mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge remote-tracking branch 'upstream/master' into Scout-out-code-problems-with-SonarQube
This commit is contained in:
commit
ecdff70c2e
@ -4,9 +4,9 @@ script:
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" = "false" ]; then sh ./scripts/badge.sh; fi'
|
||||
branches:
|
||||
only:
|
||||
- master
|
||||
- master
|
||||
except:
|
||||
- gh-pages
|
||||
- gh-pages
|
||||
git:
|
||||
submodules: false
|
||||
deploy:
|
||||
|
||||
@ -1,40 +1,41 @@
|
||||
SDKMAN – 轻松管理多个软件开发套件 (SDK) 的命令行工具
|
||||
SDKMAN:轻松管理多个软件开发套件 (SDK) 的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
你是否是一个经常在不同的 SDK 下安装和测试应用的开发者?我有一个好消息要告诉你!**SDKMAN**,一个可以帮你轻松管理多个 SDK 的命令行工具。它为安装、切换、列出和移除 SDK 提供了一个简便的方式。有了 SDKMAN,你可以在任何类 Unix 的操作系统上轻松地并行管理多个 SDK 的多个版本。它允许开发者为 JVM 安装不同的 SDK,例如 Java、Groovy、Scala、Kotlin 和 Ceylon、Ant、Gradle、Grails、Maven、SBT、Spark、Spring Boot、Vert.x,以及许多其他支持的 SDK。SDKMAN 是免费、轻量、开源、使用 **Bash** 编写的程序。
|
||||
你是否是一个经常在不同的 SDK 下安装和测试应用的开发者?我有一个好消息要告诉你!给你介绍一下 **SDKMAN**,一个可以帮你轻松管理多个 SDK 的命令行工具。它为安装、切换、列出和移除 SDK 提供了一个简便的方式。有了 SDKMAN,你可以在任何类 Unix 的操作系统上轻松地并行管理多个 SDK 的多个版本。它允许开发者为 JVM 安装不同的 SDK,例如 Java、Groovy、Scala、Kotlin 和 Ceylon、Ant、Gradle、Grails、Maven、SBT、Spark、Spring Boot、Vert.x,以及许多其他支持的 SDK。SDKMAN 是免费、轻量、开源、使用 **Bash** 编写的程序。
|
||||
|
||||
### 安装 SDKMAN
|
||||
|
||||
安装 SDKMAN 很简单。首先,确保你已经安装了 **zip** 和 **unzip** 这两个应用。它们在大多数的 Linux 发行版的默认仓库中。
|
||||
安装 SDKMAN 很简单。首先,确保你已经安装了 `zip` 和 `unzip` 这两个应用。它们在大多数的 Linux 发行版的默认仓库中。
|
||||
例如,在基于 Debian 的系统上安装 unzip,只需要运行:
|
||||
|
||||
```
|
||||
$ sudo apt-get install zip unzip
|
||||
|
||||
```
|
||||
|
||||
然后使用下面的命令安装 SDKMAN:
|
||||
|
||||
```
|
||||
$ curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
在安装完成之后,运行以下命令:
|
||||
|
||||
```
|
||||
$ source "$HOME/.sdkman/bin/sdkman-init.sh"
|
||||
|
||||
```
|
||||
|
||||
如果你希望自定义安装到其他位置,例如 **/usr/local/**,你可以这样做:
|
||||
如果你希望自定义安装到其他位置,例如 `/usr/local/`,你可以这样做:
|
||||
|
||||
```
|
||||
$ export SDKMAN_DIR="/usr/local/sdkman" && curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
确保你的用户有足够的权限访问这个目录。
|
||||
|
||||
最后,在安装完成后使用下面的命令检查一下:
|
||||
|
||||
```
|
||||
$ sdk version
|
||||
==== BROADCAST =================================================================
|
||||
@ -44,7 +45,6 @@ $ sdk version
|
||||
================================================================================
|
||||
|
||||
SDKMAN 5.7.2+323
|
||||
|
||||
```
|
||||
|
||||
恭喜你!SDKMAN 已经安装完成了。让我们接下来看如何安装和管理 SDKs 吧。
|
||||
@ -52,12 +52,13 @@ SDKMAN 5.7.2+323
|
||||
### 管理多个 SDK
|
||||
|
||||
查看可用的 SDK 清单,运行:
|
||||
|
||||
```
|
||||
$ sdk list
|
||||
|
||||
```
|
||||
|
||||
将会输出:
|
||||
|
||||
```
|
||||
================================================================================
|
||||
Available Candidates
|
||||
@ -79,18 +80,18 @@ used to pilot any type of process which can be described in terms of targets and
|
||||
tasks.
|
||||
|
||||
: $ sdk install ant
|
||||
|
||||
```
|
||||
|
||||
就像你看到的,SDK 每次列出众多 SDK 中的一个,以及该 SDK 的描述信息、官方网址和安装命令。按回车键继续下一个。
|
||||
|
||||
安装一个新的 SDK,例如 Java JDK,运行:
|
||||
|
||||
```
|
||||
$ sdk install java
|
||||
|
||||
```
|
||||
|
||||
将会输出:
|
||||
|
||||
```
|
||||
Downloading: java 8.0.172-zulu
|
||||
|
||||
@ -106,30 +107,30 @@ Installing: java 8.0.172-zulu
|
||||
Done installing!
|
||||
|
||||
Setting java 8.0.172-zulu as default.
|
||||
|
||||
```
|
||||
|
||||
如果你安装了多个 SDK,它将会提示你是否想要将当前安装的版本设置为 **默认版本**。回答 **Yes** 将会把当前版本设置为默认版本。
|
||||
如果你安装了多个 SDK,它将会提示你是否想要将当前安装的版本设置为 **默认版本**。回答 `Yes` 将会把当前版本设置为默认版本。
|
||||
|
||||
使用以下命令安装一个 SDK 的其他版本:
|
||||
|
||||
使用以下命令安装一个 SDK 的其他版本:
|
||||
```
|
||||
$ sdk install ant 1.10.1
|
||||
|
||||
```
|
||||
|
||||
如果你之前已经在本地安装了一个 SDK,你可以像下面这样设置它为本地版本。
|
||||
|
||||
```
|
||||
$ sdk install groovy 3.0.0-SNAPSHOT /path/to/groovy-3.0.0-SNAPSHOT
|
||||
|
||||
```
|
||||
|
||||
列出一个 SDK 的多个版本:
|
||||
|
||||
```
|
||||
$ sdk list ant
|
||||
|
||||
```
|
||||
|
||||
将会输出
|
||||
将会输出:
|
||||
|
||||
```
|
||||
================================================================================
|
||||
Available Ant Versions
|
||||
@ -145,32 +146,31 @@ Available Ant Versions
|
||||
* - installed
|
||||
> - currently in use
|
||||
================================================================================
|
||||
|
||||
```
|
||||
|
||||
像我之前说的,如果你安装了多个版本,SDKMAN 会提示你是否想要设置当前安装的版本为 **默认版本**。你可以回答 Yes 设置它为默认版本。当然,你也可以在稍后使用下面的命令设置:
|
||||
|
||||
```
|
||||
$ sdk default ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
上面的命令将会设置 Apache Ant 1.9.9 为默认版本。
|
||||
|
||||
你可以根据自己的需要选择使用任何已安装的 SDK 版本,仅需运行以下命令:
|
||||
你可以根据自己的需要选择使用任何已安装的 SDK 版本,仅需运行以下命令:
|
||||
|
||||
```
|
||||
$ sdk use ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
检查某个具体 SDK 当前的版本号,例如 Java,运行:
|
||||
|
||||
```
|
||||
$ sdk current java
|
||||
|
||||
Using java version 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
检查所有当下在使用的 SDK 版本号,运行:
|
||||
|
||||
```
|
||||
$ sdk current
|
||||
|
||||
@ -178,36 +178,35 @@ Using:
|
||||
|
||||
ant: 1.10.1
|
||||
java: 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
升级过时的 SDK,运行:
|
||||
|
||||
```
|
||||
$ sdk upgrade scala
|
||||
|
||||
```
|
||||
|
||||
你也可以检查所有的 SDKs 中还有哪些是过时的。
|
||||
你也可以检查所有的 SDK 中还有哪些是过时的。
|
||||
|
||||
```
|
||||
$ sdk upgrade
|
||||
|
||||
```
|
||||
|
||||
SDKMAN 有离线模式,可以让 SDKMAN 在离线时也正常运作。你可以使用下面的命令在任何时间开启或者关闭离线模式:
|
||||
|
||||
```
|
||||
$ sdk offline enable
|
||||
|
||||
$ sdk offline disable
|
||||
|
||||
```
|
||||
|
||||
要移除已安装的 SDK,运行:
|
||||
|
||||
```
|
||||
$ sdk uninstall ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
要了解更多的细节,参阅帮助章节。
|
||||
|
||||
```
|
||||
$ sdk help
|
||||
|
||||
@ -231,72 +230,68 @@ update
|
||||
flush <broadcast|archives|temp>
|
||||
|
||||
candidate : the SDK to install: groovy, scala, grails, gradle, kotlin, etc.
|
||||
use list command for comprehensive list of candidates
|
||||
eg: $ sdk list
|
||||
use list command for comprehensive list of candidates
|
||||
eg: $ sdk list
|
||||
|
||||
version : where optional, defaults to latest stable if not provided
|
||||
eg: $ sdk install groovy
|
||||
|
||||
eg: $ sdk install groovy
|
||||
```
|
||||
|
||||
### 更新 SDKMAN
|
||||
|
||||
如果有可用的新版本,可以使用下面的命令安装:
|
||||
|
||||
```
|
||||
$ sdk selfupdate
|
||||
|
||||
```
|
||||
|
||||
SDKMAN 会定期检查更新,以及让你了解如何更新的指令。
|
||||
SDKMAN 会定期检查更新,并给出让你了解如何更新的指令。
|
||||
|
||||
```
|
||||
WARNING: SDKMAN is out-of-date and requires an update.
|
||||
|
||||
$ sdk update
|
||||
Adding new candidates(s): scala
|
||||
|
||||
```
|
||||
|
||||
### 清除缓存
|
||||
|
||||
建议时不时的清理缓存(包括那些下载的 SDK 的二进制文件)。仅需运行下面的命令就可以了:
|
||||
建议时不时的清理缓存(包括那些下载的 SDK 的二进制文件)。仅需运行下面的命令就可以了:
|
||||
|
||||
```
|
||||
$ sdk flush archives
|
||||
|
||||
```
|
||||
|
||||
它也可以用于清理空的文件夹,节省一点空间:
|
||||
|
||||
```
|
||||
$ sdk flush temp
|
||||
|
||||
```
|
||||
|
||||
### 卸载 SDKMAN
|
||||
|
||||
如果你觉得不需要或者不喜欢 SDKMAN,可以使用下面的命令删除。
|
||||
|
||||
```
|
||||
$ tar zcvf ~/sdkman-backup_$(date +%F-%kh%M).tar.gz -C ~/ .sdkman
|
||||
$ rm -rf ~/.sdkman
|
||||
|
||||
```
|
||||
最后打开你的 **.bashrc**,**.bash_profile** 和/或者 **.profile**,找到并删除下面这几行。
|
||||
最后打开你的 `.bashrc`、`.bash_profile` 和/或者 `.profile`,找到并删除下面这几行。
|
||||
|
||||
```
|
||||
#THIS MUST BE AT THE END OF THE FILE FOR SDKMAN TO WORK!!!
|
||||
export SDKMAN_DIR="/home/sk/.sdkman"
|
||||
[[ -s "/home/sk/.sdkman/bin/sdkman-init.sh" ]] && source "/home/sk/.sdkman/bin/sdkman-init.sh"
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是 ZSH,就从 **.zshrc** 中删除上面这一行。
|
||||
如果你使用的是 ZSH,就从 `.zshrc` 中删除上面这一行。
|
||||
|
||||
这就是所有的内容了。我希望 SDKMAN 可以帮到你。还有更多的干货即将到来。敬请期待!
|
||||
|
||||
祝近祺!
|
||||
|
||||
|
||||
:)
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/sdkman-a-cli-tool-to-easily-manage-multiple-software-development-kits/
|
||||
@ -304,7 +299,7 @@ via: https://www.ostechnix.com/sdkman-a-cli-tool-to-easily-manage-multiple-softw
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
如何在 Linux 中快速地通过 HTTP 访问文件和文件夹
|
||||
如何在 Linux 中快速地通过 HTTP 提供文件访问服务
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天,我有很多方法来通过网络浏览器为局域网中的其他系统提供单个文件或整个目录访问。我在我的 Ubuntu 测试机上测试了这些方法,它们和下面描述的那样运行正常。如果你想知道如何在类 Unix 操作系统中通过 HTTP 轻松快速地访问文件和文件夹,以下方法之一肯定会有所帮助。
|
||||
如今,我有很多方法来通过 Web 浏览器为局域网中的其他系统提供单个文件或整个目录的访问。我在我的 Ubuntu 测试机上测试了这些方法,它们如下面描述的那样运行正常。如果你想知道如何在类 Unix 操作系统中通过 HTTP 轻松快速地提供文件和文件夹的访问服务,以下方法之一肯定会有所帮助。
|
||||
|
||||
### 在 Linux 中通过 HTTP 访问文件和文件夹
|
||||
|
||||
@ -13,50 +13,59 @@
|
||||
|
||||
我们写了一篇简要的指南来设置一个简单的 http 服务器,以便在以下链接中即时共享文件和目录。如果你有一个安装了 Python 的系统,这个方法非常方便。
|
||||
|
||||
- [如何使用 simpleHTTPserver 设置一个简单的文件服务器](https://www.ostechnix.com/how-to-setup-a-file-server-in-minutes-using-python/)
|
||||
|
||||
#### 方法 2 - 使用 Quickserve(Python)
|
||||
|
||||
此方法针对 Arch Linux 及其衍生版。有关详细信息,请查看下面的链接。
|
||||
|
||||
- [如何在 Arch Linux 中即时共享文件和文件夹](https://www.ostechnix.com/instantly-share-files-folders-arch-linux/)
|
||||
|
||||
#### 方法 3 - 使用 Ruby
|
||||
|
||||
在此方法中,我们使用 Ruby 在类 Unix 系统中通过 HTTP 提供文件和文件夹访问。按照以下链接中的说明安装 Ruby 和 Rails。
|
||||
|
||||
- [在 CentOS 和 Ubuntu 中安装 Ruby on Rails](https://www.ostechnix.com/install-ruby-rails-ubuntu-16-04/)
|
||||
|
||||
安装 Ruby 后,进入要通过网络共享的目录,例如 ostechnix:
|
||||
|
||||
```
|
||||
$ cd ostechnix
|
||||
|
||||
```
|
||||
|
||||
并运行以下命令:
|
||||
|
||||
```
|
||||
$ ruby -run -ehttpd . -p8000
|
||||
[2018-08-10 16:02:55] INFO WEBrick 1.4.2
|
||||
[2018-08-10 16:02:55] INFO ruby 2.5.1 (2018-03-29) [x86_64-linux]
|
||||
[2018-08-10 16:02:55] INFO WEBrick::HTTPServer#start: pid=5859 port=8000
|
||||
|
||||
```
|
||||
|
||||
确保在路由器或防火墙中打开端口 8000。如果该端口已被其他一些服务使用,那么请使用不同的端口。
|
||||
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - **http:// <ip-address>:8000**。
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - `http:// <ip-address>:8000`。
|
||||
|
||||
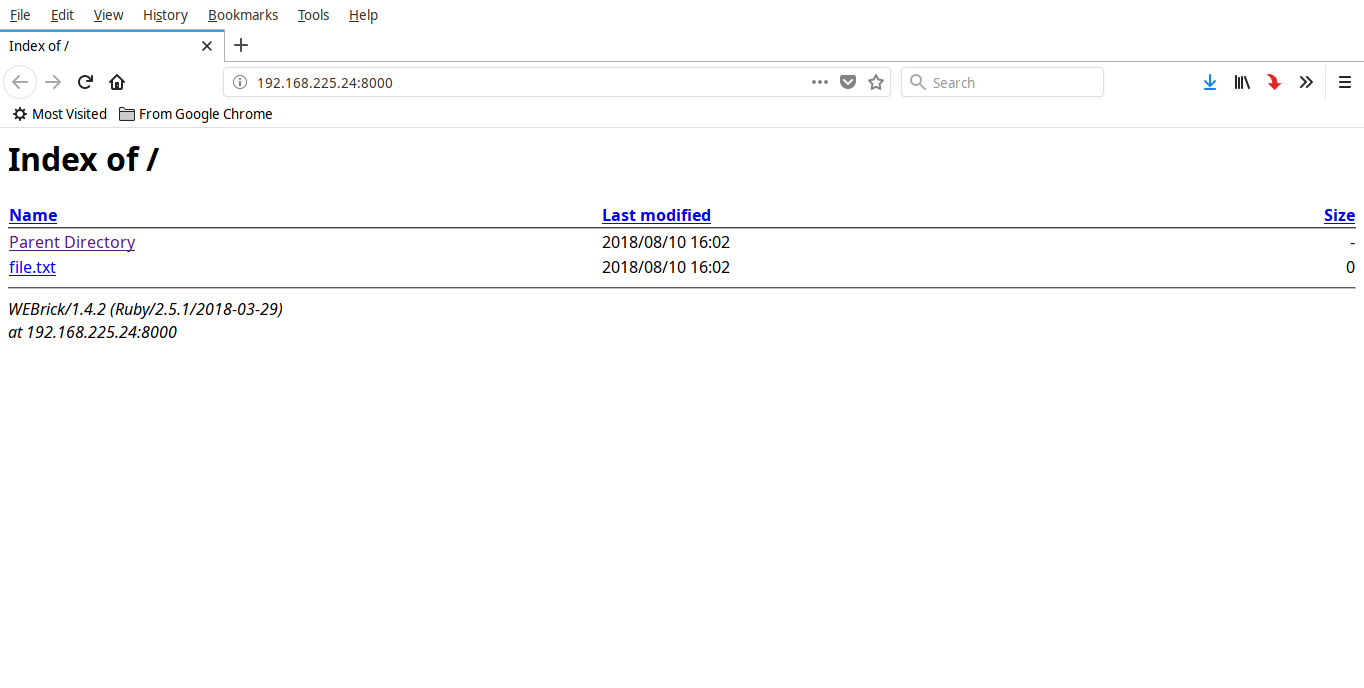
|
||||
|
||||
要停止共享,请按 **CTRL+C**。
|
||||
要停止共享,请按 `CTRL+C`。
|
||||
|
||||
#### 方法 4 - 使用 Http-server(NodeJS)
|
||||
|
||||
[**Http-server**][1] 是一个用 NodeJS 编写的简单的可用于生产的命令行 http-server。它不需要要配置,可用于通过 Web 浏览器即时共享文件和目录。
|
||||
[Http-server][1] 是一个用 NodeJS 编写的简单的可用于生产环境的命令行 http 服务器。它不需要配置,可用于通过 Web 浏览器即时共享文件和目录。
|
||||
|
||||
按如下所述安装 NodeJS。
|
||||
|
||||
- [如何在 Linux 上安装 NodeJS](https://www.ostechnix.com/install-node-js-linux/)
|
||||
|
||||
安装 NodeJS 后,运行以下命令安装 http-server。
|
||||
|
||||
```
|
||||
$ npm install -g http-server
|
||||
|
||||
```
|
||||
|
||||
现在进入任何目录并通过 HTTP 共享其内容,如下所示。
|
||||
|
||||
```
|
||||
$ cd ostechnix
|
||||
|
||||
@ -67,80 +76,81 @@ Available on:
|
||||
http://192.168.225.24:8000
|
||||
http://192.168.225.20:8000
|
||||
Hit CTRL-C to stop the server
|
||||
|
||||
```
|
||||
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - **http:// <ip-address>:8000**。
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - `http:// <ip-address>:8000`。
|
||||
|
||||

|
||||
|
||||
要停止共享,请按 **CTRL+C**。
|
||||
要停止共享,请按 `CTRL+C`。
|
||||
|
||||
#### 方法 5 - 使用 Miniserve(Rust)
|
||||
|
||||
[**Miniserve**][2] 是另一个命令行程序,它允许你通过 HTTP 快速访问文件。它是一个非常快速,易于使用的跨平台程序,它用 **Rust** 编程语言编写。与上面的程序/方法不同,它提供身份验证支持,因此你可以为共享设置用户名和密码。
|
||||
[**Miniserve**][2] 是另一个命令行程序,它允许你通过 HTTP 快速访问文件。它是一个非常快速、易于使用的跨平台程序,它用 Rust 编程语言编写。与上面的程序/方法不同,它提供身份验证支持,因此你可以为共享设置用户名和密码。
|
||||
|
||||
按下面的链接在 Linux 系统中安装 Rust。
|
||||
|
||||
- [在 Linux 上安装 Rust 编程语言](https://www.ostechnix.com/install-rust-programming-language-in-linux/)
|
||||
|
||||
安装 Rust 后,运行以下命令安装 miniserve:
|
||||
|
||||
```
|
||||
$ cargo install miniserve
|
||||
|
||||
```
|
||||
|
||||
或者,你可以在[**发布页**][3]下载二进制文件并使其可执行。
|
||||
或者,你可以在其[发布页][3]下载二进制文件并使其可执行。
|
||||
|
||||
```
|
||||
$ chmod +x miniserve-linux
|
||||
|
||||
```
|
||||
|
||||
然后,你可以使用命令运行它(假设 miniserve 二进制文件下载到当前的工作目录中):
|
||||
|
||||
```
|
||||
$ ./miniserve-linux <path-to-share>
|
||||
|
||||
```
|
||||
|
||||
**用法**
|
||||
|
||||
要提供目录访问:
|
||||
|
||||
```
|
||||
$ miniserve <path-to-directory>
|
||||
|
||||
```
|
||||
|
||||
**示例:**
|
||||
|
||||
```
|
||||
$ miniserve /home/sk/ostechnix/
|
||||
miniserve v0.2.0
|
||||
Serving path /home/sk/ostechnix at http://[::]:8080, http://localhost:8080
|
||||
Quit by pressing CTRL-C
|
||||
|
||||
```
|
||||
|
||||
现在,你可以在本地系统使用 URL – **<http://localhost:8080>** 访问共享,或者在远程系统使用 URL – **http:// <ip-address>:8080** 访问。
|
||||
现在,你可以在本地系统使用 URL – `http://localhost:8080` 访问共享,或者在远程系统使用 URL – `http://<ip-address>:8080` 访问。
|
||||
|
||||
要提供单个文件访问:
|
||||
|
||||
```
|
||||
$ miniserve <path-to-file>
|
||||
|
||||
```
|
||||
|
||||
**示例:**
|
||||
|
||||
```
|
||||
$ miniserve ostechnix/file.txt
|
||||
|
||||
```
|
||||
|
||||
带用户名和密码提供文件/文件夹访问:
|
||||
|
||||
```
|
||||
$ miniserve --auth joe:123 <path-to-share>
|
||||
|
||||
```
|
||||
|
||||
绑定到多个接口:
|
||||
|
||||
```
|
||||
$ miniserve -i 192.168.225.1 -i 10.10.0.1 -i ::1 -- <path-to-share>
|
||||
|
||||
```
|
||||
|
||||
如你所见,我只给出了 5 种方法。但是,本指南末尾附带的链接中还提供了几种方法。也去测试一下它们。此外,收藏并时不时重新访问它来检查将来是否有新的方法。
|
||||
@ -149,7 +159,9 @@ $ miniserve -i 192.168.225.1 -i 10.10.0.1 -i ::1 -- <path-to-share>
|
||||
|
||||
干杯!
|
||||
|
||||
### 资源
|
||||
|
||||
- [单行静态 http 服务器大全](https://gist.github.com/willurd/5720255)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -158,7 +170,7 @@ via: https://www.ostechnix.com/how-to-quickly-serve-files-and-folders-over-http-
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,23 @@
|
||||
适用于小型企业的 4 个开源发票工具
|
||||
======
|
||||
用基于 web 的发票软件管理你的账单,完成收款,十分简单。
|
||||
|
||||
> 用基于 web 的发票软件管理你的账单,轻松完成收款,十分简单。
|
||||
|
||||

|
||||
|
||||
无论您开办小型企业的原因是什么,保持业务发展的关键是可以盈利。收款也就意味着向客户提供发票。
|
||||
|
||||
使用 LibreOffice Writer 或 LibreOffice Calc 提供发票很容易,但有时候你需要的不止这些。从更专业的角度看。一种跟进发票的方法。提醒你何时跟进你发出的发票。
|
||||
使用 LibreOffice Writer 或 LibreOffice Calc 提供发票很容易,但有时候你需要的不止这些。从更专业的角度看,一种跟进发票的方法,可以提醒你何时跟进你发出的发票。
|
||||
|
||||
在这里有各种各样的商业闭源发票管理工具。但是开源界的产品和相对应的闭源商业工具比起来,并不差,没准还更灵活。
|
||||
在这里有各种各样的商业闭源的发票管理工具。但是开源的产品和相对应的闭源商业工具比起来,并不差,没准还更灵活。
|
||||
|
||||
让我们一起了解这 4 款基于 web 的开源发票工具,它们很适用于预算紧张的自由职业者和小型企业。2014 年,我在本文的[早期版本][1]中提到了其中两个工具。这 4 个工具用起来都很简单,并且你可以在任何设备上使用它们。
|
||||
|
||||
### Invoice Ninja
|
||||
|
||||
我不是很喜欢 ninja 这个词。尽管如此,我喜欢 [Invoice Ninja][2]。非常喜欢。它将功能融合在一个简单的界面,其中包含一组功能,可让创建,管理和向客户、消费者发送发票。
|
||||
我不是很喜欢 ninja (忍者)这个词。尽管如此,我喜欢 [Invoice Ninja][2]。非常喜欢。它将功能融合在一个简单的界面,其中包含一组可让你创建、管理和向客户、消费者发送发票的功能。
|
||||
|
||||
您可以轻松配置多个客户端,跟进付款和未结清的发票,生成报价并用电子邮件发送发票。Invoice Ninja 与其竞争对手不同,它[集成][3]了超过 40 个流行支付方式,包括 PayPal,Stripe,WePay 以及 Apple Pay。
|
||||
您可以轻松配置多个客户端,跟进付款和未结清的发票,生成报价并用电子邮件发送发票。Invoice Ninja 与其竞争对手不同,它[集成][3]了超过 40 个流行支付方式,包括 PayPal、Stripe、WePay 以及 Apple Pay。
|
||||
|
||||
[下载][4]一个可以安装到自己服务器上的版本,或者获取一个[托管版][5]的账户,都可以使用 Invoice Ninja。它有免费版,也有每月 8 美元的收费版。
|
||||
|
||||
@ -34,7 +35,7 @@ InvoicePlane 不仅可以生成或跟进发票。你还可以为任务或商品
|
||||
|
||||
[OpenSourceBilling][9] 被它的开发者称赞为“非常简单的计费软件”,当之无愧。它拥有最简洁的交互界面,配置使用起来轻而易举。
|
||||
|
||||
OpenSourceBilling 因它的商业智能仪表盘脱颖而出,它可以跟进跟进你当前和以前的发票,以及任何没有支付的款项。它以图表的形式整理信息,使之很容易阅读。
|
||||
OpenSourceBilling 因它的商业智能仪表盘脱颖而出,它可以跟进你当前和以前的发票,以及任何没有支付的款项。它以图表的形式整理信息,使之很容易阅读。
|
||||
|
||||
你可以在发票上配置很多信息。只需点几下鼠标按几下键盘,即可添加项目、税率、客户名称以及付款条件。OpenSourceBilling 将这些信息保存在你所有的发票当中,不管新发票还是旧发票。
|
||||
|
||||
@ -57,7 +58,7 @@ via: https://opensource.com/article/18/10/open-source-invoicing-tools
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
# KeeWeb – 一个开源且跨平台的密码管理工具
|
||||
KeeWeb:一个开源且跨平台的密码管理工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
@ -6,64 +7,60 @@
|
||||
|
||||
**KeePass** 就是一个这样的开源密码管理工具,它有一个官方客户端,但功能非常简单。也有许多 PC 端和手机端的其他密码管理工具,并且与 KeePass 存储加密密码的文件格式兼容。其中一个就是 **KeeWeb**。
|
||||
|
||||
KeeWeb 是一个开源、跨平台的密码管理工具,具有云同步,键盘快捷键和插件等功能。KeeWeb使用 Electron 框架,这意味着它可以在 Windows,Linux 和 Mac OS 上运行。
|
||||
KeeWeb 是一个开源、跨平台的密码管理工具,具有云同步,键盘快捷键和插件等功能。KeeWeb使用 Electron 框架,这意味着它可以在 Windows、Linux 和 Mac OS 上运行。
|
||||
|
||||
### KeeWeb 的使用
|
||||
|
||||
有两种方式可以使用 KeeWeb。第一种无需安装,直接在网页上使用,第二中就是在本地系统中安装 KeeWeb 客户端。
|
||||
|
||||
**在网页上使用 KeeWeb**
|
||||
#### 在网页上使用 KeeWeb
|
||||
|
||||
如果不想在系统中安装应用,可以去 [**https://app.keeweb.info/**][1] 使用KeeWeb。
|
||||
如果不想在系统中安装应用,可以去 [https://app.keeweb.info/][1] 使用KeeWeb。
|
||||
|
||||
|
||||
|
||||
网页端具有桌面客户端的所有功能,当然也需要联网才能进行使用。
|
||||
|
||||
**在计算机中安装 KeeWeb**
|
||||
#### 在计算机中安装 KeeWeb
|
||||
|
||||
如果喜欢客户端的舒适性和离线可用性,也可以将其安装在系统中。
|
||||
|
||||
如果使用Ubuntu/Debian,你可以去 [**releases pages**][2] 下载 KeeWeb 最新的 **.deb ** 文件,然后通过下面的命令进行安装:
|
||||
如果使用 Ubuntu/Debian,你可以去 [发布页][2] 下载 KeeWeb 最新的 .deb 文件,然后通过下面的命令进行安装:
|
||||
|
||||
```
|
||||
$ sudo dpkg -i KeeWeb-1.6.3.linux.x64.deb
|
||||
|
||||
```
|
||||
|
||||
如果用的是 Arch,在 [**AUR**][3] 上也有 KeeWeb,可以使用任何 AUR 助手进行安装,例如 [**Yay**][4]:
|
||||
如果用的是 Arch,在 [AUR][3] 上也有 KeeWeb,可以使用任何 AUR 助手进行安装,例如 [Yay][4]:
|
||||
|
||||
```
|
||||
$ yay -S keeweb
|
||||
|
||||
```
|
||||
|
||||
安装后,从菜单中或应用程序启动器启动 KeeWeb。默认界面长这样:
|
||||
安装后,从菜单中或应用程序启动器启动 KeeWeb。默认界面如下:
|
||||
|
||||
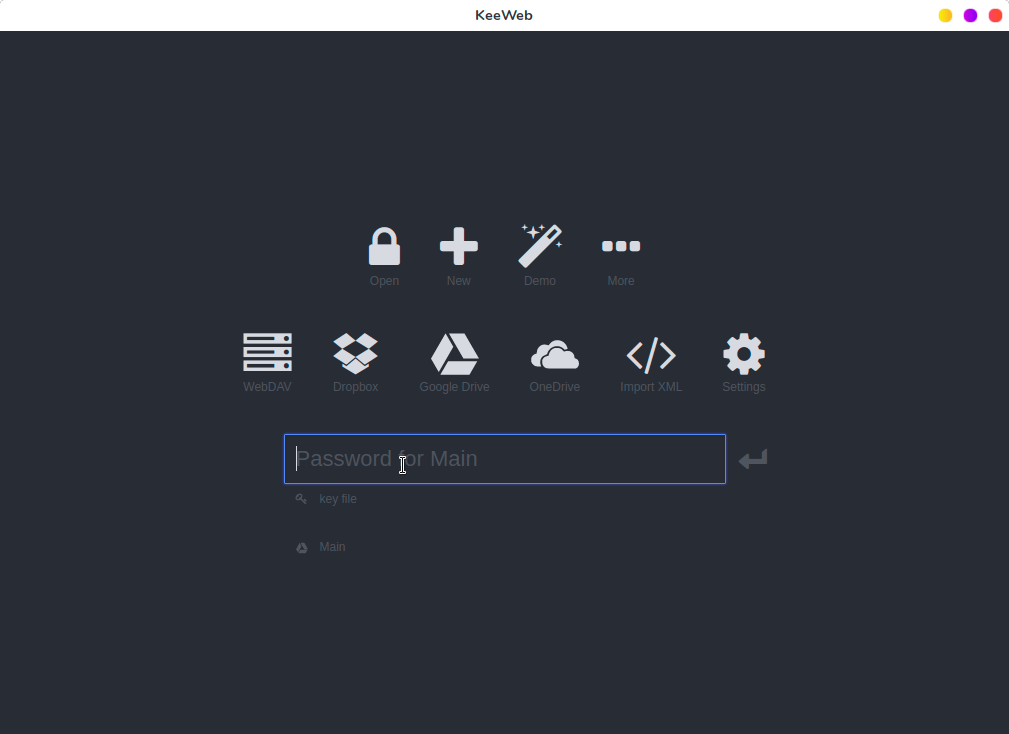
|
||||
|
||||
### 总体布局
|
||||
|
||||
KeeWeb 界面主要显示所有密码的列表,在左侧展示所有标签。单击标签将对密码进行过滤,只显示带有那个标签的密码。在右侧,显示所选帐户的所有字段。你可以设置用户名,密码,网址,或者添加自定义的备注。你甚至可以创建自己的字段并将其标记为安全字段,这在存储信用卡信息等内容时非常有用。你只需单击即可复制密码。 KeeWeb 还显示账户的创建和修改日期。已删除的密码会保留在回收站中,可以在其中还原或永久删除。
|
||||
KeeWeb 界面主要显示所有密码的列表,在左侧展示所有标签。单击标签将对密码进行筛选,只显示带有那个标签的密码。在右侧,显示所选帐户的所有字段。你可以设置用户名、密码、网址,或者添加自定义的备注。你甚至可以创建自己的字段并将其标记为安全字段,这在存储信用卡信息等内容时非常有用。你只需单击即可复制密码。 KeeWeb 还显示账户的创建和修改日期。已删除的密码会保留在回收站中,可以在其中还原或永久删除。
|
||||
|
||||

|
||||
|
||||
### KeeWeb 功能
|
||||
|
||||
**云同步**
|
||||
#### 云同步
|
||||
|
||||
KeeWeb 的主要功能之一是支持各种远程位置和云服务。除了加载本地文件,你可以从以下位置打开文件:
|
||||
|
||||
```
|
||||
1. WebDAV Servers
|
||||
2. Google Drive
|
||||
3. Dropbox
|
||||
4. OneDrive
|
||||
```
|
||||
|
||||
这意味着如果你使用多台计算机,就可以在它们之间同步密码文件,因此不必担心某台设备无法访问所有密码。
|
||||
|
||||
**密码生成器**
|
||||
#### 密码生成器
|
||||
|
||||
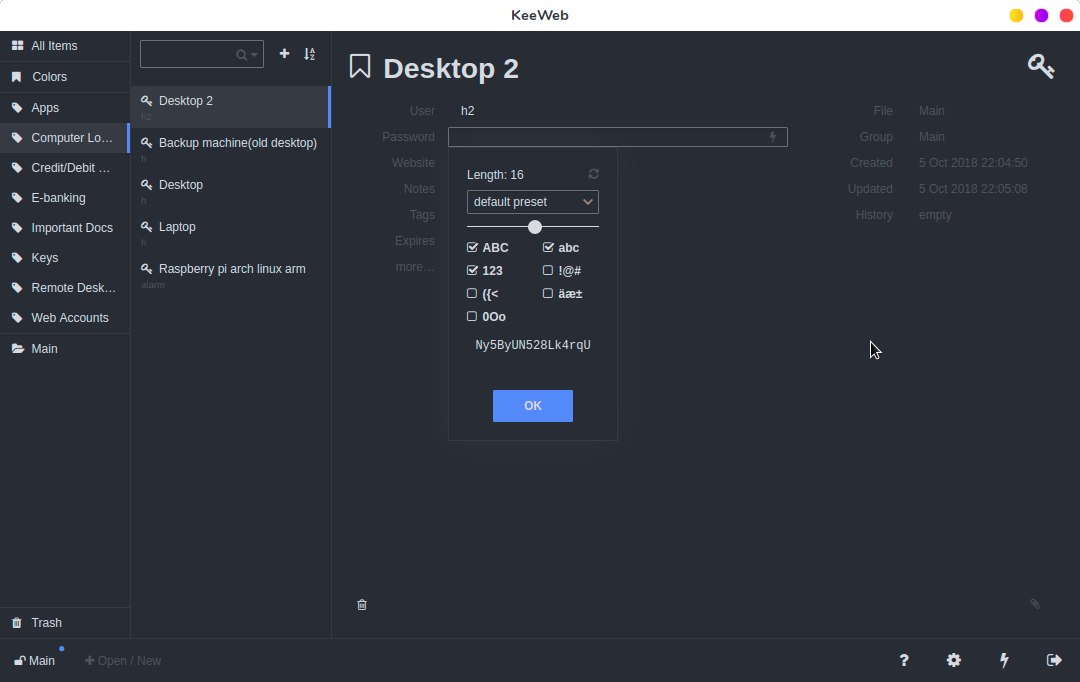
|
||||
|
||||
@ -71,13 +68,13 @@ KeeWeb 的主要功能之一是支持各种远程位置和云服务。除了加
|
||||
|
||||
为此,KeeWeb 有一个内置密码生成器,可以生成特定长度、包含指定字符的自定义密码。
|
||||
|
||||
**插件**
|
||||
#### 插件
|
||||
|
||||
|
||||
|
||||
你可以使用插件扩展 KeeWeb 的功能。 其中一些插件用于更改界面语言,而其他插件则添加新功能,例如访问 **<https://haveibeenpwned.com>** 以查看密码是否暴露。
|
||||
你可以使用插件扩展 KeeWeb 的功能。其中一些插件用于更改界面语言,而其他插件则添加新功能,例如访问 https://haveibeenpwned.com 以查看密码是否暴露。
|
||||
|
||||
**本地备份**
|
||||
#### 本地备份
|
||||
|
||||
|
||||
|
||||
@ -94,7 +91,7 @@ via: https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-man
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
设计更快的网页(二):图片替换
|
||||
======
|
||||

