mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
Merge remote-tracking branch 'lctt/master'
This commit is contained in:
commit
eaa0194ceb
@ -0,0 +1,230 @@
|
||||
Linux 包管理基础:apt、yum、dnf 和 pkg
|
||||
========================
|
||||
|
||||
![Package_Management_tw_mostov.png-307.8kB][1]
|
||||
|
||||
### 介绍
|
||||
|
||||
大多数现代的类 Unix 操作系统都提供了一种中心化的机制用来搜索和安装软件。软件通常都是存放在存储库中,并通过包的形式进行分发。处理包的工作被称为包管理。包提供了操作系统的基本组件,以及共享的库、应用程序、服务和文档。
|
||||
|
||||
包管理系统除了安装软件外,它还提供了工具来更新已经安装的包。包存储库有助于确保你的系统中使用的代码是经过审查的,并且软件的安装版本已经得到了开发人员和包维护人员的认可。
|
||||
|
||||
在配置服务器或开发环境时,我们最好了解下包在官方存储库之外的情况。某个发行版的稳定版本中的包有可能已经过时了,尤其是那些新的或者快速迭代的软件。然而,包管理无论对于系统管理员还是开发人员来说都是至关重要的技能,而已打包的软件对于主流 Linux 发行版来说也是一笔巨大的财富。
|
||||
|
||||
本指南旨在快速地介绍下在多种 Linux 发行版中查找、安装和升级软件包的基础知识,并帮助您将这些内容在多个系统之间进行交叉对比。
|
||||
|
||||
### 包管理系统:简要概述
|
||||
|
||||
大多数包系统都是围绕包文件的集合构建的。包文件通常是一个存档文件,它包含已编译的二进制文件和软件的其他资源,以及安装脚本。包文件同时也包含有价值的元数据,包括它们的依赖项,以及安装和运行它们所需的其他包的列表。
|
||||
|
||||
虽然这些包管理系统的功能和优点大致相同,但打包格式和工具却因平台而异:
|
||||
|
||||
| 操作系统 | 格式 | 工具 |
|
||||
| --- | --- | --- |
|
||||
| Debian | `.deb` | `apt`, `apt-cache`, `apt-get`, `dpkg` |
|
||||
| Ubuntu | `.deb` | `apt`, `apt-cache`, `apt-get`, `dpkg` |
|
||||
| CentOS | `.rpm` | `yum` |
|
||||
| Fedora | `.rpm` | `dnf` |
|
||||
| FreeBSD | Ports, `.txz` | `make`, `pkg` |
|
||||
|
||||
Debian 及其衍生版,如 Ubuntu、Linux Mint 和 Raspbian,它们的包格式是 `.deb`。APT 这款先进的包管理工具提供了大多数常见的操作命令:搜索存储库、安装软件包及其依赖项,并管理升级。在本地系统中,我们还可以使用 `dpkg` 程序来安装单个的 `deb` 文件,APT 命令作为底层 `dpkg` 的前端,有时也会直接调用它。
|
||||
|
||||
最近发布的 debian 衍生版大多数都包含了 `apt` 命令,它提供了一个简洁统一的接口,可用于通常由 `apt-get` 和 `apt-cache` 命令处理的常见操作。这个命令是可选的,但使用它可以简化一些任务。
|
||||
|
||||
CentOS、Fedora 和其它 Red Hat 家族成员使用 RPM 文件。在 CentOS 中,通过 `yum` 来与单独的包文件和存储库进行交互。
|
||||
|
||||
在最近的 Fedora 版本中,`yum` 已经被 `dnf` 取代,`dnf` 是它的一个现代化的分支,它保留了大部分 `yum` 的接口。
|
||||
|
||||
FreeBSD 的二进制包系统由 `pkg` 命令管理。FreeBSD 还提供了 `Ports` 集合,这是一个存在于本地的目录结构和工具,它允许用户获取源码后使用 Makefile 直接从源码编译和安装包。
|
||||
|
||||
### 更新包列表
|
||||
|
||||
大多数系统在本地都会有一个和远程存储库对应的包数据库,在安装或升级包之前最好更新一下这个数据库。另外,`yum` 和 `dnf` 在执行一些操作之前也会自动检查更新。当然你可以在任何时候对系统进行更新。
|
||||
|
||||
| 系统 | 命令 |
|
||||
| --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get update` |
|
||||
| | `sudo apt update` |
|
||||
| CentOS | `yum check-update` |
|
||||
| Fedora | `dnf check-update` |
|
||||
| FreeBSD Packages | `sudo pkg update` |
|
||||
| FreeBSD Ports | `sudo portsnap fetch update` |
|
||||
|
||||
### 更新已安装的包
|
||||
|
||||
在没有包系统的情况下,想确保机器上所有已安装的软件都保持在最新的状态是一个很艰巨的任务。你将不得不跟踪数百个不同包的上游更改和安全警报。虽然包管理器并不能解决升级软件时遇到的所有问题,但它确实使你能够使用一些命令来维护大多数系统组件。
|
||||
|
||||
在 FreeBSD 上,升级已安装的 ports 可能会引入破坏性的改变,有些步骤还需要进行手动配置,所以在通过 `portmaster` 更新之前最好阅读下 `/usr/ports/UPDATING` 的内容。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get upgrade` | 只更新已安装的包 |
|
||||
| | `sudo apt-get dist-upgrade` | 可能会增加或删除包以满足新的依赖项 |
|
||||
| | `sudo apt upgrade` | 和 `apt-get upgrade` 类似 |
|
||||
| | `sudo apt full-upgrade` | 和 `apt-get dist-upgrade` 类似 |
|
||||
| CentOS | `sudo yum update` | |
|
||||
| Fedora | `sudo dnf upgrade` | |
|
||||
| FreeBSD Packages | `sudo pkg upgrade` | |
|
||||
| FreeBSD Ports | `less /usr/ports/UPDATING` | 使用 `less` 来查看 ports 的更新提示(使用上下光标键滚动,按 q 退出)。 |
|
||||
| | `cd /usr/ports/ports-mgmt/portmaster && sudo make install && sudo portmaster -a` | 安装 `portmaster` 然后使用它更新已安装的 ports |
|
||||
|
||||
### 搜索某个包
|
||||
|
||||
大多数发行版都提供针对包集合的图形化或菜单驱动的工具,我们可以分类浏览软件,这也是一个发现新软件的好方法。然而,查找包最快和最有效的方法是使用命令行工具进行搜索。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `apt-cache search search_string` | |
|
||||
| | `apt search search_string` | |
|
||||
| CentOS | `yum search search_string` | |
|
||||
| | `yum search all search_string` | 搜索所有的字段,包括描述 |
|
||||
| Fedora | `dnf search search_string` | |
|
||||
| | `dnf search all search_string` | 搜索所有的字段,包括描述 |
|
||||
| FreeBSD Packages | `pkg search search_string` | 通过名字进行搜索 |
|
||||
| | `pkg search -f search_string` | 通过名字进行搜索并返回完整的描述 |
|
||||
| | `pkg search -D search_string` | 搜索描述 |
|
||||
| FreeBSD Ports | `cd /usr/ports && make search name=package` | 通过名字进行搜索 |
|
||||
| | `cd /usr/ports && make search key=search_string` | 搜索评论、描述和依赖 |
|
||||
|
||||
### 查看某个软件包的信息
|
||||
|
||||
在安装软件包之前,我们可以通过仔细阅读包的描述来获得很多有用的信息。除了人类可读的文本之外,这些内容通常包括像版本号这样的元数据和包的依赖项列表。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `apt-cache show package` | 显示有关包的本地缓存信息 |
|
||||
| | `apt show package` | |
|
||||
| | `dpkg -s package` | 显示包的当前安装状态 |
|
||||
| CentOS | `yum info package` | |
|
||||
| | `yum deplist package` | 列出包的依赖 |
|
||||
| Fedora | `dnf info package` | |
|
||||
| | `dnf repoquery --requires package` | 列出包的依赖 |
|
||||
| FreeBSD Packages | `pkg info package` | 显示已安装的包的信息 |
|
||||
| FreeBSD Ports | `cd /usr/ports/category/port && cat pkg-descr` | |
|
||||
|
||||
### 从存储库安装包
|
||||
|
||||
知道包名后,通常可以用一个命令来安装它及其依赖。你也可以一次性安装多个包,只需将它们全部列出来即可。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get install package` | |
|
||||
| | `sudo apt-get install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| | `sudo apt-get install -y package` | 在 `apt` 提示是否继续的地方直接默认 `yes` |
|
||||
| | `sudo apt install package` | 显示一个彩色的进度条 |
|
||||
| CentOS | `sudo yum install package` | |
|
||||
| | `sudo yum install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| | `sudo yum install -y package` | 在 `yum` 提示是否继续的地方直接默认 `yes` |
|
||||
| Fedora | `sudo dnf install package` | |
|
||||
| | `sudo dnf install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| | `sudo dnf install -y package` | 在 `dnf` 提示是否继续的地方直接默认 `yes` |
|
||||
| FreeBSD Packages | `sudo pkg install package` | |
|
||||
| | `sudo pkg install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| FreeBSD Ports | `cd /usr/ports/category/port && sudo make install` | 从源码构建安装一个 port |
|
||||
|
||||
### 从本地文件系统安装一个包
|
||||
|
||||
对于一个给定的操作系统,有时有些软件官方并没有提供相应的包,那么开发人员或供应商将需要提供包文件的下载。你通常可以通过 web 浏览器检索这些包,或者通过命令行 `curl` 来检索这些信息。将包下载到目标系统后,我们通常可以通过单个命令来安装它。
|
||||
|
||||
在 Debian 派生的系统上,`dpkg` 用来处理单个的包文件。如果一个包有未满足的依赖项,那么我们可以使用 `gdebi` 从官方存储库中检索它们。
|
||||
|
||||
在 CentOS 和 Fedora 系统上,`yum` 和 `dnf` 用于安装单个的文件,并且会处理需要的依赖。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo dpkg -i package.deb` | |
|
||||
| | `sudo apt-get install -y gdebi && sudo gdebi package.deb` | 安装 `gdebi`,然后使用 `gdebi` 安装 `package.deb` 并处理缺失的依赖|
|
||||
| CentOS | `sudo yum install package.rpm` | |
|
||||
| Fedora | `sudo dnf install package.rpm` | |
|
||||
| FreeBSD Packages | `sudo pkg add package.txz` | |
|
||||
| | `sudo pkg add -f package.txz` | 即使已经安装的包也会重新安装 |
|
||||
|
||||
### 删除一个或多个已安装的包
|
||||
|
||||
由于包管理器知道给定的软件包提供了哪些文件,因此如果某个软件不再需要了,它通常可以干净利落地从系统中清除这些文件。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get remove package` | |
|
||||
| | `sudo apt remove package` | |
|
||||
| | `sudo apt-get autoremove` | 删除不需要的包 |
|
||||
| CentOS | `sudo yum remove package` | |
|
||||
| Fedora | `sudo dnf erase package` | |
|
||||
| FreeBSD Packages | `sudo pkg delete package` | |
|
||||
| | `sudo pkg autoremove` | 删除不需要的包 |
|
||||
| FreeBSD Ports | `sudo pkg delete package` | |
|
||||
| | `cd /usr/ports/path_to_port && make deinstall` | 卸载 port |
|
||||
|
||||
### `apt` 命令
|
||||
|
||||
Debian 家族发行版的管理员通常熟悉 `apt-get` 和 `apt-cache`。较少为人所知的是简化的 `apt` 接口,它是专为交互式使用而设计的。
|
||||
|
||||
| 传统命令 | 等价的 `apt` 命令 |
|
||||
| --- | --- |
|
||||
| `apt-get update` | `apt update` |
|
||||
| `apt-get dist-upgrade` | `apt full-upgrade` |
|
||||
| `apt-cache search string` | `apt search string` |
|
||||
| `apt-get install package` | `apt install package` |
|
||||
| `apt-get remove package` | `apt remove package` |
|
||||
| `apt-get purge package` | `apt purge package` |
|
||||
|
||||
虽然 `apt` 通常是一个特定操作的快捷方式,但它并不能完全替代传统的工具,它的接口可能会随着版本的不同而发生变化,以提高可用性。如果你在脚本或 shell 管道中使用包管理命令,那么最好还是坚持使用 `apt-get` 和 `apt-cache`。
|
||||
|
||||
### 获取帮助
|
||||
|
||||
除了基于 web 的文档,请记住我们可以通过 shell 从 Unix 手册页(通常称为 man 页面)中获得大多数的命令。比如要阅读某页,可以使用 `man`:
|
||||
|
||||
```
|
||||
man page
|
||||
|
||||
```
|
||||
|
||||
在 `man` 中,你可以用箭头键导航。按 `/` 搜索页面内的文本,使用 `q` 退出。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `man apt-get` | 更新本地包数据库以及与包一起工作 |
|
||||
| | `man apt-cache` | 在本地的包数据库中搜索 |
|
||||
| | `man dpkg` | 和单独的包文件一起工作以及能查询已安装的包 |
|
||||
| | `man apt` | 通过更简洁,用户友好的接口进行最基本的操作 |
|
||||
| CentOS | `man yum` | |
|
||||
| Fedora | `man dnf` | |
|
||||
| FreeBSD Packages | `man pkg` | 和预先编译的二进制包一起工作 |
|
||||
| FreeBSD Ports | `man ports` | 和 Ports 集合一起工作 |
|
||||
|
||||
### 结论和进一步的阅读
|
||||
|
||||
本指南通过对多个系统间进行交叉对比概述了一下包管理系统的基本操作,但只涉及了这个复杂主题的表面。对于特定系统更详细的信息,可以参考以下资源:
|
||||
|
||||
* [这份指南][2] 详细介绍了 Ubuntu 和 Debian 的软件包管理。
|
||||
* 这里有一份 CentOS 官方的指南 [使用 yum 管理软件][3]
|
||||
* 这里有一个有关 Fedora 的 `dnf` 的 [wifi 页面][4] 以及一份有关 `dnf` [官方的手册][5]
|
||||
* [这份指南][6] 讲述了如何使用 `pkg` 在 FreeBSD 上进行包管理
|
||||
* 这本 [FreeBSD Handbook][7] 有一节讲述了[如何使用 Ports 集合][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/package-management-basics-apt-yum-dnf-pkg
|
||||
|
||||
译者后记:
|
||||
|
||||
从经典的 `configure` && `make` && `make install` 三部曲到 `dpkg`,从需要手处理依赖关系的 `dpkg` 到全自动化的 `apt-get`,恩~,你有没有想过接下来会是什么?译者只能说可能会是 `Snaps`,如果你还没有听过这个东东,你也许需要关注下这个公众号了:**Snapcraft**
|
||||
|
||||
作者:[Brennen Bearnes][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.digitalocean.com/community/users/bpb
|
||||
|
||||
|
||||
[1]: http://static.zybuluo.com/apollomoon/g9kiere2xuo1511ls1hi9w9w/Package_Management_tw_mostov.png
|
||||
[2]:https://www.digitalocean.com/community/tutorials/ubuntu-and-debian-package-management-essentials
|
||||
[3]: https://www.centos.org/docs/5/html/yum/
|
||||
[4]: https://fedoraproject.org/wiki/Dnf
|
||||
[5]: https://dnf.readthedocs.org/en/latest/index.html
|
||||
[6]: https://www.digitalocean.com/community/tutorials/how-to-manage-packages-on-freebsd-10-1-with-pkg
|
||||
[7]:https://www.freebsd.org/doc/handbook/
|
||||
[8]: https://www.freebsd.org/doc/handbook/ports-using.html
|
||||
[9]:https://www.freebsd.org/doc/handbook/ports-using.html
|
||||
@ -0,0 +1,173 @@
|
||||
使用 snapcraft 将 snap 包发布到商店
|
||||
==================
|
||||
|
||||

|
||||
|
||||
Ubuntu Core 已经正式发布(LCTT 译注:指 2016 年 11 月发布的 Ubuntu Snappy Core 16 ),也许是时候让你的 snap 包进入商店了!
|
||||
|
||||
### 交付和商店的概念
|
||||
|
||||
首先回顾一下我们是怎么通过商店管理 snap 包的吧。
|
||||
|
||||
每次你上传 snap 包,商店都会为其分配一个修订版本号,并且商店中针对特定 snap 包 的版本号都是唯一的。
|
||||
|
||||
但是第一次上传 snap 包的时候,我们首先要为其注册一个还没有被使用的名字,这很容易。
|
||||
|
||||
商店中所有的修订版本都可以释放到多个通道中,这些通道只是概念上定义的,以便给用户一个稳定或风险等级的参照,这些通道有:
|
||||
|
||||
* 稳定(stable)
|
||||
* 候选(candidate)
|
||||
* 测试(beta)
|
||||
* 边缘(edge)
|
||||
|
||||
理想情况下,如果我们设置了 CI/CD 过程,那么每天或在每次更新源码时都会将其推送到边缘通道。在此过程中有两件事需要考虑。
|
||||
|
||||
首先在开始的时候,你最好制作一个不受限制的 snap 包,因为在这种新范例下,snap 包的大部分功能都能不受限制地工作。考虑到这一点,你的项目开始时 `confinement` 将被设置为 `devmode`(LCTT 译注:这是 `snapcraft.yaml` 中的一个键及其可选值)。这使得你在开发的早期阶段,仍然可以让你的 snap 包进入商店。一旦所有的东西都得到了 snap 包运行的安全模型的充分支持,那么就可以将 `confinement` 修改为 `strict`。
|
||||
|
||||
好了,假设你在限制方面已经做好了,并且也开始了一个对应边缘通道的 CI/CD 过程,但是如果你也想确保在某些情况下,早期版本 master 分支新的迭代永远也不会进入稳定或候选通道,那么我们可以使用 `gadge` 设置。如果 snap 包的 `gadge` 设置为 `devel` (LCTT注:这是 `snapcraft.yaml` 中的一个键及其可选值),商店将会永远禁止你将 snap 包释放到稳定和候选通道。
|
||||
|
||||
在这个过程中,我们有时可能想要发布一个修订版本到测试通道,以便让有些用户更愿意去跟踪它(一个好的发布管理流程应该比一个随机的日常构建更有用)。这个阶段结束后,如果希望人们仍然能保持更新,我们可以选择关闭测试通道,从一个特定的时间点开始我们只计划发布到候选和稳定通道,通过关闭测试通道我们将使该通道跟随稳定列表中的下一个开放通道,在这里是候选通道。而如果候选通道跟随的是稳定通道后,那么最终得到是稳定通道了。
|
||||
|
||||
### 进入 Snapcraft
|
||||
|
||||
那么所有这些给定的概念是如何在 snapcraft 中配合使用的?首先我们需要登录:
|
||||
|
||||
```
|
||||
$ snapcraft login
|
||||
Enter your Ubuntu One SSO credentials.
|
||||
Email: sxxxxx.sxxxxxx@canonical.com
|
||||
Password: **************
|
||||
Second-factor auth: 123456
|
||||
```
|
||||
|
||||
在登录之后,我们就可以开始注册 snap 了。例如,我们想要注册一个虚构的 snap 包 awesome-database:
|
||||
|
||||
```
|
||||
$ snapcraft register awesome-database
|
||||
We always want to ensure that users get the software they expect
|
||||
for a particular name.
|
||||
|
||||
If needed, we will rename snaps to ensure that a particular name
|
||||
reflects the software most widely expected by our community.
|
||||
|
||||
For example, most people would expect ‘thunderbird’ to be published by
|
||||
Mozilla. They would also expect to be able to get other snaps of
|
||||
Thunderbird as 'thunderbird-sergiusens'.
|
||||
|
||||
Would you say that MOST users will expect 'a' to come from
|
||||
you, and be the software you intend to publish there? [y/N]: y
|
||||
|
||||
You are now the publisher for 'awesome-database'
|
||||
```
|
||||
|
||||
假设我们已经构建了 snap 包,接下来我们要做的就是把它上传到商店。我们可以在同一个命令中使用快捷方式和 `--release` 选项:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap --release edge
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 1 of 'awesome-database' created.
|
||||
|
||||
Channel Version Revision
|
||||
stable - -
|
||||
candidate - -
|
||||
beta - -
|
||||
edge 0.1 1
|
||||
|
||||
The edge channel is now open.
|
||||
```
|
||||
|
||||
如果我们试图将其发布到稳定通道,商店将会阻止我们:
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 1 stable
|
||||
Revision 1 (devmode) cannot target a stable channel (stable, grade: devel)
|
||||
```
|
||||
|
||||
这样我们不会搞砸,也不会让我们的忠实用户使用它。现在,我们将最终推出一个值得发布到稳定通道的修订版本:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 10 of 'awesome-database' created.
|
||||
```
|
||||
|
||||
注意,<ruby>版本号<rt>version</rt></ruby>(LCTT 译注:这里指的是 snap 包名中 `0.1` 这个版本号)只是一个友好的标识符,真正重要的是商店为我们生成的<ruby>修订版本号<rt>Revision</rt></ruby>(LCTT 译注:这里生成的修订版本号为 `10`)。现在让我们把它释放到稳定通道:
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 10 stable
|
||||
Channel Version Revision
|
||||
stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge 0.1 10
|
||||
|
||||
The 'stable' channel is now open.
|
||||
```
|
||||
|
||||
在这个针对我们正在使用架构最终的通道映射视图中,可以看到边缘通道将会被固定在修订版本 10 上,并且测试和候选通道将会跟随现在修订版本为 10 的稳定通道。由于某些原因,我们决定将专注于稳定性并让我们的 CI/CD 推送到测试通道。这意味着我们的边缘通道将会略微过时,为了避免这种情况,我们可以关闭这个通道:
|
||||
|
||||
```
|
||||
$ snapcraft close awesome-database edge
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
|
||||
The edge channel is now closed.
|
||||
```
|
||||
|
||||
在当前状态下,所有通道都跟随着稳定通道,因此订阅了候选、测试和边缘通道的人也将跟踪稳定通道的改动。比如就算修订版本 11 只发布到稳定通道,其他通道的人们也能看到它。
|
||||
|
||||
这个清单还提供了完整的体系结构视图,在本例中,我们只使用了 amd64。
|
||||
|
||||
### 获得更多的信息
|
||||
|
||||
有时过了一段时间,我们想知道商店中的某个 snap 包的历史记录和现在的状态是什么样的,这里有两个命令,一个是直截了当输出当前的状态,它会给我们一个熟悉的结果:
|
||||
|
||||
```
|
||||
$ snapcraft status awesome-database
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
```
|
||||
|
||||
我们也可以通过下面的命令获得完整的历史记录:
|
||||
|
||||
```
|
||||
$ snapcraft history awesome-database
|
||||
Rev. Uploaded Arch Version Channels
|
||||
3 2016-09-30T12:46:21Z amd64 0.1 stable*
|
||||
...
|
||||
...
|
||||
...
|
||||
2 2016-09-30T12:38:20Z amd64 0.1 -
|
||||
1 2016-09-30T12:33:55Z amd64 0.1 -
|
||||
```
|
||||
|
||||
### 结束语
|
||||
|
||||
希望这篇文章能让你对商店能做的事情有一个大概的了解,并让更多的人开始使用它!
|
||||
|
||||
--------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2016/11/15/making-your-snaps-available-to-the-store-using-snapcraft/
|
||||
|
||||
*译者简介:*
|
||||
|
||||
> snapcraft.io 的钉子户,对 Ubuntu Core、Snaps 和 Snapcraft 有着浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人的公众号: `Snapcraft`,近期会在上面连载几篇有关 Core snap 发布策略、交付流程和验证流程的文章,欢迎围观 :)
|
||||
|
||||
|
||||
作者:[Sergio Schvezov][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[1]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[2]:http://snapcraft.io/docs/build-snaps/publish
|
||||
155
published/20170101 What is Kubernetes.md
Normal file
155
published/20170101 What is Kubernetes.md
Normal file
@ -0,0 +1,155 @@
|
||||
一文了解 Kubernetes 是什么?
|
||||
============================================================
|
||||
|
||||
这是一篇 Kubernetes 的概览。
|
||||
|
||||
Kubernetes 是一个[自动化部署、伸缩和操作应用程序容器的开源平台][25]。
|
||||
|
||||
使用 Kubernetes,你可以快速、高效地满足用户以下的需求:
|
||||
|
||||
* 快速精准地部署应用程序
|
||||
* 即时伸缩你的应用程序
|
||||
* 无缝展现新特征
|
||||
* 限制硬件用量仅为所需资源
|
||||
|
||||
我们的目标是培育一个工具和组件的生态系统,以减缓在公有云或私有云中运行的程序的压力。
|
||||
|
||||
#### Kubernetes 的优势
|
||||
|
||||
* **可移动**: 公有云、私有云、混合云、多态云
|
||||
* **可扩展**: 模块化、插件化、可挂载、可组合
|
||||
* **自修复**: 自动部署、自动重启、自动复制、自动伸缩
|
||||
|
||||
Google 公司于 2014 年启动了 Kubernetes 项目。Kubernetes 是在 [Google 的长达 15 年的成规模的产品级任务的经验下][26]构建的,结合了来自社区的最佳创意和实践经验。
|
||||
|
||||
### 为什么选择容器?
|
||||
|
||||
想要知道你为什么要选择使用 [容器][27]?
|
||||
|
||||

|
||||
|
||||
程序部署的_传统方法_是指通过操作系统包管理器在主机上安装程序。这样做的缺点是,容易混淆程序之间以及程序和主机系统之间的可执行文件、配置文件、库、生命周期。为了达到精准展现和精准回撤,你可以搭建一台不可变的虚拟机镜像。但是虚拟机体量往往过于庞大而且不可转移。
|
||||
|
||||
容器部署的_新的方式_是基于操作系统级别的虚拟化,而非硬件虚拟化。容器彼此是隔离的,与宿主机也是隔离的:它们有自己的文件系统,彼此之间不能看到对方的进程,分配到的计算资源都是有限制的。它们比虚拟机更容易搭建。并且由于和基础架构、宿主机文件系统是解耦的,它们可以在不同类型的云上或操作系统上转移。
|
||||
|
||||
正因为容器又小又快,每一个容器镜像都可以打包装载一个程序。这种一对一的“程序 - 镜像”联系带给了容器诸多便捷。有了容器,静态容器镜像可以在编译/发布时期创建,而非部署时期。因此,每个应用不必再等待和整个应用栈其它部分进行整合,也不必和产品基础架构环境之间进行妥协。在编译/发布时期生成容器镜像建立了一个持续地把开发转化为产品的环境。相似地,容器远比虚拟机更加透明,尤其在设备监控和管理上。这一点,在容器的进程生命周期被基础架构管理而非被容器内的进程监督器隐藏掉时,尤为显著。最终,随着每个容器内都装载了单一的程序,管理容器就等于管理或部署整个应用。
|
||||
|
||||
容器优势总结:
|
||||
|
||||
* **敏捷的应用创建与部署**:相比虚拟机镜像,容器镜像的创建更简便、更高效。
|
||||
* **持续的开发、集成,以及部署**:在快速回滚下提供可靠、高频的容器镜像编译和部署(基于镜像的不可变性)。
|
||||
* **开发与运营的关注点分离**:由于容器镜像是在编译/发布期创建的,因此整个过程与基础架构解耦。
|
||||
* **跨开发、测试、产品阶段的环境稳定性**:在笔记本电脑上的运行结果和在云上完全一致。
|
||||
* **在云平台与 OS 上分发的可转移性**:可以在 Ubuntu、RHEL、CoreOS、预置系统、Google 容器引擎,乃至其它各类平台上运行。
|
||||
* **以应用为核心的管理**: 从在虚拟硬件上运行系统,到在利用逻辑资源的系统上运行程序,从而提升了系统的抽象层级。
|
||||
* **松散耦联、分布式、弹性、无拘束的[微服务][5]**:整个应用被分散为更小、更独立的模块,并且这些模块可以被动态地部署和管理,而不再是存储在大型的单用途机器上的臃肿的单一应用栈。
|
||||
* **资源隔离**:增加程序表现的可预见性。
|
||||
* **资源利用率**:高效且密集。
|
||||
|
||||
#### 为什么我需要 Kubernetes,它能做什么?
|
||||
|
||||
至少,Kubernetes 能在实体机或虚拟机集群上调度和运行程序容器。而且,Kubernetes 也能让开发者斩断联系着实体机或虚拟机的“锁链”,从**以主机为中心**的架构跃至**以容器为中心**的架构。该架构最终提供给开发者诸多内在的优势和便利。Kubernetes 提供给基础架构以真正的**以容器为中心**的开发环境。
|
||||
|
||||
Kubernetes 满足了一系列产品内运行程序的普通需求,诸如:
|
||||
|
||||
* [协调辅助进程][9],协助应用程序整合,维护一对一“程序 - 镜像”模型。
|
||||
* [挂载存储系统][10]
|
||||
* [分布式机密信息][11]
|
||||
* [检查程序状态][12]
|
||||
* [复制应用实例][13]
|
||||
* [使用横向荚式自动缩放][14]
|
||||
* [命名与发现][15]
|
||||
* [负载均衡][16]
|
||||
* [滚动更新][17]
|
||||
* [资源监控][18]
|
||||
* [访问并读取日志][19]
|
||||
* [程序调试][20]
|
||||
* [提供验证与授权][21]
|
||||
|
||||
以上兼具平台即服务(PaaS)的简化和基础架构即服务(IaaS)的灵活,并促进了在平台服务提供商之间的迁移。
|
||||
|
||||
#### Kubernetes 是一个什么样的平台?
|
||||
|
||||
虽然 Kubernetes 提供了非常多的功能,总会有更多受益于新特性的新场景出现。针对特定应用的工作流程,能被流水线化以加速开发速度。特别的编排起初是可接受的,这往往需要拥有健壮的大规模自动化机制。这也是为什么 Kubernetes 也被设计为一个构建组件和工具的生态系统的平台,使其更容易地部署、缩放、管理应用程序。
|
||||
|
||||
[<ruby>标签<rt>label</rt></ruby>][28]可以让用户按照自己的喜好组织资源。 [<ruby>注释<rt>annotation</rt></ruby>][29]让用户在资源里添加客户信息,以优化工作流程,为管理工具提供一个标示调试状态的简单方法。
|
||||
|
||||
此外,[Kubernetes 控制面板][30]是由开发者和用户均可使用的同样的 [API][31] 构建的。用户可以编写自己的控制器,比如 [<ruby>调度器<rt>scheduler</rt></ruby>][32],使用可以被通用的[命令行工具][34]识别的[他们自己的 API][33]。
|
||||
|
||||
这种[设计][35]让大量的其它系统也能构建于 Kubernetes 之上。
|
||||
|
||||
#### Kubernetes 不是什么?
|
||||
|
||||
Kubernetes 不是传统的、全包容的平台即服务(Paas)系统。它尊重用户的选择,这很重要。
|
||||
|
||||
Kubernetes:
|
||||
|
||||
* 并不限制支持的程序类型。它并不检测程序的框架 (例如,[Wildfly][22]),也不限制运行时支持的语言集合 (比如, Java、Python、Ruby),也不仅仅迎合 [12 因子应用程序][23],也不区分 _应用_ 与 _服务_ 。Kubernetes 旨在支持尽可能多种类的工作负载,包括无状态的、有状态的和处理数据的工作负载。如果某程序在容器内运行良好,它在 Kubernetes 上只可能运行地更好。
|
||||
* 不提供中间件(例如消息总线)、数据处理框架(例如 Spark)、数据库(例如 mysql),也不把集群存储系统(例如 Ceph)作为内置服务。但是以上程序都可以在 Kubernetes 上运行。
|
||||
* 没有“点击即部署”这类的服务市场存在。
|
||||
* 不部署源代码,也不编译程序。持续集成 (CI) 工作流程是不同的用户和项目拥有其各自不同的需求和表现的地方。所以,Kubernetes 支持分层 CI 工作流程,却并不监听每层的工作状态。
|
||||
* 允许用户自行选择日志、监控、预警系统。( Kubernetes 提供一些集成工具以保证这一概念得到执行)
|
||||
* 不提供也不管理一套完整的应用程序配置语言/系统(例如 [jsonnet][24])。
|
||||
* 不提供也不配合任何完整的机器配置、维护、管理、自我修复系统。
|
||||
|
||||
另一方面,大量的 PaaS 系统运行_在_ Kubernetes 上,诸如 [Openshift][36]、[Deis][37],以及 [Eldarion][38]。你也可以开发你的自定义 PaaS,整合上你自选的 CI 系统,或者只在 Kubernetes 上部署容器镜像。
|
||||
|
||||
因为 Kubernetes 运营在应用程序层面而不是在硬件层面,它提供了一些 PaaS 所通常提供的常见的适用功能,比如部署、伸缩、负载平衡、日志和监控。然而,Kubernetes 并非铁板一块,这些默认的解决方案是可供选择,可自行增加或删除的。
|
||||
|
||||
|
||||
而且, Kubernetes 不只是一个_编排系统_ 。事实上,它满足了编排的需求。 _编排_ 的技术定义是,一个定义好的工作流程的执行:先做 A,再做 B,最后做 C。相反地, Kubernetes 囊括了一系列独立、可组合的控制流程,它们持续驱动当前状态向需求的状态发展。从 A 到 C 的具体过程并不唯一。集中化控制也并不是必须的;这种方式更像是_编舞_。这将使系统更易用、更高效、更健壮、复用性、扩展性更强。
|
||||
|
||||
#### Kubernetes 这个单词的含义?k8s?
|
||||
|
||||
**Kubernetes** 这个单词来自于希腊语,含义是 _舵手_ 或 _领航员_ 。其词根是 _governor_ 和 [cybernetic][39]。 _K8s_ 是它的缩写,用 8 字替代了“ubernete”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
|
||||
|
||||
作者:[kubernetes.io][a]
|
||||
译者:[songshuang00](https://github.com/songsuhang00)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kubernetes.io/
|
||||
[1]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-do-i-need-kubernetes-and-what-can-it-do
|
||||
[2]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#how-is-kubernetes-a-platform
|
||||
[3]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-kubernetes-is-not
|
||||
[4]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-does-kubernetes-mean-k8s
|
||||
[5]:https://martinfowler.com/articles/microservices.html
|
||||
[6]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#kubernetes-is
|
||||
[7]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-containers
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#whats-next
|
||||
[9]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[10]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[11]:https://kubernetes.io/docs/concepts/configuration/secret/
|
||||
[12]:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
|
||||
[13]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[14]:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
||||
[15]:https://kubernetes.io/docs/concepts/services-networking/connect-applications-service/
|
||||
[16]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[17]:https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller/
|
||||
[18]:https://kubernetes.io/docs/tasks/debug-application-cluster/resource-usage-monitoring/
|
||||
[19]:https://kubernetes.io/docs/concepts/cluster-administration/logging/
|
||||
[20]:https://kubernetes.io/docs/tasks/debug-application-cluster/debug-application-introspection/
|
||||
[21]:https://kubernetes.io/docs/admin/authorization/
|
||||
[22]:http://wildfly.org/
|
||||
[23]:https://12factor.net/
|
||||
[24]:https://github.com/google/jsonnet
|
||||
[25]:http://www.slideshare.net/BrianGrant11/wso2con-us-2015-kubernetes-a-platform-for-automating-deployment-scaling-and-operations
|
||||
[26]:https://research.google.com/pubs/pub43438.html
|
||||
[27]:https://aucouranton.com/2014/06/13/linux-containers-parallels-lxc-openvz-docker-and-more/
|
||||
[28]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[29]:https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/
|
||||
[30]:https://kubernetes.io/docs/concepts/overview/components/
|
||||
[31]:https://kubernetes.io/docs/reference/api-overview/
|
||||
[32]:https://git.k8s.io/community/contributors/devel/scheduler.md
|
||||
[33]:https://git.k8s.io/community/contributors/design-proposals/extending-api.md
|
||||
[34]:https://kubernetes.io/docs/user-guide/kubectl-overview/
|
||||
[35]:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/principles.md
|
||||
[36]:https://www.openshift.org/
|
||||
[37]:http://deis.io/
|
||||
[38]:http://eldarion.cloud/
|
||||
[39]:http://www.etymonline.com/index.php?term=cybernetics
|
||||
@ -0,0 +1,234 @@
|
||||
一个时代的结束:Solaris 系统的那些年,那些事
|
||||
=================================
|
||||
|
||||

|
||||
|
||||
现在看来,Oracle 公司正在通过取消 Solaris 12 而[终止 Solaris 的功能开发][42],这里我们要回顾下多年来在 Phoronix 上最受欢迎的 Solaris 重大事件和新闻。
|
||||
|
||||
这里有许多关于 Solaris 的有趣/重要的回忆。
|
||||
|
||||
[
|
||||
|
||||
][1]
|
||||
|
||||
在 Sun Microsystems 时期,我真的对 Solaris 很感兴趣。在 Phoronix 上我们一直重点关注 Linux 的同时,经常也有 Solaris 的文章出现。 Solaris 玩起来很有趣,OpenSolaris/SXCE 是伟大的产物,我将 Phoronix 测试套件移植到 Solaris 上,我们与 Sun Microsystems 人员有密切的联系,也出现在 Sun 的许多活动中。
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
_在那些日子里 Sun 有一些相当独特的活动..._
|
||||
|
||||
不幸的是,自从 Oracle 公司收购了 Sun 公司, Solaris 就如坠入深渊一样。最大的打击大概是 Oracle 结束了 OpenSolaris ,并将所有 Solaris 的工作转移到专有模式...
|
||||
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
在 Sun 时代的 Solaris 有很多美好的回忆,所以 Oracle 在其计划中抹去了 Solaris 12 之后,我经常在 Phoronix 上翻回去看一些之前 Solaris 的经典文章,期待着能从 Oracle 听到 “Solaris 11” 下一代的消息,重启 Solaris 项目的开发。
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
虽然在后 Solaris 的世界中,看到 Oracle 对 ZFS 所做的事情以及他们在基于 RHEL 的 Oracle Enterprise Linux 上下的重注将会很有趣,但时间将会告诉我们一切。
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
无论如何,这是回顾自 2004 年以来我们最受欢迎的 Solaris 文章:
|
||||
|
||||
### 2016/12/1 [Oracle 或许会罐藏 Solaris][20]
|
||||
|
||||
Oracle 可能正在拔掉 Solaris 的电源插头,据一些新的传闻说。
|
||||
|
||||
### 2013/6/9 [OpenSXCE 2013.05 拯救 Solaris 社区][17]
|
||||
|
||||
作为 Solaris 社区版的社区复兴,OpenSXCE 2013.05 出现在网上。
|
||||
|
||||
### 2013/2/2 [Solaris 12 可能最终带来 Radeon KMS 驱动程序][16]
|
||||
|
||||
看起来,Oracle 可能正在准备发布自己的 AMD Radeon 内核模式设置(KMS)驱动程序,并引入到 Oracle Solaris 12 中。
|
||||
|
||||
### 2012/10/4 [Oracle Solaris 11.1 提供 300 个以上增强功能][25]
|
||||
|
||||
Oracle昨天在旧金山的 Oracle OpenWorld 会议上发布了 Solaris 11.1 。
|
||||
|
||||
[
|
||||
|
||||
][26]
|
||||
|
||||
### 2012/1/9 [Oracle 尚未澄清 Solaris 11 内核来源][19]
|
||||
|
||||
一个月前,Phoronix 是第一个注意到 Solaris 11 内核源代码通过 Torrent 站点泄漏到网上的信息。一个月后,甲骨文还没有正式评论这个情况。
|
||||
|
||||
### 2011/12/19 [Oracle Solaris 11 内核源代码泄漏][15]
|
||||
|
||||
似乎 Solaris 11的内核源代码在过去的一个周末被泄露到了网上。
|
||||
|
||||
### 2011/8/25 [对于 BSD,Solaris 的 GPU 驱动程序的悲惨状态][24]
|
||||
|
||||
昨天在邮件列表上出现了关于干掉所有旧式 Mesa 驱动程序的讨论。这些旧驱动程序没有被积极维护,支持复古的图形处理器,并且没有更新支持新的 Mesa 功能。英特尔和其他开发人员正在努力清理 Mesa 核心,以将来增强这一开源图形库。这种清理 Mesa,对 BSD 和 Solaris 用户也有一些影响。
|
||||
|
||||
### 2010/8/13 [告别 OpenSolaris,Oracle 刚刚把它干掉][8]
|
||||
|
||||
Oracle 终于宣布了他们对 Solaris 操作系统和 OpenSolaris 平台的计划,而且不是好消息。OpenSolaris 将实际死亡,未来将不会有更多的 Solaris 版本出现 - 包括长期延期的 2010 年版本。Solaris 仍然会继续存在,现在 Oracle 正在忙于明年发布的 Solaris 11,但仅在 Oracle 的企业版之后才会发布 “Solaris 11 Express” 作为 OpenSolaris 的类似产品。
|
||||
|
||||
### 2010/2/22 [Oracle 仍然要对 OpenSolaris 进行更改][12]
|
||||
|
||||
自从 Oracle 完成对 Sun Microsystems 的收购以来,已经有了许多变化,这个 Sun 最初支持的开源项目现在已经不再被 Oracle 支持,并且对其余的开源产品进行了重大改变。 Oracle 表现出并不太开放的意图的开源项目之一是 OpenSolaris 。 Solaris Express 社区版(SXCE)上个月已经关闭,并且也没有预计 3 月份发布的下一个 OpenSolaris 版本(OpenSolaris 2010.03)的信息流出。
|
||||
|
||||
### 2007/9/10 [Solaris Express 社区版 Build 72][9]
|
||||
|
||||
对于那些想要在 “印第安纳项目” 发布之前尝试 OpenSolaris 软件中最新最好的软件的人来说,现在可以使用 Solaris Express 社区版 Build 72。Solaris Express 社区版(SXCE)Build 72 可以从 OpenSolaris.org 下载。同时,预计将在下个月推出 Sun 的 “印第安纳项目” 项目的预览版。
|
||||
|
||||
### 2007/9/6 [ATI R500/600 驱动要支持 Solaris 了?][6]
|
||||
|
||||
虽然没有可用于 Solaris/OpenSolaris 或 * BSD 的 ATI fglrx 驱动程序,现在 AMD 将向 X.Org 开发人员和开源驱动程序交付规范,但对于任何使用 ATI 的 Radeon X1000 “R500” 或者 HD 2000“R600” 系列的 Solaris 用户来说,这肯定是有希望的。将于下周发布的开源 X.Org 驱动程序距离成熟尚远,但应该能够相对容易地移植到使用 X.Org 的 Solaris 和其他操作系统上。 AMD 今天宣布的针对的是 Linux 社区,但它也可以帮助使用 ATI 硬件的 Solaris/OpenSolaris 用户。特别是随着印第安纳项目的即将推出,开源 R500/600 驱动程序移植就只是时间问题了。
|
||||
|
||||
### 2007/9/5 [Solaris Express 社区版 Build 71][7]
|
||||
|
||||
Solaris Express 社区版(SXCE)现已推出 Build 71。您可以在 OpenSolaris.org 中找到有关 Solaris Express 社区版 Build 71 的更多信息。另外,在 Linux 内核峰会上,AMD 将提供 GPU 规格的消息,由此产生的 X.Org 驱动程序将来可能会导致 ATI 硬件上 Solaris/OpenSolaris 有所改善。
|
||||
|
||||
### 2007/8/27 [Linux 的 Solaris 容器][11]
|
||||
|
||||
Sun Microsystems 已经宣布,他们将很快支持适用于 Linux 应用程序的 Solaris 容器。这样可以在 Solaris 下运行 Linux 应用程序,而无需对二进制包进行任何修改。适用于 Linux 的 Solaris 容器将允许从 Linux 到 Solaris 的平滑迁移,协助跨平台开发以及其他优势。当该支持到来时,这个时代就“快到了”。
|
||||
|
||||
### 2007/8/23 [OpenSolaris 开发者峰会][10]
|
||||
|
||||
今天早些时候在 OpenSolaris 论坛上发布了第一次 OpenSolaris 开发人员峰会的消息。这次峰会将在十月份在加州大学圣克鲁斯分校举行。 Sara Dornsife 将这次峰会描述为“不是与演示文稿或参展商举行会议,而是一个亲自参与的协作工作会议,以计划下一期的印第安纳项目。” 伊恩·默多克(Ian Murdock) 将在这个“印第安纳项目”中进行主题演讲,但除此之外,该计划仍在计划之中。 Phoronix 可能会继续跟踪此事件,您可以在 Solaris 论坛上讨论此次峰会。
|
||||
|
||||
### 2007/8/18 [Solaris Express 社区版 Build 70][21]
|
||||
|
||||
名叫 "Nevada" 的 Solaris Express 社区版 Build 70 (SXCE snv_70) 现在已经发布。有关下载链接的通知可以在 OpenSolaris 论坛中找到。还有公布了其网络存储的 Build 71 版本,包括来自 Qlogic 的光纤通道 HBA 驱动程序的源代码。
|
||||
|
||||
### 2007/8/16 [IBM 使用 Sun Solaris 的系统][14]
|
||||
|
||||
Sun Microsystems 和 IBM正在举行电话会议,他们刚刚宣布,IBM 将开始在服务器上使用 Sun 的 Solaris 操作系统。这些 IBM 服务器包括基于 x86 的服务器系统以及 Blade Center 服务器。官方新闻稿刚刚发布,可以在 sun 新闻室阅读。
|
||||
|
||||
### 2007/8/9 [OpenSolaris 不会与 Linux 合并][18]
|
||||
|
||||
在旧金山的 LinuxWorld 2007 上,Andrew Morton 在主题演讲中表示, OpenSolaris 的关键组件不会出现在 Linux 内核中。事实上,莫顿甚至表示 “非常遗憾 OpenSolaris 活着”。OpenSolaris 的一些关键组件包括 Zones、ZFS 和 DTrace 。虽然印第安纳州项目有可能将这些项目转变为 GPLv3 项目... 更多信息参见 ZDNET。
|
||||
|
||||
### 2007/7/27 [Solaris Xen 已经更新][13]
|
||||
|
||||
已经有一段时间了,Solaris Xen 终于更新了。约翰·莱文(John Levon)表示,这一最新版本基于 Xen 3.0.4 和 Solaris “Nevada” Build 66。这一最新版本的改进包括 PAE 支持、HVM 支持、新的 virt-manager 工具、改进的调试支持以及管理域支持。可以在 Sun 的网站上找到 2007 年 7 月 Solaris Xen 更新的下载。
|
||||
|
||||
### 2007/7/25 [Solaris 10 7/07 HW 版本][22]
|
||||
|
||||
Solaris 10 7/07 HW 版本的文档已经上线。如 Solaris 发行注记中所述,Solaris 10 7/07 仅适用于 SPARC Enterprise M4000-M9000 服务器,并且没有 x86/x64 版本可用。所有平台的最新 Solaris 更新是 Solaris 10 11/06 。您可以在 Phoronix 论坛中讨论 Solaris 7/07。
|
||||
|
||||
### 2007/7/16 [来自英特尔的 Solaris 电信服务器][23]
|
||||
|
||||
今天宣布推出符合 NEBS、ETSI 和 ATCA 合规性的英特尔体系的 Sun Solaris 电信机架服务器和刀片服务器。在这些新的运营商级平台中,英特尔运营商级机架式服务器 TIGW1U 支持 Linux 和 Solaris 10,而 Intel NetStructure MPCBL0050 SBC 也将支持这两种操作系统。今天的新闻稿可以在这里阅读。
|
||||
|
||||
然后是 Solaris 分类中最受欢迎的特色文章:
|
||||
|
||||
### [Ubuntu vs. OpenSolaris vs. FreeBSD 基准测试][27]
|
||||
|
||||
在过去的几个星期里,我们提供了几篇关于 Ubuntu Linux 性能的深入文章。我们已经开始提供 Ubuntu 7.04 到 8.10 的基准测试,并且发现这款受欢迎的 Linux 发行版的性能随着时间的推移而变慢,随之而来的是 Mac OS X 10.5 对比 Ubuntu 8.10 的基准测试和其他文章。在本文中,我们正在比较 Ubuntu 8.10 的 64 位性能与 OpenSolaris 2008.11 和 FreeBSD 7.1 的最新测试版本。
|
||||
|
||||
### [NVIDIA 的性能:Windows vs. Linux vs. Solaris][28]
|
||||
|
||||
本周早些时候,我们预览了 Quadro FX1700,它是 NVIDIA 的中端工作站显卡之一,基于 G84GL 内核,而 G84GL 内核又源于消费级 GeForce 8600 系列。该 PCI Express 显卡提供 512MB 的视频内存,具有两个双链路 DVI 连接,并支持 OpenGL 2.1 ,同时保持最大功耗仅为 42 瓦。正如我们在预览文章中提到的,我们将不仅在 Linux 下查看此显卡的性能,还要在 Microsoft Windows 和 Sun 的 Solaris 中测试此工作站解决方案。在今天的这篇文章中,我们正在这样做,因为我们测试了 NVIDIA Quadro FX1700 512MB 与这些操作系统及其各自的二进制显示驱动程序。
|
||||
|
||||
### [FreeBSD 8.0 对比 Linux、OpenSolaris][29]
|
||||
|
||||
在 FreeBSD 8.0 的稳定版本发布的上周,我们终于可以把它放在测试台上,并用 Phoronix 测试套件进行了全面的了解。我们将 FreeBSD 8.0 的性能与早期的 FreeBSD 7.2 版本以及 Fedora 12 和 Ubuntu 9.10 还有 Sun OS 端的 OpenSolaris 2010.02 b127 快照进行了比较。
|
||||
|
||||
### [Fedora、Debian、FreeBSD、OpenBSD、OpenSolaris 基准测试][30]
|
||||
|
||||
上周我们发布了第一个 Debian GNU/kFreeBSD 基准测试,将 FreeBSD 内核捆绑在 Debian GNU 用户的 Debian GNU/Linux 上,比较了这款 Debian 系统的 32 位和 64 位性能。 我们现在扩展了这个比较,使许多其他操作系统与 Debian GNU/Linux 和 Debian GNU/kFreeBSD 的 6.0 Squeeze 快照直接进行比较,如 Fedora 12,FreeBSD 7.2,FreeBSD 8.0,OpenBSD 4.6 和 OpenSolaris 2009.06 。
|
||||
|
||||
### [AMD 上海皓龙:Linux vs. OpenSolaris 基准测试][31]
|
||||
|
||||
1月份,当我们研究了四款皓龙 2384 型号时,我们在 Linux 上发布了关于 AMD 上海皓龙 CPU 的综述。与早期的 AMD 巴塞罗那处理器 Ubuntu Linux 相比,这些 45nm 四核工作站服务器处理器的性能非常好,但是在运行 Sun OpenSolaris 操作系统时,性能如何?今天浏览的是 AMD 双核的基准测试,运行 OpenSolaris 2008.11、Ubuntu 8.10 和即将推出的 Ubuntu 9.04 版本。
|
||||
|
||||
### [OpenSolaris vs. Linux 内核基准][32]
|
||||
|
||||
本周早些时候,我们提供了 Ubuntu 9.04 与 Mac OS X 10.5.6 的基准测试,发现 Leopard 操作系统(Mac)在大多数测试中的表现要优于 Jaunty Jackalope (Ubuntu),至少在 Ubuntu 32 位是这样的。我们今天又回过来进行更多的操作系统基准测试,但这次我们正在比较 Linux 和 Sun OpenSolaris 内核的性能。我们使用的 Nexenta Core 2 操作系统将 OpenSolaris 内核与 GNU/Ubuntu 用户界面组合在同一个 Ubuntu 软件包中,但使用了 Linux 内核的 32 位和 64 位 Ubuntu 服务器安装进行测试。
|
||||
|
||||
### [Netbook 性能:Ubuntu vs. OpenSolaris][33]
|
||||
|
||||
过去,我们已经发布了 OpenSolaris vs. Linux Kernel 基准测试以及类似的文章,关注 Sun 的 OpenSolaris 与流行的 Linux 发行版的性能。我们已经看过高端 AMD 工作站的性能,但是我们从来没有比较上网本上的 OpenSolaris 和 Linux 性能。直到今天,在本文中,我们将比较戴尔 Inspiron Mini 9 上网本上的 OpenSolaris 2009.06 和 Ubuntu 9.04 的结果。
|
||||
|
||||
### [NVIDIA 图形:Linux vs. Solaris][34]
|
||||
|
||||
在 Phoronix,我们不断探索 Linux 下的不同显示驱动程序,在我们评估了 Sun 的检查工具并测试了 Solaris 主板以及覆盖其他几个领域之后,我们还没有执行图形驱动程序 Linux 和 Solaris 之间的比较。直到今天。由于印第安纳州项目,我们对 Solaris 更感兴趣,我们决定终于通过 NVIDIA 专有驱动程序提供我们在 Linux 和 Solaris 之间的第一次定量图形比较。
|
||||
|
||||
### [OpenSolaris 2008.05 向 Solaris 提供了一个新面孔][35]
|
||||
|
||||
2月初,Sun Microsystems 发布了印第安纳项目的第二个预览版本。对于那些人来说,印第安纳州项目是 Sun 的 Ian Murdock 领导的项目的代号,旨在通过解决 Solaris 的长期可用性问题,将 OpenSolaris 推向更多的台式机和笔记本电脑。我们没有对预览 2 留下什么深刻印象,因为它没有比普通用户感兴趣的 GNU/Linux 桌面更有优势。然而,随着 5 月份推出的 OpenSolaris 2008.05 印第安纳项目发布,Sun Microsystems 今天发布了该操作系统的最终测试副本。当最后看到项目印第安纳时, 我们对这个新的 OpenSolaris 版本的最初体验是远远优于我们不到三月前的体验的。
|
||||
|
||||
### [快速概览 Oracle Solaris 11][36]
|
||||
|
||||
Solaris 11 在周三发布,是七年来这个前 Sun 操作系统的第一个主要更新。在过去七年中,Solaris 家族发生了很大变化,OpenSolaris 在那个时候已经到来,但在本文中,简要介绍了全新的 Oracle Solaris 11 版本。
|
||||
|
||||
### [OpenSolaris、BSD & Linux 的新基准测试][37]
|
||||
|
||||
今天早些时候,我们对以原生的内核模块支持的 Linux 上的 ZFS 进行了基准测试,该原生模块将被公开提供,以将这个 Sun/Oracle 文件系统覆盖到更多的 Linux 用户。现在,尽管作为一个附加奖励,我们碰巧有了基于 OpenSolaris 的最新发行版的新基准,包括 OpenSolaris、OpenIndiana 和 Augustiner-Schweinshaxe,与 PC-BSD、Fedora 和 Ubuntu相比。
|
||||
|
||||
### [FreeBSD/PC-BSD 9.1 针对 Linux、Solaris、BSD 的基准][38]
|
||||
|
||||
虽然 FreeBSD 9.1 尚未正式发布,但是基于 FreeBSD 的 PC-BSD 9.1 “Isotope”版本本月已经可用。本文中的性能指标是 64 位版本的 PC-BSD 9.1 与 DragonFlyBSD 3.0.3、Oracle Solaris Express 11.1、CentOS 6.3、Ubuntu 12.10 以及 Ubuntu 13.04 开发快照的比较。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Michael Larabel 是 Phoronix.com 的作者,并于 2004 年创立了该网站,该网站重点是丰富多样的 Linux 硬件体验。 Michael 撰写了超过10,000 篇文章,涵盖了 Linux 硬件支持,Linux 性能,图形驱动程序等主题。 Michael 也是 Phoronix 测试套件、 Phoromatic 和 OpenBenchmarking.org 自动化基准测试软件的主要开发人员。可以通过 Twitter 关注他或通过 MichaelLarabel.com 联系他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.phoronix.com/scan.php?page=news_item&px=Solaris-2017-Look-Back
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/image-viewer.php?id=982&image=sun_sxce81_03_lrg
|
||||
[2]:http://www.phoronix.com/image-viewer.php?id=711&image=java7_bash_13_lrg
|
||||
[3]:http://www.phoronix.com/image-viewer.php?id=sun_sxce_farewell&image=sun_sxce_07_lrg
|
||||
[4]:http://www.phoronix.com/image-viewer.php?id=solaris_200805&image=opensolaris_indiana_03b_lrg
|
||||
[5]:http://www.phoronix.com/image-viewer.php?id=oracle_solaris_11&image=oracle_solaris11_02_lrg
|
||||
[6]:http://www.phoronix.com/scan.php?page=news_item&px=NjA0Mg
|
||||
[7]:http://www.phoronix.com/scan.php?page=news_item&px=NjAzNQ
|
||||
[8]:http://www.phoronix.com/scan.php?page=news_item&px=ODUwNQ
|
||||
[9]:http://www.phoronix.com/scan.php?page=news_item&px=NjA0Nw
|
||||
[10]:http://www.phoronix.com/scan.php?page=news_item&px=NjAwNA
|
||||
[11]:http://www.phoronix.com/scan.php?page=news_item&px=NjAxMQ
|
||||
[12]:http://www.phoronix.com/scan.php?page=news_item&px=ODAwNg
|
||||
[13]:http://www.phoronix.com/scan.php?page=news_item&px=NTkzMQ
|
||||
[14]:http://www.phoronix.com/scan.php?page=news_item&px=NTk4NA
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=MTAzMDE
|
||||
[16]:http://www.phoronix.com/scan.php?page=news_item&px=MTI5MTU
|
||||
[17]:http://www.phoronix.com/scan.php?page=news_item&px=MTM4Njc
|
||||
[18]:http://www.phoronix.com/scan.php?page=news_item&px=NTk2Ng
|
||||
[19]:http://www.phoronix.com/scan.php?page=news_item&px=MTAzOTc
|
||||
[20]:http://www.phoronix.com/scan.php?page=news_item&px=Oracle-Solaris-Demise-Rumors
|
||||
[21]:http://www.phoronix.com/scan.php?page=news_item&px=NTk4Nw
|
||||
[22]:http://www.phoronix.com/scan.php?page=news_item&px=NTkyMA
|
||||
[23]:http://www.phoronix.com/scan.php?page=news_item&px=NTg5Nw
|
||||
[24]:http://www.phoronix.com/scan.php?page=news_item&px=OTgzNA
|
||||
[25]:http://www.phoronix.com/scan.php?page=news_item&px=MTE5OTQ
|
||||
[26]:http://www.phoronix.com/image-viewer.php?id=opensolaris_200906&image=opensolaris_200906_06_lrg
|
||||
[27]:http://www.phoronix.com/vr.php?view=13149
|
||||
[28]:http://www.phoronix.com/vr.php?view=11968
|
||||
[29]:http://www.phoronix.com/vr.php?view=14407
|
||||
[30]:http://www.phoronix.com/vr.php?view=14533
|
||||
[31]:http://www.phoronix.com/vr.php?view=13475
|
||||
[32]:http://www.phoronix.com/vr.php?view=13826
|
||||
[33]:http://www.phoronix.com/vr.php?view=14039
|
||||
[34]:http://www.phoronix.com/vr.php?view=10301
|
||||
[35]:http://www.phoronix.com/vr.php?view=12269
|
||||
[36]:http://www.phoronix.com/vr.php?view=16681
|
||||
[37]:http://www.phoronix.com/vr.php?view=15476
|
||||
[38]:http://www.phoronix.com/vr.php?view=18291
|
||||
[39]:http://www.michaellarabel.com/
|
||||
[40]:https://www.phoronix.com/scan.php?page=news_topic&q=Oracle
|
||||
[41]:https://www.phoronix.com/forums/node/925794
|
||||
[42]:http://www.phoronix.com/scan.php?page=news_item&px=No-Solaris-12
|
||||
@ -0,0 +1,124 @@
|
||||
给中级 Meld 用户的有用技巧
|
||||
============================================================
|
||||
|
||||
Meld 是 Linux 上功能丰富的可视化比较和合并工具。如果你是第一次接触,你可以进入我们的[初学者指南][5],了解该程序的工作原理,如果你已经阅读过或正在使用 Meld 进行基本的比较/合并任务,你将很高兴了解本教程的东西,在本教程中,我们将讨论一些非常有用的技巧,这将让你使用工具的体验更好。
|
||||
|
||||
_但在我们跳到安装和解释部分之前,值得一提的是,本教程中介绍的所有说明和示例已在 Ubuntu 14.04 上进行了测试,而我们使用的 Meld 版本为 3.14.2_。
|
||||
|
||||
### 1、 跳转
|
||||
|
||||
你可能已经知道(我们也在初学者指南中也提到过这一点),标准滚动不是在使用 Meld 时在更改之间跳转的唯一方法 - 你可以使用向上和向下箭头键轻松地从一个更改跳转到另一个更改位于编辑区域上方的窗格中:
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
但是,这需要你将鼠标指针移动到这些箭头,然后再次单击其中一个(取决于你要去哪里 - 向上或向下)。你会很高兴知道,存在另一种更简单的方式来跳转:只需使用鼠标的滚轮即可在鼠标指针位于中央更改栏上时进行滚动。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
这样,你就可以在视线不离开或者分心的情况下进行跳转,
|
||||
|
||||
### 2、 可以对更改进行的操作
|
||||
|
||||
看下上一节的最后一个屏幕截图。你知道那些黑箭头做什么吧?默认情况下,它们允许你执行合并/更改操作 - 当没有冲突时进行合并,并在同一行发生冲突时进行更改。
|
||||
|
||||
但是你知道你可以根据需要删除个别的更改么?是的,这是可能的。为此,你需要做的是在处理更改时按下 Shift 键。你会观察到箭头被变成了十字架。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
只需点击其中任何一个,相应的更改将被删除。
|
||||
|
||||
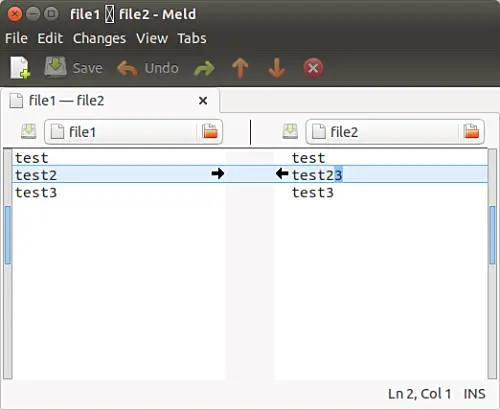
不仅是删除,你还可以确保冲突的更改不会在合并时更改行。例如,以下是一个冲突变化的例子:
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
现在,如果你点击任意两个黑色箭头,箭头指向的行将被改变,并且将变得与其他文件的相应行相似。只要你想这样做,这是没问题的。但是,如果你不想要更改任何行呢?相反,目的是将更改的行在相应行的上方或下方插入到其他文件中。
|
||||
|
||||
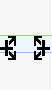
我想说的是,例如,在上面的截图中,需要在 “test23” 之上或之下添加 “test 2”,而不是将 “test23” 更改为 “test2”。你会很高兴知道在 Meld 中这是可能的。就像你按下 Shift 键删除注释一样,在这种情况下,你必须按下 Ctrl 键。
|
||||
|
||||
你会观察到当前操作将被更改为插入 - 双箭头图标将确认这一点 。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
从箭头的方向看,此操作可帮助用户将当前更改插入到其他文件中的相应更改 (如所选择的)。
|
||||
|
||||
### 3、 自定义文件在 Meld 的编辑器区域中显示的方式
|
||||
|
||||
有时候,你希望 Meld 的编辑区域中的文字大小变大(为了更好或更舒适的浏览),或者你希望文本行被包含而不是脱离视觉区域(意味着你不要想使用底部的水平滚动条)。
|
||||
|
||||
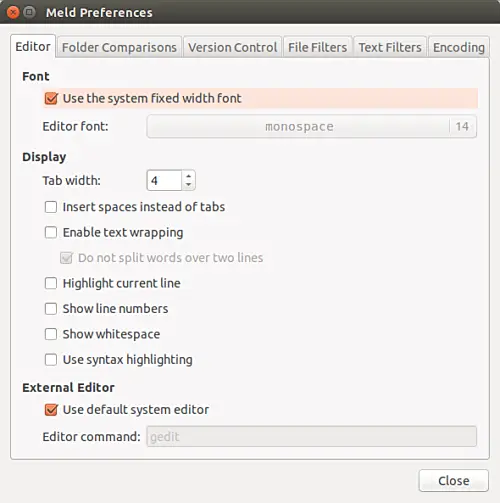
Meld 在 _Editor_ 选项卡(_Edit->Preferences->Editor_)的 _Preferences_ 菜单中提供了一些显示和字体相关的自定义选项,你可以进行这些调整:
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
在这里你可以看到,默认情况下,Meld 使用系统定义的字体宽度。只需取消选中 _Font_ 类别下的框,你将有大量的字体类型和大小选项可供选择。
|
||||
|
||||
然后在 _Display_ 部分,你将看到我们正在讨论的所有自定义选项:你可以设置 Tab 宽度、告诉工具是否插入空格而不是 tab、启用/禁用文本换行、使Meld显示行号和空白(在某些情况下非常有用)以及使用语法突出显示。
|
||||
|
||||
### 4、 过滤文本
|
||||
|
||||
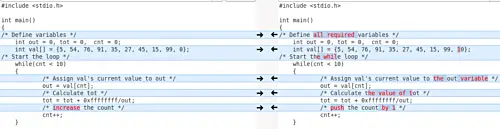
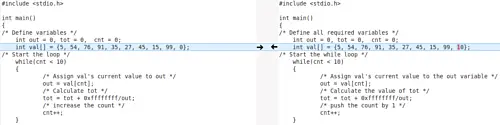
有时候,并不是所有的修改都是对你很重要的。例如,在比较两个 C 编程文件时,你可能不希望 Meld 显示注释中的更改,因为你只想专注于与代码相关的更改。因此,在这种情况下,你可以告诉 Meld 过滤(或忽略)与注释相关的更改。
|
||||
|
||||
例如,这里是 Meld 中的一个比较,其中由工具高亮了注释相关更改:
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
而在这种情况下,Meld 忽略了相同的变化,仅关注与代码相关的变更:
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
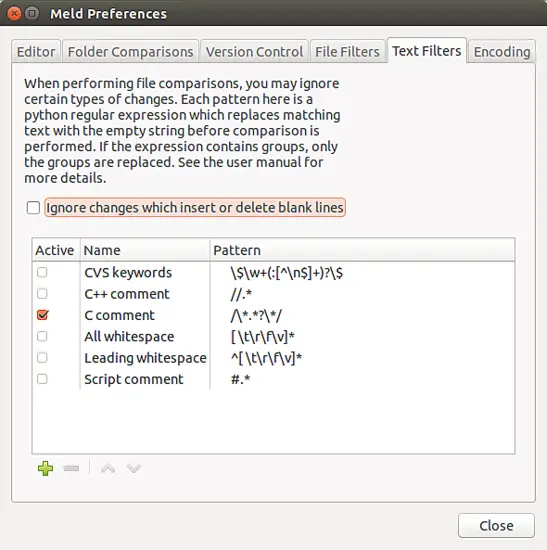
很酷,不是吗?那么这是怎么回事?为此,我是在 “_Edit->Preferences->Text Filters_” 标签中启用了 “C comments” 文本过滤器:
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
如你所见,除了 “C comments” 之外,你还可以过滤掉 C++ 注释、脚本注释、引导或所有的空格等。此外,你还可以为你处理的任何特定情况定义自定义文本过滤器。例如,如果你正在处理日志文件,并且不希望 Meld 高亮显示特定模式开头的行中的更改,则可以为该情况定义自定义文本过滤器。
|
||||
|
||||
但是,请记住,要定义一个新的文本过滤器,你需要了解 Python 语言以及如何使用该语言创建正则表达式。
|
||||
|
||||
### 总结
|
||||
|
||||
这里讨论的所有四个技巧都不是很难理解和使用(当然,除了你想立即创建自定义文本过滤器),一旦你开始使用它们,你会认为他们是真的有好处。这里的关键是要继续练习,否则你学到的任何技巧不久后都会忘记。
|
||||
|
||||
你还知道或者使用其他任何中级 Meld 的贴士和技巧么?如果有的话,欢迎你在下面的评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/
|
||||
[1]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-navigation
|
||||
[2]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-things-you-can-do-with-changes
|
||||
[3]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-filtering-text
|
||||
[4]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#conclusion
|
||||
[5]:https://linux.cn/article-8402-1.html
|
||||
[6]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-go-next-prev-9.png
|
||||
[7]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-center-area-scrolling.png
|
||||
[8]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-delete-changes.png
|
||||
[9]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-conflicting-change.png
|
||||
[10]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-ctrl-insert.png
|
||||
[11]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-editor-tab.png
|
||||
[12]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-changes-with-comments.png
|
||||
[13]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-changes-without-comments.png
|
||||
[14]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-text-filters.png
|
||||
@ -0,0 +1,68 @@
|
||||
Linux 容器轻松应对性能工程
|
||||
============================================================
|
||||
|
||||

|
||||
图片来源: CC0 Public Domain
|
||||
|
||||
应用程序的性能决定了软件能多快完成预期任务。这回答有关应用程序的几个问题,例如:
|
||||
|
||||
* 峰值负载下的响应时间
|
||||
* 与替代方案相比,它易于使用,受支持的功能和用例
|
||||
* 运营成本(CPU 使用率、内存需求、数据吞吐量、带宽等)
|
||||
|
||||
该性能分析的价值超出了服务负载所需的计算资源或满足峰值需求所需的应用实例数量的估计。性能显然与成功企业的基本要素挂钩。它揭示了用户的总体体验,包括确定什么会拖慢客户预期的响应时间,通过设计满足带宽要求的内容交付来提高客户粘性,选择最佳设备,最终帮助企业发展业务。
|
||||
|
||||
### 问题
|
||||
|
||||
当然,这是对业务服务的性能工程价值的过度简化。为了理解在完成我刚刚所描述事情背后的挑战,让我们把它放到一个真实的稍微有点复杂的场景中。
|
||||
|
||||

|
||||
|
||||
现实世界的应用程序可能托管在云端。应用程序可以利用非常大(或概念上是无穷大)的计算资源。在硬件和软件方面的需求将通过云来满足。从事开发工作的开发人员将使用云交付功能来实现更快的编码和部署。云托管不是免费的,但成本开销与应用程序的资源需求成正比。
|
||||
|
||||
除了<ruby>搜索即服务<rt>Search as a Service</rt></ruby>(SaaS)、<ruby>平台即服务<rt>Platform as a Service</rt></ruby>(PaaS)、<ruby>基础设施即服务<rt>Infrastructure as a Service</rt></ruby>(IaaS)以及<ruby>负载平衡即服务<rt>Load Balancing as a Service</rt></ruby>(LBaaS)之外,当云端管理托管程序的流量时,开发人员可能还会使用这些快速增长的云服务中的一个或多个:
|
||||
|
||||
* <ruby>安全即服务<rt>Security as a Service</rt></ruby> (SECaaS),可满足软件和用户的安全需求
|
||||
* <ruby>数据即服务<rt>Data as a Service</rt></ruby> (DaaS),为应用提供了用户需求的数据
|
||||
* <ruby>登录即服务<rt>Logging as a Service</rt></ruby> (LaaS),DaaS 的近亲,提供了日志传递和使用的分析指标
|
||||
* <ruby>搜索即服务<rt>Search as a Service</rt></ruby> (SaaS),用于应用程序的分析和大数据需求
|
||||
* <ruby>网络即服务<rt>Network as a Service</rt></ruby> (NaaS),用于通过公共网络发送和接收数据
|
||||
|
||||
云服务也呈指数级增长,因为它们使得开发人员更容易编写复杂的应用程序。除了软件复杂性之外,所有这些分布式组件的相互作用变得越来越多。用户群变得更加多元化。该软件的需求列表变得更长。对其他服务的依赖性变大。由于这些因素,这个生态系统的缺陷会引发性能问题的多米诺效应。
|
||||
|
||||
例如,假设你有一个精心编写的应用程序,它遵循安全编码实践,旨在满足不同的负载要求,并经过彻底测试。另外假设你已经将基础架构和分析工作结合起来,以支持基本的性能要求。在系统的实现、设计和架构中建立性能标准需要做些什么?软件如何跟上不断变化的市场需求和新兴技术?如何测量关键参数以调整系统以获得最佳性能?如何使系统具有弹性和自我恢复能力?你如何更快地识别任何潜在的性能问题,并尽早解决?
|
||||
|
||||
### 进入容器
|
||||
|
||||
软件[容器][2]以[微服务][3]设计或面向服务的架构(SoA)的优点为基础,提高了性能,因为包含更小的、自足的代码块的系统更容易编码,对其它系统组件有更清晰、定义良好的依赖。测试更容易,包括围绕资源利用和内存过度消耗的问题比在宏架构中更容易确定。
|
||||
|
||||
当扩容系统以增加负载能力时,容器应用程序的复制快速而简单。安全漏洞能更好地隔离。补丁可以独立版本化并快速部署。性能监控更有针对性,测量更可靠。你还可以重写和“改版”资源密集型代码,以满足不断变化的性能要求。
|
||||
|
||||
容器启动快速,停止也快速。它比虚拟机(VM)有更高效资源利用和更好的进程隔离。容器没有空闲内存和 CPU 闲置。它们允许多个应用程序共享机器,而不会丢失数据或性能。容器使应用程序可移植,因此开发人员可以构建并将应用程序发送到任何支持容器技术的 Linux 服务器上,而不必担心性能损失。容器生存在其内,并遵守其集群管理器(如 Cloud Foundry 的 Diego、[Kubernetes][4]、Apache Mesos 和 Docker Swarm)所规定的配额(比如包括存储、计算和对象计数配额)。
|
||||
|
||||
容器在性能方面表现出色,而即将到来的 “serverless” 计算(也称为<ruby>功能即服务<rt>Function as a Service</rt></ruby>(FaaS))的浪潮将扩大容器的优势。在 FaaS 时代,这些临时性或短期的容器将带来超越应用程序性能的优势,直接转化为在云中托管的间接成本的节省。如果容器的工作更快,那么它的寿命就会更短,而且计算量负载纯粹是按需的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Garima 是 Red Hat 的工程经理,专注于 OpenShift 容器平台。在加入 Red Hat 之前,Garima 帮助 Akamai Technologies&MathWorks Inc. 开创了创新。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/performance-container-world
|
||||
|
||||
作者:[Garima][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/garimavsharma
|
||||
[1]:https://opensource.com/article/17/2/performance-container-world?rate=RozKaIY39AZNxbayqFkUmtkkhoGdctOVuGOAJqVJII8
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers
|
||||
[3]:https://opensource.com/resources/what-are-microservices
|
||||
[4]:https://opensource.com/resources/what-is-kubernetes
|
||||
[5]:https://opensource.com/user/109286/feed
|
||||
[6]:https://opensource.com/article/17/2/performance-container-world#comments
|
||||
[7]:https://opensource.com/users/garimavsharma
|
||||
@ -0,0 +1,61 @@
|
||||
在 Kali Linux 的 Wireshark 中过滤数据包
|
||||
==================
|
||||
|
||||
### 介绍
|
||||
|
||||
数据包过滤可让你专注于你感兴趣的确定数据集。如你所见,Wireshark 默认会抓取_所有_数据包。这可能会妨碍你寻找具体的数据。 Wireshark 提供了两个功能强大的过滤工具,让你简单而无痛地获得精确的数据。
|
||||
|
||||
Wireshark 可以通过两种方式过滤数据包。它可以通过只收集某些数据包来过滤,或者在抓取数据包后进行过滤。当然,这些可以彼此结合使用,并且它们各自的用处取决于收集的数据和信息的多少。
|
||||
|
||||
### 布尔表达式和比较运算符
|
||||
|
||||
Wireshark 有很多很棒的内置过滤器。当开始输入任何一个过滤器字段时,你将看到它们会自动补完。这些过滤器大多数对应于用户对数据包的常见分组方式,比如仅过滤 HTTP 请求就是一个很好的例子。
|
||||
|
||||
对于其他的,Wireshark 使用布尔表达式和/或比较运算符。如果你曾经做过任何编程,你应该熟悉布尔表达式。他们是使用 `and`、`or`、`not` 来验证声明或表达式的真假。比较运算符要简单得多,它们只是确定两件或更多件事情是否彼此相等、大于或小于。
|
||||
|
||||
### 过滤抓包
|
||||
|
||||
在深入自定义抓包过滤器之前,请先查看 Wireshark 已经内置的内容。单击顶部菜单上的 “Capture” 选项卡,然后点击 “Options”。可用接口下面是可以编写抓包过滤器的行。直接移到左边一个标有 “Capture Filter” 的按钮上。点击它,你将看到一个新的对话框,其中包含内置的抓包过滤器列表。看看里面有些什么。
|
||||
|
||||

|
||||
|
||||
在对话框的底部,有一个用于创建并保存抓包过滤器的表单。按左边的 “New” 按钮。它将创建一个填充有默认数据的新的抓包过滤器。要保存新的过滤器,只需将实际需要的名称和表达式替换原来的默认值,然后单击“Ok”。过滤器将被保存并应用。使用此工具,你可以编写并保存多个不同的过滤器,以便它们将来可以再次使用。
|
||||
|
||||
抓包有自己的过滤语法。对于比较,它不使用等于号,并使用 `>` 和 `<` 来用于大于或小于。对于布尔值来说,它使用 `and`、`or` 和 `not`。
|
||||
|
||||
例如,如果你只想监听 80 端口的流量,你可以使用这样的表达式:`port 80`。如果你只想从特定的 IP 监听端口 80,你可以使用 `port 80 and host 192.168.1.20`。如你所见,抓包过滤器有特定的关键字。这些关键字用于告诉 Wireshark 如何监控数据包以及哪一个数据是要找的。例如,`host` 用于查看来自 IP 的所有流量。`src` 用于查看源自该 IP 的流量。与之相反,`dst` 只监听目标到这个 IP 的流量。要查看一组 IP 或网络上的流量,请使用 `net`。
|
||||
|
||||
### 过滤结果
|
||||
|
||||
界面的底部菜单栏是专门用于过滤结果的菜单栏。此过滤器不会更改 Wireshark 收集的数据,它只允许你更轻松地对其进行排序。有一个文本字段用于输入新的过滤器表达式,并带有一个下拉箭头以查看以前输入的过滤器。旁边是一个标为 “Expression” 的按钮,另外还有一些用于清除和保存当前表达式的按钮。
|
||||
|
||||
点击 “Expression” 按钮。你将看到一个小窗口,其中包含多个选项。左边一栏有大量的条目,每个都有附加的折叠子列表。你可以用这些来过滤所有不同的协议、字段和信息。你不可能看完所有,所以最好是大概看下。你应该注意到了一些熟悉的选项,如 HTTP、SSL 和 TCP。
|
||||
|
||||

|
||||
|
||||
子列表包含可以过滤的不同部分和请求方法。你可以看到通过 GET 和 POST 请求过滤 HTTP 请求。
|
||||
|
||||
你还可以在中间看到运算符列表。通过从每列中选择条目,你可以使用此窗口创建过滤器,而不用记住 Wireshark 可以过滤的每个条目。对于过滤结果,比较运算符使用一组特定的符号。 `==` 用于确定是否相等。`>` 用于确定一件东西是否大于另一个东西,`<` 找出是否小一些。 `>=` 和 `<=` 分别用于大于等于和小于等于。它们可用于确定数据包是否包含正确的值或按大小过滤。使用 `==` 仅过滤 HTTP GET 请求的示例如下:`http.request.method == "GET"`。
|
||||
|
||||
布尔运算符基于多个条件将小的表达式串到一起。不像是抓包所使用的单词,它使用三个基本的符号来做到这一点。`&&` 代表 “与”。当使用时,`&&` 两边的两个语句都必须为真值才行,以便 Wireshark 来过滤这些包。`||` 表示 “或”。只要两个表达式任何一个为真值,它就会被过滤。如果你正在查找所有的 GET 和 POST 请求,你可以这样使用 `||`:`(http.request.method == "GET") || (http.request.method == "POST")`。`!` 是 “非” 运算符。它会寻找除了指定的东西之外的所有东西。例如,`!http` 将展示除了 HTTP 请求之外的所有东西。
|
||||
|
||||
### 总结思考
|
||||
|
||||
过滤 Wireshark 可以让你有效监控网络流量。熟悉可以使用的选项并习惯你可以创建过滤器的强大表达式需要一些时间。然而一旦你学会了,你将能够快速收集和查找你要的网络数据,而无需梳理长长的数据包或进行大量的工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
[1]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h1-introduction
|
||||
[2]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h2-boolean-expressions-and-comparison-operators
|
||||
[3]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h3-filtering-capture
|
||||
[4]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h4-filtering-results
|
||||
[5]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h5-closing-thoughts
|
||||
@ -0,0 +1,68 @@
|
||||
开源优先:私营公司宣言
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
这是一个宣言,任何私人组织都可以用来构建其协作转型。请阅读并让我知道你的看法。
|
||||
|
||||
我[在 Linux TODO 小组中作了一个演讲][3]使用了这篇文章作为我的材料。对于那些不熟悉 TODO 小组的人,他们是在商业公司支持开源领导力的组织。相互依赖是很重要的,因为法律、安全和其他共享的知识对于开源社区向前推进是非常重要的。尤其是因为我们需要同时代表商业和公共社区的最佳利益。
|
||||
|
||||
“开源优先”意味着我们在考虑供应商出品的产品以满足我们的需求之前,首先考虑开源。要正确使用开源技术,你需要做的不仅仅是消费,还需要你的参与,以确保开源技术长期存在。要参与开源工作,你需要将工程师的工作时间分别分配给你的公司和开源项目。我们期望将开源贡献意图以及内部协作带到私营公司。我们需要定义、建立和维护一种贡献、协作和择优工作的文化。
|
||||
|
||||
### 开放花园开发
|
||||
|
||||
我们的私营公司致力于通过对技术界的贡献,成为技术的领导者。这不仅仅是使用开源代码,成为领导者需要参与。成为领导者还需要与公司以外的团体(社区)进行各种类型的参与。这些社区围绕一个特定的研发项目进行组织。每个社区的参与就像为公司工作一样。重大成果需要大量的参与。
|
||||
|
||||
### 编码更多,生活更好
|
||||
|
||||
我们必须对计算资源慷慨,对空间吝啬,并鼓励由此产生的凌乱而有创造力的结果。允许人们使用他们的业务的这些工具将改变他们。我们必须有自发的互动。我们必须通过协作来构建鼓励创造性的线上以及线下空间。无法实时联系对方,协作就不能进行。
|
||||
|
||||
### 通过精英体制创新
|
||||
|
||||
我们必须创建一个精英阶层。思想素质要超过群体结构和在其中的职位任期。按业绩晋升鼓励每个人都成为更好的人和雇员。当我们成为最好的坏人时, 充满激情的人之间的争论将会发生。我们的文化应该有鼓励异议的义务。强烈的意见和想法将会变成热情的职业道德。这些想法和意见可以来自而且应该来自所有人。它不应该改变你是谁,而是应该关心你做什么。随着精英体制的进行,我们会投资未经许可就能正确行事的团队。
|
||||
|
||||
### 项目到产品
|
||||
|
||||
由于我们的私营公司拥抱开源贡献,我们还必须在研发项目中的上游工作和实现最终产品之间实现明确的分离。项目是研发工作,快速失败以及开发功能是常态。产品是你投入生产,拥有 SLA,并使用研发项目的成果。分离至少需要分离项目和产品的仓库。正常的分离包含在项目和产品上工作的不同社区。每个社区都需要大量的贡献和参与。为了使这些活动保持独立,需要有一个客户功能以及项目到产品的 bug 修复请求的工作流程。
|
||||
|
||||
接下来,我们会强调在私营公司创建、支持和扩展开源中的主要步骤。
|
||||
|
||||
### 技术上有天赋的人的学校
|
||||
|
||||
高手必须指导没有经验的人。当你学习新技能时,你将它们传给下一个人。当你训练下一个人时,你会面临新的挑战。永远不要期待在一个位置很长时间。获得技能,变得强大,通过学习,然后继续前进。
|
||||
|
||||
### 找到最适合你的人
|
||||
|
||||
我们热爱我们的工作。我们非常喜欢它,我们想和我们的朋友一起工作。我们是一个比我们公司大的社区的一部分。我们应该永远记住招募最好的人与我们一起工作。即使不是为我们公司工作,我们将会为我们周围的人找到很棒的工作。这样的想法使雇用很棒的人成为一种生活方式。随着招聘变得普遍,那么审查和帮助新员工就会变得容易了。
|
||||
|
||||
### 即将写的
|
||||
|
||||
我将在我的博客上发布关于每个宗旨的[更多细节][4],敬请关注。
|
||||
|
||||
_这篇文章最初发表在[ Sean Robert 的博客][1]上。CC BY 许可。_
|
||||
|
||||
(题图: opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Sean A Roberts - -以同理心为主导,同时专注于结果。我实践精英体制。在这里发现的智慧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/open-source-first
|
||||
|
||||
作者:[Sean A Roberts][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sarob
|
||||
[1]:https://sarob.com/2017/01/open-source-first/
|
||||
[2]:https://opensource.com/article/17/2/open-source-first?rate=CKF77ZVh5e_DpnmSlOKTH-MuFBumAp-tIw-Rza94iEI
|
||||
[3]:https://sarob.com/2017/01/todo-open-source-presentation-17-january-2017/
|
||||
[4]:https://sarob.com/2017/02/open-source-first-project-product/
|
||||
[5]:https://opensource.com/user/117441/feed
|
||||
[6]:https://opensource.com/users/sarob
|
||||
@ -0,0 +1,222 @@
|
||||
Linux 开机引导和启动过程详解
|
||||
===========
|
||||
|
||||
|
||||
> 你是否曾经对操作系统为何能够执行应用程序而感到疑惑?那么本文将为你揭开操作系统引导与启动的面纱。
|
||||
|
||||
理解操作系统开机引导和启动过程对于配置操作系统和解决相关启动问题是至关重要的。该文章陈述了 [GRUB2 引导装载程序][1]开机引导装载内核的过程和 [systemd 初始化系统][2]执行开机启动操作系统的过程。
|
||||
|
||||
事实上,操作系统的启动分为两个阶段:<ruby>引导<rt>boot</rt></ruby>和<ruby>启动<rt>startup</rt></ruby>。引导阶段开始于打开电源开关,结束于内核初始化完成和 systemd 进程成功运行。启动阶段接管了剩余工作,直到操作系统进入可操作状态。
|
||||
|
||||
总体来说,Linux 的开机引导和启动过程是相当容易理解,下文将分节对于不同步骤进行详细说明。
|
||||
|
||||
- BIOS 上电自检(POST)
|
||||
- 引导装载程序 (GRUB2)
|
||||
- 内核初始化
|
||||
- 启动 systemd,其是所有进程之父。
|
||||
|
||||
注意,本文以 GRUB2 和 systemd 为载体讲述操作系统的开机引导和启动过程,是因为这二者是目前主流的 linux 发行版本所使用的引导装载程序和初始化软件。当然另外一些过去使用的相关软件仍然在一些 Linux 发行版本中使用。
|
||||
|
||||
### 引导过程
|
||||
|
||||
引导过程能以两种方式之一初始化。其一,如果系统处于关机状态,那么打开电源按钮将开启系统引导过程。其二,如果操作系统已经运行在一个本地用户(该用户可以是 root 或其他非特权用户),那么用户可以借助图形界面或命令行界面通过编程方式发起一个重启操作,从而触发系统引导过程。重启包括了一个关机和重新开始的操作。
|
||||
|
||||
#### BIOS 上电自检(POST)
|
||||
|
||||
上电自检过程中其实 Linux 没有什么也没做,上电自检主要由硬件的部分来完成,这对于所有操作系统都一样。当电脑接通电源,电脑开始执行 BIOS(<ruby>基本输入输出系统<rt>Basic I/O System</rt></ruby>)的 POST(<ruby>上电自检<rt>Power On Self Test</rt></ruby>)过程。
|
||||
|
||||
在 1981 年,IBM 设计的第一台个人电脑中,BIOS 被设计为用来初始化硬件组件。POST 作为 BIOS 的组成部分,用于检验电脑硬件基本功能是否正常。如果 POST 失败,那么这个电脑就不能使用,引导过程也将就此中断。
|
||||
|
||||
BIOS 上电自检确认硬件的基本功能正常,然后产生一个 BIOS [中断][3] INT 13H,该中断指向某个接入的可引导设备的引导扇区。它所找到的包含有效的引导记录的第一个引导扇区将被装载到内存中,并且控制权也将从引导扇区转移到此段代码。
|
||||
|
||||
引导扇区是引导加载器真正的第一阶段。大多数 Linux 发行版本使用的引导加载器有三种:GRUB、GRUB2 和 LILO。GRUB2 是最新的,也是相对于其他老的同类程序使用最广泛的。
|
||||
|
||||
#### GRUB2
|
||||
|
||||
GRUB2 全称是 GRand Unified BootLoader,Version 2(第二版大一统引导装载程序)。它是目前流行的大部分 Linux 发行版本的主要引导加载程序。GRUB2 是一个用于计算机寻找操作系统内核并加载其到内存的智能程序。由于 GRUB 这个单词比 GRUB2 更易于书写和阅读,在下文中,除特殊指明以外,GRUB 将代指 GRUB2。
|
||||
|
||||
GRUB 被设计为兼容操作系统[多重引导规范][4],它能够用来引导不同版本的 Linux 和其他的开源操作系统;它还能链式加载专有操作系统的引导记录。
|
||||
|
||||
GRUB 允许用户从任何给定的 Linux 发行版本的几个不同内核中选择一个进行引导。这个特性使得操作系统,在因为关键软件不兼容或其它某些原因升级失败时,具备引导到先前版本的内核的能力。GRUB 能够通过文件 `/boot/grub/grub.conf` 进行配置。(LCTT 译注:此处指 GRUB1)
|
||||
|
||||
GRUB1 现在已经逐步被弃用,在大多数现代发行版上它已经被 GRUB2 所替换,GRUB2 是在 GRUB1 的基础上重写完成。基于 Red Hat 的发行版大约是在 Fedora 15 和 CentOS/RHEL 7 时升级到 GRUB2 的。GRUB2 提供了与 GRUB1 同样的引导功能,但是 GRUB2 也是一个类似主框架(mainframe)系统上的基于命令行的前置操作系统(Pre-OS)环境,使得在预引导阶段配置更为方便和易操作。GRUB2 通过 `/boot/grub2/grub.cfg` 进行配置。
|
||||
|
||||
两个 GRUB 的最主要作用都是将内核加载到内存并运行。两个版本的 GRUB 的基本工作方式一致,其主要阶段也保持相同,都可分为 3 个阶段。在本文将以 GRUB2 为例进行讨论其工作过程。GRUB 或 GRUB2 的配置,以及 GRUB2 的命令使用均超过本文范围,不会在文中进行介绍。
|
||||
|
||||
虽然 GRUB2 并未在其三个引导阶段中正式使用这些<ruby>阶段<rt>stage</rt></ruby>名词,但是为了讨论方便,我们在本文中使用它们。
|
||||
|
||||
##### 阶段 1
|
||||
|
||||
如上文 POST(上电自检)阶段提到的,在 POST 阶段结束时,BIOS 将查找在接入的磁盘中查找引导记录,其通常位于 MBR(<ruby>主引导记录<rt>Master Boot Record</rt></ruby>),它加载它找到的第一个引导记录中到内存中,并开始执行此代码。引导代码(及阶段 1 代码)必须非常小,因为它必须连同分区表放到硬盘的第一个 512 字节的扇区中。 在[传统的常规 MBR][5] 中,引导代码实际所占用的空间大小为 446 字节。这个阶段 1 的 446 字节的文件通常被叫做引导镜像(boot.img),其中不包含设备的分区信息,分区是一般单独添加到引导记录中。
|
||||
|
||||
由于引导记录必须非常的小,它不可能非常智能,且不能理解文件系统结构。因此阶段 1 的唯一功能就是定位并加载阶段 1.5 的代码。为了完成此任务,阶段 1.5 的代码必须位于引导记录与设备第一个分区之间的位置。在加载阶段 1.5 代码进入内存后,控制权将由阶段 1 转移到阶段 1.5。
|
||||
|
||||
##### 阶段 1.5
|
||||
|
||||
如上所述,阶段 1.5 的代码必须位于引导记录与设备第一个分区之间的位置。该空间由于历史上的技术原因而空闲。第一个分区的开始位置在扇区 63 和 MBR(扇区 0)之间遗留下 62 个 512 字节的扇区(共 31744 字节),该区域用于存储阶段 1.5 的代码镜像 core.img 文件。该文件大小为 25389 字节,故此区域有足够大小的空间用来存储 core.img。
|
||||
|
||||
因为有更大的存储空间用于阶段 1.5,且该空间足够容纳一些通用的文件系统驱动程序,如标准的 EXT 和其它的 Linux 文件系统,如 FAT 和 NTFS 等。GRUB2 的 core.img 远比更老的 GRUB1 阶段 1.5 更复杂且更强大。这意味着 GRUB2 的阶段 2 能够放在标准的 EXT 文件系统内,但是不能放在逻辑卷内。故阶段 2 的文件可以存放于 `/boot` 文件系统中,一般在 `/boot/grub2` 目录下。
|
||||
|
||||
注意 `/boot` 目录必须放在一个 GRUB 所支持的文件系统(并不是所有的文件系统均可)。阶段 1.5 的功能是开始执行存放阶段 2 文件的 `/boot` 文件系统的驱动程序,并加载相关的驱动程序。
|
||||
|
||||
##### 阶段 2
|
||||
|
||||
GRUB 阶段 2 所有的文件都已存放于 `/boot/grub2` 目录及其几个子目录之下。该阶段没有一个类似于阶段 1 与阶段 1.5 的镜像文件。相应地,该阶段主要需要从 `/boot/grub2/i386-pc` 目录下加载一些内核运行时模块。
|
||||
|
||||
GRUB 阶段 2 的主要功能是定位和加载 Linux 内核到内存中,并转移控制权到内核。内核的相关文件位于 `/boot` 目录下,这些内核文件可以通过其文件名进行识别,其文件名均带有前缀 vmlinuz。你可以列出 `/boot` 目录中的内容来查看操作系统中当前已经安装的内核。
|
||||
|
||||
GRUB2 跟 GRUB1 类似,支持从 Linux 内核选择之一引导启动。Red Hat 包管理器(DNF)支持保留多个内核版本,以防最新版本内核发生问题而无法启动时,可以恢复老版本的内核。默认情况下,GRUB 提供了一个已安装内核的预引导菜单,其中包括问题诊断菜单(recuse)以及恢复菜单(如果配置已经设置恢复镜像)。
|
||||
|
||||
阶段 2 加载选定的内核到内存中,并转移控制权到内核代码。
|
||||
|
||||
#### 内核
|
||||
|
||||
内核文件都是以一种自解压的压缩格式存储以节省空间,它与一个初始化的内存映像和存储设备映射表都存储于 `/boot` 目录之下。
|
||||
|
||||
在选定的内核加载到内存中并开始执行后,在其进行任何工作之前,内核文件首先必须从压缩格式解压自身。一旦内核自解压完成,则加载 [systemd][6] 进程(其是老式 System V 系统的 [init][7] 程序的替代品),并转移控制权到 systemd。
|
||||
|
||||
这就是引导过程的结束。此刻,Linux 内核和 systemd 处于运行状态,但是由于没有其他任何程序在执行,故其不能执行任何有关用户的功能性任务。
|
||||
|
||||
### 启动过程
|
||||
|
||||
启动过程紧随引导过程之后,启动过程使 Linux 系统进入可操作状态,并能够执行用户功能性任务。
|
||||
|
||||
#### systemd
|
||||
|
||||
systemd 是所有进程的父进程。它负责将 Linux 主机带到一个用户可操作状态(可以执行功能任务)。systemd 的一些功能远较旧式 init 程序更丰富,可以管理运行中的 Linux 主机的许多方面,包括挂载文件系统,以及开启和管理 Linux 主机的系统服务等。但是 systemd 的任何与系统启动过程无关的功能均不在此文的讨论范围。
|
||||
|
||||
首先,systemd 挂载在 `/etc/fstab` 中配置的文件系统,包括内存交换文件或分区。据此,systemd 必须能够访问位于 `/etc` 目录下的配置文件,包括它自己的。systemd 借助其配置文件 `/etc/systemd/system/default.target` 决定 Linux 系统应该启动达到哪个状态(或<ruby>目标态<rt>target</rt></ruby>)。`default.target` 是一个真实的 target 文件的符号链接。对于桌面系统,其链接到 `graphical.target`,该文件相当于旧式 systemV init 方式的 **runlevel 5**。对于一个服务器操作系统来说,`default.target` 更多是默认链接到 `multi-user.target`, 相当于 systemV 系统的 **runlevel 3**。 `emergency.target` 相当于单用户模式。
|
||||
|
||||
(LCTT 译注:“target” 是 systemd 新引入的概念,目前尚未发现有官方的准确译名,考虑到其作用和使用的上下文环境,我们认为翻译为“目标态”比较贴切。以及,“unit” 是指 systemd 中服务和目标态等各个对象/文件,在此依照语境译作“单元”。)
|
||||
|
||||
注意,所有的<ruby>目标态<rt>target</rt></ruby>和<ruby>服务<rt>service</rt></ruby>均是 systemd 的<ruby>单元<rt>unit</rt></ruby>。
|
||||
|
||||
如下表 1 是 systemd 启动的<ruby>目标态<rt>target</rt></ruby>和老版 systemV init 启动<ruby>运行级别<rt>runlevel</rt></ruby>的对比。这个 **systemd 目标态别名** 是为了 systemd 向前兼容 systemV 而提供。这个目标态别名允许系统管理员(包括我自己)用 systemV 命令(例如 `init 3`)改变运行级别。当然,该 systemV 命令是被转发到 systemd 进行解释和执行的。
|
||||
|
||||
|SystemV 运行级别 | systemd 目标态 | systemd 目标态别名 | 描述 |
|
||||
|:---:|---|---|---|
|
||||
| | `halt.target` | | 停止系统运行但不切断电源。 |
|
||||
| 0 | `poweroff.target` | `runlevel0.target` | 停止系统运行并切断电源. |
|
||||
| S | `emergency.target` | | 单用户模式,没有服务进程运行,文件系统也没挂载。这是一个最基本的运行级别,仅在主控制台上提供一个 shell 用于用户与系统进行交互。|
|
||||
| 1 | `rescue.target` | `runlevel1.target` | 挂载了文件系统,仅运行了最基本的服务进程的基本系统,并在主控制台启动了一个 shell 访问入口用于诊断。 |
|
||||
| 2 | | `runlevel2.target` | 多用户,没有挂载 NFS 文件系统,但是所有的非图形界面的服务进程已经运行。 |
|
||||
| 3 | `multi-user.target` | `runlevel3.target` | 所有服务都已运行,但只支持命令行接口访问。 |
|
||||
| 4 | | `runlevel4.target` | 未使用。|
|
||||
| 5 | `graphical.target` | `runlevel5.target` | 多用户,且支持图形界面接口。|
|
||||
| 6 | `reboot.target` | `runlevel6.target` | 重启。 |
|
||||
| | `default.target` | | 这个<ruby>目标态<rt>target</rt></ruby>是总是 `multi-user.target` 或 `graphical.target` 的一个符号链接的别名。systemd 总是通过 `default.target` 启动系统。`default.target` 绝不应该指向 `halt.target`、 `poweroff.target` 或 `reboot.target`。 |
|
||||
|
||||
*表 1 老版本 systemV 的 运行级别与 systemd 与<ruby>目标态<rt>target</rt></ruby>或目标态别名的比较*
|
||||
|
||||
每个<ruby>目标态<rt>target</rt></ruby>有一个在其配置文件中描述的依赖集,systemd 需要首先启动其所需依赖,这些依赖服务是 Linux 主机运行在特定的功能级别所要求的服务。当配置文件中所有的依赖服务都加载并运行后,即说明系统运行于该目标级别。
|
||||
|
||||
systemd 也会查看老式的 systemV init 目录中是否存在相关启动文件,若存在,则 systemd 根据这些配置文件的内容启动对应的服务。在 Fedora 系统中,过时的网络服务就是通过该方式启动的一个实例。
|
||||
|
||||
如下图 1 是直接从 bootup 的 man 页面拷贝而来。它展示了在 systemd 启动过程中一般的事件序列和确保成功的启动的基本的顺序要求。
|
||||
|
||||
`sysinit.target` 和 `basic.target` 目标态可以被视作启动过程中的状态检查点。尽管 systemd 的设计初衷是并行启动系统服务,但是部分服务或功能目标态是其它服务或目标态的启动的前提。系统将暂停于检查点直到其所要求的服务和目标态都满足为止。
|
||||
|
||||
`sysinit.target` 状态的到达是以其所依赖的所有资源模块都正常启动为前提的,所有其它的单元,如文件系统挂载、交换文件设置、设备管理器的启动、随机数生成器种子设置、低级别系统服务初始化、加解密服务启动(如果一个或者多个文件系统加密的话)等都必须完成,但是在 **sysinit.target** 中这些服务与模块是可以并行启动的。
|
||||
|
||||
`sysinit.target` 启动所有的低级别服务和系统初具功能所需的单元,这些都是进入下一阶段 basic.target 的必要前提。
|
||||
|
||||
```
|
||||
local-fs-pre.target
|
||||
|
|
||||
v
|
||||
(various mounts and (various swap (various cryptsetup
|
||||
fsck services...) devices...) devices...) (various low-level (various low-level
|
||||
| | | services: udevd, API VFS mounts:
|
||||
v v v tmpfiles, random mqueue, configfs,
|
||||
local-fs.target swap.target cryptsetup.target seed, sysctl, ...) debugfs, ...)
|
||||
| | | | |
|
||||
\__________________|_________________ | ___________________|____________________/
|
||||
\|/
|
||||
v
|
||||
sysinit.target
|
||||
|
|
||||
____________________________________/|\________________________________________
|
||||
/ | | | \
|
||||
| | | | |
|
||||
v v | v v
|
||||
(various (various | (various rescue.service
|
||||
timers...) paths...) | sockets...) |
|
||||
| | | | v
|
||||
v v | v *rescue.target
|
||||
timers.target paths.target | sockets.target
|
||||
| | | |
|
||||
v \_________________ | ___________________/
|
||||
\|/
|
||||
v
|
||||
basic.target
|
||||
|
|
||||
____________________________________/| emergency.service
|
||||
/ | | |
|
||||
| | | v
|
||||
v v v *emergency.target
|
||||
display- (various system (various system
|
||||
manager.service services services)
|
||||
| required for |
|
||||
| graphical UIs) v
|
||||
| | *multi-user.target
|
||||
| | |
|
||||
\_________________ | _________________/
|
||||
\|/
|
||||
v
|
||||
*graphical.target
|
||||
```
|
||||
*图 1:systemd 的启动流程*
|
||||
|
||||
在 `sysinit.target` 的条件满足以后,systemd 接下来启动 `basic.target`,启动其所要求的所有单元。 `basic.target` 通过启动下一目标态所需的单元而提供了更多的功能,这包括各种可执行文件的目录路径、通信 sockets,以及定时器等。
|
||||
|
||||
最后,用户级目标态(`multi-user.target` 或 `graphical.target`) 可以初始化了,应该注意的是 `multi-user.target` 必须在满足图形化目标态 `graphical.target` 的依赖项之前先达成。
|
||||
|
||||
图 1 中,以 `*` 开头的目标态是通用的启动状态。当到达其中的某一目标态,则说明系统已经启动完成了。如果 `multi-user.target` 是默认的目标态,则成功启动的系统将以命令行登录界面呈现于用户。如果 `graphical.target` 是默认的目标态,则成功启动的系统将以图形登录界面呈现于用户,界面的具体样式将根据系统所配置的[显示管理器][8]而定。
|
||||
|
||||
### 故障讨论
|
||||
|
||||
最近我需要改变一台使用 GRUB2 的 Linux 电脑的默认引导内核。我发现一些 GRUB2 的命令在我的系统上不能用,也可能是我使用方法不正确。至今,我仍然不知道是何原因导致,此问题需要进一步探究。
|
||||
|
||||
`grub2-set-default` 命令没能在配置文件 `/etc/default/grub` 中成功地设置默认内核索引,以至于期望的替代内核并没有被引导启动。故在该配置文件中我手动更改 `GRUB_DEFAULT=saved` 为 `GRUB_DEFAULT=2`,2 是我需要引导的安装好的内核文件的索引。然后我执行命令 `grub2-mkconfig > /boot/grub2/grub.cfg` 创建了新的 GRUB 配置文件,该方法如预期的规避了问题,并成功引导了替代的内核。
|
||||
|
||||
### 结论
|
||||
|
||||
GRUB2、systemd 初始化系统是大多数现代 Linux 发行版引导和启动的关键组件。尽管在实际中,systemd 的使用还存在一些争议,但是 GRUB2 与 systemd 可以密切地配合先加载内核,然后启动一个业务系统所需要的系统服务。
|
||||
|
||||
尽管 GRUB2 和 systemd 都比其前任要更加复杂,但是它们更加容易学习和管理。在 man 页面有大量关于 systemd 的帮助说明,freedesktop.org 也在线收录了完整的此[帮助说明][9]。下面有更多相关信息链接。
|
||||
|
||||
### 附加资源
|
||||
|
||||
- [GNU GRUB](https://en.wikipedia.org/wiki/GNU_GRUB) (Wikipedia)
|
||||
- [GNU GRUB Manual](https://www.gnu.org/software/grub/manual/grub.html) (GNU.org)
|
||||
- [Master Boot Record](https://en.wikipedia.org/wiki/Master_boot_record) (Wikipedia)
|
||||
- [Multiboot specification](https://en.wikipedia.org/wiki/Multiboot_Specification) (Wikipedia)
|
||||
- [systemd](https://en.wikipedia.org/wiki/Systemd) (Wikipedia)
|
||||
- [systemd bootup process](https://www.freedesktop.org/software/systemd/man/bootup.html) (Freedesktop.org)
|
||||
- [systemd index of man pages](https://www.freedesktop.org/software/systemd/man/index.html) (Freedesktop.org)
|
||||
|
||||
---
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both 居住在美国北卡罗纳州的首府罗利,是一个 Linux 开源贡献者。他已经从事 IT 行业 40 余年,在 IBM 教授 OS/2 20余年。1981 年,他在 IBM 开发了第一个关于最初的 IBM 个人电脑的培训课程。他也曾在 Red Hat 教授 RHCE 课程,也曾供职于 MCI worldcom,Cico 以及北卡罗纳州等。他已经为 Linux 开源社区工作近 20 年。
|
||||
|
||||
---
|
||||
via: https://opensource.com/article/17/2/linux-boot-and-startup
|
||||
|
||||
作者:[David Both](https://opensource.com/users/dboth)
|
||||
译者: [penghuster](https://github.com/penghuster)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]: https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[2]: https://en.wikipedia.org/wiki/Systemd
|
||||
[3]: https://en.wikipedia.org/wiki/BIOS_interrupt_call
|
||||
[4]: https://en.wikipedia.org/wiki/Multiboot_Specification
|
||||
[5]: https://en.wikipedia.org/wiki/Master_boot_record
|
||||
[6]: https://en.wikipedia.org/wiki/Systemd
|
||||
[7]: https://en.wikipedia.org/wiki/Init#SysV-style
|
||||
[8]: https://opensource.com/article/16/12/yearbook-best-couple-2016-display-manager-and-window-manager
|
||||
[9]: https://www.freedesktop.org/software/systemd/man/index.html
|
||||
@ -0,0 +1,103 @@
|
||||
如何解决 VLC 视频嵌入字幕中遇到的错误
|
||||
===================
|
||||
|
||||
这会是一个有点奇怪的教程。背景故事如下。最近,我创作了一堆 [Risitas y las paelleras][4] 素材中[sweet][1] [parody][2] [的片段][3],以主角 Risitas 疯狂的笑声而闻名。和往常一样,我把它们上传到了 Youtube,但是从当我决定使用字幕起,到最终在网上可以观看时,我经历了一个漫长而曲折的历程。
|
||||
|
||||
在本指南中,我想介绍几个你可能会在创作自己的媒体时会遇到的典型问题,主要是使用字幕,然后上传到媒体共享门户网站,特别是 Youtube 中,以及如何解决这些问题。跟我来。
|
||||
|
||||
### 背景故事
|
||||
|
||||
我选择的视频编辑软件是 Kdenlive,当我创建那愚蠢的 [Frankenstein][5] 片段时开始使用这个软件,从那以后它一直是我的忠实伙伴。通常,我将文件交给带有 VP8 视频编解码器和 Vorbis 音频编解码器的 WebM 容器来渲染,因为这是 Google 所喜欢的格式。事实上,我在过去七年里上传的大约 40 个不同的片段中都没有问题。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
但是,在完成了我的 Risitas&Linux 项目之后,我遇到了一个困难。视频文件和字幕文件仍然是两个独立的实体,我需要以某种方式将它们放在一起。我最初关于字幕的文章提到了 Avidemux 和 Handbrake,这两个都是有效的选项。
|
||||
|
||||
但是,我对它们任何一个的输出都并不满意,而且由于种种原因,有些东西有所偏移。 Avidemux 不能很好处理视频编码,而 Handbrake 在最终输出中省略了几行字幕,而且字体是丑陋的。这个可以解决,但这不是今天的话题。
|
||||
|
||||
因此,我决定使用 VideoLAN(VLC) 将字幕嵌入视频。有几种方法可以做到这一点。你可以使用 “Media > Convert/Save” 选项,但这不能达到我们需要的。相反,你应该使用 “Media > Stream”,它带有一个更完整的向导,它还提供了一个我们需要的可编辑的代码转换选项 - 请参阅我的[教程][6]关于字幕的部分。
|
||||
|
||||
### 错误!
|
||||
|
||||
嵌入字幕的过程并没那么简单的。你有可能遇到几个问题。本指南应该能帮助你解决这些问题,所以你可以专注于你的工作,而不是浪费时间调试怪异的软件错误。无论如何,在使用 VLC 中的字幕时,你将会遇到一小部分可能会遇到的问题。尝试以及出错,还有书呆子的设计。
|
||||
|
||||
### 没有可播放的流
|
||||
|
||||
你可能选择了奇怪的输出设置。你要仔细检查你是否选择了正确的视频和音频编解码器。另外,请记住,一些媒体播放器可能没有所有的编解码器。此外,确保在所有要播放的系统中都测试过了。
|
||||
|
||||

|
||||
|
||||
### 字幕叠加两次
|
||||
|
||||
如果在第一步的流媒体向导中选择了 “Use a subtitle file”,则可能会发生这种情况。只需选择所需的文件,然后单击 “Stream”。取消选中该框。
|
||||
|
||||

|
||||
|
||||
### 字幕没有输出
|
||||
|
||||
这可能是两个主要原因。一、你选择了错误的封装格式。在进行编辑之前,请确保在配置文件页面上正确标记了字幕。如果格式不支持字幕,它可能无法正常工作。
|
||||
|
||||

|
||||
|
||||
二、你可能已经在最终输出中启用了字幕编解码器渲染功能。你不需要这个。你只需要将字幕叠加到视频片段上。在单击 “Stream” 按钮之前,请检查生成的流输出字符串并删除 “scodec=<something>” 的选项。
|
||||
|
||||

|
||||
|
||||
### 缺少编解码器的解决方法
|
||||
|
||||
这是一个常见的 [bug][7],取决于编码器的实现的实验性,如果你选择以下配置文件,你将很有可能会看到它:“Video - H.264 + AAC (MP4)”。该文件将被渲染,如果你选择了字幕,它们也会被叠加上,但没有任何音频。但是,我们可以用技巧来解决这个问题。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
一个可能的技巧是从命令行使用 “--sout-ffmpeg-strict=-2” 选项(可能有用)启动 VLC。另一个更安全的解决方法是采用无音频视频,但是带有字幕叠加,并将不带字幕的原始项目作为音频源用 Kdenlive 渲染。听上去很复杂,下面是详细步骤:
|
||||
|
||||
* 将现有片段(包含音频)从视频移动到音频。删除其余的。
|
||||
* 或者,使用渲染过的 WebM 文件作为你的音频源。
|
||||
* 添加新的片段 - 带有字幕,并且没有音频。
|
||||
* 将片段放置为新视频。
|
||||
* 再次渲染为 WebM。
|
||||
|
||||

|
||||
|
||||
使用其他类型的音频编解码器将很有可能可用(例如 MP3),你将拥有一个包含视频、音频和字幕的完整项目。如果你很高兴没有遗漏,你可以现在上传到 Youtube 上。但是之后 ...
|
||||
|
||||
### Youtube 视频管理器和未知格式
|
||||
|
||||
如果你尝试上传非 WebM 片段(例如 MP4),则可能会收到未指定的错误,你的片段不符合媒体格式要求。我不知道为什么 VLC 会生成一个不符合 YouTube 规定的文件。但是,修复很容易。使用 Kdenlive 重新创建视频,将会生成带有所有正确的元字段和 Youtube 喜欢的文件。回到我原来的故事,我有 40 多个片段使用 Kdenlive 以这种方式创建。
|
||||
|
||||
P.S. 如果你的片段有有效的音频,则只需通过 Kdenlive 重新运行它。如果没有,重做视频/音频。根据需要将片段静音。最终,这就像叠加一样,除了你使用的视频来自于一个片段,而音频来自于另一个片段。工作完成。
|
||||
|
||||
### 更多阅读
|
||||
|
||||
我不想用链接重复自己或垃圾信息。在“软件与安全”部分,我有 VLC 上的片段,因此你可能需要咨询。前面提到的关于 VLC 和字幕的文章已经链接到大约六个相关教程,涵盖了其他主题,如流媒体、日志记录、视频旋转、远程文件访问等等。我相信你可以像专业人员一样使用搜索引擎。
|
||||
|
||||
### 总结
|
||||
|
||||
我希望你觉得本指南有帮助。它涵盖了很多,我试图使其直接而简单,并解决流媒体爱好者和字幕爱好者在使用 VLC 时可能遇到的许多陷阱。这都与容器和编解码器相关,而且媒体世界几乎没有标准的事实,当你从一种格式转换到另一种格式时,有时你可能会遇到边际情况。
|
||||
|
||||
如果你遇到了一些错误,这里的提示和技巧应该可以至少帮助你解决一些,包括无法播放的流、丢失或重复的字幕、缺少编解码器和 Kdenlive 解决方法、YouTube 上传错误、隐藏的 VLC 命令行选项,还有一些其他东西。是的,这些对于一段文字来说是很多的。幸运的是,这些都是好东西。保重,互联网的孩子们。如果你有任何其他要求,我将来的 VLC 文章应该会涵盖,请随意给我发邮件。
|
||||
|
||||
干杯。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dedoimedo.com/computers/vlc-subtitles-errors.html
|
||||
|
||||
作者:[Dedoimedo][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
[1]:https://www.youtube.com/watch?v=MpDdGOKZ3dg
|
||||
[2]:https://www.youtube.com/watch?v=KHG6fXEba0A
|
||||
[3]:https://www.youtube.com/watch?v=TXw5lRi97YY
|
||||
[4]:https://www.youtube.com/watch?v=cDphUib5iG4
|
||||
[5]:http://www.dedoimedo.com/computers/frankenstein-media.html
|
||||
[6]:http://www.dedoimedo.com/computers/vlc-subtitles.html
|
||||
[7]:https://trac.videolan.org/vlc/ticket/6184
|
||||
@ -1,19 +1,9 @@
|
||||
了解 7z 命令开关 - 第一部分
|
||||
了解 7z 命令开关(一)
|
||||
============================================================
|
||||
|
||||
### 本篇中
|
||||
|
||||
1. [包含文件][1]
|
||||
2. [排除文件][2]
|
||||
3. [设置归档的密码][3]
|
||||
4. [设置输出目录][4]
|
||||
5. [创建多个卷][5]
|
||||
6. [设置归档的压缩级别][6]
|
||||
7. [显示归档的技术信息][7]
|
||||
|
||||
7z 无疑是一个功能强大的强大的归档工具(声称提供最高的压缩比)。在 HowtoForge 中,我们已经[已经讨论过][9]如何安装和使用它。但讨论仅限于你可以使用该工具提供的“功能字母”来使用基本功能。
|
||||
|
||||
在本教程中,我们将扩展对这个工具的说明,我们会讨论一些 7z 提供的“开关”。 但在继续之前,需要分享的是本教程中提到的所有说明和命令都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
在本教程中,我们将扩展对这个工具的说明,我们会讨论一些 7z 提供的“开关”。 但在继续之前,需要说明的是,本教程中提到的所有说明和命令都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
|
||||
**注意**:我们将使用以下截图中显示的文件来执行使用 7zip 的各种操作。
|
||||
|
||||
@ -21,18 +11,21 @@
|
||||

