mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-29 21:41:00 +08:00
commit
ea51869f96
@ -0,0 +1,169 @@
|
||||
在树莓派中开启激动人心的 Perl 之旅
|
||||
============================================================
|
||||
|
||||
> 树莓派,随心所欲。
|
||||
|
||||

|
||||
|
||||
我最近在 SVPerl (硅谷 Perl 聚会)谈到在树莓派上运行 Perl 语言的时候,有人问我,“我听说树莓派应该使用 Python ,是这样吗?”。我非常乐意回答他,这是个常见误解。树莓派可以支持任何语言: Python、Perl 和其他树莓派官方软件 Raspbian Linux 初始安装的语言。
|
||||
|
||||
看似很厉害,其实很简单。树莓派的创造者英国的计算机科学教授 Eben Upton 曾经说过,树莓派名字中的‘派’(pi),是想为了听起来像 Python,因为他喜欢这门语言。他选择了这门语言作为孩子们的启蒙语言。但是他和他的团队做了一个通用计算机。开源软件没给树莓派任何限制。我们想运行什么就运行什么,全凭自己心意。
|
||||
|
||||
我在 SVPerl 和这篇文章中还想讲第二点,就是介绍我的 “PiFlash” 脚本。虽然它是用 Perl 写的,但是不需要你有多了解 Perl 就可以在 Linux 下将树莓派系统自动化烧录到 SD 卡。这样对初学者就比较友好,避免他们在烧录 SD 卡时候,偶然擦除了整个硬盘。即使是高级用户也可以从它的自动化工作中受益,包括我,这也是我开发这个工具的原因。在 Windows 和 Mac 下也有类似的工具,但是树莓派网站没有介绍类似工具给 Linux 用户。不过,现在有了。
|
||||
|
||||
开源软件早就有自己造轮子的传统,因为他们总是崇尚“自痒自挠”去解决问题。这种方式在 Eric S 1997 年的论文和 1999 年的书籍《[大教堂与集市][8]》中早有提及,它定义了开源软件的方法论。我也是为了满足想我这样的 Linux 用户,所以写了这个脚本。
|
||||
|
||||
### 下载系统镜像
|
||||
|
||||
想要开启树莓派之旅,你首先需要为它下载一个操作系统。我们称之为“系统镜像”文件。一旦你把它下载到你的桌面、手提电脑,或者甚至是另一个树莓派中,我就需要写入或者称之为“烧录”进你的 SD卡。详细情况可以看在线文件。手动做这件事情需要一些功底,你要把系统镜像烧录到整个 SD卡,而不是其中一块分区。系统镜像必须独自包含至少一个分区,因为树莓派引导需要一个 FAT32文件系统分区,系统引导这里开始。除了引导分区,其他分区可以是操作系统内核支持的任何分区类型。
|
||||
|
||||
在大部分树莓派中,我们都运行的是某些使用 Linux 内核的发行版。已经有一系列树莓派中常用的系统镜像你可以下载使用。(当然,没什么能阻止你自己造轮子)
|
||||
|
||||
树莓派基金会向新手推荐的是“[NOOBS][9]”系统。它代表了 “New Out of the Box System”(新鲜出炉即开即用系统),显然它好像听起来像术语 “noob"”(小白),通俗点说就是 “newbie”(菜鸟)。NOOBS 是一个基于树莓派的 Linux 系统,它会给你一个菜单可以在你的树莓派上自动下载安装几个其它的系统镜像。
|
||||
|
||||
[Raspbian Linux][10] 是 Debian Linux 发行版的树莓派定制版。它是为树莓派开发的正式 Linux 发行版,并且由树莓派基金会维护。几乎所有树莓派驱动和软件都会在 Raspbian 上先试用,然后才会放到其它发行版上。其默认安装博客 Perl。
|
||||
|
||||
Ubuntu Linux (还有其社区版的 Ubuntu MATE)也将树莓派作为其支持 ARM (Advanced RISC Machines)处理器的平台之一。RISC(Reduced Instruction Set Computer)Ubuntu 是一个 Debian Linux 的商业化支持的开源分支,它也使用 DEB 包管理器。Perl 也在其中。它仅仅支持 32 位 ARM7 或者 64 位 ARM8 处理器的树莓派 2 和 3。ARM6 的树莓派 1 和 Zero 从未被 Ubuntu 构建过程支持。
|
||||
|
||||
[Fedora Linux][12] 支持树莓派2 ,而 Fedora 25 支持 3。 Fedora 是一个隶属于红帽(Red Hat)的开源项目。Fedora 是个基础,商业版的 RHEL(Red Hat Enterprise Linux)在其上增加了商业软件包和支持,所以其软件像所有的兼容红帽的发行版一样来自 RPM(Red Hat Package Manager) 软件包。就像其它发行版一样,也包括 Perl。
|
||||
|
||||
[RISC OS][13] 是一个特别针对 ARM 处理器的单用户操作系统。如果你想要一个比 Linux 系统更加简洁的小型桌面(功能更少),你可以考虑一下。它同样支持 Perl。
|
||||
|
||||
[RaspBSD][14] 是一个 FreeBSD 的树莓派发行版。它是一个基于 Unix 的系统,而不是 Linux。作为开源 Unix 的一员,它延续了 Unix 的功能,而且和 Linux 有着众多相似之处。包括有类似的开源软件带来的相似的系统环境,包括 Perl。
|
||||
|
||||
[OSMC][15],即开源多媒体中心,以及 [LibreElec][16] 电视娱乐中心,它们都基于运行 Linux 内核之上的 Kodi 娱乐中心。它是一个小巧、特化的 Linux 系统,所以不要期望它能支持 Perl。
|
||||
|
||||
[Microsoft Windows IoT Core][17] 是仅运行在树莓派3上的新成员。你需要微软开发者身份才能下载。而作为一个 Linux 极客,我根本不看它。我的 PiFlash 脚本还不支持它,但如果你找的是它,你可以去看看。
|
||||
|
||||
### PiFlash 脚本
|
||||
|
||||
如果你想看看[树莓派 SD 卡烧录指导][19],你可以找到在 Windows 或者 Mac 系统下需要下载的工具来完成烧录任务。但是对于 Linux 系统,只有一系列手工操作建议。我已经手工做过这个太多次,这很容易引发一个开发者的本能去自动化这个过程,这就是 PiFlash 脚本的起源。这有点难,因为 Linux 有太多方法可以配置,但是它们都是基于 Linux 内核的。
|
||||
|
||||
我总是觉得,手工操作潜在最大的失误恐怕就是偶然错误地擦除了某个设备,而不是擦除了 SD 卡,然后彻底清除了我本想保留在硬盘的东西。我在 SVPerl 演讲中也说了,我很惊讶地发现在听众中有犯了这种错误(而且不害怕承认)的人。因此,PiFlash 其中一个目的就是保护新手的安全,不会擦除 SD 卡之外的设备。PiFlash 脚本还会拒绝覆写包含了已经挂载的文件系统的设备。
|
||||
|
||||
对于有经验的用户,包括我,PiFlash 脚本还提供提供一个简便的自动化服务。下载完系统镜像之后,我不需要必须从 zip格式中解压缩或者提取出系统镜像。PiFlash 可以直接提取它,不管是哪种格式,并且直接烧录到 SD 卡中。
|
||||
|
||||
我把 [PiFlash 及其指导][21]发布在了 GitHub 上。
|
||||
|
||||
命令行用法如下:
|
||||
|
||||
```
|
||||
piflash [--verbose] input-file output-device
|
||||
piflash [--verbose] --SDsearch
|
||||
```
|
||||
|
||||
`input-file` 参数是你要写入的系统镜像文件,只要是你从树莓派发行版网站下载的镜像都行。`output-device` 参数是你要写入的 SD 卡的块设备路径。
|
||||
|
||||
你也可以使用 `--SDsearch` 参数列出挂载在系统中 SD 卡设备名称。
|
||||
|
||||
可选项 `--verbose` 可以输出所有的程序状态数据,它在你需要帮助时或者递送 bug 报告和自行排错时很有用。它就是我开发时用的。
|
||||
|
||||
下面的例子是我使用该脚本写入仍是 zip 存档的 Raspbian 镜像到位于 `/dev/mmcblk0` 的 SD 卡:
|
||||
|
||||
```
|
||||
piflash 2016-11-25-raspbian-jessie.img.zip /dev/mmcblk0
|
||||
```
|
||||
|
||||
如果你已经指定了 `/dev/mmcblk0p1` (SD 卡的第一分区),它会识别到这个分区不是一个正确的位置,并拒绝写入。
|
||||
|
||||
在不同的 Linux 系统中怎样去识别哪个设备是 SD 卡是一个技术活。像 mmcblk0 这种在我的笔记本上是基于 PCI 的 SD卡接口。如果我使用了 USB SD 卡接口,它就是 `/dev/sdb`,这在多硬盘的系统中不好区分。然而,只有少量的 Linux 块设备支持 SD 卡。PiFlash 在这两种情况下都会检查块设备的参数。如果全部失败,它会认为可写入、可移动的,并有着正确物理扇区数量的 USB 驱动器是 SD 卡。
|
||||
|
||||
我想这应该能涵盖大部分情况。但是,如果你使用了我不知道的 SD 卡接口呢?我乐意看到你的来信。请在输出信息中加上 `--verbos --SDsearch` 参数,以便让我可以知道你系统目前的环境。理想情况下,如果 PiFlash 脚本可以被广泛利用,我们可以构建一个开源社区去尽可能的帮助更多的树莓派用户。
|
||||
|
||||
### 树莓派的 CPAN 模块
|
||||
|
||||
[CPAN][22](Comprehensive Perl Archive Network)是一个世界范围内包含各种 Perl 模块的的下载镜像。它们都是开源的。大量 CPAN 中的模块都是历久弥坚。对于成千上百的任务,你不需要重复造轮子,只要利用别人已经发布的代码就可以了。然后,你还可以提交你的新功能。
|
||||
|
||||
尽管树莓派是个五脏俱全的 Linux 系统,支持大部分 CPAN 模块,但是这里我想强调一下专为树莓派硬件开发的东西。一般来说它们都用在测量、控制、机器人方面的嵌入式系统中。你可以通过 GPIO (General-Purpose Input/Output)针脚将你的树莓派连接到外部电子设备。
|
||||
|
||||
可以使用树莓派 GPIO 针脚的模块如下:[Device::SMBus][23]、[Device::I2C][24]、[Rpi::PIGPIO][25]、[Rpi::SPI][26]、[Rpi::WiringPi][27]、[Device::WebIO::RaspberryPI][28] 和 [Device::PiGlow][29]。树莓派支持的嵌入式模块如下:[UAV::Pilot::Wumpus::Server::Backend::RaspberryPiI2C][30]、[RPI::DHT11][31](温度/湿度)、[RPI::HCSR04][32](超声波)、[App::RPI::EnvUI][33]、[RPi::DigiPot::MCP4XXXX][34]、[RPI::ADC::ADS][35]、[Device::PaPiRus][36] 和 [Device::BCM2835::Timer][37]。
|
||||
|
||||
### 例子
|
||||
|
||||
这里有些我们在树莓派上可以用 Perl 做的事情的例子。
|
||||
|
||||
#### 例一:在 OSMC 使用 PiFlash 播放视频
|
||||
|
||||
本例中,你将练习如何设置并运行使用 OSMC 操作系统的树莓派。
|
||||
|
||||
* 到 [RaspberryPi.Org][5] 下载区,下载最新的 OSMC 版本。
|
||||
* 将空 SD 卡插入你的 Linux 电脑或者笔记本。树莓派第一代是全尺寸的 SD 卡,除此以外都在使用 microSD,你也许需要一个通用适配器才能插入它。
|
||||
* 在插入前后分别运行 `cat /proc/partitions` 命令来看看系统分给硬件的设备名称。它可能像这样 `/dev/mmcblk0` 或者 `/dev/sdb`, 用如下命令将正确的系统镜像烧录到 SD 卡:`piflash OSMC_TGT_rbp2_20170210.img.gz /dev/mmcblk0`。
|
||||
* 弹出 SD 卡,将它插入树莓派中,接上 HDMI 显示器,开机。
|
||||
* 当 OSMC 设置完毕,插入一个 USB 设备,在里面放点视频。出于示范目的,我将使用 `youtube-dl` 程序下载两个视频。运行 `youtube-dl OHF2xDrq8dY` (彭博关于英国高新产业,包括树莓派的介绍)还有 `youtube-dl nAvZMgXbE9c` (CNet 发表的“排名前五的树莓派项目”) 。将它们下载到 USB 中,然后卸载移除设备。
|
||||
* 将 USB 设备插入到 OSMC 树莓派。点击视频选项进入到外部设备。
|
||||
* 只要你能在树莓派中播放视频,那么恭喜你,你已经完成了本次练习。玩的愉快。
|
||||
|
||||
#### 例二:随机播放目录中的视频的脚本
|
||||
|
||||
这个例子将使用一个脚本在树莓派上的目录中乱序播放视频。根据视频的不同和设备的摆放位置,这可以用作信息亭显示的用途。我写这个脚本用来展示室内体验视频。
|
||||
|
||||
* 设置树莓派引导 Raspbian Linux。连接到 HDMI 监视器。
|
||||
* 从 GitHub 上下载 [do-video 脚本][6]。把它放到树莓派中。
|
||||
* 跟随该页面的安装指导。最主要的事情就是安装 omxplayer 包,它可以使用树莓派硬件视频加速功能平滑地播放视频。
|
||||
* 在家目录的 Videos 目录下放一些视频。
|
||||
* 运行 `do-video` ,这样,应该就可以播放视频了
|
||||
|
||||
#### 例三:读取 GPS 数据的脚本
|
||||
|
||||
这个例子更加深入,更有针对性。它展示了 Perl 怎么从外部设备中读取数据。在先前例子中出现的我的 GitHub上 “[Perl on Pi][6]” 有一个 gps-read.pl 脚本。它可以通过一系列端口从 GPS 读取 NMEA(国家海洋电子协会)的数据。页面还有教程,包括构建它所使用的 AdaFruit Industries 部分,但是你可以使用任何能输出 NMEA 数据的 GPS。
|
||||
|
||||
通过这些任务,我想你应该可以在树莓派上像使用其他语言一样使用 Perl了。希望你喜欢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ian Kluft - 上学开始,Ian 就对喜欢编程和飞行。他一直致力于 Unix 的工作。在 Linux 内核发布后的六个月他转向了 Linux。他有计算机科学硕士学位,并且拥有 CSSLP 资格证(认证规范开发流程专家),另一方面,他还是引航员和认证的飞机指令长。作为一个超过二十五年的认证的无线电爱好者,在近些年,他在一些电子设备上陆续做了实验,包括树莓派。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/perl-raspberry-pi
|
||||
|
||||
作者:[Ian Kluft][a]
|
||||
译者:[Taylor1024](https://github.com/Taylor1024)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ikluft
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:http://raspberrypi.org/
|
||||
[6]:https://github.com/ikluft/ikluft-tools/tree/master/perl-on-pi
|
||||
[7]:https://opensource.com/article/17/3/perl-raspberry-pi?rate=OsZH1-H_xMfLtSFqZw4SC-_nyV4yo_sgKKBJGjUsbfM
|
||||
[8]:http://www.catb.org/~esr/writings/cathedral-bazaar/
|
||||
[9]:https://www.raspberrypi.org/downloads/noobs/
|
||||
[10]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[11]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[12]:https://fedoraproject.org/wiki/Raspberry_Pi#Downloading_the_Fedora_ARM_image
|
||||
[13]:https://www.riscosopen.org/content/downloads/raspberry-pi
|
||||
[14]:http://www.raspbsd.org/raspberrypi.html
|
||||
[15]:https://osmc.tv/
|
||||
[16]:https://libreelec.tv/
|
||||
[17]:http://ms-iot.github.io/content/en-US/Downloads.htm
|
||||
[18]:http://ms-iot.github.io/content/en-US/Downloads.htm
|
||||
[19]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[20]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[21]:https://github.com/ikluft/ikluft-tools/tree/master/piflash
|
||||
[22]:http://www.cpan.org/
|
||||
[23]:https://metacpan.org/pod/Device::SMBus
|
||||
[24]:https://metacpan.org/pod/Device::I2C
|
||||
[25]:https://metacpan.org/pod/RPi::PIGPIO
|
||||
[26]:https://metacpan.org/pod/RPi::SPI
|
||||
[27]:https://metacpan.org/pod/RPi::WiringPi
|
||||
[28]:https://metacpan.org/pod/Device::WebIO::RaspberryPi
|
||||
[29]:https://metacpan.org/pod/Device::PiGlow
|
||||
[30]:https://metacpan.org/pod/UAV::Pilot::Wumpus::Server::Backend::RaspberryPiI2C
|
||||
[31]:https://metacpan.org/pod/RPi::DHT11
|
||||
[32]:https://metacpan.org/pod/RPi::HCSR04
|
||||
[33]:https://metacpan.org/pod/App::RPi::EnvUI
|
||||
[34]:https://metacpan.org/pod/RPi::DigiPot::MCP4XXXX
|
||||
[35]:https://metacpan.org/pod/RPi::ADC::ADS
|
||||
[36]:https://metacpan.org/pod/Device::PaPiRus
|
||||
[37]:https://metacpan.org/pod/Device::BCM2835::Timer
|
||||
[38]:https://opensource.com/user/120171/feed
|
||||
[39]:https://opensource.com/article/17/3/perl-raspberry-pi#comments
|
||||
[40]:https://opensource.com/users/ikluft
|
||||
@ -0,0 +1,173 @@
|
||||
使用 snapcraft 将 snap 包发布到商店
|
||||
==================
|
||||
|
||||

|
||||
|
||||
Ubuntu Core 已经正式发布(LCTT 译注:指 2016 年 11 月发布的 Ubuntu Snappy Core 16 ),也许是时候让你的 snap 包进入商店了!
|
||||
|
||||
### 交付和商店的概念
|
||||
|
||||
首先回顾一下我们是怎么通过商店管理 snap 包的吧。
|
||||
|
||||
每次你上传 snap 包,商店都会为其分配一个修订版本号,并且商店中针对特定 snap 包 的版本号都是唯一的。
|
||||
|
||||
但是第一次上传 snap 包的时候,我们首先要为其注册一个还没有被使用的名字,这很容易。
|
||||
|
||||
商店中所有的修订版本都可以释放到多个通道中,这些通道只是概念上定义的,以便给用户一个稳定或风险等级的参照,这些通道有:
|
||||
|
||||
* 稳定(stable)
|
||||
* 候选(candidate)
|
||||
* 测试(beta)
|
||||
* 边缘(edge)
|
||||
|
||||
理想情况下,如果我们设置了 CI/CD 过程,那么每天或在每次更新源码时都会将其推送到边缘通道。在此过程中有两件事需要考虑。
|
||||
|
||||
首先在开始的时候,你最好制作一个不受限制的 snap 包,因为在这种新范例下,snap 包的大部分功能都能不受限制地工作。考虑到这一点,你的项目开始时 `confinement` 将被设置为 `devmode`(LCTT 译注:这是 `snapcraft.yaml` 中的一个键及其可选值)。这使得你在开发的早期阶段,仍然可以让你的 snap 包进入商店。一旦所有的东西都得到了 snap 包运行的安全模型的充分支持,那么就可以将 `confinement` 修改为 `strict`。
|
||||
|
||||
好了,假设你在限制方面已经做好了,并且也开始了一个对应边缘通道的 CI/CD 过程,但是如果你也想确保在某些情况下,早期版本 master 分支新的迭代永远也不会进入稳定或候选通道,那么我们可以使用 `gadge` 设置。如果 snap 包的 `gadge` 设置为 `devel` (LCTT注:这是 `snapcraft.yaml` 中的一个键及其可选值),商店将会永远禁止你将 snap 包释放到稳定和候选通道。
|
||||
|
||||
在这个过程中,我们有时可能想要发布一个修订版本到测试通道,以便让有些用户更愿意去跟踪它(一个好的发布管理流程应该比一个随机的日常构建更有用)。这个阶段结束后,如果希望人们仍然能保持更新,我们可以选择关闭测试通道,从一个特定的时间点开始我们只计划发布到候选和稳定通道,通过关闭测试通道我们将使该通道跟随稳定列表中的下一个开放通道,在这里是候选通道。而如果候选通道跟随的是稳定通道后,那么最终得到是稳定通道了。
|
||||
|
||||
### 进入 Snapcraft
|
||||
|
||||
那么所有这些给定的概念是如何在 snapcraft 中配合使用的?首先我们需要登录:
|
||||
|
||||
```
|
||||
$ snapcraft login
|
||||
Enter your Ubuntu One SSO credentials.
|
||||
Email: sxxxxx.sxxxxxx@canonical.com
|
||||
Password: **************
|
||||
Second-factor auth: 123456
|
||||
```
|
||||
|
||||
在登录之后,我们就可以开始注册 snap 了。例如,我们想要注册一个虚构的 snap 包 awesome-database:
|
||||
|
||||
```
|
||||
$ snapcraft register awesome-database
|
||||
We always want to ensure that users get the software they expect
|
||||
for a particular name.
|
||||
|
||||
If needed, we will rename snaps to ensure that a particular name
|
||||
reflects the software most widely expected by our community.
|
||||
|
||||
For example, most people would expect ‘thunderbird’ to be published by
|
||||
Mozilla. They would also expect to be able to get other snaps of
|
||||
Thunderbird as 'thunderbird-sergiusens'.
|
||||
|
||||
Would you say that MOST users will expect 'a' to come from
|
||||
you, and be the software you intend to publish there? [y/N]: y
|
||||
|
||||
You are now the publisher for 'awesome-database'
|
||||
```
|
||||
|
||||
假设我们已经构建了 snap 包,接下来我们要做的就是把它上传到商店。我们可以在同一个命令中使用快捷方式和 `--release` 选项:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap --release edge
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 1 of 'awesome-database' created.
|
||||
|
||||
Channel Version Revision
|
||||
stable - -
|
||||
candidate - -
|
||||
beta - -
|
||||
edge 0.1 1
|
||||
|
||||
The edge channel is now open.
|
||||
```
|
||||
|
||||
如果我们试图将其发布到稳定通道,商店将会阻止我们:
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 1 stable
|
||||
Revision 1 (devmode) cannot target a stable channel (stable, grade: devel)
|
||||
```
|
||||
|
||||
这样我们不会搞砸,也不会让我们的忠实用户使用它。现在,我们将最终推出一个值得发布到稳定通道的修订版本:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 10 of 'awesome-database' created.
|
||||
```
|
||||
|
||||
注意,<ruby>版本号<rt>version</rt></ruby>(LCTT 译注:这里指的是 snap 包名中 `0.1` 这个版本号)只是一个友好的标识符,真正重要的是商店为我们生成的<ruby>修订版本号<rt>Revision</rt></ruby>(LCTT 译注:这里生成的修订版本号为 `10`)。现在让我们把它释放到稳定通道:
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 10 stable
|
||||
Channel Version Revision
|
||||
stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge 0.1 10
|
||||
|
||||
The 'stable' channel is now open.
|
||||
```
|
||||
|
||||
在这个针对我们正在使用架构最终的通道映射视图中,可以看到边缘通道将会被固定在修订版本 10 上,并且测试和候选通道将会跟随现在修订版本为 10 的稳定通道。由于某些原因,我们决定将专注于稳定性并让我们的 CI/CD 推送到测试通道。这意味着我们的边缘通道将会略微过时,为了避免这种情况,我们可以关闭这个通道:
|
||||
|
||||
```
|
||||
$ snapcraft close awesome-database edge
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
|
||||
The edge channel is now closed.
|
||||
```
|
||||
|
||||
在当前状态下,所有通道都跟随着稳定通道,因此订阅了候选、测试和边缘通道的人也将跟踪稳定通道的改动。比如就算修订版本 11 只发布到稳定通道,其他通道的人们也能看到它。
|
||||
|
||||
这个清单还提供了完整的体系结构视图,在本例中,我们只使用了 amd64。
|
||||
|
||||
### 获得更多的信息
|
||||
|
||||
有时过了一段时间,我们想知道商店中的某个 snap 包的历史记录和现在的状态是什么样的,这里有两个命令,一个是直截了当输出当前的状态,它会给我们一个熟悉的结果:
|
||||
|
||||
```
|
||||
$ snapcraft status awesome-database
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
```
|
||||
|
||||
我们也可以通过下面的命令获得完整的历史记录:
|
||||
|
||||
```
|
||||
$ snapcraft history awesome-database
|
||||
Rev. Uploaded Arch Version Channels
|
||||
3 2016-09-30T12:46:21Z amd64 0.1 stable*
|
||||
...
