mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
commit
eaef6a28cd
2
.gitignore
vendored
2
.gitignore
vendored
@ -3,3 +3,5 @@ members.md
|
||||
*.html
|
||||
*.bak
|
||||
.DS_Store
|
||||
sources/*/.*
|
||||
translated/*/.*
|
||||
3
.gitmodules
vendored
3
.gitmodules
vendored
@ -1,3 +0,0 @@
|
||||
[submodule "comic"]
|
||||
path = comic
|
||||
url = https://wxy@github.com/LCTT/comic.git
|
||||
29
.travis.yml
29
.travis.yml
@ -1,2 +1,27 @@
|
||||
language: c
|
||||
script: make -s check
|
||||
language: minimal
|
||||
install:
|
||||
- sudo apt-get install jq
|
||||
- git clone --depth=1 -b gh-pages https://github.com/LCTT/TranslateProject/ build && rm -rf build/.git
|
||||
script:
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" != "false" ]; then sh ./scripts/check.sh; fi'
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" = "false" ]; then sh ./scripts/badge.sh; fi'
|
||||
- 'if [ "$TRAVIS_EVENT_TYPE" = "cron" ]; then sh ./scripts/status.sh; fi'
|
||||
|
||||
branches:
|
||||
only:
|
||||
- master
|
||||
# - status
|
||||
except:
|
||||
- gh-pages
|
||||
git:
|
||||
submodules: false
|
||||
depth: false
|
||||
deploy:
|
||||
provider: pages
|
||||
skip_cleanup: true
|
||||
github_token: $GITHUB_TOKEN
|
||||
local_dir: build
|
||||
on:
|
||||
branch:
|
||||
- master
|
||||
# - status
|
||||
|
||||
@ -1,4 +0,0 @@
|
||||
# Linux中国翻译规范
|
||||
1. 翻译中出现的专有名词,可参见Dict.md中的翻译。
|
||||
2. 英文人名,如无中文对应译名,一般不译。
|
||||
2. 缩写词,一般不须翻译,可考虑旁注中文全名。
|
||||
51
Makefile
51
Makefile
@ -1,51 +0,0 @@
|
||||
DIR_PATTERN := (news|talk|tech)
|
||||
NAME_PATTERN := [0-9]{8} [a-zA-Z0-9_.,() -]*\.md
|
||||
|
||||
RULES := rule-source-added \
|
||||
rule-translation-requested \
|
||||
rule-translation-completed \
|
||||
rule-translation-revised \
|
||||
rule-translation-published
|
||||
.PHONY: check match $(RULES)
|
||||
|
||||
CHANGE_FILE := /tmp/changes
|
||||
|
||||
check: $(CHANGE_FILE)
|
||||
echo 'PR #$(TRAVIS_PULL_REQUEST) Changes:'
|
||||
cat $(CHANGE_FILE)
|
||||
echo
|
||||
echo 'Check for rules...'
|
||||
make -k $(RULES) 2>/dev/null | grep '^Rule Matched: '
|
||||
|
||||
$(CHANGE_FILE):
|
||||
git --no-pager diff $(TRAVIS_BRANCH) FETCH_HEAD --no-renames --name-status > $@
|
||||
|
||||
rule-source-added:
|
||||
echo 'Unmatched Files:'
|
||||
egrep -v '^A\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) || true
|
||||
echo '[End of Unmatched Files]'
|
||||
[ $(shell egrep '^A\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) -ge 1 ]
|
||||
[ $(shell egrep -v '^A\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 0 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-requested:
|
||||
[ $(shell egrep '^M\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-completed:
|
||||
[ $(shell egrep '^D\s*"?sources/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^A\s*"?translated/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 2 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-revised:
|
||||
[ $(shell egrep '^M\s*"?translated/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
|
||||
rule-translation-published:
|
||||
[ $(shell egrep '^D\s*"?translated/$(DIR_PATTERN)/$(NAME_PATTERN)"?' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell egrep '^A\s*"?published/$(NAME_PATTERN)' $(CHANGE_FILE) | wc -l) = 1 ]
|
||||
[ $(shell cat $(CHANGE_FILE) | wc -l) = 2 ]
|
||||
echo 'Rule Matched: $(@)'
|
||||
117
README.md
117
README.md
@ -1,34 +1,40 @@
|
||||
|
||||
[](https://lctt.github.io/new)
|
||||
[](https://lctt.github.io/translating)
|
||||
[](https://github.com/LCTT/TranslateProject/tree/master/translated)
|
||||
[](https://github.com/LCTT/TranslateProject/tree/master/published)
|
||||
|
||||
[](https://travis-ci.com/LCTT/TranslateProject)
|
||||
[](https://github.com/LCTT/TranslateProject/graphs/contributors)
|
||||
[](https://github.com/LCTT/TranslateProject/pulls?q=is%3Apr+is%3Aclosed)
|
||||
|
||||
简介
|
||||
-------------------------------
|
||||
|
||||
LCTT 是“Linux中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
[LCTT](https://linux.cn/lctt/) 是“Linux 中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
|
||||
LCTT 已经拥有几百名活跃成员,并欢迎更多的Linux志愿者加入我们的团队。
|
||||
LCTT 已经拥有几百名活跃成员,并欢迎更多的 Linux 志愿者加入我们的团队。
|
||||
|
||||

|
||||

|
||||
|
||||
LCTT 的组成
|
||||
-------------------------------
|
||||
|
||||
**选题**,负责选择合适的内容,并将原文转换为 markdown 格式,提交到 LCTT 的 [TranslateProject](https://github.com/LCTT/TranslateProject) 库中。
|
||||
|
||||
**译者**,负责从选题中选择内容进行翻译。
|
||||
|
||||
**校对**,负责将初译的文章进行文字润色、技术校对等工作。
|
||||
|
||||
**发布**,负责将校对后的文章,排版进行发布。
|
||||
- LCTT 官网: [https://linux.cn/lctt/](https://linux.cn/lctt/)
|
||||
- LCTT 状态: [https://lctt.github.io/](https://lctt.github.io/)
|
||||
|
||||
加入我们
|
||||
-------------------------------
|
||||
|
||||
请首先加入翻译组的 QQ 群,群号是:198889102,加群时请说明是“志愿者”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
请首先加入翻译组的 QQ 群,群号是:**198889102**,加群时请说明是“*志愿者*”。
|
||||
|
||||
加入的成员,请先阅读 [WIKI 如何开始](https://github.com/LCTT/TranslateProject/wiki/01-如何开始)。
|
||||
加入的成员,请:
|
||||
|
||||
1. 修改你的 QQ 群名片为“译者-您的_GitHub_ID”。
|
||||
2. 阅读 [WIKI](https://lctt.github.io/wiki) 了解如何开始。
|
||||
3. 遇到不解之处,请在群内发问。
|
||||
|
||||
如何开始
|
||||
-------------------------------
|
||||
|
||||
请阅读 [WIKI](https://github.com/LCTT/TranslateProject/wiki)。
|
||||
请阅读 [WIKI](https://lctt.github.io/wiki)。如需要协助,请在群内发问。
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
@ -65,43 +71,56 @@ LCTT 的组成
|
||||
* 2018/01/11 提升 lujun9972 成为核心成员,并加入选题组。
|
||||
* 2018/02/20 遭遇 DMCA 仓库被封。
|
||||
* 2018/05/15 提升 MjSeven 为核心成员。
|
||||
* 2018/08/01 [发布 Linux 中国通证:LCCN](https://linux.cn/article-9886-1.html)。
|
||||
* 2018/08/17 提升 pityonline 为核心成员,担任校对,并接受他的建议采用 PR 审核模式。
|
||||
* 2018/09/10 [LCTT 五周年](https://linux.cn/article-9999-1.html)。
|
||||
* 2018/10/25 重构了 CI,感谢 vizv、lujun9972、bestony。
|
||||
* 2018/11/13 [成立了项目管理委员会(PMC)](https://linux.cn/article-10279-1.html),初始成员为:@wxy (主席)、@oska874、@lujun9972、@bestony、@pityonline、@geekpi、@qhwdw。
|
||||
|
||||
核心成员
|
||||
|
||||
项目管理委员及核心成员
|
||||
-------------------------------
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
LCTT 现由项目管理委员会(PMC)进行管理,成员如下:
|
||||
|
||||
- 组长 @wxy,
|
||||
- 选题 @oska874,
|
||||
- 校对 @jasminepeng,
|
||||
- 钻石译者 @geekpi,
|
||||
- 钻石译者 @GOLinux,
|
||||
- 钻石译者 @ictlyh,
|
||||
- 技术组长 @bestony,
|
||||
- 漫画组长 @GHLandy,
|
||||
- LFS 组长 @martin2011qi,
|
||||
- 核心成员 @strugglingyouth,
|
||||
- 核心成员 @FSSlc,
|
||||
- 核心成员 @zpl1025,
|
||||
- 核心成员 @runningwater,
|
||||
- 核心成员 @bazz2,
|
||||
- 核心成员 @Vic020,
|
||||
- 核心成员 @alim0x,
|
||||
- 核心成员 @tinyeyeser,
|
||||
- 核心成员 @Locez,
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @qhwdw,
|
||||
- 核心成员 @lujun9972
|
||||
- 核心成员 @MjSeven
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
- 前任校对 @carolinewuyan,
|
||||
- 功勋成员 @vito-L,
|
||||
- 功勋成员 @willqian,
|
||||
- 功勋成员 @vizv,
|
||||
- 功勋成员 @dongfengweixiao,
|
||||
- 🎩 主席 @wxy
|
||||
- 🎩 选题 @oska874
|
||||
- 🎩 选题 @lujun9972
|
||||
- 🎩 技术 @bestony
|
||||
- 🎩 校对 @pityonline
|
||||
- 🎩 译者 @geekpi
|
||||
- 🎩 译者 @qhwdw
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
|
||||
- ❤️ 核心成员 @vizv
|
||||
- ❤️ 核心成员 @zpl1025
|
||||
- ❤️ 核心成员 @runningwater
|
||||
- ❤️ 核心成员 @FSSlc
|
||||
- ❤️ 核心成员 @Vic020
|
||||
- ❤️ 核心成员 @alim0x
|
||||
- ❤️ 核心成员 @martin2011qi
|
||||
- ❤️ 核心成员 @Locez
|
||||
- ❤️ 核心成员 @ucasFL
|
||||
- ❤️ 核心成员 @MjSeven
|
||||
|
||||
曾经做出了巨大贡献的核心成员,被列入荣誉榜:
|
||||
|
||||
- 🏆 前任选题 @DeadFire
|
||||
- 🏆 前任校对 @reinoir222
|
||||
- 🏆 前任校对 @PurlingNayuki
|
||||
- 🏆 前任校对 @carolinewuyan
|
||||
- 🏆 前任校对 @jasminepeng
|
||||
- 🏆 功勋成员 @tinyeyeser
|
||||
- 🏆 功勋成员 @vito-L
|
||||
- 🏆 功勋成员 @willqian
|
||||
- 🏆 功勋成员 @GOLinux
|
||||
- 🏆 功勋成员 @bazz2
|
||||
- 🏆 功勋成员 @ictlyh
|
||||
- 🏆 功勋成员 @dongfengweixiao
|
||||
- 🏆 功勋成员 @strugglingyouth
|
||||
- 🏆 功勋成员 @GHLandy
|
||||
- 🏆 功勋成员 @rusking
|
||||
|
||||
全部成员列表请参见: https://linux.cn/lctt-list/ 。
|
||||
|
||||
|
||||
1
comic
1
comic
@ -1 +0,0 @@
|
||||
Subproject commit e5db5b880dac1302ee0571ecaaa1f8ea7cf61901
|
||||
75
lctt2018.md
Normal file
75
lctt2018.md
Normal file
@ -0,0 +1,75 @@
|
||||
LCTT 2018:五周年纪念日
|
||||
======
|
||||
|
||||
我是老王,可能大家有不少人知道我,由于历史原因,我有好几个生日(;o),但是这些年来,我又多了一个生日,或者说纪念日——每过两年,我就要严肃认真地写一篇 [LCTT](https://linux.cn/lctt) 生日纪念文章。
|
||||
|
||||
喏,这一篇,就是今年的了,LCTT 如今已经五岁了!
|
||||
|
||||
或许如同小孩子过生日总是比较快乐,而随着年岁渐长,过生日往往有不少负担——比如说,每次写这篇纪念文章时,我就需要回忆、反思这两年的做了些什么,往往颇为汗颜。
|
||||
|
||||
不过不管怎么说,总要总结一下这两年我们做了什么,有什么不足,也发一些展望吧。
|
||||
|
||||
### 江山代有英豪出
|
||||
|
||||
LCTT,如同一般的开源贡献组织,总是有不断的新老传承。我们的翻译组,也有不少成员,由于工作学习的原因,慢慢淡出,但同时,也不断有新的成员加入并接过前辈手中的旗帜(就是没人接我的)。
|
||||
|
||||
> **加入方式**
|
||||
|
||||
> 请首先加入翻译组的 QQ 群,群号是:**198889102**,加群时请说明是“**志愿者**”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
|
||||
> 加入的成员,请先阅读 [WIKI 如何开始](https://github.com/LCTT/TranslateProject/wiki/01-%E5%A6%82%E4%BD%95%E5%BC%80%E5%A7%8B)。
|
||||
|
||||
比如说,我们这两年来,oska874 承担了主要的选题工作,然后 lujun9972 适时的出现接过了不少选题工作;再比如说,qhwdw 出现后承担了大量繁难文章的翻译,pityonline 则专注于校对,甚至其校对的严谨程度让我都甘拜下风。还有 MjSeven 也同 qhwdw 一样,以极高的翻译频率从一星译者迅速登顶五星译者。当然,还有 Bestony、Locez、VizV 等人为 LCTT 提供了不少技术支持和开发工作。
|
||||
|
||||
### 硕果累累
|
||||
|
||||
我们并没有特别的招新渠道,但是总是时不时会有新的成员慕名而来,到目前为止,我们已经有 [331](https://linux.cn/lctt-list) 位做过贡献的成员,已经翻译发布了 3885 篇译文,合计字节达 33MB 之多!
|
||||
|
||||
这两年,我们不但翻译了很多技术、新闻和评论类文章,也新增了新的翻译类型:[漫画](https://linux.cn/talk/comic/),其中一些漫画得到了很多好评。
|
||||
|
||||
我们发布的文章有一些达到了 100000+ 的访问量,这对于我们这种技术垂直内容可不容易。
|
||||
|
||||
而同时,[Linux 中国](https://linux.cn/)也发布了近万篇文章,而这一篇,应该就是第 [9999](https://linux.cn/article-9999-1.html) 篇文章,我们将在明天,进入新的篇章。
|
||||
|
||||
### 贡献者主页和贡献者证书
|
||||
|
||||
为了彰显诸位贡献者的贡献,我们为每位贡献者创立的自己的专页,并据此建立了[排行榜](https://linux.cn/lctt-list)。
|
||||
|
||||
同时,我们还特意请 Bestony 和“一一”设计开发和”贡献者证书”,大家可以在 [LCTT 贡献平台](https://lctt.linux.cn/)中领取。
|
||||
|
||||
### 规则进化
|
||||
|
||||
LCTT 最初创立时,甚至都没有采用 PR 模式。但是随着贡献者的增多,我们也逐渐在改善我们的流程、方法。
|
||||
|
||||
之前采用了很粗糙的 PR 模式,对 PR 中的文件、提交乃至于信息都没有进行硬性约束。后来在 VizV 的帮助下,建立了对 PR 的合规性检查;又在 pityonline 的督促下,采用了更为严格的 PR 审查机制。
|
||||
|
||||
LCTT 创立几年来,我们的一些流程和规范,已经成为其它一些翻译组的参考范本,我们也希望我们的这些经验,可以进一步帮助到其它的开源社区。
|
||||
|
||||
### 仓库重建和版权问题
|
||||
|
||||
今年还发生一次严重的事故,由于对选题来源把控不严和对版权问题没有引起足够的重视,我们引用的一篇文章违背了原文的版权规定,结果被原文作者投诉到 GitHub。而我并没有及时看到 GitHub 给我发的 DMCA 处理邮件,因此错过了处理窗口期,从而被 GitHub 将整个库予以删除。
|
||||
|
||||
出现这样的重大失误之后,经过大家的帮助,我们历经周折才将仓库基本恢复。这要特别感谢 VizV 的辛苦工作。
|
||||
|
||||
在此之后,我们对译文选文的规则进行了梳理,并全面清查了文章版权。这个教训对我们来说弥足沉重。
|
||||
|
||||
### 通证时代
|
||||
|
||||
在 Linux 中国及 LCTT 发展过程中,我一直小心翼翼注意商业化的问题。严格来说,没有经济支持的开源组织如同无根之木,无源之水,是长久不了的。而商业化的技术社区又难免为了三斗米而折腰。所以往往很多技术社区要么渐渐凋零,要么就变成了商业机构。
|
||||
|
||||
从中国电信辞职后,我专职运营 Linux 中国这个开源社区已经近三年了,其间也有一些商业性收入,但是仅能勉强承担基本的运营费用。
|
||||
|
||||
这种尴尬的局面,使我,以及其它的开源社区同仁们纷纷寻求更好的发展之路。
|
||||
|
||||
去年参加中国开源年会时,在闭门会上,大家的讨论启发了我和诸位同仁,我们认为,开源社区结合通证经济,似乎是一条可行的开源社区发展之路。
|
||||
|
||||
今年 8 月 1 日,我们经过了半年的论证和实验,[发布了社区通证 LCCN](https://linux.cn/article-9886-1.html),并已经初步发放到了各位译者手中。我们还在继续建设通证生态各种工具,如合约、交易商城等。
|
||||
|
||||
我们希望能够通过通证为开源社区转入新的活力,也愿意将在探索道路上遇到的问题和解决的思路、工具链分享给更多的社区。
|
||||
|
||||
### 总结
|
||||
|
||||
从上一次总结以来,这又是七百多天,时光荏苒,而 LCTT 的创立也近两千天了。我希望,我们的翻译组以及更多的贡献者可以在通证经济的推动下,找到自洽、自治的发展道路;也希望能有更多的贡献者涌现出来接过我们的大旗,将开源发扬光大。
|
||||
|
||||
wxy
|
||||
2018/9/9 夜
|
||||
77
published/201309/20190204 7 Best VPN Services For 2019.md
Normal file
77
published/201309/20190204 7 Best VPN Services For 2019.md
Normal file
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10691-1.html)
|
||||
[#]: subject: (7 Best VPN Services For 2019)
|
||||
[#]: via: (https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/)
|
||||
[#]: author: (Editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
2019 年最好的 7 款虚拟私人网络服务
|
||||
======
|
||||
|
||||
在过去三年中,全球至少有 67% 的企业面临着数据泄露,亿万用户受到影响。研究表明,如果事先对数据安全采取最基本的保护措施,那么预计有 93% 的安全问题是可以避免的。
|
||||
|
||||
糟糕的数据安全会带来极大的代价,特别是对企业而言。它会大致大规模的破坏并影响你的品牌声誉。尽管有些企业可以艰难地收拾残局,但仍有一些企业无法从事故中完全恢复。不过现在,你很幸运地可以得到数据及网络安全软件。
|
||||
|
||||

|
||||
|
||||
到了 2019 年,你可以通过**虚拟私人网络**,也就是我们熟知的 **VPN** 来保护你免受网络攻击。当涉及到在线隐私和安全时,常常存在许多不确定因素。有数百个不同的 VPN 提供商,选择合适的供应商也同时意味着在定价、服务和易用性之间谋取恰当的平衡。
|
||||
|
||||
如果你正在寻找一个可靠的 100% 经过测试和安全的 VPN,你可能需要进行详尽的调查并作出最佳选择。这里为你提供在 2019 年 7 款最好用并经过测试的 VPN 服务。
|
||||
|
||||
### 1、Vpnunlimitedapp
|
||||
|
||||
通过 VPN Unlimited,你的数据安全将得到全面的保障。此 VPN 允许你连接任何 WiFi ,而无需担心你的个人数据可能被泄露。你的数据通过 AES-256 算法加密,保护你不受第三方和黑客的窥探。无论你身处何处,这款 VPN 都可确保你在所有网站上保持匿名且不受跟踪。它提供 7 天的免费试用和多种协议支持:openvpn、IKEv2 和 KeepSolidWise。有特殊需求的用户会获得特殊的额外服务,如个人服务器、终身 VPN 订阅和个人 IP 选项。
|
||||
|
||||
### 2、VPN Lite
|
||||
|
||||
VPN Lite 是一款易于使用而且**免费**的用于上网的 VPN 服务。你可以通过它在网络上保持匿名并保护你的个人隐私。它会模糊你的 IP 并加密你的数据,这意味着第三方无法跟踪你的所有线上活动。你还可以访问网络上的全部内容。使用 VPN Lite,你可以访问在被拦截的网站。你还放心地可以访问公共 WiFi 而不必担心敏感信息被间谍软件窃取和来自黑客的跟踪和攻击。
|
||||
|
||||
### 3、HotSpot Shield
|
||||
|
||||
这是一款在 2005 年推出的大受欢迎的 VPN。这套 VPN 协议至少被全球 70% 的数据安全公司所集成,并在全球有数千台服务器。它提供两种免费模式:一种为完全免费,但会有线上广告;另一种则为七天试用。它提供军事级的数据加密和恶意软件防护。HotSpot Shield 保证网络安全并保证高速网络。
|
||||
|
||||
### 4、TunnelBear
|
||||
|
||||
如果你是一名 VPN 新手,那么 TunnelBear 将是你的最佳选择。它带有一个用户友好的界面,并配有动画熊引导。你可以在 TunnelBear 的帮助下以极快的速度连接至少 22 个国家的服务器。它使用 **AES 256-bit** 加密算法,保证无日志记录,这意味着你的数据将得到保护。你还可以在最多五台设备上获得无限流量。
|
||||
|
||||
### 5、ProtonVPN
|
||||
|
||||
这款 VPN 为你提供强大的优质服务。你的连接速度可能会受到影响,但你也可以享受到无限流量。它具有易于使用的用户界面,提供多平台兼容。 ProtonVPN 的服务据说是因为为种子下载提供了优化因而无法访问 Netflix。你可以获得如协议和加密等安全功能来保证你的网络安全。
|
||||
|
||||
### 6、ExpressVPN
|
||||
|
||||
ExpressVPN 被认为是最好的用于接触封锁和保护隐私的离岸 VPN。凭借强大的客户支持和快速的速度,它已成为全球顶尖的 VPN 服务。它提供带有浏览器扩展和自定义固件的路由。 ExpressVPN 拥有一系列令人赞叹高质量应用程序,配有大量的服务器,并且最多只能支持三台设备。
|
||||
|
||||
ExpressVPN 并不是完全免费的,恰恰相反,正是由于它所提供的高质量服务而使之成为了市场上最贵的 VPN 之一。ExpressVPN 有 30 天内退款保证,因此你可以免费试用一个月。好消息是,这是完全没有风险的。例如,如果你在短时间内需要 VPN 来绕过在线审查,这可能是你的首选解决方案。用过它之后,你就不会随意想给一个会发送垃圾邮件、缓慢的免费的程序当成试验品。
|
||||
|
||||
ExpressVPN 也是享受在线流媒体和户外安全的最佳方式之一。如果你需要继续使用它,你只需要续订或取消你的免费试用。ExpressVPN 在 90 多个国家架设有 2000 多台服务器,可以解锁 Netflix,提供快速连接,并为用户提供完全隐私。
|
||||
|
||||
### 7、PureVPN
|
||||
|
||||
虽然 PureVPN 可能不是完全免费的,但它却是此列表中最实惠的一个。用户可以注册获得 7 天的免费试用,并在之后选择任一付费计划。通过这款 VPN,你可以访问到至少 140 个国家中的 750 余台服务器。它还可以在几乎所有设备上轻松安装。它的所有付费特性仍然可以在免费试用期间使用。包括无限数据流量、IP 泄漏保护和 ISP 不可见性。它支持的系统有 iOS、Android、Windows、Linux 和 macOS。
|
||||
|
||||
### 总结
|
||||
|
||||
如今,可用的免费 VPN 服务越来越多,为什么不抓住这个机会来保护你自己和你的客户呢?在了解到有那么多优秀的 VPN 服务后,我们知道即使是最安全的免费服务也不一定就完全没有风险。你可能需要付费升级到高级版以增强保护。高级版的 VPN 为你提供了免费试用,提供无风险退款保证。无论你打算花钱购买 VPN 还是准备使用免费 VPN,我们都强烈建议你使用一个。
|
||||
|
||||
**关于作者:**
|
||||
|
||||
**Renetta K. Molina** 是一个技术爱好者和健身爱好者。她撰写有关技术、应用程序、 WordPress 和其他任何领域的文章。她喜欢在空余时间打高尔夫球和读书。她喜欢学习和尝试新事物。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/
|
||||
|
||||
作者:[Editor][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Modrisco](https://github.com/Modrisco)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -104,10 +104,10 @@ Arch Linux 也因其丰富的 Wiki 帮助文档而大受推崇。该系统基于
|
||||
][23]
|
||||
|
||||
输入下面的命令来检查网络连接。
|
||||
|
||||
|
||||
```
|
||||
ping google.com
|
||||
```
|
||||
```
|
||||
|
||||
这个单词 ping 表示网路封包搜寻。你将会看到下面的返回信息,表明 Arch Linux 已经连接到外网了。这是执行安装过程中的很关键的一点。(LCTT 译注:或许你 ping 不到那个不存在的网站,你选个存在的吧。)
|
||||
|
||||
@ -117,8 +117,8 @@ ping google.com
|
||||
|
||||
输入如下命令清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
在开始安装之前,你得先为硬盘分区。输入 `fdisk -l` ,你将会看到当前系统的磁盘分区情况。注意一开始你给 Arch Linux 系统分配的 20 GB 存储空间。
|
||||
@ -137,8 +137,8 @@ clear
|
||||
|
||||
输入下面的命令:
|
||||
|
||||
```
|
||||
cfdisk
|
||||
```
|
||||
cfdisk
|
||||
```
|
||||
|
||||
你将看到 `gpt`、`dos`、`sgi` 和 `sun` 类型,选择 `dos` 选项,然后按回车。
|
||||
@ -185,8 +185,8 @@ cfdisk
|
||||
|
||||
以同样的方式创建逻辑分区。在“退出(quit)”选项按回车键,然后输入下面的命令来清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
[
|
||||
@ -195,21 +195,21 @@ clear
|
||||
|
||||
输入下面的命令来格式化新建的分区:
|
||||
|
||||
```
|
||||
```
|
||||
mkfs.ext4 /dev/sda1
|
||||
```
|
||||
```
|
||||
|
||||
这里的 `sda1` 是分区名。使用同样的命令来格式化第二个分区 `sda3` :
|
||||
|
||||
```
|
||||
```
|
||||
mkfs.ext4 /dev/sda3
|
||||
```
|
||||
```
|
||||
|
||||
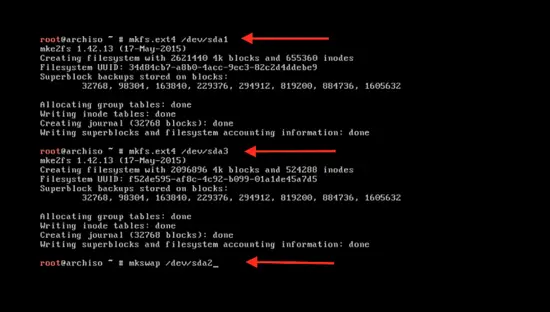
格式化 swap 分区:
|
||||
|
||||
```
|
||||
```
|
||||
mkswap /dev/sda2
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
@ -217,14 +217,14 @@ mkswap /dev/sda2
|
||||
|
||||
使用下面的命令来激活 swap 分区:
|
||||
|
||||
```
|
||||
swapon /dev/sda2
|
||||
```
|
||||
swapon /dev/sda2
|
||||
```
|
||||
|
||||
输入 clear 命令清屏:
|
||||
|
||||
```
|
||||
clear
|
||||
```
|
||||
clear
|
||||
```
|
||||
|
||||
[
|
||||
@ -233,9 +233,9 @@ clear
|
||||
|
||||
输入下面的命令来挂载主分区以开始系统安装:
|
||||
|
||||
```
|
||||
mount /dev/sda1 / mnt
|
||||
```
|
||||
```
|
||||
mount /dev/sda1 /mnt
|
||||
```
|
||||
|
||||
[
|
||||
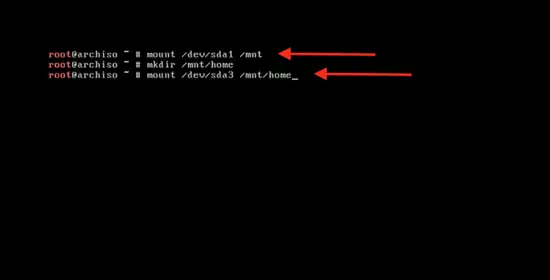
|
||||
@ -245,9 +245,9 @@ mount /dev/sda1 / mnt
|
||||
|
||||
输入下面的命令来引导系统启动:
|
||||
|
||||
```
|
||||
```
|
||||
pacstrap /mnt base base-devel
|
||||
```
|
||||
```
|
||||
|
||||
可以看到系统正在同步数据包。
|
||||
|
||||
@ -263,9 +263,9 @@ pacstrap /mnt base base-devel
|
||||
|
||||
系统基本软件安装完成后,输入下面的命令来创建 fstab 文件:
|
||||
|
||||
```
|
||||
```
|
||||
genfstab /mnt>> /mnt/etc/fstab
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
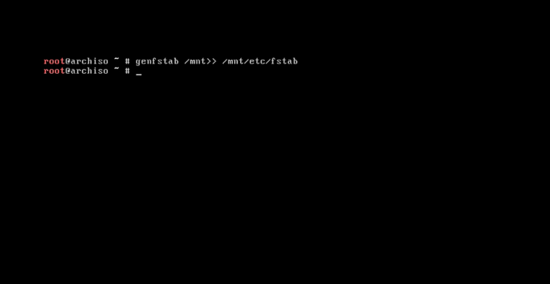
|
||||
@ -275,14 +275,14 @@ genfstab /mnt>> /mnt/etc/fstab
|
||||
|
||||
输入下面的命令来更改系统的根目录为 Arch Linux 的安装目录:
|
||||
|
||||
```
|
||||
```
|
||||
arch-chroot /mnt /bin/bash
|
||||
```
|
||||
```
|
||||
|
||||
现在来更改语言配置:
|
||||
|
||||
```
|
||||
nano /etc/local.gen
|
||||
```
|
||||
nano /etc/locale.gen
|
||||
```
|
||||
|
||||
[
|
||||
@ -297,9 +297,9 @@ nano /etc/local.gen
|
||||
|
||||
输入下面的命令来激活它:
|
||||
|
||||
```
|
||||
```
|
||||
locale-gen
|
||||
```
|
||||
```
|
||||
|
||||
按回车。
|
||||
|
||||
@ -309,8 +309,8 @@ locale-gen
|
||||
|
||||
使用下面的命令来创建 `/etc/locale.conf` 配置文件:
|
||||
|
||||
```
|
||||
nano /etc/locale.conf
|
||||
```
|
||||
nano /etc/locale.conf
|
||||
```
|
||||
|
||||
然后按回车。现在你就可以在配置文件中输入下面一行内容来为系统添加语言:
|
||||
@ -326,9 +326,9 @@ LANG=en_US.UTF-8
|
||||
][44]
|
||||
|
||||
输入下面的命令来同步时区:
|
||||
|
||||
|
||||
```
|
||||
ls user/share/zoneinfo
|
||||
ls /usr/share/zoneinfo
|
||||
```
|
||||
|
||||
下面你将看到整个世界的时区列表。
|
||||
@ -339,9 +339,9 @@ ls user/share/zoneinfo
|
||||
|
||||
输入下面的命令来选择你所在的时区:
|
||||
|
||||
```
|
||||
```
|
||||
ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
```
|
||||
```
|
||||
|
||||
或者你可以从下面的列表中选择其它名称。
|
||||
|
||||
@ -351,8 +351,8 @@ ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
|
||||
|
||||
使用下面的命令来设置标准时间:
|
||||
|
||||
```
|
||||
hwclock --systohc –utc
|
||||
```
|
||||
hwclock --systohc --utc
|
||||
```
|
||||
|
||||
硬件时钟已同步。
|
||||
@ -363,8 +363,8 @@ hwclock --systohc –utc
|
||||
|
||||
设置 root 帐号密码:
|
||||
|
||||
```
|
||||
passwd
|
||||
```
|
||||
passwd
|
||||
```
|
||||
|
||||
按回车。 然而输入你想设置的密码,按回车确认。
|
||||
@ -377,9 +377,9 @@ passwd
|
||||
|
||||
使用下面的命令来设置主机名:
|
||||
|
||||
```
|
||||
```
|
||||
nano /etc/hostname
|
||||
```
|
||||
```
|
||||
|
||||
然后按回车。输入你想设置的主机名称,按 `control + x` ,按 `y` ,再按回车 。
|
||||
|
||||
@ -389,9 +389,9 @@ nano /etc/hostname
|
||||
|
||||
启用 dhcpcd :
|
||||
|
||||
```
|
||||
```
|
||||
systemctl enable dhcpcd
|
||||
```
|
||||
```
|
||||
|
||||
这样在下一次系统启动时, dhcpcd 将会自动启动,并自动获取一个 IP 地址:
|
||||
|
||||
@ -403,9 +403,9 @@ systemctl enable dhcpcd
|
||||
|
||||
最后一步,输入以下命令来初始化 grub 安装。输入以下命令:
|
||||
|
||||
```
|
||||
```
|
||||
pacman –S grub os-rober
|
||||
```
|
||||
```
|
||||
|
||||
然后按 `y` ,将会下载相关程序。
|
||||
|
||||
@ -415,14 +415,14 @@ pacman –S grub os-rober
|
||||
|
||||
使用下面的命令来将启动加载程序安装到硬盘上:
|
||||
|
||||
```
|
||||
```
|
||||
grub-install /dev/sda
|
||||
```
|
||||
```
|
||||
|
||||
然后进行配置:
|
||||
|
||||
```
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
```
|
||||
|
||||
[
|
||||
@ -431,9 +431,9 @@ grub-mkconfig -o /boot/grub/grub.cfg
|
||||
|
||||
最后重启系统:
|
||||
|
||||
```
|
||||
```
|
||||
reboot
|
||||
```
|
||||
```
|
||||
|
||||
然后按回车 。
|
||||
|
||||
@ -459,7 +459,7 @@ reboot
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-arch-linux-on-virtualbox/
|
||||
|
||||
译者简介:
|
||||
译者简介:
|
||||
|
||||
rusking:春城初春/春水初生/春林初盛/春風十裏不如妳
|
||||
|
||||
|
||||
171
published/20180116 Command Line Heroes- Season 1- OS Wars_2.md
Normal file
171
published/20180116 Command Line Heroes- Season 1- OS Wars_2.md
Normal file
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11296-1.html)
|
||||
[#]: subject: (Command Line Heroes: Season 1: OS Wars)
|
||||
[#]: via: (https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux)
|
||||
[#]: author: (redhat https://www.redhat.com)
|
||||
|
||||
《代码英雄》第一季(2):操作系统战争(下)Linux 崛起
|
||||
======
|
||||
|
||||
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗故事。
|
||||
|
||||

|
||||
|
||||
本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(2):操作系统战争(下)](https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux) 的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/2199861a.mp3)脚本。
|
||||
|
||||
> 微软帝国控制着 90% 的用户。操作系统的完全标准化似乎是板上钉钉的事了。但是一个不太可能的英雄出现在开源反叛组织中。戴着眼镜,温文尔雅的<ruby>林纳斯·托瓦兹<rt>Linus Torvalds</rt></ruby>免费发布了他的 Linux® 程序。微软打了个趔趄,并且开始重整旗鼓而来,战场从个人电脑转向互联网。
|
||||
|
||||
**Saron Yitbarek:** 这玩意开着的吗?让我们进一段史诗般的星球大战的开幕吧,开始了。
|
||||
|
||||
配音:第二集:Linux® 的崛起。微软帝国控制着 90% 的桌面用户。操作系统的全面标准化似乎是板上钉钉的事了。然而,互联网的出现将战争的焦点从桌面转向了企业,在该领域,所有商业组织都争相构建自己的服务器。*[00:00:30]*与此同时,一个不太可能的英雄出现在开源反叛组织中。固执、戴着眼镜的 <ruby>林纳斯·托瓦兹<rt>Linus Torvalds</rt></ruby>免费发布了他的 Linux 系统。微软打了个趔趄,并且开始重整旗鼓而来。
|
||||
|
||||
**Saron Yitbarek:** 哦,我们书呆子就是喜欢那样。上一次我们讲到哪了?苹果和微软互相攻伐,试图在一场争夺桌面用户的战争中占据主导地位。*[00:01:00]* 在第一集的结尾,我们看到微软获得了大部分的市场份额。很快,由于互联网的兴起以及随之而来的开发者大军,整个市场都经历了一场地震。互联网将战场从在家庭和办公室中的个人电脑用户转移到拥有数百台服务器的大型商业客户中。
|
||||
|
||||
这意味着巨量资源的迁移。突然间,所有相关企业不仅被迫为服务器空间和网站建设付费,而且还必须集成软件来进行资源跟踪和数据库监控等工作。*[00:01:30]* 你需要很多开发人员来帮助你。至少那时候大家都是这么做的。
|
||||
|
||||
在操作系统之战的第二部分,我们将看到优先级的巨大转变,以及像林纳斯·托瓦兹和<ruby>理查德·斯托尔曼<rt>Richard Stallman</rt></ruby>这样的开源反逆者是如何成功地在微软和整个软件行业的核心地带引发恐惧的。
|
||||
|
||||
我是 Saron Yitbarek,你现在收听的是代码英雄,一款红帽公司原创的播客节目。*[00:02:00]* 每一集,我们都会给你带来“从码开始”改变技术的人的故事。
|
||||
|
||||
好。想象一下你是 1991 年时的微软。你自我感觉良好,对吧?满怀信心。确立了全球主导的地位感觉不错。你已经掌握了与其他企业合作的艺术,但是仍然将大部分开发人员、程序员和系统管理员排除在联盟之外,而他们才是真正的步兵。*[00:02:30]* 这时出现了个叫林纳斯·托瓦兹的芬兰极客。他和他的开源程序员团队正在开始发布 Linux,这个操作系统内核是由他们一起编写出来的。
|
||||
|
||||
坦白地说,如果你是微软公司,你并不会太在意 Linux,甚至不太关心开源运动,但是最终,Linux 的规模变得如此之大,以至于微软不可能不注意到。*[00:03:00]* Linux 第一个版本出现在 1991 年,当时大概有 1 万行代码。十年后,变成了 300 万行代码。如果你想知道,今天则是 2000 万行代码。
|
||||
|
||||
*[00:03:30]* 让我们停留在 90 年代初一会儿。那时 Linux 还没有成为我们现在所知道的庞然大物。这个奇怪的病毒式的操作系统只是正在这个星球上蔓延,全世界的极客和黑客都爱上了它。那时候我还太年轻,但有点希望我曾经经历过那个时候。在那个时候,发现 Linux 就如同进入了一个秘密社团一样。就像其他人分享地下音乐混音带一样,程序员与朋友们分享 Linux CD 集。
|
||||
|
||||
开发者 Tristram Oaten *[00:03:40]* 讲讲你 16 岁时第一次接触 Linux 的故事吧。
|
||||
|
||||
**Tristram Oaten:** 我和我的家人去了红海的 Hurghada 潜水度假。那是一个美丽的地方,强烈推荐。第一天,我喝了自来水。也许,我妈妈跟我说过不要这么做。我整个星期都病得很厉害,没有离开旅馆房间。*[00:04:00]* 当时我只带了一台新安装了 Slackware Linux 的笔记本电脑,我听说过这玩意并且正在尝试使用它。所有的东西都在 8 张 cd 里面。这种情况下,我只能整个星期都去了解这个外星一般的系统。我阅读手册,摆弄着终端。我记得当时我甚至不知道一个点(表示当前目录)和两个点(表示前一个目录)之间的区别。
|
||||
|
||||
*[00:04:30]* 我一点头绪都没有。犯过很多错误,但慢慢地,在这种强迫的孤独中,我突破了障碍,开始理解并明白命令行到底是怎么回事。假期结束时,我没有看过金字塔、尼罗河等任何埃及遗址,但我解锁了现代世界的一个奇迹。我解锁了 Linux,接下来的事大家都知道了。
|
||||
|
||||
**Saron Yitbarek:** 你会从很多人那里听到关于这个故事的不同说法。访问 Linux 命令行是一种革命性的体验。
|
||||
|
||||
**David Cantrell:** *[00:05:00]* 它给了我源代码。我当时的感觉是,“太神奇了。”
|
||||
|
||||
**Saron Yitbarek:** 我们正在参加一个名为 Flock to Fedora 的 2017 年 Linux 开发者大会。
|
||||
|
||||
**David Cantrell:** ……非常有吸引力。我觉得我对这个系统有了更多的控制力,它越来越吸引我。我想,从 1995 年我第一次编译 Linux 内核那时起,我就迷上了它。
|
||||
|
||||
**Saron Yitbarek:** 开发者 David Cantrell 与 Joe Brockmire。
|
||||
|
||||
**Joe Brockmeier:** *[00:05:30]* 我在 Cheap Software 转的时候发现了一套四张 CD 的 Slackware Linux。它看起来来非常令人兴奋而且很有趣,所以我把它带回家,安装在第二台电脑上,开始摆弄它,有两件事情让我感到很兴奋:一个是,我运行的不是 Windows,另一个是 Linux 的开源特性。
|
||||
|
||||
**Saron Yitbarek:** *[00:06:00]* 某种程度上来说,对命令行的使用总是存在的。在开源真正开始流行还要早的几十年前,人们(至少在开发人员中是这样)总是希望能够做到完全控制。让我们回到操作系统大战之前的那个时代,在苹果和微软为他们的 GUI 而战之前。那时也有代码英雄。<ruby>保罗·琼斯<rt>Paul Jones</rt></ruby>教授(在线图书馆 ibiblio.org 的负责人)在那个古老的时代,就是一名开发人员。
|
||||
|
||||
**Paul Jones:** *[00:06:30]* 从本质上讲,互联网在那个时候客户端-服务器架构还是比较少的,而更多的是点对点架构的。确实,我们会说,某种 VAX 到 VAX 的连接(LCTT 译注:DEC 的一种操作系统),某种科学工作站到科学工作站的连接。这并不意味着没有客户端-服务端的架构及应用程序,但这的确意味着,最初的设计是思考如何实现点对点,*[00:07:00]* 它与 IBM 一直在做的东西相对立。IBM 给你的只有哑终端,这种终端只能让你管理用户界面,却无法让你像真正的终端一样为所欲为。
|
||||
|
||||
**Saron Yitbarek:** 图形用户界面在普通用户中普及的同时,在工程师和开发人员中总是存在着一股相反的力量。早在 Linux 出现之前的二十世纪七八十年代,这股力量就存在于 Emacs 和 GNU 中。有了斯托尔曼的自由软件基金会后,总有某些人想要使用命令行,但上世纪 90 年代的 Linux 提供了前所未有的东西。
|
||||
|
||||
*[00:07:30]* Linux 和其他开源软件的早期爱好者是都是先驱。我正站在他们的肩膀上。我们都是。
|
||||
|
||||
你现在收听的是代码英雄,一款由红帽公司原创的播客。这是操作系统大战的第二部分:Linux 崛起。
|
||||
|
||||
**Steven Vaughan-Nichols:** 1998 年的时候,情况发生了变化。
|
||||
|
||||
**Saron Yitbarek:** *[00:08:00]* Steven Vaughan-Nichols 是 zdnet.com 的特约编辑,他已经写了几十年关于技术商业方面的文章了。他将向我们讲述 Linux 是如何慢慢变得越来越流行,直到自愿贡献者的数量远远超过了在 Windows 上工作的微软开发人员的数量的。不过,Linux 从未真正追上微软桌面客户的数量,这也许就是微软最开始时忽略了 Linux 及其开发者的原因。Linux 真正大放光彩的地方是在服务器机房。当企业开始线上业务时,每个企业都需要一个满足其需求的独特编程解决方案。
|
||||
|
||||
*[00:08:30]* WindowsNT 于 1993 年问世,当时它已经在与其他的服务器操作系统展开竞争了,但是许多开发人员都在想,“既然我可以通过 Apache 构建出基于 Linux 的廉价系统,那我为什么要购买 AIX 设备或大型 Windows 设备呢?”关键点在于,Linux 代码已经开始渗透到几乎所有网上的东西中。
|
||||
|
||||
**Steven Vaughan-Nichols:** *[00:09:00]* 令微软感到惊讶的是,它开始意识到,Linux 实际上已经开始有一些商业应用,不是在桌面环境,而是在商业服务器上。因此,他们发起了一场运动,我们称之为 FUD - <ruby>恐惧、不确定和怀疑<rt>fear, uncertainty and double</rt></ruby>。他们说,“哦,Linux 这玩意,真的没有那么好。它不太可靠。你一点都不能相信它”。
|
||||
|
||||
**Saron Yitbarek:** 这种软宣传式的攻击持续了一段时间。微软也不是唯一一个对 Linux 感到紧张的公司。这其实是整个行业在对抗这个奇怪新人的挑战。*[00:09:30]* 例如,任何与 UNIX 有利害关系的人都可能将 Linux 视为篡夺者。有一个案例很著名,那就是 SCO 组织(它发行过一种 UNIX 版本)在过去 10 多年里发起一系列的诉讼,试图阻止 Linux 的传播。SCO 最终失败而且破产了。与此同时,微软一直在寻找机会,他们必须要采取动作,只是不清楚具体该怎么做。
|
||||
|
||||
**Steven Vaughan-Nichols:** *[00:10:00]* 让微软真正担心的是,第二年,在 2000 年的时候,IBM 宣布,他们将于 2001 年投资 10 亿美元在 Linux 上。现在,IBM 已经不再涉足个人电脑业务。(那时)他们还没有走出去,但他们正朝着这个方向前进,他们将 Linux 视为服务器和大型计算机的未来,在这一点上,剧透警告,IBM 是正确的。*[00:10:30]* Linux 将主宰服务器世界。
|
||||
|
||||
**Saron Yitbarek:** 这已经不再仅仅是一群黑客喜欢他们对命令行的绝地武士式的控制了。金钱的投入对 Linux 助力极大。<ruby>Linux 国际<rt>Linux International</rt></ruby>的执行董事 John “Mad Dog” Hall 有一个故事可以解释为什么会这样。我们通过电话与他取得了联系。
|
||||
|
||||
**John Hall:** *[00:11:00]* 我有一个名叫 Dirk Holden 的朋友,他是德国德意志银行的系统管理员,他也参与了个人电脑上早期 X Windows 系统图形项目的工作。有一天我去银行拜访他,我说:“Dirk,你银行里有 3000 台服务器,用的都是 Linux。为什么不用 Microsoft NT 呢?”*[00:11:30]* 他看着我说:“是的,我有 3000 台服务器,如果使用微软的 Windows NT 系统,我需要 2999 名系统管理员。”他继续说道:“而使用 Linux,我只需要四个。”这真是完美的答案。
|
||||
|
||||
**Saron Yitbarek:** 程序员们着迷的这些东西恰好对大公司也极具吸引力。但由于 FUD 的作用,一些企业对此持谨慎态度。*[00:12:00]* 他们听到开源,就想:“开源。这看起来不太可靠,很混乱,充满了 BUG”。但正如那位银行经理所指出的,金钱有一种有趣的方式,可以说服人们克服困境。甚至那些只需要网站的小公司也加入了 Linux 阵营。与一些昂贵的专有选择相比,使用一个廉价的 Linux 系统在成本上是无法比拟的。如果你是一家雇佣专业人员来构建网站的商店,那么你肯定想让他们使用 Linux。
|
||||
|
||||
让我们快进几年。Linux 运行每个人的网站上。Linux 已经征服了服务器世界,然后智能手机也随之诞生。*[00:12:30]* 当然,苹果和他们的 iPhone 占据了相当大的市场份额,而且微软也希望能进入这个市场,但令人惊讶的是,Linux 也在那,已经做好准备了,迫不及待要大展拳脚。
|
||||
|
||||
作家兼记者 James Allworth。
|
||||
|
||||
**James Allworth:** 肯定还有容纳第二个竞争者的空间,那本可以是微软,但是实际上却是 Android,而 Andrid 基本上是基于 Linux 的。众所周知,Android 被谷歌所收购,现在运行在世界上大部分的智能手机上,谷歌在 Linux 的基础上创建了 Android。*[00:13:00]* Linux 使他们能够以零成本从一个非常复杂的操作系统开始。他们成功地实现了这一目标,最终将微软挡在了下一代设备之外,至少从操作系统的角度来看是这样。
|
||||
|
||||
**Saron Yitbarek:** *[00:13:30]* 这可是个大地震,很大程度上,微软有被埋没的风险。John Gossman 是微软 Azure 团队的首席架构师。他还记得当时困扰公司的困惑。
|
||||
|
||||
**John Gossman:** 像许多公司一样,微软也非常担心知识产权污染。他们认为,如果允许开发人员使用开源代码,那么他们可能只是将一些代码复制并粘贴到某些产品中,就会让某种病毒式的许可证生效从而引发未知的风险……他们也很困惑,*[00:14:00]* 我认为,这跟公司文化有关,很多公司,包括微软,都对开源开发的意义和商业模式之间的分歧感到困惑。有一种观点认为,开源意味着你所有的软件都是免费的,人们永远不会付钱。
|
||||
|
||||
**Saron Yitbarek:** 任何投资于旧的、专有软件模型的人都会觉得这里发生的一切对他们构成了威胁。当你威胁到像微软这样的大公司时,是的,他们一定会做出反应。*[00:14:30]* 他们推动所有这些 FUD —— 恐惧、不确定性和怀疑是有道理的。当时,商业运作的方式基本上就是相互竞争。不过,如果是其他公司的话,他们可能还会一直怀恨在心,抱残守缺,但到了 2013 年的微软,一切都变了。
|
||||
|
||||
微软的云计算服务 Azure 上线了,令人震惊的是,它从第一天开始就提供了 Linux 虚拟机。*[00:15:00]* <ruby>史蒂夫·鲍尔默<rt>Steve Ballmer</rt></ruby>,这位把 Linux 称为癌症的首席执行官,已经离开了,代替他的是一位新的有远见的首席执行官<ruby>萨提亚·纳德拉<rt>Satya Nadella</rt></ruby>。
|
||||
|
||||
**John Gossman:** 萨提亚有不同的看法。他属于另一个世代。比保罗、比尔和史蒂夫更年轻的世代,他对开源有不同的看法。
|
||||
|
||||
**Saron Yitbarek:** 还是来自微软 Azure 团队的 John Gossman。
|
||||
|
||||
**John Gossman:** *[00:15:30]* 大约四年前,处于实际需要,我们在 Azure 中添加了 Linux 支持。如果访问任何一家企业客户,你都会发现他们并不会才试着决定是使用 Windows 还是使用 Linux、 使用 .net 还是使用 Java ^TM 。他们在很久以前就做出了决定 —— 大约 15 年前才有这样的一些争论。*[00:16:00]* 现在,我见过的每一家公司都混合了 Linux 和 Java、Windows 和 .net、SQL Server、Oracle 和 MySQL —— 基于专有源代码的产品和开放源代码的产品。
|
||||
|
||||
如果你打算运维一个云服务,允许这些公司在云上运行他们的业务,那么你根本不能告诉他们,“你可以使用这个软件,但你不能使用那个软件。”
|
||||
|
||||
**Saron Yitbarek:** *[00:16:30]* 这正是萨提亚·纳德拉采纳的哲学思想。2014 年秋季,他站在舞台上,希望传递一个重要信息。“微软爱 Linux”。他接着说,“20% 的 Azure 业务量已经是 Linux 了,微软将始终对 Linux 发行版提供一流的支持。”没有哪怕一丝对开源的宿怨。
|
||||
|
||||
为了说明这一点,在他们的背后有一个巨大的标志,上面写着:“Microsoft ❤️ Linux”。哇噢。对我们中的一些人来说,这种转变有点令人震惊,但实际上,无需如此震惊。下面是 Steven Levy,一名科技记者兼作家。
|
||||
|
||||
**Steven Levy:** *[00:17:00]* 当你在踢足球的时候,如果草坪变滑了,那么你也许会换一种不同的鞋子。他们当初就是这么做的。*[00:17:30]* 他们不能否认现实,而且他们里面也有聪明人,所以他们必须意识到,这就是这个世界的运行方式,不管他们早些时候说了什么,即使他们对之前的言论感到尴尬,但是让他们之前关于开源多么可怕的言论影响到现在明智的决策那才真的是疯了。
|
||||
|
||||
**Saron Yitbarek:** 微软低下了它高傲的头。你可能还记得苹果公司,经过多年的孤立无援,最终转向与微软构建合作伙伴关系。现在轮到微软进行 180 度转变了。*[00:18:00]* 经过多年的与开源方式的战斗后,他们正在重塑自己。要么改变,要么死亡。Steven Vaughan-Nichols。
|
||||
|
||||
**Steven Vaughan-Nichols:** 即使是像微软这样规模的公司也无法与数千个开发着包括 Linux 在内的其它大项目的开源开发者竞争。很长时间以来他们都不愿意这么做。前微软首席执行官史蒂夫·鲍尔默对 Linux 深恶痛绝。*[00:18:30]* 由于它的 GPL 许可证,他视 Linux 为一种癌症,但一旦鲍尔默被扫地出门,新的微软领导层说,“这就好像试图命令潮流不要过来,但潮水依然会不断涌进来。我们应该与 Linux 合作,而不是与之对抗。”
|
||||
|
||||
**Saron Tiebreak:** 事实上,互联网技术史上最大的胜利之一就是微软最终决定做出这样的转变。*[00:19:00]* 当然,当微软出现在开源圈子时,老一代的铁杆 Linux 支持者是相当怀疑的。他们不确定自己是否能接受这些家伙,但正如 Vaughan-Nichols 所指出的,今天的微软已经不是以前的微软了。
|
||||
|
||||
**Steven Vaughan-Nichols:** 2017 年的微软既不是史蒂夫·鲍尔默的微软,也不是比尔·盖茨的微软。这是一家完全不同的公司,有着完全不同的方法,而且,一旦使用了开源,你就无法退回到之前。*[00:19:30]* 开源已经吞噬了整个技术世界。从未听说过 Linux 的人可能对它并不了解,但是每次他们访问 Facebook,他们都在运行 Linux。每次执行谷歌搜索时,你都在运行 Linux。
|
||||
|
||||
*[00:20:00]* 每次你用 Android 手机,你都在运行 Linux。它确实无处不在,微软无法阻止它,而且我认为以为微软能以某种方式接管它的想法,太天真了。
|
||||
|
||||
**Saron Yitbarek:** 开源支持者可能一直担心微软会像混入羊群中的狼一样,但事实是,开源软件的本质保护了它无法被完全控制。*[00:20:30]* 没有一家公司能够拥有 Linux 并以某种特定的方式控制它。Greg Kroah-Hartman 是 Linux 基金会的一名成员。
|
||||
|
||||
**Greg Kroah-Hartman:** 每个公司和个人都以自私的方式为 Linux 做出贡献。他们之所以这样做是因为他们想要解决他们所面临的问题,可能是硬件无法工作,或者是他们想要添加一个新功能来做其他事情,又或者想在他们的产品中使用它。这很棒,因为他们会把代码贡献回去,此后每个人都会从中受益,这样每个人都可以用到这份代码。正是因为这种自私,所有的公司,所有的人都能从中受益。
|
||||
|
||||
**Saron Yitbarek:** *[00:21:00]* 微软已经意识到,在即将到来的云战争中,与 Linux 作战就像与空气作战一样。Linux 和开源不是敌人,它们是空气。如今,微软以白金会员的身份加入了 Linux 基金会。他们成为 GitHub 开源项目的头号贡献者。*[00:21:30]* 2017 年 9 月,他们甚至加入了<ruby>开源促进联盟<rt>Open Source Initiative</rt></ruby>。现在,微软在开源许可证下发布了很多代码。微软的 John Gossman 描述了他们开源 .net 时所发生的事情。起初,他们并不认为自己能得到什么回报。
|
||||
|
||||
**John Gossman:** 我们本没有指望来自社区的贡献,然而,三年后,超过 50% 的对 .net 框架库的贡献来自于微软之外。这包括大量的代码。*[00:22:00]* 三星为 .net 提供了 ARM 支持。Intel 和 ARM 以及其他一些芯片厂商已经为 .net 框架贡献了特定于他们处理器的代码生成,以及数量惊人的修复、性能改进等等 —— 既有单个贡献者也有社区。
|
||||
|
||||
**Saron Yitbarek:** 直到几年前,今天的这个微软,这个开放的微软,还是不可想象的。
|
||||
|
||||
*[00:22:30]* 我是 Saron Yitbarek,这里是代码英雄。好吧,我们已经看到了为了赢得数百万桌面用户的爱而战的激烈场面。我们已经看到开源软件在专有软件巨头的背后悄然崛起,并攫取了巨大的市场份额。*[00:23:00]* 我们已经看到了一批批的代码英雄将编程领域变成了我你今天看到的这个样子。如今,大企业正在吸收开源软件,通过这一切,每个人都从他人那里受益。
|
||||
|
||||
在技术的西部荒野,一贯如此。苹果受到施乐的启发,微软受到苹果的启发,Linux 受到 UNIX 的启发。进化、借鉴、不断成长。如果比喻成大卫和歌利亚(LCTT 译注:西方经典的以弱胜强战争中的两个主角)的话,开源软件不再是大卫,但是,你知道吗?它也不是歌利亚。*[00:23:30]* 开源已经超越了传统。它已经成为其他人战斗的战场。随着开源道路变得不可避免,新的战争,那些在云计算中进行的战争,那些在开源战场上进行的战争正在加剧。
|
||||
|
||||
这是 Steven Levy,他是一名作者。
|
||||
|
||||
**Steven Levy:** 基本上,到目前为止,包括微软在内,有四到五家公司,正以各种方式努力把自己打造成为全方位的平台,比如人工智能领域。你能看到智能助手之间的战争,你猜怎么着?*[00:24:00]* 苹果有一个智能助手,叫 Siri。微软有一个,叫 Cortana。谷歌有谷歌助手。三星也有一个智能助手。亚马逊也有一个,叫 Alexa。我们看到这些战斗遍布各地。也许,你可以说,最热门的人工智能平台将控制我们生活中所有的东西,而这五家公司就是在为此而争斗。
|
||||
|
||||
**Saron Yitbarek:** *[00:24:30]* 如果你正在寻找另一个反叛者,它们就像 Linux 奇袭微软那样,偷偷躲在 Facebook、谷歌或亚马逊身后,你也许要等很久,因为正如作家 James Allworth 所指出的,成为一个真正的反叛者只会变得越来越难。
|
||||
|
||||
**James Allworth:** 规模一直以来都是一种优势,但规模优势本质上……怎么说呢,我认为以前它们在本质上是线性的,现在它们在本质上是指数型的了,所以,一旦你开始以某种方法走在前面,另一个新玩家要想赶上来就变得越来越难了。*[00:25:00]* 我认为在互联网时代这大体来说来说是正确的,无论是因为规模,还是数据赋予组织的竞争力的重要性和优势。一旦你走在前面,你就会吸引更多的客户,这就给了你更多的数据,让你能做得更好,这之后,客户还有什么理由选择排名第二的公司呢,难道是因为因为他们落后了这么远么?*[00:25:30]* 我认为在云的时代这个逻辑也不会有什么不同。
|
||||
|
||||
**Saron Yitbarek:** 这个故事始于史蒂夫·乔布斯和比尔·盖茨这样的非凡的英雄,但科技的进步已经呈现出一种众包、有机的感觉。我认为据说我们的开源英雄林纳斯·托瓦兹在第一次发明 Linux 内核时甚至没有一个真正的计划。他无疑是一位才华横溢的年轻开发者,但他也像潮汐前的一滴水一样。*[00:26:00]* 变革是不可避免的。据估计,对于一家专有软件公司来说,用他们老式的、专有的方式创建一个 Linux 发行版将花费他们超过 100 亿美元。这说明了开源的力量。
|
||||
|
||||
最后,这并不是一个专有模型所能与之竞争的东西。成功的公司必须保持开放。这是最大、最终极的教训。*[00:26:30]* 还有一点要记住:当我们连接在一起的时候,我们在已有基础上成长和建设的能力是无限的。不管这些公司有多大,我们都不必坐等他们给我们更好的东西。想想那些为了纯粹的创造乐趣而学习编码的新开发者,那些自己动手丰衣足食的人。
|
||||
|
||||
未来的优秀程序员无管来自何方,只要能够访问代码,他们就能构建下一个大项目。
|
||||
|
||||
*[00:27:00]* 以上就是我们关于操作系统战争的两个故事。这场战争塑造了我们的数字生活。争夺主导地位的斗争从桌面转移到了服务器机房,最终进入了云计算领域。过去的敌人难以置信地变成了盟友,众包的未来让一切都变得开放。*[00:27:30]* 听着,我知道,在这段历史之旅中,还有很多英雄我们没有提到,所以给我们写信吧。分享你的故事。[Redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) 。我恭候佳音。
|
||||
|
||||
在本季剩下的时间里,我们将学习今天的英雄们在创造什么,以及他们要经历什么样的战斗才能将他们的创造变为现实。让我们从壮丽的编程一线回来看看更多的传奇故事吧。我们每两周放一集新的博客。几周后,我们将为你带来第三集:敏捷革命。
|
||||
|
||||
*[00:28:00]* 代码英雄是一款红帽公司原创的播客。要想免费自动获得新一集的代码英雄,请订阅我们的节目。只要在苹果播客、Spotify、谷歌 Play,或其他应用中搜索“Command Line Heroes”。然后点击“订阅”。这样你就会第一个知道什么时候有新剧集了。
|
||||
|
||||
我是 Saron Yitbarek。感谢收听。继续编码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux
|
||||
|
||||
作者:[redhat][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.redhat.com
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,75 @@
|
||||
使用 Ledger 记录(财务)情况
|
||||
======
|
||||
|
||||
自 2005 年搬到加拿大以来,我使用 [Ledger CLI][1] 来跟踪我的财务状况。我喜欢纯文本的方式,它支持虚拟信封意味着我可以同时将我的银行帐户余额和我的虚拟分配到不同的目录下。以下是我们如何使用这些虚拟信封分别管理我们的财务状况。
|
||||
|
||||
每个月,我都有一个条目将我生活开支分配到不同的目录中,包括家庭开支的分配。W- 不要求太多, 所以我要谨慎地处理这两者之间的差别和我自己的生活费用。我们处理它的方式是我支付固定金额,这是贷记我支付的杂货。由于我们的杂货总额通常低于我预算的家庭开支,因此任何差异都会留在标签上。我过去常常给他写支票,但最近我只是支付偶尔额外的大笔费用。
|
||||
|
||||
这是个示例信封分配:
|
||||
|
||||
```
|
||||
2014.10.01 * Budget
|
||||
[Envelopes:Living]
|
||||
[Envelopes:Household] $500
|
||||
;; More lines go here
|
||||
```
|
||||
|
||||
这是设置的信封规则之一。它鼓励我正确地分类支出。所有支出都从我的 “Play” 信封中取出。
|
||||
|
||||
```
|
||||
= /^Expenses/
|
||||
(Envelopes:Play) -1.0
|
||||
```
|
||||
|
||||
这个为家庭支出报销 “Play” 信封,将金额从 “Household” 信封转移到 “Play” 信封。
|
||||
|
||||
```
|
||||
= /^Expenses:House$/
|
||||
(Envelopes:Play) 1.0
|
||||
(Envelopes:Household) -1.0
|
||||
```
|
||||
|
||||
我有一套定期的支出来模拟我的预算中的家庭开支。例如,这是 10 月份的。
|
||||
|
||||
```
|
||||
2014.10.1 * House
|
||||
Expenses:House
|
||||
Assets:Household $-500
|
||||
```
|
||||
|
||||
这是杂货交易的形式:
|
||||
|
||||
```
|
||||
2014.09.28 * No Frills
|
||||
Assets:Household:Groceries $70.45
|
||||
Liabilities:MBNA:September $-70.45
|
||||
|
||||
```
|
||||
|
||||
接着 `ledger bal Assets:Household` 就会告诉我是否欠他钱(负余额)。如果我支付大笔费用(例如:机票、通管道),那么正常家庭开支预算会逐渐减少余额。
|
||||
|
||||
我从 W- 那找到了一个为我的信用卡交易添加一个月标签的技巧,他还使用 Ledger 跟踪他的交易。它允许我再次检查条目的余额,看看前一个条目是否已被正确清除。
|
||||
|
||||
这个资产分类使用有点奇怪,但它在精神上对我有用。
|
||||
|
||||
使用 Ledger 以这种方式跟踪它可以让我跟踪我们的杂货费用以及我实际支付费用和我预算费用之间的差额。如果我最终支出超出预期,我可以从更多可自由支配的信封中移动虚拟货币,因此我的预算始终保持平衡。
|
||||
|
||||
Ledger 是一个强大的工具。相当极客,但也许更多的工作流描述可能会帮助那些正在搞清楚它的人!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
|
||||
|
||||
作者:[Sacha Chua][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://sachachua.com
|
||||
[1]:http://www.ledger-cli.org/
|
||||
[2]:http://sachachua.com/blog/category/finance/
|
||||
[3]:http://sachachua.com/blog/tag/ledger/
|
||||
[4]:http://pages.sachachua.com/sharing/blog.html?url=http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
|
||||
[5]:http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/#comments
|
||||
@ -1,49 +1,45 @@
|
||||
使用 Ftrace 跟踪内核
|
||||
使用 ftrace 跟踪内核
|
||||
============================================================
|
||||
|
||||
标签: [ftrace][8],[kernel][9],[kernel profiling][10],[kernel tracing][11],[linux][12],[tracepoints][13]
|
||||
|
||||

|
||||
|
||||
在内核级别上分析事件有很多的工具:[SystemTap][14],[ktap][15],[Sysdig][16],[LTTNG][17]等等,并且你也可以在网络上找到关于这些工具的大量介绍文章和资料。
|
||||
在内核层面上分析事件有很多的工具:[SystemTap][14]、[ktap][15]、[Sysdig][16]、[LTTNG][17] 等等,你也可以在网络上找到关于这些工具的大量介绍文章和资料。
|
||||
|
||||
而对于使用 Linux 原生机制去跟踪系统事件以及检索/分析故障信息的方面的资料却很少找的到。这就是 [ftrace][18],它是添加到内核中的第一款跟踪工具,今天我们来看一下它都能做什么,让我们从它的一些重要术语开始吧。
|
||||
|
||||
### 内核跟踪和分析
|
||||
|
||||
内核分析可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个概述 — 一个事件的总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
|
||||
<ruby>内核分析<rt>Kernel profiling</rt></ruby>可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个<ruby>概述<rt>profile</rt></ruby> — 这是一个事件总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
|
||||
|
||||
瓶颈经常发生在无法通过分析来识别的情况下。去推断出为什么会发生事件,去保存发生事件时的相关上下文,这就需要去跟踪。
|
||||
瓶颈经常发生在无法通过分析来识别的情况下。要推断出为什么会发生事件,就必须保存发生事件时的相关上下文,这就需要去<ruby>跟踪<rt>tracing</rt></ruby>。
|
||||
|
||||
跟踪可以理解为在一个正常工作的系统上活动的信息收集进程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种注册的系统事件。
|
||||
跟踪可以理解为在一个正常工作的系统上活动的信息收集过程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种系统事件。
|
||||
|
||||
跟踪程序能够同时跟踪应用级和操作系统级的事件。它们收集的信息能够用于诊断多种系统问题。
|
||||
|
||||
有时候会将跟踪与日志比较。它们两者确时很相似,但是也有不同的地方。
|
||||
|
||||
对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登陆系统、应用程序错误、数据库事务等等。
|
||||
对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登录系统、应用程序错误、数据库事务等等。
|
||||
|
||||
就像日志一样,跟踪数据可以被原样读取,但是用特定的应用程序提取的信息更有用。所有的跟踪程序都能这样做。
|
||||
|
||||
在内核跟踪和分析方面,Linux 内核有三个主要的机制:
|
||||
|
||||
* 跟踪点 —— 一种基于静态测试代码的工作机制
|
||||
|
||||
* 探针 —— 一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回。
|
||||
|
||||
* perf_events —— 一个访问 PMU(性能监视单元)的接口
|
||||
* <ruby>跟踪点<rt>tracepoint</rt></ruby>:一种基于静态测试代码的工作机制
|
||||
* <ruby>探针<rt>kprobe</rt></ruby>:一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回
|
||||
* perf_events —— 一个访问 PMU(<ruby>性能监视单元<rt>Performance Monitoring Unit</rt></ruby>)的接口
|
||||
|
||||
我并不想在这里写关于这些机制方面的内容,任何对它们感兴趣的人可以去访问 [Brendan Gregg 的博客][19]。
|
||||
|
||||
使用 ftrace,我们可以与这些机制进行交互,并可以从用户空间直接得到调试信息。下面我们将讨论这方面的详细内容。示例中的所有命令行都是在内核版本为 3.13.0-24 的 Ubuntu 14.04 中运行的。
|
||||
|
||||
### Ftrace:常用信息
|
||||
### ftrace:常用信息
|
||||
|
||||
Ftrace 是函数 Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
|
||||
ftrace 是 Function Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
|
||||
|
||||
Ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 `Ring` 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
|
||||
ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 Ring 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
|
||||
|
||||
Ftrace 工作在 debugfs 文件系统上,这是在大多数现代 Linux 分发版中默认挂载的文件系统。为开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
|
||||
ftrace 工作在 debugfs 文件系统上,在大多数现代 Linux 发行版中都默认挂载了。要开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
|
||||
|
||||
```
|
||||
# cd /sys/kernel/debug/tracing
|
||||
@ -70,16 +66,13 @@ kprobe_profile stack_max_size uprobe_profile
|
||||
我不想去描述这些文件和子目录;它们的描述在 [官方文档][20] 中已经写的很详细了。我只想去详细介绍与我们这篇文章相关的这几个文件:
|
||||
|
||||
* available_tracers —— 可用的跟踪程序
|
||||
|
||||
* current_tracer —— 正在运行的跟踪程序
|
||||
|
||||
* tracing_on —— 负责启用或禁用数据写入到 `Ring` 缓冲区的系统文件(如果启用它,在文件中添加数字 1,禁用它,添加数字 0)
|
||||
|
||||
* tracing_on —— 负责启用或禁用数据写入到 Ring 缓冲区的系统文件(如果启用它,数字 1 被添加到文件中,禁用它,数字 0 被添加)
|
||||
* trace —— 以人类友好格式保存跟踪数据的文件
|
||||
|
||||
### 可用的跟踪程序
|
||||
|
||||
我们可以使用如下的命令去查看可用的跟踪程序的一个列表
|
||||
我们可以使用如下的命令去查看可用的跟踪程序的一个列表:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing#: cat available_tracers
|
||||
@ -89,18 +82,14 @@ blk mmiotrace function_graph wakeup_rt wakeup function nop
|
||||
我们来快速浏览一下每个跟踪程序的特性:
|
||||
|
||||
* function —— 一个无需参数的函数调用跟踪程序
|
||||
|
||||
* function_graph —— 一个使用子调用的函数调用跟踪程序
|
||||
|
||||
* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 的用途)
|
||||
|
||||
* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 使用的)
|
||||
* mmiotrace —— 一个内存映射 I/O 操作跟踪程序
|
||||
|
||||
* nop —— 简化的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
|
||||
* nop —— 最简单的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
|
||||
|
||||
### 函数跟踪程序
|
||||
|
||||
在开始介绍函数跟踪程序 ftrace 之前,我们先看一下测试脚本:
|
||||
在开始介绍函数跟踪程序 ftrace 之前,我们先看一个测试脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
@ -117,7 +106,7 @@ less ${dir}/trace
|
||||
|
||||
这个脚本是非常简单的,但是还有几个需要注意的地方。命令 `sysctl ftrace.enabled=1` 启用了函数跟踪程序。然后我们通过写它的名字到 `current_tracer` 文件来启用 `current tracer`。
|
||||
|
||||
接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 `Ring` 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
|
||||
接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 Ring 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo 1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
|
||||
|
||||
我们为什么这样做呢?在两个 `echo` 命令之间,我们看到了命令 `sleep 1`。我们启用了缓冲区,运行了这个命令,然后禁用它。这将使跟踪程序采集了这个命令运行期间发生的所有系统调用的信息。
|
||||
|
||||
@ -156,21 +145,18 @@ less ${dir}/trace
|
||||
trace.sh-1295 [000] d... 90.502879: __acct_update_integrals <-acct_account_cputime
|
||||
```
|
||||
|
||||
这个输出以缓冲区中的信息条目数量和写入的条目数量开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
|
||||
这个输出以“缓冲区中的信息条目数量”和“写入的全部条目数量”开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
|
||||
|
||||
在这里有一个包含下列信息的函数列表:
|
||||
|
||||
* 进程标识符(PID)
|
||||
|
||||
* 运行这个进程的 CPU(CPU#)
|
||||
|
||||
* 进程开始时间(TIMESTAMP)
|
||||
|
||||
* 被跟踪函数的名字以及调用它的父级函数;例如,在我们输出的第一行,`rb_simple_write` 调用了 `mutex-unlock` 函数。
|
||||
|
||||
### Function_graph 跟踪程序
|
||||
### function_graph 跟踪程序
|
||||
|
||||
`function_graph` 跟踪程序的工作和函数一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
|
||||
function_graph 跟踪程序的工作和函数跟踪程序一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
|
||||
|
||||
我们来编辑一下最后一个示例的脚本:
|
||||
|
||||
@ -215,11 +201,11 @@ less ${dir}/trace
|
||||
0) ! 208.154 us | } /* ip_local_deliver_finish */
|
||||
```
|
||||
|
||||
在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(+)意思是这个函数花费的时间超过 10 毫秒;而感叹号(!)意思是这个函数花费的时间超过了 100 毫秒。
|
||||
在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(`+`)意思是这个函数花费的时间超过 10 毫秒;而感叹号(`!`)意思是这个函数花费的时间超过了 100 毫秒。
|
||||
|
||||
在 `FUNCTION_CALLS` 下面,我们可以看到每个函数调用的信息。
|
||||
|
||||
和 C 语言一样使用了花括号({)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(;)标记。
|
||||
和 C 语言一样使用了花括号(`{`)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(`;`)标记。
|
||||
|
||||
### 函数过滤器
|
||||
|
||||
@ -249,13 +235,13 @@ ftrace 还有很多过滤选项。对于它们更详细的介绍,你可以去
|
||||
|
||||
### 跟踪事件
|
||||
|
||||
我们在上面提到到跟踪点机制。跟踪点是插入的由系统事件触发的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
|
||||
我们在上面提到到跟踪点机制。跟踪点是插入的触发系统事件的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
|
||||
|
||||
静态跟踪点不会对系统有任何影响;它们只是增加几个字节用于调用测试函数以及在一个独立的节上增加一个数据结构。
|
||||
静态跟踪点不会对系统有任何影响;它们只是在测试的函数末尾增加几个字节的函数调用以及在一个独立的节上增加一个数据结构。
|
||||
|
||||
当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 `Ring` 缓冲区。
|
||||
当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 Ring 缓冲区。
|
||||
|
||||
跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(它在 [这里][22]):
|
||||
跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(取自 [这里][22]):
|
||||
|
||||
```
|
||||
{
|
||||
@ -294,7 +280,7 @@ fs kvm power scsi vfs
|
||||
ftrace kvmmmu printk signal vmscan
|
||||
```
|
||||
|
||||
所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 `Ring` 缓冲区写入:
|
||||
所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 Ring 缓冲区写入:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# cat tracing_on
|
||||
@ -306,25 +292,25 @@ root@andrei:/sys/kernel/debug/tracing# cat tracing_on
|
||||
root@andrei:/sys/kernel/debug/tracing# echo 1 > tracing_on
|
||||
```
|
||||
|
||||
在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。为了跟踪,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
|
||||
在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。对于我们的跟踪程序,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# echo nop > current_tracer
|
||||
```
|
||||
|
||||
所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出多个系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
|
||||
所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出各种系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# echo 1 > events/syscalls/sys_enter_chroot/enable
|
||||
```
|
||||
|
||||
然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息出现在输出中:
|
||||
然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [之前这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息不会出现在输出中:
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# echo 0 > tracing_on
|
||||
```
|
||||
|
||||
然后,我们去查看 `Ring` 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
|
||||
然后,我们去查看 Ring 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
|
||||
|
||||
```
|
||||
root@andrei:/sys/kernel/debug/tracing# сat trace
|
||||
@ -343,15 +329,10 @@ root@andrei:/sys/kernel/debug/tracing# сat trace
|
||||
在这篇文篇中,我们做了一个 ftrace 的功能概述。我们非常感谢你的任何意见或者补充。如果你想深入研究这个主题,我们为你推荐下列的资源:
|
||||
|
||||
* [https://www.kernel.org/doc/Documentation/trace/tracepoints.txt][1] — 一个跟踪点机制的详细描述
|
||||
|
||||
* [https://www.kernel.org/doc/Documentation/trace/events.txt][2] — 在 Linux 中跟踪系统事件的指南
|
||||
|
||||
* [https://www.kernel.org/doc/Documentation/trace/ftrace.txt][3] — ftrace 的官方文档
|
||||
|
||||
* [https://lttng.org/files/thesis/desnoyers-dissertation-2009-12-v27.pdf][4] — Mathieu Desnoyers(作者是跟踪点和 LTTNG 的创建者)的关于内核跟踪和分析的学术论文。
|
||||
|
||||
* [https://lwn.net/Articles/370423/][5] — Steven Rostedt 的关于 ftrace 功能的文章
|
||||
|
||||
* [http://alex.dzyoba.com/linux/profiling-ftrace.html][6] — 用 ftrace 分析实际案例的一个概述
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -360,7 +341,7 @@ via:https://blog.selectel.com/kernel-tracing-ftrace/
|
||||
|
||||
作者:[Andrej Yemelianov][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,129 @@
|
||||
Ubunsys:面向 Ubuntu 资深用户的一个高级系统配置工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
**Ubunsys** 是一个面向 Ubuntu 及其衍生版的基于 Qt 的高级系统工具。高级用户可以使用命令行轻松完成大多数配置。不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如 Linux Mint、Elementary OS 等。Ubunsys 可用来修改系统配置,安装、删除、更新包和旧内核,启用或禁用 `sudo` 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的 Ubuntu 系统升级到最新版本等等。以上提到的所有功能都可以通过鼠标点击完成。你不需要再依赖于命令行模式,下面是你能用 Ubunsys 做到的事:
|
||||
|
||||
* 安装、删除、更新包
|
||||
* 更新和升级软件源
|
||||
* 安装主线内核
|
||||
* 删除旧的和不再使用的内核
|
||||
* 系统整体更新
|
||||
* 将系统升级到下一个可用的版本
|
||||
* 将系统升级到最新的开发版本
|
||||
* 清理系统垃圾文件
|
||||
* 在不输入密码的情况下启用或者禁用 `sudo` 权限
|
||||
* 当你在终端输入密码时使 `sudo` 密码可见
|
||||
* 启用或禁用系统休眠
|
||||
* 启用或禁用防火墙
|
||||
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件
|
||||
* 显示或者隐藏启动项
|
||||
* 启用或禁用登录音效
|
||||
* 配置双启动
|
||||
* 启用或禁用锁屏
|
||||
* 智能系统更新
|
||||
* 使用脚本管理器更新/一次性执行脚本
|
||||
* 从 `git` 执行常规用户安装脚本
|
||||
* 检查系统完整性和缺失的 GPG 密钥
|
||||
* 修复网络
|
||||
* 修复已破损的包
|
||||
* 还有更多功能在开发中
|
||||
|
||||
**重要提示:** Ubunsys 不适用于 Ubuntu 新手。它很危险并且仍然不是稳定版。它可能会使你的系统崩溃。如果你刚接触 Ubuntu 不久,不要使用。但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险。在使用这一应用之前记着备份你自己的重要数据。
|
||||
|
||||
### 安装 Ubunsys
|
||||
|
||||
Ubunsys 开发者制作了一个 PPA 来简化安装过程,Ubunsys 现在可以在 Ubuntu 16.04 LTS、 Ubuntu 17.04 64 位版本上使用。
|
||||
|
||||
逐条执行下面的命令,将 Ubunsys 的 PPA 添加进去,并安装它。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:adgellida/ubunsys
|
||||
sudo apt-get update
|
||||
sudo apt-get install ubunsys
|
||||
```
|
||||
|
||||
如果 PPA 无法使用,你可以在[发布页面][1]根据你自己当前系统,选择正确的安装包,直接下载并安装 Ubunsys。
|
||||
|
||||
### 用途
|
||||
|
||||
一旦安装完成,从菜单栏启动 Ubunsys。下图是 Ubunsys 主界面。
|
||||
|
||||
![][3]
|
||||
|
||||
你可以看到,Ubunsys 有四个主要部分,分别是 Packages、Tweaks、System 和 Repair。在每一个标签项下面都有一个或多个子标签项以对应不同的操作。
|
||||
|
||||
**Packages**
|
||||
|
||||
这一部分允许你安装、删除和更新包。
|
||||
|
||||
![][4]
|
||||
|
||||
**Tweaks**
|
||||
|
||||
在这一部分,我们可以对系统进行多种调整,例如:
|
||||
|
||||
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件;
|
||||
* 配置双启动;
|
||||
* 启用或禁用登录音效、防火墙、锁屏、系统休眠、`sudo` 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用 `sudo` 权限(在不需要密码的情况下);
|
||||
* 在终端中输入密码时可见(禁用星号)。
|
||||
|
||||
![][5]
|
||||
|
||||
**System**
|
||||
|
||||
这一部分被进一步分成 3 个部分,每个都是针对某一特定用户类型。
|
||||
|
||||
**Normal user** 这一标签下的选项可以:
|
||||
|
||||
* 更新、升级包和软件源
|
||||
* 清理系统
|
||||
* 执行常规用户安装脚本
|
||||
|
||||
**Advanced user** 这一标签下的选项可以:
|
||||
|
||||
* 清理旧的/无用的内核
|
||||
* 安装主线内核
|
||||
* 智能包更新
|
||||
* 升级系统
|
||||
|
||||
**Developer** 这一部分可以将系统升级到最新的开发版本。
|
||||
|
||||
![][6]
|
||||
|
||||
**Repair**
|
||||
|
||||
这是 Ubunsys 的第四个也是最后一个部分。正如名字所示,这一部分能让我们修复我们的系统、网络、缺失的 GPG 密钥,和已经缺失的包。
|
||||
|
||||
![][7]
|
||||
|
||||
正如你所见,Ubunsys 可以在几次点击下就能完成诸如系统配置、系统维护和软件维护之类的任务。你不需要一直依赖于终端。Ubunsys 能帮你完成任何高级任务。再次声明,我警告你,这个应用不适合新手,而且它并不稳定。所以当你使用的时候,能会出现 bug 或者系统崩溃。在仔细研究过每一个选项的影响之后再使用它。
|
||||
|
||||
谢谢阅读!
|
||||
|
||||
### 参考资源
|
||||
|
||||
- [Ubunsys GitHub Repository][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wenwensnow](https://github.com/wenwensnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/adgellida/ubunsys/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
|
||||
[8]:https://github.com/adgellida/ubunsys
|
||||
@ -0,0 +1,183 @@
|
||||
Streams:一个新的 Redis 通用数据结构
|
||||
======
|
||||
|
||||
直到几个月以前,对于我来说,在消息传递的环境中,<ruby>流<rt>streams</rt></ruby>只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息(LCTT 译注:参见 [CAP 定理][1]) ,也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
|
||||
|
||||
然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis <ruby>列表<rt>list</rt></ruby>、<ruby>有序集<rt>sorted list</rt></ruby>、<ruby>发布/订阅<rt>Pub/Sub</rt></ruby>功能之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件建模。
|
||||
|
||||
有序集是内存消耗大户,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
|
||||
|
||||
列表有另外的问题,它在某些特定的用例中会产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
|
||||
|
||||
对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想<ruby>“即发即弃”<rt>fire-and-forget</rt></ruby>的东西:保留一个历史是很重要的,不只是因为是断开之后会重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:比如在这 10 秒范围内温度读数是多少?
|
||||
|
||||
我试图解决上述问题,我想规划一个通用的有序集合,并列入一个独特的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而告终。Redis 有个好处,它的数据结构导出更像自然的计算机科学的数据结构,而不是 “Salvatore 发明的 API”。因此,我最终停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许我会为发布/订阅增加一些历史信息,或者为列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说 “你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
|
||||
|
||||
### 起源
|
||||
|
||||
在 Redis 4.0 中引入模块之后,用户开始考虑他们自己怎么去修复这些问题。其中一个用户 Timothy Downs 通过 IRC 和我说道:
|
||||
|
||||
\<forkfork> 我计划给这个模块增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不导致 redis 内存激增的情况下做一些像发布/订阅那样的事情
|
||||
\<forkfork> 订阅者持有他们在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
|
||||
|
||||
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的契机。我需要去重新构思 “日志” 的概念是什么。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移应该怎么办?我们有范围查询可用。同样,日志通常很难进行垃圾回收:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
|
||||
|
||||
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在<ruby>对数时间<rt>logarithmic time</rt></ruby>内访问范围。同时,我开始去读关于 Kafka 的流相关的内容以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka <ruby>消费组<rt>consumer groups</rt></ruby>的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
|
||||
|
||||
### 让我们写一些代码吧
|
||||
|
||||
从 Redis 大会回来后,整个夏天我都在实现一个叫 listpack 的库。这个库是 `ziplist.c` 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:以便在各种用例中替代 ziplists。
|
||||
|
||||
结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是可索引的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我还在完成这个实现,不管怎样,现在在 Github 上的 Redis 的 streams 分支里它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有意思的事实:一,在那时只有消费群组是缺失的,加上一些不太重要的操作流的命令,但是,所有的大的方面都已经实现了。二,一旦各个方面比较稳定了之后,我决定大概用两个月的时间将所有的流的特性<ruby>向后移植<rt>backport</rt></ruby>到 4.0 分支。这意味着 Redis 用户想要使用流,不用等待 Redis 4.2 发布,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部实现。
|
||||
|
||||
### 教程:欢迎使用 Redis 的 streams
|
||||
|
||||
在某些方面,你可以认为流是 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,而是一个<ruby>字段<rt>field</rt></ruby>和<ruby>值<rt>value</rt></ruby>组成的对象。范围查询更适用而且更快。在流中,每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以<ruby>阻塞等待<rt>blocking-wait</rt></ruby>比指定的 ID 更大的元素。Redis 流的一个基本的命令是 `XADD`。是的,所有的 Redis 流命令都是以一个 `X` 为前缀的。
|
||||
|
||||
```
|
||||
> XADD mystream * sensor-id 1234 temperature 10.5
|
||||
1506871964177.0
|
||||
```
|
||||
|
||||
这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。上面示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名可以更好地利用内存。有意思的是,字段的排序是可以保证顺序的。`XADD` 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示由命令自动生成 ID。通常这样做就够了,但是也可以去强制指定一个 ID,这种情况用于复制这个命令到<ruby>从服务器<rt>slave server</rt></ruby>和 <ruby>AOF<rt>append-only file</rt></ruby> 文件。
|
||||
|
||||
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它只是一个毫秒级的 UNIX 时间戳。圆点(`.`)后面的数字 `0` 是一个序号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着,我们可以在流中增加所有想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实上它们与被添加到的实例的本地时间有关,这意味着我们可以在毫秒级的精度的范围随意查询。
|
||||
|
||||
正如你想的那样,快速添加两个条目后,结果是仅一个序号递增了。我们可以用一个 `MULTI`/`EXEC` 块来简单模拟“快速插入”:
|
||||
|
||||
```
|
||||
> MULTI
|
||||
OK
|
||||
> XADD mystream * foo 10
|
||||
QUEUED
|
||||
> XADD mystream * bar 20
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) 1506872463535.0
|
||||
2) 1506872463535.1
|
||||
```
|
||||
|
||||
在上面的示例中,也展示了无需指定任何初始<ruby>模式<rt>schema</rt></ruby>的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50-150 个消息内容)的第一个消息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,使用相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
|
||||
|
||||
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;<ruby>流播<rt>streaming</rt></ruby>,它是通过 `XREAD` 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
|
||||
|
||||
```
|
||||
> XRANGE mystream 1506871964177.0 1506871964177.0
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
```
|
||||
|
||||
不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
|
||||
|
||||
```
|
||||
> XRANGE mystream - + COUNT 2
|
||||
1) 1) 1506871964177.0
|
||||
2) 1) "sensor-id"
|
||||
2) "1234"
|
||||
3) "temperature"
|
||||
4) "10.5"
|
||||
2) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
```
|
||||
|
||||
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为 ID 的“序号” 部分可以省略。因此,你可以只指定“毫秒”时间即可,下面的命令的意思是:“从 UNIX 时间 1506872463 开始给我 10 个条目”:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
|
||||
1) 1) 1506872463535.0
|
||||
2) 1) "foo"
|
||||
2) "10"
|
||||
2) 1) 1506872463535.1
|
||||
2) 1) "bar"
|
||||
2) "20"
|
||||
```
|
||||
|
||||
关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,随后连续的 ID 只是增加了序号部分,所以可以使用 `XRANGE` 遍历整个流,接收每个调用的指定个数的元素。Redis 中的`*SCAN` 系列命令允许迭代 Redis 数据结构,尽管事实上它们不是为迭代设计的,但这样可以避免再犯相同的错误。
|
||||
|
||||
### 使用 XREAD 处理流播:阻塞新的数据
|
||||
|
||||
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 `XRANGE` 是非常完美的。然而,在使用流的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的<ruby>汇聚池<rt>pooling</rt></ruby>。(对于 *某些* 应用程序来说,这可能是个好主意,因为它们仅是偶尔连接查询的)
|
||||
|
||||
`XREAD` 命令是为读取设计的,在同一个时间,从多个流中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,就解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据,并且多个客户端可以同时访问同一份数据。
|
||||
|
||||
这里有一个典型的 `XREAD` 调用示例:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
|
||||
```
|
||||
|
||||
它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。在 `STREAMS` 选项之后指定我们想要监听的关键字,最后的是指定想要监听的 ID,指定的 ID 为 `$` 的意思是:假设我现在需要流中的所有元素,因此,只需要从下一个到达的元素开始给我。
|
||||
|
||||
如果我从另一个客户端发送这样的命令:
|
||||
|
||||
```
|
||||
> XADD otherstream * message “Hi There”
|
||||
```
|
||||
|
||||
在 `XREAD` 侧会出现什么情况呢?
|
||||
|
||||
```
|
||||
1) 1) "otherstream"
|
||||
2) 1) 1) 1506935385635.0
|
||||
2) 1) "message"
|
||||
2) "Hi There"
|
||||
```
|
||||
|
||||
与收到的数据一起,我们也得到了数据的关键字。在下次调用中,我们将使用接收到的最新消息的 ID:
|
||||
|
||||
```
|
||||
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
|
||||
```
|
||||
|
||||
依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟之后再次连接(因为它处理消息需要时间,或者其它什么原因)。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
|
||||
|
||||
### 流封顶
|
||||
|
||||
目前看起来还不错……然而,有些时候,流需要删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
|
||||
```
|
||||
|
||||
它是基本意思是,如果在流中添加新元素后发现消息数量超过了 `1000000` 个,那么就删除旧的消息,以便于元素总量重新回到 `1000000` 以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将消耗一些 CPU 资源,所以在计算 `MAXLEN` 之前,尽可能使用 `~` 符号,以表明我们不要求非常 *精确* 的 1000000 个消息,就是稍微多一些也不是大问题:
|
||||
|
||||
```
|
||||
> XADD mystream MAXLEN ~ 1000000 * foo bar
|
||||
```
|
||||
|
||||
这种方式的 XADD 仅当它可以删除整个节点的时候才会删除消息。相比普通的 `XADD`,这种方式几乎可以自由地对流进行封顶。
|
||||
|
||||
### 消费组(开发中)
|
||||
|
||||
这是第一个 Redis 中尚未实现而在开发中的特性。灵感也是来自 Kafka,尽管在这里是以不同的方式实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。相同组的所有客户端将自动得到 *不同的* 消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
|
||||
|
||||
当指定组时,能够指定一个 `RETRY <milliseconds>` 选项去扩展组:在这种情况下,如果消息没有通过 `XACK` 进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
|
||||
|
||||
### 内存使用和节省加载时间
|
||||
|
||||
因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,该格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
|
||||
|
||||
我还计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识条目为已删除,并且,当已删除条目占全部条目的比例达到指定值时,这个块将被回收重写,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
|
||||
|
||||
### 关于最终发布时间的结论
|
||||
|
||||
Redis 的流特性将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难以解决的情况:那意味着你(之前)需要创造性地“滥用”当前提供的数据结构去解决那些问题。一个非常重要的使用场景是时间序列,但是,我觉得对于其它场景来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用场景。现在,如果你想在有问题环境中评估这个新数据结构,可以更新 GitHub 上的 streams 分支开始试用。欢迎向我们报告所有的 bug。:-)
|
||||
|
||||
如果你喜欢观看视频的方式,这里有一个现场演示:https://www.youtube.com/watch?v=ELDzy9lCFHQ
|
||||
|
||||
---
|
||||
|
||||
via: http://antirez.com/news/114
|
||||
|
||||
作者:[antirez][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy), [pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://antirez.com/
|
||||
[1]: https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
|
||||
@ -1,40 +1,41 @@
|
||||
通过构建一个区块链来学习区块链技术
|
||||
想学习区块链?那就用 Python 构建一个
|
||||
======
|
||||
|
||||
> 了解区块链是如何工作的最快的方法是构建一个。
|
||||
|
||||