|
||||
|
||||

|
||||
|
||||
欢迎回到我们为了构建更快网页所写的系列文章。上一篇[文章][1]讨论了只通过图片压缩实现这个目标的方法。这个例子从一开始有 1.2MB 的“浏览器脂肪”,然后它减轻到了 488.9KB 的大小。但这还不够快!那么本文继续来给浏览器“减肥”。你可能在这个过程中会认为我们所做的事情有点疯狂,但一旦完成,你就会明白为什么要这么做了。
|
||||
|
||||
@ -21,17 +21,15 @@ $ sudo dnf install inkscape
|
||||
|
||||
![Getfedora 的页面,对其中的图片做了标记][5]
|
||||
|
||||
这次分析更好地以图形方式完成,这也就是它从屏幕截图开始的原因。上面的截图标记了页面中的所有图形元素。Fedora 网站团队已经针对两种情况措施(也有可能是四种,这样更好)来替换图像了。社交媒体的图标变成了字体的字形,而语言选择器变成了 SVG.
|
||||
这次分析以图形方式完成更好,这也就是它从屏幕截图开始的原因。上面的截图标记了页面中的所有图形元素。Fedora 网站团队已经针对两种情况措施(也有可能是四种,这样更好)来替换图像了。社交媒体的图标变成了字体的字形,而语言选择器变成了 SVG.
|
||||
|
||||
我们有几个可以替换的选择:
|
||||
|
||||
|
||||
+ CSS3
|
||||
+ 字体
|
||||
+ SVG
|
||||
+ HTML5 Canvas
|
||||
|
||||
|
||||
#### HTML5 Canvas
|
||||
|
||||
简单来说,HTML5 Canvas 是一种 HTML 元素,它允许你借助脚本语言(通常是 JavaScript)在上面绘图,不过它现在还没有被广泛使用。因为它可以使用脚本语言来绘制,所以这个元素也可以用来做动画。这里有一些使用 HTML Canvas 实现的实例,比如[三角形模式][6]、[动态波浪][7]和[字体动画][8]。不过,在这种情况下,似乎这也不是最好的选择。
|
||||
@ -42,7 +40,7 @@ $ sudo dnf install inkscape
|
||||
|
||||
#### 字体
|
||||
|
||||
另外一种方式是使用字体来装饰网页,[Fontawesome][9] 在这方面很流行。比如,在这个例子中你可以使用字体来替换“风味”和“旋转”的图标。这种方法有一个负面影响,但解决起来很容易,我们会在本系列的下一部分中来介绍。
|
||||
另外一种方式是使用字体来装饰网页,[Fontawesome][9] 在这方面很流行。比如,在这个例子中你可以使用字体来替换“Flavor”和“Spin”的图标。这种方法有一个负面影响,但解决起来很容易,我们会在本系列的下一部分中来介绍。
|
||||
|
||||
#### SVG
|
||||
|
||||
@ -94,13 +92,13 @@ inkscape:connector-curvature="0" />
|
||||
|
||||
![Inkscape - 激活节点工具][10]
|
||||
|
||||
这个例子中有五个不必要的节点——就是直线中间的那些。要删除它们,你可以使用已激活的节点工具依次选中它们,并按下 **Del** 键。然后,选中这条线的定义节点,并使用工具栏的工具把它们重新做成角。
|
||||
这个例子中有五个不必要的节点——就是直线中间的那些。要删除它们,你可以使用已激活的节点工具依次选中它们,并按下 `Del` 键。然后,选中这条线的定义节点,并使用工具栏的工具把它们重新做成角。
|
||||
|
||||
![Inkscape - 将节点变成角的工具][11]
|
||||
|
||||
如果不修复这些角,我们还有方法可以定义这条曲线,这条曲线会被保存,也就会增加文件体积。你可以手动清理这些节点,因为它无法有效的自动完成。现在,你已经为下一阶段做好了准备。
|
||||
|
||||
使用_另存为_功能,并选择_优化的 SVG_。这会弹出一个窗口,你可以在里面选择移除或保留哪些成分。
|
||||
使用“另存为”功能,并选择“优化的 SVG”。这会弹出一个窗口,你可以在里面选择移除或保留哪些成分。
|
||||
|
||||
![Inkscape - “另存为”“优化的 SVG”][12]
|
||||
|
||||
@ -121,7 +119,7 @@ insgesamt 928K
|
||||
-rw-rw-r--. 1 user user 112K 19. Feb 19:05 greyscale-pattern-opti.svg.gz
|
||||
```
|
||||
|
||||
这是我为可视化这个主题所做的一个小测试的输出。你可能应该看到光栅图形——PNG——已经被压缩,不能再被压缩了。而 SVG,一个 XML 文件正相反。它是文本文件,所以可被压缩至原来的四分之一不到。因此,现在它的体积要比 PNG 小 50 KB 左右。
|
||||
这是我为可视化这个主题所做的一个小测试的输出。你可能应该看到光栅图形——PNG——已经被压缩,不能再被压缩了。而 SVG,它是一个 XML 文件正相反。它是文本文件,所以可被压缩至原来的四分之一不到。因此,现在它的体积要比 PNG 小 50 KB 左右。
|
||||
|
||||
现代浏览器可以以原生方式处理压缩文件。所以,许多 Web 服务器都打开了 mod_deflate (Apache) 和 gzip (Nginx) 模式。这样我们就可以在传输过程中节省空间。你可以在[这儿][13]看看你的服务器是不是启用了它。
|
||||
|
||||
@ -129,18 +127,16 @@ insgesamt 928K
|
||||
|
||||
首先,没有人希望每次都要用 Inkscape 来优化 SVG. 你可以在命令行中脱离 GUI 来运行 Inkscape,但你找不到选项来将 Inkscape SVG 转换成优化的 SVG. 用这种方式只能导出光栅图像。但是我们替代品:
|
||||
|
||||
* SVGO (看起来开发过程已经不活跃了)
|
||||
* Scour
|
||||
* SVGO (看起来开发过程已经不活跃了)
|
||||
* Scour
|
||||
|
||||
|
||||
|
||||
本例中我们使用 scour 来进行优化。先来安装它:
|
||||
本例中我们使用 `scour` 来进行优化。先来安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install scour
|
||||
```
|
||||
|
||||
要想自动优化 SVG 文件,请运行 scour,就像这样:
|
||||
要想自动优化 SVG 文件,请运行 `scour`,就像这样:
|
||||
|
||||
```
|
||||
[user@localhost ]$ scour INPUT.svg OUTPUT.svg -p 3 --create-groups --renderer-workaround --strip-xml-prolog --remove-descriptive-elements --enable-comment-stripping --disable-embed-rasters --no-line-breaks --enable-id-stripping --shorten-ids
|
||||
@ -156,13 +152,13 @@ via: https://fedoramagazine.org/design-faster-web-pages-part-2-image-replacement
|
||||
作者:[Sirko Kemter][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/gnokii/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://wp.me/p3XX0v-5fJ
|
||||
[1]: https://linux.cn/article-10166-1.html
|
||||
[2]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[3]: https://fedoramagazine.org/?s=Inkscape
|
||||
[4]: https://getfedora.org
|
||||
@ -1,10 +1,11 @@
|
||||
在 Fedora 上使用 Pitivi 编辑你的视频
|
||||
在 Fedora 上使用 Pitivi 编辑视频
|
||||
======
|
||||
|
||||

|
||||
想制作一部你本周末冒险的视频吗?视频编辑有很多选择。但是,如果你在寻找一个容易上手的视频编辑器,并且也可以在官方 Fedora 仓库中找到,请尝试一下[Pitivi][1]。
|
||||
|
||||
Pitivi 是一个使用 GStreamer 框架的开源非线性视频编辑器。在 Fedora 下开箱即用,Pitivi 支持 OGG、WebM 和一系列其他格式。此外,通过 gstreamer 插件可以获得更多视频格式支持。Pitivi 也与 GNOME 桌面紧密集成,因此相比其他新的程序,它的 UI 在 Fedora Workstation 上会感觉很熟悉。
|
||||
想制作一部你本周末冒险的视频吗?视频编辑有很多选择。但是,如果你在寻找一个容易上手的视频编辑器,并且也可以在官方 Fedora 仓库中找到,请尝试一下 [Pitivi][1]。
|
||||
|
||||
Pitivi 是一个使用 GStreamer 框架的开源非线性视频编辑器。在 Fedora 下开箱即用,Pitivi 支持 OGG、WebM 和一系列其他格式。此外,通过 GStreamer 插件可以获得更多视频格式支持。Pitivi 也与 GNOME 桌面紧密集成,因此相比其他新的程序,它的 UI 在 Fedora Workstation 上会感觉很熟悉。
|
||||
|
||||
### 在 Fedora 上安装 Pitivi
|
||||
|
||||
@ -20,7 +21,7 @@ sudo dnf install pitivi
|
||||
|
||||
### 基本编辑
|
||||
|
||||
Pitivi 内置了多种工具,可以快速有效地编辑剪辑。只需将视频、音频和图像导入 Pitivi 媒体库,然后将它们拖到时间线上即可。此外,除了时间线上的简单淡入淡出过渡之外,pitivi 还允许你轻松地将剪辑的各个部分分割、修剪和分组。
|
||||
Pitivi 内置了多种工具,可以快速有效地编辑剪辑。只需将视频、音频和图像导入 Pitivi 媒体库,然后将它们拖到时间线上即可。此外,除了时间线上的简单淡入淡出过渡之外,Pitivi 还允许你轻松地将剪辑的各个部分分割、修剪和分组。
|
||||
|
||||
![][3]
|
||||
|
||||
@ -40,7 +41,7 @@ via: https://fedoramagazine.org/edit-your-videos-with-pitivi-on-fedora/
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,38 +1,39 @@
|
||||
如何在 Rasspberry Pi 上搭建 WordPress
|
||||
如何在树莓派上搭建 WordPress
|
||||
======
|
||||
|
||||
这篇简单的教程可以让你在 Rasspberry Pi 上运行你的 WordPress 网站。
|
||||
> 这篇简单的教程可以让你在树莓派上运行你的 WordPress 网站。
|
||||
|
||||

|
||||
|
||||
WordPress 是一个非常受欢迎的开源博客平台和内容管理平台(CMS)。它很容易搭建,而且还有一个活跃的开发者社区构建网站、创建主题和插件供其他人使用。
|
||||
|
||||
虽然通过一键式 WordPress 设置获得托管包很容易,但通过命令行就可以在 Linux 服务器上设置自己的托管包,而且 Raspberry Pi 是一种用来尝试它并顺便学习一些东西的相当好的途径。
|
||||
虽然通过一键式 WordPress 设置获得托管包很容易,但也可以简单地通过命令行在 Linux 服务器上设置自己的托管包,而且树莓派是一种用来尝试它并顺便学习一些东西的相当好的途径。
|
||||
|
||||
使用一个 web 堆栈的四个部分是 Linux、Apache、MySQL 和 PHP。这里是你对它们每一个需要了解的。
|
||||
一个经常使用的 Web 套件的四个部分是 Linux、Apache、MySQL 和 PHP。这里是你对它们每一个需要了解的。
|
||||
|
||||
### Linux
|
||||
|
||||
Raspberry Pi 上运行的系统是 Raspbian,这是一个基于 Debian,优化地可以很好的运行在 Raspberry Pi 硬件上的 Linux 发行版。你有两个选择:桌面版或是精简版。桌面版有一个熟悉的桌面还有很多教育软件和编程工具,像是 LibreOffice 套件、Mincraft,还有一个 web 浏览器。精简版本没有桌面环境,因此它只有命令行以及一些必要的软件。
|
||||
树莓派上运行的系统是 Raspbian,这是一个基于 Debian,为运行在树莓派硬件上而优化的很好的 Linux 发行版。你有两个选择:桌面版或是精简版。桌面版有一个熟悉的桌面还有很多教育软件和编程工具,像是 LibreOffice 套件、Mincraft,还有一个 web 浏览器。精简版本没有桌面环境,因此它只有命令行以及一些必要的软件。
|
||||
|
||||
这篇教程在两个版本上都可以使用,但是如果你使用的是精简版,你必须要有另外一台电脑去访问你的站点。
|
||||
|
||||
### Apache
|
||||
|
||||
Apache 是一个受欢迎的 web 服务器应用,你可以安装在你的 Raspberry Pi 上伺服你的 web 页面。就其自身而言,Apache 可以通过 HTTP 提供静态 HTML 文件。使用额外的模块,它也可以使用像是 PHP 的脚本语言提供动态网页。
|
||||
Apache 是一个受欢迎的 web 服务器应用,你可以安装在你的树莓派上伺服你的 web 页面。就其自身而言,Apache 可以通过 HTTP 提供静态 HTML 文件。使用额外的模块,它也可以使用像是 PHP 的脚本语言提供动态网页。
|
||||
|
||||
安装 Apache 非常简单。打开一个终端窗口,然后输入下面的命令:
|
||||
|
||||
```
|
||||
sudo apt install apache2 -y
|
||||
```
|
||||
Apache 默认放了一个测试文件在一个 web 目录中,你可以从你的电脑或是你网络中的其他计算机进行访问。只需要打开 web 浏览器,然后输入地址 **<http://localhost>**。或者(特别是你使用的是 Raspbian Lite 的话)输入你的 Pi 的 IP 地址代替 **localhost**。你应该会在你的浏览器窗口中看到这样的内容:
|
||||
|
||||
Apache 默认放了一个测试文件在一个 web 目录中,你可以从你的电脑或是你网络中的其他计算机进行访问。只需要打开 web 浏览器,然后输入地址 `<http://localhost>`。或者(特别是你使用的是 Raspbian Lite 的话)输入你的树莓派的 IP 地址代替 `localhost`。你应该会在你的浏览器窗口中看到这样的内容:
|
||||
|
||||
|
||||
|
||||
这意味着你的 Apache 已经开始工作了!
|
||||
|
||||
这个默认的网页仅仅是你文件系统里的一个文件。它在你本地的 **/var/www/html/index/html**。你可以使用 [Leafpad][2] 文本编辑器写一些 HTML 去替换这个文件的内容。
|
||||
这个默认的网页仅仅是你文件系统里的一个文件。它在你本地的 `/var/www/html/index/html`。你可以使用 [Leafpad][2] 文本编辑器写一些 HTML 去替换这个文件的内容。
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
@ -43,27 +44,27 @@ sudo leafpad index.html
|
||||
|
||||
### MySQL
|
||||
|
||||
MySQL (显然是 "my S-Q-L" 或者 "my sequel") 是一个很受欢迎的数据库引擎。就像 PHP,它被非常广泛的应用于网页服务,这也是为什么像 WordPress 一样的项目选择了它,以及这些项目是为何如此受欢迎。
|
||||
MySQL(读作 “my S-Q-L” 或者 “my sequel”)是一个很受欢迎的数据库引擎。就像 PHP,它被非常广泛的应用于网页服务,这也是为什么像 WordPress 一样的项目选择了它,以及这些项目是为何如此受欢迎。
|
||||
|
||||
在一个终端窗口中输入以下命令安装 MySQL 服务:
|
||||
在一个终端窗口中输入以下命令安装 MySQL 服务(LCTT 译注:实际上安装的是 MySQL 分支 MariaDB):
|
||||
|
||||
```
|
||||
sudo apt-get install mysql-server -y
|
||||
```
|
||||
|
||||
WordPress 使用 MySQL 存储文章、页面、用户数据、还有许多其他的内容。
|
||||
WordPress 使用 MySQL 存储文章、页面、用户数据、还有许多其他的内容。
|
||||
|
||||
### PHP
|
||||
|
||||
PHP 是一个预处理器:它是在服务器通过网络浏览器接受网页请求是运行的代码。它解决那些需要展示在网页上的内容,然后发送这些网页到浏览器上。,不像静态的 HTML,PHP 能在不同的情况下展示不同的内容。PHP 是一个在 web 上非常受欢迎的语言;很多像 Facebook 和 Wikipedia 的项目都使用 PHP 编写。
|
||||
PHP 是一个预处理器:它是在服务器通过网络浏览器接受网页请求是运行的代码。它解决那些需要展示在网页上的内容,然后发送这些网页到浏览器上。不像静态的 HTML,PHP 能在不同的情况下展示不同的内容。PHP 是一个在 web 上非常受欢迎的语言;很多像 Facebook 和 Wikipedia 的项目都使用 PHP 编写。
|
||||
|
||||
安装 PHP 和 MySQL 的插件:
|
||||
安装 PHP 和 MySQL 的插件:
|
||||
|
||||
```
|
||||
sudo apt-get install php php-mysql -y
|
||||
```
|
||||
|
||||
删除 **index.html**,然后创建 **index.php**:
|
||||
删除 `index.html`,然后创建 `index.php`:
|
||||
|
||||
```
|
||||
sudo rm index.html
|
||||
@ -82,16 +83,16 @@ sudo leafpad index.php
|
||||
|
||||
### WordPress
|
||||
|
||||
你可以使用 **wget** 命令从 [wordpress.org][3] 下载 WordPress。最新的 WordPress 总是使用 [wordpress.org/latest.tar.gz][4] 这个网址,所以你可以直接抓取这些文件,而无需到网页里面查看,现在的版本是 4.9.8。
|
||||
你可以使用 `wget` 命令从 [wordpress.org][3] 下载 WordPress。最新的 WordPress 总是使用 [wordpress.org/latest.tar.gz][4] 这个网址,所以你可以直接抓取这些文件,而无需到网页里面查看,现在的版本是 4.9.8。
|
||||
|
||||
确保你在 **/var/www/html** 目录中,然后删除里面的所有内容:
|
||||
确保你在 `/var/www/html` 目录中,然后删除里面的所有内容:
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
sudo rm *
|
||||
```
|
||||
|
||||
使用 **wget** 下载 WordPress,然后提取里面的内容,并移动提取的 WordPress 目录中的内容移动到 **html** 目录下:
|
||||
使用 `wget` 下载 WordPress,然后提取里面的内容,并移动提取的 WordPress 目录中的内容移动到 `html` 目录下:
|
||||
|
||||
```
|
||||
sudo wget http://wordpress.org/latest.tar.gz
|
||||
@ -99,13 +100,13 @@ sudo tar xzf latest.tar.gz
|
||||
sudo mv wordpress/* .
|
||||
```
|
||||
|
||||
现在可以删除压缩包和空的 **wordpress** 目录:
|
||||
现在可以删除压缩包和空的 `wordpress` 目录了:
|
||||
|
||||
```
|
||||
sudo rm -rf wordpress latest.tar.gz
|
||||
```
|
||||
|
||||
运行 **ls** 或者 **tree -L 1** 命令显示 WordPress 项目下包含的内容:
|
||||
运行 `ls` 或者 `tree -L 1` 命令显示 WordPress 项目下包含的内容:
|
||||
|
||||
```
|
||||
.
|
||||
@ -132,9 +133,9 @@ sudo rm -rf wordpress latest.tar.gz
|
||||
3 directories, 16 files
|
||||
```
|
||||
|
||||
这是 WordPress 的默认安装源。在 **wp-content** 目录中,你可以编辑你的自定义安装。
|
||||
这是 WordPress 的默认安装源。在 `wp-content` 目录中,你可以编辑你的自定义安装。
|
||||
|
||||
你现在应该把所有文件的所有权改为 Apache 用户:
|
||||
你现在应该把所有文件的所有权改为 Apache 的运行用户 `www-data`:
|
||||
|
||||
```
|
||||
sudo chown -R www-data: .
|
||||
@ -152,24 +153,27 @@ sudo mysql_secure_installation
|
||||
|
||||
你将会被问到一系列的问题。这里原来没有设置密码,但是在下一步你应该设置一个。确保你记住了你输入的密码,后面你需要使用它去连接你的 WordPress。按回车确认下面的所有问题。
|
||||
|
||||
当它完成之后,你将会看到 "All done!" 和 "Thanks for using MariaDB!" 的信息。
|
||||
当它完成之后,你将会看到 “All done!” 和 “Thanks for using MariaDB!” 的信息。
|
||||
|
||||
在终端窗口运行 **mysql** 命令:
|
||||
在终端窗口运行 `mysql` 命令:
|
||||
|
||||
```
|
||||
sudo mysql -uroot -p
|
||||
```
|
||||
输入你创建的 root 密码。你将看到 “Welcome to the MariaDB monitor.” 的欢迎信息。在 **MariaDB [(none)] >** 提示处使用以下命令,为你 WordPress 的安装创建一个数据库:
|
||||
|
||||
输入你创建的 root 密码(LCTT 译注:不是 Linux 系统的 root 密码,是 MySQL 的 root 密码)。你将看到 “Welcome to the MariaDB monitor.” 的欢迎信息。在 “MariaDB [(none)] >” 提示处使用以下命令,为你 WordPress 的安装创建一个数据库:
|
||||
|
||||
```
|
||||
create database wordpress;
|
||||
```
|
||||
|
||||
注意声明最后的分号,如果命令执行成功,你将看到下面的提示:
|
||||
|
||||
```
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
```
|
||||
把 数据库权限交给 root 用户在声明的底部输入密码:
|
||||
|
||||
把数据库权限交给 root 用户在声明的底部输入密码:
|
||||
|
||||
```
|
||||
GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPASSWORD';
|
||||
@ -181,13 +185,13 @@ GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPAS
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
按 **Ctrl+D** 退出 MariaDB 提示,返回到 Bash shell。
|
||||
按 `Ctrl+D` 退出 MariaDB 提示符,返回到 Bash shell。
|
||||
|
||||
### WordPress 配置
|
||||
|
||||
在你的 Raspberry Pi 打开网页浏览器,地址栏输入 **<http://localhost>**。选择一个你想要在 WordPress 使用的语言,然后点击 **继续**。你将会看到 WordPress 的欢迎界面。点击 **让我们开始吧** 按钮。
|
||||
在你的 树莓派 打开网页浏览器,地址栏输入 `http://localhost`。选择一个你想要在 WordPress 使用的语言,然后点击“Continue”。你将会看到 WordPress 的欢迎界面。点击 “Let's go!” 按钮。
|
||||
|
||||
按照下面这样填写基本的站点信息:
|
||||
按照下面这样填写基本的站点信息:
|
||||
|
||||
```
|
||||
Database Name: wordpress
|
||||
@ -197,22 +201,23 @@ Database Host: localhost
|
||||
Table Prefix: wp_
|
||||
```
|
||||
|
||||
点击 **提交** 继续,然后点击 **运行安装**。
|
||||
点击 “Submit” 继续,然后点击 “Run the install”。
|
||||
|
||||
|
||||
|
||||
按下面的格式填写:为你的站点设置一个标题、创建一个用户名和密码、输入你的 email 地址。点击 **安装 WordPress** 按钮,然后使用你刚刚创建的账号登录,你现在已经登录,而且你的站点已经设置好了,你可以在浏览器地址栏输入 **<http://localhost/wp-admin>** 查看你的网站。
|
||||
按下面的格式填写:为你的站点设置一个标题、创建一个用户名和密码、输入你的 email 地址。点击 “Install WordPress” 按钮,然后使用你刚刚创建的账号登录,你现在已经登录,而且你的站点已经设置好了,你可以在浏览器地址栏输入 `http://localhost/wp-admin` 查看你的网站。
|
||||
|
||||
### 永久链接
|
||||
|
||||
更改你的永久链接,使得你的 URLs 更加友好是一个很好的想法。
|
||||
更改你的永久链接设置,使得你的 URL 更加友好是一个很好的想法。
|
||||
|
||||
要这样做,首先登录你的 WordPress ,进入仪表盘。进入 **设置**,**永久链接**。选择 **文章名** 选项,然后点击 **保存更改**。接着你需要开启 Apache 的 **改写** 模块。
|
||||
要这样做,首先登录你的 WordPress ,进入仪表盘。进入 “Settings”,“Permalinks”。选择 “Post name” 选项,然后点击 “Save Changes”。接着你需要开启 Apache 的 `rewrite` 模块。
|
||||
|
||||
```
|
||||
sudo a2enmod rewrite
|
||||
```
|
||||
你还需要告诉虚拟托管服务,站点允许改写请求。为你的虚拟主机编辑 Apache 配置文件
|
||||
|
||||
你还需要告诉虚拟托管服务,站点允许改写请求。为你的虚拟主机编辑 Apache 配置文件:
|
||||
|
||||
```
|
||||
sudo leafpad /etc/apache2/sites-available/000-default.conf
|
||||
@ -226,7 +231,7 @@ sudo leafpad /etc/apache2/sites-available/000-default.conf
|
||||
</Directory>
|
||||
```
|
||||
|
||||
确保其中有像这样的内容 **< VirtualHost \*:80>**
|
||||
确保其中有像这样的内容 `<VirtualHost *:80>`:
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
@ -244,17 +249,16 @@ sudo systemctl restart apache2
|
||||
|
||||
### 下一步?
|
||||
|
||||
WordPress 是可以高度自定义的。在网站顶部横幅处点击你的站点名,你就会进入仪表盘,。在这里你可以修改主题、添加页面和文章、编辑菜单、添加插件、以及许多其他的事情。
|
||||
WordPress 是可以高度自定义的。在网站顶部横幅处点击你的站点名,你就会进入仪表盘。在这里你可以修改主题、添加页面和文章、编辑菜单、添加插件、以及许多其他的事情。
|
||||
|
||||
这里有一些你可以在 Raspberry Pi 的网页服务上尝试的有趣的事情:
|
||||
这里有一些你可以在树莓派的网页服务上尝试的有趣的事情:
|
||||
|
||||
* 添加页面和文章到你的网站
|
||||
* 从外观菜单安装不同的主题
|
||||
* 自定义你的网站主题或是创建你自己的
|
||||
* 使用你的网站服务向你的网络上的其他人显示有用的信息
|
||||
|
||||
|
||||
不要忘记,Raspberry Pi 是一台 Linux 电脑。你也可以使用相同的结构在运行着 Debian 或者 Ubuntu 的服务器上安装 WordPress。
|
||||
不要忘记,树莓派是一台 Linux 电脑。你也可以使用相同的结构在运行着 Debian 或者 Ubuntu 的服务器上安装 WordPress。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -263,7 +267,7 @@ via: https://opensource.com/article/18/10/setting-wordpress-raspberry-pi
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
理解 Linux 链接 (二)
|
||||
理解 Linux 链接(二)
|
||||
======
|
||||
> 我们继续这个系列,来看一些你所不知道的微妙之处。
|
||||
|
||||

|
||||
|
||||
在[本系列的第一篇文章中][1],我们认识了硬链接,软链接,知道在很多时候链接是非常有用的。链接看起来比较简单,但是也有一些不易察觉的奇怪的地方需要注意。这就是我们这篇文章中要讲的。例如,像一下我们在前一篇文章中创建的指向 `libblah` 的链接。请注意,我们是如何从目标文件夹中创建链接的。
|
||||
在[本系列的第一篇文章中][1],我们认识了硬链接、软链接,知道在很多时候链接是非常有用的。链接看起来比较简单,但是也有一些不易察觉的奇怪的地方需要注意。这就是我们这篇文章中要讲的。例如,像一下我们在前一篇文章中创建的指向 `libblah` 的链接。请注意,我们是如何从目标文件夹中创建链接的。
|
||||
|
||||
```
|
||||
cd /usr/local/lib
|
||||
|
||||
ln -s /usr/lib/libblah
|
||||
```
|
||||
|
||||
@ -15,35 +15,32 @@ ln -s /usr/lib/libblah
|
||||
|
||||
```
|
||||
cd /usr/lib
|
||||
|
||||
ln -s libblah /usr/local/lib
|
||||
```
|
||||
|
||||
也就是说,从原始文件夹内到目标文件夹之间的链接将不起作用。
|
||||
|
||||
出现这种情况的原因是 `ln` 会把它当作是你在 `/usr/local/lib` 中创建一个到 `/usr/local/lib` 的链接,并在 `/usr/local/lib` 中创建了从 `libblah` 到 `libblah` 的一个链接。这是因为所有链接文件获取的是文件的名称(`libblah`),而不是文件的路径,最终的结果将会产生一个坏的链接。
|
||||
出现这种情况的原因是 `ln` 会把它当作是你在 `/usr/local/lib` 中创建一个到 `/usr/local/lib` 的链接,并在 `/usr/local/lib` 中创建了从 `libblah` 到 `libblah` 的一个链接。这是因为所有链接文件获取的是文件的名称(`libblah),而不是文件的路径,最终的结果将会产生一个坏的链接。
|
||||
|
||||
然而,请看下面的这种情况。
|
||||
|
||||
```
|
||||
cd /usr/lib
|
||||
|
||||
ln -s /usr/lib/libblah /usr/local/lib
|
||||
```
|
||||
|
||||
是可以工作的。奇怪的事情又来了,不管你在文件系统的任何位置执行指令,它都可以好好的工作。使用绝对路径,也就是说,指定整个完整的路径,从根目录(`/`)开始到需要的文件或者是文件夹,是最好的实现方式。
|
||||
是可以工作的。奇怪的事情又来了,不管你在文件系统的任何位置执行这个指令,它都可以好好的工作。使用绝对路径,也就是说,指定整个完整的路径,从根目录(`/`)开始到需要的文件或者是文件夹,是最好的实现方式。
|
||||
|
||||
其它需要注意的事情是,只要 `/usr/lib` 和 `/usr/local/lib` 在一个分区上,做一个如下的硬链接:
|
||||
|
||||
```
|
||||
cd /usr/lib
|
||||
|
||||
ln libblah /usr/local/lib
|
||||
```
|
||||
|
||||
也是可以工作的,因为硬链接不依赖于指向文件系统内的文件来工作。
|
||||
|
||||
如果硬链接不起作用,那么可能是你想跨分区之间建立一个硬链接。就比如说,你有分区A上有文件 `fileA` ,并且把这个分区挂载到 `/path/to/partitionA/directory` 目录,而你又想从 `fileA` 链接到分区B上 `/path/to/partitionB/directory` 目录,这样是行不通的。
|
||||
如果硬链接不起作用,那么可能是你想跨分区之间建立一个硬链接。就比如说,你有分区 A 上有文件 `fileA` ,并且把这个分区挂载到 `/path/to/partitionA/directory` 目录,而你又想从 `fileA` 链接到分区 B 上 `/path/to/partitionB/directory` 目录,这样是行不通的。
|
||||
|
||||
```
|
||||
ln /path/to/partitionA/directory/file /path/to/partitionB/directory
|
||||
@ -63,15 +60,15 @@ ln -s /path/to/some/directory /path/to/some/other/directory
|
||||
|
||||
这将在 `/path/to/some/other/directory` 中创建 `/path/to/some/directory` 的链接,没有任何问题。
|
||||
|
||||
当你使用硬链接做同样的事情的时候,会提示你一个错误,说不允许那么做。而不允许这么做的原因量会导致无休止的递归:如果你在目录A中有一个目录B,然后你在目录B中链接A,就会出现同样的情况,在目录A中,目录A包含了目录B,而在目录B中又包含了A,然后又包含了B,等等无穷无尽。
|
||||
当你使用硬链接做同样的事情的时候,会提示你一个错误,说不允许那么做。而不允许这么做的原因量会导致无休止的递归:如果你在目录 A 中有一个目录 B,然后你在目录 B 中链接 A,就会出现同样的情况,在目录 A 中,目录 A 包含了目录 B,而在目录 B 中又包含了 A,然后又包含了 B,等等无穷无尽。
|
||||
|
||||
当然你可以在递归中使用软链接,但你为什么要那样做呢?
|
||||
|
||||
### 我应该使用硬链接还是软链接呢?
|
||||
|
||||
通常,你可以在任何地方使用软链接做任何事情。实际上,在有些情况下你只能使用软软链接。话说回来,硬链接的效率要稍高一些:它们占用的磁盘空间更少,访问速度更快。在大多数的机器上, 发你可以忽略这一点点的差异,因为:在磁盘空间越来越大,访问速度越来越快的今天,空间和速度的差异可以忽略不计。不过,如果你是在一个有小存储和低功耗的处理器上使用嵌入式系统上使用 linux, 则可能需要考虑使用硬链接。
|
||||
通常,你可以在任何地方使用软链接做任何事情。实际上,在有些情况下你只能使用软链接。话说回来,硬链接的效率要稍高一些:它们占用的磁盘空间更少,访问速度更快。在大多数的机器上,你可以忽略这一点点的差异,因为:在磁盘空间越来越大,访问速度越来越快的今天,空间和速度的差异可以忽略不计。不过,如果你是在一个有小存储和低功耗的处理器上使用嵌入式系统上使用 Linux, 则可能需要考虑使用硬链接。
|
||||
|
||||
另一个使用硬链接的原因是硬链接不容易破碎。假设你有一个软链接,而你意外的移动或者删除了它指向的文件,那么你的软链接将会破碎,并指向了一个不存在的东西。这种情况是不会发生在硬链接中的,因为硬链接直接指向的是磁盘上的数据。实际上,磁盘上的空间不不会被标记为空闲,除非最后一个指向它的硬链接把它从文件系统中擦除掉。
|
||||
另一个使用硬链接的原因是硬链接不容易损坏。假设你有一个软链接,而你意外的移动或者删除了它指向的文件,那么你的软链接将会损坏,并指向了一个不存在的东西。这种情况是不会发生在硬链接中的,因为硬链接直接指向的是磁盘上的数据。实际上,磁盘上的空间不会被标记为空闲,除非最后一个指向它的硬链接把它从文件系统中擦除掉。
|
||||
|
||||
软链接,在另一方面比硬链接可以做更多的事情,而且可以指向任何东西,可以是文件或目录。它也可以指向不在同一个分区上的文件和目录。仅这两个不同,我们就可以做出唯一的选择了。
|
||||
|
||||
@ -79,7 +76,7 @@ ln -s /path/to/some/directory /path/to/some/other/directory
|
||||
|
||||
现在我们已经介绍了文件和目录以及操作它们的工具,你是否已经准备好转到这些工具,可以浏览目录层次结构,可以查找文件中的数据,也可以检查目录。这就是我们下一期中要做的事情。下期见。
|
||||
|
||||
你可以通过Linux 基金会和edX [Linux 简介][2]了解更多关于Linux的免费课程。
|
||||
你可以通过 Linux 基金会和 edX “[Linux 简介][2]”了解更多关于 Linux 的免费课程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -87,12 +84,12 @@ via: https://www.linux.com/blog/2018/10/understanding-linux-links-part-2
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Jamkr](https://github.com/Jamkr)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/blog/intro-to-linux/2018/10/linux-links-part-1
|
||||
[1]: https://linux.cn/article-10173-1.html
|
||||
[2]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -3,33 +3,34 @@
|
||||
|
||||

|
||||
|
||||
管道命令的作用是将一个命令/程序/进程的输出发送给另一个命令/程序/进程,以便将输出结果进行进一步的处理。我们可以通过使用管道命令把多个命令组合起来,使一个命令的标准输入或输出重定向到另一个命令。两个或多个 Linux 命令之间的竖线字符(|)表示在命令之间使用管道命令。管道命令的一般语法如下所示:
|
||||
管道命令的作用是将一个命令/程序/进程的输出发送给另一个命令/程序/进程,以便将输出结果进行进一步的处理。我们可以通过使用管道命令把多个命令组合起来,使一个命令的标准输入或输出重定向到另一个命令。两个或多个 Linux 命令之间的竖线字符(`|`)表示在命令之间使用管道命令。管道命令的一般语法如下所示:
|
||||
|
||||
```
|
||||
Command-1 | Command-2 | Command-3 | …| Command-N
|
||||
```
|
||||
|
||||
`Ultimate Plumber`(简称 `UP`)是一个命令行工具,它可以用于即时预览管道命令结果。如果你在使用 Linux 时经常会用到管道命令,就可以通过它更好地运用管道命令了。它可以预先显示执行管道命令后的结果,而且是即时滚动地显示,让你可以轻松构建复杂的管道。
|
||||
Ultimate Plumber(简称 UP)是一个命令行工具,它可以用于即时预览管道命令结果。如果你在使用 Linux 时经常会用到管道命令,就可以通过它更好地运用管道命令了。它可以预先显示执行管道命令后的结果,而且是即时滚动地显示,让你可以轻松构建复杂的管道。
|
||||
|
||||
下文将会介绍如何安装 `UP` 并用它将复杂管道命令的编写变得简单。
|
||||
下文将会介绍如何安装 UP 并用它将复杂管道命令的编写变得简单。
|
||||
|
||||
|
||||
**重要警告:**
|
||||
|
||||
在生产环境中请谨慎使用 `UP`!在使用它的过程中,有可能会在无意中删除重要数据,尤其是搭配 `rm` 或 `dd` 命令时需要更加小心。勿谓言之不预。
|
||||
在生产环境中请谨慎使用 UP!在使用它的过程中,有可能会在无意中删除重要数据,尤其是搭配 `rm` 或 `dd` 命令时需要更加小心。勿谓言之不预。
|
||||
|
||||
### 使用 Ultimate Plumber 即时预览管道命令
|
||||
|
||||
下面给出一个简单的例子介绍 `UP` 的使用方法。如果需要将 `lshw` 命令的输出传递给 `UP`,只需要在终端中输入以下命令,然后回车:
|
||||
下面给出一个简单的例子介绍 `up` 的使用方法。如果需要将 `lshw` 命令的输出传递给 `up`,只需要在终端中输入以下命令,然后回车:
|
||||
|
||||
```
|
||||
$ lshw |& up
|
||||
```
|
||||
|
||||
你会在屏幕顶部看到一个输入框,如下图所示。
|
||||
|
||||

