mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
ea9e38a6d8
published
20170928 Process Monitoring.md20180130 Install AWFFull web server log analysis application on ubuntu 17.10.md
sources
talk
20180419 3 tips for organizing your open source project-s workflow on GitHub.md20180419 5 guiding principles you should know before you design a microservice.md20180420 What You Don-t Know About Linux Open Source Could Be Costing to More Than You Think.md
tech
20140403 Easily Install Android Studio in Ubuntu And Linux Mint.md20180418 Getting started with Anaconda Python for data science.md20180418 The Linux Filesystem Explained.md20180419 Migrating to Linux- Network and System Settings.md20180420 A Perl module for better debugging.md20180420 A handy way to add free books to your eReader.md20180420 How to start developing on Java in Fedora.md
translated/tech
55
published/20170928 Process Monitoring.md
Normal file
55
published/20170928 Process Monitoring.md
Normal file
@ -0,0 +1,55 @@
|
||||
对进程的监视
|
||||
======
|
||||
|
||||
由于复刻了 mon 项目到 [etbemon][1] 中,我花了一些时间做监视脚本。事实上监视一些事情通常很容易,但是决定监视什么才是困难的部分。进程监视脚本 `ps.monitor` 是我重新设计过的一个。
|
||||
|
||||
对于进程监视我有一些思路。如果你对进程监视如何做的更好有任何建议,请通过评论区告诉我。
|
||||
|
||||
给不使用 mon 的人介绍一下,如果一切 OK 该监视脚本就返回 0,而如果有问题它会返回 1,并使用标准输出显示错误信息。虽然我并不知道有谁将 mon 脚本挂进一个不同的监视系统中,但是,那样做其实很容易实现。我计划去做的一件事情就是,将来实现 mon 和其它的监视系统如 Nagios 之间的互操作性。
|
||||
|
||||
### 基本监视
|
||||
|
||||
```
|
||||
ps.monitor tor:1-1 master:1-2 auditd:1-1 cron:1-5 rsyslogd:1-1 dbus-daemon:1- sshd:1- watchdog:1-2
|
||||
```
|
||||
|
||||
我现在计划重写该进程监视脚本的某些部分。现在的功能是在命令行上列出进程名字,它包含了要监视的进程的最小和最大实例数量。上面的示例是一个监视的配置。在这里有一些限制,在这个实例中的 `master` 进程指的是 Postfix 的主进程,但是其它的守护进程使用了相同的进程名(这是那些错误的名字之一,因为它太直白了)。一个显而易见的解决方案是,给一个指定完整路径的选项,这样,那个 `/usr/lib/postfix/sbin/master` 就可以与其它命名为 `master` 的程序区分开了。
|
||||
|
||||
下一个问题是那些可能以多个用户身份运行的进程。比如 `sshd`,它有一个以 root 身份运行的单独的进程去接受新的连接请求,以及在每个登入用户的 UID 下运行的进程。因此,作为 root 用户运行的 sshd 进程的数量将比 root 登录会话的数量大 1。这意味着如果一个系统管理员直接以 root 身份通过 `ssh` 登入系统(这是有争议的,但它不是本文的主题—— 只是有些人需要这样做,所以我们必须支持这种情形),然后 master 进程崩溃了(或者系统管理员意外或者故意杀死了它),这时对于该进程丢失并不会产生警报。当然正确的做法是监视 22 号端口,查找字符串 `SSH-2.0-OpenSSH_`。有时候,守护进程的多个实例运行在需要单独监视的不同 UID 下面。因此,我们需要通过 UID 监视进程的能力。
|
||||
|
||||
在许多情形中,进程监视可以被替换为对服务端口的监视。因此,如果在 25 号端口上监视,那么有可能意味着,Postfix 的 `master` 在运行着,不用去理会其它的 `master` 进程。但是对于我而言,我可以在方便地进行多个监视,如果我得到一个关于无法向一个服务器发送邮件的 Jabber 消息,我可以通过这个来自服务器的 Jabber 消息断定 `master` 没有运行,而不需要挨个查找才能发现问题所在。
|
||||
|
||||
### SE Linux
|
||||
|
||||
我想要的一个功能就是,监视进程的 SE Linux 上下文,就像监视 UID 一样。虽然我对为其它安全系统编写一个测试不感兴趣,但是,我很乐意将别人写好的代码包含进去。因此,不管我做什么,都希望它能与多个安全系统一起灵活地工作。
|
||||
|
||||
### 短暂进程
|
||||
|
||||
大多数守护进程在进程启动期间都有一个相同名字的<ruby>次级进程<rt>second process</rt></ruby>。这意味着如果你为了精确地监视一个进程的一个实例,当 `logrotate` 或者类似的守护进程重启时,你或许会收到一个警报说有两个进程运行。如果在重启期间,恰好在一个错误的时间进行检查,你也或许会收到一个警报说,有 0 个实例。我现在处理这种情况的方法是,在与 `alertafter 2` 指令一起的次级进程失败事件之前我的服务器不发出警报。当监视处于一个失败的状态时,`failure_interval` 指令允许指定检查的时间间隔,将其设置为一个较低值时,意味着在等待一个次级进程失败结果时并不会使提示延迟太多。
|
||||
|
||||
为处理这种情况,我考虑让 `ps.monitor` 脚本在一个指定的延迟后再次进行自动检查。我认为使用一个单个参数的监视脚本来解决这个问题比起使用两个配置指令的 mon 要好一些。
|
||||
|
||||
### CPU 使用
|
||||
|
||||
mon 现在有一个 `loadavg.monitor` 脚本,它用于检查平均负载。但是它并不能捕获一个单个进程使用了太多的 CPU 时间而没有使系统平均负载上升的情况。同样,也没有捕获一个渴望获得 CPU 的进程进入沉默(例如,SETI at Home 停止运行)(LCTT 译注:SETI,由加州大学伯克利分校创建的一项利用全球的联网计算机的空闲计算资源来搜寻地外文明的科学实验计划),而其它的进程进入一个无限循环状态的情况。解决这种问题的一个方法是,让 `ps.monitor` 脚本也配置另外的一个选项去监视 CPU 的使用,但是这也可能会让人产生迷惑。另外的选择是,使用一个独立的脚本,它用来报警任何在它的生命周期或者最后几秒中,使用 CPU 时间超过指定百分比的进程,除非它在一个豁免这种检查的进程或用户的白名单中。或者每个普通用户都应该豁免这种检查,因为你压根就不知道他们什么时候运行一个文件压缩程序。也应该有一个包含排除的守护进程(像 BOINC)和系统进程(像 gzip,有几个定时任务会运行它)的简短列表。
|
||||
|
||||
### 对例外的监视
|
||||
|
||||
一个常见的编程错误是在 `setgid()` 之前调用 `setuid()`,这意味着那个程序没有权限去调用 `setgid()`。如果没有检查返回代码(而犯这种低级错误的人往往不会去检查返回代码),那么进程会保持较高的权限。检查以 GID 0 而不是 UID 0 运行的进程是很方便的。顺利说一下,对一个 Debian/Testing 工作站运行的一个快速检查显示,一个使用 GID 0 的进程并没有获得较高的权限,但是可以使用一个 `chmod 770` 命令去改变它。
|
||||
|
||||
在一个 SE Linux 系统上,应该只有一个进程与 `init_t` 域一起运行。目前在运行守护进程(比如,mysqld 和 tor)的 Debian Stretch 系统中,并不会发生策略与守护进程服务文件所请求的 systemd 的最新功能不匹配的情况。这样的问题将会不断发生,我们需要对它进行自动化测试。
|
||||
|
||||
对配置错误的自动测试可能会影响系统安全,这是一个很大的问题,我将来或许写一篇关于这方面的单独的博客文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://etbe.coker.com.au/2017/09/28/process-monitoring/
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://etbe.coker.com.au
|
||||
[1]:https://doc.coker.com.au/projects/etbe-mon/
|
||||
@ -0,0 +1,80 @@
|
||||
在 Ubuntu 17.10 上安装 AWFFull Web 服务器日志分析应用程序
|
||||
======
|
||||
|
||||
AWFFull 是基于 “Webalizer” 的 Web 服务器日志分析程序。AWFFull 以 HTML 格式生成使用统计信息以便用浏览器查看。结果以柱状和图形两种格式显示,这有利于解释数据。它提供每年、每月、每日和每小时的使用统计数据,并显示网站、URL、referrer、user agent(浏览器)、用户名、搜索字符串、进入/退出页面和国家(如果一些信息不存在于处理后日志中那么就没有)。AWFFull 支持 CLF(通用日志格式)日志文件,以及由 NCSA 等定义的组合日志格式,它还能只能地处理这些格式的变体。另外,AWFFull 还支持 wu-ftpd xferlog 格式的日志文件,它能够分析 ftp 服务器和 squid 代理日志。日志也可以通过 gzip 压缩。
|
||||
|
||||
如果检测到压缩日志文件,它将在读取时自动解压缩。压缩日志必须是 .gz 扩展名的标准 gzip 压缩。
|
||||
|
||||
### 对于 Webalizer 的修改
|
||||
|
||||
AWFFull 基于 Webalizer 的代码,并有许多或大或小的变化。包括:
|
||||
|
||||
- 不止原始统计数据:利用已发布的公式,提供额外的网站使用情况。
|
||||
- GeoIP IP 地址能更准确地检测国家。
|
||||
- 可缩放的图形
|
||||
- 与 GNU gettext 集成,能够轻松翻译。目前支持 32 种语言。
|
||||
- 在首页显示超过 12 个月的网站历史记录。
|
||||
- 额外的页面计数跟踪和排序。
|
||||
- 一些小的可视化调整,包括 Geolizer 用量中使用 Kb、Mb。
|
||||
- 额外的用于 URL 计数、进入和退出页面、站点的饼图
|
||||
- 图形上的水平线更有意义,更易于阅读。
|
||||
- User Agent 和 Referral 跟踪现在通过 PAGES 而非 HITS 进行计算。
|
||||
- 现在支持 GNU 风格的长命令行选项(例如 --help)。
|
||||
- 可以通过排除“什么不是”以及原始的“什么是”来选择页面。
|
||||
- 对被分析站点的请求以匹配的引用 URL 显示。
|
||||
- 404 错误表,并且可以生成引用 URL。
|
||||
- 生成的 html 可以使用外部 CSS 文件。
|
||||
- POST 分析总结使得手动优化配置文件性能更简单。
|
||||
- 可以将指定的 IP 和地址分配给指定的国家。
|
||||
- 便于使用其他工具详细分析的转储选项。
|
||||
- 支持检测并处理 Lotus Domin- v6 日志。
|
||||
|
||||
### 在 Ubuntu 17.10 上安装 AWFFull
|
||||
|
||||
```
|
||||
sud- apt-get install awffull
|
||||
```
|
||||
|
||||
### 配置 AWFFull
|
||||
|
||||
你必须在 `/etc/awffull/awffull.conf` 中编辑 AWFFull 配置文件。如果你在同一台计算机上运行多个虚拟站点,则可以制作多个默认配置文件的副本。
|
||||
|
||||
```
|
||||
sud- vi /etc/awffull/awffull.conf
|
||||
```
|
||||
|
||||
确保有下面这几行:
|
||||
|
||||
```
|
||||
LogFile /var/log/apache2/access.log.1
|
||||
OutputDir /var/www/html/awffull
|
||||
```
|
||||
|
||||
保存并退出文件。
|
||||
|
||||
你可以使用以下命令运行 awffull。
|
||||
|
||||
```
|
||||
awffull -c [your config file name]
|
||||
```
|
||||
|
||||
这将在 `/var/www/html/awffull` 目录下创建所有必需的文件,以便你可以使用 http://serverip/awffull/ 。
|
||||
|
||||
你应该看到类似于下面的页面:
|
||||
|
||||

|
||||
|
||||
|
||||
如果你有更多站点,你可以使用 shell 和计划任务自动化这个过程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-awffull-web-server-log-analysis-application-on-ubuntu-17-10.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
@ -0,0 +1,109 @@
|
||||
3 tips for organizing your open source project's workflow on GitHub
|
||||
======
|
||||
|
||||