|
||||
][10]
|
||||
|
||||
###
|
||||
包含文件
|
||||
### 包含文件
|
||||
|
||||
7z 工具允许你有选择地将文件包含在归档中。可以使用 -i 开关来使用此功能。
|
||||
7z 工具允许你有选择地将文件包含在归档中。可以使用 `-i` 开关来使用此功能。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
-i[r[-|0]]{@listfile|!wildcard}
|
||||
```
|
||||
|
||||
比如,如果你想在归档中只包含 “.txt” 文件,你可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ 7z a ‘-i!*.txt’ include.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -42,7 +35,9 @@ $ 7z a ‘-i!*.txt’ include.7z
|
||||
|
||||
现在,检查新创建的归档是否只包含 “.txt” 文件,你可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ 7z l include.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -54,15 +49,19 @@ $ 7z l include.7z
|
||||
|
||||
### 排除文件
|
||||
|
||||
如果你想要,你可以排除不想要的文件。可以使用 -x 开关做到。
|
||||
如果你想要,你可以排除不想要的文件。可以使用 `-x` 开关做到。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
-x[r[-|0]]]{@listfile|!wildcard}
|
||||
```
|
||||
|
||||
比如,如果你想在要创建的归档中排除 “abc.7z” ,你可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ 7z a ‘-x!abc.7z’ exclude.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -72,7 +71,9 @@ $ 7z a ‘-x!abc.7z’ exclude.7z
|
||||
|
||||
要检查最后的归档是否排除了 “abc.7z”, 你可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ 7z l exclude.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -82,25 +83,33 @@ $ 7z l exclude.7z
|
||||
|
||||
上面的截图中,你可以看到 “abc.7z” 已经从新的归档中排除了。
|
||||
|
||||
**专业提示**:假设任务是排除以 “t” 开头的所有 .7z 文件,并且包含以字母 “a” 开头的所有 .7z 文件。这可以通过以下方式组合 “-i” 和 “-x” 开关来实现:
|
||||
**专业提示**:假设任务是排除以 “t” 开头的所有 .7z 文件,并且包含以字母 “a” 开头的所有 .7z 文件。这可以通过以下方式组合 `-i` 和 `-x` 开关来实现:
|
||||
|
||||
```
|
||||
$ 7z a '-x!t*.7z' '-i!a*.7z' combination.7z
|
||||
```
|
||||
|
||||
### 设置归档密码
|
||||
|
||||
7z 同样也支持用密码保护你的归档文件。这个功能可以使用 -p 开关来实现。
|
||||
7z 同样也支持用密码保护你的归档文件。这个功能可以使用 `-p` 开关来实现。
|
||||
|
||||
```
|
||||
$ 7z a [archive-filename] -p[your-password] -mhe=[on/off]
|
||||
```
|
||||
|
||||
**注意**:-mhe 选项用来启用或者禁用归档头加密(默认是 off)。
|
||||
**注意**:`-mhe` 选项用来启用或者禁用归档头加密(默认是“off”)。
|
||||
|
||||
例子:
|
||||
|
||||
```
|
||||
$ 7z a password.7z -pHTF -mhe=on
|
||||
```
|
||||
|
||||
无需多说,当你解压密码保护的归档时,工具会向你询问密码。要解压一个密码保护的文件,使用 “e” 功能字母。下面是例子:
|
||||
无需多说,当你解压密码保护的归档时,工具会向你询问密码。要解压一个密码保护的文件,使用 `e` 功能字母。下面是例子:
|
||||
|
||||
```
|
||||
$ 7z e password.7z
|
||||
```
|
||||
|
||||
[
|
||||
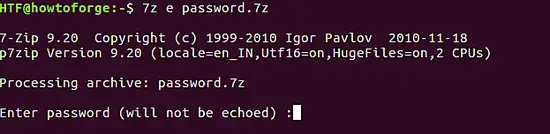
|
||||
@ -108,15 +117,19 @@ $ 7z e password.7z
|
||||
|
||||
### 设置输出目录
|
||||
|
||||
工具同样支持解压文件到你选择的目录中。这可以使用 -o 开关。无需多说,这个开关只在含有 “e” 或者 “x” 功能字母的时候有用。
|
||||
工具同样支持解压文件到你选择的目录中。这可以使用 `-o` 开关。无需多说,这个开关只在含有 `e` 或者 `x` 功能字母的时候有用。
|
||||
|
||||
```
|
||||
$ 7z [e/x] [existing-archive-filename] -o[path-of-directory]
|
||||
```
|
||||
|
||||
比如,假设下面命令工作在当前的工作目录中:
|
||||
|
||||
```
|
||||
$ 7z e output.7z -ohow/to/forge
|
||||
```
|
||||
|
||||
如 -o 开关的值所指的那样,它的目标是解压文件到 ./how/to/forge 中。
|
||||
如 `-o` 开关的值所指的那样,它的目标是解压文件到 ./how/to/forge 中。
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -124,7 +137,7 @@ $ 7z e output.7z -ohow/to/forge
|
||||
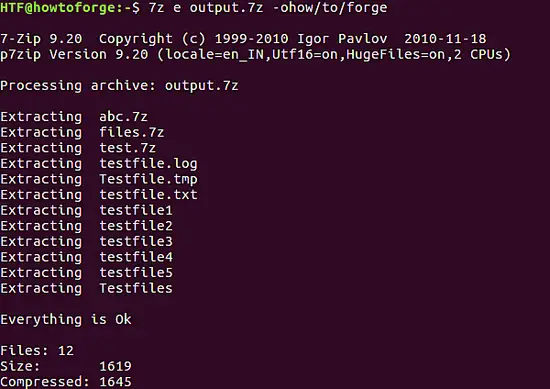
|
||||
][16]
|
||||
|
||||
在上面的截图中,你可以看到归档文件的所有内容都已经解压了。但是在哪里?要检查文件是否被解压到 ./how/to/forge,我们可以使用 “ls -R” 命令。
|
||||
在上面的截图中,你可以看到归档文件的所有内容都已经解压了。但是在哪里?要检查文件是否被解压到 ./how/to/forge,我们可以使用 `ls -R` 命令。
|
||||
|
||||
[
|
||||
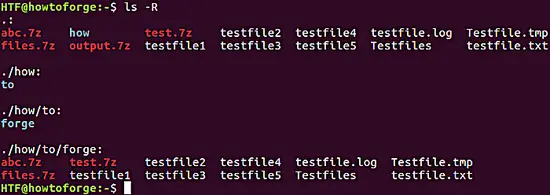
|
||||
@ -134,13 +147,15 @@ $ 7z e output.7z -ohow/to/forge
|
||||
|
||||
### 创建多个卷
|
||||
|
||||
借助 7z 工具,你可以为归档创建多个卷(较小的子档案)。当通过网络或 USB 传输大文件时,这是非常有用的。可以使用 -v 开关使用此功能。这个开关需要指定子档案的大小。
|
||||
借助 7z 工具,你可以为归档创建多个卷(较小的子档案)。当通过网络或 USB 传输大文件时,这是非常有用的。可以使用 `-v` 开关使用此功能。这个开关需要指定子档案的大小。
|
||||
|
||||
我们可以以字节(b)、千字节(k)、兆字节(m)和千兆字节(g)指定子档案大小。
|
||||
|
||||
```
|
||||
$ 7z a [archive-filename] [files-to-archive] -v[size-of-sub-archive1] -v[size-of-sub-archive2] ....
|
||||
```
|
||||
|
||||
让我们用一个例子来理解这个。请注意,我们将使用一个新的目录来执行 -v 开关的操作。
|
||||
让我们用一个例子来理解这个。请注意,我们将使用一个新的目录来执行 `-v` 开关的操作。
|
||||
|
||||
这是目录内容的截图:
|
||||
|
||||
@ -150,7 +165,9 @@ $ 7z a [archive-filename] [files-to-archive] -v[size-of-sub-archive1] -v[size-of
|
||||
|
||||
现在,我们运行下面的命令来为一个归档文件创建多个卷(每个大小 100b):
|
||||
|
||||
```
|
||||
7z a volume.7z * -v100b
|
||||
```
|
||||
|
||||
这是截图:
|
||||
|
||||
@ -158,36 +175,40 @@ $ 7z a [archive-filename] [files-to-archive] -v[size-of-sub-archive1] -v[size-of
|
||||
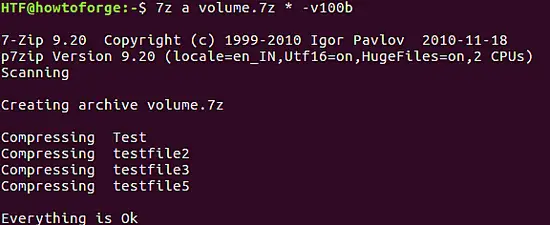
|
||||
][19]
|
||||
|
||||
现在,要查看创建的子归档,使用 “ls” 命令。
|
||||
现在,要查看创建的子归档,使用 `ls` 命令。
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
如下截图所示,一个四个卷创建了 - volume.7z.001、volume.7z.002、volume.7z.003 和 volume.7z.004
|
||||
如下截图所示,一共创建四个卷 - volume.7z.001、volume.7z.002、volume.7z.003 和 volume.7z.004
|
||||
|
||||
**注意**:你可以使用 .7z.001 归档解压文件。但是,要这么做,其他所有的卷都应该在同一个目录内。
|
||||
**注意**:你可以使用 .7z.001 归档文件来解压。但是,要这么做,其他所有的卷都应该在同一个目录内。
|
||||
|
||||
### 设置归档的压缩级别
|
||||
|
||||
7z 允许你设置归档的压缩级别。这个功能可以使用 -m 开关。7z 中有不同的压缩级别,比如:-mx0、-mx1、-mx3、-mx5、-mx7 和 -mx9
|
||||
7z 允许你设置归档的压缩级别。这个功能可以使用 `-m` 开关。7z 中有不同的压缩级别,比如:`-mx0`、`-mx1`、`-mx3`、`-mx5`、`-mx7` 和 `-mx9`。
|
||||
|
||||
这是这些压缩级别的简要说明:
|
||||
|
||||
-**mx0** = 完全不压缩 - 只是复制文件到归档中。
|
||||
-**mx1** = 消耗最少时间,但是压缩最小。
|
||||
-**mx3** = 比 -mx1 好。
|
||||
-**mx5** = 这是默认级别 (常规压缩)。
|
||||
-**mx7** = 最大化压缩。
|
||||
-**mx9** = 极端压缩。
|
||||
- `mx0` = 完全不压缩 - 只是复制文件到归档中。
|
||||
- `mx1` = 消耗最少时间,但是压缩最小。
|
||||
- `mx3` = 比 `-mx1` 好。
|
||||
- `mx5` = 这是默认级别 (常规压缩)。
|
||||
- `mx7` = 最大化压缩。
|
||||
- `mx9` = 极端压缩。
|
||||
|
||||
**注意**:关于这些压缩级别的更多信息,阅读[这里][8]。
|
||||
|
||||
```
|
||||
$ 7z a [archive-filename] [files-to-archive] -mx=[0,1,3,5,7,9]
|
||||
```
|
||||
|
||||
例如,我们在目录中有一堆文件和文件夹,我们每次尝试使用不同的压缩级别进行压缩。只是为了给你一个想法,这是当使用压缩级别 “0” 时创建存档时使用的命令。
|
||||
例如,我们在目录中有一堆文件和文件夹,我们每次尝试使用不同的压缩级别进行压缩。作为一个例子,这是当使用压缩级别 “0” 时创建存档时使用的命令。
|
||||
|
||||
```
|
||||
$ 7z a compression(-mx0).7z * -mx=0
|
||||
```
|
||||
|
||||
相似地,其他命令也这样执行。
|
||||
|
||||
@ -197,16 +218,19 @@ $ 7z a compression(-mx0).7z * -mx=0
|
||||
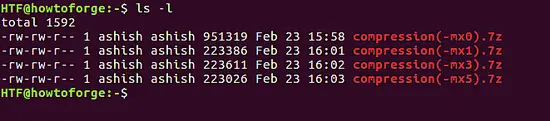
|
||||
][21]
|
||||
|
||||
###
|
||||
显示归档的技术信息
|
||||
### 显示归档的技术信息
|
||||
|
||||
如果需要,7z 还可以在标准输出中显示归档的技术信息 - 类型、物理大小、头大小等。可以使用 -slt 开关使用此功能。 此开关仅适用于带有 “l” 功能字母的情况下。
|
||||
如果需要,7z 还可以在标准输出中显示归档的技术信息 - 类型、物理大小、头大小等。可以使用 `-slt` 开关使用此功能。 此开关仅适用于带有 `l` 功能字母的情况下。
|
||||
|
||||
```
|
||||
$ 7z l -slt [archive-filename]
|
||||
```
|
||||
|
||||
比如:
|
||||
|
||||
```
|
||||
$ 7z l -slt abc.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -214,17 +238,21 @@ $ 7z l -slt abc.7z
|
||||
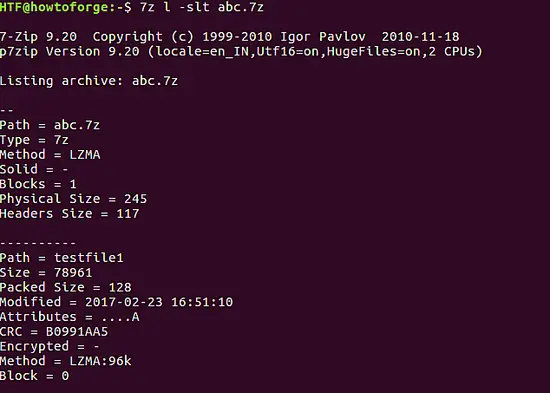
|
||||
][22]
|
||||
|
||||
# 指定创建归档的类型
|
||||
### 指定创建归档的类型
|
||||
|
||||
如果你想要创建一个非 7z 的归档文件(这是默认的创建类型),你可以使用 -t 开关来指定。
|
||||
如果你想要创建一个非 7z 的归档文件(这是默认的创建类型),你可以使用 `-t` 开关来指定。
|
||||
|
||||
```
|
||||
$ 7z a -t[specify-type-of-archive] [archive-filename] [file-to-archive]
|
||||
```
|
||||
|
||||
下面的例子展示创建了一个 .zip 文件:
|
||||
|
||||
```
|
||||
7z a -tzip howtoforge *
|
||||
```
|
||||
|
||||
输出的文件是 “howtoforge.zip”。要交叉验证它的类型,使用 “file” 命令:
|
||||
输出的文件是 “howtoforge.zip”。要交叉验证它的类型,使用 `file` 命令:
|
||||
|
||||
[
|
||||

|
||||
@ -232,17 +260,17 @@ $ 7z a -t[specify-type-of-archive] [archive-filename] [file-to-archive]
|
||||
|
||||
因此,howtoforge.zip 的确是一个 ZIP 文件。相似地,你可以创建其他 7z 支持的归档。
|
||||
|
||||
# 总结
|
||||
### 总结
|
||||
|
||||
你会同意的是 7z 的 “功能字母” 以及 “开关” 的知识可以让你充分利用这个工具。我们还没有完成开关的部分 - 其余部分将在第 2 部分中讨论。
|
||||
你将会认识到, 7z 的 “功能字母” 以及 “开关” 的知识可以让你充分利用这个工具。我们还没有完成开关的部分 - 其余部分将在第 2 部分中讨论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/understanding-7z-command-switches/
|
||||
|
||||
作者:[ Himanshu Arora][a]
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,40 +1,26 @@
|
||||
开发 Linux 调试器第五部分:源码和信号
|
||||
开发一个 Linux 调试器(四):源码和信号
|
||||
============================================================
|
||||
|
||||
在上一部分我们学习了关于 DWARF 的信息以及它如何可以被用于读取变量和将被执行的机器码和我们高层次的源码联系起来。在这一部分,我们通过实现一些我们调试器后面会使用的 DWARF 原语将它应用于实际情况。我们也会利用这个机会,使我们的调试器可以在命中一个断点时打印出当前的源码上下文。
|
||||
|
||||
* * *
|
||||
在上一部分我们学习了关于 DWARF 的信息,以及它如何被用于读取变量和将被执行的机器码与我们的高级语言的源码联系起来。在这一部分,我们将进入实践,实现一些我们调试器后面会使用的 DWARF 原语。我们也会利用这个机会,使我们的调试器可以在命中一个断点时打印出当前的源码上下文。
|
||||
|
||||
### 系列文章索引
|
||||
|
||||
随着后面文章的发布,这些链接会逐渐生效。
|
||||
|
||||
1. [启动][1]
|
||||
|
||||
1. [准备环境][1]
|
||||
2. [断点][2]
|
||||
|
||||
3. [寄存器和内存][3]
|
||||
|
||||
4. [Elves 和 dwarves][4]
|
||||
|
||||
5. [源码和信号][5]
|
||||
|
||||
6. [源码级逐步执行][6]
|
||||
|
||||
7. 源码级断点
|
||||
|
||||
8. 调用栈展开
|
||||
|
||||
9. 读取变量
|
||||
|
||||
10. 下一步
|
||||
|
||||
译者注:ELF([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format "Executable and Linkable Format") 可执行文件格式),DWARF(一种广泛使用的调试数据格式,参考 [WIKI](https://en.wikipedia.org/wiki/DWARF "DWARF WIKI"))
|
||||
* * *
|
||||
|
||||
### 设置我们的 DWARF 解析器
|
||||
|
||||
正如我在这系列文章开始时备注的,我们会使用 [`libelfin`][7] 来处理我们的 DWARF 信息。希望你已经在第一部分设置好了这些,如果没有的话,现在做吧,确保你使用我仓库的 `fbreg` 分支。
|
||||
正如我在这系列文章开始时备注的,我们会使用 [libelfin][7] 来处理我们的 DWARF 信息。希望你已经在[第一部分][1]设置好了这些,如果没有的话,现在做吧,确保你使用我仓库的 `fbreg` 分支。
|
||||
|
||||
一旦你构建好了 `libelfin`,就可以把它添加到我们的调试器。第一步是解析我们的 ELF 可执行程序并从中提取 DWARF 信息。使用 `libelfin` 可以轻易实现,只需要对`调试器`作以下更改:
|
||||
|
||||
@ -59,11 +45,9 @@ private:
|
||||
|
||||
我们使用了 `open` 而不是 `std::ifstream`,因为 elf 加载器需要传递一个 UNIX 文件描述符给 `mmap`,从而可以将文件映射到内存而不是每次读取一部分。
|
||||
|
||||
* * *
|
||||
|
||||
### 调试信息原语
|
||||
|
||||
下一步我们可以实现从程序计数器的值中提取行条目(line entries)以及函数 DWARF 信息条目(function DIEs)的函数。我们从 `get_function_from_pc` 开始:
|
||||
下一步我们可以实现从程序计数器的值中提取行条目(line entry)以及函数 DWARF 信息条目(function DIE)的函数。我们从 `get_function_from_pc` 开始:
|
||||
|
||||
```
|
||||
dwarf::die debugger::get_function_from_pc(uint64_t pc) {
|
||||
@ -83,7 +67,7 @@ dwarf::die debugger::get_function_from_pc(uint64_t pc) {
|
||||
}
|
||||
```
|
||||
|
||||
这里我采用了朴素的方法,迭代遍历编译单元直到找到一个包含程序计数器的,然后迭代遍历它的孩子直到我们找到相关函数(`DW_TAG_subprogram`)。正如我在上一篇中提到的,如果你想要的话你可以处理类似成员函数或者内联等情况。
|
||||
这里我采用了朴素的方法,迭代遍历编译单元直到找到一个包含程序计数器的,然后迭代遍历它的子节点直到我们找到相关函数(`DW_TAG_subprogram`)。正如我在上一篇中提到的,如果你想要的话你可以处理类似的成员函数或者内联等情况。
|
||||
|
||||
接下来是 `get_line_entry_from_pc`:
|
||||
|
||||
@ -108,8 +92,6 @@ dwarf::line_table::iterator debugger::get_line_entry_from_pc(uint64_t pc) {
|
||||
|
||||
同样,我们可以简单地找到正确的编译单元,然后查询行表获取相关的条目。
|
||||
|
||||
* * *
|
||||
|
||||
### 打印源码
|
||||
|
||||
当我们命中一个断点或者逐步执行我们的代码时,我们会想知道处于源码中的什么位置。
|
||||
@ -149,13 +131,11 @@ void debugger::print_source(const std::string& file_name, unsigned line, unsigne
|
||||
}
|
||||
```
|
||||
|
||||
现在我们可以打印出源码了,我们需要将这些通过钩子添加到我们的调试器。一个实现这个的好地方是当调试器从一个断点或者(最终)逐步执行得到一个信号时。到了这里,我们可能想要给我们的调试器添加一些更好的信号处理。
|
||||
|
||||
* * *
|
||||
现在我们可以打印出源码了,我们需要将这些通过钩子添加到我们的调试器。实现这个的一个好地方是当调试器从一个断点或者(最终)逐步执行得到一个信号时。到了这里,我们可能想要给我们的调试器添加一些更好的信号处理。
|
||||
|
||||
### 更好的信号处理
|
||||
|
||||
我们希望能够得知什么信号被发送给了进程,同样我们也想知道它是如何产生的。例如,我们希望能够得知是否由于命中了一个断点从而获得一个 `SIGTRAP`,还是由于逐步执行完成、或者是产生了一个新线程,等等。幸运的是,我们可以再一次使用 `ptrace`。可以给 `ptrace` 的一个命令是 `PTRACE_GETSIGINFO`,它会给你被发送给进程的最后一个信号的信息。我们类似这样使用它:
|
||||
我们希望能够得知什么信号被发送给了进程,同样我们也想知道它是如何产生的。例如,我们希望能够得知是否由于命中了一个断点从而获得一个 `SIGTRAP`,还是由于逐步执行完成、或者是产生了一个新线程等等导致的。幸运的是,我们可以再一次使用 `ptrace`。可以给 `ptrace` 的一个命令是 `PTRACE_GETSIGINFO`,它会给你被发送给进程的最后一个信号的信息。我们类似这样使用它:
|
||||
|
||||
```
|
||||
siginfo_t debugger::get_signal_info() {
|
||||
@ -268,8 +248,6 @@ void debugger::step_over_breakpoint() {
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### 测试
|
||||
|
||||
现在你应该可以在某个地址设置断点,运行程序然后看到打印出了源码,而且正在被执行的行被光标标记了出来。
|
||||
@ -280,17 +258,17 @@ void debugger::step_over_breakpoint() {
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
|
||||
作者:[TartanLlama ][a]
|
||||
作者:[Simon Brand][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[1]:https://linux.cn/article-8626-1.html
|
||||
[2]:https://linux.cn/article-8645-1.html
|
||||
[3]:https://linux.cn/article-8663-1.html
|
||||
[4]:https://linux.cn/article-8719-1.html
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://github.com/TartanLlama/libelfin/tree/fbreg
|
||||
@ -1,40 +1,26 @@
|
||||
开发 Linux 调试器第六部分:源码级逐步执行
|
||||
开发一个 Linux 调试器(六):源码级逐步执行
|
||||
============================================================
|
||||
|
||||
在前几篇博文中我们学习了 DWARF 信息以及它如何使我们将机器码和上层源码联系起来。这一次我们通过为我们的调试器添加源码级逐步调试将该知识应用于实际。
|
||||
|
||||
* * *
|
||||
|
||||
### 系列文章索引
|
||||
|
||||
随着后面文章的发布,这些链接会逐渐生效。
|
||||
|
||||
1. [启动][1]
|
||||
|
||||
1. [准备环境][1]
|
||||
2. [断点][2]
|
||||
|
||||
3. [寄存器和内存][3]
|
||||
|
||||
4. [Elves 和 dwarves][4]
|
||||
|
||||
5. [源码和信号][5]
|
||||
|
||||
6. [源码级逐步执行][6]
|
||||
|
||||
7. 源码级断点
|
||||
|
||||
8. 调用栈展开
|
||||
|
||||
9. 读取变量
|
||||
|
||||
10. 下一步
|
||||
|
||||
译者注:ELF([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format "Executable and Linkable Format") 可执行文件格式),DWARF(一种广泛使用的调试数据格式,参考 [WIKI](https://en.wikipedia.org/wiki/DWARF "DWARF WIKI"))
|
||||
* * *
|
||||
### 揭秘指令级逐步执行
|
||||
|
||||
### 暴露指令级逐步执行
|
||||
|
||||
我们已经超越了自己。首先让我们通过用户接口暴露指令级单步执行。我决定将它切分为能被其它部分代码利用的 `single_step_instruction` 和确保是否启用了某个断点的 `single_step_instruction_with_breakpoint_check`。
|
||||
我们正在超越了自我。首先让我们通过用户接口揭秘指令级单步执行。我决定将它切分为能被其它部分代码利用的 `single_step_instruction` 和确保是否启用了某个断点的 `single_step_instruction_with_breakpoint_check` 两个函数。
|
||||
|
||||
```
|
||||
void debugger::single_step_instruction() {
|
||||
@ -65,13 +51,11 @@ else if(is_prefix(command, "stepi")) {
|
||||
|
||||
利用新增的这些函数我们可以开始实现我们的源码级逐步执行函数。
|
||||
|
||||
* * *
|
||||
|
||||
### 实现逐步执行
|
||||
|
||||
我们打算编写这些函数非常简单的版本,但真正的调试器有 _thread plan_ 的概念,它封装了所有的单步信息。例如,调试器可能有一些复杂的逻辑去决定断点的位置,然后有一些回调函数用于判断单步操作是否完成。这其中有非常多的基础设施,我们只采用一种朴素的方法。我们可能会意外地跳过断点,但如果你愿意的话,你可以花一些时间把所有的细节都处理好。
|
||||
|
||||
对于跳出`step_out`,我们只是在函数的返回地址处设一个断点然后继续执行。我暂时还不想考虑调用栈展开的细节 - 这些都会在后面的部分介绍 - 但可以说返回地址就保存在栈帧开始的后 8 个字节中。因此我们会读取栈指针然后在内存相对应的地址读取值:
|
||||
对于跳出 `step_out`,我们只是在函数的返回地址处设一个断点然后继续执行。我暂时还不想考虑调用栈展开的细节 - 这些都会在后面的部分介绍 - 但可以说返回地址就保存在栈帧开始的后 8 个字节中。因此我们会读取栈指针然后在内存相对应的地址读取值:
|
||||
|
||||
```
|
||||
void debugger::step_out() {
|
||||
@ -103,7 +87,7 @@ void debugger::remove_breakpoint(std::intptr_t addr) {
|
||||
}
|
||||
```
|
||||
|
||||
接下来是跳入`step_in`。一个简单的算法是继续逐步执行指令直到新的一行。
|
||||
接下来是跳入 `step_in`。一个简单的算法是继续逐步执行指令直到新的一行。
|
||||
|
||||
```
|
||||
void debugger::step_in() {
|
||||
@ -118,7 +102,7 @@ void debugger::step_in() {
|
||||
}
|
||||
```
|
||||
|
||||
跳过`step_over` 对于我们来说是三个中最难的。理论上,解决方法就是在下一行源码中设置一个断点,但下一行源码是什么呢?它可能不是当前行后续的那一行,因为我们可能处于一个循环、或者某种条件结构之中。真正的调试器一般会检查当前正在执行什么指令然后计算出所有可能的分支目标,然后在所有分支目标中设置断点。对于一个小的项目,我不打算实现或者集成一个 x86 指令模拟器,因此我们要想一个更简单的解决办法。有几个可怕的选项,一个是一直逐步执行直到当前函数新的一行,或者在当前函数的每一行都设置一个断点。如果我们是要跳过一个函数调用,前者将会相当的低效,因为我们需要逐步执行那个调用图中的每个指令,因此我会采用第二种方法。
|
||||
跳过 `step_over` 对于我们来说是三个中最难的。理论上,解决方法就是在下一行源码中设置一个断点,但下一行源码是什么呢?它可能不是当前行后续的那一行,因为我们可能处于一个循环、或者某种条件结构之中。真正的调试器一般会检查当前正在执行什么指令然后计算出所有可能的分支目标,然后在所有分支目标中设置断点。对于一个小的项目,我不打算实现或者集成一个 x86 指令模拟器,因此我们要想一个更简单的解决办法。有几个可怕的选择,一个是一直逐步执行直到当前函数新的一行,或者在当前函数的每一行都设置一个断点。如果我们是要跳过一个函数调用,前者将会相当的低效,因为我们需要逐步执行那个调用图中的每个指令,因此我会采用第二种方法。
|
||||
|
||||
```
|
||||
void debugger::step_over() {
|
||||
@ -179,7 +163,7 @@ void debugger::step_over() {
|
||||
}
|
||||
```
|
||||
|
||||
我们需要移除我们设置的所有断点,以便不会泄露我们的逐步执行函数,为此我们把它们保存到一个 `std::vector` 中。为了设置所有断点,我们循环遍历行表条目直到找到一个不在我们函数范围内的。对于每一个,我们都要确保它不是我们当前所在的行,而且在这个位置还没有设置任何断点。
|
||||
我们需要移除我们设置的所有断点,以便不会泄露出我们的逐步执行函数,为此我们把它们保存到一个 `std::vector` 中。为了设置所有断点,我们循环遍历行表条目直到找到一个不在我们函数范围内的。对于每一个,我们都要确保它不是我们当前所在的行,而且在这个位置还没有设置任何断点。
|
||||
|
||||
```
|
||||
auto frame_pointer = get_register_value(m_pid, reg::rbp);
|
||||
@ -218,8 +202,6 @@ void debugger::step_over() {
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### 测试
|
||||
|
||||
我通过实现一个调用一系列不同函数的简单函数来进行测试:
|
||||
@ -267,17 +249,17 @@ int main() {
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
|
||||
作者:[TartanLlama ][a]
|
||||
作者:[Simon Brand][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[1]:https://linux.cn/article-8626-1.html
|
||||
[2]:https://linux.cn/article-8645-1.html
|
||||
[3]:https://linux.cn/article-8579-1.html
|
||||
[4]:https://linux.cn/article-8719-1.html
|
||||
[5]:https://linux.cn/article-8812-1.html
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://github.com/TartanLlama/minidbg/tree/tut_dwarf_step
|
||||
@ -0,0 +1,87 @@
|
||||
11 个使用 GNOME 3 桌面环境的理由
|
||||
============================================================
|
||||
|
||||
> GNOME 3 桌面的设计目的是简单、易于访问和可靠。GNOME 的受欢迎程度证明达成了这些目标。
|
||||
|
||||

|
||||
|
||||
去年年底,在我升级到 Fedora 25 后,新版本 [KDE][11] Plasma 出现了一些问题,这使我难以完成任何工作。所以我决定尝试其他的 Linux 桌面环境有两个原因。首先,我需要完成我的工作。第二,多年来一直使用 KDE,我想可能是尝试一些不同的桌面的时候了。
|
||||
|
||||
我尝试了几个星期的第一个替代桌面是我在 1 月份文章中写到的 [Cinnamon][12],然后我写了用了大约八个星期的[LXDE][13],我发现这里有很多事情我都喜欢。我用了 [GNOME 3][14] 几个星期来写了这篇文章。
|
||||
|
||||
像几乎所有的网络世界一样,GNOME 是缩写;它代表 “GNU 网络对象模型”(GNU Network Object Model)。GNOME 3 桌面设计的目的是简单、易于访问和可靠。GNOME 的受欢迎程度证明达成了这些目标。
|
||||
|
||||
GNOME 3 在需要大量屏幕空间的环境中非常有用。这意味着两个具有高分辨率的大屏幕,并最大限度地减少桌面小部件、面板和用来启动新程序之类任务的图标所需的空间。GNOME 项目有一套人机接口指南(HIG),用来定义人类应该如何与计算机交互的 GNOME 哲学。
|
||||
|
||||
### 我使用 GNOME 3 的十一个原因
|
||||
|
||||
1、 **诸多选择:** GNOME 以多种形式出现在我个人喜爱的 Fedora 等一些发行版上。你可以选择的桌面登录选项有 GNOME Classic、Xorg 上的 GNOME、GNOME 和 GNOME(Wayland)。从表面上看,启动后这些都是一样的,但它们使用不同的 X 服务器,或者使用不同的工具包构建。Wayland 在小细节上提供了更多的功能,例如动态滚动,拖放和中键粘贴。
|
||||
|
||||
2、 **入门教程:** 在用户第一次登录时会显示入门教程。它向你展示了如何执行常见任务,并提供了大量的帮助链接。教程在首次启动后关闭后也可轻松访问,以便随时访问该教程。教程非常简单直观,这为 GNOME 新用户提供了一个简单明了开始。要之后返回本教程,请点击 **Activities**,然后点击会显示程序的有九个点的正方形。然后找到并点击标为救生员图标的 **Help**。
|
||||
|
||||
3、 **桌面整洁:** 对桌面环境采用极简方法以减少杂乱,GNOME 设计为仅提供具备可用环境所必需的最低限度。你应该只能看到顶部栏(是的,它就叫这个),其他所有的都被隐藏,直到需要才显示。目的是允许用户专注于手头的任务,并尽量减少桌面上其他东西造成的干扰。
|
||||
|
||||
4、 **顶部栏:** 无论你想做什么,顶部栏总是开始的地方。你可以启动应用程序、注销、关闭电源、启动或停止网络等。不管你想做什么都很简单。除了当前应用程序之外,顶栏通常是桌面上唯一的其他对象。
|
||||
|
||||
5、 **dash:** 如下所示,在默认情况下, dash 包含三个图标。在开始使用应用程序时,会将它们添加到 dash 中,以便在其中显示最常用的应用程序。你也可以从应用程序查看器中将应用程序图标添加到 dash 中。
|
||||
|
||||
|
||||
|
||||
6、 **应用程序浏览器:** 我真的很喜欢这个可以从位于 GNOME 桌面左侧的垂直条上访问应用程序浏览器。除非有一个正在运行的程序,GNOME 桌面通常没有任何东西,所以你必须点击顶部栏上的 **Activities** 选区,点击 dash 底部的九个点组成的正方形,它是应用程序浏览器的图标。
|
||||
|
||||
|
||||
|
||||
如上所示,浏览器本身是一个由已安装的应用程序的图标组成的矩阵。矩阵下方有一对互斥的按钮,**Frequent** 和 **All**。默认情况下,应用程序浏览器会显示所有安装的应用。点击 **Frequent** 按钮,它会只显示最常用的应用程序。向上和向下滚动以找到要启动的应用程序。应用程序按名称按字母顺序显示。
|
||||
|
||||
[GNOME][6] 官网和内置的帮助有更多关于浏览器的细节。
|
||||
|
||||
7、 **应用程序就绪通知:** 当新启动的应用程序的窗口打开并准备就绪时,GNOME 会在屏幕顶部显示一个整齐的通知。只需点击通知即可切换到该窗口。与在其他桌面上搜索新打开的应用程序窗口相比,这节省了一些时间。
|
||||
|
||||
8、 **应用程序显示:** 为了访问不可见的其它运行的应用程序,点击 **Activities** 菜单。这将在桌面上的矩阵中显示所有正在运行的应用程序。点击所需的应用程序将其带到前台。虽然当前应用程序显示在顶栏中,但其他正在运行的应用程序不会。
|
||||
|
||||
9、 **最小的窗口装饰:** 桌面上打开窗口也很简单。标题栏上唯一显示的按钮是关闭窗口的 “X”。所有其他功能,如最小化、最大化、移动到另一个桌面等,可以通过在标题栏上右键单击来访问。
|
||||
|
||||
10、 **自动创建的新桌面:** 在使用下一空桌面的时候将自动创建的新的空桌面。这意味着总是有一个空的桌面在需要时可以使用。我使用的所有其他的桌面系统都可以让你在桌面活动时设置桌面数量,但必须使用系统设置手动完成。
|
||||
|
||||
11、 **兼容性:** 与我所使用的所有其他桌面一样,为其他桌面创建的应用程序可在 GNOME 上正常工作。这功能让我有可能测试这些桌面,以便我可以写出它们。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
GNOME 不像我以前用过的桌面。它的主要指导是“简单”。其他一切都要以简单易用为前提。如果你从入门教程开始,学习如何使用 GNOME 需要很少的时间。这并不意味着 GNOME 有所不足。它是一款始终保持不变的功能强大且灵活的桌面。
|
||||
|
||||
(题图:[Gunnar Wortmann][8] 通过 [Pixabay][9]。由 Opensource.com 修改。[CC BY-SA 4.0][10])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both 是位于北卡罗来纳州罗利的 Linux 和开源倡导者。他已经在 IT 行业工作了四十多年,并为 IBM 教授 OS/2 超过 20 年。在 IBM,他在 1981 年为初始的 IBM PC 写了第一个培训课程。他为红帽教授 RHCE 课程,曾在 MCI Worldcom、思科和北卡罗来纳州工作。他一直在使用 Linux 和开源软件近 20 年。
|
||||
|
||||
---------------
|
||||
|
||||
via: https://opensource.com/article/17/5/reasons-gnome
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://www.gnome.org/gnome-3/
|
||||
[7]:https://opensource.com/article/17/5/reasons-gnome?rate=MbGLV210A21ONuGAP8_Qa4REL7cKFvcllqUddib0qMs
|
||||
[8]:https://pixabay.com/en/users/karpartenhund-3077375/
|
||||
[9]:https://pixabay.com/en/garden-gnome-black-and-white-f%C3%B6hr-1584401/
|
||||
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
[12]:https://linux.cn/article-8606-1.html
|
||||
[13]:https://linux.cn/article-8434-1.html
|
||||
[14]:https://www.gnome.org/gnome-3/
|
||||
[15]:https://opensource.com/user/14106/feed
|
||||
[16]:https://opensource.com/article/17/5/reasons-gnome#comments
|
||||
[17]:https://opensource.com/users/dboth
|
||||
@ -1,72 +1,59 @@
|
||||
用 R 收集和映射推特数据的初学者向导
|
||||
============================================================
|
||||
|
||||
### 学习使用 R's twitteR 和 leaflet 包, 你就可以把任何话题的推文定位画在地图上。
|
||||
> 学习使用 R 的 twitteR 和 leaflet 包, 你就可以把任何话题的推文定位画在地图上。
|
||||
|
||||

|
||||
Image by :
|
||||

|
||||
|
||||
[琼斯·贝克][14]. [CC BY-SA 4.0][15]. 来源: [Cloud][16], [Globe][17]. Both [CC0][18].
|
||||
|
||||
当我开始学习 R ,出于研究的目的我也需要学习如何收集推特数据并对其进行映射。尽管网上关于这个话题的信息很多,但我发觉难以理解什么与收集并映射推特数据相关。我不仅是个 R 新手,而且对不同教程中技术关系不熟悉。尽管困难重重,我成功了!在这个教程里,我将以一种新手程序员都能看懂的方式攻略如何收集推特数据并将至展现在地图中。
|
||||
|
||||
程序设计和开发
|
||||
|
||||
* [新 Python 内容][1]
|
||||
|
||||
* [我们最新的 JavaScript 文章][2]
|
||||
|
||||
* [ Perl 近期投递][3]
|
||||
|
||||
* [红帽子开发者博客][4]
|
||||
当我开始学习 R ,我也需要学习如何出于研究的目的地收集推特数据并对其进行映射。尽管网上关于这个话题的信息很多,但我发觉难以理解什么与收集并映射推特数据相关。我不仅是个 R 新手,而且对各种教程中技术名词不熟悉。但尽管困难重重,我成功了!在这个教程里,我将以一种新手程序员都能看懂的方式来攻略如何收集推特数据并将至展现在地图中。
|
||||
|
||||
### 创建应用程序
|
||||
|
||||
如果你没有推特帐号,首先你需要 [注册一个][19].然后, 到 [apps.twitter.com][20] 创建一个允许你收集推特数据应用程序。别担心,创建应用程序极其简单。你创建的应用程序会与推特应用程序接口(API)相连。 想象 API 是一个多功能电子个人助手。你可以使用 API 让其他程序帮你做事。这样一来,你可以接入推特 API 令其收集数据。只需确保不要请求太多,因为推特数据请求次数是有[限制][21] 的。
|
||||
如果你没有推特帐号,首先你需要 [注册一个][19]。然后,到 [apps.twitter.com][20] 创建一个允许你收集推特数据的应用程序。别担心,创建应用程序极其简单。你创建的应用程序会与推特应用程序接口(API)相连。 想象 API 是一个多功能电子个人助手。你可以使用 API 让其它程序帮你做事。这样一来,你可以接入推特 API 令其收集数据。只需确保不要请求太多,因为推特数据请求次数是有[限制][21] 的。
|
||||
|
||||
收集推文有两个可用的 API 。你若想做一次性的推文收集,那么使用 **REST API**. 若是想在特定时间内持续收集,可以用 **streaming API**。教程中我主要使用 REST API.
|
||||
收集推文有两个可用的 API 。你若想做一次性的推文收集,那么使用 **REST API**. 若是想在特定时间内持续收集,可以用 **streaming API**。教程中我主要使用 REST API。
|
||||
|
||||
创建应用程序之后,前往 **Keys and Access Tokens** 标签。你需要 Consumer Key (API key), Consumer Secret (API secret), Access Token, 和 Access Token Secret 来在 R 中访问你的应用程序。
|
||||
创建应用程序之后,前往 **Keys and Access Tokens** 标签。你需要 Consumer Key (API key)、 Consumer Secret (API secret)、 Access Token 和 Access Token Secret 才能在 R 中访问你的应用程序。
|
||||
|
||||
### 收集推特数据
|
||||
|
||||
下一步是打开 R 准备写代码。对于初学者,我推荐使用 [RStudio][22], R 的集成开发环境 (IDE) 。我发现 RStudio 在解决问题和测试代码时很实用。 R 有访问 REST API 的包叫 **[twitteR][8]**.
|
||||
下一步是打开 R 准备写代码。对于初学者,我推荐使用 [RStudio][22],这是 R 的集成开发环境 (IDE) 。我发现 RStudio 在解决问题和测试代码时很实用。 R 有访问该 REST API 的包叫 **[twitteR][8]**。
|
||||
|
||||
打开 RStudio 并新建 RScript。做好这些之后,你需要安装和加载 **twitteR** 包:
|
||||
|
||||
```
|
||||
install.packages("twitteR")
|
||||
#installs TwitteR
|
||||
#安装 TwitteR
|
||||
library (twitteR)
|
||||
#loads TwitteR
|
||||
#载入 TwitteR
|
||||
```
|
||||
|
||||
安装并载入 **twitteR** 包之后,你得输入上文提及的应用程序的 API 信息:
|
||||
|
||||
```
|
||||
api_key <- ""
|
||||
#in the quotes, put your API key
|
||||
#在引号内放入你的 API key
|
||||
api_secret <- ""
|
||||
#in the quotes, put your API secret token
|
||||
#在引号内放入你的 API secret token
|
||||
token <- ""
|
||||
#in the quotes, put your token
|
||||
#在引号内放入你的 token
|
||||
token_secret <- ""
|
||||
#in the quotes, put your token secret
|
||||
#在引号内放入你的 token secret
|
||||
```
|
||||
|
||||
接下来,连接推特访问 API:
|
||||
接下来,连接推特访问 API:
|
||||
|
||||
```
|
||||
setup_twitter_oauth(api_key, api_secret, token, token_secret)
|
||||
```
|
||||
|
||||
我们来试试有关社区花园和农夫市场的推特研究:
|
||||
我们来试试让推特搜索有关社区花园和农夫市场:
|
||||
|
||||
```
|
||||
tweets <- searchTwitter("community garden OR #communitygarden OR farmers market OR #farmersmarket", n = 200, lang = "en")
|
||||
```
|
||||
|
||||
代码意思是搜索前200篇 **(n = 200)**英文 **(lang = "en")**推文, 包括关键词 **community garden** 或 **farmers market**或任何提及这些关键词的话题标签。
|
||||
这个代码意思是搜索前 200 篇 `(n = 200)` 英文 `(lang = "en")` 的推文, 包括关键词 `community garden` 或 `farmers market` 或任何提及这些关键词的话题标签。
|
||||
|
||||
推特搜索完成之后,在数据框中保存你的结果:
|
||||
|
||||
@ -85,9 +72,9 @@ write.csv(tweets.df, "C:\Users\YourName\Documents\ApptoMap\tweets.csv")
|
||||
|
||||
### 生成地图
|
||||
|
||||
现在你有了可以展示在地图上的数据。在此教程中,我们将用一个 R 包 **[Leaflet][9]**做一个基本的应用程序,一个热门 JavaScript 库做交互式地图。 Leaflet 使用 [**magrittr**][23] 管道运算符 (**%>%**), 使得它易于写代码因为语法更加自然。刚接触可能有点奇怪,但它确实降低了写代码的工作量。
|
||||
现在你有了可以展示在地图上的数据。在此教程中,我们将用一个 R 包 **[Leaflet][9]** 做一个基本的应用程序,这是一个生成交互式地图的热门 JavaScript 库。 Leaflet 使用 [magrittr][23] 管道运算符 (`%>%`), 因为其语法自然,易于写代码。刚接触可能有点奇怪,但它确实降低了写代码的工作量。
|
||||
|
||||
为了清晰度,在 RStudio 打开一个新的 R 脚本安装这些包:
|
||||
为了清晰起见,在 RStudio 打开一个新的 R 脚本安装这些包:
|
||||
|
||||
```
|
||||
install.packages("leaflet")
|
||||
@ -102,51 +89,47 @@ library(maps)
|
||||
read.csv("C:\Users\YourName\Documents\ApptoMap\tweets.csv", stringsAsFactors = FALSE)
|
||||
```
|
||||
|
||||
**stringAsFactors = FALSE** 意思是保留信息,不将它转化成 factors. (想了解 factors,读这篇文章["stringsAsFactors: An unauthorized biography"][24], by Roger Peng.)
|
||||
`stringAsFactors = FALSE` 意思是保留信息,不将它转化成 factors。 (想了解 factors,读这篇文章["stringsAsFactors: An unauthorized biography"][24], 作者 Roger Peng)
|
||||
|
||||
是时候制作你的 Leaflet 地图了。你将使用 **OpenStreetMap**基本地图来做你的地图:
|
||||
是时候制作你的 Leaflet 地图了。我们将使用 **OpenStreetMap**基本地图来做你的地图:
|
||||
|
||||
```
|
||||
m <- leaflet(mymap) %>% addTiles()
|
||||
```
|
||||
|
||||
我们来给基本地图加个范围。对于 **lng** 和 **lat**, 添加列名包括推文的经纬度,前面加个**~**。 **~longitude** 和 **~latitude** 在你的 **.csv** 文件中与列名相关的:
|
||||
我们在基本地图上加个圈。对于 `lng` 和 `lat`,输入包含推文的经纬度的列名,并在前面加个`~`。 `~longitude` 和 `~latitude` 指向你的 **.csv** 文件中与列名:
|
||||
|
||||
```
|
||||
m %>% addCircles(lng = ~longitude, lat = ~latitude, popup = mymap$type, weight = 8, radius = 40, color = "#fb3004", stroke = TRUE, fillOpacity = 0.8)
|
||||
```
|
||||
|
||||
运行你的代码。一个网页浏览器将会弹出并展示你的地图。这是我前面收集的推文的地图:
|
||||
运行你的代码。会弹出网页浏览器并展示你的地图。这是我前面收集的推文的地图:
|
||||
|
||||
### [leafletmap.jpg][6]
|
||||
|
||||

|
||||
|
||||
用定位、 Leaflet 和 OpenStreetMap 的推文地图, [CC-BY-SA][5]
|
||||
带定位的推文地图,使用了 Leaflet 和 OpenStreetMap [CC-BY-SA][5]
|
||||
|
||||
<add here="" leafletmap.jpg=""></add>
|
||||
|
||||
虽然你可能会对地图上的图文数量如此之小感到惊奇,典型地,只有1%的推文被地理编码了。我收集了总数为366的推文,但只有10(大概总推文的3%)是被地理编码了的。如果为能得到地理编码过的推文困扰,改变搜索关键词看看能不能得到更好的结果。
|
||||
虽然你可能会对地图上的图文数量如此之小感到惊奇,通常只有 1% 的推文记录了地理编码。我收集了总数为 366 的推文,但只有 10(大概总推文的 3%)是记录了地理编码的。如果你为得到记录了地理编码的推文而困扰,改变搜索关键词看看能不能得到更好的结果。
|
||||
|
||||
### 总结
|
||||
|
||||
对于初学者,把所有碎片结合起来去从推特数据生成一个 Leaflet 地图可能很艰难。 这个教程基于我完成这个任务的经验,我希望它能让你的学习过程变得更轻松。
|
||||
对于初学者,把以上所有碎片结合起来,从推特数据生成一个 Leaflet 地图可能很艰难。 这个教程基于我完成这个任务的经验,我希望它能让你的学习过程变得更轻松。
|
||||
|
||||
_Dorris Scott 将会在研讨会上提出这个话题, [从应用程序到地图: 用 R 收集映射社会媒体数据][10], at the [We Rise][11] Women in Tech Conference ([#WeRiseTech][12]) 六月 23-24 在亚特兰大。_
|
||||
(题图:[琼斯·贝克][14]. [CC BY-SA 4.0][15]. 来源: [Cloud][16], [Globe][17]. Both [CC0][18].)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Dorris Scott - Dorris Scott 是佐治亚大学的地理学博士生。她的研究重心是地理信息系统 (GIS), 地理数据科学, 可视化和公共卫生。她的论文是在一个 GIS 系统接口联系退伍军人福利医院的传统和非传统数据,帮助病人为他们的健康状况作出更为明朗的决定。
|
||||
|
||||
Dorris Scott - Dorris Scott 是佐治亚大学的地理学博士生。她的研究重心是地理信息系统(GIS)、 地理数据科学、可视化和公共卫生。她的论文是在一个 GIS 系统接口将退伍军人福利医院的传统和非传统数据结合起来,帮助病人为他们的健康状况作出更为明朗的决定。
|
||||
|
||||
-----------------
|
||||
via: https://opensource.com/article/17/6/collecting-and-mapping-twitter-data-using-r
|
||||
|
||||
作者:[Dorris Scott ][a]
|
||||
作者:[Dorris Scott][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,234 @@
|
||||
学习用 Python 编程时要避免的 3 个错误
|
||||
============================================================
|
||||
|
||||
> 这些错误会造成很麻烦的问题,需要数小时才能解决。
|
||||
|
||||

|
||||
|
||||
当你做错事时,承认错误并不是一件容易的事,但是犯错是任何学习过程中的一部分,无论是学习走路,还是学习一种新的编程语言都是这样,比如学习 Python。
|
||||
|
||||
为了让初学 Python 的程序员避免犯同样的错误,以下列出了我学习 Python 时犯的三种错误。这些错误要么是我长期以来经常犯的,要么是造成了需要几个小时解决的麻烦。
|
||||
|
||||
年轻的程序员们可要注意了,这些错误是会浪费一下午的!
|
||||
|
||||
### 1、 可变数据类型作为函数定义中的默认参数
|
||||
|
||||
这似乎是对的?你写了一个小函数,比如,搜索当前页面上的链接,并可选将其附加到另一个提供的列表中。
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=[]):
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
从表面看,这像是十分正常的 Python 代码,事实上它也是,而且是可以运行的。但是,这里有个问题。如果我们给 `add_to` 参数提供了一个列表,它将按照我们预期的那样工作。但是,如果我们让它使用默认值,就会出现一些神奇的事情。
|
||||
|
||||
试试下面的代码:
|
||||
|
||||
```
|
||||
def fn(var1, var2=[]):
|
||||
var2.append(var1)
|
||||
print var2
|
||||
|
||||
fn(3)
|
||||
fn(4)
|
||||
fn(5)
|
||||
```
|
||||
|
||||
可能你认为我们将看到:
|
||||
|
||||
```
|
||||
[3]
|
||||
[4]
|
||||
[5]
|
||||
```
|
||||
|
||||
但实际上,我们看到的却是:
|
||||
|
||||
```
|
||||
[3]
|
||||
[3, 4]
|
||||
[3, 4, 5]
|
||||
```
|
||||
|
||||
为什么呢?如你所见,每次都使用的是同一个列表,输出为什么会是这样?在 Python 中,当我们编写这样的函数时,这个列表被实例化为函数定义的一部分。当函数运行时,它并不是每次都被实例化。这意味着,这个函数会一直使用完全一样的列表对象,除非我们提供一个新的对象:
|
||||
|
||||
```
|
||||
fn(3, [4])
|
||||
```
|
||||
|
||||
```
|
||||
[4, 3]
|
||||
```
|
||||
|
||||
答案正如我们所想的那样。要想得到这种结果,正确的方法是:
|
||||
|
||||
```
|
||||
def fn(var1, var2=None):
|
||||
if not var2:
|
||||
var2 = []
|
||||
var2.append(var1)
|
||||
```
|
||||
|
||||
或是在第一个例子中:
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=None):
|
||||
if not add_to:
|
||||
add_to = []
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
这将在模块加载的时候移走实例化的内容,以便每次运行函数时都会发生列表实例化。请注意,对于不可变数据类型,比如[**元组**][7]、[**字符串**][8]、[**整型**][9],是不需要考虑这种情况的。这意味着,像下面这样的代码是非常可行的:
|
||||
|
||||
```
|
||||
def func(message="my message"):
|
||||
print message
|
||||
```
|
||||
|
||||
### 2、 可变数据类型作为类变量
|
||||
|
||||
这和上面提到的最后一个错误很相像。思考以下代码:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
这段代码看起来非常正常。我们有一个储存 URL 的对象。当我们调用 add_url 方法时,它会添加一个给定的 URL 到存储中。看起来非常正确吧?让我们看看实际是怎样的:
|
||||
|
||||
```
|
||||
a = URLCatcher()
|
||||
a.add_url('http://www.google.com')
|
||||
b = URLCatcher()
|
||||
b.add_url('http://www.bbc.co.hk')
|
||||
```
|
||||
|
||||
b.urls:
|
||||
|
||||
```
|
||||
['http://www.google.com', 'http://www.bbc.co.uk']
|
||||
```
|
||||
|
||||
a.urls:
|
||||
|
||||
```
|
||||
['http://www.google.com', 'http://www.bbc.co.uk']
|
||||
```
|
||||
|
||||
等等,怎么回事?!我们想的不是这样啊。我们实例化了两个单独的对象 `a` 和 `b`。把一个 URL 给了 `a`,另一个给了 `b`。这两个对象怎么会都有这两个 URL 呢?
|
||||
|
||||
这和第一个错例是同样的问题。创建类定义时,URL 列表将被实例化。该类所有的实例使用相同的列表。在有些时候这种情况是有用的,但大多数时候你并不想这样做。你希望每个对象有一个单独的储存。为此,我们修改代码为:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
def __init__(self):
|
||||
self.urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
现在,当创建对象时,URL 列表被实例化。当我们实例化两个单独的对象时,它们将分别使用两个单独的列表。
|
||||
|
||||
### 3、 可变的分配错误
|
||||
|
||||
这个问题困扰了我一段时间。让我们做出一些改变,并使用另一种可变数据类型 - [**字典**][10]。
|
||||
|
||||
```
|
||||
a = {'1': "one", '2': 'two'}
|
||||
```
|
||||
|
||||
现在,假设我们想把这个字典用在别的地方,且保持它的初始数据完整。
|
||||
|
||||
```
|
||||
b = a
|
||||
|
||||
b['3'] = 'three'
|
||||
```
|
||||
|
||||
简单吧?
|
||||
|
||||
现在,让我们看看原来那个我们不想改变的字典 `a`:
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
哇等一下,我们再看看 **b**?
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
等等,什么?有点乱……让我们回想一下,看看其它不可变类型在这种情况下会发生什么,例如一个**元组**:
|
||||
|
||||
```
|
||||
c = (2, 3)
|
||||
d = c
|
||||
d = (4, 5)
|
||||
```
|
||||
|
||||
现在 `c` 是 `(2, 3)`,而 `d` 是 `(4, 5)`。
|
||||
|
||||
这个函数结果如我们所料。那么,在之前的例子中到底发生了什么?当使用可变类型时,其行为有点像 **C** 语言的一个指针。在上面的代码中,我们令 `b = a`,我们真正表达的意思是:`b` 成为 `a` 的一个引用。它们都指向 Python 内存中的同一个对象。听起来有些熟悉?那是因为这个问题与先前的相似。其实,这篇文章应该被称为「可变引发的麻烦」。
|
||||
|
||||
列表也会发生同样的事吗?是的。那么我们如何解决呢?这必须非常小心。如果我们真的需要复制一个列表进行处理,我们可以这样做:
|
||||
|
||||
```
|
||||
b = a[:]
|
||||
```
|
||||
|
||||
这将遍历并复制列表中的每个对象的引用,并且把它放在一个新的列表中。但是要注意:如果列表中的每个对象都是可变的,我们将再次获得它们的引用,而不是完整的副本。
|
||||
|
||||
假设在一张纸上列清单。在原来的例子中相当于,A 某和 B 某正在看着同一张纸。如果有个人修改了这个清单,两个人都将看到相同的变化。当我们复制引用时,每个人现在有了他们自己的清单。但是,我们假设这个清单包括寻找食物的地方。如果“冰箱”是列表中的第一个,即使它被复制,两个列表中的条目也都指向同一个冰箱。所以,如果冰箱被 A 修改,吃掉了里面的大蛋糕,B 也将看到这个蛋糕的消失。这里没有简单的方法解决它。只要你记住它,并编写代码的时候,使用不会造成这个问题的方式。
|
||||
|
||||
字典以相同的方式工作,并且你可以通过以下方式创建一个昂贵副本:
|
||||
|
||||
```
|
||||
b = a.copy()
|
||||
```
|
||||
|
||||
再次说明,这只会创建一个新的字典,指向原来存在的相同的条目。因此,如果我们有两个相同的列表,并且我们修改字典 `a` 的一个键指向的可变对象,那么在字典 b 中也将看到这些变化。
|
||||
|
||||
可变数据类型的麻烦也是它们强大的地方。以上都不是实际中的问题;它们是一些要注意防止出现的问题。在第三个项目中使用昂贵复制操作作为解决方案在 99% 的时候是没有必要的。你的程序或许应该被改改,所以在第一个例子中,这些副本甚至是不需要的。
|
||||
|
||||
_编程快乐!在评论中可以随时提问。_
|
||||
|
||||
(题图: opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Pete Savage - Peter 是一位充满激情的开源爱好者,在过去十年里一直在推广和使用开源产品。他从 Ubuntu 社区开始,在许多不同的领域自愿参与音频制作领域的研究工作。在职业经历方面,他起初作为公司的系统管理员,大部分时间在管理和建立数据中心,之后在 Red Hat 担任 CloudForms 产品的主要测试工程师。
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python
|
||||
|
||||
作者:[Pete Savage][a]
|
||||
译者:[polebug](https://github.com/polebug)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psav
|
||||
[1]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python?rate=SfClhaQ6tQsJdKM8-YTNG00w53fsncvsNWafwuJbtqs
|
||||
[2]:http://www.google.com/
|
||||
[3]:http://www.bbc.co.uk/
|
||||
[4]:http://www.google.com/
|
||||
[5]:http://www.bbc.co.uk/
|
||||
[6]:https://opensource.com/user/36026/feed
|
||||
[7]:https://docs.python.org/2/library/functions.html?highlight=tuple#tuple
|
||||
[8]:https://docs.python.org/2/library/string.html
|
||||
[9]:https://docs.python.org/2/library/functions.html#int
|
||||
[10]:https://docs.python.org/2/library/stdtypes.html?highlight=dict#dict
|
||||
[11]:https://opensource.com/users/psav
|
||||
[12]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python#comments
|
||||
@ -0,0 +1,166 @@
|
||||
使用 Snapcraft 构建、测试并发布 Snap 软件包
|
||||
================================
|
||||
|
||||
snapcraft 是一个正在为其在 Linux 中的地位而奋斗的包管理系统,它为你重新设想了分发软件的方式。这套新的跨发行版的工具可以用来帮助你构建和发布 snap 软件包。接下来我们将会讲述怎么使用 CircleCI 2.0 来加速这个过程以及一些在这个过程中的可能遇到的问题。
|
||||
|
||||
### snap 软件包是什么?snapcraft 又是什么?
|
||||
|
||||
snap 是用于 Linux 发行版的软件包,它们在设计的时候吸取了像 Android 这样的移动平台和物联网设备上分发软件的经验教训。snapcraft 这个名字涵盖了 snap 和用来构建它们的命令行工具、这个 [snapcraft.io][1] 网站,以及在这些技术的支撑下构建的几乎整个生态系统。
|
||||
|
||||
snap 软件包被设计成用来隔离并封装整个应用程序。这些概念使得 snapcraft 提高软件安全性、稳定性和可移植性的目标得以实现,其中可移植性允许单个 snap 软件包不仅可以在 Ubuntu 的多个版本中安装,而且也可以在 Debian、Fedora 和 Arch 等发行版中安装。snapcraft 网站对其的描述如下:
|
||||
|
||||
> 为每个 Linux 桌面、服务器、云端或设备打包任何应用程序,并且直接交付更新。
|
||||
|
||||
### 在 CircleCI 2.0 上构建 snap 软件包
|
||||
|
||||
在 CircleCI 上使用 [CircleCI 2.0 语法][2] 来构建 snap 和在本地机器上基本相同。在本文中,我们将会讲解一个示例配置文件。如果您对 CircleCI 还不熟悉,或者想了解更多有关 2.0 的入门知识,您可以从 [这里][3] 开始。
|
||||
|
||||
### 基础配置
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
sudo snap install snapcraft --edge --classic
|
||||
/snap/bin/snapcraft
|
||||
```
|
||||
|
||||
这个例子使用了 `machine` 执行器来安装用于管理运行 snap 的可执行程序 `snapd` 和制作 snap 的 `snapcraft` 工具。
|
||||
|
||||
由于构建过程需要使用比较新的内核,所以我们使用了 `machine` 执行器而没有用 `docker` 执行器。在这里,Linux v4.4 已经足够满足我们的需求了。
|
||||
|
||||
### 用户空间的依赖关系
|
||||
|
||||
上面的例子使用了 `machine` 执行器,它实际上是一个内核为 Linux v4.4 的 [Ubuntu 14.04 (Trusty) 虚拟机][4]。如果 Trusty 仓库可以满足你的 project/snap 构建依赖,那就没问题。如果你的构建依赖需要其他版本,比如 Ubuntu 16.04 (Xenial),我们仍然可以在 `machine` 执行器中使用 Docker 来构建我们的 snap 软件包 。
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
docker run -v $(pwd):$(pwd) -t ubuntu:xenial sh -c "apt update -qq && apt install snapcraft -y && cd $(pwd) && snapcraft"
|
||||
|
||||
```
|
||||
|
||||
这个例子中,我们再次在 `machine` 执行器的虚拟机中安装了 `snapd`,但是我们决定将 snapcraft 安装在 Ubuntu Xenial 镜像构建的 Docker 容器中,并使用它来构建我们的 snap。这样,在 `snapcraft` 运行的过程中就可以使用在 Ubuntu 16.04 中可用的所有 `apt` 包。
|
||||
|
||||
### 测试
|
||||
|
||||
在我们的[博客](https://circleci.com/blog/)、[文档](https://circleci.com/docs/)以及互联网上已经有很多讲述如何对软件代码进行单元测试的内容。搜索你的语言或者框架和单元测试或者 CI 可以找到大量相关的信息。在 CircleCI 上构建 snap 软件包,我们最终会得到一个 `.snap` 的文件,这意味着除了创造它的代码外我们还可以对它进行测试。
|
||||
|
||||
### 工作流
|
||||
|
||||
假设我们构建的 snap 软件包是一个 webapp,我们可以通过测试套件来确保构建的 snap 可以正确的安装和运行,我们也可以试着安装它或者使用 [Selenium][5] 来测试页面加载、登录等功能正常工作。但是这里有一个问题,由于 snap 是被设计成可以在多个 Linux 发行版上运行,这就需要我们的测试套件可以在 Ubuntu 16.04、Fedora 25 和 Debian 9 等发行版中可以正常运行。这个问题我们可以通过 CircleCI 2.0 的工作流来有效地解决。
|
||||
|
||||
工作流是在最近的 CircleCI 2.0 测试版中加入的,它允许我们通过特定的逻辑流程来运行离散的任务。这样,使用单个任务构建完 snap 后,我们就可以开始并行的运行 snap 的发行版测试任务,每个任务对应一个不同的发行版的 [Docker 镜像][6] (或者在将来,还会有其他可用的执行器)。
|
||||
|
||||
这里有一个简单的例子:
|
||||
|
||||
```
|
||||
workflows:
|
||||
version: 2
|
||||
build-test-and-deploy:
|
||||
jobs:
|
||||
- build
|
||||
- acceptance_test_xenial:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_fedora_25:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_arch:
|
||||
requires:
|
||||
- build
|
||||
- publish:
|
||||
requires:
|
||||
- acceptance_test_xenial
|
||||
- acceptance_test_fedora_25
|
||||
- acceptance_test_arch
|
||||
|
||||
```
|
||||
在这个例子中首先构建了 snap,然后在四个不同的发行版上运行验收测试。如果所有的发行版都通过测试了,那么我们就可以运行发布 `job`,以便在将其推送到 snap 商店之前完成剩余的 snap 任务。
|
||||
|
||||
### 留着 .snap 包
|
||||
|
||||
为了测试我们在工作流示例中使用的 .snap 软件包,我们需要一种在构建的时候持久保存 snap 的方法。在这里我将提供两种方法:
|
||||
|
||||
1. **artifact** —— 在运行 `build` 任务的时候我们可以将 snaps 保存为一个 CircleCI 的 artifact(LCTT 译注:artifact 是 `snapcraft.yaml` 中的一个 `Plugin-specific` 关键字),然后在接下来的任务中检索它。CircleCI 工作流有自己处理共享 artifact 的方式,相关信息可以在 [这里][7] 找到。
|
||||
2. **snap 商店通道** —— 当发布 snap 软件包到 snap 商店时,有多种通道可供我们选择。将 snap 的主分支发布到 edge 通道以供内部或者用户测试已经成为一种常见做法。我们可以在 `build` 任务中完成这些工作,然后接下来的的任务就可以从 edge 通道来安装构建好的 snap 软件包。
|
||||
|
||||
第一种方法速度更快,并且它还可以在 snap 软包上传到 snap 商店供用户甚至是测试用户使用之前对 snap 进行验收测试。第二种方法的好处是我们可以从 snap 商店安装 snap,这也是 CI 运行期间的测试项之一。
|
||||
|
||||
### snap 商店的身份验证
|
||||
|
||||
[snapcraft-config-generator.py][8] 脚本可以生成商店证书并将其保存到 `.snapcraft/snapcraft.cfg` 中(注意:在运行公共脚本之前一定要对其进行检查)。如果觉得在你仓库中使用明文来保存这个文件不安全,你可以用 `base64` 编码该文件,并将其存储为一个[私有环境变量][9],或者你也可以对文件 [进行加密][10],并将密钥存储在一个私有环境变量中。
|
||||
|
||||
下面是一个示例,将商店证书放在一个加密的文件中,并在 `deploy` 环节中使用它将 snap 发布到 snap 商店中。
|
||||
|
||||
```
|
||||
- deploy:
|
||||
name: Push to Snap Store
|
||||
command: |
|
||||
openssl aes-256-cbc -d -in .snapcraft/snapcraft.encrypted -out .snapcraft/snapcraft.cfg -k $KEY
|
||||
/snap/bin/snapcraft push *.snap
|
||||
|
||||
```
|
||||
|
||||
除了 `deploy` 任务之外,工作流示例同之前的一样, `deploy` 任务只有当验收测试任务通过时才会运行。
|
||||
|
||||
### 更多的信息
|
||||
|
||||
* Alan Pope 在 [论坛中发的帖子][11]:“popey” 是 Canonical 的员工,他在 snapcraft 的论坛上写了这篇文章,并启发作者写了这篇博文。
|
||||
* [snapcraft 网站][12]: snapcraft 官方网站。
|
||||
* [snapcraft 的 CircleCI Bug 报告][13]:在 Launchpad 上有一个开放的 bug 报告页面,用来改善 CircleCI 对 snapcraft 的支持。同时这将使这个过程变得更简单并且更“正式”。期待您的支持。
|
||||
* 怎么使用 CircleCI 构建 [Nextcloud][14] 的 snap:这里有一篇题为 [“复杂应用的持续验收测试”][15] 的博文,它同时也影响了这篇博文。
|
||||
|
||||
|
||||
这篇客座文章的作者是 Ricardo Feliciano —— CircleCi 的开发者传道士。如果您也有兴趣投稿,请联系 ubuntu-iot@canonical.com。原始文章可以从 [这里][18] 找到。
|
||||
|
||||
---
|
||||
|
||||
via: https://insights.ubuntu.com/2017/06/28/build-test-and-publish-snap-packages-using-snapcraft/
|
||||
|
||||
译者简介:
|
||||
|
||||
> 常年混迹于 snapcraft.io,对 Ubuntu Core、snaps 和 snapcraft 有浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人的公众号: `Snapcraft`
|
||||
|
||||
作者:Ricardo Feliciano
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
[1]: https://snapcraft.io/
|
||||
[2]:https://circleci.com/docs/2.0/
|
||||
[3]: https://circleci.com/docs/2.0/first-steps/
|
||||
[4]: https://circleci.com/docs/1.0/differences-between-trusty-and-precise/
|
||||
[5]:http://www.seleniumhq.org/
|
||||
[6]:https://circleci.com/docs/2.0/building-docker-images/
|
||||
[7]: https://circleci.com/docs/2.0/workflows/#using-workspaces-to-share-artifacts-among-jobs
|
||||
[8]:https://gist.github.com/3v1n0/479ad142eccdd17ad7d0445762dea755
|
||||
[9]: https://circleci.com/docs/1.0/environment-variables/#setting-environment-variables-for-all-commands-without-adding-them-to-git
|
||||
[10]: https://github.com/circleci/encrypted-files
|
||||
[11]:https://forum.snapcraft.io/t/building-and-pushing-snaps-using-circleci/789
|
||||
[12]:https://snapcraft.io/
|
||||
[13]:https://bugs.launchpad.net/snapcraft/+bug/1693451
|
||||
[14]:https://nextcloud.com/
|
||||
[15]: https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[16]:https://nextcloud.com/
|
||||
[17]:https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[18]: https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
[19]:https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
@ -1,53 +1,52 @@
|
||||
物联网对 Linux 恶意软件的助长
|
||||
物联网助长了 Linux 恶意软件
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
针对 Linux 系统的恶意软件正在增长,这主要是由于连接到物联网设备的激增。
|
||||
|
||||
这是上周发布的网络安全设备制造商 [WatchGuard Technologies][4] 的一篇报告。
|
||||
这是网络安全设备制造商 [WatchGuard Technologies][4] 上周发布的的一篇报告中所披露的。
|
||||
|
||||
该报告分析了全球 26,000 多件设备收集到的数据,今年第一季度的前 10 中发现了三个针对 Linux 的恶意软件,而上一季度仅有一个。
|
||||
该报告分析了全球 26,000 多件设备收集到的数据,今年第一季度的前 10 名恶意软件中发现了三个针对 Linux 的恶意软件,而上一季度仅有一个。
|
||||
|
||||
WatchGuard 的 CTO Corey Nachreiner 和安全威胁分析师 Marc Laliberte 写道:“Linux 攻击和恶意软件正在兴起。我们相信这是因为 IoT 设备的系统性弱点与其快速增长相结合,它正在将僵尸网络作者转向 Linux 平台。”
|
||||
WatchGuard 的 CTO Corey Nachreiner 和安全威胁分析师 Marc Laliberte 写道:“Linux 上的攻击和恶意软件正在兴起。我们相信这是因为 IoT 设备的系统性弱点与其快速增长相结合的结果,它正在引导僵尸网络的作者们转向 Linux 平台。”
|
||||
|
||||
但是,他们建议“阻止入站 Telnet 和 SSH,以及使用复杂的管理密码,可以防止绝大多数潜在的攻击”。
|
||||
他们建议“阻止入站的 Telnet 和 SSH,以及使用复杂的管理密码,可以防止绝大多数潜在的攻击”。
|
||||
|
||||
### 黑客的新大道
|
||||
|
||||
Laliberte 观察到,Linux 恶意软件在去年年底随着 Mirai 僵尸网络开始增长。Mirai 在九月份曾经用来攻击部分互联网的基础设施,使数百万用户离线。
|
||||
Laliberte 观察到,Linux 恶意软件在去年年底随着 Mirai 僵尸网络开始增长。Mirai 在九月份曾经用来攻击部分互联网的基础设施,迫使数百万用户断线。
|
||||
|
||||
他告诉 LinuxInsider,“现在,随着物联网设备的飞速发展,一条全新的大道正在向攻击者开放。我们相信,随着互联网上新目标的出现,Linux 恶意软件会逐渐增多。”
|
||||
他告诉 LinuxInsider,“现在,随着物联网设备的飞速发展,一条全新的大道正在向攻击者们开放。我们相信,随着互联网上新目标的出现,Linux 恶意软件会逐渐增多。”
|
||||
|
||||
Laliberte 继续说,物联网设备制造商并没有对安全性表现出很大的关注。他们的目标是使他们的设备能够使用、便宜,制造快速。
|
||||
Laliberte 继续说,物联网设备制造商并没有对安全性表现出很大的关注。他们的目标是使他们的设备能够使用、便宜,能够快速制造。
|
||||
|
||||
他说:“他们真的不关心开发过程中的安全。”
|
||||
他说:“开发过程中他们真的不关心安全。”
|
||||
|
||||
### 微不足道的追求
|
||||
### 轻易捕获
|
||||
|
||||
[Alert Logic][5] 的网络安全宣传员 Paul Fletcher说,大多数物联网制造商都使用 Linux 的裁剪版本,因为操作系统需要最少的系统资源来运行。
|
||||
[Alert Logic][5] 的网络安全布道师 Paul Fletcher 说,大多数物联网制造商都使用 Linux 的裁剪版本,因为操作系统需要最少的系统资源来运行。
|
||||
|
||||
他告诉 LinuxInsider,“当你将大量与互联网连接的物联网设备结合在一起时,这相当于在线大量的 Linux 系统,它们可用于攻击。”
|
||||
|
||||
为了使设备易于使用,制造商使用的协议对黑客也是友好的。
|
||||
为了使设备易于使用,制造商使用的协议对黑客来说也是用户友好的。
|
||||
|
||||
Fletcher 说:“攻击者可以访问这些易受攻击的接口,然后上传并执行他们选择的恶意代码。”
|
||||
|
||||
他指出,厂商经常对设备的默认设置很差。
|
||||
他指出,厂商经常给他们的设备很差的默认设置。
|
||||
|
||||
Fletcher说:“通常,管理员帐户是空密码或易于猜测的默认密码,例如‘password123’。”
|
||||
Fletcher 说:“通常,管理员帐户是空密码或易于猜测的默认密码,例如 ‘password123’。”
|
||||
|
||||
[SANS 研究所][6] 首席研究员 Johannes B. Ullrich 表示,安全问题通常是“本身不限定 Linux”。
|
||||
[SANS 研究所][6] 首席研究员 Johannes B. Ullrich 表示,安全问题通常“本身不是 Linux 特有的”。
|
||||
|
||||
他告诉L inuxInsider,“制造商对他们如何配置设备不屑一顾,所以他们使这些设备的利用变得微不足道。”
|
||||
他告诉 LinuxInsider,“制造商对他们如何配置这些设备不屑一顾,所以他们使这些设备的利用变得非常轻易。”
|
||||
|
||||
### 10 大恶意软件
|
||||
|
||||
这些 Linux 恶意软件在 WatchGuard 的第一季度的统计数据中占据了前 10 名:
|
||||
|
||||
* Linux/Exploit,它使用几种木马来扫描可以列入僵尸网络的设备。
|
||||
|
||||
* Linux/Downloader,它使用恶意的 Linux shell 脚本。Linux 运行在许多不同的架构上,如 ARM、MIPS 和传统的 x8 6芯片组。报告解释说,一个根据架构编译的可执行文件不能在不同架构的设备上运行。因此,一些 Linux 攻击利用 dropper shell 脚本下载并安装它们所感染的体系架构的适当恶意组件。
|
||||
这些 Linux 恶意软件在 WatchGuard 的第一季度的统计数据中占据了前 10 名的位置:
|
||||
|
||||
* Linux/Exploit,它使用几种木马来扫描可以加入僵尸网络的设备。
|
||||
* Linux/Downloader,它使用恶意的 Linux shell 脚本。Linux 可以运行在许多不同的架构上,如 ARM、MIPS 和传统的 x86 芯片组。报告解释说,一个为某个架构编译的可执行文件不能在不同架构的设备上运行。因此,一些 Linux 攻击利用 dropper shell 脚本下载并安装适合它们所要感染的体系架构的恶意组件。
|
||||
* Linux/Flooder,它使用了 Linux 分布式拒绝服务工具,如 Tsunami,用于执行 DDoS 放大攻击,以及 Linux 僵尸网络(如 Mirai)使用的 DDoS 工具。报告指出:“正如 Mirai 僵尸网络向我们展示的,基于 Linux 的物联网设备是僵尸网络军队的主要目标。
|
||||
|
||||
### Web 服务器战场
|
||||
@ -56,27 +55,27 @@ WatchGuard 报告指出,敌人攻击网络的方式发生了变化。
|
||||
|
||||
公司发现,到 2016 年底,73% 的 Web 攻击针对客户端 - 浏览器和配套软件。今年头三个月发生了彻底改变,82% 的 Web 攻击集中在 Web 服务器或基于 Web 的服务上。
|
||||
|
||||
报告合著者 Nachreiner 和 Laliberte 写道:“我们不认为下载风格的攻击将会消失,但似乎攻击者已经集中力量和工具来试图利用 Web 服务器攻击。”
|
||||
报告合著者 Nachreiner 和 Laliberte 写道:“我们不认为下载式的攻击将会消失,但似乎攻击者已经集中力量和工具来试图利用 Web 服务器攻击。”
|
||||
|
||||
他们也发现,自 2006 年底以来,杀毒软件的有效性有所下降。
|
||||
|
||||
Nachreiner 和 Laliberte 报道说:“连续的第二季,我们看到使用传统的杀毒软件解决方案漏掉了使用我们更先进的解决方案可以捕获的大量恶意软件,实际上已经从 30% 上升到了 38%。”
|
||||
Nachreiner 和 Laliberte 报道说:“连续的第二个季度,我们看到使用传统的杀毒软件解决方案漏掉了使用我们更先进的解决方案可以捕获的大量恶意软件,实际上已经从 30% 上升到了 38% 漏掉了。”
|
||||
|
||||
他说:“如今网络犯罪分子使用许多精妙的技巧来重新包装恶意软件,从而避免了基于签名的检测。这就是为什么使用基本杀毒的许多网络成为诸如赎金软件之类威胁的受害者。”
|
||||
他说:“如今网络犯罪分子使用许多精妙的技巧来重新包装恶意软件,从而避免了基于签名的检测。这就是为什么使用基本的杀毒软件的许多网络成为诸如赎金软件之类威胁的受害者。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
John P. Mello Jr.自 2003 年以来一直是 ECT 新闻网记者。他的重点领域包括网络安全、IT问题、隐私权、电子商务、社交媒体、人工智能、大数据和消费电子。 他撰写和编辑了众多出版物,包括“波士顿商业杂志”、“波士顿凤凰”、“Megapixel.Net” 和 “政府安全新闻”。给 John 发邮件。
|
||||
John P. Mello Jr.自 2003 年以来一直是 ECT 新闻网记者。他的重点领域包括网络安全、IT问题、隐私权、电子商务、社交媒体、人工智能、大数据和消费电子。 他撰写和编辑了众多出版物,包括“波士顿商业杂志”、“波士顿凤凰”、“Megapixel.Net” 和 “政府安全新闻”。
|
||||
|
||||
-------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84652.html
|
||||
|
||||
作者:[John P. Mello Jr ][a]
|
||||
作者:[John P. Mello Jr][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
309
published/20170710 How Linux containers have evolved.md
Normal file
309
published/20170710 How Linux containers have evolved.md
Normal file
@ -0,0 +1,309 @@
|
||||
Linux 容器演化史
|
||||
============================================================
|
||||
|
||||
> 容器在过去几年内取得很大的进展。现在我们来回顾它发展的时间线。
|
||||
|
||||

|
||||
|
||||
### Linux 容器是如何演变的
|
||||
|
||||
在过去几年内,容器不仅成为了开发者们热议的话题,还受到了企业的关注。持续增长的关注使得在它的安全性、可扩展性以及互用性等方面的需求也得以增长。满足这些需求需要很大的工程量,下面我们讲讲在红帽这样的企业级这些工程是如何发展的。
|
||||
|
||||
我在 2013 年秋季第一次遇到 Docker 公司(Docker.io)的代表,那时我们在设法使 Red Hat Enterprise Linux (RHEL) 支持 Docker 容器(现在 Docker 项目的一部分已经更名为 _Moby_)的运行。在移植过程中,我们遇到了一些问题。处理容器镜像分层所需的写时拷贝(COW)文件系统成了我们第一个重大阻碍。Red Hat 最终贡献了一些 COW 文件系统实现,包括 [Device Mapper][13]、[btrf][14],以及 [OverlayFS][15] 的第一个版本。在 RHEL 上,我们默认使用 Device Mapper, 但是我们在 OverlayFS 上也已经取得了很大进展。
|
||||
|
||||
我们在用于启动容器的工具上遇到了第二个主要障碍。那时的上游 docker 使用 [LXC][16] 工具来启动容器,然而我们不想在 RHEL 上支持 LXC 工具集。而且在与上游 docker 合作之前,我们已经与 [libvrit][17] 团队携手构建了 [virt-sandbox][18] 工具,它使用 `libvrit-lxc` 来启动容器。
|
||||
|
||||
在那时,红帽里有员工提到一个好办法,换掉 LXC 工具集而添加桥接器,以便 docker 守护进程通过 `libvirt-lxc` 与 libvirt 通讯来启动容器。这个方案也有一些顾虑。考虑下面这个例子,使用 Docker 客户端(`docker-cli`)来启动容器,各层调用会在容器进程(`pid1OfContainer`)之前依次启动:
|
||||
|
||||
> **docker-cli → docker-daemon → libvirt-lxc → pid1OfContainer**
|
||||
|
||||
我不是很喜欢这个方案,因为它在启动容器的工具与最终的容器进程之间有两个守护进程。
|
||||
|
||||
我的团队与上游 docker 开发者合作实现了一个原生的 [Go 编程语言][19] 版本的容器运行时,叫作 [libcontainer][20]。这个库作为 [OCI 运行时规范]的最初版实现与 runc 一同发布。
|
||||
|
||||
> **docker-cli → docker-daemon @ pid1OfContainer**
|
||||
|
||||
大多数人误认为当他们执行一个容器时,容器进程是作为 `docker-cli` 的子进程运行的。实际上他们执行的是一个客户端/服务端请求操作,容器进程是在一个完全单独的环境作为子进程运行的。这个客户端/服务端请求会导致不稳定性和潜在的安全问题,而且会阻碍一些实用特性的实现。举个例子,[systemd][22] 有个叫做套接字唤醒的特性,你可以将一个守护进程设置成仅当相应的套结字被连接时才启动。这意味着你的系统可以节约内存并按需执行服务。套结字唤醒的工作原理是 systemd 代为监听 TCP 套结字,并在数据包到达套结字时启动相应的服务。一旦服务启动完毕,systemd 将套结字交给新启动的守护进程。如果将守护进程运行在基于 docker 的容器中就会出现问题。systemd 的 unit 文件通过 Docker CLI 执行容器,然而这时 systemd 却无法简单地经由 Docker CLI 将套结字转交给 Docker 守护进程。
|
||||
|
||||
类似这样的问题让我们意识到我们需要一个运行容器的替代方案。
|
||||
|
||||
#### 容器编排问题
|
||||
|
||||
上游的 docker 项目简化了容器的使用过程,同时也是一个绝佳的 Linux 容器学习工具。你可以通过一条简单的命令快速地体验如何启动一个容器,例如运行 `docker run -ti fedora sh` 然后你就立即处于一个容器之中。
|
||||
|
||||
当开始把许多容器组织成一个功能更为强大的应用时,你才能体会到容器真正的能力。但是问题在于伴随多容器应用而来的高复杂度使得简单的 Docker 命令无法胜任编排工作。你要如何管理容器应用在有限资源的集群节点间的布局与编排?如何管理它们的生命周期等等?
|
||||
|
||||
在第一届 DockerCon,至少有 7 种不同的公司/开源项目展示了其容器的编排方案。红帽演示了 [OpenShift][23] 的 [geard][24] 项目,它基于 OpenShift v2 的容器(叫作 gears)。红帽觉得我们需要重新审视容器编排,而且可能要与开源社区的其他人合作。
|
||||
|
||||
Google 则演示了 Kubernetes 容器编排工具,它来源于 Google 对其自内部架构进行编排时所积累的知识经验。OpenShift 决定放弃 Gear 项目,开始和 Google 一同开发 Kubernetes。 现在 Kubernetes 是 GitHub 上最大的社区项目之一。
|
||||
|
||||
#### Kubernetes
|
||||
|
||||
Kubernetes 原先被设计成使用 Google 的 [lmctfy][26] 容器运行时环境来完成工作。在 2014 年夏天,lmctfy 兼容了 docker。Kubernetes 还会在 kubernetes 集群的每个节点运行一个 [kubelet][27] 守护进程,这意味着原先使用 docker 1.8 的 kubernetes 工作流看起来是这样的:
|
||||
|
||||
> **kubelet → dockerdaemon @ PID1**
|
||||
|
||||
回退到了双守护进程的模式。
|
||||
|
||||
然而更糟糕的是,每次 docker 的新版本发布都使得 kubernetes 无法工作。Docker 1.10 切换镜像底层存储方案导致所有镜像重建。而 Docker 1.11 开始使用 `runc` 来启动镜像:
|
||||
|
||||
> **kubelet → dockerdaemon @ runc @PID1**
|
||||
|
||||
Docker 1.12 则增加了一个容器守护进程用于启动容器。其主要目的是为了支持 Docker Swarm (Kubernetes 的竞争者之一):
|
||||
|
||||
> **kubelet → dockerdaemon → containerd @runc @ pid1**
|
||||
|
||||
如上所述,_每一次_ docker 发布都破坏了 Kubernetes 的功能,这也是为什么 Kubernetes 和 OpenShift 请求我们为他们提供老版本 Docker 的原因。
|
||||
|
||||
现在我们有了一个三守护进程的系统,只要任何一个出现问题,整个系统都将崩溃。
|
||||
|
||||
### 走向容器标准化
|
||||
|
||||
#### CoreOS、rkt 和其它替代运行时
|
||||
|
||||
因为 docker 运行时带来的问题,几个组织都在寻求一个替代的运行时。CoreOS 就是其中之一。他们提供了一个 docker 容器运行时的替代品,叫 _rkt_ (rocket)。他们同时还引入一个标准容器规范,称作 _appc_ (App Container)。从根本上讲,他们是希望能使得所有人都使用一个标准规范来管理容器镜像中的应用。
|
||||
|
||||
这一行为为标准化工作树立了一面旗帜。当我第一次开始和上游 docker 合作时,我最大的担忧就是最终我们会分裂出多个标准。我不希望类似 RPM 和 DEB 之间的战争影响接下来 20 年的 Linux 软件部署。appc 的一个成果是它说服了上游 docker 与开源社区合作创建了一个称作 [开放容器计划(Open Container Initiative)][28] (OCI) 的标准团体。
|
||||
|
||||
OCI 已经着手制定两个规范:
|
||||
|
||||
[OCI 运行时规范][6]:OCI 运行时规范“旨在规范容器的配置、执行环境以及生命周期”。它定义了容器的磁盘存储,描述容器内运行的应用的 JSON 文件,容器的生成和执行方式。上游 docker 贡献了 libcontainer 并构建了 runc 作为 OCI 运行时规范的默认实现。
|
||||
|
||||
[OCI 镜像文件格式规范][7]:镜像文件格式规范主要基于上游 docker 所使用的镜像格式,定义了容器仓库中实际存储的容器镜像格式。该规范使得应用开发者能为应用使用单一的标准化格式。一些 appc 中描述的概念被加入到 OCI 镜像格式规范中得以保留。这两份规范 1.0 版本的发布已经临近(LCTT 译注:[已经发布](https://linux.cn/article-8778-1.html))。上游 docker 已经同意在 OCI 镜像规范定案后支持该规范。Rkt 现在既支持运行 OCI 镜像也支持传统的上游 docker 镜像。
|
||||
|
||||
OCI 通过为工业界提供容器镜像与运行时标准化的环境,帮助在工具与编排领域解放创新的力量。
|
||||
|
||||
#### 抽象运行时接口
|
||||
|
||||
得益于标准化工作, Kubernetes 编排领域也有所创新。作为 Kubernetes 的一大支持者,CoreOS 提交了一堆补丁,使 Kubernetes 除了 docker 引擎外还能通过 rkt 运行容器并且与容器通讯。Google 和 Kubernetes 上游预见到增加这些补丁和将来可能添加的容器运行时接口将给 Kubernetes 带来的代码复杂度,他们决定实现一个叫作 容器运行时接口(Container Runtime Interface) (CRI) 的 API 协议规范。于是他们将 Kubernetes 由原来的直接调用 docker 引擎改为调用 CRI,这样任何人都可以通过实现服务器端的 CRI 来创建支持
|
||||
Kubernetes 的容器运行时。Kubernetes 上游还为 CRI 开发者们创建了一个大型测试集以验证他们的运行时对 Kubernetes 的支持情况。开发者们还在努力地移除 Kubernetes 对 docker 引擎的调用并将它们隐藏在一个叫作 docker-shim 的薄抽象层后。
|
||||
|
||||
### 容器工具的创新
|
||||
|
||||
#### 伴随 skopeo 而来的容器仓库创新
|
||||
|
||||
几年前我们正与 Atomic 项目团队合作构建 [atomic CLI][29]。我们希望实现一个功能,在镜像还在镜像仓库时查看它的细节。在那时,查看仓库中的容器镜像相关 JSON 文件的唯一方法是将镜像拉取到本地服务器再通过 `docker inspect` 来查看 JSON 文件。这些镜像可能会很大,上至几个 GiB。为了允许用户在不拉取镜像的情况下查看镜像细节,我们希望在 `docker inspect` 接口添加新的 `--remote` 参数。上游 docker 拒绝了我们的代码拉取请求(PR),告知我们他们不希望将 Docker CLI 复杂化,我们可以构建我们自己的工具去实现相同的功能。
|
||||
|
||||
我们的团队在 [Antonio Murdaca][30] 的领导下执行这个提议,构建了 [skopeo][31]。Antonio 没有止步于拉取镜像相关的 JSON 文件,而是决定实现一个完整的协议,用于在容器仓库与本地主机之间拉取与推送容器镜像。
|
||||
|
||||
skopeo 现在被 atomic CLI 大量用于类似检查容器更新的功能以及 [atomic 扫描][32] 当中。Atomic 也使用 skopeo 取代上游 docker 守护进程拉取和推送镜像的功能。
|
||||
|
||||
#### Containers/image
|
||||
|
||||
我们也曾和 CoreOS 讨论过在 rkt 中使用 skopeo 的可能,然而他们表示不希望运行一个外部的协助程序,但是会考虑使用 skopeo 所使用的代码库。于是我们决定将 skopeo 分离为一个代码库和一个可执行程序,创建了 [image][8] 代码库。
|
||||
|
||||
[containers/images][33] 代码库和 skopeo 被几个其它上游项目和云基础设施工具所使用。Skopeo 和 containers/image 已经支持 docker 和多个存储后端,而且能够在容器仓库之间移动容器镜像,还拥有许多酷炫的特性。[skopeo 的一个优点][34]是它不需要任何守护进程的协助来完成任务。Containers/image 代码库的诞生使得类似[容器镜像签名][35]等增强功能得以实现。
|
||||
|
||||
#### 镜像处理与扫描的创新
|
||||
|
||||
我在前文提到 atomic CLI。我们构建这个工具是为了给容器添加不适合 docker CLI 或者我们无法在上游 docker 中实现的特性。我们也希望获得足够灵活性,将其用于开发额外的容器运行时、工具和存储系统。Skopeo 就是一例。
|
||||
|
||||
我们想要在 atomic 实现的一个功能是 `atomic mount`。从根本上讲,我们希望从 Docker 镜像存储(上游 docker 称之为 graph driver)中获取内容,把镜像挂在到某处,以便用工具来查看该镜像。如果你使用上游的 docker,查看镜像内容的唯一方法就是启动该容器。如果其中有不可信的内容,执行容器中的代码来查看它会有潜在危险。通过启动容器查看镜像内容的另一个问题是所需的工具可能没有被包含在容器镜像当中。
|
||||
|
||||
大多数容器镜像扫描器遵循以下流程:它们连接到 Docker 的套结字,执行一个 `docker save` 来创建一个 tar 打包文件,然后在磁盘上分解这个打包文件,最后查看其中的内容。这是一个很慢的过程。
|
||||
|
||||
通过 `atomic mount`,我们希望直接使用 Docker graph driver 挂载镜像。如果 docker 守护进程使用 device mapper,我们将挂载这个设备。如果它使用 overlay,我们会挂载 overlay。这个操作很快而且满足我们的需求。现在你可以执行:
|
||||
|
||||
```
|
||||
# atomic mount fedora /mnt
|
||||
# cd /mnt
|
||||
```
|
||||
|
||||
然后开始探查内容。你完成相应工作后,执行:
|
||||
|
||||
```
|
||||
# atomic umount /mnt
|
||||
```
|
||||
|
||||
我们在 `atomic scan` 中使用了这一特性,实现了一个快速的容器扫描器。
|
||||
|
||||
#### 工具协作的问题
|
||||
|
||||
其中一个严重的问题是 `atomic mount` 隐式地执行这些工作。Docker 守护进程不知道有另一个进程在使用这个镜像。这会导致一些问题(例如,如果你先挂载了 Fedora 镜像,然后某个人执行了 `docker rmi fedora` 命令,docker 守护进程移除镜像时就会产生奇怪的操作失败,同时报告说相应的资源忙碌)。Docker 守护进程可能因此进入一个奇怪的状态。
|
||||
|
||||
#### 容器存储系统
|
||||
|
||||
为了解决这个问题,我们开始尝试将从上游 docker 守护进程剥离出来的 graph driver 代码拉取到我们的代码库中。Docker 守护进程在内存中为 graph driver 完成所有锁的获取。我们想要将这些锁操作转移到文件系统中,这样我们可以支持多个不同的进程来同时操作容器的存储系统,而不用通过单一的守护进程。
|
||||
|
||||
我们创建了 [containers/storage][36] 项目,实现了容器运行、构建、存储所需的所有写时拷贝(COW)特性,同时不再需要一个单一进程来控制和监控这个过程(也就是不需要守护进程)。现在 skopeo 以及其它工具和项目可以直接利用镜像的存储系统。其它开源项目也开始使用 containers/storage,在某些时候,我们也会把这些项目合并回上游 docker 项目。
|
||||
|
||||
### 驶向创新
|
||||
|
||||
当 Kubernetes 在一个节点上使用 docker 守护进程运行容器时会发生什么?首先,Kubernetes 执行一条类似如下的命令:
|
||||
|
||||
```
|
||||
kubelet run nginx -image=nginx
|
||||
```
|
||||
|
||||
这个命令告诉 kubelet 在节点上运行 NGINX 应用程序。kubelet 调用 CRI 请求启动 NGINX 应用程序。在这时,实现了 CRI 规范的容器运行时必须执行以下步骤:
|
||||
|
||||
1. 检查本地是否存在名为 `nginx` 的容器。如果没有,容器运行时会在容器仓库中搜索标准的容器镜像。
|
||||
2. 如果镜像不存在于本地,从容器仓库下载到本地系统。
|
||||
3. 使用容器存储系统(通常是写时拷贝存储系统)解析下载的容器镜像并挂载它。
|
||||
4. 使用标准的容器运行时执行容器。
|
||||
|
||||
让我们看看上述过程使用到的特性:
|
||||
|
||||
1. OCI 镜像格式规范定义了容器仓库存储的标准镜像格式。
|
||||
2. Containers/image 代码库实现了从容器仓库拉取镜像到容器主机所需的所有特性。
|
||||
3. Containers/storage 提供了在写时拷贝的存储系统上探查并处理 OCI 镜像格式的代码库。
|
||||
4. OCI 运行时规范以及 `runc` 提供了执行容器的工具(同时也是 docker 守护进程用来运行容器的工具)。
|
||||
|
||||
这意味着我们可以利用这些工具来使用容器,而无需一个大型的容器守护进程。
|
||||
|
||||
在中等到大规模的基于 DevOps 的持续集成/持续交付环境下,效率、速度和安全性至关重要。只要你的工具遵循 OCI 规范,开发者和执行者就能在持续集成、持续交付到生产环境的自动化中自然地使用最佳的工具。大多数的容器工具被隐藏在容器编排或上层容器平台技术之下。我们预想着有朝一日,运行时和镜像工具的选择会变成容器平台的一个安装选项。
|
||||
|
||||
#### 系统(独立)容器
|
||||
|
||||
在 Atomic 项目中我们引入了<ruby>原子主机<rt>atomic host</rt></ruby>,一种新的操作系统构建方式:所有的软件可以被“原子地”升级并且大多数应用以容器的形式运行在操作系统中。这个平台的目的是证明将来所有的软件都能部署在 OCI 镜像格式中并且使用标准协议从容器仓库中拉取,然后安装到系统上。用容器镜像的形式发布软件允许你以不同的速度升级应用程序和操作系统。传统的 RPM/yum/DNF 包分发方式把应用更新锁定在操作系统的生命周期中。
|
||||
|
||||
在以容器部署基础设施时多数会遇到一个问题——有时一些应用必须在容器运行时执行之前启动。我们看一个使用 docker 的 Kubernetes 的例子:Kubernetes 为了将 pods 或者容器部署在独立的网络中,要求先建立一个网络。现在默认用于创建网络的守护进程是 [flanneld][9],而它必须在 docker 守护进程之前启动,以支持 docker 网络接口来运行 Kubernetes 的 pods。而且,flanneld 使用 [etcd][37] 来存储数据,这个守护进程必须在 flanneld 启动之前运行。
|
||||
|
||||
如果你想把 etcd 和 flanneld 部署到容器镜像中,那就陷入了鸡与鸡蛋的困境中。我们需要容器运行时来启动容器化的应用,但这些应用又需要在容器运行时之前启动。我见过几个取巧的方法尝试解决这个问题,但这些方法都不太干净利落。而且 docker 守护进程当前没有合适的方法来配置容器启动的优先级顺序。我见过一些提议,但它们看起来和 SysVInit 所使用的启动服务的方式相似(我们知道它带来的复杂度)。
|
||||
|
||||
#### systemd
|
||||
|
||||
用 systemd 替代 SysVInit 的原因之一就是为了处理服务启动的优先级和顺序,我们为什么不充分利用这种技术呢?在 Atomic 项目中我们决定在让它在没有容器运行时的情况下也能启动容器,尤其是在系统启动早期。我们增强了 atomic CLI 的功能,让用户可以安装容器镜像。当你执行 `atomic install --system etc`,它将利用 skopeo 从外部的容器仓库拉取 etcd 的 OCI 镜像,然后把它分解(扩展)为 OSTree 底层存储。因为 etcd 运行在生产环境中,我们把镜像处理为只读。接着 `atomic` 命令抓取容器镜像中的 systemd 的 unit 文件模板,用它在磁盘上创建 unit 文件来启动镜像。这个 unit 文件实际上使用 `runc` 来在主机上启动容器(虽然 `runc` 不是必需的)。
|
||||
|
||||
执行 `atomic install --system flanneld` 时会进行相似的过程,但是这时 flanneld 的 unit 文件中会指明它依赖 etcd。
|
||||
|
||||
在系统引导时,systemd 会保证 etcd 先于 flanneld 运行,并且直到 flanneld 启动完毕后再启动容器运行时。这样我们就能把 docker 守护进程和 Kubernetes 部署到系统容器当中。这也意味着你可以启动一台原子主机或者使用传统的基于 rpm 的操作系统,让整个容器编排工具栈运行在容器中。这是一个强大的特性,因为用户往往希望改动容器主机时不受这些组件影响。而且,它保持了主机的操作系统的占用最小化。
|
||||
|
||||
大家甚至讨论把传统的应用程序部署到独立/系统容器或者被编排的容器中。设想一下,可以用 `atomic install --system httpd` 命令安装一个 Apache 容器,这个容器可以和用 RPM 安装的 httpd 服务以相同的方式启动(`systemctl start httpd` ,区别是这个容器 httpd 运行在一个容器中)。存储系统可以是本地的,换言之,`/var/www` 是从宿主机挂载到容器当中的,而容器监听着本地网络的 80 端口。这表明了我们可以在不使用容器守护进程的情况下将传统的负载组件部署到一个容器中。
|
||||
|
||||
### 构建容器镜像
|
||||
|
||||
在我看来,在过去 4 年来容器发展方面最让人失落的是缺少容器镜像构建机制上的创新。容器镜像不过是将一些 tar 包文件与 JSON 文件一起打包形成的文件。基础镜像则是一个 rootfs 与一个描述该基础镜像的 JSON 文件。然后当你增加镜像层时,层与层之间的差异会被打包,同时 JSON 文件会做出相应修改。这些镜像层与基础文件一起被打包,共同构成一个容器镜像。
|
||||
|
||||
现在几乎所有人都使用 `docker build` 与 Dockerfile 格式来构建镜像。上游 docker 已经在几年前停止了接受修改或改进 Dockerfile 格式的拉取请求(PR)了。Dockerfile 在容器的演进过程中扮演了重要角色,开发者和管理员/运维人员可以通过简单直接的方式来构建镜像;然而我觉得 Dockerfile 就像一个简陋的 bash 脚本,还带来了一些尚未解决的问题,例如:
|
||||
|
||||
* 使用 Dockerfile 创建容器镜像要求运行着 Docker 守护进程。
|
||||
* 没有可以独立于 docker 命令的标准工具用于创建 OCI 镜像。
|
||||
* 甚至类似 `ansible-containers` 和 OpenShift S2I (Source2Image) 的工具也在底层使用 `docker-engine`。
|
||||
* Dockerfile 中的每一行都会创建一个新的镜像,这有助于创建容器的开发过程,这是因为构建工具能够识别 Dockerfile 中的未改动行,复用已经存在的镜像从而避免了未改动行的重复执行。但这个特性会产生_大量_的镜像层。
|
||||
* 因此,不少人希望构建机制能压制镜像消除这些镜像层。我猜想上游 docker 最后应该接受了一些提交满足了这个需求。
|
||||
* 要从受保护的站点拉取内容到容器镜像,你往往需要某种密钥。比如你为了添加 RHEL 的内容到镜像中,就需要访问 RHEL 的证书和订阅。
|
||||
* 这些密钥最终会被以层的方式保存在镜像中。开发者要费很大工夫去移除它们。
|
||||
* 为了允许在 docker 构建过程中挂载数据卷,我们在我们维护的 projectatomic/docker 中加入了 `-v volume` 选项,但是这些修改没有被上游 docker 接受。
|
||||
* 构建过程的中间产物最终会保留在容器镜像中,所以尽管 Dockerfile 易于学习,当你想要了解你要构建的镜像时甚至可以在笔记本上构建容器,但它在大规模企业环境下还不够高效。然而在自动化容器平台下,你应该不会关心用于构建 OCI 镜像的方式是否高效。
|
||||
|
||||
### Buildah 起航
|
||||
|
||||
在 DevConf.cz 2017,我让我们团队的 [Nalin Dahyabhai][38] 考虑构建被我称为 `containers-coreutils` 的工具,它基本上就是基于 containers/storage 和 containers/image 库构建的一系列可以使用类似 Dockerfile 语法的命令行工具。Nalin 为了取笑我的波士顿口音,决定把它叫做 [buildah][39]。我们只需要少量的 buildah 原语就可以构建一个容器镜像:
|
||||
|
||||
* 最小化 OS 镜像、消除不必要的工具是主要的安全原则之一。因为黑客在攻击应用时需要一些工具,如果类似 `gcc`,`make`,`dnf` 这样的工具根本不存在,就能阻碍攻击者的行动。
|
||||
* 减小容器的体积总是有益的,因为这些镜像会通过互联网拉取与推送。
|
||||
* 使用 Docker 进行构建的基本原理是在容器构建的根目录下利用命令安装或编译软件。
|
||||
* 执行 `run` 命令要求所有的可执行文件都包含在容器镜像内。只是在容器镜像中使用 `dnf` 就需要完整的 Python 栈,即使在应用中从未使用到 Python。
|
||||
* `ctr=$(buildah from fedora)`:
|
||||
* 使用 containers/image 从容器仓库拉取 Fedora 镜像。
|
||||
* 返回一个容器 ID (`ctr`)。
|
||||
* `mnt=$(buildah mount $ctr)`:
|
||||
* 挂载新建的容器镜像(`$ctr`).
|
||||
* 返回挂载点路径。
|
||||
* 现在你可以使用挂载点来写入内容。
|
||||
* `dnf install httpd –installroot=$mnt`:
|
||||
* 你可以使用主机上的命令把内容重定向到容器中,这样你可以把密钥保留在主机而不导入到容器内,同时构建所用的工具也仅仅存在于主机上。
|
||||
* 容器内不需要包含 `dnf` 或者 Python 栈,除非你的应用用到它们。
|
||||
* `cp foobar $mnt/dir`:
|
||||
* 你可以使用任何 bash 中可用的命令来构造镜像。
|
||||
* `buildah commit $ctr`:
|
||||
* 你可以随时创建一个镜像层,镜像的分层由用户而不是工具来决定。
|
||||
* `buildah config --env container=oci --entrypoint /usr/bin/httpd $ctr`:
|
||||
* Buildah 支持所有 Dockerfile 的命令。
|
||||
* `buildah run $ctr dnf -y install httpd`:
|
||||
* Buildah 支持 `run` 命令,但它是在一个锁定的容器内利用 `runc` 执行命令,而不依赖容器运行时守护进程。
|
||||
* `buildah build-using-dockerfile -f Dockerfile .`:
|
||||
|
||||
我们希望将移植类似 `ansible-containers` 和 OpenShift S2I 这样的工具,改用 `buildah` 以去除对容器运行时守护进程的依赖。
|
||||
|
||||
使用与生产环境相同的容器运行时构建容器镜像会遇到另一个大问题。为了保证安全性,我们需要把权限限制到支持容器构建与运行所需的最小权限。构建容器比起运行容器往往需要更多额外的权限。举个例子,我们默认允许 `mknod` 权限,这会允许进程创建设备节点。有些包的安装会尝试创建设备节点,然而在生产环境中的应用几乎都不会这么做。如果默认移除生产环境中容器的 `mknod` 特权会让系统更为安全。
|
||||
|
||||
另一个例子是,容器镜像默认是可读写的,因为安装过程意味着向 `/usr` 存入软件包。然而在生产环境中,我强烈建议把所有容器设为只读模式,仅仅允许它们写入 tmpfs 或者是挂载了数据卷的目录。通过分离容器的构建与运行环境,我们可以更改这些默认设置,提供一个更为安全的环境。
|
||||
|
||||
* 当然,buildah 可以使用 Dockerfile 构建容器镜像。
|
||||
|
||||
### CRI-O :一个 Kubernetes 的运行时抽象
|
||||
|
||||
Kubernetes 添加了<ruby>容器运行时接口<rt>Container Runtime Interface</rt></ruby>(CRI)接口,使 pod 可以在任何运行时上工作。虽然我不是很喜欢在我的系统上运行太多的守护进程,然而我们还是加了一个。我的团队在 [Mrunal Patel][40] 的领导下于 2016 年后期开始构建 [CRI-O] 守护进程。这是一个用来运行 OCI 应用程序的 OCI 守护进程。理论上,将来我们能够把 CRI-O 的代码直接并入 kubelet 中从而消除这个多余的守护进程。
|
||||
|
||||
不像其它容器运行时,CRI-O 的唯一目的就只是为了满足 Kubernetes 的需求。记得前文描述的 Kubernetes 运行容器的条件。
|
||||
|
||||
Kubernetes 传递消息给 kubelet 告知其运行 NGINX 服务器:
|
||||
|
||||
1. kubelet 唤醒 CRI-O 并告知它运行 NGINX。
|
||||
2. CRI-O 回应 CRI 请求。
|
||||
3. CRI-O 在容器仓库查找 OCI 镜像。
|
||||
4. CRI-O 使用 containers/image 从仓库拉取镜像到主机。
|
||||
5. CRI-O 使用 containers/storage 解压镜像到本地磁盘。
|
||||
6. CRI-O 按照 OCI 运行时规范(通常使用 `runc`)启动容器。如前文所述,Docker 守护进程也同样使用 `runc` 启动它的容器。
|
||||
7. 按照需要,kubelet 也可以使用替代的运行时启动容器,例如 Clear Containers `runcv`。
|
||||
|
||||
CRI-O 旨在成为稳定的 Kubernetes 运行平台。只有通过完整的 Kubernetes 测试集后,新版本的 CRI-O 才会被推出。所有提交到 [https://github.com/Kubernetes-incubator/cri-o][42] 的拉取请求都会运行完整的 Kubernetes 测试集。没有通过测试集的拉取请求都不会被接受。CRI-O 是完全开放的,我们已经收到了来自 Intel、SUSE、IBM、Google、Hyper.sh 等公司的代码贡献。即使不是红帽想要的特性,只要通过一定数量维护者的同意,提交给 CRI-O 的补丁就会被接受。
|
||||
|
||||
### 小结
|
||||
|
||||
我希望这份深入的介绍能够帮助你理解 Linux 容器的演化过程。Linux 容器曾经陷入一种各自为营的困境,Docker 建立起了镜像创建的事实标准,简化了容器的使用工具。OCI 则意味着业界在核心镜像格式与运行时方面的合作,这促进了工具在自动化效率、安全性、高可扩展性、易用性方面的创新。容器使我们能够以一种新奇的方式部署软件——无论是运行于主机上的传统应用还是部署在云端的微服务。而在许多方面,这一切还仅仅是个开始。
|
||||
|
||||
(题图:[Daniel Ramirez][11] [CC BY-SA 4.0][12])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel J Walsh - Daniel 有将近 30 年的计算机安全领域工作经验。他在 2001 年 8 月加入 Red Hat。
|
||||
|
||||
via: https://opensource.com/article/17/7/how-linux-containers-evolved
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
译者:[haoqixu](https://github.com/haoqixu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[2]:https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[4]:https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[5]:https://opensource.com/article/17/7/how-linux-containers-evolved?rate=k1UcW7wzh6axaB_z8ScE-U8cux6fLXXgW_vboB5tIwk
|
||||
[6]:https://github.com/opencontainers/runtime-spec/blob/master/spec.md
|
||||
[7]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[8]:https://github.com/containers/image
|
||||
[9]:https://github.com/coreos/flannel
|
||||
[10]:https://opensource.com/user/16673/feed
|
||||
[11]:https://www.flickr.com/photos/danramarch/
|
||||
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[13]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Logical_Volume_Manager_Administration/device_mapper.html
|
||||
[14]:https://btrfs.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:https://www.kernel.org/doc/Documentation/filesystems/overlayfs.txt
|
||||
[16]:https://linuxcontainers.org/
|
||||
[17]:https://libvirt.org/
|
||||
[18]:http://sandbox.libvirt.org/
|
||||
[19]:https://opensource.com/article/17/6/getting-started-go
|
||||
[20]:https://github.com/opencontainers/runc/tree/master/libcontainer
|
||||
[21]:https://github.com/opencontainers/runtime-spec
|
||||
[22]:https://opensource.com/business/15/10/lisa15-interview-alison-chaiken-mentor-graphics
|
||||
[23]:https://www.openshift.com/
|
||||
[24]:https://openshift.github.io/geard/
|
||||
[25]:https://opensource.com/resources/what-is-kubernetes
|
||||
[26]:https://github.com/google/lmctfy
|
||||
[27]:https://kubernetes.io/docs/admin/kubelet/
|
||||
[28]:https://www.opencontainers.org/
|
||||
[29]:https://github.com/projectatomic/atomic
|
||||
[30]:https://twitter.com/runc0m
|
||||
[31]:https://github.com/projectatomic/skopeo
|
||||
[32]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||
[33]:https://github.com/containers/image
|
||||
[34]:http://rhelblog.redhat.com/2017/05/11/skopeo-copy-to-the-rescue/
|
||||
[35]:https://access.redhat.com/articles/2750891
|
||||
[36]:https://github.com/containers/storage
|
||||
[37]:https://github.com/coreos/etcd
|
||||
[38]:https://twitter.com/nalind
|
||||
[39]:https://github.com/projectatomic/buildah
|
||||
[40]:https://twitter.com/mrunalp
|
||||
[41]:https://github.com/Kubernetes-incubator/cri-o
|
||||
[42]:https://github.com/Kubernetes-incubator/cri-o
|
||||
[43]:https://opensource.com/users/rhatdan
|
||||
[44]:https://opensource.com/users/rhatdan
|
||||
[45]:https://opensource.com/article/17/7/how-linux-containers-evolved#comments
|
||||
@ -0,0 +1,128 @@
|
||||
Fedora 26 助力云、服务器、工作站系统
|
||||
============================================================
|
||||
|
||||
|
||||
[Fedora 项目][4] 7 月份宣布推出 Fedora 26, 它是全面开放源代码的 Fedora 操作系统的最新版本。
|
||||
|
||||

|
||||
|
||||
Fedora Linux 是 Red Hat Enterprise Linux(RHEL)的社区版本。Fedora 26 包含一组基础包,形成针对不同用户的三个不同版本的基础。
|
||||
|
||||
Fedora <ruby>原子主机版<rt>Atomic Host Edition</rt></ruby> 是用于运行基于容器的工作的操作系统。Fedora <ruby>服务器版<rt>Server</rt></ruby>将 Fedora Server OS 安装在硬盘驱动器上。Fedora <ruby>工作站版<rt>Workstation</rt></ruby>是一款用于笔记本电脑和台式机的用户友好操作系统,它适用于广泛的用户 - 从业余爱好者和学生到企业环境中的专业人士。
|
||||
|
||||
所有这三个版本都有共同的基础和一些共同的优点。所有 Fedora 版本每年发行两次。
|
||||
|
||||
Fedora 项目是创新和新功能的测试基地。Fedora 项目负责人 Matthew Miller 说,有些特性将在即将发布的 RHEL 版本中实现。
|
||||
|
||||
他告诉 LinuxInsider:“Fedora 并没有直接参与这些产品化决策。Fedora 提供了许多想法和技术,它是 Red Hat Enterprise Linux 客户参与并提供反馈的好地方。”
|
||||
|
||||
### 强力的软件包
|
||||
|
||||
Fedora 开发人员更新和改进了所有三个版本的软件包。他们在 Fedora 26 中进行了许多错误修复和性能调整,以便在 Fedora 的用例中提供更好的用户体验。
|
||||
|
||||
这些安装包包括以下改进:
|
||||
|
||||
* 更新的编译器和语言,包括 GCC 7、Go 1.8、Python 3.6 和 Ruby 2.4;
|
||||
* DNF 2.0 是 Fedora 下一代包管理系统的最新版本,它与 Yum 的向后兼容性得到改善;
|
||||
* Anaconda 安装程序新的存储配置界面,可从设备和分区进行自下而上的配置;
|
||||
* Fedora Media Writer 更新,使用户可以为基于 ARM 的设备(如 Raspberry Pi)创建可启动 SD 卡。
|
||||
|
||||
[Endpoint Technologies Associates][5] 的总裁 Roger L. Kay 指出,云工具对于使用云的用户必不可少,尤其是程序员。
|
||||
|
||||
他对 LinuxInsider 表示:“Kubernetes 对于在混合云中编程感兴趣的程序员来说是至关重要的,这可能是目前业界更重要的发展之一。云,无论是公有云、私有云还是混合云 - 都是企业计算未来的关键。”
|
||||
|
||||
### Fedora 26 原子主机亮相
|
||||
|
||||
Linux 容器和容器编排引擎一直在普及。Fedora 26 原子主机提供了一个最小占用的操作系统,专门用于在裸机到云端的环境中运行基于容器的工作任务。
|
||||
|
||||
Fedora 26 原子主机更新大概每两周发布一次,这个时间表可以让用户及时跟上游创新。
|
||||
|
||||
Fedora 26 原子主机可用于 Amazon EC2 。OpenStack、Vagrant 镜像和标准安装程序 ISO 镜像可在 [Fedora 项目][6]网站上找到。
|
||||
|
||||
最小化的 Fedora 原子的容器镜像也在 Fedora 26 上首次亮相。
|
||||
|
||||
### 云托管
|
||||
|
||||
最新版本为 Fedora 26 原子主机提供了新功能和特性:
|
||||
|
||||
* 容器化的 Kubernetes 作为内置的 Kubernetes 二进制文件的替代品,使用户更容易地运行不同版本的容器编排引擎;
|
||||
* 最新版本的 rpm-ostree,其中包括支持直接 RPM 安装,重新加载命令和清理命令;
|
||||
* 系统容器,它提供了一种在容器中的 Fedora 原子主机上安装系统基础设施软件(如网络或 Kubernetes)的方法;
|
||||
* 更新版本的 Docker、Atomic和 Cockpit,用于增强容器构建,系统支持和负载监控。
|
||||
|
||||
根据 Fedora 项目的 Miller 所言,容器化的 Kubernetes 对于 Fedora 原子主机来说是重要的,有两个重要原因。
|
||||
|
||||
他解释说:“首先,它可以让我们从基础镜像中删除它,减小大小和复杂度。第二,在容器中提供它可以轻松地在不同版本中切换,而不会破环基础,或者为尚未准备好进行改变的人造成麻烦。”
|
||||
|
||||
### 服务器端服务
|
||||
|
||||
Fedora 26 服务器版为数据中心运营提供了一个灵活的多角色平台。它还允许用户自定义此版本的 Fedora 操作系统以满足其独特需求。
|
||||
|
||||
Fedora 26 服务器版的新功能包括 FreeIPA 4.5,它可以改进容器中运行的安全信息管理解决方案,以及 SSSD 文件缓存,以加快用户和组查询的速度。
|
||||
|
||||
Fedora 26 服务器版月底将增加称为 “Boltron” 的 Fedora 模块化技术预览。作为模块化操作系统,Boltron 使不同版本的不同应用程序能够在同一个系统上运行,这实质上允许将前沿运行时与稳定的数据库配合使用。
|
||||
|
||||
### 打磨工作站版
|
||||
|
||||
对于一般用户的新工具和功能之一是更新的 GNOME 桌面功能。开发将获得增强的生产力工具。
|
||||
|
||||
Fedora 26 工作站版附带 GNOME 3.24 和众多更新的功能调整。夜光根据时间细微地改变屏幕颜色,以减少对睡眠模式的影响。[LibreOffice][7] 5.3 是开源办公生产力套件的最新更新。
|
||||
|
||||
GNOME 3.24 提供了 Builder 和 Flatpak 的成熟版本,它为开发人员提供了更好的应用程序开发工具,它可以方便地访问各种系统,包括 Rust 和 Meson。
|
||||
|
||||
### 不只是为了开发
|
||||
|
||||
根据 [Azul Systems][8] 的首席执行官 Scott Sellers 的说法,更新的云工具将纳入针对企业用户的 Linux 发行版中。
|
||||
|
||||
他告诉 LinuxInsider:“云是新兴公司以及地球上一些最大的企业的主要开发和生产平台。”
|
||||
|
||||
Sellers说:“鉴于 Fedora 社区的前沿性质,我们预计在任何 Fedora 版本中都会强烈关注云技术,Fedora 26 不会不令人失望。”
|
||||
|
||||
他指出,Fedora 开发人员和用户社区的另一个特点就是 Fedora 团队在模块化方面所做的工作。
|
||||
|
||||
Sellers 说:“我们将密切关注这些实验功能。”
|
||||
|
||||
### 支持的升级方式
|
||||
|
||||
Sellers 说 Fedora 的用户超过其他 Linux 发行版的用户,很多都有兴趣升级到 Fedora 26,即使他们不是重度云端用户。
|
||||
|
||||
他说:“这个发行版的主要优点之一就是能提前看到先进的生产级别技术,这些最终将被整合到 RHEL 中。Fedora 26 的早期评论表明它非常稳定,修复了许多错误以及提升了性能。”
|
||||
|
||||
Fedora 的 Miller 指出,有兴趣从早期 Fedora 版本升级的用户可能比擦除现有系统安装 Fedora 26 更容易。Fedora 一次维护两个版本,中间还有一个月的重叠。
|
||||
|
||||
他说:“所以,如果你在用 Fedora 24,你应该在下个月升级。幸运的 Fedora 25 用户可以随时升级,这是 Fedora 快速滚动版本的优势之一。”
|
||||
|
||||
### 更快的发布
|
||||
|
||||
用户可以安排自己升级,而不是在发行版制作出来时进行升级。
|
||||
|
||||
也就是说,Fedora 23 或更早版本的用户应该尽快升级。社区不再为这些版本发布安全更新
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jack M. Germain 自 2003 年以来一直是 ECT 新闻网记者。他的主要重点领域是企业IT、Linux、和开源技术。他撰写了许多关于 Linux 发行版和其他开源软件的评论。发邮件联系 Jack
|
||||
|
||||
|
||||
---------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84674.html
|
||||
|
||||
作者:[Jack M. Germain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:jack.germain@newsroom.ectnews.comm
|
||||
[1]:http://www.linuxinsider.com/story/84674.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84674
|
||||
[3]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
[4]:https://getfedora.org/
|
||||
[5]:http://www.ndpta.com/
|
||||
[6]:https://getfedora.org/
|
||||
[7]:http://www.libreoffice.org/
|
||||
[8]:https://www.azul.com/
|
||||
[9]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
[10]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
@ -0,0 +1,108 @@
|
||||
免费学习 Docker 的最佳方法:Play-with-docker(PWD)
|
||||
============================================================
|
||||
|
||||
去年在柏林的分布式系统峰会上,Docker 的负责人 [Marcos Nils][15] 和 [Jonathan Leibiusky][16] 宣称已经开始研究浏览器内置 Docker 的方案,帮助人们学习 Docker。 几天后,[Play-with-docker][17](PWD)就诞生了。
|
||||
|
||||
PWD 像是一个 Docker 游乐场,用户在几秒钟内就可以运行 Docker 命令。 还可以在浏览器中安装免费的 Alpine Linux 虚拟机,然后在虚拟机里面构建和运行 Docker 容器,甚至可以使用 [Docker 集群模式][18]创建集群。 有了 Docker-in-Docker(DinD)引擎,甚至可以体验到多个虚拟机/个人电脑的效果。 除了 Docker 游乐场外,PWD 还包括一个培训站点 [training.play-with-docker.com][19],该站点提供大量的难度各异的 Docker 实验和测验。
|
||||
|
||||
如果你错过了峰会,Marcos 和 Jonathan 在最后一场 DockerCon Moby Cool Hack 会议中展示了 PWD。 观看下面的视频,深入了解其基础结构和发展路线图。
|
||||
|
||||
|
||||
|
||||
在过去几个月里,Docker 团队与 Marcos、Jonathan,还有 Docker 社区的其他活跃成员展开了密切合作,为项目添加了新功能,为培训部分增加了 Docker 实验室。
|
||||
|
||||
### PWD: 游乐场
|
||||
|
||||
以下快速的概括了游乐场的新功能:
|
||||
|
||||
#### 1、 PWD Docker Machine 驱动和 SSH
|
||||
|
||||
随着 PWD 成功的成长,社区开始问他们是否可以使用 PWD 来运行自己的 Docker 研讨会和培训。 因此,对项目进行的第一次改进之一就是创建 [PWD Docker Machine 驱动][20],从而用户可以通过自己喜爱的终端轻松创建管理 PWD 主机,包括使用 SSH 相关命令的选项。 下面是它的工作原理:
|
||||
|
||||

|
||||
|
||||
#### 2、 支持文件上传
|
||||
|
||||
Marcos 和 Jonathan 还带来了另一个炫酷的功能就是可以在 PWD 实例中通过拖放文件的方式将 Dockerfile 直接上传到 PWD 窗口。
|
||||
|
||||

|
||||
|
||||
#### 3、 模板会话
|
||||
|
||||
除了文件上传之外,PWD 还有一个功能,可以使用预定义的模板在几秒钟内启动 5 个节点的群集。
|
||||
|
||||

|
||||
|
||||
#### 4、 一键使用 Docker 展示你的应用程序
|
||||
|
||||
PWD 附带的另一个很酷的功能是它的内嵌按钮,你可以在你的站点中使用它来设置 PWD 环境,并快速部署一个构建好的堆栈,另外还有一个 [chrome 扩展][21] ,可以将 “Try in PWD” 按钮添加 DockerHub 最流行的镜像中。 以下是扩展程序的一个简短演示:
|
||||
|
||||

|
||||
|
||||
### PWD 培训站点
|
||||
|
||||
[training.play-with-docker.com][22] 站点提供了大量新的实验。有一些值得注意的两点,包括两个来源于奥斯丁召开的 DockerCon 中的动手实践的实验,还有两个是 Docker 17.06CE 版本中亮眼的新功能:
|
||||
|
||||
* [可以动手实践的 Docker 网络实验][1]
|
||||
* [可以动手实践的 Docker 编排实验][2]
|
||||
* [多阶段构建][3]
|
||||
* [Docker 集群配置文件][4]
|
||||
|
||||
总而言之,现在有 36 个实验,而且一直在增加。 如果你想贡献实验,请从查看 [GitHub 仓库][23]开始。
|
||||
|
||||
### PWD 用例
|
||||
|
||||
根据网站访问量和我们收到的反馈,很可观的说,PWD 现在有很大的吸引力。下面是一些最常见的用例:
|
||||
|
||||
* 紧跟最新开发版本,尝试新功能。
|
||||
* 快速建立集群并启动复制服务。
|
||||
* 通过互动教程学习: [training.play-with-docker.com][5]。
|
||||
* 在会议和集会上做演讲。
|
||||
* 召开需要复杂配置的高级研讨会,例如 Jérôme’的 [Docker 编排高级研讨会][6]。
|
||||
* 和社区成员协作诊断问题检测问题。
|
||||
|
||||
参与 PWD:
|
||||
|
||||
* 通过[向 PWD 提交 PR][7] 做贡献
|
||||
* 向 [PWD 培训站点][8]贡献
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Victor 是 Docker, Inc. 的高级社区营销经理。他喜欢优质的葡萄酒、象棋和足球,上述爱好不分先后顺序。 Victor 的 tweet:@vcoisne 推特。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/best-way-learn-docker-free-play-docker-pwd/
|
||||
|
||||
作者:[Victor][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/victor_c/
|
||||
[1]:http://training.play-with-docker.com/docker-networking-hol/
|
||||
[2]:http://training.play-with-docker.com/orchestration-hol/
|
||||
[3]:http://training.play-with-docker.com/multi-stage/
|
||||
[4]:http://training.play-with-docker.com/swarm-config/
|
||||
[5]:http://training.play-with-docker.com/
|
||||
[6]:https://github.com/docker/labs/tree/master/Docker-Orchestration
|
||||
[7]:https://github.com/play-with-docker/
|
||||
[8]:https://github.com/play-with-docker/training
|
||||
[9]:https://blog.docker.com/author/victor_c/
|
||||
[10]:https://blog.docker.com/tag/docker-labs/
|
||||
[11]:https://blog.docker.com/tag/docker-training/
|
||||
[12]:https://blog.docker.com/tag/docker-workshops/
|
||||
[13]:https://blog.docker.com/tag/play-with-docker/
|
||||
[14]:https://blog.docker.com/tag/pwd/
|
||||
[15]:https://www.twitter.com/marcosnils
|
||||
[16]:https://www.twitter.com/xetorthio
|
||||
[17]:http://play-with-docker.com/
|
||||
[18]:https://docs.docker.com/engine/swarm/
|
||||
[19]:http://training.play-with-docker.com/
|
||||
[20]:https://github.com/play-with-docker/docker-machine-driver-pwd/releases/tag/v0.0.5
|
||||
[21]:https://chrome.google.com/webstore/detail/play-with-docker/kibbhpioncdhmamhflnnmfonadknnoan
|
||||
[22]:http://training.play-with-docker.com/
|
||||
[23]:https://github.com/play-with-docker/play-with-docker.github.io
|
||||
@ -1,33 +1,30 @@
|
||||
如何建模可以帮助你避免在 OpenStack 中遇到问题
|
||||
============================================================
|
||||
|
||||
|
||||
### 分享或保存
|
||||
|
||||

|
||||
|
||||
_乐高的空客 A380-800模型。空客运行 OpenStack_
|
||||
|
||||
“StuckStack” 是 OpenStack 的一种部署方式,通常由于技术上但有时是商业上的原因,它无法在没有明显中断、时间和费用的情况下升级。在关于这个话题的最后一篇文章中,我们讨论了这些云中有多少陷入僵局,当时的决定与当今大部分的智慧是一致的。现在 OpenStack 已经有 7 年了,最近随着容器编排系统的增长以及更多企业开始利用公共和私有的云平台,OpenStack 正面临着压力。
|
||||
OpenStack 部署完就是一个 “<ruby>僵栈<rt>StuckStack</rt></ruby>”,一般出于技术原因,但有时是商业上的原因,它是无法在没有明显中断,也不花费时间和成本的情况下升级的。在关于这个话题的最后一篇文章中,我们讨论了这些云中有多少陷入僵局,以及当时是怎么决定的与如今的大部分常识相符。现在 OpenStack 已经有 7 年了,最近随着容器编排系统的增长以及更多企业开始利用公共和私有的云平台,OpenStack 正面临着压力。
|
||||
|
||||
|
||||
### 没有魔法解决方案
|
||||
|
||||
如果你仍在寻找一个解决方案来没有任何问题地升级你现有的 StuckStack, 那么我有坏消息给你: 有没有魔法解决方案, 你最好集中精力建立一个标准化的平台, 它可以有效地操作和升级。
|
||||
如果你仍在寻找一个可以没有任何问题地升级你现有的 <ruby>僵栈<rt>StuckStack</rt></ruby> 的解决方案,那么我有坏消息给你:没有魔法解决方案,你最好集中精力建立一个标准化的平台,它可以有效地运营和轻松地升级。
|
||||
|
||||
低成本航空业已经表明, 虽然乘客可能渴望最好的体验, 可以坐在头等舱或者商务舱喝香槟, 有足够的空间放松, 但是大多数人会选择乘坐最便宜的, 最终价值等式不保证他们付出更多的代价。工作负载是相同的。长期而言, 工作负载将运行在最经济的平台上, 因为在高价硬件或软件上运行的业务实际上并没有受益。
|
||||
廉价航空业已经表明,虽然乘客可能渴望最好的体验,可以坐在头等舱或者商务舱喝香槟,有足够的空间放松,但是大多数人会选择乘坐最便宜的,最终价值等式不要让他们付出更多的代价。工作负载是相同的。长期而言,工作负载将运行在最经济的平台上,因为在高价硬件或软件上运行的业务实际上并没有受益。
|
||||
|
||||
Amazon、Microsoft、Google 等大型公共云企业都知道,这就是为什么他们建立了高效的数据中心, 并使用模型来构建、操作和扩展基础设施。长期以来,企业一直奉行以设计、制造、市场、定价、销售,实施为一体的最优秀的硬件和软件基础设施。现实可能并不总是符合承诺,但由于成本模式在当今世界无法生存,所以现在还不重要。一些组织试图通过改用免费软件替代, 而不改变自己的行为来解决这一问题。因此, 他们发现, 他们只是将成本从软件获取变到软件操作。好消息是,那些高效运营的大型运营商使用的技术,现在可用于所有类型的组织。
|
||||
Amazon、Microsoft、Google 等大型公共云企业都知道,这就是为什么他们建立了高效的数据中心,并使用模型来构建、操作和扩展基础设施。长期以来,企业一直奉行以设计、制造、市场、定价、销售、实施为一体的最优秀的硬件和软件基础设施。现实可能并不总是符合承诺,但它现在还不重要,因为<ruby>成本模式<rt>cost model</rt></ruby>在当今世界无法生存。一些组织试图通过改用免费软件替代,而不改变自己的行为来解决这一问题。因此,他们发现,他们只是将成本从获取软件变到运营软件上。好消息是,那些高效运营的大型运营商使用的技术,现在可用于所有类型的组织。
|
||||
|
||||
### 什么是软件模型?
|
||||
|
||||
虽然许多年来, 软件程序由许多对象、进程和服务组成, 但近年来, 程序是普遍由许多单独的服务组成, 它们高度分布式地分布在数据中心的不同服务器以及跨越数据中心的服务器上。
|
||||
虽然许多年来,软件程序由许多对象、进程和服务而组成,但近年来,程序是普遍由许多单独的服务组成,它们高度分布在数据中心的不同服务器以及跨越数据中心的服务器上。
|
||||
|
||||

|
||||
|
||||
_OpenStack 服务的简单演示_
|
||||
|
||||
许多服务意味着许多软件需要配置、管理并跟踪许多物理机器。以成本效益的方式规模化地进行这一工作需要一个模型,即所有组件如何连接以及它们如何映射到物理资源。为了构建模型,我们需要有一个软件组件库,这是一种定义它们如何彼此连接以及将其部署到平台上的方法,无论是物理还是虚拟。在 Canonical 公司,我们几年前就认识到这一点,并建立了一个通用的软件建模工具 [Juju][2],使得运营商能够从 100 个通用软件服务目录中组合灵活的拓扑结构、架构和部署目标。
|
||||
许多服务意味着许多软件需要配置、管理并跟踪许多物理机器。以成本效益的方式规模化地进行这一工作需要一个模型,即所有组件如何连接以及它们如何映射到物理资源。为了构建模型,我们需要有一个软件组件库,这是一种定义它们如何彼此连接以及将其部署到平台上的方法,无论是物理的还是虚拟的。在 Canonical 公司,我们几年前就认识到这一点,并建立了一个通用的软件建模工具 [Juju][2],使得运营商能够从 100 个通用软件服务目录中组合灵活的拓扑结构、架构和部署目标。
|
||||
|
||||

|
||||
|
||||
@ -35,13 +32,13 @@ Amazon、Microsoft、Google 等大型公共云企业都知道,这就是为什
|
||||
|
||||
在 Juju 中,软件服务被定义为一种叫做 Charm 的东西。 Charms 是代码片段,它通常用 python 或 bash 编写,其中提供有关服务的信息 - 声明的接口、服务的安装方式、可连接的其他服务等。
|
||||
|
||||
Charms 可以简单或者复杂,具体取决于你想要赋予的功能。对于 OpenStack,Canonical 在上游 OpenStack 社区的帮助下,为主要 OpenStack 服务开发了一套完整的 Charms。Charms 代表了模型的说明,使其可以轻松地部署、操作扩展和复制。Charms 还定义了如何升级自身,包括在需要时执行升级的顺序以及如何在需要时优雅地暂停和恢复服务。通过将 Juju 连接到诸如[裸机即服务(MAAS)][3]这样的裸机配置系统,其中 OpenStack 的逻辑模型可以部署到物理硬件上。默认情况下,Charms 将在 LXC 容器中部署服务,从而根据云行为的需要, 提供更大的灵活性来重新定位服务。配置在 Charms 中定义,或者在部署时由第三方工具(如 Puppet 或 Chef)注入。
|
||||
Charms 可以简单或者复杂,具体取决于你想要赋予的功能。对于 OpenStack,Canonical 在上游 OpenStack 社区的帮助下,为主要 OpenStack 服务开发了一套完整的 Charms。Charms 代表了模型的说明,使其可以轻松地部署、操作扩展和复制。Charms 还定义了如何升级自身,包括在需要时执行升级的顺序以及如何在需要时优雅地暂停和恢复服务。通过将 Juju 连接到诸如 [裸机即服务(MAAS)][3] 这样的裸机配置系统,其中 OpenStack 的逻辑模型可以部署到物理硬件上。默认情况下,Charms 将在 LXC 容器中部署服务,从而根据云行为的需要,提供更大的灵活性来重新定位服务。配置在 Charms 中定义,或者在部署时由第三方工具(如 Puppet 或 Chef)注入。
|
||||
|
||||
这种方法有两个不同的好处:1 - 通过创建一个模型,我们从底层硬件抽象出每个云服务。2 - 使用已知来源的标准化组件,通过迭代组合新的架构。这种一致性使我们能够使用相同的工具部署非常不同的云架构,运行和升级这些工具是安全的。
|
||||
|
||||
通过全面自动化的配置工具和软件程序来管理硬件库存,运营商可以比使用传统企业技术或构建偏离核心的定制系统更有效地扩展基础架构。有价值的开发资源可以集中在创新应用领域,使新的软件服务更快上线,而不是改变标准的商品基础设施, 这将会导致进一步的兼容性问题。
|
||||
通过全面自动化的配置工具和软件程序来管理硬件库存,运营商可以比使用传统企业技术或构建偏离核心的定制系统更有效地扩展基础架构。有价值的开发资源可以集中在创新应用领域,使新的软件服务更快上线,而不是改变标准的商品基础设施,这将会导致进一步的兼容性问题。
|
||||
|
||||
在下一篇文章中,我将介绍部署完全建模的 OpenStack 的一些最佳实践,以及如何快速地进行操作。如果你有一个现有的 StuckStack, 那么虽然我们不能很容易地拯救它, 但是与公有云相比,我们将能够让你走上一条完全支持的、高效的基础架构以及运营成本的道路。
|
||||
在下一篇文章中,我将介绍部署完全建模的 OpenStack 的一些最佳实践,以及如何快速地进行操作。如果你有一个现有的 <ruby>僵栈<rt>StuckStack</rt></ruby>,那么虽然我们不能很容易地拯救它,但是与公有云相比,我们将能够让你走上一条完全支持的、高效的基础架构以及运营成本的道路。
|
||||
|
||||
### 即将举行的网络研讨会
|
||||
|
||||
@ -62,9 +59,9 @@ Charms 可以简单或者复杂,具体取决于你想要赋予的功能。对
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/18/stuckstack-how-modelling-helps-you-avoid-getting-a-stuck-openstack/
|
||||
|
||||
作者:[Mark Baker ][a]
|
||||
作者:[Mark Baker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
103
published/20170725 What you need to know about hybrid cloud.md
Normal file
103
published/20170725 What you need to know about hybrid cloud.md
Normal file
@ -0,0 +1,103 @@
|
||||
混合云的那些事
|
||||
============================================================
|
||||
|
||||
> 了解混合云的细节,包括它是什么以及如何使用它
|
||||
|
||||

|
||||
|
||||
在过去 10 年出现的众多技术中,云计算因其快速发展而引人注目,从一个细分领域的技术而成为了全球热点。就其本身来说,云计算已经造成了许多困惑、争论和辩论,而混合了多种类型的云计算的"混合"云计算也带来了更多的不确定性。阅读下文可以了解有关混合云的一些最常见问题的答案。
|
||||
|
||||
### 什么是混合云
|
||||
|
||||
基本上,混合云是本地基础设施、私有云和公共云(例如,第三方云服务)的灵活和集成的组合。尽管公共云和私有云服务在混合云中是绑定在一起的,但实际上,它们是独立且分开的服务实体,而可以编排在一起服务。使用公共和私有云基础设施的选择基于以下几个因素,包括成本、负载灵活性和数据安全性。
|
||||
|
||||
高级的特性,如<ruby>扩展<rt>scale-up</rt></ruby>和<ruby>延伸scale-out</rt></ruby>,可以快速扩展云应用程序的基础设施,使混合云成为具有季节性或其他可变资源需求的服务的流行选择。(<ruby>扩展<rt>scale-up</rt></ruby>意味着在特定的 Linux 实例上增加计算资源,例如 CPU 内核和内存,而<ruby>延伸scale-out</rt></ruby>则意味着提供具有相似配置的多个实例,并将它们分布到一个集群中)。
|
||||
|
||||
处于混合云解决方案中心的是开源软件,如 [OpenStack][12],它用于部署和管理虚拟机组成的大型网络。自 2010 年 10 月发布以来,OpenStack 一直在全球蓬勃发展。它的一些集成项目和工具处理核心的云计算服务,比如计算、网络、存储和身份识别,而其他数十个项目可以与 OpenStack 捆绑在一起,创建独特的、可部署的混合云解决方案。
|
||||
|
||||
### 混合云的组成部分
|
||||
|
||||
如下图所示,混合云由私有云、公有云注成,并通过内部网络连接,由编排系统、系统管理工具和自动化工具进行管理。
|
||||
|
||||

|
||||
|
||||
*混合云模型*
|
||||
|
||||
#### 公共云基础设施
|
||||
|
||||
* <ruby>基础设施即服务<rt>Infrastructure as a Service</rt></ruby>(IaaS) 从一个远程数据中心提供计算资源、存储、网络、防火墙、入侵预防服务(IPS)等。可以使用图形用户界面(GUI)或命令行接口(CLI)对这些服务进行监视和管理。公共 IaaS 用户不需要购买和构建自己的基础设施,而是根据需要使用这些服务,并根据使用情况付费。
|
||||
* <ruby>平台即服务<rt>Platform as a Service</rt></ruby>(PaaS)允许用户在其上开发、测试、管理和运行应用程序和服务器。这些包括操作系统、中间件、web 服务器、数据库等等。公共 PaaS 以模板形式为用户提供了可以轻松部署和复制的预定义服务,而不是手动实现和配置基础设施。
|
||||
* <ruby>软件即服务<rt>Software as a Service</rt></ruby>(SaaS)通过互联网交付软件。用户可以根据订阅或许可模型或帐户级别使用这些服务,在这些服务中,他们按活跃用户计费。SaaS 软件是低成本、低维护、无痛升级的,并且降低了购买新硬件、软件或带宽以支持增长的负担。
|
||||
|
||||
#### 私有云基础设施
|
||||
|
||||
* 私有 **IaaS** 和 **PaaS** 托管在孤立的数据中心中,并与公共云集成在一起,这些云可以使用远程数据中心中可用的基础设施和服务。这使私有云所有者能够在全球范围内利用公共云基础设施来扩展应用程序,并利用其计算、存储、网络等功能。
|
||||
* **SaaS** 是由公共云提供商完全监控、管理和控制的。SaaS 一般不会在公共云和私有云基础设施之间共享,并且仍然是通过公共云提供的服务。
|
||||
|
||||
#### 云编排和自动化工具
|
||||
|
||||
要规划和协调私有云和公共云实例,云编排工具是必要的。该工具应该具有智能,包括简化流程和自动化重复性任务的能力。此外,集成的自动化工具负责在设置阈值时自动扩展和延伸,以及在发生任何部分损坏或宕机时执行自修复。
|
||||
|
||||
#### 系统和配置管理工具
|
||||
|
||||
在混合云中,系统和配置工具,如 [Foreman][13],管理着私有云和公共云数据中心提供的虚拟机的完整生命周期。这些工具使系统管理员能够轻松地控制用户、角色、部署、升级和实例,并及时地应用补丁、bug 修复和增强功能。包括Foreman 工具中的 [Puppet][14],使管理员能够管理配置,并为所有供给的和注册的主机定义一个完整的结束状态。
|
||||
|
||||
### 混合云的特性
|
||||
|
||||
对于大多数组织来说,混合云是有意义的,因为这些关键特性:
|
||||
|
||||
* **可扩展性:** 在混合云中,集成的私有云和公共云实例共享每个可配置的实例的计算资源池。这意味着每个实例都可以在需要时按需扩展和延伸。
|
||||
* **快速响应:** 当私有云资源超过其阈值时,混合云的弹性支持公共云中的实例快速爆发增长。当需求高峰对运行中的应用程序需要显著的动态提升负载和容量时,这是特别有价值的。(例如,电商在假日购物季期间)
|
||||
* **可靠性:** 组织可以根据需要的成本、效率、安全性、带宽等来选择公共云服务提供商。在混合云中,组织还可以决定存储敏感数据的位置,以及是在私有云中扩展实例,还是通过公共基础设施跨地域进行扩展。另外,混合模型在多个站点上存储数据和配置的能力提供了对备份、灾难恢复和高可用性的支持。
|
||||
* **管理:** 在非集成的云环境中,管理网络、存储、实例和/或数据可能是乏味的。与混合工具相比,传统的编排工具非常有限,因此限制了决策制定和对完整的端到端进程和任务的自动化。使用混合云和有效的管理应用程序,您可以跟踪每个组件的数量增长,并通过定期优化这些组件,使年度费用最小化。
|
||||
* **安全性:** 在评估是否在云中放置应用程序和数据时,安全性和隐私是至关重要的。IT 部门必须验证所有的合规性需求和部署策略。公共云的安全性正在改善,并将继续成熟。而且,在混合云模型中,组织可以将高度敏感的信息存储在私有云中,并将其与存储在公共云中的不敏感数据集成在一起。
|
||||
* **定价:** 云定价通常基于所需的基础设施和服务水平协议(SLA)的要求。在混合云模型中,用户可以在计算资源(CPU/内存)、带宽、存储、网络、公共 IP 地址等粒度上进行比较,价格要么是固定的,要么是可变的,可以按月、小时、甚至每秒钟计量。因此,用户总是可以在公共云提供商中购买最好的价位,并相应地部署实例。
|
||||
|
||||
### 混合云如今的发展
|
||||
|
||||
尽管对公共云服务的需求很大且不断增长,并且从本地到公共云的迁移系统,仍然是大多数大型组织关注的问题。大多数人仍然在企业数据中心和老旧系统中保留关键的应用程序和数据。他们担心在公共基础设施中面临失去控制、安全威胁、数据隐私和数据真实性。因为混合云将这些问题最小化并使收益最大化,对于大多数大型组织来说,这是最好的解决方案。
|
||||
|
||||
### 预测五年后的发展
|
||||
|
||||
我预计混合云模型将在全球范围内被广泛接受,而公司的“无云”政策将在短短几年内变得非常罕见。这是我想我们会看到的:
|
||||
|
||||
* 由于混合云作为一种共担的责任,企业和公共云提供商之间将加强协作,以实施安全措施来遏制网络攻击、恶意软件、数据泄漏和其他威胁。
|
||||
* 实例的爆发性增长将会很快,因此客户可以自发地满足负载需求或进行自我修复。
|
||||
* 此外,编排或自动化工具(如 [Ansible][8])将通过继承用于解决关键问题的能力来发挥重要作用。
|
||||
* 计量和“量入为出”的概念对客户来说是透明的,并且工具将使用户能够通过监控价格波动,安全地销毁现有实例,并提供新的实例以获得最佳的可用定价。
|
||||
|
||||
(题图:[Jason Baker][10]. [CC BY-SA 4.0][11].)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Amit Das 是一名 Red Hat 的工程师,他对 Linux、云计算、DevOps 等充满热情,他坚信新的创新和技术,将以一种开放的方式的让世界更加开放,可以对社会产生积极的影响,改变许多人的生活。
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/7/what-is-hybrid-cloud
|
||||
|
||||
作者:[Amit Das][a]
|
||||
译者:[LHRchina](https://github.com/LHRchina)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/amit-das
|
||||
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||
[6]:https://opensource.com/file/364211
|
||||
[7]:https://opensource.com/article/17/7/what-is-hybrid-cloud?rate=TwB_2KyXM7iqrwDPGZpe6WultoCajdIVgp8xI4oZkTw
|
||||
[8]:https://opensource.com/life/16/8/cloud-ansible-gateway
|
||||
[9]:https://opensource.com/user/157341/feed
|
||||
[10]:https://opensource.com/users/jason-baker
|
||||
[11]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[12]:https://opensource.com/resources/openstack
|
||||
[13]:https://github.com/theforeman
|
||||
[14]:https://github.com/theforeman/puppet-foreman
|
||||
[15]:https://opensource.com/users/amit-das
|
||||
[16]:https://opensource.com/users/amit-das
|
||||
@ -1,3 +1,5 @@
|
||||
translating by wangs0622
|
||||
|
||||
Book review: Ours to Hack and to Own
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Manage the Security Vulnerabilities of Your Open Source Product
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,67 +0,0 @@
|
||||
Open Source First: A manifesto for private companies
|
||||
============================================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
This is a manifesto that any private organization can use to frame their collaboration transformation. Take a read and let me know what you think.
|
||||
|
||||
I presented [a talk at the Linux TODO group][3] using this article as my material. For those of you who are not familiar with the TODO group, they support open source leadership at commercial companies. It is important to lean on each other because legal, security, and other shared knowledge is so important for the open source community to move forward. This is especially true because we need to represent both the commercial and public community best interests.
|
||||
|
||||
"Open source first" means that we look to open source before we consider vendor-based products to meet our needs. To use open source technology correctly, you need to do more than just consume, you need to participate to ensure the open source technology survives long term. To participate in open source requires your engineer's time be split between working for your company and the open source project. We expect to bring the open source contribution intent and collaboration internal to our private company. We need to define, build, and maintain a culture of contribution, collaboration, and merit-based work.
|
||||
|
||||
### Open garden development
|
||||
|
||||
Our private company strives to be a leader in technology through its contributions to the technology community. This requires more than just the use of open source code. To be a leader requires participation. To be a leader also requires various types of participation with groups (communities) outside of the company. These communities are organized around a specific R&D project. Participation in each of these communities is much like working for a company. Substantial results require substantial participation.
|
||||
|
||||
### Code more, live better
|
||||
|
||||
We must be generous with computing resources, stingy with space, and encourage the messy, creative stew that results from this. Allowing people access to the tools of their business will transform them. We must have spontaneous interactions. We must build the online and physical spaces that encourage creativity through collaboration. Collaboration doesn't happen without access to each other in real time.
|
||||
|
||||
### Innovation through meritocracy
|
||||
|
||||
We must create a meritocracy. The quality of ideas has to overcome the group structure and tenure of those in it. Promotion by merit encourages everyone to be better people and employees. While we are being the best badasses we can be, hardy debates between passionate people will happen. Our culture should encourage the obligation to dissent. Strong opinions and ideas lead to a passionate work ethic. The ideas and opinions can and should come from all. It shouldn't make difference who you are, rather it should matter what you do. As meritocracy takes hold, we need to invest in teams that are going to do the right thing without permission.
|
||||
|
||||
### Project to product
|
||||
|
||||
As our private company embraces open source contribution, we must also create clearer separation between working upstream on an R&D project and implementing the resulting product in production. A project is R&D where failing fast and developing features is the status quo. A product is what you put into production, has SLAs, and is using the results of the R&D project. The separation requires at least separate repositories for projects and products. Normal separation consists of different communities working on the projects and products. Each of the communities require substantial contribution and participation. In order to keep these activities separate, there needs to be a workflow of customer feature and bug fix requests from project to product.
|
||||
|
||||
Next, we highlight the major steps in creating, supporting, and expanding open source at our private company.
|
||||
|
||||
### A school for the technically gifted
|
||||
|
||||
The seniors must mentor the inexperienced. As you learn new skills, you pass them on to the next person. As you train the next person, you move on to new challenges. Never expect to stay in one position for very long. Get skills, become awesome, pass learning on, and move on.
|
||||
|
||||
### Find the best people for your family
|
||||
|
||||
We love our work. We love it so much that we want to work with our friends. We are part of a community that is larger than our company. Recruiting the best people to work with us, should always be on our mind. We will find awesome jobs for the people around us, even if that isn't with our company. Thinking this way makes hiring great people a way of life. As hiring becomes common, then reviewing and helping new hires becomes easy.
|
||||
|
||||
### More to come
|
||||
|
||||
I will be posting [more details][4] about each tenet on my blog, stay tuned.
|
||||
|
||||
_This article was originally posted on [Sean Robert's blog][1]. Licensed CC BY._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Sean A Roberts - Lead with empathy while focusing on results. I practice meritocracy. Intelligent things found here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/open-source-first
|
||||
|
||||
作者:[ ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sarob
|
||||
[1]:https://sarob.com/2017/01/open-source-first/
|
||||
[2]:https://opensource.com/article/17/2/open-source-first?rate=CKF77ZVh5e_DpnmSlOKTH-MuFBumAp-tIw-Rza94iEI
|
||||
[3]:https://sarob.com/2017/01/todo-open-source-presentation-17-january-2017/
|
||||
[4]:https://sarob.com/2017/02/open-source-first-project-product/
|
||||
[5]:https://opensource.com/user/117441/feed
|
||||
[6]:https://opensource.com/users/sarob
|
||||
@ -1,3 +1,5 @@
|
||||
translating by @explosic4
|
||||
|
||||
Why working openly is hard when you just want to get stuff done
|
||||
============================================================
|
||||
|
||||
@ -85,7 +87,7 @@ So perhaps I should reconsider my GSD mentality and expand it to GMD: Get **mor
|
||||
|
||||
作者简介:
|
||||
|
||||
Jason Hibbets - Jason Hibbets is a senior community evangelist in Corporate Marketing at Red Hat where he is a community manager for Opensource.com. He has been with Red Hat since 2003 and is the author of The foundation for an open source city. Prior roles include senior marketing specialist, project manager, Red Hat Knowledgebase maintainer, and support engineer. Follow him on Twitter:
|
||||
Jason Hibbets - Jason Hibbets is a senior community evangelist in Corporate Marketing at Red Hat where he is a community manager for Opensource.com. He has been with Red Hat since 2003 and is the author of The foundation for an open source city. Prior roles include senior marketing specialist, project manager, Red Hat Knowledgebase maintainer, and support engineer. Follow him on Twitter:
|
||||
|
||||
-----------
|
||||
|
||||
|
||||
@ -1,134 +0,0 @@
|
||||
The problem with software before standards
|
||||
============================================================
|
||||
|
||||
### Open source projects need to get serious about including standards in their deliverables.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
By any measure, the rise of open source software as an alternative to the old, proprietary ways has been remarkable. Today, there are tens of millions of libraries hosted at GitHub alone, and the number of major projects is growing rapidly. As of this writing, the [Apache Software Foundation][4] hosts over [300 projects][5], while the [Linux Foundation][6] supports over 60. Meanwhile, the more narrowly focused [OpenStack Foundation][7] boasts 60,000 members living in more than 180 countries.
|
||||
|
||||
So, what could possibly be wrong with this picture?
|
||||
|
||||
What's missing is enough awareness that, while open source software can meet the great majority of user demands, standing alone it can't meet all of them. Worse yet, too many members of the open source community (business leads as well as developers) have no interest in making use of the most appropriate tools available to close the gap.
|
||||
|
||||
Let's start by identifying the problem that needs to be solved, and then see how that problem used to be solved in the past.
|
||||
|
||||
The problem is that there are often many projects trying to solve the same small piece of a larger problem. Customers want to be able to have a choice among competing products and to easily switch among products if they're not satisfied. That's not possible right now, and until this problem is solved, it will hold back open source adoption.
|
||||
|
||||
It's also not a new problem or a problem without traditional solutions. Over the course of a century and a half, user expectations of broad choice and freedom to switch vendors were satisfied through the development of standards. In the physical world, you can choose between myriad vendors of screws, light bulbs, tires, extension cords, and even of the proper shape wine glass for the pour of your choice, because standards provide the physical specifications for each of these goods. In the world of health and safety, our well-being relies on thousands of standards developed by the private sector that ensure proper results while maximizing competition.
|
||||
|
||||
When information and communications technology (ICT) came along, the same approach was taken with the formation of major organizations such as the International Telecommunication Union (ITU), International Electrotechnical Commission (IEC), and the Standards Association of the Institute of Electrical and Electronics Engineers (IEEE-SA). Close to 1,000 consortia followed to develop, promote, or test compliance with ICT standards.
|
||||
|
||||
While not all ICT standards resulted in seamless interoperability, the technology world we live in today exists courtesy of the tens of thousands of essential standards that fulfill that promise, as implemented in computers, mobile devices, Wi-Fi routers, and indeed everything else that runs on electricity.
|
||||
|
||||
The point here is that, over a very long time, a system evolved that could meet customers' desires to have broad product offerings, avoid vendor lock-in, and enjoy services on a global basis.
|
||||
|
||||
Now let's look at how open software is evolving.
|
||||
|
||||
The good news is that great software is being created. The bad news is that in many key areas, like cloud computing and network virtualization, no single foundation is developing the entire stack. Instead, discrete projects develop individual layers, or parts of layers, and then rely on real-time, goodwill-based collaboration up and down the stack among peer projects. When this process works well, the results are good but have the potential to create lock-in the same way that traditional, proprietary products could. When the process works badly, it can result in much wasted time and effort for vendors and community members, as well as disappointed customer expectations.
|
||||
|
||||
The clear way to provide a solution is to create standards that allow customers to avoid lock-in, along with encouraging the availability of multiple solutions competing through value-added features and services. But, with rare exceptions, that's not what's happening in the world of open source.
|
||||
|
||||
The main reason behind this is the prevailing opinion in the open source community is that standards are limiting, irrelevant, and unnecessary. Within a single, well-integrated stack, that may be the case. But for customers that want freedom of choice and ongoing, robust competition, the result could be a return to the bad old days of being locked into a technology, albeit with multiple vendors offering similarly integrated stacks.
|
||||
|
||||
A good description of the problem can be found in a June 14, 2017, article written by Yaron Haviv, "[We'll Be Enslaved to Proprietary Clouds Unless We Collaborate][8]":
|
||||
|
||||
> _Cross-project integration is not exactly prevalent in today's open source ecosystem, and it's a problem. Open source projects that enable large-scale collaboration and are built on a layered and modular architecture—such as Linux_ — _have proven their success time and again. But the Linux ideology stands in stark contrast to the general state of much of today's open source community._
|
||||
>
|
||||
> _Case in point: big data ecosystems, where numerous overlapping implementations rarely share components or use common APIs and layers. They also tend to lack standard wire protocols, and each processing framework (think Spark, Presto, and Flink) has its own data source API._
|
||||
>
|
||||
> _This lack of collaboration is causing angst. Without it, projects are not interchangeable, resulting in negative repercussions for customers by essentially locking them in and slowing down the evolution of projects because each one has to start from scratch and re-invent the wheel._
|
||||
|
||||
Haviv proposes two ways to resolve the situation:
|
||||
|
||||
* Closer collaboration among projects, leading to consolidation, the elimination of overlaps between multiple projects, and tighter integration within a stack;
|
||||
|
||||
* The development of APIs to make switching easier.
|
||||
|
||||
Both these approaches make sense. But unless something changes, we'll see only the first, and that's where the prospect for lock-in is found. The result would be where the industry found itself in the WinTel world of the past or throughout Apple's history, where competing product choice is sacrificed in exchange for tight integration.
|
||||
|
||||
The same thing can, and likely will, happen in the new open source world if open source projects continue to ignore the need for standards so that competition can exist within layers, and even between stacks. Where things stand today, there's almost no chance of that happening.
|
||||
|
||||
The reason is that while some projects pay lip service to develop software first and standards later, there is no real interest in following through with the standards. The main reason is that most business people and developers don't know much about standards. Unfortunately, that's all too understandable and likely to get worse. The reasons are several:
|
||||
|
||||
* Universities dedicate almost no training time to standards;
|
||||
|
||||
* Companies that used to have staffs of standards professionals have disbanded those departments and now deploy engineers with far less training to participate in standards organizations;
|
||||
|
||||
* There is little career value in establishing expertise in representing an employer in standards work;
|
||||
|
||||
* Engineers participating in standards activities may be required to further the strategic interests of their employer at the cost of what they believe to be the best technical solution;
|
||||
|
||||
* There is little to no communication between open source developers and standards professionals within many companies;
|
||||
|
||||
* Many software engineers view standards as being in direct conflict with the "four freedoms" underlying the FOSS definition.
|
||||
|
||||
Now let's look at what's going on in the world of open source:
|
||||
|
||||
* It would be difficult for any software engineer today to not know about open source;
|
||||
|
||||
* It's a tool engineers are comfortable with and often use on a daily basis;
|
||||
|
||||
* Much of the sexiest, most cutting-edge work is being done in open source projects;
|
||||
|
||||
* Developers with expertise in hot open source areas are much sought after and command substantial compensation premiums;
|
||||
|
||||
* Developers enjoy unprecedented autonomy in developing software within well-respected projects;
|
||||
|
||||
* Virtually all of the major ICT companies participate in multiple open source projects, often with a combined cost (dues plus dedicated employees) of over $1 million per year per company at the highest membership level.
|
||||
|
||||
When viewed in a vacuum, this comparison would seem to indicate that standards are headed for the ash heap of history in ICT. But the reality is more nuanced. It also ignores the reality that open source development can be a more delicate flower than many might assume. The reasons include the following:
|
||||
|
||||
* Major supporters of projects can decommit (and sometimes have done so), leading to the failure of a project;
|
||||
|
||||
* Personality and cultural conflicts within communities can lead to disruptions;
|
||||
|
||||
* The ability of key projects to more tightly integrate remains to be seen;
|
||||
|
||||
* Proprietary game playing has sometimes undercut, and in some cases caused the failure of, highly funded open source projects;
|
||||
|
||||
* Over time, individual companies may decide that their open source strategies have failed to bring the rewards they anticipated;
|
||||
|
||||
* A few well-publicized failures of key open source projects could lead vendors to back off from investing in new projects and persuade customers to be wary of committing to open source solutions.
|
||||
|
||||
Curiously enough, the collaborative entities that are addressing these issues most aggressively are standards organizations, in part because they feel (rightly) threatened by the rise of open source collaboration. Their responses include upgrading their intellectual property rights policies to allow all types of collaboration to occur under the same umbrella, including development of open source tools, inclusion of open source code in standards, and development of open source reference implementations of standards, among other types of work projects.
|
||||
|
||||
The result is that standards organizations are retooling themselves to provide an approach-neutral venue for the development of complete solutions. Those solutions can incorporate whatever type of collaborative work product, or hybrid work product, the marketplace may need. As this process continues, it is likely that vendors will begin to pursue some initiatives within standards organizations that might otherwise have made their way to open source foundations.
|
||||
|
||||
For all these reasons, it's crucial that open source projects get serious about including standards in their deliverables or otherwise partner with appropriate standards-developers to jointly provide complete solutions. The result will not only be greater product choice and less customer lock-in, but far greater confidence by customers in open source solutions, and therefore far greater demand for and use of open source products and services.
|
||||
|
||||
If that doesn't happen it will be a great shame, because the open source cause has the most to lose. It's up to the projects now to decide whether to give the market what it wants and needs or reconcile themselves to a future of decreasing influence, rather than continuing success.
|
||||
|
||||
_This was originally published on ConsortiumInfo.org's [Standards Blog][2] and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Andy Updegrove - Andy helps CEOs, management teams, and their investors build successful organizations. Regionally, he’s been a pioneer in providing business-minded legal counsel and strategic advice to high-tech companies since 1979. On the global stage, he’s represented, and usually helped launch, more than 135 worldwide standard setting, open source, promotional and advocacy consortia, including some of the largest and most influential standard setting organizations in the world.
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/7/software-standards
|
||||
|
||||
作者:[ Andy Updegrove][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andrewupdegrove
|
||||
[1]:https://opensource.com/article/17/7/software-standards?rate=kKK6oD-vGSEdDMj7OHpBMSqASMqbz3ii94q1Kj12lCI
|
||||
[2]:http://www.consortiuminfo.org/standardsblog/article.php?story=20170616133415179
|
||||
[3]:https://opensource.com/user/16796/feed
|
||||
[4]:https://www.apache.org/
|
||||
[5]:https://projects.apache.org/
|
||||
[6]:https://www.linuxfoundation.org/
|
||||
[7]:https://www.linuxfoundation.org/projects/directory
|
||||
[8]:https://www.enterprisetech.com/2017/06/14/well-enslaved-proprietary-clouds-unless-collaborate/
|
||||
[9]:https://opensource.com/users/andrewupdegrove
|
||||
[10]:https://opensource.com/users/andrewupdegrove
|
||||
[11]:https://opensource.com/article/17/7/software-standards#comments
|
||||
@ -1,232 +0,0 @@
|
||||
|
||||
42 Package Management Basics: apt, yum, dnf, pkg
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
|
||||
### Introduction
|
||||
|
||||
Most modern Unix-like operating systems offer a centralized mechanism for finding and installing software. Software is usually distributed in the form of packages, kept in repositories. Working with packages is known as package management. Packages provide the basic components of an operating system, along with shared libraries, applications, services, and documentation.
|
||||
|
||||
A package management system does much more than one-time installation of software. It also provides tools for upgrading already-installed packages. Package repositories help to ensure that code has been vetted for use on your system, and that the installed versions of software have been approved by developers and package maintainers.
|
||||
|
||||
When configuring servers or development environments, it's often necessary look beyond official repositories. Packages in the stable release of a distribution may be out of date, especially where new or rapidly-changing software is concerned. Nevertheless, package management is a vital skill for system administrators and developers, and the wealth of packaged software for major distributions is a tremendous resource.
|
||||
|
||||
This guide is intended as a quick reference for the fundamentals of finding, installing, and upgrading packages on a variety of distributions, and should help you translate that knowledge between systems.
|
||||
|
||||
### Package Management Systems: A Brief Overview
|
||||
|
||||
Most package systems are built around collections of package files. A package file is usually an archive which contains compiled binaries and other resources making up the software, along with installation scripts. Packages also contain valuable metadata, including their dependencies, a list of other packages required to install and run them.
|
||||
|
||||
While their functionality and benefits are broadly similar, packaging formats and tools vary by platform:
|
||||
|
||||
| Operating System | Format | Tool(s) |
|
||||
| --- | --- | --- |
|
||||
| Debian | `.deb` | `apt`, `apt-cache`, `apt-get`, `dpkg` |
|
||||
| Ubuntu | `.deb` | `apt`, `apt-cache`, `apt-get`, `dpkg` |
|
||||
| CentOS | `.rpm` | `yum` |
|
||||
| Fedora | `.rpm` | `dnf` |
|
||||
| FreeBSD | Ports, `.txz` | `make`, `pkg` |
|
||||
|
||||
In Debian and systems based on it, like Ubuntu, Linux Mint, and Raspbian, the package format is the `.deb`file. APT, the Advanced Packaging Tool, provides commands used for most common operations: Searching repositories, installing collections of packages and their dependencies, and managing upgrades. APT commands operate as a front-end to the lower-level `dpkg` utility, which handles the installation of individual `.deb` files on the local system, and is sometimes invoked directly.
|
||||
|
||||
Recent releases of most Debian-derived distributions include the `apt` command, which offers a concise and unified interface to common operations that have traditionally been handled by the more-specific `apt-get` and `apt-cache`. Its use is optional, but may simplify some tasks.
|
||||
|
||||
CentOS, Fedora, and other members of the Red Hat family use RPM files. In CentOS, `yum` is used to interact with both individual package files and repositories.
|
||||
|
||||
In recent versions of Fedora, `yum` has been supplanted by `dnf`, a modernized fork which retains most of `yum`'s interface.
|
||||
|
||||
FreeBSD's binary package system is administered with the `pkg` command. FreeBSD also offers the Ports Collection, a local directory structure and tools which allow the user to fetch, compile, and install packages directly from source using Makefiles. It's usually much more convenient to use `pkg`, but occasionally a pre-compiled package is unavailable, or you may need to change compile-time options.
|
||||
|
||||
### Update Package Lists
|
||||
|
||||
Most systems keep a local database of the packages available from remote repositories. It's best to update this database before installing or upgrading packages. As a partial exception to this pattern, `yum`and `dnf` will check for updates before performing some operations, but you can ask them at any time whether updates are available.
|
||||
|
||||
| System | Command |
|
||||
| --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get update` |
|
||||
| | `sudo apt update` |
|
||||
| CentOS | `yum check-update` |
|
||||
| Fedora | `dnf check-update` |
|
||||
| FreeBSD Packages | `sudo pkg update` |
|
||||
| FreeBSD Ports | `sudo portsnap fetch update` |
|
||||
|
||||
### Upgrade Installed Packages
|
||||
|
||||
Making sure that all of the installed software on a machine stays up to date would be an enormous undertaking without a package system. You would have to track upstream changes and security alerts for hundreds of different packages. While a package manager doesn't solve every problem you'll encounter when upgrading software, it does enable you to maintain most system components with a few commands.
|
||||
|
||||
On FreeBSD, upgrading installed ports can introduce breaking changes or require manual configuration steps. It's best to read `/usr/ports/UPDATING` before upgrading with `portmaster`.
|
||||
|
||||
| System | Command | Notes |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get upgrade` | Only upgrades installed packages, where possible. |
|
||||
| | `sudo apt-get dist-upgrade` | May add or remove packages to satisfy new dependencies. |
|
||||
| | `sudo apt upgrade` | Like `apt-get upgrade`. |
|
||||
| | `sudo apt full-upgrade` | Like `apt-get dist-upgrade`. |
|
||||
| CentOS | `sudo yum update` | |
|
||||
| Fedora | `sudo dnf upgrade` | |
|
||||
| FreeBSD Packages | `sudo pkg upgrade` | |
|
||||
| FreeBSD Ports | `less /usr/ports/UPDATING` | Uses `less` to view update notes for ports (use arrow keys to scroll, press q to quit). |
|
||||
| | `cd /usr/ports/ports-mgmt/portmaster && sudo make install && sudo portmaster -a` | Installs `portmaster` and uses it to update installed ports. |
|
||||
|
||||
### Find a Package
|
||||
|
||||
Most distributions offer a graphical or menu-driven front end to package collections. These can be a good way to browse by category and discover new software. Often, however, the quickest and most effective way to locate a package is to search with command-line tools.
|
||||
|
||||
| System | Command | Notes |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `apt-cache search search_string` | |
|
||||
| | `apt search search_string` | |
|
||||
| CentOS | `yum search search_string` | |
|
||||
| | `yum search all search_string` | Searches all fields, including description. |
|
||||
| Fedora | `dnf search search_string` | |
|
||||
| | `dnf search all search_string` | Searches all fields, including description. |
|
||||
| FreeBSD Packages | `pkg search search_string` | Searches by name. |
|
||||
| | `pkg search -f search_string` | Searches by name, returning full descriptions. |
|
||||
| | `pkg search -D search_string` | Searches description. |
|
||||
| FreeBSD Ports | `cd /usr/ports && make search name=package` | Searches by name. |
|
||||
| | `cd /usr/ports && make search key=search_string` | Searches comments, descriptions, and dependencies. |
|
||||
|
||||
### View Info About a Specific Package
|
||||
|
||||
When deciding what to install, it's often helpful to read detailed descriptions of packages. Along with human-readable text, these often include metadata like version numbers and a list of the package's dependencies.
|
||||
|
||||
| System | Command | Notes |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `apt-cache show package` | Shows locally-cached info about a package. |
|
||||
| | `apt show package` | |
|
||||
| | `dpkg -s package` | Shows the current installed status of a package. |
|
||||
| CentOS | `yum info package` | |
|
||||
| | `yum deplist package` | Lists dependencies for a package. |
|
||||
| Fedora | `dnf info package` | |
|
||||
| | `dnf repoquery --requires package` | Lists dependencies for a package. |
|
||||
| FreeBSD Packages | `pkg info package` | Shows info for an installed package. |
|
||||
| FreeBSD Ports | `cd /usr/ports/category/port && cat pkg-descr` | |
|
||||
|
||||
### Install a Package from Repositories
|
||||
|
||||
Once you know the name of a package, you can usually install it and its dependencies with a single command. In general, you can supply multiple packages to install simply by listing them all.
|
||||
|
||||
| System | Command | Notes |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get install package` | |
|
||||
| | `sudo apt-get install package1 package2 ...` | Installs all listed packages. |
|
||||
| | `sudo apt-get install -y package` | Assumes "yes" where `apt` would usually prompt to continue. |
|
||||
| | `sudo apt install package` | Displays a colored progress bar. |
|
||||
| CentOS | `sudo yum install package` | |
|
||||
| | `sudo yum install package1 package2 ...` | Installs all listed packages. |
|
||||
| | `sudo yum install -y package` | Assumes "yes" where `yum` would usually prompt to continue. |
|
||||
| Fedora | `sudo dnf install package` | |
|
||||
| | `sudo dnf install package1 package2 ...` | Installs all listed packages. |
|
||||
| | `sudo dnf install -y package` | Assumes "yes" where `dnf` would usually prompt to continue. |
|
||||
| FreeBSD Packages | `sudo pkg install package` | |
|
||||
| | `sudo pkg install package1 package2 ...` | Installs all listed packages. |
|
||||
| FreeBSD Ports | `cd /usr/ports/category/port && sudo make install` | Builds and installs a port from source. |
|
||||
|
||||
### Install a Package from the Local Filesystem
|
||||
|
||||
Sometimes, even though software isn't officially packaged for a given operating system, a developer or vendor will offer package files for download. You can usually retrieve these with your web browser, or via `curl` on the command line. Once a package is on the target system, it can often be installed with a single command.
|
||||
|
||||
On Debian-derived systems, `dpkg` handles individual package files. If a package has unmet dependencies, `gdebi` can often be used to retrieve them from official repositories.
|
||||
|
||||
On CentOS and Fedora systems, `yum` and `dnf` are used to install individual files, and will also handle needed dependencies.
|
||||
|
||||
| System | Command | Notes |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo dpkg -i package.deb` | |
|
||||
| | `sudo apt-get install -y gdebi&& sudo gdebi package.deb` | Installs and uses `gdebi` to install `package.deb`and retrieve any missing dependencies. |
|
||||
| CentOS | `sudo yum install package.rpm` | |
|
||||
| Fedora | `sudo dnf install package.rpm` | |
|
||||
| FreeBSD Packages | `sudo pkg add package.txz` | |
|
||||
| | `sudo pkg add -f package.txz` | Installs package even if already installed. |
|
||||
|
||||
### Remove One or More Installed Packages
|
||||
|
||||
Since a package manager knows what files are provided by a given package, it can usually remove them cleanly from a system if the software is no longer needed.
|
||||
|
||||
| System | Command | Notes |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get remove package` | |
|
||||
| | `sudo apt remove package` | |
|
||||
| | `sudo apt-get autoremove` | Removes unneeded packages. |
|
||||
| CentOS | `sudo yum remove package` | |
|
||||
| Fedora | `sudo dnf erase package` | |
|
||||
| FreeBSD Packages | `sudo pkg delete package` | |
|
||||
| | `sudo pkg autoremove` | Removes unneeded packages. |
|
||||
| FreeBSD Ports | `sudo pkg delete package` | |
|
||||
| | `cd /usr/ports/path_to_port && make deinstall` | De-installs an installed port. |
|
||||
|
||||
### The `apt` Command
|
||||
|
||||
Administrators of Debian-family distributions are generally familiar with `apt-get` and `apt-cache`. Less widely known is the simplified `apt` interface, designed specifically for interactive use.
|
||||
|
||||
| Traditional Command | `apt` Equivalent |
|
||||
| --- | --- |
|
||||
| `apt-get update` | `apt update` |
|
||||
| `apt-get dist-upgrade` | `apt full-upgrade` |
|
||||
| `apt-cache search string` | `apt search string` |
|
||||
| `apt-get install package` | `apt install package` |
|
||||
| `apt-get remove package` | `apt remove package` |
|
||||
| `apt-get purge package` | `apt purge package` |
|
||||
|
||||
While `apt` is often a quicker shorthand for a given operation, it's not intended as a complete replacement for the traditional tools, and its interface may change between versions to improve usability. If you are using package management commands inside a script or a shell pipeline, it's a good idea to stick with `apt-get` and `apt-cache`.
|
||||
|
||||
### Get Help
|
||||
|
||||
In addition to web-based documentation, keep in mind that Unix manual pages (usually referred to as man pages) are available for most commands from the shell. To read a page, use `man`:
|
||||
|
||||
```
|
||||
man page
|
||||
|
||||
```
|
||||
|
||||
In `man`, you can navigate with the arrow keys. Press / to search for text within the page, and q to quit.
|
||||
|
||||
| System | Command | Notes |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `man apt-get` | Updating the local package database and working with packages. |
|
||||
| | `man apt-cache` | Querying the local package database. |
|
||||
| | `man dpkg` | Working with individual package files and querying installed packages. |
|
||||
| | `man apt` | Working with a more concise, user-friendly interface to most basic operations. |
|
||||
| CentOS | `man yum` | |
|
||||
| Fedora | `man dnf` | |
|
||||
| FreeBSD Packages | `man pkg` | Working with pre-compiled binary packages. |
|
||||
| FreeBSD Ports | `man ports` | Working with the Ports Collection. |
|
||||
|
||||
### Conclusion and Further Reading
|
||||
|
||||
This guide provides an overview of basic operations that can be cross-referenced between systems, but only scratches the surface of a complex topic. For greater detail on a given system, you can consult the following resources:
|
||||
|
||||
* [This guide][1] covers Ubuntu and Debian package management in detail.
|
||||
|
||||
* There's an [official CentOS guide to managing software with `yum`][2].
|
||||
|
||||
* There's a [Fedora wiki page about `dnf`][3], and an [official manual for `dnf` itself][4].
|
||||
|
||||
* [This guide][5] covers FreeBSD package management using `pkg`.
|
||||
|
||||
* The [FreeBSD Handbook][6] contains a [section on using the Ports Collection][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/package-management-basics-apt-yum-dnf-pkg
|
||||
|
||||
作者:[Brennen Bearnes ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.digitalocean.com/community/users/bpb
|
||||
[1]:https://www.digitalocean.com/community/tutorials/ubuntu-and-debian-package-management-essentials
|
||||
[2]:https://www.centos.org/docs/5/html/yum/
|
||||
[3]:https://fedoraproject.org/wiki/Dnf
|
||||
[4]:https://dnf.readthedocs.org/en/latest/index.html
|
||||
[5]:https://www.digitalocean.com/community/tutorials/how-to-manage-packages-on-freebsd-10-1-with-pkg
|
||||
[6]:https://www.freebsd.org/doc/handbook/
|
||||
[7]:https://www.freebsd.org/doc/handbook/ports-using.html
|
||||
[8]:https://www.digitalocean.com/community/tags/linux-commands?type=tutorials
|
||||
[9]:https://www.digitalocean.com/community/tags/getting-started?type=tutorials
|
||||
[10]:https://www.digitalocean.com/community/tags/system-tools?type=tutorials
|
||||
[11]:https://www.digitalocean.com/community/tags/linux-basics?type=tutorials
|
||||
@ -0,0 +1,140 @@
|
||||
Running MongoDB as a Microservice with Docker and Kubernetes
|
||||
===================
|
||||
|
||||
### Introduction
|
||||
|
||||
Want to try out MongoDB on your laptop? Execute a single command and you have a lightweight, self-contained sandbox; another command removes all traces when you're done.
|
||||
|
||||
Need an identical copy of your application stack in multiple environments? Build your own container image and let your development, test, operations, and support teams launch an identical clone of your environment.
|
||||
|
||||
Containers are revolutionizing the entire software lifecycle: from the earliest technical experiments and proofs of concept through development, test, deployment, and support.
|
||||
|
||||
#### [Read the Enabling Microservices: Containers & Orchestration Explained white paper][6].
|
||||
|
||||
Orchestration tools manage how multiple containers are created, upgraded and made highly available. Orchestration also controls how containers are connected to build sophisticated applications from multiple, microservice containers.
|
||||
|
||||
The rich functionality, simple tools, and powerful APIs make container and orchestration functionality a favorite for DevOps teams who integrate them into Continuous Integration (CI) and Continuous Delivery (CD) workflows.
|
||||
|
||||
This post delves into the extra challenges you face when attempting to run and orchestrate MongoDB in containers and illustrates how these challenges can be overcome.
|
||||
|
||||
### Considerations for MongoDB
|
||||
|
||||
Running MongoDB with containers and orchestration introduces some additional considerations:
|
||||
|
||||
* MongoDB database nodes are stateful. In the event that a container fails, and is rescheduled, it's undesirable for the data to be lost (it could be recovered from other nodes in the replica set, but that takes time). To solve this, features such as the _Volume_ abstraction in Kubernetes can be used to map what would otherwise be an ephemeral MongoDB data directory in the container to a persistent location where the data survives container failure and rescheduling.
|
||||
|
||||
* MongoDB database nodes within a replica set must communicate with each other – including after rescheduling. All of the nodes within a replica set must know the addresses of all of their peers, but when a container is rescheduled, it is likely to be restarted with a different IP address. For example, all containers within a Kubernetes Pod share a single IP address, which changes when the pod is rescheduled. With Kubernetes, this can be handled by associating a Kubernetes Service with each MongoDB node, which uses the Kubernetes DNS service to provide a `hostname` for the service that remains constant through rescheduling.
|
||||
|
||||
* Once each of the individual MongoDB nodes is running (each within its own container), the replica set must be initialized and each node added. This is likely to require some additional logic beyond that offered by off the shelf orchestration tools. Specifically, one MongoDB node within the intended replica set must be used to execute the `rs.initiate` and `rs.add` commands.
|
||||
|
||||
* If the orchestration framework provides automated rescheduling of containers (as Kubernetes does) then this can increase MongoDB's resiliency since a failed replica set member can be automatically recreated, thus restoring full redundancy levels without human intervention.
|
||||
|
||||
* It should be noted that while the orchestration framework might monitor the state of the containers, it is unlikely to monitor the applications running within the containers, or backup their data. That means it's important to use a strong monitoring and backup solution such as [MongoDB Cloud Manager][1], included with [MongoDB Enterprise Advanced][2] and [MongoDB Professional][3]. Consider creating your own image that contains both your preferred version of MongoDB and the [MongoDB Automation Agent][4].
|
||||
|
||||
### Implementing a MongoDB Replica Set using Docker and Kubernetes
|
||||
|
||||
As described in the previous section, distributed databases such as MongoDB require a little extra attention when being deployed with orchestration frameworks such as Kubernetes. This section goes to the next level of detail, showing how this can actually be implemented.
|
||||
|
||||
We start by creating the entire MongoDB replica set in a single Kubernetes cluster (which would normally be within a single data center – that clearly doesn't provide geographic redundancy). In reality, little has to be changed to run across multiple clusters and those steps are described later.
|
||||
|
||||
Each member of the replica set will be run as its own pod with a service exposing an external IP address and port. This 'fixed' IP address is important as both external applications and other replica set members can rely on it remaining constant in the event that a pod is rescheduled.
|
||||
|
||||
The following diagram illustrates one of these pods and the associated Replication Controller and service.
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
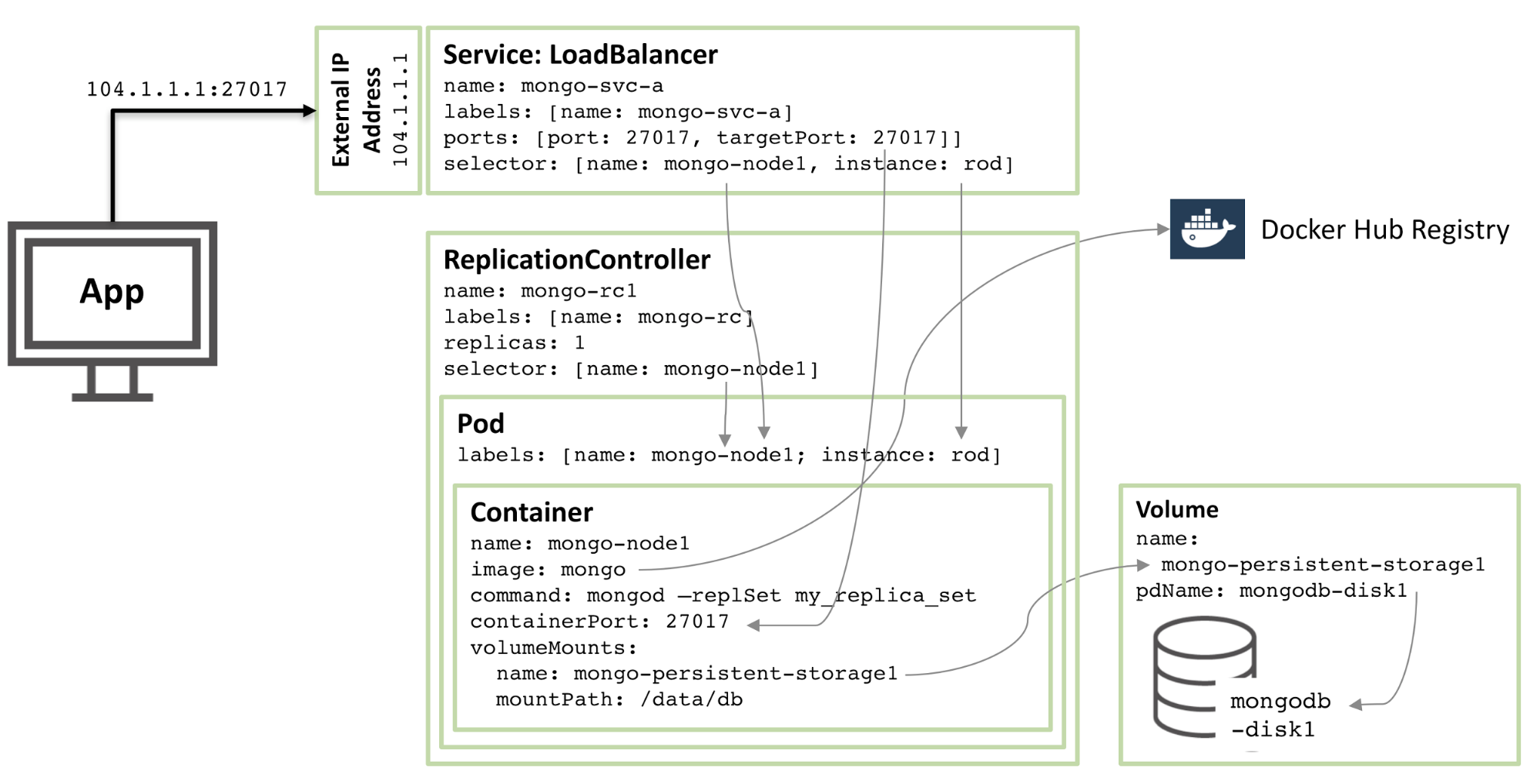
|
||||
</center>
|
||||
|
||||
Figure 1: MongoDB Replica Set member configured as a Kubernetes Pod and exposed as a service
|
||||
|
||||
Stepping through the resources described in that configuration we have:
|
||||
|
||||
* Starting at the core there is a single container named `mongo-node1`. `mongo-node1`includes an image called `mongo` which is a publicly available MongoDB container image hosted on [Docker Hub][5]. The container exposes port `27107` within the cluster.
|
||||
|
||||
* The Kubernetes _volumes_ feature is used to map the `/data/db` directory within the connector to the persistent storage element named `mongo-persistent-storage1`; which in turn is mapped to a disk named `mongodb-disk1` created in the Google Cloud. This is where MongoDB would store its data so that it is persisted over container rescheduling.
|
||||
|
||||
* The container is held within a pod which has the labels to name the pod `mongo-node`and provide an (arbitrary) instance name of `rod`.
|
||||
|
||||
* A Replication Controller named `mongo-rc1` is configured to ensure that a single instance of the `mongo-node1` pod is always running.
|
||||
|
||||
* The `LoadBalancer` service named `mongo-svc-a` exposes an IP address to the outside world together with the port of `27017` which is mapped to the same port number in the container. The service identifies the correct pod using a selector that matches the pod's labels. That external IP address and port will be used by both an application and for communication between the replica set members. There are also local IP addresses for each container, but those change when containers are moved or restarted, and so aren't of use for the replica set.
|
||||
|
||||
The next diagram shows the configuration for a second member of the replica set.
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
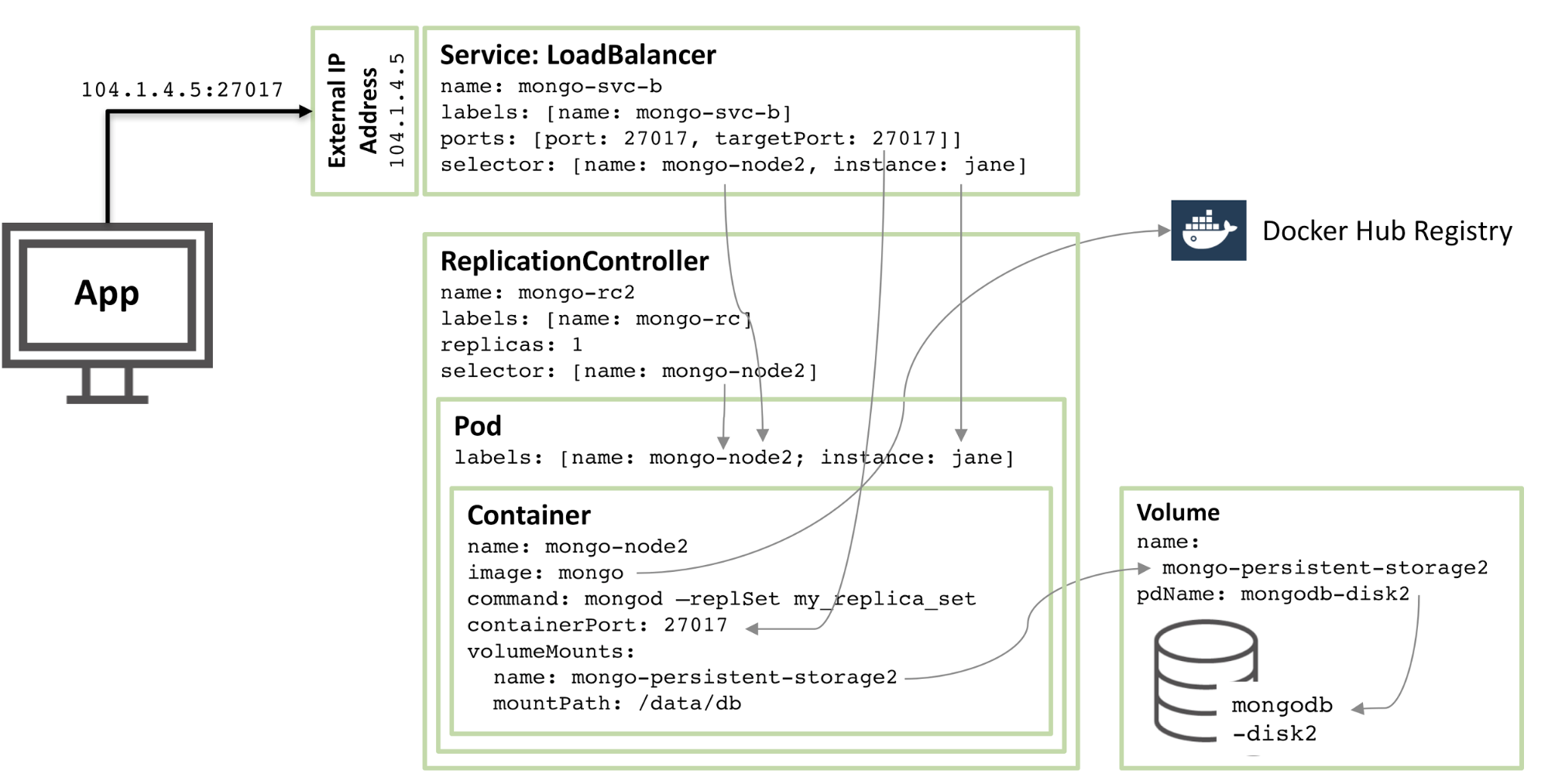
|
||||
</center>
|
||||
|
||||
Figure 2: Second MongoDB Replica Set member configured as a Kubernetes Pod
|
||||
|
||||
90% of the configuration is the same, with just these changes:
|
||||
|
||||
* The disk and volume names must be unique and so `mongodb-disk2` and `mongo-persistent-storage2` are used
|
||||
|
||||
* The Pod is assigned a label of `instance: jane` and `name: mongo-node2` so that the new service can distinguish it (using a selector) from the `rod` Pod used in Figure 1.
|
||||
|
||||
* The Replication Controller is named `mongo-rc2`
|
||||
|
||||
* The Service is named `mongo-svc-b` and gets a unique, external IP address (in this instance, Kubernetes has assigned `104.1.4.5`)
|
||||
|
||||
The configuration of the third replica set member follows the same pattern and the following figure shows the complete replica set:
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
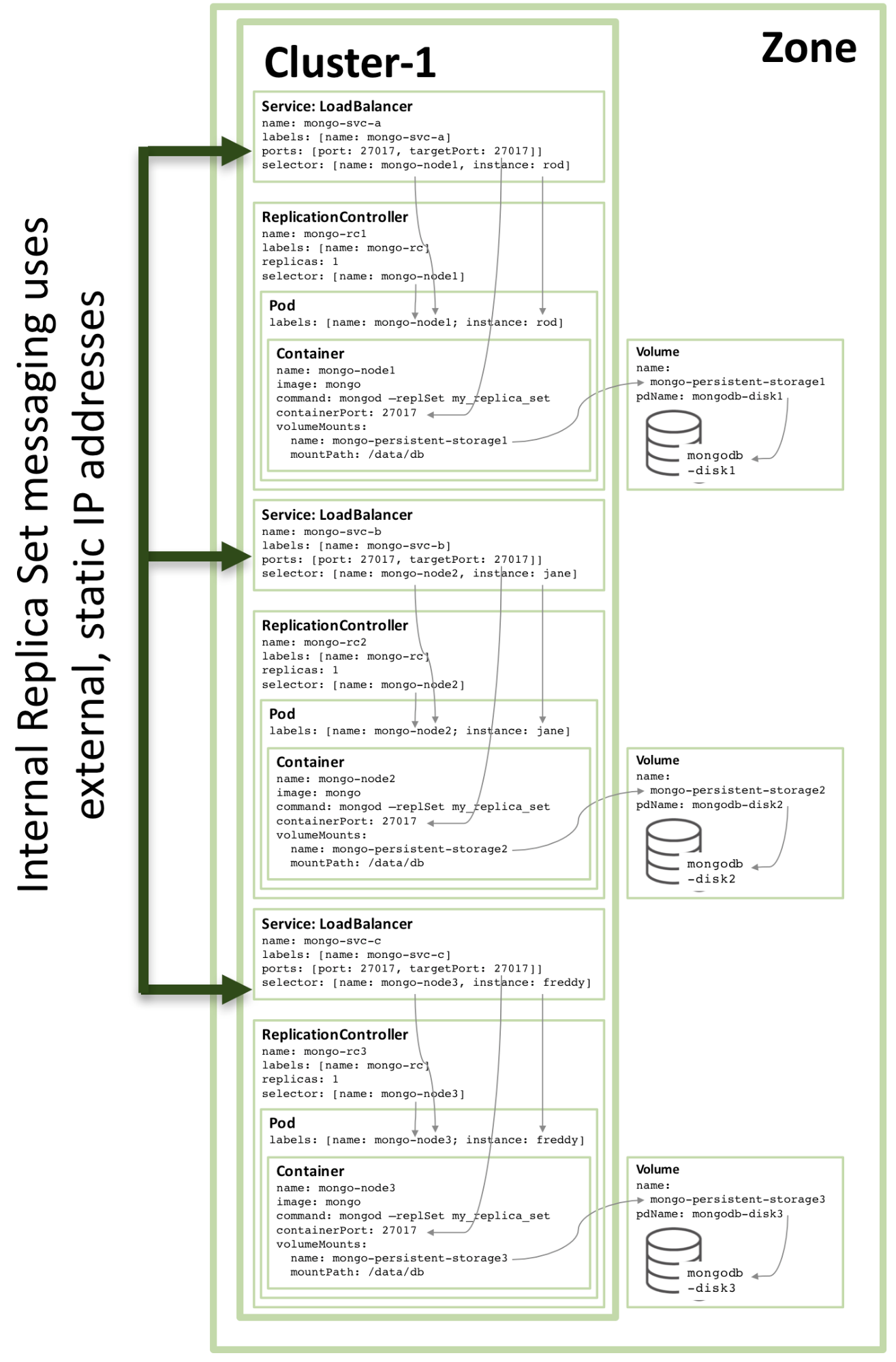
|
||||
</center>
|
||||
|
||||
Figure 3: Full Replica Set member configured as a Kubernetes Service
|
||||
|
||||
Note that even if running the configuration shown in Figure 3 on a Kubernetes cluster of three or more nodes, Kubernetes may (and often will) schedule two or more MongoDB replica set members on the same host. This is because Kubernetes views the three pods as belonging to three independent services.
|
||||
|
||||
To increase redundancy (within the zone), an additional _headless_ service can be created. The new service provides no capabilities to the outside world (and will not even have an IP address) but it serves to inform Kubernetes that the three MongoDB pods form a service and so Kubernetes will attempt to schedule them on different nodes.
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
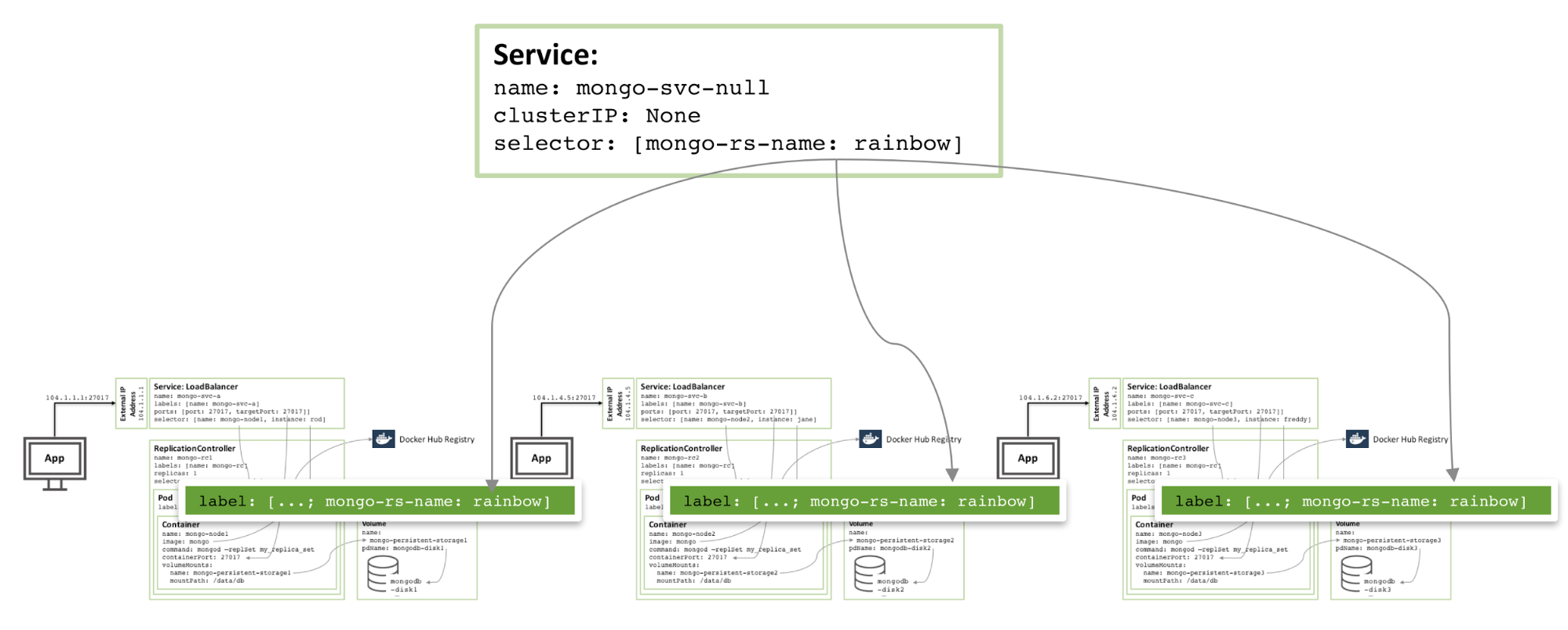
|
||||
</center>
|
||||
|
||||
Figure 4: Headless service to avoid co-locating of MongoDB replica set members
|
||||
|
||||
The actual configuration files and the commands needed to orchestrate and start the MongoDB replica set can be found in the [Enabling Microservices: Containers & Orchestration Explained white paper][7]. In particular, there are some special steps required to combine the three MongoDB instances into a functioning, robust replica set which are described in the paper.
|
||||
|
||||
#### Multiple Availability Zone MongoDB Replica Set
|
||||
|
||||
There is risk associated with the replica set created above in that everything is running in the same GCE cluster, and hence in the same availability zone. If there were a major incident that took the availability zone offline, then the MongoDB replica set would be unavailable. If geographic redundancy is required, then the three pods should be run in three different availability zones or regions.
|
||||
|
||||
Surprisingly little needs to change in order to create a similar replica set that is split between three zones – which requires three clusters. Each cluster requires its own Kubernetes YAML file that defines just the pod, Replication Controller and service for one member of the replica set. It is then a simple matter to create a cluster, persistent storage, and MongoDB node for each zone.
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
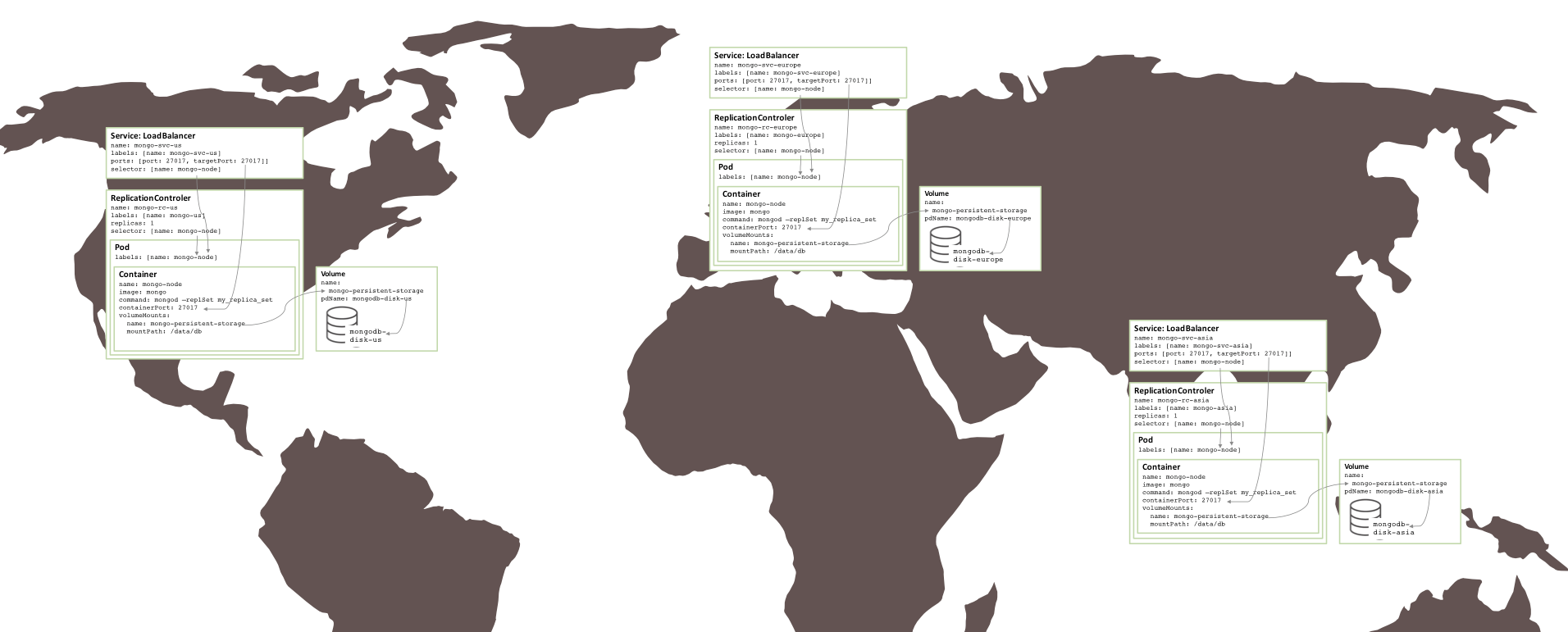
|
||||
</center>
|
||||
|
||||
Figure 5: Replica set running over multiple availability zones
|
||||
|
||||
### Next Steps
|
||||
|
||||
To learn more about containers and orchestration – both the technologies involved and the business benefits they deliver – read the [Enabling Microservices: Containers & Orchestration Explained white paper][8]. The same paper provides the complete instructions to get the replica set described in this post up and running on Docker and Kubernetes in the Google Container Engine.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Andrew is a Principal Product Marketing Manager working for MongoDB. He joined at the start last summer from Oracle where he spent 6+ years in product management, focused on High Availability. He can be contacted @andrewmorgan or through comments on his blog (clusterdb.com).
|
||||
|
||||
-------
|
||||
|
||||
via: https://www.mongodb.com/blog/post/running-mongodb-as-a-microservice-with-docker-and-kubernetes
|
||||
|
||||
作者:[Andrew Morgan ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.clusterdb.com/
|
||||
[1]:https://www.mongodb.com/cloud/
|
||||
[2]:https://www.mongodb.com/products/mongodb-enterprise-advanced
|
||||
[3]:https://www.mongodb.com/products/mongodb-professional
|
||||
[4]:https://docs.cloud.mongodb.com/tutorial/nav/install-automation-agent/
|
||||
[5]:https://hub.docker.com/_/mongo/
|
||||
[6]:https://www.mongodb.com/collateral/microservices-containers-and-orchestration-explained?jmp=inline
|
||||
[7]:https://www.mongodb.com/collateral/microservices-containers-and-orchestration-explained
|
||||
[8]:https://www.mongodb.com/collateral/microservices-containers-and-orchestration-explained
|
||||
@ -1,3 +1,4 @@
|
||||
XYenChi is Translating
|
||||
LEDE and OpenWrt
|
||||
===================
|
||||
|
||||
|
||||
164
sources/tech/20160518 Cleaning Up Your Linux Startup Process.md
Normal file
164
sources/tech/20160518 Cleaning Up Your Linux Startup Process.md
Normal file
@ -0,0 +1,164 @@
|
||||
Cleaning Up Your Linux Startup Process
|
||||
============================================================
|
||||
|
||||

|
||||
Learn how to clean up your Linux startup process.[Used with permission][1]
|
||||
|
||||
The average general-purpose Linux distribution launches all kinds of stuff at startup, including a lot of services that don't need to be running. Bluetooth, Avahi, ModemManager, ppp-dns… What are these things, and who needs them?
|
||||
|
||||
Systemd provides a lot of good tools for seeing what happens during your system startup, and controlling what starts at boot. In this article, I’ll show how to turn off startup cruft on Systemd distributions.
|
||||
|
||||
### View Boot Services
|
||||
|
||||
In the olden days, you could easily see which services were set to launch at boot by looking in /etc/init.d. Systemd does things differently. You can use the following incantation to list enabled boot services:
|
||||
|
||||
```
|
||||
systemctl list-unit-files --type=service | grep enabled
|
||||
accounts-daemon.service enabled
|
||||
anacron-resume.service enabled
|
||||
anacron.service enabled
|
||||
bluetooth.service enabled
|
||||
brltty.service enabled
|
||||
[...]
|
||||
```
|
||||
|
||||
And, there near the top is my personal nemesis: Bluetooth. I don't use it on my PC, and I don't need it running. The following commands stop it and then disable it from starting at boot:
|
||||
|
||||
```
|
||||
$ sudo systemctl stop bluetooth.service
|
||||
$ sudo systemctl disable bluetooth.service
|
||||
```
|
||||
|
||||
You can confirm by checking the status:
|
||||
|
||||
```
|
||||
$ systemctl status bluetooth.service
|
||||
bluetooth.service - Bluetooth service
|
||||
Loaded: loaded (/lib/systemd/system/bluetooth.service; disabled; vendor preset: enabled)
|
||||
Active: inactive (dead)
|
||||
Docs: man:bluetoothd(8)
|
||||
```
|
||||
|
||||
A disabled service can be started by another service. If you really want it dead, without uninstalling it, then you can mask it to prevent it from starting under any circumstances:
|
||||
|
||||
```
|
||||
$ sudo systemctl mask bluetooth.service
|
||||
Created symlink from /etc/systemd/system/bluetooth.service to /dev/null.
|
||||
```
|
||||
|
||||
Once you are satisfied that disabling a service has no bad side effects, you may elect to uninstall it.
|
||||
|
||||
You can generate a list of all services:
|
||||
|
||||
```
|
||||
$ systemctl list-unit-files --type=service
|
||||
UNIT FILE STATE
|
||||
accounts-daemon.service enabled
|
||||
acpid.service disabled
|
||||
alsa-restore.service static
|
||||
alsa-utils.service masked
|
||||
```
|
||||
|
||||
You cannot enable or disable static services, because these are dependencies of other systemd services and are not meant to run by themselves.
|
||||
|
||||
### Can I Get Rid of These Services?
|
||||
|
||||
How do you know what you need, and what you can safely disable? As always, that depends on your particular setup.
|
||||
|
||||
Here is a sampling of services and what they are for. Many services are distro-specific, so have your distribution documentation handy (i.e., Google and Stack Overflow).
|
||||
|
||||
* **accounts-daemon.service** is a potential security risk. It is part of AccountsService, which allows programs to get and manipulate user account information. I can't think of a good reason to allow this kind of behind-my-back operations, so I mask it.
|
||||
|
||||
* **avahi-daemon.service** is supposed to provide zero-configuration network discovery, and make it super-easy to find printers and other hosts on your network. I always disable it and don't miss it.
|
||||
|
||||
* **brltty.service** provides Braille device support, for example, Braille displays.
|
||||
|
||||
* **debug-shell.service** opens a giant security hole and should never be enabled except when you are using it. This provides a password-less root shell to help with debugging systemd problems.
|
||||
|
||||
* **ModemManager.service** is a DBus-activated daemon that controls mobile broadband (2G/3G/4G) interfaces. If you don't have a mobile broadband interface -- built-in, paired with a mobile phone via Bluetooth, or USB dongle -- you don't need this.
|
||||
|
||||
* **pppd-dns.service** is a relic of the dim past. If you use dial-up Internet, keep it. Otherwise, you don't need it.
|
||||
|
||||
* **rtkit-daemon.service** sounds scary, like rootkit, but you need it because it is the real-time kernel scheduler.
|
||||
|
||||
* **whoopsie.service** is the Ubuntu error reporting service. It collects crash reports and sends them to [https://daisy.ubuntu.com][2]. You may safely disable it, or you can remove it permanently by uninstalling apport.
|
||||
|
||||
* **wpa_supplicant.service** is necessary only if you use a Wi-Fi network interface.
|
||||
|
||||
### What Happens During Bootup
|
||||
|
||||
Systemd has some commands to help debug boot issues. This command replays all of your boot messages:
|
||||
|
||||
```
|
||||
$ journalctl -b
|
||||
|
||||
-- Logs begin at Mon 2016-05-09 06:18:11 PDT,
|
||||
end at Mon 2016-05-09 10:17:01 PDT. --
|
||||
May 16 06:18:11 studio systemd-journal[289]:
|
||||
Runtime journal (/run/log/journal/) is currently using 8.0M.
|
||||
Maximum allowed usage is set to 157.2M.
|
||||
Leaving at least 235.9M free (of currently available 1.5G of space).
|
||||
Enforced usage limit is thus 157.2M.
|
||||
[...]
|
||||
```
|
||||
|
||||
You can review previous boots with **journalctl -b -1**, which displays the previous startup;**journalctl -b -2** shows two boots ago, and so on.
|
||||
|
||||
This spits out a giant amount of output, which is interesting but maybe not all that useful. It has several filters to help you find what you want. Let's look at PID 1, which is the parent process for all other processes:
|
||||
|
||||
```
|
||||
$ journalctl _PID=1
|
||||
|
||||
May 08 06:18:17 studio systemd[1]: Starting LSB: Raise network interfaces....
|
||||
May 08 06:18:17 studio systemd[1]: Started LSB: Raise network interfaces..
|
||||
May 08 06:18:17 studio systemd[1]: Reached target System Initialization.
|
||||
May 08 06:18:17 studio systemd[1]: Started CUPS Scheduler.
|
||||
May 08 06:18:17 studio systemd[1]: Listening on D-Bus System Message Bus Socket
|
||||
May 08 06:18:17 studio systemd[1]: Listening on CUPS Scheduler.
|
||||
[...]
|
||||
```
|
||||
|
||||
This shows what was started -- or attempted to start.
|
||||
|
||||
One of the most useful tools is **systemd-analyze blame**, which shows which services are taking the longest to start up.
|
||||
|
||||
```
|
||||
$ systemd-analyze blame
|
||||
8.708s gpu-manager.service
|
||||
8.002s NetworkManager-wait-online.service
|
||||
5.791s mysql.service
|
||||
2.975s dev-sda3.device
|
||||
1.810s alsa-restore.service
|
||||
1.806s systemd-logind.service
|
||||
1.803s irqbalance.service
|
||||
1.800s lm-sensors.service
|
||||
1.800s grub-common.service
|
||||
```
|
||||
|
||||
This particular example doesn't show anything unusual, but if there is startup bottleneck, this command will find it.
|
||||
|
||||
You may also find these previous Systemd how-tos useful:
|
||||
|
||||
* [Understanding and Using Systemd][3]
|
||||
|
||||
* [Intro to Systemd Runlevels and Service Management Commands][4]
|
||||
|
||||
* [Here We Go Again, Another Linux Init: Intro to systemd][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/cleaning-your-linux-startup-process
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://daisy.ubuntu.com/
|
||||
[3]:https://www.linux.com/learn/understanding-and-using-systemd
|
||||
[4]:https://www.linux.com/learn/intro-systemd-runlevels-and-service-management-commands
|
||||
[5]:https://www.linux.com/learn/here-we-go-again-another-linux-init-intro-systemd
|
||||
[6]:https://www.linux.com/files/images/banner-cleanup-startuppng
|
||||
@ -0,0 +1,212 @@
|
||||
Here are all the Git commands I used last week, and what they do.
|
||||
============================================================
|
||||
|
||||
Image credit: [GitHub Octodex][6]
|
||||
|
||||
Like most newbies, I started out searching StackOverflow for Git commands, then copy-pasting answers, without really understanding what they did.
|
||||
|
||||
|
||||
|
||||
Image credit: [XKCD][7]
|
||||
|
||||
I remember thinking,“Wouldn’t it be nice if there were a list of the most common Git commands along with an explanation as to why they are useful?”
|
||||
|
||||
Well, here I am years later to compile such a list, and lay out some best practices that even intermediate-advanced developers should find useful.
|
||||
|
||||
To keep things practical, I’m basing this list off of the actual Git commands I used over the past week.
|
||||
|
||||
Almost every developer uses Git, and most likely GitHub. But the average developer probably only uses these three commands 99% of the time:
|
||||
|
||||
```
|
||||
git add --all
|
||||
git commit -am "<message>"
|
||||
git push origin master
|
||||
```
|
||||
|
||||
That’s all well and good when you’re working on a one-person team, a hackathon, or a throw-away app, but when stability and maintenance start to become a priority, cleaning up commits, sticking to a branching strategy, and writing coherent commit messages becomes important.
|
||||
|
||||
I’ll start with the list of commonly used commands to make it easier for newbies to understand what is possible with Git, then move into the more advanced functionality and best practices.
|
||||
|
||||
#### Regularly used commands
|
||||
|
||||
To initialize Git in a repository (repo), you just need to type the following command. If you don’t initialize Git, you cannot run any other Git commands within that repo.
|
||||
|
||||
```
|
||||
git init
|
||||
```
|
||||
|
||||
If you’re using GitHub and you’re pushing code to a GitHub repo that’s stored online, you’re using a remote repo. The default name (also known as an alias) for that remote repo is origin. If you’ve copied a project from Github, it already has an origin. You can view that origin with the command git remote -v, which will list the URL of the remote repo.
|
||||
|
||||
If you initialized your own Git repo and want to associate it with a GitHub repo, you’ll have to create one on GitHub, copy the URL provided, and use the command git remote add origin <URL>, with the URL provided by GitHub replacing “<URL>”. From there, you can add, commit, and push to your remote repo.
|
||||
|
||||
The last one is used when you need to change the remote repository. Let’s say you copied a repo from someone else and want to change the remote repository from the original owner’s to your own GitHub account. Follow the same process as git remote add origin, except use set-url instead to change the remote repo.
|
||||
|
||||
```
|
||||
git remote -v
|
||||
git remote add origin <url>
|
||||
git remote set-url origin <url>
|
||||
```
|
||||
|
||||
The most common way to copy a repo is to use git clone, followed by the URL of the repo.
|
||||
|
||||
Keep in mind that the remote repository will be linked to the account from which you cloned the repo. So if you cloned a repo that belongs to someone else, you will not be able to push to GitHub until you change the originusing the commands above.
|
||||
|
||||
```
|
||||
git clone <url>
|
||||
```
|
||||
|
||||
You’ll quickly find yourself using branches. If you don’t understand what branches are, there are other tutorials that are much more in-depth, and you should read those before proceeding ([here’s one][8]).
|
||||
|
||||
The command git branch lists all branches on your local machine. If you want to create a new branch, you can use git branch <name>, with <name> representing the name of the branch, such as “master”.
|
||||
|
||||
The git checkout <name> command switches to an existing branch. You can also use the git checkout -b <name> command to create a new branch and immediately switch to it. Most people use this instead of separate branch and checkout commands.
|
||||
|
||||
```
|
||||
git branch
|
||||
git branch <name>
|
||||
git checkout <name>
|
||||
git checkout -b <name>
|
||||
```
|
||||
|
||||
If you’ve made a bunch of changes to a branch, let’s call it “develop”, and you want to merge that branch back into your master branch, you use the git merge <branch> command. You’ll want to checkout the master branch, then run git merge develop to merge develop into the master branch.
|
||||
|
||||
```
|
||||
git merge <branch>
|
||||
```
|
||||
|
||||
If you’re working with multiple people, you’ll find yourself in a position where a repo was updated on GitHub, but you don’t have the changes locally. If that’s the case, you can use git pull origin <branch> to pull the most recent changes from that remote branch.
|
||||
|
||||
```
|
||||
git pull origin <branch>
|
||||
```
|
||||
|
||||
If you’re curious to see what files have been changed and what’s being tracked, you can use git status. If you want to see _how much_ each file has been changed, you can use git diff to see the number of lines changed in each file.
|
||||
|
||||
```
|
||||
git status
|
||||
git diff --stat
|
||||
```
|
||||
|
||||
### Advanced commands and best practices
|
||||
|
||||
Soon you reach a point where you want your commits to look nice and stay consistent. You might also have to fiddle around with your commit history to make your commits easier to comprehend or to revert an accidental breaking change.
|
||||
|
||||
The git log command lets you see the commit history. You’ll want to use this to see the history of your commits.
|
||||
|
||||
Your commits will come with messages and a hash, which is random series of numbers and letters. An example hash might look like this: c3d882aa1aa4e3d5f18b3890132670fbeac912f7
|
||||
|
||||
```
|
||||
git log
|
||||
```
|
||||
|
||||
Let’s say you pushed something that broke your app. Rather than fix it and push something new, you’d rather just go back one commit and try again.
|
||||
|
||||
If you want to go back in time and checkout your app from a previous commit, you can do this directly by using the hash as the branch name. This will detach your app from the current version (because you’re editing a historical record, rather than the current version).
|
||||
|
||||
```
|
||||
git checkout c3d88eaa1aa4e4d5f
|
||||
```
|
||||
|
||||
Then, if you make changes from that historical branch and you want to push again, you’d have to do a force push.
|
||||
|
||||
Caution: Force pushing is dangerous and should only be done if you absolutely must. It will overwrite the history of your app and you will lose whatever came after.
|
||||
|
||||
```
|
||||
git push -f origin master
|
||||
```
|
||||
|
||||
Other times it’s just not practical to keep everything in one commit. Perhaps you want to save your progress before trying something potentially risky, or perhaps you made a mistake and want to spare yourself the embarrassment of having an error in your version history. For that, we have git rebase.
|
||||
|
||||
Let’s say you have 4 commits in your local history (not pushed to GitHub) in which you’ve gone back and forth. Your commits look sloppy and indecisive. You can use rebase to combine all of those commits into a single, concise commit.
|
||||
|
||||
```
|
||||
git rebase -i HEAD~4
|
||||
```
|
||||
|
||||
The above command will open up your computer’s default editor (which is Vim unless you’ve set it to something else), with several options for how you can change your commits. It will look something like the code below:
|
||||
|
||||
```
|
||||
pick 130deo9 oldest commit message
|
||||
pick 4209fei second oldest commit message
|
||||
pick 4390gne third oldest commit message
|
||||
pick bmo0dne newest commit message
|
||||
```
|
||||
|
||||
In order to combine these, we need to change the “pick” option to “fixup” (as the documentation below the code says) to meld the commits and discard the commit messages. Note that in vim, you need to press “a” or “i” to be able to edit the text, and to save and exit, you need to type the escapekey followed by “shift + z + z”. Don’t ask me why, it just is.
|
||||
|
||||
```
|
||||
pick 130deo9 oldest commit message
|
||||
fixup 4209fei second oldest commit message
|
||||
fixup 4390gne third oldest commit message
|
||||
fixup bmo0dne newest commit message
|
||||
```
|
||||
|
||||
This will merge all of your commits into the commit with the message “oldest commit message”.
|
||||
|
||||
The next step is to rename your commit message. This is entirely a matter of opinion, but so long as you follow a consistent pattern, anything you do is fine. I recommend using the [commit guidelines put out by Google for Angular.js][9].
|
||||
|
||||
In order to change the commit message, use the amend flag.
|
||||
|
||||
```
|
||||
git commit --amend
|
||||
```
|
||||
|
||||
This will also open vim, and the text editing and saving rules are the same as above. To give an example of a good commit message, here’s one following the rules from the guideline:
|
||||
|
||||
```
|
||||
feat: add stripe checkout button to payments page
|
||||
```
|
||||
|
||||
```
|
||||
- add stripe checkout button
|
||||
- write tests for checkout
|
||||
```
|
||||
|
||||
One advantage to keeping with the types listed in the guideline is that it makes writing change logs easier. You can also include information in the footer (again, specified in the guideline) that references issues.
|
||||
|
||||
Note: you should avoid rebasing and squashing your commits if you are collaborating on a project, and have code pushed to GitHub. If you start changing version history under people’s noses, you could end up making everyone’s lives more difficult with bugs that are difficult to track.
|
||||
|
||||
There are an almost endless number of possible commands with Git, but these commands are probably the only ones you’ll need to know for your first few years of programming.
|
||||
|
||||
* * *
|
||||
|
||||
_Sam Corcos is the lead developer and co-founder of _ [_Sightline Maps_][10] _, the most intuitive platform for 3D printing topographical maps, as well as _ [_LearnPhoenix.io_][11] _, an intermediate-advanced tutorial site for building scalable production apps with Phoenix and React. Get $20 off of LearnPhoenix with the coupon code: _ _free_code_camp_
|
||||
|
||||
|
||||
* [Git][1]
|
||||
|
||||
* [Github][2]
|
||||
|
||||
* [Programming][3]
|
||||
|
||||
* [Software Development][4]
|
||||
|
||||
* [Web Development][5]
|
||||
|
||||
Show your support
|
||||
|
||||
Clapping shows how much you appreciated Sam Corcos’s story.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/git-cheat-sheet-and-best-practices-c6ce5321f52
|
||||
|
||||
作者:[Sam Corcos][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@SamCorcos?source=post_header_lockup
|
||||
[1]:https://medium.freecodecamp.org/tagged/git?source=post
|
||||
[2]:https://medium.freecodecamp.org/tagged/github?source=post
|
||||
[3]:https://medium.freecodecamp.org/tagged/programming?source=post
|
||||
[4]:https://medium.freecodecamp.org/tagged/software-development?source=post
|
||||
[5]:https://medium.freecodecamp.org/tagged/web-development?source=post
|
||||
[6]:https://octodex.github.com/
|
||||
[7]:https://xkcd.com/1597/
|
||||
[8]:https://guides.github.com/introduction/flow/
|
||||
[9]:https://github.com/angular/angular.js/blob/master/CONTRIBUTING.md#-git-commit-guidelines
|
||||
[10]:http://sightlinemaps.com/
|
||||
[11]:http://learnphoenix.io/
|
||||
@ -1,3 +1,4 @@
|
||||
yzca Translating
|
||||
Docker Engine swarm mode - Intro tutorial
|
||||
============================
|
||||
|
||||
|
||||
@ -1,198 +0,0 @@
|
||||
What is Kubernetes?
|
||||
============================================================
|
||||
|
||||
This page is an overview of Kubernetes.
|
||||
|
||||
* [Kubernetes is][6]
|
||||
|
||||
* [Why containers?][7]
|
||||
* [Why do I need Kubernetes and what can it do?][1]
|
||||
|
||||
* [How is Kubernetes a platform?][2]
|
||||
|
||||
* [What Kubernetes is not][3]
|
||||
|
||||
* [What does _Kubernetes_ mean? K8s?][4]
|
||||
|
||||
* [What’s next][8]
|
||||
|
||||
Kubernetes is an [open-source platform for automating deployment, scaling, and operations of application containers][25] across clusters of hosts, providing container-centric infrastructure.
|
||||
|
||||
With Kubernetes, you are able to quickly and efficiently respond to customer demand:
|
||||
|
||||
* Deploy your applications quickly and predictably.
|
||||
|
||||
* Scale your applications on the fly.
|
||||
|
||||
* Roll out new features seamlessly.
|
||||
|
||||
* Limit hardware usage to required resources only.
|
||||
|
||||
Our goal is to foster an ecosystem of components and tools that relieve the burden of running applications in public and private clouds.
|
||||
|
||||
#### Kubernetes is
|
||||
|
||||
* **Portable**: public, private, hybrid, multi-cloud
|
||||
|
||||
* **Extensible**: modular, pluggable, hookable, composable
|
||||
|
||||
* **Self-healing**: auto-placement, auto-restart, auto-replication, auto-scaling
|
||||
|
||||
Google started the Kubernetes project in 2014\. Kubernetes builds upon a [decade and a half of experience that Google has with running production workloads at scale][26], combined with best-of-breed ideas and practices from the community.
|
||||
|
||||
### Why containers?
|
||||
|
||||
Looking for reasons why you should be using [containers][27]?
|
||||
|
||||

|
||||
|
||||
The _Old Way_ to deploy applications was to install the applications on a host using the operating system package manager. This had the disadvantage of entangling the applications’ executables, configuration, libraries, and lifecycles with each other and with the host OS. One could build immutable virtual-machine images in order to achieve predictable rollouts and rollbacks, but VMs are heavyweight and non-portable.
|
||||
|
||||
The _New Way_ is to deploy containers based on operating-system-level virtualization rather than hardware virtualization. These containers are isolated from each other and from the host: they have their own filesystems, they can’t see each others’ processes, and their computational resource usage can be bounded. They are easier to build than VMs, and because they are decoupled from the underlying infrastructure and from the host filesystem, they are portable across clouds and OS distributions.
|
||||
|
||||
Because containers are small and fast, one application can be packed in each container image. This one-to-one application-to-image relationship unlocks the full benefits of containers. With containers, immutable container images can be created at build/release time rather than deployment time, since each application doesn’t need to be composed with the rest of the application stack, nor married to the production infrastructure environment. Generating container images at build/release time enables a consistent environment to be carried from development into production. Similarly, containers are vastly more transparent than VMs, which facilitates monitoring and management. This is especially true when the containers’ process lifecycles are managed by the infrastructure rather than hidden by a process supervisor inside the container. Finally, with a single application per container, managing the containers becomes tantamount to managing deployment of the application.
|
||||
|
||||
Summary of container benefits:
|
||||
|
||||
* **Agile application creation and deployment**: Increased ease and efficiency of container image creation compared to VM image use.
|
||||
|
||||
* **Continuous development, integration, and deployment**: Provides for reliable and frequent container image build and deployment with quick and easy rollbacks (due to image immutability).
|
||||
|
||||
* **Dev and Ops separation of concerns**: Create application container images at build/release time rather than deployment time, thereby decoupling applications from infrastructure.
|
||||
|
||||
* **Environmental consistency across development, testing, and production**: Runs the same on a laptop as it does in the cloud.
|
||||
|
||||
* **Cloud and OS distribution portability**: Runs on Ubuntu, RHEL, CoreOS, on-prem, Google Container Engine, and anywhere else.
|
||||
|
||||
* **Application-centric management**: Raises the level of abstraction from running an OS on virtual hardware to run an application on an OS using logical resources.
|
||||
|
||||
* **Loosely coupled, distributed, elastic, liberated [micro-services][5]**: Applications are broken into smaller, independent pieces and can be deployed and managed dynamically – not a fat monolithic stack running on one big single-purpose machine.
|
||||
|
||||
* **Resource isolation**: Predictable application performance.
|
||||
|
||||
* **Resource utilization**: High efficiency and density.
|
||||
|
||||
#### Why do I need Kubernetes and what can it do?
|
||||
|
||||
At a minimum, Kubernetes can schedule and run application containers on clusters of physical or virtual machines. However, Kubernetes also allows developers to ‘cut the cord’ to physical and virtual machines, moving from a **host-centric** infrastructure to a **container-centric** infrastructure, which provides the full advantages and benefits inherent to containers. Kubernetes provides the infrastructure to build a truly **container-centric** development environment.
|
||||
|
||||
Kubernetes satisfies a number of common needs of applications running in production, such as:
|
||||
|
||||
* [Co-locating helper processes][9], facilitating composite applications and preserving the one-application-per-container model
|
||||
|
||||
* [Mounting storage systems][10]
|
||||
|
||||
* [Distributing secrets][11]
|
||||
|
||||
* [Checking application health][12]
|
||||
|
||||
* [Replicating application instances][13]
|
||||
|
||||
* [Using Horizontal Pod Autoscaling][14]
|
||||
|
||||
* [Naming and discovering][15]
|
||||
|
||||
* [Balancing loads][16]
|
||||
|
||||
* [Rolling updates][17]
|
||||
|
||||
* [Monitoring resources][18]
|
||||
|
||||
* [Accessing and ingesting logs][19]
|
||||
|
||||
* [Debugging applications][20]
|
||||
|
||||
* [Providing authentication and authorization][21]
|
||||
|
||||
This provides the simplicity of Platform as a Service (PaaS) with the flexibility of Infrastructure as a Service (IaaS), and facilitates portability across infrastructure providers.
|
||||
|
||||
#### How is Kubernetes a platform?
|
||||
|
||||
Even though Kubernetes provides a lot of functionality, there are always new scenarios that would benefit from new features. Application-specific workflows can be streamlined to accelerate developer velocity. Ad hoc orchestration that is acceptable initially often requires robust automation at scale. This is why Kubernetes was also designed to serve as a platform for building an ecosystem of components and tools to make it easier to deploy, scale, and manage applications.
|
||||
|
||||
[Labels][28] empower users to organize their resources however they please. [Annotations][29]enable users to decorate resources with custom information to facilitate their workflows and provide an easy way for management tools to checkpoint state.
|
||||
|
||||
Additionally, the [Kubernetes control plane][30] is built upon the same [APIs][31] that are available to developers and users. Users can write their own controllers, such as [schedulers][32], with [their own APIs][33] that can be targeted by a general-purpose [command-line tool][34].
|
||||
|
||||
This [design][35] has enabled a number of other systems to build atop Kubernetes.
|
||||
|
||||
#### What Kubernetes is not
|
||||
|
||||
Kubernetes is not a traditional, all-inclusive PaaS (Platform as a Service) system. It preserves user choice where it is important.
|
||||
|
||||
Kubernetes:
|
||||
|
||||
* Does not limit the types of applications supported. It does not dictate application frameworks (e.g., [Wildfly][22]), restrict the set of supported language runtimes (for example, Java, Python, Ruby), cater to only [12-factor applications][23], nor distinguish _apps_ from _services_ . Kubernetes aims to support an extremely diverse variety of workloads, including stateless, stateful, and data-processing workloads. If an application can run in a container, it should run great on Kubernetes.
|
||||
|
||||
* Does not provide middleware (e.g., message buses), data-processing frameworks (for example, Spark), databases (e.g., mysql), nor cluster storage systems (e.g., Ceph) as built-in services. Such applications run on Kubernetes.
|
||||
|
||||
* Does not have a click-to-deploy service marketplace.
|
||||
|
||||
* Does not deploy source code and does not build your application. Continuous Integration (CI) workflow is an area where different users and projects have their own requirements and preferences, so it supports layering CI workflows on Kubernetes but doesn’t dictate how layering should work.
|
||||
|
||||
* Allows users to choose their logging, monitoring, and alerting systems. (It provides some integrations as proof of concept.)
|
||||
|
||||
* Does not provide nor mandate a comprehensive application configuration language/system (for example, [jsonnet][24]).
|
||||
|
||||
* Does not provide nor adopt any comprehensive machine configuration, maintenance, management, or self-healing systems.
|
||||
|
||||
On the other hand, a number of PaaS systems run _on_ Kubernetes, such as [Openshift][36], [Deis][37], and [Eldarion][38]. You can also roll your own custom PaaS, integrate with a CI system of your choice, or use only Kubernetes by deploying your container images on Kubernetes.
|
||||
|
||||
Since Kubernetes operates at the application level rather than at the hardware level, it provides some generally applicable features common to PaaS offerings, such as deployment, scaling, load balancing, logging, and monitoring. However, Kubernetes is not monolithic, and these default solutions are optional and pluggable.
|
||||
|
||||
Additionally, Kubernetes is not a mere _orchestration system_ . In fact, it eliminates the need for orchestration. The technical definition of _orchestration_ is execution of a defined workflow: first do A, then B, then C. In contrast, Kubernetes is comprised of a set of independent, composable control processes that continuously drive the current state towards the provided desired state. It shouldn’t matter how you get from A to C. Centralized control is also not required; the approach is more akin to _choreography_ . This results in a system that is easier to use and more powerful, robust, resilient, and extensible.
|
||||
|
||||
#### What does _Kubernetes_ mean? K8s?
|
||||
|
||||
The name **Kubernetes** originates from Greek, meaning _helmsman_ or _pilot_ , and is the root of _governor_ and [cybernetic][39]. _K8s_ is an abbreviation derived by replacing the 8 letters “ubernete” with “8”.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
|
||||
|
||||
作者:[kubernetes.io][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kubernetes.io/
|
||||
[1]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-do-i-need-kubernetes-and-what-can-it-do
|
||||
[2]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#how-is-kubernetes-a-platform
|
||||
[3]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-kubernetes-is-not
|
||||
[4]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-does-kubernetes-mean-k8s
|
||||
[5]:https://martinfowler.com/articles/microservices.html
|
||||
[6]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#kubernetes-is
|
||||
[7]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-containers
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#whats-next
|
||||
[9]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[10]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[11]:https://kubernetes.io/docs/concepts/configuration/secret/
|
||||
[12]:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
|
||||
[13]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[14]:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
||||
[15]:https://kubernetes.io/docs/concepts/services-networking/connect-applications-service/
|
||||
[16]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[17]:https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller/
|
||||
[18]:https://kubernetes.io/docs/tasks/debug-application-cluster/resource-usage-monitoring/
|
||||
[19]:https://kubernetes.io/docs/concepts/cluster-administration/logging/
|
||||
[20]:https://kubernetes.io/docs/tasks/debug-application-cluster/debug-application-introspection/
|
||||
[21]:https://kubernetes.io/docs/admin/authorization/
|
||||
[22]:http://wildfly.org/
|
||||
[23]:https://12factor.net/
|
||||
[24]:https://github.com/google/jsonnet
|
||||
[25]:http://www.slideshare.net/BrianGrant11/wso2con-us-2015-kubernetes-a-platform-for-automating-deployment-scaling-and-operations
|
||||
[26]:https://research.google.com/pubs/pub43438.html
|
||||
[27]:https://aucouranton.com/2014/06/13/linux-containers-parallels-lxc-openvz-docker-and-more/
|
||||
[28]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[29]:https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/
|
||||
[30]:https://kubernetes.io/docs/concepts/overview/components/
|
||||
[31]:https://kubernetes.io/docs/reference/api-overview/
|
||||
[32]:https://git.k8s.io/community/contributors/devel/scheduler.md
|
||||
[33]:https://git.k8s.io/community/contributors/design-proposals/extending-api.md
|
||||
[34]:https://kubernetes.io/docs/user-guide/kubectl-overview/
|
||||
[35]:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/principles.md
|
||||
[36]:https://www.openshift.org/
|
||||
[37]:http://deis.io/
|
||||
[38]:http://eldarion.cloud/
|
||||
[39]:http://www.etymonline.com/index.php?term=cybernetics
|
||||
@ -1,4 +1,4 @@
|
||||
### What is Kubernetes?
|
||||
### 【翻译中@haoqixu】What is Kubernetes?
|
||||
|
||||
Kubernetes, or k8s ( _k, 8 characters, s...get it?_ ), or “kube” if you’re into brevity, is an open source platform that automates [Linux container][3] operations. It eliminates many of the manual processes involved in deploying and scaling containerized applications. In other words, you can cluster together groups of hosts running Linux containers, and Kubernetes helps you easily and efficiently manage those clusters. These clusters can span hosts across [public][4], [private][5], or hybrid clouds.
|
||||
|
||||
|
||||
@ -1,205 +0,0 @@
|
||||
MonkeyDEcho translating
|
||||
|
||||
The End Of An Era: A Look Back At The Most Popular Solaris Milestones & News
|
||||
=================================
|
||||
|
||||

|
||||
With it looking certain now that [Oracle is ending Solaris feature development][42]with the cancelling of Solaris 12, here's a look back at the most popular Solaris news and milestones for the project over the years on Phoronix.
|
||||
|
||||
There were many great/fun Solaris memories.
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
During the Sun Microsystems days, I was genuinely interested in Solaris. There were frequent Solaris articles on Phoronix while Linux was always our main focus. Solaris was fun to play around with, OpenSolaris / SXCE was great, I ported the Phoronix Test Suite to Solaris, we had great relations with the Sun Microsystems folks, was at many Sun events, etc.
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
_Sun had some rather unique events back in the day..._
|
||||
|
||||
Unfortunately since Oracle acquired Sun, Solaris basically went downhill. The biggest blow was arguably when Oracle ended OpenSolaris and moved all their Solaris efforts back to a proprietary model...
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Lots of great memories for Solaris during the Sun days, so given Oracle wiping "Solaris 12" off their roadmap, I figured it would be fun to look back at the most-viewed Solaris stories on Phoronix while waiting to hear from Oracle about "Solaris 11.next" as their final step to likely winding down the operating system development.
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Though in a post-Solaris world it will be interesting to see what Oracle does with ZFS and if they double down on their RHEL-based Oracle Enterprise Linux. Time will tell.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Anyhow, here's a look back at our most-viewed Solaris stories since 2004:
|
||||
|
||||
**[ATI R500/600 Driver For Solaris Coming?][6]**
|
||||
_While no ATI fglrx driver is available for Solaris/OpenSolaris or *BSD, now that AMD will be offering up specifications to X.Org developers and an open-source driver, it certainly is promising for any Solaris user depending upon ATI's Radeon X1000 "R500" or HD 2000 "R600" series. The open-source X.Org driver that will be released next week is far from mature, but it should be able to be ported to Solaris and other operating systems using X.Org with relative ease. What AMD announced today is targeted for the Linux community, but it can certainly help out Solaris/OpenSolaris users that use ATI hardware. Especially with "Project Indiana" coming out soon, it's only a matter of time before the open-source R500/600 driver is ported. Tell us what you think in our Solaris forum._
|
||||
|
||||
**[Solaris Express Community Build 71][7]**
|
||||
_Build 71 of Solaris Express Community Edition (SXCE) is now available. You can find out more about Solaris Express Community Build 71 at OpenSolaris.org. On a side note, with news at the Linux Kernel Summit that AMD will be providing GPU specifications, the resulting X.Org driver could lead to an improved state for Solaris/OpenSolaris on ATI hardware in the future._
|
||||
|
||||
**[Farewell To OpenSolaris. Oracle Just Killed It Off.][8]**
|
||||
_Oracle has finally announced their plans for Solaris operating system and OpenSolaris platform and it's not good. OpenSolaris is now effectively dead and there will not be anymore OpenSolaris releases -- including the long-delayed 2010 release. Solaris will still live-on and Oracle is busy working on Solaris 11 for a release next year and there will be a "Solaris 11 Express" as being a similar product to OpenSolaris, but it will only ship after Oracle's enterprise release._
|
||||
|
||||
**[Solaris Express Community Build 72][9]**
|
||||
_For those of you wanting to try out the latest and greatest in OpenSolaris software right now prior to the release of "Project Indiana", build 72 of Solaris Express Community Edition is now available. Solaris Express Community Edition (SXCE) Build 72 can be downloaded from OpenSolaris.org. Meanwhile, the preview release of Sun's Project Indiana is expected next month._
|
||||
|
||||
**[OpenSolaris Developer Summit][10]**
|
||||
_Announced earlier today on the OpenSolaris Forums was the first-ever OpenSolaris Developer Summit. This summit is taking place in October at the University of California, Santa Cruz. Sara Dornsife describes this summit as "not a conference with presentations or exhibitors, but an in-person, collaborative working session to plan the next release of Project Indiana." Ian Murdock will be keynoting at this Project Indiana fest, but beyond that the schedule is still being planned. Phoronix may be covering this event and you can discuss this summit in our Solaris forums._
|
||||
|
||||
**[Solaris Containers For Linux][11]**
|
||||
_Sun Microsystems has announced that they will soon be supporting Solaris Containers for Linux applications. This will make it possible to run Linux applications under Solaris without any modifications to the binary package. The Solaris Containers for Linux will allow for a smoother migration from Linux to Solaris, assist in cross-platform development,and other benefits. As far as when the support will arrive, it's "coming soon"._
|
||||
|
||||
**[Oracle Still To Make OpenSolaris Changes][12]**
|
||||
_Since Oracle finished its acquisition of Sun Microsystems, there have been many changes to the open-source projects that were once supported under Sun now being discontinued by Oracle and significant changes being made to the remaining open-source products. One of the open-source projects that Oracle hasn't been too open about their intentions with has been OpenSolaris. Solaris Express Community Edition (SXCE) already closed up last month and there hasn't been too much information flowing out about the next OpenSolaris release, which is supposed to be known as OpenSolaris 2010.03 with a release date sometime in March._
|
||||
|
||||
**[Xen For Solaris Updated][13]**
|
||||
_It's been a while, but Xen for Solaris has finally been updated. John Levon poimts out that this latest build is based upon Xen 3.0.4 and Solaris "Nevada" Build 66\. Some of the improvements in this latest build include PAE support, HVM support, new virt-manager tools, improved debugging support, and last but not least is managed domain support. The download for the July 2007 Solaris Xen update can be found over at Sun's website._
|
||||
|
||||
**[IBM To Distribute Sun's Solaris][14]**
|
||||
_Sun Microsystems and IBM are holding a teleconference right now where they have just announced IBM will begin distributing Sun's Solaris operating system on select servers. These IBM servers include the x86-based system X servers as well as Blade Center Servers. The official press release has just been issued and can be read at the Sun news room._
|
||||
|
||||
**[Oracle Solaris 11 Kernel Source-Code Leaked][15]**
|
||||
_It appears that the kernel source-code to Solaris 11 was leaked onto the Internet this past weekend._
|
||||
|
||||
**[Solaris 12 Might Finally Bring Radeon KMS Driver][16]**
|
||||
_It looks like Oracle may be preparing to release their own AMD Radeon kernel mode-setting (KMS) driver for introducing into Oracle Solaris 12._
|
||||
|
||||
**[OpenSXCE 2013.05 Revives The Solaris Community][17]**
|
||||
_OpenSXCE 2013.05 is out in the wild as the community revival of the Solaris Express Community Edition._
|
||||
|
||||
**[OpenSolaris Will Not Merge With Linux][18]**
|
||||
_At LinuxWorld 2007 in San Francisco, Andrew Morton said during his keynote that no key components of OpenSolaris will appear in the Linux kernel. In fact, Morton had even stated that "It’s a great shame that OpenSolaris still exists." Some of these key OpenSolaris components include Zones, ZFS, and DTrace. Though there is the possibility that Project Indiana could turn these into GPLv3 projects... More information is available at ZDNET._
|
||||
|
||||
**[Oracle Has Yet To Clarify Solaris 11 Kernel Source][19]**
|
||||
_It was one month ago that Phoronix was the first to note the Solaris 11 kernel source-code was leaked onto the Internet via Torrent sites. One month later, Oracle still hasn't officially commented on the situation._
|
||||
|
||||
**[Oracle Might Be Canning Solaris][20]**
|
||||
_Oracle might be pulling the plug on the Solaris operating system, at least according to some new rumors._
|
||||
|
||||
**[Solaris Express Community Build 70][21]**
|
||||
_Build 70 for Solaris Express Community Edition "Nevada" (SXCE snv_70) is now available. The announcement with download links can be found in the OpenSolaris Forums. Also announced was the 71st build of their Network Storage that includes source-code from Qlogic for the fibre channel HBA driver._
|
||||
|
||||
**[Solaris 10 7/07 HW Release][22]**
|
||||
_The documentation is now online for the Solaris 10 7/07 HW Release. As noted on the Solaris Releases page, Solaris 10 7/07 is only for SPARC Enterprise M4000-M9000 servers and no x86/x64 version is available. The latest Solaris update for all platforms is Solaris 10 11/06\. You can discuss Solaris 7/07 in the Phoronix Forums._
|
||||
|
||||
**[Solaris Telecom Servers From Intel][23]**
|
||||
_Intel has announced today the availability of Intel-powered Sun Solaris telecommunications rack and blade servers that meet NEBS, ETSI, and ATCA compliance. Of these new carrier grade platforms, the Intel Carrier Grade Rack Mount Server TIGW1U supports both Linux and Solaris 10 and the Intel NetStructure MPCBL0050 SBC will support both operating systems as well. Today's press release can be read here._
|
||||
|
||||
**[The Sad State Of GPU Drivers For BSD, Solaris][24]**
|
||||
_Yesterday a discussion arose on the mailing list about killing off all the old Mesa drivers. These old drivers aren't actively maintained, support vintage graphics processors, and aren't updated to support new Mesa functionality. They're now also getting in the way as Intel and other developers work to clean up the core of Mesa as they bolster this open-source graphics library for the future. There's also some implications for BSD and Solaris users by this move to clean-up Mesa._
|
||||
|
||||
**[Oracle Solaris 11.1 Brings 300+ Enhancements][25]**
|
||||
_Oracle released Solaris 11.1 from their Oracle OpenWorld conference yesterday in San Francisco._
|
||||
|
||||
[
|
||||

|
||||
][26]
|
||||
|
||||
And then of the most-viewed featured articles with Solaris:
|
||||
|
||||
**[Ubuntu vs. OpenSolaris vs. FreeBSD Benchmarks][27]**
|
||||
_Over the past few weeks we have been providing several in-depth articles looking at the performance of Ubuntu Linux. We had begun by providing Ubuntu 7.04 to 8.10 benchmarks and had found the performance of this popular Linux distribution to become slower with time and that article was followed up with Mac OS X 10.5 vs. Ubuntu 8.10 benchmarks and other articles looking at the state of Ubuntu's performance. In this article, we are now comparing the 64-bit performance of Ubuntu 8.10 against the latest test releases of OpenSolaris 2008.11 and FreeBSD 7.1._
|
||||
|
||||
**[NVIDIA Performance: Windows vs. Linux vs. Solaris][28]**
|
||||
_Earlier this week we previewed the Quadro FX1700, which is one of NVIDIA's mid-range workstation graphics cards that is based upon the G84GL core that in turn is derived from the consumer-class GeForce 8600 series. This PCI Express graphics card offers 512MB of video memory with two dual-link DVI connections and support for OpenGL 2.1 while maintaining a maximum power consumption of just 42 Watts. As we mentioned in the preview article, we would be looking at this graphics card's performance not only under Linux but also testing this workstation solution in both Microsoft Windows and Sun's Solaris. In this article today, we are doing just that as we test the NVIDIA Quadro FX1700 512MB with each of these operating systems and their respective binary display drivers._
|
||||
|
||||
**[FreeBSD 8.0 Benchmarked Against Linux, OpenSolaris][29]**
|
||||
_With the stable release of FreeBSD 8.0 arriving last week we finally were able to put it up on the test bench and give it a thorough look over with the Phoronix Test Suite. We compared the FreeBSD 8.0 performance between it and the earlier FreeBSD 7.2 release along with Fedora 12 and Ubuntu 9.10 on the Linux side and then the OpenSolaris 2010.02 b127 snapshot on the Sun OS side._
|
||||
|
||||
**[Fedora, Debian, FreeBSD, OpenBSD, OpenSolaris Benchmarks][30]**
|
||||
_Last week we published the first Debian GNU/kFreeBSD benchmarks that compared the 32-bit and 64-bit performance of this Debian port -- that straps the FreeBSD kernel underneath a Debian GNU user-land -- to Debian GNU/Linux. We have now extended that comparison to put many other operating systems in a direct performance comparison
|
||||
to these Debian GNU/Linux and Debian GNU/kFreeBSD snapshots of 6.0 Squeeze to Fedora 12, FreeBSD 7.2, FreeBSD 8.0, OpenBSD 4.6, and OpenSolaris 2009.06._
|
||||
|
||||
**[AMD Shanghai Opteron: Linux vs. OpenSolaris Benchmarks][31]**
|
||||
_In January we published a review of the AMD Shanghai Opteron CPUs on Linux when we looked at four of the Opteron 2384 models. The performance of these 45nm quad-core workstation/server processors were great when compared to the earlier AMD Barcelona processors on Ubuntu Linux, but how is their performance when running Sun's OpenSolaris operating system? Up for viewing today are dual AMD Shanghai benchmarks when running OpenSolaris 2008.11, Ubuntu 8.10, and a daily build of the forthcoming Ubuntu 9.04 release._
|
||||
|
||||
**[OpenSolaris vs. Linux Kernel Benchmarks][32]**
|
||||
_Earlier this week we delivered benchmarks of Ubuntu 9.04 versus Mac OS X 10.5.6 and found that the Leopard operating system had performed better than the Jaunty Jackalope in a majority of the tests, at least when it came to Ubuntu 32-bit. We are back with more operating system benchmarks today, but this time we are comparing the performance of the Linux and Sun OpenSolaris kernels. We had used the Nexenta Core Platform 2 operating system that combines the OpenSolaris kernel with a GNU/Ubuntu user-land to that of the same Ubuntu package set but with the Linux kernel. Testing was done with both 32-bit and 64-bit Ubuntu server installations._
|
||||
|
||||
**[Netbook Performance: Ubuntu vs. OpenSolaris][33]**
|
||||
_In the past we have published OpenSolaris vs. Linux Kernel benchmarks and similar articles looking at the performance of Sun's OpenSolaris up against popular Linux distributions. We have looked at the performance on high-end AMD workstations, but we have never compared the OpenSolaris and Linux performance on netbooks. Well, not until today. In this article we have results comparing OpenSolaris 2009.06 and Ubuntu 9.04 on the Dell Inspiron Mini 9 netbook._
|
||||
|
||||
**[NVIDIA Graphics: Linux vs. Solaris][34]**
|
||||
_At Phoronix we are constantly exploring the different display drivers under Linux, and while we have reviewed Sun's Check Tool and test motherboards with Solaris in addition to covering a few other areas, we have yet to perform a graphics driver comparison between Linux and Solaris. That is until today. With interest in Solaris on the rise thanks to Project Indiana, we have decided to finally offer our first quantitative graphics comparison between Linux and Solaris with the NVIDIA proprietary drivers._
|
||||
|
||||
**[OpenSolaris 2008.05 Gives A New Face To Solaris][35]**
|
||||
_In early February, Sun Microsystems had released a second preview release of Project Indiana. For those out of the loop, Project Indiana is the codename for the project led by Ian Murdock at Sun that aims to push OpenSolaris on more desktop and notebook computers by addressing the long-standing usability problems of Solaris. We were far from being impressed by Preview 2 as it hadn't possessed any serious advantages over a GNU/Linux desktop that would interest normal users. However, with the release of OpenSolaris 2008.05 "Project Indiana" coming up in May, Sun Microsystems has today released a final test copy of this operating system. Our initial experience with this new OpenSolaris release is vastly better than what we had encountered less than three months ago when last looking at Project Indiana._
|
||||
|
||||
**[A Quick Tour Of Oracle Solaris 11][36]**
|
||||
_Solaris 11 was released on Wednesday as the first major update to the former Sun operating system in seven years. A lot has changed in the Solaris stack in the past seven years, and OpenSolaris has come and gone in that time, but in this article is a brief look through the brand new Oracle Solaris 11 release._
|
||||
|
||||
**[New Benchmarks Of OpenSolaris, BSD & Linux][37]**
|
||||
_Earlier today we put out benchmarks of ZFS on Linux via a native kernel module that will be made publicly available to bring this Sun/Oracle file-system over to more Linux users. Now though as a bonus we happen to have new benchmarks of the latest OpenSolaris-based distributions, including OpenSolaris, OpenIndiana, and Augustiner-Schweinshaxe, compared to PC-BSD, Fedora, and Ubuntu._
|
||||
|
||||
**[FreeBSD/PC-BSD 9.1 Benchmarked Against Linux, Solaris, BSD][38]**
|
||||
_While FreeBSD 9.1 has yet to be officially released, the FreeBSD-based PC-BSD 9.1 "Isotope" release has already been made available this month. In this article are performance benchmarks comparing the 64-bit release of PC-BSD 9.1 against DragonFlyBSD 3.0.3, Oracle Solaris Express 11.1, CentOS 6.3, Ubuntu 12.10, and a development snapshot of Ubuntu 13.04._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Michael Larabel is the principal author of Phoronix.com and founded the site in 2004 with a focus on enriching the Linux hardware experience. Michael has written more than 10,000 articles covering the state of Linux hardware support, Linux performance, graphics drivers, and other topics. Michael is also the lead developer of the Phoronix Test Suite, Phoromatic, and OpenBenchmarking.org automated benchmarking software. He can be followed via Twitter or contacted via MichaelLarabel.com.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.phoronix.com/scan.php?page=news_item&px=Solaris-2017-Look-Back
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/image-viewer.php?id=982&image=sun_sxce81_03_lrg
|
||||
[2]:http://www.phoronix.com/image-viewer.php?id=711&image=java7_bash_13_lrg
|
||||
[3]:http://www.phoronix.com/image-viewer.php?id=sun_sxce_farewell&image=sun_sxce_07_lrg
|
||||
[4]:http://www.phoronix.com/image-viewer.php?id=solaris_200805&image=opensolaris_indiana_03b_lrg
|
||||
[5]:http://www.phoronix.com/image-viewer.php?id=oracle_solaris_11&image=oracle_solaris11_02_lrg
|
||||
[6]:http://www.phoronix.com/scan.php?page=news_item&px=NjA0Mg
|
||||
[7]:http://www.phoronix.com/scan.php?page=news_item&px=NjAzNQ
|
||||
[8]:http://www.phoronix.com/scan.php?page=news_item&px=ODUwNQ
|
||||