|
||||
|
||||
在输入命令的过程中,输入管道符号并回车,就可以立即执行已经输入了的命令。`Ultimate Plumber` 会在下方的可滚动窗口中即时显示管道命令的输出。在这种状态下,你可以通过 `PgUp`/`PgDn` 键或 `ctrl + ←`/`ctrl + →` 组合键来查看结果。
|
||||
在输入命令的过程中,输入管道符号并回车,就可以立即执行已经输入了的命令。Ultimate Plumber 会在下方的可滚动窗口中即时显示管道命令的输出。在这种状态下,你可以通过 `PgUp`/`PgDn` 键或 `ctrl + ←`/`ctrl + →` 组合键来查看结果。
|
||||
|
||||
当你满意执行结果之后,可以使用 `ctrl + x` 组合键退出 `UP`。而退出前编写的管道命令则会保存在当前工作目录的文件中,并命名为 `up1.sh`。如果这个文件名已经被占用,就会命名为 `up2.sh`、`up3.sh` 等等以此类推,直到第 1000 个文件。如果你不需要将管道命令保存输出,只需要使用 `ctrl + c` 组合键退出即可。
|
||||
|
||||
@ -41,29 +42,29 @@ $ cat up2.sh
|
||||
grep network -A5 | grep : | cut -d: -f2- | paste - -
|
||||
```
|
||||
|
||||
如果通过管道发送到 `UP` 的命令运行时间太长,终端窗口的左上角会显示一个波浪号(~)字符,这就表示 `UP` 在等待前一个命令的输出结果作为输入。在这种情况下,你可能需要使用 `ctrl + s` 组合键暂时冻结 `UP` 的输入缓冲区大小。在需要解冻的时候,使用 `ctrl + q` 组合键即可。`Ultimate Plumber` 的输入缓冲区大小一般为 40 MB,到达这个限制之后,屏幕的左上角会显示一个加号。
|
||||
如果通过管道发送到 `up` 的命令运行时间太长,终端窗口的左上角会显示一个波浪号(~)字符,这就表示 `up` 在等待前一个命令的输出结果作为输入。在这种情况下,你可能需要使用 `ctrl + s` 组合键暂时冻结 `up` 的输入缓冲区大小。在需要解冻的时候,使用 `ctrl + q` 组合键即可。Ultimate Plumber 的输入缓冲区大小一般为 40 MB,到达这个限制之后,屏幕的左上角会显示一个加号。
|
||||
|
||||
以下是 `up` 命令的一个简单演示:
|
||||
|
||||
以下是 `UP` 命令的一个简单演示:
|
||||

|
||||
|
||||
### 安装 Ultimate Plumber
|
||||
|
||||
喜欢这个工具的话,你可以在你的 Linux 系统上安装使用。安装过程也相当简单,只需要在终端里执行以下两个命令就可以安装 `UP` 了。
|
||||
喜欢这个工具的话,你可以在你的 Linux 系统上安装使用。安装过程也相当简单,只需要在终端里执行以下两个命令就可以安装 `up` 了。
|
||||
|
||||
首先从 Ultimate Plumber 的[发布页面][1]下载最新的二进制文件,并将放在你系统的某个路径下,例如`/usr/local/bin/`。
|
||||
首先从 Ultimate Plumber 的[发布页面][1]下载最新的二进制文件,并将放在你系统的某个路径下,例如 `/usr/local/bin/`。
|
||||
|
||||
```
|
||||
$ sudo wget -O /usr/local/bin/up wget https://github.com/akavel/up/releases/download/v0.2.1/up
|
||||
```
|
||||
|
||||
然后向 `UP` 二进制文件赋予可执行权限:
|
||||
然后向 `up` 二进制文件赋予可执行权限:
|
||||
|
||||
```
|
||||
$ sudo chmod a+x /usr/local/bin/up
|
||||
```
|
||||
|
||||
至此,你已经完成了 `UP` 的安装,可以开始编写你的管道命令了。
|
||||
|
||||
至此,你已经完成了 `up` 的安装,可以开始编写你的管道命令了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -73,7 +74,7 @@ via: https://www.ostechnix.com/ultimate-plumber-writing-linux-pipes-with-instant
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,32 +1,28 @@
|
||||
Python 机器学习的必备技巧
|
||||
======
|
||||
|
||||
> 尝试使用 Python 掌握机器学习、人工智能和深度学习。
|
||||
|
||||

|
||||
|
||||
想要入门机器学习并不难。除了<ruby>大规模网络公开课<rt>Massive Open Online Courses</rt></ruby>(MOOCs)之外,还有很多其它优秀的免费资源。下面我分享一些我觉得比较有用的方法。
|
||||
想要入门机器学习并不难。除了<ruby>大规模网络公开课<rt>Massive Open Online Courses</rt></ruby>(MOOC)之外,还有很多其它优秀的免费资源。下面我分享一些我觉得比较有用的方法。
|
||||
|
||||
1. 阅览一些关于这方面的视频、文章或者书籍,例如 [The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World][29],你肯定会喜欢这些[关于机器学习的互动页面][30]。
|
||||
|
||||
2. 对于“机器学习”、“人工智能”、“深度学习”、“数据科学”、“计算机视觉”和“机器人技术”这一堆新名词,你需要知道它们之前的区别。你可以阅览这些领域的专家们的演讲,例如[数据科学家 Brandon Rohrer 的这个视频][1]。
|
||||
|
||||
3. 明确你自己的学习目标,并选择合适的 [Coursera 课程][3],或者参加高校的网络公开课。例如[华盛顿大学的课程][4]就很不错。
|
||||
|
||||
4. 关注优秀的博客:例如 [KDnuggets][32] 的博客、[Mark Meloon][33] 的博客、[Brandon Rohrer][34] 的博客、[Open AI][35] 的博客,这些都值得推荐。
|
||||
|
||||
5. 如果你对在线课程有很大兴趣,后文中会有如何[正确选择 MOOC 课程][31]的指导。
|
||||
|
||||
6. 最重要的是,培养自己对这些技术的兴趣。加入一些优秀的社交论坛,专注于阅读和了解,将这些技术的背景知识和发展方向理解透彻,并积极思考在日常生活和工作中如何应用机器学习或数据科学的原理。例如建立一个简单的回归模型来预测下一次午餐的成本,又或者是从电力公司的网站上下载历史电费数据,在 Excel 中进行简单的时序分析以发现某种规律。在你对这些技术产生了浓厚兴趣之后,可以观看以下这个视频。
|
||||
1. 从一些 YouTube 上的好视频开始,阅览一些关于这方面的文章或者书籍,例如 《[主算法:终极学习机器的探索将如何重塑我们的世界][29]》,而且我觉得你肯定会喜欢这些[关于机器学习的很酷的互动页面][30]。
|
||||
2. 对于“<ruby>机器学习<rt>machine learning</rt></ruby>”、“<ruby>人工智能<rt>artificial intelligence</rt></ruby>”、“<ruby>深度学习<rt>deep learning</rt></ruby>”、“<ruby>数据科学<rt>data science</rt></ruby>”、“<ruby>计算机视觉<rt>computer vision</rt></ruby>”和“<ruby>机器人技术<rt>robotics</rt></ruby>”这一堆新名词,你需要知道它们之间的区别。你可以阅览或聆听这些领域的专家们的演讲,例如这位有影响力的[数据科学家 Brandon Rohrer 的精彩视频][1]。或者这个讲述了数据科学相关的[各种角色之间的区别][2]的视频。
|
||||
3. 明确你自己的学习目标,并选择合适的 [Coursera 课程][3],或者参加高校的网络公开课,例如[华盛顿大学的课程][4]就很不错。
|
||||
4. 关注优秀的博客:例如 [KDnuggets][32] 的博客、[Mark Meloon][33] 的博客、[Brandon Rohrer][34] 的博客、[Open AI][35] 的研究博客,这些都值得推荐。
|
||||
5. 如果你热衷于在线课程,后文中会有如何[正确选择 MOOC 课程][31]的指导。
|
||||
6. 最重要的是,培养自己对这些技术的兴趣。加入一些优秀的社交论坛,不要被那些耸人听闻的头条和新闻所吸引,专注于阅读和了解,将这些技术的背景知识和发展方向理解透彻,并积极思考在日常生活和工作中如何应用机器学习或数据科学的原理。例如建立一个简单的回归模型来预测下一次午餐的成本,又或者是从电力公司的网站上下载历史电费数据,在 Excel 中进行简单的时序分析以发现某种规律。在你对这些技术产生了浓厚兴趣之后,可以观看以下这个视频。
|
||||
|
||||
<https://www.youtube.com/embed/IpGxLWOIZy4>
|
||||
|
||||
### Python 是机器学习和人工智能方面的最佳语言吗?
|
||||
|
||||
除非你是一名专业的研究一些复杂算法纯理论证明的研究人员,否则,对于一个机器学习的入门者来说,需要熟悉至少一种高级编程语言一家相关的专业知识。因为大多数情况下都是需要考虑如何将机器学习算法应用于解决实际问题,而这需要有一定的编程能力作为基础。
|
||||
除非你是一名专业的研究一些复杂算法纯理论证明的研究人员,否则,对于一个机器学习的入门者来说,需要熟悉至少一种高级编程语言。因为大多数情况下都是需要考虑如何将现有的机器学习算法应用于解决实际问题,而这需要有一定的编程能力作为基础。
|
||||
|
||||
哪一种语言是数据科学的最佳语言?这个讨论一直没有停息过。对于这方面,你可以提起精神来看一下 FreeCodeCamp 上这一篇关于[数据科学语言][6]的文章,又或者是 KDnuggets 关于 [Python 和 R][7] 之间的深入探讨。
|
||||
哪一种语言是数据科学的最佳语言?这个讨论一直没有停息过。对于这方面,你可以提起精神来看一下 FreeCodeCamp 上这一篇关于[数据科学语言][6]的文章,又或者是 KDnuggets 关于 [Python 和 R 之争][7]的深入探讨。
|
||||
|
||||
目前人们普遍认为 Python 在开发、部署、维护各方面的效率都是比较高的。与 Java、C 和 C++ 这些较为传统的语言相比,Python 的语法更为简单和高级。而且 Python 拥有活跃的社区群体、广泛的开源文化、数百个专用于机器学习的优质代码库,以及来自业界巨头(包括Google、Dropbox、Airbnb 等)的强大技术支持。
|
||||
目前人们普遍认为 Python 在开发、部署、维护各方面的效率都是比较高的。与 Java、C 和 C++ 这些较为传统的语言相比,Python 的语法更为简单和高级。而且 Python 拥有活跃的社区群体、广泛的开源文化、数百个专用于机器学习的优质代码库,以及来自业界巨头(包括 Google、Dropbox、Airbnb 等)的强大技术支持。
|
||||
|
||||
### 基础 Python 库
|
||||
|
||||
@ -46,7 +42,7 @@ Pandas 是 Python 生态中用于进行通用数据分析的最受欢迎的库
|
||||
* 选择数据子集
|
||||
* 跨行列计算
|
||||
* 查找并补充缺失的数据
|
||||
* 将操作应用于数据中的独立组
|
||||
* 将操作应用于数据中的独立分组
|
||||
* 按照多种格式转换数据
|
||||
* 组合多个数据集
|
||||
* 高级时间序列功能
|
||||
@ -68,7 +64,7 @@ Pandas 是 Python 生态中用于进行通用数据分析的最受欢迎的库
|
||||
|
||||
#### Scikit-learn
|
||||
|
||||
Scikit-learn 是机器学习方面通用的重要 Python 包。它实现了多种[分类][16]、[回归][17]和[聚类][18]算法,包括[支持向量机][19]、[随机森林][20]、[梯度增强][21]、[k-means 算法][22]和 [DBSCAN 算法][23],可以与 Python 的数值库 NumPy 和科学计算库 [SciPy][24] 结合使用。它通过兼容的接口提供了有监督和无监督的学习算法。Scikit-learn 的强壮性让它可以稳定运行在生产环境中,同时它在易用性、代码质量、团队协作、文档和性能等各个方面都有良好的表现。可以参考这篇基于 Scikit-learn 的[机器学习入门][25],或者这篇基于 Scikit-learn 的[简单机器学习用例演示][26]。
|
||||
Scikit-learn 是机器学习方面通用的重要 Python 包。它实现了多种[分类][16]、[回归][17]和[聚类][18]算法,包括[支持向量机][19]、[随机森林][20]、[梯度增强][21]、[k-means 算法][22]和 [DBSCAN 算法][23],可以与 Python 的数值库 NumPy 和科学计算库 [SciPy][24] 结合使用。它通过兼容的接口提供了有监督和无监督的学习算法。Scikit-learn 的强壮性让它可以稳定运行在生产环境中,同时它在易用性、代码质量、团队协作、文档和性能等各个方面都有良好的表现。可以参考[这篇基于 Scikit-learn 的机器学习入门][25],或者[这篇基于 Scikit-learn 的简单机器学习用例演示][26]。
|
||||
|
||||
本文使用 [CC BY-SA 4.0][28] 许可,在 [Heartbeat][27] 上首发。
|
||||
|
||||
@ -79,7 +75,7 @@ via: https://opensource.com/article/18/10/machine-learning-python-essential-hack
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,58 @@
|
||||
8 个出没于终端中的吓人命令
|
||||
======
|
||||
|
||||
> 欢迎来到 Linux 令人毛骨悚然的一面。
|
||||
|
||||

|
||||
|
||||
又是一年中的这个时候:天气变冷了、树叶变色了,各处的孩子都化妆成了小鬼、妖精和僵尸。(LCTT 译注:本文原发表于万圣节)但你知道吗, Unix (和 Linux) 和它们的各个分支也充满了令人毛骨悚然的东西?让我们来看一下我们所熟悉和喜爱的操作系统的一些令人毛骨悚然的一面。
|
||||
|
||||
### 半神(守护进程)
|
||||
|
||||
如果没有潜伏于系统中的各种<ruby>守护进程<rt>daemon</rt></ruby>,那么 Unix 就没什么不同。守护进程是运行在后台的进程,并为用户和操作系统本身提供有用的服务,比如 SSH、FTP、HTTP 等等。
|
||||
|
||||
### 僵尸(僵尸进程)
|
||||
|
||||
不时出现的僵尸进程是一种被杀死但是拒绝离开的进程。当它出现时,无疑你只能选择你有的工具来赶走它。僵尸进程通常表明产生它的进程出现了问题。
|
||||
|
||||
### 杀死(kill)
|
||||
|
||||
你不仅可以使用 `kill` 来干掉一个僵尸进程,你还可以用它杀死任何对你系统产生负面影响的进程。有一个使用太多 RAM 或 CPU 周期的进程?使用 `kill` 命令杀死它。
|
||||
|
||||
### 猫(cat)
|
||||
|
||||
`cat` 和猫科动物无关,但是与文件操作有关:`cat` 是 “concatenate” 的缩写。你甚至可以使用这个方便的命令来查看文件的内容。
|
||||
|
||||
### 尾巴(tail)
|
||||
|
||||
当你想要查看文件中最后 n 行时,`tail` 命令很有用。当你想要监控一个文件时,它也很棒。
|
||||
|
||||
### 巫师(which)
|
||||
|
||||
哦,不,它不是巫师(witch)的一种。而是打印传递给它的命令所在的文件位置的命令。例如,`which python` 将在你系统上打印每个版本的 Python 的位置。
|
||||
|
||||
### 地下室(crypt)
|
||||
|
||||
`crypt` 命令,以前称为 `mcrypt`,当你想要加密(encrypt)文件的内容时,它是很方便的,这样除了你之外没有人可以读取它。像大多数 Unix 命令一样,你可以单独使用 `crypt` 或在系统脚本中调用它。
|
||||
|
||||
### 切碎(shred)
|
||||
|
||||
当你不仅要删除文件还想要确保没有人能够恢复它时,`shred` 命令很方便。使用 `rm` 命令删除文件是不够的。你还需要覆盖该文件以前占用的空间。这就是 `shred` 的用武之地。
|
||||
|
||||
这些只是你会在 Unix 中发现的一部分令人毛骨悚然的东西。你还知道其他诡异的命令么?请随时告诉我。
|
||||
|
||||
万圣节快乐!(LCTT:可惜我们翻译完了,只能将恐怖的感觉延迟了 :D)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/spookier-side-unix-linux
|
||||
|
||||
作者:[Patrick H.Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pmullins
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# PR 检查脚本
|
||||
set -e
|
||||
|
||||
|
||||
@ -22,7 +22,12 @@ do_analyze() {
|
||||
# 统计每个类别的每个操作
|
||||
REGEX="$(get_operation_regex "$STAT" "$TYPE")"
|
||||
OTHER_REGEX="${OTHER_REGEX}|${REGEX}"
|
||||
eval "${TYPE}_${STAT}=\"\$(grep -Ec '$REGEX' /tmp/changes)\"" || true
|
||||
CHANGES_FILE="/tmp/changes_${TYPE}_${STAT}"
|
||||
eval "grep -E '$REGEX' /tmp/changes" \
|
||||
| sed 's/^[^\/]*\///g' \
|
||||
| sort > "$CHANGES_FILE" || true
|
||||
sed 's/^.*\///g' "$CHANGES_FILE" > "${CHANGES_FILE}_basename"
|
||||
eval "${TYPE}_${STAT}=$(wc -l < "$CHANGES_FILE")"
|
||||
eval echo "${TYPE}_${STAT}=\$${TYPE}_${STAT}"
|
||||
done
|
||||
done
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# 检查脚本状态
|
||||
set -e
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# PR 文件变更收集
|
||||
set -e
|
||||
|
||||
@ -31,7 +31,16 @@ git --no-pager show --summary "${MERGE_BASE}..HEAD"
|
||||
|
||||
echo "[收集] 写出文件变更列表……"
|
||||
|
||||
git diff "$MERGE_BASE" HEAD --no-renames --name-status > /tmp/changes
|
||||
RAW_CHANGES="$(git diff "$MERGE_BASE" HEAD --no-renames --name-status -z \
|
||||
| tr '\0' '\n')"
|
||||
[ -z "$RAW_CHANGES" ] && {
|
||||
echo "[收集] 无变更,退出……"
|
||||
exit 1
|
||||
}
|
||||
echo "$RAW_CHANGES" | while read -r STAT; do
|
||||
read -r NAME
|
||||
echo "${STAT} ${NAME}"
|
||||
done > /tmp/changes
|
||||
echo "[收集] 已写出文件变更列表:"
|
||||
cat /tmp/changes
|
||||
{ [ -z "$(cat /tmp/changes)" ] && echo "(无变更)"; } || true
|
||||
|
||||
@ -10,9 +10,10 @@ export TSL_DIR='translated' # 已翻译
|
||||
export PUB_DIR='published' # 已发布
|
||||
|
||||
# 定义匹配规则
|
||||
export CATE_PATTERN='(news|talk|tech)' # 类别
|
||||
export CATE_PATTERN='(talk|tech)' # 类别
|
||||
export FILE_PATTERN='[0-9]{8} [a-zA-Z0-9_.,() -]*\.md' # 文件名
|
||||
|
||||
# 获取用于匹配操作的正则表达式
|
||||
# 用法:get_operation_regex 状态 类型
|
||||
#
|
||||
# 状态为:
|
||||
@ -26,5 +27,50 @@ export FILE_PATTERN='[0-9]{8} [a-zA-Z0-9_.,() -]*\.md' # 文件名
|
||||
get_operation_regex() {
|
||||
STAT="$1"
|
||||
TYPE="$2"
|
||||
|
||||
echo "^${STAT}\\s+\"?$(eval echo "\$${TYPE}_DIR")/"
|
||||
}
|
||||
|
||||
# 确保两个变更文件一致
|
||||
# 用法:ensure_identical X类型 X状态 Y类型 Y状态 是否仅比较文件名
|
||||
#
|
||||
# 状态为:
|
||||
# - A:添加
|
||||
# - M:修改
|
||||
# - D:删除
|
||||
# 类型为:
|
||||
# - SRC:未翻译
|
||||
# - TSL:已翻译
|
||||
# - PUB:已发布
|
||||
ensure_identical() {
|
||||
TYPE_X="$1"
|
||||
STAT_X="$2"
|
||||
TYPE_Y="$3"
|
||||
STAT_Y="$4"
|
||||
NAME_ONLY="$5"
|
||||
SUFFIX=
|
||||
[ -n "$NAME_ONLY" ] && SUFFIX="_basename"
|
||||
|
||||
X_FILE="/tmp/changes_${TYPE_X}_${STAT_X}${SUFFIX}"
|
||||
Y_FILE="/tmp/changes_${TYPE_Y}_${STAT_Y}${SUFFIX}"
|
||||
|
||||
cmp "$X_FILE" "$Y_FILE" 2> /dev/null
|
||||
}
|
||||
|
||||
# 检查文章分类
|
||||
# 用法:check_category 类型 状态
|
||||
#
|
||||
# 状态为:
|
||||
# - A:添加
|
||||
# - M:修改
|
||||
# - D:删除
|
||||
# 类型为:
|
||||
# - SRC:未翻译
|
||||
# - TSL:已翻译
|
||||
check_category() {
|
||||
TYPE="$1"
|
||||
STAT="$2"
|
||||
|
||||
CHANGES="/tmp/changes_${TYPE}_${STAT}"
|
||||
! grep -Eqv "^${CATE_PATTERN}/" "$CHANGES"
|
||||
}
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
#!/bin/bash
|
||||
#!/bin/sh
|
||||
# 匹配 PR 规则
|
||||
set -e
|
||||
|
||||
@ -27,31 +27,39 @@ rule_bypass_check() {
|
||||
# 添加原文:添加至少一篇原文
|
||||
rule_source_added() {
|
||||
[ "$SRC_A" -ge 1 ] \
|
||||
&& check_category SRC A \
|
||||
&& [ "$TOTAL" -eq "$SRC_A" ] && echo "匹配规则:添加原文 ${SRC_A} 篇"
|
||||
}
|
||||
|
||||
# 申领翻译:只能申领一篇原文
|
||||
rule_translation_requested() {
|
||||
[ "$SRC_M" -eq 1 ] \
|
||||
&& check_category SRC M \
|
||||
&& [ "$TOTAL" -eq 1 ] && echo "匹配规则:申领翻译"
|
||||
}
|
||||
|
||||
# 提交译文:只能提交一篇译文
|
||||
rule_translation_completed() {
|
||||
[ "$SRC_D" -eq 1 ] && [ "$TSL_A" -eq 1 ] \
|
||||
&& ensure_identical SRC D TSL A \
|
||||
&& check_category SRC D \
|
||||
&& check_category TSL A \
|
||||
&& [ "$TOTAL" -eq 2 ] && echo "匹配规则:提交译文"
|
||||
}
|
||||
|
||||
# 校对译文:只能校对一篇
|
||||
rule_translation_revised() {
|
||||
[ "$TSL_M" -eq 1 ] \
|
||||
&& check_category TSL M \
|
||||
&& [ "$TOTAL" -eq 1 ] && echo "匹配规则:校对译文"
|
||||
}
|
||||
|
||||
# 发布译文:发布多篇译文
|
||||
rule_translation_published() {
|
||||
[ "$TSL_D" -ge 1 ] && [ "$PUB_A" -ge 1 ] && [ "$TSL_D" -eq "$PUB_A" ] \
|
||||
&& [ "$TOTAL" -eq $(($TSL_D + $PUB_A)) ] \
|
||||
&& ensure_identical SRC D TSL A 1 \
|
||||
&& check_category TSL D \
|
||||
&& [ "$TOTAL" -eq $((TSL_D + PUB_A)) ] \
|
||||
&& echo "匹配规则:发布译文 ${PUB_A} 篇"
|
||||
}
|
||||
|
||||
|
||||
@ -1,107 +0,0 @@
|
||||
Translating by FelixYFZ
|
||||
5 steps to building a cloud that meets your users' needs
|
||||
======
|
||||
|
||||

|
||||
This article was co-written with [Ian Tewksbury][1].
|
||||
|
||||
However you define it, a cloud is simply another tool for your users to perform their part of your organization's value stream. It can be easy when talking about any new paradigm or technology (the cloud is arguably both) to get distracted by the shiny newness of it. Conversations can quickly devolve into feature wish lists set off by a series of never-ending questions, all of which you probably have already considered:
|
||||
|
||||
* Will it be public, private, or hybrid?
|
||||
* Will it use virtual machines or containers, or both?
|
||||
* Will it be self-service?
|
||||
* Will it be fully automated from development to production, or will it have manual gates?
|
||||
* How fast can we make it?
|
||||
* What about tool X, Y, or Z?
|
||||
|
||||
|
||||
|
||||
The list goes on.
|
||||
|
||||
The usual approach to beginning IT modernization, or digital transformation, or whatever you call it is to start answering high-level questions in the higher-level echelons of management. The outcome of this approach is predictable: failure. After extensively researching and spending months, if not years, deploying the fanciest new technology, the new cloud is never used and falls into disrepair until it is eventually scrapped or forgotten in the dustier corners of the datacenter and budget.
|
||||
|
||||
That's because whatever was delivered was not the tool the users wanted or needed. Worse yet, it likely was a single tool when users really needed a collection of tools that could be swapped out over time as newer, shinier, upgraded tools come along that better meet their needs.
|
||||
|
||||
### Focus on what matters
|
||||
|
||||
The problem is focus, which has traditionally been on the tools. But the tools are not what add to your organization's value stream; end users making use of tools are what do that. You need to shift your focus from building your cloud—for example, the technology and the tools, to your people, your users.
|
||||
|
||||
Beyond the fact that users using tools (not the tools themselves) are what drive value, there are other reasons to focus attention on the users. The tools are for the users to use to solve their problems and allow them to create value, so it follows that if those tools don't meet those users' needs, then those tools won't be used. If you deliver tools that your users don't like, they won't use them. This is natural human behavior.
|
||||
|
||||
The IT industry got away with providing a single solution to users for decades because there were only one or two options, and the users had no power to change that. That is no longer the case. We now live in the world of technological choice. It is no longer acceptable to users to not be given a choice; they have choices in their personal technological lives, and they expect it in the workplace, too. Today's users are educated and know there are better options than the ones you've been providing.
|
||||
|
||||
As a result, outside the most physically secure locations, there is no way to stop them from just doing what they want, which we call "shadow IT." If your organization has such strict security and compliance polices that shadow IT is impossible, many of your best people will grow frustrated and leave for other organizations that offer them choices.
|
||||
|
||||
For all of these reasons, you must design your expensive and time-consuming cloud project with your end user foremost in mind.
|
||||
|
||||
### Five-step process to build a cloud for users' needs
|
||||
|
||||
Now that we know the why, let's talk about the how. How do you build a cloud for the end user? How do you start refocusing your attention from the technology to the people using that technology?
|
||||
|
||||
Through experience, we've learned that the best approach involves two things: getting constant feedback from your users, and building things iteratively.
|
||||
|
||||
Your cloud environment will continually evolve with your organization. The following five-step process will help you create a cloud that meets your users' needs.
|
||||
|
||||
#### 1\. Identify who your users will be.
|
||||
|
||||
Before you can start asking users questions, you first must identify who the users of your new cloud will be. They will likely include developers who build applications on the cloud; the operations team who will operate, maintain, and likely build the cloud; and the security team who protects your organization. For the first iteration, scope down your users to a smaller group so you're less overwhelmed by feedback. Ask each of your identified user groups to appoint two liaisons (a primary and a secondary) who will represent their team on this journey. This will also keep your first delivery small in both size and time.
|
||||
|
||||
#### 2\. Talk to your users face-to-face to get valuable input.
|
||||
|
||||
The best way to get users' feedback is through direct communication. Mass emails asking for input will self-select respondents—if you even get a response. Group discussions can be helpful, but people tend to be more candid when they have a private, attentive audience.
|
||||
|
||||
Schedule in-person, individual meetings with your first set of users to ask them questions like the following:
|
||||
|
||||
* What do you need in order to accomplish your tasks?
|
||||
* What do you want in order to accomplish your tasks?
|
||||
* What is your current, most annoying technological pain?
|
||||
* What is your current, most annoying policy or procedural pain?
|
||||
* What ideas do you have to address any of your needs, wants, or pains?
|
||||
|
||||
|
||||
|
||||
These questions are guidelines and not ideal for every organization. They should not be the only questions you ask, and they should lead to further discussion. Be sure to tell people that anything said or asked is taken as feedback, and all feedback is helpful, whether positive or negative. The outcome of these conversations will help set your development priorities.
|
||||
|
||||
Gathering this level of personalized feedback is another reason to keep your initial group of users small: It takes a lot of time to sit down with each user, but we have found it is absolutely worth the investment.
|
||||
|
||||
#### 3\. Design and deliver your first iteration of the solution.
|
||||
|
||||
Once you've collected feedback from your initial users, it is time to design and deliver a piece of functionality. We do not recommend trying to deliver the entire solution. The design and delivery phase should be short; this is to avoid making the huge mistake of spending a year building what you think is the correct solution, only to have your users reject it because it isn't beneficial to them. The specific tools you choose for building your cloud will depend on your organization and its specific needs. Just make sure that the solution you build is based on your users' feedback and that you deliver it in small chunks to solicit feedback from them as often as possible.
|
||||
|
||||
#### 4\. Ask users for feedback on the first iteration.
|
||||
|
||||
Great, now you've designed and delivered the first iteration of your fancy new cloud to your end users! You didn't spend a year doing it but instead tackled it in small pieces. Why is it important to do things in small chunks? It's because you're going back to your user groups and collecting feedback about your design and delivery. What do they like? What don't they like? Did you properly address their concerns? Is the technology great, but the process or policy side of the system still lacking?
|
||||
|
||||
Again, the questions you'll ask depend on your organization; the key here is to continue the discussions from the earlier phases. You're building this cloud for users after all, so make sure it's useful for them and a productive use of everyone's time.
|
||||
|
||||
#### 5\. Return to step 1.
|
||||
|
||||
This is an iterative process. Your first delivery should have been quick and small, and all future iterations should be, too. Don't expect to be able to follow this process once, twice, or even three times and be done. As you iterate, you will introduce more users and get better at the process. You will get more buy-in from users. You will be able to iterate faster and more reliably. And, finally, you will change your process to meet your users' needs.
|
||||
|
||||
Users are the most important part of this process, but the iteration is the second most important part because it allows you to keep going back to the users and getting more information. Throughout each phase, take note of what worked and what didn't. Be introspective and honest with yourself. Are we providing the most value possible for the time we spent? If not, try something different in the next phase. The great part about not spending too much time in each cycle is that, if something doesn't work this time, you can easily tweak it for next time, until you find an approach that works for your organization.
|
||||
|
||||
### This is just the beginning
|
||||
|
||||
Through many customer engagements, feedback gathered from users, and experiences from peers in the field, we've found time and time again that the most important thing you can do when building a cloud is to talk to your users. It seems obvious, but it is surprising how many organizations will go off and build something for months or years, then find out it isn't even useful to end users.
|
||||
|
||||
Now you know why you should keep your focus on the end users and have a process for building a cloud with them at the center. The remaining piece is the part that we all enjoy, the part where you go out and do it.
|
||||
|
||||
This article is based on "[Design your hybrid cloud for the end user—or fail][2]," a talk the authors will be giving at [Red Hat Summit 2018][3], which will be held May 8-10 in San Francisco.
|
||||
|
||||
[Register by May 7][3] to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly
|
||||
|
||||
作者:[Cameron Wyatt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cameronmwyatt
|
||||
[1]:https://opensource.com/users/itewk
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154225
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Dropbox To End Sync Support For All Filesystems Except Ext4 on Linux
|
||||
======
|
||||
Dropbox is thinking of limiting the synchronization support to only a handful of file system types: NTFS for Windows, HFS+/APFS for macOS and Ext4 for Linux.
|
||||
|
||||
@ -1,134 +0,0 @@
|
||||
translating by belitex
|
||||
|
||||
What breaks our systems: A taxonomy of black swans
|
||||
======
|
||||
|
||||
Find and fix outlier events that create issues before they trigger severe production problems.
|
||||
|
||||

|
||||
|
||||
Black swans are a metaphor for outlier events that are severe in impact (like the 2008 financial crash). In production systems, these are the incidents that trigger problems that you didn't know you had, cause major visible impact, and can't be fixed quickly and easily by a rollback or some other standard response from your on-call playbook. They are the events you tell new engineers about years after the fact.
|
||||
|
||||
Black swans, by definition, can't be predicted, but sometimes there are patterns we can find and use to create defenses against categories of related problems.
|
||||
|
||||
For example, a large proportion of failures are a direct result of changes (code, environment, or configuration). Each bug triggered in this way is distinctive and unpredictable, but the common practice of canarying all changes is somewhat effective against this class of problems, and automated rollbacks have become a standard mitigation.
|
||||
|
||||
As our profession continues to mature, other kinds of problems are becoming well-understood classes of hazards with generalized prevention strategies.
|
||||
|
||||
### Black swans observed in the wild
|
||||
|
||||
All technology organizations have production problems, but not all of them share their analyses. The organizations that publicly discuss incidents are doing us all a service. The following incidents describe one class of a problem and are by no means isolated instances. We all have black swans lurking in our systems; it's just some of us don't know it yet.
|
||||
|
||||
#### Hitting limits
|
||||
|
||||
Running headlong into any sort of limit can produce very severe incidents. A canonical example of this was [Instapaper's outage in February 2017][1] . I challenge any engineer who has carried a pager to read the outage report without a chill running up their spine. Instapaper's production database was on a filesystem that, unknown to the team running the service, had a 2TB limit. With no warning, it stopped accepting writes. Full recovery took days and required migrating its database.
|
||||
|
||||
Limits can strike in various ways. Sentry hit [limits on maximum transaction IDs in Postgres][2] . Platform.sh hit [size limits on a pipe buffer][3] . SparkPost [triggered AWS's DDoS protection][4] . Foursquare hit a performance cliff when one of its [datastores ran out of RAM][5]
|
||||
|
||||
One way to get advance knowledge of system limits is to test periodically. Good load testing (on a production replica) ought to involve write transactions and should involve growing each datastore beyond its current production size. It's easy to forget to test things that aren't your main datastores (such as Zookeeper). If you hit limits during testing, you have time to fix the problems. Given that resolution of limits-related issues can involve major changes (like splitting a datastore), time is invaluable.
|
||||
|
||||
When it comes to cloud services, if your service generates unusual loads or uses less widely used products or features (such as older or newer ones), you may be more at risk of hitting limits. It's worth load testing these, too. But warn your cloud provider first.
|
||||
|
||||
Finally, where limits are known, add monitoring (with associated documentation) so you will know when your systems are approaching those ceilings. Don't rely on people still being around to remember.
|
||||
|
||||
#### Spreading slowness
|
||||
|
||||
> "The world is much more correlated than we give credit to. And so we see more of what Nassim Taleb calls 'black swan events'—rare events happen more often than they should because the world is more correlated."
|
||||
> —[Richard Thaler][6]
|
||||
|
||||
HostedGraphite's postmortem on how an [AWS outage took down its load balancers][7] (which are not hosted on AWS) is a good example of just how much correlation exists in distributed computing systems. In this case, the load-balancer connection pools were saturated by slow connections from customers that were hosted in AWS. The same kinds of saturation can happen with application threads, locks, and database connections—any kind of resource monopolized by slow operations.
|
||||
|
||||
HostedGraphite's incident is an example of externally imposed slowness, but often slowness can result from saturation somewhere in your own system creating a cascade and causing other parts of your system to slow down. An [incident at Spotify][8] demonstrates such spread—the streaming service's frontends became unhealthy due to saturation in a different microservice. Enforcing deadlines for all requests, as well as limiting the length of request queues, can prevent such spread. Your service will serve at least some traffic, and recovery will be easier because fewer parts of your system will be broken.
|
||||
|
||||
Retries should be limited with exponential backoff and some jitter. An outage at Square, in which its [Redis datastore became overloaded][9] due to a piece of code that retried failed transactions up to 500 times with no backoff, demonstrates the potential severity of excessive retries. The [Circuit Breaker][10] design pattern can be helpful here, too.
|
||||
|
||||
Dashboards should be designed to clearly show [utilization, saturation, and errors][11] for all resources so problems can be found quickly.
|
||||
|
||||
#### Thundering herds
|
||||
|
||||
Often, failure scenarios arise when a system is under unusually heavy load. This can arise organically from users, but often it arises from systems. A surge of cron jobs that starts at midnight is a venerable example. Mobile clients can also be a source of coordinated demand if they are programmed to fetch updates at the same time (of course, it is much better to jitter such requests).
|
||||
|
||||
Events occurring at pre-configured times aren't the only source of thundering herds. Slack experienced [multiple outages][12] over a short time due to large numbers of clients being disconnected and immediately reconnecting, causing large spikes of load. CircleCI saw a [severe outage][13] when a GitLab outage ended, leading to a surge of builds queued in its database, which became saturated and very slow.
|
||||
|
||||
Almost any service can be the target of a thundering herd. Planning for such eventualities—and testing that your plan works as intended—is therefore a must. Client backoff and [load shedding][14] are often core to such approaches.
|
||||
|
||||
If your systems must constantly ingest data that can't be dropped, it's key to have a scalable way to buffer this data in a queue for later processing.
|
||||
|
||||
#### Automation systems are complex systems
|
||||
|
||||
> "Complex systems are intrinsically hazardous systems."
|
||||
> —[Richard Cook, MD][15]
|
||||
|
||||
If your systems must constantly ingest data that can't be dropped, it's key to have a scalable way to buffer this data in a queue for later processing.
|
||||
|
||||
The trend for the past several years has been strongly towards more automation of software operations. Automation of anything that can reduce your system's capacity (e.g., erasing disks, decommissioning devices, taking down serving jobs) needs to be done with care. Accidents (due to bugs or incorrect invocations) with this kind of automation can take down your system very efficiently, potentially in ways that are hard to recover from.
|
||||
|
||||
The trend for the past several years has been strongly towards more automation of software operations. Automation of anything that can reduce your system's capacity (e.g., erasing disks, decommissioning devices, taking down serving jobs) needs to be done with care. Accidents (due to bugs or incorrect invocations) with this kind of automation can take down your system very efficiently, potentially in ways that are hard to recover from.
|
||||
|
||||
Christina Schulman and Etienne Perot of Google describe some examples in their talk [Help Protect Your Data Centers with Safety Constraints][16]. One incident sent Google's entire in-house content delivery network (CDN) to disk-erase.
|
||||
|
||||
Schulman and Perot suggest using a central service to manage constraints, which limits the pace at which destructive automation can operate, and being aware of system conditions (for example, avoiding destructive operations if the service has recently had an alert).
|
||||
|
||||
Automation systems can also cause havoc when they interact with operators (or with other automated systems). [Reddit][17] experienced a major outage when its automation restarted a system that operators had stopped for maintenance. Once you have multiple automation systems, their potential interactions become extremely complex and impossible to predict.
|
||||
|
||||
It will help to deal with the inevitable surprises if all this automation writes logs to an easily searchable, central place. Automation systems should always have a mechanism to allow them to be quickly turned off (fully or only for a subset of operations or targets).
|
||||
|
||||
### Defense against the dark swans
|
||||
|
||||
These are not the only black swans that might be waiting to strike your systems. There are many other kinds of severe problem that can be avoided using techniques such as canarying, load testing, chaos engineering, disaster testing, and fuzz testing—and of course designing for redundancy and resiliency. Even with all that, at some point your system will fail.
|
||||
|
||||
To ensure your organization can respond effectively, make sure your key technical staff and your leadership have a way to coordinate during an outage. For example, one unpleasant issue you might have to deal with is a complete outage of your network. It's important to have a fail-safe communications channel completely independent of your own infrastructure and its dependencies. For instance, if you run on AWS, using a service that also runs on AWS as your fail-safe communication method is not a good idea. A phone bridge or an IRC server that runs somewhere separate from your main systems is good. Make sure everyone knows what the communications platform is and practices using it.
|
||||
|
||||
Another principle is to ensure that your monitoring and your operational tools rely on your production systems as little as possible. Separate your control and your data planes so you can make changes even when systems are not healthy. Don't use a single message queue for both data processing and config changes or monitoring, for example—use separate instances. In [SparkPost: The Day the DNS Died][4], Jeremy Blosser presents an example where critical tools relied on the production DNS setup, which failed.
|
||||
|
||||
### The psychology of battling the black swan
|
||||
|
||||
To ensure your organization can respond effectively, make sure your key technical staff and your leadership have a way to coordinate during an outage.
|
||||
|
||||
Dealing with major incidents in production can be stressful. It really helps to have a structured incident-management process in place for these situations. Many technology organizations (
|
||||
|
||||
Dealing with major incidents in production can be stressful. It really helps to have a structured incident-management process in place for these situations. Many technology organizations ( [including Google][18] ) successfully use a version of FEMA's Incident Command System. There should be a clear way for any on-call individual to call for assistance in the event of a major problem they can't resolve alone.
|
||||
|
||||
For long-running incidents, it's important to make sure people don't work for unreasonable lengths of time and get breaks to eat and sleep (uninterrupted by a pager). It's easy for exhausted engineers to make a mistake or overlook something that might resolve the incident faster.
|
||||
|
||||
### Learn more
|
||||
|
||||
There are many other things that could be said about black (or formerly black) swans and strategies for dealing with them. If you'd like to learn more, I highly recommend these two books dealing with resilience and stability in production: Susan Fowler's [Production-Ready Microservices][19] and Michael T. Nygard's [Release It!][20].
|
||||
|
||||
Laura Nolan will present [What Breaks Our Systems: A Taxonomy of Black Swans][21] at [LISA18][22], October 29-31 in Nashville, Tennessee, USA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/taxonomy-black-swans
|
||||
|
||||
作者:[Laura Nolan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lauranolan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://medium.com/making-instapaper/instapaper-outage-cause-recovery-3c32a7e9cc5f
|
||||
[2]: https://blog.sentry.io/2015/07/23/transaction-id-wraparound-in-postgres.html
|
||||
[3]: https://medium.com/@florian_7764/technical-post-mortem-of-the-august-incident-82ab4c3d6547
|
||||
[4]: https://www.usenix.org/conference/srecon18americas/presentation/blosser
|
||||
[5]: https://groups.google.com/forum/#!topic/mongodb-user/UoqU8ofp134
|
||||
[6]: https://en.wikipedia.org/wiki/Richard_Thaler
|
||||
[7]: https://blog.hostedgraphite.com/2018/03/01/spooky-action-at-a-distance-how-an-aws-outage-ate-our-load-balancer/
|
||||
[8]: https://labs.spotify.com/2013/06/04/incident-management-at-spotify/
|
||||
[9]: https://medium.com/square-corner-blog/incident-summary-2017-03-16-2f65be39297
|
||||
[10]: https://en.wikipedia.org/wiki/Circuit_breaker_design_pattern
|
||||
[11]: http://www.brendangregg.com/usemethod.html
|
||||
[12]: https://slackhq.com/this-was-not-normal-really
|
||||
[13]: https://circleci.statuspage.io/incidents/hr0mm9xmm3x6
|
||||
[14]: https://www.youtube.com/watch?v=XNEIkivvaV4
|
||||
[15]: https://web.mit.edu/2.75/resources/random/How%20Complex%20Systems%20Fail.pdf
|
||||
[16]: https://www.usenix.org/conference/srecon18americas/presentation/schulman
|
||||
[17]: https://www.reddit.com/r/announcements/comments/4y0m56/why_reddit_was_down_on_aug_11/
|
||||
[18]: https://landing.google.com/sre/book/chapters/managing-incidents.html
|
||||
[19]: http://shop.oreilly.com/product/0636920053675.do
|
||||
[20]: https://www.oreilly.com/library/view/release-it/9781680500264/
|
||||
[21]: https://www.usenix.org/conference/lisa18/presentation/nolan
|
||||
[22]: https://www.usenix.org/conference/lisa18
|
||||
@ -1,205 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to use a here documents to write data to a file in bash script
|
||||
======
|
||||
|
||||
A here document is nothing but I/O redirection that tells the bash shell to read input from the current source until a line containing only delimiter is seen.
|
||||
[![redirect output of here document to a text file][1]][1]
|
||||
This is useful for providing commands to ftp, cat, echo, ssh and many other useful Linux/Unix commands. This feature should work with bash or Bourne/Korn/POSIX shell too.
|
||||
|
||||
## heredoc syntax
|
||||
|
||||
How do I use a heredoc redirection feature (here documents) to write data to a file in my bash shell scripts? [A here document][2] is nothing but I/O redirection that tells the bash shell to read input from the current source until a line containing only delimiter is seen.This is useful for providing commands to ftp, cat, echo, ssh and many other useful Linux/Unix commands. This feature should work with bash or Bourne/Korn/POSIX shell too.
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
command <<EOF
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
EOF
|
||||
```
|
||||
|
||||
OR allow here-documents within shell scripts to be indented in a natural fashion using **EOF <**
|
||||
```
|
||||
command <<-EOF
|
||||
msg1
|
||||
msg2
|
||||
$var on line
|
||||
EOF
|
||||
```
|
||||
|
||||
OR
|
||||
```
|
||||
command <<'EOF'
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
$var won't expand as parameter substitution turned off
|
||||
by single quoting
|
||||
EOF
|
||||
```
|
||||
|
||||
OR **redirect and overwrite it** to a file named my_output_file.txt:
|
||||
```
|
||||
command << EOF > my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
OR **redirect and append it** to a file named my_output_file.txt:
|
||||
```
|
||||
command << EOF >> my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
## Examples
|
||||
|
||||
The following script will write the needed contents to a file named /tmp/output.txt:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
cat <<EOF >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
|
||||
You can view /tmp/output.txt with the [cat command][3]:
|
||||
`$ cat /tmp/output.txt`
|
||||
Sample outputs:
|
||||
```
|
||||
Status of backup as on Thu Nov 16 17:00:21 IST 2017
|
||||
Backing up files /home/vivek and /etc/
|
||||
|
||||
```
|
||||
|
||||
### Disabling pathname/parameter/variable expansion, command substitution, arithmetic expansion
|
||||
|
||||
Variable such as $HOME and command such as $(date) were interpreted substitution in script. To disable it use single quotes with 'EOF' as follows:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
# No parameter and variable expansion, command substitution, arithmetic expansion, or pathname expansion is performed on word.
|
||||
# If any part of word is quoted, the delimiter is the result of quote removal on word, and the lines in the here-document
|
||||
# are not expanded. So EOF is quoted as follows
|
||||
cat <<'EOF' >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
#!/bin/bash OUT=/tmp/output.txtecho "Starting my script..." echo "Doing something..." # No parameter and variable expansion, command substitution, arithmetic expansion, or pathname expansion is performed on word. # If any part of word is quoted, the delimiter is the result of quote removal on word, and the lines in the here-document # are not expanded. So EOF is quoted as follows cat <<'EOF' >$OUT Status of backup as on $(date) Backing up files $HOME and /etc/ EOFecho "Starting backup using rsync..."
|
||||
|
||||
You can view /tmp/output.txt with the [cat command][3]:
|
||||
`$ cat /tmp/output.txt`
|
||||
Sample outputs:
|
||||
```
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
|
||||
```
|
||||
|
||||
## A note about using tee command
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
tee /tmp/filename <<EOF >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
tee /tmp/filename <<EOF >/dev/null line 1 line 2 line 3 $(cmd) $var on $foo EOF
|
||||
|
||||
Or disable variable substitution/command substitution by quoting EOF in a single quote:
|
||||
```
|
||||
tee /tmp/filename <<'EOF' >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
tee /tmp/filename <<'EOF' >/dev/null line 1 line 2 line 3 $(cmd) $var on $foo EOF
|
||||
|
||||
Here is my updated script:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
tee $OUT <<EOF >/dev/null
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
#!/bin/bash OUT=/tmp/output.txtecho "Starting my script..." echo "Doing something..."tee $OUT <<EOF >/dev/null Status of backup as on $(date) Backing up files $HOME and /etc/ EOFecho "Starting backup using rsync..."
|
||||
|
||||
## A note about using in-memory here-docs
|
||||
|
||||
Here is my updated script:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
## in memory here docs
|
||||
## thanks https://twitter.com/freebsdfrau
|
||||
exec 9<<EOF
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
## continue
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
## do it
|
||||
cat <&9 >$OUT
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/using-heredoc-rediection-in-bash-shell-script-to-write-to-file/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2017/11/redirect-output-of-here-document-to-a-text-file.jpg
|
||||
[2]:https://bash.cyberciti.biz/guide/Here_documents
|
||||
[3]:https//www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ (See Linux/Unix cat command examples for more info)
|
||||
@ -1,71 +0,0 @@
|
||||
Excellent Free Roguelike Games
|
||||
======
|
||||
![Dungeon][1]
|
||||
|
||||
Roguelike is a sub-genre of role-playing games. It literally means "a game like Rogue". Rogue is a dungeon crawling video game, first released in 1980 by developers Michel Toy, Glenn Wichman and Ken Arnold. The game stood out from the crowd by being fiendishly addictive. The game's goal was to retrieve the Amulet of Yendor, hidden deep in the 26th level, and ascend back to the top, all set in a world based on Dungeons & Dragons.
|
||||
|
||||
The game is rightly considered to be a classic, formidably difficult yet compelling addictive. While it was popular in college and university campuses, it wasn't a big seller. At the time of its release, Rogue wasn't published under an open source license, which led to many clones being developed.
|
||||
|
||||
There is no exact definition of a roguelike, but this type of game typically has the following characteristics:
|
||||
|
||||
* High fantasy narrative background
|
||||
* Procedural level generation. Most of the game world is generated by the game for every new gameplay session. This is meant to encourage replayability
|
||||
* Turn-based dungeon exploration and combat
|
||||
* Tile-based graphics that are randomly generated
|
||||
* Random conflict outcomes
|
||||
* Permanent death - death works realistically, once you're gone, you're gone
|
||||
* High difficulty
|
||||
|
||||
|
||||
|
||||
This article compiles a wide selection of roguelike games available for Linux. If you enjoy addictive gameplay with real intensity, I heartily recommended downloading these games. Don't be put off by the primitive graphics offered by many of the games, you'll soon forget the visuals once you get immersed in playing. Remember, in roguelikes game mechanics tend to be the primary focus, with graphics being a welcome, but not essential, addition.
|
||||
|
||||
There are 16 games recommended here. All of the games are available to download without charge, and almost all are released under an open source license.
|
||||
| **Roguelike Games** |
|
||||
| --- |
|
||||
| **[Dungeon Crawl Stone Soup][1]** | A continuation of Linley’s Dungeon Crawl |
|
||||
| **[Prospector][2]** | Roguelike game set in a science fiction universe |
|
||||
| **[Dwarf Fortress][3]** | Adventure and Dwarf Fortress modes |
|
||||
| **[NetHack][4]** | Wonderfully silly, and addictive Dungeons and Dragons-style adventure game |
|
||||
| **[Angband][5]** | Along the lines of Rogue and NetHack. It is derived from the games Moria and Umoria |
|
||||
| **[Ancient Domains of Mystery][6]** | Very mature Roguelike game |
|
||||
| **[Tales of Maj’Eyal][7]** | Features tactical turn-based combat and advanced character building |
|
||||
| **[UnNetHack][8]** | Inspired fork of NetHack |
|
||||
| **[Hydra Slayer][9]** | Roguelike game based on mathematical puzzles |
|
||||
| **[Cataclysm DDA][10]** | Post-apocalyptic roguelike, set in the countryside of fictional New England |
|
||||
| **[Brogue][11]** | A direct descendant of Rogue |
|
||||
| **[Goblin Hack][12]** | Inspired by the likes of NetHack, but faster with fewer keys |
|
||||
| **[Ascii Sector][13]** | 2D trading and space flight simulator with roguelike action |
|
||||
| **[SLASH'EM][14]** | Super Lotsa Added Stuff Hack - Extended Magic |
|
||||
| **[Everything Is Fodder][15]** | Seven Day Roguelike competition entry |
|
||||
| **[Woozoolike][16]** | A simple space exploration roguelike for 7DRL 2017. |
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxlinks.com/excellent-free-roguelike-games/
|
||||
|
||||
作者:[Steve Emms][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxlinks.com/author/linuxlinks/
|
||||
[1]:https://www.linuxlinks.com/dungeoncrawlstonesoup/
|
||||
[2]:https://www.linuxlinks.com/Prospector-roguelike/
|
||||
[3]:https://www.linuxlinks.com/dwarffortress/
|
||||
[4]:https://www.linuxlinks.com/nethack/
|
||||
[5]:https://www.linuxlinks.com/angband/
|
||||
[6]:https://www.linuxlinks.com/ADOM/
|
||||
[7]:https://www.linuxlinks.com/talesofmajeyal/
|
||||
[8]:https://www.linuxlinks.com/unnethack/
|
||||
[9]:https://www.linuxlinks.com/hydra-slayer/
|
||||
[10]:https://www.linuxlinks.com/cataclysmdda/
|
||||
[11]:https://www.linuxlinks.com/brogue/
|
||||
[12]:https://www.linuxlinks.com/goblin-hack/
|
||||
[13]:https://www.linuxlinks.com/asciisector/
|
||||
[14]:https://www.linuxlinks.com/slashem/
|
||||
[15]:https://www.linuxlinks.com/everything-is-fodder/
|
||||
[16]:https://www.linuxlinks.com/Woozoolike/
|
||||
[17]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2017/12/dungeon.jpg?resize=300%2C200&ssl=1
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
For your first HTML code, let’s help Batman write a love letter
|
||||
============================================================
|
||||
|
||||
@ -553,360 +556,4 @@ We want to apply our styles to the specific div and img that we are using right
|
||||
<div id="letter-container">
|
||||
```
|
||||
|
||||
and here’s how to use this id in our embedded style as a selector:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
Notice the “#” symbol. It indicates that it is an id, and the styles inside {…} should apply to the element with that specific id only.
|
||||
|
||||
Let’s apply this to our code:
|
||||
|
||||
```
|
||||
<style>
|
||||
#letter-container{
|
||||
width:550px;
|
||||
}
|
||||
#header-bat-logo{
|
||||
width:100%;
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
```
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
Our HTML is ready with embedded styling.
|
||||
|
||||
However, you can see that as we include more styles, the <style></style> will get bigger. This can quickly clutter our main html file. So let’s go one step further and use linked styling by copying the content inside our style tag to a new file.
|
||||
|
||||
Create a new file in the project root directory and save it as style.css:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
width:550px;
|
||||
}
|
||||
#header-bat-logo{
|
||||
width:100%;
|
||||
}
|
||||
```
|
||||
|
||||
We don’t need to write `<style>` and `</style>` in our CSS file.
|
||||
|
||||
We need to link our newly created CSS file to our HTML file using the `<link>`tag in our html file. Here’s how we can do that:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
```
|
||||
|
||||
We use the link element to include external resources inside your HTML document. It is mostly used to link Stylesheets. The three attributes that we are using are:
|
||||
|
||||
* rel: Relation. What relationship the linked file has to the document. The file with the .css extension is called a stylesheet, and so we keep rel=“stylesheet”.
|
||||
|
||||
* type: the Type of the linked file; it’s “text/css” for a CSS file.
|
||||
|
||||
* href: Hypertext Reference. Location of the linked file.
|
||||
|
||||
There is no </link> at the end of the link element. So, <link> is also a self-closing tag.
|
||||
|
||||
```
|
||||
<link rel="gf" type="cute" href="girl.next.door">
|
||||
```
|
||||
|
||||
If only getting a Girlfriend was so easy :D
|
||||
|
||||
Nah, that’s not gonna happen, let’s move on.
|
||||
|
||||
Here’s the content of our loveletter.html:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
and our style.css:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
width:550px;
|
||||
}
|
||||
#header-bat-logo{
|
||||
width:100%;
|
||||
}
|
||||
```
|
||||
|
||||
Save both the files and refresh, and your output in the browser should remain the same.
|
||||
|
||||
### A Few Formalities
|
||||
|
||||
Our love letter is almost ready to deliver to Batman, but there are a few formal pieces remaining.
|
||||
|
||||
Like any other programming language, HTML has also gone through many versions since its birth year(1990). The current version of HTML is HTML5.
|
||||
|
||||
So, how would the browser know which version of HTML you are using to code your page? To tell the browser that you are using HTML5, you need to include `<!DOCTYPE html>` at top of the page. For older versions of HTML, this line used to be different, but you don’t need to learn that because we don’t use them anymore.
|
||||
|
||||
Also, in previous HTML versions, we used to encapsulate the entire document inside `<html></html>` tag. The entire file was divided into two major sections: Head, inside `<head></head>`, and Body, inside `<body></body>`. This is not required in HTML5, but we still do this for compatibility reasons. Let’s update our code with `<Doctype>`, `<html>`, `<head>` and `<body>`:
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
</head>
|
||||
<body>
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
The main content goes inside `<body>` and meta information goes inside `<head>`. So we keep the div inside `<body>` and load the stylesheets inside `<head>`.
|
||||
|
||||
Save and refresh, and your HTML page should display the same as earlier.
|
||||
|
||||
### Title in HTML
|
||||
|
||||
This is the last change. I promise.
|
||||
|
||||
You might have noticed that the title of the tab is displaying the path of the HTML file:
|
||||
|
||||
|
||||
|
||||
|
||||
We can use `<title>` tag to define a title for our HTML file. The title tag also, like the link tag, goes inside head. Let’s put “Bat Letter” in our title:
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<title>Bat Letter</title>
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
</head>
|
||||
<body>
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
Save and refresh, and you will see that instead of the file path, “Bat Letter” is now displayed on the tab.
|
||||
|
||||
Batman’s Love Letter is now complete.
|
||||
|
||||
Congratulations! You made Batman’s Love Letter in HTML.
|
||||
|
||||
|
||||

|
||||
|
||||
### What we learned
|
||||
|
||||
We learned the following new concepts:
|
||||
|
||||
* The structure of an HTML document
|
||||
|
||||
* How to write elements in HTML (<p></p>)
|
||||
|
||||
* How to write styles inside the element using the style attribute (this is called inline styling, avoid this as much as you can)
|
||||
|
||||
* How to write styles of an element inside <style>…</style> (this is called embedded styling)
|
||||
|
||||
* How to write styles in a separate file and link to it in HTML using <link> (this is called a linked stylesheet)
|
||||
|
||||
* What is a tag name, attribute, opening tag, and closing tag
|
||||
|
||||
* How to give an id to an element using id attribute
|
||||
|
||||
* Tag selectors and id selectors in CSS
|
||||
|
||||
We learned the following HTML tags:
|
||||
|
||||
* <p>: for paragraphs
|
||||
|
||||
* <br>: for line breaks
|
||||
|
||||
* <ul>, <li>: to display lists
|
||||
|
||||
* <div>: for grouping elements of our letter
|
||||
|
||||
* <h1>, <h2>: for heading and sub heading
|
||||
|
||||
* <img>: to insert an image
|
||||
|
||||
* <strong>, <em>: for bold and italic text styling
|
||||
|
||||
* <style>: for embedded styling
|
||||
|
||||
* <link>: for including external an stylesheet
|
||||
|
||||
* <html>: to wrap the entire HTML document
|
||||
|
||||
* <!DOCTYPE html>: to let the browser know that we are using HTML5
|
||||
|
||||
* <head>: to wrap meta info, like <link> and <title>
|
||||
|
||||
* <body>: for the body of the HTML page that is actually displayed
|
||||
|
||||
* <title>: for the title of the HTML page
|
||||
|
||||
We learned the following CSS properties:
|
||||
|
||||
* width: to define the width of an element
|
||||
|
||||
* CSS units: “px” and “%”
|
||||
|
||||
That’s it for the day friends, see you in the next tutorial.
|
||||
|
||||
* * *
|
||||
|
||||
Want to learn Web Development with fun and engaging tutorials?
|
||||
|
||||
[Click here to get new Web Development tutorials every week.][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Developer + Writer | supersarkar.com | twitter.com/supersarkar
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: https://medium.freecodecamp.org/for-your-first-html-code-lets-help-batman-write-a-love-letter-64c203b9360b
|
||||
|
||||
作者:[Kunal Sarkar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@supersarkar
|
||||
[1]:https://www.pexels.com/photo/batman-black-and-white-logo-93596/
|
||||
[2]:https://code.visualstudio.com/
|
||||
[3]:https://www.pexels.com/photo/batman-black-and-white-logo-93596/
|
||||
[4]:http://supersarkar.com/
|
||||
and here’s how to use th
|
||||
|
||||
@ -1,258 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Build a bikesharing app with Redis and Python
|
||||
======
|
||||
|
||||

|
||||
|
||||
I travel a lot on business. I'm not much of a car guy, so when I have some free time, I prefer to walk or bike around a city. Many of the cities I've visited on business have bikeshare systems, which let you rent a bike for a few hours. Most of these systems have an app to help users locate and rent their bikes, but it would be more helpful for users like me to have a single place to get information on all the bikes in a city that are available to rent.
|
||||
|
||||
To solve this problem and demonstrate the power of open source to add location-aware features to a web application, I combined publicly available bikeshare data, the [Python][1] programming language, and the open source [Redis][2] in-memory data structure server to index and query geospatial data.
|
||||
|
||||
The resulting bikeshare application incorporates data from many different sharing systems, including the [Citi Bike][3] bikeshare in New York City. It takes advantage of the General Bikeshare Feed provided by the Citi Bike system and uses its data to demonstrate some of the features that can be built using Redis to index geospatial data. The Citi Bike data is provided under the [Citi Bike data license agreement][4].
|
||||
|
||||
### General Bikeshare Feed Specification
|
||||
|
||||
The General Bikeshare Feed Specification (GBFS) is an [open data specification][5] developed by the [North American Bikeshare Association][6] to make it easier for map and transportation applications to add bikeshare systems into their platforms. The specification is currently in use by over 60 different sharing systems in the world.
|
||||
|
||||
The feed consists of several simple [JSON][7] data files containing information about the state of the system. The feed starts with a top-level JSON file referencing the URLs of the sub-feed data:
|
||||
```
|
||||
{
|
||||
|
||||
"data": {
|
||||
|
||||
"en": {
|
||||
|
||||
"feeds": [
|
||||
|
||||
{
|
||||
|
||||
"name": "system_information",
|
||||
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/system_information.json"
|
||||
|
||||
},
|
||||
|
||||
{
|
||||
|
||||
"name": "station_information",
|
||||
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
|
||||
|
||||
},
|
||||
|
||||
. . .
|
||||
|
||||
]
|
||||
|
||||
}
|
||||
|
||||
},
|
||||
|
||||
"last_updated": 1506370010,
|
||||
|
||||
"ttl": 10
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The first step is loading information about the bikesharing stations into Redis using data from the `system_information` and `station_information` feeds.
|
||||
|
||||
The `system_information` feed provides the system ID, which is a short code that can be used to create namespaces for Redis keys. The GBFS spec doesn't specify the format of the system ID, but does guarantee it is globally unique. Many of the bikeshare feeds use short names like coast_bike_share, boise_greenbike, or topeka_metro_bikes for system IDs. Others use familiar geographic abbreviations such as NYC or BA, and one uses a universally unique identifier (UUID). The bikesharing application uses the identifier as a prefix to construct unique keys for the given system.
|
||||
|
||||
The `station_information` feed provides static information about the sharing stations that comprise the system. Stations are represented by JSON objects with several fields. There are several mandatory fields in the station object that provide the ID, name, and location of the physical bike stations. There are also several optional fields that provide helpful information such as the nearest cross street or accepted payment methods. This is the primary source of information for this part of the bikesharing application.
|
||||
|
||||
### Building the database
|
||||
|
||||
I've written a sample application, [load_station_data.py][8], that mimics what would happen in a backend process for loading data from external sources.
|
||||
|
||||
### Finding the bikeshare stations
|
||||
|
||||
Loading the bikeshare data starts with the [systems.csv][9] file from the [GBFS repository on GitHub][5].
|
||||
|
||||
The repository's [systems.csv][9] file provides the discovery URL for registered bikeshare systems with an available GBFS feed. The discovery URL is the starting point for processing bikeshare information.
|
||||
|
||||
The `load_station_data` application takes each discovery URL found in the systems file and uses it to find the URL for two sub-feeds: system information and station information. The system information feed provides a key piece of information: the unique ID of the system. (Note: the system ID is also provided in the systems.csv file, but some of the identifiers in that file do not match the identifiers in the feeds, so I always fetch the identifier from the feed.) Details on the system, like bikeshare URLs, phone numbers, and emails, could be added in future versions of the application, so the data is stored in a Redis hash using the key `${system_id}:system_info`.
|
||||
|
||||
### Loading the station data
|
||||
|
||||
The station information provides data about every station in the system, including the system's location. The `load_station_data` application iterates over every station in the station feed and stores the data about each into a Redis hash using a key of the form `${system_id}:station:${station_id}`. The location of each station is added to a geospatial index for the bikeshare using the `GEOADD` command.
|
||||
|
||||
### Updating data
|
||||
|
||||
On subsequent runs, I don't want the code to remove all the feed data from Redis and reload it into an empty Redis database, so I carefully considered how to handle in-place updates of the data.
|
||||
|
||||
The code starts by loading the dataset with information on all the bikesharing stations for the system being processed into memory. When information is loaded for a station, the station (by key) is removed from the in-memory set of stations. Once all station data is loaded, we're left with a set containing all the station data that must be removed for that system.
|
||||
|
||||
The application iterates over this set of stations and creates a transaction to delete the station information, remove the station key from the geospatial indexes, and remove the station from the list of stations for the system.
|
||||
|
||||
### Notes on the code
|
||||
|
||||
There are a few interesting things to note in [the sample code][8]. First, items are added to the geospatial indexes using the `GEOADD` command but removed with the `ZREM` command. As the underlying implementation of the geospatial type uses sorted sets, items are removed using `ZREM`. A word of caution: For simplicity, the sample code demonstrates working with a single Redis node; the transaction blocks would need to be restructured to run in a cluster environment.
|
||||
|
||||
If you are using Redis 4.0 (or later), you have some alternatives to the `DELETE` and `HMSET` commands in the code. Redis 4.0 provides the [`UNLINK`][10] command as an asynchronous alternative to the `DELETE` command. `UNLINK` will remove the key from the keyspace, but it reclaims the memory in a separate thread. The [`HMSET`][11] command is [deprecated in Redis 4.0 and the `HSET` command is now variadic][12] (that is, it accepts an indefinite number of arguments).
|
||||
|
||||
### Notifying clients
|
||||
|
||||
At the end of the process, a notification is sent to the clients relying on our data. Using the Redis pub/sub mechanism, the notification goes out over the `geobike:station_changed` channel with the ID of the system.
|
||||
|
||||
### Data model
|
||||
|
||||
When structuring data in Redis, the most important thing to think about is how you will query the information. The two main queries the bikeshare application needs to support are:
|
||||
|
||||
* Find stations near us
|
||||
* Display information about stations
|
||||
|
||||
|
||||
|
||||
Redis provides two main data types that will be useful for storing our data: hashes and sorted sets. The [hash type][13] maps well to the JSON objects that represent stations; since Redis hashes don't enforce a schema, they can be used to store the variable station information.
|
||||
|
||||
Of course, finding stations geographically requires a geospatial index to search for stations relative to some coordinates. Redis provides [several commands][14] to build up a geospatial index using the [sorted set][15] data structure.
|
||||
|
||||
We construct keys using the format `${system_id}:station:${station_id}` for the hashes containing information about the stations and keys using the format `${system_id}:stations:location` for the geospatial index used to find stations.
|
||||
|
||||
### Getting the user's location
|
||||
|
||||
The next step in building out the application is to determine the user's current location. Most applications accomplish this through built-in services provided by the operating system. The OS can provide applications with a location based on GPS hardware built into the device or approximated from the device's available WiFi networks.
|
||||
|
||||
|
||||
|
||||
### Finding stations
|
||||
|
||||
After the user's location is found, the next step is locating nearby bikesharing stations. Redis' geospatial functions can return information on stations within a given distance of the user's current coordinates. Here's an example of this using the Redis command-line interface.
|
||||
|
||||
Imagine I'm at the Apple Store on Fifth Avenue in New York City, and I want to head downtown to Mood on West 37th to catch up with my buddy [Swatch][16]. I could take a taxi or the subway, but I'd rather bike. Are there any nearby sharing stations where I could get a bike for my trip?
|
||||
|
||||
The Apple store is located at 40.76384, -73.97297. According to the map, two bikeshare stations—Grand Army Plaza & Central Park South and East 58th St. & Madison—fall within a 500-foot radius (in blue on the map above) of the store.
|
||||
|
||||
I can use Redis' `GEORADIUS` command to query the NYC system index for stations within a 500-foot radius:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft
|
||||
|
||||
1) "NYC:station:3457"
|
||||
|
||||
2) "NYC:station:281"
|
||||
|
||||
```
|
||||
|
||||
Redis returns the two bikeshare locations found within that radius, using the elements in our geospatial index as the keys for the metadata about a particular station. The next step is looking up the names for the two stations:
|
||||
```
|
||||
127.0.0.1:6379> hget NYC:station:281 name
|
||||
|
||||
"Grand Army Plaza & Central Park S"
|
||||
|
||||
|
||||
|
||||
127.0.0.1:6379> hget NYC:station:3457 name
|
||||
|
||||
"E 58 St & Madison Ave"
|
||||
|
||||
```
|
||||
|
||||
Those keys correspond to the stations identified on the map above. If I want, I can add more flags to the `GEORADIUS` command to get a list of elements, their coordinates, and their distance from our current point:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft WITHDIST WITHCOORD ASC
|
||||
|
||||
1) 1) "NYC:station:281"
|
||||
|
||||
2) "289.1995"
|
||||
|
||||
3) 1) "-73.97371262311935425"
|
||||
|
||||
2) "40.76439830559216659"
|
||||
|
||||
2) 1) "NYC:station:3457"
|
||||
|
||||
2) "383.1782"
|
||||
|
||||
3) 1) "-73.97209256887435913"
|
||||
|
||||
2) "40.76302702144496237"
|
||||
|
||||
```
|
||||
|
||||
Looking up the names associated with those keys generates an ordered list of stations I can choose from. Redis doesn't provide directions or routing capability, so I use the routing features of my device's OS to plot a course from my current location to the selected bike station.
|
||||
|
||||
The `GEORADIUS` function can be easily implemented inside an API in your favorite development framework to add location functionality to an app.
|
||||
|
||||
### Other query commands
|
||||
|
||||
In addition to the `GEORADIUS` command, Redis provides three other commands for querying data from the index: `GEOPOS`, `GEODIST`, and `GEORADIUSBYMEMBER`.
|
||||
|
||||
The `GEOPOS` command can provide the coordinates for a given element from the geohash. For example, if I know there is a bikesharing station at West 38th and 8th and its ID is 523, then the element name for that station is NYC🚉523. Using Redis, I can find the station's longitude and latitude:
|
||||
```
|
||||
127.0.0.1:6379> geopos NYC:stations:location NYC:station:523
|
||||
|
||||
1) 1) "-73.99138301610946655"
|
||||
|
||||
2) "40.75466497634030105"
|
||||
|
||||
```
|
||||
|
||||
The `GEODIST` command provides the distance between two elements of the index. If I wanted to find the distance between the station at Grand Army Plaza & Central Park South and the station at East 58th St. & Madison, I would issue the following command:
|
||||
```
|
||||
127.0.0.1:6379> GEODIST NYC:stations:location NYC:station:281 NYC:station:3457 ft
|
||||
|
||||
"671.4900"
|
||||
|
||||
```
|
||||
|
||||
Finally, the `GEORADIUSBYMEMBER` command is similar to the `GEORADIUS` command, but instead of taking a set of coordinates, the command takes the name of another member of the index and returns all the members within a given radius centered on that member. To find all the stations within 1,000 feet of the Grand Army Plaza & Central Park South, enter the following:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUSBYMEMBER NYC:stations:location NYC:station:281 1000 ft WITHDIST
|
||||
|
||||
1) 1) "NYC:station:281"
|
||||
|
||||
2) "0.0000"
|
||||
|
||||
2) 1) "NYC:station:3132"
|
||||
|
||||
2) "793.4223"
|
||||
|
||||
3) 1) "NYC:station:2006"
|
||||
|
||||
2) "911.9752"
|
||||
|
||||
4) 1) "NYC:station:3136"
|
||||
|
||||
2) "940.3399"
|
||||
|
||||
5) 1) "NYC:station:3457"
|
||||
|
||||
2) "671.4900"
|
||||
|
||||
```
|
||||
|
||||
While this example focused on using Python and Redis to parse data and build an index of bikesharing system locations, it can easily be generalized to locate restaurants, public transit, or any other type of place developers want to help users find.
|
||||
|
||||
This article is based on [my presentation][17] at Open Source 101 in Raleigh this year.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools
|
||||
|
||||
作者:[Tague Griffith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tague
|
||||
[1]:https://www.python.org/
|
||||
[2]:https://redis.io/
|
||||
[3]:https://www.citibikenyc.com/
|
||||
[4]:https://www.citibikenyc.com/data-sharing-policy
|
||||
[5]:https://github.com/NABSA/gbfs
|
||||
[6]:http://nabsa.net/
|
||||
[7]:https://www.json.org/
|
||||
[8]:https://gist.github.com/tague/5a82d96bcb09ce2a79943ad4c87f6e15
|
||||
[9]:https://github.com/NABSA/gbfs/blob/master/systems.csv
|
||||
[10]:https://redis.io/commands/unlink
|
||||
[11]:https://redis.io/commands/hmset
|
||||
[12]:https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES
|
||||
[13]:https://redis.io/topics/data-types#Hashes
|
||||
[14]:https://redis.io/commands#geo
|
||||
[15]:https://redis.io/topics/data-types-intro#redis-sorted-sets
|
||||
[16]:https://twitter.com/swatchthedog
|
||||
[17]:http://opensource101.com/raleigh/talks/building-location-aware-apps-open-source-tools/
|
||||
@ -1,3 +1,4 @@
|
||||
translating by Auk7F7
|
||||
How to dual-boot Linux and Windows
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
A single-user, lightweight OS for your next home project | Opensource.com
|
||||
======
|
||||

|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by seriouszyx
|
||||
|
||||
5 of the Best Linux Games to Play in 2018
|
||||
======
|
||||
|
||||
|
||||
@ -1,80 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Joplin: Encrypted Open Source Note Taking And To-Do Application
|
||||
======
|
||||
**[Joplin][1] is a free and open source note taking and to-do application available for Linux, Windows, macOS, Android and iOS. Its key features include end-to-end encryption, Markdown support, and synchronization via third-party services like NextCloud, Dropbox, OneDrive or WebDAV.**
|
||||
|
||||
|
||||
|
||||
With Joplin you can write your notes in the **Markdown format** (with support for math notations and checkboxes) and the desktop app comes with 3 views: Markdown code, Markdown preview, or both side by side. **You can add attachments to your notes (with image previews) or edit them in an external Markdown editor** and have them automatically updated in Joplin each time you save the file.
|
||||
|
||||
The application should handle a large number of notes pretty well by allowing you to **organizing notes into notebooks, add tags, and search in notes**. You can also sort notes by updated date, creation date or title. **Each notebook can contain notes, to-do items, or both** , and you can easily add links to other notes (in the desktop app right click on a note and select `Copy Markdown link` , then paste the link in a note).
|
||||
|
||||
**Do-do items in Joplin support alarms** , but this feature didn't work for me on Ubuntu 18.04.
|
||||
|
||||
**Other Joplin features include:**
|
||||
|
||||
* **Optional Web Clipper extension** for Firefox and Chrome (in the Joplin desktop application go to `Tools > Web clipper options` to enable the clipper service and find download links for the Chrome / Firefox extension) which can clip simplified or complete pages, clip a selection or screenshot.
|
||||
|
||||
* **Optional command line client**.
|
||||
|
||||
* **Import Enex files (Evernote export format) and Markdown files**.
|
||||
|
||||
* **Export JEX files (Joplin Export format), PDF and raw files**.
|
||||
|
||||
* **Offline first, so the entire data is always available on the device even without an internet connection**.
|
||||
|
||||
* **Geolocation support**.
|
||||
|
||||
|
||||
|
||||
[![Joplin notes checkboxes link to other note][2]][3]
|
||||
Joplin with hidden sidebar showing checkboxes and a link to another note
|
||||
|
||||
While it doesn't offer as many features as Evernote, Joplin is a robust open source Evernote alternative. Joplin includes all the basic features, and on top of that it's open source software, it includes encryption support, and you also get to choose the service you want to use for synchronization.
|
||||
|
||||
The application was actually designed as an Evernote alternative so it can import complete Evernote notebooks, notes, tags, attachments, and note metadata like the author, creation and updated time, or geolocation.
|
||||
|
||||
Another aspect on which the Joplin development was focused was to avoid being tied to a particular company or service. This is why the application offers multiple synchronization solutions, like NextCloud, Dropbox, oneDrive and WebDav, while also making it easy to support new services. It's also easy to switch from one service to another if you change your mind.
|
||||
|
||||
**I should note that Joplin doesn't use encryption by default and you must enable this from its settings. Go to** `Tools > Encryption options` and enable the Joplin end-to-end encryption from there.
|
||||
|
||||
### Download Joplin
|
||||
|
||||
[Download Joplin][7]
|
||||
|
||||
**Joplin is available for Linux, Windows, macOS, Android and iOS. On Linux, there's an AppImage as well as an Aur package available.**
|
||||
|
||||
To run the Joplin AppImage on Linux, double click it and select `Make executable and run` if your file manager supports this. If not, you'll need to make it executable either using your file manager (should be something like: `right click > Properties > Permissions > Allow executing file as program` , but this may vary depending on the file manager you use), or from the command line:
|
||||
```
|
||||
chmod +x /path/to/Joplin-*-x86_64.AppImage
|
||||
|
||||
```
|
||||
|
||||
Replacing `/path/to/` with the path to where you downloaded Joplin. Now you can double click the Joplin Appimage file to launch it.
|
||||
|
||||
**TIP:** If you integrate Joplin to your menu and `~/.local/share/applications/appimagekit-joplin.desktop`) and adding `StartupWMClass=Joplin` at the end of the file on a new line, without modifying anything else.
|
||||
|
||||
Joplin has a **command line client** that can be [installed using npm][5] (for Debian, Ubuntu or Linux Mint, see [how to install and configure Node.js and npm][6] ).
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://joplin.cozic.net/
|
||||
[2]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s640/joplin-notes-markdown.png (Joplin notes checkboxes link to other note)
|
||||
[3]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s1600/joplin-notes-markdown.png
|
||||
[4]:https://github.com/laurent22/joplin/issues/338
|
||||
[5]:https://joplin.cozic.net/terminal/
|
||||
[6]:https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html
|
||||
|
||||
[7]: https://joplin.cozic.net/#installation
|
||||
@ -1,512 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Lab 6: Network Driver
|
||||
======
|
||||
### Lab 6: Network Driver (default final project)
|
||||
|
||||
**Due on Thursday, December 6, 2018
|
||||
**
|
||||
|
||||
### Introduction
|
||||
|
||||
This lab is the default final project that you can do on your own.
|
||||
|
||||
Now that you have a file system, no self respecting OS should go without a network stack. In this the lab you are going to write a driver for a network interface card. The card will be based on the Intel 82540EM chip, also known as the E1000.
|
||||
|
||||
##### Getting Started
|
||||
|
||||
Use Git to commit your Lab 5 source (if you haven't already), fetch the latest version of the course repository, and then create a local branch called `lab6` based on our lab6 branch, `origin/lab6`:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'my solution to lab5'
|
||||
nothing to commit (working directory clean)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab6 origin/lab6
|
||||
Branch lab6 set up to track remote branch refs/remotes/origin/lab6.
|
||||
Switched to a new branch "lab6"
|
||||
athena% git merge lab5
|
||||
Merge made by recursive.
|
||||
fs/fs.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
The network card driver, however, will not be enough to get your OS hooked up to the Internet. In the new lab6 code, we have provided you with a network stack and a network server. As in previous labs, use git to grab the code for this lab, merge in your own code, and explore the contents of the new `net/` directory, as well as the new files in `kern/`.
|
||||
|
||||
In addition to writing the driver, you will need to create a system call interface to give access to your driver. You will implement missing network server code to transfer packets between the network stack and your driver. You will also tie everything together by finishing a web server. With the new web server you will be able to serve files from your file system.
|
||||
|
||||
Much of the kernel device driver code you will have to write yourself from scratch. This lab provides much less guidance than previous labs: there are no skeleton files, no system call interfaces written in stone, and many design decisions are left up to you. For this reason, we recommend that you read the entire assignment write up before starting any individual exercises. Many students find this lab more difficult than previous labs, so please plan your time accordingly.
|
||||
|
||||
##### Lab Requirements
|
||||
|
||||
As before, you will need to do all of the regular exercises described in the lab and _at least one_ challenge problem. Write up brief answers to the questions posed in the lab and a description of your challenge exercise in `answers-lab6.txt`.
|
||||
|
||||
#### QEMU's virtual network
|
||||
|
||||
We will be using QEMU's user mode network stack since it requires no administrative privileges to run. QEMU's documentation has more about user-net [here][1]. We've updated the makefile to enable QEMU's user-mode network stack and the virtual E1000 network card.
|
||||
|
||||
By default, QEMU provides a virtual router running on IP 10.0.2.2 and will assign JOS the IP address 10.0.2.15. To keep things simple, we hard-code these defaults into the network server in `net/ns.h`.
|
||||
|
||||
While QEMU's virtual network allows JOS to make arbitrary connections out to the Internet, JOS's 10.0.2.15 address has no meaning outside the virtual network running inside QEMU (that is, QEMU acts as a NAT), so we can't connect directly to servers running inside JOS, even from the host running QEMU. To address this, we configure QEMU to run a server on some port on the _host_ machine that simply connects through to some port in JOS and shuttles data back and forth between your real host and the virtual network.
|
||||
|
||||
You will run JOS servers on ports 7 (echo) and 80 (http). To avoid collisions on shared Athena machines, the makefile generates forwarding ports for these based on your user ID. To find out what ports QEMU is forwarding to on your development host, run make which-ports. For convenience, the makefile also provides make nc-7 and make nc-80, which allow you to interact directly with servers running on these ports in your terminal. (These targets only connect to a running QEMU instance; you must start QEMU itself separately.)
|
||||
|
||||
##### Packet Inspection
|
||||
|
||||
The makefile also configures QEMU's network stack to record all incoming and outgoing packets to `qemu.pcap` in your lab directory.
|
||||
|
||||
To get a hex/ASCII dump of captured packets use `tcpdump` like this:
|
||||
|
||||
```
|
||||
tcpdump -XXnr qemu.pcap
|
||||
```
|
||||
|
||||
Alternatively, you can use [Wireshark][2] to graphically inspect the pcap file. Wireshark also knows how to decode and inspect hundreds of network protocols. If you're on Athena, you'll have to use Wireshark's predecessor, ethereal, which is in the sipbnet locker.
|
||||
|
||||
##### Debugging the E1000
|
||||
|
||||
We are very lucky to be using emulated hardware. Since the E1000 is running in software, the emulated E1000 can report to us, in a user readable format, its internal state and any problems it encounters. Normally, such a luxury would not be available to a driver developer writing with bare metal.
|
||||
|
||||
The E1000 can produce a lot of debug output, so you have to enable specific logging channels. Some channels you might find useful are:
|
||||
|
||||
| Flag | Meaning |
|
||||
| --------- | ---------------------------------------------------|
|
||||
| tx | Log packet transmit operations |
|
||||
| txerr | Log transmit ring errors |
|
||||
| rx | Log changes to RCTL |
|
||||
| rxfilter | Log filtering of incoming packets |
|
||||
| rxerr | Log receive ring errors |
|
||||
| unknown | Log reads and writes of unknown registers |
|
||||
| eeprom | Log reads from the EEPROM |
|
||||
| interrupt | Log interrupts and changes to interrupt registers. |
|
||||
|
||||
To enable "tx" and "txerr" logging, for example, use make E1000_DEBUG=tx,txerr ....
|
||||
|
||||
Note: `E1000_DEBUG` flags only work in the 6.828 version of QEMU.
|
||||
|
||||
You can take debugging using software emulated hardware one step further. If you are ever stuck and do not understand why the E1000 is not responding the way you would expect, you can look at QEMU's E1000 implementation in `hw/e1000.c`.
|
||||
|
||||
#### The Network Server
|
||||
|
||||
Writing a network stack from scratch is hard work. Instead, we will be using lwIP, an open source lightweight TCP/IP protocol suite that among many things includes a network stack. You can find more information on lwIP [here][3]. In this assignment, as far as we are concerned, lwIP is a black box that implements a BSD socket interface and has a packet input port and packet output port.
|
||||
|
||||
The network server is actually a combination of four environments:
|
||||
|
||||
* core network server environment (includes socket call dispatcher and lwIP)
|
||||
* input environment
|
||||
* output environment
|
||||
* timer environment
|
||||
|
||||
|
||||
|
||||
The following diagram shows the different environments and their relationships. The diagram shows the entire system including the device driver, which will be covered later. In this lab, you will implement the parts highlighted in green.
|
||||
|
||||
![Network server architecture][4]
|
||||
|
||||
##### The Core Network Server Environment
|
||||
|
||||
The core network server environment is composed of the socket call dispatcher and lwIP itself. The socket call dispatcher works exactly like the file server. User environments use stubs (found in `lib/nsipc.c`) to send IPC messages to the core network environment. If you look at `lib/nsipc.c` you will see that we find the core network server the same way we found the file server: `i386_init` created the NS environment with NS_TYPE_NS, so we scan `envs`, looking for this special environment type. For each user environment IPC, the dispatcher in the network server calls the appropriate BSD socket interface function provided by lwIP on behalf of the user.
|
||||
|
||||
Regular user environments do not use the `nsipc_*` calls directly. Instead, they use the functions in `lib/sockets.c`, which provides a file descriptor-based sockets API. Thus, user environments refer to sockets via file descriptors, just like how they referred to on-disk files. A number of operations (`connect`, `accept`, etc.) are specific to sockets, but `read`, `write`, and `close` go through the normal file descriptor device-dispatch code in `lib/fd.c`. Much like how the file server maintained internal unique ID's for all open files, lwIP also generates unique ID's for all open sockets. In both the file server and the network server, we use information stored in `struct Fd` to map per-environment file descriptors to these unique ID spaces.
|
||||
|
||||
Even though it may seem that the IPC dispatchers of the file server and network server act the same, there is a key difference. BSD socket calls like `accept` and `recv` can block indefinitely. If the dispatcher were to let lwIP execute one of these blocking calls, the dispatcher would also block and there could only be one outstanding network call at a time for the whole system. Since this is unacceptable, the network server uses user-level threading to avoid blocking the entire server environment. For every incoming IPC message, the dispatcher creates a thread and processes the request in the newly created thread. If the thread blocks, then only that thread is put to sleep while other threads continue to run.
|
||||
|
||||
In addition to the core network environment there are three helper environments. Besides accepting messages from user applications, the core network environment's dispatcher also accepts messages from the input and timer environments.
|
||||
|
||||
##### The Output Environment
|
||||
|
||||
When servicing user environment socket calls, lwIP will generate packets for the network card to transmit. LwIP will send each packet to be transmitted to the output helper environment using the `NSREQ_OUTPUT` IPC message with the packet attached in the page argument of the IPC message. The output environment is responsible for accepting these messages and forwarding the packet on to the device driver via the system call interface that you will soon create.
|
||||
|
||||
##### The Input Environment
|
||||
|
||||
Packets received by the network card need to be injected into lwIP. For every packet received by the device driver, the input environment pulls the packet out of kernel space (using kernel system calls that you will implement) and sends the packet to the core server environment using the `NSREQ_INPUT` IPC message.
|
||||
|
||||
The packet input functionality is separated from the core network environment because JOS makes it hard to simultaneously accept IPC messages and poll or wait for a packet from the device driver. We do not have a `select` system call in JOS that would allow environments to monitor multiple input sources to identify which input is ready to be processed.
|
||||
|
||||
If you take a look at `net/input.c` and `net/output.c` you will see that both need to be implemented. This is mainly because the implementation depends on your system call interface. You will write the code for the two helper environments after you implement the driver and system call interface.
|
||||
|
||||
##### The Timer Environment
|
||||
|
||||
The timer environment periodically sends messages of type `NSREQ_TIMER` to the core network server notifying it that a timer has expired. The timer messages from this thread are used by lwIP to implement various network timeouts.
|
||||
|
||||
### Part A: Initialization and transmitting packets
|
||||
|
||||
Your kernel does not have a notion of time, so we need to add it. There is currently a clock interrupt that is generated by the hardware every 10ms. On every clock interrupt we can increment a variable to indicate that time has advanced by 10ms. This is implemented in `kern/time.c`, but is not yet fully integrated into your kernel.
|
||||
|
||||
```
|
||||
Exercise 1. Add a call to `time_tick` for every clock interrupt in `kern/trap.c`. Implement `sys_time_msec` and add it to `syscall` in `kern/syscall.c` so that user space has access to the time.
|
||||
```
|
||||
|
||||
Use make INIT_CFLAGS=-DTEST_NO_NS run-testtime to test your time code. You should see the environment count down from 5 in 1 second intervals. The "-DTEST_NO_NS" disables starting the network server environment because it will panic at this point in the lab.
|
||||
|
||||
#### The Network Interface Card
|
||||
|
||||
Writing a driver requires knowing in depth the hardware and the interface presented to the software. The lab text will provide a high-level overview of how to interface with the E1000, but you'll need to make extensive use of Intel's manual while writing your driver.
|
||||
|
||||
```
|
||||
Exercise 2. Browse Intel's [Software Developer's Manual][5] for the E1000. This manual covers several closely related Ethernet controllers. QEMU emulates the 82540EM.
|
||||
|
||||
You should skim over chapter 2 now to get a feel for the device. To write your driver, you'll need to be familiar with chapters 3 and 14, as well as 4.1 (though not 4.1's subsections). You'll also need to use chapter 13 as reference. The other chapters mostly cover components of the E1000 that your driver won't have to interact with. Don't worry about the details right now; just get a feel for how the document is structured so you can find things later.
|
||||
|
||||
While reading the manual, keep in mind that the E1000 is a sophisticated device with many advanced features. A working E1000 driver only needs a fraction of the features and interfaces that the NIC provides. Think carefully about the easiest way to interface with the card. We strongly recommend that you get a basic driver working before taking advantage of the advanced features.
|
||||
```
|
||||
|
||||
##### PCI Interface
|
||||
|
||||
The E1000 is a PCI device, which means it plugs into the PCI bus on the motherboard. The PCI bus has address, data, and interrupt lines, and allows the CPU to communicate with PCI devices and PCI devices to read and write memory. A PCI device needs to be discovered and initialized before it can be used. Discovery is the process of walking the PCI bus looking for attached devices. Initialization is the process of allocating I/O and memory space as well as negotiating the IRQ line for the device to use.
|
||||
|
||||
We have provided you with PCI code in `kern/pci.c`. To perform PCI initialization during boot, the PCI code walks the PCI bus looking for devices. When it finds a device, it reads its vendor ID and device ID and uses these two values as a key to search the `pci_attach_vendor` array. The array is composed of `struct pci_driver` entries like this:
|
||||
|
||||
```
|
||||
struct pci_driver {
|
||||
uint32_t key1, key2;
|
||||
int (*attachfn) (struct pci_func *pcif);
|
||||
};
|
||||
```
|
||||
|
||||
If the discovered device's vendor ID and device ID match an entry in the array, the PCI code calls that entry's `attachfn` to perform device initialization. (Devices can also be identified by class, which is what the other driver table in `kern/pci.c` is for.)
|
||||
|
||||
The attach function is passed a _PCI function_ to initialize. A PCI card can expose multiple functions, though the E1000 exposes only one. Here is how we represent a PCI function in JOS:
|
||||
|
||||
```
|
||||
struct pci_func {
|
||||
struct pci_bus *bus;
|
||||
|
||||
uint32_t dev;
|
||||
uint32_t func;
|
||||
|
||||
uint32_t dev_id;
|
||||
uint32_t dev_class;
|
||||
|
||||
uint32_t reg_base[6];
|
||||
uint32_t reg_size[6];
|
||||
uint8_t irq_line;
|
||||
};
|
||||
```
|
||||
|
||||
The above structure reflects some of the entries found in Table 4-1 of Section 4.1 of the developer manual. The last three entries of `struct pci_func` are of particular interest to us, as they record the negotiated memory, I/O, and interrupt resources for the device. The `reg_base` and `reg_size` arrays contain information for up to six Base Address Registers or BARs. `reg_base` stores the base memory addresses for memory-mapped I/O regions (or base I/O ports for I/O port resources), `reg_size` contains the size in bytes or number of I/O ports for the corresponding base values from `reg_base`, and `irq_line` contains the IRQ line assigned to the device for interrupts. The specific meanings of the E1000 BARs are given in the second half of table 4-2.
|
||||
|
||||
When the attach function of a device is called, the device has been found but not yet _enabled_. This means that the PCI code has not yet determined the resources allocated to the device, such as address space and an IRQ line, and, thus, the last three elements of the `struct pci_func` structure are not yet filled in. The attach function should call `pci_func_enable`, which will enable the device, negotiate these resources, and fill in the `struct pci_func`.
|
||||
|
||||
```
|
||||
Exercise 3. Implement an attach function to initialize the E1000. Add an entry to the `pci_attach_vendor` array in `kern/pci.c` to trigger your function if a matching PCI device is found (be sure to put it before the `{0, 0, 0}` entry that mark the end of the table). You can find the vendor ID and device ID of the 82540EM that QEMU emulates in section 5.2. You should also see these listed when JOS scans the PCI bus while booting.
|
||||
|
||||
For now, just enable the E1000 device via `pci_func_enable`. We'll add more initialization throughout the lab.
|
||||
|
||||
We have provided the `kern/e1000.c` and `kern/e1000.h` files for you so that you do not need to mess with the build system. They are currently blank; you need to fill them in for this exercise. You may also need to include the `e1000.h` file in other places in the kernel.
|
||||
|
||||
When you boot your kernel, you should see it print that the PCI function of the E1000 card was enabled. Your code should now pass the `pci attach` test of make grade.
|
||||
```
|
||||
|
||||
##### Memory-mapped I/O
|
||||
|
||||
Software communicates with the E1000 via _memory-mapped I/O_ (MMIO). You've seen this twice before in JOS: both the CGA console and the LAPIC are devices that you control and query by writing to and reading from "memory". But these reads and writes don't go to DRAM; they go directly to these devices.
|
||||
|
||||
`pci_func_enable` negotiates an MMIO region with the E1000 and stores its base and size in BAR 0 (that is, `reg_base[0]` and `reg_size[0]`). This is a range of _physical memory addresses_ assigned to the device, which means you'll have to do something to access it via virtual addresses. Since MMIO regions are assigned very high physical addresses (typically above 3GB), you can't use `KADDR` to access it because of JOS's 256MB limit. Thus, you'll have to create a new memory mapping. We'll use the area above MMIOBASE (your `mmio_map_region` from lab 4 will make sure we don't overwrite the mapping used by the LAPIC). Since PCI device initialization happens before JOS creates user environments, you can create the mapping in `kern_pgdir` and it will always be available.
|
||||
|
||||
```
|
||||
Exercise 4. In your attach function, create a virtual memory mapping for the E1000's BAR 0 by calling `mmio_map_region` (which you wrote in lab 4 to support memory-mapping the LAPIC).
|
||||
|
||||
You'll want to record the location of this mapping in a variable so you can later access the registers you just mapped. Take a look at the `lapic` variable in `kern/lapic.c` for an example of one way to do this. If you do use a pointer to the device register mapping, be sure to declare it `volatile`; otherwise, the compiler is allowed to cache values and reorder accesses to this memory.
|
||||
|
||||
To test your mapping, try printing out the device status register (section 13.4.2). This is a 4 byte register that starts at byte 8 of the register space. You should get `0x80080783`, which indicates a full duplex link is up at 1000 MB/s, among other things.
|
||||
```
|
||||
|
||||
Hint: You'll need a lot of constants, like the locations of registers and values of bit masks. Trying to copy these out of the developer's manual is error-prone and mistakes can lead to painful debugging sessions. We recommend instead using QEMU's [`e1000_hw.h`][6] header as a guideline. We don't recommend copying it in verbatim, because it defines far more than you actually need and may not define things in the way you need, but it's a good starting point.
|
||||
|
||||
##### DMA
|
||||
|
||||
You could imagine transmitting and receiving packets by writing and reading from the E1000's registers, but this would be slow and would require the E1000 to buffer packet data internally. Instead, the E1000 uses _Direct Memory Access_ or DMA to read and write packet data directly from memory without involving the CPU. The driver is responsible for allocating memory for the transmit and receive queues, setting up DMA descriptors, and configuring the E1000 with the location of these queues, but everything after that is asynchronous. To transmit a packet, the driver copies it into the next DMA descriptor in the transmit queue and informs the E1000 that another packet is available; the E1000 will copy the data out of the descriptor when there is time to send the packet. Likewise, when the E1000 receives a packet, it copies it into the next DMA descriptor in the receive queue, which the driver can read from at its next opportunity.
|
||||
|
||||
The receive and transmit queues are very similar at a high level. Both consist of a sequence of _descriptors_. While the exact structure of these descriptors varies, each descriptor contains some flags and the physical address of a buffer containing packet data (either packet data for the card to send, or a buffer allocated by the OS for the card to write a received packet to).
|
||||
|
||||
The queues are implemented as circular arrays, meaning that when the card or the driver reach the end of the array, it wraps back around to the beginning. Both have a _head pointer_ and a _tail pointer_ and the contents of the queue are the descriptors between these two pointers. The hardware always consumes descriptors from the head and moves the head pointer, while the driver always add descriptors to the tail and moves the tail pointer. The descriptors in the transmit queue represent packets waiting to be sent (hence, in the steady state, the transmit queue is empty). For the receive queue, the descriptors in the queue are free descriptors that the card can receive packets into (hence, in the steady state, the receive queue consists of all available receive descriptors). Correctly updating the tail register without confusing the E1000 is tricky; be careful!
|
||||
|
||||
The pointers to these arrays as well as the addresses of the packet buffers in the descriptors must all be _physical addresses_ because hardware performs DMA directly to and from physical RAM without going through the MMU.
|
||||
|
||||
#### Transmitting Packets
|
||||
|
||||
The transmit and receive functions of the E1000 are basically independent of each other, so we can work on one at a time. We'll attack transmitting packets first simply because we can't test receive without transmitting an "I'm here!" packet first.
|
||||
|
||||
First, you'll have to initialize the card to transmit, following the steps described in section 14.5 (you don't have to worry about the subsections). The first step of transmit initialization is setting up the transmit queue. The precise structure of the queue is described in section 3.4 and the structure of the descriptors is described in section 3.3.3. We won't be using the TCP offload features of the E1000, so you can focus on the "legacy transmit descriptor format." You should read those sections now and familiarize yourself with these structures.
|
||||
|
||||
##### C Structures
|
||||
|
||||
You'll find it convenient to use C `struct`s to describe the E1000's structures. As you've seen with structures like the `struct Trapframe`, C `struct`s let you precisely layout data in memory. C can insert padding between fields, but the E1000's structures are laid out such that this shouldn't be a problem. If you do encounter field alignment problems, look into GCC's "packed" attribute.
|
||||
|
||||
As an example, consider the legacy transmit descriptor given in table 3-8 of the manual and reproduced here:
|
||||
|
||||
```
|
||||
63 48 47 40 39 32 31 24 23 16 15 0
|
||||
+---------------------------------------------------------------+
|
||||
| Buffer address |
|
||||
+---------------|-------|-------|-------|-------|---------------+
|
||||
| Special | CSS | Status| Cmd | CSO | Length |
|
||||
+---------------|-------|-------|-------|-------|---------------+
|
||||
```
|
||||
|
||||
The first byte of the structure starts at the top right, so to convert this into a C struct, read from right to left, top to bottom. If you squint at it right, you'll see that all of the fields even fit nicely into a standard-size types:
|
||||
|
||||
```
|
||||
struct tx_desc
|
||||
{
|
||||
uint64_t addr;
|
||||
uint16_t length;
|
||||
uint8_t cso;
|
||||
uint8_t cmd;
|
||||
uint8_t status;
|
||||
uint8_t css;
|
||||
uint16_t special;
|
||||
};
|
||||
```
|
||||
|
||||
Your driver will have to reserve memory for the transmit descriptor array and the packet buffers pointed to by the transmit descriptors. There are several ways to do this, ranging from dynamically allocating pages to simply declaring them in global variables. Whatever you choose, keep in mind that the E1000 accesses physical memory directly, which means any buffer it accesses must be contiguous in physical memory.
|
||||
|
||||
There are also multiple ways to handle the packet buffers. The simplest, which we recommend starting with, is to reserve space for a packet buffer for each descriptor during driver initialization and simply copy packet data into and out of these pre-allocated buffers. The maximum size of an Ethernet packet is 1518 bytes, which bounds how big these buffers need to be. More sophisticated drivers could dynamically allocate packet buffers (e.g., to reduce memory overhead when network usage is low) or even pass buffers directly provided by user space (a technique known as "zero copy"), but it's good to start simple.
|
||||
|
||||
```
|
||||
Exercise 5. Perform the initialization steps described in section 14.5 (but not its subsections). Use section 13 as a reference for the registers the initialization process refers to and sections 3.3.3 and 3.4 for reference to the transmit descriptors and transmit descriptor array.
|
||||
|
||||
Be mindful of the alignment requirements on the transmit descriptor array and the restrictions on length of this array. Since TDLEN must be 128-byte aligned and each transmit descriptor is 16 bytes, your transmit descriptor array will need some multiple of 8 transmit descriptors. However, don't use more than 64 descriptors or our tests won't be able to test transmit ring overflow.
|
||||
|
||||
For the TCTL.COLD, you can assume full-duplex operation. For TIPG, refer to the default values described in table 13-77 of section 13.4.34 for the IEEE 802.3 standard IPG (don't use the values in the table in section 14.5).
|
||||
```
|
||||
|
||||
Try running make E1000_DEBUG=TXERR,TX qemu. If you are using the course qemu, you should see an "e1000: tx disabled" message when you set the TDT register (since this happens before you set TCTL.EN) and no further "e1000" messages.
|
||||
|
||||
Now that transmit is initialized, you'll have to write the code to transmit a packet and make it accessible to user space via a system call. To transmit a packet, you have to add it to the tail of the transmit queue, which means copying the packet data into the next packet buffer and then updating the TDT (transmit descriptor tail) register to inform the card that there's another packet in the transmit queue. (Note that TDT is an _index_ into the transmit descriptor array, not a byte offset; the documentation isn't very clear about this.)
|
||||
|
||||
However, the transmit queue is only so big. What happens if the card has fallen behind transmitting packets and the transmit queue is full? In order to detect this condition, you'll need some feedback from the E1000. Unfortunately, you can't just use the TDH (transmit descriptor head) register; the documentation explicitly states that reading this register from software is unreliable. However, if you set the RS bit in the command field of a transmit descriptor, then, when the card has transmitted the packet in that descriptor, the card will set the DD bit in the status field of the descriptor. If a descriptor's DD bit is set, you know it's safe to recycle that descriptor and use it to transmit another packet.
|
||||
|
||||
What if the user calls your transmit system call, but the DD bit of the next descriptor isn't set, indicating that the transmit queue is full? You'll have to decide what to do in this situation. You could simply drop the packet. Network protocols are resilient to this, but if you drop a large burst of packets, the protocol may not recover. You could instead tell the user environment that it has to retry, much like you did for `sys_ipc_try_send`. This has the advantage of pushing back on the environment generating the data.
|
||||
|
||||
```
|
||||
Exercise 6. Write a function to transmit a packet by checking that the next descriptor is free, copying the packet data into the next descriptor, and updating TDT. Make sure you handle the transmit queue being full.
|
||||
```
|
||||
|
||||
Now would be a good time to test your packet transmit code. Try transmitting just a few packets by directly calling your transmit function from the kernel. You don't have to create packets that conform to any particular network protocol in order to test this. Run make E1000_DEBUG=TXERR,TX qemu to run your test. You should see something like
|
||||
|
||||
```
|
||||
e1000: index 0: 0x271f00 : 9000002a 0
|
||||
...
|
||||
```
|
||||
|
||||
as you transmit packets. Each line gives the index in the transmit array, the buffer address of that transmit descriptor, the cmd/CSO/length fields, and the special/CSS/status fields. If QEMU doesn't print the values you expected from your transmit descriptor, check that you're filling in the right descriptor and that you configured TDBAL and TDBAH correctly. If you get "e1000: TDH wraparound @0, TDT x, TDLEN y" messages, that means the E1000 ran all the way through the transmit queue without stopping (if QEMU didn't check this, it would enter an infinite loop), which probably means you aren't manipulating TDT correctly. If you get lots of "e1000: tx disabled" messages, then you didn't set the transmit control register right.
|
||||
|
||||
Once QEMU runs, you can then run tcpdump -XXnr qemu.pcap to see the packet data that you transmitted. If you saw the expected "e1000: index" messages from QEMU, but your packet capture is empty, double check that you filled in every necessary field and bit in your transmit descriptors (the E1000 probably went through your transmit descriptors, but didn't think it had to send anything).
|
||||
|
||||
```
|
||||
Exercise 7. Add a system call that lets you transmit packets from user space. The exact interface is up to you. Don't forget to check any pointers passed to the kernel from user space.
|
||||
```
|
||||
|
||||
#### Transmitting Packets: Network Server
|
||||
|
||||
Now that you have a system call interface to the transmit side of your device driver, it's time to send packets. The output helper environment's goal is to do the following in a loop: accept `NSREQ_OUTPUT` IPC messages from the core network server and send the packets accompanying these IPC message to the network device driver using the system call you added above. The `NSREQ_OUTPUT` IPC's are sent by the `low_level_output` function in `net/lwip/jos/jif/jif.c`, which glues the lwIP stack to JOS's network system. Each IPC will include a page consisting of a `union Nsipc` with the packet in its `struct jif_pkt pkt` field (see `inc/ns.h`). `struct jif_pkt` looks like
|
||||
|
||||
```
|
||||
struct jif_pkt {
|
||||
int jp_len;
|
||||
char jp_data[0];
|
||||
};
|
||||
```
|
||||
|
||||
`jp_len` represents the length of the packet. All subsequent bytes on the IPC page are dedicated to the packet contents. Using a zero-length array like `jp_data` at the end of a struct is a common C trick (some would say abomination) for representing buffers without pre-determined lengths. Since C doesn't do array bounds checking, as long as you ensure there's enough unused memory following the struct, you can use `jp_data` as if it were an array of any size.
|
||||
|
||||
Be aware of the interaction between the device driver, the output environment and the core network server when there is no more space in the device driver's transmit queue. The core network server sends packets to the output environment using IPC. If the output environment is suspended due to a send packet system call because the driver has no more buffer space for new packets, the core network server will block waiting for the output server to accept the IPC call.
|
||||
|
||||
```
|
||||
Exercise 8. Implement `net/output.c`.
|
||||
```
|
||||
|
||||
You can use `net/testoutput.c` to test your output code without involving the whole network server. Try running make E1000_DEBUG=TXERR,TX run-net_testoutput. You should see something like
|
||||
|
||||
```
|
||||
Transmitting packet 0
|
||||
e1000: index 0: 0x271f00 : 9000009 0
|
||||
Transmitting packet 1
|
||||
e1000: index 1: 0x2724ee : 9000009 0
|
||||
...
|
||||
```
|
||||
|
||||
and tcpdump -XXnr qemu.pcap should output
|
||||
|
||||
|
||||
```
|
||||
reading from file qemu.pcap, link-type EN10MB (Ethernet)
|
||||
-5:00:00.600186 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 30 Packet.00
|
||||
-5:00:00.610080 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 31 Packet.01
|
||||
...
|
||||
```
|
||||
|
||||
To test with a larger packet count, try make E1000_DEBUG=TXERR,TX NET_CFLAGS=-DTESTOUTPUT_COUNT=100 run-net_testoutput. If this overflows your transmit ring, double check that you're handling the DD status bit correctly and that you've told the hardware to set the DD status bit (using the RS command bit).
|
||||
|
||||
Your code should pass the `testoutput` tests of make grade.
|
||||
|
||||
```
|
||||
Question
|
||||
|
||||
1. How did you structure your transmit implementation? In particular, what do you do if the transmit ring is full?
|
||||
```
|
||||
|
||||
|
||||
### Part B: Receiving packets and the web server
|
||||
|
||||
#### Receiving Packets
|
||||
|
||||
Just like you did for transmitting packets, you'll have to configure the E1000 to receive packets and provide a receive descriptor queue and receive descriptors. Section 3.2 describes how packet reception works, including the receive queue structure and receive descriptors, and the initialization process is detailed in section 14.4.
|
||||
|
||||
```
|
||||
Exercise 9. Read section 3.2. You can ignore anything about interrupts and checksum offloading (you can return to these sections if you decide to use these features later), and you don't have to be concerned with the details of thresholds and how the card's internal caches work.
|
||||
```
|
||||
|
||||
The receive queue is very similar to the transmit queue, except that it consists of empty packet buffers waiting to be filled with incoming packets. Hence, when the network is idle, the transmit queue is empty (because all packets have been sent), but the receive queue is full (of empty packet buffers).
|
||||
|
||||
When the E1000 receives a packet, it first checks if it matches the card's configured filters (for example, to see if the packet is addressed to this E1000's MAC address) and ignores the packet if it doesn't match any filters. Otherwise, the E1000 tries to retrieve the next receive descriptor from the head of the receive queue. If the head (RDH) has caught up with the tail (RDT), then the receive queue is out of free descriptors, so the card drops the packet. If there is a free receive descriptor, it copies the packet data into the buffer pointed to by the descriptor, sets the descriptor's DD (Descriptor Done) and EOP (End of Packet) status bits, and increments the RDH.
|
||||
|
||||
If the E1000 receives a packet that is larger than the packet buffer in one receive descriptor, it will retrieve as many descriptors as necessary from the receive queue to store the entire contents of the packet. To indicate that this has happened, it will set the DD status bit on all of these descriptors, but only set the EOP status bit on the last of these descriptors. You can either deal with this possibility in your driver, or simply configure the card to not accept "long packets" (also known as _jumbo frames_ ) and make sure your receive buffers are large enough to store the largest possible standard Ethernet packet (1518 bytes).
|
||||
|
||||
```
|
||||
Exercise 10. Set up the receive queue and configure the E1000 by following the process in section 14.4. You don't have to support "long packets" or multicast. For now, don't configure the card to use interrupts; you can change that later if you decide to use receive interrupts. Also, configure the E1000 to strip the Ethernet CRC, since the grade script expects it to be stripped.
|
||||
|
||||
By default, the card will filter out _all_ packets. You have to configure the Receive Address Registers (RAL and RAH) with the card's own MAC address in order to accept packets addressed to that card. You can simply hard-code QEMU's default MAC address of 52:54:00:12:34:56 (we already hard-code this in lwIP, so doing it here too doesn't make things any worse). Be very careful with the byte order; MAC addresses are written from lowest-order byte to highest-order byte, so 52:54:00:12 are the low-order 32 bits of the MAC address and 34:56 are the high-order 16 bits.
|
||||
|
||||
The E1000 only supports a specific set of receive buffer sizes (given in the description of RCTL.BSIZE in 13.4.22). If you make your receive packet buffers large enough and disable long packets, you won't have to worry about packets spanning multiple receive buffers. Also, remember that, just like for transmit, the receive queue and the packet buffers must be contiguous in physical memory.
|
||||
|
||||
You should use at least 128 receive descriptors
|
||||
```
|
||||
|
||||
You can do a basic test of receive functionality now, even without writing the code to receive packets. Run make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput. `testinput` will transmit an ARP (Address Resolution Protocol) announcement packet (using your packet transmitting system call), which QEMU will automatically reply to. Even though your driver can't receive this reply yet, you should see a "e1000: unicast match[0]: 52:54:00:12:34:56" message, indicating that a packet was received by the E1000 and matched the configured receive filter. If you see a "e1000: unicast mismatch: 52:54:00:12:34:56" message instead, the E1000 filtered out the packet, which means you probably didn't configure RAL and RAH correctly. Make sure you got the byte ordering right and didn't forget to set the "Address Valid" bit in RAH. If you don't get any "e1000" messages, you probably didn't enable receive correctly.
|
||||
|
||||
Now you're ready to implement receiving packets. To receive a packet, your driver will have to keep track of which descriptor it expects to hold the next received packet (hint: depending on your design, there's probably already a register in the E1000 keeping track of this). Similar to transmit, the documentation states that the RDH register cannot be reliably read from software, so in order to determine if a packet has been delivered to this descriptor's packet buffer, you'll have to read the DD status bit in the descriptor. If the DD bit is set, you can copy the packet data out of that descriptor's packet buffer and then tell the card that the descriptor is free by updating the queue's tail index, RDT.
|
||||
|
||||
If the DD bit isn't set, then no packet has been received. This is the receive-side equivalent of when the transmit queue was full, and there are several things you can do in this situation. You can simply return a "try again" error and require the caller to retry. While this approach works well for full transmit queues because that's a transient condition, it is less justifiable for empty receive queues because the receive queue may remain empty for long stretches of time. A second approach is to suspend the calling environment until there are packets in the receive queue to process. This tactic is very similar to `sys_ipc_recv`. Just like in the IPC case, since we have only one kernel stack per CPU, as soon as we leave the kernel the state on the stack will be lost. We need to set a flag indicating that an environment has been suspended by receive queue underflow and record the system call arguments. The drawback of this approach is complexity: the E1000 must be instructed to generate receive interrupts and the driver must handle them in order to resume the environment blocked waiting for a packet.
|
||||
|
||||
```
|
||||
Exercise 11. Write a function to receive a packet from the E1000 and expose it to user space by adding a system call. Make sure you handle the receive queue being empty.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! If the transmit queue is full or the receive queue is empty, the environment and your driver may spend a significant amount of CPU cycles polling, waiting for a descriptor. The E1000 can generate an interrupt once it is finished with a transmit or receive descriptor, avoiding the need for polling. Modify your driver so that processing the both the transmit and receive queues is interrupt driven instead of polling.
|
||||
|
||||
Note that, once an interrupt is asserted, it will remain asserted until the driver clears the interrupt. In your interrupt handler make sure to clear the interrupt as soon as you handle it. If you don't, after returning from your interrupt handler, the CPU will jump back into it again. In addition to clearing the interrupts on the E1000 card, interrupts also need to be cleared on the LAPIC. Use `lapic_eoi` to do so.
|
||||
```
|
||||
|
||||
#### Receiving Packets: Network Server
|
||||
|
||||
In the network server input environment, you will need to use your new receive system call to receive packets and pass them to the core network server environment using the `NSREQ_INPUT` IPC message. These IPC input message should have a page attached with a `union Nsipc` with its `struct jif_pkt pkt` field filled in with the packet received from the network.
|
||||
|
||||
```
|
||||
Exercise 12. Implement `net/input.c`.
|
||||
```
|
||||
|
||||
Run `testinput` again with make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput. You should see
|
||||
|
||||
```
|
||||
Sending ARP announcement...
|
||||
Waiting for packets...
|
||||
e1000: index 0: 0x26dea0 : 900002a 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
input: 0000 5254 0012 3456 5255 0a00 0202 0806 0001
|
||||
input: 0010 0800 0604 0002 5255 0a00 0202 0a00 0202
|
||||
input: 0020 5254 0012 3456 0a00 020f 0000 0000 0000
|
||||
input: 0030 0000 0000 0000 0000 0000 0000 0000 0000
|
||||
```
|
||||
|
||||
The lines beginning with "input:" are a hexdump of QEMU's ARP reply.
|
||||
|
||||
Your code should pass the `testinput` tests of make grade. Note that there's no way to test packet receiving without sending at least one ARP packet to inform QEMU of JOS' IP address, so bugs in your transmitting code can cause this test to fail.
|
||||
|
||||
To more thoroughly test your networking code, we have provided a daemon called `echosrv` that sets up an echo server running on port 7 that will echo back anything sent over a TCP connection. Use make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-echosrv to start the echo server in one terminal and make nc-7 in another to connect to it. Every line you type should be echoed back by the server. Every time the emulated E1000 receives a packet, QEMU should print something like the following to the console:
|
||||
|
||||
```
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
e1000: index 2: 0x26ea7c : 9000036 0
|
||||
e1000: index 3: 0x26f06a : 9000039 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
```
|
||||
|
||||
At this point, you should also be able to pass the `echosrv` test.
|
||||
|
||||
```
|
||||
Question
|
||||
|
||||
2. How did you structure your receive implementation? In particular, what do you do if the receive queue is empty and a user environment requests the next incoming packet?
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
Challenge! Read about the EEPROM in the developer's manual and write the code to load the E1000's MAC address out of the EEPROM. Currently, QEMU's default MAC address is hard-coded into both your receive initialization and lwIP. Fix your initialization to use the MAC address you read from the EEPROM, add a system call to pass the MAC address to lwIP, and modify lwIP to the MAC address read from the card. Test your change by configuring QEMU to use a different MAC address.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Modify your E1000 driver to be "zero copy." Currently, packet data has to be copied from user-space buffers to transmit packet buffers and from receive packet buffers back to user-space buffers. A zero copy driver avoids this by having user space and the E1000 share packet buffer memory directly. There are many different approaches to this, including mapping the kernel-allocated structures into user space or passing user-provided buffers directly to the E1000. Regardless of your approach, be careful how you reuse buffers so that you don't introduce races between user-space code and the E1000.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Take the zero copy concept all the way into lwIP.
|
||||
|
||||
A typical packet is composed of many headers. The user sends data to be transmitted to lwIP in one buffer. The TCP layer wants to add a TCP header, the IP layer an IP header and the MAC layer an Ethernet header. Even though there are many parts to a packet, right now the parts need to be joined together so that the device driver can send the final packet.
|
||||
|
||||
The E1000's transmit descriptor design is well-suited to collecting pieces of a packet scattered throughout memory, like the packet fragments created inside lwIP. If you enqueue multiple transmit descriptors, but only set the EOP command bit on the last one, then the E1000 will internally concatenate the packet buffers from these descriptors and only transmit the concatenated buffer when it reaches the EOP-marked descriptor. As a result, the individual packet pieces never need to be joined together in memory.
|
||||
|
||||
Change your driver to be able to send packets composed of many buffers without copying and modify lwIP to avoid merging the packet pieces as it does right now.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Augment your system call interface to service more than one user environment. This will prove useful if there are multiple network stacks (and multiple network servers) each with their own IP address running in user mode. The receive system call will need to decide to which environment it needs to forward each incoming packet.
|
||||
|
||||
Note that the current interface cannot tell the difference between two packets and if multiple environments call the packet receive system call, each respective environment will get a subset of the incoming packets and that subset may include packets that are not destined to the calling environment.
|
||||
|
||||
Sections 2.2 and 3 in [this][7] Exokernel paper have an in-depth explanation of the problem and a method of addressing it in a kernel like JOS. Use the paper to help you get a grip on the problem, chances are you do not need a solution as complex as presented in the paper.
|
||||
```
|
||||
|
||||
#### The Web Server
|
||||
|
||||
A web server in its simplest form sends the contents of a file to the requesting client. We have provided skeleton code for a very simple web server in `user/httpd.c`. The skeleton code deals with incoming connections and parses the headers.
|
||||
|
||||
```
|
||||
Exercise 13. The web server is missing the code that deals with sending the contents of a file back to the client. Finish the web server by implementing `send_file` and `send_data`.
|
||||
```
|
||||
|
||||
Once you've finished the web server, start the webserver (make run-httpd-nox) and point your favorite browser at http:// _host_ : _port_ /index.html, where _host_ is the name of the computer running QEMU (If you're running QEMU on athena use `hostname.mit.edu` (hostname is the output of the `hostname` command on athena, or `localhost` if you're running the web browser and QEMU on the same computer) and _port_ is the port number reported for the web server by make which-ports . You should see a web page served by the HTTP server running inside JOS.
|
||||
|
||||
At this point, you should score 105/105 on make grade.
|
||||
|
||||
```
|
||||
Challenge! Add a simple chat server to JOS, where multiple people can connect to the server and anything that any user types is transmitted to the other users. To do this, you will have to find a way to communicate with multiple sockets at once _and_ to send and receive on the same socket at the same time. There are multiple ways to go about this. lwIP provides a MSG_DONTWAIT flag for recv (see `lwip_recvfrom` in `net/lwip/api/sockets.c`), so you could constantly loop through all open sockets, polling them for data. Note that, while `recv` flags are supported by the network server IPC, they aren't accessible via the regular `read` function, so you'll need a way to pass the flags. A more efficient approach is to start one or more environments for each connection and to use IPC to coordinate them. Conveniently, the lwIP socket ID found in the struct Fd for a socket is global (not per-environment), so, for example, the child of a `fork` inherits its parents sockets. Or, an environment can even send on another environment's socket simply by constructing an Fd containing the right socket ID.
|
||||
```
|
||||
|
||||
```
|
||||
Question
|
||||
|
||||
3. What does the web page served by JOS's web server say?
|
||||
4. How long approximately did it take you to do this lab?
|
||||
```
|
||||
|
||||
|
||||
**This completes the lab.** As usual, don't forget to run make grade and to write up your answers and a description of your challenge exercise solution. Before handing in, use git status and git diff to examine your changes and don't forget to git add answers-lab6.txt. When you're ready, commit your changes with git commit -am 'my solutions to lab 6', then make handin and follow the directions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://wiki.qemu.org/download/qemu-doc.html#Using-the-user-mode-network-stack
|
||||
[2]: http://www.wireshark.org/
|
||||
[3]: http://www.sics.se/~adam/lwip/
|
||||
[4]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/ns.png
|
||||
[5]: https://pdos.csail.mit.edu/6.828/2018/readings/hardware/8254x_GBe_SDM.pdf
|
||||
[6]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/e1000_hw.h
|
||||
[7]: http://pdos.csail.mit.edu/papers/exo:tocs.pdf
|
||||
@ -0,0 +1,119 @@
|
||||
@flowsnow is translating
|
||||
|
||||
|
||||
How I organize my knowledge as a Software Engineer
|
||||
============================================================
|
||||
|
||||
|
||||
Software Development and Technology in general are areas that evolve at a very fast pace and continuous learning is essential.
|
||||
Some minutes navigating in the internet, in places like Twitter, Medium, RSS feeds, Hacker News and other specialized sites and communities, are enough to find lots of great pieces of information from articles, case studies, tutorials, code snippets, new applications and much more.
|
||||
|
||||
Saving and organizing all that information can be a daunting task. In this post I will present some tools tools that I use to do it.
|
||||
|
||||
One of the points I consider very important regarding knowledge management is to avoid lock-in in a particular platform. All the tools I use, allow to export your data in standard formats like Markdown and HTML.
|
||||
|
||||
Note that, My workflow is not perfect and I am constantly searching for new tools and ways to optimize it. Also everyone is different, so what works for me might not working well for you.
|
||||
|
||||
### Knowledge base with NotionHQ
|
||||
|
||||
For me, the fundamental piece of Knowledge management is to have some kind of personal Knowledge base / wiki. A place where you can save links, bookmarks, notes etc in an organized manner.
|
||||
|
||||
I use [NotionHQ][7] for that matter. I use it to keep notes on various topics, having lists of resources like great libraries or tutorials grouped by programming language, bookmarking interesting blog posts and tutorials, and much more, not only related to software development but also my personal life.
|
||||
|
||||
What I really like about Notion, is how simple it is to create new content. You write it using Markdown and it is organized as tree.
|
||||
|
||||
Here is my top level pages of my "Development" workspace:
|
||||
|
||||
[][8]
|
||||
|
||||
Notion has some nice other features like integrated spreadsheets / databases and Task boards.
|
||||
|
||||
You will need to subscribe to paid Personal Plan, if you want to use Notion seriously as the free plan is somewhat limited. I think its worth the price. Notion allows to export your entire workspace to Markdown files. The export has some important problems, like loosing the page hierarchy, but hope Notion Team can improve that.
|
||||
|
||||
As a free alternative I would probably use [VuePress][9] or [GitBook][10] to host my own.
|
||||
|
||||
### Save interesting articles with Pocket
|
||||
|
||||
[Pocket][11] is one of my favorite applications ever! With Pocket you can create a reading list of articles from the Internet.
|
||||
Every time I see an article that looks interesting, I save it to Pocket using its Chrome Extension. Later on, I will read it and If I found it useful enough, I will use the "Archive" function of Pocket to permanently save that article and clean up my Pocket inbox.
|
||||
|
||||
I try to keep the Reading list small enough and keep archiving information that I have dealt with. Pocket allows you to tag articles which will make it simpler to search articles for a particular topic later in time.
|
||||
|
||||
You can also save a copy of the article in Pocket servers in case of the original site disappears, but you will need Pocket Premium for that.
|
||||
|
||||
Pocket also have a "Discover" feature which suggests similar articles based on the articles you have saved. This is a great way to find new content to read.
|
||||
|
||||
### Snippet Management with SnippetStore
|
||||
|
||||
From GitHub, to Stack Overflow answers, to blog posts, its common to find some nice code snippets that you want to save for later. It could be some nice algorithm implementation, an useful script or an example of how to do X in Y language.
|
||||
|
||||
I tried many apps from simple GitHub Gists to [Boostnote][12] until I discovered [SnippetStore][13].
|
||||
|
||||
SnippetStore is an open source snippet management app. What distinguish SnippetStore from others is its simplicity. You can organize snippets by Language or Tags and you can have multi file snippets. Its not perfect but it gets the job done. Boostnote, for example has more features, but I prefer the simpler way of organizing content of SnippetStore.
|
||||
|
||||
For abbreviations and snippets that I use on a daily basis, I prefer to use my Editor / IDE snippets feature as it is more convenient to use. I use SnippetStore more like a reference of coding examples.
|
||||
|
||||
[Cacher][14] is also an interesting alternative, since it has integrations with many editors, have a cli tool and uses GitHub Gists as backend, but 6$/month for its pro plan, its too much IMO.
|
||||
|
||||
### Managing cheat sheets with DevHints
|
||||
|
||||
[Devhints][15] is a collection of cheat sheets created by Rico Sta. Cruz. Its open source and powered by Jekyll, one of the most popular static site generator.
|
||||
|
||||
The cheat sheets are written in Markdown with some extra formatting goodies like support for columns.
|
||||
|
||||
I really like the looks of the interface and being Markdown makes in incredibly easy to add new content and keep it updated and in version control, unlike cheat sheets in PDF or Image format, that you can find on sites like [Cheatography][16].
|
||||
|
||||
As it is open source I have created my own fork, removed some cheat sheets that I dont need and add some more.
|
||||
|
||||
I use cheat sheets as reference of how to use some library or programming language or to remember some commands. Its very handy to have a single page, with all the basic syntax of a specific programming language for example.
|
||||
|
||||
I am still experimenting with this but its working great so far.
|
||||
|
||||
### Diigo
|
||||
|
||||
[Diigo][17] allows you to Annotate and Highlight parts of websites. I use it to annotate important information when studying new topics or to save particular paragraphs from articles, Stack Overflow answers or inspirational quotes from Twitter! ;)
|
||||
|
||||
* * *
|
||||
|
||||
And thats it. There might be some overlap in terms of functionality in some of the tools, but like I said in the beginning, this is an always evolving workflow, as I am always experimenting and searching for ways to improve and be more productive.
|
||||
|
||||
What about you? How to you organize your Knowledge?. Please feel free to comment below.
|
||||
|
||||
Thank you for reading.
|
||||
|
||||
------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Bruno Paz
|
||||
Web Engineer. Expert in #PHP and @Symfony Framework. Enthusiast about new technologies. Sports and @FCPorto fan!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dev.to/brpaz/how-do-i-organize-my-knowledge-as-a-software-engineer-4387
|
||||
|
||||
作者:[ Bruno Paz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[oska874](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://brunopaz.net/
|
||||
[1]:https://dev.to/brpaz
|
||||
[2]:http://twitter.com/brunopaz88
|
||||
[3]:http://github.com/brpaz
|
||||
[4]:https://dev.to/t/knowledge
|
||||
[5]:https://dev.to/t/learning
|
||||
[6]:https://dev.to/t/development
|
||||
[7]:https://www.notion.so/
|
||||
[8]:https://res.cloudinary.com/practicaldev/image/fetch/s--uMbaRUtu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/http://i.imgur.com/kRnuvMV.png
|
||||
[9]:https://vuepress.vuejs.org/
|
||||
[10]:https://www.gitbook.com/?t=1
|
||||
[11]:https://getpocket.com/
|
||||
[12]:https://boostnote.io/
|
||||
[13]:https://github.com/ZeroX-DG/SnippetStore
|
||||
[14]:https://www.cacher.io/
|
||||
[15]:https://devhints.io/
|
||||
[16]:https://cheatography.com/
|
||||
[17]:https://www.diigo.com/index
|
||||
@ -1,62 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
8 creepy commands that haunt the terminal | Opensource.com
|
||||
======
|
||||
|
||||
Welcome to the spookier side of Linux.
|
||||
|
||||

|
||||
|
||||
It’s that time of year again: The weather gets chilly, the leaves change colors, and kids everywhere transform into tiny ghosts, goblins, and zombies. But did you know that Unix (and Linux) and its various offshoots are also chock-full of creepy crawly things? Let’s take a quick look at some of the spookier aspects of the operating system we all know and love.
|
||||
|
||||
### daemon
|
||||
|
||||
Unix just wouldn’t be the same without all the various daemons that haunt the system. A `daemon` is a process that runs in the background and provides useful services to both the user and the operating system itself. Think SSH, FTP, HTTP, etc.
|
||||
|
||||
### zombie
|
||||
|
||||
Every now and then a zombie, a process that has been killed but refuses to go away, shows up. When this happens, you have no choice but to dispatch it using whatever tools you have available. A zombie usually indicates that something is wrong with the process that spawned it.
|
||||
|
||||
### kill
|
||||
|
||||
Not only can you use the `kill` command to dispatch a zombie, but you can also use it to kill any process that’s adversely affecting your system. Have a process that’s using too much RAM or CPU cycles? Dispatch it with the `kill` command.
|
||||
|
||||
### cat
|
||||
|
||||
The `cat` command has nothing to do with felines and everything to do with combining files: `cat` is short for "concatenate." You can even use this handy command to view the contents of a file.
|
||||
|
||||
|
||||
### tail
|
||||
|
||||
|
||||
The `tail` command is useful when you want to see last n number of lines in a file. It’s also great when you want to monitor a file.
|
||||
|
||||
### which
|
||||
|
||||
No, not that kind of witch, but the command that prints the location of the files associated with any command passed to it. `which python`, for example, will print the locations of every version of Python on your system.
|
||||
|
||||
### crypt
|
||||
|
||||
The `crypt` command, known these days as `mcrypt`, is handy when you want to scramble (encrypt) the contents of a file so that no one but you can read it. Like most Unix commands, you can use `crypt` standalone or within a system script.
|
||||
|
||||
### shred
|
||||
|
||||
The `shred` command is handy when you not only want to delete a file but you also want to ensure that no one will ever be able to recover it. Using the `rm` command to delete a file isn’t enough. You also need to overwrite the space that the file previously occupied. That’s where `shred` comes in.
|
||||
|
||||
These are just a few of the spooky things you’ll find hiding inside Unix. Do you know more creepy commands? Feel free to let me know.
|
||||
|
||||
Happy Halloween!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/spookier-side-unix-linux
|
||||
|
||||
作者:[Patrick H.Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pmullins
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,77 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
KRS: A new tool for gathering Kubernetes resource statistics
|
||||
======
|
||||
Zero-configuration tool simplifies gathering information, such as how many pods are running in a certain namespace.
|
||||

|
||||
|
||||
Recently I was in New York giving a talk at O'Reilly Velocity on the topic of [troubleshooting Kubernetes apps][1] and, motivated by the positive feedback and great discussions on the topic, I decided to revisit tooling in the space. It turns out that, besides [kubernetes-incubator/spartakus][2] and [kubernetes/kube-state-metrics][3], we don't really have much lightweight tooling available to collect resource stats (such as the number of pods or services in a namespace). So, I sat down on my way home and started coding on a little tool—creatively named **krs** , which is short for Kubernetes Resource Stats—that allows you to gather these stats.
|
||||
|
||||
You can use [mhausenblas/krs][5] in two ways:
|
||||
|
||||
* directly from the command line (binaries for Linux, Windows, and MacOS are available); and
|
||||
* in cluster, as a deployment, using the [launch.sh][4] script, which creates the appropriate role-based access control (RBAC) permissions on the fly.
|
||||
|
||||
|
||||
|
||||
Mind you, it's very early days, and this is heavily a work in progress. However, the 0.1 release of **krs** offers the following features:
|
||||
|
||||
* In a per-namespace basis, it periodically gathers resource stats (supporting pods, deployments, and services).
|
||||
* It exposes these stats as metrics in the [OpenMetrics format][6].
|
||||
* It can be used directly via binaries or in a containerized setup with all dependencies included.
|
||||
|
||||
|
||||
|
||||
In its current form, you need to have **kubectl** installed and configured for **krs** to work, because **krs** relies on a **kubectl get all** command to be executed to gather the stats. (On the other hand, who's using Kubernetes and doesn't have **kubectl** installed?)
|
||||
|
||||
Using **krs** is simple; [Download][7] the binary for your platform and execute it like this:
|
||||
|
||||
```
|
||||
$ krs thenamespacetowatch
|
||||
# HELP pods Number of pods in any state, for example running
|
||||
# TYPE pods gauge
|
||||
pods{namespace="thenamespacetowatch"} 13
|
||||
# HELP deployments Number of deployments
|
||||
# TYPE deployments gauge
|
||||
deployments{namespace="thenamespacetowatch"} 6
|
||||
# HELP services Number of services
|
||||
# TYPE services gauge
|
||||
services{namespace="thenamespacetowatch"} 4
|
||||
```
|
||||
|
||||
This will launch **krs** in the foreground, gathering resource stats from the namespace **thenamespacetowatch** and outputting them respectively in the OpenMetrics format on **stdout** for you to further process.
|
||||
|
||||
![krs screenshot][9]
|
||||
|
||||
Screenshot of krs in action.
|
||||
|
||||
But Michael, you may ask, why isn't it doing something useful (such as storing 'em in S3) with the metrics? Because [Unix philosophy][10].
|
||||
|
||||
For those wondering if they can directly use Prometheus or [kubernetes/kube-state-metrics][3] for this task: Well, sure you can, why not? The emphasis of **krs** is on being a lightweight and easy-to-use alternative to already available tooling—and maybe even being slightly complementary in certain aspects.
|
||||
|
||||
This was originally published on [Medium's ITNext][11] and is reprinted with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/kubernetes-resource-statistics
|
||||
|
||||
作者:[Michael Hausenblas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhausenblas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://troubleshooting.kubernetes.sh/
|
||||
[2]: https://github.com/kubernetes-incubator/spartakus
|
||||
[3]: https://github.com/kubernetes/kube-state-metrics
|
||||
[4]: https://github.com/mhausenblas/krs/blob/master/launch.sh
|
||||
[5]: https://github.com/mhausenblas/krs
|
||||
[6]: https://openmetrics.io/
|
||||
[7]: https://github.com/mhausenblas/krs/releases
|
||||
[8]: /file/412706
|
||||
[9]: https://opensource.com/sites/default/files/uploads/krs_screenshot.png (krs screenshot)
|
||||
[10]: http://harmful.cat-v.org/cat-v/
|
||||
[11]: https://itnext.io/kubernetes-resource-statistics-e8247f92b45c
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Create a containerized machine learning model
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Create A Bootable Linux USB Drive From Windows OS 7,8 and 10?
|
||||
======
|
||||
If you would like to learn about Linux, the first thing you have to do is install the Linux OS on your system.
|
||||
|
||||
@ -1,229 +0,0 @@
|
||||
translating by dianbanjiu Commandline quick tips: How to locate a file
|
||||
======
|
||||
|
||||

|
||||
|
||||
We all have files on our computers — documents, photos, source code, you name it. So many of them. Definitely more than I can remember. And if not challenging, it might be time consuming to find the right one you’re looking for. In this post, we’ll have a look at how to make sense of your files on the command line, and especially how to quickly find the ones you’re looking for.
|
||||
|
||||
Good news is there are few quite useful utilities in the Linux commandline designed specifically to look for files on your computer. We’ll have a look at three of those: ls, tree, and find.
|
||||
|
||||
### ls
|
||||
|
||||
If you know where your files are, and you just need to list them or see information about them, ls is here for you.
|
||||
|
||||
Just running ls lists all visible files and directories in the current directory:
|
||||
|
||||
```
|
||||
$ ls
|
||||
Documents Music Pictures Videos notes.txt
|
||||
```
|
||||
|
||||
Adding the **-l** option shows basic information about the files. And together with the **-h** option you’ll see file sizes in a human-readable format:
|
||||
|
||||
```
|
||||
$ ls -lh
|
||||
total 60K
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Documents
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Music
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:13 Pictures
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos
|
||||
-rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
|
||||
```
|
||||
|
||||
**Is** can also search a specific place:
|
||||
|
||||
```
|
||||
$ ls Pictures/
|
||||
trees.png wallpaper.png
|
||||
```
|
||||
|
||||
Or a specific file — even with just a part of the name:
|
||||
|
||||
```
|
||||
$ ls *.txt
|
||||
notes.txt
|
||||
```
|
||||
|
||||
Something missing? Looking for a hidden file? No problem, use the **-a** option:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
. .bash_logout .bashrc Documents Pictures notes.txt
|
||||
.. .bash_profile .vimrc Music Videos
|
||||
```
|
||||
|
||||
There are many other useful options for **ls** , and you can combine them together to achieve what you need. Learn about them by running:
|
||||
|
||||
```
|
||||
$ man ls
|
||||
```
|
||||
|
||||
### tree
|
||||
|
||||
If you want to see, well, a tree structure of your files, tree is a good choice. It’s probably not installed by default which you can do yourself using the package manager DNF:
|
||||
|
||||
```
|
||||
$ sudo dnf install tree
|
||||
```
|
||||
|
||||
Running tree without any options or parameters shows the whole tree starting at the current directory. Just a warning, this output might be huge, because it will include all files and directories:
|
||||
|
||||
```
|
||||
$ tree
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| | `-- christmas-presents.txt
|
||||
| `-- work
|
||||
| |-- project-abc
|
||||
| | |-- README.md
|
||||
| | |-- do-things.sh
|
||||
| | `-- project-notes.txt
|
||||
| `-- status-reports.txt
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
If that’s too much, I can limit the number of levels it goes using the -L option followed by a number specifying the number of levels I want to see:
|
||||
|
||||
```
|
||||
$ tree -L 2
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| `-- work
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
You can also display a tree of a specific path:
|
||||
|
||||
```
|
||||
$ tree Documents/work/
|
||||
Documents/work/
|
||||
|-- project-abc
|
||||
| |-- README.md
|
||||
| |-- do-things.sh
|
||||
| `-- project-notes.txt
|
||||
`-- status-reports.txt
|
||||
```
|
||||
|
||||
To browse and search a huge tree, you can use it together with less:
|
||||
|
||||
```
|
||||
$ tree | less
|
||||
```
|
||||
|
||||
Again, there are other options you can use with three, and you can combine them together for even more power. The manual page has them all:
|
||||
|
||||
```
|
||||
$ man tree
|
||||
```
|
||||
|
||||
### find
|
||||
|
||||
And what about files that live somewhere in the unknown? Let’s find them!
|
||||
|
||||
In case you don’t have find on your system, you can install it using DNF:
|
||||
|
||||
```
|
||||
$ sudo dnf install findutils
|
||||
```
|
||||
|
||||
Running find without any options or parameters recursively lists all files and directories in the current directory.
|
||||
|
||||
```
|
||||
$ find
|
||||
.
|
||||
./Documents
|
||||
./Documents/secret
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc
|
||||
./Documents/work/project-abc/README.md
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./.bash_logout
|
||||
./.bashrc
|
||||
./Videos
|
||||
./.bash_profile
|
||||
./.vimrc
|
||||
./Pictures
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
./notes.txt
|
||||
./Music
|
||||
```
|
||||
|
||||
But the true power of find is that you can search by name:
|
||||
|
||||
```
|
||||
$ find -name do-things.sh
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
```
|
||||
|
||||
Or just a part of a name — like the file extension. Let’s find all .txt files:
|
||||
|
||||
```
|
||||
$ find -name "*.txt"
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./notes.txt
|
||||
```
|
||||
|
||||
You can also look for files by size. That might be especially useful if you’re running out of space. Let’s list all files larger than 1 MB:
|
||||
|
||||
```
|
||||
$ find -size +1M
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
```
|
||||
|
||||
Searching a specific directory is also possible. Let’s say I want to find a file in my Documents directory, and I know it has the word “project” in its name:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*"
|
||||
Documents/work/project-abc
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
Ah! That also showed the directory. One thing I can do is to limit the search query to files only:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*" -type f
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
And again, find have many more options you can use, the man page might definitely help you:
|
||||
|
||||
```
|
||||
$ man find
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-locate-file/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,171 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
Introducing pydbgen: A random dataframe/database table generator
|
||||
======
|
||||
Simple tool generates large database files with multiple tables to practice SQL commands for data science.
|
||||
|
||||

|
||||
|
||||
When you start learning data science, often your biggest worry is not the algorithms or techniques but getting access to raw data. While there are many high-quality, real-life datasets available on the web for trying out cool machine learning techniques, I've found that the same is not true when it comes to learning SQL.
|
||||
|
||||
For data science, having a basic familiarity with SQL is almost as important as knowing how to write code in Python or R. But it's far easier to find toy datasets on Kaggle than it is to access a large enough database with real data (such as name, age, credit card, social security number, address, birthday, etc.) specifically designed or curated for machine learning tasks.
|
||||
|
||||
Wouldn't it be great to have a simple tool or library to generate a large database with multiple tables filled with data of your own choice?
|
||||
|
||||
Aside from beginners in data science, even seasoned software testers may find it useful to have a simple tool where, with a few lines of code, they can generate arbitrarily large data sets with random (fake), yet meaningful entries.
|
||||
|
||||
For this reason, I am glad to introduce a lightweight Python library called **[pydbgen][1]**. In this article, I'll briefly share some information about the package, and you can learn much more [by reading the docs][2].
|
||||
|
||||
### What is pydbgen?
|
||||
|
||||
Pydbgen is a lightweight, pure-Python library to generate random useful entries (e.g., name, address, credit card number, date, time, company name, job title, license plate number, etc.) and save them in a Pandas dataframe object, as an SQLite table in a database file, or in a Microsoft Excel file.
|
||||
|
||||
### How to install pydbgen
|
||||
|
||||
The current version (1.0.5) is hosted on PyPI (the Python Package Index repository). You need to have [Faker][3] installed to make this work. To install Pydbgen, enter:
|
||||
|
||||
```
|
||||
pip install pydbgen
|
||||
```
|
||||
|
||||
It has been tested on Python 3.6 and won't work on Python 2 installations.
|
||||
|
||||
### How to use it
|
||||
|
||||
To start using Pydbgen, initiate a **pydb** object.
|
||||
|
||||
```
|
||||
import pydbgen
|
||||
from pydbgen import pydbgen
|
||||
myDB=pydbgen.pydb()
|
||||
```
|
||||
|
||||
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
||||
|
||||
```
|
||||
myDB.city_real()
|
||||
>> 'Otterville'
|
||||
for _ in range(10):
|
||||
print(myDB.license_plate())
|
||||
>> 8NVX937
|
||||
6YZH485
|
||||
XBY-564
|
||||
SCG-2185
|
||||
XMR-158
|
||||
6OZZ231
|
||||
CJN-850
|
||||
SBL-4272
|
||||
TPY-658
|
||||
SZL-0934
|
||||
```
|
||||
|
||||
By the way, if you enter **city** instead of **city_real** , it will return fictitious city names.
|
||||
|
||||
```
|
||||
print(myDB.gen_data_series(num=8,data_type='city'))
|
||||
>>
|
||||
New Michelle
|
||||
Robinborough
|
||||
Leebury
|
||||
Kaylatown
|
||||
Hamiltonfort
|
||||
Lake Christopher
|
||||
Hannahstad
|
||||
West Adamborough
|
||||
```
|
||||
|
||||
### Generate a Pandas dataframe with random entries
|
||||
|
||||
You can choose how many and what data types will be generated. Note that everything returns as string/texts.
|
||||
|
||||
```
|
||||
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
|
||||
testdf
|
||||
```
|
||||
|
||||
The resulting dataframe looks like the following image.
|
||||
|
||||
|
||||
|
||||
### Generate a database table
|
||||
|
||||
You can choose how many and what data types will be generated. Everything is returned in the text/VARCHAR data type for the database. You can specify the database filename and the table name.
|
||||
|
||||
```
|
||||
myDB.gen_table(db_file='Testdb.DB',table_name='People',
|
||||
|
||||
fields=['name','city','street_address','email'])
|
||||
```
|
||||
|
||||
This generates a .db file which can be used with MySQL or the SQLite database server. The following image shows a database table opened in DB Browser for SQLite.
|
||||
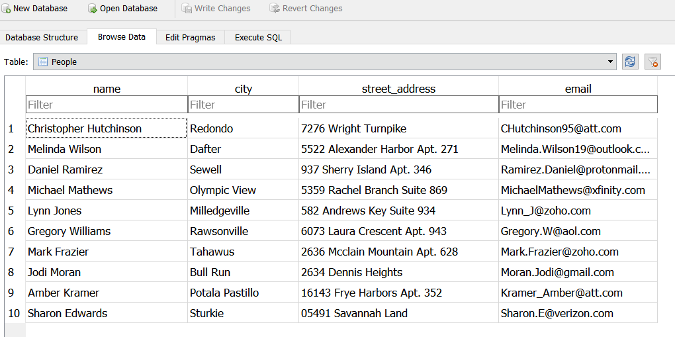
|
||||
|
||||
### Generate an Excel file
|
||||
|
||||
Similar to the examples above, the following code will generate an Excel file with random data. Note that **phone_simple** is set to **False** so it can generate complex, long-form phone numbers. This can come in handy when you want to experiment with more involved data extraction codes.
|
||||
|
||||
```
|
||||
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
||||
phone_simple=False,filename='TestExcel.xlsx')
|
||||
```
|
||||
|
||||
The resulting file looks like this image:
|
||||
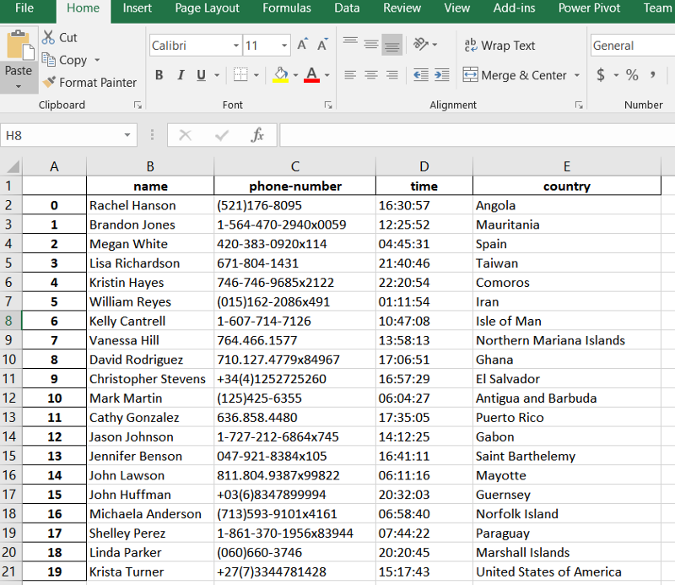
|
||||
|
||||
### Generate random email IDs for scrap use
|
||||
|
||||
A built-in method in pydbgen is **realistic_email** , which generates random email IDs from a seed name. This is helpful when you don't want to use your real email address on the web—but something close.
|
||||
|
||||
```
|
||||
for _ in range(10):
|
||||
print(myDB.realistic_email('Tirtha Sarkar'))
|
||||
>>
|
||||
Tirtha_Sarkar@gmail.com
|
||||
Sarkar.Tirtha@outlook.com
|
||||
Tirtha_S48@verizon.com
|
||||
Tirtha_Sarkar62@yahoo.com
|
||||
Tirtha.S46@yandex.com
|
||||
Tirtha.S@att.com
|
||||
Sarkar.Tirtha60@gmail.com
|
||||
TirthaSarkar@zoho.com
|
||||
Sarkar.Tirtha@protonmail.com
|
||||
Tirtha.S@comcast.net
|
||||
```
|
||||
|
||||
### Future improvements and user contributions
|
||||
|
||||
There may be many bugs in the current version—if you notice any and your program crashes during execution (except for a crash due to your incorrect entry), please let me know. Also, if you have a cool idea to contribute to the source code, the [GitHub repo][1] is open. Some questions readily come to mind:
|
||||
|
||||
* Can we integrate some machine learning/statistical modeling with this random data generator?
|
||||
* Should a visualization function be added to the generator?
|
||||
|
||||
|
||||
|
||||
The possibilities are endless and exciting!
|
||||
|
||||
If you have any questions or ideas to share, please contact me at [tirthajyoti[AT]gmail.com][4]. If you are, like me, passionate about machine learning and data science, please [add me on LinkedIn][5] or [follow me on Twitter][6]. Also, check my [GitHub repo][7] for other fun code snippets in Python, R, or MATLAB and some machine learning resources.
|
||||
|
||||
Originally published on [Towards Data Science][8]. Licensed under [CC BY-SA 4.0][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/pydbgen-random-database-table-generator
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tirthajyoti/pydbgen
|
||||
[2]: http://pydbgen.readthedocs.io/en/latest/
|
||||
[3]: https://faker.readthedocs.io/en/latest/index.html
|
||||
[4]: mailto:tirthajyoti@gmail.com
|
||||
[5]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[6]: https://twitter.com/tirthajyotiS
|
||||
[7]: https://github.com/tirthajyoti?tab=repositories
|
||||
[8]: https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5
|
||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
@ -1,308 +0,0 @@
|
||||
Some Good Alternatives To ‘du’ Command
|
||||
======
|
||||
|
||||

|
||||
|
||||
As you may already know, the **“du”** command is used to compute and summarize the file and directory space usage in Unix-like systems. If you are a heavy user of du command, you will find this guide interesting! Today, I came across five good **alternatives to du** command. There could be many, but these are the ones that I am aware of at the moment. If I came across anything in future, I will add it in this list. Also, if you know any other alternatives, please let me know in the comment section below. I will review and add them in the list as well.
|
||||
|
||||
### 1\. Ncdu
|
||||
|
||||
The **Ncdu** is the popular alternative to du command in the Linux community. The developer of Ncdu is not satisfied with the performance of the du command, so he ended up creating his own. Ncdu is simple, yet fast disk usage analyzer written using **C** programming language with an **ncurses** interface to find which directories or files are taking up more space either on a local or remote systems. We already have published a detailed guide about Ncdu. Check the following link if you are interested to know more about it.
|
||||
|
||||
### 2\. Tin Summer
|
||||
|
||||
The **Tin Summer** is used to find the build artifacts that are taking up disk space. It is also an yet another good alternative for du command. Thanks to multi-threading, Tin-summer is significantly faster than du command when calculating the size of the big directories. Unlike Du command, it reads file sizes, not disk usage. Tin SUmmer is free, open source tool written using **Rust** programming language.
|
||||
|
||||
The developer claims Tin Summer is good alternative to du command, because,
|
||||
|
||||
* It is faster on larger directories compared to du command,
|
||||
* It displays the disk usage results in human-readable format by default,
|
||||
* It uses **regex** to exclude files/directories,
|
||||
* Provides sorted and colorized output,
|
||||
* Extensible,
|
||||
* And more.
|
||||
|
||||
|
||||
|
||||
**Installing Tin Summer**
|
||||
|
||||
To install Tin Summer, open your Terminal and run the following command:
|
||||
|
||||
```
|
||||
$ curl -LSfs https://japaric.github.io/trust/install.sh | sh -s -- --git vmchale/tin-summer
|
||||
```
|
||||
|
||||
Alternatively, you can install Tin Summer using **Cargo** package manager. Make sure you have installed **Rust** on your system as described in the following link.
|
||||
|
||||
After installing Rust, run the following command to install Tin Summer:
|
||||
|
||||
```
|
||||
$ cargo install tin-summer
|
||||
```
|
||||
|
||||
If either of the above mentioned methods doesn’t not work, download the latest binary from the [**releases page**][1] and compile and install it manually.
|
||||
|
||||
**Usage**
|
||||
|
||||
To find the file sizes in a current working directory, use this command:
|
||||
|
||||
```
|
||||
$ sn f
|
||||
749 MB ./.rustup/toolchains
|
||||
749 MB ./.rustup
|
||||
147 MB ./.cargo/bin
|
||||
147 MB ./.cargo
|
||||
900 MB .
|
||||
```
|
||||
|
||||
See? It displays a nicer input in human-readable format by default. You need not to use any extra flags (like **-h** in du command) to get this result.
|
||||
|
||||
To find the file sizes in a specific directory, mention the actual path like below:
|
||||
|
||||
```
|
||||
$ sn f <path-to-the-directory>
|
||||
```
|
||||
|
||||
We can also sort the list in the output as well. To display the sorted list of the top 5 biggest directories, run:
|
||||
|
||||
```
|
||||
$ sn sort /home/sk/ -n5
|
||||
749 MB /home/sk/.rustup
|
||||
749 MB /home/sk/.rustup/toolchains
|
||||
147 MB /home/sk/.cargo
|
||||
147 MB /home/sk/.cargo/bin
|
||||
2.6 MB /home/sk/mcelog
|
||||
900 MB /home/sk/
|
||||
```
|
||||
|
||||
For your information, the last result in the above output is the total size of the biggest directories in the given directory i.e **/home/sk/**. So, don’t wonder why you get six results instead of 5.
|
||||
|
||||
To search current directory for directories with build artifacts:
|
||||
|
||||
```
|
||||
$ sn ar
|
||||
```
|
||||
|
||||
Tin Summer can also search for directories containing artifacts that occupy a certain size of the disk space. Say for example, to search for directories containing artifacts that occupy more than **100MB** of disk space, run:
|
||||
|
||||
```
|
||||
$ sn ar -t100M
|
||||
```
|
||||
|
||||
Like already mentioned, Tin Summer is faster on larger directories, but it is also slower on small ones. However, the developer assures he will find a way to fix this in the future releases!
|
||||
|
||||
To get help, run:
|
||||
|
||||
```
|
||||
$ sn --help
|
||||
```
|
||||
|
||||
For more details, check the project’s GitHub repository given at the end of this guide.
|
||||
|
||||
### 3\. Dust
|
||||
|
||||
**Dust** (du+rust=dust) is more intuitive version of du utility. It will give us an instant overview of which directories are occupying the disk space without having to use **head** or **sort** commands. Like Tin Summer, it also displays the size of each directory in human-readable format by default. It is free, open source and written using **Rust** programming language.
|
||||
|
||||
**Installing Dust**
|
||||
|
||||
Since the dust utility is written in Rust, It can be installed using “cargo” package manager like below.
|
||||
|
||||
```
|
||||
$ cargo install du-dust
|
||||
```
|
||||
|
||||
Alternatively, you can download the latest binary from the [**releases page**][2] and install it as shown below. As of writing this guide, the latest version was **0.3.1**.
|
||||
|
||||
```
|
||||
$ wget https://github.com/bootandy/dust/releases/download/v0.3.1/dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
|
||||
```
|
||||
|
||||
Extract the download file:
|
||||
|
||||
```
|
||||
$ tar -xvf dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
|
||||
```
|
||||
|
||||
Finally, copy the executable file to your $PATH, for example **/usr/local/bin**.
|
||||
|
||||
```
|
||||
$ sudo mv dust /usr/local/bin/
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
To find the total file sizes in the current directory and its sub-directories, run:
|
||||
|
||||
```
|
||||
$ dust
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||

|
||||
|
||||
We can also get the full path of all directories using **-p** flag.
|
||||
|
||||
```
|
||||
$ dust -p
|
||||
```
|
||||
|
||||
![dust 2][4]
|
||||
|
||||
To get the total size of multiple directories, just mention them with space-separated:
|
||||
|
||||
```
|
||||
$ dust <dir1> <dir2>
|
||||
```
|
||||
|
||||
Here are some more examples.
|
||||
|
||||
Show the apparent size of the files:
|
||||
|
||||
```
|
||||
$ dust -s
|
||||
```
|
||||
|
||||
Show particular number of directories only:
|
||||
|
||||
```
|
||||
$ dust -n 10
|
||||
```
|
||||
|
||||
Show 3 levels of sub-directories in the current directory:
|
||||
|
||||
```
|
||||
$ dust -d 3
|
||||
```
|
||||
|
||||
For help, run:
|
||||
|
||||
```
|
||||
$ dust -h
|
||||
```
|
||||
|
||||
For more details, refer the project’s GitHub page given at the end.
|
||||
|
||||
### 4\. Diskus
|
||||
|
||||
**Diskus** It is a simple and fast alternative command line utility to `du -sh`command. The diskus utility computes the total file size of the current directory. It is a parallelized version of `du -sh` or rather `du -sh --bytes` command. The developer of diskus utility claims that it is about **nine times faster** compared to ‘du -sh’. Diskus is minimal, fast and open source program written in **Rust** programming language.
|
||||
|
||||
**Installing diskus**
|
||||
|
||||
The diskus utility is available in [**AUR**][5], so you can install it on Arch-based systems using any AUR helper programs, for example [**Yay**][6] , as shown below.
|
||||
|
||||
```
|
||||
$ yay -S diskus
|
||||
```
|
||||
|
||||
On Ubuntu and its derivatives, download the latest diskus utility from the [**releases page**][7] and install it as shown below.
|
||||
|
||||
```
|
||||
$ wget "https://github.com/sharkdp/diskus/releases/download/v0.3.1/diskus_0.3.1_amd64.deb"
|
||||
|
||||
$ sudo dpkg -i diskus_0.3.1_amd64.deb
|
||||
```
|
||||
|
||||
Alternatively, you can install diskus using **Cargo** package manager. Make sure you have installed **Rust 1.29** or higher on your system as described in the link given above in “Installing Tin Summer” section.
|
||||
|
||||
Once you have Rust on your system, run the following command to install diskus:
|
||||
|
||||
```
|
||||
$ cargo install diskus
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
Usually, when I want to check the total disk space used by a particular directory, I use the **-sh** flags with **du** command as shown below.
|
||||
|
||||
```
|
||||
$ du -sh dir
|
||||
```
|
||||
|
||||
Here, **-s** flag indicates summary.
|
||||
|
||||
Using Diskus tool, I find the total size of current working directory with command:
|
||||
|
||||
```
|
||||
$ diskus
|
||||
```
|
||||
|
||||