|
||||
|
||||
Managing an open source project is challenging work, and the challenges grow as a project grows. Eventually, a project may need to meet different requirements and span multiple repositories. These problems aren't technical, but they are important to solve to scale a technical project. [Business process management][1] methodologies such as agile and [kanban][2] bring a method to the madness. Developers and managers can make realistic decisions for estimating deadlines and team bandwidth with an organized development focus.
|
||||
|
||||
At the [UNICEF Office of Innovation][3], we use GitHub project boards to organize development on the MagicBox project. [MagicBox][4] is a full-stack application and open source platform to serve and visualize data for decision-making in humanitarian crises and emergencies. The project spans multiple GitHub repositories and works with multiple developers. With GitHub project boards, we organize our work across multiple repositories to better understand development focus and team bandwidth.
|
||||
|
||||
Here are three tips from the UNICEF Office of Innovation on how to organize your open source projects with the built-in project boards on GitHub.
|
||||
|
||||
### 1\. Bring development discussion to issues and pull requests
|
||||
|
||||
Transparency is a critical part of an open source community. When mapping out new features or milestones for a project, the community needs to see and understand a decision or why a specific direction was chosen. Filing new GitHub issues for features and milestones is an easy way for someone to follow the project direction. GitHub issues and pull requests are the cards (or building blocks) of project boards. To be successful with GitHub project boards, you need to use issues and pull requests.
|
||||
|
||||
|
||||
![GitHub issues for magicbox-maps, MagicBox's front-end application][6]
|
||||
|
||||
GitHub issues for magicbox-maps, MagicBox's front-end application.
|
||||
|
||||
The UNICEF MagicBox team uses GitHub issues to track ongoing development milestones and other tasks to revisit. The team files new GitHub issues for development goals, feature requests, or bugs. These goals or features may come from external stakeholders or the community. We also use the issues as a place for discussion on those tasks. This makes it easy to cross-reference in the future and visualize upcoming work on one of our projects.
|
||||
|
||||
Once you begin using GitHub issues and pull requests as a way of discussing and using your project, organizing with project boards becomes easier.
|
||||
|
||||
### 2\. Set up kanban-style project boards
|
||||
|
||||
GitHub issues and pull requests are the first step. After you begin using them, it may become harder to visualize what work is in progress and what work is yet to begin. [GitHub's project boards][7] give you a platform to visualize and organize cards into different columns.
|
||||
|
||||
There are two types of project boards available:
|
||||
|
||||
* **Repository** : Boards for use in a single repository
|
||||
* **Organization** : Boards for use in a GitHub organization across multiple repositories (but private to organization members)
|
||||
|
||||
|
||||
|
||||
The choice you make depends on the structure and size of your projects. The UNICEF MagicBox team uses boards for development and documentation at the organization level, and then repository-specific boards for focused work (like our [community management board][8]).
|
||||
|
||||
#### Creating your first board
|
||||
|
||||
Project boards are found on your GitHub organization page or on a specific repository. You will see the Projects tab in the same row as Issues and Pull requests. From the page, you'll see a green button to create a new project.
|
||||
|
||||
There, you can set a name and description for the project. You can also choose templates to set up basic columns and sorting for your board. Currently, the only options are for kanban-style boards.
|
||||
|
||||
|
||||
![Creating a new GitHub project board.][10]
|
||||
|
||||
Creating a new GitHub project board.
|
||||
|
||||
After creating the project board, you can make adjustments to it as needed. You can create new columns, [set up automation][11], and add pre-existing GitHub issues and pull requests to the project board.
|
||||
|
||||
You may notice new options for the metadata in each GitHub issue and pull request. Inside of an issue or pull request, you can add it to a project board. If you use automation, it will automatically enter a column you configured.
|
||||
|
||||
### 3\. Build project boards into your workflow
|
||||
|
||||
After you set up a project board and populate it with issues and pull requests, you need to integrate it into your workflow. Project boards are effective only when actively used. The UNICEF MagicBox team uses the project boards as a way to track our progress as a team, update external stakeholders on development, and estimate team bandwidth for reaching our milestones.
|
||||
|
||||
|
||||
![Tracking progress][13]
|
||||
|
||||
Tracking progress with GitHub project boards.
|
||||
|
||||
If you are an open source project and community, consider using the project boards for development-focused meetings. It also helps remind you and other core contributors to spend five minutes each day updating progress as needed. If you're at a company using GitHub to do open source work, consider using project boards to update other team members and encourage participation inside of GitHub issues and pull requests.
|
||||
|
||||
Once you begin using the project board, yours may look like this:
|
||||
|
||||
|
||||
![Development progress board][15]
|
||||
|
||||
Development progress board for all UNICEF MagicBox repositories in organization-wide GitHub project boards.
|
||||
|
||||
### Open alternatives
|
||||
|
||||
GitHub project boards require your project to be on GitHub to take advantage of this functionality. While GitHub is a popular repository for open source projects, it's not an open source platform itself. Fortunately, there are open source alternatives to GitHub with tools to replicate the workflow explained above. [GitLab Issue Boards][16] and [Taiga][17] are good alternatives that offer similar functionality.
|
||||
|
||||
### Go forth and organize!
|
||||
|
||||
With these tools, you can bring a method to the madness of organizing your open source project. These three tips for using GitHub project boards encourage transparency in your open source project and make it easier to track progress and milestones in the open.
|
||||
|
||||
Do you use GitHub project boards for your open source project? Have any tips for success that aren't mentioned in the article? Leave a comment below to share how you make sense of your open source projects.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/keep-your-project-organized-git-repo
|
||||
|
||||
作者:[Justin W.Flory][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jflory
|
||||
[1]:https://en.wikipedia.org/wiki/Business_process_management
|
||||
[2]:https://en.wikipedia.org/wiki/Kanban_(development)
|
||||
[3]:http://unicefstories.org/about/
|
||||
[4]:http://unicefstories.org/magicbox/
|
||||
[5]:/file/393356
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-open-issues.png?itok=OcWPX575 (GitHub issues for magicbox-maps, MagicBox's front-end application)
|
||||
[7]:https://help.github.com/articles/about-project-boards/
|
||||
[8]:https://github.com/unicef/magicbox/projects/3?fullscreen=true
|
||||
[9]:/file/393361
|
||||
[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-project-boards-create-board.png?itok=pp7SXH9g (Creating a new GitHub project board.)
|
||||
[11]:https://help.github.com/articles/about-automation-for-project-boards/
|
||||
[12]:/file/393351
|
||||
[13]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-issues-metadata.png?itok=xp5auxCQ (Tracking progress)
|
||||
[14]:/file/393366
|
||||
[15]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-project-boards-overview.png?itok=QSbOOOkF (Development progress board)
|
||||
[16]:https://about.gitlab.com/features/issueboard/
|
||||
[17]:https://taiga.io/
|
||||
@ -0,0 +1,157 @@
|
||||
5 guiding principles you should know before you design a microservice
|
||||
======
|
||||
|
||||

