mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
ec632df55e
@ -8,14 +8,13 @@
|
||||
3. CPU 和内存瓶颈
|
||||
4. 网络瓶颈
|
||||
|
||||
|
||||
### 1. top - 进程活动监控命令
|
||||
|
||||
top 命令显示 Linux 的进程。它提供了一个系统的实时动态视图,即实际的进程活动。默认情况下,它显示在服务器上运行的 CPU 占用率最高的任务,并且每五秒更新一次。
|
||||
`top` 命令会显示 Linux 的进程。它提供了一个运行中系统的实时动态视图,即实际的进程活动。默认情况下,它显示在服务器上运行的 CPU 占用率最高的任务,并且每五秒更新一次。
|
||||
|
||||

|
||||
|
||||
图 01:Linux top 命令
|
||||
*图 01:Linux top 命令*
|
||||
|
||||
#### top 的常用快捷键
|
||||
|
||||
@ -23,22 +22,24 @@ top 命令显示 Linux 的进程。它提供了一个系统的实时动态视图
|
||||
|
||||
| 快捷键 | 用法 |
|
||||
| ---- | -------------------------------------- |
|
||||
| t | 是否显示总结信息 |
|
||||
| m | 是否显示内存信息 |
|
||||
| A | 根据各种系统资源的利用率对进程进行排序,有助于快速识别系统中性能不佳的任务。 |
|
||||
| f | 进入 top 的交互式配置屏幕,用于根据特定的需求而设置 top 的显示。 |
|
||||
| o | 交互式地调整 top 每一列的顺序。 |
|
||||
| r | 调整优先级(renice) |
|
||||
| k | 杀掉进程(kill) |
|
||||
| z | 开启或关闭彩色或黑白模式 |
|
||||
| `t` | 是否显示汇总信息 |
|
||||
| `m` | 是否显示内存信息 |
|
||||
| `A` | 根据各种系统资源的利用率对进程进行排序,有助于快速识别系统中性能不佳的任务。 |
|
||||
| `f` | 进入 `top` 的交互式配置屏幕,用于根据特定的需求而设置 `top` 的显示。 |
|
||||
| `o` | 交互式地调整 `top` 每一列的顺序。 |
|
||||
| `r` | 调整优先级(`renice`) |
|
||||
| `k` | 杀掉进程(`kill`) |
|
||||
| `z` | 切换彩色或黑白模式 |
|
||||
|
||||
相关链接:[Linux 如何查看 CPU 利用率?][1]
|
||||
|
||||
### 2. vmstat - 虚拟内存统计
|
||||
|
||||
vmstat 命令报告有关进程、内存、分页、块 IO、陷阱和 cpu 活动等信息。
|
||||
`vmstat` 命令报告有关进程、内存、分页、块 IO、中断和 CPU 活动等信息。
|
||||
|
||||
`# vmstat 3`
|
||||
```
|
||||
# vmstat 3
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -56,11 +57,15 @@ procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
|
||||
|
||||
#### 显示 Slab 缓存的利用率
|
||||
|
||||
`# vmstat -m`
|
||||
```
|
||||
# vmstat -m
|
||||
```
|
||||
|
||||
#### 获取有关活动和非活动内存页面的信息
|
||||
|
||||
`# vmstat -a`
|
||||
```
|
||||
# vmstat -a
|
||||
```
|
||||
|
||||
相关链接:[如何查看 Linux 的资源利用率从而找到系统瓶颈?][2]
|
||||
|
||||
@ -84,9 +89,11 @@ root pts/1 10.1.3.145 17:43 0.00s 0.03s 0.00s w
|
||||
|
||||
### 4. uptime - Linux 系统运行了多久
|
||||
|
||||
uptime 命令可以用来查看服务器运行了多长时间:当前时间、已运行的时间、当前登录的用户连接数,以及过去 1 分钟、5 分钟和 15 分钟的系统负载平均值。
|
||||
`uptime` 命令可以用来查看服务器运行了多长时间:当前时间、已运行的时间、当前登录的用户连接数,以及过去 1 分钟、5 分钟和 15 分钟的系统负载平均值。
|
||||
|
||||
`# uptime`
|
||||
```
|
||||
# uptime
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -94,13 +101,15 @@ uptime 命令可以用来查看服务器运行了多长时间:当前时间、
|
||||
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
|
||||
```
|
||||
|
||||
1 可以被认为是最佳负载值。不同的系统会有不同的负载:对于单核 CPU 系统来说,1 到 3 的负载值是可以接受的;而对于 SMP(对称多处理)系统来说,负载可以是 6 到 10。
|
||||
`1` 可以被认为是最佳负载值。不同的系统会有不同的负载:对于单核 CPU 系统来说,`1` 到 `3` 的负载值是可以接受的;而对于 SMP(对称多处理)系统来说,负载可以是 `6` 到 `10`。
|
||||
|
||||
### 5. ps - 显示系统进程
|
||||
|
||||
ps 命令显示当前运行的进程。要显示所有的进程,请使用 -A 或 -e 选项:
|
||||
`ps` 命令显示当前运行的进程。要显示所有的进程,请使用 `-A` 或 `-e` 选项:
|
||||
|
||||
`# ps -A`
|
||||
```
|
||||
# ps -A
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -132,23 +141,31 @@ ps 命令显示当前运行的进程。要显示所有的进程,请使用 -A
|
||||
55704 pts/1 00:00:00 ps
|
||||
```
|
||||
|
||||
ps 与 top 类似,但它提供了更多的信息。
|
||||
`ps` 与 `top` 类似,但它提供了更多的信息。
|
||||
|
||||
#### 显示长输出格式
|
||||
|
||||
`# ps -Al`
|
||||
```
|
||||
# ps -Al
|
||||
```
|
||||
|
||||
显示完整输出格式(它将显示传递给进程的命令行参数):
|
||||
|
||||
`# ps -AlF`
|
||||
```
|
||||
# ps -AlF
|
||||
```
|
||||
|
||||
#### 显示线程(轻量级进程(LWP)和线程的数量(NLWP))
|
||||
|
||||
`# ps -AlFH`
|
||||
```
|
||||
# ps -AlFH
|
||||
```
|
||||
|
||||
#### 在进程后显示线程
|
||||
|
||||
`# ps -AlLm`
|
||||
```
|
||||
# ps -AlLm
|
||||
```
|
||||
|
||||
#### 显示系统上所有的进程
|
||||
|
||||
@ -162,7 +179,7 @@ ps 与 top 类似,但它提供了更多的信息。
|
||||
```
|
||||
# ps -ejH
|
||||
# ps axjf
|
||||
# [pstree][4]
|
||||
# pstree
|
||||
```
|
||||
|
||||
#### 显示进程的安全信息
|
||||
@ -192,11 +209,15 @@ ps 与 top 类似,但它提供了更多的信息。
|
||||
```
|
||||
# ps -C lighttpd -o pid=
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
# pgrep lighttpd
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
# pgrep -u vivek php-cgi
|
||||
```
|
||||
@ -215,15 +236,19 @@ ps 与 top 类似,但它提供了更多的信息。
|
||||
|
||||
#### 找出占用 CPU 资源最多的前 10 个进程
|
||||
|
||||
`# ps -auxf | sort -nr -k 3 | head -10`
|
||||
```
|
||||
# ps -auxf | sort -nr -k 3 | head -10
|
||||
```
|
||||
|
||||
相关链接:[显示 Linux 上所有运行的进程][5]
|
||||
|
||||
### 6. free - 内存使用情况
|
||||
|
||||
free 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。
|
||||
`free` 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。
|
||||
|
||||
`# free `
|
||||
```
|
||||
# free
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -242,9 +267,11 @@ Swap: 1052248 0 1052248
|
||||
|
||||
### 7. iostat - CPU 平均负载和磁盘活动
|
||||
|
||||
iostat 命令用于汇报 CPU 的使用情况,以及设备、分区和网络文件系统(NFS)的 IO 统计信息。
|
||||
`iostat` 命令用于汇报 CPU 的使用情况,以及设备、分区和网络文件系统(NFS)的 IO 统计信息。
|
||||
|
||||
`# iostat `
|
||||
```
|
||||
# iostat
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -265,17 +292,21 @@ sda3 0.00 0.00 0.00 1615 0
|
||||
|
||||
### 8. sar - 监控、收集和汇报系统活动
|
||||
|
||||
sar 命令用于收集、汇报和保存系统活动信息。要查看网络统计,请输入:
|
||||
`sar` 命令用于收集、汇报和保存系统活动信息。要查看网络统计,请输入:
|
||||
|
||||
`# sar -n DEV | more`
|
||||
```
|
||||
# sar -n DEV | more
|
||||
```
|
||||
|
||||
显示 24 日的网络统计:
|
||||
|
||||
`# sar -n DEV -f /var/log/sa/sa24 | more`
|
||||
|
||||
您还可以使用 sar 显示实时使用情况:
|
||||
您还可以使用 `sar` 显示实时使用情况:
|
||||
|
||||
`# sar 4 5`
|
||||
```
|
||||
# sar 4 5
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -295,12 +326,13 @@ Average: all 2.02 0.00 0.27 0.01 0.00 97.70
|
||||
+ [如何将 Linux 系统资源利用率的数据写入文件中][53]
|
||||
+ [如何使用 kSar 创建 sar 性能图以找出系统瓶颈][54]
|
||||
|
||||
|
||||
### 9. mpstat - 监控多处理器的使用情况
|
||||
|
||||
mpstat 命令显示每个可用处理器的使用情况,编号从 0 开始。命令 mpstat -P ALL 显示了每个处理器的平均使用率:
|
||||
`mpstat` 命令显示每个可用处理器的使用情况,编号从 0 开始。命令 `mpstat -P ALL` 显示了每个处理器的平均使用率:
|
||||
|
||||
`# mpstat -P ALL`
|
||||
```
|
||||
# mpstat -P ALL
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -323,13 +355,17 @@ Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
|
||||
|
||||
### 10. pmap - 监控进程的内存使用情况
|
||||
|
||||
pmap 命令用以显示进程的内存映射,使用此命令可以查找内存瓶颈。
|
||||
`pmap` 命令用以显示进程的内存映射,使用此命令可以查找内存瓶颈。
|
||||
|
||||
`# pmap -d PID`
|
||||
```
|
||||
# pmap -d PID
|
||||
```
|
||||
|
||||
显示 PID 为 47394 的进程的内存信息,请输入:
|
||||
|
||||
`# pmap -d 47394`
|
||||
```
|
||||
# pmap -d 47394
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -362,16 +398,15 @@ mapped: 933712K writeable/private: 4304K shared: 768000K
|
||||
|
||||
最后一行非常重要:
|
||||
|
||||
* **mapped: 933712K** 映射到文件的内存量
|
||||
* **writeable/private: 4304K** 私有地址空间
|
||||
* **shared: 768000K** 此进程与其他进程共享的地址空间
|
||||
|
||||
* `mapped: 933712K` 映射到文件的内存量
|
||||
* `writeable/private: 4304K` 私有地址空间
|
||||
* `shared: 768000K` 此进程与其他进程共享的地址空间
|
||||
|
||||
相关链接:[使用 pmap 命令查看 Linux 上单个程序或进程使用的内存][8]
|
||||
|
||||
### 11. netstat - Linux 网络统计监控工具
|
||||
|
||||
netstat 命令显示网络连接、路由表、接口统计、伪装连接和多播连接等信息。
|
||||
`netstat` 命令显示网络连接、路由表、接口统计、伪装连接和多播连接等信息。
|
||||
|
||||
```
|
||||
# netstat -tulpn
|
||||
@ -380,27 +415,32 @@ netstat 命令显示网络连接、路由表、接口统计、伪装连接和多
|
||||
|
||||
### 12. ss - 网络统计
|
||||
|
||||
ss 命令用于获取套接字统计信息。它可以显示类似于 netstat 的信息。不过 netstat 几乎要过时了,ss 命令更具优势。要显示所有 TCP 或 UDP 套接字:
|
||||
`ss` 命令用于获取套接字统计信息。它可以显示类似于 `netstat` 的信息。不过 `netstat` 几乎要过时了,`ss` 命令更具优势。要显示所有 TCP 或 UDP 套接字:
|
||||
|
||||
`# ss -t -a`
|
||||
```
|
||||
# ss -t -a
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
`# ss -u -a `
|
||||
```
|
||||
# ss -u -a
|
||||
```
|
||||
|
||||
显示所有带有 SELinux 安全上下文(Security Context)的 TCP 套接字:
|
||||
显示所有带有 SELinux <ruby>安全上下文<rt>Security Context</rt></ruby>的 TCP 套接字:
|
||||
|
||||
`# ss -t -a -Z `
|
||||
```
|
||||
# ss -t -a -Z
|
||||
```
|
||||
|
||||
请参阅以下关于 ss 和 netstat 命令的资料:
|
||||
请参阅以下关于 `ss` 和 `netstat` 命令的资料:
|
||||
|
||||
+ [ss:显示 Linux TCP / UDP 网络套接字信息][56]
|
||||
+ [使用 netstat 命令获取有关特定 IP 地址连接的详细信息][57]
|
||||
|
||||
|
||||
### 13. iptraf - 获取实时网络统计信息
|
||||
|
||||
iptraf 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可以生成多种网络统计信息,包括 TCP 信息、UDP 计数、ICMP 和 OSPF 信息、以太网负载信息、节点统计信息、IP 校验错误等。它以简单的格式提供了以下信息:
|
||||
`iptraf` 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可以生成多种网络统计信息,包括 TCP 信息、UDP 计数、ICMP 和 OSPF 信息、以太网负载信息、节点统计信息、IP 校验错误等。它以简单的格式提供了以下信息:
|
||||
|
||||
* 基于 TCP 连接的网络流量统计
|
||||
* 基于网络接口的 IP 流量统计
|
||||
@ -410,41 +450,53 @@ iptraf 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可
|
||||
|
||||
![Fig.02: General interface statistics: IP traffic statistics by network interface ][9]
|
||||
|
||||
图 02:常规接口统计:基于网络接口的 IP 流量统计
|
||||
*图 02:常规接口统计:基于网络接口的 IP 流量统计*
|
||||
|
||||
![Fig.03 Network traffic statistics by TCP connection][10]
|
||||
|
||||
图 03:基于 TCP 连接的网络流量统计
|
||||
*图 03:基于 TCP 连接的网络流量统计*
|
||||
|
||||
相关链接:[在 Centos / RHEL / Fedora Linux 上安装 IPTraf 以获取网络统计信息][11]
|
||||
|
||||
### 14. tcpdump - 详细的网络流量分析
|
||||
|
||||
tcpdump 命令是简单的分析网络通信的命令。您需要充分了解 TCP/IP 协议才便于使用此工具。例如,要显示有关 DNS 的流量信息,请输入:
|
||||
`tcpdump` 命令是简单的分析网络通信的命令。您需要充分了解 TCP/IP 协议才便于使用此工具。例如,要显示有关 DNS 的流量信息,请输入:
|
||||
|
||||
`# tcpdump -i eth1 'udp port 53'`
|
||||
```
|
||||
# tcpdump -i eth1 'udp port 53'
|
||||
```
|
||||
|
||||
查看所有去往和来自端口 80 的 IPv4 HTTP 数据包,仅打印真正包含数据的包,而不是像 SYN、FIN 和仅含 ACK 这类的数据包,请输入:
|
||||
|
||||
`# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'`
|
||||
```
|
||||
# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
|
||||
```
|
||||
|
||||
显示所有目标地址为 202.54.1.5 的 FTP 会话,请输入:
|
||||
|
||||
`# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'`
|
||||
```
|
||||
# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'
|
||||
```
|
||||
|
||||
打印所有目标地址为 192.168.1.5 的 HTTP 会话:
|
||||
|
||||
`# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'`
|
||||
```
|
||||
# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'
|
||||
```
|
||||
|
||||
使用 [wireshark][12] 查看文件的详细内容,请输入:
|
||||
|
||||
`# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80`
|
||||
```
|
||||
# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80
|
||||
```
|
||||
|
||||
### 15. iotop - I/O 监控
|
||||
|
||||
iotop 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程的顺序显示 I/O 使用情况。
|
||||
`iotop` 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程的顺序显示 I/O 使用情况。
|
||||
|
||||
`$ sudo iotop`
|
||||
```
|
||||
$ sudo iotop
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -454,9 +506,11 @@ iotop 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程
|
||||
|
||||
### 16. htop - 交互式的进程查看器
|
||||
|
||||
htop 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它比 top 命令更简单易用。您无需使用 PID、无需离开 htop 界面,便可以杀掉进程或调整其调度优先级。
|
||||
`htop` 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它比 `top` 命令更简单易用。您无需使用 PID、无需离开 `htop` 界面,便可以杀掉进程或调整其调度优先级。
|
||||
|
||||
`$ htop`
|
||||
```
|
||||
$ htop
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -464,40 +518,40 @@ htop 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它
|
||||
|
||||
相关链接:[CentOS / RHEL:安装 htop——交互式文本模式进程查看器][58]
|
||||
|
||||
|
||||
### 17. atop - 高级版系统与进程监控工具
|
||||
|
||||
atop 是一个非常强大的交互式 Linux 系统负载监控器,它从性能的角度显示最关键的硬件资源信息。您可以快速查看 CPU、内存、磁盘和网络性能。它还可以从进程的级别显示哪些进程造成了相关 CPU 和内存的负载。
|
||||
`atop` 是一个非常强大的交互式 Linux 系统负载监控器,它从性能的角度显示最关键的硬件资源信息。您可以快速查看 CPU、内存、磁盘和网络性能。它还可以从进程的级别显示哪些进程造成了相关 CPU 和内存的负载。
|
||||
|
||||
`$ atop`
|
||||
```
|
||||
$ atop
|
||||
```
|
||||
|
||||
![atop Command Line Tools to Monitor Linux Performance][16]
|
||||
|
||||
相关链接:[CentOS / RHEL:安装 atop 工具——高级系统和进程监控器][59]
|
||||
|
||||
|
||||
### 18. ac 和 lastcomm
|
||||
|
||||
您一定需要监控 Linux 服务器上的进程和登录活动吧。psacct 或 acct 软件包中包含了多个用于监控进程活动的工具,包括:
|
||||
您一定需要监控 Linux 服务器上的进程和登录活动吧。`psacct` 或 `acct` 软件包中包含了多个用于监控进程活动的工具,包括:
|
||||
|
||||
|
||||
1. ac 命令:显示有关用户连接时间的统计信息
|
||||
1. `ac` 命令:显示有关用户连接时间的统计信息
|
||||
2. [lastcomm 命令][17]:显示已执行过的命令
|
||||
3. accton 命令:打开或关闭进程账号记录功能
|
||||
4. sa 命令:进程账号记录信息的摘要
|
||||
3. `accton` 命令:打开或关闭进程账号记录功能
|
||||
4. `sa` 命令:进程账号记录信息的摘要
|
||||
|
||||
相关链接:[如何对 Linux 系统的活动做详细的跟踪记录][18]
|
||||
|
||||
### 19. monit - 进程监控器
|
||||
|
||||
Monit 是一个免费且开源的进程监控软件,它可以自动重启停掉的服务。您也可以使用 Systemd、daemontools 或其他类似工具来达到同样的目的。[本教程演示如何在 Debian 或 Ubuntu Linux 上安装和配置 monit 作为进程监控器][19]。
|
||||
`monit` 是一个免费且开源的进程监控软件,它可以自动重启停掉的服务。您也可以使用 Systemd、daemontools 或其他类似工具来达到同样的目的。[本教程演示如何在 Debian 或 Ubuntu Linux 上安装和配置 monit 作为进程监控器][19]。
|
||||
|
||||
|
||||
### 20. nethogs - 找出占用带宽的进程
|
||||
### 20. NetHogs - 找出占用带宽的进程
|
||||
|
||||
NetHogs 是一个轻便的网络监控工具,它按照进程名称(如 Firefox、wget 等)对带宽进行分组。如果网络流量突然爆发,启动 NetHogs,您将看到哪个进程(PID)导致了带宽激增。
|
||||
|
||||
`$ sudo nethogs`
|
||||
```
|
||||
$ sudo nethogs
|
||||
```
|
||||
|
||||
![nethogs linux monitoring tools open source][20]
|
||||
|
||||
@ -505,31 +559,37 @@ NetHogs 是一个轻便的网络监控工具,它按照进程名称(如 Firef
|
||||
|
||||
### 21. iftop - 显示主机上网络接口的带宽使用情况
|
||||
|
||||
iftop 命令监听指定接口(如 eth0)上的网络通信情况。[它显示了一对主机的带宽使用情况][22]。
|
||||
`iftop` 命令监听指定接口(如 eth0)上的网络通信情况。[它显示了一对主机的带宽使用情况][22]。
|
||||
|
||||
`$ sudo iftop`
|
||||
```
|
||||
$ sudo iftop
|
||||
```
|
||||
|
||||
![iftop in action][23]
|
||||
|
||||
### 22. vnstat - 基于控制台的网络流量监控工具
|
||||
|
||||
vnstat 是一个简单易用的基于控制台的网络流量监视器,它为指定网络接口保留每小时、每天和每月网络流量日志。
|
||||
`vnstat` 是一个简单易用的基于控制台的网络流量监视器,它为指定网络接口保留每小时、每天和每月网络流量日志。
|
||||
|
||||
`$ vnstat `
|
||||
```
|
||||
$ vnstat
|
||||
```
|
||||
|
||||
![vnstat linux network traffic monitor][25]
|
||||
|
||||
相关链接:
|
||||
|
||||
+ [为 ADSL 或专用远程 Linux 服务器保留日常网络流量日志][60]
|
||||
+ [CentOS / RHEL:安装 vnStat 网络流量监控器以保留日常网络流量日志][61]
|
||||
+ [CentOS / RHEL:使用 PHP 网页前端接口查看 Vnstat 图表][62]
|
||||
|
||||
|
||||
### 23. nmon - Linux 系统管理员的调优和基准测量工具
|
||||
|
||||
nmon 是 Linux 系统管理员用于性能调优的利器,它在命令行显示 CPU、内存、网络、磁盘、文件系统、NFS、消耗资源最多的进程和分区信息。
|
||||
`nmon` 是 Linux 系统管理员用于性能调优的利器,它在命令行显示 CPU、内存、网络、磁盘、文件系统、NFS、消耗资源最多的进程和分区信息。
|
||||
|
||||
`$ nmon`
|
||||
```
|
||||
$ nmon
|
||||
```
|
||||
|
||||
![nmon command][26]
|
||||
|
||||
@ -537,9 +597,11 @@ nmon 是 Linux 系统管理员用于性能调优的利器,它在命令行显
|
||||
|
||||
### 24. glances - 密切关注 Linux 系统
|
||||
|
||||
glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供了大量的信息,还可以用作客户端-服务器架构。
|
||||
`glances` 是一款开源的跨平台监控工具。它在小小的屏幕上提供了大量的信息,还可以工作于客户端-服务器模式下。
|
||||
|
||||
`$ glances`
|
||||
```
|
||||
$ glances
|
||||
```
|
||||
|
||||
![Glances][28]
|
||||
|
||||
@ -547,11 +609,11 @@ glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供
|
||||
|
||||
### 25. strace - 查看系统调用
|
||||
|
||||
想要跟踪 Linux 系统的调用和信号吗?试试 strace 命令吧。它对于调试网页服务器和其他服务器问题很有用。了解如何利用其 [追踪进程][30] 并查看它在做什么。
|
||||
想要跟踪 Linux 系统的调用和信号吗?试试 `strace` 命令吧。它对于调试网页服务器和其他服务器问题很有用。了解如何利用其 [追踪进程][30] 并查看它在做什么。
|
||||
|
||||
### 26. /proc/ 文件系统 - 各种内核信息
|
||||
### 26. /proc 文件系统 - 各种内核信息
|
||||
|
||||
/proc 文件系统提供了不同硬件设备和 Linux 内核的详细信息。更多详细信息,请参阅 [Linux 内核 /proc][31] 文档。常见的 /proc 例子:
|
||||
`/proc` 文件系统提供了不同硬件设备和 Linux 内核的详细信息。更多详细信息,请参阅 [Linux 内核 /proc][31] 文档。常见的 `/proc` 例子:
|
||||
|
||||
```
|
||||
# cat /proc/cpuinfo
|
||||
@ -562,23 +624,23 @@ glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供
|
||||
|
||||
### 27. Nagios - Linux 服务器和网络监控
|
||||
|
||||
[Nagios][32] 是一款普遍使用的开源系统和网络监控软件。您可以轻松地监控所有主机、网络设备和服务,当状态异常和恢复正常时它都会发出警报通知。[FAN][33] 是“全自动 Nagios”的缩写。FAN 的目标是提供包含由 Nagios 社区提供的大多数工具包的 Nagios 安装。FAN 提供了标准 ISO 格式的 CDRom 镜像,使安装变得更加容易。除此之外,为了改善 Nagios 的用户体验,发行版还包含了大量的工具。
|
||||
[Nagios][32] 是一款普遍使用的开源系统和网络监控软件。您可以轻松地监控所有主机、网络设备和服务,当状态异常和恢复正常时它都会发出警报通知。[FAN][33] 是“全自动 Nagios”的缩写。FAN 的目标是提供包含由 Nagios 社区提供的大多数工具包的 Nagios 安装。FAN 提供了标准 ISO 格式的 CD-Rom 镜像,使安装变得更加容易。除此之外,为了改善 Nagios 的用户体验,发行版还包含了大量的工具。
|
||||
|
||||
### 28. Cacti - 基于 Web 的 Linux 监控工具
|
||||
|
||||
Cacti 是一个完整的网络图形化解决方案,旨在充分利用 RRDTool 的数据存储和图形功能。Cacti 提供了快速轮询器、高级图形模板、多种数据采集方法和用户管理功能。这些功能被包装在一个直观易用的界面中,确保可以实现从局域网到拥有数百台设备的复杂网络上的安装。它可以提供有关网络、CPU、内存、登录用户、Apache、DNS 服务器等的数据。了解如何在 CentOS / RHEL 下 [安装和配置 Cacti 网络图形化工具][34]。
|
||||
|
||||
### 29. KDE System Guard - 实时系统报告和图形化显示
|
||||
### 29. KDE 系统监控器 - 实时系统报告和图形化显示
|
||||
|
||||
KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通过 ssh 会话运行。它提供了许多功能,比如监控本地和远程主机的客户端-服务器架构。前端图形界面使用传感器来检索信息。传感器可以返回简单的值或更复杂的信息,如表格。每种类型的信息都有一个或多个显示界面,并被组织成工作表的形式,这些工作表可以分别保存和加载。所以,KSysguard 不仅是一个简单的任务管理器,还是一个控制大型服务器平台的强大工具。
|
||||
KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通过 ssh 会话运行。它提供了许多功能,比如可以监控本地和远程主机的客户端-服务器模式。前端图形界面使用传感器来检索信息。传感器可以返回简单的值或更复杂的信息,如表格。每种类型的信息都有一个或多个显示界面,并被组织成工作表的形式,这些工作表可以分别保存和加载。所以,KSysguard 不仅是一个简单的任务管理器,还是一个控制大型服务器平台的强大工具。
|
||||
|
||||
![Fig.05 KDE System Guard][35]
|
||||
|
||||
图 05:KDE System Guard {图片来源:维基百科}
|
||||
*图 05:KDE System Guard {图片来源:维基百科}*
|
||||
|
||||
详细用法,请参阅 [KSysguard 手册][36]。
|
||||
|
||||
### 30. Gnome 系统监控器
|
||||
### 30. GNOME 系统监控器
|
||||
|
||||
系统监控程序能够显示系统基本信息,并监控系统进程、系统资源使用情况和文件系统。您还可以用其修改系统行为。虽然不如 KDE System Guard 强大,但它提供的基本信息对新用户还是有用的:
|
||||
|
||||
@ -598,7 +660,7 @@ KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通
|
||||
|
||||
![Fig.06 The Gnome System Monitor application][37]
|
||||
|
||||
图 06:Gnome 系统监控程序
|
||||
*图 06:Gnome 系统监控程序*
|
||||
|
||||
### 福利:其他工具
|
||||
|
||||
@ -606,16 +668,15 @@ KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通
|
||||
|
||||
* [nmap][38] - 扫描服务器的开放端口
|
||||
* [lsof][39] - 列出打开的文件和网络连接等
|
||||
* [ntop][40] 网页工具 - ntop 是查看网络使用情况的最佳工具,与 top 命令之于进程的方式类似,即网络流量监控工具。您可以查看网络状态和 UDP、TCP、DNS、HTTP 等协议的流量分发。
|
||||
* [Conky][41] - X Window 系统的另一个很好的监控工具。它具有很高的可配置性,能够监视许多系统变量,包括 CPU 状态、内存、交换空间、磁盘存储、温度、进程、网络接口、电池、系统消息和电子邮件等。
|
||||
* [ntop][40] 基于网页的工具 - `ntop` 是查看网络使用情况的最佳工具,与 `top` 命令之于进程的方式类似,即网络流量监控工具。您可以查看网络状态和 UDP、TCP、DNS、HTTP 等协议的流量分发。
|
||||
* [Conky][41] - X Window 系统下的另一个很好的监控工具。它具有很高的可配置性,能够监视许多系统变量,包括 CPU 状态、内存、交换空间、磁盘存储、温度、进程、网络接口、电池、系统消息和电子邮件等。
|
||||
* [GKrellM][42] - 它可以用来监控 CPU 状态、主内存、硬盘、网络接口、本地和远程邮箱及其他信息。
|
||||
* [mtr][43] - mtr 将 traceroute 和 ping 程序的功能结合在一个网络诊断工具中。
|
||||
* [mtr][43] - `mtr` 将 `traceroute` 和 `ping` 程序的功能结合在一个网络诊断工具中。
|
||||
* [vtop][44] - 图形化活动监控终端
|
||||
|
||||
|
||||
如果您有其他推荐的系统监控工具,欢迎在评论区分享。
|
||||
|
||||
#### 关于作者
|
||||
### 关于作者
|
||||
|
||||
作者 Vivek Gite 是 nixCraft 的创建者,也是经验丰富的系统管理员,以及 Linux 操作系统和 Unix shell 脚本的培训师。他的客户遍布全球,行业涉及 IT、教育、国防航天研究以及非营利部门等。您可以在 [Twitter][45]、[Facebook][46] 和 [Google+][47] 上关注他。
|
||||
|
||||
@ -625,7 +686,7 @@ via: https://www.cyberciti.biz/tips/top-linux-monitoring-tools.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,22 @@
|
||||
Torrent 提速 - 为什么总是无济于事
|
||||
Torrent 提速为什么总是无济于事
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
是不是总是想要 **更快的 torrent 速度**?不管现在的速度有多块,但总是无法对此满足。我们对 torrent 速度的痴迷使我们经常从包括 YouTube 视频在内的许多网站上寻找并应用各种所谓的技巧。但是相信我,从小到大我就没发现哪个技巧有用过。因此本文我们就就来看看,为什么尝试提高 torrent 速度是行不通的。
|
||||
|
||||
## 影响速度的因素
|
||||
### 影响速度的因素
|
||||
|
||||
### 本地因素
|
||||
#### 本地因素
|
||||
|
||||
从下图中可以看到 3 台电脑分别对应的 A,B,C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1,2,3 三个连接点。
|
||||
从下图中可以看到 3 台电脑分别对应的 A、B、C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1、2、3 三个连接点。
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
若用户 A 和用户 B 之间要分享文件,他们之间直接分享就能达到最大速度了而无需使用 torrent。这个速度跟互联网什么的都没有关系。
|
||||
|
||||
+ 网线的性能
|
||||
|
||||
+ 网卡的性能
|
||||
|
||||
+ 路由器的性能
|
||||
|
||||
当谈到 torrent 的时候,人们都是在说一些很复杂的东西,但是却总是不得要点。
|
||||
@ -30,7 +29,7 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
即使你把目标降到 30 Megabytes,然而你连接到路由器的电缆/网线的性能最多只有 100 megabits 也就是 10 MegaBytes。这是一个纯粹的瓶颈问题,由一个薄弱的环节影响到了其他强健部分,也就是说这个传输速率只能达到 10 Megabytes,即电缆的极限速度。现在想象有一个 torrent 即使能够用最大速度进行下载,那也会由于你的硬件不够强大而导致瓶颈。
|
||||
|
||||
### 外部因素
|
||||
#### 外部因素
|
||||
|
||||
现在再来看一下这幅图。用户 C 在很遥远的某个地方。甚至可能在另一个国家。
|
||||
|
||||
@ -40,24 +39,23 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
第二,由于 C 与本地之间多个有连接点,其中一个点就有可能成为瓶颈所在,可能由于繁重的流量和相对薄弱的硬件导致了缓慢的速度。
|
||||
|
||||
### Seeders( 译者注:做种者) 与 Leechers( 译者注:只下载不做种的人)
|
||||
#### 做种者与吸血者
|
||||
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,一个很好的种子提供者但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,有一个很好的种子提供者,但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
|
||||
## 结论
|
||||
### 结论
|
||||
|
||||
我们尝试搞清楚哪些因素影响了 torrent 速度的好坏。不管我们如何用软件进行优化,大多数时候是这是由于物理瓶颈导致的。我从来不关心那些软件,使用默认配置对我来说就够了。
|
||||
|
||||
希望你会喜欢这篇文章,有什么想法敬请留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/increase-torrent-speed-will-never-work
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
会话与 Cookie:用户登录的原理是什么?
|
||||
======
|
||||
|
||||
Facebook、 Gmail、 Twitter 是我们每天都会用的网站(LCTT 译注:才不是呢)。它们的共同点在于都需要你登录进去后才能做进一步的操作。只有你通过认证并登录后才能在 twitter 发推,在 Facebook 上评论,以及在 Gmail上处理电子邮件。
|
||||
|
||||
[][1]
|
||||
|
||||
那么登录的原理是什么?网站是如何认证的?它怎么知道是哪个用户从哪儿登录进来的?下面我们来对这些问题进行一一解答。
|
||||
|
||||
### 用户登录的原理是什么?
|
||||
|
||||
每次你在网站的登录页面中输入用户名和密码时,这些信息都会发送到服务器。服务器随后会将你的密码与服务器中的密码进行验证。如果两者不匹配,则你会得到一个错误密码的提示。如果两者匹配,则成功登录。
|
||||
|
||||
### 登录时发生了什么?
|
||||
|
||||
登录后,web 服务器会初始化一个<ruby>会话<rt>session</rt></ruby>并在你的浏览器中设置一个 cookie 变量。该 cookie 变量用于作为新建会话的一个引用。搞晕了?让我们说的再简单一点。
|
||||
|
||||
### 会话的原理是什么?
|
||||
|
||||
服务器在用户名和密码都正确的情况下会初始化一个会话。会话的定义很复杂,你可以把它理解为“关系的开始”。
|
||||
|
||||
[][2]
|
||||
|
||||
认证通过后,服务器就开始跟你展开一段关系了。由于服务器不能象我们人类一样看东西,它会在我们的浏览器中设置一个 cookie 来将我们的关系从其他人与服务器的关系标识出来。
|
||||
|
||||
### 什么是 Cookie?
|
||||
|
||||
cookie 是网站在你的浏览器中存储的一小段数据。你应该已经见过他们了。
|
||||
|
||||
[][3]
|
||||
|
||||
当你登录后,服务器为你创建一段关系或者说一个会话,然后将唯一标识这个会话的会话 id 以 cookie 的形式存储在你的浏览器中。
|
||||
|
||||
### 什么意思?
|
||||
|
||||
所有这些东西存在的原因在于识别出你来,这样当你写评论或者发推时,服务器能知道是谁在发评论,是谁在发推。
|
||||
|
||||
当你登录后,会产生一个包含会话 id 的 cookie。这样,这个会话 id 就被赋予了那个输入正确用户名和密码的人了。
|
||||
|
||||
[][4]
|
||||
|
||||
也就是说,会话 id 被赋予给了拥有这个账户的人了。之后,所有在网站上产生的行为,服务器都能通过他们的会话 id 来判断是由谁发起的。
|
||||
|
||||
### 如何让我保持登录状态?
|
||||
|
||||
会话有一定的时间限制。这一点与现实生活中不一样,现实生活中的关系可以在不见面的情况下持续很长一段时间,而会话具有时间限制。你必须要不断地通过一些动作来告诉服务器你还在线。否则的话,服务器会关掉这个会话,而你会被登出。
|
||||
|
||||
[][5]
|
||||
|
||||
不过在某些网站上可以启用“保持登录”功能,这样服务器会将另一个唯一变量以 cookie 的形式保存到我们的浏览器中。这个唯一变量会通过与服务器上的变量进行对比来实现自动登录。若有人盗取了这个唯一标识(我们称之为 cookie stealing),他们就能访问你的账户了。
|
||||
|
||||
### 结论
|
||||
|
||||
我们讨论了登录系统的工作原理以及网站是如何进行认证的。我们还学到了什么是会话和 cookies,以及它们在登录机制中的作用。
|
||||
|
||||
我们希望你们以及理解了用户登录的工作原理,如有疑问,欢迎提问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/sessions-cookies-user-login-work
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-1.jpg
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/10/pasted-image-0-9.png
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/10/pasted-image-0-1-4.png
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/10/pasted-image-0-2-3-e1508926255472.png
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/10/pasted-image-0-3-3-e1508926314117.png
|
||||
50
published/20171211 A tour of containerd 1.0.md
Normal file
50
published/20171211 A tour of containerd 1.0.md
Normal file
@ -0,0 +1,50 @@
|
||||
containerd 1.0 探索之旅
|
||||
======
|
||||
|
||||
我们在过去的文章中讨论了一些 containerd 的不同特性,它是如何设计的,以及随着时间推移已经修复的一些问题。containerd 被用于 Docker、Kubernetes CRI、以及一些其它的项目,在这些平台中事实上都使用了 containerd,而许多人并不知道 containerd 存在于这些平台之中,这篇文章就是为这些人所写的。我将来会写更多的关于 containerd 的设计以及特性集方面的文章,但是现在,让我们从它的基础知识开始。
|
||||
|
||||
![containerd][1]
|
||||
|
||||
我认为容器生态系统有时候可能很复杂。尤其是我们所使用的术语。它是什么?一个运行时,还是别的?一个运行时 … containerd(它的发音是 “container-dee”)正如它的名字,它是一个容器守护进程,而不是一些人忽悠我的“<ruby>收集<rt>contain</rt></ruby><ruby>迷<rt>nerd</rt></ruby>”。它最初是作为 OCI 运行时(就像 runc 一样)的集成点而构建的,在过去的六个月中它增加了许多特性,使其达到了像 Docker 这样的现代容器平台以及像 Kubernetes 这样的编排平台的需求。
|
||||
|
||||
那么,你使用 containerd 能去做些什么呢?你可以拥有推送或拉取功能以及镜像管理。可以拥有容器生命周期 API 去创建、运行、以及管理容器和它们的任务。一个完整的专门用于快照管理的 API,以及一个其所依赖的开放治理的项目。如果你需要去构建一个容器平台,基本上你不需要去处理任何底层操作系统细节方面的事情。我认为关于 containerd 中最重要的部分是,它有一个版本化的并且有 bug 修复和安全补丁的稳定 API。
|
||||
|
||||
![containerd][2]
|
||||
|
||||
由于在内核中没有一个 Linux 容器这样的东西,因此容器是多种内核特性捆绑在一起而成的,当你构建一个大型平台或者分布式系统时,你需要在你的管理代码和系统调用之间构建一个抽象层,然后将这些特性捆绑粘接在一起去运行一个容器。而这个抽象层就是 containerd 的所在之处。它为稳定类型的平台层提供了一个客户端,这样平台可以构建在顶部而无需进入到内核级。因此,可以让使用容器、任务、和快照类型的工作相比通过管理调用去 clone() 或者 mount() 要友好的多。与灵活性相平衡,直接与运行时或者宿主机交互,这些对象避免了常规的高级抽象所带来的性能牺牲。结果是简单的任务很容易完成,而困难的任务也变得更有可能完成。
|
||||
|
||||
![containerd][3]
|
||||
|
||||
containerd 被设计用于 Docker 和 Kubernetes、以及想去抽象出系统调用或者在 Linux、Windows、Solaris 以及其它的操作系统上特定的功能去运行容器的其它容器系统。考虑到这些用户的想法,我们希望确保 containerd 只拥有它们所需要的东西,而没有它们不希望的东西。事实上这是不太可能的,但是至少我们想去尝试一下。虽然网络不在 containerd 的范围之内,它并不能做成让高级系统可以完全控制的东西。原因是,当你构建一个分布式系统时,网络是非常中心的地方。现在,对于 SDN 和服务发现,相比于在 Linux 上抽象出 netlink 调用,网络是更特殊的平台。大多数新的网络都是基于路由的,并且每次一个新的容器被创建或者删除时,都会请求更新路由表。服务发现、DNS 等等都需要及时被通知到这些改变。如果在 containerd 中添加对网络的管理,为了能够支持不同的网络接口、钩子、以及集成点,将会在 containerd 中增加很大的一块代码。而我们的选择是,在 containerd 中做一个健壮的事件系统,以便于多个消费者可以去订阅它们所关心的事件。我们也公开发布了一个 [任务 API][4],它可以让用户去创建一个运行任务,也可以在一个容器的网络命名空间中添加一个接口,以及在一个容器的生命周期中的任何时候,无需复杂的钩子来启用容器的进程。
|
||||
|
||||
在过去的几个月中另一个添加到 containerd 中的领域是完整的存储,以及支持 OCI 和 Docker 镜像格式的分布式系统。有了一个跨 containerd API 的完整的目录地址存储系统,它不仅适用于镜像,也适用于元数据、检查点、以及附加到容器的任何数据。
|
||||
|
||||
我们也花时间去 [重新考虑如何使用 “图驱动” 工作][5]。这些是叠加的或者允许镜像分层的块级文件系统,可以使你执行的构建更加高效。当我们添加对 devicemapper 的支持时,<ruby>图驱动<rt>graphdrivers</rt></ruby>最初是由 Solomon 和我写的。Docker 在那个时候仅支持 AUFS,因此我们在叠加文件系统之后,对图驱动进行了建模。但是,做一个像 devicemapper/lvm 这样的块级文件系统,就如同一个堆叠文件系统一样,从长远来看是非常困难的。这些接口必须基于时间的推移进行扩展,以支持我们最初认为并不需要的那些不同的特性。对于 containerd,我们使用了一个不同的方法,像快照一样做一个堆叠文件系统而不是相反。这样做起来更容易,因为堆叠文件系统比起像 BTRFS、ZFS 以及 devicemapper 这样的快照文件系统提供了更好的灵活性。因为这些文件系统没有严格的父/子关系。这有助于我们去构建出 [快照的一个小型接口][6],同时还能满足 [构建者][7] 的要求,还能减少了需要的代码数量,从长远来看这样更易于维护。
|
||||
|
||||
![][8]
|
||||
|
||||
你可以在 [Stephen Day 2017/12/7 在 KubeCon SIG Node 上的演讲][9]找到更多关于 containerd 的架构方面的详细资料。
|
||||
|
||||
除了在 1.0 代码库中的技术和设计上的更改之外,我们也将 [containerd 管理模式从长期 BDFL 模式转换为技术委员会][10],为社区提供一个独立的可信任的第三方资源。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/12/containerd-ga-features-2/
|
||||
|
||||
作者:[Michael Crosby][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/michael/
|
||||
[1]:https://i0.wp.com/blog.docker.com/wp-content/uploads/950cf948-7c08-4df6-afd9-cc9bc417cabe-6.jpg?resize=400%2C120&amp;ssl=1
|
||||
[2]:https://i1.wp.com/blog.docker.com/wp-content/uploads/4a7666e4-ebdb-4a40-b61a-26ac7c3f663e-4.jpg?resize=906%2C470&amp;ssl=1 "containerd"
|
||||
[3]:https://i1.wp.com/blog.docker.com/wp-content/uploads/2a73a4d8-cd40-4187-851f-6104ae3c12ba-1.jpg?resize=1140%2C680&amp;ssl=1
|
||||
[4]:https://github.com/containerd/containerd/blob/master/api/services/tasks/v1/tasks.proto
|
||||
[5]:https://blog.mobyproject.org/where-are-containerds-graph-drivers-145fc9b7255
|
||||
[6]:https://github.com/containerd/containerd/blob/master/api/services/snapshots/v1/snapshots.proto
|
||||
[7]:https://blog.mobyproject.org/introducing-buildkit-17e056cc5317
|
||||
[8]:https://i1.wp.com/blog.docker.com/wp-content/uploads/d0fb5eb9-c561-415d-8d57-e74442a879a2-1.jpg?resize=1140%2C556&amp;ssl=1
|
||||
[9]:https://speakerdeck.com/stevvooe/whats-happening-with-containerd-and-the-cri
|
||||
[10]:https://github.com/containerd/containerd/pull/1748
|
||||
@ -0,0 +1,125 @@
|
||||
如何在 Ubuntu 16.04 上安装和使用 Encryptpad
|
||||
==============
|
||||
|
||||
EncryptPad 是一个自由开源软件,它通过简单方便的图形界面和命令行接口来查看和修改加密的文本,它使用 OpenPGP RFC 4880 文件格式。通过 EncryptPad,你可以很容易的加密或者解密文件。你能够像保存密码、信用卡信息等私人信息,并使用密码或者密钥文件来访问。
|
||||
|
||||
### 特性
|
||||
|
||||
- 支持 windows、Linux 和 Max OS。
|
||||
- 可定制的密码生成器,可生成健壮的密码。
|
||||
- 随机的密钥文件和密码生成器。
|
||||
- 支持 GPG 和 EPD 文件格式。
|
||||
- 能够通过 CURL 自动从远程远程仓库下载密钥。
|
||||
- 密钥文件的路径能够存储在加密的文件中。如果这样做的话,你不需要每次打开文件都指定密钥文件。
|
||||
- 提供只读模式来防止文件被修改。
|
||||
- 可加密二进制文件,例如图片、视频、归档等。
|
||||
|
||||
|
||||
在这份教程中,我们将学习如何在 Ubuntu 16.04 中安装和使用 EncryptPad。
|
||||
|
||||
### 环境要求
|
||||
|
||||
- 在系统上安装了 Ubuntu 16.04 桌面版本。
|
||||
- 在系统上有 `sudo` 的权限的普通用户。
|
||||
|
||||
### 安装 EncryptPad
|
||||
|
||||
在默认情况下,EncryPad 在 Ubuntu 16.04 的默认仓库是不存在的。你需要安装一个额外的仓库。你能够通过下面的命令来添加它 :
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:nilaimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,用下面的命令来更新仓库:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
最后一步,通过下面命令安装 EncryptPad:
|
||||
|
||||
```
|
||||
sudo apt-get install encryptpad encryptcli -y
|
||||
```
|
||||
|
||||
当 EncryptPad 安装完成后,你可以在 Ubuntu 的 Dash 上找到它。
|
||||
|
||||
### 使用 EncryptPad 生成密钥和密码
|
||||
|
||||
现在,在 Ubunntu Dash 上输入 `encryptpad`,你能够在你的屏幕上看到下面的图片 :
|
||||
|
||||
[![Ubuntu DeskTop][1]][2]
|
||||
|
||||
下一步,点击 EncryptPad 的图标。你能够看到 EncryptPad 的界面,它是一个简单的文本编辑器,带有顶部菜单栏。
|
||||
|
||||
[![EncryptPad screen][3]][4]
|
||||
|
||||
首先,你需要生成一个密钥文件和密码用于加密/解密任务。点击顶部菜单栏中的 “Encryption->Generate Key”,你会看见下面的界面:
|
||||
|
||||
[![Generate key][5]][6]
|
||||
|
||||
选择文件保存的路径,点击 “OK” 按钮,你将看到下面的界面:
|
||||
|
||||
[![select path][7]][8]
|
||||
|
||||
输入密钥文件的密码,点击 “OK” 按钮 ,你将看到下面的界面:
|
||||
|
||||
[![last step][9]][10]
|
||||
|
||||
点击 “yes” 按钮来完成该过程。
|
||||
|
||||
### 加密和解密文件
|
||||
|
||||
现在,密钥文件和密码都已经生成了。可以执行加密和解密操作了。在这个文件编辑器中打开一个文件文件,点击 “encryption” 图标 ,你会看见下面的界面:
|
||||
|
||||
[![Encry operation][11]][12]
|
||||
|
||||
提供需要加密的文件和指定输出的文件,提供密码和前面产生的密钥文件。点击 “Start” 按钮来开始加密的进程。当文件被成功的加密,会出现下面的界面:
|
||||
|
||||
[![Success Encrypt][13]][14]
|
||||
|
||||
文件已经被该密码和密钥文件加密了。
|
||||
|
||||
如果你想解密被加密后的文件,打开 EncryptPad ,点击 “File Encryption” ,选择 “Decryption” 操作,提供加密文件的位置和你要保存输出的解密文件的位置,然后提供密钥文件地址,点击 “Start” 按钮,它将要求你输入密码,输入你先前加密使用的密码,点击 “OK” 按钮开始解密过程。当该过程成功完成,你会看到 “File has been decrypted successfully” 的消息 。
|
||||
|
||||
|
||||
[![decrypt ][16]][17]
|
||||
[![][18]][18]
|
||||
[![][13]]
|
||||
|
||||
|
||||
**注意:**
|
||||
|
||||
如果你遗忘了你的密码或者丢失了密钥文件,就没有其他的方法可以打开你的加密信息了。对于 EncrypePad 所支持的格式是没有后门的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-use-encryptpad-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dash.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dash.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dashboard.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-key.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-key.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-use-key-file.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-use-key-file.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-start-encryption.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-start-encryption.png
|
||||
[13]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-page.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-page.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
@ -1,11 +1,11 @@
|
||||
Docker 化编译的软件 ┈ Tianon's Ramblings ✿
|
||||
如何 Docker 化编译的软件
|
||||
======
|
||||
我最近在 [docker-library/php][1] 仓库中关闭了大量问题,最老的(并且是最长的)讨论之一是关于安装编译扩展的依赖关系,我写了一个[中篇评论][2]解释了我如何用通常的方式为我想要的软件 Docker 化的。
|
||||
|
||||
I'm going to copy most of that comment here and perhaps expand a little bit more in order to have a better/cleaner place to link to!
|
||||
我要在这复制大部分的评论,或许扩展一点点,以便有一个更好的/更干净的链接!
|
||||
我最近在 [docker-library/php][1] 仓库中关闭了大量问题,最老的(并且是最长的)讨论之一是关于安装编译扩展的依赖关系,我写了一个[中等篇幅的评论][2]解释了我如何用常规的方式为我想要的软件进行 Docker 化的。
|
||||
|
||||
我第一步是编写 `Dockerfile` 的原始版本:下载源码,运行 `./configure && make` 等,清理。然后我尝试构建我的原始版本,并希望在这过程中看到错误消息。(对真的!)
|
||||
我要在这里复制大部分的评论内容,或许扩展一点点,以便有一个更好的/更干净的链接!
|
||||
|
||||
我第一步是编写 `Dockerfile` 的原始版本:下载源码,运行 `./configure && make` 等,清理。然后我尝试构建我的原始版本,并希望在这过程中看到错误消息。(对,真的!)
|
||||
|
||||
错误信息通常以 `error: could not find "xyz.h"` 或 `error: libxyz development headers not found` 的形式出现。
|
||||
|
||||
@ -13,9 +13,9 @@ I'm going to copy most of that comment here and perhaps expand a little bit more
|
||||
|
||||
如果我在 Alpine 中构建,我将使用 <https://pkgs.alpinelinux.org/contents> 进行类似的搜索。
|
||||
|
||||
“libxyz development headers” 在某种程度上也是一样的,但是根据我的经验,对于这些 Google 对开发者来说效果更好,因为不同的发行版和项目会以不同的名字来调用这些开发包,所以有时候更难确切的知道哪一个是“正确”的。
|
||||
“libxyz development headers” 在某种程度上也是一样的,但是根据我的经验,对于这些用 Google 对开发者来说效果更好,因为不同的发行版和项目会以不同的名字来调用这些开发包,所以有时候更难确切的知道哪一个是“正确”的。
|
||||
|
||||
当我得到包名后,我将这个包名称添加到我的 `Dockerfile` 中,清理之后,然后重复操作。最终通常会构建成功。偶尔我发现某些库不在 Debian 或 Alpine 中,或者是不够新的,由此我必须从源码构建它,但这些情况在我的经验中很少见 - 因人而异。
|
||||
当我得到包名后,我将这个包名称添加到我的 `Dockerfile` 中,清理之后,然后重复操作。最终通常会构建成功。偶尔我发现某些库不在 Debian 或 Alpine 中,或者是不够新的,由此我必须从源码构建它,但这些情况在我的经验中很少见 —— 因人而异。
|
||||
|
||||
我还会经常查看 Debian(通过 <https://sources.debian.org>)或 Alpine(通过 <https://git.alpinelinux.org/cgit/aports/tree>)我要编译的软件包源码,特别关注 `Build-Depends`(如 [`php7.0=7.0.26-1` 的 `debian/control` 文件][3])以及/或者 `makedepends` (如 [`php7` 的 `APKBUILD` 文件][4])用于包名线索。
|
||||
|
||||
@ -31,7 +31,7 @@ via: https://tianon.github.io/post/2017/12/26/dockerize-compiled-software.html
|
||||
|
||||
作者:[Tianon Gravi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
用一些超酷的功能使 Vim 变得更强大
|
||||
======
|
||||
|
||||

|
||||
|
||||
Vim 是每个 Linux 发行版]中不可或缺的一部分,也是 Linux 用户最常用的工具(当然是基于终端的)。至少,这个说法对我来说是成立的。人们可能会在利用什么工具进行程序设计更好方面产生争议,的确 Vim 可能不是一个好的选择,因为有很多不同的 IDE 或其它类似于 Sublime Text 3,Atom 等使程序设计变得更加容易的成熟的文本编辑器。
|
||||
|
||||
### 我的感想
|
||||
|
||||
但我认为,Vim 应该从一开始就以我们想要的方式运作,而其它编辑器让我们按照已经设计好的方式工作,实际上不是我们想要的工作方式。我不会过多地谈论其它编辑器,因为我没有过多地使用过它们(我对 Vim 情有独钟)。
|
||||
|
||||
不管怎样,让我们用 Vim 来做一些事情吧,它完全可以胜任。
|
||||
|
||||
### 利用 Vim 进行程序设计
|
||||
|
||||
#### 执行代码
|
||||
|
||||
|
||||
考虑一个场景,当我们使用 Vim 设计 C++ 代码并需要编译和运行它时,该怎么做呢。
|
||||
|
||||
(a). 我们通过 `Ctrl + Z` 返回到终端,或者利用 `:wq` 保存并退出。
|
||||
|
||||
(b). 但是任务还没有结束,接下来需要在终端上输入类似于 `g++ fileName.cxx` 的命令进行编译。
|
||||
|
||||
(c). 接下来需要键入 `./a.out` 执行它。
|
||||
|
||||
为了让我们的 C++ 代码在 shell 中运行,需要做很多事情。但这似乎并不是利用 Vim 操作的方法( Vim 总是倾向于把几乎所有操作方法利用一两个按键实现)。那么,做这些事情的 Vim 的方式究竟是什么?
|
||||
|
||||
#### Vim 方式
|
||||
|
||||
Vim 不仅仅是一个文本编辑器,它是一种编辑文本的编程语言。这种帮助我们扩展 Vim 功能的编程语言是 “VimScript”(LCTT 译注: Vim 脚本)。
|
||||
|
||||
因此,在 VimScript 的帮助下,我们可以只需一个按键轻松地将编译和运行代码的任务自动化。
|
||||
|
||||
[][2]
|
||||
|
||||
以上是在我的 `.vimrc` 配置文件里创建的一个名为 `CPP()` 函数的片段。
|
||||
|
||||
#### 利用 VimScript 创建函数
|
||||
|
||||
在 VimScript 中创建函数的语法非常简单。它以关键字 `func` 开头,然后是函数名(在 VimScript 中函数名必须以大写字母开头,否则 Vim 将提示错误)。在函数的结尾用关键词 `endfunc`。
|
||||
|
||||
在函数的主体中,可以看到 `exec` 语句,无论您在 `exec` 关键字之后写什么,都会在 Vim 的命令模式上执行(记住,就是在 Vim 窗口的底部以 `:` 开始的命令)。现在,传递给 `exec` 的字符串是(LCTT 译注:`:!clear && g++ % && ./a.out`) -
|
||||
|
||||
[][3]
|
||||
|
||||
|
||||
当这个函数被调用时,它首先清除终端屏幕,因此只能看到输出,接着利用 `g++` 执行正在处理的文件,然后运行由前一步编译而形成的 `a.out` 文件。
|
||||
|
||||
#### 将 `Ctrl+r` 映射为运行 C++ 代码。
|
||||
|
||||
我将语句 `call CPP()` 映射到键组合 `Ctrl+r`,以便我现在可以按 `Ctrl+r` 来执行我的 C++ 代码,无需手动输入`:call CPP()` ,然后按回车键。
|
||||
|
||||
#### 最终结果
|
||||
|
||||
我们终于找到了 Vim 方式的操作方法。现在,你只需按一个(组合)键,你编写的 C++ 代码就输出在你的屏幕上,你不需要键入所有冗长的命令了。这也节省了你的时间。
|
||||
|
||||
我们也可以为其他语言实现这类功能。
|
||||
|
||||
[][4]
|
||||
|
||||
对于Python:您可以按下 `Ctrl+e` 解释执行您的代码。
|
||||
|
||||
[][5]
|
||||
|
||||
|
||||
对于Java:您现在可以按下 `Ctrl+j`,它将首先编译您的 Java 代码,然后执行您的 Java 类文件并显示输出。
|
||||
|
||||
### 进一步提高
|
||||
|
||||
所以,这就是如何在 Vim 中操作的方法。现在,我们来看看如何在 Vim 中实现所有这些。我们可以直接在 Vim 中使用这些代码片段,而另一种方法是使用 Vim 中的自动命令 `autocmd`。`autocmd` 的优点是这些命令无需用户调用,它们在用户所提供的任何特定条件下自动执行。
|
||||
|
||||
我想用 `autocmd` 实现这个,而不是对每种语言使用不同的映射,执行不同程序设计语言编译出的代码。
|
||||
|
||||
[][6]
|
||||
|
||||
在这里做的是,为所有的定义了执行相应文件类型代码的函数编写了自动命令。
|
||||
|
||||
会发生什么?当我打开任何上述提到的文件类型的缓冲区, Vim 会自动将 `Ctrl + r` 映射到函数调用,而 `<CR>` 表示回车键,这样就不需要每完成一个独立的任务就按一次回车键了。
|
||||
|
||||
为了实现这个功能,您只需将函数片段添加到 `.vimrc` 文件中,然后将所有这些 `autocmd` 也一并添加进去。这样,当您下一次打开 Vim 时,Vim 将拥有所有相应的功能来执行所有具有相同绑定键的代码。
|
||||
|
||||
### 总结
|
||||
|
||||
就这些了。希望这些能让你更爱 Vim 。我目前正在探究 Vim 中的一些内容,正阅读文档,补充 `.vimrc` 文件,当我研究出一些成果后我会再次与你分享。
|
||||
|
||||
如果你想看一下我现在的 `.vimrc` 文件,这是我的 Github 账户的链接: [MyVimrc][7]。
|
||||
|
||||
期待你的好评。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/making-vim-even-more-awesome-with-these-cool-features
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/distros
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_orig.png
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_1_orig.png
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_2_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_3_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_4_orig.png
|
||||
[7]:https://github.com/phenomenal-ab/VIm-Configurations/blob/master/.vimrc
|
||||
@ -1,40 +1,41 @@
|
||||
Telnet,爱一直在
|
||||
======
|
||||
Telnet, 是系统管理员登录远程服务器的协议和工具。然而,由于所有的通信都没有加密,包括密码,都是明文发送的。Telnet 在 SSH 被开发出来之后就基本弃用了。
|
||||
|
||||
Telnet,是系统管理员登录远程服务器的一种协议和工具。然而,由于所有的通信都没有加密,包括密码,都是明文发送的。Telnet 在 SSH 被开发出来之后就基本弃用了。
|
||||
|
||||
登录远程服务器,你可能不会也从未考虑过它。但这并不意味着 `telnet` 命令在调试远程连接问题时不是一个实用的工具。
|
||||
|
||||
本教程中,我们将探索使用 `telnet` 解决所有常见问题,“我怎么又连不上啦?”
|
||||
本教程中,我们将探索使用 `telnet` 解决所有常见问题:“我怎么又连不上啦?”
|
||||
|
||||
这种讨厌的问题通常会在安装了像web服务器、邮件服务器、ssh服务器、Samba服务器等诸如此类的事之后遇到,用户无法连接服务器。
|
||||
这种讨厌的问题通常会在安装了像 Web服务器、邮件服务器、ssh 服务器、Samba 服务器等诸如此类的事之后遇到,用户无法连接服务器。
|
||||
|
||||
`telnet` 不会解决问题但可以很快缩小问题的范围。
|
||||
|
||||
`telnet` 用来调试网络问题的简单命令和语法:
|
||||
|
||||
```
|
||||
telnet <hostname or IP> <port>
|
||||
|
||||
```
|
||||
|
||||
因为 `telnet` 最初通过端口建立连接不会发送任何数据,适用于任何协议包括加密协议。
|
||||
因为 `telnet` 最初通过端口建立连接不会发送任何数据,适用于任何协议,包括加密协议。
|
||||
|
||||
连接问题服务器有四个可能会遇到的主要问题。我们会研究这四个问题,研究他们意味着什么以及如何解决。
|
||||
连接问题服务器有四个可能会遇到的主要问题。我们会研究这四个问题,研究它们意味着什么以及如何解决。
|
||||
|
||||
本教程默认已经在 `samba.example.com` 安装了 [Samba][1] 服务器而且本地客户无法连上服务器。
|
||||
|
||||
### Error 1 - 连接挂起
|
||||
|
||||
首先,我们需要试着用 `telnet` 连接 Samba 服务器。使用下列命令 (Samba 监听端口445):
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
|
||||
```
|
||||
|
||||
有时连接会莫名停止:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
|
||||
```
|
||||
|
||||
这意味着 `telnet` 没有收到任何回应来建立连接。有两个可能的原因:
|
||||
@ -43,10 +44,10 @@ Trying 172.31.25.31...
|
||||
2. 防火墙拦截了你的请求。
|
||||
|
||||
|
||||
为了排除第 1 点,对服务器上进行一个快速 [`mtr samba.example.com`][2] 。如果服务器是可达的,那么便是防火墙(注意:防火墙总是存在的)。
|
||||
|
||||
为了排除 **1.** 在服务器上运行一个快速 [`mtr samba.example.com`][2] 。如果服务器是可达的那么便是防火墙(注意:防火墙总是存在的)。
|
||||
首先用 `iptables -L -v -n` 命令检查服务器本身有没有防火墙,没有的话你能看到以下内容:
|
||||
|
||||
首先用 `iptables -L -v -n` 命令检查服务器本身有没有防火墙, 没有的话你能看到以下内容:
|
||||
```
|
||||
iptables -L -v -n
|
||||
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
@ -57,41 +58,38 @@ Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
|
||||
|
||||
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
```
|
||||
|
||||
如果你看到其他东西那可能就是问题所在了。为了检验,停止 `iptables` 一下并再次运行 `telnet samba.example.com 445` 看看你是否能连接。如果你还是不能连接看看你的提供商或企业有没有防火墙拦截你。
|
||||
|
||||
### Error 2 - DNS 问题
|
||||
|
||||
DNS问题通常发生在你正使用的主机名没有解析到 IP 地址。错误如下:
|
||||
DNS 问题通常发生在你正使用的主机名没有解析到 IP 地址。错误如下:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Server lookup failure: samba.example.com:445, Name or service not known
|
||||
|
||||
```
|
||||
|
||||
第一步是把主机名替换成服务器的IP地址。如果你可以连上那么就是主机名的问题。
|
||||
第一步是把主机名替换成服务器的 IP 地址。如果你可以连上那么就是主机名的问题。
|
||||
|
||||
有很多发生的原因(以下是我见过的):
|
||||
|
||||
1. 域注册了吗?用 `whois` 来检验。
|
||||
2. 域过期了吗?用 `whois` 来检验。
|
||||
1. 域名注册了吗?用 `whois` 来检验。
|
||||
2. 域名过期了吗?用 `whois` 来检验。
|
||||
3. 是否使用正确的主机名?用 `dig` 或 `host` 来确保你使用的主机名解析到正确的 IP。
|
||||
4. 你的 **A** 记录正确吗?确保你没有偶然创建类似 `smaba.example.com` 的 **A** 记录。
|
||||
|
||||
|
||||
|
||||
一定要多检查几次拼写和主机名是否正确(是 `samba.example.com` 还是 `samba1.example.com`)这些经常会困扰你特别是长、难或外来主机名。
|
||||
一定要多检查几次拼写和主机名是否正确(是 `samba.example.com` 还是 `samba1.example.com`)?这些经常会困扰你,特别是比较长、难记或其它国家的主机名。
|
||||
|
||||
### Error 3 - 服务器没有侦听端口
|
||||
|
||||
这种错误发生在 `telnet` 可达服务器但是指定端口没有监听。就像这样:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
telnet: Unable to connect to remote host: Connection refused
|
||||
|
||||
```
|
||||
|
||||
有这些原因:
|
||||
@ -100,18 +98,16 @@ telnet: Unable to connect to remote host: Connection refused
|
||||
2. 你的应用服务器没有侦听预期的端口。在服务器上运行 `netstat -plunt` 来查看它究竟在干什么并看哪个端口才是对的,实际正在监听中的。
|
||||
3. 应用服务器没有运行。这可能突然而又悄悄地发生在你启动应用服务器之后。启动服务器运行 `ps auxf` 或 `systemctl status application.service` 查看运行。
|
||||
|
||||
|
||||
|
||||
### Error 4 - 连接被服务器关闭
|
||||
|
||||
这种错误发生在连接成功建立但是应用服务器建立的安全措施一连上就将其结束。错误如下:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
Connected to samba.example.com.
|
||||
Escape character is '^]'.
|
||||
<EFBFBD><EFBFBD>Connection closed by foreign host.
|
||||
|
||||
Connection closed by foreign host.
|
||||
```
|
||||
|
||||
最后一行 `Connection closed by foreign host.` 意味着连接被服务器主动终止。为了修复这个问题,需要看看应用服务器的安全设置确保你的 IP 或用户允许连接。
|
||||
@ -119,17 +115,18 @@ Escape character is '^]'.
|
||||
### 成功连接
|
||||
|
||||
成功的 `telnet` 连接如下:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
Connected to samba.example.com.
|
||||
Escape character is '^]'.
|
||||
|
||||
```
|
||||
|
||||
连接会保持一段时间只要你连接的应用服务器时限没到。
|
||||
|
||||
输入 `CTRL+]` 中止连接然后当你看到 `telnet>` 提示,输入 "quit" 并点击 ENTER 例:
|
||||
输入 `CTRL+]` 中止连接,然后当你看到 `telnet>` 提示,输入 `quit` 并按回车:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
@ -138,12 +135,11 @@ Escape character is '^]'.
|
||||
^]
|
||||
telnet> quit
|
||||
Connection closed.
|
||||
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
客户程序连不上服务器的原因有很多。确切原理很难确定特别是当客户是图形用户界面提供很少或没有错误信息。用 `telnet` 并观察输出可以让你很快确定问题所在节约很多时间。
|
||||
客户程序连不上服务器的原因有很多。确切原因很难确定,特别是当客户是图形用户界面提供很少或没有错误信息。用 `telnet` 并观察输出可以让你很快确定问题所在节约很多时间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -151,7 +147,7 @@ via: https://bash-prompt.net/guides/telnet/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,68 +3,70 @@
|
||||
|
||||

|
||||
|
||||
当你在 Web 浏览器或任何 GUI 登录中输入密码时,密码会被标记成星号 ******** 或圆形符号 ••••••••••••• 。这是内置的安全机制,以防止你附近的用户看到你的密码。但是当你在终端输入密码来执行任何 **sudo** 或 **su** 的管理任务时,你不会在输入密码的时候看见星号或者圆形符号。它不会有任何输入密码的视觉指示,也不会有任何光标移动,什么也没有。你不知道你是否输入了所有的字符。你只会看到一个空白的屏幕!
|
||||
当你在 Web 浏览器或任何 GUI 登录中输入密码时,密码会被标记成星号 `********` 或圆点符号 `•••••••••••••` 。这是内置的安全机制,以防止你附近的用户看到你的密码。但是当你在终端输入密码来执行任何 `sudo` 或 `su` 的管理任务时,你不会在输入密码的时候看见星号或者圆点符号。它不会有任何输入密码的视觉指示,也不会有任何光标移动,什么也没有。你不知道你是否输入了所有的字符。你只会看到一个空白的屏幕!
|
||||
|
||||
看看下面的截图。
|
||||
|
||||
![][2]
|
||||
|
||||
正如你在上面的图片中看到的,我已经输入了密码,但没有任何指示(星号或圆形符号)。现在,我不确定我是否输入了所有密码。这个安全机制也可以防止你附近的人猜测密码长度。当然,这种行为可以改变。这是本指南要说的。这并不困难。请继续阅读。
|
||||
正如你在上面的图片中看到的,我已经输入了密码,但没有任何指示(星号或圆点符号)。现在,我不确定我是否输入了所有密码。这个安全机制也可以防止你附近的人猜测密码长度。当然,这种行为可以改变。这是本指南要说的。这并不困难。请继续阅读。
|
||||
|
||||
#### 当你在终端输入密码时显示星号
|
||||
|
||||
要在终端输入密码时显示星号,我们需要在 **“/etc/sudoers”** 中做一些小修改。在做任何更改之前,最好备份这个文件。为此,只需运行:
|
||||
要在终端输入密码时显示星号,我们需要在 `/etc/sudoers` 中做一些小修改。在做任何更改之前,最好备份这个文件。为此,只需运行:
|
||||
|
||||
```
|
||||
sudo cp /etc/sudoers{,.bak}
|
||||
```
|
||||
|
||||
上述命令将 /etc/sudoers 备份成名为 /etc/sudoers.bak。你可以恢复它,以防万一在编辑文件后出错。
|
||||
上述命令将 `/etc/sudoers` 备份成名为 `/etc/sudoers.bak`。你可以恢复它,以防万一在编辑文件后出错。
|
||||
|
||||
接下来,使用下面的命令编辑 `/etc/sudoers`:
|
||||
|
||||
接下来,使用下面的命令编辑 **“/etc/sudoers”**:
|
||||
```
|
||||
sudo visudo
|
||||
```
|
||||
|
||||
找到下面这行:
|
||||
|
||||
```
|
||||
Defaults env_reset
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
在该行的末尾添加一个额外的单词 **“,pwfeedback”**,如下所示。
|
||||
在该行的末尾添加一个额外的单词 `,pwfeedback`,如下所示。
|
||||
|
||||
```
|
||||
Defaults env_reset,pwfeedback
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
然后,按下 **“CTRL + x”** 和 **“y”** 保存并关闭文件。重新启动终端以使更改生效。
|
||||
然后,按下 `CTRL + x` 和 `y` 保存并关闭文件。重新启动终端以使更改生效。
|
||||
|
||||
现在,当你在终端输入密码时,你会看到星号。
|
||||
|
||||
![][5]
|
||||
|
||||
如果你对在终端输入密码时看不到密码感到不舒服,那么这个小技巧会有帮助。请注意,当你输入输入密码时其他用户就可以预测你的密码长度。如果你不介意,请按照上述方法进行更改,以使你的密码可见(当然,标记为星号!)。
|
||||
如果你对在终端输入密码时看不到密码感到不舒服,那么这个小技巧会有帮助。请注意,当你输入输入密码时其他用户就可以预测你的密码长度。如果你不介意,请按照上述方法进行更改,以使你的密码可见(当然,显示为星号!)。
|
||||
|
||||
现在就是这样了。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/display-asterisks-type-password-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png
|
||||
@ -3,19 +3,19 @@ Kali Linux 是什么,你需要它吗?
|
||||
|
||||

|
||||
|
||||
如果你听到一个 13 岁的黑客吹嘘它是多么的牛逼,是有可能的,因为有 Kali Linux 的存在。尽管有可能会被称为“脚本小子”,但是事实上,Kali 仍旧是安全专家手头的重要工具(或工具集)。
|
||||
如果你听到一个 13 岁的黑客吹嘘他是多么的牛逼,是有可能的,因为有 Kali Linux 的存在。尽管有可能会被称为“脚本小子”,但是事实上,Kali 仍旧是安全专家手头的重要工具(或工具集)。
|
||||
|
||||
Kali 是一个基于 Debian 的 Linux 发行版。它的目标就是为了简单;在一个实用的工具包里尽可能多的包含渗透和审计工具。Kali 实现了这个目标。大多数做安全测试的开源工具都被囊括在内。
|
||||
Kali 是一个基于 Debian 的 Linux 发行版。它的目标就是为了简单:在一个实用的工具包里尽可能多的包含渗透和审计工具。Kali 实现了这个目标。大多数做安全测试的开源工具都被囊括在内。
|
||||
|
||||
**相关** : [4 个极好的为隐私和案例设计的 Linux 发行版][1]
|
||||
**相关** : [4 个极好的为隐私和安全设计的 Linux 发行版][1]
|
||||
|
||||
### 为什么是 Kali?
|
||||
|
||||
![Kali Linux Desktop][2]
|
||||
|
||||
[Kali][3] 是由 Offensive Security (https://www.offensive-security.com/)公司开发和维护的。它在安全领域是一家知名的、值得信赖的公司,它甚至还有一些受人尊敬的认证,来对安全从业人员做资格认证。
|
||||
[Kali][3] 是由 [Offensive Security](https://www.offensive-security.com/) 公司开发和维护的。它在安全领域是一家知名的、值得信赖的公司,它甚至还有一些受人尊敬的认证,来对安全从业人员做资格认证。
|
||||
|
||||
Kali 也是一个简便的安全解决方案。Kali 并不要求你自己去维护一个 Linux,或者收集你自己的软件和依赖。它是一个“交钥匙工程”。所有这些繁杂的工作都不需要你去考虑,因此,你只需要专注于要审计的真实工作上,而不需要去考虑准备测试系统。
|
||||
Kali 也是一个简便的安全解决方案。Kali 并不要求你自己去维护一个 Linux 系统,或者你自己去收集软件和依赖项。它是一个“交钥匙工程”。所有这些繁杂的工作都不需要你去考虑,因此,你只需要专注于要审计的真实工作上,而不需要去考虑准备测试系统。
|
||||
|
||||
### 如何使用它?
|
||||
|
||||
@ -61,7 +61,7 @@ via: https://www.maketecheasier.com/what-is-kali-linux-and-do-you-need-it/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,33 +1,43 @@
|
||||
如何使用 Ansible 创建 AWS ec2 密钥
|
||||
======
|
||||
我想使用 Ansible 工具创建 Amazon EC2 密钥对。不想使用 AWS CLI 来创建。可以使用 Ansible 来创建 AWS ec2 密钥吗?
|
||||
|
||||
你需要使用 Ansible 的 ec2_key 模块。这个模块依赖于 python-boto 2.5 版本或者更高版本。 boto 只不过是亚马逊 Web 服务的一个 Python API。你可以将 boto 用于 Amazon S3,Amazon EC2 等其他服务。简而言之,你需要安装 ansible 和 boto 模块。我们一起来看下如何安装 boto 并结合 Ansible 使用。
|
||||
**我想使用 Ansible 工具创建 Amazon EC2 密钥对。不想使用 AWS CLI 来创建。可以使用 Ansible 来创建 AWS ec2 密钥吗?**
|
||||
|
||||
你需要使用 Ansible 的 ec2_key 模块。这个模块依赖于 python-boto 2.5 版本或者更高版本。 boto 是亚马逊 Web 服务的一个 Python API。你可以将 boto 用于 Amazon S3、Amazon EC2 等其他服务。简而言之,你需要安装 Ansible 和 boto 模块。我们一起来看下如何安装 boto 并结合 Ansible 使用。
|
||||
|
||||
### 第一步 - 在 Ubuntu 上安装最新版本的 Ansible
|
||||
|
||||
你必须[给你的系统配置 PPA 来安装最新版的 Ansible][2]。为了管理你从各种 PPA(Personal Package Archives)安装软件的仓库,你可以上传 Ubuntu 源码包并编译,然后通过 Launchpad 以 apt 仓库的形式发布。键入如下命令 [apt-get 命令][3]或者 [apt 命令][4]:
|
||||
|
||||
### 第一步 - [在 Ubuntu 上安装最新版本的 Ansible][1]
|
||||
你必须[给你的系统配置 PPA 来安装最新版的 ansible][2]。为了管理你从各种 PPA(Personal Package Archives) 安装软件的仓库,你可以上传 Ubuntu 源码包并编译,然后通过 Launchpad 以 apt 仓库的形式发布。键入如下命令 [apt-get 命令][3]或者 [apt 命令][4]:
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt upgrade
|
||||
$ sudo apt install software-properties-common
|
||||
```
|
||||
接下来给你的系统的软件源中添加 ppa:ansible/ansible
|
||||
|
||||
接下来给你的系统的软件源中添加 `ppa:ansible/ansible`。
|
||||
|
||||
```
|
||||
$ sudo apt-add-repository ppa:ansible/ansible
|
||||
```
|
||||
更新你的仓库并安装ansible:
|
||||
|
||||
更新你的仓库并安装 Ansible:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install ansible
|
||||
```
|
||||
|
||||
安装 boto:
|
||||
|
||||
```
|
||||
$ pip3 install boto3
|
||||
```
|
||||
|
||||
#### 关于在CentOS/RHEL 7.x上安装Ansible的注意事项
|
||||
#### 关于在CentOS/RHEL 7.x上安装 Ansible 的注意事项
|
||||
|
||||
你[需要在 CentOS 和 RHEL 7.x 上配置 EPEL 源][5]和 [yum命令][6]
|
||||
|
||||
```
|
||||
$ cd /tmp
|
||||
$ wget https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
|
||||
@ -35,14 +45,17 @@ $ ls *.rpm
|
||||
$ sudo yum install epel-release-latest-7.noarch.rpm
|
||||
$ sudo yum install ansible
|
||||
```
|
||||
|
||||
安装 boto:
|
||||
|
||||
```
|
||||
$ pip install boto3
|
||||
```
|
||||
|
||||
### 第二步 2 – 配置 boto
|
||||
|
||||
你需要配置 AWS credentials/API 密钥。参考 “[AWS Security Credentials][7]” 文档如何创建 API key。用 mkdir 命令创建一个名为 ~/.aws 的目录,然后配置 API key:
|
||||
你需要配置 AWS credentials/API 密钥。参考 “[AWS Security Credentials][7]” 文档如何创建 API key。用 `mkdir` 命令创建一个名为 `~/.aws` 的目录,然后配置 API key:
|
||||
|
||||
```
|
||||
$ mkdir -pv ~/.aws/
|
||||
$ vi ~/.aws/credentials
|
||||
@ -54,14 +67,20 @@ aws_secret_access_key = YOUR-SECRET-ACCESS-KEY-HERE
|
||||
```
|
||||
|
||||
还需要配置默认 [AWS 区域][8]:
|
||||
`$ vi ~/.aws/config`
|
||||
|
||||
```
|
||||
$ vi ~/.aws/config
|
||||
```
|
||||
|
||||
输出样例如下:
|
||||
|
||||
```
|
||||
[default]
|
||||
region = us-west-1
|
||||
```
|
||||
|
||||
通过创建一个简单的名为 test-boto.py 的 python 程序来测试你的 boto 配置是否正确:
|
||||
通过创建一个简单的名为 `test-boto.py` 的 Python 程序来测试你的 boto 配置是否正确:
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
# A simple program to test boto and print s3 bucket names
|
||||
@ -72,20 +91,25 @@ for b in t.buckets.all():
|
||||
```
|
||||
|
||||
按下面方式来运行该程序:
|
||||
`$ python3 test-boto.py`
|
||||
|
||||
```
|
||||
$ python3 test-boto.py
|
||||
```
|
||||
|
||||
输出样例:
|
||||
|
||||
```
|
||||
nixcraft-images
|
||||
nixcraft-backups-cbz
|
||||
nixcraft-backups-forum
|
||||
|
||||
```
|
||||
|
||||
上面输出可以确定 Python-boto 可以使用 AWS API 正常工作。
|
||||
|
||||
### 步骤 3 - 使用 Ansible 创建 AWS ec2 密钥
|
||||
|
||||
创建一个名为 ec2.key.yml 的 playbook,如下所示:
|
||||
创建一个名为 `ec2.key.yml` 的剧本,如下所示:
|
||||
|
||||
```
|
||||
---
|
||||
- hosts: local
|
||||
@ -106,44 +130,54 @@ nixcraft-backups-forum
|
||||
|
||||
其中,
|
||||
|
||||
* ec2_key: – ec2 密钥对。
|
||||
* name: nixcraft_key – 密钥对的名称。
|
||||
* region: us-west-1 – 使用的 AWS 区域。
|
||||
* register: ec2_key_result : 保存生成的密钥到 ec2_key_result 变量。
|
||||
* copy: content="{{ ec2_key_result.key.private_key }}" dest="./aws.nixcraft.pem" mode=0600 : 将 ec2_key_result.key.private_key 的内容保存到当前目录的一个名为 aws.nixcraft.pem 的文件中。设置该文件的权限为 0600 (unix 文件权限).
|
||||
* when: ec2_key_result.changed : 仅仅在 ec2_key_result 改变时才保存。我们不想覆盖你的密钥文件。
|
||||
* `ec2_key:` – ec2 密钥对。
|
||||
* `name: nixcraft_key` – 密钥对的名称。
|
||||
* `region: us-west-1` – 使用的 AWS 区域。
|
||||
* `register: ec2_key_result` – 保存生成的密钥到 ec2_key_result 变量。
|
||||
* `copy: content="{{ ec2_key_result.key.private_key }}" dest="./aws.nixcraft.pem" mode=0600` – 将 `ec2_key_result.key.private_key` 的内容保存到当前目录的一个名为 `aws.nixcraft.pem` 的文件中。设置该文件的权限为 `0600` (unix 文件权限)。
|
||||
* `when: ec2_key_result.changed` – 仅仅在 `ec2_key_result` 改变时才保存。我们不想覆盖你的密钥文件。
|
||||
|
||||
你还必须创建如下 `hosts` 文件:
|
||||
|
||||
你还必须创建如下主机文件:
|
||||
```
|
||||
[local]
|
||||
localhost
|
||||
|
||||
```
|
||||
|
||||
如下运行你的 playbook:
|
||||
`$ ansible-playbook -i hosts ec2.key.yml`
|
||||
如下运行你的剧本:
|
||||
|
||||
```
|
||||
$ ansible-playbook -i hosts ec2.key.yml
|
||||
```
|
||||
|
||||

|
||||
|
||||
最后你应该有一个名为 aws.nixcraft.pem 私钥,该私钥可以和 AWS EC2 一起使用。查看你的密钥 [cat 命令][9]:
|
||||
最后你应该有一个名为 `aws.nixcraft.pem 私钥,该私钥可以和 AWS EC2 一起使用。使用 [cat 命令][9]查看你的密钥:
|
||||
|
||||
```
|
||||
$ cat aws.nixcraft.pem
|
||||
```
|
||||
|
||||
如果你有 EC2 虚拟机,请按如下方式使用:
|
||||
|
||||
```
|
||||
$ ssh -i aws.nixcraft.pem user@ec2-vm-dns-name
|
||||
```
|
||||
|
||||
#### 查看有关 python 数据结构变量名的信息,比如 ec2_key_result.changed 和 ec2_key_result.key.private_key
|
||||
**查看有关 python 数据结构变量名的信息,比如 ec2_key_result.changed 和 ec2_key_result.key.private_key**
|
||||
|
||||
你一定在想我是如何使用变量名的,比如 ec2_key_result.changed 和 ec2_key_result.key.private_key。它们在哪里定义过吗?变量的值是通过 API 调用返回的。简单地使用 -v 选项运行 ansible-playbook 命令来查看这样的信息:
|
||||
`$ ansible-playbook -v -i hosts ec2.key.yml`
|
||||
你一定在想我是如何使用变量名的,比如 `ec2_key_result.changed` 和 `ec2_key_result.key.private_key`。它们在哪里定义过吗?变量的值是通过 API 调用返回的。简单地使用 `-v` 选项运行 `ansible-playbook` 命令来查看这样的信息:
|
||||
|
||||
```
|
||||
$ ansible-playbook -v -i hosts ec2.key.yml
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 我该如何删除一个密钥?
|
||||
|
||||
使用如下 ec2-key-delete.yml:
|
||||
使用如下 `ec2-key-delete.yml`:
|
||||
|
||||
```
|
||||
---
|
||||
- hosts: local
|
||||
@ -160,8 +194,10 @@ $ ssh -i aws.nixcraft.pem user@ec2-vm-dns-name
|
||||
```
|
||||
|
||||
按照如下方式运行:
|
||||
`$ ansible-playbook -i hosts ec2-key-delete.yml`
|
||||
|
||||
```
|
||||
$ ansible-playbook -i hosts ec2-key-delete.yml
|
||||
```
|
||||
|
||||
### 关于作者
|
||||
|
||||
@ -173,7 +209,7 @@ via: https://www.cyberciti.biz/faq/how-to-create-aws-ec2-key-using-ansible/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[qianghaohao](https://github.com/qianghaohao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
Your API is missing Swagger
|
||||
======
|
||||
|
||||

|
||||
|
||||
We have all struggled through thrown together, convoluted API documentation. It is frustrating, and in the worst case, can lead to bad requests. The process of understanding an API is something most developers go through on a regular basis, so it is any wonder that the majority of APIs have horrific documentation.
|
||||
|
||||
[Swagger][1] is the solution to this problem. Swagger came out in 2011 and is an open source software framework which has many tools that help developers design, build, document, and consume RESTful APIs. Designing an API using Swagger, or documenting it after with Swagger helps everyone consumers of your API seamlessly. One of the amazing features which many people do not know about Swagger is that you can actually **generate** a client from it! That's right, if a service you're consuming has Swagger documentation you can generate a client to consume it!
|
||||
|
||||
All major languages support Swagger and connect it to your API. Depending on the language you're writing your API in you can have the Swagger documentation generated from the actual code. Here are some of the standout Swagger libraries I've seen recently.
|
||||
|
||||
### Golang
|
||||
|
||||
Golang has a couple great tools for integrating Swagger into your API. The first is [go-swagger][2], which is a tool that lets you generate the scaffolding for an API from a Swagger file. This is a fundamentally different way of thinking about APIs. Instead of building the endpoints and thinking about new ones on the fly, go-swagger gets you to think through your API before you write a single line of code. This can help visualize what you want the API to do first. Another tool which Golang has is called [Goa][3]. A quote from their website sums up what Goa is:
|
||||
|
||||
> goa provides a novel approach for developing microservices that saves time when working on independent services and helps with keeping the overall system consistent. goa uses code generation to handle both the boilerplate and ancillary artifacts such as documentation, client modules, and client tools.
|
||||
|
||||
They take designing the API before implementing it to a new level. Goa has a DSL to help you programmatically describe your entire API, from endpoints to payloads, to responses. From this DSL Goa generates a Swagger file for anyone that consumes your API, and it will enforce your endpoints output the correct data, which will keep your API and documentation in sync. This is counter-intuitive when you start, but after actually implementing an API with Goa, you will not know how you ever did it before.
|
||||
|
||||
### Python
|
||||
|
||||
[Flask][4] has a great extension for building an API with Swagger called [Flask-RESTPlus][5].
|
||||
|
||||
> If you are familiar with Flask, Flask-RESTPlus should be easy to pick up. It provides a coherent collection of decorators and tools to describe your API and expose its documentation properly using Swagger.
|
||||
|
||||
It uses python decorators to generate swagger documentation and can be used to enforce endpoint output similar to Goa. It can be very powerful and makes generating swagger from an API stupid easy.
|
||||
|
||||
### NodeJS
|
||||
|
||||
Finally, NodeJS has a powerful tool for working with Swagger called [swagger-js-codegen][6]. It can generate both servers and clients from a swagger file.
|
||||
|
||||
> This package generates a nodejs, reactjs or angularjs class from a swagger specification file. The code is generated using mustache templates and is quality checked by jshint and beautified by js-beautify.
|
||||
|
||||
It is not quite as easy to use as Goa and Flask-RESTPlus, but if Node is your thing, this will do the job. It shines when it comes to generating frontend code to interface with your API, which is perfect if you're developing a web app to go along with the API.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Swagger is a simple yet powerful representation of your RESTful API. When used properly it can help flush out your API design and make it easier to consume. Harnessing its full power can save you time by forming and visualizing your API before you write a line of code, then generate the boilerplate surrounding the core logic. And with tools like [Goa][3], [Flask-RESTPlus][5], and [swagger-js-codegen][6] which will make the whole experience of architecting and implementing an API painless, there is no excuse not to have Swagger.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ryanmccue.ca/your-api-is-missing-swagger/
|
||||
|
||||
作者:[Ryan McCue][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ryanmccue.ca/author/ryan/
|
||||
[1]:http://swagger.io
|
||||
[2]:https://github.com/go-swagger/go-swagger
|
||||
[3]:https://goa.design/
|
||||
[4]:http://flask.pocoo.org/
|
||||
[5]:https://github.com/noirbizarre/flask-restplus
|
||||
[6]:https://github.com/wcandillon/swagger-js-codegen
|
||||
@ -1,54 +0,0 @@
|
||||
5 Podcasts Every Dev Should Listen to
|
||||
======
|
||||
|
||||

|
||||
|
||||
Being a developer is a tough job, the landscape is constantly changing, and new frameworks and best practices come out every month. Having a great go-to list of podcasts keeping you up to date on the industry can make a huge difference. I've done some of the hard work and created a list of the top 5 podcasts I personally listen too.
|
||||
|
||||
### This Developer's Life
|
||||
|
||||
Unlike many developer-focused podcasts, there is no talk of code or explanations of software architecture in [This Developer's Life][1]. There are just relatable stories from other developers. This Developer's Life dives into the issues developers face in their daily lives, from a developers point of view. [Rob Conery][2] and [Scott Hanselman][3] host the show and it focuses on all aspects of a developers life. For example, what it feels like to get fired. To hit a home run. To be competitive. It is a very well made podcast and isn't just for developers, but it can also be enjoyed by those that love and live with them.
|
||||
|
||||
### Developer Tea
|
||||
|
||||
Don’t have a lot of time? [Developer Tea][4] is "A podcast for developers designed to fit inside your tea break." The podcast exists to help driven developers connect with their purpose and excel at their work so that they can make an impact. Hosted by [Jonathan Cutrell][5], the director of technology at Whiteboard, Developer Tea breaks down the news and gives useful insights into all aspects of a developers life in and out of work. Cutrell explains listener questions mixed in with news, interviews, and career advice during his show, which releases multiple episodes every week.
|
||||
|
||||
### Software Engineering Today
|
||||
|
||||
[Software Engineering Daily][6] is a daily podcast which focuses on heavily technical topics like software development and system architecture. It covering a range of topics from load balancing at scale and serverless event-driven architecture to augmented reality. Hosted by [Jeff Meyerson][7], this podcast is great for developers who have a passion for learning about complicated software topics to expand their knowledge base.
|
||||
|
||||
### Talking Code
|
||||
|
||||
The [Talking Code][8] podcast is from 2015, and contains 24 episodes which have "short expert interviews that help you decode what developers are saying." The hosts, [Josh Smith][9] and [Venkat Dinavahi][10], talk about diverse web development topics like how to become an effective junior developer and how to go from junior to senior developer, to topics like building modern web applications and making the most out of your analytics. This podcast is perfect for those getting into web development and those who look to level up their web development skills.
|
||||
|
||||
### The Laracasts Snippet
|
||||
|
||||
[The Laracasts Snippet][11] is a bite-size podcast where each episode offers a single thought on some aspect of web development. The host, [Jeffrey Way][12], is a prominent character in the Laravel community and runs the site [Laracasts][12]. His insights are broad and are useful for developers of all backgrounds.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Podcasts are on the rise and more and more developers are listening to them. With such a rapidly expanding list of new podcasts coming out it can be tough to pick the top 5, but if you listen to these podcasts, you will have a competitive edge as a developer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ryanmccue.ca/podcasts-every-developer-should-listen-too/
|
||||
|
||||
作者:[Ryan McCue][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ryanmccue.ca/author/ryan/
|
||||
[1]:http://thisdeveloperslife.com/
|
||||
[2]:https://rob.conery.io/
|
||||
[3]:https://www.hanselman.com/
|
||||
[4]:https://developertea.com/
|
||||
[5]:http://jonathancutrell.com/
|
||||
[6]:https://softwareengineeringdaily.com/
|
||||
[7]:http://jeffmeyerson.com/
|
||||
[8]:http://talkingcode.com/
|
||||
[9]:https://twitter.com/joshsmith
|
||||
[10]:https://twitter.com/venkatdinavahi
|
||||
[11]:https://laracasts.simplecast.fm/
|
||||
[12]:https://laracasts.com
|
||||
@ -1,48 +0,0 @@
|
||||
Blueprint for Simple Scalable Microservices
|
||||
======
|
||||
|
||||

|
||||
|
||||
When you're building a microservice, what do you value? A fully managed and scalable system? It's hard to know where to start with AWS; there are so many options for hosting code, you can use EC2, ECS, Elastic Beanstalk, Lambda. Everyone has patterns for deploying microservices. Using the pattern below will provide a great structure for a scalable microservice architecture.
|
||||
|
||||
### Elastic Beanstalk
|
||||
|
||||
The first and most important piece is [Elastic Beanstalk][1]. It is a great, simple way to deploy auto-scaling microservices. All you need to do is upload your code to Elastic Beanstalk via their command line tool or management console. Once it's in Elastic Beanstalk the deployment, capacity provisioning, load balancing, auto-scaling is handled by AWS.
|
||||
|
||||
### S3
|
||||
|
||||
Another important service is [S3][2]; it is an object storage built to store and retrieve data. S3 has lots of uses, from storing images, to backups. Particular use cases are storing sensitive files such as private keys, environment variable files which will be accessed and used by multiple instances or services. Finally, using S3 for less sensitive, publically accessible files like configuration files, Dockerfiles, and images.
|
||||
|
||||
### Kinesis
|
||||
|
||||
[Kinesis][3] is a tool which allows for microservices to communicate with each other and other projects like Lambda, which we will discuss farther down. Kinesis does this by real-time, persistent data streaming, which enables microservices to emit events. Data can be persisted for up to 7 days for persistent and batch processing.
|
||||
|
||||
### RDS
|
||||
|
||||
[Amazon RDS][4] is a great, fully managed relational database hosted by AWS. Using RDS over your own database server is beneficial because AWS manages everything. It makes it easy to set up, operate, and scale a relational databases.
|
||||
|
||||
### Lambda
|
||||
|
||||
Finally, [AWS Lambda][5] lets you run code without provisioning or managing servers. Lambda has many uses; you can even create the whole APIs with it. Some great uses for it in a microservice architecture are cron jobs and image manipulation. Crons can be scheduled with [CloudWatch][6].
|
||||
|
||||
### Conclusion
|
||||
|
||||
These AWS products you can create fully scalable, stateless microservices that can communicate with each other. Using Elastic Beanstalk to run microservices, S3 to store files, Kinesis to emit events and Lambdas to subscribe to them and run other tasks. Finally, RDS for easily managing and scaling relational databases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ryanmccue.ca/blueprint-for-simple-scalable-microservices/
|
||||
|
||||
作者:[Ryan McCue][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ryanmccue.ca/author/ryan/
|
||||
[1]:https://aws.amazon.com/elasticbeanstalk/?nc2=h_m1
|
||||
[2]:https://aws.amazon.com/s3/?nc2=h_m1
|
||||
[3]:https://aws.amazon.com/kinesis/?nc2=h_m1
|
||||
[4]:https://aws.amazon.com/rds/?nc2=h_m1
|
||||
[5]:https://aws.amazon.com/lambda/?nc2=h_m1
|
||||
[6]:https://aws.amazon.com/cloudwatch/?nc2=h_m1
|
||||
@ -1,60 +0,0 @@
|
||||
5 Things to Look for When You Contract Out the Backend of Your App
|
||||
======
|
||||
|
||||

|
||||
|
||||
For many app developers, it can be hard to know what to do when it comes to the backend of your app. There are a few options, Firebase, throw together a quick Node API, contract it out. I am going to make a blog post soon weighing the pros and cons of each of these options, but for now, let's assume you want the API done professionally.
|
||||
|
||||
You are going to want to look for specific things before you give the contract to some freelancer or agency.
|
||||
|
||||
### 1. Documentation
|
||||
|
||||
Documentation is one of the most important pieces here, the API could be amazing, but if it is impossible to understand which endpoints are available, what parameters they provide, and what they respond with you won't have much luck integrating the API into your app. Surprisingly this is one of the pieces with most contractors get wrong.
|
||||
|
||||
So what are you looking for? First, make sure they understand the importance of documentation, this alone makes a huge difference. Second, the should preferably be using an open standard like [Swagger][1] for documentation. If they do both of these things, you should have documentation covered.
|
||||
|
||||
### 2. Communication
|
||||
|
||||
You know the saying "communication is key," well that applies to API development. This is harder to gauge, but sometimes a developer will get the contract, and then disappear. This doesn't mean they aren't working on it, but it means there isn't a good feedback loop to sort out problems before they get too large.
|
||||
|
||||
A good way to get around this is to have a weekly, or however often you want, meeting to go over progress and make sure the API is shaping up the way you want. Even if the meeting is just going over the endpoints and confirming they are returning the data you need.
|
||||
|
||||
### 3. Error Handling
|
||||
|
||||
Error handling is crucial, this basically means if there is an error on the backend, whether it's an invalid request or an unexpected internal server error, it will be handled properly and a useful response is given to the client. It's important that they are handled gracefully. Often this can get overlooked in the API development process.
|
||||
|
||||
This is a tricky thing to look out for, but by letting them know you expect useful error messages and maybe put it into the contract, you should get the error messages you need. This may seem like a small thing but being able to present the user of your app with the actual thing they've done wrong, like "Passwords must be between 6-64 characters" improves the UX immensely.
|
||||
|
||||
### 4. Database
|
||||
|
||||
This section may be a bit controversial, but I think that 90% of apps really just need a SQL database. I know NoSQL is sexy, but you get so many extra benefits from using SQL I feel that's what you should use for the backend of your app. Of course, there are cases where NoSQL is the better option, but broadly speaking you should probably just use a SQL database.
|
||||
|
||||
SQL adds so much added flexibility by being able to add, modify, and remove columns. The option to aggregate data with a simple query is also immensely useful. And finally, the ability to do transactions and be sure all your data is valid will help you sleep better at night.
|
||||
|
||||
The reason I say all the above is because I would recommend looking for someone who is willing to build your API with a SQL database.
|
||||
|
||||
### 5. Infrastructure
|
||||
|
||||
The last major thing to look for when contracting out your backend is infrastructure. This is essential because you want your app to scale. If you get 10,000 users join your app in one day for some reason, you want your backend to handle that. Using services like [AWS Elastic Beanstalk][2] or [Heroku][3] you can create APIs which will scale up automatically with load. That means if your app takes off overnight your API will scale with the load and not buckle under it.
|
||||
|
||||
Making sure your contractor is building it with scalability in mind is key. I wrote a [post on scalable APIs][4] if you're interested in learning more about a good AWS stack.
|
||||
|
||||
### Conclusion
|
||||
|
||||
It is important to get a quality backend when you contract it out. You're paying for a professional to design and build the backend of your app, so if they're lacking in any of the above points it will reduce the chance of success for but the backend, but for your app. If you make a checklist with these points and go over them with contractors, you should be able to weed out the under-qualified applicants and focus your attention on the contractors that know what they're doing.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ryanmccue.ca/things-to-look-for-when-you-contract-out-the-backend-your-app/
|
||||
|
||||
作者:[Ryan McCue][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ryanmccue.ca/author/ryan/
|
||||
[1]:https://swagger.io/
|
||||
[2]:https://aws.amazon.com/elasticbeanstalk/
|
||||
[3]:https://www.heroku.com/
|
||||
[4]:https://ryanmccue.ca/blueprint-for-simple-scalable-microservices/
|
||||
@ -1,88 +0,0 @@
|
||||
Where to Get Your App Backend Built
|
||||
======
|
||||
|
||||

