mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
remove www.howtoforge.com
This commit is contained in:
parent
3d0be8766c
commit
eb75e70949
@ -1,103 +0,0 @@
|
||||
Linux Head Command Explained for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on the command line in Linux, you might want to take a quick look at a few initial lines of a file. For example, if a log file is continuously being updated, the requirement could be to view, say, first 10 lines of the log file every time. While viewing the file in an editor (like [vim][1]) is always an option, there exists a command line tool - dubbed **head** \- that lets you view initial few lines of a file very easily.
|
||||
|
||||
In this article, we will discuss the basics of the head command using some easy to understand examples. Please note that all steps/instructions mentioned here have been tested on Ubuntu 16.04LTS.
|
||||
|
||||
### Linux head command
|
||||
|
||||
As already mentioned in the beginning, the head command lets users view the first part of files. Here's its syntax:
|
||||
|
||||
head [OPTION]... [FILE]...
|
||||
|
||||
And following is how the command's man page describes it:
|
||||
```
|
||||
Print the first 10 lines of each FILE to standard output. With more than one FILE, precede each
|
||||
with a header giving the file name.
|
||||
```
|
||||
|
||||
The following Q&A-type examples should give you a better idea of how the tool works:
|
||||
|
||||
### Q1. How to print the first 10 lines of a file on terminal (stdout)?
|
||||
|
||||
This is quite easy using head - in fact, it's the tool's default behavior.
|
||||
|
||||
head [file-name]
|
||||
|
||||
The following screenshot shows the command in action:
|
||||
|
||||
[![How to print the first 10 lines of a file][2]][3]
|
||||
|
||||
### Q2. How to tweak the number of lines head prints?
|
||||
|
||||
While 10 is the default number of lines the head command prints, you can change this number as per your requirement. The **-n** command line option lets you do that.
|
||||
|
||||
head -n [N] [File-name]
|
||||
|
||||
For example, if you want to only print first 5 lines, you can convey this to the tool in the following way:
|
||||
|
||||
head -n 5 file1
|
||||
|
||||
[![How to tweak number of lines head prints][4]][5]
|
||||
|
||||
### Q3. How to restrict the output to a certain number of bytes?
|
||||
|
||||
Not only number of lines, you can also restrict the head command output to a specific number of bytes. This can be done using the **-c** command line option.
|
||||
|
||||
head -c [N] [File-name]
|
||||
|
||||
For example, if you want head to only display first 25 bytes, here's how you can execute it:
|
||||
|
||||
head -c 25 file1
|
||||
|
||||
[![restrict the output to a certain number of bytes][6]][7]
|
||||
|
||||
So you can see that the tool displayed only the first 25 bytes in the output.
|
||||
|
||||
Please note that [N] "may have a multiplier suffix: b 512, kB 1000, K 1024, MB 1000*1000, M 1024*1024, GB 1000*1000*1000, G 1024*1024*1024, and so on for T, P, E, Z, Y."
|
||||
|
||||
### Q4. How to have head print filename in output?
|
||||
|
||||
If for some reason, you want the head command to also print the file name in output, you can do that using the **-v** command line option.
|
||||
|
||||
head -v [file-name]
|
||||
|
||||
Here's an example:
|
||||
|
||||
[![How to have head print filename in output][8]][9]
|
||||
|
||||
So as you can see, the filename 'file 1' was displayed in the output.
|
||||
|
||||
### Q5. How to have NUL as line delimiter, instead of newline?
|
||||
|
||||
By default, the head command output is delimited by newline. But there's also an option of using NUL as the delimiter. The option **-z** or **\--zero-terminated** lets you do this.
|
||||
|
||||
head -z [file-name]
|
||||
|
||||
### Conclusion
|
||||
|
||||
As most of you'd agree, head is a simple command to understand and use, meaning there's little learning curve associated with it. The features (in terms of command line options) it offers are also limited, and we've covered almost all of them. So give these options a try, and when you're done, take a look at the command's [man page][10] to know more.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-head-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/vim-basics
|
||||
[2]:https://www.howtoforge.com/images/linux_head_command/head-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/linux_head_command/big/head-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/linux_head_command/head-n-option.png
|
||||
[5]:https://www.howtoforge.com/images/linux_head_command/big/head-n-option.png
|
||||
[6]:https://www.howtoforge.com/images/linux_head_command/head-c-option.png
|
||||
[7]:https://www.howtoforge.com/images/linux_head_command/big/head-c-option.png
|
||||
[8]:https://www.howtoforge.com/images/linux_head_command/head-v-option.png
|
||||
[9]:https://www.howtoforge.com/images/linux_head_command/big/head-v-option.png
|
||||
[10]:https://linux.die.net/man/1/head
|
||||
@ -1,314 +0,0 @@
|
||||
Personal Backups with Duplicati on Linux
|
||||
======
|
||||
|
||||
This tutorial is for performing personal backups to local USB hard drives, having encryption, deduplication and compression.
|
||||
|
||||
The procedure was tested using [Duplicati 2.0.2.1][1] on [Debian 9.2][2]
|
||||
|
||||
### Duplicati Installation
|
||||
|
||||
Download the latest version from <https://www.duplicati.com/download>
|
||||
|
||||
The software requires several libraries to work, mostly mono libraries. The easiest way to install the software is to let it fail the installation through dpkg and then install the missing packages with apt-get:
|
||||
|
||||
sudo dpkg -i duplicati_2.0.2.1-1_all.deb
|
||||
sudo apt-get --fix-broken install
|
||||
|
||||
Note that the installation of the package fails on the first instance, then we use apt to install the dependencies.
|
||||
|
||||
Start the daemon:
|
||||
|
||||
sudo systemctl start duplicati.service
|
||||
|
||||
And if you wish for it to start automatically with the OS use:
|
||||
|
||||
sudo systemctl enable duplicati.service
|
||||
|
||||
To check that the service is running:
|
||||
|
||||
netstat -ltn | grep 8200
|
||||
|
||||
And you should receive a response like this one:
|
||||
|
||||
[![][3]][4]
|
||||
|
||||
After these steps you should be able to run the browser and access the local web service at http://localhost:8200
|
||||
|
||||
[![][5]][6]
|
||||
|
||||
### Create a Backup Job
|
||||
|
||||
Go to "Add backup" to configure a new backup job:
|
||||
|
||||
[![][7]][8]
|
||||
|
||||
Set a name for the job and a passphrase for encryption. You will need the passphrase to restore files, so pick a strong password and make sure you don't forget it:
|
||||
|
||||
[![][9]][10]
|
||||
|
||||
Set the destination: the directory where you are going to store the backup files:
|
||||
|
||||
[![][11]][12]
|
||||
|
||||
Select the source files to backup. I will pick just the Desktop folder for this example:
|
||||
|
||||
[![][13]][14]
|
||||
|
||||
Specify filters and exclusions if necessary:
|
||||
|
||||
[![][15]][16]
|
||||
|
||||
Configure a schedule, or disable automatic backups if you prefer to run them manually:
|
||||
|
||||
[![][17]][18]
|
||||
|
||||
I like to use manual backups when using USB drive destinations, and scheduled if I have a server to send backups through SSH or a Cloud based destination.
|
||||
|
||||
Specify the versions to keep, and the Upload volume size (size of each partial file):
|
||||
|
||||
[![][19]][20]
|
||||
|
||||
Finally you should see the job created in a summary like this:
|
||||
|
||||
[![][21]][22]
|
||||
|
||||
### Run the Backup
|
||||
|
||||
In the last seen summary, under Home, click "run now" to start the backup job. A progress bar will be seen by the top of the screen.
|
||||
|
||||
After finishing the backup, you can see in the destination folder, a set of files called something like:
|
||||
```
|
||||
duplicati-20171206T143926Z.dlist.zip.aes
|
||||
duplicati-bdfad38a0b1f34b5db56c1de166260cd8.dblock.zip.aes
|
||||
duplicati-i00d8dff418a749aa9d67d0c54b0e4149.dindex.zip.aes
|
||||
```
|
||||
|
||||
The size of the blocks will be the one specified in the Upload volume size option. The files are compressed, and encrypted using the previously set passphrase.
|
||||
|
||||
Once finished, you will see in the summary the last backup taken and the size:
|
||||
|
||||
[![][23]][24]
|
||||
|
||||
In this case it is only 1MB because I took a test folder.
|
||||
|
||||
### Restore Files
|
||||
|
||||
To restore files, simply access the web administration in http://localhost:8200, go to the "Restore" menu and select the backup job name. Then select the files to restore and click "continue":
|
||||
|
||||
[![][25]][26]
|
||||
|
||||
Select the restore files or folders and the restoration options:
|
||||
|
||||
[![][27]][28]
|
||||
|
||||
The restoration will start running, showing a progress bar on the top of the user interface.
|
||||
|
||||
### Fixate the backup destination
|
||||
|
||||
If you use a USB drive to perform the backups, it is a good idea to specify in the /etc/fstab the UUID of the drive, so that it always mount automatically in the /mnt/backup directory (or the directory of your choosing).
|
||||
|
||||
To do so, connect your drive and check for the UUID:
|
||||
|
||||
sudo blkid
|
||||
```
|
||||
...
|
||||
/dev/sdb1: UUID="4d608d85-e138-4546-9f22-4d78bef0b6a7" TYPE="ext4" PARTUUID="983a72cb-01"
|
||||
...
|
||||
```
|
||||
|
||||
And copy the UUID to include an entry in the /etc/fstab file:
|
||||
```
|
||||
...
|
||||
UUID=4d608d85-e138-4546-9f22-4d78bef0b6a7 /mnt/backup ext4 defaults 0 0
|
||||
...
|
||||
```
|
||||
|
||||
### Remote Access to the GUI
|
||||
|
||||
By default, Duplicati listens on localhost only, and it's meant to be that way. However it includes the possibility to add a password and to be accessible from the network:
|
||||
|
||||
[![][29]][30]
|
||||
|
||||
This setting is not recommended, as Duplicati has no SSL capabilities yet. What I would recommend if you need to use the backup GUI remotely, is using an SSH tunnel.
|
||||
|
||||
To accomplish this, first enable SSH server in case you don't have it yet, the easiest way is running:
|
||||
|
||||
sudo tasksel
|
||||
|
||||
[![][31]][32]
|
||||
|
||||
Once you have the SSH server running on the Duplicati host. Go to the computer from where you want to connect to the GUI and set the tunnel
|
||||
|
||||
Let's consider that:
|
||||
|
||||
* Duplicati backups and its GUI are running in the remote host 192.168.0.150 (that we call the server).
|
||||
* The GUI on the server is listening on port 8200.
|
||||
* jorge is a valid user name in the server.
|
||||
* I will access the GUI from a host on the local port 12345.
|
||||
|
||||
|
||||
|
||||
Then to open an SSH tunnel I run on the client:
|
||||
|
||||
ssh -f jorge@192.168.0.150 -L 12345:localhost:8200 -N
|
||||
|
||||
With netstat it can be checked that the port is open for localhost:
|
||||
|
||||
netstat -ltn | grep :12345
|
||||
```
|
||||
tcp 0 0 127.0.0.1:12345 0.0.0.0:* LISTEN
|
||||
tcp6 0 0 ::1:12345 :::* LISTEN
|
||||
```
|
||||
|
||||
And now I can access the remote GUI by accessing http://127.0.0.1:12345 from the client browser
|
||||
|
||||
[![][34]][35]
|
||||
|
||||
Finally if you want to close the connection to the SSH tunnel you may kill the ssh process. First identify the PID:
|
||||
|
||||
ps x | grep "[s]sh -f"
|
||||
```
|
||||
26348 ? Ss 0:00 ssh -f [[email protected]][33] -L 12345:localhost:8200 -N
|
||||
```
|
||||
|
||||
And kill it:
|
||||
|
||||
kill -9 26348
|
||||
|
||||
Or you can do it all in one:
|
||||
|
||||
kill -9 $(ps x | grep "[s]sh -f" | cut -d" " -f1)
|
||||
|
||||
### Other Backup Repository Options
|
||||
|
||||
If you prefer to store your backups on a remote server rather than on a local hard drive, Duplicati has several options. Standard protocols such as:
|
||||
|
||||
* FTP
|
||||
* OpenStack Object Storage / Swift
|
||||
* SFTP (SSH)
|
||||
* WebDAV
|
||||
|
||||
|
||||
|
||||
And a wider list of proprietary protocols, such as:
|
||||
|
||||
* Amazon Cloud Drive
|
||||
* Amazon S3
|
||||
* Azure
|
||||
* B2 Cloud Storage
|
||||
* Box.com
|
||||
* Dropbox
|
||||
* Google Cloud Storage
|
||||
* Google Drive
|
||||
* HubiC
|
||||
* Jottacloud
|
||||
* mega.nz
|
||||
* Microsoft One Drive
|
||||
* Microsoft One Drive for Business
|
||||
* Microsoft Sharepoint
|
||||
* OpenStack Simple Storage
|
||||
* Rackspace CloudFiles
|
||||
|
||||
|
||||
|
||||
For FTP, SFTP, WebDAV is as simple as setting the server hostname or IP address, adding credentials and then using the whole previous process. As a result, I don't believe it is of any value describing them.
|
||||
|
||||
However, as I find it useful for personal matters having a cloud based backup, I will describe the configuration for Dropbox, which uses the same procedure as for Google Drive and Microsoft OneDrive.
|
||||
|
||||
#### Dropbox
|
||||
|
||||
Let's create a new backup job and set the destination to Dropbox. All the configurations are exactly the same except for the destination that should be set like this:
|
||||
|
||||
[![][36]][37]
|
||||
|
||||
Once you set up "Dropbox" from the drop-down menu, and configured the destination folder, click on the OAuth link to set the authentication.