|
||||
One of the biggest challenges for teams starting off with microservices is adhering to the Goldilocks Principle: Not too big, not too small, and not too tightly coupled. Part of this challenge arises from confusion about what, exactly, constitutes a well-designed microservice.
|
||||
|
||||
Dozens of CTOs shared their experiences through interviews, and those conversations illuminated five characteristics of well-designed microservices. This article will help guide teams as they design microservices. (For more information, check out the upcoming book [Microservices for Startups][1]). This article will briefly touch on microservice boundaries and arbitrary "rules" to avoid before diving into the five characteristics to guide your design of microservices.
|
||||
|
||||
### Microservice boundaries
|
||||
|
||||
One of the [core benefits of developing new systems with microservices][2] is that the architecture allows developers to build and modify individual components independently—but problems can arise when it comes to minimizing the number of callbacks between each API. The solution, according to Chris McFadden, VP of engineering at [SparkPost][3] , is to apply the appropriate service boundaries.
|
||||
|
||||
With respect to boundaries, in contrast to the sometimes difficult-to-grasp and abstract concept of domain-driven design (DDD)—a framework for microservices—this article focuses on practical principles for creating well-defined microservice boundaries with some of our industry's top CTOs.
|
||||
|
||||
### Avoid arbitrary "rules"
|
||||
|
||||
If you read enough advice about designing and creating a microservice, you're bound to come across some of the "rules" below. Although it's tempting to use them as guideposts for creating microservices, adhesion to these arbitrary rules is not a principled way to determine thoughtful boundaries for microservices.
|
||||
|
||||
#### "A microservice should have X lines of code"
|
||||
|
||||
Let's get one thing straight: There are no limitations on how many lines of code there are in a microservice. A microservice doesn't suddenly become a monolith just because you write a few lines of extra code. The key is ensuring there is high cohesion for the code within a service (more on this later).
|
||||
|
||||
#### "Turn each function into a microservice"
|
||||
|
||||
If a function computes something based on three input values and returns a result, is it a good candidate for a microservice? Should it be a separately deployable application of its own? This really depends on what the function is and how it serves to the entire system. Turning each function into a microservice simply might not make sense in your context.
|
||||
|
||||
Other arbitrary rules include those that don't take into account your entire context, such as the team's experience, DevOps capacity, what the service is doing, and availability needs of the data.
|
||||
|
||||
### 5 characteristics of a well-designed service
|
||||
|
||||
If you've read about microservices, you've no doubt come across advice on what makes a well-designed service. Simply put, high cohesion and loose coupling. There are [many][4] [articles][5] on these concepts to review if you're not familiar with them. And while they offer sound advice, these concepts are quite abstract. Below, based on conversations with experienced CTOs, are key characteristics to keep in mind when creating well-designed microservices.
|
||||
|
||||
#### #1: It doesn't share database tables with another service
|
||||
|
||||
In the early days of SparkPost, Chris McFadden and his team had to solve a problem that every SaaS business faces: They needed to provide basic services like authentication, account management, and billing.
|
||||
|
||||
To tackle this, they created two microservices: a Users API and an Accounts API. The Users API would handle user accounts, API keys, and authentication, while the Accounts API would handle all of the billing-related logic. A very logical separation—but before long, they spotted a problem.
|
||||
|
||||
"We had one service that was called the User API, and we had another one called the Account API. The problem was that they were actually having several calls back and forth between them. So you would do something in accounts and have a call and endpoint in users or vice versa," McFadden explained.
|
||||
|
||||
The two services were too tightly coupled.
|
||||
|
||||
When it comes to designing a microservice, it's a red flag if you have multiple services referencing the same table, as it likely means your DB is a source of coupling.
|
||||
|
||||
It is really about how the service relates to the data, which is exactly what Oleksiy Kovrin, head of [Swiftype SRE, Elastic][6], told me. "One of the main foundational principles we use when developing new services is that they should not cross database boundaries. Each service should rely on its own set of underlying data stores. This allows us to centralize access controls, audit logging, caching logic, etc.," he said.
|
||||
|
||||
Kovyrin went on to explain that if a subset of your database tables "have no or very little connections to the rest of the dataset, it is a strong signal that component could be isolated into a separate API or a separate service."
|
||||
|
||||
Darby Frey, co-founder of [Lead Honestly][7], echoed this sentiment: "Each service should have its own tables [and] should never share database tables."
|
||||
|
||||
#### #2: It has a minimal amount of database tables
|
||||
|
||||
The ideal size of a microservice is small enough, but no smaller. And the same goes for the number of database tables per service.
|
||||
|
||||
Steven Czerwinski, head of engineering, [Scaylr][8], explained during an interview that the sweet spot for Scaylr is "one or two database tables for a service."
|
||||
|
||||
SparkPost's Chris McFadden agreed: "We have a suppression microservices, and it handles, keeps track of, millions and billions of entries around suppressions, but it's all very focused just around suppression, so there's really only one or two tables there. The same goes for other services like webhooks."
|
||||
|
||||
#### #3: It's thoughtfully stateful or stateless
|
||||
|
||||
When designing your microservice, you need to ask yourself whether it requires access to a database or whether it's going to be a stateless service processing terabytes of data like emails or logs.
|
||||
|
||||
Julien Lemoine, CTO of [Algolia][9], explained, "We define the boundaries of a service by defining its input and output. Sometimes a service is a network API, but it can also be a process consuming files and producing records in a database (this is the case of our log-processing service)."
|
||||
|
||||
Be clear about statefulness up front and it will lead to a better-designed service.
|
||||
|
||||
#### #4: Its data availability needs are accounted for
|
||||
|
||||
When designing a microservice, keep in mind what services will rely on this new service and the system-wide impact if that data becomes unavailable. Taking that into account allows you to properly design data backup and recovery systems for this service
|
||||
|
||||
Steven Czerwinski mentioned that at Scaylr, critical customer row space mapping data is replicated and separated in different ways due to its importance.
|
||||
|
||||
In contrast, he added, "The per shard information, that's in its own little partition. It sucks if it goes down because that portion of the customer population is not going to have their logs available, but it's only impacting 5 percent of the customers rather than 100 percent of the customers."
|
||||
|
||||
#### #5: It's a single source of truth
|
||||
|
||||
Design a service to be the single source of truth for something in your system
|
||||
|
||||
For example, when you order something from an e-commerce site, an order ID is generated. This order ID can be used by other services to query an order service for complete information about the order. Using the [publish/subscribe pattern][10], the data that is passed around between services should be the order ID, not the attributes/information of the order itself. Only the order service has complete information and is the single source of truth for a given order.
|
||||
|
||||
### Considerations for larger teams
|
||||
|
||||
Keeping in mind the five considerations listed above, larger teams should be aware of the impacts of their organizational structure on microservice boundaries.
|
||||
|
||||
For larger organizations, where entire teams can be dedicated to owning a service, organizational consideration comes into play when determining service boundaries. And there are two considerations to consider: **independent release schedule** and **different uptime importance**.
|
||||
|
||||
"The most successful implementation of microservices we've seen is either based on a software design principle like domain-driven design, for example, and service-oriented architecture, or the ones that reflect an organizational approach," said Khash Sajadi, CEO of [Cloud66.][11]
|
||||
|
||||
"So [for the] payments team," Sajadi continued, "they have the payment service or credit card validation service, and that's the service they provide to the outside world. So it's not necessarily anything about software. It's mostly about the business unit [that] provides one more service to the outside world."
|
||||
|
||||
### The two-pizza principle
|
||||
|
||||
Amazon is a perfect example of a large organization with multiple teams. As mentioned in an article published in [API Evangelist][12], Jeff Bezos issued a mandate to all employees informing them that every team within the company had to communicate via API. Anyone who didn't would be fired.
|
||||
|
||||
This way, all the data and functionality was exposed through the interface. Bezos also managed to get every team to decouple, define what their resources are, and make them available through the API. Amazon was building a system from the ground up. This allows every team within the company to become a partner of one another.
|
||||
|
||||
I spoke to Travis Reeder, CTO of [Iron.io][13], about Bezos' internal initiative.
|
||||
|
||||
"Jeff Bezos mandated that all teams had to build API's to communicate with other teams," Reeder said. "He's also the guy who came up with the 'two-pizza' rule: A team shouldn't be larger than what two pizzas can feed.
|
||||
|
||||
"I think the same could apply here: Whatever a small team can develop, manage, and be productive with. If it starts to get unwieldy or starts to slow down, it's probably getting too big," Reeder told me.
|
||||
|
||||
### Final considerations: Is your service the right size and properly defined?
|
||||
|
||||
During the testing and implementation phase of your microservice system, there are indicators to keep in mind.
|
||||
|
||||
#### Indicator #1: Is there over-reliance between services?
|
||||
|
||||
If two services are constantly calling back to one another, then that's a strong indication of coupling and a signal that they might be better off combined into one service.
|
||||
|
||||
Going back to Chris McFadden's example where he had two API services, accounts, and users that were constantly communicating with one another, McFadden came up an idea to merge the services and decided to call it the Accuser's API. This turned out to be a fruitful strategy.
|
||||
|
||||
"What we started doing was eliminating these links [which were the] internal API calls between them," McFadden told me. "It's helped simplify the code."
|
||||
|
||||
#### Indicator #2: Does the overhead of setting up the service outweigh the benefit of having the service be independent?
|
||||
|
||||
Darby Frey explained, "Every app needs to have its logs aggregated somewhere and needs to be monitored. You need to set up alerting for it. You need to have standard operating procedures and run books for when things break. You have to manage SSH access to that thing. There's a huge foundation of things that have to exist in order for an app to just run."
|
||||
|
||||
### Key takeaways
|
||||
|
||||
Designing microservices can often feel more like an art than a science. For engineers, that may not sit well. There's lots of general advice out there, but at times it can be a bit too abstract. Let's recap the five specific characteristics to look for when designing your next set of microservices:
|
||||
|
||||
1. It doesn't share database tables with another service
|
||||
2. It has a minimal amount of database tables
|
||||
3. It's thoughtfully stateful or stateless
|
||||
4. Its data availability needs are accounted for
|
||||
5. It's a single source of truth
|
||||
|
||||
|
||||
|
||||
Next time you're designing a set of microservices and determining service boundaries, referring back to these principles should make the task easier.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/guide-design-microservices
|
||||
|
||||
作者:[Jake Lumetta][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jakelumetta
|
||||
[1]:https://buttercms.com/books/microservices-for-startups/
|
||||
[2]:https://buttercms.com/books/microservices-for-startups/should-you-always-start-with-a-monolith
|
||||
[3]:https://www.sparkpost.com/
|
||||
[4]:https://thebojan.ninja/2015/04/08/high-cohesion-loose-coupling/
|
||||
[5]:https://en.wikipedia.org/wiki/Single_responsibility_principle
|
||||
[6]:https://www.elastic.co/solutions/site-search
|
||||
[7]:https://leadhonestly.com/
|
||||
[8]:https://www.scalyr.com/
|
||||
[9]:https://www.algolia.com/
|
||||
[10]:https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern
|
||||
[11]:https://www.cloud66.com/
|
||||
[12]:https://apievangelist.com/2012/01/12/the-secret-to-amazons-success-internal-apis/
|
||||
[13]:https://www.iron.io/
|
||||
@ -0,0 +1,39 @@
|
||||
What You Don’t Know About Linux Open Source Could Be Costing to More Than You Think
|
||||
======
|
||||
|
||||
If you would like to test out Linux before completely switching it as your everyday driver, there are a number of means by which you can do it. Linux was not intended to run on Windows, and Windows was not meant to host Linux. To begin with, and perhaps most of all, Linux is open source computer software. In any event, Linux outperforms Windows on all your hardware.
|
||||
|
||||
If you’ve always wished to try out Linux but were never certain where to begin, have a look at our how to begin guide for Linux. Linux is not any different than Windows or Mac OS, it’s basically an Operating System but the leading different is the fact that it is Free for everyone. Employing Linux today isn’t any more challenging than switching from one sort of smartphone platform to another.
|
||||
|
||||
You’re most likely already using Linux, whether you are aware of it or not. Linux has a lot of distinct versions to suit nearly any sort of user. Today, Linux is a small no-brainer. Linux plays an essential part in keeping our world going.
|
||||
|
||||
Even then, it is dependent on the build of Linux that you’re using. Linux runs a lot of the underbelly of cloud operations. Linux is also different in that, even though the core pieces of the Linux operating system are usually common, there are lots of distributions of Linux, like different software alternatives. While Linux might seem intimidatingly intricate and technical to the ordinary user, contemporary Linux distros are in reality very user-friendly, and it’s no longer the case you have to have advanced skills to get started using them. Linux was the very first major Internet-centred open-source undertaking. Linux is beginning to increase the range of patches it pushes automatically, but several of the security patches continue to be opt-in only.
|
||||
|
||||
You are able to remove Linux later in case you need to. Linux plays a vital part in keeping our world going. Linux supplies a huge library of functionality which can be leveraged to accelerate development.
|
||||
|
||||
Even then, it’s dependent on the build of Linux that you’re using. Linux is also different in that, even though the core pieces of the Linux operating system are typically common, there are lots of distributions of Linux, like different software alternatives. While Linux might seem intimidatingly intricate and technical to the ordinary user, contemporary Linux distros are in fact very user-friendly, and it’s no longer the case you require to have advanced skills to get started using them. Linux runs a lot of the underbelly of cloud operations. Linux is beginning to increase the range of patches it pushes automatically, but several of the security patches continue to be opt-in only. Read More, open source projects including Linux are incredibly capable because of the contributions that all these individuals have added over time.
|
||||
|
||||
### Life After Linux Open Source
|
||||
|
||||
The development edition of the manual typically has more documentation, but might also document new characteristics that aren’t in the released version. Fortunately, it’s so lightweight you can just jump to some other version in case you don’t like it. It’s extremely hard to modify the compiled version of the majority of applications and nearly not possible to see exactly the way the developer created different sections of the program.
|
||||
|
||||
On the challenges of bottoms-up go-to-market It’s really really hard to grasp the difference between your organic product the product your developers use and love and your company product, which ought to be, effectively, a different product. As stated by the report, it’s going to be hard for developers to switch. Developers are now incredibly important and influential in the purchasing procedure. Some OpenWrt developers will attend the event and get ready to reply to your questions!
|
||||
|
||||
When the program is installed, it has to be configured. Suppose you discover that the software you bought actually does not do what you would like it to do. Open source software is much more common than you believe, and an amazing philosophy to live by. Employing open source software gives an inexpensive method to bootstrap a business. It’s more difficult to deal with closed source software generally. So regarding Application and Software, you’re all set if you are prepared to learn an alternate software or finding a means to make it run on Linux. Possibly the most famous copyleft software is Linux.
|
||||
|
||||
Article sponsored by [Vegas Palms online slots][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxaria.com/article/what-you-dont-know-about-linux-open-source-could-be-costing-to-more-than-you-think
|
||||
|
||||
作者:[Marc Fisher][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxaria.com
|
||||
[1]:https://www.vegaspalmscasino.com/casino-games/slots/
|
||||
@ -0,0 +1,98 @@
|
||||
Easily Install Android Studio in Ubuntu And Linux Mint
|
||||
======
|
||||
[Android Studio][1], Google’s own IDE for Android development, is a nice alternative to Eclipse with ADT plugin. Android Studio can be installed from its source code but in this quick post, we shall see **how to install Android Studio in Ubuntu 18.04, 16.04 and corresponding Linux Mint variants**.
|
||||
|
||||
Before you proceed to install Android Studio, make sure that you have [Java installed in Ubuntu][2].
|
||||
|
||||
![How to install Android Studio in Ubuntu][3]
|
||||
|
||||
### Install Android Studio in Ubuntu and other distributions using Snap
|
||||
|
||||
Ever since Ubuntu started focusing on Snap packages, more software have started providing easy to install Snap packages. Android Studio is one of them. Ubuntu users can simply find the Android Studio application in the Software Center and install it from there.
|
||||
|
||||
![Install Android Studio in Ubuntu from Software Center][4]
|
||||
|
||||
If you see an error while installing Android Studio from Software Center, you can use the [Snap commands][5] to install Android studio.
|
||||
```
|
||||
sudo snap install android-studio --classic
|
||||
|
||||
```
|
||||
|
||||
Easy peasy!
|
||||
|
||||
### Alternative Method 1: Install Android Studio using umake in Ubuntu
|
||||
|
||||
You can also easily install Android Studio using Ubuntu Developer Tools Center, now known as [Ubuntu Make][6]. Ubuntu Make provides a command line tool to install various development tools, IDE etc. Ubuntu Make is available in Ubuntu repository.
|
||||
|
||||
To install Ubuntu Make, use the commands below in a terminal:
|
||||
|
||||
`sudo apt-get install ubuntu-make`
|
||||
|
||||
Once you have installed Ubuntu Make, use the command below to install Android Studio in Ubuntu:
|
||||
```
|
||||
umake android
|
||||
|
||||
```
|
||||
|
||||
It will give you a couple of options in the course of the installation. I presume that you can handle it. If you decide to uninstall Android Studio, you can use the same umake tool in the following manner:
|
||||
```
|
||||
umake android --remove
|
||||
|
||||
```
|
||||
|
||||
### Alternative Method 2: Install Android Studio in Ubuntu and Linux Mint via unofficial PPA
|
||||
|
||||
Thanks to [Paolo Ratolo][7], we have a PPA which can be used to easily install Android Studio in Ubuntu 16.04, 14.04, Linux Mint and other Ubuntu based distributions. Just note that it will download around 650 MB of data. So mind your internet connection as well as data charges (if any).
|
||||
|
||||
Open a terminal and use the following commands:
|
||||
```
|
||||
sudo apt-add-repository ppa:paolorotolo/android-studio
|
||||
sudo apt-get update
|
||||
sudo apt-get install android-studio
|
||||
|
||||
```
|
||||
|
||||
Was it not easy? While installing a program from source code is fun in a way, it is always nice to have such PPAs. Once we have seen how to install Android Studio, lets see how to uninstall it.
|
||||
|
||||
### Uninstall Android Studio:
|
||||
|
||||
If you don’t have already, install PPA Purge:
|
||||
```
|
||||
sudo apt-get install ppa-purge
|
||||
|
||||
```
|
||||
|
||||
Now use the PPA Purge to purge the installed PPA:
|
||||
```
|
||||
sudo apt-get remove android-studio
|
||||
|
||||
sudo ppa-purge ppa:paolorotolo/android-studio
|
||||
|
||||
```
|
||||
|
||||
That’s it. I hope this quick helps you to **install Android Studio in Ubuntu and Linux Mint**. Before you run Android Studio, make sure to [install Java in Ubuntu][8] first. In similar posts, I advise you to read [how to install and configure Ubuntu SDK][9] and [how to easily install Microsoft Visual Studio in Ubuntu][10].
|
||||
|
||||
Any questions or suggestions are always welcomed. Ciao :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-android-studio-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:http://developer.android.com/sdk/installing/studio.html
|
||||
[2]:https://itsfoss.com/install-java-ubuntu-1404/
|
||||
[3]:https://itsfoss.com/wp-content/uploads/2014/04/Android_Studio_Ubuntu.jpeg
|
||||
[4]:https://itsfoss.com/wp-content/uploads/2014/04/install-android-studio-snap-800x469.jpg
|
||||
[5]:https://itsfoss.com/install-snap-linux/
|
||||
[6]:https://wiki.ubuntu.com/ubuntu-make
|
||||
[7]:https://plus.google.com/+PaoloRotolo
|
||||
[8]:https://itsfoss.com/install-java-ubuntu-1404/ (How To Install Java On Ubuntu 14.04)
|
||||
[9]:https://itsfoss.com/install-configure-ubuntu-sdk/
|
||||
[10]:https://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
@ -0,0 +1,117 @@
|
||||
Getting started with Anaconda Python for data science
|
||||
======
|
||||
|
||||