|
||||
...
|
||||
...
|
||||
2 2016-09-30T12:38:20Z amd64 0.1 -
|
||||
1 2016-09-30T12:33:55Z amd64 0.1 -
|
||||
```
|
||||
|
||||
### 结束语
|
||||
|
||||
希望这篇文章能让你对商店能做的事情有一个大概的了解,并让更多的人开始使用它!
|
||||
|
||||
--------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2016/11/15/making-your-snaps-available-to-the-store-using-snapcraft/
|
||||
|
||||
*译者简介:*
|
||||
|
||||
> snapcraft.io 的钉子户,对 Ubuntu Core、Snaps 和 Snapcraft 有着浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人的公众号: `Snapcraft`,近期会在上面连载几篇有关 Core snap 发布策略、交付流程和验证流程的文章,欢迎围观 :)
|
||||
|
||||
|
||||
作者:[Sergio Schvezov][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[1]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[2]:http://snapcraft.io/docs/build-snaps/publish
|
||||
155
published/201708/20170101 What is Kubernetes.md
Normal file
155
published/201708/20170101 What is Kubernetes.md
Normal file
@ -0,0 +1,155 @@
|
||||
一文了解 Kubernetes 是什么?
|
||||
============================================================
|
||||
|
||||
这是一篇 Kubernetes 的概览。
|
||||
|
||||
Kubernetes 是一个[自动化部署、伸缩和操作应用程序容器的开源平台][25]。
|
||||
|
||||
使用 Kubernetes,你可以快速、高效地满足用户以下的需求:
|
||||
|
||||
* 快速精准地部署应用程序
|
||||
* 即时伸缩你的应用程序
|
||||
* 无缝展现新特征
|
||||
* 限制硬件用量仅为所需资源
|
||||
|
||||
我们的目标是培育一个工具和组件的生态系统,以减缓在公有云或私有云中运行的程序的压力。
|
||||
|
||||
#### Kubernetes 的优势
|
||||
|
||||
* **可移动**: 公有云、私有云、混合云、多态云
|
||||
* **可扩展**: 模块化、插件化、可挂载、可组合
|
||||
* **自修复**: 自动部署、自动重启、自动复制、自动伸缩
|
||||
|
||||
Google 公司于 2014 年启动了 Kubernetes 项目。Kubernetes 是在 [Google 的长达 15 年的成规模的产品级任务的经验下][26]构建的,结合了来自社区的最佳创意和实践经验。
|
||||
|
||||
### 为什么选择容器?
|
||||
|
||||
想要知道你为什么要选择使用 [容器][27]?
|
||||
|
||||

|
||||
|
||||
程序部署的_传统方法_是指通过操作系统包管理器在主机上安装程序。这样做的缺点是,容易混淆程序之间以及程序和主机系统之间的可执行文件、配置文件、库、生命周期。为了达到精准展现和精准回撤,你可以搭建一台不可变的虚拟机镜像。但是虚拟机体量往往过于庞大而且不可转移。
|
||||
|
||||
容器部署的_新的方式_是基于操作系统级别的虚拟化,而非硬件虚拟化。容器彼此是隔离的,与宿主机也是隔离的:它们有自己的文件系统,彼此之间不能看到对方的进程,分配到的计算资源都是有限制的。它们比虚拟机更容易搭建。并且由于和基础架构、宿主机文件系统是解耦的,它们可以在不同类型的云上或操作系统上转移。
|
||||
|
||||
正因为容器又小又快,每一个容器镜像都可以打包装载一个程序。这种一对一的“程序 - 镜像”联系带给了容器诸多便捷。有了容器,静态容器镜像可以在编译/发布时期创建,而非部署时期。因此,每个应用不必再等待和整个应用栈其它部分进行整合,也不必和产品基础架构环境之间进行妥协。在编译/发布时期生成容器镜像建立了一个持续地把开发转化为产品的环境。相似地,容器远比虚拟机更加透明,尤其在设备监控和管理上。这一点,在容器的进程生命周期被基础架构管理而非被容器内的进程监督器隐藏掉时,尤为显著。最终,随着每个容器内都装载了单一的程序,管理容器就等于管理或部署整个应用。
|
||||
|
||||
容器优势总结:
|
||||
|
||||
* **敏捷的应用创建与部署**:相比虚拟机镜像,容器镜像的创建更简便、更高效。
|
||||
* **持续的开发、集成,以及部署**:在快速回滚下提供可靠、高频的容器镜像编译和部署(基于镜像的不可变性)。
|
||||
* **开发与运营的关注点分离**:由于容器镜像是在编译/发布期创建的,因此整个过程与基础架构解耦。
|
||||
* **跨开发、测试、产品阶段的环境稳定性**:在笔记本电脑上的运行结果和在云上完全一致。
|
||||
* **在云平台与 OS 上分发的可转移性**:可以在 Ubuntu、RHEL、CoreOS、预置系统、Google 容器引擎,乃至其它各类平台上运行。
|
||||
* **以应用为核心的管理**: 从在虚拟硬件上运行系统,到在利用逻辑资源的系统上运行程序,从而提升了系统的抽象层级。
|
||||
* **松散耦联、分布式、弹性、无拘束的[微服务][5]**:整个应用被分散为更小、更独立的模块,并且这些模块可以被动态地部署和管理,而不再是存储在大型的单用途机器上的臃肿的单一应用栈。
|
||||
* **资源隔离**:增加程序表现的可预见性。
|
||||
* **资源利用率**:高效且密集。
|
||||
|
||||
#### 为什么我需要 Kubernetes,它能做什么?
|
||||
|
||||
至少,Kubernetes 能在实体机或虚拟机集群上调度和运行程序容器。而且,Kubernetes 也能让开发者斩断联系着实体机或虚拟机的“锁链”,从**以主机为中心**的架构跃至**以容器为中心**的架构。该架构最终提供给开发者诸多内在的优势和便利。Kubernetes 提供给基础架构以真正的**以容器为中心**的开发环境。
|
||||
|
||||
Kubernetes 满足了一系列产品内运行程序的普通需求,诸如:
|
||||
|
||||
* [协调辅助进程][9],协助应用程序整合,维护一对一“程序 - 镜像”模型。
|
||||
* [挂载存储系统][10]
|
||||
* [分布式机密信息][11]
|
||||
* [检查程序状态][12]
|
||||
* [复制应用实例][13]
|
||||
* [使用横向荚式自动缩放][14]
|
||||
* [命名与发现][15]
|
||||
* [负载均衡][16]
|
||||
* [滚动更新][17]
|
||||
* [资源监控][18]
|
||||
* [访问并读取日志][19]
|
||||
* [程序调试][20]
|
||||
* [提供验证与授权][21]
|
||||
|
||||
以上兼具平台即服务(PaaS)的简化和基础架构即服务(IaaS)的灵活,并促进了在平台服务提供商之间的迁移。
|
||||
|
||||
#### Kubernetes 是一个什么样的平台?
|
||||
|
||||
虽然 Kubernetes 提供了非常多的功能,总会有更多受益于新特性的新场景出现。针对特定应用的工作流程,能被流水线化以加速开发速度。特别的编排起初是可接受的,这往往需要拥有健壮的大规模自动化机制。这也是为什么 Kubernetes 也被设计为一个构建组件和工具的生态系统的平台,使其更容易地部署、缩放、管理应用程序。
|
||||
|
||||
[<ruby>标签<rt>label</rt></ruby>][28]可以让用户按照自己的喜好组织资源。 [<ruby>注释<rt>annotation</rt></ruby>][29]让用户在资源里添加客户信息,以优化工作流程,为管理工具提供一个标示调试状态的简单方法。
|
||||
|
||||
此外,[Kubernetes 控制面板][30]是由开发者和用户均可使用的同样的 [API][31] 构建的。用户可以编写自己的控制器,比如 [<ruby>调度器<rt>scheduler</rt></ruby>][32],使用可以被通用的[命令行工具][34]识别的[他们自己的 API][33]。
|
||||
|
||||
这种[设计][35]让大量的其它系统也能构建于 Kubernetes 之上。
|
||||
|
||||
#### Kubernetes 不是什么?
|
||||
|
||||
Kubernetes 不是传统的、全包容的平台即服务(Paas)系统。它尊重用户的选择,这很重要。
|
||||
|
||||
Kubernetes:
|
||||
|
||||
* 并不限制支持的程序类型。它并不检测程序的框架 (例如,[Wildfly][22]),也不限制运行时支持的语言集合 (比如, Java、Python、Ruby),也不仅仅迎合 [12 因子应用程序][23],也不区分 _应用_ 与 _服务_ 。Kubernetes 旨在支持尽可能多种类的工作负载,包括无状态的、有状态的和处理数据的工作负载。如果某程序在容器内运行良好,它在 Kubernetes 上只可能运行地更好。
|
||||
* 不提供中间件(例如消息总线)、数据处理框架(例如 Spark)、数据库(例如 mysql),也不把集群存储系统(例如 Ceph)作为内置服务。但是以上程序都可以在 Kubernetes 上运行。
|
||||
* 没有“点击即部署”这类的服务市场存在。
|
||||
* 不部署源代码,也不编译程序。持续集成 (CI) 工作流程是不同的用户和项目拥有其各自不同的需求和表现的地方。所以,Kubernetes 支持分层 CI 工作流程,却并不监听每层的工作状态。
|
||||
* 允许用户自行选择日志、监控、预警系统。( Kubernetes 提供一些集成工具以保证这一概念得到执行)
|
||||
* 不提供也不管理一套完整的应用程序配置语言/系统(例如 [jsonnet][24])。
|
||||
* 不提供也不配合任何完整的机器配置、维护、管理、自我修复系统。
|
||||
|
||||
另一方面,大量的 PaaS 系统运行_在_ Kubernetes 上,诸如 [Openshift][36]、[Deis][37],以及 [Eldarion][38]。你也可以开发你的自定义 PaaS,整合上你自选的 CI 系统,或者只在 Kubernetes 上部署容器镜像。
|
||||
|
||||
因为 Kubernetes 运营在应用程序层面而不是在硬件层面,它提供了一些 PaaS 所通常提供的常见的适用功能,比如部署、伸缩、负载平衡、日志和监控。然而,Kubernetes 并非铁板一块,这些默认的解决方案是可供选择,可自行增加或删除的。
|
||||
|
||||
|
||||
而且, Kubernetes 不只是一个_编排系统_ 。事实上,它满足了编排的需求。 _编排_ 的技术定义是,一个定义好的工作流程的执行:先做 A,再做 B,最后做 C。相反地, Kubernetes 囊括了一系列独立、可组合的控制流程,它们持续驱动当前状态向需求的状态发展。从 A 到 C 的具体过程并不唯一。集中化控制也并不是必须的;这种方式更像是_编舞_。这将使系统更易用、更高效、更健壮、复用性、扩展性更强。
|
||||
|
||||
#### Kubernetes 这个单词的含义?k8s?
|
||||
|
||||
**Kubernetes** 这个单词来自于希腊语,含义是 _舵手_ 或 _领航员_ 。其词根是 _governor_ 和 [cybernetic][39]。 _K8s_ 是它的缩写,用 8 字替代了“ubernete”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
|
||||
|
||||
作者:[kubernetes.io][a]
|
||||
译者:[songshuang00](https://github.com/songsuhang00)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kubernetes.io/
|
||||
[1]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-do-i-need-kubernetes-and-what-can-it-do
|
||||
[2]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#how-is-kubernetes-a-platform
|
||||
[3]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-kubernetes-is-not
|
||||
[4]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-does-kubernetes-mean-k8s
|
||||
[5]:https://martinfowler.com/articles/microservices.html
|
||||
[6]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#kubernetes-is
|
||||
[7]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-containers
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#whats-next
|
||||
[9]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[10]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[11]:https://kubernetes.io/docs/concepts/configuration/secret/
|
||||
[12]:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
|
||||
[13]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[14]:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
||||
[15]:https://kubernetes.io/docs/concepts/services-networking/connect-applications-service/
|
||||
[16]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[17]:https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller/
|
||||
[18]:https://kubernetes.io/docs/tasks/debug-application-cluster/resource-usage-monitoring/
|
||||
[19]:https://kubernetes.io/docs/concepts/cluster-administration/logging/
|
||||
[20]:https://kubernetes.io/docs/tasks/debug-application-cluster/debug-application-introspection/
|
||||
[21]:https://kubernetes.io/docs/admin/authorization/
|
||||
[22]:http://wildfly.org/
|
||||
[23]:https://12factor.net/
|
||||
[24]:https://github.com/google/jsonnet
|
||||
[25]:http://www.slideshare.net/BrianGrant11/wso2con-us-2015-kubernetes-a-platform-for-automating-deployment-scaling-and-operations
|
||||
[26]:https://research.google.com/pubs/pub43438.html
|
||||
[27]:https://aucouranton.com/2014/06/13/linux-containers-parallels-lxc-openvz-docker-and-more/
|
||||
[28]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[29]:https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/
|
||||
[30]:https://kubernetes.io/docs/concepts/overview/components/
|
||||
[31]:https://kubernetes.io/docs/reference/api-overview/
|
||||
[32]:https://git.k8s.io/community/contributors/devel/scheduler.md
|
||||
[33]:https://git.k8s.io/community/contributors/design-proposals/extending-api.md
|
||||
[34]:https://kubernetes.io/docs/user-guide/kubectl-overview/
|
||||
[35]:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/principles.md
|
||||
[36]:https://www.openshift.org/
|
||||
[37]:http://deis.io/
|
||||
[38]:http://eldarion.cloud/
|
||||
[39]:http://www.etymonline.com/index.php?term=cybernetics
|
||||
@ -0,0 +1,234 @@
|
||||
一个时代的结束:Solaris 系统的那些年,那些事
|
||||
=================================
|
||||
|
||||

|
||||
|
||||
现在看来,Oracle 公司正在通过取消 Solaris 12 而[终止 Solaris 的功能开发][42],这里我们要回顾下多年来在 Phoronix 上最受欢迎的 Solaris 重大事件和新闻。
|
||||
|
||||
这里有许多关于 Solaris 的有趣/重要的回忆。
|
||||
|
||||
[
|
||||
|
||||
][1]
|
||||
|
||||
在 Sun Microsystems 时期,我真的对 Solaris 很感兴趣。在 Phoronix 上我们一直重点关注 Linux 的同时,经常也有 Solaris 的文章出现。 Solaris 玩起来很有趣,OpenSolaris/SXCE 是伟大的产物,我将 Phoronix 测试套件移植到 Solaris 上,我们与 Sun Microsystems 人员有密切的联系,也出现在 Sun 的许多活动中。
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
_在那些日子里 Sun 有一些相当独特的活动..._
|
||||
|
||||
不幸的是,自从 Oracle 公司收购了 Sun 公司, Solaris 就如坠入深渊一样。最大的打击大概是 Oracle 结束了 OpenSolaris ,并将所有 Solaris 的工作转移到专有模式...
|
||||
|
||||
[
|
||||
|
||||
][3]
|
||||
|
||||
在 Sun 时代的 Solaris 有很多美好的回忆,所以 Oracle 在其计划中抹去了 Solaris 12 之后,我经常在 Phoronix 上翻回去看一些之前 Solaris 的经典文章,期待着能从 Oracle 听到 “Solaris 11” 下一代的消息,重启 Solaris 项目的开发。
|
||||
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
虽然在后 Solaris 的世界中,看到 Oracle 对 ZFS 所做的事情以及他们在基于 RHEL 的 Oracle Enterprise Linux 上下的重注将会很有趣,但时间将会告诉我们一切。
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
无论如何,这是回顾自 2004 年以来我们最受欢迎的 Solaris 文章:
|
||||
|
||||
### 2016/12/1 [Oracle 或许会罐藏 Solaris][20]
|
||||
|
||||
Oracle 可能正在拔掉 Solaris 的电源插头,据一些新的传闻说。
|
||||
|
||||
### 2013/6/9 [OpenSXCE 2013.05 拯救 Solaris 社区][17]
|
||||
|
||||
作为 Solaris 社区版的社区复兴,OpenSXCE 2013.05 出现在网上。
|
||||
|
||||
### 2013/2/2 [Solaris 12 可能最终带来 Radeon KMS 驱动程序][16]
|
||||
|
||||
看起来,Oracle 可能正在准备发布自己的 AMD Radeon 内核模式设置(KMS)驱动程序,并引入到 Oracle Solaris 12 中。
|
||||
|
||||
### 2012/10/4 [Oracle Solaris 11.1 提供 300 个以上增强功能][25]
|
||||
|
||||
Oracle昨天在旧金山的 Oracle OpenWorld 会议上发布了 Solaris 11.1 。
|
||||
|
||||
[
|
||||
|
||||
][26]
|
||||
|
||||
### 2012/1/9 [Oracle 尚未澄清 Solaris 11 内核来源][19]
|
||||
|
||||
一个月前,Phoronix 是第一个注意到 Solaris 11 内核源代码通过 Torrent 站点泄漏到网上的信息。一个月后,甲骨文还没有正式评论这个情况。
|
||||
|
||||
### 2011/12/19 [Oracle Solaris 11 内核源代码泄漏][15]
|
||||
|
||||
似乎 Solaris 11的内核源代码在过去的一个周末被泄露到了网上。
|
||||
|
||||
### 2011/8/25 [对于 BSD,Solaris 的 GPU 驱动程序的悲惨状态][24]
|
||||
|
||||
昨天在邮件列表上出现了关于干掉所有旧式 Mesa 驱动程序的讨论。这些旧驱动程序没有被积极维护,支持复古的图形处理器,并且没有更新支持新的 Mesa 功能。英特尔和其他开发人员正在努力清理 Mesa 核心,以将来增强这一开源图形库。这种清理 Mesa,对 BSD 和 Solaris 用户也有一些影响。
|
||||
|
||||
### 2010/8/13 [告别 OpenSolaris,Oracle 刚刚把它干掉][8]
|
||||
|
||||
Oracle 终于宣布了他们对 Solaris 操作系统和 OpenSolaris 平台的计划,而且不是好消息。OpenSolaris 将实际死亡,未来将不会有更多的 Solaris 版本出现 - 包括长期延期的 2010 年版本。Solaris 仍然会继续存在,现在 Oracle 正在忙于明年发布的 Solaris 11,但仅在 Oracle 的企业版之后才会发布 “Solaris 11 Express” 作为 OpenSolaris 的类似产品。
|
||||
|
||||
### 2010/2/22 [Oracle 仍然要对 OpenSolaris 进行更改][12]
|
||||
|
||||
自从 Oracle 完成对 Sun Microsystems 的收购以来,已经有了许多变化,这个 Sun 最初支持的开源项目现在已经不再被 Oracle 支持,并且对其余的开源产品进行了重大改变。 Oracle 表现出并不太开放的意图的开源项目之一是 OpenSolaris 。 Solaris Express 社区版(SXCE)上个月已经关闭,并且也没有预计 3 月份发布的下一个 OpenSolaris 版本(OpenSolaris 2010.03)的信息流出。
|
||||
|
||||
### 2007/9/10 [Solaris Express 社区版 Build 72][9]
|
||||
|
||||
对于那些想要在 “印第安纳项目” 发布之前尝试 OpenSolaris 软件中最新最好的软件的人来说,现在可以使用 Solaris Express 社区版 Build 72。Solaris Express 社区版(SXCE)Build 72 可以从 OpenSolaris.org 下载。同时,预计将在下个月推出 Sun 的 “印第安纳项目” 项目的预览版。
|
||||
|
||||
### 2007/9/6 [ATI R500/600 驱动要支持 Solaris 了?][6]
|
||||
|
||||
虽然没有可用于 Solaris/OpenSolaris 或 * BSD 的 ATI fglrx 驱动程序,现在 AMD 将向 X.Org 开发人员和开源驱动程序交付规范,但对于任何使用 ATI 的 Radeon X1000 “R500” 或者 HD 2000“R600” 系列的 Solaris 用户来说,这肯定是有希望的。将于下周发布的开源 X.Org 驱动程序距离成熟尚远,但应该能够相对容易地移植到使用 X.Org 的 Solaris 和其他操作系统上。 AMD 今天宣布的针对的是 Linux 社区,但它也可以帮助使用 ATI 硬件的 Solaris/OpenSolaris 用户。特别是随着印第安纳项目的即将推出,开源 R500/600 驱动程序移植就只是时间问题了。
|
||||
|
||||
### 2007/9/5 [Solaris Express 社区版 Build 71][7]
|
||||
|
||||
Solaris Express 社区版(SXCE)现已推出 Build 71。您可以在 OpenSolaris.org 中找到有关 Solaris Express 社区版 Build 71 的更多信息。另外,在 Linux 内核峰会上,AMD 将提供 GPU 规格的消息,由此产生的 X.Org 驱动程序将来可能会导致 ATI 硬件上 Solaris/OpenSolaris 有所改善。
|
||||
|
||||
### 2007/8/27 [Linux 的 Solaris 容器][11]
|
||||
|
||||
Sun Microsystems 已经宣布,他们将很快支持适用于 Linux 应用程序的 Solaris 容器。这样可以在 Solaris 下运行 Linux 应用程序,而无需对二进制包进行任何修改。适用于 Linux 的 Solaris 容器将允许从 Linux 到 Solaris 的平滑迁移,协助跨平台开发以及其他优势。当该支持到来时,这个时代就“快到了”。
|
||||
|
||||
### 2007/8/23 [OpenSolaris 开发者峰会][10]
|
||||
|
||||
今天早些时候在 OpenSolaris 论坛上发布了第一次 OpenSolaris 开发人员峰会的消息。这次峰会将在十月份在加州大学圣克鲁斯分校举行。 Sara Dornsife 将这次峰会描述为“不是与演示文稿或参展商举行会议,而是一个亲自参与的协作工作会议,以计划下一期的印第安纳项目。” 伊恩·默多克(Ian Murdock) 将在这个“印第安纳项目”中进行主题演讲,但除此之外,该计划仍在计划之中。 Phoronix 可能会继续跟踪此事件,您可以在 Solaris 论坛上讨论此次峰会。
|
||||
|
||||
### 2007/8/18 [Solaris Express 社区版 Build 70][21]
|
||||
|
||||
名叫 "Nevada" 的 Solaris Express 社区版 Build 70 (SXCE snv_70) 现在已经发布。有关下载链接的通知可以在 OpenSolaris 论坛中找到。还有公布了其网络存储的 Build 71 版本,包括来自 Qlogic 的光纤通道 HBA 驱动程序的源代码。
|
||||
|
||||
### 2007/8/16 [IBM 使用 Sun Solaris 的系统][14]
|
||||
|
||||
Sun Microsystems 和 IBM正在举行电话会议,他们刚刚宣布,IBM 将开始在服务器上使用 Sun 的 Solaris 操作系统。这些 IBM 服务器包括基于 x86 的服务器系统以及 Blade Center 服务器。官方新闻稿刚刚发布,可以在 sun 新闻室阅读。
|
||||
|
||||
### 2007/8/9 [OpenSolaris 不会与 Linux 合并][18]
|
||||
|
||||
在旧金山的 LinuxWorld 2007 上,Andrew Morton 在主题演讲中表示, OpenSolaris 的关键组件不会出现在 Linux 内核中。事实上,莫顿甚至表示 “非常遗憾 OpenSolaris 活着”。OpenSolaris 的一些关键组件包括 Zones、ZFS 和 DTrace 。虽然印第安纳州项目有可能将这些项目转变为 GPLv3 项目... 更多信息参见 ZDNET。
|
||||
|
||||
### 2007/7/27 [Solaris Xen 已经更新][13]
|
||||
|
||||
已经有一段时间了,Solaris Xen 终于更新了。约翰·莱文(John Levon)表示,这一最新版本基于 Xen 3.0.4 和 Solaris “Nevada” Build 66。这一最新版本的改进包括 PAE 支持、HVM 支持、新的 virt-manager 工具、改进的调试支持以及管理域支持。可以在 Sun 的网站上找到 2007 年 7 月 Solaris Xen 更新的下载。
|
||||