|
||||
|
||||
A pop-up will emerge for you to login to Dropbox (or Google Drive or OneDrive depending on your choosing):
|
||||
|
||||
[![][38]][39]
|
||||
|
||||
After logging in you will be prompted to allow Duplicati app to your cloud storage:
|
||||
|
||||
[![][40]][41]
|
||||
|
||||
After finishing the last process, the AuthID field will be automatically filled in:
|
||||
|
||||
[![][42]][43]
|
||||
|
||||
Click on "Test Connection". When testing the connection you will be asked to create the folder in the case it does not exist:
|
||||
|
||||
[![][44]][45]
|
||||
|
||||
And finally it will give you a notification that the connection is successful:
|
||||
|
||||
[![][46]][47]
|
||||
|
||||
If you access your Dropbox account you will see the files, in the same format that we have seen before, under the defined folder:
|
||||
|
||||
[![][48]][49]
|
||||
|
||||
### Conclusions
|
||||
|
||||
Duplicati is a multi-platform, feature-rich, easy to use backup solution for personal computers. It supports a wide variety of backup repositories what makes it a very versatile tool that can adapt to most personal needs.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/personal-backups-with-duplicati-on-linux/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://updates.duplicati.com/beta/duplicati_2.0.2.1-1_all.deb
|
||||
[2]:https://www.debian.org/releases/stable/
|
||||
[3]:https://www.howtoforge.com/images/personal_backups_with_duplicati/installation-netstat.png
|
||||
[4]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/installation-netstat.png
|
||||
[5]:https://www.howtoforge.com/images/personal_backups_with_duplicati/installation-web.png
|
||||
[6]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/installation-web.png
|
||||
[7]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-1.png
|
||||
[8]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-1.png
|
||||
[9]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-2.png
|
||||
[10]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-2.png
|
||||
[11]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-3.png
|
||||
[12]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-3.png
|
||||
[13]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-4.png
|
||||
[14]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-4.png
|
||||
[15]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-5.png
|
||||
[16]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-5.png
|
||||
[17]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-6.png
|
||||
[18]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-6.png
|
||||
[19]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-7.png
|
||||
[20]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-7.png
|
||||
[21]:https://www.howtoforge.com/images/personal_backups_with_duplicati/create-8.png
|
||||
[22]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/create-8.png
|
||||
[23]:https://www.howtoforge.com/images/personal_backups_with_duplicati/run-1.png
|
||||
[24]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/run-1.png
|
||||
[25]:https://www.howtoforge.com/images/personal_backups_with_duplicati/restore-1.png
|
||||
[26]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/restore-1.png
|
||||
[27]:https://www.howtoforge.com/images/personal_backups_with_duplicati/restore-2.png
|
||||
[28]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/restore-2.png
|
||||
[29]:https://www.howtoforge.com/images/personal_backups_with_duplicati/remote-1.png
|
||||
[30]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/remote-1.png
|
||||
[31]:https://www.howtoforge.com/images/personal_backups_with_duplicati/remote-sshd.png
|
||||
[32]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/remote-sshd.png
|
||||
[33]:https://www.howtoforge.com/cdn-cgi/l/email-protection
|
||||
[34]:https://www.howtoforge.com/images/personal_backups_with_duplicati/remote-sshtun.png
|
||||
[35]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/remote-sshtun.png
|
||||
[36]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-1.png
|
||||
[37]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-1.png
|
||||
[38]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-2.png
|
||||
[39]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-2.png
|
||||
[40]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-4.png
|
||||
[41]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-4.png
|
||||
[42]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-5.png
|
||||
[43]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-5.png
|
||||
[44]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-6.png
|
||||
[45]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-6.png
|
||||
[46]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-7.png
|
||||
[47]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-7.png
|
||||
[48]:https://www.howtoforge.com/images/personal_backups_with_duplicati/db-8.png
|
||||
[49]:https://www.howtoforge.com/images/personal_backups_with_duplicati/big/db-8.png
|
||||
@ -1,167 +0,0 @@
|
||||
Linux touch command tutorial for beginners (6 examples)
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Linux Touch command][1]
|
||||
|
||||
2. [1\. How to change access/modification time using touch command][2]
|
||||
|
||||
3. [2\. How to change only access or modification time][3]
|
||||
|
||||
4. [3\. How to make touch use access/modification times of existing file][4]
|
||||
|
||||
5. [4\. How to create a new file using touch][5]
|
||||
|
||||
6. [5\. How to force touch to not create any new file][6]
|
||||
|
||||
7. [6\. How touch works in case of symbolic links][7]
|
||||
|
||||
8. [Conclusion][8]
|
||||
|
||||
Sometimes, while working on the command line in Linux, you might want to create a new file. Or, there may be times when the requirement is to change the timestamps of a file. Well, there exists a utility that can you can use in both these scenarios. The tool in question is **touch**, and in this tutorial, we will understand its basic functionality through easy to understand examples.
|
||||
|
||||
Please note that all examples that we'll be using here have been tested on an Ubuntu 16.04 machine.
|
||||
|
||||
### Linux Touch command
|
||||
|
||||
The touch command is primarily used to change file timestamps, but if the file (whose name is passed as an argument) doesn't exist, then the tool creates it.
|
||||
|
||||
Following is the command's generic syntax:
|
||||
|
||||
```
|
||||
touch [OPTION]... FILE...
|
||||
```
|
||||
|
||||
And here's how the man page explains this command:
|
||||
|
||||
```
|
||||
DESCRIPTION
|
||||
Update the access and modification times of each FILE to the current
|
||||
time. A FILE argument that does not exist is created empty, unless -c or -h
|
||||
is supplied. A FILE argument string of - is handled specially and causes touch to
|
||||
change the times of the file associated with standard output.
|
||||
```
|
||||
|
||||
The following Q&A type examples will give you a better idea of how the tool works.
|
||||
|
||||
### 1\. How to change access/modification time using touch command
|
||||
|
||||
This is simple, and pretty straight forward. Let's take an existing file as an example. The following screenshot shows the access and modification times for a file called 'apl.c.'
|
||||
|
||||
[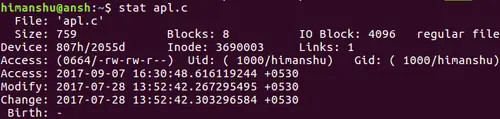][9]
|
||||
|
||||
Here's how you can use the touch command to change the file's access and modification times:
|
||||
|
||||
```
|
||||
touch apl.c
|
||||
```
|
||||
|
||||
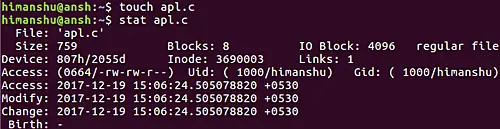
The following screenshot confirms the change in these timestamps.
|
||||
|
||||
[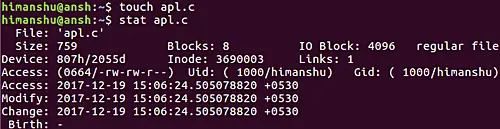][10]
|
||||
|
||||
### 2\. How to change only access or modification time
|
||||
|
||||
By default, the touch command changes both access and modification times of the input file. However, if you want, you can limit this behavior to any one of these timestamps. This means that you can either have the access time changed or the modification timestamp.
|
||||
|
||||
In case you want to only change the access time, use the -a command line option.
|
||||
|
||||
```
|
||||
touch -a [filename]
|
||||
```
|
||||
|
||||
Similarly, if the requirement is to only change the modification time, use the -m command line option.
|
||||
|
||||
```
|
||||
touch -m [filename]
|
||||
```
|
||||
|
||||
### 3\. How to make touch use access/modification times of existing file
|
||||
|
||||
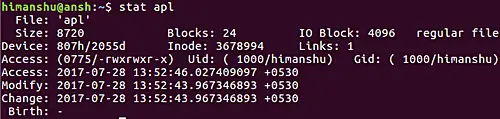
If you want, you can also force the touch command to copy access and modification timestamps from a reference file. For example, suppose we want to change the timestamps for the file 'apl.c'. Here are the current timestamps for this file:
|
||||
|
||||
[][11]
|
||||
|
||||
And this is the file which you want touch to use as its reference:
|
||||
|
||||
[][12]
|
||||
|
||||
Now, for touch to use the timestamps of 'apl' for 'apl.c', you'll need to use the -r command line option in the following way:
|
||||
|
||||
```
|
||||
touch apl.c -r apl
|
||||
```
|
||||
|
||||
[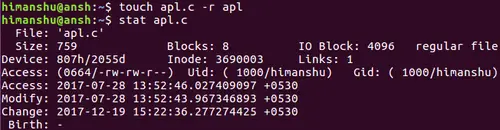][13]
|
||||
|
||||
The above screenshot shows that modification and access timestamps for 'apl.c' are now same as those for 'apl.'
|
||||
|
||||
### 4\. How to create a new file using touch
|
||||
|
||||
Creating a new file is also very easy. In fact, it happens automatically if the file name you pass as argument to the touch command doesn't exist. For example, to create a file named 'newfile', all you have to do is to run the following touch command:
|
||||
|
||||
```
|
||||
touch newfile
|
||||
```
|
||||
|
||||
### 5\. How to force touch to not create any new file
|
||||
|
||||
Just in case there's a strict requirement that the touch command shouldn't create any new files, then you can use the -c option.
|
||||
|
||||
```
|
||||
touch -c [filename]
|
||||
```
|
||||
|
||||
The following screenshot shows that since 'newfile12' didn't exist, and we used the -c command line option, the touch command didn't create the file.
|
||||
|
||||
[][14]
|
||||
|
||||
### 6\. How touch works in case of symbolic links
|
||||
|
||||
By default, if you pass a symbolic link file name to the touch command, the change in access and modification timestamps will be for the original file (one which the symbolic link refers to). However, the tool also offers an option (-h) that lets you override this behavior.
|
||||
|
||||
Here's how the man page explains the -h option:
|
||||
|
||||
```
|
||||
-h, --no-dereference
|
||||
affect each symbolic link instead of any referenced file (useful
|
||||
only on systems that can change the timestamps of a symlink)
|
||||
```
|
||||
|
||||
So when you want to change the modification and access timestamps for the symbolic link (and not the original file), use the touch command in the following way:
|
||||
|
||||
```
|
||||
touch -h [sym link file name]
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
As you'd agree, touch isn't a difficult command to understand and use. The examples/options we discussed in this tutorial should be enough to get you started with the tool. While newbies will mostly find themselves using the utility for creating new files, more experienced users play with it for multiple other purposes as well. For more information on the touch command, head to [its man page][15].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/linux-touch-command/
|
||||
|
||||
作者:[ Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/linux-touch-command/
|
||||
[1]:https://www.howtoforge.com/tutorial/linux-touch-command/#linux-touch-command
|
||||
[2]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-change-accessmodification-time-using-touch-command
|
||||
[3]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-change-only-access-or-modification-time
|
||||
[4]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-make-touch-use-accessmodification-times-of-existing-file
|
||||
[5]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-create-a-new-file-using-touch
|
||||
[6]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-to-force-touch-to-not-create-any-new-file
|
||||
[7]:https://www.howtoforge.com/tutorial/linux-touch-command/#-how-touch-works-in-case-of-symbolic-links
|
||||
[8]:https://www.howtoforge.com/tutorial/linux-touch-command/#conclusion
|
||||
[9]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-exist-file1.png
|
||||
[10]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-exist-file2.png
|
||||
[11]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-exist-file21.png
|
||||
[12]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-ref-file1.png
|
||||
[13]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-ref-file2.png
|
||||
[14]:https://www.howtoforge.com/images/linux_hostname_command/big/touch-c-option.png
|
||||
[15]:https://linux.die.net/man/1/touch
|
||||
@ -1,110 +0,0 @@
|
||||
Linux paste Command Explained For Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on the command line in Linux, there may arise a situation wherein you have to merge lines of multiple files to create more meaningful/useful data. Well, you'll be glad to know there exists a command line utility **paste** that does this for you. In this tutorial, we will discuss the basics of this command as well as the main features it offers using easy to understand examples.
|
||||
|
||||
But before we do that, it's worth mentioning that all examples mentioned in this article have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
### Linux paste command
|
||||
|
||||
As already mentioned above, the paste command merges lines of files. Here's the tool's syntax:
|
||||
|
||||
```
|
||||
paste [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
And here's how the mage of paste explains it:
|
||||
```
|
||||
Write lines consisting of the sequentially corresponding lines from each FILE, separated by TABs,
|
||||
to standard output. With no FILE, or when FILE is -, read standard input.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples should give you a better idea on how paste works.
|
||||
|
||||
### Q1. How to join lines of multiple files using paste command?
|
||||
|
||||
Suppose we have three files - file1.txt, file2.txt, and file3.txt - with following contents:
|
||||
|
||||
[![How to join lines of multiple files using paste command][1]][2]
|
||||
|
||||
And the task is to merge lines of these files in a way that each row of the final output contains index, country, and continent, then you can do that using paste in the following way:
|
||||
|
||||
paste file1.txt file2.txt file3.txt
|
||||
|
||||
[![result of merging lines][3]][4]
|
||||
|
||||
### Q2. How to apply delimiters when using paste?
|
||||
|
||||
Sometimes, there can be a requirement to add a delimiting character between entries of each resulting row. This can be done using the **-d** command line option, which requires you to provide the delimiting character you want to use.
|
||||
|
||||
For example, to apply a colon (:) as a delimiting character, use the paste command in the following way:
|
||||
|
||||
```
|
||||
paste -d : file1.txt file2.txt file3.txt
|
||||
```
|
||||
|
||||
Here's the output this command produced on our system:
|
||||
|
||||
[![How to apply delimiters when using paste][5]][6]
|
||||
|
||||
### Q3. How to change the way in which lines are merged?
|
||||
|
||||
By default, the paste command merges lines in a way that entries in the first column belongs to the first file, those in the second column are for the second file, and so on and so forth. However, if you want, you can change this so that the merge operation happens row-wise.
|
||||
|
||||
This you can do using the **-s** command line option.
|
||||
|
||||
```
|
||||
paste -s file1.txt file2.txt file3.txt
|
||||
```
|
||||
|
||||
Following is the output:
|
||||
|
||||
[![How to change the way in which lines are merged][7]][8]
|
||||
|
||||
### Q4. How to use multiple delimiters?
|
||||
|
||||
Yes, you can use multiple delimiters as well. For example, if you want to use both : and |, you can do that in the following way:
|
||||
|
||||
```
|
||||
paste -d ':|' file1.txt file2.txt file3.txt
|
||||
```
|
||||
|
||||
Following is the output:
|
||||
|
||||
[![How to use multiple delimiters][9]][10]
|
||||
|
||||
### Q5. How to make sure merged lines are NUL terminated?
|
||||
|
||||
By default, lines merged through paste end in a newline. However, if you want, you can make them NUL terminated, something which you can do using the **-z** option.
|
||||
|
||||
```
|
||||
paste -z file1.txt file2.txt file3.txt
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
As most of you'd agree, the paste command isn't difficult to understand and use. It may offer a limited set of command line options, but the tool does what it claims. You may not require it on daily basis, but paste can be a real-time saver in some scenarios. Just in case you need, [here's the tool's man page][11].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-paste-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/paste-3-files.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/paste-3-files.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/paste-basic-usage.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/paste-basic-usage.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/paste-d-option.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/paste-d-option.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/paste-s-option.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/paste-s-option.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/paste-d-mult1.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/paste-d-mult1.png
|
||||
[11]:https://linux.die.net/man/1/paste
|
||||
@ -1,224 +0,0 @@
|
||||
How to trigger commands on File/Directory changes with Incron on Debian
|
||||
======
|
||||
|
||||
This guide shows how you can install and use **incron** on a Debian 9 (Stretch) system. Incron is similar to cron, but instead of running commands based on time, it can trigger commands when file or directory events occur (e.g. a file modification, changes of permissions, etc.).
|
||||
|
||||
### 1 Prerequisites
|
||||
|
||||
* System administrator permissions (root login). All commands in this tutorial should be run as root user on the shell.
|
||||
* I will use the editor "nano" to edit files. You may replace nano with an editor of your choice or install nano with "apt-get install nano" if it is not installed on your server.
|
||||
|
||||
|
||||
|
||||
### 2 Installing Incron
|
||||
|
||||
Incron is available in the Debian repository, so we install incron with the following apt command:
|
||||
|
||||
```
|
||||
apt-get install incron
|
||||
```
|
||||
|
||||
The installation process should be similar to the one in this screenshot.