|
||||
|
||||
I tested diskus to compute the total size of different directories in my Arch Linux system. The speed of computing the total size of the directory is pretty impressive! I must admit that this utility is quite faster than ‘du -sh’. Please be mindful that it can find the size of the current directory only at the moment.
|
||||
|
||||
For getting help, run:
|
||||
|
||||
```
|
||||
$ diskus -h
|
||||
```
|
||||
|
||||
For more details about Diskus, refer the official GitHub page (link at the end).
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
### 5\. Duu
|
||||
|
||||
**Duu** , short for **D** irectory **U** sage **U** tility, is another tool to find the disk usage of given directory. It is a cross-platform, so you can use it on Windows, Mac OS and Linux operating systems. It is written in **Python** programming language.
|
||||
|
||||
**Installing Duu**
|
||||
|
||||
Make sure you have installed Python3. Python3 is available in the default repositories of most Linux distributions, so the installation wouldn’t be a problem.
|
||||
|
||||
Once Python3 is installed, download the latest Duu version from the official [**releases page**][8].
|
||||
|
||||
```
|
||||
$ wget https://github.com/jftuga/duu/releases/download/2.20/duu.py
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
To find the disk space occupied by the current working directory, simply run:
|
||||
|
||||
```
|
||||
$ python3 duu.py
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||