|
||||
|
||||
Building a great app takes lots of work. From designing the views to adding the right transitions and images. One thing which is often overlooked is the backend, connecting your app to the outside world. A backend which is not up to the same quality as your app can wreck even the most perfect user interface. That is why choosing the right option for your backend budget and needs is essential.
|
||||
|
||||
There are three main choices you have when you're getting it built. First, you have agencies, they are a company with salespeople, project managers, and developers. Second, you have market rate freelancers, they are developers who charge market rate for their work and are often in North America or western Europe. Finally, there are budget freelancers, they are inexpensive and usually in parts of Asia and South America.
|
||||
|
||||
I am going to break down the pros and cons of each of these options.
|
||||
|
||||
### Agency
|
||||
|
||||
Agencies are often a safe bet if you're looking for a more hands-off approach agencies are often the way to go, they have project managers who will manage your project and communicate your requirements to developers. This takes some of the work off of your plate and can free it up to work on your app. Agencies also often have a team of developers at their disposal, so if the developer working on your project takes a vacation, they can swap another developer in without much hassle.
|
||||
|
||||
With all these upsides there is a downside. Price. Having a sales team, a project management team, and a developer team isn't cheap. Agencies often cost quite a bit of money compared to freelancers.
|
||||
|
||||
So in summary:
|
||||
|
||||
#### Pros
|
||||
|
||||
* Hands Off
|
||||
* No Single Point of Failure
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* Very expensive
|
||||
|
||||
|
||||
|
||||
### Market Rate Freelancer
|
||||
|
||||
Another option you have are market rate freelancers, these are highly skilled developers who often have worked in agencies, but decided to go their own way and get clients themselves. They generally produce high-quality work at a lower cost than agencies.
|
||||
|
||||
The downside to freelancers is since they're only one person they might not be available right away to start your work. Especially high demand freelancers you may have to wait a few weeks or months before they start development. They also are hard to replace, if they get sick or go on vacation, it can often be hard to find someone to continue the work, unless you get a good recommendation from the freelancer.
|
||||
|
||||
#### Pros
|
||||
|
||||
* Cost Effective
|
||||
* Similar quality to agency
|
||||
* Great for short term
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* May not be available
|
||||
* Hard to replace
|
||||
|
||||
|
||||
|
||||
### Budget Freelancer
|
||||
|
||||
The last option I'm going over is budget freelancers who are often found on job boards such as Fiverr and Upwork. They work for very cheap, but that often comes at the cost of quality and communication. Often you will not get what you're looking for, or it will be very brittle code which buckles under strain.
|
||||
|
||||
If you're on a very tight budget, it may be worth rolling the dice on a highly rated budget freelancer, although you must be okay with the risk of potentially throwing the code away.
|
||||
|
||||
#### Pros
|
||||
|
||||
* Very cheap
|
||||
|
||||
|
||||
|
||||
#### Cons
|
||||
|
||||
* Often low quality
|
||||
* May not be what you asked for
|
||||
|
||||
|
||||
|
||||
### Conclusion
|
||||
|
||||
Getting the right backend for your app is important. It is often a good idea to stick with agencies or market rate freelancers due to the predictability and higher quality code, but if you're on a very tight budget rolling the dice with budget freelancers could pay off. At the end of the day, it doesn't matter where the code is from, as long as it works and does what it's supposed to do.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ryanmccue.ca/where-to-get-your-app-backend-built/
|
||||
|
||||
作者:[Ryan McCue][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ryanmccue.ca/author/ryan/
|
||||
@ -1,58 +0,0 @@
|
||||
Raspberry Pi Alternatives
|
||||
======
|
||||
A look at some of the many interesting Raspberry Pi competitors.
|
||||
|
||||
The phenomenon behind the Raspberry Pi computer series has been pretty amazing. It's obvious why it has become so popular for Linux projects—it's a low-cost computer that's actually quite capable for the price, and the GPIO pins allow you to use it in a number of electronics projects such that it starts to cross over into Arduino territory in some cases. Its overall popularity has spawned many different add-ons and accessories, not to mention step-by-step guides on how to use the platform. I've personally written about Raspberry Pis often in this space, and in my own home, I use one to control a beer fermentation fridge, one as my media PC, one to control my 3D printer and one as a handheld gaming device.
|
||||
|
||||
The popularity of the Raspberry Pi also has spawned competition, and there are all kinds of other small, low-cost, Linux-powered Raspberry Pi-like computers for sale—many of which even go so far as to add "Pi" to their names. These computers aren't just clones, however. Although some share a similar form factor to the Raspberry Pi, and many also copy the GPIO pinouts, in many cases, these other computers offer features unavailable in a traditional Raspberry Pi. Some boards offer SATA, Wi-Fi or Gigabit networking; others offer USB3, and still others offer higher-performance CPUs or more RAM. When you are choosing a low-power computer for a project or as a home server, it pays to be aware of these Raspberry Pi alternatives, as in many cases, they will perform much better. So in this article, I discuss some alternatives to Raspberry Pis that I've used personally, their pros and cons, and then provide some examples of where they work best.
|
||||
|
||||
### Banana Pi
|
||||
|
||||
I've mentioned the Banana Pi before in past articles (see "Papa's Got a Brand New NAS" in the September 2016 issue and "Banana Backups" in the September 2017 issue), and it's a great choice when you want a board with a similar form factor, similar CPU and RAM specs, and a similar price (~$30) to a Raspberry Pi but need faster I/O. The Raspberry Pi product line is used for a lot of home server projects, but it limits you to 10/100 networking and a USB2 port for additional storage. Where the Banana Pi product line really shines is in the fact that it includes both a Gigabit network port and SATA port, while still having similar GPIO expansion options and running around the same price as a Raspberry Pi.
|
||||
|
||||
Before I settled on an Odroid XU4 for my home NAS (more on that later), I first experimented with a cluster of Banana Pis. The idea was to attach a SATA disk to each Banana Pi and use software like Ceph or GlusterFS to create a storage cluster shared over the network. Even though any individual Banana Pi wasn't necessarily that fast, considering how cheap they are in aggregate, they should be able to perform reasonably well and allow you to expand your storage by adding another disk and another Banana Pi. In the end, I decided to go a more traditional and simpler route with a single server and software RAID, and now I use one Banana Pi as an image gallery server. I attached a 2.5" laptop SATA drive to the other and use it as a local backup server running BackupPC. It's a nice solution that takes up almost no space and little power to run.
|
||||
|
||||
### Orange Pi Zero
|
||||
|
||||
I was really excited when I first heard about the Raspberry Pi Zero project. I couldn't believe there was such a capable little computer for only $5, and I started imagining all of the cool projects I could use one for around the house. That initial excitement was dampened a bit by the fact that they sold out quickly, and just about every vendor settled into the same pattern: put standalone Raspberry Pi Zeros on backorder but have special $20 starter kits in stock that include various adapter cables, a micro SD card and a plastic case that I didn't need. More than a year after the release, the situation still remains largely the same. Although I did get one Pi Zero and used it for a cool Adafruit "Pi Grrl Zero" gaming project, I had to put the rest of my ideas on hold, because they just never seemed to be in stock when I wanted them.
|
||||
|
||||
The Orange Pi Zero was created by the same company that makes the entire line of Orange Pi computers that compete with the Raspberry Pi. The main thing that makes the Orange Pi Zero shine in my mind is that they have a small, square form factor that is wider than a Raspberry Pi Zero but not as long. It also includes a Wi-Fi card like the more expensive Raspberry Pi Zero W, and it runs between $6 and $9, depending on whether you opt for 256MB of RAM or 512MB of RAM. More important, they are generally in stock, so there's no need to sit on a backorder list when you have a fun project in mind.
|
||||
|
||||
The Orange Pi Zero boards themselves are pretty capable. Out of the box, they include a quad-core ARM CPU, Wi-Fi (as I mentioned before), along with a 10/100 network port and USB2\. They also include Raspberry-Pi-compatible GPIO pins, but even more interesting is that there is a $9 "NAS" expansion board for it that mounts to its 13-pin header and provides extra USB2 ports, a SATA and mSATA port, along with an IR and audio and video ports, which makes it about as capable as a more expensive Banana Pi board. Even without the expansion board, this would make a nice computer you could sit anywhere within range of your Wi-Fi and run any number of services. The main downside is you are limited to composite video, so this isn't the best choice for gaming or video-based projects.
|
||||
|
||||
Although Orange Pi Zeros are capable boards in their own right, what makes them particularly enticing to me is that they are actually available when you want them, unlike some of the other sub-$10 boards out there. There's nothing worse than having a cool idea for a cheap home project and then having to wait for a board to come off backorder.
|
||||
|
||||

|
||||
|
||||
Figure 1\. An Orange Pi Zero (right) and an Espressobin (left)
|
||||
|
||||
### Odroid XU4
|
||||
|
||||
When I was looking to replace my rack-mounted NAS at home, I first looked at all of the Raspberry Pi options, including Banana Pi and other alternatives, but none of them seemed to have quite enough horsepower for my needs. I needed a machine that not only offered Gigabit networking to act as a NAS, but one that had high-speed disk I/O as well. The Odroid XU4 fit the bill with its eight-core ARM CPU, 2GB RAM, Gigabit network and USB3 ports. Although it was around $75 (almost twice the price of a Raspberry Pi), it was a much more capable computer all while being small and low-power.
|
||||
|
||||
The entire Odroid product line is a good one to consider if you want a low-power home server but need more resources than a traditional Raspberry Pi can offer and are willing to spend a little bit extra for the privilege. In addition to a NAS, the Odroid XU4, with its more powerful CPU and extra RAM, is a good all-around server for the home. The USB3 port means you have a lot of storage options should you need them.
|
||||
|
||||
### Espressobin
|
||||
|
||||
Although the Odroid XU4 is a great home server, I still sometimes can see that it gets bogged down in disk and network I/O compared to a traditional higher-powered server. Some of this might be due to the chips that were selected for the board, and perhaps some of it has to do with the fact that I'm using both disk encryption and software RAID over USB3\. In either case, I started looking for another option to help take a bit of the storage burden off this server, and I came across the Espressobin board.
|
||||
|
||||
The Espressobin is a $50 board that launched as a popular Indiegogo campaign and is now a shipping product that you can pick up in a number of places, including Amazon. Although it costs a bit more than a Raspberry Pi 3, it includes a 64-bit dual-core ARM Cortex A53 at 1.2GHz, 1–2Gb of RAM (depending on the configuration), three Gigabit network ports with a built-in switch, a SATA port, a USB3 port, a mini-PCIe port, plus a number of other options, including two sets of GPIO headers and a nice built-in serial console running on the micro-USB port.
|
||||
|
||||
The main benefit to the Espressobin is the fact that it was designed by Marvell with chips that actually can use all of the bandwidth that the board touts. In some other boards, often you'll find a SATA2 port that's hanging off a USB2 interface or other architectural hacks that, although they will let you connect a SATA disk or Gigabit networking port, it doesn't mean you'll get the full bandwidth the spec claims. Although I intend to have my own Espressobin take over home NAS duties, it also would make a great home gateway router, general-purpose server or even a Wi-Fi access point, provided you added the right Wi-Fi card.
|
||||
|
||||
### Conclusion
|
||||
|
||||
A whole world of alternatives to Raspberry Pis exists—this list covers only some of the ones I've used myself. I hope it has encouraged you to think twice before you default to a Raspberry Pi for your next project. Although there's certainly nothing wrong with Raspberry Pis, there are several small computers that run Linux well and, in many cases, offer better hardware or other expansion options beyond the capabilities of a Raspberry Pi for a similar price.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/raspberry-pi-alternatives
|
||||
|
||||
作者:[Kyle Rankin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/kyle-rankin
|
||||
@ -1,108 +0,0 @@
|
||||
Open source is 20: How it changed programming and business forever
|
||||
======
|
||||
![][1]
|
||||
|
||||
Every company in the world now uses open-source software. Microsoft, once its greatest enemy, is [now an enthusiastic open supporter][2]. Even [Windows is now built using open-source techniques][3]. And if you ever searched on Google, bought a book from Amazon, watched a movie on Netflix, or looked at your friend's vacation pictures on Facebook, you're an open-source user. Not bad for a technology approach that turns 20 on February 3.
|
||||
|
||||
Now, free software has been around since the first computers, but the philosophy of both free software and open source are both much newer. In the 1970s and 80s, companies rose up which sought to profit by making proprietary software. In the nascent PC world, no one even knew about free software. But, on the Internet, which was dominated by Unix and ITS systems, it was a different story.
|
||||
|
||||
In the late 70s, [Richard M. Stallman][6], also known as RMS, then an MIT programmer, created a free printer utility based on its source code. But then a new laser printer arrived on the campus and he found he could no longer get the source code and so he couldn't recreate the utility. The angry [RMS created the concept of "Free Software."][7]
|
||||
|
||||
RMS's goal was to create a free operating system, [Hurd][8]. To make this happen in September 1983, [he announced the creation of the GNU project][9] (GNU stands for GNU's Not Unix -- a recursive acronym). By January 1984, he was working full-time on the project. To help build it he created the grandfather of all free software/open-source compiler system [GCC][10] and other operating system utilities. Early in 1985, he published "[The GNU Manifesto][11]," which was the founding charter of the free software movement and launched the [Free Software Foundation (FSF)][12].
|
||||
|
||||
This went well for a few years, but inevitably, [RMS collided with proprietary companies][13]. The company Unipress took the code to a variation of his [EMACS][14] programming editor and turned it into a proprietary program. RMS never wanted that to happen again so he created the [GNU General Public License (GPL)][15] in 1989. This was the first copyleft license. It gave users the right to use, copy, distribute, and modify a program's source code. But if you make source code changes and distribute it to others, you must share the modified code. While there had been earlier free licenses, such as [1980's four-clause BSD license][16], the GPL was the one that sparked the free-software, open-source revolution.
|
||||
|
||||
In 1997, [Eric S. Raymond][17] published his vital essay, "[The Cathedral and the Bazaar][18]." In it, he showed the advantages of the free-software development methodologies using GCC, the Linux kernel, and his experiences with his own [Fetchmail][19] project as examples. This essay did more than show the advantages of free software. The programming principles he described led the way for both [Agile][20] development and [DevOps][21]. Twenty-first century programming owes a large debt to Raymond.
|
||||
|
||||
Like all revolutions, free software quickly divided its supporters. On one side, as John Mark Walker, open-source expert and Strategic Advisor at Glyptodon, recently wrote, "[Free software is a social movement][22], with nary a hint of business interests -- it exists in the realm of religion and philosophy. Free software is a way of life with a strong moral code."
|
||||
|
||||
On the other were numerous people who wanted to bring "free software" to business. They would become the founders of "open source." They argued that such phrases as "Free as in freedom" and "Free speech, not beer," left most people confused about what that really meant for software.
|
||||
|
||||
The [release of the Netscape web browser source code][23] sparked a meeting of free software leaders and experts at [a strategy session held on February 3rd][24], 1998 in Palo Alto, CA. There, Eric S. Raymond, Michael Tiemann, Todd Anderson, Jon "maddog" Hall, Larry Augustin, Sam Ockman, and Christine Peterson hammered out the first steps to open source.
|
||||
|
||||
Peterson created the "open-source term." She remembered:
|
||||
|
||||
> [The introduction of the term "open source software" was a deliberate effort][25] to make this field of endeavor more understandable to newcomers and to business, which was viewed as necessary to its spread to a broader community of users. The problem with the main earlier label, "free software," was not its political connotations, but that -- to newcomers -- its seeming focus on price is distracting. A term was needed that focuses on the key issue of source code and that does not immediately confuse those new to the concept. The first term that came along at the right time and fulfilled these requirements was rapidly adopted: open source.
|
||||
|
||||
To help clarify what open source was, and wasn't, Raymond and Bruce Perens founded the [Open Source Initiative (OSI)][26]. Its purpose was, and still is, to define what are real open-source software licenses and what aren't.
|
||||
|
||||
Stallman was enraged by open source. He wrote:
|
||||
|
||||
> The two terms describe almost the same method/category of software, but they stand for [views based on fundamentally different values][27]. Open source is a development methodology; free software is a social movement. For the free software movement, free software is an ethical imperative, essential respect for the users' freedom. By contrast, the philosophy of open source considers issues in terms of how to make software 'better' -- in a practical sense only. It says that non-free software is an inferior solution to the practical problem at hand. Most discussion of "open source" pays no attention to right and wrong, only to popularity and success.
|
||||
|
||||
He saw open source as kowtowing to business and taking the focus away from the personal freedom of being able to have free access to the code. Twenty years later, he's still angry about it.
|
||||
|
||||
In a recent e-mail to me, Stallman said, it is a "common error is connecting me or my work or free software in general with the term 'Open Source.' That is the slogan adopted in 1998 by people who reject the philosophy of the Free Software Movement." In another message, he continued, "I rejected 'open source' because it was meant to bury the "free software" ideas of freedom. Open source inspired the release ofu seful free programs, but what's missing is the idea that users deserve control of their computing. We libre-software activists say, 'Software you can't change and share is unjust, so let's escape to our free replacement.' Open source says only, 'If you let users change your code, they might fix bugs.' What it does says is not wrong, but weak; it avoids saying the deeper point."
|
||||
|
||||
Philosophical conflicts aside, open source has indeed become the model for practical software development. Larry Augustin, CEO of [SugarCRM][28], the open-source customer relationship management (CRM) Software-as-a-Service (SaaS), was one of the first to practice open-source in a commercial software business. Augustin showed that a successful business could be built on open-source software.
|
||||
|
||||
Other companies quickly embraced this model. Besides Linux companies such as [Canonical][29], [Red Hat][30] and [SUSE][31], technology businesses such as [IBM][32] and [Oracle][33] also adopted it. This, in turn, led to open source's commercial success. More recently companies you would never think of for a moment as open-source businesses like [Wal-Mart][34] and [Verizon][35], now rely on open-source programs and have their own open-source projects.
|
||||
|
||||
As Jim Zemlin, director of [The Linux Foundation][36], observed in 2014:
|
||||
|
||||
> A [new business model][37] has emerged in which companies are joining together across industries to share development resources and build common open-source code bases on which they can differentiate their own products and services.
|
||||
|
||||
Today, Hall looked back and said "I look at 'closed source' as a blip in time." Raymond is unsurprised at open-source's success. In an e-mail interview, Raymond said, "Oh, yeah, it *has* been 20 years -- and that's not a big deal because we won most of the fights we needed to quite a while ago, like in the first decade after 1998."
|
||||
|
||||
"Ever since," he continued, "we've been mainly dealing with the problems of success rather than those of failure. And a whole new class of issues, like IoT devices without upgrade paths -- doesn't help so much for the software to be open if you can't patch it."
|
||||
|
||||
In other words, he concludes, "The reward of victory is often another set of battles."
|
||||
|
||||
These are battles that open source is poised to win. Jim Whitehurst, Red Hat's CEO and president told me:
|
||||
|
||||
> The future of open source is bright. We are on the cusp of a new wave of innovation that will come about because information is being separated from physical objects thanks to the Internet of Things. Over the next decade, we will see entire industries based on open-source concepts, like the sharing of information and joint innovation, become mainstream. We'll see this impact every sector, from non-profits, like healthcare, education and government, to global corporations who realize sharing information leads to better outcomes. Open and participative innovation will become a key part of increasing productivity around the world.
|
||||
|
||||
Others see open source extending beyond software development methods. Nick Hopman, Red Hat's senior director of emerging technology practices, said:
|
||||
|
||||
> Open-source is much more than just a process to develop and expose technology. Open-source is a catalyst to drive change in every facet of society -- government, policy, medical diagnostics, process re-engineering, you name it -- and can leverage open principles that have been perfected through the experiences of open-source software development to create communities that drive change and innovation. Looking forward, open-source will continue to drive technology innovation, but I am even more excited to see how it changes the world in ways we have yet to even consider.
|
||||
|
||||
Indeed. Open source has turned twenty, but its influence, and not just on software and business, will continue on for decades to come.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/open-source-turns-20/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:https://zdnet1.cbsistatic.com/hub/i/r/2018/01/08/d9527281-2972-4cb7-bd87-6464d8ad50ae/thumbnail/570x322/9d4ef9007b3a3ce34de0cc39d2b15b0c/5a4faac660b22f2aba08fc3f-1280x7201jan082018150043poster.jpg
|
||||
[2]:http://www.zdnet.com/article/microsoft-the-open-source-company/
|
||||
[3]:http://www.zdnet.com/article/microsoft-uses-open-source-software-to-create-windows/
|
||||
[4]:https://zdnet1.cbsistatic.com/hub/i/r/2016/11/18/a55b3c0c-7a8e-4143-893f-44900cb2767a/resize/220x165/6cd4e37b1904743ff1f579cb10d9e857/linux-open-source-money-penguin.jpg
|
||||
[5]:http://www.zdnet.com/article/how-do-linux-and-open-source-companies-make-money-from-free-software/
|
||||
[6]:https://stallman.org/
|
||||
[7]:https://opensource.com/article/18/2/pivotal-moments-history-open-source
|
||||
[8]:https://www.gnu.org/software/hurd/hurd.html
|
||||
[9]:https://groups.google.com/forum/#!original/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
|
||||
[10]:https://gcc.gnu.org/
|
||||
[11]:https://www.gnu.org/gnu/manifesto.en.html
|
||||
[12]:https://www.fsf.org/
|
||||
[13]:https://www.free-soft.org/gpl_history/
|
||||
[14]:https://www.gnu.org/s/emacs/
|
||||
[15]:https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[16]:http://www.linfo.org/bsdlicense.html
|
||||
[17]:http://www.catb.org/esr/
|
||||
[18]:http://www.catb.org/esr/writings/cathedral-bazaar/
|
||||
[19]:http://www.fetchmail.info/
|
||||
[20]:https://www.agilealliance.org/agile101/
|
||||
[21]:https://aws.amazon.com/devops/what-is-devops/
|
||||
[22]:https://opensource.com/business/16/11/open-source-not-free-software?sc_cid=70160000001273HAAQ
|
||||
[23]:http://www.zdnet.com/article/the-beginning-of-the-peoples-web-20-years-of-netscape/
|
||||
[24]:https://opensource.org/history
|
||||
[25]:https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
[26]:https://opensource.org
|
||||
[27]:https://www.gnu.org/philosophy/open-source-misses-the-point.html
|
||||
[28]:https://www.sugarcrm.com/
|
||||
[29]:https://www.canonical.com/
|
||||
[30]:https://www.redhat.com/en
|
||||
[31]:https://www.suse.com/
|
||||
[32]:https://developer.ibm.com/code/open/
|
||||
[33]:http://www.oracle.com/us/technologies/open-source/overview/index.html
|
||||
[34]:http://www.zdnet.com/article/walmart-relies-on-openstack/
|
||||
[35]:https://www.networkworld.com/article/3195490/lan-wan/verizon-taps-into-open-source-white-box-fervor-with-new-cpe-offering.html
|
||||
[36]:http://www.linuxfoundation.org/
|
||||
[37]:http://www.zdnet.com/article/it-takes-an-open-source-village-to-make-commercial-software/
|
||||
@ -1,62 +0,0 @@
|
||||
Security Is Not an Absolute
|
||||
======
|
||||
|
||||
If there’s one thing I wish people from outside the security industry knew when dealing with information security, it’s that **Security is not an absolute**. Most of the time, it’s not even quantifiable. Even in the case of particular threat models, it’s often impossible to make statements about the security of a system with certainty.
|
||||
|
||||
At work, I deal with a lot of very smart people who are not “security people”, but are well-meaning and trying to do the right thing. Online, I sometimes find myself in conversations on [/r/netsec][1], [/r/netsecstudents][2], [/r/asknetsec][3], or [security.stackexchange][4] where someone wants to know something about information security. Either way, it’s quite common that someone asks the fateful question: “Is this secure?”. There are actually only two answers to this question, and neither one is “Yes.”
|
||||
|
||||
The first answer is, fairly obviously, “No.” There are some ideas that are not secure under any reasonable definition of security. Imagine an employer that makes the PIN for your payroll system the day and month on which you started your new job. Clearly, all it takes is someone posting “started my new job today!” to social media, and their PIN has been outed. Consider transporting an encrypted hard drive with the password on a sticky note attached to the outside of the drive. Both of these systems have employed some form of “security control” (even if I use the term loosely), and both are clearly insecure to even the most rudimentary of attacker. Consequently, answering “Is this secure?” with a firm “No” seems appropriate.
|
||||
|
||||
The second answer is more nuanced: “It depends.” What it depends on, and whether those conditions exist in the system in use, are what many security professionals get paid to evaluate. For example, consider the employer in the previous paragraph. Instead of using a fixed scheme for PINs, they now generate a random 4-digit PIN and mail it to each new employee. Is this secure? That all depends on the threat model being applied to the scenario. If we allow an attacker unlimited attempts to log in as that user, then no 4 digit PIN (random or deterministic) is reasonably secure. On average, an attacker will need no more than 5000 requests to find the valid PIN. That can be done by a very basic script in 10s of minutes. If, on the other hand, we lock the account after 10 failed attempts, then we’ve reduced the attacker to a 0.1% chance of success for a given account. Is this secure? For a single account, this is probably reasonably secure (although most users might be uncomfortable at even a 1 in 1000 chance of an attacker succeeding against their personal account) but what if the attacker has a list of 1000 usernames? The attacker now has a **64%** chance of successfully accessing at least 1 account. I think most businesses would find those odds very much against their favor.
|
||||
|
||||
So why can’t we ever come up with an answer of “Yes, this is a secure system”? Well, there’s several factors at play here. The first is that very little in life in general is an absolute:
|
||||
|
||||
* Your doctor cannot tell you with certainty that you will be alive tomorrow.
|
||||
* A seismologist can’t say that there absolutely won’t be a 9.0 earthquake that levels a big chunk of the West Coast.
|
||||
* Your car manufacturer cannot guarantee that the 4 wheels on your car do not fall of on your way to work tomorrow.
|
||||
|
||||
|
||||
|
||||
However, all of these possibilities are very remote events. Most people are comfortable with these probabilities, largely because they do not think much about them, but even if they did, they would believe that it would not happen to them. (And almost always, they would be correct in that assumption.)
|
||||
|
||||
Unfortunately, in information security, we have three things working against us:
|
||||
|
||||
* The risks are much less understood by those seeking to understand them.
|
||||
* The reality is that there are enough security threats that are **much** more common than the events above.
|
||||
* The threats against which security must guard are **adaptive**.
|
||||
|
||||
|
||||
|
||||
Because most people have a hard time reasoning about the likelihood of attacks and threats against them, they seek absolute reassurance. They don’t want to be told “it depends”, they just want to hear “yes, you’re fine.” Many of these individuals are the hypochondriacs of the information security world – they think every possible attack will get them, and they want absolute reassurance they’re safe from those attacks. Alternatively, they don’t understand that there are degrees of security and threat models, and just want to be reassured that they are perfectly secure. Either way, the effect is the same – they don’t understand, but are afraid, and so want the reassurance of complete security.
|
||||
|
||||
We’re in an era where security breaches are unfortunately common, and developers and users alike are hearing about these vulnerabilities and breaches all the time. This causes them to pay far more attention to security then they otherwise would. By itself, this isn’t bad – all of us in the industry have been trying to get everyone’s attention about security issues for decades. Getting it now is better late than never. But because we’re so far behind the curve, the breaches being common, everytone is rushing to find out their risk and get reassurance now. Rather than consider the nuances of the situation, they just want a simple answer to “Am I secure?”
|
||||
|
||||
The last of these issues, however, is also the most unique to information security. For decades, we’ve looked for the formula to make a system perfectly secure. However, each countermeasure or security system is quickly defeated by attackers. We’re in a cat-and-mouse game, rather than an engineering discipline.
|
||||
|
||||
This isn’t to say that security is not an engineering practice – it certainly is in many ways (and my official title claims that I am an engineer), but just that it differs from other engineering areas. The forces faced by a building do not change in face of design changes by the structural engineer. Gravity remains a constant, wind forces are predictible for a given design, the seismic nature of an area is approximately known. Making the building have stronger doors does not suddenly increase the wind forces on the windows. In security, however, when we “strengthen the doors”, the attackers do turn to the “windows” of our system. Our threats are **adaptive** – for each control we implement, they adapt to attempt to circumvent that control. For this reason, a system that was believed secure against the known threats one year is completely broken the next.
|
||||
|
||||
Another form of the security absolutism is those that realize there are degrees of security, but want to take it to an almost ridiculous level of paranoia. Nearly always, these seem to be interested in forms of cryptography – perhaps because cryptography offers numbers that can be tweaked, giving an impression of differing levels of security.
|
||||
|
||||
* Generating RSA encryption keys of over 4k bits in length, even though all cryptographers agree this is pointless.
|
||||
* Asking why AES-512 doesn’t exist, even though SHA-512 does. (Because the length of a hash and the length of a key do not equal in effective strength against attacks.)
|
||||
* Setting up bizarre browser settings and then complaining about websites being broken. (Disabling all JavaScript, all cookies, all ciphers that are less than 256 bits and not perfect forward secrecy, etc.)
|
||||
|
||||
|
||||
|
||||
So the next time you want to know “Is this secure?”, consider the threat model: what are you trying to defend against? Recognize that there are no security absolutes and guarantees, and that good security engineering practice often involves compromise. Sometimes the compromise is one of usability or utility, sometimes the compromise involves working in a less-than-perfect world.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://systemoverlord.com/2018/02/05/security-is-not-an-absolute.html
|
||||
|
||||
作者:[David][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://systemoverlord.com/about
|
||||
[1]:https://reddit.com/r/netsec
|
||||
[2]:https://reddit.com/r/netsecstudents
|
||||
[3]:https://reddit.com/r/asknetsec
|
||||
[4]:https://security.stackexchange.com
|
||||
69
sources/talk/20180219 How Linux became my job.md
Normal file
69
sources/talk/20180219 How Linux became my job.md
Normal file
@ -0,0 +1,69 @@
|
||||
How Linux became my job
|
||||
======
|
||||
|
||||

|
||||
|
||||
I've been using open source since what seems like prehistoric times. Back then, there was nothing called social media. There was no Firefox, no Google Chrome (not even a Google), no Amazon, barely an internet. In fact, the hot topic of the day was the new Linux 2.0 kernel. The big technical challenges in those days? Well, the [ELF format][1] was replacing the old [a.out][2] format in binary [Linux][3] distributions, and the upgrade could be tricky on some installs of Linux.
|
||||
|
||||
How I transformed a personal interest in this fledgling young operating system to a [career][4] in open source is an interesting story.
|
||||
|
||||
### Linux for fun, not profit
|
||||
|
||||
I graduated from college in 1994 when computer labs were small networks of UNIX systems; if you were lucky they connected to this new thing called the internet. Hard to believe, I know! The "web" (as we knew it) was mostly handwritten HTML, and the `cgi-bin` directory was a new playground for enabling dynamic web interactions. Many of us were excited about these new technologies, and we taught ourselves shell scripting, [Perl][5], HTML, and all the terse UNIX commands that we had never seen on our parents' Windows 3.1 PCs.
|
||||
|
||||
`vi` and `ls` and reading my email via
|
||||
|
||||
After graduation, I joined IBM, working on a PC operating system with no access to UNIX systems, and soon my university cut off my remote access to the engineering lab. How was I going to keep usingandand reading my email via [Pine][6] ? I kept hearing about open source Linux, but I hadn't had time to look into it.
|
||||
|
||||
In 1996, I was about to begin a master's degree program at the University of Texas at Austin. I knew it would involve programming and writing papers, and who knows what else, and I didn't want to use proprietary editors or compilers or word processors. I wanted my UNIX experience!
|
||||
|
||||
So I took an old PC, found a Linux distribution—Slackware 3.0—and downloaded it, diskette after diskette, in my IBM office. Let's just say I've never looked back after that first install of Linux. In those early days, I learned a lot about makefiles and the `make` system, about building software, and about patches and source code control. Even though I started working with Linux for fun and personal knowledge, it ended up transforming my career.
|
||||
|
||||
While I was a happy Linux user, I thought open source development was still other people's work; I imagined an online mailing list of mystical [UNIX][7] geeks. I appreciated things like the Linux HOWTO project for helping with the bumps and bruises I acquired trying to add packages, upgrade my Linux distribution, or install device drivers for new hardware or a new PC. But working with source code and making modifications or submitting them upstream … that was for other people, not me.
|
||||
|
||||
### How Linux became my job
|
||||
|
||||
In 1999, I finally had a reason to combine my personal interest in Linux with my day job at IBM. I took on a skunkworks project to port the IBM Java Virtual Machine (JVM) to Linux. To ensure we were legally safe, IBM purchased a shrink-wrapped, boxed copy of Red Hat Linux 6.1 to do this work. Working with the IBM Tokyo Research lab, which wrote our JVM just-in-time (JIT) compiler, and both the AIX JVM source code and the Windows & OS/2 JVM source code reference, we had a working JVM on Linux within a few weeks, beating the announcement of Sun's official Java on Linux port by several months. Now that I had done development on the Linux platform, I was sold on it.
|
||||
|
||||
By 2000, IBM's use of Linux was growing rapidly. Due to the vision and persistence of [Dan Frye][8], IBM made a "[billion dollar bet][9]" on Linux, creating the Linux Technology Center (LTC) in 1999. Inside the LTC were kernel developers, open source contributors, device driver authors for IBM hardware, and all manner of Linux-focused open source work. Instead of remaining tangentially connected to the LTC, I wanted to be part of this exciting new area at IBM.
|
||||
|
||||
From 2003 to 2013 I was deeply involved in IBM's Linux strategy and use of Linux distributions, culminating with having a team that became the clearinghouse for about 60 different product uses of Linux across every division of IBM. I was involved in acquisitions where it was an expectation that every appliance, management system, and virtual or physical appliance-based middleware ran Linux. I became well-versed in the construction of Linux distributions, including packaging, selecting upstream sources, developing distro-maintained patch sets, doing customizations, and offering support through our distro partners.
|
||||
|
||||
Due to our downstream providers, I rarely got to submit patches upstream, but I got to contribute by interacting with [Ulrich Drepper][10] (including getting a small patch into glibc) and working on changes to the [timezone database][11], which Arthur David Olson accepted while he was maintaining it on the NIH FTP site. But I still hadn't worked as a regular contributor on an open source project as part of my work. It was time for that to change.
|
||||
|
||||
In late 2013, I joined IBM's cloud organization in the open source group and was looking for an upstream community in which to get involved. Would it be our work on Cloud Foundry, or would I join IBM's large group of contributors to OpenStack? It was neither, because in 2014 Docker took the world by storm, and IBM asked a few of us to get involved with this hot new technology. I experienced many firsts in the next few months: using GitHub, [learning a lot more about Git][12] than just `git clone`, having pull requests reviewed, writing in Go, and more. Over the next year, I became a maintainer in the Docker engine project, working with Docker on creating the next version of the image specification (to support multiple architectures), and attending and speaking at conferences about container technology.
|
||||
|
||||
### Where I am today
|
||||
|
||||
Fast forward a few years, and I've become a maintainer of open source projects, including the Cloud Native Computing Foundation (CNCF) [containerd][13] project. I've also created projects (such as [manifest-tool][14] and [bucketbench][15]). I've gotten involved in open source governance via the Open Containers Initiative (OCI), where I'm now a member of the Technical Oversight Board, and the Moby Project, where I'm a member of the Technical Steering Committee. And I've had the pleasure of speaking about open source at conferences around the world, to meetup groups, and internally at IBM.
|
||||
|
||||
Open source is now part of the fiber of my career at IBM. The connections I've made to engineers, developers, and leaders across the industry may rival the number of people I know and work with inside IBM. While open source has many of the same challenges as proprietary development teams and vendor partnerships have, in my experience the relationships and connections with people around the globe in open source far outweigh the difficulties. The sharpening that occurs with differing opinions, perspectives, and experiences can generate a culture of learning and improvement for both the software and the people involved.
|
||||
|
||||
This journey—from my first use of Linux to becoming a leader, contributor, and maintainer in today's cloud-native open source world—has been extremely rewarding. I'm looking forward to many more years of open source collaboration and interactions with people around the globe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
@ -0,0 +1,91 @@
|
||||
4 considerations when naming software development projects
|
||||
======
|
||||
|
||||

|
||||
|
||||
Working on a new open source project, you're focused on the code—getting that great new idea released so you can share it with the world. And you'll want to attract new contributors, so you need a terrific **name** for your project.
|
||||
|
||||
We've all read guides for creating names, but how do you go about choosing the right one? Keeping that cool science fiction reference you're using internally might feel fun, but it won't mean much to new users you're trying to attract. A better approach is to choose a name that's memorable to new users and developers searching for your project.
|
||||
|
||||
Names set expectations. Your project's name should showcase its functionality in the ecosystem and explain to users what your story is. In the crowded open source software world, it's important not to get entangled with other projects out there. Taking a little extra time now, before sending out that big announcement, will pay off later.
|
||||
|
||||
Here are four factors to keep in mind when choosing a name for your project.
|
||||
|
||||
### What does your project's code do?
|
||||
|
||||
Start with your project: What does it do? You know the code intimately—but can you explain what it does to a new developer? Can you explain it to a CTO or non-developer at another company? What kinds of problems does your project solve for users?
|
||||
|
||||
Your project's name needs to reflect what it does in a way that makes sense to newcomers who want to use or contribute to your project. That means considering the ecosystem for your technology and understanding if there are any naming styles or conventions used for similar kinds of projects. Imagine that you're trying to evaluate someone else's project: Would the name be appealing to you?
|
||||
|
||||
Any distribution channels you push to are also part of the ecosystem. If your code will be in a Linux distribution, [npm][1], [CPAN][2], [Maven][3], or in a Ruby Gem, you need to review any naming standards or common practices for that package manager. Review any similar existing names in that distribution channel, and get a feel for naming styles of other programs there.
|
||||
|
||||
### Who are the users and developers you want to attract?
|
||||
|
||||
The hardest aspect of choosing a new name is putting yourself in the shoes of new users. You built this project; you already know how powerful it is, so while your cool name may sound great, it might not draw in new people. You need a name that is interesting to someone new, and that tells the world what problems your project solves.
|
||||
|
||||
Great names depend on what kind of users you want to attract. Are you building an [Eclipse][4] plugin or npm module that's focused on developers? Or an analytics toolkit that brings visualizations to the average user? Understanding your user base and the kinds of open source contributors you want to attract is critical.
|
||||
|
||||
Great names depend on what kind of users you want to attract.
|
||||
|
||||
Take the time to think this through. Who does your project most appeal to, and how can it help them do their job? What kinds of problems does your code solve for end users? Understanding the target user helps you focus on what users need, and what kind of names or brands they respond to.
|
||||
|
||||
Take the time to think this through. Who does your project most appeal to, and how can it help them do their job? What kinds of problems does your code solve for end users? Understanding the target user helps you focus on what users need, and what kind of names or brands they respond to.
|
||||
|
||||
When you're open source, this equation changes a bit—your target is not just users; it's also developers who will want to contribute code back to your project. You're probably a developer, too: What kinds of names and brands excite you, and what images would entice you to try out someone else's new project?
|
||||
|
||||
Once you have a better feel of what users and potential contributors expect, use that knowledge to refine your names. Remember, you need to step outside your project and think about how the name would appeal to someone who doesn't know how amazing your code is—yet. Once someone gets to your website, does the name synchronize with what your product does? If so, move to the next step.
|
||||
|
||||
### Who else is using similar names for software?
|
||||
|
||||
Now that you've tried on a user's shoes to evaluate potential names, what's next? Figuring out if anyone else is already using a similar name. It sometimes feels like all the best names are taken—but if you search carefully, you'll find that's not true.
|
||||
|
||||
The first step is to do a few web searches using your proposed name. Search for the name, plus "software", "open source", and a few keywords for the functionality that your code provides. Look through several pages of results for each search to see what's out there in the software world.
|
||||
|
||||
The first step is to do a few web searches using your proposed name.
|
||||
|
||||
Unless you're using a completely made-up word, you'll likely get a lot of hits. The trick is understanding which search results might be a problem. Again, put on the shoes of a new user to your project. If you were searching for this great new product and saw the other search results along with your project's homepage, would you confuse them? Are the other search results even software products? If your product solves a similar problem to other search results, that's a problem: Users may gravitate to an existing product instead of a new one.
|
||||
|
||||
Unless you're using a completely made-up word, you'll likely get a lot of hits. The trick is understanding which search results might be a problem. Again, put on the shoes of a new user to your project. If you were searching for this great new product and saw the other search results along with your project's homepage, would you confuse them? Are the other search results even software products? If your product solves a similar problem to other search results, that's a problem: Users may gravitate to an existing product instead of a new one.
|
||||
|
||||
Similar non-software product names are rarely an issue unless they are famous trademarks—like Nike or Red Bull, for example—where the companies behind them won't look kindly on anyone using a similar name. Using the same name as a less famous non-software product might be OK, depending on how big your project gets.
|
||||
|
||||
### How big do you plan to grow your project?
|
||||
|
||||
Are you building a new node module or command-line utility, but not planning a career around it? Is your new project a million-dollar business idea, and you're thinking startup? Or is it something in between?
|
||||
|
||||
If your project is a basic developer utility—something useful that developers will integrate into their workflow—then you have enough data to choose a name. Think through the ecosystem and how a new user would see your potential names, and pick one. You don't need perfection, just a name you're happy with that seems right for your project.
|
||||
|
||||
If you're planning to build a business around your project, use these tips to develop a shortlist of names, but do more vetting before announcing the winner. Use for a business or major project requires some level of registered trademark search, which is usually performed by a law firm.
|
||||
|
||||
### Common pitfalls
|
||||
|
||||
Finally, when choosing a name, avoid these common pitfalls:
|
||||
|
||||
* Using an esoteric acronym. If new users don't understand the name, they'll have a hard time finding you.
|
||||
|
||||
* Using current pop-culture references. If you want your project's appeal to last, pick a name that will last.
|
||||
|
||||
* Failing to consider non-English speakers. Does the name have a specific meaning in another language that might be confusing?
|
||||
|
||||
* Using off-color jokes or potentially unsavory references. Even if it seems funny to developers, it may fall flat for newcomers and turn away contributors.
|
||||
|
||||
|
||||
|
||||
|
||||
Good luck—and remember to take the time to step out of your shoes and consider how a newcomer to your project will think of the name.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/choosing-project-names-four-key-considerations
|
||||
|
||||
作者:[Shane Curcuru][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/shane-curcuru
|
||||
[1]:https://www.npmjs.com/
|
||||
[2]:https://www.cpan.org/
|
||||
[3]:https://maven.apache.org/
|
||||
[4]:https://www.eclipse.org/
|
||||
@ -0,0 +1,55 @@
|
||||
Translating by MjSeven
|
||||
|
||||
How slowing down made me a better leader
|
||||
======
|
||||
|
||||

|
||||
|
||||
Early in my career, I thought the most important thing I could do was act. If my boss said jump, my reply was "how high?"
|
||||
|
||||
But as I've grown as a leader and manager, I've realized that the most important traits I can offer are [patience][1] and listening. This patience and listening means I'm focusing on what's really important. I'm decisive, so I do not hesitate to act. Yet I've learned that my actions are more impactful when I consider input from multiple sources and offer advice on what we should be doing—not simply reacting to an immediate request.
|
||||
|
||||
Practicing open leadership involves cultivating the patience and listening skills I need to collaborate on the [best plan of action, not just the quickest one][2]. It also gives me the tools I need to explain [why I'm saying "no"][3] (or, perhaps, "not now") to someone, so I can lead with transparency and confidence.
|
||||
|
||||
If you're in software development and practice scrum, then the following argument might resonate with you: The patience and listening a manager displays are as important as her skills in sprint planning and running the sprint demo. Forget about them, and you'll lessen the impact you're able to have.
|
||||
|
||||
### A focus on patience
|
||||
|
||||
Focus and patience do not always come easily. Often, I find myself sitting in meetings and filling my notebook with action items. My default action can be to think: "We can simply do x and y will improve!" Then I remember that things are not so linear.
|
||||
|
||||
I need to think about the other factors that can influence a situation. Pausing to take in data from multiple people and resources helps me flesh out a strategy that our organization needs for long-term success. It also helps me identify those shorter-term milestones that should lead us to deliver the business results I'm responsible for producing.
|
||||
|
||||
Here's a great example from a time when patience wasn't something I valued as I should have—and how that hurt my performance. When I was based on North Carolina, I worked with someone based in Arizona. We didn't use video conferencing technologies, so I didn't get to observe her body language when we talked. While I was responsible for delivering the results for the project I led, she was one of the two people tasked with making sure I had adequate support.
|
||||
|
||||
For whatever reason, when I talked with this person, when she asked me to do something, I did it. She would be providing input on my performance evaluation, so I wanted to make sure she was happy. At the time, I didn't possess the maturity to know I didn't need to make her happy; my focus should have been on other performance indicators. I should have spent more time listening and collaborating with her instead of picking up the first "action item" and working on it while she was still talking.
|
||||
|
||||
After six months on the job, this person gave me some tough feedback. I was angry and sad. Didn't I do everything she'd asked? I had worked long hours, nearly seven days a week for six months. How dare she criticize my performance?
|
||||
|
||||
Then, after I had my moment of anger followed by sadness, I thought about what she said. Her feedback was on point.
|
||||
|
||||
The patience and listening a manager displays are as important as her skills in sprint planning and running the sprint demo.
|
||||
|
||||
She had concerns about the project, and she held me accountable because I was responsible. We worked through the issues, and I learned that vital lesson about how to lead: Leadership does not mean "get it done right now." Leadership means putting together a strategy, then communicating and implementing plans in support of the strategy. It also means making mistakes and learning from these hiccups.
|
||||
|
||||
### Lesson learned
|
||||
|
||||
In hindsight, I realize I could have asked more questions to better understand the intent of her feedback. I also could have pushed back if the guidance from her did not align with other input I was receiving. By having the patience to listen to the various sources giving me input about the project, synthesizing what I learned, and creating a coherent plan for action, I would have been a better leader. I also would have had more purpose driving the work I was doing. Instead of reacting to a single data point, I would have been implementing a strategic plan. I also would have had a better performance evaluation.
|
||||
|
||||
I eventually had some feedback for her. Next time we worked together, I didn't want to hear the feedback after six months. I wanted to hear the feedback earlier and more often so I could learn from the mistakes sooner. An ongoing discussion about the work is what should happen on any team.
|
||||
|
||||
As I mature as a manager and leader, I hold myself to the same standards I ask my team to meet: Plan, work the plan, and reflect. Repeat. Don't let a fire drill created by an external force distract you from the plan you need to implement. Breaking work into small increments builds in space for reflections and adjustments to the plan. As Daniel Goleman writes, "Directing attention toward where it needs to go is a primal task of leadership." Don't be afraid of meeting this challenge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/2/open-leadership-patience-listening
|
||||
|
||||
作者:[Angela Robertson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/arobertson98
|
||||
[1]:https://opensource.com/open-organization/16/3/my-most-difficult-leadership-lesson
|
||||
[2]:https://opensource.com/open-organization/16/3/fastest-result-isnt-always-best-result
|
||||
[3]:https://opensource.com/open-organization/17/5/saying-no-open-organization
|
||||
105
sources/talk/20180222 3 reasons to say -no- in DevOps.md
Normal file
105
sources/talk/20180222 3 reasons to say -no- in DevOps.md
Normal file
@ -0,0 +1,105 @@
|
||||
3 reasons to say 'no' in DevOps
|
||||
======
|
||||
|
||||