|
||||
你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术是什么。
|
||||
|
||||
你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术基础是什么。
|
||||
|
||||
但是理解区块链并不容易 —— 至少对我来说是这样。我徜徉在各种难懂的视频中,并且因为示例太少而陷入深深的挫败感中。
|
||||
|
||||
我喜欢在实践中学习。这迫使我去处理被卡在代码级别上的难题。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
|
||||
我喜欢在实践中学习。这会使得我在代码层面上处理主要问题,从而可以让我坚持到底。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
|
||||
|
||||
### 开始之前 …
|
||||
|
||||
记住,区块链是一个 _不可更改的、有序的_ 被称为区块的记录链。它们可以包括事务~~(交易???校对确认一下,下同)~~、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
|
||||
记住,区块链是一个 _不可更改的、有序的_ 记录(被称为区块)的链。它们可以包括<ruby>交易<rt>transaction</rt></ruby>、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
|
||||
|
||||
如果你不知道哈希是什么,[这里有解释][1]。
|
||||
|
||||
**_本指南的目标读者是谁?_** 你应该能很容易地读和写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
|
||||
**_本指南的目标读者是谁?_** 你应该能轻松地读、写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
|
||||
|
||||
**_我需要做什么?_** 确保安装了 [Python 3.6][2]+(以及 `pip`),还需要去安装 Flask 和非常好用的 Requests 库:
|
||||
|
||||
```
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
pip install Flask==0.12.2 requests==2.18.4
|
||||
```
|
||||
|
||||
当然,你也需要一个 HTTP 客户端,像 [Postman][3] 或者 cURL。哪个都行。
|
||||
|
||||
**_最终的代码在哪里可以找到?_** 源代码在 [这里][4]。
|
||||
|
||||
* * *
|
||||
|
||||
### 第 1 步:构建一个区块链
|
||||
|
||||
打开你喜欢的文本编辑器或者 IDE,我个人 ❤️ [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将使用一个单个的文件,如果你看晕了,可以去参考 [源代码][6]。
|
||||
打开你喜欢的文本编辑器或者 IDE,我个人喜欢 [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将仅使用一个文件,如果你看晕了,可以去参考 [源代码][6]。
|
||||
|
||||
#### 描述一个区块链
|
||||
|
||||
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存事务。下面是我们的类规划:
|
||||
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存交易。下面是我们的类规划:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -58,15 +59,16 @@ class Blockchain(object):
|
||||
@property
|
||||
def last_block(self):
|
||||
# Returns the last Block in the chain
|
||||
pass
|
||||
pass
|
||||
```
|
||||
|
||||
*我们的 Blockchain 类的原型*
|
||||
|
||||
我们的区块链类负责管理链。它将存储事务并且有一些为链中增加新区块的助理性质的方法。现在我们开始去充实一些类的方法。
|
||||
我们的 `Blockchain` 类负责管理链。它将存储交易并且有一些为链中增加新区块的辅助性质的方法。现在我们开始去充实一些类的方法。
|
||||
|
||||
#### 一个区块是什么样子的?
|
||||
#### 区块是什么样子的?
|
||||
|
||||
每个区块有一个索引、一个时间戳(Unix 时间)、一个事务的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
|
||||
每个区块有一个索引、一个时间戳(Unix 时间)、一个交易的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
|
||||
|
||||
单个区块的示例应该是下面的样子:
|
||||
|
||||
@ -86,13 +88,15 @@ block = {
|
||||
}
|
||||
```
|
||||
|
||||
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。这一点非常重要,因为这就是区块链不可更改的原因:如果攻击者修改了一个早期的区块,那么所有的后续区块将包含错误的哈希。
|
||||
*我们的区块链中的块示例*
|
||||
|
||||
这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。
|
||||
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。**这一点非常重要,因为这就是区块链不可更改的原因**:如果攻击者修改了一个早期的区块,那么**所有**的后续区块将包含错误的哈希。
|
||||
|
||||
#### 添加事务到一个区块
|
||||
*这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。*
|
||||
|
||||
我们将需要一种区块中添加事务的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
|
||||
#### 添加交易到一个区块
|
||||
|
||||
我们将需要一种区块中添加交易的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
|
||||
|
||||
```
|
||||
class Blockchain(object):
|
||||
@ -113,14 +117,14 @@ class Blockchain(object):
|
||||
'amount': amount,
|
||||
})
|
||||
|
||||
return self.last_block['index'] + 1
|
||||
return self.last_block['index'] + 1
|
||||
```
|
||||
|
||||
在 `new_transaction()` 运行后将在列表中添加一个事务,它返回添加事务后的那个区块的索引 —— 那个区块接下来将被挖矿。提交事务的用户后面会用到这些。
|
||||
在 `new_transaction()` 运行后将在列表中添加一个交易,它返回添加交易后的那个区块的索引 —— 那个区块接下来将被挖矿。提交交易的用户后面会用到这些。
|
||||
|
||||
#### 创建新区块
|
||||
|
||||
当我们的区块链被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
|
||||
当我们的 `Blockchain` 被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
|
||||
|
||||
除了在我们的构造函数中创建创世区块之外,我们还需要写一些方法,如 `new_block()`、`new_transaction()` 以及 `hash()`:
|
||||
|
||||
@ -190,18 +194,18 @@ class Blockchain(object):
|
||||
|
||||
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
|
||||
block_string = json.dumps(block, sort_keys=True).encode()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
return hashlib.sha256(block_string).hexdigest()
|
||||
```
|
||||
|
||||
上面的内容简单明了 —— 我添加了一些注释和文档字符串,以使代码清晰可读。到此为止,表示我们的区块链基本上要完成了。但是,你肯定想知道新区块是如何被创建、打造或者挖矿的。
|
||||
|
||||
#### 理解工作量证明
|
||||
|
||||
一个工作量证明(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
|
||||
<ruby>工作量证明<rt>Proof of Work</rt></ruby>(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
|
||||
|
||||
我们来看一个非常简单的示例来帮助你了解它。
|
||||
|
||||
我们来解决一个问题,一些整数 x 乘以另外一个整数 y 的结果的哈希值必须以 0 结束。因此,hash(x * y) = ac23dc…0。为简单起见,我们先把 x = 5 固定下来。在 Python 中的实现如下:
|
||||
我们来解决一个问题,一些整数 `x` 乘以另外一个整数 `y` 的结果的哈希值必须以 `0` 结束。因此,`hash(x * y) = ac23dc…0`。为简单起见,我们先把 `x = 5` 固定下来。在 Python 中的实现如下:
|
||||
|
||||
```
|
||||
from hashlib import sha256
|
||||
@ -215,19 +219,21 @@ while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
|
||||
print(f'The solution is y = {y}')
|
||||
```
|
||||
|
||||
在这里的答案是 y = 21。因为它产生的哈希值是以 0 结尾的:
|
||||
在这里的答案是 `y = 21`。因为它产生的哈希值是以 0 结尾的:
|
||||
|
||||
```
|
||||
hash(5 * 21) = 1253e9373e...5e3600155e860
|
||||
```
|
||||
|
||||
在比特币中,工作量证明算法被称之为 [Hashcash][10]。与我们上面的例子没有太大的差别。这就是矿工们进行竞赛以决定谁来创建新块的算法。一般来说,其难度取决于在一个字符串中所查找的字符数量。然后矿工会因其做出的求解而得到奖励的币——在一个交易当中。
|
||||
|
||||
网络上的任何人都可以很容易地去核验它的答案。
|
||||
|
||||
#### 实现基本的 PoW
|
||||
|
||||
为我们的区块链来实现一个简单的算法。我们的规则与上面的示例类似:
|
||||
|
||||
> 找出一个数字 p,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 0 组成。
|
||||
> 找出一个数字 `p`,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 `0` 组成。
|
||||
|
||||
```
|
||||
import hashlib
|
||||
@ -266,25 +272,21 @@ class Blockchain(object):
|
||||
|
||||
guess = f'{last_proof}{proof}'.encode()
|
||||
guess_hash = hashlib.sha256(guess).hexdigest()
|
||||
return guess_hash[:4] == "0000"
|
||||
return guess_hash[:4] == "0000"
|
||||
```
|
||||
|
||||
为了调整算法的难度,我们可以修改前导 0 的数量。但是 4 个零已经足够难了。你会发现,将前导 0 的数量每增加一,那么找到正确答案所需要的时间难度将大幅增加。
|
||||
|
||||
我们的类基本完成了,现在我们开始去使用 HTTP 请求与它交互。
|
||||
|
||||
* * *
|
||||
|
||||
### 第 2 步:以 API 方式去访问我们的区块链
|
||||
|
||||
我们将去使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
|
||||
我们将使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
|
||||
|
||||
我们将创建三个方法:
|
||||
|
||||
* `/transactions/new` 在一个区块上创建一个新事务
|
||||
|
||||
* `/transactions/new` 在一个区块上创建一个新交易
|
||||
* `/mine` 告诉我们的服务器去挖矿一个新区块
|
||||
|
||||
* `/chain` 返回完整的区块链
|
||||
|
||||
#### 配置 Flask
|
||||
@ -332,33 +334,33 @@ def full_chain():
|
||||
return jsonify(response), 200
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
app.run(host='0.0.0.0', port=5000)
|
||||
```
|
||||
|
||||
对上面的代码,我们做添加一些详细的解释:
|
||||
|
||||
* Line 15:实例化我们的节点。更多关于 Flask 的知识读 [这里][7]。
|
||||
|
||||
* Line 18:为我们的节点创建一个随机的名字。
|
||||
|
||||
* Line 21:实例化我们的区块链类。
|
||||
|
||||
* Line 24–26:创建 /mine 端点,这是一个 GET 请求。
|
||||
|
||||
* Line 28–30:创建 /transactions/new 端点,这是一个 POST 请求,因为我们要发送数据给它。
|
||||
|
||||
* Line 32–38:创建 /chain 端点,它返回全部区块链。
|
||||
|
||||
* Line 24–26:创建 `/mine` 端点,这是一个 GET 请求。
|
||||
* Line 28–30:创建 `/transactions/new` 端点,这是一个 POST 请求,因为我们要发送数据给它。
|
||||
* Line 32–38:创建 `/chain` 端点,它返回全部区块链。
|
||||
* Line 40–41:在 5000 端口上运行服务器。
|
||||
|
||||
#### 事务端点
|
||||
#### 交易端点
|
||||
|
||||
这就是对一个事务的请求,它是用户发送给服务器的:
|
||||
这就是对一个交易的请求,它是用户发送给服务器的:
|
||||
|
||||
```
|
||||
{ "sender": "my address", "recipient": "someone else's address", "amount": 5}
|
||||
{
|
||||
"sender": "my address",
|
||||
"recipient": "someone else's address",
|
||||
"amount": 5
|
||||
}
|
||||
```
|
||||
|
||||
因为我们已经有了添加交易到块中的类方法,剩下的就很容易了。让我们写个函数来添加交易:
|
||||
|
||||
```
|
||||
import hashlib
|
||||
import json
|
||||
@ -383,18 +385,17 @@ def new_transaction():
|
||||
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
|
||||
|
||||
response = {'message': f'Transaction will be added to Block {index}'}
|
||||
return jsonify(response), 201
|
||||
return jsonify(response), 201
|
||||
```
|
||||
创建事务的方法
|
||||
|
||||
*创建交易的方法*
|
||||
|
||||
#### 挖矿端点
|
||||
|
||||
我们的挖矿端点是见证奇迹的地方,它实现起来很容易。它要做三件事情:
|
||||
|
||||
1. 计算工作量证明
|
||||
|
||||
2. 因为矿工(我们)添加一个事务而获得报酬,奖励矿工(我们) 1 个硬币
|
||||
|
||||
2. 因为矿工(我们)添加一个交易而获得报酬,奖励矿工(我们) 1 个币
|
||||
3. 通过将它添加到链上而打造一个新区块
|
||||
|
||||
```
|
||||
@ -434,10 +435,10 @@ def mine():
|
||||
'proof': block['proof'],
|
||||
'previous_hash': block['previous_hash'],
|
||||
}
|
||||
return jsonify(response), 200
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的区块链类的方法进行交互的。到目前为止,我们已经做到了,现在开始与我们的区块链去交互。
|
||||
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的 `Blockchain` 类的方法进行交互的。到目前为止,我们已经做完了,现在开始与我们的区块链去交互。
|
||||
|
||||
### 第 3 步:与我们的区块链去交互
|
||||
|
||||
@ -447,24 +448,33 @@ return jsonify(response), 200
|
||||
|
||||
```
|
||||
$ python blockchain.py
|
||||
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
|
||||
```
|
||||
|
||||
我们通过生成一个 GET 请求到 http://localhost:5000/mine 去尝试挖一个区块:
|
||||
我们通过生成一个 `GET` 请求到 `http://localhost:5000/mine` 去尝试挖一个区块:
|
||||
|
||||
|
||||
使用 Postman 去生成一个 GET 请求
|
||||
|
||||
我们通过生成一个 POST 请求到 http://localhost:5000/transactions/new 去创建一个区块,它带有一个包含我们的事务结构的 `Body`:
|
||||
*使用 Postman 去生成一个 GET 请求*
|
||||
|
||||
我们通过生成一个 `POST` 请求到 `http://localhost:5000/transactions/new` 去创建一个区块,请求数据包含我们的交易结构:
|
||||
|
||||
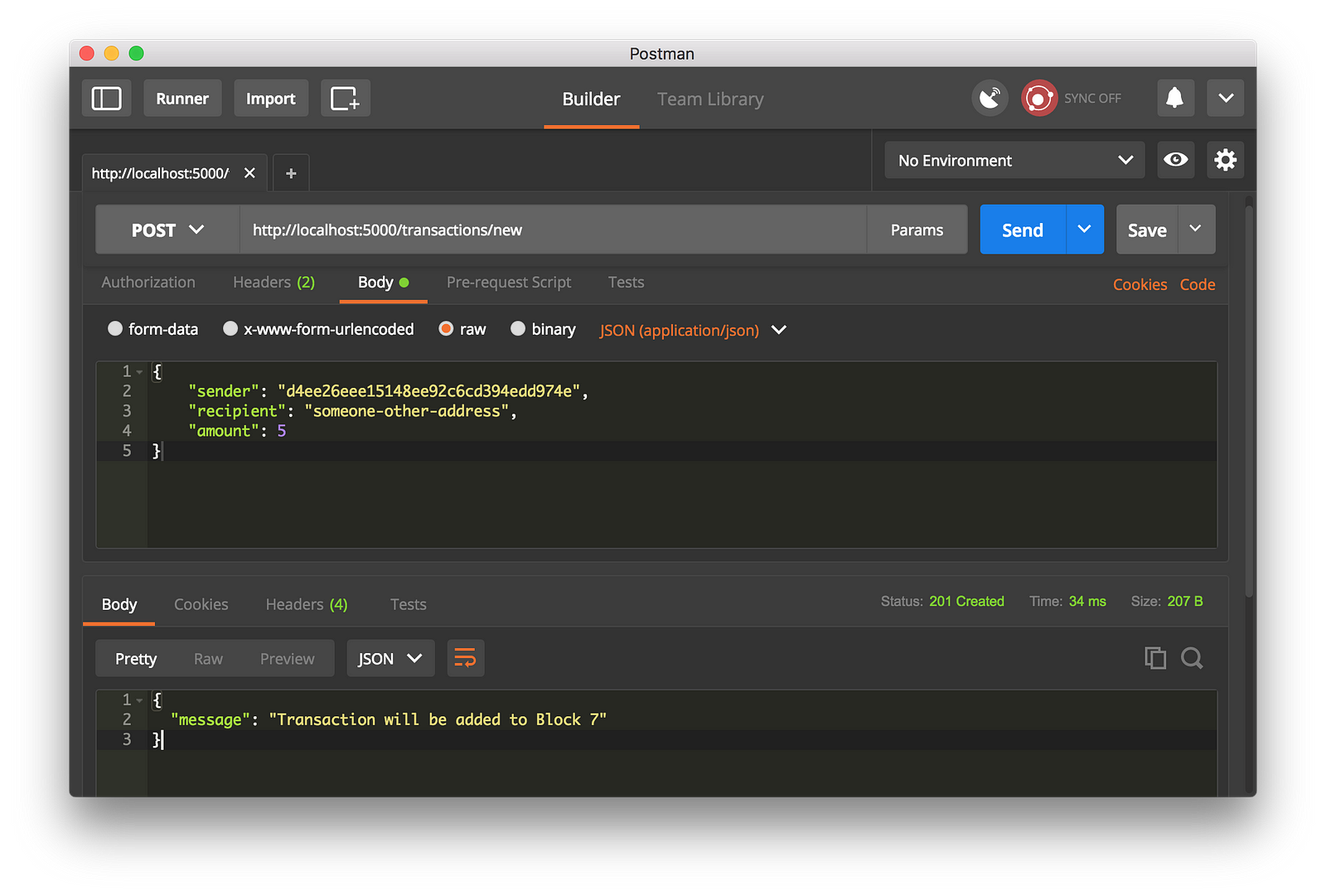
|
||||
使用 Postman 去生成一个 POST 请求
|
||||
|
||||
*使用 Postman 去生成一个 POST 请求*
|
||||
|
||||
如果你不使用 Postman,也可以使用 cURL 去生成一个等价的请求:
|
||||
|
||||
```
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee15148ee92c6cd394edd974e", "recipient": "someone-other-address", "amount": 5}' "http://localhost:5000/transactions/new"
|
||||
$ curl -X POST -H "Content-Type: application/json" -d '{
|
||||
"sender": "d4ee26eee15148ee92c6cd394edd974e",
|
||||
"recipient": "someone-other-address",
|
||||
"amount": 5
|
||||
}' "http://localhost:5000/transactions/new"
|
||||
```
|
||||
我重启动我的服务器,然后我挖到了两个区块,这样总共有了3 个区块。我们通过请求 http://localhost:5000/chain 来检查整个区块链:
|
||||
|
||||
我重启动我的服务器,然后我挖到了两个区块,这样总共有了 3 个区块。我们通过请求 `http://localhost:5000/chain` 来检查整个区块链:
|
||||
|
||||
```
|
||||
{
|
||||
"chain": [
|
||||
@ -503,18 +513,18 @@ $ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee151
|
||||
}
|
||||
],
|
||||
"length": 3
|
||||
}
|
||||
```
|
||||
### 第 4 步:共识
|
||||
|
||||
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收事务并允许我们去挖掘出新区块。但是区块链的整个重点在于它是去中心化的。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是共识问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
|
||||
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收交易并允许我们去挖掘出新区块。但是区块链的整个重点在于它是<ruby>去中心化的<rt>decentralized</rt></ruby>。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是<ruby>共识<rt>Consensus</rt></ruby>问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
|
||||
|
||||
#### 注册新节点
|
||||
|
||||
在我们能实现一个共识算法之前,我们需要一个办法去让一个节点知道网络上的邻居节点。我们网络上的每个节点都保留有一个该网络上其它节点的注册信息。因此,我们需要更多的端点:
|
||||
|
||||
1. /nodes/register 以 URLs 的形式去接受一个新节点列表
|
||||
|
||||
2. /nodes/resolve 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
|
||||
1. `/nodes/register` 以 URL 的形式去接受一个新节点列表
|
||||
2. `/nodes/resolve` 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
|
||||
|
||||
我们需要去修改我们的区块链的构造函数,来提供一个注册节点的方法:
|
||||
|
||||
@ -538,11 +548,12 @@ class Blockchain(object):
|
||||
"""
|
||||
|
||||
parsed_url = urlparse(address)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
self.nodes.add(parsed_url.netloc)
|
||||
```
|
||||
一个添加邻居节点到我们的网络的方法
|
||||
|
||||
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的内容是幂等的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
|
||||
*一个添加邻居节点到我们的网络的方法*
|
||||
|
||||
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的节点是<ruby>幂等<rt>idempotent</rt></ruby>的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
|
||||
|
||||
#### 实现共识算法
|
||||
|
||||
@ -615,12 +626,12 @@ class Blockchain(object)
|
||||
self.chain = new_chain
|
||||
return True
|
||||
|
||||
return False
|
||||
return False
|
||||
```
|
||||
|
||||
第一个方法 `valid_chain()` 是负责来检查链是否有效,它通过遍历区块链上的每个区块并验证它们的哈希和工作量证明来检查这个区块链是否有效。
|
||||
|
||||
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。
|
||||
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。**如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。**
|
||||
|
||||
在我们的 API 上来注册两个端点,一个用于添加邻居节点,另一个用于解决冲突:
|
||||
|
||||
@ -658,18 +669,20 @@ def consensus():
|
||||
'chain': blockchain.chain
|
||||
}
|
||||
|
||||
return jsonify(response), 200
|
||||
return jsonify(response), 200
|
||||
```
|
||||
|
||||
这种情况下,如果你愿意可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:[http://localhost:5000][9] 和 http://localhost:5001。
|
||||
这种情况下,如果你愿意,可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:`http://localhost:5000` 和 `http://localhost:5001`。
|
||||
|
||||
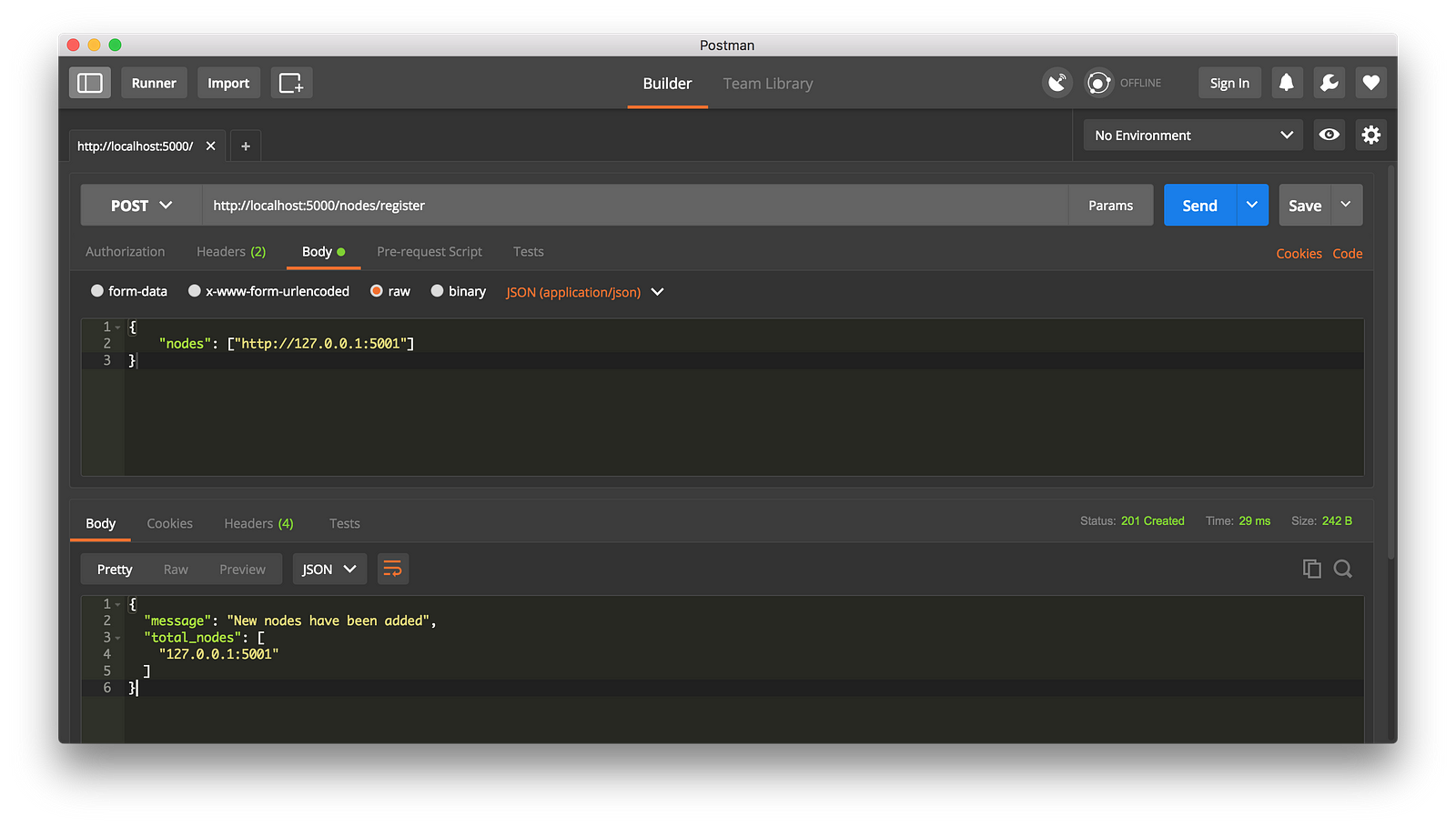
|
||||
注册一个新节点
|
||||
|
||||
*注册一个新节点*
|
||||
|
||||
我接着在节点 2 上挖出一些新区块,以确保这个链是最长的。之后我在节点 1 上以 `GET` 方式调用了 `/nodes/resolve`,这时,节点 1 上的链被共识算法替换成节点 2 上的链了:
|
||||
|
||||
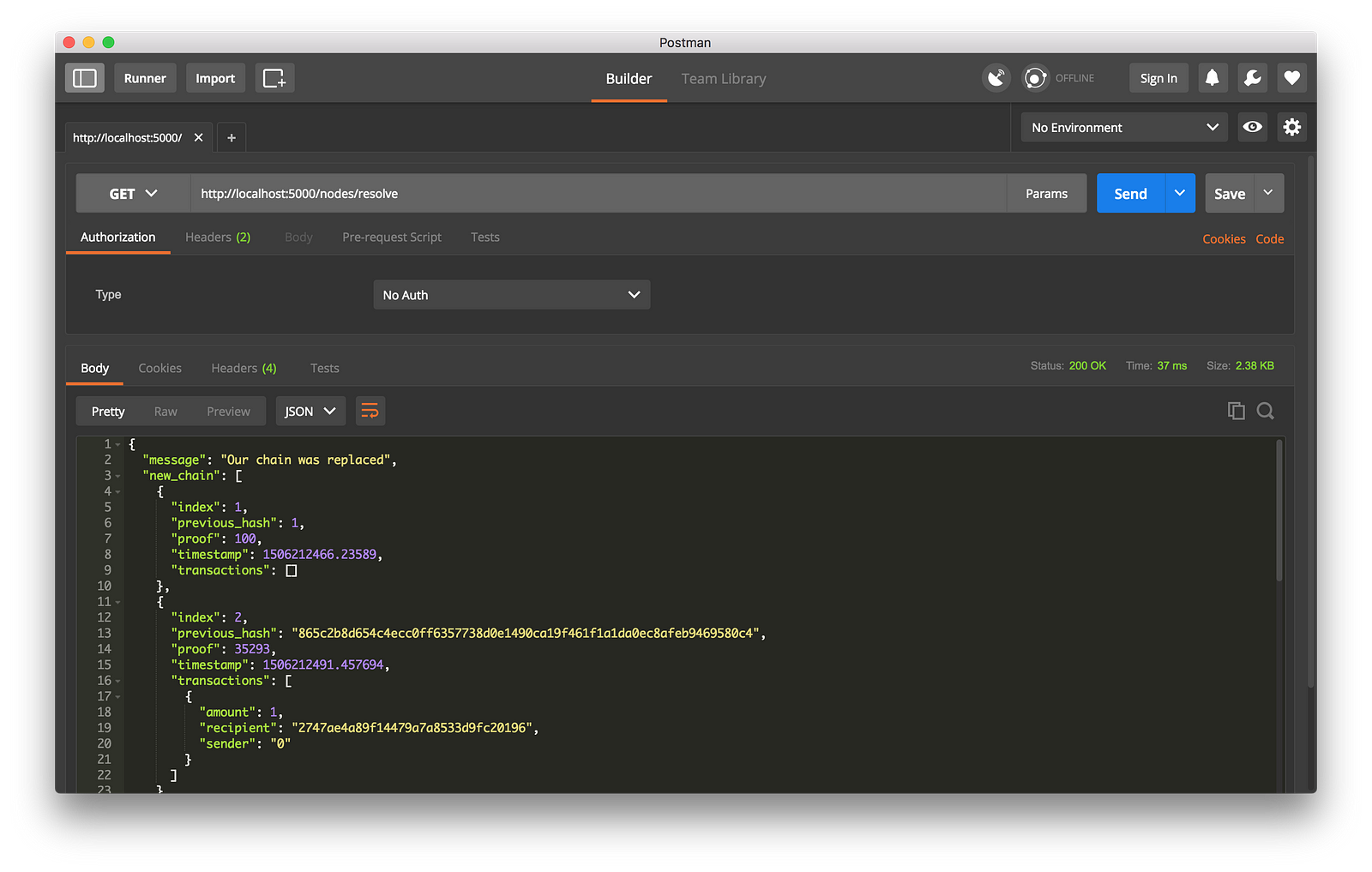
|
||||
工作中的共识算法
|
||||
|
||||
*工作中的共识算法*
|
||||
|
||||
然后将它们封装起来 … 找一些朋友来帮你一起测试你的区块链。
|
||||
|
||||
@ -677,7 +690,7 @@ return jsonify(response), 200
|
||||
|
||||
我希望以上内容能够鼓舞你去创建一些新的东西。我是加密货币的狂热拥护者,因此我相信区块链将迅速改变我们对经济、政府和记录保存的看法。
|
||||
|
||||
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备事务验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。
|
||||
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备交易验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。(LCTT 译注:第二篇并没有~!)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -685,7 +698,7 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
|
||||
作者:[Daniel van Flymen][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -699,3 +712,4 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
|
||||
[7]:http://flask.pocoo.org/docs/0.12/quickstart/#a-minimal-application
|
||||
[8]:http://localhost:5000/transactions/new
|
||||
[9]:http://localhost:5000
|
||||
[10]:https://en.wikipedia.org/wiki/Hashcash
|
||||
@ -1,12 +1,15 @@
|
||||
如何提升自动化的 ROI:4 个小提示
|
||||
======
|
||||
|
||||
> 想要在你的自动化项目上达成强 RIO?采取如下步骤来规避失败。
|
||||
|
||||

|
||||
在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对成本随着工作量的增加而增加的这一事实可以重新定义而感到震惊。
|
||||
|
||||
机器人流程自动化(RPA)似乎预示着运营的圣杯(Holy Grail):“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
|
||||
在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对于可以重新定义成本随着工作量的增加而增加的这一事实而感到震惊。
|
||||
|
||||
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处即实用可行度又高。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
|
||||
<ruby>机器人流程自动化<rt>Robotic Process Automation</rt></ruby>(RPA)似乎预示着运营的<ruby>圣杯<rt>Holy Grail</rt></ruby>:“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
|
||||
|
||||
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处真实可及。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
|
||||
|
||||
自动化的谈论都趋向于类似的话题:COO 们和他们的团队想知道,自动化操作能够给他们带来什么好处。他们想知道 RPA 平台特性和功能,以及自动化在现实中的真实案例。从这一点到概念验证的实现过程通常很短暂。
|
||||
|
||||
@ -14,7 +17,7 @@
|
||||
|
||||
但是自动化带来的现实好处有时候可能比你所预期的时间要晚。采用 RPA 的公司在其实施后可能会对它们自身的 ROI 提出一些质疑。一些人没有看到预期之中的成本节省,并对其中的原因感到疑惑。
|
||||
|
||||
## 你是不是自动化了错误的东西?
|
||||
### 你是不是自动化了错误的东西?
|
||||
|
||||
在这些情况下,自动化的愿景和现实之间的差距是什么呢?我们来分析一下它,在决定去继续进行一个自动化验证项目(甚至是一个成熟的实践)之后,我们来看一下通常会发生什么。
|
||||
|
||||
@ -26,7 +29,7 @@
|
||||
|
||||
那么,对于领导们来说,怎么才能确保实施自动化能够带来他们想要的 ROI 呢?实现这个目标有四步:
|
||||
|
||||
## 1. 教育团队
|
||||
### 1. 教育团队
|
||||
|
||||
在你的团队中,从 COO 职位以下的人中,很有可能都听说过 RPA 和运营自动化。同样很有可能他们都有许多的问题和担心。在你开始启动实施之前解决这些问题和担心是非常重要的。
|
||||
|
||||
@ -36,23 +39,23 @@
|
||||
|
||||
“实施自动化的第一步是更好地理解你的流程。”
|
||||
|
||||
## 2. 审查内部流程
|
||||
### 2. 审查内部流程
|
||||
|
||||
实施自动化的第一步是更好地理解你的流程。每个 RPA 实施之前都应该进行流程清单、动作分析、以及成本/价值的绘制练习。
|
||||
|
||||
这些练习对于理解流程中何处价值产生(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
|
||||
这些练习对于理解流程中何处产生价值(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
|
||||
|
||||
这将有助你去识别和优先考虑最合适的自动化候选者。由于能够或者可能需要自动化的任务数量较多,流程一般需要分段实施自动化,因此优先级很重要。
|
||||
|
||||
**建议**:设置一个小的工作团队,每个运营团队都参与其中。从每个运营团队中提名一个协调人 —— 一般是运营团队的领导或者团队管理者。在团队级别上组织一次研讨会,去构建流程清单、识别候选流程、以及推动购买。你的自动化合作伙伴很可能有“加速器” —— 调查问卷、计分卡等等 —— 这些将帮助你加速完成这项活动。
|
||||
|
||||
## 3. 为优先业务提供强有力的指导
|
||||
### 3. 为优先业务提供强有力的指导
|
||||
|
||||
实施自动化经常会涉及到在运营团队之间,基于业务价值对流程选择和自动化优先级上要达成共识(有时候是打破平衡)虽然团队的参与仍然是分析和实施的关键部分,但是领导仍然应该是最终的决策者。
|
||||
|
||||
**建议**:安排定期会议从工作团队中获取最新信息。除了像推动达成共识和购买之外,工作团队还应该在团队层面上去查看领导们关于 ROI、平台选择、以及自动化优先级上的指导性决定。
|
||||
|
||||
## 4. 应该推动 CIO 和 COO 的紧密合作
|
||||
### 4. 应该推动 CIO 和 COO 的紧密合作
|
||||
|
||||
当运营团队和技术团队紧密合作时,自动化的实施将异常顺利。COO 需要去帮助推动与 CIO 团队的合作。
|
||||
|
||||
@ -68,7 +71,7 @@ via: https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-
|
||||
|
||||
作者:[Rajesh Kamath][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,15 @@
|
||||
调试器到底怎样工作
|
||||
======
|
||||
|
||||
> 你也许用过调速器检查过你的代码,但你知道它们是如何做到的吗?
|
||||
|
||||

|
||||
|
||||
供图:opensource.com
|
||||
|
||||
调试器是那些大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器...使用 [Rust][2]!
|
||||
调试器是大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的那些软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器……使用 [Rust][2]!
|
||||
|
||||
在本文中,术语调试器/跟踪器可以互换。 “被跟踪者”是指正在被跟踪者跟踪的进程。
|
||||
在本文中,术语<ruby>调试器<rt>debugger</rt></ruby>和<ruby>跟踪器<rt>tracer</rt></ruby>可以互换。 “<ruby>被跟踪者<rt>Tracee</rt></ruby>”是指正在被跟踪器跟踪的进程。
|
||||
|
||||
### ptrace 系统调用
|
||||
|
||||
@ -17,59 +19,46 @@
|
||||
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
|
||||
```
|
||||
|
||||
这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是......我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
|
||||
这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是……我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
|
||||
|
||||
现在被跟踪者可以被调试器追踪,重要的变化发生了:
|
||||
|
||||
* 每当一个信号被传送到被调试者时,它就会停止,并且一个可以被 `wait` 系列系统调用捕获的等待事件被传送给跟踪器。
|
||||
* 每当一个信号被传送到被跟踪者时,它就会停止,并且一个可以被 `wait` 系列的系统调用捕获的等待事件被传送给跟踪器。
|
||||
* 每个 `execve` 系统调用都会导致 `SIGTRAP` 被传递给被跟踪者。(与之前的项目相结合,这意味着被跟踪者在一个 `execve` 完全发生之前停止。)
|
||||
|
||||
这意味着,一旦我们发出 `PTRACE_TRACEME` 请求并调用 `execve` 系统调用来实际在被跟踪者(进程上下文)中启动程序时,被跟踪者将立即停止,因为 `execve` 会传递一个 `SIGTRAP`,并且会被跟踪器中的等待事件捕获。我们如何继续?正如人们所期望的那样,`ptrace` 有大量的请求可以用来告诉被跟踪者可以继续:
|
||||
|
||||
|
||||
* `PTRACE_CONT`:这是最简单的。 被跟踪者运行,直到它接收到一个信号,此时等待事件被传递给跟踪器。这是最常见的实现真实世界调试器的“继续直至断点”和“永远继续”选项的方式。断点将在下面介绍。
|
||||
* `PTRACE_SYSCALL`:与 `PTRACE_CONT` 非常相似,但在进入系统调用之前以及在系统调用返回到用户空间之前停止。它可以与其他请求(我们将在本文后面介绍)结合使用来监视和修改系统调用的参数或返回值。系统调用追踪程序 `strace` 很大程度上使用这个请求来获知进程发起了哪些系统调用。
|
||||
* `PTRACE_SINGLESTEP`:这个很好理解。如果您之前使用过调试器(你会知道),此请求会执行下一条指令,然后立即停止。
|
||||
|
||||
|
||||
|
||||
我们可以通过各种各样的请求停止进程,但我们如何获得被调试者的状态?进程的状态大多是通过其寄存器捕获的,所以当然 `ptrace` 有一个请求来获得(或修改)寄存器:
|
||||
|
||||
* `PTRACE_GETREGS`:这个请求将给出被跟踪者刚刚被停止时的寄存器的状态。
|
||||
* `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值并使用 `PTRACE_SETREGS` 将寄存器设为新值。
|
||||
* `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值,并使用 `PTRACE_SETREGS` 将寄存器设为新值。
|
||||
* `PTRACE_PEEKUSER` 和 `PTRACE_POKEUSER`:这些允许从被跟踪者的 `USER` 区读取信息,这里保存了寄存器和其他有用的信息。 这可以用来修改单一寄存器,而避免使用更重的 `PTRACE_{GET,SET}REGS` 请求。
|
||||
|
||||
|
||||
|
||||
在调试器仅仅修改寄存器是不够的。调试器有时需要读取一部分内存,甚至对其进行修改。GDB 可以使用 `print` 得到一个内存位置或变量的值。`ptrace` 通过下面的方法实现这个功能:
|
||||
|
||||
* `PTRACE_PEEKTEXT` 和 `PTRACE_POKETEXT`:这些允许读取和写入被跟踪者地址空间中的一个字。当然,使用这个功能时被跟踪者要被暂停。
|
||||
|
||||
|
||||
|
||||
真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑x86。
|
||||
真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑 x86。
|
||||
|
||||
### 体系结构的支持
|
||||
|
||||
`ptrace` 很酷,但它是如何工作? 在前面的部分中,我们已经看到 `ptrace` 跟信号有很大关系:`SIGTRAP` 可以在单步跟踪、`execve` 之前以及系统调用前后被传送。信号可以通过一些方式产生,但我们将研究两个具体的例子,以展示信号可以被调试器用来在给定的位置停止程序(有效地创建一个断点!):
|
||||
|
||||
|
||||
* **未定义的指令**:当一个进程尝试执行一个未定义的指令,CPU 将产生一个异常。此异常通过 CPU 中断处理,内核中相应的中断处理程序被调用。这将导致一个 `SIGILL` 信号被发送给进程。 这依次导致进程被停止,跟踪器通过一个等待事件被通知,然后它可以决定后面做什么。在 x86 上,指令 `ud2` 被确保始终是未定义的。
|
||||
|
||||
* **调试中断**:前面的方法的问题是,`ud2` 指令需要占用两个字节的机器码。存在一条特殊的单字节指令能够触发一个中断,它是 `int $3`,机器码是 `0xCC`。 当该中断发出时,内核向进程发送一个 `SIGTRAP`,如前所述,跟踪器被通知。
|
||||
|
||||
|
||||
|
||||
这很好,但如何做我们胁迫的被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
|
||||
这很好,但如何我们才能胁迫被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
|
||||
|
||||
好吧,我们已经讲过了断点,那观察点呢? 当一个特定的内存位置被读或写,调试器如何停止程序? 当然你不可能为了能够读或写内存而去把每一个指令都覆盖为 `int $3`。有一组调试寄存器为了更有效的满足这个目的而被设计出来:
|
||||
|
||||
|
||||
* `DR0` 到 `DR3`:这些寄存器中的每个都包含一个地址(内存位置),调试器因为某种原因希望被跟踪者在那些地址那里停止。 其原因以掩码方式被设定在 `DR7` 寄存器中。
|
||||
* `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7`过时的别名。
|
||||
* `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7` 过时的别名。
|
||||
* `DR6`:调试状态。包含有关 `DR0` 到 `DR3` 中的哪个寄存器导致调试异常被引发的信息。这被 Linux 用来计算与 `SIGTRAP` 信号一起传递给被跟踪者的信息。
|
||||
* `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释DR0至DR3中指定的地址。位掩码控制监视点的尺寸(监视1,2,4或8个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
|
||||
|
||||
* `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释 `DR0` 至 `DR3` 中指定的地址。位掩码控制监视点的尺寸(监视1、2、4 或 8 个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
|
||||
|
||||
由于调试寄存器是进程的 `USER` 区域的一部分,调试器可以使用 `PTRACE_POKEUSER` 将值写入调试寄存器。调试寄存器只与特定进程相关,因此在进程抢占并重新获得 CPU 控制权之前,调试寄存器会被恢复。
|
||||
|
||||
@ -88,7 +77,7 @@ via: https://opensource.com/article/18/1/how-debuggers-really-work
|
||||
|
||||
作者:[Levente Kurusa][a]
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,87 @@
|
||||
为什么 DevSecOps 对 IT 领导来说如此重要
|
||||
======
|
||||
|
||||
> DevSecOps 也许不是一个优雅的词汇,但是其结果很吸引人:更强的安全、提前出现在开发周期中。来看看一个 IT 领导与 Meltdown 的拼搏。
|
||||
|
||||

|
||||
|
||||
如果 [DevOps][1] 最终是关于创造更好的软件,那也就意味着是更安全的软件。
|
||||
|
||||
而到了术语 “DevSecOps”,就像任何其他 IT 术语一样,DevSecOps —— 一个更成熟的 DevOps 的后代 ——可能容易受到炒作和盗用。但这个术语对那些拥抱了 DevOps 文化的领导者们来说具有重要的意义,并且其实践和工具可以帮助他们实现其承诺。
|
||||
|
||||
说道这里:“DevSecOps”是什么意思?
|
||||
|
||||
“DevSecOps 是开发、安全、运营的混合,”来自 [Datical][2] 的首席技术官和联合创始人 Robert 说。“这提醒我们,对我们的应用程序来说安全和创建并部署应用到生产中一样重要。”
|
||||
|
||||
**[想阅读其他首席技术官的 DevOps 文章吗?查阅我们丰富的资源,[DevOps:IT 领导者指南][3]]**
|
||||
|
||||
向非技术人员解释 DevSecOps 的一个简单的方法是:它是指将安全有意并提前加入到开发过程中。
|
||||
|
||||
“安全团队从历史上一直都被孤立于开发团队——每个团队在 IT 的不同领域都发展了很强的专业能力”,来自红帽安全策的专家 Kirsten 最近告诉我们。“不需要这样,非常关注安全也关注他们通过软件来兑现商业价值的能力的企业正在寻找能够在应用开发生命周期中加入安全的方法。他们通过在整个 CI/CD 管道中集成安全实践、工具和自动化来采用 DevSecOps。”
|
||||
|
||||
“为了能够做的更好,他们正在整合他们的团队——专业的安全人员从开始设计到部署到生产中都融入到了开发团队中了,”她说,“双方都收获了价值——每个团队都拓展了他们的技能和基础知识,使他们自己都成更有价值的技术人员。 DevOps 做的很正确——或者说 DevSecOps——提高了 IT 的安全性。”
|
||||
|
||||
IT 团队比任何以往都要求要快速频繁的交付服务。DevOps 在某种程度上可以成为一个很棒的推动者,因为它能够消除开发和运营之间通常遇到的一些摩擦,运营一直被排挤在整个过程之外直到要部署的时候,开发者把代码随便一放之后就不再去管理,他们承担更少的基础架构的责任。那种孤立的方法引起了很多问题,委婉的说,在数字时代,如果将安全孤立起来同样的情况也会发生。
|
||||
|
||||
“我们已经采用了 DevOps,因为它已经被证明通过移除开发和运营之间的阻碍来提高 IT 的绩效,”Reevess 说,“就像我们不应该在开发周期要结束时才加入运营,我们不应该在快要结束时才加入安全。”
|
||||
|
||||
### 为什么 DevSecOps 必然出现
|
||||
|
||||
或许会把 DevSecOps 看作是另一个时髦词,但对于安全意识很强的IT领导者来说,它是一个实质性的术语:在软件开发管道中安全必须是第一层面的要素,而不是部署前的最后一步的螺栓,或者更糟的是,作为一个团队只有当一个实际的事故发生的时候安全人员才会被重用争抢。
|
||||
|
||||
“DevSecOps 不只是一个时髦的术语——因为多种原因它是现在和未来 IT 将呈现的状态”,来自 [Sumo Logic] 的安全和合规副总裁 George 说道,“最重要的好处是将安全融入到开发和运营当中开提供保护的能力”
|
||||
|
||||
此外,DevSecOps 的出现可能是 DevOps 自身逐渐成熟并扎根于 IT 之中的一个征兆。
|
||||
|
||||
“企业中的 DevOps 文化已成定局,而且那意味着开发者们正以不断增长的速度交付功能和更新,特别是自我管理的组织会对合作和衡量的结果更加满意”,来自 [CYBRIC] 的首席技术官和联合创始人 Mike 说道。
|
||||
|
||||
在实施 DevOps 的同时继续保留原有安全措施的团队和公司,随着他们继续部署的更快更频繁可能正在经历越来越多的安全管理风险上的痛苦。
|
||||
|
||||
“现在的手工的安全测试方法会继续远远被甩在后面。”
|
||||
|
||||
“如今,手动的安全测试方法正被甩得越来越远,利用自动化和协作将安全测试转移到软件开发生命周期中,因此推动 DevSecOps 的文化是 IT 领导者们为增加整体的灵活性提供安全保证的唯一途径”,Kail 说。
|
||||
|
||||
转移安全测试也使开发者受益:他们能够在开放的较早的阶段验证并解决潜在的问题——这样很少需要或者甚至不需要安全人员的介入,而不是在一个新的服务或者更新部署之前在他们的代码中发现一个明显的漏洞。
|
||||
|
||||
“做的正确,DevSecOps 能够将安全融入到开发生命周期中,允许开发者们在没有安全中断的情况下更加快速容易的保证他们应用的安全”,来自 [SAS][8] 的首席信息安全员 Wilson 说道。
|
||||
|
||||
Wilson 指出静态(SAST)和源组合分析(SCA)工具,集成到团队的持续交付管道中,作为有用的技术通过给予开发者关于他们的代码中的潜在问题和第三方依赖中的漏洞的反馈来使之逐渐成为可能。
|
||||
|
||||
“因此,开发者们能够主动和迭代的缓解应用安全的问题,然后在不需要安全人员介入的情况下重新进行安全扫描。” Wilson 说。他同时指出 DevSecOps 能够帮助开发者简化更新和打补丁。
|
||||
|
||||
DevSecOps 并不意味着你不再需要安全组的意见了,就如同 DevOps 并不意味着你不再需要基础架构专家;它只是帮助你减少在生产中发现缺陷的可能性,或者减少导致降低部署速度的阻碍,因为缺陷已经在开发周期中被发现解决了。
|
||||
|
||||
“如果他们有问题或者需要帮助,我们就在这儿,但是因为已经给了开发者他们需要的保护他们应用安全的工具,我们很少在一个深入的测试中发现一个导致中断的问题,”Wilson 说道。
|
||||
|
||||
### DevSecOps 遇到 Meltdown
|
||||
|
||||
Sumo Locic 的 Gerchow 向我们分享了一个在运转中的 DevSecOps 文化的一个及时案例:当最近 [Meltdown 和 Spectre] 的消息传来的时候,团队的 DevSecOps 方法使得有了一个快速的响应来减轻风险,没有任何的通知去打扰内部或者外部的顾客,Gerchow 所说的这点对原生云、高监管的公司来说特别的重要。
|
||||
|
||||
第一步:Gerchow 的小型安全团队都具有一定的开发能力,能够通过 Slack 和它的主要云供应商协同工作来确保它的基础架构能够在 24 小时之内完成修复。
|
||||
|
||||
“接着我的团队立即开始进行系统级的修复,实现终端客户的零停机时间,不需要去开工单给工程师,如果那样那意味着你需要等待很长的变更过程。所有的变更都是通过 Slack 的自动 jira 票据进行,通过我们的日志监控和分析解决方案”,Gerchow 解释道。
|
||||
|
||||
在本质上,它听起来非常像 DevOps 文化,匹配正确的人员、过程和工具,但它明确的将安全作为文化中的一部分进行了混合。
|
||||
|
||||
“在传统的环境中,这将花费数周或数月的停机时间来处理,因为开发、运维和安全三者是相互独立的”,Gerchow 说道,“通过一个 DevSecOps 的过程和习惯,终端用户可以通过简单的沟通和当日修复获得无缝的体验。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.datical.com/
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
[4]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[5]:https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
|
||||
[6]:https://www.sumologic.com/
|
||||
[7]:https://www.cybric.io/
|
||||
[8]:https://www.sas.com/en_us/home.html
|
||||
[9]:https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-heres-what-you-need-know?intcmp=701f2000000tjyaAAA
|
||||
@ -0,0 +1,276 @@
|
||||
在 Kubernetes 上运行一个 Python 应用程序
|
||||
============================================================
|
||||
|
||||
> 这个分步指导教程教你通过在 Kubernetes 上部署一个简单的 Python 应用程序来学习部署的流程。
|
||||
|
||||

|
||||
|
||||
Kubernetes 是一个具备部署、维护和可伸缩特性的开源平台。它在提供可移植性、可扩展性以及自我修复能力的同时,简化了容器化 Python 应用程序的管理。
|
||||
|
||||
不论你的 Python 应用程序是简单还是复杂,Kubernetes 都可以帮你高效地部署和伸缩它们,在有限的资源范围内滚动升级新特性。
|
||||
|
||||
在本文中,我将描述在 Kubernetes 上部署一个简单的 Python 应用程序的过程,它包括:
|
||||
|
||||
* 创建 Python 容器镜像
|
||||
* 发布容器镜像到镜像注册中心
|
||||
* 使用持久卷
|
||||
* 在 Kubernetes 上部署 Python 应用程序
|
||||
|
||||
### 必需条件
|
||||
|
||||
你需要 Docker、`kubectl` 以及这个 [源代码][10]。
|
||||
|
||||
Docker 是一个构建和承载已发布的应用程序的开源平台。可以参照 [官方文档][11] 去安装 Docker。运行如下的命令去验证你的系统上运行的 Docker:
|
||||
|
||||
```
|
||||
$ docker info
|
||||
Containers: 0
|
||||
Images: 289
|
||||
Storage Driver: aufs
|
||||
Root Dir: /var/lib/docker/aufs
|
||||
Dirs: 289
|
||||
Execution Driver: native-0.2
|
||||
Kernel Version: 3.16.0-4-amd64
|
||||
Operating System: Debian GNU/Linux 8 (jessie)
|
||||
WARNING: No memory limit support
|
||||
WARNING: No swap limit support
|
||||
```
|
||||
|
||||
`kubectl` 是在 Kubernetes 集群上运行命令的一个命令行界面。运行下面的 shell 脚本去安装 `kubectl`:
|
||||
|
||||
```
|
||||
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
|
||||
```
|
||||
|
||||
部署到 Kubernetes 的应用要求必须是一个容器化的应用程序。我们来回顾一下 Python 应用程序的容器化过程。
|
||||
|
||||
### 一句话了解容器化
|
||||
|
||||
容器化是指将一个应用程序所需要的东西打包进一个自带操作系统的容器中。这种完整机器虚拟化的好处是,一个应用程序能够在任何机器上运行而无需考虑它的依赖项。
|
||||
|
||||
我们以 Roman Gaponov 的 [文章][12] 为参考,来为我们的 Python 代码创建一个容器。
|
||||
|
||||
### 创建一个 Python 容器镜像
|
||||
|
||||
为创建这些镜像,我们将使用 Docker,它可以让我们在一个隔离的 Linux 软件容器中部署应用程序。Docker 可以使用来自一个 Dockerfile 中的指令来自动化构建镜像。
|
||||
|
||||
这是我们的 Python 应用程序的 Dockerfile:
|
||||
|
||||
```
|
||||
FROM python:3.6
|
||||
MAINTAINER XenonStack
|
||||
|
||||
# Creating Application Source Code Directory
|
||||
RUN mkdir -p /k8s_python_sample_code/src
|
||||
|
||||
# Setting Home Directory for containers
|
||||
WORKDIR /k8s_python_sample_code/src
|
||||
|
||||
# Installing python dependencies
|
||||
COPY requirements.txt /k8s_python_sample_code/src
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
|
||||
# Copying src code to Container
|
||||
COPY . /k8s_python_sample_code/src/app
|
||||
|
||||
# Application Environment variables
|
||||
ENV APP_ENV development
|
||||
|
||||
# Exposing Ports
|
||||
EXPOSE 5035
|
||||
|
||||
# Setting Persistent data
|
||||
VOLUME ["/app-data"]
|
||||
|
||||
# Running Python Application
|
||||
CMD ["python", "app.py"]
|
||||
```
|
||||
|
||||
这个 Dockerfile 包含运行我们的示例 Python 代码的指令。它使用的开发环境是 Python 3.5。
|
||||
|
||||
### 构建一个 Python Docker 镜像
|
||||
|
||||
现在,我们可以使用下面的这个命令按照那些指令来构建 Docker 镜像:
|
||||
|
||||
```
|
||||
docker build -t k8s_python_sample_code .
|
||||
```
|
||||
|
||||
这个命令为我们的 Python 应用程序创建了一个 Docker 镜像。
|
||||
|
||||
### 发布容器镜像
|
||||
|
||||
我们可以将我们的 Python 容器镜像发布到不同的私有/公共云仓库中,像 Docker Hub、AWS ECR、Google Container Registry 等等。本教程中我们将发布到 Docker Hub。
|
||||
|
||||
在发布镜像之前,我们需要给它标记一个版本号:
|
||||
|
||||
```
|
||||
docker tag k8s_python_sample_code:latest k8s_python_sample_code:0.1
|
||||
```
|
||||
|
||||
### 推送镜像到一个云仓库
|
||||
|
||||
如果使用一个 Docker 注册中心而不是 Docker Hub 去保存镜像,那么你需要在你本地的 Docker 守护程序和 Kubernetes Docker 守护程序上添加一个容器注册中心。对于不同的云注册中心,你可以在它上面找到相关信息。我们在示例中使用的是 Docker Hub。
|
||||
|
||||
运行下面的 Docker 命令去推送镜像:
|
||||
|
||||
```
|
||||
docker push k8s_python_sample_code
|
||||
```
|
||||
|
||||
### 使用 CephFS 持久卷
|
||||
|
||||
Kubernetes 支持许多的持久存储提供商,包括 AWS EBS、CephFS、GlusterFS、Azure Disk、NFS 等等。我在示例中使用 CephFS 做为 Kubernetes 的持久卷。
|
||||
|
||||
为使用 CephFS 存储 Kubernetes 的容器数据,我们将创建两个文件:
|
||||
|
||||
`persistent-volume.yml` :
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
kind: PersistentVolume
|
||||
metadata:
|
||||
name: app-disk1
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
capacity:
|
||||
storage: 50Gi
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
cephfs:
|
||||
monitors:
|
||||
- "172.17.0.1:6789"
|
||||
user: admin
|
||||
secretRef:
|
||||
name: ceph-secret
|
||||
readOnly: false
|
||||
```
|
||||
|
||||
`persistent_volume_claim.yaml`:
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: appclaim1
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
resources:
|
||||
requests:
|
||||
storage: 10Gi
|
||||
```
|
||||
|
||||
现在,我们将使用 `kubectl` 去添加持久卷并声明到 Kubernetes 集群中:
|
||||
|
||||
```
|
||||
$ kubectl create -f persistent-volume.yml
|
||||
$ kubectl create -f persistent-volume-claim.yml
|
||||
```
|
||||
|
||||
现在,我们准备去部署 Kubernetes。
|
||||
|
||||
### 在 Kubernetes 上部署应用程序
|
||||
|
||||
为管理部署应用程序到 Kubernetes 上的最后一步,我们将创建两个重要文件:一个服务文件和一个部署文件。
|
||||
|
||||
使用下列的内容创建服务文件,并将它命名为 `k8s_python_sample_code.service.yml`:
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
labels:
|
||||
k8s-app: k8s_python_sample_code
|
||||
name: k8s_python_sample_code
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
type: NodePort
|
||||
ports:
|
||||
- port: 5035
|
||||
selector:
|
||||
k8s-app: k8s_python_sample_code
|
||||
```
|
||||
|
||||
使用下列的内容创建部署文件并将它命名为 `k8s_python_sample_code.deployment.yml`:
|
||||
|
||||
```
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: k8s_python_sample_code
|
||||
namespace: k8s_python_sample_code
|
||||
spec:
|
||||
replicas: 1
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
k8s-app: k8s_python_sample_code
|
||||
spec:
|
||||
containers:
|
||||
- name: k8s_python_sample_code
|
||||
image: k8s_python_sample_code:0.1
|
||||
imagePullPolicy: "IfNotPresent"
|
||||
ports:
|
||||
- containerPort: 5035
|
||||
volumeMounts:
|
||||
- mountPath: /app-data
|
||||
name: k8s_python_sample_code
|
||||
volumes:
|
||||
- name: <name of application>
|
||||
persistentVolumeClaim:
|
||||
claimName: appclaim1
|
||||
```
|
||||
|
||||
最后,我们使用 `kubectl` 将应用程序部署到 Kubernetes:
|
||||
|
||||
```
|
||||
$ kubectl create -f k8s_python_sample_code.deployment.yml $ kubectl create -f k8s_python_sample_code.service.yml
|
||||
```
|
||||
|
||||
现在,你的应用程序已经成功部署到 Kubernetes。
|
||||
|
||||
你可以通过检查运行的服务来验证你的应用程序是否在运行:
|
||||
|
||||
```
|
||||
kubectl get services
|
||||
```
|
||||
|
||||
或许 Kubernetes 可以解决未来你部署应用程序的各种麻烦!
|
||||
|
||||
_想学习更多关于 Python 的知识?Nanjekye 的书,[和平共处的 Python 2 和 3][7] 提供了完整的方法,让你写的代码在 Python 2 和 3 上完美运行,包括如何转换已有的 Python 2 代码为能够可靠运行在 Python 2 和 3 上的代码的详细示例。_
|
||||
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13] Joannah Nanjekye - Straight Outta 256,只要结果不问原因,充满激情的飞行员,喜欢用代码说话。[关于我的更多信息][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/running-python-application-kubernetes
|
||||
|
||||
作者:[Joannah Nanjekye][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nanjekyejoannah
|
||||
[1]:https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[2]:https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[3]:https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[4]:https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[5]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[6]:https://opensource.com/article/18/1/running-python-application-kubernetes?rate=D9iKksKbd9q9vOVb92Mg-v0Iyqn0QVO5fbIERTbSHz4
|
||||
[7]:https://www.apress.com/gp/book/9781484229545
|
||||
[8]:https://opensource.com/users/nanjekyejoannah
|
||||
[9]:https://opensource.com/user/196386/feed
|
||||
[10]:https://github.com/jnanjekye/k8s_python_sample_code/tree/master
|
||||
[11]:https://docs.docker.com/engine/installation/
|
||||
[12]:https://hackernoon.com/docker-tutorial-getting-started-with-python-redis-and-nginx-81a9d740d091
|
||||
[13]:https://opensource.com/users/nanjekyejoannah
|
||||
[14]:https://opensource.com/users/nanjekyejoannah
|
||||
[15]:https://opensource.com/users/nanjekyejoannah
|
||||
[16]:https://opensource.com/tags/python
|
||||
[17]:https://opensource.com/tags/kubernetes
|
||||
95
published/201807/20180128 Being open about data privacy.md
Normal file
95
published/201807/20180128 Being open about data privacy.md
Normal file
@ -0,0 +1,95 @@
|
||||
对数据隐私持开放的态度
|
||||
======
|
||||
|
||||
> 尽管有包括 GDPR 在内的法规,数据隐私对于几乎所有的人来说都是很重要的事情。
|
||||
|
||||

|
||||
|
||||
今天(LCTT 译注:本文发表于 2018/1/28)是<ruby>[数据隐私日][1]<rt>Data Privacy Day</rt></ruby>,(在欧洲叫“<ruby>数据保护日<rt>Data Protection Day</rt></ruby>”),你可能会认为现在我们处于一个开源的世界中,所有的数据都应该是自由的,[就像人们想的那样][2],但是现实并没那么简单。主要有两个原因:
|
||||
|
||||
1. 我们中的大多数(不仅仅是在开源中)认为至少有些关于我们自己的数据是不愿意分享出去的(我在之前发表的一篇文章中列举了一些例子[3])
|
||||
2. 我们很多人虽然在开源中工作,但事实上是为了一些商业公司或者其他一些组织工作,也是在合法的要求范围内分享数据。
|
||||
|
||||
所以实际上,数据隐私对于每个人来说是很重要的。
|
||||
|
||||
事实证明,在美国和欧洲之间,人们和政府认为让组织使用哪些数据的出发点是有些不同的。前者通常为商业实体(特别是愤世嫉俗的人们会指出是大型的商业实体)利用他们所收集到的关于我们的数据提供了更多的自由度。在欧洲,完全是另一观念,一直以来持有的多是有更多约束限制的观念,而且在 5 月 25 日,欧洲的观点可以说取得了胜利。
|
||||
|
||||
### 通用数据保护条例(GDPR)的影响
|
||||
|
||||
那是一个相当全面的声明,其实事实上这是 2016 年欧盟通过的一项称之为<ruby>通用数据保护条例<rt>General Data Protection Regulation</rt></ruby>(GDPR)的立法的日期。数据通用保护条例在私人数据怎样才能被保存,如何才能被使用,谁能使用,能被持有多长时间这些方面设置了严格的规则。它描述了什么数据属于私人数据——而且涉及的条目范围非常广泛,从你的姓名、家庭住址到你的医疗记录以及接通你电脑的 IP 地址。
|
||||
|
||||
通用数据保护条例的重要之处是它并不仅仅适用于欧洲的公司,如果你是阿根廷人、日本人、美国人或者是俄罗斯的公司而且你正在收集涉及到欧盟居民的数据,你就要受到这个条例的约束管辖。
|
||||
|
||||
“哼!” 你可能会这样说^注1 ,“我的业务不在欧洲:他们能对我有啥约束?” 答案很简单:如果你想继续在欧盟做任何生意,你最好遵守,因为一旦你违反了通用数据保护条例的规则,你将会受到你的全球总收入百分之四的惩罚。是的,你没听错,是全球总收入,而不是仅仅在欧盟某一国家的的收入,也不只是净利润,而是全球总收入。这将会让你去叮嘱告知你的法律团队,他们就会知会你的整个团队,同时也会立即去指引你的 IT 团队,确保你的行为在相当短的时间内合规。
|
||||
|
||||
看上去这和非欧盟公民没有什么相关性,但其实不然,对大多数公司来说,对所有的他们的顾客、合作伙伴以及员工实行同样的数据保护措施是件既简单又有效的事情,而不是仅针对欧盟公民实施,这将会是一件很有利的事情。^注2
|
||||
|
||||
然而,数据通用保护条例不久将在全球实施并不意味着一切都会变的很美好^注3 :事实并非如此,我们一直在丢弃关于我们自己的信息——而且允许公司去使用它。
|
||||
|
||||
有一句话是这么说的(尽管很争议):“如果你没有在付费,那么你就是产品。”这句话的意思就是如果你没有为某一项服务付费,那么其他的人就在付费使用你的数据。你有付费使用 Facebook、推特、谷歌邮箱?你觉得他们是如何赚钱的?大部分是通过广告,一些人会争论那是他们向你提供的一项服务而已,但事实上是他们在利用你的数据从广告商里获取收益。你不是一个真正的广告的顾客——只有当你从看了广告后买了他们的商品之后你才变成了他们的顾客,但直到这个发生之前,都是广告平台和广告商的关系。
|
||||
|
||||
有些服务是允许你通过付费来消除广告的(流媒体音乐平台声破天就是这样的),但从另一方面来讲,即使你认为付费的服务也可以启用广告(例如,亚马逊正在努力让 Alexa 发广告),除非我们想要开始为这些所有的免费服务付费,我们需要清楚我们所放弃的,而且在我们暴露的和不想暴露的之间做一些选择。
|
||||
|
||||
### 谁是顾客?
|
||||
|
||||
关于数据的另一个问题一直在困扰着我们,它是产生的数据量的直接结果。有许多组织一直在产生巨量的数据,包括公共的组织比如大学、医院或者是政府部门^注4 ——而且他们没有能力去储存这些数据。如果这些数据没有长久的价值也就没什么要紧的,但事实正好相反,随着处理大数据的工具正在开发中,而且这些组织也认识到他们现在以及在不久的将来将能够去挖掘这些数据。
|
||||
|
||||
然而他们面临的是,随着数据的增长和存储量无法跟上该怎么办。幸运的是——而且我是带有讽刺意味的使用了这个词^注5 ,大公司正在介入去帮助他们。“把你们的数据给我们,”他们说,“我们将免费保存。我们甚至让你随时能够使用你所收集到的数据!”这听起来很棒,是吗?这是大公司^注6 的一个极具代表性的例子,站在慈善的立场上帮助公共组织管理他们收集到的关于我们的数据。
|
||||
|
||||
不幸的是,慈善不是唯一的理由。他们是附有条件的:作为同意保存数据的交换条件,这些公司得到了将数据访问权限出售给第三方的权利。你认为公共组织,或者是被收集数据的人在数据被出售使用权使给第三方,以及在他们如何使用上能有发言权吗?我将把这个问题当做一个练习留给读者去思考。^注7
|
||||
|
||||
### 开放和积极
|
||||
|
||||
然而并不只有坏消息。政府中有一项在逐渐发展起来的“开放数据”运动鼓励各个部门免费开放大量他们的数据给公众或者其他组织。在某些情况下,这是专门立法的。许多志愿组织——尤其是那些接受公共资金的——正在开始这样做。甚至商业组织也有感兴趣的苗头。而且,有一些技术已经可行了,例如围绕不同的隐私和多方计算上,正在允许跨越多个数据集挖掘数据,而不用太多披露个人的信息——这个计算问题从未如现在比你想象的更容易。
|
||||
|
||||
这些对我们来说意味着什么呢?我之前在网站 Opensource.com 上写过关于[开源的共享福利][4],而且我越来越相信我们需要把我们的视野从软件拓展到其他区域:硬件、组织,和这次讨论有关的,数据。让我们假设一下你是 A 公司要提向另一家公司客户 B^注8 提供一项服务 。在此有四种不同类型的数据:
|
||||
|
||||
1. 数据完全开放:对 A 和 B 都是可得到的,世界上任何人都可以得到
|
||||
2. 数据是已知的、共享的,和机密的:A 和 B 可得到,但其他人不能得到
|
||||
3. 数据是公司级别上保密的:A 公司可以得到,但 B 顾客不能
|
||||
4. 数据是顾客级别保密的:B 顾客可以得到,但 A 公司不能
|
||||
|
||||
首先,也许我们对数据应该更开放些,将数据默认放到选项 1 中。如果那些数据对所有人开放——在无人驾驶、语音识别,矿藏以及人口数据统计会有相当大的作用的。^注9 如果我们能够找到方法将数据放到选项 2、3 和 4 中,不是很好吗?——或者至少它们中的一些——在选项 1 中是可以实现的,同时仍将细节保密?这就是研究这些新技术的希望。
|
||||
然而有很长的路要走,所以不要太兴奋,同时,开始考虑将你的的一些数据默认开放。
|
||||
|
||||
### 一些具体的措施
|
||||
|
||||
我们如何处理数据的隐私和开放?下面是我想到的一些具体的措施:欢迎大家评论做出更多的贡献。
|
||||
|
||||
* 检查你的组织是否正在认真严格的执行通用数据保护条例。如果没有,去推动实施它。
|
||||
* 要默认加密敏感数据(或者适当的时候用散列算法),当不再需要的时候及时删掉——除非数据正在被处理使用,否则没有任何借口让数据清晰可见。
|
||||
* 当你注册了一个服务的时候考虑一下你公开了什么信息,特别是社交媒体类的。
|
||||
* 和你的非技术朋友讨论这个话题。
|
||||
* 教育你的孩子、你朋友的孩子以及他们的朋友。然而最好是去他们的学校和他们的老师谈谈在他们的学校中展示。
|
||||
* 鼓励你所服务和志愿贡献的组织,或者和他们沟通一些推动数据的默认开放。不是去思考为什么我要使数据开放,而是从我为什么不让数据开放开始。
|
||||
* 尝试去访问一些开源数据。挖掘使用它、开发应用来使用它,进行数据分析,画漂亮的图,^注10 制作有趣的音乐,考虑使用它来做些事。告诉组织去使用它们,感谢它们,而且鼓励他们去做更多。
|
||||
|
||||
**注:**
|
||||
|
||||
1. 我承认你可能尽管不会。
|
||||
2. 假设你坚信你的个人数据应该被保护。
|
||||
3. 如果你在思考“极好的”的寓意,在这点上你并不孤独。
|
||||
4. 事实上这些机构能够有多开放取决于你所居住的地方。
|
||||
5. 假设我是英国人,那是非常非常大的剂量。
|
||||
6. 他们可能是巨大的公司:没有其他人能够负担得起这么大的存储和基础架构来使数据保持可用。
|
||||
7. 不,答案是“不”。
|
||||
8. 尽管这个例子也同样适用于个人。看看:A 可能是 Alice,B 可能是 BOb……
|
||||
9. 并不是说我们应该暴露个人的数据或者是这样的数据应该被保密,当然——不是那类的数据。
|
||||
10. 我的一个朋友当她接孩子放学的时候总是下雨,所以为了避免确认失误,她在整个学年都访问天气信息并制作了图表分享到社交媒体上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/being-open-about-data-privacy
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://en.wikipedia.org/wiki/Data_Privacy_Day
|
||||
[2]:https://en.wikipedia.org/wiki/Information_wants_to_be_free
|
||||
[3]:https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/
|
||||
[4]:https://opensource.com/article/17/11/commonwealth-open-source
|
||||
[5]:http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036
|
||||
@ -1,23 +1,25 @@
|
||||
供应链管理方面的 5 个开源软件工具
|
||||
======
|
||||
|
||||
> 跟踪您的库存和您需要的材料,用这些供应链管理工具制造产品。
|
||||
|
||||

|
||||
|
||||
本文最初发表于 2016 年 1 月 14 日,最后的更新日期为 2018 年 3 月 2 日。
|
||||
|
||||
如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
|
||||
如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数以百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
|
||||
|
||||
保持对货品、供应商、客户的持续跟踪,并且所有与它们相关的变动部分都会从中受益,并且,在某些情况下完全依赖专门的软件来帮助管理这些工作流。在本文中,我们将去了解一些免费的和开源的供应链管理方面的软件,以及它们的其中一些功能。
|
||||
保持对货品、供应商、客户的持续跟踪,而且所有与它们相关的变动部分都会受益于这些用来帮助管理工作流的专门软件,而在某些情况下需要完全依赖这些软件。在本文中,我们将去了解一些自由及开源的供应链管理方面的软件,以及它们的其中一些功能。
|
||||
|
||||
供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是合法性、最低品质要求、还是社会和环境的合规性。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
|
||||
供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是否是出于法律要求、最低品质要求、还是社会和环境责任。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
|
||||
|
||||
由于它的本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
|
||||
由于其本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
|
||||
|
||||
### Apache OFBiz
|
||||
|
||||
[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,目录、电子商务网站、帐户、和销售点,它在供应链管理方面的主要功能关注于仓库管理、履行、订单、和生产管理。它的可定制性很强,但是,它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层、和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
|
||||
[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,分类、电子商务网站、会计和 POS,它在供应链管理方面的主要功能关注于仓库管理、履行、订单和生产管理。它的可定制性很强,但是,对应的它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
|
||||
|
||||
Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 license][6] 授权的。
|
||||
Apache OFBiz 的源代码在其 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 许可证][6] 授权的。
|
||||
|
||||
如果你对它感兴趣,你也可以去查看 [opentaps][7],它是在 OFBiz 之上构建的。Opentaps 强化了 OFBiz 的用户界面,并且添加了 ERP 和 CRM 的核心功能,包括仓库管理、采购和计划。它是按 [AGPL 3.0][8] 授权使用的,对于不接受开源授权的组织,它也提供了商业授权。
|
||||
|
||||
@ -25,25 +27,25 @@ Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz
|
||||
|
||||
[OpenBoxes][9] 是一个供应链管理和存货管理项目,最初的主要设计目标是为了医疗行业中的药品跟踪管理,但是,它可以通过修改去跟踪任何类型的货品和相关的业务流。它有一个需求预测工具,可以基于历史订单数量、存储跟踪、支持多种场所、过期日期跟踪、销售点支持等进行预测,并且它还有许多其它功能,这使它成为医疗行业的理想选择,但是,它也可以用于其它行业。
|
||||
|
||||
它在 [Eclipse Public License][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
|
||||
它在 [Eclipse 公开许可证][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
|
||||
|
||||
### OpenLMIS
|
||||
|
||||
与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由络克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达 盖茨基金会。
|
||||
与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由洛克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达·盖茨基金会。
|
||||
|
||||
OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 license][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
|
||||
OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 许可证][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
|
||||
|
||||
### Odoo
|
||||
|
||||
你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和销售点连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
|
||||
你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和 POS 连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
|
||||
|
||||
Odoo 既有软件即服务的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
|
||||
Odoo 既有软件即服务(SaaS)的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
|
||||
|
||||
### xTuple
|
||||
|
||||
[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是帐务、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
|
||||
[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了其传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是会计、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
|
||||
|
||||
xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去 fork 它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
|
||||
xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去复刻它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
|
||||
|
||||
就这些,当然了,还有其它的可以帮你处理供应链管理的开源软件。如果你知道还有更好的软件,请在下面的评论区告诉我们。
|
||||
|
||||
@ -53,14 +55,14 @@ via: https://opensource.com/tools/supply-chain-management
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://en.wikipedia.org/wiki/Supply_chain_management
|
||||
[2]:https://opensource.com/business/14/7/top-5-open-source-crm-tools
|
||||
[3]:https://opensource.com/resources/top-4-open-source-erp-systems
|
||||
[3]:https://linux.cn/article-9785-1.html
|
||||
[4]:http://ofbiz.apache.org/
|
||||
[5]:http://ofbiz.apache.org/source-repositories.html
|
||||
[6]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
@ -0,0 +1,132 @@
|
||||
IT 自动化的下一步是什么: 6 大趋势
|
||||
======
|
||||
|
||||
> 自动化专家分享了一点对 [自动化][6]不远的将来的看法。请将这些保留在你的视线之内。
|
||||
|
||||

|
||||
|
||||
我们最近讨论了 [推动 IT 自动化的因素][1],可以看到[当前趋势][2]正在增长,以及那些给刚开始使用自动化部分流程的组织的 [有用的技巧][3] 。
|
||||
|
||||
噢,我们也分享了如何在贵公司[进行自动化的案例][4]及 [长期成功的关键][5]的专家建议。
|
||||
|
||||
现在,只有一个问题:自动化的下一步是什么? 我们邀请一系列专家分享一下 [自动化][6]不远的将来的看法。 以下是他们建议 IT 领域领导需密切关注的六大趋势。
|
||||
|
||||
### 1、 机器学习的成熟
|
||||
|
||||
对于关于 [机器学习][7](与“自我学习系统”相似的定义)的讨论,对于绝大多数组织的项目来说,实际执行起来它仍然为时过早。但预计这将发生变化,机器学习将在下一次 IT 自动化浪潮中将扮演着至关重要的角色。
|
||||
|
||||
[Advanced Systems Concepts, Inc.][8] 公司的工程总监 Mehul Amin 指出机器学习是 IT 自动化下一个关键增长领域之一。
|
||||
|
||||
“随着数据化的发展,自动化软件理应可以自我决策,否则这就是开发人员的责任了”,Amin 说。 “例如,开发者构建了需要执行的内容,但通过使用来自系统内部分析的软件,可以确定执行该流程的最佳系统。”
|
||||
|
||||
假设将这个系统延伸到其他地方中。Amin 指出,机器学习可以使自动化系统在必要的时候提供额外的资源,以需要满足时间线或 SLA,同样在不需要资源以及其他的可能性的时候退出。
|
||||
|
||||
显然不只有 Amin 一个人这样认为。
|
||||
|
||||
“IT 自动化正在走向自我学习的方向” ,[Sungard Availability Services][9] 公司首席架构师 Kiran Chitturi 表示,“系统将会能测试和监控自己,加强业务流程和软件交付能力。”
|
||||
|
||||
Chitturi 指出自动化测试就是个例子。脚本测试已经被广泛采用,但很快这些自动化测试流程将会更容易学习,更快发展,例如开发出新的代码或将更为广泛地影响生产环境。
|
||||
|
||||
### 2、 人工智能催生的自动化
|
||||
|
||||
上述原则同样适合与相关的(但是独立的) [人工智能][10]的领域。根据对人工智能的定义,机器学习在短时间内可能会对 IT 领域产生巨大的影响(并且我们可能会看到这两个领域的许多重叠的定义和理解)。假定新兴的人工智能技术将也会产生新的自动化机会。
|
||||
|
||||
[SolarWinds][11] 公司技术负责人 Patrick Hubbard 说,“人工智能和机器学习的整合普遍被认为对未来几年的商业成功起至关重要的作用。”
|
||||
|
||||
### 3、 这并不意味着不再需要人力
|
||||
|
||||
让我们试着安慰一下那些不知所措的人:前两种趋势并不一定意味着我们将失去工作。
|
||||
|
||||
这很可能意味着各种角色的改变,以及[全新角色][12]的创造。
|
||||
|
||||
但是在可预见的将来,至少,你不必需要对机器人鞠躬。
|
||||
|
||||
“一台机器只能运行在给定的环境变量中——它不能选择包含新的变量,在今天只有人类可以这样做,” Hubbard 解释说。“但是,对于 IT 专业人员来说,这将需要培养 AI 和自动化技能,如对程序设计、编程、管理人工智能和机器学习功能算法的基本理解,以及用强大的安全状态面对更复杂的网络攻击。”
|
||||
|
||||
Hubbard 分享一些新的工具或功能例子,例如支持人工智能的安全软件或机器学习的应用程序,这些应用程序可以远程发现石油管道中的维护需求。两者都可以提高效益和效果,自然不会代替需要信息安全或管道维护的人员。
|
||||
|
||||
“许多新功能仍需要人工监控,”Hubbard 说。“例如,为了让机器确定一些‘预测’是否可能成为‘规律’,人为的管理是必要的。”
|
||||
|
||||
即使你把机器学习和 AI 先放在一边,看待一般的 IT 自动化,同样原理也是成立的,尤其是在软件开发生命周期中。
|
||||
|
||||
[Juniper Networks][13] 公司自动化首席架构师 Matthew Oswalt ,指出 IT 自动化增长的根本原因是它通过减少操作基础设施所需的人工工作量来创造直接价值。
|
||||
|
||||
> 在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。
|
||||
|
||||
“它也将操作工作流程作为代码而不再是容易过时的文档或系统知识阶段,”Oswalt 解释说。“操作人员仍然需要在[自动化]工具响应事件方面后发挥积极作用。采用自动化的下一个阶段是建立一个能够跨 IT 频谱识别发生的有趣事件的系统,并以自主方式进行响应。在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。他们可以依靠这个系统在任何时候以同样的方式作出回应。”
|
||||
|
||||
### 4、 对自动化的焦虑将会减少
|
||||
|
||||
SolarWinds 公司的 Hubbard 指出,“自动化”一词本身就产生大量的不确定性和担忧,不仅仅是在 IT 领域,而且是跨专业领域,他说这种担忧是合理的。但一些随之而来的担忧可能被夸大了,甚至与科技产业本身共存。现实可能实际上是这方面的镇静力:当自动化的实际实施和实践帮助人们认识到这个列表中的第 3 项时,我们将看到第 4 项的出现。
|
||||
|
||||
“今年我们可能会看到对自动化焦虑的减少,更多的组织开始接受人工智能和机器学习作为增加现有人力资源的一种方式,”Hubbard 说。“自动化历史上为更多的工作创造了空间,通过降低成本和时间来完成较小任务,并将劳动力重新集中到无法自动化并需要人力的事情上。人工智能和机器学习也是如此。”
|
||||
|
||||
自动化还将减少令 IT 领导者神经紧张的一些焦虑:安全。正如[红帽][14]公司首席架构师 Matt Smith 最近[指出][15]的那样,自动化将越来越多地帮助 IT 部门降低与维护任务相关的安全风险。
|
||||
|
||||
他的建议是:“首先在维护活动期间记录和自动化 IT 资产之间的交互。通过依靠自动化,您不仅可以消除之前需要大量手动操作和手术技巧的任务,还可以降低人为错误的风险,并展示当您的 IT 组织采纳变更和新工作方法时可能发生的情况。最终,这将迅速减少对应用安全补丁的抵制。而且它还可以帮助您的企业在下一次重大安全事件中摆脱头条新闻。”
|
||||
|
||||
**[ 阅读全文: [12个企业安全坏习惯要打破。][16] ] **
|
||||
|
||||
### 5、 脚本和自动化工具将持续发展
|
||||
|
||||
许多组织看到了增加自动化的第一步,通常以脚本或自动化工具(有时称为配置管理工具)的形式作为“早期”工作。
|
||||
|
||||
但是随着各种自动化技术的使用,对这些工具的观点也在不断发展。
|
||||
|
||||
[DataVision][18] 首席运营官 Mark Abolafia 表示:“数据中心环境中存在很多重复性过程,容易出现人为错误,[Ansible][17] 等技术有助于缓解这些问题。“通过 Ansible ,人们可以为一组操作编写特定的步骤,并输入不同的变量,例如地址等,使过去长时间的过程链实现自动化,而这些过程以前都需要人为触摸和更长的交付时间。”
|
||||
|
||||
**[想了解更多关于 Ansible 这个方面的知识吗?阅读相关文章:[使用 Ansible 时的成功秘诀][19]。 ]**
|
||||
|
||||
另一个因素是:工具本身将继续变得更先进。
|
||||
|
||||
“使用先进的 IT 自动化工具,开发人员将能够在更短的时间内构建和自动化工作流程,减少易出错的编码,” ASCI 公司的 Amin 说。“这些工具包括预先构建的、预先测试过的拖放式集成,API 作业,丰富的变量使用,参考功能和对象修订历史记录。”
|
||||
|
||||
### 6、 自动化开创了新的指标机会
|
||||
|
||||
正如我们在此前所说的那样,IT 自动化不是万能的。它不会修复被破坏的流程,或者以其他方式为您的组织提供全面的灵丹妙药。这也是持续不断的:自动化并不排除衡量性能的必要性。
|
||||
|
||||
**[ 参见我们的相关文章 [DevOps 指标:你在衡量什么重要吗?][20] ]**
|
||||
|
||||
实际上,自动化应该打开了新的机会。
|
||||
|
||||
[Janeiro Digital][21] 公司架构师总裁 Josh Collins 说,“随着越来越多的开发活动 —— 源代码管理、DevOps 管道、工作项目跟踪等转向 API 驱动的平台,将这些原始数据拼接在一起以描绘组织效率提升的机会和图景”。
|
||||
|
||||
Collins 认为这是一种可能的新型“开发组织度量指标”。但不要误认为这意味着机器和算法可以突然预测 IT 所做的一切。
|
||||
|
||||
“无论是衡量个人资源还是整体团队,这些指标都可以很强大 —— 但应该用大量的背景来衡量。”Collins 说,“将这些数据用于高层次趋势并确认定性观察 —— 而不是临床评级你的团队。”
|
||||
|
||||
**想要更多这样知识, IT 领导者?[注册我们的每周电子邮件通讯][22]。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[MZqk](https://github.com/MZqk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now
|
||||
[2]:https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands
|
||||
[3]:https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips
|
||||
[4]:https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
|
||||
[5]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success
|
||||
[6]:https://enterprisersproject.com/tags/automation
|
||||
[7]:https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity
|
||||
[8]:https://www.advsyscon.com/en-us/
|
||||
[9]:https://www.sungardas.com/en/
|
||||
[10]:https://enterprisersproject.com/tags/artificial-intelligence
|
||||
[11]:https://www.solarwinds.com/
|
||||
[12]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros
|
||||
[13]:https://www.juniper.net/
|
||||
[14]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[15]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break
|
||||
[16]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ
|
||||
[17]:https://opensource.com/tags/ansible
|
||||
[18]:https://datavision.com/
|
||||
[19]:https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA
|
||||
[20]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ
|
||||
[21]:https://www.janeirodigital.com/
|
||||
[22]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,9 +1,11 @@
|
||||
Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
|
||||
Kubernetes 分布式应用部署实战:以人脸识别应用为例
|
||||
============================================================
|
||||
|
||||
# 简介
|
||||