|
||||
Like many others, I've been trying to get involved in the rapidly expanding field of data science. When I took Udemy courses on the [R][1] and [Python][2] programming languages, I downloaded and installed the applications independently. As I was trying to work through the challenges of installing data science packages like [NumPy][3] and [Matplotlib][4] and solving the various dependencies, I learned about the [Anaconda Python distribution][5].
|
||||
|
||||
Anaconda is a complete, [open source][6] data science package with a community of over 6 million users. It is easy to [download][7] and install, and it is supported on Linux, MacOS, and Windows.
|
||||
|
||||
I appreciate that Anaconda eases the frustration of getting started for new users. The distribution comes with more than 1,000 data packages as well as the [Conda][8] package and virtual environment manager, so it eliminates the need to learn to install each library independently. As Anaconda's website says, "The Python and R conda packages in the Anaconda Repository are curated and compiled in our secure environment so you get optimized binaries that 'just work' on your system."
|
||||
|
||||
I recommend using [Anaconda Navigator][9], a desktop graphical user interface (GUI) system that includes links to all the applications included with the distribution including [RStudio][10], [iPython][11], [Jupyter Notebook][12], [JupyterLab][13], [Spyder][14], [Glue][15], and [Orange][16]. The default environment is Python 3.6, but you can also easily install Python 3.5, Python 2.7, or R. The [documentation][9] is incredibly detailed and there is an excellent community of users for additional support.
|
||||
|
||||
### Installing Anaconda
|
||||
|
||||
To install Anaconda on my Linux laptop (an I3 with 4GB of RAM), I downloaded the Anaconda 5.1 Linux installer and ran `md5sum` to verify the file:
|
||||
```
|
||||
$ md5sum Anaconda3-5.1.0-Linux-x86_64.sh
|
||||
|
||||
```
|
||||
|
||||
Then I followed the directions in the [documentation][17], which instructed me to issue the following Bash command whether I was in the Bash shell or not:
|
||||
```
|
||||
$ bash Anaconda3-5.1.0-Linux-x86_64.sh
|
||||
|
||||
```
|
||||
|
||||
`/home/<user>/.bashrc`?" I allowed it and restarted the shell, which I found was necessary for the `.bashrc` environment to work correctly.
|
||||
|
||||
I followed the installation directions exactly, and the well-scripted install took about five minutes to complete. When the installation prompted: "Do you wish the installer to prepend the Anaconda install location to PATH in your?" I allowed it and restarted the shell, which I found was necessary for theenvironment to work correctly.
|
||||
|
||||
After completing the install, I launched Anaconda Navigator by entering the following at the command prompt in the shell:
|
||||
```
|
||||
$ anaconda-navigator
|
||||
|
||||
```
|
||||
|
||||
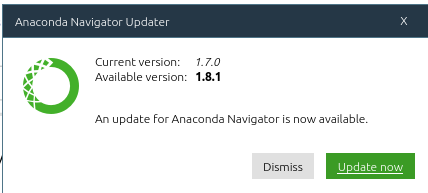
Every time Anaconda Navigator launches, it checks to see if new software is available and prompts you to update if necessary.
|
||||
|
||||
|
||||
|
||||
Anaconda updated successfully without needing to return to the command line. Anaconda's initial launch was a little slow; that plus the update meant it took a few additional minutes to get started.
|
||||
|
||||
You can also update manually by entering the following:
|
||||
```
|
||||
$ conda update anaconda-navigator
|
||||
|
||||
```
|
||||
|
||||
### Exploring and installing applications
|
||||
|
||||
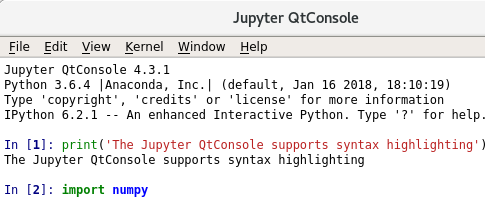
Once Navigator launched, I was free to explore the range of applications included with Anaconda Distribution. According to the documentation, the 64-bit Python 3.6 version of Anaconda [supports 499 packages][18]. The first application I explored was [Jupyter QtConsole][19]. The easy-to-use GUI supports inline figures and syntax highlighting.
|
||||
|
||||
|
||||
|
||||
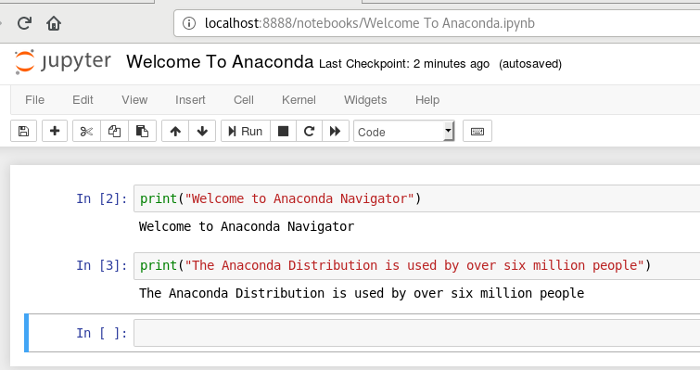
Jupyter Notebook is included with the distribution, so (unlike other Python environments I have used) there is no need for a separate install.
|
||||
|
||||
|
||||
|
||||
I was already familiar with RStudio. It's not installed by default, but it's easy to add with the click of a mouse. Other applications, including JupyterLab, Orange, Glue, and Spyder, can be launched or installed with just a mouse click.
|
||||
|
||||

|
||||
|
||||
One of the Anaconda distribution's strengths is the ability to create multiple environments. For example, if I wanted to create a Python 2.7 environment instead of the default Python 3.6, I would enter the following in the shell:
|
||||
```
|
||||
$ conda create -n py27 python=2.7 anaconda
|
||||
|
||||
```
|
||||
|
||||
Conda takes care of the entire install; to launch it, just open the shell and enter:
|
||||
```
|
||||
$ anaconda-navigator
|
||||
|
||||
```
|
||||
|
||||
Select the **py27** environment from the "Applications on" drop-down in the Anaconda GUI.
|
||||
|
||||

|
||||
|
||||
### Learn more
|
||||
|
||||
There's a wealth of information available about Anaconda if you'd like to know more. You can start by searching the [Anaconda Community][20] and its [mailing list][21].
|
||||
|
||||
Are you using Anaconda Distribution and Navigator? Let us know your impressions in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/getting-started-anaconda-python
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://www.r-project.org/
|
||||
[2]:https://www.python.org/
|
||||
[3]:http://www.numpy.org/
|
||||
[4]:https://matplotlib.org/
|
||||
[5]:https://www.anaconda.com/distribution/
|
||||
[6]:https://docs.anaconda.com/anaconda/eula
|
||||
[7]:https://www.anaconda.com/download/#linux
|
||||
[8]:https://conda.io/
|
||||
[9]:https://docs.anaconda.com/anaconda/navigator/
|
||||
[10]:https://www.rstudio.com/
|
||||
[11]:https://ipython.org/
|
||||
[12]:http://jupyter.org/
|
||||
[13]:https://blog.jupyter.org/jupyterlab-is-ready-for-users-5a6f039b8906
|
||||
[14]:https://spyder-ide.github.io/
|
||||
[15]:http://glueviz.org/
|
||||
[16]:https://orange.biolab.si/
|
||||
[17]:https://docs.anaconda.com/anaconda/install/linux
|
||||
[18]:https://docs.anaconda.com/anaconda/packages/py3.6_linux-64
|
||||
[19]:http://qtconsole.readthedocs.io/en/stable/
|
||||
[20]:https://www.anaconda.com/community/
|
||||
[21]:https://groups.google.com/a/continuum.io/forum/#!forum/anaconda
|
||||
245
sources/tech/20180418 The Linux Filesystem Explained.md
Normal file
245
sources/tech/20180418 The Linux Filesystem Explained.md
Normal file
@ -0,0 +1,245 @@
|
||||
The Linux Filesystem Explained
|
||||
======
|
||||
|
||||