|
||||
|
||||
DevOps, it has often been pointed out, is a culture that emphasizes mutual respect, cooperation, continual improvement, and aligning responsibility with authority.
|
||||
|
||||
Instead of saying no, it may be helpful to take a hint from improv comedy and say, "Yes, and..." or "Yes, but...". This opens the request from the binary nature of "yes" and "no" toward having a nuanced discussion around priority, capacity, and responsibility.
|
||||
|
||||
However, sometimes you have no choice but to give a hard "no." These should be rare and exceptional, but they will occur.
|
||||
|
||||
### Protecting yourself
|
||||
|
||||
Both Agile and DevOps have been touted as ways to improve value to the customer and business, ultimately leading to greater productivity. While reasonable people can understand that the improvements will take time to yield, and the improvements will result in higher quality of work being done, and a better quality of life for those performing it, I think we can all agree that not everyone is reasonable. The less understanding that a person has of the particulars of a given task, the more likely they are to expect that it is a combination of "simple" and "easy."
|
||||
|
||||
"You told me that [Agile/DevOps] is supposed to be all about us getting more productivity. Since we're doing [Agile/DevOps] now, you can take care of my need, right?"
|
||||
|
||||
Like "Agile," some people have tried to use "DevOps" as a stick to coerce people to do more work than they can handle. Whether the person confronting you with this question is asking in earnest or is being manipulative doesn't really matter.
|
||||
|
||||
The biggest areas of concern for me have been **capacity** , **firefighting/maintenance** , **level of quality** , and **" future me."** Many of these ultimately tie back to capacity, but they relate to a long-term effort in different respects.
|
||||
|
||||
#### Capacity
|
||||
|
||||
Capacity is simple: You know what your workload is, and how much flex occurs due to the unexpected. Exceeding your capacity will not only cause undue stress, but it could decrease the quality of your work and can injure your reputation with regards to making commitments.
|
||||
|
||||
There are several avenues of discussion that can happen from here. The simplest is "Your request is reasonable, but I don't have the capacity to work on it." This seldom ends the conversation, and a discussion will often run up the flagpole to clarify priorities or reassign work.
|
||||
|
||||
#### Firefighting/maintenance
|
||||
|
||||
It's possible that the thing that you're being asked for won't take long to do, but it will require maintenance that you'll be expected to perform, including keeping it alive and fulfilling requests for it on behalf of others.
|
||||
|
||||
An example in my mind is the Jenkins server that you're asked to stand up for someone else, but somehow end up being the sole owner and caretaker of. Even if you're careful to scope your level of involvement early on, you might be saddled with responsibility that you did not agree to. Should the service become unavailable, for example, you might be the one who is called. You might be called on to help triage a build that is failing. This is additional firefighting and maintenance work that you did not sign up for and now must fend off.
|
||||
|
||||
This needs to be addressed as soon and publicly as possible. I'm not saying that (again, for example) standing up a Jenkins instance is a "no," but rather a ["Yes, but"][1]—where all parties understand that they take on the long-term care, feeding, and use of the product. Make sure to include all your bosses in this conversation so they can have your back.
|
||||
|
||||
#### Level of quality
|
||||
|
||||
There may be times when you are presented with requirements that include a timeframe that is...problematic. Perhaps you could get a "minimum (cough) viable (cough) product" out in that time. But it wouldn't be resilient or in any way ready for production. It might impact your time and productivity. It could end up hurting your reputation.
|
||||
|
||||
The resulting conversation can get into the weeds, with lots of horse-trading about time and features. Another approach is to ask "What is driving this deadline? Where did that timeframe come from?" Discussing the bigger picture might lead to a better option, or that the timeline doesn't depend on the original date.
|
||||
|
||||
#### Future me
|
||||
|
||||
Ultimately, we are trying to protect "future you." These are lessons learned from the many times that "past me" has knowingly left "current me" to clean up. Sometimes we joke that "that's a problem for 'future me,'" but don't forget that 'future you' will just be 'you' eventually. I've cursed "past me" as a jerk many times. Do your best to keep other people from making "past you" be a jerk to "future you."
|
||||
|
||||
I recognize that I have a significant amount of privilege in this area, but if you are told that you cannot say "no" on behalf of your own welfare, you should consider whether you are respected enough to maintain your autonomy.
|
||||
|
||||
### Protecting the user experience
|
||||
|
||||
Everyone should be an advocate for the user. Regardless of whether that user is right next to you, someone down the hall, or someone you have never met and likely never will, you must care for the customer.
|
||||
|
||||
Behavior that is actively hostile to the user—whether it's a poor user experience or something more insidious like quietly violating reasonable expectations of privacy—deserves a "no." A common example of this would be automatically including people into a service or feature, forcing them to explicitly opt-out.
|
||||
|
||||
If a "no" is not welcome, it bears considering, or explicitly asking, what the company's relationship with its customers is, who the company thinks of as it's customers, and what it thinks of them.
|
||||
|
||||
When bringing up your objections, be clear about what they are. Additionally, remember that your coworkers are people too, and make it clear that you are not attacking their character; you simply find the idea disagreeable.
|
||||
|
||||
### Legal, ethical, and moral grounds
|
||||
|
||||
There might be situations that don't feel right. A simple test is to ask: "If this were to become public, or come up in a lawsuit deposition, would it be a scandal?"
|
||||
|
||||
#### Ethics and morals
|
||||
|
||||
If you are asked to lie, that should be a hard no.
|
||||
|
||||
Remember if you will the Volkswagen Emissions Scandal of 2017? The emissions systems software was written such that it recognized that the vehicle was operated in a manner consistent with an emissions test, and would run more efficiently than under normal driving conditions.
|
||||
|
||||
I don't know what you do in your job, or what your office is like, but I have a hard time imagining the Individual Contributor software engineer coming up with that as a solution on their own. In fact, I imagine a comment along the lines of "the engine engineers can't make their product pass the tests, so I need to hack the performance so that it will!"
|
||||
|
||||
When the Volkswagen scandal came public, Volkswagen officials blamed the engineers. I find it unlikely that it came from the mind and IDE of an individual software engineer. Rather, it's more likely indicates significant systemic problems within the company culture.
|
||||
|
||||
If you are asked to lie, get the request in writing, citing that the circumstances are suspect. If you are so privileged, decide whether you may decline the request on the basis that it is fundamentally dishonest and hostile to the customer, and would break the public's trust.
|
||||
|
||||
#### Legal
|
||||
|
||||
I am not a lawyer. If your work should involve legal matters, including requests from law enforcement, involve your company's legal counsel or speak with a private lawyer.
|
||||
|
||||
With that said, if you are asked to provide information for law enforcement, I believe that you are within your rights to see the documentation that justifies the request. There should be a signed warrant. You should be provided with a copy of it, or make a copy of it yourself.
|
||||
|
||||
When in doubt, begin recording and request legal counsel.
|
||||
|
||||
It has been well documented that especially in the early years of the U.S. Patriot Act, law enforcement placed so many requests of telecoms that they became standard work, and the paperwork started slipping. While tedious and potentially stressful, make sure that the legal requirements for disclosure are met.
|
||||
|
||||
If for no other reason, we would not want the good work of law enforcement to be put at risk because key evidence was improperly acquired, making it inadmissible.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
You are going to be your single biggest advocate. There may be times when you are asked to compromise for the greater good. However, you should feel that your dignity is preserved, your autonomy is respected, and that your morals remain intact.
|
||||
|
||||
If you don't feel that this is the case, get it on record, doing your best to communicate it calmly and clearly.
|
||||
|
||||
Nobody likes being declined, but if you don't have the ability to say no, there may be a bigger problem than your environment not being DevOps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/3-reasons-say-no-devops
|
||||
|
||||
作者:[H. "Waldo" Grunenwal][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/gwaldo
|
||||
[1]:http://gwaldo.blogspot.com/2015/12/fear-and-loathing-in-systems.html
|
||||
@ -1,84 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to use lftp to accelerate ftp/https download speed on Linux/UNIX
|
||||
======
|
||||
lftp is a file transfer program. It allows sophisticated FTP, HTTP/HTTPS, and other connections. If the site URL is specified, then lftp will connect to that site otherwise a connection has to be established with the open command. It is an essential tool for all a Linux/Unix command line users. I have already written about [Linux ultra fast command line download accelerator][1] such as Axel and prozilla. lftp is another tool for the same job with more features. lftp can handle seven file access methods:
|
||||
|
||||
1. ftp
|
||||
2. ftps
|
||||
3. http
|
||||
4. https
|
||||
5. hftp
|
||||
6. fish
|
||||
7. sftp
|
||||
8. file
|
||||
|
||||
|
||||
|
||||
### So what is unique about lftp?
|
||||
|
||||
* Every operation in lftp is reliable, that is any not fatal error is ignored, and the operation is repeated. So if downloading breaks, it will be restarted from the point automatically. Even if FTP server does not support REST command, lftp will try to retrieve the file from the very beginning until the file is transferred completely.
|
||||
* lftp has shell-like command syntax allowing you to launch several commands in parallel in the background.
|
||||
* lftp has a builtin mirror which can download or update a whole directory tree. There is also a reverse mirror (mirror -R) which uploads or updates a directory tree on the server. The mirror can also synchronize directories between two remote servers, using FXP if available.
|
||||
|
||||
|
||||
|
||||
### How to use lftp as download accelerator
|
||||
|
||||
lftp has pget command. It allows you download files in parallel. The syntax is
|
||||
`lftp -e 'pget -n NUM -c url; exit'`
|
||||
For example, download <http://kernel.org/pub/linux/kernel/v2.6/linux-2.6.22.2.tar.bz2> file using pget in 5 parts:
|
||||
```
|
||||
$ cd /tmp
|
||||
$ lftp -e 'pget -n 5 -c http://kernel.org/pub/linux/kernel/v2.6/linux-2.6.22.2.tar.bz2'
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
45108964 bytes transferred in 57 seconds (775.3K/s)
|
||||
lftp :~>quit
|
||||
|
||||
```
|
||||
|
||||
Where,
|
||||
|
||||
1. pget – Download files in parallel
|
||||
2. -n 5 – Set maximum number of connections to 5
|
||||
3. -c – Continue broken transfer if lfile.lftp-pget-status exists in the current directory
|
||||
|
||||
|
||||
|
||||
### How to use lftp to accelerate ftp/https download on Linux/Unix
|
||||
|
||||
Another try with added exit command:
|
||||
`$ lftp -e 'pget -n 10 -c https://cdn.kernel.org/pub/linux/kernel/v4.x/linux-4.15.tar.xz; exit'`
|
||||
|
||||
[Linux-lftp-command-demo][https://www.cyberciti.biz/tips/wp-content/uploads/2007/08/Linux-lftp-command-demo.mp4]
|
||||
|
||||
### A note about parallel downloading
|
||||
|
||||
Please note that by using download accelerator you are going to put a load on remote host. Also note that lftp may not work with sites that do not support multi-source downloads or blocks such requests at firewall level.
|
||||
|
||||
NA command offers many other features. Refer to [lftp][2] man page for more information:
|
||||
`man lftp`
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][3], [Facebook][4], [Google+][5]. Get the **latest tutorials on SysAdmin, Linux/Unix and open source topics via[my RSS/XML feed][6]**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-download-accelerator.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/tips/download-accelerator-for-linux-command-line-tools.html
|
||||
[2]:https://lftp.yar.ru/
|
||||
[3]:https://twitter.com/nixcraft
|
||||
[4]:https://facebook.com/nixcraft
|
||||
[5]:https://plus.google.com/+CybercitiBiz
|
||||
[6]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -1,220 +0,0 @@
|
||||
translating by ucasFL
|
||||
|
||||
How does gdb work?
|
||||
============================================================
|
||||
|
||||
Hello! Today I was working a bit on my [ruby stacktrace project][1] and I realized that now I know a couple of things about how gdb works internally.
|
||||
|
||||
Lately I’ve been using gdb to look at Ruby programs, so we’re going to be running gdb on a Ruby program. This really means the Ruby interpreter. First, we’re going to print out the address of a global variable: `ruby_current_thread`:
|
||||
|
||||
### getting a global variable
|
||||
|
||||
Here’s how to get the address of the global `ruby_current_thread`:
|
||||
|
||||
```
|
||||
$ sudo gdb -p 2983
|
||||
(gdb) p & ruby_current_thread
|
||||
$2 = (rb_thread_t **) 0x5598a9a8f7f0 <ruby_current_thread>
|
||||
|
||||
```
|
||||
|
||||
There are a few places a variable can live: on the heap, the stack, or in your program’s text. Global variables are part of your program! You can think of them as being allocated at compile time, kind of. It turns out we can figure out the address of a global variable pretty easily! Let’s see how `gdb` came up with `0x5598a9a8f7f0`.
|
||||
|
||||
We can find the approximate region this variable lives in by looking at a cool file in `/proc` called `/proc/$pid/maps`.
|
||||
|
||||
```
|
||||
$ sudo cat /proc/2983/maps | grep bin/ruby
|
||||
5598a9605000-5598a9886000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a86000-5598a9a8b000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a8b000-5598a9a8d000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
|
||||
```
|
||||
|
||||
So! There’s this starting address `5598a9605000` That’s _like_ `0x5598a9a8f7f0`, but different. How different? Well, here’s what I get when I subtract them:
|
||||
|
||||
```
|
||||
(gdb) p/x 0x5598a9a8f7f0 - 0x5598a9605000
|
||||
$4 = 0x48a7f0
|
||||
|
||||
```
|
||||
|
||||
“What’s that number?”, you might ask? WELL. Let’s look at the **symbol table**for our program with `nm`.
|
||||
|
||||
```
|
||||
sudo nm /proc/2983/exe | grep ruby_current_thread
|
||||
000000000048a7f0 b ruby_current_thread
|
||||
|
||||
```
|
||||
|
||||
What’s that we see? Could it be `0x48a7f0`? Yes it is! So!! If we want to find the address of a global variable in our program, all we need to do is look up the name of the variable in the symbol table, and then add that to the start of the range in `/proc/whatever/maps`, and we’re done!
|
||||
|
||||
So now we know how gdb does that. But gdb does so much more!! Let’s skip ahead to…
|
||||
|
||||
### dereferencing pointers
|
||||
|
||||
```
|
||||
(gdb) p ruby_current_thread
|
||||
$1 = (rb_thread_t *) 0x5598ab3235b0
|
||||
|
||||
```
|
||||
|
||||
The next thing we’re going to do is **dereference** that `ruby_current_thread`pointer. We want to see what’s in that address! To do that, gdb will run a bunch of system calls like this:
|
||||
|
||||
```
|
||||
ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
|
||||
|
||||
```
|
||||
|
||||
You remember this address `0x5598a9a8f7f0`? gdb is asking “hey, what’s in that address exactly”? `2983` is the PID of the process we’re running gdb on. It’s using the `ptrace` system call which is how gdb does everything.
|
||||
|
||||
Awesome! So we can dereference memory and figure out what bytes are at what memory addresses. Some useful gdb commands to know here are `x/40w variable` and `x/40b variable` which will display 40 words / bytes at a given address, respectively.
|
||||
|
||||
### describing structs
|
||||
|
||||
The memory at an address looks like this. A bunch of bytes!
|
||||
|
||||
```
|
||||
(gdb) x/40b ruby_current_thread
|
||||
0x5598ab3235b0: 16 -90 55 -85 -104 85 0 0
|
||||
0x5598ab3235b8: 32 47 50 -85 -104 85 0 0
|
||||
0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
|
||||
0x5598ab3235c8: 0 0 2 0 0 0 0 0
|
||||
0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
|
||||
|
||||
```
|
||||
|
||||
That’s useful, but not that useful! If you are a human like me and want to know what it MEANS, you need more. Like this:
|
||||
|
||||
```
|
||||
(gdb) p *(ruby_current_thread)
|
||||
$8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
|
||||
stack_size = 131072, cfp = 0x7f9f73d9ada0, safe_level = 0, raised_flag = 0,
|
||||
last_status = 8, state = 0, waiting_fd = -1, passed_block = 0x0,
|
||||
passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
|
||||
top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
|
||||
140322820187904,
|
||||
|
||||
```
|
||||
|
||||
GOODNESS. That is a lot more useful. How does gdb know that there are all these cool fields like `stack_size`? Enter DWARF. DWARF is a way to store extra debugging data about your program, so that debuggers like gdb can do their job better! It’s generally stored as part of a binary. If I run `dwarfdump` on my Ruby binary, I get some output like this:
|
||||
|
||||
(I’ve redacted it heavily to make it easier to understand)
|
||||
|
||||
```
|
||||
DW_AT_name "rb_thread_struct"
|
||||
DW_AT_byte_size 0x000003e8
|
||||
DW_TAG_member
|
||||
DW_AT_name "self"
|
||||
DW_AT_type <0x00000579>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 0
|
||||
DW_TAG_member
|
||||
DW_AT_name "vm"
|
||||
DW_AT_type <0x0000270c>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 8
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack"
|
||||
DW_AT_type <0x000006b3>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 16
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack_size"
|
||||
DW_AT_type <0x00000031>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 24
|
||||
DW_TAG_member
|
||||
DW_AT_name "cfp"
|
||||
DW_AT_type <0x00002712>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 32
|
||||
DW_TAG_member
|
||||
DW_AT_name "safe_level"
|
||||
DW_AT_type <0x00000066>
|
||||
|
||||
```
|
||||
|
||||
So. The name of the type of `ruby_current_thread` is `rb_thread_struct`. It has size `0x3e8` (or 1000 bytes), and it has a bunch of member items. `stack_size` is one of them, at an offset of 24, and it has type 31\. What’s 31? No worries! We can look that up in the DWARF info too!
|
||||
|
||||
```
|
||||
< 1><0x00000031> DW_TAG_typedef
|
||||
DW_AT_name "size_t"
|
||||
DW_AT_type <0x0000003c>
|
||||
< 1><0x0000003c> DW_TAG_base_type
|
||||
DW_AT_byte_size 0x00000008
|
||||
DW_AT_encoding DW_ATE_unsigned
|
||||
DW_AT_name "long unsigned int"
|
||||
|
||||
```
|
||||
|
||||
So! `stack_size` has type `size_t`, which means `long unsigned int`, and is 8 bytes. That means that we can read the stack size!
|
||||
|
||||
How that would break down, once we have the DWARF debugging data, is:
|
||||
|
||||
1. Read the region of memory that `ruby_current_thread` is pointing to
|
||||
|
||||
2. Add 24 bytes to get to `stack_size`
|
||||
|
||||
3. Read 8 bytes (in little-endian format, since we’re on x86)
|
||||
|
||||
4. Get the answer!
|
||||
|
||||
Which in this case is 131072 or 128 kb.
|
||||
|
||||
To me, this makes it a lot more obvious what debugging info is **for** – if we didn’t have all this extra metadata about what all these variables meant, we would have no idea what the bytes at address `0x5598ab3235b0` meant.
|
||||
|
||||
This is also why you can install debug info for a program separately from your program – gdb doesn’t care where it gets the extra debug info from.
|
||||
|
||||
### DWARF is confusing
|
||||
|
||||
I’ve been reading a bunch of DWARF info recently. Right now I’m using libdwarf which hasn’t been the best experience – the API is confusing, you initialize everything in a weird way, and it’s really slow (it takes 0.3 seconds to read all the debugging data out of my Ruby program which seems ridiculous). I’ve been told that libdw from elfutils is better.
|
||||
|
||||
Also, I casually remarked that you can look at `DW_AT_data_member_location` to get the offset of a struct member! But I looked up on Stack Overflow how to actually do that and I got [this answer][2]. Basically you start with a check like:
|
||||
|
||||
```
|
||||
dwarf_whatform(attrs[i], &form, &error);
|
||||
if (form == DW_FORM_data1 || form == DW_FORM_data2
|
||||
form == DW_FORM_data2 || form == DW_FORM_data4
|
||||
form == DW_FORM_data8 || form == DW_FORM_udata) {
|
||||
|
||||
```
|
||||
|
||||
and then it keeps GOING. Why are there 8 million different `DW_FORM_data` things I need to check for? What is happening? I have no idea.
|
||||
|
||||
Anyway my impression is that DWARF is a large and complicated standard (and possibly the libraries people use to generate DWARF are subtly incompatible?), but it’s what we have, so that’s what we work with!
|
||||
|
||||
I think it’s really cool that I can write code that reads DWARF and my code actually mostly works. Except when it crashes. I’m working on that.
|
||||
|
||||
### unwinding stacktraces
|
||||
|
||||
In an earlier version of this post, I said that gdb unwinds stacktraces using libunwind. It turns out that this isn’t true at all!
|
||||
|
||||
Someone who’s worked on gdb a lot emailed me to say that they actually spent a ton of time figuring out how to unwind stacktraces so that they can do a better job than libunwind does. This means that if you get stopped in the middle of a weird program with less debug info than you might hope for that’s done something strange with its stack, gdb will try to figure out where you are anyway. Thanks <3
|
||||
|
||||
### other things gdb does
|
||||
|
||||
The few things I’ve described here (reading memory, understanding DWARF to show you structs) aren’t everything gdb does – just looking through Brendan Gregg’s [gdb example from yesterday][3], we see that gdb also knows how to
|
||||
|
||||
* disassemble assembly
|
||||
|
||||
* show you the contents of your registers
|
||||
|
||||
and in terms of manipulating your program, it can
|
||||
|
||||
* set breakpoints and step through a program
|
||||
|
||||
* modify memory (!! danger !!)
|
||||
|
||||
Knowing more about how gdb works makes me feel a lot more confident when using it! I used to get really confused because gdb kind of acts like a C REPL sometimes – you type `ruby_current_thread->cfp->iseq`, and it feels like writing C code! But you’re not really writing C at all, and it was easy for me to run into limitations in gdb and not understand why.
|
||||
|
||||
Knowing that it’s using DWARF to figure out the contents of the structs gives me a better mental model and have more correct expectations! Awesome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://jvns.ca/blog/2016/06/12/a-weird-system-call-process-vm-readv/
|
||||
[2]:https://stackoverflow.com/questions/25047329/how-to-get-struct-member-offset-from-dwarf-info
|
||||
[3]:http://www.brendangregg.com/blog/2016-08-09/gdb-example-ncurses.html
|
||||
@ -1,139 +0,0 @@
|
||||
Ultimate guide to securing SSH sessions
|
||||
======
|
||||
Hi Linux-fanatics, in this tutorial we will be discussing some ways with which we make our ssh server more secure. OpenSSH is currently used by default to work on servers as physical access to servers is very limited. We use ssh to copy/backup files/folders, to remotely execute commands etc. But these ssh connections might not be as secure as we believee & we must make some changes to our default settings to make them more secure.
|
||||
|
||||
Here are steps needed to secure our ssh sessions,
|
||||
|
||||
### Use complex username & password
|
||||
|
||||
This is first of the problem that needs to be addressed, I have known users who have '12345' as their password. It seems they are inviting hackers to get themselves hacked. You should always have a complex password.
|
||||
|
||||
It should have at-least 8 characters with numbers & alphabets, lower case & upper case letter, and also special characters. A good example would be " ** ** _vXdrf23#$wd_**** " , it is not a word so dictionary attack will be useless & has uppercase, lowercase characters, numbers & special characters.
|
||||
|
||||
### Limit user logins
|
||||
|
||||
Not all the users are required to have access to ssh in an organization, so we should make changes to our configuration file to limit user logins. Let's say only Bob & Susan are authorized have access to ssh, so open your configuration file
|
||||
|
||||
```
|
||||
$ vi /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
& add the allowed users to the bottom of the file
|
||||
|
||||
```
|
||||
AllowUsers bob susan
|
||||
```
|
||||
|
||||
Save the file & restart the service. Now only Bob & Susan will have access to ssh , others won't be able to access ssh.
|
||||
|
||||
### Configure Idle logout time
|
||||
|
||||
|
||||
Once logged into ssh sessions, there is default time before sessions logs out on it own. By default idle logout time is 60 minutes, which according to me is way to much. Consider this, you logged into a session , executed some commands & then went out to get a cup of coffee but you forgot to log-out of the ssh. Just think what could be done in the 60 seconds, let alone in 60 minutes.
|
||||
|
||||
So, its wise to reduce idle log-out time to something around 5 minutes & it can be done in config file only. Open '/etc/ssh/sshd_config' & change the values
|
||||
|
||||
```
|
||||
ClientAliveInterval 300
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
|
||||
Its in seconds, so configure them accordingly.
|
||||
|
||||
### Disable root logins
|
||||
|
||||
As we know root have access to anything & everything on the server, so we must disable root access through ssh session. Even if it is needed to complete a task that only root can do, we can escalate the privileges of a normal user.
|
||||
|
||||
To disable root access, open your configuration file & change the following parameter
|
||||
|
||||
```
|
||||
PermitRootLogin no
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
|
||||
This will disable root access to ssh sessions.
|
||||
|
||||
### Enable Protocol 2
|
||||
|
||||
SSH protocol 1 had man in the middle attack issues & other security issues as well, all these issues were addressed in Protocol 2. So protocol 1 must not be used at any cost. To change the protocol , open your sshd_config file & change the following parameter
|
||||
|
||||
```
|
||||
Protocol 2
|
||||
```
|
||||
|
||||
### Enable a warning screen
|
||||
|
||||
It would be a good idea to enable a warning screen stating a warning about misuse of ssh, just before a user logs into the session. To create a warning screen, create a file named **" warning"** in **/etc/** folder (or any other folder) & write something like "We monitor all our sessions on continuously. Don't misuse your access or else you will be prosecuted" or whatever you wish to warn. You can also consult legal team about this warning to make it more official.
|
||||
|
||||
After this file is create, open sshd_config file & enter the following parameter into the file
|
||||
|
||||
```
|
||||
Banner /etc/issue
|
||||
```
|
||||
|
||||
now you warning message will be displayed each time someone tries to access the session.
|
||||
|
||||
### Use non-standard ssh port
|
||||
|
||||
By default, ssh uses port 22 & all the brute force scripts are written for port 22 only. So to make your sessions even more secure, use a non-standard port like 15000. But make sure before selecting a port that its not being used by some other service.
|
||||
|
||||
To change port, open sshd_config & change the following parameter
|
||||
|
||||
```
|
||||
Port 15000
|
||||
```
|
||||
|
||||
Save & restart the service and you can access the ssh only with this new port. To start a session with custom port use the following command
|
||||
|
||||
```
|
||||
$ ssh -p 15000 {server IP}
|
||||
```
|
||||
|
||||
** Note:-** If using firewall, open the port on your firewall & we must also change the SELinux settings if using a custom port for ssh. Run the following command to update the SELinux label
|
||||
|
||||
```
|
||||
$ semanage port -a -t ssh_port_t -p tcp 15000
|
||||
```
|
||||
|
||||
### Limit IP access
|
||||
|
||||
If you have an environment where your server is accessed by only limited number of IP addresses, you can also allow access to those IP addresses only. Open sshd_config file & enter the following with your custom port
|
||||
|
||||
```
|
||||
Port 15000
|
||||
ListenAddress 192.168.1.100
|
||||
ListenAddress 192.168.1.115
|
||||
```
|
||||
|
||||
Now ssh session will only be available to these mentioned IPs with the custom port 15000.
|
||||
|
||||
### Disable empty passwords
|
||||
|
||||
As mentioned already that you should only use complex username & passwords, so using an empty password for remote login is a complete no-no. To disable empty passwords, open sshd_config file & edit the following parameter
|
||||
|
||||
```
|
||||
PermitEmptyPasswords no
|
||||
```
|
||||
|
||||
### Use public/private key based authentication
|
||||
|
||||
Using Public/Private key based authentication has its advantages i.e. you no longer need to enter the password when entering into a session (unless you are using a passphrase to decrypt the key) & no one can have access to your server until & unless they have the right authentication key. Process to setup public/private key based authentication is discussed in [**this tutorial here**][1].
|
||||
|
||||
So, this completes our tutorial on securing your ssh server. If having any doubts or issues, please leave a message in the comment box below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/ultimate-guide-to-securing-ssh-sessions/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/configure-ssh-server-publicprivate-key/
|
||||
[2]:https://www.facebook.com/techlablinux/
|
||||
[3]:https://twitter.com/LinuxTechLab
|
||||
[4]:https://plus.google.com/+linuxtechlab
|
||||
[5]:http://linuxtechlab.com/contact-us-2/
|
||||
@ -1,164 +0,0 @@
|
||||
Create your first Ansible server (automation) setup
|
||||
======
|
||||
Automation/configuration management tools are the new craze in the IT world, organizations are moving towards adopting them. There are many tools that are available in market like Puppet, Chef, Ansible etc & in this tutorial, we are going to learn about Ansible.
|
||||
|
||||
Ansible is an open source configuration tool; that is used to deploy, configure & manage servers. Ansible is one of the easiest automation tool to learn and master. It does not require you to learn complicated programming language like ruby (used in puppet & chef) & uses YAML, which is a very simple language. Also it does not require any special agent to be installed on client machines & only requires client machines to have python and ssh installed, both of these are usually available on systems.
|
||||
|
||||
## Pre-requisites
|
||||
|
||||
Before we move onto installation part, let's discuss the pre-requisites for Ansible
|
||||
|
||||
1. For server, we will need a machine with either CentOS or RHEL 7 installed & EPEL repository enabled
|
||||
|
||||
To enable epel repository, use the commands below,
|
||||
|
||||
**RHEL/CentOS 7**
|
||||
|
||||
```
|
||||
$ rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-10.noarch.rpm
|
||||
```
|
||||
|
||||
**RHEL/CentOS 6 (64 Bit)**
|
||||
|
||||
```
|
||||
$ rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
**RHEL/CentOS 6 (32 Bit)**
|
||||
|
||||
```
|
||||
$ rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
2. For client machines, Open SSH & python should be installed. Also we need to configure password less login for ssh session (create public-private keys). To create public-private keys & configure password less login for ssh session, refer to our article "
|
||||
|
||||
[Setting up SSH Server for Public/Private keys based Authentication (Password-less login)][1]"
|
||||
|
||||
|
||||
|
||||
## Installation
|
||||
|
||||
Once we have epel repository enabled, we can now install anisble using yum,
|
||||
|
||||
```
|
||||
$ yum install ansible
|
||||
```
|
||||
|
||||
## Configuring Ansible hosts
|
||||
|
||||
We will now configure hosts that we want Ansible to manage. To do that we need to edit the file **/etc/ansible/host** s & add the clients in following syntax,
|
||||
|
||||
```
|
||||
[group-name]
|
||||
alias ansible_ssh_host=host_IP_address
|
||||
```
|
||||
|
||||
where, alias is the alias name given to hosts we adding & it can be anything,
|
||||
|
||||
host_IP_address is where we enter the IP address for the hosts.
|
||||
|
||||
For this tutorial, we are going to add 2 clients/hosts for ansible to manage, so let's create an entry for these two hosts in the configuration file,
|
||||
|
||||
```
|
||||
$ vi /etc/ansible/hosts
|
||||
[test_clients]
|
||||
client1 ansible_ssh_host=192.168.1.101
|
||||
client2 ansible_ssh_host=192.168.1.10
|
||||
```
|
||||
|
||||
Save file & exit it. Now as mentioned in pre-requisites, we should have a password less login to these clients from the ansible server. To check if that's the case, ssh into the clients and we should be able to login without password,
|
||||
|
||||
```
|
||||
$ ssh root@192.168.1.101
|
||||
```
|
||||
|
||||
If that's working, then we can move further otherwise we need to create Public/Private keys for ssh session (Refer to article mentioned above in pre-requisites).
|
||||
|
||||
We are using root to login to other servers but we can use other local users as well & we need to define it for Ansible whatever user we will be using. To do so, we will first create a folder named 'group_vars' in '/etc/ansible'
|
||||
|
||||
```
|
||||
$ cd /etc/ansible
|
||||
$ mkdir group_vars
|
||||
```
|
||||
|
||||
Next, we will create a file named after the group we have created in 'etc/ansible/hosts' i.e. test_clients
|
||||
|
||||
```
|
||||
$ vi test_clients
|
||||
```
|
||||
|
||||
& add the ifollowing information about the user,
|
||||
|
||||
```
|
||||
--
|
||||
ansible_ssh_user:root
|
||||
```
|
||||
|
||||
**Note :-** File will start with '--' (minus symbol), so keep not of that.
|
||||
|
||||
If we want to use same user for all the groups created, then we can create only a single file named 'all' to mention the user details for ssh login, instead of creating a file for every group.
|
||||
|
||||
```
|
||||
$ vi /etc/ansible/group_vars/all
|
||||
--
|
||||
ansible_ssh_user: root
|
||||
```
|
||||
|
||||
Similarly, we can setup files for individual hosts as well.
|
||||
|
||||
Now, the setup for the clients has been done. We will now push some simple commands to all the clients being managed by Ansible.
|
||||
|
||||
## Testing hosts
|
||||
|
||||
To check the connectivity of all the hosts, we will issue a command,
|
||||
|
||||
```
|
||||
$ ansible -m ping all
|
||||
```
|
||||
|
||||
If all the hosts are properly connected, it should return the following output,
|
||||
|
||||
```
|
||||
client1 | SUCCESS = > {
|
||||
" changed": false,
|
||||
" ping": "pong"
|
||||
}
|
||||
client2 | SUCCESS = > {
|
||||
" changed": false,
|
||||
" ping": "pong"
|
||||
}
|
||||
```
|
||||
|
||||
We can also issue command to an individual host,
|
||||
|
||||
```
|
||||
$ ansible -m ping client1
|
||||
```
|
||||
|
||||
or to the multiple hosts,
|
||||
|
||||
```
|
||||
$ ansible -m ping client1:client2
|
||||
```
|
||||
|
||||
or even to a single group,
|
||||
|
||||
```
|
||||
$ ansible -m ping test_client
|
||||
```
|
||||
|
||||
This complete our tutorial on setting up an Ansible server, in our future posts we will further explore funtinalities offered by Ansible. If any having doubts or queries regarding this post, use the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-first-ansible-server-automation-setup/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/configure-ssh-server-publicprivate-key/
|
||||
@ -1,3 +1,5 @@
|
||||
yangjiaqiang 翻译中
|
||||
|
||||
How To Set Up PF Firewall on FreeBSD to Protect a Web Server
|
||||
======
|
||||
|
||||
|
||||
@ -1,265 +0,0 @@
|
||||
translating by liuxinyu123
|
||||
|
||||
Useful Linux Commands that you should know
|
||||
======
|
||||
If you are Linux system administrator or just a Linux enthusiast/lover, than
|
||||
you love & use command line aks CLI. Until some years ago majority of Linux
|
||||
work was accomplished using CLI only & even there are some limitations to GUI
|
||||
. Though there are plenty of Linux distributions that can complete tasks with
|
||||
GUI but still learning CLI is major part of mastering Linux.
|
||||
|
||||
To this effect, we present you list of useful Linux commands that you should
|
||||
know.
|
||||
|
||||
**Note:-** There is no definite order to all these commands & all of these
|
||||
commands are equally important to learn & master in order to excel in Linux
|
||||
administration. One more thing, we have only used some of the options for each
|
||||
command for an example, you can refer to 'man pages' for complete list of
|
||||
options for each command.
|
||||
|
||||
### 1- top command
|
||||
|
||||
'top' command displays the real time summary/information of our system. It
|
||||
also displays the processes and all the threads that are running & are being
|
||||
managed by the system kernel.
|
||||
|
||||
Information provided by top command includes uptime, number of users, Load
|
||||
average, running/sleeping/zombie processes, CPU usage in percentage based on
|
||||
users/system etc, system memory free & used, swap memory etc.
|
||||
|
||||
To use top command, open terminal & execute the comamnd,
|
||||
|
||||
**$ top**
|
||||
|
||||
To exit out the command, either press 'q' or 'ctrl+c'.
|
||||
|
||||
### 2- free command
|
||||
|
||||
'free' command is used to specifically used to get the information about
|
||||
system memory or RAM. With this command we can get information regarding
|
||||
physical memory, swap memory as well as system buffers. It provided amount of
|
||||
total, free & used memory available on the system.
|
||||
|
||||
To use this utility, execute following command in terminal
|
||||
|
||||
**$ free**
|
||||
|
||||
It will present all the data in kb or kilobytes, for megabytes use options
|
||||
'-m' & '-g ' for gb.
|
||||
|
||||
#### 3- cp command
|
||||
|
||||
'cp' or copy command is used to copy files among the folders. Syntax for using
|
||||
'cp' command is,
|
||||
|
||||
**$ cp source destination**
|
||||
|
||||
### 4- cd command
|
||||
|
||||
'cd' command is used for changing directory . We can switch among directories
|
||||
using cd command.
|
||||
|
||||
To use it, execute
|
||||
|
||||
**$ cd directory_location**
|
||||
|
||||
### 5- ifconfig
|
||||
|
||||
'Ifconfig' is very important utility for viewing & configuring network
|
||||
information on Linux machine.
|
||||
|
||||
To use it, execute
|
||||
|
||||
**$ ifconfig**
|
||||
|
||||
This will present the network information of all the networking devices on the
|
||||
system. There are number of options that can be used with 'ifconfig' for
|
||||
configuration, in fact they are some many options that we have created a
|
||||
separate article for it ( **Read it here ||[IFCONFIG command : Learn with some
|
||||
examples][1]** ).
|
||||
|
||||
### 6- crontab command
|
||||
|
||||
'Crontab' is another important utility that is used schedule a job on Linux
|
||||
system. With crontab, we can make sure that a command or a script is executed
|
||||
at the pre-defined time. To create a cron job, run
|
||||
|
||||
**$ crontab -e**
|
||||
|
||||
To display all the created jobs, run
|
||||
|
||||
**$ crontab -l**
|
||||
|
||||
You can read our detailed article regarding crontab ( **Read it here ||[
|
||||
Scheduling Important Jobs with Crontab][2]** )
|
||||
|
||||
### 7- cat command
|
||||
|
||||
'cat' command has many uses, most common use is that it's used to display
|
||||
content of a file,
|
||||
|
||||
**$ cat file.txt**
|
||||
|
||||
But it can also be used to merge two or more file using the syntax below,
|
||||
|
||||
**$ cat file1 file2 file3 file4 > file_new**
|
||||
|
||||
We can also use 'cat' command to clone a whole disk ( **Read it here ||
|
||||
[Cloning Disks using dd & cat commands for Linux systems][3]** )
|
||||
|
||||
### 8- df command
|
||||
|
||||
'df' command is used to show the disk utilization of our whole Linux file
|
||||
system. Simply run.
|
||||
|
||||
**$ df**
|
||||
|
||||
& we will be presented with disk complete utilization of all the partitions on
|
||||
our Linux machine.
|
||||
|
||||
### 9- du command
|
||||
|
||||
'du' command shows the amount of disk that is being utilized by the files &
|
||||
directories on our Linux machine. To run it, type
|
||||
|
||||
**$ du /directory**
|
||||
|
||||
( **Recommended Read :[Use of du & df commands with examples][4]** )
|
||||
|
||||
### 10- mv command
|
||||
|
||||
'mv' command is used to move the files or folders from one location to
|
||||
another. Command syntax for moving the files/folders is,
|
||||
|
||||
**$ mv /source/filename /destination**
|
||||
|
||||
We can also use 'mv' command to rename a file/folder. Syntax for changing name
|
||||
is,
|
||||
|
||||
**$ mv file_oldname file_newname**
|
||||
|
||||
### 11- rm command
|
||||
|
||||
'rm' command is used to remove files\folders from Linux system. To use it, run
|
||||
|
||||
**$ rm filename**
|
||||
|
||||
We can also use '-rf' option with 'rm' command to completely remove a
|
||||
file\folder from the system but we must use this with caution.
|
||||
|
||||
### 12- vi/vim command
|
||||
|
||||
VI or VIM is very famous & one of the widely used CLI-based text editor for
|
||||
Linux. It takes some time to master it but it has a great number of utilities,
|
||||
which makes it a favorite for Linux users.
|
||||
|
||||
For detailed knowledge of VIM, kindly refer to the articles [**Beginner 's
|
||||
Guide to LVM (Logical Volume Management)** & **Working with Vi/Vim Editor :
|
||||
Advanced concepts.**][5]
|
||||
|
||||
### 13- ssh command
|
||||
|
||||
SSH utility is to remotely access another machine from the current Linux
|
||||
machine. To access a machine, execute
|
||||
|
||||
**$ ssh[[email protected]][6] OR machine_name**
|
||||
|
||||
Once we have remote access to machine, we can work on CLI of that machine as
|
||||
if we are working on local machine.
|
||||
|
||||
### 14- tar command
|
||||
|
||||
'tar' command is used to compress & extract the files\folders. To compress the
|
||||
files\folders using tar, execute
|
||||
|
||||
**$ tar -cvf file.tar file_name**
|
||||
|
||||
where file.tar will be the name of compressed folder & 'file_name' is the name
|
||||
of source file or folders. To extract a compressed folder,
|
||||
|
||||
**$ tar -xvf file.tar**
|
||||
|
||||
For more details on 'tar' command, read [**Tar command : Compress & Decompress
|
||||
the files\directories**][7]
|
||||
|
||||
### 15- locate command
|
||||
|
||||
'locate' command is used to locate files & folders on your Linux machines. To
|
||||
use it, run
|
||||
|
||||
**$ locate file_name**
|
||||
|
||||
### 16- grep command
|
||||
|
||||
'grep' command another very important command that a Linux administrator
|
||||
should know. It comes especially handy when we want to grab a keyword or
|
||||
multiple keywords from a file. Syntax for using it is,
|
||||
|
||||
**$ grep 'pattern' file.txt**
|
||||
|
||||
It will search for 'pattern' in the file 'file.txt' and produce the output on
|
||||
the screen. We can also redirect the output to another file,
|
||||
|
||||
**$ grep 'pattern' file.txt > newfile.txt**
|
||||
|
||||
### 17- ps command
|
||||
|
||||
'ps' command is especially used to get the process id of a running process. To
|
||||
get information of all the processes, run
|
||||
|
||||
**$ ps -ef**
|
||||
|
||||
To get information regarding a single process, executed
|
||||
|
||||
**$ ps -ef | grep java**
|
||||
|
||||
### 18- kill command
|
||||
|
||||
'kill' command is used to kill a running process. To kill a process we will
|
||||
need its process id, which we can get using above 'ps' command. To kill a
|
||||
process, run
|
||||
|
||||
**$ kill -9 process_id**
|
||||
|
||||
### 19- ls command
|
||||
|
||||
'ls' command is used list all the files in a directory. To use it, execute
|
||||
|
||||
**$ ls**
|
||||
|
||||
### 20- mkdir command
|
||||
|
||||
To create a directory in Linux machine, we use command 'mkdir'. Syntax for
|
||||
using 'mkdir' is
|
||||
|
||||
**$ mkdir new_dir**
|
||||
|
||||
These were some of the useful linux commands that every System Admin should
|
||||
know, we will soon be sharing another list of some more important commands
|
||||
that you should know being a Linux lover. You can also leave your suggestions
|
||||
and queries in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/useful-linux-commands-you-should-know/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com
|
||||
[1]:http://linuxtechlab.com/ifconfig-command-learn-examples/
|
||||
[2]:http://linuxtechlab.com/scheduling-important-jobs-crontab/
|
||||
[3]:http://linuxtechlab.com/linux-disk-cloning-using-dd-cat-commands/
|
||||
[4]:http://linuxtechlab.com/du-df-commands-examples/
|
||||
[5]:http://linuxtechlab.com/working-vivim-editor-advanced-concepts/
|
||||
[6]:/cdn-cgi/l/email-protection#bbcec8dec9d5dad6defbf2ebdadfdfc9dec8c8
|
||||
[7]:http://linuxtechlab.com/tar-command-compress-decompress-files
|
||||
[8]:https://www.facebook.com/linuxtechlab/
|
||||
[9]:https://twitter.com/LinuxTechLab
|
||||
[10]:https://plus.google.com/+linuxtechlab
|
||||
[11]:http://linuxtechlab.com/contact-us-2/
|
||||
|
||||
@ -1,137 +0,0 @@
|
||||
Two Easy Ways To Install Bing Desktop Wallpaper Changer On Linux
|
||||
======
|
||||
Are you bored with Linux desktop background and wants to set good looking wallpapers but don't know where to find? Don't worry we are here to help you.
|
||||
|
||||
We all knows about bing search engine but most of us don't use that for some reasons and every one like Bing website background wallpapers which is very beautiful and stunning high-resolution images.
|
||||
|
||||
If you would like to have these images as your desktop wallpapers you can do it manually but it's very difficult to download a new image daily and then set it as wallpaper. That's where automatic wallpaper changers comes into picture.
|
||||
|
||||
[Bing Desktop Wallpaper Changer][1] will automatically downloads and changes desktop wallpaper to Bing Photo of the Day. All the wallpapers are stored in `/home/[user]/Pictures/BingWallpapers/`.
|
||||
|
||||
### Method-1 : Using Utkarsh Gupta Shell Script
|
||||
|
||||
This small python script, automatically downloading and changing the desktop wallpaper to Bing Photo of the day. The script runs automatically at the startup and works on GNU/Linux with Gnome or Cinnamon and there is no manual work and installer does everything for you.
|
||||
|
||||
From version 2.0+, the Installer works like a normal Linux binary commands and It requests sudo permissions for some of the task.
|
||||
|
||||
Just clone the repository and navigate to project's directory then run the shell script to install Bing Desktop Wallpaper Changer.
|
||||
```
|
||||
$ https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer/archive/master.zip
|
||||
$ unzip master
|
||||
$ cd bing-desktop-wallpaper-changer-master
|
||||
|
||||
```
|
||||
|
||||
Run the `installer.sh` file with `--install` option to install Bing Desktop Wallpaper Changer. This will download and set Bing Photo of the Day for your Linux desktop.
|
||||
```
|
||||
$ ./installer.sh --install
|
||||
|
||||
Bing-Desktop-Wallpaper-Changer
|
||||
BDWC Installer v3_beta2
|
||||
|
||||
GitHub:
|
||||
Contributors:
|
||||
.
|
||||
.
|
||||
[sudo] password for daygeek: **
|
||||
|
||||
******
|
||||
|
||||
**
|
||||
.
|
||||
Where do you want to install Bing-Desktop-Wallpaper-Changer?
|
||||
Entering 'opt' or leaving input blank will install in /opt/bing-desktop-wallpaper-changer
|
||||
Entering 'home' will install in /home/daygeek/bing-desktop-wallpaper-changer
|
||||
Install Bing-Desktop-Wallpaper-Changer in (opt/home)? : **
|
||||
|
||||
Press Enter
|
||||
|
||||
**
|
||||
|
||||
Should we create bing-desktop-wallpaper-changer symlink to /usr/bin/bingwallpaper so you could easily execute it?
|
||||
Create symlink for easy execution, e.g. in Terminal (y/n)? : **
|
||||
|
||||
y
|
||||
|
||||
**
|
||||
|
||||
Should bing-desktop-wallpaper-changer needs to autostart when you log in? (Add in Startup Application)
|
||||
Add in Startup Application (y/n)? : **
|
||||
|
||||
y
|
||||
|
||||
**
|
||||
.
|
||||
.
|
||||
Executing bing-desktop-wallpaper-changer...
|
||||
|
||||
|
||||
Finished!!
|
||||
|
||||
```
|
||||
|
||||
[![][2]![][2]][3]
|
||||
|
||||
To uninstall the script.
|
||||
```
|
||||
$ ./installer.sh --uninstall
|
||||
|
||||
```
|
||||
|
||||
Navigate to help page to know more options about this script.
|
||||
```
|
||||
$ ./installer.sh --help
|
||||
|
||||
```
|
||||
|
||||
### Method-2 : Using GNOME Shell extension
|
||||
|
||||
Lightweight [GNOME shell extension][4] to change your wallpaper every day to Microsoft Bing's wallpaper. It will also show a notification containing the title and the explanation of the image.
|
||||
|
||||
This extension is based extensively on the NASA APOD extension by Elinvention and inspired by Bing Desktop WallpaperChanger by Utkarsh Gupta.
|
||||
|
||||
### Features
|
||||
|
||||
* Fetches the Bing wallpaper of the day and sets as both lock screen and desktop wallpaper (these are both user selectable)
|
||||
* Optionally force a specific region (i.e. locale)
|
||||
* Automatically selects the highest resolution (and most appropriate wallpaper) in multiple monitor setups
|
||||
* Optionally clean up Wallpaper directory after between 1 and 7 days (delete oldest first)
|
||||
* Only attempts to download wallpapers when they have been updated
|
||||
* Doesn't poll continuously - only once per day and on startup (a refresh is scheduled when Bing is due to update)
|
||||
|
||||
|
||||
|
||||
### How to install
|
||||
|
||||
Visit [extenisons.gnome.org][5] website and drag the toggle button to `ON` then hit `Install` button to install bing wallpaper GNOME extension.
|
||||
[![][2]![][2]][6]
|
||||
|
||||
After install the bing wallpaper GNOME extension, it will automatically download and set bing Photo of the Day for your Linux desktop, also it shows the notification about the wallpaper.
|
||||
[![][2]![][2]][7]
|
||||
|
||||
Tray indicator, will help you to perform few operations also open settings.
|
||||
[![][2]![][2]][8]
|
||||
|
||||
Customize the settings based on your requirement.
|
||||
[![][2]![][2]][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-linux-5.png
|
||||
[4]:https://github.com/neffo/bing-wallpaper-gnome-extension
|
||||
[5]:https://extensions.gnome.org/extension/1262/bing-wallpaper-changer/
|
||||
[6]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-1.png
|
||||
[7]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-2.png
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-3.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-4.png
|
||||
@ -1,62 +0,0 @@
|
||||
Improve Your Mental Mettle with These Open Source Puzzle Games
|
||||
======
|
||||
### Tax Your Brain, Not Your Wallet
|
||||
|
||||
Puzzle video games are a type of game that focuses on puzzle solving. A puzzle is a problem or set of problems a player has to solve within the confines of the game.
|
||||
|
||||
The puzzle genre often tests problem-solving skills enhancing both analytical and critical thinking skills. Word completion, pattern recognition, logical reasoning, persistence, and sequence solving are some of the skills often required to prosper here. Some games offer unlimited time or attempts to solve a puzzle, others present time-limited exercises which increase the difficulty of the puzzle. Most puzzle games are basic in graphics but are very addictive.
|
||||
|
||||
This genre owes its origins to puzzles and brain teasers. Traditional thinking games such as Hangman, Mastermind, and the mathematical game Nim were early computer implementations.
|
||||
|
||||
Software developers can shape a gamer's brain in a multitude of directions -- cognitive awareness, logistics, reflexes, memory, to cite a selection -- puzzle games are appealing for all ages.
|
||||
|
||||
Many of the biggest computer games concentrate on explosion-filled genres. But there's still strong demand for compelling puzzle games. It's a neglected genre in the mainstream. Here are our picks of the best games. We only advocate open source games here. And we give preference to games that run on multiple operating systems.
|
||||
|
||||
|
||||
**PUZZLE GAMES**
|
||||
|
||||
| --- | --- |
|
||||
| **[Trackballs][1]** | Inspired by Marble Madness |
|
||||
| **[Fish Fillets - Next Generation][2]** | Port of the Puzzle Game Fish Fillets |
|
||||
| **[Frozen Bubble][3]** | A clone of the popular “Puzzle Bobble” game |
|
||||
| **[Neverball][4]** | Tilt the Floor to Roll a Ball Game |
|
||||
| **[Crack Attack!][5]** | Based on the Super Nintendo classic Tetris Attack
|
||||
|
|
||||
| **[Brain Workshop][6]** | Dual N-Back Game |
|
||||
| **[Angry, Drunken Dwarves][7]** | “Falling Blocks” Puzzle Game |
|
||||
| **[gbrainy][8]** | Brain Teaser Game for GNOME |
|
||||
| **[Enigma][9]** | Huge Collection of Puzzle Games |
|
||||
| **[Amoebax][10]** | Cute and Addictive Action-Puzzle Game |
|
||||
| **[Dinothawr][11]** | Save your frozen friends by pushing them onto lava |
|
||||
| **[Pingus][12]** | Lemmings Like Game |
|
||||
| **[Kmahjongg][13]** | Remove Matching Mahjongg Tiles to Clear the Board |
|
||||
|
||||
|
||||
For other games, check out our **[Games Portal page][14]**.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ossblog.org/improve-your-mental-mettle-with-these-open-source-puzzle-games/
|
||||
|
||||
作者:[Steve Emms][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ossblog.org/author/steve/
|
||||
[1]:https://www.ossblog.org/trackballs-inspired-marble-madness/
|
||||
[2]:https://www.ossblog.org/fish-fillets-ng-port-puzzle-game-fish-fillets/
|
||||
[3]:https://www.ossblog.org/frozen-bubble-puzzle-bobble-style-game/
|
||||
[4]:https://www.ossblog.org/neverball-tilt-floor-roll-ball-game/
|
||||
[5]:https://www.ossblog.org/crack-attack-based-super-nintendo-classic-tetris-attack/
|
||||
[6]:https://www.ossblog.org/brain-workshop-dual-n-back-game/
|
||||
[7]:https://www.ossblog.org/angry-drunken-dwarves-falling-blocks-puzzle-game/
|
||||
[8]:https://www.ossblog.org/gbrainy-brain-teaser-game-gnome/
|
||||
[9]:https://www.ossblog.org/enigma-huge-collection-puzzle-games/
|
||||
[10]:https://www.ossblog.org/amoebax-cute-addictive-action-puzzle-game/
|
||||
[11]:https://www.ossblog.org/dinothawr-save-frozen-friends/
|
||||
[12]:https://www.ossblog.org/pingus-lemmings-like-game/
|
||||
[13]:https://www.ossblog.org/kmahjongg-remove-matching-mahjongg-tiles-clear-board/
|
||||
[14]:https://www.ossblog.org/free-games/
|
||||
@ -1,103 +0,0 @@
|
||||
Linux Head Command Explained for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on the command line in Linux, you might want to take a quick look at a few initial lines of a file. For example, if a log file is continuously being updated, the requirement could be to view, say, first 10 lines of the log file every time. While viewing the file in an editor (like [vim][1]) is always an option, there exists a command line tool - dubbed **head** \- that lets you view initial few lines of a file very easily.
|
||||
|
||||
In this article, we will discuss the basics of the head command using some easy to understand examples. Please note that all steps/instructions mentioned here have been tested on Ubuntu 16.04LTS.
|
||||
|
||||
### Linux head command
|
||||
|
||||
As already mentioned in the beginning, the head command lets users view the first part of files. Here's its syntax:
|
||||
|
||||
head [OPTION]... [FILE]...
|
||||
|
||||
And following is how the command's man page describes it:
|
||||
```
|
||||
Print the first 10 lines of each FILE to standard output. With more than one FILE, precede each
|
||||
with a header giving the file name.
|
||||
```
|
||||
|
||||
The following Q&A-type examples should give you a better idea of how the tool works:
|
||||
|
||||
### Q1. How to print the first 10 lines of a file on terminal (stdout)?
|
||||
|
||||
This is quite easy using head - in fact, it's the tool's default behavior.
|
||||
|
||||
head [file-name]
|
||||
|
||||
The following screenshot shows the command in action:
|
||||
|
||||
[![How to print the first 10 lines of a file][2]][3]
|
||||
|
||||
### Q2. How to tweak the number of lines head prints?
|
||||
|
||||
While 10 is the default number of lines the head command prints, you can change this number as per your requirement. The **-n** command line option lets you do that.
|
||||
|
||||
head -n [N] [File-name]
|
||||
|
||||
For example, if you want to only print first 5 lines, you can convey this to the tool in the following way:
|
||||
|
||||
head -n 5 file1
|
||||
|
||||
[![How to tweak number of lines head prints][4]][5]
|
||||
|
||||
### Q3. How to restrict the output to a certain number of bytes?
|
||||
|
||||
Not only number of lines, you can also restrict the head command output to a specific number of bytes. This can be done using the **-c** command line option.
|
||||
|
||||
head -c [N] [File-name]
|
||||
|
||||
For example, if you want head to only display first 25 bytes, here's how you can execute it:
|
||||
|
||||
head -c 25 file1
|
||||
|
||||
[![restrict the output to a certain number of bytes][6]][7]
|
||||
|
||||
So you can see that the tool displayed only the first 25 bytes in the output.
|
||||
|
||||
Please note that [N] "may have a multiplier suffix: b 512, kB 1000, K 1024, MB 1000*1000, M 1024*1024, GB 1000*1000*1000, G 1024*1024*1024, and so on for T, P, E, Z, Y."
|
||||
|
||||
### Q4. How to have head print filename in output?
|
||||
|
||||
If for some reason, you want the head command to also print the file name in output, you can do that using the **-v** command line option.
|
||||
|
||||
head -v [file-name]
|
||||
|
||||
Here's an example:
|
||||
|
||||
[![How to have head print filename in output][8]][9]
|
||||
|
||||
So as you can see, the filename 'file 1' was displayed in the output.
|
||||
|
||||
### Q5. How to have NUL as line delimiter, instead of newline?
|
||||
|
||||
By default, the head command output is delimited by newline. But there's also an option of using NUL as the delimiter. The option **-z** or **\--zero-terminated** lets you do this.
|
||||
|
||||
head -z [file-name]
|
||||
|
||||
### Conclusion
|
||||
|
||||
As most of you'd agree, head is a simple command to understand and use, meaning there's little learning curve associated with it. The features (in terms of command line options) it offers are also limited, and we've covered almost all of them. So give these options a try, and when you're done, take a look at the command's [man page][10] to know more.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-head-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/vim-basics
|
||||
[2]:https://www.howtoforge.com/images/linux_head_command/head-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/linux_head_command/big/head-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/linux_head_command/head-n-option.png
|
||||
[5]:https://www.howtoforge.com/images/linux_head_command/big/head-n-option.png
|
||||
[6]:https://www.howtoforge.com/images/linux_head_command/head-c-option.png
|
||||
[7]:https://www.howtoforge.com/images/linux_head_command/big/head-c-option.png
|
||||
[8]:https://www.howtoforge.com/images/linux_head_command/head-v-option.png
|
||||
[9]:https://www.howtoforge.com/images/linux_head_command/big/head-v-option.png
|
||||
[10]:https://linux.die.net/man/1/head
|
||||
@ -1,217 +0,0 @@
|
||||
**translating by [erlinux](https://github.com/erlinux)**
|
||||
Operating a Kubernetes network
|
||||
============================================================
|
||||
|
||||
I’ve been working on Kubernetes networking a lot recently. One thing I’ve noticed is, while there’s a reasonable amount written about how to **set up** your Kubernetes network, I haven’t seen much about how to **operate** your network and be confident that it won’t create a lot of production incidents for you down the line.
|
||||
|
||||
In this post I’m going to try to convince you of three things: (all I think pretty reasonable :))
|
||||
|
||||
* Avoiding networking outages in production is important
|
||||
|
||||
* Operating networking software is hard
|
||||
|
||||
* It’s worth thinking critically about major changes to your networking infrastructure and the impact that will have on your reliability, even if very fancy Googlers say “this is what we do at Google”. (google engineers are doing great work on Kubernetes!! But I think it’s important to still look at the architecture and make sure it makes sense for your organization.)
|
||||
|
||||
I’m definitely not a Kubernetes networking expert by any means, but I have run into a few issues while setting things up and definitely know a LOT more about Kubernetes networking than I used to.
|
||||
|
||||
### Operating networking software is hard
|
||||
|
||||
Here I’m not talking about operating physical networks (I don’t know anything about that), but instead about keeping software like DNS servers & load balancers & proxies working correctly.
|
||||
|
||||
I have been working on a team that’s responsible for a lot of networking infrastructure for a year, and I have learned a few things about operating networking infrastructure! (though I still have a lot to learn obviously). 3 overall thoughts before we start:
|
||||
|
||||
* Networking software often relies very heavily on the Linux kernel. So in addition to configuring the software correctly you also need to make sure that a bunch of different sysctls are set correctly, and a misconfigured sysctl can easily be the difference between “everything is 100% fine” and “everything is on fire”.
|
||||
|
||||
* Networking requirements change over time (for example maybe you’re doing 5x more DNS lookups than you were last year! Maybe your DNS server suddenly started returning TCP DNS responses instead of UDP which is a totally different kernel workload!). This means software that was working fine before can suddenly start having issues.
|
||||
|
||||
* To fix a production networking issues you often need a lot of expertise. (for example see this [great post by Sophie Haskins on debugging a kube-dns issue][1]) I’m a lot better at debugging networking issues than I was, but that’s only after spending a huge amount of time investing in my knowledge of Linux networking.
|
||||
|
||||
I am still far from an expert at networking operations but I think it seems important to:
|
||||
|
||||
1. Very rarely make major changes to the production networking infrastructure (because it’s super disruptive)
|
||||
|
||||
2. When you _are_ making major changes, think really carefully about what the failure modes are for the new network architecture are
|
||||
|
||||
3. Have multiple people who are able to understand your networking setup
|
||||
|
||||
Switching to Kubernetes is obviously a pretty major networking change! So let’s talk about what some of the things that can go wrong are!
|
||||
|
||||
### Kubernetes networking components
|
||||
|
||||
The Kubernetes networking components we’re going to talk about in this post are:
|
||||
|
||||
* Your overlay network backend (like flannel/calico/weave net/romana)
|
||||
|
||||
* `kube-dns`
|
||||
|
||||
* `kube-proxy`
|
||||
|
||||
* Ingress controllers / load balancers
|
||||
|
||||
* The `kubelet`
|
||||
|
||||
If you’re going to set up HTTP services you probably need all of these. I’m not using most of these components yet but I’m trying to understand them, so that’s what this post is about.
|
||||
|
||||
### The simplest way: Use host networking for all your containers
|
||||
|
||||
Let’s start with the simplest possible thing you can do. This won’t let you run HTTP services in Kubernetes. I think it’s pretty safe because there are less moving parts.
|
||||
|
||||
If you use host networking for all your containers I think all you need to do is:
|
||||
|
||||
1. Configure the kubelet to configure DNS correctly inside your containers
|
||||
|
||||
2. That’s it
|
||||
|
||||
If you use host networking for literally every pod you don’t need kube-dns or kube-proxy. You don’t even need a working overlay network.
|
||||
|
||||
In this setup your pods can connect to the outside world (the same way any process on your hosts would talk to the outside world) but the outside world can’t connect to your pods.
|
||||
|
||||
This isn’t super important (I think most people want to run HTTP services inside Kubernetes and actually communicate with those services) but I do think it’s interesting to realize that at some level all of this networking complexity isn’t strictly required and sometimes you can get away without using it. Avoiding networking complexity seems like a good idea to me if you can.
|
||||
|
||||
### Operating an overlay network
|
||||
|
||||
The first networking component we’re going to talk about is your overlay network. Kubernetes assumes that every pod has an IP address and that you can communicate with services inside that pod by using that IP address. When I say “overlay network” this is what I mean (“the system that lets you refer to a pod by its IP address”).
|
||||
|
||||
All other Kubernetes networking stuff relies on the overlay networking working correctly. You can read more about the [kubernetes networking model here][10].
|
||||
|
||||
The way Kelsey Hightower describes in [kubernetes the hard way][11] seems pretty good but it’s not really viable on AWS for clusters more than 50 nodes or so, so I’m not going to talk about that.
|
||||
|
||||
There are a lot of overlay network backends (calico, flannel, weaveworks, romana) and the landscape is pretty confusing. But as far as I’m concerned an overlay network has 2 responsibilities:
|
||||
|
||||
1. Make sure your pods can send network requests outside your cluster
|
||||
|
||||
2. Keep a stable mapping of nodes to subnets and keep every node in your cluster updated with that mapping. Do the right thing when nodes are added & removed.
|
||||
|
||||
Okay! So! What can go wrong with your overlay network?
|
||||
|
||||
* The overlay network is responsible for setting up iptables rules (basically `iptables -A -t nat POSTROUTING -s $SUBNET -j MASQUERADE`) to ensure that containers can make network requests outside Kubernetes. If something goes wrong with this rule then your containers can’t connect to the external network. This isn’t that hard (it’s just a few iptables rules) but it is important. I made a [pull request][2] because I wanted to make sure this was resilient
|
||||
|
||||
* Something can go wrong with adding or deleting nodes. We’re using the flannel hostgw backend and at the time we started using it, node deletion [did not work][3].
|
||||
|
||||
* Your overlay network is probably dependent on a distributed database (etcd). If that database has an incident, this can cause issues. For example [https://github.com/coreos/flannel/issues/610][4] says that if you have data loss in your flannel etcd cluster it can result in containers losing network connectivity. (this has now been fixed)
|
||||
|
||||
* You upgrade Docker and everything breaks
|
||||
|
||||
* Probably more things!
|
||||
|
||||
I’m mostly talking about past issues in Flannel here but I promise I’m not picking on Flannel – I actually really **like** Flannel because I feel like it’s relatively simple (for instance the [vxlan backend part of it][12] is like 500 lines of code) and I feel like it’s possible for me to reason through any issues with it. And it’s obviously continuously improving. They’ve been great about reviewing pull requests.
|
||||
|
||||
My approach to operating an overlay network so far has been:
|
||||
|
||||
* Learn how it works in detail and how to debug it (for example the hostgw network backend for Flannel works by creating routes, so you mostly just need to do `sudo ip route list` to see whether it’s doing the correct thing)
|
||||
|
||||
* Maintain an internal build so it’s easy to patch it if needed
|
||||
|
||||
* When there are issues, contribute patches upstream
|
||||
|
||||
I think it’s actually really useful to go through the list of merged PRs and see bugs that have been fixed in the past – it’s a bit time consuming but is a great way to get a concrete list of kinds of issues other people have run into.
|
||||
|
||||
It’s possible that for other people their overlay networks just work but that hasn’t been my experience and I’ve heard other folks report similar issues. If you have an overlay network setup that is a) on AWS and b) works on a cluster more than 50-100 nodes where you feel more confident about operating it I would like to know.
|
||||
|
||||
### Operating kube-proxy and kube-dns?
|
||||
|
||||
Now that we have some thoughts about operating overlay networks, let’s talk about
|
||||
|
||||
There’s a question mark next to this one because I haven’t done this. Here I have more questions than answers.
|
||||
|
||||
Here’s how Kubernetes services work! A service is a collection of pods, which each have their own IP address (like 10.1.0.3, 10.2.3.5, 10.3.5.6)
|
||||
|
||||
1. Every Kubernetes service gets an IP address (like 10.23.1.2)
|
||||
|
||||
2. `kube-dns` resolves Kubernetes service DNS names to IP addresses (so my-svc.my-namespace.svc.cluster.local might map to 10.23.1.2)
|
||||
|
||||
3. `kube-proxy` sets up iptables rules in order to do random load balancing between them. Kube-proxy also has a userspace round-robin load balancer but my impression is that they don’t recommend using it.
|
||||
|
||||
So when you make a request to `my-svc.my-namespace.svc.cluster.local`, it resolves to 10.23.1.2, and then iptables rules on your local host (generated by kube-proxy) redirect it to one of 10.1.0.3 or 10.2.3.5 or 10.3.5.6 at random.
|
||||
|
||||
Some things that I can imagine going wrong with this:
|
||||
|
||||
* `kube-dns` is misconfigured
|
||||
|
||||
* `kube-proxy` dies and your iptables rules don’t get updated
|
||||
|
||||
* Some issue related to maintaining a large number of iptables rules
|
||||
|
||||
Let’s talk about the iptables rules a bit, since doing load balancing by creating a bajillion iptables rules is something I had never heard of before!
|
||||
|
||||
kube-proxy creates one iptables rule per target host like this: (these rules are from [this github issue][13])
|
||||
|
||||
```
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.20000000019 -j KUBE-SEP-E4QKA7SLJRFZZ2DD[b][c]
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.25000000000 -j KUBE-SEP-LZ7EGMG4DRXMY26H
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-RKIFTWKKG3OHTTMI
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-CGDKBCNM24SZWCMS
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -j KUBE-SEP-RI4SRNQQXWSTGE2Y
|
||||
|
||||
```
|
||||
|
||||
So kube-proxy creates a **lot** of iptables rules. What does that mean? What are the implications of that in for my network? There’s a great talk from Huawei called [Scale Kubernetes to Support 50,000 services][14] that says if you have 5,000 services in your kubernetes cluster, it takes **11 minutes** to add a new rule. If that happened to your real cluster I think it would be very bad.
|
||||
|
||||
I definitely don’t have 5,000 services in my cluster, but 5,000 isn’t SUCH a bit number. The proposal they give to solve this problem is to replace this iptables backend for kube-proxy with IPVS which is a load balancer that lives in the Linux kernel.
|
||||
|
||||
It seems like kube-proxy is going in the direction of various Linux kernel based load balancers. I think this is partly because they support UDP load balancing, and other load balancers (like HAProxy) don’t support UDP load balancing.
|
||||
|
||||
But I feel comfortable with HAProxy! Is it possible to replace kube-proxy with HAProxy! I googled this and I found this [thread on kubernetes-sig-network][15] saying:
|
||||
|
||||
> kube-proxy is so awesome, we have used in production for almost a year, it works well most of time, but as we have more and more services in our cluster, we found it was getting hard to debug and maintain. There is no iptables expert in our team, we do have HAProxy&LVS experts, as we have used these for several years, so we decided to replace this distributed proxy with a centralized HAProxy. I think this maybe useful for some other people who are considering using HAProxy with kubernetes, so we just update this project and make it open source: [https://github.com/AdoHe/kube2haproxy][5]. If you found it’s useful , please take a look and give a try.
|
||||
|
||||
So that’s an interesting option! I definitely don’t have answers here, but, some thoughts:
|
||||
|
||||
* Load balancers are complicated
|
||||
|
||||
* DNS is also complicated
|
||||
|
||||
* If you already have a lot of experience operating one kind of load balancer (like HAProxy), it might make sense to do some extra work to use that instead of starting to use an entirely new kind of load balancer (like kube-proxy)
|
||||
|
||||
* I’ve been thinking about where we want to be using kube-proxy or kube-dns at all – I think instead it might be better to just invest in Envoy and rely entirely on Envoy for all load balancing & service discovery. So then you just need to be good at operating Envoy.
|
||||
|
||||
As you can see my thoughts on how to operate your Kubernetes internal proxies are still pretty confused and I’m still not super experienced with them. It’s totally possible that kube-proxy and kube-dns are fine and that they will just work fine but I still find it helpful to think through what some of the implications of using them are (for example “you can’t have 5,000 Kubernetes services”).
|
||||
|
||||
### Ingress
|
||||
|
||||
If you’re running a Kubernetes cluster, it’s pretty likely that you actually need HTTP requests to get into your cluster so far. This blog post is already too long and I don’t know much about ingress yet so we’re not going to talk about that.
|
||||
|
||||
### Useful links
|
||||
|
||||
A couple of useful links, to summarize:
|
||||
|
||||
* [The Kubernetes networking model][6]
|
||||
|
||||
* How GKE networking works: [https://www.youtube.com/watch?v=y2bhV81MfKQ][7]
|
||||
|
||||
* The aforementioned talk on `kube-proxy` performance: [https://www.youtube.com/watch?v=4-pawkiazEg][8]
|
||||
|
||||
### I think networking operations is important
|
||||
|
||||
My sense of all this Kubernetes networking software is that it’s all still quite new and I’m not sure we (as a community) really know how to operate all of it well. This makes me worried as an operator because I really want my network to keep working! :) Also I feel like as an organization running your own Kubernetes cluster you need to make a pretty large investment into making sure you understand all the pieces so that you can fix things when they break. Which isn’t a bad thing, it’s just a thing.
|
||||
|
||||
My plan right now is just to keep learning about how things work and reduce the number of moving parts I need to worry about as much as possible.
|
||||
|
||||
As usual I hope this was helpful and I would very much like to know what I got wrong in this post!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/10/10/operating-a-kubernetes-network/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:http://blog.sophaskins.net/blog/misadventures-with-kube-dns/
|
||||
[2]:https://github.com/coreos/flannel/pull/808
|
||||
[3]:https://github.com/coreos/flannel/pull/803
|
||||
[4]:https://github.com/coreos/flannel/issues/610
|
||||
[5]:https://github.com/AdoHe/kube2haproxy
|
||||
[6]:https://kubernetes.io/docs/concepts/cluster-administration/networking/#kubernetes-model
|
||||
[7]:https://www.youtube.com/watch?v=y2bhV81MfKQ
|
||||
[8]:https://www.youtube.com/watch?v=4-pawkiazEg
|
||||
[9]:https://jvns.ca/categories/kubernetes
|
||||
[10]:https://kubernetes.io/docs/concepts/cluster-administration/networking/#kubernetes-model
|
||||
[11]:https://github.com/kelseyhightower/kubernetes-the-hard-way/blob/master/docs/11-pod-network-routes.md
|
||||
[12]:https://github.com/coreos/flannel/tree/master/backend/vxlan
|
||||
[13]:https://github.com/kubernetes/kubernetes/issues/37932
|
||||
[14]:https://www.youtube.com/watch?v=4-pawkiazEg
|
||||
[15]:https://groups.google.com/forum/#!topic/kubernetes-sig-network/3NlBVbTUUU0
|
||||
@ -1,4 +1,5 @@
|
||||
Make “rm” Command To Move The Files To “Trash Can” Instead Of Removing Them Completely
|
||||
amwps290 translating
|
||||
Make “rm” Command To Move The Files To “Trash Can” Instead Of Removing Them Completely
|
||||
======
|
||||
Human makes mistake because we are not a programmed devices so, take additional care while using `rm` command and don't use `rm -rf *` at any point of time. When you use rm command it will delete the files permanently and doesn't move those files to `Trash Can` like how file manger does.
|
||||
|
||||
|
||||
@ -1,91 +0,0 @@
|
||||
Four Hidden Costs and Risks of Sudo Can Lead to Cybersecurity Risks and Compliance Problems on Unix and Linux Servers
|
||||
======
|
||||
It is always a philosophical debate as to whether to use open source software in a regulated environment. Open source software is crowd sourced, and developers from all over the world contribute to packages that are later included in Operating System distributions. In the case of ‘sudo’, a package designed to provide privileged access included in many Linux distributions, the debate is whether it meets the requirements of an organization, and to what level it can be relied upon to deliver compliance information to auditors.
|
||||
|
||||
There are four hidden costs or risks that must be considered when evaluating whether sudo is meeting your organization’s cybersecurity and compliance needs on its Unix and Linux systems, including administrative, forensics and audit, business continuity, and vendor support. Although sudo is a low-cost solution, it may come at a high price in a security program, and when an organization is delivering compliance data to satisfy auditors. In this article, we will review these areas while identifying key questions that should be answered to measure acceptable levels of risk. While every organization is different, there are specific risk/cost considerations that make a strong argument for replacing sudo with a commercially-supported solution.
|
||||
|
||||
### Administrative Costs
|
||||
|
||||
There are several hidden administrative costs is using sudo for Unix and Linux privilege management. For example, with sudo, you also need to run a third-party automation management system (like CFEngine or Puppet) plus third party authentication modules on the box. And, if you plan to externalize the box at all, you’re going to have to replace sudo with that supplier’s version of sudo. So, you end up maintaining sudo, a third-party management system, a third-party automation system, and may have to replace it all if you want to authenticate against something external to the box. A commercial solution would help to consolidate this functionality and simplify the overall management of Unix and Linux servers.
|
||||
|
||||
Another complexity with sudo is that everything is local, meaning it can be extremely time-consuming to manage as environments grow. And as we all know, time is money. With sudo, you have to rely on local systems on the server to keep logs locally, rotate them, send them to an archival environment, and ensure that no one is messing with any of the other related subsystems. This can be a complex and time-consuming process. A commercial solution would combine all of this activity together, including binary pushes and retention, upgrades, logs, archival, and more.
|
||||
|
||||
Unix and Linux systems by their very nature are decentralized, so managing each host separately leads to administrative costs and inefficiencies which in turn leads to risks. A commercial solution centralizes management and policy development across all hosts, introducing enterprise level consistency and best practices to a privileged access management program.
|
||||
|
||||
### Forensics & Audit Risks
|
||||
|
||||
Administrative costs aside, let’s look at the risks associated with not being able to produce log data for forensic investigations. Why is this a challenge for sudo? The sudo package is installed locally on individual servers, and configuration files are maintained on each server individually. There are some tools such as Puppet or Chef that can monitor these files for changes, and replace files with known good copies when a change is detected, but those tools only work after a change takes place. These tools usually operate on a schedule, often checking once or twice per day, so if a system is compromised, or authorization files are changed, it may be several hours before the system is restored to a known good state. The question is, what can happen in those hours?
|
||||
|
||||
There is currently no keystroke logging within sudo, and since any logs of sudo activity are stored locally on servers, they can be tampered with by savvy administrators. Event logs are typically collected with normal system logs, but once again, this requires additional configuration and management of these tools. When advanced users are granted administrative access on servers, it is possible that log data can be modified, or deleted, and all evidence of their activities erased with very little indication that events took place. Now, the question is, has this happened, or is it continuing to happen?
|
||||
|
||||
With sudo, there is no log integrity – no chain of custody on logs – meaning logs can’t be non-repudiated and therefore can’t be used in legal proceedings in most jurisdictions. This is a significant risk to organizations, especially in criminal prosecution, termination, or other disciplinary actions. Third-party commercial solutions’ logs are tamper-proof, which is just not possible with sudo.
|
||||
|
||||
Large organizations typically collect a tremendous amount of data, including system logs, access information, and other system information from all their systems. This data is then sent to a SIEM for analytics, and reporting. SIEM tools do not usually deliver real-time alerting when uncharacteristic events happen on systems, and often configuration of events is difficult and time consuming. For this reason, SIEM solutions are rarely relied upon for alerting within an enterprise environment. Here the question is, what is an acceptable delay from the time an event takes place until someone is alerted?
|
||||
|
||||
Correlating log activity with other data to determine a broader pattern of abuse is also impossible with sudo. Commercial solutions gather logs into one place with searchable indices. Some commercial solutions even correlate this log data against other sources to identify uncharacteristic behavior that could be a warning that a serious security issue is afoot. Commercial solutions therefore provide greater forensic benefits than sudo.
|
||||
|
||||
Another gotcha with sudo is that change management processes can’t be verified. It is always a best practice to review change records, and to validate that what was performed during the change matches the implementation that was proposed. ITIL and other security frameworks require validation of change management practices. Sudo can’t do this. Commercial solutions can do this through reviewing session command recording history and file integrity monitoring without revealing the underlying session data.
|
||||
|
||||
There is no session recording with sudo. Session logs are one of the best forensic tools available for investigating what happened on servers. It’s human nature that people tend to be more cautious when they know they can be watched. Sudo doesn’t provide session recordings.
|
||||
|
||||
Finally, there is no segregation of duties with sudo. Most security and compliance frameworks require true separation of duties, and using a tool such as sudo just “skins” over the segregation of duties aspect. All of these deficiencies – lack of log integrity, lack of session monitoring, no change management – introduces risk when organizations must prove compliance or investigate anomalies.
|
||||
|
||||
### Business Continuity Risks
|
||||
|
||||
Sudo is open source. There is no indemnification if there is a critical error. Also, there is no rollback with sudo, so there is always the chance that mistakes will bring and entire system down with no one to call for support. Sure, it is possible to centralize sudo through a third-party tool such as Puppet or CFEngine, but you still end up managing multiple files across multiple groups of systems manually (or managed as one huge policy). With this approach, there is greater risk that mistakes will break every system at once. A commercial solution would have policy roll-back capability that would limit the damage done.
|
||||
|
||||
### Lack of Enterprise Support
|
||||
|
||||
Since sudo is an open source package, there is no official service level for when packages must be updated to respond to identified security flaws, or vulnerabilities. By mid-2017, there have already been two vulnerabilities identified in sudo with a CVSS score greater than six (CVE Sudo Vulnerabilities). Over the past several years, there have been a number of vulnerabilities discovered in sudo that took as many as three years to patch ([CVE-2013-2776][1] , [CVE-2013-2777][2] , [CVE-2013-1776][3]). The question here is, what exploits have been used in the past several months or years? A commercial solution that replaces sudo would eliminate this problem.
|
||||
|
||||
### Ten Questions to Measure Risk in Your Unix and Linux Environment
|
||||
|
||||
Unix and Linux systems present high-value targets for external attackers and malicious insiders. Expect to be breached if you share accounts, provide unfettered root access, or let files and sessions go unmonitored. Gaining root or other privileged credentials makes it easy for attackers to fly under the radar and access sensitive systems and data. And as we have reviewed, sudo isn’t going to help.
|
||||
|
||||
In balancing costs vs. an acceptable level of risk to your Unix and Linux environment, consider these 10 questions:
|
||||
|
||||
1. How much time are Unix/Linux admins spending just trying to keep up? Can your organization benefit from automation?
|
||||
|
||||
2. Are you able to keep up with the different platform and version changes to your Unix/Linux systems?
|
||||
|
||||
3. As you grow and more hosts are added, how much more time will admins need to keep up with policy? Is adding personnel an option?
|
||||
|
||||
4. What about consistency across systems? Modifying individual sudoers files with multiple admins makes that very difficult. Wouldn’t systems become siloed if not consistently managed?
|
||||
|
||||
5. What happens when you bring in new or different Linux or Unix platforms? How will that complicate the management of the environment?
|
||||
|
||||
6. How critical is it for compliance or legal purposes to know whether a policy file or log has been tampered with?
|
||||
|
||||
7. Do you have a way to verify that the sudoers file hasn’t been modified without permission?
|
||||
|
||||
8. How do you know what admins actually did once they became root? Do you have a command history for their activity?
|
||||
|
||||
9. What would it cost the business if a mission-critical Unix/Linux host goes down? With sudo, how quickly could the team troubleshoot and fix the problem?
|
||||
|
||||
10. Can you demonstrate to the board that you have a backup if there is a significant outage?
|
||||
|
||||
### Benefits of Using a Commercial Solution
|
||||
|
||||
Although they come at a higher cost than free open source solutions, commercial solutions provide an effective way to mitigate the general issues related to sudo. Solutions that offer centralized management ease the pressure on monitoring and maintaining remote systems, centralized logging of events, and keystroke recording are the cornerstone of audit expectations for most enterprises.
|
||||
|
||||
Commercial solutions usually have a regular release cycle, and can typically deliver patches in response to vulnerabilities in hours, or days from the time they’re reported. Commercial solutions like PowerBroker for Unix & Linux by BeyondTrust provide event logging on separate infrastructure that is inaccessible to privileged users, and this eliminates the possibility of log tampering. PowerBroker also provides strong, centralized policy controls that are managed within an infrastructure separate from systems under management; this eliminates the possibility of rogue changes to privileged access policies in server environments. Strong policy control also moves security posture from ‘Respond’ to ‘Prevent’, and advanced features provide the ability to integrate with other enterprise tools, and conditionally alert when privileged access sessions begin, or end.
|
||||
|
||||
### Conclusion
|
||||
|
||||
For organizations that are serious about incorporating a strong privileged access management program into their security program, there is no question that a commercial product delivers much better than an open source offering such as sudo. Eliminating the possibility of malicious behavior using strong controls, centralized log file collection, and centralized policy management is far better than relying on questionable, difficult to manage controls delivered within sudo. In calculating an acceptable level of risk to your tier-1 Unix and Linux systems, all of these costs and benefits must be considered.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/four-hidden-costs-and-risks-sudo-can-lead-cybersecurity-risks-and-compliance-problems-unix-a
|
||||
|
||||
作者:[Chad Erbe][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/chad-erbe
|
||||
[1]:https://www.cvedetails.com/cve/CVE-2013-2776/
|
||||
[2]:https://www.cvedetails.com/cve/CVE-2013-2777/
|
||||
[3]:https://www.cvedetails.com/cve/CVE-2013-1776/
|
||||
@ -1,106 +0,0 @@
|
||||
Highly Addictive Open Source Puzzle Game
|
||||
======
|
||||

|
||||
|
||||
### About Wizznic!
|
||||
|
||||
This is an open source game inspired by the classic Puzznic, a tile-matching puzzle arcade game developed and produced by Taito in 1989. The game is way more than a clone of Puzznic. But like Puzznic, it's a frighteningly addictive game. If you like puzzle games, Wizznic! is definitely a recommended download.
|
||||
|
||||
The premise of the game is quite simple, but many of the levels are fiendishly difficult. The objective of each level is to make all the bricks vanish. The bricks disappear when they touch others of the same kind. The bricks are heavy, so you can only push them sideways, but not lift them up. The level has to be cleared of bricks before the time runs out, or you lose a life. With all but the first game pack, you only have 3 lives.
|
||||
|
||||
### Installation
|
||||
|
||||
I've mostly played Wizznic! on a Beelink S1 mini PC running a vanilla Ubuntu 17.10 installation. The mini PC only has on-board graphics, but this game doesn't require any fancy graphics card. I needed to install three SDL libraries before the game's binary would start. Many Linux users will already have these libraries installed on their PC, but they are trivial to install.
|
||||
|
||||
`sudo apt install libsdl-dev`
|
||||
`sudo apt-get install libsdl-image1.2`
|
||||
`sudo apt-get install libsdl-mixer1.2`
|
||||
|
||||
The full source code is available on GitHub available under an open source license, so you can compile the source code if you really want. The Windows binary works 'out of the box'.
|
||||
|
||||
### Wizznic! in action
|
||||
|
||||
To give a flavour of Wizznic! in action, here's a short YouTube video of the game in action. Apologies for the poor quality sound, this is my first video made with the Beelink S1 mini PC (see footnote).
|
||||
|
||||
### Screenshots
|
||||
|
||||
#### Level 4 from the Wizznic! 1 Official Pack
|
||||
|
||||
![Wizznic! Level4][1]
|
||||
|
||||
The puzzles in the first pack offer a gentle introduction to the game.
|
||||
|
||||
#### Game Editor
|
||||
|
||||
![Wizznic! Editor][2]
|
||||
|
||||
The game sports its own puzzle creator. With the game editor, it's simple to make your own puzzles and share them with your friends, colleagues, and the rest of the world.
|
||||
|
||||
Features of the game include:
|
||||
|
||||
* Atmospheric music - composed by SeanHawk
|
||||
* 2 game modes: Career, Arcade
|
||||
* Many hours of mind-bending puzzles to master
|
||||
* Create your own graphics (background images, tile sets, fonts), sound, levels, and packs
|
||||
* Built-in game editor - create your own puzzles
|
||||
* Play your own music
|
||||
* High Score table for each level
|
||||
* Skip puzzles after two failed attempts to solve them
|
||||
* Game can be controlled with the mouse, no keyboard needed
|
||||
* Level packs:
|
||||
* Wizznic! 1 - Official Pack with 20 levels, 5 lives. A fairly gentle introduction
|
||||
* Wizznic! 2 - Official Pack with 20 levels
|
||||
* Wizznic Silver - Proof of concept with 8 levels
|
||||
* Nes levels - NES Puzznic with 31 levels
|
||||
* Puzznic! S.4 - Stage 4 from Puzznic with 10 levels
|
||||
* Puzznic! S.8 - Stage 8 from Puzznic with 10 levels
|
||||
* Puzznic! S.9 - Stage 9 from Puzznic with 10 levels
|
||||
* Puzznic! S.10 - Stage 10 from Puzznic with 9 levels
|
||||
* Puzznic! S.11 - Stage 11 from Puzznic with 10 levels
|
||||
* Puzznic! S.12 - Stage 12 from Puzznic with 10 levels
|
||||
* Puzznic! S.13 - Stage 13 from Puzznic with 10 levels
|
||||
* Puzznic! S.14 - Stage 14 from Puzznic with 10 levels
|
||||
|
||||
|
||||
|
||||
### Command-Line Options
|
||||
|
||||
![Wizznic Command Options][3]
|
||||
|
||||
By default OpenGL is enabled, but it can be disabled. There are options to play the game in full screen mode, or scale to a 640×480 window. There's also Oculus Rift support, and the ability to dump screenshots of the levels.
|
||||
|
||||
**OS** **Supported** **Notes** ![][4]![][5] Besides Linux and Windows, there are official binaries available for Pandora, GP2X Wiz, GCW-Zero. There are also unofficial ports available for Android, Debian, Ubuntu, Gentoo, FreeBSD, Haiku, Amiga OS4, Canoo, Dingux, Motorola ZN5, U9, E8, EM30, VE66, EM35, and Playstation Portable.
|
||||
|
||||
Homepage: **[wizznic.org][6]**
|
||||
Developer: Jimmy Christensen (Programming, Graphics, Sound Direction), ViperMD (Graphics)
|
||||
License: GNU GPL v3
|
||||
Written in: **[C][7]**
|
||||
|
||||
![][8]![][5] ![][9]![][10]
|
||||
|
||||
**Footnote**
|
||||
|
||||
The game's audio is way better. I probably should have tried the record facility available from the command line (see later); instead I used vokoscreen to make the video.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ossblog.org/wizznic-highly-addictive-open-source-puzzle-game/
|
||||
|
||||
作者:[Steve Emms][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ossblog.org/author/steve/
|
||||
[1]:https://i0.wp.com/www.ossblog.org/wp-content/uploads/2017/10/Wizznic-Level4.png?resize=640%2C510&ssl=1
|
||||
[2]:https://i0.wp.com/www.ossblog.org/wp-content/uploads/2017/10/Wizznic-Editor.png?resize=640%2C510&ssl=1
|
||||
[3]:https://i2.wp.com/www.ossblog.org/wp-content/uploads/2017/10/Wizznic-CommandOptions.png?resize=800%2C397&ssl=1
|
||||
[4]:https://i1.wp.com/www.ossblog.org/wp-content/uploads/2017/01/linux.png?resize=48%2C48&ssl=1
|
||||
[5]:https://i2.wp.com/www.ossblog.org/wp-content/uploads/2017/01/tick.png?resize=49%2C48&ssl=1
|
||||
[6]:http://wizznic.org/
|
||||
[7]:https://www.ossblog.org/c-programming-language-profile/
|
||||
[8]:https://i2.wp.com/www.ossblog.org/wp-content/uploads/2017/01/windows.png?resize=48%2C48&ssl=1
|
||||
[9]:https://i0.wp.com/www.ossblog.org/wp-content/uploads/2017/01/apple_green.png?resize=48%2C48&ssl=1
|
||||
[10]:https://i1.wp.com/www.ossblog.org/wp-content/uploads/2017/01/cross.png?resize=48%2C48&ssl=1
|
||||
@ -1,347 +0,0 @@
|
||||
Complete Guide for Using AsciiDoc in Linux
|
||||
======
|
||||
**Brief: This detailed guide discusses the advantages of using AsciiDoc and shows you how to install and use AsciiDoc in Linux.**
|
||||
|
||||
Over the years I used many different tools to write articles, reports or documentation. I think all started for me with Luc Barthelet's Epistole on Apple IIc from the French editor Version Soft. Then I switched to GUI tools with the excellent Microsoft Word 5 for Apple Macintosh, then the less convincing (to me) StarOffice on Sparc Solaris, that was already known as OpenOffice when I definitively switched to Linux. All these tools were really [word-processors][1].
|
||||
|
||||
But I was never really convinced by [WYSIWYG][2] editors. So I investigated many different more-or-less human-readable text formats: [troff][3], [HTML][4], [RTF][5], [TeX][6]/[LaTeX][7], [XML][8] and finally [AsciiDoc][9] which is the tool I use the most today. In fact, I am using it right now to write this article!
|
||||
|
||||
If I made that history, it was because somehow the loop is closed. Epistole was a word-processor of the text-console era. As far as I remember, there were menus and you can use the mouse to select text -- but most of the formatting was done by adding non-intrusive tags into the text. Just like it is done with AsciiDoc. Of course, it was not the first software to do that. But it was the first I used!
|
||||
|
||||
|
||||
![Controlling text alignment in Luc Barthelet's Epistole \(1985-Apple II\) by using commands embedded into the text][11]
|
||||
|
||||
### Why AsciiDoc (or any other text file format)?
|
||||
|
||||
I see two advantages in using text formats for writing: first, there is a clear separation between the content and the presentation. This argument is open to discussion since some text formats like TeX or HTML require a good discipline to adhere to that separation. And on the other hand, you can somehow achieve some level of separation by using [templates and stylesheets][12] with WYSIWYG editors. I agree with that. But I still find presentation issues intrusive with GUI tools. Whereas, when using text formats, you can focus on the content only without any font style or widow line disturbing you in your writing. But maybe it's just me? However, I can't count the number of times I stopped my writing just to fix some minor styling issue -- and having lost my inspiration when I came back to the text. If you disagree or have a different experience, don't hesitate to contradict me using the comment section below!
|
||||
|
||||
Anyway, my second argument will be less subject to personal interpretation: documents based on text formats are highly interoperable. Not only you can edit them with any text editor on any platform, but you can easily manage text revisions with a tool such as [git][13] or [SVN][14], or automate text modification using common tools such as [sed][15], [AWK][16], [Perl][17] and so on. To give you a concrete example, when using a text-based format like AsciiDoc, I only need one command to produce highly personalized mailing from a master document, whereas the same job using a WYSIWYG editor would have required a clever use of "fields" and going through several wizard screens.
|
||||
|
||||
### What is AsciiDoc?
|
||||
|
||||
Strictly speaking, AsciiDoc is a file format. It defines syntactic constructs that will help a processor to understand the semantics of the various parts of your text. Usually in order to produce a nicely formatted output.
|
||||
|
||||
Even if that definition could seem abstract, this is something simple: some keywords or characters in your document have a special meaning that will change the rendering of the document. This is the exact same concept as the tags in HTML. But a key difference with AsciiDoc is the property of the source document to remain easily human readable.
|
||||
|
||||
Check [our GitHub repository][18] to compare how the same output can be produced using few common text files format: (coffee manpage idea courtesy of <http://www.linuxjournal.com/article/1158>)
|
||||
|
||||
* `coffee.man` uses the venerable troff processor (based on the 1964 [RUNOFF][19] program). It's mostly used today to write [man pages][20]. You can try it after having downloaded the `coffee.*` files by typing `man ./coffee.man` at your command prompt.
|
||||
* `coffee.tex` uses the LaTeX syntax (1985) to achieve mostly the same result but for a PDF output. LaTeX is a typesetting program especially well suited for scientific publications because of its ability to nicely format mathematical formulae and tables. You can produce the PDF from the LaTeX source using `pdflatex coffee.tex`
|
||||
* `coffee.html` is using the HTML format (1991) to describe the page. You can directly open that file with your favorite web browser to see the result.
|
||||
* `coffee.adoc`, finally, is using the AsciiDoc syntax (2002). You can produce both HTML and PDF from that file:
|
||||
|
||||
|
||||
```
|
||||
asciidoc coffee.adoc # HTML output
|
||||
a2x --format pdf ./coffee.adoc # PDF output (dblatex)
|
||||
a2x --fop --format pdf ./coffee.adoc # PDF output (Apache FOP)
|
||||
```
|
||||
|
||||
Now you've seen the result, open those four files using your favorite [text editor][21] (nano, vim, SublimeText, gedit, Atom, … ) and compare the sources: there are great chances you will agree the AsciiDoc sources are easier to read -- and probably to write too.
|
||||
|
||||
|
||||
![Who is who? Could you guess which of these example files is written using AsciiDoc?][22]
|
||||
|
||||
### How to install AsciiDoc in Linux?
|
||||
|
||||
AsciiDoc is relatively complex to install because of the many dependencies. I mean complex if you want to install it from sources. For most of us, using our package manager is probably the best way:
|
||||
```
|
||||
apt-get install asciidoc fop
|
||||
```
|
||||
|
||||
or the following command:
|
||||
```
|
||||
yum install acsiidoc fop
|
||||
```
|
||||
|
||||
(fop is only required if you need the [Apache FOP][23] backend for PDF generation -- this is the PDF backend I use myself)
|
||||
|
||||
More details about the installation can be found on [the official AsciiDoc website][24]. For now, all you need now is a little bit of patience, since, at least on my minimal Debian system, installing AsciiDoc require 360MB to be downloaded (mostly because of the LaTeX dependency). Which, depending on your Internet bandwidth, may give you plenty of time to read the rest of this article.
|
||||
|
||||
### AsciiDoc Tutorial: How to write in AsciiDoc?
|
||||
|
||||
|
||||
![AsciiDoc tutorial for Linux][25]
|
||||
|
||||
I said it several times, AsciiDoc is a human-readable text file format. So, you can write your documents using the text editor of your choice. There are even dedicated text editors. But I will not talk about them here-- simply because I don't use them. But if are using one of them, don't hesitate to share your feedback using the comment section at the end of this article.
|
||||
|
||||
I do not intend to create yet another AsciiDoc syntax tutorial here: there are plenty of them already available on the web. So I will only mention the very basic syntactic constructs you will use in virtually any document. From the simple "coffee" command example quoted above, you may see:
|
||||
|
||||
* **titles** in AsciiDoc are identified by underlying them with `===` or `---` (depending on the title level),
|
||||
* **bold** character spans are written between starts,
|
||||
* and **italics** between underscores.
|
||||
|
||||
|
||||
|
||||
Those are pretty common convention probably dating back to the pre-HTML email era. In addition, you may need two other common constructs, not illustrated in my previous example: **hyperlinks** and **images** inclusion, whose syntax is pretty self-explanatory.
|
||||
```
|
||||
// HyperText links
|
||||
link:http://dashing-kazoo.flywheelsites.com[ItsFOSS Linux Blog]
|
||||
|
||||
// Inline Images
|
||||
image:https://itsfoss.com/wp-content/uploads/2017/06/itsfoss-text-logo.png[ItsFOSS Text Logo]
|
||||
|
||||
// Block Images
|
||||
image::https://itsfoss.com/wp-content/uploads/2017/06/itsfoss-text-logo.png[ItsFOSS Text Logo]
|
||||
```
|
||||
|
||||
But the AsciiDoc syntax is much richer than that. If you want more, I can point you to that nice AsciiDoc cheatsheet: <http://powerman.name/doc/asciidoc>
|
||||
|
||||
### How to render the final output?
|
||||
|
||||
I will assume here you have already written some text following the AsciiDoc format. If this is not the case, you can download [here][26] some example files copied straight out of the AsciiDoc documentation:
|
||||
```
|
||||
# Download the AsciiDoc User Guide source document
|
||||
BASE='https://raw.githubusercontent.com/itsfoss/asciidoc-intro/master'
|
||||
wget "${BASE}"/{asciidoc.txt,customers.csv}
|
||||
```
|
||||
|
||||
Since AsciiDoc is human-readable, you can send the AsciiDoc source text directly to someone by email, and the recipient will be able to read that message without further ado. But, you may want to provide some more nicely formatted output. For example as HTML for web publication (just like I've done it for this article). Or as PDF for print or display usage.
|
||||
|
||||
In all cases, you need a processor. In fact, under the hood, you will need several processors. Because your AsciiDoc document will be transformed into various intermediate formats before producing the final output. Since several tools are used, the output of one being the input of the next one, we sometimes speak of a toolchain.
|
||||
|
||||
Even if I explain some inner working details here, you have to understand most of that will be hidden from you. Unless maybe when you initially have to install the tools-- or if you want to fine-tune some steps of the process.
|
||||
|
||||
#### In practice?
|
||||
|
||||
For HTML output, you only need the `asciidoc` tool. For more complicated toolchains, I encourage you to use the `a2x` tool (part of the AsciiDoc distribution) that will trigger the necessary processors in order:
|
||||
```
|
||||
# All examples are based on the AsciiDoc User Guide source document
|
||||
|
||||
# HTML output
|
||||
asciidoc asciidoc.txt
|
||||
firefox asciidoc.html
|
||||
|
||||
# XHTML output
|
||||
a2x --format=xhtml asciidoc.txt
|
||||
|
||||
# PDF output (LaTeX processor)
|
||||
a2x --format=pdf asciidoc.txt
|
||||
|
||||
# PDF output (FOP processor)
|
||||
a2x --fop --format=pdf asciidoc.txt
|
||||
```
|
||||
|
||||
Even if it can directly produce an HTML output, the core functionality of the `asciidoc` tool remains to transform the AsciiDoc document to the intermediate [DocBook][27] format. DocBook is a XML-based format commonly used for (but not limited to) technical documentation publishing. DocBook is a semantic format. That means it describes your document content. But not its presentation. So formatting will be the next step of the transformation. For that, whatever is the output format, the DocBook intermediate document is processed through an [XSLT][28] processor to produce either directly the output (e.g. XHTML), or another intermediate format.
|
||||
|
||||
This is the case when you generate a PDF document where the DocBook document will be (at your will) converted either as a LaTeX intermediate representation or as [XSL-FO][29] (a XML-based language for page description). Finally, a dedicated tool will convert that representation to PDF.
|
||||
|
||||
The extra steps for PDF generations are notably justified by the fact the toolchain has to handle pagination for the PDF output. Something this is not necessary for a "stream" format like HTML.
|
||||
|
||||
#### dblatex or fop?
|
||||
|
||||
Since there are two PDF backends, the usual question is "Which is the best?" Something I can't answer for you.
|
||||
|
||||
Both processors have [pros and cons][30]. And ultimately, the choice will be a compromise between your needs and your tastes. So I encourage you to take the time to try both of them before choosing the backend you will use. If you follow the LaTeX path, [dblatex][31] will be the backend used to produce the PDF. Whereas it will be [Apache FOP][32] if you prefer using the XSL-FO intermediate format. So don't forget to take a look at the documentation of these tools to see how easy it will be to customize the output to your needs. Unless of course if you are satisfied with the default output!
|
||||
|
||||
### How to customize the output of AsciiDoc?
|
||||
|
||||
#### AsciiDoc to HTML
|
||||
|
||||
Out of the box, AsciiDoc produces pretty nice documents. But sooner or later you will what to customize their appearance.
|
||||
|
||||
The exact changes will depend on the backend you use. For the HTML output, most changes can be done by changing the [CSS][33] stylesheet associated with the document.
|
||||
|
||||
For example, let's say I want to display all section headings in red, I could create the following `custom.css` file:
|
||||
```
|
||||
h2 {
|
||||
color: red;
|
||||
}
|
||||
```
|
||||
|
||||
And process the document using the slightly modified command:
|
||||
```
|
||||
# Set the 'stylesheet' attribute to
|
||||
# the absolute path to our custom CSS file
|
||||
asciidoc -a stylesheet=$PWD/custom.css asciidoc.txt
|
||||
```
|
||||
|
||||
You can also make changes at a finer level by attaching a role attribute to an element. This will translate into a class attribute in the generated HTML.
|
||||
|
||||
For example, try to modify our test document to add the role attribute to the first paragraph of the text:
|
||||
```
|
||||
[role="summary"]
|
||||
AsciiDoc is a text document format ....
|
||||
```
|
||||
|
||||
Then add the following rule to the `custom.css` file:
|
||||
```
|
||||
.summary {
|
||||
font-style: italic;
|
||||
}
|
||||
```
|
||||
|
||||
Re-generate the document:
|
||||
```
|
||||
asciidoc -a stylesheet=$PWD/custom.css asciidoc.txt
|
||||
```
|
||||
|
||||
|
||||
![AsciiDoc HTML output with custom CSS to display the first paragraph in italics and section headings in color][34]
|
||||
|
||||
1. et voila: the first paragraph is now displayed in italic. With a little bit of creativity, some patience and a couple of CSS tutorials, you should be able to customize your document at your wills.
|
||||
|
||||
|
||||
|
||||
#### AsciiDoc to PDF
|
||||
|
||||
Customizing the PDF output is somewhat more complex. Not from the author's perspective since the source text will remain identical. Eventually using the same role attribute as above to identify the parts that need a special treatment.
|
||||
|
||||
But you can no longer use CSS to define the formatting for PDF output. For the most common settings, there are parameters you can set from the command line. Some parameters can be used both with the dblatex and the fop backends, others are specific to each backend.
|
||||
|
||||
For the list of dblatex supported parameters, see <http://dblatex.sourceforge.net/doc/manual/sec-params.html>
|
||||
|
||||
For the list of DocBook XSL parameters, see <http://docbook.sourceforge.net/release/xsl/1.75.2/doc/param.html>
|
||||
|
||||
Since margin adjustment is a pretty common requirement, you may also want to take a look at that: <http://docbook.sourceforge.net/release/xsl/current/doc/fo/general.html>
|
||||
|
||||
If the parameter names are somewhat consistent between the two backends, the command-line arguments used to pass those values to the backends differ between dblatex and fop. So, double check first your syntax if apparently, this isn't working. But to be honest, while writing this article I wasn't able to make the `body.font.family` parameter work with the dblatex backend. Since I usually use fop, maybe did I miss something? If you have more clues about that, I will be more than happy to read your suggestions in the comment section at the end of this article!
|
||||
|
||||
Worth mentioning using non-standard fonts-- even with fop-require some extra work. But it's pretty well documented on the Apache website: <https://xmlgraphics.apache.org/fop/trunk/fonts.html#bulk>
|
||||
```
|
||||
# XSL-FO/FOP
|
||||
a2x -v --format pdf \
|
||||
--fop \
|
||||
--xsltproc-opts='--stringparam page.margin.inner 10cm' \
|
||||
--xsltproc-opts='--stringparam body.font.family Helvetica' \
|
||||
--xsltproc-opts='--stringparam body.font.size 8pt' \
|
||||
asciidoc.txt
|
||||
|
||||
# dblatex
|
||||
# (body.font.family _should_ work, but, apparently, it isn't ?!?)
|
||||
a2x -v --format pdf \
|
||||
--dblatex-opts='--param page.margin.inner=10cm' \
|
||||
--dblatex-opts='--stringparam body.font.family Helvetica' \
|
||||
asciidoc.txt
|
||||
```
|
||||
|
||||
#### Fine-grained setting for PDF generation
|
||||
|
||||
Global parameters are nice if you just need to adjust some pre-defined settings. But if you want to fine-tune the document (or completely change the layout) you will need some extra efforts.
|
||||
|
||||
At the core of the DocBook processing there is [XSLT][28]. XSLT is a computer language, expressed in XML notation, that allows to write arbitrary transformation from an XML document to … something else. XML or not.
|
||||
|
||||
For example, you will need to extend or modify the [DocBook XSL stylesheet][35] to produce the XSL-FO code for the new styles you may want. And if you use the dblatex backend, this may require modifying the corresponding DocBook-to-LaTeX XSLT stylesheet. In that latter case you may also need to use a custom LaTeX package. But I will not focus on that since dblatex is not the backend I use myself. I can only point you to the [official documentation][36] if you want to know more. But once again, if you're familiar with that, please share your tips and tricks in the comment section!
|
||||
|
||||
Even while focusing only on fop, I don't really have the room here to detail the entire procedure. So, I will just show you the changes you could use to obtain a similar result as the one obtained with few CSS lines in HTML output above. That is: section titles in red and a summary paragraph in italics.
|
||||
|
||||
The trick I use here is to create a new XSLT stylesheet, importing the original DocBook stylesheet, but overriding the attribute sets or template for the elements we want to change:
|
||||
```
|
||||
<?xml version='1.0'?>
|
||||
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
|
||||
xmlns:exsl="http://exslt.org/common" exclude-result-prefixes="exsl"
|
||||
xmlns:fo="http://www.w3.org/1999/XSL/Format"
|
||||
version='1.0'>
|
||||
|
||||
<!-- Import the default DocBook stylesheet for XSL-FO -->
|
||||
<xsl:import href="/etc/asciidoc/docbook-xsl/fo.xsl" />
|
||||
|
||||
<!--
|
||||
DocBook XSL defines many attribute sets you can
|
||||
use to control the output elements
|
||||
-->
|
||||
<xsl:attribute-set name="section.title.level1.properties">
|
||||
<xsl:attribute name="color">#FF0000</xsl:attribute>
|
||||
</xsl:attribute-set>
|
||||
|
||||
<!--
|
||||
For fine-grained changes, you will need to write
|
||||
or override XSLT templates just like I did it below
|
||||
for 'summary' simpara (paragraphs)
|
||||
-->
|
||||
<xsl:template match="simpara[@role='summary']">
|
||||
<!-- Capture inherited result -->
|
||||
<xsl:variable name="baseresult">
|
||||
<xsl:apply-imports/>
|
||||
</xsl:variable>
|
||||
|
||||
<!-- Customize the result -->
|
||||
<xsl:for-each select="exsl:node-set($baseresult)/node()">
|
||||
<xsl:copy>
|
||||
<xsl:copy-of select="@*"/>
|
||||
<xsl:attribute name="font-style">italic</xsl:attribute>
|
||||
<xsl:copy-of select="node()"/>
|
||||
</xsl:copy>
|
||||
</xsl:for-each>
|
||||
</xsl:template>
|
||||
|
||||
|
||||
</xsl:stylesheet>
|
||||
```
|
||||
|
||||
Then, you have to request `a2x` to use that custom XSL stylesheet to produce the output rather than the default one using the `--xsl-file` option:
|
||||
```
|
||||
a2x -v --format pdf \
|
||||
--fop \
|
||||
--xsl-file=./custom.xsl \
|
||||
asciidoc.txt
|
||||
```
|
||||
|
||||
![AsciiDoc PDF output generated from Apache FOP using a custom XSLT to display the first paragraph in italics and section headings in color][37]
|
||||
|
||||
With a little bit of familiarity with XSLT, the hints given here and some queries on your favorite search engine, I think you should be able to start customizing the XSL-FO output.
|
||||
|
||||
But I will not lie, some apparently simple changes in the document output may require you to spend quite some times searching through the DocBook XML and XSL-FO manuals, examining the stylesheets sources and performing a couple of tests before you finally achieve what you want.
|
||||
|
||||
### My opinion
|
||||
|
||||
Writing documents using a text format has tremendous advantages. And if you need to publish to HTML, there is not much reason for not using AsciiDoc. The syntax is clean and neat, processing is simple and changing the presentation if needed, mostly require easy to acquire CSS skills.
|
||||
|
||||
And even if you don't use the HTML output directly, HTML can be used as an interchange format with many WYSIWYG applications today. As an example, this is was I've done here: I copied the HTML output of this article into the WordPress edition area, thus conserving all formatting, without having to type anything directly into WordPress.
|
||||
|
||||
If you need to publish to PDF-- the advantages remain the same for the writer. Things will be certainly harsher if you need to change the default layout in depth though. In a corporate environment, that probably means hiring a document designed skilled with XSLT to produce the set of stylesheets that will suit your branding or technical requirements-- or for someone in the team to acquire those skills. But once done it will be a pleasure to write text with AsciiDoc. And seeing those writings being automatically converted to beautiful HTML pages or PDF documents!
|
||||
|
||||
Finally, if you find AsciiDoc either too simplistic or too complex, you may take a look at some other file formats with similar goals: [Markdown][38], [Textile][39], [reStructuredText][40] or [AsciiDoctor][41] to name few. Even if based on concepts dating back to the early days of computing, the human-readable text format ecosystem is pretty rich. Probably richer it was only 20 years ago. As a proof, many modern [static web site generators][42] are based on them. Unfortunately, this is out of the scope for this article. So, let us know if you want to hear more about that!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/asciidoc-guide/
|
||||
|
||||
作者:[Sylvain Leroux][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/sylvain/
|
||||
[1]:https://www.computerhope.com/jargon/w/wordssor.htm
|
||||
[2]:https://en.wikipedia.org/wiki/WYSIWYG
|
||||
[3]:https://en.wikipedia.org/wiki/Troff
|
||||
[4]:https://en.wikipedia.org/wiki/HTML
|
||||
[5]:https://en.wikipedia.org/wiki/Rich_Text_Format
|
||||
[6]:https://en.wikipedia.org/wiki/TeX
|
||||
[7]:https://en.wikipedia.org/wiki/LaTeX
|
||||
[8]:https://en.wikipedia.org/wiki/XML
|
||||
[9]:https://en.wikipedia.org/wiki/AsciiDoc
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09//epistole-manual-command-example-version-soft-luc-barthelet-1985.png
|
||||
[12]:https://wiki.openoffice.org/wiki/Documentation/OOo3_User_Guides/Getting_Started/Templates_and_Styles
|
||||
[13]:https://en.wikipedia.org/wiki/Git
|
||||
[14]:https://en.wikipedia.org/wiki/Apache_Subversion
|
||||
[15]:https://en.wikipedia.org/wiki/Sed
|
||||
[16]:https://en.wikipedia.org/wiki/AWK
|
||||
[17]:https://en.wikipedia.org/wiki/Perl
|
||||
[18]:https://github.com/itsfoss/asciidoc-intro/tree/master/coffee
|
||||
[19]:https://en.wikipedia.org/wiki/TYPSET_and_RUNOFF
|
||||
[20]:https://en.wikipedia.org/wiki/Man_page
|
||||
[21]:https://en.wikipedia.org/wiki/Text_editor
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09//troff-latex-html-asciidoc-compare-source-code.png
|
||||
[23]:https://en.wikipedia.org/wiki/Formatting_Objects_Processor
|
||||
[24]:http://www.methods.co.nz/asciidoc/INSTALL.html
|
||||
[25]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/asciidoc-tutorial-linux.jpg
|
||||
[26]:https://raw.githubusercontent.com/itsfoss/asciidoc-intro/master
|
||||
[27]:https://en.wikipedia.org/wiki/DocBook
|
||||
[28]:https://en.wikipedia.org/wiki/XSLT
|
||||
[29]:https://en.wikipedia.org/wiki/XSL_Formatting_Objects
|
||||
[30]:http://www.methods.co.nz/asciidoc/userguide.html#_pdf_generation
|
||||
[31]:http://dblatex.sourceforge.net/
|
||||
[32]:https://xmlgraphics.apache.org/fop/
|
||||
[33]:https://en.wikipedia.org/wiki/Cascading_Style_Sheets
|
||||
[34]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09//asciidoc-html-output-custom-role-italic-paragraph-color-heading.png
|
||||
[35]:http://www.sagehill.net/docbookxsl/
|
||||
[36]:http://dblatex.sourceforge.net/doc/manual/sec-custom.html
|
||||
[37]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/09//asciidoc-fop-output-custom-role-italic-paragraph-color-heading.png
|
||||
[38]:https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
|
||||
[39]:https://txstyle.org/
|
||||
[40]:http://docutils.sourceforge.net/docs/user/rst/quickstart.html
|
||||
[41]:http://asciidoctor.org/
|
||||
[42]:https://www.smashingmagazine.com/2015/11/modern-static-website-generators-next-big-thing/
|
||||
@ -1,124 +0,0 @@
|
||||
The 10 best ways to secure your Android phone
|
||||
======
|
||||
![][1]
|
||||
|
||||
The [most secure smartphones are Android smartphones][2]. Don't buy that? Apple's latest version of [iOS 11 was cracked a day -- a day! -- after it was released][3].
|
||||
|
||||
So Android is perfect? Heck no!
|
||||
|
||||
Android is under constant attack and older versions are far more vulnerable than new ones. Way too many smartphone vendors still don't issue [Google's monthly Android security patches][4] in a timely fashion, or at all. And, zero-day attacks still pop up.
|
||||
|
||||
So, what can you do to protect yourself? A lot actually.
|
||||
|
||||
Here are my top 10 ways to keep you and your Android device safe from attackers. Many of these are pretty simple, but security is really more about doing safe things every time than fancy complicated security tricks.
|
||||
|
||||
**1) Only buy smartphones from vendors who release Android patches quickly.**
|
||||
|
||||
I recently got a [Google Pixel 2][5]. There were many reasons for this, but number one with a bullet was that Google makes sure its smartphones, such as the Pixel, the Pixel 2, Nexus 5X, and 6P get the freshest updates. This means they get the newest security patches as they're released.
|
||||
|
||||
As for other major vendors, [Android Authority][6], the leading Android publication, found, the [best vendors for keeping their phones up to date][7] were, in order, from best to worse: LG, Motorola, HTC, Sony, Xiaomi, OnePlus, and Samsung.
|
||||
|
||||
**2) Lock your phone.**
|
||||
|
||||
I know, it's so simple. But, people still don't do it. Trust me. You're more likely to get into trouble by a pickpocket snatching your phone and running wild with your credit-card accounts than you from malware.
|
||||
|
||||
What's the best way to lock your phone? Well, it's not sexy, but the good old [PIN remains the safest way][8]. Fingerprints, patterns, voice-recognition, iris scanning, etc. -- they're all more breakable. Just don't, for the sake of [Android Oreo][9] cookies, use 1-2-3-4, as your PIN. Thank you.
|
||||
|
||||
**3) Use two-factor authentication.**
|
||||
|
||||
While you're securing your phone, let's lock down your Google services as well. The best way of doing this is with [Google's own two-factor authentication][10].
|
||||
|
||||
Here's how to do it: Login-in to your [Google account and head to the two-step verification settings page][11]. Once there, choose "Using 2-step verification" from the menu. From there, follow the prompts. You'll be asked for your phone number. You can get verification codes by voice or SMS on your phone. I find texting easier.
|
||||
|
||||
In seconds, you'll get a call with your verification number. You then enter this code into your web browser's data entry box Your device will then ask you if you want it to remember the computer you're using. If you answer, "yes" that programs will be authorized for use for 30-days. Finally, you turn on 2-step verification and you're done.
|
||||
|
||||
You can also make this even simpler by using [Google Prompt][12]. With this you can authorize Google apps by simply entering "yes" when prompted on your phone.
|
||||
|
||||
**4) Only use apps from the Google Play Store.**
|
||||
|
||||
Seriously. The vast majority of Android malware comes from unreliable third party application sources. Sure, bogus apps make it into the Google Play Store from time to time, like the [ones which messaged premium-rate text services][13], but they're exception, not the rule.
|
||||
|
||||
Google has also kept working on making the Play Store safer than ever. For example, [Google Play Protect][14] can automatically scan your Android device for malware when you install programs. Make sure it's on by going to Settings > Security > Play Protect. For maximum security, click Full scanning and "Scan device for security threats" on.
|
||||
|
||||
**5) Use device encryption.**
|
||||
|
||||
The next person who wants to [snoop in your phone may not be a crook, but a US Customs and Border Protection (CBP) agent][15]. If that idea creeps you out, you can put a roadblock in their way with encryption. That may land you in hot water with Homeland Security, but it's your call.
|
||||
|
||||
To encrypt your device, go to Settings > Security > Encrypt Device and follow the prompts.
|
||||
|
||||
By the way, the CBP also states "border searches conducted by CBP do not extend to information that is located solely on remote servers." So, your data may actually be safer in the cloud in this instance.
|
||||
|
||||
**6) Use a Virtual Private Network.**
|
||||
|
||||
If you're on the road -- whether it's your local coffee shop or the remote office in Singapore -- you're going to want to use free Wi-Fi. We all do. We all take big chances when we do since they tend of be as secure as a net built out of thread. To [make yourself safer you'll want to use a mobile Virtual Private Network (VPN)][16].
|
||||
|
||||
In my experience, the best of these are: [F-Secure Freedome VPN][17], [KeepSolid VPN Unlimited][18], [NordVPN][19], [Private Internet Access][20], and [TorGuard][21]. What you don't want to do, no matter how tempted you may be, is to use a free VPN service. None of them work worth a darn.
|
||||
|
||||
**7) Password management.**
|
||||
|
||||
When it comes to passwords, you have choices: 1) use the same password for everything, which is really dumb. 2) Write down your passwords on paper, which isn't as bad an idea as it sounds so long as you don't put them on a sticky note on your PC screen; 3) Memorize all your passwords, not terribly practical. Or, 4) use a password management program.
|
||||
|
||||
Now Google comes with one built-in, but if you don't want to put all your security eggs in one cloud basket, you can use other mobile password management programs. The best of the bunch are: [LastPass][22], [1Password][23], and [Dashlane][24].
|
||||
|
||||
**8) Use anti-virus software.**
|
||||
|
||||
While Google Play Protect does a good job of protecting your phone, when it comes to malware protection I believe is using a belt and suspenders. For my anti-virus (A/V) suspenders, I use Germany's [AV-TEST][25], an independent malware detection lab, results as my guide.
|
||||
|
||||
So, the best freeware A/V program today is [Avast Mobile Security & Antivirus][26]. It's other security features, like its phone tracker, doesn't work that well, but it's good at finding and deleting malware. The best freemium A/V software is [Norton Mobile Security][27]. All its components work well and if you elect to go for the full package, it's only $25 for 10 devices.
|
||||
|
||||
**9) Turn off connections when you don't need them.**
|
||||
|
||||
If you're not using Wi-Fi or Bluetooth, turn them off. Besides saving some battery life, network connections can be used to attack you. The [BlueBorne Bluetooth][28] hackers are still alive, well, and ready to wreck your day. Don't give it a chance.
|
||||
|
||||
True, [Android was patched to stop this attack in its September 2017 release][29]. Google's device family got the patch and [Samsung deployed it][30]. Has your vendor protected your device yet? Odds are they haven't.
|
||||
|
||||
**10) If you don't use an app, uninstall it.**
|
||||
|
||||
Every application comes with its own security problems. Most Android software vendors do a good job of updating their programs. Most of them. If you're not using an application, get rid of it. The fewer program doors you have into your smartphone, the fewer chances an attacker has to invade it.
|
||||
|
||||
If you follow up with all these suggestions, your phone will be safer. It won't be perfectly safe -- nothing is in this world. But, you'll be much more secure than you are now, and that's not a small thing.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/the-ten-best-ways-to-secure-your-android-phone/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:https://zdnet1.cbsistatic.com/hub/i/r/2017/10/18/7147d044-cb9a-4e88-abc2-02279b21b74a/thumbnail/570x322/c665fa2b5bca56e1b98ec3a23bb2c90b/59e4fb2460b299f92c13a408-1280x7201oct182017131932poster.jpg
|
||||
[2]:http://www.zdnet.com/article/the-worlds-most-secure-smartphones-and-why-theyre-all-androids/
|
||||
[3]:http://www.zdnet.com/article/ios-11-hacked-by-security-researchers-day-after-release/
|
||||
[4]:http://www.zdnet.com/article/googles-october-android-patches-have-landed-theres-a-big-fix-for-dnsmasq-bug/
|
||||
[5]:http://www.zdnet.com/product/google-pixel-2-xl/
|
||||
[6]:https://www.androidauthority.com/
|
||||
[7]:https://www.androidauthority.com/android-oem-update-speed-743073/
|
||||
[8]:http://fieldguide.gizmodo.com/whats-the-most-secure-way-to-lock-your-smartphone-1796948710
|
||||
[9]:http://www.zdnet.com/article/why-android-oreo-stacks-up-well-as-a-major-update/
|
||||
[10]:http://www.zdnet.com/article/how-to-use-google-two-factor-authentication/
|
||||
[11]:https://accounts.google.com/SmsAuthConfig
|
||||
[12]:https://support.google.com/accounts/answer/7026266?co=GENIE.Platform%3DAndroid&hl=en
|
||||
[13]:http://www.zdnet.com/article/android-malware-in-google-play-racked-up-4-2-million-downloads-so-are-you-a-victim/
|
||||
[14]:http://www.zdnet.com/article/google-play-protect-now-rolling-out-to-android-devices/
|
||||
[15]:http://www.zdnet.com/article/us-customs-says-border-agents-cant-search-cloud-data-from-travelers-phones/
|
||||
[16]:http://www.zdnet.com/article/what-you-must-know-about-mobile-vpns-to-protect-your-privacy/
|
||||
[17]:https://www.f-secure.com/en_US/web/home_us/freedome
|
||||
[18]:https://www.vpnunlimitedapp.com/en
|
||||
[19]:https://nordvpn.com/special/2ydeal/?utm_source=aff307&utm_medium=affiliate&utm_term=&utm_content=&utm_campaign=off15
|
||||
[20]:http://dw.cbsi.com/redir?ttag=vpn&topicbrcrm=virtual-private-network-services<ype=is&merid=50000882&mfgId=50000882&oid=2703-9234_1-0&ontid=9234&edId=3&siteid=1&channelid=6028&rsid=cbsicnetglobalsite&sc=US&sl=en&destUrl=https://www.privateinternetaccess.com/pages/buy-vpn/cnet
|
||||
[21]:https://torguard.net/
|
||||
[22]:https://play.google.com/store/apps/details?id=com.lastpass.lpandroid
|
||||
[23]:https://play.google.com/store/apps/details?id=com.agilebits.onepassword
|
||||
[24]:https://play.google.com/store/apps/details?id=com.dashlane
|
||||
[25]:https://www.av-test.org/
|
||||
[26]:https://play.google.com/store/apps/details?id=com.avast.android.mobilesecurity&hl=en
|
||||
[27]:https://my.norton.com/mobile/home
|
||||
[28]:http://www.zdnet.com/article/bluetooth-security-flaw-blueborne-iphone-android-windows-devices-at-risk/
|
||||
[29]:https://source.android.com/security/bulletin/2017-09-01
|
||||
[30]:https://www.sammobile.com/2017/09/25/samsung-rolls-security-patches-fix-blueborne-vulnerability/
|
||||
@ -1,68 +0,0 @@
|
||||
Take Linux and Run With It
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
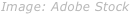
|
||||
|
||||
|
||||
"How do you run an operating system?" may seem like a simple question, since most of us are accustomed to turning on our computers and seeing our system spin up. However, this common model is only one way of running an operating system. As one of Linux's greatest strengths is versatility, Linux offers the most methods and environments for running it.
|
||||
|
||||
To unleash the full power of Linux, and maybe even find a use for it you hadn't thought of, consider some less conventional ways of running it -- specifically, ones that don't even require installation on a computer's hard drive.
|
||||
|
||||
### We'll Do It Live!
|
||||
|
||||
Live-booting is a surprisingly useful and popular way to get the full Linux experience on the fly. While hard drives are where OSes reside most of the time, they actually can be installed to most major storage media, including CDs, DVDs and USB flash drives.
|
||||
|
||||
When an OS is installed to some device other than a computer's onboard hard drive and subsequently booted instead of that onboard drive, it's called "live-booting" or running a "live session."
|
||||
|
||||
At boot time, the user simply selects an external storage source for the hardware to look for boot information. If found, the computer follows the external device's boot instructions, essentially ignoring the onboard drive until the next time the user boots normally. Optical media are increasingly rare these days, so by far the most typical form that an external OS-carrying device takes is a USB stick.
|
||||
|
||||
Most mainstream Linux distributions offer a way to run a live session as a way of trying them out. The live session doesn't save any user activity, and the OS resets to the clean default state after every shutdown.
|
||||
|
||||
Live Linux sessions can be used for more than testing a distro, though. One application is for executing system repair for critically malfunctioning onboard (usually also Linux) systems. If an update or configuration made the onboard system unbootable, a full system backup is required, or the hard drive has sustained serious file corruption, the only recourse is to start up a live system and perform maintenance on the onboard drive.
|
||||
|
||||
In these and similar scenarios, the onboard drive cannot be manipulated or corrected while also keeping the system stored on it running, so a live system takes on those burdens instead, leaving all but the problematic files on the onboard drive at rest.
|
||||
|
||||
Live sessions also are perfectly suited for handling sensitive information. If you don't want a computer to retain any trace of the operations executed or information handled on it, especially if you are using hardware you can't vouch for -- like a public library or hotel business center computer -- a live session will provide you all the desktop computing functions to complete your task while retaining no trace of your session once you're finished. This is great for doing online banking or password input that you don't want a computer to remember.
|
||||
|
||||
### Linux Virtually Anywhere
|
||||
|
||||
Another approach for implementing Linux for more on-demand purposes is to run a virtual machine on another host OS. A virtual machine, or VM, is essentially a small computer running inside another computer and contained in a single large file.
|
||||
|
||||
To run a VM, users simply install a hypervisor program (a kind of launcher for the VM), select a downloaded Linux OS image file (usually ending with a ".iso" file extension), and walk through the setup process.
|
||||
|
||||
Most of the settings can be left at their defaults, but the key ones to configure are the amount of RAM and hard drive storage to lease to the VM. Fortunately, since Linux has a light footprint, you don't have to set these very high: 2 GB of RAM and 16 GB of storage should be plenty for the VM while still letting your host OS thrive.
|
||||
|
||||
So what does this offer that a live system doesn't? First, whereas live systems are ephemeral, VMs can retain the data stored on them. This is great if you want to set up your Linux VM for a special use case, like software development or even security.
|
||||
|
||||
When used for development, a Linux VM gives you the solid foundation of Linux's programming language suites and coding tools, and it lets you save your projects right in the VM to keep everything organized.
|
||||
|
||||
If security is your goal, Linux VMs allow you to impose an extra layer between a potential hazard and your system. If you do your browsing from the VM, a malicious program would have to compromise not only your virtual Linux system, but also the hypervisor -- and _then_ your host OS, a technical feat beyond all but the most skilled and determined adversaries.
|
||||
|
||||
Second, you can start up your VM on demand from your host system, without having to power it down and start it up again as you would have to with a live session. When you need it, you can quickly bring up the VM, and when you're finished, you just shut it down and go back to what you were doing before.
|
||||
|
||||
Your host system continues running normally while the VM is on, so you can attend to tasks simultaneously in each system.
|
||||
|
||||
### Look Ma, No Installation!
|
||||
|
||||
Just as there is no one form that Linux takes, there's also no one way to run it. Hopefully, this brief primer on the kinds of systems you can run has given you some ideas to expand your use models.
|
||||
|
||||
The best part is that if you're not sure how these can help, live booting and virtual machines don't hurt to try!
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html
|
||||
|
||||
作者:[ Jonathan Terrasi ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html#searchbyline
|
||||
[1]:https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html#
|
||||
[2]:https://www.linuxinsider.com/perl/mailit/?id=84951
|
||||
[3]:https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html
|
||||
[4]:https://www.linuxinsider.com/story/Take-Linux-and-Run-With-It-84951.html
|
||||
@ -1,114 +0,0 @@
|
||||
GParted The Complete Partition Editor For Linux
|
||||
======
|
||||
|
||||

|
||||
**Partition editing**is a task which not only requires carefulness but also a stable environment. Today GParted is one of the leading partition editing tools on Linux environment.
|
||||
|
||||
**GParted**is not only easy but also remains powerful at the same time. Today I am going to list out the installation as well as basics to use GParted which will be helpful to newbies.
|
||||
|
||||
### How to install GParted?
|
||||
|
||||
Downloading and installing gparted is not a much difficult task. Today GParted is available on almost all distros and can be easily installed from their specific software center. Just go to software center and search “GParted” or use command line package manager to install it.
|
||||
|
||||
[][1] In case you don’t have a software center or GParted isn’t available on software center you can always grab it from its official website.[Download][2]
|
||||
|
||||
#### The Basics
|
||||
|
||||
Using GParted isn’t difficult. When I opened it for the first time 3 years ago, sure I was confused for a moment but I was quickly able to use it. Launching GParted requires admin privileges so it requires your password for launching. This is normal.
|
||||
|
||||
[][3]
|
||||
|
||||
Below is the screen that GParted will display when you launch it the first time i.e. all your partitions of the hard disk (It will differ PC to PC).
|
||||
|
||||
[][4]
|
||||
|
||||
The screen presented is not only simple but also effective. You will see that from left to right it displays address of the partition, type of partition, the mount point ( “/” indicates root), Label of partition (In case you name your partitions like I do), total size of partition and capacity used and unused as well as flags (never ever touch a partition with a flag unless you know what you are doing). The key sign in front of file systems indicates that the partition is currently mounted means used by the system. Right-click and select “unmount” to unmount it.
|
||||
|
||||
You can see that it displays all sorts of information that you need to know about a particular partition you want to mess with. The bar with filled and unfilled portion indicates your hard disk. Also a simple thing “dev/sda” goes for hard disk while “dev/sdb” goes for your removable drives mostly flash drives (differs).
|
||||
|
||||
You can change working on drives by clicking on the box at top right corner saying “dev/sda”. The tweaks you want are available on different options at the menu bar.
|
||||
|
||||
[][5]
|
||||
|
||||
This is my flash drive which I switched using the top right corner box as I told above. See it now indicates different details. Also as my drive is based on different format the color of bar changed. This is a really helpful feature as it indicates that partition changes if color differs. Editing external drives is also same as editing internal.
|
||||
|
||||
#### Tweaking The Partitions
|
||||
|
||||
Tweaking partition requires your full attention as this is somewhat risky because if it's done wrong, you will destroy your data. Keeping this point in mind proceed.
|
||||
|
||||
Select a partition you want to work on rather it is on hard drive or flash drive is non-relevant. If the partition is mounted, unmount it. After unmounting the editing options will become available.
|
||||
|
||||
[][6]
|
||||
|
||||
This options can be accessed by menu bar or right mouse button too. The first option is for creating a new partition, the second one to delete, third one to resize partition, the fourth one to copy, fifth to paste. The last options are important as the second last is to revert changes and the last one is to apply changes.
|
||||
|
||||
GParted doesn’t make changes in real time but keeps track of changes done by you. So you can easily revert a change if it is caused by mistake. Lastly, you can apply it and save changes.
|
||||
|
||||
Now let’s come to editing part.
|
||||
|
||||
Let us assume you want to create a new partition by deleting existing one. Select partition of your choice hit the delete key and it will be deleted. Now for creating a new partition select that first option on the menu bar that indicates “new”.
|
||||
|
||||
You will get the following options.
|
||||
|
||||
[][7]
|
||||
|
||||
Here you can easily resize the partition by either entering values manually or drag the bar. If you want to change alignment do it with align option. You can choose whether to keep partition primary or secondary by option “create as”. Name the partition in Label and choose the appropriate file system. In case you want to access this partition on other OS like windows better use “
|
||||
|
||||
[NTFS][8]
|
||||
|
||||
” format.
|
||||
|
||||
There are times when data partition table is hampered. GParted handles this thing well too. There is the option to create new data partition table under device option. Remember creating data partition will destroy present data.
|
||||
|
||||
[][9]
|
||||
|
||||
But what to do when you already having a pen drive on which you want to do data rescue? Gparted helps here too. Reach data rescue option under device section from the menu bar. This option requires the installation of additional components that can be accessed from software center.
|
||||
|
||||
[][10]
|
||||
|
||||
You can also align flags to certain partition by option “flags”. Remember not to mess with flags unless you know what you are doing. There are a lot of other tweaks too to explore and use. Do that but remember mess with something unless you know what you are doing.
|
||||
|
||||
#### Applying Tweaks
|
||||
|
||||
[][11]
|
||||
|
||||
After you have done tweaking you need to apply them. This could be done by using apply option I mentioned above. It will give you a warning. Check out if everything is proper before applying and proceed the warning to apply tweaks and your changes are done. Enjoy!.
|
||||
|
||||
#### Other Features
|
||||
|
||||
Gparted offers live environment image files to boot and repair partitions in case of something wrong that can be downloaded from the website. GParted also shows tweaks it can do on your system, partition information and many others. Remember options will be differently available as per system.
|
||||
|
||||
[][12]
|
||||
|
||||
### Conclusion
|
||||
|
||||
Here we reach the end of my long article.
|
||||
|
||||
**GParted**is a really nice, powerful software that has great capabilities. There is also a nice community on _GParted_ that will surely help you in case you come across a bug or doubt in which we [LinuxAndUbuntu][13]are too included. The power of GParted will help you to do almost all partition related task but you should be careful about what you are doing.
|
||||
|
||||
Remember to always check out in the last what you are applying and is it right or not. In case you run across a problem don’t hesitate to comment and ask as we are always willing to help you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/gparted-the-complete-partition-editor-for-linux
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-gparted-from-software-center_orig.jpg
|
||||
[2]:http://gparted.org/download.php
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/type-password-to-provide-for-admin-privileges_orig.png
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gparted-user-interface-in-linux_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edit-usb-partition-in-gparted_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gparted-menu-bar_orig.png
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-new-partition-with-gparted_orig.png
|
||||
[8]:http://www.linuxandubuntu.com/home/fdisk-command-to-manage-disk-partitions-in-linux
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/select-table-type-in-gparted_orig.jpg
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/scan-disk-partition-in-gparted_orig.jpg
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/apply-changes-to-disk-in-gparted-partition-editor_orig.png
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/file-system-support-in-gparted_orig.png
|
||||
[13]:http://www.linuxandubuntu.com/
|
||||
@ -1,101 +0,0 @@
|
||||
How to Run Diablo II with the GLIDE-to-OpenGL Wrapper
|
||||
======
|
||||

|
||||
|
||||
**[Diablo II][1] is usually a breeze to run on Linux, thanks to WINE and so often times you need no special tricks. However, if you're like me and experience a few glitches and washed out colours in the standard fullscreen mode, you have two options: run the game in windowed mode and go without cinematics, or install a GLIDE-OpenGL wrapper and get the game running properly in its fullscreen glory again, without the glitches and colour problems. I detail how to do that in this article.**
|
||||
|
||||
Yes, that's right, unless you run Diablo II in fullscreen, the cinematics won't work for some reason! I'm fairly sure this happens even on Windows if the game is in windowed mode, so while it's a curious side effect, it is what it is. And this is a game from 2001 we're talking about!
|
||||
|
||||
Old or not though, Diablo II is undoubtedly one of my favourite games of all time. While not exactly Linux related (the game itself has never had a Linux port), I've sunk countless hours into the game in years past. So it's very pleasing to me that the game is very easily playable in Linux using WINE and generally from what I've known the game has needed little to no modification to run properly in WINE. However, it seems since the patches released in the last couple of years that Blizzard removed DirectDraw as a video rendering option from the game for some reason, leaving the game with just one option - Direct3D. Which seems to be the culprit of the fullscreen issues, which apparently even happens on modern Windows machines, so we're not even necessarily talking about a WINE issue here.
|
||||
|
||||
For any users running into the fullscreen glitches and washed out colour palette, as long as you don't care about in-game cinematics and playing the game in a small 800x600 (the game's maximum resolution) window, you could just run the game in windowed mode (with the `-w` switch) and it will work fine.
|
||||
|
||||
Example:
|
||||
```
|
||||
wine ~/.wine/drive_c/Program\ Files\ \(x86\)/Diablo\ II/Game.exe -w
|
||||
```
|
||||
|
||||
However, again, no cinematics here. Which may not bother you, but for mine the movies are one of the great and memorable aspects of Diablo II. Thankfully, there is a way to get the game running fullscreen correctly, with working movies, and plus the technique also gets the game running in it's original 4:3 aspect ratio, instead of the weird stretched out 16:9 state it does by default. Again, this may not be your preference, but personally I like it! Let's get to it.
|
||||
|
||||
### The GLIDE to OpenGL wrapper
|
||||
|
||||
Okay, so we said that the game only has one video mode now, that being Direct3D. Well, that's not completely true - the game still has the ancient GLIDE/3DFX mode available and gamers for years have known that for whatever reason, Diablo II actually runs better with GLIDE than Direct3D for hardware that supports it.
|
||||
|
||||
Problem is... no modern video cards actually support the now defunct GLIDE anymore and 3DFX (the company) was taken over long ago by NVIDIA, so the whole thing kind of went the way of the dodo. Running the game with the `-3dfx` switch by default will only net you a crash to desktop (sad face).
|
||||
|
||||
Thankfully, there is a wrapper available, seemingly made specifically for Diablo II, that actually translates the GLIDE interface to OpenGL. And being Linux users, OpenGL certainly suits us.
|
||||
|
||||
So, assuming you have the game installed and fully patched (seriously, it's pretty much just click and install with WINE, exactly as you would in Windows. It's easy), you'll want to download the [GLIDE3-to-OpenGL-Wrapper by Sven Labusch][2].
|
||||
|
||||
Extract the files from the downloaded archive to your Diablo II game folder (eg. `~/.wine/drive_c/Program Files (x86)/Diablo II/`)
|
||||
|
||||
The following is [from a forum guide][3] originally for Windows users, but it worked fine for me on Linux as well. The first two steps you should have already done, but then follow the instructions to configure the wrapper. You'll obviously have to make sure that glide-init.exe is executed with WINE.
|
||||
|
||||
> 1) download GLIDE WRAPPER ( <http://www.svenswrapper.de/english/> ).
|
||||
> 2) extract file in the Diablo 2 folder, where the 'Diablo II.exe' is.
|
||||
> 3) launch glide-init.exe.
|
||||
> 4) Click on 'English/Deutsch' to change the language to english.
|
||||
> 5) Click on 'OpenGL Info', then 'Query OpenGL info', wait for the query to finish.
|
||||
> 6) Click on 'Setting':
|
||||
> -uncheck 'windows-mode'.
|
||||
> -check 'captured mouse'.
|
||||
> -uncheck 'keep aspect ratio'.
|
||||
> -uncheck 'vertical synchronization'.
|
||||
> -select 'no' for 'fps-limit'.
|
||||
> -select '1600x1200' for 'static size.
|
||||
> -uncheck 'window extra'.
|
||||
> -select 'auto' for 'refreshrate'.
|
||||
> -check 'desktopresolution'.
|
||||
> 7) Click on 'renderer':
|
||||
> -select '64 mb' for 'texture-memory'.
|
||||
> -select '2048x2048' for 'buffer texture size'.
|
||||
> -uncheck ALL box EXCEPT 'shader-gama'.
|
||||
> 8) Click on 'Extension':
|
||||
> -check ALL box.
|
||||
> 9) Click on 'Quit'.
|
||||
|
||||
Make sure to follow that procedure exactly.
|
||||
|
||||
Now, you should be able to launch the game with the `-3dfx` switch and be all good!
|
||||
```
|
||||
wine ~/.wine/drive_c/Program\ Files\ \(x86\)/Diablo\ II/Game.exe -3dfx
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
Yes, the black bars will be unavoidable with the 4:3 aspect ratio (I'm playing on a 27 inch monitor with 1080p resolution), but at least the game looks as it was originally intended. Actually playing the game I don't even notice the black borders.
|
||||
|
||||
### Making the switch persistent
|
||||
|
||||
If you want the game to always launch with the `-3dfx` switch, even from the applications menu shortcut, then simply open the .desktop file with your favourite text editor.
|
||||
|
||||
Example (with the Lord of Destruction expansion installed):
|
||||
```
|
||||
gedit .local/share/applications/wine/Programs/Diablo\ II/Diablo\ II\ -\ Lord\ of\ Destruction.desktop
|
||||
```
|
||||
|
||||
And simply add the `-3dfx` switch to the end of the line beginning with " **Exec=** ". Make sure it's at the very end! And then save and exit.
|
||||
|
||||
And that's it! Running the game as standard from your applications menu should start the game up in its GLIDE/OpenGL magical glory.
|
||||
|
||||
Happy demon slaying!
|
||||
|
||||
### About the author
|
||||
|
||||
Andrew Powell is the editor and owner of The Linux Rain who loves all things Linux, gaming and everything in between.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.thelinuxrain.com/articles/how-to-run-diablo-2-glide-opengl-wrapper
|
||||
|
||||
作者:[Andrew Powell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.thelinuxrain.com
|
||||
[1]:http://us.blizzard.com/en-us/games/d2/
|
||||
[2]:http://www.svenswrapper.de/english/downloads.html
|
||||
[3]:https://us.battle.net/forums/en/bnet/topic/20752595513
|
||||
[4]:http://www.thelinuxrain.com/content/01-articles/198-how-to-run-diablo-2-glide-opengl-wrapper/diablo2-linux.jpg
|
||||
@ -1,142 +0,0 @@
|
||||
Finding Files with mlocate: Part 3
|
||||
======
|
||||
|
||||