[9]:http://www.phoronix.com/scan.php?page=news_item&px=NjA0Nw
|
||||
[10]:http://www.phoronix.com/scan.php?page=news_item&px=NjAwNA
|
||||
[11]:http://www.phoronix.com/scan.php?page=news_item&px=NjAxMQ
|
||||
[12]:http://www.phoronix.com/scan.php?page=news_item&px=ODAwNg
|
||||
[13]:http://www.phoronix.com/scan.php?page=news_item&px=NTkzMQ
|
||||
[14]:http://www.phoronix.com/scan.php?page=news_item&px=NTk4NA
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=MTAzMDE
|
||||
[16]:http://www.phoronix.com/scan.php?page=news_item&px=MTI5MTU
|
||||
[17]:http://www.phoronix.com/scan.php?page=news_item&px=MTM4Njc
|
||||
[18]:http://www.phoronix.com/scan.php?page=news_item&px=NTk2Ng
|
||||
[19]:http://www.phoronix.com/scan.php?page=news_item&px=MTAzOTc
|
||||
[20]:http://www.phoronix.com/scan.php?page=news_item&px=Oracle-Solaris-Demise-Rumors
|
||||
[21]:http://www.phoronix.com/scan.php?page=news_item&px=NTk4Nw
|
||||
[22]:http://www.phoronix.com/scan.php?page=news_item&px=NTkyMA
|
||||
[23]:http://www.phoronix.com/scan.php?page=news_item&px=NTg5Nw
|
||||
[24]:http://www.phoronix.com/scan.php?page=news_item&px=OTgzNA
|
||||
[25]:http://www.phoronix.com/scan.php?page=news_item&px=MTE5OTQ
|
||||
[26]:http://www.phoronix.com/image-viewer.php?id=opensolaris_200906&image=opensolaris_200906_06_lrg
|
||||
[27]:http://www.phoronix.com/vr.php?view=13149
|
||||
[28]:http://www.phoronix.com/vr.php?view=11968
|
||||
[29]:http://www.phoronix.com/vr.php?view=14407
|
||||
[30]:http://www.phoronix.com/vr.php?view=14533
|
||||
[31]:http://www.phoronix.com/vr.php?view=13475
|
||||
[32]:http://www.phoronix.com/vr.php?view=13826
|
||||
[33]:http://www.phoronix.com/vr.php?view=14039
|
||||
[34]:http://www.phoronix.com/vr.php?view=10301
|
||||
[35]:http://www.phoronix.com/vr.php?view=12269
|
||||
[36]:http://www.phoronix.com/vr.php?view=16681
|
||||
[37]:http://www.phoronix.com/vr.php?view=15476
|
||||
[38]:http://www.phoronix.com/vr.php?view=18291
|
||||
[39]:http://www.michaellarabel.com/
|
||||
[40]:https://www.phoronix.com/scan.php?page=news_topic&q=Oracle
|
||||
[41]:https://www.phoronix.com/forums/node/925794
|
||||
[42]:http://www.phoronix.com/scan.php?page=news_item&px=No-Solaris-12
|
||||
@ -1,134 +0,0 @@
|
||||
Useful Meld tips/tricks for intermediate users
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [1\. Navigation][1]
|
||||
2. [2\. Things you can do with changes][2]
|
||||
3. [4\. Filtering text][3]
|
||||
|
||||
* [Conclusion][4]
|
||||
|
||||
Meld is a feature-rich visual comparison and merging tool available for Linux. If you're new to the tool, you can head to our [beginner's guide][5] to get a quick know-how of how the utility works. However, if you've already read that, or are already using Meld for basic comparison/merging tasks, you'll be glad to know that in this tutorial, we will be discussing some really useful tips/tricks that will make your experience with the tool even better.
|
||||
|
||||
_But before we jump onto the installation and explanation part, it'd be worth sharing that all the instructions and examples presented in this tutorial have been tested on Ubuntu 14.04 and the Meld version we've used is 3.14.2_.
|
||||
|
||||
### Meld tips/tricks for intermediate users
|
||||
|
||||
### 1\. Navigation
|
||||
|
||||
As you might already know (and we've also mentioned this in our beginner's guide), standard scrolling is not the only way to navigate between changes while using Meld - you can easily switch from one change to another using the up and down arrow keys located in the pane that sits above the edit area:
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
However, this requires you to move your mouse pointer to these arrows and then click one of them (depending on where you want to go - up or down) repeatedly. You'll be glad to know that there exists an even easier way to jump between changes: just use your mouse's scroll wheel to perform scrolling when mouse pointer is on the central change bar.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
This way, you can navigate between changes without taking your eyes off them, or getting distracted.
|
||||
|
||||
### 2\. Things you can do with changes
|
||||
|
||||
Just look at the last screenshot in the previous section. You know what those black arrows do, right? By default, they let you perform the merge/change operation - merge when there's no confliction, and change when there's a conflict in the same line.
|
||||
|
||||
But do you know you can delete individual changes if you want. Yes, that's possible. For this, all you have to do is to press the Shift key when dealing with changes. You'll observe that arrows get converted into crosses.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Just click any of them, and the corresponding change will get deleted.
|
||||
|
||||
Not only delete, you can also make sure that conflicting changes do not change the lines when merged. For example, here's an example of a conflicting change:
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Now, if you click any the two black arrows, the line where the arrow points will get changed, and will become similar to the corresponding line of other file. That's fine as long as you want this to happen. But what if you don't want any of the lines to get changed? Instead, the aim is to insert the changed line above or below the corresponding line in other file.
|
||||
|
||||
What I am trying to say is that, for example, in the screenshot above, the need is to add 'test 2' above or below 'test23', rather than changing 'test23' to 'test2'. You'll be glad to know that even that's possible with Meld. Just like you press the Shift key to delete comments, in this case, you'll have to press the Ctrl key.
|
||||
|
||||
And you'll observe that the current action will be changed to insert - the dual arrow icons will confirm this.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
As clear from the direction of arrows, this action helps users to insert the current change above or below (as selected) the corresponding change in other file.
|
||||
|
||||
### 3\. Customize the way files are displayed in Meld's editor area
|
||||
|
||||
There might be times when you would want the text size in Meld's editor area to be a bit large (for better or more comfortable viewing), or you would want the text lines to wrap instead of going out of visual area (meaning you don't want to use the horizontal scroll bar at the bottom).
|
||||
|
||||
Meld provides some display- and font-related customization options in its _Preferences_ menu under the _Editor_ tab (_Edit->Preferences->Editor_) where you'll be able to make these kind of tweaks:
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
So here you can see that, by default, Meld uses the system defined font width. Just uncheck that box under the _Font_ category, and you'll have a plethora of font type and size options to select from.
|
||||
|
||||
Then in the _Display_ section, you'll see all the customization options we were talking about: you can set Tab width, tell the tool whether or not to insert spaces instead of tabs, enable/disable text wrapping, make Meld show line numbers and whitespaces (very useful in some cases) as well as use syntax highlighting.
|
||||
|
||||
### 4\. Filtering text
|
||||
|
||||
There are times when not all the changes that Meld shows are important to you. For example, while comparing two C programming files, you may not want changes in comments to be shown by Meld as you only want to focus on code-related changes. So, in that case, you can tell Meld to filter (or ignore) comment-related changes.
|
||||
|
||||
For example, here's a Meld comparison where comment-related changes are highlighted by the tool:
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
And here's the case where Meld has ignored the same changes, focusing only on the code-related changes:
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Cool, isn't it? So, how did that happen? Well, for this, what I did was, I enabled the 'C comments' text filter in _Edit->Preferences->Text Filters_ tab:
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
As you can see, aside from 'C comments', you can also filter out C++ comments, Script comments, leading or all whitespaces, and more. What more, you can also define custom text filters for any specific case you are dealing with. For example, if you are dealing with log-files and don't want changes in lines that begin with a particular pattern to be highlighted by Meld, then you can define a custom text filter for that case.
|
||||
|
||||
However, keep in mind that in order to define a new text filter, you need to know Python language as well as how to create regular expressions in that language.
|
||||
|
||||
### Conclusion
|
||||
|
||||
All the four tips/tricks discussed here aren't very difficult to understand and use (except, of course, if you want to create custom text filters right away), and once you start using them, you'll agree that they are really beneficial. The key here is to keep practicing, otherwise any tip/trick you learn will slip out of your mind in no time.
|
||||
|
||||
Do you know or use any other intermediate level Meld tip or trick? If yes, then you are welcome to share that in comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/
|
||||
|
||||
作者:[Ansh ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/
|
||||
[1]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-navigation
|
||||
[2]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-things-you-can-do-with-changes
|
||||
[3]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-filtering-text
|
||||
[4]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#conclusion
|
||||
[5]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux/
|
||||
[6]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-go-next-prev-9.png
|
||||
[7]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-center-area-scrolling.png
|
||||
[8]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-delete-changes.png
|
||||
[9]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-conflicting-change.png
|
||||
[10]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-ctrl-insert.png
|
||||
[11]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-editor-tab.png
|
||||
[12]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-changes-with-comments.png
|
||||
[13]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-changes-without-comments.png
|
||||
[14]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-text-filters.png
|
||||
@ -1,70 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Performance made easy with Linux containers
|
||||
============================================================
|
||||
|
||||

|
||||
Image credits : CC0 Public Domain
|
||||
|
||||
Performance for an application determines how quickly your software can complete the intended task. It answers questions about the application, such as:
|
||||
|
||||
* Response time under peak load
|
||||
* Ease of use, supported functionality, and use cases compared to an alternative
|
||||
* Operational costs (CPU usage, memory needs, data throughput, bandwidth, etc.)
|
||||
|
||||
The value of this performance analysis extends beyond the estimation of the compute resources needed to serve the load or the number of application instances needed to meet the peak demand. Performance is clearly tied to the fundamentals of a successful business. It informs the overall user experience, including identifying what slows down customer-expected response times, improving customer stickiness by designing content delivery optimized to their bandwidth, choosing the best device, and ultimately helping enterprises grow their business.
|
||||
|
||||
### The problem
|
||||
|
||||
Of course, this is an oversimplification of the value of performance engineering for business services. To understand the challenges behind accomplishing what I've just described, let's make this real and just a little bit complicated.
|
||||
|
||||

|
||||
|
||||
Real-world applications are likely hosted on the cloud. An application could avail to very large (or conceptually infinite) amounts of compute resources. Its needs in terms of both hardware and software would be met via the cloud. The developers working on it would use the cloud-offered features for enabling faster coding and deployment. Cloud hosting doesn't come free, but the cost overhead is proportional to the resource needs of the application.
|
||||
|
||||
Outside of Search as a Service (SaaS), Platform as a Service (PaaS), Infrastructure as a Service (IaaS), and Load Balancing as a Service (LBaaS), which is when the cloud takes care of traffic management for this hosted app, a developer probably may also use one or more of these fast-growing cloud services:
|
||||
|
||||
* Security as a Service (SECaaS), which meets security needs for software and the user
|
||||
* Data as a Service (DaaS), which provides a user's data on demand for application
|
||||
* Logging as a Service (LaaS), DaaS's close cousin, which provides analytic metrics on delivery and usage of logs
|
||||
* Search as a Service (SaaS), which is for the analytics and big data needs of the app
|
||||
* Network as a Service (NaaS), which is for sending and receiving data across public networks
|
||||
|
||||
Cloud-powered services are also growing exponentially because they make writing complex apps easier for developers. In addition to the software complexity, the interplay of all these distributed components becomes more involved. The user base becomes more diverse. The list of requirements for the software becomes longer. The dependencies on other services becomes larger. Because of these factors, the flaws in this ecosystem can trigger a domino effect of performance problems.
|
||||
|
||||
For example, assume you have a well-written application that follows secure coding practices, is designed to meet varying load requirements, and is thoroughly tested. Assume also that you have the infrastructure and analytics work in tandem to support the basic performance requirements. What does it take to build performance standards into the implementation, design, and architecture of your system? How can the software keep up with evolving market needs and emerging technologies? How do you measure the key parameters to tune a system for optimal performance as it ages? How can the system be made resilient and self-recovering? How can you identify any underlying performance problems faster and resolved them sooner?
|
||||
|
||||
### Enter containers
|
||||
|
||||
Software [containers][2] backed with the merits of [microservices][3] design, or Service-oriented Architecture (SoA), improves performance because a system comprising of smaller, self-sufficient code blocks is easier to code and has cleaner, well-defined dependencies on other system components. It is easier to test and problems, including those around resource utilization and memory over-consumption, are more easily identified than in a giant monolithic architecture.
|
||||
|
||||
When scaling the system to serve increased load, the containerized applications replicate fast and easy. Security flaws are better isolated. Patches can be versioned independently and deployed fast. Performance monitoring is more targeted and the measurements are more reliable. You can also rewrite and "facelift" resource-intensive code pieces to meet evolving performance requirements.
|
||||
|
||||
Containers start fast and stop fast. They enable efficient resource utilization and far better process isolation than Virtual Machines (VMs). Containers do not have idle memory and CPU overhead. They allow for multiple applications to share a machine without the loss of data or performance. Containers make applications portable, so developers can build and ship apps to any server running Linux that has support for container technology, without worrying about performance penalties. Containers live within their means and abide by the quotas (examples include storage, compute, and object count quotas) as imposed by their cluster manager, such as Cloud Foundry's Diego, [Kubernetes][4], Apache Mesos, and Docker Swarm.
|
||||
|
||||
While containers show merit in performance, the coming wave of "serverless" computing, also known as Function as a Service (FaaS), is set to extend the benefits of containers. In the FaaS era, these ephemeral or short-lived containers will drive the benefits beyond application performance and translate directly to savings in overhead costs of hosting in the cloud. If the container does its job faster, then it lives for a shorter time, and the computation overload is purely on demand.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Garima is a Engineering Manager at Red Hat focussed on OpenShift Container Platform. Prior to Red Hat, Garima helped fuel innovation at Akamai Technologies & MathWorks Inc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/performance-container-world
|
||||
|
||||
作者:[Garima][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/garimavsharma
|
||||
[1]:https://opensource.com/article/17/2/performance-container-world?rate=RozKaIY39AZNxbayqFkUmtkkhoGdctOVuGOAJqVJII8
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers
|
||||
[3]:https://opensource.com/resources/what-are-microservices
|
||||
[4]:https://opensource.com/resources/what-is-kubernetes
|
||||
[5]:https://opensource.com/user/109286/feed
|
||||
[6]:https://opensource.com/article/17/2/performance-container-world#comments
|
||||
[7]:https://opensource.com/users/garimavsharma
|
||||
@ -1,3 +1,5 @@
|
||||
翻译中 by zionfuo
|
||||
|
||||
How to take screenshots on Linux using Scrot
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,257 +0,0 @@
|
||||
penghuster is translating
|
||||
An introduction to the Linux boot and startup processes
|
||||
============================================================
|
||||
|
||||
> Ever wondered what it takes to get your system ready to run applications? Here's what is going on under the hood.
|
||||
|
||||
|
||||

|
||||
>Image by : [Penguin][15], [Boot][16]. Modified by Opensource.com. [CC BY-SA 4.0][17].
|
||||
|
||||
Understanding the Linux boot and startup processes is important to being able to both configure Linux and to resolving startup issues. This article presents an overview of the bootup sequence using the [GRUB2 bootloader][18] and the startup sequence as performed by the [systemd initialization system][19].
|
||||
|
||||
In reality, there are two sequences of events that are required to boot a Linux computer and make it usable: _boot_ and _startup_ . The _boot_ sequence starts when the computer is turned on, and is completed when the kernel is initialized and systemd is launched. The _startup_ process then takes over and finishes the task of getting the Linux computer into an operational state.
|
||||
|
||||
Overall, the Linux boot and startup process is fairly simple to understand. It is comprised of the following steps which will be described in more detail in the following sections.
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
* [What are Linux containers?][2]
|
||||
* [Managing devices in Linux][3]
|
||||
* [Download Now: Linux commands cheat sheet][4]
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
* BIOS POST
|
||||
* Boot loader (GRUB2)
|
||||
* Kernel initialization
|
||||
* Start systemd, the parent of all processes.
|
||||
|
||||
Note that this article covers GRUB2 and systemd because they are the current boot loader and initialization software for most major distributions. Other software options have been used historically and are still found in some distributions.
|
||||
|
||||
### The boot process
|
||||
|
||||
The boot process can be initiated in one of a couple ways. First, if power is turned off, turning on the power will begin the boot process. If the computer is already running a local user, including root or an unprivileged user, the user can programmatically initiate the boot sequence by using the GUI or command line to initiate a reboot. A reboot will first do a shutdown and then restart the computer.
|
||||
|
||||
### BIOS POST
|
||||
|
||||
The first step of the Linux boot process really has nothing whatever to do with Linux. This is the hardware portion of the boot process and is the same for any operating system. When power is first applied to the computer it runs the POST (Power On Self Test) which is part of the BIOS (Basic I/O System).
|
||||
|
||||
When IBM designed the first PC back in 1981, BIOS was designed to initialize the hardware components. POST is the part of BIOS whose task is to ensure that the computer hardware functioned correctly. If POST fails, the computer may not be usable and so the boot process does not continue.
|
||||
|
||||
BIOS POST checks the basic operability of the hardware and then it issues a BIOS [interrupt][20], INT 13H, which locates the boot sectors on any attached bootable devices. The first boot sector it finds that contains a valid boot record is loaded into RAM and control is then transferred to the code that was loaded from the boot sector.
|
||||
|
||||
The boot sector is really the first stage of the boot loader. There are three boot loaders used by most Linux distributions, GRUB, GRUB2, and LILO. GRUB2 is the newest and is used much more frequently these days than the other older options.
|
||||
|
||||
### GRUB2
|
||||
|
||||
GRUB2 stands for "GRand Unified Bootloader, version 2" and it is now the primary bootloader for most current Linux distributions. GRUB2 is the program which makes the computer just smart enough to find the operating system kernel and load it into memory. Because it is easier to write and say GRUB than GRUB2, I may use the term GRUB in this document but I will be referring to GRUB2 unless specified otherwise.
|
||||
|
||||
GRUB has been designed to be compatible with the [multiboot specification][21] which allows GRUB to boot many versions of Linux and other free operating systems; it can also chain load the boot record of proprietary operating systems.
|
||||
|
||||
GRUB can also allow the user to choose to boot from among several different kernels for any given Linux distribution. This affords the ability to boot to a previous kernel version if an updated one fails somehow or is incompatible with an important piece of software. GRUB can be configured using the /boot/grub/grub.conf file.
|
||||
|
||||
GRUB1 is now considered to be legacy and has been replaced in most modern distributions with GRUB2, which is a rewrite of GRUB1\. Red Hat based distros upgraded to GRUB2 around Fedora 15 and CentOS/RHEL 7\. GRUB2 provides the same boot functionality as GRUB1 but GRUB2 is also a mainframe-like command-based pre-OS environment and allows more flexibility during the pre-boot phase. GRUB2 is configured with /boot/grub2/grub.cfg.
|
||||
|
||||
The primary function of either GRUB is to get the Linux kernel loaded into memory and running. Both versions of GRUB work essentially the same way and have the same three stages, but I will use GRUB2 for this discussion of how GRUB does its job. The configuration of GRUB or GRUB2 and the use of GRUB2 commands is outside the scope of this article.
|
||||
|
||||
Although GRUB2 does not officially use the stage notation for the three stages of GRUB2, it is convenient to refer to them in that way, so I will in this article.
|
||||
|
||||
#### Stage 1
|
||||
|
||||
As mentioned in the BIOS POST section, at the end of POST, BIOS searches the attached disks for a boot record, usually located in the Master Boot Record (MBR), it loads the first one it finds into memory and then starts execution of the boot record. The bootstrap code, i.e., GRUB2 stage 1, is very small because it must fit into the first 512-byte sector on the hard drive along with the partition table. The total amount of space allocated for the actual bootstrap code in a [classic generic MBR][22] is 446 bytes. The 446 Byte file for stage 1 is named boot.img and does not contain the partition table which is added to the boot record separately.
|
||||
|
||||
Because the boot record must be so small, it is also not very smart and does not understand filesystem structures. Therefore the sole purpose of stage 1 is to locate and load stage 1.5\. In order to accomplish this, stage 1.5 of GRUB must be located in the space between the boot record itself and the first partition on the drive. After loading GRUB stage 1.5 into RAM, stage 1 turns control over to stage 1.5.
|
||||
|
||||
#### Stage 1.5
|
||||
|
||||
As mentioned above, stage 1.5 of GRUB must be located in the space between the boot record itself and the first partition on the disk drive. This space was left unused historically for technical reasons. The first partition on the hard drive begins at sector 63 and with the MBR in sector 0, that leaves 62 512-byte sectors—31,744 bytes—in which to store the core.img file which is stage 1.5 of GRUB. The core.img file is 25,389 Bytes so there is plenty of space available between the MBR and the first disk partition in which to store it.
|
||||
|
||||
Because of the larger amount of code that can be accommodated for stage 1.5, it can have enough code to contain a few common filesystem drivers, such as the standard EXT and other Linux filesystems, FAT, and NTFS. The GRUB2 core.img is much more complex and capable than the older GRUB1 stage 1.5\. This means that stage 2 of GRUB2 can be located on a standard EXT filesystem but it cannot be located on a logical volume. So the standard location for the stage 2 files is in the /boot filesystem, specifically /boot/grub2.
|
||||
|
||||
Note that the /boot directory must be located on a filesystem that is supported by GRUB. Not all filesystems are. The function of stage 1.5 is to begin execution with the filesystem drivers necessary to locate the stage 2 files in the /boot filesystem and load the needed drivers.
|
||||
|
||||
#### Stage 2
|
||||
|
||||
All of the files for GRUB stage 2 are located in the /boot/grub2 directory and several subdirectories. GRUB2 does not have an image file like stages 1 and 2\. Instead, it consists mostly of runtime kernel modules that are loaded as needed from the /boot/grub2/i386-pc directory.
|
||||
|
||||
The function of GRUB2 stage 2 is to locate and load a Linux kernel into RAM and turn control of the computer over to the kernel. The kernel and its associated files are located in the /boot directory. The kernel files are identifiable as they are all named starting with vmlinuz. You can list the contents of the /boot directory to see the currently installed kernels on your system.
|
||||
|
||||
GRUB2, like GRUB1, supports booting from one of a selection of Linux kernels. The Red Hat package manager, DNF, supports keeping multiple versions of the kernel so that if a problem occurs with the newest one, an older version of the kernel can be booted. By default, GRUB provides a pre-boot menu of the installed kernels, including a rescue option and, if configured, a recovery option.
|
||||
|
||||
Stage 2 of GRUB2 loads the selected kernel into memory and turns control of the computer over to the kernel.
|
||||
|
||||
### Kernel
|
||||
|
||||
All of the kernels are in a self-extracting, compressed format to save space. The kernels are located in the /boot directory, along with an initial RAM disk image, and device maps of the hard drives.
|
||||
|
||||
After the selected kernel is loaded into memory and begins executing, it must first extract itself from the compressed version of the file before it can perform any useful work. Once the kernel has extracted itself, it loads [systemd][23], which is the replacement for the old [SysV init][24] program, and turns control over to it.
|
||||
|
||||
This is the end of the boot process. At this point, the Linux kernel and systemd are running but unable to perform any productive tasks for the end user because nothing else is running.
|
||||
|
||||
### The startup process
|
||||
|
||||
The startup process follows the boot process and brings the Linux computer up to an operational state in which it is usable for productive work.
|
||||
|
||||
### systemd
|
||||
|
||||
systemd is the mother of all processes and it is responsible for bringing the Linux host up to a state in which productive work can be done. Some of its functions, which are far more extensive than the old init program, are to manage many aspects of a running Linux host, including mounting filesystems, and starting and managing system services required to have a productive Linux host. Any of systemd's tasks that are not related to the startup sequence are outside the scope of this article.
|
||||
|
||||
First, systemd mounts the filesystems as defined by **/etc/fstab**, including any swap files or partitions. At this point, it can access the configuration files located in /etc, including its own. It uses its configuration file, **/etc/systemd/system/default.target**, to determine which state or target, into which it should boot the host. The **default.target** file is only a symbolic link to the true target file. For a desktop workstation, this is typically going to be the graphical.target, which is equivalent to **runlevel**** 5** in the old SystemV init. For a server, the default is more likely to be the **multi-user.target** which is like **runlevel**** 3** in SystemV. The **emergency.target** is similar to single user mode.
|
||||
|
||||
Note that targets and services are systemd units.
|
||||
|
||||
Table 1, below, is a comparison of the systemd targets with the old SystemV startup runlevels. The **systemd target aliases** are provided by systemd for backward compatibility. The target aliases allow scripts—and many sysadmins like myself—to use SystemV commands like **init 3** to change runlevels. Of course, the SystemV commands are forwarded to systemd for interpretation and execution.
|
||||
|
||||
|SystemV Runlevel | systemd target | systemd target aliases | Description |
|
||||
|:--
|
||||
| | halt.target | | Halts the system without powering it down. |
|
||||
| 0 | poweroff.target | runlevel0.target | Halts the system and turns the power off. |
|
||||
| S | emergency.target | | Single user mode. No services are running; filesystems are not mounted. This is the most basic level of operation with only an emergency shell running on the main console for the user to interact with the system. |
|
||||
| 1 | rescue.target | runlevel1.target | A base system including mounting the filesystems with only the most basic services running and a rescue shell on the main console. |
|
||||
| 2 | | runlevel2.target | Multiuser, without NFS but all other non-GUI services running. |
|
||||
| 3 | multi-user.target | runlevel3.target | All services running but command line interface (CLI) only. |
|
||||
| 4 | | runlevel4.target | Unused. |
|
||||
| 5 | graphical.target | runlevel5.target | multi-user with a GUI. |
|
||||
| 6 | reboot.target | runlevel6.target | Reboot |
|
||||
| | default.target | | This target is always aliased with a symbolic link to either multi-user.target or graphical.target. systemd always uses the default.target to start the system. The default.target should never be aliased to halt.target, poweroff.target, or reboot.target. |
|
||||
|
||||
_Table 1: Comparison of SystemV runlevels with systemd targets and some target aliases._
|
||||
|
||||
Each target has a set of dependencies described in its configuration file. systemd starts the required dependencies. These dependencies are the services required to run the Linux host at a specific level of functionality. When all of the dependencies listed in the target configuration files are loaded and running, the system is running at that target level.
|
||||
|
||||
systemd also looks at the legacy SystemV init directories to see if any startup files exist there. If so, systemd used those as configuration files to start the services described by the files. The deprecated network service is a good example of one of those that still use SystemV startup files in Fedora.
|
||||
|
||||
Figure 1, below, is copied directly from the **bootup** [man page][25]. It shows the general sequence of events during systemd startup and the basic ordering requirements to ensure a successful startup.
|
||||
|
||||
The **sysinit.target** and **basic.target** targets can be considered as checkpoints in the startup process. Although systemd has as one of its design goals to start system services in parallel, there are still certain services and functional targets that must be started before other services and targets can be started. These checkpoints cannot be passed until all of the services and targets required by that checkpoint are fulfilled.
|
||||
|
||||
So the **sysinit.target** is reached when all of the units on which it depends are completed. All of those units, mounting filesystems, setting up swap files, starting udev, setting the random generator seed, initiating low-level services, and setting up cryptographic services if one or more filesystems are encrypted, must be completed, but within the **sysinit****.target **those tasks can be performed in parallel.
|
||||
|
||||
The **sysinit.target** starts up all of the low-level services and units required for the system to be marginally functional and that are required to enable moving on to the basic.target.
|
||||
|
||||
|
|
||||
```
|
||||
local-fs-pre.target
|
||||
|
|
||||
v
|
||||
(various mounts and (various swap (various cryptsetup
|
||||
fsck services...) devices...) devices...) (various low-level (various low-level
|
||||
| | | services: udevd, API VFS mounts:
|
||||
v v v tmpfiles, random mqueue, configfs,
|
||||
local-fs.target swap.target cryptsetup.target seed, sysctl, ...) debugfs, ...)
|
||||
| | | | |
|
||||
\__________________|_________________ | ___________________|____________________/
|
||||
\|/
|
||||
v
|
||||
sysinit.target
|
||||
|
|
||||
____________________________________/|\________________________________________
|
||||
/ | | | \
|
||||
| | | | |
|
||||
v v | v v
|
||||
(various (various | (various rescue.service
|
||||
timers...) paths...) | sockets...) |
|
||||
| | | | v
|
||||
v v | v rescue.target
|
||||
timers.target paths.target | sockets.target
|
||||
| | | |
|
||||
v \_________________ | ___________________/
|
||||
\|/
|
||||
v
|
||||
basic.target
|
||||
|
|
||||
____________________________________/| emergency.service
|
||||
/ | | |
|
||||
| | | v
|
||||
v v v emergency.target
|
||||
display- (various system (various system
|
||||
manager.service services services)
|
||||
| required for |
|
||||
| graphical UIs) v
|
||||
| | multi-user.target
|
||||
| | |
|
||||
\_________________ | _________________/
|
||||
\|/
|
||||
v
|
||||
graphical.target
|
||||
```
|
||||
|
|
||||
|
||||
_Figure 1: The systemd startup map._
|
||||
|
||||
After the **sysinit.target** is fulfilled, systemd next starts the **basic.target**, starting all of the units required to fulfill it. The basic target provides some additional functionality by starting units that re required for the next target. These include setting up things like paths to various executable directories, communication sockets, and timers.
|
||||
|
||||
Finally, the user-level targets, **multi-user.target** or **graphical.target** can be initialized. Notice that the **multi-user.****target**must be reached before the graphical target dependencies can be met.
|
||||
|
||||
The underlined targets in Figure 1, are the usual startup targets. When one of these targets is reached, then startup has completed. If the **multi-user.target** is the default, then you should see a text mode login on the console. If **graphical.target** is the default, then you should see a graphical login; the specific GUI login screen you see will depend on the default [display manager][26] you use.
|
||||
|
||||
### Issues
|
||||
|
||||
I recently had a need to change the default boot kernel on a Linux computer that used GRUB2\. I found that some of the commands did not seem to work properly for me, or that I was not using them correctly. I am not yet certain which was the case, and need to do some more research.
|
||||
|
||||
The grub2-set-default command did not properly set the default kernel index for me in the **/etc/default/grub** file so that the desired alternate kernel did not boot. So I manually changed /etc/default/grub **GRUB_DEFAULT=saved** to **GRUB_DEFAULT=****2** where 2 is the index of the installed kernel I wanted to boot. Then I ran the command **grub2-mkconfig ****> /boot/grub2/grub.cfg** to create the new grub configuration file. This circumvention worked as expected and booted to the alternate kernel.
|
||||
|
||||
### Conclusions
|
||||
|
||||
GRUB2 and the systemd init system are the key components in the boot and startup phases of most modern Linux distributions. Despite the fact that there has been controversy surrounding systemd especially, these two components work together smoothly to first load the kernel and then to start up all of the system services required to produce a functional Linux system.
|
||||
|
||||
Although I do find both GRUB2 and systemd more complex than their predecessors, they are also just as easy to learn and manage. The man pages have a great deal of information about systemd, and freedesktop.org has the complete set of [systemd man pages][27] online. Refer to the resources, below, for more links.
|
||||
|
||||
### Additional resources
|
||||
|
||||
* [GNU GRUB][6] (Wikipedia)
|
||||
* [GNU GRUB Manual][7] (GNU.org)
|
||||
* [Master Boot Record][8] (Wikipedia)
|
||||
* [Multiboot specification][9] (Wikipedia)
|
||||
* [systemd][10] (Wikipedia)
|
||||
* [sy][11][stemd bootup process][12] (Freedesktop.org)
|
||||
* [systemd index of man pages][13] (Freedesktop.org)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||
|
||||
---------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/linux-boot-and-startup
|
||||
|
||||
作者:[David Both ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[7]:https://www.gnu.org/software/grub/manual/grub.html
|
||||
[8]:https://en.wikipedia.org/wiki/Master_boot_record
|
||||
[9]:https://en.wikipedia.org/wiki/Multiboot_Specification
|
||||
[10]:https://en.wikipedia.org/wiki/Systemd
|
||||
[11]:https://www.freedesktop.org/software/systemd/man/bootup.html
|
||||
[12]:https://www.freedesktop.org/software/systemd/man/bootup.html
|
||||
[13]:https://www.freedesktop.org/software/systemd/man/index.html
|
||||
[14]:https://opensource.com/article/17/2/linux-boot-and-startup?rate=zi3QD2ADr8eV0BYSxcfeaMxZE3mblRhuswkBOhCQrmI
|
||||
[15]:https://pixabay.com/en/penguins-emperor-antarctic-life-429136/
|
||||
[16]:https://pixabay.com/en/shoe-boots-home-boots-house-1519804/
|
||||
[17]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[18]:https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[19]:https://en.wikipedia.org/wiki/Systemd
|
||||
[20]:https://en.wikipedia.org/wiki/BIOS_interrupt_call
|
||||
[21]:https://en.wikipedia.org/wiki/Multiboot_Specification
|
||||
[22]:https://en.wikipedia.org/wiki/Master_boot_record
|
||||
[23]:https://en.wikipedia.org/wiki/Systemd
|
||||
[24]:https://en.wikipedia.org/wiki/Init#SysV-style
|
||||
[25]:http://man7.org/linux/man-pages/man7/bootup.7.html
|
||||
[26]:https://opensource.com/article/16/12/yearbook-best-couple-2016-display-manager-and-window-manager
|
||||
[27]:https://www.freedesktop.org/software/systemd/man/index.html
|
||||
[28]:https://opensource.com/user/14106/feed
|
||||
[29]:https://opensource.com/article/17/2/linux-boot-and-startup#comments
|
||||
[30]:https://opensource.com/users/dboth
|
||||
@ -0,0 +1,119 @@
|
||||
ucasFL translating
|
||||
Know your Times Tables, but... do you know your "Hash Tables"?
|
||||
============================================================
|
||||
|
||||
Diving into the world of Hash Tables and understanding the underlying mechanics is _extremely_ interesting, and very rewarding. So lets get into it and get started from the beginning.
|
||||
|
||||
A Hash Table is a common data structure used in many modern day Software applications. It provides a dictionary-like functionality, giving you the ability to perform opertations such as inserting, removing and deleting items inside it. Let’s just say I want to find what the definition of what “Apple” is, and I know the defintion is stored in my defined Hash Table. I will query my Hash Table to give me a defintion. The _entry_ inside my Hash Table might look something like this `"Apple" => "A green fruit of fruity goodness"`. So, “Apple” is my _key_ and “A green fruit of fruity goodness” is my associated _value_ .
|
||||
|
||||
One more example just so we’re clear, take below the contents of a Hash Table:
|
||||
|
||||
|
||||
```
|
||||
1234
|
||||
```
|
||||
|
||||
```
|
||||
"bread" => "solid""water" => "liquid""soup" => "liquid""corn chips" => "solid"
|
||||
```
|
||||
|
||||
|
||||
I want to look up if _bread_ is a solid or liquid, So I will query the Hash Table to give me the associated value, and the table will return to me with “solid”. Ok so we got the generally gist of how it functions. Another important concept to note with Hash Tables is the fact that every key is unique. Let’s say tomorrow, I feel like having a bread milkshake (which is a _liquid_ ), we now need to update the Hash Table to reflect its change from solid to liquid! So we add the entry into the dictionary, the key : “bread” and the value : “liquid”. Can you spot what has changed in the table below?
|
||||
|
||||
|
||||
```
|
||||
1234
|
||||
```
|
||||
|
||||
```
|
||||
"bread" => "liquid""water" => "liquid""soup" => "liquid""corn chips" => "solid"
|
||||
```
|
||||
|
||||
|
||||
That’s right, bread has been updated to have the value “liquid”.
|
||||
|
||||
**Keys are unique**, my bread can’t be both a liquid and a solid. But what makes this data structure so special from the rest? Why not just use an [Array][1] instead? It depends on the nature of the problem. You may very well be better off using a Array for a particular problem, and that also brings me to the point, **choose the data structure that is most suited to your problem**. Example, If all you need to do is store a simple grocery list, an Array would do just fine. Consider the two problems below, each problem is very different in nature.
|
||||
|
||||
1. I need a grocery list of fruit
|
||||
|
||||
2. I need a grocery list of fruit and how much each it will cost me (per kilogram).
|
||||
|
||||
As you can see below, an Array might be a better choice for storing the fruit for the grocery list. But a Hash Table looks like a better choice for looking up the cost of each item.
|
||||
|
||||
|
||||
```
|
||||
123456789
|
||||
```
|
||||
|
||||
```
|
||||
//Example Array ["apple, "orange", "pear", "grape"] //Example Hash Table { "apple" : 3.05, "orange" : 5.5, "pear" : 8.4, "grape" : 12.4 }
|
||||
```
|
||||
|
||||
|
||||
There are literally so many oppurtunities to [use][2] Hash Tables.
|
||||
|
||||
### Time and what that means to you
|
||||
|
||||
[A brush up on time and space complexity][3].
|
||||
|
||||
On average it takes a Hash Table O(1) to search, insert and delete entries in the Hash Table. For the unaware, O(1) is spoken as “Big O 1” and represents constant time. Meaning that the running time to perform each operation is not dependent on the amount of data in the dataset. We can also _promise_ that for searching, inserting and deleting items will take constant time, “IF AND ONLY” IF the implementation of the Hash Table is done right. If it’s not, then it can be really slow _O(n)_ , especially if everything hashes to the same position/slot in the Hash Table.
|
||||
|
||||
### Building a good Hash Table
|
||||
|
||||
So far we now understand how to use a Hash Table, but what if we wanted to **build** one? Essentially what we need to do is map a string (eg. “dog”) to a **hash code** (a generated number), which maps to an index of an Array. You might ask, why not just go straight to using indexes? Why bother? Well this way it allows us to find out immediately where “dog” is located by quering directly for “dog”, `String name = Array["dog"] //name is "Lassy"`. But with using an index to look up the name, we could be in the likely situation that we do not know the index where the name is located. For example, `String name = Array[10] // name is now "Bob"` - that’s not my dog’s name! And that is the benefit of mapping the string to a hash code (which corresponds to an index of an Array). We can get the index of the Array by using the modulo operator with the size of the Hash Table, `index = hash_code % table_size`.
|
||||
|
||||
Another situation that we want to avoid is having two keys mapping to the same index, this is called a **hash collision** and they’re very likely to happen if the hash function is not properly implemented. But the truth is that every hash function _with more inputs than outputs_ there is some chance of collision. To demonstrate a simple collision take the following two function outputs below:
|
||||
|
||||
`int cat_idx = hashCode("cat") % table_size; //cat_idx is now equal to 1`
|
||||
|
||||
`int dog_idx = hashCode("dog") % table_size; //dog_idx is now also equal 1`
|
||||
|
||||
We can see that both Array indexes are now 1! And as such the values will overwrite each other because they are being written to the same index. Like if we tried to look up the value for “cat” it would then return “Lassy”. Not what we wanted after all. There are various methods of [resolving hash collisions][4], the more popular one is called **Chaining**. The idea with chaining is that there is a Linked List for each index of an Array. If a collision occurs, the value will be stored inside that Linked List. Thus in the previous example, we would get the value we requested, but it we would need to search a Linked List attached to the index 1 of the Array. Hashing with Chaining achieves O(1 + α) time where α is the load factor which can be represented as n/k, n being the number of entries in the Hash Table and k being the number of slots available in the Hash Table. But remember this only holds true if the keys that you give are particularly random (relying on [SUHA][5])).
|
||||
|
||||
This is a big assumption to make, as there is always a possibility that non-equal keys will hash to the same slot. One solution to this is to take the reliance of randomness away from what keys are given to the Hash Table, and put the randomness on how the keys will be hashed to increase the likeliness of _very few conflicts_ occuring. And this is known as…
|
||||
|
||||
### Universal Hashing
|
||||
|
||||
The concept is pretty simple, select _at random_ a hash function h from the set universal hash family to compute the hash code. So in other words, choose any random hash function to hash the key! And by following this method it provides a _very low_ probability that the hashes of two distinct keys will not be the same. I will keep this one short, but if you don’t trust me then trust [Mathematics][6] instead. Also another thing to watch out for is when implementing this method be careful of having a bad universal hash family. It can blow out the time and space complexity to O(U) where U is the size of the family. And where the challenge lies is finding a Hash family that does not take too much time to compute, and too much space to store.
|
||||
|
||||
### A Hash function of the Gods
|
||||
|
||||
The search for perfection is inevitable. What if we could construct a _Perfect hash function_ where we could just map things to a set of integers with absolutely _no collisions_ . Good news is we can do this, Well kind of.. but our data has to be static (which means no insertions/deletes/updates can assured constant time). One approach to achieve a perfect hash function is to use _2-Level Hashing_ , it is basically a combination of the last two ideas we previously discussed. It uses _Universal Hashing_ to select which hash function to use, and then combines it with _Chaining_ , but this time instead of using a Linked List data structure we use another Hash Table! Let’s see how this looks visually below:
|
||||
|
||||
[][8]
|
||||
|
||||
**But how does this work and how can we ensure no lookup collisions?**
|
||||
|
||||
Well it works in reverse to the [Birthday paradox][7]. It states that in a set of N randomly chosen people, some pair will have the same birthday. But if the number of days in a year far outwighs the number of people (squared) then there is a damn good possibility that no pair of people will share the same birthday. So how it relates is, for each chained Hash Table is the size of the first-level Hash Table _squared_ . That is if 2 elements happen to hash to the same slot, then the size of the chained Hash Table will be of size 4\. Most of the time the chained Tables will be very sparse/empty.
|
||||
|
||||
Repeat the following two steps to ensure no look up collisions,
|
||||
|
||||
* Select a hash from the universal hash family
|
||||
|
||||
* If we get a collision, then select another hash from the universal hash family.
|
||||
|
||||
Literally that is it, (Well.. for an O(N^2) space solution anyway). If space is a concern, then a different approach is obviously needed. But the great thing is that we will only ever have to do this process on average **twice**.
|
||||
|
||||
### Summing up
|
||||
|
||||
A Hash Table is only as good as it’s _Hash function_ . Deriving a _Perfect hash function_ is much harder to achieve without losing in particular areas such as functionality, time and space. I invite you to always consider Hash Tables when solving a problem as they offer great performance benefits and they can make a noticeable difference in the usability of your application. Hash Tables and Perfect hash functions are often used in Real-time programming applications. And have been widely implemented in algorithms around the world. Hash Tables are here to stay.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zeroequalsfalse.press/2017/02/20/hashtables/
|
||||
|
||||
作者:[Marty Jacobs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zeroequalsfalse.press/about
|
||||
[1]:https://en.wikipedia.org/wiki/Array_data_type
|
||||
[2]:https://en.wikipedia.org/wiki/Hash_table#Uses
|
||||
[3]:https://www.hackerearth.com/practice/basic-programming/complexity-analysis/time-and-space-complexity/tutorial/
|
||||
[4]:https://en.wikipedia.org/wiki/Hash_table#Collision_resolution
|
||||
[5]:https://en.wikipedia.org/wiki/SUHA_(computer_science
|
||||
[6]:https://en.wikipedia.org/wiki/Universal_hashing#Mathematical_guarantees
|
||||
[7]:https://en.wikipedia.org/wiki/Birthday_problem
|
||||
[8]:http://www.zeroequalsfalse.press/2017/02/20/hashtables/Diagram.png
|
||||
203
sources/tech/20170227 Ubuntu Core in LXD containers.md
Normal file
203
sources/tech/20170227 Ubuntu Core in LXD containers.md
Normal file
@ -0,0 +1,203 @@
|
||||
Translating By LHRchina
|
||||
|
||||
|
||||
Ubuntu Core in LXD containers
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
### What’s Ubuntu Core?
|
||||
|
||||
Ubuntu Core is a version of Ubuntu that’s fully transactional and entirely based on snap packages.
|
||||
|
||||
Most of the system is read-only. All installed applications come from snap packages and all updates are done using transactions. Meaning that should anything go wrong at any point during a package or system update, the system will be able to revert to the previous state and report the failure.
|
||||
|
||||
The current release of Ubuntu Core is called series 16 and was released in November 2016.
|
||||
|
||||
Note that on Ubuntu Core systems, only snap packages using confinement can be installed (no “classic” snaps) and that a good number of snaps will not fully work in this environment or will require some manual intervention (creating user and groups, …). Ubuntu Core gets improved on a weekly basis as new releases of snapd and the “core” snap are put out.
|
||||
|
||||
### Requirements
|
||||
|
||||
As far as LXD is concerned, Ubuntu Core is just another Linux distribution. That being said, snapd does require unprivileged FUSE mounts and AppArmor namespacing and stacking, so you will need the following:
|
||||
|
||||
* An up to date Ubuntu system using the official Ubuntu kernel
|
||||
|
||||
* An up to date version of LXD
|
||||
|
||||
### Creating an Ubuntu Core container
|
||||
|
||||
The Ubuntu Core images are currently published on the community image server.
|
||||
You can launch a new container with:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc launch images:ubuntu-core/16 ubuntu-core
|
||||
Creating ubuntu-core
|
||||
Starting ubuntu-core
|
||||
```
|
||||
|
||||
The container will take a few seconds to start, first executing a first stage loader that determines what read-only image to use and setup the writable layers. You don’t want to interrupt the container in that stage and “lxc exec” will likely just fail as pretty much nothing is available at that point.
|
||||
|
||||
Seconds later, “lxc list” will show the container IP address, indicating that it’s booted into Ubuntu Core:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list
|
||||
+-------------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+-------------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
| ubuntu-core | RUNNING | 10.90.151.104 (eth0) | 2001:470:b368:b2b5:216:3eff:fee1:296f (eth0) | PERSISTENT | 0 |
|
||||
+-------------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
You can then interact with that container the same way you would any other:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap list
|
||||
Name Version Rev Developer Notes
|
||||
core 16.04.1 394 canonical -
|
||||
pc 16.04-0.8 9 canonical -
|
||||
pc-kernel 4.4.0-45-4 37 canonical -
|
||||
root@ubuntu-core:~#
|
||||
```
|
||||
|
||||
### Updating the container
|
||||
|
||||
If you’ve been tracking the development of Ubuntu Core, you’ll know that those versions above are pretty old. That’s because the disk images that are used as the source for the Ubuntu Core LXD images are only refreshed every few months. Ubuntu Core systems will automatically update once a day and then automatically reboot to boot onto the new version (and revert if this fails).
|
||||
|
||||
If you want to immediately force an update, you can do it with:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap refresh
|
||||
pc-kernel (stable) 4.4.0-53-1 from 'canonical' upgraded
|
||||
core (stable) 16.04.1 from 'canonical' upgraded
|
||||
root@ubuntu-core:~# snap version
|
||||
snap 2.17
|
||||
snapd 2.17
|
||||
series 16
|
||||
root@ubuntu-core:~#
|
||||
```
|
||||
|
||||
And then reboot the system and check the snapd version again:
|
||||
|
||||
```
|
||||
root@ubuntu-core:~# reboot
|
||||
root@ubuntu-core:~#
|
||||
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap version
|
||||
snap 2.21
|
||||
snapd 2.21
|
||||
series 16
|
||||
root@ubuntu-core:~#
|
||||
```
|
||||
|
||||
You can get an history of all snapd interactions with
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core snap changes
|
||||
ID Status Spawn Ready Summary
|
||||
1 Done 2017-01-31T05:14:38Z 2017-01-31T05:14:44Z Initialize system state
|
||||
2 Done 2017-01-31T05:14:40Z 2017-01-31T05:14:45Z Initialize device
|
||||
3 Done 2017-01-31T05:21:30Z 2017-01-31T05:22:45Z Refresh all snaps in the system
|
||||
```
|
||||
|
||||
### Installing some snaps
|
||||
|
||||
Let’s start with the simplest snaps of all, the good old Hello World:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap install hello-world
|
||||
hello-world 6.3 from 'canonical' installed
|
||||
root@ubuntu-core:~# hello-world
|
||||
Hello World!
|
||||
```
|
||||
|
||||
And then move on to something a bit more useful:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap install nextcloud
|
||||
nextcloud 11.0.1snap2 from 'nextcloud' installed
|
||||
```
|
||||
|
||||
Then hit your container over HTTP and you’ll get to your newly deployed Nextcloud instance.
|
||||
|
||||
If you feel like testing the latest LXD straight from git, you can do so with:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc config set ubuntu-core security.nesting true
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap install lxd --edge
|
||||
lxd (edge) git-c6006fb from 'canonical' installed
|
||||
root@ubuntu-core:~# lxd init
|
||||
Name of the storage backend to use (dir or zfs) [default=dir]:
|
||||
|
||||
We detected that you are running inside an unprivileged container.
|
||||
This means that unless you manually configured your host otherwise,
|
||||
you will not have enough uid and gid to allocate to your containers.
|
||||
|
||||
LXD can re-use your container's own allocation to avoid the problem.
|
||||
Doing so makes your nested containers slightly less safe as they could
|
||||
in theory attack their parent container and gain more privileges than
|
||||
they otherwise would.
|
||||
|
||||
Would you like to have your containers share their parent's allocation (yes/no) [default=yes]?
|
||||
Would you like LXD to be available over the network (yes/no) [default=no]?
|
||||
Would you like stale cached images to be updated automatically (yes/no) [default=yes]?
|
||||
Would you like to create a new network bridge (yes/no) [default=yes]?
|
||||
What should the new bridge be called [default=lxdbr0]?
|
||||
What IPv4 address should be used (CIDR subnet notation, “auto” or “none”) [default=auto]?
|
||||
What IPv6 address should be used (CIDR subnet notation, “auto” or “none”) [default=auto]?
|
||||
LXD has been successfully configured.
|
||||
```
|
||||
|
||||
And because container inception never gets old, lets run Ubuntu Core 16 inside Ubuntu Core 16:
|
||||
|
||||
```
|
||||
root@ubuntu-core:~# lxc launch images:ubuntu-core/16 nested-core
|
||||
Creating nested-core
|
||||
Starting nested-core
|
||||
root@ubuntu-core:~# lxc list
|
||||
+-------------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+-------------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| nested-core | RUNNING | 10.71.135.21 (eth0) | fd42:2861:5aad:3842:216:3eff:feaf:e6bd (eth0) | PERSISTENT | 0 |
|
||||
+-------------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
If you ever wanted to try Ubuntu Core, this is a great way to do it. It’s also a great tool for snap authors to make sure their snap is fully self-contained and will work in all environments.
|
||||
|
||||
Ubuntu Core is a great fit for environments where you want to ensure that your system is always up to date and is entirely reproducible. This does come with a number of constraints that may or may not work for you.
|
||||
|
||||
And lastly, a word of warning. Those images are considered as good enough for testing, but aren’t officially supported at this point. We are working towards getting fully supported Ubuntu Core LXD images on the official Ubuntu image server in the near future.
|
||||
|
||||
### Extra information
|
||||
|
||||
The main LXD website is at: [https://linuxcontainers.org/lxd][2] Development happens on Github at: [https://github.com/lxc/lxd][3]
|
||||
Mailing-list support happens on: [https://lists.linuxcontainers.org][4]
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
Try LXD online: [https://linuxcontainers.org/lxd/try-it][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/02/27/ubuntu-core-in-lxd-containers/
|
||||
|
||||
作者:[Stéphane Graber ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/stgraber/
|
||||
[1]:https://insights.ubuntu.com/author/stgraber/
|
||||
[2]:https://linuxcontainers.org/lxd
|
||||
[3]:https://github.com/lxc/lxd
|
||||
[4]:https://lists.linuxcontainers.org/
|
||||
[5]:https://linuxcontainers.org/lxd/try-it
|
||||
@ -1,107 +0,0 @@
|
||||
# How to work around video and subtitle embed errors
|
||||
|
||||
|
||||
This is going to be a slightly weird tutorial. The background story is as follows. Recently, I created a bunch of [sweet][1] [parody][2] [clips][3] of the [Risitas y las paelleras][4] sketch, famous for its insane laughter by the protagonist, Risitas. As always, I had them uploaded to Youtube, but from the moment I decided on what subtitles to use to the moment when the videos finally became available online, there was a long and twisty journey.
|
||||
|
||||
In this guide, I would like to present several typical issues that you may encounter when creating your own media, mostly with subtitles and the subsequent upload to media sharing portals, specifically Youtube, and how you can work around those. After me.
|
||||
|
||||
### The background story
|
||||
|
||||
My software of choice for video editing is Kdenlive, which I started using when I created the most silly [Frankenstein][5] clip, and it's been my loyal companion ever since. Normally, I render files to WebM container, with VP8 video codec and Vorbis audio codec, because that's what Google likes. Indeed, I had no issues with the roughly 40 different clips I uploaded in the last seven odd years.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
However, after I completed my Risitas & Linux project, I was in a bit of a predicament. The video file and the subtitle file were still two separate entities, and I needed somehow to put them together. My original article for subtitles work mentions Avidemux and Handbrake, and both these are valid options.
|
||||
|
||||
However, I was not too happy with the output generated by either one of these, and for a variety of reasons, something was ever so slightly off. Avidemux did not handle the video codecs well, whereas Handbrake omitted a couple of lines of subtitle text from the final product, and the font was ugly. Solvable, but not the topic for today.
|
||||
|
||||
Therefore, I decided to use VideoLAN (VLC) to embed subtitles onto the video. There are several ways to do this. You can use the Media > Convert/Save option, but this one does not have everything we need. Instead, you should use Media > Stream, which comes with a more fully fledged wizard, and it also offers an editable summary of the transcoding options, which we DO need - see my [tutorial][6] on subtitles for this please.
|
||||
|
||||
### Errors!
|
||||
|
||||
The process of embedding subtitles is not trivial. You will most likely encounter several problems along the way. This guide should help you work around these so you can focus on your work and not waste time debugging weird software errors. Anyhow, here's a small but probable collection of issues you will face while working with subtitles in VLC. Trial & error, but also nerdy design.
|
||||
|
||||
### No playable streams
|
||||
|
||||
You have probably chosen weird output settings. You might want to double check you have selected the right video and audio codecs. Also, remember that some media players may not have all the codecs. Also, make sure you test on the system you want these clips to play.
|
||||
|
||||

|
||||
|
||||
### Subtitles overlaid twice
|
||||
|
||||
This can happen if you check the box that reads Use a subtitle file in the first step of the streaming media wizard. Just select the file you need and click Stream. Leave the box unchecked.
|
||||
|
||||

|
||||
|
||||
### No subtitle output is generated
|
||||
|
||||
This can happen for two main reasons. One, you have selected the wrong encapsulation format. Do make sure the subtitles are marked correctly on the profile page when you edit it before proceeding. If the format does not support subtitles, it might not work.
|
||||
|
||||

|
||||
|
||||
Two, you may have left the subtitle codec render enabled in the final output. You do not need this. You only need to overlay the subtitles onto the video clip. Please check the generated stream output string and delete an option that reads scodec=<something> before you click the Stream button.
|
||||
|
||||

|
||||
|
||||
### Missing codecs + workaround
|
||||
|
||||
This is a common [bug][7] due to how experimental codecs are implemented, and you will most likely see it if you choose the following profile: Video - H.264 + AAC (MP4). The file will be rendered, and if you selected subtitles, they will be overlaid, too, but without any audio. However, we can fix this with a hack.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
One possible hack is to start VLC from command line with the --sout-ffmpeg-strict=-2 option (might work). The other and more sureway workaround is to take the audio-less video but with the subtitles overlayed and re-render it through Kdenlive with the original project video render without subtitles as an audio source. Sounds complicated, so in detail:
|
||||
|
||||
* Move existing clips (containing audio) from video to audio. Delete the rest.
|
||||
|
||||
* Alternatively, use rendered WebM file as your audio source.
|
||||
|
||||
* Add new clip - the one we created with embedded subtitles AND no audio.
|
||||
|
||||
* Place the clip as new video.
|
||||
|
||||
* Render as WebM again.
|
||||
|
||||

|
||||
|
||||
Using other types of audio codecs will most likely work (e.g. MP3), and you will have a complete project with video, audio and subtitles. If you're happy that nothing is missing, you can now upload to Youtube. But then ...
|
||||
|
||||
### Youtube video manager & unknown format
|
||||
|
||||
If you're trying to upload a non-WebM clip (say MP4), you might get an unspecified error that your clip does not meet the media format requirements. I was not sure why VLC generated a non-Youtube-compliant file. However, again, the fix is easy. Use Kdenlive to recreate the video, and this should result in a file that has all the right meta fields and whatnot that Youtube likes. Back to my original story and the 40-odd clips created through Kdenlive this way.
|
||||
|
||||
P.S. If your clip has valid audio, then just re-run it through Kdenlive. If it does not, do the video/audio trick from before. Mute clips as necessary. In the end, this is just like overlay, except you're using the video source from one clip and audio from another for the final render. Job done.
|
||||
|
||||
### More reading
|
||||
|
||||
I do not wish to repeat myself or spam unnecessarily with links. I have loads of clips on VLC in the Software & Security section, so you might want to consult those. The earlier mentioned article on VLC & Subtitles has links to about half a dozen related tutorials, covering additional topics like streaming, logging, video rotation, remote file access, and more. I'm sure you can work the search engine like pros.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I hope you find this guide helpful. It covers a lot, and I tried to make it linear and simple and address as many pitfalls entrepreneuring streamers and subtitle lovers may face when working with VLC. It's all about containers and codecs, but also the fact there are virtually no standards in the media world, and when you go from one format to another, sometimes you may encounter corner cases.
|
||||
|
||||
If you do hit an error or three, the tips and tricks here should help you solve at least some of them, including unplayable streams, missing or duplicate subtitles, missing codecs and the wicked Kdenlive workaround, Youtube upload errors, hidden VLC command line options, and a few other extras. Quite a lot for a single piece of text, right. Luckily, all good stuff. Take care, children of the Internet. And if you have any other requests as to what next my future VLC articles should cover, do feel liberated enough to send an email.
|
||||
|
||||
Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dedoimedo.com/computers/vlc-subtitles-errors.html
|
||||
|
||||
作者:[Dedoimedo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
[1]:https://www.youtube.com/watch?v=MpDdGOKZ3dg
|
||||
[2]:https://www.youtube.com/watch?v=KHG6fXEba0A
|
||||
[3]:https://www.youtube.com/watch?v=TXw5lRi97YY
|
||||
[4]:https://www.youtube.com/watch?v=cDphUib5iG4
|
||||
[5]:http://www.dedoimedo.com/computers/frankenstein-media.html
|
||||
[6]:http://www.dedoimedo.com/computers/vlc-subtitles.html
|
||||
[7]:https://trac.videolan.org/vlc/ticket/6184
|
||||
@ -1,76 +0,0 @@
|
||||
Developer-defined application delivery
|
||||
============================================================
|
||||
|
||||
How load balancers help you manage the complexity of distributed systems.
|
||||
|
||||
|
||||

|
||||
|
||||
Cloud-native applications are designed to draw upon the performance, scalability, and reliability benefits of distributed systems. Unfortunately, distributed systems often come at the cost of added complexity. As individual components of your application are distributed across networks, and those networks have communication gaps or experience degraded performance, your distributed application components need to continue to function independently.
|
||||
|
||||
To avoid inconsistencies in application state, distributed systems should be designed with an understanding that components will fail. Nowhere is this more prominent than in the network. Consequently, at their core, distributed systems rely heavily on load balancing—the distribution of requests across two or more systems—in order to be resilient in the face of network disruption and horizontally scale as system load fluctuates.
|
||||
|
||||
Get O'Reilly's weekly Systems Engineering and Operations newsletter[
|
||||

|
||||
][5]
|
||||
|
||||
As distributed systems become more and more prevalent in the design and delivery of cloud-native applications, load balancers saturate infrastructure design at every level of modern application architecture. In their most commonly thought-of configuration, load balancers are deployed in front of the application, handling requests from the outside world. However, the emergence of microservices means that load balancers play a critical role behind the scenes: i.e. managing the flow between _services_ .
|
||||
|
||||
Therefore, when you work with cloud-native applications and distributed systems, your load balancer takes on other role(s):
|
||||
|
||||
* As a reverse proxy to provide caching and increased security as it becomes the go-between for external clients.
|
||||
* As an API gateway by providing protocol translation (e.g. REST to AMQP).
|
||||
* It may handle security (i.e. running a web application firewall).
|
||||
* It may take on application management tasks such as rate limiting and HTTP/2 support.
|
||||
|
||||
Given their clearly expanded capabilities beyond that of balancing traffic, load balancers can be more broadly referred to as Application Delivery Controllers (ADCs).
|
||||
|
||||
### Developers defining infrastructure
|
||||
|
||||
Historically, ADCs were purchased, deployed, and managed by IT professionals most commonly to run enterprise-architected applications. For physical load balancer equipment (e.g. F5, Citrix, Brocade, etc.), this largely remains the case. Cloud-native applications with their distributed systems design and ephemeral infrastructure require load balancers to be as dynamic as the infrastructure (e.g. containers) upon which they run. These are often software load balancers (e.g. NGINX and load balancers from public cloud providers). Cloud-native applications are typically developer-led initiatives, which means that developers are creating the application (e.g. microservices) and the infrastructure (Kubernetes and NGINX). Developers are increasingly making or heavily influencing decisions for load balancing (and other) infrastructure.
|
||||
|
||||
As a decision maker, the developer of cloud-native applications generally isn't aware of, or influenced by, enterprise infrastructure requirements or existing deployments, both considering that these deployments are often new and often deployments within a public or private cloud environment. Because cloud technologies have abstracted infrastructure into programmable APIs, developers are defining the way that applications are built at each layer of that infrastructure. In the case of the load balancer, developers choose which type to use, how it gets deployed, and which functions to enable. They programmatically encode how the load balancer behaves—how it dynamically responds to the needs of the application as the application grows, shrinks and evolves in functionality over the lifetime of application deployments. Developers are defining infrastructure as code—both infrastructure configuration and its operation as code.
|
||||
|
||||
### Why developers are defining infrastructure
|
||||
|
||||
The practice of writing this code— _how applications are built and deployed_ —has undergone a fundamental shift, which can be characterized in many ways. Stated pithily, this fundamental shift has been driven by two factors: the time it takes to bring new application functionality to market ( _time to market_ ) and the time it takes for an application user to derive value from the offering ( _time to value_ ). As a result, new applications are written to be continuously delivered (as a service), not downloaded and installed.
|
||||
|
||||
Time-to-market and time-to-value pressures aren’t new, but they are joined by other factors that are increasing the decisioning-making power developers have:
|
||||
|
||||
* Cloud: the ability to define infrastructure as code via API.
|
||||
* Scale: the need to run operations efficiently in large environments.
|
||||
* Speed: the need to deliver application functionality now; for businesses to be competitive.
|
||||
* Microservices: abstraction of framework and tool choice, further empowering developers to make infrastructure decisions.
|
||||
|
||||
In addition to the above factors, it’s worth noting the impact of open source. With the prevalence and power of open source software, developers have a plethora of application infrastructure—languages, runtimes, frameworks, databases, load balancers, managed services, etc.—at their fingertips. The rise of microservices has democratized the selection of application infrastructure, allowing developers to choose best-for-purpose tooling. In the case of choice of load balancer, those that tightly integrate with and respond to the dynamic nature of cloud-native applications rise to the top of the heap.
|
||||
|
||||
### Conclusion
|
||||
|
||||
As you are mulling over your cloud-native application design, join me for a discussion on _[Load Balancing in the Cloud with NGINX and Kubernetes][8]_ . We'll examine the load balancing capabilities of different public clouds and container platforms and walk through a case study involving a bloat-a-lith—an overstuffed monolithic application. We'll look at how it was broken into smaller, independent services and how capabilities of NGINX and Kubernetes came to its rescue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Lee Calcote is an innovative thought leader, passionate about developer platforms and management software for clouds, containers, infrastructure and applications. Advanced and emerging technologies have been a consistent focus through Calcote’s tenure at SolarWinds, Seagate, Cisco and Pelco. An organizer of technology meetups and conferences, a writer, author, speaker, he is active in the tech community.
|
||||
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://www.oreilly.com/learning/developer-defined-application-delivery
|
||||
|
||||
作者:[Lee Calcote][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/7f693-lee-calcote
|
||||
[1]:https://pixabay.com/en/ship-containers-products-shipping-84139/
|
||||
[2]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[3]:https://www.oreilly.com/people/7f693-lee-calcote
|
||||
[4]:http://www.oreilly.com/pub/e/3864?intcmp=il-webops-webcast-reg-webcast_new_site_developer_defined_application_delivery_text_cta
|
||||
[5]:https://www.oreilly.com/learning/developer-defined-application-delivery?imm_mid=0ee8c5&cmp=em-webops-na-na-newsltr_20170310
|
||||
[6]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[7]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[8]:http://www.oreilly.com/pub/e/3864?intcmp=il-webops-webcast-reg-webcast_new_site_developer_defined_application_delivery_body_text_cta
|
||||
@ -1,3 +1,5 @@
|
||||
翻译中++++++++++++++
|
||||
++++++++++++++
|
||||
Getting started with Perl on the Raspberry Pi
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,310 +0,0 @@
|
||||
ucasFL translating
|
||||
|
||||
STUDY RUBY PROGRAMMING WITH OPEN-SOURCE BOOKS
|
||||
============================================================
|
||||
|
||||
### Open Source Ruby Books
|
||||
|
||||
Ruby is a general purpose, scripting, structured, flexible, fully object-oriented programming language developed by Yukihiro “Matz” Matsumoto. It features a fully dynamic type system, which means that the majority of its type checking is performed at run-time rather than at compilation. This stops programmers having to overly worry about integer and string types. Ruby has automatic memory management. The language shares many similar traits with Python, Perl, Lisp, Ada, Eiffel, and Smalltalk.
|
||||
|
||||
Ruby’s popularity was enhanced by the Ruby on Rails framework, a full-stack web framework which has been used to create many popular applications including Basecamp, GitHub, Shopify, Airbnb, Twitch, SoundCloud, Hulu, Zendesk, Square, and Highrise.
|
||||
|
||||
Ruby possesses a high portability running on Linux, Windows, Mac OS X, Cygwin, FreeBSD, NetBSD, OpenBSD, BSD/OS, Solaris, Tru64 UNIX, HP-UX, and many other operating systems. The TIOBE Programming Community index currently ranks Ruby in 12th place.
|
||||
|
||||
This compilation makes 9 strong recommendations. There are books here for beginner, intermediate, and advanced programmers. All of the texts are, of course, released under an open source license.
|
||||
|
||||
This article is part of [OSSBlog’s series of open source programming books][18].
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Best Practices][1]
|
||||
|
||||
By Gregory Brown (328 pages)
|
||||
|
||||
Ruby Best Practices is for programmers who want to use Ruby as experienced Rubyists do. Written by the developer of the Ruby project Prawn, this book explains how to design beautiful APIs and domain-specific languages with Ruby, as well as how to work with functional programming ideas and techniques that can simplify your code and make you more productive.
|
||||
|
||||
Ruby Best Practices is much more about how to go about solving problems in Ruby than it is about the exact solution you should use. The book is not targeted at the Ruby beginner, and will be of little use to someone new to programming. The book assumes a reasonable technical understanding of Ruby, and some experience in developing software with it.
|
||||
|
||||
The book is split into two parts, with eight chapters forming its core and three appendixes included as supplementary material.
|
||||
|
||||
This book provides a wealth of information on:
|
||||
|
||||
* Driving Code Through Tests – covers a number testing philosophies and techniques. Use mocks and stubs
|
||||
* Designing Beautiful APIs with special focus on Ruby’s secret powers: Flexible argument processing and code blocks
|
||||
* Mastering the Dynamic Toolkit showing developers how to build flexible interfaces, implementing per-object behaviour, extending and modifying pre-existing code, and building classes and modules programmatically
|
||||
* Text Processing and File Management focusing on regular expressions, working with files, the tempfile standard library, and text-processing strategies
|
||||
* Functional Programming Techniques highlighting modular code organisation, memoization, infinite lists, and higher-order procedures
|
||||
* Understand how and why things can go wrong explaining how to work with logger
|
||||
* Reduce Cultural Barriers by leveraging Ruby’s multilingual capabilities
|
||||
* Skillful Project Maintenance
|
||||
|
||||
The book is open source, released under the Creative Commons NC-SA license.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [I Love Ruby][2]
|
||||
|
||||
By Karthikeyan A K (246 pages)
|
||||
|
||||
I Love Ruby explains fundamental concepts and techniques in greater depth than traditional introductions. This approach provides a solid foundation for writing useful, correct, maintainable, and efficient Ruby code.
|
||||
|
||||
Chapters cover:
|
||||
|
||||
* Variables
|
||||
* Strings
|
||||
* Comparison and Logic
|
||||
* Loops
|
||||
* Arrays
|
||||
* Hashes and Symbols
|
||||
* Ranges
|
||||
* Functions
|
||||
* Variable Scope
|
||||
* Classes & Objects
|
||||
* Rdoc
|
||||
* Modules and Mixins
|
||||
* Date and Time
|
||||
* Files
|
||||
* Proc, Lambdas and Blocks
|
||||
* Multi Threading
|
||||
* Exception Handling
|
||||
* Regular Expressions
|
||||
* Gems
|
||||
* Meta Programming
|
||||
|
||||
Permission is granted to copy, distribute and/or modify the book under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Programming Ruby – The Pragmatic Programmer’s Guide][3]
|
||||
|
||||
By David Thomas, Andrew Hunt (HTML)
|
||||
|
||||
Programming Ruby is a tutorial and reference for the Ruby programming language. Use Ruby, and you will write better code, be more productive, and make programming a more enjoyable experience.
|
||||
|
||||
Topics covered include:
|
||||
|
||||
* Classes, Objects and Variables
|
||||
* Containers, Blocks and Iterators
|
||||
* Standard Types
|
||||
* More about Methods
|
||||
* Expressions
|
||||
* Exceptions, Catch and Throw
|
||||
* Modules
|
||||
* Basic Input and Output
|
||||
* Threads and Processes
|
||||
* When Trouble Strikes
|
||||
* Ruby and its World, the Web, Tk, and Microsoft Windows
|
||||
* Extending Ruby
|
||||
* Reflection, ObjectSpace and Distributed Ruby
|
||||
* Standard Library
|
||||
* Object-Oriented Design Libraries
|
||||
* Network and Web Libraries
|
||||
* Embedded Documentation
|
||||
* Interactive Ruby Shell
|
||||
|
||||
The first edition of this book is released under the Open Publication License, v1.0 or later. An updated Second Edition of this book, covering Ruby 1.8 and including descriptions of all the new libraries is available, but is not released under a freely distributable license.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Why’s (Poignant) Guide to Ruby][4]
|
||||
|
||||
By why the lucky stiff (176 pages)
|
||||
|
||||
Why’s (poignant) Guide to Ruby is an introductory book to the Ruby programming language. The book includes some wacky humour and goes off-topic on occasions. The book includes jokes that are known within the Ruby community as well as cartoon characters.
|
||||
|
||||
The contents of the book:
|
||||
|
||||
* About this book
|
||||
* Kon’nichi wa, Ruby
|
||||
* A Quick (and Hopefully Painless) Ride Through Ruby (with Cartoon Foxes): basic introduction to central Ruby concepts
|
||||
* Floating Little Leaves of Code: evaluation and values, hashes and lists
|
||||
* Them What Make the Rules and Them What Live the Dream: case/when, while/until, variable scope, blocks, methods, class definitions, class attributes, objects, modules, introspection in IRB, dup, self, rbconfig module
|
||||
* Downtown: metaprogramming, regular expressions
|
||||
* When You Wish Upon a Beard: send method, new methods in existing classes
|
||||
* Heaven’s Harp
|
||||
|
||||
This book is made available under the Creative Commons Attribution-ShareAlike License.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Hacking Guide][5]
|
||||
|
||||
By Minero Aoki – translated by Vincent Isambart and Clifford Escobar Caoille (HTML)
|
||||
|
||||
This book has the following goals:
|
||||
|
||||
* To have knowledge of the structure of Ruby
|
||||
* To gain knowledge about language processing systems in general
|
||||
* To acquire skills in reading source code
|
||||
|
||||
This book has four main parts:
|
||||
|
||||
* Objects
|
||||
* Syntactic analysis
|
||||
* Evaluation
|
||||
* Peripheral around the evaluator
|
||||
|
||||
Knowledge about the C language and the basics of object-oriented programming is needed to get the most from the book. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike2.5 license.
|
||||
|
||||
The official support site of the original book is [i.loveruby.net/ja/rhg/][10]
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [The Book Of Ruby][6]
|
||||
|
||||
By How Collingbourne (425 pages)
|
||||
|
||||
The Book Of Ruby is a free in-depth tutorial to Ruby programming.
|
||||
|
||||
The Book Of Ruby is provided in the form of a PDF document in which each chapter is accompanied by ready-to-run source code for all the examples. There is also an Introduction which explains how to use the source code in Ruby In Steel or any other editor/IDE of your choice plus appendices and an index. It concentrates principally on version 1.8.x of the Ruby language.
|
||||
|
||||
The book is divided up into bite-sized chunks. Each chapter introduces a theme which is subdivided into sub-topics. Each programming topic is accompanied by one or more small self-contained, ready-to-run Ruby programs.
|
||||
|
||||
* Strings, Numbers, Classes, and Objects – getting and putting input, strings and embedded evaluation, numbers, testing a condition: if … then, local and global variables, classes and objects, instance variables, messages, methods and polymorphism, constructors, and inspecting objects
|
||||
* Class Hierarchies, Attributes, and Class Variables – superclasses and subclasses, passing arguments to the superclass, accessor methods, ‘set’ accessors, attribute readers and writers, calling methods of a superclass, and class variables
|
||||
* Strings and Ranges – user-defined string delimiters, backquotes, and more
|
||||
* Arrays and Hashes – shows how to create a list of objects
|
||||
* Loops and Iterators – for loops, blocks, while loops, while modifiers, and until loops
|
||||
* Conditional Statements – If..Then..Else, And..Or..Not, If..Elsif, unless, if and unless modifiers, and case statements
|
||||
* Methods – class methods, class variables, what are class methods for, ruby constructors, singleton methods, singleton classes, overriding methods and more
|
||||
* Passing Arguments and Returning Values – instance methods, class methods, singleton methods, returning values, returning multiple values, default and multiple arguments, assignment and parameter passing, and more
|
||||
* Exception Handling – covers rescue, ensure, else, error numbers, retry, and raise
|
||||
* Blocks, Procs, and Lambdas – explains why they are special to Ruby
|
||||
* Symbols – symbols and strings, symbols and variables, and why symbols should be used
|
||||
* Modules and Mixins
|
||||
* Files and IO – opening and closing files, files and directories, copying files, directory enquiries, a discursion into recursion, and sorting by size
|
||||
* YAML – includes nested sequences, saving YAML data and more
|
||||
* Marshal – offers an alternative way of saving and loading data
|
||||
* Regular Expressions – making matches, match groups, and more
|
||||
* Threads – shows you how to run more than one task at a time
|
||||
* Debugging and Testing – covers the interactive ruby shell (IRB.exe), debugging, and unit testing
|
||||
* Ruby on Rails – goes through a hands-on guide to create a blog
|
||||
* Dynamic Programming – self-modifying programs, eval magic, special types of eval, adding variables and methods, and more
|
||||
|
||||
The book is distributed by SapphireSteel Software – developers of the Ruby In Steel IDE for Visual Studio. Readers may copy or distribute the text and programs of The Book Of Ruby (free edition).
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [The Little Book Of Ruby][7]
|
||||
|
||||
By Huw Collingbourne (87 pages)
|
||||
|
||||
The Little Book of Ruby is a step-by-step tutorial to programming in Ruby. It guides the reader through the fundamentals of Ruby. It shares content with The Book of Ruby, but aims to be a simpler guide to the main features of Ruby.
|
||||
|
||||
Chapters cover:
|
||||
|
||||
* Strings and Methods – including embedded evaluation. Details the syntax to Ruby methods
|
||||
* Classes and Objects – explains how to create new types of objects
|
||||
* Class Hierarchies – a class which is a ‘special type ’ of some other class simply ‘inherits’ the features of that other class
|
||||
* Accessors, Attributes, Class Variables – accessor methods, attribute readers and writers, attributes create variables, calling methods of a superclass, and class variables are explored
|
||||
* Arrays – learn how to create a list of objects: arrays including multi-dimensional arrays,
|
||||
* Hashes – create, indexing into a hash, and hash operations are covered
|
||||
* Loops and Iterators – for loops, blocks, while loops, while modifiers, and until loops
|
||||
* Conditional Statements – If..Then..Else, And..Or..Not, If..Elsif, unless, if and unless modifiers, and case statements
|
||||
* Modules and Mixins – including module methods, modules as namespaces, module ‘instance methods’, included modules or ‘mixins’, including modules from files, and pre-defined modules
|
||||
* Saving Files, Moving on..
|
||||
|
||||
This book can be copied and distributed freely as long as the text is not modified and the copyright notice is retained.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Kestrels, Quirky Birds, and Hopeless Egocentricity][8]
|
||||
|
||||
By Reg “raganwald” Braithwaite (123 pages)
|
||||
|
||||
Kestrels, Quirky Birds, and Hopeless Egocentricity collects Reg “Raganwald” Braithwaite’s series of essays about Combinatory Logic, Method Combinators, and Ruby Meta-Programing into a convenient e-book.
|
||||
|
||||
The book provides a gentle introduction to Combinatory Logic, applied using the Ruby programming language. Combinatory Logic is a mathematical notation that is powerful enough to handle set theory and issues in computability.
|
||||
|
||||
In this book, the reader meets some of the standard combinators, and for each one the book explores some of its ramifications when writing programs using the Ruby programming language. In Combinatory Logic, combinators combine and alter each other, and the book’s Ruby examples focus on combining and altering Ruby code. From simple examples like the K Combinator and Ruby’s .tap method, the books works up to meta-programming with aspects and recursive combinators.
|
||||
|
||||
The book is published under the MIT license.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Programming][9]
|
||||
|
||||
By Wikibooks.org (261 pages)
|
||||
|
||||
Ruby is an interpreted, object-oriented programming language.
|
||||
|
||||
The book is broken down into several sections and is intended to be read sequentially.
|
||||
|
||||
* Getting started – shows users how to install and begin using Ruby in an environment
|
||||
* Basic Ruby – explains the main features of the syntax of Ruby. It covers, amongst other things, strings, encoding, writing methods, classes and objects, and exceptions
|
||||
* Ruby Semantic reference
|
||||
* Built in classes
|
||||
* Available modules covers some of the standard library
|
||||
* Intermediate Ruby covers a selection of slightly more advanced topics
|
||||
|
||||
This book is published under the Creative Commons Attribution-ShareAlike 3.0 Unported license.
|
||||
|
||||
|
|
||||
|
||||
* * *
|
||||
|
||||
In no particular order, I’ll close with useful free-to-download Ruby programming books which are not released under an open source license.
|
||||
|
||||
* [Mr. Neighborly’s Humble Little Ruby Book][11] – an easy to read, easy to follow guide to all things Ruby.
|
||||
* [Introduction to Programming with Ruby][12] – learn the basic foundational building blocks of programming, starting from the very beginning
|
||||
* [Object Oriented Programming with Ruby][13] – learn the basic foundational building blocks of object oriented programming, starting from the very beginning
|
||||
* [Core Ruby Tools][14] – provides a short tour of four core Ruby tools: Gems, Ruby Version Managers, Bundler, and Rake.
|
||||
* [Learn Ruby the Hard Way, 3rd Edition][15] – a simple book designed to start your programming adventures
|
||||
* [Learn to Program][16] – by Chris Pine
|
||||
* [Ruby Essentials][17] – designed to provide a concise and easy to follow guide to learning Ruby.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ossblog.org/study-ruby-programming-with-open-source-books/
|
||||
|
||||
作者:[Steve Emms ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ossblog.org/author/steve/
|
||||
[1]:https://github.com/practicingruby/rbp-book/tree/gh-pages/pdfs
|
||||
[2]:https://mindaslab.github.io/I-Love-Ruby/
|
||||
[3]:http://ruby-doc.com/docs/ProgrammingRuby/
|
||||
[4]:http://poignant.guide/
|
||||
[5]:http://ruby-hacking-guide.github.io/
|
||||
[6]:http://www.sapphiresteel.com/ruby-programming/The-Book-Of-Ruby.html
|
||||
[7]:http://www.sapphiresteel.com/ruby-programming/The-Book-Of-Ruby.html
|
||||
[8]:https://leanpub.com/combinators
|
||||
[9]:https://en.wikibooks.org/wiki/Ruby_Programming
|
||||
[10]:http://i.loveruby.net/ja/rhg/
|
||||
[11]:http://www.humblelittlerubybook.com/
|
||||
[12]:https://launchschool.com/books/ruby
|
||||
[13]:https://launchschool.com/books/oo_ruby
|
||||
[14]:https://launchschool.com/books/core_ruby_tools
|
||||
[15]:https://learnrubythehardway.org/book/
|
||||
[16]:https://pine.fm/LearnToProgram
|
||||
[17]:http://www.techotopia.com/index.php/Ruby_Essentials
|
||||
[18]:https://www.ossblog.org/opensourcebooks/
|
||||
@ -1,3 +1,5 @@
|
||||
MonkeyDEcho translating
|
||||
|
||||
Introduction to functional programming
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Writing a Time Series Database from Scratch
|
||||
Translating by Torival Writing a Time Series Database from Scratch
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
@ -1,99 +0,0 @@
|
||||
11 reasons to use the GNOME 3 desktop environment for Linux
|
||||
============================================================
|
||||
|
||||
### The GNOME 3 desktop was designed with the goals of being simple, easy to access, and reliable. GNOME's popularity attests to the achievement of those goals.
|
||||
|
||||
|
||||

|
||||
>Image by : [Gunnar Wortmann][8] via [Pixabay][9]. Modified by Opensource.com. [CC BY-SA 4.0][10].
|
||||
|
||||
Late last year, an upgrade to Fedora 25 caused issues with the new version of [KDE][11] Plasma that made it difficult for me to get any work done. So I decided to try other Linux desktop environments for two reasons. First, I needed to get my work done. Second, having been using KDE exclusively for many years, I thought it might be time to try some different desktops.
|
||||
|
||||
The first alternate desktop I tried for several weeks was [Cinnamon][12] which I wrote about in January, and then I wrote about [LXDE][13] which I used for about eight weeks and I have found many things about it that I like. I have used [GNOME 3][14] for a few weeks to research this article.
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
Like almost everything else in the cyberworld, GNOME is an acronym; it stands for GNU Network Object Model. The GNOME 3 desktop was designed with the goals of being simple, easy to access, and reliable. GNOME's popularity attests to the achievement of those goals.
|
||||
|
||||
GNOME 3 is useful in environments where lots of screen real-estate is needed. That means both large screens with high resolution, and minimizing the amount of space needed by the desktop widgets, panels, and icons to allow access to tasks like launching new programs. The GNOME project has a set of Human Interface Guidelines (HIG) that are used to define the GNOME philosophy for how humans should interface with the computer.
|
||||
|
||||
### My eleven reasons for using GNOME 3
|
||||
|
||||
1. **Choice:** GNOME is available in many forms on some distributions like my personal favorite, Fedora. The login options for your desktop of choice are GNOME Classic, GNOME on Xorg, GNOME, and GNOME (Wayland). On the surface, these all look the same once they are launched but they use different X servers or are built with different toolkits. Wayland provides more functionality for the little niceties of the desktop such as kinetic scrolling, drag-and-drop, and paste with middle click.
|
||||
|
||||
2. **Getting started tutorial:** The getting started tutorial is displayed the first time a user logs into the desktop. It shows how to perform common tasks and provides a link to more extensive help. The tutorial is also easily accessible after it is dismissed on first boot so it can be accessed at any time. It is very simple and straightforward and provides users new to GNOME an easy and obvious starting point. To return to the tutorial later, click on **Activities**, then click on the square of nine dots which displays the applications. Then find and click on the life preserver icon labeled, **Help**.
|
||||
|
||||
3. **Clean deskto****p:** With a minimalist approach to a desktop environment in order to reduce clutter, GNOME is designed to present only the minimum necessary to have a functional environment. You should see only the top bar (yes, that is what it is called) and all else is hidden until needed. The intention is to allow the user to focus on the task at hand and to minimize the distractions caused by other stuff on the desktop.
|
||||
|
||||
4. **The top bar:** The top bar is always the place to start, no matter what you want to do. You can launch applications, log out, power off, start or stop the network, and more. This makes life simple when you want to do anything. Aside from the current application, the top bar is usually the only other object on the desktop.
|
||||
|
||||
5. **The dash:** The dash contains three icons by default, as shown below. As you start using applications, they are added to the dash so that your most frequently used applications are displayed there. You can also add application icons to the dash yourself from the application viewer.
|
||||
|
||||

|
||||
|
||||
6. **A****pplication ****v****iewer:** I really like the application viewer that is accessible from the vertical bar on the left side of the GNOME desktop,, above. The GNOME desktop normally has nothing on it unless there is a running program so you must click on the **Activities** selection on the top bar, click on the square consisting of nine dots at the bottom of the dash, which is the icon for the viewer.
|
||||
|
||||

|
||||
|
||||
The viewer itself is a matrix consisting of the icons of the installed applications as shown above. There is a pair of mutually exclusive buttons below the matrix, **Frequent **and **All**. By default, the application viewer shows all installed applications. Click on the **Frequent** button and it shows only the applications used most frequently. Scroll up and down to locate the application you want to launch. The applications are displayed in alphabetical order by name.
|
||||
|
||||
The [GNOME][6] website and the built-in help have more detail on the viewer.
|
||||
|
||||
7. **Application ready n****otification****s:** GNOME has a neat notifier that appears at top of screen when the window for a newly launched app is open and ready. Simply click on the notification to switch to that window. This saved me some time compared to searching for the newly opened application window on some other desktops.
|
||||
|
||||
8. **A****pplication ****display****:** In order to access a different running application that is not visible you click on the activity menu. This displays all of the running applications in a matrix on the desktop. Click on the desired application to bring it to the foreground. Although the current application is displayed in the Top Bar, other running applications are not.
|
||||
|
||||
9. **Minimal w****indow decorations:** Open windows on the desktop are also quite simple. The only button apparent on the title bar is the "**X**" button to close a window. All other functions such as minimize, maximize, move to another desktop, and so on, are accessible with a right-click on the title bar.
|
||||
|
||||
10. **New d****esktops are automatically created: **New empty desktops created automatically when the next empty one down is used. This means that there will always be one empty desktop and available when needed. All of the other desktops I have used allow you to set the number of desktops while the desktop is active, too, but it must be done manually using the system settings.
|
||||
|
||||
11. **Compatibility:** As with all of the other desktops I have used, applications created for other desktops will work correctly on GNOME. This is one of the features that has made it possible for me to test all of these desktops so that I can write about them.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
GNOME is a desktop unlike any other I have used. Its prime directive is "simplicity." Everything else takes a back seat to simplicity and ease of use. It takes very little time to learn how to use GNOME if you start with the getting started tutorial. That does not mean that GNOME is deficient in any way. It is a powerful and flexible desktop that stays out of the way at all times.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||
|
||||
---------------
|
||||
|
||||
via: https://opensource.com/article/17/5/reasons-gnome
|
||||
|
||||
作者:[David Both ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://www.gnome.org/gnome-3/
|
||||
[7]:https://opensource.com/article/17/5/reasons-gnome?rate=MbGLV210A21ONuGAP8_Qa4REL7cKFvcllqUddib0qMs
|
||||
[8]:https://pixabay.com/en/users/karpartenhund-3077375/
|
||||
[9]:https://pixabay.com/en/garden-gnome-black-and-white-f%C3%B6hr-1584401/
|
||||
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
[12]:https://opensource.com/article/17/1/cinnamon-desktop-environment
|
||||
[13]:https://opensource.com/article/17/3/8-reasons-use-lxde
|
||||
[14]:https://www.gnome.org/gnome-3/
|
||||
[15]:https://opensource.com/user/14106/feed
|
||||
[16]:https://opensource.com/article/17/5/reasons-gnome#comments
|
||||
[17]:https://opensource.com/users/dboth
|
||||
82
sources/tech/20170531 DNS Infrastructure at GitHub.md
Normal file
82
sources/tech/20170531 DNS Infrastructure at GitHub.md
Normal file
@ -0,0 +1,82 @@
|
||||
[DNS Infrastructure at GitHub][1]
|
||||
============================================================
|
||||
|
||||
|
||||
At GitHub we recently revamped how we do DNS from the ground up. This included both how we [interact with external DNS providers][4] and how we serve records internally to our hosts. To do this, we had to design and build a new DNS infrastructure that could scale with GitHub’s growth and across many data centers.
|
||||
|
||||
Previously GitHub’s DNS infrastructure was fairly simple and straightforward. It included a local, forwarding only DNS cache on every server and a pair of hosts that acted as both caches and authorities used by all these hosts. These hosts were available both on the internal network as well as public internet. We configured zone stubs in the caching daemon to direct queries locally rather than recurse on the internet. We also had NS records set up at our DNS providers that pointed specific internal zones to the public IPs of this pair of hosts for queries external to our network.
|
||||
|
||||
This configuration worked for many years but was not without its downsides. Many applications are highly sensitive to resolving DNS queries and any performance or availability issues we ran into would cause queuing and degraded performance at best and customer impacting outages at worst. Configuration and code changes can cause large unexpected changes in query rates. As such scaling beyond these two hosts became an issue. Due to the network configuration of these hosts we would just need to keep adding IPs and hosts which has its own problems. While attempting to fire fight and remediate these issues, the old system made it difficult to identify causes due to a lack of metrics and visibility. In many cases we resorted to `tcpdump` to identify traffic and queries in question. Another issue was running on public DNS servers we run the risk of leaking internal network information. As a result we decided to build something better and began to identify our requirements for the new system.
|
||||
|
||||
We set out to design a new DNS infrastructure that would improve the aforementioned operational issues including scaling and visibility, as well as introducing some additional requirements. We wanted to continue to run our public DNS zones via external DNS providers so whatever system we build needed to be vendor agnostic. Additionally, we wanted this system to be capable of serving both our internal and external zones, meaning internal zones were only available on our internal network unless specifically configured otherwise and external zones are resolvable without leaving our internal network. We wanted the new DNS architecture to allow both a [deploy-based workflow for making changes][5] as well as API access to our records for automated changes via our inventory and provisioning systems. The new system could not have any external dependencies; too much relies on DNS functioning for it to get caught in a cascading failure. This includes connectivity to other data centers and DNS services that may reside there. Our old system mixed the use of caches and authorities on the same host; we wanted to move to a tiered design with isolated roles. Lastly, we wanted a system that could support many data center environments whether it be EC2 or bare metal.
|
||||
|
||||
### Implementation
|
||||
|
||||
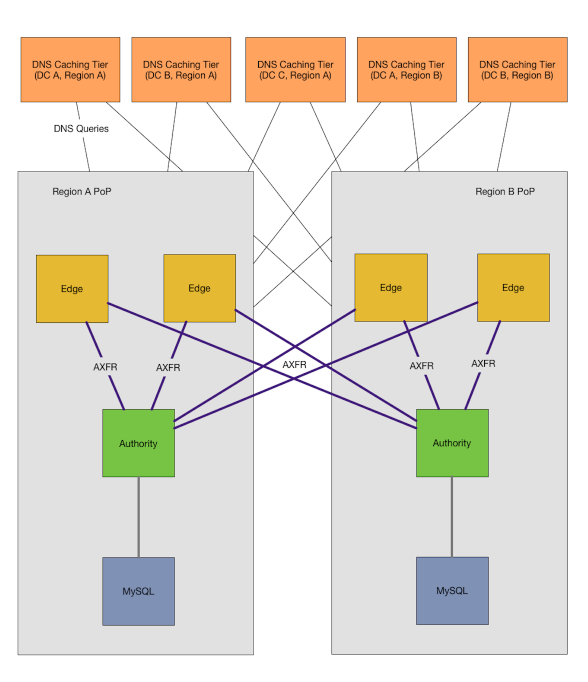
|
||||
|
||||
To build this system we identified three classes of hosts: caches, edges, and authorities. Caches serve as recursive resolvers and DNS “routers” caching responses from the edge tier. The edge tier, running a DNS authority daemon, responds to queries from the caching tier for zones it is configured to zone transfer from the authority tier. The authority tier serve as hidden DNS masters as our canonical source for DNS data, servicing zone transfers from the edge hosts as well as providing an HTTP API for creating, modifying or deleting records.
|
||||
|
||||
In our new configuration, caches live in each data center meaning application hosts don’t need to traverse a data center boundary to retrieve a record. The caches are configured to map zones to the edge hosts within their region in order to route our internal zones to our own hosts. Any zone that is not explicitly configured will recurse on the internet to resolve an answer.
|
||||
|
||||
The edge hosts are regional hosts, living in our network edge PoPs (Point of Presence). Our PoPs have one or more data centers that rely on them for external connectivity, without the PoP the data center can’t get to the internet and the internet can’t get to them. The edges perform zone transfers with all authorities regardless of what region or location they exist in and store those zones locally on their disk.
|
||||
|
||||
Our authorities are also regional hosts, only containing zones applicable to the region it is contained in. Our inventory and provisioning systems determine which regional authority a zone lives in and will create and delete records via an HTTP API as servers come and go. OctoDNS maps zones to regional authorities and uses the same API to create static records and to ensure dynamic sources are in sync. We have an additional separate authority for external domains, such as github.com, to allow us to query our external domains during a disruption to connectivity. All records are stored in MySQL.
|
||||
|
||||
### Operability
|
||||
|
||||
|
||||
|
||||
One huge benefit of moving to a more modern DNS infrastructure is observability. Our old DNS system had little to no metrics and limited logging. A large factor in deciding which DNS servers to use was the breadth and depth of metrics they produce. We finalized on [Unbound][6] for the caches, [NSD][7] for the edge hosts and [PowerDNS][8] for the authorities, all of which have been proven in DNS infrastructures much larger than at GitHub.
|
||||
|
||||
When running in our bare metal data centers, caches are accessed via a private [anycast][9] IP resulting in it reaching the nearest available cache host. The caches have been deployed in a rack aware manner that provides some level of balanced load between them and isolation against some power and network failure modes. When a cache host fails, servers that would normally use it for lookups will now automatically be routed to the next closest cache, keeping latency low as well as providing tolerance to some failure modes. Anycast allows us to scale the number of caches behind a single IP address unlike our previous configuration, giving us the ability to run as many caching hosts as DNS demand requires.
|
||||
|
||||
Edge hosts perform zone transfers with the authority tier, regardless of region or location. Our zones are not large enough that keeping a copy of all of them in every region is a problem. This means for every zone, all caches will have access to a local edge server with a local copy of all zones even when a region is offline or upstream providers are having connectivity issues. This change alone has proven to be quite resilient in the face of connectivity issues and has helped keep GitHub available during failures that not long ago would have caused customer facing outages.
|
||||
|
||||
These zone transfers include both our internal and external zones from their respective authorities. As you might guess zones like github.com are external and zones like github.net are generally internal. The difference between them is only the types of use and data stored in them. Knowing which zones are internal and external gives us some flexibility in our configuration.
|
||||
|
||||
```
|
||||
$ dig +short github.com
|
||||
192.30.253.112
|
||||
192.30.253.113
|
||||
|
||||
```
|
||||
|
||||
Public zones are [sync’d][10] to external DNS providers and are records GitHub users use everyday. Addtionally, public zones are completely resolvable within our network without needing to communicate with our external providers. This means any service that needs to look up `api.github.com` can do so without needing to rely on external network connectivity. We also use the stub-first configuration option of Unbound which gives a lookup a second chance if our internal DNS service is down for some reason by looking it up externally when it fails.
|
||||
|
||||
```
|
||||
$ dig +short time.github.net
|
||||
10.127.6.10
|
||||
|
||||
```
|
||||
|
||||
Most of the `github.net` zone is completely private, inaccessible from the internet and only contains [RFC 1918][11] IP addresses. Private zones are split up per region and site. Each region and/or site has a set of sub-zones applicable to that location, sub-zones for management network, service discovery, specific service records and yet to be provisioned hosts that are in our inventory. Private zones also include reverse lookup zones for PTRs.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Replacing an old system with a new one that is ready to serve millions of customers is never easy. Using a pragmatic, requirements based approach to designing and implementing our new DNS system resulted in a DNS infrastructure that was able to hit the ground running and will hopefully grow with GitHub into the future.
|
||||
|
||||
Want to help the GitHub SRE team solve interesting problems like this? We’d love for you to join us. [Apply Here][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://githubengineering.com/dns-infrastructure-at-github/
|
||||
|
||||
作者:[Joe Williams ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/joewilliams
|
||||
[1]:https://githubengineering.com/dns-infrastructure-at-github/
|
||||
[2]:https://github.com/joewilliams
|
||||
[3]:https://github.com/joewilliams
|
||||
[4]:https://githubengineering.com/enabling-split-authority-dns-with-octodns/
|
||||
[5]:https://githubengineering.com/enabling-split-authority-dns-with-octodns/
|
||||
[6]:https://unbound.net/
|
||||
[7]:https://www.nlnetlabs.nl/projects/nsd/
|
||||
[8]:https://powerdns.com/
|
||||
[9]:https://en.wikipedia.org/wiki/Anycast
|
||||
[10]:https://githubengineering.com/enabling-split-authority-dns-with-octodns/
|
||||
[11]:http://www.faqs.org/rfcs/rfc1918.html
|
||||
[12]:https://boards.greenhouse.io/github/jobs/669805#.WPVqJlPyvUI
|
||||
@ -1,4 +1,4 @@
|
||||
(翻译中 by runningwater)
|
||||
Translating by Snapcrafter
|
||||
A user's guide to links in the Linux filesystem
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,228 +0,0 @@
|
||||
|
||||
polebug is translating
|
||||
|
||||
3 mistakes to avoid when learning to code in Python
|
||||
============================================================
|
||||
|
||||
### These errors created big problems that took hours to solve.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
It's never easy to admit when you do things wrong, but making errors is part of any learning process, from learning to walk to learning a new programming language, such as Python.
|
||||
|
||||
Here's a list of three things I got wrong when I was learning Python, presented so that newer Python programmers can avoid making the same mistakes. These are errors that either I got away with for a long time or that that created big problems that took hours to solve.
|
||||
|
||||
Take heed young coders, some of these mistakes are afternoon wasters!
|
||||
|
||||
### 1\. Mutable data types as default arguments in function definitions
|
||||
|
||||
It makes sense right? You have a little function that, let's say, searches for links on a current page and optionally appends it to another supplied list.
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=[]):
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
On the face of it, this looks like perfectly normal Python, and indeed it is. It works. But there are issues with it. If we supply a list for the **add_to** parameter, it works as expected. If, however, we let it use the default, something interesting happens.
|
||||
|
||||
Try the following code:
|
||||
|
||||
```
|
||||
def fn(var1, var2=[]):
|
||||
var2.append(var1)
|
||||
print var2
|
||||
|
||||
fn(3)
|
||||
fn(4)
|
||||
fn(5)
|
||||
```
|
||||
|
||||
You may expect that we would see:
|
||||
|
||||
**[3]
|
||||
[4]
|
||||
[5]**
|
||||
|
||||
But we actually see this:
|
||||
|
||||
**[3]
|
||||
[3, 4]
|
||||
[3, 4, 5]**
|
||||
|
||||
Why? Well, you see, the same list is used each time. In Python, when we write the function like this, the list is instantiated as part of the function's definition. It is not instantiated each time the function is run. This means that the function keeps using the exact same list object again and again, unless of course we supply another one:
|
||||
|
||||
```
|
||||
fn(3, [4])
|
||||
```
|
||||
|
||||
**[4, 3]**
|
||||
|
||||
Just as expected. The correct way to achieve the desired result is:
|
||||
|
||||
```
|
||||
def fn(var1, var2=None):
|
||||
if not var2:
|
||||
var2 = []
|
||||
var2.append(var1)
|
||||
```
|
||||
|
||||
Or, in our first example:
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=None):
|
||||
if not add_to:
|
||||
add_to = []
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
This moves the instantiation from module load time so that it happens every time the function runs. Note that for immutable data types, like [**tuples**][7], [**strings**][8], or [**ints**][9], this is not necessary. That means it is perfectly fine to do something like:
|
||||
|
||||
```
|
||||
def func(message="my message"):
|
||||
print message
|
||||
```
|
||||
|
||||
### 2\. Mutable data types as class variables
|
||||
|
||||
Hot on the heels of the last error is one that is very similar. Consider the following:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
This code looks perfectly normal. We have an object with a storage of URLs. When we call the **add_url** method, it adds a given URL to the store. Perfect right? Let's see it in action:
|
||||
|
||||
```
|
||||
a = URLCatcher()
|
||||
a.add_url('http://www.google.')
|
||||
b = URLCatcher()
|
||||
b.add_url('http://www.bbc.co.')
|
||||
```
|
||||
|
||||
**b.urls
|
||||
['[http://www.google.com][2]', '[http://www.bbc.co.uk][3]']**
|
||||
|
||||
**a.urls
|
||||
['[http://www.google.com][4]', '[http://www.bbc.co.uk][5]']**
|
||||
|
||||
Wait, what?! We didn't expect that. We instantiated two separate objects, **a** and **b**. **A** was given one URL and **b** the other. How is it that both objects have both URLs?
|
||||
|
||||
Turns out it's kinda the same problem as in the first example. The URLs list is instantiated when the class definition is created. All instances of that class use the same list. Now, there are some cases where this is advantageous, but the majority of the time you don't want to do this. You want each object to have a separate store. To do that, we would modify the code like:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
def __init__(self):
|
||||
self.urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
Now the URLs list is instantiated when the object is created. When we instantiate two separate objects, they will be using two separate lists.
|
||||
|
||||
### 3\. Mutable assignment errors
|
||||
|
||||
This one confused me for a while. Let's change gears a little and use another mutable datatype, the [**dict**][10].
|
||||
|
||||
```
|
||||
a = {'1': "one", '2': 'two'}
|
||||
```
|
||||
|
||||
Now let's assume we want to take that **dict** and use it someplace else, leaving the original intact.
|
||||
|
||||
```
|
||||
b = a
|
||||
|
||||
b['3'] = 'three'
|
||||
```
|
||||
|
||||
Simple eh?
|
||||
|
||||
Now let's look at our original dict, **a**, the one we didn't want to modify:
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
Whoa, hold on a minute. What does **b** look like then?
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
Wait what? But… let's step back and see what happens with our other immutable types, a **tuple** for instance:
|
||||
|
||||
```
|
||||
c = (2, 3)
|
||||
d = c
|
||||
d = (4, 5)
|
||||
```
|
||||
|
||||
Now **c** is:
|
||||
**(2, 3)**
|
||||
|
||||
While **d** is:
|
||||
**(4, 5)**
|
||||
|
||||
That functions as expected. So what happened in our example? When using mutable types, we get something that behaves a little more like a pointer from C. When we said **b = a** in the code above, what we really meant was: **b** is now also a reference to **a**. They both point to the same object in Python's memory. Sound familiar? That's because it's similar to the previous problems. In fact, this post should really have been called, "The Trouble with Mutables."
|
||||
|
||||
Does the same thing happen with lists? Yes. So how do we get around it? Well, we have to be very careful. If we really need to copy a list for processing, we can do so like:
|
||||
|
||||
```
|
||||
b = a[:]
|
||||
```
|
||||
|
||||
This will go through and copy a reference to each item in the list and place it in a new list. But be warned: If any objects in the list are mutable, we will again get references to those, rather than complete copies.
|
||||
|
||||
Imagine having a list on a piece of paper. In the original example, Person A and Person B are looking at the same piece of paper. If someone changes that list, both people will see the same changes. When we copy the references, each person now has their own list. But let's suppose that this list contains places to search for food. If "fridge" is first on the list, even when it is copied, both entries in both lists point to the same fridge. So if the fridge is modified by Person A, by say eating a large gateaux, Person B will also see that the gateaux is missing. There is no easy way around this. It is just something that you need to remember and code in a way that will not cause an issue.
|
||||
|
||||
Dicts function in the same way, and you can create this expensive copy by doing:
|
||||
|
||||
```
|
||||
b = a.copy()
|
||||
```
|
||||
|
||||
Again, this will only create a new dictionary pointing to the same entries that were present in the original. Thus, if we have two lists that are identical and we modify a mutable object that is pointed to by a key from dict 'a', the dict object present in dict 'b' will also see those changes.
|
||||
|
||||
The trouble with mutable data types is that they are powerful. None of the above are real problems; they are things to keep in mind to prevent issues. The expensive copy operations presented as solutions in the third item are unnecessary 99% of the time. Your program can and probably should be modified so that those copies are not even required in the first place.
|
||||
|
||||
_Happy coding! And feel free to ask questions in the comments._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Pete Savage - Peter is a passionate Open Source enthusiast who has been promoting and using Open Source products for the last 10 years. He has volunteered in many different areas, starting in the Ubuntu community, before moving off into the realms of audio production and later into writing. Career wise he spent much of his early years managing and building datacenters as a sysadmin, before ending up working for Red Hat as a Principal Quailty Engineer for the CloudForms product. He occasionally pops out a
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python
|
||||
|
||||
作者:[Pete Savage ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psav
|
||||
[1]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python?rate=SfClhaQ6tQsJdKM8-YTNG00w53fsncvsNWafwuJbtqs
|
||||
[2]:http://www.google.com/
|
||||
[3]:http://www.bbc.co.uk/
|
||||
[4]:http://www.google.com/
|
||||
[5]:http://www.bbc.co.uk/
|
||||
[6]:https://opensource.com/user/36026/feed
|
||||
[7]:https://docs.python.org/2/library/functions.html?highlight=tuple#tuple
|
||||
[8]:https://docs.python.org/2/library/string.html
|
||||
[9]:https://docs.python.org/2/library/functions.html#int
|
||||
[10]:https://docs.python.org/2/library/stdtypes.html?highlight=dict#dict
|
||||
[11]:https://opensource.com/users/psav
|
||||
[12]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python#comments
|
||||
@ -0,0 +1,310 @@
|
||||
[MySQL infrastructure testing automation at GitHub][31]
|
||||
============================================================
|
||||
|
||||
Our MySQL infrastructure is a critical component to GitHub. MySQL serves GitHub.com, GitHub’s API, authentication and more. Every `git` request touches MySQL in some way. We are tasked with keeping the data available, and maintaining its integrity. Even while our MySQL clusters serve traffic, we need to be able to perform tasks such as heavy duty cleanups, ad-hoc updates, online schema migrations, cluster topology refactoring, pooling and load balancing and more. We have the infrastructure to automate away such operations; in this post we share a few examples of how we build trust in our infrastructure through continuous testing. It is essentially how we sleep well at night.
|
||||
|
||||
### Backups[][36]
|
||||
|
||||
It is incredibly important to take backups of your data. If you are not taking backups of your database, it is likely a matter of time before this will become an issue. Percona [Xtrabackup][37]is the tool we have been using for issuing full backups for our MySQL databases. If there is data that we need to be certain is saved, we have a server that is backing up the data.
|
||||
|
||||
In addition to the full binary backups, we run logical backups several times a day. These backups allow our engineers to get a copy of recent data. There are times that they would like a complete set of data from a table so they can test an index change on a production sized table or see data from a certain point of time. Hubot allows us to restore a backed up table and will ping us when the table is ready to use.
|
||||
|
||||

|
||||
**tomkrouper**.mysql backup-list locations
|
||||

|
||||
**Hubot**
|
||||
```
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
| Backup ID | Table Name | Donor Host | Backup Start | Backup End | File Name |
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
| 1699494 | locations | db-mysql-0903 | 2017-07-01 22:09:17 | 2017-07-01 22:09:17 | backup-mycluster-locations-1498593122.sql.gz |
|
||||
| 1699133 | locations | db-mysql-0903 | 2017-07-01 16:11:37 | 2017-07-01 16:11:39 | backup-mycluster-locations-1498571521.sql.gz |
|
||||
| 1698772 | locations | db-mysql-0903 | 2017-07-01 10:09:21 | 2017-07-01 10:09:22 | backup-mycluster-locations-1498549921.sql.gz |
|
||||
| 1698411 | locations | db-mysql-0903 | 2017-07-01 04:12:32 | 2017-07-01 04:12:32 | backup-mycluster-locations-1498528321.sql.gz |
|
||||
| 1698050 | locations | db-mysql-0903 | 2017-06-30 22:18:23 | 2017-06-30 22:18:23 | backup-mycluster-locations-1498506721.sql.gz |
|
||||
| ...
|
||||
| 1262253 | locations | db-mysql-0088 | 2016-08-01 01:58:51 | 2016-08-01 01:58:54 | backup-mycluster-locations-1470034801.sql.gz |
|
||||
| 1064984 | locations | db-mysql-0088 | 2016-04-04 13:07:40 | 2016-04-04 13:07:43 | backup-mycluster-locations-1459494001.sql.gz |
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
|
||||
```
|
||||
|
||||

|
||||
**tomkrouper**.mysql restore 1699133
|
||||

|
||||
**Hubot**A restore job has been created for the backup job 1699133\. You will be notified in #database-ops when the restore is complete.
|
||||

|
||||
**Hubot**[@tomkrouper][1]: the locations table has been restored as locations_2017_07_01_16_11 in the restores database on db-mysql-0482
|
||||
|
||||
The data is loaded onto a non-production database which is accessible to the engineer requesting the restore.
|
||||
|
||||
The last way we keep a “backup” of data around is we use [delayed replicas][38]. This is less of a backup and more of a safeguard. For each production cluster we have a host that has replication delayed by 4 hours. If a query is run that shouldn’t have, we can run `mysql panic` in chatops. This will cause all of our delayed replicas to stop replication immediately. This will also page the on-call DBA. From there we can use delayed replica to verify there is an issue, and then fast forward the binary logs to the point right before the error. We can then restore this data to the master, thus recovering data to that point.
|
||||
|
||||
Backups are great, however they are worthless if some unknown or uncaught error occurs corrupting the backup. A benefit of having a script to restore backups is it allows us to automate the verification of backups via cron. We have set up a dedicated host for each cluster that runs a restore of the latest backup. This ensures that the backup ran correctly and that we are able to retrieve the data from the backup.
|
||||
|
||||
Depending on dataset size, we run several restores per day. Restored servers are expected to join the replication stream and to be able to catch up with replication. This tests not only that we took a restorable backup, but also that we correctly identified the point in time at which it was taken and can further apply changes from that point in time. We are alerted if anything goes wrong in the restore process.
|
||||
|
||||
We furthermore track the time the restore takes, so we have a good idea of how long it will take to build a new replica or restore in cases of emergency.
|
||||
|
||||
The following is an output from an automated restore process, written by Hubot in our robots chat room.
|
||||
|
||||

|
||||
**Hubot**gh-mysql-backup-restore: db-mysql-0752: restore_log.id = 4447
|
||||
gh-mysql-backup-restore: db-mysql-0752: Determining backup to restore for cluster 'prodcluster'.
|
||||
gh-mysql-backup-restore: db-mysql-0752: Enabling maintenance mode
|
||||
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
|
||||
gh-mysql-backup-restore: db-mysql-0752: Disabling Puppet
|
||||
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Removing MySQL files
|
||||
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-restore
|
||||
gh-mysql-backup-restore: db-mysql-0752: Restore file: xtrabackup-notify-2017-07-02_0000.xbstream
|
||||
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-prepare
|
||||
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Update file ownership
|
||||
gh-mysql-backup-restore: db-mysql-0752: Upgrade MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Backup Host: db-mysql-0034
|
||||
gh-mysql-backup-restore: db-mysql-0752: Setting up replication
|
||||
gh-mysql-backup-restore: db-mysql-0752: Starting replication
|
||||
gh-mysql-backup-restore: db-mysql-0752: Replication catch-up
|
||||
gh-mysql-backup-restore: db-mysql-0752: Restore complete (replication running)
|
||||
gh-mysql-backup-restore: db-mysql-0752: Enabling Puppet
|
||||
gh-mysql-backup-restore: db-mysql-0752: Disabling maintenance mode
|
||||
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
|
||||
gh-mysql-backup-restore: db-mysql-0752: Restore process complete.
|
||||
|
||||
One thing we use backups for is adding a new replica to an existing set of MySQL servers. We will initiate the build of a new server, and once we are notified it is ready, we can start a restore of the latest backup for that particular cluster. We have a script in place that runs all of the restore commands that we would otherwise have to do by hand. Our automated restore system essentially uses the same script. This simplifies the system build process and allows us to have a host up and running with a handful of chat commands opposed to dozens of manual processes. Shown below is a restore kicked manually in chat:
|
||||
|
||||

|
||||
**jessbreckenridge**.mysql backup-restore -H db-mysql-0007 -o -r magic_word=daily_rotating_word
|
||||

|
||||
**Hubot**[@jessbreckenridge][2] gh-mysql-backup-restore: db-mysql-0007: Determining backup to restore for cluster 'mycluster'.
|
||||
[@jessbreckenridge][3] gh-mysql-backup-restore: db-mysql-0007: restore_log.id = 4449
|
||||
[@jessbreckenridge][4] gh-mysql-backup-restore: db-mysql-0007: Enabling maintenance mode
|
||||
[@jessbreckenridge][5] gh-mysql-backup-restore: db-mysql-0007: Setting orchestrator downtime
|
||||
[@jessbreckenridge][6] gh-mysql-backup-restore: db-mysql-0007: Disabling Puppet
|
||||
[@jessbreckenridge][7] gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
|
||||
[@jessbreckenridge][8] gh-mysql-backup-restore: db-mysql-0007: Removing MySQL files
|
||||
[@jessbreckenridge][9] gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-restore
|
||||
[@jessbreckenridge][10] gh-mysql-backup-restore: db-mysql-0007: Restore file: xtrabackup-mycluster-2017-07-02_0015.xbstream
|
||||
[@jessbreckenridge][11] gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-prepare
|
||||
[@jessbreckenridge][12] gh-mysql-backup-restore: db-mysql-0007: Update file ownership
|
||||
[@jessbreckenridge][13] gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
|
||||
[@jessbreckenridge][14] gh-mysql-backup-restore: db-mysql-0007: Upgrade MySQL
|
||||
[@jessbreckenridge][15] gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
|
||||
[@jessbreckenridge][16] gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
|
||||
[@jessbreckenridge][17] gh-mysql-backup-restore: db-mysql-0007: Setting up replication
|
||||
[@jessbreckenridge][18] gh-mysql-backup-restore: db-mysql-0007: Starting replication
|
||||
[@jessbreckenridge][19] gh-mysql-backup-restore: db-mysql-0007: Backup Host: db-mysql-0201
|
||||
[@jessbreckenridge][20] gh-mysql-backup-restore: db-mysql-0007: Replication catch-up
|
||||
[@jessbreckenridge][21] gh-mysql-backup-restore: db-mysql-0007: Replication behind by 4589 seconds, waiting 1800 seconds before next check.
|
||||
[@jessbreckenridge][22] gh-mysql-backup-restore: db-mysql-0007: Restore complete (replication running)
|
||||
[@jessbreckenridge][23] gh-mysql-backup-restore: db-mysql-0007: Enabling puppet
|
||||
[@jessbreckenridge][24] gh-mysql-backup-restore: db-mysql-0007: Disabling maintenance mode
|
||||
|
||||
### Failovers[][39]
|
||||
|
||||
[We use orchestrator][40] to perform automated failovers for masters and intermediate masters. We expect `orchestrator` to correctly detect master failure, designate a replica for promotion, heal the topology under said designated replica, make the promotion. We expect VIPs to change, pools to change, clients to reconnect, `puppet` to run essential components on promoted master, and more. A failover is a complex task that touches many aspects of our infrastructure.
|
||||
|
||||
To build trust in our failovers we set up a _production-like_ , test cluster, and we continuously crash it to observe failovers.
|
||||
|
||||
The _production-like_ cluster is a replication setup that is identical in all aspects to our production clusters: types of hardware, operating systems, MySQL versions, network environments, VIP, `puppet` configurations, [haproxy setup][41], etc. The only thing different to this cluster is that it doesn’t send/receive production traffic.
|
||||
|
||||
We emulate a write load on the test cluster, while avoiding replication lag. The write load is not too heavy, but has queries that are intentionally contending to write on same datasets. This isn’t too interesting in normal times, but proves to be useful upon failovers, as we will shortly describe.
|
||||
|
||||
Our test cluster has representative servers from three data centers. We would _like_ the failover to promote a replacement replica from within the same data center. We would _like_ to be able to salvage as many replicas as possible under such constraint. We _require_ that both apply whenever possible. `orchestrator` has no prior assumption on the topology; it must react on whatever the state was at time of the crash.
|
||||
|
||||
We, however, are interested in creating complex and varying scenarios for failovers. Our failover testing script prepares the grounds for the failover:
|
||||
|
||||
* It identifies existing master
|
||||
|
||||
* It refactors the topology to have representatives of all three data centers under the master. Different DCs have different network latencies and are expected to react in different timing to master’s crash.
|
||||
|
||||
* It chooses a crash method. We choose from shooting the master (`kill -9`) or network partitioning it: `iptables -j REJECT` (nice-ish) or `iptables -j DROP`(unresponsive).
|
||||
|
||||
The script proceeds to crash the master by chosen method, and waits for `orchestrator` to reliably detect the crash and to perform failover. While we expect detection and promotion to both complete within `30` seconds, the script relaxes this expectation a bit, and sleeps for a designated time before looking into failover results. It will then:
|
||||
|
||||
* Check that a new (different) master is in place
|
||||
|
||||
* There is a good number of replicas in the cluster
|
||||
|
||||
* The master is writable
|
||||
|
||||
* Writes to the master are visible on the replicas
|
||||
|
||||
* Internal service discovery entries are updated (identity of new master is as expected; old master removed)
|
||||
|
||||
* Other internal checks
|
||||
|
||||
These tests confirm that the failover was successful, not only MySQL-wise but also on our larger infrastructure scope. A VIP has been assumed; specific services have been started; information got to where it was supposed to go.
|
||||
|
||||
The script further proceeds to restore the failed server:
|
||||
|
||||
* Restoring it from backup, thereby implicitly testing our backup/restore procedure
|
||||
|
||||
* Verifying server configuration is as expected (the server no longer believes it’s the master)
|
||||
|
||||
* Returning it to the replication cluster, expecting to find data written on the master
|
||||
|
||||
Consider the following visualization of a scheduled failover test: from having a well-running cluster, to seeing problems on some replicas, to diagnosing the master (`7136`) is dead, to choosing a server to promote (`a79d`), refactoring the topology below that server, to promoting it (failover successful), to restoring the dead master and placing it back into the cluster.
|
||||
|
||||
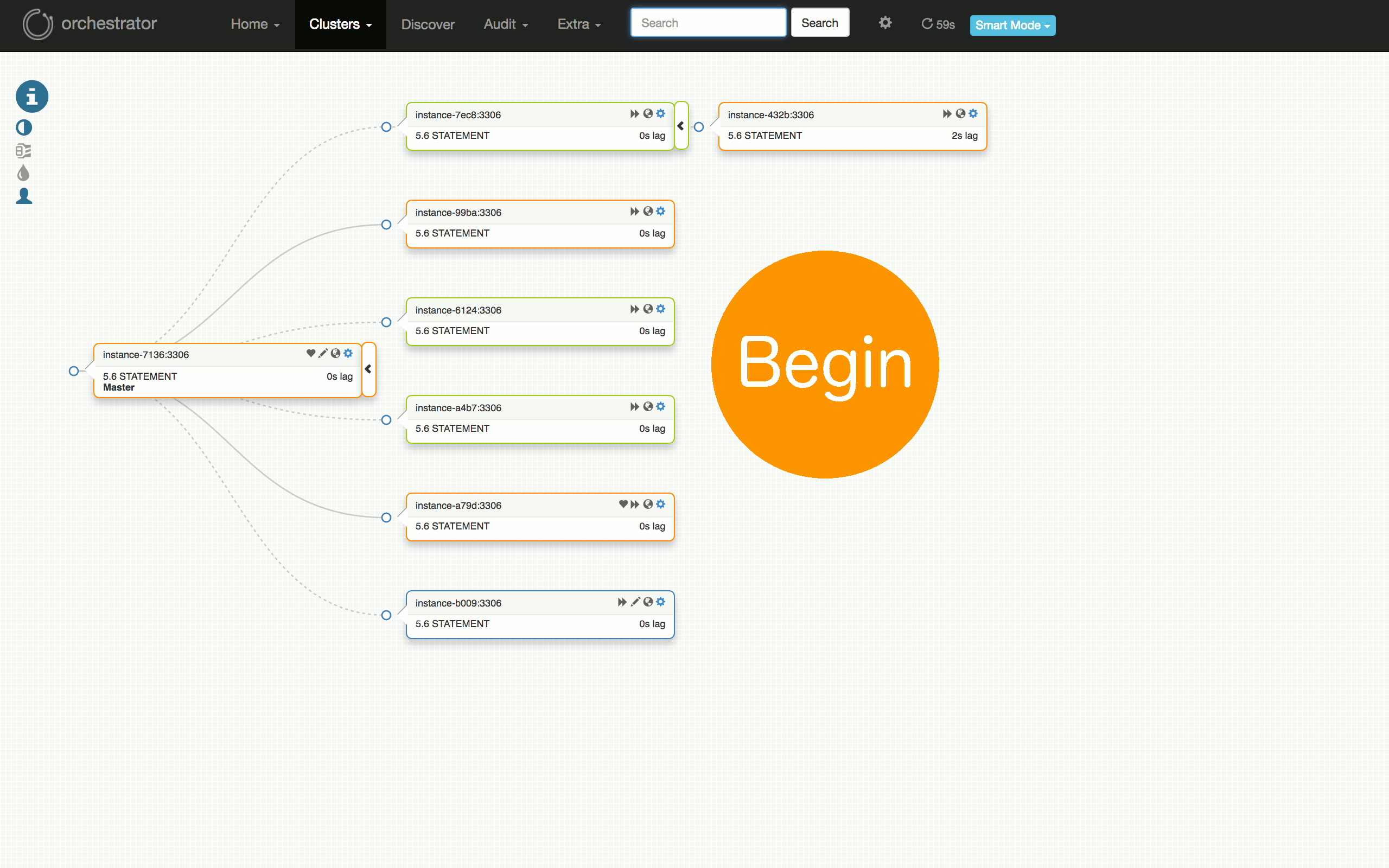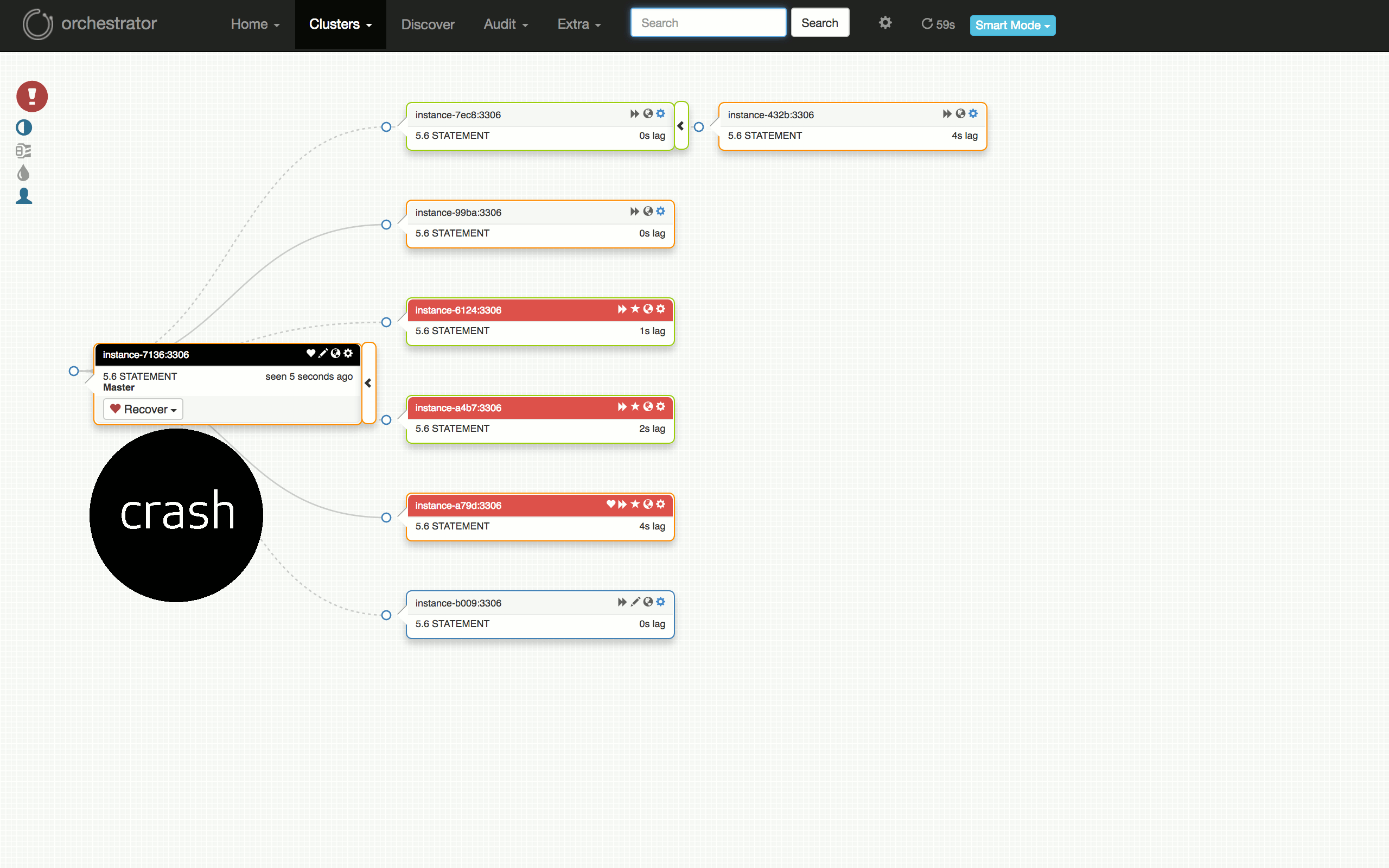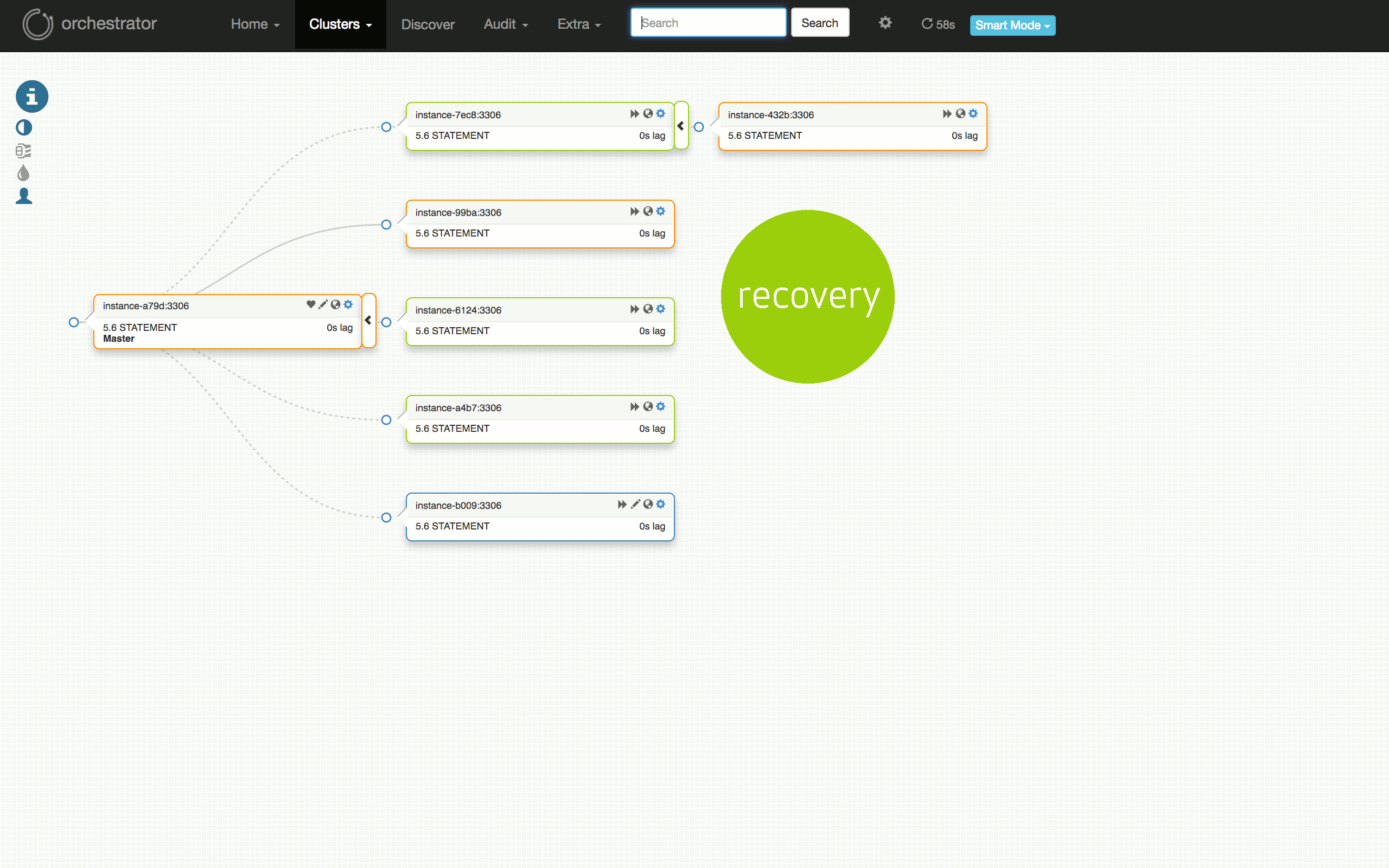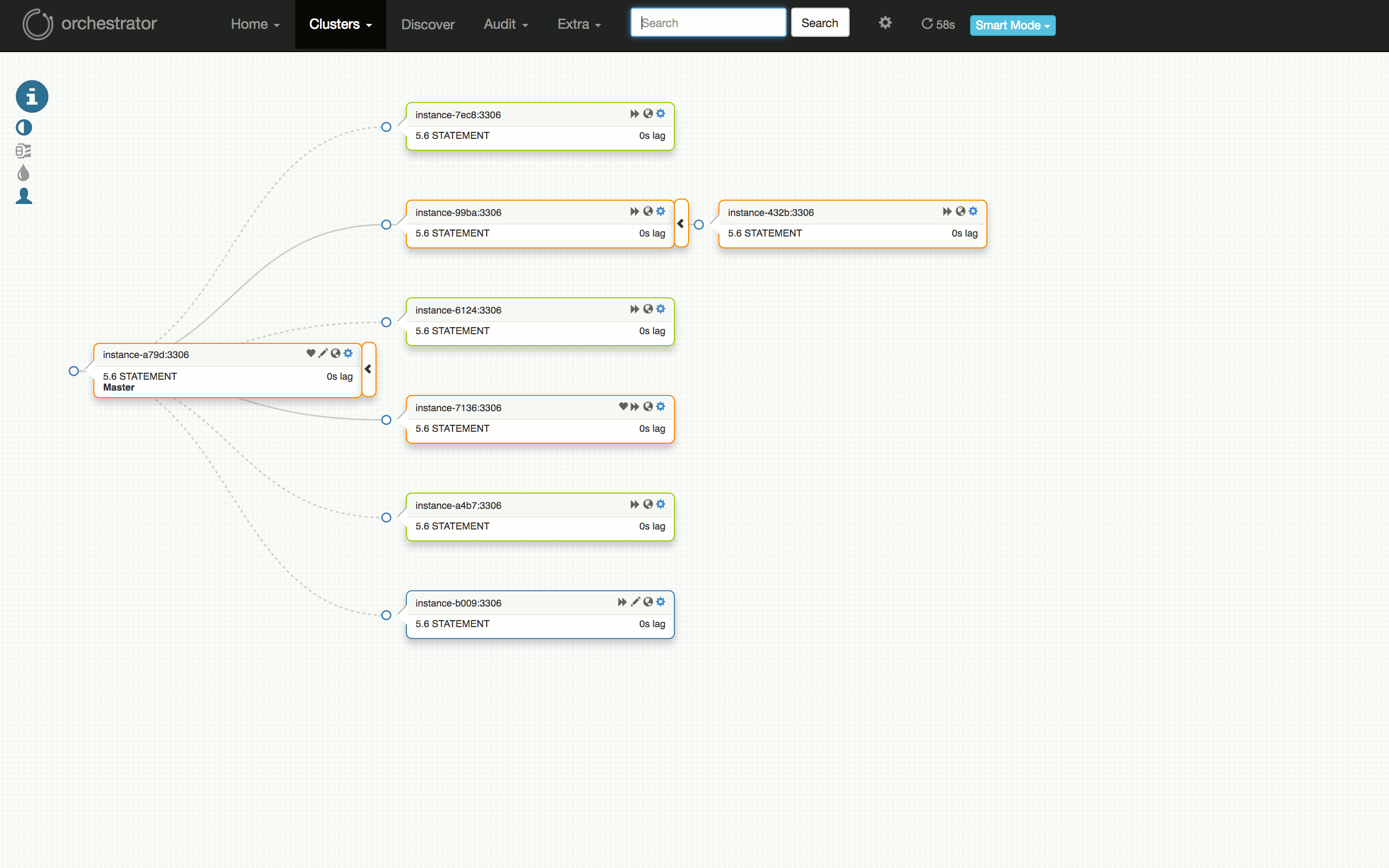
|
||||
|
||||
#### What would a test failure look like?
|
||||
|
||||
Our testing script uses a stop-the-world approach. A single failure in any of the failover components fails the entire test, disabling any future automated tests until a human resolves the matter. We get alerted and proceed to check the status and logs.
|
||||
|
||||
The script would fail on an unacceptable detection or failover time; on backup/restore issues; on losing too many servers; on unexpected configuration following the failover; etc.
|
||||
|
||||
We need to be certain `orchestrator` connects the servers correctly. This is where the contending write load comes useful: if set up incorrectly, replication is easily susceptible to break. We would get `DUPLICATE KEY` or other errors to suggest something went wrong.
|
||||
|
||||
This is particularly important as we make improvements and introduce new behavior to `orchestrator`, and allows us to test such changes in a safe environment.
|
||||
|
||||
#### Coming up: chaos testing
|
||||
|
||||
The testing procedure illustrated above will catch (and has caught) problems on many parts of our infrastructure. Is it enough?
|
||||
|
||||
In a production environment there’s always something else. Something about the particular test method that won’t apply to our production clusters. They don’t share the same traffic and traffic manipulation, nor the exact same set of servers. The types of failure can vary.
|
||||
|
||||
We are designing chaos testing for our production clusters. Chaos testing would literally destroy pieces in our production, but on expected schedule and under sufficiently controlled manner. Chaos testing introduces a higher level of trust in the recovery mechanism and affects (thus tests) larger parts of our infrastructure and application.
|
||||
|
||||
This is delicate work: while we acknowledge the need for chaos testing, we also wish to avoid unnecessary impact to our service. Different tests will differ in risk level and impact, and we will work to ensure availability of our service.
|
||||
|
||||
### Schema migrations[][42]
|
||||
|
||||
[We use gh-ost][43] to run live schema migrations. `gh-ost` is stable, but also under active developments, with major new features being added or planned.
|
||||
|
||||
`gh-ost` migrates tables by copying data onto a _ghost_ table, applying ongoing changes intercepted by the binary logs onto the _ghost_ table, even as the original table is being written to. It then swaps the _ghost_ table in place of the original table. At migration completion GitHub proceeds to work with a table generated and populated by `gh-ost`.
|
||||
|
||||
At this time almost all of GitHub’s MySQL data has been recreated by `gh-ost`, and most of it multiple times. We must have high trust in `gh-ost` to let it tamper with our data over and over again, even in face of active development. Here’s how we gain this trust.
|
||||
|
||||
`gh-ost` provides a testing-in-production capability. It supports running a migration on a replica, in much the same way as it would run on the master: `gh-ost` would connect to the replica and treat it as if it were the master. It would parse its binary logs the same way it would for a real master migration. However it would copy rows and apply binlog events to the replica, and avoid making writes onto the master.
|
||||
|
||||
We run `gh-ost`-dedicated replicas in production. These replicas do not serve production traffic. Each such replica retrieves the current list of production tables and iterates them in random order. One by one it picks a table and performs a replica-migration on that table. The migration doesn’t actually modify table structure, but instead runs a trivial `ENGINE=InnoDB`. The test runs the migration even as the table is being used in production, thus copying real production data and applying true production traffic off the binary logs.
|
||||
|
||||
These migrations can be audited. Here’s how we can inspect status of running tests from chat:
|
||||
|
||||

|
||||
**ggunson**.migration test-status
|
||||

|
||||
**Hubot**
|
||||
```
|
||||
# Migrating `prod`.`pull_requests`; Ghost table is `prod`.`_pull_requests_gho`
|
||||
# Migrating ghost-db-mysql-0007:3306; inspecting ghost-db-mysql-0007:3306; executing on ghost-db-mysql-0007
|
||||
# Migration started at Mon Jan 30 02:13:39 -0800 2017
|
||||
# chunk-size: 2500; max-lag-millis: 1500ms; max-load: Threads_running=30; critical-load: Threads_running=1000; nice-ratio: 0.000000
|
||||
# throttle-additional-flag-file: /tmp/gh-ost.throttle
|
||||
# panic-flag-file: /tmp/ghost-test-panic.flag
|
||||
# Serving on unix socket: /tmp/gh-ost.test.sock
|
||||
Copy: 57992500/86684838 66.9%; Applied: 57708; Backlog: 1/100; Time: 3h28m38s(total), 3h28m36s(copy); streamer: mysql-bin.000576:142993938; State: migrating; ETA: 1h43m12s
|
||||
```
|
||||
|
||||
When a test migration completes copying of table data it stops replication and performs the cut-over, replacing the original table with the _ghost_ table, and then swaps back. We’re not interested in actually replacing the data. Instead we are left with both the original table and the _ghost_ table, which should both be identical. We verify that by checksumming the entire table data for both tables.
|
||||
|
||||
A test can complete with:
|
||||
|
||||
* _success_ : All went well and checksum is identical. We expect to see this.
|
||||
|
||||
* _failure_ : Execution problem. This can occasionally happen due to the migration process being killed, a replication issue etc., and is typically unrelated to `gh-ost` itself.
|
||||
|
||||
* _checksum failure_ : table data inconsistency. For a tested branch, this call for fixes. For an ongoing `master` branch test, this would imply immediate blocking of production migrations. We don’t get the latter.
|
||||
|
||||
Test results are audited, sent to robot chatrooms, sent as events to our metrics systems. Each vertical line in the following graph represents a successful migration test:
|
||||
|
||||
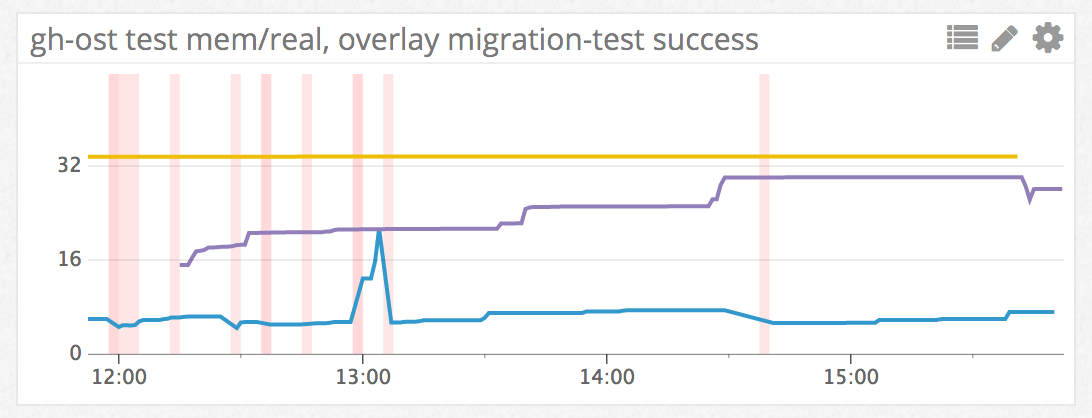
|
||||
|
||||
These tests run continuously. We are notified by alerts in case of failures. And of course we can always visit the robots chatroom to know what’s going on.
|
||||
|
||||
#### Testing new versions
|
||||
|
||||
We continuously improve `gh-ost`. Our development flow is based on `git` branches, which we then offer to merge via [pull requests][44].
|
||||
|
||||
A submitted `gh-ost` pull request goes through Continuous Integration (CI) which runs basic compilation and unit tests. Once past this, the PR is technically eligible for merging, but even more interestingly it is [eligible for deployment via Heaven][45]. Being the sensitive component in our infrastructure that it is, we take care to deploy `gh-ost` branches for intensive testing before merging into `master`.
|
||||
|
||||

|
||||
**shlomi-noach**.deploy gh-ost/fix-reappearing-throttled-reasons to prod/ghost-db-mysql-0007
|
||||

|
||||
**Hubot**[@shlomi-noach][25] is deploying gh-ost/fix-reappearing-throttled-reasons (baee4f6) to production (ghost-db-mysql-0007).
|
||||
[@shlomi-noach][26]'s production deployment of gh-ost/fix-reappearing-throttled-reasons (baee4f6) is done! (2s)
|
||||
[@shlomi-noach][27], make sure you watch for exceptions in haystack
|
||||

|
||||
**jonahberquist**.deploy gh-ost/interactive-command-question to prod/ghost-db-mysql-0012
|
||||

|
||||
**Hubot**[@jonahberquist][28] is deploying gh-ost/interactive-command-question (be1ab17) to production (ghost-db-mysql-0012).
|
||||
[@jonahberquist][29]'s production deployment of gh-ost/interactive-command-question (be1ab17) is done! (2s)
|
||||
[@jonahberquist][30], make sure you watch for exceptions in haystack
|
||||

|
||||
**shlomi-noach**.wcid gh-ost
|
||||

|
||||
**Hubot**shlomi-noach testing fix-reappearing-throttled-reasons 41 seconds ago: ghost-db-mysql-0007
|
||||
jonahberquist testing interactive-command-question 7 seconds ago: ghost-db-mysql-0012
|
||||
|
||||
Nobody is in the queue.
|
||||
|
||||
Some PRs are small and do not affect the data itself. Changes to status messages, interactive commands etc. are of lesser impact to the `gh-ost` app. Others pose significant changes to the migration logic and operation. We would tests these rigorously, running through our production tables fleet until satisfied these changes do not pose data corruption threat.
|
||||
|
||||
### Summary[][46]
|
||||
|
||||
Throughout testing we build trust in our systems. By automating these tests, in production, we get repetitive confirmation that everything is working as expected. As we continue to develop our infrastructure we also follow up by adapting tests to cover the newest changes.
|
||||
|
||||
Production always surprises with scenarios not covered by tests. The more we test on production environment, the more input we get on our app’s expectations and our infrastructure’s capabilities.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://githubengineering.com/mysql-testing-automation-at-github/
|
||||
|
||||
作者:[tomkrouper ][a], [Shlomi Noach][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/tomkrouper
|
||||
[b]:https://github.com/shlomi-noach
|
||||
[1]:https://github.com/tomkrouper
|
||||
[2]:https://github.com/jessbreckenridge
|
||||
[3]:https://github.com/jessbreckenridge
|
||||
[4]:https://github.com/jessbreckenridge
|
||||
[5]:https://github.com/jessbreckenridge
|
||||
[6]:https://github.com/jessbreckenridge
|
||||
[7]:https://github.com/jessbreckenridge
|
||||
[8]:https://github.com/jessbreckenridge
|
||||
[9]:https://github.com/jessbreckenridge
|
||||
[10]:https://github.com/jessbreckenridge
|
||||
[11]:https://github.com/jessbreckenridge
|
||||
[12]:https://github.com/jessbreckenridge
|
||||
[13]:https://github.com/jessbreckenridge
|
||||
[14]:https://github.com/jessbreckenridge
|
||||
[15]:https://github.com/jessbreckenridge
|
||||
[16]:https://github.com/jessbreckenridge
|
||||
[17]:https://github.com/jessbreckenridge
|
||||
[18]:https://github.com/jessbreckenridge
|
||||
[19]:https://github.com/jessbreckenridge
|
||||
[20]:https://github.com/jessbreckenridge
|
||||
[21]:https://github.com/jessbreckenridge
|
||||
[22]:https://github.com/jessbreckenridge
|
||||
[23]:https://github.com/jessbreckenridge
|
||||
[24]:https://github.com/jessbreckenridge
|
||||
[25]:https://github.com/shlomi-noach
|
||||
[26]:https://github.com/shlomi-noach
|
||||
[27]:https://github.com/shlomi-noach
|
||||
[28]:https://github.com/jonahberquist
|
||||
[29]:https://github.com/jonahberquist
|
||||
[30]:https://github.com/jonahberquist
|
||||
[31]:https://githubengineering.com/mysql-testing-automation-at-github/
|
||||
[32]:https://github.com/tomkrouper
|
||||
[33]:https://github.com/tomkrouper
|
||||
[34]:https://github.com/shlomi-noach
|
||||
[35]:https://github.com/shlomi-noach
|
||||
[36]:https://githubengineering.com/mysql-testing-automation-at-github/#backups
|
||||
[37]:https://www.percona.com/software/mysql-database/percona-xtrabackup
|
||||
[38]:https://dev.mysql.com/doc/refman/5.6/en/replication-delayed.html
|
||||
[39]:https://githubengineering.com/mysql-testing-automation-at-github/#failovers
|
||||
[40]:http://githubengineering.com/orchestrator-github/
|
||||
[41]:https://githubengineering.com/context-aware-mysql-pools-via-haproxy/
|
||||
[42]:https://githubengineering.com/mysql-testing-automation-at-github/#schema-migrations
|
||||
[43]:http://githubengineering.com/gh-ost-github-s-online-migration-tool-for-mysql/
|
||||
[44]:https://github.com/github/gh-ost/pulls
|
||||
[45]:https://githubengineering.com/deploying-branches-to-github-com/
|
||||
[46]:https://githubengineering.com/mysql-testing-automation-at-github/#summary
|
||||
@ -1,199 +0,0 @@
|
||||
cygmris is translating
|
||||
|
||||
OpenStack in a Snap
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
OpenStack is complex and many of the community members are working hard to make the deployment and operation of OpenStack easier. Much of this time is focused on tools such as Ansible, Puppet, Kolla, Juju, Triple-O, Chef (to name a few). But what if we step down a level and also make the package experience easier?
|
||||
|
||||
With snaps we’re working on doing just that. Snaps are a new way of delivering software. The following description from [snapcraft.io][2] provides a good summary of the core benefits of snaps: _“Snaps are quick to install, easy to create, safe to run, and they update automatically and transactionally so your app is always fresh and never broken.”_
|
||||
|
||||
### Bundled software
|
||||
|
||||
A single snap can deliver multiple pieces of software from different sources to provide a solution that gets you up and running fast. You’ll notice that installing a snap is quick. That’s because when you install a snap, that single snap bundles all of its dependencies. That’s a bit different from installing a deb, where all of the dependencies get pulled down and installed separately.
|
||||
|
||||
### Snaps are easy to create
|
||||
|
||||
In my time working on Ubuntu, I’ve spent much of it working on Debian packaging for OpenStack. It’s a niche skill that takes quite a bit of time to understand the nuances of. When compared with snaps, the difference in complexity between deb packages and snaps is like night and day. Snaps are just plain simple to work on, and even quite fun!
|
||||
|
||||
### A few more features of snaps
|
||||
|
||||
* Each snap is installed in it’s own read-only squashfs filesystem.
|
||||
|
||||
* Each snap is run in a strict environment sandboxed by AppArmor and seccomp policy.
|
||||
|
||||
* Snaps are transactional. New versions of a snap install to a new read-only squashfs filesystem. If an upgrade fails, it will roll-back to the old version.
|
||||
|
||||
* Snaps will auto-refresh when new versions are available.
|
||||
|
||||
* OpenStack Snaps are guaranteed to be aligned with OpenStack’s upper-constraints. Packagers no longer need to maintain separate packages for the OpenStack dependency chain. Woo-hoo!
|
||||
|
||||
### Introducing the OpenStack Snaps!
|
||||
|
||||
We currently have the following projects snapped:
|
||||
|
||||
* **Keystone** – This snap provides the OpenStack identity service.
|
||||
|
||||
* **Glance** – This snap provides the OpenStack image service.
|
||||
|
||||
* **Neutron** – This snap specifically provides the ‘neutron-server’ process as part of a snap based OpenStack deployment.
|
||||
|
||||
* **Nova** – This snap provides the Nova controller component of an OpenStack deployment.
|
||||
|
||||
* **Nova-hypervisor** – This snap provides the hypervisor component of an OpenStack deployment, configured to use Libvirt/KVM + Open vSwitch which are installed using deb packages. This snap also includes nova-lxd, allowing for use of nova-lxd instead of KVM.
|
||||
|
||||
This is enough to get a minimal working OpenStack cloud. You can find the source for all of the OpenStack snaps on [github][3]. For more details on the OpenStack snaps please refer to the individual READMEs in the upstream repositories. There you can find more details for managing the snaps, such as overriding default configs, restarting services, setting up aliases, and more.
|
||||
|
||||
### Want to create your own OpenStack snap?
|
||||
|
||||
Check out the [snap cookie cutter][4]. I’ll be writing a blog post soon that walks you through using the snap cookie cutter. It’s really simple and will help get the creation of a new OpenStack snap bootstrapped in no time.
|
||||
|
||||
### Testing the OpenStack snaps
|
||||
|
||||
We’ve been using a simple script for initial testing of the OpenStack snaps. The script installs the snaps on a single node and provides additional post-install configuration for services. To try it out:
|
||||
|
||||
```
|
||||
git clone https://github.com/openstack-snaps/snap-test
|
||||
cd snap-test
|
||||
./snap-deploy
|
||||
```
|
||||
|
||||
At this point we’ve been doing all of our testing on Ubuntu Xenial (16.04). Also note that this will install and configure quite a bit of software on your system so you’ll likely want to run it on a disposable machine.
|
||||
|
||||
### Tracking OpenStack
|
||||
|
||||
Today you can install snaps from the edge channel of the snap store. For example:
|
||||
|
||||
```
|
||||
sudo snap install --edge keystone
|
||||
```
|
||||
|
||||
The OpenStack team is working toward getting CI/CD in place to enable publishing snaps across tracks for OpenStack releases (Ie. a track for ocata, another track for pike, etc). Within each track will be 4 different channels. The edge channel for each track will contain the tip of the OpenStack project’s corresponding branch, with the beta, candidate and release channels being reserved for released versions. This should result in an experience such as:
|
||||
|
||||
```
|
||||
sudo snap install --channel=ocata/stable keystone
|
||||
sudo snap install --channel=pike/edge keystone
|
||||
```
|
||||
|
||||
### Poking around
|
||||
|
||||
Snaps have various environment variables available to them that simplify the creation of the snap. They’re all documented [here][6]. You probably won’t need to know much about them to be honest, however there are a few locations that you’ll want to be familiar with once you’ve installed a snap:
|
||||
|
||||
### _$SNAP == /snap/<snap-name>/current_
|
||||
|
||||
This is where the snap and all of it’s files are mounted. Everything here is read-only. In my current install of keystone, $SNAP is /snap/keystone/91\. Fortunately you don’t need to know the current version number as there’s a symlink to that directory at /snap/keystone/current.
|
||||
|
||||
```
|
||||
$ ls /snap/keystone/current/
|
||||
bin etc pysqlite2-doc usr
|
||||
command-manage.wrapper include snap var
|
||||
command-nginx.wrapper lib snap-openstack.yaml
|
||||
command-uwsgi.wrapper meta templates
|
||||
|
||||
$ ls /snap/keystone/current/bin/
|
||||
alembic oslo-messaging-send-notification
|
||||
convert-json oslo-messaging-zmq-broker
|
||||
jsonschema oslo-messaging-zmq-proxy
|
||||
keystone-manage oslopolicy-checker
|
||||
keystone-wsgi-admin oslopolicy-list-redundant
|
||||
keystone-wsgi-public oslopolicy-policy-generator
|
||||
lockutils-wrapper oslopolicy-sample-generator
|
||||
make_metadata.py osprofiler
|
||||
mako-render parse_xsd2.py
|
||||
mdexport.py pbr
|
||||
merge_metadata.py pybabel
|
||||
migrate snap-openstack
|
||||
migrate-repository sqlformat
|
||||
netaddr uwsgi
|
||||
oslo-config-generator
|
||||
|
||||
$ ls /snap/keystone/current/usr/bin/
|
||||
2to3 idle pycompile python2.7-config
|
||||
2to3-2.7 pdb pydoc python2-config
|
||||
cautious-launcher pdb2.7 pydoc2.7 python-config
|
||||
compose pip pygettext pyversions
|
||||
dh_python2 pip2 pygettext2.7 run-mailcap
|
||||
easy_install pip2.7 python see
|
||||
easy_install-2.7 print python2 smtpd.py
|
||||
edit pyclean python2.7
|
||||
|
||||
$ ls /snap/keystone/current/lib/python2.7/site-packages/
|
||||
...
|
||||
```
|
||||
|
||||
### _$SNAP_COMMON == /var/snap/<snap-name>/common_
|
||||
|
||||
This directory is used for system data that is common across revisions of a snap. This is where you’ll override default config files and access log files.
|
||||
|
||||
```
|
||||
$ ls /var/snap/keystone/common/
|
||||
etc fernet-keys lib lock log run
|
||||
|
||||
$ sudo ls /var/snap/keystone/common/etc/
|
||||
keystone nginx uwsgi
|
||||
|
||||
$ ls /var/snap/keystone/common/log/
|
||||
keystone.log nginx-access.log nginx-error.log uwsgi.log
|
||||
```
|
||||
|
||||
### Strict confinement
|
||||
|
||||
The snaps all run under strict confinement, where each snap is run in a restricted environment that is sandboxed with seccomp and AppArmor policy. More details on snap confinement can be viewed [here][7].
|
||||
|
||||
### New features/updates coming for snaps
|
||||
|
||||
There are a few features and updates coming for snaps that I’m looking forward to:
|
||||
|
||||
* We’re working on getting libvirt AppArmor policy in place so that the nova-hypervisor snap can access qcow2 backing files.
|
||||
* For now, as a work-around, you can put virt-aa-helper in complain mode: sudo aa-complain /usr/lib/libvirt/virt-aa-helper
|
||||
|
||||
* We’re also working on getting additional snapd interface policy in place that will enable network connectivity for deployed instances.
|
||||
* For now you can install the nova-hypervisor snap in devmode, which disables security confinement: snap install –devmode –edge nova-hypervisor
|
||||
|
||||
* Auto-connecting nova-hypervisor interfaces. We’re working on getting the interfaces for the nova-hypervisor defined automatically at install time.
|
||||
* Interfaces define the AppArmor and seccomp policy that enables a snap to access resources on the system.
|
||||
|
||||
* For now you can manually connect the required interfaces as described in the nova-hypervisor snap’s README.
|
||||
|
||||
* Auto-alias support for commands. We’re working on getting auto-alias support defined for commands across the snaps, where aliases will be defined automatically at install time.
|
||||
* This enables use of the traditional command names. Instead of ‘nova.manage db sync‘ you’ll be able to issue ‘nova-manage db sync’ right after installing the snap.
|
||||
|
||||
* For now you can manually enable aliases after the snap is installed, such as ‘snap alias nova.manage nova-manage’. See the snap READMEs for more details.
|
||||
|
||||
* Auto-alias support for daemons. Currently snappy only supports aliases for commands (not daemons). Once alias support is available for daemons, we’ll set them up to be automatically configured at install time.
|
||||
* This enables use of the traditional unit file names. Instead of ‘systemctl restart snap.nova.nova-compute’ you’ll be able to issue ‘systemctl restart nova-compute’.
|
||||
|
||||
* Asset tracking for snaps. This will enables tracking of versions used to build the snap which can be re-used in future builds.
|
||||
|
||||
If you’d like to chat more about snaps you can find us on IRC in #openstack-snaps on freenode. We welcome your feedback and contributions! Thanks and have fun! Corey
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Corey Bryant is an Ubuntu core developer and software engineer at Canonical on the OpenStack Engineering team, primarily focusing on OpenStack packaging for Ubuntu and OpenStack charm development for Juju. He's passionate about open-source software and enjoys working with people from all over the world on a common cause.
|
||||
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: 网址
|
||||
|
||||
作者:[ Corey Bryant ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/corey-bryant/
|
||||
[1]:https://insights.ubuntu.com/author/corey-bryant/
|
||||
[2]:http://snapcraft.io/
|
||||
[3]:https://github.com/openstack?utf8=%E2%9C%93&q=snap-&type=&language=
|
||||
[4]:https://github.com/openstack-snaps/snap-cookiecutter/blob/master/README.rst
|
||||
[5]:https://github.com/openstack-snaps/snap-test
|
||||
[6]:https://snapcraft.io/docs/reference/env
|
||||
[7]:https://snapcraft.io/docs/reference/confinement
|
||||
@ -1,4 +1,5 @@
|
||||
The changing face of the hybrid cloud
|
||||
Translating by ZH1122
|
||||
The changing face of the hybrid cloud
|
||||
============================================================
|
||||
|
||||
### Terms and concepts around cloud computing are still new, but evolving.
|
||||
|
||||
@ -1,350 +0,0 @@
|
||||
【haoqixu翻译中】How Linux containers have evolved
|
||||
============================================================
|
||||
|
||||
### Containers have come a long way in the past few years. We walk through the timeline.
|
||||
|
||||
|
||||

|
||||
Image credits :
|
||||
|
||||
[Daniel Ramirez][11]. [CC BY-SA 4.0][12]
|
||||
|
||||
In the past few years, containers have become a hot topic among not just developers, but also enterprises. This growing interest has caused an increased need for security improvements and hardening, and preparing for scaleability and interoperability. This has necessitated a lot of engineering, and here's the story of how much of that engineering has happened at an enterprise level at Red Hat.
|
||||
|
||||
When I first met up with representatives from Docker Inc. (Docker.io) in the fall of 2013, we were looking at how to make Red Hat Enterprise Linux (RHEL) use Docker containers. (Part of the Docker project has since been rebranded as _Moby_ .) We had several problems getting this technology into RHEL. The first big hurdle was getting a supported Copy On Write (COW) file system to handle container image layering. Red Hat ended up contributing a few COW implementations, including [Device Mapper][13], [btrfs][14], and the first version of [OverlayFS][15]. For RHEL, we defaulted to Device Mapper, although we are getting a lot closer on OverlayFS support.
|
||||
|
||||
Linux Containers
|
||||
|
||||
* [What are Linux containers?][1]
|
||||
|
||||
* [What is Docker?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [An introduction to container terminology][4]
|
||||
|
||||
The next major hurdle was on the tooling to launch the container. At that time, upstream docker was using [LXC][16]tools for launching containers, and we did not want to support LXC tools set in RHEL. Prior to working with upstream docker, I had been working with the [libvirt][17] team on a tool called [virt-sandbox][18], which used **libvirt-lxc** for launching containers.
|
||||
|
||||
At the time, some people at Red Hat thought swapping out the LXC tools and adding a bridge so the Docker daemon would communicate with libvirt using **libvirt-lxc** to launch containers was a good idea. There were serious concerns with this approach. Consider the following example of starting a container with the Docker client (**docker-cli**) and the layers of calls before the container process (**pid1OfContainer**) is started:
|
||||
|
||||
**docker-cli → docker-daemon → libvirt-lxc → pid1OfContainer**
|
||||
|
||||
I did not like the idea of having two daemons between your tool to launch containers and the final running container.
|
||||
|
||||
My team worked hard with the upstream docker developers on a native [Go programming language][19] implementation of the container runtime, called [libcontainer][20]. This library eventually got released as the initial implementation of the [OCI Runtime Specification][21]along with runc.
|
||||
|
||||
**docker- ****cli**** → docker-daemon @ pid1OfContainer**
|
||||
|
||||
Although most people mistakenly think that when they execute a container, the container process is a child of the **docker-cli**, they actually have executed a client/server operation and the container process is running as a child of a totally separate environment. This client/server operation can lead to instability and potential security concerns, and it blocks useful features. For example, [systemd][22] has a feature called socket activation, where you can set up a daemon to run only when a process connects to a socket. This means your system uses less memory and only has services executing when they are needed. The way socket activation works is systemd listens at a TCP socket, and when a packet arrives for the socket, systemd activates the service that normally listens on the socket. Once the service is activated, systemd hands the socket to the newly started daemon. Moving this daemon into a Docker-based container causes issues. The unit file would start the container using the Docker CLI and there was no easy way for systemd to pass the connected socket to the Docker daemon through the Docker CLI.
|
||||
|
||||
Problems like this made us realize that we needed alternate ways to run containers.
|
||||
|
||||
### The container orchestration problem
|
||||
|
||||
The upstream docker project made using containers easy, and it continues to be a great tool for learning about Linux containers. You can quickly experience launching a container by running a simple command like **docker run -ti fedora sh** and instantly you are in a container.
|
||||
|
||||
The real power of containers comes about when you start to run many containers simultaneously and hook them together into a more powerful application. The problem with setting up a multi-container application is the complexity quickly grows and wiring it up using simple Docker commands falls apart. How do you manage the placement or orchestration of container applications across a cluster of nodes with limited resources? How does one manage their lifecycle, and so on?
|
||||
|
||||
At the first DockerCon, at least seven different companies/open source projects showed how you could orchestrate containers. Red Hat's [OpenShift][23] had a project called [geard][24], loosely based on OpenShift v2 containers (called "gears"), which we were demonstrating. Red Hat decided that we needed to re-look at orchestration and maybe partner with others in the open source community.
|
||||
|
||||
Google was demonstrating [Kubernetes][25] container orchestration based on all of the knowledge Google had developed in orchestrating their own internal architecture. OpenShift decided to drop our Gear project and start working with Google on Kubernetes. Kubernetes is now one of the largest community projects on GitHub.
|
||||
|
||||
#### Kubernetes
|
||||
|
||||
Kubernetes was developed to use Google's [lmctfy][26] container runtime. Lmctfy was ported to work with Docker during the summer of 2014\. Kubernetes runs a daemon on each node in the Kubernetes cluster called a [kubelet][27]. This means the original Kubernetes with Docker 1.8 workflow looked something like:
|
||||
|
||||
**kubelet → dockerdaemon @ PID1**
|
||||
|
||||
Back to the two-daemon system.
|
||||
|
||||
But it gets worse. With every release of Docker, Kubernetes broke.Docker 1.10 Switched the backing store causing a rebuilding of all images.Docker 1.11 started using **runc** to launch containers:
|
||||
|
||||
**kubelet → dockerdaemon @ runc @PID1**
|
||||
|
||||
Docker 1.12 added a container daemon to launch containers. Its main purpose was to satisfy Docker Swarm (a Kubernetes competitor):
|
||||
|
||||
**kubelet → dockerdaemon → containerd @runc @ pid1**
|
||||
|
||||
As was stated previously, _every_ Docker release has broken Kubernetes functionality, which is why Kubernetes and OpenShift require us to ship older versions of Docker for their workloads.
|
||||
|
||||
Now we have a three-daemon system, where if anything goes wrong on any of the daemons, the entire house of cards falls apart.
|
||||
|
||||
### Toward container standardization
|
||||
|
||||
### CoreOS, rkt, and the alternate runtime
|
||||
|
||||
Due to the issues with the Docker runtime, several organizations were looking at alternative runtimes. One such organization was CoreOS. CoreOS had offered an alternative container runtime to upstream docker, called _rkt_ (rocket). They also introduced a standard container specification called _appc_ (App Container). Basically, they wanted to get everyone to use a standard specification for how you store applications in a container image bundle.
|
||||
|
||||
This threw up red flags. When I first started working on containers with upstream docker, my biggest fear is that we would end up with multiple specifications. I did not want an RPM vs. Debian-like war to affect the next 20 years of shipping Linux software. One good outcome from the appc introduction was that it convinced upstream docker to work with the open source community to create a standards body called the [Open Container Initiative][28] (OCI).
|
||||
|
||||
The OCI has been working on two specifications:
|
||||
|
||||
**[OCI Runtime Specification][6]**: The OCI Runtime Specification "aims to specify the configuration, execution environment, and lifecycle of a container." It defines what a container looks like on disk, the JSON file that describes the application(s) that will run within the container, and how to spawn and execute the container. Upstream docker contributed the libcontainer work and built runc as a default implementation of the OCI Runtime Specification.
|
||||
|
||||
**[OCI Image Format Specification][7]**: The Image Format Specification is based mainly on the upstream docker image format and defines the actual container image bundle that sits at container registries. This specification allows application developers to standardize on a single format for their applications. Some of the ideas described in appc, although it still exists, have been added to the OCI Image Format Specification. Both of these OCI specifications are nearing 1.0 release. Upstream docker has agreed to support the OCI Image Specification once it is finalized. Rkt now supports running OCI images as well as traditional upstream docker images.
|
||||
|
||||
The Open Container Initiative, by providing a place for the industry to standardize around the container image and the runtime, has helped free up innovation in the areas of tooling and orchestration.
|
||||
|
||||
### Abstracting the runtime interface
|
||||
|
||||
One of the innovations taking advantage of this standardization is in the area of Kubernetes orchestration. As a big supporter of the Kubernetes effort, CoreOS submitted a bunch of patches to Kubernetes to add support for communicating and running containers via rkt in addition to the upstream docker engine. Google and upstream Kubernetes saw that adding these patches and possibly adding new container runtime interfaces in the future was going to complicate the Kubernetes code too much. The upstream Kubernetes team decided to implement an API protocol specification called the Container Runtime Interface (CRI). Then they would rework Kubernetes to call into CRI rather than to the Docker engine, so anyone who wants to build a container runtime interface could just implement the server side of the CRI and they could support Kubernetes. Upstream Kubernetes created a large test suite for CRI developers to test against to prove they could service Kubernetes. There is an ongoing effort to remove all of Docker-engine calls from Kubernetes and put them behind a shim called the docker-shim.
|
||||
|
||||
### Innovations in container tooling
|
||||
|
||||
### Container registry innovations with skopeo
|
||||
|
||||
A few years ago, we were working with the Project Atomic team on the [atomic CLI][29] . We wanted the ability to examine a container image when it sat on a container registry. At that time, the only way to look at the JSON data associated with a container image at a container registry was to pull the image to the local server and then you could use **docker inspect** to read the JSON files. These images can be huge, up to multiple gigabytes. Because we wanted to allow users to examine the images and decide not to pull them, we wanted to add a new **--remote** interface to **docker inspect**. Upstream docker rejected the pull request, telling us that they did not want to complicate the Docker CLI, and that we could easily build our own tooling to do the same.
|
||||
|
||||
My team, led by [Antonio Murdaca][30], ran with the idea and created [skopeo][31]. Antonio did not stop at just pulling the JSON file associated with the image—he decided to implement the entire protocol for pulling and pushing container images from container registries to/from the local host.
|
||||
|
||||
Skopeo is now used heavily within the atomic CLI for things such as checking for new updates for containers and inside of [atomic scan][32]. Atomic also uses skopeo for pulling and pushing images, instead of using the upstream docker daemon.
|
||||
|
||||
### Containers/image
|
||||
|
||||
We had been talking to CoreOS about potentially using skopeo with rkt, and they said that they did not want to **exec** out to a helper application, but would consider using the library that skopeo used. We decided to split skopeo apart into a library and executable and created **[image][8]**.
|
||||
|
||||
The [containers/image][33] library and skopeo are used in several other upstream projects and cloud infrastructure tools. Skopeo and containers/image have evolved to support multiple storage backends in addition to Docker, and it has the ability to move container images between container registries and many cool features. A [nice thing about skopeo][34]is it does not require any daemons to do its job. The breakout of containers/image library has also allowed us to add enhancements such as [container image signing][35].
|
||||
|
||||
### Innovations in image handling and scanning
|
||||
|
||||
I mentioned the **atomic** CLI command earlier in this article. We built this tool to add features to containers that did not fit in with the Docker CLI, and things that we did not feel we could get into the upstream docker. We also wanted to allow flexibility to support additional container runtimes, tools, and storage as they developed. Skopeo is an example of this.
|
||||
|
||||
One feature we wanted to add to atomic was **atomic mount**. Basically we wanted to take content that was stored in the Docker image store (upstream docker calls this a graph driver), and mount the image somewhere, so that tools could examine the image. Currently if you use upstream docker, the only way to look at an image is to start the container. If you have untrusted content, executing code inside of the container to look at the image could be dangerous. The second problem with examining an image by starting it is that the tools to examine the container are probably not in the container image.
|
||||
|
||||
Most container image scanners seem to have the following pattern: They connect to the Docker socket, do a **docker save** to create a tarball, then explode the tarball on disk, and finally examine the contents. This is a slow operation.
|
||||
|
||||
With **atomic mount**, we wanted to go into the Docker graph driver and mount the image. If the Docker daemon was using device mapper, we would mount the device. If it was using overlay, we would mount the overlay. This is an incredibly quick operation and satisfies our needs. You can now do:
|
||||
|
||||
```
|
||||
# atomic mount fedora /mnt
|
||||
# cd /mnt
|
||||
```
|
||||
|
||||
And start examining the content. When you are done, do a:
|
||||
|
||||
```
|
||||
# atomic umount /mnt
|
||||
```
|
||||
|
||||
We use this feature inside of **atomic scan**, which allows you to have some of the fastest container scanners around.
|
||||
|
||||
#### **Issues with tool coordination**
|
||||
|
||||
One big problem is that **atomic mount** is doing this under the covers. The Docker daemon does not know that another process is using the image. This could cause problems (for example, if you mounted the Fedora image above and then someone went and executed **docker rmi fedora**, the Docker daemon would fail weirdly when trying to remove the Fedora image saying it was busy). The Docker daemon could get into a weird state.
|
||||
|
||||
### Containers storage
|
||||
|
||||
To solve this issue, we started looking at pulling the graph driver code out of the upstream docker daemon into its own repository. The Docker daemon did all of its locking in memory for the graph driver. We wanted to move this locking into the file system so that we could have multiple distinct processes able to manipulate the container storage at the same time, without having to go through a single daemon process.
|
||||
|
||||
We created a project called [container/storage][36], which can do all of the COW features required for running, building, and storing containers, without requiring one process to control and monitor it (i.e., no daemon required). Now skopeo and other tools and projects can take advantage of the storage. Other open source projects have begun to use containers/storage, and at some point we would like to merge this project back into the upstream docker project.
|
||||
|
||||
### Undock and let's innovate
|
||||
|
||||
If you think about what happens when Kubernetes runs a container on a node with the Docker daemon, first Kubernetes executes a command like:
|
||||
|
||||
```
|
||||
kubelet run nginx –image=nginx
|
||||
```
|
||||
|
||||
This command tells the kubelet to run the NGINX application on the node. The kubelet calls into the CRI and asks it to start the NGINX application. At this point, the container runtime that implemented the CRI must do the following steps:
|
||||
|
||||
1. Check local storage for a container named **nginx**. If not local, the container runtime will search for a standardized container image at a container registry.
|
||||
|
||||
2. If the image is not in local storage, download it from the container registry to the local system.
|
||||
|
||||
3. Explode the the download container image on top of container storage—usually a COW storage—and mount it up.
|
||||
|
||||
4. Execute the container using a standardized container runtime.
|
||||
|
||||
Let's look at the features described above:
|
||||
|
||||
1. OCI Image Format Specification defines the standard image format for images stored at container registries.
|
||||
|
||||
2. Containers/image is the library that implements all features needed to pull a container image from a container registry to a container host.
|
||||
|
||||
3. Containers/storage provides a library to exploding OCI Image Formats onto COW storage and allows you to work with the image.
|
||||
|
||||
4. OCI Runtime Specification and **runc** provide tools for executing the containers (the same tool that the Docker daemon uses for running containers).
|
||||
|
||||
This means we can use these tools to implement the ability to use containers without requiring a big container daemon.
|
||||
|
||||
In a moderate- to large-scale DevOps-based CI/CD environment, efficiency, speed, and security are important. And as long as your tools conform to the OCI specifications, then a developer or an operator should be using the best tools for automation through the CI/CD pipeline and into production. Most of the container tooling is hidden beneath orchestration or higher-up container platform technology. We envision a time in which runtime or image bundle tool selection perhaps becomes an installation option of the container platform.
|
||||
|
||||
### System (standalone) containers
|
||||
|
||||
On Project Atomic we introduced the **atomic host**, a new way of building an operating system in which the software can be "atomicly" updated and most of the applications that run on it will be run as containers. Our goal with this platform is to prove that most software can be shipped in the future in OCI Image Format, and use standard protocols to get images from container registries and install them on your system. Providing software as container images allows you to update the host operating system at a different pace than the applications that run on it. The traditional RPM/yum/DNF way of distributing packages locks the applications to the live cycle of the host operating systems.
|
||||
|
||||
One problem we see with shipping most of the infrastructure as containers is that sometimes you must run an application before the container runtime daemon is executing. Let's look at our Kubernetes example running with the Docker daemon: Kubernetes requires a network to be set up so that it can put its pods/containers into isolated networks. The default daemon we use for this currently is **[flanneld][9]**, which must be running before the Docker daemon is started in order to hand the Docker daemon the network interfaces to run the Kubernetes pods. Also, flanneld uses [**etcd**][37] for its data store. This daemon is required to be run before flanneld is started.
|
||||
|
||||
If we want to ship etcd and flanneld as container images, we have a chicken and egg situation. We need the container runtime daemon to start the containerized applications, but these applications need to be running before the container runtime daemon is started. I have seen several hacky setups to try to handle this situation, but none of them are clean. Also, the Docker daemon currently has no decent way to configure the priority order that containers start. I have seen suggestions on this, but they all look like the old SysVInit way of starting services (and we know the complexities that caused).
|
||||
|
||||
### systemd
|
||||
|
||||
One reason for replacing SysVInit with systemd was to handle the priority and ordering of starting services, so why not take advantage of this technology? In Project Atomic, we decided that we wanted to run containers on the host without requiring a container runtime daemon, especially for early boot. We enhanced the atomic CLI to allow you to install container images. If you execute** atomic install --system etcd**, it uses skopeo to go out to a container registries and pulls down the etcd OCI Image. Then it explodes (or expands) the image onto an OSTree backing store. Because we are running etcd in production, we treat the image as read-only. Next the **atomic** command grabs the systemd unit file template from the container image and creates a unit file on disk to start the image. The unit file actually uses **runc** to start the container on the host (although **runc** is not necessary).