|
||||
|
||||
伙计们,请做好准备,下面将是一段漫长的旅程,期望你能够乐在其中。
|
||||
## 简介
|
||||
|
||||
伙计们,请搬好小板凳坐好,下面将是一段漫长的旅程,期望你能够乐在其中。
|
||||
|
||||
我将基于 [Kubernetes][5] 部署一个分布式应用。我曾试图编写一个尽可能真实的应用,但由于时间和精力有限,最终砍掉了很多细节。
|
||||
|
||||
@ -11,17 +13,17 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
|
||||
|
||||
让我们开始吧。
|
||||
|
||||
# 应用
|
||||
## 应用
|
||||
|
||||
### TL;DR
|
||||
|
||||
|
||||
|
||||
应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
|
||||
该应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
|
||||
|
||||
这是一个人脸识别服务,通过比较已知个人的图片,识别给定图片对应的个人。前端页面用表格形式简要的展示图片及对应的个人。具体而言,向 [接收器][6] 发送请求,请求包含指向一个图片的链接。图片可以位于任何位置。接受器将图片地址存储到数据库 (MySQL) 中,然后向队列发送处理请求,请求中包含已保存图片的 ID。这里我们使用 [NSQ][8] 建立队列。
|
||||
|
||||
[图片处理][9]服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的[人脸识别][10]后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
|
||||
[图片处理][9] 服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的 [人脸识别][10] 后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
|
||||
|
||||
标记为失败的图片可以通过计划任务等方式进行重试。
|
||||
|
||||
@ -33,39 +35,31 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
|
||||
|
||||
```
|
||||
curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image/post
|
||||
|
||||
```
|
||||
|
||||
此时,接收器将<ruby>路径<rt>path</rt></ruby>存储到共享数据库集群中,对应的条目包括数据库服务提供的 ID。本应用采用”持久层提供条目对象唯一标识“的模型。获得条目 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
|
||||
此时,接收器将<ruby>路径<rt>path</rt></ruby>存储到共享数据库集群中,该实体存储后将从数据库服务收到对应的 ID。本应用采用“<ruby>实体对象<rt>Entity Object</rt></ruby>的唯一标识由持久层提供”的模型。获得实体 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
|
||||
|
||||
### 图片处理器
|
||||
|
||||
从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go routines,具体为:
|
||||
从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go <ruby>协程<rt>routine</rt></ruby>,具体为:
|
||||
|
||||
### Consume
|
||||
|
||||
这是一个 NSQ 消费者,需要完成三项任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个 routine 处理。最后,告知第二个 routine 处理新任务,方法为 [sync.Condition][12]。
|
||||
这是一个 NSQ 消费者,需要完成三项必需的任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个协程处理。最后,告知第二个协程处理新任务,方法为 [sync.Condition][12]。
|
||||
|
||||
### ProcessImages
|
||||
|
||||
该 routine 会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该 routine 并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
|
||||
该协程会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该协程并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
|
||||
|
||||
* 与人脸识别服务建立 gRPC 连接,其中人脸识别服务会在人脸识别部分进行介绍
|
||||
|
||||
* 从数据库获取图片对应的条目
|
||||
|
||||
* 从数据库获取图片对应的实体
|
||||
* 为 [断路器][1] 准备两个函数
|
||||
* 函数 1: 用于 RPC 方法调用的主函数
|
||||
|
||||
* 函数 2: 基于 ping 的断路器健康检查
|
||||
|
||||
* 调用函数 1 将图片路径发送至人脸识别服务,其中路径应该是人脸识别服务可以访问的,最好是共享的,例如 NFS
|
||||
|
||||
* 如果调用失败,将图片条目状态更新为 FAILEDPROCESSING
|
||||
|
||||
* 如果调用失败,将图片实体状态更新为 FAILEDPROCESSING
|
||||
* 如果调用成功,返回值是一个图片的名字,对应数据库中的一个个人。通过联合 SQL 查询,获取对应个人的 ID
|
||||
|
||||
* 将数据库中的图片条目状态更新为 PROCESSED,更新图片被识别成的个人的 ID
|
||||
* 将数据库中的图片实体状态更新为 PROCESSED,更新图片被识别成的个人的 ID
|
||||
|
||||
这个服务可以复制多份同时运行。
|
||||
|
||||
@ -89,7 +83,7 @@ curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image
|
||||
|
||||
注意:我曾经试图使用 [GoCV][14],这是一个极好的 Go 库,但欠缺所需的 C 绑定。推荐马上了解一下这个库,它会让你大吃一惊,例如编写若干行代码即可实现实时摄像处理。
|
||||
|
||||
这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg, hannibal_2.jpg, gergely_1.jpg, john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person, person_images`,具体如下:
|
||||
这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg`、 `hannibal_2.jpg`、 `gergely_1.jpg`、 `john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person`、 `person_images`,具体如下:
|
||||
|
||||
```
|
||||
+----+----------+
|
||||
@ -126,13 +120,13 @@ NSQ 是 Go 编写的小规模队列,可扩展且占用系统内存较少。NSQ
|
||||
|
||||
### 配置
|
||||
|
||||
为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 .env 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
|
||||
为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 `.env` 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
|
||||
|
||||
### 应用小结
|
||||
|
||||
这就是待部署应用的全部架构信息。应用的各个组件都是可变更的,他们之间仅通过数据库、消息队列和 gRPC 进行耦合。考虑到更新机制的原理,这是部署分布式应用所必须的;在部署部分我会继续分析。
|
||||
|
||||
# 使用 Kubernetes 部署应用
|
||||
## 使用 Kubernetes 部署应用
|
||||
|
||||
### 基础知识
|
||||
|
||||
@ -144,55 +138,51 @@ Kubernetes 是容器化服务及应用的管理器。它易于扩展,可以管
|
||||
|
||||
在 Kubernetes 中,你给出期望的应用状态,Kubernetes 会尽其所能达到对应的状态。状态可以是已部署、已暂停,有 2 个副本等,以此类推。
|
||||
|
||||
Kubernetes 使用标签和注释标记组件,包括服务,部署,副本组,守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与 应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
|
||||
Kubernetes 使用标签和注释标记组件,包括服务、部署、副本组、守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
|
||||
|
||||
### Kubernetes 集群
|
||||
|
||||
要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求 Nodes 并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
|
||||
要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求节点并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
|
||||
|
||||
### 节点 (Nodes)
|
||||
### 节点
|
||||
|
||||
节点是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
|
||||
<ruby>节点<rt>node</rt></ruby>是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
|
||||
|
||||
### Pods
|
||||
### Pod
|
||||
|
||||
Pods 是本地容器组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和 虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
|
||||
Pod 是本地容器逻辑上组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
|
||||
|
||||
### 部署 (Deployments)
|
||||
### 部署
|
||||
|
||||
在 Kubernetes 中创建任何类型的资源时,后台使用一个部署,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
|
||||
在 Kubernetes 中创建任何类型的资源时,后台使用一个<ruby>部署<rt>deployment</rt></ruby>组件,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
|
||||
|
||||
### 服务 (Services)
|
||||
### 服务
|
||||
|
||||
默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,mysql,内部 API 或前端,都需要长期运行并使用保持不变的 IP 或 更佳的 DNS 记录。
|
||||
默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,MySQL、内部 API 或前端,都需要长期运行并使用保持不变的 IP 或更好的 DNS 记录。
|
||||
|
||||
为解决这个问题,Kubernetes 提供了服务组件,可以定义访问模式,支持的模式包括负载均衡,简单 IP 或 内部 DNS。
|
||||
为解决这个问题,Kubernetes 提供了<ruby>服务<rt>service</rt></ruby>组件,可以定义访问模式,支持的模式包括负载均衡、简单 IP 或内部 DNS。
|
||||
|
||||
Kubernetes 如何获知服务运行正常呢?你可以配置健康性检查和可用性检查。健康性检查是指检查容器是否处于运行状态,但容器处于运行状态并不意味着服务运行正常。对此,你应该使用可用性检查,即请求应用的一个特别<ruby>接口<rt>endpoint</rt></ruby>。
|
||||
|
||||
由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络,服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
|
||||
由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络、服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
|
||||
|
||||
### DNS / 服务发现
|
||||
|
||||
在 Kubernetes 集群中创建服务后,该服务会从名为 kube-proxy 和 kube-dns 的特殊 Kubernetes 部署中获取一个 DNS 记录。他们两个用于提供集群内的服务发现。如果你有一个正在运行的 mysql 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
|
||||
在 Kubernetes 集群中创建服务后,该服务会从名为 `kube-proxy` 和 `kube-dns` 的特殊 Kubernetes 部署中获取一个 DNS 记录。它们两个用于提供集群内的服务发现。如果你有一个正在运行的 MySQL 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
|
||||
|
||||
* `mysql` – 服务的名称
|
||||
|
||||
* `default` – 命名空间的名称
|
||||
|
||||
* `svc` – 对应服务分类
|
||||
|
||||
* `cluster.local` – 本地集群的域名
|
||||
|
||||
可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 提供程序并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
|
||||
可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 服务,并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
|
||||
|
||||
* 节点端口方式 – `kubectl get -o jsonpath="{.spec.ports[0].nodePort}" services mysql`
|
||||
|
||||
* 负载均衡方式 – `kubectl get -o jsonpath="{.spec.ports[0].LoadBalancer}" services mysql`
|
||||
|
||||
### 模板文件
|
||||
|
||||
类似 Docker Compose, TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
|
||||
类似 Docker Compose、TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
|
||||
|
||||
以 Nginx 部署为例,查看下面的 yaml 模板:
|
||||
|
||||
@ -218,26 +208,26 @@ spec: #(4)
|
||||
image: nginx:1.7.9
|
||||
ports:
|
||||
- containerPort: 80
|
||||
|
||||
```
|
||||
|
||||
在这个示例部署中,我们做了如下操作:
|
||||
|
||||
* (1) 使用 kind 关键字定义模板类型
|
||||
* (2) 使用 metadata 关键字,增加该部署的识别信息,使用 labels 标记每个需要创建的资源 (3)
|
||||
* (4) 然后使用 spec 关键字描述所需的状态
|
||||
* (5) nginx 应用需要 3 个副本
|
||||
* (6) Pod 中容器的模板定义部分
|
||||
* 容器名称为 nginx
|
||||
* 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
|
||||
* (1) 使用 `kind` 关键字定义模板类型
|
||||
* (2) 使用 `metadata` 关键字,增加该部署的识别信息
|
||||
* (3) 使用 `labels` 标记每个需要创建的资源
|
||||
* (4) 然后使用 `spec` 关键字描述所需的状态
|
||||
* (5) nginx 应用需要 3 个副本
|
||||
* (6) Pod 中容器的模板定义部分
|
||||
* 容器名称为 nginx
|
||||
* 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
|
||||
|
||||
### 副本组 (ReplicaSet)
|
||||
### 副本组
|
||||
|
||||
副本组是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
|
||||
<ruby>副本组<rt>ReplicaSet</rt></ruby>是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
|
||||
|
||||
### 守护进程组 (DaemonSet)
|
||||
### 守护进程组
|
||||
|
||||
上面提到 Kubernetes 始终使用标签,还有印象吗?守护进程组是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
|
||||
上面提到 Kubernetes 始终使用标签,还有印象吗?<ruby>守护进程组<rt>DaemonSet</rt></ruby>是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
|
||||
|
||||
例如,你将所有节点增加 `logger` 或 `mission_critical` 的标签,以便运行日志 / 审计服务的守护进程。接着,你创建一个守护进程组并使用 `logger` 或 `mission_critical` 节点选择器。Kubernetes 会查找具有该标签的节点,确保守护进程的实例一直运行在这些节点中。因而,节点中运行的所有进程都可以在节点内访问对应的守护进程。
|
||||
|
||||
@ -253,7 +243,7 @@ spec: #(4)
|
||||
|
||||
### Kubernetes 部分小结
|
||||
|
||||
Kubernetes 是容器编排的便捷工具,工作单元为 Pods,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
|
||||
Kubernetes 是容器编排的便捷工具,工作单元为 Pod,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
|
||||
|
||||
截至目前,Kubernetes 原生支持所有主流云服务供应商,而且完全开源。如果你愿意,可以贡献代码;如果你希望对工作原理有深入了解,可以查阅代码:[GitHub 上的 Kubernetes 项目][22]。
|
||||
|
||||
@ -272,7 +262,7 @@ kubectl get nodes -o yaml
|
||||
|
||||
### 构建容器
|
||||
|
||||
Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python,NSQ 和 MySQL 使用对应的容器。
|
||||
Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python、NSQ 和 MySQL 使用对应的容器。
|
||||
|
||||
### 上下文
|
||||
|
||||
@ -293,9 +283,9 @@ Switched to context "kube-face-cluster".
|
||||
```
|
||||
此后,所有 `kubectl` 命令都会使用 `face` 命名空间。
|
||||
|
||||
(译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
|
||||
(LCTT 译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
|
||||
|
||||
### 应用部署
|
||||
## 应用部署
|
||||
|
||||
Pods 和 服务概览:
|
||||
|
||||
@ -318,7 +308,6 @@ type: Opaque
|
||||
data:
|
||||
mysql_password: base64codehere
|
||||
mysql_userpassword: base64codehere
|
||||
|
||||
```
|
||||
|
||||
其中 base64 编码通过如下命令生成:
|
||||
@ -326,10 +315,9 @@ data:
|
||||
```
|
||||
echo -n "ubersecurepassword" | base64
|
||||
echo -n "root:ubersecurepassword" | base64
|
||||
|
||||
```
|
||||
|
||||
(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 mysql_password, 仅包含密码;另一条对应 mysql_userpassword,包含用户和密码。后文会用到 mysql_userpassword,但没有提及相应的生成)
|
||||
(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 `mysql_password`,仅包含密码;另一条对应 `mysql_userpassword`,包含用户和密码。后文会用到 `mysql_userpassword`,但没有提及相应的生成)
|
||||
|
||||
我的部署 yaml 对应部分如下:
|
||||
|
||||
@ -362,13 +350,12 @@ echo -n "root:ubersecurepassword" | base64
|
||||
|
||||
其中 `presistentVolumeClain` 是关键,告知 Kubernetes 当前资源需要持久化存储。持久化存储的提供方式对用户透明。类似 Pods,如果想了解更多细节,参考文档:[Kubernetes 持久化存储][27]。
|
||||
|
||||
(LCTT 译注:使用 presistentVolumeClain 之前需要创建 presistentVolume,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
|
||||
(LCTT 译注:使用 `presistentVolumeClain` 之前需要创建 `presistentVolume`,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
|
||||
|
||||
使用如下命令部署 MySQL 服务:
|
||||
|
||||
```
|
||||
kubectl apply -f mysql.yaml
|
||||
|
||||
```
|
||||
|
||||
这里比较一下 `create` 和 `apply`。`apply` 是一种<ruby>宣告式<rt>declarative</rt></ruby>的对象配置命令,而 `create` 是<ruby>命令式<rt>imperative</rt>的命令。当下我们需要知道的是,`create` 通常对应一项任务,例如运行某个组件或创建一个部署;相比而言,当我们使用 `apply` 的时候,用户并没有指定具体操作,Kubernetes 会根据集群目前的状态定义需要执行的操作。故如果不存在名为 `mysql` 的服务,当我执行 `apply -f mysql.yaml` 时,Kubernetes 会创建该服务。如果再次执行这个命令,Kubernetes 会忽略该命令。但如果我再次运行 `create`,Kubernetes 会报错,告知服务已经创建。
|
||||
@ -460,7 +447,7 @@ volumes:
|
||||
|
||||
```
|
||||
|
||||
(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,person_images 表中的 person_id 列数字都小 1,作者默认 id 从 0 开始,但应该是从 1 开始)
|
||||
(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,`person_images` 表中的 `person_id` 列数字都小 1,作者默认 `id` 从 0 开始,但应该是从 1 开始)
|
||||
|
||||
运行如下命令查看引导脚本是否正确执行:
|
||||
|
||||
@ -489,7 +476,6 @@ mysql>
|
||||
|
||||
```
|
||||
kubectl logs deployment/mysql -f
|
||||
|
||||
```
|
||||
|
||||
### NSQ 查询
|
||||
@ -505,7 +491,7 @@ NSQ 查询将以内部服务的形式运行。由于不需要外部访问,这
|
||||
|
||||
```
|
||||
|
||||
那么,内部 DNS 对应的条目类似于:`nsqlookup.default.svc.cluster.local`。
|
||||
那么,内部 DNS 对应的实体类似于:`nsqlookup.default.svc.cluster.local`。
|
||||
|
||||
无头服务的更多细节,可以参考:[无头服务][32]。
|
||||
|
||||
@ -517,7 +503,7 @@ args: ["--broadcast-address=nsqlookup.default.svc.cluster.local"]
|
||||
|
||||
```
|
||||
|
||||
你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,nsqlookup 使用 `hostname` (LCTT 译注:这里是指容器的主机名,而不是 hostname 字符串本身)作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
|
||||
你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,`nsqlookup` 使用容器的主机名作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
|
||||
|
||||
NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsqd 守护进程的回调。在 Dockerfile 中暴露相应端口,在 Kubernetes 模板中使用它们,类似如下:
|
||||
|
||||
@ -533,6 +519,7 @@ NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsq
|
||||
```
|
||||
|
||||
服务模板:
|
||||
|
||||
```
|
||||
spec:
|
||||
ports:
|
||||
@ -592,13 +579,13 @@ NSQ 守护进程也需要一些调整的参数配置:
|
||||
|
||||
```
|
||||
|
||||
其中我们配置了 lookup-tcp-address 和 broadcast-address 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
|
||||
其中我们配置了 `lookup-tcp-address` 和 `broadcast-address` 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
|
||||
|
||||
#### 对外公开
|
||||
|
||||
下面即将创建第一个对外公开的服务。有两种方式可供选择。考虑到该 API 负载较高,可以使用负载均衡的方式。另外,如果希望将其部署到生产环境中的任选节点,也应该使用负载均衡方式。
|
||||
|
||||
但由于我使用的本地集群只有一个节点,那么使用 `节点端口` 的方式就足够了。`节点端口` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `<NodeIP>:<NodePort>` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
|
||||
但由于我使用的本地集群只有一个节点,那么使用 `NodePort` 的方式就足够了。`NodePort` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `<NodeIP>:<NodePort>` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
|
||||
|
||||
更多信息,请参考文档:[服务发布][33]。
|
||||
|
||||
@ -643,7 +630,7 @@ spec:
|
||||
|
||||
### 图片处理器
|
||||
|
||||
图片处理器用于将图片传送至识别组件。它需要访问 nslookupd, mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
|
||||
图片处理器用于将图片传送至识别组件。它需要访问 nslookupd、 mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
|
||||
|
||||
```
|
||||
---
|
||||
@ -781,7 +768,7 @@ curl -d '{"path":"/unknown_people/unknown220.jpg"}' http://192.168.99.100:30251/
|
||||
|
||||
```
|
||||
|
||||
图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 known_foler 文件中找到 unknown220.jpg 对应个人的图片,最后返回匹配图片的名称。
|
||||
图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 `known_folder` 文件中找到 `unknown220.jpg` 对应个人的图片,最后返回匹配图片的名称。
|
||||
|
||||
查看日志,大致信息如下:
|
||||
|
||||
@ -861,9 +848,9 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
|
||||
|
||||
```
|
||||
|
||||
### 滚动更新 (Rolling Update)
|
||||
## 滚动更新
|
||||
|
||||
滚动更新过程中会发生什么呢?
|
||||
<ruby>滚动更新<rt>Rolling Update</rt></ruby>过程中会发生什么呢?
|
||||
|
||||
|
||||
|
||||
@ -871,7 +858,7 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
|
||||
|
||||
目前的 API 一次只能处理一个图片,不能批量处理,对此我并不满意。
|
||||
|
||||
#### 代码
|
||||
### 代码
|
||||
|
||||
目前,我们使用下面的代码段处理单个图片的情形:
|
||||
|
||||
@ -900,7 +887,7 @@ func main() {
|
||||
|
||||
这里,你可能会说你并不需要保留旧代码;某些情况下,确实如此。因此,我们打算直接修改旧代码,让其通过少量参数调用新代码。这样操作操作相当于移除了旧代码。当所有客户端迁移完毕后,这部分代码也可以安全地删除。
|
||||
|
||||
#### 新的 Endpoint
|
||||
### 新的接口
|
||||
|
||||
让我们添加新的路由方法:
|
||||
|
||||
@ -941,7 +928,7 @@ func PostImage(w http.ResponseWriter, r *http.Request) {
|
||||
|
||||
```
|
||||
|
||||
当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片 PR][34] 中可以找到更多的修改方式。
|
||||
当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片的 PR][34] 中可以找到更多的修改方式。
|
||||
|
||||
至此,我们使用两种方法调用接收器:
|
||||
|
||||
@ -958,7 +945,7 @@ curl -d '{"paths":[{"path":"unknown4456.jpg"}]}' http://127.0.0.1:8000/images/po
|
||||
|
||||
为了简洁,我不打算为 NSQ 和其它组件增加批量图片处理的能力。这些组件仍然是一次处理一个图片。这部分修改将留给你作为扩展内容。 :)
|
||||
|
||||
#### 新镜像
|
||||
### 新镜像
|
||||
|
||||
为实现滚动更新,我首先需要为接收器服务创建一个新的镜像。新镜像使用新标签,告诉大家版本号为 v1.1。
|
||||
|
||||
@ -969,11 +956,11 @@ docker build -t skarlso/kube-receiver-alpine:v1.1 .
|
||||
|
||||
新镜像创建后,我们可以开始滚动更新了。
|
||||
|
||||
#### 滚动更新
|
||||
### 滚动更新
|
||||
|
||||
在 Kubernetes 中,可以使用多种方式完成滚动更新。
|
||||
|
||||
##### 手动更新
|
||||
#### 手动更新
|
||||
|
||||
不妨假设在我配置文件中使用的容器版本为 `v1.0`,那么实现滚动更新只需运行如下命令:
|
||||
|
||||
@ -991,7 +978,7 @@ kubectl rolling-update receiver --rollback
|
||||
|
||||
容器将回滚到使用上一个版本镜像,操作简捷无烦恼。
|
||||
|
||||
##### 应用新的配置文件
|
||||
#### 应用新的配置文件
|
||||
|
||||
手动更新的不足在于无法版本管理。
|
||||
|
||||
@ -1051,7 +1038,7 @@ kubectl delete services -all
|
||||
|
||||
```
|
||||
|
||||
# 写在最后的话
|
||||
## 写在最后的话
|
||||
|
||||
各位看官,本文就写到这里了。我们在 Kubernetes 上编写、部署、更新和扩展(老实说,并没有实现)了一个分布式应用。
|
||||
|
||||
@ -1065,9 +1052,9 @@ Gergely 感谢你阅读本文。
|
||||
|
||||
via: https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/
|
||||
|
||||
作者:[hannibal ][a]
|
||||
作者:[hannibal][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,15 @@
|
||||
我们能否建立一个服务于用户而非广告商的社交网络?
|
||||
=====
|
||||
|
||||
> 找出 Human Connection 是如何将透明度和社区放在首位的。
|
||||
|
||||

|
||||
|
||||
如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的,中立的,透明的在线平台来迎接我们这个时代的挑战。
|
||||
如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的、中立的、透明的在线平台来迎接我们这个时代的挑战。
|
||||
|
||||
开放的原则可能会成为让我们到达那里的方法(to 校正者:这句上下文没有理解)。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
|
||||
开放的原则也许是让我们达成这一目标的方法。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
|
||||
|
||||
这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们自然倾向,于乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
|
||||
这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们的自然趋势,与乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
|
||||
|
||||
为了实现一个以解决方案为导向的平台的梦想,让人们通过与慈善机构、社区团体和社会变革活动人士的接触,围绕社会公益事业采取行动,Human Connection 将开放的价值观作为社会创新的载体。
|
||||
|
||||
@ -15,31 +17,28 @@
|
||||
|
||||
### 首先是透明
|
||||
|
||||
透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript, Vue, nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
|
||||
透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript、Vue、nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
|
||||
|
||||
但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些对让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
|
||||
但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
|
||||
|
||||
为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team (to 校正者:这里如果可以,请翻译得稍微优雅,我想不出来一个词)活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
|
||||
为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team 活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
|
||||
|
||||
对透明的承诺意味着,所有在 Human Connection 上公开分享的用户贡献者将在 Creative Commons 许可下发布,最终作为数据包下载。通过让大众知识变得可用,特别是以一种分散的方式,我们创造了一个多元化社会的机会。
|
||||
|
||||
一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用[联合国宪章(UN Charter)][4]和“世界人权宣言(Universal Declaration of Human Rights)”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (译者注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
|
||||
有一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用<ruby>[联合国宪章][4]<rt>UN Charter</rt></ruby>和“<ruby>世界人权宣言<rt>Universal Declaration of Human Rights</rt></ruby>”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (LCTT 译注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
|
||||
|
||||
### 一个合作的社会
|
||||
|
||||
以一种[以社区为中心的协作方法][5]来编写 Human Connection 平台是超越社交网络实际应用理念的基础。我们的团队是通过找到问题的答案来驱动:“是什么让一个社交网络真正地社会化?”
|
||||
|
||||
一个抛弃了以利润为导向的算法,为广告商而不是最终用户服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并破坏(to 校正:这里译为改变较好)现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
|
||||
一个抛弃了以利润为导向的算法、为最终用户而不是广告商服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并变革现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
|
||||
|
||||
我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎索邦大学(University Sorbonne)的国家东方语言与文明研究所(National Institute for Oriental Languages and Civilizations (INALCO) )和德国斯图加特媒体大学(Stuttgart Media University )合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
|
||||
|
||||
* 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“采取行动(Take Action)”领域,每个人都可以实现。
|
||||
|
||||
* “Versus” 功能是另一个定义结果的方式(to 校正者:这句话稍微注意一下)。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
|
||||
我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎<ruby>索邦大学<rt>University Sorbonne</rt></ruby>的<ruby>国家东方语言与文明研究所<rt>National Institute for Oriental Languages and Civilizations</rt></ruby>(INALCO)和德国<ruby>斯图加特媒体大学<rt>Stuttgart Media University</rt></ruby>合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
|
||||
|
||||
* 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“<ruby>采取行动<rt>Take Action</rt></ruby>”领域,每个人都可以实现。
|
||||
* “Versus” 功能是另一个成果。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
|
||||
* 今天的社交网络并没有提供很多过滤内容的选项。研究表明,情绪过滤选项可以帮助我们根据日常情绪驾驭社交空间,并可能通过在我们希望仅看到令人振奋的内容的那一天时,不显示悲伤或难过的帖子来潜在地保护我们的情绪健康。
|
||||
|
||||
|
||||
Human Connection 邀请改革者合作开发一个网络,有可能动员世界各地的个人和团体将负面新闻变成 “Can Do”,并与慈善机构和非营利组织一起参与社会创新项目。
|
||||
|
||||
[订阅我们的每周时事通讯][12]以了解有关开放组织的更多信息。
|
||||
@ -51,7 +50,7 @@ via: https://opensource.com/open-organization/18/3/open-social-human-connection
|
||||
|
||||
作者:[Dennis Hack][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -51,7 +51,7 @@
|
||||
|
||||
对于基于 Debian 的发行版,包括 Debian、Ubuntu、Linux Mint、Elementary OS 等,它们的底层命令行工具是 dpkg,高级工具称为 apt。在 Ubuntu 上管理已安装软件的图形工具是 Ubuntu Software(图 3)。对于 Debian 和 Linux Mint,图形工具称为<ruby>新立得<rt>Synaptic</rt></ruby>,它也可以安装在 Ubuntu 上。
|
||||
|
||||
你也可以在 Debian 相关发行版上安装一个基于文本的图形化工具 aptitude。它比 <ruby>新立得<rt>synaptic</rt></ruy>更强大,并且即使你只能访问命令行也能工作。如果你想通过各种选项进行各种操作,你可以试试这个,但它使用起来比新立得更复杂。其它发行版也可能有自己独特的工具。
|
||||
你也可以在 Debian 相关发行版上安装一个基于文本的图形化工具 aptitude。它比新立得更强大,并且即使你只能访问命令行也能工作。如果你想通过各种选项进行各种操作,你可以试试这个,但它使用起来比新立得更复杂。其它发行版也可能有自己独特的工具。
|
||||
|
||||
### 命令行工具
|
||||
|
||||
@ -0,0 +1,178 @@
|
||||
在 Linux 上如何得到一个段错误的核心转储
|
||||
============================================================
|
||||
|
||||
本周工作中,我花了整整一周的时间来尝试调试一个段错误。我以前从来没有这样做过,我花了很长时间才弄清楚其中涉及的一些基本事情(获得核心转储、找到导致段错误的行号)。于是便有了这篇博客来解释如何做那些事情!
|
||||
|
||||
在看完这篇博客后,你应该知道如何从“哦,我的程序出现段错误,但我不知道正在发生什么”到“我知道它出现段错误时的堆栈、行号了! “。
|
||||
|
||||
### 什么是段错误?
|
||||
|
||||
“<ruby>段错误<rt>segmentation fault</rt></ruby>”是指你的程序尝试访问不允许访问的内存地址的情况。这可能是由于:
|
||||
|
||||
* 试图解引用空指针(你不被允许访问内存地址 `0`);
|
||||
* 试图解引用其他一些不在你内存(LCTT 译注:指不在合法的内存地址区间内)中的指针;
|
||||
* 一个已被破坏并且指向错误的地方的 <ruby>C++ 虚表指针<rt>C++ vtable pointer</rt></ruby>,这导致程序尝试执行没有执行权限的内存中的指令;
|
||||
* 其他一些我不明白的事情,比如我认为访问未对齐的内存地址也可能会导致段错误(LCTT 译注:在要求自然边界对齐的体系结构,如 MIPS、ARM 中更容易因非对齐访问产生段错误)。
|
||||
|
||||
这个“C++ 虚表指针”是我的程序发生段错误的情况。我可能会在未来的博客中解释这个,因为我最初并不知道任何关于 C++ 的知识,并且这种虚表查找导致程序段错误的情况也是我所不了解的。
|
||||
|
||||
但是!这篇博客后不是关于 C++ 问题的。让我们谈论的基本的东西,比如,我们如何得到一个核心转储?
|
||||
|
||||
### 步骤1:运行 valgrind
|
||||
|
||||
我发现找出为什么我的程序出现段错误的最简单的方式是使用 `valgrind`:我运行
|
||||
|
||||
```
|
||||
valgrind -v your-program
|
||||
```
|
||||
|
||||
这给了我一个故障时的堆栈调用序列。 简洁!
|
||||
|
||||
但我想也希望做一个更深入调查,并找出些 `valgrind` 没告诉我的信息! 所以我想获得一个核心转储并探索它。
|
||||
|
||||
### 如何获得一个核心转储
|
||||
|
||||
<ruby>核心转储<rt>core dump</rt></ruby>是您的程序内存的一个副本,并且当您试图调试您的有问题的程序哪里出错的时候它非常有用。
|
||||
|
||||
当您的程序出现段错误,Linux 的内核有时会把一个核心转储写到磁盘。 当我最初试图获得一个核心转储时,我很长一段时间非常沮丧,因为 - Linux 没有生成核心转储!我的核心转储在哪里?
|
||||
|
||||
这就是我最终做的事情:
|
||||
|
||||
1. 在启动我的程序之前运行 `ulimit -c unlimited`
|
||||
2. 运行 `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
|
||||
|
||||
### ulimit:设置核心转储的最大尺寸
|
||||
|
||||
`ulimit -c` 设置核心转储的最大尺寸。 它往往设置为 0,这意味着内核根本不会写核心转储。 它以千字节为单位。 `ulimit` 是按每个进程分别设置的 —— 你可以通过运行 `cat /proc/PID/limit` 看到一个进程的各种资源限制。
|
||||
|
||||
例如这些是我的系统上一个随便一个 Firefox 进程的资源限制:
|
||||
|
||||
```
|
||||
$ cat /proc/6309/limits
|
||||
Limit Soft Limit Hard Limit Units
|
||||
Max cpu time unlimited unlimited seconds
|
||||
Max file size unlimited unlimited bytes
|
||||
Max data size unlimited unlimited bytes
|
||||
Max stack size 8388608 unlimited bytes
|
||||
Max core file size 0 unlimited bytes
|
||||
Max resident set unlimited unlimited bytes
|
||||
Max processes 30571 30571 processes
|
||||
Max open files 1024 1048576 files
|
||||
Max locked memory 65536 65536 bytes
|
||||
Max address space unlimited unlimited bytes
|
||||
Max file locks unlimited unlimited locks
|
||||
Max pending signals 30571 30571 signals
|
||||
Max msgqueue size 819200 819200 bytes
|
||||
Max nice priority 0 0
|
||||
Max realtime priority 0 0
|
||||
Max realtime timeout unlimited unlimited us
|
||||
```
|
||||
|
||||
内核在决定写入多大的核心转储文件时使用<ruby>软限制<rt>soft limit</rt></ruby>(在这种情况下,`max core file size = 0`)。 您可以使用 shell 内置命令 `ulimit`(`ulimit -c unlimited`) 将软限制增加到<ruby>硬限制<rt>hard limit</rt></ruby>。
|
||||
|
||||
### kernel.core_pattern:核心转储保存在哪里
|
||||
|
||||
`kernel.core_pattern` 是一个内核参数,或者叫 “sysctl 设置”,它控制 Linux 内核将核心转储文件写到磁盘的哪里。
|
||||
|
||||
内核参数是一种设定您的系统全局设置的方法。您可以通过运行 `sysctl -a` 得到一个包含每个内核参数的列表,或使用 `sysctl kernel.core_pattern` 来专门查看 `kernel.core_pattern` 设置。
|
||||
|
||||
所以 `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t` 将核心转储保存到目录 `/tmp` 下,并以 `core` 加上一系列能够标识(出故障的)进程的参数构成的后缀为文件名。
|
||||
|
||||
如果你想知道这些形如 `%e`、`%p` 的参数都表示什么,请参考 [man core][1]。
|
||||
|
||||
有一点很重要,`kernel.core_pattern` 是一个全局设置 —— 修改它的时候最好小心一点,因为有可能其它系统功能依赖于把它被设置为一个特定的方式(才能正常工作)。
|
||||
|
||||
### kernel.core_pattern 和 Ubuntu
|
||||
|
||||
默认情况下在 ubuntu 系统中,`kernel.core_pattern` 被设置为下面的值:
|
||||
|
||||
```
|
||||
$ sysctl kernel.core_pattern
|
||||
kernel.core_pattern = |/usr/share/apport/apport %p %s %c %d %P
|
||||
```
|
||||
|
||||
这引起了我的迷惑(这 apport 是干什么的,它对我的核心转储做了什么?)。以下关于这个我了解到的:
|
||||
|
||||
* Ubuntu 使用一种叫做 apport 的系统来报告 apt 包有关的崩溃信息。
|
||||
* 设定 `kernel.core_pattern=|/usr/share/apport/apport %p %s %c %d %P` 意味着核心转储将被通过管道送给 `apport` 程序。
|
||||
* apport 的日志保存在文件 `/var/log/apport.log` 中。
|
||||
* apport 默认会忽略来自不属于 Ubuntu 软件包一部分的二进制文件的崩溃信息
|
||||
|
||||
我最终只是跳过了 apport,并把 `kernel.core_pattern` 重新设置为 `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`,因为我在一台开发机上,我不在乎 apport 是否工作,我也不想尝试让 apport 把我的核心转储留在磁盘上。
|
||||
|
||||
### 现在你有了核心转储,接下来干什么?
|
||||
|
||||
好的,现在我们了解了 `ulimit` 和 `kernel.core_pattern` ,并且实际上在磁盘的 `/tmp` 目录中有了一个核心转储文件。太好了!接下来干什么?我们仍然不知道该程序为什么会出现段错误!
|
||||
|
||||
下一步将使用 `gdb` 打开核心转储文件并获取堆栈调用序列。
|
||||
|
||||
### 从 gdb 中得到堆栈调用序列
|
||||
|
||||
你可以像这样用 `gdb` 打开一个核心转储文件:
|
||||
|
||||
```
|
||||
$ gdb -c my_core_file
|
||||
```
|
||||
|
||||
接下来,我们想知道程序崩溃时的堆栈是什么样的。在 `gdb` 提示符下运行 `bt` 会给你一个<ruby>调用序列<rt>backtrace</rt></ruby>。在我的例子里,`gdb` 没有为二进制文件加载符号信息,所以这些函数名就像 “??????”。幸运的是,(我们通过)加载符号修复了它。
|
||||
|
||||
下面是如何加载调试符号。
|
||||
|
||||
```
|
||||
symbol-file /path/to/my/binary
|
||||
sharedlibrary
|
||||
```
|
||||
|
||||
这从二进制文件及其引用的任何共享库中加载符号。一旦我这样做了,当我执行 `bt` 时,gdb 给了我一个带有行号的漂亮的堆栈跟踪!
|
||||
|
||||
如果你想它能工作,二进制文件应该以带有调试符号信息的方式被编译。在试图找出程序崩溃的原因时,堆栈跟踪中的行号非常有帮助。:)
|
||||
|
||||
### 查看每个线程的堆栈
|
||||
|
||||
通过以下方式在 `gdb` 中获取每个线程的调用栈!
|
||||
|
||||
```
|
||||
thread apply all bt full
|
||||
```
|
||||
|
||||
### gdb + 核心转储 = 惊喜
|
||||
|
||||
|
||||
如果你有一个带调试符号的核心转储以及 `gdb`,那太棒了!您可以上下查看调用堆栈(LCTT 译注:指跳进调用序列不同的函数中以便于查看局部变量),打印变量,并查看内存来得知发生了什么。这是最好的。
|
||||
|
||||
如果您仍然正在基于 gdb 向导来工作上,只打印出栈跟踪与bt也可以。 :)
|
||||
|
||||
### ASAN
|
||||
|
||||
另一种搞清楚您的段错误的方法是使用 AddressSanitizer 选项编译程序(“ASAN”,即 `$CC -fsanitize=address`)然后运行它。 本文中我不准备讨论那个,因为本文已经相当长了,并且在我的例子中打开 ASAN 后段错误消失了,可能是因为 ASAN 使用了一个不同的内存分配器(系统内存分配器,而不是 tcmalloc)。
|
||||
|
||||
在未来如果我能让 ASAN 工作,我可能会多写点有关它的东西。(LCTT 译注:这里指使用 ASAN 也能复现段错误)
|
||||
|
||||
### 从一个核心转储得到一个堆栈跟踪真的很亲切!
|
||||
|
||||
这个博客听起来很多,当我做这些的时候很困惑,但说真的,从一个段错误的程序中获得一个堆栈调用序列不需要那么多步骤:
|
||||
|
||||
1. 试试用 `valgrind`
|
||||
|
||||
如果那没用,或者你想要拿到一个核心转储来调查:
|
||||
|
||||
1. 确保二进制文件编译时带有调试符号信息;
|
||||
2. 正确的设置 `ulimit` 和 `kernel.core_pattern`;
|
||||
3. 运行程序;
|
||||
4. 一旦你用 `gdb` 调试核心转储了,加载符号并运行 `bt`;
|
||||
5. 尝试找出发生了什么!
|
||||
|
||||
我可以使用 `gdb` 弄清楚有个 C++ 的虚表条目指向一些被破坏的内存,这有点帮助,并且使我感觉好像更懂了 C++ 一点。也许有一天我们会更多地讨论如何使用 `gdb` 来查找问题!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/04/28/debugging-a-segfault-on-linux/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about/
|
||||
[1]:http://man7.org/linux/man-pages/man5/core.5.html
|
||||
359
published/201807/20180429 Passwordless Auth- Client.md
Normal file
359
published/201807/20180429 Passwordless Auth- Client.md
Normal file
@ -0,0 +1,359 @@
|
||||
无密码验证:客户端
|
||||
======
|
||||
|
||||
我们继续 [无密码验证][1] 的文章。上一篇文章中,我们用 Go 写了一个 HTTP 服务,用这个服务来做无密码验证 API。今天,我们为它再写一个 JavaScript 客户端。
|
||||
|
||||
我们将使用 [这里的][2] 这个单页面应用程序(SPA)来展示使用的技术。如果你还没有读过它,请先读它。
|
||||
|
||||
记住流程:
|
||||
|
||||
- 用户输入其 email。
|
||||
- 用户收到一个带有魔法链接的邮件。
|
||||
- 用户点击该链接、
|
||||
- 用户验证成功。
|
||||
|
||||
对于根 URL(`/`),我们将根据验证的状态分别使用两个不同的页面:一个是带有访问表单的页面,或者是已验证通过的用户的欢迎页面。另一个页面是验证回调的重定向页面。
|
||||
|
||||
### 伺服
|
||||
|
||||
我们将使用相同的 Go 服务器来为客户端提供服务,因此,在我们前面的 `main.go` 中添加一些路由:
|
||||
|
||||
```
|
||||
router.Handle("GET", "/...", http.FileServer(SPAFileSystem{http.Dir("static")}))
|
||||
```
|
||||
|
||||
```
|
||||
type SPAFileSystem struct {
|
||||
fs http.FileSystem
|
||||
}
|
||||
|
||||
func (spa SPAFileSystem) Open(name string) (http.File, error) {
|
||||
f, err := spa.fs.Open(name)
|
||||
if err != nil {
|
||||
return spa.fs.Open("index.html")
|
||||
}
|
||||
return f, nil
|
||||
}
|
||||
```
|
||||
|
||||
这个伺服文件放在 `static` 下,配合 `static/index.html` 作为回调。
|
||||
|
||||
你可以使用你自己的服务器,但是你得在服务器上启用 [CORS][3]。
|
||||
|
||||
### HTML
|
||||
|
||||
我们来看一下那个 `static/index.html` 文件。
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="utf-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>Passwordless Demo</title>
|
||||
<link rel="shortcut icon" href="data:,">
|
||||
<script src="/js/main.js" type="module"></script>
|
||||
</head>
|
||||
<body></body>
|
||||
</html>
|
||||
```
|
||||
|
||||
单页面应用程序的所有渲染由 JavaScript 来完成,因此,我们使用了一个空的 body 部分和一个 `main.js` 文件。
|
||||
|
||||
我们将使用 [上篇文章][2] 中的 Router。
|
||||
|
||||
### 渲染
|
||||
|
||||
现在,我们使用下面的内容来创建一个 `static/js/main.js` 文件:
|
||||
|
||||
```
|
||||
import Router from 'https://unpkg.com/@nicolasparada/router'
|
||||
import { isAuthenticated } from './auth.js'
|
||||
|
||||
const router = new Router()
|
||||
|
||||
router.handle('/', guard(view('home')))
|
||||
router.handle('/callback', view('callback'))
|
||||
router.handle(/^\//, view('not-found'))
|
||||
|
||||
router.install(async resultPromise => {
|
||||
document.body.innerHTML = ''
|
||||
document.body.appendChild(await resultPromise)
|
||||
})
|
||||
|
||||
function view(name) {
|
||||
return (...args) => import(`/js/pages/${name}-page.js`)
|
||||
.then(m => m.default(...args))
|
||||
}
|
||||
|
||||
function guard(fn1, fn2 = view('welcome')) {
|
||||
return (...args) => isAuthenticated()
|
||||
? fn1(...args)
|
||||
: fn2(...args)
|
||||
}
|
||||
```
|
||||
|
||||
与上篇文章不同的是,我们实现了一个 `isAuthenticated()` 函数和一个 `guard()` 函数,使用它去渲染两种验证状态的页面。因此,当用户访问 `/` 时,它将根据用户是否通过了验证来展示主页或者是欢迎页面。
|
||||
|
||||
### 验证
|
||||
|
||||
现在,我们来编写 `isAuthenticated()` 函数。使用下面的内容来创建一个 `static/js/auth.js` 文件:
|
||||
|
||||
```
|
||||
export function getAuthUser() {
|
||||
const authUserItem = localStorage.getItem('auth_user')
|
||||
const expiresAtItem = localStorage.getItem('expires_at')
|
||||
|
||||
if (authUserItem !== null && expiresAtItem !== null) {
|
||||
const expiresAt = new Date(expiresAtItem)
|
||||
|
||||
if (!isNaN(expiresAt.valueOf()) && expiresAt > new Date()) {
|
||||
try {
|
||||
return JSON.parse(authUserItem)
|
||||
} catch (_) { }
|
||||
}
|
||||
}
|
||||
|
||||
return null
|
||||
}
|
||||
|
||||
export function isAuthenticated() {
|
||||
return localStorage.getItem('jwt') !== null && getAuthUser() !== null
|
||||
}
|
||||
```
|
||||
|
||||
当有人登入时,我们将保存 JSON 格式的 web 令牌、它的过期日期,以及在 `localStorage` 上的当前已验证用户。这个模块就是这个用处。
|
||||
|
||||
* `getAuthUser()` 用于从 `localStorage` 获取已认证的用户,以确认 JSON 格式的 Web 令牌没有过期。
|
||||
* `isAuthenticated()` 在前面的函数中用于去检查它是否没有返回 `null`。
|
||||
|
||||
### 获取
|
||||
|
||||
在继续这个页面之前,我将写一些与服务器 API 一起使用的 HTTP 工具。
|
||||
|
||||
我们使用以下的内容去创建一个 `static/js/http.js` 文件:
|
||||
|
||||
```
|
||||
import { isAuthenticated } from './auth.js'
|
||||
|
||||
function get(url, headers) {
|
||||
return fetch(url, {
|
||||
headers: Object.assign(getAuthHeader(), headers),
|
||||
}).then(handleResponse)
|
||||
}
|
||||
|
||||
function post(url, body, headers) {
|
||||
return fetch(url, {
|
||||
method: 'POST',
|
||||
headers: Object.assign(getAuthHeader(), { 'content-type': 'application/json' }, headers),
|
||||
body: JSON.stringify(body),
|
||||
}).then(handleResponse)
|
||||
}
|
||||
|
||||
function getAuthHeader() {
|
||||
return isAuthenticated()
|
||||
? { authorization: `Bearer ${localStorage.getItem('jwt')}` }
|
||||
: {}
|
||||
}
|
||||
|
||||
export async function handleResponse(res) {
|
||||
const body = await res.clone().json().catch(() => res.text())
|
||||
const response = {
|
||||
statusCode: res.status,
|
||||
statusText: res.statusText,
|
||||
headers: res.headers,
|
||||
body,
|
||||
}
|
||||
if (!res.ok) {
|
||||
const message = typeof body === 'object' && body !== null && 'message' in body
|
||||
? body.message
|
||||
: typeof body === 'string' && body !== ''
|
||||
? body
|
||||
: res.statusText
|
||||
const err = new Error(message)
|
||||
throw Object.assign(err, response)
|
||||
}
|
||||
return response
|
||||
}
|
||||
|
||||
export default {
|
||||
get,
|
||||
post,
|
||||
}
|
||||
```
|
||||
|
||||
这个模块导出了 `get()` 和 `post()` 函数。它们是 `fetch` API 的封装。当用户是已验证的,这二个函数注入一个 `Authorization: Bearer <token_here>` 头到请求中;这样服务器就能对我们进行身份验证。
|
||||
|
||||
### 欢迎页
|
||||
|
||||
我们现在来到欢迎页面。用如下的内容创建一个 `static/js/pages/welcome-page.js` 文件:
|
||||
|
||||
```
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Passwordless Demo</h1>
|
||||
<h2>Access</h2>
|
||||
<form id="access-form">
|
||||
<input type="email" placeholder="Email" autofocus required>
|
||||
<button type="submit">Send Magic Link</button>
|
||||
</form>
|
||||
`
|
||||
|
||||
export default function welcomePage() {
|
||||
const page = template.content.cloneNode(true)
|
||||
|
||||
page.getElementById('access-form')
|
||||
.addEventListener('submit', onAccessFormSubmit)
|
||||
|
||||
return page
|
||||
}
|
||||
```
|
||||
|
||||
这个页面使用一个 `HTMLTemplateElement` 作为视图。这只是一个输入用户 email 的简单表单。
|
||||
|
||||
为了避免干扰,我将跳过错误处理部分,只是将它们输出到控制台上。
|
||||
|
||||
现在,我们来写 `onAccessFormSubmit()` 函数。
|
||||
|
||||
```
|
||||
import http from '../http.js'
|
||||
|
||||
function onAccessFormSubmit(ev) {
|
||||
ev.preventDefault()
|
||||
|
||||
const form = ev.currentTarget
|
||||
const input = form.querySelector('input')
|
||||
const email = input.value
|
||||
|
||||
sendMagicLink(email).catch(err => {
|
||||
console.error(err)
|
||||
if (err.statusCode === 404 && wantToCreateAccount()) {
|
||||
runCreateUserProgram(email)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
function sendMagicLink(email) {
|
||||
return http.post('/api/passwordless/start', {
|
||||
email,
|
||||
redirectUri: location.origin + '/callback',
|
||||
}).then(() => {
|
||||
alert('Magic link sent. Go check your email inbox.')
|
||||
})
|
||||
}
|
||||
|
||||
function wantToCreateAccount() {
|
||||
return prompt('No user found. Do you want to create an account?')
|
||||
}
|
||||
```
|
||||
|
||||
它对 `/api/passwordless/start` 发起了 POST 请求,请求体中包含 `email` 和 `redirectUri`。在本例中它返回 `404 Not Found` 状态码时,我们将创建一个用户。
|
||||
|
||||
```
|
||||
function runCreateUserProgram(email) {
|
||||
const username = prompt("Enter username")
|
||||
if (username === null) return
|
||||
|
||||
http.post('/api/users', { email, username })
|
||||
.then(res => res.body)
|
||||
.then(user => sendMagicLink(user.email))
|
||||
.catch(console.error)
|
||||
}
|
||||
```
|
||||
|
||||
这个用户创建程序,首先询问用户名,然后使用 email 和用户名做一个 `POST` 请求到 `/api/users`。成功之后,给创建的用户发送一个魔法链接。
|
||||
|
||||
### 回调页
|
||||
|
||||
这是访问表单的全部功能,现在我们来做回调页面。使用如下的内容来创建一个 `static/js/pages/callback-page.js` 文件:
|
||||
|
||||
```
|
||||
import http from '../http.js'
|
||||
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Authenticating you</h1>
|
||||
`
|
||||
|
||||
export default function callbackPage() {
|
||||
const page = template.content.cloneNode(true)
|
||||
|
||||
const hash = location.hash.substr(1)
|
||||
const fragment = new URLSearchParams(hash)
|
||||
for (const [k, v] of fragment.entries()) {
|
||||
fragment.set(decodeURIComponent(k), decodeURIComponent(v))
|
||||
}
|
||||
const jwt = fragment.get('jwt')
|
||||
const expiresAt = fragment.get('expires_at')
|
||||
|
||||
http.get('/api/auth_user', { authorization: `Bearer ${jwt}` })
|
||||
.then(res => res.body)
|
||||
.then(authUser => {
|
||||
localStorage.setItem('jwt', jwt)
|
||||
localStorage.setItem('auth_user', JSON.stringify(authUser))
|
||||
localStorage.setItem('expires_at', expiresAt)
|
||||
|
||||
location.replace('/')
|
||||
})
|
||||
.catch(console.error)
|
||||
|
||||
return page
|
||||
}
|
||||
```
|
||||
|
||||
请记住……当点击魔法链接时,我们会来到 `/api/passwordless/verify_redirect`,它将把我们重定向到重定向 URI,我们将放在哈希中的 JWT 和过期日期传递给 `/callback`。
|
||||
|
||||
回调页面解码 URL 中的哈希,提取这些参数去做一个 `GET` 请求到 `/api/auth_user`,用 JWT 保存所有数据到 `localStorage` 中。最后,重定向到主页面。
|
||||
|
||||
### 主页
|
||||
|
||||
创建如下内容的 `static/pages/home-page.js` 文件:
|
||||
|
||||
```
|
||||
import { getAuthUser } from '../auth.js'
|
||||
|
||||
export default function homePage() {
|
||||
const authUser = getAuthUser()
|
||||
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Passwordless Demo</h1>
|
||||
<p>Welcome back, ${authUser.username} 👋</p>
|
||||
<button id="logout-button">Logout</button>
|
||||
`
|
||||
|
||||
const page = template.content
|
||||
|
||||
page.getElementById('logout-button')
|
||||
.addEventListener('click', logout)
|
||||
|
||||
return page
|
||||
}
|
||||
|
||||
function logout() {
|
||||
localStorage.clear()
|
||||
location.reload()
|
||||
}
|
||||
```
|
||||
|
||||
这个页面用于欢迎已验证用户,同时也有一个登出按钮。`logout()` 函数的功能只是清理掉 `localStorage` 并重载这个页面。
|
||||
|
||||
这就是全部内容了。我猜你在此之前已经看过这个 [demo][4] 了。当然,这些源代码也在同一个 [仓库][5] 中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/passwordless-auth-client/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://nicolasparada.netlify.com/
|
||||
[1]:https://linux.cn/article-9748-1.html
|
||||
[2]:https://linux.cn/article-9815-1.html
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS
|
||||
[4]:https://go-passwordless-demo.herokuapp.com/
|
||||
[5]:https://github.com/nicolasparada/go-passwordless-demo
|
||||
@ -0,0 +1,406 @@
|
||||
日常 Python 编程优雅之道
|
||||
======
|
||||
|
||||
> 3 个可以使你的 Python 代码更优雅、可读、直观和易于维护的工具。
|
||||
|
||||

|
||||
|
||||
Python 提供了一组独特的工具和语言特性来使你的代码更加优雅、可读和直观。为正确的问题选择合适的工具,你的代码将更易于维护。在本文中,我们将研究其中的三个工具:魔术方法、迭代器和生成器,以及方法魔术。
|
||||
|
||||
### 魔术方法
|
||||
|
||||
魔术方法可以看作是 Python 的管道。它们被称为“底层”方法,用于某些内置的方法、符号和操作。你可能熟悉的常见魔术方法是 `__init__()`,当我们想要初始化一个类的新实例时,它会被调用。
|
||||
|
||||
你可能已经看过其他常见的魔术方法,如 `__str__` 和 `__repr__`。Python 中有一整套魔术方法,通过实现其中的一些方法,我们可以修改一个对象的行为,甚至使其行为类似于内置数据类型,例如数字、列表或字典。
|
||||
|
||||
让我们创建一个 `Money` 类来示例:
|
||||
|
||||
```
|
||||
class Money:
|
||||
|
||||
currency_rates = {
|
||||
'$': 1,
|
||||
'€': 0.88,
|
||||
}
|
||||
|
||||
def __init__(self, symbol, amount):
|
||||
self.symbol = symbol
|
||||
self.amount = amount
|
||||
|
||||
def __repr__(self):
|
||||
return '%s%.2f' % (self.symbol, self.amount)
|
||||
|
||||
def convert(self, other):
|
||||
""" Convert other amount to our currency """
|
||||
new_amount = (
|
||||
other.amount / self.currency_rates[other.symbol]
|
||||
* self.currency_rates[self.symbol])
|
||||
|
||||
return Money(self.symbol, new_amount)
|
||||
```
|
||||
|
||||
该类定义为给定的货币符号和汇率定义了一个货币汇率,指定了一个初始化器(也称为构造函数),并实现 `__repr__`,因此当我们打印这个类时,我们会看到一个友好的表示,例如 `$2.00` ,这是一个带有货币符号和金额的 `Money('$', 2.00)` 实例。最重要的是,它定义了一种方法,允许你使用不同的汇率在不同的货币之间进行转换。
|
||||
|
||||
打开 Python shell,假设我们已经定义了使用两种不同货币的食品的成本,如下所示:
|
||||
|
||||
```
|
||||
>>> soda_cost = Money('$', 5.25)
|
||||
>>> soda_cost
|
||||
$5.25
|
||||
|
||||
>>> pizza_cost = Money('€', 7.99)
|
||||
>>> pizza_cost
|
||||
€7.99
|
||||
```
|
||||
|
||||
我们可以使用魔术方法使得这个类的实例之间可以相互交互。假设我们希望能够将这个类的两个实例一起加在一起,即使它们是不同的货币。为了实现这一点,我们可以在 `Money` 类上实现 `__add__` 这个魔术方法:
|
||||
|
||||
```
|
||||
class Money:
|
||||
|
||||
# ... previously defined methods ...
|
||||
|
||||
def __add__(self, other):
|
||||
""" Add 2 Money instances using '+' """
|
||||
new_amount = self.amount + self.convert(other).amount
|
||||
return Money(self.symbol, new_amount)
|
||||
```
|
||||
|
||||
现在我们可以以非常直观的方式使用这个类:
|
||||
|
||||
```
|
||||
>>> soda_cost = Money('$', 5.25)
|
||||
>>> pizza_cost = Money('€', 7.99)
|
||||
>>> soda_cost + pizza_cost
|
||||
$14.33
|
||||
>>> pizza_cost + soda_cost
|
||||
€12.61
|
||||
```
|
||||
|
||||
当我们将两个实例加在一起时,我们得到以第一个定义的货币符号所表示的结果。所有的转换都是在底层无缝完成的。如果我们想的话,我们也可以为减法实现 `__sub__`,为乘法实现 `__mul__` 等等。阅读[模拟数字类型][1]或[魔术方法指南][2]来获得更多信息。
|
||||
|
||||
我们学习到 `__add__` 映射到内置运算符 `+`。其他魔术方法可以映射到像 `[]` 这样的符号。例如,在字典中通过索引或键来获得一项,其实是使用了 `__getitem__` 方法:
|
||||
|
||||
```
|
||||
>>> d = {'one': 1, 'two': 2}
|
||||
>>> d['two']
|
||||
2
|
||||
>>> d.__getitem__('two')
|
||||
2
|
||||
```
|
||||
|
||||
一些魔术方法甚至映射到内置函数,例如 `__len__()` 映射到 `len()`。
|
||||
|
||||
```
|
||||
class Alphabet:
|
||||
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
|
||||
|
||||
def __len__(self):
|
||||
return len(self.letters)
|
||||
|
||||
>>> my_alphabet = Alphabet()
|
||||
>>> len(my_alphabet)
|
||||
26
|
||||
```
|
||||
|
||||
### 自定义迭代器
|
||||
|
||||
对于新的和经验丰富的 Python 开发者来说,自定义迭代器是一个非常强大的但令人迷惑的主题。
|
||||
|
||||
许多内置类型,例如列表、集合和字典,已经实现了允许它们在底层迭代的协议。这使我们可以轻松地遍历它们。
|
||||
|
||||
```
|
||||
>>> for food in ['Pizza', 'Fries']:
|
||||
|
||||
print(food + '. Yum!')
|
||||
|
||||
Pizza. Yum!
|
||||
Fries. Yum!
|
||||
```
|
||||
|
||||
我们如何迭代我们自己的自定义类?首先,让我们来澄清一些术语。
|
||||
|
||||
* 要成为一个可迭代对象,一个类需要实现 `__iter__()`
|
||||
* `__iter__()` 方法需要返回一个迭代器
|
||||
* 要成为一个迭代器,一个类需要实现 `__next__()`(或[在 Python 2][3]中是 `next()`),当没有更多的项要迭代时,必须抛出一个 `StopIteration` 异常。
|
||||
|
||||
呼!这听起来很复杂,但是一旦你记住了这些基本概念,你就可以在任何时候进行迭代。
|
||||
|
||||
我们什么时候想使用自定义迭代器?让我们想象一个场景,我们有一个 `Server` 实例在不同的端口上运行不同的服务,如 `http` 和 `ssh`。其中一些服务处于 `active` 状态,而其他服务则处于 `inactive` 状态。
|
||||
|
||||
```
|
||||
class Server:
|
||||
|
||||
services = [
|
||||
{'active': False, 'protocol': 'ftp', 'port': 21},
|
||||
{'active': True, 'protocol': 'ssh', 'port': 22},
|
||||
{'active': True, 'protocol': 'http', 'port': 80},
|
||||
]
|
||||
```
|
||||
|
||||
当我们遍历 `Server` 实例时,我们只想遍历那些处于 `active` 的服务。让我们创建一个 `IterableServer` 类:
|
||||
|
||||
```
|
||||
class IterableServer:
|
||||
def __init__(self):
|
||||
self.current_pos = 0
|
||||
def __next__(self):
|
||||
pass # TODO: 实现并记得抛出 StopIteration
|
||||
```
|
||||
|
||||
首先,我们将当前位置初始化为 `0`。然后,我们定义一个 `__next__()` 方法来返回下一项。我们还将确保在没有更多项返回时抛出 `StopIteration`。到目前为止都很好!现在,让我们实现这个 `__next__()` 方法。
|
||||
|
||||
```
|
||||
class IterableServer:
|
||||
def __init__(self):
|
||||
self.current_pos = 0. # 我们初始化当前位置为 0
|
||||
def __iter__(self): # 我们可以在这里返回 self,因为实现了 __next__
|
||||
return self
|
||||
def __next__(self):
|
||||
while self.current_pos < len(self.services):
|
||||
service = self.services[self.current_pos]
|
||||
self.current_pos += 1
|
||||
if service['active']:
|
||||
return service['protocol'], service['port']
|
||||
raise StopIteration
|
||||
next = __next__ # 可选的 Python2 兼容性
|
||||
```
|
||||
|
||||
我们对列表中的服务进行遍历,而当前的位置小于服务的个数,但只有在服务处于活动状态时才返回。一旦我们遍历完服务,就会抛出一个 `StopIteration` 异常。
|
||||
|
||||
|
||||
因为我们实现了 `__next__()` 方法,当它耗尽时,它会抛出 `StopIteration`。我们可以从 `__iter__()` 返回 `self`,因为 `IterableServer` 类遵循 `iterable` 协议。
|
||||
|
||||
现在我们可以遍历一个 `IterableServer` 实例,这将允许我们查看每个处于活动的服务,如下所示:
|
||||
|
||||
```
|
||||
>>> for protocol, port in IterableServer():
|
||||
|
||||
print('service %s is running on port %d' % (protocol, port))
|
||||
|
||||
service ssh is running on port 22
|
||||
|
||||
service http is running on port 21
|
||||
|
||||
```
|
||||
|
||||
太棒了,但我们可以做得更好!在这样类似的实例中,我们的迭代器不需要维护大量的状态,我们可以简化代码并使用 [generator(生成器)][4] 来代替。
|
||||
|
||||
```
|
||||
class Server:
|
||||
services = [
|
||||
{'active': False, 'protocol': 'ftp', 'port': 21},
|
||||
{'active': True, 'protocol': 'ssh', 'port': 22},
|
||||
{'active': True, 'protocol': 'http', 'port': 21},
|
||||
]
|
||||
def __iter__(self):
|
||||
for service in self.services:
|
||||
if service['active']:
|
||||
yield service['protocol'], service['port']
|
||||
```
|
||||
|
||||
`yield` 关键字到底是什么?在定义生成器函数时使用 yield。这有点像 `return`,虽然 `return` 在返回值后退出函数,但 `yield` 会暂停执行直到下次调用它。这允许你的生成器的功能在它恢复之前保持状态。查看 [yield 的文档][5]以了解更多信息。使用生成器,我们不必通过记住我们的位置来手动维护状态。生成器只知道两件事:它现在需要做什么以及计算下一个项目需要做什么。一旦我们到达执行点,即 `yield` 不再被调用,我们就知道停止迭代。
|
||||
|
||||
这是因为一些内置的 Python 魔法。在 [Python 关于 `__iter__()` 的文档][6]中我们可以看到,如果 `__iter__()` 是作为一个生成器实现的,它将自动返回一个迭代器对象,该对象提供 `__iter__()` 和 `__next__()` 方法。阅读这篇很棒的文章,深入了解[迭代器,可迭代对象和生成器][7]。
|
||||
|
||||
### 方法魔法
|
||||
|
||||
由于其独特的方面,Python 提供了一些有趣的方法魔法作为语言的一部分。
|
||||
|
||||
其中一个例子是别名功能。因为函数只是对象,所以我们可以将它们赋值给多个变量。例如:
|
||||
|
||||
```
|
||||
>>> def foo():
|
||||
return 'foo'
|
||||
>>> foo()
|
||||
'foo'
|
||||
>>> bar = foo
|
||||
>>> bar()
|
||||
'foo'
|
||||
```
|
||||
|
||||
我们稍后会看到它的作用。
|
||||
|
||||
Python 提供了一个方便的内置函数[称为 `getattr()`][8],它接受 `object, name, default` 参数并在 `object` 上返回属性 `name`。这种编程方式允许我们访问实例变量和方法。例如:
|
||||
|
||||
```
|
||||
>>> class Dog:
|
||||
sound = 'Bark'
|
||||
def speak(self):
|
||||
print(self.sound + '!', self.sound + '!')
|
||||
|
||||
>>> fido = Dog()
|
||||
|
||||
>>> fido.sound
|
||||
'Bark'
|
||||
>>> getattr(fido, 'sound')
|
||||
'Bark'
|
||||
|
||||
>>> fido.speak
|
||||
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
|
||||
>>> getattr(fido, 'speak')
|
||||
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
|
||||
|
||||
|
||||
>>> fido.speak()
|
||||
Bark! Bark!
|
||||
>>> speak_method = getattr(fido, 'speak')
|
||||
>>> speak_method()
|
||||
Bark! Bark!
|
||||
```
|
||||
|
||||
这是一个很酷的技巧,但是我们如何在实际中使用 `getattr` 呢?让我们看一个例子,我们编写一个小型命令行工具来动态处理命令。
|
||||
|
||||
```
|
||||
class Operations:
|
||||
def say_hi(self, name):
|
||||
print('Hello,', name)
|
||||
def say_bye(self, name):
|
||||
print ('Goodbye,', name)
|
||||
def default(self, arg):
|
||||
print ('This operation is not supported.')
|
||||
|
||||
if __name__ == '__main__':
|
||||
operations = Operations()
|
||||
# 假设我们做了错误处理
|
||||
command, argument = input('> ').split()
|
||||
func_to_call = getattr(operations, command, operations.default)
|
||||
func_to_call(argument)
|
||||
```
|
||||
|
||||
脚本的输出是:
|
||||
|
||||
```
|
||||
$ python getattr.py
|
||||
> say_hi Nina
|
||||
Hello, Nina
|
||||
> blah blah
|
||||
This operation is not supported.
|
||||
```
|
||||
|
||||
接下来,我们来看看 `partial`。例如,`functool.partial(func, *args, **kwargs)` 允许你返回一个新的 [partial 对象][9],它的行为类似 `func`,参数是 `args` 和 `kwargs`。如果传入更多的 `args`,它们会被附加到 `args`。如果传入更多的 `kwargs`,它们会扩展并覆盖 `kwargs`。让我们通过一个简短的例子来看看:
|
||||
|
||||
```
|
||||
>>> from functools import partial
|
||||
>>> basetwo = partial(int, base=2)
|
||||
>>> basetwo
|
||||
<functools.partial object at 0x1085a09f0>
|
||||
>>> basetwo('10010')
|
||||
18
|
||||
|
||||
# 这等同于
|
||||
>>> int('10010', base=2)
|
||||
```
|
||||
|
||||
让我们看看在我喜欢的一个[名为 `agithub`][10] 的库中的一些示例代码中,这个方法魔术是如何结合在一起的,这是一个(名字起得很 low 的) REST API 客户端,它具有透明的语法,允许你以最小的配置快速构建任何 REST API 原型(不仅仅是 GitHub)。我发现这个项目很有趣,因为它非常强大,但只有大约 400 行 Python 代码。你可以在大约 30 行配置代码中添加对任何 REST API 的支持。`agithub` 知道协议所需的一切(`REST`、`HTTP`、`TCP`),但它不考虑上游 API。让我们深入到它的实现中。
|
||||
|
||||
以下是我们如何为 GitHub API 和任何其他相关连接属性定义端点 URL 的简化版本。在这里查看[完整代码][11]。
|
||||
|
||||
```
|
||||
class GitHub(API):
|
||||
def __init__(self, token=None, *args, **kwargs):
|
||||
props = ConnectionProperties(api_url = kwargs.pop('api_url', 'api.github.com'))
|
||||
self.setClient(Client(*args, **kwargs))
|
||||
self.setConnectionProperties(props)
|
||||
```
|
||||
|
||||
然后,一旦配置了[访问令牌][12],就可以开始使用 [GitHub API][13]。
|
||||
|
||||
```
|
||||
>>> gh = GitHub('token')
|
||||
>>> status, data = gh.user.repos.get(visibility='public', sort='created')
|
||||
>>> # ^ 映射到 GET /user/repos
|
||||
>>> data
|
||||
... ['tweeter', 'snipey', '...']
|
||||
```
|
||||
|
||||
请注意,你要确保 URL 拼写正确,因为我们没有验证 URL。如果 URL 不存在或出现了其他任何错误,将返回 API 抛出的错误。那么,这一切是如何运作的呢?让我们找出答案。首先,我们将查看一个 [`API` 类][14]的简化示例:
|
||||
|
||||
```
|
||||
class API:
|
||||
# ... other methods ...
|
||||
def __getattr__(self, key):
|
||||
return IncompleteRequest(self.client).__getattr__(key)
|
||||
__getitem__ = __getattr__
|
||||
```
|
||||
|
||||
在 `API` 类上的每次调用都会调用 [`IncompleteRequest` 类][15]作为指定的 `key`。
|
||||
|
||||
```
|
||||
class IncompleteRequest:
|
||||
# ... other methods ...
|
||||
def __getattr__(self, key):
|
||||
if key in self.client.http_methods:
|
||||
htmlMethod = getattr(self.client, key)
|
||||
return partial(htmlMethod, url=self.url)
|
||||
else:
|
||||
self.url += '/' + str(key)
|
||||
return self
|
||||
__getitem__ = __getattr__
|
||||
|
||||
class Client:
|
||||
http_methods = ('get') # 还有 post, put, patch 等等。
|
||||
def get(self, url, headers={}, **params):
|
||||
return self.request('GET', url, None, headers)
|
||||
```
|
||||
|
||||
如果最后一次调用不是 HTTP 方法(如 `get`、`post` 等),则返回带有附加路径的 `IncompleteRequest`。否则,它从[`Client` 类][16]获取 HTTP 方法对应的正确函数,并返回 `partial`。
|
||||
|
||||
如果我们给出一个不存在的路径会发生什么?
|
||||
|
||||
```
|
||||
>>> status, data = this.path.doesnt.exist.get()
|
||||
>>> status
|
||||
... 404
|
||||
```
|
||||
|
||||
因为 `__getattr__` 别名为 `__getitem__`:
|
||||
|
||||
```
|
||||
>>> owner, repo = 'nnja', 'tweeter'
|
||||
>>> status, data = gh.repos[owner][repo].pulls.get()
|
||||
>>> # ^ Maps to GET /repos/nnja/tweeter/pulls
|
||||
>>> data
|
||||
.... # {....}
|
||||
```
|
||||
|
||||
这真心是一些方法魔术!
|
||||
|
||||
### 了解更多
|
||||
|
||||
Python 提供了大量工具,使你的代码更优雅,更易于阅读和理解。挑战在于找到合适的工具来完成工作,但我希望本文为你的工具箱添加了一些新工具。而且,如果你想更进一步,你可以在我的博客 [nnja.io][17] 上阅读有关装饰器、上下文管理器、上下文生成器和命名元组的内容。随着你成为一名更好的 Python 开发人员,我鼓励你到那里阅读一些设计良好的项目的源代码。[Requests][18] 和 [Flask][19] 是两个很好的起步的代码库。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/elegant-solutions-everyday-python-problems
|
||||
|
||||
作者:[Nina Zakharenko][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nnja
|
||||
[1]:https://docs.python.org/3/reference/datamodel.html#emulating-numeric-types
|
||||
[2]:https://rszalski.github.io/magicmethods/
|
||||
[3]:https://docs.python.org/2/library/stdtypes.html#iterator.next
|
||||
[4]:https://docs.python.org/3/library/stdtypes.html#generator-types
|
||||
[5]:https://docs.python.org/3/reference/expressions.html#yieldexpr
|
||||
[6]:https://docs.python.org/3/reference/datamodel.html#object.__iter__
|
||||
[7]:http://nvie.com/posts/iterators-vs-generators/
|
||||
[8]:https://docs.python.org/3/library/functions.html#getattr
|
||||
[9]:https://docs.python.org/3/library/functools.html#functools.partial
|
||||
[10]:https://github.com/mozilla/agithub
|
||||
[11]:https://github.com/mozilla/agithub/blob/master/agithub/GitHub.py
|
||||
[12]:https://github.com/settings/tokens
|
||||
[13]:https://developer.github.com/v3/repos/#list-your-repositories
|
||||
[14]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L30-L58
|
||||
[15]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L60-L100
|
||||
[16]:https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L102-L231
|
||||
[17]:http://nnja.io
|
||||
[18]:https://github.com/requests/requests
|
||||
[19]:https://github.com/pallets/flask
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/164/
|
||||
[21]:https://us.pycon.org/2018/
|
||||
@ -0,0 +1,165 @@
|
||||
在 Linux 命令行中自定义文本颜色
|
||||
======
|
||||
|
||||
> 在 Linux 命令行当中使用不同颜色以期提供一种根据文件类型来识别文件的简单方式。你可以修改这些颜色,但是在做之前应该对你做的事情有充分的理由。
|
||||
|
||||

|
||||
|
||||
如果你在 Linux 命令行上花费了大量的时间(如果没有,那么你可能不会读这篇文章),你无疑注意到了 `ls` 以多种不同的颜色显示文件。你可能也注意到了一些区别 —— 目录是一种颜色,可执行文件是另一种颜色等等。
|
||||
|
||||
这一切是如何发生的呢?以及,你可以选择哪些选项来改变颜色分配可能就不是很多人都知道的。
|
||||
|
||||
一种方法是运行 `dircolors` 命令得到一大堆展示了如何指定这些颜色的数据。它会显示以下这些东西:
|
||||
|
||||
```
|
||||
$ dircolors
|
||||
LS_COLORS='rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do
|
||||
=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg
|
||||
=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01
|
||||
;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01
|
||||
;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=0
|
||||
1;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31
|
||||
:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.
|
||||
xz=01;31:*.zst=01;31:*.tzst=01;31:*.bz2=01;31:*.bz=01;31:*.t
|
||||
bz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.j
|
||||
ar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.a
|
||||
lz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.r
|
||||
z=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.mjpg=01;35:*.
|
||||
mjpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:
|
||||
*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:
|
||||
*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;3
|
||||
5:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;
|
||||
35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01
|
||||
;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01
|
||||
;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01
|
||||
;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;3
|
||||
5:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;3
|
||||
5:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;3
|
||||
6:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;
|
||||
36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;
|
||||
36:*.spx=00;36:*.xspf=00;36:';
|
||||
export LS_COLORS
|
||||
```
|
||||
|
||||
如果你擅长解析文件,那么你可能会注意到这个列表有一种<ruby>模式<rt>patten</rt></ruby>。用冒号分隔开,你会看到这样的东西:
|
||||
|
||||
```
|
||||
$ dircolors | tr ":" "\n" | head -10
|
||||
LS_COLORS='rs=0
|
||||
di=01;34
|
||||
ln=01;36
|
||||
mh=00
|
||||
pi=40;33
|
||||
so=01;35
|
||||
do=01;35
|
||||
bd=40;33;01
|
||||
cd=40;33;01
|
||||
or=40;31;01
|
||||
```
|
||||
|
||||
OK,这里有一个模式 —— 一系列定义,有一到三个数字组件。我们来看看其中的一个定义。
|
||||
|
||||
```
|
||||
pi=40;33
|
||||
```
|
||||
|
||||
有些人可能会问的第一个问题是“pi 是什么?”在这里,我们研究的是颜色和文件类型,所以这显然不是以 3.14 开头的那个有趣的数字。当然不是,这个 “pi” 代表 “pipe(管道)” —— Linux 系统上的一种特殊类型的文件,它可以将数据从一个程序传递给另一个程序。所以,让我们建立一个管道。
|
||||
|
||||
```
|
||||
$ mknod /tmp/mypipe p
|
||||
$ ls -l /tmp/mypipe
|
||||
prw-rw-r-- 1 shs shs 0 May 1 14:00 /tmp/mypipe
|
||||
```
|
||||
|
||||
当我们在终端窗口中查看我们的管道和其他几个文件时,颜色差异非常明显。
|
||||
|
||||
![font colors][1]
|
||||
|
||||
在 `pi` 的定义中(如上所示),“40” 使文件在终端(或 PuTTY)窗口中使用黑色背景显示,31 使字体颜色变红。管道是特殊的文件,这种特殊的处理使它们在目录列表中突出显示。
|
||||
|
||||
`bd` 和 `cd` 定义是相同的 —— `40;33;01`,它有一个额外的设置。这个设置会导致 <ruby>块设备<rt>block device</rt></ruby>(bd)和 <ruby>字符设备<rt>character device</rt></ruby>(cd)以黑色背景,橙色字体和另一种效果显示 —— 字符将以粗体显示。
|
||||
|
||||
以下列表显示由<ruby>文件类型<rt>file type</rt></ruby>所指定的颜色和字体分配:
|
||||
|
||||
```
|
||||
setting file type
|
||||
======= =========
|
||||
rs=0 reset to no color
|
||||
di=01;34 directory
|
||||
ln=01;36 link
|
||||
mh=00 multi-hard link
|
||||
pi=40;33 pipe
|
||||
so=01;35 socket
|
||||
do=01;35 door
|
||||
bd=40;33;01 block device
|
||||
cd=40;33;01 character device
|
||||
or=40;31;01 orphan
|
||||
mi=00 missing?
|
||||
su=37;41 setuid
|
||||
sg=30;43 setgid
|
||||
ca=30;41 file with capability
|
||||
tw=30;42 directory with sticky bit and world writable
|
||||
ow=34;42 directory that is world writable
|
||||
st=37;44 directory with sticky bit
|
||||
ex=01;93 executable
|
||||
```
|
||||
|
||||
你可能已经注意到,在 `dircolors` 命令输出中,我们的大多数定义都以星号开头(例如,`*.wav=00;36`)。这些按<ruby>文件扩展名<rt>file extension</rt></ruby>而不是文件类型定义显示属性。这有一个示例:
|
||||
|
||||
```
|
||||
$ dircolors | tr ":" "\n" | tail -10
|
||||
*.mpc=00;36
|
||||
*.ogg=00;36
|
||||
*.ra=00;36
|
||||
*.wav=00;36
|
||||
*.oga=00;36
|
||||
*.opus=00;36
|
||||
*.spx=00;36
|
||||
*.xspf=00;36
|
||||
';
|
||||
export LS_COLORS
|
||||
```
|
||||
|
||||
这些设置(上面列表中所有的 `00;36`)将使这些文件名以青色显示。可用的颜色如下所示。
|
||||
|
||||
![all colors][2]
|
||||
|
||||
### 如何改变设置
|
||||
|
||||
你要使用 `ls` 的别名来打开颜色显示功能。这通常是 Linux 系统上的默认设置,看起来是这样的:
|
||||
|
||||
```
|
||||
alias ls='ls --color=auto'
|
||||
```
|
||||
|
||||
如果要关闭字体颜色,可以运行 `unalias ls` 命令,然后文件列表将仅以默认字体颜色显示。
|
||||
|
||||
你可以通过修改 `$LS_COLORS` 设置和导出修改后的设置来更改文本颜色。
|
||||
|
||||
```
|
||||
$ export LS_COLORS='rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;...
|
||||
```
|
||||
|
||||
注意:上面的命令由于太长被截断了。
|
||||
|
||||
如果希望文本颜色的修改是永久性的,则需要将修改后的 `$LS_COLORS` 定义添加到一个启动文件中,例如 `.bashrc`。
|
||||
|
||||
### 更多关于命令行文本
|
||||
|
||||
你可以在 NetworkWorld 的 [2016 年 11 月][3]的帖子中找到有关文本颜色的其他信息。
|
||||
|
||||
---
|
||||
|
||||
via: https://www.networkworld.com/article/3269587/linux/customizing-your-text-colors-on-the-linux-command-line.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://images.idgesg.net/images/article/2018/05/font-colors-100756483-large.jpg
|
||||
[2]: https://images.techhive.com/images/article/2016/11/all-colors-100691990-large.jpg
|
||||
[3]: https://www.networkworld.com/article/3138909/linux/coloring-your-world-with-ls-colors.html
|
||||
@ -0,0 +1,134 @@
|
||||
如何轻松地检查 Ubuntu 版本以及其它系统信息
|
||||
======
|
||||
|
||||
> 摘要:想知道你正在使用的 Ubuntu 具体是什么版本吗?这篇文档将告诉你如何检查你的 Ubuntu 版本、桌面环境以及其他相关的系统信息。
|
||||
|
||||
通常,你能非常容易的通过命令行或者图形界面获取你正在使用的 Ubuntu 的版本。当你正在尝试学习一篇互联网上的入门教材或者正在从各种各样的论坛里获取帮助的时候,知道当前正在使用的 Ubuntu 确切的版本号、桌面环境以及其他的系统信息将是尤为重要的。
|
||||
|
||||
在这篇简短的文章中,作者将展示各种检查 [Ubuntu][1] 版本以及其他常用的系统信息的方法。
|
||||
|
||||
### 如何在命令行检查 Ubuntu 版本
|
||||
|
||||
这个是获得 Ubuntu 版本的最好的办法。我本想先展示如何用图形界面做到这一点,但是我决定还是先从命令行方法说起,因为这种方法不依赖于你使用的任何[桌面环境][2]。 你可以在 Ubuntu 的任何变种系统上使用这种方法。
|
||||
|
||||
打开你的命令行终端 (`Ctrl+Alt+T`), 键入下面的命令:
|
||||
|
||||
```
|
||||
lsb_release -a
|
||||
```
|
||||
|
||||
上面命令的输出应该如下:
|
||||
|
||||
```
|
||||
No LSB modules are available.
|
||||
Distributor ID: Ubuntu
|
||||
Description: Ubuntu 16.04.4 LTS
|
||||
Release: 16.04
|
||||
Codename: xenial
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][3]
|
||||
|
||||
正像你所看到的,当前我的系统安装的 Ubuntu 版本是 Ubuntu 16.04, 版本代号: Xenial。
|
||||
|
||||
且慢!为什么版本描述中显示的是 Ubuntu 16.04.4 而发行版本是 16.04?到底哪个才是正确的版本?16.04 还是 16.04.4? 这两者之间有什么区别?
|
||||
|
||||
如果言简意赅的回答这个问题的话,那么答案应该是你正在使用 Ubuntu 16.04。这个是基准版本,而 16.04.4 进一步指明这是 16.04 的第四个补丁版本。你可以将补丁版本理解为 Windows 世界里的服务包。在这里,16.04 和 16.04.4 都是正确的版本号。
|
||||
|
||||
那么输出的 Xenial 又是什么?那正是 Ubuntu 16.04 的版本代号。你可以阅读下面这篇文章获取更多信息:[了解 Ubuntu 的命名惯例][4]。
|
||||
|
||||
#### 其他一些获取 Ubuntu 版本的方法
|
||||
|
||||
你也可以使用下面任意的命令得到 Ubuntu 的版本:
|
||||
|
||||
```
|
||||
cat /etc/lsb-release
|
||||
```
|
||||
|
||||
输出如下信息:
|
||||
|
||||
```
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=16.04
|
||||
DISTRIB_CODENAME=xenial
|
||||
DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][5]
|
||||
|
||||
|
||||
你还可以使用下面的命令来获得 Ubuntu 版本:
|
||||
|
||||
```
|
||||
cat /etc/issue
|
||||
```
|
||||
|
||||
|
||||
命令行的输出将会如下:
|
||||
|
||||
```
|
||||
Ubuntu 16.04.4 LTS \n \l
|
||||
```
|
||||
|
||||
不要介意输出末尾的\n \l. 这里 Ubuntu 版本就是 16.04.4,或者更加简单:16.04。
|
||||
|
||||
|
||||
### 如何在图形界面下得到 Ubuntu 版本
|
||||
|
||||
在图形界面下获取 Ubuntu 版本更是小事一桩。这里我使用了 Ubuntu 18.04 的图形界面系统 GNOME 的屏幕截图来展示如何做到这一点。如果你在使用 Unity 或者别的桌面环境的话,显示可能会有所不同。这也是为什么我推荐使用命令行方式来获得版本的原因:你不用依赖形形色色的图形界面。
|
||||
|
||||
下面我来展示如何在桌面环境获取 Ubuntu 版本。
|
||||
|
||||
进入‘系统设置’并点击下面的‘详细信息’栏。
|
||||
|
||||
![Finding Ubuntu version graphically][6]
|
||||
|
||||
你将会看到系统的 Ubuntu 版本和其他和桌面系统有关的系统信息 这里的截图来自 [GNOME][7] 。
|
||||
|
||||
![Finding Ubuntu version graphically][8]
|
||||
|
||||
### 如何知道桌面环境以及其他的系统信息
|
||||
|
||||
你刚才学习的是如何得到 Ubuntu 的版本信息,那么如何知道桌面环境呢? 更进一步, 如果你还想知道当前使用的 Linux 内核版本呢?
|
||||
|
||||
有各种各样的命令你可以用来得到这些信息,不过今天我想推荐一个命令行工具, 叫做 [Neofetch][9]。 这个工具能在命令行完美展示系统信息,包括 Ubuntu 或者其他 Linux 发行版的系统图标。
|
||||
|
||||
用下面的命令安装 Neofetch:
|
||||
|
||||
```
|
||||
sudo apt install neofetch
|
||||
```
|
||||
|
||||
安装成功后,运行 `neofetch` 将会优雅的展示系统的信息如下。
|
||||
|
||||
![System information in Linux terminal][10]
|
||||
|
||||
如你所见,`neofetch` 完全展示了 Linux 内核版本、Ubuntu 的版本、桌面系统版本以及环境、主题和图标等等信息。
|
||||
|
||||
|
||||
希望我如上展示方法能帮到你更快的找到你正在使用的 Ubuntu 版本和其他系统信息。如果你对这篇文章有其他的建议,欢迎在评论栏里留言。
|
||||
|
||||
再见。:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.ubuntu.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Desktop_environment
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-1-800x216.jpeg
|
||||
[4]:https://itsfoss.com/linux-code-names/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-2-800x185.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-version-system-settings.jpeg
|
||||
[7]:https://www.gnome.org/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/checking-ubuntu-version-gui.jpeg
|
||||
[9]:https://itsfoss.com/display-linux-logo-in-ascii/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-system-information-terminal-800x400.jpeg
|
||||
@ -2,7 +2,8 @@ Android 工程师的一年
|
||||
============================================================
|
||||
|
||||