|
||||
In the previous articles in this short series, we [introduced the mlocate][1] (or just locate) command, and then discussed some ways [the updatedb tool][2] can be used to help you find that one particular file in a thousand.
|
||||
|
||||
You are probably also aware of xargs as well as the find command. Our trusty friend locate can also play nicely with the --null option of xargs by outputting all of the results onto one line (without spaces which isn't great if you want to read it yourself) by using the -0 switch like this:
|
||||
```
|
||||
# locate -0 .bash
|
||||
```
|
||||
|
||||
An option I like to use (if I remember to use it -- because the locate command rarely needs to be queried twice thanks to its simple syntax) is the -e option.
|
||||
```
|
||||
# locate -e .bash
|
||||
```
|
||||
|
||||
For the curious, that -e switch means "existing." And, in this case, you can use -e to ensure that any files returned by the locate command do actually exist at the time of the query on your filesystems.
|
||||
|
||||
It's almost magical, that even on a slow machine, the mastery of the modern locate command allows us to query its file database and then check against the actual existence of many files in seemingly no time whatsoever. Let's try a quick test with a file search that's going to return a zillion results and use the time command to see how long it takes both with and without the -e option being enabled.
|
||||
|
||||
I'll choose files with the compressed .gz extension. Starting with a count, you can see there's not quite a zillion but a fair number of files ending in .gz on my machine, note the -c for "count":
|
||||
```
|
||||
# locate -c .gz
|
||||
7539
|
||||
```
|
||||
|
||||
This time, we'll output the list but time it and see the abbreviated results as follows:
|
||||
```
|
||||
# time locate .gz
|
||||
real 0m0.091s
|
||||
user 0m0.025s
|
||||
sys 0m0.012s
|
||||
```
|
||||
|
||||
That's pretty swift, but it's only reading from the overnight-run database. Let's get it to do a check against those 7,539 files, too, to see if they truly exist and haven't been deleted or renamed since last night:
|
||||
```
|
||||
# time locate -e .gz
|
||||
real 0m0.096s
|
||||
user 0m0.028s
|
||||
sys 0m0.055s
|
||||
```
|
||||
|
||||
The speed difference is nominal as you can see. There's no point in talking about lightning or blink-and-you-miss-it, because those aren't suitable yardsticks. Relative to the other indexing service I mentioned previously, let's just say that's pretty darned fast.
|
||||
|
||||
If you need to move the efficient database file used by the locate command (in my version it lives here: /var/lib/mlocate/mlocate.db) then that's also easy to do. You may wish to do this, for example, because you've generated a massive database file (it's only 1.1MB in my case so it's really tiny in reality), which needs to be put onto a faster filesystem.
|
||||
|
||||
Incidentally, even the mlocate utility appears to have created an slocate group of users on my machine, so don't be too alarmed if you see something similar, as shown here from a standard file listing:
|
||||
```
|
||||
-rw-r-----. 1 root slocate 1.1M Jan 11 11:11 /var/lib/mlocate/mlocate.db
|
||||
```
|
||||
|
||||
Back to the matter in hand. If you want to move away from /var/lib/mlocate as your directory being used by the database then you can use this command syntax (and you'll have to become the "root" user with sudo -i or su - for at least the first command to work correctly):
|
||||
```
|
||||
# updatedb -o /home/chrisbinnie/my_new.db
|
||||
# locate -d /home/chrisbinnie/my_new.db SEARCH_TERM
|
||||
```
|
||||
|
||||
Obviously, replace your database name and path. The SEARCH_TERM element is the fragment of the filename that you're looking for (wildcards and all).
|
||||
|
||||
If you remember I mentioned that you need to run updatedb command as the superuser to reach all the areas of your filesystems.
|
||||
|
||||
This next example should cover two useful scenarios in one. According to the manual, you can also create a "private" database for standard users as follows:
|
||||
```
|
||||
# updatedb -l 0 -o DATABASE -U source_directory
|
||||
```
|
||||
|
||||
Here the previously seen -o option means that we output our database to a file (obviously called DATABASE). The -l 0 addition apparently means that the "visibility" of the database file is affected. It means (if I'm reading the docs correctly) that my user can read it but, otherwise, without that option, only the locate command can.
|
||||
|
||||
The second useful scenario for this example is that we can create a little database file specifying exactly which path its top-level should be. Have a look at the database-root or -U source_directory option in our example. If you don't specify a new root file path, then the whole filesystem(s) is scanned instead.
|
||||
|
||||
If you want to get clever and chuck a couple of top-level source directories into one command, then you can manage that having created two separate databases. Very useful for scripting methinks.
|
||||
|
||||
You can achieve that with this command:
|
||||
```
|
||||
# locate -d /home/chrisbinnie/database_one -d /home/chrisbinnie/database_two SEARCH_TERM
|
||||
```
|
||||
|
||||
The manual dutifully warns however that ALL users that can read the DATABASE file can also get the complete list of files in the subdirectories of the chosen source_directory. So use these commands with some care.
|
||||
|
||||
### Priced To Sell
|
||||
|
||||
Back to the mind-blowing simplicity of the locate command in use on a day-to-day basis. There are many times when newbies may confused with case-sensitivity on Unix-type systems. Simply use the conventional -i option to ignore case entirely when using the flexible locate command:
|
||||
```
|
||||
# locate -i ChrisBinnie.pdf
|
||||
```
|
||||
|
||||
If you have a file structure that has a number of symlinks holding it together, then there might be occasion when you want to remove broken symlinks from the search results. You can do that with this command:
|
||||
```
|
||||
# locate -Le chrisbinnie_111111.xml
|
||||
```
|
||||
|
||||
If you needed to limit the search results then you could use this functionality, also in a script for example (similar to the -c option for counting), as so:
|
||||
```
|
||||
# locate -l25 *.gz
|
||||
```
|
||||
|
||||
This command simply stops after outputting the first 25 files that were found. When piped through the grep command, it's very useful on a super busy system.
|
||||
|
||||
### Popular Area
|
||||
|
||||
We briefly touched upon performance earlier, and I happened to see this [nicely written blog entry][3], where the author discusses thoughts on the trade-offs between the database size becoming unwieldy and the speed at which results are delivered.
|
||||
|
||||
What piqued my interest are the comments on how the original locate command was written and what limiting factors were considered during its creation. Namely how disk space isn't quite so precious any longer and nor is the delivery of results even when 700,000 files are involved.
|
||||
|
||||
I'm certain that the author(s) of mlocate and its forebears would have something to say in response to that blog post. I suspect that holding onto the file permissions to give us the "secure" and "slocate" functionality in the database might be a fairly big hit in terms of overhead. And, as much as I enjoyed the post, I won't be writing a Bash script to replace mlocate any time soon. I'm more than happy with the locate command and extol its qualities at every opportunity.
|
||||
|
||||
### Sold
|
||||
|
||||
I hope you've acquired enough insight into the superb locate command to prune, tweak, adjust, and tune it to your unique set of requirements. As we've seen, it's fast, convenient, powerful, and efficient. Additionally, you can ignore the "root" user demands and use it within scripts for very specific tasks.
|
||||
|
||||
My favorite aspect, however, is when I'm awakened in the middle of the night because of an emergency. It's not a good look, having to remember the complex find command and typing it slowly with bleary eyes (and managing to add lots of typos):
|
||||
```
|
||||
# find . -type f -name "*.gz"
|
||||
```
|
||||
|
||||
Instead of that, I can just use the simple locate command:
|
||||
```
|
||||
# locate *.gz
|
||||
```
|
||||
|
||||
As has been said, any fool can create something bigger, bolder, and tougher, but it takes a bit of genius to create something simpler. And, in terms of introducing more people to the venerable Unix-type command line, there's little argument that the locate command welcomes them with open arms.
|
||||
|
||||
Learn more about essential sysadmin skills: Download the [Future Proof Your SysAdmin Career][4] ebook now.
|
||||
|
||||
Chris Binnie's latest book, Linux Server Security: Hack and Defend, shows how hackers launch sophisticated attacks to compromise servers, steal data, and crack complex passwords, so you can learn how to defend against these attacks. In the book, he also talks you through making your servers invisible, performing penetration testing, and mitigating unwelcome attacks. You can find out more about DevSecOps and Linux security via his website ([http://www.devsecops.cc][5]).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2017/11/finding-files-mlocate-part-3
|
||||
|
||||
作者:[Chris Binnie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/chrisbinnie
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/finding-files-mlocate
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/finding-files-mlocate-part-2
|
||||
[3]:http://jvns.ca/blog/2015/03/05/how-the-locate-command-works-and-lets-rewrite-it-in-one-minute/
|
||||
[4]:https://go.pardot.com/l/6342/2017-07-17/3vwshv?utm_source=linco&utm_medium=blog&utm_campaign=sysadmin&utm_content=promo
|
||||
[5]:http://www.devsecops.cc/
|
||||
@ -1,143 +0,0 @@
|
||||
HankChow Translating
|
||||
|
||||
How do groups work on Linux?
|
||||
============================================================
|
||||
|
||||
Hello! Last week, I thought I knew how users and groups worked on Linux. Here is what I thought:
|
||||
|
||||
1. Every process belongs to a user (like `julia`)
|
||||
|
||||
2. When a process tries to read a file owned by a group, Linux a) checks if the user `julia` can access the file, and b) checks which groups `julia` belongs to, and whether any of those groups owns & can access that file
|
||||
|
||||
3. If either of those is true (or if the ‘any’ bits are set right) then the process can access the file
|
||||
|
||||
So, for example, if a process is owned by the `julia` user and `julia` is in the `awesome` group, then the process would be allowed to read this file.
|
||||
|
||||
```
|
||||
r--r--r-- 1 root awesome 6872 Sep 24 11:09 file.txt
|
||||
|
||||
```
|
||||
|
||||
I had not thought carefully about this, but if pressed I would have said that it probably checks the `/etc/group` file at runtime to see what groups you’re in.
|
||||
|
||||
### that is not how groups work
|
||||
|
||||
I found out at work last week that, no, what I describe above is not how groups work. In particular Linux does **not** check which groups a process’s user belongs to every time that process tries to access a file.
|
||||
|
||||
Here is how groups actually work! I learned this by reading Chapter 9 (“Process Credentials”) of [The Linux Programming Interface][1] which is an incredible book. As soon as I realized that I did not understand how users and groups worked, I opened up the table of contents with absolute confidence that it would tell me what’s up, and I was right.
|
||||
|
||||
### how users and groups checks are done
|
||||
|
||||
They key new insight for me was pretty simple! The chapter starts out by saying that user and group IDs are **attributes of the process**:
|
||||
|
||||
* real user ID and group ID;
|
||||
|
||||
* effective user ID and group ID;
|
||||
|
||||
* saved set-user-ID and saved set-group-ID;
|
||||
|
||||
* file-system user ID and group ID (Linux-specific); and
|
||||
|
||||
* supplementary group IDs.
|
||||
|
||||
This means that the way Linux **actually** does group checks to see a process can read a file is:
|
||||
|
||||
* look at the process’s group IDs & supplementary group IDs (from the attributes on the process, **not** by looking them up in `/etc/group`)
|
||||
|
||||
* look at the group on the file
|
||||
|
||||
* see if they match
|
||||
|
||||
Generally when doing access control checks it uses the **effective** user/group ID, not the real user/group ID. Technically when accessing a file it actually uses the **file-system** ids but those are usually the same as the effective uid/gid.
|
||||
|
||||
### Adding a user to a group doesn’t put existing processes in that group
|
||||
|
||||
Here’s another fun example that follows from this: if I create a new `panda` group and add myself (bork) to it, then run `groups` to check my group memberships – I’m not in the panda group!
|
||||
|
||||
```
|
||||
bork@kiwi~> sudo addgroup panda
|
||||
Adding group `panda' (GID 1001) ...
|
||||
Done.
|
||||
bork@kiwi~> sudo adduser bork panda
|
||||
Adding user `bork' to group `panda' ...
|
||||
Adding user bork to group panda
|
||||
Done.
|
||||
bork@kiwi~> groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd
|
||||
|
||||
```
|
||||
|
||||
no `panda` in that list! To double check, let’s try making a file owned by the `panda`group and see if I can access it:
|
||||
|
||||
```
|
||||
$ touch panda-file.txt
|
||||
$ sudo chown root:panda panda-file.txt
|
||||
$ sudo chmod 660 panda-file.txt
|
||||
$ cat panda-file.txt
|
||||
cat: panda-file.txt: Permission denied
|
||||
|
||||
```
|
||||
|
||||
Sure enough, I can’t access `panda-file.txt`. No big surprise there. My shell didn’t have the `panda` group as a supplementary GID before, and running `adduser bork panda` didn’t do anything to change that.
|
||||
|
||||
### how do you get your groups in the first place?
|
||||
|
||||
So this raises kind of a confusing question, right – if processes have groups baked into them, how do you get assigned your groups in the first place? Obviously you can’t assign yourself more groups (that would defeat the purpose of access control).
|
||||
|
||||
It’s relatively clear how processes I **execute** from my shell (bash/fish) get their groups – my shell runs as me, and it has a bunch of group IDs on it. Processes I execute from my shell are forked from the shell so they get the same groups as the shell had.
|
||||
|
||||
So there needs to be some “first” process that has your groups set on it, and all the other processes you set inherit their groups from that. That process is called your **login shell** and it’s run by the `login` program (`/bin/login`) on my laptop. `login` runs as root and calls a C function called `initgroups` to set up your groups (by reading `/etc/group`). It’s allowed to set up your groups because it runs as root.
|
||||
|
||||
### let’s try logging in again!
|
||||
|
||||
So! Let’s say I am running in a shell, and I want to refresh my groups! From what we’ve learned about how groups are initialized, I should be able to run `login` to refresh my groups and start a new login shell!
|
||||
|
||||
Let’s try it:
|
||||
|
||||
```
|
||||
$ sudo login bork
|
||||
$ groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd panda
|
||||
$ cat panda-file.txt # it works! I can access the file owned by `panda` now!
|
||||
|
||||
```
|
||||
|
||||
Sure enough, it works! Now the new shell that `login` spawned is part of the `panda` group! Awesome! This won’t affect any other shells I already have running. If I really want the new `panda` group everywhere, I need to restart my login session completely, which means quitting my window manager and logging in again.
|
||||
|
||||
### newgrp
|
||||
|
||||
Somebody on Twitter told me that if you want to start a new shell with a new group that you’ve been added to, you can use `newgrp`. Like this:
|
||||
|
||||
```
|
||||
sudo addgroup panda
|
||||
sudo adduser bork panda
|
||||
newgrp panda # starts a new shell, and you don't have to be root to run it!
|
||||
|
||||
```
|
||||
|
||||
You can accomplish the same(ish) thing with `sg panda bash` which will start a `bash` shell that runs with the `panda` group.
|
||||
|
||||
### setuid sets the effective user ID
|
||||
|
||||
I’ve also always been a little vague about what it means for a process to run as “setuid root”. It turns out that setuid sets the effective user ID! So if I (`julia`) run a setuid root process (like `passwd`), then the **real** user ID will be set to `julia`, and the **effective** user ID will be set to `root`.
|
||||
|
||||
`passwd` needs to run as root, but it can look at its real user ID to see that `julia`started the process, and prevent `julia` from editing any passwords except for `julia`’s password.
|
||||
|
||||
### that’s all!
|
||||
|
||||
There are a bunch more details about all the edge cases and exactly how everything works in The Linux Programming Interface so I will not get into all the details here. That book is amazing. Everything I talked about in this post is from Chapter 9, which is a 17-page chapter inside a 1300-page book.
|
||||
|
||||
The thing I love most about that book is that reading 17 pages about how users and groups work is really approachable, self-contained, super useful, and I don’t have to tackle all 1300 pages of it at once to learn helpful things :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/20/groups/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://man7.org/tlpi/
|
||||
@ -1,187 +0,0 @@
|
||||
translating by zrszrszr
|
||||
12 MySQL/MariaDB Security Best Practices for Linux
|
||||
============================================================
|
||||
|
||||
MySQL is the world’s most popular open source database system and MariaDB (a fork of MySQL) is the world’s fastest growing open source database system. After installing MySQL server, it is insecure in it’s default configuration, and securing it is one of the essential tasks in general database management.
|
||||
|
||||
This will contribute to hardening and boosting of overall Linux server security, as attackers always scan vulnerabilities in any part of a system, and databases have in the past been key target areas. A common example is the brute-forcing of the root password for the MySQL database.
|
||||
|
||||
In this guide, we will explain useful MySQL/MariaDB security best practice for Linux.
|
||||
|
||||
### 1\. Secure MySQL Installation
|
||||
|
||||
This is the first recommended step after installing MySQL server, towards securing the database server. This script facilitates in improving the security of your MySQL server by asking you to:
|
||||
|
||||
* set a password for the root account, if you didn’t set it during installation.
|
||||
|
||||
* disable remote root user login by removing root accounts that are accessible from outside the local host.
|
||||
|
||||
* remove anonymous-user accounts and test database which by default can be accessed by all users, even anonymous users.
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
```
|
||||
|
||||
After running it, set the root password and answer the series of questions by entering [Yes/Y] and press [Enter].
|
||||
|
||||
[][2]
|
||||
|
||||
Secure MySQL Installation
|
||||
|
||||
### 2\. Bind Database Server To Loopback Address
|
||||
|
||||
This configuration will restrict access from remote machines, it tells the MySQL server to only accept connections from within the localhost. You can set it in main configuration file.
|
||||
|
||||
```
|
||||
# vi /etc/my.cnf [RHEL/CentOS]
|
||||
# vi /etc/mysql/my.conf [Debian/Ubuntu]
|
||||
OR
|
||||
# vi /etc/mysql/mysql.conf.d/mysqld.cnf [Debian/Ubuntu]
|
||||
```
|
||||
|
||||
Add the following line below under `[mysqld]` section.
|
||||
|
||||
```
|
||||
bind-address = 127.0.0.1
|
||||
```
|
||||
|
||||
### 3\. Disable LOCAL INFILE in MySQL
|
||||
|
||||
As part of security hardening, you need to disable local_infile to prevent access to the underlying filesystem from within MySQL using the following directive under `[mysqld]` section.
|
||||
|
||||
```
|
||||
local-infile=0
|
||||
```
|
||||
|
||||
### 4\. Change MYSQL Default Port
|
||||
|
||||
The Port variable sets the MySQL port number that will be used to listen on TCP/ IP connections. The default port number is 3306 but you can change it under the [mysqld] section as shown.
|
||||
|
||||
```
|
||||
Port=5000
|
||||
```
|
||||
|
||||
### 5\. Enable MySQL Logging
|
||||
|
||||
Logs are one of the best ways to understand what happens on a server, in case of any attacks, you can easily see any intrusion-related activities from log files. You can enable MySQL logging by adding the following variable under the `[mysqld]` section.
|
||||
|
||||
```
|
||||
log=/var/log/mysql.log
|
||||
```
|
||||
|
||||
### 6\. Set Appropriate Permission on MySQL Files
|
||||
|
||||
Ensure that you have appropriate permissions set for all mysql server files and data directories. The /etc/my.conf file should only be writeable to root. This blocks other users from changing database server configurations.
|
||||
|
||||
```
|
||||
# chmod 644 /etc/my.cnf
|
||||
```
|
||||
|
||||
### 7\. Delete MySQL Shell History
|
||||
|
||||
All commands you execute on MySQL shell are stored by the mysql client in a history file: ~/.mysql_history. This can be dangerous, because for any user accounts that you will create, all usernames and passwords typed on the shell will recorded in the history file.
|
||||
|
||||
```
|
||||
# cat /dev/null > ~/.mysql_history
|
||||
```
|
||||
|
||||
### 8\. Don’t Run MySQL Commands from Commandline
|
||||
|
||||
As you already know, all commands you type on the terminal are stored in a history file, depending on the shell you are using (for example ~/.bash_history for bash). An attacker who manages to gain access to this history file can easily see any passwords recorded there.
|
||||
|
||||
It is strongly not recommended to type passwords on the command line, something like this:
|
||||
|
||||
```
|
||||
# mysql -u root -ppassword_
|
||||
```
|
||||
[][3]
|
||||
|
||||
Connect MySQL with Password
|
||||
|
||||
When you check the last section of the command history file, you will see the password typed above.
|
||||
|
||||
```
|
||||
# history
|
||||
```
|
||||
[][4]
|
||||
|
||||
Check Command History
|
||||
|
||||
The appropriate way to connect MySQL is.
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
Enter password:
|
||||
```
|
||||
|
||||
### 9\. Define Application-Specific Database Users
|
||||
|
||||
For each application running on the server, only give access to a user who is in charge of a database for a given application. For example, if you have a wordpress site, create a specific user for the wordpress site database as follows.
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
MariaDB [(none)]> CREATE DATABASE osclass_db;
|
||||
MariaDB [(none)]> CREATE USER 'osclassdmin'@'localhost' IDENTIFIED BY 'osclass@dmin%!2';
|
||||
MariaDB [(none)]> GRANT ALL PRIVILEGES ON osclass_db.* TO 'osclassdmin'@'localhost';
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
MariaDB [(none)]> exit
|
||||
```
|
||||
|
||||
and remember to always remove user accounts that are no longer managing any application database on the server.
|
||||
|
||||
### 10\. Use Additional Security Plugins and Libraries
|
||||
|
||||
MySQL includes a number of security plugins for: authenticating attempts by clients to connect to mysql server, password-validation and securing storage for sensitive information, which are all available in the free version.
|
||||
|
||||
You can find more here: [https://dev.mysql.com/doc/refman/5.7/en/security-plugins.html][5]
|
||||
|
||||
### 11\. Change MySQL Passwords Regularly
|
||||
|
||||
This is a common piece of information/application/system security advice. How often you do this will entirely depend on your internal security policy. However, it can prevent “snoopers” who might have been tracking your activity over an long period of time, from gaining access to your mysql server.
|
||||
|
||||
```
|
||||
MariaDB [(none)]> USE mysql;
|
||||
MariaDB [(none)]> UPDATE user SET password=PASSWORD('YourPasswordHere') WHERE User='root' AND Host = 'localhost';
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
### 12\. Update MySQL Server Package Regularly
|
||||
|
||||
It is highly recommended to upgrade mysql/mariadb packages regularly to keep up with security updates and bug fixes, from the vendor’s repository. Normally packages in default operating system repositories are outdated.
|
||||
|
||||
```
|
||||
# yum update
|
||||
# apt update
|
||||
```
|
||||
|
||||
After making any changes to the mysql/mariadb server, always restart the service.
|
||||
|
||||
```
|
||||
# systemctl restart mariadb #RHEL/CentOS
|
||||
# systemctl restart mysql #Debian/Ubuntu
|
||||
```
|
||||
|
||||
Read Also: [15 Useful MySQL/MariaDB Performance Tuning and Optimization Tips][6]
|
||||
|
||||
That’s all! We love to hear from you via the comment form below. Do share with us any MySQL/MariaDB security tips missing in the above list.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.tecmint.com/mysql-mariadb-security-best-practices-for-linux/
|
||||
|
||||
作者:[ Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/learn-mysql-mariadb-for-beginners/
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2017/12/Secure-MySQL-Installation.png
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2017/12/Connect-MySQL-with-Password.png
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/12/Check-Command-History.png
|
||||
[5]:https://dev.mysql.com/doc/refman/5.7/en/security-plugins.html
|
||||
[6]:https://www.tecmint.com/mysql-mariadb-performance-tuning-and-optimization/
|
||||
[7]:https://www.tecmint.com/author/aaronkili/
|
||||
[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by yizhuoyan
|
||||
|
||||
5 Tips to Improve Technical Writing for an International Audience
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,115 +0,0 @@
|
||||
Create a free Apache SSL certificate with Let’s Encrypt on CentOS & RHEL
|
||||
======
|
||||
|
||||
Let's Encrypt is a free, automated & open certificate authority that is supported by ISRG, Internet Security Research Group. Let's encrypt provides X.509 certificates for TLS (Transport Layer Security) encryption via automated process which includes creation, validation, signing, installation, and renewal of certificates for secure websites.
|
||||
|
||||
In this tutorial, we are going to discuss how to create an apache SSL certificate with Let's Encrypt certificate on Centos/RHEL 6 & 7\. To automate the Let's encrypt process, we will use Let's encrypt recommended ACME client i.e. CERTBOT, there are other ACME Clients as well but we will be using Certbot only.
|
||||
|
||||
Certbot can automate certificate issuance and installation with no downtime, it automatically enables HTTPS on your website. It also has expert modes for people who don't want auto-configuration. It's easy to use, works on many operating systems, and has great documentation.
|
||||
|
||||
**(Recommended Read:[Complete guide for Apache TOMCAT installation on Linux][1])**
|
||||
|
||||
Let's start with Pre-requisites for creating an Apache SSL certificate with Let's Encrypt on CentOS, RHEL 6 &7…..
|
||||
|
||||
|
||||
## Pre-requisites
|
||||
|
||||
**1-** Obviously we will need Apache server to installed on our machine. We can install it with the following command,
|
||||
|
||||
**# yum install httpd**
|
||||
|
||||
For detailed Apache installation procedure, refer to our article[ **Step by Step guide to configure APACHE server.**][2]
|
||||
|
||||
**2-** Mod_ssl should also be installed on the systems. Install it using the following command,
|
||||
|
||||
**# yum install mod_ssl**
|
||||
|
||||
**3-** Epel Repositories should be installed & enables. EPEL repositories are required as not all the dependencies can be resolved with default repos, hence EPEL repos are also required. Install them using the following command,
|
||||
|
||||
**RHEL/CentOS 7**
|
||||
|
||||
**# rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/packages/e/epel-release-7-11.noarch.rpm**
|
||||
|
||||
**RHEL/CentOS 6 (64 Bit)**
|
||||
|
||||
**# rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm**
|
||||
|
||||
**RHEL/CentOS 6 (32 Bit)**
|
||||
|
||||
**# rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm**
|
||||
|
||||
Now let's start with procedure to install Let's Encrypt on CentOS /RHEL 7.
|
||||
|
||||
## Let's encrypt on CentOS RHEL 7
|
||||
|
||||
Installation on CentOS 7 can easily performed with yum, with the following command,
|
||||
|
||||
**$ yum install certbot-apache**
|
||||
|
||||
Once installed, we can now create the SSL certificate with following command,
|
||||
|
||||
**$ certbot -apache**
|
||||
|
||||
Now just follow the on screen instructions to generate the certificate. During the setup, you will also be asked to enforce the HTTPS or to use HTTP , select either of the one you like. But if you enforce HTTPS, than all the changes required to use HTTPS will made by certbot setup otherwise we will have to make changes on our own.
|
||||
|
||||
We can also generate certificate for multiple websites with single command,
|
||||
|
||||
**$ certbot -apache -d example.com -d test.com**
|
||||
|
||||
We can also opt to create certificate only, without automatically making any changes to any configuration files, with the following command,
|
||||
|
||||
**$ certbot -apache certonly**
|
||||
|
||||
Certbot issues SSL certificates hae 90 days validity, so we need to renew the certificates before that period is over. Ideal time to renew the certificate would be around 60 days. Run the following command, to renew the certifcate,
|
||||
|
||||
**$ certbot renew**
|
||||
|
||||
We can also automate the renewal process with a crontab job. Open the crontab & create a job,
|
||||
|
||||
**$ crontab -e**
|
||||
|
||||
**0 0 1 * comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md /usr/bin/certbot renew >> /var/log/letsencrypt.log**
|
||||
|
||||
This job will renew you certificate 1st of every month at 12 AM.
|
||||
|
||||
## Let's Encrypt on CentOS 6
|
||||
|
||||
For using Let's encrypt on Centos 6, there are no cerbot packages for CentOS 6 but that does not mean we can't make use of let's encrypt on CentOS/RHEL 6, instead we can use the certbot script for creating/renewing the certificates. Install the script with the following command,
|
||||
|
||||
**# wget https://dl.eff.org/certbot-auto**
|
||||
|
||||
**# chmod a+x certbot-auto**
|
||||
|
||||
Now we can use it similarly as we used commands for CentOS 7 but instead of certbot, we will use script. To create new certificate,
|
||||
|
||||
**# sh path/certbot-auto -apache -d example.com**
|
||||
|
||||
To create only cert, use
|
||||
|
||||
**# sh path/certbot-auto -apache certonly**
|
||||
|
||||
To renew cert, use
|
||||
|
||||
**# sh path/certbot-auto renew**
|
||||
|
||||
For creating a cron job, use
|
||||
|
||||
**# crontab -e**
|
||||
|
||||
**0 0 1 * * sh path/certbot-auto renew >> /var/log/letsencrypt.log**
|
||||
|
||||
This was our tutorial on how to install and use let's encrypt on CentOS , RHEL 6 & 7 for creating a free SSL certificate for Apache servers. Please do leave your questions or queries down below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-free-apache-ssl-certificate-lets-encrypt-on-centos-rhel/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/complete-guide-apache-tomcat-installation-linux/
|
||||
[2]:http://linuxtechlab.com/beginner-guide-configure-apache/
|
||||
@ -1,314 +0,0 @@
|
||||
Personal Backups with Duplicati on Linux
|
||||
======
|
||||
|
||||
This tutorial is for performing personal backups to local USB hard drives, having encryption, deduplication and compression.
|
||||
|
||||
The procedure was tested using [Duplicati 2.0.2.1][1] on [Debian 9.2][2]
|
||||
|
||||
### Duplicati Installation
|
||||
|
||||
Download the latest version from <https://www.duplicati.com/download>
|
||||
|
||||
The software requires several libraries to work, mostly mono libraries. The easiest way to install the software is to let it fail the installation through dpkg and then install the missing packages with apt-get:
|
||||
|
||||
sudo dpkg -i duplicati_2.0.2.1-1_all.deb
|
||||
sudo apt-get --fix-broken install
|
||||
|
||||
Note that the installation of the package fails on the first instance, then we use apt to install the dependencies.
|
||||
|
||||
Start the daemon:
|
||||
|
||||
sudo systemctl start duplicati.service
|
||||
|
||||
And if you wish for it to start automatically with the OS use:
|
||||
|
||||
sudo systemctl enable duplicati.service
|
||||
|
||||
To check that the service is running:
|
||||
|
||||
netstat -ltn | grep 8200
|
||||
|
||||
And you should receive a response like this one:
|
||||
|
||||
[![][3]][4]
|
||||
|
||||
After these steps you should be able to run the browser and access the local web service at http://localhost:8200
|
||||
|
||||
[![][5]][6]
|
||||
|
||||
### Create a Backup Job
|
||||
|
||||
Go to "Add backup" to configure a new backup job:
|
||||
|
||||
[![][7]][8]
|
||||
|
||||
Set a name for the job and a passphrase for encryption. You will need the passphrase to restore files, so pick a strong password and make sure you don't forget it:
|
||||
|
||||
[![][9]][10]
|
||||
|
||||
Set the destination: the directory where you are going to store the backup files:
|
||||
|
||||
[![][11]][12]
|
||||
|
||||
Select the source files to backup. I will pick just the Desktop folder for this example:
|
||||
|
||||
[![][13]][14]
|
||||
|
||||
Specify filters and exclusions if necessary:
|
||||
|
||||
[![][15]][16]
|
||||
|
||||
Configure a schedule, or disable automatic backups if you prefer to run them manually:
|
||||
|
||||
[![][17]][18]
|
||||
|
||||
I like to use manual backups when using USB drive destinations, and scheduled if I have a server to send backups through SSH or a Cloud based destination.
|
||||
|
||||
Specify the versions to keep, and the Upload volume size (size of each partial file):
|
||||
|
||||
[![][19]][20]
|
||||
|
||||
Finally you should see the job created in a summary like this:
|
||||
|
||||
[![][21]][22]
|
||||
|
||||
### Run the Backup
|
||||
|
||||
In the last seen summary, under Home, click "run now" to start the backup job. A progress bar will be seen by the top of the screen.
|
||||
|
||||
After finishing the backup, you can see in the destination folder, a set of files called something like:
|
||||
```
|
||||
duplicati-20171206T143926Z.dlist.zip.aes
|
||||
duplicati-bdfad38a0b1f34b5db56c1de166260cd8.dblock.zip.aes
|
||||
duplicati-i00d8dff418a749aa9d67d0c54b0e4149.dindex.zip.aes
|
||||
```
|
||||
|
||||
The size of the blocks will be the one specified in the Upload volume size option. The files are compressed, and encrypted using the previously set passphrase.
|
||||
|
||||
Once finished, you will see in the summary the last backup taken and the size:
|
||||
|
||||
[![][23]][24]
|
||||
|
||||
In this case it is only 1MB because I took a test folder.
|
||||
|
||||
### Restore Files
|
||||
|
||||
To restore files, simply access the web administration in http://localhost:8200, go to the "Restore" menu and select the backup job name. Then select the files to restore and click "continue":
|
||||
|
||||
[![][25]][26]
|
||||
|
||||
Select the restore files or folders and the restoration options:
|
||||
|
||||
[![][27]][28]
|
||||
|
||||
The restoration will start running, showing a progress bar on the top of the user interface.
|
||||
|
||||
### Fixate the backup destination
|
||||
|
||||
If you use a USB drive to perform the backups, it is a good idea to specify in the /etc/fstab the UUID of the drive, so that it always mount automatically in the /mnt/backup directory (or the directory of your choosing).
|
||||
|
||||
To do so, connect your drive and check for the UUID:
|
||||
|
||||
sudo blkid
|
||||
```
|
||||
...
|
||||
/dev/sdb1: UUID="4d608d85-e138-4546-9f22-4d78bef0b6a7" TYPE="ext4" PARTUUID="983a72cb-01"
|
||||
...
|
||||
```
|
||||
|
||||
And copy the UUID to include an entry in the /etc/fstab file:
|
||||
```
|
||||
...
|
||||
UUID=4d608d85-e138-4546-9f22-4d78bef0b6a7 /mnt/backup ext4 defaults 0 0
|
||||
...
|
||||
```
|
||||
|
||||
### Remote Access to the GUI
|
||||
|
||||
By default, Duplicati listens on localhost only, and it's meant to be that way. However it includes the possibility to add a password and to be accessible from the network:
|
||||
|
||||
[![][29]][30]
|
||||
|
||||
This setting is not recommended, as Duplicati has no SSL capabilities yet. What I would recommend if you need to use the backup GUI remotely, is using an SSH tunnel.
|
||||
|
||||
To accomplish this, first enable SSH server in case you don't have it yet, the easiest way is running:
|
||||
|
||||
sudo tasksel
|
||||
|
||||
[![][31]][32]
|
||||
|
||||
Once you have the SSH server running on the Duplicati host. Go to the computer from where you want to connect to the GUI and set the tunnel
|
||||
|
||||
Let's consider that:
|
||||
|
||||
* Duplicati backups and its GUI are running in the remote host 192.168.0.150 (that we call the server).
|
||||
* The GUI on the server is listening on port 8200.
|
||||
* jorge is a valid user name in the server.
|
||||
* I will access the GUI from a host on the local port 12345.
|
||||
|
||||
|
||||
|
||||
Then to open an SSH tunnel I run on the client:
|
||||
|
||||
ssh -f jorge@192.168.0.150 -L 12345:localhost:8200 -N
|
||||
|
||||
With netstat it can be checked that the port is open for localhost:
|
||||
|
||||
netstat -ltn | grep :12345
|
||||
```
|
||||
tcp 0 0 127.0.0.1:12345 0.0.0.0:* LISTEN
|
||||
tcp6 0 0 ::1:12345 :::* LISTEN
|
||||
```
|
||||
|
||||
And now I can access the remote GUI by accessing http://127.0.0.1:12345 from the client browser
|
||||
|
||||
[![][34]][35]
|
||||
|
||||
Finally if you want to close the connection to the SSH tunnel you may kill the ssh process. First identify the PID:
|
||||
|
||||
ps x | grep "[s]sh -f"
|
||||
```
|
||||
26348 ? Ss 0:00 ssh -f [[email protected]][33] -L 12345:localhost:8200 -N
|
||||
```
|
||||
|
||||
And kill it:
|
||||
|
||||
kill -9 26348
|
||||
|
||||
Or you can do it all in one:
|
||||
|
||||
kill -9 $(ps x | grep "[s]sh -f" | cut -d" " -f1)
|
||||
|
||||
### Other Backup Repository Options
|
||||
|
||||
If you prefer to store your backups on a remote server rather than on a local hard drive, Duplicati has several options. Standard protocols such as:
|
||||
|
||||
* FTP
|
||||
* OpenStack Object Storage / Swift
|
||||
* SFTP (SSH)
|
||||
* WebDAV
|
||||
|
||||
|
||||
|
||||
And a wider list of proprietary protocols, such as:
|
||||
|
||||
* Amazon Cloud Drive
|
||||
* Amazon S3
|
||||
* Azure
|
||||
* B2 Cloud Storage
|
||||
* Box.com
|
||||
* Dropbox
|
||||
* Google Cloud Storage
|
||||
* Google Drive
|
||||
* HubiC
|
||||
* Jottacloud
|
||||
* mega.nz
|
||||
* Microsoft One Drive
|
||||
* Microsoft One Drive for Business
|
||||
* Microsoft Sharepoint
|
||||
* OpenStack Simple Storage
|
||||
* Rackspace CloudFiles
|
||||
|
||||
|
||||
|
||||
For FTP, SFTP, WebDAV is as simple as setting the server hostname or IP address, adding credentials and then using the whole previous process. As a result, I don't believe it is of any value describing them.
|
||||
|
||||
However, as I find it useful for personal matters having a cloud based backup, I will describe the configuration for Dropbox, which uses the same procedure as for Google Drive and Microsoft OneDrive.
|
||||
|
||||
#### Dropbox
|
||||
|
||||
Let's create a new backup job and set the destination to Dropbox. All the configurations are exactly the same except for the destination that should be set like this:
|
||||
|
||||
[![][36]][37]
|
||||
|
||||
Once you set up "Dropbox" from the drop-down menu, and configured the destination folder, click on the OAuth link to set the authentication.
|
||||
|
||||
A pop-up will emerge for you to login to Dropbox (or Google Drive or OneDrive depending on your choosing):
|
||||
|
||||
[![][38]][39]
|
||||
|
||||
After logging in you will be prompted to allow Duplicati app to your cloud storage:
|
||||
|
||||
[![][40]][41]
|
||||
|
||||
After finishing the last process, the AuthID field will be automatically filled in:
|
||||
|
||||
[![][42]][43]
|
||||
|
||||
Click on "Test Connection". When testing the connection you will be asked to create the folder in the case it does not exist:
|
||||
|
||||
[![][44]][45]
|
||||
|
||||
And finally it will give you a notification that the connection is successful:
|
||||
|
||||
[![][46]][47]
|
||||
|
||||
If you access your Dropbox account you will see the files, in the same format that we have seen before, under the defined folder:
|
||||
|
||||
[![][48]][49]
|
||||
|
||||
### Conclusions
|
||||
|
||||
Duplicati is a multi-platform, feature-rich, easy to use backup solution for personal computers. It supports a wide variety of backup repositories what makes it a very versatile tool that can adapt to most personal needs.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/personal-backups-with-duplicati-on-linux/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://updates.duplicati.com/beta/duplicati_2.0.2.1-1_all.deb
|
||||
[2]:https://www.debian.org/releases/stable/
|
||||
[3]:https://www.howtoforge.com/images/personal_backups_with_duplicati/installation-netstat.png
|
||||
[4]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/installation-netstat.png
|
||||
[5]:https://www.howtoforge.com/images/personal_backups_with_duplicati/installation-web.png
|
||||
[6]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/installation-web.png
|
||||
[7]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-1.png
|
||||
[8]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-1.png
|
||||
[9]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-2.png
|
||||
[10]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-2.png
|
||||
[11]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-3.png
|
||||
[12]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-3.png
|
||||
[13]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-4.png
|
||||
[14]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-4.png
|
||||
[15]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-5.png
|
||||
[16]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-5.png
|
||||
[17]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-6.png
|
||||
[18]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-6.png
|
||||
[19]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-7.png
|
||||
[20]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-7.png
|
||||
[21]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-8.png
|
||||
[22]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-8.png
|
||||
[23]:https://www.howtoforge.com/images/personal_backups_with_duplicati/run-1.png
|
||||
[24]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/run-1.png
|
||||
[25]:https://www.howtoforge.com/images/personal_backups_with_duplicati/restore-1.png
|
||||
[26]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/restore-1.png
|
||||
[27]:https://www.howtoforge.com/images/personal_backups_with_duplicati/restore-2.png
|
||||
[28]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/restore-2.png
|
||||
[29]:https://www.howtoforge.com/images/personal_backups_with_duplicati/remote-1.png
|
||||
[30]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/remote-1.png
|
||||
[31]:https://www.howtoforge.com/images/personal_backups_with_duplicati/remote-sshd.png
|
||||
[32]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/remote-sshd.png
|
||||
[33]:https://www.howtoforge.com/cdn-cgi/l/email-protection
|
||||
[34]:https://www.howtoforge.com/images/personal_backups_with_duplicati/remote-sshtun.png
|
||||
[35]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/remote-sshtun.png
|
||||
[36]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-1.png
|
||||
[37]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-1.png
|
||||
[38]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-2.png
|
||||
[39]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-2.png
|
||||
[40]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-4.png
|
||||
[41]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-4.png
|
||||
[42]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-5.png
|
||||
[43]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-5.png
|
||||
[44]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-6.png
|
||||
[45]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-6.png
|
||||
[46]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-7.png
|
||||
[47]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-7.png
|
||||
[48]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-8.png
|
||||
[49]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-8.png
|
||||
@ -1,269 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Mail transfer agent (MTA) basics
|
||||
======
|
||||
|
||||
## Overview
|
||||
|
||||
In this tutorial, learn to:
|
||||
|
||||
* Use the `mail` command.
|
||||
* Create mail aliases.
|
||||
* Configure email forwarding.
|
||||
* Understand common mail transfer agent (MTA) programs such as postfix, sendmail, qmail, and exim.
|
||||
|
||||
|
||||
|
||||
## Controlling where your mail goes
|
||||
|
||||
Email on a Linux system is delivered using MTAs. Your MTA delivers mail to other users on your system and MTAs communicate with each other to deliver mail all over a group of systems or all over the world.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
To get the most from the tutorials in this series, you need a basic knowledge of Linux and a working Linux system on which you can practice the commands covered in this tutorial. You should be familiar with GNU and UNIX commands. Sometimes different versions of a program format output differently, so your results might not always look exactly like the listings shown here.
|
||||
|
||||
In this tutorial, I use Ubuntu 14.04 LTS and sendmail 8.14.4 for the sendmail examples.
|
||||
|
||||
## Mail transfer
|
||||
|
||||
Mail transfer agents such as sendmail deliver mail between users and between systems. Most Internet mail uses the Simple Mail Transfer Protocol (SMTP), but local mail may be transferred through files or sockets among other possibilities. Mail is a store and forward operation, so mail is stored in some kind of file or database until a user collects it or a receiving system or communication link is available. Configuring and securing an MTA is quite a complex task, most of which is beyond the scope of this introductory tutorial.
|
||||
|
||||
## The mail command
|
||||
|
||||
If you use SMTP email, you probably know that there are many, many mail clients that you can use, including `mail`, `mutt`, `alpine`, `notmuch`, and a host of other console and graphical mail clients. The `mail` command is an old standby that can be used to script the sending of mail as well as receive and manage your incoming mail.
|
||||
|
||||
You can use `mail` interactively to send messages by passing a list of addressees, or with no arguments you can use it to look at your incoming mail. Listing 1 shows how to send a message to user steve and user pat on your system with a carbon copy to user bob. When prompted for the cc:user and the subject, enter the body and complete the message by pressing **Ctrl+D** (hold down the Ctrl key and press D).
|
||||
|
||||
##### Listing 1. Using `mail` interactively to send mail
|
||||
```
|
||||
ian@attic4-u14:~$ mail steve,pat
|
||||
Cc: bob
|
||||
Subject: Test message 1
|
||||
This is a test message
|
||||
|
||||
Ian
|
||||
```
|
||||
|
||||
If all is well, your mail is sent. If there is an error, you will see an error message. For example, if you typed an invalid name as a recipient, the mail is not sent. Note that in this example, all users are on your local system and therefore all must be valid users.
|
||||
|
||||
You can also send mail non-interactively using the command line. Listing 2 shows how to send a small message to users steve and pat. This capability is particularly useful in scripts. Different versions of the `mail` command are available in different packages. Some support a `-c` option for cc:, but the version I am using here does not, so I specify only the to: addresses.
|
||||
|
||||
Listing 2. Using `mail` non-interactively
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t steve,pat -s "Test message 2" <<< "Another test.\n\nIan"
|
||||
```
|
||||
|
||||
If you use `mail` with no options you will see a list of your incoming mail as shown in Listing 3. You see that user steve has the two messages I sent above, plus an earlier one from me and a later one from user bob. All the mail is marked as 'N' for new mail.
|
||||
|
||||
Listing 3. Using `mail` for incoming mail
|
||||
```
|
||||
steve@attic4-u14:~$ mail
|
||||
"/var/mail/steve": 4 messages 4 new
|
||||
>N 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
N 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
N 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
The currently selected message is shown with a '>', which is message number 1 in Listing 3. If you press **Enter** , the first page of the next unread message will be displayed. Press the **Space bar** to page through the message. When you finish reading the message and return to the '?' prompt, press **Enter** again to view the next message, and so on. At any '?' prompt you can type 'h' to see the list of message headers again. The ones you have read will now show 'R' in the status as shown in Listing 4.
|
||||
|
||||
Listing 4. Using 'h' to display mail headers
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
Here Steve has read the three messages from Ian but has not read the message from Bob. You can select individual messages by number, and you can also delete messages that you don't want by typing 'd', or '3d' to delete the third message. If you type 'q' you will quit the `mail` command. Messages that you have read will be transferred to the mbox file in your home directory and the unread messages will remain in your inbox, by default in /var/mail/$(id -un). See Listing 5.
|
||||
|
||||
Listing 5. Using 'q' to quit `mail`
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
? q
|
||||
Saved 3 messages in /home/steve/mbox
|
||||
Held 1 message in /var/mail/steve
|
||||
You have mail in /var/mail/steve
|
||||
```
|
||||
|
||||
If you type 'x' to exit instead of 'q' to quit, your mailbox will be left unchanged. Because this is on the /var file system, your system administrator may allow mail to be kept there only for a limited time. To reread or otherwise process mail that has been saved to your local mbox file, use the `-f` option to specify the file you want to read. For example `mail -f mbox`.
|
||||
|
||||
## Mail aliases
|
||||
|
||||
In the previous section you saw how mail can be sent to various users on a system. You can use a fully qualified name, such as ian@myexampledomain.com to send mail to a user on another system.
|
||||
|
||||
Sometimes you might want all the mail for a user to go to some other place. For example, you may have a server farm and want all the root mail to go to a central system administrator. Or you may want to create a mailing list where mail goes to several people. To do this, you use aliases that allow you to define one or more destinations for a given user name. The destinations may be other user mail boxes, files, pipes, or commands that do further processing. You do this by specifying the aliases in /etc/mail/aliases or /etc/aliases. Depending on your system, you may find that one of these is a symbolic link to the other, or you may have only one of them. You need root authority to change the aliases file.
|
||||
|
||||
The general form of an alias is
|
||||
name: addr_1, addr_2, addr_3, ...
|
||||
where the name is a local user name to alias or an alias and the addr_1, addr_2, ... are one or more aliases. Aliases can be a local user, a local file name, another alias, a command, an include file, or an external address.
|
||||
|
||||
So how does sendmail distinguish the aliases (the addr-N values)?
|
||||
|
||||
* A local user name is a text string that matches the name of a user on this system. Technically this means it can be found using the `getpwnam` call .
|
||||
* A local file name is a full path and file name that starts with '/'. It must be writeable by `sendmail`. Messages are appended to the file.
|
||||
* A command starts with the pipe symbol (|). Messages are sent to the command using standard input.
|
||||
* An include file alias starts with :include: and specifies a path and file name. The aliases in file are added to the aliases for this name.
|
||||
* An external address is an email address such as john@somewhere.com.
|
||||
|
||||
|
||||
|
||||
You should find an example file, such as /usr/share/sendmail/examples/db/aliases that was installed with your sendmail package. It contains some recommended aliases for postmaster, MAILER-DAEMON, abuse, and spam. In Listing 6, I have combined entries from the example file on my Ubuntu 14.04 LTS system with some rather artificial examples that illustrate several of the possibilities.
|
||||
|
||||
Listing 6. Somewhat artificial /etc/mail/aliases example
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/mail/aliases
|
||||
# First include some default system aliases from
|
||||
# /usr/share/sendmail/examples/db/aliases
|
||||
|
||||
#
|
||||
# Mail aliases for sendmail
|
||||
#
|
||||
# You must run newaliases(1) after making changes to this file.
|
||||
#
|
||||
|
||||
# Required aliases
|
||||
postmaster: root
|
||||
MAILER-DAEMON: postmaster
|
||||
|
||||
# Common aliases
|
||||
abuse: postmaster
|
||||
spam: postmaster
|
||||
|
||||
# Other aliases
|
||||
|
||||
# Send steve's mail to bob and pat instead
|
||||
steve: bob,pat
|
||||
|
||||
# Send pat's mail to a file in her home directory and also to her inbox.
|
||||
# Finally send it to a command that will make another copy.
|
||||
pat: /home/pat/accumulated-mail,
|
||||
\pat,
|
||||
|/home/pat/makemailcopy.sh
|
||||
|
||||
# Mailing list for system administrators
|
||||
sysadmins: :include: /etc/aliases-sysadmins
|
||||
```
|
||||
|
||||
Note that pat is both an alias and a user of the system. Alias expansion is recursive, so if an alias is also a name, then it will be expanded. Sendmail does not send mail twice to a given user, so if you just put 'pat' as an alias for 'pat', then it would be ignored since sendmail had already found and processed 'pat'. To avoid this problem, you prefix an alias name with a '\' to indicate that it is a name not subject to further aliasing. This way, pat's mail can be sent to her normal inbox as well as the file and command.
|
||||
|
||||
Lines in the aliases that start with '$' are comments and are ignored. Lines that start with blanks are treated as continuation lines.
|
||||
|
||||
The include file /etc/aliases-sysadmins is shown in Listing 7.
|
||||
|
||||
Listing 7. The /etc/aliases-sysadmins include file
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/aliases-sysadmins
|
||||
|
||||
# Mailing list for system administrators
|
||||
bob,pat
|
||||
```
|
||||
|
||||
## The newaliases command
|
||||
|
||||
Most configuration files used by sendmail are compiled into database files. This is also true for mail aliases. You use the `newaliases` command to compile your /etc/mail/aliases and any included files to /etc/mail/aliases.db. Note that `newaliases` is equivalent to `sendmail -bi`. Listing 8 shows an example.
|
||||
|
||||
Listing 8. Rebuild the database for the mail aliases file
|
||||
```
|
||||
ian@attic4-u14:~$ sudo newaliases
|
||||
/etc/mail/aliases: 7 aliases, longest 62 bytes, 184 bytes total
|
||||
ian@attic4-u14:~$ ls -l /etc/mail/aliases*
|
||||
lrwxrwxrwx 1 root smmsp 10 Dec 8 15:48 /etc/mail/aliases -> ../aliases
|
||||
-rw-r----- 1 smmta smmsp 12288 Dec 13 23:18 /etc/mail/aliases.db
|
||||
```
|
||||
|
||||
## Examples of using aliases
|
||||
|
||||
Listing 9 shows a simple shell script that is used as a command in my alias example.
|
||||
|
||||
Listing 9. The makemailcopy.sh script
|
||||
```
|
||||
ian@attic4-u14:~$ cat ~pat/makemailcopy.sh
|
||||
#!/bin/bash
|
||||
|
||||
# Note: Target file ~/mail-copy must be writeable by sendmail!
|
||||
cat >> ~pat/mail-copy
|
||||
```
|
||||
|
||||
Listing 10 shows the files that are updated when you put all this to the test.
|
||||
|
||||
Listing 10. The /etc/aliases-sysadmins include file
|
||||
```
|
||||
ian@attic4-u14:~$ date
|
||||
Wed Dec 13 22:54:22 EST 2017
|
||||
ian@attic4-u14:~$ mail -t sysadmins -s "sysadmin test 1" <<< "Testing mail"
|
||||
ian@attic4-u14:~$ ls -lrt $(find /var/mail ~pat -type f -mmin -3 2>/dev/null )
|
||||
-rw-rw---- 1 pat mail 2046 Dec 13 22:54 /home/pat/mail-copy
|
||||
-rw------- 1 pat mail 13240 Dec 13 22:54 /var/mail/pat
|
||||
-rw-rw---- 1 pat mail 9442 Dec 13 22:54 /home/pat/accumulated-mail
|
||||
-rw-rw---- 1 bob mail 12522 Dec 13 22:54 /var/mail/bob
|
||||
```
|
||||
|
||||
Some points to note:
|
||||
|
||||
* There is a user 'mail' with group name 'mail' that is used by sendmail.
|
||||
* User mail is stored by sendmail in /var/mail which is also the home directory of user 'mail'. The inbox for user 'ian' defaults to /var/mail/ian.
|
||||
* If you want sendmail to write files in a user directory, the file must be writeable by sendmail. Rather than making it world writeable, it is customary to make it group writeable and make the group 'mail'. You may need a system administrator to do this for you.
|
||||
|
||||
|
||||
|
||||
## Using a .forward file to forward mail
|
||||
|
||||
The aliases file must be managed by a system administrator. Individual users can enable forwarding of their own mail using a .forward file in their own home directory. You can put anything in your .forward file that is allowed on the right side of the aliases file. The file contains plain text and does not need to be compiled. When mail is destined for you, sendmail checks for a .forward file in your home directory and processes the entries the same way it processes aliases.
|
||||
|
||||
## Mail queues and the mailq command
|
||||
|
||||
Linux mail handling uses a store-and-forward model. You have already seen that your incoming mail is stored in a file in /var/mail until you read it. Outgoing mail is also stored until a receiving server connection is available. You use the `mailq` command to see what mail is queued. Listing 11 shows an example of mail being sent to an external user, ian@attic4-c6, and the result of running the `mailq` command. In this case, there is currently no active link to attic4-c6, so the mail will remain queued until a link becomes active.
|
||||
|
||||
Listing 11. Using the `mailq` command
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t ian@attic4-c6 -s "External mail" <<< "Testing external mail queues"
|
||||
ian@attic4-u14:~$ mailq
|
||||
MSP Queue status...
|
||||
/var/spool/mqueue-client is empty
|
||||
Total requests: 0
|
||||
MTA Queue status...
|
||||
/var/spool/mqueue (1 request)
|
||||
-----Q-ID----- --Size-- -----Q-Time----- ------------Sender/Recipient-----------
|
||||
vBE4mdE7025908* 29 Wed Dec 13 23:48 <ian@attic4-u14.hopto.org>
|
||||
<ian@attic4-c6.hopto.org>
|
||||
Total requests: 1
|
||||
```
|
||||
|
||||
## Other mail transfer agents
|
||||
|
||||
In response to security issues with sendmail, several other mail transfer agents were developed during the 1990's. Postfix is perhaps the most popular, but qmail and exim are also widely used.
|
||||
|
||||
Postfix started life at IBM research as an alternative to sendmail. It attempts to be fast, easy to administer, and secure. The outside looks somewhat like sendmail, but the inside is completely different.
|
||||
|
||||
Qmail is a secure, reliable, efficient, simple message transfer agent developerd by Dan Bernstein. However, the core qmail package has not been updated for many years. Qmail and several other packages have now been collected into IndiMail.
|
||||
|
||||
Exim is another MTA developed at the University of Cambridge. Originally, the name stood for EXperimental Internet Mailer.
|
||||
|
||||
All of these MTAs were designed as sendmail replacements, so they all have some form of sendmail compatibility. Each can handle aliases and .forward files. Some provide a `sendmail` command as a front end to the particular MTA's own command. Most allow the usual sendmail options, although some options might be ignore silently. The `mailq` command is supported directly or by an alternate command with a similar function. For example, you can use `mailq` or `exim -bp` to display the exim mail queue. Needless to say, output can look different compared to that produced by sendmail's `mailq` command.
|
||||
|
||||
See Related topics where you can find more information on all of these MTAs.
|
||||
|
||||
This concludes your introduction to mail transfer agents on Linux.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-3/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
@ -1,167 +0,0 @@
|
||||
Linux touch command tutorial for beginners (6 examples)
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Linux Touch command][1]
|
||||
|
||||
2. [1\. How to change access/modification time using touch command][2]
|
||||
|
||||
3. [2\. How to change only access or modification time][3]
|
||||
|
||||
4. [3\. How to make touch use access/modification times of existing file][4]
|
||||
|
||||
5. [4\. How to create a new file using touch][5]
|
||||
|
||||
6. [5\. How to force touch to not create any new file][6]
|
||||
|
||||
7. [6\. How touch works in case of symbolic links][7]
|
||||
|
||||
8. [Conclusion][8]
|
||||
|
||||
Sometimes, while working on the command line in Linux, you might want to create a new file. Or, there may be times when the requirement is to change the timestamps of a file. Well, there exists a utility that can you can use in both these scenarios. The tool in question is **touch**, and in this tutorial, we will understand its basic functionality through easy to understand examples.
|
||||
|
||||
Please note that all examples that we'll be using here have been tested on an Ubuntu 16.04 machine.
|
||||
|
||||
### Linux Touch command
|
||||
|
||||
The touch command is primarily used to change file timestamps, but if the file (whose name is passed as an argument) doesn't exist, then the tool creates it.
|
||||
|
||||
Following is the command's generic syntax:
|
||||
|
||||
```
|
||||
touch [OPTION]... FILE...
|
||||
```
|
||||
|
||||
And here's how the man page explains this command:
|
||||
|
||||
```
|
||||
DESCRIPTION
|
||||
Update the access and modification times of each FILE to the current
|
||||
time. A FILE argument that does not exist is created empty, unless -c or -h
|
||||
is supplied. A FILE argument string of - is handled specially and causes touch to
|
||||
change the times of the file associated with standard output.
|
||||
```
|
||||
|
||||
The following Q&A type examples will give you a better idea of how the tool works.
|
||||
|
||||
### 1\. How to change access/modification time using touch command
|
||||
|
||||
This is simple, and pretty straight forward. Let's take an existing file as an example. The following screenshot shows the access and modification times for a file called 'apl.c.'
|
||||
|
||||
[][9]
|
||||
|
||||
Here's how you can use the touch command to change the file's access and modification times:
|
||||
|
||||
```
|
||||
touch apl.c
|
||||
```
|
||||
|
||||
The following screenshot confirms the change in these timestamps.
|
||||
|
||||
[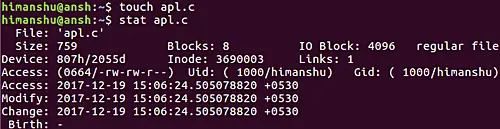][10]
|
||||
|
||||
### 2\. How to change only access or modification time
|
||||
|
||||
By default, the touch command changes both access and modification times of the input file. However, if you want, you can limit this behavior to any one of these timestamps. This means that you can either have the access time changed or the modification timestamp.
|
||||
|
||||
In case you want to only change the access time, use the -a command line option.
|
||||
|
||||
```
|
||||
touch -a [filename]
|
||||
```
|
||||
|
||||
Similarly, if the requirement is to only change the modification time, use the -m command line option.
|
||||
|
||||
```
|
||||
touch -m [filename]
|
||||
```
|
||||
|
||||
### 3\. How to make touch use access/modification times of existing file
|
||||
|
||||
If you want, you can also force the touch command to copy access and modification timestamps from a reference file. For example, suppose we want to change the timestamps for the file 'apl.c'. Here are the current timestamps for this file:
|
||||
|
||||
[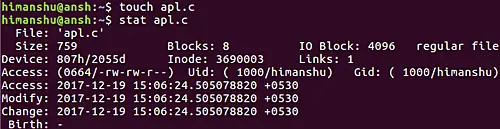][11]
|
||||
|
||||
And this is the file which you want touch to use as its reference:
|
||||
|
||||
[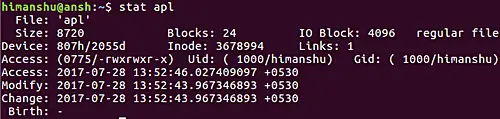][12]
|
||||
|
||||
Now, for touch to use the timestamps of 'apl' for 'apl.c', you'll need to use the -r command line option in the following way:
|
||||
|
||||
```
|
||||
touch apl.c -r apl
|
||||
```
|
||||
|
||||
[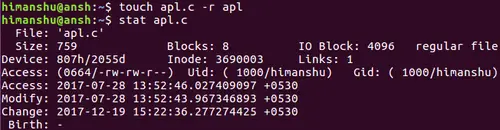][13]
|
||||
|
||||
The above screenshot shows that modification and access timestamps for 'apl.c' are now same as those for 'apl.'
|
||||
|
||||
### 4\. How to create a new file using touch
|
||||
|
||||
Creating a new file is also very easy. In fact, it happens automatically if the file name you pass as argument to the touch command doesn't exist. For example, to create a file named 'newfile', all you have to do is to run the following touch command:
|
||||
|
||||
```
|
||||
touch newfile
|
||||
```
|
||||
|
||||
### 5\. How to force touch to not create any new file
|
||||
|
||||
Just in case there's a strict requirement that the touch command shouldn't create any new files, then you can use the -c option.
|
||||
|
||||
```
|
||||
touch -c [filename]
|
||||
```
|
||||
|
||||
The following screenshot shows that since 'newfile12' didn't exist, and we used the -c command line option, the touch command didn't create the file.
|
||||
|
||||
[][14]
|
||||
|
||||
### 6\. How touch works in case of symbolic links
|
||||
|
||||
By default, if you pass a symbolic link file name to the touch command, the change in access and modification timestamps will be for the original file (one which the symbolic link refers to). However, the tool also offers an option (-h) that lets you override this behavior.
|
||||
|
||||
Here's how the man page explains the -h option:
|
||||
|
||||
```
|
||||
-h, --no-dereference
|
||||
affect each symbolic link instead of any referenced file (useful
|
||||
only on systems that can change the timestamps of a symlink)
|
||||
```
|
||||
|
||||
So when you want to change the modification and access timestamps for the symbolic link (and not the original file), use the touch command in the following way:
|
||||
|
||||
```
|
||||
touch -h [sym link file name]
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
As you'd agree, touch isn't a difficult command to understand and use. The examples/options we discussed in this tutorial should be enough to get you started with the tool. While newbies will mostly find themselves using the utility for creating new files, more experienced users play with it for multiple other purposes as well. For more information on the touch command, head to [its man page][15].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/linux-touch-command/
|
||||
|
||||
作者:[ Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/linux-touch-command/
|
||||
[1]:https://www.howtoforge.com/tutorial/linux-touch-command/#linux-touch-command
|
||||
[2]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-change-accessmodification-time-using-touch-command
|
||||
[3]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-change-only-access-or-modification-time
|
||||
[4]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-make-touch-use-accessmodification-times-of-existing-file
|
||||
[5]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-create-a-new-file-using-touch
|
||||
[6]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-force-touch-to-not-create-any-new-file
|
||||
[7]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-touch-works-in-case-of-symbolic-links
|
||||
[8]:https://www.howtoforge.com/tutorial/linux-touch-command/#conclusion
|
||||
[9]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-exist-file1.png
|
||||
[10]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-exist-file2.png
|
||||
[11]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-exist-file21.png
|
||||
[12]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-ref-file1.png
|
||||
[13]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-ref-file2.png
|
||||
[14]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-c-option.png
|
||||
[15]:https://linux.die.net/man/1/touch
|
||||
@ -1,145 +0,0 @@
|
||||
My first Rust macro
|
||||
============================================================
|
||||
|
||||
Last night I wrote a Rust macro for the first time!! The most striking thing to me about this was how **easy** it was – I kind of expected it to be a weird hard finicky thing, and instead I found that I could go from “I don’t know how macros work but I think I could do this with a macro” to “wow I’m done” in less than an hour.
|
||||
|
||||
I used [these examples][2] to figure out how to write my macro.
|
||||
|
||||
### what’s a macro?
|
||||
|
||||
There’s more than one kind of macro in Rust –
|
||||
|
||||
* macros defined using `macro_rules` (they have an exclamation mark and you call them like functions – `my_macro!()`)
|
||||
|
||||
* “syntax extensions” / “procedural macros” like `#[derive(Debug)]` (you put these like annotations on your functions)
|
||||
|
||||
* built-in macros like `println!`
|
||||
|
||||
[Macros in Rust][3] and [Macros in Rust part II][4] seems like a nice overview of the different kinds with examples
|
||||
|
||||
I’m not actually going to try to explain what a macro **is**, instead I will just show you what I used a macro for yesterday and hopefully that will be interesting. I’m going to be talking about `macro_rules!`, I don’t understand syntax extension/procedural macros yet.
|
||||
|
||||
### compiling the `get_stack_trace` function for 30 different Ruby versions
|
||||
|
||||
I’d written some functions that got the stack trace out of a running Ruby program (`get_stack_trace`). But the function I wrote only worked for Ruby 2.2.0 – here’s what it looked like. Basically it imported some structs from `bindings::ruby_2_2_0` and then used them.
|
||||
|
||||
```
|
||||
use bindings::ruby_2_2_0::{rb_control_frame_struct, rb_thread_t, RString};
|
||||
fn get_stack_trace(pid: pid_t) -> Vec<String> {
|
||||
// some code using rb_control_frame_struct, rb_thread_t, RString
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Let’s say I wanted to instead have a version of `get_stack_trace` that worked for Ruby 2.1.6. `bindings::ruby_2_2_0` and `bindings::ruby_2_1_6` had basically all the same structs in them. But `bindings::ruby_2_1_6::rb_thread_t` wasn’t the **same** as `bindings::ruby_2_2_0::rb_thread_t`, it just had the same name and most of the same struct members.
|
||||
|
||||
So I could implement a working function for Ruby 2.1.6 really easily! I just need to basically replace `2_2_0` for `2_1_6`, and then the compiler would generate different code (because `rb_thread_t` is different). Here’s a sketch of what the Ruby 2.1.6 version would look like:
|
||||
|
||||
```
|
||||
use bindings::ruby_2_1_6::{rb_control_frame_struct, rb_thread_t, RString};
|
||||
fn get_stack_trace(pid: pid_t) -> Vec<String> {
|
||||
// some code using rb_control_frame_struct, rb_thread_t, RString
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### what I wanted to do
|
||||
|
||||
I basically wanted to write code like this, to generate a `get_stack_trace` function for every Ruby version. The code inside `get_stack_trace` would be the same in every case, it’s just the `use bindings::ruby_2_1_3` that needed to be different
|
||||
|
||||
```
|
||||
pub mod ruby_2_1_3 {
|
||||
use bindings::ruby_2_1_3::{rb_control_frame_struct, rb_thread_t, RString};
|
||||
fn get_stack_trace(pid: pid_t) -> Vec<String> {
|
||||
// insert code here
|
||||
}
|
||||
}
|
||||
pub mod ruby_2_1_4 {
|
||||
use bindings::ruby_2_1_4::{rb_control_frame_struct, rb_thread_t, RString};
|
||||
fn get_stack_trace(pid: pid_t) -> Vec<String> {
|
||||
// same code
|
||||
}
|
||||
}
|
||||
pub mod ruby_2_1_5 {
|
||||
use bindings::ruby_2_1_5::{rb_control_frame_struct, rb_thread_t, RString};
|
||||
fn get_stack_trace(pid: pid_t) -> Vec<String> {
|
||||
// same code
|
||||
}
|
||||
}
|
||||
pub mod ruby_2_1_6 {
|
||||
use bindings::ruby_2_1_6::{rb_control_frame_struct, rb_thread_t, RString};
|
||||
fn get_stack_trace(pid: pid_t) -> Vec<String> {
|
||||
// same code
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### macros to the rescue!
|
||||
|
||||
This really repetitive thing was I wanted to do was a GREAT fit for macros. Here’s what using `macro_rules!` to do this looked like!
|
||||
|
||||
```
|
||||
macro_rules! ruby_bindings(
|
||||
($ruby_version:ident) => (
|
||||
pub mod $ruby_version {
|
||||
use bindings::$ruby_version::{rb_control_frame_struct, rb_thread_t, RString};
|
||||
fn get_stack_trace(pid: pid_t) -> Vec<String> {
|
||||
// insert code here
|
||||
}
|
||||
}
|
||||
));
|
||||
|
||||
```
|
||||
|
||||
I basically just needed to put my code in and insert `$ruby_version` in the places I wanted it to go in. So simple! I literally just looked at an example, tried the first thing I thought would work, and it worked pretty much right away.
|
||||
|
||||
(the [actual code][5] is more lines and messier but the usage of macros is exactly as simple in this example)
|
||||
|
||||
I was SO HAPPY about this because I’d been worried getting this to work would be hard but instead it was so easy!!
|
||||
|
||||
### dispatching to the right code
|
||||
|
||||
Then I wrote some super simple dispatch code to call the right code depending on which Ruby version was running!
|
||||
|
||||
```
|
||||
let version = get_api_version(pid);
|
||||
let stack_trace_function = match version.as_ref() {
|
||||
"2.1.1" => stack_trace::ruby_2_1_1::get_stack_trace,
|
||||
"2.1.2" => stack_trace::ruby_2_1_2::get_stack_trace,
|
||||
"2.1.3" => stack_trace::ruby_2_1_3::get_stack_trace,
|
||||
"2.1.4" => stack_trace::ruby_2_1_4::get_stack_trace,
|
||||
"2.1.5" => stack_trace::ruby_2_1_5::get_stack_trace,
|
||||
"2.1.6" => stack_trace::ruby_2_1_6::get_stack_trace,
|
||||
"2.1.7" => stack_trace::ruby_2_1_7::get_stack_trace,
|
||||
"2.1.8" => stack_trace::ruby_2_1_8::get_stack_trace,
|
||||
// and like 20 more versions
|
||||
_ => panic!("OH NO OH NO OH NO"),
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
### it works!
|
||||
|
||||
I tried out my prototype, and it totally worked! The same program could get stack traces out the running Ruby program for all of the ~10 different Ruby versions I tried – it figured which Ruby version was running, called the right code, and got me stack traces!!
|
||||
|
||||
Previously I’d compile a version for Ruby 2.2.0 but then if I tried to use it for any other Ruby version it would crash, so this was a huge improvement.
|
||||
|
||||
There are still more issues with this approach that I need to sort out. The two main ones right now are: firstly the ruby binary that ships with Debian doesn’t have symbols and I need the address of the current thread, and secondly it’s still possible that `#ifdefs` will ruin my day.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/12/24/my-first-rust-macro/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/ruby-profiler
|
||||
[2]:https://gist.github.com/jfager/5936197
|
||||
[3]:https://www.ncameron.org/blog/macros-in-rust-pt1/
|
||||
[4]:https://www.ncameron.org/blog/macros-in-rust-pt2/
|
||||
[5]:https://github.com/jvns/ruby-stacktrace/blob/b0b92863564e54da59ea7f066aff5bb0d92a4968/src/lib.rs#L249-L393
|
||||
@ -1,138 +0,0 @@
|
||||
SoftMaker for Linux Is a Solid Microsoft Office Alternative
|
||||
======
|
||||

|
||||
|
||||
|
||||
[SoftMaker Office][6] could be a first-class professional-strength replacement for Microsoft Office on the Linux desktop.
|
||||
|
||||
The Linux OS has its share of lightweight word processors and a few nearly worthy standalone spreadsheet apps, but very few high-end integrated office suites exist for Linux users. Generally, Linux office suites lack a really solid slide presentation creation tool.
|
||||
|
||||
![PlanMaker Presentations][7]
|
||||
|
||||
PlanMaker Presentations is a near-perfect Microsoft Powerpoint clone.
|
||||
|
||||
Most Linux users opt for [LibreOffice][9] -- or maybe the withering [OpenOffice][10] -- or online subscriptions to Microsoft Office through Web browser apps.
|
||||
|
||||
However, high-performing options for Linux office suites exist. The SoftMaker office suite product line is one such contender to replace Microsoft Office.
|
||||
|
||||
The latest beta release of SoftMaker Office 2018 is fully compatible with Microsoft Office. It offers a completely redesigned user interface that allows users to work with either classic or ribbon menus.
|
||||
|
||||
![SoftMaker UI Panel][11]
|
||||
|
||||
On first use, you choose the user interface you prefer. You can change your default option at any time from the UI Panel in Settings.
|
||||
|
||||
SoftMaker offers a complete line of free and paid office suite products that run on Android devices, Linux distros, and Windows or macOS PCs.
|
||||
|
||||
![][12]
|
||||
|
||||
### Rethinking Options
|
||||
|
||||
The beta version of this commercial Linux office suite is free. When the final version is released, two Linux commercial versions will be available. The licenses for both let you run SoftMaker Office on five computers. It will be priced at US$69.95, or $99.95 if you want a few dictionary add-on tools included.
|
||||
|
||||
Check out the free beta of the commercial version. A completely free open source-licensed version called "SoftMaker FreeOffice 2018," will be available soon. Switching is seamless. The FreeOffice line is distributed under the Mozilla Public License.
|
||||
|
||||
The FreeOffice 2018 release will have the same ribbon interface option as SoftMaker Office 2018. The exact feature list is not finalized yet, according to Sales Manager Jordan Popov. Both the free and the paid versions will contain fully functional TextMaker, PlanMaker, and Presentations, just like the paid Linux SoftMaker Office 2018 release. The Linux edition has the Thunderbird email management client.
|
||||
|
||||
When I reviewed SoftMaker FreeOffice 2016 and SoftMaker Office 2016, I found the paid and free versions to be almost identical in functionality and features. So opting for the free versus paid versions of the 2018 office suites might be a no-brainer.
|
||||
|
||||
The value here is that the free open source and both commercial versions of the 2018 releases are true 64-bit products. Previous releases required some 32-bit dependencies to run on 64-bit architecture.
|
||||
|
||||
### First Look Impressive
|
||||
|
||||
The free version (FreeOffice 2018 for Linux) is not yet available for review. SoftMaker expects to release FreeOffice 2018 for Linux it at the end of the first quarter of 2018.
|
||||
|
||||
So I took the free beta release of Office 2018 for a spin to check out the performance of the ribbon user interface. Its performance was impressive.
|
||||
|
||||
I regularly use the latest version of LibreOffice and earlier versions of FreeOffice. Their user interfaces mimic standard drop-down menus.
|
||||
|
||||
It took me some time to gegt used to the ribbon menu, since I was unfamiliar with using it on Microsoft Office, but I came to like it.
|
||||
|
||||
### How It Works
|
||||
|
||||
The process is a bit different than scrolling down drop-down menus. You click on a category in the toolbar row at the top of the application window and then scan across the lateral display of boxed lists of functions.
|
||||
|
||||
The lateral array of clickable menu choices changes with each toolbar category selected. Once I learned what was where, my appreciation for the "ribbon effect" grew.
|
||||
|
||||
![TextMaker screen shot][13]
|
||||
|
||||
The ribbon interface gives users a different look and feel when creating or editing documents on the Linux desktop.
|
||||
|
||||
The labels are: File, Home, Insert, Layout, References, Mailings, Review and View. Click the action you want and instantly see it applied. There are no cascading menus.
|
||||
|
||||
At first, I did not like not having any customizations available for things like often-used actions. Then I right-clicked on an item in the ribbon and discovered a pop-up menu.
|
||||
|
||||
This provides a way to customize a Quick Action Bar, customize the ribbon display choices, and show the Quick Action toolbar as a separate toolbar. That prompted me to sit up straight and dig in with eyes wide open.
|
||||
|
||||
### Great User Experience
|
||||
|
||||
I process a significant number of graphics-heavy documents each week that are produced with Microsoft Office. I edit many of these documents and create many more.
|
||||
|
||||
Much of my work goes to users of Microsoft Office. LibreOffice and SoftMaker Office applications have little to no trouble handling native Microsoft file formats such as DOCX, XLSX and PPTX.
|
||||
|
||||
LibreOffice formatting -- both on screen and printed versions -- are well-done most times. SoftMaker's document renderings are even more exact.
|
||||
|
||||
The beta release of SoftMaker Office 2018 for Linux is even better. Especially with SoftMaker Office 2018, I can exchange files directly with Microsoft Office users without conversion. This obviates the need to import or export documents.
|
||||
|
||||
Given the nearly indistinguishable performance between previous paid and free versions of SoftMaker products, it seems safe to expect the same type of performance from FreeOffice 2018 when it arrives.
|
||||
|
||||
### Expanding Office Reach
|
||||
|
||||
SoftOffice products can give you a complete cross-platform continuity for your office suite needs.
|
||||
|
||||
Four Android editions are available:
|
||||
|
||||
* SoftMaker Office Mobile is the paid or commercial version for Android phones. You can find it in Google Play as TextMaker Mobile, PlanMaker Mobile and Presentations Mobile.
|
||||
* SoftMaker FreeOffice Mobile is the free version for Android phones. You can find it in Google Play as the FREE OFFICE version of TextMaker Mobile, PlanMaker Mobile, Presentations Mobile.
|
||||
* SoftMaker Office HD is the paid or commercial version for Android tablets. You can find it in Google Play as TextMaker HD, PlanMaker HD and Presentations HD.
|
||||
* SoftMaker Office HD Basic is the free version for Android tablets. You can find it in Google Play as TextMaker HD Basic, PlanMaker HD Basic and Presentations HD Basic.
|
||||
|
||||
|
||||
|
||||
Also available are TextMaker HD Trial, PlanMaker HD Trial and Presentations HD Trial in Google Play. These apps work only for 30 days but have all the features of the full version (Office HD).
|
||||
|
||||
### Bottom Line
|
||||
|
||||
The easy access to the free download of SoftMaker Office 2018 gives you nothing to lose in checking out its suitability as a Microsoft Office replacement. If you decide to upgrade to the paid Linux release, you will pay $69.95 for a proprietary license. That is the same price as the Home and Student editions of Microsoft Office 365.
|
||||
|
||||
If you opt for the free open source version, FreeOffice 2018, when it is released, you still could have a top-of-the-line alternative to other Linux tools that play well with Microsoft Office.
|
||||
|
||||
Download the [SoftMaker Office 2018 beta][15].
|
||||
|
||||
### Want to Suggest a Review?
|
||||
|
||||
Is there a Linux software application or distro you'd like to suggest for review? Something you love or would like to get to know? Please [email your ideas to me][16], and I'll consider them for a future Linux Picks and Pans column. And use the Reader Comments feature below to provide your input! ![][17]
|
||||
|
||||
### about the author
|
||||
|
||||
![][18] **Jack M. Germain** has been an ECT News Network reporter since 2003. His main areas of focus are enterprise IT, Linux and open source technologies. He has written numerous reviews of Linux distros and other open source software. [Email Jack.][19]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxinsider.com/story/SoftMaker-for-Linux-Is-a-Solid-Microsoft-Office-Alternative-85018.html
|
||||
|
||||
作者:[Jack M. Germain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxinsider.com
|
||||
[1]:https://www.linuxinsider.com/images/2008/atab.gif
|
||||
[2]:https://www.linuxinsider.com/images/sda/all_ec_134x30.png
|
||||
[4]:https://www.linuxinsider.com/adsys/count/10019/?nm=1-allec-ci-lin-1&ENN_rnd=15154948085323&ign=0/ign.gif
|
||||
[5]:https://www.linuxinsider.com/images/article_images/linux5stars_580x24.jpg
|
||||
[6]:http://www.softmaker.com/en/softmaker-office-linux
|
||||
[7]:https://www.linuxinsider.com/article_images/2017/85018_620x358-small.jpg
|
||||
[8]:https://www.linuxinsider.com/article_images/2017/85018_990x572.jpg (::::topclose:true)
|
||||
[9]:http://www.libreoffice.org/
|
||||
[10]:http://www.openoffice.org/
|
||||
[11]:https://www.linuxinsider.com/article_images/2017/85018_620x439.jpg
|
||||
[12]:https://www.linuxinsider.com/adsys/count/10087/?nm=1i-lin_160-1&ENN_rnd=15154948084583&ign=0/ign.gif
|
||||
[13]:https://www.linuxinsider.com/article_images/2017/85018_620x264-small.jpg
|
||||
[14]:https://www.linuxinsider.com/article_images/2017/85018_990x421.jpg (::::topclose:true)
|
||||
[15]:http://www.softmaker.com/en/softmaker-office-linux-
|
||||
[16]:mailto:jack.germain@
|
||||
[17]:https://www.ectnews.com/images/end-enn.gif
|
||||
[18]:https://www.linuxinsider.com/images/rws572389/Jack%20M.%20Germain.jpg
|
||||
[19]:mailto:jack.germain@newsroom.ectnews.comm
|
||||
@ -1,131 +0,0 @@
|
||||
Forgotten FOSS Games: Boson
|
||||
======
|
||||
|
||||

|
||||
|
||||
Back in September of 1999, just about a year after the KDE project had shipped its first release ever, Thomas Capricelli announced "our attempt to make a Real Time Strategy game (RTS) for the KDE project" on the [kde-announce][1] mailing list. Boson 0.1, as the attempt was called, was based on Qt 1.4, the KDE 1.x libraries, and described as being "Warcraft-like".
|
||||
|
||||
Development continued at a fast pace over the following year. 3D artists and sound designers were invited to contribute, and basic game play (e.g. collecting oil and minerals) started working. The core engine gained much-needed features. A map editor was already part of the package. Four releases later, on October 30, 2000, the release of version 0.5 was celebrated as a major milestone, also because Boson had been ported to Qt 2.2.1 & KDE 2.0 to match the development of the projects it was based on. Then the project suddenly went into hiatus, as it happens so often with ambitious open source game projects. A new set of developers revived Boson one year later, in 2001, and decided to port the game to Qt 3, the KDE 3 libraries and the recently introduced libkdegames library.
|
||||
|
||||
![][2]
|
||||
|
||||
By version 0.6 (released in June of 2002) the project was on a very good path again, having been extended with all the features players were used to from similar RTS titles, e.g. fog of war, path-finding, units defending themselves automatically, the destruction of a radar/satellite station leading to the disappearance of the minimap, and so on. The game came with its own soundtrack (you had the choice between "Jungle" and "Progressive), although the tracks did sound a bit… similar to each other, and Techno hadn't been a thing in game soundtracks since Command and Conquer: Tiberian Sun. More maps and sound effects tightened the atmosphere, but there was no computer opponent with artificial intelligence, so you absolutely had to play over a local network or online.
|
||||
|
||||
Sadly the old websites at <http://aquila.rezel.enst.fr/boson/> and <http://boson.eu.org> are no longer online, and YouTube was not a thing back then, so most of the old artwork, videos and roadmaps are lost. But the [Sourceforce page][3] has survived, and the [Subversion repository][4] contains screenshots from version 0.7 on and some older ones from unknown version numbers.
|
||||
|
||||
### From 2D to 3D
|
||||
|
||||
It might be hard to believe nowadays, but Boson was a 2D game until the release of version 0.7 in January of 2003. So it didn't look like Warcraft 3 (released in 2002), but much more like Warcraft 2 or the first five Command & Conquer titles. The engine was extended with OpenGL support and now "just" loaded the existing 3D models instead of forcing the developers to pre-render them into 2D sprites. Why so late? Because your average Linux installation simply didn't have OpenGL support when Boson was created back in 1999. The first XFree86 release to include GLX (OpenGL Extension to the X Window System) was version 4.0, published in 2000. And then it took a while to get OpenGL acceleration working in the major Linux graphics drivers (Matrox G200/G400, NVIDIA Riva TNT, ATI RagePro, S3 ViRGE and Intel 810). I can't say it was trivial to set up a Linux Desktop with hardware accelerated 3D until Ubuntu 7.04 put all the bits together for the first time and made it easy to install the proprietary NVIDIA drivers through the "Additional Drivers" settings dialogue.
|
||||
|
||||
|
||||
|
||||
So when Boson switched to OpenGL in January of 2003, that sucked. You now absolutely needed hardware acceleration to be able play it, and well, it was January of 2003. GPUs still used [AGP][5] slots back then, ATI was still an independent company, the Athlon64 would not be released before September 2003, and you were happy if you even owned a GeForce FX or a Radeon 9000 card. Luckily I did, and when I came across Boson, I immediately downloaded it, built it on my Gentoo machine and ran it on my three-monitor setup (two 15″ TFTs and one 21″ CRT). After debugging 3D hardware acceleration for a day or two, naturally…
|
||||
|
||||
![][6]
|
||||
|
||||
Boson wasn't finished or even really playable back then (still no computer opponent, only a few units working, no good maps etc.), but it showed promise, especially in light of the recent release of Command & Conquer: Generals in February of 2003. The thought of having an actual open source alternative to a recently released AAA video game title was so encouraging that I started to make small contributions, mainly by [reporting bugs][7]. The cursor icon theme I created using Cinema 4D never made it into a release.
|
||||
|
||||
### Development hell
|
||||
|
||||
Boson went through four releases in 2003 alone, all the way up to version 0.10. Performance was improved, the engine was extended with support for Python scripts, adaptive level of detail, smoke, lighting, day/night switches, and flying units. The 3D models started to look nice, an elementary Artificial Intelligence opponent was added (!), and the list of dependencies grew longer. Release notices like "Don't crash when using proprietary NVidia drivers and no usable font was found (reported to NVidia nearly a year ago)" are a kind reminder that proprietary graphics drivers already were a pain to work with back then, in case anybody forgot.
|
||||
|
||||
![][8]
|
||||
|
||||
An important task from version 0.10 on was to remove (or at least weaken) the dependencies on Qt and KDE. To be honest I never really got why the whole game, or for that matter any application ever, had to be based on Qt and KDE to begin with. Qt is a very, very intrusive thing. It's not just a library full of cool stuff, it's a framework. It locks you into its concept of what an application is and how it is supposed to work, and what your code should look like and how it is supposed to be structured. You need a whole toolchain with a metacompiler because your code isn't even standard C++.
|
||||
|
||||
Every time the Qt/KDE developers decide to break the ABI, deprecate a component or come up with a new and (supposedly) better solution to an existing solution, you have to follow - and that has happened way too often. Just ask the KDE developers how many times they had to port KDE just because Qt decided to change everything for the umpteenth time, and now imagine you depend on both Qt **and** KDE. Pretty much everything Qt offers can be solved in a less intrusive way nowadays.
|
||||
|
||||

|
||||
|
||||
Maybe the original Boson developers just wanted to take advantage of Qt's 2D graphics subsystem to make development easier. Or make sure the game can run on more than one platform (at least one release was known to work on FreeBSD). Or they hoped to become a part of the official KDE family to keep the project visible and attract more developers. Whatever the reason might have been, the cleanup was in full swing. aRts (the audio subsystem used by KDE 2 and 3) was replaced by the more standard OpenAL library. [libUFO][9] (which is one of the very few projects relying on the XUL language Mozilla uses to design UIs for Firefox and other application, BTW) was used to draw the on-screen menus.
|
||||
|
||||
The release of version 0.11 was delayed for 16 months due to the two main developers being busy with other stuff, but the changelog was very long and exciting. "Realistic" water and environmental objects like trees were added to the maps, the engine learned how to handle wind. The path-finding algorithm and the artificial intelligence opponent became smarter, and everything seemed to slowly come together.
|
||||
|
||||

|
||||
|
||||
By the time version 0.12 was released eight months later, Boson had working power plants, animated turrets, a new radar system and much more. Version 0.13, the last one to ever be officially released, again shipped an impressive amount of new features and improvements, but most of the changes were not really visible.
|
||||
|
||||
Version 0.13 had been released in October of 2006, and after December of the same year the commit rate suddenly dropped to zero. There were only two commits in the whole year of 2007, followed by an unsucessful attempt to revive the project in 2008. In 2011 the "Help wanted" text was finally removed from the (broken) website and Boson was officially declared dead.
|
||||
|
||||
### Let's Play Boson!
|
||||
|
||||
The game no longer even builds on modern GNU/Linux distributions, mostly due to the unavailability of Qt 3 and the KDE 3 libraries and some other oddities. I managed to install Ubuntu 11.04 LTS in a VirtualBox, which was the last Ubuntu release to have Boson in its repositories. Don't be surprised by how bad the performance is, as far as I can tell it's not the fault of VirtualBox. Boson never ran fast on any kind of hardware and did everything in a single thread, probably losing a lot of performance when synchronizing with various subsystems.
|
||||
|
||||
Here's a video of me trying to play. First I enable the eye candy (the shaders) and start one of the maps in the official "campaign" in which I am immediately attacked by the enemy and don't really have time to concentrate on resource collection, only to have the game crash on me before I loose to the enemy. Then I start a map without an enemy (there is supposed to be one, but my units never find it) so I have more time to actually explore all the options, buildings and units.
|
||||
|
||||
Sound didn't work in this release, so I added some tracks of the official soundtrack to the audio track of the video.
|
||||
|
||||
https://www.youtube.com/embed/18sqwNjlBow?feature=oembed
|
||||
|
||||
You can clearly see that the whole codebase was still in full developer mode back in 2006. There are multiple checkboxes for debugging information at the top of the screen, some debugging text scrolls over the actual text of the game UI. Everything can be configured in the Options dialogue, and you can easily break the game by fiddling with internal settings like the OpenGL update interval. Set it too low (the default is 50 Hz), and the internal logic will get confused. Clearly this is because the OpenGL renderer and the game logic run in the same thread, something one would probably no longer do nowadays.
|
||||
|
||||
|
||||
|
||||
The game menu has all the standard options. There are three available campaigns, each one with its own missions. The mission overview hints that each map could have different conditions for winning and loosing, e.g. in the "Lost Village" mission you are not supposed to destroy the houses in the occupied village. There are ten available colours for the players and three different species: Human, Neutral and "Smackware". No idea where that Name comes from, judging from the unit models it looks like it was just another human player with different units.
|
||||
|
||||
There is only a single type of artificial intelligence for the computer opponent. Pretty much all other RTS games offer multiple different opponent AIs. These are either following completely different strategies or are based on a few basic types of AIs which are limited by some external influences, e.g. limiting the rate of resources they get/can collect, or limiting them to certain unit types.
|
||||
|
||||
|
||||
|
||||
The game itself does not look very attractive, even with the "realistic-looking" water. Smoke looks okay, but smoke is easy. There is nothing going on on the maps: The ground has only a single texture, the shoreline is very edgy at many points, there is no vegetation except for some lonely trees. Shadows look "wrong"(but enabling them seemed to cause crashes anyways). All the standard mouse and keyboard bindings (assign the selected units to a group, select group, move, attack, etc.) are there and working.
|
||||
|
||||
One of the lesser common features is that you can zoom out of the map completely and the engine marks all units with a coloured rectangle. This is something Command & Conquer never had, but games like Supreme Commander did too.
|
||||
|
||||
![][10]
|
||||
|
||||
![][12]
|
||||
|
||||
The game logic is identical to all the other "traditional" Base Building RTS games. You start with a base (Boson calls it the Command Bunker) and optionally some additional buildings and units. The Command Bunker builds all buildings, factory buildings produce units, electrical power or can fight units. Some buildings change the game, e.g. the existence of a Radar will show enemy units on the mini-map even if they are currently inside the fog of war. Some units can gather resources (Minerals and Oil in case of Boson) and bring them to refineries, each unit and building comes at the cost of a defined amount of these resources. Buildings require electrical power. Since war is mostly a game of logistics, finding and securing resources and destroying the opponent before the resources run out is key. There is a "Tech Tree" with dependencies, which prevents you from being able to build everything right from the start. For example advanced units require the existence of a Tech Center or something similar.
|
||||
|
||||
There are basically two types of user interfaces for RTS games: In the first one building units and buildings is part of the UI itself. There is a central menu, often at the left or at the right of the screen, which shows all options and when you click one production starts regardless of whether your base or factory buildings are visible on the screen right now or not. In the second one you have to select the your Command Bunker or each of the factories manually and choose from their individual menus. Boson uses the second type. The menu items are not very clear and not easily visible, but I guess once you're accustomed to them the item locations move to muscle memory.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
In total the game could probably already look quiet nice if somebody made a couple of nice maps and cleaned up the user interface. But there is a long list of annoying bugs. Units often simply stop if they encounter an obstacle. Mineral and Oil Harvesters are supposed to shuttle between the location of the resource and a refinery automatically, but their internal state machine seems to fail a lot. Send the collector to a Mineral Mine, it doesn't start to collect. Click around a lot, it suddenly starts to collect. When it it full, it doesn't go back to the refinery or goes there and doesn't unload. Sometimes the whole cycle works for a while and then breaks while you're not looking. Frustrating.
|
||||
|
||||
Vehicles also sometimes go through water when they're not supposed to, or even go through the map geometry (!). This points at some major problem with collision detection.
|
||||
|
||||

|
||||
|
||||
The win/loose message does look a bit… beta as well 😉
|
||||
|
||||
[![][14]][14]
|
||||
|
||||
### Why was it never finished?
|
||||
|
||||
I think there were many reasons why Boson died. The engine was completely home-grown and lacking a lot in features, testing and performance. The less important subsystems, like audio output, were broken more often than not. There was no "real" focus on getting the basic parts (collecting resources, producing units, fighting battles) fully (!) working before time was spent on less important details like water, smoke, wind etc. Also there were many technical challenges. Most users wouldn't even have been able to enjoy the game even in 2006 due to the missing 3D acceleration on many Linux distributions (Ubuntu pretty much solved that in 2007, not earlier). Qt 4 had been released in 2006, and porting from Qt 3 to Qt 4 was not exactly easy. The KDE project decided to take this as an opportunity to overhaul pretty much every bit of code, leading to the KDE 4 Desktop. Boson didn't really need any of the functionality in either Qt or KDE, but it would have had been necessary to port everything anyways for no good reason.
|
||||
|
||||
Also the competition became much stronger after 2004. The full source code for [Warzone 2100][15], an actual commercial RTS game with much more complicated game play, had been released under an open source license in 2004 and is still being maintained today. Fans of Total Annihilation started to work on 3D viewers for the game, leading to [Total Annihilation 3D][16] and the [Spring RTS][17] engine.
|
||||
|
||||
Boson never had a big community of active players, so there was no pool new developers could have been recruited from. Obviously it died when the last few developers carrying it along no longer felt it was worth the time, and I think it is clear that the amount of work required to turn the game into something playable would still have been very high.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.lieberbiber.de/2017/12/29/forgotten-foss-games-boson/
|
||||
|
||||
作者:[sturmflut][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://marc.info/?l=kde-announce&r=1&w=2
|
||||
[2]:http://www.lieberbiber.de/wp-content/uploads/2017/03/client8.jpg
|
||||
[3]:http://boson.sourceforge.net
|
||||
[4]:https://sourceforge.net/p/boson/code/HEAD/tree/
|
||||
[5]:https://en.wikipedia.org/wiki/Accelerated_Graphics_Port
|
||||
[6]:http://www.lieberbiber.de/wp-content/uploads/2017/03/0.8-1-1024x768.jpg
|
||||
[7]:https://sourceforge.net/p/boson/code/3888/
|
||||
[8]:http://www.lieberbiber.de/wp-content/uploads/2017/03/0.9-1.jpg
|
||||
[9]:http://libufo.sourceforge.net/
|
||||
[10]:http://www.lieberbiber.de/wp-content/uploads/2017/12/boson_game_1.png.wm-1024x510.jpg
|
||||
[11]:http://www.lieberbiber.de/wp-content/uploads/2017/12/boson_game_1.png.wm.jpg
|
||||
[12]:http://www.lieberbiber.de/wp-content/uploads/2017/12/boson_maximum_zoom_out.png.wm-1024x511.jpg
|
||||
[13]:http://www.lieberbiber.de/wp-content/uploads/2017/12/boson_maximum_zoom_out.png.wm.jpg
|
||||
[14]:http://www.lieberbiber.de/wp-content/uploads/2017/12/boson_game_end.png.85.jpg
|
||||
[15]:http://wz2100.net/
|
||||
[16]:https://github.com/zuzuf/TA3D
|
||||
[17]:https://en.wikipedia.org/wiki/Spring_Engine
|
||||
@ -1,146 +0,0 @@
|
||||
translate by cyleft
|
||||
10 Reasons Why Linux Is Better Than Windows
|
||||
======
|
||||
It is often seen that people get confused over choosing Windows or Linux as host operating system in both
|
||||
|
||||
[server][1]
|
||||
|
||||
and desktop spaces. People will focus on aspects of cost, the functionality provided, hardware compatibility, support, reliability, security, pre-built software, cloud-readiness etc. before they finalize. In this regard, this article covers ten reasons of using Linux over Windows.
|
||||
|
||||
## 10 Reasons Why Linux Is Better Than Windows
|
||||
|
||||
### 1. Total cost of ownership
|
||||
|
||||

|
||||
|
||||
The most obvious advantage is that Linux is free whereas Windows is not. Windows license cost is different for both desktop and server versions. In case of Linux OS either it can be desktop or server, distro comes with no cost. Not only the OS even the related applications are completely free and open source.
|
||||
|
||||
For personal use, a single Windows OS license fee may appear inexpensive but when considered for business, more employees means more cost. Not only the OS license cost, organization need to be ready to pay for applications like MS Office, Exchange, SharePoint that run on Windows.
|
||||
|
||||
|
||||
|
||||
In Windows world, you cannot modify the OS as its source code is not open source. Same is the case with proprietary applications running on it. However, in case of Linux, a user can download even the source code of a Linux OS, change it and use it spending no money. Though some Linux distros charge for support, they are inexpensive when compared to Windows license price.
|
||||
|
||||
### 2. Beginner friendly and easy to use
|
||||
|
||||
[][2]
|
||||
|
||||
Windows OS is one of the simplest desktop OS available today. Its graphical user-friendliness is exceptional. Though Windows has a relatively minimal learning curve, Linux distros like Ubuntu, Elementary OS, Linux Mint etc. are striving to improve the user experience that makes transition from Windows to Linux become smooth and easy.
|
||||
|
||||
|
||||
|
||||
Linux distros allow user to choose one of the various desktop environments available:
|
||||
|
||||
[Cinnamon][3]
|
||||
|
||||
,
|
||||
|
||||
[MATE][4]
|
||||
|
||||
,
|
||||
|
||||
[KDE][5]
|
||||
|
||||
,
|
||||
|
||||