|
||||
### 2007/7/25 [Solaris 10 7/07 HW 版本][22]
|
||||
|
||||
Solaris 10 7/07 HW 版本的文档已经上线。如 Solaris 发行注记中所述,Solaris 10 7/07 仅适用于 SPARC Enterprise M4000-M9000 服务器,并且没有 x86/x64 版本可用。所有平台的最新 Solaris 更新是 Solaris 10 11/06 。您可以在 Phoronix 论坛中讨论 Solaris 7/07。
|
||||
|
||||
### 2007/7/16 [来自英特尔的 Solaris 电信服务器][23]
|
||||
|
||||
今天宣布推出符合 NEBS、ETSI 和 ATCA 合规性的英特尔体系的 Sun Solaris 电信机架服务器和刀片服务器。在这些新的运营商级平台中,英特尔运营商级机架式服务器 TIGW1U 支持 Linux 和 Solaris 10,而 Intel NetStructure MPCBL0050 SBC 也将支持这两种操作系统。今天的新闻稿可以在这里阅读。
|
||||
|
||||
然后是 Solaris 分类中最受欢迎的特色文章:
|
||||
|
||||
### [Ubuntu vs. OpenSolaris vs. FreeBSD 基准测试][27]
|
||||
|
||||
在过去的几个星期里,我们提供了几篇关于 Ubuntu Linux 性能的深入文章。我们已经开始提供 Ubuntu 7.04 到 8.10 的基准测试,并且发现这款受欢迎的 Linux 发行版的性能随着时间的推移而变慢,随之而来的是 Mac OS X 10.5 对比 Ubuntu 8.10 的基准测试和其他文章。在本文中,我们正在比较 Ubuntu 8.10 的 64 位性能与 OpenSolaris 2008.11 和 FreeBSD 7.1 的最新测试版本。
|
||||
|
||||
### [NVIDIA 的性能:Windows vs. Linux vs. Solaris][28]
|
||||
|
||||
本周早些时候,我们预览了 Quadro FX1700,它是 NVIDIA 的中端工作站显卡之一,基于 G84GL 内核,而 G84GL 内核又源于消费级 GeForce 8600 系列。该 PCI Express 显卡提供 512MB 的视频内存,具有两个双链路 DVI 连接,并支持 OpenGL 2.1 ,同时保持最大功耗仅为 42 瓦。正如我们在预览文章中提到的,我们将不仅在 Linux 下查看此显卡的性能,还要在 Microsoft Windows 和 Sun 的 Solaris 中测试此工作站解决方案。在今天的这篇文章中,我们正在这样做,因为我们测试了 NVIDIA Quadro FX1700 512MB 与这些操作系统及其各自的二进制显示驱动程序。
|
||||
|
||||
### [FreeBSD 8.0 对比 Linux、OpenSolaris][29]
|
||||
|
||||
在 FreeBSD 8.0 的稳定版本发布的上周,我们终于可以把它放在测试台上,并用 Phoronix 测试套件进行了全面的了解。我们将 FreeBSD 8.0 的性能与早期的 FreeBSD 7.2 版本以及 Fedora 12 和 Ubuntu 9.10 还有 Sun OS 端的 OpenSolaris 2010.02 b127 快照进行了比较。
|
||||
|
||||
### [Fedora、Debian、FreeBSD、OpenBSD、OpenSolaris 基准测试][30]
|
||||
|
||||
上周我们发布了第一个 Debian GNU/kFreeBSD 基准测试,将 FreeBSD 内核捆绑在 Debian GNU 用户的 Debian GNU/Linux 上,比较了这款 Debian 系统的 32 位和 64 位性能。 我们现在扩展了这个比较,使许多其他操作系统与 Debian GNU/Linux 和 Debian GNU/kFreeBSD 的 6.0 Squeeze 快照直接进行比较,如 Fedora 12,FreeBSD 7.2,FreeBSD 8.0,OpenBSD 4.6 和 OpenSolaris 2009.06 。
|
||||
|
||||
### [AMD 上海皓龙:Linux vs. OpenSolaris 基准测试][31]
|
||||
|
||||
1月份,当我们研究了四款皓龙 2384 型号时,我们在 Linux 上发布了关于 AMD 上海皓龙 CPU 的综述。与早期的 AMD 巴塞罗那处理器 Ubuntu Linux 相比,这些 45nm 四核工作站服务器处理器的性能非常好,但是在运行 Sun OpenSolaris 操作系统时,性能如何?今天浏览的是 AMD 双核的基准测试,运行 OpenSolaris 2008.11、Ubuntu 8.10 和即将推出的 Ubuntu 9.04 版本。
|
||||
|
||||
### [OpenSolaris vs. Linux 内核基准][32]
|
||||
|
||||
本周早些时候,我们提供了 Ubuntu 9.04 与 Mac OS X 10.5.6 的基准测试,发现 Leopard 操作系统(Mac)在大多数测试中的表现要优于 Jaunty Jackalope (Ubuntu),至少在 Ubuntu 32 位是这样的。我们今天又回过来进行更多的操作系统基准测试,但这次我们正在比较 Linux 和 Sun OpenSolaris 内核的性能。我们使用的 Nexenta Core 2 操作系统将 OpenSolaris 内核与 GNU/Ubuntu 用户界面组合在同一个 Ubuntu 软件包中,但使用了 Linux 内核的 32 位和 64 位 Ubuntu 服务器安装进行测试。
|
||||
|
||||
### [Netbook 性能:Ubuntu vs. OpenSolaris][33]
|
||||
|
||||
过去,我们已经发布了 OpenSolaris vs. Linux Kernel 基准测试以及类似的文章,关注 Sun 的 OpenSolaris 与流行的 Linux 发行版的性能。我们已经看过高端 AMD 工作站的性能,但是我们从来没有比较上网本上的 OpenSolaris 和 Linux 性能。直到今天,在本文中,我们将比较戴尔 Inspiron Mini 9 上网本上的 OpenSolaris 2009.06 和 Ubuntu 9.04 的结果。
|
||||
|
||||
### [NVIDIA 图形:Linux vs. Solaris][34]
|
||||
|
||||
在 Phoronix,我们不断探索 Linux 下的不同显示驱动程序,在我们评估了 Sun 的检查工具并测试了 Solaris 主板以及覆盖其他几个领域之后,我们还没有执行图形驱动程序 Linux 和 Solaris 之间的比较。直到今天。由于印第安纳州项目,我们对 Solaris 更感兴趣,我们决定终于通过 NVIDIA 专有驱动程序提供我们在 Linux 和 Solaris 之间的第一次定量图形比较。
|
||||
|
||||
### [OpenSolaris 2008.05 向 Solaris 提供了一个新面孔][35]
|
||||
|
||||
2月初,Sun Microsystems 发布了印第安纳项目的第二个预览版本。对于那些人来说,印第安纳州项目是 Sun 的 Ian Murdock 领导的项目的代号,旨在通过解决 Solaris 的长期可用性问题,将 OpenSolaris 推向更多的台式机和笔记本电脑。我们没有对预览 2 留下什么深刻印象,因为它没有比普通用户感兴趣的 GNU/Linux 桌面更有优势。然而,随着 5 月份推出的 OpenSolaris 2008.05 印第安纳项目发布,Sun Microsystems 今天发布了该操作系统的最终测试副本。当最后看到项目印第安纳时, 我们对这个新的 OpenSolaris 版本的最初体验是远远优于我们不到三月前的体验的。
|
||||
|
||||
### [快速概览 Oracle Solaris 11][36]
|
||||
|
||||
Solaris 11 在周三发布,是七年来这个前 Sun 操作系统的第一个主要更新。在过去七年中,Solaris 家族发生了很大变化,OpenSolaris 在那个时候已经到来,但在本文中,简要介绍了全新的 Oracle Solaris 11 版本。
|
||||
|
||||
### [OpenSolaris、BSD & Linux 的新基准测试][37]
|
||||
|
||||
今天早些时候,我们对以原生的内核模块支持的 Linux 上的 ZFS 进行了基准测试,该原生模块将被公开提供,以将这个 Sun/Oracle 文件系统覆盖到更多的 Linux 用户。现在,尽管作为一个附加奖励,我们碰巧有了基于 OpenSolaris 的最新发行版的新基准,包括 OpenSolaris、OpenIndiana 和 Augustiner-Schweinshaxe,与 PC-BSD、Fedora 和 Ubuntu相比。
|
||||
|
||||
### [FreeBSD/PC-BSD 9.1 针对 Linux、Solaris、BSD 的基准][38]
|
||||
|
||||
虽然 FreeBSD 9.1 尚未正式发布,但是基于 FreeBSD 的 PC-BSD 9.1 “Isotope”版本本月已经可用。本文中的性能指标是 64 位版本的 PC-BSD 9.1 与 DragonFlyBSD 3.0.3、Oracle Solaris Express 11.1、CentOS 6.3、Ubuntu 12.10 以及 Ubuntu 13.04 开发快照的比较。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Michael Larabel 是 Phoronix.com 的作者,并于 2004 年创立了该网站,该网站重点是丰富多样的 Linux 硬件体验。 Michael 撰写了超过10,000 篇文章,涵盖了 Linux 硬件支持,Linux 性能,图形驱动程序等主题。 Michael 也是 Phoronix 测试套件、 Phoromatic 和 OpenBenchmarking.org 自动化基准测试软件的主要开发人员。可以通过 Twitter 关注他或通过 MichaelLarabel.com 联系他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.phoronix.com/scan.php?page=news_item&px=Solaris-2017-Look-Back
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/image-viewer.php?id=982&image=sun_sxce81_03_lrg
|
||||
[2]:http://www.phoronix.com/image-viewer.php?id=711&image=java7_bash_13_lrg
|
||||
[3]:http://www.phoronix.com/image-viewer.php?id=sun_sxce_farewell&image=sun_sxce_07_lrg
|
||||
[4]:http://www.phoronix.com/image-viewer.php?id=solaris_200805&image=opensolaris_indiana_03b_lrg
|
||||
[5]:http://www.phoronix.com/image-viewer.php?id=oracle_solaris_11&image=oracle_solaris11_02_lrg
|
||||
[6]:http://www.phoronix.com/scan.php?page=news_item&px=NjA0Mg
|
||||
[7]:http://www.phoronix.com/scan.php?page=news_item&px=NjAzNQ
|
||||
[8]:http://www.phoronix.com/scan.php?page=news_item&px=ODUwNQ
|
||||
[9]:http://www.phoronix.com/scan.php?page=news_item&px=NjA0Nw
|
||||
[10]:http://www.phoronix.com/scan.php?page=news_item&px=NjAwNA
|
||||
[11]:http://www.phoronix.com/scan.php?page=news_item&px=NjAxMQ
|
||||
[12]:http://www.phoronix.com/scan.php?page=news_item&px=ODAwNg
|
||||
[13]:http://www.phoronix.com/scan.php?page=news_item&px=NTkzMQ
|
||||
[14]:http://www.phoronix.com/scan.php?page=news_item&px=NTk4NA
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=MTAzMDE
|
||||
[16]:http://www.phoronix.com/scan.php?page=news_item&px=MTI5MTU
|
||||
[17]:http://www.phoronix.com/scan.php?page=news_item&px=MTM4Njc
|
||||
[18]:http://www.phoronix.com/scan.php?page=news_item&px=NTk2Ng
|
||||
[19]:http://www.phoronix.com/scan.php?page=news_item&px=MTAzOTc
|
||||
[20]:http://www.phoronix.com/scan.php?page=news_item&px=Oracle-Solaris-Demise-Rumors
|
||||
[21]:http://www.phoronix.com/scan.php?page=news_item&px=NTk4Nw
|
||||
[22]:http://www.phoronix.com/scan.php?page=news_item&px=NTkyMA
|
||||
[23]:http://www.phoronix.com/scan.php?page=news_item&px=NTg5Nw
|
||||
[24]:http://www.phoronix.com/scan.php?page=news_item&px=OTgzNA
|
||||
[25]:http://www.phoronix.com/scan.php?page=news_item&px=MTE5OTQ
|
||||
[26]:http://www.phoronix.com/image-viewer.php?id=opensolaris_200906&image=opensolaris_200906_06_lrg
|
||||
[27]:http://www.phoronix.com/vr.php?view=13149
|
||||
[28]:http://www.phoronix.com/vr.php?view=11968
|
||||
[29]:http://www.phoronix.com/vr.php?view=14407
|
||||
[30]:http://www.phoronix.com/vr.php?view=14533
|
||||
[31]:http://www.phoronix.com/vr.php?view=13475
|
||||
[32]:http://www.phoronix.com/vr.php?view=13826
|
||||
[33]:http://www.phoronix.com/vr.php?view=14039
|
||||
[34]:http://www.phoronix.com/vr.php?view=10301
|
||||
[35]:http://www.phoronix.com/vr.php?view=12269
|
||||
[36]:http://www.phoronix.com/vr.php?view=16681
|
||||
[37]:http://www.phoronix.com/vr.php?view=15476
|
||||
[38]:http://www.phoronix.com/vr.php?view=18291
|
||||
[39]:http://www.michaellarabel.com/
|
||||
[40]:https://www.phoronix.com/scan.php?page=news_topic&q=Oracle
|
||||
[41]:https://www.phoronix.com/forums/node/925794
|
||||
[42]:http://www.phoronix.com/scan.php?page=news_item&px=No-Solaris-12
|
||||
@ -0,0 +1,124 @@
|
||||
给中级 Meld 用户的有用技巧
|
||||
============================================================
|
||||
|
||||
Meld 是 Linux 上功能丰富的可视化比较和合并工具。如果你是第一次接触,你可以进入我们的[初学者指南][5],了解该程序的工作原理,如果你已经阅读过或正在使用 Meld 进行基本的比较/合并任务,你将很高兴了解本教程的东西,在本教程中,我们将讨论一些非常有用的技巧,这将让你使用工具的体验更好。
|
||||
|
||||
_但在我们跳到安装和解释部分之前,值得一提的是,本教程中介绍的所有说明和示例已在 Ubuntu 14.04 上进行了测试,而我们使用的 Meld 版本为 3.14.2_。
|
||||
|
||||
### 1、 跳转
|
||||
|
||||
你可能已经知道(我们也在初学者指南中也提到过这一点),标准滚动不是在使用 Meld 时在更改之间跳转的唯一方法 - 你可以使用向上和向下箭头键轻松地从一个更改跳转到另一个更改位于编辑区域上方的窗格中:
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
但是,这需要你将鼠标指针移动到这些箭头,然后再次单击其中一个(取决于你要去哪里 - 向上或向下)。你会很高兴知道,存在另一种更简单的方式来跳转:只需使用鼠标的滚轮即可在鼠标指针位于中央更改栏上时进行滚动。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
这样,你就可以在视线不离开或者分心的情况下进行跳转,
|
||||
|
||||
### 2、 可以对更改进行的操作
|
||||
|
||||
看下上一节的最后一个屏幕截图。你知道那些黑箭头做什么吧?默认情况下,它们允许你执行合并/更改操作 - 当没有冲突时进行合并,并在同一行发生冲突时进行更改。
|
||||
|
||||
但是你知道你可以根据需要删除个别的更改么?是的,这是可能的。为此,你需要做的是在处理更改时按下 Shift 键。你会观察到箭头被变成了十字架。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
只需点击其中任何一个,相应的更改将被删除。
|
||||
|
||||
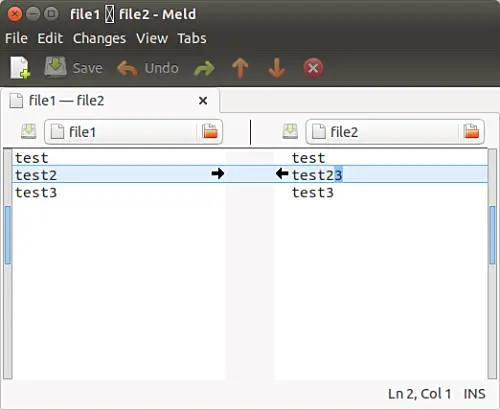
不仅是删除,你还可以确保冲突的更改不会在合并时更改行。例如,以下是一个冲突变化的例子:
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
现在,如果你点击任意两个黑色箭头,箭头指向的行将被改变,并且将变得与其他文件的相应行相似。只要你想这样做,这是没问题的。但是,如果你不想要更改任何行呢?相反,目的是将更改的行在相应行的上方或下方插入到其他文件中。
|
||||
|
||||
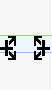
我想说的是,例如,在上面的截图中,需要在 “test23” 之上或之下添加 “test 2”,而不是将 “test23” 更改为 “test2”。你会很高兴知道在 Meld 中这是可能的。就像你按下 Shift 键删除注释一样,在这种情况下,你必须按下 Ctrl 键。
|
||||
|
||||
你会观察到当前操作将被更改为插入 - 双箭头图标将确认这一点 。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
从箭头的方向看,此操作可帮助用户将当前更改插入到其他文件中的相应更改 (如所选择的)。
|
||||
|
||||
### 3、 自定义文件在 Meld 的编辑器区域中显示的方式
|
||||
|
||||
有时候,你希望 Meld 的编辑区域中的文字大小变大(为了更好或更舒适的浏览),或者你希望文本行被包含而不是脱离视觉区域(意味着你不要想使用底部的水平滚动条)。
|
||||
|
||||
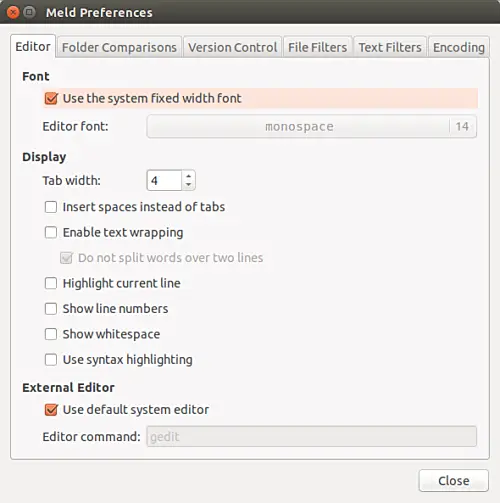
Meld 在 _Editor_ 选项卡(_Edit->Preferences->Editor_)的 _Preferences_ 菜单中提供了一些显示和字体相关的自定义选项,你可以进行这些调整:
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
在这里你可以看到,默认情况下,Meld 使用系统定义的字体宽度。只需取消选中 _Font_ 类别下的框,你将有大量的字体类型和大小选项可供选择。
|
||||
|
||||
然后在 _Display_ 部分,你将看到我们正在讨论的所有自定义选项:你可以设置 Tab 宽度、告诉工具是否插入空格而不是 tab、启用/禁用文本换行、使Meld显示行号和空白(在某些情况下非常有用)以及使用语法突出显示。
|
||||
|
||||
### 4、 过滤文本
|
||||
|
||||
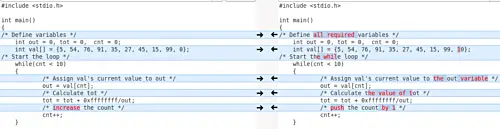
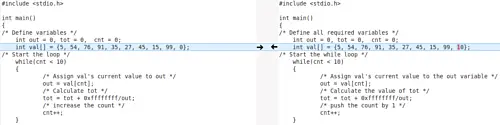
有时候,并不是所有的修改都是对你很重要的。例如,在比较两个 C 编程文件时,你可能不希望 Meld 显示注释中的更改,因为你只想专注于与代码相关的更改。因此,在这种情况下,你可以告诉 Meld 过滤(或忽略)与注释相关的更改。
|
||||
|
||||
例如,这里是 Meld 中的一个比较,其中由工具高亮了注释相关更改:
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
而在这种情况下,Meld 忽略了相同的变化,仅关注与代码相关的变更:
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
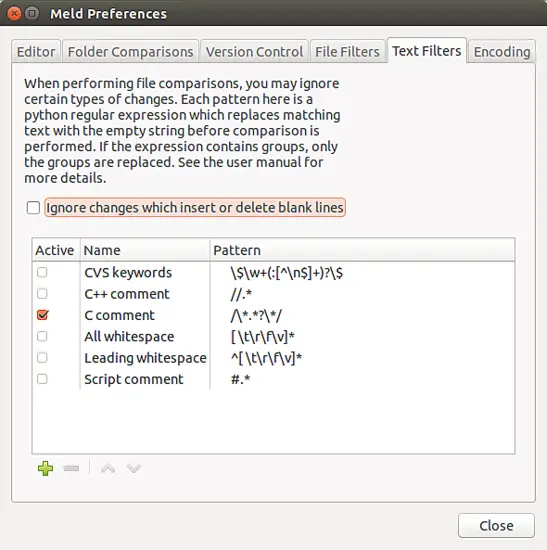
很酷,不是吗?那么这是怎么回事?为此,我是在 “_Edit->Preferences->Text Filters_” 标签中启用了 “C comments” 文本过滤器:
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
如你所见,除了 “C comments” 之外,你还可以过滤掉 C++ 注释、脚本注释、引导或所有的空格等。此外,你还可以为你处理的任何特定情况定义自定义文本过滤器。例如,如果你正在处理日志文件,并且不希望 Meld 高亮显示特定模式开头的行中的更改,则可以为该情况定义自定义文本过滤器。
|
||||
|
||||
但是,请记住,要定义一个新的文本过滤器,你需要了解 Python 语言以及如何使用该语言创建正则表达式。
|
||||
|
||||
### 总结
|
||||
|
||||
这里讨论的所有四个技巧都不是很难理解和使用(当然,除了你想立即创建自定义文本过滤器),一旦你开始使用它们,你会认为他们是真的有好处。这里的关键是要继续练习,否则你学到的任何技巧不久后都会忘记。
|
||||
|
||||
你还知道或者使用其他任何中级 Meld 的贴士和技巧么?如果有的话,欢迎你在下面的评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/
|
||||
[1]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-navigation
|
||||
[2]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-things-you-can-do-with-changes
|
||||
[3]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-filtering-text
|
||||
[4]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#conclusion
|
||||
[5]:https://linux.cn/article-8402-1.html
|
||||
[6]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-go-next-prev-9.png
|
||||
[7]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-center-area-scrolling.png
|
||||
[8]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-delete-changes.png
|
||||
[9]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-conflicting-change.png
|
||||
[10]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-ctrl-insert.png
|
||||
[11]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-editor-tab.png
|
||||
[12]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-changes-with-comments.png
|
||||
[13]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-changes-without-comments.png
|
||||
[14]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-text-filters.png
|
||||
@ -0,0 +1,68 @@
|
||||
Linux 容器轻松应对性能工程
|
||||
============================================================
|
||||
|
||||

|
||||
图片来源: CC0 Public Domain
|
||||
|
||||
应用程序的性能决定了软件能多快完成预期任务。这回答有关应用程序的几个问题,例如:
|
||||
|
||||
* 峰值负载下的响应时间
|
||||
* 与替代方案相比,它易于使用,受支持的功能和用例
|
||||
* 运营成本(CPU 使用率、内存需求、数据吞吐量、带宽等)
|
||||
|
||||
该性能分析的价值超出了服务负载所需的计算资源或满足峰值需求所需的应用实例数量的估计。性能显然与成功企业的基本要素挂钩。它揭示了用户的总体体验,包括确定什么会拖慢客户预期的响应时间,通过设计满足带宽要求的内容交付来提高客户粘性,选择最佳设备,最终帮助企业发展业务。
|
||||
|
||||
### 问题
|
||||
|
||||
当然,这是对业务服务的性能工程价值的过度简化。为了理解在完成我刚刚所描述事情背后的挑战,让我们把它放到一个真实的稍微有点复杂的场景中。
|
||||
|
||||

|
||||
|
||||
现实世界的应用程序可能托管在云端。应用程序可以利用非常大(或概念上是无穷大)的计算资源。在硬件和软件方面的需求将通过云来满足。从事开发工作的开发人员将使用云交付功能来实现更快的编码和部署。云托管不是免费的,但成本开销与应用程序的资源需求成正比。
|
||||
|
||||
除了<ruby>搜索即服务<rt>Search as a Service</rt></ruby>(SaaS)、<ruby>平台即服务<rt>Platform as a Service</rt></ruby>(PaaS)、<ruby>基础设施即服务<rt>Infrastructure as a Service</rt></ruby>(IaaS)以及<ruby>负载平衡即服务<rt>Load Balancing as a Service</rt></ruby>(LBaaS)之外,当云端管理托管程序的流量时,开发人员可能还会使用这些快速增长的云服务中的一个或多个:
|
||||
|
||||
* <ruby>安全即服务<rt>Security as a Service</rt></ruby> (SECaaS),可满足软件和用户的安全需求
|
||||
* <ruby>数据即服务<rt>Data as a Service</rt></ruby> (DaaS),为应用提供了用户需求的数据
|
||||
* <ruby>登录即服务<rt>Logging as a Service</rt></ruby> (LaaS),DaaS 的近亲,提供了日志传递和使用的分析指标
|
||||
* <ruby>搜索即服务<rt>Search as a Service</rt></ruby> (SaaS),用于应用程序的分析和大数据需求
|
||||
* <ruby>网络即服务<rt>Network as a Service</rt></ruby> (NaaS),用于通过公共网络发送和接收数据
|
||||
|
||||
云服务也呈指数级增长,因为它们使得开发人员更容易编写复杂的应用程序。除了软件复杂性之外,所有这些分布式组件的相互作用变得越来越多。用户群变得更加多元化。该软件的需求列表变得更长。对其他服务的依赖性变大。由于这些因素,这个生态系统的缺陷会引发性能问题的多米诺效应。
|
||||
|
||||
例如,假设你有一个精心编写的应用程序,它遵循安全编码实践,旨在满足不同的负载要求,并经过彻底测试。另外假设你已经将基础架构和分析工作结合起来,以支持基本的性能要求。在系统的实现、设计和架构中建立性能标准需要做些什么?软件如何跟上不断变化的市场需求和新兴技术?如何测量关键参数以调整系统以获得最佳性能?如何使系统具有弹性和自我恢复能力?你如何更快地识别任何潜在的性能问题,并尽早解决?