|
||||
|
||||
Similar things happen if you execute **atomic install --system flanneld**, except this time the flanneld unit file specifies that it needs etcd unit running before it starts.
|
||||
|
||||
When the system boots up, systemd ensures that etcd is running before flanneld, and that the container runtime is not started until after flanneld is started. This allows you to move the Docker daemon and Kubernetes into system containers. This means you can boot up an atomic host or a traditional rpm-based operating system that runs the entire container orchestration stack as containers. This is powerful because we know customers want to continue to patch their container hosts independently of these components. Furthermore, it keeps the host's operating system footprint to a minimum.
|
||||
|
||||
There even has been discussion about putting traditional applications into containers that can run either as standalone/system containers or as an orchestrated container. Consider an Apache container that you could install with the **atomic install --system httpd** command. This container image would be started the same way you start an rpm-based httpd service (**systemctl start httpd** except httpd will be started in a container). The storage could be local, meaning /var/www from the host gets mounted into the container, and the container listens on the local network at port 80\. This shows that you could run traditional workloads on a host inside of a container without requiring a container runtime daemon.
|
||||
|
||||
### Building container images
|
||||
|
||||
From my perspective, one of the saddest things about container innovation over the past four years has been the lack of innovation on mechanisms to build container images. A container image is nothing more than a tarball of tarballs and some JSON files. The base image of a container is a rootfs along with an JSON file describing the base image. Then as you add layers, the difference between the layers gets tar’d up along with changes to the JSON file. These layers and the base file get tar'd up together to form the container image.
|
||||
|
||||
Almost everyone is building with the **docker build** and the Dockerfile format. Upstream docker stopped accepting pull requests to modify or improve Dockerfile format and builds a couple of years ago. The Dockerfile played an important part in the evolution of containers. Developers or administrators/operators could build containers in a simple and straightforward manner; however, in my opinion, the Dockerfile is really just a poor man’s bash script and creates several problems that have never been solved. For example:
|
||||
|
||||
* To build a container image, Dockerfile requires a Docker daemon to be running.
|
||||
* No one has built standard tooling to create the OCI image outside of executing Docker commands.
|
||||
|
||||
* Even tools such as **ansible-containers** and OpenShift S2I (Source2Image) use **docker-engine** under the covers.
|
||||
|
||||
* Each line in a Dockerfile creates a new image, which helps in the development process of creating the container because the tooling is smart enough to know that the lines in the Dockerfile have not changed, so the existing images can be used and the lines do not need to be reprocessed. This can lead to a _huge_ number of layers.
|
||||
* Because of these, several people have requested mechanisms to squash the images eliminating the layers. I think upstream docker finally has accepted something to satisfy the need.
|
||||
|
||||
* To pull content from secured sites to put into your container image, often you need some form of secrets. For example you need access to the RHEL certificates and subscriptions in order to add RHEL content to an image.
|
||||
* These secrets can end up in layers stored in the image. And the developer needs to jump through hoops to remove the secrets.
|
||||
|
||||
* To allow volumes to be mounted in during Docker build, we have added a **-v** volume switch to the projectatomic/docker package that we ship, but upstream docker has not accepted these patches.
|
||||
|
||||
* Build artifacts end up inside of the container image. So although Dockerfiles are great for getting started or building containers on a laptop while trying to understand the image you may want to build, they really are not an effective or efficient means to build images in a high-scaled enterprise environment. And behind an automated container platform, you shouldn't care if you are using a more efficient means to build OCI-compliant images.
|
||||
|
||||
### Undock with Buildah
|
||||
|
||||
At DevConf.cz 2017, I asked [Nalin Dahyabhai][38] on my team to look at building what I called **containers-coreutils**, basically, to use the containers/storage and containers/image libraries and build a series of command-line tools that could mimic the syntax of the Dockerfile. Nalin decided to call it [buildah][39], making fun of my Boston accent. With a few buildah primitives, you can build a container image:
|
||||
|
||||
* One of the main concepts of security is to keep the amount of content inside of an OS image as small as possible to eliminate unwanted tools. The idea is that a hacker might need tools to break through an application, and if the tools such as **gcc**, **make**, **dnf** are not present, the attacker can be stopped or confined.
|
||||
|
||||
* Because these images are being pulled and pushed over the internet, shrinking the size of the container is always a good idea.
|
||||
|
||||
* How Docker build works is commands to install software or compile software have to be in the **uildroot** of the container.
|
||||
|
||||
* Executing the **run** command requires all of the executables to be inside of the container image. Just using **dnf** inside of the container image requires that the entire Python stack be present, even if you never use Python in the application.
|
||||
|
||||
* **ctr=$(buildah from fedora)**:
|
||||
* Uses containers/image to pull the Fedora image from a container registry.
|
||||
|
||||
* Returns a container ID (**ctr**).
|
||||
|
||||
* **mnt=$(buildah mount $ctr)**:
|
||||
* Mounts up the newly created container image (**$ctr**).
|
||||
|
||||
* Returns the path to the mount point.
|
||||
|
||||
* You can now use this mount point to write content.
|
||||
|
||||
* **dnf install httpd –installroot=$mnt**:
|
||||
* You can use commands on the host to redirect content into the container, which means you can keep your secrets on the host, you don't have to put them inside of the container, and your build tools can be kept on the host.
|
||||
|
||||
* You don't need **dnf** inside of the container or the Python stack unless your application is going to use it.
|
||||
|
||||
* **cp foobar $mnt/dir**:
|
||||
* You can use any command available in bash to populate the container.
|
||||
|
||||
* **buildah commit $ctr**:
|
||||
* You can create a layer whenever you decide. You control the layers rather than the tool.
|
||||
|
||||
* **buildah config --env container=oci --entrypoint /usr/bin/httpd $ctr**:
|
||||
* All of the commands available inside of Dockerfile can be specified.
|
||||
|
||||
* **buildah run $ctr dnf -y install httpd**:
|
||||
* Buildah **run** is supported, but instead of relying on a container runtime daemon, buildah executes **runc** to run the command inside of a locked down container.
|
||||
|
||||
* **buildah build-using-dockerfile -f Dockerfile .**:
|
||||
|
||||
We want to move tools like **ansible-containers** and OpenShift S2I to use **buildah**rather than requiring a container runtime daemon.
|
||||
|
||||
Another big issue with building in the same container runtime that is used to run containers in production is that you end up with the lowest common denominator when it comes to security. Building containers tends to require a lot more privileges than running containers. For example, we allow the **mknod** capability by default. The **mknod** capability allows processes to create device nodes. Some package installs attempt to create device nodes, yet in production almost no applications do. Removing the **mknod** capability from your containers in production would make your systems more secure.
|
||||
|
||||
Another example is that we default container images to read/write because the install process means writing packages to **/usr**. Yet in production, I argue that you really should run all of your containers in read-only mode. Only allow the containers to write to **tmpfs** or directories that have been volume mounted into the container. By splitting the running of containers from the building, we could change the defaults and make for a much more secure environment.
|
||||
|
||||
* And yes, buildah can build a container image using a Dockerfile.
|
||||
|
||||
### CRI-O a runtime abstraction for Kubernetes
|
||||
|
||||
Kubernetes added an API to plug in any runtime for the pods called Container Runtime Interface (CRI). I am not a big fan of having lots of daemons running on my system, but we have added another. My team led by [Mrunal Patel][40] started working on [CRI-O][41] daemon in late 2016\. This is a Container Runtime Interface daemon for running OCI-based applications. Theoretically, in the future we could compile in the CRI-O code directly into the kubelet to eliminate the second daemon.
|
||||
|
||||
Unlike other container runtimes, CRI-O's only purpose in life is satisfying Kubernetes' needs. Remember the steps described above for what Kubernetes need to run a container.
|
||||
|
||||
Kubernetes sends a message to the kubelet that it wants it to run the NGINX server:
|
||||
|
||||
1. The kubelet calls out to the CRI-O to tell it to run NGINX.
|
||||
|
||||
2. CRI-O answers the CRI request.
|
||||
|
||||
3. CRI-O finds an OCI Image at a container registry.
|
||||
|
||||
4. CRI-O uses containers/image to pull the image from the registry to the host.
|
||||
|
||||
5. CRI-O unpacks the image onto local storage using containers/storage.
|
||||
|
||||
6. CRI-O launches a OCI Runtime Specification, usually **runc**, and starts the container. As I stated previously, the Docker daemon launches its containers using **runc**, in exactly the same way.
|
||||
|
||||
7. If desired, the kubelet could also launch the container using an alternate runtime, such as Clear Containers **runv**.
|
||||
|
||||
CRI-O is intended to be a stable platform for running Kubernetes, and we will not ship a new version of CRI-O unless it passes the entire Kubernetes test suite. All pull requests that go to [https://github.com/Kubernetes-incubator/cri-o][42] run against the entire Kubernetes test suite. You can not get a pull request into CRI-O without passing the tests. CRI-O is fully open, and we have had contributors from several different companies, including Intel, SUSE, IBM, Google, Hyper.sh. As long as a majority of maintainers agree to a patch to CRI-O, it will get accepted, even if the patch is not something that Red Hat wants.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I hope this deep dive helps you understand how Linux containers have evolved. At one point, Linux containers were an every-vendor-for-themselves situation. Docker helped focus on a de facto standard for image creation and simplifying the tools used to work with containers. The Open Container Initiative now means that the industry is working around a core image format and runtime, which fosters innovation around making tooling more efficient for automation, more secure, highly scalable, and easier to use. Containers allow us to examine installing software in new and novel ways—whether they are traditional applications running on a host, or orchestrated micro-services running in the cloud. In many ways, this is just the beginning.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel J Walsh - Daniel Walsh has worked in the computer security field for almost 30 years. Dan joined Red Hat in August 2001.
|
||||
|
||||
via: https://opensource.com/article/17/7/how-linux-containers-evolved
|
||||
|
||||
作者:[ Daniel J Walsh (Red Hat)][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[2]:https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[4]:https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[5]:https://opensource.com/article/17/7/how-linux-containers-evolved?rate=k1UcW7wzh6axaB_z8ScE-U8cux6fLXXgW_vboB5tIwk
|
||||
[6]:https://github.com/opencontainers/runtime-spec/blob/master/spec.md
|
||||
[7]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[8]:https://github.com/containers/imagehttps://github.com/containers/image
|
||||
[9]:https://github.com/coreos/flannel
|
||||
[10]:https://opensource.com/user/16673/feed
|
||||
[11]:https://www.flickr.com/photos/danramarch/
|
||||
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[13]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Logical_Volume_Manager_Administration/device_mapper.html
|
||||
[14]:https://btrfs.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:https://www.kernel.org/doc/Documentation/filesystems/overlayfs.txt
|
||||
[16]:https://linuxcontainers.org/
|
||||
[17]:https://libvirt.org/
|
||||
[18]:http://sandbox.libvirt.org/
|
||||
[19]:https://opensource.com/article/17/6/getting-started-go
|
||||
[20]:https://github.com/opencontainers/runc/tree/master/libcontainer
|
||||
[21]:https://github.com/opencontainers/runtime-spec
|
||||
[22]:https://opensource.com/business/15/10/lisa15-interview-alison-chaiken-mentor-graphics
|
||||
[23]:https://www.openshift.com/
|
||||
[24]:https://openshift.github.io/geard/
|
||||
[25]:https://opensource.com/resources/what-is-kubernetes
|
||||
[26]:https://github.com/google/lmctfy
|
||||
[27]:https://kubernetes.io/docs/admin/kubelet/
|
||||
[28]:https://www.opencontainers.org/
|
||||
[29]:https://github.com/projectatomic/atomic
|
||||
[30]:https://twitter.com/runc0m
|
||||
[31]:https://github.com/projectatomic/skopeohttps://github.com/projectatomic/skopeo
|
||||
[32]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||
[33]:https://github.com/containers/image
|
||||
[34]:http://rhelblog.redhat.com/2017/05/11/skopeo-copy-to-the-rescue/
|
||||
[35]:https://access.redhat.com/articles/2750891
|
||||
[36]:https://github.com/containers/storage
|
||||
[37]:https://github.com/coreos/etcd
|
||||
[38]:https://twitter.com/nalind
|
||||
[39]:https://github.com/projectatomic/buildah
|
||||
[40]:https://twitter.com/mrunalp
|
||||
[41]:https://github.com/Kubernetes-incubator/cri-o
|
||||
[42]:https://github.com/Kubernetes-incubator/cri-o
|
||||
[43]:https://opensource.com/users/rhatdan
|
||||
[44]:https://opensource.com/users/rhatdan
|
||||
[45]:https://opensource.com/article/17/7/how-linux-containers-evolved#comments
|
||||
@ -1,138 +0,0 @@
|
||||
Fedora 26 Powers Up Cloud, Server, Workstation Systems
|
||||
============================================================
|
||||
|
||||
|
||||
[**What Every CSO Must Know About Open Source | Download the White Paper**][9]
|
||||
[][10]Flexera Software shares application security strategies for security and engineering teams to manage open source.
|
||||
**[Download Now!][3]**
|
||||
|
||||
The [Fedora Project][4] this week announced the general availability of Fedora 26, the latest version of the fully open source Fedora operating system.
|
||||
|
||||

|
||||
|
||||
Fedora Linux is the community version of Red Hat Enterprise Linux, or RHEL. Fedora 26 comprises a set of base packages that form the foundation of three distinct editions targeting different users.
|
||||
|
||||
Fedora Atomic Host edition is an operating system for running container-based workloads. Fedora Server edition installs the Fedora Server OS on a hard drive. Fedora Workstation edition is a user-friendly operating system for laptops and desktop computers, suitable for a broad range of users -- from hobbyists and students to professionals in corporate environments.
|
||||
|
||||
All three editions share a common base and some common strengths. All of the Fedora editions are released twice a year.
|
||||
|
||||
The Fedora Project is a testing ground for innovations and new features. Some will be implemented in upcoming releases of RHEL, said Matthew Miller, Fedora Project Leader.
|
||||
|
||||
"Fedora is not directly involved in those productization decisions," he told LinuxInsider. "Fedora provides a look at many ideas and technologies, and it is a great place for Red Hat Enterprise Linux customers to get involved and provide feedback."
|
||||
|
||||
### Package Power
|
||||
|
||||
The Fedora developers updated and improved the packages powering all three editions. They made numerous bug fixes and performance tweaks in Fedora 26 to provide an enhanced user experience across Fedora's use cases.
|
||||
|
||||
These packages include the following improvements:
|
||||
|
||||
* Updated compilers and languages, including GNU Compiler Collection 7, Go 1.8, Python 3.6 and Ruby 2.4;
|
||||
|
||||
* DNF 2.0, the latest version of Fedora's next-generation package management system with improved backward compatibility with Yum;
|
||||
|
||||
* A new storage configuration screen for the Anaconda installation program, which enables bottom-up configuration from devices and partitions; and
|
||||
|
||||
* Fedora Media Writer updates that enable users to create bootable SD cards for ARM-based devices, like Raspberry Pi.
|
||||
|
||||
The cloud tools are essential to users with a cloud presence, especially programmers, noted Roger L. Kay, president of [Endpoint Technologies Associates][5].
|
||||
|
||||
"Kubernetes is essential for programmers interested in writing from the hybrid cloud, which is arguably one of the more important developments in the industry at the moment," he told LinuxInsider. "Cloud -- public, private and hybrid -- is key to the future of enterprise computing."
|
||||
|
||||
### Fedora 26 Atomic Host Makeover
|
||||
|
||||
Linux containers and container orchestration engines have been expanding in popularity. Fedora 26 Atomic Host offers a minimal-footprint operating system tailored for running container-based workloads across environments, from bare metal to the cloud.
|
||||
|
||||
Fedora 26 Atomic Host updates are delivered roughly every two weeks, a schedule that lets users keep pace with upstream innovation.
|
||||
|
||||
Fedora 26 Atomic Host is available for Amazon EC2\. Images for OpenStack, Vagrant, and standard installer ISO images are available on the [Fedora Project][6]website.
|
||||
|
||||
A minimal Fedora Atomic container image also made its debut with Fedora 26.
|
||||
|
||||
### Cloud Hosting
|
||||
|
||||
The latest release brings new capabilities and features to Fedora 26 Atomic Host:
|
||||
|
||||
* Containerized Kubernetes as an alternative to built-in Kubernetes binaries, enabling users to run different versions of the container orchestration engine more easily;
|
||||
|
||||
* The latest version of rpm-ostree, which includes support for direct RPM install, a reload command, and a clean-up command;
|
||||
|
||||
* System Containers, which provide a way of installing system infrastructure software, like networking or Kubernetes, on Fedora Atomic Host in a container; and
|
||||
|
||||
* Updated versions of Docker, Atomic and Cockpit for enhanced container building, system support and workload monitoring.
|
||||
|
||||
Containerizing Kubernetes is important for Fedora Atomic Host for two big reasons, according to the Fedora Project's Miller.
|
||||
|
||||
"First, it lets us remove it from the base image, reducing the size and complexity there," he explained. "Second, providing it in a container makes it easy to swap in different versions without disrupting the base or causing trouble for people who are not ready for a change quite yet."
|
||||
|
||||
### Server-Side Services
|
||||
|
||||
Fedora 26 Server provides a flexible, multi-role platform for data center operations. It also allows users to customize this edition of the Fedora operating system to fit their unique needs.
|
||||
|
||||
New features for Fedora 26 Server include FreeIPA 4.5, which improves running the security information management solution in containers, and SSSD file caching to speed up the resolution of user and group queries.
|
||||
|
||||
Fedora 26 Server edition later this month will add a preview of Fedora's modularity technology delivered as "Boltron." As a modular operating system, Boltron enables different versions of different applications to run on the same system, essentially allowing for leading-edge runtimes to be paired with stable databases.
|
||||
|
||||
### Workstation Workout
|
||||
|
||||
Among the new tools and features for general users is updated GNOME desktop functionality. Devs will get enhanced productivity tools.
|
||||
|
||||
Fedora 26 Workstation comes with GNOME 3.24 and numerous updated functionality tweaks. Night Light subtly changes screen color based on time of day to reduce effect on sleep patterns. [LibreOffice][7] 5.3 is the latest update to the open source office productivity suite.
|
||||
|
||||
GNOME 3.24 provides mature versions of Builder and Flatpak to give devs better application development tools for easier access across the board to a variety of systems, including Rust and Meson.
|
||||
|
||||
### Not Just for Devs
|
||||
|
||||
The inclusion of updated cloud tools in a Linux distro targeting enterprise users is significant, according to Scott Sellers, CEO of [Azul Systems][8].
|
||||
|
||||
"The cloud is a primary development and production platform for emerging companies, as well as some of the largest enterprises on the planet," he told LinuxInsider.
|
||||
|
||||
"Given the cutting-edge nature of the Fedora community, we would expect a strong cloud focus in any Fedora release, and Fedora 26 does not disappoint," Sellers said.
|
||||
|
||||
The other feature set of immediate interest to the Fedora developer and user community is the work the Fedora team did in terms of modularity, he noted.
|
||||
|
||||
"We will be looking at these experimental features closely," Sellers said.
|
||||
|
||||
### Supportive Upgrade Path
|
||||
|
||||
Users of Fedora, more than users of other Linux distros, have a vested interest in upgrading to Fedora 26, even if they are not heavy cloud users, according to Sellers.
|
||||
|
||||
"One of the primary advantages of this distro is to get an early look at production-grade advanced technologies that [eventually] will be integrated into RHEL," he said. "Early reviews of Fedora 26 suggest that it is very stable, with lots of bug fixes as well as performance enhancements."
|
||||
|
||||
Users interested in upgrading from earlier Fedora editions may find an easier approach than wiping existing systems to install Fedora 26, noted Fedora's Miller. Fedora maintains two releases at a time, plus a month of overlap.
|
||||
|
||||
"So, if you are on Fedora 24, you should upgrade in the next month," he said. "Happy Fedora 25 users can take their time. This is one of the advantages of Fedora over fast-moving rolling releases."
|
||||
|
||||
### Faster Delivery
|
||||
|
||||
Users can schedule their own upgrades rather than having to take them when the distro makes them.
|
||||
|
||||
That said, users of Fedora 23 or earlier should upgrade soon. The community no longer produces security updates for those releases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jack M. Germain has been an ECT News Network reporter since 2003. His main areas of focus are enterprise IT, Linux and open source technologies. He has written numerous reviews of Linux distros and other open source software. Email Jack.
|
||||
|
||||
|
||||
---------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84674.html
|
||||
|
||||
作者:[ Jack M. Germain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:jack.germain@newsroom.ectnews.comm
|
||||
[1]:http://www.linuxinsider.com/story/84674.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84674
|
||||
[3]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
[4]:https://getfedora.org/
|
||||
[5]:http://www.ndpta.com/
|
||||
[6]:https://getfedora.org/
|
||||
[7]:http://www.libreoffice.org/
|
||||
[8]:https://www.azul.com/
|
||||
[9]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
[10]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
@ -1,122 +0,0 @@
|
||||
translating by flowsnow
|
||||
|
||||
THE BEST WAY TO LEARN DOCKER FOR FREE: PLAY-WITH-DOCKER (PWD)
|
||||
============================================================
|
||||
|
||||
|
||||
Last year at the Distributed System Summit in Berlin, Docker captains[ Marcos Nils][15] and[ Jonathan Leibiusky][16] started hacking on an in-browser solution to help people learn Docker. A few days later, [Play-with-docker][17] (PWD) was born.
|
||||
|
||||
PWD is a Docker playground which allows users to run Docker commands in a matter of seconds. It gives the experience of having a free Alpine Linux Virtual Machine in browser, where you can build and run Docker containers and even create clusters in[ Docker Swarm Mode][18]. Under the hood Docker-in-Docker (DinD) is used to give the effect of multiple VMs/PCs. In addition to the playground, PWD also includes a training site composed of a large set of Docker labs and quizzes from beginner to advanced level available at [training.play-with-docker.com][19].
|
||||
|
||||
In case you missed it, Marcos and Jonathan presented PWD during the last DockerCon Moby Cool Hack session. Watch the video below for a deep dive into the infrastructure and roadmaps.
|
||||
|
||||
|
||||
Over the past few months, the Docker team has been working closely with Marcos, Jonathan and other active members of the Docker community to add new features to the project and Docker labs to the training section.
|
||||
|
||||
### PWD: the Playground
|
||||
|
||||
Here is a quick recap of what’s new with the Docker playground:
|
||||
|
||||
##### 1\. PWD Docker Machine driver and SSH
|
||||
|
||||
As PWD success grew, the community started to ask if they could use PWD to run their own Docker workshops and trainings. So one of the first improvements made to the project was the creation of [PWD Docker machine driver][20], which allows users to create and manage their PWD hosts easily through their favorite terminal including the option to use ssh related commands. Here is how it works:
|
||||
|
||||

|
||||
|
||||
##### 2\. Adding support for file upload
|
||||
|
||||
Another cool feature brought to you by Marcos and Jonathan is the ability to upload your Dockerfile directly into your PWD windows with a simple drag and drop of your file in your PWD instance.
|
||||
|
||||

|
||||
|
||||
##### 3\. Templated session
|
||||
|
||||
In addition to file upload, PWD also has a feature which lets you spin up a 5 nodes swarm in a matter of seconds using predefined templates.
|
||||
|
||||
#####
|
||||

|
||||
|
||||
##### 4\. Showcasing your applications with Docker in a single click
|
||||
|
||||
Another cool feature that comes with PWD is its embeddable button that you can use in your sites to set up a PWD environment and deploy a compose stack right away and a [chrome extension][21] that adds the “Try in PWD” button to the most popular images in DockerHub. Here’s a short demo of the extension in action:
|
||||
|
||||

|
||||
|
||||
### PWD: the Training Site
|
||||
|
||||
A number of new labs are available on [training.play-with-docker.com][22]. Some notable highlights include two labs that were originally hands-on labs from DockerCon in Austin, and a couple that highlight new features that are stable in Docker 17.06CE:
|
||||
|
||||
* [Docker Networking Hands-on Lab][1]
|
||||
|
||||
* [Docker Orchstration Hands-on Lab][2]
|
||||
|
||||
* [Multi-stage builds][3]
|
||||
|
||||
* [Docker swarm config files][4]
|
||||
|
||||
All in all, there are now 36 labs, with more being added all the time. If you want to contribute a lab, check out the [GitHub repo][23] and get started.
|
||||
|
||||
### PWD: the Use Cases
|
||||
|
||||
With the traffic to the site and the feedback we’ve received, it’s fair to say that PWD has a lot of traction right now. Here are some of the most common use-cases:
|
||||
|
||||
* Try new features fast as it’s updated with the latest dev versions.
|
||||
|
||||
* Set up clusters in no-time and launch replicated services.
|
||||
|
||||
* Learn through it’s interactive tutorials: [training.play-with-docker.com][5].
|
||||
|
||||
* Give presentations at conferences and meetups.
|
||||
|
||||
* Allow to run advanced workshops that’d usually require complex setups, such as Jérôme’s [advanced Docker Orchestration workshop][6]
|
||||
|
||||
* Collaborate with community members to diagnose and detect issues.
|
||||
|
||||
Get involved with PWD:
|
||||
|
||||
* Contribute to [PWD by submitting PRs][7]
|
||||
|
||||
* Contribute to the [PWD training site][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介;
|
||||
|
||||
Victor is the Sr. Community Marketing Manager at Docker, Inc. He likes fine wines, chess and soccer in no particular order. Victor tweets at @vcoisne.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/best-way-learn-docker-free-play-docker-pwd/
|
||||
|
||||
作者:[Victor ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/victor_c/
|
||||
[1]:http://training.play-with-docker.com/docker-networking-hol/
|
||||
[2]:http://training.play-with-docker.com/orchestration-hol/
|
||||
[3]:http://training.play-with-docker.com/multi-stage/
|
||||
[4]:http://training.play-with-docker.com/swarm-config/
|
||||
[5]:http://training.play-with-docker.com/
|
||||
[6]:https://github.com/docker/labs/tree/master/Docker-Orchestration
|
||||
[7]:https://github.com/play-with-docker/
|
||||
[8]:https://github.com/play-with-docker/training
|
||||
[9]:https://blog.docker.com/author/victor_c/
|
||||
[10]:https://blog.docker.com/tag/docker-labs/
|
||||
[11]:https://blog.docker.com/tag/docker-training/
|
||||
[12]:https://blog.docker.com/tag/docker-workshops/
|
||||
[13]:https://blog.docker.com/tag/play-with-docker/
|
||||
[14]:https://blog.docker.com/tag/pwd/
|
||||
[15]:https://www.twitter.com/marcosnils
|
||||
[16]:https://www.twitter.com/xetorthio
|
||||
[17]:http://play-with-docker.com/
|
||||
[18]:https://docs.docker.com/engine/swarm/
|
||||
[19]:http://training.play-with-docker.com/
|
||||
[20]:https://github.com/play-with-docker/docker-machine-driver-pwd/releases/tag/v0.0.5
|
||||
[21]:https://chrome.google.com/webstore/detail/play-with-docker/kibbhpioncdhmamhflnnmfonadknnoan
|
||||
[22]:http://training.play-with-docker.com/
|
||||
[23]:https://github.com/play-with-docker/play-with-docker.github.io
|
||||
@ -1,134 +0,0 @@
|
||||
translating by LHRchina
|
||||
What you need to know about hybrid cloud
|
||||
============================================================
|
||||
|
||||
### Learn the ins and outs of hybrid cloud, including what it is and how to use it.
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Jason Baker][10]. [CC BY-SA 4.0][11].
|
||||
|
||||
Of the many technologies that have emerged over the past decade, cloud computing is notable for its rapid advance from a niche technology to global domination. On its own, cloud computing has created a lot of confusion, arguments, and debates, and "hybrid" cloud, which blends several types of cloud computing, has created even more uncertainty. Read on for answers to some of the most common questions about hybrid cloud.
|
||||
|
||||
### What is a hybrid cloud?
|
||||
|
||||
Basically, a hybrid cloud is a flexible and integrated combination of on-premises infrastructure, private cloud, and public (i.e., third-party) cloud platforms. Even though public and private cloud services are bound together in a hybrid cloud, in practice they remain unique and separate entities with services that can be orchestrated together. The choice to use both public and private cloud infrastructure is based on several factors, including cost, load flexibility, and data security.
|
||||
|
||||
Advanced features, such as scale-up and scale-out, can quickly expand a cloud application's infrastructure on demand, making hybrid cloud a popular choice for services with seasonal or other variable resource demands. (Scaling up means to increase compute resources, such as CPU cores and memory, on a specific Linux instance, whereas scaling out means to provision multiple instances with similar configurations and distribute them into a cluster.)
|
||||
|
||||
Explore the open source cloud
|
||||
|
||||
* [What is the cloud?][1]
|
||||
|
||||
* [What is OpenStack?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [Why the operating system matters for containers][4]
|
||||
|
||||
* [Keeping Linux containers safe and secure][5]
|
||||
|
||||
At the center of hybrid cloud solutions sits open source software, such as [OpenStack][12], that deploys and manages large networks of virtual machines. Since its initial release in October 2010, OpenStack has been thriving globally. Some of its integrated projects and tools handle core cloud computing services, such as compute, networking, storage, and identity, while dozens of other projects can be bundled together with OpenStack to create unique and deployable hybrid cloud solutions.
|
||||
|
||||
### Components of the hybrid cloud
|
||||
|
||||
As illustrated in the graphic below, a hybrid cloud consists of private cloud, public cloud, and the internal network connected and managed through orchestration, system management, and automation tools.
|
||||
|
||||
### [hybridcloud1.jpg][6]
|
||||
|
||||

|
||||
|
||||
Model of the hybrid cloud
|
||||
|
||||
### Public cloud infrastructure:
|
||||
|
||||
* **Infrastructure as a Service (IaaS) **provides compute resources, storage, networking, firewall, intrusion prevention services (IPS), etc. from a remote data center. These services can be monitored and managed using a graphical user interface (GUI) or a command line interface (CLI). Rather than purchasing and building their own infrastructure, public IaaS users consume these services as needed and pay based on usage.
|
||||
|
||||
* **Platform as a Service (PaaS)** allows users to develop, test, manage, and run applications and servers. These include the operating system, middleware, web servers, database, and so forth. Public PaaS provides users with predefined services in the form of templates that can be easily deployed and replicated, instead of manually implementing and configuring infrastructure.
|
||||
|
||||
* **Software as a Service (SaaS)** delivers software through the internet. Users can consume these services under a subscription or license model or at the account level, where they are billed as active users. SaaS software is low cost, low maintenance, painless to upgrade, and reduces the burden of buying new hardware, software, or bandwidth to support growth.
|
||||
|
||||
### Private cloud infrastructure:
|
||||
|
||||
* Private **IaaS and PaaS** are hosted in isolated data centers and integrated with public clouds that can consume the infrastructure and services available in remote data centers. This enables a private cloud owner to leverage public cloud infrastructure to expand applications and utilize their compute, storage, networking, and so forth across the globe.
|
||||
|
||||
* **SaaS** is completely monitored, managed, and controlled by public cloud providers. SaaS is generally not shared between public and private cloud infrastructure and remains a service provided through a public cloud.
|
||||
|
||||
### Cloud orchestration and automation tools:
|
||||
|
||||
A cloud orchestration tool is necessary for planning and coordinating private and public cloud instances. This tool should inherit intelligence, including the capability to streamline processes and automate repetitive tasks. Further, an integrated automation tool is responsible for automatically scaling up and scaling out when a set threshold is crossed, as well as performing self-healing if any fractional damage or downtime occurs.
|
||||
|
||||
### System and configuration management tools:
|
||||
|
||||
In a hybrid cloud, system and configuration tools, such as [Foreman][13], manage the complete lifecycles of the virtual machines provisioned in private and public cloud data centers. These tools give system administrators the power to easily control users, roles, deployments, upgrades, and instances and to apply patches, bugfixes, and enhancements in a timely manner. Including [Puppet][14] in the Foreman tool enables administrators to manage configurations and define a complete end state for all provisioned and registered hosts.
|
||||
|
||||
### Hybrid cloud features
|
||||
|
||||
The hybrid cloud makes sense for most organizations because of these key features:
|
||||
|
||||
* **Scalability:** In a hybrid cloud, integrated private and public cloud instances share a pool of compute resources for each provisioned instance. This means each instance can scale up or out anytime, as needed.
|
||||
|
||||
* **Rapid response:** Hybrid clouds' elasticity supports rapid bursting of instances in the public cloud when private cloud resources exceed their threshold. This is especially valuable when peaks in demand produce significant and variable increases in load and capacity for a running application (e.g., online retailers during the holiday shopping season).
|
||||
|
||||
* **Reliability:** Organizations can choose among public cloud providers based on the cost, efficiency, security, bandwidth, etc. that match their needs. In a hybrid cloud, organizations can also decide where to store sensitive data and whether to expand instances in a private cloud or to expand geographically through public infrastructure. Also, the hybrid model's ability to store data and configurations across multiple sites supports backup, disaster recovery, and high availability.
|
||||
|
||||
* **Management:** Managing networking, storage, instances, and/or data can be tedious in non-integrated cloud environments. Traditional orchestration tools, in comparison to hybrid tools, are extremely modest and consequently limit decision making and automation for complete end-to-end processes and tasks. With hybrid cloud and an effective management application, you can keep track of every component as their numbers grow and, by regularly optimizing those components, minimize annual expense.
|
||||
|
||||
* **Security:** Security and privacy are critical when evaluating whether to place applications and data in the cloud. The IT department must verify all compliance requirements and deployment policies. Security in the public cloud is improving and continues to mature. And, in the hybrid cloud model, organizations can store highly sensitive information in the private cloud and integrate it with less sensitive data stored in the public cloud.
|
||||
|
||||
* **Pricing:** Cloud pricing is generally based on the infrastructure and service level agreement required. In the hybrid cloud model, users can compare costs at a granular level for compute resources (CPU/memory), bandwidth, storage, networking, public IP address, etc. Prices are either fixed or variable and can be metered monthly, hourly, or even per second. Therefore, users can always shop for the best pricing among public cloud providers and deploy their instances accordingly.
|
||||
|
||||
### Where hybrid cloud is today
|
||||
|
||||
Although there is a large and growing demand for public cloud offerings and migrating systems from on-premises to the public cloud, most large organizations remain concerned. Most still keep critical applications and data in corporate data centers and legacy systems. They fear losing control, security threats, data privacy, and data authenticity in public infrastructure. Because hybrid cloud minimizes these problems and maximizes benefits, it's the best solution for most large organizations.
|
||||
|
||||
### Where we'll be five years from now
|
||||
|
||||
I expect that the hybrid cloud model will be highly accepted globally, and corporate "no-cloud" policies will be rare, within only a handful of years. Here is what else I think we will see:
|
||||
|
||||
* Since hybrid cloud acts as a shared responsibility, there will be increased coordination between corporate and public cloud providers for implementing security measures to curb cyber attacks, malware, data leakage, and other threats.
|
||||
|
||||
* Bursting of instances will be rapid, so customers can spontaneously meet load requirements or perform self-healing.
|
||||
|
||||
* Further, orchestration or automation tools (such as [Ansible][8]) will play a significant role by inheriting intelligence for solving critical situations.
|
||||
|
||||
* Metering and the concept of "pay-as-you-go" will be transparent to customers, and tools will enable users to make decisions by monitoring fluctuating prices, safely destroy existing instances, and provision new instances to get the best available pricing.
|
||||
|
||||
What predictions do you have for hybrid cloud—and cloud computing in general—over the next five years? Please share your opinions in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Amit Das - Amit works as an engineer in Red Hat, and is passionate about Linux, Cloud computing, DevOps etc. He is a strong believer that new innovation and technology, in a open way which makes world more open, can positively impact the society and change many lives.
|
||||
|
||||
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/7/what-is-hybrid-cloud
|
||||
|
||||
作者:[Amit Das ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/amit-das
|
||||
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||
[6]:https://opensource.com/file/364211
|
||||
[7]:https://opensource.com/article/17/7/what-is-hybrid-cloud?rate=TwB_2KyXM7iqrwDPGZpe6WultoCajdIVgp8xI4oZkTw
|
||||
[8]:https://opensource.com/life/16/8/cloud-ansible-gateway
|
||||
[9]:https://opensource.com/user/157341/feed
|
||||
[10]:https://opensource.com/users/jason-baker
|
||||
[11]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[12]:https://opensource.com/resources/openstack
|
||||
[13]:https://github.com/theforeman
|
||||
[14]:https://github.com/theforeman/puppet-foreman
|
||||
[15]:https://opensource.com/users/amit-das
|
||||
[16]:https://opensource.com/users/amit-das
|
||||
@ -0,0 +1,213 @@
|
||||
Designing a Microservices Architecture for Failure
|
||||
============================================================
|
||||
|
||||
|
||||
A Microservices architecture makes it possible to **isolate failures**through well-defined service boundaries. But like in every distributed system, there is a **higher chance** for network, hardware or application level issues. As a consequence of service dependencies, any component can be temporarily unavailable for their consumers. To minimize the impact of partial outages we need to build fault tolerant services that can **gracefully** respond to certain types of outages.
|
||||
|
||||
This article introduces the most common techniques and architecture patterns to build and operate a **highly available microservices** system based on [RisingStack’s Node.js Consulting & Development experience][3].
|
||||
|
||||
_If you are not familiar with the patterns in this article, it doesn’t necessarily mean that you do something wrong. Building a reliable system always comes with an extra cost._
|
||||
|
||||
### The Risk of the Microservices Architecture
|
||||
|
||||
The microservices architecture moves application logic to services and uses a network layer to communicate between them. Communicating over a network instead of in-memory calls brings extra latency and complexity to the system which requires cooperation between multiple physical and logical components. The increased complexity of the distributed system leads to a higher chance of particular **network failures**.
|
||||
|
||||
One of the biggest advantage of a microservices architecture over a monolithic one is that teams can independently design, develop and deploy their services. They have full ownership over their service's lifecycle. It also means that teams have no control over their service dependencies as it's more likely managed by a different team. With a microservices architecture, we need to keep in mind that provider **services can be temporarily unavailable** by broken releases, configurations, and other changes as they are controlled by someone else and components move independently from each other.
|
||||
|
||||
### Graceful Service Degradation
|
||||
|
||||
One of the best advantages of a microservices architecture is that you can isolate failures and achieve graceful service degradation as components fail separately. For example, during an outage customers in a photo sharing application maybe cannot upload a new picture, but they can still browse, edit and share their existing photos.
|
||||
|
||||

|
||||
|
||||
_Microservices fail separately (in theory)_
|
||||
|
||||
In most of the cases, it's hard to implement this kind of graceful service degradation as applications in a distributed system depend on each other, and you need to apply several failover logics _(some of them will be covered by this article later)_ to prepare for temporary glitches and outages.
|
||||
|
||||

|
||||
|
||||
_Services depend on each other and fail together without failover logics._
|
||||
|
||||
### Change management
|
||||
|
||||
Google’s site reliability team has found that roughly **70% of the outages are caused by changes** in a live system. When you change something in your service - you deploy a new version of your code or change some configuration - there is always a chance for failure or the introduction of a new bug.
|
||||
|
||||
In a microservices architecture, services depend on each other. This is why you should minimize failures and limit their negative effect. To deal with issues from changes, you can implement change management strategies and **automatic rollouts**.
|
||||
|
||||
For example, when you deploy new code, or you change some configuration, you should apply these changes to a subset of your instances gradually, monitor them and even automatically revert the deployment if you see that it has a negative effect on your key metrics.
|
||||
|
||||

|
||||
|
||||
_Change Management - Rolling Deployment_
|
||||
|
||||
Another solution could be that you run two production environments. You always deploy to only one of them, and you only point your load balancer to the new one after you verified that the new version works as it is expected. This is called blue-green, or red-black deployment.
|
||||
|
||||
**Reverting code is not a bad thing.** You shouldn’t leave broken code in production and then think about what went wrong. Always revert your changes when it’s necessary. The sooner the better.
|
||||
|
||||
#### Want to learn more about building reliable mircoservices architectures?
|
||||
|
||||
##### Check out our upcoming trainings!
|
||||
|
||||
[MICROSERVICES TRAININGS ][4]
|
||||
|
||||
### Health-check and Load Balancing
|
||||
|
||||
Instances continuously start, restart and stop because of failures, deployments or autoscaling. It makes them temporarily or permanently unavailable. To avoid issues, your load balancer should **skip unhealthy instances** from the routing as they cannot serve your customers' or sub-systems' need.
|
||||
|
||||
Application instance health can be determined via external observation. You can do it with repeatedly calling a `GET /health`endpoint or via self-reporting. Modern **service discovery** solutions continuously collect health information from instances and configure the load-balancer to route traffic only to healthy components.
|
||||
|
||||
### Self-healing
|
||||
|
||||
Self-healing can help to recover an application. We can talk about self-healing when an application can **do the necessary steps** to recover from a broken state. In most of the cases, it is implemented by an external system that watches the instances health and restarts them when they are in a broken state for a longer period. Self-healing can be very useful in most of the cases, however, in certain situations it **can cause trouble** by continuously restarting the application. This might happen when your application cannot give positive health status because it is overloaded or its database connection times out.
|
||||
|
||||
Implementing an advanced self-healing solution which is prepared for a delicate situation - like a lost database connection - can be tricky. In this case, you need to add extra logic to your application to handle edge cases and let the external system know that the instance is not needed to restart immediately.
|
||||
|
||||
### Failover Caching
|
||||
|
||||
Services usually fail because of network issues and changes in our system. However, most of these outages are temporary thanks to self-healing and advanced load-balancing we should find a solution to make our service work during these glitches. This is where **failover caching** can help and provide the necessary data to our application.
|
||||
|
||||
Failover caches usually use **two different expiration dates**; a shorter that tells how long you can use the cache in a normal situation, and a longer one that says how long can you use the cached data during failure.
|
||||
|
||||
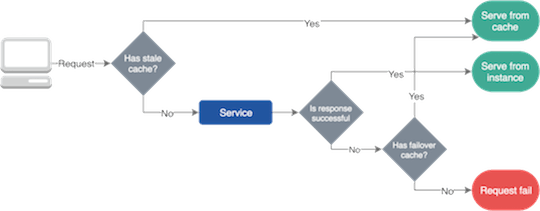
|
||||
|
||||
_Failover Caching_
|
||||
|
||||
It’s important to mention that you can only use failover caching when it serves **the outdated data better than nothing**.
|
||||
|
||||
To set cache and failover cache, you can use standard response headers in HTTP.
|
||||
|
||||
For example, with the `max-age` header you can specify the maximum amount of time a resource will be considered fresh. With the `stale-if-error` header, you can determine how long should the resource be served from a cache in the case of a failure.
|
||||
|
||||
Modern CDNs and load balancers provide various caching and failover behaviors, but you can also create a shared library for your company that contains standard reliability solutions.
|
||||
|
||||
### Retry Logic
|
||||
|
||||
There are certain situations when we cannot cache our data or we want to make changes to it, but our operations eventually fail. In these cases, we can **retry our action** as we can expect that the resource will recover after some time or our load-balancer sends our request to a healthy instance.
|
||||
|
||||
You should be careful with adding retry logic to your applications and clients, as a larger amount of **retries can make things even worse** or even prevent the application from recovering.
|
||||
|
||||
In distributed system, a microservices system retry can trigger multiple other requests or retries and start a **cascading effect**. To minimize the impact of retries, you should limit the number of them and use an exponential backoff algorithm to continually increase the delay between retries until you reach the maximum limit.
|
||||
|
||||
As a retry is initiated by the client _(browser, other microservices, etc.)_ and the client doesn't know that the operation failed before or after handling the request, you should prepare your application to handle **idempotency**. For example, when you retry a purchase operation, you shouldn't double charge the customer. Using a unique **idempotency-key** for each of your transactions can help to handle retries.
|
||||
|
||||
### Rate Limiters and Load Shedders
|
||||
|
||||
Rate limiting is the technique of defining how many requests can be received or processed by a particular customer or application during a timeframe. With rate limiting, for example, you can filter out customers and microservices who are responsible for **traffic peaks**, or you can ensure that your application doesn’t overload until autoscaling can’t come to rescue.
|
||||
|
||||
You can also hold back lower-priority traffic to give enough resources to critical transactions.
|
||||
|
||||

|
||||
|
||||
_A rate limiter can hold back traffic peaks_
|
||||
|
||||
A different type of rate limiter is called the _concurrent request limiter_ . It can be useful when you have expensive endpoints that shouldn’t be called more than a specified times, while you still want to serve traffic.
|
||||
|
||||
A _fleet usage load shedder_ can ensure that there are always enough resources available to **serve critical transactions**. It keeps some resources for high priority requests and doesn’t allow for low priority transactions to use all of them. A load shedder makes its decisions based on the whole state of the system, rather than based on a single user’s request bucket size. Load shedders **help your system to recover**, since they keep the core functionalities working while you have an ongoing incident.
|
||||
|
||||
To read more about rate limiters and load shredders, I recommend checking out [Stripe’s article][5].
|
||||
|
||||
### Fail Fast and Independently
|
||||
|
||||
In a microservices architecture we want to prepare our services **to fail fast and separately**. To isolate issues on service level, we can use the _bulkhead pattern_ . You can read more about bulkheads later in this blog post.
|
||||
|
||||
We also want our components to **fail fast** as we don't want to wait for broken instances until they timeout. Nothing is more disappointing than a hanging request and an unresponsive UI. It's not just wasting resources but also screwing up the user experience. Our services are calling each other in a chain, so we should pay an extra attention to prevent hanging operations before these delays sum up.
|
||||
|
||||
The first idea that would come to your mind would be applying fine grade timeouts for each service calls. The problem with this approach is that you cannot really know what's a good timeout value as there are certain situations when network glitches and other issues happen that only affect one-two operations. In this case, you probably don’t want to reject those requests if there’s only a few of them timeouts.
|
||||
|
||||
We can say that achieving the fail fast paradigm in microservices by **using timeouts is an anti-pattern** and you should avoid it. Instead of timeouts, you can apply the _circuit-breaker_ pattern that depends on the success / fail statistics of operations.
|
||||
|
||||
#### Want to learn more about building reliable mircoservices architectures?
|
||||
|
||||
##### Check out our upcoming trainings!
|
||||
|
||||
[MICROSERVICES TRAININGS ][6]
|
||||
|
||||
### Bulkheads
|
||||
|
||||
Bulkhead is used in the industry to **partition** a ship **into sections**, so that sections can be sealed off if there is a hull breach.
|
||||
|
||||
The concept of bulkheads can be applied in software development to **segregate resources**.
|
||||
|
||||
By applying the bulkheads pattern, we can **protect limited resources** from being exhausted. For example, we can use two connection pools instead of a shared on if we have two kinds of operations that communicate with the same database instance where we have limited number of connections. As a result of this client - resource separation, the operation that timeouts or overuses the pool won't bring all of the other operations down.
|
||||
|
||||
One of the main reasons why Titanic sunk was that its bulkheads had a design failure, and the water could pour over the top of the bulkheads via the deck above and flood the entire hull.
|
||||
|
||||

|
||||
|
||||
_Bulkheads in Titanic (they didn't work)_
|
||||
|
||||
### Circuit Breakers
|
||||
|
||||
To limit the duration of operations, we can use timeouts. Timeouts can prevent hanging operations and keep the system responsive. However, using static, fine tuned timeouts in microservices communication is an **anti-pattern** as we’re in a highly dynamic environment where it's almost impossible to come up with the right timing limitations that work well in every case.
|
||||
|
||||
Instead of using small and transaction-specific static timeouts, we can use circuit breakers to deal with errors. Circuit breakers are named after the real world electronic component because their behavior is identical. You can **protect resources** and **help them to recover** with circuit breakers. They can be very useful in a distributed system where a repetitive failure can lead to a snowball effect and bring the whole system down.
|
||||
|
||||
A circuit breaker opens when a particular type of **error occurs multiple times** in a short period. An open circuit breaker prevents further requests to be made - like the real one prevents electrons from flowing. Circuit breakers usually close after a certain amount of time, giving enough space for underlying services to recover.
|
||||
|
||||
Keep in mind that not all errors should trigger a circuit breaker. For example, you probably want to skip client side issues like requests with `4xx` response codes, but include `5xx` server-side failures. Some circuit breakers can have a half-open state as well. In this state, the service sends the first request to check system availability, while letting the other requests to fail. If this first request succeeds, it restores the circuit breaker to a closed state and lets the traffic flow. Otherwise, it keeps it open.
|
||||
|
||||

|
||||
|
||||
_Circuit Breaker_
|
||||
|
||||
### Testing for Failures
|
||||
|
||||
You should continually **test your system against common issues** to make sure that your services can **survive various failures**. You should test for failures frequently to keep your team prepared for incidents.
|
||||
|
||||
For testing, you can use an external service that identifies groups of instances and randomly terminates one of the instances in this group. With this, you can prepare for a single instance failure, but you can even shut down entire regions to simulate a cloud provider outage.
|
||||
|
||||
One of the most popular testing solutions is the [ChaosMonkey][7]resiliency tool by Netflix.
|
||||
|
||||
### Outro
|
||||
|
||||
Implementing and running a reliable service is not easy. It takes a lot of effort from your side and also costs money to your company.
|
||||
|
||||
Reliability has many levels and aspects, so it is important to find the best solution for your team. You should make reliability a factor in your business decision processes and allocate enough budget and time for it.
|
||||
|
||||
### Key Takeways
|
||||
|
||||
* Dynamic environments and distributed systems - like microservices - lead to a higher chance of failures.
|
||||
|
||||
* Services should fail separately, achieve graceful degradation to improve user experience.
|
||||
|
||||
* 70% of the outages are caused by changes, reverting code is not a bad thing.
|
||||
|
||||
* Fail fast and independently. Teams have no control over their service dependencies.
|
||||
|
||||
* Architectural patterns and techniques like caching, bulkheads, circuit breakers and rate-limiters help to build reliable microservices.
|
||||
|
||||
To learn more about running a reliable service check out our free [Node.js Monitoring, Alerting & Reliability 101 e-book][8]. In case you need help with implementing a microservices system, reach out to us at [@RisingStack][9] on Twitter, or enroll in our upcoming [Building Microservices with Node.js][10].
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
作者简介
|
||||
|
||||
[Péter Márton][2]
|
||||
|
||||
CTO at RisingStack, microservices and brewing beer with Node.js
|
||||
|
||||
[https://twitter.com/slashdotpeter][1]</footer>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.risingstack.com/designing-microservices-architecture-for-failure/
|
||||
|
||||
作者:[ Péter Márton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.risingstack.com/author/peter-marton/
|
||||
[1]:https://twitter.com/slashdotpeter
|
||||
[2]:https://blog.risingstack.com/author/peter-marton/
|
||||
[3]:https://risingstack.com/
|
||||
[4]:https://blog.risingstack.com/training-building-microservices-node-js/?utm_source=rsblog&utm_medium=roadblock-new&utm_content=/designing-microservices-architecture-for-failure/
|
||||
[5]:https://stripe.com/blog/rate-limiters
|
||||
[6]:https://blog.risingstack.com/training-building-microservices-node-js/?utm_source=rsblog&utm_medium=roadblock-new
|
||||
[7]:https://github.com/Netflix/chaosmonkey
|
||||
[8]:https://trace.risingstack.com/monitoring-ebook
|
||||
[9]:https://twitter.com/RisingStack
|
||||
[10]:https://blog.risingstack.com/training-building-microservices-node-js/
|
||||
[11]:https://blog.risingstack.com/author/peter-marton/
|
||||
@ -0,0 +1,201 @@
|
||||
The user’s home dashboard in our app, AlignHow we built our first full-stack JavaScript web app in three weeks
|
||||
============================================================
|
||||
|
||||
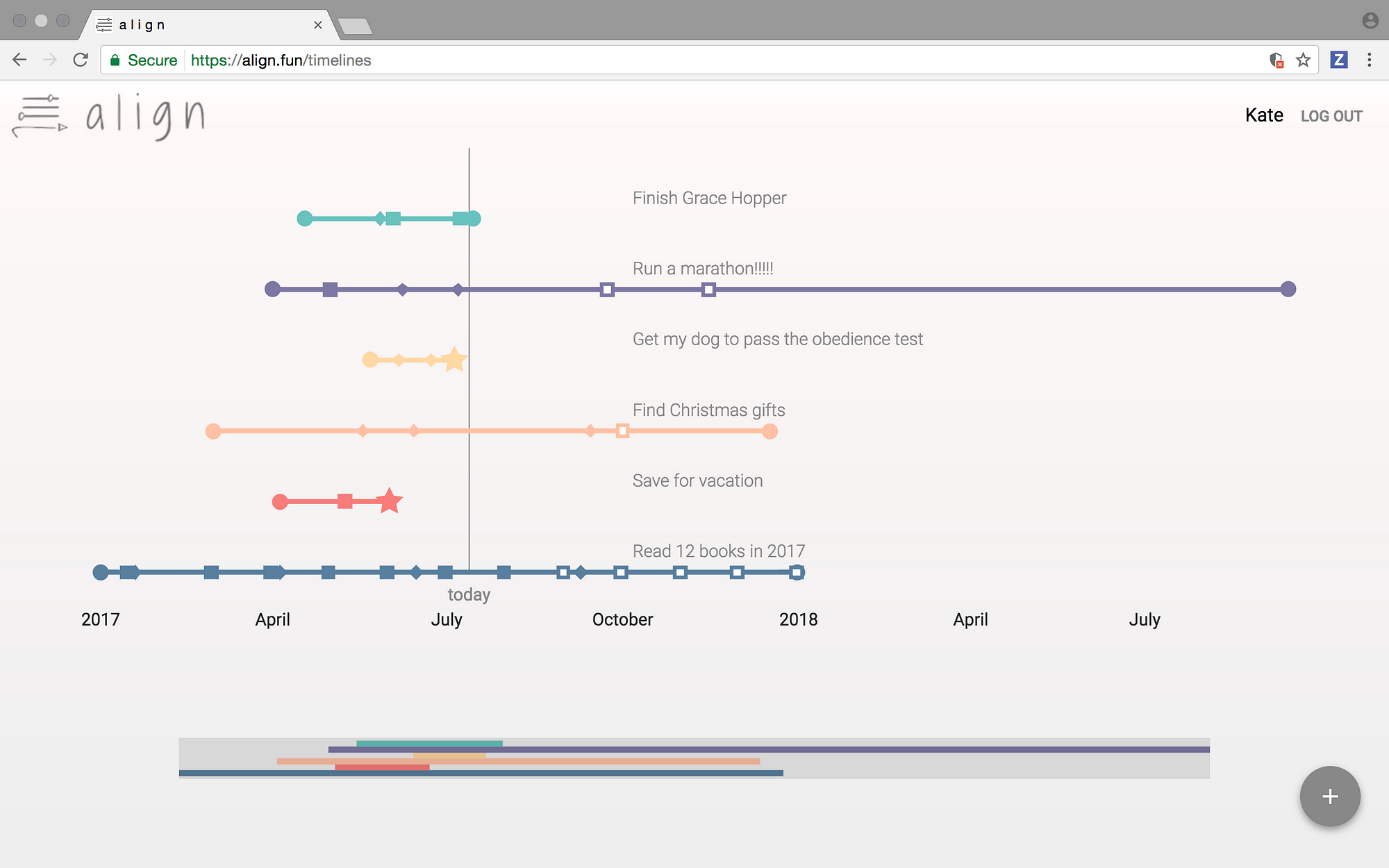
|
||||
|
||||
### A simple step-by-step guide to go from idea to deployed app
|
||||
|
||||
My three months of coding bootcamp at the Grace Hopper Program have come to a close, and the title of this article is actually not quite true — I’ve now built _three_ full-stack apps: [an e-commerce store from scratch][3], a [personal hackathon project][4] of my choice, and finally, a three-week capstone project. That capstone project was by far the most intensive— a three week journey with two teammates — and it is my proudest achievement from bootcamp. It is the first robust, complex app I have ever fully built and designed.
|
||||
|
||||
As most developers know, even when you “know how to code”, it can be really overwhelming to embark on the creation of your first full-stack app. The JavaScript ecosystem is incredibly vast: with package managers, modules, build tools, transpilers, databases, libraries, and decisions to be made about all of them, it’s no wonder that so many budding coders never build anything beyond Codecademy tutorials. That’s why I want to walk you through a step-by-step guide of the decisions and steps my team took to create our live app, Align.
|
||||
|
||||
* * *
|
||||
|
||||
First, some context. Align is a web app that uses an intuitive timeline interface to help users set long-term goals and manage them over time.Our stack includes Firebase for back-end services and React on the front end. My teammates and I explain more in this short video:
|
||||
|
||||
[video](https://youtu.be/YacM6uYP2Jo)
|
||||
|
||||
Demoing Align @ Demo Day Live // July 10, 2017
|
||||
|
||||
So how did we go from Day 1, when we were assigned our teams, to the final live app? Here’s a rundown of the steps we took:
|
||||
|
||||
* * *
|
||||
|
||||
### Step 1: Ideate
|
||||
|
||||
The first step was to figure out what exactly we wanted to build. In my past life as a consultant at IBM, I led ideation workshops with corporate leaders. Pulling from that, I suggested to my group the classic post-it brainstorming strategy, in which we all scribble out as many ideas as we can — even ‘stupid ones’ — so that people’s brains keep moving and no one avoids voicing ideas out of fear.
|
||||
|
||||

|
||||
|
||||
After generating a few dozen app ideas, we sorted them into categories to gain a better understanding of what themes we were collectively excited about. In our group, we saw a clear trend towards ideas surrounding self-improvement, goal-setting, nostalgia, and personal development. From that, we eventually honed in on a specific idea: a personal dashboard for setting and managing long-term goals, with elements of memory-keeping and data visualization over time.
|
||||
|
||||
From there, we created a set of user stories — descriptions of features we wanted to have, from an end-user perspective — to elucidate what exactly we wanted our app to do.
|
||||
|
||||
### Step 2: Wireframe UX/UI
|
||||
|
||||
Next, on a white board, we drew out the basic views we envisioned in our app. We incorporated our set of user stories to understand how these views would work in a skeletal app framework.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
These sketches ensured we were all on the same page, and provided a visual blueprint going forward of what exactly we were all working towards.
|
||||
|
||||
### Step 3: Choose a data structure and type of database
|
||||
|
||||
It was now time to design our data structure. Based on our wireframes and user stories, we created a list in a Google doc of the models we would need and what attributes each should include. We knew we needed a ‘goal’ model, a ‘user’ model, a ‘milestone’ model, and a ‘checkin’ model, as well as eventually a ‘resource’ model, and an ‘upload’ model.
|
||||
|
||||
|
||||

|
||||
Our initial sketch of our data models
|
||||
|
||||
After informally sketching the models out, we needed to choose a _type _ of database: ‘relational’ vs. ‘non-relational’ (a.k.a. ‘SQL’ vs. ‘NoSQL’). Whereas SQL databases are table-based and need predefined schema, NoSQL databases are document-based and have dynamic schema for unstructured data.
|
||||
|
||||
For our use case, it didn’t matter much whether we used a SQL or a No-SQL database, so we ultimately chose Google’s cloud NoSQL database Firebasefor other reasons:
|
||||
|
||||
1. It could hold user image uploads in its cloud storage
|
||||
|
||||
2. It included WebSocket integration for real-time updating
|
||||
|
||||
3. It could handle our user authentication and offer easy OAuth integration
|
||||
|
||||
Once we chose a database, it was time to understand the relations between our data models. Since Firebase is NoSQL, we couldn’t create join tables or set up formal relations like _“Checkins belongTo Goals”_ . Instead, we needed to figure out what the JSON tree would look like, and how the objects would be nested (or not). Ultimately, we structured our model like this:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
Our final Firebase data scheme for the Goal object. Note that Milestones & Checkins are nested under Goals.
|
||||
|
||||
_(Note: Firebase prefers shallow, normalized data structures for efficiency, but for our use case, it made most sense to nest it, since we would never be pulling a Goal from the database without its child Milestones and Checkins.)_
|
||||
|
||||
### Step 4: Set up Github and an agile workflow
|
||||
|
||||
We knew from the start that staying organized and practicing agile development would serve us well. We set up a Github repo, on which weprevented merging to master to force ourselves to review each other’s code.
|
||||
|
||||
|
||||
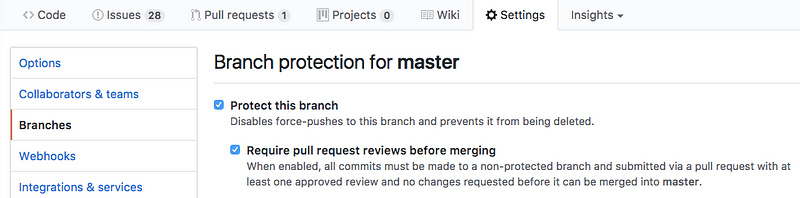
|
||||
|
||||
We also created an agile board on [Waffle.io][5], which is free and has easy integration with Github. On the Waffle board, we listed our user stories as well as bugs we knew we needed to fix. Later, when we started coding, we would each create git branches for the user story we were currently working on, moving it from swim lane to swim lane as we made progress.
|
||||
|
||||
|
||||
|
||||
|
||||
We also began holding “stand-up” meetings each morning to discuss the previous day’s progress and any blockers each of us were encountering. This meeting often decided the day’s flow — who would be pair programming, and who would work on an issue solo.
|
||||
|
||||
I highly recommend some sort of structured workflow like this, as it allowed us to clearly define our priorities and make efficient progress without any interpersonal conflict.
|
||||
|
||||
### Step 5: Choose & download a boilerplate
|
||||
|
||||
Because the JavaScript ecosystem is so complicated, we opted not to build our app from absolute ground zero. It felt unnecessary to spend valuable time wiring up our Webpack build scripts and loaders, and our symlink that pointed to our project directory. My team chose the [Firebones][6] skeleton because it fit our use case, but there are many open-source skeleton options available to choose from.
|
||||
|
||||
### Step 6: Write back-end API routes (or Firebase listeners)
|
||||
|
||||
If we weren’t using a cloud-based database, this would have been the time to start writing our back-end Express routes to make requests to our database. But since we were using Firebase, which is already in the cloud and has a different way of communicating with code, we just worked to set up our first successful database listener.
|
||||
|
||||
To ensure our listener was working, we coded out a basic user form for creating a Goal, and saw that, indeed, when we filled out the form, our database was live-updating. We were connected!
|
||||
|
||||
### Step 7: Build a “Proof Of Concept”
|
||||
|
||||
Our next step was to create a “proof of concept” for our app, or a prototype of the most difficult fundamental features to implement, demonstrating that our app _could _ eventuallyexist. For us, this meant finding a front-end library to satisfactorily render timelines, and connecting it to Firebase successfully to display some seed data in our database.
|
||||
|
||||
|
||||

|
||||
Basic Victory.JS timelines
|
||||
|
||||
We found Victory.JS, a React library built on D3, and spent a day reading the documentation and putting together a very basic example of a _VictoryLine_ component and a _VictoryScatter_ component to visually display data from the database. Indeed, it worked! We were ready to build.
|
||||
|
||||
### Step 8: Code out the features
|
||||
|
||||
Finally, it was time to build out all the exciting functionality of our app. This is a giant step that will obviously vary widely depending on the app you’re personally building. We looked at our wireframes and started coding out the individual user stories in our Waffle. This often included touching both front-end and back-end code (for example, creating a front-end form and also connecting it to the database). Our features ranged from major to minor, and included things like:
|
||||
|
||||
* ability to create new goals, milestones, and checkins
|
||||
|
||||
* ability to delete goals, milestones, and checkins
|
||||
|
||||
* ability to change a timeline’s name, color, and details
|
||||
|
||||
* ability to zoom in on timelines
|
||||
|
||||
* ability to add links to resources
|
||||
|
||||
* ability to upload media
|
||||
|
||||
* ability to bubble up resources and media from milestones and checkins to their associated goals
|
||||
|
||||
* rich text editor integration
|
||||
|
||||
* user signup / authentication / OAuth
|
||||
|
||||
* popover to view timeline options
|
||||
|
||||
* loading screens
|
||||
|
||||
For obvious reasons, this step took up the bulk of our time — this phase is where most of the meaty code happened, and each time we finished a feature, there were always more to build out!
|
||||
|
||||
### Step 9: Choose and code the design scheme
|
||||
|
||||
Once we had an MVP of the functionality we desired in our app, it was time to clean it up and make it pretty. My team used Material-UI for components like form fields, menus, and login tabs, which ensured everything looked sleek, polished, and coherent without much in-depth design knowledge.
|
||||
|
||||
|
||||
|
||||
This was one of my favorite features to code out. Its beauty is so satisfying!
|
||||
|
||||
We spent a while choosing a color scheme and editing the CSS, which provided us a nice break from in-the-trenches coding. We also designed alogo and uploaded a favicon.
|
||||
|
||||
### Step 10: Find and squash bugs
|
||||
|
||||
While we should have been using test-driven development from the beginning, time constraints left us with precious little time for anything but features. This meant that we spent the final two days simulating every user flow we could think of and hunting our app for bugs.
|
||||
|
||||
|
||||

|
||||
|
||||
This process was not the most systematic, but we found plenty of bugs to keep us busy, including a bug in which the loading screen would last indefinitely in certain situations, and one in which the resource component had stopped working entirely. Fixing bugs can be annoying, but when it finally works, it’s extremely satisfying.
|
||||
|
||||
### Step 11: Deploy the live app
|
||||
|
||||
The final step was to deploy our app so it would be available live! Because we were using Firebase to store our data, we deployed to Firebase Hosting, which was intuitive and simple. If your back end uses a different database, you can use Heroku or DigitalOcean. Generally, deployment directions are readily available on the hosting site.
|
||||
|
||||
We also bought a cheap domain name on Namecheap.com to make our app more polished and easy to find.
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
And that was it — we were suddenly the co-creators of a real live full-stack app that someone could use! If we had a longer runway, Step 12 would have been to run A/B testing on users, so we could better understand how actual users interact with our app and what they’d like to see in a V2.
|
||||
|
||||
For now, however, we’re happy with the final product, and with the immeasurable knowledge and understanding we gained throughout this process. Check out Align [here][7]!
|
||||
|
||||
|
||||

|
||||
Team Align: Sara Kladky (left), Melanie Mohn (center), and myself.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/ladies-storm-hackathons/how-we-built-our-first-full-stack-javascript-web-app-in-three-weeks-8a4668dbd67c?imm_mid=0f581a&cmp=em-web-na-na-newsltr_20170816
|
||||
|
||||
作者:[Sophia Ciocca ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@sophiaciocca?source=post_header_lockup
|
||||
[1]:https://medium.com/@sophiaciocca?source=post_header_lockup
|
||||
[2]:https://medium.com/@sophiaciocca?source=post_header_lockup
|
||||
[3]:https://github.com/limitless-leggings/limitless-leggings
|
||||
[4]:https://www.youtube.com/watch?v=qyLoInHNjoc
|
||||
[5]:http://www.waffle.io/
|
||||
[6]:https://github.com/FullstackAcademy/firebones
|
||||
[7]:https://align.fun/
|
||||
[8]:https://github.com/align-capstone/align
|
||||
[9]:https://github.com/sophiaciocca
|
||||
[10]:https://github.com/Kladky
|
||||
[11]:https://github.com/melaniemohn
|
||||
537
sources/tech/20170811 UP – deploy serverless apps in seconds.md
Normal file
537
sources/tech/20170811 UP – deploy serverless apps in seconds.md
Normal file
@ -0,0 +1,537 @@
|
||||
UP – deploy serverless apps in seconds
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Last year I wrote [Blueprints for Up][1], describing how most of the building blocks are available to create a great serverless experience on AWS with minimal effort. This post talks about the initial alpha release of [Up][2].
|
||||
|
||||
Why focus on serverless? For starters it’s cost-effective since you pay on-demand, only for what you use. Serverless options are self-healing, as each request is isolated and considered to be “stateless.” And finally it scales indefinitely with ease — there are no machines or clusters to manage. Deploy your code and you’re done.
|
||||
|
||||
Roughly a month ago I decided to start working on it over at [apex/up][3], and wrote the first small serverless sample application [tj/gh-polls][4] for live SVG GitHub user polls. It worked well and costs less than $1/month to serve millions of polls, so I thought I’d go ahead with the project and see if I can offer open-source and commercial variants.
|
||||
|
||||
The long-term goal is to provide a “Bring your own Heroku” of sorts, supporting many platforms. While Platform-as-a-Service is nothing new, the serverless ecosystem is making this kind of program increasingly trivial. This said, AWS and others often suffer in terms of UX due to the flexibility they provide. Up abstracts the complexity away, while still providing you with a virtually ops-free solution.
|
||||
|
||||
### Installation
|
||||
|
||||
You can install Up with the following command, and view the [temporary documentation][5] to get started. Or if you’re sketched out by install scripts, grab a [binary release][6]. (Keep in mind that this project is still early on.)
|
||||
|
||||
```
|
||||
curl -sfL https://raw.githubusercontent.com/apex/up/master/install.sh | sh
|
||||
```
|
||||
|
||||
To upgrade to the latest version at any time just run:
|
||||
|
||||
```
|
||||
up upgrade
|
||||
```
|
||||
|
||||
You may also install via NPM:
|
||||
|
||||
```
|
||||
npm install -g up
|
||||
```
|
||||
|
||||
### Features
|
||||
|
||||
What features does the early alpha provide? Let’s take a look! Keep in mind that Up is not a hosted service, so you’ll need an AWS account and [AWS credentials][8]. If you’re not familiar at all with AWS you may want to hold off until that process is streamlined.
|
||||
|
||||
The first question I always get is: how does up(1) differ from [apex(1)][9]? Apex focuses on deploying functions, for pipelines and event processing, while Up focuses on apps, apis, and static sites, aka single deployable units. Apex does not provision API Gateway, SSL certs, or DNS for you, nor does it provide URL rewriting, script injection and so on.
|
||||
|
||||
#### Single command serverless apps
|
||||
|
||||
Up lets you deploy apps, apis, and static sites with a single command. To create an application all you need is a single file, in the case of Node.js, an `./app.js` listening on `PORT` which is provided by Up. Note that if you’re using a `package.json` Up will detect and utilize the `start` and `build`scripts.
|
||||
|
||||
```
|
||||
const http = require('http')
|
||||
const { PORT = 3000 } = process.env
|
||||
```
|
||||
|
||||
```
|
||||
http.createServer((req, res) => {
|
||||
res.end('Hello World\n')
|
||||
}).listen(PORT)
|
||||
```
|
||||
|
||||
Additional [runtimes][10] are supported out of the box, such as `main.go` for Golang, so you can deploy Golang, Python, Crystal, or Node.js applications in seconds.
|
||||
|
||||
```
|
||||
package main
|
||||
```
|
||||
|
||||
```
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"net/http"
|
||||
"os"
|
||||
)
|
||||
```
|
||||
|
||||
```
|
||||
func main() {
|
||||
addr := ":" + os.Getenv("PORT")
|
||||
http.HandleFunc("/", hello)
|
||||
log.Fatal(http.ListenAndServe(addr, nil))
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
func hello(w http.ResponseWriter, r *http.Request) {
|
||||
fmt.Fprintln(w, "Hello World from Go")
|
||||
}
|
||||
```
|
||||
|
||||
To deploy the application type `up` to create the resources required, and deploy the application itself. There are no smoke and mirrors here, once it says “complete”, you’re done, the app is immediately available — there is no remote build process.
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
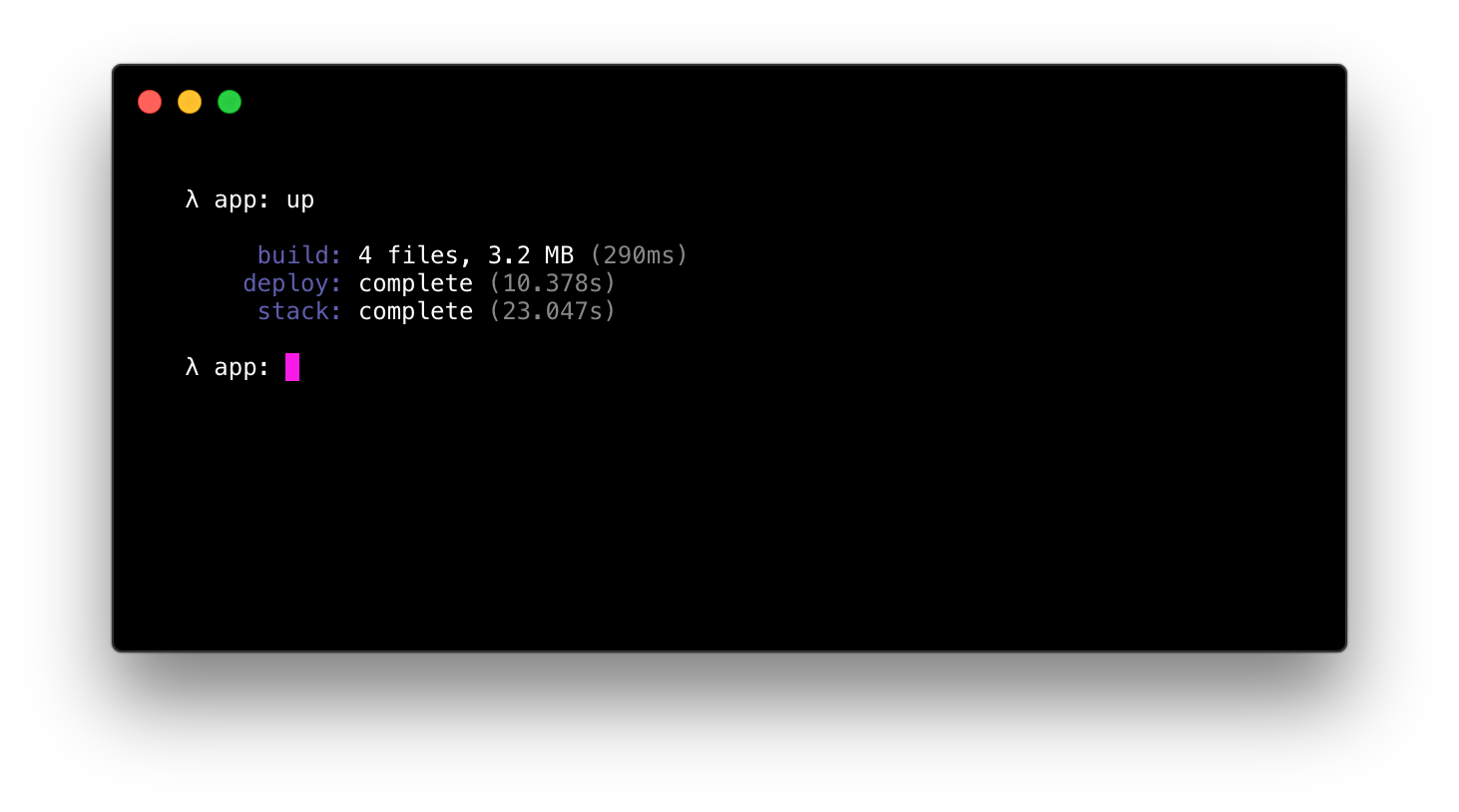
|
||||
|
||||
The subsequent deploys will be even quicker since the stack is already provisioned:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
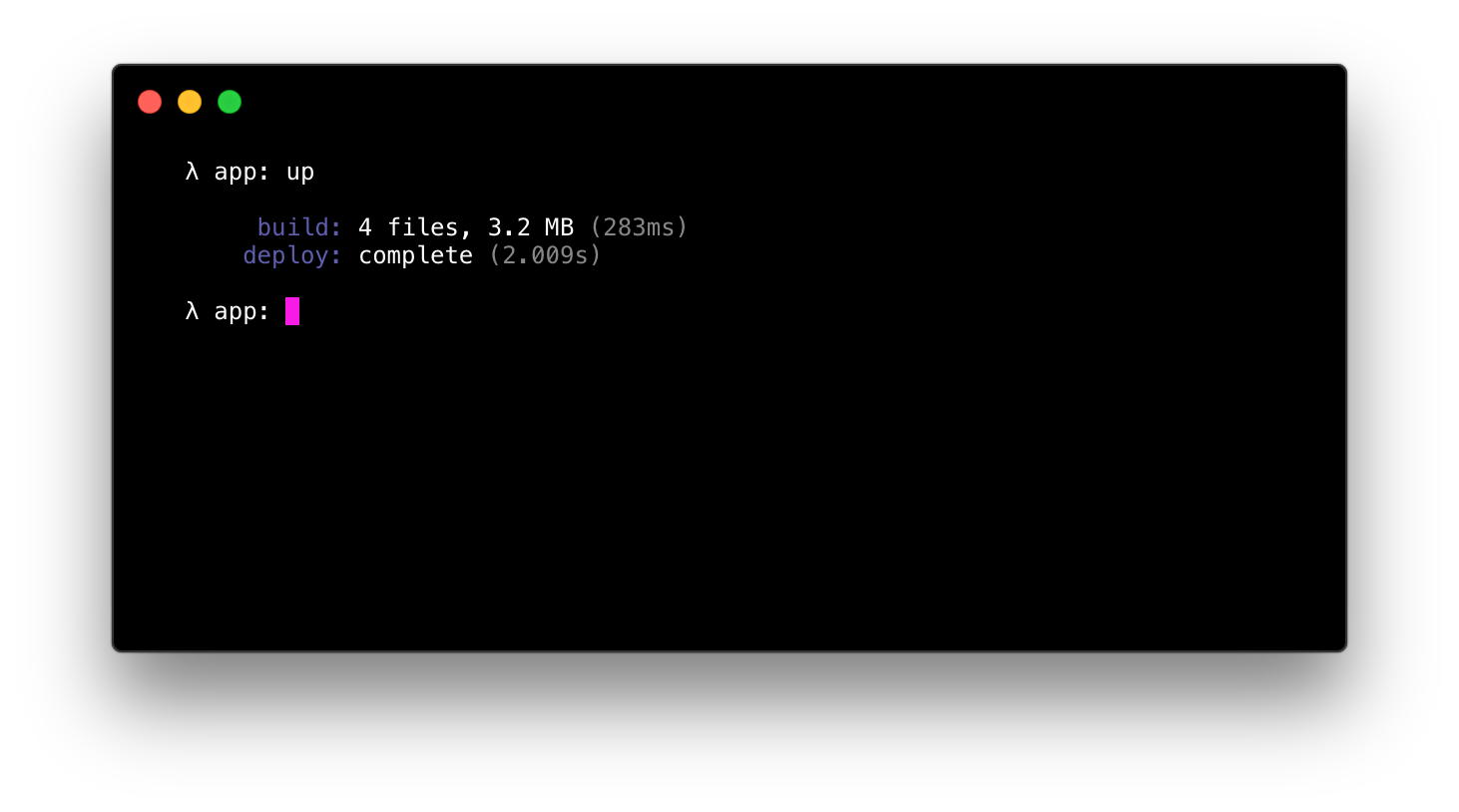
|
||||
|
||||
Test out your app with `up url --open` to view it in the browser, `up url --copy` to save the URL to the clipboard, or try it with curl:
|
||||
|
||||
```
|
||||
curl `up url`
|
||||
Hello World
|
||||
```
|
||||
|
||||
To delete the app and its resources just type `up stack delete`:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
Deploy to the staging or production environments using `up staging` or `up production` , and `up url --open production` for example. Note that custom domains are not yet available, [they will be shortly][11]. Later you’ll also be able to “promote” a release to other stages.
|
||||
|
||||
#### Reverse proxy
|
||||
|
||||
One feature which makes Up unique is that it doesn’t just simply deploy your code, it places a Golang reverse proxy in front of your application. This provides many features such as URL rewriting, redirection, script injection and more, which we’ll look at further in the post.
|
||||
|
||||
#### Infrastructure as code
|
||||
|
||||
Up follows modern best practices in terms of configuration, as all changes to the infrastructure can be previewed before applying, and the use of IAM policies can also restrict developer access to prevent mishaps. A side benefit is that it helps self-document your infrastructure as well.
|
||||
|
||||
Here’s an example of configuring some (dummy) DNS records and free SSL certificates via AWS ACM which utilizes LetsEncrypt.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"dns": {
|
||||
"myapp.com": [
|
||||
{
|
||||
"name": "myapp.com",
|
||||
"type": "A",
|
||||
"ttl": 300,
|
||||
"value": ["35.161.83.243"]
|
||||
},
|
||||
{
|
||||
"name": "blog.myapp.com",
|
||||
"type": "CNAME",
|
||||
"ttl": 300,
|
||||
"value": ["34.209.172.67"]
|
||||
},
|
||||
{
|
||||
"name": "api.myapp.com",
|
||||
"type": "A",
|
||||
"ttl": 300,
|
||||
"value": ["54.187.185.18"]
|
||||
}
|
||||
]
|
||||
},
|
||||
"certs": [
|
||||
{
|
||||
"domains": ["myapp.com", "*.myapp.com"]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
When you deploy the application the first time via `up` all the permissions required, API Gateway, Lambda function, ACM certs, Route53 DNS records and others are created for you.
|
||||
|
||||
[ChangeSets][12] are not yet implemented but you will be able to preview further changes with `up stack plan` and commit them with `up stack apply`, much like you would with Terraform.
|
||||
|
||||
Check out the [configuration documentation][13] for more information.
|
||||
|
||||
#### Global deploys
|
||||
|
||||
The `regions` array allows you to specify target regions for your app. For example if you’re only interested in a single region you’d use:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["us-west-2"]
|
||||
}
|
||||
```
|
||||
|
||||
If your customers are concentrated in North America, you may want to use all of the US and CA regions:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["us-*", "ca-*"]
|
||||
}
|
||||
```
|
||||
|
||||
Lastly of course you can target all 14 regions currently supported:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["*"]
|
||||
}
|
||||
```
|
||||
|
||||
Multi-region support is still a work-in-progress as a few new AWS features are required to tie things together.
|
||||
|
||||
#### Static file serving
|
||||
|
||||
Up supports static file serving out of the box, with HTTP cache support, so you can use CloudFront or any other CDN in front of your application to dramatically reduce latency.
|
||||
|
||||
By default the working directory is served (`.`) when `type` is “static”, however you may provide a `static.dir` as well:
|
||||
|
||||
```
|
||||
{ "name": "app", "type": "static", "static": { "dir": "public" }}
|
||||
```
|
||||
|
||||
#### Build hooks
|
||||
|
||||
The build hooks allow you to define custom actions when deploying or performing other operations. A common example would be to bundle Node.js apps using Webpack or Browserify, greatly reducing the file size, as node_modules is _huge_ .
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"hooks": {
|
||||
"build": "browserify --node server.js > app.js",
|
||||
"clean": "rm app.js"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Script and stylesheet injection
|
||||
|
||||
Up allows you to inject scripts and styles, either inline or paths in a declarative manner. It even supports a number of “canned” scripts for Google Analytics and [Segment][14], just copy & paste your write key.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "site",
|
||||
"type": "static",
|
||||
"inject": {
|
||||
"head": [
|
||||
{
|
||||
"type": "segment",
|
||||
"value": "API_KEY"
|
||||
},
|
||||
{
|
||||
"type": "inline style",
|
||||
"file": "/css/primer.css"
|
||||
}
|
||||
],
|
||||
"body": [
|
||||
{
|
||||
"type": "script",
|
||||
"value": "/app.js"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Rewrites and redirects
|
||||
|
||||
Up supports redirects and URL rewriting via the `redirects` object, which maps path patterns to a new location. If `status` is omitted (or 200) then it is a rewrite, otherwise it is a redirect.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"type": "static",
|
||||
"redirects": {
|
||||
"/blog": {
|
||||
"location": "https://blog.apex.sh/",
|
||||
"status": 301
|
||||
},
|
||||
"/docs/:section/guides/:guide": {
|
||||
"location": "/help/:section/:guide",
|
||||
"status": 302
|
||||
},
|
||||
"/store/*": {
|
||||
"location": "/shop/:splat"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
A common use-case for rewrites is for SPAs (Single Page Apps), where you want to serve the `index.html` file regardless of the path. Unless of course the file exists.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"type": "static",
|
||||
"redirects": {
|
||||
"/*": {
|
||||
"location": "/",
|
||||
"status": 200
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
If you want to force the rule regardless of a file existing, just add `"force": true` .
|
||||
|
||||
#### Environment variables
|
||||
|
||||
Secrets will be in the next release, however for now plain-text environment variables are supported:
|
||||
|
||||
```
|
||||
{
|
||||
"name": "api",
|
||||
"environment": {
|
||||
"API_FEATURE_FOO": "1",
|
||||
"API_FEATURE_BAR": "0"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### CORS support
|
||||
|
||||
The [CORS][16] support allows you to to specify which (if any) domains can access your API from the browser. If you wish to allow any site to access your API, just enable it:
|
||||
|
||||
```
|
||||
{
|
||||
"cors": {
|
||||
"enable": true
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You can also customize access, for example restricting API access to your front-end or SPA only.
|
||||
|
||||
```
|
||||
{
|
||||
"cors": {
|
||||
"allowed_origins": ["https://myapp.com"],
|
||||
"allowed_methods": ["HEAD", "GET", "POST", "PUT", "DELETE"],
|
||||
"allowed_headers": ["Content-Type", "Authorization"]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Logging
|
||||
|
||||
For the low price of $0.5/GB you can utilize CloudWatch logs for structured log querying and tailing. Up implements a custom [query language][18] used to improve upon what CloudWatch provides, purpose-built for querying structured JSON logs.
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
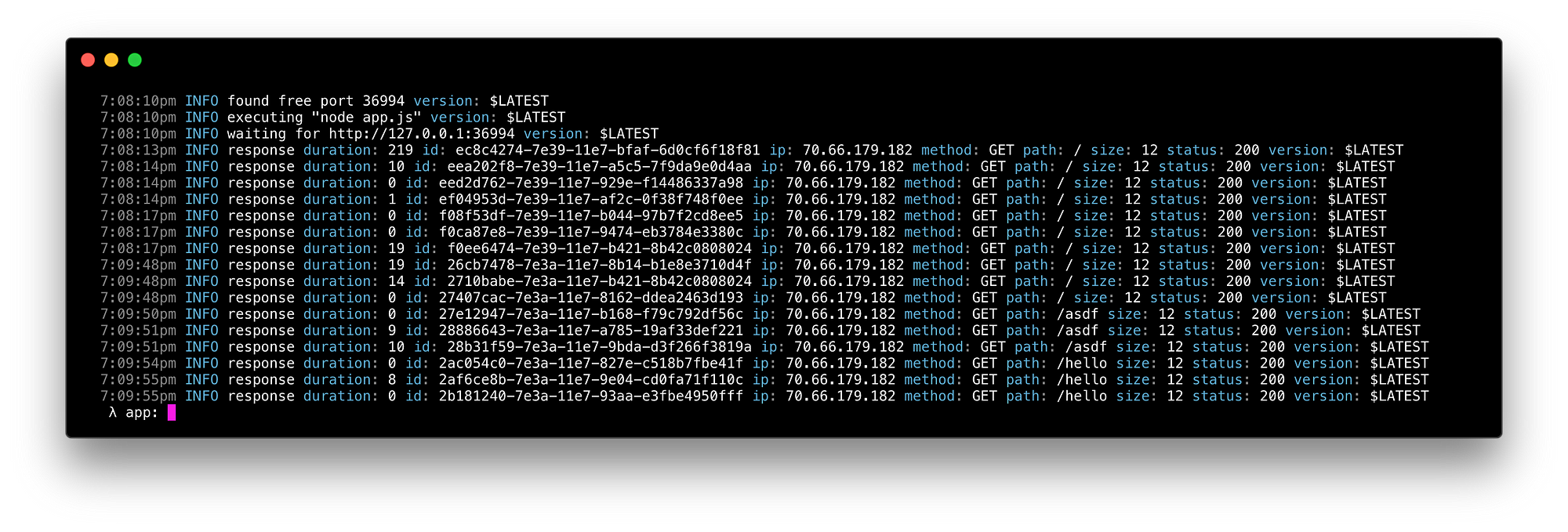
|
||||
|
||||
You can query existing logs:
|
||||
|
||||
```
|
||||
up logs
|
||||
```
|
||||
|
||||
Tail live logs:
|
||||
|
||||
```
|
||||
up logs -f
|
||||
```
|
||||
|
||||
Or filter on either of them, for example only showing 200 GET / HEAD requests that take more than 5 milliseconds to complete:
|
||||
|
||||
```
|
||||
up logs 'method in ("GET", "HEAD") status = 200 duration >= 5'
|
||||
```
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
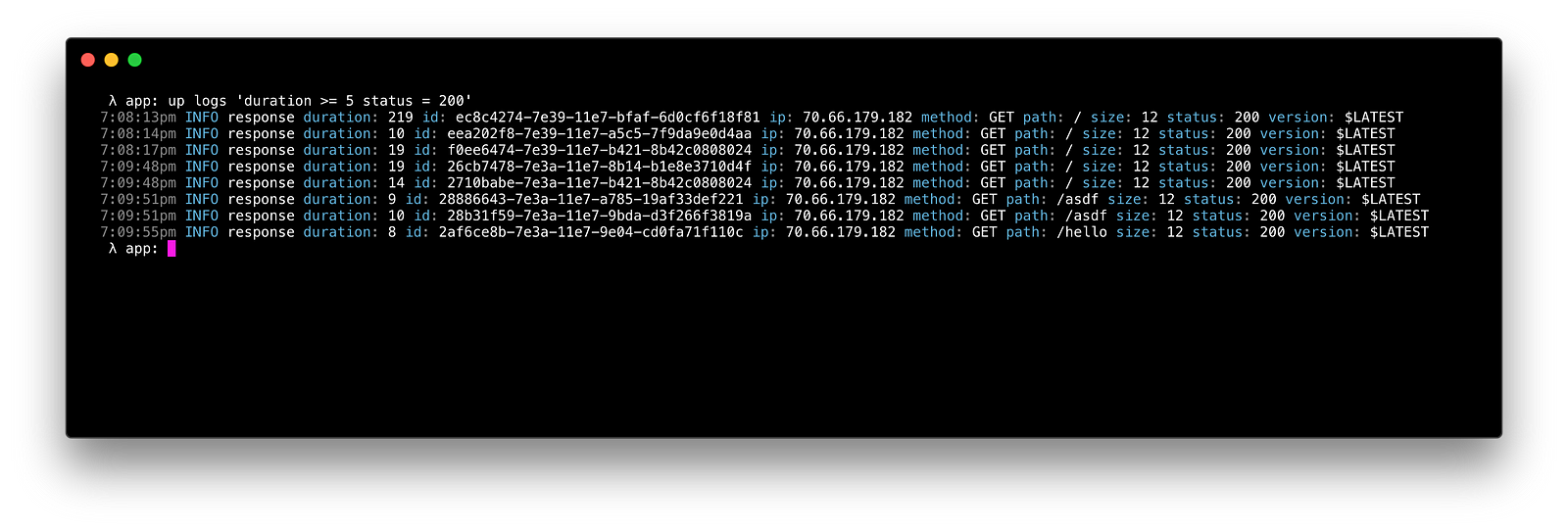
|
||||
|
||||
The query language is quite flexible, here are some more examples from `up help logs`
|
||||
|
||||
```
|
||||
Show logs from the past 5 minutes.
|
||||
$ up logs
|
||||
```
|
||||
|
||||
```
|
||||
Show logs from the past 30 minutes.
|
||||
$ up logs -s 30m
|
||||
```
|
||||
|
||||
```
|
||||
Show logs from the past 5 hours.
|
||||
$ up logs -s 5h
|
||||
```
|
||||
|
||||
```
|
||||
Show live log output.
|
||||
$ up logs -f
|
||||
```
|
||||
|
||||
```
|
||||
Show error logs.
|
||||
$ up logs error
|
||||
```
|
||||
|
||||
```
|
||||
Show error and fatal logs.
|
||||
$ up logs 'error or fatal'
|
||||
```
|
||||
|
||||
```
|
||||
Show non-info logs.
|
||||
$ up logs 'not info'
|
||||
```
|
||||
|
||||
```
|
||||
Show logs with a specific message.
|
||||
$ up logs 'message = "user login"'
|
||||
```
|
||||
|
||||
```
|
||||
Show 200 responses with latency above 150ms.
|
||||
$ up logs 'status = 200 duration > 150'
|
||||
```
|
||||
|
||||
```
|
||||
Show 4xx and 5xx responses.
|
||||
$ up logs 'status >= 400'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails containing @apex.sh.
|
||||
$ up logs 'user.email contains "@apex.sh"'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails ending with @apex.sh.
|
||||
$ up logs 'user.email = "*@apex.sh"'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails starting with tj@.
|
||||
$ up logs 'user.email = "tj@*"'
|
||||
```
|
||||
|
||||
```
|
||||
Show errors from /tobi and /loki
|
||||
$ up logs 'error and (path = "/tobi" or path = "/loki")'
|
||||
```
|
||||
|
||||
```
|
||||
Show the same as above with 'in'
|
||||
$ up logs 'error and path in ("/tobi", "/loki")'
|
||||
```
|
||||
|
||||
```
|
||||
Show logs with a more complex query.
|
||||
$ up logs 'method in ("POST", "PUT") ip = "207.*" status = 200 duration >= 50'
|
||||
```
|
||||
|
||||
```
|
||||
Pipe JSON error logs to the jq tool.
|
||||
$ up logs error | jq
|
||||
```
|
||||
|
||||
Note that the `and` keyword is implied, though you can use it if you prefer.
|
||||
|
||||
#### Cold start times
|
||||
|
||||
This is a property of AWS Lambda as a platform, but the cold start times are typically well below 1 second, and in the future I plan on providing an option to keep them warm.
|
||||
|
||||
#### Config validation
|
||||
|
||||
The `up config` command outputs the resolved configuration, complete with defaults and inferred runtime settings – it also serves the dual purpose of validating configuration, as any error will result in exit > 0.
|
||||
|
||||
#### Crash recovery
|
||||
|
||||
Another benefit of using Up as a reverse proxy is performing crash recovery — restarting your server upon crashes and re-attempting the request before responding to the client with an error.
|
||||
|
||||
For example suppose your Node.js application crashes with an uncaught exception due to an intermittent database issue, Up can retry this request before ever responding to the client. Later this behaviour will be more customizable.
|
||||
|
||||
#### Continuous integration friendly
|
||||
|
||||
It’s hard to call this a feature, but thanks to Golang’s relatively small and isolated binaries, you can install Up in a CI in a second or two.
|
||||
|
||||
#### HTTP/2
|
||||
|
||||
Up supports HTTP/2 out of the box via API Gateway, reducing the latency for serving apps and sites with with many assets. I’ll do more comprehensive testing against many platforms in the future, but Up’s latency is already favourable:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
#### Error pages
|
||||
|
||||
Up provides a default error page which you may customize with `error_pages` if you’d like to provide a support email or tweak the color.
|
||||
|
||||
```
|
||||
{ "name": "site", "type": "static", "error_pages": { "variables": { "support_email": "support@apex.sh", "color": "#228ae6" } }}
|
||||
```
|
||||
|
||||
By default it looks like this:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
If you’d like to provide custom templates you may create one or more of the following files. The most specific file takes precedence.
|
||||
|
||||
* `error.html` – Matches any 4xx or 5xx
|
||||
|
||||
* `5xx.html` – Matches any 5xx error
|
||||
|
||||
* `4xx.html` – Matches any 4xx error
|
||||
|
||||
* `CODE.html` – Matches a specific code such as 404.html
|
||||
|
||||
Check out the [docs][22] to read more about templating.
|
||||
|
||||
### Scaling and cost
|
||||
|
||||
So you’ve made it this far, but how well does Up scale? Currently API Gateway and AWS are the target platform, so you’re not required to make any changes in order to scale, just deploy your code and it’s done. You pay only for what you actually use, on-demand, and no manual intervention is required for scaling.
|
||||
|
||||
AWS offers 1,000,000 requests per month for free, but you can use [http://serverlesscalc.com][23] to plug in your expected traffic. In the future Up will provide additional platforms, so that if one becomes prohibitively expensive, you can migrate to another!
|
||||
|
||||
### The Future
|
||||
|
||||
That’s all for now! It may not look like much, but it’s clocking-in above 10,000 lines of code already, and I’ve just begun development. Take a look at the issue queue for a small look at what to expect in the future, assuming the project becomes sustainable.
|
||||
|
||||
If you find the free version useful please consider donating on [OpenCollective][24], as I do not make any money working on it. I will be working on early access to the Pro version shortly, with a discounted annual price for early adopters. Either the Pro or Enterprise editions will provide the source as well, so internal hotfixes and customizations can be made.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/up-b3db1ca930ee
|
||||
|
||||
作者:[TJ Holowaychuk ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@tjholowaychuk?source=post_header_lockup
|
||||
[1]:https://medium.com/@tjholowaychuk/blueprints-for-up-1-5f8197179275
|
||||
[2]:https://github.com/apex/up
|
||||
[3]:https://github.com/apex/up
|
||||
[4]:https://github.com/tj/gh-polls
|
||||
[5]:https://github.com/apex/up/tree/master/docs
|
||||
[6]:https://github.com/apex/up/releases
|
||||
[7]:https://raw.githubusercontent.com/apex/up/master/install.sh
|
||||
[8]:https://github.com/apex/up/blob/master/docs/aws-credentials.md
|
||||
[9]:https://github.com/apex/apex
|
||||
[10]:https://github.com/apex/up/blob/master/docs/runtimes.md
|
||||
[11]:https://github.com/apex/up/issues/166
|
||||
[12]:https://github.com/apex/up/issues/115
|
||||
[13]:https://github.com/apex/up/blob/master/docs/configuration.md
|
||||
[14]:https://segment.com/
|
||||
[15]:https://blog.apex.sh/
|
||||
[16]:https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS
|
||||
[17]:https://myapp.com/
|
||||
[18]:https://github.com/apex/up/blob/master/internal/logs/parser/grammar.peg
|
||||
[19]:http://twitter.com/apex
|
||||
[20]:http://twitter.com/apex
|
||||
[21]:http://twitter.com/apex
|
||||
[22]:https://github.com/apex/up/blob/master/docs/configuration.md#error-pages
|
||||
[23]:http://serverlesscalc.com/
|
||||
[24]:https://opencollective.com/apex-up
|
||||
188
sources/tech/20170816 Kubernetes at GitHub.md
Normal file
188
sources/tech/20170816 Kubernetes at GitHub.md
Normal file
@ -0,0 +1,188 @@
|
||||
[Kubernetes at GitHub][10]
|
||||
============================================================
|
||||
|
||||
Over the last year, GitHub has gradually evolved the infrastructure that runs the Ruby on Rails application responsible for `github.com` and `api.github.com`. We reached a big milestone recently: all web and API requests are served by containers running in [Kubernetes][13] clusters deployed on our [metal cloud][14]. Moving a critical application to Kubernetes was a fun challenge, and we’re excited to share some of what we’ve learned with you today.
|
||||
|
||||
### Why change?[][15]
|
||||
|
||||
Before this move, our main Ruby on Rails application (we call it `github/github`) was configured a lot like it was eight years ago: [Unicorn][16] processes managed by a Ruby process manager called [God][17] running on Puppet-managed servers. Similarly, our [chatops deployment][18] worked a lot like it did when it was first introduced: Capistrano established SSH connections to each frontend server, then [updated the code in place][19] and restarted application processes. When peak request load exceeded available frontend CPU capacity, GitHub Site Reliability Engineers would [provision additional capacity][20] and add it to the pool of active frontend servers.
|
||||
|
||||
|
||||
|
||||
While our basic production approach didn’t change much in those years, GitHub itself changed a lot: new features, larger software communities, more GitHubbers on staff, and way more requests per second. As we grew, this approach began to exhibit new problems. Many teams wanted to extract the functionality they were responsible for from this large application into a smaller service that could run and be deployed independently. As the number of services we ran increased, the SRE team began supporting similar configurations for dozens of other applications, increasing the percentage of our time we spent on server maintenance, provisioning, and other work not directly related to improving the overall GitHub experience. New services took days, weeks, or months to deploy depending on their complexity and the SRE team’s availability. Over time, it became clear that this approach did not provide our engineers the flexibility they needed to continue building a world-class service. Our engineers needed a self-service platform they could use to experiment, deploy, and scale new services. We also needed that same platform to fit the needs of our core Ruby on Rails application so that engineers and/or robots could respond to changes in demand by allocating additional compute resources in seconds instead of hours, days, or longer.
|
||||
|
||||
In response to those needs, the SRE, Platform, and Developer Experience teams began a joint project that led us from an initial evaluation of container orchestration platforms to where we are today: deploying the code that powers `github.com` and `api.github.com` to Kubernetes clusters dozens of times per day. This post aims to provide a high-level overview of the work involved in that journey.
|
||||
|
||||
### Why Kubernetes?[][21]
|
||||
|
||||
As a part of evaluating the existing landscape of “platform as a service” tools, we took a closer look at Kubernetes, a project from Google that described itself at the time as _an open-source system for automating deployment, scaling, and management of containerized applications_ . Several qualities of Kubernetes stood out from the other platforms we evaluated: the vibrant open source community supporting the project, the first run experience (which allowed us to deploy a small cluster and an application in the first few hours of our initial experiment), and a wealth of information available about the [experience][22]that motivated its design.
|
||||
|
||||
These experiments quickly grew in scope: a small project was assembled to build a Kubernetes cluster and deployment tooling in support of an upcoming hack week to gain some practical experience with the platform. Our experience with this project as well as the feedback from engineers who used it was overwhelmingly positive. It was time to expand our experiments, so we started planning a larger rollout.
|
||||
|
||||
### Why start with `github/github`?[][23]
|
||||
|
||||
At the earliest stages of this project, we made a deliberate decision to target the migration of a critical workload: `github/github`. Many factors contributed to this decision, but a few stood out:
|
||||
|
||||
* We knew that the deep knowledge of this application throughout GitHub would be useful during the process of migration.
|
||||
|
||||
* We needed self-service capacity expansion tooling to handle continued growth.
|
||||
|
||||
* We wanted to make sure the habits and patterns we developed were suitable for large applications as well as smaller services.
|
||||
|
||||
* We wanted to better insulate the app from differences between development, staging, production, enterprise, and other environments.
|
||||
|
||||
* We knew that migrating a critical, high-visibility workload would encourage further Kubernetes adoption at GitHub.
|
||||
|
||||
Given the critical nature of the workload we chose to migrate, we needed to build a high level of operational confidence before serving any production traffic.
|
||||
|
||||
### Rapid iteration and confidence building with a review lab[][24]
|
||||
|
||||
As a part of this migration, we designed, prototyped, and validated a replacement for the service currently provided by our frontend servers using Kubernetes primitives like Pods, Deployments, and Services. Some validation of this new design could be performed by running `github/github`’s existing test suites in a container rather than on a server configured similarly to frontend servers, but we also needed to observe how this container behaved as a part of a larger set of Kubernetes resources. It quickly became clear that an environment that supported exploratory testing of the combination of Kubernetes and the services we intended to run would be necessary during the validation phase.
|
||||
|
||||
Around the same time, we observed that our existing patterns for exploratory testing of `github/github` pull requests had begun to show signs of growing pains. As the rate of deploys increased along with the number of engineers working on the project, so did the utilization of the several [additional deploy environments][25] used as a part of the process of validating a pull request to `github/github`. The small number of fully-featured deploy environments were usually booked solid during peak working hours, which slowed the process of deploying a pull request. Engineers frequently requested the ability to test more of the various production subsystems on “branch lab.” While branch lab allowed concurrent deployment from many engineers, it only started a single Unicorn process for each, which meant it was only useful when testing API and UI changes. These needs overlapped substantially enough for us to combine the projects and start work on a new Kubernetes-powered deployment environment for `github/github` called “review lab.”
|
||||
|
||||
In the process of building review lab, we shipped a handful of sub-projects, each of which could likely be covered in their own blog post. Along the way, we shipped:
|
||||
|
||||
* A Kubernetes cluster running in an AWS VPC managed using a combination of [Terraform][2] and [kops][3].
|
||||
|
||||
* A set of Bash integration tests that exercise ephemeral Kubernetes clusters, used heavily in the beginning of the project to gain confidence in Kubernetes.
|
||||
|
||||
* A Dockerfile for `github/github`.
|
||||
|
||||
* Enhancements to our internal CI platform to support building and publishing containers to a container registry.
|
||||
|
||||
* YAML representations of 50+ Kubernetes resources, checked into `github/github`.
|
||||
|
||||
* Enhancements to our internal deployment application to support deploying Kubernetes resources from a repository into a Kubernetes namespace, as well as the creation of Kubernetes secrets from our internal secret store.
|
||||
|
||||
* A service that combines haproxy and consul-template to route traffic from Unicorn pods to the existing services that publish service information there.
|
||||
|
||||
* A service that reads Kubernetes events and sends abnormal ones to our internal error tracking system.
|
||||
|
||||
* A [chatops-rpc][4]-compatible service called `kube-me` that exposes a limited set of `kubectl` commands to users via chat.
|
||||
|
||||
The end result is a chat-based interface for creating an isolated deployment of GitHub for any pull request. Once a pull request passed all required CI jobs, a user can deploy their pull request to review lab like so:
|
||||
|
||||

|
||||
**jnewland**.deploy https://github.com/github/github/pull/4815162342 to review-lab
|
||||

|
||||
**Hubot**[@jnewland][1]'s review-lab deployment of github/add-pre-stop-hook (00cafefe) is done! (12 ConfigMaps, 17 Deployments, 1 Ingress, 1 Namespace, 6 Secrets, and 23 Services)(77.62s) your lab is available at https://jnewland.review-lab.github.com
|
||||
|
||||
Like branch lab before it, labs are cleaned up one day after their last deploy. As each lab is created in its own Kubernetes namespace, cleanup is as simple as deleting the namespace, which our deployment system performs automatically when necessary.
|
||||
|
||||
Review lab was a successful project with a number of positive outcomes. Before making this environment generally available to engineers, it served as an essential proving ground and prototyping environment for our Kubernetes cluster design as well as the design and configuration of the Kubernetes resources that now describe the `github/github` Unicorn workload. After release, it exposed a large number of engineers to a new style of deployment, helping us build confidence via feedback from interested engineers as well as continued use from engineers who didn’t notice any change. And just recently, we observed some engineers on our High Availability team use review lab to experiment with the interaction between Unicorn and the behavior of a new experimental subsystem by deploying it to a shared lab. We’re extremely pleased with the way that this environment empowers engineers to experiment and solve problems in a self-service manner.
|
||||
|
||||
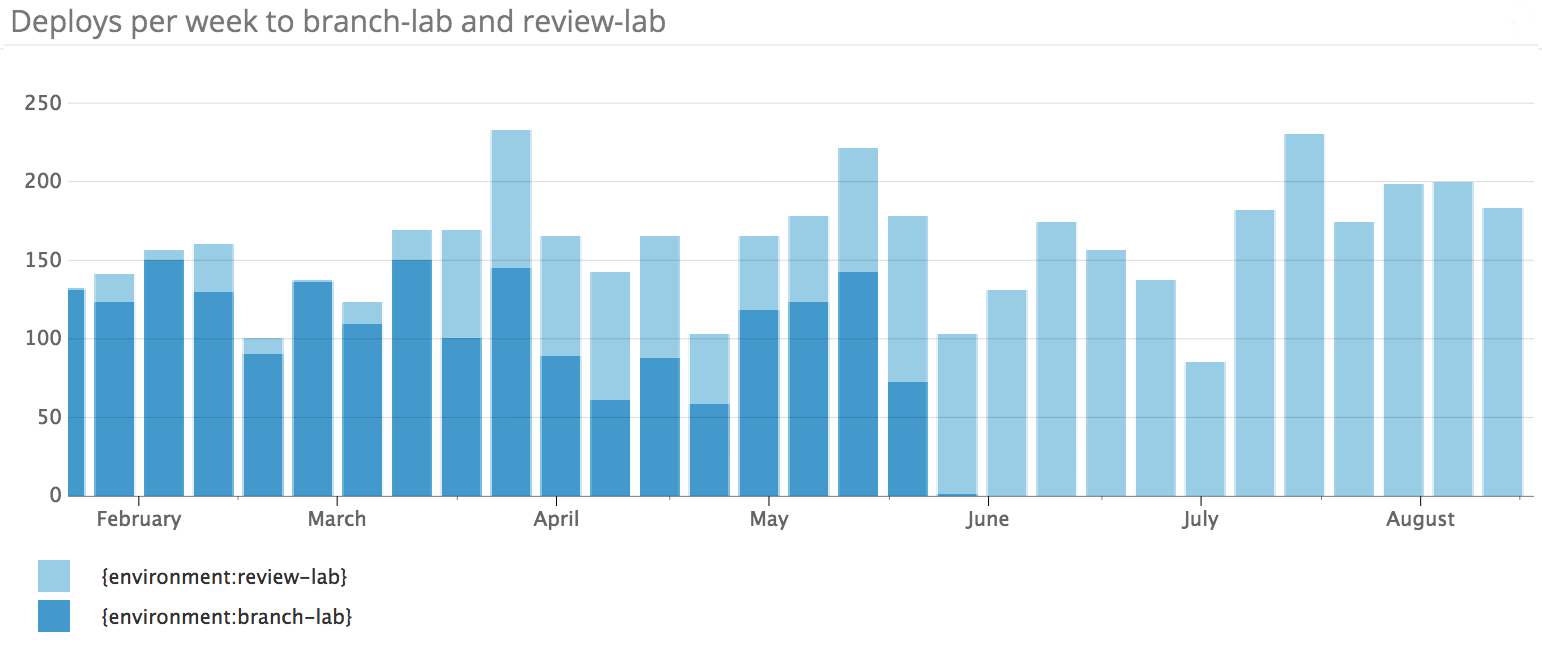
|
||||
|
||||
### Kubernetes on Metal[][26]
|
||||
|
||||
With review lab shipped, our attention shifted to `github.com`. To satisfy the performance and reliability requirements of our flagship service - which depends on low-latency access to other data services - we needed to build out Kubernetes infrastructure that supported the [metal cloud][27] we run in our physical data centers and POPs. Again, nearly a dozen subprojects were involved in this effort:
|
||||
|
||||
* A timely and thorough post about [container networking][5] helped us select the [Calico][6]network provider, which provided the out-of-the box functionality we needed to ship a cluster quickly in `ipip` mode while giving us the flexibility to explore peering with our network infrastructure later.
|
||||
|
||||
* Following no less than a dozen reads of [@kelseyhightower][7]’s indispensable [Kubernetes the hard way][8], we assembled a handful of manually provisioned servers into a temporary Kubernetes cluster that passed the same set of integration tests we used to exercise our AWS clusters.
|
||||
|
||||
* We built a small tool to generate the CA and configuration necessary for each cluster in a format that could be consumed by our internal Puppet and secret systems.
|
||||
|
||||
* We Puppetized the configuration of two instance roles - Kubernetes nodes and Kubernetes apiservers - in a fashion that allows a user to provide the name of an already-configured cluster to join at provision time.
|
||||
|
||||
* We built a small Go service to consume container logs, append metadata in key/value format to each line, and send them to the hosts’ local syslog endpoint.
|
||||
|
||||
* We enhanced [GLB][9], our internal load balancing service, to support Kubernetes NodePort Services.
|
||||
|
||||
The combination of all of this hard work resulted in a cluster that passed our internal acceptance tests. Given that, we were fairly confident that the same set of inputs (the Kubernetes resources in use by review lab), the same set of data (the network services review lab connected to over a VPN), and same tools would create a similar result. In less than a week’s time - much of which was spent on internal communication and sequencing in the event the migration had significant impact - we were able to migrate this entire workload from a Kubernetes cluster running on AWS to one running inside one of our data centers.
|
||||
|
||||
### Raising the confidence bar[][28]
|
||||
|
||||
With a successful and repeatable pattern for assembling Kubernetes clusters on our metal cloud, it was time to build confidence in the ability of our Unicorn deployment to replace the pool of current frontend servers. At GitHub, it is common practice for engineers and their teams to validate new functionality by creating a [Flipper][29] feature and then opting into it as soon as it is viable to do so. After enhancing our deployment system to deploy a new set of Kubernetes resources to a `github-production` namespace in parallel with our existing production servers and enhancing GLB to support routing staff requests to a different backend based on a Flipper-influenced cookie, we allowed staff to opt-in to the experimental Kubernetes backend with a button in our [mission control bar][30]:
|
||||
|
||||
|
||||
|
||||
The load from internal users helped us find problems, fix bugs, and start getting comfortable with Kubernetes in production. During this period, we worked to increase our confidence by simulating procedures we anticipated performing in the future, writing runbooks, and performing failure tests. We also routed small amounts of production traffic to this cluster to confirm our assumptions about performance and reliability under load, starting with 100 requests per second and expanding later to 10% of the requests to `github.com` and `api.github.com`. With several of these simulations under our belt, we paused briefly to re-evaluate the risk of a full migration.
|
||||
|
||||
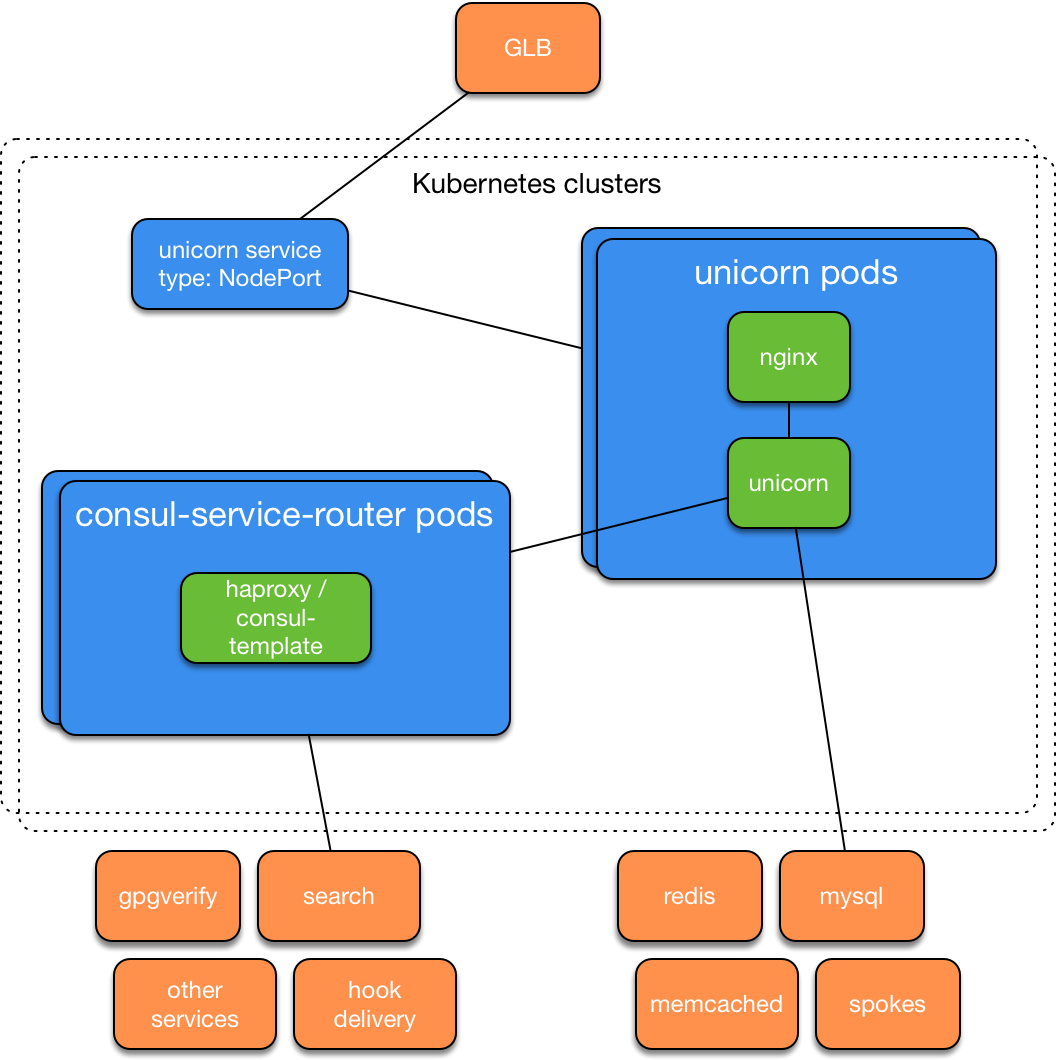
|
||||
|
||||
### Cluster Groups[][31]
|
||||
|
||||
Several of our failure tests produced results we didn’t expect. Particularly, a test that simulated the failure of a single apiserver node disrupted the cluster in a way that negatively impacted the availability of running workloads. Investigations into the results of these tests did not produce conclusive results, but helped us identify that the disruption was likely related to an interaction between the various clients that connect to the Kubernetes apiserver (like `calico-agent`, `kubelet`, `kube-proxy`, and `kube-controller-manager`) and our internal load balancer’s behavior during an apiserver node failure. Given that we had observed a Kubernetes cluster degrade in a way that might disrupt service, we started looking at running our flagship application on multiple clusters in each site and automating the process of diverting requests away from a unhealthy cluster to the other healthy ones.
|
||||
|
||||
Similar work was already on our roadmap to support deploying this application into multiple independently-operated sites, and other positive trade-offs of this approach - including presenting a viable story for low-disruption cluster upgrades and associating clusters with existing failure domains like shared network and power devices - influenced us to go down this route. We eventually settled on a design that uses our deployment system’s support for deploying to multiple “partitions” and enhanced it to support cluster-specific configuration via a custom Kubernetes resource annotation, forgoing the existing federation solutions for an approach that allowed us to use the business logic already present in our deployment system.
|
||||
|
||||
### From 10% to 100%[][32]
|
||||
|
||||
With Cluster Groups in place, we gradually converted frontend servers into Kubernetes nodes and increased the percentage of traffic routed to Kubernetes. Alongside a number of other responsible engineering groups, we completed the frontend transition in just over a month while keeping performance and error rates within our targets.
|
||||
|
||||
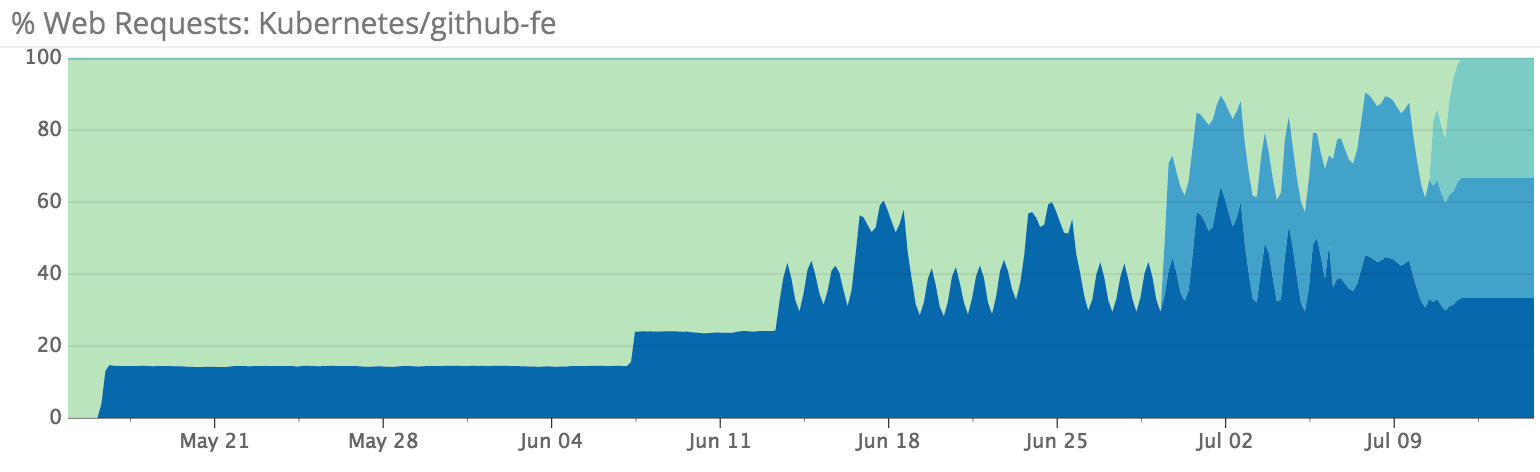
|
||||
|
||||
During this migration, we encountered an issue that persists to this day: during times of high load and/or high rates of container churn, some of our Kubernetes nodes will kernel panic and reboot. While we’re not satisfied with this situation and are continuing to investigate it with high priority, we’re happy that Kubernetes is able to route around these failures automatically and continue serving traffic within our target error bounds. We’ve performed a handful of failure tests that simulated kernel panics with `echo c > /proc/sysrq-trigger` and have found this to be a useful addition to our failure testing patterns.
|
||||
|
||||
### What’s next?[][33]
|
||||
|
||||
We’re inspired by our experience migrating this application to Kubernetes, and are looking forward to migrating more soon. While scope of our first migration was intentionally limited to stateless workloads, we’re excited about experimenting with patterns for running stateful services on Kubernetes.
|
||||
|
||||
During the last phase of this project, we also shipped a workflow for deploying new applications and services into a similar group of Kubernetes clusters. Over the last several months, engineers have already deployed dozens of applications to this cluster. Each of these applications would have previously required configuration management and provisioning support from SREs. With a self-service application provisioning workflow in place, SRE can devote more of our time to delivering infrastructure products to the rest of the engineering organization in support of our best practices, building toward a faster and more resilient GitHub experience for everyone.
|
||||
|
||||
### Thanks[][34]
|
||||
|
||||
We’d like to extend our deep thanks to the entire Kubernetes team for their software, words, and guidance along the way. I’d also like to thank the following GitHubbers for their incredible work on this project: [@samlambert][35], [@jssjr][36], [@keithduncan][37], [@jbarnette][38], [@sophaskins][39], [@aaronbbrown][40], [@rhettg][41], [@bbasata][42], and [@gamefiend][43].
|
||||
|
||||
### Come work with us![][44]
|
||||
|
||||
Want to help the GitHub SRE team solve interesting problems like this? We’d love for you to join us. Apply [here][45]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://githubengineering.com/kubernetes-at-github/
|
||||
|
||||
作者:[jnewland ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/jnewland
|
||||
[1]:https://github.com/jnewland
|
||||
[2]:https://github.com/hashicorp/terraform
|
||||
[3]:https://github.com/kubernetes/kops
|
||||
[4]:https://github.com/bhuga/hubot-chatops-rpc
|
||||
[5]:https://jvns.ca/blog/2016/12/22/container-networking/
|
||||
[6]:https://www.projectcalico.org/
|
||||
[7]:https://github.com/kelseyhightower
|
||||
[8]:https://github.com/kelseyhightower/kubernetes-the-hard-way
|
||||
[9]:https://githubengineering.com/introducing-glb/
|
||||
[10]:https://githubengineering.com/kubernetes-at-github/
|
||||
[11]:https://github.com/jnewland
|
||||
[12]:https://github.com/jnewland
|
||||
[13]:https://github.com/kubernetes/kubernetes/
|
||||
[14]:https://githubengineering.com/githubs-metal-cloud/
|
||||
[15]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#why-change
|
||||
[16]:https://github.com/blog/517-unicorn
|
||||
[17]:http://godrb.com/
|
||||
[18]:https://githubengineering.com/deploying-branches-to-github-com/
|
||||
[19]:https://github.com/blog/470-deployment-script-spring-cleaning
|
||||
[20]:https://githubengineering.com/githubs-metal-cloud/
|
||||
[21]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#why-kubernetes
|
||||
[22]:http://queue.acm.org/detail.cfm?id=2898444
|
||||
[23]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#why-start-with-githubgithub
|
||||
[24]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#rapid-iteration-and-confidence-building-with-a-review-lab
|
||||
[25]:https://githubengineering.com/deploying-branches-to-github-com/#deploy-environments
|
||||
[26]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#kubernetes-on-metal
|
||||
[27]:https://githubengineering.com/githubs-metal-cloud/
|
||||
[28]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#raising-the-confidence-bar
|
||||
[29]:https://github.com/jnunemaker/flipper
|
||||
[30]:https://github.com/blog/1252-how-we-keep-github-fast
|
||||
[31]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#cluster-groups
|
||||
[32]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#from-10-to-100
|
||||
[33]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#whats-next
|
||||
[34]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#thanks
|
||||
[35]:https://github.com/samlambert
|
||||
[36]:https://github.com/jssjr
|
||||
[37]:https://github.com/keithduncan
|
||||
[38]:https://github.com/jbarnette
|
||||
[39]:https://github.com/sophaskins
|
||||
[40]:https://github.com/aaronbbrown
|
||||
[41]:https://github.com/rhettg
|
||||
[42]:https://github.com/bbasata
|
||||
[43]:https://github.com/gamefiend
|
||||
[44]:https://githubengineering.com/kubernetes-at-github/?utm_source=webopsweekly&utm_medium=email#come-work-with-us
|
||||
[45]:https://boards.greenhouse.io/github/jobs/788701
|
||||
@ -0,0 +1,93 @@
|
||||
Creating better disaster recovery plans
|
||||
============================================================
|
||||
|
||||
Five questions for Tanya Reilly: How service interdependencies make recovery harder and why it’s a good idea to deliberately and preemptively manage dependencies.
|
||||
|
||||
[Register for the O'Reilly Velocity Conference][5] to join Tanya Reilly and other industry experts. Use code ORM20 to save 20% on your conference pass (Gold, Silver, and Bronze passes).
|
||||
|
||||
I recently asked Tanya Reilly, Site Reliability Engineer at Google, to share her thoughts on how to make better disaster recovery plans. Tanya is presenting a session titled [_Have you tried turning it off and turning it on again?_][9] at the O’Reilly Velocity Conference, taking place Oct. 1-4 in New York.
|
||||
|
||||
### 1\. What are the most common mistakes people make when planning their backup systems strategy?
|
||||
|
||||
The classic line is "you don't need a backup strategy, you need a restore strategy." If you have backups, but you haven't tested restoring them, you don't really have backups. Testing doesn't just mean knowing you can get the data back; it means knowing how to put it back into the database, how to handle incremental changes, how to reinstall the whole thing if you need to. It means being sure that your recovery path doesn't rely on some system that could be lost at the same time as the data.
|
||||
|
||||
But testing restores is tedious. It's the sort of thing that people will cut corners on if they're busy. It's worth taking the time to make it as simple and painless and automated as possible; never rely on human willpower for anything! At the same time, you have to be sure that the people involved know what to do, so it's good to plan regular wide-scale disaster tests. Recovery exercises are a great way to find out that the documentation for the process is missing or out of date, or that you don't have enough resources (disk, network, etc.) to transfer and reinsert the data.
|
||||
|
||||
### 2\. What are the most common challenges in creating a disaster recovery (DR) plan?
|
||||
|
||||
I think a lot of DR is an afterthought: "We have this great system, and our business relies on it ... I guess we should do DR for it?" And by that point, the system is extremely complex, full of interdependencies and hard to duplicate.
|
||||
|
||||
The first time something is installed, it's often hand-crafted by a human who is tweaking things and getting it right, and sometimes that's the version that sticks around. When you build the _second_ one, it's hard to be sure it's exactly the same. Even in sites with serious config management, you can leave something out, or let it get out of date.
|
||||
|
||||
Encrypted backups aren't much use if you've lost access to the decryption key, for example. And any parts that are only used in a disaster may have bit-rotted since you last checked in on them. The only way to be sure you've covered everything is to fail over in earnest. Plan your disaster for a time when you're ready for it!
|
||||
|
||||
It's better if you can design the system so that the disaster recovery modes are part of normal operation. If your service is designed from the start to be replicated, adding more replicas is a regular operation and probably automated. There are no new pathways; it's just a capacity problem. But there can still be some forgotten components of the system that only run in one or two places. An occasional scheduled fake disaster is good for shaking those out.
|
||||
|
||||
By the way, those forgotten components could include information that's only in one person's brain, so if you find yourself saying, "We can't do our DR failover test until X is back from vacation," then that person is a dangerous single point of failure.
|
||||
|
||||
Parts of the system that are only used in disasters need the most testing, or they'll fail you when you need them. The fewer of those you have, the safer you are and the less toilsome testing you have to do.
|
||||
|
||||
### 3\. Why do service interdependencies make recovery harder after a disaster?
|
||||
|
||||
If you've got just one binary, then recovering it is relatively easy: you start that binary back up. But we increasingly break out common functionality into separate services. Microservices mean we have more flexibility and less reinvention of wheels: if we need a backend to do something and one already exists, great, we can just use that. But someone needs to keep a big picture of what depends on what, because it can get very tangled very fast.
|
||||
|
||||
#### MANAGE, GROW, AND EVOLVE YOUR SYSTEMS
|
||||
|
||||
|
||||
You may know what backends you use directly, but you might not notice when new ones are added into libraries you use. You might depend on something that also indirectly depends on you. After an outage, you can end up with a deadlock: two systems that each can't start until the other is running and providing some functionality. It's a hard situation to recover from!
|
||||
|
||||
You can even end up with things that indirectly depend on themselves—for example, a device that you need to configure to bring up the network, but you can't get to it while the network is down. Often people have thought about these circular dependencies in advance and have some sort of fallback plan, but those are inherently the road less traveled: they're only intended to be used in extreme cases, and they follow a different path through your systems or processes or code. This means they're more likely to have a bug that won't be uncovered until you really, really need them to work.
|
||||
|
||||
### 4\. You advise people to start deliberately managing their dependencies long before they think they need to in order to ward off potentially catastrophic system failure. Why is this important and what’s your advice for doing it effectively?
|
||||
|
||||
Managing your dependencies is essential for being sure you can recover from a disaster. It makes operating the systems easier too. If your dependencies aren't reliable, you can't be reliable, so you need to know what they are.
|
||||
|
||||
It's possible to start managing dependencies after they've become chaotic, but it's much, much easier if you start early. You can set policies on the use of various services—for example, you must be this high in the stack to depend on this set of systems. You can introduce a culture of thinking about dependencies by making it a regular part of design document review. But bear in mind that lists of dependencies will quickly become stale; it's best if you have programmatic dependency discovery, and even dependency enforcement. [My Velocity talk][10] covers more about how we do that.
|
||||
|
||||
The other advantage of starting early is that you can split up your services into vertical "strata," where the functionality in each stratum must be able to come completely online before the next one begins. So, for example, you could say that the network has to be able to completely start up without using any other services. Then, say, your storage systems should depend on nothing but the network, the application backends should only depend on network and storage, and so on. Different strata will make sense for different architectures.
|
||||
|
||||
If you plan this in advance, it's much easier for new services to choose dependencies. Each one should only depend on services lower in the stack. You can still end up with cycles—things in the same stratum depending on each other—but they're more tightly contained and easier to deal with on a case-by-case basis.
|
||||
|
||||
### 5\. What other parts of the program for Velocity NY are of interest to you?
|
||||
|
||||
I've got my whole Tuesday and Wednesday schedule completely worked out! As you might have gathered, I care a lot about making huge interdependent systems manageable, so I'm looking forward to hearing [Carin Meier's thoughts on managing system complexity][11], [Sarah Wells on microservices][12] and [Baron Schwartz on observability][13]. I'm fascinated to hear [Jon Moore's story][14] on how Comcast went from yearly release cycles to releasing daily. And as an ex-sysadmin, I'm looking forward to hearing [where Bryan Liles sees that role going][15].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nikki McDonald
|
||||
|
||||
Nikki McDonald is a content director at O'Reilly Media, Inc. She lives in Ann Arbor, Michigan.
|
||||
|
||||
Tanya Reilly
|
||||
|
||||
Tanya Reilly has been a Systems Administrator and Site Reliability Engineer at Google since 2005, working on low-level infrastructure like distributed locking, load balancing, and bootstrapping. Before Google, she was a Systems Administrator at eircom.net, Ireland’s largest ISP, and before that she was the entire IT Department for a small software house.
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/creating-better-disaster-recovery-plans
|
||||
|
||||
作者:[ Nikki McDonald][a],[Tanya Reilly][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/nikki-mcdonald
|
||||
[b]:https://www.oreilly.com/people/5c97a-tanya-reilly
|
||||
[1]:https://pixabay.com/en/crane-baukran-load-crane-crane-arm-2436704/
|
||||
[2]:https://conferences.oreilly.com/velocity/vl-ny?intcmp=il-webops-confreg-reg-vlny17_new_site_right_rail_cta
|
||||
[3]:https://www.oreilly.com/people/nikki-mcdonald
|
||||
[4]:https://www.oreilly.com/people/5c97a-tanya-reilly
|
||||
[5]:https://conferences.oreilly.com/velocity/vl-ny?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_text_cta
|
||||
[6]:https://www.oreilly.com/ideas/creating-better-disaster-recovery-plans
|
||||
[7]:https://conferences.oreilly.com/velocity/vl-ny?intcmp=il-webops-confreg-reg-vlny17_new_site_right_rail_cta
|
||||
[8]:https://conferences.oreilly.com/velocity/vl-ny?intcmp=il-webops-confreg-reg-vlny17_new_site_right_rail_cta
|
||||
[9]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/61400?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[10]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/61400?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[11]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/62779?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[12]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/61597?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[13]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/61630?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[14]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/62733?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[15]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/62893?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
@ -0,0 +1,728 @@
|
||||
Go vs .NET Core in terms of HTTP performance
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Hello Friends!
|
||||
|
||||
Lately I’ve heard a lot of discussion around the new .NET Core and its performance especially on web servers.
|
||||
|
||||
I didn’t want to start comparing two different things, so I did patience for quite long for a more stable version.
|
||||
|
||||
This Monday, Microsoft [announced the .NET Core version 2.0][7], so I feel ready to do it! Do you?
|
||||
|
||||
As we already mentioned, we will compare two identical things here, in terms of application, the expected response and the stability of their run times, so we will not try to put more things in the game like `JSON` or `XML`encoders and decoders, just a simple text message. To achieve a fair comparison we will use the [MVC architecture pattern][8] on both sides, Go and .NET Core.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
[Go][9] (or Golang): is a [rapidly growing][10] open source programming language designed for building simple, fast, and reliable software.
|
||||
|
||||
There are not lot of web frameworks for Go with MVC support but, luckily for us Iris does the job.
|
||||
|
||||
[Iris][11]: A fast, simple and efficient micro web framework for Go. It provides a beautifully expressive and easy to use foundation for your next website, API, or distributed app.
|
||||
|
||||
[C#][12]: is a general-purpose, object-oriented programming language. Its development team is led by [Anders Hejlsberg][13].
|
||||
|
||||
[.NET Core][14]: Develop high performance applications in less time, on any platform.
|
||||
|
||||
Download Go from [https://golang.org/dl][15] and .NET Core from [https://www.microsoft.com/net/core][16].
|
||||
|
||||
After you’ve download and install these, you will need Iris from Go’s side. Installation is very easy, just open your terminal and execute:
|
||||
|
||||
```
|
||||
go get -u github.com/kataras/iris
|
||||
```
|
||||
|
||||
### Benchmarking
|
||||
|
||||
#### Hardware
|
||||
|
||||
* Processor: Intel(R) Core(TM) i7–4710HQ CPU @ 2.50GHz 2.50GHz
|
||||
|
||||
* RAM: 8.00 GB
|
||||
|
||||
#### Software
|
||||
|
||||
* OS: Microsoft Windows [Version 10.0.15063], power plan is “High performance”
|
||||
|
||||
* HTTP Benchmark Tool: [https://github.com/codesenberg/bombardier][1], latest version 1.1
|
||||
|
||||
* .NET Core: [https://www.microsoft.com/net/core][2], latest version 2.0
|
||||
|
||||
* Iris: [https://github.com/kataras/iris][3], latest version 8.3 built with [go1.8.3][4]
|
||||
|
||||
Both of the applications will just return the text “value” on request path “api/values/{id}”.
|
||||
|
||||
.NET Core MVC
|
||||
|
||||
|
||||

|
||||
Logo designed by [Pablo Iglesias][5].
|
||||
|
||||
Created using `dotnet new webapi` . That `webapi`template will generate the code for you, including the `return “value” `on `GET `method requests.
|
||||
|
||||
_Source Code_
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.IO;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore;
|
||||
using Microsoft.AspNetCore.Hosting;
|
||||
using Microsoft.Extensions.Configuration;
|
||||
using Microsoft.Extensions.Logging;
|
||||
|
||||
namespace netcore_mvc
|
||||
{
|
||||
public class Program
|
||||
{
|
||||
public static void Main(string[] args)
|
||||
{
|
||||
BuildWebHost(args).Run();
|
||||
}
|
||||
|
||||
public static IWebHost BuildWebHost(string[] args) =>
|
||||
WebHost.CreateDefaultBuilder(args)
|
||||
.UseStartup<Startup>()
|
||||
.Build();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore.Builder;
|
||||
using Microsoft.AspNetCore.Hosting;
|
||||
using Microsoft.Extensions.Configuration;
|
||||
using Microsoft.Extensions.DependencyInjection;
|
||||
using Microsoft.Extensions.Logging;
|
||||
using Microsoft.Extensions.Options;
|
||||
|
||||
namespace netcore_mvc
|
||||
{
|
||||
public class Startup
|
||||
{
|
||||
public Startup(IConfiguration configuration)
|
||||
{
|
||||
Configuration = configuration;
|
||||
}
|
||||
|
||||
public IConfiguration Configuration { get; }
|
||||
|
||||
// This method gets called by the runtime. Use this method to add services to the container.
|
||||
public void ConfigureServices(IServiceCollection services)
|
||||
{
|
||||
services.AddMvcCore();
|
||||
}
|
||||
|
||||
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
|
||||
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
|
||||
{
|
||||
app.UseMvc();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore.Mvc;
|
||||
|
||||
namespace netcore_mvc.Controllers
|
||||
{
|
||||
// ValuesController is the equivalent
|
||||
// `ValuesController` of the Iris 8.3 mvc application.
|
||||
[Route("api/[controller]")]
|
||||
public class ValuesController : Controller
|
||||
{
|
||||
// Get handles "GET" requests to "api/values/{id}".
|
||||
[HttpGet("{id}")]
|
||||
public string Get(int id)
|
||||
{
|
||||
return "value";
|
||||
}
|
||||
|
||||
// Put handles "PUT" requests to "api/values/{id}".
|
||||
[HttpPut("{id}")]
|
||||
public void Put(int id, [FromBody]string value)
|
||||
{
|
||||
}
|
||||
|
||||
// Delete handles "DELETE" requests to "api/values/{id}".
|
||||
[HttpDelete("{id}")]
|
||||
public void Delete(int id)
|
||||
{
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
_Start the .NET Core web server_
|
||||
|
||||
```
|
||||
$ cd netcore-mvc
|
||||
$ dotnet run -c Release
|
||||
Hosting environment: Production
|
||||
Content root path: C:\mygopath\src\github.com\kataras\iris\_benchmarks\netcore-mvc
|
||||
Now listening on: http://localhost:5000
|
||||
Application started. Press Ctrl+C to shut down.
|
||||
```
|
||||
|
||||
_Target and run the HTTP benchmark tool_
|
||||
|
||||
```
|
||||
$ bombardier -c 125 -n 5000000 http://localhost:5000/api/values/5
|
||||
Bombarding http://localhost:5000/api/values/5 with 5000000 requests using 125 connections
|
||||
5000000 / 5000000 [=====================================================] 100.00% 2m3s
|
||||
Done!
|
||||
Statistics Avg Stdev Max
|
||||
Reqs/sec 40226.03 8724.30 161919
|
||||
Latency 3.09ms 1.40ms 169.12ms
|
||||
HTTP codes:
|
||||
1xx - 0, 2xx - 5000000, 3xx - 0, 4xx - 0, 5xx - 0
|
||||
others - 0
|
||||
Throughput: 8.91MB/s
|
||||
```
|
||||
|
||||
Iris MVC
|
||||
|
||||
|
||||

|
||||
Logo designed by [Santosh Anand][6].
|
||||
|
||||
_Source Code_
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"github.com/kataras/iris"
|
||||
"github.com/kataras/iris/_benchmarks/iris-mvc/controllers"
|
||||
)
|
||||
|
||||
func main() {
|
||||
app := iris.New()
|
||||
app.Controller("/api/values/{id}", new(controllers.ValuesController))
|
||||
app.Run(iris.Addr(":5000"), iris.WithoutVersionChecker)
|
||||
}
|
||||
view raw
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
package controllers
|
||||
|
||||
import "github.com/kataras/iris/mvc"
|
||||
|
||||
// ValuesController is the equivalent
|
||||
// `ValuesController` of the .net core 2.0 mvc application.
|
||||
type ValuesController struct {
|
||||
mvc.Controller
|
||||
}
|
||||
|
||||
// Get handles "GET" requests to "api/values/{id}".
|
||||
func (vc *ValuesController) Get() {
|
||||
// id,_ := vc.Params.GetInt("id")
|
||||
vc.Ctx.WriteString("value")
|
||||
}
|
||||
|
||||
// Put handles "PUT" requests to "api/values/{id}".
|
||||
func (vc *ValuesController) Put() {}
|
||||
|
||||
// Delete handles "DELETE" requests to "api/values/{id}".
|
||||
func (vc *ValuesController) Delete() {}
|
||||
```
|
||||
|
||||
|
||||
_Start the Go web server_
|
||||
|
||||
```
|
||||
$ cd iris-mvc
|
||||
$ go run main.go
|
||||
Now listening on: http://localhost:5000
|
||||
Application started. Press CTRL+C to shut down.
|
||||
```
|
||||
|
||||
_Target and run the HTTP benchmark tool_
|
||||
|
||||
```
|
||||
$ bombardier -c 125 -n 5000000 http://localhost:5000/api/values/5
|
||||
Bombarding http://localhost:5000/api/values/5 with 5000000 requests using 125 connections
|
||||
5000000 / 5000000 [======================================================] 100.00% 47s
|
||||
Done!
|
||||
Statistics Avg Stdev Max
|
||||
Reqs/sec 105643.81 7687.79 122564
|
||||
Latency 1.18ms 366.55us 22.01ms
|
||||
HTTP codes:
|
||||
1xx - 0, 2xx - 5000000, 3xx - 0, 4xx - 0, 5xx - 0
|
||||
others - 0
|
||||
Throughput: 19.65MB/s
|
||||
```
|
||||
|
||||
For those who understand better by images, I did print my screen too!
|
||||
|
||||
Click [here][23] to see these screenshots.
|
||||
|
||||
#### Summary
|
||||
|
||||
* Time to complete the `5000000 requests` - smaller is better.
|
||||
|
||||
* Reqs/sec — bigger is better.
|
||||
|
||||
* Latency — smaller is better
|
||||
|
||||
* Throughput — bigger is better.
|
||||
|
||||
* Memory usage — smaller is better.
|
||||
|
||||
* LOC (Lines Of Code) — smaller is better.
|
||||
|
||||
.NET Core MVC Application, written using 86 lines of code, ran for 2 minutes and 8 seconds serving 39311.56 requests per second within 3.19mslatency in average and 229.73ms max, the memory usage of all these was ~126MB (without the dotnet host).
|
||||
|
||||
Iris MVC Application, written using 27 lines of code, ran for 47 secondsserving 105643.71 requests per second within 1.18ms latency in average and 22.01ms max, the memory usage of all these was ~12MB.
|
||||
|
||||
> There is also another benchmark with templates, scroll to the bottom.
|
||||
|
||||
Update 20 August 2017
|
||||
|
||||
As [Josh Clark][24] and [Scott Hanselman][25] pointed out on this [re-twee][26]t , on .NET Core `Startup.cs` file the line with `services.AddMvc();` can be replaced with `services.AddMvcCore();` . I followed their helpful instructions and re-run the benchmarks. The article now contains the latest benchmark output for the .NET Core application with the change both Josh and Scott noted.
|
||||
|
||||
|
||||
@topdawgevh @shanselman they also used AddMvc() instead of AddMvcCore()... doesn't one include more middleware?
|
||||
|
||||
— @clarkis117
|
||||
|
||||
@clarkis117 @topdawgevh Cool @MakisMaropoulos we'll take a look. @ben_a_adams @davidfowl. Good learnings on how to make easier performant defaults.
|
||||
|
||||
— @shanselman
|
||||
|
||||
@shanselman @clarkis117 @topdawgevh @ben_a_adams @davidfowl @shanselman @ben_a_adams @davidfowl Thank you for your feedback! I did update the results, no difference. I'm open for any other suggestion
|
||||
|
||||
— @MakisMaropoulos
|
||||
|
||||
>It had a small difference but not as huge (8.91MB/s from 8.61MB/s)
|
||||
|
||||
|
||||
|
||||
For those who want to compare with the standard `services.AddMvc(); `you can see the old output by pressing [here][27].
|
||||
|
||||
* * *
|
||||
|
||||
### Can you stay a bit longer for one more?
|
||||
|
||||
Let’s run one more benchmark, spawn `1000000 requests` but this time we expect `HTML` generated by templates via the view engine.
|
||||
|
||||
#### .NET Core MVC with Templates
|
||||
|
||||
|
||||
```
|
||||
using System;
|
||||
|
||||
namespace netcore_mvc_templates.Models
|
||||
{
|
||||
public class ErrorViewModel
|
||||
{
|
||||
public string Title { get; set; }
|
||||
public int Code { get; set; }
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Diagnostics;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore.Mvc;
|
||||
using netcore_mvc_templates.Models;
|
||||
|
||||
namespace netcore_mvc_templates.Controllers
|
||||
{
|
||||
public class HomeController : Controller
|
||||
{
|
||||
public IActionResult Index()
|
||||
{
|
||||
return View();
|
||||
}
|
||||
|
||||
public IActionResult About()
|
||||
{
|
||||
ViewData["Message"] = "Your application description page.";
|
||||
|
||||
return View();
|
||||
}
|
||||
|
||||
public IActionResult Contact()
|
||||
{
|
||||
ViewData["Message"] = "Your contact page.";
|
||||
|
||||
return View();
|
||||
}
|
||||
|
||||
public IActionResult Error()
|
||||
{
|
||||
return View(new ErrorViewModel { Title = "Error", Code = 500});
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.IO;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore;
|
||||
using Microsoft.AspNetCore.Hosting;
|
||||
using Microsoft.Extensions.Configuration;
|
||||
using Microsoft.Extensions.Logging;
|
||||
|
||||
namespace netcore_mvc_templates
|
||||
{
|
||||
public class Program
|
||||
{
|
||||
public static void Main(string[] args)
|
||||
{
|
||||
BuildWebHost(args).Run();
|
||||
}
|
||||
|
||||
public static IWebHost BuildWebHost(string[] args) =>
|
||||
WebHost.CreateDefaultBuilder(args)
|
||||
.UseStartup<Startup>()
|
||||
.Build();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore.Builder;
|
||||
using Microsoft.AspNetCore.Hosting;
|
||||
using Microsoft.Extensions.Configuration;
|
||||
using Microsoft.Extensions.DependencyInjection;
|
||||
|
||||
namespace netcore_mvc_templates
|
||||
{
|
||||
public class Startup
|
||||
{
|
||||
public Startup(IConfiguration configuration)
|
||||
{
|
||||
Configuration = configuration;
|
||||
}
|
||||
|
||||
public IConfiguration Configuration { get; }
|
||||
|
||||
// This method gets called by the runtime. Use this method to add services to the container.
|
||||
public void ConfigureServices(IServiceCollection services)
|
||||
{
|
||||
/* An unhandled exception was thrown by the application.
|
||||
System.InvalidOperationException: No service for type
|
||||
'Microsoft.AspNetCore.Mvc.ViewFeatures.ITempDataDictionaryFactory' has been registered.
|
||||
Solution: Use AddMvc() instead of AddMvcCore() in Startup.cs and it will work.
|
||||
*/
|
||||
// services.AddMvcCore();
|
||||
services.AddMvc();
|
||||
}
|
||||
|
||||
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
|
||||
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
|
||||
{
|
||||
app.UseStaticFiles();
|
||||
|
||||
app.UseMvc(routes =>
|
||||
{
|
||||
routes.MapRoute(
|
||||
name: "default",
|
||||
template: "{controller=Home}/{action=Index}/{id?}");
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
/*
|
||||
wwwroot/css
|
||||
wwwroot/images
|
||||
wwwroot/js
|
||||
wwwroot/lib
|
||||
wwwroot/favicon.ico
|
||||
|
||||
|
||||
Views/Shared/_Layout.cshtml
|
||||
Views/Shared/Error.cshtml
|
||||
|
||||
Views/Home/About.cshtml
|
||||
Views/Home/Contact.cshtml
|
||||
Views/Home/Index.cshtml
|
||||
|
||||
These files are quite long to be shown in this article but you can view them at:
|
||||
https://github.com/kataras/iris/tree/master/_benchmarks/netcore-mvc-templates
|
||||
```
|
||||
|
||||
|
||||
_Start the .NET Core web server_
|
||||
|
||||
```
|
||||
$ cd netcore-mvc-templates
|
||||
$ dotnet run -c Release
|
||||
Hosting environment: Production
|
||||
Content root path: C:\mygopath\src\github.com\kataras\iris\_benchmarks\netcore-mvc-templates
|
||||
Now listening on: http://localhost:5000
|
||||
Application started. Press Ctrl+C to shut down.
|
||||
```
|
||||
|
||||
_Target and run the HTTP benchmark tool_
|
||||
|
||||
```
|
||||
Bombarding http://localhost:5000 with 1000000 requests using 125 connections
|
||||
1000000 / 1000000 [====================================================] 100.00% 1m20s
|
||||
Done!
|
||||
Statistics Avg Stdev Max
|
||||
Reqs/sec 11738.60 7741.36 125887
|
||||
Latency 10.10ms 22.10ms 1.97s
|
||||
HTTP codes:
|
||||
1xx — 0, 2xx — 1000000, 3xx — 0, 4xx — 0, 5xx — 0
|
||||
others — 0
|
||||
Throughput: 89.03MB/s
|
||||
```
|
||||
|
||||
#### Iris MVC with Templates
|
||||
|
||||
```
|
||||
package controllers
|
||||
|
||||
import "github.com/kataras/iris/mvc"
|
||||
|
||||
type AboutController struct{ mvc.Controller }
|
||||
|
||||
func (c *AboutController) Get() {
|
||||
c.Data["Title"] = "About"
|
||||
c.Data["Message"] = "Your application description page."
|
||||
c.Tmpl = "about.html"
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
package controllers
|
||||
|
||||
import "github.com/kataras/iris/mvc"
|
||||
|
||||
type ContactController struct{ mvc.Controller }
|
||||
|
||||
func (c *ContactController) Get() {
|
||||
c.Data["Title"] = "Contact"
|
||||
c.Data["Message"] = "Your contact page."
|
||||
c.Tmpl = "contact.html"
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
package models
|
||||
|
||||
// HTTPError a silly structure to keep our error page data.
|
||||
type HTTPError struct {
|
||||
Title string
|
||||
Code int
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
package controllers
|
||||
|
||||
import "github.com/kataras/iris/mvc"
|
||||
|
||||
type IndexController struct{ mvc.Controller }
|
||||
|
||||
func (c *IndexController) Get() {
|
||||
c.Data["Title"] = "Home Page"
|
||||
c.Tmpl = "index.html"
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"github.com/kataras/iris/_benchmarks/iris-mvc-templates/controllers"
|
||||
|
||||
"github.com/kataras/iris"
|
||||
"github.com/kataras/iris/context"
|
||||
)
|
||||
|
||||
const (
|
||||
// templatesDir is the exactly the same path that .NET Core is using for its templates,
|
||||
// in order to reduce the size in the repository.
|
||||
// Change the "C\\mygopath" to your own GOPATH.
|
||||
templatesDir = "C:\\mygopath\\src\\github.com\\kataras\\iris\\_benchmarks\\netcore-mvc-templates\\wwwroot"
|
||||
)
|
||||
|
||||
func main() {
|
||||
app := iris.New()
|
||||
app.Configure(configure)
|
||||
|
||||
app.Controller("/", new(controllers.IndexController))
|
||||
app.Controller("/about", new(controllers.AboutController))
|
||||
app.Controller("/contact", new(controllers.ContactController))
|
||||
|
||||
app.Run(iris.Addr(":5000"), iris.WithoutVersionChecker)
|
||||
}
|
||||
|
||||
func configure(app *iris.Application) {
|
||||
app.RegisterView(iris.HTML("./views", ".html").Layout("shared/layout.html"))
|
||||
app.StaticWeb("/public", templatesDir)
|
||||
app.OnAnyErrorCode(onError)
|
||||
}
|
||||
|
||||
type err struct {
|
||||
Title string
|
||||
Code int
|
||||
}
|
||||
|
||||
func onError(ctx context.Context) {
|
||||
ctx.ViewData("", err{"Error", ctx.GetStatusCode()})
|
||||
ctx.View("shared/error.html")
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
/*
|
||||
../netcore-mvc-templates/wwwroot/css
|
||||
../netcore-mvc-templates/wwwroot/images
|
||||
../netcore-mvc-templates/wwwroot/js
|
||||
../netcore-mvc-templates/wwwroot/lib
|
||||
../netcore-mvc-templates/wwwroot/favicon.ico
|
||||
views/shared/layout.html
|
||||
views/shared/error.html
|
||||
views/about.html
|
||||
views/contact.html
|
||||
views/index.html
|
||||
These files are quite long to be shown in this article but you can view them at:
|
||||
https://github.com/kataras/iris/tree/master/_benchmarks/iris-mvc-templates
|
||||
*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
_Start the Go web server_
|
||||
|
||||
```
|
||||
$ cd iris-mvc-templates
|
||||
$ go run main.go
|
||||
Now listening on: http://localhost:5000
|
||||
Application started. Press CTRL+C to shut down.
|
||||
|
||||
```
|
||||
|
||||
_Target and run the HTTP benchmark tool_
|
||||
|
||||
```
|
||||
Bombarding http://localhost:5000 with 1000000 requests using 125 connections
|
||||
1000000 / 1000000 [======================================================] 100.00% 37s
|
||||
Done!
|
||||
Statistics Avg Stdev Max
|
||||
Reqs/sec 26656.76 1944.73 31188
|
||||
Latency 4.69ms 1.20ms 22.52ms
|
||||
HTTP codes:
|
||||
1xx — 0, 2xx — 1000000, 3xx — 0, 4xx — 0, 5xx — 0
|
||||
others — 0
|
||||
Throughput: 192.51MB/s
|
||||
```
|
||||
|
||||
Summary
|
||||
|
||||
* Time to complete the `1000000 requests` — smaller is better.
|
||||
|
||||
* Reqs/sec — bigger is better.
|
||||
|
||||
* Latency — smaller is better
|
||||
|
||||
* Memory usage — smaller is better.
|
||||
|
||||
* Throughput — bigger is better.
|
||||
|
||||
.NET Core MVC with Templates Application ran for 1 minute and 20 seconds serving 11738.60 requests per second with 89.03MB/s within 10.10ms latency in average and 1.97s max, the memory usage of all these was ~193MB (without the dotnet host).
|
||||
|
||||
Iris MVC with Templates Application ran for 37 seconds serving 26656.76requests per second with 192.51MB/s within 1.18ms latency in average and 22.52ms max, the memory usage of all these was ~17MB.
|
||||
|
||||
### What next?
|
||||
|
||||
Download the example source code from [there ][32]and run the same benchmarks from your machine, then come back here and share your results with the rest of us!
|
||||
|
||||
For those who want to add other go or c# .net core web frameworks to the list please push a PR to the `_benchmarks` folder inside [this repository][33].
|
||||
|
||||
I need to personally thanks the [dev.to][34] team for sharing my article at their twitter account, as well.
|
||||
|
||||
Go vs .NET Core in terms of HTTP performance { author: @MakisMaropoulos } https://t.co/IXL5LSpnjX
|
||||
|
||||
— @ThePracticalDev
|
||||
|
||||
|
||||
Thank you all for the 100% green feedback, have fun!
|
||||
|
||||
#### Update: Monday, 21 August 2017
|
||||
|
||||
A lot of people reached me saying that want to see a new benchmarking article based on the .NET Core’s lower level Kestrel this time.
|
||||
|
||||
So I did, follow the below link to learn the performance difference between Kestrel and Iris, it contains a sessions storage management benchmark too!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/go-vs-net-core-in-terms-of-http-performance-7535a61b67b8
|
||||
|
||||
作者:[ Gerasimos Maropoulos][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@kataras?source=post_header_lockup
|
||||
[1]:https://github.com/codesenberg/bombardier
|
||||
[2]:https://www.microsoft.com/net/core
|
||||
[3]:https://github.com/kataras/iris
|
||||
[4]:https://golang.org/
|
||||
[5]:https://github.com/campusMVP/dotnetCoreLogoPack
|
||||
[6]:https://github.com/santoshanand
|
||||
[7]:https://blogs.msdn.microsoft.com/dotnet/2017/08/14/announcing-net-core-2-0/
|
||||
[8]:https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller
|
||||
[9]:https://golang.org/
|
||||
[10]:http://www.tiobe.com/tiobe-index/
|
||||
[11]:http://iris-go.com/
|
||||
[12]:https://en.wikipedia.org/wiki/C_Sharp_%28programming_language%29
|
||||
[13]:https://twitter.com/ahejlsberg
|
||||
[14]:https://www.microsoft.com/net/
|
||||
[15]:https://golang.org/dl
|
||||
[16]:https://www.microsoft.com/net/core
|
||||
[17]:http://localhost:5000/
|
||||
[18]:http://localhost:5000/api/values/5
|
||||
[19]:http://localhost:5000/api/values/5
|
||||
[20]:http://localhost:5000/
|
||||
[21]:http://localhost:5000/api/values/5
|
||||
[22]:http://localhost:5000/api/values/5
|
||||
[23]:https://github.com/kataras/iris/tree/master/_benchmarks/screens
|
||||
[24]:https://twitter.com/clarkis117
|
||||
[25]:https://twitter.com/shanselman
|
||||
[26]:https://twitter.com/shanselman/status/899005786826788865
|
||||
[27]:https://github.com/kataras/iris/blob/master/_benchmarks/screens/5m_requests_netcore-mvc.png
|
||||
[28]:http://localhost:5000/
|
||||
[29]:http://localhost:5000/
|
||||
[30]:http://localhost:5000/
|
||||
[31]:http://localhost:5000/
|
||||
[32]:https://github.com/kataras/iris/tree/master/_benchmarks
|
||||
[33]:https://github.com/kataras/iris
|
||||
[34]:https://dev.to/kataras/go-vsnet-core-in-terms-of-http-performance
|
||||
144
sources/tech/20170818 How to recover from a git mistake.md
Normal file
144
sources/tech/20170818 How to recover from a git mistake.md
Normal file
@ -0,0 +1,144 @@
|
||||
How to recover from a git mistake
|
||||
============================================================
|
||||
|
||||
### Don't let an error in a git command wipe out days of work.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Today my colleague almost lost everything that he did over four days of work. Because of an incorrect **git **command, he dropped the changes he'd saved on [stash][20]. After this sad episode, we looked for a way to try to recover his work... and we did it!
|
||||
|
||||
First a warning: When you are implementing a big feature, split it in small pieces and commit it regularly. It's not a good idea to work for a long time without committing your changes.
|
||||
|
||||
Now that we've gotten that out of the way, let's demonstrate how to recover changes accidentally dropped from stash.
|
||||
|
||||
My example repository, which has only one source file, **main.c**, looks like this:
|
||||
|
||||
### [missing_data_from_stash_01.jpeg][9]
|
||||
|
||||

|
||||
|
||||
José Guilherme Vanz, [CC BY][1]
|
||||
|
||||
It has only one commit, the initial commit:
|
||||
|
||||
### [missing_data_from_stash_02.jpeg][10]
|
||||
|
||||

|
||||
|
||||
José Guilherme Vanz, [CC BY][2]
|
||||
|
||||
The first version of our file is:
|
||||
|
||||
### [missing_data_from_stash_03.jpeg][11]
|
||||
|
||||

|
||||
|
||||
José Guilherme Vanz, [CC BY][3]
|
||||
|
||||
I'll start to code something. For this example, I do not need to make a big change, just something to put in the stash, so I will just add a new line. The **git-diff** output should be:
|
||||
|
||||
### [missing_data_from_stash_04.jpeg][12]
|
||||
|
||||

|
||||
|
||||
José Guilherme Vanz, [CC BY][4]
|
||||
|
||||
Now, suppose that I want to pull some new changes from a remote repository, but I'm not ready to commit my change. Instead, I decide to stash it, pull the remote repository's changes, then apply my change back to the master. I execute the following command to move my change to stash:
|
||||
|
||||
```
|
||||
git stash
|
||||
```
|
||||
|
||||
Looking into the stash with **git stash list**, I can see my change there:
|
||||
|
||||
### [missing_data_from_stash_06.jpeg][13]
|
||||
|
||||

|
||||
|
||||
José Guilherme Vanz, [CC BY][5]
|
||||
|
||||
My code is in a safe place and the master branch is clean (I can check this with **git status**). Now I just need to pull the remote repository changes, then apply my change on the master, and I should be set.
|
||||
|
||||
But I accidentally execute:
|
||||
|
||||
```
|
||||
git stash drop
|
||||
```
|
||||
|
||||
which deletes the stash, instead of:
|
||||
|
||||
```
|
||||
git stash pop
|
||||
```
|
||||
|
||||
which would have applied the stash before dropping it from my stack. If I execute **git stash list** again, I can see I dropped my change from the stash without applying it on the master branch. OMG! Who can help me?
|
||||
|
||||
Good news: **git** did not delete the object that contains my change; it just removed the reference to it. To prove this, I use the **git-fsck** command, which verifies the connectivity and validity of the objects in the database. Here's the output after I executed the **git-fsck** command on the repository:
|
||||
|
||||
### [missing_data_from_stash_07.jpeg][14]
|
||||
|
||||

|
||||
|
||||
José Guilherme Vanz, [CC BY][6]
|
||||
|
||||
With the **--unreachable **argument, I asked **git-fsck** to show me the objects that are unreachable. As you can see, it showed no unreachable objects. After I dropped the changes on my stash, I executed the same command, and received a different output:
|
||||
|
||||
### [missing_data_from_stash_08.jpeg][15]
|
||||
|
||||

|
||||
|
||||
José Guilherme Vanz, [CC BY][7]
|
||||
|
||||
Now there are three unreachable objects. But which one is my change? Actually, I don't know. I have to search for it by executing the **git-show** command to see each object.
|
||||
|
||||
### [missing_data_from_stash_09.jpeg][16]
|
||||
|
||||

|
||||
|
||||
José Guilherme Vanz, [CC BY][8]
|
||||
|
||||
There it is! The ID **95ccbd927ad4cd413ee2a28014c81454f4ede82c** corresponds to my change. Now that I found the missing change, I can recover it! One solution is check out the ID into a new branch or apply the commit directly. If you have the ID of the object with your changes, you can decide the best way to put changes on the master branch again. For this example, I will use **git-stash** to apply the commit on my master branch again.
|
||||
|
||||
```
|
||||
git stash apply 95ccbd927ad4cd413ee2a28014c81454f4ede82c
|
||||
```
|
||||
|
||||
Another important thing to remember is **git** runs its garbage collector periodically. After a **gc** execution, you can no longer see the unreachable objects using **git-fsck**.
|
||||
|
||||
_This article was [originally published][18] on the author's blog and is reprinted with permission. _
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/8/recover-dropped-data-stash
|
||||
|
||||
作者:[Jose Guilherme Vanz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jvanz
|
||||
[1]:https://creativecommons.org/licenses/by/4.0/
|
||||
[2]:https://creativecommons.org/licenses/by/4.0/
|
||||
[3]:https://creativecommons.org/licenses/by/4.0/
|
||||
[4]:https://creativecommons.org/licenses/by/4.0/
|
||||
[5]:https://creativecommons.org/licenses/by/4.0/
|
||||
[6]:https://creativecommons.org/licenses/by/4.0/
|
||||
[7]:https://creativecommons.org/licenses/by/4.0/
|
||||
[8]:https://creativecommons.org/licenses/by/4.0/
|
||||
[9]:https://opensource.com/file/366691
|
||||
[10]:https://opensource.com/file/366696
|
||||
[11]:https://opensource.com/file/366701
|
||||
[12]:https://opensource.com/file/366706
|
||||
[13]:https://opensource.com/file/366711
|
||||
[14]:https://opensource.com/file/366716
|
||||
[15]:https://opensource.com/file/366721
|
||||
[16]:https://opensource.com/file/366726
|
||||
[17]:https://opensource.com/article/17/8/recover-dropped-data-stash?rate=BUOLRB3pka4kgSQFTTEfX7_HJrX6duyjronp9GABnGU
|
||||
[18]:http://jvanz.com/recovering-missed-data-from-stash.html#recovering-missed-data-from-stash
|
||||
[19]:https://opensource.com/user/94726/feed
|
||||
[20]:https://www.git-scm.com/docs/git-stash
|
||||
[21]:https://opensource.com/users/jvanz
|
||||
[22]:https://opensource.com/users/jvanz
|
||||
[23]:https://opensource.com/article/17/8/recover-dropped-data-stash#comments
|
||||
@ -0,0 +1,40 @@
|
||||
OpenShift on OpenStack: Delivering Applications Better Together
|
||||
============================================================
|
||||
|
||||
Have you ever asked yourself, where should I run OpenShift? The answer is anywhere—it runs great on bare metal, on virtual machines, in a private cloud or in the public cloud. But, there are some reasons why people are moving to private and public clouds related to automation around full stack exposition and consumption of resources. A traditional operating system has always been about [exposition and consumption of hardware resources][2]—hardware provides resources, applications consume them, and the operating system has always been the traffic cop. But a traditional operating system has always been confined to a single machine[1].
|
||||
|
||||
Well, in the cloud-native world, this now means expanding this concept to include multiple operating system instances. That’s where OpenStack and OpenShift come in. In a cloud-native world, virtual machines, storage volumes and network segments all become dynamically provisioned building blocks. We architect our applications from these building blocks. They are typically paid for by the hour or minute and deprovisioned when they are no longer needed. But you need to think of them as dynamically provisioned capacity for applications. OpenStack is really good at dynamically provisioning capacity (exposition), and OpenShift is really good at dynamically provisioning applications (consumption), but how do we glue them together to provide a dynamic, highly programmable, multi-node operating system?
|
||||
|
||||
To understand, let’s take a look at what would happen if we installed OpenShift in a traditional environment— imagine we want to provide developers with dynamic access to create new applications or imagine we want to provide lines of business with access to provision new copies of existing applications to meet contractual obligations. Each application would need access to persistent storage. Persistent storage is not ephemeral, and in a traditional environment, this is provisioned by filing a ticket. That’s OK, we could wire up OpenShift to file a ticket every time it needs storage. A storage admin could log into the enterprise storage array and carve off volumes as needed, then hand them back to OpenShift to satisfy applications. But this would be a horribly slow, manual process—and, you would probably have storage administrators quit.
|
||||
|
||||

|
||||
|
||||
In a cloud-native world, we should think about this as a policy-driven, automated process. The storage administrator becomes more strategic, setting policies, quota, and service levels (silver, gold, etc.), but the actual provisioning becomes dynamic.
|
||||
|
||||

|
||||
|
||||
A dynamic process scales to multiple applications – this could be lines of business or even new applications being tested by developers. From 10s of applications to 1000s of applications, dynamic provisioning provides a cloud native experience.
|
||||
|
||||

|
||||
|
||||
The demo video below, shows how dynamic storage provisioning works with Red Hat OpenStack Platform (Cinder volumes) and Red Hat OpenShift Container Platform – but dynamic provisioning isn’t restricted to storage alone. Imagine an environment where nodes are scaled up automatically as an instance of OpenShift needs more capacity. Imagine carving off network segments for load testing a particular instance of OpenShift before pushing a particularly sensitive application change. The reasons why you need dynamic provisioning of IT building blocks goes on and on. OpenStack is really designed to do this in a programmatic, API driven way. :
|
||||
|
||||
[YOUTUBE VIDEO](https://youtu.be/PfWmAS9Fc7I)
|
||||
|
||||
OpenShift and OpenStack deliver applications better together. OpenStack dynamically provisions resources, while OpenShift dynamically consumes them. Together, they provide a flexible cloud-native solution for all of your container and virtual machine needs.
|
||||
|
||||
[1] High availability clustering and some specialized operating systems bridged this gap to an extent, but was generally an edge case in computing.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.openshift.com/openshift-on-openstack-delivering-applications-better-together/
|
||||
|
||||
作者:[SCOTT MCCARTY ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.openshift.com/author/smccartyredhat-com/
|
||||
[1]:https://blog.openshift.com/author/smccartyredhat-com/
|
||||
[2]:https://docs.google.com/presentation/d/139_dxpiYc5JR8yKAP8pl-FcZmOFQCuV8RyDxZqOOcVE/edit
|
||||
@ -0,0 +1,420 @@
|
||||
Your Serverless Raspberry Pi cluster with Docker
|
||||
============================================================
|
||||
|
||||
|
||||
This blog post will show you how to create your own Serverless Raspberry Pi cluster with Docker and the [OpenFaaS][33] framework. People often ask me what they should do with their cluster and this application is perfect for the credit-card sized device - want more compute power? Scale by adding more RPis.
|
||||
|
||||
> "Serverless" is a design pattern for event-driven architectures just like "bridge", "facade", "factory" and "cloud" are also abstract concepts - [so is "serverless"][21].
|
||||
|
||||
Here's my cluster for the blog post - with brass stand-offs used to separate each device.
|
||||
|
||||
|
||||
|
||||
### What is Serverless and why does it matter to you?
|
||||
|
||||
> As an industry we have some explaining to do regarding what the term "serverless" means. For the sake of this blog post let us assume that it is a new architectural pattern for event-driven architectures and that it lets you write tiny, reusable functions in whatever language you like. [Read more on Serverless here][22].
|
||||
|
||||
|
||||
_Serverless is an architectural pattern resulting in: Functions as a Service, or FaaS_
|
||||
|
||||
Serverless functions can do anything, but usually work on a given input - such as an event from GitHub, Twitter, PayPal, Slack, your Jenkins CI pipeline - or in the case of a Raspberry Pi - maybe a real-world sensor input such as a PIR motion sensor, laser tripwire or even a temperature gauge.
|
||||
|
||||

|
||||
|
||||
Let's also assume that serverless functions tend to make use of third-party back-end services to become greater than the sum of their parts.
|
||||
|
||||
For more background information checkout my latest blog post - [Introducing Functions as a Service (FaaS)][34]
|
||||
|
||||
### Overview
|
||||
|
||||
We'll be using [OpenFaaS][35] which lets you turn any single host or cluster into a back-end to run serverless functions. Any binary, script or programming language that can be deployed with Docker will work on [OpenFaaS][36] and you can chose on a scale between speed and flexibility. The good news is a UI and metrics are also built-in.
|
||||
|
||||
Here's what we'll do:
|
||||
|
||||
* Set up Docker on one or more hosts (Raspberry Pi 2/3)
|
||||
|
||||
* Join them together in a Docker Swarm
|
||||
|
||||
* Deploy [OpenFaaS][23]
|
||||
|
||||
* Write our first function in Python
|
||||
|
||||
### Docker Swarm
|
||||
|
||||
Docker is a technology for packaging and deploying applications, it also has clustering built-in which is secure by default and only takes one line to set up. OpenFaaS uses Docker and Swarm to spread your serverless functions across all your available RPis.
|
||||
|
||||

|
||||
_Pictured: 3x Raspberry Pi Zero_
|
||||
|
||||
I recommend using Raspberry Pi 2 or 3 for this project along with an Ethernet switch and a [powerful USB multi-adapter][37].
|
||||
|
||||
### Prepare Raspbian
|
||||
|
||||
Flash [Raspbian Jessie Lite][38] to an SD card, 8GB will do but 16GB is recommended.
|
||||
|
||||
_Note: do not download Raspbian Stretch_
|
||||
|
||||
> The community is helping the Docker team to ready support for Raspbian Stretch, but it's not yet seamless. Please download Jessie Lite from the [RPi foundation's archive here][24]
|
||||
|
||||
I recommend using [Etcher.io][39] to flash the image.
|
||||
|
||||
> Before booting the RPi you'll need to create a file in the boot partition called "ssh". Just keep the file blank. This enables remote logins.
|
||||
|
||||
* Power up and change the hostname
|
||||
|
||||
Now power up the RPi and connect with `ssh`
|
||||
|
||||
```
|
||||
$ ssh pi@raspberrypi.local
|
||||
|
||||
```
|
||||
|
||||
> The password is `raspberry`.
|
||||
|
||||
Use the `raspi-config` utility to change the hostname to `swarm-1` or similar and then reboot.
|
||||
|
||||
While you're here you can also change the memory split between the GPU (graphics) and the system to 16mb.
|
||||
|
||||
* Now install Docker
|
||||
|
||||
We can use a utility script for this:
|
||||
|
||||
```
|
||||
$ curl -sSL https://get.docker.com | sh
|
||||
|
||||
```
|
||||
|
||||
> This installation method may change in the future. As noted above you need to be running Jessie so we have a known configuration.
|
||||
|
||||
You may see a warning like this, but you can ignore it and you should end up with Docker CE 17.05:
|
||||
|
||||
```
|
||||
WARNING: raspbian is no longer updated @ https://get.docker.com/
|
||||
Installing the legacy docker-engine package...
|
||||
|
||||
```
|
||||
|
||||
After, make sure your user account can access the Docker client with this command:
|
||||
|
||||
```
|
||||
$ usermod pi -aG docker
|
||||
|
||||
```
|
||||
|
||||
> If your username isn't `pi` then replace `pi` with `alex` for instance.
|
||||
|
||||
* Change the default password
|
||||
|
||||
Type in `$sudo passwd pi` and enter a new password, please don't skip this step!
|
||||
|
||||
* Repeat
|
||||
|
||||
Now repeat the above for each of the RPis.
|
||||
|
||||
### Create your Swarm cluster
|
||||
|
||||
Log into the first RPi and type in the following:
|
||||
|
||||
```
|
||||
$ docker swarm init
|
||||
Swarm initialized: current node (3ra7i5ldijsffjnmubmsfh767) is now a manager.
|
||||
|
||||
To add a worker to this swarm, run the following command:
|
||||
|
||||
docker swarm join \
|
||||
--token SWMTKN-1-496mv9itb7584pzcddzj4zvzzfltgud8k75rvujopw15n3ehzu-af445b08359golnzhncbdj9o3 \
|
||||
192.168.0.79:2377
|
||||
|
||||
```
|
||||
|
||||
You'll see the output with your join token and the command to type into the other RPis. So log into each one with `ssh` and paste in the command.
|
||||
|
||||
Give this a few seconds to connect then on the first RPi check all your nodes are listed:
|
||||
|
||||
```
|
||||
$ docker node ls
|
||||
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
|
||||
3ra7i5ldijsffjnmubmsfh767 * swarm1 Ready Active Leader
|
||||
k9mom28s2kqxocfq1fo6ywu63 swarm3 Ready Active
|
||||
y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
|
||||
|
||||
```
|
||||
|
||||
Congratulations! You have a Raspberry Pi cluster!
|
||||
|
||||
_*More on clusters_
|
||||
|
||||
You can see my three hosts up and running. Only one is a manager at this point. If our manager were to go _down_ then we'd be in an unrecoverable situation. The way around this is to add redundancy by promoting more of the nodes to managers - they will still run workloads, unless you specifically set up your services to only be placed on workers.
|
||||
|
||||
To upgrade a worker to a manager, just type in `docker node promote <node_name>`from one of your managers.
|
||||
|
||||
> Note: Swarm commands such as `docker service ls` or `docker node ls` can only be done on the manager.
|
||||
|
||||
For a deeper dive into how managers and workers keep "quorum" head over to the [Docker Swarm admin guide][40].
|
||||
|
||||
### OpenFaaS
|
||||
|
||||
Now let's move on to deploying a real application to enable Serverless functions to run on our cluster. [OpenFaaS][41] is a framework for Docker that lets any process or container become a serverless function - at scale and on any hardware or cloud. Thanks to Docker and Golang's portability it also runs very well on a Raspberry Pi.
|
||||
|
||||

|
||||
|
||||
> Please show your support and **star** the [OpenFaaS][25] repository on GitHub.
|
||||
|
||||
Log into the first RPi (where we ran `docker swarm init`) and clone/deploy the project:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas/
|
||||
$ cd faas
|
||||
$ ./deploy_stack.armhf.sh
|
||||
Creating network func_functions
|
||||
Creating service func_gateway
|
||||
Creating service func_prometheus
|
||||
Creating service func_alertmanager
|
||||
Creating service func_nodeinfo
|
||||
Creating service func_markdown
|
||||
Creating service func_wordcount
|
||||
Creating service func_echoit
|
||||
|
||||
```
|
||||
|
||||
Your other RPis will now be instructed by Docker Swarm to start pulling the Docker images from the internet and extracting them to the SD card. The work will be spread across all the RPis so that none of them are overworked.
|
||||
|
||||
This could take a couple of minutes, so you can check when it's done by typing in:
|
||||
|
||||
```
|
||||
$ watch 'docker service ls'
|
||||
ID NAME MODE REPLICAS IMAGE PORTS
|
||||
57ine9c10xhp func_wordcount replicated 1/1 functions/alpine:latest-armhf
|
||||
d979zipx1gld func_prometheus replicated 1/1 alexellis2/prometheus-armhf:1.5.2 *:9090->9090/tcp
|
||||
f9yvm0dddn47 func_echoit replicated 1/1 functions/alpine:latest-armhf
|
||||
lhbk1fc2lobq func_markdown replicated 1/1 functions/markdownrender:latest-armhf
|
||||
pj814yluzyyo func_alertmanager replicated 1/1 alexellis2/alertmanager-armhf:0.5.1 *:9093->9093/tcp
|
||||
q4bet4xs10pk func_gateway replicated 1/1 functions/gateway-armhf:0.6.0 *:8080->8080/tcp
|
||||
v9vsvx73pszz func_nodeinfo replicated 1/1 functions/nodeinfo:latest-armhf
|
||||
|
||||
```
|
||||
|
||||
We want to see 1/1 listed on all of our services.
|
||||
|
||||
Given any service name you can type in the following to see which RPi it was scheduled to:
|
||||
|
||||
```
|
||||
$ docker service ps func_markdown
|
||||
ID IMAGE NODE STATE
|
||||
func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
|
||||
|
||||
```
|
||||
|
||||
The state should be `Running` - if it says `Pending` then the image could still be on its way down from the internet.
|
||||
|
||||
At that point, find the IP address of your RPi and open that in a web-browser on port 8080:
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
|
||||
```
|
||||
|
||||
For example if your IP was: 192.168.0.100 - then go to [http://192.168.0.100:8080][42]
|
||||
|
||||
At this point you should see the FaaS UI also called the API Gateway. This is where you can define, test and invoke your functions.
|
||||
|
||||
Click on the Markdown conversion function called func_markdown and type in some Markdown (this is what Wikipedia uses to write its content).
|
||||
|
||||
Then hit invoke. You'll see the invocation count go up and the bottom half of the screen shows the result of your function:
|
||||
|
||||
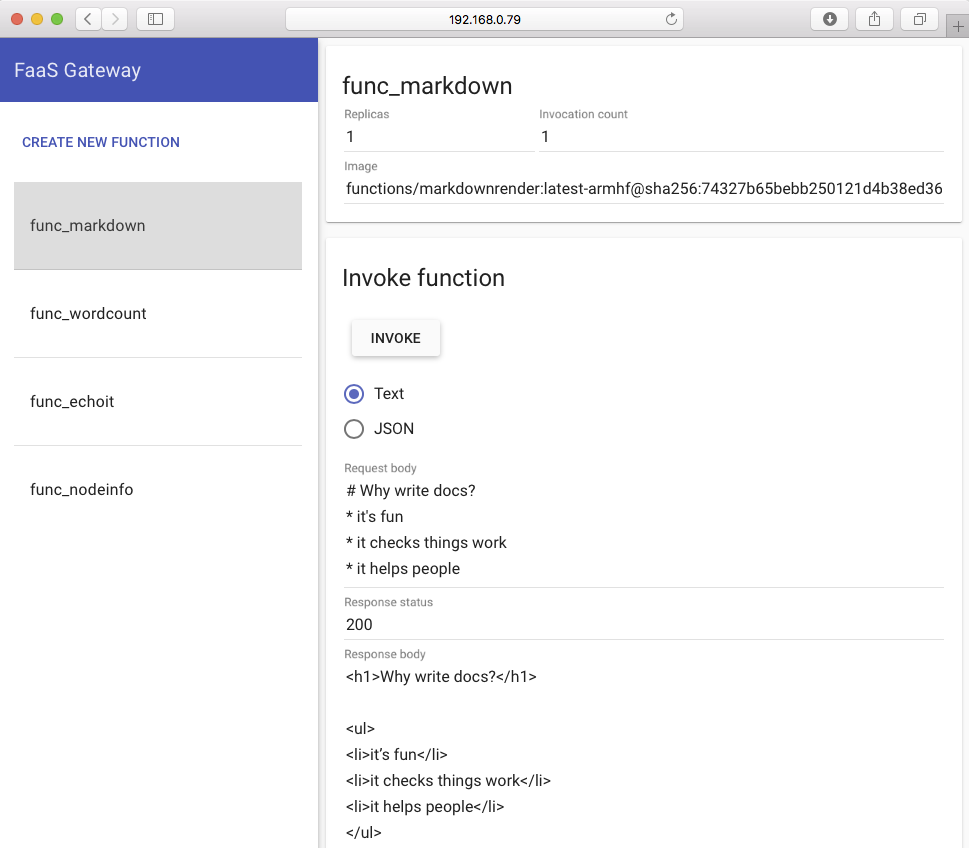
|
||||
|
||||
### Deploy your first serverless function:
|
||||
|
||||
There is already a tutorial written for this section, but we'll need to get the RPi set up with a couple of custom steps first.
|
||||
|
||||
* Get the FaaS-CLI
|
||||
|
||||
```
|
||||
$ curl -sSL cli.openfaas.com | sudo sh
|
||||
armv7l
|
||||
Getting package https://github.com/alexellis/faas-cli/releases/download/0.4.5-b/faas-cli-armhf
|
||||
|
||||
```
|
||||
|
||||
* Clone the samples:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas-cli
|
||||
$ cd faas-cli
|
||||
|
||||
```
|
||||
|
||||
* Patch the samples for Raspberry Pi
|
||||
|
||||
We'll temporarily update our templates so they work with the Raspberry Pi:
|
||||
|
||||
```
|
||||
$ cp template/node-armhf/Dockerfile template/node/
|
||||
$ cp template/python-armhf/Dockerfile template/python/
|
||||
|
||||
```
|
||||
|
||||
The reason for doing this is that the Raspberry Pi has a different processor to most computers we interact with on a daily basis.
|
||||
|
||||
> Get up to speed on Docker on the Raspberry Pi - read: [5 Things you need to know][26]
|
||||
|
||||
Now you can follow the same tutorial written for PC, Laptop and Cloud available below, but we are going to run a couple of commands first for the Raspberry Pi.
|
||||
|
||||
* [Your first serverless Python function with OpenFaaS][27]
|
||||
|
||||
Pick it up at step 3:
|
||||
|
||||
* Instead of placing your functions in `~/functions/hello-python` - place them inside the `faas-cli` folder we just cloned from GitHub.
|
||||
|
||||
* Also replace "localhost" for the IP address of your first RPi in the `stack.yml`file.
|
||||
|
||||
Note that the Raspberry Pi may take a few minutes to download your serverless function to the relevant RPi. You can check on your services to make sure you have 1/1 replicas showing up with this command:
|
||||
|
||||
```
|
||||
$ watch 'docker service ls'
|
||||
pv27thj5lftz hello-python replicated 1/1 alexellis2/faas-hello-python-armhf:latest
|
||||
|
||||
```
|
||||
|
||||
**Continue the tutorial:** [Your first serverless Python function with OpenFaaS][43]
|
||||
|
||||
For more information on working with Node.js or other languages head over to the main [FaaS repo][44]
|
||||
|
||||
### Check your function metrics
|
||||
|
||||
With a Serverless experience, you don't want to spend all your time managing your functions. Fortunately [Prometheus][45] metrics are built into OpenFaaS meaning you can keep track of how long each functions takes to run and how often it's being called.
|
||||
|
||||
_Metrics drive auto-scaling_
|
||||
|
||||
If you generate enough load on any of of the functions then OpenFaaS will auto-scale your function and when the demand eases off you'll get back to a single replica again.
|
||||
|
||||
Here is a sample query you can paste into Safari, Chrome etc:
|
||||
|
||||
Just change the IP address to your own.
|
||||
|
||||
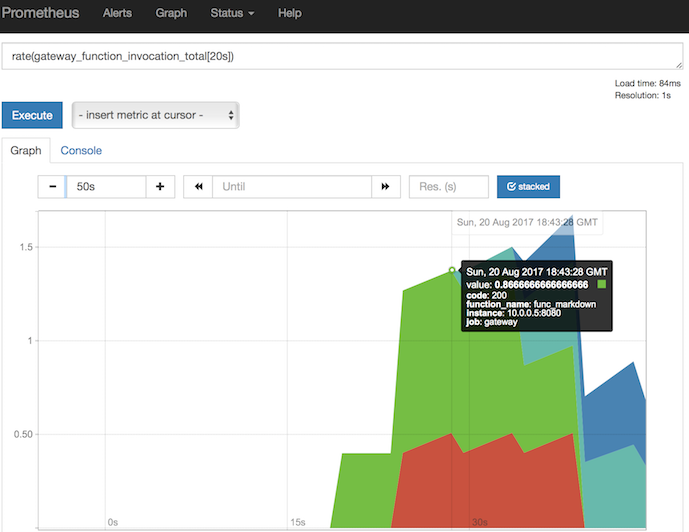
|
||||
|
||||
```
|
||||
http://192.168.0.25:9090/graph?g0.range_input=15m&g0.stacked=1&g0.expr=rate(gateway_function_invocation_total%5B20s%5D)&g0.tab=0&g1.range_input=1h&g1.expr=gateway_service_count&g1.tab=0
|
||||
|
||||
```
|
||||
|
||||
The queries are written in PromQL - Prometheus query language. The first one shows us how often the function is being called:
|
||||
|
||||
```
|
||||
rate(gateway_function_invocation_total[20s])
|
||||
|
||||
```
|
||||
|
||||
The second query shows us how many replicas we have of each function, there should be only one of each at the start:
|
||||
|
||||
```
|
||||
gateway_service_count
|
||||
|
||||
```
|
||||
|
||||
If you want to trigger auto-scaling you could try the following on the RPi:
|
||||
|
||||
```
|
||||
$ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello world" ; done
|
||||
|
||||
```
|
||||
|
||||
Check the Prometheus "alerts" page, and see if you are generating enough load for the auto-scaling to trigger, if you're not then run the command in a few additional Terminal windows too.
|
||||
|
||||
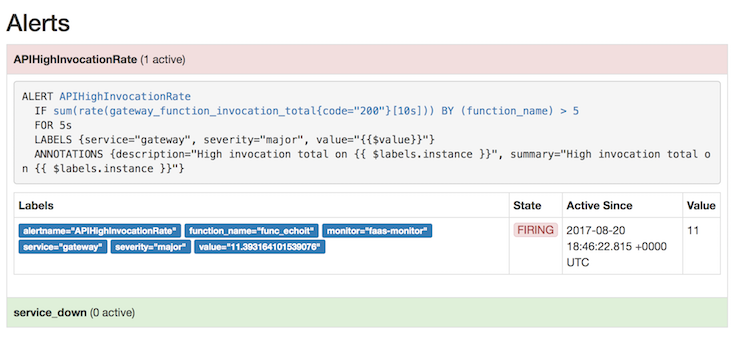
|
||||
|
||||
After you reduce the load, the replica count shown in your second graph and the `gateway_service_count` metric will go back to 1 again.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
We've now set up Docker, Swarm and run OpenFaaS - which let us treat our Raspberry Pi like one giant computer - ready to crunch through code.
|
||||
|
||||
> Please show support for the project and **Star** the [FaaS GitHub repository][28]
|
||||
|
||||
How did you find setting up your Docker Swarm first cluster and running OpenFaaS? Please share a picture or a Tweet on Twitter [@alexellisuk][46]
|
||||
|
||||
**Watch my Dockercon video of OpenFaaS**
|
||||
|
||||
I presented OpenFaaS (then called FaaS) [at Dockercon in Austin][47] - watch this video for a high-level introduction and some really interactive demos Alexa and GitHub.
|
||||
|
||||
** 此处有iframe,请手动处理 **
|
||||
|
||||
Got questions? Ask in the comments below - or send your email over to me for an invite to my Raspberry Pi, Docker and Serverless Slack channel where you can chat with like-minded people about what you're working on.
|
||||
|
||||
**Want to learn more about Docker on the Raspberry Pi?**
|
||||
|
||||
I'd suggest starting with [5 Things you need to know][48] which covers things like security and and the subtle differences between RPi and a regular PC.
|
||||
|
||||
* [Dockercon tips: Docker & Raspberry Pi][18]
|
||||
|
||||
* [Control GPIO with Docker Swarm][19]
|
||||
|
||||
* [Is that a Docker Engine in your pocket??][20]
|
||||
|
||||
_Share on Twitter_
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.alexellis.io/your-serverless-raspberry-pi-cluster/
|
||||
|
||||
作者:[Alex Ellis ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/alexellisuk
|
||||
[1]:https://twitter.com/alexellisuk
|
||||
[2]:https://twitter.com/intent/tweet?in_reply_to=898978596773138436
|
||||
[3]:https://twitter.com/intent/retweet?tweet_id=898978596773138436
|
||||
[4]:https://twitter.com/intent/like?tweet_id=898978596773138436
|
||||
[5]:https://twitter.com/alexellisuk
|
||||
[6]:https://twitter.com/alexellisuk
|
||||
[7]:https://twitter.com/Docker
|
||||
[8]:https://twitter.com/Raspberry_Pi
|
||||
[9]:https://twitter.com/alexellisuk/status/898978596773138436
|
||||
[10]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||
[11]:https://twitter.com/alexellisuk
|
||||
[12]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[13]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[14]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[15]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[16]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||
[17]:https://support.twitter.com/articles/20175256
|
||||
[18]:https://blog.alexellis.io/dockercon-tips-docker-raspberry-pi/
|
||||
[19]:https://blog.alexellis.io/gpio-on-swarm/
|
||||
[20]:https://blog.alexellis.io/docker-engine-in-your-pocket/
|
||||
[21]:https://news.ycombinator.com/item?id=15052192
|
||||
[22]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||
[23]:https://github.com/alexellis/faas
|
||||
[24]:http://downloads.raspberrypi.org/raspbian_lite/images/raspbian_lite-2017-07-05/
|
||||
[25]:https://github.com/alexellis/faas
|
||||
[26]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||
[27]:https://blog.alexellis.io/first-faas-python-function
|
||||
[28]:https://github.com/alexellis/faas
|
||||
[29]:https://blog.alexellis.io/tag/docker/
|
||||
[30]:https://blog.alexellis.io/tag/raspberry-pi/
|
||||
[31]:https://blog.alexellis.io/tag/openfaas/
|
||||
[32]:https://blog.alexellis.io/tag/faas/
|
||||
[33]:https://github.com/alexellis/faas
|
||||
[34]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||
[35]:https://github.com/alexellis/faas
|
||||
[36]:https://github.com/alexellis/faas
|
||||
[37]:https://www.amazon.co.uk/Anker-PowerPort-Family-Sized-Technology-Smartphones/dp/B00PK1IIJY
|
||||
[38]:http://downloads.raspberrypi.org/raspbian/images/raspbian-2017-07-05/
|
||||
[39]:https://etcher.io/
|
||||
[40]:https://docs.docker.com/engine/swarm/admin_guide/
|
||||
[41]:https://github.com/alexellis/faas
|
||||
[42]:http://192.168.0.100:8080/
|
||||
[43]:https://blog.alexellis.io/first-faas-python-function
|
||||
[44]:https://github.com/alexellis/faas
|
||||
[45]:https://prometheus.io/
|
||||
[46]:https://twitter.com/alexellisuk
|
||||
[47]:https://blog.alexellis.io/dockercon-2017-captains-log/
|
||||
[48]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||
200
sources/tech/20170821 Getting started with ImageMagick.md
Normal file
200
sources/tech/20170821 Getting started with ImageMagick.md
Normal file
@ -0,0 +1,200 @@
|
||||
Getting started with ImageMagick
|
||||
============================================================
|
||||
|
||||
### Learn common ways to view and modify images with this lightweight image editor.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
In a recent article about [lightweight image viewers][8], author Scott Nesbitt mentioned display, one of the components in [ImageMagick][9]. ImageMagick is not merely an image viewer—it offers a large number of utilities and options for image editing. This tutorial will explain more about using the **display** command and other command-line utilities in ImageMagick.
|
||||
|
||||
With a number of excellent image editors available, you may be wondering why someone would choose a mainly non-GUI, command-line based program like ImageMagick. For one thing, it is rock-solid dependable. But an even bigger benefit is that it allows you to set up methods to edit a large number of images in a particular way.
|
||||
|
||||
This introduction to common ImageMagick commands should get you started.
|
||||
|
||||
### The display command
|
||||
|
||||
Let's start with the command Scott mentioned: **display**. Say you have a directory with a lot of images you want to look at. Start **display** with the following command:
|
||||
|
||||
```
|
||||
cd Pictures
|
||||
display *.JPG
|
||||
```
|
||||
|
||||
This will load your JPG files sequentially in alphanumeric order, one at a time in a simple window. Left-clicking on an image brings up a simple, standalone menu (the only GUI feature you'll see in ImageMagick).
|
||||
|
||||
### [display_menu.png][1]
|
||||
|
||||