[Xfce][6]
|
||||
|
||||
, LXDE, GNOME etc. If a Windows user is looking to migrate to Linux,
|
||||
|
||||
[WINE][7]
|
||||
|
||||
(Wine Is Not an Emulator) can be installed to have a feel of MS Windows on a Linux system.
|
||||
|
||||
### 3. Reliability
|
||||
|
||||
Linux is more reliable when compared to Windows. Linux will rock with its top-notch design, built-in security resulting un-parallel up-time. Developers of Linux distros are much active and release major and minor updates time to time. Traditionally Unix-like systems are known for running for years without a single failure or having a situation which demands a restart. This is an important factor especially choosing a server system. Definitely Linux being a UNIX-like system, it will be a better choice.
|
||||
|
||||
### 4. Hardware
|
||||
|
||||
[][8]
|
||||
|
||||
Linux systems are known for consuming fewer system resources (RAM, disk space etc.) when compared to Windows. Hardware vendors already realized the popularity of Linux and started making Linux compliant hardware/drivers. When running the OS on older hardware, Windows is slower.
|
||||
|
||||
|
||||
|
||||
Linux distros like Lubuntu, Knoppix, LXLE, antiX, Puppy Linux are best suitable for aging machines. Old horses like 386 or 486 machines with decent RAM (>= 124/256) can run Linux.
|
||||
|
||||
### 5. Software
|
||||
|
||||
No doubt that Windows has a large set of commercial software available. Linux, on the other hand, makes use of open source software available for free. Linux armed with easy to use package managers which aid in installing and un-installing desired software applications. Linux is armed with decent desktop themes certainly run faster than Windows.
|
||||
|
||||
|
||||
|
||||
For developers, the Linux terminal offers superior environment when compared to Windows. The exhaustive GNU compilers and utilities will be definitely useful for programming. Administrators can make use of package managers to manage software and of course, Linux has the unbeatable CLI interface.
|
||||
|
||||
|
||||
|
||||
Have you heard about Tiny Core Linux? It comes at only 11MB size with the graphical desktop environment. You can choose to install from the hundreds of available Linux distros based on your need. Following table presents a partial list of Linux distros filtered based on need:
|
||||
|
||||
[][9]
|
||||
|
||||
### 6. Security
|
||||
|
||||
[][10]
|
||||
|
||||
Microsoft Windows OS is infamous for being vulnerable to malware, trojans, and viruses. Linux is almost non-vulnerable and more secure due to its inherent design. Linux does not require the use of commercial anti-virus/anti-malware packages.
|
||||
|
||||
Linux respects privacy. Unlike windows, it does not generate logs and upload data from your machine. A user should be well aware of Windows privacy policy.
|
||||
|
||||
### 7. Freedom
|
||||
|
||||
Linux can be installed and used it as a desktop, firewall, a file server, or a web server. Linux allows a user to control every aspect of the operating systems. As Linux is an open-source operating system, it allows a user to modify its source (even source code of applications) itself as per the user requirements. Linux allows the user to install only the desired software nothing else (no bloatware). Linux allows full freedom to install open source applications its vast repository. Windows will bore you with its default desktop theme whereas with Linux you can choose from many desktop themes available.
|
||||
|
||||
You can breathe fresh air after choosing a Linux distro from an available list of Linux distros.
|
||||
|
||||
With USB live-mode option, you can give a try to test a Linux distro before you finalize one for you. Booting via live-mode does not install the OS on a hard disk. Just go and give a try, you will fall in love.
|
||||
|
||||
### 8. Annoying crashes and reboots
|
||||
|
||||
There are times when Windows suddenly shows an annoying message saying that the machine needs to be restarted. Apart from showing “Applying update of 5 of 361.” kind messages, Windows will confuse you with several types of updates critical, security, definition, update rollup, service pack, tool, feature pack. I did not remember how many times the Windows rebooted last time to apply an update.
|
||||
|
||||
When undergoing a software update or installing/uninstalling software on Linux systems, generally it does not need a machine reboot. Most of the system configuration changes can be done while the system is up.
|
||||
|
||||
### 9. Server segment
|
||||
|
||||
[][11]
|
||||
|
||||
Linux is installed on the majority of servers demonstrating that it is the best choice with the minimal resource footprint. Even rivals are using Linux on their offerings. As software applications are moving to cloud platforms, windows servers are getting phased out to make room for Linux servers. Majority of the supercomputers to run on Linux.
|
||||
|
||||
Though the battle between Linux and Windows continue in desktop-segment when comes to server-segment Linux evolves as a clear winner. Organizations rely on servers because they want their applications to run 24x7x365 with no or limited downtime. Linux already became favorite of most of the datacenters.
|
||||
|
||||
### 10. Linux is everywhere
|
||||
|
||||
[][12]
|
||||
|
||||
Yes, Linux is everywhere. From smallest device to largest supercomputers, Linux is everywhere. It can be a car, router, phone, medical devices, plane, TV, satellite, watch or school tablet, Linux will be there.
|
||||
|
||||
The inventor Linus Torvalds himself would not have imagined about this kind of success when he was writing the Linux kernel first time. Kudos to Linus and Stallman for their contribution.
|
||||
|
||||
## Conclusion
|
||||
|
||||
There is a saying - variety is the spice of life. It is true with respect to Linux distros. There are more than 600 active different distros to choose. Each is different on its own and meant for the specific purpose. Linux distros are highly customizable when compared to Windows. The above reasons mentioned are is just the tip of the iceberg. There is so much more than you could with Linux. Linux is powerful, flexible, secure, reliable, stable, fun… than Windows. One should always keep in mind that - free is not the best just like expensive is not the best. Linux will undoubtedly emerge as the winner when all aspects are considered. There is no reason why you would not choose Linux instead of Windows. Let us know your thoughts how you feel about Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/10-reasons-why-linux-is-better-than-windows
|
||||
|
||||
作者:[Ramakrishna Jujare][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/how-to-configure-sftp-server-on-centos
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux-mint-easy-to-use_orig.jpg
|
||||
[3]:http://www.linuxandubuntu.com/home/cinnamon-desktop-the-best-desktop-environment-for-new-linux-user
|
||||
[4]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-ubuntu-mate-1710
|
||||
[5]:http://www.linuxandubuntu.com/home/best-kde-linux-distributions-for-your-desktop
|
||||
[6]:http://www.linuxandubuntu.com/home/xfce-desktop-environment-a-linux-desktop-environment-for-everyone
|
||||
[7]:http://www.linuxandubuntu.com/home/how-to-install-wine-and-run-windows-apps-in-linux
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux-better-hardware-support_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux_1_orig.png
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/linux-is-more-secure-than-windows.jpeg
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux-server_orig.jpg
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux-is-everywhere_orig.jpg
|
||||
@ -1,134 +0,0 @@
|
||||
Best Linux Music Players To Stream Online Music
|
||||
======
|
||||

|
||||
|
||||
For all the music lovers, what better way to enjoy music and relax than to stream your music online. Below are some of the best Linux music players out there you can use to stream music online and how you can get them running on your machine. It will be worth your while.
|
||||
|
||||
## Best Linux Music Players To Stream Online Music
|
||||
|
||||
### Spotify
|
||||
|
||||
[][1]
|
||||
|
||||
Spotify is known to be one of the best apps to stream online music. Spotify allows you to stream music and when you are offline, you can listen to your local files on your machine. Your music is organised into various genres to which the music belongs. Spotify allows you to see what your friends are listening to and also try them out yourself. The app looks great and is well organized, it is easy to search for songs. All you have to do is type into the search box and Wallah! You get the music you are searching for online.
|
||||
|
||||
The app is cross-platform and allows you to stream your favorite tunes. There are some catches though. You will need to create an account with Spotify to use the app. You can do so using Facebook or your email. You also have a choice to upgrade to premium which will be worth your money since you have access to high quality music and you can listen to music from any of your devices. Apparently Spotify is not available in every country. You can install Spotify by typing the following commands in the terminal:
|
||||
|
||||
```
|
||||
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 0DF731E45CE24F27EEEB1450EFDC8610341D9410
|
||||
|
||||
echo deb http://repository.spotify.com stable non-free | sudo tee /etc/apt/sources.list.d/spotify.list
|
||||
|
||||
sudo apt-get update && sudo apt-get install spotify-client
|
||||
|
||||
Once you have run the commands, you can start Spotify from your list of applications.
|
||||
```
|
||||
|
||||
### Amarok
|
||||
|
||||
[][2]
|
||||
|
||||
Amarok is an open source media player that can play online music as well as local music files that you have on your PC. It has the capability of fetching online lyrics of any song whether online or playing locally, and the best bit about that is that the lyrics can scroll automatically. It is easy to customize to your preference.
|
||||
|
||||
When you close Amarok, you have the option to let the music keep playing and a menu attach to the system tray to let you control your music so that it doesn’t use up all your resources as you enjoy your music. It has various services that you can choose from to stream your music from. It also integrates with the system tray as an icon with a menu that you can control music on. Amarok is available on the ubuntu software center for download and install. You can also use the following command in the terminal to install:
|
||||
|
||||
```
|
||||
sudo apt-get update && sudo apt-get install amarok
|
||||
```
|
||||
|
||||
[][3] _Amarok in the notification area to control music play._ [][4] _Some of the internet services found in amarok._ [][5] _Amarok integrates with the top bar when you close the main window._
|
||||
|
||||
### Audacious
|
||||
|
||||
[][6]
|
||||
|
||||
Audacious is a simple, easy to use and customisable audio player. It is an open source audio player that you can stream your online music from. Audacious is not resource hungry leaving a lot for other applications, when you use it, you’ll feel that the app is light and has no impact on your system resources. In addition, you have the advantage of changing the theme to the theme you want. The themes are based on GTK and Winamp classic themes. You have the option to record music that you are streaming in case it pleases your ears. The player comes with visualizations that keep you feeling the rhythm. Audacious is available on the ubuntu software center for download and install. Alternatively, you can type the following to install it in ubuntu terminal:
|
||||
|
||||
```
|
||||
sudo apt-get update && sudo apt-get install audacious
|
||||
```
|
||||
|
||||
[][7] _Audacious has various themes to choose from._
|
||||
|
||||
### Rhythmbox
|
||||
|
||||
[][8]
|
||||
|
||||
Rhythmbox is an inbuilt app that comes with the GNOME desktop experience, however, if you want it on other distros, you will have to install it. It is a lightweight music player that you can use to stream your music. It is easy to use and not as complicated as other music players that stream online music. To install Rhythmbox, type the following commands in the terminal:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:fossfreedom/rhythmbox
|
||||
|
||||
sudo apt-get update && sudo apt-get install rhythmbox
|
||||
```
|
||||
|
||||
### VLC Media Player
|
||||
|
||||
[][9]
|
||||
|
||||
VLC is one of the most famous open source media players out there. The player has options to stream your music from, it is easy to use and even plays any time of media. It has tons of features for you to discover such as recording music streams, updating cover art for your tracks and even has an equaliser you can tweak around with so that your music comes out the way you want it to. You can add your own skins, or download and apply them, mess with the UI of the app to your preferences. To install, type the following commands into the terminal:
|
||||
|
||||
```
|
||||
sudo apt-get update && sudo apt-get install vlc
|
||||
```
|
||||
|
||||
### Harmony
|
||||
|
||||
[][10]
|
||||
|
||||
Harmony is an almost free online music streaming application. It’s almost free because you have an untimed free version that you can upgrade to a one time paid version. The free version has that annoying dialog reminding you to upgrade your installation. It has a great user interface and easy to use. It also has the capability of playing local files. You can install any compatible plugin of your choice thus getting more from your music player. It has multiple streaming sources options so that you can enjoy the most out of the Internet. All you have to do is enable the source you wish to stream media from and you are good to go.
|
||||
|
||||
In order to get the application on your machine, you will need to install using the official .deb file. To get the application, you will have to get it from the official site
|
||||
|
||||
[here][11]
|
||||
|
||||
. I would have wished if the creators of this app made an official PPA that one could use to install via the terminal.
|
||||
|
||||
### Mellow Player
|
||||
|
||||
[][12]
|
||||
|
||||
The Mellow player is an across-platform open source and free music player that allows you to play online music. Mellow player has over 16 supported online music services that you can choose to stream from. There are options to install plugins that lets you install the service you want. If you want to install it, you will have to get it from the official site
|
||||
|
||||
[here][13]
|
||||
|
||||
. It comes in form of an app image that is easy to install since it doesn’t mess with other files since all required files come sandboxed as an app image. When you download the file, you will need to change the file properties by typing the following commands in the terminal:
|
||||
|
||||
```
|
||||
chmod +x MellowPlayer-x86_64.AppImage
|
||||
```
|
||||
|
||||
Then running it as follows:
|
||||
|
||||
```
|
||||
sudo ./MellowPlayer-x86_64.AppImage
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
|
||||
There are plenty of Linux music players out there but those are the best you would want to try out. All in all, the music players have their pros and cons, but the most important part is to sit down, open the app, start streaming your music and relax. The music players may or may not meet your expectations, but don’t forget to enjoy the next app incase the first isn’t for you. Enjoy!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-linux-music-players-to-stream-online-music
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/spotify_orig.png
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/amarok_orig.png
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/amarok_1_orig.png
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/amarok_2_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/amarok_3_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/audacious_orig.png
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/amarok_4_orig.png
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/rhythmbox_orig.png
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vlc-media-player_orig.png
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/harmony_orig.png
|
||||
[11]:https://getharmony.xyz/download
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/mellow-player_orig.png
|
||||
[13]:https://colinduquesnoy.github.io/MellowPlayer/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
How To Find (Top-10) Largest Files In Linux
|
||||
======
|
||||
When you are running out of disk space in system, you may prefer to check with df command or du command or ncdu command but all these will tell you only current directory files and doesn't shows the system wide files.
|
||||
|
||||
@ -1,254 +0,0 @@
|
||||
translating by ucasFL
|
||||
|
||||
How does gdb call functions?
|
||||
============================================================
|
||||
|
||||
(previous gdb posts: [how does gdb work? (2016)][4] and [three things you can do with gdb (2014)][5])
|
||||
|
||||
I discovered this week that you can call C functions from gdb! I thought this was cool because I’d previously thought of gdb as mostly a read-only debugging tool.
|
||||
|
||||
I was really surprised by that (how does that WORK??). As I often do, I asked [on Twitter][6] how that even works, and I got a lot of really useful answers! My favorite answer was [Evan Klitzke’s example C code][7] showing a way to do it. Code that _works_ is very exciting!
|
||||
|
||||
I believe (through some stracing & experiments) that that example C code is different from how gdb actually calls functions, so I’ll talk about what I’ve figured out about what gdb does in this post and how I’ve figured it out.
|
||||
|
||||
There is a lot I still don’t know about how gdb calls functions, and very likely some things in here are wrong.
|
||||
|
||||
### What does it mean to call a C function from gdb?
|
||||
|
||||
Before I get into how this works, let’s talk quickly about why I found it surprising / nonobvious.
|
||||
|
||||
So, you have a running C program (the “target program”). You want to run a function from it. To do that, you need to basically:
|
||||
|
||||
* pause the program (because it is already running code!)
|
||||
|
||||
* find the address of the function you want to call (using the symbol table)
|
||||
|
||||
* convince the program (the “target program”) to jump to that address
|
||||
|
||||
* when the function returns, restore the instruction pointer and registers to what they were before
|
||||
|
||||
Using the symbol table to figure out the address of the function you want to call is pretty straightforward – here’s some sketchy (but working!) Rust code that I’ve been using on Linux to do that. This code uses the [elf crate][8]. If I wanted to find the address of the `foo` function in PID 2345, I’d run `elf_symbol_value("/proc/2345/exe", "foo")`.
|
||||
|
||||
```
|
||||
fn elf_symbol_value(file_name: &str, symbol_name: &str) -> Result<u64, Box<std::error::Error>> {
|
||||
// open the ELF file
|
||||
let file = elf::File::open_path(file_name).ok().ok_or("parse error")?;
|
||||
// loop over all the sections & symbols until you find the right one!
|
||||
let sections = &file.sections;
|
||||
for s in sections {
|
||||
for sym in file.get_symbols(&s).ok().ok_or("parse error")? {
|
||||
if sym.name == symbol_name {
|
||||
return Ok(sym.value);
|
||||
}
|
||||
}
|
||||
}
|
||||
None.ok_or("No symbol found")?
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This won’t totally work on its own, you also need to look at the memory maps of the file and add the symbol offset to the start of the place that file is mapped. But finding the memory maps isn’t so hard, they’re in `/proc/PID/maps`.
|
||||
|
||||
Anyway, this is all to say that finding the address of the function to call seemed straightforward to me but that the rest of it (change the instruction pointer? restore the registers? what else?) didn’t seem so obvious!
|
||||
|
||||
### You can’t just jump
|
||||
|
||||
I kind of said this already but – you can’t just find the address of the function you want to run and then jump to that address. I tried that in gdb (`jump foo`) and the program segfaulted. Makes sense!
|
||||
|
||||
### How you can call C functions from gdb
|
||||
|
||||
First, let’s see that this is possible. I wrote a tiny C program that sleeps for 1000 seconds and called it `test.c`:
|
||||
|
||||
```
|
||||
#include <unistd.h>
|
||||
|
||||
int foo() {
|
||||
return 3;
|
||||
}
|
||||
int main() {
|
||||
sleep(1000);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Next, compile and run it:
|
||||
|
||||
```
|
||||
$ gcc -o test test.c
|
||||
$ ./test
|
||||
|
||||
```
|
||||
|
||||
Finally, let’s attach to the `test` program with gdb:
|
||||
|
||||
```
|
||||
$ sudo gdb -p $(pgrep -f test)
|
||||
(gdb) p foo()
|
||||
$1 = 3
|
||||
(gdb) quit
|
||||
|
||||
```
|
||||
|
||||
So I ran `p foo()` and it ran the function! That’s fun.
|
||||
|
||||
### Why is this useful?
|
||||
|
||||
a few possible uses for this:
|
||||
|
||||
* it lets you treat gdb a little bit like a C REPL, which is fun and I imagine could be useful for development
|
||||
|
||||
* utility functions to display / navigate complex data structures quickly while debugging in gdb (thanks [@invalidop][1])
|
||||
|
||||
* [set an arbitrary process’s namespace while it’s running][2] (featuring a not-so-surprising appearance from my colleague [nelhage][3]!)
|
||||
|
||||
* probably more that I don’t know about
|
||||
|
||||
### How it works
|
||||
|
||||
I got a variety of useful answers on Twitter when I asked how calling functions from gdb works! A lot of them were like “well you get the address of the function from the symbol table” but that is not the whole story!!
|
||||
|
||||
One person pointed me to this nice 2 part series on how gdb works that they’d written: [Debugging with the natives, part 1][9] and [Debugging with the natives, part 2][10]. Part 1 explains approximately how calling functions works (or could work – figuring out what gdb **actually** does isn’t trivial, but I’ll try my best!).
|
||||
|
||||
The steps outlined there are:
|
||||
|
||||
1. Stop the process
|
||||
|
||||
2. Create a new stack frame (far away from the actual stack)
|
||||
|
||||
3. Save all the registers
|
||||
|
||||
4. Set the registers to the arguments you want to call your function with
|
||||
|
||||
5. Set the stack pointer to the new stack frame
|
||||
|
||||
6. Put a trap instruction somewhere in memory
|
||||
|
||||
7. Set the return address to that trap instruction
|
||||
|
||||
8. Set the instruction pointer register to the address of the function you want to call
|
||||
|
||||
9. Start the process again!
|
||||
|
||||
I’m not going to go through how gdb does all of these (I don’t know!) but here are a few things I’ve learned about the various pieces this evening.
|
||||
|
||||
**Create a stack frame**
|
||||
|
||||
If you’re going to run a C function, most likely it needs a stack to store variables on! You definitely don’t want it to clobber your current stack. Concretely – before gdb calls your function (by setting the instruction pointer to it and letting it go), it needs to set the **stack pointer** to… something.
|
||||
|
||||
There was some speculation on Twitter about how this works:
|
||||
|
||||
> i think it constructs a new stack frame for the call right on top of the stack where you’re sitting!
|
||||
|
||||
and:
|
||||
|
||||
> Are you certain it does that? It could allocate a pseudo stack, then temporarily change sp value to that location. You could try, put a breakpoint there and look at the sp register address, see if it’s contiguous to your current program register?
|
||||
|
||||
I did an experiment where (inside gdb) I ran:`
|
||||
|
||||
```
|
||||
(gdb) p $rsp
|
||||
$7 = (void *) 0x7ffea3d0bca8
|
||||
(gdb) break foo
|
||||
Breakpoint 1 at 0x40052a
|
||||
(gdb) p foo()
|
||||
Breakpoint 1, 0x000000000040052a in foo ()
|
||||
(gdb) p $rsp
|
||||
$8 = (void *) 0x7ffea3d0bc00
|
||||
|
||||
```
|
||||
|
||||
This seems in line with the “gdb constructs a new stack frame for the call right on top of the stack where you’re sitting” theory, since the stack pointer (`$rsp`) goes from being `...bca8` to `..bc00` – stack pointers grow downward, so a `bc00`stack pointer is **after** a `bca8` pointer. Interesting!
|
||||
|
||||
So it seems like gdb just creates the new stack frames right where you are. That’s a bit surprising to me!
|
||||
|
||||
**change the instruction pointer**
|
||||
|
||||
Let’s see whether gdb changes the instruction pointer!
|
||||
|
||||
```
|
||||
(gdb) p $rip
|
||||
$1 = (void (*)()) 0x7fae7d29a2f0 <__nanosleep_nocancel+7>
|
||||
(gdb) b foo
|
||||
Breakpoint 1 at 0x40052a
|
||||
(gdb) p foo()
|
||||
Breakpoint 1, 0x000000000040052a in foo ()
|
||||
(gdb) p $rip
|
||||
$3 = (void (*)()) 0x40052a <foo+4>
|
||||
|
||||
```
|
||||
|
||||
It does! The instruction pointer changes from `0x7fae7d29a2f0` to `0x40052a` (the address of the `foo` function).
|
||||
|
||||
I stared at the strace output and I still don’t understand **how** it changes, but that’s okay.
|
||||
|
||||
**aside: how breakpoints are set!!**
|
||||
|
||||
Above I wrote `break foo`. I straced gdb while running all of this and understood almost nothing but I found ONE THING that makes sense to me!!
|
||||
|
||||
Here are some of the system calls that gdb uses to set a breakpoint. It’s really simple! It replaces one instruction with `cc` (which [https://defuse.ca/online-x86-assembler.htm][11] tells me means `int3` which means `send SIGTRAP`), and then once the program is interrupted, it puts the instruction back the way it was.
|
||||
|
||||
I was putting a breakpoint on a function `foo` with the address `0x400528`.
|
||||
|
||||
This `PTRACE_POKEDATA` is how gdb changes the code of running programs.
|
||||
|
||||
```
|
||||
// change the 0x400528 instructions
|
||||
25622 ptrace(PTRACE_PEEKTEXT, 25618, 0x400528, [0x5d00000003b8e589]) = 0
|
||||
25622 ptrace(PTRACE_POKEDATA, 25618, 0x400528, 0x5d00000003cce589) = 0
|
||||
// start the program running
|
||||
25622 ptrace(PTRACE_CONT, 25618, 0x1, SIG_0) = 0
|
||||
// get a signal when it hits the breakpoint
|
||||
25622 ptrace(PTRACE_GETSIGINFO, 25618, NULL, {si_signo=SIGTRAP, si_code=SI_KERNEL, si_value={int=-1447215360, ptr=0x7ffda9bd3f00}}) = 0
|
||||
// change the 0x400528 instructions back to what they were before
|
||||
25622 ptrace(PTRACE_PEEKTEXT, 25618, 0x400528, [0x5d00000003cce589]) = 0
|
||||
25622 ptrace(PTRACE_POKEDATA, 25618, 0x400528, 0x5d00000003b8e589) = 0
|
||||
|
||||
```
|
||||
|
||||
**put a trap instruction somewhere**
|
||||
|
||||
When gdb runs a function, it **also** puts trap instructions in a bunch of places! Here’s one of them (per strace). It’s basically replacing one instruction with `cc` (`int3`).
|
||||
|
||||
```
|
||||
5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
|
||||
5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
|
||||
5908 ptrace(PTRACE_POKEDATA, 5810, 0x7f6fa7c0b260, 0x48f389fd894853cc) = 0
|
||||
|
||||
```
|
||||
|
||||
What’s `0x7f6fa7c0b260`? Well, I looked in the process’s memory maps, and it turns it’s somewhere in `/lib/x86_64-linux-gnu/libc-2.23.so`. That’s weird! Why is gdb putting trap instructions in libc?
|
||||
|
||||
Well, let’s see what function that’s in. It turns out it’s `__libc_siglongjmp`. The other functions gdb is putting traps in are `__longjmp`, `____longjmp_chk`, `dl_main`, and `_dl_close_worker`.
|
||||
|
||||
Why? I don’t know! Maybe for some reason when our function `foo()` returns, it’s calling `longjmp`, and that is how gdb gets control back? I’m not sure.
|
||||
|
||||
### how gdb calls functions is complicated!
|
||||
|
||||
I’m going to stop there (it’s 1am!), but now I know a little more!
|
||||
|
||||
It seems like the answer to “how does gdb call a function?” is definitely not that simple. I found it interesting to try to figure a little bit of it out and hopefully you have too!
|
||||
|
||||
I still have a lot of unanswered questions about how exactly gdb does all of these things, but that’s okay. I don’t really need to know the details of how this works and I’m happy to have a slightly improved understanding.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:https://twitter.com/invalidop/status/949161146526781440
|
||||
[2]:https://github.com/baloo/setns/blob/master/setns.c
|
||||
[3]:https://github.com/nelhage
|
||||
[4]:https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
[5]:https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
[6]:https://twitter.com/b0rk/status/948060808243765248
|
||||
[7]:https://github.com/eklitzke/ptrace-call-userspace/blob/master/call_fprintf.c
|
||||
[8]:https://cole14.github.io/rust-elf
|
||||
[9]:https://www.cl.cam.ac.uk/~srk31/blog/2016/02/25/#native-debugging-part-1
|
||||
[10]:https://www.cl.cam.ac.uk/~srk31/blog/2017/01/30/#native-debugging-part-2
|
||||
[11]:https://defuse.ca/online-x86-assembler.htm
|
||||
@ -1,110 +0,0 @@
|
||||
Linux paste Command Explained For Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on the command line in Linux, there may arise a situation wherein you have to merge lines of multiple files to create more meaningful/useful data. Well, you'll be glad to know there exists a command line utility **paste** that does this for you. In this tutorial, we will discuss the basics of this command as well as the main features it offers using easy to understand examples.
|
||||
|
||||
But before we do that, it's worth mentioning that all examples mentioned in this article have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
### Linux paste command
|
||||
|
||||
As already mentioned above, the paste command merges lines of files. Here's the tool's syntax:
|
||||
|
||||
```
|
||||
paste [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
And here's how the mage of paste explains it:
|
||||
```
|
||||
Write lines consisting of the sequentially corresponding lines from each FILE, separated by TABs,
|
||||
to standard output. With no FILE, or when FILE is -, read standard input.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples should give you a better idea on how paste works.
|
||||
|
||||
### Q1. How to join lines of multiple files using paste command?
|
||||
|
||||
Suppose we have three files - file1.txt, file2.txt, and file3.txt - with following contents:
|
||||
|
||||
[![How to join lines of multiple files using paste command][1]][2]
|
||||
|
||||
And the task is to merge lines of these files in a way that each row of the final output contains index, country, and continent, then you can do that using paste in the following way:
|
||||
|
||||
paste file1.txt file2.txt file3.txt
|
||||
|
||||
[![result of merging lines][3]][4]
|
||||
|
||||
### Q2. How to apply delimiters when using paste?
|
||||
|
||||
Sometimes, there can be a requirement to add a delimiting character between entries of each resulting row. This can be done using the **-d** command line option, which requires you to provide the delimiting character you want to use.
|
||||
|
||||
For example, to apply a colon (:) as a delimiting character, use the paste command in the following way:
|
||||
|
||||
```
|
||||
paste -d : file1.txt file2.txt file3.txt
|
||||
```
|
||||
|
||||
Here's the output this command produced on our system:
|
||||
|
||||
[![How to apply delimiters when using paste][5]][6]
|
||||
|
||||
### Q3. How to change the way in which lines are merged?
|
||||
|
||||
By default, the paste command merges lines in a way that entries in the first column belongs to the first file, those in the second column are for the second file, and so on and so forth. However, if you want, you can change this so that the merge operation happens row-wise.
|
||||
|
||||
This you can do using the **-s** command line option.
|
||||
|
||||
```
|
||||
paste -s file1.txt file2.txt file3.txt
|
||||
```
|
||||
|
||||
Following is the output:
|
||||
|
||||
[![How to change the way in which lines are merged][7]][8]
|
||||
|
||||
### Q4. How to use multiple delimiters?
|
||||
|
||||
Yes, you can use multiple delimiters as well. For example, if you want to use both : and |, you can do that in the following way:
|
||||
|
||||
```
|
||||
paste -d ':|' file1.txt file2.txt file3.txt
|
||||
```
|
||||
|
||||
Following is the output:
|
||||
|
||||
[![How to use multiple delimiters][9]][10]
|
||||
|
||||
### Q5. How to make sure merged lines are NUL terminated?
|
||||
|
||||
By default, lines merged through paste end in a newline. However, if you want, you can make them NUL terminated, something which you can do using the **-z** option.
|
||||
|
||||
```
|
||||
paste -z file1.txt file2.txt file3.txt
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
As most of you'd agree, the paste command isn't difficult to understand and use. It may offer a limited set of command line options, but the tool does what it claims. You may not require it on daily basis, but paste can be a real-time saver in some scenarios. Just in case you need, [here's the tool's man page][11].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-paste-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/paste-3-files.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/paste-3-files.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/paste-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/paste-basic-usage.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/paste-d-option.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/paste-d-option.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/paste-s-option.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/paste-s-option.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/paste-d-mult1.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/paste-d-mult1.png
|
||||
[11]:https://linux.die.net/man/1/paste
|
||||
@ -1,789 +0,0 @@
|
||||
translating by lujun9972
|
||||
Linux Filesystem Events with inotify
|
||||
======
|
||||
|
||||
Triggering scripts with incron and systemd.
|
||||
|
||||
It is, at times, important to know when things change in the Linux OS. The uses to which systems are placed often include high-priority data that must be processed as soon as it is seen. The conventional method of finding and processing new file data is to poll for it, usually with cron. This is inefficient, and it can tax performance unreasonably if too many polling events are forked too often.
|
||||
|
||||
Linux has an efficient method for alerting user-space processes to changes impacting files of interest. The inotify Linux system calls were first discussed here in Linux Journal in a [2005 article by Robert Love][6] who primarily addressed the behavior of the new features from the perspective of C.
|
||||
|
||||
However, there also are stable shell-level utilities and new classes of monitoring dæmons for registering filesystem watches and reporting events. Linux installations using systemd also can access basic inotify functionality with path units. The inotify interface does have limitations—it can't monitor remote, network-mounted filesystems (that is, NFS); it does not report the userid involved in the event; it does not work with /proc or other pseudo-filesystems; and mmap() operations do not trigger it, among other concerns. Even with these limitations, it is a tremendously useful feature.
|
||||
|
||||
This article completes the work begun by Love and gives everyone who can write a Bourne shell script or set a crontab the ability to react to filesystem changes.
|
||||
|
||||
### The inotifywait Utility
|
||||
|
||||
Working under Oracle Linux 7 (or similar versions of Red Hat/CentOS/Scientific Linux), the inotify shell tools are not installed by default, but you can load them with yum:
|
||||
|
||||
```
|
||||
|
||||
# yum install inotify-tools
|
||||
Loaded plugins: langpacks, ulninfo
|
||||
ol7_UEKR4 | 1.2 kB 00:00
|
||||
ol7_latest | 1.4 kB 00:00
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package inotify-tools.x86_64 0:3.14-8.el7 will be installed
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
==============================================================
|
||||
Package Arch Version Repository Size
|
||||
==============================================================
|
||||
Installing:
|
||||
inotify-tools x86_64 3.14-8.el7 ol7_latest 50 k
|
||||
|
||||
Transaction Summary
|
||||
==============================================================
|
||||
Install 1 Package
|
||||
|
||||
Total download size: 50 k
|
||||
Installed size: 111 k
|
||||
Is this ok [y/d/N]: y
|
||||
Downloading packages:
|
||||
inotify-tools-3.14-8.el7.x86_64.rpm | 50 kB 00:00
|
||||
Running transaction check
|
||||
Running transaction test
|
||||
Transaction test succeeded
|
||||
Running transaction
|
||||
Warning: RPMDB altered outside of yum.
|
||||
Installing : inotify-tools-3.14-8.el7.x86_64 1/1
|
||||
Verifying : inotify-tools-3.14-8.el7.x86_64 1/1
|
||||
|
||||
Installed:
|
||||
inotify-tools.x86_64 0:3.14-8.el7
|
||||
|
||||
Complete!
|
||||
|
||||
```
|
||||
|
||||
The package will include two utilities (inotifywait and inotifywatch), documentation and a number of libraries. The inotifywait program is of primary interest.
|
||||
|
||||
Some derivatives of Red Hat 7 may not include inotify in their base repositories. If you find it missing, you can obtain it from [Fedora's EPEL repository][7], either by downloading the inotify RPM for manual installation or adding the EPEL repository to yum.
|
||||
|
||||
Any user on the system who can launch a shell may register watches—no special privileges are required to use the interface. This example watches the /tmp directory:
|
||||
|
||||
```
|
||||
|
||||
$ inotifywait -m /tmp
|
||||
Setting up watches.
|
||||
Watches established.
|
||||
|
||||
```
|
||||
|
||||
If another session on the system performs a few operations on the files in /tmp:
|
||||
|
||||
```
|
||||
|
||||
$ touch /tmp/hello
|
||||
$ cp /etc/passwd /tmp
|
||||
$ rm /tmp/passwd
|
||||
$ touch /tmp/goodbye
|
||||
$ rm /tmp/hello /tmp/goodbye
|
||||
|
||||
```
|
||||
|
||||
those changes are immediately visible to the user running inotifywait:
|
||||
|
||||
```
|
||||
|
||||
/tmp/ CREATE hello
|
||||
/tmp/ OPEN hello
|
||||
/tmp/ ATTRIB hello
|
||||
/tmp/ CLOSE_WRITE,CLOSE hello
|
||||
/tmp/ CREATE passwd
|
||||
/tmp/ OPEN passwd
|
||||
/tmp/ MODIFY passwd
|
||||
/tmp/ CLOSE_WRITE,CLOSE passwd
|
||||
/tmp/ DELETE passwd
|
||||
/tmp/ CREATE goodbye
|
||||
/tmp/ OPEN goodbye
|
||||
/tmp/ ATTRIB goodbye
|
||||
/tmp/ CLOSE_WRITE,CLOSE goodbye
|
||||
/tmp/ DELETE hello
|
||||
/tmp/ DELETE goodbye
|
||||
|
||||
```
|
||||
|
||||
A few relevant sections of the manual page explain what is happening:
|
||||
|
||||
```
|
||||
|
||||
$ man inotifywait | col -b | sed -n '/diagnostic/,/helpful/p'
|
||||
inotifywait will output diagnostic information on standard error and
|
||||
event information on standard output. The event output can be config-
|
||||
ured, but by default it consists of lines of the following form:
|
||||
|
||||
watched_filename EVENT_NAMES event_filename
|
||||
|
||||
watched_filename
|
||||
is the name of the file on which the event occurred. If the
|
||||
file is a directory, a trailing slash is output.
|
||||
|
||||
EVENT_NAMES
|
||||
are the names of the inotify events which occurred, separated by
|
||||
commas.
|
||||
|
||||
event_filename
|
||||
is output only when the event occurred on a directory, and in
|
||||
this case the name of the file within the directory which caused
|
||||
this event is output.
|
||||
|
||||
By default, any special characters in filenames are not escaped
|
||||
in any way. This can make the output of inotifywait difficult
|
||||
to parse in awk scripts or similar. The --csv and --format
|
||||
options will be helpful in this case.
|
||||
|
||||
```
|
||||
|
||||
It also is possible to filter the output by registering particular events of interest with the -e option, the list of which is shown here:
|
||||
|
||||
| access | create | move_self |
|
||||
|========|========|===========|
|
||||
| attrib | delete | moved_to |
|
||||
| close_write | delete_self | moved_from |
|
||||
| close_nowrite | modify | open |
|
||||
| close | move | unmount |
|
||||
|
||||
A common application is testing for the arrival of new files. Since inotify must be given the name of an existing filesystem object to watch, the directory containing the new files is provided. A trigger of interest is also easy to provide—new files should be complete and ready for processing when the close_write trigger fires. Below is an example script to watch for these events:
|
||||
|
||||
```
|
||||
|
||||
#!/bin/sh
|
||||
unset IFS # default of space, tab and nl
|
||||
# Wait for filesystem events
|
||||
inotifywait -m -e close_write \
|
||||
/tmp /var/tmp /home/oracle/arch-orcl/ |
|
||||
while read dir op file
|
||||
do [[ "${dir}" == '/tmp/' && "${file}" == *.txt ]] &&
|
||||
echo "Import job should start on $file ($dir $op)."
|
||||
|
||||
[[ "${dir}" == '/var/tmp/' && "${file}" == CLOSE_WEEK*.txt ]] &&
|
||||
echo Weekly backup is ready.
|
||||
|
||||
[[ "${dir}" == '/home/oracle/arch-orcl/' && "${file}" == *.ARC ]]
|
||||
&&
|
||||
su - oracle -c 'ORACLE_SID=orcl ~oracle/bin/log_shipper' &
|
||||
|
||||
[[ "${dir}" == '/tmp/' && "${file}" == SHUT ]] && break
|
||||
|
||||
((step+=1))
|
||||
done
|
||||
|
||||
echo We processed $step events.
|
||||
|
||||
```
|
||||
|
||||
There are a few problems with the script as presented—of all the available shells on Linux, only ksh93 (that is, the AT&T Korn shell) will report the "step" variable correctly at the end of the script. All the other shells will report this variable as null.
|
||||
|
||||
The reason for this behavior can be found in a brief explanation on the manual page for Bash: "Each command in a pipeline is executed as a separate process (i.e., in a subshell)." The MirBSD clone of the Korn shell has a slightly longer explanation:
|
||||
|
||||
```
|
||||
|
||||
# man mksh | col -b | sed -n '/The parts/,/do so/p'
|
||||
The parts of a pipeline, like below, are executed in subshells. Thus,
|
||||
variable assignments inside them fail. Use co-processes instead.
|
||||
|
||||
foo | bar | read baz # will not change $baz
|
||||
foo | bar |& read -p baz # will, however, do so
|
||||
|
||||
```
|
||||
|
||||
And, the pdksh documentation in Oracle Linux 5 (from which MirBSD mksh emerged) has several more mentions of the subject:
|
||||
|
||||
```
|
||||
|
||||
General features of at&t ksh88 that are not (yet) in pdksh:
|
||||
- the last command of a pipeline is not run in the parent shell
|
||||
- `echo foo | read bar; echo $bar' prints foo in at&t ksh, nothing
|
||||
in pdksh (ie, the read is done in a separate process in pdksh).
|
||||
- in pdksh, if the last command of a pipeline is a shell builtin, it
|
||||
is not executed in the parent shell, so "echo a b | read foo bar"
|
||||
does not set foo and bar in the parent shell (at&t ksh will).
|
||||
This may get fixed in the future, but it may take a while.
|
||||
|
||||
$ man pdksh | col -b | sed -n '/BTW, the/,/aware/p'
|
||||
BTW, the most frequently reported bug is
|
||||
echo hi | read a; echo $a # Does not print hi
|
||||
I'm aware of this and there is no need to report it.
|
||||
|
||||
```
|
||||
|
||||
This behavior is easy enough to demonstrate—running the script above with the default bash shell and providing a sequence of example events:
|
||||
|
||||
```
|
||||
|
||||
$ cp /etc/passwd /tmp/newdata.txt
|
||||
$ cp /etc/group /var/tmp/CLOSE_WEEK20170407.txt
|
||||
$ cp /etc/passwd /tmp/SHUT
|
||||
|
||||
```
|
||||
|
||||
gives the following script output:
|
||||
|
||||
```
|
||||
|
||||
# ./inotify.sh
|
||||
Setting up watches.
|
||||
Watches established.
|
||||
Import job should start on newdata.txt (/tmp/ CLOSE_WRITE,CLOSE).
|
||||
Weekly backup is ready.
|
||||
We processed events.
|
||||
|
||||
```
|
||||
|
||||
Examining the process list while the script is running, you'll also see two shells, one forked for the control structure:
|
||||
|
||||
```
|
||||
|
||||
$ function pps { typeset a IFS=\| ; ps ax | while read a
|
||||
do case $a in *$1*|+([!0-9])) echo $a;; esac; done }
|
||||
|
||||
$ pps inot
|
||||
PID TTY STAT TIME COMMAND
|
||||
3394 pts/1 S+ 0:00 /bin/sh ./inotify.sh
|
||||
3395 pts/1 S+ 0:00 inotifywait -m -e close_write /tmp /var/tmp
|
||||
3396 pts/1 S+ 0:00 /bin/sh ./inotify.sh
|
||||
|
||||
```
|
||||
|
||||
As it was manipulated in a subshell, the "step" variable above was null when control flow reached the echo. Switching this from #/bin/sh to #/bin/ksh93 will correct the problem, and only one shell process will be seen:
|
||||
|
||||
```
|
||||
|
||||
# ./inotify.ksh93
|
||||
Setting up watches.
|
||||
Watches established.
|
||||
Import job should start on newdata.txt (/tmp/ CLOSE_WRITE,CLOSE).
|
||||
Weekly backup is ready.
|
||||
We processed 2 events.
|
||||
|
||||
$ pps inot
|
||||
PID TTY STAT TIME COMMAND
|
||||
3583 pts/1 S+ 0:00 /bin/ksh93 ./inotify.sh
|
||||
3584 pts/1 S+ 0:00 inotifywait -m -e close_write /tmp /var/tmp
|
||||
|
||||
```
|
||||
|
||||
Although ksh93 behaves properly and in general handles scripts far more gracefully than all of the other Linux shells, it is rather large:
|
||||
|
||||
```
|
||||
|
||||
$ ll /bin/[bkm]+([aksh93]) /etc/alternatives/ksh
|
||||
-rwxr-xr-x. 1 root root 960456 Dec 6 11:11 /bin/bash
|
||||
lrwxrwxrwx. 1 root root 21 Apr 3 21:01 /bin/ksh ->
|
||||
/etc/alternatives/ksh
|
||||
-rwxr-xr-x. 1 root root 1518944 Aug 31 2016 /bin/ksh93
|
||||
-rwxr-xr-x. 1 root root 296208 May 3 2014 /bin/mksh
|
||||
lrwxrwxrwx. 1 root root 10 Apr 3 21:01 /etc/alternatives/ksh ->
|
||||
/bin/ksh93
|
||||
|
||||
```
|
||||
|
||||
The mksh binary is the smallest of the Bourne implementations above (some of these shells may be missing on your system, but you can install them with yum). For a long-term monitoring process, mksh is likely the best choice for reducing both processing and memory footprint, and it does not launch multiple copies of itself when idle assuming that a coprocess is used. Converting the script to use a Korn coprocess that is friendly to mksh is not difficult:
|
||||
|
||||
```
|
||||
|
||||
#!/bin/mksh
|
||||
unset IFS # default of space, tab and nl
|
||||
# Wait for filesystem events
|
||||
inotifywait -m -e close_write \
|
||||
/tmp/ /var/tmp/ /home/oracle/arch-orcl/ \
|
||||
2</dev/null |& # Launch as Korn coprocess
|
||||
|
||||
while read -p dir op file # Read from Korn coprocess
|
||||
do [[ "${dir}" == '/tmp/' && "${file}" == *.txt ]] &&
|
||||
print "Import job should start on $file ($dir $op)."
|
||||
|
||||
[[ "${dir}" == '/var/tmp/' && "${file}" == CLOSE_WEEK*.txt ]] &&
|
||||
print Weekly backup is ready.
|
||||
|
||||
[[ "${dir}" == '/home/oracle/arch-orcl/' && "${file}" == *.ARC ]]
|
||||
&&
|
||||
su - oracle -c 'ORACLE_SID=orcl ~oracle/bin/log_shipper' &
|
||||
|
||||
[[ "${dir}" == '/tmp/' && "${file}" == SHUT ]] && break
|
||||
|
||||
((step+=1))
|
||||
done
|
||||
|
||||
echo We processed $step events.
|
||||
```
|
||||
|
||||
|
||||
Note that the Korn and Bolsky reference on the Korn shell outlines the following requirements in a program operating as a coprocess:
|
||||
|
||||
Caution: The co-process must:
|
||||
+ Send each output message to standard output.
|
||||
+ Have a Newline at the end of each message.
|
||||
+ Flush its standard output whenever it writes a message.
|
||||
|
||||
An fflush(NULL) is found in the main processing loop of the inotifywait source, and these requirements appear to be met.
|
||||
|
||||
The mksh version of the script is the most reasonable compromise for efficient use and correct behavior, and I have explained it at some length here to save readers trouble and frustration—it is important to avoid control structures executing in subshells in most of the Borne family. However, hopefully all of these ersatz shells someday fix this basic flaw and implement the Korn behavior correctly.
|
||||
|
||||
### A Practical Application—Oracle Log Shipping
|
||||
|
||||
Oracle databases that are configured for hot backups produce a stream of "archived redo log files" that are used for database recovery. These are the most critical backup files that are produced in an Oracle database.
|
||||
|
||||
These files are numbered sequentially and are written to a log directory configured by the DBA. An inotifywatch can trigger activities to compress, encrypt and/or distribute the archived logs to backup and disaster recovery servers for safekeeping. You can configure Oracle RMAN to do most of these functions, but the OS tools are more capable, flexible and simpler to use.
|
||||
|
||||
There are a number of important design parameters for a script handling archived logs:
|
||||
|
||||
* A "critical section" must be established that allows only a single process to manipulate the archived log files at a time. Oracle will sometimes write bursts of log files, and inotify might cause the handler script to be spawned repeatedly in a short amount of time. Only one instance of the handler script can be allowed to run—any others spawned during the handler's lifetime must immediately exit. This will be achieved with a textbook application of the flock program from the util-linux package.
|
||||
|
||||
* The optimum compression available for production applications appears to be [lzip][1]. The author claims that the integrity of his archive format is [superior to many more well known utilities][2], both in compression ability and also structural integrity. The lzip binary is not in the standard repository for Oracle Linux—it is available in EPEL and is easily compiled from source.
|
||||
|
||||
* Note that [7-Zip][3] uses the same LZMA algorithm as lzip, and it also will perform AES encryption on the data after compression. Encryption is a desirable feature, as it will exempt a business from [breach disclosure laws][4] in most US states if the backups are lost or stolen and they contain "Protected Personal Information" (PPI), such as birthdays or Social Security Numbers. The author of lzip does have harsh things to say regarding the quality of 7-Zip archives using LZMA2, and the openssl enc program can be used to apply AES encryption after compression to lzip archives or any other type of file, as I discussed in a [previous article][5]. I'm foregoing file encryption in the script below and using lzip for clarity.
|
||||
|
||||
* The current log number will be recorded in a dot file in the Oracle user's home directory. If a log is skipped for some reason (a rare occurrence for an Oracle database), log shipping will stop. A missing log requires an immediate and full database backup (either cold or hot)—successful recoveries of Oracle databases cannot skip logs.
|
||||
|
||||
* The scp program will be used to copy the log to a remote server, and it should be called repeatedly until it returns successfully.
|
||||
|
||||
* I'm calling the genuine '93 Korn shell for this activity, as it is the most capable scripting shell and I don't want any surprises.
|
||||
|
||||
Given these design parameters, this is an implementation:
|
||||
|
||||
```
|
||||
|
||||
# cat ~oracle/archutils/process_logs
|
||||
|
||||
#!/bin/ksh93
|
||||
|
||||
set -euo pipefail
|
||||
IFS=$'\n\t' # http://redsymbol.net/articles/unofficial-bash-strict-mode/
|
||||
|
||||
(
|
||||
flock -n 9 || exit 1 # Critical section-allow only one process.
|
||||
|
||||
ARCHDIR=~oracle/arch-${ORACLE_SID}
|
||||
|
||||
APREFIX=${ORACLE_SID}_1_
|
||||
|
||||
ASUFFIX=.ARC
|
||||
|
||||
CURLOG=$(<~oracle/.curlog-$ORACLE_SID)
|
||||
|
||||
File="${ARCHDIR}/${APREFIX}${CURLOG}${ASUFFIX}"
|
||||
|
||||
[[ ! -f "$File" ]] && exit
|
||||
|
||||
while [[ -f "$File" ]]
|
||||
do ((NEXTCURLOG=CURLOG+1))
|
||||
|
||||
NextFile="${ARCHDIR}/${APREFIX}${NEXTCURLOG}${ASUFFIX}"
|
||||
|
||||
[[ ! -f "$NextFile" ]] && sleep 60 # Ensure ARCH has finished
|
||||
|
||||
nice /usr/local/bin/lzip -9q "$File"
|
||||
|
||||
until scp "${File}.lz" "yourcompany.com:~oracle/arch-$ORACLE_SID"
|
||||
do sleep 5
|
||||
done
|
||||
|
||||
CURLOG=$NEXTCURLOG
|
||||
|
||||
File="$NextFile"
|
||||
done
|
||||
|
||||
echo $CURLOG > ~oracle/.curlog-$ORACLE_SID
|
||||
|
||||
) 9>~oracle/.processing_logs-$ORACLE_SID
|
||||
|
||||
```
|
||||
|
||||
The above script can be executed manually for testing even while the inotify handler is running, as the flock protects it.
|
||||
|
||||
A standby server, or a DataGuard server in primitive standby mode, can apply the archived logs at regular intervals. The script below forces a 12-hour delay in log application for the recovery of dropped or damaged objects, so inotify cannot be easily used in this case—cron is a more reasonable approach for delayed file processing, and a run every 20 minutes will keep the standby at the desired recovery point:
|
||||
|
||||
```
|
||||
|
||||
# cat ~oracle/archutils/delay-lock.sh
|
||||
|
||||
#!/bin/ksh93
|
||||
|
||||
(
|
||||
flock -n 9 || exit 1 # Critical section-only one process.
|
||||
|
||||
WINDOW=43200 # 12 hours
|
||||
|
||||
LOG_DEST=~oracle/arch-$ORACLE_SID
|
||||
|
||||
OLDLOG_DEST=$LOG_DEST-applied
|
||||
|
||||
function fage { print $(( $(date +%s) - $(stat -c %Y "$1") ))
|
||||
} # File age in seconds - Requires GNU extended date & stat
|
||||
|
||||
cd $LOG_DEST
|
||||
|
||||
of=$(ls -t | tail -1) # Oldest file in directory
|
||||
|
||||
[[ -z "$of" || $(fage "$of") -lt $WINDOW ]] && exit
|
||||
|
||||
for x in $(ls -rt) # Order by ascending file mtime
|
||||
do if [[ $(fage "$x") -ge $WINDOW ]]
|
||||
then y=$(basename $x .lz) # lzip compression is optional
|
||||
|
||||
[[ "$y" != "$x" ]] && /usr/local/bin/lzip -dkq "$x"
|
||||
|
||||
$ORACLE_HOME/bin/sqlplus '/ as sysdba' > /dev/null 2>&1 <<-EOF
|
||||
recover standby database;
|
||||
$LOG_DEST/$y
|
||||
cancel
|
||||
quit
|
||||
EOF
|
||||
|
||||
[[ "$y" != "$x" ]] && rm "$y"
|
||||
|
||||
mv "$x" $OLDLOG_DEST
|
||||
fi
|
||||
|
||||
done
|
||||
) 9> ~oracle/.recovering-$ORACLE_SID
|
||||
|
||||
```
|
||||
|
||||
I've covered these specific examples here because they introduce tools to control concurrency, which is a common issue when using inotify, and they advance a few features that increase reliability and minimize storage requirements. Hopefully enthusiastic readers will introduce many improvements to these approaches.
|
||||
|
||||
### The incron System
|
||||
|
||||
Lukas Jelinek is the author of the incron package that allows users to specify tables of inotify events that are executed by the master incrond process. Despite the reference to "cron", the package does not schedule events at regular intervals—it is a tool for filesystem events, and the cron reference is slightly misleading.
|
||||
|
||||
The incron package is available from EPEL. If you have installed the repository, you can load it with yum:
|
||||
|
||||
```
|
||||
|
||||
# yum install incron
|
||||
Loaded plugins: langpacks, ulninfo
|
||||
Resolving Dependencies
|
||||
--> Running transaction check
|
||||
---> Package incron.x86_64 0:0.5.10-8.el7 will be installed
|
||||
--> Finished Dependency Resolution
|
||||
|
||||
Dependencies Resolved
|
||||
|
||||
=================================================================
|
||||
Package Arch Version Repository Size
|
||||
=================================================================
|
||||
Installing:
|
||||
incron x86_64 0.5.10-8.el7 epel 92 k
|
||||
|
||||
Transaction Summary
|
||||
==================================================================
|
||||
Install 1 Package
|
||||
|
||||
Total download size: 92 k
|
||||
Installed size: 249 k
|
||||
Is this ok [y/d/N]: y
|
||||
Downloading packages:
|
||||
incron-0.5.10-8.el7.x86_64.rpm | 92 kB 00:01
|
||||
Running transaction check
|
||||
Running transaction test
|
||||
Transaction test succeeded
|
||||
Running transaction
|
||||
Installing : incron-0.5.10-8.el7.x86_64 1/1
|
||||
Verifying : incron-0.5.10-8.el7.x86_64 1/1
|
||||
|
||||
Installed:
|
||||
incron.x86_64 0:0.5.10-8.el7
|
||||
|
||||
Complete!
|
||||
|
||||
```
|
||||
|
||||
On a systemd distribution with the appropriate service units, you can start and enable incron at boot with the following commands:
|
||||
|
||||
```
|
||||
|
||||
# systemctl start incrond
|
||||
# systemctl enable incrond
|
||||
Created symlink from
|
||||
/etc/systemd/system/multi-user.target.wants/incrond.service
|
||||
to /usr/lib/systemd/system/incrond.service.
|
||||
|
||||
```
|
||||
|
||||
In the default configuration, any user can establish incron schedules. The incrontab format uses three fields:
|
||||
|
||||
```
|
||||
path> <mask> <command>
|
||||
```
|
||||
|
||||
Below is an example entry that was set with the -e option:
|
||||
|
||||
```
|
||||
|
||||
$ incrontab -e #vi session follows
|
||||
|
||||
$ incrontab -l
|
||||
/tmp/ IN_ALL_EVENTS /home/luser/myincron.sh $@ $% $#
|
||||
|
||||
```
|
||||
|
||||
You can record a simple script and mark it with execute permission:
|
||||
|
||||
```
|
||||
|
||||
$ cat myincron.sh
|
||||
#!/bin/sh
|
||||
|
||||
echo -e "path: $1 op: $2 \t file: $3" >> ~/op
|
||||
|
||||
$ chmod 755 myincron.sh
|
||||
|
||||
```
|
||||
|
||||
Then, if you repeat the original /tmp file manipulations at the start of this article, the script will record the following output:
|
||||
|
||||
```
|
||||
|
||||
$ cat ~/op
|
||||
|
||||
path: /tmp/ op: IN_ATTRIB file: hello
|
||||
path: /tmp/ op: IN_CREATE file: hello
|
||||
path: /tmp/ op: IN_OPEN file: hello
|
||||
path: /tmp/ op: IN_CLOSE_WRITE file: hello
|
||||
path: /tmp/ op: IN_OPEN file: passwd
|
||||
path: /tmp/ op: IN_CLOSE_WRITE file: passwd
|
||||
path: /tmp/ op: IN_MODIFY file: passwd
|
||||
path: /tmp/ op: IN_CREATE file: passwd
|
||||
path: /tmp/ op: IN_DELETE file: passwd
|
||||
path: /tmp/ op: IN_CREATE file: goodbye
|
||||
path: /tmp/ op: IN_ATTRIB file: goodbye
|
||||
path: /tmp/ op: IN_OPEN file: goodbye
|
||||
path: /tmp/ op: IN_CLOSE_WRITE file: goodbye
|
||||
path: /tmp/ op: IN_DELETE file: hello
|
||||
path: /tmp/ op: IN_DELETE file: goodbye
|
||||
|
||||
```
|
||||
|
||||
While the IN_CLOSE_WRITE event on a directory object is usually of greatest interest, most of the standard inotify events are available within incron, which also offers several unique amalgams:
|
||||
|
||||
```
|
||||
|
||||
$ man 5 incrontab | col -b | sed -n '/EVENT SYMBOLS/,/child process/p'
|
||||
|
||||
EVENT SYMBOLS
|
||||
|
||||
These basic event mask symbols are defined:
|
||||
|
||||
IN_ACCESS File was accessed (read) (*)
|
||||
IN_ATTRIB Metadata changed (permissions, timestamps, extended
|
||||
attributes, etc.) (*)
|
||||
IN_CLOSE_WRITE File opened for writing was closed (*)
|
||||
IN_CLOSE_NOWRITE File not opened for writing was closed (*)
|
||||
IN_CREATE File/directory created in watched directory (*)
|
||||
IN_DELETE File/directory deleted from watched directory (*)
|
||||
IN_DELETE_SELF Watched file/directory was itself deleted
|
||||
IN_MODIFY File was modified (*)
|
||||
IN_MOVE_SELF Watched file/directory was itself moved
|
||||
IN_MOVED_FROM File moved out of watched directory (*)
|
||||
IN_MOVED_TO File moved into watched directory (*)
|
||||
IN_OPEN File was opened (*)
|
||||
|
||||
When monitoring a directory, the events marked with an asterisk (*)
|
||||
above can occur for files in the directory, in which case the name
|
||||
field in the returned event data identifies the name of the file within
|
||||
the directory.
|
||||
|
||||
The IN_ALL_EVENTS symbol is defined as a bit mask of all of the above
|
||||
events. Two additional convenience symbols are IN_MOVE, which is a com-
|
||||
bination of IN_MOVED_FROM and IN_MOVED_TO, and IN_CLOSE, which combines
|
||||
IN_CLOSE_WRITE and IN_CLOSE_NOWRITE.
|
||||
|
||||
The following further symbols can be specified in the mask:
|
||||
|
||||
IN_DONT_FOLLOW Don't dereference pathname if it is a symbolic link
|
||||
IN_ONESHOT Monitor pathname for only one event
|
||||
IN_ONLYDIR Only watch pathname if it is a directory
|
||||
|
||||
Additionally, there is a symbol which doesn't appear in the inotify sym-
|
||||
bol set. It is IN_NO_LOOP. This symbol disables monitoring events until
|
||||
the current one is completely handled (until its child process exits).
|
||||
|
||||
```
|
||||
|
||||
The incron system likely presents the most comprehensive interface to inotify of all the tools researched and listed here. Additional configuration options can be set in /etc/incron.conf to tweak incron's behavior for those that require a non-standard configuration.
|
||||
|
||||
### Path Units under systemd
|
||||
|
||||
When your Linux installation is running systemd as PID 1, limited inotify functionality is available through "path units" as is discussed in a lighthearted [article by Paul Brown][8] at OCS-Mag.
|
||||
|
||||
The relevant manual page has useful information on the subject:
|
||||
|
||||
```
|
||||
|
||||
$ man systemd.path | col -b | sed -n '/Internally,/,/systems./p'
|
||||
|
||||
Internally, path units use the inotify(7) API to monitor file systems.
|
||||
Due to that, it suffers by the same limitations as inotify, and for
|
||||
example cannot be used to monitor files or directories changed by other
|
||||
machines on remote NFS file systems.
|
||||
|
||||
```
|
||||
|
||||
Note that when a systemd path unit spawns a shell script, the $HOME and tilde (~) operator for the owner's home directory may not be defined. Using the tilde operator to reference another user's home directory (for example, ~nobody/) does work, even when applied to the self-same user running the script. The Oracle script above was explicit and did not reference ~ without specifying the target user, so I'm using it as an example here.
|
||||
|
||||
Using inotify triggers with systemd path units requires two files. The first file specifies the filesystem location of interest:
|
||||
|
||||
```
|
||||
|
||||
$ cat /etc/systemd/system/oralog.path
|
||||
|
||||
[Unit]
|
||||
Description=Oracle Archivelog Monitoring
|
||||
Documentation=http://docs.yourserver.com
|
||||
|
||||
[Path]
|
||||
PathChanged=/home/oracle/arch-orcl/
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
```
|
||||
|
||||
The PathChanged parameter above roughly corresponds to the close-write event used in my previous direct inotify calls. The full collection of inotify events is not (currently) supported by systemd—it is limited to PathExists, PathChanged and PathModified, which are described in man systemd.path.
|
||||
|
||||
The second file is a service unit describing a program to be executed. It must have the same name, but a different extension, as the path unit:
|
||||
|
||||
```
|
||||
|
||||
$ cat /etc/systemd/system/oralog.service
|
||||
|
||||
[Unit]
|
||||
Description=Oracle Archivelog Monitoring
|
||||
Documentation=http://docs.yourserver.com
|
||||
|
||||
[Service]
|
||||
Type=oneshot
|
||||
Environment=ORACLE_SID=orcl
|
||||
ExecStart=/bin/sh -c '/root/process_logs >> /tmp/plog.txt 2>&1'
|
||||
|
||||
```
|
||||
|
||||
The oneshot parameter above alerts systemd that the program that it forks is expected to exit and should not be respawned automatically—the restarts are limited to triggers from the path unit. The above service configuration will provide the best options for logging—divert them to /dev/null if they are not needed.
|
||||
|
||||
Use systemctl start on the path unit to begin monitoring—a common error is using it on the service unit, which will directly run the handler only once. Enable the path unit if the monitoring should survive a reboot.
|
||||
|
||||
Although this limited functionality may be enough for some casual uses of inotify, it is a shame that the full functionality of inotifywait and incron are not represented here. Perhaps it will come in time.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Although the inotify tools are powerful, they do have limitations. To repeat them, inotify cannot monitor remote (NFS) filesystems; it cannot report the userid involved in a triggering event; it does not work with /proc or other pseudo-filesystems; mmap() operations do not trigger it; and the inotify queue can overflow resulting in lost events, among other concerns.
|
||||
|
||||
Even with these weaknesses, the efficiency of inotify is superior to most other approaches for immediate notifications of filesystem activity. It also is quite flexible, and although the close-write directory trigger should suffice for most usage, it has ample tools for covering special use cases.
|
||||
|
||||
In any event, it is productive to replace polling activity with inotify watches, and system administrators should be liberal in educating the user community that the classic crontab is not an appropriate place to check for new files. Recalcitrant users should be confined to Ultrix on a VAX until they develop sufficient appreciation for modern tools and approaches, which should result in more efficient Linux systems and happier administrators.
|
||||
|
||||
### Sidenote: Archiving /etc/passwd
|
||||
|
||||
Tracking changes to the password file involves many different types of inotify triggering events. The vipw utility commonly will make changes to a temporary file, then clobber the original with it. This can be seen when the inode number changes:
|
||||
|
||||
```
|
||||
|
||||
# ll -i /etc/passwd
|
||||
199720973 -rw-r--r-- 1 root root 3928 Jul 7 12:24 /etc/passwd
|
||||
|
||||
# vipw
|
||||
[ make changes ]
|
||||
You are using shadow passwords on this system.
|
||||
Would you like to edit /etc/shadow now [y/n]? n
|
||||
|
||||
# ll -i /etc/passwd
|
||||
203784208 -rw-r--r-- 1 root root 3956 Jul 7 12:24 /etc/passwd
|
||||
|
||||
```
|
||||
|
||||
The destruction and replacement of /etc/passwd even occurs with setuid binaries called by unprivileged users:
|
||||
|
||||
```
|
||||
|
||||
$ ll -i /etc/passwd
|
||||
203784196 -rw-r--r-- 1 root root 3928 Jun 29 14:55 /etc/passwd
|
||||
|
||||
$ chsh
|
||||
Changing shell for fishecj.
|
||||
Password:
|
||||
New shell [/bin/bash]: /bin/csh
|
||||
Shell changed.
|
||||
|
||||
$ ll -i /etc/passwd
|
||||
199720970 -rw-r--r-- 1 root root 3927 Jul 7 12:23 /etc/passwd
|
||||
|
||||
```
|
||||
|
||||
For this reason, all inotify triggering events should be considered when tracking this file. If there is concern with an inotify queue overflow (in which events are lost), then the OPEN, ACCESS and CLOSE_NOWRITE,CLOSE triggers likely can be immediately ignored.
|
||||
|
||||
All other inotify events on /etc/passwd might run the following script to version the changes into an RCS archive and mail them to an administrator:
|
||||
|
||||
```
|
||||
|
||||
#!/bin/sh
|
||||
|
||||
# This script tracks changes to the /etc/passwd file from inotify.
|
||||
# Uses RCS for archiving. Watch for UID zero.
|
||||
|
||||
PWMAILS=Charlie.Root@openbsd.org
|
||||
|
||||
TPDIR=~/track_passwd
|
||||
|
||||
cd $TPDIR
|
||||
|
||||
if diff -q /etc/passwd $TPDIR/passwd
|
||||
then exit # they are the same
|
||||
else sleep 5 # let passwd settle
|
||||
diff /etc/passwd $TPDIR/passwd 2>&1 | # they are DIFFERENT
|
||||
mail -s "/etc/passwd changes $(hostname -s)" "$PWMAILS"
|
||||
cp -f /etc/passwd $TPDIR # copy for checkin
|
||||
|
||||
# "SCCS, the source motel! Programs check in and never check out!"
|
||||
# -- Ken Thompson
|
||||
|
||||
rcs -q -l passwd # lock the archive
|
||||
ci -q -m_ passwd # check in new ver
|
||||
co -q passwd # drop the new copy
|
||||
fi > /dev/null 2>&1
|
||||
|
||||
```
|
||||
|
||||
Here is an example email from the script for the above chfn operation:
|
||||
|
||||
```
|
||||
|
||||
-----Original Message-----
|
||||
From: root [mailto:root@myhost.com]
|
||||
Sent: Thursday, July 06, 2017 2:35 PM
|
||||
To: Fisher, Charles J. ;
|
||||
Subject: /etc/passwd changes myhost
|
||||
|
||||
57c57
|
||||
< fishecj:x:123:456:Fisher, Charles J.:/home/fishecj:/bin/bash
|
||||
---
|
||||
> fishecj:x:123:456:Fisher, Charles J.:/home/fishecj:/bin/csh
|
||||
|
||||
```
|
||||
|
||||
Further processing on the third column of /etc/passwd might detect UID zero (a root user) or other important user classes for emergency action. This might include a rollback of the file from RCS to /etc and/or SMS messages to security contacts.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/linux-filesystem-events-inotify
|
||||
|
||||
作者:[Charles Fisher][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:http://www.nongnu.org/lzip
|
||||
[2]:http://www.nongnu.org/lzip/xz_inadequate.html
|
||||
[3]:http://www.7-zip.org
|
||||
[4]:http://www.ncsl.org/research/telecommunications-and-information-technology/security-breach-notification-laws.aspx
|
||||
[5]:http://www.linuxjournal.com/content/flat-file-encryption-openssl-and-gpg
|
||||
[6]:http://www.linuxjournal.com/article/8478
|
||||
[7]:https://fedoraproject.org/wiki/EPEL
|
||||
[8]:http://www.ocsmag.com/2015/09/02/monitoring-file-access-for-dummies
|
||||
@ -1,163 +0,0 @@
|
||||
Profiler adventures: resolving symbol addresses is hard!
|
||||
============================================================
|
||||
|
||||
The other day I posted [How does gdb call functions?][1]. In that post I said:
|
||||
|
||||
> Using the symbol table to figure out the address of the function you want to call is pretty straightforward
|
||||
|
||||
Unsurprisingly, it turns out that figuring out the address in memory corresponding to a given symbol is actually not really that straightforward. This is actually something I’ve been doing in my profiler, and I think it’s interesting, so I thought I’d write about it!
|
||||
|
||||
Basically the problem I’ve been trying to solve is – I have a symbol (like `ruby_api_version`), and I want to figure out which address that symbol is mapped to in my target process’s memory (so that I can get the data in it, like the Ruby process’s Ruby version). So far I’ve run into (and fixed!) 3 issues when trying to do this:
|
||||
|
||||
1. When binaries are loaded into memory, they’re loaded at a random address (so I can’t just read the symbol table)
|
||||
|
||||
2. The symbol I want isn’t necessary in the “main” binary (`/proc/PID/exe`, sometimes it’s in some other dynamically linked library)
|
||||
|
||||
3. I need to look at the ELF program header to adjust which address I look at for the symbol
|
||||
|
||||
I’ll start with some background, and then explain these 3 things! (I actually don’t know what gdb does)
|
||||
|
||||
### what’s a symbol?
|
||||
|
||||
Most binaries have functions and variables in them. For instance, Perl has a global variable called `PL_bincompat_options` and a function called `Perl_sv_catpv_mg`.
|
||||
|
||||
Sometimes binaries need to look up functions from another binary (for example, if the binary is a dynamically linked library, you need to look up its functions by name). Also sometimes you’re debugging your code and you want to know what function an address corresponds to.
|
||||
|
||||
Symbols are how you look up functions / variables in a binary. They’re in a section called the “symbol table”. The symbol table is basically an index for your binary! Sometimes they’re missing (“stripped”). There are a lot of binary formats, but this post is just about the usual binary format on Linux: ELF.
|
||||
|
||||
### how do you get the symbol table of a binary?
|
||||
|
||||
A thing that I learned today (or at least learned and then forgot) is that there are 2 possible sections symbols can live in: `.symtab` and `.dynsym`. `.dynsym` is the “dynamic symbol table”. According to [this page][2], the dynsym is a smaller version of the symtab that only contains global symbols.
|
||||
|
||||
There are at least 3 ways to read the symbol table of a binary on Linux: you can use nm, objdump, or readelf.
|
||||
|
||||
* **read the .symtab**: `nm $FILE`, `objdump --syms $FILE`, `readelf -a $FILE`
|
||||
|
||||
* **read the .dynsym**: `nm -D $FILE`, `objdump --dynamic-syms $FILE`, `readelf -a $FILE`
|
||||
|
||||
`readelf -a` is the same in both cases because `readelf -a` just shows you everything in an ELF file. It’s my favorite because I don’t need to guess where the information I want is, I can just print out everything and then use grep.
|
||||
|
||||
Here’s an example of some of the symbols in `/usr/bin/perl`. You can see that each symbol has a **name**, a **value**, and a **type**. The value is basically the offset of the code/data corresponding to that symbol in the binary. (except some symbols have value 0\. I think that has something to do with dynamic linking but I don’t understand it so we’re not going to get into it)
|
||||
|
||||
```
|
||||
$ readelf -a /usr/bin/perl
|
||||
...
|
||||
Num: Value Size Type Ndx Name
|
||||
523: 00000000004d6590 49 FUNC 14 Perl_sv_catpv_mg
|
||||
524: 0000000000543410 7 FUNC 14 Perl_sv_copypv
|
||||
525: 00000000005a43e0 202 OBJECT 16 PL_bincompat_options
|
||||
526: 00000000004e6d20 2427 FUNC 14 Perl_pp_ucfirst
|
||||
527: 000000000044a8c0 1561 FUNC 14 Perl_Gv_AMupdate
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
### the question we want to answer: what address is a symbol mapped to?
|
||||
|
||||
That’s enough background!
|
||||
|
||||
Now – suppose I’m a debugger, and I want to know what address the `ruby_api_version` symbol is mapped to. Let’s use readelf to look at the relevant Ruby binary!
|
||||
|
||||
```
|
||||
readelf -a ~/.rbenv/versions/2.1.6/bin/ruby | grep ruby_api_version
|
||||
365: 00000000001f9180 12 OBJECT GLOBAL DEFAULT 15 ruby_api_version
|
||||
|
||||
```
|
||||
|
||||
Neat! The offset of `ruby_api_version` is `0x1f9180`. We’re done, right? Of course not! :)
|
||||
|
||||
### Problem 1: ASLR (Address space layout randomization)
|
||||
|
||||
Here’s the first issue: when Linux loads a binary into memory (like `~/.rbenv/versions/2.1.6/bin/ruby`), it doesn’t just load it at the `0` address. Instead, it usually adds a random offset. Wikipedia’s article on ASLR explains why:
|
||||
|
||||
> Address space layout randomization (ASLR) is a memory-protection process for operating systems (OSes) that guards against buffer-overflow attacks by randomizing the location where system executables are loaded into memory.
|
||||
|
||||
We can see this happening in practice: I started `/home/bork/.rbenv/versions/2.1.6/bin/ruby` 3 times and every time the process gets mapped to a different place in memory. (`0x56121c86f000`, `0x55f440b43000`, `0x56163334a000`)
|
||||
|
||||
Here we’re meeting our good friend `/proc/$PID/maps` – this file contains a list of memory maps for a process. The memory maps tell us every address range in the process’s virtual memory (it turns out virtual memory isn’t contiguous! Instead process get a bunch of possibly-disjoint memory maps!). This file is so useful! You can find the address of the stack, the heap, every dynamically loaded library, anonymous memory maps, and probably more.
|
||||
|
||||
```
|
||||
$ cat /proc/(pgrep -f 2.1.6)/maps | grep 'bin/ruby'
|
||||
56121c86f000-56121caf0000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
56121ccf0000-56121ccf5000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
56121ccf5000-56121ccf7000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
$ cat /proc/(pgrep -f 2.1.6)/maps | grep 'bin/ruby'
|
||||
55f440b43000-55f440dc4000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
55f440fc4000-55f440fc9000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
55f440fc9000-55f440fcb000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
$ cat /proc/(pgrep -f 2.1.6)/maps | grep 'bin/ruby'
|
||||
56163334a000-5616335cb000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5616337cb000-5616337d0000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5616337d0000-5616337d2000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
|
||||
```
|
||||
|
||||
Okay, so in the last example we see that our binary is mapped at `0x56163334a000`. If we combine this with the knowledge that `ruby_api_version` is at `0x1f9180`, then that means that we just need to look that the address `0x1f9180 + 0x56163334a000` to find our variable, right?
|
||||
|
||||
Yes! In this case, that works. But in other cases it won’t! So that brings us to problem 2.
|
||||
|
||||
### Problem 2: dynamically loaded libraries
|
||||
|
||||
Next up, I tried running system Ruby: `/usr/bin/ruby`. This binary has basically no symbols at all! Disaster! In particular it does not have a `ruby_api_version`symbol.
|
||||
|
||||
But when I tried to print the `ruby_api_version` variable with gdb, it worked!!! Where was gdb finding my symbol? I found the answer with the help of our good friend: `/proc/PID/maps`
|
||||
|
||||
It turns out that `/usr/bin/ruby` dynamically loads a library called `libruby-2.3`. You can see it in the memory maps here:
|
||||
|
||||
```
|
||||
$ cat /proc/(pgrep -f /usr/bin/ruby)/maps | grep libruby
|
||||
7f2c5d789000-7f2c5d9f1000 r-xp 00000000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
|
||||
7f2c5d9f1000-7f2c5dbf0000 ---p 00268000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
|
||||
7f2c5dbf0000-7f2c5dbf6000 r--p 00267000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
|
||||
7f2c5dbf6000-7f2c5dbf7000 rw-p 0026d000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
|
||||
|
||||
```
|
||||
|
||||
And if we read it with `readelf`, we find the address of that symbol!
|
||||
|
||||
```
|
||||
readelf -a /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0 | grep ruby_api_version
|
||||
374: 00000000001c72f0 12 OBJECT GLOBAL DEFAULT 13 ruby_api_version
|
||||
|
||||
```
|
||||
|
||||
So in this case the address of the symbol we want is `0x7f2c5d789000` (the start of the libruby-2.3 memory map) plus `0x1c72f0`. Nice! But we’re still not done. There is (at least) one more mystery!
|
||||
|
||||
### Problem 3: the `vaddr` offset in the ELF program header
|
||||
|
||||
This one I just figured out today so it’s the one I have the shakiest understanding of. Here’s what happened.
|
||||
|
||||
I was running system ruby on Ubuntu 14.04: Ruby 1.9.3\. And my usual code (find the libruby map, get its address, get the symbol offset, add them up) wasn’t working!!! I was confused.
|
||||
|
||||
But I’d asked Julian if he knew of any weird stuff I need to worry about a while back and he said “well, you should read the code for `dlsym`, you’re trying to do basically the same thing”. So I decided to, instead of randomly guessing, go read the code for `dlsym`.
|
||||
|
||||
The man page for `dlsym` says “dlsym, dlvsym - obtain address of a symbol in a shared object or executable”. Perfect!!
|
||||
|
||||
[Here’s the dlsym code from musl I read][3]. (musl is like glibc, but, different. Maybe easier to read? I don’t understand it that well.)
|
||||
|
||||
The dlsym code says (on line 1468) `return def.dso->base + def.sym->st_value;` That sounds like what I’m doing!! But what’s `dso->base`? It looks like `base = map - addr_min;`, and `addr_min = ph->p_vaddr;`. (there’s also some stuff that makes sure `addr_min` is aligned with the page size which I should maybe pay attention to.)
|
||||
|
||||
So the code I want is something like `map_base - ph->p_vaddr + sym->st_value`.
|
||||
|
||||
I looked up this `vaddr` thing in the ELF program header, subtracted it from my calculation, and voilà! It worked!!!
|
||||
|
||||
### there are probably more problems!
|
||||
|
||||
I imagine I will discover even more ways that I am calculating the symbol address wrong. It’s interesting that such a seemingly simple thing (“what’s the address of this symbol?”) is so complicated!
|
||||
|
||||
It would be nice to be able to just call `dlsym` and have it do all the right calculations for me, but I think I can’t because the symbol is in a different process. Maybe I’m wrong about that though! I would like to be wrong about that. If you know an easier way to do all this I would very much like to know!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/01/09/resolving-symbol-addresses/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/
|
||||
[2]:https://blogs.oracle.com/ali/inside-elf-symbol-tables
|
||||
[3]:https://github.com/esmil/musl/blob/194f9cf93da8ae62491b7386edf481ea8565ae4e/src/ldso/dynlink.c#L1451
|
||||
@ -1,224 +0,0 @@
|
||||
How to trigger commands on File/Directory changes with Incron on Debian
|
||||
======
|
||||
|
||||
This guide shows how you can install and use **incron** on a Debian 9 (Stretch) system. Incron is similar to cron, but instead of running commands based on time, it can trigger commands when file or directory events occur (e.g. a file modification, changes of permissions, etc.).
|
||||
|
||||
### 1 Prerequisites
|
||||
|
||||
* System administrator permissions (root login). All commands in this tutorial should be run as root user on the shell.
|
||||
* I will use the editor "nano" to edit files. You may replace nano with an editor of your choice or install nano with "apt-get install nano" if it is not installed on your server.
|
||||
|
||||
|
||||
|
||||
### 2 Installing Incron
|
||||
|
||||
Incron is available in the Debian repository, so we install incron with the following apt command:
|
||||
|
||||
```
|
||||
apt-get install incron
|
||||
```
|
||||
|
||||
The installation process should be similar to the one in this screenshot.
|
||||
|
||||
[![Installing Incron on Debian 9][1]][2]
|
||||
|
||||
### 3 Using Incron
|
||||
|
||||
Incron usage is very much like cron usage. You have the incrontab command that let's you list (-l), edit (-e), and remove (-r) incrontab entries.
|
||||
|
||||
To learn more about it, see:
|
||||
|
||||
```
|
||||
man incrontab
|
||||
```
|
||||
|
||||
There you also find the following section:
|
||||
|
||||
```
|
||||
If /etc/incron.allow exists only users listed here may use incron. Otherwise if /etc/incron.deny exists only users NOT listed here may use incron. If none of these files exists everyone is allowed to use incron. (Important note: This behavior is insecure and will be probably changed to be compatible with the style used by ISC Cron.) Location of these files can be changed in the configuration.
|
||||
```
|
||||
|
||||
This means if we want to use incrontab as root, we must either delete /etc/incron.allow (which is unsafe because then every system user can use incrontab)...
|
||||
|
||||
```
|
||||
rm -f /etc/incron.allow
|
||||
```
|
||||
|
||||
... or add root to that file (recommended). Open the /etc/incron.allow file with nano:
|
||||
|
||||
```
|
||||
nano /etc/incron.allow
|
||||
```
|
||||
|
||||
And add the following line. Then save the file.
|
||||
```
|
||||
root
|
||||
```
|
||||
|
||||
Before you do this, you will get error messages like this one when trying to use incrontab:
|
||||
|
||||
```
|
||||
server1:~# incrontab -l
|
||||
user 'root' is not allowed to use incron
|
||||
```
|
||||
|
||||
|
||||
|
||||
Afterwards it works:
|
||||
|
||||
```
|
||||
server1:~# incrontab -l
|
||||
no table for root
|
||||
```
|
||||
|
||||
|
||||
|
||||
We can use the command:
|
||||
|
||||
```
|
||||
incrontab -e
|
||||
```
|
||||
|
||||
To create incron jobs. Before we do this, we take a look at the incron man page:
|
||||
|
||||
```
|
||||
man 5 incrontab
|
||||
```
|
||||
|
||||
The man page explains the format of the crontabs. Basically, the format is as follows...
|
||||
|
||||
```
|
||||
<path> <mask> <command>
|
||||
```
|
||||
|
||||
...where <path> can be a directory (meaning the directory and/or the files directly in that directory (not files in subdirectories of that directory!) are watched) or a file.
|
||||
|
||||
<mask> can be one of the following:
|
||||
|
||||
IN_ACCESS File was accessed (read) (*)
|
||||
IN_ATTRIB Metadata changed (permissions, timestamps, extended attributes, etc.) (*)
|
||||
IN_CLOSE_WRITE File opened for writing was closed (*)
|
||||
IN_CLOSE_NOWRITE File not opened for writing was closed (*)
|
||||
IN_CREATE File/directory created in watched directory (*)
|
||||
IN_DELETE File/directory deleted from watched directory (*)
|
||||
IN_DELETE_SELF Watched file/directory was itself deleted
|
||||
IN_MODIFY File was modified (*)
|
||||
IN_MOVE_SELF Watched file/directory was itself moved
|
||||
IN_MOVED_FROM File moved out of watched directory (*)
|
||||
IN_MOVED_TO File moved into watched directory (*)
|
||||
IN_OPEN File was opened (*)
|
||||
|
||||
When monitoring a directory, the events marked with an asterisk (*) above can occur for files in the directory, in which case the name field in the
|
||||
returned event data identifies the name of the file within the directory.
|
||||
|
||||
The IN_ALL_EVENTS symbol is defined as a bit mask of all of the above events. Two additional convenience symbols are IN_MOVE, which is a combination of IN_MOVED_FROM and IN_MOVED_TO, and IN_CLOSE which combines IN_CLOSE_WRITE and IN_CLOSE_NOWRITE.
|
||||
|
||||
The following further symbols can be specified in the mask:
|
||||
|
||||
IN_DONT_FOLLOW Don't dereference pathname if it is a symbolic link
|
||||
IN_ONESHOT Monitor pathname for only one event
|
||||
IN_ONLYDIR Only watch pathname if it is a directory
|
||||
|
||||
Additionally, there is a symbol which doesn't appear in the inotify symbol set. It is IN_NO_LOOP. This symbol disables monitoring events until the current one is completely handled (until its child process exits).
|
||||
|
||||
<command> is the command that should be run when the event occurs. The following wildcards may be used inside the command specification:
|
||||
|
||||
```
|
||||
$$ dollar sign
|
||||
#@ watched filesystem path (see above)
|
||||
$# event-related file name
|
||||
$% event flags (textually)
|
||||
$& event flags (numerically)
|
||||
```
|
||||
|
||||
If you watch a directory, then [[email protected]][3] holds the directory path and $# the file that triggered the event. If you watch a file, then [[email protected]][3] holds the complete path to the file and $# is empty.
|
||||
|
||||
If you need the wildcards but are not sure what they translate to, you can create an incron job like this. Open the incron incrontab:
|
||||
|
||||
```
|
||||
incrontab -e
|
||||
```
|
||||
|
||||
and add the following line:
|
||||
|
||||
```
|
||||
/tmp/ IN_MODIFY echo "$$ $@ $# $% $&"
|
||||
```
|
||||
|
||||
Then you create or modify a file in the /tmp directory and take a look at /var/log/syslog - this log shows when an incron job was triggered, if it succeeded or if there were errors, and what the actual command was that it executed (i.e., the wildcards are replaced with their real values).
|
||||
|
||||
```
|
||||
tail /var/log/syslog
|
||||
```
|
||||
|
||||
```
|
||||
...
|
||||
Jan 10 13:52:35 server1 incrond[1012]: (root) CMD (echo "$ /tmp .hello.txt.swp IN_MODIFY 2")
|
||||
Jan 10 13:52:36 server1 incrond[1012]: (root) CMD (echo "$ /tmp .hello.txt.swp IN_MODIFY 2")
|
||||
Jan 10 13:52:39 server1 incrond[1012]: (root) CMD (echo "$ /tmp hello.txt IN_MODIFY 2")
|
||||
Jan 10 13:52:39 server1 incrond[1012]: (root) CMD (echo "$ /tmp .hello.txt.swp IN_MODIFY 2")
|
||||
```
|
||||
|
||||
In this example I've edited the file /tmp/hello.txt; as you see [[email protected]][3] translates to /tmp, $# to _hello.txt_ , $% to IN_CREATE, and $& to 256. I used an editor that created a temporary .txt.swp file which results in the additional lines in syslog.
|
||||
|
||||
Now enough theory. Let's create our first incron jobs. I'd like to monitor the file /etc/apache2/apache2.conf and the directory /etc/apache2/vhosts/, and whenever there are changes, I want incron to restart Apache. This is how we do it:
|
||||
|
||||
```
|
||||
incrontab -e
|
||||
```
|
||||
```
|
||||
/etc/apache2/apache2.conf IN_MODIFY /usr/sbin/service apache2 restart
|
||||
/etc/apache2/sites-available/ IN_MODIFY /usr/sbin/service apache2 restart
|
||||
```
|
||||
|
||||
That's it. For test purposes, you can modify your Apache configuration and take a look at /var/log/syslog, and you should see that incron restarts Apache.
|
||||
|
||||
**NOTE** : Do not do any action from within an incron job in a directory that you monitor to avoid loops. **Example:** When you monitor the /tmp directory for changes and each change triggers a script that writes a log file in /tmp, this will cause a loop and might bring your system to high load or even crash it.
|
||||
|
||||
To list all defined incron jobs, you can run:
|
||||
|
||||
```
|
||||
incrontab -l
|
||||
```
|
||||
|
||||
```
|
||||
server1:~# incrontab -l
|
||||
/etc/apache2/apache2.conf IN_MODIFY /usr/sbin/service apache2 restart
|
||||
/etc/apache2/vhosts/ IN_MODIFY /usr/sbin/service apache2 restart
|
||||
```
|
||||
|
||||
|
||||
|
||||
To delete all incron jobs of the current user, run:
|
||||
|
||||
```
|
||||
incrontab -r
|
||||
```
|
||||
|
||||
```
|
||||
server1:~# incrontab -r
|
||||
removing table for user 'root'
|
||||
table for user 'root' successfully removed
|
||||
```
|
||||
|
||||
### 4 Links
|
||||
|
||||
Debian http://www.debian.org
|
||||
Incron Software: http://inotify.aiken.cz/?section=incron&page=about&lang=en
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/trigger-commands-on-file-or-directory-changes-with-incron-on-debian-9/
|
||||
|
||||
作者:[Till Brehm][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/trigger-commands-on-file-or-directory-changes-with-incron-on-debian-8/incron-debian-9.png
|
||||
[2]:https://www.howtoforge.com/images/trigger-commands-on-file-or-directory-changes-with-incron-on-debian-8/big/incron-debian-9.png
|
||||
@ -1,90 +0,0 @@
|
||||
Translating by Torival BASH drivers, start your engines
|
||||
======
|
||||
|
||||

|
||||
|
||||
There's always more than one way to do a job in the shell, and there may not be One Best Way to do that job, either.
|
||||
|
||||
Nevertheless, different commands with the same output can differ in how long they take, how much memory they use and how hard they make the CPU work.
|
||||
|
||||
Out of curiosity I trialled 6 different ways to get the last 5 characters from each line of a text file, which is a simple text-processing task. The 6 commands are explained below and are abbreviated here as awk5, echo5, grep5, rev5, sed5 and tail5. These were also the names of the files generated by the commands.
|
||||
|
||||
### Tracking performance
|
||||
|
||||
I ran the trial on a 1.6GB UTF-8 text file with 1559391514 characters on 3570866 lines, or an average of 437 characters per line, and no blank lines. The last 5 characters on every line were alphanumeric.
|
||||
|
||||
To time the 6 commands I used **time** (the BASH shell built-in, not GNU **time** ) and while the commands were running I checked **top** to follow memory and CPU usage. My system is the Dell OptiPlex 9020 Micro described [here][1] and runs Debian 9.
|
||||
|
||||
All 6 commands used between 1 and 1.4GB of memory (VIRT in **top** ), and awk5, echo5, grep5 and sed5 ran at close to 100% CPU usage. Interestingly,
|
||||
rev5 ran at ca 30% CPU and tail5 at ca 15%.
|
||||
|
||||
To ensure that all 6 commands had done the same job, I did a **diff** on the 6 output files, each about 21 MB:
|
||||
|
||||
![][2]
|
||||
|
||||
### And the winner is...
|
||||
|
||||
Here are the elapsed times:
|
||||
|
||||
![][3]
|
||||
|
||||
Well, AWK (GNU AWK 4.1.4) is really fast. Sure, all 6 commands could process a 100-line file zippety-quick, but for big text-processing jobs, fire up your AWK.
|
||||
|
||||
### Commands used
|
||||
```
|
||||
awk '{print substr($0,length($0)-4,5)}' file > awk5
|
||||
```
|
||||
|
||||
awk5 used AWK's substring function. The function works on the whole line ($0), starts at the 4th character back from the last character (length($0)-4) and returns 5 characters (5).
|
||||
```
|
||||
#!/bin/bash
|
||||
while read line; do echo "${line: -5}"; done < file > echo5
|
||||
exit
|
||||
```
|
||||
|
||||
echo5 was run as a script and uses a **while** loop for processing one line at a time. The BASH string function "${line: -5}" returns the last 5 characters in "$line".
|
||||
```
|
||||
grep -o '.....$' file > grep5
|
||||
```
|
||||
|
||||
In grep5, **grep** searches each line for the last 5 characters (.....$) and returns (with the -o option) just that searched-for string.
|
||||
```
|
||||
#!/bin/bash
|
||||
while read line; do rev <<<"$line" | cut -c1-5 | rev; done < file > rev5
|
||||
exit
|
||||
```
|
||||
|
||||
The rev5 trick in this script has appeared often in online forums. Each line is first reversed with **rev** , then **cut** is used to return the first 5 characters, then the 5-character string is reversed with **rev**.
|
||||
```
|
||||
sed 's/.*\(.....\)/\1/' file > sed5
|
||||
```
|
||||
|
||||
sed5 is a simple use of **sed** (GNU sed 4.4) but was surprisingly slow in the trial. In each line, **sed** replaces zero or more characters leading up to the last 5 with just those last 5 (as a backreference).
|
||||
```
|
||||
#!/bin/bash
|
||||
while read line; do tail -c 6 <<<"$line"; done < file > tail5
|
||||
exit
|
||||
```
|
||||
|
||||
The "-c 6" in the tail5 script means that **tail** captures the last 5 characters in each line plus the newline character at the end.
|
||||
|
||||
Actually, the "-c" option captures bytes, not characters, meaning if the line ends in multi-byte characters the output will be corrupt. But would you really want to use the ultra-slow **tail** for this job in the first place?
|
||||
|
||||
### About the Author
|
||||
|
||||
Bob Mesibov is Tasmanian, retired and a keen Linux tinkerer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.thelinuxrain.com/articles/bash-drivers-start-your-engines
|
||||
|
||||
作者:[Bob Mesibov][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.thelinuxrain.com
|
||||
[1]:http://www.thelinuxrain.com/articles/debian-9-on-a-dell-optiplex-9020-micro
|
||||
[2]:http://www.thelinuxrain.com/content/01-articles/201-bash-drivers-start-your-engines/1.png
|
||||
[3]:http://www.thelinuxrain.com/content/01-articles/201-bash-drivers-start-your-engines/2.png
|
||||
@ -1,374 +0,0 @@
|
||||
How to Install Snipe-IT Asset Management Software on Debian 9
|
||||
======
|
||||
|
||||
Snipe-IT is a free and open source IT assets management web application that can be used for tracking licenses, accessories, consumables, and components. It is written in PHP language and uses MySQL to store its data. It is a cross-platform application that works on all the major operating system like, Linux, Windows and Mac OS X. It easily integrates with Active Directory, LDAP and supports two-factor authentication with Google Authenticator.
|
||||
|
||||
In this tutorial, we will learn how to install Snipe-IT on Debian 9 server.
|
||||
|
||||
### Requirements
|
||||
|
||||
* A server running Debian 9.
|
||||
* A non-root user with sudo privileges.
|
||||
|
||||
|
||||
|
||||
### Getting Started
|
||||
|
||||
Before installing any packages, it is recommended to update the system package with the latest version. You can do this by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
Next, restart the system to apply all the updates. Then install other required packages with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install git curl unzip wget -y
|
||||
```
|
||||
|
||||
Once all the packages are installed, you can proceed to the next step.
|
||||
|
||||
### Install LAMP Server
|
||||
|
||||
Snipe-IT runs on Apache web server, so you will need to install LAMP (Apache, MariaDB, PHP) to your system.
|
||||
|
||||
First, install Apache, PHP and other PHP libraries with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install apache2 libapache2-mod-php php php-pdo php-mbstring php-tokenizer php-curl php-mysql php-ldap php-zip php-fileinfo php-gd php-dom php-mcrypt php-bcmath -y
|
||||
```
|
||||
|
||||
Once all the packages are installed, start Apache service and enable it to start on boot with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start apache2
|
||||
sudo systemctl enable apache2
|
||||
```
|
||||
|
||||
### Install and Configure MariaDB
|
||||
|
||||
Snipe-IT uses MariaDB to store its data. So you will need to install MariaDB to your system. By default, the latest version of the MariaDB is not available in the Debian 9 repository. So you will need to install MariaDB repository to your system.
|
||||
|
||||
First, add the APT key with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install software-properties-common -y
|
||||
sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
|
||||
```
|
||||
|
||||
Next, add the MariaDB repository using the following command:
|
||||
|
||||
```
|
||||
sudo add-apt-repository 'deb [arch=amd64,i386,ppc64el] http://nyc2.mirrors.digitalocean.com/mariadb/repo/10.1/debian stretch main'
|
||||
```
|
||||
|
||||
Next, update the repository with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
Once the repository is updated, you can install MariaDB with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install mariadb-server mariadb-client -y
|
||||
```
|
||||
|
||||
Next, start the MariaDB service and enable it to start on boot time with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start mysql
|
||||
sudo systemctl start mysql
|
||||
```
|
||||
|
||||
You can check the status of MariaDB server with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl status mysql
|
||||
```
|
||||
|
||||
If everything is fine, you should see the following output:
|
||||
```
|
||||
? mariadb.service - MariaDB database server
|
||||
Loaded: loaded (/lib/systemd/system/mariadb.service; enabled; vendor preset: enabled)
|
||||
Active: active (running) since Mon 2017-12-25 08:41:25 EST; 29min ago
|
||||
Process: 618 ExecStartPost=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
|
||||
Process: 615 ExecStartPost=/etc/mysql/debian-start (code=exited, status=0/SUCCESS)
|
||||
Process: 436 ExecStartPre=/bin/sh -c [ ! -e /usr/bin/galera_recovery ] && VAR= || VAR=`/usr/bin/galera_recovery`; [ $? -eq 0 ] && systemc
|
||||
Process: 429 ExecStartPre=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
|
||||
Process: 418 ExecStartPre=/usr/bin/install -m 755 -o mysql -g root -d /var/run/mysqld (code=exited, status=0/SUCCESS)
|
||||
Main PID: 574 (mysqld)
|
||||
Status: "Taking your SQL requests now..."
|
||||
Tasks: 27 (limit: 4915)
|
||||
CGroup: /system.slice/mariadb.service
|
||||
??574 /usr/sbin/mysqld
|
||||
|
||||
Dec 25 08:41:07 debian systemd[1]: Starting MariaDB database server...
|
||||
Dec 25 08:41:14 debian mysqld[574]: 2017-12-25 8:41:14 140488893776448 [Note] /usr/sbin/mysqld (mysqld 10.1.26-MariaDB-0+deb9u1) starting as p
|
||||
Dec 25 08:41:25 debian systemd[1]: Started MariaDB database server.
|
||||
|
||||
```
|
||||
|
||||
Next, secure your MariaDB by running the following script:
|
||||
|
||||
```
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
Answer all the questions as shown below:
|
||||
```
|
||||
Set root password? [Y/n] n
|
||||
Remove anonymous users? [Y/n] y
|
||||
Disallow root login remotely? [Y/n] y
|
||||
Remove test database and access to it? [Y/n] y
|
||||
Reload privilege tables now? [Y/n] y
|
||||
|
||||
```
|
||||
|
||||
Once MariaDB is secured, log in to MariaDB shell with the following command:
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
```
|
||||
|
||||
Enter your root password when prompt, then create a database for Snipe-IT with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> create database snipeitdb character set utf8;
|
||||
```
|
||||
|
||||
Next, create a user for Snipe-IT and grant all privileges to the Snipe-IT with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> GRANT ALL PRIVILEGES ON snipeitdb.* TO 'snipeit'@'localhost' IDENTIFIED BY 'password';
|
||||
```
|
||||
|
||||
Next, flush the privileges with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> flush privileges;
|
||||
```
|
||||
|
||||
Finally, exit from the MariaDB console using the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> quit
|
||||
```
|
||||
|
||||
### Install Snipe-IT
|
||||
|
||||
You can download the latest version of the Snipe-IT from Git repository with the following command:
|
||||
|
||||
```
|
||||
git clone https://github.com/snipe/snipe-it snipe-it
|
||||
```
|
||||
|
||||
Next, move the downloaded directory to the apache root directory with the following command:
|
||||
|
||||
```
|
||||
sudo mv snipe-it /var/www/
|
||||
```
|
||||
|
||||
Next, you will need to install Composer to your system. You can install it with the following command:
|
||||
|
||||
```
|
||||
curl -sS https://getcomposer.org/installer | php
|
||||
sudo mv composer.phar /usr/local/bin/composer
|
||||
```
|
||||
|
||||
Next, change the directory to snipe-it and Install PHP dependencies using Composer with the following command:
|
||||
|
||||
```
|
||||
cd /var/www/snipe-it
|
||||
sudo composer install --no-dev --prefer-source
|
||||
```
|
||||
Next, generate the "APP_Key" with the following command:
|
||||
|
||||
```
|
||||
sudo php artisan key:generate
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
**************************************
|
||||
* Application In Production! *
|
||||
**************************************
|
||||
|
||||
Do you really wish to run this command? (yes/no) [no]:
|
||||
> yes
|
||||
|
||||
Application key [base64:uWh7O0/TOV10asWpzHc0DH1dOxJHprnZw2kSOnbBXww=] set successfully.
|
||||
|
||||
```
|
||||
|
||||
Next, you will need to populate MySQL with Snipe-IT's default database schema. You can do this by running the following command:
|
||||
|
||||
```
|
||||
sudo php artisan migrate
|
||||
```
|
||||
|
||||
Type yes, when prompted to confirm that you want to perform the migration:
|
||||
```
|
||||
**************************************
|
||||
* Application In Production! *
|
||||
**************************************
|
||||
|
||||
Do you really wish to run this command? (yes/no) [no]:
|
||||
> yes
|
||||
|
||||
Migration table created successfully.
|
||||
|
||||
```
|
||||
|
||||
Next, copy sample .env file and make some changes in it:
|
||||
|
||||
```
|
||||
sudo cp .env.example .env
|
||||
sudo nano .env
|
||||
```
|
||||
|
||||
Change the following lines:
|
||||
```
|
||||
APP_URL=http://example.com
|
||||
APP_TIMEZONE=US/Eastern
|
||||
APP_LOCALE=en
|
||||
|
||||
# --------------------------------------------
|
||||
# REQUIRED: DATABASE SETTINGS
|
||||
# --------------------------------------------
|
||||
DB_CONNECTION=mysql
|
||||
DB_HOST=localhost
|
||||
DB_DATABASE=snipeitdb
|
||||
DB_USERNAME=snipeit
|
||||
DB_PASSWORD=password
|
||||
DB_PREFIX=null
|
||||
DB_DUMP_PATH='/usr/bin'
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished.
|
||||
|
||||
Next, provide the appropriate ownership and file permissions with the following command:
|
||||
|
||||
```
|
||||
sudo chown -R www-data:www-data storage public/uploads
|
||||
sudo chmod -R 755 storage public/uploads
|
||||
```
|
||||
|
||||
### Configure Apache For Snipe-IT
|
||||
|
||||
Next, you will need to create an apache virtual host directive for Snipe-IT. You can do this by creating `snipeit.conf` file inside `/etc/apache2/sites-available` directory:
|
||||
|
||||
```
|
||||
sudo nano /etc/apache2/sites-available/snipeit.conf
|
||||
```
|
||||
|
||||
Add the following lines:
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
ServerAdmin webmaster@example.com
|
||||
<Directory /var/www/snipe-it/public>
|
||||
Require all granted
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
DocumentRoot /var/www/snipe-it/public
|
||||
ServerName example.com
|
||||
ErrorLog /var/log/apache2/snipeIT.error.log
|
||||
CustomLog /var/log/apache2/access.log combined
|
||||
</VirtualHost>
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished. Then, enable virtual host with the following command:
|
||||
|
||||
```
|
||||
sudo a2ensite snipeit.conf
|
||||
```
|
||||
|
||||
Next, enable PHP mcrypt, mbstring module and Apache rewrite module with the following command:
|
||||
|
||||
```
|
||||
sudo phpenmod mcrypt
|
||||
sudo phpenmod mbstring
|
||||
sudo a2enmod rewrite
|
||||
```
|
||||
|
||||
Finally, restart apache web server to apply all the changes:
|
||||
|
||||
```
|
||||
sudo systemctl restart apache2
|
||||
```
|
||||
|
||||
### Configure Firewall
|
||||
|
||||
By default, Snipe-IT runs on port 80, so you will need to allow port 80 through the firewall. By default, UFW firewall is not installed in Debian 9, so you will need to install it first. You can install it by just running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install ufw -y
|
||||
```
|
||||
|
||||
Once UFW is installed, enable it to start on boot time with the following command:
|
||||
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
Next, allow port 80 using the following command:
|
||||
|
||||
```
|
||||
sudo ufw allow 80
|
||||
```
|
||||
|
||||
Next, reload the UFW firewall rule with the following command:
|
||||
|
||||
```
|
||||
sudo ufw reload
|
||||
```
|
||||
|
||||
### Access Snipe-IT
|
||||
|
||||
Everything is now installed and configured, it's time to access Snipe-IT web interface.
|
||||
|
||||
Open your web browser and type the <http://example.com> URL, you will be redirected to the following page:
|
||||
|
||||
[![Snipe-IT Checks the system][2]][3]
|
||||
|
||||
The above page will do a system check to make sure your configuration looks correct. Next, click on the **Create Database Table** button you should see the following page:
|
||||
|
||||
[![Create database table][4]][5]
|
||||
|
||||
Here, click on the **Create User** page, you should see the following page:
|
||||
|
||||
[![Create user][6]][7]
|
||||
|
||||
Here, provide your Site name, Domain name, Admin username, and password, then click on the **Save User** button, you should see the Snipe-IT default dashboard as below:
|
||||
|
||||
[![Snipe-IT Dashboard][8]][9]
|
||||
|
||||
### Conclusion
|
||||
|
||||
In the above tutorial, we have learned to install Snipe-IT on Debian 9 server. We have also learned to configure Snipe-IT through web interface.I hope you have now enough knowledge to deploy Snipe-IT in your production environment. For more information you can refer Snipe-IT [Documentation Page][10].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-snipe-it-on-debian-9/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page1.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page1.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page2.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page2.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page3.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page3.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page4.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page4.png
|
||||
[10]:https://snipe-it.readme.io/docs
|
||||
@ -1,43 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
What is the deal with GraphQL?
|
||||
======
|
||||
|
||||