|
||||
|
||||
### 进入容器
|
||||
|
||||
软件[容器][2]以[微服务][3]设计或面向服务的架构(SoA)的优点为基础,提高了性能,因为包含更小的、自足的代码块的系统更容易编码,对其它系统组件有更清晰、定义良好的依赖。测试更容易,包括围绕资源利用和内存过度消耗的问题比在宏架构中更容易确定。
|
||||
|
||||
当扩容系统以增加负载能力时,容器应用程序的复制快速而简单。安全漏洞能更好地隔离。补丁可以独立版本化并快速部署。性能监控更有针对性,测量更可靠。你还可以重写和“改版”资源密集型代码,以满足不断变化的性能要求。
|
||||
|
||||
容器启动快速,停止也快速。它比虚拟机(VM)有更高效资源利用和更好的进程隔离。容器没有空闲内存和 CPU 闲置。它们允许多个应用程序共享机器,而不会丢失数据或性能。容器使应用程序可移植,因此开发人员可以构建并将应用程序发送到任何支持容器技术的 Linux 服务器上,而不必担心性能损失。容器生存在其内,并遵守其集群管理器(如 Cloud Foundry 的 Diego、[Kubernetes][4]、Apache Mesos 和 Docker Swarm)所规定的配额(比如包括存储、计算和对象计数配额)。
|
||||
|
||||
容器在性能方面表现出色,而即将到来的 “serverless” 计算(也称为<ruby>功能即服务<rt>Function as a Service</rt></ruby>(FaaS))的浪潮将扩大容器的优势。在 FaaS 时代,这些临时性或短期的容器将带来超越应用程序性能的优势,直接转化为在云中托管的间接成本的节省。如果容器的工作更快,那么它的寿命就会更短,而且计算量负载纯粹是按需的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Garima 是 Red Hat 的工程经理,专注于 OpenShift 容器平台。在加入 Red Hat 之前,Garima 帮助 Akamai Technologies&MathWorks Inc. 开创了创新。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/performance-container-world
|
||||
|
||||
作者:[Garima][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/garimavsharma
|
||||
[1]:https://opensource.com/article/17/2/performance-container-world?rate=RozKaIY39AZNxbayqFkUmtkkhoGdctOVuGOAJqVJII8
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers
|
||||
[3]:https://opensource.com/resources/what-are-microservices
|
||||
[4]:https://opensource.com/resources/what-is-kubernetes
|
||||
[5]:https://opensource.com/user/109286/feed
|
||||
[6]:https://opensource.com/article/17/2/performance-container-world#comments
|
||||
[7]:https://opensource.com/users/garimavsharma
|
||||
@ -0,0 +1,69 @@
|
||||
如何管理开源产品的安全漏洞
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
在 ELC + OpenIoT 峰会上,英特尔安全架构师 Ryan Ware 将会解释如何应对漏洞洪流,并管理你产品的安全性。
|
||||
|
||||
在开发开源软件时, 你需要考虑的安全漏洞也许会将你吞没。<ruby>常见漏洞及曝光<rt>Common Vulnerabilities and Exposures</rt></ruby>(CVE)ID、零日漏洞和其他漏洞似乎每天都在公布。随着这些信息洪流,你怎么能保持不掉队?
|
||||
|
||||
英特尔安全架构师 Ryan Ware 表示:“如果你发布了基于 Linux 内核 4.4.1 的产品,该内核截止今日已经有 9 个针对该内核的 CVE。这些都会影响你的产品,尽管事实上当你配载它们时还不知道。”
|
||||
|
||||
在 [ELC][6] + [OpenIoT 峰会][7]上,英特尔安全架构师 Ryan Ware 的演讲将介绍如何实施并成功管理产品的安全性的策略。在他的演讲中,Ware 讨论了最常见的开发者错误,跟上最新的漏洞的策略等等。
|
||||
|
||||
**Linux.com:让我们从头开始。你能否简要介绍一下常见漏洞和曝光(CVE),零日以及其他漏洞么?它们是什么,为什么重要?**
|
||||
|
||||
Ryan Ware:好问题。<ruby>常见漏洞及曝光<rt>Common Vulnerabilities and Exposures</rt></ruby>(CVE)是按美国政府的要求由 MITR Corporation(一个非营利组织)维护的数据库。其目前由美国国土安全部资助。它是在 1999 年创建的,以包含有关所有公布的安全漏洞的信息。这些漏洞中的每一个都有自己的标识符(CVE-ID),并且可以被引用。 CVE 这个术语,已经从指整个数据库逐渐演变成代表一个单独的安全漏洞: 一个 CVE 漏洞。
|
||||
|
||||
出现于 CVE 数据库中的许多漏洞最初是零日漏洞。这些漏洞出于不管什么原因没有遵循更有序的如“<ruby>责任揭秘<rt>Responsible Disclosure</rt></ruby>”这样的披露过程。关键在于,如果没有软件供应商能够通过某种类型的修复(通常是软件补丁)来进行响应,那么它们就成为了公开和可利用的。这些和其他未打补丁的软件漏洞至关重要,因为在修补软件之前,漏洞是可以利用的。在许多方面,发布 CVE 或者零日就像是开枪。在你比赛结束之前,你的客户很容易受到伤害。
|
||||
|
||||
**Linux.com:有多少漏洞?你如何确定那些与你的产品相关?**
|
||||
|
||||
Ryan:在探讨有多少之前,以任何形式发布软件的任何人都应该记住。即使你采取一切努力确保你发布的软件没有已知的漏洞,你的软件*也会*存在漏洞。它们只是不知道而已。例如,如果你发布了一个基于 Linux 内核 4.4.1 的产品,那么截止今日,已经有了 9 个CVE。这些都会影响你的产品,尽管事实上在你使用它们时不知道。
|
||||
|
||||
此时,CVE 数据库包含 80,957 个条目(截止至 2017 年 1 月 30 日),包括最早可追溯到 1999 年的所有记录,当时有 894 个已记录问题。迄今为止,一年中出现最大的数字的是 2014 年,当时记录了 7,946 个问题。也就是说,我认为过去两年该数字减少并不是因为安全漏洞的减少。这是我将在我的谈话中说到的东西。
|
||||
|
||||
**Linux.com:开发人员可以使用哪些策略来跟上这些信息?**
|
||||
|
||||
Ryan:开发人员可以通过各种方式跟上这些如洪水般涌来的漏洞信息。我最喜欢的工具之一是 [CVE Details][8]。它以一种非常容易理解的方式展示了来自 MITRE 的信息。它最好的功能是创建自定义 RSS 源的能力,以便你可以跟踪你关心的组件的漏洞。那些具有更复杂的追踪需求的人可以从下载 MITR CVE 数据库(免费提供)开始,并定期更新。其他优秀工具,如 cvechecker,可以让你检查软件中已知的漏洞。
|
||||
|
||||
对于软件栈中的关键部分,我还推荐一个非常有用的工具:参与到上游社区中。这些是最理解你所使用的软件的人。世界上没有比他们更好的专家。与他们一起合作。
|
||||
|
||||
**Linux.com:你怎么知道你的产品是否解决了所有漏洞?有推荐的工具吗?**
|
||||
|
||||
Ryan:不幸的是,正如我上面所说,你永远无法从你的产品中移除所有的漏洞。上面提到的一些工具是关键。但是,我还没有提到一个对你发布的任何产品来说都是至关重要的部分:软件更新机制。如果你无法在当场更新产品软件,则当客户受到影响时,你无法解决安全问题。你的软件必须能够更新,更新过程越容易,你的客户将受到更好的保护。
|
||||
|
||||
**Linux.com:开发人员还需要知道什么才能成功管理安全漏洞?**
|
||||
|
||||
Ryan:有一个我反复看到的错误。开发人员总是需要牢记将攻击面最小化的想法。这是什么意思?在实践中,这意味着只包括你的产品实际需要的东西!这不仅包括确保你不将无关的软件包加入到你的产品中,而且还可以关闭不需要的功能的配置来编译项目。
|
||||
|
||||
这有什么帮助?想象这是 2014 年。你刚刚上班就看到 Heartbleed 的技术新闻。你知道你在产品中包含 OpenSSL,因为你需要执行一些基本的加密功能,但不使用 TLS 心跳,该问题与该漏洞相关。你愿意:
|
||||
|
||||
a. 花费时间与客户和合作伙伴合作,通过关键的软件更新来修复这个高度安全问题?
|
||||
|
||||
b. 只需要告诉你的客户和合作伙伴,你使用 “-DOPENSSL_NO_HEARTBEATS” 标志编译 OpenSSL 产品,他们不会受到损害,你就可以专注于新功能和其他生产活动。
|
||||
|
||||
最简单解决漏洞的方法是你不包含这个漏洞。
|
||||
|
||||
(题图:[Creative Commons Zero][2] Pixabay)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/event/elcna/2017/2/how-manage-security-vulnerabilities-your-open-source-product
|
||||
|
||||
作者:[AMBER ANKERHOLZ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/aankerholz
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/ryan-ware01jpg
|
||||
[4]:https://www.linux.com/files/images/security-software-vulnerabilitiesjpg
|
||||
[5]:http://events.linuxfoundation.org/events/embedded-linux-conference/program/schedule?utm_source=linux&utm_campaign=elc17&utm_medium=blog&utm_content=video-blog
|
||||
[6]:http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[7]:http://events.linuxfoundation.org/events/openiot-summit
|
||||
[8]:http://www.cvedetails.com/
|
||||
@ -0,0 +1,61 @@
|
||||
在 Kali Linux 的 Wireshark 中过滤数据包
|
||||
==================
|
||||
|
||||
### 介绍
|
||||
|
||||
数据包过滤可让你专注于你感兴趣的确定数据集。如你所见,Wireshark 默认会抓取_所有_数据包。这可能会妨碍你寻找具体的数据。 Wireshark 提供了两个功能强大的过滤工具,让你简单而无痛地获得精确的数据。
|
||||
|
||||
Wireshark 可以通过两种方式过滤数据包。它可以通过只收集某些数据包来过滤,或者在抓取数据包后进行过滤。当然,这些可以彼此结合使用,并且它们各自的用处取决于收集的数据和信息的多少。
|
||||
|
||||
### 布尔表达式和比较运算符
|
||||
|
||||
Wireshark 有很多很棒的内置过滤器。当开始输入任何一个过滤器字段时,你将看到它们会自动补完。这些过滤器大多数对应于用户对数据包的常见分组方式,比如仅过滤 HTTP 请求就是一个很好的例子。
|
||||
|
||||
对于其他的,Wireshark 使用布尔表达式和/或比较运算符。如果你曾经做过任何编程,你应该熟悉布尔表达式。他们是使用 `and`、`or`、`not` 来验证声明或表达式的真假。比较运算符要简单得多,它们只是确定两件或更多件事情是否彼此相等、大于或小于。
|
||||
|
||||
### 过滤抓包
|
||||
|
||||
在深入自定义抓包过滤器之前,请先查看 Wireshark 已经内置的内容。单击顶部菜单上的 “Capture” 选项卡,然后点击 “Options”。可用接口下面是可以编写抓包过滤器的行。直接移到左边一个标有 “Capture Filter” 的按钮上。点击它,你将看到一个新的对话框,其中包含内置的抓包过滤器列表。看看里面有些什么。
|
||||
|
||||

|
||||
|
||||
在对话框的底部,有一个用于创建并保存抓包过滤器的表单。按左边的 “New” 按钮。它将创建一个填充有默认数据的新的抓包过滤器。要保存新的过滤器,只需将实际需要的名称和表达式替换原来的默认值,然后单击“Ok”。过滤器将被保存并应用。使用此工具,你可以编写并保存多个不同的过滤器,以便它们将来可以再次使用。
|
||||
|
||||
抓包有自己的过滤语法。对于比较,它不使用等于号,并使用 `>` 和 `<` 来用于大于或小于。对于布尔值来说,它使用 `and`、`or` 和 `not`。
|
||||
|
||||
例如,如果你只想监听 80 端口的流量,你可以使用这样的表达式:`port 80`。如果你只想从特定的 IP 监听端口 80,你可以使用 `port 80 and host 192.168.1.20`。如你所见,抓包过滤器有特定的关键字。这些关键字用于告诉 Wireshark 如何监控数据包以及哪一个数据是要找的。例如,`host` 用于查看来自 IP 的所有流量。`src` 用于查看源自该 IP 的流量。与之相反,`dst` 只监听目标到这个 IP 的流量。要查看一组 IP 或网络上的流量,请使用 `net`。
|
||||
|
||||
### 过滤结果
|
||||
|
||||
界面的底部菜单栏是专门用于过滤结果的菜单栏。此过滤器不会更改 Wireshark 收集的数据,它只允许你更轻松地对其进行排序。有一个文本字段用于输入新的过滤器表达式,并带有一个下拉箭头以查看以前输入的过滤器。旁边是一个标为 “Expression” 的按钮,另外还有一些用于清除和保存当前表达式的按钮。
|
||||
|
||||
点击 “Expression” 按钮。你将看到一个小窗口,其中包含多个选项。左边一栏有大量的条目,每个都有附加的折叠子列表。你可以用这些来过滤所有不同的协议、字段和信息。你不可能看完所有,所以最好是大概看下。你应该注意到了一些熟悉的选项,如 HTTP、SSL 和 TCP。
|
||||
|
||||

|
||||
|
||||
子列表包含可以过滤的不同部分和请求方法。你可以看到通过 GET 和 POST 请求过滤 HTTP 请求。
|
||||
|
||||
你还可以在中间看到运算符列表。通过从每列中选择条目,你可以使用此窗口创建过滤器,而不用记住 Wireshark 可以过滤的每个条目。对于过滤结果,比较运算符使用一组特定的符号。 `==` 用于确定是否相等。`>` 用于确定一件东西是否大于另一个东西,`<` 找出是否小一些。 `>=` 和 `<=` 分别用于大于等于和小于等于。它们可用于确定数据包是否包含正确的值或按大小过滤。使用 `==` 仅过滤 HTTP GET 请求的示例如下:`http.request.method == "GET"`。
|
||||
|
||||
布尔运算符基于多个条件将小的表达式串到一起。不像是抓包所使用的单词,它使用三个基本的符号来做到这一点。`&&` 代表 “与”。当使用时,`&&` 两边的两个语句都必须为真值才行,以便 Wireshark 来过滤这些包。`||` 表示 “或”。只要两个表达式任何一个为真值,它就会被过滤。如果你正在查找所有的 GET 和 POST 请求,你可以这样使用 `||`:`(http.request.method == "GET") || (http.request.method == "POST")`。`!` 是 “非” 运算符。它会寻找除了指定的东西之外的所有东西。例如,`!http` 将展示除了 HTTP 请求之外的所有东西。
|
||||
|
||||
### 总结思考
|
||||
|
||||
过滤 Wireshark 可以让你有效监控网络流量。熟悉可以使用的选项并习惯你可以创建过滤器的强大表达式需要一些时间。然而一旦你学会了,你将能够快速收集和查找你要的网络数据,而无需梳理长长的数据包或进行大量的工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
[1]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h1-introduction
|
||||
[2]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h2-boolean-expressions-and-comparison-operators
|
||||
[3]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h3-filtering-capture
|
||||
[4]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h4-filtering-results
|
||||
[5]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h5-closing-thoughts
|
||||
@ -0,0 +1,68 @@
|
||||
开源优先:私营公司宣言
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
这是一个宣言,任何私人组织都可以用来构建其协作转型。请阅读并让我知道你的看法。
|
||||
|
||||
我[在 Linux TODO 小组中作了一个演讲][3]使用了这篇文章作为我的材料。对于那些不熟悉 TODO 小组的人,他们是在商业公司支持开源领导力的组织。相互依赖是很重要的,因为法律、安全和其他共享的知识对于开源社区向前推进是非常重要的。尤其是因为我们需要同时代表商业和公共社区的最佳利益。
|
||||
|
||||
“开源优先”意味着我们在考虑供应商出品的产品以满足我们的需求之前,首先考虑开源。要正确使用开源技术,你需要做的不仅仅是消费,还需要你的参与,以确保开源技术长期存在。要参与开源工作,你需要将工程师的工作时间分别分配给你的公司和开源项目。我们期望将开源贡献意图以及内部协作带到私营公司。我们需要定义、建立和维护一种贡献、协作和择优工作的文化。
|
||||
|
||||
### 开放花园开发
|
||||
|
||||
我们的私营公司致力于通过对技术界的贡献,成为技术的领导者。这不仅仅是使用开源代码,成为领导者需要参与。成为领导者还需要与公司以外的团体(社区)进行各种类型的参与。这些社区围绕一个特定的研发项目进行组织。每个社区的参与就像为公司工作一样。重大成果需要大量的参与。
|
||||
|
||||
### 编码更多,生活更好
|
||||
|
||||
我们必须对计算资源慷慨,对空间吝啬,并鼓励由此产生的凌乱而有创造力的结果。允许人们使用他们的业务的这些工具将改变他们。我们必须有自发的互动。我们必须通过协作来构建鼓励创造性的线上以及线下空间。无法实时联系对方,协作就不能进行。
|
||||
|
||||
### 通过精英体制创新
|
||||
|
||||
我们必须创建一个精英阶层。思想素质要超过群体结构和在其中的职位任期。按业绩晋升鼓励每个人都成为更好的人和雇员。当我们成为最好的坏人时, 充满激情的人之间的争论将会发生。我们的文化应该有鼓励异议的义务。强烈的意见和想法将会变成热情的职业道德。这些想法和意见可以来自而且应该来自所有人。它不应该改变你是谁,而是应该关心你做什么。随着精英体制的进行,我们会投资未经许可就能正确行事的团队。
|
||||
|
||||
### 项目到产品
|
||||
|
||||
由于我们的私营公司拥抱开源贡献,我们还必须在研发项目中的上游工作和实现最终产品之间实现明确的分离。项目是研发工作,快速失败以及开发功能是常态。产品是你投入生产,拥有 SLA,并使用研发项目的成果。分离至少需要分离项目和产品的仓库。正常的分离包含在项目和产品上工作的不同社区。每个社区都需要大量的贡献和参与。为了使这些活动保持独立,需要有一个客户功能以及项目到产品的 bug 修复请求的工作流程。
|
||||
|
||||
接下来,我们会强调在私营公司创建、支持和扩展开源中的主要步骤。
|
||||
|
||||
### 技术上有天赋的人的学校
|
||||
|
||||
高手必须指导没有经验的人。当你学习新技能时,你将它们传给下一个人。当你训练下一个人时,你会面临新的挑战。永远不要期待在一个位置很长时间。获得技能,变得强大,通过学习,然后继续前进。
|
||||
|
||||
### 找到最适合你的人
|
||||
|
||||
我们热爱我们的工作。我们非常喜欢它,我们想和我们的朋友一起工作。我们是一个比我们公司大的社区的一部分。我们应该永远记住招募最好的人与我们一起工作。即使不是为我们公司工作,我们将会为我们周围的人找到很棒的工作。这样的想法使雇用很棒的人成为一种生活方式。随着招聘变得普遍,那么审查和帮助新员工就会变得容易了。
|
||||
|
||||
### 即将写的
|
||||
|
||||
我将在我的博客上发布关于每个宗旨的[更多细节][4],敬请关注。
|
||||
|
||||
_这篇文章最初发表在[ Sean Robert 的博客][1]上。CC BY 许可。_
|
||||
|
||||
(题图: opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Sean A Roberts - -以同理心为主导,同时专注于结果。我实践精英体制。在这里发现的智慧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/open-source-first
|
||||
|
||||
作者:[Sean A Roberts][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sarob
|
||||
[1]:https://sarob.com/2017/01/open-source-first/
|
||||
[2]:https://opensource.com/article/17/2/open-source-first?rate=CKF77ZVh5e_DpnmSlOKTH-MuFBumAp-tIw-Rza94iEI
|
||||
[3]:https://sarob.com/2017/01/todo-open-source-presentation-17-january-2017/
|
||||
[4]:https://sarob.com/2017/02/open-source-first-project-product/
|
||||
[5]:https://opensource.com/user/117441/feed
|
||||
[6]:https://opensource.com/users/sarob
|
||||
@ -0,0 +1,222 @@
|
||||
Linux 开机引导和启动过程详解
|
||||
===========
|
||||
|
||||
|
||||
> 你是否曾经对操作系统为何能够执行应用程序而感到疑惑?那么本文将为你揭开操作系统引导与启动的面纱。
|
||||
|
||||
理解操作系统开机引导和启动过程对于配置操作系统和解决相关启动问题是至关重要的。该文章陈述了 [GRUB2 引导装载程序][1]开机引导装载内核的过程和 [systemd 初始化系统][2]执行开机启动操作系统的过程。
|
||||
|
||||
事实上,操作系统的启动分为两个阶段:<ruby>引导<rt>boot</rt></ruby>和<ruby>启动<rt>startup</rt></ruby>。引导阶段开始于打开电源开关,结束于内核初始化完成和 systemd 进程成功运行。启动阶段接管了剩余工作,直到操作系统进入可操作状态。
|
||||
|
||||
总体来说,Linux 的开机引导和启动过程是相当容易理解,下文将分节对于不同步骤进行详细说明。
|
||||
|
||||
- BIOS 上电自检(POST)
|
||||
- 引导装载程序 (GRUB2)
|
||||
- 内核初始化
|
||||
- 启动 systemd,其是所有进程之父。
|
||||
|
||||
注意,本文以 GRUB2 和 systemd 为载体讲述操作系统的开机引导和启动过程,是因为这二者是目前主流的 linux 发行版本所使用的引导装载程序和初始化软件。当然另外一些过去使用的相关软件仍然在一些 Linux 发行版本中使用。
|
||||
|
||||
### 引导过程
|
||||
|
||||
引导过程能以两种方式之一初始化。其一,如果系统处于关机状态,那么打开电源按钮将开启系统引导过程。其二,如果操作系统已经运行在一个本地用户(该用户可以是 root 或其他非特权用户),那么用户可以借助图形界面或命令行界面通过编程方式发起一个重启操作,从而触发系统引导过程。重启包括了一个关机和重新开始的操作。
|
||||
|
||||
#### BIOS 上电自检(POST)
|
||||
|
||||
上电自检过程中其实 Linux 没有什么也没做,上电自检主要由硬件的部分来完成,这对于所有操作系统都一样。当电脑接通电源,电脑开始执行 BIOS(<ruby>基本输入输出系统<rt>Basic I/O System</rt></ruby>)的 POST(<ruby>上电自检<rt>Power On Self Test</rt></ruby>)过程。
|
||||
|
||||
在 1981 年,IBM 设计的第一台个人电脑中,BIOS 被设计为用来初始化硬件组件。POST 作为 BIOS 的组成部分,用于检验电脑硬件基本功能是否正常。如果 POST 失败,那么这个电脑就不能使用,引导过程也将就此中断。
|
||||
|
||||
BIOS 上电自检确认硬件的基本功能正常,然后产生一个 BIOS [中断][3] INT 13H,该中断指向某个接入的可引导设备的引导扇区。它所找到的包含有效的引导记录的第一个引导扇区将被装载到内存中,并且控制权也将从引导扇区转移到此段代码。
|
||||
|
||||
引导扇区是引导加载器真正的第一阶段。大多数 Linux 发行版本使用的引导加载器有三种:GRUB、GRUB2 和 LILO。GRUB2 是最新的,也是相对于其他老的同类程序使用最广泛的。
|
||||
|
||||
#### GRUB2
|
||||
|
||||
GRUB2 全称是 GRand Unified BootLoader,Version 2(第二版大一统引导装载程序)。它是目前流行的大部分 Linux 发行版本的主要引导加载程序。GRUB2 是一个用于计算机寻找操作系统内核并加载其到内存的智能程序。由于 GRUB 这个单词比 GRUB2 更易于书写和阅读,在下文中,除特殊指明以外,GRUB 将代指 GRUB2。
|
||||
|
||||
GRUB 被设计为兼容操作系统[多重引导规范][4],它能够用来引导不同版本的 Linux 和其他的开源操作系统;它还能链式加载专有操作系统的引导记录。
|
||||
|
||||
GRUB 允许用户从任何给定的 Linux 发行版本的几个不同内核中选择一个进行引导。这个特性使得操作系统,在因为关键软件不兼容或其它某些原因升级失败时,具备引导到先前版本的内核的能力。GRUB 能够通过文件 `/boot/grub/grub.conf` 进行配置。(LCTT 译注:此处指 GRUB1)
|
||||
|
||||
GRUB1 现在已经逐步被弃用,在大多数现代发行版上它已经被 GRUB2 所替换,GRUB2 是在 GRUB1 的基础上重写完成。基于 Red Hat 的发行版大约是在 Fedora 15 和 CentOS/RHEL 7 时升级到 GRUB2 的。GRUB2 提供了与 GRUB1 同样的引导功能,但是 GRUB2 也是一个类似主框架(mainframe)系统上的基于命令行的前置操作系统(Pre-OS)环境,使得在预引导阶段配置更为方便和易操作。GRUB2 通过 `/boot/grub2/grub.cfg` 进行配置。