|
||||
|
||||
[![Installing Incron on Debian 9][1]][2]
|
||||
|
||||
### 3 Using Incron
|
||||
|
||||
Incron usage is very much like cron usage. You have the incrontab command that let's you list (-l), edit (-e), and remove (-r) incrontab entries.
|
||||
|
||||
To learn more about it, see:
|
||||
|
||||
```
|
||||
man incrontab
|
||||
```
|
||||
|
||||
There you also find the following section:
|
||||
|
||||
```
|
||||
If /etc/incron.allow exists only users listed here may use incron. Otherwise if /etc/incron.deny exists only users NOT listed here may use incron. If none of these files exists everyone is allowed to use incron. (Important note: This behavior is insecure and will be probably changed to be compatible with the style used by ISC Cron.) Location of these files can be changed in the configuration.
|
||||
```
|
||||
|
||||
This means if we want to use incrontab as root, we must either delete /etc/incron.allow (which is unsafe because then every system user can use incrontab)...
|
||||
|
||||
```
|
||||
rm -f /etc/incron.allow
|
||||
```
|
||||
|
||||
... or add root to that file (recommended). Open the /etc/incron.allow file with nano:
|
||||
|
||||
```
|
||||
nano /etc/incron.allow
|
||||
```
|
||||
|
||||
And add the following line. Then save the file.
|
||||
```
|
||||
root
|
||||
```
|
||||
|
||||
Before you do this, you will get error messages like this one when trying to use incrontab:
|
||||
|
||||
```
|
||||
server1:~# incrontab -l
|
||||
user 'root' is not allowed to use incron
|
||||
```
|
||||
|
||||
|
||||
|
||||
Afterwards it works:
|
||||
|
||||
```
|
||||
server1:~# incrontab -l
|
||||
no table for root
|
||||
```
|
||||
|
||||
|
||||
|
||||
We can use the command:
|
||||
|
||||
```
|
||||
incrontab -e
|
||||
```
|
||||
|
||||
To create incron jobs. Before we do this, we take a look at the incron man page:
|
||||
|
||||
```
|
||||
man 5 incrontab
|
||||
```
|
||||
|
||||
The man page explains the format of the crontabs. Basically, the format is as follows...
|
||||
|
||||
```
|
||||
<path> <mask> <command>
|
||||
```
|
||||
|
||||
...where <path> can be a directory (meaning the directory and/or the files directly in that directory (not files in subdirectories of that directory!) are watched) or a file.
|
||||
|
||||
<mask> can be one of the following:
|
||||
|
||||
IN_ACCESS File was accessed (read) (*)
|
||||
IN_ATTRIB Metadata changed (permissions, timestamps, extended attributes, etc.) (*)
|
||||
IN_CLOSE_WRITE File opened for writing was closed (*)
|
||||
IN_CLOSE_NOWRITE File not opened for writing was closed (*)
|
||||
IN_CREATE File/directory created in watched directory (*)
|
||||
IN_DELETE File/directory deleted from watched directory (*)
|
||||
IN_DELETE_SELF Watched file/directory was itself deleted
|
||||
IN_MODIFY File was modified (*)
|
||||
IN_MOVE_SELF Watched file/directory was itself moved
|
||||
IN_MOVED_FROM File moved out of watched directory (*)
|
||||
IN_MOVED_TO File moved into watched directory (*)
|
||||
IN_OPEN File was opened (*)
|
||||
|
||||
When monitoring a directory, the events marked with an asterisk (*) above can occur for files in the directory, in which case the name field in the
|
||||
returned event data identifies the name of the file within the directory.
|
||||
|
||||
The IN_ALL_EVENTS symbol is defined as a bit mask of all of the above events. Two additional convenience symbols are IN_MOVE, which is a combination of IN_MOVED_FROM and IN_MOVED_TO, and IN_CLOSE which combines IN_CLOSE_WRITE and IN_CLOSE_NOWRITE.
|
||||
|
||||
The following further symbols can be specified in the mask:
|
||||
|
||||
IN_DONT_FOLLOW Don't dereference pathname if it is a symbolic link
|
||||
IN_ONESHOT Monitor pathname for only one event
|
||||
IN_ONLYDIR Only watch pathname if it is a directory
|
||||
|
||||
Additionally, there is a symbol which doesn't appear in the inotify symbol set. It is IN_NO_LOOP. This symbol disables monitoring events until the current one is completely handled (until its child process exits).
|
||||
|
||||
<command> is the command that should be run when the event occurs. The following wildcards may be used inside the command specification:
|
||||
|
||||
```
|
||||
$$ dollar sign
|
||||
#@ watched filesystem path (see above)
|
||||
$# event-related file name
|
||||
$% event flags (textually)
|
||||
$& event flags (numerically)
|
||||
```
|
||||
|
||||
If you watch a directory, then [[email protected]][3] holds the directory path and $# the file that triggered the event. If you watch a file, then [[email protected]][3] holds the complete path to the file and $# is empty.
|
||||
|
||||
If you need the wildcards but are not sure what they translate to, you can create an incron job like this. Open the incron incrontab:
|
||||
|
||||
```
|
||||
incrontab -e
|
||||
```
|
||||
|
||||
and add the following line:
|
||||
|
||||
```
|
||||
/tmp/ IN_MODIFY echo "$$ $@ $# $% $&"
|
||||
```
|
||||
|
||||
Then you create or modify a file in the /tmp directory and take a look at /var/log/syslog - this log shows when an incron job was triggered, if it succeeded or if there were errors, and what the actual command was that it executed (i.e., the wildcards are replaced with their real values).
|
||||
|
||||
```
|
||||
tail /var/log/syslog
|
||||
```
|
||||
|
||||
```
|
||||
...
|
||||
Jan 10 13:52:35 server1 incrond[1012]: (root) CMD (echo "$ /tmp .hello.txt.swp IN_MODIFY 2")
|
||||
Jan 10 13:52:36 server1 incrond[1012]: (root) CMD (echo "$ /tmp .hello.txt.swp IN_MODIFY 2")
|
||||
Jan 10 13:52:39 server1 incrond[1012]: (root) CMD (echo "$ /tmp hello.txt IN_MODIFY 2")
|
||||
Jan 10 13:52:39 server1 incrond[1012]: (root) CMD (echo "$ /tmp .hello.txt.swp IN_MODIFY 2")
|
||||
```
|
||||
|
||||
In this example I've edited the file /tmp/hello.txt; as you see [[email protected]][3] translates to /tmp, $# to _hello.txt_ , $% to IN_CREATE, and $& to 256. I used an editor that created a temporary .txt.swp file which results in the additional lines in syslog.
|
||||
|
||||
Now enough theory. Let's create our first incron jobs. I'd like to monitor the file /etc/apache2/apache2.conf and the directory /etc/apache2/vhosts/, and whenever there are changes, I want incron to restart Apache. This is how we do it:
|
||||
|
||||
```
|
||||
incrontab -e
|
||||
```
|
||||
```
|
||||
/etc/apache2/apache2.conf IN_MODIFY /usr/sbin/service apache2 restart
|
||||
/etc/apache2/sites-available/ IN_MODIFY /usr/sbin/service apache2 restart
|
||||
```
|
||||
|
||||
That's it. For test purposes, you can modify your Apache configuration and take a look at /var/log/syslog, and you should see that incron restarts Apache.
|
||||
|
||||
**NOTE** : Do not do any action from within an incron job in a directory that you monitor to avoid loops. **Example:** When you monitor the /tmp directory for changes and each change triggers a script that writes a log file in /tmp, this will cause a loop and might bring your system to high load or even crash it.
|
||||
|
||||
To list all defined incron jobs, you can run:
|
||||
|
||||
```
|
||||
incrontab -l
|
||||
```
|
||||
|
||||
```
|
||||
server1:~# incrontab -l
|
||||
/etc/apache2/apache2.conf IN_MODIFY /usr/sbin/service apache2 restart
|
||||
/etc/apache2/vhosts/ IN_MODIFY /usr/sbin/service apache2 restart
|
||||
```
|
||||
|
||||
|
||||
|
||||
To delete all incron jobs of the current user, run:
|
||||
|
||||
```
|
||||
incrontab -r
|
||||
```
|
||||
|
||||
```
|
||||
server1:~# incrontab -r
|
||||
removing table for user 'root'
|
||||
table for user 'root' successfully removed
|
||||
```
|
||||
|
||||
### 4 Links
|
||||
|
||||
Debian http://www.debian.org
|
||||
Incron Software: http://inotify.aiken.cz/?section=incron&page=about&lang=en
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/trigger-commands-on-file-or-directory-changes-with-incron-on-debian-9/
|
||||
|
||||
作者:[Till Brehm][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/trigger-commands-on-file-or-directory-changes-with-incron-on-debian-8/incron-debian-9.png
|
||||
[2]:https://www.howtoforge.com/images/trigger-commands-on-file-or-directory-changes-with-incron-on-debian-8/big/incron-debian-9.png
|
||||
@ -1,374 +0,0 @@
|
||||
How to Install Snipe-IT Asset Management Software on Debian 9
|
||||
======
|
||||
|
||||
Snipe-IT is a free and open source IT assets management web application that can be used for tracking licenses, accessories, consumables, and components. It is written in PHP language and uses MySQL to store its data. It is a cross-platform application that works on all the major operating system like, Linux, Windows and Mac OS X. It easily integrates with Active Directory, LDAP and supports two-factor authentication with Google Authenticator.
|
||||
|
||||
In this tutorial, we will learn how to install Snipe-IT on Debian 9 server.
|
||||
|
||||
### Requirements
|
||||
|
||||
* A server running Debian 9.
|
||||
* A non-root user with sudo privileges.
|
||||
|
||||
|
||||
|
||||
### Getting Started
|
||||
|
||||
Before installing any packages, it is recommended to update the system package with the latest version. You can do this by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
Next, restart the system to apply all the updates. Then install other required packages with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install git curl unzip wget -y
|
||||
```
|
||||
|
||||
Once all the packages are installed, you can proceed to the next step.
|
||||
|
||||
### Install LAMP Server
|
||||
|
||||
Snipe-IT runs on Apache web server, so you will need to install LAMP (Apache, MariaDB, PHP) to your system.
|
||||
|
||||
First, install Apache, PHP and other PHP libraries with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install apache2 libapache2-mod-php php php-pdo php-mbstring php-tokenizer php-curl php-mysql php-ldap php-zip php-fileinfo php-gd php-dom php-mcrypt php-bcmath -y
|
||||
```
|
||||
|
||||
Once all the packages are installed, start Apache service and enable it to start on boot with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start apache2
|
||||
sudo systemctl enable apache2
|
||||
```
|
||||
|
||||
### Install and Configure MariaDB
|
||||
|
||||
Snipe-IT uses MariaDB to store its data. So you will need to install MariaDB to your system. By default, the latest version of the MariaDB is not available in the Debian 9 repository. So you will need to install MariaDB repository to your system.
|
||||
|
||||
First, add the APT key with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install software-properties-common -y
|
||||
sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
|
||||
```
|
||||
|
||||
Next, add the MariaDB repository using the following command:
|
||||
|
||||
```
|
||||
sudo add-apt-repository 'deb [arch=amd64,i386,ppc64el] http://nyc2.mirrors.digitalocean.com/mariadb/repo/10.1/debian stretch main'
|
||||
```
|
||||
|
||||
Next, update the repository with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
Once the repository is updated, you can install MariaDB with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install mariadb-server mariadb-client -y
|
||||
```
|
||||
|
||||
Next, start the MariaDB service and enable it to start on boot time with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start mysql
|
||||
sudo systemctl start mysql
|
||||
```
|
||||
|
||||
You can check the status of MariaDB server with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl status mysql
|
||||
```
|
||||
|
||||
If everything is fine, you should see the following output:
|
||||
```
|
||||
? mariadb.service - MariaDB database server
|
||||
Loaded: loaded (/lib/systemd/system/mariadb.service; enabled; vendor preset: enabled)
|
||||
Active: active (running) since Mon 2017-12-25 08:41:25 EST; 29min ago
|
||||
Process: 618 ExecStartPost=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
|
||||
Process: 615 ExecStartPost=/etc/mysql/debian-start (code=exited, status=0/SUCCESS)
|
||||
Process: 436 ExecStartPre=/bin/sh -c [ ! -e /usr/bin/galera_recovery ] && VAR= || VAR=`/usr/bin/galera_recovery`; [ $? -eq 0 ] && systemc
|
||||
Process: 429 ExecStartPre=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
|
||||
Process: 418 ExecStartPre=/usr/bin/install -m 755 -o mysql -g root -d /var/run/mysqld (code=exited, status=0/SUCCESS)
|
||||
Main PID: 574 (mysqld)
|
||||
Status: "Taking your SQL requests now..."
|
||||
Tasks: 27 (limit: 4915)
|
||||
CGroup: /system.slice/mariadb.service
|
||||
??574 /usr/sbin/mysqld
|
||||
|
||||
Dec 25 08:41:07 debian systemd[1]: Starting MariaDB database server...
|
||||
Dec 25 08:41:14 debian mysqld[574]: 2017-12-25 8:41:14 140488893776448 [Note] /usr/sbin/mysqld (mysqld 10.1.26-MariaDB-0+deb9u1) starting as p
|
||||
Dec 25 08:41:25 debian systemd[1]: Started MariaDB database server.
|
||||
|
||||
```
|
||||
|
||||
Next, secure your MariaDB by running the following script:
|
||||
|
||||
```
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
Answer all the questions as shown below:
|
||||
```
|
||||
Set root password? [Y/n] n
|
||||
Remove anonymous users? [Y/n] y
|
||||
Disallow root login remotely? [Y/n] y
|
||||
Remove test database and access to it? [Y/n] y
|
||||
Reload privilege tables now? [Y/n] y
|
||||
|
||||
```
|
||||
|
||||
Once MariaDB is secured, log in to MariaDB shell with the following command:
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
```
|
||||
|
||||
Enter your root password when prompt, then create a database for Snipe-IT with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> create database snipeitdb character set utf8;
|
||||
```
|
||||
|
||||
Next, create a user for Snipe-IT and grant all privileges to the Snipe-IT with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> GRANT ALL PRIVILEGES ON snipeitdb.* TO 'snipeit'@'localhost' IDENTIFIED BY 'password';
|
||||
```
|
||||
|
||||
Next, flush the privileges with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> flush privileges;
|
||||
```
|
||||
|
||||
Finally, exit from the MariaDB console using the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> quit
|
||||
```
|
||||
|
||||
### Install Snipe-IT
|
||||
|
||||
You can download the latest version of the Snipe-IT from Git repository with the following command:
|
||||
|
||||
```
|
||||
git clone https://github.com/snipe/snipe-it snipe-it
|
||||
```
|
||||
|
||||
Next, move the downloaded directory to the apache root directory with the following command:
|
||||
|
||||
```
|
||||
sudo mv snipe-it /var/www/
|
||||
```
|
||||
|
||||
Next, you will need to install Composer to your system. You can install it with the following command:
|
||||
|
||||
```
|
||||
curl -sS https://getcomposer.org/installer | php
|
||||
sudo mv composer.phar /usr/local/bin/composer
|
||||
```
|
||||
|
||||
Next, change the directory to snipe-it and Install PHP dependencies using Composer with the following command:
|
||||
|
||||
```
|
||||
cd /var/www/snipe-it
|
||||
sudo composer install --no-dev --prefer-source
|
||||
```
|
||||
Next, generate the "APP_Key" with the following command:
|
||||
|
||||
```
|
||||
sudo php artisan key:generate
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
**************************************
|
||||
* Application In Production! *
|
||||
**************************************
|
||||
|
||||
Do you really wish to run this command? (yes/no) [no]:
|
||||
> yes
|
||||
|
||||
Application key [base64:uWh7O0/TOV10asWpzHc0DH1dOxJHprnZw2kSOnbBXww=] set successfully.