|
||||
|
||||
There has been lots of talks lately about this thing called [GraphQL][1]. It is a relatively new technology coming out of Facebook and is starting to be widely adopted by large companies like [Github][2], Facebook, Twitter, Yelp, and many others. Basically, GraphQL is an alternative to REST, it replaces many dumb endpoints, `/user/1`, `/user/1/comments` with `/graphql` and you use the post body or query string to request the data you need, like, `/graphql?query={user(id:1){id,username,comments{text}}}`. You pick the pieces of data you need and can nest down to relations to avoid multiple calls. This is a different way of thinking about a backend, but in some situations, it makes practical sense.
|
||||
|
||||
### My Experience with GraphQL
|
||||
|
||||
Originally when I heard about it I was very skeptical, after dabbling in [Apollo Server][3] I was not convinced. Why would you use some silly new technology when you can simply build REST endpoints! But after digging deeper and learning more about its use cases, I came around. I still think REST has a place and will be important for the foreseeable future, but with how bad many APIs and their documentation are, this can be a breath of fresh air...
|
||||
|
||||
### Why Use GraphQL Over REST?
|
||||
|
||||
Although I have used GraphQL, and think it is a compelling and exciting technology, I believe it does not replace REST. That being said there are compelling reasons to pick GraphQL over REST in some situations. When you are building mobile apps or web apps which are made with high mobile traffic in mind GraphQL really shines. The reason for this is mobile data. REST uses many calls and often returns unused data whereas, with GraphQL, you can define precisely what you want to be returned for minimal data usage.
|
||||
|
||||
You can get do all the above with REST by making multiple endpoints available, but that also adds complexity to the project. It also means there will be back and forth between the front and backend teams.
|
||||
|
||||
### What Should You Use?
|
||||
|
||||
GraphQL is a new technology which is now mainstream. But many developers are not aware of it or choose not to learn it because they think it's a fad. I feel like for most projects you can get away using either REST or GraphQL. Developing using GraphQL has great benefits like enforcing documentation, which helps teams work better together, and provides clear expectations for each query. This will likely speed up development after the initial hurdle of wrapping your head around GraphQL.
|
||||
|
||||
Although I have been comparing GraphQL and REST, I think in most cases a mixture of the two will produce the best results. Combine the strengths of both instead of seeing it strightly as just using GraphQL or just using REST.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
Both technologies are here to stay. And done right both technologies can make fast and efficient backends. GraphQL has an edge up because it allows the client to query only the data they need by default, but that is at a potential sacrifice of endpoint speed. Ultimately, if I were starting a new project, I would go with a mix of both GraphQL and REST.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ryanmccue.ca/what-is-the-deal-with-graphql/
|
||||
|
||||
作者:[Ryan McCue][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ryanmccue.ca/author/ryan/
|
||||
[1]:http://graphql.org/
|
||||
[2]:https://developer.github.com/v4/
|
||||
[3]:https://github.com/apollographql/apollo-server
|
||||
@ -1,96 +0,0 @@
|
||||
Linux yes Command Tutorial for Beginners (with Examples)
|
||||
======
|
||||
|
||||
Most of the Linux commands you encounter do not depend on other operations for users to unlock their full potential, but there exists a small subset of command line tool which you can say are useless when used independently, but become a must-have or must-know when used with other command line operations. One such tool is **yes** , and in this tutorial, we will discuss this command with some easy to understand examples.
|
||||
|
||||
But before we do that, it's worth mentioning that all examples provided in this tutorial have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
### Linux yes command
|
||||
|
||||
The yes command in Linux outputs a string repeatedly until killed. Following is the syntax of the command:
|
||||
|
||||
```
|
||||
yes [STRING]...
|
||||
yes OPTION
|
||||
```
|
||||
|
||||
And here's what the man page says about this tool:
|
||||
```
|
||||
Repeatedly output a line with all specified STRING(s), or 'y'.
|
||||
```
|
||||
|
||||
The following Q&A-type examples should give you a better idea about the usage of yes.
|
||||
|
||||
### Q1. How yes command works?
|
||||
|
||||
As the man page says, the yes command produces continuous output - 'y' by default, or any other string if specified by user. Here's a screenshot that shows the yes command in action:
|
||||
|
||||
[![How yes command works][1]][2]
|
||||
|
||||
I could only capture the last part of the output as the output frequency was so fast, but the screenshot should give you a good idea about what kind of output the tool produces.
|
||||
|
||||
You can also provide a custom string for the yes command to use in output. For example:
|
||||
|
||||
```
|
||||
yes HTF
|
||||
```
|
||||
|
||||
[![Repeat word with yes command][3]][4]
|
||||
|
||||
### Q2. Where yes command helps the user?
|
||||
|
||||
That's a valid question. Reason being, from what yes does, it's difficult to imagine the usefulness of the tool. But you'll be surprised to know that yes can not only save your time, but also automate some mundane tasks.
|
||||
|
||||
For example, consider the following scenario:
|
||||
|
||||
[![Where yes command helps the user][5]][6]
|
||||
|
||||
You can see that user has to type 'y' for each query. It's in situation like these where yes can help. For the above scenario specifically, you can use yes in the following way:
|
||||
|
||||
```
|
||||
yes | rm -ri test
|
||||
```
|
||||
|
||||
[![yes command in action][7]][8]
|
||||
|
||||
So the command made sure user doesn't have to write 'y' each time when rm asked for it. Of course, one would argue that we could have simply removed the '-i' option from the rm command. That's right, I took this example as it's simple enough to make people understand the situations in which yes can be helpful.
|
||||
|
||||
Another - and probably more relevant - scenario would be when you're using the fsck command, and don't want to enter 'y' each time system asks your permission before fixing errors.
|
||||
|
||||
### Q3. Is there any use of yes when it's used alone?
|
||||
|
||||
Yes, there's at-least one use: to tell how well a computer system handles high amount of loads. Reason being, the tool utilizes 100% processor for systems that have a single processor. In case you want to apply this test on a system with multiple processors, you need to run a yes process for each processor.
|
||||
|
||||
### Q4. What command line options yes offers?
|
||||
|
||||
The tool only offers generic command line options: --help and --version. As the names suggests. the former displays help information related to the command, while the latter one outputs version related information.
|
||||
|
||||
[![What command line options yes offers][9]][10]
|
||||
|
||||
### Conclusion
|
||||
|
||||
So now you'd agree that there could be several scenarios where the yes command would be of help. There are no command line options unique to yes, so effectively, there's no learning curve associated with the tool. Just in case you need, here's the command's [man page][11].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-yes-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/yes-def-output.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/yes-def-output.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/yes-custom-string.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/yes-custom-string.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/rm-ri-output.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/rm-ri-output.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/yes-in-action.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/yes-in-action.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/yes-help-version1.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/yes-help-version1.png
|
||||
[11]:https://linux.die.net/man/1/yes
|
||||
@ -1,77 +0,0 @@
|
||||
What a GNU C Compiler Bug looks like
|
||||
======
|
||||
Back in December a Linux Mint user sent a [strange bug report][1] to the darktable mailing list. Apparently the GNU C Compiler (GCC) on his system exited with the following error message, breaking the build process:
|
||||
```
|
||||
cc1: error: unrecognized command line option '-Wno-format-truncation' [-Werror]
|
||||
cc1: all warnings being treated as errors
|
||||
src/iop/CMakeFiles/colortransfer.dir/build.make:67: recipe for target 'src/iop/CMakeFiles/colortransfer.dir/introspection_colortransfer.c.o' failed make[2]: 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh [src/iop/CMakeFiles/colortransfer.dir/introspection_colortransfer.c.o] Error 1 CMakeFiles/Makefile2:6323: recipe for target 'src/iop/CMakeFiles/colortransfer.dir/all' failed
|
||||
|
||||
make[1]: 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh [src/iop/CMakeFiles/colortransfer.dir/all] Error 2
|
||||
|
||||
```
|
||||
|
||||
`-Wno-format-truncation` is a rather new GCC feature which instructs the compiler to issue a warning if it can already deduce at compile time that calls to formatted I/O functions like `snprintf()` or `vsnprintf()` might result in truncated output.
|
||||
|
||||
That's definitely neat, but Linux Mint 18.3 (just like Ubuntu 16.04 LTS) uses GCC 5.4.0, which doesn't support this feature. And darktable relies on a chain of CMake macros to make sure it doesn't use any flags the compiler doesn't know about:
|
||||
```
|
||||
CHECK_COMPILER_FLAG_AND_ENABLE_IT(-Wno-format-truncation)
|
||||
|
||||
```
|
||||
|
||||
So why did this even happen? I logged into one of my Ubuntu 16.04 installations and tried to reproduce the problem. Which wasn't hard, I just had to check out the git tree in question and build it. Boom, same error.
|
||||
|
||||
### The solution
|
||||
|
||||
It turns out that while `-Wformat-truncation` isn't a valid option for GCC 5.4.0 (it's not documented), this version silently accepts the negation under some circumstances (!):
|
||||
```
|
||||
|
||||
sturmflut@hogsmeade:/tmp$ gcc -Wformat-truncation -o test test.c
|
||||
gcc: error: unrecognized command line option '-Wformat-truncation'
|
||||
sturmflut@hogsmeade:/tmp$ gcc -Wno-format-truncation -o test test.c
|
||||
sturmflut@hogsmeade:/tmp$
|
||||
|
||||
```
|
||||
|
||||
(test.c just contains an empty main() method).
|
||||
|
||||
Because darktable uses `CHECK_COMPILER_FLAG_AND_ENABLE_IT(-Wno-format-truncation)`, it is fooled into thinking this compiler version actually supports `-Wno-format-truncation` at all times. The simple test case used by the CMake macro doesn't fail, but the compiler later decides to no longer silently accept the invalid command line option for some reason.
|
||||
|
||||
One of the cases which triggered this was when the source file under compilation had already generated some other warnings before. If I forced a serialized build using `make -j1` on a clean darktable checkout on this machine, `./src/iop/colortransfer.c` actually was the first file which caused any
|
||||
compiler warnings at all, so this is why the process failed exactly there.
|
||||
|
||||
The minimum test case to trigger this behavior in GCC 5.4.0 is a C file with a `main()` function with a parameter which has the wrong type, like this one:
|
||||
```
|
||||
|
||||
int main(int argc, int argv)
|
||||
{
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Then add `-Wall` to make sure the compiler will treat this as a warning, and it fails:
|
||||
```
|
||||
|
||||
sturmflut@hogsmeade:/tmp$ gcc -Wall -Wno-format-truncation -o test test.c
|
||||
test.c:1:5: warning: second argument of 'main' should be 'char **' [-Wmain]
|
||||
int main(int argc, int argv)
|
||||
^
|
||||
cc1: warning: unrecognized command line option '-Wno-format-truncation'
|
||||
|
||||
```
|
||||
|
||||
If you omit `-Wall`, the compiler will not generate the first warning and also not complain about `-Wno-format-truncation`.
|
||||
|
||||
I've never run into this before, but I guess Ubuntu 16.04 is going to stay with us for a while since it is the current LTS release until May 2018, and even after that it will still be supported until 2021. So this buggy GCC version will most likely also stay alive for quite a while. Which is why the check for this flag has been removed from the
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.lieberbiber.de/2018/01/14/what-a-gnu-compiler-bug-looks-like/
|
||||
|
||||
作者:[sturmflut][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.lieberbiber.de/author/sturmflut/
|
||||
[1]:https://www.mail-archive.com/darktable-dev@lists.darktable.org/msg02760.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Partclone – A Versatile Free Software for Partition Imaging and Cloning
|
||||
======
|
||||
|
||||
|
||||
@ -1,253 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Analyzing the Linux boot process
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image by : Penguin, Boot. Modified by Opensource.com. CC BY-SA 4.0.
|
||||
|
||||
The oldest joke in open source software is the statement that "the code is self-documenting." Experience shows that reading the source is akin to listening to the weather forecast: sensible people still go outside and check the sky. What follows are some tips on how to inspect and observe Linux systems at boot by leveraging knowledge of familiar debugging tools. Analyzing the boot processes of systems that are functioning well prepares users and developers to deal with the inevitable failures.
|
||||
|
||||
In some ways, the boot process is surprisingly simple. The kernel starts up single-threaded and synchronous on a single core and seems almost comprehensible to the pitiful human mind. But how does the kernel itself get started? What functions do [initial ramdisk][1] ) and bootloaders perform? And wait, why is the LED on the Ethernet port always on?
|
||||
|
||||
Read on for answers to these and other questions; the [code for the described demos and exercises][2] is also available on GitHub.
|
||||
|
||||
### The beginning of boot: the OFF state
|
||||
|
||||
#### Wake-on-LAN
|
||||
|
||||
The OFF state means that the system has no power, right? The apparent simplicity is deceptive. For example, the Ethernet LED is illuminated because wake-on-LAN (WOL) is enabled on your system. Check whether this is the case by typing:
|
||||
```
|
||||
$# sudo ethtool <interface name>
|
||||
```
|
||||
|
||||
where `<interface name>` might be, for example, `eth0`. (`ethtool` is found in Linux packages of the same name.) If "Wake-on" in the output shows `g`, remote hosts can boot the system by sending a [MagicPacket][3]. If you have no intention of waking up your system remotely and do not wish others to do so, turn WOL off either in the system BIOS menu, or via:
|
||||
```
|
||||
$# sudo ethtool -s <interface name> wol d
|
||||
```
|
||||
|
||||
The processor that responds to the MagicPacket may be part of the network interface or it may be the [Baseboard Management Controller][4] (BMC).
|
||||
|
||||
#### Intel Management Engine, Platform Controller Hub, and Minix
|
||||
|
||||
The BMC is not the only microcontroller (MCU) that may be listening when the system is nominally off. x86_64 systems also include the Intel Management Engine (IME) software suite for remote management of systems. A wide variety of devices, from servers to laptops, includes this technology, [which enables functionality][5] such as KVM Remote Control and Intel Capability Licensing Service. The [IME has unpatched vulnerabilities][6], according to [Intel's own detection tool][7]. The bad news is, it's difficult to disable the IME. Trammell Hudson has created an [me_cleaner project][8] that wipes some of the more egregious IME components, like the embedded web server, but could also brick the system on which it is run.
|
||||
|
||||
The IME firmware and the System Management Mode (SMM) software that follows it at boot are [based on the Minix operating system][9] and run on the separate Platform Controller Hub processor, not the main system CPU. The SMM then launches the Universal Extensible Firmware Interface (UEFI) software, about which much has [already been written][10], on the main processor. The Coreboot group at Google has started a breathtakingly ambitious [Non-Extensible Reduced Firmware][11] (NERF) project that aims to replace not only UEFI but early Linux userspace components such as systemd. While we await the outcome of these new efforts, Linux users may now purchase laptops from Purism, System76, or Dell [with IME disabled][12], plus we can hope for laptops [with ARM 64-bit processors][13].
|
||||
|
||||
#### Bootloaders
|
||||
|
||||
Besides starting buggy spyware, what function does early boot firmware serve? The job of a bootloader is to make available to a newly powered processor the resources it needs to run a general-purpose operating system like Linux. At power-on, there not only is no virtual memory, but no DRAM until its controller is brought up. A bootloader then turns on power supplies and scans buses and interfaces in order to locate the kernel image and the root filesystem. Popular bootloaders like U-Boot and GRUB have support for familiar interfaces like USB, PCI, and NFS, as well as more embedded-specific devices like NOR- and NAND-flash. Bootloaders also interact with hardware security devices like [Trusted Platform Modules][14] (TPMs) to establish a chain of trust from earliest boot.
|
||||
|
||||
![Running the U-boot bootloader][16]
|
||||
|
||||
Running the U-boot bootloader in the sandbox on the build host.
|
||||
|
||||
The open source, widely used [U-Boot ][17]bootloader is supported on systems ranging from Raspberry Pi to Nintendo devices to automotive boards to Chromebooks. There is no syslog, and when things go sideways, often not even any console output. To facilitate debugging, the U-Boot team offers a sandbox in which patches can be tested on the build-host, or even in a nightly Continuous Integration system. Playing with U-Boot's sandbox is relatively simple on a system where common development tools like Git and the GNU Compiler Collection (GCC) are installed:
|
||||
```
|
||||
|
||||
|
||||
$# git clone git://git.denx.de/u-boot; cd u-boot
|
||||
|
||||
$# make ARCH=sandbox defconfig
|
||||
|
||||
$# make; ./u-boot
|
||||
|
||||
=> printenv
|
||||
|
||||
=> help
|
||||
```
|
||||
|
||||
That's it: you're running U-Boot on x86_64 and can test tricky features like [mock storage device][2] repartitioning, TPM-based secret-key manipulation, and hotplug of USB devices. The U-Boot sandbox can even be single-stepped under the GDB debugger. Development using the sandbox is 10x faster than testing by reflashing the bootloader onto a board, and a "bricked" sandbox can be recovered with Ctrl+C.
|
||||
|
||||
### Starting up the kernel
|
||||
|
||||
#### Provisioning a booting kernel
|
||||
|
||||
Upon completion of its tasks, the bootloader will execute a jump to kernel code that it has loaded into main memory and begin execution, passing along any command-line options that the user has specified. What kind of program is the kernel? `file /boot/vmlinuz` indicates that it is a bzImage, meaning a big compressed one. The Linux source tree contains an [extract-vmlinux tool][18] that can be used to uncompress the file:
|
||||
```
|
||||
|
||||
|
||||
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
|
||||
|
||||
$# file vmlinux
|
||||
|
||||
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
|
||||
|
||||
linked, stripped
|
||||
```
|
||||
|
||||
The kernel is an [Executable and Linking Format][19] (ELF) binary, like Linux userspace programs. That means we can use commands from the `binutils` package like `readelf` to inspect it. Compare the output of, for example:
|
||||
```
|
||||
|
||||
|
||||
$# readelf -S /bin/date
|
||||
|
||||
$# readelf -S vmlinux
|
||||
```
|
||||
|
||||
The list of sections in the binaries is largely the same.
|
||||
|
||||
So the kernel must start up something like other Linux ELF binaries ... but how do userspace programs actually start? In the `main()` function, right? Not precisely.
|
||||
|
||||
Before the `main()` function can run, programs need an execution context that includes heap and stack memory plus file descriptors for `stdio`, `stdout`, and `stderr`. Userspace programs obtain these resources from the standard library, which is `glibc` on most Linux systems. Consider the following:
|
||||
```
|
||||
|
||||
|
||||
$# file /bin/date
|
||||
|
||||
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
|
||||
|
||||
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
|
||||
|
||||
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
|
||||
|
||||
stripped
|
||||
```
|
||||
|
||||
ELF binaries have an interpreter, just as Bash and Python scripts do, but the interpreter need not be specified with `#!` as in scripts, as ELF is Linux's native format. The ELF interpreter [provisions a binary][20] with the needed resources by calling `_start()`, a function available from the `glibc` source package that can be [inspected via GDB][21]. The kernel obviously has no interpreter and must provision itself, but how?
|
||||
|
||||
Inspecting the kernel's startup with GDB gives the answer. First install the debug package for the kernel that contains an unstripped version of `vmlinux`, for example `apt-get install linux-image-amd64-dbg`, or compile and install your own kernel from source, for example, by following instructions in the excellent [Debian Kernel Handbook][22]. `gdb vmlinux` followed by `info files` shows the ELF section `init.text`. List the start of program execution in `init.text` with `l *(address)`, where `address` is the hexadecimal start of `init.text`. GDB will indicate that the x86_64 kernel starts up in the kernel's file [arch/x86/kernel/head_64.S][23], where we find the assembly function `start_cpu0()` and code that explicitly creates a stack and decompresses the zImage before calling the `x86_64 start_kernel()` function. ARM 32-bit kernels have the similar [arch/arm/kernel/head.S][24]. `start_kernel()` is not architecture-specific, so the function lives in the kernel's [init/main.c][25]. `start_kernel()` is arguably Linux's true `main()` function.
|
||||
|
||||
### From start_kernel() to PID 1
|
||||
|
||||
#### The kernel's hardware manifest: the device-tree and ACPI tables
|
||||
|
||||
At boot, the kernel needs information about the hardware beyond the processor type for which it has been compiled. The instructions in the code are augmented by configuration data that is stored separately. There are two main methods of storing this data: [device-trees][26] and [ACPI tables][27]. The kernel learns what hardware it must run at each boot by reading these files.
|
||||
|
||||
For embedded devices, the device-tree is a manifest of installed hardware. The device-tree is simply a file that is compiled at the same time as kernel source and is typically located in `/boot` alongside `vmlinux`. To see what's in the binary device-tree on an ARM device, just use the `strings` command from the `binutils` package on a file whose name matches `/boot/*.dtb`, as `dtb` refers to a device-tree binary. Clearly the device-tree can be modified simply by editing the JSON-like files that compose it and rerunning the special `dtc` compiler that is provided with the kernel source. While the device-tree is a static file whose file path is typically passed to the kernel by the bootloader on the command line, a [device-tree overlay][28] facility has been added in recent years, where the kernel can dynamically load additional fragments in response to hotplug events after boot.
|
||||
|
||||
x86-family and many enterprise-grade ARM64 devices make use of the alternative Advanced Configuration and Power Interface ([ACPI][27]) mechanism. In contrast to the device-tree, the ACPI information is stored in the `/sys/firmware/acpi/tables` virtual filesystem that is created by the kernel at boot by accessing onboard ROM. The easy way to read the ACPI tables is with the `acpidump` command from the `acpica-tools` package. Here's an example:
|
||||
|
||||
![ACPI tables on Lenovo laptops][30]
|
||||
|
||||
|
||||
ACPI tables on Lenovo laptops are all set for Windows 2001.
|
||||
|
||||
Yes, your Linux system is ready for Windows 2001, should you care to install it. ACPI has both methods and data, unlike the device-tree, which is more of a hardware-description language. ACPI methods continue to be active post-boot. For example, starting the command `acpi_listen` (from package `apcid`) and opening and closing the laptop lid will show that ACPI functionality is running all the time. While temporarily and dynamically [overwriting the ACPI tables][31] is possible, permanently changing them involves interacting with the BIOS menu at boot or reflashing the ROM. If you're going to that much trouble, perhaps you should just [install coreboot][32], the open source firmware replacement.
|
||||
|
||||
#### From start_kernel() to userspace
|
||||
|
||||
The code in [init/main.c][25] is surprisingly readable and, amusingly, still carries Linus Torvalds' original copyright from 1991-1992. The lines found in `dmesg | head` on a newly booted system originate mostly from this source file. The first CPU is registered with the system, global data structures are initialized, and the scheduler, interrupt handlers (IRQs), timers, and console are brought one-by-one, in strict order, online. Until the function `timekeeping_init()` runs, all timestamps are zero. This part of the kernel initialization is synchronous, meaning that execution occurs in precisely one thread, and no function is executed until the last one completes and returns. As a result, the `dmesg` output will be completely reproducible, even between two systems, as long as they have the same device-tree or ACPI tables. Linux is behaving like one of the RTOS (real-time operating systems) that runs on MCUs, for example QNX or VxWorks. The situation persists into the function `rest_init()`, which is called by `start_kernel()` at its termination.
|
||||
|
||||
![Summary of early kernel boot process.][34]
|
||||
|
||||
Summary of early kernel boot process.
|
||||
|
||||
The rather humbly named `rest_init()` spawns a new thread that runs `kernel_init()`, which invokes `do_initcalls()`. Users can spy on `initcalls` in action by appending `initcall_debug` to the kernel command line, resulting in `dmesg` entries every time an `initcall` function runs. `initcalls` pass through seven sequential levels: early, core, postcore, arch, subsys, fs, device, and late. The most user-visible part of the `initcalls` is the probing and setup of all the processors' peripherals: buses, network, storage, displays, etc., accompanied by the loading of their kernel modules. `rest_init()` also spawns a second thread on the boot processor that begins by running `cpu_idle()` while it waits for the scheduler to assign it work.
|
||||
|
||||
`kernel_init()` also [sets up symmetric multiprocessing][35] (SMP). With more recent kernels, find this point in `dmesg` output by looking for "Bringing up secondary CPUs..." SMP proceeds by "hotplugging" CPUs, meaning that it manages their lifecycle with a state machine that is notionally similar to that of devices like hotplugged USB sticks. The kernel's power-management system frequently takes individual cores offline, then wakes them as needed, so that the same CPU hotplug code is called over and over on a machine that is not busy. Observe the power-management system's invocation of CPU hotplug with the [BCC tool][36] called `offcputime.py`.
|
||||
|
||||
Note that the code in `init/main.c` is nearly finished executing when `smp_init()` runs: The boot processor has completed most of the one-time initialization that the other cores need not repeat. Nonetheless, the per-CPU threads must be spawned for each core to manage interrupts (IRQs), workqueues, timers, and power events on each. For example, see the per-CPU threads that service softirqs and workqueues in action via the `ps -o psr` command.
|
||||
```
|
||||
|
||||
|
||||
$\# ps -o pid,psr,comm $(pgrep ksoftirqd)
|
||||
|
||||
PID PSR COMMAND
|
||||
|
||||
7 0 ksoftirqd/0
|
||||
|
||||
16 1 ksoftirqd/1
|
||||
|
||||
22 2 ksoftirqd/2
|
||||
|
||||
28 3 ksoftirqd/3
|
||||
|
||||
|
||||
|
||||
$\# ps -o pid,psr,comm $(pgrep kworker)
|
||||
|
||||
PID PSR COMMAND
|
||||
|
||||
4 0 kworker/0:0H
|
||||
|
||||
18 1 kworker/1:0H
|
||||
|
||||
24 2 kworker/2:0H
|
||||
|
||||
30 3 kworker/3:0H
|
||||
|
||||
[ . . . ]
|
||||
```
|
||||
|
||||
where the PSR field stands for "processor." Each core must also host its own timers and `cpuhp` hotplug handlers.
|
||||
|
||||
How is it, finally, that userspace starts? Near its end, `kernel_init()` looks for an `initrd` that can execute the `init` process on its behalf. If it finds none, the kernel directly executes `init` itself. Why then might one want an `initrd`?
|
||||
|
||||
#### Early userspace: who ordered the initrd?
|
||||
|
||||
Besides the device-tree, another file path that is optionally provided to the kernel at boot is that of the `initrd`. The `initrd` often lives in `/boot` alongside the bzImage file vmlinuz on x86, or alongside the similar uImage and device-tree for ARM. List the contents of the `initrd` with the `lsinitramfs` tool that is part of the `initramfs-tools-core` package. Distro `initrd` schemes contain minimal `/bin`, `/sbin`, and `/etc` directories along with kernel modules, plus some files in `/scripts`. All of these should look pretty familiar, as the `initrd` for the most part is simply a minimal Linux root filesystem. The apparent similarity is a bit deceptive, as nearly all the executables in `/bin` and `/sbin` inside the ramdisk are symlinks to the [BusyBox binary][37], resulting in `/bin` and `/sbin` directories that are 10x smaller than glibc's.
|
||||
|
||||
Why bother to create an `initrd` if all it does is load some modules and then start `init` on the regular root filesystem? Consider an encrypted root filesystem. The decryption may rely on loading a kernel module that is stored in `/lib/modules` on the root filesystem ... and, unsurprisingly, in the `initrd` as well. The crypto module could be statically compiled into the kernel instead of loaded from a file, but there are various reasons for not wanting to do so. For example, statically compiling the kernel with modules could make it too large to fit on the available storage, or static compilation may violate the terms of a software license. Unsurprisingly, storage, network, and human input device (HID) drivers may also be present in the `initrd`--basically any code that is not part of the kernel proper that is needed to mount the root filesystem. The `initrd` is also a place where users can stash their own [custom ACPI][38] table code.
|
||||
|
||||
![Rescue shell and a custom <code>initrd</code>.][40]
|
||||
|
||||
Having some fun with the rescue shell and a custom `initrd`.
|
||||
|
||||
`initrd`'s are also great for testing filesystems and data-storage devices themselves. Stash these test tools in the `initrd` and run your tests from memory rather than from the object under test.
|
||||
|
||||
At last, when `init` runs, the system is up! Since the secondary processors are now running, the machine has become the asynchronous, preemptible, unpredictable, high-performance creature we know and love. Indeed, `ps -o pid,psr,comm -p 1` is liable to show that userspace's `init` process is no longer running on the boot processor.
|
||||
|
||||
### Summary
|
||||
|
||||
The Linux boot process sounds forbidding, considering the number of different pieces of software that participate even on simple embedded devices. Looked at differently, the boot process is rather simple, since the bewildering complexity caused by features like preemption, RCU, and race conditions are absent in boot. Focusing on just the kernel and PID 1 overlooks the large amount of work that bootloaders and subsidiary processors may do in preparing the platform for the kernel to run. While the kernel is certainly unique among Linux programs, some insight into its structure can be gleaned by applying to it some of the same tools used to inspect other ELF binaries. Studying the boot process while it's working well arms system maintainers for failures when they come.
|
||||
|
||||
To learn more, attend Alison Chaiken's talk, [Linux: The first second][41], at [linux.conf.au][42], which will be held January 22-26 in Sydney.
|
||||
|
||||
Thanks to [Akkana Peck][43] for originally suggesting this topic and for many corrections.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/analyzing-linux-boot-process
|
||||
|
||||
作者:[Alison Chaiken][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[2]:https://github.com/chaiken/LCA2018-Demo-Code
|
||||
[3]:https://en.wikipedia.org/wiki/Wake-on-LAN
|
||||
[4]:https://lwn.net/Articles/630778/
|
||||
[5]:https://www.youtube.com/watch?v=iffTJ1vPCSo&index=65&list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
|
||||
[6]:https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&languageid=en-fr
|
||||
[7]:https://www.intel.com/content/www/us/en/support/articles/000025619/software.html
|
||||
[8]:https://github.com/corna/me_cleaner
|
||||
[9]:https://lwn.net/Articles/738649/
|
||||
[10]:https://lwn.net/Articles/699551/
|
||||
[11]:https://trmm.net/NERF
|
||||
[12]:https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled
|
||||
[13]:https://lwn.net/Articles/733837/
|
||||
[14]:https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639
|
||||
[15]:/file/383501
|
||||
[16]:https://opensource.com/sites/default/files/u128651/linuxboot_1.png (Running the U-boot bootloader)
|
||||
[17]:http://www.denx.de/wiki/DULG/Manual
|
||||
[18]:https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux
|
||||
[19]:http://man7.org/linux/man-pages/man5/elf.5.html
|
||||
[20]:https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html
|
||||
[21]:https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e
|
||||
[22]:http://kernel-handbook.alioth.debian.org/
|
||||
[23]:https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S
|
||||
[24]:https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S
|
||||
[25]:https://github.com/torvalds/linux/blob/master/init/main.c
|
||||
[26]:https://www.youtube.com/watch?v=m_NyYEBxfn8
|
||||
[27]:http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf
|
||||
[28]:http://lwn.net/Articles/616859/
|
||||
[29]:/file/383506
|
||||
[30]:https://opensource.com/sites/default/files/u128651/linuxboot_2.png (ACPI tables on Lenovo laptops)
|
||||
[31]:https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt
|
||||
[32]:https://www.coreboot.org/Supported_Motherboards
|
||||
[33]:/file/383511
|
||||
[34]:https://opensource.com/sites/default/files/u128651/linuxboot_3.png (Summary of early kernel boot process.)
|
||||
[35]:http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc
|
||||
[36]:http://www.brendangregg.com/ebpf.html
|
||||
[37]:https://www.busybox.net/
|
||||
[38]:https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt
|
||||
[39]:/file/383516
|
||||
[40]:https://opensource.com/sites/default/files/u128651/linuxboot_4.png (Rescue shell and a custom <code>initrd</code>.)
|
||||
[41]:https://rego.linux.conf.au/schedule/presentation/16/
|
||||
[42]:https://linux.conf.au/index.html
|
||||
[43]:http://shallowsky.com/
|
||||
@ -1,225 +0,0 @@
|
||||
How to Install and Use iostat on Ubuntu 16.04 LTS
|
||||
======
|
||||
|
||||
iostat also known as input/output statistics is a popular Linux system monitoring tool that can be used to collect statistics of input and output devices. It allows users to identify performance issues of local disk, remote disk and system information. The iostat create reports, the CPU Utilization report, the Device Utilization report and the Network Filesystem report.
|
||||
|
||||
In this tutorial, we will learn how to install iostat on Ubuntu 16.04 and how to use it.
|
||||
|
||||
### Prerequisite
|
||||
|
||||
* Ubuntu 16.04 desktop installed on your system.
|
||||
* Non-root user with sudo privileges setup on your system
|
||||
|
||||
|
||||
|
||||
### Install iostat
|
||||
|
||||
By default, iostat is included with sysstat package in Ubuntu 16.04. You can easily install it by just running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install sysstat -y
|
||||
```
|
||||
|
||||
Once sysstat is installed, you can proceed to the next step.
|
||||
|
||||
### iostat Basic Example
|
||||
|
||||
Let's start by running the iostat command without any argument. This will displays information about the CPU usage, and I/O statistics of your system:
|
||||
|
||||
```
|
||||
iostat
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
22.67 0.52 6.99 1.88 0.00 67.94
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 15.15 449.15 119.01 771022 204292
|
||||
|
||||
```
|
||||
|
||||
In the above output, the first line display, Linux kernel version and hostname. Next two lines displays CPU statistics like, average CPU usage, percentage of time the CPU were idle and waited for I/O response, percentage of waiting time of virtual CPU and the percentage of time the CPU is idle. Next two lines displays the device utilization report like, number of blocks read and write per second and total block reads and write per second.
|
||||
|
||||
By default iostat displays the report with current date. If you want to display the current time, run the following command:
|
||||
|
||||
```
|
||||
iostat -t
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
Saturday 16 December 2017 09:44:55 IST
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.37 0.31 6.93 1.28 0.00 70.12
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 9.48 267.80 79.69 771022 229424
|
||||
|
||||
```
|
||||
|
||||
To check the version of the iostat, run the following command:
|
||||
|
||||
```
|
||||
iostat -V
|
||||
```
|
||||
|
||||
Output:
|
||||
```
|
||||
sysstat version 10.2.0
|
||||
(C) Sebastien Godard (sysstat orange.fr)
|
||||
|
||||
```
|
||||
|
||||
You can listout all the options available with iostat command using the following command:
|
||||
|
||||
```
|
||||
iostat --help
|
||||
```
|
||||
|
||||
Output:
|
||||
```
|
||||
Usage: iostat [ options ] [ [ ] ]
|
||||
Options are:
|
||||
[ -c ] [ -d ] [ -h ] [ -k | -m ] [ -N ] [ -t ] [ -V ] [ -x ] [ -y ] [ -z ]
|
||||
[ -j { ID | LABEL | PATH | UUID | ... } ]
|
||||
[ [ -T ] -g ] [ -p [ [,...] | ALL ] ]
|
||||
[ [...] | ALL ]
|
||||
|
||||
```
|
||||
|
||||
### iostat Advance Usage Example
|
||||
|
||||
If you want to view only the device report only once, run the following command:
|
||||
|
||||
```
|
||||
iostat -d
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 12.18 353.66 102.44 771022 223320
|
||||
|
||||
```
|
||||
|
||||
To view the device report continuously for every 5 seconds, for 3 times:
|
||||
|
||||
```
|
||||
iostat -d 5 3
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 11.77 340.71 98.95 771022 223928
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 2.00 0.00 8.00 0 40
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 0.60 0.00 3.20 0 16
|
||||
|
||||
```
|
||||
|
||||
If you want to view the statistics of specific devices, run the following command:
|
||||
|
||||
```
|
||||
iostat -p sda
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.69 0.36 6.98 1.44 0.00 69.53
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 11.00 316.91 92.38 771022 224744
|
||||
sda1 0.07 0.27 0.00 664 0
|
||||
sda2 0.01 0.05 0.00 128 0
|
||||
sda3 0.07 0.27 0.00 648 0
|
||||
sda4 10.56 315.21 92.35 766877 224692
|
||||
sda5 0.12 0.48 0.02 1165 52
|
||||
sda6 0.07 0.32 0.00 776 0
|
||||
|
||||
```
|
||||
|
||||
You can also view the statistics of multiple devices with the following command:
|
||||
|
||||
```
|
||||
iostat -p sda, sdb, sdc
|
||||
```
|
||||
|
||||
If you want to displays the device I/O statistics in MB/second, run the following command:
|
||||
|
||||
```
|
||||
iostat -m
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.39 0.31 6.94 1.30 0.00 70.06
|
||||
|
||||
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
|
||||
sda 9.67 0.27 0.08 752 223
|
||||
|
||||
```
|
||||
|
||||
If you want to view the extended information for a specific partition (sda4), run the following command:
|
||||
|
||||
```
|
||||
iostat -x sda4
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.26 0.28 6.87 1.19 0.00 70.39
|
||||
|
||||
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
|
||||
sda4 0.79 4.65 5.71 2.68 242.76 73.28 75.32 0.35 41.80 43.66 37.84 4.55 3.82
|
||||
|
||||
```
|
||||
|
||||
If you want to displays only the CPU usage statistics, run the following command:
|
||||
|
||||
```
|
||||
iostat -c
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.45 0.33 6.96 1.34 0.00 69.91
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-use-iostat-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
@ -1,125 +0,0 @@
|
||||
Avoiding Server Disaster
|
||||
======
|
||||
|
||||
Worried that your server will go down? You should be. Here are some disaster-planning tips for server owners.
|
||||
|
||||
If you own a car or a house, you almost certainly have insurance. Insurance seems like a huge waste of money. You pay it every year and make sure that you get the best possible price for the best possible coverage, and then you hope you never need to use the insurance. Insurance seems like a really bad deal—until you have a disaster and realize that had it not been for the insurance, you might have been in financial ruin.
|
||||
|
||||
Unfortunately, disasters and mishaps are a fact of life in the computer industry. And so, just as you pay insurance and hope never to have to use it, you also need to take time to ensure the safety and reliability of your systems—not because you want disasters to happen, or even expect them to occur, but rather because you have to.
|
||||
|
||||
If your website is an online brochure for your company and then goes down for a few hours or even days, it'll be embarrassing and annoying, but not financially painful. But, if your website is your business, when your site goes down, you're losing money. If that's the case, it's crucial to ensure that your server and software are not only unlikely to go down, but also easily recoverable if and when that happens.
|
||||
|
||||
Why am I writing about this subject? Well, let's just say that this particular problem hit close to home for me, just before I started to write this article. After years of helping clients around the world to ensure the reliability of their systems, I made the mistake of not being as thorough with my own. ("The shoemaker's children go barefoot", as the saying goes.) This means that just after launching my new online product for Python developers, a seemingly trivial upgrade turned into a disaster. The precautions I put in place, it turns out, weren't quite enough—and as I write this, I'm still putting my web server together. I'll survive, as will my server and business, but this has been a painful and important lesson—one that I'll do almost anything to avoid repeating in the future.
|
||||
|
||||
So in this article, I describe a number of techniques I've used to keep servers safe and sound through the years, and to reduce the chances of a complete meltdown. You can think of these techniques as insurance for your server, so that even if something does go wrong, you'll be able to recover fairly quickly.
|
||||
|
||||
I should note that most of the advice here assumes no redundancy in your architecture—that is, a single web server and (at most) a single database server. If you can afford to have a bunch of servers of each type, these sorts of problems tend to be much less frequent. However, that doesn't mean they go away entirely. Besides, although people like to talk about heavy-duty web applications that require massive iron in order to run, the fact is that many businesses run on small, one- and two-computer servers. Moreover, those businesses don't need more than that; the ROI (return on investment) they'll get from additional servers cannot be justified. However, the ROI from a good backup and recovery plan is huge, and thus worth the investment.
|
||||
|
||||
### The Parts of a Web Application
|
||||
|
||||
Before I can talk about disaster preparation and recovery, it's important to consider the different parts of a web application and what those various parts mean for your planning.
|
||||
|
||||
For many years, my website was trivially small and simple. Even if it contained some simple programs, those generally were used for sending email or for dynamically displaying different assets to visitors. The entire site consisted of some static HTML, images, JavaScript and CSS. No database or other excitement was necessary.
|
||||
|
||||
At the other end of the spectrum, many people have full-blown web applications, sitting on multiple servers, with one or more databases and caches, as well as HTTP servers with extensively edited configuration files.
|
||||
|
||||
But even when considering those two extremes, you can see that a web application consists of only a few parts:
|
||||
|
||||
* The application software itself.
|
||||
|
||||
* Static assets for that application.
|
||||
|
||||
* Configuration file(s) for the HTTP server(s).
|
||||
|
||||
* Database configuration files.
|
||||
|
||||
* Database schema and contents.
|
||||
|
||||
Assuming that you're using a high-level language, such as Python, Ruby or JavaScript, everything in this list either is a file or can be turned into one. (All databases make it possible to "dump" their contents onto disk, into a format that then can be loaded back into the database server.)
|
||||
|
||||
Consider a site containing only application software, static assets and configuration files. (In other words, no database is involved.) In many cases, such a site can be backed up reliably in Git. Indeed, I prefer to keep my sites in Git, backed up on a commercial hosting service, such as GitHub or Bitbucket, and then deployed using a system like Capistrano.
|
||||
|
||||
In other words, you develop the site on your own development machine. Whenever you are happy with a change that you've made, you commit the change to Git (on your local machine) and then do a git push to your central repository. In order to deploy your application, you then use Capistrano to do a cap deploy, which reads the data from the central repository, puts it into the appropriate place on the server's filesystem, and you're good to go.
|
||||
|
||||
This system keeps you safe in a few different ways. The code itself is located in at least three locations: your development machine, the server and the repository. And those central repositories tend to be fairly reliable, if only because it's in the financial interest of the hosting company to ensure that things are reliable.
|
||||
|
||||
I should add that in such a case, you also should include the HTTP server's configuration files in your Git repository. Those files aren't likely to change very often, but I can tell you from experience, if you're recovering from a crisis, the last thing you want to think about is how your Apache configuration files should look. Copying those files into your Git repository will work just fine.
|
||||
|
||||
### Backing Up Databases
|
||||
|
||||
You could argue that the difference between a "website" and a "web application" is a database. Databases long have powered the back ends of many web applications and for good reason—they allow you to store and retrieve data reliably and flexibly. The power that modern open-source databases provides was unthinkable just a decade or two ago, and there's no reason to think that they'll be any less reliable in the future.
|
||||
|
||||
And yet, just because your database is pretty reliable doesn't mean that it won't have problems. This means you're going to want to keep a snapshot ("dump") of the database's contents around, in case the database server corrupts information, and you need to roll back to a previous version.
|
||||
|
||||
My favorite solution for such a problem is to dump the database on a regular basis, preferably hourly. Here's a shell script I've used, in one form or another, for creating such regular database dumps:
|
||||
|
||||
```
|
||||
|
||||
#!/bin/sh
|
||||
|
||||
BACKUP_ROOT="/home/database-backups/"
|
||||
YEAR=`/bin/date +'%Y'`
|
||||
MONTH=`/bin/date +'%m'`
|
||||
DAY=`/bin/date +'%d'`
|
||||
|
||||
DIRECTORY="$BACKUP_ROOT/$YEAR/$MONTH/$DAY"
|
||||
USERNAME=dbuser
|
||||
DATABASE=dbname
|
||||
HOST=localhost
|
||||
PORT=3306
|
||||
|
||||
/bin/mkdir -p $DIRECTORY
|
||||
|
||||
/usr/bin/mysqldump -h $HOST --databases $DATABASE -u $USERNAME
|
||||
↪| /bin/gzip --best --verbose >
|
||||
↪$DIRECTORY/$DATABASE-dump.gz
|
||||
|
||||
```
|
||||
|
||||
The above shell script starts off by defining a bunch of variables, from the directory in which I want to store the backups, to the parts of the date (stored in $YEAR, $MONTH and $DAY). This is so I can have a separate directory for each day of the month. I could, of course, go further and have separate directories for each hour, but I've found that I rarely need more than one backup from a day.
|
||||
|
||||
Once I have defined those variables, I then use the mkdir command to create a new directory. The -p option tells mkdir that if necessary, it should create all of the directories it needs such that the entire path will exist.
|
||||
|
||||
Finally, I then run the database's "dump" command. In this particular case, I'm using MySQL, so I'm using the mysqldump command. The output from this command is a stream of SQL that can be used to re-create the database. I thus take the output from mysqldump and pipe it into gzip, which compresses the output file. Finally, the resulting dumpfile is placed, in compressed form, inside the daily backup directory.
|
||||
|
||||
Depending on the size of your database and the amount of disk space you have on hand, you'll have to decide just how often you want to run dumps and how often you want to clean out old ones. I know from experience that dumping every hour can cause some load problems. On one virtual machine I've used, the overall administration team was unhappy that I was dumping and compressing every hour, which they saw as an unnecessary use of system resources.
|
||||
|
||||
If you're worried your system will run out of disk space, you might well want to run a space-checking program that'll alert you when the filesystem is low on free space. In addition, you can run a cron job that uses find to erase all dumpfiles from before a certain cutoff date. I'm always a bit nervous about programs that automatically erase backups, so I generally prefer not to do this. Rather, I run a program that warns me if the disk usage is going above 85% (which is usually low enough to ensure that I can fix the problem in time, even if I'm on a long flight). Then I can go in and remove the problematic files by hand.
|
||||
|
||||
When you back up your database, you should be sure to back up the configuration for that database as well. The database schema and data, which are part of the dumpfile, are certainly important. However, if you find yourself having to re-create your server from scratch, you'll want to know precisely how you configured the database server, with a particular emphasis on the filesystem configuration and memory allocations. I tend to use PostgreSQL for most of my work, and although postgresql.conf is simple to understand and configure, I still like to keep it around with my dumpfiles.
|
||||
|
||||
Another crucial thing to do is to check your database dumps occasionally to be sure that they are working the way you want. It turns out that the backups I thought I was making weren't actually happening, in no small part because I had modified the shell script and hadn't double-checked that it was creating useful backups. Occasionally pulling out one of your dumpfiles and restoring it to a separate (and offline!) database to check its integrity is a good practice, both to ensure that the dump is working and that you remember how to restore it in the case of an emergency.
|
||||
|
||||
### Storing Backups
|
||||
|
||||
But wait. It might be great to have these backups, but what if the server goes down entirely? In the case of the code, I mentioned to ensure that it was located on more than one machine, ensuring its integrity. By contrast, your database dumps are now on the server, such that if the server fails, your database dumps will be inaccessible.
|
||||
|
||||
This means you'll want to have your database dumps stored elsewhere, preferably automatically. How can you do that?
|
||||
|
||||
There are a few relatively easy and inexpensive solutions to this problem. If you have two servers—ideally in separate physical locations—you can use rsync to copy the files from one to the other. Don't rsync the database's actual files, since those might get corrupted in transfer and aren't designed to be copied when the server is running. By contrast, the dumpfiles that you have created are more than able to go elsewhere. Setting up a remote server, with a user specifically for handling these backup transfers, shouldn't be too hard and will go a long way toward ensuring the safety of your data.
|
||||
|
||||
I should note that using rsync in this way basically requires that you set up passwordless SSH, so that you can transfer without having to be physically present to enter the password.
|
||||
|
||||
Another possible solution is Amazon's Simple Storage Server (S3), which offers astonishing amounts of disk space at very low prices. I know that many companies use S3 as a simple (albeit slow) backup system. You can set up a cron job to run a program that copies the contents of a particular database dumpfile directory onto a particular server. The assumption here is that you're not ever going to use these backups, meaning that S3's slow searching and access will not be an issue once you're working on the server.
|
||||
|
||||
Similarly, you might consider using Dropbox. Dropbox is best known for its desktop client, but it has a "headless", text-based client that can be used on Linux servers without a GUI connected. One nice advantage of Dropbox is that you can share a folder with any number of people, which means you can have Dropbox distribute your backup databases everywhere automatically, including to a number of people on your team. The backups arrive in their Dropbox folder, and you can be sure that the LAMP is conditional.
|
||||
|
||||
Finally, if you're running a WordPress site, you might want to consider VaultPress, a for-pay backup system. I must admit that in the weeks before I took my server down with a database backup error, I kept seeing ads in WordPress for VaultPress. "Who would buy that?", I asked myself, thinking that I'm smart enough to do backups myself. Of course, after disaster occurred and my database was ruined, I realized that $30/year to back up all of my data is cheap, and I should have done it before.
|
||||
|
||||
### Conclusion
|
||||
|
||||
When it comes to your servers, think less like an optimistic programmer and more like an insurance agent. Perhaps disaster won't strike, but if it does, will you be able to recover? Making sure that even if your server is completely unavailable, you'll be able to bring up your program and any associated database is crucial.
|
||||
|
||||
My preferred solution involves combining a Git repository for code and configuration files, distributed across several machines and services. For the databases, however, it's not enough to dump your database; you'll need to get that dump onto a separate machine, and preferably test the backup file on a regular basis. That way, even if things go wrong, you'll be able to get back up in no time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/avoiding-server-disaster
|
||||
|
||||
作者:[Reuven M.Lerner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/1000891
|
||||
@ -1,106 +0,0 @@
|
||||
How To List and Delete iptables Firewall Rules
|
||||
======
|
||||
![How To List and Delete iptables Firewall Rules][1]
|
||||
|
||||
We'll show you, how to list and delete iptables firewall rules. Iptables is a command line utility that allows system administrators to configure the packet filtering rule set on Linux. iptables requires elevated privileges to operate and must be executed by user root, otherwise it fails to function.
|
||||
|
||||
### How to List iptables Firewall Rules
|
||||
|
||||
Iptables allows you to list all the rules which are already added to the packet filtering rule set. In order to be able to check this you need to have SSH access to the server. [Connect to your Linux VPS via SSH][2] and run the following command:
|
||||
```
|
||||
sudo iptables -nvL
|
||||
```
|
||||
|
||||
To run the command above your user need to have `sudo` privileges. Otherwise, you need to [add sudo user on your Linux VPS][3] or use the root user.
|
||||
|
||||
If there are no rules added to the packet filtering ruleset the output should be similar to the one below:
|
||||
```
|
||||
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
```
|
||||
|
||||
Since NAT (Network Address Translation) can also be configured via iptables, you can use iptables to list the NAT rules:
|
||||
```
|
||||
sudo iptables -t nat -n -L -v
|
||||
```
|
||||
|
||||
The output will be similar to the one below if there are no rules added:
|
||||
```
|
||||
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
```
|
||||
|
||||
If this is the case we recommend you to check our tutorial on How to [Set Up a Firewall with iptables on Ubuntu and CentOS][4] to make your server more secure.
|
||||
|
||||
### How to Delete iptables Firewall Rules
|
||||
|
||||
At some point, you may need to remove a specific iptables firewall rule on your server. For that purpose you need to use the following syntax:
|
||||
```
|
||||
iptables [-t table] -D chain rulenum
|
||||
```
|
||||
|
||||
For example, if you have a firewall rule to block all connections from 111.111.111.111 to your server on port 22 and you want to remove that rule, you can use the following command:
|
||||
```
|
||||
sudo iptables -D INPUT -s 111.111.111.111 -p tcp --dport 22 -j DROP
|
||||
```
|
||||
|
||||
Now that you removed the iptables firewall rule you need to save the changes to make them persistent.
|
||||
|
||||
In case you are using [Ubuntu VPS][5] you need to install additional package for that purpose. To install the required package use the following command:
|
||||
```
|
||||
sudo apt-get install iptables-persistent
|
||||
```
|
||||
|
||||
On **Ubutnu 14.04** you can save and reload the firewall rules using the commands below:
|
||||
```
|
||||
sudo /etc/init.d/iptables-persistent save
|
||||
sudo /etc/init.d/iptables-persistent reload
|
||||
```
|
||||
|
||||
On **Ubuntu 16.04** use the following commands instead:
|
||||
```
|
||||
sudo netfilter-persistent save
|
||||
sudo netfilter-persistent reload
|
||||
```
|
||||
|
||||
If you are using [CentOS VPS][6] you can save the changes using the command below:
|
||||
```
|
||||
service iptables save
|
||||
```
|
||||
|
||||
Of course, you don't have to list and delete iptables firewall rules if you use one of our [Managed VPS Hosting][7] services, in which case you can simply ask our expert Linux admins to help you list and delete iptables firewall rules on your server. They are available 24×7 and will take care of your request immediately.
|
||||
|
||||
**PS**. If you liked this post, on how to list and delete iptables firewall rules, please share it with your friends on the social networks using the buttons on the left or simply leave a reply below. Thanks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/how-to-list-and-delete-iptables-firewall-rules/
|
||||
|
||||
作者:[RoseHosting][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/01/How-To-List-and-Delete-iptables-Firewall-Rules.jpg
|
||||
[2]:https://www.rosehosting.com/blog/connect-to-your-linux-vps-via-ssh/
|
||||
[3]:https://www.rosehosting.com/blog/how-to-create-a-sudo-user-on-ubuntu/
|
||||
[4]:https://www.rosehosting.com/blog/how-to-set-up-a-firewall-with-iptables-on-ubuntu-and-centos/
|
||||
[5]:https://www.rosehosting.com/ubuntu-vps.html
|
||||
[6]:https://www.rosehosting.com/centos-vps.html
|
||||
[7]:https://www.rosehosting.com/managed-vps-hosting.html
|
||||
@ -1,102 +0,0 @@
|
||||
How to Install Tripwire IDS (Intrusion Detection System) on Linux
|
||||
============================================================
|
||||
|
||||
|
||||
Tripwire is a popular Linux Intrusion Detection System (IDS) that runs on systems in order to detect if unauthorized filesystem changes occurred over time.
|
||||
|
||||
In CentOS and RHEL distributions, tripwire is not a part of official repositories. However, the tripwire package can be installed via [Epel repositories][1].
|
||||
|
||||
To begin, first install Epel repositories in CentOS and RHEL system, by issuing the below command.
|
||||
|
||||
```
|
||||
# yum install epel-release
|
||||
```
|
||||
|
||||
After you’ve installed Epel repositories, make sure you update the system with the following command.
|
||||
|
||||
```
|
||||
# yum update
|
||||
```
|
||||
|
||||
After the update process finishes, install Tripwire IDS software by executing the below command.
|
||||
|
||||
```
|
||||
# yum install tripwire
|
||||
```
|
||||
|
||||
Fortunately, tripwire is a part of Ubuntu and Debian default repositories and can be installed with following commands.
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install tripwire
|
||||
```
|
||||
|
||||
On Ubuntu and Debian, the tripwire installation will be asked to choose and confirm a site key and local key passphrase. These keys are used by tripwire to secure its configuration files.
|
||||
|
||||
[][2]
|
||||
|
||||
Create Tripwire Site and Local Key
|
||||
|
||||
On CentOS and RHEL, you need to create tripwire keys with the below command and supply a passphrase for site key and local key.
|
||||
|
||||
```
|
||||
# tripwire-setup-keyfiles
|
||||
```
|
||||
[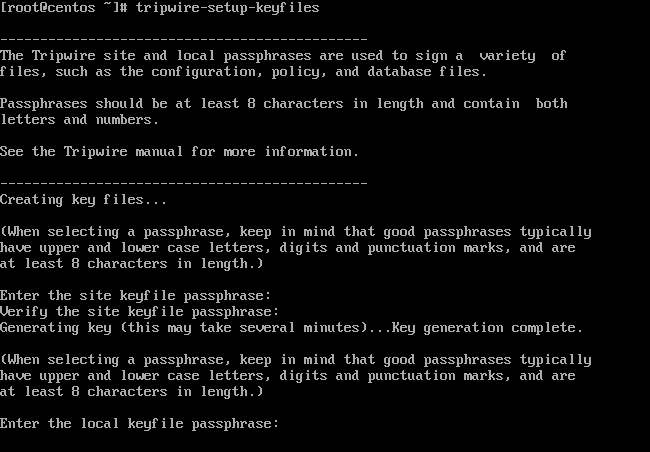][3]
|
||||
|
||||
Create Tripwire Keys
|
||||
|
||||
In order to validate your system, you need to initialize Tripwire database with the following command. Due to the fact that the database hasn’t been initialized yet, tripwire will display a lot of false-positive warnings.
|
||||
|
||||
```
|
||||
# tripwire --init
|
||||
```
|
||||
[][4]
|
||||
|
||||
Initialize Tripwire Database
|
||||
|
||||
Finally, generate a tripwire system report in order to check the configurations by issuing the below command. Use `--help` switch to list all tripwire check command options.
|
||||
|
||||
```
|
||||
# tripwire --check --help
|
||||
# tripwire --check
|
||||
```
|
||||
|
||||
After tripwire check command completes, review the report by opening the file with the extension `.twr` from /var/lib/tripwire/report/ directory with your favorite text editor command, but before that you need to convert to text file.
|
||||
|
||||
```
|
||||
# twprint --print-report --twrfile /var/lib/tripwire/report/tecmint-20170727-235255.twr > report.txt
|
||||
# vi report.txt
|
||||
```
|
||||
[][5]
|
||||
|
||||
Tripwire System Report
|
||||
|
||||
That’s It! you have successfully installed Tripwire on Linux server. I hope you can now easily configure your [Tripwire IDS][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
-------
|
||||
|
||||
via: https://www.tecmint.com/install-tripwire-ids-intrusion-detection-system-on-linux/
|
||||
|
||||
作者:[ Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2018/01/Create-Site-and-Local-key.png
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2018/01/Create-Tripwire-Keys.png
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2018/01/Initialize-Tripwire-Database.png
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2018/01/Tripwire-System-Report.png
|
||||
[6]:https://www.tripwire.com/
|
||||
[7]:https://www.tecmint.com/author/cezarmatei/
|
||||
[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,188 +0,0 @@
|
||||
translating by cncuckoo
|
||||
|
||||
Linux mv Command Explained for Beginners (8 Examples)
|
||||
======
|
||||
|
||||
Just like [cp][1] for copying and rm for deleting, Linux also offers an in-built command for moving and renaming files. It's called **mv**. In this article, we will discuss the basics of this command line tool using easy to understand examples. Please note that all examples used in this tutorial have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
#### Linux mv command
|
||||
|
||||
As already mentioned, the mv command in Linux is used to move or rename files. Following is the syntax of the command:
|
||||
|
||||
```
|
||||
mv [OPTION]... [-T] SOURCE DEST
|
||||
mv [OPTION]... SOURCE... DIRECTORY
|
||||
mv [OPTION]... -t DIRECTORY SOURCE...
|
||||
```
|
||||
|
||||
And here's what the man page says about it:
|
||||
```
|
||||
Rename SOURCE to DEST, or move SOURCE(s) to DIRECTORY.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples will give you a better idea on how this tool works.
|
||||
|
||||
#### Q1. How to use mv command in Linux?
|
||||
|
||||
If you want to just rename a file, you can use the mv command in the following way:
|
||||
|
||||
```
|
||||
mv [filename] [new_filename]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
mv names.txt fullnames.txt
|
||||
```
|
||||
|
||||
[![How to use mv command in Linux][2]][3]
|
||||
|
||||
Similarly, if the requirement is to move a file to a new location, use the mv command in the following way:
|
||||
|
||||
```
|
||||
mv [filename] [dest-dir]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
mv fullnames.txt /home/himanshu/Downloads
|
||||
```
|
||||
|
||||
[![Linux mv command][4]][5]
|
||||
|
||||
#### Q2. How to make sure mv prompts before overwriting?
|
||||
|
||||
By default, the mv command doesn't prompt when the operation involves overwriting an existing file. For example, the following screenshot shows the existing full_names.txt was overwritten by mv without any warning or notification.
|
||||
|
||||
[![How to make sure mv prompts before overwriting][6]][7]
|
||||
|
||||
However, if you want, you can force mv to prompt by using the **-i** command line option.
|
||||
|
||||
```
|
||||
mv -i [file_name] [new_file_name]
|
||||
```
|
||||
|
||||
[![the -i command option][8]][9]
|
||||
|
||||
So the above screenshots clearly shows that **-i** leads to mv asking for user permission before overwriting an existing file. Please note that in case you want to explicitly specify that you don't want mv to prompt before overwriting, then use the **-f** command line option.
|
||||
|
||||
#### Q3. How to make mv not overwrite an existing file?
|
||||
|
||||
For this, you need to use the **-n** command line option.
|
||||
|
||||
```
|
||||
mv -n [filename] [new_filename]
|
||||
```
|
||||
|
||||
The following screenshot shows the mv operation wasn't successful as a file with name 'full_names.txt' already existed and the command had -n option in it.
|
||||
|
||||
[![How to make mv not overwrite an existing file][10]][11]
|
||||
|
||||
Note:
|
||||
```
|
||||
If you specify more than one of -i, -f, -n, only the final one takes effect.
|
||||
```
|
||||
|
||||
#### Q4. How to make mv remove trailing slashes (if any) from source argument?
|
||||
|
||||
To remove any trailing slashes from source arguments, use the **\--strip-trailing-slashes** command line option.
|
||||
|
||||
```
|
||||
mv --strip-trailing-slashes [source] [dest]
|
||||
```
|
||||
|
||||
Here's how the official documentation explains the usefulness of this option:
|
||||
```
|
||||
This is useful when a
|
||||
|
||||
source
|
||||
|
||||
argument may have a trailing slash and specify a symbolic link to a directory. This scenario is in fact rather common because some shells can automatically append a trailing slash when performing file name completion on such symbolic links. Without this option,
|
||||
|
||||
mv
|
||||
|
||||
, for example, (via the system's rename function) must interpret a trailing slash as a request to dereference the symbolic link and so must rename the indirectly referenced
|
||||
|
||||
directory
|
||||
|
||||
and not the symbolic link. Although it may seem surprising that such behavior be the default, it is required by POSIX and is consistent with other parts of that standard.
|
||||
```
|
||||
|
||||
#### Q5. How to make mv treat destination as normal file?
|
||||
|
||||
To be absolutely sure that the destination entity is treated as a normal file (and not a directory), use the **-T** command line option.
|
||||
|
||||
```
|
||||
mv -T [source] [dest]
|
||||
```
|
||||
|
||||
Here's why this command line option exists:
|
||||
```
|
||||
This can help avoid race conditions in programs that operate in a shared area. For example, when the command 'mv /tmp/source /tmp/dest' succeeds, there is no guarantee that /tmp/source was renamed to /tmp/dest: it could have been renamed to/tmp/dest/source instead, if some other process created /tmp/dest as a directory. However, if mv -T /tmp/source /tmp/dest succeeds, there is no question that/tmp/source was renamed to /tmp/dest.
|
||||
```
|
||||
```
|
||||
In the opposite situation, where you want the last operand to be treated as a directory and want a diagnostic otherwise, you can use the --target-directory (-t) option.
|
||||
```
|
||||
|
||||
#### Q6. How to make mv move file only when its newer than destination file?
|
||||
|
||||
Suppose there exists a file named fullnames.txt in Downloads directory of your system, and there's a file with same name in your home directory. Now, you want to update ~/Downloads/fullnames.txt with ~/fullnames.txt, but only when the latter is newer. Then in this case, you'll have to use the **-u** command line option.
|
||||
|
||||
```
|
||||
mv -u ~/fullnames.txt ~/Downloads/fullnames.txt
|
||||
```
|
||||
|
||||
This option is particularly useful in cases when you need to take such decisions from within a shell script.
|
||||
|
||||
#### Q7. How make mv emit details of what all it is doing?
|
||||
|
||||
If you want mv to output information explaining what exactly it's doing, then use the **-v** command line option.
|
||||
|
||||
```
|
||||
mv -v [filename] [new_filename]
|
||||
```
|
||||
|
||||
For example, the following screenshots shows mv emitting some helpful details of what exactly it did.
|
||||
|
||||
[![How make mv emit details of what all it is doing][12]][13]
|
||||
|
||||
#### Q8. How to force mv to create backup of existing destination files?
|
||||
|
||||
This you can do using the **-b** command line option. The backup file created this way will have the same name as the destination file, but with a tilde (~) appended to it. Here's an example:
|
||||
|
||||
[![How to force mv to create backup of existing destination files][14]][15]
|
||||
|
||||
#### Conclusion
|
||||
|
||||
As you'd have guessed by now, mv is as important as cp and rm for the functionality it offers - renaming/moving files around is also one of the basic operations after all. We've discussed a majority of command line options this tool offers. So you can just practice them and start using the command. To know more about mv, head to its [man page][16].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-mv-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/linux-cp-command/
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/mv-rename-ex.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/big/mv-rename-ex.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/mv-transfer-file.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/big/mv-transfer-file.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/mv-overwrite.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/big/mv-overwrite.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/mv-prompt-overwrite.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/big/mv-prompt-overwrite.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/mv-n-option.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/big/mv-n-option.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/mv-v-option.png
|
||||
[13]:https://www.howtoforge.com/images/command-tutorial/big/mv-v-option.png
|
||||
[14]:https://www.howtoforge.com/images/command-tutorial/mv-b-option.png
|
||||
[15]:https://www.howtoforge.com/images/command-tutorial/big/mv-b-option.png
|
||||
[16]:https://linux.die.net/man/1/mv
|
||||
@ -1,153 +0,0 @@
|
||||
PlayOnLinux For Easier Use Of Wine
|
||||
======
|
||||
|
||||

|
||||
|
||||
[PlayOnLinux][1] is a free program that helps to install, run, and manage Windows software on Linux. It can also manage virtual C: drives (known as Wine prefixes), and download and install certain Windows libraries for getting some software to run on Wine properly. Creating different drives using different Wine versions is also possible. It is very handy because what runs well in one version may not run as well (if at all) on a newer version. There is [PlayOnMac][2] for macOS and PlayOnBSD for FreeBSD.
|
||||
|
||||
[Wine][3] is the compatibility layer that allows many programs developed for Windows to run under operating systems such as Linux, FreeBSD, macOS and other UNIX systems. The app database ([AppDB][4]) gives users an overview of a multitude of programs that will function on Wine, however successfully.
|
||||
|
||||
Both programs can be obtained using your distribution’s software center or package manager for convenience.
|
||||
|
||||
### Installing Programs Using PlayOnLinux
|
||||
|
||||
Installing software is easy. PlayOnLinux has hundreds of scripts to aid in installing different software with which to run the setup. In the sidebar, select “Install Software”. You will find several categories to choose from.
|
||||
|
||||
|
||||
|
||||
Hundreds of games can be installed this way.
|
||||
|
||||
[][5]
|
||||
|
||||
Office software can be installed as well, including Microsoft Office as shown here.
|
||||
|
||||
[][6]
|
||||
|
||||
Let’s install Notepad++ using the script. You can select the script to read the compatibility rating according to PlayOnLinux, and an overview of the program. To get a better idea of compatibility, refer to the WineHQ App Database and find “Browse Apps” to find a program like Notepad++.
|
||||
|
||||
[][7]
|
||||
|
||||
Once you press “Install”, if you are using PlayOnLinux for the first time, you will encounter two popups: one to give you tips when installing programs with a script, and the other to not submit bug reports to WineHQ because PlayOnLinux has nothing to do with them.
|
||||
|
||||
|
||||
|
||||
During the installation, I was given the choice to either download the setup executable, or select one on the computer. I downloaded the file but received a File Mismatch error; however, I continued and it was successful. It’s not perfect, but it is functional. (It is possible to submit bug reports to PlayOnLinux if the option is given.)
|
||||
|
||||
[][8]
|
||||
|
||||
Nevertheless, I was able to install Notepad++ successfully, run it, and update it to the latest version (at the time of writing 7.5.3) from version 7.4.2.
|
||||
|
||||
|
||||
|
||||
Also during installation, it created a virtual C: drive specifically for Notepad++. As there are no other Wine versions available for PlayOnLinux to use, it defaults to using the version installed on the system. In this case, it is more than adequate for Notepad++ to run smoothly.
|
||||
|
||||
### Installing Non-Listed Programs
|
||||
|
||||
You can also install a program that is not on the list by pressing “Install Non-Listed Program” on the bottom-left corner of the install menu. Bear in mind that there is no script to install certain libraries to make things work properly. You will need to do this yourself. Look at the Wine AppDB for information for your program. Also, if the app isn’t listed, it doesn’t mean that it won’t work with Wine. It just means no one has given any information about it.
|
||||
|
||||
|
||||
|
||||
I’ve installed Graphmatica, a graph plotting program, using this method. First I selected the option to install it on a new virtual drive.
|
||||
|
||||
[][9]
|
||||
|
||||
Then I selected the option to install additional libraries after creating the drive and select a Wine version to use in doing so.
|
||||
|
||||
[][10]
|
||||
|
||||
I then proceeded to select Gecko (which encountered an error for some reason), and Mono 2.10 to install.
|
||||
|
||||
[][11]
|
||||
|
||||
Finally, I installed Graphmatica. It’s as simple as that.
|
||||
|
||||
[][12]
|
||||
|
||||
A launcher can be created after installation. A list of executables found in the drive will appear. Search for the app executable (may not always be obvious) which may have its icon, select it and give it a display name. The icon will appear on the desktop.
|
||||
|
||||
[][13]
|
||||
[][14]
|
||||
|
||||
### Multiple “C:” Drives
|
||||
|
||||
Now that we have easily installed a program, let’s have a look at the drive configuration. In the main window, press “Configure” in the toolbar and this window will show.
|
||||
|
||||
[][15]
|
||||
|
||||
On the left are the drives that are found within PlayOnLinux. To the right, the “General” tab allows you to create shortcuts of programs installed on that virtual drive.
|
||||
|
||||
|
||||
|
||||
The “Wine” tab has 8 buttons, including those to launch the Wine configuration program (winecfg), control panel, registry editor, command prompt, etc.
|
||||
|
||||
[][16]
|
||||
|
||||
“Install Components” allows you to select different Windows libraries like DirectX 9, .NET Framework versions 2 – 4.5, Visual C++ runtime, etc., like [winetricks][17].
|
||||
|
||||
[][18]
|
||||
|
||||
“Display” allows the user to control advanced graphics settings like GLSL support, video memory size, and more. And “Miscellaneous” is for other actions like running an executable found anywhere on the computer to be run under the selected virtual drive.
|
||||
|
||||
### Creating Virtual Drives Without Installing Programs
|
||||
|
||||
To create a drive without installing software, simply press “New” below the list of drives to launch the virtual drive creator. Drives are created using the same method used in installing programs not found in the install menu. Follow the prompts, select either a 32-bit or 64-bit installation (in this case we only have 32-bit versions so select 32-bit), choose the Wine version, and give the drive a name. Once completed, it will appear in the drive list.
|
||||
|
||||
[][19]
|
||||
|
||||
### Managing Wine Versions
|
||||
|
||||
Entire Wine versions can be downloaded using the manager. To access this through the menu bar, press “Tools” and select “Manage Wine versions”. Sometimes different software can behave differently between Wine versions. A Wine update can break something that made your application work in the previous version; thus rendering the application broken or completely unusable. Therefore, this feature is one of the highlights of PlayOnLinux.
|
||||
|
||||
|
||||
|
||||
If you’re still on the configuration window, in the “General” tab, you can also access the version manager by pressing the “+” button next to the Wine version field.
|
||||
|
||||
[][20]
|
||||
|
||||
To install a version of Wine (32-bit or 64-bit), simply select the version, and press the “>” button to download and install it. After installation, if setup executables for Mono, and/or the Gecko HTML engine have not yet been downloaded by PlayOnLinux, they will be downloaded.
|
||||
|
||||
|
||||
|
||||
I went ahead and installed the 2.21-staging version of Wine afterward.
|
||||
|
||||
[][21]
|
||||
|
||||
To remove a version, press the “<” button.
|
||||
|
||||
### Conclusion
|
||||
|
||||
This article demonstrated how to use PlayOnLinux to easily install Windows software into separate virtual C: drives, create and manage virtual drives, and manage several Wine versions. The software isn’t perfect, but it is still functional and useful. Managing different drives with different Wine versions is one of the key features of PlayOnLinux. It is a lot easier to use a front-end for Wine such as PlayOnLinux than pure Wine.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/playonlinux-for-easier-use-of-wine
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:https://www.playonlinux.com/en/
|
||||
[2]:https://www.playonmac.com
|
||||
[3]:https://www.winehq.org/
|
||||
[4]:http://appdb.winehq.org/
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_1_orig.png
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_2_orig.png
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_3_orig.png
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_4_orig.png
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_5_orig.png
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_6_orig.png
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_7_orig.png
|
||||
[13]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_8_orig.png
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_9_orig.png
|
||||
[15]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_10_orig.png
|
||||
[16]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_11_orig.png
|
||||
[17]:https://github.com/Winetricks/winetricks
|
||||
[18]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_12_orig.png
|
||||
[19]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_13_orig.png
|
||||
[20]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_14_orig.png
|
||||
[21]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_15_orig.png
|
||||
@ -1,66 +0,0 @@
|
||||
socat as a handler for multiple reverse shells · System Overlord
|
||||
======
|
||||
|
||||
I was looking for a new way to handle multiple incoming reverse shells. My shells needed to be encrypted and I preferred not to use Metasploit in this case. Because of the way I was deploying my implants, I wasn't able to use separate incoming port numbers or other ways of directing the traffic to multiple listeners.
|
||||
|
||||
Obviously, it's important to keep each reverse shell separated, so I couldn't just have a listener redirecting all the connections to STDIN/STDOUT. I also didn't want to wait for sessions serially - obviously I wanted to be connected to all of my implants simultaneously. (And allow them to disconnect/reconnect as needed due to loss of network connectivity.)
|
||||
|
||||
As I was thinking about the problem, I realized that I basically wanted `tmux` for reverse shells. So I began to wonder if there was some way to connect `openssl s_server` or something similar to `tmux`. Given the limitations of `s_server`, I started looking at `socat`. Despite it's versatility, I've actually only used it once or twice before this, so I spent a fair bit of time reading the man page and the examples.
|
||||
|
||||
I couldn't find a way to get `socat` to talk directly to `tmux` in a way that would spawn each connection as a new window (file descriptors are not passed to the newly-started process in `tmux new-window`), so I ended up with a strange workaround. I feel a little bit like Rube Goldberg inventing C2 software (and I need to get something more permanent and featureful eventually, but this was a quick and dirty PoC), but I've put together a chain of `socat` to get a working solution.
|
||||
|
||||
My implementation works by having a single `socat` process receive the incoming connections (forking on incoming connection), and executing a script that first starts a `socat` instance within tmux, and then another `socat` process to copy from the first to the second over a UNIX domain socket.
|
||||
|
||||
Yes, this is 3 socat processes. It's a little ridiculous, but I couldn't find a better approach. Roughly speaking, the communications flow looks a little like this:
|
||||
```
|
||||
TLS data <--> socat listener <--> script stdio <--> socat <--> unix socket <--> socat in tmux <--> terminal window
|
||||
|
||||
```
|
||||
|
||||
Getting it started is fairly simple. Begin by generating your SSL certificate. In this case, I'm using a self-signed certificate, but obviously you could go through a commercial CA, Let's Encrypt, etc.
|
||||
```
|
||||
openssl req -newkey rsa:2048 -nodes -keyout server.key -x509 -days 30 -out server.crt
|
||||
cat server.key server.crt > server.pem
|
||||
|
||||
```
|
||||
|
||||
Now we will create the script that is run on each incoming connection. This script needs to launch a `tmux` window running a `socat` process copying from a UNIX domain socket to `stdio` (in tmux), and then connecting another `socat` between the `stdio` coming in to the UNIX domain socket.
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
SOCKDIR=$(mktemp -d)
|
||||
SOCKF=${SOCKDIR}/usock
|
||||
|
||||
# Start tmux, if needed
|
||||
tmux start
|
||||
# Create window
|
||||
tmux new-window "socat UNIX-LISTEN:${SOCKF},umask=0077 STDIO"
|
||||
# Wait for socket
|
||||
while test ! -e ${SOCKF} ; do sleep 1 ; done
|
||||
# Use socat to ship data between the unix socket and STDIO.
|
||||
exec socat STDIO UNIX-CONNECT:${SOCKF}
|
||||
```
|
||||
|
||||
The while loop is necessary to make sure that the last `socat` process does not attempt to open the UNIX domain socket before it has been created by the new `tmux` child process.
|
||||
|
||||
Finally, we can launch the `socat` process that will accept the incoming requests (handling all the TLS steps) and execute our per-connection script:
|
||||
```
|
||||
socat OPENSSL-LISTEN:8443,cert=server.pem,reuseaddr,verify=0,fork EXEC:./socatscript.sh
|
||||
|
||||
```
|
||||
|
||||
This listens on port 8443, using the certificate and private key contained in `server.pem`, performs a `fork()` on accepting each incoming connection (so they do not block each other) and disables certificate verification (since we're not expecting our clients to provide a certificate). On the other side, it launches our script, providing the data from the TLS connection via STDIO.
|
||||
|
||||
At this point, an incoming TLS connection connects, and is passed through our processes to eventually arrive on the `STDIO` of a new window in the running `tmux` server. Each connection gets its own window, allowing us to easily see and manage the connections for our implants.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://systemoverlord.com/2018/01/20/socat-as-a-handler-for-multiple-reverse-shells.html
|
||||
|
||||
作者:[David][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://systemoverlord.com/about
|
||||
@ -1,117 +0,0 @@
|
||||
Installing Awstat for analyzing Apache logs
|
||||
======
|
||||
AWSTAT is free an very powerful log analyser tool for apache log files. After analyzing logs from apache, it present them in easy to understand graphical format. Awstat is short for Advanced Web statistics & it works on command line interface or on CGI.
|
||||
|
||||
In this tutorial, we will be installing AWSTAT on our Centos 7 machine for analyzing apache logs.
|
||||
|
||||
( **Recommended read** :[ **Scheduling important jobs with crontab**][1])
|
||||
|
||||
### Pre-requisites
|
||||
|
||||
**1-** A website hosted on apache web server, to create one read below mentioned tutorials on apache web servers,
|
||||
|
||||
( **Recommended reads** - [**installing Apache**][2], [**Securing apache with SSL cert**][3] & **hardening tips for apache** )
|
||||
|
||||
**2-** Epel repository enabled on the system, as Awstat packages are not available on default repositories. To enable epel-repo , run
|
||||
|
||||
```
|
||||
$ rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-10.noarch.rpm
|
||||
```
|
||||
|
||||
### Installing Awstat
|
||||
|
||||
Once the epel-repository has been enabled on the system, awstat can be installed by running,
|
||||
|
||||
```
|
||||
$ yum install awstat
|
||||
```
|
||||
|
||||
When awstat is installed, it creates a file for apache at '/etc/httpd/conf.d/awstat.conf' with some configurations. These configurations are good to be used incase web server &awstat are configured on the same machine but if awstat is on different machine than the webserver, then some changes are to be made to the file.
|
||||
|
||||
#### Configuring Apache for Awstat
|
||||
|
||||
To configure awstat for a remote web server, open /etc/httpd/conf.d/awstat.conf, & update the parameter 'Allow from' with the IP address of the web server
|
||||
|
||||
```
|
||||
$ vi /etc/httpd/conf.d/awstat.conf
|
||||
|
||||
<Directory "/usr/share/awstats/wwwroot">
|
||||
Options None
|
||||
AllowOverride None
|
||||
<IfModulemod_authz_core.c>
|
||||
# Apache 2.4
|
||||
Require local
|
||||
</IfModule>
|
||||
<IfModule !mod_authz_core.c>
|
||||
# Apache 2.2
|
||||
Order allow,deny
|
||||
Allow from 127.0.0.1
|
||||
Allow from 192.168.1.100
|
||||
</IfModule>
|
||||
</Directory>
|
||||
```
|
||||
|
||||
Save the file & restart the apache services to implement the changes,
|
||||
|
||||
```
|
||||
$ systemctl restart httpd
|
||||
```
|
||||
|
||||
#### Configuring AWSTAT
|
||||
|
||||
For every website that we add to awstat, a different configuration file needs to be created with the website information . An example file is created in folder '/etc/awstats' by the name 'awstats.localhost.localdomain.conf', we can make copies of it & configure our website with this,
|
||||
|
||||
```
|
||||
$ cd /etc/awstats
|
||||
$ cp awstats.localhost.localdomain.conf awstats.linuxtechlab.com.conf
|
||||
```
|
||||
|
||||
Now open the file & edit the following three parameters to match your website,
|
||||
|
||||
```
|
||||
$ vi awstats.linuxtechlab.com.conf
|
||||
|
||||
LogFile="/var/log/httpd/access.log"
|
||||
SiteDomain="linuxtechlab.com"
|
||||
HostAliases=www.linuxtechlab.com localhost 127.0.0.1
|
||||
```
|
||||
|
||||
Last step is to update the configuration file, which can be done executing the command below,
|
||||
|
||||
```
|
||||
/usr/share/awstats/wwwroot/cgi-bin/awstats.pl -config=linuxtechlab.com -update
|
||||
```
|
||||
|
||||
#### Checking the awstat page
|
||||
|
||||
To test/check the awstat page, open web-browser & enter the following URL in the address bar,
|
||||
**https://linuxtechlab.com/awstats/awstats.pl?config=linuxtechlab.com**
|
||||
|
||||
![awstat][5]
|
||||
|
||||
**Note-** we can also schedule a cron job to update the awstat on regular basis. An example for the crontab
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
0 1 * * * /usr/share/awstats/wwwroot/cgi-bin/awstats.pl -config=linuxtechlab.com–update
|
||||
```
|
||||
|
||||
We now end our tutorial on installing Awstat for analyzing apache logs, please leave your comments/queries in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/installing-awstat-analyzing-apache-logs/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/scheduling-important-jobs-crontab/
|
||||
[2]:http://linuxtechlab.com/beginner-guide-configure-apache/
|
||||
[3]:http://linuxtechlab.com/create-ssl-certificate-apache-server/
|
||||
[4]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=602%2C312
|
||||
[5]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/04/awstat.jpg?resize=602%2C312
|
||||
@ -1,325 +0,0 @@
|
||||
leemeans translating
|
||||
Creating an Adventure Game in the Terminal with ncurses
|
||||
======
|
||||
How to use curses functions to read the keyboard and manipulate the screen.
|
||||
|
||||
My [previous article][1] introduced the ncurses library and provided a simple program that demonstrated a few curses functions to put text on the screen. In this follow-up article, I illustrate how to use a few other curses functions.
|
||||
|
||||
### An Adventure
|
||||
|
||||
When I was growing up, my family had an Apple II computer. It was on this machine that my brother and I taught ourselves how to write programs in AppleSoft BASIC. After writing a few math puzzles, I moved on to creating games. Having grown up in the 1980s, I already was a fan of the Dungeons and Dragons tabletop games, where you role-played as a fighter or wizard on some quest to defeat monsters and plunder loot in strange lands. So it shouldn't be surprising that I also created a rudimentary adventure game.
|
||||
|
||||
The AppleSoft BASIC programming environment supported a neat feature: in standard resolution graphics mode (GR mode), you could probe the color of a particular pixel on the screen. This allowed a shortcut to create an adventure game. Rather than create and update an in-memory map that was transferred to the screen periodically, I could rely on GR mode to maintain the map for me, and my program could query the screen as the player's character moved around the screen. Using this method, I let the computer do most of the hard work. Thus, my top-down adventure game used blocky GR mode graphics to represent my game map.
|
||||
|
||||
My adventure game used a simple map that represented a large field with a mountain range running down the middle and a large lake on the upper-left side. I might crudely draw this map for a tabletop gaming campaign to include a narrow path through the mountains, allowing the player to pass to the far side.
|
||||
|
||||

|
||||
|
||||
Figure 1. A simple Tabletop Game Map with a Lake and Mountains
|
||||
|
||||
You can draw this map in cursesusing characters to represent grass, mountains and water. Next, I describe how to do just that using curses functions and how to create and play a similar adventure game in the Linux terminal.
|
||||
|
||||
### Constructing the Program
|
||||
|
||||
In my last article, I mentioned that most curses programs start with the same set of instructions to determine the terminal type and set up the curses environment:
|
||||
|
||||
```
|
||||
initscr();
|
||||
cbreak();
|
||||
noecho();
|
||||
|
||||
```
|
||||
|
||||
For this program, I add another statement:
|
||||
|
||||
```
|
||||
keypad(stdscr, TRUE);
|
||||
|
||||
```
|
||||
|
||||
The TRUE flag allows curses to read the keypad and function keys from the user's terminal. If you want to use the up, down, left and right arrow keys in your program, you need to use keypad(stdscr, TRUE) here.
|
||||
|
||||
Having done that, you now can start drawing to the terminal screen. The curses functions include several ways to draw text on the screen. In my previous article, I demonstrated the addch() and addstr() functions and their associated mvaddch() and mvaddstr() counterparts that first moved to a specific location on the screen before adding text. To create the adventure game map on the terminal, you can use another set of functions: vline() and hline(), and their partner functions mvvline() and mvhline(). These mv functions accept screen coordinates, a character to draw and how many times to repeat that character. For example, mvhline(1, 2, '-', 20) will draw a line of 20 dashes starting at line 1, column 2.
|
||||
|
||||
To draw the map to the terminal screen programmatically, let's define this draw_map() function:
|
||||
|
||||
```
|
||||
#define GRASS ' '
|
||||
#define EMPTY '.'
|
||||
#define WATER '~'
|
||||
#define MOUNTAIN '^'
|
||||
#define PLAYER '*'
|
||||
|
||||
void draw_map(void)
|
||||
{
|
||||
int y, x;
|
||||
|
||||
/* draw the quest map */
|
||||
|
||||
/* background */
|
||||
|
||||
for (y = 0; y < LINES; y++) {
|
||||
mvhline(y, 0, GRASS, COLS);
|
||||
}
|
||||
|
||||
/* mountains, and mountain path */
|
||||
|
||||
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
|
||||
mvvline(0, x, MOUNTAIN, LINES);
|
||||
}
|
||||
|
||||
mvhline(LINES / 4, 0, GRASS, COLS);
|
||||
|
||||
/* lake */
|
||||
|
||||
for (y = 1; y < LINES / 2; y++) {
|
||||
mvhline(y, 1, WATER, COLS / 3);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
In drawing this map, note the use of mvvline() and mvhline() to fill large chunks of characters on the screen. I created the fields of grass by drawing horizontal lines (mvhline) of characters starting at column 0, for the entire height and width of the screen. I added the mountains on top of that by drawing vertical lines (mvvline), starting at row 0, and a mountain path by drawing a single horizontal line (mvhline). And, I created the lake by drawing a series of short horizontal lines (mvhline). It may seem inefficient to draw overlapping rectangles in this way, but remember that curses doesn't actually update the screen until I call the refresh() function later.
|
||||
|
||||
Having drawn the map, all that remains to create the game is to enter a loop where the program waits for the user to press one of the up, down, left or right direction keys and then moves a player icon appropriately. If the space the player wants to move into is unoccupied, it allows the player to go there.
|
||||
|
||||
You can use curses as a shortcut. Rather than having to instantiate a version of the map in the program and replicate this map to the screen, you can let the screen keep track of everything for you. The inch() function, and associated mvinch() function, allow you to probe the contents of the screen. This allows you to query curses to find out whether the space the player wants to move into is already filled with water or blocked by mountains. To do this, you'll need a helper function that you'll use later:
|
||||
|
||||
```
|
||||
int is_move_okay(int y, int x)
|
||||
{
|
||||
int testch;
|
||||
|
||||
/* return true if the space is okay to move into */
|
||||
|
||||
testch = mvinch(y, x);
|
||||
return ((testch == GRASS) || (testch == EMPTY));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
As you can see, this function probes the location at column y, row x and returns true if the space is suitably unoccupied, or false if not.
|
||||
|
||||
That makes it really easy to write a navigation loop: get a key from the keyboard and move the user's character around depending on the up, down, left and right arrow keys. Here's a simplified version of that loop:
|
||||
|
||||
```
|
||||
|
||||
do {
|
||||
ch = getch();
|
||||
|
||||
/* test inputted key and determine direction */
|
||||
|
||||
switch (ch) {
|
||||
case KEY_UP:
|
||||
if ((y > 0) && is_move_okay(y - 1, x)) {
|
||||
y = y - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_DOWN:
|
||||
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
|
||||
y = y + 1;
|
||||
}
|
||||
break;
|
||||
case KEY_LEFT:
|
||||
if ((x > 0) && is_move_okay(y, x - 1)) {
|
||||
x = x - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_RIGHT
|
||||
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
|
||||
x = x + 1;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
while (1);
|
||||
|
||||
```
|
||||
|
||||
To use this in a game, you'll need to add some code inside the loop to allow other keys (for example, the traditional WASD movement keys), provide a method for the user to quit the game and move the player's character around the screen. Here's the program in full:
|
||||
|
||||
```
|
||||
|
||||
/* quest.c */
|
||||
|
||||
#include
|
||||
#include
|
||||
|
||||
#define GRASS ' '
|
||||
#define EMPTY '.'
|
||||
#define WATER '~'
|
||||
#define MOUNTAIN '^'
|
||||
#define PLAYER '*'
|
||||
|
||||
int is_move_okay(int y, int x);
|
||||
void draw_map(void);
|
||||
|
||||
int main(void)
|
||||
{
|
||||
int y, x;
|
||||
int ch;
|
||||
|
||||
/* initialize curses */
|
||||
|
||||
initscr();
|
||||
keypad(stdscr, TRUE);
|
||||
cbreak();
|
||||
noecho();
|
||||
|
||||
clear();
|
||||
|
||||
/* initialize the quest map */
|
||||
|
||||
draw_map();
|
||||
|
||||
/* start player at lower-left */
|
||||
|
||||
y = LINES - 1;
|
||||
x = 0;
|
||||
|
||||
do {
|
||||
/* by default, you get a blinking cursor - use it to indicate player */
|
||||
|
||||
mvaddch(y, x, PLAYER);
|
||||
move(y, x);
|
||||
refresh();
|
||||
|
||||
ch = getch();
|
||||
|
||||
/* test inputted key and determine direction */
|
||||
|
||||
switch (ch) {
|
||||
case KEY_UP:
|
||||
case 'w':
|
||||
case 'W':
|
||||
if ((y > 0) && is_move_okay(y - 1, x)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
y = y - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_DOWN:
|
||||
case 's':
|
||||
case 'S':
|
||||
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
y = y + 1;
|
||||
}
|
||||
break;
|
||||
case KEY_LEFT:
|
||||
case 'a':
|
||||
case 'A':
|
||||
if ((x > 0) && is_move_okay(y, x - 1)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
x = x - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_RIGHT:
|
||||
case 'd':
|
||||
case 'D':
|
||||
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
|
||||
mvaddch(y, x, EMPTY);
|
||||
x = x + 1;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
while ((ch != 'q') && (ch != 'Q'));
|
||||
|
||||
endwin();
|
||||
|
||||
exit(0);
|
||||
}
|
||||
|
||||
int is_move_okay(int y, int x)
|
||||
{
|
||||
int testch;
|
||||
|
||||
/* return true if the space is okay to move into */
|
||||
|
||||
testch = mvinch(y, x);
|
||||
return ((testch == GRASS) || (testch == EMPTY));
|
||||
}
|
||||
|
||||
void draw_map(void)
|
||||
{
|
||||
int y, x;
|
||||
|
||||
/* draw the quest map */
|
||||
|
||||
/* background */
|
||||
|
||||
for (y = 0; y < LINES; y++) {
|
||||
mvhline(y, 0, GRASS, COLS);
|
||||
}
|
||||
|
||||
/* mountains, and mountain path */
|
||||
|
||||
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
|
||||
mvvline(0, x, MOUNTAIN, LINES);
|
||||
}
|
||||
|
||||
mvhline(LINES / 4, 0, GRASS, COLS);
|
||||
|
||||
/* lake */
|
||||
|
||||
for (y = 1; y < LINES / 2; y++) {
|
||||
mvhline(y, 1, WATER, COLS / 3);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
In the full program listing, you can see the complete arrangement of curses functions to create the game:
|
||||
|
||||
1) Initialize the curses environment.
|
||||
|
||||
2) Draw the map.
|
||||
|
||||
3) Initialize the player coordinates (lower-left).
|
||||
|
||||
4) Loop:
|
||||
|
||||
* Draw the player's character.
|
||||
|
||||
* Get a key from the keyboard.
|
||||
|
||||
* Adjust the player's coordinates up, down, left or right, accordingly.
|
||||
|
||||
* Repeat.
|
||||
|
||||
5) When done, close the curses environment and exit.
|
||||
|
||||
### Let's Play
|
||||
|
||||
When you run the game, the player's character starts in the lower-left corner. As the player moves around the play area, the program creates a "trail" of dots. This helps show where the player has been before, so the player can avoid crossing the path unnecessarily.
|
||||
|
||||