|
||||
Back in 1996 I learned how to install software on my spanking new Linux before really understanding the topography of the filesystem. This turned out to be a problem, not so much for programs, because they would just magically work even though I hadn't a clue of where the actual executable files landed. The problem was the documentation.
|
||||
|
||||
You see, back then, Linux was not the intuitive, user-friendly system it is today. You had to read a lot. You had to know things about the frequency rate of your CRT monitor and the ins and outs of your noisy dial-up modem, among hundreds of other things. I soon realized I would need to spend some time getting a handle on how the directories were organized and what all their exotic names like /etc (not for miscellaneous files), /usr (not for user files), and /*bin *(not a trash can) meant.
|
||||
|
||||
This tutorial will help you get up to speed faster than I did.
|
||||
|
||||
### Structure
|
||||
|
||||
It makes sense to explore the Linux filesystem from a terminal window, not because the author is a grumpy old man and resents new kids and their pretty graphical tools -- although there is some truth to that -- but because a terminal, despite being text-only, has better tools to show the map of Linux's directory tree.
|
||||
|
||||
In fact, that is the name of the first tool you'll install to help you on the way: _tree_. If you are using Ubuntu or Debian, you can do:
|
||||
```
|
||||
sudo apt install tree
|
||||
|
||||
```
|
||||
|
||||
On Red Hat or Fedora, do:
|
||||
```
|
||||
sudo dnf install tree
|
||||
|
||||
```
|
||||
|
||||
For SUSE/openSUSE use `zypper`:
|
||||
```
|
||||
sudo zypper install tree
|
||||
|
||||
```
|
||||
|
||||
For Arch-like distros (Manjaro, Antergos, etc.) use:
|
||||
```
|
||||
sudo pacman -S tree
|
||||
|
||||
```
|
||||
|
||||
... and so on.
|
||||
|
||||
Once installed, stay in your terminal window and run _tree_ like this:
|
||||
```
|
||||
tree /
|
||||
|
||||
```
|
||||
|
||||
`The /` in the instruction above refers to the _root_ directory. The root directory is the one from which all other directories branch off from. When you run `tree` and tell it to start with _/_ , you will see the whole directory tree, all directories and all the subdirectories in the whole system, with all their files, fly by.
|
||||
|
||||
If you have been using your system for some time, this may take a while, because, even if you haven't generated many files yourself, a Linux system and its apps are always logging, cacheing, and storing temporal files. The number of entries in the file system can grow quite quickly.
|
||||
|
||||
Don't feel overwhelmed, though. Instead, try this:
|
||||
```
|
||||
tree -L 1 /
|
||||
|
||||
```
|
||||
|
||||
And you should see what is shown in Figure 1.
|
||||
|
||||

|
||||
|
||||
The instruction above can be translated as " _show me only the 1st Level of the directory tree starting at / (root)_ ". The `-L` option tells `tree` how many levels down you want to see.
|
||||
|
||||
Most Linux distributions will show you the same or a very similar layout to what you can see in the image above. This means that even if you feel confused now, master this, and you will have a handle on most, if not all, Linux installations in the whole wide world.
|
||||
|
||||
To get you started on the road to mastery, let's look at what each directory is used for. While we go through each, you can peek at their contents using ls.
|
||||
|
||||
### Directories
|
||||
|
||||
From top to bottom, the directories you are seeing are as follows.
|
||||
|
||||
#### _/bin_
|
||||
|
||||
_/bin_ is the directory that contains _bin_ aries, that is, some of the applications and programs you can run. You will find the _ls_ program mentioned above in this directory, as well as other basic tools for making and removing files and directories, moving them around, and so on. There are more _bin_ directories in other parts of the file system tree, but we'll be talking about those in a minute.
|
||||
|
||||
#### _/boot_
|
||||
|
||||
The _/boot_ directory contains files required for starting your system. Do I have to say this? Okay, I'll say it: **DO NOT TOUCH!**. If you mess up one of the files in here, you may not be able to run your Linux and it is a pain to repair. On the other hand, don't worry too much about destroying your system by accident: you have to have superuser privileges to do that.
|
||||
|
||||
#### _/dev_
|
||||
|
||||
_/dev_ contains _dev_ ice files. Many of these are generated at boot time or even on the fly. For example, if you plug in a new webcam or a USB pendrive into your machine, a new device entry will automagically pop up here.
|
||||
|
||||
#### _/etc_
|
||||
|
||||
_/etc_ is the directory where names start to get confusing. _/etc_ gets its name from the earliest Unixes and it was literally "et cetera" because it was the dumping ground for system files administrators were not sure where else to put.
|
||||
|
||||
Nowadays, it would be more appropriate to say that _etc_ stands for "Everything to configure," as it contains most, if not all system-wide configuration files. For example, the files that contain the name of your system, the users and their passwords, the names of machines on your network and when and where the partitions on your hard disks should be mounted are all in here. Again, if you are new to Linux, it may be best if you don't touch too much in here until you have a better understanding of how things work.
|
||||
|
||||
#### _/home_
|
||||
|
||||
_/home_ is where you will find your users' personal directories. In my case, under _/home_ there are two directories: _/home/paul_ , which contains all my stuff; and _/home/guest_ , in case anybody needs to borrow my computer.
|
||||
|
||||
#### _/lib_
|
||||
|
||||
_/lib_ is where _lib_ raries live. Libraries are files containing code that your applications can use. They contain snippets of code that applications use to draw windows on your desktop, control peripherals, or send files to your hard disk.
|
||||
|
||||
There are more _lib_ directories scattered around the file system, but this one, the one hanging directly off of _/_ is special in that, among other things, it contains the all-important kernel modules. The kernel modules are drivers that make things like your video card, sound card, WiFi, printer, and so on, work.
|
||||
|
||||
#### _/media_
|
||||
|
||||
The _/media_ directory is where external storage will be automatically mounted when you plug it in and try to access it. As opposed to most of the other items on this list, _/media_ does not hail back to 1970s, mainly because inserting and detecting storage (pendrives, USB hard disks, SD cards, external SSDs, etc) on the fly, while a computer is running, is a relatively new thing.
|
||||
|
||||
#### _/mnt_
|
||||
|
||||
The _/mnt_ directory, however, is a bit of remnant from days gone by. This is where you would manually mount storage devices or partitions. It is not used very often nowadays.
|
||||
|
||||
#### _/opt_
|
||||
|
||||
The _/opt_ directory is often where software you compile (that is, you build yourself from source code and do not install from your distribution repositories) sometimes lands. Applications will end up in the _/opt/bin_ directory and libraries in the _/opt/lib_ directory.
|
||||
|
||||
A slight digression: another place where applications and libraries end up in is _/usr/local_ , When software gets installed here, there will also be _/usr/local/bin_ and _/usr/local/lib_ directories. What determines which software goes where is how the developers have configured the files that control the compilation and installation process.
|
||||
|
||||
#### _/proc_
|
||||
|
||||
_/proc_ , like _/dev_ is a virtual directory. It contains information about your computer, such as information about your CPU and the kernel your Linux system is running. As with _/dev_ , the files and directories are generated when your computer starts, or on the fly, as your system is running and things change.
|
||||
|
||||
#### _/root_
|
||||
|
||||
_/root_ is the home directory of the superuser (also known as the "Administrator") of the system. It is separate from the rest of the users' home directories BECAUSE YOU ARE NOT MEANT TO TOUCH IT. Keep your own stuff in you own directories, people.
|
||||
|
||||
#### _/run_
|
||||
|
||||
_/run_ is another new directory. System processes use it to store temporary data for their own nefarious reasons. This is another one of those DO NOT TOUCH folders.
|
||||
|
||||
#### _/sbin_
|
||||
|
||||
_/sbin_ is similar to _/bin_ , but it contains applications that only the superuser (hence the initial _s_ ) will need. You can use these applications with the `sudo` command that temporarily concedes you superuser powers on many distributions. _/sbin_ typically contains tools that can install stuff, delete stuff and format stuff. As you can imagine, some of these instructions are lethal if you use them improperly, so handle with care.
|
||||
|
||||
#### _/usr_
|
||||
|
||||
The _/usr_ directory was where users' home directories were originally kept back in the early days of UNIX. However, now _/home_ is where users kept their stuff as we saw above. These days, _/usr_ contains a mish-mash of directories which in turn contain applications, libraries, documentation, wallpapers, icons and a long list of other stuff that need to be shared by applications and services.
|
||||
|
||||
You will also find _bin_ , _sbin_ and _lib_ directories in _/usr_. What is the difference with their root-hanging cousins? Not much nowadays. Originally, the _/bin_ directory (hanging off of root) would contain very basic commands, like `ls`, `mv` and `rm`; the kind of commands that would come pre-installed in all UNIX/Linux installations, the bare minimum to run and maintain a system. _/usr/bin_ on the other hand would contain stuff the users would install and run to use the system as a work station, things like word processors, web browsers, and other apps.
|
||||
|
||||
But many modern Linux distributions just put everything into _/usr/bin_ and have _/bin_ point to _/usr/bin_ just in case erasing it completely would break something. So, while Debian, Ubuntu and Mint still keep _/bin_ and _/usr/bin_ (and _/sbin_ and _/usr/sbin_ ) separate; others, like Arch and its derivatives just have one "real" directory for binaries, _/usr/bin_ , and the rest or _*bin_ s are "fake" directories that point to _/usr/bin_.
|
||||
|
||||
#### _/srv_
|
||||
|
||||
The _/srv_ directory contains data for servers. If you are running a web server from your Linux box, your HTML files for your sites would go into _/srv/http_ (or _/srv/www_ ). If you were running an FTP server, your files would go into _/srv/ftp_.
|
||||
|
||||
#### _/sys_
|
||||
|
||||
_/sys_ is another virtual directory like _/proc_ and _/dev_ and also contains information from devices connected to your computer.
|
||||
|
||||
In some cases you can also manipulate those devices. I can, for example, change the brightness of the screen of my laptop by modifying the value stored in the _/sys/devices/pci0000:00/0000:00:02.0/drm/card1/card1-eDP-1/intel_backlight/brightness_ file (on your machine you will probably have a different file). But to do that you have to become superuser. The reason for that is, as with so many other virtual directories, messing with the contents and files in _/sys_ can be dangerous and you can trash your system. DO NOT TOUCH until you are sure you know what you are doing.
|
||||
|
||||
#### _/tmp_
|
||||
|
||||
_/tmp_ contains temporary files, usually placed there by applications that you are running. The files and directories often (not always) contain data that an application doesn't need right now, but may need later on. So, to free up RAM, it gets stored here.
|
||||
|
||||
You can also use _/tmp_ to store your own temporary files -- _/tmp_ is one of the few directories hanging of _/_ which you can actually interact with without becoming superuser. The problem is that applications sometimes don't come back to retrieve and delete files and directories and _/tmp_ can often end up eating up space on your hard disk, filling it up with junk. Later on in this series we'll see how to clean it up.
|
||||
|
||||
#### _/var_
|
||||
|
||||
_/var_ was originally given its name because its contents was deemed _variable_ , in that it changed frequently. Today it is a bit of a misnomer because there are many other directories that also contain data that changes frequently, especially the virtual directories we saw above.
|
||||
|
||||
Be that as it may, _/var_ contains things like logs in the _/var/log_ subdirectories. Logs are files that register events that happen on the system. If something fails in the kernel, it will be logged in a file in _/var/log_ ; if someone tries to break into your computer from outside, your firewall will also log the attempt here. It also contains _spools_ for tasks. These "tasks" can be the jobs you send to a shared printer when you have to wait because another user is printing a long document, or mail that is waiting to be delivered to users on the system.
|
||||
|
||||
Your system may have some more directories we haven't mentioned above. In the screenshot, for example, there is a _/snap_ directory. That's because the shot was captured on an Ubuntu system. Ubuntu has recently incorporated [snap][1] packages as a way of distributing software. The _/snap_ directory contains all the files and the software installed from snaps.
|
||||
|
||||
### Digging Deeper
|
||||
|
||||
That is the root directory covered, but many of the subdirectories lead to their own set of files and subdirectories. Figure 2 gives you an overall idea of what the basic file system tree looks like (the image is kindly supplied under a CC By-SA license by Paul Gardner) and [Wikipedia has a break down with a summary of what each directory is used for][2].
|
||||
|
||||
|
||||
![filesystem][4]
|
||||
|
||||
Figure 2: Standard Unix filesystem hierarchy.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Paul Gardner
|
||||
|
||||
To explore the filesystem yourself, use the `cd` command:
|
||||
```
|
||||
cd
|
||||
|
||||
```
|
||||
|
||||
will take you to the directory of your choice ( _cd_ stands for _change directory_.
|
||||
|
||||
If you get confused,
|
||||
```
|
||||
pwd
|
||||
|
||||
```
|
||||
|
||||
will always tell you where you ( _pwd_ stands for _print working directory_ ). Also,
|
||||
```
|
||||
cd
|
||||
|
||||
```
|
||||
|
||||
with no options or parameters, will take you back to your own home directory, where things are safe and cosy.
|
||||
|
||||
Finally,
|
||||
```
|
||||
cd ..
|
||||
|
||||
```
|
||||
|
||||
will take you up one level, getting you one level closer to the _/_ root directory. If you are in _/usr/share/wallpapers_ and run `cd ..`, you will move up to _/usr/share_.
|
||||
|
||||
To see what a directory contains, use
|
||||
```
|
||||
ls
|
||||
|
||||
```
|
||||
|
||||
or simply
|
||||
```
|
||||
ls
|
||||
|
||||
```
|
||||
|
||||
to list the contents of the directory you are in right now.
|
||||
|
||||
And, of course, you always have `tree` to get an overview of what lays within a directory. Try it on _/usr/share_ \-- there is a lot of interesting stuff in there.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Although there are minor differences between Linux distributions, the layout for their filesystems are mercifully similar. So much so that you could say: once you know one, you know them all. And the best way to know the filesystem is to explore it. So go forth with `tree`, `ls`, and `cd` into uncharted territory.
|
||||
|
||||
You cannot damage your filesystem just by looking at it, so move from one directory to another and take a look around. Soon you'll discover that the Linux filesystem and how it is laid out really makes a lot of sense, and you will intuitively know where to find apps, documentation, and other resources.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][6]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/4/linux-filesystem-explained
|
||||
|
||||
作者:[PAUL BROWN][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.ubuntu.com/desktop/snappy
|
||||
[2]:https://en.wikipedia.org/wiki/Unix_filesystem#Conventional_directory_layout
|
||||
[3]:https://www.linux.com/files/images/standard-unix-filesystem-hierarchypng
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/standard-unix-filesystem-hierarchy.png?itok=CVqmyk6P (filesystem)
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,116 @@
|
||||
Migrating to Linux: Network and System Settings
|
||||
======
|
||||
|
||||