|
||||
|
||||
```
|
||||
|
||||
Next, you will need to populate MySQL with Snipe-IT's default database schema. You can do this by running the following command:
|
||||
|
||||
```
|
||||
sudo php artisan migrate
|
||||
```
|
||||
|
||||
Type yes, when prompted to confirm that you want to perform the migration:
|
||||
```
|
||||
**************************************
|
||||
* Application In Production! *
|
||||
**************************************
|
||||
|
||||
Do you really wish to run this command? (yes/no) [no]:
|
||||
> yes
|
||||
|
||||
Migration table created successfully.
|
||||
|
||||
```
|
||||
|
||||
Next, copy sample .env file and make some changes in it:
|
||||
|
||||
```
|
||||
sudo cp .env.example .env
|
||||
sudo nano .env
|
||||
```
|
||||
|
||||
Change the following lines:
|
||||
```
|
||||
APP_URL=http://example.com
|
||||
APP_TIMEZONE=US/Eastern
|
||||
APP_LOCALE=en
|
||||
|
||||
# --------------------------------------------
|
||||
# REQUIRED: DATABASE SETTINGS
|
||||
# --------------------------------------------
|
||||
DB_CONNECTION=mysql
|
||||
DB_HOST=localhost
|
||||
DB_DATABASE=snipeitdb
|
||||
DB_USERNAME=snipeit
|
||||
DB_PASSWORD=password
|
||||
DB_PREFIX=null
|
||||
DB_DUMP_PATH='/usr/bin'
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished.
|
||||
|
||||
Next, provide the appropriate ownership and file permissions with the following command:
|
||||
|
||||
```
|
||||
sudo chown -R www-data:www-data storage public/uploads
|
||||
sudo chmod -R 755 storage public/uploads
|
||||
```
|
||||
|
||||
### Configure Apache For Snipe-IT
|
||||
|
||||
Next, you will need to create an apache virtual host directive for Snipe-IT. You can do this by creating `snipeit.conf` file inside `/etc/apache2/sites-available` directory:
|
||||
|
||||
```
|
||||
sudo nano /etc/apache2/sites-available/snipeit.conf
|
||||
```
|
||||
|
||||
Add the following lines:
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
ServerAdmin webmaster@example.com
|
||||
<Directory /var/www/snipe-it/public>
|
||||
Require all granted
|
||||
AllowOverride All
|
||||
</Directory>
|
||||
DocumentRoot /var/www/snipe-it/public
|
||||
ServerName example.com
|
||||
ErrorLog /var/log/apache2/snipeIT.error.log
|
||||
CustomLog /var/log/apache2/access.log combined
|
||||
</VirtualHost>
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished. Then, enable virtual host with the following command:
|
||||
|
||||
```
|
||||
sudo a2ensite snipeit.conf
|
||||
```
|
||||
|
||||
Next, enable PHP mcrypt, mbstring module and Apache rewrite module with the following command:
|
||||
|
||||
```
|
||||
sudo phpenmod mcrypt
|
||||
sudo phpenmod mbstring
|
||||
sudo a2enmod rewrite
|
||||
```
|
||||
|
||||
Finally, restart apache web server to apply all the changes:
|
||||
|
||||
```
|
||||
sudo systemctl restart apache2
|
||||
```
|
||||
|
||||
### Configure Firewall
|
||||
|
||||
By default, Snipe-IT runs on port 80, so you will need to allow port 80 through the firewall. By default, UFW firewall is not installed in Debian 9, so you will need to install it first. You can install it by just running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install ufw -y
|
||||
```
|
||||
|
||||
Once UFW is installed, enable it to start on boot time with the following command:
|
||||
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
Next, allow port 80 using the following command:
|
||||
|
||||
```
|
||||
sudo ufw allow 80
|
||||
```
|
||||
|
||||
Next, reload the UFW firewall rule with the following command:
|
||||
|
||||
```
|
||||
sudo ufw reload
|
||||
```
|
||||
|
||||
### Access Snipe-IT
|
||||
|
||||
Everything is now installed and configured, it's time to access Snipe-IT web interface.
|
||||
|
||||
Open your web browser and type the <http://example.com> URL, you will be redirected to the following page:
|
||||
|
||||
[![Snipe-IT Checks the system][2]][3]
|
||||
|
||||
The above page will do a system check to make sure your configuration looks correct. Next, click on the **Create Database Table** button you should see the following page:
|
||||
|
||||
[![Create database table][4]][5]
|
||||
|
||||
Here, click on the **Create User** page, you should see the following page:
|
||||
|
||||
[![Create user][6]][7]
|
||||
|
||||
Here, provide your Site name, Domain name, Admin username, and password, then click on the **Save User** button, you should see the Snipe-IT default dashboard as below:
|
||||
|
||||
[![Snipe-IT Dashboard][8]][9]
|
||||
|
||||
### Conclusion
|
||||
|
||||
In the above tutorial, we have learned to install Snipe-IT on Debian 9 server. We have also learned to configure Snipe-IT through web interface.I hope you have now enough knowledge to deploy Snipe-IT in your production environment. For more information you can refer Snipe-IT [Documentation Page][10].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-snipe-it-on-debian-9/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page1.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page1.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page2.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page2.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page3.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page3.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page4.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page4.png
|
||||
[10]:https://snipe-it.readme.io/docs
|
||||
@ -1,96 +0,0 @@
|
||||
Linux yes Command Tutorial for Beginners (with Examples)
|
||||
======
|
||||
|
||||
Most of the Linux commands you encounter do not depend on other operations for users to unlock their full potential, but there exists a small subset of command line tool which you can say are useless when used independently, but become a must-have or must-know when used with other command line operations. One such tool is **yes** , and in this tutorial, we will discuss this command with some easy to understand examples.
|
||||
|
||||
But before we do that, it's worth mentioning that all examples provided in this tutorial have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
### Linux yes command
|
||||
|
||||
The yes command in Linux outputs a string repeatedly until killed. Following is the syntax of the command:
|
||||
|
||||
```
|
||||
yes [STRING]...
|
||||
yes OPTION
|
||||
```
|
||||
|
||||
And here's what the man page says about this tool:
|
||||
```
|
||||
Repeatedly output a line with all specified STRING(s), or 'y'.
|
||||
```
|
||||
|
||||
The following Q&A-type examples should give you a better idea about the usage of yes.
|
||||
|
||||
### Q1. How yes command works?
|
||||
|
||||
As the man page says, the yes command produces continuous output - 'y' by default, or any other string if specified by user. Here's a screenshot that shows the yes command in action:
|
||||
|
||||
[![How yes command works][1]][2]
|
||||
|
||||
I could only capture the last part of the output as the output frequency was so fast, but the screenshot should give you a good idea about what kind of output the tool produces.
|
||||
|
||||
You can also provide a custom string for the yes command to use in output. For example:
|
||||
|
||||
```
|
||||
yes HTF
|
||||
```
|
||||
|
||||
[![Repeat word with yes command][3]][4]
|
||||
|
||||
### Q2. Where yes command helps the user?
|
||||
|
||||
That's a valid question. Reason being, from what yes does, it's difficult to imagine the usefulness of the tool. But you'll be surprised to know that yes can not only save your time, but also automate some mundane tasks.
|
||||
|
||||
For example, consider the following scenario:
|
||||
|
||||
[![Where yes command helps the user][5]][6]
|
||||
|
||||
You can see that user has to type 'y' for each query. It's in situation like these where yes can help. For the above scenario specifically, you can use yes in the following way:
|
||||
|
||||
```
|
||||
yes | rm -ri test
|
||||
```
|
||||
|
||||
[![yes command in action][7]][8]
|
||||
|
||||
So the command made sure user doesn't have to write 'y' each time when rm asked for it. Of course, one would argue that we could have simply removed the '-i' option from the rm command. That's right, I took this example as it's simple enough to make people understand the situations in which yes can be helpful.
|
||||
|
||||
Another - and probably more relevant - scenario would be when you're using the fsck command, and don't want to enter 'y' each time system asks your permission before fixing errors.
|
||||
|
||||
### Q3. Is there any use of yes when it's used alone?
|
||||
|
||||
Yes, there's at-least one use: to tell how well a computer system handles high amount of loads. Reason being, the tool utilizes 100% processor for systems that have a single processor. In case you want to apply this test on a system with multiple processors, you need to run a yes process for each processor.
|
||||
|
||||
### Q4. What command line options yes offers?
|
||||
|
||||
The tool only offers generic command line options: --help and --version. As the names suggests. the former displays help information related to the command, while the latter one outputs version related information.
|
||||
|
||||
[![What command line options yes offers][9]][10]
|
||||
|
||||
### Conclusion
|
||||
|
||||
So now you'd agree that there could be several scenarios where the yes command would be of help. There are no command line options unique to yes, so effectively, there's no learning curve associated with the tool. Just in case you need, here's the command's [man page][11].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-yes-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/yes-def-output.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/yes-def-output.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/yes-custom-string.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/yes-custom-string.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/rm-ri-output.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/rm-ri-output.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/yes-in-action.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/yes-in-action.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/yes-help-version1.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/yes-help-version1.png
|
||||
[11]:https://linux.die.net/man/1/yes
|
||||
@ -1,225 +0,0 @@
|
||||
How to Install and Use iostat on Ubuntu 16.04 LTS
|
||||
======
|
||||
|
||||
iostat also known as input/output statistics is a popular Linux system monitoring tool that can be used to collect statistics of input and output devices. It allows users to identify performance issues of local disk, remote disk and system information. The iostat create reports, the CPU Utilization report, the Device Utilization report and the Network Filesystem report.
|
||||
|
||||
In this tutorial, we will learn how to install iostat on Ubuntu 16.04 and how to use it.
|
||||
|
||||
### Prerequisite
|
||||
|
||||
* Ubuntu 16.04 desktop installed on your system.
|
||||
* Non-root user with sudo privileges setup on your system
|
||||
|
||||
|
||||
|
||||
### Install iostat
|
||||
|
||||
By default, iostat is included with sysstat package in Ubuntu 16.04. You can easily install it by just running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install sysstat -y
|
||||
```
|
||||
|
||||
Once sysstat is installed, you can proceed to the next step.
|
||||
|
||||
### iostat Basic Example
|
||||
|
||||
Let's start by running the iostat command without any argument. This will displays information about the CPU usage, and I/O statistics of your system:
|
||||
|
||||
```
|
||||
iostat
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
22.67 0.52 6.99 1.88 0.00 67.94
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 15.15 449.15 119.01 771022 204292
|
||||
|
||||
```
|
||||
|
||||
In the above output, the first line display, Linux kernel version and hostname. Next two lines displays CPU statistics like, average CPU usage, percentage of time the CPU were idle and waited for I/O response, percentage of waiting time of virtual CPU and the percentage of time the CPU is idle. Next two lines displays the device utilization report like, number of blocks read and write per second and total block reads and write per second.
|
||||
|
||||
By default iostat displays the report with current date. If you want to display the current time, run the following command:
|
||||
|
||||
```
|
||||
iostat -t
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
Saturday 16 December 2017 09:44:55 IST
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.37 0.31 6.93 1.28 0.00 70.12
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 9.48 267.80 79.69 771022 229424
|
||||
|
||||
```
|
||||
|
||||
To check the version of the iostat, run the following command:
|
||||
|
||||
```
|
||||
iostat -V
|
||||
```
|
||||
|
||||
Output:
|
||||
```
|
||||
sysstat version 10.2.0
|
||||
(C) Sebastien Godard (sysstat orange.fr)
|
||||
|
||||
```
|
||||
|
||||
You can listout all the options available with iostat command using the following command:
|
||||
|
||||
```
|
||||
iostat --help
|
||||
```
|
||||
|
||||
Output:
|
||||
```
|
||||
Usage: iostat [ options ] [ [ ] ]
|
||||
Options are:
|
||||
[ -c ] [ -d ] [ -h ] [ -k | -m ] [ -N ] [ -t ] [ -V ] [ -x ] [ -y ] [ -z ]
|
||||
[ -j { ID | LABEL | PATH | UUID | ... } ]
|
||||
[ [ -T ] -g ] [ -p [ [,...] | ALL ] ]
|
||||
[ [...] | ALL ]
|
||||
|
||||
```
|
||||
|
||||
### iostat Advance Usage Example
|
||||
|
||||
If you want to view only the device report only once, run the following command:
|
||||
|
||||
```
|
||||
iostat -d
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 12.18 353.66 102.44 771022 223320
|
||||
|
||||
```
|
||||
|
||||
To view the device report continuously for every 5 seconds, for 3 times:
|
||||
|
||||
```
|
||||
iostat -d 5 3
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 11.77 340.71 98.95 771022 223928
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 2.00 0.00 8.00 0 40
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 0.60 0.00 3.20 0 16
|
||||
|
||||
```
|
||||
|
||||
If you want to view the statistics of specific devices, run the following command:
|
||||
|
||||
```
|
||||
iostat -p sda
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.69 0.36 6.98 1.44 0.00 69.53
|
||||
|
||||
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
|
||||
sda 11.00 316.91 92.38 771022 224744
|
||||
sda1 0.07 0.27 0.00 664 0
|
||||
sda2 0.01 0.05 0.00 128 0
|
||||
sda3 0.07 0.27 0.00 648 0
|
||||
sda4 10.56 315.21 92.35 766877 224692
|
||||
sda5 0.12 0.48 0.02 1165 52
|
||||
sda6 0.07 0.32 0.00 776 0
|
||||
|
||||
```
|
||||
|
||||
You can also view the statistics of multiple devices with the following command:
|
||||
|
||||
```
|
||||
iostat -p sda, sdb, sdc
|
||||
```
|
||||
|
||||
If you want to displays the device I/O statistics in MB/second, run the following command:
|
||||
|
||||
```
|
||||
iostat -m
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.39 0.31 6.94 1.30 0.00 70.06
|
||||
|
||||
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
|
||||
sda 9.67 0.27 0.08 752 223
|
||||
|
||||
```
|
||||
|
||||
If you want to view the extended information for a specific partition (sda4), run the following command:
|
||||
|
||||
```
|
||||
iostat -x sda4
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.26 0.28 6.87 1.19 0.00 70.39
|
||||
|
||||
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
|
||||
sda4 0.79 4.65 5.71 2.68 242.76 73.28 75.32 0.35 41.80 43.66 37.84 4.55 3.82
|
||||
|
||||
```
|
||||
|
||||
If you want to displays only the CPU usage statistics, run the following command:
|
||||
|
||||
```
|
||||
iostat -c
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
|
||||
|
||||
avg-cpu: %user %nice %system %iowait %steal %idle
|
||||
21.45 0.33 6.96 1.34 0.00 69.91
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-use-iostat-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
@ -1,188 +0,0 @@
|
||||
translating by cncuckoo
|
||||
|
||||
Linux mv Command Explained for Beginners (8 Examples)
|
||||
======
|
||||
|
||||
Just like [cp][1] for copying and rm for deleting, Linux also offers an in-built command for moving and renaming files. It's called **mv**. In this article, we will discuss the basics of this command line tool using easy to understand examples. Please note that all examples used in this tutorial have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
#### Linux mv command
|
||||
|
||||
As already mentioned, the mv command in Linux is used to move or rename files. Following is the syntax of the command:
|
||||
|
||||
```
|
||||
mv [OPTION]... [-T] SOURCE DEST
|
||||
mv [OPTION]... SOURCE... DIRECTORY
|
||||
mv [OPTION]... -t DIRECTORY SOURCE...