|
||||
>妙绝的绘画来自 [Miquel Beltran][0]
|
||||
|
||||
> 这幅妙绝的绘画来自 [Miquel Beltran][0]
|
||||
|
||||
我的技术生涯,从两年前算起。开始是 QA 测试员,一年后就转入开发人员角色。没怎么努力,也没有投入过多的个人时间。
|
||||
|
||||
@ -12,7 +13,7 @@ Android 工程师的一年
|
||||
|
||||
我的第一个职位角色, Android 开发者,开始于一年前。我工作的这家公司,可以花一半的时间去尝试其它角色的工作,这给我从 QA 职位转到 Android 开发者职位创造了机会。
|
||||
|
||||
这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了[ Android 基础纳米学位][3]、[Andriod 工程师纳米学位][4]课程,也获得了[ Google 开发者认证][5]。这部分的详细故事在[这儿][6]。
|
||||
这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了 [Android 基础纳米学位][3]、[Andriod 工程师纳米学位][4]课程,也获得了 [Google 开发者认证][5]。这部分的详细故事在[这儿][6]。
|
||||
|
||||
两个月后,公司雇佣了另一位 QA,我转向全职工作。挑战从此开始!
|
||||
|
||||
@ -46,29 +47,27 @@ Android 工程师的一年
|
||||
|
||||
一个例子就是拉取代码进行公开展示和代码审查。有是我会请同事私下检查我的代码,并不想被公开拉取,向任何人展示。
|
||||
|
||||
其他时候,当我做代码审查时,会花好几分钟盯着"批准"按纽犹豫不决,在担心审查通过的会被其他同事找出毛病。
|
||||
其他时候,当我做代码审查时,会花好几分钟盯着“批准”按纽犹豫不决,在担心审查通过的代码会被其他同事找出毛病。
|
||||
|
||||
当我在一些事上持反对意见时,由于缺乏相关知识,担心被坐冷板凳,从来没有大声说出来过。
|
||||
|
||||
> 某些时间我会请同事私下[...]检查我的代码,以避免被公开展示。
|
||||
|
||||
* * *
|
||||
|
||||
### 新的公司,新的挑战
|
||||
|
||||
后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被[ Babbel ][7]邀请去参加初级 Android 工程师职位的招聘流程。
|
||||
后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被 [Babbel][7] 邀请去参加初级 Android 工程师职位的招聘流程。
|
||||
|
||||
我见到了他们的团队,同时自告奋勇的在他们办公室主持了一次本地会议。此事让我下定决心要申请这个职位。我喜欢公司的箴言:全民学习。其次,公司每个人都非常友善,在那儿工作看起来很愉快!但我没有马上申请,因为我认为自己不够好,所以为什么能申请呢?
|
||||
|
||||
还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的应该程序来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
|
||||
还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的程序的形式来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
|
||||
|
||||
#### 招聘过程
|
||||
|
||||
我用周未的时间来完成编码挑战的项目,并在周一就立即发送过去。不久就受邀去当场面试。
|
||||
|
||||
技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
|
||||
技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的地方、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
|
||||
|
||||
最后,通过面试,得到 offer, 我授受了!
|
||||
最后,通过面试,得到 offer,我授受了!
|
||||
|
||||
我的 Android 工程师生涯的第一年,有九个月在一个公司,后面三个月在当前的公司。
|
||||
|
||||
@ -88,7 +87,7 @@ Android 工程师的一年
|
||||
|
||||
两次三次后,压力就堵到胸口。为什么我还不知道?为什么就那么难理解?这种状态让我焦虑万分。
|
||||
|
||||
我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有是,仅仅需要的就是更多的时间、更多的练习,最终会"在大脑中完全演绎" :-)
|
||||
我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有时,仅仅需要的就是更多的时间、更多的练习,最终会“在大脑中完全演绎” :-)
|
||||
|
||||
例如,我常常为 Java 的接口类和抽象类所困扰,不管看了多少的例子,还是不能完全明白他们之间的区别。但一旦我使用后,即使还不能解释其工作原理,也知道了怎么使用以及什么时候使用。
|
||||
|
||||
@ -102,19 +101,13 @@ Android 工程师的一年
|
||||
|
||||
工程师的角色不仅仅是编码,而是广泛的技能。 我仍然处于旅程的起点,在掌握它的道路上,我想着重于以下几点:
|
||||
|
||||
* 交流:因为英文不是我的母语,所以有的时候我会努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
|
||||
|
||||
* 提有建设性的反馈意见: 我想给同事有意义的反馈,这样我们一起共同发展。
|
||||
|
||||
* 为我的成就感到骄傲: 我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
|
||||
|
||||
* 不要着迷于不知道的事情: 当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
|
||||
|
||||
* 多和同事分享知识。我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
|
||||
|
||||
* 耐心和持续学习: 和现在一样的保持不断学习,但对自己要有更多耐心。
|
||||
|
||||
* 自我保健: 随时注意休息,不要为难自己。 放松也富有成效。
|
||||
* 交流:因为英文不是我的母语,所以有的时候我需要努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
|
||||
* 提有建设性的反馈意见:我想给同事有意义的反馈,这样我们一起共同发展。
|
||||
* 为我的成就感到骄傲:我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
|
||||
* 不要着迷于不知道的事情:当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
|
||||
* 多和同事分享知识:我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
|
||||
* 耐心和持续学习:和现在一样的保持不断学习,但对自己要有更多耐心。
|
||||
* 自我保健:随时注意休息,不要为难自己。 放松也富有成效。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -122,7 +115,7 @@ via: https://proandroiddev.com/a-year-as-android-engineer-55e2a428dfc8
|
||||
|
||||
作者:[Lara Martín][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,90 @@
|
||||
使用 Xenlism 主题对你的 Linux 桌面进行令人惊叹的改造
|
||||
============================================================
|
||||
|
||||
> 简介:Xenlism 主题包提供了一个美观的 GTK 主题、彩色图标和简约的壁纸,将你的 Linux 桌面转变为引人注目的操作系统。
|
||||
|
||||
除非我找到一些非常棒的东西,否则我不会每天都把整篇文章献给一个主题。我曾经经常发布主题和图标。但最近,我更喜欢列出[最佳 GTK 主题][6]和图标主题。这对我和你来说都更方便,你可以在一个地方看到许多美丽的主题。
|
||||
|
||||
在 [Pop OS 主题][7]套件之后,Xenlism 是另一个让我对它的外观感到震惊的主题。
|
||||
|
||||

|
||||
|
||||
Xenlism GTK 主题基于 Arc 主题,其得益于许多主题的灵感。GTK 主题提供类似于 macOS 的 Windows 按钮,我既不特别喜欢,也没有特别不喜欢。GTK 主题采用扁平、简约的布局,我喜欢这样。
|
||||
|
||||
Xenlism 套件中有两个图标主题。Xenlism Wildfire 是以前的,已经进入我们的[最佳图标主题][8]列表。
|
||||
|
||||

|
||||
|
||||
*Xenlism Wildfire 图标*
|
||||
|
||||
Xenlsim Storm 是一个相对较新的图标主题,但同样美观。
|
||||
|
||||

|
||||
|
||||
*Xenlism Storm 图标*
|
||||
|
||||
Xenlism 主题在 GPL 许可下开源。
|
||||
|
||||
### 如何在 Ubuntu 18.04 上安装 Xenlism 主题包
|
||||
|
||||
Xenlism 开发提供了一种通过 PPA 安装主题包的更简单方法。尽管 PPA 可用于 Ubuntu 16.04,但我发现 GTK 主题不适用于 Unity。它适用于 Ubuntu 18.04 中的 GNOME 桌面。
|
||||
|
||||
打开终端(`Ctrl+Alt+T`)并逐个使用以下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:xenatt/xenlism
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
该 PPA 提供四个包:
|
||||
|
||||
* xenlism-finewalls:一组壁纸,可直接在 Ubuntu 的壁纸中使用。截图中使用了其中一个壁纸。
|
||||
* xenlism-minimalism-theme:GTK 主题
|
||||
* xenlism-storm:一个图标主题(见前面的截图)
|
||||
* xenlism-wildfire-icon-theme:具有多种颜色变化的另一个图标主题(文件夹颜色在变体中更改)
|
||||
|
||||
你可以自己决定要安装的主题组件。就个人而言,我认为安装所有组件没有任何损害。
|
||||
|
||||
```
|
||||
sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wildfire-icon-theme xenlism-finewalls
|
||||
```
|
||||
|
||||
你可以使用 GNOME Tweaks 来更改主题和图标。如果你不熟悉该过程,我建议你阅读本教程以学习[如何在 Ubuntu 18.04 GNOME 中安装主题][9]。
|
||||
|
||||
### 在其他 Linux 发行版中获取 Xenlism 主题
|
||||
|
||||
你也可以在其他 Linux 发行版上安装 Xenlism 主题。各种 Linux 发行版的安装说明可在其网站上找到:
|
||||
|
||||
[安装 Xenlism 主题][10]
|
||||
|
||||
### 你怎么看?
|
||||
|
||||
我知道不是每个人都会同意我,但我喜欢这个主题。我想你将来会在 It's FOSS 的教程中会看到 Xenlism 主题的截图。
|
||||
|
||||
你喜欢 Xenlism 主题吗?如果不喜欢,你最喜欢什么主题?在下面的评论部分分享你的意见。
|
||||
|
||||
### 关于作者
|
||||
|
||||
我是一名专业软件开发人员,也是 It's FOSS 的创始人。我是一名狂热的 Linux 爱好者和开源爱好者。我使用 Ubuntu 并相信分享知识。除了Linux,我喜欢经典侦探之谜。我是 Agatha Christie 作品的忠实粉丝。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/xenlism-theme/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/author/abhishek/
|
||||
[2]:https://itsfoss.com/xenlism-theme/#comments
|
||||
[3]:https://itsfoss.com/category/desktop/
|
||||
[4]:https://itsfoss.com/tag/themes/
|
||||
[5]:https://itsfoss.com/tag/xenlism/
|
||||
[6]:https://itsfoss.com/best-gtk-themes/
|
||||
[7]:https://itsfoss.com/pop-icon-gtk-theme-ubuntu/
|
||||
[8]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[9]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[10]:http://xenlism.github.io/minimalism/#install
|
||||
246
published/201807/20180522 How to Run Your Own Git Server.md
Normal file
246
published/201807/20180522 How to Run Your Own Git Server.md
Normal file
@ -0,0 +1,246 @@
|
||||
搭建属于你自己的 Git 服务器
|
||||
======
|
||||
|
||||
|
||||
|
||||
> 在本文中,我们的目的是让你了解如何设置属于自己的Git服务器。
|
||||
|
||||
[Git][1] 是由 [Linux Torvalds 开发][2]的一个版本控制系统,现如今正在被全世界大量开发者使用。许多公司喜欢使用基于 Git 版本控制的 GitHub 代码托管。[根据报道,GitHub 是现如今全世界最大的代码托管网站][3]。GitHub 宣称已经有 920 万用户和 2180 万个仓库。许多大型公司现如今也将代码迁移到 GitHub 上。[甚至于谷歌,一家搜索引擎公司,也正将代码迁移到 GitHub 上][4]。
|
||||
|
||||
### 运行你自己的 Git 服务器
|
||||
|
||||
GitHub 能提供极佳的服务,但却有一些限制,尤其是你是单人或是一名 coding 爱好者。GitHub 其中之一的限制就是其中免费的服务没有提供代码私有托管业务。[你不得不支付每月 7 美金购买 5 个私有仓库][5],并且想要更多的私有仓库则要交更多的钱。
|
||||
|
||||
万一你想要私有仓库或需要更多权限控制,最好的方法就是在你的服务器上运行 Git。不仅你能够省去一笔钱,你还能够在你的服务器有更多的操作。在大多数情况下,大多数高级 Linux 用户已经拥有自己的服务器,并且在这些服务器上方式 Git 就像“啤酒一样免费”(LCTT 译注:指免费软件)。
|
||||
|
||||
在这篇教程中,我们主要讲在你的服务器上,使用两种代码管理的方法。一种是运行一个纯 Git 服务器,另一个是使用名为 [GitLab][6] 的 GUI 工具。在本教程中,我在 VPS 上运行的操作系统是 Ubuntu 14.04 LTS。
|
||||
|
||||
### 在你的服务器上安装 Git
|
||||
|
||||
在本篇教程中,我们考虑一个简单案例,我们有一个远程服务器和一台本地服务器,现在我们需要使用这两台机器来工作。为了简单起见,我们就分别叫它们为远程服务器和本地服务器。
|
||||
|
||||
首先,在两边的机器上安装 Git。你可以从依赖包中安装 Git,在本文中,我们将使用更简单的方法:
|
||||
|
||||
```
|
||||
sudo apt-get install git-core
|
||||
```
|
||||
|
||||
为 Git 创建一个用户。
|
||||
|
||||
```
|
||||
sudo useradd git
|
||||
passwd git
|
||||
```
|
||||
|
||||
为了容易的访问服务器,我们设置一个免密 ssh 登录。首先在你本地电脑上创建一个 ssh 密钥:
|
||||
|
||||
```
|
||||
ssh-keygen -t rsa
|
||||
```
|
||||
|
||||
这时会要求你输入保存密钥的路径,这时只需要点击回车保存在默认路径。第二个问题是输入访问远程服务器所需的密码。它生成两个密钥——公钥和私钥。记下您在下一步中需要使用的公钥的位置。
|
||||
|
||||
现在您必须将这些密钥复制到服务器上,以便两台机器可以相互通信。在本地机器上运行以下命令:
|
||||
|
||||
```
|
||||
cat ~/.ssh/id_rsa.pub | ssh git@remote-server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
|
||||
```
|
||||
|
||||
现在,用 `ssh` 登录进服务器并为 Git 创建一个项目路径。你可以为你的仓库设置一个你想要的目录。
|
||||
|
||||
现在跳转到该目录中:
|
||||
|
||||
```
|
||||
cd /home/swapnil/project-1.git
|
||||
```
|
||||
|
||||
现在新建一个空仓库:
|
||||
|
||||
```
|
||||
git init --bare
|
||||
Initialized empty Git repository in /home/swapnil/project-1.git
|
||||
```
|
||||
|
||||
现在我们需要在本地机器上新建一个基于 Git 版本控制仓库:
|
||||
|
||||
```
|
||||
mkdir -p /home/swapnil/git/project
|
||||
```
|
||||
|
||||
进入我们创建仓库的目录:
|
||||
|
||||
```
|
||||
cd /home/swapnil/git/project
|
||||
```
|
||||
|
||||
现在在该目录中创建项目所需的文件。留在这个目录并启动 `git`:
|
||||
|
||||
```
|
||||
git init
|
||||
Initialized empty Git repository in /home/swapnil/git/project
|
||||
```
|
||||
|
||||
把所有文件添加到仓库中:
|
||||
|
||||
```
|
||||
git add .
|
||||
```
|
||||
|
||||
现在,每次添加文件或进行更改时,都必须运行上面的 `add` 命令。 您还需要为每个文件更改都写入提交消息。提交消息基本上说明了我们所做的更改。
|
||||
|
||||
```
|
||||
git commit -m "message" -a
|
||||
[master (root-commit) 57331ee] message
|
||||
2 files changed, 2 insertions(+)
|
||||
create mode 100644 GoT.txt
|
||||
create mode 100644 writing.txt
|
||||
```
|
||||
|
||||
在这种情况下,我有一个名为 GoT(《权力的游戏》的点评)的文件,并且我做了一些更改,所以当我运行命令时,它指定对文件进行更改。 在上面的命令中 `-a` 选项意味着提交仓库中的所有文件。 如果您只更改了一个,则可以指定该文件的名称而不是使用 `-a`。
|
||||
|
||||
举一个例子:
|
||||
|
||||
```
|
||||
git commit -m "message" GoT.txt
|
||||
[master e517b10] message
|
||||
1 file changed, 1 insertion(+)
|
||||
```
|
||||
|
||||
到现在为止,我们一直在本地服务器上工作。现在我们必须将这些更改推送到远程服务器上,以便通过互联网访问,并且可以与其他团队成员进行协作。
|
||||
|
||||
```
|
||||
git remote add origin ssh://git@remote-server/repo-<wbr< a="">>path-on-server..git
|
||||
```
|
||||
|
||||
现在,您可以使用 `pull` 或 `push` 选项在服务器和本地计算机之间推送或拉取:
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
如果有其他团队成员想要使用该项目,则需要将远程服务器上的仓库克隆到其本地计算机上:
|
||||
|
||||
```
|
||||
git clone git@remote-server:/home/swapnil/project.git
|
||||
```
|
||||
|
||||
这里 `/home/swapnil/project.git` 是远程服务器上的项目路径,在你本机上则会改变。
|
||||
|
||||
然后进入本地计算机上的目录(使用服务器上的项目名称):
|
||||
|
||||
```
|
||||
cd /project
|
||||
```
|
||||
|
||||
现在他们可以编辑文件,写入提交更改信息,然后将它们推送到服务器:
|
||||
|
||||
```
|
||||
git commit -m 'corrections in GoT.txt story' -a
|
||||
```
|
||||
|
||||
然后推送改变:
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
我认为这足以让一个新用户开始在他们自己的服务器上使用 Git。 如果您正在寻找一些 GUI 工具来管理本地计算机上的更改,则可以使用 GUI 工具,例如 QGit 或 GitK for Linux。
|
||||
|
||||
|
||||
|
||||
### 使用 GitLab
|
||||
|
||||
这是项目所有者和协作者的纯命令行解决方案。这当然不像使用 GitHub 那么简单。不幸的是,尽管 GitHub 是全球最大的代码托管商,但是它自己的软件别人却无法使用。因为它不是开源的,所以你不能获取源代码并编译你自己的 GitHub。这与 WordPress 或 Drupal 不同,您无法下载 GitHub 并在您自己的服务器上运行它。
|
||||
|
||||
像往常一样,在开源世界中,是没有终结的尽头。GitLab 是一个非常优秀的项目。这是一个开源项目,允许用户在自己的服务器上运行类似于 GitHub 的项目管理系统。
|
||||
|
||||
您可以使用 GitLab 为团队成员或公司运行类似于 GitHub 的服务。您可以使用 GitLab 在公开发布之前开发私有项目。
|
||||
|
||||
GitLab 采用传统的开源商业模式。他们有两种产品:免费的开源软件,用户可以在自己的服务器上安装,以及类似于 GitHub 的托管服务。
|
||||
|
||||
可下载版本有两个版本,免费的社区版和付费企业版。企业版基于社区版,但附带针对企业客户的其他功能。它或多或少与 WordPress.org 或 Wordpress.com 提供的服务类似。
|
||||
|
||||
社区版具有高度可扩展性,可以在单个服务器或群集上支持 25000 个用户。GitLab 的一些功能包括:Git 仓库管理,代码评论,问题跟踪,活动源和维基。它配备了 GitLab CI,用于持续集成和交付。
|
||||
|
||||
Digital Ocean 等许多 VPS 提供商会为用户提供 GitLab 服务。 如果你想在你自己的服务器上运行它,你可以手动安装它。GitLab 为不同的操作系统提供了软件包。 在我们安装 GitLab 之前,您可能需要配置 SMTP 电子邮件服务器,以便 GitLab 可以在需要时随时推送电子邮件。官方推荐使用 Postfix。所以,先在你的服务器上安装 Postfix:
|
||||
|
||||
```
|
||||
sudo apt-get install postfix
|
||||
```
|
||||
|
||||
在安装 Postfix 期间,它会问你一些问题,不要跳过它们。 如果你一不小心跳过,你可以使用这个命令来重新配置它:
|
||||
|
||||
```
|
||||
sudo dpkg-reconfigure postfix
|
||||
```
|
||||
|
||||
运行此命令时,请选择 “Internet Site”并为使用 Gitlab 的域名提供电子邮件 ID。
|
||||
|
||||
我是这样输入的:
|
||||
|
||||
```
|
||||
xxx@x.com
|
||||
```
|
||||
|
||||
用 Tab 键并为 postfix 创建一个用户名。接下来将会要求你输入一个目标邮箱。
|
||||
|
||||
在剩下的步骤中,都选择默认选项。当我们安装且配置完成后,我们继续安装 GitLab。
|
||||
|
||||
我们使用 `wget` 来下载软件包(用 [最新包][7] 替换下载链接):
|
||||
|
||||
```
|
||||
wget https://downloads-packages.s3.amazonaws.com/ubuntu-14.04/gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
```
|
||||
|
||||
然后安装这个包:
|
||||
|
||||
```
|
||||
sudo dpkg -i gitlab_7.9.4-omnibus.1-1_amd64.deb
|
||||
```
|
||||
|
||||
现在是时候配置并启动 GitLab 了。
|
||||
|
||||
```
|
||||
sudo gitlab-ctl reconfigure
|
||||
```
|
||||
|
||||
您现在需要在配置文件中配置域名,以便您可以访问 GitLab。打开文件。
|
||||
|
||||
```
|
||||
nano /etc/gitlab/gitlab.rb
|
||||
```
|
||||
|
||||
在这个文件中编辑 `external_url` 并输入服务器域名。保存文件,然后从 Web 浏览器中打开新建的一个 GitLab 站点。
|
||||
|
||||
|
||||
|
||||
默认情况下,它会以系统管理员的身份创建 `root`,并使用 `5iveL!fe` 作为密码。 登录到 GitLab 站点,然后更改密码。
|
||||
|
||||
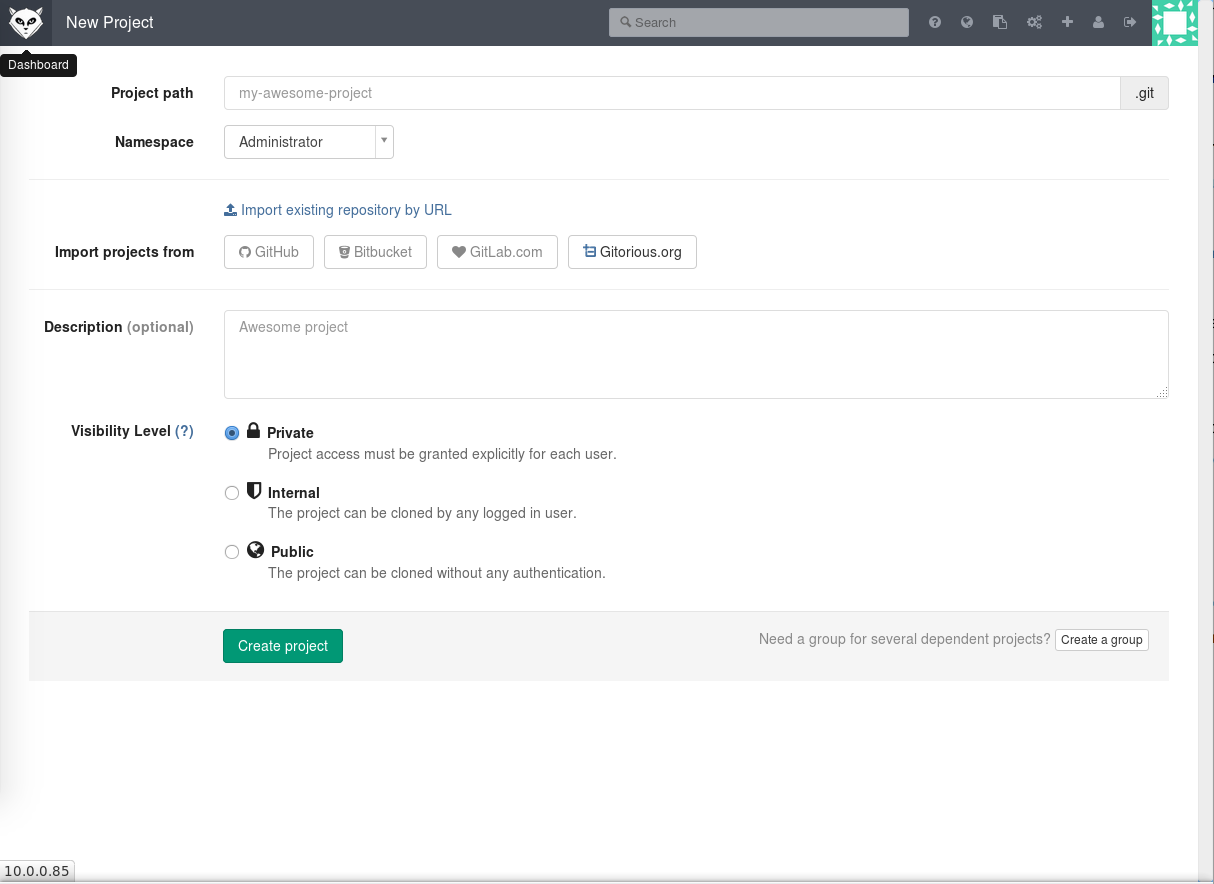
|
||||
|
||||
密码更改后,登录该网站并开始管理您的项目。
|
||||
|
||||

|
||||
|
||||
GitLab 有很多选项和功能。最后,我借用电影“黑客帝国”中的经典台词:“不幸的是,没有人知道 GitLab 可以做什么。你必须亲自尝试一下。”
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/how-run-your-own-git-server
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://github.com/git/git
|
||||
[2]:https://www.linuxfoundation.org/blog/10-years-of-git-an-interview-with-git-creator-linus-torvalds/
|
||||
[3]:https://github.com/about/press
|
||||
[4]:http://google-opensource.blogspot.com/2015/03/farewell-to-google-code.html
|
||||
[5]:https://github.com/pricing
|
||||
[6]:https://about.gitlab.com/
|
||||
[7]:https://about.gitlab.com/downloads/
|
||||
@ -0,0 +1,228 @@
|
||||
你所不了解的 Bash:关于 Bash 数组的介绍
|
||||
======
|
||||
|
||||
> 进入这个古怪而神奇的 Bash 数组的世界。
|
||||
|
||||

|
||||
|
||||
尽管软件工程师常常使用命令行来进行各种开发,但命令行中的数组似乎总是一个模糊的东西(虽然不像正则操作符 `=~` 那么复杂隐晦)。除开隐晦和有疑问的语法,[Bash][1] 数组其实是非常有用的。
|
||||
|
||||
### 稍等,这是为什么?
|
||||
|
||||
写 Bash 相关的东西很难,但如果是写一篇像手册那样注重怪异语法的文章,就会非常简单。不过请放心,这篇文章的目的就是让你不用去读该死的使用手册。
|
||||
|
||||
#### 真实(通常是有用的)示例
|
||||
|
||||
为了这个目的,想象一下真实世界的场景以及 Bash 是怎么帮忙的:你正在公司里面主导一个新工作,评估并优化内部数据管线的运行时间。首先,你要做个参数扫描分析来评估管线使用线程的状况。简单起见,我们把这个管道当作一个编译好的 C++ 黑盒子,这里面我们能够调整的唯一的参数是用于处理数据的线程数量:`./pipeline --threads 4`。
|
||||
|
||||
### 基础
|
||||
|
||||
我们首先要做的事是定义一个数组,用来容纳我们想要测试的 `--threads` 参数:
|
||||
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
```
|
||||
|
||||
本例中,所有元素都是数字,但参数并不一定是数字,Bash 中的数组可以容纳数字和字符串,比如 `myArray=(1 2 "three" 4 "five")` 就是个有效的表达式。就像 Bash 中其它的变量一样,确保赋值符号两边没有空格。否则 Bash 将会把变量名当作程序来执行,把 `=` 当作程序的第一个参数。
|
||||
|
||||
现在我们初始化了数组,让我们解析它其中的一些元素。仅仅输入 `echo $allThreads` ,你能发现,它只会输出第一个元素。
|
||||
|
||||
要理解这个产生的原因,需要回到上一步,回顾我们一般是怎么在 Bash 中输出变量。考虑以下场景:
|
||||
|
||||
```
|
||||
type="article"
|
||||
echo "Found 42 $type"
|
||||
```
|
||||
|
||||
假如我们得到的变量 `$type` 是一个单词,我们想要添加在句子结尾一个 `s`。我们无法直接把 `s` 加到 `$type` 里面,因为这会把它变成另一个变量,`$types`。尽管我们可以利用像 `echo "Found 42 "$type"s"` 这样的代码形变,但解决这个问题的最好方法是用一个花括号:`echo "Found 42 ${type}s"`,这让我们能够告诉 Bash 变量名的起止位置(有趣的是,JavaScript/ES6 在 [template literals][2] 中注入变量和表达式的语法和这里是一样的)
|
||||
|
||||
事实上,尽管 Bash 变量一般不用花括号,但在数组中需要用到花括号。这反而允许我们指定要访问的索引,例如 `echo ${allThreads[1]}` 返回的是数组中的第二个元素。如果不写花括号,比如 `echo $allThreads[1]`,会导致 Bash 把 `[1]` 当作字符串然后输出。
|
||||
|
||||
是的,Bash 数组的语法很怪,但是至少他们是从 0 开始索引的,不像有些语言(说的就是你,`R` 语言)。
|
||||
|
||||
### 遍历数组
|
||||
|
||||
上面的例子中我们直接用整数作为数组的索引,我们现在考虑两种其他情况:第一,如果想要数组中的第 `$i` 个元素,这里 `$i` 是一个代表索引的变量,我们可以这样 `echo ${allThreads[$i]}` 解析这个元素。第二,要输出一个数组的所有元素,我们把数字索引换成 `@` 符号(你可以把 `@` 当作表示 `all` 的符号):`echo ${allThreads[@]}`。
|
||||
|
||||
#### 遍历数组元素
|
||||
|
||||
记住上面讲过的,我们遍历 `$allThreads` 数组,把每个值当作 `--threads` 参数启动管线:
|
||||
|
||||
```
|
||||
for t in ${allThreads[@]}; do
|
||||
./pipeline --threads $t
|
||||
done
|
||||
```
|
||||
|
||||
#### 遍历数组索引
|
||||
|
||||
接下来,考虑一个稍稍不同的方法。不遍历所有的数组元素,我们可以遍历所有的索引:
|
||||
|
||||
```
|
||||
for i in ${!allThreads[@]}; do
|
||||
./pipeline --threads ${allThreads[$i]}
|
||||
done
|
||||
```
|
||||
|
||||
一步一步看:如之前所见,`${allThreads[@]}` 表示数组中的所有元素。前面加了个感叹号,变成 `${!allThreads[@]}`,这会返回数组索引列表(这里是 0 到 7)。换句话说。`for` 循环就遍历所有的索引 `$i` 并从 `$allThreads` 中读取第 `$i` 个元素,当作 `--threads` 选项的参数。
|
||||
|
||||
这看上去很辣眼睛,你可能奇怪为什么我要一开始就讲这个。这是因为有时候在循环中需要同时获得索引和对应的值,例如,如果你想要忽视数组中的第一个元素,使用索引可以避免额外创建在循环中累加的变量。
|
||||
|
||||
### 填充数组
|
||||
|
||||
到目前为止,我们已经能够用给定的 `--threads` 选项启动管线了。现在假设按秒计时的运行时间输出到管线。我们想要捕捉每个迭代的输出,然后把它保存在另一个数组中,因此我们最终可以随心所欲的操作它。
|
||||
|
||||
#### 一些有用的语法
|
||||
|
||||
在深入代码前,我们要多介绍一些语法。首先,我们要能解析 Bash 命令的输出。用这个语法可以做到:`output=$( ./my_script.sh )`,这会把命令的输出存储到变量 `$output` 中。
|
||||
|
||||
我们需要的第二个语法是如何把我们刚刚解析的值添加到数组中。完成这个任务的语法看起来很熟悉:
|
||||
|
||||
```
|
||||
myArray+=( "newElement1" "newElement2" )
|
||||
```
|
||||
|
||||
#### 参数扫描
|
||||
|
||||
万事具备,执行参数扫描的脚步如下:
|
||||
|
||||
```
|
||||
allThreads=(1 2 4 8 16 32 64 128)
|
||||
allRuntimes=()
|
||||
for t in ${allThreads[@]}; do
|
||||
runtime=$(./pipeline --threads $t)
|
||||
allRuntimes+=( $runtime )
|
||||
done
|
||||
```
|
||||
|
||||
就是这个了!
|
||||
|
||||
### 还有什么能做的?
|
||||
|
||||
这篇文章中,我们讲过使用数组进行参数扫描的场景。我敢保证有很多理由要使用 Bash 数组,这里就有两个例子:
|
||||
|
||||
#### 日志警告
|
||||
|
||||
本场景中,把应用分成几个模块,每一个都有它自己的日志文件。我们可以编写一个 cron 任务脚本,当某个模块中出现问题标志时向特定的人发送邮件:
|
||||
|
||||
```
|
||||
# 日志列表,发生问题时应该通知的人
|
||||
logPaths=("api.log" "auth.log" "jenkins.log" "data.log")
|
||||
logEmails=("jay@email" "emma@email" "jon@email" "sophia@email")
|
||||
|
||||
# 在每个日志中查找问题标志
|
||||
for i in ${!logPaths[@]};
|
||||
do
|
||||
log=${logPaths[$i]}
|
||||
stakeholder=${logEmails[$i]}
|
||||
numErrors=$( tail -n 100 "$log" | grep "ERROR" | wc -l )
|
||||
|
||||
# 如果近期发现超过 5 个错误,就警告负责人
|
||||
if [[ "$numErrors" -gt 5 ]];
|
||||
then
|
||||
emailRecipient="$stakeholder"
|
||||
emailSubject="WARNING: ${log} showing unusual levels of errors"
|
||||
emailBody="${numErrors} errors found in log ${log}"
|
||||
echo "$emailBody" | mailx -s "$emailSubject" "$emailRecipient"
|
||||
fi
|
||||
done
|
||||
```
|
||||
|
||||
#### API 查询
|
||||
|
||||
如果你想要生成一些分析数据,分析你的 Medium 帖子中用户评论最多的。由于我们无法直接访问数据库,SQL 不在我们考虑范围,但我们可以用 API!
|
||||
|
||||
为了避免陷入关于 API 授权和令牌的冗长讨论,我们将会使用 [JSONPlaceholder][3],这是一个面向公众的测试服务 API。一旦我们查询每个帖子,解析出每个评论者的邮箱,我们就可以把这些邮箱添加到我们的结果数组里:
|
||||
|
||||
```
|
||||
endpoint="https://jsonplaceholder.typicode.com/comments"
|
||||
allEmails=()
|
||||
|
||||
# 查询前 10 个帖子
|
||||
for postId in {1..10};
|
||||
do
|
||||
# 执行 API 调用,获取该帖子评论者的邮箱
|
||||
response=$(curl "${endpoint}?postId=${postId}")
|
||||
|
||||
# 使用 jq 把 JSON 响应解析成数组
|
||||
allEmails+=( $( jq '.[].email' <<< "$response" ) )
|
||||
done
|
||||
```
|
||||
|
||||
注意这里我是用 [jq 工具][4] 从命令行里解析 JSON 数据。关于 `jq` 的语法超出了本文的范围,但我强烈建议你了解它。
|
||||
|
||||
你可能已经想到,使用 Bash 数组在数不胜数的场景中很有帮助,我希望这篇文章中的示例可以给你思维的启发。如果你从自己的工作中找到其它的例子想要分享出来,请在帖子下方评论。
|
||||
|
||||
### 请等等,还有很多东西!
|
||||
|
||||
由于我们在本文讲了很多数组语法,这里是关于我们讲到内容的总结,包含一些还没讲到的高级技巧:
|
||||
|
||||
| 语法 | 效果 |
|
||||
|:--|:--|
|
||||
| `arr=()` | 创建一个空数组 |
|
||||
| `arr=(1 2 3)` | 初始化数组 |
|
||||
| `${arr[2]}` | 取得第三个元素 |
|
||||
| `${arr[@]}` | 取得所有元素 |
|
||||
| `${!arr[@]}` | 取得数组索引 |
|
||||
| `${#arr[@]}` | 计算数组长度 |
|
||||
| `arr[0]=3` | 覆盖第 1 个元素 |
|
||||
| `arr+=(4)` | 添加值 |
|
||||
| `str=$(ls)` | 把 `ls` 输出保存到字符串 |
|
||||
| `arr=( $(ls) )` | 把 `ls` 输出的文件保存到数组里 |
|
||||
| `${arr[@]:s:n}` | 取得从索引 `s` 开始的 `n` 个元素 |
|
||||
|
||||
### 最后一点思考
|
||||
|
||||
正如我们所见,Bash 数组的语法很奇怪,但我希望这篇文章让你相信它们很有用。只要你理解了这些语法,你会发现以后会经常使用 Bash 数组。
|
||||
|
||||
#### Bash 还是 Python?
|
||||
|
||||
问题来了:什么时候该用 Bash 数组而不是其他的脚本语法,比如 Python?
|
||||
|
||||
对我而言,完全取决于需求——如果你可以只需要调用命令行工具就能立马解决问题,你也可以用 Bash。但有些时候,当你的脚本属于一个更大的 Python 项目时,你也可以用 Python。
|
||||
|
||||
比如,我们可以用 Python 来实现参数扫描,但我们只用编写一个 Bash 的包装:
|
||||
|
||||
```
|
||||
import subprocess
|
||||
|
||||
all_threads = [1, 2, 4, 8, 16, 32, 64, 128]
|
||||
all_runtimes = []
|
||||
|
||||
# 用不同的线程数字启动管线
|
||||
for t in all_threads:
|
||||
cmd = './pipeline --threads {}'.format(t)
|
||||
|
||||
# 使用子线程模块获得返回的输出
|
||||
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)
|
||||
output = p.communicate()[0]
|
||||
all_runtimes.append(output)
|
||||
```
|
||||
|
||||
由于本例中没法避免使用命令行,所以可以优先使用 Bash。
|
||||
|
||||
#### 羞耻的宣传时间
|
||||
|
||||
如果你喜欢这篇文章,这里还有很多类似的文章! [在此注册,加入 OSCON][5],2018 年 7 月 17 号我会在这做一个主题为 [你所不了解的 Bash][6] 的在线编码研讨会。没有幻灯片,不需要门票,只有你和我在命令行里面敲代码,探索 Bash 中的奇妙世界。
|
||||
|
||||
本文章由 [Medium] 首发,再发布时已获得授权。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays
|
||||
|
||||
作者:[Robert Aboukhalil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/robertaboukhalil
|
||||
[1]:https://opensource.com/article/17/7/bash-prompt-tips-and-tricks
|
||||
[2]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals
|
||||
[3]:https://github.com/typicode/jsonplaceholder
|
||||
[4]:https://stedolan.github.io/jq/
|
||||
[5]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
[6]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67166
|
||||
[7]:https://medium.com/@robaboukhalil/the-weird-wondrous-world-of-bash-arrays-a86e5adf2c69
|
||||
@ -0,0 +1,86 @@
|
||||
2018 年 6 月 COPR 中值得尝试的 4 个很酷的新项目
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR 是个人软件仓库[集合][1],它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
|
||||
|
||||
这是 COPR 中一组新的有趣项目。
|
||||
|
||||
### Ghostwriter
|
||||
|
||||
[Ghostwriter][2] 是 [Markdown][3] 格式的文本编辑器,它有一个最小的界面。它以 HTML 格式提供文档预览,并为 Markdown 提供语法高亮显示。它提供了仅高亮显示当前正在编写的段落或句子的选项。此外,Ghostwriter 可以将文档导出为多种格式,包括 PDF 和 HTML。最后,它有所谓的“海明威”模式,其中删除被禁用,迫使用户现在智能编写,而在稍后编辑。
|
||||
|
||||
![][4]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 Ghostwriter。要安装 Ghostwriter,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable scx/ghostwriter
|
||||
sudo dnf install ghostwriter
|
||||
```
|
||||
|
||||
### Lector
|
||||
|
||||
[Lector][5] 是一个简单的电子书阅读器程序。Lector 支持最常见的电子书格式,如 EPUB、MOBI 和 AZW,以及漫画书格式 CBZ 和 CBR。它很容易设置 —— 只需指定包含电子书的目录即可。你可以使用表格或书籍封面浏览 Lector 库内的书籍。Lector 的功能包括书签、用户自定义标签和内置字典。![][6]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 26、27、28 和 Rawhide 提供Lector。要安装 Lector,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable bugzy/lector
|
||||
sudo dnf install lector
|
||||
```
|
||||
|
||||
### Ranger
|
||||
|
||||
Ranerger 是一个基于文本的文件管理器,它带有 Vim 键绑定。它以三列显示目录结构。左边显示父目录,中间显示当前目录的内容,右边显示所选文件或目录的预览。对于文本文件,Ranger 将文件的实际内容作为预览。![][7]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 27、28 和 Rawhide 提供 Ranger。要安装 Ranger,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable fszymanski/ranger
|
||||
sudo dnf install ranger
|
||||
```
|
||||
|
||||
### PrestoPalette
|
||||
|
||||
PrestoPeralette 是一款帮助创建平衡调色板的工具。PrestoPalette 的一个很好的功能是能够使用光照来影响调色板的亮度和饱和度。你可以将创建的调色板导出为 PNG 或 JSON。
|
||||
|
||||
![][8]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 PrestoPalette。要安装 PrestoPalette,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable dagostinelli/prestopalette
|
||||
sudo dnf install prestopalette
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-june-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:http://wereturtle.github.io/ghostwriter/
|
||||
[3]:https://daringfireball.net/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/05/ghostwriter.png
|
||||
[5]:https://github.com/BasioMeusPuga/Lector
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/05/lector.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/05/ranger.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/05/prestopalette.png
|
||||
71
published/201807/20180606 6 Open Source AI Tools to Know.md
Normal file
71
published/201807/20180606 6 Open Source AI Tools to Know.md
Normal file
@ -0,0 +1,71 @@
|
||||
你应该了解的 6 个开源 AI 工具
|
||||
======
|
||||
|
||||
> 让我们来看看几个任何人都能用的自由开源的 AI 工具。
|
||||
|
||||

|
||||
|
||||
在开源领域,不管你的想法是多少的新颖独到,先去看一下别人是否已经做成了这个概念,总是一个很明智的做法。对于有兴趣借助不断成长的<ruby>人工智能<rt>Artificial Intelligence</rt></ruby>(AI)的力量的组织和个人来说,许多优秀的工具不仅是自由开源的,而且在很多的情况下,它们都已经过测试和久经考验的。
|
||||
|
||||
在领先的公司和非盈利组织中,AI 的优先级都非常高,并且这些公司和组织都开源了很有价值的工具。下面的举例是任何人都可以使用的自由开源的 AI 工具。
|
||||
|
||||
### Acumos
|
||||
|
||||
[Acumos AI][1] 是一个平台和开源框架,使用它可以很容易地去构建、共享和分发 AI 应用。它规范了运行一个“开箱即用的”通用 AI 环境所需要的<ruby>基础设施栈<rt>infrastructure stack</rt></ruby>和组件。这使得数据科学家和模型训练者可以专注于它们的核心竞争力,而不用在无止境的定制、建模,以及训练一个 AI 实现上浪费时间。
|
||||
|
||||
Acumos 是 [LF 深度学习基金会][2] 的一部分,它是 Linux 基金会中的一个组织,它支持在人工智能、<ruby>机器学习<rt>machine learning</rt><ruby>、以及<ruby>深度学习<rt>deep learning</rt></ruby>方面的开源创新。它的目标是让这些重大的新技术可用于开发者和数据科学家,包括那些在深度学习和 AI 上经验有限的人。LF 深度学习基金会 [最近批准了一个项目生命周期和贡献流程][3],并且它现在正接受项目贡献的建议。
|
||||
|
||||
### Facebook 的框架
|
||||
|
||||
Facebook [开源了][4] 其中心机器学习系统,它设计用于做一些大规模的人工智能任务,以及一系列其它的 AI 技术。这个工具是经过他们公司验证使用的平台的一部分。Facebook 也开源了一个叫 [Caffe2][5] 的深度学习和人工智能的框架。
|
||||
|
||||
### CaffeOnSpark
|
||||
|
||||
**说到 Caffe**。 Yahoo 也在开源许可证下发布了它自己的关键的 AI 软件。[CaffeOnSpark 工具][6] 是基于深度学习的,它是人工智能的一个分支,在帮助机器识别人类语言,或者照片、视频的内容方面非常有用。同样地,IBM 的机器学习程序 [SystemML][7] 可以通过 Apache 软件基金会自由地共享和修改。
|
||||
|
||||
### Google 的工具
|
||||
|
||||
Google 花费了几年的时间开发了它自己的 [TensorFlow][8] 软件框架,用于去支持它的 AI 软件和其它预测和分析程序。TensorFlow 是你可能都已经在使用的一些 Google 工具背后的引擎,包括 Google Photos 和在 Google app 中使用的语言识别。
|
||||
|
||||
Google 开源了两个 [AIY 套件][9],它可以让个人很容易地使用人工智能,它们专注于计算机视觉和语音助理。这两个套件将用到的所有组件封装到一个盒子中。该套件目前在美国的 Target 中有售,并且它是基于开源的树莓派平台的 —— 有越来越多的证据表明,在开源和 AI 交集中将发生非常多的事情。
|
||||
|
||||
### H2O.ai
|
||||
|
||||
我 [以前介绍过][10] H2O.ai,它在机器学习和人工智能领域中占有一席之地,因为它的主要工具是自由开源的。你可以获取主要的 H2O 平台和 Sparkling Water,它与 Apache Spark 一起工作,只需要去 [下载][11] 它们即可。这些工具遵循 Apache 2.0 许可证,它是一个非常灵活的开源许可证,你甚至可以在 Amazon Web 服务(AWS)和其它的集群上运行它们,而这仅需要几百美元而已。
|
||||
|
||||
### Microsoft 入局
|
||||
|
||||
“我们的目标是让 AI 大众化,让每个人和组织获得更大的成就,“ Microsoft CEO 萨提亚·纳德拉 [说][12]。因此,微软持续迭代它的 [Microsoft Cognitive Toolkit][13](CNTK)。它是一个能够与 TensorFlow 和 Caffe 去竞争的一个开源软件框架。Cognitive Toolkit 可以工作在 64 位的 Windows 和 Linux 平台上。
|
||||
|
||||
Cognitive Toolkit 团队的报告称,“Cognitive Toolkit 通过允许用户去创建、训练,以及评估他们自己的神经网络,以使企业级的、生产系统级的 AI 成为可能,这些神经网络可能跨多个 GPU 以及多个机器在大量的数据集中高效伸缩。”
|
||||
|
||||
---
|
||||
|
||||
从来自 Linux 基金会的新电子书中学习更多的有关 AI 知识。Ibrahim Haddad 的 [开源 AI:项目、洞察和趋势][14] 调查了 16 个流行的开源 AI 项目—— 深入研究了他们的历史、代码库、以及 GitHub 的贡献。 [现在可以免费下载这个电子书][14]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/6-open-source-ai-tools-know
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.acumos.org/
|
||||
[2]:https://www.linuxfoundation.org/projects/deep-learning/
|
||||
[3]:https://www.linuxfoundation.org/blog/lf-deep-learning-foundation-announces-project-contribution-process/
|
||||
[4]:https://code.facebook.com/posts/1687861518126048/facebook-to-open-source-ai-hardware-design/
|
||||
[5]:https://venturebeat.com/2017/04/18/facebook-open-sources-caffe2-a-new-deep-learning-framework/
|
||||
[6]:http://yahoohadoop.tumblr.com/post/139916563586/caffeonspark-open-sourced-for-distributed-deep
|
||||
[7]:https://systemml.apache.org/
|
||||
[8]:https://www.tensorflow.org/
|
||||
[9]:https://www.techradar.com/news/google-assistant-sweetens-raspberry-pi-with-ai-voice-control
|
||||
[10]:https://www.linux.com/news/sparkling-water-bridging-open-source-machine-learning-and-apache-spark
|
||||
[11]:http://www.h2o.ai/download
|
||||
[12]:https://blogs.msdn.microsoft.com/uk_faculty_connection/2017/02/10/microsoft-cognitive-toolkit-cntk/
|
||||
[13]:https://www.microsoft.com/en-us/cognitive-toolkit/
|
||||
[14]:https://www.linuxfoundation.org/publications/open-source-ai-projects-insights-and-trends/
|
||||
226
published/201807/20180606 Getting started with Buildah.md
Normal file
226
published/201807/20180606 Getting started with Buildah.md
Normal file
@ -0,0 +1,226 @@
|
||||
Buildah 入门
|
||||
======
|
||||
|
||||
> Buildah 提供一种灵活、可脚本编程的方式,来使用你熟悉的工具创建精简、高效的容器镜像。
|
||||
|
||||

|
||||
|
||||
[Buildah][1] 是一个命令行工具,可以方便、快捷的构建与<ruby>[开放容器标准][2]<rt>Open Container Initiative</rt></ruby>(OCI)兼容的容器镜像,这意味着其构建的镜像与 Docker 和 Kubernetes 兼容。该工具可作为 Docker 守护进程 `docker build` 命令(即使用传统的 Dockerfile 构建镜像)的一种<ruby>简单<rt>drop-in</rt></ruby>替换,而且更加灵活,允许构建镜像时使用你擅长的工具。Buildah 可以轻松与脚本集成并生成<ruby>流水线<rt>pipeline</rt></ruby>,最好之处在于构建镜像不再需要运行容器守护进程(LCTT 译注:这里主要是指 Docker 守护进程)。
|
||||
|
||||
### docker build 的简单替换
|
||||
|
||||
目前你可能使用 Dockerfile 和 `docker build` 命令构建镜像,那么你可以马上使用 Buildah 进行替代。Buildah 的 `build-using-dockerfile` (或 `bud`)子命令与 `docker build` 基本等价,因此可以轻松的与已有脚本结合或构建流水线。
|
||||
|
||||
类似我的上一篇关于 Buildah 的[文章][3],我也将以使用源码安装 “GNU Hello” 为例进行说明,对应的 Dockerfile 文件如下:
|
||||
|
||||
```
|
||||
FROM fedora:28
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
RUN dnf install -y tar gzip gcc make \
|
||||
&& dnf clean all
|
||||
|
||||
ADD http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz /tmp/hello-2.10.tar.gz
|
||||
|
||||
RUN tar xvzf /tmp/hello-2.10.tar.gz -C /opt
|
||||
|
||||
WORKDIR /opt/hello-2.10
|
||||
|
||||
RUN ./configure
|
||||
RUN make
|
||||
RUN make install
|
||||
RUN hello -v
|
||||
ENTRYPOINT "/usr/local/bin/hello"
|
||||
```
|
||||
|
||||
使用 Buildah 从 Dockerfile 构建镜像也很简单,使用 `buildah bud -t hello .` 替换 `docker build -t hello .` 即可:
|
||||
|
||||
```
|
||||
[chris@krang] $ sudo buildah bud -t hello .
|
||||
STEP 1: FROM fedora:28
|
||||
Getting image source signatures
|
||||
Copying blob sha256:e06fd16225608e5b92ebe226185edb7422c3f581755deadf1312c6b14041fe73
|
||||
81.48 MiB / 81.48 MiB [====================================================] 8s
|
||||
Copying config sha256:30190780b56e33521971b0213810005a69051d720b73154c6e473c1a07ebd609
|
||||
2.29 KiB / 2.29 KiB [======================================================] 0s
|
||||
Writing manifest to image destination
|
||||
Storing signatures
|
||||
STEP 2: LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
STEP 3: RUN dnf install -y tar gzip gcc make && dnf clean all
|
||||
|
||||
<考虑篇幅,略去后续输出>
|
||||
```
|
||||
|
||||
镜像构建完毕后,可以使用 `buildah images` 命令查看这个新镜像:
|
||||
|
||||
```
|
||||
[chris@krang] $ sudo buildah images
|
||||
IMAGE ID IMAGE NAME CREATED AT SIZE
|
||||
30190780b56e docker.io/library/fedora:28 Mar 7, 2018 16:53 247 MB
|
||||
6d54bef73e63 docker.io/library/hello:latest May 3, 2018 15:24 391.8 MB
|
||||
```
|
||||
|
||||
新镜像的标签为 `hello:latest`,我们可以将其推送至远程镜像仓库,可以使用 [CRI-O][4] 或其它 Kubernetes CRI 兼容的运行时来运行该镜像,也可以推送到远程仓库。如果你要测试对 Docker build 命令的替代性,你可以将镜像拷贝至 docker 守护进程的本地镜像存储中,这样 Docker 也可以使用该镜像。使用 `buildah push` 可以很容易的完成推送操作:
|
||||
|
||||
```
|
||||
[chris@krang] $ sudo buildah push hello:latest docker-daemon:hello:latest
|
||||
Getting image source signatures
|
||||
Copying blob sha256:72fcdba8cff9f105a61370d930d7f184702eeea634ac986da0105d8422a17028
|
||||
247.02 MiB / 247.02 MiB [==================================================] 2s
|
||||
Copying blob sha256:e567905cf805891b514af250400cc75db3cb47d61219750e0db047c5308bd916
|
||||
144.75 MiB / 144.75 MiB [==================================================] 1s
|
||||
Copying config sha256:6d54bef73e638f2e2dd8b7bf1c4dfa26e7ed1188f1113ee787893e23151ff3ff
|
||||
1.59 KiB / 1.59 KiB [======================================================] 0s
|
||||
Writing manifest to image destination
|
||||
Storing signatures
|
||||
|
||||
[chris@krang] $ sudo docker images | head -n2
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
docker.io/hello latest 6d54bef73e63 2 minutes ago 398 MB
|
||||
|
||||
[chris@krang] $ sudo docker run -t hello:latest
|
||||
Hello, world!
|
||||
```
|
||||
|
||||
### 若干差异
|
||||
|
||||
与 Docker build 不同,Buildah 不会自动的将 Dockerfile 中的每条指令产生的变更提到新的<ruby>分层<rt>layer</rt></ruby>中,只是简单的每次从头到尾执行构建。类似于<ruby>自动化<rt>automation</rt></ruby>和<ruby>流水线构建<rt>build pipeline</rt></ruby>,这种<ruby>无缓存构建<rt>non-cached</rt></ruby>方式的好处是可以提高构建速度,在指令较多时尤为明显。从<ruby>自动部署<rt>automated deployment</rt></ruby>或<ruby>持续交付<rt>continuous delivery</rt></ruby>的视角来看,使用这种方式可以快速的将新变更落实到生产环境中。
|
||||
|
||||
但从实际角度出发,缓存机制的缺乏对镜像开发不利,毕竟缓存层可以避免一遍遍的执行构建,从而显著的节省时间。自动分层只在 `build-using-dockerfile` 命令中生效。但我们在下面会看到,Buildah 原生命令允许我们选择将变更提交到硬盘的时间,提高了开发的灵活性。
|
||||
|
||||
### Buildah 原生命令
|
||||
|
||||
Buildah _真正_ 有趣之处在于它的原生命令,你可以在容器构建过程中使用这些命令进行交互。相比与使用 `build-using-dockerfile/bud` 命令执行每次构建,Buildah 提供命令让你可以与构建过程中的临时容器进行交互。(Docker 也使用临时或<ruby> _中间_ <rt>intermediate</rt></ruby>容器,但你无法在镜像构建过程中与其交互。)
|
||||
|
||||
还是使用 “GNU Hello” 为例,考虑使用如下 Buildah 命令构建的镜像:
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
|
||||
set -o errexit
|
||||
|
||||
# Create a container
|
||||
container=$(buildah from fedora:28)
|
||||
|
||||
# Labels are part of the "buildah config" command
|
||||
buildah config --label maintainer="Chris Collins <collins.christopher@gmail.com>" $container
|
||||
|
||||
# Grab the source code outside of the container
|
||||
curl -sSL http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz -o hello-2.10.tar.gz
|
||||
|
||||
buildah copy $container hello-2.10.tar.gz /tmp/hello-2.10.tar.gz
|
||||
|
||||
buildah run $container dnf install -y tar gzip gcc make
|
||||
buildah run $container dnf clean all
|
||||
buildah run $container tar xvzf /tmp/hello-2.10.tar.gz -C /opt
|
||||
|
||||
# Workingdir is also a "buildah config" command
|
||||
buildah config --workingdir /opt/hello-2.10 $container
|
||||
|
||||
buildah run $container ./configure
|
||||
buildah run $container make
|
||||
buildah run $container make install
|
||||
buildah run $container hello -v
|
||||
|
||||
# Entrypoint, too, is a “buildah config” command
|
||||
buildah config --entrypoint /usr/local/bin/hello $container
|
||||
|
||||
# Finally saves the running container to an image
|
||||
buildah commit --format docker $container hello:latest
|
||||
```
|
||||
|
||||
我们可以一眼看出这是一个 Bash 脚本而不是 Dockerfile。基于 Buildah 的原生命令,可以轻易的使用任何脚本语言或你擅长的自动化工具编写脚本。形式可以是 makefile、Python 脚本或其它你擅长的类型。
|
||||
|
||||
这个脚本做了哪些工作呢?首先,Buildah 命令 `container=$(buildah from fedora:28)` 基于 fedora:28 镜像创建了一个正在运行的容器,将容器名(`buildah from` 命令的返回值)保存到变量中,便于后续使用。后续所有命令都是有 `$container` 变量指明需要操作的容器。这些命令的功能大多可以从名称看出:`buildah copy` 将文件拷贝至容器,`buildah run` 会在容器中执行命令。可以很容易的将上述命令与 Dockerfile 中的指令对应起来。
|
||||
|
||||
最后一条命令 `buildah commit` 将容器提交到硬盘上的镜像中。当不使用 Dockerfile 而是使用 Buildah 命令构建镜像时,你可以使用 `commit` 命令决定何时保存变更。在上例中,所有的变更是一起提交的;但也可以增加中间提交,让你可以选择作为起点的<ruby>缓存点<rt>cache point</rt></ruby>。(例如,执行完 `dnf install` 命令后将变更缓存到硬盘是特别有意义的,一方面因为该操作耗时较长,另一方面每次执行的结果也确实相同。)
|
||||
|
||||
### 挂载点,安装目录以及 chroot
|
||||
|
||||
另一个可以大大增加构建镜像灵活性的 Buildah 命令是 `buildah mount`,可以将容器的根目录挂载到你主机的一个挂载点上。例如:
|
||||
|
||||
```
|
||||
[chris@krang] $ container=$(sudo buildah from fedora:28)
|
||||
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
|
||||
[chris@krang] $ echo $mountpoint
|
||||
/var/lib/containers/storage/overlay2/463eda71ec74713d8cebbe41ee07da5f6df41c636f65139a7bd17b24a0e845e3/merged
|
||||
[chris@krang] $ cat ${mountpoint}/etc/redhat-release
|
||||
Fedora release 28 (Twenty Eight)
|
||||
[chris@krang] $ ls ${mountpoint}
|
||||
bin dev home lib64 media opt root sbin sys usr
|
||||
boot etc lib lost+found mnt proc run srv tmp var
|
||||
```
|
||||
|
||||
这太棒了,你可以通过与挂载点交互对容器镜像进行修改。这允许你使用主机上的工具进行构建和安装软件,不用将这些构建工具打包到容器镜像本身中。例如,在我们上面的 Bash 脚本中,我们需要安装 tar、Gzip、GCC 和 make,在容器内编译 “GNU Hello”。如果使用挂载点,我仍使用同样的工具进行构建,但下载的压缩包和 tar、Gzip 等 RPM 包都在主机而不是容器和生成的镜像内:
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
|
||||
set -o errexit
|
||||
|
||||
# Create a container
|
||||
container=$(buildah from fedora:28)
|
||||
mountpoint=$(buildah mount $container)
|
||||
|
||||
buildah config --label maintainer="Chris Collins <collins.christopher@gmail.com>" $container
|
||||
|
||||
curl -sSL http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz \
|
||||
-o /tmp/hello-2.10.tar.gz
|
||||
tar xvzf src/hello-2.10.tar.gz -C ${mountpoint}/opt
|
||||
|
||||
pushd ${mountpoint}/opt/hello-2.10
|
||||
./configure
|
||||
make
|
||||
make install DESTDIR=${mountpoint}
|
||||
popd
|
||||
|
||||
chroot $mountpoint bash -c "/usr/local/bin/hello -v"
|
||||
|
||||
buildah config --entrypoint "/usr/local/bin/hello" $container
|
||||
buildah commit --format docker $container hello
|
||||
buildah unmount $container
|
||||
```
|
||||
|
||||
在上述脚本中,需要提到如下几点:
|
||||
|
||||
1. `curl` 命令将压缩包下载到主机中,而不是镜像中;
|
||||
2. (主机中的) `tar` 命令将压缩包中的源代码解压到容器的 `/opt` 目录;
|
||||
3. `configure`,`make` 和 `make install` 命令都在主机的挂载点目录中执行,而不是在容器内;
|
||||
4. 这里的 `chroot` 命令用于将挂载点本身当作根路径并测试 "hello" 是否正常工作;类似于前面例子中用到的 `buildah run` 命令。
|
||||
|
||||
|
||||
这个脚本更加短小,使用大多数 Linux 爱好者都很熟悉的工具,最后生成的镜像也更小(没有 tar 包,没有额外的软件包等)。你甚至可以使用主机系统上的包管理器为容器安装软件。例如,(出于某种原因)你希望安装 GNU Hello 的同时在容器中安装 [NGINX][5]:
|
||||
|
||||
```
|
||||
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
|
||||
[chris@krang] $ sudo dnf install nginx --installroot $mountpoint
|
||||
[chris@krang] $ sudo chroot $mountpoint nginx -v
|
||||
nginx version: nginx/1.12.1
|
||||
```
|
||||
|
||||
在上面的例子中,DNF 使用 `--installroot` 参数将 NGINX 安装到容器中,可以通过 chroot 进行校验。
|
||||
|
||||
### 快来试试吧!
|
||||
|
||||
Buildah 是一种轻量级、灵活的容器镜像构建方法,不需要在主机上运行完整的 Docker 守护进程。除了提供基于 Dockerfile 构建容器的开箱即用支持,Buildah 还可以很容易的与脚本或你喜欢的构建工具相结合,特别是可以使用主机上已有的工具构建容器镜像。Buildah 生成的容器体积更小,更便于网络传输,占用更小的存储空间,而且潜在的受攻击面更小。快来试试吧!
|
||||
|
||||
**[阅读相关的故事,[使用 Buildah 创建小体积的容器][6]]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/getting-started-buildah
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clcollins
|
||||
[1]:https://github.com/projectatomic/buildah
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:http://chris.collins.is/2017/08/17/buildah-a-new-way-to-build-container-images/
|
||||
[4]:http://cri-o.io/
|
||||
[5]:https://www.nginx.com/
|
||||
[6]:https://linux.cn/article-9719-1.html
|
||||
@ -0,0 +1,77 @@
|
||||
GitLab 的付费套餐现在可以免费用于开源项目
|
||||
======
|
||||
|
||||
最近在开源社区发生了很多事情。首先,[微软收购了 GitHub][1],然后人们开始寻找 [GitHub 替代套餐][2],甚至在 Linus Torvalds 发布 [Linux Kernel 4.17][3] 时没有花一点时间考虑它。好吧,如果你一直关注我们,我认为你知道这一切。
|
||||
|
||||
但是,如今,GitLab 做出了一个明智的举措,为教育机构和开源项目免费提供高级套餐。当许多开发人员有兴趣将他们的开源项目迁移到 GitLab 时,没有更好的时机来提供这些了。
|
||||
|
||||
### GitLab 的高级套餐现在对开源项目和教育机构免费
|
||||
|
||||
![GitLab Logo][4]
|
||||
|
||||
在今天(2018/6/7)[发布的博客][5]中,GitLab 宣布其**旗舰**和黄金套餐现在对教育机构和开源项目免费。虽然我们已经知道为什么 GitLab 做出这个举动(一个完美的时机!),但他们还是解释了他们让它免费的动机:
|
||||
|
||||
> 我们让 GitLab 对教育机构免费,因为我们希望学生使用我们最先进的功能。许多大学已经运行了 GitLab。如果学生使用 GitLab 旗舰和黄金套餐的高级功能,他们将把这些高级功能的经验带到他们的工作场所。
|
||||
>
|
||||
> 我们希望有更多的开源项目使用 GitLab。GitLab.com 上的公共项目已经拥有 GitLab 旗舰套餐的所有功能。像 [Gnome][6] 和 [Debian][7] 这样的项目已经在自己的服务器运行开源版 GitLab 。随着今天的宣布,在专有软件上运行的开源项目可以使用 GitLab 提供的所有功能,同时我们通过向非开源组织收费来建立可持续的业务模式。
|
||||
|
||||
### GitLab 提供的这些“免费”套餐是什么?
|
||||
|
||||
![GitLab Pricing][8]
|
||||
|
||||
GitLab 有两类产品。一个是你可以在自己的云托管服务如 [Digital Ocean][9] 上运行的软件。另一个是 Gitlab 软件既服务,其中托管由 GitLab 本身管理,你在 GitLab.com 上获得一个帐户。
|
||||
|
||||
![GitLab Pricing for hosted service][10]
|
||||
|
||||
黄金套餐是托管类别中最高的产品,而旗舰套餐是自托管类别中的最高产品。
|
||||
|
||||
你可以在 GitLab 定价页面上获得有关其功能的更多详细信息。请注意,支持服务不包括在套餐中。你必须单独购买。
|
||||
|
||||
### 你必须符合某些条件才能使用此优惠
|
||||
|
||||
GitLab 还提到 —— 该优惠对谁有效。以下是他们在博客文章中写的内容:
|
||||
|
||||
> 1. **教育机构:**任何为了学习、教育的机构,并且/或者由合格的教育机构、教职人员、学生训练。教育目的不包括商业,专业或任何其他营利目的。
|
||||
>
|
||||
> 2. **开源项目:**任何使用[标准开源许可证][11]且非商业性的项目。它不应该有付费支持或付费贡献者。
|
||||
>
|
||||
|
||||
|
||||
虽然免费套餐不包括支持,但是当你迫切需要专家帮助解决问题时,你仍然可以支付每用户每月 4.95 美元的额外费用 —— 当你特别需要一个专家来解决问题时,这是一个非常合理的价格。
|
||||
|
||||
GitLab 还为学生们添加了一条说明:
|
||||
|
||||
> 为减轻 GitLab 的管理负担,只有教育机构才能代表学生申请。如果你是学生并且你的教育机构不申请,你可以在 GitLab.com 上使用公共项目的所有功能,使用私人项目的免费功能,或者自己付费。
|
||||
|
||||
### 总结
|
||||
|
||||
现在 GitLab 正在加快脚步,你如何看待它?
|
||||
|
||||
你有 [GitHub][12] 上的项目吗?你会切换么?或者,幸运的是,你从一开始就碰巧使用 GitLab?
|
||||
|
||||
请在下面的评论栏告诉我们你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/gitlab-free-open-source/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://itsfoss.com/microsoft-github/
|
||||
[2]:https://itsfoss.com/github-alternatives/
|
||||
[3]:https://itsfoss.com/linux-kernel-4-17/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/GitLab-logo-800x450.png
|
||||
[5]:https://about.gitlab.com/2018/06/05/gitlab-ultimate-and-gold-free-for-education-and-open-source/
|
||||
[6]:https://www.gnome.org/news/2018/05/gnome-moves-to-gitlab-2/
|
||||
[7]:https://salsa.debian.org/public
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-pricing.jpeg
|
||||
[9]:https://m.do.co/c/d58840562553
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/06/gitlab-hosted-service-800x273.jpeg
|
||||
[11]:https://itsfoss.com/open-source-licenses-explained/
|
||||
[12]:https://github.com/
|
||||
@ -1,15 +1,17 @@
|
||||
Mesos 和 Kubernetes:不是竞争者
|
||||
======
|
||||
|
||||
> 人们经常用 x 相对于 y 这样的术语来考虑问题,但是它并不是一个技术对另一个技术的问题。Ben Hindman 在这里解释了 Mesos 是如何对另外一种技术进行补充的。
|
||||
|
||||

|
||||
|
||||
Mesos 的起源可以追溯到 2009 年,当时,Ben Hindman 还是加州大学伯克利分校研究并行编程的博士生。他们在 128 核的芯片上做大规模的并行计算,并尝试去解决多个问题,比如怎么让软件和库在这些芯片上运行更高效。他与同学们讨论能否借鉴并行处理和多线程的思想,并将它们应用到集群管理上。
|
||||
Mesos 的起源可以追溯到 2009 年,当时,Ben Hindman 还是加州大学伯克利分校研究并行编程的博士生。他们在 128 核的芯片上做大规模的并行计算,以尝试去解决多个问题,比如怎么让软件和库在这些芯片上运行更高效。他与同学们讨论能否借鉴并行处理和多线程的思想,并将它们应用到集群管理上。
|
||||
|
||||
Hindman 说 "最初,我们专注于大数据” 。那时,大数据非常热门,并且 Hadoop 是其中一个热门技术。“我们发现,人们在集群上运行像 Hadoop 这样的程序与运行多线程应用和并行应用很相似。Hindman 说。
|
||||
Hindman 说 “最初,我们专注于大数据” 。那时,大数据非常热门,而 Hadoop 就是其中的一个热门技术。“我们发现,人们在集群上运行像 Hadoop 这样的程序与运行多线程应用及并行应用很相似。”Hindman 说。
|
||||
|
||||
但是,它们的效率并不高,因此,他们开始去思考,如何通过集群管理和资源管理让它们运行的更好。”我们查看了那个时间很多的不同技术“ Hindman 回忆道。
|
||||
但是,它们的效率并不高,因此,他们开始去思考,如何通过集群管理和资源管理让它们运行的更好。“我们查看了那个时期很多的各种技术” Hindman 回忆道。
|
||||
|
||||
然而,Hindman 和他的同事们,决定去采用一种全新的方法。”我们决定去对资源管理创建一个低级的抽象,然后在此之上运行调度服务和做其它的事情。“ Hindman 说,“基本上,这就是 Mesos 的本质 —— 将资源管理部分从调度部分中分离出来。”
|
||||
然后,Hindman 和他的同事们决定去采用一种全新的方法。“我们决定对资源管理创建一个低级的抽象,然后在此之上运行调度服务和做其它的事情。” Hindman 说,“基本上,这就是 Mesos 的本质 —— 将资源管理部分从调度部分中分离出来。”
|
||||
|
||||
他成功了,并且 Mesos 从那时开始强大了起来。
|
||||
|
||||
@ -17,21 +19,21 @@ Hindman 说 "最初,我们专注于大数据” 。那时,大数据非常热
|
||||
|
||||
这个项目发起于 2009 年。在 2010 年时,团队决定将这个项目捐献给 Apache 软件基金会(ASF)。它在 Apache 孵化,并于 2013 年成为顶级项目(TLP)。
|
||||
|
||||
为什么 Mesos 社区选择 Apache 软件基金会有很多的原因,比如,Apache 许可证,以及他们已经拥有了一个充满活力的此类项目的许多其它社区。
|
||||
为什么 Mesos 社区选择 Apache 软件基金会有很多的原因,比如,Apache 许可证,以及基金会已经拥有了一个充满活力的其它此类项目的社区。
|
||||
|
||||
与影响力也有关系。许多在 Mesos 上工作的人,也参与了 Apache,并且许多人也致力于像 Hadoop 这样的项目。同时,来自 Mesos 社区的许多人也致力于其它大数据项目,比如 Spark。这种交叉工作使得这三个项目 —— Hadoop、Mesos、以及 Spark —— 成为 ASF 的项目。
|
||||
与影响力也有关系。许多在 Mesos 上工作的人也参与了 Apache,并且许多人也致力于像 Hadoop 这样的项目。同时,来自 Mesos 社区的许多人也致力于其它大数据项目,比如 Spark。这种交叉工作使得这三个项目 —— Hadoop、Mesos,以及 Spark —— 成为 ASF 的项目。
|
||||
|
||||
与商业也有关系。许多公司对 Mesos 很感兴趣,并且开发者希望它能由一个中立的机构来维护它,而不是让它成为一个私有项目。
|
||||
|
||||
### 谁在用 Mesos?
|
||||
|
||||
更好的问题应该是,谁不在用 Mesos?从 Apple 到 Netflix 每个都在用 Mesos。但是,Mesos 也面临任何技术在早期所面对的挑战。”最初,我要说服人们,这是一个很有趣的新技术。它叫做“容器”,因为它不需要使用虚拟机“ Hindman 说。
|
||||
更好的问题应该是,谁不在用 Mesos?从 Apple 到 Netflix 每个都在用 Mesos。但是,Mesos 也面临任何技术在早期所面对的挑战。“最初,我要说服人们,这是一个很有趣的新技术。它叫做‘容器’,因为它不需要使用虚拟机” Hindman 说。
|
||||
|
||||
从那以后,这个行业发生了许多变化,现在,只要与别人聊到基础设施,必然是从”容器“开始的 —— 感谢 Docker 所做出的工作。今天再也不需要说服工作了,而在 Mesos 出现的早期,前面提到的像 Apple、Netflix、以及 PayPal 这样的公司。他们已经知道了容器化替代虚拟机给他们带来的技术优势。”这些公司在容器化成为一种现象之前,已经明白了容器化的价值所在“, Hindman 说。
|
||||
从那以后,这个行业发生了许多变化,现在,只要与别人聊到基础设施,必然是从”容器“开始的 —— 感谢 Docker 所做出的工作。今天再也不需要做说服工作了,而在 Mesos 出现的早期,前面提到的像 Apple、Netflix,以及 PayPal 这样的公司。他们已经知道了容器替代虚拟机给他们带来的技术优势。“这些公司在容器成为一种现象之前,已经明白了容器的价值所在”, Hindman 说。
|
||||
|
||||
可以在这些公司中看到,他们有大量的容器而不是虚拟机。他们所做的全部工作只是去管理和运行这些容器,并且他们欣然接受了 Mesos。在 Mesos 早期就使用它的公司有 Apple、Netflix、PayPal、Yelp、OpenTable、和 Groupon。
|
||||
可以在这些公司中看到,他们有大量的容器而不是虚拟机。他们所做的全部工作只是去管理和运行这些容器,并且他们欣然接受了 Mesos。在 Mesos 早期就使用它的公司有 Apple、Netflix、PayPal、Yelp、OpenTable 和 Groupon。
|
||||
|
||||
“大多数组织使用 Mesos 来运行任意需要的服务” Hindman 说,“但也有些公司用它做一些非常有趣的事情,比如,数据处理、数据流、分析负载和应用程序。“
|
||||
“大多数组织使用 Mesos 来运行各种服务” Hindman 说,“但也有些公司用它做一些非常有趣的事情,比如,数据处理、数据流、分析任务和应用程序。“
|
||||
|
||||
这些公司采用 Mesos 的其中一个原因是,资源管理层之间有一个明晰的界线。当公司运营容器的时候,Mesos 为他们提供了很好的灵活性。
|
||||
|
||||
@ -43,11 +45,11 @@ Hindman 说 "最初,我们专注于大数据” 。那时,大数据非常热
|
||||
|
||||
人们经常用 x 相对于 y 这样的术语来考虑问题,但是它并不是一个技术对另一个技术的问题。大多数的技术在一些领域总是重叠的,并且它们可以是互补的。“我不喜欢将所有的这些东西都看做是竞争者。我认为它们中的一些与另一个在工作中是互补的,” Hindman 说。
|
||||
|
||||
“事实上,名字 Mesos 表示它处于 ‘中间’;它是一种中间的 OS,” Hindman 说,“我们有一个容器调度器的概念,它能够运行在像 Mesos 这样的东西之上。当 Kubernetes 刚出现的时候,我们实际上在 Mesos 的生态系统中接受它的,并将它看做是运行在 Mesos 之上、DC/OS 之中的另一种方式的容器。”
|
||||
“事实上,名字 Mesos 表示它处于 ‘中间’;它是一种中间的操作系统”, Hindman 说,“我们有一个容器调度器的概念,它能够运行在像 Mesos 这样的东西之上。当 Kubernetes 刚出现的时候,我们实际上在 Mesos 的生态系统中接受了它,并将它看做是在 Mesos 上的 DC/OS 中运行容器的另一种方式。”
|
||||
|
||||
Mesos 也复活了一个名为 [Marathon][1](一个用于 Mesos 和 DC/OS 的容器编排器)的项目,它在 Mesos 生态系统中是做的最好的容器编排器。但是,Marathon 确实无法与 Kubernetes 相比较。“Kubernetes 比 Marathon 做的更多,因此,你不能将它们简单地相互交换,” Hindman 说,“与此同时,我们在 Mesos 中做了许多 Kubernetes 中没有的东西。因此,这些技术之间是互补的。”
|
||||
Mesos 也复活了一个名为 [Marathon][1](一个用于 Mesos 和 DC/OS 的容器编排器)的项目,它成为了 Mesos 生态系统中最重要的成员。但是,Marathon 确实无法与 Kubernetes 相比较。“Kubernetes 比 Marathon 做的更多,因此,你不能将它们简单地相互交换,” Hindman 说,“与此同时,我们在 Mesos 中做了许多 Kubernetes 中没有的东西。因此,这些技术之间是互补的。”
|
||||
|
||||
不要将这些技术视为相互之间是敌对的关系,它们应该被看做是对行业有益的技术。它们不是技术上的重复;它们是多样化的。据 Hindman 说,“对于开源领域的终端用户来说,这可能会让他们很困惑,因为他们很难去知道哪个技术适用于哪种负载,但这是被称为开源的这种东西最令人讨厌的本质所在。“
|
||||
不要将这些技术视为相互之间是敌对的关系,它们应该被看做是对行业有益的技术。它们不是技术上的重复;它们是多样化的。据 Hindman 说,“对于开源领域的终端用户来说,这可能会让他们很困惑,因为他们很难去知道哪个技术适用于哪种任务,但这是这个被称之为开源的本质所在。“
|
||||
|
||||
这只是意味着有更多的选择,并且每个都是赢家。
|
||||
|
||||
@ -58,7 +60,7 @@ via: https://www.linux.com/blog/2018/6/mesos-and-kubernetes-its-not-competition
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,59 @@
|
||||
BLUI:创建游戏 UI 的简单方法
|
||||
======
|
||||
|
||||
> 开源游戏开发插件运行虚幻引擎的用户使用基于 Web 的编程方式创建独特的用户界面元素。
|
||||
|
||||

|
||||
|
||||
游戏开发引擎在过去几年中变得越来越易于使用。像 Unity 这样一直免费使用的引擎,以及最近从基于订阅的服务切换到免费服务的<ruby>虚幻引擎<rt>Unreal Engine</rt></ruby>,允许独立开发者使用 AAA 发行商相同达到行业标准的工具。虽然这些引擎都不是开源的,但每个引擎都能够促进其周围的开源生态系统的发展。
|
||||
|
||||
这些引擎中可以包含插件以允许开发人员通过添加特定程序来增强引擎的基本功能。这些程序的范围可以从简单的资源包到更复杂的事物,如人工智能 (AI) 集成。这些插件来自不同的创作者。有些是由引擎开发工作室和有些是个人提供的。后者中的很多是开源插件。
|
||||
|
||||
### 什么是 BLUI?
|
||||
|
||||
作为独立游戏开发工作室的一员,我体验到了在专有游戏引擎上使用开源插件的好处。Aaron Shea 开发的一个开源插件 [BLUI][1] 对我们团队的开发过程起到了重要作用。它允许我们使用基于 Web 的编程(如 HTML/CSS 和 JavaScript)创建用户界面 (UI) 组件。尽管<ruby>虚幻引擎<rt>Unreal Engine</rt></ruby>(我们选择的引擎)有一个实现了类似目的的内置 UI 编辑器,我们也选择使用这个开源插件。我们选择使用开源替代品有三个主要原因:它们的可访问性、易于实现以及伴随的开源程序活跃的、支持性好的在线社区。
|
||||
|
||||
在虚幻引擎的最早版本中,我们在游戏中创建 UI 的唯一方法是通过引擎的原生 UI 集成,使用 Autodesk 的 Scaleform 程序,或通过在虚幻社区中传播的一些选定的基于订阅的虚幻引擎集成。在这些情况下,这些解决方案要么不能为独立开发者提供有竞争力的 UI 解决方案,对于小型团队来说太昂贵,要么只能为大型团队和 AAA 开发者提供。
|
||||
|
||||
在商业产品和虚幻引擎的原生整合失败后,我们向独立社区寻求解决方案。我们在那里发现了 BLUI。它不仅与虚幻引擎无缝集成,而且还保持了一个强大且活跃的社区,经常推出更新并确保独立开发人员可以轻松访问文档。BLUI 使开发人员能够将 HTML 文件导入虚幻引擎,并在程序内部对其进行编程。这使得通过 web 语言创建的 UI 能够集成到游戏的代码、资源和其他元素中,并拥有所有 HTML、CSS、Javascript 和其他网络语言的能力。它还为开源 [Chromium Embedded Framework][2] 提供全面支持。
|
||||
|
||||
### 安装和使用 BLUI
|
||||
|
||||
使用 BLUI 的基本过程包括首先通过 HTML 创建 UI。开发人员可以使用任何工具来实现此目的,包括<ruby>自举<rt>bootstrapped</rt> JavaScript 代码、外部 API 或任何数据库代码。一旦这个 HTML 页面完成,你可以像安装任何虚幻引擎插件那样安装它,并加载或创建一个项目。项目加载后,你可以将 BLUI 函数放在虚幻引擎 UI 图纸中的任何位置,或者通过 C++ 进行硬编码。开发人员可以通过其 HTML 页面调用函数,或使用 BLUI 的内部函数轻松更改变量。
|
||||
|
||||
![Integrating BLUI into Unreal Engine 4 blueprints][4]
|
||||
|
||||
*将 BLUI 集成到虚幻 4 图纸中。*
|
||||
|
||||
在我们当前的项目中,我们使用 BLUI 将 UI 元素与游戏中的音轨同步,为游戏机制的节奏方面提供视觉反馈。将定制引擎编程与 BLUI 插件集成很容易。
|
||||
|
||||
![Using BLUI to sync UI elements with the soundtrack.][6]
|
||||
|
||||
*使用 BLUI 将 UI 元素与音轨同步。*
|
||||
|
||||
通过 BLUI GitHub 页面上的[文档][7],将 BLUI 集成到虚幻 4 中是一个轻松的过程。还有一个由支持虚幻引擎开发人员组成的[论坛][8],他们乐于询问和回答关于插件以及实现该工具时出现的任何问题。
|
||||
|
||||
### 开源优势
|
||||
|
||||
开源插件可以在专有游戏引擎的范围内扩展创意。他们继续降低进入游戏开发的障碍,并且可以产生前所未有的游戏内的机制和资源。随着对专有游戏开发引擎的访问持续增长,开源插件社区将变得更加重要。不断增长的创造力必将超过专有软件,开源代码将会填补这些空白,并促进开发真正独特的游戏。而这种新颖性正是让独立游戏如此美好的原因!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blui-game-development-plugin
|
||||
|
||||
作者:[Uwana lkaiddi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/uwikaiddi
|
||||
[1]:https://github.com/AaronShea/BLUI
|
||||
[2]:https://bitbucket.org/chromiumembedded/cef
|
||||
[3]:/file/400616
|
||||
[4]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-integratingblui.png (Integrating BLUI into Unreal Engine 4 blueprints)
|
||||
[5]:/file/400621
|
||||
[6]:https://opensource.com/sites/default/files/uploads/blui_gaming_plugin-syncui.png (Using BLUI to sync UI elements with the soundtrack.)
|
||||
[7]:https://github.com/AaronShea/BLUI/wiki
|
||||
[8]:https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui
|
||||
@ -0,0 +1,122 @@
|
||||
可代替 Dropbox 的 5 个开源软件
|
||||
=====
|
||||
|
||||
> 寻找一个不会破坏你的安全、自由或银行资产的文件共享应用。
|
||||
|
||||

|
||||
|
||||
Dropbox 在文件共享应用中是个 800 磅的大猩猩。尽管它是个极度流行的工具,但你可能仍想使用一个软件去替代它。
|
||||
|
||||
也行你出于各种好的理由,包括安全和自由,这使你决定用[开源方式][1]。亦或是你已经被数据泄露吓坏了,或者定价计划不能满足你实际需要的存储量。
|
||||
|
||||
幸运的是,有各种各样的开源文件共享应用,可以提供给你更多的存储容量,更好的安全性,并且以低于 Dropbox 很多的价格来让你掌控你自己的数据。有多低呢?如果你有一定的技术和一台 Linux 服务器可供使用,那尝试一下免费的应用吧。
|
||||
|
||||
这里有 5 个最好的可以代替 Dropbox 的开源应用,以及其他一些,你可能想考虑使用。
|
||||
|
||||
### ownCloud
|
||||
|
||||
|
||||
|
||||
[ownCloud][2] 发布于 2010 年,是本文所列应用中最老的,但是不要被这件事蒙蔽:它仍然十分流行(根据该公司统计,有超过 150 万用户),并且由由 1100 个参与者的社区积极维护,定期发布更新。
|
||||
|
||||
它的主要特点——文件共享和文档写作功能和 Dropbox 的功能相似。它们的主要区别(除了它的[开源协议][3])是你的文件可以托管在你的私人 Linux 服务器或云上,给予用户对自己数据完全的控制权。(自托管是本文所列应用的一个普遍的功能。)
|
||||
|
||||
使用 ownCloud,你可以通过 Linux、MacOS 或 Windows 的客户端和安卓、iOS 的移动应用程序来同步和访问文件。你还可以通过带有密码保护的链接分享给其他人来协作或者上传和下载。数据传输通过端到端加密(E2EE)和 SSL 加密来保护安全。你还可以通过使用它的 [市场][4] 中的各种各样的第三方应用来扩展它的功能。当然,它也提供付费的、商业许可的企业版本。
|
||||
|
||||
ownCloud 提供了详尽的[文档][5],包括安装指南和针对用户、管理员、开发者的手册。你可以从 GitHub 仓库中获取它的[源码][6]。
|
||||
|
||||
### NextCloud
|
||||
|
||||
|
||||
|
||||
[NextCloud][7] 在 2016 年从 ownCloud 分裂出来,并且具有很多相同的功能。 NextCloud 以它的高安全性和法规遵从性作为它的一个独特的[推崇的卖点][8]。它具有 HIPAA (医疗) 和 GDPR (隐私)法规遵从功能,并提供广泛的数据策略约束、加密、用户管理和审核功能。它还在传输和存储期间对数据进行加密,并且集成了移动设备管理和身份验证机制 (包括 LDAP/AD、单点登录、双因素身份验证等)。
|
||||
|
||||
像本文列表里的其他应用一样, NextCloud 是自托管的,但是如果你不想在自己的 Linux 上安装 NextCloud 服务器,该公司与几个[提供商][9]达成了伙伴合作,提供安装和托管,并销售服务器、设备和服务支持。在[市场][10]中提供了大量的apps 来扩展它的功能。
|
||||
|
||||
NextCloud 的[文档][11]为用户、管理员和开发者提供了详细的信息,并且它的论坛、IRC 频道和社交媒体提供了基于社区的支持。如果你想贡献或者获取它的源码、报告一个错误、查看它的 AGPLv3 许可,或者想了解更多,请访问它的[GitHub 项目主页][12]。
|
||||
|
||||
### Seafile
|
||||
|
||||
|
||||
|
||||
与 ownCloud 或 NextCloud 相比,[Seafile][13] 或许没有花里胡哨的卖点(app 生态),但是它能完成任务。实质上, 它充当了 Linux 服务器上的虚拟驱动器,以扩展你的桌面存储,并允许你使用密码保护和各种级别的权限(即只读或读写) 有选择地共享文件。
|
||||
|
||||
它的协作功能包括文件夹权限控制,密码保护的下载链接和像 Git 一样的版本控制和记录。文件使用双因素身份验证、文件加密和 AD/LDAP 集成进行保护,并且可以从 Windows、MacOS、Linux、iOS 或 Android 设备进行访问。
|
||||
|
||||
更多详细信息, 请访问 Seafile 的 [GitHub 仓库][14]、[服务手册][15]、[wiki][16] 和[论坛][17]。请注意, Seafile 的社区版在 [GPLv2][18] 下获得许可,但其专业版不是开源的。
|
||||
|
||||
### OnionShare
|
||||
|
||||
|
||||
|
||||
[OnionShare][19] 是一个很酷的应用:如果你想匿名,它允许你安全地共享单个文件或文件夹。不需要设置或维护服务器,所有你需要做的就是[下载和安装][20],无论是在 MacOS, Windows 还是 Linux 上。文件始终在你自己的计算机上; 当你共享文件时,OnionShare 创建一个 web 服务器,使其可作为 Tor 洋葱服务访问,并生成一个不可猜测的 .onion URL,这个 URL 允许收件人通过 [Tor 浏览器][21]获取文件。
|
||||
|
||||
你可以设置文件共享的限制,例如限制可以下载的次数或使用自动停止计时器,这会设置一个严格的过期日期/时间,超过这个期限便不可访问(即使尚未访问该文件)。
|
||||
|
||||
OnionShare 在 [GPLv3][22] 之下被许可;有关详细信息,请查阅其 [GitHub 仓库][22],其中还包括[文档][23],介绍了这个易用的文件共享软件的特点。
|
||||
|
||||
### Pydio Cells
|
||||
|
||||
|
||||
|
||||
[Pydio Cells][24] 在 2018 年 5 月推出了稳定版,是对 Pydio 共享应用程序的核心服务器代码的彻底大修。由于 Pydio 的基于 PHP 的后端的限制,开发人员决定用 Go 服务器语言和微服务体系结构重写后端。(前端仍然是基于 PHP 的)。
|
||||
|
||||
Pydio Cells 包括通常的共享和版本控制功能,以及应用程序中的消息接受、移动应用程序(Android 和 iOS),以及一种社交网络风格的协作方法。安全性包括基于 OpenID 连接的身份验证、rest 加密、安全策略等。企业发行版中包含着高级功能,但在社区(家庭)版本中,对于大多数中小型企业和家庭用户来说,依然是足够的。
|
||||
|
||||
您可以 在 Linux 和 MacOS 里[下载][25] Pydio Cells。有关详细信息, 请查阅 [文档常见问题][26]、[源码库][27] 和 [AGPLv3 许可证][28]
|
||||
|
||||
### 其他
|
||||
|
||||
如果以上选择不能满足你的需求,你可能想考虑其他开源的文件共享型应用。
|
||||
|
||||
* 如果你的主要目的是在设备间同步文件而不是分享文件,考察一下 [Syncthing][29]。
|
||||
* 如果你是一个 Git 的粉丝而不需要一个移动应用。你可能更喜欢 [SparkleShare][30]。
|
||||
* 如果你主要想要一个地方聚合所有你的个人数据, 看看 [Cozy][31]。
|
||||
* 如果你想找一个轻量级的或者专注于文件共享的工具,考察一下 [Scott Nesbitt's review][32]——一个罕为人知的工具。
|
||||
|
||||
哪个是你最喜欢的开源文件共享应用?在评论中让我们知悉。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/alternatives/dropbox
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[distant1219](https://github.com/distant1219)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://opensource.com/open-source-way
|
||||
[2]:https://owncloud.org/
|
||||
[3]:https://www.gnu.org/licenses/agpl-3.0.html
|
||||
[4]:https://marketplace.owncloud.com/
|
||||
[5]:https://doc.owncloud.com/
|
||||
[6]:https://github.com/owncloud
|
||||
[7]:https://nextcloud.com/
|
||||
[8]:https://nextcloud.com/secure/
|
||||
[9]:https://nextcloud.com/providers/
|
||||
[10]:https://apps.nextcloud.com/
|
||||
[11]:https://nextcloud.com/support/
|
||||
[12]:https://github.com/nextcloud
|
||||
[13]:https://www.seafile.com/en/home/
|
||||
[14]:https://github.com/haiwen/seafile
|
||||
[15]:https://manual.seafile.com/
|
||||
[16]:https://seacloud.cc/group/3/wiki/
|
||||
[17]:https://forum.seafile.com/
|
||||
[18]:https://github.com/haiwen/seafile/blob/master/LICENSE.txt
|
||||
[19]:https://onionshare.org/
|
||||
[20]:https://onionshare.org/#downloads
|
||||
[21]:https://www.torproject.org/
|
||||
[22]:https://github.com/micahflee/onionshare/blob/develop/LICENSE
|
||||
[23]:https://github.com/micahflee/onionshare/wiki
|
||||
[24]:https://pydio.com/en
|
||||
[25]:https://pydio.com/download/
|
||||
[26]:https://pydio.com/en/docs/faq
|
||||
[27]:https://github.com/pydio/cells
|
||||
[28]:https://github.com/pydio/pydio-core/blob/develop/LICENSE
|
||||
[29]:https://syncthing.net/
|
||||
[30]:http://www.sparkleshare.org/
|
||||
[31]:https://cozy.io/en/
|
||||
[32]:https://opensource.com/article/17/3/file-sharing-tools
|
||||
@ -1,33 +1,35 @@
|
||||
使用 Open edX 托管课程入门
|
||||
使用 Open edX 托管课程
|
||||
======
|
||||
|
||||
> Open edX 为各种规模和类型的组织提供了一个强大而多功能的开源课程管理的解决方案。要不要了解一下。
|
||||
|
||||