|
||||
In this series, we provide an overview of fundamentals to help you successfully make the transition to Linux from another operating system. If you missed the earlier articles in the series, you can find them here:
|
||||
|
||||
[Part 1 - An Introduction][1]
|
||||
|
||||
[Part 2 - Disks, Files, and Filesystems][2]
|
||||
|
||||
[Part 3 - Graphical Environments][3]
|
||||
|
||||
[Part 4 - The Command Line][4]
|
||||
|
||||
[Part 5 - Using sudo][5]
|
||||
|
||||
[Part 6 - Installing Software][6]
|
||||
|
||||
Linux gives you a lot of control over network and system settings. On your desktop, Linux lets you tweak just about anything on the system. Most of these settings are exposed in plain text files under the /etc directory. Here I describe some of the most common settings you’ll use on your desktop Linux system.
|
||||
|
||||
A lot of settings can be found in the Settings program, and the available options will vary by Linux distribution. Usually, you can change the background, tweak sound volume, connect to printers, set up displays, and more. While I won't talk about all of the settings here, you can certainly explore what's in there.
|
||||
|
||||
### Connect to the Internet
|
||||
|
||||
Connecting to the Internet in Linux is often fairly straightforward. If you are wired through an Ethernet cable, Linux will usually get an IP address and connect automatically when the cable is plugged in or at startup if the cable is already connected.
|
||||
|
||||
If you are using wireless, in most distributions there is a menu, either in the indicator panel or in settings (depending on your distribution), where you can select the SSID for your wireless network. If the network is password protected, it will usually prompt you for the password. Afterward, it connects, and the process is fairly smooth.
|
||||
|
||||
You can adjust network settings in the graphical environment by going into settings. Sometimes this is called System Settings or just Settings. Often you can easily spot the settings program because its icon is a gear or a picture of tools (Figure 1).
|
||||
|
||||
|
||||
![Network Settings][8]
|
||||
|
||||
Figure 1: Gnome Desktop Network Settings Indicator Icon.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
### Network Interface Names
|
||||
|
||||
Under Linux, network devices have names. Historically, these are given names like eth0 and wlan0 -- or Ethernet and wireless, respectively. Newer Linux systems have been using different names that appear more esoteric, like enp4s0 and wlp5s0. If the name starts with en, it's a wired Ethernet interface. If it starts with wl, it's a wireless interface. The rest of the letters and numbers reflect how the device is connected to hardware.
|
||||
|
||||
### Network Management from the Command Line
|
||||
|
||||
If you want more control over your network settings, or if you are managing network connections without a graphical desktop, you can also manage the network from the command line.
|
||||
|
||||
Note that the most common service used to manage networks in a graphical desktop is the Network Manager, and Network Manager will often override setting changes made on the command line. If you are using the Network Manager, it's best to change your settings in its interface so it doesn't undo the changes you make from the command line or someplace else.
|
||||
|
||||
Changing settings in the graphical environment is very likely to be interacting with the Network Manager, and you can also change Network Manager settings from the command line using the tool called nmtui. The nmtui tool provides all the settings that you find in the graphical environment but gives it in a text-based semi-graphical interface that works on the command line (Figure 2).
|
||||
|
||||

|
||||
|
||||
On the command line, there is an older tool called ifconfig to manage networks and a newer one called ip. On some distributions, ifconfig is considered to be deprecated and is not even installed by default. On other distributions, ifconfig is still in use.
|
||||
|
||||
Here are some commands that will allow you to display and change network settings:
|
||||
|
||||

|
||||
|
||||
### Process and System Information
|
||||
|
||||
In Windows, you can go into the Task Manager to see a list of the all the programs and services that are running. You can also stop programs from running. And you can view system performance in some of the tabs displayed there.
|
||||
|
||||
You can do similar things in Linux both from the command line and from graphical tools. In Linux, there are a few graphical tools available depending on your distribution. The most common ones are System Monitor or KSysGuard. In these tools, you can see system performance, see a list of processes, and even kill processes (Figure 3).
|
||||
|
||||

|
||||
|
||||
In these tools, you can also view global network traffic on your system (Figure 4).
|
||||
|
||||
|
||||
![System Monitor][11]
|
||||
|
||||
Figure 4: Screenshot of Gnome System Monitor.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
### Managing Process and System Usage
|
||||
|
||||
There are also quite a few tools you can use from the command line. The command ps can be used to list processes on your system. By default, it will list processes running in your current terminal session. But you can list other processes by giving it various command line options. You can get more help on ps with the commands info ps, or man ps.
|
||||
|
||||
Most folks though want to get a list of processes because they would like to stop the one that is using up too much memory or CPU time. In this case, there are two commands that make this task much easier. These are top and htop (Figure 5).
|
||||
|
||||

|
||||
|
||||
The top and htop tools work very similarly to each other. These commands update their list every second or two and re-sort the list so that the task using the most CPU is at the top. You can also change the sorting to sort by other resources as well such as memory usage.
|
||||
|
||||
In either of these programs (top and htop), you can type '?' to get help, and 'q' to quit. With top, you can press 'k' to kill a process and then type in the unique PID number for the process to kill it.
|
||||
|
||||
With htop, you can highlight a task by pressing down arrow or up arrow to move the highlight bar, and then press F9 to kill the task followed by Enter to confirm.
|
||||
|
||||
The information and tools provided in this series will help you get started with Linux. With a little time and patience, you'll feel right at home.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][12]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/4/migrating-linux-network-and-system-settings
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
[3]:https://www.linux.com/blog/learn/2017/12/migrating-linux-graphical-environments
|
||||
[4]:https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line
|
||||
[5]:https://www.linux.com/blog/learn/2018/3/migrating-linux-using-sudo
|
||||
[6]:https://www.linux.com/blog/learn/2018/3/migrating-linux-installing-software
|
||||
[7]:https://www.linux.com/files/images/figure-1png-2
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/figure-1_2.png?itok=J-C6q-t5 (Network Settings)
|
||||
[9]:https://www.linux.com/licenses/category/used-permission
|
||||
[10]:https://www.linux.com/files/images/figure-4png-1
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/figure-4_1.png?itok=boI-L1mF (System Monitor)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
80
sources/tech/20180420 A Perl module for better debugging.md
Normal file
80
sources/tech/20180420 A Perl module for better debugging.md
Normal file
@ -0,0 +1,80 @@
|
||||
A Perl module for better debugging
|
||||
======
|
||||
|
||||

|
||||
It's occasionally useful to have a block of Perl code that you use only for debugging or development tweaking. That's fine, but having blocks like this can be expensive to performance, particularly if the decision whether to execute it is made at runtime.
|
||||
|
||||
[Curtis "Ovid" Poe][1] recently wrote a module that can help with this problem: [Keyword::DEVELOPMENT][2]. The module utilizes Keyword::Simple and the pluggable keyword architecture introduced in Perl 5.012 to create a new keyword: DEVELOPMENT. It uses the value of the PERL_KEYWORD_DEVELOPMENT environment variable to determine whether or not a block of code is to be executed.
|
||||
|
||||
Using it couldn't be easier:
|
||||
```
|
||||
use Keyword::DEVELOPMENT;
|
||||
|
||||
|
||||
|
||||
sub doing_my_big_loop {
|
||||
|
||||
my $self = shift;
|
||||
|
||||
DEVELOPMENT {
|
||||
|
||||
# insert expensive debugging code here!
|
||||
|
||||
}
|
||||
|
||||
}Keyworddoing_my_big_loopDEVELOPMENT
|
||||
|
||||
```
|
||||
|
||||
At compile time, the code inside the DEVELOPMENT block is optimized away and simply doesn't exist.
|
||||
|
||||
Do you see the advantage here? Set up the PERL_KEYWORD_DEVELOPMENT environment variable to be true on your sandbox and false on your production environment, and valuable debugging tools can be committed to your code repo, always there when you need them.
|
||||
|
||||
You could also use this module, in the absence of a more evolved configuration management system, to handle variations in settings between production and development or test environments:
|
||||
```
|
||||
sub connect_to_my_database {
|
||||
|
||||
|
||||
|
||||
my $dsn = "dbi:mysql:productiondb";
|
||||
|
||||
my $user = "db_user";
|
||||
|
||||
my $pass = "db_pass";
|
||||
|
||||
|
||||
|
||||
DEVELOPMENT {
|
||||
|
||||
# Override some of that config information
|
||||
|
||||
$dsn = "dbi:mysql:developmentdb";
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
my $db_handle = DBI->connect($dsn, $user, $pass);
|
||||
|
||||
}connect_to_my_databaseDEVELOPMENTDBI
|
||||
|
||||
```
|
||||
|
||||
Later enhancement to this snippet would have you reading in configuration information from somewhere else, perhaps from a YAML or INI file, but I hope you see the utility here.
|
||||
|
||||
I looked at the source code for Keyword::DEVELOPMENT and spent about a half hour wondering, "Gosh, why didn't I think of that?" Once Keyword::Simple is installed, the module that Curtis has given us is surprisingly simple. It's an elegant solution to something I've needed in my own coding practice for a long time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/perl-module-debugging-code
|
||||
|
||||
作者:[Ruth Holloway][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/druthb
|
||||
[1]:https://metacpan.org/author/OVID
|
||||
[2]:https://metacpan.org/pod/release/OVID/Keyword-DEVELOPMENT-0.04/lib/Keyword/DEVELOPMENT.pm
|
||||
@ -0,0 +1,179 @@
|
||||
A handy way to add free books to your eReader
|
||||
======
|
||||
|
||||