|
||||
|
||||
两个 GRUB 的最主要作用都是将内核加载到内存并运行。两个版本的 GRUB 的基本工作方式一致,其主要阶段也保持相同,都可分为 3 个阶段。在本文将以 GRUB2 为例进行讨论其工作过程。GRUB 或 GRUB2 的配置,以及 GRUB2 的命令使用均超过本文范围,不会在文中进行介绍。
|
||||
|
||||
虽然 GRUB2 并未在其三个引导阶段中正式使用这些<ruby>阶段<rt>stage</rt></ruby>名词,但是为了讨论方便,我们在本文中使用它们。
|
||||
|
||||
##### 阶段 1
|
||||
|
||||
如上文 POST(上电自检)阶段提到的,在 POST 阶段结束时,BIOS 将查找在接入的磁盘中查找引导记录,其通常位于 MBR(<ruby>主引导记录<rt>Master Boot Record</rt></ruby>),它加载它找到的第一个引导记录中到内存中,并开始执行此代码。引导代码(及阶段 1 代码)必须非常小,因为它必须连同分区表放到硬盘的第一个 512 字节的扇区中。 在[传统的常规 MBR][5] 中,引导代码实际所占用的空间大小为 446 字节。这个阶段 1 的 446 字节的文件通常被叫做引导镜像(boot.img),其中不包含设备的分区信息,分区是一般单独添加到引导记录中。
|
||||
|
||||
由于引导记录必须非常的小,它不可能非常智能,且不能理解文件系统结构。因此阶段 1 的唯一功能就是定位并加载阶段 1.5 的代码。为了完成此任务,阶段 1.5 的代码必须位于引导记录与设备第一个分区之间的位置。在加载阶段 1.5 代码进入内存后,控制权将由阶段 1 转移到阶段 1.5。
|
||||
|
||||
##### 阶段 1.5
|
||||
|
||||
如上所述,阶段 1.5 的代码必须位于引导记录与设备第一个分区之间的位置。该空间由于历史上的技术原因而空闲。第一个分区的开始位置在扇区 63 和 MBR(扇区 0)之间遗留下 62 个 512 字节的扇区(共 31744 字节),该区域用于存储阶段 1.5 的代码镜像 core.img 文件。该文件大小为 25389 字节,故此区域有足够大小的空间用来存储 core.img。
|
||||
|
||||
因为有更大的存储空间用于阶段 1.5,且该空间足够容纳一些通用的文件系统驱动程序,如标准的 EXT 和其它的 Linux 文件系统,如 FAT 和 NTFS 等。GRUB2 的 core.img 远比更老的 GRUB1 阶段 1.5 更复杂且更强大。这意味着 GRUB2 的阶段 2 能够放在标准的 EXT 文件系统内,但是不能放在逻辑卷内。故阶段 2 的文件可以存放于 `/boot` 文件系统中,一般在 `/boot/grub2` 目录下。
|
||||
|
||||
注意 `/boot` 目录必须放在一个 GRUB 所支持的文件系统(并不是所有的文件系统均可)。阶段 1.5 的功能是开始执行存放阶段 2 文件的 `/boot` 文件系统的驱动程序,并加载相关的驱动程序。
|
||||
|
||||
##### 阶段 2
|
||||
|
||||
GRUB 阶段 2 所有的文件都已存放于 `/boot/grub2` 目录及其几个子目录之下。该阶段没有一个类似于阶段 1 与阶段 1.5 的镜像文件。相应地,该阶段主要需要从 `/boot/grub2/i386-pc` 目录下加载一些内核运行时模块。
|
||||
|
||||
GRUB 阶段 2 的主要功能是定位和加载 Linux 内核到内存中,并转移控制权到内核。内核的相关文件位于 `/boot` 目录下,这些内核文件可以通过其文件名进行识别,其文件名均带有前缀 vmlinuz。你可以列出 `/boot` 目录中的内容来查看操作系统中当前已经安装的内核。
|
||||
|
||||
GRUB2 跟 GRUB1 类似,支持从 Linux 内核选择之一引导启动。Red Hat 包管理器(DNF)支持保留多个内核版本,以防最新版本内核发生问题而无法启动时,可以恢复老版本的内核。默认情况下,GRUB 提供了一个已安装内核的预引导菜单,其中包括问题诊断菜单(recuse)以及恢复菜单(如果配置已经设置恢复镜像)。
|
||||
|
||||
阶段 2 加载选定的内核到内存中,并转移控制权到内核代码。
|
||||
|
||||
#### 内核
|
||||
|
||||
内核文件都是以一种自解压的压缩格式存储以节省空间,它与一个初始化的内存映像和存储设备映射表都存储于 `/boot` 目录之下。
|
||||
|
||||
在选定的内核加载到内存中并开始执行后,在其进行任何工作之前,内核文件首先必须从压缩格式解压自身。一旦内核自解压完成,则加载 [systemd][6] 进程(其是老式 System V 系统的 [init][7] 程序的替代品),并转移控制权到 systemd。
|
||||
|
||||
这就是引导过程的结束。此刻,Linux 内核和 systemd 处于运行状态,但是由于没有其他任何程序在执行,故其不能执行任何有关用户的功能性任务。
|
||||
|
||||
### 启动过程
|
||||
|
||||
启动过程紧随引导过程之后,启动过程使 Linux 系统进入可操作状态,并能够执行用户功能性任务。
|
||||
|
||||
#### systemd
|
||||
|
||||
systemd 是所有进程的父进程。它负责将 Linux 主机带到一个用户可操作状态(可以执行功能任务)。systemd 的一些功能远较旧式 init 程序更丰富,可以管理运行中的 Linux 主机的许多方面,包括挂载文件系统,以及开启和管理 Linux 主机的系统服务等。但是 systemd 的任何与系统启动过程无关的功能均不在此文的讨论范围。
|
||||
|
||||
首先,systemd 挂载在 `/etc/fstab` 中配置的文件系统,包括内存交换文件或分区。据此,systemd 必须能够访问位于 `/etc` 目录下的配置文件,包括它自己的。systemd 借助其配置文件 `/etc/systemd/system/default.target` 决定 Linux 系统应该启动达到哪个状态(或<ruby>目标态<rt>target</rt></ruby>)。`default.target` 是一个真实的 target 文件的符号链接。对于桌面系统,其链接到 `graphical.target`,该文件相当于旧式 systemV init 方式的 **runlevel 5**。对于一个服务器操作系统来说,`default.target` 更多是默认链接到 `multi-user.target`, 相当于 systemV 系统的 **runlevel 3**。 `emergency.target` 相当于单用户模式。
|
||||
|
||||
(LCTT 译注:“target” 是 systemd 新引入的概念,目前尚未发现有官方的准确译名,考虑到其作用和使用的上下文环境,我们认为翻译为“目标态”比较贴切。以及,“unit” 是指 systemd 中服务和目标态等各个对象/文件,在此依照语境译作“单元”。)
|
||||
|
||||
注意,所有的<ruby>目标态<rt>target</rt></ruby>和<ruby>服务<rt>service</rt></ruby>均是 systemd 的<ruby>单元<rt>unit</rt></ruby>。
|
||||
|
||||
如下表 1 是 systemd 启动的<ruby>目标态<rt>target</rt></ruby>和老版 systemV init 启动<ruby>运行级别<rt>runlevel</rt></ruby>的对比。这个 **systemd 目标态别名** 是为了 systemd 向前兼容 systemV 而提供。这个目标态别名允许系统管理员(包括我自己)用 systemV 命令(例如 `init 3`)改变运行级别。当然,该 systemV 命令是被转发到 systemd 进行解释和执行的。
|
||||
|
||||
|SystemV 运行级别 | systemd 目标态 | systemd 目标态别名 | 描述 |
|
||||
|:---:|---|---|---|
|
||||
| | `halt.target` | | 停止系统运行但不切断电源。 |
|
||||
| 0 | `poweroff.target` | `runlevel0.target` | 停止系统运行并切断电源. |
|
||||
| S | `emergency.target` | | 单用户模式,没有服务进程运行,文件系统也没挂载。这是一个最基本的运行级别,仅在主控制台上提供一个 shell 用于用户与系统进行交互。|
|
||||
| 1 | `rescue.target` | `runlevel1.target` | 挂载了文件系统,仅运行了最基本的服务进程的基本系统,并在主控制台启动了一个 shell 访问入口用于诊断。 |
|
||||
| 2 | | `runlevel2.target` | 多用户,没有挂载 NFS 文件系统,但是所有的非图形界面的服务进程已经运行。 |
|
||||
| 3 | `multi-user.target` | `runlevel3.target` | 所有服务都已运行,但只支持命令行接口访问。 |
|
||||
| 4 | | `runlevel4.target` | 未使用。|
|
||||
| 5 | `graphical.target` | `runlevel5.target` | 多用户,且支持图形界面接口。|
|
||||
| 6 | `reboot.target` | `runlevel6.target` | 重启。 |
|
||||
| | `default.target` | | 这个<ruby>目标态<rt>target</rt></ruby>是总是 `multi-user.target` 或 `graphical.target` 的一个符号链接的别名。systemd 总是通过 `default.target` 启动系统。`default.target` 绝不应该指向 `halt.target`、 `poweroff.target` 或 `reboot.target`。 |
|
||||
|
||||
*表 1 老版本 systemV 的 运行级别与 systemd 与<ruby>目标态<rt>target</rt></ruby>或目标态别名的比较*
|
||||
|
||||
每个<ruby>目标态<rt>target</rt></ruby>有一个在其配置文件中描述的依赖集,systemd 需要首先启动其所需依赖,这些依赖服务是 Linux 主机运行在特定的功能级别所要求的服务。当配置文件中所有的依赖服务都加载并运行后,即说明系统运行于该目标级别。
|
||||
|
||||
systemd 也会查看老式的 systemV init 目录中是否存在相关启动文件,若存在,则 systemd 根据这些配置文件的内容启动对应的服务。在 Fedora 系统中,过时的网络服务就是通过该方式启动的一个实例。
|
||||
|
||||
如下图 1 是直接从 bootup 的 man 页面拷贝而来。它展示了在 systemd 启动过程中一般的事件序列和确保成功的启动的基本的顺序要求。
|
||||
|
||||
`sysinit.target` 和 `basic.target` 目标态可以被视作启动过程中的状态检查点。尽管 systemd 的设计初衷是并行启动系统服务,但是部分服务或功能目标态是其它服务或目标态的启动的前提。系统将暂停于检查点直到其所要求的服务和目标态都满足为止。
|
||||
|
||||
`sysinit.target` 状态的到达是以其所依赖的所有资源模块都正常启动为前提的,所有其它的单元,如文件系统挂载、交换文件设置、设备管理器的启动、随机数生成器种子设置、低级别系统服务初始化、加解密服务启动(如果一个或者多个文件系统加密的话)等都必须完成,但是在 **sysinit.target** 中这些服务与模块是可以并行启动的。
|
||||
|
||||
`sysinit.target` 启动所有的低级别服务和系统初具功能所需的单元,这些都是进入下一阶段 basic.target 的必要前提。
|
||||
|
||||
```
|
||||
local-fs-pre.target
|
||||
|
|
||||
v
|
||||
(various mounts and (various swap (various cryptsetup
|
||||
fsck services...) devices...) devices...) (various low-level (various low-level
|
||||
| | | services: udevd, API VFS mounts:
|
||||
v v v tmpfiles, random mqueue, configfs,
|
||||
local-fs.target swap.target cryptsetup.target seed, sysctl, ...) debugfs, ...)
|
||||
| | | | |
|
||||
\__________________|_________________ | ___________________|____________________/
|
||||
\|/
|
||||
v
|
||||
sysinit.target
|
||||
|
|
||||
____________________________________/|\________________________________________
|
||||
/ | | | \
|
||||
| | | | |
|
||||
v v | v v
|
||||
(various (various | (various rescue.service
|
||||
timers...) paths...) | sockets...) |
|
||||
| | | | v
|
||||
v v | v *rescue.target
|
||||
timers.target paths.target | sockets.target
|
||||
| | | |
|
||||
v \_________________ | ___________________/
|
||||
\|/
|
||||
v
|
||||
basic.target
|
||||
|
|
||||
____________________________________/| emergency.service
|
||||
/ | | |
|
||||
| | | v
|
||||
v v v *emergency.target
|
||||
display- (various system (various system
|
||||
manager.service services services)
|
||||
| required for |
|
||||
| graphical UIs) v
|
||||
| | *multi-user.target
|
||||
| | |
|
||||
\_________________ | _________________/
|
||||
\|/
|
||||
v
|
||||
*graphical.target
|
||||
```
|
||||
*图 1:systemd 的启动流程*
|
||||
|
||||
在 `sysinit.target` 的条件满足以后,systemd 接下来启动 `basic.target`,启动其所要求的所有单元。 `basic.target` 通过启动下一目标态所需的单元而提供了更多的功能,这包括各种可执行文件的目录路径、通信 sockets,以及定时器等。
|
||||
|
||||
最后,用户级目标态(`multi-user.target` 或 `graphical.target`) 可以初始化了,应该注意的是 `multi-user.target` 必须在满足图形化目标态 `graphical.target` 的依赖项之前先达成。
|
||||
|
||||
图 1 中,以 `*` 开头的目标态是通用的启动状态。当到达其中的某一目标态,则说明系统已经启动完成了。如果 `multi-user.target` 是默认的目标态,则成功启动的系统将以命令行登录界面呈现于用户。如果 `graphical.target` 是默认的目标态,则成功启动的系统将以图形登录界面呈现于用户,界面的具体样式将根据系统所配置的[显示管理器][8]而定。
|
||||
|
||||
### 故障讨论
|
||||
|
||||
最近我需要改变一台使用 GRUB2 的 Linux 电脑的默认引导内核。我发现一些 GRUB2 的命令在我的系统上不能用,也可能是我使用方法不正确。至今,我仍然不知道是何原因导致,此问题需要进一步探究。
|
||||
|
||||
`grub2-set-default` 命令没能在配置文件 `/etc/default/grub` 中成功地设置默认内核索引,以至于期望的替代内核并没有被引导启动。故在该配置文件中我手动更改 `GRUB_DEFAULT=saved` 为 `GRUB_DEFAULT=2`,2 是我需要引导的安装好的内核文件的索引。然后我执行命令 `grub2-mkconfig > /boot/grub2/grub.cfg` 创建了新的 GRUB 配置文件,该方法如预期的规避了问题,并成功引导了替代的内核。
|
||||
|
||||
### 结论
|
||||
|
||||
GRUB2、systemd 初始化系统是大多数现代 Linux 发行版引导和启动的关键组件。尽管在实际中,systemd 的使用还存在一些争议,但是 GRUB2 与 systemd 可以密切地配合先加载内核,然后启动一个业务系统所需要的系统服务。
|
||||
|
||||
尽管 GRUB2 和 systemd 都比其前任要更加复杂,但是它们更加容易学习和管理。在 man 页面有大量关于 systemd 的帮助说明,freedesktop.org 也在线收录了完整的此[帮助说明][9]。下面有更多相关信息链接。
|
||||
|
||||
### 附加资源
|
||||
|
||||
- [GNU GRUB](https://en.wikipedia.org/wiki/GNU_GRUB) (Wikipedia)
|
||||
- [GNU GRUB Manual](https://www.gnu.org/software/grub/manual/grub.html) (GNU.org)
|
||||
- [Master Boot Record](https://en.wikipedia.org/wiki/Master_boot_record) (Wikipedia)
|
||||
- [Multiboot specification](https://en.wikipedia.org/wiki/Multiboot_Specification) (Wikipedia)
|
||||
- [systemd](https://en.wikipedia.org/wiki/Systemd) (Wikipedia)
|
||||
- [systemd bootup process](https://www.freedesktop.org/software/systemd/man/bootup.html) (Freedesktop.org)
|
||||
- [systemd index of man pages](https://www.freedesktop.org/software/systemd/man/index.html) (Freedesktop.org)
|
||||
|
||||
---
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both 居住在美国北卡罗纳州的首府罗利,是一个 Linux 开源贡献者。他已经从事 IT 行业 40 余年,在 IBM 教授 OS/2 20余年。1981 年,他在 IBM 开发了第一个关于最初的 IBM 个人电脑的培训课程。他也曾在 Red Hat 教授 RHCE 课程,也曾供职于 MCI worldcom,Cico 以及北卡罗纳州等。他已经为 Linux 开源社区工作近 20 年。
|
||||
|
||||
---
|
||||
via: https://opensource.com/article/17/2/linux-boot-and-startup
|
||||
|
||||
作者:[David Both](https://opensource.com/users/dboth)
|
||||
译者: [penghuster](https://github.com/penghuster)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]: https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[2]: https://en.wikipedia.org/wiki/Systemd
|
||||
[3]: https://en.wikipedia.org/wiki/BIOS_interrupt_call
|
||||
[4]: https://en.wikipedia.org/wiki/Multiboot_Specification
|
||||
[5]: https://en.wikipedia.org/wiki/Master_boot_record
|
||||
[6]: https://en.wikipedia.org/wiki/Systemd
|
||||
[7]: https://en.wikipedia.org/wiki/Init#SysV-style
|
||||
[8]: https://opensource.com/article/16/12/yearbook-best-couple-2016-display-manager-and-window-manager
|
||||
[9]: https://www.freedesktop.org/software/systemd/man/index.html
|
||||
@ -0,0 +1,113 @@
|
||||
听说过时间表,但是你是否知道“哈希表”
|
||||
============================================================
|
||||
|
||||
探索<ruby>哈希表<rt>hash table</rt></ruby>的世界并理解其底层的机制是非常有趣的,并且将会受益匪浅。所以,让我们了解它,并从头开始探索吧。
|
||||
|
||||
哈希表是许多现代软件应用程序中一种常见的数据结构。它提供了类似字典的功能,使你能够在其中执行插入、删除和删除等操作。这么说吧,比如我想找出“苹果”的定义是什么,并且我知道该定义被存储在了我定义的哈希表中。我将查询我的哈希表来得到定义。它在哈希表内的记录看起来可能像:`"苹果" => "一种拥有水果之王之称的绿色水果"`。这里,“苹果”是我的关键字,而“一种拥有水果之王之称的水果”是与之关联的值。
|
||||
|
||||
还有一个例子可以让我们更清楚,哈希表的内容如下:
|
||||
|
||||
```
|
||||
"面包" => "固体"
|
||||
"水" => "液体"
|
||||
"汤" => "液体"
|
||||
"玉米片" => "固体"
|
||||
```
|
||||
|
||||
我想知道*面包*是固体还是液体,所以我将查询哈希表来获取与之相关的值,该哈希表将返回“固体”给我。现在,我们大致了解了哈希表是如何工作的。使用哈希表需要注意的另一个重要概念是每一个关键字都是唯一的。如果到了明天,我拥有一个面包奶昔(它是液体),那么我们需要更新哈希表,把“固体”改为“液体”来反映哈希表的改变。所以,我们需要添加一条记录到字典中:关键字为“面包”,对应的值为“液体”。你能发现下面的表发生了什么变化吗?(LCTT 译注:不知道这个“面包奶昔”是一种什么食物,大约是一种面包做的奶昔,总之你就理解成作者把液体的“面包奶昔”当成一种面包吧。)
|
||||
|
||||
```
|
||||
"面包" => "液体"
|
||||
"水" => "液体"
|
||||
"汤" => "液体"
|
||||
"玉米片" => "固体"
|
||||
```
|
||||
|
||||
没错,“面包”对应的值被更新为了“液体”。
|
||||
|
||||
**关键字是唯一的**,我的面包不能既是液体又是固体。但是,是什么使得该数据结构与其他数据结构相比如此特殊呢?为什么不使用一个[数组][1]来代替呢?它取决于问题的本质。对于某一个特定的问题,使用数组来描述可能会更好,因此,我们需要注意的关键点就是,**我们应该选择最适合问题的数据结构**。例如,如果你需要做的只是存储一个简单的杂货列表,那么使用数组会很适合。考虑下面的两个问题,两个问题的本质完全不同。
|
||||
|
||||
1. 我需要一个水果的列表
|
||||
2. 我需要一个水果的列表以及各种水果的价格(每千克)
|
||||
|
||||
正如你在下面所看到的,用数组来存储水果的列表可能是更好的选择。但是,用哈希表来存储每一种水果的价格看起来是更好的选择。
|
||||
|
||||
|
||||
```
|
||||
//示例数组
|
||||
["苹果", "桔子", "梨子", "葡萄"]
|
||||
//示例哈希表
|
||||
{ "苹果" : 3.05,
|
||||
"桔子" : 5.5,
|
||||
"梨子" : 8.4,
|
||||
"葡萄" : 12.4
|
||||
}
|
||||
```
|
||||
|
||||
实际上,有许多的机会需要[使用][2]哈希表。
|
||||
|
||||
### 时间以及它对你的意义
|
||||
|
||||
[这是对时间复杂度和空间复杂度的一个复习][3]。
|
||||
|
||||
平均情况下,在哈希表中进行搜索、插入和删除记录的时间复杂度均为 `O(1)` 。实际上,`O(1)` 读作“大 O 1”,表示常数时间。这意味着执行每一种操作的运行时间不依赖于数据集中数据的数量。我可以保证,查找、插入和删除项目均只花费常数时间,“当且仅当”哈希表的实现方式正确时。如果实现不正确,可能需要花费很慢的 `O(n)` 时间,尤其是当所有的数据都映射到了哈希表中的同一位置/点。
|
||||
|
||||
### 构建一个好的哈希表
|
||||
|
||||
到目前为止,我们已经知道如何使用哈希表了,但是如果我们想**构建**一个哈希表呢?本质上我们需要做的就是把一个字符串(比如 “狗”)映射到一个哈希代码(一个生成的数),即映射到一个数组的索引。你可能会问,为什么不直接使用索引呢?为什么要这么麻烦呢?因为通过这种方式我们可以直接查询 “狗” 并立即得到 “狗” 所在的位置,`String name = Array["狗"] // 名字叫拉斯`。而使用索引查询名称时,可能出现的情况是我们不知道名称所在的索引。比如,`String name = Array[10] // 该名字现在叫鲍勃` - 那不是我的狗的名字。这就是把一个字符串映射到一个哈希代码的益处(对应于一个数组的索引而言)。我们可以通过使用模运算符和哈希表的大小来计算出数组的索引:`index = hash_code % table_size`。
|
||||
|
||||
我们需要避免的另一种情况是两个关键字映射到同一个索引,这叫做**哈希碰撞**,如果哈希函数实现的不好,这很容易发生。实际上,每一个输入比输出多的哈希函数都有可能发生碰撞。通过下面的同一个函数的两个输出来展示一个简单的碰撞:
|
||||
|
||||
```
|
||||
int cat_idx = hashCode("猫") % table_size; //cat_idx 现在等于 1
|
||||
int dog_idx = hashCode("狗") % table_size; //dog_idx 也等于 1
|
||||
```
|
||||
|
||||
我们可以看到,现在两个数组的索引均是 1 。这样将会出现两个值相互覆盖,因为它们被写到了相同的索引中。如果我们查找 “猫” 的值,将会返回 “拉斯” ,但是这并不是我们想要的。有许多可以[解决哈希碰撞][4]的方法,但是更受欢迎的一种方法叫做**链接**。链接的想法就是对于数组的每一个索引位置都有一个链表,如果碰撞发生,值就被存到链表中。因此,在前面的例子中,我们将会得到我们需要的值,但是我们需要搜索数组中索引为 1 的位置上的链表。伴有链接的哈希实现需要 `O(1 + α)` 时间,其中 α 是装载因子,它可以表示为 n/k,其中 n 是哈希表中的记录数目,k 是哈希表中可用位置的数目。但是请记住,只有当你给出的关键字非常随机时,这一结论才正确(依赖于 [SUHA][5])。