|
||||
|
||||
Figure 2\. The player starts the game in the lower-left corner.
|
||||
|
||||

|
||||
|
||||
Figure 3\. The player can move around the play area, such as around the lake and through the mountain pass.
|
||||
|
||||
To create a complete adventure game on top of this, you might add random encounters with various monsters as the player navigates his or her character around the play area. You also could include special items the player could discover or loot after defeating enemies, which would enhance the player's abilities further.
|
||||
|
||||
But to start, this is a good program for demonstrating how to use the curses functions to read the keyboard and manipulate the screen.
|
||||
|
||||
### Next Steps
|
||||
|
||||
This program is a simple example of how to use the curses functions to update and read the screen and keyboard. You can do so much more with curses, depending on what you need your program to do. In a follow up article, I plan to show how to update this sample program to use colors. In the meantime, if you are interested in learning more about curses, I encourage you to read Pradeep Padala's [NCURSES Programming HOWTO][2] at the Linux Documentation Project.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/creating-adventure-game-terminal-ncurses
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/jim-hall
|
||||
[1]:http://www.linuxjournal.com/content/getting-started-ncurses
|
||||
[2]:http://tldp.org/HOWTO/NCURSES-Programming-HOWTO
|
||||
@ -1,113 +0,0 @@
|
||||
Linux kill Command Tutorial for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on a Linux machine, you'll see that an application or a command line process gets stuck (becomes unresponsive). Then in those cases, terminating it is the only way out. Linux command line offers a utility that you can use in these scenarios. It's called **kill**.
|
||||
|
||||
In this tutorial, we will discuss the basics of kill using some easy to understand examples. But before we do that, it's worth mentioning that all examples in the article have been tested on an Ubuntu 16.04 machine.
|
||||
|
||||
#### Linux kill command
|
||||
|
||||
The kill command is usually used to kill a process. Internally it sends a signal, and depending on what you want to do, there are different signals that you can send using this tool. Following is the command's syntax:
|
||||
|
||||
```
|
||||
kill [options] <pid> [...]
|
||||
```
|
||||
|
||||
And here's how the tool's man page describes it:
|
||||
```
|
||||
The default signal for kill is TERM. Use -l or -L to list available signals. Particularly useful
|
||||
signals include HUP, INT, KILL, STOP, CONT, and 0. Alternate signals may be specified in three ways:
|
||||
-9, -SIGKILL or -KILL. Negative PID values may be used to choose whole process groups; see the PGID
|
||||
column in ps command output. A PID of -1 is special; it indicates all processes except the kill
|
||||
process itself and init.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples should give you a better idea of how the kill command works.
|
||||
|
||||
#### Q1. How to terminate a process using kill command?
|
||||
|
||||
This is very easy - all you need to do is to get the pid of the process you want to kill, and then pass it to the kill command.
|
||||
|
||||
```
|
||||
kill [pid]
|
||||
```
|
||||
|
||||
For example, I wanted to kill the 'gthumb' process on my system. So i first used the ps command to fetch the application's pid, and then passed it to the kill command to terminate it. Here's the screenshot showing all this:
|
||||
|
||||
[![How to terminate a process using kill command][1]][2]
|
||||
|
||||
#### Q2. How to send a custom signal?
|
||||
|
||||
As already mentioned in the introduction section, TERM is the default signal that kill sends to the application/process in question. However, if you want, you can send any other signal that kill supports using the **-s** command line option.
|
||||
|
||||
```
|
||||
kill -s [signal] [pid]
|
||||
```
|
||||
|
||||
For example, if a process isn't responding to the TERM signal (which allows the process to do final cleanup before quitting), you can go for the KILL signal (which doesn't let process do any cleanup). Following is the command you need to run in that case.
|
||||
|
||||
```
|
||||
kill -s KILL [pid]
|
||||
```
|
||||
|
||||
#### Q3. What all signals you can send using kill?
|
||||
|
||||
Of course, the next logical question that'll come to your mind is how to know which all signals you can send using kill. Well, thankfully, there exists a command line option **-l** that lists all supported signals.
|
||||
|
||||
```
|
||||
kill -l
|
||||
```
|
||||
|
||||
Following is the output the above command produced on our system:
|
||||
|
||||
[![What all signals you can send using kill][3]][4]
|
||||
|
||||
#### Q4. What are the other ways in which signal can be sent?
|
||||
|
||||
In one of the previous examples, we told you if you want to send the KILL signal, you can do it in the following way:
|
||||
|
||||
```
|
||||
kill -s KILL [pid]
|
||||
```
|
||||
|
||||
However, there are a couple of other alternatives as well:
|
||||
|
||||
```
|
||||
kill -s SIGKILL [pid]
|
||||
|
||||
kill -s 9 [pid]
|
||||
```
|
||||
|
||||
The corresponding number can be known using the -l option we've already discussed in the previous example.
|
||||
|
||||
#### Q5. How to kill all running process in one go?
|
||||
|
||||
In case a user wants to kill all processes that they can (this depends on their privilege level), then instead of specifying a large number of process IDs, they can simply pass the -1 option to kill.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
kill -s KILL -1
|
||||
```
|
||||
|
||||
#### Conclusion
|
||||
|
||||
The kill command is pretty straightforward to understand and use. There's a slight learning curve in terms of the list of signal options it offers, but as we explained in here, there's an option to take a quick look at that list as well. Just practice whatever we've discussed and you should be good to go. For more information, head to the tool's [man page][5].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-kill-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/kill-default.png
|
||||
[2]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/kill-default.png
|
||||
[3]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/kill-l-option.png
|
||||
[4]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/kill-l-option.png
|
||||
[5]:https://linux.die.net/man/1/kill
|
||||
@ -1,109 +0,0 @@
|
||||
5 Real World Uses for Redis
|
||||
============================================================
|
||||
|
||||
|
||||
Redis is a powerful in-memory data structure store which has many uses including a database, a cache, and a message broker. Most people often think of it a simple key-value store, but it has so much more power. I will be going over some real world examples of some of the many things Redis can do for you.
|
||||
|
||||
### 1\. Full Page Cache
|
||||
|
||||
The first thing is full page caching. If you are using server-side rendered content, you do not want to re-render each page for every single request. Using a cache like Redis, you can cache regularly requested content and drastically decrease latency for your most requested pages, and most frameworks have hooks for caching your pages with Redis.
|
||||
Simple Commands
|
||||
|
||||
```
|
||||
// Set the page that will last 1 minute
|
||||
SET key "<html>...</html>" EX 60
|
||||
|
||||
// Get the page
|
||||
GET key
|
||||
|
||||
```
|
||||
|
||||
### 2\. Leaderboard
|
||||
|
||||
One of the places Redis shines is for leaderboards. Because Redis is in-memory, it can deal with incrementing and decrementing very fast and efficiently. Compare this to running a SQL query every request the performance gains are huge! This combined with Redis's sorted sets means you can grab only the highest rated items in the list in milliseconds, and it is stupid easy to implement.
|
||||
Simple Commands
|
||||
|
||||
```
|
||||
// Add an item to the sorted set
|
||||
ZADD sortedSet 1 "one"
|
||||
|
||||
// Get all items from the sorted set
|
||||
ZRANGE sortedSet 0 -1
|
||||
|
||||
// Get all items from the sorted set with their score
|
||||
ZRANGE sortedSet 0 -1 WITHSCORES
|
||||
|
||||
```
|
||||
|
||||
### 3\. Session Storage
|
||||
|
||||
The most common use for Redis I have seen is session storage. Unlike other session stores like Memcache, Redis can persist data so in the situation where your cache goes down when it comes back up all the data will still be there. Although this isn't mission critical to be persisted, this feature can save your users lots of headaches. No one likes their session to be randomly dropped for no reason.
|
||||
Simple Commands
|
||||
|
||||
```
|
||||
// Set session that will last 1 minute
|
||||
SET randomHash "{userId}" EX 60
|
||||
|
||||
// Get userId
|
||||
GET randomHash
|
||||
|
||||
```
|
||||
|
||||
### 4\. Queue
|
||||
|
||||
One of the less common, but very useful things you can do with Redis is queue things. Whether it's a queue of emails or data to be consumed by another application, you can create an efficient queue it in Redis. Using this functionality is easy and natural for any developer who is familiar with Stacks and pushing and popping items.
|
||||
Simple Commands
|
||||
|
||||
```
|
||||
// Add a Message
|
||||
HSET messages <id> <message>
|
||||
ZADD due <due_timestamp> <id>
|
||||
|
||||
// Recieving Message
|
||||
ZRANGEBYSCORE due -inf <current_timestamp> LIMIT 0 1
|
||||
HGET messages <message_id>
|
||||
|
||||
// Delete Message
|
||||
ZREM due <message_id>
|
||||
HDEL messages <message_id>
|
||||
|
||||
```
|
||||
|
||||
### 5\. Pub/Sub
|
||||
|
||||
The final real world use for Redis I am going to bring up in this post is pub/sub. This is one of the most powerful features Redis has built in; the possibilities are limitless. You can create a real-time chat system with it, trigger notifications for friend requests on social networks, etc... This feature is one of the most underrated features Redis offers but is very powerful, yet simple to use.
|
||||
Simple Commands
|
||||
|
||||
```
|
||||
// Add a message to a channel
|
||||
PUBLISH channel message
|
||||
|
||||
// Recieve messages from a channel
|
||||
SUBSCRIBE channel
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
I hope you enjoyed this list of some of the many real world uses for Redis. This is just scratching the surface of what Redis can do for you, but I hope it gave you some ideas of how you can use the full potential Redis has to offer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Hi, my name is Ryan! I am a Software Developer with experience in many web frameworks and libraries including NodeJS, Django, Golang, and Laravel.
|
||||
|
||||
|
||||
-------------------
|
||||
|
||||
|
||||
via: https://ryanmccue.ca/5-real-world-uses-for-redis/
|
||||
|
||||
作者:[Ryan McCue ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ryanmccue.ca/author/ryan/
|
||||
[1]:https://ryanmccue.ca/author/ryan/
|
||||
@ -1,363 +0,0 @@
|
||||
translating by lujun9972
|
||||
Advanced Python Debugging with pdb
|
||||
======
|
||||
|
||||
|
||||
|
||||
Python's built-in [`pdb`][1] module is extremely useful for interactive debugging, but has a bit of a learning curve. For a long time, I stuck to basic `print`-debugging and used `pdb` on a limited basis, which meant I missed out on a lot of features that would have made debugging faster and easier.
|
||||
|
||||
In this post I will show you a few tips I've picked up over the years to level up my interactive debugging skills.
|
||||
|
||||
## Print debugging vs. interactive debugging
|
||||
|
||||
First, why would you want to use an interactive debugger instead of inserting `print` or `logging` statements into your code?
|
||||
|
||||
With `pdb`, you have a lot more flexibility to run, resume, and alter the execution of your program without touching the underlying source. Once you get good at this, it means more time spent diving into issues and less time context switching back and forth between your editor and the command line.
|
||||
|
||||
Also, by not touching the underlying source code, you will have the ability to step into third party code (e.g. modules installed from PyPI) and the standard library.
|
||||
|
||||
## Post-mortem debugging
|
||||
|
||||
The first workflow I used after moving away from `print` debugging was `pdb`'s "post-mortem debugging" mode. This is where you run your program as usual, but whenever an unhandled exception is thrown, you drop down into the debugger to poke around in the program state. After that, you attempt to make a fix and repeat the process until the problem is resolved.
|
||||
|
||||
You can run an existing script with the post-mortem debugger by using Python's `-mpdb` option:
|
||||
```
|
||||
python3 -mpdb path/to/script.py
|
||||
|
||||
```
|
||||
|
||||
From here, you are dropped into a `(Pdb)` prompt. To start execution, you use the `continue` or `c` command. If the program executes successfully, you will be taken back to the `(Pdb)` prompt where you can restart the execution again. At this point, you can use `quit` / `q` or Ctrl+D to exit the debugger.
|
||||
|
||||
If the program throws an unhandled exception, you'll also see a `(Pdb)` prompt, but with the program execution stopped at the line that threw the exception. From here, you can run Python code and debugger commands at the prompt to inspect the current program state.
|
||||
|
||||
## Testing our basic workflow
|
||||
|
||||
To see how these basic debugging steps work, I'll be using this (buggy) program:
|
||||
```
|
||||
import random
|
||||
|
||||
MAX = 100
|
||||
|
||||
def main(num_loops=1000):
|
||||
for i in range(num_loops):
|
||||
num = random.randint(0, MAX)
|
||||
denom = random.randint(0, MAX)
|
||||
result = num / denom
|
||||
print("{} divided by {} is {:.2f}".format(num, denom, result))
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
arg = sys.argv[-1]
|
||||
if arg.isdigit():
|
||||
main(arg)
|
||||
else:
|
||||
main()
|
||||
|
||||
```
|
||||
|
||||
We're expecting the program to do some basic math operations on random numbers in a loop and print the result. Try running it normally and you will see one of the bugs:
|
||||
```
|
||||
$ python3 script.py
|
||||
2 divided by 30 is 0.07
|
||||
65 divided by 41 is 1.59
|
||||
0 divided by 70 is 0.00
|
||||
...
|
||||
38 divided by 26 is 1.46
|
||||
Traceback (most recent call last):
|
||||
File "script.py", line 16, in <module>
|
||||
main()
|
||||
File "script.py", line 7, in main
|
||||
result = num / denom
|
||||
ZeroDivisionError: division by zero
|
||||
|
||||
```
|
||||
|
||||
Let's try post-mortem debugging this error:
|
||||
```
|
||||
$ python3 -mpdb script.py
|
||||
> ./src/script.py(1)<module>()
|
||||
-> import random
|
||||
(Pdb) c
|
||||
49 divided by 46 is 1.07
|
||||
...
|
||||
Traceback (most recent call last):
|
||||
File "/usr/lib/python3.4/pdb.py", line 1661, in main
|
||||
pdb._runscript(mainpyfile)
|
||||
File "/usr/lib/python3.4/pdb.py", line 1542, in _runscript
|
||||
self.run(statement)
|
||||
File "/usr/lib/python3.4/bdb.py", line 431, in run
|
||||
exec(cmd, globals, locals)
|
||||
File "<string>", line 1, in <module>
|
||||
File "./src/script.py", line 1, in <module>
|
||||
import random
|
||||
File "./src/script.py", line 7, in main
|
||||
result = num / denom
|
||||
ZeroDivisionError: division by zero
|
||||
Uncaught exception. Entering post mortem debugging
|
||||
Running 'cont' or 'step' will restart the program
|
||||
> ./src/script.py(7)main()
|
||||
-> result = num / denom
|
||||
(Pdb) num
|
||||
76
|
||||
(Pdb) denom
|
||||
0
|
||||
(Pdb) random.randint(0, MAX)
|
||||
56
|
||||
(Pdb) random.randint(0, MAX)
|
||||
79
|
||||
(Pdb) random.randint(0, 1)
|
||||
0
|
||||
(Pdb) random.randint(1, 1)
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
Once the post-mortem debugger kicks in, we can inspect all of the variables in the current frame and even run new code to help us figure out what's wrong and attempt to make a fix.
|
||||
|
||||
## Dropping into the debugger from Python code using `pdb.set_trace`
|
||||
|
||||
Another technique that I used early on, after starting to use `pdb`, was forcing the debugger to run at a certain line of code before an error occurred. This is a common next step after learning post-mortem debugging because it feels similar to debugging with `print` statements.
|
||||
|
||||
For example, in the above code, if we want to stop execution before the division operation, we could add a `pdb.set_trace` call to our program here:
|
||||
```
|
||||
import pdb; pdb.set_trace()
|
||||
result = num / denom
|
||||
|
||||
```
|
||||
|
||||
And then run our program without `-mpdb`:
|
||||
```
|
||||
$ python3 script.py
|
||||
> ./src/script.py(10)main()
|
||||
-> result = num / denom
|
||||
(Pdb) num
|
||||
94
|
||||
(Pdb) denom
|
||||
19
|
||||
|
||||
```
|
||||
|
||||
The problem with this method is that you have to constantly drop these statements into your source code, remember to remove them afterwards, and switch between running your code with `python` vs. `python -mpdb`.
|
||||
|
||||
Using `pdb.set_trace` gets the job done, but **breakpoints** are an even more flexible way to stop the debugger at any line (even third party or standard library code), without needing to modify any source code. Let's learn about breakpoints and a few other useful commands.
|
||||
|
||||
## Debugger commands
|
||||
|
||||
There are over 30 commands you can give to the interactive debugger, a list that can be seen by using the `help` command when at the `(Pdb)` prompt:
|
||||
```
|
||||
(Pdb) help
|
||||
|
||||
Documented commands (type help <topic>):
|
||||
========================================
|
||||
EOF c d h list q rv undisplay
|
||||
a cl debug help ll quit s unt
|
||||
alias clear disable ignore longlist r source until
|
||||
args commands display interact n restart step up
|
||||
b condition down j next return tbreak w
|
||||
break cont enable jump p retval u whatis
|
||||
bt continue exit l pp run unalias where
|
||||
|
||||
```
|
||||
|
||||
You can use `help <topic>` for more information on a given command.
|
||||
|
||||
Instead of walking through each command, I'll list out the ones I've found most useful and what arguments they take.
|
||||
|
||||
**Setting breakpoints** :
|
||||
|
||||
* `l(ist)`: displays the source code of the currently running program, with line numbers, for the 10 lines around the current statement.
|
||||
* `l 1,999`: displays the source code of lines 1-999. I regularly use this to see the source for the entire program. If your program only has 20 lines, it'll just show all 20 lines.
|
||||
* `b(reakpoint)`: displays a list of current breakpoints.
|
||||
* `b 10`: set a breakpoint at line 10. Breakpoints are referred to by a numeric ID, starting at 1.
|
||||
* `b main`: set a breakpoint at the function named `main`. The function name must be in the current scope. You can also set breakpoints on functions in other modules in the current scope, e.g. `b random.randint`.
|
||||
* `b script.py:10`: sets a breakpoint at line 10 in `script.py`. This gives you another way to set breakpoints in another module.
|
||||
* `clear`: clears all breakpoints.
|
||||
* `clear 1`: clear breakpoint 1.
|
||||
|
||||
|
||||
|
||||
**Stepping through execution** :
|
||||
|
||||
* `c(ontinue)`: execute until the program finishes, an exception is thrown, or a breakpoint is hit.
|
||||
* `s(tep)`: execute the next line, whatever it is (your code, stdlib, third party code, etc.). Use this when you want to step down into function calls you're interested in.
|
||||
* `n(ext)`: execute the next line in the current function (will not step into downstream function calls). Use this when you're only interested in the current function.
|
||||
* `r(eturn)`: execute the remaining lines in the current function until it returns. Use this to skip over the rest of the function and go up a level. For example, if you've stepped down into a function by mistake.
|
||||
* `unt(il) [lineno]`: execute until the current line exceeds the current line number. This is useful when you've stepped into a loop but want to let the loop continue executing without having to manually step through every iteration. Without any argument, this command behaves like `next` (with the loop skipping behavior, once you've stepped through the loop body once).
|
||||
|
||||
|
||||
|
||||
**Moving up and down the stack** :
|
||||
|
||||
* `w(here)`: shows an annotated view of the stack trace, with your current frame marked by `>`.
|
||||
* `u(p)`: move up one frame in the current stack trace. For example, when post-mortem debugging, you'll start off on the lowest level of the stack and typically want to move `up` a few times to help figure out what went wrong.
|
||||
* `d(own)`: move down one frame in the current stack trace.
|
||||
|
||||
|
||||
|
||||
**Additional commands and tips** :
|
||||
|
||||
* `pp <expression>`: This will "pretty print" the result of the given expression using the [`pprint`][2] module. Example:
|
||||
|
||||
|
||||
```
|
||||
(Pdb) stuff = "testing the pp command in pdb with a big list of strings"
|
||||
(Pdb) pp [(i, x) for (i, x) in enumerate(stuff.split())]
|
||||
[(0, 'testing'),
|
||||
(1, 'the'),
|
||||
(2, 'pp'),
|
||||
(3, 'command'),
|
||||
(4, 'in'),
|
||||
(5, 'pdb'),
|
||||
(6, 'with'),
|
||||
(7, 'a'),
|
||||
(8, 'big'),
|
||||
(9, 'list'),
|
||||
(10, 'of'),
|
||||
(11, 'strings')]
|
||||
|
||||
```
|
||||
|
||||
* `!<python code>`: sometimes the Python code you run in the debugger will be confused for a command. For example `c = 1` will trigger the `continue` command. To force the debugger to execute Python code, prefix the line with `!`, e.g. `!c = 1`.
|
||||
|
||||
* Pressing the Enter key at the `(Pdb)` prompt will execute the previous command again. This is most useful after the `s`/`n`/`r`/`unt` commands to quickly step through execution line-by-line.
|
||||
|
||||
* You can run multiple commands on one line by separating them with `;;`, e.g. `b 8 ;; c`.
|
||||
|
||||
* The `pdb` module can take multiple `-c` arguments on the command line to execute commands as soon as the debugger starts.
|
||||
|
||||
|
||||
|
||||
|
||||
Example:
|
||||
```
|
||||
python3 -mpdb -cc script.py # run the program without you having to enter an initial "c" at the prompt
|
||||
python3 -mpdb -c "b 8" -cc script.py # sets a breakpoint on line 8 and runs the program
|
||||
|
||||
```
|
||||
|
||||
## Restart behavior
|
||||
|
||||
Another thing that can shave time off debugging is understanding how `pdb`'s restart behavior works. You may have noticed that after execution stops, `pdb` will give a message like, "The program finished and will be restarted," or "The script will be restarted." When I first started using `pdb`, I would always quit and re-run `python -mpdb ...` to make sure that my code changes were getting picked up, which was unnecessary in most cases.
|
||||
|
||||
When `pdb` says it will restart the program, or when you use the `restart` command, code changes to the script you're debugging will be reloaded automatically. Breakpoints will still be set after reloading, but may need to be cleared and re-set due to line numbers shifting. Code changes to other imported modules will not be reloaded -- you will need to `quit` and re-run the `-mpdb` command to pick those up.
|
||||
|
||||
## Watches
|
||||
|
||||
One feature you may miss from other interactive debuggers is the ability to "watch" a variable change throughout the program's execution. `pdb` does not include a watch command by default, but you can get something similar by using `commands`, which lets you run arbitrary Python code whenever a breakpoint is hit.
|
||||
|
||||
To watch what happens to the `denom` variable in our example program:
|
||||
```
|
||||
$ python3 -mpdb script.py
|
||||
> ./src/script.py(1)<module>()
|
||||
-> import random
|
||||
(Pdb) b 9
|
||||
Breakpoint 1 at ./src/script.py:9
|
||||
(Pdb) commands
|
||||
(com) silent
|
||||
(com) print("DENOM: {}".format(denom))
|
||||
(com) c
|
||||
(Pdb) c
|
||||
DENOM: 77
|
||||
71 divided by 77 is 0.92
|
||||
DENOM: 27
|
||||
100 divided by 27 is 3.70
|
||||
DENOM: 10
|
||||
82 divided by 10 is 8.20
|
||||
DENOM: 20
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
We first set a breakpoint (which is assigned ID 1), then use `commands` to start entering a block of commands. These commands function as if you had typed them at the `(Pdb)` prompt. They can be either Python code or additional `pdb` commands.
|
||||
|
||||
Once we start the `commands` block, the prompt changes to `(com)`. The `silent` command means the following commands will not be echoed back to the screen every time they're executed, which makes reading the output a little easier.
|
||||
|
||||
After that, we run a `print` statement to inspect the variable, similar to what we might do when `print` debugging. Finally, we end with a `c` to continue execution, which ends the command block. Typing `c` again at the `(Pdb)` prompt starts execution and we see our new `print` statement running.
|
||||
|
||||
If you'd rather stop execution instead of continuing, you can use `end` instead of `c` in the command block.
|
||||
|
||||
## Running pdb from the interpreter
|
||||
|
||||
Another way to run `pdb` is via the interpreter, which is useful when you're experimenting interactively and would like to drop into `pdb` without running a standalone script.
|
||||
|
||||
For post-mortem debugging, all you need is a call to `pdb.pm()` after an exception has occurred:
|
||||
```
|
||||
$ python3
|
||||
>>> import script
|
||||
>>> script.main()
|
||||
17 divided by 60 is 0.28
|
||||
...
|
||||
56 divided by 94 is 0.60
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
File "./src/script.py", line 9, in main
|
||||
result = num / denom
|
||||
ZeroDivisionError: division by zero
|
||||
>>> import pdb
|
||||
>>> pdb.pm()
|
||||
> ./src/script.py(9)main()
|
||||
-> result = num / denom
|
||||
(Pdb) num
|
||||
4
|
||||
(Pdb) denom
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
If you want to step through normal execution instead, use the `pdb.run()` function:
|
||||
```
|
||||
$ python3
|
||||
>>> import script
|
||||
>>> import pdb
|
||||
>>> pdb.run("script.main()")
|
||||
> <string>(1)<module>()
|
||||
(Pdb) b script:6
|
||||
Breakpoint 1 at ./src/script.py:6
|
||||
(Pdb) c
|
||||
> ./src/script.py(6)main()
|
||||
-> for i in range(num_loops):
|
||||
(Pdb) n
|
||||
> ./src/script.py(7)main()
|
||||
-> num = random.randint(0, MAX)
|
||||
(Pdb) n
|
||||
> ./src/script.py(8)main()
|
||||
-> denom = random.randint(0, MAX)
|
||||
(Pdb) n
|
||||
> ./src/script.py(9)main()
|
||||
-> result = num / denom
|
||||
(Pdb) n
|
||||
> ./src/script.py(10)main()
|
||||
-> print("{} divided by {} is {:.2f}".format(num, denom, result))
|
||||
(Pdb) n
|
||||
66 divided by 70 is 0.94
|
||||
> ./src/script.py(6)main()
|
||||
-> for i in range(num_loops):
|
||||
|
||||
```
|
||||
|
||||
This one is a little trickier than `-mpdb` because you don't have the ability to step through an entire program. Instead, you'll need to manually set a breakpoint, e.g. on the first statement of the function you're trying to execute.
|
||||
|
||||
## Conclusion
|
||||
|
||||
Hopefully these tips have given you a few new ideas on how to use `pdb` more effectively. After getting a handle on these, you should be able to pick up the [other commands][3] and start customizing `pdb` via a `.pdbrc` file ([example][4]).
|
||||
|
||||
You can also look into other front-ends for debugging, like [pdbpp][5], [pudb][6], and [ipdb][7], or GUI debuggers like the one included in PyCharm. Happy debugging!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/stevek/advanced-python-debugging-with-pdb-g56gvmpfa
|
||||
|
||||
作者:[Steven Kryskalla][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/stevek
|
||||
[1]:https://docs.python.org/3/library/pdb.html
|
||||
[2]:https://docs.python.org/3/library/pprint.html
|
||||
[3]:https://docs.python.org/3/library/pdb.html#debugger-commands
|
||||
[4]:https://nedbatchelder.com/blog/200704/my_pdbrc.html
|
||||
[5]:https://pypi.python.org/pypi/pdbpp/
|
||||
[6]:https://pypi.python.org/pypi/pudb/
|
||||
[7]:https://pypi.python.org/pypi/ipdb
|
||||
@ -1,173 +0,0 @@
|
||||
How to make your LXD containers get IP addresses from your LAN using a bridge
|
||||
======
|
||||
**Background** : LXD is a hypervisor that manages machine containers on Linux distributions. You install LXD on your Linux distribution and then you can launch machine containers into your distribution running all sort of (other) Linux distributions.
|
||||
|
||||
In the previous post, we saw how to get our LXD container to receive an IP address from the local network (instead of getting the default private IP address), using **macvlan**.
|
||||
|
||||
In this post, we are going to see how to use a **bridge** to make our containers get an IP address from the local network. Specifically, we are going to see how to do this using NetworkManager. If you have several public IP addresses, you can use this method (or the other with the **macvlan** ) in order to expose your LXD containers directly to the Internet.
|
||||
|
||||
### Creating the bridge with NetworkManager
|
||||
|
||||
See this post [How to configure a Linux bridge with Network Manager on Ubuntu][1] on how to create the bridge with NetworkManager. It explains that you
|
||||
|
||||
1. Use **NetworkManager** to **Add a New Connection** , a **Bridge**.
|
||||
2. When configuring the **Bridge** , you specify the real network connection (the device, like **eth0** or **enp3s12** ) that will be **the slave of the bridge**. You can verify the device of the network connection if you run **ip route list 0.0.0.0/0**.
|
||||
3. Then, you can remove the old network connection and just keep the slave. The slave device ( **bridge0** ) will now be the device that gets you your LAN IP address.
|
||||
|
||||
|
||||
|
||||
At this point you would have again network connectivity. Here is the new device, **bridge0**.
|
||||
```
|
||||
$ ifconfig bridge0
|
||||
bridge0 Link encap:Ethernet HWaddr 00:e0:4b:e0:a8:c2
|
||||
inet addr:192.168.1.64 Bcast:192.168.1.255 Mask:255.255.255.0
|
||||
inet6 addr: fe80::d3ca:7a11:f34:fc76/64 Scope:Link
|
||||
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||
RX packets:9143 errors:0 dropped:0 overruns:0 frame:0
|
||||
TX packets:7711 errors:0 dropped:0 overruns:0 carrier:0
|
||||
collisions:0 txqueuelen:1000
|
||||
RX bytes:7982653 (7.9 MB) TX bytes:1056263 (1.0 MB)
|
||||
```
|
||||
|
||||
### Creating a new profile in LXD for bridge networking
|
||||
|
||||
In LXD, there is a default profile and then you can create additional profile that either are independent from the default (like in the **macvlan** post), or can be chained with the default profile. Now we see the latter.
|
||||
|
||||
First, create a new and empty LXD profile, called **bridgeprofile**.
|
||||
```
|
||||
$ lxc create profile bridgeprofile
|
||||
```
|
||||
|
||||
Here is the fragment to add to the new profile. The **eth0** is the interface name in the container, so for the Ubuntu containers it does not change. Then, **bridge0** is the interface that was created by NetworkManager. If you created that bridge by some other way, add here the appropriate interface name. The **EOF** at the end is just a marker when we copy and past to the profile.
|
||||
```
|
||||
description: Bridged networking LXD profile
|
||||
devices:
|
||||
eth0:
|
||||
name: eth0
|
||||
nictype: bridged
|
||||
parent: bridge0
|
||||
type: nic
|
||||
**EOF**
|
||||
```
|
||||
|
||||
Paste the fragment to the new profile.
|
||||
```
|
||||
$ cat <<EOF | lxc profile edit bridgeprofile
|
||||
(paste here the full fragment from earlier)
|
||||
```
|
||||
|
||||
The end result should look like the following.
|
||||
```
|
||||
$ lxc profile show bridgeprofile
|
||||
config: {}
|
||||
description: Bridged networking LXD profile
|
||||
devices:
|
||||
eth0:
|
||||
name: eth0
|
||||
nictype: bridged
|
||||
parent: bridge0
|
||||
type: nic
|
||||
name: bridgeprofile
|
||||
used_by:
|
||||
```
|
||||
|
||||
If it got messed up, delete the profile and start over again. Here is the command.
|
||||
```
|
||||
$ lxc profile delete profile_name_to_delete
|
||||
```
|
||||
|
||||
### Creating containers with the bridge profile
|
||||
|
||||
Now we are ready to create a new container that will use the bridge. We need to specify first the default profile, then the new profile. This is because the new profile will overwrite the network settings of the default profile.
|
||||
```
|
||||
$ lxc launch -p default -p bridgeprofile ubuntu:x mybridge
|
||||
Creating mybridgeStarting mybridge
|
||||
```
|
||||
|
||||
Here is the result.
|
||||
```
|
||||
$ lxc list
|
||||
+-------------|---------|---------------------|------+
|
||||
| mytest | RUNNING | 192.168.1.72 (eth0) | |
|
||||
+-------------|---------|---------------------|------+
|
||||
| ... | ... |
|
||||
```
|
||||
|
||||
The container **mybridge** is accessible from the local network.
|
||||
|
||||
### Changing existing containers to use the bridge profile
|
||||
|
||||
Suppose we have an existing container that was created with the default profile, and got the LXD NAT network. Can we switch it to use the bridge profile?
|
||||
|
||||
Here is the existing container.
|
||||
```
|
||||
$ lxc launch ubuntu:x mycontainer
|
||||
Creating mycontainerStarting mycontainer
|
||||
```
|
||||
|
||||
Let's assign **mycontainer** to use the new profile, " **default,bridgeprofile "**.
|
||||
```
|
||||
$ lxc profile assign mycontainer default,bridgeprofile
|
||||
```
|
||||
|
||||
Now we just need to restart the networking in the container.
|
||||
```
|
||||
$ lxc exec mycontainer -- systemctl restart networking.service
|
||||
```
|
||||
|
||||
This can take quite some time, 10 to 20 seconds. Be patient. Obviously, we could simply restart the container. However, since it can take quite some time to get the IP address, it is more practical to know exactly when you get the new IP address.
|
||||
|
||||
Let's see how it looks!
|
||||
```
|
||||
$ lxc list ^mycontainer$
|
||||
+----------------|-------------|---------------------|------+
|
||||
| NAME | STATE | IPV4 | IPV6 |
|
||||
+----------------|-------------|---------------------|------+
|
||||
| mycontainer | RUNNING | 192.168.1.76 (eth0) | |
|
||||
+----------------|-------------|---------------------|------+
|
||||
```
|
||||
|
||||
It is great! It got a LAN IP address! In the **lxc list** command, we used the filter **^mycontainer$** , which means to show only the container with the exact name **mycontainer**. By default, **lxc list** does a substring search when it tries to match a container name. Those **^** and **$** characters are related to Linux/Unix in general, where **^** means **start** , and **$** means **end**. Therefore, **^mycontainer$** means the exact string **mycontainer**!
|
||||
|
||||
### Changing bridged containers to use the LXD NAT
|
||||
|
||||
Let's switch back from using the bridge, to using the LXD NAT network. We stop the container, then assign just the **default** profile and finally start the container.
|
||||
```
|
||||
$ lxc stop mycontainer
|
||||
$ lxc profile assign mycontainer default
|
||||
Profiles default applied to mycontainer
|
||||
$ lxc start mycontainer
|
||||
```
|
||||
|
||||
Let's have a look at it,
|
||||
```
|
||||
$ lxc list ^mycontainer$
|
||||
+-------------|---------|----------------------|--------------------------------+
|
||||
| NAME | STATE | IPV4 | IPV6 |
|
||||
+-------------|---------|----------------------|--------------------------------+
|
||||
| mycontainer | RUNNING | 10.52.252.101 (eth0) | fd42:cba6:...:fe10:3f14 (eth0) |
|
||||
+-------------|---------|----------------------|--------------------------------+
|
||||
```
|
||||
|
||||
**NOTE** : I tried to assign the **default** profile while the container was running in bridged mode. It made a mess with the networking and the container could not get an IPv4 IP address anymore. It could get an IPv6 address though. Therefore, use as a rule of thumb to stop a container before assigning a different profile.
|
||||
|
||||
**NOTE #2** : If your container has a LAN IP address, it is important to stop the container so that your router's DHCP server gets the notification to remove the DHCP lease. Most routers remember the MAC address of a new computer, and a new container gets a new random MAC address. Therefore, do not delete or kill containers that have a LAN IP address but rather stop them first. Your router's DHCP lease table is only that big.
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this post we saw how to selectively get ours containers to receive a LAN IP address. This requires to set the host network interface to be the slave of the bridge. It is a bit invasive compared to [using a **macvlan**][2], but offers the ability for the containers and the host to communicate with each other over the LAN.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.simos.info/how-to-make-your-lxd-containers-get-ip-addresses-from-your-lan-using-a-bridge/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.simos.info/author/simos/
|
||||
[1]:http://ask.xmodulo.com/configure-linux-bridge-network-manager-ubuntu.html (Permalink to How to configure a Linux bridge with Network Manager on Ubuntu)
|
||||
[2]:https://blog.simos.info/how-to-make-your-lxd-container-get-ip-addresses-from-your-lan/
|
||||
@ -1,225 +0,0 @@
|
||||
How to use LXD instance types
|
||||
======
|
||||
**Background** : LXD is a hypervisor that manages machine containers on Linux distributions. You install LXD on your Linux distribution and then you can launch machine containers into your distribution running all sort of (other) Linux distributions.
|
||||
|
||||
When you launch a new LXD container, there is a parameter for an instance type. Here it is,
|
||||
```
|
||||
$ lxc launch --help
|
||||
Usage: lxc launch [ <remote>:]<image> [<remote>:][<name>] [--ephemeral|-e] [--profile|-p <profile>...] [--config|-c <key=value>...] [--type|-t <instance type>]
|
||||
|
||||
Create and start containers from images.
|
||||
|
||||
Not specifying -p will result in the default profile.
|
||||
Specifying "-p" with no argument will result in no profile.
|
||||
|
||||
Examples:
|
||||
lxc launch ubuntu:16.04 u1
|
||||
|
||||
Options:
|
||||
-c, --config (= map[]) Config key/value to apply to the new container
|
||||
--debug (= false) Enable debug mode
|
||||
-e, --ephemeral (= false) Ephemeral container
|
||||
--force-local (= false) Force using the local unix socket
|
||||
--no-alias (= false) Ignore aliases when determining what command to run
|
||||
-p, --profile (= []) Profile to apply to the new container
|
||||
**-t (= "") Instance type**
|
||||
--verbose (= false) Enable verbose mode
|
||||
```
|
||||
|
||||
What do we put for Instance type? Here is the documentation,
|
||||
|
||||
<https://lxd.readthedocs.io/en/latest/containers/#instance-types>
|
||||
|
||||
Simply put, an instance type is just a mnemonic shortcut for specific pair of CPU cores and RAM memory settings. For CPU you specify the number of cores and for RAM memory the amount in GB (assuming your own computer has enough cores and RAM so that LXD can allocate them to the newly created container).
|
||||
|
||||
You would need an instance type if you want to create a machine container that resembles in the specs as close as possible what you will be installing later on, on AWS (Amazon), Azure (Microsoft) or GCE (Google).
|
||||
|
||||
The instance type can have any of the following forms,
|
||||
|
||||
* `<instance type>` for example: **t2.micro** (LXD figures out that this refers to AWS t2.micro, therefore 1 core, 1GB RAM).
|
||||
* `<cloud>:<instance type>` for example, **aws:t2.micro** (LXD quickly looks into the AWS types, therefore 1core, 1GB RAM).
|
||||
* `c<CPU>-m<RAM in GB>` for example, **c1-m1** (LXD explicitly allocates one core, and 1GB RAM).
|
||||
|
||||
|
||||
|
||||
Where do these mnemonics like **t2.micro** come from? The documentation says from <https://github.com/dustinkirkland/instance-type/tree/master/yaml>
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
There are three sets of instance types, **aws** , **azure** and **gce**. Their names are listed in [the LXD instance type index file ][3]**.yaml,**
|
||||
```
|
||||
aws: "aws.yaml"
|
||||
gce: "gce.yaml"
|
||||
azure: "azure.yaml"
|
||||
|
||||
```
|
||||
|
||||
Over there, there are YAML configuration files for each of AWS, Azure and GCE, and in them there are settings for CPU cores and RAM memory.
|
||||
|
||||
The actual URLs that the LXD client will be using, are
|
||||
|
||||
<https://uk.images.linuxcontainers.org/meta/instance-types/aws.yaml>
|
||||
|
||||
Sample for AWS:
|
||||
```
|
||||
t2.large:
|
||||
cpu: 2.0
|
||||
mem: 8.0
|
||||
t2.medium:
|
||||
cpu: 2.0
|
||||
mem: 4.0
|
||||
t2.micro:
|
||||
cpu: 1.0
|
||||
mem: 1.0
|
||||
t2.nano:
|
||||
cpu: 1.0
|
||||
mem: 0.5
|
||||
t2.small:
|
||||
cpu: 1.0
|
||||
mem: 2.0
|
||||
```
|
||||
|
||||
<https://uk.images.linuxcontainers.org/meta/instance-types/azure.yaml>
|
||||
|
||||
Sample for Azure:
|
||||
```
|
||||
ExtraSmall:
|
||||
cpu: 1.0
|
||||
mem: 0.768
|
||||
Large:
|
||||
cpu: 4.0
|
||||
mem: 7.0
|
||||
Medium:
|
||||
cpu: 2.0
|
||||
mem: 3.5
|
||||
Small:
|
||||
cpu: 1.0
|
||||
mem: 1.75
|
||||
Standard_A1_v2:
|
||||
cpu: 1.0
|
||||
mem: 2.0
|
||||
```
|
||||
|
||||
<https://uk.images.linuxcontainers.org/meta/instance-types/gce.yaml>
|
||||
|
||||
Sample for GCE:
|
||||
```
|
||||
f1-micro:
|
||||
cpu: 0.2
|
||||
mem: 0.6
|
||||
g1-small:
|
||||
cpu: 0.5
|
||||
mem: 1.7
|
||||
n1-highcpu-16:
|
||||
cpu: 16.0
|
||||
mem: 14.4
|
||||
n1-highcpu-2:
|
||||
cpu: 2.0
|
||||
mem: 1.8
|
||||
n1-highcpu-32:
|
||||
cpu: 32.0
|
||||
mem: 28.8
|
||||
```
|
||||
|
||||
Let's see an example. Here, all of the following are all equivalent! Just run one of them to get a 1 CPU core/1GB RAM container.
|
||||
```
|
||||
$ lxc launch ubuntu:x -t t2.micro aws-t2-micro
|
||||
|
||||
$ lxc launch ubuntu:x -t aws:t2.micro aws-t2-micro
|
||||
|
||||
$ lxc launch ubuntu:x -t c1-m1 aws-t2-micro
|
||||
```
|
||||
|
||||
Let's verify that the constraints have been actually set for the container.
|
||||
```
|
||||
$ lxc config get aws-t2-micro limits.cpu
|
||||
1
|
||||
|
||||
$ lxc config get aws-t2-micro limits.cpu.allowance
|
||||
|
||||
|
||||
$ lxc config get aws-t2-micro limits.memory
|
||||
1024MB
|
||||
|
||||
$ lxc config get aws-t2-micro limits.memory.enforce
|
||||
|
||||
|
||||
```
|
||||
|
||||
There are generic limits for 1 CPU core and 1024MB/1GB RAM. For more, see [LXD resource control][4].
|
||||
|
||||
If you already have a running container and you wanted to set limits live (no need to restart it), here is how you would do that.
|
||||
```
|
||||
$ lxc launch ubuntu:x mycontainer
|
||||
Creating mycontainer
|
||||
Starting mycontainer
|
||||
|
||||
$ lxc config set mycontainer limits.cpu 1
|
||||
$ lxc config set mycontainer limits.memory 1GB
|
||||
```
|
||||
|
||||
Let's see the config with the limits,
|
||||
```
|
||||
$ lxc config show mycontainer
|
||||
architecture: x86_64
|
||||
config:
|
||||
image.architecture: amd64
|
||||
image.description: ubuntu 16.04 LTS amd64 (release) (20180126)
|
||||
image.label: release
|
||||
image.os: ubuntu
|
||||
image.release: xenial
|
||||
image.serial: "20180126"
|
||||
image.version: "16.04"
|
||||
limits.cpu: "1"
|
||||
limits.memory: 1GB
|
||||
...
|
||||
```
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
#### I tried to the the memory limit but I get an error!
|
||||
|
||||
I got this error,
|
||||
```
|
||||
$ lxc config set mycontainer limits.memory 1
|
||||
error: Failed to set cgroup memory.limit_in_bytes="1": setting cgroup item for the container failed
|
||||
Exit 1
|
||||
```
|
||||
|
||||
When you set the memory limit ( **limits.memory** ), you need to append a specifier like **GB** (as in 1GB). Because the number there is in bytes if no specifier is present, and one byte of memory is not going to work.
|
||||
|
||||
#### I cannot set the limits in lxc launch -config!
|
||||
|
||||
How do I use **lxc launch -config ConfigurationGoesHere**?
|
||||
|
||||
Here is the documentation:
|
||||
```
|
||||
$ lxc launch --help
|
||||
Usage: lxc launch [ <remote>:]<image> ... [--config|-c <key=value>...]
|
||||
```
|
||||
|
||||
Here it is,
|
||||
```
|
||||
$ lxc launch ubuntu:x --config limits.cpu=1 --config limits.memory=1GB mycontainer
|
||||
Creating mycontainer
|
||||
Starting mycontainer
|
||||
```
|
||||
|
||||
That is, use multiple **- config** parameters.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.simos.info/how-to-use-lxd-instance-types/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.simos.info/author/simos/
|
||||
[1]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2018/01/lxd-instance-types.png?resize=750%2C277&ssl=1
|
||||
[2]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2018/01/lxd-instance-types.png?ssl=1
|
||||
[3]:https://uk.images.linuxcontainers.org/meta/instance-types/.yaml
|
||||
[4]:https://stgraber.org/2016/03/26/lxd-2-0-resource-control-412/
|
||||
@ -1,401 +0,0 @@
|
||||
Install Zabbix Monitoring Server and Agent on Debian 9
|
||||
======
|
||||
|
||||
Monitoring tools are used to continuously keep track of the status of the system and send out alerts and notifications if anything goes wrong. Also, monitoring tools help you to ensure that your critical systems, applications and services are always up and running. Monitoring tools are a supplement for your network security, allowing you to detect malicious traffic, where it's coming from and how to cancel it.
|
||||
|
||||
Zabbix is a free, open source and the ultimate enterprise-level monitoring tool designed for real-time monitoring of millions of metrics collected from tens of thousands of servers, virtual machines and network devices. Zabbix has been designed to skill from small environment to large environment. Its web front-end is written in PHP, backend is written in C and uses MySQL, PostgreSQL, SQLite, Oracle or IBM DB2 to store data. Zabbix provides graphing functionality that allows you to get an overview of the current state of specific nodes and the network
|
||||
|
||||
Some of the major features of the Zabbix are listed below:
|
||||
|
||||
* Monitoring Servers, Databases, Applications, Network Devices, Vmware hypervisor, Virtual Machines and much more.
|
||||
* Special designed to support small to large environments to improve the quality of your services and reduce operating costs by avoiding downtime.
|
||||
* Fully open source, so you don't need to pay anything.
|
||||
* Provide user friendly web interface to do everything from a central location.
|
||||
* Comes with SNMP to monitor Network device and IPMI to monitor Hardware device.
|
||||
* Web-based front end that allows full system control from a browser.
|
||||
|
||||
This tutorial will walk you through the step by step instruction of how to install Zabbix Server and Zabbix agent on Debian 9 server. We will also explain how to add the Zabbix agent to the Zabbix server for monitoring.
|
||||
|
||||
#### Requirements
|
||||
|
||||
* Two system with Debian 9 installed.
|
||||
* Minimum 1 GB of RAM and 10 DB of disk space required. Amount of RAM and Disk space depends on the number of hosts and the parameters that are being monitored.
|
||||
* A non-root user with sudo privileges setup on your server.
|
||||
|
||||
|
||||
|
||||
#### Getting Started
|
||||
|
||||
Before starting, it is necessary to update your server's package repository to the latest stable version. You can update it by just running the following command on both instances:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
Next, restart your system to apply these changes.
|
||||
|
||||
#### Install Apache, PHP and MariaDB
|
||||
|
||||
Zabbix runs on Apache web server, written in PHP and uses MariaDB/MySQL to store their data. So in order to install Zabbix, you will require Apache, MariaDB and PHP to work. First, install Apache, PHP and Other PHP modules by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install apache2 libapache2-mod-php7.0 php7.0 php7.0-xml php7.0-bcmath php7.0-mbstring -y
|
||||
```
|
||||
|
||||
Next, you will need to add MariaDB repository to your system. Because, latest version of the MariaDB is not available in Debian 9 default repository.
|
||||
|
||||
You can add the repository by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install software-properties-common -y
|
||||
sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 0xF1656F24C74CD1D8
|
||||
sudo add-apt-repository 'deb [arch=amd64] http://www.ftp.saix.net/DB/mariadb/repo/10.1/debian stretch main'
|
||||
```
|
||||
|
||||
Next, update the repository by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
Finally, install the MariaDB server with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install mariadb-server -y
|
||||
```
|
||||
|
||||
By default, MariaDB installation is not secured. So you will need to secure it first. You can do this by running the mysql_secure_installation script.
|
||||
|
||||
```
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
Answer all the questions as shown below:
|
||||
```
|
||||
|
||||
Enter current password for root (enter for none): Enter
|
||||
Set root password? [Y/n]: Y
|
||||
New password:
|
||||
Re-enter new password:
|
||||
Remove anonymous users? [Y/n]: Y
|
||||
Disallow root login remotely? [Y/n]: Y
|
||||
Remove test database and access to it? [Y/n]: Y
|
||||
Reload privilege tables now? [Y/n]: Y
|
||||
|
||||
```
|
||||
|
||||
The above script will set the root password, remove test database, remove anonymous user and Disallow root login from a remote location.
|
||||
|
||||
Once the MariaDB installation is secured, start the Apache and MariaDB service and enable them to start on boot time by running the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start apache2
|
||||
sudo systemctl enable apache2
|
||||
sudo systemctl start mysql
|
||||
sudo systemctl enable mysql
|
||||
```
|
||||
|
||||
#### Installing Zabbix Server
|
||||
|
||||
By default, Zabbix is available in the Debian 9 repository, but it might be outdated. So it is recommended to install most recent version from the official Zabbix repositories. You can download and add the latest version of the Zabbix repository with the following command:
|
||||
|
||||
```
|
||||
wget http://repo.zabbix.com/zabbix/3.0/debian/pool/main/z/zabbix-release/zabbix-release_3.0-2+stretch_all.deb
|
||||
```
|
||||
|
||||
Next, install the downloaded repository with the following command:
|
||||
|
||||
```
|
||||
sudo dpkg -i zabbix-release_3.0-2+stretch_all.deb
|
||||
```
|
||||
|
||||
Next, update the package cache and install Zabbix server with web front-end and Mysql support by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get install zabbix-server-mysql zabbix-frontend-php -y
|
||||
```
|
||||
|
||||
You will also need to install the Zabbix agent to collect data about the Zabbix server status itself:
|
||||
|
||||
```
|
||||
sudo apt-get install zabbix-agent -y
|
||||
```
|
||||
|
||||
After installing Zabbix agent, start the Zabbix agent service and enable it to start on boot time by running the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start zabbix-agent
|
||||
sudo systemctl enable zabbix-agent
|
||||
```
|
||||
|
||||
#### Configuring Zabbix Database
|
||||
|
||||
Zabbix uses MariaDB/MySQL as a database backend. So, you will need to create a MySQL database and User for zabbix installation:
|
||||
|
||||
First, log into MySQL shell with the following command:
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
```
|
||||
|
||||
Enter your root password, then create a database for Zabbix with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> CREATE DATABASE zabbixdb character set utf8 collate utf8_bin;
|
||||
```
|
||||
|
||||
Next, create a user for Zabbix, assign a password and grant all privileges on Zabbix database with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> CREATE user zabbix identified by 'password';
|
||||
MariaDB [(none)]> GRANT ALL PRIVILEGES on zabbixdb.* to zabbixuser@localhost identified by 'password';
|
||||
```
|
||||
|
||||
Next, flush the privileges with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
Finally, exit from the MySQL shell with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> exit;
|
||||
```
|
||||
|
||||
Next, import initial schema and data to the newly created database with the following command:
|
||||
|
||||
```
|
||||
cd /usr/share/doc/zabbix-server-mysql*/
|
||||
zcat create.sql.gz | mysql -u zabbix -p zabbixdb
|
||||
```
|
||||
|
||||
#### Configuring Zabbix
|
||||
|
||||
Zabbix creates its own configuration file at `/etc/zabbix/apache.conf`. Edit this file and update the Timezone and PHP setting as per your need:
|
||||
|
||||
```
|
||||
sudo nano /etc/zabbix/apache.conf
|
||||
```
|
||||
|
||||
Change the file as shown below:
|
||||
```
|
||||
php_value max_execution_time 300
|
||||
php_value memory_limit 128M
|
||||
php_value post_max_size 32M
|
||||
php_value upload_max_filesize 8M
|
||||
php_value max_input_time 300
|
||||
php_value always_populate_raw_post_data -1
|
||||
php_value date.timezone Asia/Kolkata
|
||||
|
||||
```
|
||||
|
||||
Save the file when you are finished.
|
||||
|
||||
Next, you will need to update the database details for Zabbix. You can do this by editing `/etc/zabbix/zabbix_server.conf` file:
|
||||
|
||||
```
|
||||
sudo nano /etc/zabbix/zabbix_server.conf
|
||||
```
|
||||
|
||||
Change the following lines:
|
||||
```
|
||||
DBHost=localhost
|
||||
DBName=zabbixdb
|
||||
DBUser=zabbixuser
|
||||
DBPassword=password
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished. Then restart all the services with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl restart apache2
|
||||
sudo systemctl restart mysql
|
||||
sudo systemctl restart zabbix-server
|
||||
```
|
||||
|
||||
#### Configuring Firewall
|
||||
|
||||
Before proceeding, you will need to configure the UFW firewall to secure Zabbix server.
|
||||
|
||||
First, make sure UFW is installed on your system. Otherewise, you can install it by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install ufw -y
|
||||
```
|
||||
|
||||
Next, enable the UFW firewall:
|
||||
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
Next, allow port 10050, 10051 and 80 through UFW with the following command:
|
||||
|
||||
```
|
||||
sudo ufw allow 10050/tcp
|
||||
sudo ufw allow 10051/tcp
|
||||
sudo ufw allow 80/tcp
|
||||
```
|
||||
|
||||
Finally, reload the firewall to apply these changes with the following command:
|
||||
|
||||
```
|
||||
sudo ufw reload
|
||||
```
|
||||
|
||||
Once the UFW firewall is configured you can proceed to install the Zabbix server via web interface.
|
||||
|
||||
#### Accessing Zabbix Web Installation Wizard
|
||||
|
||||
Once everything is fine, it's time to access Zabbix web installation wizard.
|
||||
|
||||
Open your web browser and navigate the <http://zabbix-server-ip/zabbix> URL , you will be redirected to the following page:
|
||||
|
||||
[![Zabbix 3.0][2]][3]
|
||||
|
||||
Click on the **Next step** button, you should see the following page:
|
||||
|
||||
[![Zabbix Prerequisites][4]][5]
|
||||
|
||||
Here, all the Zabbix pre-requisites are checked and verified, then click on the **Next step** button you should see the following page:
|
||||
|
||||
[![Database Configuration][6]][7]
|
||||
|
||||
Here, provide the Zabbix database name, database user and password then click on the **Next step** button, you should see the following page:
|
||||
|
||||
[![Zabbix Server Details][8]][9]
|
||||
|
||||
Here, specify the Zabbix server details and Port number then click on the **Next step** button, you should see the pre-installation summary of Zabbix Server in following page:
|
||||
|
||||
[![Installation summary][10]][11]
|
||||
|
||||
Next, click on the **Next step** button to start the Zabbix installation. Once the Zabbix installation is completed successfully, you should see the following page:
|
||||
|
||||
[![Zabbix installed successfully][12]][13]
|
||||
|
||||
Here, click on the **Finish** button, it will redirect to the Zabbix login page as shown below:
|
||||
|
||||
[![Login to Zabbix][14]][15]
|
||||
|
||||
Here, provide username as Admin and password as zabbix then click on the **Sign in** button. You should see the Zabbix server dashboard in the following image:
|
||||
|
||||
[![Zabbix Dashboard][16]][17]
|
||||
|
||||
Your Zabbix web installation is now finished.
|
||||
|
||||
#### Install Zabbix Agent
|
||||
|
||||
Now your Zabbix server is up and functioning. It's time to add Zabbix agent node to the Zabbix Server for Monitoring.
|
||||
|
||||
First, log into Zabbix agent instance and add the Zabbix repository with the following command:
|
||||
|
||||
```
|
||||
wget http://repo.zabbix.com/zabbix/3.0/debian/pool/main/z/zabbix-release/zabbix-release_3.0-2+stretch_all.deb
|
||||
sudo dpkg -i zabbix-release_3.0-2+stretch_all.deb
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
Once you have configured Zabbix repository on your system, install the Zabbix agent by just running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install zabbix-agent -y
|
||||
```
|
||||
|
||||
Once the Zabbix agent is installed, you will need to configure Zabbix agent to communicate with Zabbix server. You can do this by editing the Zabbix agent configuration file:
|
||||
|
||||
```
|
||||
sudo nano /etc/zabbix/zabbix_agentd.conf
|
||||
```
|
||||
|
||||
Change the file as shown below:
|
||||
```
|
||||
#Zabbix Server IP Address / Hostname
|
||||
|
||||
Server=192.168.0.103
|
||||
|
||||
#Zabbix Agent Hostname
|
||||
|
||||
Hostname=zabbix-agent
|
||||
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished, then restart the Zabbix agent service and enable it to start on boot time with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl restart zabbix-agent
|
||||
sudo systemctl enable zabbix-agent
|
||||
```
|
||||
|
||||
#### Add Zabbix Agent Node to Zabbix Server
|
||||
|
||||
Next, you will need to add the Zabbix agent node to the Zabbix server for monitoring. First, log in to the Zabbix server web interface.
|
||||
|
||||
[![Zabbix UI][18]][19]
|
||||
|
||||
Next, Click on **Configuration --> Hosts -> Create Host**, you should see the following page:
|
||||
|
||||
[![Create Host in Zabbix][20]][21]
|
||||
|
||||
Here, specify the Hostname, IP address and Group names of Zabbix agent. Then navigate to Templates tab, you should see the following page:
|
||||
|
||||
[![specify the Hostname, IP address and Group name][22]][23]
|
||||
|
||||
Here, search appropriate templates and click on **Add** button, you should see the following page:
|
||||
|
||||
[![OS Template][24]][25]
|
||||
|
||||
Finally, click on **Add** button again. You will see your new host with green labels indicating that everything is working fine.
|
||||
|
||||
[![Hast successfully added to Zabbix][26]][27]
|
||||
|
||||
If you have extra servers and network devices that you want to monitor, log into each host, install the Zabbix agent and add each host from the Zabbix web interface.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
Congratulations! you have successfully installed the Zabbix server and Zabbix agent in Debian 9 server. You have also added Zabbix agent node to the Zabbix server for monitoring. You can now easily list the current issue and past history, get the latest data of hosts, list the current problems and also visualized the collected resource statistics such as CPU load, CPU utilization, Memory usage, etc via graphs. I hope you can now easily install and configure Zabbix on Debian 9 server and deploy it on production environment. Compared to other monitoring software, Zabbix allows you to build your own maps of different network segments while monitoring many hosts. You can also monitor Windows host using Zabbix windows agent. For more information, you can refer the [Zabbix Documentation Page][28]. Feel free to ask me if you have any questions.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-zabbix-monitoring-server-and-agent-on-debian-9/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
[2]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-welcome-page.png
|
||||
[3]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-welcome-page.png
|
||||
[4]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-pre-requisite-check-page.png
|
||||
[5]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-pre-requisite-check-page.png
|
||||
[6]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-db-config-page.png
|
||||
[7]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-db-config-page.png
|
||||
[8]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-server-details.png
|
||||
[9]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-server-details.png
|
||||
[10]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-pre-installation-summary.png
|
||||
[11]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-pre-installation-summary.png
|
||||
[12]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-install-success.png
|
||||
[13]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-install-success.png
|
||||
[14]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-login-page.png
|
||||
[15]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-login-page.png
|
||||
[16]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-welcome-dashboard.png
|
||||
[17]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-welcome-dashboard.png
|
||||
[18]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-welcome-dashboard1.png
|
||||
[19]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-welcome-dashboard1.png
|
||||
[20]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-host1.png
|
||||
[21]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-host1.png
|
||||
[22]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-add-templates.png
|
||||
[23]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-add-templates.png
|
||||
[24]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-select-templates.png
|
||||
[25]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-select-templates.png
|
||||
[26]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-dashboard.png
|
||||
[27]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-dashboard.png
|
||||
[28]:https://www.zabbix.com/documentation/3.2/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Parsing HTML with Python
|
||||
======
|
||||
|
||||
|
||||
@ -1,583 +0,0 @@
|
||||
Rapid, Secure Patching: Tools and Methods
|
||||
======
|
||||
|
||||
It was with some measure of disbelief that the computer science community greeted the recent [EternalBlue][1]-related exploits that have torn through massive numbers of vulnerable systems. The SMB exploits have kept coming (the most recent being [SMBLoris][2] presented at the last DEF CON, which impacts multiple SMB protocol versions, and for which Microsoft will issue no corrective patch. Attacks with these tools [incapacitated critical infrastructure][3] to the point that patients were even turned away from the British National Health Service.
|
||||
|
||||
It is with considerable sadness that, during this SMB catastrophe, we also have come to understand that the famous Samba server presented an exploitable attack surface on the public internet in sufficient numbers for a worm to propagate successfully. I previously [have discussed SMB security][4] in Linux Journal, and I am no longer of the opinion that SMB server processes should run on Linux.
|
||||
|
||||
In any case, systems administrators of all architectures must be able to down vulnerable network servers and patch them quickly. There is often a need for speed and competence when working with a large collection of Linux servers. Whether this is due to security situations or other concerns is immaterial—the hour of greatest need is not the time to begin to build administration tools. Note that in the event of an active intrusion by hostile parties, [forensic analysis][5] may be a legal requirement, and no steps should be taken on the compromised server without a careful plan and documentation. Especially in this new era of the black hats, computer professionals must step up their game and be able to secure vulnerable systems quickly.
|
||||
|
||||
### Secure SSH Keypairs
|
||||
|
||||
Tight control of a heterogeneous UNIX environment must begin with best-practice use of SSH authentication keys. I'm going to open this section with a simple requirement. SSH private keys must be one of three types: Ed25519, ECDSA using the E-521 curve or RSA keys of 3072 bits. Any key that does not meet those requirements should be retired (in particular, DSA keys must be removed from service immediately).
|
||||
|
||||
The [Ed25519][6] key format is associated with Daniel J. Bernstein, who has such a preeminent reputation in modern cryptography that the field is becoming a DJB [monoculture][7]. The Ed25519 format is deigned for speed, security and size economy. If all of your SSH servers are recent enough to support Ed25519, then use it, and consider nothing else.
|
||||
|
||||
[Guidance on creating Ed25519 keys][8] suggests 100 rounds for a work factor in the "-o" secure format. Raising the number of rounds raises the strength of the encrypted key against brute-force attacks (should a file copy of the private key fall into hostile hands), at the cost of more work and time in decrypting the key when ssh-add is executed. Although there always is [controversy and discussion][9] with security advances, I will repeat the guidance here and suggest that the best format for a newly created SSH key is this:
|
||||
|
||||
```
|
||||
|
||||
ssh-keygen -a 100 -t ed25519
|
||||
|
||||
```
|
||||
|
||||
Your systems might be too old to support Ed25519—Oracle/CentOS/Red Hat 7 have this problem (the 7.1 release introduced support). If you cannot upgrade your old SSH clients and servers, your next best option is likely E-521, available in the ECDSA key format.
|
||||
|
||||
The ECDSA curves came from the US government's National Institute of Standards (NIST). The best known and most implemented of all of the NIST curves are P-256, P-384 and E-521\. All three curves are approved for secret communications by a variety of government entities, but a number of cryptographers have [expressed growing suspicion][10] that the P-256 and P-384 curves are tainted. Well known cryptographer Bruce Schneier [has remarked][11]: "I no longer trust the constants. I believe the NSA has manipulated them through their relationships with industry." However, DJB [has expressed][12] limited praise of the E-521 curve: "To be fair I should mention that there's one standard NIST curve using a nice prime, namely 2521 – 1; but the sheer size of this prime makes it much slower than NIST P-256." All of the NIST curves have greater issues with "side channel" attacks than Ed25519—P-521 is certainly a step down, and many assert that none of the NIST curves are safe. In summary, there is a slight risk that a powerful adversary exists with an advantage over the P-256 and P-384 curves, so one is slightly inclined to avoid them. Note that even if your OpenSSH (source) release is capable of E-521, it may be [disabled by your vendor][13] due to patent concerns, so E-521 is not an option in this case. If you cannot use DJB's 2255 – 19 curve, this command will generate an E-521 key on a capable system:
|
||||
|
||||
```
|
||||
|
||||
ssh-keygen -o -a 100 -b 521 -t ecdsa
|
||||
|
||||
```
|
||||
|
||||
And, then there is the unfortunate circumstance with SSH servers that support neither ECDSA nor Ed25519\. In this case, you must fall back to RSA with much larger key sizes. An absolute minimum is the modern default of 2048 bits, but 3072 is a wiser choice:
|
||||
|
||||
```
|
||||
|
||||
ssh-keygen -o -a 100 -b 3072 -t rsa
|
||||
|
||||
```
|
||||
|
||||
Then in the most lamentable case of all, when you must use old SSH clients that are not able to work with private keys created with the -o option, you can remove the password on id_rsa and create a naked key, then use OpenSSL to encrypt it with AES256 in the PKCS#8 format, as [first documented by Martin Kleppmann][14]. Provide a blank new password for the keygen utility below, then supply a new password when OpenSSL reprocesses the key:
|
||||
|
||||
```
|
||||
|
||||
$ cd ~/.ssh
|
||||
|
||||
$ cp id_rsa id_rsa-orig
|
||||
|
||||
$ ssh-keygen -p -t rsa
|
||||
Enter file in which the key is (/home/cfisher/.ssh/id_rsa):
|
||||
Enter old passphrase:
|
||||
Key has comment 'cfisher@localhost.localdomain'
|
||||
Enter new passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved with the new passphrase.
|
||||
|
||||
$ openssl pkcs8 -topk8 -v2 aes256 -in id_rsa -out id_rsa-strong
|
||||
Enter Encryption Password:
|
||||
Verifying - Enter Encryption Password:
|
||||
|
||||
mv id_rsa-strong id_rsa
|
||||
chmod 600 id_rsa
|
||||
|
||||
```
|
||||
|
||||
After creating all of these keys on a newer system, you can compare the file sizes:
|
||||
|
||||
```
|
||||
|
||||
$ ll .ssh
|
||||
total 32
|
||||
-rw-------. 1 cfisher cfisher 801 Aug 10 21:30 id_ecdsa
|
||||
-rw-r--r--. 1 cfisher cfisher 283 Aug 10 21:30 id_ecdsa.pub
|
||||
-rw-------. 1 cfisher cfisher 464 Aug 10 20:49 id_ed25519
|
||||
-rw-r--r--. 1 cfisher cfisher 111 Aug 10 20:49 id_ed25519.pub
|
||||
-rw-------. 1 cfisher cfisher 2638 Aug 10 21:45 id_rsa
|
||||
-rw-------. 1 cfisher cfisher 2675 Aug 10 21:42 id_rsa-orig
|
||||
-rw-r--r--. 1 cfisher cfisher 583 Aug 10 21:42 id_rsa.pub
|
||||
|
||||
```
|
||||
|
||||
Although they are relatively enormous, all versions of OpenSSH that I have used have been compatible with the RSA private key in PKCS#8 format. The Ed25519 public key is now small enough to fit in 80 columns without word wrap, and it is as convenient as it is efficient and secure.
|
||||
|
||||
Note that PuTTY may have problems using various versions of these keys, and you may need to remove passwords for a successful import into the PuTTY agent.
|
||||
|
||||
These keys represent the most secure formats available for various OpenSSH revisions. They really aren't intended for PuTTY or other general interactive activity. Although one hopes that all users create strong keys for all situations, these are enterprise-class keys for major systems activities. It might be wise, however, to regenerate your system host keys to conform to these guidelines.
|
||||
|
||||
These key formats may soon change. Quantum computers are causing increasing concern for their ability to run [Shor's Algorithm][15], which can be used to find prime factors to break these keys in reasonable time. The largest commercially available quantum computer, the [D-Wave 2000Q][16], effectively [presents under 200 qubits][17] for this activity, which is not (yet) powerful enough for a successful attack. NIST [announced a competition][18] for a new quantum-resistant public key system with a deadline of November 2017 In response, a team including DJB has released source code for [NTRU Prime][19]. It does appear that we will likely see a post-quantum public key format for OpenSSH (and potentially TLS 1.3) released within the next two years, so take steps to ease migration now.
|
||||
|
||||
Also, it's important for SSH servers to restrict their allowed ciphers, MACs and key exchange lest strong keys be wasted on broken crypto (3DES, MD5 and arcfour should be long-disabled). My [previous guidance][20] on the subject involved the following (three) lines in the SSH client and server configuration (note that formatting in the sshd_config file requires all parameters on the same line with no spaces in the options; line breaks have been added here for clarity):
|
||||
|
||||
```
|
||||
|
||||
Ciphers chacha20-poly1305@openssh.com,
|
||||
aes256-gcm@openssh.com,
|
||||
aes128-gcm@openssh.com,
|
||||
aes256-ctr,
|
||||
aes192-ctr,
|
||||
aes128-ctr
|
||||
|
||||
MACs hmac-sha2-512-etm@openssh.com,
|
||||
hmac-sha2-256-etm@openssh.com,
|
||||
hmac-ripemd160-etm@openssh.com,
|
||||
umac-128-etm@openssh.com,
|
||||
hmac-sha2-512,
|
||||
hmac-sha2-256,
|
||||
hmac-ripemd160,
|
||||
umac-128@openssh.com
|
||||
|
||||
KexAlgorithms curve25519-sha256@libssh.org,
|
||||
diffie-hellman-group-exchange-sha256
|
||||
|
||||
```
|
||||
|
||||
Since the previous publication, RIPEMD160 is likely no longer safe and should be removed. Older systems, however, may support only SHA1, MD5 and RIPEMD160\. Certainly remove MD5, but users of PuTTY likely will want to retain SHA1 when newer MACs are not an option. Older servers can present a challenge in finding a reasonable Cipher/MAC/KEX when working with modern systems.
|
||||
|
||||
At this point, you should have strong keys for secure clients and servers. Now let's put them to use.
|
||||
|
||||
### Scripting the SSH Agent
|
||||
|
||||
Modern OpenSSH distributions contain the ssh-copy-id shell script for easy key distribution. Below is an example of installing a specific, named key in a remote account:
|
||||
|
||||
```
|
||||
|
||||
$ ssh-copy-id -i ~/.ssh/some_key.pub person@yourserver.com
|
||||
ssh-copy-id: INFO: Source of key(s) to be installed:
|
||||
"/home/cfisher/.ssh/some_key.pub"
|
||||
ssh-copy-id: INFO: attempting to log in with the new key(s),
|
||||
to filter out any that are already installed
|
||||
ssh-copy-id: INFO: 1 key(s) remain to be installed --
|
||||
if you are prompted now it is to install the new keys
|
||||
person@yourserver.com's password:
|
||||
|
||||
Number of key(s) added: 1
|
||||
|
||||
Now try logging into the machine, with:
|
||||
"ssh 'person@yourserver.com'"
|
||||
and check to make sure that only the key(s) you wanted were added.
|
||||
|
||||
```
|
||||
|
||||
If you don't have the ssh-copy-id script, you can install a key manually with the following command:
|
||||
|
||||
```
|
||||
|
||||
$ ssh person@yourserver.com 'cat >> ~/.ssh/authorized_keys' < \
|
||||
~/.ssh/some_key.pub
|
||||
|
||||
```
|
||||
|
||||
If you have SELinux enabled, you might have to mark a newly created authorized_keys file with a security type; otherwise, the sshd server dæmon will be prevented from reading the key (the syslog may report this issue):
|
||||
|
||||
```
|
||||
|
||||
$ ssh person@yourserver.com 'chcon -t ssh_home_t
|
||||
↪~/.ssh/authorized_keys'
|
||||
|
||||
```
|
||||
|
||||
Once your key is installed, test it in a one-time use with the -i option (note that you are entering a local key password, not a remote authentication password):
|
||||
|
||||
```
|
||||
|
||||
$ ssh -i ~/.ssh/some_key person@yourserver.com
|
||||
Enter passphrase for key '/home/v-fishecj/.ssh/some_key':
|
||||
Last login: Wed Aug 16 12:20:26 2017 from 10.58.17.14
|
||||
yourserver $
|
||||
|
||||
```
|
||||
|
||||
General, interactive users likely will cache their keys with an agent. In the example below, the same password is used on all three types of keys that were created in the previous section:
|
||||
|
||||
```
|
||||
|
||||
$ eval $(ssh-agent)
|
||||
Agent pid 4394
|
||||
|
||||
$ ssh-add
|
||||
Enter passphrase for /home/cfisher/.ssh/id_rsa:
|
||||
Identity added: ~cfisher/.ssh/id_rsa (~cfisher/.ssh/id_rsa)
|
||||
Identity added: ~cfisher/.ssh/id_ecdsa (cfisher@init.com)
|
||||
Identity added: ~cfisher/.ssh/id_ed25519 (cfisher@init.com)
|
||||
|
||||
```
|
||||
|
||||
The first command above launches a user agent process, which injects environment variables (named SSH_AGENT_SOCK and SSH_AGENT_PID) into the parent shell (via eval). The shell becomes aware of the agent and passes these variables to the programs that it runs from that point forward.
|
||||
|
||||
When launched, the ssh-agent has no credentials and is unable to facilitate SSH activity. It must be primed by adding keys, which is done with ssh-add. When called with no arguments, all of the default keys will be read. It also can be called to add a custom key:
|
||||
|
||||
```
|
||||
|
||||
$ ssh-add ~/.ssh/some_key
|
||||
Enter passphrase for /home/cfisher/.ssh/some_key:
|
||||
Identity added: /home/cfisher/.ssh/some_key
|
||||
↪(cfisher@localhost.localdomain)
|
||||
|
||||
```
|
||||
|
||||
Note that the agent will not retain the password on the key. ssh-add uses any and all passwords that you enter while it runs to decrypt keys that it finds, but the passwords are cleared from memory when ssh-add terminates (they are not sent to ssh-agent). This allows you to upgrade to new key formats with minimal inconvenience, while keeping the keys reasonably safe.
|
||||
|
||||
The current cached keys can be listed with ssh-add -l (from, which you can deduce that "some_key" is an Ed25519):
|
||||
|
||||
```
|
||||
|
||||
$ ssh-add -l
|
||||
3072 SHA256:cpVFMZ17oO5n/Jfpv2qDNSNcV6ffOVYPV8vVaSm3DDo
|
||||
/home/cfisher/.ssh/id_rsa (RSA)
|
||||
521 SHA256:1L9/CglR7cstr54a600zDrBbcxMj/a3RtcsdjuU61VU
|
||||
cfisher@localhost.localdomain (ECDSA)
|
||||
256 SHA256:Vd21LEM4lixY4rIg3/Ht/w8aoMT+tRzFUR0R32SZIJc
|
||||
cfisher@localhost.localdomain (ED25519)
|
||||
256 SHA256:YsKtUA9Mglas7kqC4RmzO6jd2jxVNCc1OE+usR4bkcc
|
||||
cfisher@localhost.localdomain (ED25519)
|
||||
|
||||
```
|
||||
|
||||
While a "primed" agent is running, the SSH clients may use (trusting) remote servers fluidly, with no further prompts for credentials:
|
||||
|
||||
```
|
||||
|
||||
$ sftp person@yourserver.com
|
||||
Connected to yourserver.com.
|
||||
sftp> quit
|
||||
|
||||
$ scp /etc/passwd person@yourserver.com:/tmp
|
||||
passwd 100% 2269 65.8KB/s 00:00
|
||||
|
||||
$ ssh person@yourserver.com
|
||||
(motd for yourserver.com)
|
||||
$ ls -l /tmp/passwd
|
||||
-rw-r--r-- 1 root wheel 2269 Aug 16 09:07 /tmp/passwd
|
||||
$ rm /tmp/passwd
|
||||
$ exit
|
||||
Connection to yourserver.com closed.
|
||||
|
||||
```
|
||||
|
||||
The OpenSSH agent can be locked, preventing any further use of the credentials that it holds (this might be appropriate when suspending a laptop):
|
||||
|
||||
```
|
||||
|
||||
$ ssh-add -x
|
||||
Enter lock password:
|
||||
Again:
|
||||
Agent locked.
|
||||
|
||||
$ ssh yourserver.com
|
||||
Enter passphrase for key '/home/cfisher/.ssh/id_rsa': ^C
|
||||
|
||||
```
|
||||
|
||||
It will provide credentials again when it is unlocked:
|
||||
|
||||
```
|
||||
|
||||
$ ssh-add -X
|
||||
Enter lock password:
|
||||
Agent unlocked.
|
||||
|
||||
```
|
||||
|
||||
You also can set ssh-agent to expire keys after a time limit with the -t option, which may be useful for long-lived agents that must clear keys after a set daily shift.
|
||||
|
||||
General shell users may cache many types of keys with a number of differing agent implementations. In addition to the standard OpenSSH agent, users may rely upon PuTTY's pageant.exe, GNOME keyring or KDE Kwallet, among others (the use of the PUTTY agent could likely fill an article on its own).
|
||||
|
||||
However, the goal here is to create "enterprise" keys for critical server controls. You likely do not want long-lived agents in order to limit the risk of exposure. When scripting with "enterprise" keys, you will run an agent only for the duration of the activity, then kill it at completion.
|
||||
|
||||
There are special options for accessing the root account with OpenSSH—the PermitRootLogin parameter can be added to the sshd_config file (usually found in /etc/ssh). It can be set to a simple yes or no, forced-commands-only, which will allow only explicitly-authorized programs to be executed, or the equivalent options prohibit-password or without-password, both of which will allow access to the keys generated here.
|
||||
|
||||
Many hold that root should not be allowed any access. [Michael W. Lucas][21] addresses the question in SSH Mastery:
|
||||
|
||||
> Sometimes, it seems that you need to allow users to SSH in to the system as root. This is a colossally bad idea in almost all environments. When users must log in as a regular user and then change to root, the system logs record the user account, providing accountability. Logging in as root destroys that audit trail....It is possible to override the security precautions and make sshd permit a login directly as root. It's such a bad idea that I'd consider myself guilty of malpractice if I told you how to do it. Logging in as root via SSH almost always means you're solving the wrong problem. Step back and look for other ways to accomplish your goal.
|
||||
|
||||
When root action is required quickly on more than a few servers, the above advice can impose painful delays. Lucas' direct criticism can be addressed by allowing only a limited set of "bastion" servers to issue root commands over SSH. Administrators should be forced to log in to the bastions with unprivileged accounts to establish accountability.
|
||||
|
||||
However, one problem with remotely "changing to root" is the [statistical use of the Viterbi algorithm][22] Short passwords, the su - command and remote SSH calls that use passwords to establish a trinary network configuration are all uniquely vulnerable to timing attacks on a user's keyboard movement. Those with the highest security concerns will need to compensate.
|
||||
|
||||
For the rest of us, I recommend that PermitRootLogin without-password be set for all target machines.
|
||||
|
||||
Finally, you can easily terminate ssh-agent interactively with the -k option:
|
||||
|
||||
```
|
||||
|
||||
$ eval $(ssh-agent -k)
|
||||
Agent pid 4394 killed
|
||||
|
||||
```
|
||||
|
||||
With these tools and the intended use of them in mind, here is a complete script that runs an agent for the duration of a set of commands over a list of servers for a common named user (which is not necessarily root):
|
||||
|
||||
```
|
||||
|
||||
# cat artano
|
||||
|
||||
#!/bin/sh
|
||||
|
||||
if [[ $# -lt 1 ]]; then echo "$0 - requires commands"; exit; fi
|
||||
|
||||
R="-R5865:127.0.0.1:5865" # set to "-2" if you don't want
|
||||
↪port forwarding
|
||||
|
||||
eval $(ssh-agent -s)
|
||||
|
||||
function cleanup { eval $(ssh-agent -s -k); }
|
||||
|
||||
trap cleanup EXIT
|
||||
|
||||
function remsh { typeset F="/tmp/${1}" h="$1" p="$2";
|
||||
↪shift 2; echo "#$h"
|
||||
if [[ "$ARTANO" == "PARALLEL" ]]
|
||||
then ssh "$R" -p "$p" "$h" "$@" < /dev/null >>"${F}.out"
|
||||
↪2>>"${F}.err" &
|
||||
else ssh "$R" -p "$p" "$h" "$@"
|
||||
fi } # HOST PORT CMD
|
||||
|
||||
if ssh-add ~/.ssh/master_key
|
||||
then remsh yourserver.com 22 "$@"
|
||||
remsh container.yourserver.com 2200 "$@"
|
||||
remsh anotherserver.com 22 "$@"
|
||||
# Add more hosts here.
|
||||
else echo Bad password - killing agent. Try again.
|
||||
fi
|
||||
|
||||
wait
|
||||
|
||||
#######################################################################
|
||||
# Examples: # Artano is an epithet of a famous mythical being
|
||||
# artano 'mount /patchdir' # you will need an fstab entry for this
|
||||
# artano 'umount /patchdir'
|
||||
# artano 'yum update -y 2>&1'
|
||||
# artano 'rpm -Fvh /patchdir/\*.rpm'
|
||||
#######################################################################
|
||||
|
||||
```
|
||||
|
||||
This script runs all commands in sequence on a collection of hosts by default. If the ARTANO environment variable is set to PARALLEL, it instead will launch them all as background processes simultaneously and append their STDOUT and STDERR to files in /tmp (this should be no problem when dealing with fewer than a hundred hosts on a reasonable server). The PARALLEL setting is useful not only for pushing changes faster, but also for collecting audit results.
|
||||
|
||||
Below is an example using the yum update agent. The source of this particular invocation had to traverse a firewall and relied on a proxy setting in the /etc/yum.conf file, which used the port-forwarding option (-R) above:
|
||||
|
||||
```
|
||||
|
||||
# ./artano 'yum update -y 2>&1'
|
||||
Agent pid 3458
|
||||
Enter passphrase for /root/.ssh/master_key:
|
||||
Identity added: /root/.ssh/master_key (/root/.ssh/master_key)
|
||||
#yourserver.com
|
||||
Loaded plugins: langpacks, ulninfo
|
||||
No packages marked for update
|
||||
#container.yourserver.com
|
||||
Loaded plugins: langpacks, ulninfo
|
||||
No packages marked for update
|
||||
#anotherserver.com
|
||||
Loaded plugins: langpacks, ulninfo
|
||||
No packages marked for update
|
||||
Agent pid 3458 killed
|
||||
|
||||
```
|
||||
|
||||
The script can be used for more general maintenance functions. Linux installations running the XFS filesystem should "defrag" periodically. Although this normally would be done with cron, it can be a centralized activity, stored in a separate script that includes only on the appropriate hosts:
|
||||
|
||||
```
|
||||
|
||||
&1'
|
||||
Agent pid 7897
|
||||
Enter passphrase for /root/.ssh/master_key:
|
||||
Identity added: /root/.ssh/master_key (/root/.ssh/master_key)
|
||||
#yourserver.com
|
||||
#container.yourserver.com
|
||||
#anotherserver.com
|
||||
Agent pid 7897 killed
|
||||
|
||||
```
|
||||
|
||||
An easy method to collect the contents of all authorized_keys files for all users is the following artano script (this is useful for system auditing and is coded to remove file duplicates):
|
||||
|
||||
```
|
||||
|
||||
artano 'awk -F: {print\$6\"/.ssh/authorized_keys\"} \
|
||||
/etc/passwd | sort -u | xargs grep . 2> /dev/null'
|
||||
|
||||
```
|
||||
|
||||
It is convenient to configure NFS mounts for file distribution to remote nodes. Bear in mind that NFS is clear text, and sensitive content should not traverse untrusted networks while unencrypted. After configuring an NFS server on host 1.2.3.4, I add the following line to the /etc/fstab file on all the clients and create the /patchdir directory. After the change, the artano script can be used to mass-mount the directory if the network configuration is correct:
|
||||
|
||||
```
|
||||
|
||||
# tail -1 /etc/fstab
|
||||
1.2.3.4:/var/cache/yum/x86_64/7Server/ol7_latest/packages
|
||||
↪/patchdir nfs4 noauto,proto=tcp,port=2049 0 0
|
||||
|
||||
```
|
||||
|
||||
Assuming that the NFS server is mounted, RPMs can be upgraded from images stored upon it (note that Oracle Spacewalk or Red Hat Satellite might be a more capable patch method):
|
||||
|
||||
```
|
||||
|
||||
# ./artano 'rpm -Fvh /patchdir/\*.rpm'
|
||||
Agent pid 3203
|
||||
Enter passphrase for /root/.ssh/master_key:
|
||||
Identity added: /root/.ssh/master_key (/root/.ssh/master_key)
|
||||
#yourserver.com
|
||||
Preparing... ########################
|
||||
Updating / installing...
|
||||
xmlsec1-1.2.20-7.el7_4 ########################
|
||||
xmlsec1-openssl-1.2.20-7.el7_4 ########################
|
||||
Cleaning up / removing...
|
||||
xmlsec1-openssl-1.2.20-5.el7 ########################
|
||||
xmlsec1-1.2.20-5.el7 ########################
|
||||
#container.yourserver.com
|
||||
Preparing... ########################
|
||||
Updating / installing...
|
||||
xmlsec1-1.2.20-7.el7_4 ########################
|
||||
xmlsec1-openssl-1.2.20-7.el7_4 ########################
|
||||
Cleaning up / removing...
|
||||
xmlsec1-openssl-1.2.20-5.el7 ########################
|
||||
xmlsec1-1.2.20-5.el7 ########################
|
||||
#anotherserver.com
|
||||
Preparing... ########################
|
||||
Updating / installing...
|
||||
xmlsec1-1.2.20-7.el7_4 ########################
|
||||
xmlsec1-openssl-1.2.20-7.el7_4 ########################
|
||||
Cleaning up / removing...
|
||||
xmlsec1-openssl-1.2.20-5.el7 ########################
|
||||
xmlsec1-1.2.20-5.el7 ########################
|
||||
Agent pid 3203 killed
|
||||
|
||||
```
|
||||
|
||||
I am assuming that my audience is already experienced with package tools for their preferred platforms. However, to avoid criticism that I've included little actual discussion of patch tools, the following is a quick reference of RPM manipulation commands, which is the most common package format on enterprise systems:
|
||||
|
||||
* rpm -Uvh package.i686.rpm — install or upgrade a package file.
|
||||
|
||||
* rpm -Fvh package.i686.rpm — upgrade a package file, if an older version is installed.
|
||||
|
||||
* rpm -e package — remove an installed package.
|
||||
|
||||
* rpm -q package — list installed package name and version.
|
||||
|
||||
* rpm -q --changelog package — print full changelog for installed package (including CVEs).
|
||||
|
||||
* rpm -qa — list all installed packages on the system.
|
||||
|
||||
* rpm -ql package — list all files in an installed package.
|
||||
|
||||
* rpm -qpl package.i686.rpm — list files included in a package file.
|
||||
|
||||
* rpm -qi package — print detailed description of installed package.
|
||||
|
||||
* rpm -qpi package — print detailed description of package file.
|
||||
|
||||
* rpm -qf /path/to/file — list package that installed a particular file.
|
||||
|
||||
* rpm --rebuild package.src.rpm — unpack and build a binary RPM under /usr/src/redhat.
|
||||
|
||||
* rpm2cpio package.src.rpm | cpio -icduv — unpack all package files in the current directory.
|
||||
|
||||
Another important consideration for scripting the SSH agent is limiting the capability of an authorized key. There is a [specific syntax][23] for such limitations Of particular interest is the from="" clause, which will restrict logins on a key to a limited set of hosts. It is likely wise to declare a set of "bastion" servers that will record non-root logins that escalate into controlled users who make use of the enterprise keys.
|
||||
|
||||
An example entry might be the following (note that I've broken this line, which is not allowed syntax but done here for clarity):
|
||||
|
||||
```
|
||||
|
||||
from="*.c2.security.yourcompany.com,4.3.2.1" ssh-ed25519
|
||||
↪AAAAC3NzaC1lZDI1NTE5AAAAIJSSazJz6A5x6fTcDFIji1X+
|
||||
↪svesidBonQvuDKsxo1Mx
|
||||
|
||||
```
|
||||
|
||||
A number of other useful restraints can be placed upon authorized_keys entries. The command="" will restrict a key to a single program or script and will set the SSH_ORIGINAL_COMMAND environment variable to the client's attempted call—scripts can set alarms if the variable does not contain approved contents. The restrict option also is worth consideration, as it disables a large set of SSH features that can be both superfluous and dangerous.
|
||||
|
||||
Although it is possible to set server identification keys in the known_hosts file to a @revoked status, this cannot be done with the contents of authorized_keys. However, a system-wide file for forbidden keys can be set in the sshd_config with RevokedKeys. This file overrides any user's authorized_keys. If set, this file must exist and be readable by the sshd server process; otherwise, no keys will be accepted at all (so use care if you configure it on a machine where there are obstacles to physical access). When this option is set, use the artano script to append forbidden keys to the file quickly when they should be disallowed from the network. A clear and convenient file location would be /etc/ssh/revoked_keys.
|
||||
|
||||
It is also possible to establish a local Certificate Authority (CA) for OpenSSH that will [allow keys to be registered with an authority][24] with expiration dates. These CAs can [become quite elaborate][25] in their control over an enterprise. Although the maintenance of an SSH CA is beyond the scope of this article, keys issued by such CAs should be strong by adhering to the requirements for Ed25519/E-521/RSA-3072.
|
||||
|
||||
### pdsh
|
||||
|
||||
Many higher-level tools for the control of collections of servers exist that are much more sophisticated than the script I've presented here. The most famous is likely [Puppet][26], which is a Ruby-based configuration management system for enterprise control. Puppet has a somewhat short list of supported operating systems. If you are looking for low-level control of Android, Tomato, Linux smart terminals or other "exotic" POSIX, Puppet is likely not the appropriate tool. Another popular Ruby-based tool is [Chef][27], which is known for its complexity. Both Puppet and Chef require Ruby installations on both clients and servers, and they both will catalog any SSH keys that they find, so this key strength discussion is completely applicable to them.
|
||||
|
||||
There are several similar Python-based tools, including [Ansible][28], [Bcfg2][29], [Fabric][30] and [SaltStack][31]. Of these, only Ansible can run "agentless" over a bare SSH connection; the rest will require agents that run on target nodes (and this likely includes a Python runtime).
|
||||
|
||||
Another popular configuration management tool is [CFEngine][32], which is coded in C and claims very high performance. [Rudder][33] has evolved from portions of CFEngine and has a small but growing user community.
|
||||
|
||||
Most of the previously mentioned packages are licensed commercially and some are closed source.
|
||||
|
||||
The closest low-level tool to the activities presented here is the Parallel Distributed Shell (pdsh), which can be found in the [EPEL repository][34]. The pdsh utilities grew out of an IBM-developed package named dsh designed for the control of compute clusters. Install the following packages from the repository to use pdsh:
|
||||
|
||||
```
|
||||
|
||||
# rpm -qa | grep pdsh
|
||||
pdsh-2.31-1.el7.x86_64
|
||||
pdsh-rcmd-ssh-2.31-1.el7.x86_64
|
||||
|
||||
```
|
||||
|
||||
An SSH agent must be running while using pdsh with encrypted keys, and there is no obvious way to control the destination port on a per-host basis as was done with the artano script. Below is an example using pdsh to run a command on three remote servers:
|
||||
|
||||
```
|
||||
|
||||
# eval $(ssh-agent)
|
||||
Agent pid 17106
|
||||
|
||||
# ssh-add ~/.ssh/master_key
|
||||
Enter passphrase for /root/.ssh/master_key:
|
||||
Identity added: /root/.ssh/master_key (/root/.ssh/master_key)
|
||||
|
||||
# pdsh -w hosta.com,hostb.com,hostc.com uptime
|
||||
hosta: 13:24:49 up 13 days, 2:13, 6 users, load avg: 0.00, 0.01, 0.05
|
||||
hostb: 13:24:49 up 7 days, 21:15, 5 users, load avg: 0.05, 0.04, 0.05
|
||||
hostc: 13:24:49 up 9 days, 3:26, 3 users, load avg: 0.00, 0.01, 0.05
|
||||
|
||||
# eval $(ssh-agent -k)
|
||||
Agent pid 17106 killed
|
||||
|
||||
```
|
||||
|
||||
The -w option above defines a host list. It allows for limited arithmetic expansion and can take the list of hosts from standard input if the argument is a dash (-). The PDSH_SSH_ARGS and PDSH_SSH_ARGS_APPEND environment variables can be used to pass custom options to the SSH call. By default, 32 sessions will be launched in parallel, and this "fanout/sliding window" will be maintained by launching new host invocations as existing connections complete and close. You can adjust the size of the "fanout" either with the -f option or the FANOUT environment variable. It's interesting to note that there are two file copy commands: pdcp and rpdcp, which are analogous to scp.
|
||||
|
||||
Even a low-level utility like pdsh lacks some flexibility that is available by scripting OpenSSH, so prepare to feel even greater constraints as more complicated tools are introduced.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Modern Linux touches us in many ways on diverse platforms. When the security of these systems is not maintained, others also may touch our platforms and turn them against us. It is important to realize the maintenance obligations when you add any Linux platform to your environment. This obligation always exists, and there are consequences when it is not met.
|
||||
|
||||
In a security emergency, simple, open and well understood tools are best. As tool complexity increases, platform portability certainly declines, the number of competent administrators also falls, and this likely impacts speed of execution. This may be a reasonable trade in many other aspects, but in a security context, it demands a much more careful analysis. Emergency measures must be documented and understood by a wider audience than is required for normal operations, and using more general tools facilitates that discussion.
|
||||
|
||||
I hope the techniques presented here will prompt that discussion for those who have not yet faced it.
|
||||
|
||||
### Disclaimer
|
||||
|
||||
The views and opinions expressed in this article are those of the author and do not necessarily reflect those of Linux Journal.
|
||||
|
||||
### Note:
|
||||
|
||||
An exploit [compromising Ed25519][35] was recently demonstrated that relies upon custom hardware changes to derive a usable portion of a secret key. Physical hardware security is a basic requirement for encryption integrity, and many common algorithms are further vulnerable to cache timing or other side channel attacks that can be performed by the unprivileged processes of other users. Use caution when granting access to systems that process sensitive data.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/rapid-secure-patching-tools-and-methods
|
||||
|
||||
作者:[Charles Fisher][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/charles-fisher
|
||||
[1]:https://en.wikipedia.org/wiki/EternalBlue
|
||||
[2]:http://securityaffairs.co/wordpress/61530/hacking/smbloris-smbv1-flaw.html
|
||||
[3]:http://www.telegraph.co.uk/news/2017/05/13/nhs-cyber-attack-everything-need-know-biggest-ransomware-offensive
|
||||
[4]:http://www.linuxjournal.com/content/smbclient-security-windows-printing-and-file-transfer
|
||||
[5]:https://staff.washington.edu/dittrich/misc/forensics
|
||||
[6]:https://ed25519.cr.yp.to
|
||||
[7]:http://www.metzdowd.com/pipermail/cryptography/2016-March/028824.html
|
||||
[8]:https://blog.g3rt.nl/upgrade-your-ssh-keys.html
|
||||
[9]:https://news.ycombinator.com/item?id=12563899
|
||||
[10]:http://safecurves.cr.yp.to/rigid.html
|
||||
[11]:https://en.wikipedia.org/wiki/Curve25519
|
||||
[12]:http://blog.cr.yp.to/20140323-ecdsa.html
|
||||
[13]:https://lwn.net/Articles/573166
|
||||
[14]:http://martin.kleppmann.com/2013/05/24/improving-security-of-ssh-private-keys.html
|
||||
[15]:https://en.wikipedia.org/wiki/Shor's_algorithm
|
||||
[16]:https://www.dwavesys.com/d-wave-two-system
|
||||
[17]:https://crypto.stackexchange.com/questions/40893/can-or-can-not-d-waves-quantum-computers-use-shors-and-grovers-algorithm-to-f
|
||||
[18]:https://yro.slashdot.org/story/16/12/21/2334220/nist-asks-public-for-help-with-quantum-proof-cryptography
|
||||
[19]:https://ntruprime.cr.yp.to/index.html
|
||||
[20]:http://www.linuxjournal.com/content/cipher-security-how-harden-tls-and-ssh
|
||||
[21]:https://www.michaelwlucas.com/tools/ssh
|
||||
[22]:https://people.eecs.berkeley.edu/~dawnsong/papers/ssh-timing.pdf
|
||||
[23]:https://man.openbsd.org/sshd#AUTHORIZED_KEYS_FILE_FORMAT
|
||||
[24]:https://ef.gy/hardening-ssh
|
||||
[25]:https://code.facebook.com/posts/365787980419535/scalable-and-secure-access-with-ssh
|
||||
[26]:https://puppet.com
|
||||
[27]:https://www.chef.io
|
||||
[28]:https://www.ansible.com
|
||||
[29]:http://bcfg2.org
|
||||
[30]:http://www.fabfile.org
|
||||
[31]:https://saltstack.com
|
||||
[32]:https://cfengine.com
|
||||
[33]:http://www.rudder-project.org/site
|
||||
[34]:https://fedoraproject.org/wiki/EPEL
|
||||
[35]:https://research.kudelskisecurity.com/2017/10/04/defeating-eddsa-with-faults
|
||||
@ -1,174 +0,0 @@
|
||||
Ansible: Making Things Happen
|
||||
======
|
||||
In my [last article][1], I described how to configure your server and clients so you could connect to each client from the server. Ansible is a push-based automation tool, so the connection is initiated from your "server", which is usually just a workstation or a server you ssh in to from your workstation. In this article, I explain how modules work and how you can use Ansible in ad-hoc mode from the command line.
|
||||
|
||||
Ansible is supposed to make your job easier, so the first thing you need to learn is how to do familiar tasks. For most sysadmins, that means some simple command-line work. Ansible has a few quirks when it comes to command-line utilities, but it's worth learning the nuances, because it makes for a powerful system.
|
||||
|
||||
### Command Module
|
||||
|
||||
This is the safest module to execute remote commands on the client machine. As with most Ansible modules, it requires Python to be installed on the client, but that's it. When Ansible executes commands using the Command Module, it does not process those commands through the user's shell. This means some variables like $HOME are not available. It also means stream functions (redirects, pipes) don't work. If you don't need to redirect output or to reference the user's home directory as a shell variable, the Command Module is what you want to use. To invoke the Command Module in ad-hoc mode, do something like this:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -m command -a "whoami"
|
||||
|
||||
```
|
||||
|
||||
Your output should show SUCCESS for each host referenced and then return the user name that the user used to log in. You'll notice that the user is not root, unless that's the user you used to connect to the client computer.
|
||||
|
||||
If you want to see the elevated user, you'll add another argument to the ansible command. You can add -b in order to "become" the elevated user (or the sudo user). So, if you were to run the same command as above with a "-b" flag:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -b -m command -a "whoami"
|
||||
|
||||
```
|
||||
|
||||
you should see a similar result, but the whoami results should say root instead of the user you used to connect. That flag is important to use, especially if you try to run remote commands that require root access!
|
||||
|
||||
### Shell Module
|
||||
|
||||
There's nothing wrong with using the Shell Module to execute remote commands. It's just important to know that since it uses the remote user's environment, if there's something goofy with the user's account, it might cause problems that the Command Module avoids. If you use the Shell Module, however, you're able to use redirects and pipes. You can use the whoami example to see the difference. This command:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -m command -a "whoami > myname.txt"
|
||||
|
||||
```
|
||||
|
||||
should result in an error about > not being a valid argument. Since the Command Module doesn't run inside any shell, it interprets the greater-than character as something you're trying to pass to the whoami command. If you use the Shell Module, however, you have no problems:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -m shell -a "whom > myname.txt"
|
||||
|
||||
```
|
||||
|
||||
This should execute and give you a SUCCESS message for each host, but there should be nothing returned as output. On the remote machine, however, there should be a file called myname.txt in the user's home directory that contains the name of the user. My personal policy is to use the Command Module whenever possible and to use the Shell Module if needed.
|
||||
|
||||
### The Raw Module
|
||||
|
||||
Functionally, the Raw Module works like the Shell Module. The key difference is that Ansible doesn't do any error checking, and STDERR, STDOUT and Return Code is returned. Other than that, Ansible has no idea what happens, because it just executes the command over SSH directly. So while the Shell Module will use /bin/sh by default, the Raw Module just uses whatever the user's personal default shell might be.
|
||||
|
||||
Why would a person decide to use the Raw Module? It doesn't require Python on the remote computer—at all. Although it's true that most servers have Python installed by default, or easily could have it installed, many embedded devices don't and can't have Python installed. For most configuration management tools, not having an agent program installed means the remote device can't be managed. With Ansible, if all you have is SSH, you still can execute remote commands using the Raw Module. I've used the Raw Module to manage Bitcoin miners that have a very minimal embedded environment. It's a powerful tool, and when you need it, it's invaluable!
|
||||
|
||||
### Copy Module
|
||||
|
||||
Although it's certainly possible to do file and folder manipulation with the Command and Shell Modules, Ansible includes a module specifically for copying files to the server. Even though it requires learning a new syntax for copying files, I like to use it because Ansible will check to see whether a file exists, and whether it's the same file. That means it copies the file only if it needs to, saving time and bandwidth. It even will make backups of existing files! I can't tell you how many times I've used scp and sshpass in a Bash FOR loop and dumped files on servers, even if they didn't need them. Ansible makes it easy and doesn't require FOR loops and IP iterations.
|
||||
|
||||
The syntax is a little more complicated than with Command, Shell or Raw. Thankfully, as with most things in the Ansible world, it's easy to understand—for example:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -b -m copy \
|
||||
-a "src=./updated.conf dest=/etc/ntp.conf \
|
||||
owner=root group=root mode=0644 backup=yes"
|
||||
|
||||
```
|
||||
|
||||
This will look in the current directory (on the Ansible server/workstation) for a file called updated.conf and then copy it to each host. On the remote system, the file will be put in /etc/ntp.conf, and if a file already exists, and it's different, the original will be backed up with a date extension. If the files are the same, Ansible won't make any changes.
|
||||
|
||||
I tend to use the Copy Module when updating configuration files. It would be perfect for updating configuration files on Bitcoin miners, but unfortunately, the Copy Module does require that the remote machine has Python installed. Nevertheless, it's a great way to update common files on many remote machines with one simple command. It's also important to note that the Copy Module supports copying remote files to other locations on the remote filesystem using the remote_src=true directive.
|
||||
|
||||
### File Module
|
||||
|
||||
The File Module has a lot in common with the Copy Module, but if you try to use the File Module to copy a file, it doesn't work as expected. The File Module does all its actions on the remote machine, so src and dest are all references to the remote filesystem. The File Module often is used for creating directories, creating links or deleting remote files and folders. The following will simply create a folder named /etc/newfolder on the remote servers and set the mode:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -b -m file \
|
||||
-a "path=/etc/newfolder state=directory mode=0755"
|
||||
|
||||
```
|
||||
|
||||
You can, of course, set the owner and group, along with a bunch of other options, which you can learn about on the Ansible doc site. I find I most often will either create a folder or symbolically link a file using the File Module. To create a symlink:
|
||||
|
||||
```
|
||||
|
||||
sensible host_or_groupname -b -m file \
|
||||
-a "src=/etc/ntp.conf dest=/home/user/ntp.conf \
|
||||
owner=user group=user state=link"
|
||||
|
||||
```
|
||||
|
||||
Notice that the state directive is how you inform Ansible what you actually want to do. There are several state options:
|
||||
|
||||
* link — create symlink.
|
||||
|
||||
* directory — create directory.
|
||||
|
||||
* hard — create hardlink.
|
||||
|
||||
* touch — create empty file.
|
||||
|
||||
* absent — delete file or directory recursively.
|
||||
|
||||
This might seem a bit complicated, especially when you easily could do the same with a Command or Shell Module command, but the clarity of using the appropriate module makes it more difficult to make mistakes. Plus, learning these commands in ad-hoc mode will make playbooks, which consist of many commands, easier to understand (I plan to cover this in my next article).
|
||||
|
||||
### File Management
|
||||
|
||||