|
||||
|
||||
Here's what you'll find in the **display** menu:
|
||||
|
||||
* **File** contains the options _Open, Next, Former, Select, Save, Print, Delete, New, Visual Directory_ , and _Quit_ . _Select _ picks a specific image file to display, _Visual Directory_ shows all of the files (not just the images) in the current working directory. If you want to scroll through all the selected images, you can use _Next_ and _Former_ , but it's easier to use their keyboard shortcuts (Spacebar for the next image and Backspace for the previous).
|
||||
|
||||
* **Edit** offers _Undo, Redo, Cut, Copy_ , and _Paste_ , which are just auxiliary commands to more specific editing process. _Undo _ is especially useful when you're playing around with different edits to see what they do.
|
||||
|
||||
* **View** has _Half Size, Original Size, Double Size, Resize, Apply, Refresh_ , and _Restore_ . These are mostly self-explanatory and, unless you save the image after applying one of them, the image file isn't changed. _Resize_ brings up a dialog to name a specific size either in pixels, with or without constrained dimensions, or a percentage. I'm not sure what _Apply _ does.
|
||||
|
||||
* **Transform** shows _Crop, Chop, Flop, Flip, Rotate Right, Rotate Left, Rotate, Shear, Roll_ , and _Trim Edges_ . _Chop _ uses a click-drag operation to cut out a vertical or horizontal section of the image, pasting the edges together. The best way to learn how these features work is to play with them, rather than reading about them.
|
||||
|
||||
* **Enhance** provides _Hue, Saturation, Brightness, Gamma, Spiff, Dull, Contrast Stretch, Sigmoidal Contrast, Normalize, Equalize, Negate, Grayscale, Map_ , and _Quantize_ . These are operations for color manipulation and adjusting brightness and contrast.
|
||||
|
||||
* **Effects** has _Despeckle, Emboss, Reduce Noise, Add Noise, Sharpen, Blur, Threshold, Edge Detect, Spread, Shade, Raise_ , and _Segment_ . These are fairly standard image editing effects.
|
||||
|
||||
* **F/X** options are _Solarize, Sepia Tone, Swirl, Implode, Vignette, Wave, Oil Paint_ , and _Charcoal Draw_ , also very common effects in image editors.
|
||||
|
||||
* **Image Edit** contains _Annotate, Draw, Color, Matte, Composite, Add Border, Add Frame, Comment, Launch_ , and _Region of Interest_ . _Launch _ will open the current image in GIMP (in my Fedora at least). _Region of Interest_ allows you to select an area to apply editing; press Esc to deselect the region.
|
||||
|
||||
* **Miscellany** offers _Image Info, Zoom Image, Show Preview, Show Histogram, Show Matte, Background, Slide Show_ , and _Preferences_ . _Show Preview_ seems interesting, but I struggled to get it to work.
|
||||
|
||||
* **Help** shows _Overview, Browse Documentation_ , and _About Display_ . _Overview_ gives a lot of basic information about display and includes a large number of built-in keyboard equivalents for various commands and operations. In my Fedora, _Browse Documentation_ took me nowhere.
|
||||
|
||||
Although **display**'s GUI interface provides a reasonably competent image editor, ImageMagick also provides 89 command-line options, many of which correspond to the menu items above. For example, if I'm displaying a directory of digital images that are larger than my screen size, rather than resizing them individually after they appear on my screen, I can specify:
|
||||
|
||||
```
|
||||
display -resize 50% *.JPG
|
||||
```
|
||||
|
||||
Many of the operations in the menus above can also be done by adding an option in the command line. But there are others that aren't available from the menu, including **‑monochrome**, which converts the image to black and white (not grayscale), and **‑colors**, where you can specify how many colors to use in the image. For example, try these out:
|
||||
|
||||
```
|
||||
display -resize 50% -monochrome *.JPG
|
||||
```
|
||||
|
||||
```
|
||||
display -resize 50% -colors 8 *.JPG
|
||||
```
|
||||
|
||||
These operations create interesting images. Try enhancing colors or making other edits after reducing colors. Remember, unless you save and overwrite them, the original files remain unchanged.
|
||||
|
||||
### The convert command
|
||||
|
||||
The **convert** command has 237 options—yes 237—that provide a wide range of things you can do (some of which display can also do). I'll only cover a few of them, mostly sticking with image manipulation. Two simple things you can do with **convert** would be:
|
||||
|
||||
```
|
||||
convert DSC_0001.JPG dsc0001.png
|
||||
```
|
||||
|
||||
```
|
||||
convert *.bmp *.png
|
||||
```
|
||||
|
||||
The first command would convert a single file (DSC_0001) from JPG to PNG format without changing the original. The second would do this operation on all the BMP images in a directory.
|
||||
|
||||
If you want to see the formats ImageMagick can work with, type:
|
||||
|
||||
```
|
||||
identify -list format
|
||||
```
|
||||
|
||||
Let's pick through a few interesting ways we can use the **convert** command to manipulate images. Here is the general format for this command:
|
||||
|
||||
```
|
||||
convert inputfilename [options] outputfilename
|
||||
```
|
||||
|
||||
You can have multiple options, and they are done in the order they are arranged, from left to right.
|
||||
|
||||
Here are a couple of simple options:
|
||||
|
||||
```
|
||||
convert monochrome_source.jpg -monochrome monochrome_example.jpg
|
||||
```
|
||||
|
||||
### [monochrome_demo.jpg][2]
|
||||
|
||||

