936 2021-07-14 13:55 /home/tux/Footage/
|
||||
```
|
||||
|
||||
当文件特别大时,它们可能难以阅读。使用 `--human-readable`(简写 `-h`)选项可以使文件大小更容易阅读:
|
||||
|
||||
|
||||
```
|
||||
$ \du --separate-dirs --all --time \
|
||||
\--threshold=1G --human-readable ~/Footage/
|
||||
1.8G 2021-07-14 13:55 /home/tux/Footage/snowfall.mp4
|
||||
1.6G 2020-04-11 13:10 /home/tux/Footage/waterfall.mp4
|
||||
8.5G 2021-07-14 13:55 /home/tux/Footage/
|
||||
```
|
||||
|
||||
### 查看可用磁盘空间
|
||||
|
||||
如果只是想获得一个驱动器上还剩下多少磁盘空间的摘要,请阅读我们关于 [df 命令][2]的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/check-disk-space-linux-du
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/du-splash.png?itok=nRLlI-5A (Check disk usage)
|
||||
[2]: https://opensource.com/article/21/7/use-df-check-free-disk-space-linux
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: subject: (Use df to check free disk space on Linux)
|
||||
[#]: via: (https://opensource.com/article/21/7/check-disk-space-linux-df)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (piaoshi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
使用 df 命令查看 Linux 上的可用磁盘空间。
|
||||
======
|
||||
利用 df 命令查看 Linux 磁盘还剩多少空间。
|
||||
![Free disk space][1]
|
||||
|
||||
磁盘空间已经不像计算机早期那样珍贵,但无论你有多少磁盘空间,总有耗尽的可能。计算机需要一些磁盘空间才能启动运行,所以为了确保你没有在无意间用尽了所有的硬盘空间,偶尔检查一下是非常必要的。在 Linux 终端,你可以用 df 命令来做这件事。
|
||||
|
||||
df 命令可以显示文件系统中可用的磁盘空间。
|
||||
|
||||
要想使输出结果易于阅读,你可以加上 --human-readable(或其简写 -h)选项:
|
||||
|
||||
```
|
||||
$ df --human-readable
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/sda1 1.0T 525G 500G 52% /
|
||||
```
|
||||
|
||||
在这个例子中,计算机的磁盘已经用了 52%,还有 500 GB 可用空间。
|
||||
|
||||
由于 Linux 完整地看待所有挂载设备的文件系统,df 命令会展示出连接到计算机上的每个存储设备的详细信息。如果你有很多磁盘,那么输出结果将会反映出来:
|
||||
|
||||
```
|
||||
$ df --human-readable
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/root 110G 45G 61G 43% /
|
||||
devtmpfs 12G 0 12G 0% /dev
|
||||
tmpfs 12G 848K 12G 1% /run
|
||||
/dev/sda1 1.6T 1.3T 191G 87% /home
|
||||
/dev/sdb1 917G 184G 687G 22% /penguin
|
||||
/dev/sdc1 57G 50G 4.5G 92% /sneaker
|
||||
/dev/sdd1 3.7T 2.4T 1.3T 65% /tux
|
||||
```
|
||||
|
||||
在这个例子中,计算机的 `/home` 目录已经用了 87%,剩下 191 GB 的可用空间。
|
||||
|
||||
### 查看总的可用磁盘空间
|
||||
|
||||
如果你的文件系统确实很复杂,而你希望看到所有磁盘的总空间,可以使用 --total 选项:
|
||||
|
||||
```
|
||||
$ df --human-readable --total
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/root 110G 45G 61G 43% /
|
||||
devtmpfs 12G 0 12G 0% /dev
|
||||
tmpfs 12G 848K 12G 1% /run
|
||||
/dev/sda1 1.6T 1.3T 191G 87% /home
|
||||
/dev/sdb1 917G 184G 687G 22% /penguin
|
||||
/dev/sdc1 57G 50G 4.5G 92% /sneaker
|
||||
/dev/sdd1 3.7T 2.4T 1.3T 65% /tux
|
||||
total 6.6T 4.0T 2.5T 62% -
|
||||
```
|
||||
|
||||
输出的最后一行展示了文件系统的总空间、已用总空间、可用总空间。
|
||||
|
||||
### 查看磁盘空间使用情况
|
||||
|
||||
如果你想大概了解哪些文件占用了磁盘空间,请阅读我们关于 [du 命令][2] 的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/7/check-disk-space-linux-df
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[piaoshi](https://github.com/piaoshi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/df-splash.png?itok=AGXQm737 (Free disk space)
|
||||
[2]: https://opensource.com/article/21/7/check-used-disk-space-linux-du
|
||||
Loading…
Reference in New Issue
Block a user