|
||||
I do a lot of reading on my tablet every day. While I have bought a few eBooks, I enjoy finding things for free on [Project Gutenberg][1]; it rekindles fond memories of browsing through the stacks of a library for something to catch my interest. There are various ways to search the PG website by title or author, but this presumes you have some idea of what you’re looking for.
|
||||
|
||||
I have used the [Magic Catalog][2], but I seem to have seen or read every book listed there that interests me, and as far as I can tell the catalog is about ten years old. In 2017 alone, PG added 2,423 books to its catalog, so perhaps 20,000 have been added over the last ten years.
|
||||
|
||||
From the Project Gutenberg website, you can link to the [Offline Catalogs][3] and download a plain-text list of all the books freely available, but the file is 6.6 MB—a little unwieldy. Even the list for 2017 only is a bit tedious to scan. So I decided to make my own web page from this list, including links to each book (similar to the Magic Catalog), and turn that into an eBook. This turned out to be easier than you might expect. The trick is to use `regex`; specifically, `regex` as featured in [Kwrite][4].
|
||||
|
||||
First, strip out the preamble text, which explains various details about Project Gutenberg. The listing begins after that:
|
||||
```
|
||||
~ ~ ~ ~ Posting Dates for the below eBooks: 1 Dec 2017 to 31 Dec 2017 ~ ~ ~ ~
|
||||
|
||||
|
||||
|
||||
TITLE and AUTHOR ETEXT NO.
|
||||
|
||||
|
||||
|
||||
The Origin and Development of Christian Dogma, by Charles A. H. Tuthill 56279
|
||||
|
||||
[Subtitle: An essay in the science of history]
|
||||
|
||||
|
||||
|
||||
Frank Merriwell's Endurance, by Burt L. Standish 56278
|
||||
|
||||
[Subtitle: or A Square Shooter]
|
||||
|
||||
|
||||
|
||||
Derelicts, by James Sprunt 56277
|
||||
|
||||
[Subtitle: An Account of Ships Lost at Sea in General Commercial
|
||||
|
||||
Traffic and a Brief History of Blockade Runners Stranded Along
|
||||
|
||||
the North Carolina Coast 1861-1865]
|
||||
|
||||
|
||||
|
||||
Comical Pilgrim; or, Travels of a Cynick Philosopher..., by Anonymous 56276
|
||||
|
||||
[Subtitle: Thro' the most Wicked Parts of the World, Namely,
|
||||
|
||||
England, Wales, Scotland, Ireland, and Holland]
|
||||
|
||||
|
||||
|
||||
I'r Aifft Ac Yn Ol, by D. Rhagfyr Jones 56275
|
||||
|
||||
[Language: Welsh]
|
||||
|
||||
```
|
||||
|
||||
This shows the structure of the text file. The 5-digit number is the search term for each book—for example, the first book would be found here: <http://www.gutenberg.org/ebooks/56279>. Each book is separated from the next by an empty line.
|
||||
|
||||
To start, download the file `GUTINDEX.2017`, load it into Kwrite, strip off the preamble, and Save As `GUTINDEX.2017.xhtml`, so the original is unedited just in case. You might as well put in the `xhtml` preamble:
|
||||
```
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
|
||||
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN"
|
||||
|
||||
"http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
|
||||
|
||||
|
||||
|
||||
<html xmlns="http://www.w3.org/1999/xhtml">
|
||||
|
||||
<head>
|
||||
|
||||
<title>GutIndex 2017</title>
|
||||
|
||||
</head>
|
||||
|
||||
<body>
|
||||
|
||||
```
|
||||
|
||||
Then at the bottom of the file:
|
||||
```
|
||||
</body>
|
||||
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
I’m not a fan of the `~ ~ ~ ~` (four tildes separated by three spaces), so select Edit > Replace in Kwrite to bring up the Replace dialog at the bottom. You don’t need to select Regular expression as the Mode, but you’ll need it later, so go ahead and do that.
|
||||
|
||||
In Find, enter `~ ~ ~ ~` and nothing in Replace. Click Replace All, and they all disappear, with the message: 24 replacements.
|
||||
|
||||
Now let’s make the links. In Find, enter: `(\d\d\d\d\d)`. (You must include the parentheses.)
|
||||
|
||||
In Replace, enter: `<a href=”http://www.gutenberg.org/ebooks/\1”>\1</a>`
|
||||
|
||||
This searches for a sequence of 5 digits and replaces it with the link information, which includes the particular 5-digit number twice, denoted by `\1`. Now summon the courage to click Replace All (remember that you can undo this if you’ve made a mistake), and the magic happens: 2423 replacements. Here’s a fragment:
|
||||
```
|
||||
The Origin and Development of Christian Dogma, by Charles A. H. Tuthill <a href="http://www.gutenberg.org/ebooks/56279">56279</a>
|
||||
|
||||
[Subtitle: An essay in the science of history]
|
||||
|
||||
|
||||
|
||||
Frank Merriwell's Endurance, by Burt L. Standish <a href="http://www.gutenberg.org/ebooks/56278">56278</a>
|
||||
|
||||
[Subtitle: or A Square Shooter]
|
||||
|
||||
|
||||
|
||||
Derelicts, by James Sprunt <a href="http://www.gutenberg.org/ebooks/56277">56277</a>
|
||||
|
||||
[Subtitle: An Account of Ships Lost at Sea in General Commercial
|
||||
|
||||
Traffic and a Brief History of Blockade Runners Stranded Along
|
||||
|
||||
the North Carolina Coast 1861-1865]
|
||||
|
||||
```
|
||||
|
||||
Witness the power of `regex`! Now let's create paragraphs to separate these individual books as whitespace and newlines mean nothing to HTML. Here is where we use that empty line between books. Before we do that, though, let’s eliminate the lines that contain headings:
|
||||
```
|
||||
TITLE and AUTHOR ETEXT NO.
|
||||
|
||||
```
|
||||
|
||||
We're doing this because they’re unnecessary, and the second heading is not going to line up with the ebook number anyway. I wanted to get rid of this line and the extra newline characters, and since there were only 12, I went through the file manually—but you can facilitate this by using Edit > Find, searching for ETEXT.
|
||||
|
||||
Now more `regex`. In Find, enter: `\n\n`
|
||||
|
||||
In Replace, enter: `</p>\n\n<p>`
|
||||
|
||||
Then Replace All. I leave in the two newline characters so the text file is easier to read. You will need to manually add `</p>` at the end of the list. At the beginning, you'll see this:
|
||||
```
|
||||
Posting Dates for the below eBooks: 1 Dec 2017 to 31 Dec 2017 </p>
|
||||
|
||||
|
||||
|
||||
<p>The Origin and Development of Christian Dogma, by Charles A. H. Tuthill <a href="http://www.gutenberg.org/ebooks/56279">56279</a>
|
||||
|
||||
```
|
||||
|
||||
I’d like to make the posting dates a header, but I also want to eliminate `Posting Dates for the below eBooks:` since simply showing the dates is enough. In Find, enter: `Posting Dates for the below eBooks:`, and in Replace, enter: `<h3>` (or `<h4>`).
|
||||
|
||||
Now let's fix that trailing `</p>` for each header. You could do this manually, but if you're feeling lazy, enter `2017 </p>` in Find, and `</h3>` in Replace. With each of these, there's a slight risk of doing too much, but the feedback will tell you how many replacements there are (there should be 12). And you always have Undo.
|
||||
|
||||
Now for some manual cleanup. Because you added the `<p>` and `</p>` tags, and because of the new `<h3>` tags, there will be extra paragraph tags and a mismatch in the region of these headers. You could simply scan the file at these points, or get some help by entering `<h3>` in the Find space, clicking Find All to highlight them, and scrolling down the file to get rid of any unneeded tags.
|
||||
|
||||
The other problem I found with XHTML was ampersands scattered throughout. Since XHTML is stricter than HTML, replace the `&` with `&`. You may want to replace these individually using Replace instead of Replace All.
|
||||
|
||||
Some of the lines in the text file have some sort of control character that acts like ` ` (a non-breaking space). To fix this, highlight one in Kwrite—they show up as a faint baseline with a vertical bump—paste it into Find, and enter a space in Replace. This maintains visual spacing as text but is ignored as HTML (by the way, there were 12,586 of these in the document).
|
||||
|
||||
Here's how it looks in a narrowed browser window:
|
||||
|
||||

|
||||
|
||||
Clicking a link takes you to the book's Project Gutenberg page, where you can view or download it.
|
||||
|
||||
I used [Sigil][5] to convert this to an eBook, which was probably the easiest part of the process. Start Sigil, then select "Add Existing Files" from the toolbar and select your XHTML or HTML file. To create a chapter for each month, scroll down to the monthly header line, place the cursor at the beginning of the line, then Split at Cursor (Ctrl + Return) to create 12 chapters. You can also use the headers to create a table of contents; it’s also a good idea to edit the metadata to give it a title that will show up in your eBook reader (you can make yourself the author). Finally, save the file, and you’re done.
|
||||
|
||||
Happy reading!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/browse-project-gutenberg-library
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:http://www.gutenberg.org/wiki/Main_Page
|
||||
[2]:http://freekindlebooks.org/MagicCatalog/magiccatalog.html
|
||||
[3]:http://www.gutenberg.org/wiki/Gutenberg:Offline_Catalogs
|
||||
[4]:https://www.kde.org/applications/utilities/kwrite/
|
||||
[5]:https://sigil-ebook.com/
|
||||
@ -0,0 +1,122 @@
|
||||
How to start developing on Java in Fedora
|
||||
======
|
||||
|
||||

|
||||
Java is one of the most popular programming languages in the world. It is widely-used to develop IOT appliances, Android apps, web, and enterprise applications. This article will provide a quick guide to install and configure your workstation using [OpenJDK][1].