|
||||
|
||||
```
|
||||
convert DSC_0008.jpg -charcoal 1.2 charcoal_example.jpg
|
||||
```
|
||||
|
||||
### [charcoal_demo.jpg][3]
|
||||
|
||||

|
||||
|
||||
The **‑monochrome** option has no associated setting, but the **‑charcoal** variable needs an associated factor. In my experience, it needs to be a small number (even less than 1) to achieve something that resembles a charcoal drawing, otherwise you get pretty heavy blobs of black. Even so, the sharp edges in an image are quite distinct, unlike in a charcoal drawing.
|
||||
|
||||
Now let's look at these:
|
||||
|
||||
```
|
||||
convert DSC_0032.JPG -edge 3 edge_demo.jpg
|
||||
```
|
||||
|
||||
```
|
||||
convert DSC_0032.JPG -colors 4 reduced4_demo.jpg
|
||||
```
|
||||
|
||||
```
|
||||
convert DSC_0032.JPG -colors 4 -edge 3 reduced+edge_demo.jpg
|
||||
```
|
||||
|
||||
### [reduced_demo.jpg][4]
|
||||
|
||||

|
||||
|
||||
The original image is in the upper left. In the first command, I applied an **‑edge**option with a setting of 3 (see the upper-right image)—anything less than that was too subtle for my liking. In the second command (the lower-left image), we have reduced the number of colors to four, which doesn't look much different from the original. But look what happens when we combine these two in the third command (lower-right image)! Perhaps it's a bit garish, but who would have expected this result from the original image or either option on its own?
|
||||
|
||||
The **‑canny** command provided another surprise. This is another kind of edge detector, called a "multi-stage algorithm." Using **‑canny** alone produces a mostly black image and some white lines. I followed that with a **‑negate** command:
|
||||
|
||||
```
|
||||
convert DSC_0049.jpg -canny 0x1 -negate canny_egret.jpg
|
||||
convert DSC_0023.jpg -canny 0x1 -negate canny_ship.jpg
|
||||
```
|
||||
|
||||
### [canny_demos.jpg][5]
|
||||
|
||||