|
||||
|
||||
As you can see in the above output, Duu utility will display a nice summary of total number of files and directories and their total size in bytes, KB and MB. It will also display the total size of each item.
|
||||
|
||||
To display the total disk usage of a specific directory, just mention the full path like below:
|
||||
|
||||
```
|
||||
$ python3 duu.py /home/sk/Downloads/
|
||||
```
|
||||
|
||||
For more details, refer Duu github page included at the end.
|
||||
|
||||
And, that’s all for now. Hope this was useful. You know now five alternatives to du command. Personally, I prefer Ncdu over all of them given in this guide. Now is your turn. Give them a try and let us know your thoughts on these tools in the comment section below.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/some-good-alternatives-to-du-command/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/vmchale/tin-summer/releases
|
||||
[2]: https://github.com/bootandy/dust/releases
|
||||
[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2018/11/dust-2.png
|
||||
[5]: https://aur.archlinux.org/packages/diskus-bin/
|
||||
[6]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[7]: https://github.com/sharkdp/diskus/releases
|
||||
[8]: https://github.com/jftuga/duu/releases
|
||||
@ -0,0 +1,108 @@
|
||||
|
||||
构建满足客户需求的一套云环境的5个步骤
|
||||
======
|
||||
|
||||

|
||||
这篇文是和[Ian Teksbury][1]共同完成的。
|
||||
|
||||
无论你如何定义,云就是你的用户展现组织价值的另一个工具。当谈论新的范例或者技术的时候是很容易被,(云是两者兼有)它的新特性所分心。由一系列无止境的问题引发的对话能够很快的被发展为功能愿景清单,所有的这些都是你可能已经考虑到的。
|
||||
* 是公有云,私有云还是混合云?
|
||||
* 将会使用虚拟机还是容器,或者是两者?
|
||||
* 将会提供自助服务吗?
|
||||
* 将会完全自动的从开发转移到生产,还是它将需要手动操作?
|
||||
* 我们能以多块的速度创建?
|
||||
* 关于工具X,Y,还有Z?
|
||||
|
||||
这样的清单还可以列举很多。
|
||||
|
||||
开始现代化,或者数字转型,无论你是如何称呼的,通常方法是开始回答高级管理层的一些高层次问题,这种方法的结果是可以预想到的:失败。经过大范围的调研并且花费了数月的时间,如果不是几年,部署这个最炫的新技术,新的云技术从未被使用过而且陷入了荒废直到它最终被丢弃或者遗忘在数据中心的一角和预算中。
|
||||
|
||||
因为无论你交付的是什么工具都不是用户所想要或者需要的。更加糟糕的是,当用户真正需要的是一个单独的工具时,一系列其他的工具就会被用户抛弃因为新的,闪光的
|
||||
升级的工具能够更好的满足他们的需求。
|
||||
|
||||
### 议题聚焦
|
||||
|
||||
问题是关注,传统一直是关注工具。但工具并不是要增加到组织价值中的东西;终端用户利用它做什么。你需要将你的注意力从创建云(列入技术和工具)转移到你的人员和用户身上。
|
||||
|
||||
事实上,使用工具的用户(而不是工具本身)是驱动价值的因素,聚焦注意力在用户身上也是由其他原因的。工具是给用户使用去解决他们的问题并允许他们创造价值的,
|
||||
所有这就导致了如果那些工具不能满足那些用户的需求,那么那些工具将不会被使用。如果你交付给你的用户的工具并不是他们喜欢的,他们将不会使用,这就是人类的
|
||||
人性行为。
|
||||
|
||||
数十年来,IT产业只为用户提供一种解决方案,因为仅有一个或两个选项,用户是没有权力去改变的。现在情况已经不同了。我们现在生活在一个技术选择的世界中。
|
||||
不给用户一个选择的机会的情况将不会被接受的;他们在个人的科技生活中有选择,同时希望在工作中也有选择。现在的用户都是受过教育的并且知道将会有比你提供的机会更好的选择。
|
||||
|
||||
因此,在物理上的最安全的地点之外,没有能够阻止他们只做他们自己想要的东西的方法,我们称之为“影子IT。”如果你的组织由如此严格的安全策略和承诺策略,许多员工将会感到灰心丧气并且会离职去其他能提供更好机会的公司。
|
||||
|
||||
基于以上所有的原因,你必须牢记要首先和你的终端用户设计你的昂贵又费时的云项目。
|
||||
|
||||
### 创建满足用户需求的云五个步骤的过程
|
||||
|
||||
既然我们已经知道了为什么,接下来我们来讨论一下怎么做。你如何去为终端用户创建一个云?你怎样重新将你的注意力从技术转移到使用技术的用户身上?
|
||||
根据以往的经验,我们知道最好的方法中包含两件重要的事情:从你的用户中得到及时的反馈,创建中和用户进行更多的互动。
|
||||
|
||||
你的云环境将继续随着你的组织不段发展。下面的五个步骤将会帮助你创建满足用户需求的云环境。
|
||||
|
||||
### 1\. 识别谁将是你的用户
|
||||
|
||||
在你开始询问用户问题之前,你首先必须识别谁将是你的新的云环境的用户。他们可能包括将在云上创建开发应用的开发者。也可能是运营,维护或者或者创建云的运维团队;还可能是保护组织的安全团队。在第一次迭代时,将你的用户数量缩小至人数较少的小组防止你被大量的反馈所淹没,让你识别的每个小组指派两个代表(一个主要的一个辅助的)。这将使你的第一次交付在大小和时间上都很小。
|
||||
|
||||
#### 2\. 和你的用户面对面的交谈来收获有价值的输入。
|
||||
|
||||
The best way to get users' feedback is through direct communication. Mass emails asking for input will self-select respondents—if you even get a response. Group discussions can be helpful, but people tend to be more candid when they have a private, attentive audience.
|
||||
获得反馈的最佳途径是和用户直接交谈。如果你收到回复,大量的邮件要求你输入信息,你会选择自动回复。小组讨论会很有帮助的,但是当人们有私密的,吸引人注意的观众,他们会比较的坦诚。
|
||||
|
||||
和你的第一批用户安排面对面的个人的会谈并且向他们询问以下的问题:
|
||||
|
||||
* 为了完成你的任务,你需要什么?
|
||||
* 为了完成你的任务,你想要什么?
|
||||
* 你现在最头疼的技术点是什么?
|
||||
* 你现在最头疼的政策或者程序是哪个?
|
||||
* 为了满足你的需求你有什么想法,欲望还是疼痛?
|
||||
|
||||
这些问题只是指导性的并不一定适合每个组。你不应该只询问这些问题,他们应该导向更深层次的讨论。确保告诉用户任何所说的和被问的都会被反馈的。所有的反馈都是有帮助的,无论是消极的还是积极的。这些对话将会帮助你设置你的开发优先级。
|
||||
|
||||
收集这种个性化的反馈是保持初始用户群较小的另一个原因:将会花费你大量的时间来和每个用户交流,但是我们已经发现这是相当值得付出的投入。
|
||||
|
||||
#### 3\. 设计并交付你的解决方案的第一个版本
|
||||
|
||||
一旦你收到初始用户的反馈,就是时候开始去设计并交付一部分的功能了。我们不推荐尝试一次性交付整个解决方案。设计和交付的时期要短;这是为了避免犯一个需要你花费一年的时间去寻找解决方案的错误,只会让你的用户拒绝它,因为对他们来说毫无用处。创建你的云所需要的工具取决于你的组织和它的特殊需求。只需确保你的解决方案是建立在用户的反馈的基础上的,你将功能小块化的交付并且要经常的去征求用户的反馈。
|
||||
|
||||
#### 4\. 询问用户对第一个版本的反馈
|
||||
|
||||
太棒了,现在你已经设计并向你的用户交付了你的炫酷的新的云环境的第一个版本!你并不是花费一整年去完成它而是将它处理成小的模块。为什么将其分为小的模块如此重要呢?因为你要回归你的用户并且向他们收集关于你的设计和交付的功能。他们喜欢什么?不喜欢什么?你正确的处理了他们所关注的吗?是技术功能上很厉害,但系统进程或者策略方面仍然欠缺?
|
||||
|
||||
再重申一次,你要问的问题取决于你的组织;这里的关键是继续前一个阶段的讨论。毕竟你正在为用户创建云环境,所以确保它对用户来说是有用的并且能够有效利用每个人的时间。
|
||||
|
||||
#### 5\. 回到第一步。
|
||||
|
||||
这是一个互动的过程。你的第一次交付应该是快速而小规模的,而且以后的迭代也应该是这样的。不要期待仅仅按照这个流程完成了一次,两次即使是三次就能完成。
|
||||
一旦你持续的迭代,你将会吸引更多的用户从而能够在这个过程中得到更好的回报。你将会从用户那里得到更多的支持。你能狗迭代的更迅速并且更可靠。到最后,你
|
||||
将会通过改变你的进程来满足用户的需求。
|
||||
|
||||
用户是这个过程中最重要的一部分,但迭代是第二重要的因为它让你能够回到用户中进行持续沟通从而得到更多有用的信息。在每个阶段,记录那些是有效的哪些没有起到应有的效果。要自省,要对自己诚实。我们所花费的时间提供了最有价值的了吗?如果不是,在下一个阶段尝试些不同的。在每次循环中不要花费太多时间的重要部分是,如果某部分在这次不起作用,你能够很容易的在写一次中调整它,知道你找到能够在你组织中起作用的方法。
|
||||
|
||||
### 这仅仅是开始
|
||||
|
||||
通过许多客户的约定,从他们那里收集反馈,以及在这个领域的同行的经验,我们一次次的发现在你创建云的时候最重要事就是和你的用户交谈。这看起来是很明显的,
|
||||
但很让人惊讶的是很多组织却偏离了这个方向去花费数月或者数年的时间去创建,然后最终发现它对终端用户甚至一点用处都没有。
|
||||
|
||||
现在你已经知道为什么你需要将你的注意力集中到终端用户身上并且在中心节点和用户有一个一起创建云的互动过程。剩下的是我们所喜欢的部分,你出去做的部分。
|
||||
|
||||
这篇文章是基于"[为终端用户设计混合云或者失败],"一篇作者将在[Red Hat Summit 2018][3]上发表的文章,并且将于5月8日至10日在旧金山举行
|
||||
|
||||
[在5月7号前注册][3]将会节省US$500。在支付页面使用折扣码**OPEN18**将会享受到折扣。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly
|
||||
|
||||
作者:[Cameron Wyatt][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cameronmwyatt
|
||||
[1]:https://opensource.com/users/itewk
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154225
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
@ -0,0 +1,122 @@
|
||||
让系统崩溃的黑天鹅分类
|
||||
======
|
||||
|
||||
在严重的故障发生之前,找到引起问题的异常事件,并修复它。
|
||||
|
||||

|
||||
|
||||
黑天鹅用来比喻造成严重影响的小概率事件(比如 2008 年的金融危机)。在生产环境的系统中,黑天鹅是指这样的事情:它引发了你不知道的问题,造成了重大影响,不能快速修复或回滚,也不能用值班说明书上的其他标准响应来解决。它是事发几年后你还在给新人说起的事件。
|
||||
|
||||
从定义上看,黑天鹅是不可预测的,不过有时候我们能找到其中的一些模式,针对有关联的某一类问题准备防御措施。
|
||||
|
||||
例如,大部分故障的直接原因是变更(代码、环境或配置)。虽然这种方式触发的 bug 是独特的,不可预测的,但是常见的金丝雀发布对避免这类问题有一定的作用,而且自动回滚已经成了一种标准止损策略。
|
||||
|
||||
随着我们的专业性不断成熟,一些其他的问题也正逐渐变得容易理解,被归类到某种风险并有普适的预防策略。
|
||||
|
||||
### 公布出来的黑天鹅事件
|
||||
|
||||
所有科技公司都有生产环境的故障,只不过并不是所有公司都会分享他们的事故分析。那些公开讨论事故的公司帮了我们的忙。下列事故都描述了某一类问题,但它们绝对不是只属于一个类别。我们的系统中都有黑天鹅在潜伏着,只是有些人还不知道而已。
|
||||
|
||||
#### 达到上限
|
||||
|
||||
达到任何类型的限制都会引发严重事故。这类问题的一个典型例子是 2017 年 2 月 [Instapaper 的一次服务中断][1]。我把这份事故报告给任何一个运维工作者看,他们读完都会脊背发凉。Instapaper 生产环境的数据库所在的文件系统有 2 TB 的大小限制,但是数据库服务团队并不知情。在没有任何报错的情况下,数据库不再接受任何写入了。完全恢复需要好几天,而且还得迁移数据库。
|
||||
|
||||
资源限制有各式各样的触发场景。Sentry 遇到了 [Postgres 的最大事务 ID 限制][2]。Platform.sh 遇到了[管道缓冲区大小限制][3]。SparkPost [触发了 AWS 的 DDos 保护][4]。Foursquare 在他们的一个 [MongoDB 耗尽内存][5]时遭遇了性能骤降。
|
||||
|
||||
提前了解系统限制的一个办法是定期做测试。好的压力测试(在生产环境的副本上做)应该包含写入事务,并且应该把每一种数据存储都写到超过当前生产环境的容量。压力测试时很容易忽略的是次要存储(比如 Zookeeper)。如果你是在测试时遇到了资源限制,那么你还有时间去解决问题。鉴于这种资源限制问题的解决方案可能涉及重大的变更(比如数据存储拆分),所以时间是非常宝贵的。
|
||||
|
||||
说到云产品的使用,如果你的服务产生了异常的负载,或者你用的产品或功能还没有被广泛使用(比如老旧的或者新兴的),那么你遇到资源上限的风险很大。对这些云产品做一下压力测试是值得的。不过,做之前要提醒一下你的云服务提供商。
|
||||
|
||||
最后,知道了哪里有限制之后,要增加监控(和对应文档),这样你才能知道系统在什么时候接近了资源上限。不要寄希望于那些还在维护服务的人会记得。
|
||||
|
||||
#### 扩散的慢请求
|
||||
|
||||
> “这个世界的关联性远比我们想象中更大。所以我们看到了更多 Nassim Taleb 所说的‘黑天鹅事件’ —— 即罕见事件以更高的频率离谱地发生了,因为世界是相互关联的”
|
||||
> — [Richard Thaler][6]
|
||||
|
||||
HostedGraphite 的负载均衡器并没有托管在 AWS 上,却[被 AWS 的服务中断给搞垮了][7],他们关于这次事故原因的分析报告很好地诠释了分布式计算系统之间存在多么大的关联。在这个事件里,负载均衡器的连接池被来自 AWS 上的客户访问占满了,因为这些连接很耗时。同样的现象还会发生在应用的线程、锁、数据库连接上 —— 任何能被慢操作占满的资源。
|
||||
|
||||
这个 HostedGraphite 的例子中,慢速连接是外部系统施加的,不过慢速连接经常是由内部某个系统的饱和所引起的,饱和与慢操作的级联,拖慢了系统中的其他部分。[Spotify 的一个事故][8]就说明了这样的传播 —— 流媒体服务的前端被另一个微服务的饱和所影响,造成健康检查失败。强制给所有请求设置超时时间,以及限制请求队列的长度,可以预防这一类故障传播。这样即使有问题,至少你的服务还能承担一些流量,而且因为整体上你的系统里故障的部分更少了,恢复起来也会更快。
|
||||
|
||||
重试的间隔应该用指数退避来限制一下,并加入一些时间抖动。Square 有一次服务中断是 [Redis 存储的过载][9],原因是有一段代码对失败的事务重试了 500 次,没有任何重试退避的方案,也说明了过度重试的潜在风险。另外,针对这种情况,[断路器][10]设计模式也是有用的。
|
||||
|
||||
应该设计出监控仪表盘来清晰地展示所有资源的[使用率,饱和度和报错][11],这样才能快速发现问题。
|
||||
|
||||
#### 突发的高负载
|
||||
|
||||
系统在异常高的负载下经常会发生故障。用户天然会引发高负载,不过也常常是由系统引发的。午夜突发的 cron 定时任务是老生常谈了。如果程序让移动客户端同时去获取更新,这些客户端也会造成突发的大流量(当然,给这种请求加入时间抖动会好很多)。
|
||||
|
||||
在预定时刻同时发生的事件并不是突发大流量的唯一原因。Slack 经历过一次短时间内的[多次服务中断][12],原因是非常多的客户端断开连接后立即重连,造成了突发的大负载。 CircleCI 也经历过一次[严重的服务中断][13],当时 Gitlab 从故障中恢复了,所以数据库里积累了大量的构建任务队列,服务变得饱和而且缓慢。
|
||||
|
||||
几乎所有的服务都会受突发的高负载所影响。所以对这类可能出现的事情做应急预案——并测试一下预案能否正常工作——是必须的。客户端退避和[减载][14]通常是这些方案的核心。
|
||||
|
||||
如果你的系统必须不间断地接收数据,并且数据不能被丢掉,关键是用可伸缩的方式把数据缓冲到队列中,后续再处理。
|
||||
|
||||
#### 自动化系统是复杂的系统
|
||||
|
||||
> “复杂的系统本身就是有风险的系统”
|
||||
> —— [Richard Cook, MD][15]
|
||||
|
||||
过去几年里软件的运维操作趋势是更加自动化。任何可能降低系统容量的自动化操作(比如擦除磁盘,退役设备,关闭服务)都应该谨慎操作。这类自动化操作的故障(由于系统有 bug 或者有不正确的调用)能很快地搞垮你的系统,而且可能很难恢复。
|
||||
|
||||
谷歌的 Christina Schulman 和 Etienne Perot 在[用安全规约协助保护你的数据中心][16]的演讲中给了一些例子。其中一次事故是将谷歌整个内部的内容分发网络(CDN)提交给了擦除磁盘的自动化系统。
|
||||
|
||||
Schulman 和 Perot 建议使用一个中心服务来管理规约,限制破坏性自动化操作的速度,并能感知到系统状态(比如避免在最近有告警的服务上执行破坏性的操作)。
|
||||
|
||||
自动化系统在与运维人员(或其他自动化系统)交互时,也可能造成严重事故。[Reddit][17] 遭遇过一次严重的服务中断,当时他们的自动化系统重启了一个服务,但是这个服务是运维人员停掉做维护的。一旦有了多个自动化系统,它们之间潜在的交互就变得异常复杂和不可预测。
|
||||
|
||||
所有的自动化系统都把日志输出到一个容易搜索的中心存储上,能帮助到对这类不可避免的意外情况的处理。自动化系统总是应该具备这样一种机制,即允许快速地关掉它们(完全关掉或者只关掉其中一部分操作或一部分目标)。
|
||||
|
||||
### 防止黑天鹅事件
|
||||
|
||||
可能在等着击垮系统的黑天鹅可不止上面这些。有很多其他的严重问题是能通过一些技术来避免的,像金丝雀发布,压力测试,混沌工程,灾难测试和模糊测试——当然还有冗余性和弹性的设计。但是即使用了这些技术,有时候你的系统还是会有故障。
|
||||
|
||||
为了确保你的组织能有效地响应,在服务中断期间,请保证关键技术人员和领导层有办法沟通协调。例如,有一种你可能需要处理的烦人的事情,那就是网络完全中断。拥有故障时仍然可用的通信通道非常重要,这个通信通道要完全独立于你们自己的基础设施和基础设施的依赖。举个例子,假如你使用 AWS,那么把故障时可用的通信服务部署在 AWS 上就不明智了。在和你的主系统无关的地方,运行电话网桥或 IRC 服务器是比较好的方案。确保每个人都知道这个通信平台,并练习使用它。
|
||||
|
||||
另一个原则是,确保监控和运维工具对生产环境系统的依赖尽可能的少。将控制平面和数据平面分开,你才能在系统不健康的时候做变更。不要让数据处理和配置变更或监控使用同一个消息队列,比如——应该使用不同的消息队列实例。在 [SparkPost: DNS 挂掉的那一天][4] 这个演讲中,Jeremy Blosser 讲了一个这类例子,很关键的工具依赖了生产环境的 DNS 配置,但是生产环境的 DNS 出了问题。
|
||||
|
||||
### 对抗黑天鹅的心理学
|
||||
|
||||
处理生产环境的重大事故时会产生很大的压力。为这些场景制定结构化的事故管理流程确实是有帮助的。很多科技公司([包括谷歌][18])成功地使用了联邦应急管理局事故指挥系统的某个版本。对于每一个值班的人,遇到了他们无法独立解决的重大问题时,都应该有一个明确的寻求协助的方法。
|
||||
|
||||
对于那些持续很长时间的事故,有一点很重要,要确保工程师不会连续工作到不合理的时长,确保他们不会不吃不睡(没有报警打扰的睡觉)。疲惫不堪的工程师很容易犯错或者漏掉了可能更快解决故障的信息。
|
||||
|
||||
### 了解更多
|
||||
|
||||
关于黑天鹅(或者以前的黑天鹅)事件以及应对策略,还有很多其他的事情可以说。如果你想了解更多,我强烈推荐你去看这两本书,它们是关于生产环境中的弹性和稳定性的:Susan Fowler 写的[生产微服务][19],还有 Michael T. Nygard 的 [Release It!][20]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/taxonomy-black-swans
|
||||
|
||||
作者:[Laura Nolan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[BeliteX](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lauranolan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://medium.com/making-instapaper/instapaper-outage-cause-recovery-3c32a7e9cc5f
|
||||
[2]: https://blog.sentry.io/2015/07/23/transaction-id-wraparound-in-postgres.html
|
||||
[3]: https://medium.com/@florian_7764/technical-post-mortem-of-the-august-incident-82ab4c3d6547
|
||||
[4]: https://www.usenix.org/conference/srecon18americas/presentation/blosser
|
||||
[5]: https://groups.google.com/forum/#!topic/mongodb-user/UoqU8ofp134
|
||||
[6]: https://en.wikipedia.org/wiki/Richard_Thaler
|
||||
[7]: https://blog.hostedgraphite.com/2018/03/01/spooky-action-at-a-distance-how-an-aws-outage-ate-our-load-balancer/
|
||||
[8]: https://labs.spotify.com/2013/06/04/incident-management-at-spotify/
|
||||
[9]: https://medium.com/square-corner-blog/incident-summary-2017-03-16-2f65be39297
|
||||
[10]: https://en.wikipedia.org/wiki/Circuit_breaker_design_pattern
|
||||
[11]: http://www.brendangregg.com/usemethod.html
|
||||
[12]: https://slackhq.com/this-was-not-normal-really
|
||||
[13]: https://circleci.statuspage.io/incidents/hr0mm9xmm3x6
|
||||
[14]: https://www.youtube.com/watch?v=XNEIkivvaV4
|
||||
[15]: https://web.mit.edu/2.75/resources/random/How%20Complex%20Systems%20Fail.pdf
|
||||
[16]: https://www.usenix.org/conference/srecon18americas/presentation/schulman
|
||||
[17]: https://www.reddit.com/r/announcements/comments/4y0m56/why_reddit_was_down_on_aug_11/
|
||||
[18]: https://landing.google.com/sre/book/chapters/managing-incidents.html
|
||||
[19]: http://shop.oreilly.com/product/0636920053675.do
|
||||
[20]: https://www.oreilly.com/library/view/release-it/9781680500264/
|
||||
[21]: https://www.usenix.org/conference/lisa18/presentation/nolan
|
||||
[22]: https://www.usenix.org/conference/lisa18
|
||||
@ -0,0 +1,207 @@
|
||||
Bash脚本中如何使用 here 文档将数据写入文件
|
||||
======
|
||||
|
||||
<ruby>here 文档<rt>here document</rt></ruby> (LCTT译注:here文档又称作 heredoc )不是什么特殊的东西,只是一种 I/O 重定向方式,它告诉bash shell从当前源读取输入,直到读取到只有分隔符的行。
|
||||
![redirect output of here document to a text file][1]
|
||||
这对于向 ftp,cat,echo,ssh 和许多其他有用的 Linux/Unix 命令提供指令很有用。 此功能适用于 bash也适用于 Bourne,Korn,POSIX 这三种 shell。
|
||||
|
||||
## here 文档语法
|
||||
|
||||
语法是:
|
||||
```
|
||||
command <<EOF
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
EOF
|
||||
```
|
||||
|
||||
或者允许shell脚本中的 here 文档使用 **EOF<<-** 以自然的方式缩进
|
||||
|
||||
```
|
||||
command <<-EOF
|
||||
msg1
|
||||
msg2
|
||||
$var on line
|
||||
EOF
|
||||
```
|
||||
|
||||
或者
|
||||
```
|
||||
command <<'EOF'
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
$var won't expand as parameter substitution turned off
|
||||
by single quoting
|
||||
EOF
|
||||
```
|
||||
|
||||
或者 **重定向并将其覆盖** 到名为my_output_file.txt的文件中:
|
||||
```
|
||||
command << EOF > my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
或**重定向并将其追加**到名为my_output_file.txt的文件中:
|
||||
|
||||
```
|
||||
command << EOF >> my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
## 示例
|
||||
|
||||
以下脚本将所需内容写入名为/tmp/output.txt的文件中:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
cat <<EOF >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
你可以使用[cat命令][3]查看/tmp/output.txt文件:
|
||||
|
||||
```
|
||||
$ cat /tmp/output.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Status of backup as on Thu Nov 16 17:00:21 IST 2017
|
||||
Backing up files /home/vivek and /etc/
|
||||
|
||||
```
|
||||
|
||||
### 禁用路径名/参数/变量扩展,命令替换,算术扩展
|
||||
|
||||
像 $HOME 这类变量和像 $(date) 这类命令在脚本中会被解释为替换。 要禁用它,请使用带有 'EOF' 这样带有单引号的形式,如下所示:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
# No parameter and variable expansion, command substitution, arithmetic expansion, or pathname expansion is performed on word.
|
||||
# If any part of word is quoted, the delimiter is the result of quote removal on word, and the lines in the here-document
|
||||
# are not expanded. So EOF is quoted as follows
|
||||
cat <<'EOF' >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
你可以使用[cat命令][3]查看/tmp/output.txt文件:
|
||||
|
||||
```
|
||||
$ cat /tmp/output.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
|
||||
```
|
||||
|
||||
## 关于 tee 命令的使用
|
||||
|
||||
语法是:
|
||||
```
|
||||
tee /tmp/filename <<EOF >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
或者通过在单引号中引用EOF来禁用变量替换和命令替换:
|
||||
|
||||
```
|
||||
tee /tmp/filename <<'EOF' >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
这是我更新的脚本:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
tee $OUT <<EOF >/dev/null
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
## 关于内存 here 文档的使用
|
||||
|
||||
这是我更新的脚本:
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
## in memory here docs
|
||||
## thanks https://twitter.com/freebsdfrau
|
||||
exec 9<<EOF
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
## continue
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
## do it
|
||||
cat <&9 >$OUT
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/using-heredoc-rediection-in-bash-shell-script-to-write-to-file/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cyberciti.biz
|
||||
[1]: https://www.cyberciti.biz/media/new/faq/2017/11/redirect-output-of-here-document-to-a-text-file.jpg
|
||||
[2]: https://bash.cyberciti.biz/guide/Here_documents
|
||||
[3]: https//www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ "See Linux/Unix cat command examples for more info"
|
||||
70
translated/tech/20171229 Excellent Free Roguelike Games.md
Normal file
70
translated/tech/20171229 Excellent Free Roguelike Games.md
Normal file
@ -0,0 +1,70 @@
|
||||
最棒的免费 Roguelike 游戏
|
||||
======
|
||||
![地牢][1]
|
||||
|
||||
Roguelike 属于角色扮演游戏的一个子流派,它从字面上理解就是“类 Rogue 游戏”。Rogue 是一个地牢爬行视频游戏,第一个版本由开发者 Michel Toy、Glenn Wichman 和 Ken Arnold 在 1980 年发布,由于极易上瘾使得它从一众游戏中脱颖而出。整个游戏的目标是深入第 26 层,取回 Yendor 的护身符并回到地面,所有设定都基于龙与地下城的世界观。
|
||||
|
||||
Rogue 被认为是一个经典、极其困难并且让人废寝忘食的游戏。虽然它在大学校园中非常受欢迎,但并不十分畅销。在 Rogue 发布时,它并没有使用开源证书,导致了爱好者们开发了许多克隆版本。
|
||||
|
||||
对于 Roguelike 游戏并没有一个明确的定义,但是此类游戏会拥有下述的典型特征:
|
||||
|
||||
* 高度魔幻的叙事背景;
|
||||
* 程序化生成关卡。游戏世界中的大部分地图在每次开始游戏时重新生成,也就意味着鼓励多周目;
|
||||
* 回合制的地牢探险和战斗;
|
||||
* 基于图块随机生成的图形;
|
||||
* 随机的战斗结果;
|
||||
* 永久死亡——死亡现实地起作用,一旦死亡你就需要重新开始
|
||||
* 高难度
|
||||
|
||||
|
||||
此篇文章收集了大量 Linux 平台可玩的 Roguelike 游戏。如果你享受提供真实紧张感的上瘾游戏体验,我衷心推荐你下载这些游戏。不要被其中很多游戏的原始画面劝退,一旦你沉浸其中你会很快忽略简陋的画面。记住,在 Roguelike 游戏中应是游戏机制占主导,画面只是一个加分项而不是必需项。
|
||||
|
||||
此处推荐 16 款游戏。所有的游戏都可免费下载,并且大部分采用开源证书发布。
|
||||
| **Roguelike 游戏** |
|
||||
| --- |
|
||||
| **[Dungeon Crawl Stone Soup][1]** | Linley’s Dungeon Crawl 的续作 |
|
||||
| **[Prospector][2]** | 基于科幻小说世界观的 Roguelike 游戏 |
|
||||
| **[Dwarf Fortress][3]** | 冒险和侏儒塔防 |
|
||||
| **[NetHack][4]** | 非常怪诞并且令人上瘾的龙与地下城风格冒险游戏 |
|
||||
| **[Angband][5]** | 沿着 Rogue 和 NetHack 的路线,它源于游戏 Moria 和 Umoria |
|
||||
| **[Ancient Domains of Mystery][6]** | 非常成熟的 Roguelike 游戏 |
|
||||
| **[Tales of Maj’Eyal][7]** | 特色的策略回合制战斗与先进的角色培养系统 |
|
||||
| **[UnNetHack][8]** | NetHack 的创新复刻 |
|
||||
| **[Hydra Slayer][9]** | 基于数学谜题的 Roguelike 游戏 |
|
||||
| **[Cataclysm DDA][10]** | 后启示录风格 Roguelike 游戏,设定于虚构的新英格兰乡下|
|
||||
| **[Brogue][11]** | Rogue 的正统续作 |
|
||||
| **[Goblin Hack][12]** | 受 NetHack 启发的游戏, 但密钥更少游戏流程更快 |
|
||||
| **[Ascii Sector][13]** | 拥有 Roguelike 动作系统的 2D 版贸易和太空飞行模拟器 |
|
||||
| **[SLASH'EM][14]** | Super Lotsa Added Stuff Hack - Extended Magic |
|
||||
| **[Everything Is Fodder][15]** | Seven Day Roguelike 比赛入口 |
|
||||
| **[Woozoolike][16]** | 7DRL 2017 比赛中一款简单的太空探索 Roguelike 游戏 |
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxlinks.com/excellent-free-roguelike-games/
|
||||
|
||||
作者:[Steve Emms][a]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxlinks.com/author/linuxlinks/
|
||||
[1]:https://www.linuxlinks.com/dungeoncrawlstonesoup/
|
||||
[2]:https://www.linuxlinks.com/Prospector-roguelike/
|
||||
[3]:https://www.linuxlinks.com/dwarffortress/
|
||||
[4]:https://www.linuxlinks.com/nethack/
|
||||
[5]:https://www.linuxlinks.com/angband/
|
||||
[6]:https://www.linuxlinks.com/ADOM/
|
||||
[7]:https://www.linuxlinks.com/talesofmajeyal/
|
||||
[8]:https://www.linuxlinks.com/unnethack/
|
||||
[9]:https://www.linuxlinks.com/hydra-slayer/
|
||||
[10]:https://www.linuxlinks.com/cataclysmdda/
|
||||
[11]:https://www.linuxlinks.com/brogue/
|
||||
[12]:https://www.linuxlinks.com/goblin-hack/
|
||||
[13]:https://www.linuxlinks.com/asciisector/
|
||||
[14]:https://www.linuxlinks.com/slashem/
|
||||
[15]:https://www.linuxlinks.com/everything-is-fodder/
|
||||
[16]:https://www.linuxlinks.com/Woozoolike/
|
||||
[17]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2017/12/dungeon.jpg?resize=300%2C200&ssl=1
|
||||
@ -0,0 +1,206 @@
|
||||
使用Redis和Python构建一个共享单车的应用程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
我经常出差。但不是一个汽车狂热分子,所以当我有空闲时,我更喜欢在城市中散步或者骑单车。我参观过的许多城市都有共享单车系统,你可以租个单车用几个小时。大多数系统都有一个应用程序来帮助用户定位和租用他们的单车,但对于像我这样的用户来说,在一个地方可以获得可租赁的城市中所有单车的信息会更有帮助。
|
||||
|
||||
为了解决这个问题并且展示开源的强大还有为 Web 应用程序添加位置感知的功能,我组合了可用的公开的共享单车数据,[Python][1] 编程语言以及开源的 [Redis][2] 内存数据结构服务,用来索引和查询地理空间数据。
|
||||
|
||||
由此诞生的共享单车应用程序包含来自很多不同的共享系统的数据,包括纽约市的 [Citi Bike][3] 共享单车系统(LCTT 译注:Citi Bike 是纽约市的一个私营公共单车系统。在2013年5月27日正式营运,是美国最大的公共单车系统。Citi Bike 的名称有两层意思。Citi 是计划赞助商花旗银行(CitiBank)的名字。同时,Citi 和英文中“城市(city)”一词的读音相同)。它利用了花旗单车系统提供的 <ruby>通用共享单车数据流<rt>General Bikeshare Feed</rt></ruby>,并利用其数据演示了一些使用 Redis 地理空间数据索引的功能。 花旗单车数据可以在 [花旗单车数据许可协议][4] 下提供。
|
||||
|
||||
### 通用共享单车数据流规范
|
||||
|
||||
通用共享单车数据流规范(GBFS)是由 [北美共享单车协会][6] 开发的 [开放数据规范][5],旨在使地图程序和运输程序更容易的将共享单车系统添加到对应平台中。 目前世界上有 60 多个不同的共享系统使用该规范。
|
||||
|
||||
Feed 流由几个简单的 [JSON][7] 数据文件组成,其中包含系统状态的信息。 Feed 流以引用了子 Feed 流数据的URL 的顶级 JSON 文件开头:
|
||||
|
||||
```
|
||||
{
|
||||
"data": {
|
||||
"en": {
|
||||
"feeds": [
|
||||
{
|
||||
"name": "system_information",
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/system_information.json"
|
||||
},
|
||||
{
|
||||
"name": "station_information",
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
|
||||
},
|
||||
. . .
|
||||
]
|
||||
}
|
||||
},
|
||||
"last_updated": 1506370010,
|
||||
"ttl": 10
|
||||
}
|
||||
```
|
||||
|
||||
第一步是使用 `system_information` 和 `station_information` 的数据将共享单车站的信息加载到Redis中。
|
||||
|
||||
`system_information` 提供系统 ID,系统 ID 可用于为 Redis 密钥创建命名空间的简短编码。 GBFS 规范没有指定系统 ID 的格式,但需要确保它是全局唯一的。许多共享单车数据流使用诸如coast_bike_share,boise_greenbike 或者 topeka_metro_bikes 这样的短名称作为系统 ID。其他的使用常见的地理缩写,例如 NYC 或者 BA,并且使用通用唯一标识符(UUID)。 共享单车应用程序使用标识符作为前缀来为指定系统构造唯一键。
|
||||
|
||||
`station_information feed` 提供组成整个系统的共享单车站的静态信息。车站由具有多个字段的 JSON 对象表示。车站对象中有几个必填字段,用于提供物理单车站的 ID,名称和位置。还有几个可选字段提供有用的信息,例如最近的十字路口,可接受的付款方式。这是共享单车应用程序这一部分的主要信息来源。
|
||||
|
||||
### 建立数据库
|
||||
|
||||
我编写了一个示例应用程序 [load_station_data.py][8],它模仿后端进程中从外部源加载数据时会发生什么。
|
||||
|
||||
### 查找共享单车站
|
||||
|
||||
从 [GitHub 上 GBFS 仓库][5]中的 [systems.csv][9] 文件开始加载共享单车数据。
|
||||
|
||||
仓库中的 [systems.csv][9] 文件为已注册的共享单车系统提供可用的 GBFS 源发现的 URL。 发现的URL是处理共享单车信息的起点。
|
||||
|
||||
`load_station_data` 程序获取系统文件中找到的每个 URL,并使用它来查找两个子数据流的URL:系统信息和车站信息。 系统信息提供提供了一条关键信息:系统的唯一 ID。 (注意:系统 ID 也在 systems.csv 文件中提供,但文件中的某些标识符与数据流中的标识符不匹配,因此我总是从数据流中获取标识符。)系统上的详细信息,比如共享单车 URLS,电话号码和电子邮件, 可以在程序的后续版本中添加,因此使用 `${system_id}:system_info` 这个键将数据存储在 Redis 中。
|
||||
|
||||
### 载入车站数据
|
||||
|
||||
车站信息提供系统中每个车站的数据,包括系统的位置。 load_station_data 程序遍历车站数据流中的每个车站,并使用 `${system_id}:station:${station_id}` 形式的键将每个车站的数据存储到 Redis 中。 使用 `GEOADD` 命令将每个车站的位置添加到共享单车的地理空间索引中。
|
||||
|
||||
### 更新数据
|
||||
|
||||
在后续运行中,我不希望代码从 Redis 中删除所有 Feed 数据并将其重新加载到空的 Redis 数据库中,因此我仔细考虑了如何处理数据的原地更新。
|
||||
|
||||
代码首先将所有共享单车站的信息数据集加载到正在处理到内存中的系统中的。 为单个车站加载信息时,将从内存中的车站集合按照存储在 Redis 的键中删除该站。 加载完所有车站数据后,我们将留下一个包含该系统必须删除的所有车站数据的集合。
|
||||
|
||||
程序创建一个事务删除这组车站的信息,从地理空间索引中删除车站的键,并从系统的车站列表中删除车站。
|
||||
|
||||
### 代码注意点
|
||||
|
||||
需要注意在[示例代码][8]中有一些有趣的事情。 首先,使用 `GEOADD` 命令将所有数据项添加到地理空间索引中,使用 `ZREM` 命令将其删除。 由于地理空间类型的底层实现使用了有序集合,因此需要使用ZREM删除数据项。 需要注意的是:为简单起见,示例代码演示了如何使用单个 Redis 节点; 为了在集群环境中运行,需要重新构建事务块。
|
||||
|
||||
如果你使用的是 Redis 4.0(或更高版本),则可以在代码中使用 `DELETE` 和 `HMSET` 命令。 Redis 4.0 提供 `UNLINK` 命令作为 `DELETE` 命令的异步版本的替代。 `UNLINK` 命令将从键空间中删除键,但它会在单独的线程中回收内存。 在 Redis 4.0 中 [`HMSET` 命令已经被弃用了而且`HSET` 命令现在接收可变参数][12](即,它接受的参数个数不定)。
|
||||
|
||||
### 通知客户端
|
||||
|
||||
处理结束时,会向依赖我们数据的客户发送通知。 使用 Redis 发布/订阅机制,通知将通过 `geobike:station_changed` 通道和系统 ID 一起发出。
|
||||
|
||||
### 数据模型
|
||||
|
||||
在 Redis 中构建数据时,最重要的考虑因素是如何查询信息。 共享单车程序需要支持的两个主要查询是:
|
||||
|
||||
- 找到我们附近的车站
|
||||
- 显示车站相关的信息
|
||||
|
||||
Redis 提供了两种主要数据类型用于存储数据:哈希和有序集。 哈希类型很好地映射到表示车站的 JSON 对象; 由于 Redis 哈希不使用固定结构,因此它们可用于存储可变的车站信息。
|
||||
|
||||
当然,在地理位置上寻找站点需要地理空间索引来搜索相对于某些坐标的站点。 Redis 提供了几个使用有序集数据结构构建地理空间索引的命令。
|
||||
|
||||
我们使用 `${system_id}:station:${station_id}` 这种格式的键存储车站相关的信息,使用格 `${system_id}:stations:location` 这种格式的键查找车站的地理空间索引。
|
||||
|
||||
### 获取用户位置
|
||||
|
||||
构建应用程序的下一步是确定用户的当前位置。 大多数应用程序通过操作系统提供的内置服务来实现此目的。 操作系统可以基于设备内置的 GPS 硬件为应用程序提供定位,或者从设备的可用 WiFi 网络提供近似的定位。
|
||||
|
||||