|
||||
|
||||
这是做了一个很大的假设,因为总是有可能任何不相等的关键字都散列到同一点。这一问题的一个解决方法是去除哈希表中关键字对随机性的依赖,转而把随机性集中于关键字是如何被散列的,从而减少矛盾发生的可能性。这被称为……
|
||||
|
||||
### 通用散列
|
||||
|
||||
这个观念很简单,从<ruby>通用散列<rt>universal hash</rt></ruby>家族集合随机选择一个哈希函数 h 来计算哈希代码。换句话来说,就是选择任何一个随机的哈希函数来散列关键字。通过这种方法,两个不同的关键字的散列结果相同的可能性将非常低(LCTT 译注:原文是“not be the same”,应是笔误)。我只是简单的提一下,如果不相信我那么请相信[数学][6]。实现这一方法时需要注意的另一件事是如果选择了一个不好的通用散列家族,它会把时间和空间复杂度拖到 `O(U)`,其中 U 是散列家族的大小。而其中的挑战就是找到一个不需要太多时间来计算,也不需要太多空间来存储的哈希家族。
|
||||
|
||||
### 上帝哈希函数
|
||||
|
||||
追求完美是人的天性。我们是否能够构建一个*完美的哈希函数*,从而能够把关键字映射到整数集中,并且几乎*没有碰撞*。好消息是我们能够在一定程度上做到,但是我们的数据必须是静态的(这意味着在一定时间内没有插入/删除/更新)。一个实现完美哈希函数的方法就是使用 <ruby>2 级哈希<rt>2-Level Hashing</rt></ruby>,它基本上是我们前面讨论过的两种方法的组合。它使用*通用散列*来选择使用哪个哈希函数,然后通过*链接*组合起来,但是这次不是使用链表数据结构,而是使用另一个哈希表。让我们看一看下面它是怎么实现的:
|
||||
|
||||
[][8]
|
||||
|
||||
**但是这是如何工作的以及我们如何能够确保无需关心碰撞?**
|
||||
|
||||
它的工作方式与[生日悖论][7]相反。它指出,在随机选择的一堆人中,会有一些人生日相同。但是如果一年中的天数远远大于人数(平方以上),那么有极大的可能性所有人的生日都不相同。所以这二者是如何相关的?对于每一个链接哈希表,其大小均为第一级哈希表大小的平方。那就是说,如果有两个元素被散列到同一个点,那么链接哈希表的大小将为 4 。大多数时候,链接哈希表将会非常稀疏/空。
|
||||
|
||||
重复下面两步来确保无需担心碰撞:
|
||||
|
||||
* 从通用散列家族中选择一个哈希函数来计算
|
||||
* 如果发生碰撞,那么继续从通用散列家族中选择另一个哈希函数来计算
|
||||
|
||||
字面上看就是这样(这是一个 `O(n^2)` 空间的解)。如果需要考虑空间问题,那么显然需要另一个不同的方法。但是值得庆幸的是,该过程平均只需要进行**两次**。
|
||||
|
||||
### 总结
|
||||
|
||||
只有具有一个好的哈希函数才能算得上是一个好的哈希表。在同时保证功能实现、时间和空间的提前下构建一个完美的哈希函数是一件很困难的事。我推荐你在解决问题的时候首先考虑哈希表,因为它能够为你提供巨大的性能优势,而且它能够对应用程序的可用性产生显著差异。哈希表和完美哈希函数常被用于实时编程应用中,并且在各种算法中都得到了广泛应用。你见或者不见,哈希表就在这儿。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zeroequalsfalse.press/2017/02/20/hashtables/
|
||||
|
||||
作者:[Marty Jacobs][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zeroequalsfalse.press/about
|
||||
[1]:https://en.wikipedia.org/wiki/Array_data_type
|
||||
[2]:https://en.wikipedia.org/wiki/Hash_table#Uses
|
||||
[3]:https://www.hackerearth.com/practice/basic-programming/complexity-analysis/time-and-space-complexity/tutorial/
|
||||
[4]:https://en.wikipedia.org/wiki/Hash_table#Collision_resolution
|
||||
[5]:https://en.wikipedia.org/wiki/SUHA_(computer_science
|
||||
[6]:https://en.wikipedia.org/wiki/Universal_hashing#Mathematical_guarantees
|
||||
[7]:https://en.wikipedia.org/wiki/Birthday_problem
|
||||
[8]:http://www.zeroequalsfalse.press/2017/02/20/hashtables/Diagram.png
|
||||
@ -1,28 +1,29 @@
|
||||
# 如何解决视频和嵌入字幕错误
|
||||
如何解决 VLC 视频嵌入字幕中遇到的错误
|
||||
===================
|
||||
|
||||
这会是一个有点奇怪的教程。背景故事如下。最近,我创作了一堆 [Risitas y las paelleras][4] 素材中[甜蜜][1][模仿][2][片段][3],以主角 Risitas 疯狂的笑声而闻名。和往常一样,我把它们上传到了 Youtube,但是当我决定使用字幕到最终在网上可以观看,我经历了一个漫长而曲折的历程。
|
||||
这会是一个有点奇怪的教程。背景故事如下。最近,我创作了一堆 [Risitas y las paelleras][4] 素材中[sweet][1] [parody][2] [的片段][3],以主角 Risitas 疯狂的笑声而闻名。和往常一样,我把它们上传到了 Youtube,但是从当我决定使用字幕起,到最终在网上可以观看时,我经历了一个漫长而曲折的历程。
|
||||
|
||||
在本指南中,我想介绍几个你可能会在创作自己的媒体时会遇到的典型问题,主要是使用字幕,然后上传到媒体共享门户,特别是 Youtube 中,以及如何解决这些问题。跟我来。
|
||||
在本指南中,我想介绍几个你可能会在创作自己的媒体时会遇到的典型问题,主要是使用字幕,然后上传到媒体共享门户网站,特别是 Youtube 中,以及如何解决这些问题。跟我来。
|
||||
|
||||
### 背景故事
|
||||
|
||||
我选择的视频编辑软件是 Kdenlive,当我创建那愚蠢的 [Frankenstein][5] 片段时开始使用这个软件,从那以后一直是我的忠实伙伴。通常,我将文件交给具有 VP8 视频编解码器和 Vorbis 音频编解码器的 WebM 容器渲染,因为这是 Google 所喜欢的。事实上,我在过去七年里上传的大约 40 个不同的片段中都没有问题。
|
||||
我选择的视频编辑软件是 Kdenlive,当我创建那愚蠢的 [Frankenstein][5] 片段时开始使用这个软件,从那以后它一直是我的忠实伙伴。通常,我将文件交给带有 VP8 视频编解码器和 Vorbis 音频编解码器的 WebM 容器来渲染,因为这是 Google 所喜欢的格式。事实上,我在过去七年里上传的大约 40 个不同的片段中都没有问题。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
但是,在完成了我的 Risitas&Linux 项目之后,我遇到了一个困难。视频文件和字幕文件仍然是两个独立的实体,我需要以某种方式将它们放在一起。我的原文中关于字幕提到了 Avidemux 和 Handbrake,这两个都是有效的选项。
|
||||
但是,在完成了我的 Risitas&Linux 项目之后,我遇到了一个困难。视频文件和字幕文件仍然是两个独立的实体,我需要以某种方式将它们放在一起。我最初关于字幕的文章提到了 Avidemux 和 Handbrake,这两个都是有效的选项。
|
||||
|
||||
但是,我对任何一个的输出都并不满意,而且由于种种原因,有些东西有所偏移。 Avidemux 不能很好处理视频编码,而 Handbrake 在最终输出中省略了几行字幕,而且字体是丑陋的。这个可以解决,但这不是今天的话题。
|
||||
但是,我对它们任何一个的输出都并不满意,而且由于种种原因,有些东西有所偏移。 Avidemux 不能很好处理视频编码,而 Handbrake 在最终输出中省略了几行字幕,而且字体是丑陋的。这个可以解决,但这不是今天的话题。
|
||||
|
||||
因此,我决定使用 VideoLAN(VLC) 将字幕嵌入视频。有几种方法可以做到这一点。你可以使用 “Media > Convert/Save” 选项,但这不能达到我们需要的。相反,你应该使用 “Media > Stream”,它带有一个更完整的向导,它还提供了一个我们需要的可编辑的代码转换选项 - 请参阅我的[教程][6]关于字幕的部分。
|
||||
|
||||
### 错误!
|
||||
|
||||
嵌入字幕的过程并不是微不足道的。你有可能遇到几个问题。本指南应该能帮助你解决这些问题,所以你可以专注于你的工作,而不是浪费时间调试怪异的软件错误。无论如何,在使用 VLC 中的字幕时,你将会遇到一小部分可能会遇到的问题。尝试以及出错,还有书呆子的设计。
|
||||
嵌入字幕的过程并没那么简单的。你有可能遇到几个问题。本指南应该能帮助你解决这些问题,所以你可以专注于你的工作,而不是浪费时间调试怪异的软件错误。无论如何,在使用 VLC 中的字幕时,你将会遇到一小部分可能会遇到的问题。尝试以及出错,还有书呆子的设计。
|
||||
|
||||
### 无可播放的流
|
||||
### 没有可播放的流
|
||||
|
||||
你可能选择了奇怪的输出设置。你要仔细检查你是否选择了正确的视频和音频编解码器。另外,请记住,一些媒体播放器可能没有所有的编解码器。此外,确保在所有要播放的系统中都测试过了。
|
||||
|
||||
@ -30,60 +31,55 @@
|
||||
|
||||
### 字幕叠加两次
|
||||
|
||||
如果在第一步的流媒体向导中选择了 “Use a subtitle file”,则可能会发生这种情况。只需选择所需的文件,然后单击“Stream”。取消选中该框。
|
||||
如果在第一步的流媒体向导中选择了 “Use a subtitle file”,则可能会发生这种情况。只需选择所需的文件,然后单击 “Stream”。取消选中该框。
|
||||
|
||||

|
||||
|
||||
### 字幕没有输出
|
||||
|
||||
这可能是两个主要原因。一,你选择了错误的封装格式。在进行编辑之前,请确保在配置文件页面上正确标记了字幕。如果格式不支持字幕,它可能无法正常工作。
|
||||
这可能是两个主要原因。一、你选择了错误的封装格式。在进行编辑之前,请确保在配置文件页面上正确标记了字幕。如果格式不支持字幕,它可能无法正常工作。
|
||||
|
||||

|
||||
|
||||
二,你可能已经在最终输出中启用了字幕编解码器渲染功能。你不需要这个。你只需要将字幕叠加到视频片段上。在单击 “Stream” 按钮之前,请检查生成的流输出字符串并删除 “scodec=<something>” 的选项。
|
||||
二、你可能已经在最终输出中启用了字幕编解码器渲染功能。你不需要这个。你只需要将字幕叠加到视频片段上。在单击 “Stream” 按钮之前,请检查生成的流输出字符串并删除 “scodec=<something>” 的选项。
|
||||
|
||||

|
||||
|
||||
### 缺少编解码器+解决方法
|
||||
### 缺少编解码器的解决方法
|
||||
|
||||
这是一个常见的 [bug][7],取决于编码器的实现的实验性,如果你选择以下配置文件,你将很有可能会看到它:“Video - H.264 + AAC (MP4)”。该文件将被渲染,如果你选择了字幕,它们也将被覆盖,但没有任何音频。但是,我们可以用技巧来解决这个问题。
|
||||
这是一个常见的 [bug][7],取决于编码器的实现的实验性,如果你选择以下配置文件,你将很有可能会看到它:“Video - H.264 + AAC (MP4)”。该文件将被渲染,如果你选择了字幕,它们也会被叠加上,但没有任何音频。但是,我们可以用技巧来解决这个问题。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
一个可能的技巧是从命令行使用 --sout-ffmpeg-strict=-2 选项(可能有用)启动 VLC。另一个更安全的解决方法是采用无音频视频,但是会有字幕重叠,并将原始项目不带字幕的作为音频源用 Kdenlive 渲染。听上去很复杂,下面是详细步骤:
|
||||
一个可能的技巧是从命令行使用 “--sout-ffmpeg-strict=-2” 选项(可能有用)启动 VLC。另一个更安全的解决方法是采用无音频视频,但是带有字幕叠加,并将不带字幕的原始项目作为音频源用 Kdenlive 渲染。听上去很复杂,下面是详细步骤:
|
||||
|
||||
* 将现有片段(包含音频)从视频移动到音频。删除其余的。
|
||||
|
||||
* 或者,使用渲染过的 WebM 文件作为你的音频源。
|
||||
|
||||
* 添加新的片段 - 带有字幕,并且没有音频。
|
||||
|
||||
* 将片段放置为新视频。
|
||||
|
||||
* 再次渲染为 WebM。
|
||||
|
||||

|
||||
|
||||
使用其他类型的音频编解码器将很有可能可用(例如 MP3),你将拥有一个包含视频,音频和字幕的完整项目。如果你很高兴没有遗漏,你可以现在上传到 Youtube 上。但是之后 ...
|
||||
使用其他类型的音频编解码器将很有可能可用(例如 MP3),你将拥有一个包含视频、音频和字幕的完整项目。如果你很高兴没有遗漏,你可以现在上传到 Youtube 上。但是之后 ...
|
||||
|
||||
### Youtube 视频管理器和未知格式
|
||||
|
||||
如果你尝试上传非 WebM 片段(例如 MP4),则可能会收到未指定的错误,你的片段不符合媒体格式要求。我不知道为什么 VLC 生成一个不符合 YouTube 规定的文件。但是,修复很容易。使用 Kdenlive 重新创建视频,其中有所有正确的元字段和 Youtube 喜欢的。回到我原来的故事,我有 40 多个片段使用 Kdenlive 以这种方式创建。
|
||||
如果你尝试上传非 WebM 片段(例如 MP4),则可能会收到未指定的错误,你的片段不符合媒体格式要求。我不知道为什么 VLC 会生成一个不符合 YouTube 规定的文件。但是,修复很容易。使用 Kdenlive 重新创建视频,将会生成带有所有正确的元字段和 Youtube 喜欢的文件。回到我原来的故事,我有 40 多个片段使用 Kdenlive 以这种方式创建。
|
||||
|
||||
P.S. 如果你的片段有有效的音频,则只需通过 Kdenlive 重新运行它。如果没有,重做视频/音频。根据需要将片段静音。最终, 这就像叠加一样, 除了你使用的视频来自于一个片段而音频来自于另一个片段用于最终渲染。工作完成。
|
||||
P.S. 如果你的片段有有效的音频,则只需通过 Kdenlive 重新运行它。如果没有,重做视频/音频。根据需要将片段静音。最终,这就像叠加一样,除了你使用的视频来自于一个片段,而音频来自于另一个片段。工作完成。
|
||||
|
||||
### 更多阅读
|
||||
|
||||
|
||||
我不想用链接重复自己或垃圾邮件。在“软件与安全”部分,我有 VLC 上的片段,因此你可能需要咨询。前面提到的关于 VLC 和字幕的文章已经链接到大约六个相关教程,涵盖了其他主题,如流媒体、日志记录、视频旋转、远程文件访问等等。我相信你可以像专业人员一样使用搜索引擎。
|
||||
我不想用链接重复自己或垃圾信息。在“软件与安全”部分,我有 VLC 上的片段,因此你可能需要咨询。前面提到的关于 VLC 和字幕的文章已经链接到大约六个相关教程,涵盖了其他主题,如流媒体、日志记录、视频旋转、远程文件访问等等。我相信你可以像专业人员一样使用搜索引擎。
|
||||
|
||||
### 总结
|
||||
|
||||
我希望你觉得本指南有帮助。它涵盖了很多,我试图使其线性并简单,并解决流媒体爱好者和字幕爱好者在使用 VLC 时可能遇到的许多陷阱。这都与容器和编解码器相关,而且媒体世界几乎没有标准的事实,当你从一种格式转换到另一种格式时,有时你可能会遇到边际情况。
|
||||
我希望你觉得本指南有帮助。它涵盖了很多,我试图使其直接而简单,并解决流媒体爱好者和字幕爱好者在使用 VLC 时可能遇到的许多陷阱。这都与容器和编解码器相关,而且媒体世界几乎没有标准的事实,当你从一种格式转换到另一种格式时,有时你可能会遇到边际情况。
|
||||
|
||||
如果你遇到了一些错误,这里的提示和技巧应该可以至少帮助你解决一些,包括无法播放的流、丢失或重复的字幕、缺少编解码器和 Kdenlive 解决方法、YouTube 上传错误、隐藏的 VLC 命令行选项,还有一些其他东西。是的,这些对于一段文字来说是很多的。幸运的是,这些都是好东西。保重, 互联网的孩子们。如果你有任何其他要求,我将来的 VLC 文章应该会涵盖,请随意给我发邮件。
|
||||
如果你遇到了一些错误,这里的提示和技巧应该可以至少帮助你解决一些,包括无法播放的流、丢失或重复的字幕、缺少编解码器和 Kdenlive 解决方法、YouTube 上传错误、隐藏的 VLC 命令行选项,还有一些其他东西。是的,这些对于一段文字来说是很多的。幸运的是,这些都是好东西。保重,互联网的孩子们。如果你有任何其他要求,我将来的 VLC 文章应该会涵盖,请随意给我发邮件。
|
||||
|
||||
干杯。
|
||||
|
||||
@ -91,9 +87,9 @@ P.S. 如果你的片段有有效的音频,则只需通过 Kdenlive 重新运
|
||||
|
||||
via: http://www.dedoimedo.com/computers/vlc-subtitles-errors.html
|
||||
|
||||
作者:[Dedoimedo ][a]
|
||||
作者:[Dedoimedo][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,9 @@
|
||||
了解 7z 命令开关 - 第一部分
|
||||
了解 7z 命令开关(一)
|
||||
============================================================
|
||||
|
||||
### 本篇中
|
||||
|
||||
1. [包含文件][1]
|
||||
2. [排除文件][2]
|
||||
3. [设置归档的密码][3]
|
||||
4. [设置输出目录][4]
|
||||
5. [创建多个卷][5]
|
||||
6. [设置归档的压缩级别][6]
|
||||
7. [显示归档的技术信息][7]
|
||||
|
||||
7z 无疑是一个功能强大的强大的归档工具(声称提供最高的压缩比)。在 HowtoForge 中,我们已经[已经讨论过][9]如何安装和使用它。但讨论仅限于你可以使用该工具提供的“功能字母”来使用基本功能。
|
||||
|
||||
在本教程中,我们将扩展对这个工具的说明,我们会讨论一些 7z 提供的“开关”。 但在继续之前,需要分享的是本教程中提到的所有说明和命令都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
在本教程中,我们将扩展对这个工具的说明,我们会讨论一些 7z 提供的“开关”。 但在继续之前,需要说明的是,本教程中提到的所有说明和命令都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
|
||||
**注意**:我们将使用以下截图中显示的文件来执行使用 7zip 的各种操作。
|
||||
|
||||
@ -21,18 +11,21 @@
|
||||

|
||||
][10]
|
||||
|
||||
###
|
||||
包含文件
|
||||
### 包含文件
|
||||
|
||||
7z 工具允许你有选择地将文件包含在归档中。可以使用 -i 开关来使用此功能。
|
||||
7z 工具允许你有选择地将文件包含在归档中。可以使用 `-i` 开关来使用此功能。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
-i[r[-|0]]{@listfile|!wildcard}
|
||||
```
|
||||
|
||||
比如,如果你想在归档中只包含 “.txt” 文件,你可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ 7z a ‘-i!*.txt’ include.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -42,7 +35,9 @@ $ 7z a ‘-i!*.txt’ include.7z
|
||||
|
||||
现在,检查新创建的归档是否只包含 “.txt” 文件,你可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ 7z l include.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -54,15 +49,19 @@ $ 7z l include.7z
|
||||
|
||||
### 排除文件
|
||||
|
||||
如果你想要,你可以排除不想要的文件。可以使用 -x 开关做到。
|
||||
如果你想要,你可以排除不想要的文件。可以使用 `-x` 开关做到。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
-x[r[-|0]]]{@listfile|!wildcard}
|
||||
```
|
||||
|
||||
比如,如果你想在要创建的归档中排除 “abc.7z” ,你可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ 7z a ‘-x!abc.7z’ exclude.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -72,7 +71,9 @@ $ 7z a ‘-x!abc.7z’ exclude.7z
|
||||
|
||||
要检查最后的归档是否排除了 “abc.7z”, 你可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ 7z l exclude.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -82,25 +83,33 @@ $ 7z l exclude.7z
|
||||
|
||||
上面的截图中,你可以看到 “abc.7z” 已经从新的归档中排除了。
|
||||
|
||||
**专业提示**:假设任务是排除以 “t” 开头的所有 .7z 文件,并且包含以字母 “a” 开头的所有 .7z 文件。这可以通过以下方式组合 “-i” 和 “-x” 开关来实现:
|
||||
**专业提示**:假设任务是排除以 “t” 开头的所有 .7z 文件,并且包含以字母 “a” 开头的所有 .7z 文件。这可以通过以下方式组合 `-i` 和 `-x` 开关来实现:
|
||||
|
||||
```
|
||||
$ 7z a '-x!t*.7z' '-i!a*.7z' combination.7z
|
||||
```
|
||||
|
||||
### 设置归档密码
|
||||
|
||||
7z 同样也支持用密码保护你的归档文件。这个功能可以使用 -p 开关来实现。
|
||||
7z 同样也支持用密码保护你的归档文件。这个功能可以使用 `-p` 开关来实现。
|
||||
|
||||
```
|
||||
$ 7z a [archive-filename] -p[your-password] -mhe=[on/off]
|
||||
```
|
||||
|
||||
**注意**:-mhe 选项用来启用或者禁用归档头加密(默认是 off)。
|
||||
**注意**:`-mhe` 选项用来启用或者禁用归档头加密(默认是“off”)。
|
||||
|
||||
例子:
|
||||
|
||||
```
|
||||
$ 7z a password.7z -pHTF -mhe=on
|
||||
```
|
||||
|
||||
无需多说,当你解压密码保护的归档时,工具会向你询问密码。要解压一个密码保护的文件,使用 “e” 功能字母。下面是例子:
|
||||
无需多说,当你解压密码保护的归档时,工具会向你询问密码。要解压一个密码保护的文件,使用 `e` 功能字母。下面是例子:
|
||||
|
||||
```
|
||||
$ 7z e password.7z
|
||||
```
|
||||
|
||||
[
|
||||
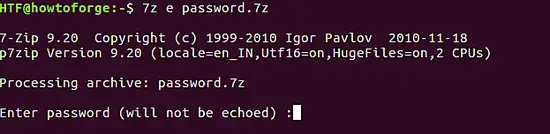
|
||||
@ -108,15 +117,19 @@ $ 7z e password.7z
|
||||
|
||||
### 设置输出目录
|
||||
|
||||
工具同样支持解压文件到你选择的目录中。这可以使用 -o 开关。无需多说,这个开关只在含有 “e” 或者 “x” 功能字母的时候有用。
|
||||
工具同样支持解压文件到你选择的目录中。这可以使用 `-o` 开关。无需多说,这个开关只在含有 `e` 或者 `x` 功能字母的时候有用。
|
||||
|
||||
```
|
||||
$ 7z [e/x] [existing-archive-filename] -o[path-of-directory]
|
||||
```
|
||||
|
||||
比如,假设下面命令工作在当前的工作目录中:
|
||||
|
||||
```
|
||||
$ 7z e output.7z -ohow/to/forge
|
||||
```
|
||||
|
||||
如 -o 开关的值所指的那样,它的目标是解压文件到 ./how/to/forge 中。
|
||||
如 `-o` 开关的值所指的那样,它的目标是解压文件到 ./how/to/forge 中。
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -124,7 +137,7 @@ $ 7z e output.7z -ohow/to/forge
|
||||
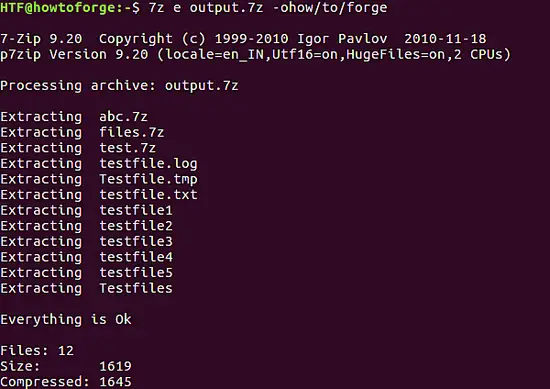
|
||||
][16]
|
||||
|
||||
在上面的截图中,你可以看到归档文件的所有内容都已经解压了。但是在哪里?要检查文件是否被解压到 ./how/to/forge,我们可以使用 “ls -R” 命令。
|
||||
在上面的截图中,你可以看到归档文件的所有内容都已经解压了。但是在哪里?要检查文件是否被解压到 ./how/to/forge,我们可以使用 `ls -R` 命令。
|
||||
|
||||
[
|
||||
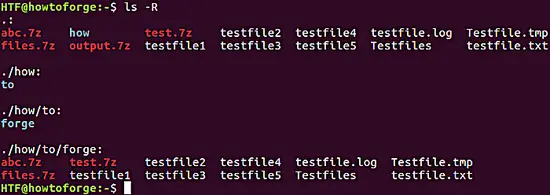
|
||||
@ -134,13 +147,15 @@ $ 7z e output.7z -ohow/to/forge
|
||||
|
||||
### 创建多个卷
|
||||
|
||||
借助 7z 工具,你可以为归档创建多个卷(较小的子档案)。当通过网络或 USB 传输大文件时,这是非常有用的。可以使用 -v 开关使用此功能。这个开关需要指定子档案的大小。
|
||||
借助 7z 工具,你可以为归档创建多个卷(较小的子档案)。当通过网络或 USB 传输大文件时,这是非常有用的。可以使用 `-v` 开关使用此功能。这个开关需要指定子档案的大小。
|
||||
|
||||
我们可以以字节(b)、千字节(k)、兆字节(m)和千兆字节(g)指定子档案大小。
|
||||
|
||||
```
|
||||
$ 7z a [archive-filename] [files-to-archive] -v[size-of-sub-archive1] -v[size-of-sub-archive2] ....