|
||||
|
||||
It's a bit minimalist, but I think it resembles a pen-and-ink drawing, a rather remarkable difference from the original photos. It doesn't work well with all images; generally, it works best with images with sharp lines. Elements that are out of focus are likely to disappear; notice how the background sandbar in the egret picture doesn't show up because it is blurred. Also notice in the ship picture, while most edges show up very well, without colors we lose the gestalt of the picture, so perhaps this could be the basis for some digital coloration or even coloring after printing.
|
||||
|
||||
### The montage command
|
||||
|
||||
Finally, I want to talk about the **montage** command. I've already shown examples of it above, where I have combined single images into composites.
|
||||
|
||||
Here's how I generated the charcoal example (note that it would all be on one line):
|
||||
|
||||
```
|
||||
montage -label %f DSC_0008.jpg charcoal_example.jpg -geometry +10+10
|
||||
-resize 25% -shadow -title 'charcoal demo' charcoal_demo.jpg
|
||||
```
|
||||
|
||||
The **-label** option labels each image with its filename (**%f**) underneath. Without the **‑geometry** option, all the images would be thumbnail size (120 pixels wide), and **+10+10** manages the border size. Next, I resized the entire final composite (**‑resize 25%**) and added a shadow (with no settings, so it's the default), and finally created a **title** for the montage.
|
||||
|
||||
You can place all the image names at the end, with the last image name the file where the montage is saved. This might be useful to create an alias for the command and all its options, then I can simply type the alias followed by the appropriate filenames. I've done this on occasion to reduce the typing needed to create a series of montages.
|
||||
|
||||
In the **‑canny** examples, I had four images in the montage. I added the **‑tile**option, specifically **‑tile 2x**, which created a montage of two columns. I could have specified a **matrix**, **‑tile 2x2**, or **‑tile x2** to produce the same result.
|
||||
|
||||
There is a lot more to learn about ImageMagick, so I plan to write more about it, maybe even about using [Perl][10] to script ImageMagick commands. ImageMagick has extensive [documentation][11], although the site is short on examples or showing results, and I think the best way to learn is by experimenting and changing various settings and options.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Greg Pittman - Greg is a retired neurologist in Louisville, Kentucky, with a long-standing interest in computers and programming, beginning with Fortran IV in the 1960s. When Linux and open source software came along, it kindled a commitment to learning more, and eventually contributing. He is a member of the Scribus Team.
|
||||
|
||||
---------------------
|
||||
|
||||
via: https://opensource.com/article/17/8/imagemagick
|
||||
|
||||
作者:[Greg Pittman ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://opensource.com/file/367401
|
||||
[2]:https://opensource.com/file/367391
|
||||
[3]:https://opensource.com/file/367396
|
||||
[4]:https://opensource.com/file/367381
|
||||
[5]:https://opensource.com/file/367406
|
||||
[6]:https://opensource.com/article/17/8/imagemagick?rate=W2W3j4nu4L14gOClu1RhT7GOMDS31pUdyw-dsgFNqYI
|
||||
[7]:https://opensource.com/user/30666/feed
|
||||
[8]:https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop
|
||||
[9]:https://www.imagemagick.org/script/index.php
|
||||
[10]:https://opensource.com/sitewide-search?search_api_views_fulltext=perl
|
||||
[11]:https://imagemagick.org/script/index.php
|
||||
[12]:https://opensource.com/users/greg-p
|
||||
[13]:https://opensource.com/users/greg-p
|
||||
[14]:https://opensource.com/article/17/8/imagemagick#comments
|
||||
@ -0,0 +1,75 @@
|
||||
Linux Installation Types: Server Vs. Desktop
|
||||
============================================================
|
||||
|
||||
The kernel is the heart of any Linux installation
|
||||
|
||||
|
||||
I have previously covered obtaining and installing Ubuntu Linux, and this time I will touch on desktop and server installations. Both types of installation address certain needs. The different installs are downloaded separately from Ubuntu. You can choose which one you need from _[Ubuntu.com/downloads][1]_ .
|
||||
|
||||
Regardless of the installation type, there are some similarities.
|
||||
|
||||
|
||||

|
||||
|
||||
**Packages can be added from the desktop system graphical user interface or from the server system command line.**
|
||||
|
||||
Both utilize the same kernel and package manager system. The package manager system is a repository of programs that are precompiled to run on almost any Ubuntu system. Programs are grouped into packages and then packages are installed. Packages can be added from the desktop system graphical user interface or from the server system command line.
|
||||
|
||||
Programs are installed with a program called apt-get. This is a package manager system or program manager system. The end user simply types at the command line “apt-get install (package-name)” and Ubuntu will automatically get the software package and install it.
|
||||
|
||||
Packages usually install commands that have documentation that is accessed via the man pages (which is a topic unto itself). They are accessed by typing “man (command).” This will bring up a page that describes the command with details on usage. An end-user can also Google any Linux command or package and find a wealth of information about it, as well.
|
||||
|
||||
As an example, after installing the Network Attached Storage suite of packages, one would administer it via the command line, with the GUI, or with a program called Webmin. Webmin installs a web-based administrative interface for configuring most Linux packages, and it’s popular with the server-only install crowd because it installs as a webpage and does not require a GUI. It also allows for administering the server remotely.
|
||||
|
||||
Most, if not all, of these Linux-based package installs have videos and web pages dedicated to helping you run whatever package you install. Just search YouTube for “Linux Ubuntu NAS,” and you will find a video instructing you on how to setup and configure this service. There are also videos dedicated to the setup and operation of Webmin.
|
||||
|
||||
The kernel is the heart of any Linux installation. Since the kernel is modular, it is incredibly small (as the name suggests). I have run a Linux server installation from a small 32 MB compact flash. That is not a typo — 32 MB of space! Most of the space utilized by a Linux system is used by the packages installed.
|
||||
|
||||
|
||||

|
||||
|
||||
**The desktop install ISO is fairly large and has a number of optional install packages not found on the server install ISO. This installation is designed for workstation or daily desktop use.**
|
||||
|
||||
**SERVER**
|
||||
|
||||
The server install ISO is the smallest download from Ubuntu. It is a stripped down version of the operating system optimized for server operations. This version does not have a GUI. By default, it is completely run from the command line.
|
||||
|
||||
Removing the GUI and other components streamlines the system and maximizes performance. Any necessary packages that are not initially installed can be added later via the command line package manager. Since there is no GUI, all configuration, troubleshooting and package management must be done from a command line. A lot of administrators will use the server installation to get a clean or minimal system and then add only the certain packages that they require. This includes the ability to add a desktop GUI system and make a streamlined desktop system.
|
||||
|
||||
A Linux server could be used at the radio station as an Apache web server or a database server. Those are the real apps that require the horsepower, and that’s why they are usually run with a server install and no GUI. SNORT and Cacti are other applications that could be run on your Linux server (both covered in a previous article, found here: [_http://tinyurl.com/yd8dyegu_][2] ).
|
||||
|
||||
|
||||

|
||||
|
||||
**Packages are installed via the apt-get package manager system, just like the server install. The difference between the two is that on a desktop install, the apt-get package manager has a nice GUI front end.**
|
||||
|
||||
**DESKTOP**
|
||||
|
||||
The desktop install ISO is fairly large and has a number of optional install packages not found on the server install ISO. This installation is designed for workstation or daily desktop use. This installation type allows for the customization of packages (programs) or a default desktop configuration can be selected.
|
||||
|
||||
Packages are installed via the apt-get package manager system, just like the server install. The difference between the two is that on a desktop install, the apt-get package manager has a nice GUI front end. This allows for packages to be installed or removed easily from the system with the click of a mouse! The desktop install will setup a GUI and a lot of packages related to a desktop operating system.
|
||||
|
||||
This system is ready to go after being installed and can be a nice replacement to your windows or Mac desktop computer. It has a lot of packages including an Office suite and web browser.
|
||||
|
||||
Linux is a mature and powerful operating system. Regardless of the installation type, it can be configured to fit almost any need. From a powerful database server to a basic desktop operating system used for web browsing and writing letters to grandma, the sky is the limit and the packages available are almost inexhaustible. If you can think of a problem that requires a computerized solution, Linux probably has software for free or low cost to address that problem.
|
||||
|
||||
By offering two installation starting points, Ubuntu has done a great job of getting people started in the right direction.
|
||||
|
||||
_Cottingham is a former radio chief engineer, now working in streaming media._
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.radiomagonline.com/deep-dig/0005/linux-installation-types-server-vs-desktop/39123
|
||||
|
||||
作者:[Chris Cottingham ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://www.ubuntu.com/download
|
||||
[2]:http://tinyurl.com/yd8dyegu
|
||||
[3]:http://www.radiomagonline.com/author/chris-cottingham
|
||||
@ -0,0 +1,116 @@
|
||||
Manage your finances with LibreOffice Calc
|
||||
============================================================
|
||||
|
||||
### Do you wonder where all your money goes? This well-designed spreadsheet can answer that question at a glance.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
If you're like most people, you don't have a bottomless bank account. You probably need to watch your monthly spending carefully.
|
||||
|
||||
There are many ways to do that, but that quickest and easiest way is to use a spreadsheet. Many folks create a very basic spreadsheet to do the job, one that consists of two long columns with a total at the bottom. That works, but it's kind of blah.
|
||||
|
||||
I'm going to walk you through creating a more scannable and (I think) more visually appealing personal expense spreadsheet using LibreOffice Calc.
|
||||
|
||||
Say you don't use LibreOffice? That's OK. You can use the information in this article with spreadsheet tools like [Gnumeric][7], [Calligra Sheets][8], or [EtherCalc][9].
|
||||
|
||||
### Start by making a list of your expenses
|
||||
|
||||
Don't bother firing up LibreOffice Calc just yet. Sit down with pen and paper and list your regular monthly expenses. Take your time, go through your records, and note everything, no matter how small. Don't worry about how much you're spending. Focus on where you're putting your money.
|
||||
|
||||
Once you've done that, group your expenses under headings that make the most sense to you. For example, group your gas, electric, and water bills under the heading Utilities. You might also want to have a group of expenses with a name like Various for those unexpected expenses we all run into each month.
|
||||
|
||||
### Create the spreadsheet
|
||||
|
||||
Start LibreOffice Calc and create an empty spreadsheet. Leave three blank rows at the top of the spreadsheet. We'll come back to them.
|
||||
|
||||
There's a reason you grouped your expenses: Those groups will become blocks on the spreadsheet. Let's start by putting your most important expense group (e.g., Home) at the top of the spreadsheet.
|
||||
|
||||
Type that expense group's name in the first cell of the fourth row from the top of sheet. Make it stand out by putting it in a larger (12 points is good), bold font.
|
||||
|
||||
In the row below that heading, add the following three columns:
|
||||
|
||||
* Expense
|
||||
|
||||
* Date
|
||||
|
||||
* Amount
|
||||
|
||||
Type the names of the expenses within that group into the cells under the Expense column.
|
||||
|
||||
Next, select the cells under the Date heading. Click the **Format** menu and select **Number Format > Date**. Repeat that for the cells under the Amount heading, and choose **Number Format > Currency**.
|
||||
|
||||
You'll have something that looks like this:
|
||||
|
||||
### [spreadsheet-expense-block.png][1]
|
||||
|
||||

|
||||
|
||||
That's one group of expenses out of the way. Instead of creating a new block for each expense group, copy what you created and paste it beside the first block. I recommend having rows of three blocks, with an empty column between them.
|
||||
|
||||
You'll have something like this:
|
||||
|
||||
### [spreadsheet-expense-rows.png][2]
|
||||
|
||||

|
||||
|
||||
Repeat that for all your expense groups.
|
||||
|
||||
### Total it all up
|
||||
|
||||
It's one thing to see all your individual expenses, but you'll also want to view totals for each group of expenses and for all of your expenses together.
|
||||
|
||||
Let's start by totaling the amounts for each expense group. You can get LibreOffice Calc to do that automatically. Highlight a cell at the bottom of the Amount column and then click the **Sum** button on the Formula toolbar.
|
||||
|
||||
### [spreadsheet-sum-button.png][3]
|
||||
|
||||

|
||||
|
||||
Click the first cell in the Amount column and drag the cursor to the last cell in the column. Then, press Enter.
|
||||
|
||||
### [spreadsheet-totaled-expenses.png][4]
|
||||
|
||||