|
||||
|
||||
### 查找车站
|
||||
|
||||
找到用户的位置后,下一步是找到附近的共享单车站。 Redis 的地理空间功能可以返回用户当前坐标在给定距离内的所有车站信息。 以下是使用 Redis 命令行界面的示例。
|
||||
|
||||
想象一下,我正在纽约市第五大道的苹果零售店,我想要向市中心方向前往位于西 37 街的 MOOD 布料店,与我的好友 [Swatch][16] 相遇。 我可以坐出租车或地铁,但我更喜欢骑单车。 附近有没有我可以使用的单车共享站呢?
|
||||
|
||||
苹果零售店位于 40.76384,-73.97297。 根据地图显示,在零售店 500 英尺半径范围内(地图上方的蓝色)有两个单车站,分别是陆军广场中央公园南单车站和东 58 街麦迪逊单车站。
|
||||
|
||||
我可以使用 Redis 的 `GEORADIUS` 命令查询 500 英尺半径范围内的车站的 NYC 系统索引:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft
|
||||
1) "NYC:station:3457"
|
||||
2) "NYC:station:281"
|
||||
```
|
||||
|
||||
Redis 使用地理空间索引中的元素作为特定车站的元数据的键,返回在该半径内找到的两个共享单车站。 下一步是查找两个站的名称:
|
||||
```
|
||||
127.0.0.1:6379> hget NYC:station:281 name
|
||||
"Grand Army Plaza & Central Park S"
|
||||
|
||||
127.0.0.1:6379> hget NYC:station:3457 name
|
||||
"E 58 St & Madison Ave"
|
||||
```
|
||||
|
||||
这些键对应于上面地图上标识的车站。 如果需要,可以在 `GEORADIUS` 命令中添加更多标志来获取元素列表,每个元素的坐标以及它们与当前点的距离:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft WITHDIST WITHCOORD ASC
|
||||
1) 1) "NYC:station:281"
|
||||
2) "289.1995"
|
||||
3) 1) "-73.97371262311935425"
|
||||
2) "40.76439830559216659"
|
||||
2) 1) "NYC:station:3457"
|
||||
2) "383.1782"
|
||||
3) 1) "-73.97209256887435913"
|
||||
2) "40.76302702144496237"
|
||||
```
|
||||
|
||||
查找与这些键关联的名称会生成一个我可以从中选择的车站的有序列表。 Redis 不提供路线的功能,因此我使用设备操作系统的路线功能绘制从当前位置到所选单车站的路线。
|
||||
|
||||
`GEORADIUS` 函数可以很轻松的在你喜欢的开发框架的 API 里实现,就可以向应用程序添加位置功能了。
|
||||
|
||||
### 其他的查询命令
|
||||
|
||||
除了 `GEORADIUS` 命令外,Redis 还提供了另外三个用于查询索引数据的命令:`GEOPOS`,`GEODIST` 和 `GEORADIUSBYMEMBER`。
|
||||
|
||||
`GEOPOS` 命令可以为 <ruby>地理哈希<rt>geohash</rt></ruby> 中的给定元素提供坐标(LCTT译注:geohash 是一种将二维的经纬度编码为一位的字符串的一种算法,常用于基于距离的查找算法和推荐算法)。 例如,如果我知道西 38 街 8 号有一个共享单车站,ID 是 523,那么该站的元素名称是`NYC:station:523`。 使用 Redis,我可以找到该站的经度和纬度:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> geopos NYC:stations:location NYC:station:523
|
||||
1) 1) "-73.99138301610946655"
|
||||
2) "40.75466497634030105"
|
||||
```
|
||||
|
||||
`GEODIST` 命令提供两个索引元素之间的距离。 如果我想找到陆军广场中央公园南单车站与东 58 街麦迪逊单车站之间的距离,我会使用以下命令:
|
||||
```
|
||||
127.0.0.1:6379> GEODIST NYC:stations:location NYC:station:281 NYC:station:3457 ft
|
||||
"671.4900"
|
||||
```
|
||||
|
||||
最后,`GEORADIUSBYMEMBER` 命令与 `GEORADIUS` 命令类似,但该命令不是采用一组坐标,而是采用索引的另一个成员的名称,并返回以该成员为中心的给定半径内的所有成员。 要查找陆军广场中央公园南单车站 1000 英尺范围内的所有车站,请输入以下内容:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUSBYMEMBER NYC:stations:location NYC:station:281 1000 ft WITHDIST
|
||||
1) 1) "NYC:station:281"
|
||||
2) "0.0000"
|
||||
2) 1) "NYC:station:3132"
|
||||
2) "793.4223"
|
||||
3) 1) "NYC:station:2006"
|
||||
2) "911.9752"
|
||||
4) 1) "NYC:station:3136"
|
||||
2) "940.3399"
|
||||
5) 1) "NYC:station:3457"
|
||||
2) "671.4900"
|
||||
```
|
||||
|
||||
虽然此示例侧重于使用 Python 和 Redis 来解析数据并构建共享单车系统位置的索引,但可以很容易地衍生为定位餐馆,公共交通或者是开发人员希望帮助用户找到的任何其他类型的场所。
|
||||
|
||||
本文基于今年我在北卡罗来纳州罗利市的开源 101 会议上的[演讲][17]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools
|
||||
|
||||
作者:[Tague Griffith][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tague
|
||||
[1]: https://www.python.org/
|
||||
[2]: https://redis.io/
|
||||
[3]: https://www.citibikenyc.com/
|
||||
[4]: https://www.citibikenyc.com/data-sharing-policy
|
||||
[5]: https://github.com/NABSA/gbfs
|
||||
[6]: http://nabsa.net/
|
||||
[7]: https://www.json.org/
|
||||
[8]: https://gist.github.com/tague/5a82d96bcb09ce2a79943ad4c87f6e15
|
||||
[9]: https://github.com/NABSA/gbfs/blob/master/systems.csv
|
||||
[10]: https://redis.io/commands/unlink
|
||||
[11]: https://redis.io/commands/hmset
|
||||
[12]: https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES
|
||||
[13]: https://redis.io/topics/data-types#Hashes
|
||||
[14]: https://redis.io/commands#geo
|
||||
[15]: https://redis.io/topics/data-types-intro#redis-sorted-sets
|
||||
[16]: https://twitter.com/swatchthedog
|
||||
[17]: http://opensource101.com/raleigh/talks/building-location-aware-apps-open-source-tools/
|
||||
@ -1,6 +1,7 @@
|
||||
Sed 命令完全指南
|
||||
======
|
||||
在前面的文章中,我展示了 [Sed 命令的基本用法][1],它是一个功能强大的流编辑器。今天,我们准备去了解关于 Sed 更多的知识,深入了解 Sed 的运行模式。这将是你全面了解 Sed 命令的一个机会,深入挖掘它的运行细节和精妙之处。因此,如果你已经做好了准备,那就打开终端吧,[下载测试文件][2] 然后坐在电脑前:开始我们的探索之旅吧!
|
||||
|
||||
在前面的文章中,我展示了 [Sed 命令的基本用法][1], Sed 是一个实用的流编辑器。今天,我们准备去了解关于 Sed 更多的知识,深入了解 Sed 的运行模式。这将是你全面了解 Sed 命令的一个机会,深入挖掘它的运行细节和精妙之处。因此,如果你已经做好了准备,那就打开终端吧,[下载测试文件][2] 然后坐在电脑前:开始我们的探索之旅吧!
|
||||
|
||||
### 关于 Sed 的一点点理论知识
|
||||
|
||||
@ -10,24 +11,17 @@ Sed 命令完全指南
|
||||
|
||||
要准确理解 Sed 命令,你必须先了解工具的运行模式。
|
||||
|
||||
当处理数据时,Sed 从输入源一次读入一行,并将它保存到所谓的 `pattern` 空间中。所有 Sed 的变动都发生在 `pattern` 空间。变动都是由命令行上或外部 Sed 脚本文件提供的单字母命令来描述的。大多数 Sed 命令都可以由一个地址或一个地址范围作为前导来限制它们的作用范围。
|
||||
当处理数据时,Sed 从输入源一次读入一行,并将它保存到所谓的<ruby>模式空间<rt>pattern space</rt></ruby>中。所有 Sed 的变换都发生在模式空间。变换都是由命令行上或外部 Sed 脚本文件提供的单字母命令来描述的。大多数 Sed 命令都可以由一个地址或一个地址范围作为前导来限制它们的作用范围。
|
||||
|
||||
默认情况下,Sed 在结束每个处理循环后输出 `pattern` 空间中的内容,也就是说,输出发生在输入的下一个行覆盖 `pattern` 空间之前。我们可以将这种运行模式总结如下:
|
||||
|
||||
1. 尝试将下一个行读入到 `pattern` 空间中
|
||||
|
||||
2. 如果读取成功:
|
||||
默认情况下,Sed 在结束每个处理循环后输出模式空间中的内容,也就是说,输出发生在输入的下一个行覆盖模式空间之前。我们可以将这种运行模式总结如下:
|
||||
|
||||
1. 尝试将下一个行读入到模式空间中
|
||||
2. 如果读取成功:
|
||||
1. 按脚本中的顺序将所有命令应用到与那个地址匹配的当前输入行上
|
||||
|
||||
2. 如果 sed 没有以静默(`-n`)模式运行,那么将输出 `pattern` 空间中的所有内容(可能会是修改过的)。
|
||||
|
||||
2. 如果 sed 没有以静默模式(`-n`)运行,那么将输出模式空间中的所有内容(可能会是修改过的)。
|
||||
3. 重新回到 1。
|
||||
|
||||
|
||||
|
||||
|
||||
因此,在每个行被处理完毕之后, `pattern` 空间中的内容将被丢弃,它并不适合长时间保存内容。基于这种目的,Sed 有第二个缓冲区:`hold` 空间。除非你显式地要求它将数据置入到 `hold` 空间、或从`hode` 空间中取得数据,否则 Sed 从不清除 `hold` 空间的内容。在我们后面学习到 `exchange`、`get`、`hold` 命令时将深入研究它。
|
||||
因此,在每个行被处理完毕之后,模式空间中的内容将被丢弃,它并不适合长时间保存内容。基于这种目的,Sed 有第二个缓冲区:<ruby>保持空间<rt>hold space</rt></ruby>。除非你显式地要求它将数据置入到保持空间、或从保持空间中取得数据,否则 Sed 从不清除保持空间的内容。在我们后面学习到 `exchange`、`get`、`hold` 命令时将深入研究它。
|
||||
|
||||
#### Sed 的抽象机制
|
||||
|
||||
@ -35,47 +29,42 @@ Sed 命令完全指南
|
||||
|
||||
的确,Sed 可以被视为是[抽象机制][5]的实现,它的[状态][6]由三个[缓冲区][7] 、两个[寄存器][8]和两个[标志][9]来定义的:
|
||||
|
||||
* **三个缓冲区**用于去保存任意长度的文本。是的,是三个!在前面的基本运行模式中我们谈到了两个: `pattern` 空间和 `hold` 空间,但是 Sed 还有第三个缓冲区:追加队列。从 Sed 脚本的角度来看,它是一个只写缓冲区,Sed 将在它运行时的预定义阶段来自动刷新它(一般是在从输入源读入一个新行之前,或仅在它退出运行之前)。
|
||||
|
||||
* Sed 也维护**两个寄存器**:行计数器(LC)用于保存从输入源读取的行数,而程序计数器(PC)总是用来保存下一个将要运行的命令的索引(就是脚本中的位置),Sed 将它作为它的主循环的一部分来自动增加 PC。但在使用特定的命令时,脚本也会直接修改 PC 去跳过或重复程序的一部分。这就像使用 Sed 实现的一个循环或条件语句。更多内容将在下面的专用分支一节中描述。
|
||||
|
||||
* 最后,**两个标志**可以被某些 Sed 命令的行为所修改:自动输出(AP)标志和替换标志(SF)。当自动输出标志 AP 被设置时,Sed 将在 `pattern` 空间的内容被覆盖前自动输出(尤其是(包括但不限于)在从输入源读入一个新行之前)。当自动输出标准被清除时(即:没有设置),Sed 在脚本中没有显式命令的情况下,将不会输出 `pattern` 空间中的内容。你可以通过在“静默模式”(使用命令行选项 `-n` 或者在第一行或脚本中使用特殊注释 `#n`)运行 Sed 命令来清除自动输出标志。当它的地址和查找模式与 `pattern` 空间中的内容都匹配时,“替换标志”将被替换命令(`s` 命令)设置。替换标志在每个新的循环开始时、或当从输入源读入一个新行时、或获得条件分支之后将被清除。我们将在分支一节中详细研究这一话题。
|
||||
|
||||
|
||||
|
||||
* **三个缓冲区**用于去保存任意长度的文本。是的,是三个!在前面的基本运行模式中我们谈到了两个:模式空间和保持空间,但是 Sed 还有第三个缓冲区:<ruby>追加队列<rt>append queue</rt></ruby>。从 Sed 脚本的角度来看,它是一个只写缓冲区,Sed 将在它运行时的预定义阶段来自动刷新它(一般是在从输入源读入一个新行之前,或仅在它退出运行之前)。
|
||||
* Sed 也维护**两个寄存器**:<ruby>行计数器<rt>line counter</rt></ruby>(LC)用于保存从输入源读取的行数,而<ruby>程序计数器<rt>program counter</rt></ruby>(PC)总是用来保存下一个将要运行的命令的索引(就是脚本中的位置),Sed 将它作为它的主循环的一部分来自动增加 PC。但在使用特定的命令时,脚本也可以直接修改 PC 去跳过或重复执行程序的一部分。这就像使用 Sed 实现的一个循环或条件语句。更多内容将在下面的专用分支一节中描述。
|
||||
* 最后,**两个标志**可以修改某些 Sed 命令的行为:<ruby>自动输出<rt>auto-print</rt></ruby>(AP)标志和<ruby替换<rt> substitution</rt></ruby>(SF)标志。当自动输出标志 AP 被设置时,Sed 将在模式空间的内容被覆盖前自动输出(尤其是,包括但不限于,在从输入源读入一个新行之前)。当自动输出标志被清除时(即:没有设置),Sed 在脚本中没有显式命令的情况下,将不会输出模式空间中的内容。你可以通过在“静默模式”(使用命令行选项 `-n` 或者在第一行或脚本中使用特殊注释 `#n`)运行 Sed 命令来清除自动输出标志。当它的地址和查找模式与模式空间中的内容都匹配时,替换标志 SF 将被替换命令(`s` 命令)设置。替换标志在每个新的循环开始时、或当从输入源读入一个新行时、或获得条件分支之后将被清除。我们将在分支一节中详细研究这一话题。
|
||||
|
||||
另外,Sed 维护一个进入到它的地址范围(关于地址范围的更多知识将在地址范围一节详细描述)的命令列表,以及用于读取和写入数据的两个文件句柄(你将在读取和写入命令的描述中获得更多有关文件句柄的内容)。
|
||||
|
||||
#### 一个更精确的 Sed 运行模式
|
||||
|
||||
由于一张图胜过千言万语,所以我画了一个流程图去描述 Sed 的运行模式。我将两个东西放在了旁边,像处理多个输入文件或错误处理,但是我认为这足够你去理解任何 Sed 程序的行为了,并且可以避免你在编写你自己的 Sed 脚本时浪费在摸索上的时间。
|
||||
一图胜千言,所以我画了一个流程图去描述 Sed 的运行模式。我将两个东西放在了旁边,像处理多个输入文件或错误处理,但是我认为这足够你去理解任何 Sed 程序的行为了,并且可以避免你在编写你自己的 Sed 脚本时浪费在摸索上的时间。
|
||||
|
||||
![The Sed execution model][10]
|
||||
|
||||
你可能已经注意到,在上面的流程图上我并没有描述特定的命令动作。对于命令,我们将逐个详细讲解。因此,不用着急,我们马上开始!
|
||||
|
||||
### print 命令
|
||||
### 打印命令
|
||||
|
||||
print 命令(`p`)是用于输出在它运行时 `pattern` 空间中的内容。它并不会以任何方式改变 Sed 抽象机制中的状态。
|
||||
打印命令(`p`)是用于输出在它运行那一刻模式空间中的内容。它并不会以任何方式改变 Sed 抽象机制中的状态。
|
||||
|
||||
![The Sed `print` command][11]
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
sed -e 'p' inputfile
|
||||
|
||||
```
|
||||
|
||||
上面的命令将输出输入文件中每一行的内容两次,因为你一旦显式地要求使用 `print` 命令时,将会在每个处理循环结束时再隐式地输出一次(因为在这里我们不是在“静默模式”中运行 Sed)。
|
||||
上面的命令将输出输入文件中每一行的内容……两次,因为你一旦显式地要求使用 `p` 命令时,将会在每个处理循环结束时再隐式地输出一次(因为在这里我们不是在“静默模式”中运行 Sed)。
|
||||
|
||||
如果我们不想每个行看到两次,我们可以用两种方式去解决它:
|
||||
|
||||
```
|
||||
sed -n -e 'p' inputfile # 在静默模式中显式输出
|
||||
sed -e '' inputfile # 空的"什么都不做的"程序,隐式输出
|
||||
|
||||
sed -e '' inputfile # 空的“什么都不做的”程序,隐式输出
|
||||
```
|
||||
|
||||
注意:`-e` 选项是引入一个 Sed 命令。它被用于区分命令和文件名。由于一个 Sed 表达式必须包含至少一个命令,所以对于第一个命令,`-e` 标志不是必需的。但是,由于我个人使用习惯问题,为了与在这里的大多数的一个命令行上给出多个 Sed 表达式的更复杂的案例保持一致性。你自己去判断这是一个好习惯还是坏习惯,并且在本文的后面部分还将延用这一习惯。
|
||||
注意:`-e` 选项是引入一个 Sed 命令。它被用于区分命令和文件名。由于一个 Sed 表达式必须包含至少一个命令,所以对于第一个命令,`-e` 标志不是必需的。但是,由于我个人使用习惯问题,为了与在这里的大多数的一个命令行上给出多个 Sed 表达式的更复杂的案例保持一致性,我添加了它。你自己去判断这是一个好习惯还是坏习惯,并且在本文的后面部分还将延用这一习惯。
|
||||
|
||||
### 地址
|
||||
|
||||
@ -83,20 +72,20 @@ sed -e '' inputfile # 空的"什么都不做的"程序,隐式输出
|
||||
|
||||
#### 行号
|
||||
|
||||
一个 Sed 的地址既可以是一个行号(`$` 表示“最后一行”)也可以是一个正则表达式。在使用行号时,你需要记住 Sed 中的行数是从 1 开始的 — 并且需要注意的是,它不是从 0 行开始的。
|
||||
Sed 的地址既可以是一个行号(`$` 表示“最后一行”)也可以是一个正则表达式。在使用行号时,你需要记住 Sed 中的行数是从 1 开始的 —— 并且需要注意的是,它**不是**从 0 行开始的。
|
||||
|
||||
```
|
||||
sed -n -e '1p' inputfile # 仅输出文件的第一行
|
||||
sed -n -e '5p' inputfile # 仅输出第 5 行
|
||||
sed -n -e '$p' inputfile # 输出文件的最后一行
|
||||
sed -n -e '0p' inputfile # 结果将是报错,因为 0 不是有效的行号
|
||||
|
||||
```
|
||||
|
||||
根据 [POSIX 规范][12],如果你指定了几个输出文件,那么它的行号是累加的。换句话说,当 Sed 打开一个新输入文件时,它的行计数器是不会被重置的。因此,以下的两个命令所做的事情是一样的。仅输出一行文本:
|
||||
|
||||
```
|
||||
sed -n -e '1p' inputfile1 inputfile2 inputfile3
|
||||
cat inputfile1 inputfile2 inputfile3 | sed -n -e '1p'
|
||||
|
||||
```
|
||||
|
||||
实际上,确实在 POSIX 中规定了多个文件是如何处理的:
|
||||
@ -104,9 +93,9 @@ cat inputfile1 inputfile2 inputfile3 | sed -n -e '1p'
|
||||
> 如果指定了多个文件,将按指定的文件命名顺序进行读取并被串联编辑。
|
||||
|
||||
但是,一些 Sed 的实现提供了命令行选项去改变这种行为,比如, GNU Sed 的 `-s` 标志(在使用 GNU Sed `-i` 标志时,它也被隐式地应用):
|
||||
|
||||
```
|
||||
sed -sn -e '1p' inputfile1 inputfile2 inputfile3
|
||||
|
||||
```
|
||||
|
||||
如果你的 Sed 实现支持这种非标准选项,那么关于它的具体细节请查看 `man` 手册页。
|
||||
@ -117,123 +106,137 @@ sed -sn -e '1p' inputfile1 inputfile2 inputfile3
|
||||
|
||||
正如它的名字,一个[正则表达式][13]是描述一个字符串集合的方法。如果一个指定的字符串符合一个正则表达式所描述的集合,那么我们就认为这个字符串与正则表达式匹配。
|
||||
|
||||
一个正则表达式也可以包含必须完全匹配的文本字符。例如,所有的字母和数字,以及大部分可以打印的字符。但是,一些符号有特定意义:
|
||||
|
||||
* 它们可能相当于锚,像 `^` 和 `$` 它们分别表示一个行的开始和结束;
|
||||
|
||||
* 对于整个字符集,另外的符号可能做为占位符(比如圆点 `.` 可以匹配任意单个字符,或者方括号用于定义一个自定义的字符集);
|
||||
|
||||
* 另外的是表示重复出现的数量(像 [Kleene 星号][14] 表示前面的模式出现 0、1 或多次);
|
||||
|
||||
|
||||
正则表达式可以包含必须完全匹配的文本字符。例如,所有的字母和数字,以及大部分可以打印的字符。但是,一些符号有特定意义:
|
||||
|
||||
* 它们相当于锚,像 `^` 和 `$` 它们分别表示一个行的开始和结束;
|
||||
* 能够做为整个字符集的占位符的其它符号(比如圆点 `.` 可以匹配任意单个字符,或者方括号 `[]` 用于定义一个自定义的字符集);
|
||||
* 另外的是表示重复出现的数量(像 [克莱尼星号(`*`)][14] 表示前面的模式出现 0、1 或多次);
|
||||
|
||||
这篇文章的目的不是给大家讲正则表达式。因此,我只粘几个示例。但是,你可以在网络上随便找到很多关于正则表达式的教程,正则表达式的功能非常强大,它可用于许多标准的 Unix 命令和编程语言中,并且是每个 Unix 用户应该掌握的技能。
|
||||
|
||||
下面是使用 Sed 地址的几个示例:
|
||||
|
||||
```
|
||||
sed -n -e '/systemd/p' inputfile # 仅输出包含字符串"systemd"的行
|
||||
sed -n -e '/nologin$/p' inputfile # 仅输出以"nologin"结尾的行
|
||||
sed -n -e '/^bin/p' inputfile # 仅输出以"bin"开头的行
|
||||
sed -n -e '/systemd/p' inputfile # 仅输出包含字符串“systemd”的行
|
||||
sed -n -e '/nologin$/p' inputfile # 仅输出以“nologin”结尾的行
|
||||
sed -n -e '/^bin/p' inputfile # 仅输出以“bin”开头的行
|
||||
sed -n -e '/^$/p' inputfile # 仅输出空行(即:开始和结束之间什么都没有的行)
|
||||
sed -n -e '/./p' inputfile # 仅输出包含一个字符的行(即:非空行)
|
||||
sed -n -e '/^.$/p' inputfile # 仅输出确实只包含一个字符的行
|
||||
sed -n -e '/admin.*false/p' inputfile # 仅输出包含字符串"admin"后面有字符串"false"的行(在它们之间有任意数量的任意字符)
|
||||
sed -n -e '/1[0,3]/p' inputfile # 仅输出包含一个"1"并且后面是一个"0"或"3"的行
|
||||
sed -n -e '/1[0-2]/p' inputfile # 仅输出包含一个"1"并且后面是一个"0"、"1"、"2"或"3"的行
|
||||
sed -n -e '/1.*2/p' inputfile # 仅输出包含字符"1"后面是一个"2"(在它们之间有任意数量的字符)的行
|
||||
sed -n -e '/1[0-9]*2/p' inputfile # 仅输出包含字符"1"后面跟着0、1、或更多数字,最后面是一个"2"的行
|
||||
|
||||
sed -n -e '/./p' inputfile # 仅输出包含字符的行(即:非空行)
|
||||
sed -n -e '/^.$/p' inputfile # 仅输出只包含一个字符的行
|
||||
sed -n -e '/admin.*false/p' inputfile # 仅输出包含字符串“admin”后面有字符串“false”的行(在它们之间有任意数量的任意字符)
|
||||
sed -n -e '/1[0,3]/p' inputfile # 仅输出包含一个“1”并且后面是一个“0”或“3”的行
|
||||
sed -n -e '/1[0-2]/p' inputfile # 仅输出包含一个“1”并且后面是一个“0”、“1”、“2”或“3”的行
|
||||
sed -n -e '/1.*2/p' inputfile # 仅输出包含字符“1”后面是一个“2”(在它们之间有任意数量的字符)的行
|
||||
sed -n -e '/1[0-9]*2/p' inputfile # 仅输出包含字符“1”后面跟着“0”、“1”、或更多数字,最后面是一个“2”的行
|
||||
```
|
||||
|
||||
如果你想在正则表达式(包括正则表达式分隔符)中去除字符的特殊意义,你可以在它前面使用一个斜杠:
|
||||
如果你想在正则表达式(包括正则表达式分隔符)中去除字符的特殊意义,你可以在它前面使用一个反斜杠:
|
||||
|
||||
```
|
||||
# 输出所有包含字符串"/usr/sbin/nologin"的行
|
||||
# 输出所有包含字符串“/usr/sbin/nologin”的行
|
||||
sed -ne '/\/usr\/sbin\/nologin/p' inputfile
|
||||
|
||||
```
|
||||
|
||||
并不是限制你只能使用反斜杠作为地址中正则表达式的分隔符。你可以通过在第一个分隔符前面加上斜杠的方式,来使用任何你认为适合你需要和偏好的其它字符作为正则表达式的分隔符。当你用地址与带文件路径的字符一起来匹配的时,是非常有用的:
|
||||
并不限制你只能使用斜杠作为地址中正则表达式的分隔符。你可以通过在第一个分隔符前面加上反斜杠(`\`)的方式,来使用任何你认为适合你需要和偏好的其它字符作为正则表达式的分隔符。当你用地址与带文件路径的字符一起来匹配的时,是非常有用的:
|
||||
|
||||
```
|
||||
# 以下两个命令是完全相同的
|
||||
sed -ne '/\/usr\/sbin\/nologin/p' inputfile
|
||||
sed -ne '\=/usr/sbin/nologin=p' inputfile
|
||||
|
||||
```
|
||||
|
||||
#### 扩展的正则表达式
|
||||
|
||||
默认情况下,Sed 的正则表达式引擎仅理解 [POSIX 基本正则表达式][15] 的语法。如果你需要用到 [扩展的正则表达式][16],你必须在 Sed 命令上添加 `-E` 标志。扩展的正则表达式在基本的正则表达式基础上增加了一组额外的特性,并且很多都是很重要的,他们所要求的斜杠要少很多。我们来比较一下:
|
||||
默认情况下,Sed 的正则表达式引擎仅理解 [POSIX 基本正则表达式][15] 的语法。如果你需要用到 [扩展正则表达式][16],你必须在 Sed 命令上添加 `-E` 标志。扩展正则表达式在基本正则表达式基础上增加了一组额外的特性,并且很多都是很重要的,它们所要求的反斜杠要少很多。我们来比较一下:
|
||||
|
||||
```
|
||||
sed -n -e '/\(www\)\|\(mail\)/p' inputfile
|
||||
sed -En -e '/(www)|(mail)/p' inputfile
|
||||
|
||||
```
|
||||
|
||||
#### 括号量词
|
||||
#### 花括号量词
|
||||
|
||||
正则表达式之所以强大的一个原因是[范围量词][17]`{,}`。事实上,当你写一个不太精确匹配的正则表达式时,量词 `*` 就是一个非常完美的符号。但是,你需要显式在它边上添加一个下限和上限,这样就有了很好的灵活性。当量词范围的下限省略时,下限被假定为 0。当上限被省略时,上限被假定为无限大:
|
||||
正则表达式之所以强大的一个原因是[范围量词][17] `{,}`。事实上,当你写一个不太精确匹配的正则表达式时,量词 `*` 就是一个非常完美的符号。但是,(用花括号量词)你可以显式在它边上添加一个下限和上限,这样就有了很好的灵活性。当量词范围的下限省略时,下限被假定为 0。当上限被省略时,上限被假定为无限大:
|
||||
|
||||
|括号| 速记词 |解释|
|
||||
| 括号 | 速记词 | 解释 |
|
||||
| --- | ----- | ---- |
|
||||
| `{,}` | `*` | 前面的规则出现 0、1、或许多遍 |
|
||||
| `{,1}` | `?` | 前面的规则出现 0 或 1 遍 |
|
||||
| `{1,}` | `+` | 前面的规则出现 1 或许多遍 |
|
||||
| `{n,n}` | `{n}` | 前面的规则精确地出现 n 遍 |
|
||||
|
||||
| {,} | * | 前面的规则出现 0、1、或许多遍 |
|
||||
| {,1} | ? | 前面的规则出现 0 或 1 遍 |
|
||||
| {1,} | + | 前面的规则出现 1 或许多遍 |
|
||||
| {n,n} | {n} | 前面的规则精确地出现 n 遍 |
|
||||
花括号在基本正则表达式中也是可以使用的,但是它要求使用反斜杠。根据 POSIX 规范,在基本正则表达式中可以使用的量词仅有星号(`*`)和花括号(使用反斜杠,如 `\{m,n\}`)。许多正则表达式引擎都扩展支持 `\?` 和 `\+`。但是,为什么魔鬼如此有诱惑力呢?因为,如果你需要这些量词,使用扩展正则表达式将不但易于写而且可移植性更好。
|
||||
|
||||
括号在基本的正则表达式中也是可以使用的,但是它要求使用反斜杠。根据 POSIX 规范,在基本的正则表达式中可以使用的量词仅有星号(`*`)和括号(使用反斜杠 `\{m,n\}`)。许多正则表达式引擎都扩展支持 `\?` 和 `\+`。但是,为什么魔鬼如此有诱惑力呢?因为,如果你需要这些量词,使用扩展的正则表达式将不但易于写而且可移植性更好。
|
||||
为什么我要花点时间去讨论关于正则表达式的花括号量词,这是因为在 Sed 脚本中经常用这个特性去计数字符。
|
||||
|
||||
为什么我要花点时间去讨论关于正则表达式的括号量词,这是因为在 Sed 脚本中经常用这个特性去计数字符。
|
||||
```
|
||||
sed -En -e '/^.{35}$/p' inputfile # 输出精确包含 35 个字符的行
|
||||
sed -En -e '/^.{0,35}$/p' inputfile # 输出包含 35 个字符或更少字符的行
|
||||
sed -En -e '/^.{,35}$/p' inputfile # 输出包含 35 个字符或更少字符的行
|
||||
sed -En -e '/^.{35,}$/p' inputfile # 输出包含 35 个字符或更多字符的行
|
||||
sed -En -e '/.{35}/p' inputfile # 你自己指出它的输出内容(这是留给你的测试题)
|
||||
|
||||
```
|
||||
|
||||
#### 地址范围
|
||||
|
||||
到目前为止,我们使用的所有地址都是唯一地址。在我们使用一个唯一地址时,命令是应用在与那个地址匹配的行上。但是,Sed 也支持地址范围。Sed 命令可以应用到那个地址范围中从开始到结束的所有地址中的所有行上:
|
||||
|
||||
```
|
||||
sed -n -e '1,5p' inputfile # 仅输出 1 到 5 行
|
||||
sed -n -e '5,$p' inputfile # 从第 5 行输出到文件结尾
|
||||
sed -n -e '/www/,/systemd/p' inputfile # 输出与正则表达式 /www/ 匹配的第一行到与接下来匹配正则表达式 /systemd/ 的行为止
|
||||
```
|
||||
(LCTT 译注:下面用的一个生成的列表例子,如下供参考:)
|
||||
|
||||
sed -n -e '/www/,/systemd/p' inputfile # 输出与正则表达式 /www/ 匹配的第一行到与正则表达式 /systemd/ 匹配的接下来的行
|
||||
|
||||
```
|
||||
printf "%s\n" {a,b,c}{d,e,f} | cat -n
|
||||
1 ad
|
||||
2 ae
|
||||
3 af
|
||||
4 bd
|
||||
5 be
|
||||
6 bf
|
||||
7 cd
|
||||
8 ce
|
||||
9 cf
|
||||
```
|
||||
|
||||
如果在开始和结束地址上使用了同一个行号,那么范围就缩小为那个行。事实上,如果第二个地址的数字小于或等于地址范围中选定的第一个行的数字,那么仅有一个行被选定:
|
||||
|
||||
```
|
||||
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,4p'
|
||||
4 bd
|
||||
4 bd
|
||||
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,3p'
|
||||
4 bd
|
||||
|
||||
4 bd
|
||||
```
|
||||
|
||||
这就有点难了,但是在前面的段落中给出的规则也适用于起始地址是正则表达式的情况。在那种情况下,Sed 将对正则表达式匹配的第一个行的行号和给定的作为结束地址的显式的行号进行比较。再强调一次,如果结束行号小于或等于起始行号,那么这个范围将缩小为一行:
|
||||
下面有点难了,但是在前面的段落中给出的规则也适用于起始地址是正则表达式的情况。在那种情况下,Sed 将对正则表达式匹配的第一个行的行号和给定的作为结束地址的显式的行号进行比较。再强调一次,如果结束行号小于或等于起始行号,那么这个范围将缩小为一行:
|
||||
|
||||
(LCTT 译注:此处作者陈述有误,Sed 会在处理以正则表达式表示的开始行时,并不会同时测试结束表达式:从匹配开始行的正则表达式开始,直到不匹配时,才会测试结束行的表达式——无论是否是正则表达式——并在结束的表达式测试不通过时停止,并循环此测试。)
|
||||
|
||||
```
|
||||
# 这个 /b/,4 地址将匹配三个单行
|
||||
# 因为每个匹配的行有一个行号 >= 4
|
||||
#(LCTT 译注:结果正确,但是说明不正确。4、5、6 行都会因为匹配开始正则表达式而通过,第 7 行因为不匹配开始正则表达式,所以开始比较行数: 7 > 4,遂停止。)
|
||||
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/b/,4p'
|
||||
4 bd
|
||||
5 be
|
||||
6 bf
|
||||
4 bd
|
||||
5 be
|
||||
6 bf
|
||||
|
||||
# 你自己指出匹配的范围是多少
|
||||
# 第二个例子:
|
||||
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/d/,4p'
|
||||
1 ad
|
||||
2 ae
|
||||
3 af
|
||||
4 bd
|
||||
7 cd
|
||||
|
||||
1 ad
|
||||
2 ae
|
||||
3 af
|
||||
4 bd
|
||||
7 cd
|
||||
```
|
||||
|
||||
但是,当结束地址是一个正则表达式时,Sed 的行为将不一样。在那种情况下,地址范围的第一行将不会与结束地址进行检查,因此地址范围将至少包含两行(当然,如果输入数据不足的情况除外):
|
||||
|
||||
(LCTT 译注:如上译注,当满足开始的正则表达式时,并不会测试结束的表达式;仅当不满足开始的表达式时,才会测试结束表达式。)
|
||||
|
||||
```
|
||||
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/b/,/d/p'
|
||||
4 bd
|
||||
@ -246,60 +249,64 @@ printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,/d/p'
|
||||
5 be
|
||||
6 bf
|
||||
7 cd
|
||||
|
||||
```
|
||||
|
||||
#### 互补
|
||||
(LCTT 译注:对地址范围的总结,当满足开始的条件时,从该行开始,并不测试该行是否满足结束的条件;从下一行开始测试结束条件,并在结束条件不满足时结束;然后对剩余的行,再从开始条件开始匹配,以此循环——也就是说,匹配结果可以是非连续的单/多行。大家可以调整上述命令行的条件以理解。)
|
||||
|
||||
#### 补集
|
||||
|
||||
在一个地址选择行后面添加一个感叹号(`!`)表示不匹配那个地址。例如:
|
||||
|
||||
```
|
||||
sed -n -e '5!p' inputfile # 输出除了第 5 行外的所有行
|
||||
sed -n -e '5,10!p' inputfile # 输出除了第 5 到 10 之间的所有行
|
||||
sed -n -e '/sys/!p' inputfile # 输出除了包含字符串"sys"的所有行
|
||||
|
||||
sed -n -e '/sys/!p' inputfile # 输出除了包含字符串“sys”的所有行
|
||||
```
|
||||
|
||||
#### 连接
|
||||
#### 交集
|
||||
|
||||
(LCTT 译注:原文标题为“合集”,应为“交集”)
|
||||
|
||||
Sed 允许在一个块中使用花括号 `{…}` 组合命令。你可以利用这个特性去组合几个地址的交集。例如,我们来比较下面两个命令的输出:
|
||||
|
||||
Sed 允许在一个块中使用括号 (`{…}`) 组合命令。你可以利用这个特性去组合几个地址。例如,我们来比较下面两个命令的输出:
|
||||
```
|
||||
sed -n -e '/usb/{
|
||||
/daemon/p
|
||||
}' inputfile
|
||||
|
||||
sed -n -e '/usb.*daemon/p' inputfile
|
||||
|
||||
```
|
||||
|
||||
通过在一个块中嵌套命令,我们将在任意顺序中选择包含字符串 “usb” 和 “daemon” 的行。而正则表达式 “usb.*daemon” 将仅匹配在字符串 “daemon” 前面包含 “usb” 字符串的行。
|
||||
|
||||
离题太长时间后,我们现在重新回去学习各种 Sed 命令。
|
||||
|
||||
### quit 命令
|
||||
### 退出命令
|
||||
|
||||
quit 命令(`q`)是指在当前的迭代循环处理结束之后停止 Sed。
|
||||
退出命令(`q`)是指在当前的迭代循环处理结束之后停止 Sed。
|
||||
|
||||
![The Sed `quit` command][18]
|
||||
![The Sed quit command][18]
|
||||
|
||||
quit 命令是在到达输入文件的尾部之前停止处理输入的方法。为什么会有人想去那样做呢?
|
||||
`q` 命令是在到达输入文件的尾部之前停止处理输入的方法。为什么会有人想去那样做呢?
|
||||
|
||||
很好的问题,如果你还记得,我们可以使用下面的命令来输出文件中第 1 到第 5 的行:
|
||||
|
||||
```
|
||||
sed -n -e '1,5p' inputfile
|
||||
|
||||
```
|
||||
|
||||
对于 大多数 Sed 的实现,工具将循环读取输入文件的所有行,那怕是你只处理结果中的前 5 行。如果你的输入文件包含了几百万行(或者更糟糕的情况是,你从一个无限的数据流(比如像 `/dev/urandom` )中读取)。
|
||||
对于大多数 Sed 的实现方式,工具将循环读取输入文件的所有行,那怕是你只处理结果中的前 5 行。如果你的输入文件包含了几百万行(或者更糟糕的情况是,你从一个无限的数据流,比如像 `/dev/urandom` 中读取)将有重大影响。
|
||||
|
||||
使用退出命令,相同的程序可以被修改的更高效:
|
||||
|
||||
使用 quit 命令,相同的程序可以被修改的更高效:
|
||||
```
|
||||
sed -e '5q' inputfile
|
||||
|
||||
```
|
||||
|
||||
由于我在这里并不使用 `-n` 选项,Sed 将在每个循环结束后隐式输出 `pattern` 空间的内容。但是在你处理完第 5 行后,它将退出,并且因此不会去读取更多的数据。
|
||||
由于我在这里并不使用 `-n` 选项,Sed 将在每个循环结束后隐式输出模式空间的内容。但是在你处理完第 5 行后,它将退出,并且因此不会去读取更多的数据。
|
||||
|
||||
我们能够使用一个类似的技巧只输出文件中一个特定的行。这也是从命令行中提供多个 Sed 表达式的几种方法。下面的三个变体都可以从 Sed 中接受几个命令,要么是不同的 `-e` 选项,要么是在相同的表达式中新起一行,或用分号(`;`)隔开:
|
||||
|
||||
我们能够使用一个类似的技巧只输出文件中一个特定的行。那将是一个好机会,你将看到从命令行中提供多个 Sed 表达式的几种方法。下面的三个变体都可以从 Sed 中接受命令,要么是不同的 `-e` 选项,要么是在相同的表达式中新起一行或用分号(`;`)隔开:
|
||||
```
|
||||
sed -n -e '5p' -e '5q' inputfile
|
||||
|
||||
@ -309,10 +316,10 @@ sed -n -e '
|
||||
' inputfile
|
||||
|
||||
sed -n -e '5p;5q' inputfile
|
||||
|
||||
```
|
||||
|
||||
如果你还记得,我们在前面看到过能够使用括号将命令组合起来,在这里我们使用它来防止相同的地址重复两次:
|
||||
如果你还记得,我们在前面看到过能够使用花括号将命令组合起来,在这里我们使用它来防止相同的地址重复两次:
|
||||
|
||||
```
|
||||
# 组合命令
|
||||
sed -e '5{
|
||||
@ -320,15 +327,14 @@ sed -e '5{
|
||||
q
|
||||
}' inputfile
|
||||
|
||||
# Which can be shortened as:
|
||||
# 可以简写为:
|
||||
sed '5{p;q;}' inputfile
|
||||
|
||||
# As a POSIX extension, some implementations makes the semi-colon before the closing bracket optional:
|
||||
# 作为 POSIX 扩展,有些实现方式可以省略闭花括号之前的分号:
|
||||
sed '5{p;q}' inputfile
|
||||
|
||||
```
|
||||
|
||||
### substitution 命令
|
||||
### 替换命令
|
||||
|
||||
你可以将替换命令想像为 Sed 的“查找替换”功能,这个功能在大多数的“所见即所得”的编辑器上都能找到。Sed 的替换命令与之类似,但比它们更强大。替换命令是 Sed 中最著名的命令之一,在网上有大量的关于这个命令的文档。
|
||||
|
||||
@ -340,9 +346,9 @@ sed '5{p;q}' inputfile
|
||||
|
||||
* 命令和它的参数是用任意一个字符来分隔的。这主要看你的习惯,在 99% 的时间中我都使用斜杠,但也会用其它的字符:`sed s%:%-----% inputfile`、`sed sX:X-----X inputfile` 或者甚至是 `sed 's : ----- ' inputfile`
|
||||
|
||||
* 默认情况下,替换命令仅被应用到 `pattern` 空间中匹配到的第一个字符串上。你可以通过在命令之后指定一个匹配指数作为标志来改变这种情况:`sed 's/:/-----/1' inputfile`、`sed 's/:/-----/2' inputfile`、`sed 's/:/-----/3' inputfile`、…
|
||||
* 默认情况下,替换命令仅被应用到模式空间中匹配到的第一个字符串上。你可以通过在命令之后指定一个匹配指数作为标志来改变这种情况:`sed 's/:/-----/1' inputfile`、`sed 's/:/-----/2' inputfile`、`sed 's/:/-----/3' inputfile`、…
|
||||
|
||||
* 如果你想执行一个全面的替换(即:在 `pattern` 空间上的每个非重叠匹配),你需要增加 `g` 标志:`sed 's/:/-----/g' inputfile`
|
||||
* 如果你想执行一个全面的替换(即:在模式空间上的每个非重叠匹配),你需要增加 `g` 标志:`sed 's/:/-----/g' inputfile`
|
||||
|
||||
* 在字符串替换中,出现的任何一个 `&` 符号都将被与查找模式匹配的子字符串替换:`sed 's/:/-&&&-/g' inputfile`、`sed 's/…./& /g' inputfile`
|
||||
|
||||
@ -373,9 +379,9 @@ sed -En -e '
|
||||
|
||||
```
|
||||
|
||||
注意在替换命令结束部分的 `g` 选项。这个选项改变了它的行为,因此它将查找全部的 `pattern` 空间并替换,如果没有那个选项,它只替换查找到的第一个。
|
||||
注意在替换命令结束部分的 `g` 选项。这个选项改变了它的行为,因此它将查找全部的模式空间并替换,如果没有那个选项,它只替换查找到的第一个。
|
||||
|
||||
顺便说一下,这也是使用前面讲过的输出(`p`)命令的好机会,可以在命令运行时输出修改前后时刻 `pattern` 空间的内容。因此,为了获得替换前后的内容,我可以这样写:
|
||||
顺便说一下,这也是使用前面讲过的输出(`p`)命令的好机会,可以在命令运行时输出修改前后时刻模式空间的内容。因此,为了获得替换前后的内容,我可以这样写:
|
||||
```
|
||||
sed -En -e '
|
||||
/sonia/{
|
||||
@ -396,7 +402,7 @@ sed -En -e '/sonia/s/[0-9]+/1100/gp' inputfile
|
||||
|
||||
#### delete 命令
|
||||
|
||||
删除命令(`d`)用于清除 `pattern` 空间的内容,然后立即开始下一个处理循环。这样它将会跳过隐式输出 `pattern` 空间内容的行为,即便是你设置了自动输出标志(AP)也不会输出。
|
||||
删除命令(`d`)用于清除模式空间的内容,然后立即开始下一个处理循环。这样它将会跳过隐式输出模式空间内容的行为,即便是你设置了自动输出标志(AP)也不会输出。
|
||||
|
||||
![The Sed `delete` command][22]
|
||||
|
||||
@ -416,7 +422,7 @@ sed -e '/systemd/d' inputfile
|
||||
|
||||
#### next 命令
|
||||
|
||||
如果 Sed 命令不是在静默模式中运行,这个命令将输出当前 `pattern` 空间的内容,然后,在任何情况下它将读取下一个输入行到 `pattern` 空间中,并使用新的 `pattern` 空间中的内容来运行当前循环中剩余的命令。
|
||||
如果 Sed 命令不是在静默模式中运行,这个命令将输出当前模式空间的内容,然后,在任何情况下它将读取下一个输入行到模式空间中,并使用新的模式空间中的内容来运行当前循环中剩余的命令。
|
||||
|
||||
![The Sed `next` command][23]
|
||||
|
||||
@ -426,7 +432,7 @@ cat -n inputfile | sed -n -e 'n;n;p'
|
||||
|
||||
```
|
||||
|
||||
在上面的例子中,Sed 将隐式地读取输入文件的第一行。但是 `next` 命令将丢弃对 `pattern` 空间中的内容的输出(不输出是因为使用了 `-n` 选项),并从输入文件中读取下一行来替换 `pattern` 空间中的内容。而第二个 `next` 命令做的事情和前一个是一模一样的,这就实现了跳过输入文件 2 行的目的。最后,这个脚本显式地输出包含在 `pattern ` 空间中的输入文件的第三行的内容。然后,Sed 将启动一个新的循环,由于 `next` 命令,它会隐式地读取第 4 行的内容,然后跳过它,同样地也跳过第 5 行,并输出第 6 行。如此循环,直到文件结束。总体来看,这个脚本就是读取输入文件然后每三行输出一行。
|
||||
在上面的例子中,Sed 将隐式地读取输入文件的第一行。但是 `next` 命令将丢弃对模式空间中的内容的输出(不输出是因为使用了 `-n` 选项),并从输入文件中读取下一行来替换模式空间中的内容。而第二个 `next` 命令做的事情和前一个是一模一样的,这就实现了跳过输入文件 2 行的目的。最后,这个脚本显式地输出包含在 `pattern ` 空间中的输入文件的第三行的内容。然后,Sed 将启动一个新的循环,由于 `next` 命令,它会隐式地读取第 4 行的内容,然后跳过它,同样地也跳过第 5 行,并输出第 6 行。如此循环,直到文件结束。总体来看,这个脚本就是读取输入文件然后每三行输出一行。
|
||||
|
||||
使用 next 命令,我们也可以找到一些显示输入文件的前五行的几种方法:
|
||||
```
|
||||
@ -446,13 +452,13 @@ cat -n inputfile | sed -n '/pulse/{n;n;p}' # 输出下面的行
|
||||
|
||||
```
|
||||
|
||||
### 使用 `hold` 空间
|
||||
### 使用保持空间
|
||||
|
||||
到目前为止,我们所看到的命令都是仅使用了 `pattern` 空间。但是,我们在文章的开始部分已经提到过,还有第二个缓冲区:`hold` 空间,它完全由用户管理。它就是我们在第二节中描述的目标。
|
||||
到目前为止,我们所看到的命令都是仅使用了模式空间。但是,我们在文章的开始部分已经提到过,还有第二个缓冲区:保持空间,它完全由用户管理。它就是我们在第二节中描述的目标。
|
||||
|
||||
#### exchange 命令
|
||||
|
||||
正如它的名字所表示的,exchange 命令(`x`)将交换 `hold` 空间和 `pattern` 空间的内容。记住,你只要没有把任何东西放入到 `hold` 空间中,那么 `hold` 空间就是空的。
|
||||
正如它的名字所表示的,exchange 命令(`x`)将交换保持空间和模式空间的内容。记住,你只要没有把任何东西放入到保持空间中,那么保持空间就是空的。
|
||||
|
||||
![The Sed `exchange` command][24]
|
||||
|
||||
@ -462,7 +468,7 @@ cat -n inputfile | sed -n -e 'x;n;p;x;p;q'
|
||||
|
||||
```
|
||||
|
||||
当然,在你设置 `hold` 之后你并没有立即使用它的内容,因为只要你没有显式地去修改它, `hold` 空间中的内容就保持不变。在下面的例子中,我在输入一个文件的前五行后,使用它去删除第一行:
|
||||
当然,在你设置 `hold` 之后你并没有立即使用它的内容,因为只要你没有显式地去修改它,保持空间中的内容就保持不变。在下面的例子中,我在输入一个文件的前五行后,使用它去删除第一行:
|
||||
```
|
||||
cat -n inputfile | sed -n -e '
|
||||
1{x;n} # 交换 hold 和 pattern 空间
|
||||
@ -484,13 +490,13 @@ cat -n inputfile | sed -n -e '
|
||||
|
||||
#### hold 命令
|
||||
|
||||
hold 命令(`h`)是用于将 `pattern` 空间中的内容保存到 `hold` 空间中。但是,与 exchange 命令不同的是,`pattern` 空间中的内容不会被改变。hold 命令有两种用法:
|
||||
hold 命令(`h`)是用于将模式空间中的内容保存到保持空间中。但是,与 exchange 命令不同的是,模式空间中的内容不会被改变。hold 命令有两种用法:
|
||||
|
||||
* `h`
|
||||
将复制 `pattern` 空间中的内容到 `hold` 空间中,将覆盖 `hold` 空间中任何已经存在的内容。
|
||||
将复制模式空间中的内容到保持空间中,将覆盖保持空间中任何已经存在的内容。
|
||||
|
||||
* `H`
|
||||
使用一个独立的新行,追加 `pattern` 空间中的内容到 `hold` 空间中。
|
||||
使用一个独立的新行,追加模式空间中的内容到保持空间中。
|
||||
|
||||
|
||||
|
||||
@ -518,13 +524,13 @@ cat -n inputfile | sed -n -e '
|
||||
|
||||
#### get 命令
|
||||
|
||||
get 命令(`g`)与 hold 命令恰好相反:它从 `hold` 空间中取得内容并将它置入到 `pattern` 空间中。同样它也有两种方式:
|
||||
get 命令(`g`)与 hold 命令恰好相反:它从保持空间中取得内容并将它置入到模式空间中。同样它也有两种方式:
|
||||
|
||||
* `g`
|
||||
它将复制 `hold` 空间中的内容并将其放入到 `pattern` 空间,覆盖 `pattern`空间中已存在的任何内容
|
||||
它将复制保持空间中的内容并将其放入到模式空间,覆盖 `pattern`空间中已存在的任何内容
|
||||
|
||||
* `G`
|
||||
使用一个单独的新行,追加 `hold` 空间中的内容到 `pattern` 空间中
|
||||
使用一个单独的新行,追加保持空间中的内容到模式空间中
|
||||
|
||||
|
||||
|
||||
@ -551,13 +557,13 @@ cat -n inputfile | sed -En -e '
|
||||
现在你已经更熟悉使用 hold 空间了,我们回到 print、delete 和 next 命令。我们已经讨论了小写的 `p`、`d` 和 `n` 命令了。而它们也有大写的版本。因为每个命令都有大小写版本,似乎是 Sed 的习惯,这些命令的大写版本将与多行缓冲区有关:
|
||||
|
||||
* `P`
|
||||
将 `pattern` 空间中第一个新行之前的内容输出
|
||||
将模式空间中第一个新行之前的内容输出
|
||||
|
||||
* `D`
|
||||
删除 `pattern` 空间中的内容并且包含新行,然后不读取任何新的输入而是使用剩余的文本去重启一个循环
|
||||
删除模式空间中的内容并且包含新行,然后不读取任何新的输入而是使用剩余的文本去重启一个循环
|
||||
|
||||
* `N`
|
||||
使用一个换行符作为新旧数据的分隔符,然后读取并追加一个输入的新行到 `pattern` 空间。继续运行当前的循环。
|
||||
使用一个换行符作为新旧数据的分隔符,然后读取并追加一个输入的新行到模式空间。继续运行当前的循环。
|
||||
|
||||
|
||||
|
||||
@ -600,7 +606,7 @@ sed < inputfile -En -e '
|
||||
|
||||
### 分支
|
||||
|
||||
我们刚才已经看到,Sed 因为有 `hold` 空间所以有了缓存的功能。其实它还有测试和分支的指令。因为有这些特性使得 Sed 是一个[图灵完备][30]的语言。虽然它可能看起来很傻,但意味着你可以使用 Sed 写任何程序。你可以实现任何你的目的,但并不意味着实现起来会很容易,而且结果也不一定会很高效。
|
||||
我们刚才已经看到,Sed 因为有保持空间所以有了缓存的功能。其实它还有测试和分支的指令。因为有这些特性使得 Sed 是一个[图灵完备][30]的语言。虽然它可能看起来很傻,但意味着你可以使用 Sed 写任何程序。你可以实现任何你的目的,但并不意味着实现起来会很容易,而且结果也不一定会很高效。
|
||||
|
||||
但是,不用担心。在本文中,我们将使用能够展示测试和分支功能的最简单的例子。虽然这些功能乍一看似乎很有限,但请记住,有些人用 Sed 写了 <http://www.catonmat.net/ftp/sed/dc.sed> [calculators]、<http://www.catonmat.net/ftp/sed/sedtris.sed> [Tetris] 或许多其它类型的应用程序!
|
||||
|
||||
@ -769,7 +775,7 @@ $a\# end
|
||||
|
||||
#### change 命令
|
||||
|
||||
change 命令(`c\`)就像 `d` 命令一样删除 `pattern` 空间的内容并开始一个新的循环。唯一的不同在于,当命令运行之后,用户提供的文本是写往输出的。
|
||||
change 命令(`c\`)就像 `d` 命令一样删除模式空间的内容并开始一个新的循环。唯一的不同在于,当命令运行之后,用户提供的文本是写往输出的。
|
||||
|
||||
![The Sed `change` command][34]
|
||||
```
|
||||
@ -861,7 +867,7 @@ Sed 的设计思想是,所有的文本转换都将写入到进程的标准输
|
||||
|
||||
#### write 命令
|
||||
|
||||
write 命令(`w`)追加 `pattern` 空间的内容到给定的目标文件中。POSIX 要求在 Sed 处理任何数据之前,目标文件能够被 Sed 所创建。如果给定的目标文件已经存在,它将被覆写。
|
||||
write 命令(`w`)追加模式空间的内容到给定的目标文件中。POSIX 要求在 Sed 处理任何数据之前,目标文件能够被 Sed 所创建。如果给定的目标文件已经存在,它将被覆写。
|
||||
|
||||
![The Sed `write` command][38]
|
||||
|
||||
@ -887,7 +893,7 @@ cat server
|
||||
|
||||
#### 替换命令的写入标志
|
||||
|
||||
在前面,我们已经学习了替换命令,它有一个 `p` 选项用于在替换之后输出 `pattern` 空间的内容。同样它也提供一个类似功能的 `w` 选项,用于在替换之后将 `pattern` 空间的内容输出到一个文件中:
|
||||
在前面,我们已经学习了替换命令,它有一个 `p` 选项用于在替换之后输出模式空间的内容。同样它也提供一个类似功能的 `w` 选项,用于在替换之后将模式空间的内容输出到一个文件中:
|
||||
```
|
||||
sed < inputfile -ne '
|
||||
s/:.*\/nologin$//w server
|
||||
@ -921,7 +927,7 @@ cat server
|
||||
|
||||
#### 明确的 print 命令
|
||||
|
||||
这个 `l`(小写的字母 `l`)作用类似于 print 命令(`p`),但它是以精确的格式去输出 `pattern` 空间的内容。以下引用自 [POSIX 标准][12]:
|
||||
这个 `l`(小写的字母 `l`)作用类似于 print 命令(`p`),但它是以精确的格式去输出模式空间的内容。以下引用自 [POSIX 标准][12]:
|
||||
|
||||
> 在 XBD 转义序列中列出的字符和相关的动作(‘\\\’、‘\a’、‘\b’、‘\f’、‘\r’、‘\t’、‘\v’)将被写为相应的转义序列;在那个表中的 ‘\n’ 是不适用的。不在那个表中的不可打印字符将被写为一个三位八进制数字(在前面使用一个 <反斜杠>),表示字符中的每个字节(最重要的字节在前面)。长行应该被换行,通过写一个 <反斜杠>后跟一个 <换行符> 来表示换行点;发生换行时的长度是不确定的,但应该适合输出设备的具体情况。每个行应该以一个 ‘$’ 标记结束。
|
||||
|
||||
@ -931,7 +937,7 @@ cat server
|
||||
|
||||
#### transliterate 命令
|
||||
|
||||
<ruby>移译<rt>transliterate</rt></ruby>(`y`)命令允许映射 `pattern` 空间的字符从一个源集到一个目标集。它非常类似于 `tr` 命令,但是限制更多。
|
||||
<ruby>移译<rt>transliterate</rt></ruby>(`y`)命令允许映射模式空间的字符从一个源集到一个目标集。它非常类似于 `tr` 命令,但是限制更多。
|
||||
|
||||
![The Sed `transliterate` command][43]
|
||||
```
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
Joplin:开源加密笔记及待办事项应用
|
||||
======
|
||||
**[Joplin][1] 是一个免费开源的笔记和待办事项应用,可用于 Linux、Windows、macOS、Android 和 iOS。它的主要功能包括端到端加密,Markdown 支持以及通过 NextCloud、Dropbox、OneDrive 或 WebDAV 等第三方服务进行同步。**
|
||||
|
||||

|
||||
|
||||
在 Joplin 中你可以用 **Markdown格式**(支持数学符号和复选框)记笔记,桌面程序有 3 种视图:Markdown 代码、Markdown 预览或两者并排。**你可以在笔记中添加附件(使用图像预览)或在外部 Markdown 编辑器中编辑它们**并在每次保存文件时自动在 Joplin 中更新它们。
|
||||
|
||||
这个应用应该可以很好地处理大量笔记,它允许你**将笔记组织到笔记本中、添加标签和搜索**。你还可以按更新日期、创建日期或标题对笔记进行排序。**每个笔记本可以包含笔记、待办事项或两者**,你可以轻松添加其他笔记的链接(在桌面应用中右键单击笔记并选择 `Copy Markdown link`,然后在笔记中添加链接)。
|
||||
|
||||
**Joplin 中的待办事项支持警报**,但在 Ubuntu 18.04 上,此功能我无法使用。
|
||||
|
||||
**其他 Joplin 功能包括:**
|
||||
|
||||
* **Firefox 和 Chrome 中可选的 Web Clipper 扩展**(在 Joplin 桌面应用中进入 `Tools > Web clipper options` 以启用剪切服务并找到 Chrome/Firefox 扩展程序的下载链接),它可以剪切简单或完整的页面、剪切选中的区域或者截图。
|
||||
|
||||
* **可选命令行客户端**。
|
||||
|
||||
* **导入 Enex 文件(Evernote 导出格式)和 Markdown 文件**。
|
||||
|
||||
* **导出 JEX 文件(Joplin 导出格式)、PDF 和原始文件**。
|
||||
|
||||
* **离线优先,因此即使没有互联网连接,所有数据也始终可在设备上查看**。
|
||||
|
||||
* **地理位置支持**。
|
||||
|
||||
|
||||
|
||||
[![Joplin notes checkboxes link to other note][2]][3]
|
||||
Joplin 带有显示复选框和指向另一个笔记链接的隐藏侧边栏
|
||||
|
||||
虽然它没有提供与 Evernote 一样多的功能,但 Joplin 是一个强大的开源 Evernote 替代品。Joplin 包含所有基本功能,除了它是开源软件之外,它还包括加密支持,你还可以选择用于同步的服务。
|
||||
|
||||
该应用实际上被设计为 Evernote 替代品,因此它可以导入完整的 Evernote 笔记本、笔记、标签、附件和笔记元数据,如作者、创建和更新时间或地理位置。
|
||||
|
||||
Joplin 开发重点关注的另一个方面是避免与特定公司或服务挂钩。这就是为什么该应用提供多种同步方案,如 NextCloud、Dropbox、oneDrive 和 WebDav,同时也容易支持新的服务。如果你改变主意,也很容易从一种服务切换到另一种服务。
|
||||
|
||||
**我注意到 Joplin 默认情况下不使用加密,你必须在设置中启用此功能。进入**`Tools> Encryption options` 并在这里启用 Joplin 端到端加密。
|
||||
|
||||
### 下载 Joplin
|
||||
|
||||
[Download Joplin][7]
|
||||
|
||||
**Joplin 适用于 Linux、Windows、macOS、Android 和 iOS。在 Linux 上,还有 AppImage 和 Aur 包。**
|
||||
|
||||
要在 Linux 上运行 Joplin AppImage,请双击它并选择 `Make executable and run` (如果文件管理器支持这个)。如果不支持,你需要使用你的文件管理器使它可执行(应该类似这样:`右键单击>属性>权限>允许作为程序执行`,但这可能会因你使用的文件管理器而有所不同),或者从命令行:
|
||||
```
|
||||
chmod +x /path/to/Joplin-*-x86_64.AppImage
|
||||
|
||||
```
|
||||
|
||||
用你下载 Joplin 的路径替换 `/path/to/`。现在,你可以双击 Joplin Appimage 文件来启动它。
|
||||
|
||||
**提示:**如果你将 Joplin 集成到你的菜单中,而它的图标没有显示在你 dock/应用切换器中,你可以打开 Joplin 的桌面文件(如果你使用 appimagekit 集成,它应该在 `~/.local/share/applications/appimagekit-joplin.desktop`)并在文件末尾添加 `StartupWMClass=Joplin` 其他不变来修复。
|
||||
|
||||
Joplin 有一个**命令行客户端**,它可以[使用 npm 安装][5](对于 Debian、Ubuntu 或 Linux Mint,请参阅[如何安装和配置 Node.js 和 npm][6])。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://joplin.cozic.net/
|
||||
[2]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s640/joplin-notes-markdown.png (Joplin notes checkboxes link to other note)
|
||||
[3]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s1600/joplin-notes-markdown.png
|
||||
[4]:https://github.com/laurent22/joplin/issues/338
|
||||
[5]:https://joplin.cozic.net/terminal/
|
||||
[6]:https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html
|
||||
|
||||
[7]: https://joplin.cozic.net/#installation
|
||||
507
translated/tech/20181016 Lab 6- Network Driver.md
Normal file
507
translated/tech/20181016 Lab 6- Network Driver.md
Normal file
@ -0,0 +1,507 @@
|
||||
实验 6:网络驱动程序
|
||||
======
|
||||
### 实验 6:网络驱动程序(缺省的最终设计)
|
||||
|
||||
### 简介
|
||||
|
||||
这个实验是缺省的最终项目中你自己能够做的最后的实验。
|
||||
|
||||
现在你有了一个文件系统,一个典型的操作系统都应该有一个网络栈。在本实验中,你将继续为一个网卡去写一个驱动程序。这个网卡基于 Intel 82540EM 芯片,也就是众所周知的 E1000 芯片。
|
||||
|
||||
##### 预备知识
|
||||
|
||||
使用 Git 去提交你的实验 5 的源代码(如果还没有提交的话),获取课程仓库的最新版本,然后创建一个名为 `lab6` 的本地分支,它跟踪我们的远程分支 `origin/lab6`:
|
||||
|
||||
```c
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'my solution to lab5'
|
||||
nothing to commit (working directory clean)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab6 origin/lab6
|
||||
Branch lab6 set up to track remote branch refs/remotes/origin/lab6.
|
||||
Switched to a new branch "lab6"
|
||||
athena% git merge lab5
|
||||
Merge made by recursive.
|
||||
fs/fs.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
然后,仅有网卡驱动程序并不能够让你的操作系统接入因特网。在新的实验 6 的代码中,我们为你提供了网络栈和一个网络服务器。与以前的实验一样,使用 git 去拉取这个实验的代码,合并到你自己的代码中,并去浏览新的 `net/` 目录中的内容,以及在 `kern/` 中的新文件。
|
||||
|
||||
除了写这个驱动程序以外,你还需要去创建一个访问你的驱动程序的系统调用。你将要去实现那些在网络服务器中缺失的代码,以便于在网络栈和你的驱动程序之间传输包。你还需要通过完成一个 web 服务器来将所有的东西连接到一起。你的新 web 服务器还需要你的文件系统来提供所需要的文件。
|
||||
|
||||
大部分的内核设备驱动程序代码都需要你自己去从头开始编写。本实验提供的指导比起前面的实验要少一些:没有框架文件、没有现成的系统调用接口、并且很多设计都由你自己决定。因此,我们建议你在开始任何单独练习之前,阅读全部的编写任务。许多学生都反应这个实验比前面的实验都难,因此请根据你的实际情况计划你的时间。
|
||||
|
||||
##### 实验要求
|
||||
|
||||
与以前一样,你需要做实验中全部的常规练习和至少一个挑战问题。在实验中写出你的详细答案,并将挑战问题的方案描述写入到 `answers-lab6.txt` 文件中。
|
||||
|
||||
#### QEMU 的虚拟网络
|
||||
|
||||
我们将使用 QEMU 的用户模式网络栈,因为它不需要以管理员权限运行。QEMU 的文档的[这里][1]有更多关于用户网络的内容。我们更新后的 makefile 启用了 QEMU 的用户模式网络栈和虚拟的 E1000 网卡。
|
||||
|
||||
缺省情况下,QEMU 提供一个运行在 IP 地址 10.2.2.2 上的虚拟路由器,它给 JOS 分配的 IP 地址是 10.0.2.15。为了简单起见,我们在 `net/ns.h` 中将这些缺省值硬编码到网络服务器上。
|
||||
|
||||
虽然 QEMU 的虚拟网络允许 JOS 随意连接因特网,但 JOS 的 10.0.2.15 的地址并不能在 QEMU 中的虚拟网络之外使用(也就是说,QEMU 还得做一个 NAT),因此我们并不能直接连接到 JOS 上运行的服务器,即便是从运行 QEMU 的主机上连接也不行。为解决这个问题,我们配置 QEMU 在主机的某些端口上运行一个服务器,这个服务器简单地连接到 JOS 中的一些端口上,并在你的真实主机和虚拟网络之间传递数据。
|
||||
|
||||
你将在端口 7(echo)和端口 80(http)上运行 JOS,为避免在共享的 Athena 机器上发生冲突,makefile 将为这些端口基于你的用户 ID 来生成转发端口。你可以运行 `make which-ports` 去找出是哪个 QEMU 端口转发到你的开发主机上。为方便起见,makefile 也提供 `make nc-7` 和 `make nc-80`,它允许你在终端上直接与运行这些端口的服务器去交互。(这些目标仅能连接到一个运行中的 QEMU 实例上;你必须分别去启动它自己的 QEMU)
|
||||
|
||||
##### 包检查
|
||||
|
||||
makefile 也可以配置 QEMU 的网络栈去记录所有的入站和出站数据包,并将它保存到你的实验目录中的 `qemu.pcap` 文件中。
|
||||
|
||||
使用 `tcpdump` 命令去获取一个捕获的 hex/ASCII 包转储:
|
||||
|
||||
```
|
||||
tcpdump -XXnr qemu.pcap
|
||||
```
|
||||
|
||||
或者,你可以使用 [Wireshark][2] 以图形化界面去检查 pcap 文件。Wireshark 也知道如何去解码和检查成百上千的网络协议。如果你在 Athena 上,你可以使用 Wireshark 的前辈:ethereal,它运行在加锁的保密互联网协议网络中。
|
||||
|
||||
##### 调试 E1000
|
||||
|
||||
我们非常幸运能够去使用仿真硬件。由于 E1000 是在软件中运行的,仿真的 E1000 能够给我们提供一个人类可读格式的报告、它的内部状态以及它遇到的任何问题。通常情况下,对祼机上做驱动程序开发的人来说,这是非常难能可贵的。
|
||||
|
||||
E1000 能够产生一些调试输出,因此你可以去打开一个专门的日志通道。其中一些对你有用的通道如下:
|
||||
|
||||
| 标志 | 含义 |
|
||||
| --------- | :----------------------- |
|
||||
| tx | 包发送日志 |
|
||||
| txerr | 包发送错误日志 |
|
||||
| rx | 到 RCTL 的日志通道 |
|
||||
| rxfilter | 入站包过滤日志 |
|
||||
| rxerr | 接收错误日志 |
|
||||
| unknown | 未知寄存器的读写日志 |
|
||||
| eeprom | 读取 EEPROM 的日志 |
|
||||
| interrupt | 中断和中断寄存器变更日志 |
|
||||
|
||||
例如,你可以使用 `make E1000_DEBUG=tx,txerr` 去打开 "tx" 和 "txerr" 日志功能。
|
||||
|
||||
注意:`E1000_DEBUG` 标志仅能在打了 6.828 补丁的 QEMU 版本上工作。
|
||||
|
||||
你可以使用软件去仿真硬件,来做进一步的调试工作。如果你使用它时卡壳了,不明白为什么 E1000 没有如你预期那样响应你,你可以查看在 `hw/e1000.c` 中的 QEMU 的 E1000 实现。
|
||||
|
||||
#### 网络服务器
|
||||
|
||||
从头开始写一个网络栈是很困难的。因此我们将使用 lwIP,它是一个开源的、轻量级 TCP/IP 协议套件,它能做包括一个网络栈在内的很多事情。你能在 [这里][3] 找到很多关于 IwIP 的信息。在这个任务中,对我们而言,lwIP 就是一个实现了一个 BSD 套接字接口和拥有一个包输入端口和包输出端口的黑盒子。
|
||||
|
||||
一个网络服务器其实就是一个有以下四个环境的混合体:
|
||||
|
||||
* 核心网络服务器环境(包括套接字调用派发器和 lwIP)
|
||||
* 输入环境
|
||||
* 输出环境
|
||||
* 定时器环境
|
||||
|
||||
|
||||
|
||||
下图展示了各个环境和它们之间的关系。下图展示了包括设备驱动的整个系统,我们将在后面详细讲到它。在本实验中,你将去实现图中绿色高亮的部分。
|
||||
|
||||
![Network server architecture][4]
|
||||
|
||||
##### 核心网络服务器环境
|
||||
|
||||
核心网络服务器环境由套接字调用派发器和 IwIP 自身组成的。套接字调用派发器就像一个文件服务器一样。用户环境使用 stubs(可以在 `lib/nsipc.c` 中找到它)去发送 IPC 消息到核心网络服务器环境。如果你看了 `lib/nsipc.c`,你就会发现核心网络服务器与我们创建的文件服务器 `i386_init` 的工作方式是一样的,`i386_init` 是使用 NS_TYPE_NS 创建的 NS 环境,因此我们检查 `envs`,去查找这个特殊的环境类型。对于每个用户环境的 IPC,网络服务器中的派发器将调用相应的、由 IwIP 提供的、代表用户的 BSD 套接字接口函数。
|
||||
|
||||
普通用户环境不能直接使用 `nsipc_*` 调用。而是通过在 `lib/sockets.c` 中的函数来使用它们,这些函数提供了基于文件描述符的套接字 API。以这种方式,用户环境通过文件描述符来引用套接字,就像它们引用磁盘上的文件一样。一些操作(`connect`、`accept`、等等)是特定于套接字的,但 `read`、`write`、和 `close` 是通过 `lib/fd.c` 中一般的文件描述符设备派发代码的。就像文件服务器对所有的打开的文件维护唯一的内部 ID 一样,lwIP 也为所有的打开的套接字生成唯一的 ID。不论是文件服务器还是网络服务器,我们都使用存储在 `struct Fd` 中的信息去映射每个环境的文件描述符到这些唯一的 ID 空间上。
|
||||
|
||||
尽管看起来文件服务器的网络服务器的 IPC 派发器行为是一样的,但它们之间还有很重要的差别。BSD 套接字调用(像 `accept` 和 `recv`)能够无限期阻塞。如果派发器让 lwIP 去执行其中一个调用阻塞,派发器也将被阻塞,并且在整个系统中,同一时间只能有一个未完成的网络调用。由于这种情况是无法接受的,所以网络服务器使用用户级线程以避免阻塞整个服务器环境。对于每个入站 IPC 消息,派发器将创建一个线程,然后在新创建的线程上来处理请求。如果线程被阻塞,那么只有那个线程被置入休眠状态,而其它线程仍然处于运行中。
|
||||
|
||||
除了核心网络环境外,还有三个辅助环境。核心网络服务器环境除了接收来自用户应用程序的消息之外,它的派发器也接收来自输入环境和定时器环境的消息。
|
||||
|
||||
##### 输出环境
|
||||
|
||||
在为用户环境套接字调用提供服务时,lwIP 将为网卡生成用于发送的包。IwIP 将使用 `NSREQ_OUTPUT` 去发送在 IPC 消息页参数中附加了包的 IPC 消息。输出环境负责接收这些消息,并通过你稍后创建的系统调用接口来转发这些包到设备驱动程序上。
|
||||
|
||||
##### 输入环境
|
||||
|
||||
网卡接收到的包需要传递到 lwIP 中。输入环境将每个由设备驱动程序接收到的包拉进内核空间(使用你将要实现的内核系统调用),并使用 `NSREQ_INPUT` IPC 消息将这些包发送到核心网络服务器环境。
|
||||
|
||||
包输入功能是独立于核心网络环境的,因为在 JOS 上同时实现接收 IPC 消息并从设备驱动程序中查询或等待包有点困难。我们在 JOS 中没有实现 `select` 系统调用,这是一个允许环境去监视多个输入源以识别准备处理哪个输入的系统调用。
|
||||
|
||||
如果你查看了 `net/input.c` 和 `net/output.c`,你将会看到在它们中都需要去实现那个系统调用。这主要是因为实现它要依赖你的系统调用接口。在你实现了驱动程序和系统调用接口之后,你将要为这两个辅助环境写这个代码。
|
||||
|
||||
##### 定时器环境
|
||||
|
||||
定时器环境周期性发送 `NSREQ_TIMER` 类型的消息到核心服务器,以提醒它那个定时器已过期。IwIP 使用来自线程的定时器消息来实现各种网络超时。
|
||||
|
||||
### Part A:初始化和发送包
|
||||
|
||||
你的内核还没有一个时间概念,因此我们需要去添加它。这里有一个由硬件产生的每 10 ms 一次的时钟中断。每收到一个时钟中断,我们将增加一个变量值,以表示时间已过去 10 ms。它在 `kern/time.c` 中已实现,但还没有完全集成到你的内核中。
|
||||
|
||||
```markdown
|
||||
练习 1、为 `kern/trap.c` 中的每个时钟中断增加一个到 `time_tick` 的调用。实现 `sys_time_msec` 并增加到 `kern/syscall.c` 中的 `syscall`,以便于用户空间能够访问时间。
|
||||
```
|
||||
|
||||
使用 `make INIT_CFLAGS=-DTEST_NO_NS run-testtime` 去测试你的代码。你应该会看到环境计数从 5 开始以 1 秒为间隔减少。"-DTEST_NO_NS” 参数禁止在网络服务器环境上启动,因为在当前它将导致 JOS 崩溃。
|
||||
|
||||
#### 网卡
|
||||
|
||||
写驱动程序要求你必须深入了解硬件和软件中的接口。本实验将给你提供一个如何使用 E1000 接口的高度概括的文档,但是你在写驱动程序时还需要大量去查询 Intel 的手册。
|
||||
|
||||
```markdown
|
||||
练习 2、为开发 E1000 驱动,去浏览 Intel 的 [软件开发者手册][5]。这个手册涵盖了几个与以太网控制器紧密相关的东西。QEMU 仿真了 82540EM。
|
||||
|
||||
现在,你应该去浏览第 2 章,以对设备获得一个整体概念。写驱动程序时,你需要熟悉第 3 到 14 章,以及 4.1(不包括 4.1 的子节)。你也应该去参考第 13 章。其它章涵盖了 E1000 的组件,你的驱动程序并不与这些组件去交互。现在你不用担心过多细节的东西;只需要了解文档的整体结构,以便于你后面需要时容易查找。
|
||||
|
||||
在阅读手册时,记住,E1000 是一个拥有很多高级特性的很复杂的设备,一个能让 E1000 工作的驱动程序仅需要它一小部分的特性和 NIC 提供的接口即可。仔细考虑一下,如何使用最简单的方式去使用网卡的接口。我们强烈推荐你在使用高级特性之前,只去写一个基本的、能够让网卡工作的驱动程序即可。
|
||||
```
|
||||
|
||||
##### PCI 接口
|
||||
|
||||
E1000 是一个 PCI 设备,也就是说它是插到主板的 PCI 总线插槽上的。PCI 总线有地址、数据、和中断线,并且 PCI 总线允许 CPU 与 PCI 设备通讯,以及 PCI 设备去读取和写入内存。一个 PCI 设备在它能够被使用之前,需要先发现它并进行初始化。发现 PCI 设备是 PCI 总线查找已安装设备的过程。初始化是分配 I/O 和内存空间、以及协商设备所使用的 IRQ 线的过程。
|
||||
|
||||
我们在 `kern/pci.c` 中已经为你提供了使用 PCI 的代码。PCI 初始化是在引导期间执行的,PCI 代码遍历PCI 总线来查找设备。当它找到一个设备时,它读取它的供应商 ID 和设备 ID,然后使用这两个值作为关键字去搜索 `pci_attach_vendor` 数组。这个数组是由像下面这样的 `struct pci_driver` 条目组成:
|
||||
|
||||
```c
|
||||
struct pci_driver {
|
||||
uint32_t key1, key2;
|
||||
int (*attachfn) (struct pci_func *pcif);
|
||||
};
|
||||
```
|
||||
|
||||
如果发现的设备的供应商 ID 和设备 ID 与数组中条目匹配,那么 PCI 代码将调用那个条目的 `attachfn` 去执行设备初始化。(设备也可以按类别识别,那是通过 `kern/pci.c` 中其它的驱动程序表来实现的。)
|
||||
|
||||
绑定函数是传递一个 _PCI 函数_ 去初始化。一个 PCI 卡能够发布多个函数,虽然这个 E1000 仅发布了一个。下面是在 JOS 中如何去表示一个 PCI 函数:
|
||||
|
||||
```c
|
||||
struct pci_func {
|
||||
struct pci_bus *bus;
|
||||
|
||||
uint32_t dev;
|
||||
uint32_t func;
|
||||
|
||||
uint32_t dev_id;
|
||||
uint32_t dev_class;
|
||||
|
||||
uint32_t reg_base[6];
|
||||
uint32_t reg_size[6];
|
||||
uint8_t irq_line;
|
||||
};
|
||||
```
|
||||
|
||||
上面的结构反映了在 Intel 开发者手册里第 4.1 节的表 4-1 中找到的一些条目。`struct pci_func` 的最后三个条目我们特别感兴趣的,因为它们将记录这个设备协商的内存、I/O、以及中断资源。`reg_base` 和 `reg_size` 数组包含最多六个基址寄存器或 BAR。`reg_base` 为映射到内存中的 I/O 区域(对于 I/O 端口而言是基 I/O 端口)保存了内存的基地址,`reg_size` 包含了以字节表示的大小或来自 `reg_base` 的相关基值的 I/O 端口号,而 `irq_line` 包含了为中断分配给设备的 IRQ 线。在表 4-2 的后半部分给出了 E1000 BAR 的具体涵义。
|
||||
|
||||
当设备调用了绑定函数后,设备已经被发现,但没有被启用。这意味着 PCI 代码还没有确定分配给设备的资源,比如地址空间和 IRQ 线,也就是说,`struct pci_func` 结构的最后三个元素还没有被填入。绑定函数将调用 `pci_func_enable`,它将去启用设备、协商这些资源、并在结构 `struct pci_func` 中填入它。
|
||||
|
||||
```markdown
|
||||
练习 3、实现一个绑定函数去初始化 E1000。添加一个条目到 `kern/pci.c` 中的数组 `pci_attach_vendor` 上,如果找到一个匹配的 PCI 设备就去触发你的函数(确保一定要把它放在表末尾的 `{0, 0, 0}` 条目之前)。你在 5.2 节中能找到 QEMU 仿真的 82540EM 的供应商 ID 和设备 ID。在引导期间,当 JOS 扫描 PCI 总线时,你也可以看到列出来的这些信息。
|
||||
|
||||
到目前为止,我们通过 `pci_func_enable` 启用了 E1000 设备。通过本实验我们将添加更多的初始化。
|
||||
|
||||
我们已经为你提供了 `kern/e1000.c` 和 `kern/e1000.h` 文件,这样你就不会把构建系统搞糊涂了。不过它们现在都是空的;你需要在本练习中去填充它们。你还可能在内核的其它地方包含这个 `e1000.h` 文件。
|
||||
|
||||
当你引导你的内核时,你应该会看到它输出的信息显示 E1000 的 PCI 函数已经启用。这时你的代码已经能够通过 `make grade` 的 `pci attach` 测试了。
|
||||
```
|
||||
|
||||
##### 内存映射的 I/O
|
||||
|
||||
软件与 E1000 通过内存映射的 I/O(MMIO) 来沟通。你在 JOS 的前面部分可能看到过 MMIO 两次:CGA 控制台和 LAPIC 都是通过写入和读取“内存”来控制和查询设备的。但这些读取和写入不是去往内存芯片的,而是直接到这些设备的。
|
||||
|
||||
`pci_func_enable` 为 E1000 协调一个 MMIO 区域,来存储它在 BAR 0 的基址和大小(也就是 `reg_base[0]` 和 `reg_size[0]`),这是一个分配给设备的一段物理内存地址,也就是说你可以通过虚拟地址访问它来做一些事情。由于 MMIO 区域一般分配高位物理地址(一般是 3GB 以上的位置),因此你不能使用 `KADDR` 去访问它们,因为 JOS 被限制为最大使用 256MB。因此,你可以去创建一个新的内存映射。我们将使用 `MMIOBASE`(从实验 4 开始,你的 `mmio_map_region` 区域应该确保不能被 LAPIC 使用的映射所覆盖)以上的部分。由于在 JOS 创建用户环境之前,PCI 设备就已经初始化了,因此你可以在 `kern_pgdir` 处创建映射,并且让它始终可用。
|
||||
|
||||
```markdown
|
||||
练习 4、在你的绑定函数中,通过调用 `mmio_map_region`(它就是你在实验 4 中写的,是为了支持 LAPIC 内存映射)为 E1000 的 BAR 0 创建一个虚拟地址映射。
|
||||
|
||||
你将希望在一个变量中记录这个映射的位置,以便于后面访问你映射的寄存器。去看一下 `kern/lapic.c` 中的 `lapic` 变量,它就是一个这样的例子。如果你使用一个指针指向设备寄存器映射,一定要声明它为 `volatile`;否则,编译器将允许缓存它的值,并可以在内存中再次访问它。
|
||||
|
||||
为测试你的映射,尝试去输出设备状态寄存器(第 12.4.2 节)。这是一个在寄存器空间中以字节 8 开头的 4 字节寄存器。你应该会得到 `0x80080783`,它表示以 1000 MB/s 的速度启用一个全双工的链路,以及其它信息。
|
||||
```
|
||||
|
||||
提示:你将需要一些常数,像寄存器位置和掩码位数。如果从开发者手册中复制这些东西很容易出错,并且导致调试过程很痛苦。我们建议你使用 QEMU 的 [`e1000_hw.h`][6] 头文件做为基准。我们不建议完全照抄它,因为它定义的值远超过你所需要,并且定义的东西也不见得就是你所需要的,但它仍是一个很好的参考。
|
||||
|
||||
##### DMA
|
||||
|
||||
你可能会认为是从 E1000 的寄存器中通过写入和读取来传送和接收数据包的,其实这样做会非常慢,并且还要求 E1000 在其中去缓存数据包。相反,E1000 使用直接内存访问(DMA)从内存中直接读取和写入数据包,而且不需要 CPU 参与其中。驱动程序负责为发送和接收队列分配内存、设置 DMA 描述符、以及配置 E1000 使用的队列位置,而在这些设置完成之后的其它工作都是异步方式进行的。发送包的时候,驱动程序复制它到发送队列的下一个 DMA 描述符中,并且通知 E1000 下一个发送包已就绪;当轮到这个包发送时,E1000 将从描述符中复制出数据。同样,当 E1000 接收一个包时,它从接收队列中将它复制到下一个 DMA 描述符中,驱动程序将能在下一次读取到它。
|
||||
|
||||
总体来看,接收队列和发送队列非常相似。它们都是由一系列的描述符组成。虽然这些描述符的结构细节有所不同,但每个描述符都包含一些标志和包含了包数据的一个缓存的物理地址(发送到网卡的数据包,或网卡将接收到的数据包写入到由操作系统分配的缓存中)。
|
||||
|
||||
队列被实现为一个环形数组,意味着当网卡或驱动到达数组末端时,它将重新回到开始位置。它有一个头指针和尾指针,队列的内容就是这两个指针之间的描述符。硬件就是从头开始移动头指针去消费描述符,在这期间驱动程序不停地添加描述符到尾部,并移动尾指针到最后一个描述符上。发送队列中的描述符表示等待发送的包(因此,在平静状态下,发送队列是空的)。对于接收队列,队列中的描述符是表示网卡能够接收包的空描述符(因此,在平静状态下,接收队列是由所有的可用接收描述符组成的)。正确的更新尾指针寄存器而不让 E1000 产生混乱是很有难度的;要小心!
|
||||
|
||||
指向到这些数组及描述符中的包缓存地址的指针都必须是物理地址,因为硬件是直接在物理内存中且不通过 MMU 来执行 DMA 的读写操作的。
|
||||
|
||||
#### 发送包
|
||||
|
||||
E1000 中的发送和接收功能本质上是独立的,因此我们可以同时进行发送接收。我们首先去攻克简单的数据包发送,因为我们在没有先去发送一个 “I'm here!" 包之前是无法测试接收包功能的。
|
||||
|
||||
首先,你需要初始化网卡以准备发送,详细步骤查看 14.5 节(不必着急看子节)。发送初始化的第一步是设置发送队列。队列的详细结构在 3.4 节中,描述符的结构在 3.3.3 节中。我们先不要使用 E1000 的 TCP offload 特性,因此你只需专注于 “传统的发送描述符格式” 即可。你应该现在就去阅读这些章节,并要熟悉这些结构。
|
||||
|
||||
##### C 结构
|
||||
|
||||
你可以用 C `struct` 很方便地描述 E1000 的结构。正如你在 `struct Trapframe` 中所看到的结构那样,C `struct` 可以让你很方便地在内存中描述准确的数据布局。C 可以在字段中插入数据,但是 E1000 的结构就是这样布局的,这样就不会是个问题。如果你遇到字段对齐问题,进入 GCC 查看它的 "packed” 属性。
|
||||
|
||||
查看手册中表 3-8 所给出的一个传统的发送描述符,将它复制到这里作为一个示例:
|
||||
|
||||
```
|
||||
63 48 47 40 39 32 31 24 23 16 15 0
|
||||
+---------------------------------------------------------------+
|
||||
| Buffer address |
|
||||
+---------------|-------|-------|-------|-------|---------------+
|
||||
| Special | CSS | Status| Cmd | CSO | Length |
|
||||
+---------------|-------|-------|-------|-------|---------------+
|
||||
```
|
||||
|
||||
从结构右上角第一个字节开始,我们将它转变成一个 C 结构,从上到下,从右到左读取。如果你从右往左看,你将看到所有的字段,都非常适合一个标准大小的类型:
|
||||
|
||||
```c
|
||||
struct tx_desc
|
||||
{
|
||||
uint64_t addr;
|
||||
uint16_t length;
|
||||
uint8_t cso;
|
||||
uint8_t cmd;
|
||||
uint8_t status;
|
||||
uint8_t css;
|
||||
uint16_t special;
|
||||
};
|
||||
```
|
||||
|
||||
你的驱动程序将为发送描述符数组去保留内存,并由发送描述符指向到包缓冲区。有几种方式可以做到,从动态分配页到在全局变量中简单地声明它们。无论你如何选择,记住,E1000 是直接访问物理内存的,意味着它能访问的任何缓存区在物理内存中必须是连续的。
|
||||
|
||||
处理包缓存也有几种方式。我们推荐从最简单的开始,那就是在驱动程序初始化期间,为每个描述符保留包缓存空间,并简单地将包数据复制进预留的缓冲区中或从其中复制出来。一个以太网包最大的尺寸是 1518 字节,这就限制了这些缓存区的大小。主流的成熟驱动程序都能够动态分配包缓存区(即:当网络使用率很低时,减少内存使用量),或甚至跳过缓存区,直接由用户空间提供(就是“零复制”技术),但我们还是从简单开始为好。
|
||||
|
||||
```markdown
|
||||
练习 5、执行一个 14.5 节中的初始化步骤(它的子节除外)。对于寄存器的初始化过程使用 13 节作为参考,对发送描述符和发送描述符数组参考 3.3.3 节和 3.4 节。
|
||||
|
||||
要记住,在发送描述符数组中要求对齐,并且数组长度上有限制。因为 TDLEN 必须是 128 字节对齐的,而每个发送描述符是 16 字节,你的发送描述符数组必须是 8 个发送描述符的倍数。并且不能使用超过 64 个描述符,以及不能在我们的发送环形缓存测试中溢出。
|
||||
|
||||
对于 TCTL.COLD,你可以假设为全双工操作。对于 TIPG、IEEE 802.3 标准的 IPG(不要使用 14.5 节中表上的值),参考在 13.4.34 节中表 13-77 中描述的缺省值。
|
||||
```
|
||||
|
||||
尝试运行 `make E1000_DEBUG=TXERR,TX qemu`。如果你使用的是打了 6.828 补丁的 QEMU,当你设置 TDT(发送描述符尾部)寄存器时你应该会看到一个 “e1000: tx disabled" 的信息,并且不会有更多 "e1000” 信息了。
|
||||
|
||||
现在,发送初始化已经完成,你可以写一些代码去发送一个数据包,并且通过一个系统调用使它可以访问用户空间。你可以将要发送的数据包添加到发送队列的尾部,也就是说复制数据包到下一个包缓冲区中,然后更新 TDT 寄存器去通知网卡在发送队列中有另外的数据包。(注意,TDT 是一个进入发送描述符数组的索引,不是一个字节偏移量;关于这一点文档中说明的不是很清楚。)
|
||||
|
||||
但是,发送队列只有这么大。如果网卡在发送数据包时卡住或发送队列填满时会发生什么状况?为了检测这种情况,你需要一些来自 E1000 的反馈。不幸的是,你不能只使用 TDH(发送描述符头)寄存器;文档上明确说明,从软件上读取这个寄存器是不可靠的。但是,如果你在发送描述符的命令字段中设置 RS 位,那么,当网卡去发送在那个描述符中的数据包时,网卡将设置描述符中状态字段的 DD 位,如果一个描述符中的 DD 位被设置,你就应该知道那个描述符可以安全地回收,并且可以用它去发送其它数据包。
|
||||
|
||||
如果用户调用你的发送系统调用,但是下一个描述符的 DD 位没有设置,表示那个发送队列已满,该怎么办?在这种情况下,你该去决定怎么办了。你可以简单地丢弃数据包。网络协议对这种情况的处理很灵活,但如果你丢弃大量的突发数据包,协议可能不会去重新获得它们。可能需要你替代网络协议告诉用户环境让它重传,就像你在 `sys_ipc_try_send` 中做的那样。在环境上回推产生的数据是有好处的。
|
||||
|
||||
```
|
||||
练习 6、写一个函数去发送一个数据包,它需要检查下一个描述符是否空闲、复制包数据到下一个描述符并更新 TDT。确保你处理的发送队列是满的。
|
||||
```
|
||||
|
||||
现在,应该去测试你的包发送代码了。通过从内核中直接调用你的发送函数来尝试发送几个包。在测试时,你不需要去创建符合任何特定网络协议的数据包。运行 `make E1000_DEBUG=TXERR,TX qemu` 去测试你的代码。你应该看到类似下面的信息:
|
||||
|
||||
```c
|
||||
e1000: index 0: 0x271f00 : 9000002a 0
|
||||
...
|
||||
```
|
||||
|
||||
在你发送包时,每行都给出了在发送数组中的序号、那个发送的描述符的缓存地址、`cmd/CSO/length` 字段、以及 `special/CSS/status` 字段。如果 QEMU 没有从你的发送描述符中输出你预期的值,检查你的描述符中是否有合适的值和你配置的正确的 TDBAL 和 TDBAH。如果你收到的是 "e1000: TDH wraparound @0, TDT x, TDLEN y" 的信息,意味着 E1000 的发送队列持续不断地运行(如果 QEMU 不去检查它,它将是一个无限循环),这意味着你没有正确地维护 TDT。如果你收到了许多 "e1000: tx disabled" 的信息,那么意味着你没有正确设置发送控制寄存器。
|
||||
|
||||
一旦 QEMU 运行,你就可以运行 `tcpdump -XXnr qemu.pcap` 去查看你发送的包数据。如果从 QEMU 中看到预期的 "e1000: index” 信息,但你捕获的包是空的,再次检查你发送的描述符,是否填充了每个必需的字段和位。(E1000 或许已经遍历了你的发送描述符,但它认为不需要去发送)
|
||||
|
||||
```
|
||||
练习 7、添加一个系统调用,让你从用户空间中发送数据包。详细的接口由你来决定。但是不要忘了检查从用户空间传递给内核的所有指针。
|
||||
```
|
||||
|
||||
#### 发送包:网络服务器
|
||||
|
||||
现在,你已经有一个系统调用接口可以发送包到你的设备驱动程序端了。输出辅助环境的目标是在一个循环中做下面的事情:从核心网络服务器中接收 `NSREQ_OUTPUT` IPC 消息,并使用你在上面增加的系统调用去发送伴随这些 IPC 消息的数据包。这个 `NSREQ_OUTPUT` IPC 是通过 `net/lwip/jos/jif/jif.c` 中的 `low_level_output` 函数来发送的。它集成 lwIP 栈到 JOS 的网络系统。每个 IPC 将包含一个页,这个页由一个 `union Nsipc` 和在 `struct jif_pkt pkt` 字段中的一个包组成(查看 `inc/ns.h`)。`struct jif_pkt` 看起来像下面这样:
|
||||
|
||||
```c
|
||||
struct jif_pkt {
|
||||
int jp_len;
|
||||
char jp_data[0];
|
||||
};
|
||||
```
|
||||
|
||||
`jp_len` 表示包的长度。在 IPC 页上的所有后续字节都是为了包内容。在结构的结尾处使用一个长度为 0 的数组来表示缓存没有一个预先确定的长度(像 `jp_data` 一样),这是一个常见的 C 技巧(也有人说这是一个令人讨厌的做法)。因为 C 并不做数组边界的检查,只要你确保结构后面有足够的未使用内存即可,你可以把 `jp_data` 作为一个任意大小的数组来使用。
|
||||
|
||||
当设备驱动程序的发送队列中没有足够的空间时,一定要注意在设备驱动程序、输出环境和核心网络服务器之间的交互。核心网络服务器使用 IPC 发送包到输出环境。如果输出环境在由于一个发送包的系统调用而挂起,导致驱动程序没有足够的缓存去容纳新数据包,这时核心网络服务器将阻塞以等待输出服务器去接收 IPC 调用。
|
||||
|
||||
```markdown
|
||||
练习 8、实现 `net/output.c`。
|
||||
```
|
||||
|
||||
你可以使用 `net/testoutput.c` 去测试你的输出代码而无需整个网络服务器参与。尝试运行 `make E1000_DEBUG=TXERR,TX run-net_testoutput`。你将看到如下的输出:
|
||||
|
||||
```c
|
||||
Transmitting packet 0
|
||||
e1000: index 0: 0x271f00 : 9000009 0
|
||||
Transmitting packet 1
|
||||
e1000: index 1: 0x2724ee : 9000009 0
|
||||
...
|
||||
```
|
||||
|
||||
运行 `tcpdump -XXnr qemu.pcap` 将输出:
|
||||
|
||||
|
||||
```c
|
||||
reading from file qemu.pcap, link-type EN10MB (Ethernet)
|
||||
-5:00:00.600186 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 30 Packet.00
|
||||
-5:00:00.610080 [|ether]
|
||||
0x0000: 5061 636b 6574 2030 31 Packet.01
|
||||
...
|
||||
```
|
||||
|
||||
使用更多的数据包去测试,可以运行 `make E1000_DEBUG=TXERR,TX NET_CFLAGS=-DTESTOUTPUT_COUNT=100 run-net_testoutput`。如果它导致你的发送队列溢出,再次检查你的 DD 状态位是否正确,以及是否告诉硬件去设置 DD 状态位(使用 RS 命令位)。
|
||||
|
||||
你的代码应该会通过 `make grade` 的 `testoutput` 测试。
|
||||
|
||||
```
|
||||
问题
|
||||
|
||||
1、你是如何构造你的发送实现的?在实践中,如果发送缓存区满了,你该如何处理?
|
||||
```
|
||||
|
||||
|
||||
### Part B:接收包和 web 服务器
|
||||
|
||||
#### 接收包
|
||||
|
||||
就像你在发送包中做的那样,你将去配置 E1000 去接收数据包,并提供一个接收描述符队列和接收描述符。在 3.2 节中描述了接收包的操作,包括接收队列结构和接收描述符、以及在 14.4 节中描述的详细的初始化过程。
|
||||
|
||||
```
|
||||
练习 9、阅读 3.2 节。你可以忽略关于中断和 offload 校验和方面的内容(如果在后面你想去使用这些特性,可以再返回去阅读),你现在不需要去考虑阈值的细节和网卡内部缓存是如何工作的。
|
||||
```
|
||||
|
||||
除了接收队列是由一系列的等待入站数据包去填充的空缓存包以外,接收队列的其它部分与发送队列非常相似。所以,当网络空闲时,发送队列是空的(因为所有的包已经被发送出去了),而接收队列是满的(全部都是空缓存包)。
|
||||
|
||||
当 E1000 接收一个包时,它首先与网卡的过滤器进行匹配检查(例如,去检查这个包的目标地址是否为这个 E1000 的 MAC 地址),如果这个包不匹配任何过滤器,它将忽略这个包。否则,E1000 尝试从接收队列头部去检索下一个接收描述符。如果头(RDH)追上了尾(RDT),那么说明接收队列已经没有空闲的描述符了,所以网卡将丢弃这个包。如果有空闲的接收描述符,它将复制这个包的数据到描述符指向的缓存中,设置这个描述符的 DD 和 EOP 状态位,并递增 RDH。
|
||||
|
||||
如果 E1000 在一个接收描述符中接收到了一个比包缓存还要大的数据包,它将按需从接收队列中检索尽可能多的描述符以保存数据包的全部内容。为表示发生了这种情况,它将在所有的这些描述符上设置 DD 状态位,但仅在这些描述符的最后一个上设置 EOP 状态位。在你的驱动程序上,你可以去处理这种情况,也可以简单地配置网卡拒绝接收这种”长包“(这种包也被称为”巨帧“),你要确保接收缓存有足够的空间尽可能地去存储最大的标准以太网数据包(1518 字节)。
|
||||
|
||||
```markdown
|
||||
练习 10、设置接收队列并按 14.4 节中的流程去配置 E1000。你可以不用支持 ”长包“ 或多播。到目前为止,我们不用去配置网卡使用中断;如果你在后面决定去使用接收中断时可以再去改。另外,配置 E1000 去除以太网的 CRC 校验,因为我们的评级脚本要求必须去掉校验。
|
||||
|
||||
默认情况下,网卡将过滤掉所有的数据包。你必须使用网卡的 MAC 地址去配置接收地址寄存器(RAL 和 RAH)以接收发送到这个网卡的数据包。你可以简单地硬编码 QEMU 的默认 MAC 地址 52:54:00:12:34:56(我们已经在 lwIP 中硬编码了这个地址,因此这样做不会有问题)。使用字节顺序时要注意;MAC 地址是从低位字节到高位字节的方式来写的,因此 52:54:00:12 是 MAC 地址的低 32 位,而 34:56 是它的高 16 位。
|
||||
|
||||
E1000 的接收缓存区大小仅支持几个指定的设置值(在 13.4.22 节中描述的 RCTL.BSIZE 值)。如果你的接收包缓存够大,并且拒绝长包,那你就不用担心跨越多个缓存区的包。另外,要记住的是,和发送一样,接收队列和包缓存必须是连接的物理内存。
|
||||
|
||||
你应该使用至少 128 个接收描述符。
|
||||
```
|
||||
|
||||
现在,你可以做接收功能的基本测试了,甚至都无需写代码去接收包了。运行 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput`。`testinput` 将发送一个 ARP(地址解析协议)通告包(使用你的包发送的系统调用),而 QEMU 将自动回复它,即便是你的驱动尚不能接收这个回复,你也应该会看到一个 "e1000: unicast match[0]: 52:54:00:12:34:56" 的消息,表示 E1000 接收到一个包,并且匹配了配置的接收过滤器。如果你看到的是一个 "e1000: unicast mismatch: 52:54:00:12:34:56” 消息,表示 E1000 过滤掉了这个包,意味着你的 RAL 和 RAH 的配置不正确。确保你按正确的顺序收到了字节,并不要忘记设置 RAH 中的 "Address Valid” 位。如果你没有收到任何 "e1000” 消息,或许是你没有正确地启用接收功能。
|
||||
|
||||
现在,你准备去实现接收数据包。为了接收数据包,你的驱动程序必须持续跟踪希望去保存下一下接收到的包的描述符(提示:按你的设计,这个功能或许已经在 E1000 中的一个寄存器来实现了)。与发送类似,官方文档上表示,RDH 寄存器状态并不能从软件中可靠地读取,因为确定一个包是否被发送到描述符的包缓存中,你需要去读取描述符中的 DD 状态位。如果 DD 位被设置,你就可以从那个描述符的缓存中复制出这个数据包,然后通过更新队列的尾索引 RDT 来告诉网卡那个描述符是空闲的。
|
||||
|
||||
如果 DD 位没有被设置,表明没有接收到包。这就与发送队列满的情况一样,这时你可以有几种做法。你可以简单地返回一个 ”重传“ 错误来要求对端重发一次。对于满的发送队列,由于那是个临时状况,这种做法还是很好的,但对于空的接收队列来说就不太合理了,因为接收队列可能会保持好长一段时间的空的状态。第二个方法是挂起调用环境,直到在接收队列中处理了这个包为止。这个策略非常类似于 `sys_ipc_recv`。就像在 IPC 的案例中,因为我们每个 CPU 仅有一个内核栈,一旦我们离开内核,栈上的状态就会被丢弃。我们需要设置一个标志去表示那个环境由于接收队列下溢被挂起并记录系统调用参数。这种方法的缺点是过于复杂:E1000 必须被指示去产生接收中断,并且驱动程序为了恢复被阻塞等待一个包的环境,必须处理这个中断。
|
||||
|
||||
```
|
||||
练习 11、写一个函数从 E1000 中接收一个包,然后通过一个系统调用将它发布到用户空间。确保你将接收队列处理成空的。
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!如果发送队列是满的或接收队列是空的,环境和你的驱动程序可能会花费大量的 CPU 周期是轮询、等待一个描述符。一旦完成发送或接收描述符,E1000 能够产生一个中断,以避免轮询。修改你的驱动程序,处理发送和接收队列是以中断而不是轮询的方式进行。
|
||||
|
||||
注意,一旦确定为中断,它将一直处于中断状态,直到你的驱动程序明确处理完中断为止。在你的中断服务程序中,一旦处理完成要确保清除掉中断状态。如果你不那样做,从你的中断服务程序中返回后,CPU 将再次跳转到你的中断服务程序中。除了在 E1000 网卡上清除中断外,也需要使用 `lapic_eoi` 在 LAPIC 上清除中断。
|
||||
```
|
||||
|
||||
#### 接收包:网络服务器
|
||||
|
||||
在网络服务器输入环境中,你需要去使用你的新的接收系统调用以接收数据包,并使用 `NSREQ_INPUT` IPC 消息将它传递到核心网络服务器环境。这些 IPC 输入消息应该会有一个页,这个页上绑定了一个 `union Nsipc`,它的 `struct jif_pkt pkt` 字段中有从网络上接收到的包。
|
||||
|
||||
```markdown
|
||||
练习 12、实现 `net/input.c`。
|
||||
```
|
||||
|
||||
使用 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput` 再次运行 `testinput`,你应该会看到:
|
||||
|
||||
```c
|
||||
Sending ARP announcement...
|
||||
Waiting for packets...
|
||||
e1000: index 0: 0x26dea0 : 900002a 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
input: 0000 5254 0012 3456 5255 0a00 0202 0806 0001
|
||||
input: 0010 0800 0604 0002 5255 0a00 0202 0a00 0202
|
||||
input: 0020 5254 0012 3456 0a00 020f 0000 0000 0000
|
||||
input: 0030 0000 0000 0000 0000 0000 0000 0000 0000
|
||||
```
|
||||
|
||||
"input:” 打头的行是一个 QEMU 的 ARP 回复的十六进制转储。
|
||||
|
||||
你的代码应该会通过 `make grade` 的 `testinput` 测试。注意,在没有发送至少一个包去通知 QEMU 中的 JOS 的 IP 地址上时,是没法去测试包接收的,因此在你的发送代码中的 bug 可能会导致测试失败。
|
||||
|
||||
为彻底地测试你的网络代码,我们提供了一个称为 `echosrv` 的守护程序,它在端口 7 上设置运行 `echo` 的服务器,它将回显通过 TCP 连接发送给它的任何内容。使用 `make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-echosrv` 在一个终端中启动 `echo` 服务器,然后在另一个终端中通过 `make nc-7` 去连接它。你输入的每一行都被这个服务器回显出来。每次在仿真的 E1000 上接收到一个包,QEMU 将在控制台上输出像下面这样的内容:
|
||||
|
||||
```c
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
e1000: index 2: 0x26ea7c : 9000036 0
|
||||
e1000: index 3: 0x26f06a : 9000039 0
|
||||
e1000: unicast match[0]: 52:54:00:12:34:56
|
||||
```
|
||||
|
||||
做到这一点后,你应该也就能通过 `echosrv` 的测试了。
|
||||
|
||||
```
|
||||
问题
|
||||
|
||||
2、你如何构造你的接收实现?在实践中,如果接收队列是空的并且一个用户环境要求下一个入站包,你怎么办?
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
小挑战!在开发者手册中阅读关于 EEPROM 的内容,并写出从 EEPROM 中加载 E1000 的 MAC 地址的代码。目前,QEMU 的默认 MAC 地址是硬编码到你的接收初始化代码和 lwIP 中的。修复你的初始化代码,让它能够从 EEPROM 中读取 MAC 地址,和增加一个系统调用去传递 MAC 地址到 lwIP 中,并修改 lwIP 去从网卡上读取 MAC 地址。通过配置 QEMU 使用一个不同的 MAC 地址去测试你的变更。
|
||||
```
|
||||
|
||||
```
|
||||
小挑战!修改你的 E1000 驱动程序去使用 "零复制" 技术。目前,数据包是从用户空间缓存中复制到发送包缓存中,和从接收包缓存中复制回到用户空间缓存中。一个使用 ”零复制“ 技术的驱动程序可以通过直接让用户空间和 E1000 共享包缓存内存来实现。还有许多不同的方法去实现 ”零复制“,包括映射内容分配的结构到用户空间或直接传递用户提供的缓存到 E1000。不论你选择哪种方法,都要注意你如何利用缓存的问题,因为你不能在用户空间代码和 E1000 之间产生争用。
|
||||
```
|
||||
|
||||
```
|
||||
小挑战!把 ”零复制“ 的概念用到 lwIP 中。
|
||||
|
||||
一个典型的包是由许多头构成的。用户发送的数据被发送到 lwIP 中的一个缓存中。TCP 层要添加一个 TCP 包头,IP 层要添加一个 IP 包头,而 MAC 层有一个以太网头。甚至还有更多的部分增加到包上,这些部分要正确地连接到一起,以便于设备驱动程序能够发送最终的包。
|
||||
|
||||
E1000 的发送描述符设计是非常适合收集分散在内存中的包片段的,像在 IwIP 中创建的包的帧。如果你排队多个发送描述符,但仅设置最后一个描述符的 EOP 命令位,那么 E1000 将在内部把这些描述符串成包缓存,并在它们标记完 EOP 后仅发送串起来的缓存。因此,独立的包片段不需要在内存中把它们连接到一起。
|
||||
|
||||
修改你的驱动程序,以使它能够发送由多个缓存且无需复制的片段组成的包,并且修改 lwIP 去避免它合并包片段,因为它现在能够正确处理了。
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!增加你的系统调用接口,以便于它能够为多于一个的用户环境提供服务。如果有多个网络栈(和多个网络服务器)并且它们各自都有自己的 IP 地址运行在用户模式中,这将是非常有用的。接收系统调用将决定它需要哪个环境来转发每个入站的包。
|
||||
|
||||
注意,当前的接口并不知道两个包之间有何不同,并且如果多个环境去调用包接收的系统调用,各个环境将得到一个入站包的子集,而那个子集可能并不包含调用环境指定的那个包。
|
||||
|
||||
在 [这篇][7] 外内核论文的 2.2 节和 3 节中对这个问题做了深度解释,并解释了在内核中(如 JOS)处理它的一个方法。用这个论文中的方法去解决这个问题,你不需要一个像论文中那么复杂的方案。
|
||||
```
|
||||
|
||||
#### Web 服务器
|
||||
|
||||
一个最简单的 web 服务器类型是发送一个文件的内容到请求的客户端。我们在 `user/httpd.c` 中提供了一个非常简单的 web 服务器的框架代码。这个框架内码处理入站连接并解析请求头。
|
||||
|
||||
```markdown
|
||||
练习 13、这个 web 服务器中缺失了发送一个文件的内容到客户端的处理代码。通过实现 `send_file` 和 `send_data` 完成这个 web 服务器。
|
||||
```
|
||||
|
||||
在你完成了这个 web 服务器后,启动这个 web 服务器(`make run-httpd-nox`),使用你喜欢的浏览器去浏览 http:// _host_ : _port_ /index.html 地址。其中 _host_ 是运行 QEMU 的计算机的名字(如果你在 athena 上运行 QEMU,使用 `hostname.mit.edu`(其中 hostname 是在 athena 上运行 `hostname` 命令的输出,或者如果你在运行 QEMU 的机器上运行 web 浏览器的话,直接使用 `localhost`),而 _port_ 是 web 服务器运行 `make which-ports` 命令报告的端口号。你应该会看到一个由运行在 JOS 中的 HTTP 服务器提供的一个 web 页面。
|
||||
|
||||
到目前为止,你的评级测试得分应该是 105 分(满分为105)。
|
||||
|
||||
```markdown
|
||||
小挑战!在 JOS 中添加一个简单的聊天服务器,多个人可以连接到这个服务器上,并且任何用户输入的内容都被发送到其它用户。为实现它,你需要找到一个一次与多个套接字通讯的方法,并且在同一时间能够在同一个套接字上同时实现发送和接收。有多个方法可以达到这个目的。lwIP 为 `recv`(查看 `net/lwip/api/sockets.c` 中的 `lwip_recvfrom`)提供了一个 MSG_DONTWAIT 标志,以便于你不断地轮询所有打开的套接字。注意,虽然网络服务器的 IPC 支持 `recv` 标志,但是通过普通的 `read` 函数并不能访问它们,因此你需要一个方法来传递这个标志。一个更高效的方法是为每个连接去启动一个或多个环境,并且使用 IPC 去协调它们。而且碰巧的是,对于一个套接字,在结构 Fd 中找到的 lwIP 套接字 ID 是全局的(不是每个环境私有的),因此,比如一个 `fork` 的子环境继承了它的父环境的套接字。或者,一个环境通过构建一个包含了正确套接字 ID 的 Fd 就能够发送到另一个环境的套接字上。
|
||||
```
|
||||
|
||||
```
|
||||
问题
|
||||
|
||||
3、由 JOS 的 web 服务器提供的 web 页面显示了什么?
|
||||
4. 你做这个实验大约花了多长的时间?
|
||||
```
|
||||
|
||||
**本实验到此结束了。**一如既往,不要忘了运行 `make grade` 并去写下你的答案和挑战问题的解决方案的描述。在你动手之前,使用 `git status` 和 `git diff` 去检查你的变更,并不要忘了去 `git add answers-lab6.txt`。当你完成之后,使用 `git commit -am 'my solutions to lab 6’` 去提交你的变更,然后 `make handin` 并关注它的动向。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://wiki.qemu.org/download/qemu-doc.html#Using-the-user-mode-network-stack
|
||||
[2]: http://www.wireshark.org/
|
||||
[3]: http://www.sics.se/~adam/lwip/
|
||||
[4]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/ns.png
|
||||
[5]: https://pdos.csail.mit.edu/6.828/2018/readings/hardware/8254x_GBe_SDM.pdf
|
||||
[6]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/e1000_hw.h
|
||||
[7]: http://pdos.csail.mit.edu/papers/exo:tocs.pdf
|
||||
@ -1,53 +1,50 @@
|
||||
zianglei translating
|
||||
How Do We Find Out The Installed Packages Came From Which Repository?
|
||||
======
|
||||
Sometimes you might want to know the installed packages came from which repository. This will helps you to troubleshoot when you are facing the package conflict issue.
|
||||
# 我们如何得知安装的包来自哪个仓库?
|
||||
|
||||
Because [third party vendor repositories][1] are holding the latest version of package and sometime it will causes the issue when you are trying to install any packages due to incompatibility.
|
||||
有时候你可能想知道安装的软件包来自于哪个仓库。这将帮助你在遇到包冲突问题时进行故障排除。
|
||||
|
||||
Everything is possible in Linux because you can able to install a packages on your system even though when the package is not available on your distribution.
|
||||
因为[第三方仓库][1]拥有最新版本的软件包,所以有时候当你试图安装一些包的时候会出现兼容性的问题。
|
||||
|
||||
Also, you can able to install a package with latest version when your distribution don’t have it. How?
|
||||
在 Linux 上一切都是可能的,因为你可以安装一个即使在你的发行版系统上不能使用的包。
|
||||
|
||||
That’s why third party repositories are came in the picture. They are allowing users to install all the available packages from their repositories.
|
||||
你也可以安装一个最新版本的包即使你的发行版系统仓库还没有这个版本,怎么做到的呢?
|
||||
|
||||
Almost all the distributions are allowing third party repositories. Some of the distribution officially suggesting few of third party repositories which are not replacing the base packages badly like CentOS officially suggesting us to install [EPEL repository][2].
|
||||
这就是为什么出现了第三方仓库。它们允许用户从库中安装所有可用的包。
|
||||
|
||||
[List of Major repositories][1] and it’s details are below.
|
||||
几乎所有的发行版系统都允许第三方软件库。一些发行版还会官方推荐一些不会取代基础仓库的第三方仓库,例如 CentOS 官方推荐安装 [EPEL 库][2]。
|
||||
|
||||
* **`CentOS:`** [EPEL][2], [ELRepo][3], etc is [CentOS Community Approved Repositories][4].
|
||||
* **`Fedora:`** [RPMfusion repo][5] is commonly used by most of the [Fedora][6] users.
|
||||
* **`ArchLinux:`** ArchLinux community repository contains packages that have been adopted by Trusted Users from the Arch User Repository.
|
||||
* **`openSUSE:`** [Packman repo][7] offers various additional packages for openSUSE, especially but not limited to multimedia related applications and libraries that are on the openSUSE Build Service application blacklist. It’s the largest external repository of openSUSE packages.
|
||||
* **`Ubuntu:`** Personal Package Archives (PPAs) are a kind of repository. Developers create them in order to distribute their software. You can find this information on the PPA’s Launchpad page. Also, you can enable Cananical partners repositories.
|
||||
下面是常用的仓库列表和它们的详细信息。
|
||||
|
||||
* **`CentOS:`** [EPEL][2], [ELRepo][3] 等是 [Centos 社区认证仓库](4)。
|
||||
* **`Fedora:`** [RPMfusion repo][5] 是经常被很多 [Fedora][6] 用户使用的仓库。
|
||||
* **`ArchLinux:`** ArchLinux 社区仓库包含了来自于 Arch 用户仓库的已经被信任用户 ( Trusted User ) 审核通过的软件包。
|
||||
* **`openSUSE:`** [Packman repo][7] 为 openSUSE 提供了各种附加的软件包,特别是但不限于那些在 openSUSE Build Service 应用黑名单上的与多媒体相关的应用和库。它是 openSUSE 软件包的最大外部软件库。
|
||||
* **`Ubuntu:`** Personal Package Archives (PPAs) 是一种软件仓库。开发者们可以创建这种仓库来分发他们的软件。你可以在 PPA 导航页面( PPA’s Launchpad page )找到相关信息。同时,你也可以启用 Cananical 合作伙伴软件仓库。
|
||||
|
||||
### 仓库是什么?
|
||||
|
||||
### What Is Repository?
|
||||
软件仓库是存储特定的应用程序的软件包的集中场所。
|
||||
|
||||
A software repository is a central place which stores the software packages for the particular application.
|
||||
所有的 Linux 发行版都在维护他们自己的仓库,并允许用户在他们的机器上获取和安装包。
|
||||
|
||||
All the Linux distributions are maintaining their own repositories and they allow users to retrieve and install packages on their machine.
|
||||
每个厂商都提供了各自的包管理工具来管理它们的仓库,例如搜索、安装、更新、升级、删除等等。
|
||||
|
||||
Each vendor offered a unique package management tool to manage their repositories such as search, install, update, upgrade, remove, etc.
|
||||
大部分 Linux 发行版除了 RHEL 和 SUSE 以外都是免费的。要访问付费的仓库,你需要购买订阅。
|
||||
|
||||
Most of the Linux distributions comes as freeware except RHEL and SUSE. To access their repositories you need to buy a subscriptions.
|
||||
### 为什么我们需要启用第三方仓库?
|
||||
|
||||
### Why do we need to enable third party repositories?
|
||||
在 Linux 里,并不建议从源代码安装包,因为这样做可能会在升级软件和系统的时候产生很多问题,这也是为什么我们建议从库中安装包而不是从源代码安装。
|
||||
|
||||
In Linux, installing a package from source is not advisable as this might cause so many issues while upgrading the package or system that’s why we are advised to install a package from repo instead of source.
|
||||
### 在 RHEL/CentOS 系统上我们如何得知安装的软件包来自哪个仓库?
|
||||
|
||||
### How Do We Find Out The Installed Packages Came From Which Repository on RHEL/CentOS Systems?
|
||||
这可以通过很多方法实现。我们会给你所有可能的选择,你可以选择一个对你来说最合适的。
|
||||
|
||||
This can be done in multiple ways. Here we will be giving you all the possible options and you can choose which one is best for you.
|
||||
### 方法-1:使用 Yum 命令
|
||||
|
||||
### Method-1: Using Yum Command
|
||||
RHEL 和 CentOS 系统使用 RPM 包因此我们能够使用 [Yum 包管理器][8] 来获得信息。
|
||||
|
||||
RHEL & CentOS systems are using RPM packages hence we can use the [Yum Package Manager][8] to get this information.
|
||||
YUM 即 Yellodog Updater,Modified 是适用于基于 RPM 的系统例如 Red Hat Enterpise Linux (RHEL)和 CentOS 的一个开源命令行前端包管理工具。
|
||||
|
||||
YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
|
||||
|
||||
Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
|
||||
Yum 是从发行版仓库和其他第三方库中获取、安装、删除、查询和管理 RPM 包的一个主要工具。
|
||||
|
||||
```
|
||||
# yum info apachetop
|
||||
@ -70,11 +67,12 @@ Description : ApacheTop watches a logfile generated by Apache (in standard commo
|
||||
: fields in combined) and generates human-parsable output in realtime.
|
||||
```
|
||||
|
||||
The **`apachetop`** package is coming from **`epel repo`**.
|
||||
|
||||
### Method-2: Using Yumdb Command
|
||||
**`apachetop`** 包来自 **`epel repo`**。
|
||||
|
||||
Yumdb info provides information similar to yum info but additionally it provides package checksum data, type, user info (who installed the package). Since yum 3.2.26 yum has started storing additional information outside of the rpmdatabase (where user indicates it was installed by the user, and dep means it was brought in as a dependency).
|
||||
### 方法-2:使用 Yumdb 命令
|
||||
|
||||
Yumdb info 提供了类似于 yum info 的信息但是它又提供了包校验和数据、类型、用户信息(谁安装的软件包)。从 yum 3.2.26 开始,yum 已经开始在 rpmdatabase 之外存储额外的信息( user 表示软件是用户安装的,dep 表示它是作为依赖项引入的)。
|
||||
|
||||
```
|
||||
# yumdb info lighttpd
|
||||
@ -95,13 +93,13 @@ lighttpd-1.4.50-1.el7.x86_64
|
||||
var_uuid = ce328b07-9c0a-4765-b2ad-59d96a257dc8
|
||||
```
|
||||
|
||||
The **`lighttpd`** package is coming from **`epel repo`**.
|
||||
**`lighttpd`** 包来自 **`epel repo`**。
|
||||
|
||||
### Method-3: Using RPM Command
|
||||
### 方法-3:使用 RPM 命令
|
||||
|
||||
[RPM command][9] stands for Red Hat Package Manager is a powerful, command line Package Management utility for Red Hat based system such as (RHEL, CentOS, Fedora, openSUSE & Mageia) distributions.
|
||||
[RPM 命令][9] 即 Red Hat Package Manager 是一个适用于基于 Red Hat 的系统(例如 RHEL, CentOS, Fedora, openSUSE & Mageia)的强大的命令行包管理工具。
|
||||
|
||||
The utility allow you to install, upgrade, remove, query & verify the software on your Linux system/server. RPM files comes with .rpm extension. RPM package built with required libraries and dependency which will not conflicts other packages were installed on your system.
|
||||
这个工具允许你在你的 Linux 系统/服务器上安装、更新、移除、查询和验证软件。RPM 文件具有 .rpm 后缀名。RPM 包是用必需的库和依赖关系构建的,不会与系统上安装的其他包冲突。
|
||||
|
||||
```
|
||||
# rpm -qi apachetop
|
||||
@ -128,12 +126,11 @@ combined logformat, although it doesn't (yet) make use of any of the extra
|
||||
fields in combined) and generates human-parsable output in realtime.
|
||||
```
|
||||
|
||||
The **`apachetop`** package is coming from **`epel repo`**.
|
||||
**`apachetop`** 包来自 **`epel repo`**。
|
||||
|
||||
### Method-4: Using Repoquery Command
|
||||
|
||||
repoquery is a program for querying information from YUM repositories similarly to rpm queries.
|
||||
|
||||
repoquery 是一个从 YUM 库查询信息的程序,类似于 rpm 查询。
|
||||
```
|
||||
# repoquery -i httpd
|
||||
|
||||
@ -153,13 +150,13 @@ The Apache HTTP Server is a powerful, efficient, and extensible
|
||||
web server.
|
||||
```
|
||||
|
||||
The **`httpd`** package is coming from **`CentOS updates repo`**.
|
||||
**`httpd`** 包来自 **`CentOS updates repo`**。
|
||||
|
||||
### How Do We Find Out The Installed Packages Came From Which Repository on Fedora System?
|
||||
### 在 Fedora 系统上我们如何得知安装的包来自哪个仓库?
|
||||
|
||||
DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for back-end. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally.
|
||||
DNF 是 Dandified yum 的缩写。我们可以说 DNF 是使用 hawkey/libsolv 库作为后端的下一代 yum 包管理器( yum 的分支)。从 Fedora 18 开始 Aleš Kozumplík 开始开发 DNF 并最终在 Fedora 22 上得以应用/启用。
|
||||
|
||||
[Dnf command][10] is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
|
||||
[Dnf 命令][10] 用于在 Fedora 22 以及之后的系统上安装、更新、搜索和删除包。它会自动解决依赖并使安装包的过程变得顺畅,不会出现任何问题。
|
||||
|
||||
```
|
||||
$ dnf info tilix
|
||||
@ -195,12 +192,11 @@ Description : Tilix is a tiling terminal emulator with the following features:
|
||||
: GNOME Human Interface Guidelines (HIG).
|
||||
```
|
||||
|
||||
The **`tilix`** package is coming from **`Fedora updates repo`**.
|
||||
**`tilix`** 包来自 **`Fedora updates repo`**。
|
||||
|
||||
### How Do We Find Out The Installed Packages Came From Which Repository on openSUSE System?
|
||||
|
||||
Zypper is a command line package manager which makes use of libzypp. [Zypper command][11] provides functions like repository access, dependency solving, package installation, etc.
|
||||
### 在 openSUSE 系统上我们如何得知安装的包来自哪个仓库?
|
||||
|
||||
Zypper 是一个使用 libzypp 的命令行包管理器。[Zypper 命令][11] 提供了存储库访问、依赖处理、包安装等功能。
|
||||
```
|
||||
$ zypper info nano
|
||||
|
||||
@ -226,10 +222,11 @@ Description :
|
||||
```
|
||||
|
||||
The **`nano`** package is coming from **`openSUSE Main repo (OSS)`**.
|
||||
**`nano`** 包来自于 **`openSUSE Main repo(OSS)`**。
|
||||
|
||||
### How Do We Find Out The Installed Packages Came From Which Repository on ArchLinux System?
|
||||
### 在 ArchLinux 系统上我们如何得知安装的包来自哪个仓库?
|
||||
|
||||
[Pacman command][12] stands for package manager utility. pacman is a simple command-line utility to install, build, remove and manage Arch Linux packages. Pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
|
||||
[Pacman 命令][12] 即包管理器工具( package manager utility ),是一个简单的用来安装、构建、删除和管理 Arch Linux 软件包的命令行工具。Pacman 使用 libalpm( Arch Linux Package Managment ( ALPM )library)作为后端来执行所有的操作。
|
||||
|
||||
```
|
||||
# pacman -Ss chromium
|
||||
@ -247,9 +244,9 @@ community/fcitx-mozc 2.17.2313.102-1
|
||||
Input)
|
||||
```
|
||||
|
||||
The **`chromium`** package is coming from **`ArchLinux extra repo`**.
|
||||
**`chromium`** 包来自 **`ArchLinux extra repo`**。
|
||||
|
||||
Alternatively, we can use the following option to get the detailed information about the package.
|
||||
或者,我们可以使用以下选项获得关于包的详细信息。
|
||||
|
||||
```
|
||||
# pacman -Si chromium
|
||||
@ -277,15 +274,15 @@ Build Date : Fri 19 Feb 2016 04:17:12 AM IST
|
||||
Validated By : MD5 Sum SHA-256 Sum Signature
|
||||
```
|
||||
|
||||
The **`chromium`** package is coming from **`ArchLinux extra repo`**.
|
||||
**`chromium`** 包来自 **`ArchLinux extra repo`**。
|
||||
|
||||
### How Do We Find Out The Installed Packages Came From Which Repository on Debian Based Systems?
|
||||
### 在基于 Debian 的系统上我们如何得知安装的包来自哪个仓库?
|
||||
|
||||
It can be done in two ways on Debian based systems such as Ubuntu, LinuxMint, etc.,
|
||||
在基于 Debian 的系统例如 Ubuntu,LinuxMint 上可以使用两种方法实现。
|
||||
|
||||
### Method-1: Using apt-cache Command
|
||||
### 方法-1:使用 apt-cache 命令
|
||||
|
||||
The [apt-cache command][13] can display much of the information stored in APT’s internal database. This information is a sort of cache since it is gathered from the different sources listed in the sources.list file. This happens during the apt update operation.
|
||||
[apt-cache 命令][13] 可以显示存储在 APT 内部数据库的很多信息。这些信息是一种缓存,因为它们是从列在 source.list 文件里的不同的源中获得的。这个过程发生在 apt 更新操作期间。
|
||||
|
||||
```
|
||||
$ apt-cache policy python3
|
||||
@ -300,11 +297,11 @@ python3:
|
||||
100 /var/lib/dpkg/status
|
||||
```
|
||||
|
||||
The **`python3`** package is coming from **`Ubuntu updates repo`**.
|
||||
**`python3`** 包来自 **`Ubuntu updates repo`**。
|
||||
|
||||
### Method-2: Using apt Command
|
||||
### 方法-2:使用 apt 命令
|
||||
|
||||
[APT command][14] stands for Advanced Packaging Tool (APT) which is replacement for apt-get, like how DNF came to picture instead of YUM. It’s feature rich command-line tools with included all the futures in one command (APT) such as apt-cache, apt-search, dpkg, apt-cdrom, apt-config, apt-key, etc..,. and several other unique features. For example we can easily install .dpkg packages through APT but we can’t do through Apt-Get similar more features are included into APT command. APT-GET replaced by APT Due to lock of futures missing in apt-get which was not solved.
|
||||
[APT 命令][14] 即 Advanced Packaging Tool(APT)是 apt-get 命令的替代品,就像 DNF 是如何取代 YUM 一样。它是具有丰富功能的命令行工具并将所有的功能例如 apt-cache、apt-search、dpkg、apt-cdrom、apt-config、apt-ket 等包含在一个命令(APT)中,并且还有几个独特的功能。例如我们可以通过 APT 轻松安装 .dpkg 包但我们不能使用 Apt-Get 命令安装,更多类似的功能都被包含进了 APT 命令。APT-GET 因缺失了很多未被解决的特性而被 apt 取代。
|
||||
|
||||
```
|
||||
$ apt -a show notepadqq
|
||||
@ -337,8 +334,7 @@ Description: Notepad++-like editor for Linux
|
||||
Text editor with support for multiple programming
|
||||
languages, multiple encodings and plugin support.
|
||||
```
|
||||
|
||||
The **`notepadqq`** package is coming from **`Launchpad PPA`**.
|
||||
**`notepadqq`** 包来自 **`Launchpad PPA`**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -346,7 +342,7 @@ via: https://www.2daygeek.com/how-do-we-find-out-the-installed-packages-came-fro
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[zianglei](https://github.com/zianglei)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,74 @@
|
||||
KRS:一个收集 Kubernetes 资源统计数据的新工具
|
||||
======
|
||||
零配置工具简化了信息收集,例如在某个命名空间中运行了多少个 pod。
|
||||