|
||||
```
|
||||
|
||||
让我们用一个例子来理解这个。请注意,我们将使用一个新的目录来执行 -v 开关的操作。
|
||||
让我们用一个例子来理解这个。请注意,我们将使用一个新的目录来执行 `-v` 开关的操作。
|
||||
|
||||
这是目录内容的截图:
|
||||
|
||||
@ -150,7 +165,9 @@ $ 7z a [archive-filename] [files-to-archive] -v[size-of-sub-archive1] -v[size-of
|
||||
|
||||
现在,我们运行下面的命令来为一个归档文件创建多个卷(每个大小 100b):
|
||||
|
||||
```
|
||||
7z a volume.7z * -v100b
|
||||
```
|
||||
|
||||
这是截图:
|
||||
|
||||
@ -158,36 +175,40 @@ $ 7z a [archive-filename] [files-to-archive] -v[size-of-sub-archive1] -v[size-of
|
||||
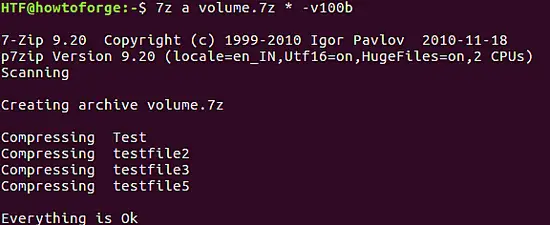
|
||||
][19]
|
||||
|
||||
现在,要查看创建的子归档,使用 “ls” 命令。
|
||||
现在,要查看创建的子归档,使用 `ls` 命令。
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
如下截图所示,一个四个卷创建了 - volume.7z.001、volume.7z.002、volume.7z.003 和 volume.7z.004
|
||||
如下截图所示,一共创建四个卷 - volume.7z.001、volume.7z.002、volume.7z.003 和 volume.7z.004
|
||||
|
||||
**注意**:你可以使用 .7z.001 归档解压文件。但是,要这么做,其他所有的卷都应该在同一个目录内。
|
||||
**注意**:你可以使用 .7z.001 归档文件来解压。但是,要这么做,其他所有的卷都应该在同一个目录内。
|
||||
|
||||
### 设置归档的压缩级别
|
||||
|
||||
7z 允许你设置归档的压缩级别。这个功能可以使用 -m 开关。7z 中有不同的压缩级别,比如:-mx0、-mx1、-mx3、-mx5、-mx7 和 -mx9
|
||||
7z 允许你设置归档的压缩级别。这个功能可以使用 `-m` 开关。7z 中有不同的压缩级别,比如:`-mx0`、`-mx1`、`-mx3`、`-mx5`、`-mx7` 和 `-mx9`。
|
||||
|
||||
这是这些压缩级别的简要说明:
|
||||
|
||||
-**mx0** = 完全不压缩 - 只是复制文件到归档中。
|
||||
-**mx1** = 消耗最少时间,但是压缩最小。
|
||||
-**mx3** = 比 -mx1 好。
|
||||
-**mx5** = 这是默认级别 (常规压缩)。
|
||||
-**mx7** = 最大化压缩。
|
||||
-**mx9** = 极端压缩。
|
||||
- `mx0` = 完全不压缩 - 只是复制文件到归档中。
|
||||
- `mx1` = 消耗最少时间,但是压缩最小。
|
||||
- `mx3` = 比 `-mx1` 好。
|
||||
- `mx5` = 这是默认级别 (常规压缩)。
|
||||
- `mx7` = 最大化压缩。
|
||||
- `mx9` = 极端压缩。
|
||||
|
||||
**注意**:关于这些压缩级别的更多信息,阅读[这里][8]。
|
||||
|
||||
```
|
||||
$ 7z a [archive-filename] [files-to-archive] -mx=[0,1,3,5,7,9]
|
||||
```
|
||||
|
||||
例如,我们在目录中有一堆文件和文件夹,我们每次尝试使用不同的压缩级别进行压缩。只是为了给你一个想法,这是当使用压缩级别 “0” 时创建存档时使用的命令。
|
||||
例如,我们在目录中有一堆文件和文件夹,我们每次尝试使用不同的压缩级别进行压缩。作为一个例子,这是当使用压缩级别 “0” 时创建存档时使用的命令。
|
||||
|
||||
```
|
||||
$ 7z a compression(-mx0).7z * -mx=0
|
||||
```
|
||||
|
||||
相似地,其他命令也这样执行。
|
||||
|
||||
@ -197,16 +218,19 @@ $ 7z a compression(-mx0).7z * -mx=0
|
||||
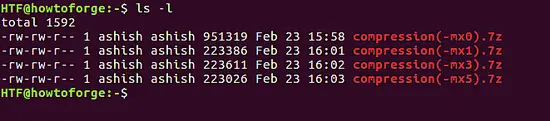
|
||||
][21]
|
||||
|
||||
###
|
||||
显示归档的技术信息
|
||||
### 显示归档的技术信息
|
||||
|
||||
如果需要,7z 还可以在标准输出中显示归档的技术信息 - 类型、物理大小、头大小等。可以使用 -slt 开关使用此功能。 此开关仅适用于带有 “l” 功能字母的情况下。
|
||||
如果需要,7z 还可以在标准输出中显示归档的技术信息 - 类型、物理大小、头大小等。可以使用 `-slt` 开关使用此功能。 此开关仅适用于带有 `l` 功能字母的情况下。
|
||||
|
||||
```
|
||||
$ 7z l -slt [archive-filename]
|
||||
```
|
||||
|
||||
比如:
|
||||
|
||||
```
|
||||
$ 7z l -slt abc.7z
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
@ -214,17 +238,21 @@ $ 7z l -slt abc.7z
|
||||
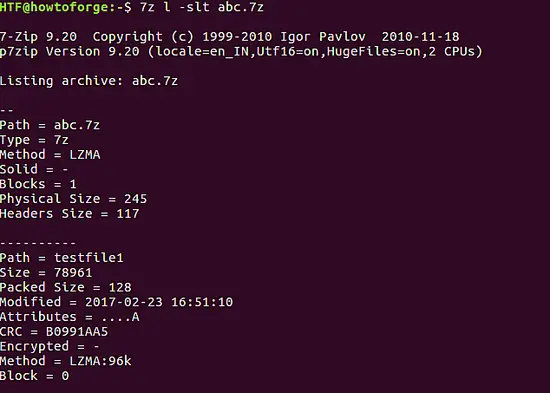
|
||||
][22]
|
||||
|
||||
# 指定创建归档的类型
|
||||
### 指定创建归档的类型
|
||||
|
||||
如果你想要创建一个非 7z 的归档文件(这是默认的创建类型),你可以使用 -t 开关来指定。
|
||||
如果你想要创建一个非 7z 的归档文件(这是默认的创建类型),你可以使用 `-t` 开关来指定。
|
||||
|
||||
```
|
||||
$ 7z a -t[specify-type-of-archive] [archive-filename] [file-to-archive]
|
||||
```
|
||||
|
||||
下面的例子展示创建了一个 .zip 文件:
|
||||
|
||||
```
|
||||
7z a -tzip howtoforge *
|
||||
```
|
||||
|
||||
输出的文件是 “howtoforge.zip”。要交叉验证它的类型,使用 “file” 命令:
|
||||
输出的文件是 “howtoforge.zip”。要交叉验证它的类型,使用 `file` 命令:
|
||||
|
||||
[
|
||||

|
||||
@ -232,17 +260,17 @@ $ 7z a -t[specify-type-of-archive] [archive-filename] [file-to-archive]
|
||||
|
||||
因此,howtoforge.zip 的确是一个 ZIP 文件。相似地,你可以创建其他 7z 支持的归档。
|
||||
|
||||
# 总结
|
||||
### 总结
|
||||
|
||||
你会同意的是 7z 的 “功能字母” 以及 “开关” 的知识可以让你充分利用这个工具。我们还没有完成开关的部分 - 其余部分将在第 2 部分中讨论。
|
||||
你将会认识到, 7z 的 “功能字母” 以及 “开关” 的知识可以让你充分利用这个工具。我们还没有完成开关的部分 - 其余部分将在第 2 部分中讨论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/understanding-7z-command-switches/
|
||||
|
||||
作者:[ Himanshu Arora][a]
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
通过开源书籍学习 RUBY 编程
|
||||
通过开源书籍学习 Ruby 编程
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
### 开源的 Ruby 书籍
|
||||
|
||||
Ruby 是由 Yukihiro “Matz” Matsumoto 开发的一门通用目的、脚本化、结构化、灵活且完全面向对象的编程语言。它具有一个完全动态类型系统,这意味着它的大多数类型检查是在运行的时候进行,而非编译的时候。因此程序员不必过分担心是整数类型还是字符串类型。Ruby 会自动进行内存管理,它具有许多和 Python、Perl、Lisp、Ada、Eiffel 和 Smalltalk 相同的特性。
|
||||
@ -13,11 +15,10 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
|
||||
这篇文章是[ OSSBlog 的系列文章开源编程书籍][18]的一部分。
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Best Practices][1]
|
||||
### 《[Ruby Best Practices][1]》
|
||||
|
||||

|
||||
|
||||
作者: Gregory Brown (328 页)
|
||||
|
||||
@ -31,26 +32,24 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
|
||||
* 通过测试驱动代码 - 涉及了大量的测试哲学和技术。使用 mocks 和 stubs
|
||||
* 通过利用 Ruby 神秘的力量来设计漂亮的 API:灵活的参数处理和代码块
|
||||
* 利用动态工具包向开发者展示如何构建灵活的界面,实现对象行为,扩展和修改已有代码,以及程序化地构建类和模块
|
||||
* 利用动态工具包向开发者展示如何构建灵活的界面,实现单对象行为,扩展和修改已有代码,以及程序化地构建类和模块
|
||||
* 文本处理和文件管理集中于正则表达式,文件、临时文件标准库以及文本处理策略实战
|
||||
|
||||
|
||||
* 函数式编程技术优化模块代码组织、存储、无穷目录以及更高顺序程序。
|
||||
* 函数式编程技术优化了模块代码组织、存储、无穷目录以及更高顺序程序。
|
||||
* 理解代码如何出错以及为什么会出错,阐述如何处理日志记录
|
||||
* 通过利用 Ruby 的多语言能力削弱文化屏障
|
||||
* 熟练的项目维护
|
||||
|
||||
本书为开源书籍,在 CC NC-SA 许可证下发布。
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
[在此下载《Ruby Best Practices》][1]。
|
||||
|
||||
### [I Love Ruby][2]
|
||||
### 《[I Love Ruby][2]》
|
||||
|
||||

|
||||
|
||||
作者: Karthikeyan A K (246 页)
|
||||
|
||||
《I Love Ruby》以比传统介绍更高的深度阐述了基本概念和技术。该方法为编写有用、正确、易维护和高效的 Ruby 代码提供了一个坚实的基础。
|
||||
《I Love Ruby》以比传统的介绍更高的深度阐述了基本概念和技术。该方法为编写有用、正确、易维护和高效的 Ruby 代码提供了一个坚实的基础。
|
||||
|
||||
章节内容涵盖:
|
||||
|
||||
@ -75,15 +74,15 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
* Gems
|
||||
* 元编程
|
||||
|
||||
在 GNU 自由文档许可证有效期内,你可以复制、发布和修改本书,1.3 或任何更新版本由自由软件基金会发布。
|
||||
在 GNU 自由文档许可证之下,你可以复制、发布和修改本书,1.3 或任何之后版本由自由软件基金会发布。
|
||||
|
||||
[点此下载《I Love Ruby》][2]。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Programming Ruby – The Pragmatic Programmer’s Guide][3]
|
||||
|
||||

|
||||
|
||||
作者: David Thomas, Andrew Hunt (HTML)
|
||||
|
||||
《Programming Ruby – The Pragmatic Programmer’s Guide》是一本 Ruby 编程语言的教程和参考书。使用 Ruby,你将能够写出更好的代码,更加有效率,并且使编程变成更加享受的体验。
|
||||
@ -111,12 +110,11 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
|
||||
这本书的第一版在开放发布许可证 1.0 版或更新版的许可下发布。本书更新后的第二版涉及 Ruby 1.8 ,并且包括所有可用新库的描述,但是它不是在免费发行许可证下发布的。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
[点此下载《Programming Ruby – The Pragmatic Programmer’s Guide》][3]。
|
||||
|
||||
### [Why’s (Poignant) Guide to Ruby][4]
|
||||
### 《[Why’s (Poignant) Guide to Ruby][4]》
|
||||
|
||||

|
||||
|
||||
作者:why the lucky stiff (176 页)
|
||||
|
||||
@ -135,12 +133,11 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
|
||||
本书在 CC-SA 许可证许可下可用。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
[点此下载《Why’s (poignant) Guide to Ruby》][4]。
|
||||
|
||||
### [Ruby Hacking Guide][5]
|
||||
### 《[Ruby Hacking Guide][5]》
|
||||
|
||||

|
||||
|
||||
作者: Minero Aoki ,翻译自 Vincent Isambart 和 Clifford Escobar Caoille (HTML)
|
||||
|
||||
@ -161,12 +158,11 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
|
||||
原书的官方支持网站为 [i.loveruby.net/ja/rhg/][10]
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
[点此下载《Ruby Hacking Guide》][5]
|
||||
|
||||
### [The Book Of Ruby][6]
|
||||
### 《[The Book Of Ruby][6]》
|
||||
|
||||

|
||||
|
||||
作者: How Collingbourne (425 页)
|
||||
|
||||
@ -174,7 +170,7 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
|
||||
《The Book Of Ruby》以 PDF 文件格式提供,并且每一个章节的所有例子都伴有可运行的源代码。同时,也有一个介绍来阐述如何在 Steel 或其他任何你喜欢的编辑器/IDE 中运行这些 Ruby 代码。它主要集中于 Ruby 语言的 1.8.x 版本。
|
||||
|
||||
本书被分成字节大小的块。每一个章节介绍一个主题,并且分成几个不同的子话题。每一个编程主题由一个或多个小的自包含、可运行的 Ruby 程序构成。
|
||||
本书被分成很小的块。每一个章节介绍一个主题,并且分成几个不同的子话题。每一个编程主题由一个或多个小的自包含、可运行的 Ruby 程序构成。
|
||||
|
||||
* 字符串、数字、类和对象 - 获取输入和输出、字符串和外部评估、数字和条件测试:if ... then、局部变量和全局变量、类和对象、实例变量、消息、方法、多态性、构造器和检属性和类变量 - 超类和子类,超类传参,访问器方法,’set‘ 访问器,属性读写器、超类的方法调用,以及类变量
|
||||
* 类等级、属性和类变量 - 超类和子类,超类传参,访问器方法,’set‘ 访问器,属性读写器、超类的方法调用,以及类变量
|
||||
@ -199,12 +195,12 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
|
||||
本书由 SapphireSteel Software 发布,SapphireSteel Software 是用于 Visual Studio 的 Ruby In Steel 集成开发环境的开发者。读者可以复制和发布本书的文本和代码(免费版)
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
[点此下载《The Book Of Ruby》][6]
|
||||
|
||||
### [The Little Book Of Ruby][7]
|
||||
|
||||
### 《[The Little Book Of Ruby][7]》
|
||||
|
||||

|
||||
|
||||
作者: Huw Collingbourne (87 页)
|
||||
|
||||
@ -225,12 +221,11 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
|
||||
本书可免费复制和发布,只需保留原始文本且注明版权信息。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
[点此下载《The Little Book of Ruby》][7]
|
||||
|
||||
### [Kestrels, Quirky Birds, and Hopeless Egocentricity][8]
|
||||
### 《[Kestrels, Quirky Birds, and Hopeless Egocentricity][8]》
|
||||
|
||||

|
||||
|
||||
作者: Reg “raganwald” Braithwaite (123 页)
|
||||
|
||||
@ -242,12 +237,11 @@ Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、
|
||||
|
||||
本书在 MIT 许可证许可下发布。
|
||||
|
||||
[点此下载《Kestrels, Quirky Birds, and Hopeless Egocentricity》][8]
|
||||
|
||||
### 《[Ruby Programming][9]》
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Programming][9]
|
||||
|
||||
作者: Wikibooks.org (261 页)
|
||||
|
||||
@ -264,15 +258,15 @@ Ruby 是一种解释性、面向对象的编程语言。
|
||||
|
||||
本书在 CC-SA 3.0 本地化许可证许可下发布。
|
||||
|
||||
|
|
||||
[点此下载《Ruby Programming》][9]
|
||||
|
||||
* * *
|
||||
|
||||
无特定顺序,我将在结束前推荐一些没有在开源许可证下发布但可以免费下载的 Ruby 编程书籍。
|
||||
|
||||
* [Mr. Neighborly 的 Humble Little Ruby Book][11] – 一个易读易学的 Ruby 完全指南。
|
||||
* [Introduction to Programming with Ruby][12] – 学习编程时最基本的构建块,一切从零开始。
|
||||
* [Object Oriented Programming with Ruby][13] – 学习编程时最基本的构建块,一切从零开始。
|
||||
* [Introduction to Programming with Ruby][12] – 学习编程的基础知识,一切从零开始。
|
||||
* [Object Oriented Programming with Ruby][13] – 学习编程的基础知识,一切从零开始。
|
||||
* [Core Ruby Tools][14] – 对 Ruby 的四个核心工具 Gems、Ruby Version Managers、Bundler 和 Rake 进行了简短的概述。
|
||||
* [Learn Ruby the Hard Way, 3rd Edition][15] – 一本适合初学者的入门书籍。
|
||||
* [Learn to Program][16] – 来自 Chris Pine。
|
||||
@ -282,9 +276,9 @@ Ruby 是一种解释性、面向对象的编程语言。
|
||||
|
||||
via: https://www.ossblog.org/study-ruby-programming-with-open-source-books/
|
||||
|
||||
作者:[Steve Emms ][a]
|
||||
作者:[Steve Emms][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,40 +1,26 @@
|
||||
开发 Linux 调试器第五部分:源码和信号
|
||||
开发一个 Linux 调试器(四):源码和信号
|
||||
============================================================
|
||||
|
||||
在上一部分我们学习了关于 DWARF 的信息以及它如何可以被用于读取变量和将被执行的机器码和我们高层次的源码联系起来。在这一部分,我们通过实现一些我们调试器后面会使用的 DWARF 原语将它应用于实际情况。我们也会利用这个机会,使我们的调试器可以在命中一个断点时打印出当前的源码上下文。
|
||||
|
||||
* * *
|
||||
在上一部分我们学习了关于 DWARF 的信息,以及它如何被用于读取变量和将被执行的机器码与我们的高级语言的源码联系起来。在这一部分,我们将进入实践,实现一些我们调试器后面会使用的 DWARF 原语。我们也会利用这个机会,使我们的调试器可以在命中一个断点时打印出当前的源码上下文。
|
||||
|
||||
### 系列文章索引
|
||||
|
||||
随着后面文章的发布,这些链接会逐渐生效。
|
||||
|
||||
1. [启动][1]
|
||||
|
||||
1. [准备环境][1]
|
||||
2. [断点][2]
|
||||
|
||||
3. [寄存器和内存][3]
|
||||
|
||||
4. [Elves 和 dwarves][4]
|
||||
|
||||
5. [源码和信号][5]
|
||||
|
||||
6. [源码级逐步执行][6]
|
||||
|
||||
7. 源码级断点
|
||||
|
||||
8. 调用栈展开
|
||||
|
||||
9. 读取变量
|
||||
|
||||
10. 下一步
|
||||
|
||||
译者注:ELF([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format "Executable and Linkable Format") 可执行文件格式),DWARF(一种广泛使用的调试数据格式,参考 [WIKI](https://en.wikipedia.org/wiki/DWARF "DWARF WIKI"))
|
||||
* * *
|
||||
|
||||
### 设置我们的 DWARF 解析器
|
||||
|
||||
正如我在这系列文章开始时备注的,我们会使用 [`libelfin`][7] 来处理我们的 DWARF 信息。希望你已经在第一部分设置好了这些,如果没有的话,现在做吧,确保你使用我仓库的 `fbreg` 分支。
|
||||
正如我在这系列文章开始时备注的,我们会使用 [libelfin][7] 来处理我们的 DWARF 信息。希望你已经在[第一部分][1]设置好了这些,如果没有的话,现在做吧,确保你使用我仓库的 `fbreg` 分支。
|
||||
|
||||
一旦你构建好了 `libelfin`,就可以把它添加到我们的调试器。第一步是解析我们的 ELF 可执行程序并从中提取 DWARF 信息。使用 `libelfin` 可以轻易实现,只需要对`调试器`作以下更改:
|
||||
|
||||
@ -59,11 +45,9 @@ private:
|
||||
|
||||
我们使用了 `open` 而不是 `std::ifstream`,因为 elf 加载器需要传递一个 UNIX 文件描述符给 `mmap`,从而可以将文件映射到内存而不是每次读取一部分。
|
||||
|
||||
* * *
|
||||
|
||||
### 调试信息原语
|
||||
|
||||
下一步我们可以实现从程序计数器的值中提取行条目(line entries)以及函数 DWARF 信息条目(function DIEs)的函数。我们从 `get_function_from_pc` 开始:
|
||||
下一步我们可以实现从程序计数器的值中提取行条目(line entry)以及函数 DWARF 信息条目(function DIE)的函数。我们从 `get_function_from_pc` 开始:
|
||||
|
||||
```
|
||||
dwarf::die debugger::get_function_from_pc(uint64_t pc) {
|
||||
@ -83,7 +67,7 @@ dwarf::die debugger::get_function_from_pc(uint64_t pc) {
|
||||
}
|
||||
```
|
||||
|
||||
这里我采用了朴素的方法,迭代遍历编译单元直到找到一个包含程序计数器的,然后迭代遍历它的孩子直到我们找到相关函数(`DW_TAG_subprogram`)。正如我在上一篇中提到的,如果你想要的话你可以处理类似成员函数或者内联等情况。
|
||||
这里我采用了朴素的方法,迭代遍历编译单元直到找到一个包含程序计数器的,然后迭代遍历它的子节点直到我们找到相关函数(`DW_TAG_subprogram`)。正如我在上一篇中提到的,如果你想要的话你可以处理类似的成员函数或者内联等情况。
|
||||
|
||||
接下来是 `get_line_entry_from_pc`:
|
||||
|
||||
@ -108,8 +92,6 @@ dwarf::line_table::iterator debugger::get_line_entry_from_pc(uint64_t pc) {
|
||||
|
||||