|
||||
|
||||
### Installing the compiler and tools
|
||||
|
||||
Installing the compiler, or Java Development Kit (JDK), is easy to do in Fedora. At the time of this article, versions 8 and 9 are available. Simply open a terminal and enter:
|
||||
```
|
||||
sudo dnf install java-1.8.0-openjdk-devel
|
||||
|
||||
```
|
||||
|
||||
This will install the JDK for version 8. For version 9, enter:
|
||||
```
|
||||
sudo dnf install java-9-openjdk-devel
|
||||
|
||||
```
|
||||
|
||||
For the developer who requires additional tools and libraries such as Ant and Maven, the **Java Development** group is available. To install the suite, enter:
|
||||
```
|
||||
sudo dnf group install "Java Development"
|
||||
|
||||
```
|
||||
|
||||
To verify the compiler is installed, run:
|
||||
```
|
||||
javac -version
|
||||
|
||||
```
|
||||
|
||||
The output shows the compiler version and looks like this:
|
||||
```
|
||||
javac 1.8.0_162
|
||||
|
||||
```
|
||||
|
||||
### Compiling applications
|
||||
|
||||
You can use any basic text editor such as nano, vim, or gedit to write applications. This example provides a simple “Hello Fedora” program.
|
||||
|
||||
Open your favorite text editor and enter the following:
|
||||
```
|
||||
public class HelloFedora {
|
||||
|
||||
|
||||
public static void main (String[] args) {
|
||||
System.out.println("Hello Fedora!");
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Save the file as HelloFedora.java. In the terminal change to the directory containing the file and do:
|
||||
```
|
||||
javac HelloFedora.java
|
||||
|
||||
```
|
||||
|
||||
The compiler will complain if it runs into any syntax errors. Otherwise it will simply display the shell prompt beneath.
|
||||
|
||||
You should now have a file called HelloFedora, which is the compiled program. Run it with the following command:
|
||||
```
|
||||
java HelloFedora
|
||||
|
||||
```
|
||||
|
||||
And the output will display:
|
||||
```
|
||||
Hello Fedora!
|
||||
|
||||
```
|
||||
|
||||
### Installing an Integrated Development Environment (IDE)
|
||||
|
||||
Some programs may be more complex and an IDE can make things flow smoothly. There are quite a few IDEs available for Java programmers including:
|
||||
|
||||
+ Geany, a basic IDE that loads quickly, and provides built-in templates
|
||||
+ Anjuta
|
||||
+ GNOME Builder, which has been covered in the article Builder – a new IDE specifically for GNOME app developers
|
||||
|
||||
However, one of the most popular open-source IDE’s, mainly written in Java, is [Eclipse][2]. Eclipse is available in the official repositories. To install it, run this command:
|
||||
```
|
||||
sudo dnf install eclipse-jdt
|
||||
|
||||
```
|
||||
|
||||
When the installation is complete, a shortcut for Eclipse appears in the desktop menu.
|
||||
|
||||
For more information on how to use Eclipse, consult the [User Guide][3] available on their website.
|
||||
|
||||
### Browser plugin
|
||||
|
||||
If you’re developing web applets and need a plugin for your browser, [IcedTea-Web][4] is available. Like OpenJDK, it is open source and easy to install in Fedora. Run this command:
|
||||
```
|
||||
sudo dnf install icedtea-web
|
||||
|
||||
```
|
||||
|
||||
As of Firefox 52, the web plugin no longer works. For details visit the Mozilla support site at [https://support.mozilla.org/en-US/kb/npapi-plugins?as=u&utm_source=inproduct][5].
|
||||
|
||||
Congratulations, your Java development environment is ready to use.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/start-developing-java-fedora/
|
||||
|
||||
作者:[Shaun Assam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/sassam/
|
||||
[1]:http://openjdk.java.net/
|
||||
[2]:https://www.eclipse.org/
|
||||
[3]:http://help.eclipse.org/oxygen/nav/0
|
||||
[4]:https://icedtea.classpath.org/wiki/IcedTea-Web
|
||||
[5]:https://support.mozilla.org/en-US/kb/npapi-plugins?as=u&utm_source=inproduct
|
||||
@ -1,54 +0,0 @@
|
||||
监视进程
|
||||
======
|
||||
|
||||
由于 fork 了 Mon 项目到 [etbemon [1]][1] 中,我花了一些时间做监视脚本。事实上监视一些事情通常很容易,但是决定监视什么才是困难的部分。进程监视脚本 ps.monitor 是我重新设计过的一个。
|
||||
|
||||
对于进程监视我有一些思路。如果你对进程监视如何做的更好有任何建议,请通过评论区告诉我。
|
||||
|
||||
对于不使用 Mon 的人来说,如果一切 OK 监视脚本就返回 0,而如果有问题它会返回 1,并使用标准输出显示错误信息。虽然我并不知道有谁将 Mon 脚本挂进一个不同的监视系统中,但是,那样做其实很容易实现。我计划去做的一件事情就是,将来实现 mon 和其它的监视系统如 Nagios 之间的互操作性。
|
||||
|
||||
### 基本监视
|
||||
```
|
||||
ps.monitor tor:1-1 master:1-2 auditd:1-1 cron:1-5 rsyslogd:1-1 dbus-daemon:1- sshd:1- watchdog:1-2
|
||||
```
|
||||
|
||||
我现在计划重写进程监视脚本的一些分类。现在的功能是在命令行上有一个进程名字的列表,它包含了有疑问的实例进程的最小和最大数量。上面的示例是一个监视器的配置。在这里有一些限制,在这个实例中的 "master" 进程引用到 Postfix 的主进程,但是其它的守护进程使用了相同的进程名(这是其中一个错误的名字,因为它太显眼了)。一个显而易见的解决方案是,给一个指定完整路径的选项,这样,那个 /usr/lib/postfix/sbin/master 就可以与其它命名为 “master” 的程序区分开了。
|
||||
|
||||
下一个问题是那些可能代表多个用户运行的进程。比如 sshd,它有一个以 root 身份运行的单独的进程去接受新的连接请求,以及在每个登入用户的 UID 下运行的进程。因此,作为 root 用户运行的 sshd 进程的数量将多于 root 会话的数量。这意味着如果一个系统管理员直接以 root 身份通过 ssh 登入系统(这是有争议的,但它不是本文的主题—— 只是有些人需要这样做,所以我们支持),然后 master 进程崩溃了(或者系统管理员意外或者故意杀死了它),这时对于进程丢失并不会产生警报。当然正确的做法是监视 22 号端口,查找字符串 "SSH-2.0-OpenSSH_"。有时候,守护进程的多个实例运行在需要单独监视的不同 UIDs 下面。因此,我们需要通过 UID 监视进程的能力。
|
||||
|
||||
在许多案例中,进程监视可以被替换为对服务端口的监视。因此,如果在 25 号端口上监视,那么有可能意味着,一个运行着 Postfix 的 “master",而不用去理会其它的 "master” 进程。但是对于我而言,我可以在多个监视中很方便地找到它,如果我得到一个关于无法向一个服务器发送邮件的 Jabber 消息,我可以通过这个来自服务器的 Jabber 消息断定 “master" 没有运行,而不需要挨个查找才能发现问题所在。
|
||||
|
||||
### SE Linux
|
||||
|
||||
我想要的一个功能就是,监视 SE Linux 进程上下文,就像监视 UIDs 一样。虽然我对为其它安全系统编写一个测试不感兴趣,但是,我很乐意将别人写好的代码包含进去。因此,不管我做什么,都希望它能与多个安全系统一起灵活地工作。
|
||||
|
||||
### 短暂进程
|
||||
|
||||
大多数守护进程在进程启动期间都有一个相同名字的次级进程(second process)。这意味着如果你为了精确地监视一个进程的实例,你或许会收到一个警报说,当 ”logrotate" 或者类似的守护进程重启时有两个进程运行。如果在重启期间,恰好在一个错误的时间进行检查,你也或许会收到一个警报说,有 0 个实例。我现在处理这种情况的方法是,在与 "alertafter 2" 指令一起的次级进程失败事件之前我的服务器不发出警报。当监视处于一个失败的状态时,"failure_interval" 指令允许指定检查的时间间隔,将其设置为一个低值时,意味着在等待一个次级进程失败结果时并不会使提示延迟太多。
|
||||
|
||||
为处理这种情况,我考虑让 ps.monitor 脚本在一个指定的延迟后再次进行自动检查。我认为使用一个单个参数的监视脚本来解决这个问题比起使用两个配置指令的 mon 要好一些。
|
||||
|
||||
### CPU 使用
|
||||
|
||||
Mon 现在有一个 loadavg.monitor 脚本,它用于检查平均负载。但是它并不能捕获一个单个进程使用了太多的 CPU 时间而没有使系统平均负载上升的情况。同样,也没有捕获一个渴望获得 CPU 的进程进入沉默(例如,在家用服务器上 SETI 运行变少)(译者注:SETI,由加州大学伯克利分校创建的一项利用全球的联网计算机的空闲计算资源来搜寻地外文明的科学实验计划)而其它的进程进入一个无限循环状态的情况。解决这种问题的一个方法是,让 ps.monitor 脚本也配置另外的一个选项去监视 CPU 的使用,但是这也可能会让人产生迷惑。另外的选择是,使用一个独立的脚本,它用来报警任何在它的生命周期或者最后几秒中,使用 CPU 时间超过指定百分比的进程,除非它在一个进程白名单中以及是一个豁免这种检查的用户。或者每个普通用户都应该豁免这种检查,因为当它们运行一个文件压缩程序时,你压根就不知道。这里还有一个包含排除的守护进程(像 BOINC)和系统进程(像 gzip,它是由几个定时任务运行的)的简短列表。
|
||||
|
||||
### 对例外的监视
|
||||
|
||||
一个常见的编程错误是在 setgid() 之前调用 setuid(),这意味着那个程序没有权限去调用 setgid()。如果没有检查返回代码(而犯这种低级错误的人往往不会去检查返回代码),那么进程会保持较高的权限。检查以 GID 0 而不是 UID 0 运行的进程是很方便的。顺利说一下,对一个 Debian/测试工作站运行的一个快速检查显示,一个使用 GID 0 的进程并没有获得较高的权限,但是可以使用一个 chmod 770 命令去改变它。
|
||||
|
||||
在一个 SE Linux 系统上,应该只有一个进程与 init_t 域一起运行。目前在运行守护进程(比如,mysqld 和 tor)的扩展系统中,并不会发生策略与守护进程服务文件所请求的 systemd 的最新功能不匹配的情况。这样的问题将会不断发生,我们需要对它进行自动化测试。
|
||||
|
||||
对配置错误的自动测试可能会影响系统安全,这是一个很大的问题,我将来或许写一篇关于这方面的单独的博客文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://etbe.coker.com.au/2017/09/28/process-monitoring/
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://etbe.coker.com.au
|
||||
[1]:https://doc.coker.com.au/projects/etbe-mon/
|
||||
@ -1,89 +0,0 @@
|
||||
在 Ubuntu 17.10 上安装 AWFFull Web 服务器日志分析应用程序
|
||||
======
|
||||
|
||||
|
||||
AWFFull 是基于 “Webalizer” 的 Web 服务器日志分析程序。AWFFull 以 HTML 格式生成使用统计信息以便用浏览器查看。结果以柱状和图形两种格式显示,这有利于解释。它提供每年、每月、每日和每小时使用统计数据,并显示网站、URL、referrer、user agent(浏览器)、用户名、搜索字符串、进入/退出页面和国家(如果一些信息不存在于处理后日志中那么就没有)。AWFFull 支持 CLF(通用日志格式)日志文件,以及由 NCSA 和其他人定义的组合日志格式,它还能只能地处理这些格式的变体。另外,AWFFull 还支持 wu-ftpd xferlog 格式的日志文件,它能够分析 ftp 服务器和 squid 代理日志。日志也可以通过 gzip 压缩。
|
||||
|
||||
如果检测到压缩日志文件,它将在读取时自动解压缩。压缩日志必须是 .gz 扩展名的标准 gzip 压缩。
|
||||
|
||||
### 对于 Webalizer 的修改
|
||||
|
||||
AWFFull 基于 Webalizer 的代码,并有许多大的和小的变化。包括:
|
||||
|
||||
o 不止原始统计数据:利用已发布的公式,提供额外的网站使用情况。
|
||||
|
||||
o GeoIP IP 地址能更准确地检测国家。
|
||||
|
||||
o 可缩放的图形
|
||||
|
||||
o 与 GNU gettext 集成,能够轻松翻译。目前支持 32 种语言。
|
||||
|
||||
o 在首页显示超过 12 个月的网站历史记录。
|
||||
|
||||
o 额外的页面计数跟踪和排序。
|
||||
|
||||
o 一些小的可视化调整,包括 Geolizer 使用在卷中使用 Kb、Mb。
|
||||
|
||||
o 额外的用于 URL 计数、进入和退出页面、站点的饼图
|
||||
|
||||
o 图形上的水平线更有意义,更易于阅读。
|
||||
|
||||
o User Agent 和 Referral 跟踪现在通过 PAGES 而非 HITS 进行计算。
|
||||
|
||||
o 现在支持 GNU 风格的长命令行选项(例如 --help)。
|
||||
|
||||
o 可以通过排除“什么不是”以及原始的“什么是”来选择页面。
|
||||
|
||||
o 对被分析站点的请求以匹配的引用 URL 显示。
|
||||
|
||||
o 404 错误表,并且可以生成引用 URL。
|
||||
|
||||
o 外部 CSS 文件可以与生成的 html 一起使用。
|
||||
|
||||
o POST 分析总结使得手动优化配置文件性能更简单。
|
||||
|
||||
o 指定的 IP 和地址可以分配给指定的国家。
|
||||
|
||||
o 便于使用其他工具详细分析的转储选项。
|
||||
|
||||
o 支持检测并处理 Lotus Domino v6 日志。
|
||||
|
||||
**在 Ubuntu 17.10 上安装 awffull**
|
||||
|
||||
> sudo apt-get install awffull
|
||||
|
||||
### 配置 AWFFULL
|
||||
|
||||
你必须在 /etc/awffull/awffull.conf 中编辑 awffull 配置文件。如果你在同一台计算机上运行多个虚拟站点,则可以制作多个默认配置文件的副本。
|
||||
|
||||
> sudo vi /etc/awffull/awffull.conf
|
||||
|
||||
确保有下面这几行
|
||||
|
||||
> LogFile /var/log/apache2/access.log.1
|
||||
> OutputDir /var/www/html/awffull
|
||||
|
||||
保存并退出文件
|
||||
|
||||
你可以使用以下命令运行 awffull
|
||||
|
||||
> awffull -c [your config file name]
|
||||
|
||||
这将在 /var/www/html/awffull 目录下创建所有必需的文件,以便你可以使用 http://serverip/awffull/
|
||||
|
||||
你应该看到类似于下面的页面
|
||||
|
||||
如果你有更多站点,你可以使用 shell 和计划任务自动化这个过程。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-awffull-web-server-log-analysis-application-on-ubuntu-17-10.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
Loading…
Reference in New Issue
Block a user