|
||||
|
||||
[Open edX 平台][2] 是一个免费和开源的课程管理系统,它是 [全世界][3] 都在使用的大规模网络公开课(MOOCs)以及小型课程和培训模块的托管平台。在 Open edX 的 [第七个主要发行版][1] 中,到现在为止,它已经提供了超过 8,000 个原创课程和 5000 万个课程注册数。你可以使用你自己的本地设备或者任何行业领先的云基础设施服务提供商来安装这个平台,但是,随着项目的[服务提供商][4]名单越来越长,来自它们中的软件即服务(SaaS)的可用模型也越来越多了。
|
||||
[Open edX 平台][2] 是一个自由开源的课程管理系统,它是 [全世界][3] 都在使用的大规模网络公开课(MOOC)以及小型课程和培训模块的托管平台。在 Open edX 的 [第七个主要发行版][1] 中,到现在为止,它已经提供了超过 8,000 个原创课程和 5000 万个课程注册数。你可以使用你自己的本地设备或者任何行业领先的云基础设施服务提供商来安装这个平台,而且,随着项目的[服务提供商][4]名单越来越长,来自它们中的软件即服务(SaaS)的可用模型也越来越多了。
|
||||
|
||||
Open edX 平台被来自世界各地的顶尖教育机构、私人公司、公共机构、非政府组织、非营利机构、以及教育技术初创企业广泛地使用,并且项目服务提供商的全球社区持续让越来越小的组织可以访问这个平台。如果你打算向广大的读者设计和提供教育内容,你应该考虑去使用 Open edX 平台。
|
||||
Open edX 平台被来自世界各地的顶尖教育机构、私人公司、公共机构、非政府组织、非营利机构,以及教育技术初创企业广泛地使用,并且该项目的服务提供商全球社区不断地让甚至更小的组织也可以访问这个平台。如果你打算向广大的读者设计和提供教育内容,你应该考虑去使用 Open edX 平台。
|
||||
|
||||
### 安装
|
||||
|
||||
安装这个软件有多种方式,这可能是不一个不受欢迎的惊喜,至少刚开始是这样。但是不管你是以何种方式 [安装 Open edX][5],最终你都得到的是有相同功能的应用程序。默认安装包含一个为在线学习者提供的、全功能的学习管理系统(LMS),和一个全功能的课程管理工作室(CMS),CMS 可以让你的讲师团队用它来编写原创课程内容。你可以把 CMS 当做是课程内容设计和管理的 “[Wordpress][6]”,把 LMS 当做是课程销售、分发、和消费的 “[Magento][7]”。
|
||||
安装这个软件有多种方式,这可能有点让你难以选择,至少刚开始是这样。但是不管你是以何种方式 [安装 Open edX][5],最终你都得到的是有相同功能的应用程序。默认安装包含一个为在线学习者提供的、全功能的学习管理系统(LMS),和一个全功能的课程管理工作室(CMS),CMS 可以让你的讲师团队用它来编写原创课程内容。你可以把 CMS 当做是课程内容设计和管理的 “[Wordpress][6]”,把 LMS 当做是课程销售、分发、和消费的 “[Magento][7]”。
|
||||
|
||||
Open edX 是设备无关的和完全响应式的应用软件,并且不用花费很多的努力就可发布一个原生的 iOS 和 Android apps,它可以无缝地集成到你的实例后端。Open edX 平台的代码库、原生移动应用、以及安装脚本都发布在 [GitHub][8] 上。
|
||||
Open edX 是设备无关的、完全响应式的应用软件,并且不用花费很多的努力就可发布一个原生的 iOS 和 Android 应用,它可以无缝地集成到你的实例后端。Open edX 平台的代码库、原生移动应用、以及安装脚本都发布在 [GitHub][8] 上。
|
||||
|
||||
#### 有何期望
|
||||
|
||||
Open edX 平台的 [GitHub 仓库][9] 包含适用于各种类型组织的、性能很好的、产品级的代码。来自数百个机构的数千名程序员定期为 edX 仓库做贡献,并且这个平台是一个名副其实的,研究如何去构建和管理一个复杂的企业级应用的好案例。因此,尽管你可能会遇到大量的类似如何将平台迁移到生产环境中的问题,但是你不应该对 Open edX 平台代码库本身的质量和健状性担忧。
|
||||
Open edX 平台的 [GitHub 仓库][9] 包含适用于各种类型的组织的、性能很好的、产品级的代码。来自数百个机构的数千名程序员经常为 edX 仓库做贡献,并且这个平台是一个名副其实的、研究如何去构建和管理一个复杂的企业级应用的好案例。因此,尽管你可能会遇到大量的类似“如何将平台迁移到生产环境中”的问题,但是你无需对 Open edX 平台代码库本身的质量和健状性担忧。
|
||||
|
||||
通过少量的培训,你的讲师就可以去设计很好的在线课程。但是请记住,Open edX 是通过它的 [XBlock][10] 组件架构可扩展的,因此,通过他们和你的努力,你的讲师将有可能将好的课程变成精品课程。
|
||||
通过少量的培训,你的讲师就可以去设计不错的在线课程。但是请记住,Open edX 是通过它的 [XBlock][10] 组件架构进行扩展的,因此,通过他们和你的努力,你的讲师将有可能将不错的课程变成精品课程。
|
||||
|
||||
这个平台在单服务器环境下也运行的很好,并且它是高度模块化的,几乎可以进行无限地水平扩展。它也是主题化的和本地化的,平台的功能和外观可以根据你的需要进行几乎无限制地调整。平台在你的设备上可以按需安装并可靠地运行。
|
||||
|
||||
#### 一些封装要求
|
||||
#### 需要一些封装
|
||||
|
||||
请记住,有大量的 edX 软件模块是不包含在默认安装中的,并且这些模块提供的经常都是组织所需要的功能。比如,分析模块、电商模块、以及课程的通知/公告模块都是不包含在默认安装中的,并且这些单独的模块都是值得安装的。另外,在数据备份/恢复和系统管理方面要完全依赖你自己去处理。幸运的是,有关这方面的内容,社区有越来越多的文档和如何去做的文章。你可以通过 Google 和 Bing 去搜索,以帮助你在生产环境中安装它们。
|
||||
请记住,有大量的 edX 软件模块是不包含在默认安装中的,并且这些模块提供的经常都是各种组织所需要的功能。比如,分析模块、电商模块,以及课程的通知/公告模块都是不包含在默认安装中的,并且这些单独的模块都是值得安装的。另外,在数据备份/恢复和系统管理方面要完全依赖你自己去处理。幸运的是,有关这方面的内容,社区有越来越多的文档和如何去做的文章。你可以通过 Google 和 Bing 去搜索,以帮助你在生产环境中安装它们。
|
||||
|
||||
虽然有很多文档良好的程序,但是根据你的技能水平,配置 [oAuth][11] 和 [SSL/TLS][12],以及使用平台的 [REST API][13] 可能对你是一个挑战。另外,一些组织要求将 MySQL 和/或 MongoDB 数据库在中心化环境中管理,如果你正好是这种情况,你还需要将这些服务从默认平台安装中分离出来。edX 设计团队已经尽可能地为你做了简化,但是由于它是一个非常重大的更改,因此可能需要一些时间去实现。
|
||||
|
||||
如果你面临资源和/或技术上的困难 —— 不要气馁,Open edX 社区 SaaS 提供商,像 [appsembler][14] 和 [eduNEXT][15],提供了引人入胜的替代方案去进行 DIY 安装,尤其是如果你只适应窗口方式操作。
|
||||
如果你面临资源和/或技术上的困难 —— 不要气馁,Open edX 社区 SaaS 提供商,像 [appsembler][14] 和 [eduNEXT][15],提供了引人入胜的替代方案去进行 DIY 安装,尤其是如果你只想简单购买就行。
|
||||
|
||||
### 技术栈
|
||||
|
||||
@ -35,7 +37,7 @@ Open edX 平台的 [GitHub 仓库][9] 包含适用于各种类型组织的、性
|
||||
|
||||
![edx-architecture.png][24]
|
||||
|
||||
Open edX 技术栈(CC BY,来自 edX)
|
||||
*Open edX 技术栈(CC BY,来自 edX)*
|
||||
|
||||
将这些组件安装并配置好本身就是一件非常不容易的事情,但是以这样的一种方式将所有的组件去打包,并适合于任意规模和复杂性的组织,并且能够按他们的需要进行任意调整搭配而无需在代码上做重大改动,看起来似乎是不可能的事情 —— 它就是这种情况,直到你看到主要的平台配置参数安排和命名是多少的巧妙和直观。请注意,平台的组织结构有一个学习曲线,但是,你所学习的一切都是值的去学习的,不仅是对这个项目,对一般意义上的大型 IT 项目都是如此。
|
||||
|
||||
@ -43,7 +45,7 @@ Open edX 技术栈(CC BY,来自 edX)
|
||||
|
||||
### 采用
|
||||
|
||||
edX 项目能够迅速得到世界范围内的采纳,很大程度上取决于软件的运行情况。这一点也不奇怪,这个项目成功地吸引了大量才华卓越的人参与其中,他们作为程序员、项目顾问、翻译者、技术作者、以及博客作者参与了项目的贡献。一年一次的 [Open edX 会议][27]、[官方的 edX Google Group][28]、以及 [Open edX 服务提供商名单][4] 是了解这个多样化的、不断成长的生态系统的非常好的起点。我作为相对而言的新人,我发现参与和直接从事这个项目的各个方面是非常容易的。
|
||||
edX 项目能够迅速得到世界范围内的采纳,很大程度上取决于该软件的运行情况。这一点也不奇怪,这个项目成功地吸引了大量才华卓越的人参与其中,他们作为程序员、项目顾问、翻译者、技术作者、以及博客作者参与了项目的贡献。一年一次的 [Open edX 会议][27]、[官方的 edX Google Group][28]、以及 [Open edX 服务提供商名单][4] 是了解这个多样化的、不断成长的生态系统的非常好的起点。我作为相对而言的新人,我发现参与和直接从事这个项目的各个方面是非常容易的。
|
||||
|
||||
祝你学习之旅一切顺利,并且当你构思你的项目时,你可以随时联系我。
|
||||
|
||||
@ -54,7 +56,7 @@ via: https://opensource.com/article/18/6/getting-started-open-edx
|
||||
作者:[Lawrence Mc Daniel][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,160 @@
|
||||
如何在 Linux 上检查用户所属组
|
||||
======
|
||||
|
||||
将用户添加到现有组是 Linux 管理员的常规活动之一。这是一些在大环境中工作的管理员的日常活动。
|
||||
|
||||
甚至我会因为业务需求而在我的环境中每天都在进行这样的活动。它是帮助你识别环境中现有组的重要命令之一。
|
||||
|
||||
此外,这些命令还可以帮助你识别用户所属的组。所有用户都列在 `/etc/passwd` 中,组列在 `/etc/group` 中。
|
||||
|
||||
无论我们使用什么命令,都将从这些文件中获取信息。此外,每个命令都有其独特的功能,可帮助用户单独获取所需的信息。
|
||||
|
||||
### 什么是 /etc/passwd?
|
||||
|
||||
`/etc/passwd` 是一个文本文件,其中包含登录 Linux 系统所必需的每个用户信息。它维护有用的用户信息,如用户名、密码、用户 ID、组 ID、用户 ID 信息、家目录和 shell。passwd 每行包含了用户的详细信息,共有如上所述的 7 个字段。
|
||||
|
||||
```
|
||||
$ grep "daygeek" /etc/passwd
|
||||
daygeek:x:1000:1000:daygeek,,,:/home/daygeek:/bin/bash
|
||||
```
|
||||
|
||||
### 什么是 /etc/group?
|
||||
|
||||
`/etc/group` 是一个文本文件,用于定义用户所属的组。我们可以将多个用户添加到单个组中。它允许用户访问其他用户文件和文件夹,因为 Linux 权限分为三类:用户、组和其他。它维护有关组的有用信息,例如组名、组密码,组 ID(GID)和成员列表。每个都在一个单独的行。组文件每行包含了每个组的详细信息,共有 4 个如上所述字段。
|
||||
|
||||
这可以通过使用以下方法来执行。
|
||||
|
||||
* `groups`: 显示一个组的所有成员。
|
||||
* `id`: 打印指定用户名的用户和组信息。
|
||||
* `lid`: 显示用户的组或组的用户。
|
||||
* `getent`: 从 Name Service Switch 库中获取条目。
|
||||
* `grep`: 代表“<ruby>全局正则表达式打印<rt>global regular expression print</rt></ruby>”,它能打印匹配的模式。
|
||||
|
||||
### 什么是 groups 命令?
|
||||
|
||||
`groups` 命令打印每个给定用户名的主要组和任何补充组的名称。
|
||||
|
||||
```
|
||||
$ groups daygeek
|
||||
daygeek : daygeek adm cdrom sudo dip plugdev lpadmin sambashare
|
||||
```
|
||||
|
||||
如果要检查与当前用户关联的组列表。只需运行 `groups` 命令,无需带任何用户名。
|
||||
|
||||
```
|
||||
$ groups
|
||||
daygeek adm cdrom sudo dip plugdev lpadmin sambashare
|
||||
```
|
||||
|
||||
### 什么是 id 命令?
|
||||
|
||||
id 代表 “<ruby>身份<rt>identity</rt></ruby>”。它打印真实有效的用户和组 ID。打印指定用户或当前用户的用户和组信息。
|
||||
|
||||
```
|
||||
$ id daygeek
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
```
|
||||
|
||||
如果要检查与当前用户关联的组列表。只运行 `id` 命令,无需带任何用户名。
|
||||
|
||||
```
|
||||
$ id
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
```
|
||||
|
||||
### 什么是 lid 命令?
|
||||
|
||||
它显示用户的组或组的用户。显示有关包含用户名的组或组名称中包含的用户的信息。此命令需要管理员权限。
|
||||
|
||||
```
|
||||
$ sudo lid daygeek
|
||||
adm(gid=4)
|
||||
cdrom(gid=24)
|
||||
sudo(gid=27)
|
||||
dip(gid=30)
|
||||
plugdev(gid=46)
|
||||
lpadmin(gid=108)
|
||||
daygeek(gid=1000)
|
||||
sambashare(gid=124)
|
||||
```
|
||||
|
||||
### 什么是 getent 命令?
|
||||
|
||||
`getent` 命令显示 Name Service Switch 库支持的数据库中的条目,它们在 `/etc/nsswitch.conf` 中配置。
|
||||
|
||||
```
|
||||
$ getent group | grep daygeek
|
||||
adm:x:4:syslog,daygeek
|
||||
cdrom:x:24:daygeek
|
||||
sudo:x:27:daygeek
|
||||
dip:x:30:daygeek
|
||||
plugdev:x:46:daygeek
|
||||
lpadmin:x:118:daygeek
|
||||
daygeek:x:1000:
|
||||
sambashare:x:128:daygeek
|
||||
```
|
||||
|
||||
如果你只想打印关联的组名称,请在上面的命令中使用 `awk`。
|
||||
|
||||
```
|
||||
$ getent group | grep daygeek | awk -F: '{print $1}'
|
||||
adm
|
||||
cdrom
|
||||
sudo
|
||||
dip
|
||||
plugdev
|
||||
lpadmin
|
||||
daygeek
|
||||
sambashare
|
||||
```
|
||||
|
||||
运行以下命令仅打印主群组信息。
|
||||
|
||||
```
|
||||
$ getent group daygeek
|
||||
daygeek:x:1000:
|
||||
|
||||
```
|
||||
|
||||
### 什么是 grep 命令?
|
||||
|
||||
`grep` 代表 “<ruby>全局正则表达式打印<rt>global regular expression print</rt></ruby>”,它能打印文件匹配的模式。
|
||||
|
||||
```
|
||||
$ grep "daygeek" /etc/group
|
||||
adm:x:4:syslog,daygeek
|
||||
cdrom:x:24:daygeek
|
||||
sudo:x:27:daygeek
|
||||
dip:x:30:daygeek
|
||||
plugdev:x:46:daygeek
|
||||
lpadmin:x:118:daygeek
|
||||
daygeek:x:1000:
|
||||
sambashare:x:128:daygeek
|
||||
```
|
||||
|
||||
如果你只想打印关联的组名称,请在上面的命令中使用 `awk`。
|
||||
|
||||
```
|
||||
$ grep "daygeek" /etc/group | awk -F: '{print $1}'
|
||||
adm
|
||||
cdrom
|
||||
sudo
|
||||
dip
|
||||
plugdev
|
||||
lpadmin
|
||||
daygeek
|
||||
sambashare
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
@ -0,0 +1,120 @@
|
||||
如何在 Linux 中使用一个命令升级所有软件
|
||||
======
|
||||
|
||||

|
||||
|
||||
众所周知,让我们的 Linux 系统保持最新状态会用到多种包管理器。比如说,在 Ubuntu 中,你无法使用 `sudo apt update` 和 `sudo apt upgrade` 命令升级所有软件。此命令仅升级使用 APT 包管理器安装的应用程序。你有可能使用 `cargo`、[pip][1]、`npm`、`snap` 、`flatpak` 或 [Linuxbrew][2] 包管理器安装了其他软件。你需要使用相应的包管理器才能使它们全部更新。
|
||||
|
||||
再也不用这样了!跟 `topgrade` 打个招呼,这是一个可以一次性升级系统中所有软件的工具。
|
||||
|
||||
你无需运行每个包管理器来更新包。这个 `topgrade` 工具通过检测已安装的软件包、工具、插件并运行相应的软件包管理器来更新 Linux 中的所有软件,用一条命令解决了这个问题。它是自由而开源的,使用 **rust 语言**编写。它支持 GNU/Linux 和 Mac OS X.
|
||||
|
||||
### 在 Linux 中使用一个命令升级所有软件
|
||||
|
||||
`topgrade` 存在于 AUR 中。因此,你可以在任何基于 Arch 的系统中使用 [Yay][3] 助手程序安装它。
|
||||
|
||||
```
|
||||
$ yay -S topgrade
|
||||
```
|
||||
|
||||
在其他 Linux 发行版上,你可以使用 `cargo` 包管理器安装 `topgrade`。要安装 cargo 包管理器,请参阅以下链接:
|
||||
|
||||
- [在 Linux 安装 rust 语言][12]
|
||||
|
||||
然后,运行以下命令来安装 `topgrade`。
|
||||
|
||||
```
|
||||
$ cargo install topgrade
|
||||
```
|
||||
|
||||
安装完成后,运行 `topgrade` 以升级 Linux 系统中的所有软件。
|
||||
|
||||
```
|
||||
$ topgrade
|
||||
```
|
||||
|
||||
一旦调用了 `topgrade`,它将逐个执行以下任务。如有必要,系统会要求输入 root/sudo 用户密码。
|
||||
|
||||
1、 运行系统的包管理器:
|
||||
|
||||
* Arch:运行 `yay` 或者回退到 [pacman][4]
|
||||
* CentOS/RHEL:运行 `yum upgrade`
|
||||
* Fedora :运行 `dnf upgrade`
|
||||
* Debian/Ubuntu:运行 `apt update` 和 `apt dist-upgrade`
|
||||
* Linux/macOS:运行 `brew update` 和 `brew upgrade`
|
||||
|
||||
2、 检查 Git 是否跟踪了以下路径。如果有,则拉取它们:
|
||||
|
||||
* `~/.emacs.d` (无论你使用 Spacemacs 还是自定义配置都应该可用)
|
||||
* `~/.zshrc`
|
||||
* `~/.oh-my-zsh`
|
||||
* `~/.tmux`
|
||||
* `~/.config/fish/config.fish`
|
||||
* 自定义路径
|
||||
|
||||
3、 Unix:运行 `zplug` 更新
|
||||
|
||||
4、 Unix:使用 TPM 升级 `tmux` 插件
|
||||
|
||||
5、 运行 `cargo install-update`
|
||||
|
||||
6、 升级 Emacs 包
|
||||
|
||||
7、 升级 Vim 包。对以下插件框架均可用:
|
||||
|
||||
* NeoBundle
|
||||
* [Vundle][5]
|
||||
* Plug
|
||||
|
||||
8、 升级 [npm][6] 全局安装的包
|
||||
|
||||
9、 升级 Atom 包
|
||||
|
||||
10、 升级 [Flatpak][7] 包
|
||||
|
||||
11、 升级 [snap][8] 包
|
||||
|
||||
12、 Linux:运行 `fwupdmgr` 显示固件升级。 (仅查看。实际不会执行升级)
|
||||
|
||||
13、 运行自定义命令。
|
||||
|
||||
最后,`topgrade` 将运行 `needrestart` 以重新启动所有服务。在 Mac OS X 中,它会升级 App Store 程序。
|
||||
|
||||
我的 Ubuntu 18.04 LTS 测试环境的示例输出:
|
||||
|
||||
![][10]
|
||||
|
||||
好处是如果一个任务失败,它将自动运行下一个任务并完成所有其他后续任务。最后,它将显示摘要,其中包含运行的任务数量,成功的数量和失败的数量等详细信息。
|
||||
|
||||
![][11]
|
||||
|
||||
**建议阅读:**
|
||||
|
||||
就个人而言,我喜欢创建一个像 `topgrade` 程序的想法,并使用一个命令升级使用各种包管理器安装的所有软件。我希望你也觉得它有用。还有更多的好东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-upgrade-everything-using-a-single-command-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[5]:https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
[6]:https://www.ostechnix.com/manage-nodejs-packages-using-npm/
|
||||
[7]:https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
[8]:https://www.ostechnix.com/install-snap-packages-arch-linux-fedora/
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/06/topgrade-2.png
|
||||
[12]:https://www.ostechnix.com/install-rust-programming-language-in-linux/
|
||||
@ -3,45 +3,46 @@
|
||||
|
||||

|
||||
|
||||
Pipenv 的目标是将最好的打包世界(bundler、composer、npm、cargo、yarn 等)带到 Python 世界。它试图解决一些问题,并简化整个管理过程。
|
||||
Pipenv 的目标是将打包界(bundler、composer、npm、cargo、yarn 等)最好的东西带到 Python 世界来。它试图解决一些问题,并简化整个管理过程。
|
||||
|
||||
目前,Python 程序依赖项的管理有时似乎是一个挑战。开发人员通常为每个新项目创建一个[虚拟环境][1],并使用 [pip][2] 将依赖项安装到其中。此外,他们必须将已安装的软件包集保存到 requirements.txt 文件中。我们看到过许多旨在自动化此工作流程的工具和包装程序。但是,仍然需要结合多个程序,并且 requirements.txt 格式本身并不适用于更复杂的场景。
|
||||
目前,Python 程序依赖项的管理有时似乎是一个挑战。开发人员通常为每个新项目创建一个[虚拟环境][1],并使用 [pip][2] 将依赖项安装到其中。此外,他们必须将已安装的软件包的集合保存到 `requirements.txt` 文件中。我们看到过许多旨在自动化此工作流程的工具和包装程序。但是,仍然需要结合多个程序,并且 `requirements.txt` 格式本身并不适用于更复杂的场景。
|
||||
|
||||
### 一个统治它们的工具
|
||||
|
||||
Pipenv 正确地管理复杂的相互依赖关系,它还提供已安装包的手动记录。例如,开发、测试和生产环境通常需要一组不同的包。过去,每个项目需要维护多个 requirements.txt。Pipenv 使用 [TOML][4] 语法引入了新的 [Pipfile][3] 格式。多亏这种格式,你终于可以在单个文件中维护不同环境的多组需求。
|
||||
Pipenv 可以正确地管理复杂的相互依赖关系,它还提供已安装包的手动记录。例如,开发、测试和生产环境通常需要一组不同的包。过去,每个项目需要维护多个 `requirements.txt`。Pipenv 使用 [TOML][4] 语法引入了新的 [Pipfile][3] 格式。多亏这种格式,你终于可以在单个文件中维护不同环境的多组需求。
|
||||
|
||||
在将第一行代码提交到项目中仅一年后,Pipenv 已成为管理 Python 程序依赖关系的官方推荐工具。现在它终于在 Fedora 仓库中提供。
|
||||
|
||||
### 在 Fedora 上安装 Pipenv
|
||||
|
||||
在全新安装 Fedora 28 及更高版本后,你只需在终端上运行此命令即可安装 Pipenv:
|
||||
|
||||
```
|
||||
$ sudo dnf install pipenv
|
||||
|
||||
```
|
||||
|
||||
现在,你的系统已准备好在 Pipenv 的帮助下开始使用新的 Python 3 程序。
|
||||
|
||||
重要的是,虽然这个工具为程序提供了很好的解决方案,但它并不是为处理库需求而设计的。编写 Python 库时,不需要固定依赖项。你应该在 setup.py 文件中指定 install_requires。
|
||||
重要的是,虽然这个工具为程序提供了很好的解决方案,但它并不是为处理库需求而设计的。编写 Python 库时,不需要固定依赖项。你应该在 `setup.py` 文件中指定 `install_requires`。
|
||||
|
||||
### 基本依赖管理
|
||||
|
||||
首先为项目创建一个目录:
|
||||
|
||||
```
|
||||
$ mkdir new-project && cd new-project
|
||||
|
||||
```
|
||||
|
||||
接下来是为此项目创建虚拟环境:
|
||||
|
||||
```
|
||||
$ pipenv --three
|
||||
|
||||
```
|
||||
|
||||
这里的 -three 选项将虚拟环境的 Python 版本设置为 Python 3。
|
||||
这里的 `-three` 选项将虚拟环境的 Python 版本设置为 Python 3。
|
||||
|
||||
安装依赖项:
|
||||
|
||||
```
|
||||
$ pipenv install requests
|
||||
Installing requests…
|
||||
@ -49,31 +50,29 @@ Adding requests to Pipfile's [packages]…
|
||||
Pipfile.lock not found, creating…
|
||||
Locking [dev-packages] dependencies…
|
||||
Locking [packages] dependencies…
|
||||
|
||||
```
|
||||
|
||||
最后生成 lockfile:
|
||||
|
||||
```
|
||||
$ pipenv lock
|
||||
Locking [dev-packages] dependencies…
|
||||
Locking [packages] dependencies…
|
||||
Updated Pipfile.lock (b14837)
|
||||
|
||||
```
|
||||
|
||||
你还可以检查依赖关系图:
|
||||
|
||||
```
|
||||
$ pipenv graph
|
||||
- certifi [required: >=2017.4.17, installed: 2018.4.16]
|
||||
- certifi [required: >=2017.4.17, installed: 2018.4.16]
|
||||
- chardet [required: <3.1.0,>=3.0.2, installed: 3.0.4]
|
||||
- idna [required: <2.8,>=2.5, installed: 2.7]
|
||||
- urllib3 [required: >=1.21.1,<1.24, installed: 1.23]
|
||||
|
||||
```
|
||||
|
||||
有关 Pipenv 及其命令的更多详细信息,请参见[文档][5]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/install-pipenv-fedora/
|
||||
@ -81,7 +80,7 @@ via: https://fedoramagazine.org/install-pipenv-fedora/
|
||||
作者:[Michal Cyprian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
TrueOS 不再想要成为“桌面 BSD”了
|
||||
============================================================
|
||||
|
||||
|
||||
[TrueOS][9] 很快会有一些非常重大的变化。今天,我们将了解桌面 BSD 领域将会发生什么。
|
||||
|
||||
### 通告
|
||||
|
||||

|
||||
|
||||
[TrueOS][10] 背后的团队[宣布][11],他们将改变项目的重点。到目前为止,TrueOS 使用开箱即用的图形用户界面来轻松安装 BSD。然而,它现在将成为“一个先进的操作系统,保留你所知道和喜欢的 ZFS([OpenZFS][12])和 [FreeBSD][13]的所有稳定性,并添加额外的功能来创造一个全新的、创新的操作系统。我们的目标是创建一个核心操作系统,该系统具有模块化、实用性,非常适合自己动手和高级用户。“
|
||||
|
||||
从本质上讲,TrueOs 将成为 FreeBSD 的下游分支。他们将集成更新一些的软件到系统中,例如 [OpenRC][14] 和 [LibreSSL][15]。他们希望能坚持 6 个月的发布周期。
|
||||
|
||||
其目标是使 TrueOS 成为可以作为其他项目构建的基础。缺少图形部分以使其更加地与发行版无关。
|
||||
|
||||
### 桌面用户如何?
|
||||
|
||||
如果你读过我的[TrueOS 评论][17]并且有兴趣尝试使用桌面 BSD 或已经使用 TrueOS,请不要担心(这对于生活来说也是一个很好的建议)。TrueOS 的所有桌面元素都将剥离到 [Project Trident][18]。目前,Project Trident 网站的细节不多。他们仿佛还在进行剥离的幕后工作。
|
||||
|
||||
如果你目前拥有 TrueOS,则无需担心迁移。TrueOS 团队表示,“对于那些希望迁移到其他基于 FreeBSD 的发行版,如 Project Trident 或 [GhostBSD][19] 的人而言将会有迁移方式。”
|
||||
|
||||
### 想法
|
||||
|
||||
当我第一次阅读该公告时,坦率地说有点担心。改变名字可能是一个坏主意。客户将习惯使用一个名称,但如果产品名称发生变化,他们可能很容易失去对项目的跟踪。TrueOS 经历过名称更改。该项目于 2006 年启动时,它被命名为 PC-BSD,但在 2016 年,名称更改为 TrueOS。它让我想起了[ArchMerge 和 Arcolinux 传奇][21]。
|
||||
|
||||
话虽这么说,我认为这对 BSD 的桌面用户来说是一件好事。我常听见对 PC-BSD 和 TrueOS 的一个批评是它不是很精致。剥离项目的两个部分将有助于提高相关开发人员的关注度。TrueOS 团队将能够为缓慢进展的 FreeBSD 添加更新的功能,Project Trident 团队将能够改善用户的桌面体验。
|
||||
|
||||
我希望两个团队都好。请记住,当有人为开源而努力时,即使是我们不会使用的部分,我们也都会受益。
|
||||
|
||||
你对 TrueOS 和 Project Trident 的未来有何看法?请在下面的评论中告诉我们。
|
||||
|
||||
|
||||
------------------------------
|
||||
|
||||
关于作者:
|
||||
|
||||
我叫 John Paul Wohlscheid。我是一个有抱负的神秘作家,喜欢玩技术,尤其是 Linux。你可以在[我的个人网站][23]关注我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/trueos-plan-change/
|
||||
|
||||
作者:[John Paul Wohlscheid][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/john/
|
||||
[1]:https://itsfoss.com/author/john/
|
||||
[2]:https://itsfoss.com/trueos-plan-change/#comments
|
||||
[3]:https://itsfoss.com/category/bsd/
|
||||
[4]:https://itsfoss.com/category/news/
|
||||
[5]:https://itsfoss.com/tag/bsd/
|
||||
[6]:https://itsfoss.com/tag/freebsd/
|
||||
[7]:https://itsfoss.com/tag/project-trident/
|
||||
[8]:https://itsfoss.com/tag/trueos/
|
||||
[9]:https://www.trueos.org/
|
||||
[10]:https://www.trueos.org/
|
||||
[11]:https://www.trueos.org/blog/trueosdownstream/
|
||||
[12]:http://open-zfs.org/wiki/Main_Page
|
||||
[13]:https://www.freebsd.org/
|
||||
[14]:https://en.wikipedia.org/wiki/OpenRC
|
||||
[15]:http://www.libressl.org/
|
||||
[16]:https://itsfoss.com/midnightbsd-founder-lucas-holt/
|
||||
[17]:https://itsfoss.com/trueos-bsd-review/
|
||||
[18]:http://www.project-trident.org/
|
||||
[19]:https://www.ghostbsd.org/
|
||||
[20]:https://itsfoss.com/interview-freedos-jim-hall/
|
||||
[21]:https://itsfoss.com/archlabs-vs-archmerge/
|
||||
[22]:http://reddit.com/r/linuxusersgroup
|
||||
[23]:http://johnpaulwohlscheid.work/
|
||||
@ -0,0 +1,100 @@
|
||||
区块链进化简史:为什么开源是其核心所在
|
||||
======
|
||||
|
||||
> 从比特币到下一代区块链。
|
||||
|
||||

|
||||
|
||||
当开源项目开发下一个新版本时,用后缀 “-ng” 表示 “下一代”的情况并不鲜见。幸运的是,到目前为止,快速演进的区块链成功地避开了这个命名陷阱。但是在这个开源生态系统的演进过程中,改变是不断发生的,而好的创意以典型的开源方式在许多不同的项目中被采用、交融和演进。
|
||||
|
||||
在本文中,我将审视不同代次的区块链,并且看一看在处理这个生态系统遇到的问题时出现什么创意。当然,任何对生态系统进行分类的尝试都有其局限性的 —— 和不同意见者的 —— 但是这也将为混乱的区块链项目提供了一个粗略的指南。
|
||||
|
||||
### 始作俑者:比特币
|
||||
|
||||
第一代的区块链起源于 <ruby>[比特币][1]<rt>Bitcoin</rt></ruby> 区块链,这是以去中心化、点对点加密货币为基础的<ruby>总帐<rt>ledger</rt></ruby>,它从 [Slashdot][2] 网站上的杂谈变成了一个主流话题。
|
||||
|
||||
这个区块链是一个分布式总帐,它对所有用户的<ruby>交易<rt>transaction</rt></ruby>保持跟踪,以避免他们<ruby>双重支付<rt>double-spending</rt></ruby>(双花)货币(在历史上,这个任务是委托给第三方—— 银行 ——来做的)。为防范攻击者在系统上捣乱,总帐被复制到每个参与到比特币网络的计算机上,并且每次只允许一台计算机去更新总帐。为决定哪台计算机能够获得更新总帐的权力,系统安排在比特币网络上的计算机之间每 10 分钟进行一场竞赛,这将消耗它们的(许多)能源才能参与竞赛。赢家将获得将前 10 分钟发生的交易写入到总帐(区块链中的“区块”)的权力,并且为赢家写入区块链的工作给予一些比特币奖励。这种方式被称为<ruby>工作量证明<rt>proof of work</rt></ruby>(PoW)共识机制。
|
||||
|
||||
这就是区块链最有趣的地方。比特币以[开源项目][3]的方式发布于 2009 年 1 月 。在 2010 年,由于意识到这些元素中的许多是可以调整的,围绕比特币聚集起了一个社区 —— [bitcointalk 论坛][4],来开始各种实验。
|
||||
|
||||
起初,看到的比特币区块链是一个分布式数据库的形式, [Namecoin][5] 项目出现后,建议去保存任意数据到它的事务数据库中。如果区块链能够记录金钱的转移,那么它也应该能够记录其它资产的转移,比如域名。这正是 Namecoin 的主要使用场景,它上线于 2011 年 4 月 —— 也就是比特币出现两年后。
|
||||
|
||||
Namecoin 调整的地方是区块链的内容,<ruby>[莱特币][6]<rt>Litecoin</rt></ruby> 调整的是两个技术部分:一是将两个区块的时间间隔从 10 分钟减少到 2.5 分钟,二是改变了竞赛方式(用 [scrypt][7] 来替换了 SHA-256 安全哈希算法)。这是能够做到的,因为比特币是以开源软件的方式来发布的,而莱特币本质上与比特币在其它部分是完全相同的。莱特币是修改了比特币共识机制的第一个分叉,这也为其它的更多“币”铺平了道路。
|
||||
|
||||
沿着这条道路,基于比特币代码库的各种变种越来越多。其中一些扩展了比特币的用途,比如 [Zerocash][8] 协议,它专注于提供交易的匿名性和可替换性,但它最终分拆为它自己的货币 —— [Zcash][9]。
|
||||
|
||||
虽然 Zcash 带来了它自己的创新,使用了最近被称为“<ruby>零知识证明<rt>zero-knowledge proof</rt></ruby>”的加密技术,但它维持着与大多数主要的比特币代码库的兼容性,这意味着它能够从上游的比特币创新中获益。
|
||||
|
||||
另外的项目 —— [CryptoNote][10],它萌芽于相同的社区,但是并没有使用相同的代码,它以比特币为背景来构建的,但又与之不同。它发布于 2012 年 12 月,由于它的出现,导致了几种加密货币的诞生,最著名的 <ruby>[门罗币][11]<rt>Monero</rt></ruby> (2014)就是其中之一。门罗币与 Zcash 使用了不同的方法,但解决了相同的问题:隐私性和可替换性。
|
||||
|
||||
就像在开源世界中经常出现的案例一样,做同样的工作有不止一个的工具可用。
|
||||
|
||||
### 下一代:“Blockchain-ng”
|
||||
|
||||
但是,到目前为止,所有的这些变体只是改进加密货币或者扩展它们去支持其它类型的事务。因此,这就引出了第二代区块链。
|
||||
|
||||
一旦社区开始去修改区块链的用法和调整技术部分时,对于一些想去扩展和重新思考它们未来的人来说,这种调整花费不了多长时间的。比特币的长期追随者 —— [Vitalik Buterin][12] 在 2013 年底建议,区域链的事务应该能够表示一个状态机的状态变化,将区域链视为能够运行应用程序(“<ruby>智能合约<rt>smart contract</rt></ruby>”)的分布式计算机。这个项目 —— <ruby>[以太坊][13]<rt>Ethereum</rt></ruby>,上线于 2015 年 4 月。它在运行分布式应用程序方面取得了巨大的成功,它的一些非常流行的分布式应用程序(<ruby>[加密猫][14]<rt>CryptoKitties</rt></ruby>)甚至导致以太坊区块链变慢。
|
||||
|
||||
这证明了目前的区块链存在一个很大的局限性:速度和容量。(速度通常用每秒事务数来测量,简称 TPS)有几个提议都建议去解决这个速度问题,从<ruby>分片<rt>sharding</rt></ruby>到<ruby>侧链<rt>sidechain</rt></ruby>,以及一个被称为“<ruby>第二层<rt>second-layer</rt></ruby>”的解决方案。这里需要更多的创新。
|
||||
|
||||
随着“智能合约”这个词开始流行起来,并且用已经被证实仍然很慢的技术去运行它们,那么就需要实现其它的思路:<ruby>许可区块链<rt>Permissioned blockchain</rt></ruby>。到目前为止,我们所介绍的所有区块链网络有两个没有明说的特征:一是它们是公开的(任何人都可以看到它们的功能),二是它们不需要许可(任何人都可以加入它们)。这两个部分是运行一个分布式的、非基于第三方的货币应该具有的和必需具有的条件。
|
||||
|
||||
随着区块链被认为出现与加密货币越来越明显的分离趋势,开始去考虑一些隐私、许可场景是很有意义的。一个有业务关系但不需要彼此完全信任的财团类型的参与者,能够从这些区块链类型中获益 —— 比如,物流链上的参与者,定期进行双边结算或者使用一个清算中心的金融、保险、或医疗保健机构。
|
||||
|
||||
一旦你将设置从“任何人都可以加入”变为“仅邀请者方可加入”,进一步对区块链构建区块的方式进行改变和调整将变得可能,那么对一些人来说,结果将变得非常有趣。
|
||||
|
||||
首先,设计用来保护网络不受恶意或者垃圾参与者的影响的工作量证明(PoW)可以被替换为更简单的和更少资源消耗的一些东西,比如,基于 [Raft][15] 的共识协议。在更高级别的安全性和更快的速度之间进行权衡,采用更简单的共识算法。对于更多群体来说这样更理想,因为他们可以用基于加密技术的担保来取代其它的基于法律关系的担保,例如为避免由于竞争而产生的大量能源消耗,而工作量证明就是这种情况。另外一个创新的地方是,使用 <ruby>[股权证明][16]<rt>Proof of Stake</rt></ruby>(PoS),它是公共网络共识机制的一个重量级的竞争者。它将可能像许可链网络一样找到它自己的实现方式。
|
||||
|
||||
有几个项目可以让创建许可区块链变得更简单,包括 [Quorum][17] (以太坊的一个分叉)和 [Hyperledger][18] 的 [Fabric][19] 和 [Sawtooth][20],这是基于新代码的两个开源项目。
|
||||
|
||||
许可区块链可以避免公共的、非许可方式的区块链中某些错综复杂的问题,但是它自己也存在一些问题。正确地管理参与者是其中的一个问题:谁可以加入?如何辨别他们?如何将他们从网络上移除?网络上的一个实体是否去管理一个中央公共密钥基础设施(PKI)?
|
||||
|
||||
### 区块链的开放本质
|
||||
|
||||
到目前为止的所有案例中,有一件事情是很明确的:使用一个区块链的目标是去提升网络中的参与者和它产生的数据的信任水平,理想情况下,不需要做进一步的工作即可足以使用它。
|
||||
|
||||
只有为这个网络提供动力的软件是自由和开源的,才能达到这种信任水平。即便是一个正确的、专用的、分布式区块链,它的本质仍然是运行着相同的第三方代码的私有代理的集合。从本质上来说,区块链的源代码必须是开源的,但仅是开源还不够。随着生态系统持续成长,这既是最低限度的担保也是进一步创新的源头。
|
||||
|
||||
最后,值得一提的是,虽然区块链的开放本质被认为是创新和变化的源头,它也被认为是一种治理形式:代码治理,用户期望运行的任何一个特定版本,都应该包含他们认为的整个网络应该包含的功能和方法。在这方面,需要说明的一点是,一些区块链的开放本质正在“变味”。但是这一问题正在解决。
|
||||
|
||||
### 第三和第四代:治理
|
||||
|
||||
接下来,我正在考虑第三代和第四代区块链:区块链将内置治理工具,并且项目将去解决棘手的大量不同区块链之间互连互通的问题,以便于它们之间可以交换信息和价值。
|
||||
|
||||
---
|
||||
关于作者
|
||||
|
||||
axel simon: 长期的自由及开源软件爱好者,就职于 Red Hat ,关注安全和区块链技术,以及分布式系统和协议。致力于保护互联网及其成就(知识分享、信息访问、去中心化和网络中立)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/blockchain-guide-next-generation
|
||||
|
||||
作者:[Axel Simon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/axel
|
||||
[1]:https://bitcoin.org
|
||||
[2]:https://slashdot.org/
|
||||
[3]:https://github.com/bitcoin/bitcoin
|
||||
[4]:https://bitcointalk.org/
|
||||
[5]:https://www.namecoin.org/
|
||||
[6]:https://litecoin.org/
|
||||
[7]:https://en.wikipedia.org/wiki/Scrypt
|
||||
[8]:http://zerocash-project.org/index
|
||||
[9]:https://z.cash
|
||||
[10]:https://cryptonote.org/
|
||||
[11]:https://en.wikipedia.org/wiki/Monero_(cryptocurrency)
|
||||
[12]:https://en.wikipedia.org/wiki/Vitalik_Buterin
|
||||
[13]:https://ethereum.org
|
||||
[14]:http://cryptokitties.co/
|
||||
[15]:https://en.wikipedia.org/wiki/Raft_(computer_science)
|
||||
[16]:https://www.investopedia.com/terms/p/proof-stake-pos.asp
|
||||
[17]:https://www.jpmorgan.com/global/Quorum
|
||||
[18]:https://hyperledger.org/
|
||||
[19]:https://www.hyperledger.org/projects/fabric
|
||||
[20]:https://www.hyperledger.org/projects/sawtooth
|
||||
43
published/201807/20180702 My first sysadmin mistake.md
Normal file
43
published/201807/20180702 My first sysadmin mistake.md
Normal file
@ -0,0 +1,43 @@
|
||||
我的第一个系统管理员错误
|
||||
======
|
||||
|
||||
> 如何在崩溃的局面中集中精力寻找解决方案。
|
||||
|
||||

|
||||
|
||||
如果你在 IT 领域工作,你知道事情永远不会像你想象的那样完好。在某些时候,你会遇到错误或出现问题,你最终必须解决问题。这就是系统管理员的工作。
|
||||
|
||||
作为人类,我们都会犯错误。我们不是已经犯错,就是即将犯错。结果,我们最终还必须解决自己的错误。总是这样。我们都会失误、敲错字母或犯错。
|
||||
|
||||
作为一名年轻的系统管理员,我艰难地学到了这一课。我犯了一个大错。但是多亏了上级的指导,我学会了不去纠缠于我的错误,而是制定一个“错误策略”来做正确的事情。从错误中吸取教训。克服它,继续前进。
|
||||
|
||||
我的第一份工作是一家小公司的 Unix 系统管理员。真的,我是一名生嫩的系统管理员,但我大部分时间都独自工作。我们是一个小型 IT 团队,只有我们三个人。我是 20 或 30 台 Unix 工作站和服务器的唯一系统管理员。另外两个支持 Windows 服务器和桌面。
|
||||
|
||||
任何阅读这篇文章的系统管理员都不会对此感到意外,作为一个不成熟的初级系统管理员,我最终在错误的目录中运行了 `rm` 命令——作为 root 用户。我以为我正在为我们的某个程序删除一些陈旧的缓存文件。相反,我错误地清除了 `/etc` 目录中的所有文件。糟糕。
|
||||
|
||||
我意识到犯了错误是看到了一条错误消息,“`rm` 无法删除某些子目录”。但缓存目录应该只包含文件!我立即停止了 `rm` 命令,看看我做了什么。然后我惊慌失措。一下子,无数个想法涌入了我的脑中。我刚刚销毁了一台重要的服务器吗?系统会怎么样?我会被解雇吗?
|
||||
|
||||
幸运的是,我运行的是 `rm *` 而不是 `rm -rf *`,因此我只删除了文件。子目录仍在那里。但这并没有让我感觉更好。
|
||||
|
||||
我立刻去找我的主管告诉她我做了什么。她看到我对自己的错误感到愚蠢,但这是我犯的。尽管紧迫,她花了几分钟时间跟我做了一些指导。她说:“你不是第一个这样做的人,在你这种情况下,别人会怎么做?”这帮助我平静下来并专注。我开始更少考虑我刚刚做的愚蠢事情,而更多地考虑我接下来要做的事情。
|
||||
|
||||
我做了一个简单的策略:不要重启服务器。使用相同的系统作为模板,并重建 `/etc` 目录。
|
||||
|
||||
制定了行动计划后,剩下的就很容易了。只需运行正确的命令即可从另一台服务器复制 `/etc` 文件并编辑配置,使其与系统匹配。多亏了我对所有东西都做记录的习惯,我使用已有的文档进行最后的调整。我避免了完全恢复服务器,这意味着一个巨大的宕机事件。
|
||||
|
||||
可以肯定的是,我从这个错误中吸取了教训。在接下来作为系统管理员的日子中,我总是在运行任何命令之前确认我所在的目录。
|
||||
|
||||
我还学习了构建“错误策略”的价值。当事情出错时,恐慌并思考接下来可能发生的所有坏事是很自然的。这是人性。但是制定一个“错误策略”可以帮助我不再担心出了什么问题,而是专注于让事情变得更好。我仍然会想一下,但是知道我接下来的步骤可以让我“克服它”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/my-first-sysadmin-mistake
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
@ -0,0 +1,147 @@
|
||||
如何在绝大部分类型的机器上安装 NVIDIA 显卡驱动
|
||||
======
|
||||
|
||||

|
||||
|
||||
无论是研究还是娱乐,安装一个最新的显卡驱动都能提升你的计算机性能,并且使你能全方位地实现新功能。本安装指南使用 Fedora 28 的新的第三方仓库来安装 NVIDIA 驱动。它将引导您完成硬件和软件两方面的安装,并且涵盖需要让你的 NVIDIA 显卡启动和运行起来的一切知识。这个流程适用于任何支持 UEFI 的计算机和任意新的 NVIDIA 显卡。
|
||||
|
||||
### 准备
|
||||
|
||||
本指南依赖于下面这些材料:
|
||||
|
||||
* 一台使用 [UEFI][1] 的计算机,如果你不确定你的电脑是否有这种固件,请运行 `sudo dmidecode -t 0`。如果输出中出现了 “UEFI is supported”,你的安装过程就可以继续了。不然的话,虽然可以在技术上更新某些电脑来支持 UEFI,但是这个过程的要求很苛刻,我们通常不建议你这么使用。
|
||||
* 一个现代的、支持 UEFI 的 NVIDIA 的显卡
|
||||
* 一个满足你的 NVIDIA 显卡的功率和接线要求的电源(有关详细信息,请参考“硬件和修改”的章节)
|
||||
* 网络连接
|
||||
* Fedora 28 系统
|
||||
|
||||
### 安装实例
|
||||
|
||||
这个安装示例使用的是:
|
||||
|
||||
* 一台 Optiplex 9010 的主机(一台相当老的机器)
|
||||
* [NVIDIA GeForce GTX 1050 Ti XLR8 游戏超频版 4 GB GDDR5 PCI Express 3.0 显卡][2]
|
||||
* 为了满足新显卡的电源要求,电源升级为 [EVGA – 80 PLUS 600 W ATX 12V/EPS 12V][3],这个最新的电源(PSU)比推荐的最低要求高了 300 W,但在大部分情况下,满足推荐的最低要求就足够了。
|
||||
* 然后,当然的,Fedora 28 也别忘了.
|
||||
|
||||
### 硬件和修改
|
||||
|
||||
#### 电源(PSU)
|
||||
|
||||
打开你的台式机的机箱,检查印刷在电源上的最大输出功率。然后,查看你的 NVIDIA 显卡的文档,确定推荐的最小电源功率要求(以瓦特为单位)。除此之外,检查你的显卡,看它是否需要额外的接线,例如 6 针连接器,大多数的入门级显卡只从主板获取电力,但是有一些显卡需要额外的电力,如果出现以下情况,你需要升级你的电源:
|
||||
|
||||
1. 你的电源的最大输出功率低于显卡建议的最小电源功率。注意:根据一些显卡厂家的说法,比起推荐的功率,预先构建的系统可能会需要更多或更少的功率,而这取决于系统的配置。如果你使用的是一个特别耗电或者特别节能的配置,请灵活决定你的电源需求。
|
||||
2. 你的电源没有提供必须的接线口来为你的显卡供电。
|
||||
|
||||
电源的更换很容易,但是在你拆除你当前正在使用的电源之前,请务必注意你的接线布局。除此之外,请确保你选择的电源适合你的机箱。
|
||||
|
||||
#### CPU
|
||||
|
||||
虽然在大多数老机器上安装高性能的 NVIDIA 显卡是可能的,但是一个缓慢或受损的 CPU 会阻碍显卡性能的发挥,如果要计算在你的机器上瓶颈效果的影响,请点击[这里][4]。了解你的 CPU 性能来避免高性能的显卡和 CPU 无法保持匹配是很重要的。升级你的 CPU 是一个潜在的考虑因素。
|
||||
|
||||
#### 主板
|
||||
|
||||
在继续进行之前,请确认你的主板和你选择的显卡是兼容的。你的显卡应该插在最靠近散热器的 PCI-E x16 插槽中。确保你的设置为显卡预留了足够的空间。此外,请注意,现在大部分的显卡使用的都是 PCI-E 3.0 技术。虽然这些显卡如果插在 PCI-E 3.0 插槽上会运行地最好,但如果插在一个旧版的插槽上的话,性能也不会受到太大的影响。
|
||||
|
||||
### 安装
|
||||
|
||||
1、 首先,打开终端更新你的包管理器(如果没有更新的话):
|
||||
|
||||
```
|
||||
sudo dnf update
|
||||
```
|
||||
|
||||
2、 然后,使用这条简单的命令进行重启:
|
||||
|
||||
```
|
||||
reboot
|
||||
```
|
||||
|
||||
3、 在重启之后,安装 Fedora 28 的工作站的仓库:
|
||||
|
||||
```
|
||||
sudo dnf install fedora-workstation-repositories
|
||||
```
|
||||
|
||||
4、 接着,设置 NVIDIA 驱动的仓库:
|
||||
|
||||
```
|
||||
sudo dnf config-manager --set-enabled rpmfusion-nonfree-nvidia-driver
|
||||
```
|
||||
|
||||
5、 然后,再次重启。
|
||||
|
||||
6、 在这次重启之后,通过下面这条命令验证是否添加了仓库:
|
||||
|
||||
```
|
||||
sudo dnf repository-packages rpmfusion-nonfree-nvidia-driver info
|
||||
```
|
||||
|
||||
如果加载了多个 NVIDIA 工具和它们各自的 spec 文件,请继续进行下一步。如果没有,你可能在添加新仓库的时候遇到了一个错误。你应该再试一次。
|
||||
|
||||
7、 登录,连接到互联网,然后打开“软件”应用程序。点击“加载项>硬件驱动> NVIDIA Linux 图形驱动>安装”。
|
||||
|
||||
如果你使用更老的显卡或者想使用多个显卡,请进一步查看 [RPMFusion 指南][8]。最后,要确保启动成功,设置 `/etc/gdm/custom.conf` 中的 `WaylandEnable=false`,确认避免使用安全启动。
|
||||
接着,再一次重启。
|
||||
|
||||
8、这个过程完成后,关闭所有的应用并**关机**。拔下电源插头,然后按下电源按钮以释放余电,避免你被电击。如果你对电源有开关,关闭它。
|
||||
|
||||
9、 最后,安装显卡,拔掉老的显卡并将新的显卡插入到正确的 PCI-E x16 插槽中。成功安装新的显卡之后,关闭你的机箱,插入电源 ,然后打开计算机,它应该会成功启动。
|
||||
|
||||
**注意:** 要禁用此安装中使用的 NVIDIA 驱动仓库,或者要禁用所有的 Fedora 工作站仓库,请参考这个 [Fedora Wiki 页面][6]。
|
||||
|
||||
### 验证
|
||||
|
||||
1、 如果你新安装的 NVIDIA 显卡已连接到你的显示器并显示正确,则表明你的 NVIDIA 驱动程序已成功和显卡建立连接。
|
||||
|
||||
如果你想去查看你的设置,或者验证驱动是否在正常工作(这里,主板上安装了两块显卡),再次打开 “NVIDIA X 服务器设置应用程序”。这次,你应该不会得到错误信息提示,并且系统会给出有关 X 的设置文件和你的 NVIDIA 显卡的信息。(请参考下面的屏幕截图)
|
||||
|
||||
![NVIDIA X Server Settings][7]
|
||||
|
||||
通过这个应用程序,你可以根据你的需要需改 X 配置文件,并可以监控显卡的性能,时钟速度和温度信息。
|
||||
|
||||
2、 为确保新显卡以满功率运行,显卡性能测试是非常必要的。GL Mark 2,是一个提供后台处理、构建、照明、纹理等等有关信息的标准工具。它提供了一个优秀的解决方案。GL Mark 2 记录了各种各样的图形测试的帧速率,然后输出一个总体的性能评分(这被称为 glmark2 分数)。
|
||||
|
||||
**注意:** glxgears 只会测试你的屏幕或显示器的性能,不会测试显卡本身,请使用 GL Mark 2。
|
||||
|
||||
要运行 GLMark2:
|
||||
|
||||
1. 打开终端并关闭其他所有的应用程序
|
||||
2. 运行 `sudo dnf install glmark2` 命令
|
||||
3. 运行 `glmark2` 命令
|
||||
4. 允许运行完整的测试来得到最好的结果。检查帧速率是否符合你对这块显卡的预期。如果你想要额外的验证,你可以查阅网站来确认是否已有你这块显卡的 glmark2 测试评分被公布到网上,你可以比较这个分数来评估你这块显卡的性能。
|
||||
5. 如果你的帧速率或者 glmark2 评分低于预期,请思考潜在的因素。CPU 造成的瓶颈?其他问题导致?
|
||||
|
||||
|
||||
如果诊断的结果很好,就开始享受你的新显卡吧。
|
||||
|
||||
### 参考链接
|
||||
|
||||
- [How to benchmark your GPU on Linux][9]
|
||||
- [How to install a graphics card][10]
|
||||
- [The Fedora Wiki Page][6]
|
||||
- [The Bottlenecker][4]
|
||||
- [What Is Unified Extensible Firmware Interface (UEFI)][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/install-nvidia-gpu/
|
||||
|
||||
作者:[Justice del Castillo][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/justice/
|
||||
[1]:https://whatis.techtarget.com/definition/Unified-Extensible-Firmware-Interface-UEFI
|
||||
[2]:https://www.cnet.com/products/pny-geforce-gtx-xlr8-gaming-1050-ti-overclocked-edition-graphics-card-gf-gtx-1050-ti-4-gb/specs/
|
||||
[3]:https://www.evga.com/products/product.aspx?pn=100-B1-0600-KR
|
||||
[4]:http://thebottlenecker.com (Home: The Bottle Necker)
|
||||
[5]:https://bytebucket.org/kenneym/fedora-28-nvidia-gpu-installation/raw/7bee7dc6effe191f1f54b0589fa818960a8fa18b/nvidia_xserver_error.jpg?token=c6a7effe35f1c592a155a4a46a068a19fd060a91 (NVIDIA X Sever Prompt)
|
||||
[6]:https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories
|
||||
[7]:https://bytebucket.org/kenneym/fedora-28-nvidia-gpu-installation/raw/7bee7dc6effe191f1f54b0589fa818960a8fa18b/NVIDIA_XCONFIG.png?token=64e1a7be21e5e9ba157f029b65e24e4eef54d88f (NVIDIA X Server Settings)
|
||||
[8]:https://rpmfusion.org/Howto/NVIDIA?highlight=%28CategoryHowto%29
|
||||
[9]: https://www.howtoforge.com/tutorial/linux-gpu-benchmark/
|
||||
[10]: https://www.pcworld.com/article/2913370/components-graphics/how-to-install-a-graphics-card.html
|
||||
@ -0,0 +1,60 @@
|
||||
macOS 和 Linux 的内核有什么区别
|
||||
======
|
||||
|
||||
有些人可能会认为 macOS 和 Linux 内核之间存在相似之处,因为它们可以处理类似的命令和类似的软件。有些人甚至认为苹果公司的 macOS 是基于 Linux 的。事实上是,两个内核有着截然不同的历史和特征。今天,我们来看看 macOS 和 Linux 的内核之间的区别。
|
||||
|
||||
![macOS vs Linux][1]
|
||||
|
||||
### macOS 内核的历史
|
||||
|
||||
我们将从 macOS 内核的历史开始。1985 年,由于与首席执行官 John Sculley 和董事会不和,<ruby>史蒂夫·乔布斯<rt>Steve Jobs</rt></ruby>离开了苹果公司。然后,他成立了一家名为 [NeXT][2] 的新电脑公司。乔布斯希望将一款(带有新操作系统的)新计算机快速推向市场。为了节省时间,NeXT 团队使用了卡耐基梅隆大学的 [Mach 内核][3] 和部分 BSD 代码库来创建 [NeXTSTEP 操作系统][4]。
|
||||
|
||||
NeXT 从来没有取得过财务上的成功,部分归因于乔布斯花钱的习惯,就像他还在苹果公司一样。与此同时,苹果公司曾多次试图更新其操作系统,甚至与 IBM 合作,但从未成功。1997年,苹果公司以 4.29 亿美元收购了 NeXT。作为交易的一部分,史蒂夫·乔布斯回到了苹果公司,同时 NeXTSTEP 成为了 macOS 和 iOS 的基础。
|
||||
|
||||
### Linux 内核的历史
|
||||
|
||||
与 macOS 内核不同,Linux 的创建并非源于商业尝试。相反,它是由[芬兰计算机科学专业学生<ruby>林纳斯·托瓦兹<rt>Linus Torvalds</rt></ruby>于 1991 年创建的][5]。最初,内核是按照林纳斯自己的计算机的规格编写的,因为他想利用其新的 80386 处理器(的特性)。林纳斯[于 1991 年 8 月在 Usenet 上][6]发布了他的新内核代码。很快,他就收到了来自世界各地的代码和功能建议。次年,Orest Zborowski 将 X Window 系统移植到 Linux,使其能够支持图形用户界面。
|
||||
|
||||
在过去的 27 年中,Linux 已经慢慢成长并增加了不少功能。这不再是一个学生的小型项目。现在它运行在[世界上][7]大多数的[计算设备][8]和[超级计算机][9]上。不错!
|
||||
|
||||
### macOS 内核的特性
|
||||
|
||||
macOS 内核被官方称为 XNU。这个[首字母缩写词][10]代表“XNU is Not Unix”。根据 [苹果公司的 Github 页面][10],XNU 是“将卡耐基梅隆大学开发的 Mach 内核和 FreeBSD 组件整合而成的混合内核,加上用于编写驱动程序的 C++ API”。代码的 BSD 子系统部分[“在微内核系统中通常实现为用户空间的服务”][11]。Mach 部分负责底层工作,例如多任务、内存保护、虚拟内存管理、内核调试支持和控制台 I/O。
|
||||
|
||||
### Linux 内核的特性
|
||||
|
||||
虽然 macOS 内核结合了微内核([Mach][12])和宏内核([BSD][13])的特性,但 Linux 只是一个宏内核。[宏内核][14]负责管理 CPU、内存、进程间通信、设备驱动程序、文件系统和系统服务调用( LCTT 译注:原文为 system server calls,但结合 Linux 内核的构成,译者认为这里翻译成系统服务调用更合适,即 system service calls)。
|
||||
|
||||
### 用一句话总结 Linux 和 Mac 的区别
|
||||
|
||||
macOS 内核(XNU)比 Linux 历史更悠久,并且基于两个更古老一些的代码库的结合;另一方面,Linux 新一些,是从头开始编写的,并且在更多设备上使用。
|
||||
|
||||
如果您发现这篇文章很有趣,请花一点时间在社交媒体,黑客新闻或 [Reddit][15] 上分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mac-linux-difference/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/macos-vs-linux-kernels.jpeg
|
||||
[2]:https://en.wikipedia.org/wiki/NeXT
|
||||
[3]:https://en.wikipedia.org/wiki/Mach_(kernel)
|
||||
[4]:https://en.wikipedia.org/wiki/NeXTSTEP
|
||||
[5]:https://www.cs.cmu.edu/%7Eawb/linux.history.html
|
||||
[6]:https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ
|
||||
[7]:https://www.zdnet.com/article/sorry-windows-android-is-now-the-most-popular-end-user-operating-system/
|
||||
[8]:https://www.linuxinsider.com/story/31855.html
|
||||
[9]:https://itsfoss.com/linux-supercomputers-2017/
|
||||
[10]:https://github.com/apple/darwin-xnu
|
||||
[11]:http://osxbook.com/book/bonus/ancient/whatismacosx/arch_xnu.html
|
||||
[12]:https://en.wikipedia.org/wiki/Mach_(kernel
|
||||
[13]:https://en.wikipedia.org/wiki/FreeBSD
|
||||
[14]:https://www.howtogeek.com/howto/31632/what-is-the-linux-kernel-and-what-does-it-do/
|
||||
[15]:http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,97 @@
|
||||
如何在 Linux 系统中使用 dd 命令而不会损毁你的磁盘
|
||||
===========
|
||||
|
||||
> 使用 Linux 中的 dd 工具安全、可靠地制作一个驱动器、分区和文件系统的完整镜像。
|
||||
|
||||

|
||||
|
||||
*这篇文章节选自 Manning 出版社出版的图书 [Linux in Action][1]的第 4 章。*
|
||||
|
||||
你是否正在从一个即将损坏的存储驱动器挽救数据,或者要把本地归档进行远程备份,或者要把一个别处的活动分区做个完整的副本,那么你需要懂得如何安全而可靠的复制驱动器和文件系统。幸运的是,`dd` 是一个可以使用的简单而又功能强大的镜像复制命令,从现在到未来很长的时间内,也许直到永远都不会出现比 `dd` 更好的工具了。
|
||||
|
||||
### 对驱动器和分区做个完整的副本
|
||||
|
||||
仔细研究后,你会发现你可以使用 `dd` 做各种任务,但是它最重要的功能是处理磁盘分区。当然,你可以使用 `tar` 命令或者 `scp` 命令从一台计算机复制整个文件系统的文件,然后把这些文件原样粘贴在另一台刚刚安装好 Linux 操作系统的计算机中。但是,因为那些文件系统归档不是完整的映像文件,所以在复制文件的过程中需要计算机操作系统的运行作为基础。
|
||||
|
||||
另一方面,使用 `dd` 可以对任何数字信息完美的进行逐个字节的镜像。但是不论何时何地,当你要对分区进行操作时,我要告诉你早期的 Unix 管理员曾开过这样的玩笑:“ dd 的意思是<ruby>磁盘毁灭者<rt>disk destroyer</rt></ruby>”(LCTT 译注:`dd` 原意是<ruby>磁盘复制<rt>disk dump</rt></ruby>)。 在使用 `dd` 命令的时候,如果你输入了哪怕是一个字母,也可能立即永久性的擦除掉整个磁盘驱动器里的所有重要的数据。因此,一定要注意命令的拼写格式规范。
|
||||
|
||||
**记住:** 在按下回车键执行 `dd` 命令之前,暂时停下来仔细的认真思考一下。
|
||||
|
||||
### dd 命令的基本操作
|
||||
|
||||
现在你已经得到了适当的提醒,我们将从简单的事情开始。假设你要对代号为 `/dev/sda` 的整个磁盘数据创建精确的映像,你已经插入了一块空的磁盘驱动器 (理想情况下具有与代号为 `/dev/sda` 的磁盘驱动器相同的容量)。语法很简单: `if=` 定义源驱动器,`of=` 定义你要将数据保存到的文件或位置:
|
||||
|
||||
```
|
||||
# dd if=/dev/sda of=/dev/sdb
|
||||
```
|
||||
|
||||
接下来的例子将要对 `/dev/sda` 驱动器创建一个 .img 的映像文件,然后把该文件保存的你的用户帐号家目录:
|
||||
|
||||
```
|
||||
# dd if=/dev/sda of=/home/username/sdadisk.img
|
||||
```
|
||||
|
||||
上面的命令针对整个驱动器创建映像文件,你也可以针对驱动器上的单个分区进行操作。下面的例子针对驱动器的单个分区进行操作,同时使用了一个 `bs` 参数用于设置单次拷贝的字节数量 (此例中是 4096)。设定 `bs` 参数值可能会影响 `dd` 命令的整体操作速度,该参数的理想设置取决于你的硬件配置和其它考虑。
|
||||
|
||||
```
|
||||
# dd if=/dev/sda2 of=/home/username/partition2.img bs=4096
|
||||
```
|
||||
|
||||
数据的恢复非常简单:通过颠倒 `if` 和 `of` 参数可以有效的完成任务。在此例中,`if=` 使用你要恢复的映像,`of=` 使用你想要写入映像的目标驱动器:
|
||||
|
||||
```
|
||||
# dd if=sdadisk.img of=/dev/sdb
|
||||
```
|
||||
|
||||
你也可以在一条命令中同时完成创建和拷贝任务。下面的例子中将使用 SSH 从远程驱动器创建一个压缩的映像文件,并把该文件保存到你的本地计算机中:
|
||||
|
||||
```
|
||||
# ssh username@54.98.132.10 "dd if=/dev/sda | gzip -1 -" | dd of=backup.gz
|
||||
```
|
||||
|
||||
你应该经常测试你的归档,确保它们可正常使用。如果它是你创建的启动驱动器,将它粘贴到计算机中,看看它是否能够按预期启动。如果它是普通分区的数据,挂载该分区,确保文件都存在而且可以正常的访问。
|
||||
|
||||
### 使用 dd 擦除磁盘数据
|
||||
|
||||
多年以前,我的一个负责政府海外大使馆安全的朋友曾经告诉我,在他当时在任的时候, 政府会给每一个大使馆提供一个官方版的锤子。为什么呢? 一旦大使馆设施可能被不友善的人员侵占,就会使用这个锤子毁坏所有的硬盘.
|
||||
|
||||
为什么要那样做?为什么不是删除数据就好了?你在开玩笑,对吧?所有人都知道从存储设备中删除包含敏感信息的文件实际上并没有真正移除这些数据。除非使用锤子彻底的毁坏这些存储介质,否则,只要有足够的时间和动机, 几乎所有的内容都可以从几乎任何数字存储介质重新获取。
|
||||
|
||||
但是,你可以使用 `dd` 命令让坏人非常难以获得你的旧数据。这个命令需要花费一些时间在 `/dev/sda1` 分区的每个扇区写入数百万个 `0`(LCTT 译注:是指 0x0 字节,意即 NUL ,而不是数字 0 ):
|
||||
|
||||
```
|
||||
# dd if=/dev/zero of=/dev/sda1
|
||||
```
|
||||
|
||||
还有更好的方法。通过使用 `/dev/urandom` 作为源文件,你可以在磁盘上写入随机字符:
|
||||
|
||||
```
|
||||
# dd if=/dev/urandom of=/dev/sda1
|
||||
```
|
||||
|
||||
### 监控 dd 的操作
|
||||
|
||||
由于磁盘或磁盘分区的归档可能需要很长的时间,因此你可能需要在命令中添加进度查看器。安装管道查看器(在 Ubuntu 系统上安装命令为 `sudo apt install pv`),然后把 `pv` 命令和 `dd` 命令结合在一起。使用 `pv`,最终的命令是这样的:
|
||||
|
||||
```
|
||||
# dd if=/dev/urandom | pv | dd of=/dev/sda1
|
||||
|
||||
4,14MB 0:00:05 [ 98kB/s] [ <=> ]
|
||||
```
|
||||
|
||||
想要推迟备份和磁盘管理工作?有了 `dd` 工具,你不会有太多的借口。它真的非常简单,但是要小心。祝你好运!
|
||||
|
||||
----------------
|
||||
|
||||
via:https://opensource.com/article/18/7/how-use-dd-linux
|
||||
|
||||
作者:[David Clinton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[SunWave](https://github.com/SunWave)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]: https://opensource.com/users/remyd
|
||||
[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
@ -0,0 +1,79 @@
|
||||
6 个可以帮你理解互联网工作原理的 RFC
|
||||
======
|
||||
|
||||
> 以及 3 个有趣的 RFC。
|
||||
|
||||

|
||||
|
||||
阅读源码是开源软件的重要组成部分。这意味着用户可以查看代码并了解做了什么。
|
||||
|
||||
但“阅读源码”并不仅适用于代码。理解代码实现的标准同样重要。这些标准编写在由<ruby>[互联网工程任务组][1]<rt>Internet Engineering Task Force</rt></ruby>(IETF)发布的称为“<ruby>意见征集<rt>Requests for Comment</rt></ruby>”(RFC)的文档中。多年来已经发布了数以千计的 RFC,因此我们收集了一些我们的贡献者认为必读的内容。
|
||||
|
||||
### 6 个必读的 RFC
|
||||
|
||||
#### RFC 2119 - 在 RFC 中用于指示需求级别的关键字
|
||||
|
||||
这是一个快速阅读,但它对了解其它 RFC 非常重要。 [RFC 2119][2] 定义了后续 RFC 中使用的需求级别。 “MAY” 究竟意味着什么?如果标准说 “SHOULD”,你*真的*必须这样做吗?通过为需求提供明确定义的分类,RFC 2119 有助于避免歧义。
|
||||
|
||||
#### RFC 3339 - 互联网上的日期和时间:时间戳
|
||||
|
||||
时间是全世界程序员的祸根。 [RFC 3339][3] 定义了如何格式化时间戳。基于 [ISO 8601][4] 标准,3339 为我们提供了一种表达时间的常用方法。例如,像星期几这样的冗余信息不应该包含在存储的时间戳中,因为它很容易计算。
|
||||
|
||||
#### RFC 1918 - 私有互联网的地址分配
|
||||
|
||||
有属于每个人的互联网,也有只属于你的互联网。私有网络一直在使用,[RFC 1918][5] 定义了这些网络。当然,你可以在路由器上设置在内部使用公网地址,但这是一个坏主意。或者,你可以将未使用的公共 IP 地址视为内部网络。在任何一种情况下都表明你从未阅读过 RFC 1918。
|
||||
|
||||
#### RFC 1912 - 常见的 DNS 操作和配置错误
|
||||
|
||||
一切都是 #@%@ 的 DNS 问题,对吧? [RFC 1912][6] 列出了管理员在试图保持互联网运行时所犯的错误。虽然它是在 1996 年发布的,但 DNS(以及人们犯的错误)并没有真正改变这么多。为了理解我们为什么首先需要 DNS,如今我们再来看看 [RFC 289 - 我们希望正式的主机列表是什么样子的][7] 就知道了。
|
||||
|
||||
#### RFC 2822 — 互联网邮件格式
|
||||
|
||||
想想你知道什么是有效的电子邮件地址么?如果你知道有多少个站点不接受我邮件地址中 “+” 的话,你就知道你知道不知道了。 [RFC 2822][8] 定义了有效的电子邮件地址。它还详细介绍了电子邮件的其余部分。
|
||||
|
||||
#### RFC 7231 - 超文本传输协议(HTTP/1.1):语义和内容
|
||||
|
||||
想想看,几乎我们在网上做的一切都依赖于 HTTP。 [RFC 7231][9] 是该协议的最新更新。它有超过 100 页,定义了方法、请求头和状态代码。
|
||||
|
||||
### 3 个应该阅读的 RFC
|
||||
|
||||
好吧,并非每个 RFC 都是严肃的。
|
||||
|
||||
#### RFC 1149 - 在禽类载体上传输 IP 数据报的标准
|
||||
|
||||
网络以多种不同方式传递数据包。 [RFC 1149][10] 描述了鸽子载体的使用。当我距离州际高速公路一英里以外时,它们的可靠性不会低于我的移动提供商。
|
||||
|
||||
#### RFC 2324 — 超文本咖啡壶控制协议(HTCPCP/1.0)
|
||||
|
||||
咖啡对于完成工作非常重要,当然,我们需要一个用于管理咖啡壶的程序化界面。 [RFC 2324][11] 定义了一个用于与咖啡壶交互的协议,并添加了 HTTP 418(“我是一个茶壶”)。
|
||||
|
||||
#### RFC 69 — M.I.T.的分发列表更改
|
||||
|
||||
[RFC 69][12] 是否是第一个误导取消订阅请求的发布示例?
|
||||
|
||||
你必须阅读的 RFC 是什么(无论它们是否严肃)?在评论中分享你的列表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/requests-for-comments-to-know
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://www.ietf.org
|
||||
[2]:https://www.rfc-editor.org/rfc/rfc2119.txt
|
||||
[3]:https://www.rfc-editor.org/rfc/rfc3339.txt
|
||||
[4]:https://www.iso.org/iso-8601-date-and-time-format.html
|
||||
[5]:https://www.rfc-editor.org/rfc/rfc1918.txt
|
||||
[6]:https://www.rfc-editor.org/rfc/rfc1912.txt
|
||||
[7]:https://www.rfc-editor.org/rfc/rfc289.txt
|
||||
[8]:https://www.rfc-editor.org/rfc/rfc2822.txt
|
||||
[9]:https://www.rfc-editor.org/rfc/rfc7231.txt
|
||||
[10]:https://www.rfc-editor.org/rfc/rfc1149.txt
|
||||
[11]:https://www.rfc-editor.org/rfc/rfc2324.txt
|
||||
[12]:https://www.rfc-editor.org/rfc/rfc69.txt
|
||||
@ -0,0 +1,127 @@
|
||||
如何在 Android 上借助 Wine 来运行 Windows Apps
|
||||
======
|
||||
|
||||

|
||||
|
||||
Wine(一种 Linux 上的程序,不是你喝的葡萄酒)是在类 Unix 操作系统上运行 Windows 程序的一个自由开源的兼容层。创建于 1993 年,借助它你可以在 Linux 和 macOS 操作系统上运行很多 Windows 程序,虽然有时可能还需要做一些小修改。现在,Wine 项目已经发布了 3.0 版本,这个版本兼容 Android 设备。
|
||||
|
||||
在本文中,我们将向你展示,在你的 Android 设备上如何借助 Wine 来运行 Windows Apps。
|
||||
|
||||
**相关阅读** : [如何使用 Winepak 在 Linux 上轻松安装 Windows 游戏][1]
|
||||
|
||||
### 在 Wine 上你可以运行什么?
|
||||
|
||||
Wine 只是一个兼容层,而不是一个全功能的仿真器,因此,你需要一个 x86 的 Android 设备才能完全发挥出它的优势。但是,大多数消费者手中的 Android 设备都是基于 ARM 的。
|
||||
|
||||
因为大多数人使用的是基于 ARM 的 Android 设备,所以有一个限制,只有适配在 Windows RT 上运行的那些 App 才能够使用 Wine 在基于 ARM 的 Android 上运行。但是随着发展,能够在 ARM 设备上运行的 App 数量越来越多。你可以在 XDA 开发者论坛上的这个 [帖子][2] 中找到兼容的这些 App 的清单。
|
||||
|
||||
在 ARM 上能够运行的一些 App 的例子如下:
|
||||
|
||||
* [Keepass Portable][3]: 一个密码钱包
|
||||
* [Paint.NET][4]: 一个图像处理程序
|
||||
* [SumatraPDF][5]: 一个 PDF 文档阅读器,也能够阅读一些其它的文档类型
|
||||
* [Audacity][6]: 一个数字录音和编辑程序
|
||||
|
||||
也有一些再度流行的开源游戏,比如,[Doom][7] 和 [Quake 2][8],以及它们的开源克隆,比如 [OpenTTD][9] 和《运输大亨》的一个版本。
|
||||
|
||||
随着 Wine 在 Android 上越来越普及,能够在基于 ARM 的 Android 设备上的 Wine 中运行的程序越来越多。Wine 项目致力于在 ARM 上使用 QEMU 去仿真 x86 的 CPU 指令,在该项目完成后,能够在 Android 上运行的 App 将会迅速增加。
|
||||
|
||||
### 安装 Wine
|
||||
|
||||
在安装 Wine 之前,你首先需要去确保你的设备的设置 “允许从 Play 商店之外的其它源下载和安装 APK”。对于本文的用途,你需要去许可你的设备从未知源下载 App。
|
||||
|
||||
1、 打开你手机上的设置,然后选择安全选项。
|
||||
|
||||
![wine-android-security][10]
|
||||
|
||||
2、 向下拉并点击 “Unknown Sources” 的开关。
|
||||
|
||||
![wine-android-unknown-sources][11]
|
||||
|
||||
3、 接受风险警告。
|
||||
|
||||
![wine-android-unknown-sources-warning][12]
|
||||
|
||||
4、 打开 [Wine 安装站点][13],并点选列表中的第一个选择框。下载将自动开始。
|
||||
|
||||
![wine-android-download-button][14]
|
||||
|
||||
5、 下载完成后,从下载目录中打开它,或者下拉通知菜单并点击这里的已完成的下载。
|
||||
|
||||
6、 开始安装程序。它将提示你它需要访问和记录音频,并去修改、删除、和读取你的 SD 卡。你也可为程序中使用的一些 App 授予访问音频的权利。
|
||||
|
||||
![wine-android-app-access][15]
|
||||
|
||||
7、 安装完成后,点击程序图标去打开它。
|
||||
|
||||
![wine-android-icon-small][16]
|
||||
|
||||
当你打开 Wine 后,它模仿的是 Windows 7 的桌面。
|
||||
|
||||
![wine-android-desktop][17]
|
||||
|
||||
Wine 有一个缺点是,你得有一个外接键盘去进行输入。如果你在一个小屏幕上运行它,并且触摸非常小的按钮很困难,你也可以使用一个外接鼠标。
|
||||
|
||||
你可以通过触摸 “开始” 按钮去打开两个菜单 —— “控制面板”和“运行”。
|
||||
|
||||
![wine-android-start-button][18]
|
||||
|
||||
### 使用 Wine 来工作
|
||||
|
||||
当你触摸 “控制面板” 后你将看到三个选项 —— 添加/删除程序、游戏控制器、和 Internet 设定。
|
||||
|
||||
使用 “运行”,你可以打开一个对话框去运行命令。例如,通过输入 `iexplore` 来启动 “Internet Explorer”。
|
||||
|
||||
![wine-android-run][19]
|
||||
|
||||
### 在 Wine 中安装程序
|
||||
|
||||
1、 在你的 Android 设备上下载应用程序(或通过云来同步)。一定要记住下载的程序保存的位置。
|
||||
|
||||
2、 打开 Wine 命令提示符窗口。
|
||||
|
||||
3、 输入程序的位置路径。如果你把下载的文件保存在 SD 卡上,输入:
|
||||
|
||||
```
|
||||
cd sdcard/Download/[filename.exe]
|
||||
```
|
||||
|
||||
4、 在 Android 上运行 Wine 中的文件,只需要简单地输入 EXE 文件的名字即可。
|
||||
|
||||
如果这个支持 ARM 的文件是兼容的,它将会运行。如果不兼容,你将看到一大堆错误信息。在这种情况下,在 Android 上的 Wine 中安装的 Windows 软件可能会损坏或丢失。
|
||||
|
||||
这个在 Android 上使用的新版本的 Wine 仍然有许多问题。它并不能在所有的 Android 设备上正常工作。它可以在我的 Galaxy S6 Edge 上运行的很好,但是在我的 Galaxy Tab 4 上却不能运行。许多游戏也不能正常运行,因为图形驱动还不支持 Direct3D。因为触摸屏还不是全扩展的,所以你需要一个外接的键盘和鼠标才能很轻松地操作它。
|
||||
|
||||
即便是在早期阶段的发布版本中存在这样那样的问题,但是这种技术还是值得深思的。当然了,你要想在你的 Android 智能手机上运行 Windows 程序而不出问题,可能还需要等待一些时日。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-windows-apps-android-with-wine/
|
||||
|
||||
作者:[Tracey Rosenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/traceyrosenberger/
|
||||
[1]:https://www.maketecheasier.com/winepak-install-windows-games-linux/ "How to Easily Install Windows Games on Linux with Winepak"
|
||||
[2]:https://forum.xda-developers.com/showthread.php?t=2092348
|
||||
[3]:http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip
|
||||
[4]:http://forum.xda-developers.com/showthread.php?t=2411497
|
||||
[5]:http://forum.xda-developers.com/showthread.php?t=2098594
|
||||
[6]:http://forum.xda-developers.com/showthread.php?t=2103779
|
||||
[7]:http://forum.xda-developers.com/showthread.php?t=2175449
|
||||
[8]:http://forum.xda-developers.com/attachment.php?attachmentid=1640830&amp;d=1358070370
|
||||
[9]:http://forum.xda-developers.com/showpost.php?p=36674868&amp;postcount=151
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-security.png "wine-android-security"
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources.jpg "wine-android-unknown-sources"
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources-warning.png "wine-android-unknown-sources-warning"
|
||||
[13]:https://dl.winehq.org/wine-builds/android/
|
||||
[14]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-download-button.png "wine-android-download-button"
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-app-access.jpg "wine-android-app-access"
|
||||
[16]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-icon-small.jpg "wine-android-icon-small"
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-desktop.png "wine-android-desktop"
|
||||
[18]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-start-button.png "wine-android-start-button"
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-Run.png "wine-android-run"
|
||||
@ -0,0 +1,215 @@
|
||||
Debian 打包入门
|
||||
======
|
||||
|
||||
> 创建 CardBook 软件包、本地 Debian 仓库,并修复错误。
|
||||
|
||||

|
||||
|
||||
我在 GSoC(LCTT 译注:Google Summer Of Code,一项针对学生进行的开源项目训练营,一般在夏季进行。)的任务中有一项是为用户构建 Thunderbird <ruby>扩展<rt>add-ons</rt></ruby>。一些非常流行的扩展,比如 [Lightning][1] (日历行事历)已经拥有了 deb 包。
|
||||
|
||||
另外一个重要的用于管理基于 CardDav 和 vCard 标准的联系人的扩展 [Cardbook][2] ,还没有一个 deb 包。
|
||||
|
||||
我的导师, [Daniel][3] 鼓励我去为它制作一个包,并上传到 [mentors.debian.net][4]。因为这样就可以使用 `apt-get` 来安装,简化了安装流程。这篇博客描述了我是如何从头开始学习为 CardBook 创建一个 Debian 包的。
|
||||
|
||||
首先,我是第一次接触打包,我在从源码构建包的基础上进行了大量研究,并检查它的协议是是否与 [DFSG][5] 兼容。
|
||||
|
||||
我从多个 Debian Wiki 中的指南中进行学习,比如 [打包介绍][6]、 [构建一个包][7],以及一些博客。
|
||||
|
||||
我还研究了包含在 [Lightning 扩展包][8]的 amd64 文件。
|
||||
|
||||
我创建的包可以在[这里][9]找到。
|
||||
|
||||
![Debian Package!][10]
|
||||
|
||||
*Debian 包*
|
||||
|
||||
### 创建一个空的包
|
||||
|
||||
我从使用 `dh_make` 来创建一个 `debian` 目录开始。
|
||||
|
||||
```
|
||||
# Empty project folder
|
||||
$ mkdir -p Debian/cardbook
|
||||
```
|
||||
|
||||
```
|
||||
# create files
|
||||
$ dh_make\
|
||||
> --native \
|
||||
> --single \
|
||||
> --packagename cardbook_1.0.0 \
|
||||
> --email minkush@example.com
|
||||
```
|
||||
|
||||
一些重要的文件,比如 `control`、`rules`、`changelog`、`copyright` 等文件被初始化其中。
|
||||
|
||||
所创建的文件的完整列表如下:
|
||||
|
||||
```
|
||||
$ find /debian
|
||||
debian/
|
||||
debian/rules
|
||||
debian/preinst.ex
|
||||
debian/cardbook-docs.docs
|
||||
debian/manpage.1.ex
|
||||
debian/install
|
||||
debian/source
|
||||
debian/source/format
|
||||
debian/cardbook.debhelper.lo
|
||||
debian/manpage.xml.ex
|
||||
debian/README.Debian
|
||||
debian/postrm.ex
|
||||
debian/prerm.ex
|
||||
debian/copyright
|
||||
debian/changelog
|
||||
debian/manpage.sgml.ex
|
||||
debian/cardbook.default.ex
|
||||
debian/README
|
||||
debian/cardbook.doc-base.EX
|
||||
debian/README.source
|
||||
debian/compat
|
||||
debian/control
|
||||
debian/debhelper-build-stamp
|
||||
debian/menu.ex
|
||||
debian/postinst.ex
|
||||
debian/cardbook.substvars
|
||||
debian/files
|
||||
```
|
||||
|
||||
我了解了 Debian 系统中 [Dpkg][11] 包管理器及如何用它安装、删除和管理包。
|
||||
|
||||
我使用 `dpkg` 命令创建了一个空的包。这个命令创建一个空的包文件以及四个名为 `.changes`、`.deb`、 `.dsc`、 `.tar.gz` 的文件。
|
||||
|
||||
- `.dsc` 文件包含了所发生的修改和签名
|
||||
- `.deb` 文件是用于安装的主要包文件。
|
||||
- `.tar.gz` (tarball)包含了源代码
|
||||
|
||||
这个过程也在 `/usr/share` 目录下创建了 `README` 和 `changelog` 文件。它们包含了关于这个包的基本信息比如描述、作者、版本。
|
||||
|
||||
我安装这个包,并检查这个包安装的内容。我的新包中包含了版本、架构和描述。
|
||||
|
||||
```
|
||||
$ dpkg -L cardbook
|
||||
/usr
|
||||
/usr/share
|
||||
/usr/share/doc
|
||||
/usr/share/doc/cardbook
|
||||
/usr/share/doc/cardbook/README.Debian
|
||||
/usr/share/doc/cardbook/changelog.gz
|
||||
/usr/share/doc/cardbook/copyright
|
||||
```
|
||||
|
||||
### 包含 CardBook 源代码
|
||||
|
||||
在成功的创建了一个空包以后,我在包中添加了实际的 CardBook 扩展文件。 CardBook 的源代码托管在 [Gitlab][12] 上。我将所有的源码文件包含在另外一个目录,并告诉打包命令哪些文件需要包含在这个包中。
|
||||
|
||||
我使用 `vi` 编辑器创建一个 `debian/install` 文件并列举了需要被安装的文件。在这个过程中,我花费了一些时间去学习基于 Linux 终端的文本编辑器,比如 `vi` 。这让我熟悉如何在 `vi` 中编辑、创建文件和快捷方式。
|
||||
|
||||
当这些完成后,我在变更日志中更新了包的版本并记录了我所做的改变。
|
||||
|
||||
```
|
||||
$ dpkg -l | grep cardbook
|
||||
ii cardbook 1.1.0 amd64 Thunderbird add-on for address book
|
||||
```
|
||||
|
||||
![Changelog][13]
|
||||
|
||||
*更新完包的变更日志*
|
||||
|
||||
在重新构建完成后,重要的依赖和描述信息可以被加入到包中。 Debian 的 `control` 文件可以用来添加额外的必须项目和依赖。
|
||||
|
||||
### 本地 Debian 仓库
|
||||
|
||||
在不创建本地存储库的情况下,CardBook 可以使用如下的命令来安装:
|
||||
|
||||
```
|
||||
$ sudo dpkg -i cardbook_1.1.0.deb
|
||||
```
|
||||
|
||||
为了实际测试包的安装,我决定构建一个本地 Debian 存储库。没有它,`apt-get` 命令将无法定位包,因为它没有在 Debian 的包软件列表中。
|
||||
|
||||
为了配置本地 Debian 存储库,我复制我的包 (.deb)为放在 `/tmp` 目录中的 `Packages.gz` 文件。
|
||||
|
||||
![Packages-gz][14]
|
||||
|
||||
*本地 Debian 仓库*
|
||||
|
||||
为了使它工作,我了解了 `apt` 的配置和它查找文件的路径。
|
||||
|
||||
我研究了一种在 `apt-config` 中添加文件位置的方法。最后,我通过在 APT 中添加 `*.list` 文件来添加包的路径,并使用 `apt-cache` 更新APT缓存来完成我的任务。
|
||||
|
||||
因此,最新的 CardBook 版本可以成功的通过 `apt-get install cardbook` 来安装了。
|
||||
|
||||
![Package installation!][15]
|
||||
|
||||
*使用 apt-get 安装 CardBook*
|
||||
|
||||
### 修复打包错误和 Bugs
|
||||
|
||||
我的导师 Daniel 在这个过程中帮了我很多忙,并指导我如何进一步进行打包。他告诉我使用 [Lintian][16] 来修复打包过程中出现的常见错误和最终使用 [dput][17] 来上传 CardBook 包。
|
||||
|
||||
> Lintian 是一个用于发现策略问题和 Bug 的包检查器。它是 Debian 维护者们在上传包之前广泛使用的自动化检查 Debian 策略的工具。
|
||||
|
||||
我上传了该软件包的第二个更新版本到 Debian 目录中的 [Salsa 仓库][18] 的一个独立分支中。
|
||||
|
||||
我从 Debian backports 上安装 Lintian 并学习在一个包上用它来修复错误。我研究了它用在其错误信息中的缩写,和如何查看 Lintian 命令返回的详细内容。
|
||||
|
||||
```
|
||||
$ lintian -i -I --show-overrides cardbook_1.2.0.changes
|
||||
```
|
||||
|
||||
最初,在 `.changes` 文件上运行命令时,我惊讶地看到显示出来了大量错误、警告和注释!
|
||||
|
||||
![Package Error Brief!][19]
|
||||
|
||||
*在包上运行 Lintian 时看到的大量报错*
|
||||
|
||||
![Lintian error1!][20]
|
||||
|
||||
*详细的 Lintian 报错*
|
||||
|
||||
![Lintian error2!][23]
|
||||
|
||||
*详细的 Lintian 报错 (2) 以及更多*
|
||||
|
||||
我花了几天时间修复与 Debian 包策略违例相关的一些错误。为了消除一个简单的错误,我必须仔细研究每一项策略和 Debian 的规则。为此,我参考了 [Debian 策略手册][21] 以及 [Debian 开发者参考][22]。
|
||||
|
||||
我仍然在努力使它变得完美无暇,并希望很快可以将它上传到 mentors.debian.net!
|
||||
|
||||
如果 Debian 社区中使用 Thunderbird 的人可以帮助修复这些报错就太感谢了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://minkush.me/cardbook-debian-package/
|
||||
|
||||
作者:[Minkush Jain][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://minkush.me/cardbook-debian-package/#
|
||||
[1]:https://addons.mozilla.org/en-US/thunderbird/addon/lightning/
|
||||
[2]:https://addons.mozilla.org/nn-NO/thunderbird/addon/cardbook/?src=hp-dl-featured
|
||||
[3]:https://danielpocock.com/
|
||||
[4]:https://mentors.debian.net/
|
||||
[5]:https://wiki.debian.org/DFSGLicenses
|
||||
[6]:https://wiki.debian.org/Packaging/Intro
|
||||
[7]:https://wiki.debian.org/BuildingAPackage
|
||||
[8]:https://packages.debian.org/stretch/amd64/lightning/filelist
|
||||
[9]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package/Debian
|
||||
[10]:http://minkush.me/img/posts/13.png
|
||||
[11]:https://packages.debian.org/stretch/dpkg
|
||||
[12]:https://gitlab.com/CardBook/CardBook
|
||||
[13]:http://minkush.me/img/posts/15.png
|
||||
[14]:http://minkush.me/img/posts/14.png
|
||||
[15]:http://minkush.me/img/posts/11.png
|
||||
[16]:https://packages.debian.org/stretch/lintian
|
||||
[17]:https://packages.debian.org/stretch/dput
|
||||
[18]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package
|
||||
[19]:http://minkush.me/img/posts/16.png (Running Lintian on package)
|
||||
[20]:http://minkush.me/img/posts/10.png
|
||||
[21]:https://www.debian.org/doc/debian-policy/
|
||||
[22]:https://www.debian.org/doc/manuals/developers-reference/
|
||||
[23]:http://minkush.me/img/posts/17.png
|
||||
@ -0,0 +1,67 @@
|
||||
在 Fedora 28 Workstation 使用 emoji 加速输入
|
||||
======
|
||||
|
||||

|
||||
|
||||
Fedora 28 Workstation 添加了一个功能允许你使用键盘快速搜索、选择和输入 emoji。emoji,这种可爱的表意文字是 Unicode 的一部分,在消息传递中使用得相当广泛,特别是在移动设备上。你可能听过这样的成语:“一图胜千言”。这正是 emoji 所提供的:简单的图像供你在交流中使用。Unicode 的每个版本都增加了更多 emoji,在最近的 Unicode 版本中添加了 200 多个 emoji。本文向你展示如何使它们在你的 Fedora 系统中易于使用。
|
||||
|
||||
很高兴看到 emoji 的数量在增长。但与此同时,它带来了如何在计算设备中输入它们的挑战。许多人已经将这些符号用于移动设备或社交网站中的输入。
|
||||
|
||||
[**编者注:**本文是对此主题以前发表过的文章的更新]。
|
||||
|
||||
### 在 Fedora 28 Workstation 上启用 emoji 输入
|
||||
|
||||
新的 emoji 输入法默认出现在 Fedora 28 Workstation 中。要使用它,必须使用“区域和语言设置”对话框启用它。从 Fedora Workstation 设置打开“区域和语言”对话框,或在“概要”中搜索它。
|
||||
|
||||
[![Region & Language settings tool][1]][2]
|
||||
|
||||
选择 `+` 控件添加输入源。出现以下对话框:
|
||||
|
||||
[![Adding an input source][3]][4]
|
||||
|
||||
选择最后选项(三个点)来完全展开选择。然后,在列表底部找到“Other”并选择它:
|
||||
|
||||
[![Selecting other input sources][5]][6]
|
||||
|
||||
在下面的对话框中,找到 “Typing Booster” 选项并选择它:
|
||||
|
||||
[![][7]][8]
|
||||
|
||||
这个高级输入法由 iBus 在背后支持。该高级输入法可通过列表右侧的齿轮图标在列表中识别。
|
||||
|
||||
输入法下拉菜单自动出现在 GNOME Shell 顶部栏中。确认你的默认输入法 —— 在此示例中为英语(美国) - 被选为当前输入法,你就可以输入了。
|
||||
|
||||
[![Input method dropdown in Shell top bar][9]][10]
|
||||
|
||||
### 使用新的表情符号输入法
|
||||
|
||||
现在 emoji 输入法启用了,按键盘快捷键 `Ctrl+Shift+E` 搜索 emoji。将出现一个弹出对话框,你可以在其中输入搜索词,例如 “smile” 来查找匹配的符号。
|
||||
|
||||
[![Searching for smile emoji][11]][12]
|
||||
|
||||
使用箭头键翻页列表。然后按回车进行选择,字形将替换输入内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41-1024x718.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46-1024x839.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15-1024x839.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41-1024x839.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41.png
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24-300x244.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31-290x300.png
|
||||
[12]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31.png
|
||||
@ -0,0 +1,40 @@
|
||||
在 Arch 用户仓库(AUR)中发现恶意软件
|
||||
======
|
||||
|
||||
7 月 7 日,有一个 AUR 软件包被改入了一些恶意代码,提醒 [Arch Linux][1] 用户(以及一般的 Linux 用户)在安装之前应该尽可能检查所有由用户生成的软件包。
|
||||
|
||||
[AUR][3](即 Arch(Linux)用户仓库)包含包描述,也称为 PKGBUILD,它使得从源代码编译包变得更容易。虽然这些包非常有用,但它们永远不应被视为安全的,并且用户应尽可能在使用之前检查其内容。毕竟,AUR 在网页中以粗体显示 “**AUR 包是用户制作的内容。任何使用该提供的文件的风险由你自行承担。**”
|
||||
|
||||
这次[发现][4]包含恶意代码的 AUR 包证明了这一点。[acroread][5] 于 7 月 7 日(看起来它以前是“孤儿”,意思是它没有维护者)被一位名为 “xeactor” 的用户修改,它包含了一行从 pastebin 使用 `curl` 下载脚本的命令。然后,该脚本下载了另一个脚本并安装了一个 systemd 单元以定期运行该脚本。
|
||||
|
||||
**看来有[另外两个][2] AUR 包以同样的方式被修改。所有违规软件包都已删除,并暂停了用于上传它们的用户帐户(它们注册在更新软件包的同一天)。**
|
||||
|
||||
这些恶意代码没有做任何真正有害的事情 —— 它只是试图上传一些系统信息,比如机器 ID、`uname -a` 的输出(包括内核版本、架构等)、CPU 信息、pacman 信息,以及 `systemctl list-units`(列出 systemd 单元信息)的输出到 pastebin.com。我说“试图”是因为第二个脚本中存在错误而没有实际上传系统信息(上传函数为 “upload”,但脚本试图使用其他名称 “uploader” 调用它)。
|
||||
|
||||
此外,将这些恶意脚本添加到 AUR 的人将脚本中的个人 Pastebin API 密钥以明文形式留下,再次证明他们真的不明白他们在做什么。(LCTT 译注:意即这是一个菜鸟“黑客”,还不懂得如何有经验地隐藏自己。)
|
||||
|
||||
尝试将此信息上传到 Pastebin 的目的尚不清楚,特别是原本可以上传更加敏感信息的情况下,如 GPG / SSH 密钥。
|
||||
|
||||
**更新:** Reddit用户 u/xanaxdroid_ [提及][6]同一个名为 “xeactor” 的用户也发布了一些加密货币挖矿软件包,因此他推测 “xeactor” 可能正计划添加一些隐藏的加密货币挖矿软件到 AUR([两个月][7]前的一些 Ubuntu Snap 软件包也是如此)。这就是 “xeactor” 可能试图获取各种系统信息的原因。此 AUR 用户上传的所有包都已删除,因此我无法检查。
|
||||
|
||||
**另一个更新:**你究竟应该在那些用户生成的软件包检查什么(如 AUR 中发现的)?情况各有不同,我无法准确地告诉你,但你可以从寻找任何尝试使用 `curl`、`wget`和其他类似工具下载内容的东西开始,看看他们究竟想要下载什么。还要检查从中下载软件包源的服务器,并确保它是官方来源。不幸的是,这不是一个确切的“科学做法”。例如,对于 Launchpad PPA,事情变得更加复杂,因为你必须懂得 Debian 如何打包,并且这些源代码是可以直接更改的,因为它托管在 PPA 中并由用户上传的。使用 Snap 软件包会变得更加复杂,因为在安装之前你无法检查这些软件包(据我所知)。在后面这些情况下,作为通用解决方案,我觉得你应该只安装你信任的用户/打包器生成的软件包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html
|
||||
[3]:https://aur.archlinux.org/
|
||||
[4]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html
|
||||
[5]:https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/
|
||||
[7]:https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html
|
||||
@ -0,0 +1,74 @@
|
||||
15 个适用于 MacOS 的开源应用程序
|
||||
======
|
||||
|
||||
> 钟爱开源的用户不会觉得在非 Linux 操作系统上使用他们喜爱的应用有多难。
|
||||
|
||||

|
||||
|
||||
只要有可能的情况下,我都会去选择使用开源工具。不久之前,我回到大学去攻读教育领导学硕士学位。即便是我将喜欢的 Linux 笔记本电脑换成了一台 MacBook Pro(因为我不能确定校园里能够接受 Linux),我还是决定继续使用我喜欢的工具,哪怕是在 MacOS 上也是如此。
|
||||
|
||||
幸运的是,它很容易,并且没有哪个教授质疑过我用的是什么软件。即然如此,我就不能秘而不宣。
|
||||
|
||||
我知道,我的一些同学最终会在学区担任领导职务,因此,我与我的那些使用 MacOS 或 Windows 的同学分享了关于下面描述的这些开源软件。毕竟,开源软件是真正地自由和友好的。我也希望他们去了解它,并且愿意以很少的一些成本去提供给他们的学生去使用这些世界级的应用程序。他们中的大多数人都感到很惊讶,因为,众所周知,开源软件除了有像你和我这样的用户之外,压根就没有销售团队。
|
||||
|
||||
### 我的 MacOS 学习曲线
|
||||
|
||||
虽然大多数的开源工具都能像以前我在 Linux 上使用的那样工作,只是需要不同的安装方法。但是,经过这个过程,我学习了这些工具在 MacOS 上的一些细微差别。像 [yum][1]、[DNF][2]、和 [APT][3] 在 MacOS 的世界中压根不存在 —— 我真的很怀念它们。
|
||||
|
||||
一些 MacOS 应用程序要求依赖项,并且安装它们要比我在 Linux 上习惯的方法困难很多。尽管如此,我仍然没有放弃。在这个过程中,我学会了如何在我的新平台上保留最好的软件。即便是 MacOS 大部分的核心也是 [开源的][4]。
|
||||
|
||||
此外,我的 Linux 的知识背景让我使用 MacOS 的命令行很轻松很舒适。我仍然使用命令行去创建和拷贝文件、添加用户、以及使用其它的像 `cat`、`tac`、`more`、`less` 和 `tail` 这样的 [实用工具][5]。
|
||||
|
||||
### 15 个适用于 MacOS 的非常好的开源应用程序
|
||||
|
||||
* 在大学里,要求我使用 DOCX 的电子版格式来提交我的工作,而这其实很容易,最初我使用的是 [OpenOffice][6],而后来我使用的是 [LibreOffice][7] 去完成我的论文。
|
||||
* 当我因为演示需要去做一些图像时,我使用的是我最喜欢的图像应用程序 [GIMP][8] 和 [Inkscape][9]。
|
||||
* 我喜欢的播客创建工具是 [Audacity][10]。它比起 Mac 上搭载的专有应用程序更加简单。我使用它去录制访谈和为视频演示创建配乐。
|
||||
* 在 MacOS 上我最早发现的多媒体播放器是 [VideoLan][11] (VLC)。
|
||||
* MacOS 内置的专有视频创建工具是一个非常好的产品,但是你也可以很轻松地去安装和使用 [OpenShot][12],它是一个非常好的内容创建工具。
|
||||
* 当我需要在我的客户端上分析网络时,我在我的 Mac 上使用了易于安装的 [Nmap][13] (Network Mapper) 和 [Wireshark][14] 工具。
|
||||
* 当我为图书管理员和其它教育工作者提供培训时,我在 MacOS 上使用 [VirtualBox][15] 去做 Raspbian、Fedora、Ubuntu 和其它 Linux 发行版的示范操作。
|
||||
* 我使用 [Etcher.io][16] 在我的 MacBook 上制作了一个引导盘,下载 ISO 文件,将它刻录到一个 U 盘上。
|
||||
* 我认为 [Firefox][17] 比起 MacBook Pro 自带的专有浏览器更易用更安全,并且它允许我跨操作系统去同步我的书签。
|
||||
* 当我使用电子书阅读器时,[Calibre][18] 是当之无愧的选择。它很容易去下载和安装,你甚至只需要几次点击就能将它配置为一台 [教室中使用的电子书服务器][19]。
|
||||
* 最近我给中学的学生教 Python 课程,我发现它可以很容易地从 [Python.org][20] 上下载和安装 Python 3 及 IDLE3 编辑器。我也喜欢学习数据科学,并与学生分享。不论你是对 Python 还是 R 感兴趣,我都建议你下载和 [安装][21] [Anaconda 发行版][22]。它包含了非常好的 iPython 编辑器、RStudio、Jupyter Notebooks、和 JupyterLab,以及其它一些应用程序。
|
||||
* [HandBrake][23] 是一个将你家里的旧的视频 DVD 转成 MP4 的工具,这样你就可以将它们共享到 YouTube、Vimeo、或者你的 MacOS 上的 [Kodi][24] 服务器上。
|
||||
|
||||
现在轮到你了:你在 MacOS(或 Windows)上都使用什么样的开源软件?在下面的评论区共享出来吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/open-source-tools-macos
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Yum_(software)
|
||||
[2]:https://en.wikipedia.org/wiki/DNF_(software)
|
||||
[3]:https://en.wikipedia.org/wiki/APT_(Debian)
|
||||
[4]:https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/OSX_Technology_Overview/SystemTechnology/SystemTechnology.html
|
||||
[5]:https://www.gnu.org/software/coreutils/coreutils.html
|
||||
[6]:https://www.openoffice.org/
|
||||
[7]:https://www.libreoffice.org/
|
||||
[8]:https://www.gimp.org/
|
||||
[9]:https://inkscape.org/en/
|
||||
[10]:https://www.audacityteam.org/
|
||||
[11]:https://www.videolan.org/index.html
|
||||
[12]:https://www.openshot.org/
|
||||
[13]:https://nmap.org/
|
||||
[14]:https://www.wireshark.org/
|
||||
[15]:https://www.virtualbox.org/
|
||||
[16]:https://etcher.io/
|
||||
[17]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[18]:https://calibre-ebook.com/
|
||||
[19]:https://opensource.com/article/17/6/raspberrypi-ebook-server
|
||||
[20]:https://www.python.org/downloads/release/python-370/
|
||||
[21]:https://opensource.com/article/18/4/getting-started-anaconda-python
|
||||
[22]:https://www.anaconda.com/download/#macos
|
||||
[23]:https://handbrake.fr/
|
||||
[24]:https://kodi.tv/download
|
||||
@ -0,0 +1,94 @@
|
||||
6 个开源的数字货币钱包
|
||||
======
|
||||
|
||||
> 想寻找一个可以存储和交易你的比特币、以太坊和其它数字货币的软件吗?这里有 6 个开源的软件可以选择。
|
||||
|
||||

|
||||
|
||||
没有数字货币钱包,像比特币和以太坊这样的数字货币只不过是又一个空想罢了。这些钱包对于保存、发送、以及接收数字货币来说是必需的东西。
|
||||
|
||||
迅速成长的 [数字货币][1] 之所以是革命性的,都归功于它的去中心化,该网络中没有中央权威,每个人都享有平等的权力。开源技术是数字货币和 [区块链][2] 网络的核心所在。它使得这个充满活力的新兴行业能够从去中心化中获益 —— 比如,不可改变、透明和安全。
|
||||
|
||||
如果你正在寻找一个自由开源的数字货币钱包,请继续阅读,并开始去探索以下的选择能否满足你的需求。
|
||||
|
||||
### 1、 Copay
|
||||
|
||||
[Copay][3] 是一个能够很方便地存储比特币的开源数字货币钱包。这个软件以 [MIT 许可证][4] 发布。
|
||||
|
||||
Copay 服务器也是开源的。因此,开发者和比特币爱好者可以在服务器上部署他们自己的应用程序来完全控制他们的活动。
|
||||
|
||||
Copay 钱包能让你手中的比特币更加安全,而不是去信任不可靠的第三方。它允许你使用多重签名来批准交易,并且支持在同一个 app 钱包内支持存储多个独立的钱包。
|
||||
|
||||
Copay 可以在多种平台上使用,比如 Android、Windows、MacOS、Linux、和 iOS。
|
||||
|
||||
### 2、 MyEtherWallet
|
||||
|
||||
正如它的名字所示,[MyEtherWallet][5] (缩写为 MEW) 是一个以太坊钱包。它是开源的(遵循 [MIT 许可证][6])并且是完全在线的,可以通过 web 浏览器来访问它。
|
||||
|
||||
这个钱包的客户端界面非常简洁,它可以让你自信而安全地参与到以太坊区块链中。
|
||||
|
||||
### 3、 mSIGNA
|
||||
|
||||
[mSIGNA][7] 是一个功能强大的桌面版应用程序,用于在比特币网络上完成交易。它遵循 [MIT 许可证][8] 并且在 MacOS、Windows、和 Linux 上可用。
|
||||
|
||||
这个区块链钱包可以让你完全控制你存储的比特币。其中一些特性包括用户友好性、灵活性、去中心化的离线密钥生成能力、加密的数据备份,以及多设备同步功能。
|
||||
|
||||
### 4、 Armory
|
||||
|
||||
[Armory][9] 是一个在你的计算机上产生和保管比特币私钥的开源钱包(遵循 [GNU AGPLv3][10])。它通过使用冷存储和支持多重签名的能力增强了安全性。
|
||||
|
||||
使用 Armory,你可以在完全离线的计算机上设置一个钱包;你将通过<ruby>仅查看<rt>watch-only</rt></ruby>功能在因特网上查看你的比特币具体信息,这样有助于改善安全性。这个钱包也允许你去创建多个地址,并使用它们去完成不同的事务。
|
||||
|
||||
Armory 可用于 MacOS、Windows、和几个比较有特色的 Linux 平台上(包括树莓派)。
|
||||
|
||||
### 5、 Electrum
|
||||
|
||||
[Electrum][11] 是一个既对新手友好又具备专家功能的比特币钱包。它遵循 [MIT 许可证][12] 来发行。
|
||||
|
||||
Electrum 可以在你的本地机器上使用较少的资源来实现本地加密你的私钥,支持冷存储,并且提供多重签名能力。
|
||||
|
||||
它在各种操作系统和设备上都可以使用,包括 Windows、MacOS、Android、iOS 和 Linux,并且也可以在像 [Trezor][13] 这样的硬件钱包中使用。
|
||||
|
||||
### 6、 Etherwall
|
||||
|
||||
[Etherwall][14] 是第一款可以在桌面计算机上存储和发送以太坊的钱包。它是一个遵循 [GPLv3 许可证][15] 的开源钱包。
|
||||
|
||||
Etherwall 非常直观而且速度很快。更重要的是,它增加了你的私钥安全性,你可以在一个全节点或瘦节点上来运行它。它作为全节点客户端运行时,可以允许你在本地机器上下载整个以太坊区块链。
|
||||
|
||||
Etherwall 可以在 MacOS、Linux 和 Windows 平台上运行,并且它也支持 Trezor 硬件钱包。
|
||||
|
||||
### 智者之言
|
||||
|
||||
自由开源的数字钱包在让更多的人快速上手数字货币方面扮演至关重要的角色。
|
||||
|
||||
在你使用任何数字货币软件钱包之前,你一定要确保你的安全,而且一定要记住并完全遵循确保你的资金安全的最佳实践。
|
||||
|
||||
如果你喜欢的开源数字货币钱包不在以上的清单中,请在下面的评论区共享出你所知道的开源钱包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/crypto-wallets
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drmjg
|
||||
[1]:https://www.liveedu.tv/guides/cryptocurrency/
|
||||
[2]:https://opensource.com/tags/blockchain
|
||||
[3]:https://copay.io/
|
||||
[4]:https://github.com/bitpay/copay/blob/master/LICENSE
|
||||
[5]:https://www.myetherwallet.com/
|
||||
[6]:https://github.com/kvhnuke/etherwallet/blob/mercury/LICENSE.md
|
||||
[7]:https://ciphrex.com/
|
||||
[8]:https://github.com/ciphrex/mSIGNA/blob/master/LICENSE
|
||||
[9]:https://www.bitcoinarmory.com/
|
||||
[10]:https://github.com/etotheipi/BitcoinArmory/blob/master/LICENSE
|
||||
[11]:https://electrum.org/#home
|
||||
[12]:https://github.com/spesmilo/electrum/blob/master/LICENCE
|
||||
[13]:https://trezor.io/
|
||||
[14]:https://www.etherwall.com/
|
||||
[15]:https://github.com/almindor/etherwall/blob/master/LICENSE
|
||||
@ -0,0 +1,110 @@
|
||||
使用 Wttr.in 在你的终端中显示天气预报
|
||||
======
|
||||
|
||||
|
||||
|
||||
[wttr.in][1] 是一个功能丰富的天气预报服务,它支持在命令行显示天气。它可以(根据你的 IP 地址)自动检测你的位置,也支持指定位置或搜索地理位置(如城市、山区等)等。哦,另外**你不需要安装它 —— 你只需要使用 cURL 或 Wget**(见下文)。
|
||||
|
||||
wttr.in 功能包括:
|
||||
|
||||
* **显示当前天气以及 3 天内的天气预报,分为早晨、中午、傍晚和夜晚**(包括温度范围、风速和风向、可见度、降水量和概率)
|
||||
* **可以显示月相**
|
||||
* **基于你的 IP 地址自动检测位置**
|
||||
* **允许指定城市名称、3 字母的机场代码、区域代码、GPS 坐标、IP 地址或域名**。你还可以指定地理位置,如湖泊、山脉、地标等)
|
||||
* **支持多语言位置名称**(查询字符串必须以 Unicode 指定)
|
||||
* **支持指定**天气预报显示的语言(它支持超过 50 种语言)
|
||||
* **来自美国的查询使用 USCS 单位用于,世界其他地方使用公制系统**,但你可以通过附加 `?u` 使用 USCS,附加 `?m` 使用公制系统。 )
|
||||
* **3 种输出格式:终端的 ANSI,浏览器的 HTML 和 PNG**
|
||||
|
||||
就像我在文章开头提到的那样,使用 wttr.in,你只需要 cURL 或 Wget,但你也可以在你的服务器上[安装它][3]。 或者你可以安装 [wego][4],这是一个使用 wtter.in 的终端气候应用,虽然 wego 要求注册一个 API 密钥来安装。
|
||||
|
||||
**在使用 wttr.in 之前,请确保已安装 cURL。**在 Debian、Ubuntu 或 Linux Mint(以及其他基于 Debian 或 Ubuntu 的 Linux 发行版)中,使用以下命令安装 cURL:
|
||||
|
||||
```
|
||||
sudo apt install curl
|
||||
```
|
||||
|
||||
### wttr.in 命令行示例
|
||||
|
||||
获取你所在位置的天气(wttr.in 会根据你的 IP 地址猜测你的位置):
|
||||
|
||||
```
|
||||
curl wttr.in
|
||||
```
|
||||
|
||||
通过在 `curl` 之后添加 `-4`,强制 cURL 将名称解析为 IPv4 地址(如果你用 IPv6 访问 wttr.in 有问题):
|
||||
|
||||
```
|
||||
curl -4 wttr.in
|
||||
```
|
||||
|
||||
如果你想检索天气预报保存为 png,**还可以使用 Wget**(而不是 cURL),或者你想这样使用它:
|
||||
|
||||
```
|
||||
wget -O- -q wttr.in
|
||||
```
|
||||
|
||||
如果相对 cURL 你更喜欢 Wget ,可以在下面的所有命令中用 `wget -O- -q` 替换 `curl`。
|
||||
|
||||
指定位置:
|
||||
|
||||
```
|
||||
curl wttr.in/Dublin
|
||||
```
|
||||
|
||||
显示地标的天气信息(本例中为艾菲尔铁塔):
|
||||
|
||||
```
|
||||
curl wttr.in/~Eiffel+Tower
|
||||
```
|
||||
|
||||
获取 IP 地址位置的天气信息(以下 IP 属于 GitHub):
|
||||
|
||||
```
|
||||
curl wttr.in/@192.30.253.113
|
||||
```
|
||||
|
||||
使用 USCS 单位检索天气:
|
||||
|
||||
```
|
||||
curl wttr.in/Paris?u
|
||||
```
|
||||
|
||||
如果你在美国,强制 wttr.in 使用公制系统(SI):
|
||||
|
||||
```
|
||||
curl wttr.in/New+York?m
|
||||
```
|
||||
|
||||
使用 Wget 将当前天气和 3 天预报下载为 PNG 图像:
|
||||
|
||||
```
|
||||
wget wttr.in/Istanbul.png
|
||||
```
|
||||
|
||||
你可以指定 PNG 的[透明度][5],这在你要使用一个脚本自动添加天气信息到某些图片(比如墙纸)上有用。
|
||||
|
||||
**对于其他示例,请查看 wttr.in [项目页面][2]或在终端中输入:**
|
||||
|
||||
```
|
||||
curl wttr.in/:help
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://wttr.in/
|
||||
[2]:https://github.com/chubin/wttr.in
|
||||
[3]:https://github.com/chubin/wttr.in#installation
|
||||
[4]:https://github.com/schachmat/wego
|
||||
[5]:https://github.com/chubin/wttr.in#supported-formats
|
||||
88
published/201807/20180710 Getting started with Perlbrew.md
Normal file
88
published/201807/20180710 Getting started with Perlbrew.md
Normal file
@ -0,0 +1,88 @@
|
||||
Perlbrew 入门
|
||||
======
|
||||
|
||||
> 用 Perlbrew 在你系统上安装多个版本的 Perl。
|
||||
|
||||