|
||||
```
|
||||
|
||||
And here's what the man page says about it:
|
||||
```
|
||||
Rename SOURCE to DEST, or move SOURCE(s) to DIRECTORY.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples will give you a better idea on how this tool works.
|
||||
|
||||
#### Q1. How to use mv command in Linux?
|
||||
|
||||
If you want to just rename a file, you can use the mv command in the following way:
|
||||
|
||||
```
|
||||
mv [filename] [new_filename]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
mv names.txt fullnames.txt
|
||||
```
|
||||
|
||||
[![How to use mv command in Linux][2]][3]
|
||||
|
||||
Similarly, if the requirement is to move a file to a new location, use the mv command in the following way:
|
||||
|
||||
```
|
||||
mv [filename] [dest-dir]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
mv fullnames.txt /home/himanshu/Downloads
|
||||
```
|
||||
|
||||
[![Linux mv command][4]][5]
|
||||
|
||||
#### Q2. How to make sure mv prompts before overwriting?
|
||||
|
||||
By default, the mv command doesn't prompt when the operation involves overwriting an existing file. For example, the following screenshot shows the existing full_names.txt was overwritten by mv without any warning or notification.
|
||||
|
||||
[![How to make sure mv prompts before overwriting][6]][7]
|
||||
|
||||
However, if you want, you can force mv to prompt by using the **-i** command line option.
|
||||
|
||||
```
|
||||
mv -i [file_name] [new_file_name]
|
||||
```
|
||||
|
||||
[![the -i command option][8]][9]
|
||||
|
||||
So the above screenshots clearly shows that **-i** leads to mv asking for user permission before overwriting an existing file. Please note that in case you want to explicitly specify that you don't want mv to prompt before overwriting, then use the **-f** command line option.
|
||||
|
||||
#### Q3. How to make mv not overwrite an existing file?
|
||||
|
||||
For this, you need to use the **-n** command line option.
|
||||
|
||||
```
|
||||
mv -n [filename] [new_filename]
|
||||
```
|
||||
|
||||
The following screenshot shows the mv operation wasn't successful as a file with name 'full_names.txt' already existed and the command had -n option in it.
|
||||
|
||||
[![How to make mv not overwrite an existing file][10]][11]
|
||||
|
||||
Note:
|
||||
```
|
||||
If you specify more than one of -i, -f, -n, only the final one takes effect.
|
||||
```
|
||||
|
||||
#### Q4. How to make mv remove trailing slashes (if any) from source argument?
|
||||
|
||||
To remove any trailing slashes from source arguments, use the **\--strip-trailing-slashes** command line option.
|
||||
|
||||
```
|
||||
mv --strip-trailing-slashes [source] [dest]
|
||||
```
|
||||
|
||||
Here's how the official documentation explains the usefulness of this option:
|
||||
```
|
||||
This is useful when a
|
||||
|
||||
source
|
||||
|
||||
argument may have a trailing slash and specify a symbolic link to a directory. This scenario is in fact rather common because some shells can automatically append a trailing slash when performing file name completion on such symbolic links. Without this option,
|
||||
|
||||
mv
|
||||
|
||||
, for example, (via the system's rename function) must interpret a trailing slash as a request to dereference the symbolic link and so must rename the indirectly referenced
|
||||
|
||||
directory
|
||||
|
||||
and not the symbolic link. Although it may seem surprising that such behavior be the default, it is required by POSIX and is consistent with other parts of that standard.
|
||||
```
|
||||
|
||||
#### Q5. How to make mv treat destination as normal file?
|
||||
|
||||
To be absolutely sure that the destination entity is treated as a normal file (and not a directory), use the **-T** command line option.
|
||||
|
||||
```
|
||||
mv -T [source] [dest]
|
||||
```
|
||||
|
||||
Here's why this command line option exists:
|
||||
```
|
||||
This can help avoid race conditions in programs that operate in a shared area. For example, when the command 'mv /tmp/source /tmp/dest' succeeds, there is no guarantee that /tmp/source was renamed to /tmp/dest: it could have been renamed to/tmp/dest/source instead, if some other process created /tmp/dest as a directory. However, if mv -T /tmp/source /tmp/dest succeeds, there is no question that/tmp/source was renamed to /tmp/dest.
|
||||
```
|
||||
```
|
||||
In the opposite situation, where you want the last operand to be treated as a directory and want a diagnostic otherwise, you can use the --target-directory (-t) option.
|
||||
```
|
||||
|
||||
#### Q6. How to make mv move file only when its newer than destination file?
|
||||
|
||||
Suppose there exists a file named fullnames.txt in Downloads directory of your system, and there's a file with same name in your home directory. Now, you want to update ~/Downloads/fullnames.txt with ~/fullnames.txt, but only when the latter is newer. Then in this case, you'll have to use the **-u** command line option.
|
||||
|
||||
```
|
||||
mv -u ~/fullnames.txt ~/Downloads/fullnames.txt
|
||||
```
|
||||
|
||||
This option is particularly useful in cases when you need to take such decisions from within a shell script.
|
||||
|
||||
#### Q7. How make mv emit details of what all it is doing?
|
||||
|
||||
If you want mv to output information explaining what exactly it's doing, then use the **-v** command line option.
|
||||
|
||||
```
|
||||
mv -v [filename] [new_filename]
|
||||
```
|
||||
|
||||
For example, the following screenshots shows mv emitting some helpful details of what exactly it did.
|
||||
|
||||
[![How make mv emit details of what all it is doing][12]][13]
|
||||
|
||||
#### Q8. How to force mv to create backup of existing destination files?
|
||||
|
||||
This you can do using the **-b** command line option. The backup file created this way will have the same name as the destination file, but with a tilde (~) appended to it. Here's an example:
|
||||
|
||||
[![How to force mv to create backup of existing destination files][14]][15]
|
||||
|
||||
#### Conclusion
|
||||
|
||||
As you'd have guessed by now, mv is as important as cp and rm for the functionality it offers - renaming/moving files around is also one of the basic operations after all. We've discussed a majority of command line options this tool offers. So you can just practice them and start using the command. To know more about mv, head to its [man page][16].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-mv-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/linux-cp-command/
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/mv-rename-ex.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/big/mv-rename-ex.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/mv-transfer-file.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/big/mv-transfer-file.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/mv-overwrite.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/big/mv-overwrite.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/mv-prompt-overwrite.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/big/mv-prompt-overwrite.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/mv-n-option.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/big/mv-n-option.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/mv-v-option.png
|
||||
[13]:https://www.howtoforge.com/images/command-tutorial/big/mv-v-option.png
|
||||
[14]:https://www.howtoforge.com/images/command-tutorial/mv-b-option.png
|
||||
[15]:https://www.howtoforge.com/images/command-tutorial/big/mv-b-option.png
|
||||
[16]:https://linux.die.net/man/1/mv
|
||||
@ -1,113 +0,0 @@
|
||||
Linux kill Command Tutorial for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on a Linux machine, you'll see that an application or a command line process gets stuck (becomes unresponsive). Then in those cases, terminating it is the only way out. Linux command line offers a utility that you can use in these scenarios. It's called **kill**.
|
||||
|
||||
In this tutorial, we will discuss the basics of kill using some easy to understand examples. But before we do that, it's worth mentioning that all examples in the article have been tested on an Ubuntu 16.04 machine.
|
||||
|
||||
#### Linux kill command
|
||||
|
||||
The kill command is usually used to kill a process. Internally it sends a signal, and depending on what you want to do, there are different signals that you can send using this tool. Following is the command's syntax:
|
||||
|
||||
```
|
||||
kill [options] <pid> [...]
|
||||
```
|
||||
|
||||
And here's how the tool's man page describes it:
|
||||
```
|
||||
The default signal for kill is TERM. Use -l or -L to list available signals. Particularly useful
|
||||
signals include HUP, INT, KILL, STOP, CONT, and 0. Alternate signals may be specified in three ways:
|
||||
-9, -SIGKILL or -KILL. Negative PID values may be used to choose whole process groups; see the PGID
|
||||
column in ps command output. A PID of -1 is special; it indicates all processes except the kill
|
||||
process itself and init.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples should give you a better idea of how the kill command works.
|
||||
|
||||
#### Q1. How to terminate a process using kill command?
|
||||
|
||||
This is very easy - all you need to do is to get the pid of the process you want to kill, and then pass it to the kill command.
|
||||
|
||||
```
|
||||
kill [pid]
|
||||
```
|
||||
|
||||
For example, I wanted to kill the 'gthumb' process on my system. So i first used the ps command to fetch the application's pid, and then passed it to the kill command to terminate it. Here's the screenshot showing all this:
|
||||
|
||||
[![How to terminate a process using kill command][1]][2]
|
||||
|
||||
#### Q2. How to send a custom signal?
|
||||
|
||||
As already mentioned in the introduction section, TERM is the default signal that kill sends to the application/process in question. However, if you want, you can send any other signal that kill supports using the **-s** command line option.
|
||||
|
||||
```
|
||||
kill -s [signal] [pid]
|
||||
```
|
||||
|
||||
For example, if a process isn't responding to the TERM signal (which allows the process to do final cleanup before quitting), you can go for the KILL signal (which doesn't let process do any cleanup). Following is the command you need to run in that case.
|
||||
|
||||
```
|
||||
kill -s KILL [pid]
|
||||
```
|
||||
|
||||
#### Q3. What all signals you can send using kill?
|
||||
|
||||
Of course, the next logical question that'll come to your mind is how to know which all signals you can send using kill. Well, thankfully, there exists a command line option **-l** that lists all supported signals.
|
||||
|
||||
```
|
||||
kill -l
|
||||
```
|
||||
|
||||
Following is the output the above command produced on our system:
|
||||
|
||||
[![What all signals you can send using kill][3]][4]
|
||||
|
||||
#### Q4. What are the other ways in which signal can be sent?
|
||||
|
||||
In one of the previous examples, we told you if you want to send the KILL signal, you can do it in the following way:
|
||||
|
||||
```
|
||||
kill -s KILL [pid]
|
||||
```
|
||||
|
||||
However, there are a couple of other alternatives as well:
|
||||
|
||||
```
|
||||
kill -s SIGKILL [pid]
|
||||
|
||||
kill -s 9 [pid]
|
||||
```
|
||||
|
||||
The corresponding number can be known using the -l option we've already discussed in the previous example.
|
||||
|
||||
#### Q5. How to kill all running process in one go?
|
||||
|
||||
In case a user wants to kill all processes that they can (this depends on their privilege level), then instead of specifying a large number of process IDs, they can simply pass the -1 option to kill.
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
kill -s KILL -1
|
||||
```
|
||||
|
||||
#### Conclusion
|
||||
|
||||
The kill command is pretty straightforward to understand and use. There's a slight learning curve in terms of the list of signal options it offers, but as we explained in here, there's an option to take a quick look at that list as well. Just practice whatever we've discussed and you should be good to go. For more information, head to the tool's [man page][5].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-kill-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/kill-default.png
|
||||
[2]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/kill-default.png
|
||||
[3]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/kill-l-option.png
|
||||
[4]:https://www.howtoforge.com/images/usage_of_pfsense_to_block_dos_attack_/big/kill-l-option.png
|
||||
[5]:https://linux.die.net/man/1/kill
|
||||
@ -1,401 +0,0 @@
|
||||
Install Zabbix Monitoring Server and Agent on Debian 9
|
||||
======
|
||||
|
||||
Monitoring tools are used to continuously keep track of the status of the system and send out alerts and notifications if anything goes wrong. Also, monitoring tools help you to ensure that your critical systems, applications and services are always up and running. Monitoring tools are a supplement for your network security, allowing you to detect malicious traffic, where it's coming from and how to cancel it.
|
||||
|
||||
Zabbix is a free, open source and the ultimate enterprise-level monitoring tool designed for real-time monitoring of millions of metrics collected from tens of thousands of servers, virtual machines and network devices. Zabbix has been designed to skill from small environment to large environment. Its web front-end is written in PHP, backend is written in C and uses MySQL, PostgreSQL, SQLite, Oracle or IBM DB2 to store data. Zabbix provides graphing functionality that allows you to get an overview of the current state of specific nodes and the network
|
||||
|
||||
Some of the major features of the Zabbix are listed below:
|
||||
|
||||
* Monitoring Servers, Databases, Applications, Network Devices, Vmware hypervisor, Virtual Machines and much more.
|
||||
* Special designed to support small to large environments to improve the quality of your services and reduce operating costs by avoiding downtime.
|
||||
* Fully open source, so you don't need to pay anything.
|
||||
* Provide user friendly web interface to do everything from a central location.
|
||||
* Comes with SNMP to monitor Network device and IPMI to monitor Hardware device.
|
||||
* Web-based front end that allows full system control from a browser.
|
||||
|
||||
This tutorial will walk you through the step by step instruction of how to install Zabbix Server and Zabbix agent on Debian 9 server. We will also explain how to add the Zabbix agent to the Zabbix server for monitoring.
|
||||
|
||||
#### Requirements
|
||||
|
||||
* Two system with Debian 9 installed.
|
||||
* Minimum 1 GB of RAM and 10 DB of disk space required. Amount of RAM and Disk space depends on the number of hosts and the parameters that are being monitored.
|
||||
* A non-root user with sudo privileges setup on your server.
|
||||
|
||||
|
||||
|
||||
#### Getting Started
|
||||
|
||||
Before starting, it is necessary to update your server's package repository to the latest stable version. You can update it by just running the following command on both instances:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
Next, restart your system to apply these changes.