|
||||
|
||||
Now let's do something with the two or three blank rows you left at the top of the spreadsheet. That's where you'll put the grand total of all your expenses. I advise putting it up there so it's visible whenever you open the file.
|
||||
|
||||
In one of the cells at the top left of the sheet, type something like Grand Total or _T_ otal for the Month. Then, in the cell beside it, type **=SUM()**. That's the LibreOffice Calc function that adds the values of specific cells on a spreadsheet.
|
||||
|
||||
Instead of manually entering the names of the cells to add, press and hold Ctrl on your keyboard. Then click the cells where you totaled each group of expenses on your spreadsheet.
|
||||
|
||||
### Finishing up
|
||||
|
||||
You have a sheet for a tracking a month's expenses. Having a spreadsheet for a single month's expenses is a bit of a waste. Why not use it to track your monthly expenses for the full year instead?
|
||||
|
||||
Right-click on the tab at the bottom of the spreadsheet and select **Move or Copy Sheet**. In the window that pops up, click **-move to end position-** and press Enter. Repeat that until you have 12 sheets—one for each month. Rename each sheet for each month of the year, then save the spreadsheet with a descriptive name like _Monthly Expenses 2017.ods_ .
|
||||
|
||||
Now that your setup is out of the way, you're ready to use the spreadsheet. While using a spreadsheet to track your expenses won't, by itself, put you on firmer financial footing, it can help you keep on top of and control what you're spending each month.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Scott Nesbitt - I'm a long-time user of free/open source software, and write various things for both fun and profit. I don't take myself too seriously. You can find me at these fine establishments on the web: Twitter, Mastodon, GitHub,
|
||||
|
||||
----------------
|
||||
|
||||
via: https://opensource.com/article/17/8/budget-libreoffice-calc
|
||||
|
||||
作者:[Scott Nesbitt ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/file/366811
|
||||
[2]:https://opensource.com/file/366831
|
||||
[3]:https://opensource.com/file/366821
|
||||
[4]:https://opensource.com/file/366826
|
||||
[5]:https://opensource.com/article/17/8/budget-libreoffice-calc?rate=C87fXAfGoIpA1OuF-Zx1nv-98UN9GgbFUz4tl_bKug4
|
||||
[6]:https://opensource.com/user/14925/feed
|
||||
[7]:http://www.gnumeric.org/
|
||||
[8]:https://www.calligra.org/sheets/
|
||||
[9]:https://ethercalc.net/
|
||||
[10]:https://opensource.com/users/scottnesbitt
|
||||
[11]:https://opensource.com/users/scottnesbitt
|
||||
[12]:https://opensource.com/article/17/8/budget-libreoffice-calc#comments
|
||||
121
sources/tech/20170822 Getting Started With GitHub.md
Normal file
121
sources/tech/20170822 Getting Started With GitHub.md
Normal file
@ -0,0 +1,121 @@
|
||||
Translating by firmianay
|
||||
|
||||
### [Getting Started With GitHub][11]
|
||||
|
||||
|
||||
[][1]
|
||||
|
||||
[Github][13] is an online platform built to promote code hosting, version control and collaboration among individuals working on a common project. Projects can be handled from anywhere through the platform. (Hosting and reviewing code, managing projects and building software with other developers around the world) **The GitHub platform** offers project handling to both open-source and private projects. Features offered in regards to team project handling include; **GitHub** Flow and GitHub Pages. These functions make it easy for teams with regular deployments to in handling the workflow. GitHub pages, on the other hand, provides a place for showcasing open source projects, displaying resumes, hosting blogs among others.
|
||||
|
||||
Individual projects can also be easily handled with the aid of GitHub as it provides essential tools for projects handling. It also makes it easier to share one's project with the world.
|
||||
|
||||
### Signing Up for GitHub and Starting a Project
|
||||
|
||||
When starting a new project on GitHub, you must first create an account here using your email address.
|
||||
[][2] Then, on verification of the address, the user will be automatically logged into their GitHub account.
|
||||
|
||||
#### 1\. Creating a Repository
|
||||
|
||||
After which, one is taken to the next page that allows for the creation of a repository. A repository is a storage for all project files including revision history. Repositories are either, public or private. Public repositories are visible to everyone, however, the owner chooses an individual who can commit to the project. On the other hand, private <u>repositories</u> provide extra control to who can view the repositories. As a result, public repositories are suitable for open source software projects while private repositories are mostly suited to private or closed source projects.
|
||||
|
||||
* After filling the “Repository Name” and filling the “Short Description”
|
||||
|
||||
* Check the “Initialize this repository with a README”.
|
||||
|
||||
* Finally, click the “Create Repository” button at the bottom.
|
||||
|
||||
[][3]
|
||||
|
||||
#### 2\. Adding a Branch
|
||||
|
||||
In _GitHub_ , branches are a way of working on various versions of a single repository simultaneously. By default, any single repository created is assigned a branch called MASTER and it is considered the final branch. In GitHub, branches are useful in experimenting and editing of repositories before committing them to the master (Final branch).
|
||||
|
||||
For personal suitability, it is always necessary to add several other branches to suit different projects. Creating a branch off the master branch is the same as copying the master as it was at that instant. [][4] Creating branches is similar to saving a single file in different versions. This is achieved by renaming according to the task being carried out on a particular repository.
|
||||
|
||||
Branches also prove useful in keeping bug fixes and feature work separated from the master branch. After necessary changes, these branches are merged into the master branch.
|
||||
|
||||
To make a branch after creating the repository;
|
||||
|
||||
* Go to your new repository by clicking on the repository name in this case, “Hello-World”.
|
||||
|
||||
* Click on the “Branch-Master” button at the top to see a drop-down menu with a blank field for filling the branch name.
|
||||
|
||||
* Enter the branch name, in this case, ”readme-edits”.
|
||||
|
||||
* Press “Enter” or click on the blue “create- branch” box
|
||||
|
||||
By now two branches have been created; master and readme-edits.
|
||||
|
||||
#### 3\. Making and Committing Changes
|
||||
|
||||
This step provides guidelines on how changes are made to a repository and saved. In GitHub, commits is the word used to refer to saved changes. Each commit is also associated with a commit message that contains a history of the saved changes and why particular changes were made. This makes it easy for other contributors to follow what was done and why.
|
||||
To make and commit changes to a repository, the following are the steps;
|
||||
|
||||
* Click on the repository name “Hello-World”.
|
||||
|
||||
* To view and edit the file, click on the pencil icon in the upper right corner.
|
||||
|
||||
[][5]
|
||||
|
||||
* In the editor, write something to ascertain that you can make changes.
|
||||
|
||||
* Write briefly in the commit message field to explain why and how the changes were made.
|
||||
|
||||
* Click on commit changes button to save the changes.
|
||||
|
||||
Please note that these changes only affect the readme-edits branch and not the master branch. [][6]
|
||||
|
||||
#### 4\. Opening a Pull Request
|
||||
|
||||
Pull request is a feature that allows a contributor to propose and request someone to review and merge certain changes to their branch. Pull requests also show the difference (diffs) from several branches. Changes, additions, and subtractions are usually shown in red and green colors. Pull requests can be started as soon as a commit is made. Even when the code is not finished.
|
||||
To open a pull request:
|
||||
|
||||
* Click the pull request tab.
|
||||
|
||||
* Select the readme-edits branch to compare with the master.
|
||||
|
||||
* Determine the requirements and be sure it is what you want to submit.
|
||||
|
||||
* Click on the create pull request green button and assign it a title.
|
||||
|
||||
* Press enter.
|
||||
|
||||
[][7] [][8] [][9] The user can demonstrate this by trying to create and saving a pull request.
|
||||
|
||||
#### 5\. Merging the Pull Request
|
||||
|
||||
This final step involves bringing readme-edits and master branches together. The merge Pull button shows up in case the readme-edits and the master branch do not conflict.
|
||||
[][10] When merging pulls, there is need to ensure that the comments and other fields are filled properly. To merge pulls:
|
||||
|
||||
* Click on the merge pull request button.
|
||||
|
||||
* Confirm the merge.
|
||||
|
||||
* Press the purple delete branch button to delete the readme-edits branch since it is already incorporated in the master.
|
||||
|
||||
This article provides a simple guideline to getting started with GitHub and other basic operations of the GitHub platform.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/getting-started-with-github
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/getting-started-with-github
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/github-homepage_orig.jpg
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-a-github-repository_orig.jpg
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/add-a-branch-to-github-repository_orig.jpg
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/commit-changes-to-github-repository_orig.jpg
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/commit-branch-to-master_orig.jpg
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/github-pull-request_orig.jpg
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/compare-commit-changes-github_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/open-a-pull-request-in-github-repository_orig.jpg
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/merge-the-pull-request-github_orig.jpg
|
||||
[11]:http://www.linuxandubuntu.com/home/getting-started-with-github
|
||||
[12]:http://www.linuxandubuntu.com/home/getting-started-with-github#comments
|
||||
[13]:https://github.com/
|
||||
@ -0,0 +1,188 @@
|
||||
Running WordPress in a Kubernetes Cluster
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
As a developer I try to keep my eye on the progression of technologies that I might not use every day, but are important to understand as they might indirectly affect my work. For example the recent rise of containerization, [popularized by Docker][8], used for hosting web apps at scale. I’m not technically a devops person but as I build web apps on a daily basis it’s good for me to keep my eye on how these technologies are progressing.
|
||||
|
||||
A good example of this progression is the rapid development of container orchestration platforms that allow you to easily deploy, scale and manage containerized applications. The main players at the moment seem to be [Kubernetes (by Google)][9], [Docker Swarm][10] and [Apache Mesos][11]. If you want a good intro to each of these technologies and their differences I recommend giving [this article][12] a read.
|
||||
|
||||
In this article, we’re going to start simple and take a look at the Kubernetes platform and how you can set up a WordPress site on a single node cluster on your local machine.
|
||||
|
||||
### Installing Kubernetes
|
||||
|
||||
The [Kubernetes docs][13] have a great interactive tutorial that covers a lot of this stuff but for the purpose of this article I’m just going to cover installation and usage on macOS.
|
||||
|
||||
The first thing we need to do is install Kubernetes on your local machine. We’re going to use a tool called [Minikube][14] which is specifically designed to make it easy to set up a Kubernetes cluster on your local machine for testing.
|
||||
|
||||
As per the Minikube docs, there are a few prerequisites before we get going. Make sure you have a Hypervisor installed (‘m going to use Virtualbox). Next we need to [install the Kubernetes command-line tool][15] (known as `kubectl`). If you use Homebrew this is as simple as running:
|
||||
|
||||
```
|
||||
$ brew install kubectl
|
||||
|
||||
```
|
||||
|
||||
Now we can actually [install Minikube][16]:
|
||||
|
||||
```
|
||||
$ curl -Lo minikube https://storage.googleapis.com/minikube/releases/v0.21.0/minikube-darwin-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
Finally we want to [start Minikube][17] which will create a virtual machine which will act as our single-node Kubernetes cluster. At this point I should state that, although we’re running things locally in this article, most of the following concepts will apply when running a full Kubernetes cluster on [real servers][18]. On a multi-node cluster a “master” node would be responsible for managing the other worker nodes (VM’s or physical servers) and Kubernetes would automate the distribution and scheduling of application containers across the cluster.
|
||||
|
||||
```
|
||||
$ minikube start --vm-driver=virtualbox
|
||||
|
||||
```
|
||||
|
||||
### Installing Helm
|
||||
|
||||
At this point we should now have a (single node) Kubernetes cluster running on our local machine. We can now interact with Kubernetes in any way we want. I found [kubernetesbyexample.com][19] to be a good introduction to Kubernetes concepts and terms if you want to start playing around.
|
||||
|
||||
While we could set things up manually, we’re actually going to use a separate tool to install our WordPress application to our Kubernetes cluster. [Helm][20] is labelled as a “package manager for Kubernetes” and works by allowing you to easily deploy pre-built software packages to your cluster, known as “Charts”. You can think of a Chart as a group of container definitions and configs that are designed for a specific application (such as WordPress). First let’s install Helm on our local machine:
|
||||
|
||||
```
|
||||
$ brew install kubernetes-helm
|
||||
|
||||
```
|
||||
|
||||
Next we need to install Helm on our cluster. Thankfully this is as simple as running:
|
||||
|
||||
```
|
||||
$ helm init
|
||||
|
||||
```
|
||||
|
||||
### Installing WordPress
|
||||
|
||||
Now that Helm is running on our cluster we can install the [WordPress chart][21] by running:
|
||||
|
||||
```
|
||||
$ helm install --namespace wordpress --name wordpress --set serviceType=NodePort stable/wordpress
|
||||
|
||||
```
|
||||
|
||||
The will install and run WordPress in a container and MariaDB in a container for the database. This is known as a “Pod” in Kubernetes. A [Pod][22] is basically an abstraction that represents a group of one or more application containers and some shared resources for those containers (e.g. storage volumes, networking etc.).
|
||||
|
||||
We give the release a namespace and a name to keep things organized and make them easy to find. We also set the `serviceType` to `NodePort`. This is important because, by default, the service type will be set to `LoadBalancer` and, as we currently don’t have a load balancer for our cluster, we wouldn’t be able to access our WordPress site from outside the cluster.
|
||||
|
||||
In the last part of the output from this command you will notice some helpful instructions on how to access your WordPress site. Run these commands to get the external IP address and port for our WordPress site:
|
||||
|
||||
```
|
||||
$ export NODE_PORT=$(kubectl get --namespace wordpress -o jsonpath="{.spec.ports[0].nodePort}" services wordpress-wordpress)
|
||||
$ export NODE_IP=$(kubectl get nodes --namespace wordpress -o jsonpath="{.items[0].status.addresses[0].address}")
|
||||
$ echo http://$NODE_IP:$NODE_PORT/admin
|
||||
|
||||
```
|
||||
|
||||
You should now be able to visit the resulting URL (ignoring the `/admin` bit) and see WordPress running on your very own Kubernetes cluster!
|
||||
|
||||
### Scaling WordPress
|
||||
|
||||
One of the great things about container orchestration platforms such as Kubernetes is that it makes scaling and managing your application really simple. Let’s check the status of our deployments:
|
||||
|
||||
```
|
||||
$ kubectl get deployments --namespace=wordpress
|
||||
|
||||
```
|
||||
|
||||
[][23]
|
||||
|
||||
We should see that we have 2 deployments, one for the Mariadb database and one for WordPress itself. Now let’s say your WordPress site is starting to see a lot of traffic and we want to split the load over multiple instances. We can scale our `wordpress-wordpress` deployment by running a simple command:
|
||||
|
||||
```
|
||||
$ kubectl scale --replicas 2 deployments wordpress-wordpress --namespace=wordpress
|
||||
|
||||
```
|
||||
|
||||
If we run the `kubectl get deployments` command again we should now see something like this:
|
||||
|
||||
[][24]
|
||||
|
||||
You’ve just scaled up your WordPress site! Easy peasy, right? There are now multiple WordPress containers that traffic can be load-balanced across. For more info on Kubernetes scaling check out [this tutorial][25].
|
||||
|
||||
### High Availability
|
||||
|
||||
Another great feature of platforms such as Kubernetes is the ability to not only scale easily, but to provide high availability by implementing self-healing components. Say one of your WordPress deployments fails for some reason. Kubernetes will automatically replace the deployment instantly. We can simulate this by deleting one of the pods running in our WordPress deployment.
|
||||
|
||||
First get a list of pods by running:
|
||||
|
||||
```
|
||||
$ kubectl get pods --namespace=wordpress
|
||||
|
||||
```
|
||||
|
||||
[][26]
|
||||
|
||||
Then delete one of the pods:
|
||||
|
||||
```
|
||||
$ kubectl delete pod {POD-ID} --namespace=wordpress
|
||||
|
||||
```
|
||||
|
||||
If you run the `kubectl get pods` command again you should see Kubernetes spinning up the replacement pod straight away.
|
||||
|
||||
[][27]
|
||||
|
||||
### Going Further
|
||||
|
||||
We’ve only really scratched the surface of what Kubernetes can do. If you want to delve a bit deeper, I would recommend having a look at some of the following features:
|
||||
|
||||
* [Horizontal scaling][2]
|
||||
|
||||
* [Self healing][3]
|
||||
|
||||
* [Automated rollouts and rollbacks][4]
|
||||
|
||||
* [Secret management][5]
|
||||
|
||||
Have you ever run WordPress on a container platform? Have you ever used Kubernetes (or another container orchestration platform) and got any good tips? How do you normally scale your WordPress sites? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gilbert loves to build software. From jQuery scripts to WordPress plugins to full blown SaaS apps, Gilbert has been creating elegant software his whole career. Probably most famous for creating the Nivo Slider.
|
||||
|
||||
|
||||
--------
|
||||
|
||||
|
||||
via: https://deliciousbrains.com/running-wordpress-kubernetes-cluster/
|
||||
|
||||
作者:[ Gilbert Pellegrom][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://deliciousbrains.com/author/gilbert-pellegrom/
|
||||
[1]:https://deliciousbrains.com/author/gilbert-pellegrom/
|
||||
[2]:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
||||
[3]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/#what-is-a-replicationcontroller
|
||||
[4]:https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#what-is-a-deployment
|
||||
[5]:https://kubernetes.io/docs/concepts/configuration/secret/
|
||||
[6]:https://deliciousbrains.com/running-wordpress-kubernetes-cluster/
|
||||
[7]:https://deliciousbrains.com/running-wordpress-kubernetes-cluster/
|
||||
[8]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[9]:https://kubernetes.io/
|
||||
[10]:https://docs.docker.com/engine/swarm/
|
||||
[11]:http://mesos.apache.org/
|
||||
[12]:https://mesosphere.com/blog/docker-vs-kubernetes-vs-apache-mesos/
|
||||
[13]:https://kubernetes.io/docs/tutorials/kubernetes-basics/
|
||||
[14]:https://kubernetes.io/docs/getting-started-guides/minikube/
|
||||
[15]:https://kubernetes.io/docs/tasks/tools/install-kubectl/
|
||||
[16]:https://github.com/kubernetes/minikube/releases
|
||||
[17]:https://kubernetes.io/docs/getting-started-guides/minikube/#quickstart
|
||||
[18]:https://kubernetes.io/docs/tutorials/kubernetes-basics/
|
||||
[19]:http://kubernetesbyexample.com/
|
||||
[20]:https://docs.helm.sh/
|
||||
[21]:https://kubeapps.com/charts/stable/wordpress
|
||||
[22]:https://kubernetes.io/docs/tutorials/kubernetes-basics/explore-intro/
|
||||
[23]:https://cdn.deliciousbrains.com/content/uploads/2017/08/07120711/image4.png
|
||||
[24]:https://cdn.deliciousbrains.com/content/uploads/2017/08/07120710/image2.png
|
||||
[25]:https://kubernetes.io/docs/tutorials/kubernetes-basics/scale-intro/
|
||||
[26]:https://cdn.deliciousbrains.com/content/uploads/2017/08/07120711/image3.png
|
||||
[27]:https://cdn.deliciousbrains.com/content/uploads/2017/08/07120709/image1.png
|
||||
387
sources/tech/20170823 How Machines Learn A Practical Guide.md
Normal file
387
sources/tech/20170823 How Machines Learn A Practical Guide.md
Normal file
@ -0,0 +1,387 @@
|
||||
How Machines Learn: A Practical Guide
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
You may have heard about machine learning from interesting applications like spam filtering, optical character recognition, and computer vision.
|
||||
|
||||
Getting started with machine learning is long process that involves going through several resources. There are books for newbies, academic papers, guided exercises, and standalone projects. It’s easy to lose track of what you need to learn among all these options.
|
||||
|
||||
So in today’s post, I’ll list seven steps (and 50+ resources) that can help you get started in this exciting field of Computer Science, and ramp up toward becoming a machine learning hero.
|
||||
|
||||
Note that this list of resources is not exhaustive and is meant to get you started. There are many more resources around.
|
||||
|
||||
### 1\. Get the necessary background knowledge
|
||||
|
||||
You might remember from DataCamp’s [Learn Data Science][77] infographic that mathematics and statistics are key to starting machine learning (ML). The foundations might seem quite easy because it’s just three topics. But don’t forget that these are in fact three broad topics.
|
||||
|
||||
There are two things that are very important to keep in mind here:
|
||||
|
||||
* First, you’ll definitely want some further guidance on what exactly you need to cover to get started.
|
||||
|
||||
* Second, these are the foundations of your further learning. Don’t be scared to take your time. Get the knowledge on which you’ll build everything.
|
||||
|
||||
The first point is simple: it’s a good idea to cover linear algebra and statistics. These two are the bare minimum that one should understand. But while you’re at it, you should also try to cover topics such as optimization and advanced calculus. They will come in handy when you’re getting deeper into ML.
|
||||
|
||||
Here are some pointers on where to get started if you are starting from zero:
|
||||
|
||||
* [Khan Academy][1] is a good resource for beginners. Consider taking the Linear Algebra and Calculus courses.
|
||||
|
||||
* Go to [MIT OpenCourseWare][2] and take the[ Linear Algebra][3] course.
|
||||
|
||||
* Take [this Coursera course][4] for an introduction to descriptive statistics, probability theory, and inferential statistics.
|
||||
|
||||
|
||||

|
||||
Statistics is one of the keys to learning ML
|
||||
|
||||
If you’re more into books, consider the following:
|
||||
|
||||
* [_Linear Algebra and Its Applications_][5] _,_
|
||||
|
||||
* [_Applied Linear Algebra_][6] ,
|
||||
|
||||
* [_3,000 Solved Problems in Linear Algebra_][7] _,_
|
||||
|
||||
* [MIT Online Texbooks][8]
|
||||
|
||||
However, in most cases, you’ll start off already knowing some things about statistics and mathematics. Or maybe you have already gone through all the theory resources listed above.
|
||||
|
||||
In these cases, it’s a good idea to recap and assess your knowledge honestly. Are there any areas that you need to revise or are you good for now?
|
||||
|
||||
If you’re all set, it’s time to go ahead and apply all that knowledge with R or Python. As a general guideline, it’s a good idea to pick one and get started with that language. Later, you can still add the other programming language to your skill set.
|
||||
|
||||
Why is all this programming knowledge necessary?
|
||||
|
||||
Well, you’ll see that the courses listed above (or those you have taken in school or university) will provide you with a more theoretical (and not applied) introduction to mathematics and statistics topics. However, ML is very applied and you’ll need to be able to apply all the topics you have learned. So it’s a good idea to go over the materials again, but this time in an applied way.
|
||||
|
||||
If you want to master the basics of R and Python, consider the following courses:
|
||||
|
||||
* DataCamp’s introductory Python or R courses: [Intro to Python for Data Science][9] or [Introduction to R Programming][10].
|
||||
|
||||
* Introductory Python and R courses from Edx: [Introduction to Python for Data Science][11] and [Introduction to R for Data Science][12].
|
||||
|
||||
* There are many other free courses out there. Check out [Coursera][13] or [Codeacademy][14] for more.
|
||||
|
||||
When you have nailed down the basics, check out DataCamp’s blog on the [40+ Python Statistics For Data Science Resources][78]. This post offers 40+ resources on the statistics topics you need to know to get started with data science (and by extension also ML).
|
||||
|
||||
Also make sure you check out [this SciPy tutorial][79] on vectors and arrays and [this workshop][80] on Scientific Computing with Python.
|
||||
|
||||
To get hands-on with Python and calculus, you can check out the [SymPy package][81].
|
||||
|
||||
### 2\. Don’t be scared to invest in the “theory” of ML
|
||||
|
||||
A lot of people don’t make the effort to go through some more theoretical material because it’s “dry” or “boring.” But going through the theory and really investing your time in it is essential and invaluable in the long run. You’ll better understand new advancements in machine learning, and you’ll be able to link back to your background knowledge. This will help you stay motivated.
|
||||
|
||||
Additionally, the theory doesn’t need to be boring. As you read in the introduction, there are so many materials that will make it easier for you to get into it.
|
||||
|
||||
Books are one of the best ways to absorb the theoretical knowledge. They force you to stop and think once in a while. Of course, reading books is a very static thing to do and it might not agree with your learning style. Nonetheless, try out the following books and see if it might be something for you:
|
||||
|
||||
* [_Machine Learning textbook_][15] , by Tom Mitchell might be old but it’s gold. This book goes over the most important topics in machine learning in a well-explained and step-by-step way.
|
||||
|
||||
* _Machine Learning: The Art and Science of Algorithms that Make Sense of Data _ (you can see the slides of the book [here][16]): this book is great for beginners. There are many real-life applications discussed, which you might find lacking in Tom Mitchell’s book.
|
||||
|
||||
* [_Machine Learning Yearning_][17] : this book by Andrew Ng is not yet complete, but it’s bound to be an excellent reference for those who are learning ML.
|
||||
|
||||
* [_Algorithms and Data Structures_][18] by Jurg Nievergelt and Klaus Hinrichs
|
||||
|
||||
* Also check out the [_Data Mining for the Masses_][19] by Matthew North. You’ll find that this book guides you through some of the most difficult topics.
|
||||
|
||||
* [_Introduction to Machine Learning_][20] by Alex Smola and S.V.N. Vishwanathan.
|
||||
|
||||
|
||||

|
||||
Take your time to read books and to study the material covered in them
|
||||
|
||||
Videos / MOOCs are awesome for those who learn by watching and listening. There are a lot of MOOCs and videos out there, but it can also be hard to find your way through all those materials. Below is a list of the most notable ones:
|
||||
|
||||
* [This well-known Machine Learning MOOC][21], taught by Andrew Ng, introduces you to Machine Learning and the theory. Don’t worry — it’s well-explained and takes things step-by-step, so it’s excellent for beginners.
|
||||
|
||||
* The [playlist of the MIT Open Courseware 6034 course][22]: already a bit more advanced. You’ll definitely need some previous work on ML theory before you start this series, but you won’t regret it.
|
||||
|
||||
At this point, it’s important for you to go over the separate techniques and grasp the whole picture. This starts with understanding key concepts: the distinction between supervised and unsupervised learning, classification and regression, and so on. Manual (written) exercises can come in handy. They can help you understand how algorithms work and how you should go about them. You’ll most often find these written exercises in courses from universities. Check out [this ML course][82] by Portland State University.
|
||||
|
||||
### 3\. Get hands-on
|
||||
|
||||
Knowing the theory and understanding the algorithms by reading and watching is all good. But you also need to surpass this stage and get started with some exercises. You’ll learn to implement these algorithms and apply the theory that you’ve learned.
|
||||
|
||||
First, you have tutorials which introduce you to the basics of machine learning in Python and R. The best way is, of course, to go for interactive tutorials:
|
||||
|
||||
* In [Python Machine Learning: Scikit-Learn Tutorial][23], you will learn more about well-known algorithms KMeans and Support Vector Machines (SVM) to construct models with Scikit-Learn.
|
||||
|
||||
* [Machine Learning in R for beginners][24] introduces you to ML in R with the class and caret packages.
|
||||
|
||||
* [Keras Tutorial: Deep Learning in Python covers ][25]how to build Multi-Layer Perceptrons (MLPs) for classification and regression tasks, step-by-step.
|
||||
|
||||
Also check out the following tutorials, which are static and will require you to work in an IDE:
|
||||
|
||||
* [Machine Learning in Python, Step By Step][26]: step-by-step tutorial with Scikit-Learn.
|
||||
|
||||
* [Develop Your First Neural Network in Python With Keras Step-By-Step][27]: learn how to develop your first neural network with Keras thanks to this tutorial.
|
||||
|
||||
* There are many more that you can consider, but the tutorials of [Machine Learning Mastery][28] are very good.
|
||||
|
||||
Besides the tutorials, there are also courses. Taking courses will help you apply the concepts that you’ve learned in a focused way. Experienced instructors will help you. Here are some interactive courses for Python and ML:
|
||||
|
||||
* [Supervised Learning with scikit-learn][29]: you’ll learn how to build predictive models, tune their parameters, and predict how well they will perform on unseen data. All while using real world datasets. You’ll do so with Scikit-Learn.
|
||||
|
||||
* [Unsupervised Learning in Python][30]: shows you how to cluster, transform, visualize, and extract insights from unlabeled datasets. At the end of the course, you’ll build a recommender system.
|
||||
|
||||
* [Deep Learning in Python][31]: you’ll gain hands-on, practical knowledge of how to use deep learning with Keras 2.0, the latest version of a cutting-edge library for deep learning in Python.
|
||||
|
||||
* [Applied Machine Learning in Python][32]: introduces the learner to applied ML and focuses more on the techniques and methods than on the statistics behind these methods.
|
||||
|
||||
|
||||
|
||||

|
||||
After the theory, take your time to apply the knowledge you have gained.
|
||||
|
||||
For those who are learning ML with R, there are also these interactive courses:
|
||||
|
||||
* [Introduction to Machine Learning][33] gives you a broad overview of the discipline’s most common techniques and applications. You’ll gain more insight into the assessment and training of different ML models. The rest of the course focuses on an introduction to three of the most basic ML tasks: classification, regression, and clustering.
|
||||
|
||||
* [R: Unsupervised Learning][34] provides a basic introduction to clustering and dimensionality reduction in R from a ML perspective. This allows you to get from data to insights as quickly as possible.
|
||||
|
||||
* [Practical Machine Learning][35] covers the basic components of building and applying prediction functions with an emphasis on practical applications.
|
||||
|
||||
Lastly, there are also books that go over ML topics in a very applied way. If you’re looking to learn with the help of text and an IDE, check out these books:
|
||||
|
||||
* The [_Python Machine Learning Book_][36] by Sebastian Raschka
|
||||
|
||||
* The [Introduction to Artificial Neural Networks and Deep Learning: A Practical Guide with Applications in Python][37] by Sebastian Raschka
|
||||
|
||||
* [_Machine Learning with R_][38] by Brett Lantz
|
||||
|
||||
### 4\. Practice
|
||||
|
||||
Practice is even more important than getting hands-on and revising the material with Python. This step was probably the hardest one for me. Check out how other people have implemented ML algorithms when you have done some exercises. Then, get started on your own projects that illustrate your understanding of ML algorithms and theories.
|
||||
|
||||
One of the most straightforward ways is to see the exercises a tiny bit bigger. You want to do a bigger exercise which requires you to do more data cleaning and feature engineering.
|
||||
|
||||
* Start with[ Kaggle][39]. If you need additional help to conquer the so-called “data fear,” check out the [Kaggle Python Tutorial on Machine Learning][40]and[ Kaggle R Tutorial on Machine Learning][41]. These will bring you up to speed in no time.
|
||||
|
||||
* Afterwards, you can also start doing challenges by yourself. Check out these sites, where you can find lots of ML datasets: [UCI Machine Learning Repository][42], [Public datasets for machine learning][43], and [data.world][44].
|
||||
|
||||
|
||||

|
||||
Practice makes perfect.
|
||||
|
||||
### 5\. Projects
|
||||
|
||||
Doing small exercises is good. But in the end, you’ll want to make a project in which you can demonstrate your understanding of the ML algorithms with which you’ve been working.
|
||||
|
||||
The best exercise is to implement your own ML algorithm. You can read more about why you should do this exercise and what you can learn from it in the following pages:
|
||||
|
||||
* [Why is there a need to manually implement machine learning algorithms when there are many advanced APIs like tensorflow available?][45]
|
||||
|
||||
* [Why Implement Machine Learning Algorithms From Scratch?][46]
|
||||
|
||||
* [What I Learned Implementing a Classifier from Scratch in Python][47]
|
||||
|
||||
Next, you can check out the following posts and repositories. They’ll give you some inspiration from others and will show how they have implemented ML algorithms.
|
||||
|
||||
* [How to Implement a Machine Learning Algorithm][48]
|
||||
|
||||
* [ML From Scratch][49]
|
||||
|
||||
* [Machine Learning Algorithms From Scratch][50]
|
||||
|
||||
|
||||
|
||||

|
||||
Projects can be hard at start, but they’ll increase your understanding even more.
|
||||
|
||||
### 6\. Don’t stop
|
||||
|
||||
Learning ML is something that should never stop. As many will confirm, there are always new things to learn — even when you’ve been working in this area for a decade.
|
||||
|
||||
There are, for example, ML trends such as deep learning which are very popular right now. You might also focus on other topics that aren’t central at this point but which might be in the future. Check out this [interesting question and the answers][83] if you want to know more.
|
||||
|
||||
Papers may not be the first thing that spring to mind when you’re worried about mastering the basics. But they are your way to get up to date with the latest research. Papers are not for those who are just starting out. They are definitely a good fit for those who are more advanced.
|
||||
|
||||
* [Top 20 Recent Research Papers on Machine Learning and Deep Learning][51]
|
||||
|
||||
* [Journal of Machine Learning Research][52]
|
||||
|
||||
* [Awesome Deep Learning Papers][53]
|
||||
|
||||
* [What are some of the best research papers/books for Machine learning?][54]
|
||||
|
||||
Other technologies are also something to consider. But don’t worry about them when you’re just starting out. You can, for example, focus on adding Python or R (depending on which one you already know) to your skill set. You can look through this post to find interesting resources.
|
||||
|
||||
If you also want to move towards big data, you could consider looking into Spark. Here are some interesting resources:
|
||||
|
||||
* [Introduction to Spark in R with sparklyr][55]
|
||||
|
||||
* [Data Science And Engineering With Spark][56]
|
||||
|
||||
* [Introduction to Apache Spark][57]
|
||||
|
||||
* [Distributed Machine Learning with Apache Spark][58]
|
||||
|
||||
* [Big Data Analysis with Apache Spark][59]
|
||||
|
||||
* [Apache Spark in Python: Beginner’s Guide][60]
|
||||
|
||||
* [PySpark RDD Cheat Sheet][61]
|
||||
|
||||
* [PySpark SQL Cheat Sheet][62].
|
||||
|
||||
Other programming languages, such as Java, JavaScript, C, and C++ are gaining importance in ML. In the long run, you can consider also adding one of these languages to your to-do list. You can use these blog posts to guide your choice:
|
||||
|
||||
* [Most Popular Programming Languages for Machine Learning and Data Science][63]
|
||||
|
||||
* [The Most Popular Language For Machine Learning And Data Science Is…][64]
|
||||
|
||||
|
||||

|
||||
You’re never done learning.
|
||||
|
||||
### 7\. Make use of all the material that is out there
|
||||
|
||||
Machine learning is a difficult topic which can make you lose your motivation at some point. Or maybe you feel you need a change. In such cases, remember that there’s a lot of material on which you can fall back. Check out the following resources:
|
||||
|
||||
Podcasts. Great resource for continuing your journey into ML and staying up-to-date with the latest developments in the field:
|
||||
|
||||
* [Talking Machines][65]
|
||||
|
||||
* [Data Skeptic][66]
|
||||
|
||||
* [Linear Digressions][67]
|
||||
|
||||
* [This Week in Machine Learning & AI][68]
|
||||
|
||||
* [Learning Machines 101][69]
|
||||
|
||||
There are, of course, many more podcasts.
|
||||
|
||||
Documentation and package source code are two ways to get deeper into the implementation of the ML algorithms. Check out some of these repositories:
|
||||
|
||||
* [Scikit- Learn][70]: Well-known Python ML package
|
||||
|
||||
* [Keras][71]: Deep learning package for Python
|
||||
|
||||
* [caret][72]: very popular R package for Classification and Regression Training
|
||||
|
||||
Visualizations are one of the newest and trendiest ways to get into the theory of ML. They’re fantastic for beginners, but also very interesting for more advanced learners. The following visualizations will intrigue you and will help you gain more understanding into the workings of ML:
|
||||
|
||||
* [A visual introduction to machine learning][73]
|
||||
|
||||
* [Distill][74] makes ML Research clear, dynamic and vivid.
|
||||
|
||||
* [Tensorflow — Neural Network Playground][75] if you’re looking to play around with neural network architectures.
|
||||
|
||||
* More here:[ What are the best visualizations of machine learning algorithms?][76]
|
||||
|
||||
|
||||

|
||||
Some variety in your learning can and will motivate you even more.
|
||||
|
||||
### You Can Get Started Now
|
||||
|
||||
Now it’s up to you. Learning ML is something that’s a continuous process, so the sooner you get started, the better. You have all of the tools in your hands now to get started. Good luck and make sure to let us know how you’re progressing.
|
||||
|
||||
_This post is based on an answer I gave to the Quora question _ [_How Does A Total Beginner Start To Learn Machine Learning_][84] _._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Karlijn Willems
|
||||
|
||||
Data Science Journalist
|
||||
|
||||
-----------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/how-machines-learn-a-practical-guide-203aae23cafb
|
||||
|
||||
作者:[ Karlijn Willems][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@kacawi
|
||||
[1]:http://www.khanacademy.org/
|
||||
[2]:https://ocw.mit.edu/index.htm
|
||||
[3]:https://ocw.mit.edu/courses/mathematics/18-06-linear-algebra-spring-2010/
|
||||
[4]:https://www.coursera.org/learn/basic-statistics
|
||||
[5]:https://www.amazon.com/Linear-Algebra-Its-Applications-4th/dp/0030105676
|
||||
[6]:https://www.amazon.com/Applied-Linear-Algebra-3rd-Noble/dp/0130412600
|
||||
[7]:https://www.amazon.de/Solved-Problems-Linear-Algebra-Schaums/dp/0070380236
|
||||
[8]:https://ocw.mit.edu/courses/online-textbooks/
|
||||
[9]:https://www.datacamp.com/courses/intro-to-python-for-data-science
|
||||
[10]:https://www.datacamp.com/courses/free-introduction-to-r
|
||||
[11]:https://www.edx.org/course/introduction-python-data-science-microsoft-dat208x-5
|
||||
[12]:https://www.edx.org/course/introduction-r-data-science-microsoft-dat204x-4
|
||||
[13]:http://www.coursera.org/
|
||||
[14]:https://www.codecademy.com/
|
||||
[15]:http://www.cs.cmu.edu/~tom/mlbook.html
|
||||
[16]:http://www.cs.bris.ac.uk/~flach/mlbook/materials/mlbook-beamer.pdf
|
||||
[17]:http://www.mlyearning.org/
|
||||
[18]:https://www.amazon.com/Algorithms-Data-Structures-Applications-Practitioner/dp/0134894286
|
||||
[19]:https://www.amazon.com/Data-Mining-Masses-Matthew-North/dp/0615684378
|
||||
[20]:http://alex.smola.org/drafts/thebook.pdf
|
||||
[21]:https://www.coursera.org/learn/machine-learning
|
||||
[22]:https://youtu.be/TjZBTDzGeGg?list=PLnvKubj2-I2LhIibS8TOGC42xsD3-liux
|
||||
[23]:https://www.datacamp.com/community/tutorials/machine-learning-python
|
||||
[24]:https://www.datacamp.com/community/tutorials/machine-learning-in-r
|
||||
[25]:https://www.datacamp.com/community/tutorials/deep-learning-python
|
||||
[26]:http://machinelearningmastery.com/machine-learning-in-python-step-by-step/
|
||||
[27]:http://machinelearningmastery.com/tutorial-first-neural-network-python-keras/
|
||||
[28]:http://www.machinelearningmastery.com/
|
||||
[29]:https://www.datacamp.com/courses/supervised-learning-with-scikit-learn
|
||||
[30]:https://www.datacamp.com/courses/unsupervised-learning-in-python
|
||||
[31]:https://www.datacamp.com/courses/deep-learning-in-python
|
||||
[32]:https://www.coursera.org/learn/python-machine-learning
|
||||
[33]:https://www.datacamp.com/courses/introduction-to-machine-learning-with-r
|
||||
[34]:https://www.datacamp.com/courses/unsupervised-learning-in-r
|
||||
[35]:https://www.coursera.org/learn/practical-machine-learning
|
||||
[36]:https://github.com/rasbt/python-machine-learning-book
|
||||
[37]:https://github.com/rasbt/deep-learning-book
|
||||
[38]:https://books.google.be/books/about/Machine_Learning_with_R.html?id=ZQu8AQAAQBAJ&source=kp_cover&redir_esc=y
|
||||
[39]:http://www.kaggle.com/
|
||||
[40]:https://www.datacamp.com/community/open-courses/kaggle-python-tutorial-on-machine-learning
|
||||
[41]:https://www.datacamp.com/community/open-courses/kaggle-tutorial-on-machine-learing-the-sinking-of-the-titanic
|
||||
[42]:http://archive.ics.uci.edu/ml/
|
||||
[43]:http://homepages.inf.ed.ac.uk/rbf/IAPR/researchers/MLPAGES/mldat.htm
|
||||
[44]:https://data.world/
|
||||
[45]:https://www.quora.com/Why-is-there-a-need-to-manually-implement-machine-learning-algorithms-when-there-are-many-advanced-APIs-like-tensorflow-available
|
||||
[46]:http://www.kdnuggets.com/2016/05/implement-machine-learning-algorithms-scratch.html
|
||||
[47]:http://www.jeannicholashould.com/what-i-learned-implementing-a-classifier-from-scratch.html
|
||||
[48]:http://machinelearningmastery.com/how-to-implement-a-machine-learning-algorithm/
|
||||
[49]:https://github.com/eriklindernoren/ML-From-Scratch
|
||||
[50]:https://github.com/madhug-nadig/Machine-Learning-Algorithms-from-Scratch
|
||||
[51]:http://www.kdnuggets.com/2017/04/top-20-papers-machine-learning.html
|
||||
[52]:http://www.jmlr.org/
|
||||
[53]:https://github.com/terryum/awesome-deep-learning-papers
|
||||
[54]:https://www.quora.com/What-are-some-of-the-best-research-papers-books-for-Machine-learning
|
||||
[55]:https://www.datacamp.com/courses/introduction-to-spark-in-r-using-sparklyr
|
||||
[56]:https://www.edx.org/xseries/data-science-engineering-apache-spark
|
||||
[57]:https://www.edx.org/course/introduction-apache-spark-uc-berkeleyx-cs105x
|
||||
[58]:https://www.edx.org/course/distributed-machine-learning-apache-uc-berkeleyx-cs120x
|
||||
[59]:https://www.edx.org/course/big-data-analysis-apache-spark-uc-berkeleyx-cs110x
|
||||
[60]:https://www.datacamp.com/community/tutorials/apache-spark-python
|
||||
[61]:https://www.datacamp.com/community/blog/pyspark-cheat-sheet-python
|
||||
[62]:https://www.datacamp.com/community/blog/pyspark-sql-cheat-sheet
|
||||
[63]:https://fossbytes.com/popular-top-programming-languages-machine-learning-data-science/
|
||||
[64]:http://www.kdnuggets.com/2017/01/most-popular-language-machine-learning-data-science.html
|
||||
[65]:http://www.thetalkingmachines.com/
|
||||
[66]:https://dataskeptic.com/
|
||||
[67]:http://lineardigressions.com/
|
||||
[68]:https://twimlai.com/
|
||||
[69]:http://www.learningmachines101.com/
|
||||
[70]:https://github.com/scikit-learn/scikit-learn
|
||||
[71]:http://www.github.com/fchollet/keras
|
||||
[72]:http://topepo/caret
|
||||
[73]:http://www.r2d3.us/visual-intro-to-machine-learning-part-1/
|
||||
[74]:http://distill.pub/
|
||||
[75]:http://playground.tensorflow.org/
|
||||
[76]:https://www.quora.com/What-are-the-best-visualizations-of-machine-learning-algorithms
|
||||
[77]:https://www.datacamp.com/community/tutorials/learn-data-science-infographic
|
||||
[78]:https://www.datacamp.com/community/tutorials/python-statistics-data-science
|
||||
[79]:https://www.datacamp.com/community/tutorials/python-scipy-tutorial
|
||||
[80]:http://www.math.pitt.edu/~siam/workshops/python10/python.pdf
|
||||
[81]:http://docs.sympy.org/latest/tutorial/calculus.html
|
||||
[82]:http://web.cecs.pdx.edu/~mm/MachineLearningSpring2017/
|
||||
[83]:https://www.quora.com/Should-I-quit-machine-learning
|
||||
[84]:https://www.quora.com/How-does-a-total-beginner-start-to-learn-machine-learning/answer/Karlijn-Willems-1
|
||||
@ -0,0 +1,125 @@
|
||||
Using Ansible for deploying serverless applications
|
||||
============================================================
|
||||
|
||||
### Serverless is another step in the direction of managed services and plays nice with Ansible's agentless architecture.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
[Ansible][8] is designed as the simplest deployment tool that actually works. What that means is that it's not a full programming language. You write YAML templates that define tasks and list whatever tasks you need to automate your job.
|
||||
|
||||
Most people think of Ansible as a souped-up version of "SSH in a 'for' loop," and that's true for simple use cases. But really Ansible is about _tasks_ , not about SSH. For a lot of use cases, we connect via SSH but also support things like Windows Remote Management (WinRM) for Windows machines, different protocols for network devices, and the HTTPS APIs that are the lingua franca of cloud services.
|
||||
|
||||
More on Ansible
|
||||
|
||||
* [How Ansible works][1]
|
||||
|
||||
* [Free Ansible eBooks][2]
|
||||
|
||||
* [Ansible quick start video][3]
|
||||
|
||||
* [Download and install Ansible][4]
|
||||
|
||||
In a cloud, Ansible can operate on two separate layers: the control plane and the on-instance resources. The control plane consists of everything _not_ running on the OS. This includes setting up networks, spawning instances, provisioning higher-level services like Amazon's S3 or DynamoDB, and everything else you need to keep your cloud infrastructure secure and serving customers.
|
||||
|
||||
On-instance work is what you already know Ansible for: starting and stopping services, templating config files, installing packages, and everything else OS-related that you can do over SSH.
|
||||
|
||||
Now, what about [serverless][9]? Depending who you ask, serverless is either the ultimate extension of the continued rush to the public cloud or a wildly new paradigm where everything is an API call, and it's never been done before.
|
||||
|
||||
Ansible takes the first view. Before "serverless" was a term of art, users had to manage and provision EC2 instances, virtual private cloud (VPC) networks, and everything else. Serverless is another step in the direction of managed services and plays nice with Ansible's agentless architecture.
|
||||
|
||||
Before we go into a [Lambda][10] example, let's look at a simpler task for provisioning a CloudFormation stack:
|
||||
|
||||
```
|
||||
- name: Build network
|
||||
cloudformation:
|
||||
stack_name: prod-vpc
|
||||
state: present
|
||||
template: base_vpc.yml
|
||||
```
|
||||
|
||||
Writing a task like this takes just a couple minutes, but it brings the last semi-manual step involved in building your infrastructure—clicking "Create Stack"—into a playbook with everything else. Now your VPC is just another task you can call when building up a new region.
|
||||
|
||||
Since cloud providers are the real source of truth when it comes to what's really happening in your account, Ansible has a number of ways to pull that back and use the IDs, names, and other parameters to filter and query running instances or networks. Take for example the **cloudformation_facts** module that we can use to get the subnet IDs, network ranges, and other data back out of the template we just created.
|
||||
|
||||
```
|
||||
- name: Pull all new resources back in as a variable
|
||||
cloudformation_facts:
|
||||
stack_name: prod-vpc
|
||||
register: network_stack
|
||||
```
|
||||
|
||||
For serverless applications, you'll definitely need a complement of Lambda functions in addition to any other DynamoDB tables, S3 buckets, and whatever else. Fortunately, by using the **lambda** modules, Lambda functions can be created in the same way as the stack from the last tasks:
|
||||
|
||||
```
|
||||
- lambda:
|
||||
name: sendReportMail
|
||||
zip_file: "{{ deployment_package }}"
|
||||
runtime: python3.6
|
||||
handler: report.send
|
||||
memory_size: 1024
|
||||
role: "{{ iam_exec_role }}"
|
||||
register: new_function
|
||||
```
|
||||
|
||||
If you have another tool that you prefer for shipping the serverless parts of your application, that works as well. The open source [Serverless Framework][11] has its own Ansible module that will work just as well:
|
||||
|
||||
```
|
||||
- serverless:
|
||||
service_path: '{{ project_dir }}'
|
||||
stage: dev
|
||||
register: sls
|
||||
- name: Serverless uses CloudFormation under the hood, so you can easily pull info back into Ansible
|
||||
cloudformation_facts:
|
||||
stack_name: "{{ sls.service_name }}"
|
||||
register: sls_facts
|
||||
```
|
||||
|
||||
That's not quite everything you need, since the serverless project also must exist, and that's where you'll do the heavy lifting of defining your functions and event sources. For this example, we'll make a single function that responds to HTTP requests. The Serverless Framework uses YAML as its config language (as does Ansible), so this should look familiar.
|
||||
|
||||
```
|
||||
# serverless.yml
|
||||
service: fakeservice
|
||||
|
||||
provider:
|
||||
name: aws
|
||||
runtime: python3.6
|
||||
|
||||
functions:
|
||||
main:
|
||||
handler: test_function.handler
|
||||
events:
|
||||
- http:
|
||||
path: /
|
||||
method: get
|
||||
```
|
||||
|
||||
At [AnsibleFest][12], I'll be covering this example and other in-depth deployment strategies to take the best advantage of the Ansible playbooks and infrastructure you already have, along with new serverless practices. Whether you're able to be there or not, I hope these examples can get you started using Ansible—whether or not you have any servers to manage.
|
||||
|
||||
_AnsibleFest is a _ _day-long_ _ conference bringing together hundreds of Ansible users, developers, and industry partners. Join us for product updates, inspirational talks, tech deep dives, hands-on demos and a day of networking. Get your tickets to AnsibleFest in San Francisco on September 7\. Save 25% on [**registration**][6] with the discount code **OPENSOURCE**._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/8/ansible-serverless-applications
|
||||
|
||||
作者:[Ryan Scott Brown ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ryansb
|
||||
[1]:https://www.ansible.com/how-ansible-works?intcmp=701f2000000h4RcAAI
|
||||
[2]:https://www.ansible.com/ebooks?intcmp=701f2000000h4RcAAI
|
||||
[3]:https://www.ansible.com/quick-start-video?intcmp=701f2000000h4RcAAI
|
||||
[4]:https://docs.ansible.com/ansible/latest/intro_installation.html?intcmp=701f2000000h4RcAAI
|
||||
[5]:https://opensource.com/article/17/8/ansible-serverless-applications?rate=zOgBPQUEmiTctfbajpu_TddaH-8b-ay3pFCK0b43vFw
|
||||
[6]:https://www.eventbrite.com/e/ansiblefest-san-francisco-2017-tickets-34008433139
|
||||
[7]:https://opensource.com/user/12043/feed
|
||||
[8]:https://www.ansible.com/
|
||||
[9]:https://en.wikipedia.org/wiki/Serverless_computing
|
||||
[10]:https://aws.amazon.com/lambda/
|
||||
[11]:https://serverless.com/
|
||||
[12]:https://www.ansible.com/ansiblefest?intcmp=701f2000000h4RcAAI
|
||||
[13]:https://opensource.com/users/ryansb
|
||||
[14]:https://opensource.com/users/ryansb
|
||||
@ -0,0 +1,294 @@
|
||||
Using Kubernetes for Local Development — Minikube
|
||||
============================================================
|
||||
|
||||
If you ops team are using Docker and Kubernetes, it is recommended to adopt the same or similar technologies in development. This will reduce the number of incompatibility and portability problems and makes everyone consider the application container a common responsibility of both Dev and Ops teams.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
This blog post introduces the usage of Kubernetes in development mode and it is inspired from a screencast that you can find in [Painless Docker Course][10].
|
||||
|
||||
][1]
|
||||
|
||||
Minikube is a tool that makes developers’ life easy by allowing them to use and run a Kubernetes cluster in a local machine.
|
||||
|
||||
In this blog post, for the examples that I tested, I am using Linux Mint 18, but it doesn’t change nothing apart the installation part.
|
||||
|
||||
```
|
||||
cat /etc/lsb-release
|
||||
```
|
||||
|
||||
```
|
||||
DISTRIB_ID=LinuxMint
|
||||
DISTRIB_RELEASE=18.1
|
||||
DISTRIB_CODENAME=serena
|
||||
DISTRIB_DESCRIPTION=”Linux Mint 18.1 Serena”
|
||||
```
|
||||
|
||||
|
||||

|
||||
|
||||
#### Prerequisites
|
||||
|
||||
In order to work with Minkube, we should have Kubectl and Minikube installed + some virtualization drivers.
|
||||
|
||||
* For OS X, install [xhyve driver][2], [VirtualBox][3], or [VMware Fusion][4], then Kubectl and Minkube
|
||||
|
||||
```
|
||||
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl
|
||||
```
|
||||
|
||||
```
|
||||
chmod +x ./kubectl
|
||||
```
|
||||
|
||||
```
|
||||
sudo mv ./kubectl /usr/local/bin/kubectl
|
||||
```
|
||||
|
||||
```
|
||||
curl -Lo minikube https://storage.googleapis.com/minikube/releases/v0.21.0/minikube-darwin-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/
|
||||
```
|
||||
|
||||
* For Windows, install [VirtualBox][6] or [Hyper-V][7] then Kubectl and Minkube
|
||||
|
||||
```
|
||||
curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.7.0/bin/windows/amd64/kubectl.exe
|
||||
```
|
||||
|
||||
Add the binary to your PATH (This [article][11] explains how to modify the PATH)
|
||||
|
||||
Download the `minikube-windows-amd64.exe` file, rename it to `minikube.exe`and add it to your path.
|
||||
|
||||
Find the last release [here][12].
|
||||
|
||||
* For Linux, install [VirtualBox][8] or [KVM][9] then Kubectl and Minkube
|
||||
|
||||
```
|
||||
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
|
||||
```
|
||||
|
||||
```
|
||||
chmod +x ./kubectl
|
||||
```
|
||||
|
||||
```
|
||||
sudo mv ./kubectl /usr/local/bin/kubectl
|
||||
```
|
||||
|
||||
```
|
||||
curl -Lo minikube https://storage.googleapis.com/minikube/releases/v0.21.0/minikube-linux-amd64 && chmod +x minikube && sudo mv minikube /usr/local/bin/
|
||||
```
|
||||
|
||||
#### Using Minikube
|
||||
|
||||
Let’s start by creating an image from this Dockerfile:
|
||||
|
||||
```
|
||||
FROM busybox
|
||||
ADD index.html /www/index.html
|
||||
EXPOSE 8000
|
||||
CMD httpd -p 8000 -h /www; tail -f /dev/null
|
||||
```
|
||||
|
||||
Add something you’d like to see in the index.html page.
|
||||
|
||||
Build the image:
|
||||
|
||||
```
|
||||
docker build -t eon01/hello-world-web-server .
|
||||
```
|
||||
|
||||
Let’s run the container to test it:
|
||||
|
||||
```
|
||||
docker run -d --name webserver -p 8000:8000 eon01/hello-world-web-server
|
||||
```
|
||||
|
||||
This is the output of docker ps:
|
||||
|
||||
```
|
||||
docker ps
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
2ad8d688d812 eon01/hello-world-web-server "/bin/sh -c 'httpd..." 3 seconds ago Up 2 seconds 0.0.0.0:8000->8000/tcp webserver
|
||||
```
|
||||
|
||||
Let’s commit the image and upload it to the public Docker Hub. You can use your own private registry:
|
||||
|
||||
```
|
||||
docker commit webserver
|
||||
docker push eon01/hello-world-web-server
|
||||
```
|
||||
|
||||
Remove the container since we will use it with Minikube
|
||||
|
||||
```
|
||||
docker rm -f webserver
|
||||
```
|
||||
|
||||
Time to start Minikube:
|
||||
|
||||
```
|
||||
minkube start
|
||||
```
|
||||
|
||||
Check the status:
|
||||
|
||||
```
|
||||
minikube status
|
||||
```
|
||||
|
||||
We are running a single node:
|
||||
|
||||
```
|
||||
kubectl get node
|
||||
```
|
||||
|
||||
Run the webserver:
|
||||
|
||||
```
|
||||
kubectl run webserver --image=eon01/hello-world-web-server --port=8000
|
||||
```
|
||||
|
||||
A webserver should have it’s port exposed:
|
||||
|
||||
```
|
||||
kubectl expose deployment webserver --type=NodePort
|
||||
```
|
||||
|
||||
In order to get the service url type:
|
||||
|
||||
```
|
||||
minikube service webserver --url
|
||||
```
|
||||
|
||||
We can see the content of the web page using :
|
||||
|
||||
```
|
||||
curl $(minikube service webserver --url)
|
||||
```
|
||||
|
||||
To show a summary of the running cluster run:
|
||||
|
||||
```
|
||||
kubectl cluster-info
|
||||
```
|
||||
|
||||
For more details:
|
||||
|
||||
```
|
||||
kubectl cluster-info dump
|
||||
```
|
||||
|
||||
We can also list the pods using:
|
||||
|
||||
```
|
||||
kubectl get pods
|
||||
```
|
||||
|
||||
And to access to the dashboard use:
|
||||
|
||||
```
|
||||
minikube dashboard
|
||||
```
|
||||
|
||||
If you would like to access the frontend of the web application type:
|
||||
|
||||
```
|
||||
kubectl proxy
|
||||
```
|
||||
|
||||
If we want to execute a command inside the container, get the pod id using:
|
||||
|
||||
```
|
||||
kubetctl get pods
|
||||
```
|
||||
|
||||
Then use it like :
|
||||
|
||||
```
|
||||
kubectl exec webserver-2022867364-0v1p9 -it -- /bin/sh
|
||||
```
|
||||
|
||||
To finish, delete all deployments:
|
||||
|
||||
```
|
||||
kubectl delete deployments --all
|
||||
```
|
||||
|
||||
Delete all pods:
|
||||
|
||||
```
|
||||
kubectl delete pods --all
|
||||
```
|
||||
|
||||
And stop Minikube
|
||||
|
||||
```
|
||||
minikube stop
|
||||
```
|
||||
|
||||
I hope you enjoyed this introduction.
|
||||
|
||||
### Connect Deeper
|
||||
|
||||
If you resonated with this article, you can find more interesting contents in [Painless Docker Course][13].
|
||||
|
||||
We, [Eralabs][14], will be happy to help you on your Docker and Cloud Computing projects, [contact us][15] and we will be happy to hear about your projects.
|
||||
|
||||
Please subscribe to [DevOpsLinks][16] : An Online Community Of Thousands Of IT Experts & DevOps Enthusiast From All Over The World.
|
||||
|
||||
You may be also interested in joining our newsletter [Shipped][17], a newsletter focused on containers, orchestration and serverless technologies.
|
||||
|
||||
You can find me on [Twitter][18], [Clarity][19] or my [website][20] and you can also check my books: [SaltStack For DevOps][21].
|
||||
|
||||
Don’t forget to join my last project [Jobs For DevOps][22] !
|
||||
|
||||
If you liked this post, please recommend it and share it with your followers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aymen El Amri
|
||||
Cloud & Software Architect, Entrepreneur, Author, CEO www.eralabs.io, Founder www.devopslinks.com, Personal Page : www.aymenelamri.com
|
||||
|
||||
-------------------
|
||||
|
||||
|
||||
via: https://medium.com/devopslinks/using-kubernetes-minikube-for-local-development-c37c6e56e3db
|
||||
|
||||
作者:[Aymen El Amri ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@eon01
|
||||
[1]:http://painlessdocker.com/
|
||||
[2]:https://git.k8s.io/minikube/docs/drivers.md#xhyve-driver
|
||||
[3]:https://www.virtualbox.org/wiki/Downloads
|
||||
[4]:https://www.vmware.com/products/fusion
|
||||
[5]:https://storage.googleapis.com/kubernetes-release/release/stable.txt%29/bin/darwin/amd64/kubectl
|
||||
[6]:https://www.virtualbox.org/wiki/Downloads
|
||||
[7]:https://msdn.microsoft.com/en-us/virtualization/hyperv_on_windows/quick_start/walkthrough_install
|
||||
[8]:https://www.virtualbox.org/wiki/Downloads
|
||||
[9]:http://www.linux-kvm.org/
|
||||
[10]:http://painlessdocker.com/
|
||||
[11]:https://www.windows-commandline.com/set-path-command-line/
|
||||
[12]:https://github.com/kubernetes/minikube/releases
|
||||
[13]:http://painlessdocker.com/
|
||||
[14]:http://eralabs.io/
|
||||
[15]:http://eralabs.io/
|
||||
[16]:http://devopslinks.com/
|
||||
[17]:http://shipped.devopslinks.com/
|
||||
[18]:https://twitter.com/eon01
|
||||
[19]:https://clarity.fm/aymenelamri/
|
||||
[20]:http://aymenelamri.com/
|
||||
[21]:http://saltstackfordevops.com/
|
||||
[22]:http://jobsfordevops.com/
|
||||
@ -0,0 +1,132 @@
|
||||
Why open source should be the first choice for cloud-native environments
|
||||
============================================================
|
||||
|
||||
### For the same reasons Linux beat out proprietary software, open source should be the first choice for cloud-native environments.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Jason Baker][6]. [CC BY-SA 4.0][7]. Source: [Cloud][8], [Globe][9]. Both [CC0][10].
|
||||
|
||||
Let's take a trip back in time to the 1990s, when proprietary software reigned, but open source was starting to come into its own. What caused this switch, and more importantly, what can we learn from it today as we shift into cloud-native environments?
|
||||
|
||||
### An infrastructure history lesson
|
||||
|
||||
I'll begin with a highly opinionated, open source view of infrastructure's history over the past 30 years. In the 1990s, Linux was merely a blip on most organizations' radar, if they knew anything about it. You had early buy-in from companies that quickly saw the benefits of Linux, mostly as a cheap replacement for proprietary Unix, but the standard way of deploying a server was with a proprietary form of Unix or—increasingly—by using Microsoft Windows NT.
|
||||
|
||||
The proprietary nature of this tooling provided a fertile ecosystem for even more proprietary software. Software was boxed up to be sold in stores. Even open source got in on the packaging game; you could buy Linux on the shelf instead of tying up your internet connection downloading it from free sources. Going to the store or working with your software vendor was just how you got software.
|
||||
|
||||
### [ubuntu_box.png][1]
|
||||
|
||||

|
||||
|
||||
Ubuntu box packaging on a Best Buy shelf
|
||||
|
||||
Where I think things changed was with the rise of the LAMP stack (Linux, Apache, MySQL, and PHP/Perl/Python).
|
||||
|
||||
Where I think things changed was with the rise of the LAMP stack (Linux, Apache, MySQL, and PHP/Perl/Python).The LAMP stack is a major success story. It was stable, scalable, and relatively user-friendly. At the same time, I started seeing dissatisfaction with proprietary solutions. Once customers had this taste of open source in the LAMP stack, they changed what they expected from software, including:
|
||||
|
||||
* reluctance to be locked in by a vendor,
|
||||
|
||||
* concern over security,
|
||||
|
||||
* desire to fix bugs themselves, and
|
||||
|
||||
* recognition that innovation is stifled when software is developed in isolation.
|
||||
|
||||
On the technical side, we also saw a massive change in how organizations use software. Suddenly, downtime for a website was unacceptable. There was a move to a greater reliance on scaling and automation. In the past decade especially, we've seen a move from the traditional "pet" model of infrastructure to a "cattle" model, where servers can be swapped out and replaced, rather than kept and named. Companies work with massive amounts of data, causing a greater focus on data retention and the speed of processing and returning that data to users.
|
||||
|
||||
Open source, with open communities and increasing investment from major companies, provided the foundation to satisfy this change in how we started using software. Systems administrators' job descriptions began requiring skill with Linux and familiarity with open source technologies and methodologies. Through the open sourcing of things like Chef cookbooks and Puppet modules, administrators could share the configuration of their tooling. No longer were we individually configuring and tuning MySQL in silos; we created a system for handling
|
||||
|
||||
Open source is ubiquitous today, and so is the tooling surrounding it.the basic parts so we could focus on the more interesting engineering work that brought specific value to our employers.
|
||||
|
||||
Open source is ubiquitous today, and so is the tooling surrounding it. Companies once hostile to the idea are not only embracing open source through interoperability programs and outreach, but also by releasing their own open source software projects and building communities around it.
|
||||
|
||||
### [microsoft_linux_stick.png][2]
|
||||
|
||||

|
||||
|
||||
A "Microsoft
|
||||

|
||||
Linux" USB stick
|
||||
|
||||
### Turning to the cloud
|
||||
|
||||
Today, we're living in a world of DevOps and clouds. We've reaped the rewards of the innovation that open source movements brought. There's a sharp rise in what Tim O'Reilly called "[inner-sourcing][11]," where open source software development practices are adopted inside of companies. We're sharing deployment configurations for cloud platforms. Tools like Terraform are even allowing us to write and share how we deploy to specific platforms.
|
||||
|
||||
Today, we're living in a world of DevOps and clouds.But what about these platforms themselves?
|
||||
|
||||
> "Most people just consume the cloud without thinking ... many users are sinking cost into infrastructure that is not theirs, and they are giving up data and information about themselves without thinking."
|
||||
> —Edward Snowden, OpenStack Summit, May 9, 2017
|
||||
|
||||
It's time to put more thought into our knee-jerk reaction to move or expand to the cloud.
|
||||
|
||||
As Snowden highlighted, now we risk of losing control of the data that we maintain for our users and customers. Security aside, if we look back at our list of reasons for switching to open source, high among them were also concerns about vendor lock-in and the inability to drive innovation or even fix bugs.
|
||||
|
||||
Before you lock yourself and/or your company into a proprietary platform, consider the following questions:
|
||||
|
||||
* Is the service I'm using adhering to open standards, or am I locked in?
|
||||
|
||||
* What is my recourse if the service vendor goes out of business or is bought by a competitor?
|
||||
|
||||
* Does the vendor have a history of communicating clearly and honestly with its customers about downtime, security, etc.?
|
||||
|
||||
* Does the vendor respond to bugs and feature requests, even from smaller customers?
|
||||
|
||||
* Will the vendor use our data in a way that I'm not comfortable with (or worse, isn't allowed by our own customer agreements)?
|
||||
|
||||
* Does the vendor have a plan to handle long-term, escalating costs of growth, particularly if initial costs are low?
|
||||
|
||||
You may go through this questionnaire, discuss each of the points, and still decide to use a proprietary solution. That's fine; companies do it all the time. However, if you're like me and would rather find a more open solution while still benefiting from the cloud, you do have options.
|
||||
|
||||
### Beyond the proprietary cloud
|
||||
|
||||
As you look beyond proprietary cloud solutions, your first option to go open source is by investing in a cloud provider whose core runs on open source software. [OpenStack][12] is the industry leader, with more than 100 participating organizations and thousands of contributors in its seven-year history (including me for a time). The OpenStack project has proven that interfacing with multiple OpenStack-based clouds is not only possible, but relatively trivial. The APIs are similar between cloud companies, so you're not necessarily locked in to a specific OpenStack vendor. As an open source project, you can still influence the features, bug requests, and direction of the infrastructure.
|
||||
|
||||
The second option is to continue to use proprietary clouds at a basic level, but within an open source container orchestration system. Whether you select [DC/OS][13] (built on [Apache Mesos][14]), [Kubernetes][15], or [Docker in swarm mode][16], these platforms allow you to treat the virtual machines served up by proprietary cloud systems as independent Linux machines and install your platform on top of that. All you need is Linux—and don't get immediately locked into the cloud-specific tooling or platforms. Decisions can be made on a case-by-case basis about whether to use specific proprietary backends, but if you do, try to keep an eye toward the future should a move be required.
|
||||
|
||||
With either option, you also have the choice to depart from the cloud entirely. You can deploy your own OpenStack cloud or move your container platform in-house to your own data center.
|
||||
|
||||
### Making a moonshot
|
||||
|
||||
To conclude, I'd like to talk a bit about open source project infrastructures. Back in March, participants from various open source projects convened at the [Southern California Linux Expo][17] to talk about running open source infrastructures for their projects. (For more, read my [summary of this event][18].) I see the work these projects are doing as the final step in the open sourcing of infrastructure. Beyond the basic sharing that we're doing now, I believe companies and organizations can make far more of their infrastructures open source without giving up the "secret sauce" that distinguishes them from competitors.
|
||||
|
||||
The open source projects that have open sourced their infrastructures have proven the value of allowing multiple companies and organizations to submit educated bug reports, and even patches and features, to their infrastructure. Suddenly you can invite part-time contributors. Your customers can derive confidence by knowing what your infrastructure looks like "under the hood."
|
||||
|
||||
Want more evidence? Visit [Open Source Infrastructure][19]'s website to learn more about the projects making their infrastructures open source (and the extensive amount of infrastructure they've released).
|
||||
|
||||
_Learn more in Elizabeth K. Joseph's talk, [The Open Sourcing of Infrastructure][4], at FOSSCON August 26th in Philadelphia._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/8/open-sourcing-infrastructure
|
||||
|
||||
作者:[ Elizabeth K. Joseph][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pleia2
|
||||
[1]:https://opensource.com/file/366596
|
||||
[2]:https://opensource.com/file/366591
|
||||
[3]:https://opensource.com/article/17/8/open-sourcing-infrastructure?rate=PdT-huv5y5HFZVMHOoRoo_qd95RG70y4DARqU5pzgkU
|
||||
[4]:https://fosscon.us/node/12637
|
||||
[5]:https://opensource.com/user/25923/feed
|
||||
[6]:https://opensource.com/users/jason-baker
|
||||
[7]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[8]:https://pixabay.com/en/clouds-sky-cloud-dark-clouds-1473311/
|
||||
[9]:https://pixabay.com/en/globe-planet-earth-world-1015311/
|
||||
[10]:https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[11]:https://opensource.com/life/16/11/create-internal-innersource-community
|
||||
[12]:https://www.openstack.org/
|
||||
[13]:https://dcos.io/
|
||||
[14]:http://mesos.apache.org/
|
||||
[15]:https://kubernetes.io/
|
||||
[16]:https://docs.docker.com/engine/swarm/
|
||||
[17]:https://www.socallinuxexpo.org/
|
||||
[18]:https://opensource.com/article/17/3/growth-open-source-project-infrastructures
|
||||
[19]:https://opensourceinfra.org/
|
||||
[20]:https://opensource.com/users/pleia2
|
||||
[21]:https://opensource.com/users/pleia2
|
||||
@ -0,0 +1,239 @@
|
||||
Half a dozen clever Linux command line tricks
|
||||
============================================================
|
||||
|
||||
### Some very useful commands for making life on the command line more rewarding
|
||||
|
||||

|
||||
[Micah Elizabeth Scott][32] [(CC BY 2.0)][33]RELATED
|
||||
|
||||
|
||||
Working on the Linux command can be a lot of fun, but it can be even more fun when you use commands that take less work on your part or display information in interesting and useful ways. In today’s post, we’re going to look at half a dozen commands that might make your time on the command line more profitable.
|
||||
|
||||
### watch
|
||||
|
||||
The watch command will repeatedly run whatever command you give it and show you the output. By default, it runs the command every two seconds. Each successive running of the command overwrites what it displayed on the previous run, so you're always looking at the latest data.
|
||||
|
||||
You might use it when you’re waiting for someone to log in. In this case, you would use the command “watch who” or maybe “watch -n 15 who” to have the command run every 15 seconds instead of every two seconds. The date and time will appear in the upper right-hand corner of your terminal window.
|
||||
|
||||
```
|
||||
$ watch -n 5 who
|
||||
Every 5.0s: who stinkbug: Wed Aug 23 14:52:15 2017
|
||||
|
||||
shs pts/0 2017-08-23 14:45 (192.168.0.11)
|
||||
zoe pts/1 2017-08-23 08:15 (192.168.0.19)
|
||||
```
|
||||
|
||||
You might also use it to watch a log file. If nothing changes in the data you’re displaying, only the date/time display in the corner of the window will change.
|
||||
|
||||
|
||||
|
||||
```
|
||||
$ watch tail /var/log/syslog
|
||||
Every 2.0s: tail /var/log/syslog stinkbug: Wed Aug 23 15:16:37 2017
|
||||
|
||||
Aug 23 14:45:01 stinkbug CRON[7214]: (root) CMD (command -v debian-sa1 > /dev/nu
|
||||
ll && debian-sa1 1 1)
|
||||
Aug 23 14:45:17 stinkbug systemd[1]: Started Session 179 of user shs.
|
||||
Aug 23 14:55:01 stinkbug CRON[7577]: (root) CMD (command -v debian-sa1 > /dev/nu
|
||||
ll && debian-sa1 1 1)
|
||||
Aug 23 15:05:01 stinkbug CRON[7582]: (root) CMD (command -v debian-sa1 > /dev/nu
|
||||
ll && debian-sa1 1 1)
|
||||
Aug 23 15:08:48 stinkbug systemd[1]: Starting Cleanup of Temporary Directories...
|
||||
Aug 23 15:08:48 stinkbug systemd-tmpfiles[7584]: [/usr/lib/tmpfiles.d/var.conf:1
|
||||
4] Duplicate line for path "/var/log", ignoring.
|
||||
Aug 23 15:08:48 stinkbug systemd[1]: Started Cleanup of Temporary Directories.
|
||||
Aug 23 15:13:41 stinkbug systemd[1]: Started Session 182 of user shs.
|
||||
Aug 23 15:14:29 stinkbug systemd[1]: Started Session 183 of user shs.
|
||||
Aug 23 15:15:01 stinkbug CRON[7828]: (root) CMD (command -v debian-sa1 > /dev/nu
|
||||
ll && debian-sa1 1 1)
|
||||
```
|
||||
|
||||
This output is similar to what you’d see using tail -f /var/log/syslog.
|
||||
|
||||
### look
|
||||
|
||||
The name might suggest that look does something similar to watch, but it’s entirely different. The look command searches for words that begin with some particular string.
|
||||
|
||||
```
|
||||
$ look ecl
|
||||
eclectic
|
||||
eclectic's
|
||||
eclectically
|
||||
eclecticism
|
||||
eclecticism's
|
||||
eclectics
|
||||
eclipse
|
||||
eclipse's
|
||||
eclipsed
|
||||
eclipses
|
||||
eclipsing
|
||||
ecliptic
|
||||
ecliptic's
|
||||
```
|
||||
|
||||
The look command is generally helpful with spelling and used the /usr/share/dict/words file unless you specify a file name with a command like this one:
|
||||
|
||||
```
|
||||
$ look esac .bashrc
|
||||
esac
|
||||
esac
|
||||
esac
|
||||
```
|
||||
|
||||
In this case, it acts like grep following by an awk command that prints only the first word on the matching lines.
|
||||
|
||||
|
||||
### man -k
|
||||
|
||||
The man -k command lists man pages that include the specified word. It basically works like the apropos command.
|
||||
|
||||
```
|
||||
$ man -k logrotate
|
||||
dh_installlogrotate (1) - install logrotate config files
|
||||
logrotate (8) - rotates, compresses, and mails system logs
|
||||
logrotate.conf (5) - rotates, compresses, and mails system logs
|
||||
```
|
||||
|
||||
### help
|
||||
|
||||
While you may be tempted to use this command when you’re utterly frustrated, what the help command actually does is show you a list of shell built-ins. What’s most surprising is how many of these variables exist. You’re likely to see something like this and then start to wonder what all of these built-ins might do for you:
|
||||
|
||||
```
|
||||
$ help
|
||||
GNU bash, version 4.4.7(1)-release (i686-pc-linux-gnu)
|
||||
These shell commands are defined internally. Type `help' to see this list.
|
||||
Type `help name' to find out more about the function `name'.
|
||||
Use `info bash' to find out more about the shell in general.
|
||||
Use `man -k' or `info' to find out more about commands not in this list.
|
||||
|
||||
A star (*) next to a name means that the command is disabled.
|
||||
|
||||
job_spec [&] history [-c] [-d offset] [n] or hist>
|
||||
(( expression )) if COMMANDS; then COMMANDS; [ elif C>
|
||||
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs >
|
||||
: kill [-s sigspec | -n signum | -sigs>
|
||||
[ arg... ] let arg [arg ...]
|
||||
[[ expression ]] local [option] name[=value] ...
|
||||
alias [-p] [name[=value] ... ] logout [n]
|
||||
bg [job_spec ...] mapfile [-d delim] [-n count] [-O or>
|
||||
bind [-lpsvPSVX] [-m keymap] [-f file> popd [-n] [+N | -N]
|
||||
break [n] printf [-v var] format [arguments]
|
||||
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
|
||||
caller [expr] pwd [-LP]
|
||||
case WORD in [PATTERN [| PATTERN]...)> read [-ers] [-a array] [-d delim] [->
|
||||
cd [-L|[-P [-e]] [-@]] [dir] readarray [-n count] [-O origin] [-s>
|
||||
command [-pVv] command [arg ...] readonly [-aAf] [name[=value] ...] o>
|
||||
compgen [-abcdefgjksuv] [-o option] [> return [n]
|
||||
complete [-abcdefgjksuv] [-pr] [-DE] > select NAME [in WORDS ... ;] do COMM>
|
||||
compopt [-o|+o option] [-DE] [name ..> set [-abefhkmnptuvxBCHP] [-o option->
|
||||
continue [n] shift [n]
|
||||
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
|
||||
declare [-aAfFgilnrtux] [-p] [name[=v> source filename [arguments]
|
||||
dirs [-clpv] [+N] [-N] suspend [-f]
|
||||
disown [-h] [-ar] [jobspec ... | pid > test [expr]
|
||||
echo [-neE] [arg ...] time [-p] pipeline
|
||||
enable [-a] [-dnps] [-f filename] [na> times
|
||||
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
|
||||
exec [-cl] [-a name] [command [argume> true
|
||||
exit [n] type [-afptP] name [name ...]
|
||||
export [-fn] [name[=value] ...] or ex> typeset [-aAfFgilnrtux] [-p] name[=v>
|
||||
false ulimit [-SHabcdefiklmnpqrstuvxPT] [l>
|
||||
fc [-e ename] [-lnr] [first] [last] o> umask [-p] [-S] [mode]
|
||||
fg [job_spec] unalias [-a] name [name ...]
|
||||
for NAME [in WORDS ... ] ; do COMMAND> unset [-f] [-v] [-n] [name ...]
|
||||
for (( exp1; exp2; exp3 )); do COMMAN> until COMMANDS; do COMMANDS; done
|
||||
function name { COMMANDS ; } or name > variables - Names and meanings of so>
|
||||
getopts optstring name [arg] wait [-n] [id ...]
|
||||
hash [-lr] [-p pathname] [-dt] [name > while COMMANDS; do COMMANDS; done
|
||||
help [-dms] [pattern ...] { COMMANDS ; }
|
||||
```
|
||||
|
||||
### stat -c
|
||||
|
||||
The stat command displays the vital statistics for a file — its size, owner, group, inode number, permissions, modification and access times. It’s a very useful command that displays more detail than a simple ls -l.
|
||||
|
||||
```
|
||||
$ stat .bashrc
|
||||
File: .bashrc
|
||||
Size: 4048 Blocks: 8 IO Block: 4096 regular file
|
||||
Device: 806h/2054d Inode: 421481 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
|
||||
Access: 2017-08-23 15:13:41.781809933 -0400
|
||||
Modify: 2017-06-21 17:37:11.875157790 -0400
|
||||
Change: 2017-06-21 17:37:11.899157791 -0400
|
||||
Birth: -
|
||||
```
|
||||
|
||||
With the -c option, you can specify the fields you want to see. If, for example, you want to see just the file name and access rights for a file or series of files, you might do this:
|
||||
|
||||
```
|
||||
$ stat -c '%n %a' .bashrc
|
||||
.bashrc 644
|
||||
```
|
||||
|
||||
In this command, the %n represents the name of each file, while %a represents the access rights. A %u would be the numeric UID and %U the username.
|
||||
|
||||
```
|
||||
$ stat -c '%n %a' bin/*
|
||||
bin/loop 700
|
||||
bin/move2nohup 700
|
||||
bin/nohup.out 600
|
||||
bin/show_release 700
|
||||
|
||||
$ stat -c '%n %a %U' bin/*
|
||||
bin/loop 700 shs
|
||||
bin/move2nohup 700 shs
|
||||
bin/nohup.out 600 root
|
||||
bin/show_release 700 shs
|
||||
```
|
||||
|
||||
### TAB
|
||||
|
||||
If you’re not using the tab command for filename completion, you’re really missing out on a very useful command line trick. The tab command provides filename completion (including directories when you’re using cd). It fills in as much of a name as possible before it hits an ambiguity (more than one file starting with the same letters. If you have a file named bigplans and another named bigplans2017, you’ll hear a sound and have to decide whether to press enter or “2” and tab again to select the second file.
|
||||
|
||||
Join the Network World communities on [Facebook][30] and [LinkedIn][31] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3219684/linux/half-a-dozen-clever-linux-command-line-tricks.html
|
||||
|
||||
作者:[ Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.networkworld.com/article/3203369/lan-wan/10-most-important-open-source-networking-projects.html
|
||||
[2]:https://www.networkworld.com/article/3203369/lan-wan/10-most-important-open-source-networking-projects.html#tk.nww_nsdr_ndxprmomod
|
||||
[3]:https://www.networkworld.com/article/3188295/linux/linux-mint-18-1-mostly-smooth-but-some-sharp-edges.html
|
||||
[4]:https://www.networkworld.com/article/3188295/linux/linux-mint-18-1-mostly-smooth-but-some-sharp-edges.html#tk.nww_nsdr_ndxprmomod
|
||||
[5]:https://www.networkworld.com/article/3167272/linux/open-source-users-its-time-for-extreme-vetting.html
|
||||
[6]:https://www.networkworld.com/article/3167272/linux/open-source-users-its-time-for-extreme-vetting.html#tk.nww_nsdr_ndxprmomod
|
||||
[7]:https://www.networkworld.com/article/3218728/linux/how-log-rotation-works-with-logrotate.html
|
||||
[8]:https://www.networkworld.com/article/3194830/linux/10-unix-commands-every-mac-and-linux-user-should-know.html
|
||||
[9]:https://www.networkworld.com/article/3208389/linux/unix-how-random-is-random.html
|
||||
[10]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[11]:https://www.networkworld.com/article/3219826/mobile/prime-members-get-60-off-nucleus-anywhere-intercom-with-amazon-alexa-right-now-deal-alert.html
|
||||
[12]:https://www.networkworld.com/article/3106867/consumer-electronics/32-off-pulse-solo-dimmable-led-light-with-dual-channel-bluetooth-speakers-deal-alert.html
|
||||
[13]:https://www.networkworld.com/article/3219685/mobile/57-off-rockbirds-6-pack-led-mini-super-bright-3-mode-tactical-flashlights-deal-alert.html
|
||||
[14]:https://www.networkworld.com/insider
|
||||
[15]:https://twitter.com/intent/tweet?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html&via=networkworld&text=Half+a+dozen+clever+Linux+command+line+tricks
|
||||
[16]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html
|
||||
[17]:http://www.linkedin.com/shareArticle?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html&title=Half+a+dozen+clever+Linux+command+line+tricks
|
||||
[18]:https://plus.google.com/share?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html
|
||||
[19]:http://reddit.com/submit?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html&title=Half+a+dozen+clever+Linux+command+line+tricks
|
||||
[20]:http://www.stumbleupon.com/submit?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html
|
||||
[21]:https://www.networkworld.com/article/3219684/linux/half-a-dozen-clever-linux-command-line-tricks.html#email
|
||||
[22]:https://www.networkworld.com/article/3218728/linux/how-log-rotation-works-with-logrotate.html
|
||||
[23]:https://www.networkworld.com/article/3194830/linux/10-unix-commands-every-mac-and-linux-user-should-know.html
|
||||
[24]:https://www.networkworld.com/article/3208389/linux/unix-how-random-is-random.html
|
||||
[25]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[26]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[27]:https://www.networkworld.com/article/3219826/mobile/prime-members-get-60-off-nucleus-anywhere-intercom-with-amazon-alexa-right-now-deal-alert.html
|
||||
[28]:https://www.networkworld.com/article/3106867/consumer-electronics/32-off-pulse-solo-dimmable-led-light-with-dual-channel-bluetooth-speakers-deal-alert.html
|
||||
[29]:https://www.networkworld.com/article/3219685/mobile/57-off-rockbirds-6-pack-led-mini-super-bright-3-mode-tactical-flashlights-deal-alert.html
|
||||
[30]:https://www.facebook.com/NetworkWorld/
|
||||
[31]:https://www.linkedin.com/company/network-world
|
||||
[32]:https://www.flickr.com/photos/micahdowty/4630801442/in/photolist-84d4Wb-p29iHU-dscgLx-pXKT7a-pXKT7v-azMz3V-azMz7M-4Amp2h-6iyQ51-4nf4VF-5C1gt6-6P4PwG-po6JEA-p6C5Wg-6RcRbH-7GAmbK-dCkRnT-7ETcBp-4Xbhrw-dXrN8w-dXm83Z-dXrNvQ-dXrMZC-dXrMPN-pY4GdS-azMz8X-bfNoF4-azQe61-p1iUtm-87i3vj-7enNsv-6sqvJy-dXm8aD-6smkyX-5CFfGm-dXm8dD-6sqviw-6sqvVU-dXrMVd-6smkXc-dXm7Ug-deuxUg-6smker-Hd15p-6squyf-aGtnxn-6smjRX-5YtTUN-nynqYm-ea5o3c
|
||||
[33]:https://creativecommons.org/licenses/by/2.0/legalcode
|
||||
@ -0,0 +1,213 @@
|
||||
Splitting and Re-Assembling Files in Linux
|
||||
============================================================
|
||||
|
||||

|
||||
The very useful csplit command divides single files into multiple files. Carla Schroder explains.[Creative Commons Attribution][1]
|
||||
|
||||
Linux has several utilities for splitting up files. So why would you want to split your files? One use case is to split a large file into smaller sizes so that it fits on smaller media, like USB sticks. This is also a good trick to transfer files via USB sticks when you're stuck with FAT32, which has a maximum file size of 4GB, and your files are bigger than that. Another use case is to speed up network file transfers, because parallel transfers of small files are usually faster.
|
||||
|
||||
We'll learn how to use `csplit, split`, and `cat` to chop up and then put files back together. These work on any file type: text, image, audio, .iso, you name it.
|
||||
|
||||
### Split Files With csplit
|
||||
|
||||
`csplit` is one of those funny little commands that has been around forever, and when you discover it you wonder how you ever made it through life without it. `csplit` divides single files into multiple files. This example demonstrates its simplest invocation, which divides the file foo.txt into three files, split at line numbers 17 and 33:
|
||||
|
||||
```
|
||||
$ csplit foo.txt 17 33
|
||||
2591
|
||||
3889
|
||||
2359
|
||||
```
|
||||
|
||||
`csplit` creates three new files in the current directory, and prints the sizes of your new files in bytes. By default, each new file is named `xx _nn_` :
|
||||
|
||||
```
|
||||
$ ls
|
||||
xx00
|
||||
xx01
|
||||
xx02
|
||||
```
|
||||
|
||||
You can view the first ten lines of each of your new files all at once with the `head` command:
|
||||
|
||||
```
|
||||
$ head xx*
|
||||
|
||||
==> xx00 <==
|
||||
Foo File
|
||||
by Carla Schroder
|
||||
|
||||
Foo text
|
||||
|
||||
Foo subheading
|
||||
|
||||
More foo text
|
||||
|
||||
==> xx01 <==
|
||||
Foo text
|
||||
|
||||
Foo subheading
|
||||
|
||||
More foo text
|
||||
|
||||
==> xx02 <==
|
||||
Foo text
|
||||
|
||||
Foo subheading
|
||||
|
||||
More foo text
|
||||
```
|
||||
|
||||
What if you want to split a file into several files all containing the same number of lines? Specify the number of lines, and then enclose the number of repetitions in curly braces. This example repeats the split 4 times, and dumps the leftover in the last file:
|
||||
|
||||
```
|
||||
$ csplit foo.txt 5 {4}
|
||||
57
|
||||
1488
|
||||
249
|
||||
1866
|
||||
3798
|
||||
```
|
||||
|
||||
You may use the asterisk wildcard to tell `csplit` to repeat your split as many times as possible. Which sounds cool, but it fails if the file does not divide evenly:
|
||||
|
||||
```
|
||||
$ csplit foo.txt 10 {*}
|
||||
1545
|
||||
2115
|
||||
1848
|
||||
1901
|
||||
csplit: '10': line number out of range on repetition 4
|
||||
1430
|
||||
```
|
||||
|
||||
The default behavior is to delete the output files on errors. You can foil this with the `-k` option, which will not remove the output files when there are errors. Another gotcha is every time you run `csplit` it overwrites the previous files it created, so give your splits new filenames to save them. Use `--prefix= _prefix_` to set a different file prefix:
|
||||
|
||||
```
|
||||
$ csplit -k --prefix=mine foo.txt 5 {*}
|
||||
57
|
||||
1488
|
||||
249
|
||||
1866
|
||||
993
|
||||
csplit: '5': line number out of range on repetition 9
|
||||
437
|
||||
|
||||
$ ls
|
||||
mine00
|
||||
mine01
|
||||
mine02
|
||||
mine03
|
||||
mine04
|
||||
mine05
|
||||
```
|
||||
|
||||
The `-n` option changes the number of digits used to number your files:
|
||||
|
||||
```
|
||||
|
||||
$ csplit -n 3 --prefix=mine foo.txt 5 {4}
|
||||
57
|
||||
1488
|
||||
249
|
||||
1866
|
||||
1381
|
||||
3798
|
||||
|
||||
$ ls
|
||||
mine000
|
||||
mine001
|
||||
mine002
|
||||
mine003
|
||||
mine004
|
||||
mine005
|
||||
```
|
||||
|
||||
The "c" in `csplit` is "context". This means you can split your files based on all manner of arbitrary matches and clever regular expressions. This example splits the file into two parts. The first file ends at the line that precedes the line containing the first occurrence of "fie", and the second file starts with the line that includes "fie".
|
||||
|
||||
```
|
||||
$ csplit foo.txt /fie/
|
||||
```
|
||||
|
||||
Split the file at every occurrence of "fie":
|
||||
|
||||
```
|
||||
$ csplit foo.txt /fie/ {*}
|
||||
```
|
||||
|
||||
Split the file at the first 5 occurrences of "fie":
|
||||
|
||||
```
|
||||
$ csplit foo.txt /fie/ {5}
|
||||
```
|
||||
|
||||
Copy only the content that starts with the line that includes "fie", and omit everything that comes before it:
|
||||
|
||||
```
|
||||
$ csplit myfile %fie%
|
||||
```
|
||||
|
||||
### Splitting Files into Sizes
|
||||
|
||||
`split` is similar to `csplit`. It splits files into specific sizes, which is fabulous when you're splitting large files to copy to small media, or for network transfers. The default size is 1000 lines:
|
||||
|
||||
```
|
||||
$ split foo.mv
|
||||
$ ls -hl
|
||||
266K Aug 21 16:58 xaa
|
||||
267K Aug 21 16:58 xab
|
||||
315K Aug 21 16:58 xac
|
||||
[...]
|
||||
```
|
||||
|
||||
They come out to a similar size, but you can specify any size you want. This example is 20 megabytes:
|
||||
|
||||
```
|
||||
$ split -b 20M foo.mv
|
||||
```
|
||||
|
||||
The size abbreviations are K, M, G, T, P, E, Z, Y (powers of 1024), or KB, MB, GB, and so on for powers of 1000.
|
||||
|
||||
Choose your own prefix and suffix for the filenames:
|
||||
|
||||
```
|
||||
$ split -a 3 --numeric-suffixes=9 --additional-suffix=mine foo.mv SB
|
||||
240K Aug 21 17:44 SB009mine
|
||||
214K Aug 21 17:44 SB010mine
|
||||
220K Aug 21 17:44 SB011mine
|
||||
```
|
||||
|
||||
The `-a` controls how many numeric digits there are. `--numeric-suffixes` sets the starting point for numbering. The default prefix is x, and you can set a different prefix by typing it after the filename.
|
||||
|
||||
### Putting Split Files Together
|
||||
|
||||
You probably want to reassemble your files at some point. Good old `cat` takes care of this:
|
||||
|
||||
```
|
||||
$ cat SB0* > foo2.txt
|
||||
```
|
||||
|
||||
The asterisk wildcard in the example will snag any file that starts with SB0, which may not give the results you want. You can make a more exact match with question mark wildcards, using one per character:
|
||||
|
||||
```
|
||||
$ cat SB0?????? > foo2.txt
|
||||
```
|
||||
|
||||
As always, consult the relevant and man and info pages for complete command options.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/8/splitting-and-re-assembling-files-linux
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[2]:https://www.linux.com/files/images/split-filespng
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
49
sources/tech/20170824 Understanding OPNFV Starts Here.md
Normal file
49
sources/tech/20170824 Understanding OPNFV Starts Here.md
Normal file
@ -0,0 +1,49 @@
|
||||
Understanding OPNFV Starts Here
|
||||
============================================================
|
||||
|
||||

|
||||
The "Understanding OPNFV" book provides a high-level understanding of what OPNFV is and how it can help you or your organization. Download now.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
If telecom operators or enterprises were to build their networks from scratch today, they would likely build them as software-defined resources, similar to Google or Facebook’s infrastructure. That’s the premise of Network Functions Virtualization (NFV).
|
||||
|
||||
NFV is a once in a generation disruption that will completely transform how networks are built and operated. And, [OPNFV][3] is a leading open source NFV project that aims to accelerate the adoption of this technology.
|
||||
|
||||
Are you a telecom operator or connected enterprise employee wondering which open source projects might help you with your NFV transformation initiatives? Or a technology vendor attempting to position your products and services in the new NFV world? Or perhaps an engineer, network operator or business leader wanting to progress your career using open source projects (case in point, in 2013 Rackspace [stated][4] that network engineers with OpenStack skills made, on average, 13 percent more salary than their counterparts)? If any of this applies to you, the _Understanding OPNFV_ book is a perfect resource for you.
|
||||
|
||||

|
||||
In 11 easy-to-read chapters and over 144 pages, this book (written by Nick Chase from Mirantis and me) covers an entire range of topics from an overview of NFV, NFV transformation, all aspects of the OPNFV project, to VNF onboarding. After reading this book, you will have an excellent high-level understanding of what OPNFV is and how it can help you or your organization. This book is not specifically meant for developers, though it may be useful for background information. If you are a developer looking to get involved in a specific OPNFV project as a contributor, then [wiki.opnfv.org][5] is still the best resource for you.
|
||||
|
||||
In this blog series, we will give you a flavor of portions of the book — in terms of what’s there and what you might learn.
|
||||
|
||||
Let’s start with the first chapter. Chapter 1, no surprise, provides an introduction to NFV. It gives a super-brief overview of NFV in terms of business drivers (the need for differentiated services, cost pressures and need for agility), what NFV is and what benefits you can expect from NFV.
|
||||
|
||||
Briefly, NFV enables complex network functions to be performed on compute nodes in data centers. A network function performed on a compute node is called a Virtualized Network Function (VNF). So that VNFs can behave as a network, NFV also adds the mechanisms to determine how they can be chained together to provide control over traffic within a network.
|
||||
|
||||
Although most people think of it in terms of telecommunications, NFV encompasses a broad set of use cases, from Role Based Access Control (RBAC) based on application or traffic type, to Content Delivery Networks (CDN) that manage content at the edges of the network (where it is often needed), to the more obvious telecom-related use cases such as Evolved Packet Core (EPC) and IP Multimedia System (IMS).
|
||||
|
||||
Additionally, some of the main benefits include increased revenue, improved customer experience, reduced operational expenditure (OPEX), reduced capital expenditures (CAPEX) and freed-up resources for new projects. This section also provides results of a concrete NFV total-cost-of-ownership (TCO) analysis. Treatment of these topics is brief since we assume you will have some NFV background; however, if you are new to NFV, not to worry — the introductory material is adequate to understand the rest of the book.
|
||||
|
||||
The chapter concludes with a summary of NFV requirements — security, performance, interoperability, ease-of-operations and some specific requirements such as service assurance and service function chaining. No NFV architecture or technology can be truly successful without meeting these requirements.
|
||||
|
||||
After reading this chapter, you will have a good overview of why NFV is important, what NFV is, and what is technically required to make NFV successful. We will look at following chapters in upcoming blog posts.
|
||||
|
||||
This book has proven to be our most popular giveaway at industry events and a Chinese version is now under development! But you can [download the eBook in PDF][6] right now, or [order a printed version][7] on Amazon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/opnfv/2017/8/understanding-opnfv-starts-here
|
||||
|
||||
作者:[AMAR KAPADIA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/akapadia
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/network-transformationpng
|
||||
[3]:https://www.opnfv.org/
|
||||
[4]:https://blog.rackspace.com/solving-the-openstack-talent-gap
|
||||
[5]:https://wiki.opnfv.org/
|
||||
[6]:https://www.opnfv.org/resources/download-understanding-opnfv-ebook
|
||||
[7]:https://www.amazon.com/dp/B071LQY724/ref=cm_sw_r_cp_ep_dp_pgFMzbM8YHJA9
|
||||
@ -0,0 +1,173 @@
|
||||
Guide to Linux App Is a Handy Tool for Every Level of Linux User
|
||||
============================================================
|
||||
|
||||

|
||||
The Guide to Linux app is not perfect, but it's a great tool to help you learn your way around Linux commands.[Used with permission][7]Essence Infotech LLP
|
||||
|
||||
|
||||
Remember when you first started out with Linux? Depending on the environment you’re coming from, the learning curve can be somewhat challenging. Take, for instance, the number of commands found in _ /usr/bin_ alone. On my current Elementary OS system, that number is 1,944\. Of course, not all of those are actual commands (or commands I would use), but the number is significant.
|
||||
|
||||
Because of that (and many other differences from other platforms), new users (and some already skilled users) need a bit of help now and then.
|
||||
|
||||
For every administrator, there are certain skills that are must-have:
|
||||
|
||||
* Understanding of the platform
|
||||
|
||||
* Understanding commands
|
||||
|
||||
* Shell scripting
|
||||
|
||||
When you seek out assistance, sometimes you’ll be met with RTFM (Read the Fine/Freaking/Funky Manual). That doesn’t always help when you have no idea what you’re looking for. That’s when you’ll be glad for apps like [Guide to Linux][15].
|
||||
|
||||
Unlike most of the content you’ll find here on Linux.com, this particular article is about an Android app. Why? Because this particular app happens to be geared toward helping users learn Linux.
|
||||
|
||||
And it does a fine job.
|
||||
|
||||
I’m going to give you fair warning about this app—it’s not perfect. Guide to Linux is filled with broken English, bad punctuation, and (if you’re a purist) it never mentions GNU. On top of that, one particular feature (one that would normally be very helpful to users) doesn’t function enough to be useful. Outside of that, Guide to Linux might well be one of your best bets for having a mobile “pocket guide” to the Linux platform.
|
||||
|
||||
With this app, you’ll enjoy:
|
||||
|
||||
* Offline usage.
|
||||
|
||||
* Linux Tutorial.
|
||||
|
||||
* Details of all basic and advanced Linux commands of Linux.
|
||||
|
||||
* Includes command examples and syntax.
|
||||
|
||||
* Dedicated Shell Script module.
|
||||
|
||||
On top of that, Guide to Linux is free (although it does contain ads). If you want to get rid of the ads, there’s an in-app purchase ($2.99 USD/year) to take care of that.
|
||||
|
||||
Let’s install this app and then take a look at the constituent parts.
|
||||
|
||||
### Installation
|
||||
|
||||
Like all Android apps, installation of Guide to Linux is incredibly simple. All you have to do is follow these easy steps:
|
||||
|
||||
1. Open up the Google Play Store on your Android device
|
||||
|
||||
2. Search for Guide to Linux
|
||||
|
||||
3. Locate and tap the entry by Essence Infotech
|
||||
|
||||
4. Tap Install
|
||||
|
||||
5. Allow the installation to complete
|
||||
|
||||
### [guidetolinux1.jpg][8]
|
||||
|
||||

|
||||
|
||||
Figure 1: The Guide to Linux main window.[Used with permission][1]
|
||||
|
||||
Once installed, you’ll find the launcher for Guide to Linux in either your App Drawer or on your home screen (or both). Tap the icon to launch the app.
|
||||
|
||||
### Usage
|
||||
|
||||
Let’s take a look at the individual features that make up Guide to Linux. You will probably find some features more helpful than others, and your experience will vary. Before we break it down, I’ll make mention of the interface. The developer has done a great job of creating an easy-to-use interface for the app.
|
||||
|
||||
From the main window (Figure 1), you can gain easy access to the four features.
|
||||
|
||||
Tap any one of the four icons to launch a feature and you’re ready to learn.
|
||||
|
||||
### [guidetolinux2.jpg][9]
|
||||
|
||||

|
||||
|
||||
Figure 2: The tutorial begins at the beginning.[Used with permission][2]
|
||||
|
||||
### Tutorial
|
||||
|
||||
Let’s start out with the most newbie-friendly feature of the app—Tutorial. Open up that feature and you’ll be greeted by the first section of the tutorial, “Introduction to the Linux Operating System” (Figure 2).
|
||||
|
||||
If you tap the “hamburger menu” (three horizontal lines in the top left corner), the Table of Contents are revealed (Figure 3), so you can select any of the available sections within the Tutorial.
|
||||
|
||||
### [guidetolinux3.jpg][10]
|
||||
|
||||

|
||||
|
||||
Figure 3: The Tutorial Table of Contents.[Used with permission][3]
|
||||
|
||||
Unless you haven’t figured it out by now, the Tutorial section of Guide to Linux is a collection of short essays on each topic. The essays include pictures and (in some cases) links that will send you to specific web sites (as needed to suit a topic). There is no interaction here, just reading. However, this is a great place to start, as the developer has done a solid job of describing the various sections (grammar notwithstanding).
|
||||
|
||||
Although you will see a search option at the top of the window, I haven’t found that feature to be even remotely effective—but it’s there for you to try.
|
||||
|
||||
For new Linux users, looking to add Linux administration to their toolkit, you’ll want to read through this entire Tutorial. Once you’ve done that, move on to the next section.
|
||||
|
||||
### Commands
|
||||
|
||||
The Commands feature is like having the man pages, in hand, for many of the most frequently used Linux commands. When you first open this, you will be greeted by an introduction that explains the advantage of using commands.
|
||||
|
||||
### [guidetolinux4.jpg][11]
|
||||
|
||||

|
||||
|
||||
Figure 4: The Commands sidebar allows you to check out any of the listed commands.[Used with permission][4]
|
||||
|
||||
Once you’ve read through that you can either tap the right-facing arrow (at the bottom of the screen) or tap the “hamburger menu” and then select the command you want to learn about from the sidebar (Figure 4).
|
||||
|
||||
Tap on one of the commands and you can then read through the explanation of the command in question. Each page explains the command and its options as well as offers up examples of how to use the command.
|
||||
|
||||
### Shell Script
|
||||
|
||||
At this point, you’re starting to understand Linux and you have a solid grasp on commands. Now it’s time to start understanding shell scripts. This section is set up in the same fashion as is the Tutorial and Commands sections.
|
||||
|
||||
You can open up a sidebar Table of Contents to take and then open up any of the sections that comprise the Shell Script tutorial (Figure 5).
|
||||
|
||||
### [guidetolinux-5-new.jpg][12]
|
||||
|
||||

|
||||
|
||||
Figure 5: The Shell Script section should look familiar by now.[Used with permission][5]
|
||||
|
||||
Once again, the developer has done a great job of explaining how to get the most out of shell scripting. For anyone interested in learning the ins and outs of shell scripting, this is a pretty good place to start.
|
||||
|
||||
### Terminal
|
||||
|
||||
Now we get to the section where your mileage may vary. The developer has included a terminal emulator with the app. Unfortunately, when installing this on an unrooted Android device, you’ll find yourself locked into a read-only file system, where most of the commands simply won’t work. However, I did install Guide to Linux on a Pixel 2 (via the Android app store) and was able to get a bit more usage from the feature (if only slightly). On a OnePlus 3 (not rooted), no matter what directory I change into, I get the same “permission denied” error, even for a simple ls command.
|
||||
|
||||
On the Chromebook, however, all is well (Figure 6). Sort of. We’re still working with a read-only file system (so you cannot actually work with or create new files).
|
||||
|
||||
### [guidetolinux6.jpg][13]
|
||||
|
||||

|
||||
|
||||
Figure 6: Finally able to (sort of) work with the terminal emulator.[Used with permission][6]
|
||||
|
||||
Remember, this isn’t actually a full-blown terminal, but a way for new users to understand how the terminal works. Unfortunately, most users are going to find themselves frustrated with this feature of the tool, simply because they cannot put to use what they’ve learned within the other sections. It might behoove the developer to re-tool the terminal feature as a sandboxed Linux file system, so users could actually learn with it. Every time a user would open that tool, it could revert to its original state. Just a thought.
|
||||
|
||||
### In the end…
|
||||
|
||||
Even with the terminal feature being a bit hamstrung by the read-only filesystem (almost to the point of being useless), Guide to Linux is a great tool for users new to Linux. With this guide to Linux, you’ll learn enough about Linux, commands, and shell scripting to feel like you have a head start, even before you install that first distribution.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][16]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/8/guide-linux-app-handy-tool-every-level-linux-user
|
||||
|
||||
作者:[ JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/used-permission
|
||||
[7]:https://www.linux.com/licenses/category/used-permission
|
||||
[8]:https://www.linux.com/files/images/guidetolinux1jpg
|
||||
[9]:https://www.linux.com/files/images/guidetolinux2jpg
|
||||
[10]:https://www.linux.com/files/images/guidetolinux3jpg-0
|
||||
[11]:https://www.linux.com/files/images/guidetolinux4jpg
|
||||
[12]:https://www.linux.com/files/images/guidetolinux-5-newjpg
|
||||
[13]:https://www.linux.com/files/images/guidetolinux6jpg-0
|
||||
[14]:https://www.linux.com/files/images/guide-linuxpng
|
||||
[15]:https://play.google.com/store/apps/details?id=com.essence.linuxcommands
|
||||
[16]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[17]:https://www.addtoany.com/share#url=https%3A%2F%2Fwww.linux.com%2Flearn%2Fintro-to-linux%2F2017%2F8%2Fguide-linux-app-handy-tool-every-level-linux-user&title=Guide%20to%20Linux%20App%20Is%20a%20Handy%20Tool%20for%20Every%20Level%20of%20Linux%20User
|
||||
@ -0,0 +1,198 @@
|
||||
Happy anniversary, Linux: A look back at where it all began
|
||||
============================================================
|
||||
|
||||
### Installing SLS 1.05 shows just how far the Linux kernel has come in 26 years.
|
||||
|
||||

|
||||
Image by : [litlnemo][25]. Modified by Opensource.com. [CC BY-SA 2.0.][26]
|
||||
|
||||
I first installed Linux in 1993\. I ran MS-DOS at the time, but I really liked the Unix systems in our campus computer lab, where I spent much of my time as an undergraduate university student. When I heard about Linux, a free version of Unix that I could run on my 386 computer at home, I immediately wanted to try it out. My first Linux distribution was [Softlanding Linux System][27] (SLS) 1.03, with Linux kernel 0.99 alpha patch level 11\. That required a whopping 2MB of RAM, or 4MB if you wanted to compile programs, and 8MB to run X windows.
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
I thought Linux was a huge step up from the world of MS-DOS. While Linux lacked the breadth of applications and games available on MS-DOS, I found Linux gave me a greater degree of flexibility. Unlike MS-DOS, I could now do true multi-tasking, running more than one program at a time. And Linux provided a wealth of tools, including a C compiler that I could use to build my own programs.
|
||||
|
||||
A year later, I upgraded to SLS 1.05, which sported the brand-new Linux kernel 1.0\. More importantly, Linux 1.0 introduced kernel modules. With modules, you no longer needed to completely recompile your kernel to support new hardware; instead you loaded one of the 63 included Linux kernel modules. SLS 1.05 included this note about modules in the distribution's README file:
|
||||
|
||||
> Modularization of the kernel is aimed squarely at reducing, and eventually eliminating, the requirements for recompiling the kernel, either for changing/modifying device drivers or for dynamic access to infrequently required drivers. More importantly, perhaps, the efforts of individual working groups need no longer affect the development of the kernel proper. In fact, a binary release of the official kernel should now be possible.
|
||||
|
||||
On August 25, the Linux kernel will reach its 26th anniversary. To celebrate, I reinstalled SLS 1.05 to remind myself what the Linux 1.0 kernel was like and to recognize how far Linux has come since the 1990s. Join me on this journey into Linux nostalgia!
|
||||
|
||||
### Installation
|
||||
|
||||
Softlanding Linux System was the first true "distribution" that included an install program. Yet the install process isn't the same smooth process you find in modern distributions. Instead of booting from an install CD-ROM, I needed to boot my system from an install floppy, then run the install program from the **login** prompt.
|
||||
|
||||
### [install1.png][6]
|
||||
|
||||

|
||||
|
||||
A neat feature introduced in SLS 1.05 was the color-enabled text-mode installer. When I selected color mode, the installer switched to a light blue background with black text, instead of the plain white-on-black text used by our primitive forbearers.
|
||||
|
||||
### [install2.png][7]
|
||||
|
||||

|
||||
|
||||
The SLS installer is a simple affair, scrolling text from the bottom of the screen, but it does the job. By responding to a few simple prompts, I was able to create a partition for Linux, put an ext2 filesystem on it, and install Linux. Installing SLS 1.05, including X windows and development tools, required about 85MB of disk space. That may not sound like much space by today's standards, but when Linux 1.0 came out, 120MB hard drives were still common.
|
||||
|
||||
### [install10.png][8]
|
||||
|
||||

|
||||
|
||||
### [firstboot1.png][9]
|
||||
|
||||

|
||||
|
||||
### System level
|
||||
|
||||
When I first booted into Linux, my memory triggered a few system things about this early version of Linux. First, Linux doesn't take up much space. After booting the system and running a few utilities to check it out, Linux occupied less than 4MB of memory. On a system with 16MB of memory, that meant lots left over to run programs.
|
||||
|
||||
### [uname-df.png][10]
|
||||
|
||||

|
||||
|
||||
The familiar **/proc** meta filesystem exists in Linux 1.0, although it doesn't provide much information compared to what you see in modern systems. In Linux 1.0, **/proc** includes interfaces to probe basic system statistics like **meminfo** and **stat**.
|
||||
|
||||
### [proc.png][11]
|
||||
|
||||

|
||||
|
||||
The **/etc** directory on this system is pretty bare. Notably, SLS 1.05 borrows the **rc** scripts from [BSD Unix][28] to control system startup. Everything gets started via **rc**scripts, with local system changes defined in the **rc.local** file. Later, most Linux distributions would adopt the more familiar **init** scripts from [Unix System V][29], then the [systemd][30] initialization system.
|
||||
|
||||
### [etc.png][12]
|
||||
|
||||

|
||||
|
||||
### What you can do
|
||||
|
||||
With my system up and running, it was time to get to work. So, what can you do with this early Linux system?
|
||||
|
||||
Let's start with basic file management. Every time you log in, SLS reminds you about the Softlanding menu shell (MESH), a file-management program that modern users might recognize as similar to [Midnight Commander][31]. Users in the 1990s would have compared MESH more closely to [Norton Commander][32], arguably the most popular third-party file manager available on MS-DOS.
|
||||
|
||||
### [mesh.png][13]
|
||||
|
||||
")
|
||||
|
||||
Aside from MESH, there are relatively few full-screen applications included with SLS 1.05\. But you can find the familiar user tools, including the Elm mail reader, the GNU Emacs programmable editor, and the venerable Vim editor.
|
||||
|
||||
### [elm.png][14]
|
||||
|
||||

|
||||
|
||||
### [emacs19.png][15]
|
||||
|
||||

|
||||
|
||||
SLS 1.05 even included a version of Tetris that you could play at the terminal.
|
||||
|
||||
### [tetris.png][16]
|
||||
|
||||

|
||||
|
||||
In the 1990s, most residential internet access was via dial-up connections, so SLS 1.05 included the Minicom modem-dialer application. Minicom provided a direct connection to the modem and required users to navigate the Hayes modem **AT** commands to do basic functions like dial a number or hang up the phone. Minicom also supported macros and other neat features to make it easier to connect to your local modem pool.
|
||||
|
||||
### [minicom.png][17]
|
||||
|
||||

|
||||
|
||||
But what if you wanted to write a document? SLS 1.05 existed long before the likes of LibreOffice or OpenOffice. Linux just didn't have those applications in the early 1990s. Instead, if you wanted to use a word processor, you likely booted your system into MS-DOS and ran your favorite word processor program, such as WordPerfect or the shareware GalaxyWrite.
|
||||
|
||||
But all Unix systems include a set of simple text formatting programs, called nroff and troff. On Linux systems, these are combined into the GNU groff package, and SLS 1.05 includes a version of groff. One of my tests with SLS 1.05 was to generate a simple text document using nroff.
|
||||
|
||||
### [paper-me-emacs.png][18]
|
||||
|
||||

|
||||
|
||||
### [paper-me-out.png][19]
|
||||
|
||||

|
||||
|
||||
### Running X windows
|
||||
|
||||
Getting X windows to perform was not exactly easy, as the SLS install file promised:
|
||||
|
||||
> Getting X windows to run on your PC can sometimes be a bit of a sobering experience, mostly because there are so many types of video cards for the PC. Linux X11 supports only VGA type video cards, but there are so many types of VGAs that only certain ones are fully supported. SLS comes with two X windows servers. The full color one, XFree86, supports some or all ET3000, ET4000, PVGA1, GVGA, Trident, S3, 8514, Accelerated cards, ATI plus, and others.
|
||||
>
|
||||
> The other server, XF86_Mono, should work with virtually any VGA card, but only in monochrome mode. Accordingly, it also uses less memory and should be faster than the color one. But of course it doesn't look as nice.
|
||||
>
|
||||
> The bulk of the X windows configuration information is stored in the directory "/usr/X386/lib/X11/". In particular, the file "Xconfig" defines the timings for the monitor and the video card. By default, X windows is set up to use the color server, but you can switch to using the monochrome server x386mono, if the color one gives you trouble, since it should support any standard VGA. Essentially, this just means making /usr/X386/bin/X a link to it.
|
||||
>
|
||||
> Just edit Xconfig to set the mouse device type and timings, and enter "startx".
|
||||
|
||||
If that sounds confusing, it is. Configuring X windows by hand really can be a sobering experience. Fortunately, SLS 1.05 included the syssetup program to help you define various system components, including display settings for X windows. After a few prompts, and some experimenting and tweaking, I was finally able to launch X windows!
|
||||
|
||||
### [syssetup.png][20]
|
||||
|
||||

|
||||
|
||||
But this is X windows from 1994, and the concept of a desktop didn't exist yet. My options were either FVWM (a virtual window manager) or TWM (the tabbed window manager). TWM was straightforward to set up and provided a simple, yet functional, graphical environment.
|
||||
|
||||
### [twm_720.png][21]
|
||||
|
||||

|
||||
|
||||
### Shutdown
|
||||
|
||||
As much as I enjoyed exploring my Linux roots, eventually it was time to return to my modern desktop. I originally ran Linux on a 32-bit 386 computer with just 8MB of memory and a 120MB hard drive, and my system today is much more powerful. I can do so much more on my dual-core, 64-bit Intel Core i5 CPU with 4GB of memory and a 128GB solid-state drive running Linux kernel 4.11.11\. So, after my experiments with SLS 1.05 were over, it was time to leave.
|
||||
|
||||
### [shutdown-h.png][22]
|
||||
|
||||

|
||||
|
||||
So long, Linux 1.0\. It's good to see how well you've grown up.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/8/linux-anniversary
|
||||
|
||||
作者:[Jim Hall ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/365166
|
||||
[7]:https://opensource.com/file/365171
|
||||
[8]:https://opensource.com/file/365176
|
||||
[9]:https://opensource.com/file/365161
|
||||
[10]:https://opensource.com/file/365221
|
||||
[11]:https://opensource.com/file/365196
|
||||
[12]:https://opensource.com/file/365156
|
||||
[13]:https://opensource.com/file/365181
|
||||
[14]:https://opensource.com/file/365146
|
||||
[15]:https://opensource.com/file/365151
|
||||
[16]:https://opensource.com/file/365211
|
||||
[17]:https://opensource.com/file/365186
|
||||
[18]:https://opensource.com/file/365191
|
||||
[19]:https://opensource.com/file/365226
|
||||
[20]:https://opensource.com/file/365206
|
||||
[21]:https://opensource.com/file/365236
|
||||
[22]:https://opensource.com/file/365201
|
||||
[23]:https://opensource.com/article/17/8/linux-anniversary?rate=XujKSFS7GfDmxcV7Jf_HUK_MdrW15Po336fO3G8s1m0
|
||||
[24]:https://opensource.com/user/126046/feed
|
||||
[25]:https://www.flickr.com/photos/litlnemo/19777182/
|
||||
[26]:https://creativecommons.org/licenses/by-sa/2.0/
|
||||
[27]:https://en.wikipedia.org/wiki/Softlanding_Linux_System
|
||||
[28]:https://en.wikipedia.org/wiki/Berkeley_Software_Distribution
|
||||
[29]:https://en.wikipedia.org/wiki/UNIX_System_V
|
||||
[30]:https://en.wikipedia.org/wiki/Systemd
|
||||
[31]:https://midnight-commander.org/
|
||||
[32]:https://en.wikipedia.org/wiki/Norton_Commander
|
||||
[33]:https://opensource.com/users/jim-hall
|
||||
[34]:https://opensource.com/users/jim-hall
|
||||
[35]:https://opensource.com/article/17/8/linux-anniversary#comments
|
||||
@ -0,0 +1,136 @@
|
||||
在标准建立之前,软件所存在的问题
|
||||
============================================================
|
||||
|
||||
### 开源项目需要认真对待交付成果中所包含的标准
|
||||
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
无论以何种标准来衡量,开源软件作为旧软件的替代品而崛起,以独特的方式取得了不错的效果。 如今,仅 Github 中就有着数千万的代码仓库,其中重要项目的数量也在快速增长。在本文撰写的时候,[Apache软件基金会][4] 开展了超过 [300个项目][5], [Linux基金会][6] 支持的项目也超过了 60 个。与此同时,[OpenStack 基金会][7] 在 180 多个国家拥有超过 60,000 名成员。
|
||||
|
||||
这样说来,图中的内容可能是错误的吧?
|
||||
|
||||
开源软件在面对用户的众多需求时,由于缺少足够的意识,而无法独自去解决全部需求。 更糟糕的是,许多开源软件社区的成员(业务主管以及开发者)对利用合适的工具解决这一问题并不感兴趣。
|
||||
|
||||
让我们开始找出那些有待解决的问题,看看这些问题在过去是如何被处理的。
|
||||
|
||||
问题存在于:通常许多项目都在试图解决一个大问题当中重复的一小部分。 客户希望能够在竞争产品之间做出选择,不满意的话还能够选择其他产品。但是现在看来,在问题被解决之前都是不可能的,这一问题将会阻止开源软件的使用。
|
||||
|
||||
这已经不是一个新的问题了,并且至今没有传统意义上的解决方法。在一个半世纪以来,用户期望有更多的选择和自由来变换厂商,而这一直是通过制定的标准来实现的。在现实当中,你可以对螺丝钉、灯泡、轮胎、扩展卡的厂商做出无数多的选择,甚至于对独特形状的红酒杯也倾注你的选择。因为标准为这里的每一件物品都提供了物理规格。而在健康和安全领域,我们的幸福也依赖于成千上万的标准,这些标准是由各自企业制定的,以确保在最大化的竞争中能够有完美的结果。
|
||||
|
||||
随着信息与通信技术(ICT)的发展,同样类似的方式形成了一些重要的组织机构,例如:国际电信联盟(ITU),国际电工委员会(IEC),以及电气与电子工程师学会标准协会(IEEE-SA)。有将近 1000 家企业遵循 ICT 标准来进行开发、推广以及测试。
|
||||
|
||||
如今在我们生活的科技世界里,执行着成千上万必不可少的标准,这些标准包含了计算机、移动设备、Wi-Fi 路由器以及其他一切依赖电力来运行的东西,但并不是所有的 ICT 标准都能做到无缝对接。
|
||||
|
||||
关键的一点,在很长的一段时间里,由于客户对拥有种类丰富的产品,避免受制于供应商,并且享受全球范围内的服务的渴望,逐渐演变出了这一体系。
|
||||
|
||||
现在让我们来看看开源软件是如何演进的。
|
||||
|
||||
好消息是伟大的软件已经被创造出来了。坏消息是对于像云计算和虚拟化网络这样的关键领域,没有任何单独的基金会在开发全部的堆栈。取而代之的是,单个项目开发单独一层或者多层,依靠每个项目所花费的时间及友好合作,最终堆叠成栈。当这一过程运行良好时,它不会创造出潜在的受制于传统的专有产品。相反,坏的结果就是它会浪费开发商、社区成员的时间和努力,同时也会辜负客户的期望。
|
||||
|
||||
制定标准是最明确的解决方法
|
||||
。鼓励多个解决方案通过对附加的服务和功能进行有益的竞争,避免客户选择受限。当然也存在着例外,就如同开源世界正在发生的情况。
|
||||
|
||||
这背后的主要原因在于,开源社区的主流观点是:标准意味着限制、落后和多余。对于一个完整的堆栈中的单独一层来说,可能就是这样。但客户想要的自由,是要通过不断地选择,激烈的竞争的。结果就回到了之前的坏结果上,尽管多个厂商提供相似的集成堆栈,但却被锁定在一个技术上。
|
||||
|
||||
在 Yaron Haviv 于 2017 年 6 月 14 日所写的 “[We'll Be Enslaved to Proprietary Clouds Unless We Collaborate][8]” 一文中,就有对这一问题有着很好的描述。
|
||||
|
||||
> _在今天的开源生态系统当中存在一个问题,跨项目整合并不普遍。开源项目能够进行大型合作,构建出分层的模块化的架构,比如说 Linux _ — _已经一次又一次的证明了他的成功。但是与 Linux 的意识形成鲜明对比的就是如今许多开源社区的日常状态。_
|
||||
>
|
||||
> _举个例子:大数据生态系统,就是依赖众多共享组件或通用 API 和层的堆叠来实现的。这一过程同样缺少标准的线路协议,同时,每个处理框架( think Spark, Presto, and Flink)都拥有独立的数据源 API。_
|
||||
>
|
||||
> _这种缺乏合作正在造成担忧。如果不这样的话,项目就会变得不通用,结果对客户产生了负面影响。因为每个人都不得不从头开始,重新开发,这基本上就锁定了客户,减缓了项目的发展。_
|
||||
|
||||
Haviv 提出了两种解决方法:
|
||||
|
||||
* 项目之间更紧密的合作,联合多个项目消除重叠的部分,使堆栈内的整合更加密切;
|
||||
|
||||
* 开发 API ,使切换更加容易。
|
||||
|
||||
这两种方法都能达到目的。但除非事情能有所改变,我们将只会看到第一种方法,这就是前边展望中发现的技术锁定。结果会发现工业界,无论是过去 WinTel 的世界,或者纵观苹果的历史,他们自身相互竞争的产品都是以牺牲选择来换取紧密整合的。
|
||||
|
||||
同样的事情似乎很有可能发生在新的开源界,如果开源项目继续忽视对标准的需求,那么竞争会存在于层内,甚至是堆栈间。如果现在能够做到的话,这样的问题可能就不会发生了。
|
||||
|
||||
因为如果口惠无实开发软件优先,标准之后的话,对于标准的制定就没有真正的兴趣。主要原因是,大多数的商人和开发者对标准知之甚少。不幸的是,我们能够理解这些使事情变得糟糕的原因。这些原因有几个:
|
||||
|
||||
* 大学几乎很少对标准进行培训;
|
||||
|
||||
* 过去拥有标准专业人员的公司遣散了这些部门,新部署的工程师接受标准组织的培训又远远不够;
|
||||
|
||||
* 雇主代表缺足够的标准相关的经验价值;
|
||||
|
||||
* 工程师参与标准活动将会是最佳的技术解决方案,可能会对雇主的花费有更加深远的战略意义;
|
||||
|
||||
* 在许多公司内部,标准专业人员与开源开发者之间鲜又交流;
|
||||
|
||||
* 许多软件工程师将标准视为与 FOSS 定义的“四大自由”有着直接冲突。
|
||||
|
||||
现在,让我们来看看在开源界正在发生什么:
|
||||
|
||||
* 今天大多数的软件工程师鲜有不知道开源的;
|
||||
|
||||
* 工程师们每天都在享受着开源工具所带来的便利;
|
||||
|
||||
* 许多令人激动的最前沿的工作正是在开源项目中完成的;
|
||||
|
||||
* 在热门的开源领域,有经验的开发者广受欢迎,并获得了大量实质性的奖励;
|
||||
|
||||
* 在备受好评的项目中,开发者在软件开发过程中享受到了空前的自主权;
|
||||
|
||||
* 事实上,几乎所有的大型 ICT 公司都参与了多个开源项目,最高级别的成员当中,通常每个公司每年的合并成本(会费加上投入的雇员)都超过了一百万美元。
|
||||
|
||||
如果脱离实际的话,这个比喻似乎暗示着标准是走向 ICT 历史的灰烬。但现实却有很大差别。一个被忽视的事实是,开源开发是比常人所认为的更为娇嫩的花朵。这样比喻的原因是:
|
||||
|
||||
* 项目的主要支持者们可以撤回(已经做过的事情),这将导致一个项目的失败;
|
||||
|
||||
* 社区内的个性和文化冲突会导致社区的瓦解;
|
||||
|
||||
* 重要项目更加紧密的整合能力有待观察;
|
||||
|
||||
* 高资助的开源项目,有时专有权在博弈中被削弱,在某些情况下会导致失败。
|
||||
|
||||
* 随着时间的推移,可能个别公司决定的开源策略没能给他们带来预期的回报;
|
||||
|
||||
* 对开源项目的失败引起过多关注,会导致厂商放弃一些投资中的新项目,并说服客户谨慎选择开源方案。
|
||||
|
||||
奇怪的是,最积极解决这些问题的协作单位是标准组织,部分原因是,他们已经感受到了开源合作的崛起所带来的威胁。他们的回应包括更新知识产权策略以允许在此基础上各种类型的合作,开发开源工具,包含开源代码的标准,以及在其他类型的工作项目中开发开源手册。
|
||||
|
||||
结果就是,这些标准组织调整自己成为一个近乎中立的角色,为完整方案的开发提供平台。这些方案能够包含市场上需要的各种类型的合作产品,以及混合工作产品。随着此过程的继续,很有可能使厂商们乐意推行一些包含了标准组织在内的举措,否则他们可能会走向开源基金。
|
||||
|
||||
重要的是,由于这些原因,开源项目开始认真对待项目交付所包含的标准,或者与标准开发商合作,共同为完整的方案做准备。这不仅会有更多的产品选择,对客户更少的限制,而且也给客户在开源方案上更大的信心,同时也对开源产品和服务有更多的需求。
|
||||
|
||||
倘若这一切不发生的话,将会是一个很大的遗憾,因为这是开源所导致的巨大损失。而这取决于如今的项目所做的决定,是供给市场所需,还是甘心于未来日趋下降的影响力,而不是持续的成功。
|
||||
|
||||
_本文源自 ConsortiumInfo.org的 [Standards Blog][2],并已获得出版许可_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Andy Updegrove - Andy helps 的 CEO, 管理团队,由他们的投资者建立的成功的组织。他曾作为一名先驱,自1979年起,就为高科技公司提供商业头脑的法律顾问和策略建议。在全球舞台上,他经常作为代表,帮助推动超过135部全球标准的制定,宣传开源,主张联盟,其中包括一些世界上最大,最具影响力的标准制定机构。
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/7/software-standards
|
||||
|
||||
作者:[ Andy Updegrove][a]
|
||||
译者:[softpaopao](https://github.com/softpaopao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andrewupdegrove
|
||||
[1]:https://opensource.com/article/17/7/software-standards?rate=kKK6oD-vGSEdDMj7OHpBMSqASMqbz3ii94q1Kj12lCI
|
||||
[2]:http://www.consortiuminfo.org/standardsblog/article.php?story=20170616133415179
|
||||
[3]:https://opensource.com/user/16796/feed
|
||||
[4]:https://www.apache.org/
|
||||
[5]:https://projects.apache.org/
|
||||
[6]:https://www.linuxfoundation.org/
|
||||
[7]:https://www.linuxfoundation.org/projects/directory
|
||||
[8]:https://www.enterprisetech.com/2017/06/14/well-enslaved-proprietary-clouds-unless-collaborate/
|
||||
[9]:https://opensource.com/users/andrewupdegrove
|
||||
[10]:https://opensource.com/users/andrewupdegrove
|
||||
[11]:https://opensource.com/article/17/7/software-standards#comments
|
||||
@ -1,73 +0,0 @@
|
||||
# 在 Kali Linux 的 Wireshark 中过滤数据包
|
||||
|
||||
内容
|
||||
|
||||
* * [1. 介绍][1]
|
||||
|
||||
* [2. 布尔表达式和比较运算符][2]
|
||||
|
||||
* [3. 过滤抓包][3]
|
||||
|
||||
* [4. 过滤结果][4]
|
||||
|
||||
* [5. 总结思考][5]
|
||||
|
||||
### 介绍
|
||||
|
||||
过滤可让你专注于你有兴趣查看的精确数据集。如你所见,Wireshark 默认会抓取_所有_数据包。这可能会妨碍你寻找具体的数据。 Wireshark 提供了两个功能强大的过滤工具,让你简单并且无痛苦地获得精确的数据。
|
||||
|
||||
Wireshark 可以通过两种方式过滤数据包。它可以过滤只收集某些数据包,或者在抓取数据包后进行过滤。当然,这些可以彼此结合使用,并且它们各自的用处取决于收集的数据和信息的多少。
|
||||
|
||||
### 布尔表达式和比较运算符
|
||||
|
||||
Wireshark 有很多很棒的内置过滤器。输入任何一个过滤器字段,你将看到它们会自动完成。大多数对应于用户在数据包之间会出现的更常见的区别。仅过滤 HTTP 请求将是一个很好的例子。
|
||||
|
||||
对于其他的,Wireshark 使用布尔表达式和/或比较运算符。如果你曾经做过任何编程,你应该熟悉布尔表达式。他们是使用 “and”、“or”、“not” 来验证声明或表达的真假。比较运算符要简单得多他们只是确定两件或更多件事情是否相等、大于或小于彼此。
|
||||
|
||||
### 过滤抓包
|
||||
|
||||
在深入自定义抓包过滤器之前,请先查看 Wireshark 已经内置的内容。单击顶部菜单上的 “Capture” 选项卡,然后点击 “Options”。可用接口下面是可以编写抓包过滤器的行。直接移到左边一个标有 “Capture Filter” 的按钮上。点击它,你将看到一个新的对话框,其中包含内置的抓包过滤器列表。看看里面有些什么。
|
||||
|
||||

|
||||
|
||||
|
||||
在对话框的底部,有一个小的表单来创建并保存抓包过滤器。按左边的 “New” 按钮。它将创建一个有默认数据的新的抓包过滤器。要保存新的过滤器,只需将实际需要的名称和表达式替换原来的默认值,然后单击“Ok”。过滤器将被保存并应用。使用此工具,你可以编写并保存多个不同的过滤器,并让它们将来可以再次使用。
|
||||
|
||||
抓包有自己的过滤语法。对于比较,它不使用等于号,并使用 `>` 来用于大于或小于。对于布尔值来说,它使用 “and”、“or” 和 “not”。
|
||||
|
||||
例如,如果你只想监听 80 端口的流量,你可以使用这样的表达式:`port 80`。如果你只想从特定的 IP 监听端口 80,你可以 `port 80 and host 192.168.1.20`。如你所见,抓包过滤器有特定的关键字。这些关键字用于告诉 Wireshark 如何监控数据包以及哪些数据。例如,`host` 用于查看来自 IP 的所有流量。`src`用于查看源自该 IP 的流量。与之相反,`net` 只监听目标到这个 IP 的流量。要查看一组 IP 或网络上的流量,请使用 `net`。
|
||||
|
||||
### 过滤结果
|
||||
|
||||
界面的底部菜单栏是专门用于过滤结果的菜单栏。此过滤器不会更改 Wireshark 收集的数据,它只允许你更轻松地对其进行排序。有一个文本字段用于输入新的过滤器表达式,并带有一个下拉箭头以查看以前输入的过滤器。旁边是一个标为 “Expression” 的按钮,另外还有一些用于清除和保存当前表达式的按钮。
|
||||
|
||||
点击 “Expression” 按钮。你将看到一个小窗口,其中包含多个选项。左边一栏有大量的条目,每个都有额外的折叠子列表。这些都是你可以过滤的所有不同的协议、字段和信息。你不可能看完所有,所以最好是大概看下。你应该注意到了一些熟悉的选项,如 HTTP、SSL 和 TCP。
|
||||
|
||||

|
||||
|
||||
子列表包含可以过滤的不同部分和请求方法。你可以看到通过 GET 和 POST 请求过滤 HTTP 请求。
|
||||
|
||||
你还可以在中间看到运算符列表。通过从每列中选择条目,你可以使用此窗口创建过滤器,而不用记住 Wireshark 可以过滤的每个条目。对于过滤结果,比较运算符使用一组特定的符号。 `==` 用于确定是否相等。`>`确定一件东西是否大于另一个东西,`<` 找出是否小一些。 `>=` 和 `<=` 分别用于大于等于和小于等于。它们可用于确定数据包是否包含正确的值或按大小过滤。使用 `==` 仅过滤 HTTP GET 请求的示例如下:`http.request.method == "GET"`。
|
||||
|
||||
布尔运算符基于多个条件将小的表达式串到一起。不像是抓包所使用的单词,它使用三个基本的符号来做到这一点。`&&` 代表 “and”。当使用时,`&&` 两边的两个语句都必须为 true,以便 Wireshark 来过滤这些包。`||` 表示 “或”。只要两个表达式任何一个为 true,它就会被过滤。如果你正在查找所有的 GET 和 POST 请求,你可以这样使用 `||`:`(http.request.method == "GET") || (http.request.method == "POST")`。`!`是 “not” 运算符。它会寻找除了指定的东西之外的所有东西。例如,`!http` 将展示除了 HTTP 请求之外的所有东西。
|
||||
|
||||
### 总结思考
|
||||
|
||||
过滤 Wireshark 可以让你有效监控网络流量。熟悉可以使用的选项并习惯你可以创建过滤器的强大表达式需要一些时间。然而一旦你做了,你将能够快速收集和查找你要的网络数据,而无需梳理长长的数据包或进行大量的工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
|
||||
作者:[Nick Congleton ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
[1]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h1-introduction
|
||||
[2]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h2-boolean-expressions-and-comparison-operators
|
||||
[3]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h3-filtering-capture
|
||||
[4]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h4-filtering-results
|
||||
[5]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h5-closing-thoughts
|
||||
@ -0,0 +1,75 @@
|
||||
开发者定义的应用交付
|
||||
============================================================
|
||||
|
||||
负载均衡器如何帮助你管理分布式系统的复杂性。
|
||||
|
||||
|
||||

|
||||
|
||||
原生云应用旨在利用分布式系统的性能、可扩展性和可靠性优势。不幸的是,分布式系统往往以额外的复杂性为代价。由于你程序的各个组件分布在网络中,并且这些网络有通信障碍或者性能降级,因此你的分布式程序组件需要继续独立运行。
|
||||
|
||||
为了避免程序状态的不一致,分布式系统设计应该有一个共识,即组件会失效。没有什么比网络更突出。因此,在其核心,分布式系统在很大程度上依赖于负载平衡-跨两个或多个系统的请求分布,以便在面临网络中断和在系统负载波动时水平缩放时具有弹性。
|
||||
|
||||
Get O'Reilly's weekly Systems Engineering and Operations newsletter[
|
||||

|
||||
][5]
|
||||
|
||||
随着分布式系统在原生云程序的设计和交付中越来越普及,负载平衡器在现代应用程序体系结构的各个层次都浸透了基础结构设计。在常见配置中,负载平衡器部署在应用程序前面,处理来自外部世界的请求。然而,微服务的出现意味着负载平衡器在幕后发挥关键作用:即管理_服务_之间的流。
|
||||
|
||||
因此,当你使用原生云程序和分布式系统时,负载均衡器将承担其他角色:
|
||||
|
||||
* 作为提供缓存和增加安全性的反向代理,因为它成为外部客户端的中间件。
|
||||
* 作为通过提供协议转换(例如 REST 到 AMQP)的 API 网关。
|
||||
* 它可以处理安全性(即运行 Web 应用程序防火墙)。
|
||||
* 它可能承担应用程序管理任务,如速率限制和 HTTP/2 支持。
|
||||
|
||||
鉴于它们的扩展能力远大于平衡流量,负载平衡器可以更广泛地称为应用交付控制器(ADC)。
|
||||
|
||||
### 开发人员定义基础设施
|
||||
|
||||
从历史上看,ADC 是由 IT 专业人员购买、部署和管理的,最常见的是运行企业架构的应用程序。对于物理负载平衡器设备(如 F5、Citrix、Brocade等),这种情况在很大程度上仍然存在。具有分布式系统设计和临时基础结构的云原生应用要求负载平衡器与它们运行时的基础结构 (如容器) 一样具有动态特性。这些通常是软件负载均衡器(例如来自公共云提供商的 NGINX 和负载平衡器)。云原生应用通常是开发人员主导的计划,这意味着开发人员正在创建应用程序(例如微服务器)和基础设施(Kubernetes 和 NGINX)。开发人员越来越多地对负载平衡 (和其他) 基础结构的决策做出或产生大量影响。
|
||||
|
||||
作为决策者,云原生应用的开发人员通常不会意识到企业基础架构要求或现有部署的影响,同时考虑到这些部署通常是新的,并且经常在公共或私有云环境中进行部署。云技术将基础设施抽象为可编程 API,开发人员正在定义应用程序在该基础架构的每一层构建的方式。在有负载平衡器的情况下,开发人员会选择要使用的类型,部署方式以及启用哪些功能。它们以编程方式对负载平衡器的行为进行编码 - 随着程序在部署的生存期内增长、收缩和功能上进化时,它如何动态响应应用程序的需要。开发人员将基础结构定义为代码-包括基础结构配置和代码操作。
|
||||
|
||||
### 开发者为什么定义基础架构?
|
||||
|
||||
编写这个代码-_如何构建和部署应用程序_-的实践已经发生了根本性的转变,它体现在很多方面。令人遗憾的是,这种根本性的转变是由两个因素驱动的:将新的应用功能推向市场(_上市时间_)所需的时间以及应用用户从产品(_时间到价值_)中获得价值所需的时间。因此,新的程序写出来被持续地交付(作为服务),没有下载和安装。
|
||||
|
||||
上市时间和时间价值的压力并不是新的,但由于其他因素的加剧,这些因素正在加强开发者的决策权力:
|
||||
|
||||
* 云:通过 API 定义基础架构作为代码的能力。
|
||||
* 伸缩:需要在大型环境中高效运行操作。
|
||||
* 速度:马上需要交付应用功能,为企业争取竞争力。
|
||||
* 微服务:抽象框架和工具选择,进一步赋予开发人员基础架构决策权力。
|
||||
|
||||
除了上述因素外,值得注意的是开源的影响。随着开源软件的普及和发展,开发人员掌握了许多应用程序基础设施 - 语言、运行时、框架、数据库、负载均衡器、托管服务等。微服务的兴起使应用程序基础设施的选择民主化,允许开发人员选择最佳的工具。在选择负载平衡器的情况下,与云原生应用的动态性质紧密集成并响应的那些应用程序将上升到最高。
|
||||
|
||||
### 总结
|
||||
|
||||
当你在仔细考虑你的云原生应用设计时,请与我一起讨论_[在云中使用 NGINX 和 Kubernetes 进行负载平衡][8]_。我们将检测不同公共云和容器平台的负载平衡功能,并通过一个宏应用的案例研究。我们将看看它是如何被变成成较小的,独立的服务,以及 NGINX 和 Kubernetes 的能力如何拯救它的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Lee Calcote 是一位创新的思想领袖,对开发者平台和云、容器、基础设施和应用的管理软件充满热情。先进的和新兴的技术一直是 Calcote 在 SolarWinds、Seagate、Cisco 和 Pelco 时的关注重点。技术会议和聚会的组织者、写作者、作家、演讲者,他活跃在技术社区。
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://www.oreilly.com/learning/developer-defined-application-delivery
|
||||
|
||||
作者:[Lee Calcote][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/7f693-lee-calcote
|
||||
[1]:https://pixabay.com/en/ship-containers-products-shipping-84139/
|
||||
[2]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[3]:https://www.oreilly.com/people/7f693-lee-calcote
|
||||
[4]:http://www.oreilly.com/pub/e/3864?intcmp=il-webops-webcast-reg-webcast_new_site_developer_defined_application_delivery_text_cta
|
||||
[5]:https://www.oreilly.com/learning/developer-defined-application-delivery?imm_mid=0ee8c5&cmp=em-webops-na-na-newsltr_20170310
|
||||
[6]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[7]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[8]:http://www.oreilly.com/pub/e/3864?intcmp=il-webops-webcast-reg-webcast_new_site_developer_defined_application_delivery_body_text_cta
|
||||
@ -0,0 +1,309 @@
|
||||
通过开源书籍学习 RUBY 编程
|
||||
============================================================
|
||||
|
||||
### 开源的 Ruby 书籍
|
||||
|
||||
Ruby 是由 Yukihiro “Matz” Matsumoto 开发的一门通用目的、脚本化、结构化、灵活且完全面向对象的编程语言。它具有一个完全动态类型系统,这意味着它的大多数类型检查是在运行的时候进行,而非编译的时候。因此程序员不必过分担心是整数类型还是字符串类型。Ruby 会自动进行内存管理,它具有许多和 Python、Perl、Lisp、Ada、Eiffel 和 Smalltalk 相同的特性。
|
||||
|
||||
Ruby on Rails 框架对于 Ruby 的流行起到了重要作用,它是一个全栈 Web 框架,目前已被用来创建许多受欢迎的应用,包括 Basecamp、GitHub、Shopify、Airbnb、Twitch、SoundCloud、Hulu、Zendesk、Square 和 Highise 。
|
||||
|
||||
Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、FreeBSD、NetBSD、OpenBSD、BSD/OS、Solaris、Tru64 UNIX、HP-UX 以及其他许多系统上均可运行。目前,Ruby 在 TIOBE 编程社区排名 12 。
|
||||
|
||||
这篇文章有 9 本很优秀的推荐书籍,有针对包括初学者、中级程序员和高级程序员的书籍。当然,所有的书籍都是在开源许可下发布的。
|
||||
|
||||
这篇文章是[ OSSBlog 的系列文章开源编程书籍][18]的一部分。
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Best Practices][1]
|
||||
|
||||
作者: Gregory Brown (328 页)
|
||||
|
||||
《Ruby Best Practices》适合那些希望像有经验的 Ruby 专家一样使用 Ruby 的程序员。本书是由 Ruby 项目 Prawn 的开发者所撰写的,它阐述了如何使用 Ruby 设计美丽的 API 和特定领域语言,以及如何利用函数式编程想法和技术,从而简化代码,提高效率。
|
||||
|
||||
《Ruby Best Practices》 更多的内容是关于如何使用 Ruby 来解决问题,它阐述的是你应该使用的最佳解决方案。这本书不是针对 Ruby 初学者的,所以对于编程新手也不会有太多帮助。这本书的假想读者应该对 Ruby 的相应技术有一定理解,并且拥有一些使用 Ruby 来开发软件的经验。
|
||||
|
||||
这本书分为两部分,前八章组成本书的核心部分,后三章附录作为补充材料。
|
||||
|
||||
这本书提供了大量的信息:
|
||||
|
||||
* 通过测试驱动代码 - 涉及了大量的测试哲学和技术。使用 mocks 和 stubs
|
||||
* 通过利用 Ruby 神秘的力量来设计漂亮的 API:灵活的参数处理和代码块
|
||||
* 利用动态工具包向开发者展示如何构建灵活的界面,实现对象行为,扩展和修改已有代码,以及程序化地构建类和模块
|
||||
* 文本处理和文件管理集中于正则表达式,文件、临时文件标准库以及文本处理策略实战
|
||||
|
||||
|
||||
* 函数式编程技术优化模块代码组织、存储、无穷目录以及更高顺序程序。
|
||||
* 理解代码如何出错以及为什么会出错,阐述如何处理日志记录
|
||||
* 通过利用 Ruby 的多语言能力削弱文化屏障
|
||||
* 熟练的项目维护
|
||||
|
||||
本书为开源书籍,在 CC NC-SA 许可证下发布。
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [I Love Ruby][2]
|
||||
|
||||
作者: Karthikeyan A K (246 页)
|
||||
|
||||
《I Love Ruby》以比传统介绍更高的深度阐述了基本概念和技术。该方法为编写有用、正确、易维护和高效的 Ruby 代码提供了一个坚实的基础。
|
||||
|
||||
章节内容涵盖:
|
||||
|
||||
* 变量
|
||||
* 字符串
|
||||
* 比较和逻辑
|
||||
* 循环
|
||||
* 数组
|
||||
* 哈希和符号
|
||||
* Ranges
|
||||
* 函数
|
||||
* 变量作用域
|
||||
* 类 & 对象
|
||||
* Rdoc
|
||||
* 模块和 Mixins
|
||||
* 日期和时间
|
||||
* 文件
|
||||
* Proc、匿名 和 块
|
||||
* 多线程
|
||||
* 异常处理
|
||||
* 正则表达式
|
||||
* Gems
|
||||
* 元编程
|
||||
|
||||
在 GNU 自由文档许可证有效期内,你可以复制、发布和修改本书,1.3 或任何更新版本由自由软件基金会发布。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Programming Ruby – The Pragmatic Programmer’s Guide][3]
|
||||
|
||||
作者: David Thomas, Andrew Hunt (HTML)
|
||||
|
||||
《Programming Ruby – The Pragmatic Programmer’s Guide》是一本 Ruby 编程语言的教程和参考书。使用 Ruby,你将能够写出更好的代码,更加有效率,并且使编程变成更加享受的体验。
|
||||
|
||||
内容涵盖以下部分:
|
||||
|
||||
* 类、对象和变量
|
||||
* 容器、块和迭代器
|
||||
* 标准类型
|
||||
* 更多方法
|
||||
* 表达式
|
||||
* 异常、捕获和抛出
|
||||
* 模块
|
||||
* 基本输入和输出
|
||||
* 线程和进程
|
||||
* 何时抓取问题
|
||||
* Ruby 和它的世界、Web、Tk 和 微软 Windows
|
||||
* 扩展 Ruby
|
||||
* 映像、对象空间和分布式 Ruby
|
||||
* 标准库
|
||||
* 面向对象设计库
|
||||
* 网络和 Web 库
|
||||
* 嵌入式文件
|
||||
* 交互式 Ruby shell
|
||||
|
||||
这本书的第一版在开放发布许可证 1.0 版或更新版的许可下发布。本书更新后的第二版涉及 Ruby 1.8 ,并且包括所有可用新库的描述,但是它不是在免费发行许可证下发布的。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Why’s (Poignant) Guide to Ruby][4]
|
||||
|
||||
作者:why the lucky stiff (176 页)
|
||||
|
||||
《Why’s (poignant) Guide to Ruby》是一本 Ruby 编程语言的介绍书籍。该书包含一些冷幽默,偶尔也会出现一些和主题无关的内容。本书包含的笑话在 Ruby 社区和卡通角色中都很出名。
|
||||
|
||||
本书的内容包括:
|
||||
|
||||
* 关于本书
|
||||
* Kon’nichi wa, Ruby
|
||||
* 一个快速(希望是无痛苦的)的 Ruby 浏览(伴随卡通角色):Ruby 核心概念的基本介绍
|
||||
* 代码浮动小叶:评估和值,哈希和列表
|
||||
* 组成规则的核心部分:case/when、while/until、变量作用域、块、方法、类定义、类属性、对象、模块、IRB 中的内省、dup、self 和 rbconfig 模块
|
||||
* 中心:元编程、正则表达式
|
||||
* 当你打算靠近胡须时:在已存在类中发送一个新方法
|
||||
* 天堂演奏
|
||||
|
||||
本书在 CC-SA 许可证许可下可用。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Hacking Guide][5]
|
||||
|
||||
作者: Minero Aoki ,翻译自 Vincent Isambart 和 Clifford Escobar Caoille (HTML)
|
||||
|
||||
通过阅读本书可以达成下面的目标:
|
||||
|
||||
* 拥有关于 Ruby 结构的知识
|
||||
* 掌握一般语言处理的知识
|
||||
* 收获阅读源代码的技能
|
||||
|
||||
本书分为四个部分:
|
||||
|
||||
* 对象
|
||||
* 动态分析
|
||||
* 评估
|
||||
* 外部评估
|
||||
|
||||
要想从本书中收获最多的东西,需要具备一定 C 语言的知识和基本的面向对象编程知识。本书在 CC-NC-SA 许可证许可下发布。
|
||||
|
||||
原书的官方支持网站为 [i.loveruby.net/ja/rhg/][10]
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [The Book Of Ruby][6]
|
||||
|
||||
作者: How Collingbourne (425 页)
|
||||
|
||||
《The Book Of Ruby》是一本免费的 Ruby 编程高级教程。
|
||||
|
||||
《The Book Of Ruby》以 PDF 文件格式提供,并且每一个章节的所有例子都伴有可运行的源代码。同时,也有一个介绍来阐述如何在 Steel 或其他任何你喜欢的编辑器/IDE 中运行这些 Ruby 代码。它主要集中于 Ruby 语言的 1.8.x 版本。
|
||||
|
||||
本书被分成字节大小的块。每一个章节介绍一个主题,并且分成几个不同的子话题。每一个编程主题由一个或多个小的自包含、可运行的 Ruby 程序构成。
|
||||
|
||||
* 字符串、数字、类和对象 - 获取输入和输出、字符串和外部评估、数字和条件测试:if ... then、局部变量和全局变量、类和对象、实例变量、消息、方法、多态性、构造器和检属性和类变量 - 超类和子类,超类传参,访问器方法,’set‘ 访问器,属性读写器、超类的方法调用,以及类变量
|
||||
* 类等级、属性和类变量 - 超类和子类,超类传参,访问器方法,’set‘ 访问器,属性读写器、超类的方法调用,以及类变量
|
||||
* 字符串和 Ranges - 用户自定义字符串定界符、引号等更多
|
||||
* 数组和哈希 - 展示如何创建一系列对象
|
||||
* 循环和迭代器 - for 循环、代码块、while 循环、while 修改器以及 until 循环
|
||||
* 条件语句 - If..Then..Else、And..Or..Not、If..Elsif、unless、if 和 unless 修改器、以及 case 语句
|
||||
* 方法 - 类方法、类变量、类方法是用来干什么的、Ruby 构造器、单例方法、单例类、重载方法以及更多
|
||||
* 传递参数和返回值 - 实例方法、类方法、单例方法、返回值、返回多重值、默认参数和多重参数、赋值和常量传递以及更多
|
||||
* 异常处理 - 涉及 rescue、ensure、else、错误数量、retry 和 raise
|
||||
* 块、Procs 和 匿名 - 阐述为什么它们对 Ruby 来说很特殊
|
||||
* 符号 - 符号和字符串、符号和变量以及为什么应该使用符号
|
||||
* 模块和 Mixins
|
||||
* 文件和 IO - 打开和关闭文件、文件和目录、复制文件、目录询问、一个关于递归的讨论以及按大小排序
|
||||
* YAML - 包括嵌套序列,保存 YAML 数据以及更多
|
||||
* Marshal - 提供一个保存和加载数据的可选择方式
|
||||
* 正则表达式 - 进行匹配、匹配群组以及更多
|
||||
* 线程 - 向你展示如何同时运行多个任务
|
||||
* 调试和测试 - 涉及交互式 Ruby shell(IRB.exe)、debugging 和 单元测试
|
||||
* Ruby on Rails - 浏览一个创建博客的实践指南
|
||||
* 动态编程 - 自修改程序、重运算魔法、特殊类型的运算、添加变量和方法以及更多
|
||||
|
||||
本书由 SapphireSteel Software 发布,SapphireSteel Software 是用于 Visual Studio 的 Ruby In Steel 集成开发环境的开发者。读者可以复制和发布本书的文本和代码(免费版)
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [The Little Book Of Ruby][7]
|
||||
|
||||
作者: Huw Collingbourne (87 页)
|
||||
|
||||
《The Little Book of Ruby》是一本一步接一步的 Ruby 编程教程。它指导读者浏览 Ruby 的基础。另外,它分享了《The Book of Ruby》一书的内容,但是它旨在作为一个简化的教程来阐述 Ruby 的主要特性。
|
||||
|
||||
章节内容涵盖:
|
||||
|
||||
* 字符串和方法 - 包括外部评估。详细描述了 Ruby 方法的语法
|
||||
* 类和对象 - 阐述如何创建一个新类型的对象
|
||||
* 类等级 - 一个特殊类型的类,其为一些其他类的简化并且继承了其他一些类的特性
|
||||
* 访问器、属性、类变量 - 访问器方法,属性读写器,属性创建变量,调用超类方法以及类变量探索
|
||||
* 数组 - 学习如何创建一系列对象:数组包括多维数组
|
||||
* 哈希 - 涉及创建哈希表,为哈希表建立索引以及哈希操作等
|
||||
* 循环和迭代器 - for 循环、块、while 循环、while 修饰器以及 until 循环
|
||||
* 条件语句 - If..Then..Else、And..Or..Not、If..Elsif、unless、if 和 unless 修饰器以及 case 语句
|
||||
* 模块和 Mixins - 包括模块方法、模块作为名字空间模块实例方法、模块或 'mixins'、来自文件的模块和预定义模块
|
||||
* 保存文件以及更多内容
|
||||
|
||||
本书可免费复制和发布,只需保留原始文本且注明版权信息。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Kestrels, Quirky Birds, and Hopeless Egocentricity][8]
|
||||
|
||||
作者: Reg “raganwald” Braithwaite (123 页)
|
||||
|
||||
《Kestrels, Quirky Birds, and Hopeless Egocentricity》是通过收集 “Raganwald” Braithwaite 的关于组合逻辑、Method Combinators 以及 Ruby 元编程的系列文章而形成的一本方便的电子书。
|
||||
|
||||
本书提供了通过使用 Ruby 编程语言来应用组合逻辑的一个基本介绍。组合逻辑是一种数学表示方法,它足够强大,从而用于解决集合论问题以及计算中的问题。
|
||||
|
||||
在这本书中,读者会会探讨到一些标准的 Combinators,并且对于每一个 Combinators,书中都用 Ruby 编程语言写程序探讨了它的一些结果。在组合逻辑上,Combinators 之间组合并相互改变,书中的 Ruby 例子注重组合和修改 Ruby 代码。通过像 K Combinator 和 .tap 方法这样的简单例子,本书阐述了元编程的理念和递归 Combinators 。
|
||||
|
||||
本书在 MIT 许可证许可下发布。
|
||||
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Programming][9]
|
||||
|
||||
作者: Wikibooks.org (261 页)
|
||||
|
||||
Ruby 是一种解释性、面向对象的编程语言。
|
||||
|
||||
本书被分为几个部分,从而方便按顺序阅读。
|
||||
|
||||
* 开始 - 向读者展示如何在其中一个操作系统环境中安装并开始使用 Ruby
|
||||
* Ruby 基础 - 阐述 Ruby 语法的主要特性。它涵盖了字符串、编码、写方法、类和对象以及异常等内容
|
||||
* Ruby 语义参考
|
||||
* 内建类
|
||||
* 可用模块,涵盖一些标准库
|
||||
* 中级 Ruby 涉及一些稍微高级的话题
|
||||
|
||||
本书在 CC-SA 3.0 本地化许可证许可下发布。
|
||||
|
||||
|
|
||||
|
||||
* * *
|
||||
|
||||
无特定顺序,我将在结束前推荐一些没有在开源许可证下发布但可以免费下载的 Ruby 编程书籍。
|
||||
|
||||
* [Mr. Neighborly 的 Humble Little Ruby Book][11] – 一个易读易学的 Ruby 完全指南。
|
||||
* [Introduction to Programming with Ruby][12] – 学习编程时最基本的构建块,一切从零开始。
|
||||
* [Object Oriented Programming with Ruby][13] – 学习编程时最基本的构建块,一切从零开始。
|
||||
* [Core Ruby Tools][14] – 对 Ruby 的四个核心工具 Gems、Ruby Version Managers、Bundler 和 Rake 进行了简短的概述。
|
||||
* [Learn Ruby the Hard Way, 3rd Edition][15] – 一本适合初学者的入门书籍。
|
||||
* [Learn to Program][16] – 来自 Chris Pine。
|
||||
* [Ruby Essentials][17] – 一个准确且简单易学的 Ruby 学习指南。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ossblog.org/study-ruby-programming-with-open-source-books/
|
||||
|
||||
作者:[Steve Emms ][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ossblog.org/author/steve/
|
||||
[1]:https://github.com/practicingruby/rbp-book/tree/gh-pages/pdfs
|
||||
[2]:https://mindaslab.github.io/I-Love-Ruby/
|
||||
[3]:http://ruby-doc.com/docs/ProgrammingRuby/
|
||||
[4]:http://poignant.guide/
|
||||
[5]:http://ruby-hacking-guide.github.io/
|
||||
[6]:http://www.sapphiresteel.com/ruby-programming/The-Book-Of-Ruby.html
|
||||
[7]:http://www.sapphiresteel.com/ruby-programming/The-Book-Of-Ruby.html
|
||||
[8]:https://leanpub.com/combinators
|
||||
[9]:https://en.wikibooks.org/wiki/Ruby_Programming
|
||||
[10]:http://i.loveruby.net/ja/rhg/
|
||||
[11]:http://www.humblelittlerubybook.com/
|
||||
[12]:https://launchschool.com/books/ruby
|
||||
[13]:https://launchschool.com/books/oo_ruby
|
||||
[14]:https://launchschool.com/books/core_ruby_tools
|
||||
[15]:https://learnrubythehardway.org/book/
|
||||
[16]:https://pine.fm/LearnToProgram
|
||||
[17]:http://www.techotopia.com/index.php/Ruby_Essentials
|
||||
[18]:https://www.ossblog.org/opensourcebooks/
|
||||
@ -1,47 +1,47 @@
|
||||
Writing a Linux Debugger Part 7: Source-level breakpoints
|
||||
开发一个 Linux 调试器(七):源码层断点
|
||||
============================================================
|
||||
|
||||
Setting breakpoints on memory addresses is all well and good, but it doesn’t provide the most user-friendly tool. We’d like to be able to set breakpoints on source lines and function entry addresses as well, so that we can debug at the same abstraction level as our code.
|
||||
在内存地址上设置断点是可以的,但它没有提供最方便用户的工具。我们希望能够在源代码行和函数入口地址上设置断点,以便我们可以在与代码相同的抽象级中别进行调试。
|
||||
|
||||
This post will add source-level breakpoints to our debugger. With all of the support we already have available to us, this is a lot easier than it may first sound. We’ll also add a command to get the type and address of a symbol, which can be useful for locating code or data and understanding linking concepts.
|
||||
这篇文章将会添加源码层断点到我们的调试器中。通过所有我们已经支持的,这比起最初听起来容易得多。我们还将添加一个命令来获取符号的类型和地址,这对于定位代码或数据以及理解链接概念非常有用。
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
### 系列索引
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
随着后面文章的发布,这些链接会逐渐生效。
|
||||
|
||||
1. [Setup][1]
|
||||
1. [准备环境][1]
|
||||
|
||||
2. [Breakpoints][2]
|
||||
2. [断点][2]
|
||||
|
||||
3. [Registers and memory][3]
|
||||
3. [寄存器和内存][3]
|
||||
|
||||
4. [Elves and dwarves][4]
|
||||
4. [Elves 和 dwarves][4]
|
||||
|
||||
5. [Source and signals][5]
|
||||
5. [源码和信号][5]
|
||||
|
||||
6. [Source-level stepping][6]
|
||||
6. [源码层逐步执行][6]
|
||||
|
||||
7. [Source-level breakpoints][7]
|
||||
7. [源码层断点][7]
|
||||
|
||||
8. [Stack unwinding][8]
|
||||
8. [调用栈][8]
|
||||
|
||||
9. Reading variables
|
||||
9. 读取变量
|
||||
|
||||
10. Next steps
|
||||
10. 之后步骤
|
||||
|
||||
* * *
|
||||
|
||||
### Breakpoints
|
||||
### 断点
|
||||
|
||||
### DWARF
|
||||
|
||||
The [Elves and dwarves][9] post described how DWARF debug information works and how it can be used to map the machine code back to the high-level source. Recall that DWARF contains the address ranges of functions and a line table which lets you translate code positions between abstraction levels. We’ll be using these capabilities to implement our breakpoints.
|
||||
[Elves 和 dwarves][9] 这篇文章,描述了 DWARF 调试信息是如何工作的,以及如何用它来将机器码映射到高层源码中。回想一下,DWARF 包含函数的地址范围和一个允许你在抽象层之间转换代码位置的行表。我们将使用这些功能来实现我们的断点。
|
||||
|
||||
### Function entry
|
||||
### 函数入口
|
||||
|
||||
Setting breakpoints on function names can be complex if you want to take overloading, member functions and such into account, but we’re going to iterate through all of the compilation units and search for functions with names which match what we’re looking for. The DWARF information will look something like this:
|
||||
如果你考虑重载、成员函数等等,那么在函数名上设置断点可能有点复杂,但是我们将遍历所有的编译单元,并搜索与我们正在寻找的名称匹配的函数。DWARF 信息如下所示:
|
||||
|
||||
```
|
||||
< 0><0x0000000b> DW_TAG_compile_unit
|
||||
@ -68,7 +68,7 @@ LOCAL_SYMBOLS:
|
||||
|
||||
```
|
||||
|
||||
We want to match against `DW_AT_name` and use `DW_AT_low_pc`(the start address of the function) to set our breakpoint.
|
||||
我们想要匹配 `DW_AT_name` 并使用 `DW_AT_low_pc`(函数的起始地址)来设置我们的断点。
|
||||
|
||||
```
|
||||
void debugger::set_breakpoint_at_function(const std::string& name) {
|
||||
@ -85,13 +85,13 @@ void debugger::set_breakpoint_at_function(const std::string& name) {
|
||||
}
|
||||
```
|
||||
|
||||
The only bit of that code which looks a bit weird is the `++entry`. The problem is that the `DW_AT_low_pc` for a function doesn’t point at the start of the user code for that function, it points to the start of the prologue. The compiler will usually output a prologue and epilogue for a function which carries out saving and restoring registers, manipulating the stack pointer and suchlike. This isn’t very useful for us, so we increment the line entry by one to get the first line of the user code instead of the prologue. The DWARF line table actually has some functionality to mark an entry as the first line after the function prologue, but not all compilers output this, so I’ve taken the naive approach.
|
||||
这代码看起来有点奇怪的唯一一点是 `++entry`。 问题是函数的 `DW_AT_low_pc` 不指向该函数的用户代码的起始地址,它指向 prologue 的开始。编译器通常会输出一个函数的 prologue 和 epilogue,它们用于执行保存和恢复堆栈、操作堆栈指针等。这对我们来说不是很有用,所以我们将入口行加一来获取用户代码的第一行而不是 prologue。DWARF 行表实际上具有一些功能,用于将入口标记为函数 prologue 之后的第一行,但并不是所有编译器都输出该函数,因此我采用了原始的方法。
|
||||
|
||||
### Source line
|
||||
### 源码行
|
||||
|
||||
To set a breakpoint on a high-level source line, we translate this line number into an address by looking it up in the DWARF. We’ll iterate through the compilation units looking for one whose name matches the given file, then look for the entry which corresponds to the given line.
|
||||
要在高层源码行上设置一个断点,我们要将这个行号转换成 DWARF 中的一个地址。我们将遍历编译单元,寻找一个名称与给定文件匹配的编译单元,然后查找与给定行对应的入口。
|
||||
|
||||
The DWARF will look something like this:
|
||||
DWARF 看山去有点像这样:
|
||||
|
||||
```
|
||||
.debug_line: line number info for a single cu
|
||||
@ -119,7 +119,7 @@ IS=val ISA number, DI=val discriminator value
|
||||
|
||||
```
|
||||
|
||||
So if we want to set a breakpoint on line 5 of `ab.cpp`, we look up the entry which corresponds to that line (`0x004004e3`) and set a breakpoint there.
|
||||
所以如果我们想要在 `ab.cpp` 的第五行设置一个断点,我们查找与行 (`0x004004e3`) 相关的入口并设置一个断点。
|
||||
|
||||
```
|
||||
void debugger::set_breakpoint_at_source_line(const std::string& file, unsigned line) {
|
||||
@ -138,15 +138,15 @@ void debugger::set_breakpoint_at_source_line(const std::string& file, unsigned l
|
||||
}
|
||||
```
|
||||
|
||||
My `is_suffix` hack is there so you can type `c.cpp` for `a/b/c.cpp`. Of course you should actually use a sensible path handling library or something; I’m lazy. The `entry.is_stmt` is checking that the line table entry is marked as the beginning of a statement, which is set by the compiler on the address it thinks is the best target for a breakpoint.
|
||||
我这里的 `is_suffix` hack,这样你可以为 `a/b/c.cpp` 输入 `c.cpp`。当然你应该使用大小写敏感路径处理库或者其他东西。我很懒。`entry.is_stmt` 是检查行表入口是否被标记为一个语句的开头,这是由编译器根据它认为是断点的最佳目标的地址设置的。
|
||||
|
||||
* * *
|
||||
|
||||
### Symbol lookup
|
||||
### 符号查找
|
||||
|
||||
When we get down to the level of object files, symbols are king. Functions are named with symbols, global variables are named with symbols, you get a symbol, we get a symbol, everyone gets a symbol. In a given object file, some symbols might reference other object files or shared libraries, where the linker will patch things up to create an executable program from the symbol reference spaghetti.
|
||||
当我们在对象文件层时,符号是王者。函数用符号命名,全局变量用符号命名,得到一个符号,我们得到一个符号,每个人都得到一个符号。 在给定的对象文件中,一些符号可能引用其他对象文件或共享库,链接器将从符号引用创建一个可执行程序。
|
||||
|
||||
Symbols can be looked up in the aptly-named symbol table, which is stored in ELF sections in the binary. Fortunately, `libelfin` has a fairly nice interface for doing this, so we don’t need to deal with all of the ELF nonsense ourselves. To give you an idea of what we’re dealing with, here is a dump of the `.symtab` section of a binary, produced with `readelf`:
|
||||
可以在正确命名的符号表中查找符号,它存储在二进制文件的 ELF 部分中。幸运的是,`libelfin` 有一个不错的接口来做这件事,所以我们不需要自己处理所有的 ELF 的事情。为了让你知道我们在处理什么,下面是一个二进制文件的 `.symtab` 部分的转储,它由 `readelf` 生成:
|
||||
|
||||
```
|
||||
Num: Value Size Type Bind Vis Ndx Name
|
||||
@ -220,9 +220,9 @@ Num: Value Size Type Bind Vis Ndx Name
|
||||
|
||||
```
|
||||
|
||||
You can see lots of symbols for sections in the object file, symbols which are used by the implementation for setting up the environment, and at the end you can see the symbol for `main`.
|
||||
你可以在对象文件中看到用于设置环境的很多符号,最后还可以看到 `main` 符号。
|
||||
|
||||
We’re interested in the type, name, and value (address) of the symbol. We’ll have a `symbol_type` enum for the type and use a `std::string` for the name and `std::uintptr_t` for the address:
|
||||
我们对符号的类型、名称和值(地址)感兴趣。我们有一个 `symbol_type` 类型的枚举,并使用一个 `std::string` 作为名称,`std::uintptr_t` 作为地址:
|
||||
|
||||
```
|
||||
enum class symbol_type {
|
||||
@ -250,7 +250,7 @@ struct symbol {
|
||||
};
|
||||
```
|
||||
|
||||
We’ll need to map between the symbol type we get from `libelfin` and our enum since we don’t want the dependency poisoning this interface. Fortunately I picked the same names for everything, so this is dead easy:
|
||||
我们需要将从 `libelfin` 获得的符号类型映射到我们的枚举,因为我们不希望依赖关系破环这个接口。幸运的是,我为所有的东西选了同样的名字,所以这样很简单:
|
||||
|
||||
```
|
||||
symbol_type to_symbol_type(elf::stt sym) {
|
||||
@ -265,7 +265,7 @@ symbol_type to_symbol_type(elf::stt sym) {
|
||||
};
|
||||
```
|
||||
|
||||
Lastly we want to look up the symbol. For illustrative purposes I loop through the sections of the ELF looking for symbol tables, then collect any symbols I find in them into a `std::vector`. A smarter implementation would build up a map from names to symbols so that you only have to look at all the data once.
|
||||
最后我们要查找符号。为了说明的目的,我循环查找符号表的 ELF 部分,然后收集我在其中找到的任意符号到 `std::vector` 中。更智能的实现将建立从名称到符号的映射,这样你只需要查看一次数据就行了。
|
||||
|
||||
```
|
||||
std::vector<symbol> debugger::lookup_symbol(const std::string& name) {
|
||||
@ -289,15 +289,15 @@ std::vector<symbol> debugger::lookup_symbol(const std::string& name) {
|
||||
|
||||
* * *
|
||||
|
||||
### Adding commands
|
||||
### 添加命令
|
||||
|
||||
As always, we need to add some more commands to expose the functionality to users. For breakpoints I’ve gone for a GDB-style interface, where the kind of breakpoint is inferred from the argument you pass rather than requiring explicit switches:
|
||||
一如往常,我们需要添加一些更多的命令来向用户暴露功能。对于断点,我使用 GDB 风格的接口,其中断点类型是通过你传递的参数推断的,而不用要求显式切换:
|
||||
|
||||
* `0x<hexadecimal>` -> address breakpoint
|
||||
* `0x<hexadecimal>` -> 断点地址
|
||||
|
||||
* `<line>:<filename>` -> line number breakpoint
|
||||
* `<line>:<filename>` -> 断点行号
|
||||
|
||||
* `<anything else>` -> function name breakpoint
|
||||
* `<anything else>` -> 断点函数名
|
||||
|
||||
```
|
||||
else if(is_prefix(command, "break")) {
|
||||
@ -315,7 +315,7 @@ As always, we need to add some more commands to expose the functionality to user
|
||||
}
|
||||
```
|
||||
|
||||
For symbols we’ll lookup the symbol and print out any matches we find:
|
||||
对于符号,我们将查找符号并打印出我们发现的任何匹配项:
|
||||
|
||||
```
|
||||
else if(is_prefix(command, "symbol")) {
|
||||
@ -328,22 +328,22 @@ else if(is_prefix(command, "symbol")) {
|
||||
|
||||
* * *
|
||||
|
||||
### Testing it out
|
||||
### 测试一下
|
||||
|
||||
Fire up your debugger on a simple binary, play around with setting source-level breakpoints. Setting a breakpoint on some `foo` and seeing my debugger stop on it was one of the most rewarding moments of this project for me.
|
||||
在一个简单的二进制文件上启动调试器,并设置源代码级别的断点。在一些 `foo` 上设置一个断点,看到我的调试器停在它上面是我这个项目最有价值的时刻之一。
|
||||
|
||||
Symbol lookup can be tested by adding some functions or global variables to your program and looking up the names of them. Note that if you’re compiling C++ code you’ll need to take [name mangling][10] into account as well.
|
||||
符号查找可以通过在程序中添加一些函数或全局变量并查找它们的名称来进行测试。请注意,如果你正在编译 C++ 代码,你还需要考虑[名称重整][10]。
|
||||
|
||||
That’s all for this post. Next time I’ll show how to add stack unwinding support to the debugger.
|
||||
本文就这些了。下一次我将展示如何向调试器添加堆栈展开支持。
|
||||
|
||||
You can find the code for this post [here][11].
|
||||
你可以在[这里][11]找到这篇文章的代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/06/19/writing-a-linux-debugger-source-break/
|
||||
|
||||
作者:[Simon Brand ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,172 +0,0 @@
|
||||
# 使用 Snapcraft 构建、测试并发布 Snaps
|
||||
|
||||
---
|
||||
|
||||
这篇客座文章的作者是 Ricardo Feliciano —— CircleCi 的开发者传道士。如果您也有兴趣投稿,请联系 ubuntu-iot@canonical.com。
|
||||
|
||||
`Snapcraft` 是一个正在为其在 Linux 中的位置而奋斗的包管理系统,它为你重新想象了分发软件的方式。你可以使用一系列新的跨版本工具来构建和发布 `Snaps`。接下来我们将会讲述怎么使用 `CircleCI 2.0` 来加速这个过程
|
||||
以及一些在这个过程中的可能遇到的问题。
|
||||
|
||||
### Snaps 是什么?Snapcraft 又是什么?
|
||||
|
||||
`Snaps` 是用于 Linux 发行版的软件包,它们在设计的时候吸取了在移动平台,比如 Android 以及物联网设备,分发软件的经验教训。`Snapcraft` 这个名字涵盖了 Snaps 和用来构建它们的命令行工具,[snapcraft.io][1],以及在这些技术的支撑下构建的几乎整个生态系统。
|
||||
|
||||
Snaps 被设计成用来隔离并封装整个应用程序。这些概念使得 Snapcraft 提高软件安全性、稳定性和可移植性的目标得以实现,其中可移植性允许单个 `snap` 包不仅可以在 Ubuntu 的多个版本中安装,而且也可以在 Debian、Fedora 和 Arch 等发行版中安装。Snapcraft 网站对其的描述如下:
|
||||
> 为每个 Linux 桌面、服务器、云或设备打包任何应用程序,并且直接交付更新。
|
||||
|
||||
### 在 CircleCI 2.0 上构建 Snaps
|
||||
|
||||
在 CircleCI 上使用 [CircleCI 2.0 语法][2] 来构建 Snaps 和在本地机器上基本相同。在本文中,我们将会讲解一个示例配置文件。如果您对 CircleCI 还不熟悉,或者想了解更多有关 2.0 的入门知识,您可以从 [这里][3] 开始。
|
||||
|
||||
### 基础配置
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
sudo snap install snapcraft --edge --classic
|
||||
/snap/bin/snapcraft
|
||||
```
|
||||
|
||||
这个例子使用了 `machine` 执行器来安装用于管理运行 Snaps 的 `snapd` 和制作 Snaps 的 `Snapcraft`。
|
||||
|
||||
由于构建过程需要使用比较新的内核,所以我们使用了 `machine` 执行器而没有用 `docker` 执行器。在这里,Linux v4.4 已经足够满足我们的需求了。
|
||||
|
||||
### 用户空间的依赖关系
|
||||
|
||||
上面的例子使用了 `machine` 执行器,它实际上是一个内核为 Linux v4.4 的 [Ubuntu 14.04 (Trusty) 虚拟机][4]。你的 project/snap 可以很方便的使用 Trusty 仓库来构建依赖关系。如果需要构建其他版本的依赖关系,比如 Ubuntu 16.04 (Xenial),我们仍然可以在 `machine` 执行器中使用 `Docker` 来构建我们的 Snaps 。
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
docker run -v $(pwd):$(pwd) -t ubuntu:xenial sh -c "apt update -qq && apt install snapcraft -y && cd $(pwd) && snapcraft"
|
||||
|
||||
```
|
||||
这个例子中,我们同样在 `machine` 执行器的虚拟机中安装了 `snapd`,但是我们决定将 Snapcraft 安装在 Ubuntu Xenial 镜像构建的 Docker 容器中,并使用它来构建我们的 Snaps。这样,在 `Snapcraft` 运行的过程中就可以使用所有在 Ubuntu 16.04 中可用的 `apt` 包。
|
||||
|
||||
### 测试
|
||||
|
||||
在我们的博客、文档以及互联网上已经有很多讲述如何对软件代码进行单元测试的内容。如果你用语言或者框架外加单元测试或者 CI 为关键词进行搜索的话将会出现大量相关的信息。在 CircleCI 上构建 Snaps 我们最终会得到一个 `.snap` 的文件,这意味着除了创造它的代码外我们还可以对它进行测试。
|
||||
|
||||
### 工作流
|
||||
|
||||
假设我们构建的 Snaps 是一个 `webapp`,我们可以通过测试套件来确保构建的 Snaps 可以正确的安装和运行,我们也可以试着安装它或者使用 [Selenium][5] 来测试页面加载、登录等功能。但是这里有一个问题,由于 Snaps 是被设计成可以在多个 Linux 发行版上运行,这就需要我们的测试套件可以在 Ubuntu 16.04、Fedora 25 和 Debian 9 等发行版中可以正常运行。这个问题我们可以通过 CircleCI 2.0 的工作流来有效地解决。
|
||||
|
||||
工作流是在最近的 CircleCI 2.0 测试版中加入的,它允许我们通过特定的逻辑流程来运行离散的任务。这样,使用单个任务构建完 Snaps 后,我们就可以开始并行的运行所有的 snap 发行版测试任务,每个任务对应一个不同的发行版的 [Docker 镜像][6] (或者在将来,还会有其他可用的执行器)。
|
||||
|
||||
这里有一个简单的例子:
|
||||
|
||||
```
|
||||
workflows:
|
||||
version: 2
|
||||
build-test-and-deploy:
|
||||
jobs:
|
||||
- build
|
||||
- acceptance_test_xenial:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_fedora_25:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_arch:
|
||||
requires:
|
||||
- build
|
||||
- publish:
|
||||
requires:
|
||||
- acceptance_test_xenial
|
||||
- acceptance_test_fedora_25
|
||||
- acceptance_test_arch
|
||||
|
||||
```
|
||||
在这个例子中首先构建了 Snaps,然后在四个不同的发行版上运行验收测试。如果所有的发行版都通过测试了,那么我们就可以运行发布 `job`,以便在将其推送到 snap 商店之前完成剩余的 snap 任务。
|
||||
|
||||
### 保存 .snap 包
|
||||
|
||||
为了测试我们在工作流示例中使用的 Snaps,我们需要一种在构建的时候保存 Snaps 的方法。在这里我将提供两种方法:
|
||||
|
||||
1. **artifacts** —— 在运行 `build` 任务的时候我们可以将 Snaps 保存为一个 CircleCI artifact(artifact 也是 snapcraft.yaml 中的一个 `Plugin-specific keywords` 暂时可以不翻译 ),然后在接下来的任务中检索它。CircleCI 工作流有自己处理共享 artifacts 的方式,相关信息可以在 [这里][7] 找到。
|
||||
|
||||
2. **snap 商店通道** —— 当发布 Snaps 到 snap 商店时,有多种通道可供我们选择。将 Snaps 的主分支发布到边缘通道以供内部或者用户测试已经成为一种常见做法。我们可以在构建任务的时候完成这些工作,然后接下来的的任务就可以从边缘通道来安装构建好的 Snaps。
|
||||
|
||||
第一种方法速度更快,并且它还可以在 Snaps 上传到 snap 商店供用户甚至是测试用户使用之前对 Snaps 进行验收测试。第二种方法的好处是我们可以从 snap 商店安装 Snaps,这也是 CI 运行期间的一个测试项。
|
||||
|
||||
### Snap 商店的身份验证
|
||||
|
||||
[snapcraft-config-generator.py][8] 脚本可以生成商店证书并将其保存到 `.snapcraft/snapcraft.cfg` 中(注意:在运行公共脚本之前一定要对其进行检查)。如果觉得使用明文来保存这个文件不安全,你可以用 `base64` 编码文件,并将其存储为 [私有环境变量][9],或者你也可以对文件 [进行加密][10],并将密钥存储在一个私有环境变量中。
|
||||
|
||||
下面是一个示例,将商店证书放在一个加密的文件中,并在 `deploy` 中使用它将 Snaps 发布到 snap 商店中。
|
||||
|
||||
```
|
||||
- deploy:
|
||||
name: Push to Snap Store
|
||||
command: |
|
||||
openssl aes-256-cbc -d -in .snapcraft/snapcraft.encrypted -out .snapcraft/snapcraft.cfg -k $KEY
|
||||
/snap/bin/snapcraft push *.snap
|
||||
|
||||
```
|
||||
|
||||
和前面的工作流示例一样,替代部署步骤的 `deploy` 任务也只有当验收测试任务通过时才会运行。
|
||||
|
||||
### 更多的信息
|
||||
|
||||
* Alan Pope 在 [论坛中发的帖子][11]:“popey” 是 Canonical 的员工,他在 Snapcraft 的论坛上写了这篇文章,并启发作者写了这篇博文。
|
||||
|
||||
* [Snapcraft 网站][12]: Snapcraft 官方网站。
|
||||
|
||||
* [Snapcraft 的 CircleCI Bug 报告][13]:在 Launchpad 上有一个开放的 bug 报告页面,用来改善 CircleCI 对 Snapcraft 的支持。同时这将使这个过程变得更简单并且更“正式”。期待您的支持。
|
||||
|
||||
* 怎么使用 CircleCI 构建 [Nextcloud][14] 的 Snaps:这里有一篇题为 [“复杂应用的持续验收测试”][15] 的博文,它同时也影响了这篇博文。
|
||||
|
||||
|
||||
|
||||
原始文章可以从 [这里][18] 找到。
|
||||
|
||||
---
|
||||
|
||||
via: https://insights.ubuntu.com/2017/06/28/build-test-and-publish-snap-packages-using-snapcraft/
|
||||
|
||||
译者简介:
|
||||
> 常年混迹于 snapcraft.io,对 Ubuntu Core、Snaps 和 Snapcraft 有浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人的公众号: `Snapcraft`
|
||||
|
||||
作者:[Guest ][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/guest/
|
||||
|
||||
|
||||
[1]: https://snapcraft.io/
|
||||
[2]:https://circleci.com/docs/2.0/
|
||||
[3]: https://circleci.com/docs/2.0/first-steps/
|
||||
[4]: https://circleci.com/docs/1.0/differences-between-trusty-and-precise/
|
||||
[5]:http://www.seleniumhq.org/
|
||||
[6]:https://circleci.com/docs/2.0/building-docker-images/
|
||||
[7]: https://circleci.com/docs/2.0/workflows/#using-workspaces-to-share-artifacts-among-jobs
|
||||
[8]:https://gist.github.com/3v1n0/479ad142eccdd17ad7d0445762dea755
|
||||
[9]: https://circleci.com/docs/1.0/environment-variables/#setting-environment-variables-for-all-commands-without-adding-them-to-git
|
||||
[10]: https://github.com/circleci/encrypted-files
|
||||
[11]:https://forum.snapcraft.io/t/building-and-pushing-snaps-using-circleci/789
|
||||
[12]:https://snapcraft.io/
|
||||
[13]:https://bugs.launchpad.net/snapcraft/+bug/1693451
|
||||
[14]:https://nextcloud.com/
|
||||
[15]: https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[16]:https://nextcloud.com/
|
||||
[17]:https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[18]: https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
[19]:https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
195
translated/tech/20170706 OpenStack in a Snap.md
Normal file
195
translated/tech/20170706 OpenStack in a Snap.md
Normal file
@ -0,0 +1,195 @@
|
||||
在 Snap 中玩转 OpenStack
|
||||
================================
|
||||
|
||||

|
||||
|
||||
OpenStack 非常复杂,许多社区成员都在努力使 OpenStack 的部署和操作更加容易。其中大部分时间都用来改善相关工具,如:Ansible、Puppet、Kolla、Juju、Triple-O 和 Chef (举几个例子)。但是,如果我们降低一下标准,并且还能使包的体验更加简单,将会怎样呢?
|
||||
|
||||
我们正在努力通过 snap 包来实现这一点。snap 包是一种新兴的软件分发方式,这段来自 [snapcraft.io][1] 的介绍很好的总结了它的主要优点:_snap 包可以快速安装、易于创建、安全运行而且能自动事物更新,因此你的应用程序总是能保持最新的状态并且永远不会被破坏。_
|
||||
|
||||
### 捆绑软件
|
||||
|
||||
单个 snap 包可以内嵌多个不同来源的软件,从而提供一个能够快速启动和运行的解决方案。当你安装 snap 包时,你会发现安装速度是很快的,这是因为单个 snap 包捆绑了所有它需要的依赖。这和安装 deb 包有些不同,因为它需要下载所有的依赖然后分别进行安装。
|
||||
|
||||
### Snap 包制作简单
|
||||
|
||||
在 Ubuntu 工作,我花了很多时间为 Debian 制作 OpenStack 的安装包。这是一种很特殊技能,需要花很长时间才能理解其中的细微差别。与 snap 包相比,deb 包和 snap 包在复杂性上的差异有天壤之别。snap 包简单易行,并且相当有趣。
|
||||
|
||||
### Snap 包其他的特性
|
||||
|
||||
* 每个 snap 包都安装在其独有的只读 squashfs 文件系统中。
|
||||
|
||||
* 每个 snap 包都运行在一个由 AppArmor 和 seccomp 策略构建的严格沙箱环境中。
|
||||
|
||||
* snap 包能事物更新。新版本的 snap 包会安装到一个新的只读 squashfs 文件系统中。如果升级失败,它将回滚到旧版本。
|
||||
|
||||
* 当有新版本可用时,snap 包将自动更新。
|
||||
|
||||
* OpenStack 的 snap 包能保证与 OpenStack 的上游约束保持一致。打包的人不需要再为 OpenStack 依赖链维护单独的包。这真是太爽了!
|
||||
|
||||
### OpenStack snap 包介绍
|
||||
|
||||
现在,下面这些项目已经有了相应的 snap 包:
|
||||
|
||||
* `Keystone` —— 这个 snap 包为 OpenStack 提供了身份服务。
|
||||
* `Glance` —— 这个 snap 包为 OpenStack 提供了镜像服务。
|
||||
* `Neutron` —— 这个 snap 包专门提供了 `网络-服务器` 过程,作为 OpenStack 部署过程的一个 snap 包。(原文:**Neutron** – This snap specifically provides the `neutron-server` process as part of a snap based OpenStack deployment.)
|
||||
|
||||
* `Nova` —— 这个 snap 包提供 OpenStack 部署过程中的 Nova 控制器组件。
|
||||
* `Nova-hypervisor` —— 这个 snap 包提供 OpenStack 部署过程中的 hypervisor 组件,并且配置使用通过 deb 包安装的 Libvirt/KVM + Open vSwitch 组合。这个 snap 包同时也包含 nava-lxd,这允许我们使用 nova-lxd 而不用 KVM。
|
||||
|
||||
这些 snpa 包已经能让我们部署一个简单可工作的 OpenStack 云。你可以在 [github][2] 上找到所有这些 OpenStack snap 包的源码。有关 OpenStack snap 包更多的细节,请参考上游存储库中各自的 README。在那里,你可以找到更多有关管理 snap 包的信息,比如覆盖默认配置、重启服务、设置别名等等。
|
||||
|
||||
### 想要创建自己的 OpenStack snap 包吗?
|
||||
|
||||
查看 [snap cookie 工具][3]。我很快就会写一篇博文,告诉你如何使用 snap cookie 工具。它非常简单,并且能帮助你在任何时候创建一个新的 OpenStack snap 包。
|
||||
|
||||
### 测试 OpenStack snap 包
|
||||
|
||||
我们已经用简单的脚本初步测试了 OpenStack snap 包。这个脚本会在单个节点上安装 sanp 包,还会在安装后提供额外的配置服务。来尝试下吧:
|
||||
|
||||
```
|
||||
git clone https://github.com/openstack-snaps/snap-test
|
||||
cd snap-test
|
||||
./snap-deploy
|
||||
```
|
||||
|
||||
这样,我们就已经在 Ubuntu Xenial(16.04) 上做了所有的测试。要注意的是,这将在你的系统上安装和配置相当多的软件,因此你最好在可自由使用的机器上运行它。
|
||||
|
||||
### 追踪 OpenStack
|
||||
|
||||
现在,你可以从 snap 商店的边缘通道来安装 snap 包,比如:
|
||||
|
||||
```
|
||||
sudo snap install --edge keystone
|
||||
```
|
||||
OpenStack 团队正在努力使 CI/CD 配置到位,以便让 snap 包的发布能够交叉追踪 OpenStack 的发布(比如一个追踪 Ocata,另一个追踪 Pike 等)。每个轨道都有 4 个不同的通道。每个轨道的边缘通道将包含 OpenStack 项目对应分支最近的内容,测试、候选和稳定通道被保留用于已发布的版本。这样我们将看到如下的用法:
|
||||
|
||||
```
|
||||
sudo snap install --channel=ocata/stable keystone
|
||||
sudo snap install --channel=pike/edge keystone
|
||||
```
|
||||
|
||||
### 闲逛(原文:Poking around)
|
||||
|
||||
我们可以使用多个环境变量来简化 snap 包的制作。[这里][5] 有相关的说明。实际上,你无需深入的研究他们,但是在安装完 snap 包后,你也许会想要了解这些位置:
|
||||
|
||||
|
||||
### $SNAP == /snap/< snap-name >/current (这里 < snap-name > 显示有问题,所以多加了空格)
|
||||
|
||||
|
||||
这是 snap 包和它所有的文件挂载的位置。所有东西都是只读的。比如我当前安装的 keystone,$SNAP 就是 /snap/keystone/91。幸好,你不需要知道当前版本号,因为在 /snap/keystone/(LCTT注:/snap/keystone/current/) 中有一个软链接指向当前正在使用版本对应的文件夹。
|
||||
|
||||
```
|
||||
$ ls /snap/keystone/current/
|
||||
bin etc pysqlite2-doc usr
|
||||
command-manage.wrapper include snap var
|
||||
command-nginx.wrapper lib snap-openstack.yaml
|
||||
command-uwsgi.wrapper meta templates
|
||||
|
||||
$ ls /snap/keystone/current/bin/
|
||||
alembic oslo-messaging-send-notification
|
||||
convert-json oslo-messaging-zmq-broker
|
||||
jsonschema oslo-messaging-zmq-proxy
|
||||
keystone-manage oslopolicy-checker
|
||||
keystone-wsgi-admin oslopolicy-list-redundant
|
||||
keystone-wsgi-public oslopolicy-policy-generator
|
||||
lockutils-wrapper oslopolicy-sample-generator
|
||||
make_metadata.py osprofiler
|
||||
mako-render parse_xsd2.py
|
||||
mdexport.py pbr
|
||||
merge_metadata.py pybabel
|
||||
migrate snap-openstack
|
||||
migrate-repository sqlformat
|
||||
netaddr uwsgi
|
||||
oslo-config-generator
|
||||
|
||||
$ ls /snap/keystone/current/usr/bin/
|
||||
2to3 idle pycompile python2.7-config
|
||||
2to3-2.7 pdb pydoc python2-config
|
||||
cautious-launcher pdb2.7 pydoc2.7 python-config
|
||||
compose pip pygettext pyversions
|
||||
dh_python2 pip2 pygettext2.7 run-mailcap
|
||||
easy_install pip2.7 python see
|
||||
easy_install-2.7 print python2 smtpd.py
|
||||
edit pyclean python2.7
|
||||
|
||||
$ ls /snap/keystone/current/lib/python2.7/site-packages/
|
||||
...
|
||||
```
|
||||
|
||||
### $SNAP_COMMON == /var/snap/< snap-name >/common (这里 < snap-name > 显示有问题,所以多加了空格)
|
||||
|
||||
这个目录用于存放系统数据,对于 snap 包的多个修订版本这些数据是共用的。在这里,你可以覆盖默认配置文件和访问日志文件。
|
||||
|
||||
```
|
||||
$ ls /var/snap/keystone/common/
|
||||
etc fernet-keys lib lock log run
|
||||
|
||||
$ sudo ls /var/snap/keystone/common/etc/
|
||||
keystone nginx uwsgi
|
||||
|
||||
$ ls /var/snap/keystone/common/log/
|
||||
keystone.log nginx-access.log nginx-error.log uwsgi.log
|
||||
```
|
||||
|
||||
### 严格限制
|
||||
|
||||
每个 snap 包都是在一个由 seccomp 和 AppArmor 策略构建的严格限制的环境中运行的。更多关于 snap 约束的细节可以在 [这里][7] 查看。
|
||||
|
||||
### snap 包即将到来的新特性和更新
|
||||
|
||||
|
||||
我正在期待 snap 包一些即将到来的新特性和更新(LCTT注:此文发表于 7 月 6 日):
|
||||
|
||||
* 我们正在致力于实现 libvirt AppArmor 策略,这样 nova-hypervisor 的 snap 包就能够访问 qcow2 的支持文件(英文:backing files)。
|
||||
* 现在,作为一种变通方法,你可以将 virt-aa-helper 放在 complain 模式下:`sudo aa-complain /usr/lib/libvirt/virt-aa-helper`。
|
||||
|
||||
* 我们还在为 snapd 开发额外的接口策略,以便为部署的实例启用网络连接。
|
||||
* 现在你可以在 devmode 模式下安装 nova-hypervisor snap 包,它会禁用安全限制:`snap install -devmode -edge nova-hypervisor`。
|
||||
|
||||
* 自动连接 nova-hypervisor 的接口。我们正在努力实现在安装时自动定义 nova - hypervisor 接口。
|
||||
* 定义 AppArmor 和 seccomp 策略的接口可以允许 snap 包访问系统的资源。
|
||||
* 现在,你可以手动连接需要接口,在 nova-hypervisor snap 包的 README 中有相关的描述。
|
||||
|
||||
* 命令自动定义别名。我们正在努力实现 snap 包在安装时为命令自动定义别名。
|
||||
* 这使得我们可以使用传统的命令名。安装 snap 包后,你将可以使用 `nova-manage db sync` 而无需再用 `nova.manage db sync`。
|
||||
* 现在,你可以在安装 snap 包后手动设置别名,比如:`snap alias nova.manage nova-manage`。如想获取更多细节请查看 snap 包的 README 。
|
||||
|
||||
* 守护进程自动定义别名。当前 snappy 仅支持为命令(非守护进程)定义别名。一旦针对守护进程的别名可用了,我们将设置它们在安装的时候自动配置。
|
||||
* 这使得我们可以使用额外的单元文件名。我们可以使用 `systemctl restart nova-compute` 而无需再用 `systemctl restart snap.nova.nova-compute`。
|
||||
|
||||
* snap 包资产跟踪。这使得我们可以追踪用来构建 snap 包的版本以便在将来构建时重复使用。
|
||||
|
||||
如果你想多聊一些关于 snap 包的内容,你可以在 freenode 的 #openstack-snaps 这样的 IRC 上找到我们。我们欢迎你的反馈和贡献!感谢并祝你玩得开心!Corey
|
||||
|
||||
------
|
||||
|
||||
作者简介:
|
||||
|
||||
Corey Bryant 是 Ubuntu 的核心开发者和 Canonical 公司 OpenStack 工程团队的软件工程师,他主要专注于为 Ubuntu 提供 OpenStack 的安装包以及为 Juju 进行 OpenStack 的魅力开发。他对开源软件充满热情,喜欢与来自世界各地的人一起工作。
|
||||
|
||||
译者简介:
|
||||
|
||||
> snapcraft.io 的钉子户,对 Ubuntu Core、Snaps 和 Snapcraft 有着浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人的公众号: `Snapcraft`,最近会在上面连载几篇有关 Core snap 发布策略、交付流程和验证流程的文章,欢迎围观 :)
|
||||
|
||||
------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/06/openstack-in-a-snap/
|
||||
|
||||
作者:[Corey Bryant][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/corey-bryant/
|
||||
|
||||
[1]: http://snapcraft.io/
|
||||
[2]:https://github.com/openstack?utf8=%E2%9C%93&q=snap-&type=&language=
|
||||
[3]:https://github.com/openstack-snaps/snap-cookiecutter/blob/master/README.rst
|
||||
[4]:https://snapcraft.io/docs/reference/env
|
||||
[5]: https://snapcraft.io/docs/reference/env
|
||||
[6]:https://snapcraft.io/docs/reference/confinement
|
||||
[7]: https://snapcraft.io/docs/reference/confinement
|
||||
343
translated/tech/GDB-common-commands.md
Normal file
343
translated/tech/GDB-common-commands.md
Normal file
@ -0,0 +1,343 @@
|
||||
# 常用的 GDB 命令中文释义
|
||||
|
||||
## 目录
|
||||
|
||||
- [break](#break) -- 缩写 `b`,在指定的行或函数处设置断点
|
||||
- [info breakpoints](#info-breakpoints) -- 简写 `i b`,打印未删除的所有断点,观察点和捕获点的列表
|
||||
- [disable](#disable) -- 禁用断点,可以缩写为 `dis`
|
||||
- [enable](#enable) -- 启用断点
|
||||
- [clear](#clear) -- 清除指定行或函数处的断点
|
||||
- [delete](#delete) -- 缩写 `d`,删除断点
|
||||
- [tbreak](#tbreak) -- 设置临时断点,参数同 `break`,但在程序第一次停住后会被自动删除
|
||||
- [watch](#watch) -- 为表达式(或变量)设置观察点,当表达式(或变量)的值有变化时,停住程序
|
||||
- [step](#step) -- 缩写 `s`,单步跟踪,如果有函数调用,会进入该函数
|
||||
- [reverse-step](#reverse-step) -- 反向单步跟踪,如果有函数调用,会进入该函数
|
||||
- [next](#next) -- 缩写 `n`,单步跟踪,如果有函数调用,不会进入该函数
|
||||
- [reverse-next](#reverse-next) -- 反向单步跟踪,如果有函数调用,不会进入该函数
|
||||
- [return](#return) -- 使选定的栈帧返回到其调用者
|
||||
- [finish](#finish) -- 缩写 `fin`,执行直到选择的栈帧返回
|
||||
- [until](#until) -- 缩写 `u`,执行直到...(用于跳过循环、递归函数调用)
|
||||
- [continue](#continue) -- 同义词 `c`,恢复程序执行
|
||||
- [print](#print) -- 缩写 `p`,打印表达式 EXP 的值
|
||||
- [x](#x) -- 查看内存
|
||||
- [display](#display) -- 每次程序停止时打印表达式 EXP 的值(自动显示)
|
||||
- [info display](#info-display) -- 打印早先设置为自动显示的表达式列表
|
||||
- [disable display](#disable-display) -- 禁用自动显示
|
||||
- [enable display](#enable-display) -- 启用自动显示
|
||||
- [undisplay](#undisplay) -- 删除自动显示项
|
||||
- [help](#help) -- 缩写 `h`,打印命令列表(带参数时查找命令的帮助)
|
||||
- [attach](#attach) -- 挂接到已在运行的进程来调试
|
||||
- [run](#run) -- 缩写 `r`,启动被调试的程序
|
||||
- [backtrace](#backtrace) -- 缩写 `bt`,查看程序调用栈的信息
|
||||
- [ptype](#ptype) -- 打印类型 TYPE 的定义
|
||||
|
||||
------
|
||||
|
||||
## break
|
||||
|
||||
使用 `break` 命令(缩写 `b`)来设置断点。 参见[官方文档][1]。
|
||||
|
||||
- `break` 当不带参数时,在所选栈帧中执行的下一条指令处设置断点。
|
||||
- `break <function-name>` 在函数体入口处打断点,在 C++ 中可以使用 `class::function` 或 `function(type, ...)` 格式来指定函数名。
|
||||
- `break <line-number>` 在当前源码文件指定行的开始处打断点。
|
||||
- `break -N` `break +N` 在当前源码行前面或后面的 `N` 行开始处打断点,`N` 为正整数。
|
||||
- `break <filename:linenum>` 在源码文件 `filename` 的 `linenum` 行处打断点。
|
||||
- `break <filename:function>` 在源码文件 `filename` 的 `function` 函数入口处打断点。
|
||||
- `break <address>` 在程序指令的地址处打断点。
|
||||
- `break ... if <cond>` 设置条件断点,`...` 代表上述参数之一(或无参数),`cond` 为条件表达式,仅在 `cond` 值非零时停住程序。
|
||||
|
||||
## info breakpoints
|
||||
|
||||
查看断点,观察点和捕获点的列表。用法:
|
||||
`info breakpoints [list…]`
|
||||
`info break [list…]`
|
||||
`list…` 用来指定若干个断点的编号(可省略),可以是 `2`, `1-3`, `2 5` 等。
|
||||
|
||||
## disable
|
||||
|
||||
禁用一些断点。 参见[官方文档][2]。
|
||||
参数是用空格分隔的断点编号。
|
||||
要禁用所有断点,不加参数。
|
||||
禁用的断点不会被忘记,但直到重新启用才有效。
|
||||
用法: `disable [breakpoints] [list…]`
|
||||
`breakpoints` 是 `disable` 的子命令(可省略),`list…` 同 `info breakpoints` 中的描述。
|
||||
|
||||
## enable
|
||||
|
||||
启用一些断点。 参见[官方文档][2]。
|
||||
给出断点编号(以空格分隔)作为参数。
|
||||
没有参数时,所有断点被启用。
|
||||
|
||||
- `enable [breakpoints] [list…]` 启用指定的断点(或所有定义的断点)。
|
||||
- `enable [breakpoints] once list…` 临时启用指定的断点。GDB 在停止您的程序后立即禁用这些断点。
|
||||
- `enable [breakpoints] delete list…` 使指定的断点启用一次,然后删除。一旦您的程序停止,GDB 就会删除这些断点。等效于用 `tbreak` 设置的断点。
|
||||
|
||||
`breakpoints` 同 `disable` 中的描述。
|
||||
|
||||
## clear
|
||||
|
||||
在指定行或函数处清除断点。 参见[官方文档][3]。
|
||||
参数可以是行号,函数名称或 `*` 跟一个地址。
|
||||
|
||||
- `clear` 当不带参数时,清除所选栈帧在执行的源码行中的所有断点。
|
||||
- `clear <function>`, `clear <filename:function>` 删除在命名函数的入口处设置的任何断点。
|
||||
- `clear <linenum>`, `clear <filename:linenum>` 删除在指定的文件指定的行号的代码中设置的任何断点。
|
||||
- `clear <address>` 清除指定程序指令的地址处的断点。
|
||||
|
||||
## delete
|
||||
|
||||
删除一些断点或自动显示表达式。 参见[官方文档][3]。
|
||||
参数是用空格分隔的断点编号。
|
||||
要删除所有断点,不加参数。
|
||||
用法: `delete [breakpoints] [list…]`
|
||||
|
||||
## tbreak
|
||||
|
||||
设置临时断点。参数形式同 `break` 一样。 参见[官方文档][1]。
|
||||
除了断点是临时的之外像 `break` 一样,所以在命中时会被删除。
|
||||
|
||||
## watch
|
||||
|
||||
为表达式设置观察点。 参见[官方文档][4]。
|
||||
用法: `watch [-l|-location] <expr>`
|
||||
每当一个表达式的值改变时,观察点就会停止执行您的程序。
|
||||
如果给出了 `-l` 或者 `-location`,则它会对 `expr` 求值并观察它所指向的内存。
|
||||
例如,`watch *(int *)0x12345678` 将在指定的地址处观察一个 4 字节的区域(假设 int 占用 4 个字节)。
|
||||
|
||||
## step
|
||||
|
||||
单步执行程序,直到到达不同的源码行。 参见[官方文档][5]。
|
||||
用法: `step [N]`
|
||||
参数 `N` 表示执行 N 次(或由于另一个原因直到程序停止)。
|
||||
警告:如果当控制在没有调试信息的情况下编译的函数中使用 `step` 命令,则执行将继续进行,
|
||||
直到控制到达具有调试信息的函数。 同样,它不会进入没有调试信息编译的函数。
|
||||
要执行没有调试信息的函数,请使用 `stepi` 命令,后文再述。
|
||||
|
||||
## reverse-step
|
||||
|
||||
反向步进程序,直到到达另一个源码行的开头。 参见[官方文档][6]。
|
||||
用法: `reverse-step [N]`
|
||||
参数 `N` 表示执行 N 次(或由于另一个原因直到程序停止)。
|
||||
|
||||
## next
|
||||
|
||||
单步执行程序,执行完子程序调用。 参见[官方文档][5]。
|
||||
用法: `next [N]`
|
||||
与 `step` 不同,如果当前的源代码行调用子程序,则此命令不会进入子程序,而是继续执行,将其视为单个源代码行。
|
||||
|
||||
## reverse-next
|
||||
|
||||
反向步进程序,执行完子程序调用。 参见[官方文档][6]。
|
||||
用法: `reverse-next [N]`
|
||||
如果要执行的源代码行调用子程序,则此命令不会进入子程序,调用被视为一个指令。
|
||||
参数 `N` 表示执行 N 次(或由于另一个原因直到程序停止)。
|
||||
|
||||
## return
|
||||
|
||||
您可以使用 `return` 命令取消函数调用的执行。 参见[官方文档][7]。
|
||||
如果你给出一个表达式参数,它的值被用作函数的返回值。
|
||||
`return <expression>` 将 `expression` 的值作为函数的返回值并使函数直接返回。
|
||||
|
||||
## finish
|
||||
|
||||
执行直到选定的栈帧返回。 参见[官方文档][5]。
|
||||
用法: `finish`
|
||||
返回后,返回的值将被打印并放入到值历史记录中。
|
||||
|
||||
## until
|
||||
|
||||
执行直到程序到达大于当前栈帧或当前栈帧中的指定位置(与 [break](#break) 命令相同的参数)的源码行。 参见[官方文档][5]。
|
||||
此命令用于通过一个多次的循环,以避免单步执行。
|
||||
`until <location>` 或 `u <location>` 继续运行程序,直到达到指定的位置,或者当前栈帧返回。
|
||||
|
||||
## continue
|
||||
|
||||
在信号或断点之后,继续运行被调试的程序。 参见[官方文档][5]。
|
||||
用法: `continue [N]`
|
||||
如果从断点开始,可以使用数字 `N` 作为参数,这意味着将该断点的忽略计数设置为 `N - 1`(以便断点在第 N 次到达之前不会中断)。
|
||||
如果启用了非停止模式(使用 `show non-stop` 查看),则仅继续当前线程,否则程序中的所有线程都将继续。
|
||||
|
||||
## print
|
||||
|
||||
求值并打印表达式 EXP 的值。 参见[官方文档][8]。
|
||||
可访问的变量是所选栈帧的词法环境,以及范围为全局或整个文件的所有变量。
|
||||
用法: `print [expr]` 或 `print /f [expr]`
|
||||
`expr` 是一个(在源代码语言中的)表达式。
|
||||
默认情况下,`expr` 的值以适合其数据类型的格式打印;您可以通过指定 `/f` 来选择不同的格式,其中 `f` 是一个指定格式的字母;参见[输出格式][9]。
|
||||
如果省略 `expr`,GDB 再次显示最后一个值。
|
||||
要以每行一个成员带缩进的格式打印结构体变量请使用命令 `set print pretty on`,取消则使用命令 `set print pretty off`。
|
||||
可使用命令 `show print` 查看所有打印的设置。
|
||||
|
||||
## x
|
||||
|
||||
检查内存。 参见[官方文档][10]。
|
||||
用法: `x/nfu <addr>` 或 `x <addr>`
|
||||
`n`, `f`, 和 `u` 都是可选参数,用于指定要显示的内存以及如何格式化。
|
||||
`addr` 是要开始显示内存的地址的表达式。
|
||||
`n` 重复次数(默认值是 1),指定要显示多少个单位(由 `u` 指定)的内存值。
|
||||
`f` 显示格式(初始默认值是 `x`),显示格式是 `print('x','d','u','o','t','a','c','f','s')` 使用的格式之一,再加 `i`(机器指令)。
|
||||
`u` 单位大小,`b` 表示单字节,`h` 表示双字节,`w` 表示四字节,`g` 表示八字节。
|
||||
例如:
|
||||
`x/3uh 0x54320` 表示从地址 0x54320 开始以无符号十进制整数的方式,双字节为单位显示 3 个内存值。
|
||||
`x/16xb 0x7f95b7d18870` 表示从地址 0x7f95b7d18870 开始以十六进制整数的方式,单字节为单位显示 16 个内存值。
|
||||
|
||||
## display
|
||||
|
||||
每次程序停止时打印表达式 EXP 的值。 参见[官方文档][11]。
|
||||
用法: `display <expr>`, `display/fmt <expr>` 或 `display/fmt <addr>`
|
||||
`fmt` 用于指定显示格式。像 [print](#print) 命令里的 `/f` 一样。
|
||||
对于格式 `i` 或 `s`,或者包括单位大小或单位数量,将表达式 `addr` 添加为每次程序停止时要检查的内存地址。
|
||||
|
||||
## info display
|
||||
|
||||
打印自动显示的表达式列表,每个表达式都带有项目编号,但不显示其值。
|
||||
包括被禁用的表达式和不能立即显示的表达式(当前不可用的自动变量)。
|
||||
|
||||
## undisplay
|
||||
|
||||
取消某些表达式在程序停止时自动显示。
|
||||
参数是表达式的编号(使用 `info display` 查询编号)。
|
||||
不带参数表示取消所有自动显示表达式。
|
||||
`delete display` 具有与此命令相同的效果。
|
||||
|
||||
## disable display
|
||||
|
||||
禁用某些表达式在程序停止时自动显示。
|
||||
禁用的显示项目不会被自动打印,但不会被忘记。 它可能稍后再次被启用。
|
||||
参数是表达式的编号(使用 `info display` 查询编号)。
|
||||
不带参数表示禁用所有自动显示表达式。
|
||||
|
||||
## enable display
|
||||
|
||||
启用某些表达式在程序停止时自动显示。
|
||||
参数是重新显示的表达式的编号(使用 `info display` 查询编号)。
|
||||
不带参数表示启用所有自动显示表达式。
|
||||
|
||||
## help
|
||||
|
||||
打印命令列表。 参见[官方文档][12]。
|
||||
您可以使用不带参数的 `help`(缩写为 `h`)来显示命令的类别名的简短列表。
|
||||
使用 `help <class>` 您可以获取该类中各个命令的列表。
|
||||
使用 `help <command>` 显示如何使用该命令的简述。
|
||||
|
||||
## attach
|
||||
|
||||
挂接到 GDB 之外的进程或文件。 参见[官方文档][13]。
|
||||
该命令可以将进程 ID 或设备文件作为参数。
|
||||
对于进程 ID,您必须具有向进程发送信号的权限,并且必须具有与调试器相同的有效的 uid。
|
||||
用法: `attach <process-id>`
|
||||
GDB 在安排调试指定的进程之后做的第一件事是停住它。
|
||||
您可以使用所有通过 `run` 命令启动进程时可以使用的 GDB 命令来检查和修改挂接的进程。
|
||||
|
||||
## run
|
||||
|
||||
启动被调试的程序。 参见[官方文档][14]。
|
||||
可以直接指定参数,也可以用 [set args][15] 设置(启动所需的)参数。
|
||||
例如: `run arg1 arg2 ...` 等效于
|
||||
|
||||
```
|
||||
set args arg1 arg2 ...
|
||||
run
|
||||
```
|
||||
|
||||
还允许使用 `>`, `<`, 或 `>>` 进行输入和输出重定向。
|
||||
|
||||
## backtrace
|
||||
|
||||
打印整个栈的回溯。 参见[官方文档][16]。
|
||||
|
||||
- `bt` 打印整个栈的回溯,每个栈帧一行。
|
||||
- `bt n` 类似于上,但只打印最内层的 n 个栈帧。
|
||||
- `bt -n` 类似于上,但只打印最外层的 n 个栈帧。
|
||||
- `bt full n` 类似于 `bt n`,还打印局部变量的值。
|
||||
|
||||
`where` 和 `info stack`(缩写 `info s`) 是 `backtrace` 的别名。调用栈信息类似如下:
|
||||
|
||||
```
|
||||
(gdb) where
|
||||
#0 vconn_stream_run (vconn=0x99e5e38) at lib/vconn-stream.c:232
|
||||
#1 0x080ed68a in vconn_run (vconn=0x99e5e38) at lib/vconn.c:276
|
||||
#2 0x080dc6c8 in rconn_run (rc=0x99dbbe0) at lib/rconn.c:513
|
||||
#3 0x08077b83 in ofconn_run (ofconn=0x99e8070, handle_openflow=0x805e274 <handle_openflow>) at ofproto/connmgr.c:1234
|
||||
#4 0x08075f92 in connmgr_run (mgr=0x99dc878, handle_openflow=0x805e274 <handle_openflow>) at ofproto/connmgr.c:286
|
||||
#5 0x08057d58 in ofproto_run (p=0x99d9ba0) at ofproto/ofproto.c:1159
|
||||
#6 0x0804f96b in bridge_run () at vswitchd/bridge.c:2248
|
||||
#7 0x08054168 in main (argc=4, argv=0xbf8333e4) at vswitchd/ovs-vswitchd.c:125
|
||||
```
|
||||
|
||||
## ptype
|
||||
|
||||
打印类型 TYPE 的定义。 参见[官方文档][17]。
|
||||
用法: `ptype[/FLAGS] TYPE-NAME | EXPRESSION`
|
||||
参数可以是由 `typedef` 定义的类型名, 或者 `struct STRUCT-TAG` 或者 `class CLASS-NAME` 或者 `union UNION-TAG` 或者 `enum ENUM-TAG`。
|
||||
所选的栈帧的词法上下文用于查找该名字。
|
||||
类似的命令是 `whatis`,区别在于 `whatis` 不展开由 `typedef` 定义的数据类型,而 `ptype` 会展开,举例如下:
|
||||
|
||||
```
|
||||
/* 类型声明与变量定义 */
|
||||
typedef double real_t;
|
||||
struct complex {
|
||||
real_t real;
|
||||
double imag;
|
||||
};
|
||||
typedef struct complex complex_t;
|
||||
|
||||
complex_t var;
|
||||
real_t *real_pointer_var;
|
||||
```
|
||||
|
||||
这两个命令给出了如下输出:
|
||||
|
||||
```
|
||||
(gdb) whatis var
|
||||
type = complex_t
|
||||
(gdb) ptype var
|
||||
type = struct complex {
|
||||
real_t real;
|
||||
double imag;
|
||||
}
|
||||
(gdb) whatis complex_t
|
||||
type = struct complex
|
||||
(gdb) whatis struct complex
|
||||
type = struct complex
|
||||
(gdb) ptype struct complex
|
||||
type = struct complex {
|
||||
real_t real;
|
||||
double imag;
|
||||
}
|
||||
(gdb) whatis real_pointer_var
|
||||
type = real_t *
|
||||
(gdb) ptype real_pointer_var
|
||||
type = double *
|
||||
```
|
||||
|
||||
|
||||
|
||||
------
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [Debugging with GDB](https://sourceware.org/gdb/current/onlinedocs/gdb/)
|
||||
|
||||
------
|
||||
|
||||
编译者:[robot527](https://github.com/robot527)
|
||||
|
||||
[1]: https://sourceware.org/gdb/current/onlinedocs/gdb/Set-Breaks.html
|
||||
[2]: https://sourceware.org/gdb/current/onlinedocs/gdb/Disabling.html
|
||||
[3]: https://sourceware.org/gdb/current/onlinedocs/gdb/Delete-Breaks.html
|
||||
[4]: https://sourceware.org/gdb/current/onlinedocs/gdb/Set-Watchpoints.html
|
||||
[5]: https://sourceware.org/gdb/current/onlinedocs/gdb/Continuing-and-Stepping.html
|
||||
[6]: https://sourceware.org/gdb/current/onlinedocs/gdb/Reverse-Execution.html
|
||||
[7]: https://sourceware.org/gdb/current/onlinedocs/gdb/Returning.html
|
||||
[8]: https://sourceware.org/gdb/current/onlinedocs/gdb/Data.html
|
||||
[9]: https://sourceware.org/gdb/current/onlinedocs/gdb/Output-Formats.html
|
||||
[10]: https://sourceware.org/gdb/current/onlinedocs/gdb/Memory.html
|
||||
[11]: https://sourceware.org/gdb/current/onlinedocs/gdb/Auto-Display.html
|
||||
[12]: https://sourceware.org/gdb/current/onlinedocs/gdb/Help.html
|
||||
[13]: https://sourceware.org/gdb/current/onlinedocs/gdb/Attach.html
|
||||
[14]: https://sourceware.org/gdb/current/onlinedocs/gdb/Starting.html
|
||||
[15]: https://sourceware.org/gdb/current/onlinedocs/gdb/Arguments.html
|
||||
[16]: https://sourceware.org/gdb/current/onlinedocs/gdb/Backtrace.html
|
||||
[17]: https://sourceware.org/gdb/current/onlinedocs/gdb/Symbols.html
|
||||
|
||||
Loading…
Reference in New Issue
Block a user