|
||||
|
||||
有比在系统上安装了 Perl 更好的事情吗?那就是在系统中安装了多个版本的 Perl。使用 [Perlbrew][1] 你可以做到这一点。但是为什么呢,除了让你包围在 Perl 下之外,有什么好处吗?
|
||||
|
||||
简短的回答是,不同版本的 Perl 是......不同的。程序 A 可能依赖于较新版本中不推荐使用的行为,而程序 B 需要去年无法使用的新功能。如果你安装了多个版本的 Perl,则每个脚本都可以使用最适合它的版本。如果您是开发人员,这也会派上用场,你可以针对多个版本的 Perl 测试你的程序,这样无论你的用户运行什么,你都知道它能否工作。
|
||||
|
||||
### 安装 Perlbrew
|
||||
|
||||
另一个好处是 Perlbrew 会安装 Perl 到用户的家目录。这意味着每个用户都可以管理他们的 Perl 版本(以及相关的 CPAN 包),而无需与系统管理员联系。自助服务意味着为用户提供更快的安装,并为系统管理员提供更多时间来解决难题。
|
||||
|
||||
第一步是在你的系统上安装 Perlbrew。许多 Linux 发行版已经在包仓库中拥有它,因此你只需要 `dnf install perlbrew`(或者适用于你的发行版的命令)。你还可以使用 `cpan App::perlbrew` 从 CPAN 安装 `App::perlbrew` 模块。或者你可以在 [install.perlbrew.pl][2] 下载并运行安装脚本。
|
||||
|
||||
要开始使用 Perlbrew,请运行 `perlbrew init`。
|
||||
|
||||
### 安装新的 Perl 版本
|
||||
|
||||
假设你想尝试最新的开发版本(撰写本文时为 5.27.11)。首先,你需要安装包:
|
||||
|
||||
```
|
||||
perlbrew install 5.27.11
|
||||
```
|
||||
|
||||
### 切换 Perl 版本
|
||||
|
||||
现在你已经安装了新版本,你可以将它用于该 shell:
|
||||
|
||||
```
|
||||
perlbrew use 5.27.11
|
||||
```
|
||||
|
||||
或者你可以将其设置为你帐户的默认 Perl 版本(假设你按照 `perlbrew init` 的输出设置了你的配置文件):
|
||||
|
||||
```
|
||||
perlbrew switch 5.27.11
|
||||
```
|
||||
|
||||
### 运行单个脚本
|
||||
|
||||
你也可以用特定版本的 Perl 运行单个命令:
|
||||
|
||||
```
|
||||
perlberew exec 5.27.11 myscript.pl
|
||||
```
|
||||
|
||||
或者,你可以针对所有已安装的版本运行命令。如果你想针对各种版本运行测试,这尤其方便。在这种情况下,请指定版本为 `perl`:
|
||||
|
||||
```
|
||||
plperlbrew exec perl myscriptpl
|
||||
```
|
||||
|
||||
### 安装 CPAN 模块
|
||||
|
||||
如果你想安装 CPAN 模块,`cpanm` 包是一个易于使用的界面,可以很好地与 Perlbrew 一起使用。用下面命令安装它:
|
||||
|
||||
```
|
||||
perlbrew install-cpanm
|
||||
```
|
||||
|
||||
然后,你可以使用 `cpanm` 命令安装 CPAN 模块:
|
||||
|
||||
```
|
||||
cpanm CGI::simple
|
||||
```
|
||||
|
||||
### 但是等下,还有更多!
|
||||
|
||||
本文介绍了基本的 Perlbrew 用法。还有更多功能和选项可供选择。从查看 `perlbrew help` 的输出开始,或查看[App::perlbrew 文档][3]。你还喜欢 Perlbrew 的其他什么功能?让我们在评论中知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/perlbrew
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://perlbrew.pl/
|
||||
[2]:https://raw.githubusercontent.com/gugod/App-perlbrew/master/perlbrew-install
|
||||
[3]:https://metacpan.org/pod/App::perlbrew
|
||||
366
published/201807/20180710 Python Sets What Why and How.md
Normal file
366
published/201807/20180710 Python Sets What Why and How.md
Normal file
@ -0,0 +1,366 @@
|
||||
Python 集合是什么,为什么应该使用以及如何使用?
|
||||
=====
|
||||
|
||||