Anyone who manages multiple distributions knows it can be tricky to handle the various package managers. Ansible handles this in a couple ways. There are specific modules for apt and yum, but there's also a generic module called "package" that will install on the remote computer regardless of whether it's Red Hat- or Debian/Ubuntu-based.
|
||||
|
||||
Unfortunately, while Ansible usually can detect the type of package manager it needs to use, it doesn't have a way to fix packages with different names. One prime example is Apache. On Red Hat-based systems, the package is "httpd", but on Debian/Ubuntu systems, it's "apache2". That means some more complex things need to happen in order to install the correct package automatically. The individual modules, however, are very easy to use. I find myself just using apt or yum as appropriate, just like when I manually manage servers. Here's an apt example:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -b -m apt \
|
||||
-a "update_cache=yes name=apache2 state=latest"
|
||||
|
||||
```
|
||||
|
||||
With this one simple line, all the host machines will run apt-get update (that's the update_cache directive at work), then install apache2's latest version including any dependencies required. Much like the File Module, the state directive has a few options:
|
||||
|
||||
* latest — get the latest version, upgrading existing if needed.
|
||||
|
||||
* absent — remove package if installed.
|
||||
|
||||
* present — make sure package is installed, but don't upgrade existing.
|
||||
|
||||
The Yum Module works similarly to the Apt Module, but I generally don't bother with the update_cache directive, because yum updates automatically. Although very similar, installing Apache on a Red Hat-based system looks like this:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -b -m yum \
|
||||
-a "name=httpd state=present"
|
||||
|
||||
```
|
||||
|
||||
The difference with this example is that if Apache is already installed, it won't update, even if an update is available. Sometimes updating to the latest version isn't want you want, so this stops that from accidentally happening.
|
||||
|
||||
### Just the Facts, Ma'am
|
||||
|
||||
One frustrating thing about using Ansible in ad-hoc mode is that you don't have access to the "facts" about the remote systems. In my next article, where I plan to explore creating playbooks full of various tasks, you'll see how you can reference the facts Ansible learns about the systems. It makes Ansible far more powerful, but again, it can be utilized only in playbook mode. Nevertheless, it's possible to use ad-hoc mode to peek at the sorts information Ansible gathers. If you run the setup module, it will show you all the details from a remote system:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -b -m setup
|
||||
|
||||
```
|
||||
|
||||
That command will spew a ton of variables on your screen. You can scroll through them all to see the vast amount of information Ansible pulls from the host machines. In fact, it shows so much information, it can be overwhelming. You can filter the results:
|
||||
|
||||
```
|
||||
|
||||
ansible host_or_groupname -b -m setup -a "filter=*family*"
|
||||
|
||||
```
|
||||
|
||||
That should just return a single variable, ansible_os_family, which likely will be Debian or Red Hat. When you start building more complex Ansible setups with playbooks, it's possible to insert some logic and conditionals in order to use yum where appropriate and apt where the system is Debian-based. Really, the facts variables are incredibly useful and make building playbooks that much more exciting.
|
||||
|
||||
But, that's for another article, because you've come to the end of the second installment. Your assignment for now is to get comfortable using Ansible in ad-hoc mode, doing one thing at a time. Most people think ad-hoc mode is just a stepping stone to more complex Ansible setups, but I disagree. The ability to configure hundreds of servers consistently and reliably with a single command is nothing to scoff at. I love making elaborate playbooks, but just as often, I'll use an ad-hoc command in a situation that used to require me to ssh in to a bunch of servers to do simple tasks. Have fun with Ansible; it just gets more interesting from here!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/ansible-making-things-happen
|
||||
|
||||
作者:[Shawn Powers][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/shawn-powers
|
||||
[1]:http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin
|
||||
@ -1,212 +0,0 @@
|
||||
Introduction to AWS for Data Scientists
|
||||
======
|
||||
![sky-690293_1920][1]
|
||||
|
||||
These days, many businesses use cloud based services; as a result various companies have started building and providing such services. Amazon [began the trend][2], with Amazon Web Services (AWS). While AWS began in 2006 as a side business, it now makes [$14.5 billion in revenue each year][3].
|
||||
|
||||
Other leaders in this area include:
|
||||
|
||||
* Google--Google Cloud Platform (GCP)
|
||||
* Microsoft--Azure Cloud Services
|
||||
* IBM--IBM Cloud
|
||||
|
||||
|
||||
|
||||
Cloud services are useful to businesses of all sizes--small companies benefit from the low cost, as compared to buying servers. Larger companies gain reliability and productivity, with less cost, since the services run on optimum energy and maintenance.
|
||||
|
||||
These services are also powerful tools that you can use to ease your work. Setting up a Hadoop cluster to work with Spark manually could take days if it's your first time, but AWS sets that up for you in minutes.
|
||||
|
||||
We are going to focus on AWS here because it comes with more products relevant to data scientists. In general, we can say familiarity with AWS helps data scientists to:
|
||||
|
||||
1. Prepare the infrastructure they need for their work (e.g. Hadoop clusters) with ease
|
||||
2. Easily set up necessary tools (e.g. Spark)
|
||||
3. Decrease expenses significantly--such as by paying for huge Hadoop clusters only when needed
|
||||
4. Spend less time on maintenance, as there's no need for tasks like manually backing up data
|
||||
5. Develop products and features that are ready to launch without needing help from engineers (or, at least, needing very little help)
|
||||
|
||||
|
||||
|
||||
In this post, I'll give an overview of useful AWS services for data scientists -- what they are, why they're useful, and how much they cost.
|
||||
|
||||
### Elastic Compute Cloud (EC2)
|
||||
|
||||
Many other AWS services are built around EC2, making it a core piece of AWS. EC2s are in fact (virtual) servers that you can rent from Amazon and set up or run any program/application on it. These servers come in different operating systems and Amazon charges you based on the computing power and capacity of the server (i.e. Hard Drive capacity, CPU, Memory, etc.) and the duration the server been up.
|
||||
|
||||
#### EC2 benefits
|
||||
|
||||
For example, you can rent a Linux or Windows server with computation power and storage capacity that fits your specific needs and Amazon charges you based on these specifications and the duration you use the server. Note that previously AWS charged at least for one hour for each instance you run, but they recently changed their policy to [per-second billing][4].
|
||||
|
||||
One of the good things about EC2 is its scalability--by changing memory, number of vCPUs, bandwidth, and so on, you can easily scale your system up or down. Therefore, if you think a system doesn't have enough power for running a specific task or a calculation in your project is taking too long, you can scale up to finish your work and later scale down again to reduce the cost. EC2 is also very reliable, since Amazon takes care of the maintenance.
|
||||
|
||||
#### EC2 cost
|
||||
|
||||
EC2 instances are relatively low-cost, and there are different types of instances for different use cases. For example, there are instances that are optimized for computation and those have relatively lower cost on CPU usage. Or those optimized for memory have lower cost on memory usage.
|
||||
|
||||
To give you an idea on EC2 cost, a general purpose medium instance with 2 vCPUs and 4 GIG of memory (at the time of writing this article) costs $0.0464 per hour for a linux server, see [Amazon EC2 Pricing][5] for prices and more information. AWS also now has [spot instance pricing][6], which calculates the price based on supply/demand at the time and provides up to a 90% discount for short term usages depending on the time you want to use the instance. For example, the same instance above costs $0.0173 per hour on spot pricing plan.
|
||||
|
||||
Note that you have to add storage costs to the above as well. Most EC2 instances use Elastic Block Store (EBS) systems, which cost around $0.1/GIG/month; see the prices [here][7]. [Storage optimized instances][8] use Solid State Drive (SSD) systems, which are more expensive.
|
||||
|
||||
![Ec2cost][9]
|
||||
|
||||
EBS acts like an external hard drive. You can attach it to an instance, de-attach it, and re-attach it to another instance. You can also stop or terminate an instance after your work is done and not pay for the instance when it is idle.
|
||||
|
||||
If you stop an instance, AWS will still keep the EBS live and as a result the data you have on the hard drive will remain intact (it's like powering off your computer). Later you can restart stopped instances and get access to the data you generated, or even tools you installed there in the previous sessions. However, when you stop an instance instead of terminating it, Amazon will still charge you for the attached EBS (~$0.1/GIG/month). If you terminate the instance, the EBS will get cleaned so you will lose all the data on that instance, but you no longer need to pay for the EBS.
|
||||
|
||||
If you need to keep the data on EBS for your future use (let's say you have custom tools installed on that instance and you don't want to redo your work again later) you can make a snapshot of the EBS and can later restore it in a new EBS and attach it to a new instance.
|
||||
|
||||
Snapshots get stored on S3 (Amazon's cheap storage system; we will get to it later) so it will cost you less ($0.05 per GB-month) to keep the data in EBS like that. However, it takes time (depending on the size of the EBS) to get snapshot and restoring it. Besides, reattaching a restored EBS to EC2 instance is not that straight forward, so it only make sense to use a snapshot like that if you know you are not going to use that EBS for a while.
|
||||
|
||||
Note that to scale an instance up or down, you have to first stop the instance and then change the instance specifications. You can't decrease the EBS size, only increase it, and it's more difficult. You have to:
|
||||
|
||||
1. Stop the instance
|
||||
2. Make a snapshot out of the EBS
|
||||
3. Restore the snapshot in an EBS with the new size
|
||||
4. De-attach previous EBS
|
||||
5. Attach the new one.
|
||||
|
||||
|
||||
|
||||
### Simple Storage Service (S3)
|
||||
|
||||
S3 is AWS object (file) storage service. S3 is like Dropbox or Google drive, but way more scalable and is made particularly to work with codes and applications.
|
||||
|
||||
S3 doesn't provide a user friendly interface since it is designed to work with online applications, not the end user. Therefore, working with S3 through APIs is easier than through its web console and there are many libraries and APIs developed (in various languages) to work with this service. For example, [Boto3][10] is a S3 library written in Python (in fact Boto3 is suitable for working with many other AWS services as well) .
|
||||
|
||||
S3 stores files based on `bucket`s and `key`s. Buckets are similar to root folders, and keys are similar to subfolders and files. So if you store a file named `my_file.txt` on s3 like `myproject/mytextfiles/my_file.txt`, then "myproject" is the bucket you are using and then `mytextfiles/my_file.txt` is the key to that file. This is important to know since APIs will ask for the bucket and key separately when you want to retrieve your file from s3.
|
||||
|
||||
#### S3 benefits
|
||||
|
||||
There is no limit on the size of data you can store on S3--you just have to pay for the storage based on the size you need per month.
|
||||
|
||||
S3 is also very reliable and "[it is designed to deliver 99.999999999% durability][11]". However, the service may not be always up. On February 28th, 2017 some of s3 servers went down for couple of hours and that disrupted many applications such as Slack, Trello, etc. see [these][12] [articles][13] for more information on this incident.
|
||||
|
||||
#### S3 cost
|
||||
|
||||
The cost is low, starting at $0.023 per GB per month for standard access, if you want to get access to these files regularly. It could go down even lower if you don't need to load data too frequently. See [Amazon S3 Pricing][14] for more information.
|
||||
|
||||
AWS may charge you for other S3 related actions such as requests through APIs, but the cost for those are insignificant (less than $0.05 per 1,000 requests in most cases).
|
||||
|
||||
### Relational Database Service (RDS)
|
||||
|
||||
AWS RDS is a relational database service in the cloud. RDS currently supports SQL Server, MySQL, PostgreSQL, ORACLE, and a couple of other SQL-based frameworks. AWS sets up the system you need and configures the parameters so you can have a relational database up and running in minutes. RDS also handles backup, recovery, software patching, failure detection, and repairs by itself so you don't need to maintain the system.
|
||||
|
||||
#### RDS benefits
|
||||
|
||||
RDS is scalable, both computing power and the storage capacity can be scaled up or down easily. RDS system runs on EC2 servers (as I mentioned EC2 servers are the core of most of AWS services, including RDS service) so by computing power here we mean the computing power of the EC2 server our RDS service is running on, and you can scale up the computing power of this system up to 32 vCPUs and 244 GiB of RAM and changing the scale would not take more than few minutes.
|
||||
|
||||
Scaling the storage requirements up or down is also possible. [Amazon Aurora][15] is a version of MySQL and PostgreSQL with some additional features, and can automatically scale up when more storage space is needed (you can define the maximum). The MySQL, MariaDB, Oracle, and PostgreSQL engines allow you to scale up on the fly without downtime.
|
||||
|
||||
#### RDS cost
|
||||
|
||||
The [cost of RDS servers][16] is based on three factors: computational power, storage, and data transfer.
|
||||
|
||||
![RDSpricing][17]
|
||||
|
||||
For example, a PostgreSQL system with medium computational power (2 vCPUs and 8 gig of memory) costs $0.182 per hour; you can pay less if you go under a one- or three-year contract.
|
||||
|
||||
For storage, there are a [variety of options and prices][18]. If you choose single availability zone General Purpose SSD Storage (gp2), a good option for data scientists, the cost for a server in north Virginia at the time of writing this article is $0.115 per GB-month, and you can select from 5 GB to 16 TB of SSD.
|
||||
|
||||
For data transfer, the cost varies a little based on the source and destination of data (one of which is RDS). For example, all data transferred from the internet into RDS is free. The first gig of data transferred from RDS to the internet is free as well, and for the next 10 terabytes of data in a month it costs $0.09 per GB; the cost decreases for transfering more data than that.
|
||||
|
||||
### Redshift
|
||||
|
||||
Redshift is Amazon's data warehouse service; it is a distributed system (something like the Hadoop framework) which lets you store huge amounts of data and get queries. The difference between this service and RDS is its high capacity and ability to work with big data (terabytes and petabytes). You can use simple SQL queries on Redshift as well.
|
||||
|
||||
Redshift works on a distributed framework--data is distributed on different nodes (servers) connected on a cluster. Simply put, queries on a distributed system run in parallel on all the nodes and then the results get collected from each node and get summarized.
|
||||
|
||||
#### Redshift benefits
|
||||
|
||||
Redshift is highly scalable, meaning in theory (depending on the query, network structure and design, service specification, etc.) the speed of getting query out of 1 terabyte of data and 1 petabyte of data can match by scaling up (adding more cluster to) the system.
|
||||
|
||||
When you create a table on Redshift, you can choose one of three distribution styles: EVEN, KEY, or ALL.
|
||||
|
||||
* EVEN means the table rows will get distributed over all the nodes evenly. Then queries involving that table get distributed over the cluster and run in parallel, summarized at the end. Per Amazon's documentation, "[EVEN distribution is appropriate when a table does not participate in joins][19]".
|
||||
|
||||
* ALL means that on each node there will be a copy of this table, so if you query for a join on that table, the table is already there on all the nodes and there is no need for copying the required data across the network from node to node. The problem is "[ALL distribution multiplies the storage required by the number of nodes in the cluster, and so it takes much longer to load, update, or insert data into multiple tables][19]".
|
||||
|
||||
* In the KEY style, distribution rows of the table are distributed based on the values in one column, in an attempt to keep the rows with the same value of that column in the same node. Physically storing matching values on the same nodes make joining on that specific column faster in parallel systems, see more information [here][19].
|
||||
|
||||
|
||||
|
||||
|
||||
#### Redshift cost
|
||||
|
||||
Redshift has two types of instances: Dense Compute or Dense Storage. Dense Compute is optimized for fast querying and it is cost effective for less than 500GB of data in size (~$5,500/TB/Year for a three-year contract with partial upfront).
|
||||
|
||||
Dense Storage is optimized for high size storage (~$1,000/TB/Year for a three-year contract with partial upfront) and is cost effective for +500GB, but it is slower. You can find more general pricing [here][20].
|
||||
|
||||
You can also save a large amount of data on S3 and use [Amazon Redshift Spectrum][21] to run SQL query on that data. For Redshift Spectrum, AWS charges you by the number of bytes scanned by Redshift Spectrum per query; and $5 per terabyte of data scanned (10 megabyte minimum per query).
|
||||
|
||||
### Elastic MapReduce (EMR)
|
||||
|
||||
EMR is suitable for setting up Hadoop clusters with Spark and other distributed type applications. A Hadoop cluster can be used as a compute engine or a (distributed) storage system. However, if the data is so big that you need a distributed system to handle it, Redshift is more suitable and way cheaper than storing in EMR.
|
||||
|
||||
There are three types of [nodes][22] on a cluster:
|
||||
|
||||
* The master node (you only have one) is responsible for managing the cluster. It distributes the workloads to the core and task nodes, tracks the status of tasks, and monitors the health of the cluster.
|
||||
* Core nodes run tasks and store the data.
|
||||
* Task nodes can only run tasks.
|
||||
|
||||
|
||||
|
||||
#### EMR benefits
|
||||
|
||||
Since you can set EMR to install Apache Spark, this service is good for for cleaning, reformatting, and analyzing big data. You can use EMR on-demand, meaning you can set it to grab the code and data from a source (e.g. S3 for the code, and S3 or RDS for the data), run the task on the cluster, and store the results somewhere (again s3, RDS, or Redshift) and terminate the cluster.
|
||||
|
||||
By using the service in such a way, you can reduce the cost of your cluster significantly. In my opinion, EMR is one of the most useful AWS services for data scientists.
|
||||
|
||||
To setup an EMR cluster, you need to first configure applications you want to have on the cluster. Note that different versions of EMR come with different versions of the applications. For example, if you configure EMR version 5.10.0 to install Spark, the default version of the Spark for this version is 2.2.0. So if your code works only on Spark 1.6, you need to run EMR on the 4.x version. EMR will set up the network and configures all the nodes on the cluster along with needed tools.
|
||||
|
||||
An EMR cluster comes with one master instance and a number of core nodes (slave instances). You can choose the number of core nodes, and can even select to have no core node and only use the master server for your work. Like other services, you can choose the computational power of the servers and the storage size available on each node. You can use autoscale option for your core nodes, meaning you can add rules to the system to add/remove core node (up to a maximum number you choose) if needed while running your code. See [Using Automatic Scaling in Amazon EMR][23] for more information on auto scaling.
|
||||
|
||||
#### EMR pricing
|
||||
|
||||
EMR pricing is based on the computational power you choose for different instances (master, core and task nodes). Basically, it is the cost of the EC2 servers plus the cost of EMR. You can find detailed pricing [here][24].
|
||||
|
||||
![EMRpricing][25]
|
||||
|
||||
### Conclusion
|
||||
|
||||
I have developed many end-to-end data-driven products (including reporting, machine learning models, and product health checking systems) for our company using Python and Spark on AWS, which later became good sources of income for the company.
|
||||
|
||||
Experience working with cloud services, especially a well-known one like AWS, is a huge plus in your data scientist career. Many companies depend on these services now and use them constantly, so you being familiar with these services will give them the confidence that you need less training to get on board. With more and more people moving into data science, you want your resume to stand out as much as possible.
|
||||
|
||||
Do you have cloud tips to add? [Let us know][26].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.dataquest.io/blog/introduction-to-aws-for-data-scientists/
|
||||
|
||||
作者:[Read More][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.dataquest.io/blog/author/armin/
|
||||
[1]:/blog/content/images/2018/01/sky-690293_1920.jpg
|
||||
[2]:http://www.computerweekly.com/feature/A-history-of-cloud-computing
|
||||
[3]:https://www.forbes.com/sites/bobevans1/2017/07/28/ibm-beats-amazon-in-12-month-cloud-revenue-15-1-billion-to-14-5-billion/#53c3e14c39d6
|
||||
[4]:https://aws.amazon.com/blogs/aws/new-per-second-billing-for-ec2-instances-and-ebs-volumes/
|
||||
[5]:https://aws.amazon.com/ec2/pricing/on-demand/
|
||||
[6]:https://aws.amazon.com/ec2/spot/pricing/
|
||||
[7]:https://aws.amazon.com/ebs/pricing/
|
||||
[8]:https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/storage-optimized-instances.html
|
||||
[9]:/blog/content/images/2018/01/Ec2cost.png
|
||||
[10]:https://boto3.readthedocs.io
|
||||
[11]:https://aws.amazon.com/s3/
|
||||
[12]:https://aws.amazon.com/message/41926/
|
||||
[13]:https://venturebeat.com/2017/02/28/aws-is-investigating-s3-issues-affecting-quora-slack-trello/
|
||||
[14]:https://aws.amazon.com/s3/pricing/
|
||||
[15]:https://aws.amazon.com/rds/aurora/
|
||||
[16]:https://aws.amazon.com/rds/postgresql/pricing/
|
||||
[17]:/blog/content/images/2018/01/RDSpricing.png
|
||||
[18]:https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_Storage.html
|
||||
[19]:http://docs.aws.amazon.com/redshift/latest/dg/c_choosing_dist_sort.html
|
||||
[20]:https://aws.amazon.com/redshift/pricing/
|
||||
[21]:https://aws.amazon.com/redshift/spectrum/
|
||||
[22]:http://docs.aws.amazon.com/emr/latest/DeveloperGuide/emr-nodes.html
|
||||
[23]:https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-automatic-scaling.html
|
||||
[24]:https://aws.amazon.com/emr/pricing/
|
||||
[25]:/blog/content/images/2018/01/EMRpricing.png
|
||||
[26]:https://twitter.com/dataquestio
|
||||
@ -1,239 +0,0 @@
|
||||
Python + Memcached: Efficient Caching in Distributed Applications – Real Python
|
||||
======
|
||||
|
||||
When writing Python applications, caching is important. Using a cache to avoid recomputing data or accessing a slow database can provide you with a great performance boost.
|
||||
|
||||
Python offers built-in possibilities for caching, from a simple dictionary to a more complete data structure such as [`functools.lru_cache`][2]. The latter can cache any item using a [Least-Recently Used algorithm][3] to limit the cache size.
|
||||
|
||||
Those data structures are, however, by definition local to your Python process. When several copies of your application run across a large platform, using a in-memory data structure disallows sharing the cached content. This can be a problem for large-scale and distributed applications.
|
||||
|
||||
|
||||
|
||||
Therefore, when a system is distributed across a network, it also needs a cache that is distributed across a network. Nowadays, there are plenty of network servers that offer caching capability—we already covered [how to use Redis for caching with Django][4].
|
||||
|
||||
As you’re going to see in this tutorial, [memcached][5] is another great option for distributed caching. After a quick introduction to basic memcached usage, you’ll learn about advanced patterns such as “cache and set” and using fallback caches to avoid cold cache performance issues.
|
||||
|
||||
### Installing memcached
|
||||
|
||||
Memcached is [available for many platforms][6]:
|
||||
|
||||
* If you run **Linux** , you can install it using `apt-get install memcached` or `yum install memcached`. This will install memcached from a pre-built package but you can alse build memcached from source, [as explained here][6].
|
||||
* For **macOS** , using [Homebrew][7] is the simplest option. Just run `brew install memcached` after you’ve installed the Homebrew package manager.
|
||||
* On **Windows** , you would have to compile memcached yourself or find [pre-compiled binaries][8].
|
||||
|
||||
|
||||
|
||||
Once installed, memcached can simply be launched by calling the `memcached` command:
|
||||
```
|
||||
$ memcached
|
||||
|
||||
```
|
||||
|
||||
Before you can interact with memcached from Python-land you’ll need to install a memcached client library. You’ll see how to do this in the next section, along with some basic cache access operations.
|
||||
|
||||
### Storing and Retrieving Cached Values Using Python
|
||||
|
||||
If you never used memcached, it is pretty easy to understand. It basically provides a giant network-available dictionary. This dictionary has a few properties that are different from a classical Python dictionnary, mainly:
|
||||
|
||||
* Keys and values have to be bytes
|
||||
* Keys and values are automatically deleted after an expiration time
|
||||
|
||||
|
||||
|
||||
Therefore, the two basic operations for interacting with memcached are `set` and `get`. As you might have guessed, they’re used to assign a value to a key or to get a value from a key, respectively.
|
||||
|
||||
My preferred Python library for interacting with memcached is [`pymemcache`][9]—I recommend using it. You can simply [install it using pip][10]:
|
||||
```
|
||||
$ pip install pymemcache
|
||||
|
||||
```
|
||||
|
||||
The following code shows how you can connect to memcached and use it as a network-distributed cache in your Python applications:
|
||||
```
|
||||
>>> from pymemcache.client import base
|
||||
|
||||
# Don't forget to run `memcached' before running this next line:
|
||||
>>> client = base.Client(('localhost', 11211))
|
||||
|
||||
# Once the client is instantiated, you can access the cache:
|
||||
>>> client.set('some_key', 'some value')
|
||||
|
||||
# Retrieve previously set data again:
|
||||
>>> client.get('some_key')
|
||||
'some value'
|
||||
|
||||
```
|
||||
|
||||
memcached network protocol is really simple an its implementation extremely fast, which makes it useful to store data that would be otherwise slow to retrieve from the canonical source of data or to compute again:
|
||||
|
||||
While straightforward enough, this example allows storing key/value tuples across the network and accessing them through multiple, distributed, running copies of your application. This is simplistic, yet powerful. And it’s a great first step towards optimizing your application.
|
||||
|
||||
### Automatically Expiring Cached Data
|
||||
|
||||
When storing data into memcached, you can set an expiration time—a maximum number of seconds for memcached to keep the key and value around. After that delay, memcached automatically removes the key from its cache.
|
||||
|
||||
What should you set this cache time to? There is no magic number for this delay, and it will entirely depend on the type of data and application that you are working with. It could be a few seconds, or it might be a few hours.
|
||||
|
||||
Cache invalidation, which defines when to remove the cache because it is out of sync with the current data, is also something that your application will have to handle. Especially if presenting data that is too old or or stale is to be avoided.
|
||||
|
||||
Here again, there is no magical recipe; it depends on the type of application you are building. However, there are several outlying cases that should be handled—which we haven’t yet covered in the above example.
|
||||
|
||||
A caching server cannot grow infinitely—memory is a finite resource. Therefore, keys will be flushed out by the caching server as soon as it needs more space to store other things.
|
||||
|
||||
Some keys might also be expired because they reached their expiration time (also sometimes called the “time-to-live” or TTL.) In those cases the data is lost, and the canonical data source must be queried again.
|
||||
|
||||
This sounds more complicated than it really is. You can generally work with the following pattern when working with memcached in Python:
|
||||
```
|
||||
from pymemcache.client import base
|
||||
|
||||
|
||||
def do_some_query():
|
||||
# Replace with actual querying code to a database,
|
||||
# a remote REST API, etc.
|
||||
return 42
|
||||
|
||||
|
||||
# Don't forget to run `memcached' before running this code
|
||||
client = base.Client(('localhost', 11211))
|
||||
result = client.get('some_key')
|
||||
|
||||
if result is None:
|
||||
# The cache is empty, need to get the value
|
||||
# from the canonical source:
|
||||
result = do_some_query()
|
||||
|
||||
# Cache the result for next time:
|
||||
client.set('some_key', result)
|
||||
|
||||
# Whether we needed to update the cache or not,
|
||||
# at this point you can work with the data
|
||||
# stored in the `result` variable:
|
||||
print(result)
|
||||
|
||||
```
|
||||
|
||||
> **Note:** Handling missing keys is mandatory because of normal flush-out operations. It is also obligatory to handle the cold cache scenario, i.e. when memcached has just been started. In that case, the cache will be entirely empty and the cache needs to be fully repopulated, one request at a time.
|
||||
|
||||
This means you should view any cached data as ephemeral. And you should never expect the cache to contain a value you previously wrote to it.
|
||||
|
||||
### Warming Up a Cold Cache
|
||||
|
||||
Some of the cold cache scenarios cannot be prevented, for example a memcached crash. But some can, for example migrating to a new memcached server.
|
||||
|
||||
When it is possible to predict that a cold cache scenario will happen, it is better to avoid it. A cache that needs to be refilled means that all of the sudden, the canonical storage of the cached data will be massively hit by all cache users who lack a cache data (also known as the [thundering herd problem][11].)
|
||||
|
||||
pymemcache provides a class named `FallbackClient` that helps in implementing this scenario as demonstrated here:
|
||||
```
|
||||
from pymemcache.client import base
|
||||
from pymemcache import fallback
|
||||
|
||||
|
||||
def do_some_query():
|
||||
# Replace with actual querying code to a database,
|
||||
# a remote REST API, etc.
|
||||
return 42
|
||||
|
||||
|
||||
# Set `ignore_exc=True` so it is possible to shut down
|
||||
# the old cache before removing its usage from
|
||||
# the program, if ever necessary.
|
||||
old_cache = base.Client(('localhost', 11211), ignore_exc=True)
|
||||
new_cache = base.Client(('localhost', 11212))
|
||||
|
||||
client = fallback.FallbackClient((new_cache, old_cache))
|
||||
|
||||
result = client.get('some_key')
|
||||
|
||||
if result is None:
|
||||
# The cache is empty, need to get the value
|
||||
# from the canonical source:
|
||||
result = do_some_query()
|
||||
|
||||
# Cache the result for next time:
|
||||
client.set('some_key', result)
|
||||
|
||||
print(result)
|
||||
|
||||
```
|
||||
|
||||
The `FallbackClient` queries the old cache passed to its constructor, respecting the order. In this case, the new cache server will always be queried first, and in case of a cache miss, the old one will be queried—avoiding a possible return-trip to the primary source of data.
|
||||
|
||||
If any key is set, it will only be set to the new cache. After some time, the old cache can be decommissioned and the `FallbackClient` can be replaced directed with the `new_cache` client.
|
||||
|
||||
### Check And Set
|
||||
|
||||
When communicating with a remote cache, the usual concurrency problem comes back: there might be several clients trying to access the same key at the same time. memcached provides a check and set operation, shortened to CAS, which helps to solve this problem.
|
||||
|
||||
The simplest example is an application that wants to count the number of users it has. Each time a visitor connects, a counter is incremented by 1. Using memcached, a simple implementation would be:
|
||||
```
|
||||
def on_visit(client):
|
||||
result = client.get('visitors')
|
||||
if result is None:
|
||||
result = 1
|
||||
else:
|
||||
result += 1
|
||||
client.set('visitors', result)
|
||||
|
||||
```
|
||||
|
||||
However, what happens if two instances of the application try to update this counter at the same time?
|
||||
|
||||
The first call `client.get('visitors')` will return the same number of visitors for both of them, let’s say it’s 42. Then both will add 1, compute 43, and set the number of visitors to 43. That number is wrong, and the result should be 44, i.e. 42 + 1 + 1.
|
||||
|
||||
To solve this concurrency issue, the CAS operation of memcached is handy. The following snippet implements a correct solution:
|
||||
```
|
||||
def on_visit(client):
|
||||
while True:
|
||||
result, cas = client.gets('visitors')
|
||||
if result is None:
|
||||
result = 1
|
||||
else:
|
||||
result += 1
|
||||
if client.cas('visitors', result, cas):
|
||||
break
|
||||
|
||||
```
|
||||
|
||||
The `gets` method returns the value, just like the `get` method, but it also returns a CAS value.
|
||||
|
||||
What is in this value is not relevant, but it is used for the next method `cas` call. This method is equivalent to the `set` operation, except that it fails if the value has changed since the `gets` operation. In case of success, the loop is broken. Otherwise, the operation is restarted from the beginning.
|
||||
|
||||
In the scenario where two instances of the application try to update the counter at the same time, only one succeeds to move the counter from 42 to 43. The second instance gets a `False` value returned by the `client.cas` call, and have to retry the loop. It will retrieve 43 as value this time, will increment it to 44, and its `cas` call will succeed, thus solving our problem.
|
||||
|
||||
Incrementing a counter is interesting as an example to explain how CAS works because it is simplistic. However, memcached also provides the `incr` and `decr` methods to increment or decrement an integer in a single request, rather than doing multiple `gets`/`cas` calls. In real-world applications `gets` and `cas` are used for more complex data type or operations
|
||||
|
||||
Most remote caching server and data store provide such a mechanism to prevent concurrency issues. It is critical to be aware of those cases to make proper use of their features.
|
||||
|
||||
### Beyond Caching
|
||||
|
||||
The simple techniques illustrated in this article showed you how easy it is to leverage memcached to speed up the performances of your Python application.
|
||||
|
||||
Just by using the two basic “set” and “get” operations you can often accelerate data retrieval or avoid recomputing results over and over again. With memcached you can share the cache accross a large number of distributed nodes.
|
||||
|
||||
Other, more advanced patterns you saw in this tutorial, like the Check And Set (CAS) operation allow you to update data stored in the cache concurrently across multiple Python threads or processes while avoiding data corruption.
|
||||
|
||||
If you are interested into learning more about advanced techniques to write faster and more scalable Python applications, check out [Scaling Python][12]. It covers many advanced topics such as network distribution, queuing systems, distributed hashing, and code profiling.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://realpython.com/blog/python/python-memcache-efficient-caching/
|
||||
|
||||
作者:[Julien Danjou][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://realpython.com/team/jdanjou/
|
||||
[1]:https://realpython.com/blog/categories/python/
|
||||
[2]:https://docs.python.org/3/library/functools.html#functools.lru_cache
|
||||
[3]:https://en.wikipedia.org/wiki/Cache_replacement_policies#Least_Recently_Used_(LRU)
|
||||
[4]:https://realpython.com/blog/python/caching-in-django-with-redis/
|
||||
[5]:http://memcached.org
|
||||
[6]:https://github.com/memcached/memcached/wiki/Install
|
||||
[7]:https://brew.sh/
|
||||
[8]:https://commaster.net/content/installing-memcached-windows
|
||||
[9]:https://pypi.python.org/pypi/pymemcache
|
||||
[10]:https://realpython.com/learn/python-first-steps/#11-pythons-power-packagesmodules
|
||||
[11]:https://en.wikipedia.org/wiki/Thundering_herd_problem
|
||||
[12]:https://scaling-python.com
|
||||
@ -1,128 +0,0 @@
|
||||
10 things I love about Vue
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
I love Vue. When I first looked at it in 2016, perhaps I was coming from a perspective of JavaScript framework fatigue. I’d already had experience with Backbone, Angular, React, among others and I wasn’t overly enthusiastic to try a new framework. It wasn’t until I read a comment on hacker news describing Vue as the ‘new jquery’ of JavaScript, that my curiosity was piqued. Until that point, I had been relatively content with React — it is a good framework based on solid design principles centred around view templates, virtual DOM and reacting to state, and Vue also provides these great things. In this blog post, I aim to explore why Vue is the framework for me. I choose it above any other that I have tried. Perhaps you will agree with some of my points, but at the very least I hope to give you some insight into what it is like to develop modern JavaScript applications with Vue.
|
||||
|
||||
1\. Minimal Template Syntax
|
||||
|
||||
The template syntax which you are given by default from Vue is minimal, succinct and extendable. Like many parts of Vue, it’s easy to not use the standard template syntax and instead use something like JSX (there is even an official page of documentation about how to do this), but I don’t know why you would want to do that to be honest. For all that is good about JSX, there are some valid criticisms: by blurring the line between JavaScript and HTML, it makes it a bit too easy to start writing complex code in your template which should instead be separated out and written elsewhere in your JavaScript view code.
|
||||
|
||||
Vue instead uses standard HTML to write your templates, with a minimal template syntax for simple things such as iteratively creating elements based on the view data.
|
||||
|
||||
```
|
||||
<template>
|
||||
<div id="app">
|
||||
<ul>
|
||||
<li v-for='number in numbers' :key='number'>{{ number }}</li>
|
||||
</ul>
|
||||
<form @submit.prevent='addNumber'>
|
||||
<input type='text' v-model='newNumber'>
|
||||
<button type='submit'>Add another number</button>
|
||||
</form>
|
||||
</div>
|
||||
</template>
|
||||
|
||||
<script>
|
||||
export default {
|
||||
name: 'app',
|
||||
methods: {
|
||||
addNumber() {
|
||||
const num = +this.newNumber;
|
||||
if (typeof num === 'number' && !isNaN(num)) {
|
||||
this.numbers.push(num);
|
||||
}
|
||||
}
|
||||
},
|
||||
data() {
|
||||
return {
|
||||
newNumber: null,
|
||||
numbers: [1, 23, 52, 46]
|
||||
};
|
||||
}
|
||||
}
|
||||
</script>
|
||||
|
||||
<style lang="scss">
|
||||
ul {
|
||||
padding: 0;
|
||||
li {
|
||||
list-style-type: none;
|
||||
color: blue;
|
||||
}
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
|
||||
I also like the short-bindings provided by Vue, ‘:’ for binding data variables into your template and ‘@’ for binding to events. It’s a small thing, but it feels nice to type and keeps your components succinct.
|
||||
|
||||
2\. Single File Components
|
||||
|
||||
When most people write Vue, they do so using ‘single file components’. Essentially it is a file with the suffix .vue containing up to 3 parts (the css, html and javascript) for each component.
|
||||
|
||||
This coupling of technologies feels right. It makes it easy to understand each component in a single place. It also has the nice side effect of encouraging you to keep your code short for each component. If the JavaScript, CSS and HTML for your component is taking up too many lines then it might be time to modularise further.
|
||||
|
||||
When it comes to the <style> tag of a Vue component, we can add the ‘scoped’ attribute. This will fully encapsulate the styling to this component. Meaning if we had a .name CSS selector defined in this component, it won’t apply that style in any other component. I much prefer this approach of styling view components to the approaches of writing CSS in JS which seems popular in other leading frameworks.
|
||||
|
||||
Another very nice thing about single file components is that they are actually valid HTML5 files. <template>, <script>, <style> are all part of the official w3c specification. This means that many tools you use as part of your development process (such as linters) can work out of the box or with minimal adaptation.
|
||||
|
||||
3\. Vue as the new jQuery
|
||||
|
||||
Really these two libraries are not similar and are doing different things. Let me provide you with a terrible analogy that I am actually quite fond of to describe the relationship of Vue and jQuery: The Beatles and Led Zeppelin. The Beatles need no introduction, they were the biggest group of the 1960s and were supremely influential. It gets harder to pin the accolade of ‘biggest group of the 1970s’ but sometimes that goes to Led Zeppelin. You could say that the musical relationship between the Beatles and Led Zeppelin is tenuous and their music is distinctively different, but there is some prior art and influence to accept. Maybe 2010s JavaScript world is like the 1970s music world and as Vue gets more radio plays, it will only attract more fans.
|
||||
|
||||
Some of the philosophy that made jQuery so great is also present in Vue: a really easy learning curve but with all the power you need to build great web applications based on modern web standards. At its core, Vue is really just a wrapper around JavaScript objects.
|
||||
|
||||
4\. Easily extensible
|
||||
|
||||
As mentioned, Vue uses standard HTML, JS and CSS to build its components as a default, but it is really easy to plug in other technologies. If we want to use pug instead of HTML or typescript instead of JS or sass instead of CSS, it’s just a matter of installing the relevant node modules and adding an attribute to the relevant section of our single file component. You could even mix and match components within a project — e.g. some components using HTML and others using pug — although I’m not sure doing this is the best practice.
|
||||
|
||||
5\. Virtual DOM
|
||||
|
||||
The virtual DOM is used in many frameworks these days and it is great. It means the framework can work out what has changed in our state and then efficiently apply DOM updates, minimizing re-rendering and optimising the performance of our application. Everyone and their mother has a Virtual DOM these days, so whilst it’s not something unique, it’s still very cool.
|
||||
|
||||
6\. Vuex is great
|
||||
|
||||
For most applications, managing state becomes a tricky issue which using a view library alone can not solve. Vue’s solution to this is the vuex library. It’s easy to setup and integrates very well with vue. Those familiar with redux will be at home here, but I find that the integration between vue and vuex is neater and more minimal than that of react and redux. Soon-to-be-standard JavaScript provides the object spread operator which allows us to merge in state or functions to manipulate state from vuex into the components that need it.
|
||||
|
||||
7\. Vue CLI
|
||||
|
||||
The CLI provided by Vue is really great and makes it easy to get started with a webpack project with Vue. Single file components support, babel, linting, testing and a sensible project structure can all be created with a single command in your terminal.
|
||||
|
||||
There is one thing, however I miss from the CLI and that is the ‘vue build’.
|
||||
|
||||
```
|
||||
try this: `echo '<template><h1>Hello World!</h1></template>' > Hello.vue && vue build Hello.vue -o`
|
||||
```
|
||||
|
||||
It looked so simple to build and run components and test them in the browser. Unfortunately this command was later removed from vue, instead the recommendation is to now use poi. Poi is basically a wrapper around webpack, but I don’t think it quite gets to the same point of simplicity as the quoted tweet.
|
||||
|
||||
8\. Re-rendering optimizations worked out for you
|
||||
|
||||
In Vue, you don’t have to manually state which parts of the DOM should be re-rendered. I never was a fan of the management on react components, such as ‘shouldComponentUpdate’ in order to stop the whole DOM tree re-rendering. Vue is smart about this.
|
||||
|
||||
9\. Easy to get help
|
||||
|
||||
Vue has reached a critical mass of developers using the framework to build a wide variety of applications. The documentation is very good. Should you need further help, there are multiple channels available with many active users: stackoverflow, discord, twitter etc. — this should give you some more confidence in building an application over some other frameworks with less users.
|
||||
|
||||
10\. Not maintained by a single corporation
|
||||
|
||||
I think it’s a good thing for an open source library to not have the voting rights of its direction steered too much by a single corporation. Issues such as the react licensing issue (now resolved) are not something Vue has had to deal with.
|
||||
|
||||
In summary, I think Vue is an excellent choice for whatever JavaScript project you might be starting next. The available ecosystem is larger than I covered in this blog post. For a more full-stack offering you could look at Nuxt.js. And if you want some re-usable styled components you could look at something like Vuetify. Vue has been one of the fastest growing frameworks of 2017 and I predict the growth is not going to slow down for 2018\. If you have a spare 30 minutes, why not dip your toes in and see what Vue has to offer for yourself?
|
||||
|
||||
P.S. — The documentation gives you a great comparison to other frameworks here: [https://vuejs.org/v2/guide/comparison.html][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@dalaidunc/10-things-i-love-about-vue-505886ddaff2
|
||||
|
||||
作者:[Duncan Grant ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@dalaidunc
|
||||
[1]:https://vuejs.org/v2/guide/comparison.html
|
||||
@ -1,262 +0,0 @@
|
||||
Shallow vs Deep Copying of Python Objects – Real Python
|
||||
======
|
||||
|
||||
Assignment statements in Python do not create copies of objects, they only bind names to an object. For immutable objects, that usually doesn’t make a difference.
|
||||
|
||||
But for working with mutable objects or collections of mutable objects, you might be looking for a way to create “real copies” or “clones” of these objects.
|
||||
|
||||
Essentially, you’ll sometimes want copies that you can modify without automatically modifying the original at the same time. In this article I’m going to give you the rundown on how to copy or “clone” objects in Python 3 and some of the caveats involved.
|
||||
|
||||
> **Note:** This tutorial was written with Python 3 in mind but there is little difference between Python 2 and 3 when it comes to copying objects. When there are differences I will point them out in the text.
|
||||
|
||||
Let’s start by looking at how to copy Python’s built-in collections. Python’s built-in mutable collections like [lists, dicts, and sets][3] can be copied by calling their factory functions on an existing collection:
|
||||
```
|
||||
new_list = list(original_list)
|
||||
new_dict = dict(original_dict)
|
||||
new_set = set(original_set)
|
||||
|
||||
```
|
||||
|
||||
However, this method won’t work for custom objects and, on top of that, it only creates shallow copies. For compound objects like lists, dicts, and sets, there’s an important difference between shallow and deep copying:
|
||||
|
||||
* A **shallow copy** means constructing a new collection object and then populating it with references to the child objects found in the original. In essence, a shallow copy is only one level deep. The copying process does not recurse and therefore won’t create copies of the child objects themselves.
|
||||
|
||||
* A **deep copy** makes the copying process recursive. It means first constructing a new collection object and then recursively populating it with copies of the child objects found in the original. Copying an object this way walks the whole object tree to create a fully independent clone of the original object and all of its children.
|
||||
|
||||
|
||||
|
||||
|
||||
I know, that was a bit of a mouthful. So let’s look at some examples to drive home this difference between deep and shallow copies.
|
||||
|
||||
**Free Bonus:** [Click here to get access to a chapter from Python Tricks: The Book][4] that shows you Python's best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
|
||||
|
||||
### Making Shallow Copies
|
||||
|
||||
In the example below, we’ll create a new nested list and then shallowly copy it with the `list()` factory function:
|
||||
```
|
||||
>>> xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> ys = list(xs) # Make a shallow copy
|
||||
|
||||
```
|
||||
|
||||
This means `ys` will now be a new and independent object with the same contents as `xs`. You can verify this by inspecting both objects:
|
||||
```
|
||||
>>> xs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> ys
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
To confirm `ys` really is independent from the original, let’s devise a little experiment. You could try and add a new sublist to the original (`xs`) and then check to make sure this modification didn’t affect the copy (`ys`):
|
||||
```
|
||||
>>> xs.append(['new sublist'])
|
||||
>>> xs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9], ['new sublist']]
|
||||
>>> ys
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
As you can see, this had the expected effect. Modifying the copied list at a “superficial” level was no problem at all.
|
||||
|
||||
However, because we only created a shallow copy of the original list, `ys` still contains references to the original child objects stored in `xs`.
|
||||
|
||||
These children were not copied. They were merely referenced again in the copied list.
|
||||
|
||||
Therefore, when you modify one of the child objects in `xs`, this modification will be reflected in `ys` as well—that’s because both lists share the same child objects. The copy is only a shallow, one level deep copy:
|
||||
```
|
||||
>>> xs[1][0] = 'X'
|
||||
>>> xs
|
||||
[[1, 2, 3], ['X', 5, 6], [7, 8, 9], ['new sublist']]
|
||||
>>> ys
|
||||
[[1, 2, 3], ['X', 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
In the above example we (seemingly) only made a change to `xs`. But it turns out that both sublists at index 1 in `xs` and `ys` were modified. Again, this happened because we had only created a shallow copy of the original list.
|
||||
|
||||
Had we created a deep copy of `xs` in the first step, both objects would’ve been fully independent. This is the practical difference between shallow and deep copies of objects.
|
||||
|
||||
Now you know how to create shallow copies of some of the built-in collection classes, and you know the difference between shallow and deep copying. The questions we still want answers for are:
|
||||
|
||||
* How can you create deep copies of built-in collections?
|
||||
* How can you create copies (shallow and deep) of arbitrary objects, including custom classes?
|
||||
|
||||
|
||||
|
||||
The answer to these questions lies in the `copy` module in the Python standard library. This module provides a simple interface for creating shallow and deep copies of arbitrary Python objects.
|
||||
|
||||
### Making Deep Copies
|
||||
|
||||
Let’s repeat the previous list-copying example, but with one important difference. This time we’re going to create a deep copy using the `deepcopy()` function defined in the `copy` module instead:
|
||||
```
|
||||
>>> import copy
|
||||
>>> xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> zs = copy.deepcopy(xs)
|
||||
|
||||
```
|
||||
|
||||
When you inspect `xs` and its clone `zs` that we created with `copy.deepcopy()`, you’ll see that they both look identical again—just like in the previous example:
|
||||
```
|
||||
>>> xs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> zs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
However, if you make a modification to one of the child objects in the original object (`xs`), you’ll see that this modification won’t affect the deep copy (`zs`).
|
||||
|
||||
Both objects, the original and the copy, are fully independent this time. `xs` was cloned recursively, including all of its child objects:
|
||||
```
|
||||
>>> xs[1][0] = 'X'
|
||||
>>> xs
|
||||
[[1, 2, 3], ['X', 5, 6], [7, 8, 9]]
|
||||
>>> zs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
You might want to take some time to sit down with the Python interpreter and play through these examples right about now. Wrapping your head around copying objects is easier when you get to experience and play with the examples firsthand.
|
||||
|
||||
By the way, you can also create shallow copies using a function in the `copy` module. The `copy.copy()` function creates shallow copies of objects.
|
||||
|
||||
This is useful if you need to clearly communicate that you’re creating a shallow copy somewhere in your code. Using `copy.copy()` lets you indicate this fact. However, for built-in collections it’s considered more Pythonic to simply use the list, dict, and set factory functions to create shallow copies.
|
||||
|
||||
### Copying Arbitrary Python Objects
|
||||
|
||||
The question we still need to answer is how do we create copies (shallow and deep) of arbitrary objects, including custom classes. Let’s take a look at that now.
|
||||
|
||||
Again the `copy` module comes to our rescue. Its `copy.copy()` and `copy.deepcopy()` functions can be used to duplicate any object.
|
||||
|
||||
Once again, the best way to understand how to use these is with a simple experiment. I’m going to base this on the previous list-copying example. Let’s start by defining a simple 2D point class:
|
||||
```
|
||||
class Point:
|
||||
def __init__(self, x, y):
|
||||
self.x = x
|
||||
self.y = y
|
||||
|
||||
def __repr__(self):
|
||||
return f'Point({self.x!r}, {self.y!r})'
|
||||
|
||||
```
|
||||
|
||||
I hope you agree that this was pretty straightforward. I added a `__repr__()` implementation so that we can easily inspect objects created from this class in the Python interpreter.
|
||||
|
||||
> **Note:** The above example uses a [Python 3.6 f-string][5] to construct the string returned by `__repr__`. On Python 2 and versions of Python 3 before 3.6 you’d use a different string formatting expression, for example:
|
||||
```
|
||||
> def __repr__(self):
|
||||
> return 'Point(%r, %r)' % (self.x, self.y)
|
||||
>
|
||||
```
|
||||
|
||||
Next up, we’ll create a `Point` instance and then (shallowly) copy it, using the `copy` module:
|
||||
```
|
||||
>>> a = Point(23, 42)
|
||||
>>> b = copy.copy(a)
|
||||
|
||||
```
|
||||
|
||||
If we inspect the contents of the original `Point` object and its (shallow) clone, we see what we’d expect:
|
||||
```
|
||||
>>> a
|
||||
Point(23, 42)
|
||||
>>> b
|
||||
Point(23, 42)
|
||||
>>> a is b
|
||||
False
|
||||
|
||||
```
|
||||
|
||||
Here’s something else to keep in mind. Because our point object uses primitive types (ints) for its coordinates, there’s no difference between a shallow and a deep copy in this case. But I’ll expand the example in a second.
|
||||
|
||||
Let’s move on to a more complex example. I’m going to define another class to represent 2D rectangles. I’ll do it in a way that allows us to create a more complex object hierarchy—my rectangles will use `Point` objects to represent their coordinates:
|
||||
```
|
||||
class Rectangle:
|
||||
def __init__(self, topleft, bottomright):
|
||||
self.topleft = topleft
|
||||
self.bottomright = bottomright
|
||||
|
||||
def __repr__(self):
|
||||
return (f'Rectangle({self.topleft!r}, '
|
||||
f'{self.bottomright!r})')
|
||||
|
||||
```
|
||||
|
||||
Again, first we’re going to attempt to create a shallow copy of a rectangle instance:
|
||||
```
|
||||
rect = Rectangle(Point(0, 1), Point(5, 6))
|
||||
srect = copy.copy(rect)
|
||||
|
||||
```
|
||||
|
||||
If you inspect the original rectangle and its copy, you’ll see how nicely the `__repr__()` override is working out, and that the shallow copy process worked as expected:
|
||||
```
|
||||
>>> rect
|
||||
Rectangle(Point(0, 1), Point(5, 6))
|
||||
>>> srect
|
||||
Rectangle(Point(0, 1), Point(5, 6))
|
||||
>>> rect is srect
|
||||
False
|
||||
|
||||
```
|
||||
|
||||
Remember how the previous list example illustrated the difference between deep and shallow copies? I’m going to use the same approach here. I’ll modify an object deeper in the object hierarchy, and then you’ll see this change reflected in the (shallow) copy as well:
|
||||
```
|
||||
>>> rect.topleft.x = 999
|
||||
>>> rect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
>>> srect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
|
||||
```
|
||||
|
||||
I hope this behaved how you expected it to. Next, I’ll create a deep copy of the original rectangle. Then I’ll apply another modification and you’ll see which objects are affected:
|
||||
```
|
||||
>>> drect = copy.deepcopy(srect)
|
||||
>>> drect.topleft.x = 222
|
||||
>>> drect
|
||||
Rectangle(Point(222, 1), Point(5, 6))
|
||||
>>> rect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
>>> srect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
|
||||
```
|
||||
|
||||
Voila! This time the deep copy (`drect`) is fully independent of the original (`rect`) and the shallow copy (`srect`).
|
||||
|
||||
We’ve covered a lot of ground here, and there are still some finer points to copying objects.
|
||||
|
||||
It pays to go deep (ha!) on this topic, so you may want to study up on the [`copy` module documentation][6]. For example, objects can control how they’re copied by defining the special methods `__copy__()` and `__deepcopy__()` on them.
|
||||
|
||||
### 3 Things to Remember
|
||||
|
||||
* Making a shallow copy of an object won’t clone child objects. Therefore, the copy is not fully independent of the original.
|
||||
* A deep copy of an object will recursively clone child objects. The clone is fully independent of the original, but creating a deep copy is slower.
|
||||
* You can copy arbitrary objects (including custom classes) with the `copy` module.
|
||||
|
||||
|
||||
|
||||
If you’d like to dig deeper into other intermediate-level Python programming techniques, check out this free bonus:
|
||||
|
||||
**Free Bonus:** [Click here to get access to a chapter from Python Tricks: The Book][4] that shows you Python's best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://realpython.com/blog/python/copying-python-objects/
|
||||
|
||||
作者:[Dan Bader][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://realpython.com/team/dbader/
|
||||
[1]:https://realpython.com/blog/categories/fundamentals/
|
||||
[2]:https://realpython.com/blog/categories/python/
|
||||
[3]:https://realpython.com/learn/python-first-steps/
|
||||
[4]:https://realpython.com/blog/python/copying-python-objects/
|
||||
[5]:https://dbader.org/blog/python-string-formatting
|
||||
[6]:https://docs.python.org/3/library/copy.html
|
||||
@ -1,131 +0,0 @@
|
||||
Error establishing a database connection
|
||||
======
|
||||
![Error establishing a database connection][1]
|
||||
|
||||
Error establishing a database connection, is a very common error when you try to access your WordPress site. The database stores all the important information for your website, including your posts, comments, site configuration, user accounts, theme and plugin settings and so on. If the connection to your database cannot be established, your WordPress website will not load, and more then likely will give you the error: “Error establishing a database connection” In this tutorial we will show you, how to fix Error establishing a database connection in WordPress.
|
||||
|
||||
The most common cause for “Error establishing a database connection” issue, is one of the following:
|
||||
|
||||
Your database has been corrupted
|
||||
Incorrect login credentials in your WordPress configuration file (wp-config.php)
|
||||
Your MySQL service stopped working due to insufficient memory on the server (due to heavy traffic), or server problems
|
||||
|
||||
![Error establishing a database connection][2]
|
||||
|
||||
### 1. Requirements
|
||||
|
||||
In order to troubleshoot “Error establishing a database connection” issue, a few requirements must be met:
|
||||
|
||||
* SSH access to your server
|
||||
* The database is located on the same server
|
||||
* You need to know your database username, user password, and name of the database
|
||||
|
||||
|
||||
|
||||
Also before you try to fix “Error establishing a database connection” error, it is highly recommended that you make a backup of both your website and database.
|
||||
|
||||
### 1. Corrupted database
|
||||
|
||||
The first step to do when trying to troubleshoot “Error establishing a database connection” problem is to check whether this error is present for both the front-end and the back-end of the your site. You can access your back-end via <http://www.yourdomain.com/wp-admin> (replace “yourdomain” with your actual domain name)
|
||||
|
||||
If the error remains the same for both your front-end and back-end then you should move to the next step.
|
||||
|
||||
If you are able to access the back-end via <https://www.yourdomain.com/wp-admin, > and you see the following message:
|
||||
```
|
||||
“One or more database tables are unavailable. The database may need to be repaired”
|
||||
|
||||
```
|
||||
|
||||
it means that your database has been corrupted and you need to try to repair it.
|
||||
|
||||
To do this, you must first enable the repair option in your wp-config.php file, located inside the WordPress site root directory, by adding the following line:
|
||||
```
|
||||
define('WP_ALLOW_REPAIR', true);
|
||||
|
||||
```
|
||||
|
||||
Now you can navigate to this this page: <https://www.yourdomain.com/wp-admin/maint/repair.php> and click the “Repair and Optimize Database button.”
|
||||
|
||||
For security reasons, remember to turn off the repair option be deleting the line we added before in the wp-config.php file.
|
||||
|
||||
If this does not fix the problem or the database cannot be repaired you will probably need to restore it from a backup if you have one available.
|
||||
|
||||
### 2. Check your wp-config.php file
|
||||
|
||||
Another, probably most common reason, for failed database connection is because of incorrect database information set in your WordPress configuration file.
|
||||
|
||||
The configuration file resides in your WordPress site root directory and it is called wp-config.php .
|
||||
|
||||
Open the file and locate the following lines:
|
||||
```
|
||||
define('DB_NAME', 'database_name');
|
||||
define('DB_USER', 'database_username');
|
||||
define('DB_PASSWORD', 'database_password');
|
||||
define('DB_HOST', 'localhost');
|
||||
|
||||
```
|
||||
|
||||
Make sure the correct database name, username, and password are set. Database host should be set to “localhost”.
|
||||
|
||||
If you ever change your database username and password you should always update this file as well.
|
||||
|
||||
If everything is set up properly and you are still getting the “Error establishing a database connection” error then the problem is probably on the server side and you should move on to the next step of this tutorial.
|
||||
|
||||
### 3. Check your server
|
||||
|
||||
Depending on the resources available, during high traffic hours, your server might not be able to handle all the load and it may stop your MySQL server.
|
||||
|
||||
You can either contact your hosting provider about this or you can check it yourself if the MySQL server is properly running.
|
||||
|
||||
To check the status of MySQL, log in to your server via [SSH][3] and use the following command:
|
||||
```
|
||||
systemctl status mysql
|
||||
|
||||
```
|
||||
|
||||
Or you can check if it is up in your active processes with:
|
||||
```
|
||||
ps aux | grep mysql
|
||||
|
||||
```
|
||||
|
||||
If your MySQL is not running you can start it with the following commands:
|
||||
```
|
||||
systemctl start mysql
|
||||
|
||||
```
|
||||
|
||||
You may also need to check the memory usage on your server.
|
||||
|
||||
To check how much RAM you have available you can use the following command:
|
||||
```
|
||||
free -m
|
||||
|
||||
```
|
||||
|
||||
If your server is running low on memory you may want to consider upgrading your server.
|
||||
|
||||
### 4. Conclusion
|
||||
|
||||
Most of the time. the “Error establishing a database connection” error can be fixed by following one of the steps above.
|
||||
|
||||
![How to Fix the Error Establishing a Database Connection in WordPress][4]Of course, you don’t have to fix, Error establishing a database connection, if you use one of our [WordPress VPS Hosting Services][5], in which case you can simply ask our expert Linux admins to help you fix the Error establishing a database connection in WordPress, for you. They are available 24×7 and will take care of your request immediately.
|
||||
|
||||
**PS**. If you liked this post, on how to fix the Error establishing a database connection in WordPress, please share it with your friends on the social networks using the buttons on the left or simply leave a reply below. Thanks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/error-establishing-a-database-connection/
|
||||
|
||||
作者:[RoseHosting][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/02/error-establishing-a-database-connection.jpg
|
||||
[2]:https://www.rosehosting.com/blog/wp-content/uploads/2018/02/Error-establishing-a-database-connection-e1517474875180.png
|
||||
[3]:https://www.rosehosting.com/blog/connect-to-your-linux-vps-via-ssh/
|
||||
[4]:https://www.rosehosting.com/blog/wp-content/uploads/2018/02/How-to-Fix-the-Error-Establishing-a-Database-Connection-in-WordPress.jpg
|
||||
[5]:https://www.rosehosting.com/wordpress-hosting.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Check Your Linux PC for Meltdown or Spectre Vulnerability
|
||||
======
|
||||
|
||||
|
||||
@ -1,106 +0,0 @@
|
||||
How to use lxc remote with the LXD snap
|
||||
======
|
||||
**Background** : LXD is a hypervisor that manages machine containers on Linux distributions. You install LXD on your Linux distribution and then you can launch machine containers into your distribution running all sort of (other) Linux distributions.
|
||||
|
||||
You have installed the LXD snap and you are happy using it. However, you are developing LXD and you would like to use your freshly compiled LXD client (executable: **lxc** ) on the LXD snap.
|
||||
|
||||
Let’s run our compile lxc executable.
|
||||
```
|
||||
$ ./lxc list
|
||||
LXD socket not found; is LXD installed and running?
|
||||
Exit 1
|
||||
|
||||
```
|
||||
|
||||
By default it cannot access the LXD server from the snap. We need to [set up a remote LXD host][1] and then configure the client to be able to connect to that remote LXD server.
|
||||
|
||||
### Configuring the remote LXD server (snap)
|
||||
|
||||
We run the following on the LXD snap,
|
||||
```
|
||||
$ which lxd
|
||||
/snap/bin/lxd
|
||||
|
||||
$ sudo lxd init
|
||||
Do you want to configure a new storage pool (yes/no) [default=yes]? no
|
||||
Would you like LXD to be available over the network (yes/no) [default=no]? yes
|
||||
Address to bind LXD to (not including port) [default=all]: press_enter_to_accept_default
|
||||
Port to bind LXD to [default=8443]: press_enter_to_accept_default
|
||||
Trust password for new clients: type_a_password
|
||||
Again: type_the_same_password
|
||||
Do you want to configure the LXD bridge (yes/no) [default=yes]? no
|
||||
LXD has been successfully configured.
|
||||
|
||||
$
|
||||
|
||||
```
|
||||
|
||||
Now the snap LXD server is configured to accept remote connections, and the clients much be configured with the correct trust password.
|
||||
|
||||
### Configuring the client (compiled lxc)
|
||||
|
||||
Let’s configure now the compiled lxc client.
|
||||
|
||||
First, here is how the unconfigured compiled lxc client would react,
|
||||
```
|
||||
$ ./lxc list
|
||||
LXD socket not found; is LXD installed and running?
|
||||
Exit 1
|
||||
|
||||
```
|
||||
|
||||
Now we add the remote, given the name **lxd.snap** , which binds on localhost (127.0.0.1). It asks to verify the certificate fingerprint. I am not aware how to view the fingerprint from inside the snap. We type the one-time password that we set earlier and we are good to go.
|
||||
```
|
||||
$ lxc remote add lxd.snap 127.0.0.1
|
||||
Certificate fingerprint: 2c5829064cf795e29388b0d6310369fcf693257650b5c90c922a2d10f542831e
|
||||
ok (y/n)? y
|
||||
Admin password for lxd.snap: type_that_password
|
||||
Client certificate stored at server: lxd.snap
|
||||
|
||||
$ lxc remote list
|
||||
+-----------------|------------------------------------------|---------------|-----------|--------|--------+
|
||||
| NAME | URL | PROTOCOL | AUTH TYPE | PUBLIC | STATIC |
|
||||
+-----------------|------------------------------------------|---------------|-----------|--------|--------+
|
||||
| images | https://images.linuxcontainers.org | simplestreams | | YES | NO |
|
||||
+-----------------|------------------------------------------|---------------|-----------|--------|--------+
|
||||
| local (default) | unix:// | lxd | tls | NO | YES |
|
||||
+-----------------|------------------------------------------|---------------|-----------|--------|--------+
|
||||
| lxd.snap | https://127.0.0.1:8443 | lxd | tls | NO | NO |
|
||||
+-----------------|------------------------------------------|---------------|-----------|--------|--------+
|
||||
| ubuntu | https://cloud-images.ubuntu.com/releases | simplestreams | | YES | YES |
|
||||
+-----------------|------------------------------------------|---------------|-----------|--------|--------+
|
||||
| ubuntu-daily | https://cloud-images.ubuntu.com/daily | simplestreams | | YES | YES |
|
||||
+-----------------|------------------------------------------|---------------|-----------|--------|--------+
|
||||
|
||||
```
|
||||
|
||||
Still, the default remote is **local**. That means that **./lxc** will not work yet. We need to make **lxd.snap** the default remote.
|
||||
```
|
||||
$ ./lxc list
|
||||
LXD socket not found; is LXD installed and running?
|
||||
Exit 1
|
||||
|
||||
$ ./lxc remote set-default lxd.snap
|
||||
|
||||
$ ./lxc list
|
||||
... now it works ...
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
We saw how to get a client to access a LXD server. A more advanced scenario would be to have two LXD servers, and set them up so that each one can connect to the other.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.simos.info/how-to-use-lxc-remote-with-the-lxd-snap/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.simos.info/author/simos/
|
||||
[1]:https://stgraber.org/2016/04/12/lxd-2-0-remote-hosts-and-container-migration-612/
|
||||
@ -1,176 +0,0 @@
|
||||
Managing network connections using IFCONFIG & NMCLI commands
|
||||
======
|
||||
Earlier we have discussed how we can configure network connections using three different methods i.e. by editing network interface file, by using GUI & by using nmtui command ([ **READ ARTICLE HERE**][1]). In this tutorial, we are going to use two other methods to configure network connections on our RHEL/CentOS machines.
|
||||
First utility that we will be using is ‘ifconfig’ & we can configure network on almost any Linux distribution using this method.
|
||||
|
||||
### Using Ifconfig
|
||||
|
||||
#### View current network settings
|
||||
|
||||
To view network settings for all the active network interfaces, run
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
```
|
||||
|
||||
To view network settings all active, inactive interfaces, run
|
||||
|
||||
```
|
||||
$ ifconfig -a
|
||||
```
|
||||
|
||||
|
||||
Or to view network settings for a particular interface, run
|
||||
|
||||
```
|
||||
$ ifconfig enOs3
|
||||
```
|
||||
|
||||
#### Assigning IP address to an interface
|
||||
|
||||
To assign network information on an interface i.e. IP address, netmask & broadcast address, syntax is
|
||||
ifconfig enOs3 IP_ADDRESS netmask SUBNET broadcast BROADCAST_ADDRESS
|
||||
here, we need to pass information as per our network configurations. An example would be
|
||||
|
||||
```
|
||||
$ ifconfig enOs3 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
|
||||
```
|
||||
|
||||
|
||||
This will assign IP 192.168.1.100 on our network interface enOs3. We can also just modify IP or subnet or broadcast address by running the above command with only that parameter like,
|
||||
|
||||
```
|
||||
$ ifconfig enOs3 192.168.1.100
|
||||
$ ifconfig enOs3 netmask 255.255.255.0
|
||||
$ ifconfig enOs3 broadcast 192.168.1.255
|
||||
```
|
||||
|
||||
|
||||
#### Enabling or disabling a network interface
|
||||
|
||||
To enable a network interface, run
|
||||
|
||||
```
|
||||
$ ifconfig enOs3 up
|
||||
```
|
||||
|
||||
|
||||
To disable a network interface, run
|
||||
|
||||
```
|
||||
$ ifconfig enOs3 down
|
||||
```
|
||||
|
||||
|
||||
( **Recommended read** :- [**Assigning multiple IP addresses to a single NIC**][2])
|
||||
|
||||
**Note:-** When using ifconfig , entries for the gateway address are to be made in /etc/network file or use the following ‘route’ command to add a default gateway,
|
||||
|
||||
```
|
||||
$ route add default gw 192.168.1.1 enOs3
|
||||
```
|
||||
|
||||
|
||||
For adding DNS, make an entry in /etc/resolv.conf.
|
||||
|
||||
### Using NMCLI
|
||||
|
||||
NetworkManager is used as default networking service on RHEL/CentOS 7 versions. It is a very powerful & useful utility for configuring and maintaining network connections. & to control the NetworkManager daemon we can use ‘nmcli’.
|
||||
|
||||
**Syntax** for using nmcli is,
|
||||
```
|
||||
$ nmcli [ OPTIONS ] OBJECT { COMMAND | help }
|
||||
```
|
||||
|
||||
#### Viewing current network settings
|
||||
|
||||
To display the status of NetworkManager, run
|
||||
|
||||
```
|
||||
$ nmcli general status
|
||||
```
|
||||
|
||||
|
||||
to display only the active connections,
|
||||
|
||||
```
|
||||
$ nmcli connection show -a
|
||||
```
|
||||
|
||||
|
||||
to display all active and inactive connections, run
|
||||
|
||||
```
|
||||
$ nmcli connection show
|
||||
```
|
||||
|
||||
|
||||
to display a list of devices recognized by NetworkManager and their current status, run
|
||||
|
||||
```
|
||||
$ nmcli device status
|
||||
```
|
||||
|
||||
|
||||
#### Assigning IP address to an interface
|
||||
|
||||
To assign IP address & default gateway to a network interface, syntax for command is as follows,
|
||||
|
||||
```
|
||||
$ nmcli connection add type ethernet con-name CONNECTION_name ifname INTERFACE_name ip4 IP_address gw4 GATEWAY_address
|
||||
```
|
||||
|
||||
|
||||
Change the fields as per you network information, an example would be
|
||||
|
||||
```
|
||||
$ nmcli connection add type ethernet con-name office ifname enOs3 ip4 192.168.1.100 gw4 192.168.1.1
|
||||
```
|
||||
|
||||
|
||||
Unlike ifconfig command , we can set up a DNS address using nmcli command. To assign a DNS server to an interface, run
|
||||
|
||||
```
|
||||
$ nmcli connection modify office ipv4.dns “8.8.8.8”
|
||||
```
|
||||
|
||||
|
||||
Lastly, we will bring up the newly added connection,
|
||||
|
||||
```
|
||||
$ nmcli connection up office ifname enOs3
|
||||
```
|
||||
|
||||
|
||||
#### Enabling or disabling a network interface
|
||||
|
||||
For enabling an interface using nnmcli, run
|
||||
|
||||
```
|
||||
$ nmcli device connect enOs3
|
||||
```
|
||||
|
||||
|
||||
To disable an interface, run
|
||||
|
||||
```
|
||||
$ nmcli device disconnect enOs3
|
||||
```
|
||||
|
||||
|
||||
That’s it guys. There are many other uses for both of these commands but examples mentioned here should get you started. If having any issues/queries, please mention them in the comment box down below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/managing-network-using-ifconfig-nmcli-commands/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/configuring-ip-address-rhel-centos/
|
||||
[2]:http://linuxtechlab.com/ip-aliasing-multiple-ip-single-nic/
|
||||
@ -1,191 +0,0 @@
|
||||
Shell Scripting: Dungeons, Dragons and Dice
|
||||
======
|
||||
In my [last article][1], I talked about a really simple shell script for a game called Bunco, which is a dice game played in rounds where you roll three dice and compare your values to the round number. Match all three and match the round number, and you just got a bunco for 25 points. Otherwise, any die that match the round are worth one point each. It's simple—a game designed for people who are getting tipsy at the local pub, and it also is easy to program.
|
||||
|
||||
The core function in the Bunco program was one that produced a random number between 1–6 to simulate rolling a six-sided die. It looked like this:
|
||||
|
||||
```
|
||||
|
||||
rolldie()
|
||||
{
|
||||
local result=$1
|
||||
rolled=$(( ( $RANDOM % 6 ) + 1 ))
|
||||
eval $result=$rolled
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
It's invoked with a variable name as the single argument, and it will load a random number between 1–6 into that value—for example:
|
||||
|
||||
```
|
||||
|
||||
rolldie die1
|
||||
|
||||
```
|
||||
|
||||
will assign a value 1..6 to $die1\. Make sense?
|
||||
|
||||
If you can do that, however, what's to stop you from having a second argument that specifies the number of sides of the die you want to "roll" with the function? Something like this:
|
||||
|
||||
```
|
||||
|
||||
rolldie()
|
||||
{
|
||||
local result=$1 sides=$2
|
||||
rolled=$(( ( $RANDOM % $sides ) + 1 ))
|
||||
eval $result=$rolled
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To test it, let's just write a tiny wrapper that simply asks for a 20-sided die (d20) result:
|
||||
|
||||
```
|
||||
|
||||
rolldie die 20
|
||||
echo resultant roll is $die
|
||||
|
||||
```
|
||||
|
||||
Easy enough. To make it a bit more useful, let's allow users to specify a sequence of dice rolls, using the standard D&D notation of nDm—that is, n m-sided dice. Bunco would have been done with 3d6, for example (three six-sided die). Got it?
|
||||
|
||||
Since you might well have starting flags too, let's build that into the parsing loop using the ever handy getopt:
|
||||
|
||||
```
|
||||
|
||||
while getopts "h" arg
|
||||
do
|
||||
case "$arg" in
|
||||
* ) echo "dnd-dice NdM {NdM}"
|
||||
echo "NdM = N M-sided dice"; exit 0 ;;
|
||||
esac
|
||||
done
|
||||
shift $(( $OPTIND - 1 ))
|
||||
for request in $* ; do
|
||||
echo "Rolling: $request"
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
With a well formed notation like 3d6, it's easy to break up the argument into its component parts, like so:
|
||||
|
||||
```
|
||||
|
||||
dice=$(echo $request | cut -dd -f1)
|
||||
sides=$(echo $request | cut -dd -f2)
|
||||
echo "Rolling $dice $sides-sided dice"
|
||||
|
||||
```
|
||||
|
||||
To test it, let's give it some arguments and see what the program outputs:
|
||||
|
||||
```
|
||||
|
||||
$ dnd-dice 3d6 1d20 2d100 4d3 d5
|
||||
Rolling 3 6-sided dice
|
||||
Rolling 1 20-sided dice
|
||||
Rolling 2 100-sided dice
|
||||
Rolling 4 3-sided dice
|
||||
Rolling 5-sided dice
|
||||
|
||||
```
|
||||
|
||||
Ah, the last one points out a mistake in the script. If there's no number of dice specified, the default should be 1\. You theoretically could default to a six-sided die too, but that's not anywhere near so safe an assumption.
|
||||
|
||||
With that, you're close to a functional program because all you need is a loop to process more than one die in a request. It's easily done with a while loop, but let's add some additional smarts to the script:
|
||||
|
||||
```
|
||||
|
||||
for request in $* ; do
|
||||
dice=$(echo $request | cut -dd -f1)
|
||||
sides=$(echo $request | cut -dd -f2)
|
||||
echo "Rolling $dice $sides-sided dice"
|
||||
sum=0 # reset
|
||||
while [ ${dice:=1} -gt 0 ] ; do
|
||||
rolldie die $sides
|
||||
echo " dice roll = $die"
|
||||
sum=$(( $sum + $die ))
|
||||
dice=$(( $dice - 1 ))
|
||||
done
|
||||
echo " sum total = $sum"
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
This is pretty solid actually, and although the output statements need to be cleaned up a bit, the code's basically fully functional:
|
||||
|
||||
```
|
||||
|
||||
$ dnd-dice 3d6 1d20 2d100 4d3 d5
|
||||
Rolling 3 6-sided dice
|
||||
dice roll = 5
|
||||
dice roll = 6
|
||||
dice roll = 5
|
||||
sum total = 16
|
||||
Rolling 1 20-sided dice
|
||||
dice roll = 16
|
||||
sum total = 16
|
||||
Rolling 2 100-sided dice
|
||||
dice roll = 76
|
||||
dice roll = 84
|
||||
sum total = 160
|
||||
Rolling 4 3-sided dice
|
||||
dice roll = 2
|
||||
dice roll = 2
|
||||
dice roll = 1
|
||||
dice roll = 3
|
||||
sum total = 8
|
||||
Rolling 5-sided dice
|
||||
dice roll = 2
|
||||
sum total = 2
|
||||
|
||||
```
|
||||
|
||||
Did you catch that I fixed the case when $dice has no value? It's tucked into the reference in the while statement. Instead of referring to it as $dice, I'm using the notation ${dice:=1}, which uses the value specified unless it's null or no value, in which case the value 1 is assigned and used. It's a handy and a perfect fix in this case.
|
||||
|
||||
In a game, you generally don't care much about individual die values; you just want to sum everything up and see what the total value is. So if you're rolling 4d20, for example, it's just a single value you calculate and share with the game master or dungeon master.
|
||||
|
||||
A bit of output statement cleanup and you can do that:
|
||||
|
||||
```
|
||||
|
||||
$ dnd-dice.sh 3d6 1d20 2d100 4d3 d5
|
||||
3d6 = 16
|
||||
1d20 = 13
|
||||
2d100 = 74
|
||||
4d3 = 8
|
||||
d5 = 2
|
||||
|
||||
```
|
||||
|
||||
Let's run it a second time just to ensure you're getting different values too:
|
||||
|
||||
```
|
||||
|
||||
3d6 = 11
|
||||
1d20 = 10
|
||||
2d100 = 162
|
||||
4d3 = 6
|
||||
d5 = 3
|
||||
|
||||
```
|
||||
|
||||
There are definitely different values, and it's a pretty useful script, all in all.
|
||||
|
||||
You could create a number of variations with this as a basis, including what some gamers enjoy called "exploding dice". The idea is simple: if you roll the best possible value, you get to roll again and add the second value too. Roll a d20 and get a 20? You can roll again, and your result is then 20 + whatever the second value is. Where this gets crazy is that you can do this for multiple cycles, so a d20 could become 30, 40 or even 50.
|
||||
|
||||
And, that's it for this article. There isn't much else you can do with dice at this point. In my next article, I'll look at...well, you'll have to wait and see! Don't forget, if there's a topic you'd like me to tackle, please send me a note!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/shell-scripting-dungeons-dragons-and-dice
|
||||
|
||||
作者:[Dave Taylor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/dave-taylor
|
||||
[1]:http://www.linuxjournal.com/content/shell-scripting-bunco-game
|
||||
@ -1,84 +0,0 @@
|
||||
Evolving Your Own Life: Introducing Biogenesis
|
||||
======
|
||||
|
||||
Biogenesis provides a platform where you can create entire ecosystems of lifeforms and see how they interact and how the system as a whole evolves over time.
|
||||
|
||||
You always can get the latest version from the project's main [website][1], but it also should be available in the package management systems for most distributions. For Debian-based distributions, install Biogenesis with the following command:
|
||||
|
||||
```
|
||||
|
||||
sudo apt-get install biogenesis
|
||||
|
||||
```
|
||||
|
||||
If you do download it directly from the project website, you also need to have a Java virtual machine installed in order to run it.
|
||||
|
||||
To start it, you either can find the appropriate entry in the menu of your desktop environment, or you simply can type biogenesis in a terminal window. When it first starts, you will get an empty window within which to create your world.
|
||||
|
||||

|
||||
|
||||
Figure 1\. When you first start Biogenesis, you get a blank canvas so you can start creating your world.
|
||||
|
||||
The first step is to create a world. If you have a previous instance that you want to continue with, click the Game→Open menu item and select the appropriate file. If you want to start fresh, click Game→New to get a new world with a random selection of organisms.
|
||||
|
||||

|
||||
|
||||
Figure 2\. When you launch a new world, you get a random selection of organisms to start your ecosystem.
|
||||
|
||||
The world starts right away, with organisms moving and potentially interacting immediately. However, you can pause the world by clicking on the icon that is second from the right in the toolbar. Alternatively, you also can just press the p key to pause and resume the evolution of the world.
|
||||
|
||||
At the bottom of the window, you'll find details about the world as it currently exists. There is a display of the frames per second, along with the current time within the world. Next, there is a count of the current population of organisms. And finally, there is a display of the current levels of oxygen and carbon dioxide. You can adjust the amount of carbon dioxide within the world either by clicking the relevant icon in the toolbar or selecting the World menu item and then clicking either Increase CO2 or Decrease CO2.
|
||||
|
||||
There also are several parameters that govern how the world works and how your organisms will fare. If you select World→Parameters, you'll see a new window where you can play with those values.
|
||||
|
||||

|
||||
|
||||
Figure 3\. The parameter configuration window allows you to set parameters on the physical characteristics of the world, along with parameters that control the evolution of your organisms.
|
||||
|
||||
The General tab sets the amount of time per frame and whether hardware acceleration is used for display purposes. The World tab lets you set the physical characteristics of the world, such as the size and the initial oxygen and carbon dioxide levels. The Organisms tab allows you to set the initial number of organisms and their initial energy levels. You also can set their life span and mutation rate, among other items. The Metabolism tab lets you set the parameters around photosynthetic metabolism. And, the Genes tab allows you to set the probabilities and costs for the various genes that can be used to define your organisms.
|
||||
|
||||
What about the organisms within your world though? If you click on one of the organisms, it will be highlighted and the display will change.
|
||||
|
||||

|
||||
|
||||
Figure 4\. You can select individual organisms to find information about them, as well as apply different types of actions.
|
||||
|
||||
The icon toolbar at the top of the window will change to provide actions that apply to organisms. At the bottom of the window is an information bar describing the selected organism. It shows physical characteristics of the organism, such as age, energy and mass. It also describes its relationships to other organisms. It does this by displaying the number of its children and the number of its victims, as well as which generation it is.
|
||||
|
||||
If you want even more detail about an organism, click the Examine genes button in the bottom bar. This pops up a new window called the Genetic Laboratory that allows you to look at and alter the genes making up this organism. You can add or delete genes, as well as change the parameters of existing genes.
|
||||
|
||||

|
||||
|
||||
Figure 5\. The Genetic Laboratory allows you to play with the individual genes that make up an organism.
|
||||
|
||||
Right-clicking on a particular organism displays a drop-down menu that provides even more tools to work with. The first one allows you to track the selected organism as the world evolves. The next two entries allow you either to feed your organism extra food or weaken it. Normally, organisms need a certain amount of energy before they can reproduce. Selecting the fourth entry forces the selected organism to reproduce immediately, regardless of the energy level. You also can choose either to rejuvenate or outright kill the selected organism. If you want to increase the population of a particular organism quickly, simply copy and paste a number of a given organism.
|
||||
|
||||
Once you have a particularly interesting organism, you likely will want to be able to save it so you can work with it further. When you right-click an organism, one of the options is to export the organism to a file. This pops up a standard save dialog box where you can select the location and filename. The standard file ending for Biogenesis genetic code files is .bgg. Once you start to have a collection of organisms you want to work with, you can use them within a given world by right-clicking a blank location on the canvas and selecting the import option. This allows you to pull those saved organisms back into a world that you are working with.
|
||||
|
||||
Once you have allowed your world to evolve for a while, you probably will want to see how things are going. Clicking World→Statistics will pop up a new window where you can see what's happening within your world.
|
||||
|
||||

|
||||
|
||||
Figure 6\. The statistics window gives you a breakdown of what's happening within the world you have created.
|
||||
|
||||
The top of the window gives you the current statistics, including the time, the number of organisms, how many are dead, and the oxygen and carbon dioxide levels. It also provides a bar with the relative proportions of the genes.
|
||||
|
||||
Below this pane is a list of some remarkable organisms within your world. These are organisms that have had the most children, the most victims or those that are the most infected. This way, you can focus on organisms that are good at the traits you're interested in.
|
||||
|
||||
On the right-hand side of the window is a display of the world history to date. The top portion displays the history of the population, and the bottom portion displays the history of the atmosphere. As your world continues evolving, click the update button to get the latest statistics.
|
||||
|
||||
This software package could be a great teaching tool for learning about genetics, the environment and how the two interact. If you find a particularly interesting organism, be sure to share it with the community at the project website. It might be worth a look there for starting organisms too, allowing you to jump-start your explorations.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/evolving-your-own-life-introducing-biogenesis
|
||||
|
||||
作者:[Joey Bernard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/joey-bernard
|
||||
[1]:http://biogenesis.sourceforge.net
|
||||
@ -1,133 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Python Hello World and String Manipulation
|
||||
======
|
||||
|
||||
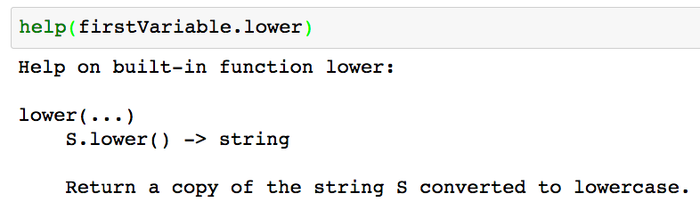
|
||||
|
||||
Before starting, I should mention that the [code][1] used in this blog post and in the [video][2] below is available on my github.
|
||||
|
||||
With that, let’s get started! If you get lost, I recommend opening the [video][3] below in a separate tab.
|
||||
|
||||
[Hello World and String Manipulation Video using Python][2]
|
||||
|
||||
#### ** Get Started (Prerequisites)
|
||||
|
||||
Install Anaconda (Python) on your operating system. You can either download anaconda from the [official site][4] and install on your own or you can follow these anaconda installation tutorials below.
|
||||
|
||||
Install Anaconda on Windows: [Link][5]
|
||||
|
||||
Install Anaconda on Mac: [Link][6]
|
||||
|
||||
Install Anaconda on Ubuntu (Linux): [Link][7]
|
||||
|
||||
#### Open a Jupyter Notebook
|
||||
|
||||
Open your terminal (Mac) or command line and type the following ([see 1:16 in the video to follow along][8]) to open a Jupyter Notebook:
|
||||
```
|
||||
jupyter notebook
|
||||
|
||||
```
|
||||
|
||||
#### Print Statements/Hello World
|
||||
|
||||
Type the following into a cell in Jupyter and type **shift + enter** to execute code.
|
||||
```
|
||||
# This is a one line comment
|
||||
print('Hello World!')
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of printing ‘Hello World!’
|
||||
|
||||
#### Strings and String Manipulation
|
||||
|
||||
Strings are a special type of a python class. As objects, in a class, you can call methods on string objects using the .methodName() notation. The string class is available by default in python, so you do not need an import statement to use the object interface to strings.
|
||||
```
|
||||
# Create a variable
|
||||
# Variables are used to store information to be referenced
|
||||
# and manipulated in a computer program.
|
||||
firstVariable = 'Hello World'
|
||||
print(firstVariable)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of printing the variable firstVariable
|
||||
```
|
||||
# Explore what various string methods
|
||||
print(firstVariable.lower())
|
||||
print(firstVariable.upper())
|
||||
print(firstVariable.title())
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of using .lower(), .upper() , and title() methods
|
||||
```
|
||||
# Use the split method to convert your string into a list
|
||||
print(firstVariable.split(' '))
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of using the split method (in this case, split on space)
|
||||
```
|
||||
# You can add strings together.
|
||||
a = "Fizz" + "Buzz"
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
string concatenation
|
||||
|
||||
#### Look up what Methods Do
|
||||
|
||||
For new programmers, they often ask how you know what each method does. Python provides two ways to do this.
|
||||
|
||||
1. (works in and out of Jupyter Notebook) Use **help** to lookup what each method does.
|
||||
|
||||
|
||||
|
||||
![][9]
|
||||
Look up what each method does
|
||||
|
||||
2. (Jupyter Notebook exclusive) You can also look up what a method does by having a question mark after a method.
|
||||
|
||||
|
||||
```
|
||||
# To look up what each method does in jupyter (doesnt work outside of jupyter)
|
||||
firstVariable.lower?
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Look up what each method does in Jupyter
|
||||
|
||||
#### Closing Remarks
|
||||
|
||||
Please let me know if you have any questions either here or in the comments section of the [youtube video][2]. The code in the post is also available on my [github][1]. Part 2 of the tutorial series is [Simple Math][10].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulation-gdgwd8ymp
|
||||
|
||||
作者:[Michael][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/mgalarny
|
||||
[1]:https://github.com/mGalarnyk/Python_Tutorials/blob/master/Python_Basics/Intro/Python3Basics_Part1.ipynb
|
||||
[2]:https://www.youtube.com/watch?v=JqGjkNzzU4s
|
||||
[3]:https://www.youtube.com/watch?v=kApPBm1YsqU
|
||||
[4]:https://www.continuum.io/downloads
|
||||
[5]:https://medium.com/@GalarnykMichael/install-python-on-windows-anaconda-c63c7c3d1444
|
||||
[6]:https://medium.com/@GalarnykMichael/install-python-on-mac-anaconda-ccd9f2014072
|
||||
[7]:https://medium.com/@GalarnykMichael/install-python-on-ubuntu-anaconda-65623042cb5a
|
||||
[8]:https://youtu.be/JqGjkNzzU4s?t=1m16s
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==
|
||||
[10]:https://medium.com/@GalarnykMichael/python-basics-2-simple-math-4ac7cc928738
|
||||
@ -1,51 +0,0 @@
|
||||
Translating by Torival Linear Regression Classifier from scratch using Numpy and Stochastic gradient descent as an optimization technique
|
||||
======
|
||||
|
||||
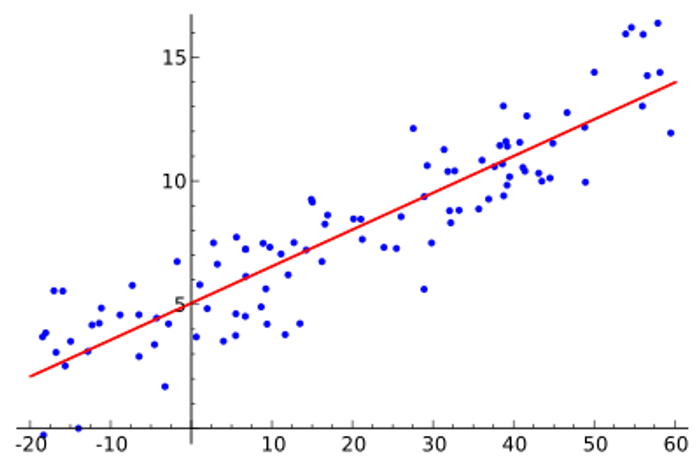
|
||||
|
||||
In statistics, linear regression is a linear approach for modelling the relationship between a scalar dependent variable y and one or more explanatory variables (or independent variables) denoted X. The case of one explanatory variable is called simple linear regression. For more than one explanatory variable, the process is called multiple linear regression.
|
||||
|
||||
As you may know the equation of line with a slope **m** and intercept **c** is given by **y=mx+c** .Now in our dataset **x** is a feature and **y** is the label that is the output.
|
||||
|
||||
Now we will start with some random values of m and c and by using our classifier we will adjust their values so that we obtain a line with the best fit.
|
||||
|
||||
Suppose we have a dataset with a single feature given by **X=[1,2,3,4,5,6,7,8,9,10]** and label/output being **Y=[1,4,9,16,25,36,49,64,81,100]**.We start with random value of **m** being **1** and **c** being **0**. Now starting with the first data point which is **x=1** we will calculate its corresponding output which is **y=m*x+c** - > **y=1-1+0** - > **y=1** .
|
||||
|
||||
Now this is our guess for the given input.Now we will subtract the calculated y which is our guess whith the actual output which is **y(original)=1** to calculate the error which is **y(guess)-y(original)** which can also be termed as our cost function when we take the square of its mean and our aim is to minimize this cost.
|
||||
|
||||
After each iteration through the data points we will change our values of **m** and **c** such that the obtained m and c gives the line with the best fit.Now how we can do this?
|
||||
|
||||
The answer is using **Gradient Descent Technique**.
|
||||
|
||||
![Gd_demystified.png][1]
|
||||
|
||||
In gradient descent we look to minimize the cost function and in order to minimize the cost function we need to minimize the error which is given by **error=y(guess)-y(original)**.
|
||||
|
||||
|
||||
Now error depends on two values **m** and **c** . Now if we take the partial derivative of error with respect to **m** and **c** we can get to know the oreintation i.e whether we need to increase the values of m and c or decrease them in order to obtain the line of best fit.
|
||||
|
||||
Now error depends on two values **m** and **c**.So on taking partial derivative of error with respect to **m** we get **x** and taking partial derivative of error with repsect to **c** we get a constant.
|
||||
|
||||
So if we apply two changes that is **m=m-error*x** and **c=c-error*1** after every iteration we can adjust the value of m and c to obtain the line with the best fit.
|
||||
|
||||
Now error can be negative as well as positive.When the error is negative it means our **m** and **c** are smaller than the actual **m** and **c** and hence we would need to increase their values and if the error is positive we would need to decrease their values that is what we are doing.
|
||||
|
||||
But wait we also need a constant called the learning_rate so that we don't increase or decrease the values of **m** and **c** with a steep rate .so we need to multiply **m=m-error * x * learning_rate** and **c=c-error * 1 * learning_rate** so as to make the process smooth.
|
||||
|
||||
So we need to update **m** to **m=m-error * x * learning_rate** and **c** to **c=c-error * 1 * learning_rate** to obtain the line with the best fit and this is our linear regreesion model using stochastic gradient descent meaning of stochastic being that we are updating the values of m and c in every iteration.
|
||||
|
||||
You can check the full code in python :[https://github.com/assassinsurvivor/MachineLearning/blob/master/Regression.py][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/prakharthapak/linear-regression-classifier-from-scratch-using-numpy-and-stochastic-gradient-descent-as-an-optimization-technique-gf5gm9yti
|
||||
|
||||
作者:[Prakhar Thapak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/prakharthapak
|
||||
[1]:https://process.filestackapi.com/cache=expiry:max/5TXRH28rSo27kTNZLgdN
|
||||
[2]:https://www.codementor.io/prakharthapak/here
|
||||
@ -1,191 +0,0 @@
|
||||
Linux md5sum Command Explained For Beginners (5 Examples)
|
||||
======
|
||||
|
||||
When downloading files, particularly installation files from websites, it is a good idea to verify that the download is valid. A website will often display a hash value for each file so that you can make sure the download completed correctly. In this article, we will be discussing the md5sum tool that you can use to validate the download. Two other utilities, sha256sum and sha512sum, work the same way as md5sum.
|
||||
|
||||
### Linux md5sum command
|
||||
|
||||
The md5sum command prints a 32-character (128-bit) checksum of the given file, using the MD5 algorithm. Following is the command syntax of this command line tool:
|
||||
|
||||
```
|
||||
md5sum [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
And here's how md5sum's man page explains it:
|
||||
```
|
||||
Print or check MD5 (128-bit) checksums.
|
||||
|
||||
```
|
||||
|
||||
The following Q&A-styled examples will give you an even better idea of the basic usage of md5sum.
|
||||
|
||||
Note: We'll be using three files named file1.txt, file2.txt, and file3.txt as the input files in our examples. The text in each file is listed below.
|
||||
|
||||
file1.txt:
|
||||
```
|
||||
hi
|
||||
hello
|
||||
how are you
|
||||
thanks.
|
||||
|
||||
```
|
||||
|
||||
file2.txt:
|
||||
```
|
||||
hi
|
||||
hello to you
|
||||
I am fine
|
||||
Your welcome!
|
||||
|
||||
```
|
||||
|
||||
file3.txt:
|
||||
```
|
||||
hallo
|
||||
Guten Tag
|
||||
Wie geht es dir
|
||||
Danke.
|
||||
|
||||
```
|
||||
|
||||
### Q1. How to display the hash value?
|
||||
|
||||
Use the command without any options to display the hash value and the filename.
|
||||
|
||||
```
|
||||
md5sum file1.txt
|
||||
```
|
||||
|
||||
Here's the output this command produced on our system:
|
||||
```
|
||||
[Documents]$ md5sum file1.txt
|
||||
1ff38cc592c4c5d0c8e3ca38be8f1eb1 file1.txt
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
The output can also be displayed in a BSD-style format using the --tag option.
|
||||
|
||||
md5sum --tag file1.txt
|
||||
```
|
||||
[Documents]$ md5sum --tag file1.txt
|
||||
MD5 (file1.txt) = 1ff38cc592c4c5d0c8e3ca38be8f1eb1
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
### Q2. How to validate multiple files?
|
||||
|
||||
The md5sum command can validate multiple files at one time. We will add file2.txt and file3.txt to demonstrate the capabilities.
|
||||
|
||||
If you write the hashes to a file, you can use that file to check whether any of the files have changed. Here we are writing the hashes of the files to the file hashes, and then using that to validate that none of the files have changed.
|
||||
|
||||
```
|
||||
md5sum file1.txt file2.txt file3.txt > hashes
|
||||
md5sum --check hashes
|
||||
```
|
||||
|
||||
```
|
||||
[Documents]$ md5sum file1.txt file2.txt file3.txt > hashes
|
||||
[Documents]$ md5sum --check hashes
|
||||
file1.txt: OK
|
||||
file2.txt: OK
|
||||
file3.txt: OK
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
Now we will change file3.txt, adding a single exclamation mark to the end of the file, and rerun the command.
|
||||
|
||||
```
|
||||
echo "!" >> file3.txt
|
||||
md5sum --check hashes
|
||||
```
|
||||
|
||||
```
|
||||
[Documents]$ md5sum --check hashes
|
||||
file1.txt: OK
|
||||
file2.txt: OK
|
||||
file3.txt: FAILED
|
||||
md5sum: WARNING: 1 computed checksum did NOT match
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
You can see that file3.txt has changed.
|
||||
|
||||
### Q3. How to display only modified files?
|
||||
|
||||
If you have many files to check, you may want to display only the files that have changed. Using the "\--quiet" option, md5sum will only list the files that have changed.
|
||||
|
||||
```
|
||||
md5sum --quiet --check hashes
|
||||
```
|
||||
|
||||
```
|
||||
[Documents]$ md5sum --quiet --check hashes
|
||||
file3.txt: FAILED
|
||||
md5sum: WARNING: 1 computed checksum did NOT match
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
### Q4. How to detect changes in a script?
|
||||
|
||||
You may want to use md5sum in a script. Using the "\--status" option, md5sum won't print any output. Instead, the status code returns 0 if there are no changes, and 1 if the files don't match. The following script hashes.sh will return a 1 in the status code, because the files have changed. The script file is below:
|
||||
|
||||
```
|
||||
sh hashes.sh
|
||||
```
|
||||
|
||||
```
|
||||
hashes.sh:
|
||||
#!/bin/bash
|
||||
md5sum --status --check hashes
|
||||
Result=$?
|
||||
echo "File check status is: $Result"
|
||||
exit $Result
|
||||
|
||||
[Documents]$ sh hashes.sh
|
||||
File check status is: 1
|
||||
[[email protected] Documents]$
|
||||
|
||||
```
|
||||
|
||||
### Q5. How to identify invalid hash values?
|
||||
|
||||
md5sum can let you know if you have invalid hashes when you compare files. To warn you if any hash values are incorrect, you can use the --warn option. For this last example, we will use sed to insert an extra character at the beginning of the third line. This will change the hash value in the file hashes, making it invalid.
|
||||
|
||||
```
|
||||
sed -i '3s/.*/a&/' hashes
|
||||
md5sum --warn --check hashes
|
||||
```
|
||||
|
||||
This shows that the third line has an invalid hash.
|
||||
```
|
||||
[Documents]$ sed -i '3s/.*/a&/' hashes
|
||||
[Documents]$ md5sum --warn --check hashes
|
||||
file1.txt: OK
|
||||
file2.txt: OK
|
||||
md5sum: hashes: 3: improperly formatted MD5 checksum line
|
||||
md5sum: WARNING: 1 line is improperly formatted
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
The md5sum is a simple command which can quickly validate one or multiple files to determine whether any of them have changed from the original file. For more information on md5sum, see it's [man page.][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-md5sum-command/
|
||||
|
||||
作者:[David Paige][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/
|
||||
[1]:https://linux.die.net/man/1/md5sum
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user