|
||||
|
||||
#### Install Apache, PHP and MariaDB
|
||||
|
||||
Zabbix runs on Apache web server, written in PHP and uses MariaDB/MySQL to store their data. So in order to install Zabbix, you will require Apache, MariaDB and PHP to work. First, install Apache, PHP and Other PHP modules by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install apache2 libapache2-mod-php7.0 php7.0 php7.0-xml php7.0-bcmath php7.0-mbstring -y
|
||||
```
|
||||
|
||||
Next, you will need to add MariaDB repository to your system. Because, latest version of the MariaDB is not available in Debian 9 default repository.
|
||||
|
||||
You can add the repository by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install software-properties-common -y
|
||||
sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 0xF1656F24C74CD1D8
|
||||
sudo add-apt-repository 'deb [arch=amd64] http://www.ftp.saix.net/DB/mariadb/repo/10.1/debian stretch main'
|
||||
```
|
||||
|
||||
Next, update the repository by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
Finally, install the MariaDB server with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install mariadb-server -y
|
||||
```
|
||||
|
||||
By default, MariaDB installation is not secured. So you will need to secure it first. You can do this by running the mysql_secure_installation script.
|
||||
|
||||
```
|
||||
sudo mysql_secure_installation
|
||||
```
|
||||
|
||||
Answer all the questions as shown below:
|
||||
```
|
||||
|
||||
Enter current password for root (enter for none): Enter
|
||||
Set root password? [Y/n]: Y
|
||||
New password:
|
||||
Re-enter new password:
|
||||
Remove anonymous users? [Y/n]: Y
|
||||
Disallow root login remotely? [Y/n]: Y
|
||||
Remove test database and access to it? [Y/n]: Y
|
||||
Reload privilege tables now? [Y/n]: Y
|
||||
|
||||
```
|
||||
|
||||
The above script will set the root password, remove test database, remove anonymous user and Disallow root login from a remote location.
|
||||
|
||||
Once the MariaDB installation is secured, start the Apache and MariaDB service and enable them to start on boot time by running the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start apache2
|
||||
sudo systemctl enable apache2
|
||||
sudo systemctl start mysql
|
||||
sudo systemctl enable mysql
|
||||
```
|
||||
|
||||
#### Installing Zabbix Server
|
||||
|
||||
By default, Zabbix is available in the Debian 9 repository, but it might be outdated. So it is recommended to install most recent version from the official Zabbix repositories. You can download and add the latest version of the Zabbix repository with the following command:
|
||||
|
||||
```
|
||||
wget http://repo.zabbix.com/zabbix/3.0/debian/pool/main/z/zabbix-release/zabbix-release_3.0-2+stretch_all.deb
|
||||
```
|
||||
|
||||
Next, install the downloaded repository with the following command:
|
||||
|
||||
```
|
||||
sudo dpkg -i zabbix-release_3.0-2+stretch_all.deb
|
||||
```
|
||||
|
||||
Next, update the package cache and install Zabbix server with web front-end and Mysql support by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get install zabbix-server-mysql zabbix-frontend-php -y
|
||||
```
|
||||
|
||||
You will also need to install the Zabbix agent to collect data about the Zabbix server status itself:
|
||||
|
||||
```
|
||||
sudo apt-get install zabbix-agent -y
|
||||
```
|
||||
|
||||
After installing Zabbix agent, start the Zabbix agent service and enable it to start on boot time by running the following command:
|
||||
|
||||
```
|
||||
sudo systemctl start zabbix-agent
|
||||
sudo systemctl enable zabbix-agent
|
||||
```
|
||||
|
||||
#### Configuring Zabbix Database
|
||||
|
||||
Zabbix uses MariaDB/MySQL as a database backend. So, you will need to create a MySQL database and User for zabbix installation:
|
||||
|
||||
First, log into MySQL shell with the following command:
|
||||
|
||||
```
|
||||
mysql -u root -p
|
||||
```
|
||||
|
||||
Enter your root password, then create a database for Zabbix with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> CREATE DATABASE zabbixdb character set utf8 collate utf8_bin;
|
||||
```
|
||||
|
||||
Next, create a user for Zabbix, assign a password and grant all privileges on Zabbix database with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> CREATE user zabbix identified by 'password';
|
||||
MariaDB [(none)]> GRANT ALL PRIVILEGES on zabbixdb.* to zabbixuser@localhost identified by 'password';
|
||||
```
|
||||
|
||||
Next, flush the privileges with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
Finally, exit from the MySQL shell with the following command:
|
||||
|
||||
```
|
||||
MariaDB [(none)]> exit;
|
||||
```
|
||||
|
||||
Next, import initial schema and data to the newly created database with the following command:
|
||||
|
||||
```
|
||||
cd /usr/share/doc/zabbix-server-mysql*/
|
||||
zcat create.sql.gz | mysql -u zabbix -p zabbixdb
|
||||
```
|
||||
|
||||
#### Configuring Zabbix
|
||||
|
||||
Zabbix creates its own configuration file at `/etc/zabbix/apache.conf`. Edit this file and update the Timezone and PHP setting as per your need:
|
||||
|
||||
```
|
||||
sudo nano /etc/zabbix/apache.conf
|
||||
```
|
||||
|
||||
Change the file as shown below:
|
||||
```
|
||||
php_value max_execution_time 300
|
||||
php_value memory_limit 128M
|
||||
php_value post_max_size 32M
|
||||
php_value upload_max_filesize 8M
|
||||
php_value max_input_time 300
|
||||
php_value always_populate_raw_post_data -1
|
||||
php_value date.timezone Asia/Kolkata
|
||||
|
||||
```
|
||||
|
||||
Save the file when you are finished.
|
||||
|
||||
Next, you will need to update the database details for Zabbix. You can do this by editing `/etc/zabbix/zabbix_server.conf` file:
|
||||
|
||||
```
|
||||
sudo nano /etc/zabbix/zabbix_server.conf
|
||||
```
|
||||
|
||||
Change the following lines:
|
||||
```
|
||||
DBHost=localhost
|
||||
DBName=zabbixdb
|
||||
DBUser=zabbixuser
|
||||
DBPassword=password
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished. Then restart all the services with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl restart apache2
|
||||
sudo systemctl restart mysql
|
||||
sudo systemctl restart zabbix-server
|
||||
```
|
||||
|
||||
#### Configuring Firewall
|
||||
|
||||
Before proceeding, you will need to configure the UFW firewall to secure Zabbix server.
|
||||
|
||||
First, make sure UFW is installed on your system. Otherewise, you can install it by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install ufw -y
|
||||
```
|
||||
|
||||
Next, enable the UFW firewall:
|
||||
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
Next, allow port 10050, 10051 and 80 through UFW with the following command:
|
||||
|
||||
```
|
||||
sudo ufw allow 10050/tcp
|
||||
sudo ufw allow 10051/tcp
|
||||
sudo ufw allow 80/tcp
|
||||
```
|
||||
|
||||
Finally, reload the firewall to apply these changes with the following command:
|
||||
|
||||
```
|
||||
sudo ufw reload
|
||||
```
|
||||
|
||||
Once the UFW firewall is configured you can proceed to install the Zabbix server via web interface.
|
||||
|
||||
#### Accessing Zabbix Web Installation Wizard
|
||||
|
||||
Once everything is fine, it's time to access Zabbix web installation wizard.
|
||||
|
||||
Open your web browser and navigate the <http://zabbix-server-ip/zabbix> URL , you will be redirected to the following page:
|
||||
|
||||
[![Zabbix 3.0][2]][3]
|
||||
|
||||
Click on the **Next step** button, you should see the following page:
|
||||
|
||||
[![Zabbix Prerequisites][4]][5]
|
||||
|
||||
Here, all the Zabbix pre-requisites are checked and verified, then click on the **Next step** button you should see the following page:
|
||||
|
||||
[![Database Configuration][6]][7]
|
||||
|
||||
Here, provide the Zabbix database name, database user and password then click on the **Next step** button, you should see the following page:
|
||||
|
||||
[![Zabbix Server Details][8]][9]
|
||||
|
||||
Here, specify the Zabbix server details and Port number then click on the **Next step** button, you should see the pre-installation summary of Zabbix Server in following page:
|
||||
|
||||
[![Installation summary][10]][11]
|
||||
|
||||
Next, click on the **Next step** button to start the Zabbix installation. Once the Zabbix installation is completed successfully, you should see the following page:
|
||||
|
||||
[![Zabbix installed successfully][12]][13]
|
||||
|
||||
Here, click on the **Finish** button, it will redirect to the Zabbix login page as shown below:
|
||||
|
||||
[![Login to Zabbix][14]][15]
|
||||
|
||||
Here, provide username as Admin and password as zabbix then click on the **Sign in** button. You should see the Zabbix server dashboard in the following image:
|
||||
|
||||
[![Zabbix Dashboard][16]][17]
|
||||
|
||||
Your Zabbix web installation is now finished.
|
||||
|
||||
#### Install Zabbix Agent
|
||||
|
||||
Now your Zabbix server is up and functioning. It's time to add Zabbix agent node to the Zabbix Server for Monitoring.
|
||||
|
||||
First, log into Zabbix agent instance and add the Zabbix repository with the following command:
|
||||
|
||||
```
|
||||
wget http://repo.zabbix.com/zabbix/3.0/debian/pool/main/z/zabbix-release/zabbix-release_3.0-2+stretch_all.deb
|
||||
sudo dpkg -i zabbix-release_3.0-2+stretch_all.deb
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
Once you have configured Zabbix repository on your system, install the Zabbix agent by just running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install zabbix-agent -y
|
||||
```
|
||||
|
||||
Once the Zabbix agent is installed, you will need to configure Zabbix agent to communicate with Zabbix server. You can do this by editing the Zabbix agent configuration file:
|
||||
|
||||
```
|
||||
sudo nano /etc/zabbix/zabbix_agentd.conf
|
||||
```
|
||||
|
||||
Change the file as shown below:
|
||||
```
|
||||
#Zabbix Server IP Address / Hostname
|
||||
|
||||
Server=192.168.0.103
|
||||
|
||||
#Zabbix Agent Hostname
|
||||
|
||||
Hostname=zabbix-agent
|
||||
|
||||
|
||||
```
|
||||
|
||||
Save and close the file when you are finished, then restart the Zabbix agent service and enable it to start on boot time with the following command:
|
||||
|
||||
```
|
||||
sudo systemctl restart zabbix-agent
|
||||
sudo systemctl enable zabbix-agent
|
||||
```
|
||||
|
||||
#### Add Zabbix Agent Node to Zabbix Server
|
||||
|
||||
Next, you will need to add the Zabbix agent node to the Zabbix server for monitoring. First, log in to the Zabbix server web interface.
|
||||
|
||||
[![Zabbix UI][18]][19]
|
||||
|
||||
Next, Click on **Configuration --> Hosts -> Create Host**, you should see the following page:
|
||||
|
||||
[![Create Host in Zabbix][20]][21]
|
||||
|
||||
Here, specify the Hostname, IP address and Group names of Zabbix agent. Then navigate to Templates tab, you should see the following page:
|
||||
|
||||
[![specify the Hostname, IP address and Group name][22]][23]
|
||||
|
||||
Here, search appropriate templates and click on **Add** button, you should see the following page:
|
||||
|
||||
[![OS Template][24]][25]
|
||||
|
||||
Finally, click on **Add** button again. You will see your new host with green labels indicating that everything is working fine.
|
||||
|
||||
[![Hast successfully added to Zabbix][26]][27]
|
||||
|
||||
If you have extra servers and network devices that you want to monitor, log into each host, install the Zabbix agent and add each host from the Zabbix web interface.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
Congratulations! you have successfully installed the Zabbix server and Zabbix agent in Debian 9 server. You have also added Zabbix agent node to the Zabbix server for monitoring. You can now easily list the current issue and past history, get the latest data of hosts, list the current problems and also visualized the collected resource statistics such as CPU load, CPU utilization, Memory usage, etc via graphs. I hope you can now easily install and configure Zabbix on Debian 9 server and deploy it on production environment. Compared to other monitoring software, Zabbix allows you to build your own maps of different network segments while monitoring many hosts. You can also monitor Windows host using Zabbix windows agent. For more information, you can refer the [Zabbix Documentation Page][28]. Feel free to ask me if you have any questions.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-zabbix-monitoring-server-and-agent-on-debian-9/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
[2]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-welcome-page.png
|
||||
[3]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-welcome-page.png
|
||||
[4]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-pre-requisite-check-page.png
|
||||
[5]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-pre-requisite-check-page.png
|
||||
[6]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-db-config-page.png
|
||||
[7]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-db-config-page.png
|
||||
[8]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-server-details.png
|
||||
[9]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-server-details.png
|
||||
[10]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-pre-installation-summary.png
|
||||
[11]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-pre-installation-summary.png
|
||||
[12]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-install-success.png
|
||||
[13]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-install-success.png
|
||||
[14]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-login-page.png
|
||||
[15]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-login-page.png
|
||||
[16]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-welcome-dashboard.png
|
||||
[17]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-welcome-dashboard.png
|
||||
[18]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-welcome-dashboard1.png
|
||||
[19]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-welcome-dashboard1.png
|
||||
[20]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-host1.png
|
||||
[21]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-host1.png
|
||||
[22]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-add-templates.png
|
||||
[23]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-add-templates.png
|
||||
[24]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-select-templates.png
|
||||
[25]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-select-templates.png
|
||||
[26]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/Screenshot-of-zabbix-agent-dashboard.png
|
||||
[27]:https://www.howtoforge.com/images/install_zabbix_monitoring_server_and_agent_on_debian_9/big/Screenshot-of-zabbix-agent-dashboard.png
|
||||
[28]:https://www.zabbix.com/documentation/3.2/
|
||||
@ -1,191 +0,0 @@
|
||||
Linux md5sum Command Explained For Beginners (5 Examples)
|
||||
======
|
||||
|
||||
When downloading files, particularly installation files from websites, it is a good idea to verify that the download is valid. A website will often display a hash value for each file so that you can make sure the download completed correctly. In this article, we will be discussing the md5sum tool that you can use to validate the download. Two other utilities, sha256sum and sha512sum, work the same way as md5sum.
|
||||
|
||||
### Linux md5sum command
|
||||
|
||||
The md5sum command prints a 32-character (128-bit) checksum of the given file, using the MD5 algorithm. Following is the command syntax of this command line tool:
|
||||
|
||||
```
|
||||
md5sum [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
And here's how md5sum's man page explains it:
|
||||
```
|
||||
Print or check MD5 (128-bit) checksums.
|
||||
|
||||
```
|
||||
|
||||
The following Q&A-styled examples will give you an even better idea of the basic usage of md5sum.
|
||||
|
||||
Note: We'll be using three files named file1.txt, file2.txt, and file3.txt as the input files in our examples. The text in each file is listed below.
|
||||
|
||||
file1.txt:
|
||||
```
|
||||
hi
|
||||
hello
|
||||
how are you
|
||||
thanks.
|
||||
|
||||
```
|
||||
|
||||
file2.txt:
|
||||
```
|
||||
hi
|
||||
hello to you
|
||||
I am fine
|
||||
Your welcome!
|
||||
|
||||
```
|
||||
|
||||
file3.txt:
|
||||
```
|
||||
hallo
|
||||
Guten Tag
|
||||
Wie geht es dir
|
||||
Danke.