|
||||
|
||||
最近我在纽约的 O'Reilly Velocity 就 [Kubernetes 应用故障排除][1]的主题发表了演讲,并且在积极的反馈和讨论的推动下,我决定重新审视这个领域的工具。结果,除了 [kubernetes-incubator/spartakus][2] 和 [kubernetes/kube-state-metrics][3] 之外,我们还没有太多的轻量级工具来收集资源统计数据(例如命名空间中的 pod 或服务)。所以,我在回家的路上开始编写一个小工具 - 创造性地命名为 **krs**,它是 Kubernetes Resource Stats 的简称 ,它允许你收集这些统计数据。
|
||||
|
||||
你可以通过两种方式使用 [mhausenblas/krs][5]:
|
||||
|
||||
* 直接在命令行(有 Linux、Windows 和 MacOS 的二进制文件),以及
|
||||
* 在集群中使用 [launch.sh][4] 脚本部署,该脚本动态创建适当的基于角色的访问控制 (RBAC) 权限。
|
||||
|
||||
|
||||
提醒你,它还在早期,并且还在开发中。但是,**krs** 的 0.1 版本提供以下功能:
|
||||
|
||||
* 在每个命名空间的基础上,它定期收集资源统计信息(支持 pod、部署和服务)。
|
||||
* 它以 [OpenMetrics 格式][6]公开这些统计。
|
||||
* 它可以直接通过二进制文件使用,也可以在包含所有依赖项的容器化设置中使用。
|
||||
|
||||
|
||||
|
||||
目前,你需要安装并配置 **kubectl**,因为 **krs** 依赖于执行 **kubectl get all** 命令来收集统计数据。(另一方面,谁会使用 Kubernetes 但没有安装 **kubectl**?)
|
||||
|
||||
使用 **krs** 很简单。[下载][7]适合你平台的二进制文件,并按如下方式执行:
|
||||
|
||||
```
|
||||
$ krs thenamespacetowatch
|
||||
# HELP pods Number of pods in any state, for example running
|
||||
# TYPE pods gauge
|
||||
pods{namespace="thenamespacetowatch"} 13
|
||||
# HELP deployments Number of deployments
|
||||
# TYPE deployments gauge
|
||||
deployments{namespace="thenamespacetowatch"} 6
|
||||
# HELP services Number of services
|
||||
# TYPE services gauge
|
||||
services{namespace="thenamespacetowatch"} 4
|
||||
```
|
||||
|
||||
这将在前台启动 **krs**,从名称空间 **thenamespacetowatch** 收集资源统计信息,并分别在**标准输出**中以 OpenMetrics 格式输出它们,以供你进一步处理。
|
||||
|
||||
![krs screenshot][9]
|
||||
|
||||
krs 实战截屏
|
||||
|
||||
也许你会问,Michael,为什么不做一些有用的事(例如将指标存储在 S3 中)?因为 [Unix 哲学][10]
|
||||
|
||||
对于那些想知道他们是否可以直接使用 Prometheus 或 [kubernetes/kube-state-metrics][3] 来完成这项任务的人:是的,你可以,为什么不行呢? **krs** 的重点是作为已有工具的轻量级且易于使用的替代品 - 甚至可能在某些方面略微互补。
|
||||
|
||||
本文最初发表在 [Medium 的 ITNext][11] 上,并获得授权转载。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/kubernetes-resource-statistics
|
||||
|
||||
作者:[Michael Hausenblas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhausenblas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://troubleshooting.kubernetes.sh/
|
||||
[2]: https://github.com/kubernetes-incubator/spartakus
|
||||
[3]: https://github.com/kubernetes/kube-state-metrics
|
||||
[4]: https://github.com/mhausenblas/krs/blob/master/launch.sh
|
||||
[5]: https://github.com/mhausenblas/krs
|
||||
[6]: https://openmetrics.io/
|
||||
[7]: https://github.com/mhausenblas/krs/releases
|
||||
[8]: /file/412706
|
||||
[9]: https://opensource.com/sites/default/files/uploads/krs_screenshot.png (krs screenshot)
|
||||
[10]: http://harmful.cat-v.org/cat-v/
|
||||
[11]: https://itnext.io/kubernetes-resource-statistics-e8247f92b45c
|
||||
@ -0,0 +1,228 @@
|
||||
命令行快捷提示:如何定位一个文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们都会有文件存储在电脑里 —— 目录,相片,源代码等等。它们是如此之多。也无疑超出了我的记忆范围。要是毫无目标,找到正确的那一个可能会很费时间。在这篇文章里我们来看一下如何在命令行里找到需要的文件,特别是快速找到你想要的那一个。
|
||||
|
||||
好消息是 Linux 命令行专门设计了很多非常有用的命令行工具在你的电脑上查找文件。下面我们看一下它们其中三个:ls、tree 和 tree。
|
||||
|
||||
### ls
|
||||
|
||||
如果你知道文件在哪里,你只需要列出它们或者查看有关它们的信息,ls 就是为此而生的。
|
||||
|
||||
只需运行 ls 就可以列出当下目录中所有可见的文件和目录:
|
||||
|
||||
```
|
||||
$ ls
|
||||
Documents Music Pictures Videos notes.txt
|
||||
```
|
||||
|
||||
添加 **-l** 选项可以查看文件的相关信息。同时再加上 **-h** 选项,就可以用一种人们易读的格式查看文件的大小:
|
||||
|
||||
```
|
||||
$ ls -lh
|
||||
total 60K
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Documents
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Music
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:13 Pictures
|
||||
drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos
|
||||
-rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
|
||||
```
|
||||
|
||||
**ls** 也可以搜索一个指定位置:
|
||||
|
||||
```
|
||||
$ ls Pictures/
|
||||
trees.png wallpaper.png
|
||||
```
|
||||
|
||||
或者一个指定文件 —— 即便只跟着名字的一部分:
|
||||
|
||||
```
|
||||
$ ls *.txt
|
||||
notes.txt
|
||||
```
|
||||
|
||||
少了点什么?想要查看一个隐藏文件?没问题,使用 **-a** 选项:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
. .bash_logout .bashrc Documents Pictures notes.txt
|
||||
.. .bash_profile .vimrc Music Videos
|
||||
```
|
||||
|
||||
**ls** 还有很多其他有用的选项,你可以把它们组合在一起获得你想要的效果。可以使用以下命令了解更多:
|
||||
|
||||
```
|
||||
$ man ls
|
||||
```
|
||||
|
||||
### tree
|
||||
|
||||
如果你想查看你的文件的树状结构,tree 是一个不错的选择。可能你的系统上没有默认安装它,你可以使用包管理 DNF 手动安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install tree
|
||||
```
|
||||
|
||||
如果不带任何选项或者参数地运行 tree,将会以当前目录开始,显示出包含其下所有目录和文件的一个树状图。提醒一下,这个输出可能会非常大,因为它包含了这个目录下的所有目录和文件:
|
||||
|
||||
```
|
||||
$ tree
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| | `-- christmas-presents.txt
|
||||
| `-- work
|
||||
| |-- project-abc
|
||||
| | |-- README.md
|
||||
| | |-- do-things.sh
|
||||
| | `-- project-notes.txt
|
||||
| `-- status-reports.txt
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
如果列出的太多了,使用 -L 选项,并在其后加上你想查看的层级数,可以限制列出文件的层级:
|
||||
|
||||
```
|
||||
$ tree -L 2
|
||||
.
|
||||
|-- Documents
|
||||
| |-- notes.txt
|
||||
| |-- secret
|
||||
| `-- work
|
||||
|-- Music
|
||||
|-- Pictures
|
||||
| |-- trees.png
|
||||
| `-- wallpaper.png
|
||||
|-- Videos
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
你也可以显示一个指定目录的树状图:
|
||||
|
||||
```
|
||||
$ tree Documents/work/
|
||||
Documents/work/
|
||||
|-- project-abc
|
||||
| |-- README.md
|
||||
| |-- do-things.sh
|
||||
| `-- project-notes.txt
|
||||
`-- status-reports.txt
|
||||
```
|
||||
|
||||
如果使用 tree 列出的是一个很大的树状图,你可以把它跟 less 组合使用:
|
||||
|
||||
```
|
||||
$ tree | less
|
||||
```
|
||||
|
||||
再一次,tree 有很多其他的选项可以使用,你可以把他们组合在一起发挥更强大的作用。man 手册页有所有这些选项:
|
||||
|
||||
```
|
||||
$ man tree
|
||||
```
|
||||
|
||||
### find
|
||||
|
||||
那么如果不知道文件在哪里呢?就让我们来找到它们吧!
|
||||
|
||||
要是你的系统中没有 find,你可以使用 DNF 安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install findutils
|
||||
```
|
||||
|
||||
运行 find 时如果没有添加任何选项或者参数,它将会递归列出当前目录下的所有文件和目录。
|
||||
|
||||
```
|
||||
$ find
|
||||
.
|
||||
./Documents
|
||||
./Documents/secret
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc
|
||||
./Documents/work/project-abc/README.md
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./.bash_logout
|
||||
./.bashrc
|
||||
./Videos
|
||||
./.bash_profile
|
||||
./.vimrc
|
||||
./Pictures
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
./notes.txt
|
||||
./Music
|
||||
```
|
||||
|
||||
但是 find 真正强大的是你可以使用文件名进行搜索:
|
||||
|
||||
```
|
||||
$ find -name do-things.sh
|
||||
./Documents/work/project-abc/do-things.sh
|
||||
```
|
||||
|
||||
或者仅仅是名字的一部分 —— 像是文件后缀。我们来找一下所有的 .txt 文件:
|
||||
|
||||
```
|
||||
$ find -name "*.txt"
|
||||
./Documents/secret/christmas-presents.txt
|
||||
./Documents/notes.txt
|
||||
./Documents/work/status-reports.txt
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./notes.txt
|
||||
```
|
||||
你也可以根据大小寻找文件。如果你的空间不足的时候,这种方法也许特别有用。现在来列出所有大于 1 MB 的文件:
|
||||
|
||||
```
|
||||
$ find -size +1M
|
||||
./Pictures/trees.png
|
||||
./Pictures/wallpaper.png
|
||||
```
|
||||
|
||||
当然也可以搜索一个具体的目录。假如我想在我的 Documents 文件夹下找一个文件,而且我知道它的名字里有 “project” 这个词:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*"
|
||||
Documents/work/project-abc
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
除了文件它还显示目录。你可以限制仅搜索查询文件:
|
||||
|
||||
```
|
||||
$ find Documents -name "*project*" -type f
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
最后再一次,find 还有很多供你使用的选项,要是你想使用它们,man 手册页绝对可以帮到你:
|
||||
|
||||
```
|
||||
$ man find
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/commandline-quick-tips-locate-file/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/asamalik/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,169 @@
|
||||
pydbgen:一个数据库随机生成器
|
||||
======
|
||||
> 用这个简单的工具生成大型数据库,让你更好地研究数据科学。
|
||||
|
||||

|
||||
|
||||
在研究数据科学的过程中,最麻烦的往往不是算法或者技术,而是如何获取到一批原始数据。尽管网上有很多真实优质的数据集可以用于机器学习,然而在学习 SQL 时却不是如此。
|
||||
|
||||
对于数据科学来说,熟悉 SQL 的重要性不亚于了解 Python 或 R 编程。如果想收集诸如姓名、年龄、信用卡信息、地址这些信息用于机器学习任务,在 Kaggle 上查找专门的数据集比使用足够大的真实数据库要容易得多。
|
||||
|
||||
如果有一个简单的工具或库来帮助你生成一个大型数据库,表里还存放着大量你需要的数据,岂不美哉?
|
||||
|
||||
不仅仅是数据科学的入门者,即使是经验丰富的软件测试人员也会需要这样一个简单的工具,只需编写几行代码,就可以通过随机(但是是假随机)生成任意数量但有意义的数据集。
|
||||
|
||||
因此,我要推荐这个名为 [pydbgen][1] 的轻量级 Python 库。在后文中,我会简要说明这个库的相关内容,你也可以[阅读它的文档][2]详细了解更多信息。
|
||||
|
||||
### pydbgen 是什么
|
||||
|
||||
`pydbgen` 是一个轻量的纯 Python 库,它可以用于生成随机但有意义的数据记录(包括姓名、地址、信用卡号、日期、时间、公司名称、职位、车牌号等等),存放在 Pandas Dataframe 对象中,并保存到 SQLite 数据库或 Excel 文件。
|
||||
|
||||
### 如何安装 pydbgen
|
||||
|
||||
目前 1.0.5 版本的 pydbgen 托管在 PyPI(<ruby>Python 包索引存储库<rt>Python Package Index repository</rt></ruby>)上,并且对 [Faker][3] 有依赖关系。安装 pydbgen 只需要执行命令:
|
||||
|
||||
```
|
||||
pip install pydbgen
|
||||
```
|
||||
|
||||
已经在 Python 3.6 环境下测试安装成功,但在 Python 2 环境下无法正常安装。
|
||||
|
||||
### 如何使用 pydbgen
|
||||
|
||||
在使用 `pydbgen` 之前,首先要初始化 `pydb` 对象。
|
||||
|
||||
```
|
||||
import pydbgen
|
||||
from pydbgen import pydbgen
|
||||
myDB=pydbgen.pydb()
|
||||
```
|
||||
|
||||
Then you can access the various internal functions exposed by the **pydb** object. For example, to print random US cities, enter:
|
||||
随后就可以调用 `pydb` 对象公开的各种内部函数了。可以按照下面的例子,输出随机的美国城市和车牌号码:
|
||||
|
||||
```
|
||||
myDB.city_real()
|
||||
>> 'Otterville'
|
||||
for _ in range(10):
|
||||
print(myDB.license_plate())
|
||||
>> 8NVX937
|
||||
6YZH485
|
||||
XBY-564
|
||||
SCG-2185
|
||||
XMR-158
|
||||
6OZZ231
|
||||
CJN-850
|
||||
SBL-4272
|
||||
TPY-658
|
||||
SZL-0934
|
||||
```
|
||||
|
||||
另外,如果你输入的是 city 而不是 city_real,返回的将会是虚构的城市名。
|
||||
|
||||
```
|
||||
print(myDB.gen_data_series(num=8,data_type='city'))
|
||||
>>
|
||||
New Michelle
|
||||
Robinborough
|
||||
Leebury
|
||||
Kaylatown
|
||||
Hamiltonfort
|
||||
Lake Christopher
|
||||
Hannahstad
|
||||
West Adamborough
|
||||
```
|
||||
|
||||
### 生成随机的 Pandas Dataframe
|
||||
|
||||
你可以指定生成数据的数量和种类,但需要注意的是,返回结果均为字符串或文本类型。
|
||||
|
||||
```
|
||||
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])
|
||||
testdf
|
||||
```
|
||||
|
||||
最终产生的 Dataframe 类似下图所示。
|
||||
|
||||

|
||||
|
||||
### 生成数据库表
|
||||
|
||||
你也可以指定生成数据的数量和种类,而返回结果是数据库中的文本或者变长字符串类型。在生成过程中,你可以指定对应的数据库文件名和表名。
|
||||
|
||||
```
|
||||
myDB.gen_table(db_file='Testdb.DB',table_name='People',
|
||||
|
||||
fields=['name','city','street_address','email'])
|
||||
```
|
||||
|
||||
上面的例子种生成了一个能被 MySQL 和 SQLite 支持的 `.db` 文件。下图则显示了这个文件中的数据表在 SQLite 可视化客户端中打开的画面。
|
||||

|
||||
|
||||
### 生成 Excel 文件
|
||||
|
||||
和上面的其它示例类似,下面的代码可以生成一个具有随机数据的 Excel 文件。值得一提的是,通过将`phone_simple` 参数设为 `False` ,可以生成较长较复杂的电话号码。如果你想要提高自己在数据提取方面的能力,不妨尝试一下这个功能。
|
||||
|
||||
```
|
||||
myDB.gen_excel(num=20,fields=['name','phone','time','country'],
|
||||
phone_simple=False,filename='TestExcel.xlsx')
|
||||
```
|
||||
|
||||
最终的结果类似下图所示:
|
||||

|
||||
|
||||
### 生成随机电子邮箱地址
|
||||
|
||||
`pydbgen` 内置了一个 `realistic_email` 方法,它基于种子来生成随机的电子邮箱地址。如果你不想在网络上使用真实的电子邮箱地址时,这个功能可以派上用场。
|
||||
|
||||
```
|
||||
for _ in range(10):
|
||||
print(myDB.realistic_email('Tirtha Sarkar'))
|
||||
>>
|
||||
Tirtha_Sarkar@gmail.com
|
||||
Sarkar.Tirtha@outlook.com
|
||||
Tirtha_S48@verizon.com
|
||||
Tirtha_Sarkar62@yahoo.com
|
||||
Tirtha.S46@yandex.com
|
||||
Tirtha.S@att.com
|
||||
Sarkar.Tirtha60@gmail.com
|
||||
TirthaSarkar@zoho.com
|
||||
Sarkar.Tirtha@protonmail.com
|
||||
Tirtha.S@comcast.net
|
||||
```
|
||||
|
||||
### 未来的改进和用户贡献
|
||||
|
||||
目前的版本中并不完美。如果你发现了 pydbgen 的 bug 导致 pydbgen 在运行期间发生崩溃,请向我反馈。如果你打算对这个项目贡献代码,[也随时欢迎你][1]。当然现在也还有很多改进的方向:
|
||||
|
||||
* pydbgen 作为随机数据生成器,可以集成一些机器学习或统计建模的功能吗?
|
||||
* pydbgen 是否会添加可视化功能?
|
||||
|
||||
一切皆有可能!
|
||||
|
||||
如果你有任何问题或想法想要分享,都可以通过 [tirthajyoti@gmail.com][4] 与我联系。如果你像我一样对机器学习和数据科学感兴趣,也可以添加我的 [LinkedIn][5] 或在 [Twitter][6] 上关注我。另外,还可以在我的 [GitHub][7] 上找到更多 Python、R 或 MATLAB 的有趣代码和机器学习资源。
|
||||
|
||||
本文以 [CC BY-SA 4.0][9] 许可在 [Towards Data Science][8] 首发。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/pydbgen-random-database-table-generator
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/tirthajyoti/pydbgen
|
||||
[2]: http://pydbgen.readthedocs.io/en/latest/
|
||||
[3]: https://faker.readthedocs.io/en/latest/index.html
|
||||
[4]: mailto:tirthajyoti@gmail.com
|
||||
[5]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[6]: https://twitter.com/tirthajyotiS
|
||||
[7]: https://github.com/tirthajyoti?tab=repositories
|
||||
[8]: https://towardsdatascience.com/introducing-pydbgen-a-random-dataframe-database-table-generator-b5c7bdc84be5
|
||||
[9]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
|
||||
@ -0,0 +1,305 @@
|
||||
几个用于替代 du 命令的更好选择
|
||||
======
|
||||
|
||||

|
||||
|
||||
大家对 `du` 命令应该都不陌生,它可以在类 Unix 系统中对文件和目录的空间使用情况进行计算和汇总。如果你也经常需要使用 `du` 命令,你会对以下内容感兴趣的。我发现了五个可以替代原有的 `du` 命令的更好的工具。当然,如果后续有更多更好的选择,我会继续列出来。如果你有其它推荐,也欢迎在评论中留言。
|
||||
|
||||
### ncdu
|
||||
|
||||
`ncdu` 作为普通 `du` 的替代品,这在 Linux 社区中已经很流行了。`ncdu` 正是基于开发者们对 `du` 的性能不满意而被开发出来的。`ncdu` 是一个使用 C 语言和 ncurses 接口开发的简易快速的磁盘用量分析器,可以用来查看目录或文件在本地或远程系统上占用磁盘空间的情况。如果你有兴趣查看关于 `ncdu` 的详细介绍,可以浏览《[如何在 Linux 上使用 ncdu 查看磁盘占用量][9]》这一篇文章。
|
||||
|
||||
### tin-summer
|
||||
|
||||
`tin-summer` 是使用 Rust 语言编写的免费开源工具,它可以用于查找占用磁盘空间的文件,它也是 `du` 命令的另一个替代品。由于使用了多线程,因此 `tin-summer` 在计算大目录的大小时会比 `du` 命令快得多。`tin-summer` 与 `du` 命令之间的区别是前者读取文件的大小,而后者则读取磁盘使用情况。
|
||||
|
||||
`tin-summer` 的开发者认为它可以替代 `du`,因为它具有以下优势:
|
||||
|
||||
* 在大目录的操作速度上比 `du` 更快;
|
||||
* 在显示结果上默认采用易读格式;
|
||||
* 可以使用正则表达式排除文件或目录;
|
||||
* 可以对输出进行排序和着色处理;
|
||||
* 可扩展,等等。
|
||||
|
||||
|
||||
|
||||
**安装 tin-summer**
|
||||
|
||||
要安装 `tin-summer`,只需要在终端中执行以下命令:
|
||||
|
||||
```
|
||||
$ curl -LSfs https://japaric.github.io/trust/install.sh | sh -s -- --git vmchale/tin-summer
|
||||
```
|
||||
|
||||
你也可以使用 `cargo` 软件包管理器安装 `tin-summer`,但你需要在系统上先安装 Rust。在 Rust 已经安装好的情况下,执行以下命令:
|
||||
|
||||
```
|
||||
$ cargo install tin-summer
|
||||
```
|
||||
|
||||
如果上面提到的这两种方法都不能成功安装 `tin-summer`,还可以从它的[软件发布页][1]下载最新版本的二进制文件编译,进行手动安装。
|
||||
|
||||
**用法**
|
||||
|
||||
如果需要查看当前工作目录的文件大小,可以执行以下命令:
|
||||
|
||||
```
|
||||
$ sn f
|
||||
749 MB ./.rustup/toolchains
|
||||
749 MB ./.rustup
|
||||
147 MB ./.cargo/bin
|
||||
147 MB ./.cargo
|
||||
900 MB .
|
||||
```
|
||||
|
||||
不需要进行额外声明,它也是默认以易读的格式向用户展示数据。在使用 `du` 命令的时候,则必须加上额外的 `-h` 参数才能得到同样的效果。
|
||||
|
||||
只需要按以下的形式执行命令,就可以查看某个特定目录的文件大小。
|
||||
|
||||
```
|
||||
$ sn f <path-to-the-directory>
|
||||
```
|
||||
|
||||
还可以对输出结果进行排序,例如下面的命令可以输出指定目录中最大的 5 个文件或目录:
|
||||
|
||||
```
|
||||
$ sn sort /home/sk/ -n5
|
||||
749 MB /home/sk/.rustup
|
||||
749 MB /home/sk/.rustup/toolchains
|
||||
147 MB /home/sk/.cargo
|
||||
147 MB /home/sk/.cargo/bin
|
||||
2.6 MB /home/sk/mcelog
|
||||
900 MB /home/sk/
|
||||
```
|
||||
|
||||
顺便一提,上面结果中的最后一行是指定目录 `/home/sk` 的总大小。所以不要惊讶为什么输入的是 5 而实际输出了 6 行结果。
|
||||
|
||||
在当前目录下查找带有构建工程的目录,可以使用以下命令:
|
||||
|
||||
```
|
||||
$ sn ar
|
||||
```
|
||||
|
||||
`tin-summer` 同样支持查找指定大小的带有构建工程的目录。例如执行以下命令可以查找到大小在 100 MB 以上的带有构建工程的目录:
|
||||
|
||||
```
|
||||
$ sn ar -t100M
|
||||
```
|
||||
|
||||
如上文所说,`tin-summer` 在操作大目录的时候速度比较快,因此在操作小目录的时候,速度会相对比较慢一些。不过它的开发者已经表示,将会在以后的版本中优化这个缺陷。
|
||||
|
||||
要获取相关的帮助,可以执行以下命令:
|
||||
|
||||
```
|
||||
$ sn --help
|
||||
```
|
||||
|
||||
如果想要更详尽的介绍,可以查看[这个项目的 GitHub 页面][10]。
|
||||
|
||||
### dust
|
||||
|
||||
`dust` (含义是 `du` + `rust` = `dust`)使用 Rust 编写,是一个免费、开源的更直观的 `du` 工具。它可以在不需要 `head` 或`sort` 命令的情况下即时显示目录占用的磁盘空间。与 `tin-summer` 一样,它会默认情况以易读的格式显示每个目录的大小。
|
||||
|
||||
**安装 dust**
|
||||
|
||||
由于 `dust` 也是使用 Rust 编写,因此它也可以通过 `cargo` 软件包管理器进行安装:
|
||||
|
||||
```
|
||||
$ cargo install du-dust
|
||||
```
|
||||
|
||||
也可以从它的[软件发布页][2]下载最新版本的二进制文件,并按照以下步骤安装。在写这篇文章的时候,最新的版本是 0.3.1。
|
||||
|
||||
```
|
||||
$ wget https://github.com/bootandy/dust/releases/download/v0.3.1/dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
|
||||
```
|
||||
|
||||
抽取文件:
|
||||
|
||||
```
|
||||
$ tar -xvf dust-v0.3.1-x86_64-unknown-linux-gnu.tar.gz
|
||||
```
|
||||
|
||||
最后将可执行文件复制到你的 `$PATH`(例如 `/usr/local/bin`)下:
|
||||
|
||||
```
|
||||
$ sudo mv dust /usr/local/bin/
|
||||
```
|
||||
|
||||
**用法**
|
||||
|
||||
需要查看当前目录及所有子目录下的文件大小,可以执行以下命令:
|
||||
|
||||
```
|
||||
$ dust
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||