|
||||
|
||||
Python 配备了几种内置数据类型来帮我们组织数据。这些结构包括列表、字典、元组和集合。
|
||||
|
||||
根据 Python 3 文档:
|
||||
|
||||
> 集合是一个*无序*集合,没有*重复元素*。基本用途包括*成员测试*和*消除重复的条目*。集合对象还支持数学运算,如*并集*、*交集*、*差集*和*对等差分*。
|
||||
|
||||
在本文中,我们将回顾并查看上述定义中列出的每个要素的示例。让我们马上开始,看看如何创建它。
|
||||
|
||||
### 初始化一个集合
|
||||
|
||||
有两种方法可以创建一个集合:一个是给内置函数 `set()` 提供一个元素列表,另一个是使用花括号 `{}`。
|
||||
|
||||
使用内置函数 `set()` 来初始化一个集合:
|
||||
|
||||
```
|
||||
>>> s1 = set([1, 2, 3])
|
||||
>>> s1
|
||||
{1, 2, 3}
|
||||
>>> type(s1)
|
||||
<class 'set'>
|
||||
```
|
||||
|
||||
使用 `{}`:
|
||||
|
||||
|
||||
```
|
||||
>>> s2 = {3, 4, 5}
|
||||
>>> s2
|
||||
{3, 4, 5}
|
||||
>>> type(s2)
|
||||
<class 'set'>
|
||||
>>>
|
||||
```
|
||||
|
||||
如你所见,这两种方法都是有效的。但问题是,如果我们想要一个空的集合呢?
|
||||
|
||||
```
|
||||
>>> s = {}
|
||||
>>> type(s)
|
||||
<class 'dict'>
|
||||
```
|
||||
|
||||
没错,如果我们使用空花括号,我们将得到一个字典而不是一个集合。=)
|
||||
|
||||
值得一提的是,为了简单起见,本文中提供的所有示例都将使用整数集合,但集合可以包含 Python 支持的所有 <ruby>[可哈希的][6]<rt>hashable</rt></ruby> 数据类型。换句话说,即整数、字符串和元组,而不是*列表*或*字典*这样的可变类型。
|
||||
|
||||
```
|
||||
>>> s = {1, 'coffee', [4, 'python']}
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
TypeError: unhashable type: 'list'
|
||||
```
|
||||
|
||||
既然你知道了如何创建一个集合以及它可以包含哪些类型的元素,那么让我们继续看看*为什么*我们总是应该把它放在我们的工具箱中。
|
||||
|
||||
### 为什么你需要使用它
|
||||
|
||||
写代码时,你可以用不止一种方法来完成它。有些被认为是相当糟糕的,另一些则是清晰的、简洁的和可维护的,或者是 “<ruby>[Python 式的][7]<rt>pythonic</rt></ruby>”。
|
||||
|
||||
根据 [Hitchhiker 对 Python 的建议][8]:
|
||||
|
||||
> 当一个经验丰富的 Python 开发人员(<ruby>Python 人<rt>Pythonista</rt></ruby>)调用一些不够 “<ruby>Python 式的<rt>pythonic</rt></ruby>” 的代码时,他们通常认为着这些代码不遵循通用指南,并且无法被认为是以一种好的方式(可读性)来表达意图。
|
||||
|
||||
让我们开始探索 Python 集合那些不仅可以帮助我们提高可读性,还可以加快程序执行时间的方式。
|
||||
|
||||
#### 无序的集合元素
|
||||
|
||||
首先你需要明白的是:你无法使用索引访问集合中的元素。
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s[0]
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
TypeError: 'set' object does not support indexing
|
||||
```
|
||||
|
||||
或者使用切片修改它们:
|
||||
|
||||
```
|
||||
>>> s[0:2]
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
TypeError: 'set' object is not subscriptable
|
||||
```
|
||||
|
||||
但是,如果我们需要删除重复项,或者进行组合列表(与)之类的数学运算,那么我们可以,并且*应该*始终使用集合。
|
||||
|
||||
我不得不提一下,在迭代时,集合的表现优于列表。所以,如果你需要它,那就加深对它的喜爱吧。为什么?好吧,这篇文章并不打算解释集合的内部工作原理,但是如果你感兴趣的话,这里有几个链接,你可以阅读它:
|
||||
|
||||
* [时间复杂度][1]
|
||||
* [set() 是如何实现的?][2]
|
||||
* [Python 集合 vs 列表][3]
|
||||
* [在列表中使用集合是否有任何优势或劣势,以确保独一无二的列表条目?][4]
|
||||
|
||||
#### 没有重复项
|
||||
|
||||
写这篇文章的时候,我总是不停地思考,我经常使用 `for` 循环和 `if` 语句检查并删除列表中的重复元素。记得那时我的脸红了,而且不止一次,我写了类似这样的代码:
|
||||
|
||||
```
|
||||
>>> my_list = [1, 2, 3, 2, 3, 4]
|
||||
>>> no_duplicate_list = []
|
||||
>>> for item in my_list:
|
||||
... if item not in no_duplicate_list:
|
||||
... no_duplicate_list.append(item)
|
||||
...
|
||||
>>> no_duplicate_list
|
||||
[1, 2, 3, 4]
|
||||
```
|
||||
|
||||
或者使用列表解析:
|
||||
|
||||
```
|
||||
>>> my_list = [1, 2, 3, 2, 3, 4]
|
||||
>>> no_duplicate_list = []
|
||||
>>> [no_duplicate_list.append(item) for item in my_list if item not in no_duplicate_list]
|
||||
[None, None, None, None]
|
||||
>>> no_duplicate_list
|
||||
[1, 2, 3, 4]
|
||||
```
|
||||
|
||||
但没关系,因为我们现在有了武器装备,没有什么比这更重要的了:
|
||||
|
||||
```
|
||||
>>> my_list = [1, 2, 3, 2, 3, 4]
|
||||
>>> no_duplicate_list = list(set(my_list))
|
||||
>>> no_duplicate_list
|
||||
[1, 2, 3, 4]
|
||||
>>>
|
||||
```
|
||||
|
||||
现在让我们使用 `timeit` 模块,查看列表和集合在删除重复项时的执行时间:
|
||||
|
||||
```
|
||||
>>> from timeit import timeit
|
||||
>>> def no_duplicates(list):
|
||||
... no_duplicate_list = []
|
||||
... [no_duplicate_list.append(item) for item in list if item not in no_duplicate_list]
|
||||
... return no_duplicate_list
|
||||
...
|
||||
>>> # 首先,让我们看看列表的执行情况:
|
||||
>>> print(timeit('no_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=1000))
|
||||
0.0018683355819786227
|
||||
```
|
||||
|
||||
```
|
||||
>>> from timeit import timeit
|
||||
>>> # 使用集合:
|
||||
>>> print(timeit('list(set([1, 2, 3, 1, 2, 3, 4]))', number=1000))
|
||||
0.0010220493243764395
|
||||
>>> # 快速而且干净 =)
|
||||
```
|
||||
|
||||
使用集合而不是列表推导不仅让我们编写*更少的代码*,而且还能让我们获得*更具可读性*和*高性能*的代码。
|
||||
|
||||
注意:请记住集合是无序的,因此无法保证在将它们转换回列表时,元素的顺序不变。
|
||||
|
||||
[Python 之禅][9]:
|
||||
|
||||
> <ruby>优美胜于丑陋<rt>Beautiful is better than ugly.</rt></ruby>
|
||||
|
||||
> <ruby>明了胜于晦涩<rt>Explicit is better than implicit.</rt></ruby>
|
||||
|
||||
> <ruby>简洁胜于复杂<rt>Simple is better than complex.</rt></ruby>
|
||||
|
||||
> <ruby>扁平胜于嵌套<rt>Flat is better than nested.</rt></ruby>
|
||||
|
||||
集合不正是这样美丽、明了、简单且扁平吗?
|
||||
|
||||
#### 成员测试
|
||||
|
||||
每次我们使用 `if` 语句来检查一个元素,例如,它是否在列表中时,意味着你正在进行成员测试:
|
||||
|
||||
```
|
||||
my_list = [1, 2, 3]
|
||||
>>> if 2 in my_list:
|
||||
... print('Yes, this is a membership test!')
|
||||
...
|
||||
Yes, this is a membership test!
|
||||
```
|
||||
|
||||
在执行这些操作时,集合比列表更高效:
|
||||
|
||||
```
|
||||
>>> from timeit import timeit
|
||||
>>> def in_test(iterable):
|
||||
... for i in range(1000):
|
||||
... if i in iterable:
|
||||
... pass
|
||||
...
|
||||
>>> timeit('in_test(iterable)',
|
||||
... setup="from __main__ import in_test; iterable = list(range(1000))",
|
||||
... number=1000)
|
||||
12.459663048726043
|
||||
```
|
||||
|
||||
```
|
||||
>>> from timeit import timeit
|
||||
>>> def in_test(iterable):
|
||||
... for i in range(1000):
|
||||
... if i in iterable:
|
||||
... pass
|
||||
...
|
||||
>>> timeit('in_test(iterable)',
|
||||
... setup="from __main__ import in_test; iterable = set(range(1000))",
|
||||
... number=1000)
|
||||
.12354438152988223
|
||||
```
|
||||
|
||||
注意:上面的测试来自于[这个][10] StackOverflow 话题。
|
||||
|
||||
因此,如果你在巨大的列表中进行这样的比较,尝试将该列表转换为集合,它应该可以加快你的速度。
|
||||
|
||||
### 如何使用
|
||||
|
||||
现在你已经了解了集合是什么以及为什么你应该使用它,现在让我们快速浏览一下,看看我们如何修改和操作它。
|
||||
|
||||
#### 添加元素
|
||||
|
||||
根据要添加的元素数量,我们要在 `add()` 和 `update()` 方法之间进行选择。
|
||||
|
||||
`add()` 适用于添加单个元素:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s.add(4)
|
||||
>>> s
|
||||
{1, 2, 3, 4}
|
||||
```
|
||||
|
||||
`update()` 适用于添加多个元素:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s.update([2, 3, 4, 5, 6])
|
||||
>>> s
|
||||
{1, 2, 3, 4, 5, 6}
|
||||
```
|
||||
|
||||
请记住,集合会移除重复项。
|
||||
|
||||
#### 移除元素
|
||||
|
||||
如果你希望在代码中尝试删除不在集合中的元素时收到警报,请使用 `remove()`。否则,`discard()` 提供了一个很好的选择:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s.remove(3)
|
||||
>>> s
|
||||
{1, 2}
|
||||
>>> s.remove(3)
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
KeyError: 3
|
||||
```
|
||||
|
||||
`discard()` 不会引起任何错误:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3}
|
||||
>>> s.discard(3)
|
||||
>>> s
|
||||
{1, 2}
|
||||
>>> s.discard(3)
|
||||
>>> # 什么都不会发生
|
||||
```
|
||||
|
||||
我们也可以使用 `pop()` 来随机丢弃一个元素:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3, 4, 5}
|
||||
>>> s.pop() # 删除一个任意的元素
|
||||
1
|
||||
>>> s
|
||||
{2, 3, 4, 5}
|
||||
```
|
||||
|
||||
或者 `clear()` 方法来清空一个集合:
|
||||
|
||||
```
|
||||
>>> s = {1, 2, 3, 4, 5}
|
||||
>>> s.clear() # 清空集合
|
||||
>>> s
|
||||
set()
|
||||
```
|
||||
|
||||
#### union()
|
||||
|
||||
`union()` 或者 `|` 将创建一个新集合,其中包含我们提供集合中的所有元素:
|
||||
|
||||
```
|
||||
>>> s1 = {1, 2, 3}
|
||||
>>> s2 = {3, 4, 5}
|
||||
>>> s1.union(s2) # 或者 's1 | s2'
|
||||
{1, 2, 3, 4, 5}
|
||||
```
|
||||
|
||||
#### intersection()
|
||||
|
||||
`intersection` 或 `&` 将返回一个由集合共同元素组成的集合:
|
||||
|
||||
```
|
||||
>>> s1 = {1, 2, 3}
|
||||
>>> s2 = {2, 3, 4}
|
||||
>>> s3 = {3, 4, 5}
|
||||
>>> s1.intersection(s2, s3) # 或者 's1 & s2 & s3'
|
||||
{3}
|
||||
```
|
||||
|
||||
#### difference()
|
||||
|
||||
使用 `diference()` 或 `-` 创建一个新集合,其值在 “s1” 中但不在 “s2” 中:
|
||||
|
||||
```
|
||||
>>> s1 = {1, 2, 3}
|
||||
>>> s2 = {2, 3, 4}
|
||||
>>> s1.difference(s2) # 或者 's1 - s2'
|
||||
{1}
|
||||
```
|
||||
|
||||
#### symmetric_diference()
|
||||
|
||||
`symetric_difference` 或 `^` 将返回集合之间的不同元素。
|
||||
|
||||
```
|
||||
>>> s1 = {1, 2, 3}
|
||||
>>> s2 = {2, 3, 4}
|
||||
>>> s1.symmetric_difference(s2) # 或者 's1 ^ s2'
|
||||
{1, 4}
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
我希望在阅读本文之后,你会知道集合是什么,如何操纵它的元素以及它可以执行的操作。知道何时使用集合无疑会帮助你编写更清晰的代码并加速你的程序。
|
||||
|
||||
如果你有任何疑问,请发表评论,我很乐意尝试回答。另外,不要忘记,如果你已经理解了集合,它们在 [Python Cheatsheet][12] 中有自己的[一席之地][11],在那里你可以快速参考并重新认知你已经知道的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.pythoncheatsheet.org/blog/python-sets-what-why-how
|
||||
|
||||
作者:[wilfredinni][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.pythoncheatsheet.org/author/wilfredinni
|
||||
[1]:https://wiki.python.org/moin/TimeComplexity
|
||||
[2]:https://stackoverflow.com/questions/3949310/how-is-set-implemented
|
||||
[3]:https://stackoverflow.com/questions/2831212/python-sets-vs-lists
|
||||
[4]:https://mail.python.org/pipermail/python-list/2011-June/606738.html
|
||||
[5]:https://www.pythoncheatsheet.org/author/wilfredinni
|
||||
[6]:https://docs.python.org/3/glossary.html#term-hashable
|
||||
[7]:http://docs.python-guide.org/en/latest/writing/style/
|
||||
[8]:http://docs.python-guide.org/en/latest/
|
||||
[9]:https://www.python.org/dev/peps/pep-0020/
|
||||
[10]:https://stackoverflow.com/questions/2831212/python-sets-vs-lists
|
||||
[11]:https://www.pythoncheatsheet.org/#sets
|
||||
[12]:https://www.pythoncheatsheet.org/
|
||||
|
||||
@ -0,0 +1,64 @@
|
||||
4 个提高你在 Thunderbird 上隐私的加载项
|
||||
======
|
||||
|
||||

|
||||
|
||||
Thunderbird 是由 [Mozilla][1] 开发的流行的免费电子邮件客户端。与 Firefox 类似,Thunderbird 提供了大量加载项来用于额外功能和自定义。本文重点介绍四个加载项,以改善你的隐私。
|
||||
|
||||
### Enigmail
|
||||
|
||||
使用 GPG(GNU Privacy Guard)加密电子邮件是保持其内容私密性的最佳方式。如果你不熟悉 GPG,请[查看我们在这里的入门介绍][2]。
|
||||
|
||||
[Enigmail][3] 是使用 OpenPGP 和 Thunderbird 的首选加载项。实际上,Enigmail 与 Thunderbird 集成良好,可让你加密、解密、数字签名和验证电子邮件。
|
||||
|
||||
### Paranoia
|
||||
|
||||
[Paranoia][4] 可让你查看有关收到的电子邮件的重要信息。用一个表情符号显示电子邮件在到达收件箱之前经过的服务器之间的加密状态。
|
||||
|
||||
黄色、快乐的表情告诉你所有连接都已加密。蓝色、悲伤的表情意味着有一个连接未加密。最后,红色的、害怕的表情表示在多个连接上该消息未加密。
|
||||
|
||||
还有更多有关这些连接的详细信息,你可以用来检查哪台服务器用于投递邮件。
|
||||
|
||||
### Sensitivity Header
|
||||
|
||||
[Sensitivity Header][5] 是一个简单的加载项,可让你选择外发电子邮件的隐私级别。使用选项菜单,你可以选择敏感度:正常、个人、隐私和机密。
|
||||
|
||||
添加此标头不会为电子邮件添加额外的安全性。但是,某些电子邮件客户端或邮件传输/用户代理(MTA/MUA)可以使用此标头根据敏感度以不同方式处理邮件。
|
||||
|
||||
请注意,开发人员将此加载项标记为实验性的。
|
||||
|
||||
### TorBirdy
|
||||
|
||||
如果你真的担心自己的隐私,[TorBirdy][6] 就是给你设计的加载项。它将 Thunderbird 配置为使用 [Tor][7] 网络。
|
||||
|
||||
据其[文档][8]所述,TorBirdy 为以前没有使用 Tor 的电子邮件帐户提供了少量隐私保护。
|
||||
|
||||
> 请记住,跟之前使用 Tor 访问的电子邮件帐户相比,之前没有使用 Tor 访问的电子邮件帐户提供**更少**的隐私/匿名/更弱的假名。但是,TorBirdy 仍然对现有帐户或实名电子邮件地址有用。例如,如果你正在寻求隐匿位置 —— 你经常旅行并且不想通过发送电子邮件来披露你的所有位置 —— TorBirdy 非常有效!
|
||||
|
||||
请注意,要使用此加载项,必须在系统上安装 Tor。
|
||||
|
||||
照片由 [Braydon Anderson][9] 在 [Unsplash][10] 上发布。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-addons-privacy-thunderbird/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://www.mozilla.org/en-US/
|
||||
[2]:https://fedoramagazine.org/gnupg-a-fedora-primer/
|
||||
[3]:https://addons.mozilla.org/en-US/thunderbird/addon/enigmail/
|
||||
[4]:https://addons.mozilla.org/en-US/thunderbird/addon/paranoia/?src=cb-dl-users
|
||||
[5]:https://addons.mozilla.org/en-US/thunderbird/addon/sensitivity-header/?src=cb-dl-users
|
||||
[6]:https://addons.mozilla.org/en-US/thunderbird/addon/torbirdy/?src=cb-dl-users
|
||||
[7]:https://www.torproject.org/
|
||||
[8]:https://trac.torproject.org/projects/tor/wiki/torbirdy
|
||||
[9]:https://unsplash.com/photos/wOHH-NUTvVc?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[10]:https://unsplash.com/search/photos/privacy?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,174 @@
|
||||
在 Ubuntu 18.04 LTS 上安装 Microsoft Windows 字体
|
||||
======
|
||||
|
||||

|
||||
|
||||
大多数教育机构仍在使用 Microsoft 字体, 我不清楚其他国家是什么情况。但在泰米尔纳德邦(印度的一个州), **Times New Roman** 和 **Arial** 字体主要被用于大学和学校的几乎所有文档工作、项目和作业。不仅是教育机构,而且一些小型组织、办公室和商店仍在使用 MS Windows 字体。以防万一,如果你需要在 Ubuntu 桌面版上使用 Microsoft 字体,请按照以下步骤安装。
|
||||
|
||||
**免责声明**: Microsoft 已免费发布其核心字体。 但**请注意 Microsoft 字体是禁止使用在其他操作系统中**。在任何 Linux 操作系统中安装 MS 字体之前请仔细阅读 EULA 。我们不负责这种任何种类的盗版行为。
|
||||
|
||||
(LCTT 译注:本文只做技术探讨,并不代表作者、译者和本站鼓励任何行为。)
|
||||
|
||||
### 在 Ubuntu 18.04 LTS 桌面版上安装 MS 字体
|
||||
|
||||
如下所示安装 MS TrueType 字体:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install ttf-mscorefonts-installer
|
||||
```
|
||||
|
||||
然后将会出现 Microsoft 的最终用户协议向导,点击 **OK** 以继续。
|
||||
|
||||
![][2]
|
||||
|
||||
点击 **Yes** 已接受 Microsoft 的协议:
|
||||
|
||||
![][3]
|
||||
|
||||
安装字体之后, 我们需要使用命令行来更新字体缓存:
|
||||
|
||||
```
|
||||
$ sudo fc-cache -f -v
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
/usr/share/fonts: caching, new cache contents: 0 fonts, 6 dirs
|
||||
/usr/share/fonts/X11: caching, new cache contents: 0 fonts, 4 dirs
|
||||
/usr/share/fonts/X11/Type1: caching, new cache contents: 8 fonts, 0 dirs
|
||||
/usr/share/fonts/X11/encodings: caching, new cache contents: 0 fonts, 1 dirs
|
||||
/usr/share/fonts/X11/encodings/large: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/X11/misc: caching, new cache contents: 89 fonts, 0 dirs
|
||||
/usr/share/fonts/X11/util: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cMap: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap: caching, new cache contents: 0 fonts, 5 dirs
|
||||
/usr/share/fonts/cmap/adobe-cns1: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap/adobe-gb1: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap/adobe-japan1: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap/adobe-japan2: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/cmap/adobe-korea1: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/usr/share/fonts/opentype: caching, new cache contents: 0 fonts, 2 dirs
|
||||
/usr/share/fonts/opentype/malayalam: caching, new cache contents: 3 fonts, 0 dirs
|
||||
/usr/share/fonts/opentype/noto: caching, new cache contents: 24 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype: caching, new cache contents: 0 fonts, 46 dirs
|
||||
/usr/share/fonts/truetype/Gargi: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Gubbi: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Nakula: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Navilu: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Sahadeva: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/Sarai: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/abyssinica: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/dejavu: caching, new cache contents: 6 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/droid: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-beng-extra: caching, new cache contents: 6 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-deva-extra: caching, new cache contents: 3 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-gujr-extra: caching, new cache contents: 5 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-guru-extra: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-kalapi: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-orya-extra: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/fonts-telu-extra: caching, new cache contents: 2 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/freefont: caching, new cache contents: 12 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/kacst: caching, new cache contents: 15 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/kacst-one: caching, new cache contents: 2 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lao: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/liberation: caching, new cache contents: 16 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/liberation2: caching, new cache contents: 12 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-assamese: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-bengali: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-devanagari: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-gujarati: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-kannada: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-malayalam: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-oriya: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-punjabi: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-tamil: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-tamil-classical: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/lohit-telugu: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/malayalam: caching, new cache contents: 11 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/msttcorefonts: caching, new cache contents: 60 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/noto: caching, new cache contents: 2 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/openoffice: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/padauk: caching, new cache contents: 4 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/pagul: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/samyak: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/samyak-fonts: caching, new cache contents: 3 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/sinhala: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/tibetan-machine: caching, new cache contents: 1 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/tlwg: caching, new cache contents: 58 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/ttf-khmeros-core: caching, new cache contents: 2 fonts, 0 dirs
|
||||
/usr/share/fonts/truetype/ubuntu: caching, new cache contents: 13 fonts, 0 dirs
|
||||
/usr/share/fonts/type1: caching, new cache contents: 0 fonts, 1 dirs
|
||||
/usr/share/fonts/type1/gsfonts: caching, new cache contents: 35 fonts, 0 dirs
|
||||
/usr/local/share/fonts: caching, new cache contents: 0 fonts, 0 dirs
|
||||
/home/sk/.local/share/fonts: skipping, no such directory
|
||||
/home/sk/.fonts: skipping, no such directory
|
||||
/var/cache/fontconfig: cleaning cache directory
|
||||
/home/sk/.cache/fontconfig: cleaning cache directory
|
||||
/home/sk/.fontconfig: not cleaning non-existent cache directory
|
||||
fc-cache: succeeded
|
||||
```
|
||||
|
||||
### 在 Linux 和 Windows 双启动的机器上安装 MS 字体
|
||||
|
||||
如果你有 Linux 和 Windows 的双启动系统,你可以轻松地从 Windows C 驱动器上安装 MS 字体。
|
||||
你所要做的就是挂载 Windows 分区(C:/windows)。
|
||||
|
||||
我假设你已经在 Linux 中将 `C:\Windows` 分区挂载在了 `/Windowsdrive` 目录下。
|
||||
|
||||
现在,将字体位置链接到你的 Linux 系统的字体文件夹,如下所示:
|
||||
|
||||
```
|
||||
ln -s /Windowsdrive/Windows/Fonts /usr/share/fonts/WindowsFonts
|
||||
```
|
||||
|
||||
链接字体文件之后,使用命令行重新生成 fontconfig 缓存:
|
||||
|
||||
```
|
||||
fc-cache
|
||||
```
|
||||
|
||||
或者,将所有的 Windows 字体复制到 `/usr/share/fonts` 目录下并使用一下命令安装字体:
|
||||
|
||||
```
|
||||
mkdir /usr/share/fonts/WindowsFonts
|
||||
cp /Windowsdrive/Windows/Fonts/* /usr/share/fonts/WindowsFonts
|
||||
chmod 755 /usr/share/fonts/WindowsFonts/*
|
||||
```
|
||||
|
||||
最后,使用命令行重新生成 fontconfig 缓存:
|
||||
|
||||
```
|
||||
fc-cache
|
||||
```
|
||||
|
||||
|
||||
### 测试 Windows 字体
|
||||
|
||||
安装 MS 字体后打开 LibreOffice 或 GIMP。 现在,你将会看到 Microsoft coretype 字体。
|
||||
|
||||
![][4]
|
||||
|
||||
就是这样, 希望这本指南有用。我再次警告你,在其他操作系统中使用 MS 字体是被禁止的。在安装 MS 字体之前请先阅读 Microsoft 许可协议。
|
||||
|
||||
如果你觉得我们的指南有用,请在你的社区、专业网络上分享并支持我们。还有更多好东西在等着我们。持续访问!
|
||||
|
||||
庆祝吧!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/install-microsoft-windows-fonts-ubuntu-16-04/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/07/ms-fonts-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2016/07/ms-fonts-2.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/07/ms-fonts-3.png
|
||||
@ -0,0 +1,157 @@
|
||||
如何强制用户在下次登录 Linux 时更改密码
|
||||
======
|
||||
|
||||
当你使用默认密码创建用户时,你必须强制用户在下一次登录时更改密码。
|
||||
|
||||
当你在一个组织中工作时,此选项是强制性的。因为老员工可能知道默认密码,他们可能会也可能不会尝试不当行为。
|
||||
|
||||
这是安全投诉之一,所以,确保你必须以正确的方式处理此事而无任何失误。即使是你的团队成员也要一样做。
|
||||
|
||||
大多数用户都很懒,除非你强迫他们更改密码,否则他们不会这样做。所以要做这个实践。
|
||||
|
||||
出于安全原因,你需要经常更改密码,或者至少每个月更换一次。
|
||||
|
||||
确保你使用的是难以猜测的密码(大小写字母,数字和特殊字符的组合)。它至少应该为 10-15 个字符。
|
||||
|
||||
我们运行了一个 shell 脚本来在 Linux 服务器中创建一个用户账户,它会自动为用户附加一个密码,密码是实际用户名和少量数字的组合。
|
||||
|
||||
我们可以通过使用以下两种方法来实现这一点:
|
||||
|
||||
* passwd 命令
|
||||
* chage 命令
|
||||
|
||||
**建议阅读:**
|
||||
|
||||
- [如何在 Linux 上检查用户所属的组][1]
|
||||
- [如何在 Linux 上检查创建用户的日期][2]
|
||||
- [如何在 Linux 中重置/更改用户密码][3]
|
||||
- [如何使用 passwd 命令管理密码过期和老化][4]
|
||||
|
||||
### 方法 1:使用 passwd 命令
|
||||
|
||||
`passwd` 的意思是“密码”。它用于更新用户的身份验证令牌。`passwd` 命令/实用程序用于设置、修改或更改用户的密码。
|
||||
|
||||
普通的用户只能更改自己的账户,但超级用户可以更改任何账户的密码。
|
||||
|
||||
此外,我们还可以使用其他选项,允许用户执行其他活动,例如删除用户密码、锁定或解锁用户账户、设置用户账户的密码过期时间等。
|
||||
|
||||
在 Linux 中这可以通过调用 Linux-PAM 和 Libuser API 执行。
|
||||
|
||||
在 Linux 中创建用户时,用户详细信息将存储在 `/etc/passwd` 文件中。`passwd` 文件将每个用户的详细信息保存为带有七个字段的单行。
|
||||
|
||||
此外,在 Linux 系统中创建新用户时,将更新以下四个文件。
|
||||
|
||||
* `/etc/passwd`: 用户详细信息将在此文件中更新。
|
||||
* `/etc/shadow`: 用户密码信息将在此文件中更新。
|
||||
* `/etc/group`: 新用户的组详细信息将在此文件中更新。
|
||||
* `/etc/gshadow`: 新用户的组密码信息将在此文件中更新。
|
||||
|
||||
#### 如何使用 passwd 命令执行此操作
|
||||
|
||||
我们可以使用 `passwd` 命令并添加 `-e` 选项来执行此操作。
|
||||
|
||||
为了测试这一点,让我们创建一个新用户账户,看看它是如何工作的。
|
||||
|
||||
```
|
||||
# useradd -c "2g Admin - Magesh M" magesh && passwd magesh
|
||||
Changing password for user magesh.
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
使用户账户的密码失效,那么在下次登录尝试期间,用户将被迫更改密码。
|
||||
|
||||
```
|
||||
# passwd -e magesh
|
||||
Expiring password for user magesh.
|
||||
passwd: Success
|
||||
```
|
||||
|
||||
当我第一次尝试使用此用户登录系统时,它要求我设置一个新密码。
|
||||
|
||||
```
|
||||
login as: magesh
|
||||
[email protected]'s password:
|
||||
You are required to change your password immediately (root enforced)
|
||||
WARNING: Your password has expired.
|
||||
You must change your password now and login again!
|
||||
Changing password for user magesh.
|
||||
Changing password for magesh.
|
||||
(current) UNIX password:
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
Connection to localhost closed.
|
||||
```
|
||||
|
||||
### 方法 2:使用 chage 命令
|
||||
|
||||
`chage` 意即“改变时间”。它会更改用户密码过期信息。
|
||||
|
||||
`chage` 命令会改变上次密码更改日期之后需要修改密码的天数。系统使用此信息来确定用户何时必须更改他/她的密码。
|
||||
|
||||
它允许用户执行其他活动,例如设置帐户到期日期,到期后设置密码失效,显示帐户过期信息,设置密码更改前的最小和最大天数以及设置到期警告天数。
|
||||
|
||||
#### 如何使用 chage 命令执行此操作
|
||||
|
||||
让我们在 `chage` 命令的帮助下,通过添加 `-d` 选项执行此操作。
|
||||
|
||||
为了测试这一点,让我们创建一个新用户帐户,看看它是如何工作的。我们将创建一个名为 `thanu` 的用户帐户。
|
||||
|
||||
```
|
||||
# useradd -c "2g Editor - Thanisha M" thanu && passwd thanu
|
||||
Changing password for user thanu.
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
要实现这一点,请使用 `chage` 命令将用户的上次密码更改日期设置为 0。
|
||||
|
||||
```
|
||||
# chage -d 0 thanu
|
||||
|
||||
# chage -l thanu
|
||||
Last password change : Jul 18, 2018
|
||||
Password expires : never
|
||||
Password inactive : never
|
||||
Account expires : never
|
||||
Minimum number of days between password change : 0
|
||||
Maximum number of days between password change : 99999
|
||||
Number of days of warning before password expires : 7
|
||||
```
|
||||
|
||||
当我第一次尝试使用此用户登录系统时,它要求我设置一个新密码。
|
||||
|
||||
```
|
||||
login as: thanu
|
||||
[email protected]'s password:
|
||||
You are required to change your password immediately (root enforced)
|
||||
WARNING: Your password has expired.
|
||||
You must change your password now and login again!
|
||||
Changing password for user thanu.
|
||||
Changing password for thanu.
|
||||
(current) UNIX password:
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
Connection to localhost closed.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/
|
||||
[2]:https://www.2daygeek.com/how-to-check-user-created-date-on-linux/
|
||||
[3]:https://www.2daygeek.com/passwd-command-examples/
|
||||
[4]:https://www.2daygeek.com/passwd-command-examples-part-l/
|
||||
@ -0,0 +1,71 @@
|
||||
如何检查 Linux 中的可用磁盘空间
|
||||
======
|
||||
|
||||
> 用这里列出的方便的工具来跟踪你的磁盘利用率。
|
||||
|
||||

|
||||
|
||||
跟踪磁盘利用率信息是系统管理员(和其他人)的日常待办事项列表之一。Linux 有一些内置的使用程序来帮助提供这些信息。
|
||||
|
||||
### df
|
||||
|
||||
`df` 命令意思是 “disk-free”,显示 Linux 系统上可用和已使用的磁盘空间。
|
||||
|
||||
`df -h` 以人类可读的格式显示磁盘空间。
|
||||
|
||||
`df -a` 显示文件系统的完整磁盘使用情况,即使 Available(可用) 字段为 0。
|
||||
|
||||
|
||||
|
||||
`df -T` 显示磁盘使用情况以及每个块的文件系统类型(例如,xfs、ext2、ext3、btrfs 等)。
|
||||
|
||||
`df -i` 显示已使用和未使用的 inode。
|
||||
|
||||
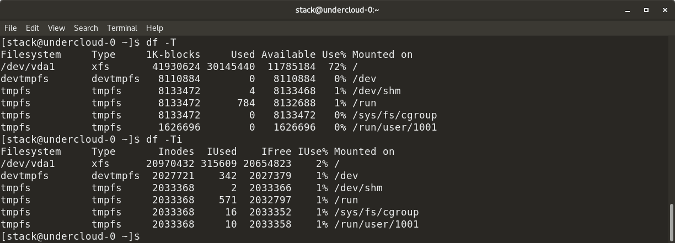
|
||||
|
||||
### du
|
||||
|
||||
`du` 显示文件,目录等的磁盘使用情况,默认情况下以 kb 为单位显示。
|
||||
|
||||
`du -h` 以人类可读的方式显示所有目录和子目录的磁盘使用情况。
|
||||
|
||||
`du -a` 显示所有文件的磁盘使用情况。
|
||||
|
||||
`du -s` 提供特定文件或目录使用的总磁盘空间。
|
||||
|
||||
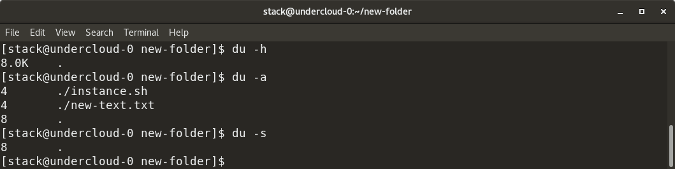
|
||||
|
||||
### ls -al
|
||||
|
||||
`ls -al` 列出了特定目录的全部内容及大小。
|
||||
|
||||
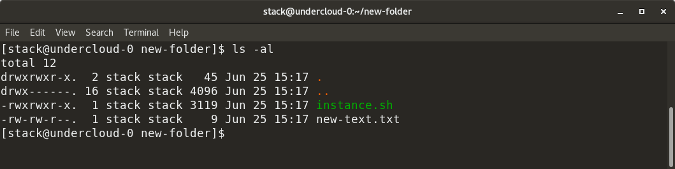
|
||||
|
||||
### stat
|
||||
|
||||
`stat <文件/目录> `显示文件/目录或文件系统的大小和其他统计信息。
|
||||
|
||||
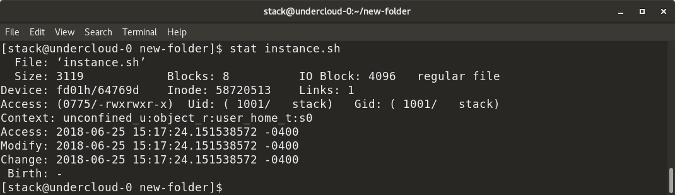
|
||||
|
||||
### fdisk -l
|
||||
|
||||
`fdisk -l` 显示磁盘大小以及磁盘分区信息。
|
||||
|
||||
|
||||
|
||||
这些是用于检查 Linux 文件空间的大多数内置实用程序。有许多类似的工具,如 [Disks][1](GUI 工具),[Ncdu][2] 等,它们也显示磁盘空间的利用率。你有你最喜欢的工具而它不在这个列表上吗?请在评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/how-check-free-disk-space-linux
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:https://wiki.gnome.org/Apps/Disks
|
||||
[2]:https://dev.yorhel.nl/ncdu
|
||||
@ -0,0 +1,137 @@
|
||||
学习如何使用 Python 构建你自己的 Twitter 机器人
|
||||
======
|
||||
|
||||

|
||||
|
||||
Twitter 允许用户将博客帖子和文章[分享][1]给全世界。使用 Python 和 Tweepy 库使得创建一个 Twitter 机器人来接管你的所有的推特变得非常简单。这篇文章告诉你如何去构建这样一个机器人。希望你能将这些概念也同样应用到其他的在线服务的项目中去。
|
||||
|
||||
### 开始
|
||||
|
||||
[tweepy][2] 库可以让创建一个 Twitter 机器人的过程更加容易上手。它包含了 Twitter 的 API 调用和一个很简单的接口。
|
||||
|
||||
下面这些命令使用 `pipenv` 在一个虚拟环境中安装 tweepy。如果你没有安装 `pipenv`,可以看一看我们之前的文章[如何在 Fedora 上安装 Pipenv][3]。
|
||||
|
||||
```
|
||||
$ mkdir twitterbot
|
||||
$ cd twitterbot
|
||||
$ pipenv --three
|
||||
$ pipenv install tweepy
|
||||
$ pipenv shell
|
||||
```
|
||||
|
||||
### Tweepy —— 开始
|
||||
|
||||
要使用 Twitter API ,机器人需要通过 Twitter 的授权。为了解决这个问题, tweepy 使用了 OAuth 授权标准。你可以通过在 <https://apps.twitter.com/> 创建一个新的应用来获取到凭证。
|
||||
|
||||
|
||||
#### 创建一个新的 Twitter 应用
|
||||
|
||||
当你填完了表格并点击了“<ruby>创建你自己的 Twitter 应用<rt>Create your Twitter application</rt></ruby>”的按钮后,你可以获取到该应用的凭证。 Tweepy 需要<ruby>用户密钥<rt>API Key</rt></ruby>和<ruby>用户密码<rt>API Secret</rt></ruby>,这些都可以在 “<ruby>密钥和访问令牌<rt>Keys and Access Tokens</rt></ruby>” 中找到。
|
||||
|
||||
![][4]
|
||||
|
||||
向下滚动页面,使用“<ruby>创建我的访问令牌<rt>Create my access token</rt></ruby>”按钮生成一个“<ruby>访问令牌<rt>Access Token</rt></ruby>” 和一个“<ruby>访问令牌密钥<rt>Access Token Secret</rt></ruby>”。
|
||||
|
||||
#### 使用 Tweppy —— 输出你的时间线
|
||||
|
||||
现在你已经有了所需的凭证了,打开一个文件,并写下如下的 Python 代码。
|
||||
|
||||
```
|
||||
import tweepy
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
api = tweepy.API(auth)
|
||||
public_tweets = api.home_timeline()
|
||||
for tweet in public_tweets:
|
||||
print(tweet.text)
|
||||
```
|
||||
|
||||
在确保你正在使用你的 Pipenv 虚拟环境后,执行你的程序。
|
||||
|
||||
```
|
||||
$ python tweet.py
|
||||
```
|
||||
|
||||
上述程序调用了 `home_timeline` 方法来获取到你时间线中的 20 条最近的推特。现在这个机器人能够使用 tweepy 来获取到 Twitter 的数据,接下来尝试修改代码来发送 tweet。
|
||||
|
||||
#### 使用 Tweepy —— 发送一条推特
|
||||
|
||||
要发送一条推特 ,有一个容易上手的 API 方法 `update_status` 。它的用法很简单:
|
||||
|
||||
```
|
||||
api.update_status("The awesome text you would like to tweet")
|
||||
```
|
||||
|
||||
Tweepy 拓展为制作 Twitter 机器人准备了非常多不同有用的方法。要获取 API 的详细信息,请查看[文档][5]。
|
||||
|
||||
|
||||
### 一个杂志机器人
|
||||
|
||||
接下来我们来创建一个搜索 Fedora Magazine 的推特并转推这些的机器人。
|
||||
|
||||
为了避免多次转推相同的内容,这个机器人存放了最近一条转推的推特的 ID 。 两个助手函数 `store_last_id` 和 `get_last_id` 将会帮助存储和保存这个 ID。
|
||||
|
||||
然后,机器人使用 tweepy 搜索 API 来查找 Fedora Magazine 的最近的推特并存储这个 ID。
|
||||
|
||||
```
|
||||
import tweepy
|
||||
|
||||
def store_last_id(tweet_id):
|
||||
""" Stores a tweet id in text file """
|
||||
with open('lastid', 'w') as fp:
|
||||
fp.write(str(tweet_id))
|
||||
|
||||
|
||||
def get_last_id():
|
||||
""" Retrieve the list of tweets that were
|
||||
already retweeted """
|
||||
|
||||
with open('lastid') as fp:
|
||||
return fp.read()
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
|
||||
api = tweepy.API(auth)
|
||||
|
||||
try:
|
||||
last_id = get_last_id()
|
||||
except FileNotFoundError:
|
||||
print("No retweet yet")
|
||||
last_id = None
|
||||
|
||||
for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items():
|
||||
if tweet.user.name == 'Fedora Project':
|
||||
store_last_id(tweet.id)
|
||||
#tweet.retweet()
|
||||
print(f'"{tweet.text}" was retweeted')
|
||||
```
|
||||
|
||||
为了只转推 Fedora Magazine 的推特 ,机器人搜索内容包含 fedoramagazine.org 和由 「Fedora Project」 Twitter 账户发布的推特。
|
||||
|
||||
### 结论
|
||||
|
||||
在这篇文章中你看到了如何使用 tweepy 的 Python 库来创建一个自动阅读、发送和搜索推特的 Twitter 应用。现在,你能使用你自己的创造力来创造一个你自己的 Twitter 机器人。
|
||||
|
||||
这篇文章的演示源码可以在 [Github][6] 找到。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-build-twitter-bot-python/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://twitter.com
|
||||
[2]:https://tweepy.readthedocs.io/en/v3.5.0/
|
||||
[3]:https://linux.cn/article-9827-1.html
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-19-20-17-17.png
|
||||
[5]:http://docs.tweepy.org/en/v3.5.0/api.html#id1
|
||||
[6]:https://github.com/cverna/magabot
|
||||
63
published/201807/20190909 Firefox 69 available in Fedora.md
Normal file
63
published/201807/20190909 Firefox 69 available in Fedora.md
Normal file
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11354-1.html)
|
||||
[#]: subject: (Firefox 69 available in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/firefox-69-available-in-fedora/)
|
||||
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
Firefox 69 已可在 Fedora 中获取
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
当你安装 Fedora Workstation 时,你会发现它包括了世界知名的 Firefox 浏览器。 Mozilla 基金会以开发 Firefox 以及其他促进开放、安全和隐私的互联网项目为己任。Firefox 有快速的浏览引擎和大量的隐私功能。
|
||||
|
||||
开发者社区不断改进和增强 Firefox。最新版本 Firefox 69 于最近发布,你可在稳定版 Fedora 系统(30 及更高版本)中获取它。继续阅读以获得更多详情。
|
||||
|
||||
### Firefox 69 中的新功能
|
||||
|
||||
最新版本的 Firefox 包括<ruby>[增强跟踪保护][2]<rt>Enhanced Tracking Protection</rt></ruby>(ETP)。当你使用带有新(或重置)配置文件的 Firefox 69 时,浏览器会使网站更难以跟踪你的信息或滥用你的计算机资源。
|
||||
|
||||
例如,不太正直的网站使用脚本让你的系统进行大量计算来产生加密货币,这称为<ruby>[加密挖矿][3]<rt>cryptomining</rt></ruby>。加密挖矿在你不知情或未经许可的情况下发生,因此是对你的系统的滥用。Firefox 69 中的新标准设置可防止网站遭受此类滥用。
|
||||
|
||||
Firefox 69 还有其他设置,可防止识别或记录你的浏览器指纹,以供日后使用。这些改进为你提供了额外的保护,免于你的活动被在线追踪。
|
||||
|
||||
另一个常见的烦恼是在没有提示的情况下播放视频。视频播放也会占用更多的 CPU,你可能不希望未经许可就在你的笔记本上发生这种情况。Firefox 使用<ruby>[阻止自动播放][4]<rt>Block Autoplay</rt></ruby>这个功能阻止了这种情况的发生。而 Firefox 69 还允许你停止静默开始播放的视频。此功能可防止不必要的突然的噪音。它还解决了更多真正的问题 —— 未经许可使用计算机资源。
|
||||
|
||||
新版本中还有许多其他新功能。在 [Firefox 发行说明][5]中阅读有关它们的更多信息。
|
||||
|
||||
### 如何获得更新
|
||||
|
||||
Firefox 69 存在于稳定版 Fedora 30、预发布版 Fedora 31 和 Rawhide 仓库中。该更新由 Fedora 的 Firefox 包维护者提供。维护人员还确保更新了 Mozilla 的网络安全服务(nss 包)。我们感谢 Mozilla 项目和 Firefox 社区在提供此新版本方面的辛勤工作。
|
||||
|
||||
如果你使用的是 Fedora 30 或更高版本,请在 Fedora Workstation 上使用*软件中心*,或在任何 Fedora 系统上运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf --refresh upgrade firefox
|
||||
```
|
||||
|
||||
如果你使用的是 Fedora 29,请[帮助测试更新][6],这样它可以变得稳定,让所有用户可以轻松使用。
|
||||
|
||||
Firefox 可能会提示你升级个人设置以使用新设置。要使用新功能,你应该这样做。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/firefox-69-available-in-fedora/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/09/firefox-v69-816x345.jpg
|
||||
[2]: https://blog.mozilla.org/blog/2019/09/03/todays-firefox-blocks-third-party-tracking-cookies-and-cryptomining-by-default/
|
||||
[3]: https://www.webopedia.com/TERM/C/cryptocurrency-mining.html
|
||||
[4]: https://support.mozilla.org/kb/block-autoplay
|
||||
[5]: https://www.mozilla.org/en-US/firefox/69.0/releasenotes/
|
||||
[6]: https://bodhi.fedoraproject.org/updates/FEDORA-2019-89ae5bb576
|
||||
115
published/20180704 BASHing data- Truncated data items.md
Normal file
115
published/20180704 BASHing data- Truncated data items.md
Normal file
@ -0,0 +1,115 @@
|
||||
如何发现截断的数据项
|
||||
======
|
||||
|
||||
**截断**(形容词):缩写、删节、缩减、剪切、剪裁、裁剪、修剪……
|
||||
|
||||
数据项被截断的一种情况是将其输入到数据库字段中,该字段的字符限制比数据项的长度要短。例如,字符串:
|
||||
|
||||
```
|
||||
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE of Yermo CA
|
||||
```
|
||||
|
||||
是 60 个字符长。如果你将其输入到具有 50 个字符限制的“位置”字段,则可以获得:
|
||||
|
||||
```
|
||||
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE #末尾带有一个空格
|
||||
```
|
||||
|
||||
截断也可能导致数据错误,比如你打算输入:
|
||||
|
||||
```
|
||||
Sally Ann Hunter (aka Sally Cleveland)
|
||||
```
|
||||
|
||||
但是你忘记了闭合的括号:
|
||||
|
||||
```
|
||||
Sally Ann Hunter (aka Sally Cleveland
|
||||
```
|
||||
|
||||
这会让使用数据的用户觉得 Sally 是否有被修剪掉了数据项的其它的别名。
|
||||
|
||||
截断的数据项很难检测。在审核数据时,我使用三种不同的方法来查找可能的截断,但我仍然可能会错过一些。
|
||||
|
||||
**数据项的长度分布。**第一种方法是捕获我在各个字段中找到的大多数截断的数据。我将字段传递给 `awk` 命令,该命令按字段宽度计算数据项,然后我使用 `sort` 以宽度的逆序打印计数。例如,要检查以 `tab` 分隔的文件 `midges` 中的第 33 个字段:
|
||||
|
||||
```
|
||||
awk -F"\t" 'NR>1 {a[length($33)]++} \
|
||||
END {for (i in a) print i FS a[i]}' midges | sort -nr
|
||||
```
|
||||
|
||||
![distro1][1]
|
||||
|
||||
最长的条目恰好有 50 个字符,这是可疑的,并且在该宽度处存在数据项的“凸起”,这更加可疑。检查这些 50 个字符的项目会发现截断:
|
||||
|
||||
![distro2][2]
|
||||
|
||||
我用这种方式检查的其他数据表有 100、200 和 255 个字符的“凸起”。在每种情况下,这种“凸起”都包含明显的截断。
|
||||
|
||||
**未匹配的括号。**第二种方法查找类似 `...(Sally Cleveland` 的数据项。一个很好的起点是数据表中所有标点符号的统计。这里我检查文件 `mag2`:
|
||||
|
||||
```
|
||||
grep -o "[[:punct:]]" file | sort | uniqc
|
||||
```
|
||||
|
||||
![punct][3]
|
||||
|
||||
请注意,`mag2` 中的开括号和闭括号的数量不相等。要查看发生了什么,我使用 `unmatched` 函数,它接受三个参数并检查数据表中的所有字段。第一个参数是文件名,第二个和第三个是开括号和闭括号,用引号括起来。
|
||||
|
||||
```
|
||||
unmatched()
|
||||
{
|
||||
awk -F"\t" -v start="$2" -v end="$3" \
|
||||
'{for (i=1;i<=NF;i++) \
|
||||
if (split($i,a,start) != split($i,b,end)) \
|
||||
print "line "NR", field "i":\n"$i}' "$1"
|
||||
}
|
||||
```
|
||||
|
||||
如果在字段中找到开括号和闭括号之间不匹配,则 `unmatched` 会报告行号和字段号。这依赖于 `awk` 的 `split` 函数,它返回由分隔符分隔的元素数(包括空格)。这个数字总是比分隔符的数量多一个:
|
||||
|
||||
![split][4]
|
||||
|
||||
这里 `ummatched` 检查 `mag2` 中的圆括号并找到一些可能的截断:
|
||||
|
||||
![unmatched][5]
|
||||
|
||||
我使用 `unmatched` 来找到不匹配的圆括号 `()`、方括号 `[]`、花括号 `{}` 和尖括号 `<>`,但该函数可用于任何配对的标点字符。
|
||||
|
||||
**意外的结尾。**第三种方法查找以尾随空格或非终止标点符号结尾的数据项,如逗号或连字符。这可以在单个字段上用 `cut` 用管道输入到 `grep` 完成,或者用 `awk` 一步完成。在这里,我正在检查以制表符分隔的表 `herp5` 的字段 47,并提取可疑数据项及其行号:
|
||||
|
||||
```
|
||||
cut -f47 herp5 | grep -n "[ ,;:-]$"
|
||||
或
|
||||
awk -F"\t" '$47 ~ /[ ,;:-]$/ {print NR": "$47}' herp5
|
||||
```
|
||||
|
||||
![herps5][6]
|
||||
|
||||
用于制表符分隔文件的 awk 命令的全字段版本是:
|
||||
|
||||
```
|
||||
awk -F"\t" '{for (i=1;i<=NF;i++) if ($i ~ /[ ,;:-]$/) \
|
||||
print "line "NR", field "i":\n"$i}' file
|
||||
```
|
||||
|
||||
**谨慎的想法。**在我对字段进行的验证测试期间也会出现截断。例如,我可能会在“年”的字段中检查合理的 4 位数条目,并且有个 `198` 可能是 198n?还是 1898 年?带有丢失字符的截断数据项是个谜。 作为数据审计员,我只能报告(可能的)字符损失,并建议数据编制者或管理者恢复(可能)丢失的字符。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.polydesmida.info/BASHing/2018-07-04.html
|
||||
|
||||
作者:[polydesmida][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.polydesmida.info/
|
||||
[1]:https://www.polydesmida.info/BASHing/img1/2018-07-04_1.png
|
||||
[2]:https://www.polydesmida.info/BASHing/img1/2018-07-04_2.png
|
||||
[3]:https://www.polydesmida.info/BASHing/img1/2018-07-04_3.png
|
||||
[4]:https://www.polydesmida.info/BASHing/img1/2018-07-04_4.png
|
||||
[5]:https://www.polydesmida.info/BASHing/img1/2018-07-04_5.png
|
||||
[6]:https://www.polydesmida.info/BASHing/img1/2018-07-04_6.png
|
||||
@ -5,47 +5,47 @@
|
||||
|
||||
### 网络自动化
|
||||
|
||||
随着 IT 行业的技术变化,从服务器虚拟化到公有云和私有云,以及自服务能力、容器化应用、平台即服务(PaaS)交付,有一直以来落后的一个领域就是网络。
|
||||
随着 IT 行业的技术变化,从服务器虚拟化到公有云和私有云,以及自服务能力、容器化应用、平台即服务(PaaS)交付,而一直以来落后的一个领域就是网络。
|
||||
|
||||
在过去的五年多,网络行业似乎有很多新的趋势出现,它们中的很多被归入到软件定义网络(SDN)。
|
||||
在过去的五年多,网络行业似乎有很多新的趋势出现,它们中的很多被归入到<ruby>软件定义网络<rt>software-defined networking</rt></ruby>(SDN)。
|
||||
|
||||
>注意
|
||||
>注意:
|
||||
|
||||
> SDN 是新出现的一种构建、管理、操作和部署网络的方法。SDN 最初的定义是出于将控制层和数据层(包转发)物理分离的需要,并且,解耦合的控制层必须管理好各自的设备。
|
||||
|
||||
> 如今,在 SDN 旗下已经有许多技术,包括<ruby>基于控制器的网络<rt>controller-based networks</rt></ruby>、网络设备上的 API、网络自动化、白盒交换机、策略网络化、网络功能虚拟化(NFV)等等。
|
||||
> 如今,在 SDN 旗下已经有许多技术,包括<ruby>基于控制器的网络<rt>controller-based networks</rt></ruby>、网络设备 API、网络自动化、<ruby>白盒交换机<rt>whitebox switche</rt></ruby>、策略网络化、<ruby>网络功能虚拟化<rt>Network Functions Virtualization</rt></ruby>(NFV)等等。
|
||||
|
||||
> 由于这篇报告的目的,我们参考 SDN 的解决方案作为我们的解决方案,其中包括一个网络控制器作为解决方案的一部分,并且提升了该网络的可管理性,但并不需要从数据层解耦控制层。
|
||||
> 出于这篇报告的目的,我们参考 SDN 的解决方案作为我们的解决方案,其中包括一个网络控制器作为解决方案的一部分,并且提升了该网络的可管理性,但并不需要从数据层解耦控制层。
|
||||
|
||||
这些趋势的之一是,网络设备的 API 作为管理和操作这些设备的一种方法而出现,真正地提供了机器对机器的通讯。当需要自动化和构建网络应用时 API 简化了开发过程,在数据如何建模时提供了更多结构。例如,当启用 API 的设备以 JSON/XML 返回数据时,它是结构化的,并且比返回原生文本信息、需要手工去解析的仅支持命令行的设备更易于使用。
|
||||
这些趋势的之一是,网络设备的 API 作为管理和操作这些设备的一种方法而出现,真正地提供了机器对机器的通讯。当需要自动化和构建网络应用时 API 简化了开发过程,在数据如何建模时提供了更多结构。例如,当启用 API 的设备以 JSON/XML 返回数据时,它是结构化的,并且比返回原生文本信息 —— 需要手工去解析的仅支持命令行的设备更易于使用。
|
||||
|
||||
在 API 之前,用于配置和管理网络设备的两个主要机制是命令行接口(CLI)和简单网络管理协议(SNMP)。让我们来了解一下它们,CLI 是一个设备的人机界面,而 SNMP 并不是为设备提供的实时编程接口。
|
||||
|
||||
幸运的是,因为很多供应商争相为设备增加 API,有时候 _只是因为_ 它被放到需求建议书(RFP)中,这就带来了一个非常好的副作用 —— 支持网络自动化。当真正的 API 发布时,访问设备内数据的过程,以及管理配置,就会被极大简化,因此,我们将在本报告中对此进行评估。虽然使用许多传统方法也可以实现自动化,比如,CLI/SNMP。
|
||||
|
||||
> 注意
|
||||
> 注意:
|
||||
|
||||
> 随着未来几个月或几年的网络设备更新,供应商的 API 无疑应该被做为采购网络设备(虚拟和物理)的关键决策标准而测试和使用。如果供应商提供一些库或集成到自动化工具中,或者如果被用于一个开放的标准或协议,用户应该知道数据是如何通过设备建模的,API 使用的传输类型是什么。
|
||||
> 随着未来几个月或几年(LCTT 译注:本文发表于 2016 年)的网络设备更新,供应商的 API 无疑应该被做为采购网络设备(虚拟和物理)的关键决策标准而测试和使用。如果供应商提供一些库或集成到自动化工具中,或者如果被用于一个开放的标准或协议,用户应该知道数据是如何通过设备建模的,API 使用的传输类型是什么。
|
||||
|
||||
总而言之,网络自动化,像大多数类型的自动化一样,是为了更快地工作。工作的更快是好事,降低部署和配置改变的时间并不总是许多 IT 组织需要去解决的问题。
|
||||
总而言之,网络自动化,像大多数类型的自动化一样,是为了更快地工作。工作的更快是好事,减少部署和配置改变的时间并不总是许多 IT 组织需要去解决的问题。
|
||||
|
||||
包括速度在内,我们现在看看这些各种类型的 IT 组织逐渐采用网络自动化的几种原因。你应该注意到,同样的原则也适用于其它类型的自动化。
|
||||
|
||||
### 简化架构
|
||||
#### 简化架构
|
||||
|
||||
今天,每个网络都是一片独特的“雪花”,并且,网络工程师们为能够通过一次性的改变来解决传输和网络应用问题而感到自豪,而这最终导致网络不仅难以维护和管理,而且也很难去实现自动化。
|
||||
今天,每个网络都是一片独特的“雪花”,并且,网络工程师们为能够通过一次性的网络改变来解决传输和应用问题而感到自豪,而这最终导致网络不仅难以维护和管理,而且也很难去实现自动化。
|
||||
|
||||
网络自动化和管理需要从一开始就包含到新的架构和设计中去部署,而不是作为一个二级或三级项目。哪个特性可以跨不同的供应商工作?哪个扩展可以跨不同的平台工作?当使用特别的网络设备平台时,API 类型或者自动化工程是什么?当这些问题在设计过程之前得到答案,最终的架构将变成简单的、可重复的、并且易于维护 _和_ 自动化的,在整个网络中将很少启用供应商专用的扩展。
|
||||
网络自动化和管理需要从一开始就包含到新的架构和设计中去部署,而不是作为一个二级或三级项目。哪个特性可以跨不同的供应商工作?哪个扩展可以跨不同的平台工作?当使用具体的网络设备平台时,API 类型或者自动化工程是什么?当这些问题在设计过程之前得到答案,最终的架构将变成简单的、可重复的、并且易于维护 _和_ 自动化的,在整个网络中将很少启用供应商专用的扩展。
|
||||
|
||||
### 确定的结果
|
||||
#### 确定的结果
|
||||
|
||||
在一个企业组织中,<ruby>改变审查会议<rt>change review meeting</rt></ruby>会评估面临的网络变化、它们对外部系统的影响、以及回滚计划。在人们通过 CLI 来执行这些 _面临的变化_ 的世界上,输入错误的命令造成的影响是灾难性的。想像一下,一个有 3 位、4 位、5位,或者 50 位工程师的团队。每位工程师应对 _面临的变化_ 都有他们自己的独特的方法。并且,在管理这些变化的期间,一个人使用 CLI 或者 GUI 的能力并不会消除和减少出现错误的机率。
|
||||
|
||||
使用经过验证和测试过的网络自动化可以帮助实现更多的可预测行为,并且使执行团队更有可能实现确实性结果,在保证任务没有人为错误的情况下首次正确完成的道路上更进一步。
|
||||
使用经过验证的和测试过的网络自动化可以帮助实现更多的可预测行为,并且使执行团队更有可能实现确实性的结果,首次在保证任务没有人为错误的情况下正确完成的道路上更进一步。
|
||||
|
||||
### 业务灵活性
|
||||
#### 业务灵活性
|
||||
|
||||
不用说,网络自动化不仅为部署变化提供速度和灵活性,而且使得根据业务需要去从网络设备中检索数据的速度变得更快。自从服务器虚拟化到来以后,服务器和虚拟化使得管理员有能力在瞬间去部署一个新的应用程序。而且,随着应用程序可以更快地部署,随之浮现的问题是为什么还需要花费如此长的时间配置一个 VLAN(虚拟局域网)、路由器、FW ACL(防火墙的访问控制列表)或者负载均衡策略呢?
|
||||
不用说,网络自动化不仅为部署变化提供了速度和灵活性,而且使得根据业务需要去从网络设备中检索数据的速度变得更快。自从服务器虚拟化到来以后,服务器和虚拟化使得管理员有能力在瞬间去部署一个新的应用程序。而且,随着应用程序可以更快地部署,随之浮现的问题是为什么还需要花费如此长的时间配置一个 VLAN(虚拟局域网)、路由器、FW ACL(防火墙的访问控制列表)或者负载均衡策略呢?
|
||||
|
||||
通过了解在一个组织内最常见的工作流和 _为什么_ 真正需要改变网络,部署如 Ansible 这样的现代的自动化工具将使这些变得非常简单。
|
||||
|
||||
@ -61,9 +61,9 @@ _Ansible 是一个无需代理和可扩展的超级简单的自动化平台。_
|
||||
|
||||
让我们更深入地了解它的细节,并且看一看那些使 Ansible 在行业内获得广泛认可的属性。
|
||||
|
||||
### 简单
|
||||
#### 简单
|
||||
|
||||
Ansible 的其中一个吸引人的属性是,使用它你 _不_ 需要特定的编程技能。所有的指令,或者任务都是自动化的,以一个标准的、任何人都可以理解的人类可读的数据格式的文档化。在 30 分钟之内完成安装和自动化任务的情况并不罕见!
|
||||
Ansible 的其中一个吸引人的属性是,使用它你 **不** 需要特定的编程技能。所有的指令,或者说任务都是自动化的,以一个标准的、任何人都可以理解的人类可读的数据格式的文档化。在 30 分钟之内完成安装和自动化任务的情况并不罕见!
|
||||
|
||||
例如,下列来自一个 Ansible <ruby>剧本<rt>playbook</rt></ruby>的任务用于去确保在一个 VLAN 存在于一个 Cisco Nexus 交换机中:
|
||||
|
||||
@ -73,90 +73,83 @@ Ansible 的其中一个吸引人的属性是,使用它你 _不_ 需要特定
|
||||
|
||||
你无需熟悉或写任何代码就可以明确地看出它将要做什么!
|
||||
|
||||
> 注意
|
||||
> 注意:
|
||||
|
||||
> 这个报告的下半部分涉到 Ansible 术语(<ruby>剧本<rt>playbook</rt></ruby>、<ruby>行动<rt>play</rt></ruby>、<ruby>任务<rt>task</rt></ruby>、<ruby>模块<rt>module</rt></ruby>等等)的细节。在我们使用 Ansible 进行网络自动化时,提及这些关键概念时我们会有一些简短的示例。
|
||||
> 这个报告的下半部分涉到 Ansible 术语(<ruby>剧本<rt>playbook</rt></ruby>、<ruby>剧集<rt>play</rt></ruby>、<ruby>任务<rt>task</rt></ruby>、<ruby>模块<rt>module</rt></ruby>等等)的细节。在我们使用 Ansible 进行网络自动化时,提及这些关键概念时我们会有一些简短的示例。
|
||||
|
||||
### 无代理
|
||||
#### 无代理
|
||||
|
||||
如果你看到市面上的其它工具,比如 Puppet 和 Chef,你学习它们会发现,一般情况下,它们要求每个实现自动化的设备必须安装特定的软件。这种情况在 Ansible 上 _并不_需要,这就是为什么 Ansible 是实现网络自动化的最佳选择的主要原因。
|
||||
如果你看过市面上的其它工具,比如 Puppet 和 Chef,你会发现,一般情况下,它们要求每个实现自动化的设备必须安装特定的软件。这种情况在 Ansible 上 _并不_需要,这就是为什么 Ansible 是实现网络自动化的最佳选择的主要原因。
|
||||
|
||||
它很好理解,那些 IT 自动化工具,包括 Puppet、Chef、CFEngine、SaltStack、和 Ansible,它们最初构建是为管理和自动化配置 Linux 主机,以跟得上部署的应用程序增长的步伐。因为 Linux 系统是被配置成自动化的,要安装代理并不是一个技术难题。如果有的话,它会担误安装过程,因为,现在有 _N_ 多个(你希望去实现自动化的)主机需要在它们上面部署软件。
|
||||
这很好理解,那些 IT 自动化工具,包括 Puppet、Chef、CFEngine、SaltStack、和 Ansible,它们最初构建是为管理和自动化配置 Linux 主机,以跟得上部署的应用程序增长的步伐。因为 Linux 系统是被配置成自动化的,要安装代理并不是一个技术难题。如果有的话,它也只会延误安装过程,因为,现在有 _N_ 多个(你希望去实现自动化的)主机需要在它们上面部署软件。
|
||||
|
||||
再加上,当使用代理时,它们需要的 DNS 和 NTP 配置更加复杂。这些都是大多数环境中已经配置好的服务,但是,当你希望快速地获取一些东西或者只是简单地想去测试一下它能做什么的时候,它将极大地担误整个设置和安装的过程。
|
||||
再加上,当使用代理时,它们需要的 DNS 和 NTP 配置更加复杂。这些都是大多数环境中已经配置好的服务,但是,当你希望快速地获取一些东西或者只是简单地想去测试一下它能做什么的时候,它将极大地耽误整个设置和安装的过程。
|
||||
|
||||
由于本报告只是为介绍利用 Ansible 实现网络自动化,它最有价值的是,Ansible 作为一个无代理平台,对于系统管理员来说,它更具有吸引力,这是为什么呢?
|
||||
由于本报告只是为介绍利用 Ansible 实现网络自动化,我们希望指出,Ansible 作为一个无代理平台,对于网络管理员来说,其比对系统管理员更具有吸引力。这是为什么呢?
|
||||
|
||||
正如前面所说的那样,对网络管理员来说,它是非常有吸引力的,Linux 操作系统是开源的,并且,任何东西都可以安装在它上面。对于网络来说,虽然它正在逐渐改变,但事实并非如此。如果我们更广泛地部署网络操作系统,如 Cisco IOS,它就是这样的一个例子,并且问一个问题, _“第三方软件能否部署在基于 IOS (译者注:此处的 IOS,指的是思科的网络操作系统 IOS)的平台上吗?”_它并不会给你惊喜,它的回答是 _NO_。
|
||||
正如前面所说的那样,对网络管理员来说,它是非常有吸引力的,Linux 操作系统是开源的,并且,任何东西都可以安装在它上面。对于网络来说,却并非如此,虽然它正在逐渐改变。如果我们更广泛地部署网络操作系统,如 Cisco IOS,它就是这样的一个例子,并且问一个问题, _“第三方软件能否部署在基于 IOS (LCTT 译注:此处的 IOS,指的是思科的网络操作系统 IOS)的平台上吗?”_毫无疑问,它的回答是 _NO_。
|
||||
|
||||
在过去的二十多年里,几乎所有的网络操作系统都是闭源的,并且,垂直整合到底层的网络硬件中。在一个网络设备中(路由器、交换机、负载均衡、防火墙、等等),不需要供应商的支持,有一个像 Ansible 这样的自动化平台,从头开始去构建一个无代理、可扩展的自动化平台,就像是它专门为网络行业订制的一样。我们最终将开始减少并消除与网络的人工交互。
|
||||
在过去的二十多年里,几乎所有的网络操作系统都是闭源的,并且,垂直整合到底层的网络硬件中。没有供应商的支持,在一个网络设备中(路由器、交换机、负载均衡、防火墙、等等)载入一个代理并不那么轻松。有一个像 Ansible 这样的自动化平台,从头开始去构建一个无代理、可扩展的自动化平台,就像是它专门为网络行业订制的一样。我们最终将开始减少并消除与网络的人工交互。
|
||||
|
||||
### 可扩展
|
||||
#### 可扩展
|
||||
|
||||
Ansible 的可扩展性也非常的好。作为一个开源的,并且从代码开始将在网络行业中发挥重要的作用,有一个可扩展的平台是必需的。这意味着如果供应商或社区不提供一个特定的特性或功能,开源社区,终端用户,消费者,顾问者,或者,任何可能去 _扩展_ Ansible 的人,去启用一个给定的功能集。过去,网络供应商或者工具供应商通过一个 hook 去提供插件和集成。想像一下,使用一个像 Ansible 这样的自动化平台,并且,你选择的网络供应商发布了你 _真正_ 需要的自动化的一个新特性。从理论上说,网络供应商或者 Ansible 可以发行一个新的插件去实现自动化这个独特的特性,这是一件非常好的事情,从你的内部工程师到你的增值分销商(VARs)或者你的顾问中的任何人,都可以去提供这种集成。
|
||||
|
||||
正如前面所说的那样,Ansible 实际上是极具扩展性的,Ansible 最初就是为自动化应用程序和系统构建的。这是因为,Ansible 的可扩展性是被网络供应商编写集成的,包括但不限于 Cisco、Arista、Juniper、F5、HP、A10、Cumulus、和 Palo Alto Networks。
|
||||
Ansible 的可扩展性也非常的好。从开源、代码开始在网络行业中发挥重要的作用时起,有一个可扩展的平台是必需的。这意味着如果供应商或社区不提供一个特定的特性或功能,开源社区、终端用户、消费者、顾问,或者任何的人能够 _扩展_ Ansible 来启用一个给定的功能集。过去,网络供应商或者工具供应商通过一个 hook 去提供新的插件和集成。想像一下,使用一个像 Ansible 这样的自动化平台,并且,你选择的网络供应商发布了你 _真正_ 需要的一个自动化的新特性。从理论上说,网络供应商或者 Ansible 可以发行一个新的插件去实现自动化这个独特的特性,这是一件非常好的事情,从你的内部工程师到你的增值分销商(VAR)或者你的顾问中的任何一个人,都可以去提供这种集成。
|
||||
|
||||
正如前面所说的那样,Ansible 实际上是极具扩展性的,Ansible 最初就是为自动化应用程序和系统构建的。这是因为,Ansible 的可扩展性来自于其集成性是为网络供应商编写的,包括但不限于 Cisco、Arista、Juniper、F5、HP、A10、Cumulus 和 Palo Alto Networks。
|
||||
|
||||
### 对于网络自动化,为什么要使用 Ansible?
|
||||
|
||||
我们已经简单了解除了 Ansible 是什么,以及一些网络自动化的好处,但是,对于网络自动化,我们为什么要使用 Ansible?
|
||||
|
||||
在一个完全透明的环境下,已经说的很多的理由是 Ansible 可以做什么,比如,作为一个很大的自动化应用程序部署平台,但是,我们现在要深入一些,更多地关注于网络,并且继续总结一些更需要注意的其它关键点。
|
||||
大家很清楚,使得 Ansible 成为如此伟大的一个自动化应用部署平台的许多原因已经被大家所提及了。但是,我们现在要深入一些,更多地关注于网络,并且继续总结一些更需要注意的其它关键点。
|
||||
|
||||
#### 无代理
|
||||
|
||||
### 无代理
|
||||
在实现网络自动化的时候,无代理架构的重要性并不是重点强调的,特别是当它适用于现有的自动化设备时。如果,我们看一下当前网络中已经安装的各种设备时,从 DMZ 和园区,到分支机构和数据中心,最大份额的设备 _并不_ 具有最新 API 的设备。从自动化的角度来看,API 可以使做一些事情变得很简单,像 Ansible 这样的无代理平台有可能去自动化和管理那些 _老旧(传统)_ 的设备。例如,_基于 CLI 的设备_,它的工具可以被用于任何网络环境中。
|
||||
|
||||
> 注意:
|
||||
|
||||
在实现网络自动化的时候,无代理架构的重要性并不是重点强调的,特别是当它适用于现有的自动化设备时。如果,我们看一下当前网络中已经安装的各种设备时,从 DMZ 和园区,到分支和数据中心,最大份额的设备 _并不_ 具有最新 API 的设备。从自动化的角度来看,API 可以使做一些事情变得很简单,像 Ansible 这样的无代理平台有可能去自动化和管理那些 _传统_ 的设备。例如,_基于CLI 的设备_,它的工具可以被用于任何网络环境中。
|
||||
> 如果仅支持 CLI 的设备已经集成进 Ansible,它的机制就像是,怎么在设备上通过协议如 telnet、SSH 和 SNMP 去进行只读访问和读写操作。
|
||||
|
||||
###### 注意
|
||||
作为一个独立的网络设备,像路由器、交换机、和防火墙正在持续去增加 API 的支持,SDN 解决方案也正在出现。SDN 解决方案的其中一个常见主题是,它们都提供一个单点集成和策略管理,通常是以一个 SDN 控制器的形式出现。这对于 Cisco ACI、VMware NSX、Big Switch Big Cloud Fabric 和 Juniper Contrail,以及其它的 SDN 提供者,比如 Nuage、Plexxi、Plumgrid、Midokura 和 Viptela,是一个真实的解决方案。这甚至包含开源的控制器,比如 OpenDaylight。
|
||||
|
||||
如果仅 CLI 的设备已经集成进 Ansible,它的机制就像是,怎么在设备上通过协议如 telnet、SSH、和 SNMP,去进行只读访问和读写操作。
|
||||
所有的这些解决方案都简化了网络管理,就像它们可以让一个管理员开始从“box-by-box”管理(LCTT 译者注:指的是单个设备挨个去操作的意思)迁移到网络范围的管理。这是在正确方向上迈出的很大的一步,这些解决方案并不能消除在变更期间中人类犯错的机率。例如,比起配置 _N_ 个交换机,你可能需要去配置一个单个的 GUI,它需要很长的时间才能实现所需要的配置改变 —— 它甚至可能更复杂,毕竟,相对于一个 CLI,他们更喜欢 GUI!另外,你可能有不同类型的 SDN 解决方案部署在每个应用程序、网络、区域或者数据中心。
|
||||
|
||||
作为一个独立的网络设备,像路由器、交换机、和防火墙持续去增加 APIs 的支持,SDN 解决方案也正在出现。SDN 解决方案的其中一个主题是,它们都提供一个单点集成和策略管理,通常是以一个 SDN 控制器的形式出现。这是真实的解决方案,比如,Cisco ACI、VMware NSX、Big Switch Big Cloud Fabric、和 Juniper Contrail,同时,其它的 SDN 提供者,比如 Nuage、Plexxi、Plumgrid、Midokura、和 Viptela。甚至包含开源的控制器,比如 OpenDaylight。
|
||||
在需要自动化的网络中,对于配置管理、监视和数据收集,当行业开始向基于控制器的网络架构中迁移时,这些需求并不会消失。
|
||||
|
||||
所有的这些解决方案都简化了网络管理,就像他们允许一个管理员去开始从“box-by-box”管理(译者注:指的是单个设备挨个去操作的意思)迁移到网络范围的管理。这是在正确方向上迈出的很大的一步,这些解决方案并不能消除在改变窗口中人类犯错的机率。例如,比起配置 _N_ 个交换机,你可能需要去配置一个单个的 GUI,它需要很长的时间才能实现所需要的配置改变 — 它甚至可能更复杂,毕竟,相对于一个 CLI,他们更喜欢 GUI!另外,你可能有不同类型的 SDN 解决方案部署在每个应用程序、网络、区域、或者数据中心。
|
||||
大量的软件定义网络中都部署有控制器,几乎所有的控制器都<ruby>提供<rt>expose</rt></ruby>一个最新的 REST API。并且,因为 Ansible 是一个无代理架构,它实现自动化是非常简单的,而不仅仅是对那些没有 API 的传统设备,但也有通过 REST API 的软件定义网络解决方案,在所有的终端上不需要有额外的软件(LCTT 译注:指的是代理)。最终的结果是,使用 Ansible,无论有或没有 API,可以使任何类型的设备都能够自动化。
|
||||
|
||||
在需要自动化的网络中,对于配置管理、监视、和数据收集,当行业开始向基于控制器的网络架构中迁移时,这些需求并不会消失。
|
||||
#### 自由开源软件(FOSS)
|
||||
|
||||
大量的软件定义网络中都部署有控制器,所有最新的控制器都提供(expose)一个最新的 REST API。并且,因为 Ansible 是一个无代理架构,它实现自动化是非常简单的,而不仅仅是没有 API 的传统设备,但也有通过 REST APIs 的软件定义网络解决方案,在所有的终端上不需要有额外的软件(译者注:指的是代理)。最终的结果是,使用 Ansible,无论有或没有 API,可以使任何类型的设备都能够自动化。
|
||||
Ansible 是一个开源软件,它的全部代码在 GitHub 上都是公开可访问的,使用 Ansible 是完全免费的。它可以在几分钟内完成安装并为网络工程师提供有用的价值。Ansible 这个开源项目,或者 Ansible 公司,在它们交付软件之前,你不会遇到任何一个销售代表。那是显而易见的事实,因为它是一个真正的开源项目,但是,作为开源的、社区驱动的软件项目在网络行业中的使用是非常少的,但是,也在逐渐增加,我们想明确指出这一点。
|
||||
|
||||
同样需要指出的一点是,Ansible, Inc. 也是一个公司,它也需要去赚钱,对吗?虽然 Ansible 是开源的,它也有一个叫 Ansible Tower 的企业产品,它增加了一些特性,比如,基于规则的访问控制(RBAC)、报告、 web UI、REST API、多租户等等,(相比 Ansible)它更适合于企业去部署。并且,更重要的是,Ansible Tower 甚至可以最多在 10 台设备上 _免费_ 使用,至少,你可以去体验一下,它是否会为你的组织带来好处,而无需花费一分钱,并且,也不需要与无数的销售代表去打交道。
|
||||
|
||||
### 免费和开源软件(FOSS)
|
||||
#### 可扩展性
|
||||
|
||||
Ansible 是一个开源软件,它的全部代码在 GitHub 上都是公开的、可访问的,使用 Ansible 是完全免费的。它可以在几分钟内完成安装并为网络工程师提供有用的价值。Ansible,这个开源项目,或者 Ansible 公司,在它们交付软件之前,你不会遇到任何一个销售代表。那是显而易见的事实,因为它是一个真正的开源项目,但是,开源项目的使用,在网络行业中社区驱动的软件是非常少的,但是,也在逐渐增加,我们想明确指出这一点。
|
||||
我们在前面说过,Ansible 主要是为部署 Linux 应用程序而构建的自动化平台,虽然从早期开始已经扩展到 Windows。需要指出的是,Ansible 开源项目并没有“自动化网络基础设施”的目标。事实上是,Ansible 社区更明白如何在底层的 Ansible 架构上更具灵活性和可扩展性,对于他们的自动化需要(包括网络)更容易成为一个 _扩展_ 的 Ansible。在过去的两年中,部署有许多的 Ansible 集成,许多是有行业独立人士进行的,比如,Matt Oswalt、Jason Edelman、Kirk Byers、Elisa Jasinska、David Barroso、Michael Ben-Ami、Patrick Ogenstad 和 Gabriele Gerbino,也有网络系统供应商的领导者,比如,Arista、Juniper、Cumulus、Cisco、F5、和 Palo Alto Networks。
|
||||
|
||||
同样需要指出的一点是,Ansible, Inc. 也是一个公司,它也需要去赚钱,对吗?虽然 Ansible 是开源的,它也有一个叫 Ansible Tower 的企业产品,它增加了一些特性,比如,基于规则的访问控制(RBAC)、报告、 web UI、REST APIs、多租户、等等,(相比 Ansible)它更适合于企业去部署。并且,更重要的是,Ansible Tower 甚至可以最多在 10 台设备上 _免费_ 使用,至少,你可以去体验一下,它是否会为你的组织带来好处,而无需花费一分钱,并且,也不需要与无数的销售代表去打交道。
|
||||
#### 集成到已存在的 DevOps 工作流中
|
||||
|
||||
Ansible 在 IT 组织中被用于应用程序部署。它被用于需要管理部署、监视和管理各种类型的应用程序的运维团队中。通过将 Ansible 集成到网络基础设施中,当新应用程序到来或迁移后,它扩展了可能的范围。而不是去等待一个新的顶架交换机(LCTT 译注:TOR,一种数据中心设备接入的方式)的到来、去添加一个 VLAN、或者去检查接口的速度/双工,所有的这些以网络为中心的任务都可以被自动化,并且可以集成到 IT 组织内已经存在的工作流中。
|
||||
|
||||
### 可扩展性
|
||||
#### 幂等性
|
||||
|
||||
我们在前面说过,Ansible 主要是为部署 Linux 应用程序而构建的自动化平台,虽然从早期开始已经扩展到 Windows。需要指出的是,Ansible 开源项目并没有自动化网络基础设施的目标。事实上是,Ansible 社区更多地理解了在底层的 Ansible 架构上怎么更具灵活性和可扩展性,对于他们的自动化需要,它变成了 _扩展_ 的 Ansible,它包含了网络。在过去的两年中,部署有许多的 Ansible 集成,许多行业独立人士(industry independents),比如,Matt Oswalt、Jason Edelman、Kirk Byers、Elisa Jasinska、David Barroso、Michael Ben-Ami、Patrick Ogenstad、和 Gabriele Gerbino,以及网络系统供应商的领导者,比如,Arista、Juniper、Cumulus、Cisco、F5、和 Palo Alto Networks。
|
||||
术语<ruby>幂等性<rt>idempotency</rt></ruby> (读作 item-potency)经常用于软件开发的领域中,尤其是当使用 REST API 工作的时候,以及在 _DevOps_ 自动化和配置管理框架的领域中,包括 Ansible。Ansible 的其中一个信念是,所有的 Ansible 模块(集成的)应该是幂等的。那么,对于一个模块来说,幂等是什么意思呢?毕竟,对大多数网络工程师来说,这是一个新的术语。
|
||||
|
||||
答案很简单。幂等性的本质是允许定义的任务,运行一次或者上千次都不会在目标系统上产生不利影响,仅仅是一种一次性的改变。换句话说,如果有一个要做的改变去使系统进入到它期望的状态,这种改变完成之后,并且,如果这个设备已经达到这种状态,就不会再发生改变。这不像大多数传统的定制脚本和拷贝、黏贴到那些终端窗口中的 CLI 命令。当相同的命令或者脚本在同一个系统上重复运行,(有时候)会出现错误。即使是粘贴一组命令到一个路由器中,也可能会遇到一些使你的其余的配置失效的错误。好玩吧?
|
||||
|
||||
### 集成到已存在的 DevOps 工作流中
|
||||
另外的例子是,如果你有一个配置 10 个 VLAN 的文件文件或者脚本,那么 _每次_ 运行这个脚本,相同的命令命令会被输入 10 次。如果使用一个幂等的 Ansible 模块,首先会从网络设备中采集已存在的配置,并且,每个新的 VLAN 被配置后会再次检查当前配置。仅仅当这个新的 VLAN 需要被添加(或者,比如说改变 VLAN 名字)是一个变更,命令才会真实地推送到设备。
|
||||
|
||||
Ansible 在 IT 组织中被用于应用程序部署。它被用于需要管理部署、监视、和管理各种类型的应用程序的操作团队中。通过将 Ansible 集成到网络基础设施中,当新应用程序到来或迁移后,它扩展了可能的范围。而不是去等待一个新的顶架交换机(TOR,译者注:一种数据中心设备接入的方式)的到来、去添加一个 VLAN、或者去检查接口的速度/双工,所有的这些以网络为中心的任务都可以被自动化,并且可以集成到 IT 组织内已经存在的工作流中。
|
||||
当一个技术越来越复杂,幂等性的价值就越高,在你修改的时候,你并不能注意到 _已存在_ 的网络设备的状态,而仅仅是从一个网络配置和策略角度去尝试达到 _期望的_ 状态。
|
||||
|
||||
#### 网络范围的和临时(Ad Hoc)的改变
|
||||
|
||||
### 幂等性
|
||||
用配置管理工具解决的其中一个问题是,配置“飘移”(当设备的期望配置逐渐漂移,或者改变,随着时间的推移,手动改变和/或在一个环境中使用了多个不同的工具),事实上,这也是像 Puppet 和 Chef 所使用的地方。代理商<ruby>电联<rt>phone home</rt></ruby>到前端服务器,验证它的配置,并且,如果需要变更,则改变它。这个方法是非常简单的。如果有故障了,需要去排除怎么办?你通常需要跳过管理系统,直接连到设备,找到并修复它,然后,马上离开,对不对?果然,在下次当代理电连回来,这个修复问题的改变被覆盖了(基于主/前端服务器是怎么配置的)。在高度自动化的环境中,一次性的改变应该被限制,但是,仍然允许使用它们(LCTT 译注:指的是一次性改变)的工具是非常有价值的。正如你想到的,其中一个这样的工具是 Ansible。
|
||||
|
||||
术语 _幂等性_ (明显能提升项目的效能) 经常用于软件开发的领域中,尤其是当使用 REST APIs工作的时候,以及在 _DevOps_ 自动化和配置管理框架的领域中,包括 Ansible。Ansible 的其中一个信念是,所有的 Ansible 模块(集成的)应该是幂等的。那么,对于一个模块来说,幂等是什么意思呢?毕竟,对大多数网络工程师来说,这是一个新的术语。
|
||||
因为 Ansible 是无代理的,这里并没有一个默认的推送或者拉取去防止配置漂移。自动化任务被定义在 Ansible <ruby剧本<rt>playbook</rt></ruby>中,当使用 Ansible 时,它让用户去运行剧本。如果剧本在一个给定的时间间隔内运行,并且你没有用 Ansible Tower,你肯定知道任务的执行频率;如果你只是在终端提示符下使用一个原生的 Ansible 命令行,那么该剧本就运行一次,并且仅运行一次。
|
||||
|
||||
答案很简单。幂等性的本质是允许定义的任务,运行一次或者上千次都不会在目标系统上产生不利影响,仅仅是一种一次性的改变。换句话说,如果一个请求的改变去使系统进入到它期望的状态,这种改变完成之后,并且,如果这个设备已经达到这种状态,它不会再发生改变。这不像大多数传统的定制脚本,和拷贝(copy),以及过去的那些终端窗口中的 CLI 命令。当相同的命令或者脚本在同一个系统上重复运行,会出现错误(有时候)。以前,粘贴一组命令到一个路由器中,然后得到一些使你的其余的配置失效的错误类型?好玩吧?
|
||||
|
||||
另外的例子是,如果你有一个配置 10 个 VLANs 的文件文件或者脚本,那么 _每次_ 运行这个脚本,相同的命令命令会被输入 10 次。如果使用一个幂等的 Ansible 模块,首先会从网络设备中采集已存在的配置,并且,每个新的 VLAN 被配置后会再次检查当前配置。仅仅是这个新的 VLAN 需要去被添加(或者,改变 VLAN 名字,作为一个示例)是一个改变,或者命令真实地推送到设备。
|
||||
|
||||
当一个技术越来越复杂,幂等性的价值就越高,在你修改的时候,你并不能注意到 _已存在_ 的网络设备的状态,仅仅是从一个网络配置和策略角度去尝试达到 _期望的_ 状态。
|
||||
|
||||
|
||||
### 网络范围的和临时(Ad Hoc)的改变
|
||||
|
||||
用配置管理工具解决的其中一个问题是,配置“飘移”(当设备的期望配置逐渐漂移,或者改变,随着时间的推移手动改变和/或在一个环境中使用了多个不同的工具),事实上,这也是像 Puppet 和 Chef 得到使用的地方。代理商 _phone home_ 到前端服务器,验证它的配置,并且,如果需要一个改变,则改变它。这个方法是非常简单的。如果有故障了,需要去排除怎么办?你通常需要通过管理系统,直接连到设备,找到并修复它,然后,马上离开,对不对?果然,在下次当代理的电话打到家里,修复问题的改变被覆盖了(基于主/前端服务器是怎么配置的)。在高度自动化的环境中,一次性的改变应该被限制,但是,仍然允许它们(译者注:指的是一次性改变)使用的工具是非常有价值的。正如你想到的,其中一个这样的工具是 Ansible。
|
||||
|
||||
因为 Ansible 是无代理的,这里并没有一个默认的推送或者拉取去防止配置漂移。自动化任务被定义在 Ansible playbook 中,当使用 Ansible 时,它推送到用户去运行 playbook。如果 playbook 在一个给定的时间间隔内运行,并且你没有用 Ansible Tower,你肯定知道任务的执行频率;如果你正好在终端提示符下使用一个原生的 Ansible 命令行,playbook 运行一次,并且仅运行一次。
|
||||
|
||||
缺省运行的 playbook 对网络工程师是很具有吸引力的,让人欣慰的是,在设备上手动进行的改变不会自动被覆盖。另外,当需要的时候,一个 playbook 运行的设备范围很容易被改变,即使是对一个单个设备进行自动化的单次改变,Ansible 仍然可以用,设备的 _范围_ 由一个被称为 Ansible 清单(inventory)的文件决定;这个清单可以是一台设备或者是一千台设备。
|
||||
缺省运行一次的剧本对网络工程师是很具有吸引力的,让人欣慰的是,在设备上手动进行的改变不会自动被覆盖。另外,当需要的时候,一个剧本所运行的设备范围很容易被改变,即使是对一个单个设备进行自动化的单次变更,Ansible 仍然可以用,设备的 _范围_ 由一个被称为 Ansible <ruby>清单<rt>inventory</rt></ruby>的文件决定;这个清单可以是一台设备或者是一千台设备。
|
||||
|
||||
下面展示的一个清单文件示例,它定义了两组共六台设备:
|
||||
|
||||
@ -172,13 +165,13 @@ leaf3
|
||||
leaf4
|
||||
```
|
||||
|
||||
为了自动化所有的主机,你的 play 定义的 playbook 的一个片段看起来应该是这样的:
|
||||
为了自动化所有的主机,你的剧本中的<ruby>剧集<rt>play</rt></ruby>定义的一个片段看起来应该是这样的:
|
||||
|
||||
```
|
||||
hosts: all
|
||||
```
|
||||
|
||||
并且,一个自动化的叶子节点交换机,它看起来应该像这样:
|
||||
并且,要只自动化一个叶子节点交换机,它看起来应该像这样:
|
||||
|
||||
```
|
||||
hosts: leaf1
|
||||
@ -190,27 +183,27 @@ hosts: leaf1
|
||||
hosts: core-switches
|
||||
```
|
||||
|
||||
###### 注意
|
||||
> 注意
|
||||
|
||||
正如前面所说的那样,这个报告的后面部分将详细介绍 playbooks、plays、和清单(inventories)。
|
||||
> 正如前面所说的那样,这个报告的后面部分将详细介绍剧本、剧集、和清单。
|
||||
|
||||
因为能够很容易地对一台设备或者 _N_ 台设备进行自动化,所以在需要对这些设备进行一次性改变时,Ansible 成为了最佳的选择。在网络范围内的改变它也做的很好:可以是关闭给定类型的所有接口、配置接口描述、或者是在一个跨企业园区布线的网络中添加 VLANs。
|
||||
因为能够很容易地对一台设备或者 _N_ 台设备进行自动化,所以在需要对这些设备进行一次性变更时,Ansible 成为了最佳的选择。在网络范围内的变更它也做的很好:可以是关闭给定类型的所有接口、配置接口描述、或者是在一个跨企业园区布线的网络中添加 VLAN。
|
||||
|
||||
### 使用 Ansible 实现网络任务自动化
|
||||
|
||||
这个报告从两个方面逐渐深入地讲解一些技术。第一个方面是围绕 Ansible 架构和它的细节,第二个方面是,从一个网络的角度,讲解使用 Ansible 可以完成什么类型的自动化。在这一章中我们将带你去详细了解第二方面的内容。
|
||||
|
||||
自动化一般被认为是速度快,但是,考虑到一些任务并不要求速度,这就是为什么一些 IT 团队没有认识到自动化的价值所在。VLAN 配置是一个非常好的例子,因为,你可能会想,“创建一个 VLAN 到底有多快?一般情况下每天添加多少个 VLANs?我真的需要自动化吗?”
|
||||
自动化一般被认为是速度快,但是,考虑到一些任务并不要求速度,这就是为什么一些 IT 团队没有认识到自动化的价值所在。VLAN 配置是一个非常好的例子,因为,你可能会想,“创建一个 VLAN 到底有多快?一般情况下每天添加多少个 VLAN?我真的需要自动化吗?”
|
||||
|
||||
在这一节中,我们专注于另外几种有意义的自动化任务,比如,设备准备、数据收集、报告、和遵从情况。但是,需要注意的是,正如我们前面所说的,自动化为你、你的团队、以及你的精确的更可预测的结果和更多的确定性,提供了更快的速度和敏捷性。
|
||||
在这一节中,我们专注于另外几种有意义的自动化任务,比如,设备准备、数据收集、报告和遵从情况。但是,需要注意的是,正如我们前面所说的,自动化为你、你的团队、以及你的精确的更可预测的结果和更多的确定性,提供了更快的速度和敏捷性。
|
||||
|
||||
### 设备准备
|
||||
#### 设备准备
|
||||
|
||||
为网络自动化开始使用 Ansible 的最容易也是最快的方法是,为设备最初投入使用创建设备配置文件,并且将配置文件推送到网络设备中。
|
||||
为网络自动化开始使用 Ansible 的最容易也是最快的方法是,为设备的最初投入使用创建设备配置文件,并且将配置文件推送到网络设备中。
|
||||
|
||||
如果我们去完成这个过程,它将分解为两步,第一步是创建一个配置文件,第二步是推送这个配置到设备中。
|
||||
|
||||
首先,我们需要去从供应商配置文件的底层专用语法(CLI)中解耦 _输入_。这意味着我们需要对配置参数中分离出文件和值,比如,VLANs、域信息、接口、路由、和其它的内容、等等,然后,当然是一个配置的模块文件。在这个示例中,这里有一个标准模板,它可以用于所有设备的初始部署。Ansible 将帮助提供配置模板中需要的输入和值之间的部分。几秒钟之内,Ansible 可以生成数百个可靠的和可预测的配置文件。
|
||||
首先,我们需要去从供应商配置文件的底层专用语法(CLI)中解耦 _输入_。这意味着我们需要对配置参数中分离出文件和值,比如,VLAN、域信息、接口、路由、和其它的内容等等,然后,当然是一个配置的模块文件。在这个示例中,这里有一个标准模板,它可以用于所有设备的初始部署。Ansible 将帮助提供配置模板中需要的输入和值之间的部分。几秒钟之内,Ansible 可以生成数百个可靠的和可预测的配置文件。
|
||||
|
||||
让我们快速的看一个示例,它使用当前的配置,并且分解它到一个模板和单独的一个(作为一个输入源的)变量文件中。
|
||||
|
||||
@ -238,13 +231,13 @@ vlan 50
|
||||
|
||||
如果我们提取输入值,这个文件将被转换成一个模板。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
Ansible 使用基于 Python 的 Jinja2 模板化语言,因此,这个被命名为 _leaf.j2_ 的文件是一个 Jinja2 模板。
|
||||
> Ansible 使用基于 Python 的 Jinja2 模板化语言,因此,这个被命名为 _leaf.j2_ 的文件是一个 Jinja2 模板。
|
||||
|
||||
注意,下列的示例中,_双大括号({{)_ 代表一个变量。
|
||||
注意,下列的示例中,_双大括号(`{{}}`)_ 代表一个变量。
|
||||
|
||||
模板看起来像这些,并且给它命名为 _leaf.j2_:
|
||||
模板看起来像这些,并且给它命名为 `leaf.j2`:
|
||||
|
||||
```
|
||||
!
|
||||
@ -273,17 +266,17 @@ vlans:
|
||||
- { id: 50, name: misc }
|
||||
```
|
||||
|
||||
这意味着,如果管理 VLANs 的团队希望在网络设备中添加一个 VLAN,很简单,他们只需要在变量文件中改变它,然后,使用 Ansible 中一个叫 `template` 的模块,去重新生成一个新的配置文件。这整个过程也是幂等的;仅仅是在模板或者值发生改变时,它才会去生成一个新的配置文件。
|
||||
这意味着,如果管理 VLAN 的团队希望在网络设备中添加一个 VLAN,很简单,他们只需要在变量文件中改变它,然后,使用 Ansible 中一个叫 `template` 的模块,去重新生成一个新的配置文件。这整个过程也是幂等的;仅仅是在模板或者值发生改变时,它才会去生成一个新的配置文件。
|
||||
|
||||
一旦配置文件生成,它需要去 _推送_ 到网络设备。推送配置文件到网络设备使用一个叫做 `napalm_install_config`的开源的 Ansible 模块。
|
||||
|
||||
接下来的示例是一个简单的 playbook 去 _构建并推送_ 一个配置文件到网络设备。同样地,playbook 使用一个名叫 `template` 的模块去构建配置文件,然后使用一个名叫 `napalm_install_config` 的模块去推送它们,并且激活它作为设备上运行的新的配置文件。
|
||||
接下来的示例是一个 _构建并推送_ 一个配置文件到网络设备的简单剧本。同样地,该剧本使用一个名叫 `template` 的模块去构建配置文件,然后使用一个名叫 `napalm_install_config` 的模块去推送它们,并且激活它作为设备上运行的新的配置文件。
|
||||
|
||||
虽然没有详细解释示例中的每一行,但是,你仍然可以看明白它们实际上做了什么。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
下面的 playbook 介绍了新的概念,比如,内置变量 `inventory_hostname`。这些概念包含在 [Ansible 术语和入门][1] 中。
|
||||
> 下面的剧本介绍了新的概念,比如,内置变量 `inventory_hostname`。这些概念包含在 [Ansible 术语和入门][1] 中。
|
||||
|
||||
```
|
||||
---
|
||||
@ -310,17 +303,17 @@ vlans:
|
||||
replace_config=0
|
||||
```
|
||||
|
||||
这个两步的过程是一个使用 Ansible 进行网络自动化入门的简单方法。通过模板简化了你的配置,构建配置文件,然后,推送它们到网络设备 — 因此,被称为 _BUILD 和 PUSH_ 方法。
|
||||
这个两步的过程是一个使用 Ansible 进行网络自动化入门的简单方法。通过模板简化了你的配置,构建配置文件,然后,推送它们到网络设备 — 因此,被称为 `BUILD` 和 `PUSH` 方法。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
像这样的更详细的例子,请查看 [Ansible 网络集成][2]。
|
||||
> 像这样的更详细的例子,请查看 [Ansible 网络集成][2]。
|
||||
|
||||
### 数据收集和监视
|
||||
#### 数据收集和监视
|
||||
|
||||
监视工具一般使用 SNMP — 这些工具拉某些管理信息库(MIBs),然后给监视工具返回数据。基于返回的数据,它可能多于也可能少于你真正所需要的数据。如果接口基于返回的数据统计你正在拉的内容,你可能会返回在 _show interface_ 命令中显示的计数器。如果你仅需要 _interface resets_ 并且,希望去看到与重置相关的邻接 CDP/LLDP 的接口,那该怎么做呢?当然,这也可以使用当前的技术;可以运行多个显示命令去手动解析输出信息,或者,使用基于 SNMP 的工具,在 GUI 中切换不同的选项卡(Tab)找到真正你所需要的数据。Ansible 怎么能帮助我们去完成这些工作呢?
|
||||
监视工具一般使用 SNMP —— 这些工具拉取某些管理信息库(MIB),然后给监视工具返回数据。基于返回的数据,它可能多于也可能少于你真正所需要的数据。如果接口基于返回的数据统计你正在拉取的内容,你可能会返回在 `show interface` 命令中显示的计数器。如果你仅需要 `interface resets` 并且,希望去看到与重置相关的邻接 CDP/LLDP 的接口,那该怎么做呢?当然,这也可以使用当前的技术;可以运行多个显示命令去手动解析输出信息,或者,使用基于 SNMP 的工具,在 GUI 中切换不同的选项卡(Tab)找到真正你所需要的数据。Ansible 怎么能帮助我们去完成这些工作呢?
|
||||
|
||||
由于 Ansible 是完全开放并且是可扩展的,它可以精确地去收集和监视所需要的计数器或者值。这可能需要一些预先的定制工作,但是,最终这些工作是非常有价值的。因为采集的数据是你所需要的,而不是供应商提供给你的。Ansible 也提供直观的方法去执行某些条件任务,这意味着基于正在返回的数据,你可以执行子任务,它可以收集更多的数据或者产生一个配置改变。
|
||||
由于 Ansible 是完全开源并且是可扩展的,它可以精确地去收集和监视所需要的计数器或者值。这可能需要一些预先的定制工作,但是,最终这些工作是非常有价值的。因为采集的数据是你所需要的,而不是供应商提供给你的。Ansible 也提供了执行某些条件任务的直观方法,这意味着基于正在返回的数据,你可以执行子任务,它可以收集更多的数据或者产生一个配置改变。
|
||||
|
||||
网络设备有 _许多_ 统计和隐藏在里面的临时数据,而 Ansible 可以帮你提取它们。
|
||||
|
||||
@ -342,26 +335,23 @@ vlans:
|
||||
|
||||
你现在可以决定某些事情,而不需要事先知道是什么类型的设备。你所需要知道的仅仅是设备的只读通讯字符串。
|
||||
|
||||
#### 迁移
|
||||
|
||||
### 迁移
|
||||
从一个平台迁移到另外一个平台,可能是从同一个供应商或者是从不同的供应商,迁移从来都不是件容易的事。供应商可能提供一个脚本或者一个工具去帮助你迁移。Ansible 可以被用于去为所有类型的网络设备构建配置模板,然后,操作系统用这个方法去为所有的供应商生成一个配置文件,然后作为一个(通用数据模型的)输入设置。当然,如果有供应商专用的扩展,它也是会被用到的。这种灵活性不仅对迁移有帮助,而且也可以用于<ruby>灾难恢复<rt>disaster recovery</rt></ruby>(DR),它在生产系统中不同的交换机型号之间和灾备数据中心中是经常使用的,即使是在不同的供应商的设备上。
|
||||
|
||||
从一个平台迁移到另外一个平台,可能是从同一个供应商或者是从不同的供应商,迁移从来都不是件容易的事。供应商可能提供一个脚本或者一个工具去帮助你迁移。Ansible 可以被用于去为所有类型的网络设备构建配置模板,然后,操作系统用这个方法去为所有的供应商生成一个配置文件,然后作为一个(通用数据模型的)输入设置。当然,如果有供应商专用的扩展,它也是会被用到的。这种灵活性不仅对迁移有帮助,而且也可以用于灾难恢复(DR),它在生产系统中不同的交换机型号之间和灾备数据中心中是经常使用的,即使是在不同的供应商的设备上。
|
||||
#### 配置管理
|
||||
|
||||
正如前面所说的,配置管理是最常用的自动化类型。Ansible 可以很容易地做到创建<ruby>角色<rt>role</rt></ruby>去简化基于任务的自动化。从更高的层面来看,角色是指针对一个特定设备组的可重用的自动化任务的逻辑分组。关于角色的另一种说法是,认为角色就是相关的<ruby>工作流<rt>workflow</rt></ruby>。首先,在开始自动化添加值之前,需要理解工作流和过程。不论是开始一个小的自动化任务还是扩展它,理解工作流和过程都是非常重要的。
|
||||
|
||||
### 配置管理
|
||||
|
||||
正如前面所说的,配置管理是最常用的自动化类型。Ansible 可以很容易地做到创建 _角色(roles)_ 去简化基于任务的自动化。从更高的层面来看,角色是指针对一个特定设备组的可重用的自动化任务的逻辑分组。关于角色的另一种说法是,认为角色就是相关的工作流(workflows)。首先,在开始自动化添加值之前,需要理解工作流和过程。不论是开始一个小的自动化任务还是扩展它,理解工作流和过程都是非常重要的。
|
||||
|
||||
例如,一组自动化配置路由器和交换机的任务是非常常见的,并且它们也是一个很好的起点。但是,配置在哪台网络设备上?配置的 IP 地址是什么?或许需要一个 IP 地址管理方案?一旦用一个给定的功能分配了 IP 地址并且已经部署,DNS 也更新了吗?DHCP 的范围需要创建吗?
|
||||
例如,一组自动化地配置路由器和交换机的任务是非常常见的,并且它们也是一个很好的起点。但是,配置在哪台网络设备上?配置的 IP 地址是什么?或许需要一个 IP 地址管理方案?一旦用一个给定的功能分配了 IP 地址并且已经部署,DNS 也更新了吗?DHCP 的范围需要创建吗?
|
||||
|
||||
你可以看到工作流是怎么从一个小的任务开始,然后逐渐扩展到跨不同的 IT 系统?因为工作流持续扩展,所以,角色也一样(持续扩展)。
|
||||
|
||||
#### 遵从性
|
||||
|
||||
### 遵从性
|
||||
和其它形式的自动化工具一样,用任何形式的自动化工具产生配置改变都被视为风险。手工去产生改变可能看上去风险更大,正如你看到的和亲身经历过的那样,Ansible 有能力去做自动数据收集、监视、和配置构建,这些都是“只读的”和“低风险”的动作。其中一个 _低风险_ 使用案例是,使用收集的数据进行配置遵从性检查和配置验证。部署的配置是否满足安全要求?是否配置了所需的网络?协议 XYZ 禁用了吗?因为每个模块、或者用 Ansible 返回数据的整合,它只是非常简单地 _声明_ 那些事是 _TRUE_ 还是 _FALSE_。然后接着基于 _它_ 是 _TRUE_ 或者是 _FALSE_, 接着由你决定应该发生什么 —— 或许它只是被记录下来,或者,也可能执行一个复杂操作。
|
||||
|
||||
和其它形式的自动化工具一样,用任何形式的自动化工具产生配置改变都视为风险。手工去产生改变可能看上去风险更大,正如你看到的和亲身经历过的那样,Ansible 有能力去做自动数据收集、监视、和配置构建,这些都是“只读的”和“低风险”的动作。其中一个 _低风险_ 使用案例是,使用收集的数据进行配置遵从性检查和配置验证。部署的配置是否满足安全要求?是否配置了所需的网络?协议 XYZ 禁用了吗?因为每个模块、或者用 Ansible 返回数据的整合,它只是非常简单地 _声明_ 那些事是 _TRUE_ 还是 _FALSE_。然后接着基于 _它_ 是 _TRUE_ 或者是 _FALSE_, 接着由你决定应该发生什么 —— 或许它只是被记录下来,或者,也可能执行一个复杂操作。
|
||||
|
||||
### 报告
|
||||
#### 报告
|
||||
|
||||
我们现在知道,Ansible 也可以用于去收集数据和执行遵从性检查。Ansible 可以根据你想要做的事情去从设备中返回和收集数据。或许返回的数据成为其它的任务的输入,或者你想去用它创建一个报告。从模板中生成报告,并将真实的数据插入到模板中,创建和使用报告模板的过程与创建配置模板的过程是相同的。
|
||||
|
||||
@ -369,22 +359,21 @@ vlans:
|
||||
|
||||
创建报告的用处很多,不仅是为行政管理,也为了运营工程师,因为它们通常有双方都需要的不同指标。
|
||||
|
||||
|
||||
### Ansible 怎么工作
|
||||
|
||||
从一个网络自动化的角度理解了 Ansible 能做什么之后,我们现在看一下 Ansible 是怎么工作的。你将学习到从一个 Ansible 管理主机到一个被自动化的节点的全部通讯流。首先,我们回顾一下,Ansible 是怎么 _开箱即用的(out of the box)_,然后,我们看一下 Ansible 怎么去做到的,具体说就是,当网络设备自动化时,Ansible _模块_是怎么去工作的。
|
||||
从一个网络自动化的角度理解了 Ansible 能做什么之后,我们现在看一下 Ansible 是怎么工作的。你将学习到从一个 Ansible 管理主机到一个被自动化的节点的全部通讯流。首先,我们回顾一下,Ansible 是怎么<ruby>开箱即用<rt>out of the box</rt></ruby>的,然后,我们看一下 Ansible 怎么去做到的,具体说就是,当网络设备自动化时,Ansible _模块_是怎么去工作的。
|
||||
|
||||
### 开箱即用
|
||||
#### 开箱即用
|
||||
|
||||
到目前为止,你已经明白了,Ansible 是一个自动化平台。实际上,它是一个安装在一台单个服务器上或者企业中任何一位管理员的笔记本中的轻量级的自动化平台。当然,(安装在哪里?)这是由你来决定的。在基于 Linux 的机器上,使用一些实用程序(比如 pip、apt、和 yum)安装 Ansible 是非常容易的。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
在本报告的其余部分,安装 Ansible 的机器被称为 _控制主机_。
|
||||
> 在本报告的其余部分,安装 Ansible 的机器被称为<ruby>控制主机<rt>control host</rt></ruby>。
|
||||
|
||||
控制主机将执行在 Ansible 的 playbook (不用担心,稍后我们将讲到 playbook 和其它的 Ansible 术语)中定义的所有自动化任务。现在,我们只需要知道,一个 playbook 是简单的一组自动化任务和在给定数量的主机上执行的指令。
|
||||
控制主机将执行定义在 Ansible 的<ruby>剧本<rt>playbook</rt></ruby> (不用担心,稍后我们将讲到剧本和其它的 Ansible 术语)中的所有自动化任务。现在,我们只需要知道,一个剧本是简单的一组自动化任务和在给定数量的主机上执行的指令。
|
||||
|
||||
当一个 playbook 创建之后,你还需要去定义它要自动化的主机。映射一个 playbook 和要自动化运行的主机,是通过一个被称为 Ansible 清单的文件。这是一个前面展示的示例,但是,这里是同一个清单文件的另外两个组:`cisco` 和 `arista`:
|
||||
当一个剧本创建之后,你还需要去定义它要自动化的主机。映射一个剧本和要自动化运行的主机,是通过一个被称为 Ansible <ruby>清单<rt>inventory</rt></ruby>的文件。这是一个前面展示的示例,但是,这里是同一个清单文件的另外两个组:`cisco` 和 `arista`:
|
||||
|
||||
```
|
||||
[cisco]
|
||||
@ -396,13 +385,13 @@ sfo1.acme.com
|
||||
sfo2.acme.com
|
||||
```
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
你也可以在清单文件中使用 IP 地址,而不是主机名。对于这样的示例,主机名将是通过 DNS 可解析的。
|
||||
> 你也可以在清单文件中使用 IP 地址,而不是主机名。对于这样的示例,主机名将是通过 DNS 可解析的。
|
||||
|
||||
正如你所看到的,Ansible 清单文件是一个文本文件,它列出了主机和主机组。然后,你可以在 playbook 中引用一个具体的主机或者组,以此去决定对给定的 play 和 playbook 在哪台主机上进行自动化。下面展示了两个示例。
|
||||
正如你所看到的,Ansible 清单文件是一个文本文件,它列出了主机和主机组。然后,你可以在剧本中引用一个具体的主机或者组,以此去决定对给定的<ruby>剧集<rt>play</rt></ruby>和剧本在哪台主机上进行自动化。下面展示了两个示例。
|
||||
|
||||
展示的第一个示例它看上去像是,你想去自动化 `cisco` 组中所有的主机,而展示的第二个示例只对 _nyc1.acme.com_ 主机进行自动化:
|
||||
展示的第一个示例它看上去像是,你想去自动化 `cisco` 组中所有的主机,而展示的第二个示例只对 `nyc1.acme.com` 主机进行自动化:
|
||||
|
||||
```
|
||||
---
|
||||
@ -424,7 +413,7 @@ sfo2.acme.com
|
||||
- TASKS YOU WANT TO AUTOMATE
|
||||
```
|
||||
|
||||
现在,我们已经理解了基本的清单文件,我们可以看一下(在控制主机上的)Ansible 是怎么与 _开箱即用_ 的设备通讯的,和在 Linux 终端上自动化的任务。这里需要明白一个重要的观点就是,需要去自动化的网络设备通常是不一样的。(译者注:指的是设备的类型、品牌、型号等等)
|
||||
现在,我们已经理解了基本的清单文件,我们可以看一下(在控制主机上的)Ansible 是怎么与 _开箱即用_ 的设备通讯的,和在 Linux 终端上自动化的任务。这里需要明白一个重要的观点就是,需要去自动化的网络设备通常是不一样的。(LCTT 译注:指的是设备的类型、品牌、型号等等)
|
||||
|
||||
Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求。它们是 SSH 和 Python。
|
||||
|
||||
@ -434,31 +423,26 @@ Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求
|
||||
|
||||
如果我们详细解释这个开箱即用工作流,它将分解成如下的步骤:
|
||||
|
||||
1. 当一个 Ansible play 被执行,控制主机使用 SSH 连接到基于 Linux 的目标节点。
|
||||
|
||||
2. 对于每个任务,也就是说,Ansible 模块将在这个 play 中被执行,通过 SSH 发送 Python 代码并直接在远程系统中执行。
|
||||
|
||||
1. 当执行一个 Ansible 剧集时,控制主机使用 SSH 连接到基于 Linux 的目标节点。
|
||||
2. 对于每个任务,也就是说,Ansible 模块将在这个剧集中被执行,通过 SSH 发送 Python 代码并直接在远程系统中执行。
|
||||
3. 在远程系统上运行的每个 Ansible 模块将返回 JSON 数据到控制主机。这些数据包含有信息,比如,配置改变、任务成功/失败、以及其它模块特定的数据。
|
||||
|
||||
4. JSON 数据返回给 Ansible,然后被用于去生成报告,或者被用作接下来模块的输入。
|
||||
5. 在剧集中为每个任务重复第 3 步。
|
||||
6. 在剧本中为每个剧集重复第 1 步。
|
||||
|
||||
5. 在 play 中为每个任务重复第 3 步。
|
||||
|
||||
6. 在 playbook 中为每个 play 重复第 1 步。
|
||||
|
||||
是不是意味着每个网络设备都可以被 Ansible 开箱即用?因为它们也都支持 SSH,确实,网络设备都支持 SSH,但是,它是第一个和第二要求的组合限制了网络设备可能的功能。
|
||||
是不是意味着每个网络设备都可以被 Ansible 开箱即用?因为它们也都支持 SSH,确实,网络设备都支持 SSH,但是,第一个和第二要求的组合限制了网络设备可能的功能。
|
||||
|
||||
刚开始时,大多数网络设备并不支持 Python,因此,使用默认的 Ansible 连接机制是无法进行的。换句话说,在过去的几年里,供应商在几个不同的设备平台上增加了 Python 支持。但是,这些平台中的大多数仍然缺乏必要的集成,以允许 Ansible 去直接通过 SSH 访问一个 Linux shell,并以适当的权限去拷贝所需的代码、创建临时目录和文件、以及在设备中执行代码。尽管 Ansible 中所有的这些部分都可以在基于 Linux 的网络设备上使用 SSH/Python 在本地运行,它仍然需要网络设备供应商去更进一步开放他们的系统。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
值的注意的是,Arista 确实也提供了原生的集成,因为它可以放弃 SSH 用户,直接进入到一个 Linux shell 中访问 Python 引擎,它可以允许 Ansible 去使用默认连接机制。因为我们调用了 Arista,我们也需要着重强调与 Ansible 默认连接机制一起工作的 Cumulus。这是因为 Cumulus Linux 是原生 Linux,并且它并不需要为 Cumulus Linux 操作系统使用供应商 API。
|
||||
> 值的注意的是,Arista 确实也提供了原生的集成,因为它可以无需 SSH 用户,直接进入到一个 Linux shell 中访问 Python 引擎,它可以允许 Ansible 去使用其默认连接机制。因为我们调用了 Arista,我们也需要着重强调与 Ansible 默认连接机制一起工作的 Cumulus。这是因为 Cumulus Linux 是原生 Linux,并且它并不需要为 Cumulus Linux 操作系统使用供应商 API。
|
||||
|
||||
### Ansible 网络集成
|
||||
#### Ansible 网络集成
|
||||
|
||||
前面的节讲到过 Ansible 默认的工作方式。我们看一下,在开始一个 _play_ 之后,Ansible 是怎么去设置一个到设备的连接、通过执行拷贝 Python 代码到设备去运行任务、运行代码、和返回结果给 Ansible 控制主机。
|
||||
前面的节讲到过 Ansible 默认的工作方式。我们看一下,在开始一个 _剧集_ 之后,Ansible 是怎么去设置一个到设备的连接、通过拷贝 Python 代码到设备、运行代码、和返回结果给 Ansible 控制主机来执行任务。
|
||||
|
||||
在这一节中,我们将看一看,当使用 Ansible 进行自动化网络设备时都做了什么。正如前面讲过的,Ansible 是一个可拔插的连接架构。对于 _大多数_ 的网络集成, `connection` 参数设置为 `local`。在 playbook 中大多数的连接类型都设置为 `local`,如下面的示例所展示的:
|
||||
在这一节中,我们将看一看,当使用 Ansible 进行自动化网络设备时都做了什么。正如前面讲过的,Ansible 是一个可拔插的连接架构。对于 _大多数_ 的网络集成, `connection` 参数设置为 `local`。在剧本中大多数的连接类型都设置为 `local`,如下面的示例所展示的:
|
||||
|
||||
```
|
||||
---
|
||||
@ -471,15 +455,15 @@ Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求
|
||||
- TASKS YOU WANT TO AUTOMATE
|
||||
```
|
||||
|
||||
注意在 play 中是怎么定义的,这个示例增加 `connection` 参数去和前面节中的示例进行比较。
|
||||
注意在剧集中是怎么定义的,这个示例增加 `connection` 参数去和前面节中的示例进行比较。
|
||||
|
||||
这告诉 Ansible 不要通过 SSH 去连接到目标设备,而是连接到本地机器运行这个 playbook。基本上,这是把连接职责委托给 playbook 中 _任务_ 节中使用的真实的 Ansible 模块。每个模块类型的委托权利允许这个模块在必要时以各种形式去连接到设备。这可能是 Juniper 和 HP Comware7 的 NETCONF、Arista 的 eAPI、Cisco Nexus 的 NX-API、或者甚至是基于传统系统的 SNMP,它们没有可编程的 API。
|
||||
这告诉 Ansible 不要通过 SSH 去连接到目标设备,而是连接到本地机器运行这个剧本。基本上,这是把连接职责委托给剧本中<ruby>任务<rt>task</rt></ruby> 节中使用的真实的 Ansible 模块。每个模块类型的委托权利允许这个模块在必要时以各种形式去连接到设备。这可能是 Juniper 和 HP Comware7 的 NETCONF、Arista 的 eAPI、Cisco Nexus 的 NX-API、或者甚至是基于传统系统的 SNMP,它们没有可编程的 API。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
网络集成在 Ansible 中是以 Ansible 模块的形式带来的。尽管我们持续使用术语来吊你的胃口,比如,playbooks、plays、任务、和讲到的关键概念 `模块`,这些术语中的每一个都会在 [Ansible 术语和入门][3] 和 [动手实践使用 Ansible 去进行网络自动化][4] 中详细解释。
|
||||
> 网络集成在 Ansible 中是以 Ansible 模块的形式带来的。尽管我们持续使用术语来吊你的胃口,比如,剧本、剧集、任务、和讲到的关键概念模块,这些术语中的每一个都会在 [Ansible 术语和入门][3] 和 [动手实践使用 Ansible 去进行网络自动化][4] 中详细解释。
|
||||
|
||||
让我们看一看另外一个 playbook 的示例:
|
||||
让我们看一看另外一个剧本的示例:
|
||||
|
||||
```
|
||||
---
|
||||
@ -492,22 +476,21 @@ Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求
|
||||
- nxos_vlan: vlan_id=10 name=WEB_VLAN
|
||||
```
|
||||
|
||||
你注意到了吗,这个 playbook 现在包含一个任务,并且这个任务使用了 `nxos_vlan` 模块。`nxos_vlan` 模块是一个 Python 文件,并且,在这个文件中它是使用 NX-API 连接到 Cisco 的 NX-OS 设备。可是,这个连接可能是使用其它设备 API 设置的,这就是为什么供应商和用户像我们这样能够去建立自己的集成的原因。集成(模块)通常是以每特性(per-feature)为基础完成的,虽然,你已经看到了像 `napalm_install_config` 这样的模块,它们也可以被用来 _推送_ 一个完整的配置文件。
|
||||
你注意到了吗,这个剧本现在包含一个任务,并且这个任务使用了 `nxos_vlan` 模块。`nxos_vlan` 模块是一个 Python 文件,并且,在这个文件中它是使用 NX-API 连接到 Cisco 的 NX-OS 设备。可是,这个连接可能是使用其它设备 API 设置的,这就是为什么供应商和用户像我们这样能够去建立自己的集成的原因。集成(模块)通常是以<ruby>每特性<rt>per-feature</rt></ruby>为基础完成的,虽然,你已经看到了像 `napalm_install_config` 这样的模块,它们也可以被用来 _推送_ 一个完整的配置文件。
|
||||
|
||||
主要区别之一是使用的默认连接机制,Ansible 启动一个持久的 SSH 连接到设备,并且这个连接为一个给定的 play 持续。当在一个模块中发生连接设置和拆除时,与许多使用 `connection=local` 的网络模块一样,对发生在 play 级别上的 _每个_ 任务,Ansible 将登入/登出设备。
|
||||
主要区别之一是使用的默认连接机制,Ansible 启动一个持久的 SSH 连接到设备,并且对于一个给定的剧集而已该连接将持续存在。当在一个模块中发生连接设置和拆除时,与许多使用 `connection=local` 的网络模块一样,对发生在剧集级别上的 _每个_ 任务,Ansible 将登入/登出设备。
|
||||
|
||||
而在传统的 Ansible 形式下,每个网络模块返回 JSON 数据。仅有的区别是相对于目标节点,数据的推取发生在本地的 Ansible 控制主机上。相对于每供应商(per vendor)和模块类型,数据返回到 playbook,但是作为一个示例,许多的 Cisco NX-OS 模块返回已存在的状态、建议状态、和最终状态,以及发送到设备的命令(如果有的话)。
|
||||
而在传统的 Ansible 形式下,每个网络模块返回 JSON 数据。仅有的区别是相对于目标节点,数据的推取发生在本地的 Ansible 控制主机上。相对于<ruby>每供应商<rt>per vendor</rt></ruby>和模块类型,数据返回到剧本,但是作为一个示例,许多的 Cisco NX-OS 模块返回已存在的状态、建议状态、和最终状态,以及发送到设备的命令(如果有的话)。
|
||||
|
||||
作为使用 Ansible 进行网络自动化的开始,最重要的是,为 Ansible 的连接设备/拆除过程,记着去设置连接参数为 `local`,并且将它留在模块中。这就是为什么模块支持不同类型的供应商平台,它将与设备使用不同的方式进行通讯。
|
||||
|
||||
|
||||
### Ansible 术语和入门
|
||||
|
||||
这一章我们将介绍许多 Ansible 的术语和报告中前面部分出现过的关键概念。比如, _清单文件_、_playbook_、_play_、_任务_、和 _模块_。我们也会去回顾一些其它的概念,这些术语和概念对我们学习使用 Ansible 去进行网络自动化非常有帮助。
|
||||
这一章我们将介绍许多 Ansible 的术语和报告中前面部分出现过的关键概念。比如, <ruby>清单文件<rt>inventory file</rt></ruby>、<ruby>剧本<rt>playbook</rt></ruby>、<ruby>剧集<rt>play</rt></ruby>、<ruby>任务<rt>task</rt></ruby>和<ruby>模块<rt>module</rt></ruby>。我们也会去回顾一些其它的概念,这些术语和概念对我们学习使用 Ansible 去进行网络自动化非常有帮助。
|
||||
|
||||
在这一节中,我们将引用如下的一个简单的清单文件和 playbook 的示例,它们将在后面的章节中持续出现。
|
||||
在这一节中,我们将引用如下的一个简单的清单文件和剧本的示例,它们将在后面的章节中持续出现。
|
||||
|
||||
_清单示例_:
|
||||
_清单示例_ :
|
||||
|
||||
```
|
||||
# sample inventory file
|
||||
@ -528,7 +511,7 @@ core1
|
||||
core2
|
||||
```
|
||||
|
||||
_playbook 示例_:
|
||||
_剧本示例_ :
|
||||
|
||||
```
|
||||
---
|
||||
@ -577,54 +560,50 @@ _playbook 示例_:
|
||||
- 50
|
||||
```
|
||||
|
||||
### 清单文件
|
||||
#### 清单文件
|
||||
|
||||
使用一个清单文件,比如前面提到的那个,允许我们去为自动化任务指定主机、和使用每个 play 顶部节中(如果存在)的参数 `hosts` 所引用的主机/组指定的主机组。
|
||||
使用一个清单文件,比如前面提到的那个,允许我们去为自动化任务指定主机、和使用每个剧集顶部节中(如果存在)的参数 `hosts` 所引用的主机/组指定的主机组。
|
||||
|
||||
它也可能在一个清单文件中存储变量。如这个示例中展示的那样。如果变量在同一行视为一台主机,它是一个具体主机变量。如果变量定义在方括号中(“[ ]”),比如,`[all:vars]`,它的意思是指变量在组中的范围 `all`,它是一个默认组,包含了清单文件中的 _所有_ 主机。
|
||||
它也可能在一个清单文件中存储变量。如这个示例中展示的那样。如果变量在同一行视为一台主机,它是一个具体主机变量。如果变量定义在方括号中(`[ ]`),比如,`[all:vars]`,它的意思是指变量在组中的范围 `all`,它是一个默认组,包含了清单文件中的 _所有_ 主机。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
清单文件是使用 Ansible 开始自动化的快速方法,但是,你应该已经有一个真实的网络设备源,比如一个网络管理工具或者 CMDB,它可以去创建和使用一个动态的清单脚本,而不是一个静态的清单文件。
|
||||
> 清单文件是使用 Ansible 开始自动化的快速方法,但是,你应该已经有一个真实的网络设备源,比如一个网络管理工具或者 CMDB,它可以去创建和使用一个动态的清单脚本,而不是一个静态的清单文件。
|
||||
|
||||
### Playbook
|
||||
#### 剧本
|
||||
|
||||
playbook 是去运行自动化网络设备的顶级对象。在我们的示例中,它是一个 _site.yml_ 文件,如前面的示例所展示的。一个 playbook 使用 YAML 去定义一组自动化任务,并且,每个 playbook 由一个或多个 plays 组成。这类似于一个橄榄球的剧本。就像在橄榄球赛中,团队有剧集组成的剧本,Ansible 的 playbooks 也是由 play 组成的。
|
||||
剧本是去运行自动化网络设备的顶级对象。在我们的示例中,它是 `site.yml` 文件,如前面的示例所展示的。一个剧本使用 YAML 去定义一组自动化任务,并且,每个剧本由一个或多个剧集组成。这类似于一个橄榄球的剧本。就像在橄榄球赛中,团队有剧集组成的剧本,Ansible 的剧本也是由剧集组成的。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
YAML 是一种被所有编程语言支持的数据格式。YAML 本身就是 JSON 的超集,并且,YAML 文件非常易于识别,因为它总是三个破折号(连字符)开始,比如,`---`。
|
||||
> YAML 是一种被所有编程语言支持的数据格式。YAML 本身就是 JSON 的超集,并且,YAML 文件非常易于识别,因为它总是三个破折号(连字符)开始,比如,`---`。
|
||||
|
||||
|
||||
### Play
|
||||
#### 剧集
|
||||
|
||||
一个 Ansible playbook 可以存在一个或多个 plays。在前面的示例中,它在 playbook 中有两个 plays。每个 play 开始的地方都有一个 _header_ 节,它定义了具体的参数。
|
||||
一个 Ansible 剧本可以存在一个或多个剧集。在前面的示例中,它在剧本中有两个剧集。每个剧集开始的地方都有一个 _头部_,它定义了具体的参数。
|
||||
|
||||
示例中两个 plays 都定义了下面的参数:
|
||||
示例中两个剧集都定义了下面的参数:
|
||||
|
||||
`name`
|
||||
|
||||
文件 `PLAY 1 - Top of Rack (TOR) Switches` 是任意内容的,它在 playbook 运行的时候,去改善 playbook 运行和报告期间的可读性。这是一个可选参数。
|
||||
文件 `PLAY 1 - Top of Rack (TOR) Switches` 是任意内容的,它在剧本运行的时候,去改善剧本运行和报告期间的可读性。这是一个可选参数。
|
||||
|
||||
`hosts`
|
||||
|
||||
正如前面讲过的,这是在特定的 play 中要去进行自动化的主机或主机组。这是一个必需参数。
|
||||
正如前面讲过的,这是在特定的剧集中要去进行自动化的主机或主机组。这是一个必需参数。
|
||||
|
||||
`connection`
|
||||
|
||||
正如前面讲过的,这是 play 连接机制的类型。这是个可选参数,但是,对于网络自动化 plays,一般设置为 `local`。
|
||||
正如前面讲过的,这是剧集连接机制的类型。这是个可选参数,但是,对于网络自动化剧集,一般设置为 `local`。
|
||||
|
||||
每个剧集都是由一个或多个任务组成。
|
||||
|
||||
|
||||
每个 play 都是由一个或多个任务组成。
|
||||
|
||||
|
||||
|
||||
### 任务
|
||||
#### 任务
|
||||
|
||||
任务是以声明的方式去表示自动化的内容,而不用担心底层的语法或者操作是怎么执行的。
|
||||
|
||||
在我们的示例中,第一个 play 有两个任务。每个任务确保存在 10 个 VLAN。第一个任务是为 Cisco Nexus 设备的,而第二个任务是为 Arista 设备的:
|
||||
在我们的示例中,第一个剧集有两个任务。每个任务确保存在 10 个 VLAN。第一个任务是为 Cisco Nexus 设备的,而第二个任务是为 Arista 设备的:
|
||||
|
||||
```
|
||||
tasks:
|
||||
@ -638,19 +617,17 @@ tasks:
|
||||
when: vendor == "nxos"
|
||||
```
|
||||
|
||||
任务也可以使用 `name` 参数,就像 plays 一样。和 plays 一样,文本内容是任意的,并且当 playbook 运行时显示,去改善 playbook 运行和报告期间的可读性。它对每个任务都是可选参数。
|
||||
任务也可以使用 `name` 参数,就像剧集一样。和剧集一样,文本内容是任意的,并且当剧本运行时显示,去改善剧本运行和报告期间的可读性。它对每个任务都是可选参数。
|
||||
|
||||
示例任务中的下一行是以 `nxos_vlan` 开始的。它告诉我们这个任务将运行一个叫 `nxos_vlan` 的 Ansible 模块。
|
||||
|
||||
现在,我们将进入到模块中。
|
||||
|
||||
#### 模块
|
||||
|
||||
在 Ansible 中理解模块的概念是至关重要的。虽然任何编辑语言都可以用来写 Ansible 模块,只要它们能够返回 JSON 键/值对即可,但是,几乎所有的模块都是用 Python 写的。在我们示例中,我们看到有两个模块被运行: `nxos_vlan` 和 `eos_vlan`。这两个模块都是 Python 文件;而事实上,在你不能看到剧本的时候,真实的文件名分别是 `eos_vlan.py` 和 `nxos_vlan.py`。
|
||||
|
||||
### 模块
|
||||
|
||||
在 Ansible 中理解模块的概念是至关重要的。虽然任何编辑语言都可以用来写 Ansible 模块,只要它们能够返回 JSON 键 — 值对即可,但是,几乎所有的模块都是用 Python 写的。在我们示例中,我们看到有两个模块被运行: `nxos_vlan` 和 `eos_vlan`。这两个模块都是 Python 文件;而事实上,在你不能看到 playbook 的时候,真实的文件名分别是 _eos_vlan.py_ 和 _nxos_vlan.py_。
|
||||
|
||||
让我们看一下前面的示例中第一个 play 中的第一个 任务:
|
||||
让我们看一下前面的示例中第一个剧集中的第一个任务:
|
||||
|
||||
```
|
||||
- name: ENSURE VLAN 10 EXISTS ON CISCO TOR SWITCHES
|
||||
@ -678,48 +655,39 @@ tasks:
|
||||
|
||||
用于登入到交换机的密码。
|
||||
|
||||
示例中最后的片断部分使用了一个 `when` 语句。这是在一个剧集中使用的 Ansible 的执行条件任务。正如我们所了解的,在这个剧集的 `tor` 组中有多个设备和设备类型。使用 `when` 基于任意标准去提供更多的选择。这里我们仅自动化 Cisco 设备,因为,我们在这个任务中使用了 `nxos_vlan` 模块,在下一个任务中,我们仅自动化 Arista 设备,因为,我们使用了 `eos_vlan` 模块。
|
||||
|
||||
示例中最后的片断部分使用了一个 `when` 语句。这是在一个 play 中使用的 Ansible 的执行条件任务。正如我们所了解的,在这个 play 的 `tor` 组中有多个设备和设备类型。使用 `when` 基于任意标准去提供更多的选择。这里我们仅自动化 Cisco 设备,因为,我们在这个任务中使用了 `nxos_vlan` 模块,在下一个任务中,我们仅自动化 Arista 设备,因为,我们使用了 `eos_vlan` 模块。
|
||||
> 注意:
|
||||
|
||||
###### 注意
|
||||
|
||||
这并不是区分设备的唯一方法。这里仅是演示如何使用 `when`,并且可以在清单文件中定义变量。
|
||||
> 这并不是区分设备的唯一方法。这里仅是演示如何使用 `when`,并且可以在清单文件中定义变量。
|
||||
|
||||
在清单文件中定义变量是一个很好的开端,但是,如果你继续使用 Ansible,你将会为了扩展性、版本控制、对给定文件的改变最小化而去使用基于 YAML 的变量。这也将简化和改善清单文件和每个使用的变量的可读性。在设备准备的构建/推送方法中讲过一个变量文件的示例。
|
||||
|
||||
在最后的示例中,关于任务有几点需要去搞清楚:
|
||||
|
||||
* Play 1 任务 1 展示了硬编码了 `username` 和 `password` 作为参数进入到具体的模块中(`nxos_vlan`)。
|
||||
|
||||
* Play 1 任务 1 和 play 2 在模块中使用了变量,而不是硬编码它们。这掩饰了 `username` 和 `password` 参数,但是,需要值得注意的是,(在这个示例中)这些变量是从清单文件中提取出现的。
|
||||
|
||||
* Play 1 中为进入到模块中的参数使用了一个 _水平的(horizontal)_ 的 key=value 语法,虽然 play 2 使用了垂直的(vertical) key=value 语法。它们都工作的非常好。你也可以使用垂直的 YAML “key: value” 语法。
|
||||
|
||||
* 最后的任务也介绍了在 Ansible 中怎么去使用一个 _loop_ 循环。它通过使用 `with_items` 来完成,并且它类似于一个 for 循环。那个特定的任务是循环进入五个 VLANs 中去确保在交换机中它们都存在。注意:它也可能被保存在一个外部的 YAML 变量文件中。还需要注意的一点是,不使用 `with_items` 的替代方案是,每个 VLAN 都有一个任务 —— 如果这样做,它就失去了弹性!
|
||||
|
||||
* 剧集 1 任务 1 展示了硬编码了 `username` 和 `password` 作为参数进入到具体的模块中(`nxos_vlan`)。
|
||||
* 剧集 1 任务 1 和 剧集 2 在模块中使用了变量,而不是硬编码它们。这掩饰了 `username` 和 `password` 参数,但是,需要值得注意的是,(在这个示例中)这些变量是从清单文件中提取出现的。
|
||||
* 剧集 1 中为进入到模块中的参数使用了一个 _水平的_ 的 key=value 语法,虽然剧集 2 使用了垂直的 key=value 语法。它们都工作的非常好。你也可以使用垂直的 YAML “key: value” 语法。
|
||||
* 最后的任务也介绍了在 Ansible 中怎么去使用一个循环。它通过使用 `with_items` 来完成,并且它类似于一个 for 循环。那个特定的任务是循环进入五个 VLAN 中去确保在交换机中它们都存在。注意:它也可能被保存在一个外部的 YAML 变量文件中。还需要注意的一点是,不使用 `with_items` 的替代方案是,每个 VLAN 都有一个任务 —— 如果这样做,它就失去了弹性!
|
||||
|
||||
### 动手实践使用 Ansible 去进行网络自动化
|
||||
|
||||
在前面的章节中,提供了 Ansible 术语的一个概述。它已经覆盖了大多数具体的 Ansible 术语,比如 playbooks、plays、任务、模块、和清单文件。这一节将继续提供示例去讲解使用 Ansible 实现网络自动化,而且将提供在不同类型的设备中自动化工作的模块的更多细节。示例中的将要进行自动化设备由多个供应商提供,包括 Cisco、Arista、Cumulus、和 Juniper。
|
||||
在前面的章节中,提供了 Ansible 术语的一个概述。它已经覆盖了大多数具体的 Ansible 术语,比如剧本、剧集、任务、模块和清单文件。这一节将继续提供示例去讲解使用 Ansible 实现网络自动化,而且将提供在不同类型的设备中自动化工作的模块的更多细节。示例中的将要进行自动化设备由多个供应商提供,包括 Cisco、Arista、Cumulus、和 Juniper。
|
||||
|
||||
在本节中的示例,假设的前提条件如下:
|
||||
|
||||
* Ansible 已经安装。
|
||||
|
||||
* 在设备中(NX-API、eAPI、NETCONF)适合的 APIs 已经启用。
|
||||
|
||||
* 用户在系统上有通过 API 去产生改变的适当权限。
|
||||
|
||||
* 所有的 Ansible 模块已经在系统中存在,并且也在库的路径变量中。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
可以在 _ansible.cfg_ 文件中设置模块和库路径。在你运行一个 playbook 时,你也可以使用 `-M` 标志从命令行中去改变它。
|
||||
> 可以在 `ansible.cfg` 文件中设置模块和库路径。在你运行一个剧本时,你也可以使用 `-M` 标志从命令行中去改变它。
|
||||
|
||||
在本节中示例使用的清单如下。(删除了密码,IP 地址也发生了变化)。在这个示例中,(和前面的示例一样)某些主机名并不是完全合格域名(FQDNs)。
|
||||
在本节中示例使用的清单如下。(删除了密码,IP 地址也发生了变化)。在这个示例中,(和前面的示例一样)某些主机名并不是完全合格域名(FQDN)。
|
||||
|
||||
|
||||
### 清单文件
|
||||
#### 清单文件
|
||||
|
||||
```
|
||||
[cumulus]
|
||||
@ -735,19 +703,19 @@ nx1 hostip=5.6.7.8 un=USERNAME pwd=PASSWORD
|
||||
vsrx hostip=9.10.11.12 un=USERNAME pwd=PASSWORD
|
||||
```
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
正如你所知道的,Ansible 支持将密码存储在一个加密文件中的功能。如果你想学习关于这个特性的更多内容,请查看在 Ansible 网站上的文档中的 [Ansible Vault][5] 部分。
|
||||
> 正如你所知道的,Ansible 支持将密码存储在一个加密文件中的功能。如果你想学习关于这个特性的更多内容,请查看在 Ansible 网站上的文档中的 [Ansible Vault][5] 部分。
|
||||
|
||||
这个清单文件有四个组,每个组定义了一台单个的主机。让我们详细回顾一下每一节:
|
||||
|
||||
Cumulus
|
||||
**Cumulus**
|
||||
|
||||
主机 `cvx` 是一个 Cumulus Linux (CL) 交换机,并且它是 `cumulus` 组中的唯一设备。记住,CL 是原生 Linux,因此,这意味着它是使用默认连接机制(SSH)连到到需要自动化的 CL 交换机。因为 `cvx` 在 DNS 或者 _/etc/hosts_ 文件中没有定义,我们将让 Ansible 知道不要在清单文件中定义主机名,而是在 `ansible_ssh_host` 中定义的名字/IP。登陆到 CL 交换机的用户名被定义在 playbook 中,但是,你可以看到密码使用变量 `ansible_ssh_pass` 定义在清单文件中。
|
||||
主机 `cvx` 是一个 Cumulus Linux (CL) 交换机,并且它是 `cumulus` 组中的唯一设备。记住,CL 是原生 Linux,因此,这意味着它是使用默认连接机制(SSH)连到到需要自动化的 CL 交换机。因为 `cvx` 在 DNS 或者 `/etc/hosts` 文件中没有定义,我们将让 Ansible 知道不要在清单文件中定义主机名,而是在 `ansible_ssh_host` 中定义的名字/IP。登陆到 CL 交换机的用户名被定义在 playbook 中,但是,你可以看到密码使用变量 `ansible_ssh_pass` 定义在清单文件中。
|
||||
|
||||
Arista
|
||||
**Arista**
|
||||
|
||||
被称为 `veos1` 的是一台运行 EOS 的 Arista 交换机。它是在 `arista` 组中唯一的主机。正如你在 Arista 中看到的,在清单文件中并没有其它的参数存在。这是因为 Arista 为它们的设备使用了一个特定的配置文件。在我们的示例中它的名字为 _.eapi.conf_,它存在在 home 目录中。下面是正确使用配置文件的这个功能的示例:
|
||||
被称为 `veos1` 的是一台运行 EOS 的 Arista 交换机。它是在 `arista` 组中唯一的主机。正如你在 Arista 中看到的,在清单文件中并没有其它的参数存在。这是因为 Arista 为它们的设备使用了一个特定的配置文件。在我们的示例中它的名字为 `.eapi.conf`,它存在在 home 目录中。下面是正确使用配置文件的这个功能的示例:
|
||||
|
||||
```
|
||||
[connection:veos1]
|
||||
@ -756,27 +724,26 @@ username: unadmin
|
||||
password: pwadmin
|
||||
```
|
||||
|
||||
这个文件包含了定义在配置文件中的 Ansible 连接到设备(和 Arista 的被称为 _pyeapi_ 的 Python 库)所需要的全部信息。
|
||||
这个文件包含了定义在配置文件中的 Ansible 连接到设备(和 Arista 的被称为 `pyeapi` 的 Python 库)所需要的全部信息。
|
||||
|
||||
Cisco
|
||||
**Cisco**
|
||||
|
||||
和 Cumulus 和 Arista 一样,这里仅有一台主机(`nx1`)存在于 `cisco` 组中。这是一台 NX-OS-based Cisco Nexus 交换机。注意在这里为 `nx1` 定义了三个变量。它们包括 `un` 和 `pwd`,这是为了在 playbook 中访问和为了进入到 Cisco 模块去连接到设备。另外,这里有一个称为 `hostip` 的参数,它是必需的,因为,`nx1` 没有在 DNS 中或者是 _/etc/hosts_ 配置文件中定义。
|
||||
和 Cumulus 和 Arista 一样,这里仅有一台主机(`nx1`)存在于 `cisco` 组中。这是一台 NX-OS-based Cisco Nexus 交换机。注意在这里为 `nx1` 定义了三个变量。它们包括 `un` 和 `pwd`,这是为了在 playbook 中访问和为了进入到 Cisco 模块去连接到设备。另外,这里有一个称为 `hostip` 的参数,它是必需的,因为,`nx1` 没有在 DNS 中或者是 `/etc/hosts` 配置文件中定义。
|
||||
|
||||
> 注意:
|
||||
|
||||
###### 注意
|
||||
> 如果自动化一个原生的 Linux 设备,我们可以将这个参数命名为任何东西。`ansible_ssh_host` 被用于到如我们看到的那个 Cumulus 示例(如果在清单文件中的定义不能被解析)。在这个示例中,我们将一直使用 `ansible_ssh_host`,但是,它并不是必需的,因为我们将这个变量作为一个参数进入到 Cisco 模块,而 `ansible_ssh_host` 是在使用默认的 SSH 连接机制时自动检查的。
|
||||
|
||||
如果自动化一个原生的 Linux 设备,我们可以将这个参数命名为任何东西。`ansible_ssh_host` 被用于到如我们看到的那个 Cumulus 示例(如果在清单文件中的定义不能被解析)。在这个示例中,我们将一直使用 `ansible_ssh_host`,但是,它并不是必需的,因为我们将这个变量作为一个参数进入到 Cisco 模块,而 `ansible_ssh_host` 是在使用默认的 SSH 连接机制时自动检查的。
|
||||
|
||||
Juniper
|
||||
**Juniper**
|
||||
|
||||
和前面的三个组和主机一样,在 `juniper` 组中有一个单个的主机 `vsrx`。它在清单文件中的设置与 Cisco 相同,因为两者在 playbook 中使用了相同的方式。
|
||||
|
||||
|
||||
### Playbook
|
||||
#### 剧本
|
||||
|
||||
接下来的 playbook 有四个不同的 plays。每个 play 是基于特定的供应商类型的设备组的自动化构建的。注意,那是在一个单个的 playbook 中执行这些任务的唯一的方法。这里还有其它的方法,它可以使用条件(`when` 语句)或者创建 Ansible 角色(它在这个报告中没有介绍)。
|
||||
接下来的剧本有四个不同的剧集。每个剧集是基于特定的供应商类型的设备组的自动化构建的。注意,那是在一个单个的剧本中执行这些任务的唯一的方法。这里还有其它的方法,它可以使用条件(`when` 语句)或者创建 Ansible 角色(它在这个报告中没有介绍)。
|
||||
|
||||
这里有一个 playbook 的示例:
|
||||
这里有一个剧本的示例:
|
||||
|
||||
```
|
||||
---
|
||||
@ -833,29 +800,29 @@ Juniper
|
||||
diffs_file=junpr.diff
|
||||
```
|
||||
|
||||
你将注意到,前面的两个 plays 是非常类似的,我们已经在最初的 Cisco 和 Arista 示例中讲过了。唯一的区别是每个要自动化的组(`cisco` and `arista`) 定义了它们自己的 play,我们在前面介绍使用 `when` 条件时比较过。
|
||||
你将注意到,前面的两个剧集是非常类似的,我们已经在最初的 Cisco 和 Arista 示例中讲过了。唯一的区别是每个要自动化的组(`cisco` and `arista`) 定义了它们自己的剧集,我们在前面介绍使用 `when` 条件时比较过。
|
||||
|
||||
这里有一个不正确的或者是错误的方式去做这些。这取决于你预先知道的信息是什么和适合你的环境和使用的最佳案例是什么,但我们的目的是为了展示做同一件事的几种不同的方法。
|
||||
|
||||
第三个 play 是在 Cumulus Linux 交换机的 `swp1` 接口上进行自动化配置。在这个 play 中的第一个任务是去确认 `swp1` 是一个三层接口,并且它配置的 IP 地址是 100.10.10.1。因为 Cumulus Linux 是原生的 Linux,网络服务在改变后需要重启才能生效。这也可以使用 Ansible 的操作来达到这个目的(这已经超出了本报告讨论的范围),这里有一个被称为 `service` 的 Ansible 核心模块来做这些,但它会中断交换机上的网络;使用 `ifreload` 重新启动则不会中断。
|
||||
第三个剧集是在 Cumulus Linux 交换机的 `swp1` 接口上进行自动化配置。在这个剧集中的第一个任务是去确认 `swp1` 是一个三层接口,并且它配置的 IP 地址是 100.10.10.1。因为 Cumulus Linux 是原生的 Linux,网络服务在改变后需要重启才能生效。这也可以使用 Ansible 的操作来达到这个目的(这已经超出了本报告讨论的范围),这里有一个被称为 `service` 的 Ansible 核心模块来做这些,但它会中断交换机上的网络;使用 `ifreload` 重新启动则不会中断。
|
||||
|
||||
本节到现在为止,我们已经讲解了专注于特定任务的 Ansible 模块,比如,配置接口和 VLANs。第四个 play 使用了另外的选项。我们将看到一个 _pushes_ 模块,它是一个完整的配置文件并且立即激活它作为正在运行的新的配置。这里将使用 `napalm_install_config`来展示前面的示例,但是,这个示例使用了一个 Juniper 专用的模块。
|
||||
本节到现在为止,我们已经讲解了专注于特定任务的 Ansible 模块,比如,配置接口和 VLAN。第四个剧集使用了另外的选项。我们将看到一个 `pushes` 模块,它是一个完整的配置文件并且立即激活它作为正在运行的新的配置。这里将使用 `napalm_install_config` 来展示前面的示例,但是,这个示例使用了一个 Juniper 专用的模块。
|
||||
|
||||
`junos_install_config` 模块接受几个参数,如下面的示例中所展示的。到现在为止,你应该理解了什么是 `user`、`passwd`、和 `host`。其它的参数定义如下:
|
||||
|
||||
`file`
|
||||
`file`:
|
||||
|
||||
这是一个从 Ansible 控制主机拷贝到 Juniper 设备的配置文件。
|
||||
|
||||
`logfile`
|
||||
`logfile`:
|
||||
|
||||
这是可选的,但是,如果你指定它,它会被用于存储运行这个模块时生成的信息。
|
||||
|
||||
`overwrite`
|
||||
`overwrite`:
|
||||
|
||||
当你设置为 yes/true 时,完整的配置将被发送的配置覆盖。(默认是 false)
|
||||
|
||||
`diffs_file`
|
||||
`diffs_file`:
|
||||
|
||||
这是可选的,但是,如果你指定它,当应用配置时,它将存储生成的差异。当应用配置时将存储一个生成的差异。当正好更改了主机名,但是,仍然发送了一个完整的配置文件时会生成一个差异,如下的示例:
|
||||
|
||||
@ -867,11 +834,11 @@ Juniper
|
||||
```
|
||||
|
||||
|
||||
上面已经介绍了 playbook 概述的细节。现在,让我们看看当 playbook 运行时发生了什么:
|
||||
上面已经介绍了剧本概述的细节。现在,让我们看看当剧本运行时发生了什么:
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
注意:`-i` 标志是用于指定使用的清单文件。也可以设置环境变量 `ANSIBLE_HOSTS`,而不用每次运行 playbook 时都去使用一个 `-i` 标志。
|
||||
> `-i` 标志是用于指定使用的清单文件。也可以设置环境变量 `ANSIBLE_HOSTS`,而不用每次运行剧本时都去使用一个 `-i` 标志。
|
||||
|
||||
```
|
||||
ntc@ntc:~/ansible/multivendor$ ansible-playbook -i inventory demo.yml
|
||||
@ -949,12 +916,11 @@ veos1 : ok=1 changed=0 unreachable=0 failed=0
|
||||
vsrx : ok=1 changed=0 unreachable=0 failed=0
|
||||
```
|
||||
|
||||
注意:这里有 0 个改变,但是,每次运行任务,正如期望的那样,它们都返回 “ok”。说明在这个 playbook 中的每个模块都是幂等的。
|
||||
|
||||
注意:这里有 0 个改变,但是,每次运行任务,正如期望的那样,它们都返回 “ok”。说明在这个剧本中的每个模块都是幂等的。
|
||||
|
||||
### 总结
|
||||
|
||||
Ansible 是一个超级简单的、无代理和可扩展的自动化平台。网络社区持续不断地围绕 Ansible 去重整它作为一个能够执行一些自动化网络任务的平台,比如,做配置管理、数据收集和报告,等等。你可以使用 Ansible 去推送完整的配置文件,配置具体的使用幂等模块的网络资源,比如,接口、VLANs,或者,简单地自动收集信息,比如,领居、序列号、启动时间、和接口状态,以及按你的需要定制一个报告。
|
||||
Ansible 是一个超级简单的、无代理和可扩展的自动化平台。网络社区持续不断地围绕 Ansible 去重整它作为一个能够执行一些自动化网络任务的平台,比如,做配置管理、数据收集和报告,等等。你可以使用 Ansible 去推送完整的配置文件,配置具体的使用幂等模块的网络资源,比如,接口、VLAN,或者,简单地自动收集信息,比如,领居、序列号、启动时间、和接口状态,以及按你的需要定制一个报告。
|
||||
|
||||
因为它的架构,Ansible 被证明是一个在这里可用的、非常好的工具,它可以帮助你实现从传统的基于 _CLI/SNMP_ 的网络设备到基于 _API 驱动_ 的现代化网络设备的自动化。
|
||||
|
||||
@ -968,7 +934,7 @@ Ansible 是一个超级简单的、无代理和可扩展的自动化平台。网
|
||||
|
||||

|
||||
|
||||
Jason Edelman,CCIE 15394 & VCDX-NV 167,出生并成长于新泽西州的一位网络工程师。他是一位典型的 “CLI 爱好者” 和 “路由器小子”。在几年前,他决定更多地关注于软件、开发实践、以及怎么与网络工程融合。Jason 目前经营着一个小的咨询公司,公司名为:Network to Code(http://networktocode.com/),帮助供应商和终端用户利用新的工具和技术来减少他们的低效率操作...
|
||||
Jason Edelman,CCIE 15394 & VCDX-NV 167,出生并成长于新泽西州的一位网络工程师。他是一位典型的 “CLI 爱好者” 和 “路由器小子”。在几年前,他决定更多地关注于软件、开发实践、以及怎么与网络工程融合。Jason 目前经营着一个小的咨询公司,公司名为:Network to Code( http://networktocode.com/ ),帮助供应商和终端用户利用新的工具和技术来减少他们的低效率操作...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -976,7 +942,7 @@ via: https://www.oreilly.com/learning/network-automation-with-ansible
|
||||
|
||||
作者:[Jason Edelman][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,603 @@
|
||||
献给命令行重度用户的一组实用 BASH 脚本
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天,我偶然发现了一组适用于命令行重度用户的实用 BASH 脚本,这些脚本被称为 **Bash-Snippets**,它们对于那些整天都与终端打交道的人来说可能会很有帮助。想要查看你居住地的天气情况?它为你做了。想知道股票价格?你可以运行显示股票当前详细信息的脚本。觉得无聊?你可以看一些 YouTube 视频。这些全部在命令行中完成,你无需安装任何严重消耗内存的 GUI 应用程序。
|
||||
|
||||
在撰写本文时,Bash-Snippets 提供以下 19 个实用工具:
|
||||
|
||||
1. **Cheat** – Linux 命令备忘单。
|
||||
2. **Cloudup** – 一个将 GitHub 仓库备份到 bitbucket 的工具。
|
||||
3. **Crypt** – 加解密文件。
|
||||
4. **Cryptocurrency** – 前 10 大加密货币的实时汇率转换。
|
||||
5. **Currency** – 货币转换器。
|
||||
6. **Geo** – 提供 wan、lan、router、dns、mac 和 ip 的详细信息。
|
||||
7. **Lyrics** – 从命令行快速获取给定歌曲的歌词。
|
||||
8. **Meme** – 创造命令行表情包。
|
||||
9. **Movies** – 搜索并显示电影详情。
|
||||
10. **Newton** – 执行数值计算一直到符号数学解析。(to 校正:这里不理解)
|
||||
11. **Qrify** – 将给定的字符串转换为二维码。
|
||||
12. **Short** – 缩短 URL
|
||||
13. **Siteciphers** – 检查给定 https 站点启用或禁用的密码。
|
||||
14. **Stocks** – 提供某些股票的详细信息。
|
||||
15. **Taste** – 推荐引擎提供三个类似的项目,如提供物品(如书籍、音乐、艺术家、电影和游戏等。)
|
||||
16. **Todo** – 命令行待办事项管理。
|
||||
17. **Transfer** – 从命令行快速传输文件。
|
||||
18. **Weather** – 显示你所在地的天气详情。
|
||||
19. **Youtube-Viewer** – 从终端观看 YouTube 视频。
|
||||
|
||||
作者可能会在将来添加更多实用程序和/或功能,因此我建议你密切关注该项目的网站或 GitHub 页面以供将来更新。
|
||||
|
||||
### 安装
|
||||
|
||||
你可以在任何支持 BASH 的操作系统上安装这些脚本。
|
||||
|
||||
首先,克隆 git 仓库,使用以下命令:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
```
|
||||
|
||||
进入目录:
|
||||
|
||||
```
|
||||
$ cd Bash-Snippets/
|
||||
```
|
||||
|
||||
切换到最新的稳定版本:
|
||||
|
||||
```
|
||||
$ git checkout v1.22.0
|
||||
```
|
||||
|
||||
最后,使用以下命令安装 Bash-Snippets:
|
||||
|
||||
```
|
||||
$ sudo ./install.sh
|
||||
```
|
||||
|
||||
这将询问你要安装哪些脚本。只需输入 `Y` 并按回车键即可安装相应的脚本。如果你不想安装某些特定脚本,输入 `N` 并按回车键。
|
||||
|
||||
```
|
||||
Do you wish to install currency [Y/n]: y
|
||||
```
|
||||
|
||||
要安装所有脚本,运行:
|
||||
|
||||
```
|
||||
$ sudo ./install.sh all
|
||||
```
|
||||
|
||||
要安装特定的脚本,比如 currency,运行:
|
||||
|
||||
```
|
||||
$ sudo ./install.sh currency
|
||||
```
|
||||
|
||||
你也可以使用 [Linuxbrew][1] 包管理器来安装它。
|
||||
|
||||
安装所有的工具,运行:
|
||||
|
||||
```
|
||||
$ brew install bash-snippets
|
||||
```
|
||||
|
||||
安装特定的工具:
|
||||
|
||||
```
|
||||
$ brew install bash-snippets --without-all-tools --with-newton --with-weather
|
||||
```
|
||||
|
||||
另外,对于那些基于 Debian 系统的,例如 Ubuntu、Linux Mint,可以添加 PPA 源:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:navanchauhan/bash-snippets
|
||||
$ sudo apt update
|
||||
$ sudo apt install bash-snippets
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
**需要网络连接**才能使用这些工具。用法很简单。让我们来看看如何使用其中的一些脚本,我假设你已经安装了所有脚本。
|
||||
|
||||
#### 1、 Currency – 货币转换器
|
||||
|
||||
这个脚本根据实时汇率转换货币。输入当前货币代码和要交换的货币,以及交换的金额,如下所示:
|
||||
|
||||
```
|
||||
$ currency
|
||||
What is the base currency: INR
|
||||
What currency to exchange to: USD
|
||||
What is the amount being exchanged: 10
|
||||
|
||||
=========================
|
||||
| INR to USD
|
||||
| Rate: 0.015495
|
||||
| INR: 10
|
||||
| USD: .154950
|
||||
=========================
|
||||
```
|
||||
|
||||
你也可以在单条命令中传递所有参数,如下所示:
|
||||
|
||||
```
|
||||
$ currency INR USD 10
|
||||
```
|
||||
|
||||
参考以下屏幕截图:
|
||||
|
||||
[![Bash-Snippets][2]][3]
|
||||
|
||||
#### 2、 Stocks – 显示股票价格详细信息
|
||||
|
||||
如果你想查看一只股票价格的详细信息,输入股票即可,如下所示:
|
||||
|
||||
```
|
||||
$ stocks Intel
|
||||
|
||||
INTC stock info
|
||||
=============================================
|
||||
| Exchange Name: NASDAQ
|
||||
| Latest Price: 34.2500
|
||||
| Close (Previous Trading Day): 34.2500
|
||||
| Price Change: 0.0000
|
||||
| Price Change Percentage: 0.00%
|
||||
| Last Updated: Jul 12, 4:00PM EDT
|
||||
=============================================
|
||||
```
|
||||
|
||||
上面输出了 **Intel 股票** 的详情。
|
||||
|
||||
#### 3、 Weather – 显示天气详细信息
|
||||
|
||||
让我们查看以下天气详细信息,运行以下命令:
|
||||
|
||||
```
|
||||
$ weather
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][4]
|
||||
|
||||
正如你在上面屏幕截图中看到的那样,它提供了 3 天的天气预报。不使用任何参数的话,它将根据你的 IP 地址显示天气详细信息。你还可以显示特定城市或国家/地区的天气详情,如下所示:
|
||||
|
||||
```
|
||||
$ weather Chennai
|
||||
```
|
||||
|
||||
同样,你可以查看输入以下命令来查看月相(月亮的形态):
|
||||
|
||||
```
|
||||
$ weather moon
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][5]
|
||||
|
||||
#### 4、 Crypt – 加解密文件
|
||||
|
||||
此脚本对 openssl 做了一层包装,允许你快速轻松地加密和解密文件。
|
||||
|
||||
要加密文件,使用以下命令:
|
||||
|
||||
```
|
||||
$ crypt -e [original file] [encrypted file]
|
||||
```
|
||||
|
||||
例如,以下命令将加密 `ostechnix.txt`,并将其保存在当前工作目录下,名为 `encrypt_ostechnix.txt`。
|
||||
|
||||
```
|
||||
$ crypt -e ostechnix.txt encrypt_ostechnix.txt
|
||||
```
|
||||
|
||||
输入两次文件密码:
|
||||
|
||||
```
|
||||
Encrypting ostechnix.txt...
|
||||
enter aes-256-cbc encryption password:
|
||||
Verifying - enter aes-256-cbc encryption password:
|
||||
Successfully encrypted
|
||||
```
|
||||
|
||||
上面命令将使用 **AES 256 位密钥**加密给定文件。密码不要保存在纯文本文件中。你可以加密 .pdf、.txt、 .docx、 .doc、 .png、 .jpeg 类型的文件。
|
||||
|
||||
要解密文件,使用以下命令:
|
||||
|
||||
```
|
||||
$ crypt -d [encrypted file] [output file]
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
$ crypt -d encrypt_ostechnix.txt ostechnix.txt
|
||||
```
|
||||
|
||||
输入密码解密:
|
||||
|
||||
```
|
||||
Decrypting encrypt_ostechnix.txt...
|
||||
enter aes-256-cbc decryption password:
|
||||
Successfully decrypted
|
||||
|
||||
```
|
||||
|
||||
#### 5、 Movies – 查看电影详情
|
||||
|
||||
使用这个脚本,你可以查看电影详情。
|
||||
|
||||
以下命令显示了一部名为 “mother” 的电影的详情:
|
||||
|
||||
```
|
||||
$ movies mother
|
||||
|
||||
==================================================
|
||||
| Title: Mother
|
||||
| Year: 2009
|
||||
| Tomato: 95%
|
||||
| Rated: R
|
||||
| Genre: Crime, Drama, Mystery
|
||||
| Director: Bong Joon Ho
|
||||
| Actors: Hye-ja Kim, Bin Won, Goo Jin, Je-mun Yun
|
||||
| Plot: A mother desperately searches for the killer who framed her son for a girl's horrific murder.
|
||||
==================================================
|
||||
```
|
||||
|
||||
#### 6、 显示类似条目
|
||||
|
||||
要使用这个脚本,你需要从**[这里][6]** 获取 API 密钥。不过不用担心,它完全是免费的。一旦你获得 API 密钥后,将以下行添加到 `~/.bash_profile`:`export TASTE_API_KEY=”你的 API 密钥放在这里”`。(LCTT 译注: TasteDive 是一个推荐引擎,它会根据你的品味推荐相关项目。)
|
||||
|
||||
现在你可以根据你提供的项目查看类似项目,如下所示:
|
||||
|
||||
```
|
||||
$ taste -i Red Hot Chilli Peppers
|
||||
```
|
||||
|
||||
#### 7、 Short – 缩短 URL
|
||||
|
||||
这个脚本会缩短给定的 URL。
|
||||
|
||||
```
|
||||
$ short <URL>
|
||||
```
|
||||
|
||||
#### 8、 Geo – 显示网络的详情
|
||||
|
||||
|
||||
这个脚本会帮助你查找网络的详细信息,例如广域网、局域网、路由器、 dns、mac 地址和 ip 地址。
|
||||
|
||||
例如,要查找你的局域网 ip,运行:
|
||||
|
||||
```
|
||||
$ geo -l
|
||||
```
|
||||
|
||||
我系统上的输出:
|
||||
|
||||
```
|
||||
192.168.43.192
|
||||
```
|
||||
|
||||
查看广域网 ip:
|
||||
|
||||
```
|
||||
$ geo -w
|
||||
```
|
||||
|
||||
在终端中输入 `geo` 来查看更多详细信息。
|
||||
|
||||
```
|
||||
$ geo
|
||||
Geo
|
||||
Description: Provides quick access for wan, lan, router, dns, mac, and ip geolocation data
|
||||
Usage: geo [flag]
|
||||
-w Returns WAN IP
|
||||
-l Returns LAN IP(s)
|
||||
-r Returns Router IP
|
||||
-d Returns DNS Nameserver
|
||||
-m Returns MAC address for interface. Ex. eth0
|
||||
-g Returns Current IP Geodata
|
||||
Examples:
|
||||
geo -g
|
||||
geo -wlrdgm eth0
|
||||
Custom Geo Output =>
|
||||
[all] [query] [city] [region] [country] [zip] [isp]
|
||||
Example: geo -a 8.8.8.8 -o city,zip,isp
|
||||
-o [options] Returns Specific Geodata
|
||||
-a [address] For specific ip in -s
|
||||
-v Returns Version
|
||||
-h Returns Help Screen
|
||||
-u Updates Bash-Snippets
|
||||
```
|
||||
|
||||
#### 9、 Cheat – 显示 Linux 命令的备忘单
|
||||
|
||||
想参考 Linux 命令的备忘单吗?这是可能的。以下命令将显示 `curl` 命令的备忘单:
|
||||
|
||||
```
|
||||
$ cheat curl
|
||||
```
|
||||
|
||||
只需用你选择的命令替换 `curl` 即可显示其备忘单。这对于快速参考你要使用的任何命令非常有用。
|
||||
|
||||
#### 10、 Youtube-Viewer – 观看 YouTube 视频
|
||||
|
||||
使用此脚本,你可以直接在终端上搜索或打开 YouTube 视频。(LCTT 译注:在媒体播放器中,而不是文本的终端中打开)
|
||||
|
||||
让我们来看一些有关 **Ed Sheeran** 的视频。
|
||||
|
||||
```
|
||||
$ ytview Ed Sheeran
|
||||
```
|
||||
|
||||
从列表中选择要播放的视频。所选内容将在你的默认媒体播放器中播放。
|
||||
|
||||
![][7]
|
||||
|
||||
要查看艺术家的近期视频,你可以使用:
|
||||
|
||||
```
|
||||
$ ytview -c [channel name]
|
||||
```
|
||||
|
||||
要寻找视频,只需输入:
|
||||
|
||||
```
|
||||
$ ytview -s [videoToSearch]
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
$ ytview [videoToSearch]
|
||||
```
|
||||
|
||||
#### 11、 cloudup – 备份 GitHub 仓库到 bitbucket
|
||||
|
||||
你在 GitHub 上托管过任何项目吗?如果托管过,那么你可以随时间 GitHub 仓库备份到 **bitbucket**,它是一种用于源代码和开发项目的基于 Web 的托管服务。
|
||||
|
||||
你可以使用 `-a` 选项一次性备份指定用户的所有 GitHub 仓库,或者备份单个仓库。
|
||||
|
||||
要备份 GitHub 仓库,运行:
|
||||
|
||||
```
|
||||
$ cloudup
|
||||
```
|
||||
|
||||
系统将要求你输入 GitHub 用户名, 要备份的仓库名称以及 bitbucket 用户名和密码等。
|
||||
|
||||
#### 12、 Qrify – 将字符串转换为二维码
|
||||
|
||||
这个脚本将任何给定的文本字符串转换为二维码。这对于发送链接或者保存一串命令到手机非常有用。
|
||||
|
||||
```
|
||||
$ qrify convert this text into qr code
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][8]
|
||||
|
||||
很酷,不是吗?
|
||||
|
||||
#### 13、 Cryptocurrency
|
||||
|
||||
它将显示十大加密货币实时汇率。
|
||||
|
||||
输入以下命令,然后单击回车来运行:
|
||||
|
||||
```
|
||||
$ cryptocurrency
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
|
||||
#### 14、 Lyrics
|
||||
|
||||
这个脚本从命令行快速获取一首歌曲的歌词。
|
||||
|
||||
例如,我将获取 “who is it” 歌曲的歌词,这是一首由 <ruby>迈克尔·杰克逊<rt>Michael Jackson</rt></ruby> 演唱的流行歌曲。
|
||||
|
||||
```
|
||||
$ lyrics -a michael jackson -s who is it
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
#### 15、 Meme
|
||||
|
||||
这个脚本允许你从命令行创建简单的表情贴图。它比基于 GUI 的表情包生成器快得多。
|
||||
|
||||
要创建一个表情贴图,只需输入:
|
||||
|
||||
```
|
||||
$ meme -f mymeme
|
||||
Enter the name for the meme's background (Ex. buzz, doge, blb ): buzz
|
||||
Enter the text for the first line: THIS IS A
|
||||
Enter the text for the second line: MEME
|
||||
```
|
||||
|
||||
这将在你当前的工作目录创建 jpg 文件。
|
||||
|
||||
#### 16、 Newton
|
||||
|
||||
厌倦了解决复杂的数学问题?你来对了。Newton 脚本将执行数值计算,乃至于符号数学解析。
|
||||
|
||||
![][11]
|
||||
|
||||
#### 17、 Siteciphers
|
||||
|
||||
这个脚本可以帮助你检查在给定的 https 站点上启用/禁用哪些加密算法。(LCTT 译注:指 HTTPS 通讯中采用的加密算法)
|
||||
|
||||
```
|
||||
$ siteciphers google.com
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
#### 18、 Todo
|
||||
|
||||
它允许你直接从终端创建日常任务。
|
||||
|
||||
让我们来创建一些任务。
|
||||
|
||||
```
|
||||
$ todo -a The first task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
```
|
||||
|
||||
要添加其它任务,只需添加任务名称重新运行上述命令即可。
|
||||
|
||||
```
|
||||
$ todo -a The second task
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). The second task Tue Jun 26 14:52:29 IST 2018
|
||||
```
|
||||
|
||||
要查看任务列表,运行:
|
||||
|
||||
```
|
||||
$ todo -g
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
02). A The second task Tue Jun 26 14:51:46 IST 2018
|
||||
```
|
||||
|
||||
一旦你完成了任务,就可以将其从列表中删除,如下所示:
|
||||
|
||||
```
|
||||
$ todo -r 2
|
||||
Sucessfully removed task number 2
|
||||
01). The first task Tue Jun 26 14:51:30 IST 2018
|
||||
```
|
||||
|
||||
要清除所有任务,运行:
|
||||
|
||||
```
|
||||
$ todo -c
|
||||
Tasks cleared.
|
||||
```
|
||||
|
||||
#### 19、 Transfer
|
||||
|
||||
Transfer 脚本允许你通过互联网快速轻松地传输文件和目录。
|
||||
|
||||
让我们上传一个文件:
|
||||
|
||||
```
|
||||
$ transfer test.txt
|
||||
Uploading test.txt
|
||||
################################################################################################################################################ 100.0%
|
||||
Success!
|
||||
Transfer Download Command: transfer -d desiredOutputDirectory ivmfj test.txt
|
||||
Transfer File URL: https://transfer.sh/ivmfj/test.txt
|
||||
```
|
||||
|
||||
该文件将上传到 transfer.sh 站点。Transfer.sh 允许你一次上传最大 **10 GB** 的文件。所有共享文件在 **14 天**后自动过期。如你所见,任何人都可以通过 Web 浏览器访问 URL 或使用 transfer 目录来下载文件,当然,transfer 必须安装在他/她的系统中。
|
||||
|
||||
现在从你的系统中移除文件。
|
||||
|
||||
```
|
||||
$ rm -fr test.txt
|
||||
```
|
||||
|
||||
现在,你可以随时(14 天内)从 transfer.sh 站点下载该文件,如下所示:
|
||||
|
||||
```
|
||||
$ transfer -d Downloads ivmfj test.txt
|
||||
```
|
||||
|
||||
获取关于此实用脚本的更多详情,参考以下指南。
|
||||
|
||||
* [用命令行在互联网上共享文件的一个简单快捷方法](https://www.ostechnix.com/easy-fast-way-share-files-internet-command-line/)
|
||||
|
||||
### 获得帮助
|
||||
|
||||
如果你不知道如何使用特定脚本,只需输入该脚本的名称,然后按下 ENTER 键,你将会看到使用细节。以下示例显示 Qrify 脚本的帮助信息。
|
||||
|
||||
```
|
||||
$ qrify
|
||||
Qrify
|
||||
Usage: qrify [stringtoturnintoqrcode]
|
||||
Description: Converts strings or urls into a qr code.
|
||||
-u Update Bash-Snippet Tools
|
||||
-m Enable multiline support (feature not working yet)
|
||||
-h Show the help
|
||||
-v Get the tool version
|
||||
Examples:
|
||||
qrify this is a test string
|
||||
qrify -m two\\nlines
|
||||
qrify github.com # notice no http:// or https:// this will fail
|
||||
|
||||
```
|
||||
|
||||
### 更新脚本
|
||||
|
||||
你可以随时使用 `-u` 选项更新已安装的工具。以下命令更新 “weather” 工具。
|
||||
|
||||
```
|
||||
$ weather -u
|
||||
```
|
||||
|
||||
### 卸载
|
||||
|
||||
你可以使用以下命令来卸载这些工具。
|
||||
|
||||
克隆仓库:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexanderepstein/Bash-Snippets
|
||||
```
|
||||
|
||||
进入 Bash-Snippets 目录:
|
||||
|
||||
```
|
||||
$ cd Bash-Snippets
|
||||
```
|
||||
|
||||
运行以下命令来卸载脚本:
|
||||
|
||||
```
|
||||
$ sudo ./uninstall.sh
|
||||
```
|
||||
|
||||
输入 `y`,并按下回车键来移除每个脚本。
|
||||
|
||||
```
|
||||
Do you wish to uninstall currency [Y/n]: y
|
||||
```
|
||||
|
||||
**另请阅读:**
|
||||
|
||||
- [Cli.Fyi —— 快速而简单地获取诸如 IP、电子邮件、域名等信息的方式](https://www.ostechnix.com/cli-fyi-quick-easy-way-fetch-information-ips-emails-domains-lots/)
|
||||
|
||||
好了,这就是全部了。我必须承认,在测试这些脚本时我印象很深刻。我真的很喜欢将所有有用的脚本组合到一个包中的想法。感谢开发者。试一试,你不会失望的。
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/collection-useful-bash-scripts-heavy-commandline-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_001.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_002-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_003.png
|
||||
[6]:https://tastedive.com/account/api_access
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/07/ytview-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk_005.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/07/cryptocurrency.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/07/lyrics.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/07/newton.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/07/siteciphers.png
|
||||
@ -0,0 +1,150 @@
|
||||
ArchI0:Arch Linux 应用自动安装脚本
|
||||
======
|
||||
|
||||

|
||||
|
||||
Arch 用户你们好!今天,我偶然发现了一个叫做 “**ArchI0**” 的实用工具,它是基于命令行菜单的 Arch Linux 应用自动安装脚本。使用此脚本是为基于 Arch 的发行版安装所有必要的应用最简易的方式。请注意**此脚本仅适用于菜鸟级使用者**。中高级使用者可以轻松掌握[如何使用 pacman][1]来完成这件事。如果你想学习如何使用 Arch Linux,我建议你一个个手动安装所有的软件。对那些仍是菜鸟并且希望为自己基于 Arch 的系统快速安装所有必要应用的用户,可以使用此脚本。
|
||||
|
||||
### ArchI0 – Arch Linux 应用自动安装脚本
|
||||
|
||||
此脚本的开发者已经制作了 **ArchI0live** 和 **ArchI0** 两个脚本。你可以通过 ArchI0live 测试应用,无需安装。这可能有助于在将脚本安装到系统之前了解其实际内容。
|
||||
|
||||
### 安装 ArchI0
|
||||
|
||||
要安装此脚本,使用如下命令通过 Git 克隆 ArchI0 脚本仓库:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/SifoHamlaoui/ArchI0.git
|
||||
```
|
||||
|
||||
上面的命令会克隆 ArchI0 的 Github 仓库内容,在你当前目录的一个名为 ArchI0 的文件夹里。使用如下命令进入此目录:
|
||||
|
||||
```
|
||||
$ cd ArchI0/
|
||||
```
|
||||
|
||||
使用如下命令赋予脚本可执行权限:
|
||||
|
||||
```
|
||||
$ chmod +x ArchI0live.sh
|
||||
```
|
||||
|
||||
使用如下命令执行脚本:
|
||||
|
||||
```
|
||||
$ sudo ./ArchI0live.sh
|
||||
|
||||
```
|
||||
|
||||
此脚本需要以 root 或 sudo 用户身份执行,因为安装应用需要 root 权限。
|
||||
|
||||
> **注意:** 有些人想知道此脚本中开头的那些命令是做什么的,第一个命令是下载 **figlet**,因为此脚本的 logo 是使用 figlet 显示的。第二个命令是安装用来打开并查看许可协议文件的 **Leafpad**。第三个命令是安装用于从 sourceforge 下载文件的 **wget**。第四和第五个命令是下载许可协议文件并用 leafpad 打开。此外,最后的第 6 条命令是在阅读许可协议文件之后关闭它。
|
||||
|
||||
输入你的 Arch Linux 系统架构然后按回车键。当其请求安装此脚本时,键入 `y` 然后按回车键。
|
||||
|
||||
![][3]
|
||||
|
||||
一旦开始安装,将会重定向至主菜单。
|
||||
|
||||
![][4]
|
||||
|
||||
正如前面的截图, ArchI0 包含有 13 类、90 个容易安装的程序。这 90 个程序刚好足够配置一个完整的 Arch Linux 桌面,可执行日常活动。键入 `a` 可查看关于此脚本的信息,键入 `q` 可退出此脚本。
|
||||
|
||||
安装后无需执行 ArchI0live 脚本。可以直接使用如下命令启动:
|
||||
|
||||
```
|
||||
$ sudo ArchI0
|
||||
```
|
||||
|
||||
它会每次询问你选择 Arch Linux 发行版的架构。
|
||||
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
Preparing To Run Script
|
||||
Checking For ROOT: PASSED
|
||||
What Is Your OS Architecture? {32/64} 64
|
||||
```
|
||||
|
||||
从现在开始,你可以从主菜单列出的类别选择要安装的程序。要查看特定类别下的可用程序列表,输入类别号即可。举个例子,要查看**文本编辑器**分类下的可用程序列表,输入 **1** 然后按回车键。
|
||||
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ R00T MENU ]
|
||||
Make A Choice
|
||||
1) Text Editors
|
||||
2) FTP/Torrent Applications
|
||||
3) Download Managers
|
||||
4) Network managers
|
||||
5) VPN clients
|
||||
6) Chat Applications
|
||||
7) Image Editors
|
||||
8) Video editors/Record
|
||||
9) Archive Handlers
|
||||
10) Audio Applications
|
||||
11) Other Applications
|
||||
12) Development Environments
|
||||
13) Browser/Web Plugins
|
||||
14) Dotfiles
|
||||
15) Usefull Links
|
||||
------------------------
|
||||
a) About ArchI0 Script
|
||||
q) Leave ArchI0 Script
|
||||
|
||||
Choose An Option: 1
|
||||
```
|
||||
|
||||
接下来,选择你想安装的程序。要返回至主菜单,输入 `q` 然后按回车键。
|
||||
|
||||
我想安装 Emacs,所以我输入 `3`。
|
||||
|
||||
```
|
||||
This script Is under GPLv3 License
|
||||
|
||||
[ TEXT EDITORS ]
|
||||
[ Option ] [ Description ]
|
||||
1) GEdit
|
||||
2) Geany
|
||||
3) Emacs
|
||||
4) VIM
|
||||
5) Kate
|
||||
---------------------------
|
||||
q) Return To Main Menu
|
||||
|
||||
Choose An Option: 3
|
||||
```
|
||||
|
||||
现在,Emacs 将会安装至你的 Arch Linux 系统。
|
||||
|
||||
![][5]
|
||||
|
||||
所选择的应用安装完成后,你可以按回车键返回主菜单。
|
||||
|
||||
### 结论
|
||||
|
||||
毫无疑问,此脚本让 Arch Linux 用户使用起来更加容易,特别是刚开始使用的人。如果你正寻找快速简单无需使用 pacman 安装应用的方法,此脚本是一个不错的选择。试用一下并在下面的评论区让我们知道你对此脚本的看法。
|
||||
|
||||
就这些。希望这个工具能帮到你。我们每天都会推送实用的指南。如果你觉得我们的指南挺实用,请分享至你的社交网络,专业圈子并支持我们。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/archi0-arch-linux-applications-automatic-installation-script/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://www.ostechnix.com/getting-started-pacman/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_003.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/07/sk@sk-ArchI0_004-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/07/pacman-as-superuser_005.png
|
||||
@ -1,47 +1,42 @@
|
||||
How to use Fio (Flexible I/O Tester) to Measure Disk Performance in Linux
|
||||
如何在 Linux 中使用 Fio 来测评硬盘性能
|
||||
======
|
||||
|
||||