|
||||
|
||||
```
|
||||
|
||||
### Q1. How to display the hash value?
|
||||
|
||||
Use the command without any options to display the hash value and the filename.
|
||||
|
||||
```
|
||||
md5sum file1.txt
|
||||
```
|
||||
|
||||
Here's the output this command produced on our system:
|
||||
```
|
||||
[Documents]$ md5sum file1.txt
|
||||
1ff38cc592c4c5d0c8e3ca38be8f1eb1 file1.txt
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
The output can also be displayed in a BSD-style format using the --tag option.
|
||||
|
||||
md5sum --tag file1.txt
|
||||
```
|
||||
[Documents]$ md5sum --tag file1.txt
|
||||
MD5 (file1.txt) = 1ff38cc592c4c5d0c8e3ca38be8f1eb1
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
### Q2. How to validate multiple files?
|
||||
|
||||
The md5sum command can validate multiple files at one time. We will add file2.txt and file3.txt to demonstrate the capabilities.
|
||||
|
||||
If you write the hashes to a file, you can use that file to check whether any of the files have changed. Here we are writing the hashes of the files to the file hashes, and then using that to validate that none of the files have changed.
|
||||
|
||||
```
|
||||
md5sum file1.txt file2.txt file3.txt > hashes
|
||||
md5sum --check hashes
|
||||
```
|
||||
|
||||
```
|
||||
[Documents]$ md5sum file1.txt file2.txt file3.txt > hashes
|
||||
[Documents]$ md5sum --check hashes
|
||||
file1.txt: OK
|
||||
file2.txt: OK
|
||||
file3.txt: OK
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
Now we will change file3.txt, adding a single exclamation mark to the end of the file, and rerun the command.
|
||||
|
||||
```
|
||||
echo "!" >> file3.txt
|
||||
md5sum --check hashes
|
||||
```
|
||||
|
||||
```
|
||||
[Documents]$ md5sum --check hashes
|
||||
file1.txt: OK
|
||||
file2.txt: OK
|
||||
file3.txt: FAILED
|
||||
md5sum: WARNING: 1 computed checksum did NOT match
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
You can see that file3.txt has changed.
|
||||
|
||||
### Q3. How to display only modified files?
|
||||
|
||||
If you have many files to check, you may want to display only the files that have changed. Using the "\--quiet" option, md5sum will only list the files that have changed.
|
||||
|
||||
```
|
||||
md5sum --quiet --check hashes
|
||||
```
|
||||
|
||||
```
|
||||
[Documents]$ md5sum --quiet --check hashes
|
||||
file3.txt: FAILED
|
||||
md5sum: WARNING: 1 computed checksum did NOT match
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
### Q4. How to detect changes in a script?
|
||||
|
||||
You may want to use md5sum in a script. Using the "\--status" option, md5sum won't print any output. Instead, the status code returns 0 if there are no changes, and 1 if the files don't match. The following script hashes.sh will return a 1 in the status code, because the files have changed. The script file is below:
|
||||
|
||||
```
|
||||
sh hashes.sh
|
||||
```
|
||||
|
||||
```
|
||||
hashes.sh:
|
||||
#!/bin/bash
|
||||
md5sum --status --check hashes
|
||||
Result=$?
|
||||
echo "File check status is: $Result"
|
||||
exit $Result
|
||||
|
||||
[Documents]$ sh hashes.sh
|
||||
File check status is: 1
|
||||
[[email protected] Documents]$
|
||||
|
||||
```
|
||||
|
||||
### Q5. How to identify invalid hash values?
|
||||
|
||||
md5sum can let you know if you have invalid hashes when you compare files. To warn you if any hash values are incorrect, you can use the --warn option. For this last example, we will use sed to insert an extra character at the beginning of the third line. This will change the hash value in the file hashes, making it invalid.
|
||||
|
||||
```
|
||||
sed -i '3s/.*/a&/' hashes
|
||||
md5sum --warn --check hashes
|
||||
```
|
||||
|
||||
This shows that the third line has an invalid hash.
|
||||
```
|
||||
[Documents]$ sed -i '3s/.*/a&/' hashes
|
||||
[Documents]$ md5sum --warn --check hashes
|
||||
file1.txt: OK
|
||||
file2.txt: OK
|
||||
md5sum: hashes: 3: improperly formatted MD5 checksum line
|
||||
md5sum: WARNING: 1 line is improperly formatted
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
The md5sum is a simple command which can quickly validate one or multiple files to determine whether any of them have changed from the original file. For more information on md5sum, see it's [man page.][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-md5sum-command/
|
||||
|
||||
作者:[David Paige][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/
|
||||
[1]:https://linux.die.net/man/1/md5sum
|
||||
@ -1,271 +0,0 @@
|
||||
How to Install and Configure XWiki on Ubuntu 16.04
|
||||
======
|
||||
|
||||
XWiki is a free and open source wiki software written in Java runs on a servlet container like Tomcat, JBoss etc. XWiki uses databases such as MySQL or PostgreSQL to store its information. XWiki allows us to store structured data and execute the server script within wiki interface. You can host multiple blogs and manage or view your files and folders using XWiki.
|
||||
|
||||
XWiki comes with lots of features, some of them are listed below:
|
||||
|
||||
* Supports version control and ACL.
|
||||
* Allows you to search the full wiki using wildcards.
|
||||
* Easily export wiki pages to PDF, ODT, RTF, XML and HTML.
|
||||
* Content organization and content import.
|
||||
* Page editing using WYSIWYG editor.
|
||||
|
||||
|
||||
|
||||
### Requirements
|
||||
|
||||
* A server running Ubuntu 16.04.
|
||||
* A non-root user with sudo privileges.
|
||||
|
||||
|
||||
|
||||
Before starting, you will need to update the Ubuntu repository to the latest version. You can do this using the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get upgrade -y
|
||||
```
|
||||
|
||||
Once the repository is updated, restart the system to apply all the updates.
|
||||
|
||||
### Install Java
|
||||
|
||||
Xwiki is a Java-based application, so you will need to install Java 8 first. By default Java 8 is not available in the Ubuntu repository. You can install Java 8 by adding the webupd8team PPA repository to your system.
|
||||
|
||||
First, add the PPA by running the following command:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:webupd8team/java
|
||||
```
|
||||
|
||||
Next, update the repository with the following command:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
Once the repository is up to date, you can install Java 8 by running the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install oracle-java8-installer -y
|
||||
```
|
||||
|
||||
After installing Java, you can check the version of Java with the following command:
|
||||
|
||||
```
|
||||
java -version
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
Java version "1.8.0_91"
|
||||
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
|
||||
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
|
||||
|
||||
```
|
||||
|
||||
### Download and Install Xwiki
|
||||
|
||||
Next, you will need to download the setup file provided by XWiki. You can download it using the following command:
|
||||
|
||||
```
|
||||
wget <http://download.forge.ow2.org/xwiki/xwiki-enterprise-installer-generic-8.1-standard.jar>
|
||||
```
|
||||
|
||||
Once the download is completed, you can install the downloaded package file using the java command as shown below:
|
||||
|
||||
```
|
||||
sudo java -jar xwiki-enterprise-installer-generic-8.1-standard.jar
|
||||
```
|
||||
|
||||
You should see the following output:
|
||||
```
|
||||
28 Jan, 2018 6:57:37 PM INFO: Logging initialized at level 'INFO'
|
||||
28 Jan, 2018 6:57:37 PM INFO: Commandline arguments:
|
||||
28 Jan, 2018 6:57:37 PM INFO: Detected platform: ubuntu_linux,version=3.19.0-25-generic,arch=x64,symbolicName=null,javaVersion=1.7.0_151
|
||||
28 Jan, 2018 6:57:37 PM WARNING: Failed to determine hostname and IP address
|
||||
Welcome to the installation of XWiki Enterprise 8.1!
|
||||
The homepage is at: http://xwiki.org/
|
||||
|
||||
Press 1 to continue, 2 to quit, 3 to redisplay
|
||||
|
||||
```
|
||||
|
||||
Now, press **`1`** to continue the installation, you should see the following output:
|
||||
```
|
||||
Please read the following information:
|
||||
|
||||
XWiki Enterprise - Readme
|
||||
|
||||
|
||||
XWiki Enterprise Overview
|
||||
XWiki Enterprise is a second generation Wiki engine, features professional features like
|
||||
Wiki, Blog, Comments, User Rights, LDAP Authentication, PDF Export, and a lot more.
|
||||
XWiki Enterprise also includes an advanced form and scripting engine which makes it an ideal
|
||||
development environment for constructing data-based intranet applications. It has powerful
|
||||
extensibility features, supports scripting, extensions and is based on a highly modular
|
||||
architecture. The scripting engine allows to access a powerful API for accessing the XWiki
|
||||
repository in read and write mode.
|
||||
XWiki Enterprise is used by major companies around the world and has strong
|
||||
Support for a professional usage of XWiki.
|
||||
Pointers
|
||||
Here are some pointers to get you started with XWiki once you have finished installing it:
|
||||
|
||||
The documentation can be found on the XWiki.org web site
|
||||
If you notice any issue please file a an issue in our issue tracker
|
||||
If you wish to talk to XWiki users or developers please use our
|
||||
Mailing lists & Forum
|
||||
You can also access XWiki's
|
||||
source code
|
||||
If you need commercial support please visit the
|
||||
Support page
|
||||
|
||||
|
||||
|
||||
Press 1 to continue, 2 to quit, 3 to redisplay
|
||||
|
||||
```
|
||||
|
||||
Now, press **`1`** to continue the installation, you should see the following output:
|
||||
```
|
||||
See the NOTICE file distributed with this work for additional
|
||||
information regarding copyright ownership.
|
||||
This is free software; you can redistribute it and/or modify it
|
||||
under the terms of the GNU Lesser General Public License as
|
||||
published by the Free Software Foundation; either version 2.1 of
|
||||
the License, or (at your option) any later version.
|
||||
This software is distributed in the hope that it will be useful,
|
||||
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
|
||||
Lesser General Public License for more details.
|
||||
You should have received a copy of the GNU Lesser General Public
|
||||
License along with this software; if not, write to the Free
|
||||
Software Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA
|
||||
02110-1301 USA, or see the FSF site: http://www.fsf.org.
|
||||
|
||||
Press 1 to accept, 2 to reject, 3 to redisplay
|
||||
|
||||
```
|
||||
|
||||
Now, press **`1`** to accept the license agreement, you should see the following output:
|
||||
```
|
||||
Select the installation path: [/usr/local/XWiki Enterprise 8.1]
|
||||
|
||||
Press 1 to continue, 2 to quit, 3 to redisplay
|
||||
|
||||
```
|
||||
|
||||
Now, press enter and press **1** to select default installation path, you should see the following output:
|
||||
```
|
||||
[x] Pack 'Core' required
|
||||
????????????????????????????????????????????????????????????????????????????????
|
||||
[x] Include optional pack 'Default Wiki'
|
||||
????????????????????????????????????????????????????????????????????????????????
|
||||
Enter Y for Yes, N for No:
|
||||
Y
|
||||
Press 1 to continue, 2 to quit, 3 to redisplay
|
||||
|
||||
```
|
||||
|
||||
Now, press **`Y`** and press **`1`** to continue the installation, you should see the following output:
|
||||
```
|
||||
[ Starting to unpack ]
|
||||
[ Processing package: Core (1/2) ]
|
||||
[ Processing package: Default Wiki (2/2) ]
|
||||
[ Unpacking finished ]
|
||||
|
||||
```
|
||||
|
||||
Now, you will be asked to create shortcuts for the user, you can press ' **`Y'`** to add them. Next, you will be asked to generate an automatic installation script, just press Enter to select default value, once the installation is finished, you should see the following output:
|
||||
```
|
||||
????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????
|
||||
Generate an automatic installation script
|
||||
????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????
|
||||
Enter Y for Yes, N for No:
|
||||
Y
|
||||
Select the installation script (path must be absolute)[/usr/local/XWiki Enterprise 8.1/auto-install.xml]
|
||||
|
||||
Installation was successful
|
||||
application installed on /usr/local/XWiki Enterprise 8.1
|
||||
[ Writing the uninstaller data ... ]
|
||||
[ Console installation done ]
|
||||
|
||||
```
|
||||
|
||||
Now, XWiki is installed on your system, it's time to start XWiki startup script as shown below:
|
||||
|
||||
```
|
||||
cd /usr/local/XWiki Enterprise 8.1
|
||||
sudo bash start_xwiki.sh
|
||||
```
|
||||
|
||||
Please, wait for sometime to start processes. Now, you should see some messages on terminal as shown below:
|
||||
```
|
||||
start_xwiki.sh: 79: start_xwiki.sh:
|
||||
Starting Jetty on port 8080, please wait...
|
||||
2018-01-28 19:12:41.842:INFO::main: Logging initialized @1266ms
|
||||
2018-01-28 19:12:42.905:INFO:oejs.Server:main: jetty-9.2.13.v20150730
|
||||
2018-01-28 19:12:42.956:INFO:oejs.AbstractNCSARequestLog:main: Opened /usr/local/XWiki Enterprise 8.1/data/logs/2018_01_28.request.log
|
||||
2018-01-28 19:12:42.965:INFO:oejdp.ScanningAppProvider:main: Deployment monitor [file:/usr/local/XWiki%20Enterprise%208.1/jetty/contexts/] at interval 0
|
||||
2018-01-28 19:13:31,485 [main] INFO o.x.s.s.i.EmbeddedSolrInstance - Starting embedded Solr server...
|
||||
2018-01-28 19:13:31,507 [main] INFO o.x.s.s.i.EmbeddedSolrInstance - Using Solr home directory: [data/solr]
|
||||
2018-01-28 19:13:43,371 [main] INFO o.x.s.s.i.EmbeddedSolrInstance - Started embedded Solr server.
|
||||
2018-01-28 19:13:46.556:INFO:oejsh.ContextHandler:main: Started [email protected]{/xwiki,file:/usr/local/XWiki%20Enterprise%208.1/webapps/xwiki/,AVAILABLE}{/xwiki}
|
||||
2018-01-28 19:13:46.697:INFO:oejsh.ContextHandler:main: Started [email protected]{/,file:/usr/local/XWiki%20Enterprise%208.1/webapps/root/,AVAILABLE}{/root}
|
||||
2018-01-28 19:13:46.776:INFO:oejs.ServerConnector:main: Started [email protected]{HTTP/1.1}{0.0.0.0:8080}
|
||||
|
||||
```
|
||||
|
||||
XWiki is now up and running, it's time to access XWiki web interface.