|
||||
|
||||
带上 `-p` 参数可以按照从当前目录起始的完整目录显示。
|
||||
|
||||
```
|
||||
$ dust -p
|
||||
```
|
||||
|
||||
![dust 2][4]
|
||||
|
||||
如果需要查看多个目录的大小,只需要同时列出这些目录,并用空格分隔开即可:
|
||||
|
||||
```
|
||||
$ dust <dir1> <dir2>
|
||||
```
|
||||
|
||||
下面再多举几个例子,例如:
|
||||
|
||||
显示文件的长度:
|
||||
|
||||
```
|
||||
$ dust -s
|
||||
```
|
||||
|
||||
只显示 10 个目录:
|
||||
|
||||
```
|
||||
$ dust -n 10
|
||||
```
|
||||
|
||||
查看当前目录下最多 3 层子目录:
|
||||
|
||||
```
|
||||
$ dust -d 3
|
||||
```
|
||||
|
||||
查看帮助:
|
||||
|
||||
```
|
||||
$ dust -h
|
||||
```
|
||||
|
||||
如果想要更详尽的介绍,可以查看[这个项目的 GitHub 页面][11]。
|
||||
|
||||
### diskus
|
||||
|
||||
`diskus` 也是使用 Rust 编写的一个小型、快速的开源工具,它可以用于替代 `du -sh` 命令。`diskus` 将会计算当前目录下所有文件的总大小,它的效果相当于 `du -sh` 或 `du -sh --bytes`,但其开发者表示 `diskus` 的运行速度是 `du -sh` 的 9 倍。
|
||||
|
||||
**安装 diskus**
|
||||
|
||||
`diskus` 已经存放于 <ruby>Arch Linux 社区用户软件仓库<rt>Arch Linux User-community Repository</rt></ruby>([AUR][5])当中,可以通过任何一种 AUR 帮助工具(例如 [`yay`][6])把它安装在基于 Arch 的系统上:
|
||||
|
||||
```
|
||||
$ yay -S diskus
|
||||
```
|
||||
|
||||
对于 Ubuntu 及其衍生发行版,可以在 `diskus` 的[软件发布页][7]上下载最新版的软件包并安装:
|
||||
|
||||
```
|
||||
$ wget "https://github.com/sharkdp/diskus/releases/download/v0.3.1/diskus_0.3.1_amd64.deb"
|
||||
|
||||
$ sudo dpkg -i diskus_0.3.1_amd64.deb
|
||||
```
|
||||
|
||||
还可以使用 `cargo` 软件包管理器安装 `diskus`,但必须在系统上先安装 Rust 1.29+。
|
||||
|
||||
安装好 Rust 之后,就可以使用以下命令安装 `diskus`:
|
||||
|
||||
```
|
||||
$ cargo install diskus
|
||||
```
|
||||
|
||||
**用法**
|
||||
|
||||
在通常情况下,如果需要查看某个目录的大小,我会使用形如 `du -sh` 的命令。
|
||||
|
||||
```
|
||||
$ du -sh dir
|
||||
```
|
||||
|
||||
这里的 `-s` 参数表示显示总大小。
|
||||
|
||||
如果使用 `diskus`,直接就可以显示当前目录的总大小。
|
||||
|
||||
```
|
||||
$ diskus
|
||||
```
|
||||
|
||||

|
||||
|
||||
我使用 `diskus` 查看 Arch Linux 系统上各个目录的总大小,这个工具的速度确实比 `du -sh` 快得多。但是它目前只能显示当前目录的大小。
|
||||
|
||||
要获取相关的帮助,可以执行以下命令:
|
||||
|
||||
```
|
||||
$ diskus -h
|
||||
```
|
||||
|
||||
如果想要更详尽的介绍,可以查看[这个项目的 GitHub 页面][12]。
|
||||
|
||||
### duu
|
||||
|
||||
`duu` 是 Directory Usage Utility 的缩写。它是使用 Python 编写的查看指定目录大小的工具。它具有跨平台的特性,因此在 Windows、Mac OS 和 Linux 系统上都能够使用。
|
||||
|
||||
**安装 duu**
|
||||
|
||||
安装这个工具之前需要先安装 Python 3。不过目前很多 Linux 发行版的默认软件仓库中都带有 Python 3,所以这个依赖并不难解决。
|
||||
|
||||
Python 3 安装完成后,从 `duu` 的[软件发布页][8]下载其最新版本。
|
||||
|
||||
```
|
||||
$ wget https://github.com/jftuga/duu/releases/download/2.20/duu.py
|
||||
```
|
||||
|
||||
**用法**
|
||||
|
||||
要查看当前目录的大小,只需要执行以下命令:
|
||||
|
||||
```
|
||||
$ python3 duu.py
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||

|
||||
|
||||
从上图可以看出,`duu` 会显示当前目录下文件的数量情况,按照 Byte、KB、MB 单位显示这些文件的总大小,以及每个文件的大小。
|
||||
|
||||
如果需要查看某个目录的大小,只需要声明目录的绝对路径即可:
|
||||
|
||||
```
|
||||
$ python3 duu.py /home/sk/Downloads/
|
||||
```
|
||||
|
||||
如果想要更详尽的介绍,可以查看[这个项目的 GitHub 页面][13]。
|
||||
|
||||
以上就是 `du` 命令的五种替代方案,希望这篇文章能够帮助到你。就我自己而言,我并不会在这五种工具之间交替使用,我更喜欢使用 `ncdu`。欢迎在下面的评论区发表你对这些工具的评论。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/some-good-alternatives-to-du-command/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/vmchale/tin-summer/releases
|
||||
[2]: https://github.com/bootandy/dust/releases
|
||||
[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2018/11/dust-2.png
|
||||
[5]: https://aur.archlinux.org/packages/diskus-bin/
|
||||
[6]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[7]: https://github.com/sharkdp/diskus/releases
|
||||
[8]: https://github.com/jftuga/duu/releases
|
||||
[9]: https://www.ostechnix.com/check-disk-space-usage-linux-using-ncdu/
|
||||
[10]: https://github.com/vmchale/tin-summer
|
||||
[11]: https://github.com/bootandy/dust
|
||||
[12]: https://github.com/sharkdp/diskus
|
||||
[13]: https://github.com/jftuga/duu
|
||||
|
||||
Loading…
Reference in New Issue
Block a user