|
||||
|
||||
Fio which stands for Flexible I/O Tester [is a free and open source][1] disk I/O tool used both for benchmark and stress/hardware verification developed by Jens Axboe.
|
||||
Fio(Flexible I/O Tester) 是一款由 Jens Axboe 开发的用于测评和压力/硬件验证的[自由开源][1]的软件。
|
||||
|
||||
It has support for 19 different types of I/O engines (sync, mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio, and more), I/O priorities (for newer Linux kernels), rate I/O, forked or threaded jobs, and much more. It can work on block devices as well as files.
|
||||
它支持 19 种不同类型的 I/O 引擎 (sync、mmap、libaio、posixaio、SG v3、splice、null、network、 syslet、guasi、solarisaio,以及更多), I/O 优先级(针对较新的 Linux 内核),I/O 速度,fork 的任务或线程任务等等。它能够在块设备和文件上工作。
|
||||
|
||||
Fio accepts job descriptions in a simple-to-understand text format. Several example job files are included. Fio displays all sorts of I/O performance information, including complete IO latencies and percentiles.
|
||||
Fio 接受一种非常简单易于理解的文本格式的任务描述。软件默认包含了几个示例任务文件。 Fio 展示了所有类型的 I/O 性能信息,包括完整的 IO 延迟和百分比。
|
||||
|
||||
It is in wide use in many places, for both benchmarking, QA, and verification purposes. It supports Linux, FreeBSD, NetBSD, OpenBSD, OS X, OpenSolaris, AIX, HP-UX, Android, and Windows.
|
||||
它被广泛的应用在非常多的地方,包括测评、QA,以及验证用途。它支持 Linux 、FreeBSD 、NetBSD、 OpenBSD、 OS X、 OpenSolaris、 AIX、 HP-UX、 Android 以及 Windows。
|
||||
|
||||
In this tutorial, we will be using Ubuntu 16 and you are required to have sudo or root privileges to the computer. We will go over the installation and use of fio.
|
||||
在这个教程,我们将使用 Ubuntu 16 ,你需要拥有这台电脑的 `sudo` 或 root 权限。我们将完整的进行安装和 Fio 的使用。
|
||||
|
||||
### Installing fio from Source
|
||||
### 使用源码安装 Fio
|
||||
|
||||
我们要去克隆 GitHub 上的仓库。安装所需的依赖,然后我们将会从源码构建应用。首先,确保我们安装了 Git 。
|
||||
|
||||
We are going to clone the repo on GitHub. Install the prerequisites, and then we will build the packages from the source code. Lets' start by making sure we have git installed.
|
||||
```
|
||||
|
||||
sudo apt-get install git
|
||||
|
||||
|
||||
```
|
||||
|
||||
For centOS users you can use:
|
||||
```
|
||||
CentOS 用户可以执行下述命令:
|
||||
|
||||
```
|
||||
sudo yum install git
|
||||
|
||||
|
||||
```
|
||||
|
||||
Now we change directory to /opt and clone the repo from Github:
|
||||
```
|
||||
现在,我们切换到 `/opt` 目录,并从 Github 上克隆仓库:
|
||||
|
||||
```
|
||||
cd /opt
|
||||
git clone https://github.com/axboe/fio
|
||||
|
||||
|
||||
```
|
||||
|
||||
You should see the output below:
|
||||
```
|
||||
你应该会看到下面这样的输出:
|
||||
|
||||
```
|
||||
Cloning into 'fio'...
|
||||
remote: Counting objects: 24819, done.
|
||||
remote: Compressing objects: 100% (44/44), done.
|
||||
@ -49,72 +44,60 @@ remote: Total 24819 (delta 39), reused 62 (delta 32), pack-reused 24743
|
||||
Receiving objects: 100% (24819/24819), 16.07 MiB | 0 bytes/s, done.
|
||||
Resolving deltas: 100% (16251/16251), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
|
||||
```
|
||||
|
||||
Now, we change directory into the fio codebase by typing the command below inside the opt folder:
|
||||
```
|
||||
现在,我们通过在 `/opt` 目录下输入下方的命令切换到 Fio 的代码目录:
|
||||
|
||||
```
|
||||
cd fio
|
||||
|
||||
|
||||
```
|
||||
|
||||
We can finally build fio from source using the `make` build utility bu using the commands below:
|
||||
```
|
||||
最后,我们可以使用下面的命令来使用 `make` 从源码构建软件:
|
||||
|
||||
```
|
||||
# ./configure
|
||||
# make
|
||||
# make install
|
||||
|
||||
|
||||
```
|
||||
|
||||
### Installing fio on Ubuntu
|
||||
### 在 Ubuntu 上安装 Fio
|
||||
|
||||
For Ubuntu and Debian, fio is available on the main repository. You can easily install fio using the standard package managers such as yum and apt-get.
|
||||
对于 Ubuntu 和 Debian 来说, Fio 已经在主仓库内。你可以很容易的使用类似 `yum` 和 `apt-get` 的标准包管理器来安装 Fio。
|
||||
|
||||
对于 Ubuntu 和 Debian ,你只需要简单的执行下述命令:
|
||||
|
||||
For Ubuntu and Debian you can simple use:
|
||||
```
|
||||
|
||||
sudo apt-get install fio
|
||||
|
||||
|
||||
```
|
||||
|
||||
For CentOS/Redhat you can simple use:
|
||||
On CentOS, you might need to install EPEL repository to your system before you can have access to fio. You can install it by running the following command:
|
||||
```
|
||||
对于 CentOS/Redhat 你只需要简单执行下述命令。
|
||||
|
||||
在 CentOS ,你可能在你能安装 Fio 前需要去安装 EPEL 仓库到你的系统中。你可以通过执行下述命令来安装它:
|
||||
|
||||
```
|
||||
sudo yum install epel-release -y
|
||||
|
||||
|
||||
```
|
||||
|
||||
You can then install fio using the command below:
|
||||
```
|
||||
你可以执行下述命令来安装 Fio:
|
||||
|
||||
```
|
||||
sudo yum install fio -y
|
||||
|
||||
|
||||
```
|
||||
|
||||
### Disk Performace testing with Fio
|
||||
### 使用 Fio 进行磁盘性能测试
|
||||
|
||||
With Fio is installed on your system. It's time to see how to use Fio with some examples below. We are going to perform a random write, read and read and write test.
|
||||
|
||||
### Performing a Random Write Test
|
||||
现在 Fio 已经安装到了你的系统中。现在是时候看一些如何使用 Fio 的例子了。我们将进行随机写、读和读写测试。
|
||||
|
||||
### 执行随机写测试
|
||||
|
||||
执行下面的命令来开始。这个命令将要同一时间执行两个进程,写入共计 4GB( 4 个任务 x 512MB = 2GB) 文件:
|
||||
|
||||
Let's start by running the following command. This command will write a total 4GB file [4 jobs x 512 MB = 2GB] running 2 processes at a time:
|
||||
```
|
||||
|
||||
sudo fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --direct=0 --size=512M --numjobs=2 --runtime=240 --group_reporting
|
||||
|
||||
|
||||
```
|
||||
```
|
||||
|
||||
```
|
||||
...
|
||||
fio-2.2.10
|
||||
Starting 2 processes
|
||||
@ -143,23 +126,20 @@ Run status group 0 (all jobs):
|
||||
|
||||
Disk stats (read/write):
|
||||
sda: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%
|
||||
|
||||
|
||||
```
|
||||
|
||||
### Performing a Random Read Test
|
||||
### 执行随机读测试
|
||||
|
||||
我们将要执行一个随机读测试,我们将会尝试读取一个随机的 2GB 文件。
|
||||
|
||||
We are going to perform a random read test now, we will be trying to read a random 2Gb file
|
||||
```
|
||||
|
||||
sudo fio --name=randread --ioengine=libaio --iodepth=16 --rw=randread --bs=4k --direct=0 --size=512M --numjobs=4 --runtime=240 --group_reporting
|
||||
|
||||
|
||||
```
|
||||
|
||||
You should see the output below:
|
||||
```
|
||||
你应该会看到下面这样的输出:
|
||||
|
||||
```
|
||||
...
|
||||
fio-2.2.10
|
||||
Starting 4 processes
|
||||
@ -195,25 +175,20 @@ Run status group 0 (all jobs):
|
||||
|
||||
Disk stats (read/write):
|
||||
sda: ios=521587/871, merge=0/1142, ticks=96664/612, in_queue=97284, util=99.85%
|
||||
|
||||
|
||||
```
|
||||
|
||||
Finally, we want to show a sample read-write test to see how the kind out output that fio returns.
|
||||
最后,我们想要展示一个简单的随机读-写测试来看一看 Fio 返回的输出类型。
|
||||
|
||||
### Read Write Performance Test
|
||||
### 读写性能测试
|
||||
|
||||
下述命令将会测试 USB Pen 驱动器 (`/dev/sdc1`) 的随机读写性能:
|
||||
|
||||
The command below will measure random read/write performance of USB Pen drive (/dev/sdc1):
|
||||
```
|
||||
|
||||
sudo fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=random_read_write.fio --bs=4k --iodepth=64 --size=4G --readwrite=randrw --rwmixread=75
|
||||
|
||||
|
||||
```
|
||||
|
||||
Below is the outout we get from the command above.
|
||||
下面的内容是我们从上面的命令得到的输出:
|
||||
```
|
||||
|
||||
fio-2.2.10
|
||||
Starting 1 process
|
||||
Jobs: 1 (f=1): [m(1)] [100.0% done] [217.8MB/74452KB/0KB /s] [55.8K/18.7K/0 iops] [eta 00m:00s]
|
||||
@ -233,11 +208,9 @@ Run status group 0 (all jobs):
|
||||
|
||||
Disk stats (read/write):
|
||||
sda: ios=774141/258944, merge=1463/899, ticks=748800/150316, in_queue=900720, util=99.35%
|
||||
|
||||
|
||||
```
|
||||
|
||||
We hope you enjoyed this tutorial and enjoyed following along, Fio is a very useful tool and we hope you can use it in your next debugging activity. If you enjoyed reading this post feel free to leave a comment of questions. Go ahead and clone the repo and play around with the code.
|
||||
我们希望你能喜欢这个教程并且享受接下来的内容,Fio 是一个非常有用的工具,并且我们希望你能在你下一次 Debugging 活动中使用到它。如果你喜欢这个文章,欢迎留下评论和问题。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -245,8 +218,8 @@ We hope you enjoyed this tutorial and enjoyed following along, Fio is a very use
|
||||
via: https://wpmojo.com/how-to-use-fio-to-measure-disk-performance-in-linux/
|
||||
|
||||
作者:[Alex Pearson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
195
published/201808/20171009 Considering Pythons Target Audience.md
Normal file
195
published/201808/20171009 Considering Pythons Target Audience.md
Normal file
@ -0,0 +1,195 @@
|
||||
盘点 Python 的目标受众
|
||||
======
|
||||
|
||||
Python 是为谁设计的?
|
||||
|
||||
几年前,我在 python-dev 邮件列表中,以及在活跃的 CPython 核心开发人员和认为参与这一过程不是有效利用个人时间和精力的人中[强调][17]说,“CPython 的发展太快了也太慢了” 是很多冲突的原因之一。
|
||||
|
||||
我一直认为事实确实如此,但这也是一个要点,在这几年中我也花费了很多时间去反思它。在我写那篇文章的时候,我还在波音防务澳大利亚公司(Boeing Defence Australia)工作。下个月,我离开了波音进入红帽亚太(Red Hat Asia-Pacific),并且开始在大企业的[开源供应链管理][18]方面取得了<ruby>再分发者<rt>redistributor</rt></ruby>层面的视角。
|
||||
|
||||
### Python 的参考解析器使用情况
|
||||
|
||||
我尝试将 CPython 的使用情况分解如下,尽管看起来有些过于简化(注意,这些分类的界线并不是很清晰,他们仅关注于考虑新软件特性和版本发布后不同因素的影响):
|
||||
|
||||
* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,*不会去*编写或维护生产级别的软件。例如:
|
||||
* 澳大利亚的[数字课程][1]
|
||||
* Lorena A. Barba 的 [AeroPython][2]
|
||||
* 个人类的自动化和爱好者的项目:主要且经常是一类自写自用的软件。例如:
|
||||
* my Digital Blasphemy [图片下载器][3]
|
||||
* Paul Fenwick 的 (Inter)National [Rick Astley Hotline][4]
|
||||
* <ruby>组织<rt>organisational</rt></ruby>过程自动化:主要且经常是为组织利益而编写的。例如:
|
||||
* CPython 的[核心工作流工具][5]
|
||||
* Linux 发行版的开发、构建和发行管理工具
|
||||
* “<ruby>一劳永逸<rt>Set-and-forget</rt></ruby>” 的基础设施:这类软件在其生命周期中几乎不会升级,但在底层平台可能会升级(这种说法有时候有些争议)。例如:
|
||||
* 大多数自我管理的企业或机构的基础设施(在那些资金充足的可持续工程计划中,这种情况是让人非常不安的)
|
||||
* 拨款资助的软件(当最初的拨款耗尽时,维护通常会终止)
|
||||
* 有严格认证要求的软件(如果没有绝对必要的话,从经济性考虑,重新认证比常规升级来说要昂贵很多)
|
||||
* 没有自动升级功能的嵌入式软件系统
|
||||
* 持续升级的基础设施:具有健壮支撑的工程学模型的软件,对于依赖和平台升级通常是例行的,不必关心源码变更。例如:
|
||||
* Facebook 的 Python 服务基础设施
|
||||
* 滚动发布的 Linux 分发版
|
||||
* 大多数的公共 PaaS 无服务器环境(Heroku、OpenShift、AWS Lambda、Google Cloud Functions、Azure Cloud Functions 等等)
|
||||
* 长周期性升级的标准的操作环境:对其核心组件进行常规升级,但这些升级以年为单位进行,而不是周或月。例如:
|
||||
* [VFX 平台][6]
|
||||
* 长期支持(LTS)的 Linux 分发版
|
||||
* CPython 和 Python 标准库
|
||||
* 基础设施管理和编排工具(如 OpenStack、Ansible)
|
||||
* 硬件控制系统
|
||||
* 短生命周期的软件:软件仅被使用一次,然后就丢弃或忽略,而不是随后接着升级。例如:
|
||||
* <ruby>临时<rt>Ad hoc</rt></ruby>自动化脚本
|
||||
* 被确定为 “终止” 的单用户游戏(你玩了一次后,甚至都忘了去卸载它们,或许在一个新的设备上都不打算再去安装了)
|
||||
* 不具备(或不完整)状态保存的单用户游戏(如果你卸载并重安装它们,游戏体验也不会有什么大的变化)
|
||||
* 特定事件的应用程序(这些应用程序与特定的事件捆绑,一旦事件结束,这些应用程序就不再有用了)
|
||||
* 常规用途的应用程序:部署后定期升级的软件。例如:
|
||||
* 业务管理软件
|
||||
* 个人和专业的生产力应用程序(如 Blender)
|
||||
* 开发工具和服务(如 Mercurial、Buildbot、Roundup)
|
||||
* 多用户游戏,和其它明显处于持续状态还没有被定义为 “终止” 的游戏
|
||||
* 有自动升级功能的嵌入式软件系统
|
||||
* 共享的抽象层:在一个特定的问题领域中,设计用于让工作更高效的软件组件。即便是你没有亲自掌握该领域的所有错综复杂的东西。例如:
|
||||
* 大多数的<ruby>运行时<rt>runtime</rt></ruby>库和框架都归入这一类(如 Django、Flask、Pyramid、SQL Alchemy、NumPy、SciPy、requests)
|
||||
* 适合归入这一类的许多测试和类型推断工具(如 pytest、Hypothesis、vcrpy、behave、mypy)
|
||||
* 其它应用程序的插件(如 Blender plugins、OpenStack hardware adapters)
|
||||
* 本身就代表了 “Python 世界” 基准的标准库(那是一个[难以置信的复杂][7]的世界观)
|
||||
|
||||
### CPython 主要服务于哪些受众?
|
||||
|
||||
从根本上说,CPython 和标准库的主要受众是哪些呢?是那些不管出于什么原因,将有限的标准库和从 PyPI 显式声明安装的第三方库组合起来所提供的服务还不能够满足需求的那些人。
|
||||
|
||||
为了更进一步简化上面回顾的不同用法和部署模型,宏观地将最大的 Python 用户群体分开来看,一类是在一些感兴趣的环境中将 Python 作为一种 _脚本语言_ 使用的人;另外一种是将它用作一个 _应用程序开发语言_ 的人,他们最终发布的是一种产品而不是他们的脚本。
|
||||
|
||||
把 Python 作为一种脚本语言来使用的开发者的典型特性包括:
|
||||
|
||||
* 主要的工作单元是由一个 Python 文件组成的(或 Jupyter notebook),而不是一个 Python 和元数据文件的目录
|
||||
* 没有任何形式的单独的构建步骤 —— 是*作为*一个脚本分发的,类似于分发一个独立的 shell 脚本的方式
|
||||
* 没有单独的安装步骤(除了下载这个文件到一个合适的位置),因为在目标系统上要求预配置运行时环境
|
||||
* 没有显式的规定依赖关系,除了最低的 Python 版本,或一个预期的运行环境声明。如果需要一个标准库以外的依赖项,他们会通过一个环境脚本去提供(无论是操作系统、数据分析平台、还是嵌入 Python 运行时的应用程序)
|
||||
* 没有单独的测试套件,使用 “通过你给定的输入,这个脚本是否给出了你期望的结果?” 这种方式来进行测试
|
||||
* 如果在执行前需要测试,它将以<ruby>试运行<rt>dry run></rt></ruby>和<ruby>预览<rt>preview</rt></ruby>模式来向用户展示软件*将*怎样运行
|
||||
* 如果使用静态代码分析工具,则通过集成到用户的软件开发环境中,而不是为每个脚本单独设置
|
||||
|
||||
相比之下,使用 Python 作为一个应用程序开发语言的开发者特征包括:
|
||||
|
||||
* 主要的工作单元是由 Python 和元数据文件组成的目录,而不是单个 Python 文件
|
||||
* 在发布之前有一个单独的构建步骤去预处理应用程序,哪怕是把它的这些文件一起打包进一个 Python sdist、wheel 或 zipapp 中
|
||||
* 应用程序是否有独立的安装步骤做预处理,取决于它是如何打包的,和支持的目标环境
|
||||
* 外部的依赖明确存在于项目目录下的一个元数据文件中,要么是直接在项目目录中(如 `pyproject.toml`、`requirements.txt`、`Pipfile`),要么是作为生成的发行包的一部分(如 `setup.py`、`flit.ini`)
|
||||
* 有独立的测试套件,或者作为一个 Python API 的一个单元测试,或者作为功能接口的集成测试,或者是两者都有
|
||||
* 静态分析工具的使用是在项目级配置的,并作为测试管理的一部分,而不是作为依赖
|
||||
|
||||
作为以上分类的一个结果,CPython 和标准库的主要用途是,在相应的 CPython 特性发布后,为教育和<ruby>临时<rt>ad hoc</rt></ruby>的 Python 脚本环境提供 3-5 年基础维护服务。
|
||||
|
||||
对于临时脚本使用的情况,这个 3-5 年的延迟是由于再分发者给用户开发新版本的延迟造成的,以及那些再分发版本的用户们花在修改他们的标准操作环境上的时间。
|
||||
|
||||
对于教育环境中的情况是,教育工作者需要一些时间去评估新特性,然后决定是否将它们包含进教学的课程中。
|
||||
|
||||
### 这些相关问题的原因是什么?
|
||||
|
||||
这篇文章很大程度上是受 Twitter 上对[我的这个评论][8]的讨论的启发,它援引了定义在 [PEP 411][9] 中<ruby>临时<rt>Provisional</rt></ruby> API 的情形,作为一个开源项目的例子,对用户发出事实上的邀请,请其作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
|
||||
|
||||
这些回复包括一些在更高级别的库中支持临时 API 的困难程度的一些沮丧性表述,没有这些库做临时状态的传递,因此而被限制为只有临时 API 的最新版本才支持这些相关特性,而不是任何早期版本的迭代。
|
||||
|
||||
我的[主要回应][10]是,建议开源提供者应该强制实施有限支持,通过这种强制的有限支持可以让个人的维护努力变得可持续。这意味着,如果对临时 API 的老版本提供迭代支持是非常痛苦的,那么,只有在项目开发人员自己需要、或有人为此支付费用时,他们才会去提供支持。这与我的这个观点是类似的,那就是,志愿者提供的项目是否应该免费支持老的、商业性质的、长周期的 Python 版本,这对他们来说是非常麻烦的事,我[不认为他们应该这样做][11],正如我所期望的那样,大多数这样的需求都来自于管理差劲的惯性,而不是真正的需求(真正的需求,应该去支付费用来解决问题)。
|
||||
|
||||
而我的[第二个回应][12]是去实现这一点,尽管多年来一直在讨论这个问题(比如,在上面链接中最早在 2011 年的一篇的文章中,以及在 Python 3 问答的回复中的[这里][13]、[这里][14]、和[这里][15],以及去年的这篇文章 [Python 包生态系统][16]中也提到了一些),但我从来没有真实地尝试直接去解释它在标准库设计过程中的影响。
|
||||
|
||||
如果没有这些背景,设计过程中的一部分,比如临时 API 的引入,或者是<ruby>受启发而不同于它<rt>inspired-by-not-the-same-as</rt></ruby>的引入,看起来似乎是完全没有意义的,因为他们看起来似乎是在尝试对 API 进行标准化,而实际上并没有。
|
||||
|
||||
### 适合进入 PyPI 规划的方面有哪些?
|
||||
|
||||
*任何*提交给 python-ideas 或 python-dev 的提案所面临的第一个门槛就是清楚地回答这个问题:“为什么 PyPI 上的模块不够好?”。绝大多数的提案都在这一步失败了,为了通过这一步,这里有几个常见的话题:
|
||||
|
||||
* 比起下载一个合适的第三方库,新手一般可能更倾向于从互联网上 “复制粘贴” 错误的指导。(这就是为什么存在 `secrets` 库的原因:它使得人们很少去使用 `random` 模块,由于安全敏感的原因,它预期用于游戏和模拟统计)
|
||||
* 该模块旨在提供一个参考实现,并允许与其它的竞争实现之间提供互操作性,而不是对所有人的所有事物都是必要的。(如 `asyncio`、`wsgiref`、`unittest`、和 `logging` 都是这种情况)
|
||||
* 该模块是预期用于标准库的其它部分(如 `enum` 就是这种情况,像 `unittest` 一样)
|
||||
* 该模块是被设计用于支持语言之外的一些语法(如 `contextlib`、`asyncio` 和 `typing`)
|
||||
* 该模块只是普通的临时的脚本用途(如 `pathlib` 和 `ipaddress`)
|
||||
* 该模块被用于一个教育环境(例如,`statistics` 模块允许进行交互式地探索统计的概念,尽管你可能根本就不会用它来做完整的统计分析)
|
||||
|
||||
只通过了前面的 “PyPI 是不是明显不够好” 的检查,一个模块还不足以确保被纳入标准库中,但它已经足以将问题转变为 “在未来几年中,你所推荐的要包含的库能否对一般的入门级 Python 开发人员的经验有所提升?”
|
||||
|
||||
标准库中的 `ensurepip` 和 `venv` 模块的引入也明确地告诉再分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
|
||||
|
||||
### 当添加它们到标准库中时,为什么一些 API 会被修改?
|
||||
|
||||
现有的第三方模块有时候会被批量地采用到标准库中,在其它情况下,实际上添加的是吸收了用户对现有 API 体验之后进行重新设计和重新实现的 API,但是会根据另外的设计考虑和已经成为其中一部分的语言实现参考来进行一些删除或细节修改。
|
||||
|
||||
例如,与流行的第三方库 `path.py`、`pathlib` 的前身不同,它们并*没有*定义字符串子类,而是以独立的类型替代。作为解决文件互操作性问题的结果,定义了文件系统路径协议,它允许使用文件系统路径的接口去使用更多的对象。
|
||||
|
||||
为了在 “IP 地址” 这个概念的教学上提供一个更好的工具,`ipaddress` 模块设计调整为明确地将主机接口定义与地址和网络的定义区分开(IP 地址被关联到特定的 IP 网络),而最原始的 `ipaddr` 模块中,在网络术语的使用方式上不那么严格。
|
||||
|
||||
另外的情况是,标准库将综合多种现有的方法的来构建,以及为早已存在的库定义 API 时,还有可能依赖不存在的语法特性。比如,`asyncio` 和 `typing` 模块就全部考虑了这些因素,虽然在 PEP 557 中正在考虑将后者所考虑的因素应用到 `dataclasses` API 上。(它可以被总结为 “像属性一样,但是使用可变注释作为字段声明”)。
|
||||
|
||||
这类修改的原理是,这类库不会消失,并且它们的维护者对标准库维护相关的那些限制通常并不感兴趣(特别是相对缓慢的发布节奏)。在这种情况下,在标准库文档的更新版本中使用 “See Also” 链接指向原始模块的做法非常常见,尤其是在第三方版本额外提供了标准库模块中忽略的那些特性时。
|
||||
|
||||
### 为什么一些 API 是以临时的形式被添加的?
|
||||
|
||||
虽然 CPython 维护了 API 的弃用策略,但在没有正当理由的情况下,我们通常不会去使用该策略(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
|
||||
|
||||
然而在实践中,当添加这种受已有的第三方启发而不是直接精确拷贝第三方设计的新 API 时,所承担的风险要高于一些正常设计决定可能出现问题的风险。
|
||||
|
||||
当我们考虑到这种改变的风险比平常要高,我们将相关的 API 标记为临时,表示保守的终端用户要避免完全依赖它们,而共享抽象层的开发者可能希望对他们准备去支持的那个临时 API 的版本考虑实施比平时更严格的限制。
|
||||
|
||||
### 为什么只有一些标准库 API 被升级?
|
||||
|
||||
这里简短的回答得到升级的主要 API 有哪些:
|
||||
|
||||
* 不太可能有大量的外部因素干扰的附加更新的
|
||||
* 无论是对临时脚本用例还是对促进将来多个第三方解决方案之间的互操作性,都有明显好处的
|
||||
* 对这方面感兴趣的人提交了一个可接受的建议的
|
||||
|
||||
如果在将模块用于应用程序开发目的时(如 `datetime`),现有模块的限制主要是显而易见的,如果再分发者通过第三方方案很容易地实现了改进,(如 `requests`),或者如果标准库的发布节奏与所需要的包之间真的存在冲突,(如 `certifi`),那么,建议对标准库版本进行改变的因素将显著减少。
|
||||
|
||||
从本质上说,这和上面关于 PyPI 问题正好相反:因为从应用程序开发人员体验的角度来说,PyPI 的分发机制通常已经够好了,这种分发方式的改进是有意义的,允许再分发者和平台提供者自行决定将哪些内容作为他们缺省提供的一部分。
|
||||
|
||||
假设在 3-5 年时间内,缺省出现了被认为是改变带来的可感知的价值时,才会将这些改变纳入到 CPython 和标准库中。
|
||||
|
||||
### 标准库任何部分都有独立的版本吗?
|
||||
|
||||
是的,就像是 `ensurepip` 使用的捆绑模式(CPython 发行了一个 `pip` 的最新捆绑版本,而并没有把它放进标准库中),将来可能被应用到其它模块中。
|
||||
|
||||
最有可能的第一个候选者是 `distutils` 构建系统,因为切换到这种模式将允许构建系统在多个发行版本之间保持一致。
|
||||
|
||||
这种处理方式的其它可能候选者是 Tcl/Tk 图形套件和 IDLE 编辑器,它们已经被拆分,并且一些开发者将其改为可选安装项。
|
||||
|
||||
### 这些注意事项为什么很重要?
|
||||
|
||||
从本质上说,那些积极参与开源开发的人就是那些致力于开源应用程序和共享抽象层的人。
|
||||
|
||||
那些写一些临时脚本或为学生设计一些教学习题的人,通常不认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、市场研究员、动画师、平面设计师等等。
|
||||
|
||||
对于一种语言,当我们全部的担心都是开发人员的经验时,那么我们就可以根据人们所知道的内容、他们使用的工具种类、他们所遵循的开发流程种类、构建和部署他们软件的方法等假定,来做大量的简化。
|
||||
|
||||
当应用程序运行时作为脚本引擎广泛流行时,事情会变得更加复杂。做好任何一项工作已经很困难,并且作为单个项目的一部分来平衡两个受众的需求会导致双方经常不理解和不相信。
|
||||
|
||||
这篇文章不是为了说明我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是去合理地回应那些对添加到 Python 标准库中的看上去很荒谬的特性的质疑,它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
|
||||
|
||||
---
|
||||
|
||||
via: http://www.curiousefficiency.org/posts/2017/10/considering-pythons-target-audience.html
|
||||
|
||||
作者:[Nick Coghlan][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.curiousefficiency.org/pages/about.html
|
||||
[1]: https://aca.edu.au/#home-unpack
|
||||
[2]: https://github.com/barbagroup/AeroPython
|
||||
[3]: https://nbviewer.jupyter.org/urls/bitbucket.org/ncoghlan/misc/raw/default/notebooks/Digital%20Blasphemy.ipynb
|
||||
[4]: https://github.com/pjf/rickastley
|
||||
[5]: https://github.com/python/core-workflow
|
||||
[6]: http://www.vfxplatform.com/
|
||||
[7]: http://www.curiousefficiency.org/posts/2015/10/languages-to-improve-your-python.html#broadening-our-horizons
|
||||
[8]: https://twitter.com/ncoghlan_dev/status/916994106819088384
|
||||
[9]: https://www.python.org/dev/peps/pep-0411/
|
||||
[10]: https://twitter.com/ncoghlan_dev/status/917092464355241984
|
||||
[11]: http://www.curiousefficiency.org/posts/2015/04/stop-supporting-python26.html
|
||||
[12]: https://twitter.com/ncoghlan_dev/status/917088410162012160
|
||||
[13]: http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#wouldn-t-a-python-2-8-release-help-ease-the-transition
|
||||
[14]: http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#doesn-t-this-make-python-look-like-an-immature-and-unstable-platform
|
||||
[15]: http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#what-about-insert-other-shiny-new-feature-here
|
||||
[16]: http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html
|
||||
[17]: http://www.curiousefficiency.org/posts/2011/04/musings-on-culture-of-python-dev.html
|
||||
[18]: http://community.redhat.com/blog/2015/02/the-quid-pro-quo-of-open-infrastructure/
|
||||
@ -0,0 +1,70 @@
|
||||
用于与非 Linux 用户一同工作的 Linux 命令行工具
|
||||
======
|
||||
> 如果你在 Linux 终端工作,那么与非 Linux 用户一同工作时可能遇到困难。这些工具有助于文档兼容性和企业即时消息。
|
||||
|
||||

|
||||
|
||||
我大部分时间都在使用 Shell(命令行、终端或其它随便什么你使用的平台)上。但是,当我需要与大量其他人合作时,这可能会有点挑战,特别是在大型企业公司中 —— 除了 shell 外其他都使用。
|
||||
|
||||
当公司内的其他人使用与你不同的平台时,问题就会变得更加严重。我倾向于使用 Linux。如果我在 Linux 终端上做了很多日常工作,而我的大多数同事都使用 Windows 10(完全使用 GUI 端),那么事情就会变得……有问题。
|
||||
|
||||
- **Network World 上另外一篇文章:**[**11 个没用但很酷的 Linux 终端技巧**][1]
|
||||
|
||||
幸运的是,在过去的几年里,我已经想出如何处理这些问题。我已经找到了在非 Unix 的企业环境中使用 Linux(或其他类 Unix 系统)Shell 的方法。这些工具/技巧同样适用于在公司服务器上工作的系统管理员们,就像对开发人员或营销人员一样。
|
||||
|
||||
让我们首先关注对于大公司中的许多人来说似乎最难解决的两个方面:文档兼容性和企业即时消息。
|
||||
|
||||
### Linux 和非 Linux 系统之间的文档兼容性
|
||||
|
||||
出现的最大问题之一是简单的文字处理文档的兼容性。
|
||||
|
||||
假设你的公司已在 Microsoft Office 上进行了标准化。这让你难过。但不要失去希望!有很多方法可以使它(基本)可用 —— 甚至在 shell 中。
|
||||
|
||||
两个工具在我的武器库中至关重要:[Pandoc][2] 和 [Wordgrinder][3]。
|
||||
|
||||
Wordgrinder 是一个简单、直观的文字处理器。它可能不像 LibreOffice 那样功能齐全(或者,实际上,任何主要的 GUI 文字处理应用程序),但速度很快。它很稳定。它有足够的功能(和文件格式)来完成工作。事实上,我完全在 Wordgrinder 中写了我的大部分文章和书籍。
|
||||
|
||||
但是有一个问题(你知道肯定会有)。
|
||||
|
||||
Wordgrinder 不支持 .doc(或 .docx)文件。这意味着它无法读取使用 Windows 和 MS Office 的同事发送给你的大多数文件。
|
||||
|
||||
这就是 Pandoc 的用武之地。它是一个简单的文档转换器,可以将各种文件作为输入(MS Word、LibreOffice、HTML、markdown 等)并将它们转换为其他内容。它支持的格式数量绝对是惊人的 —— PDF、ePub、各种幻灯片格式。它确实使格式之间的文档转换变得轻而易举。
|
||||
|
||||
这并不是说我不会偶尔遇到格式或功能问题。要转换有大量自定义格式、某些脚本和嵌入式图表的 Word 文档?是的,在这个过程中会丢失很多。
|
||||
|
||||
但实际上,Pandoc(用于转换文件)和 Wordgrinder(用于文档编辑)的组合已经证明非常有用和强大。
|
||||
|
||||
### Linux 和非 Linux 系统之间的企业即时消息传递
|
||||
|
||||
每家公司都喜欢在即时通讯系统上实现标准化 —— 所有员工都可以使用它来保持实时联系。
|
||||
|
||||
在命令行中,这可能会变得棘手。如果贵公司使用 Google 环聊怎么办?或者 Novell GroupWise Messenger 怎么样?既没有官方支持,也没有基于终端的客户端。
|
||||
|
||||
谢天谢地,还有 [Finch 和 Hangups][4]。
|
||||
|
||||
Finch 是 Pidgin(开源,多协议消息客户端)的终端版本。它支持各种协议,包括 Novell GroupWise、(很快会死的)AOL Instant Messenger 以及其他一些协议。
|
||||
|
||||
而 Hangups 是 Google Hangouts 客户端的开源实现 —— 包含消息历史记录和精美的标签界面。
|
||||
|
||||
这些方案都不会为你提供语音或视频聊天功能,但对于基于文本的消息,它们的工作得非常好。它们并不完美(Finch 的用户界面需要时间习惯),但它们肯定足以与你的同事保持联系。
|
||||
|
||||
这些方案能否让你在纯文本 shell 中舒适地过完一个工作日?可能不会。就个人而言,我发现(使用这些工具和其他工具)我可以轻松地将 80% 的时间花在纯文本界面上。
|
||||
|
||||
这感觉很棒。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3235688/linux/linux-command-line-tools-for-working-with-non-linux-users.html
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Bryan-Lunduke/
|
||||
[1]:http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html#tk.nww-fsb
|
||||
[2]:https://www.youtube.com/watch?v=BkTYHChkDoE
|
||||
[3]:https://www.youtube.com/watch?v=WnMyamBgKFE
|
||||
[4]:https://www.youtube.com/watch?v=19lbWnYOsTc
|
||||
115
published/201808/20171102 Using User Namespaces on Docker.md
Normal file
115
published/201808/20171102 Using User Namespaces on Docker.md
Normal file
@ -0,0 +1,115 @@
|
||||
使用 Docker 的用户名字空间功能
|
||||
======
|
||||
|
||||
<ruby>用户名字空间<rt>User Namespaces</rt></ruby> 于 Docker 1.10 版本正式纳入其中,该功能允许主机系统将自身的 `uid` 和 `gid` 映射为容器进程中的另一个 `uid` 和 `gid`。这对 Docker 的安全性来说是一项巨大的改进。下面我会通过一个案例来展示一下用户名字空间能够解决的问题,以及如何启用该功能。
|
||||
|
||||
### 创建一个 Docker Machine
|
||||
|
||||
如果你已经创建好了一台用来试验用户名字空间的 docker <ruby>机器<rt>Machine</rt></ruby>,那么可以跳过这一步。我在自己的 Macbook 上安装了 Docker Toolbox,因此我只需用 `docker-machine` 命令就很简单地创建一个基于 VirtualBox 的 Docker 机器(这里假设主机名为 `host1`):
|
||||
|
||||
```
|
||||
# Create host1
|
||||
$ docker-machine create --driver virtualbox host1
|
||||
|
||||
# Login to host1
|
||||
$ docker-machine ssh host1
|
||||
```
|
||||
|
||||
### 理解在用户名字空间未启用的情况下,非 root 用户能做什么
|
||||
|
||||
在启用用户名字空间前,我们先来看一下会有什么问题。Docker 到底哪个地方做错了?首先,使用 Docker 的一大优势在于用户在容器中可以拥有 root 权限,因此用户可以很方便地安装软件包。但是在 Linux 容器技术中这也是一把双刃剑。只要经过少许操作,非 root 用户就能以 root 的权限访问主机系统中的内容,比如 `/etc`。下面是操作步骤。
|
||||
|
||||
```
|
||||
# Run a container and mount host1's /etc onto /root/etc
|
||||
$ docker run --rm -v /etc:/root/etc -it ubuntu
|
||||
|
||||
# Make some change on /root/etc/hosts
|
||||
root@34ef23438542:/# vi /root/etc/hosts
|
||||
|
||||
# Exit from the container
|
||||
root@34ef23438542:/# exit
|
||||
|
||||
# Check /etc/hosts
|
||||
$ cat /etc/hosts
|
||||
```
|
||||
|
||||
你可以看到,步骤简单到难以置信,很明显 Docker 并不适用于运行在多人共享的电脑上。但是现在,通过用户名字空间,Docker 可以避免这个问题。
|
||||
|
||||
### 启用用户名字空间
|
||||
|
||||
```
|
||||
# Create a user called "dockremap"
|
||||
$ sudo adduser dockremap
|
||||
|
||||
# Setup subuid and subgid
|
||||
$ sudo sh -c 'echo dockremap:500000:65536 > /etc/subuid'
|
||||
$ sudo sh -c 'echo dockremap:500000:65536 > /etc/subgid'
|
||||
```
|
||||
|
||||
然后,打开 `/etc/init.d/docker`,并在 `/usr/local/bin/docker daemon` 后面加上 `--userns-remap=default`,像这样:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/init.d/docker
|
||||
|
||||
/usr/local/bin/docker daemon --userns-remap=default -D -g "$DOCKER_DIR" -H unix:// $DOCKER_HOST $EXTRA_ARGS >> "$DOCKER_LOGFILE" 2>&1 &
|
||||
```
|
||||
|
||||
然后重启 Docker:
|
||||
|
||||
```
|
||||
$ sudo /etc/init.d/docker restart
|
||||
```
|
||||
|
||||
这就完成了!
|
||||
|
||||
**注意**:若你使用的是 CentOS 7,则你需要了解两件事。
|
||||
|
||||
1. 内核默认并没有启用用户名字空间。运行下面命令并重启系统,可以启用该功能。
|
||||
|
||||
```
|
||||
sudo grubby --args="user_namespace.enable=1" \
|
||||
--update-kernel=/boot/vmlinuz-3.10.0-XXX.XX.X.el7.x86_64
|
||||
```
|
||||
|
||||
2. CentOS 7 使用 `systemctl` 来管理服务,因此你需要编辑的文件是 `/usr/lib/systemd/system/docker.service`。
|
||||
|
||||
### 确认用户名字空间是否正常工作
|
||||
|
||||
若一切都配置妥当,则你应该无法再在容器中编辑 host1 上的 `/etc` 了。让我们来试一下。
|
||||
|
||||
```
|
||||
# Create a container and mount host1's /etc to container's /root/etc
|
||||
$ docker run --rm -v /etc:/root/etc -it ubuntu
|
||||
|
||||
# Check the owner of files in /root/etc, which should be "nobody nogroup".
|
||||
root@d5802c5e670a:/# ls -la /root/etc
|
||||
total 180
|
||||
drwxr-xr-x 11 nobody nogroup 1100 Mar 21 23:31 .
|
||||
drwx------ 3 root root 4096 Mar 21 23:50 ..
|
||||
lrwxrwxrwx 1 nobody nogroup 19 Mar 21 23:07 acpi -> /usr/local/etc/acpi
|
||||
-rw-r--r-- 1 nobody nogroup 48 Mar 10 22:09 boot2docker
|
||||
drwxr-xr-x 2 nobody nogroup 60 Mar 21 23:07 default
|
||||
|
||||
# Try creating a file in /root/etc
|
||||
root@d5802c5e670a:/# touch /root/etc/test
|
||||
touch: cannot touch '/root/etc/test': Permission denied
|
||||
|
||||
# Try deleting a file
|
||||
root@d5802c5e670a:/# rm /root/etc/hostname
|
||||
rm: cannot remove '/root/etc/hostname': Permission denied
|
||||
```
|
||||
|
||||
好了,太棒了。这就是用户名字空间的工作方式。
|
||||
|
||||
---
|
||||
|
||||
via: https://coderwall.com/p/s_ydlq/using-user-namespaces-on-docker
|
||||
|
||||
作者:[Koji Tanaka][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://coderwall.com/kjtanaka
|
||||
@ -1,58 +1,52 @@
|
||||
# [Google 为树莓派 Zero W 发布了基于TensorFlow 的视觉识别套件][26]
|
||||
|
||||
Google 为树莓派 Zero W 发布了基于TensorFlow 的视觉识别套件
|
||||
===============
|
||||
|
||||

|
||||
|
||||
Google 发行了一个 45 美元的 “AIY Vision Kit”,它是运行在树莓派 Zero W 上的基于 TensorFlow 的视觉识别开发套件,它使用了一个带 Movidius 芯片的 “VisionBonnet” 板。
|
||||
|
||||
为加速设备上的神经网络,Google 的 AIY 视频套件继承了早期树莓派上运行的 [AIY 项目][7] 的语音/AI 套件,这个型号的树莓派随五月份的 MagPi 杂志一起赠送。与语音套件和老的 Google 硬纸板 VR 查看器一样,这个新的 AIY 视觉套件也使用一个硬纸板包装。这个套件和 [Cloud Vision API][8] 是不一样的,它使用了一个在 2015 年演示过的基于树莓派的 GoPiGo 机器人,它完全在本地的处理能力上运行,而不需要使用一个云端连接。这个 AIY 视觉套件现在可以 45 美元的价格去预订,将在 12 月份发货。
|
||||
为加速该设备上的神经网络,Google 的 AIY 视频套件继承了早期树莓派上运行的 [AIY 项目][7] 的语音/AI 套件,这个型号的树莓派随五月份的 MagPi 杂志一起赠送。与语音套件和老的 Google 硬纸板 VR 查看器一样,这个新的 AIY 视觉套件也使用一个硬纸板包装。这个套件和 [Cloud Vision API][8] 是不一样的,它使用了一个在 2015 年演示过的基于树莓派的 GoPiGo 机器人,它完全在本地的处理能力上运行,而不需要使用一个云端连接。这个 AIY 视觉套件现在可以 45 美元的价格去预订,将在 12 月份发货。
|
||||
|
||||
[][9] [][10]
|
||||
|
||||
[][9] [][10]
|
||||
**AIY 视觉套件,完整包装(左)和树莓派 Zero W**
|
||||
(点击图片放大)
|
||||
*AIY 视觉套件,完整包装(左)和树莓派 Zero W*
|
||||
|
||||
这个套件的主要处理部分除了所需要的 [树莓派 Zero W][21] 单片机之外 —— 一个基于 ARM11 的 1 GHz 的 Broadcom BCM2836 片上系统,另外的就是 Google 最新的 VisionBonnet RPi 附件板。这个 VisionBonnet pHAT 附件板使用了一个 Movidius MA2450,它是 [Movidius Myriad 2 VPU][22] 版的处理器。在 VisionBonnet 上,处理器为神经网络运行了 Google 的开源机器学习库 [TensorFlow][23]。因为这个芯片,使得视觉处理的速度最高达每秒 30 帧。
|
||||
|
||||
这个套件的主要处理部分除了所需要的 [树莓派 Zero W][21] 单片机之外 —— 一个基于 ARM11 的 1 GHz 的 Broadcom BCM2836 片上系统,另外的就是 Google 最新的 VisionBonnet RPi 附件板。这个 VisionBonnet pHAT 附件板使用了一个 Movidius MA2450,它是 [Movidius Myriad 2 VPU][22] 版的处理器。在 VisionBonnet 上,处理器为神经网络运行了 Google 的开源机器学习库 [TensorFlow][23]。因为这个芯片,便得视觉处理的速度最高达每秒 30 帧。
|
||||
|
||||
这个 AIY 视觉套件要求用户提供一个树莓派 Zero W、一个 [树莓派摄像机 v2][11]、以及一个 16GB 的 micro SD 卡,它用来下载基于 Linux 的 OS 镜像。这个套件包含了 VisionBonnet、一个 RGB 街机风格的按钮、一个压电扬声器、一个广角镜头套件、以及一个包裹它们的硬纸板。还有一些就是线缆、支架、安装螺母、以及连接部件。
|
||||
这个 AIY 视觉套件要求用户提供一个树莓派 Zero W、一个 [树莓派摄像机 v2][11]、以及一个 16GB 的 micro SD 卡,它用来下载基于 Linux 的 OS 镜像。这个套件包含了 VisionBonnet、一个 RGB 街机风格的按钮、一个压电扬声器、一个广角镜头套件、以及一个包裹它们的硬纸板。还有一些就是线缆、支架、安装螺母,以及连接部件。
|
||||
|
||||
|
||||
[][12] [][13]
|
||||
**AIY 视觉套件组件(左)和 VisonBonnet 附件板**
|
||||
(点击图片放大)
|
||||
|
||||
*AIY 视觉套件组件(左)和 VisonBonnet 附件板*
|
||||
|
||||
有三个可用的神经网络模型。一个是通用的模型,它可以识别常见的 1,000 个东西,一个是面部检测模型,它可以对 “快乐程度” 进行评分,从 “悲伤” 到 “大笑”,还有一个模型可以用来辨别图像内容是狗、猫、还是人。这个 1,000-image 模型源自 Google 的开源 [MobileNets][24],它是基于 TensorFlow 家族的计算机视觉模型,它设计用于资源受限的移动或者嵌入式设备。
|
||||
|
||||
MobileNet 模型是低延时、低功耗,和参数化的,以满足资源受限的不同使用案例。Google 说,这个模型可以用于构建分类、检测、嵌入、以及分隔。在本月的早些时候,Google 发布了一个开发者预览版,它是一个对 Android 和 iOS 移动设备友好的 [TensorFlow Lite][14] 库,它与 MobileNets 和 Android 神经网络 API 是兼容的。
|
||||
有三个可用的神经网络模型。一个是通用的模型,它可以识别常见的 1000 个东西,一个是面部检测模型,它可以对 “快乐程度” 进行评分,从 “悲伤” 到 “大笑”,还有一个模型可以用来辨别图像内容是狗、猫、还是人。这个 1000 个图片模型源自 Google 的开源 [MobileNets][24],它是基于 TensorFlow 家族的计算机视觉模型,它设计用于资源受限的移动或者嵌入式设备。
|
||||
|
||||
MobileNet 模型是低延时、低功耗,和参数化的,以满足资源受限的不同使用情景。Google 说,这个模型可以用于构建分类、检测、嵌入、以及分隔。在本月的早些时候,Google 发布了一个开发者预览版,它是一个对 Android 和 iOS 移动设备友好的 [TensorFlow Lite][14] 库,它与 MobileNets 和 Android 神经网络 API 是兼容的。
|
||||
|
||||
[][15]
|
||||
**AIY 视觉套件包装图**
|
||||
(点击图像放大)
|
||||
|
||||
*AIY 视觉套件包装图*
|
||||
|
||||
除了提供这三个模型之外,AIY 视觉套件还提供了基本的 TensorFlow 代码和一个编译器,因此用户可以去开发自己的模型。另外,Python 开发者可以写一些新软件去定制 RGB 按钮颜色、压电元素声音、以及在 VisionBonnet 上的 4x GPIO 针脚,它可以添加另外的指示灯、按钮、或者伺服机构。Potential 模型包括识别食物、基于可视化输入来打开一个狗门、当你的汽车偏离车道时发出文本信息、或者根据识别到的人的面部表情来播放特定的音乐。
|
||||
|
||||
|
||||
[][16] [][17]
|
||||
**Myriad 2 VPU 结构图(左)和参考板**
|
||||
(点击图像放大)
|
||||
|
||||
*Myriad 2 VPU 结构图(左)和参考板*
|
||||
|
||||
Movidius Myriad 2 处理器在一个标称 1W 的功耗下提供每秒万亿次浮点运算的性能。在被 Intel 收购之前,这个芯片最早出现在 Tango 项目的参考平台上,并内置在 2016 年 5 月由 Movidius 首次亮相的、Ubuntu 驱动的 USB 的 [Fathom][25] 神经网络处理棒中。根据 Movidius 的说法,Myriad 2 目前已经在 “市场上数百万的设备上使用”。
|
||||
|
||||
**更多信息**
|
||||
|
||||
AIY 视觉套件可以在 Micro Center 上预订,价格为 $44.99,预计在 12 月初发货。更多信息请参考 AIY 视觉套件的 [公告][18]、[Google 博客][19]、以及 [Micro Center 购物页面][20]。
|
||||
AIY 视觉套件可以在 Micro Center 上预订,价格为 $44.99,预计在(2017 年) 12 月初发货。更多信息请参考 AIY 视觉套件的 [公告][18]、[Google 博客][19]、以及 [Micro Center 购物页面][20]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
|
||||
作者:[ Eric Brown][a]
|
||||
作者:[Eric Brown][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user