|
||||
|
||||
### Access XWiki
|
||||
|
||||
XWiki runs on port **8080** , so you will need to allow port 8080 through the firewall. First, enable the UFW firewall with the following command:
|
||||
|
||||
```
|
||||
sudo ufw enable
|
||||
```
|
||||
|
||||
Next, allow port **8080** through the UFW firewall with the following command:
|
||||
|
||||
```
|
||||
sudo ufw allow 8080/tcp
|
||||
```
|
||||
|
||||
Next, reload the firewall rules to apply all the changes by running the following command:
|
||||
|
||||
```
|
||||
sudo ufw reload
|
||||
```
|
||||
|
||||
You can get the status of the UFW firewall with the following command:
|
||||
|
||||
```
|
||||
sudo ufw status
|
||||
```
|
||||
|
||||
Now, open your web browser and type the URL **<http://your-server-ip:8080>** , you will be redirected to the XWiki home page as shown below:
|
||||
|
||||
[![XWiki Dashboard][1]][2]
|
||||
|
||||
You can stop the XWiki server at any time by pressing **`Ctrl + C`** button in the terminal.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Congratulations! you have successfully installed and configured XWiki on Ubuntu 16.04 server. I hope you can now easily host your own wiki site using XWiki on Ubuntu 16.04 server. For more information, you can check the XWiki official documentation page at <https://www.xwiki.org/xwiki/bin/view/Documentation/>. Feel free to comments me if you have any questions.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-configure-xwiki-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_and_configure_xwiki_on_ubuntu_1604/Screenshot-of-xwiki-dashboard.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_and_configure_xwiki_on_ubuntu_1604/big/Screenshot-of-xwiki-dashboard.png
|
||||
@ -1,441 +0,0 @@
|
||||
translated by cyleft
|
||||
|
||||
How to Install Gogs Go Git Service on Ubuntu 16.04
|
||||
======
|
||||
|
||||
Gogs is free and open source Git service written in Go language. Gogs is a painless self-hosted git service that allows you to create and run your own Git server on a minimal hardware server. Gogs web-UI is very similar to GitHub and offers support for MySQL, PostgreSQL, and SQLite database.
|
||||
|
||||
In this tutorial, we will show you step-by-step how to install and configure your own Git service using Gogs on Ubuntu 16.04. This tutorial will cover details including, how to install Go on Ubuntu system, install PostgreSQL, and install and configure Nginx web server as a reverse proxy for Go application.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
* Ubuntu 16.04
|
||||
* Root privileges
|
||||
|
||||
|
||||
|
||||
### What we will do
|
||||
|
||||
1. Update and Upgrade System
|
||||
2. Install and Configure PostgreSQL
|
||||
3. Install Go and Git
|
||||
4. Install Gogs
|
||||
5. Configure Gogs
|
||||
6. Running Gogs as a Service
|
||||
7. Install and Configure Nginx as a Reverse Proxy
|
||||
8. Testing
|
||||
|
||||
|
||||
|
||||
Before going any further, update all Ubuntu repositories and upgrade all packages.
|
||||
|
||||
Run the apt commands below.
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt upgrade
|
||||
```
|
||||
|
||||
### Step 2 - Install and Configure PostgreSQL
|
||||
|
||||
Gogs offers support for MySQL, PostgreSQL, SQLite3, MSSQL, and TiDB database systems.
|
||||
|
||||
In this guide, we will be using PostgreSQL as a database for our Gogs installations.
|
||||
|
||||
Install PostgreSQL using the apt command below.
|
||||
|
||||
```
|
||||
sudo apt install -y postgresql postgresql-client libpq-dev
|
||||
```
|
||||
|
||||
After the installation is complete, start the PostgreSQL service and enable it to launch everytime at system boot.
|
||||
|
||||
```
|
||||
systemctl start postgresql
|
||||
systemctl enable postgresql
|
||||
```
|
||||
|
||||
PostgreSQL database has been installed on an Ubuntu system.
|
||||
|
||||
Next, we need to create a new database and user for Gogs.
|
||||
|
||||
Login as the 'postgres' user and run the 'psql' command to get the PostgreSQL shell.
|
||||
|
||||
```
|
||||
su - postgres
|
||||
psql
|
||||
```
|
||||
|
||||
Create a new user named 'git', and give the user privileges for 'CREATEDB'.
|
||||
|
||||
```
|
||||
CREATE USER git CREATEDB;
|
||||
\password git
|
||||
```
|
||||
|
||||
Create a database named 'gogs_production', and set the 'git' user as the owner of the database.
|
||||
|
||||
```
|
||||
CREATE DATABASE gogs_production OWNER git;
|
||||
```
|
||||
|
||||
[![Create the Gogs database][1]][2]
|
||||
|
||||
New PostgreSQL database 'gogs_production' and user 'git' for Gogs installation has been created.
|
||||
|
||||
### Step 3 - Install Go and Git
|
||||
|
||||
Install Git from the repository using the apt command below.
|
||||
|
||||
```
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
Now add new user 'git' to the system.
|
||||
|
||||
```
|
||||
sudo adduser --disabled-login --gecos 'Gogs' git
|
||||
```
|
||||
|
||||
Login as the 'git' user and create a new 'local' directory.
|
||||
|
||||
```
|
||||
su - git
|
||||
mkdir -p /home/git/local
|
||||
```
|
||||
|
||||
Go to the 'local' directory and download 'Go' (the latest version) using the wget command as shown below.
|
||||
|
||||
```
|
||||
cd ~/local
|
||||
wget <https://dl.google.com/go/go1.9.2.linux-amd64.tar.gz>
|
||||
```
|
||||
|
||||
[![Install Go and Git][3]][4]
|
||||
|
||||
Extract the go compressed file, then remove it.
|
||||
|
||||
```
|
||||
tar -xf go1.9.2.linux-amd64.tar.gz
|
||||
rm -f go1.9.2.linux-amd64.tar.gz
|
||||
```
|
||||
|
||||
'Go' binary file has been downloaded in the '~/local/go' directory. Now we need to setup the environment - we need to define the 'GOROOT' and 'GOPATH directories so we can run a 'go' command on the system under 'git' user.
|
||||
|
||||
Run all of the following commands.
|
||||
|
||||
```
|
||||
cd ~/
|
||||
echo 'export GOROOT=$HOME/local/go' >> $HOME/.bashrc
|
||||
echo 'export GOPATH=$HOME/go' >> $HOME/.bashrc
|
||||
echo 'export PATH=$PATH:$GOROOT/bin:$GOPATH/bin' >> $HOME/.bashrc
|
||||
```
|
||||
|
||||
And reload Bash by running the 'source ~/.bashrc' command as shown below.
|
||||
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
Make sure you're using Bash as your default shell.
|
||||
|
||||
[![Install Go programming language][5]][6]
|
||||
|
||||
Now run the 'go' command for checking the version.
|
||||
|
||||
```
|
||||
go version
|
||||
```
|
||||
|
||||
And make sure you get the result as shown in the following screenshot.
|
||||
|
||||
[![Check the go version][7]][8]
|
||||
|
||||
Go is now installed on the system under 'git' user.
|
||||
|
||||
### Step 4 - Install Gogs Go Git Service
|
||||
|
||||
Login as the 'git' user and download 'Gogs' from GitHub using the 'go' command.
|
||||
|
||||
```
|
||||
su - git
|
||||
go get -u github.com/gogits/gogs
|
||||
```
|
||||
|
||||
The command will download all Gogs source code in the 'GOPATH/src' directory.
|
||||
|
||||
Go to the '$GOPATH/src/github.com/gogits/gogs' directory and build gogs using commands below.
|
||||
|
||||
```
|
||||
cd $GOPATH/src/github.com/gogits/gogs
|
||||
go build
|
||||
```
|
||||
|
||||
And make sure you get no error.
|
||||
|
||||
Now run Gogs Go Git Service using the command below.
|
||||
|
||||
```
|
||||
./gogs web
|
||||
```
|
||||
|
||||
The command will run Gogs on the default port 3000.
|
||||
|
||||
[![Install Gogs Go Git Service][9]][10]
|
||||
|
||||
Open your web browser and type your server IP address with port 3000, mine is <http://192.168.33.10:3000/>
|
||||
|
||||
And you should get the result as shown below.
|
||||
|
||||
[![Gogs web installer][11]][12]
|
||||
|
||||
Gogs is installed on the Ubuntu system. Now back to your terminal and press 'Ctrl + c' to exit.
|
||||
|
||||
### Step 5 - Configure Gogs Go Git Service
|
||||
|
||||
In this step, we will create a custom configuration for Gogs.
|
||||
|
||||
Goto the Gogs installation directory and create a new 'custom/conf' directory.
|
||||
|
||||
```
|
||||
cd $GOPATH/src/github.com/gogits/gogs
|
||||
mkdir -p custom/conf/
|
||||
```
|
||||
|
||||
Copy default configuration to the custom directory and edit it using [vim][13].
|
||||
|
||||
```
|
||||
cp conf/app.ini custom/conf/app.ini
|
||||
vim custom/conf/app.ini
|
||||
```
|
||||
|
||||
In the ' **[server]** ' section, change the server 'HOST_ADDR' with '127.0.0.1'.
|
||||
```
|
||||
[server]
|
||||
PROTOCOL = http
|
||||
DOMAIN = localhost
|
||||
ROOT_URL = %(PROTOCOL)s://%(DOMAIN)s:%(HTTP_PORT)s/
|
||||
HTTP_ADDR = 127.0.0.1
|
||||
HTTP_PORT = 3000
|
||||
|
||||
```
|
||||
|
||||
In the ' **[database]** ' section, change everything with your own database info.
|
||||
```
|
||||
[database]
|
||||
DB_TYPE = postgres
|
||||
HOST = 127.0.0.1:5432
|
||||
NAME = gogs_production
|
||||
USER = git
|
||||
PASSWD = [email protected]#
|
||||
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Now verify the configuration by running the command as shown below.
|
||||
|
||||
```
|
||||
./gogs web
|
||||
```
|
||||
|
||||
And make sure you get the result as following.
|
||||
|
||||
[![Configure the service][14]][15]
|
||||
|
||||
Gogs is now running with our custom configuration, under 'localhost' with port 3000.
|
||||
|
||||
### Step 6 - Running Gogs as a Service
|
||||
|
||||
In this step, we will configure Gogs as a service on Ubuntu system. We will create a new service file configuration 'gogs.service' under the '/etc/systemd/system' directory.
|
||||
|
||||
Go to the '/etc/systemd/system' directory and create a new service file 'gogs.service' using the [vim][13] editor.
|
||||
|
||||
```
|
||||
cd /etc/systemd/system
|
||||
vim gogs.service
|
||||
```
|
||||
|
||||
Paste the following gogs service configuration there.
|
||||
```
|
||||
[Unit]
|
||||
Description=Gogs
|
||||
After=syslog.target
|
||||
After=network.target
|
||||
After=mariadb.service mysqld.service postgresql.service memcached.service redis.service
|
||||
|
||||
[Service]
|
||||
# Modify these two values and uncomment them if you have
|
||||
# repos with lots of files and get an HTTP error 500 because
|
||||
# of that
|
||||
###
|
||||
#LimitMEMLOCK=infinity
|
||||
#LimitNOFILE=65535
|
||||
Type=simple
|
||||
User=git
|
||||
Group=git
|
||||
WorkingDirectory=/home/git/go/src/github.com/gogits/gogs
|
||||
ExecStart=/home/git/go/src/github.com/gogits/gogs/gogs web
|
||||
Restart=always
|
||||
Environment=USER=git HOME=/home/git
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
Now reload the systemd services.
|
||||
|
||||
```
|
||||
systemctl daemon-reload
|
||||
```
|
||||
|
||||
Start gogs service and enable it to launch everytime at system boot using the systemctl command.
|
||||
|
||||
```
|
||||
systemctl start gogs
|
||||
systemctl enable gogs
|
||||
```
|
||||
|
||||
[![Run gogs as a service][16]][17]
|
||||
|
||||
Gogs is now running as a service on Ubuntu system.
|
||||
|
||||
Check it using the commands below.
|
||||
|
||||
```
|
||||
netstat -plntu
|
||||
systemctl status gogs
|
||||
```
|
||||
|
||||
And you should get the result as shown below.
|
||||
|
||||
[![Gogs is listening on the network interface][18]][19]
|
||||
|
||||
### Step 7 - Configure Nginx as a Reverse Proxy for Gogs
|
||||
|
||||
In this step, we will configure Nginx as a reverse proxy for Gogs. We will be using Nginx packages from its own repository.
|
||||
|
||||
Add Nginx repository using the add-apt command.
|
||||
|
||||
```
|
||||
sudo add-apt-repository -y ppa:nginx/stable
|
||||
```
|
||||
|
||||
Now update all Ubuntu repositories and install Nginx using the apt command below.
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install nginx -y
|
||||
```
|
||||
|
||||
Next, goto the '/etc/nginx/sites-available' directory and create new virtual host file 'gogs'.
|
||||
|
||||
```
|
||||
cd /etc/nginx/sites-available
|
||||
vim gogs
|
||||
```
|
||||
|
||||
Paste the following configuration there.
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
server_name git.hakase-labs.co;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:3000;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
**Note:**
|
||||
|
||||
Change the 'server_name' line with your own domain name.
|
||||
|
||||
Now activate a new virtual host and test the nginx configuration.
|
||||
|
||||
```
|
||||
ln -s /etc/nginx/sites-available/gogs /etc/nginx/sites-enabled/
|
||||
nginx -t
|
||||
```
|
||||
|
||||
Make sure there is no error, then restart the Nginx service.
|
||||
|
||||
```
|
||||
systemctl restart nginx
|
||||
```
|
||||
|
||||
[![Nginx reverse proxy for gogs][20]][21]
|
||||
|
||||
### Step 8 - Testing
|
||||
|
||||
Open your web browser and type your gogs URL, mine is <http://git.hakase-labs.co>
|
||||
|
||||
Now you will get the installation page. On top of the page, type all of your PostgreSQL database info.
|
||||
|
||||
[![Gogs installer][22]][23]
|
||||
|
||||
Now scroll to the bottom, and click the 'Admin account settings' dropdown.
|
||||
|
||||
Type your admin user, password, and email.
|
||||
|
||||
[![Type in the gogs install settings][24]][25]
|
||||
|
||||
Then click the 'Install Gogs' button.
|
||||
|
||||
And you will be redirected to the Gogs user Dashboard as shown below.
|
||||
|
||||
[![Gogs dashboard][26]][27]
|
||||
|
||||
Below is Gogs 'Admin Dashboard'.
|
||||
|
||||
[![Browse the Gogs dashboard][28]][29]
|
||||
|
||||
Gogs is now installed with PostgreSQL database and Nginx web server on Ubuntu 16.04 server
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-gogs-go-git-service-on-ubuntu-1604/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/server-monitoring-with-shinken-on-ubuntu-16-04/
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/1.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/1.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/2.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/2.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/3.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/3.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/4.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/4.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/5.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/5.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/6.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/6.png
|
||||
[13]:https://www.howtoforge.com/vim-basics
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/7.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/7.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/8.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/8.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/9.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/9.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/10.png
|
||||
[21]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/10.png
|
||||
[22]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/11.png
|
||||
[23]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/11.png
|
||||
[24]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/12.png
|
||||
[25]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/12.png
|
||||
[26]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/13.png
|
||||
[27]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/13.png
|
||||
[28]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/14.png
|
||||
[29]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/14.png
|
||||
Loading…
Reference in New Issue
Block a user