同样,我们可以简单地找到正确的编译单元,然后查询行表获取相关的条目。
|
||||
|
||||
* * *
|
||||
|
||||
### 打印源码
|
||||
|
||||
当我们命中一个断点或者逐步执行我们的代码时,我们会想知道处于源码中的什么位置。
|
||||
@ -149,13 +131,11 @@ void debugger::print_source(const std::string& file_name, unsigned line, unsigne
|
||||
}
|
||||
```
|
||||
|
||||
现在我们可以打印出源码了,我们需要将这些通过钩子添加到我们的调试器。一个实现这个的好地方是当调试器从一个断点或者(最终)逐步执行得到一个信号时。到了这里,我们可能想要给我们的调试器添加一些更好的信号处理。
|
||||
|
||||
* * *
|
||||
现在我们可以打印出源码了,我们需要将这些通过钩子添加到我们的调试器。实现这个的一个好地方是当调试器从一个断点或者(最终)逐步执行得到一个信号时。到了这里,我们可能想要给我们的调试器添加一些更好的信号处理。
|
||||
|
||||
### 更好的信号处理
|
||||
|
||||
我们希望能够得知什么信号被发送给了进程,同样我们也想知道它是如何产生的。例如,我们希望能够得知是否由于命中了一个断点从而获得一个 `SIGTRAP`,还是由于逐步执行完成、或者是产生了一个新线程,等等。幸运的是,我们可以再一次使用 `ptrace`。可以给 `ptrace` 的一个命令是 `PTRACE_GETSIGINFO`,它会给你被发送给进程的最后一个信号的信息。我们类似这样使用它:
|
||||
我们希望能够得知什么信号被发送给了进程,同样我们也想知道它是如何产生的。例如,我们希望能够得知是否由于命中了一个断点从而获得一个 `SIGTRAP`,还是由于逐步执行完成、或者是产生了一个新线程等等导致的。幸运的是,我们可以再一次使用 `ptrace`。可以给 `ptrace` 的一个命令是 `PTRACE_GETSIGINFO`,它会给你被发送给进程的最后一个信号的信息。我们类似这样使用它:
|
||||
|
||||
```
|
||||
siginfo_t debugger::get_signal_info() {
|
||||
@ -268,8 +248,6 @@ void debugger::step_over_breakpoint() {
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### 测试
|
||||
|
||||
现在你应该可以在某个地址设置断点,运行程序然后看到打印出了源码,而且正在被执行的行被光标标记了出来。
|
||||
@ -280,17 +258,17 @@ void debugger::step_over_breakpoint() {
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
|
||||
作者:[TartanLlama ][a]
|
||||
作者:[Simon Brand][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[1]:https://linux.cn/article-8626-1.html
|
||||
[2]:https://linux.cn/article-8645-1.html
|
||||
[3]:https://linux.cn/article-8663-1.html
|
||||
[4]:https://linux.cn/article-8719-1.html
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://github.com/TartanLlama/libelfin/tree/fbreg
|
||||
@ -1,40 +1,26 @@
|
||||
开发 Linux 调试器第六部分:源码级逐步执行
|
||||
开发一个 Linux 调试器(六):源码级逐步执行
|
||||
============================================================
|
||||
|
||||
在前几篇博文中我们学习了 DWARF 信息以及它如何使我们将机器码和上层源码联系起来。这一次我们通过为我们的调试器添加源码级逐步调试将该知识应用于实际。
|
||||
|
||||
* * *
|
||||
|
||||
### 系列文章索引
|
||||
|
||||
随着后面文章的发布,这些链接会逐渐生效。
|
||||
|
||||
1. [启动][1]
|
||||
|
||||
1. [准备环境][1]
|
||||
2. [断点][2]
|
||||
|
||||
3. [寄存器和内存][3]
|
||||
|
||||
4. [Elves 和 dwarves][4]
|
||||
|
||||
5. [源码和信号][5]
|
||||
|
||||
6. [源码级逐步执行][6]
|
||||
|
||||
7. 源码级断点
|
||||
|
||||
8. 调用栈展开
|
||||
|
||||
9. 读取变量
|
||||
|
||||
10. 下一步
|
||||
|
||||
译者注:ELF([Executable and Linkable Format](https://en.wikipedia.org/wiki/Executable_and_Linkable_Format "Executable and Linkable Format") 可执行文件格式),DWARF(一种广泛使用的调试数据格式,参考 [WIKI](https://en.wikipedia.org/wiki/DWARF "DWARF WIKI"))
|
||||
* * *
|
||||
### 揭秘指令级逐步执行
|
||||
|
||||
### 暴露指令级逐步执行
|
||||
|
||||
我们已经超越了自己。首先让我们通过用户接口暴露指令级单步执行。我决定将它切分为能被其它部分代码利用的 `single_step_instruction` 和确保是否启用了某个断点的 `single_step_instruction_with_breakpoint_check`。
|
||||
我们正在超越了自我。首先让我们通过用户接口揭秘指令级单步执行。我决定将它切分为能被其它部分代码利用的 `single_step_instruction` 和确保是否启用了某个断点的 `single_step_instruction_with_breakpoint_check` 两个函数。
|
||||
|
||||
```
|
||||
void debugger::single_step_instruction() {
|
||||
@ -65,13 +51,11 @@ else if(is_prefix(command, "stepi")) {
|
||||
|
||||
利用新增的这些函数我们可以开始实现我们的源码级逐步执行函数。
|
||||
|
||||
* * *
|
||||
|
||||
### 实现逐步执行
|
||||
|
||||
我们打算编写这些函数非常简单的版本,但真正的调试器有 _thread plan_ 的概念,它封装了所有的单步信息。例如,调试器可能有一些复杂的逻辑去决定断点的位置,然后有一些回调函数用于判断单步操作是否完成。这其中有非常多的基础设施,我们只采用一种朴素的方法。我们可能会意外地跳过断点,但如果你愿意的话,你可以花一些时间把所有的细节都处理好。
|
||||
|
||||
对于跳出`step_out`,我们只是在函数的返回地址处设一个断点然后继续执行。我暂时还不想考虑调用栈展开的细节 - 这些都会在后面的部分介绍 - 但可以说返回地址就保存在栈帧开始的后 8 个字节中。因此我们会读取栈指针然后在内存相对应的地址读取值:
|
||||
对于跳出 `step_out`,我们只是在函数的返回地址处设一个断点然后继续执行。我暂时还不想考虑调用栈展开的细节 - 这些都会在后面的部分介绍 - 但可以说返回地址就保存在栈帧开始的后 8 个字节中。因此我们会读取栈指针然后在内存相对应的地址读取值:
|
||||
|
||||
```
|
||||
void debugger::step_out() {
|
||||
@ -103,7 +87,7 @@ void debugger::remove_breakpoint(std::intptr_t addr) {
|
||||
}
|
||||
```
|
||||
|
||||
接下来是跳入`step_in`。一个简单的算法是继续逐步执行指令直到新的一行。
|
||||
接下来是跳入 `step_in`。一个简单的算法是继续逐步执行指令直到新的一行。
|
||||
|
||||
```
|
||||
void debugger::step_in() {
|
||||
@ -118,7 +102,7 @@ void debugger::step_in() {
|
||||
}
|
||||
```
|
||||
|
||||
跳过`step_over` 对于我们来说是三个中最难的。理论上,解决方法就是在下一行源码中设置一个断点,但下一行源码是什么呢?它可能不是当前行后续的那一行,因为我们可能处于一个循环、或者某种条件结构之中。真正的调试器一般会检查当前正在执行什么指令然后计算出所有可能的分支目标,然后在所有分支目标中设置断点。对于一个小的项目,我不打算实现或者集成一个 x86 指令模拟器,因此我们要想一个更简单的解决办法。有几个可怕的选项,一个是一直逐步执行直到当前函数新的一行,或者在当前函数的每一行都设置一个断点。如果我们是要跳过一个函数调用,前者将会相当的低效,因为我们需要逐步执行那个调用图中的每个指令,因此我会采用第二种方法。
|
||||
跳过 `step_over` 对于我们来说是三个中最难的。理论上,解决方法就是在下一行源码中设置一个断点,但下一行源码是什么呢?它可能不是当前行后续的那一行,因为我们可能处于一个循环、或者某种条件结构之中。真正的调试器一般会检查当前正在执行什么指令然后计算出所有可能的分支目标,然后在所有分支目标中设置断点。对于一个小的项目,我不打算实现或者集成一个 x86 指令模拟器,因此我们要想一个更简单的解决办法。有几个可怕的选择,一个是一直逐步执行直到当前函数新的一行,或者在当前函数的每一行都设置一个断点。如果我们是要跳过一个函数调用,前者将会相当的低效,因为我们需要逐步执行那个调用图中的每个指令,因此我会采用第二种方法。
|
||||
|
||||
```
|
||||
void debugger::step_over() {
|
||||
@ -179,7 +163,7 @@ void debugger::step_over() {
|
||||
}
|
||||
```
|
||||
|
||||
我们需要移除我们设置的所有断点,以便不会泄露我们的逐步执行函数,为此我们把它们保存到一个 `std::vector` 中。为了设置所有断点,我们循环遍历行表条目直到找到一个不在我们函数范围内的。对于每一个,我们都要确保它不是我们当前所在的行,而且在这个位置还没有设置任何断点。
|
||||
我们需要移除我们设置的所有断点,以便不会泄露出我们的逐步执行函数,为此我们把它们保存到一个 `std::vector` 中。为了设置所有断点,我们循环遍历行表条目直到找到一个不在我们函数范围内的。对于每一个,我们都要确保它不是我们当前所在的行,而且在这个位置还没有设置任何断点。
|
||||
|
||||
```
|
||||
auto frame_pointer = get_register_value(m_pid, reg::rbp);
|
||||
@ -218,8 +202,6 @@ void debugger::step_over() {
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### 测试
|
||||
|
||||
我通过实现一个调用一系列不同函数的简单函数来进行测试:
|
||||
@ -267,17 +249,17 @@ int main() {
|
||||
|
||||
via: https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
|
||||
作者:[TartanLlama ][a]
|
||||
作者:[Simon Brand][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[1]:https://linux.cn/article-8626-1.html
|
||||
[2]:https://linux.cn/article-8645-1.html
|
||||
[3]:https://linux.cn/article-8579-1.html
|
||||
[4]:https://linux.cn/article-8719-1.html
|
||||
[5]:https://linux.cn/article-8812-1.html
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://github.com/TartanLlama/minidbg/tree/tut_dwarf_step
|
||||
@ -0,0 +1,87 @@
|
||||
11 个使用 GNOME 3 桌面环境的理由
|
||||
============================================================
|
||||
|
||||
> GNOME 3 桌面的设计目的是简单、易于访问和可靠。GNOME 的受欢迎程度证明达成了这些目标。
|
||||
|
||||

|
||||
|
||||
去年年底,在我升级到 Fedora 25 后,新版本 [KDE][11] Plasma 出现了一些问题,这使我难以完成任何工作。所以我决定尝试其他的 Linux 桌面环境有两个原因。首先,我需要完成我的工作。第二,多年来一直使用 KDE,我想可能是尝试一些不同的桌面的时候了。
|
||||
|
||||
我尝试了几个星期的第一个替代桌面是我在 1 月份文章中写到的 [Cinnamon][12],然后我写了用了大约八个星期的[LXDE][13],我发现这里有很多事情我都喜欢。我用了 [GNOME 3][14] 几个星期来写了这篇文章。
|
||||
|
||||
像几乎所有的网络世界一样,GNOME 是缩写;它代表 “GNU 网络对象模型”(GNU Network Object Model)。GNOME 3 桌面设计的目的是简单、易于访问和可靠。GNOME 的受欢迎程度证明达成了这些目标。
|
||||
|
||||
GNOME 3 在需要大量屏幕空间的环境中非常有用。这意味着两个具有高分辨率的大屏幕,并最大限度地减少桌面小部件、面板和用来启动新程序之类任务的图标所需的空间。GNOME 项目有一套人机接口指南(HIG),用来定义人类应该如何与计算机交互的 GNOME 哲学。
|
||||
|
||||
### 我使用 GNOME 3 的十一个原因
|
||||
|
||||
1、 **诸多选择:** GNOME 以多种形式出现在我个人喜爱的 Fedora 等一些发行版上。你可以选择的桌面登录选项有 GNOME Classic、Xorg 上的 GNOME、GNOME 和 GNOME(Wayland)。从表面上看,启动后这些都是一样的,但它们使用不同的 X 服务器,或者使用不同的工具包构建。Wayland 在小细节上提供了更多的功能,例如动态滚动,拖放和中键粘贴。
|
||||
|
||||
2、 **入门教程:** 在用户第一次登录时会显示入门教程。它向你展示了如何执行常见任务,并提供了大量的帮助链接。教程在首次启动后关闭后也可轻松访问,以便随时访问该教程。教程非常简单直观,这为 GNOME 新用户提供了一个简单明了开始。要之后返回本教程,请点击 **Activities**,然后点击会显示程序的有九个点的正方形。然后找到并点击标为救生员图标的 **Help**。
|
||||
|
||||
3、 **桌面整洁:** 对桌面环境采用极简方法以减少杂乱,GNOME 设计为仅提供具备可用环境所必需的最低限度。你应该只能看到顶部栏(是的,它就叫这个),其他所有的都被隐藏,直到需要才显示。目的是允许用户专注于手头的任务,并尽量减少桌面上其他东西造成的干扰。
|
||||
|
||||
4、 **顶部栏:** 无论你想做什么,顶部栏总是开始的地方。你可以启动应用程序、注销、关闭电源、启动或停止网络等。不管你想做什么都很简单。除了当前应用程序之外,顶栏通常是桌面上唯一的其他对象。
|
||||
|
||||
5、 **dash:** 如下所示,在默认情况下, dash 包含三个图标。在开始使用应用程序时,会将它们添加到 dash 中,以便在其中显示最常用的应用程序。你也可以从应用程序查看器中将应用程序图标添加到 dash 中。
|
||||
|
||||
|
||||
|
||||
6、 **应用程序浏览器:** 我真的很喜欢这个可以从位于 GNOME 桌面左侧的垂直条上访问应用程序浏览器。除非有一个正在运行的程序,GNOME 桌面通常没有任何东西,所以你必须点击顶部栏上的 **Activities** 选区,点击 dash 底部的九个点组成的正方形,它是应用程序浏览器的图标。
|
||||
|
||||
|
||||
|
||||
如上所示,浏览器本身是一个由已安装的应用程序的图标组成的矩阵。矩阵下方有一对互斥的按钮,**Frequent** 和 **All**。默认情况下,应用程序浏览器会显示所有安装的应用。点击 **Frequent** 按钮,它会只显示最常用的应用程序。向上和向下滚动以找到要启动的应用程序。应用程序按名称按字母顺序显示。
|
||||
|
||||
[GNOME][6] 官网和内置的帮助有更多关于浏览器的细节。
|
||||
|
||||
7、 **应用程序就绪通知:** 当新启动的应用程序的窗口打开并准备就绪时,GNOME 会在屏幕顶部显示一个整齐的通知。只需点击通知即可切换到该窗口。与在其他桌面上搜索新打开的应用程序窗口相比,这节省了一些时间。
|
||||
|
||||
8、 **应用程序显示:** 为了访问不可见的其它运行的应用程序,点击 **Activities** 菜单。这将在桌面上的矩阵中显示所有正在运行的应用程序。点击所需的应用程序将其带到前台。虽然当前应用程序显示在顶栏中,但其他正在运行的应用程序不会。
|
||||
|
||||
9、 **最小的窗口装饰:** 桌面上打开窗口也很简单。标题栏上唯一显示的按钮是关闭窗口的 “X”。所有其他功能,如最小化、最大化、移动到另一个桌面等,可以通过在标题栏上右键单击来访问。
|
||||
|
||||
10、 **自动创建的新桌面:** 在使用下一空桌面的时候将自动创建的新的空桌面。这意味着总是有一个空的桌面在需要时可以使用。我使用的所有其他的桌面系统都可以让你在桌面活动时设置桌面数量,但必须使用系统设置手动完成。
|
||||
|
||||
11、 **兼容性:** 与我所使用的所有其他桌面一样,为其他桌面创建的应用程序可在 GNOME 上正常工作。这功能让我有可能测试这些桌面,以便我可以写出它们。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
GNOME 不像我以前用过的桌面。它的主要指导是“简单”。其他一切都要以简单易用为前提。如果你从入门教程开始,学习如何使用 GNOME 需要很少的时间。这并不意味着 GNOME 有所不足。它是一款始终保持不变的功能强大且灵活的桌面。
|
||||
|
||||
(题图:[Gunnar Wortmann][8] 通过 [Pixabay][9]。由 Opensource.com 修改。[CC BY-SA 4.0][10])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both 是位于北卡罗来纳州罗利的 Linux 和开源倡导者。他已经在 IT 行业工作了四十多年,并为 IBM 教授 OS/2 超过 20 年。在 IBM,他在 1981 年为初始的 IBM PC 写了第一个培训课程。他为红帽教授 RHCE 课程,曾在 MCI Worldcom、思科和北卡罗来纳州工作。他一直在使用 Linux 和开源软件近 20 年。
|
||||
|
||||
---------------
|
||||
|
||||
via: https://opensource.com/article/17/5/reasons-gnome
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://www.gnome.org/gnome-3/
|
||||
[7]:https://opensource.com/article/17/5/reasons-gnome?rate=MbGLV210A21ONuGAP8_Qa4REL7cKFvcllqUddib0qMs
|
||||
[8]:https://pixabay.com/en/users/karpartenhund-3077375/
|
||||
[9]:https://pixabay.com/en/garden-gnome-black-and-white-f%C3%B6hr-1584401/
|
||||
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
[12]:https://linux.cn/article-8606-1.html
|
||||
[13]:https://linux.cn/article-8434-1.html
|
||||
[14]:https://www.gnome.org/gnome-3/
|
||||
[15]:https://opensource.com/user/14106/feed
|
||||
[16]:https://opensource.com/article/17/5/reasons-gnome#comments
|
||||
[17]:https://opensource.com/users/dboth
|
||||
173
published/201708/20170702 Beyond public key encryption.md
Normal file
173
published/201708/20170702 Beyond public key encryption.md
Normal file
@ -0,0 +1,173 @@
|
||||
公钥加密之外
|
||||
============================================================
|
||||
|
||||
关于应用密码学最令人扼腕也最引人入胜的一件事就是*我们在现实中实际使用的密码学是多么的少*。这并不是指密码学在业界没有被广泛的应用————事实上它的应用很广泛。我想指出的是,迄今为止密码学研究人员开发了如此多实用的技术,但工业界平常使用的却少之又少。实际上,除了少数个别情况,我们现今使用的绝大部分密码学技术是在 21 世纪初^(注1) 就已经存在的技术。
|
||||
|
||||

|
||||
|
||||
大多数人并不在意这点,但作为一个工作在研究与应用交汇领域的密码学家,这让我感到不开心。我不能完全解决这个问题,我*能*做的,就是谈论一部分这些新的技术。在这个夏天里,这就是我想要做的:谈论。具体来说,在接下来的几个星期里,我将会写一系列讲述这些没有被看到广泛使用的前沿密码学技术的文章。
|
||||
|
||||
今天我要从一个非常简单的问题开始:在公钥加密之外还有什么(可用的加密技术)?具体地说,我将讨论几个过去 20 年里开发出的技术,它们可以让我们走出传统的公钥加密的概念的局限。
|
||||
|
||||
这是一篇专业的技术文章,但是不会有太困难的数学内容。对于涉及方案的实际定义,我会提供一些原论文的链接,以及一些背景知识的参考资料。在这里,我们的关注点是解释这些方案在做什么————以及它们在现实中可以怎样被应用。
|
||||
|
||||
### 基于身份的加密
|
||||
|
||||
在 20 世纪 80 年代中期,以为名叫<ruby>阿迪·萨莫尔<rt>Adi Shamir</rt></ruby>的密码学家提出了一个 [全新的想法][3] 。这个想法,简单来说,就是*摒弃公钥*。
|
||||
|
||||
为了理解 萨莫尔 的想法从何而来,我们最好先了解一些关于公钥加密的东西。在公钥加密的发明之前,所有的加密技术都牵涉到密钥。处理这样的密钥是相当累赘的工作。在你可以安全地通信之前,你需要和你的伙伴交换密钥。这一过程非常的困难,而且当通信规模增大时不能很好地运作。
|
||||
|
||||
公钥加密(由 [Diffie-Hellman][4] 和萨莫尔的 [RSA][5] 密码系统发展而来的)通过极大地简化密钥分配的过程给密码学带来了革命性的改变。比起分享密钥,用户现在只要将他们的*公共*密钥发送给其他使用者。有了公钥,公钥的接收者可以加密给你的信息(或者验证你的数字签名),但是又不能用该公钥来进行解密(或者产生数字签名)。这一部分要通过你自己保存的私有密钥来完成。
|
||||
|
||||
尽管公钥的使用改进了密码学应用的许多方面,它也带来了一系列新的挑战。从实践中的情况来看,拥有公钥往往只是成功的一半————人们通常还需要安全地分发这些公钥。
|
||||
|
||||
举一个例子,想象一下我想要给你发送一封 PGP 加密的电子邮件。在我可以这么做之前,我需要获得一份你的公钥的拷贝。我要怎么获得呢?显然我们可以亲自会面,然后当面交换这个密钥————但(由于面基的麻烦)没有人会愿意这样做。通过电子的方式获得你的公钥会更理想。在现实中,这意味着要么(1)我们必须通过电子邮件交换公钥, 要么(2)我必须通过某个第三方基础设施,比如一个 [网站][6] 或者 [密钥服务器][7] ,来获得你的密钥。现在我们面临这样的问题:如果电子邮件或密钥服务器是*不值得信赖的*(或者简单的来说允许任何人以 [你的名义][9] [上传密钥][8] ),我就可能会意外下载到恶意用户的密钥。当我给“你”发送一条消息的时候,也许我实际上正在将消息加密发送给 Mallory.
|
||||
|
||||

|
||||
|
||||
*Mallory*
|
||||
|
||||
解决这个问题——关于交换公钥和验证它们的来源的问题——激励了*大量的*实践密码工程,包括整个 [web PKI][10] (网络公钥基础设施)。在大部分情况下,这些系统非常奏效。但是萨莫尔并不满意。如果,他这样问道,我们能做得更好吗?更具体地说,他这样思考:*我们是否可以用一些更好的技术去替换那些麻烦的公钥?*
|
||||
|
||||
萨莫尔的想法非常令人激动。他提出的是一个新的公钥加密形式,在这个方案中用户的“公钥”可以就是他们的*身份*。这个身份可以是一个名字(比如 “Matt Green”)或者某些诸如电子邮箱地址这样更准确的信息。事实上,“身份”是什么并不重要。重要的是这个公钥可以是一个任意的字符串————而*不是*一大串诸如“ 7cN5K4pspQy3ExZV43F6pQ6nEKiQVg6sBkYPg1FG56Not ”这样无意义的字符组合。
|
||||
|
||||
当然,使用任意字符串作为公钥会造成一个严重的问题。有意义的身份听起来很棒————但我们无法拥有它们。如果我的公钥是 “Matt Green” ,我要怎么得到的对应的私钥?如果*我*能获得那个私钥,又有谁来阻止*其他的某些 Matt Green* 获得同样的私钥,进而读取我的消息。进而考虑一下这个,谁来阻止任意的某个*不是*名为 Matt Green 的人来获得它。啊,我们现在陷入了 [Zooko 三难困境][11] 。
|
||||
|
||||
萨莫尔的想法因此要求稍微更多一点的手段。相比期望身份可以全世界范围使用,他提出了一个名为“<ruby>密钥生成机构<rt>key generation authority</rt></ruby>”的特殊服务器,负责产生私钥。在设立初期,这个机构会产生一个<ruby>最高公共密钥<rt>master public key</rt></ruby>(MPK),这个公钥将会向全世界公布。如果你想要加密一条消息给“Matt Green”(或者验证我的签名),你可以用我的身份和我们达成一致使用的权威机构的唯一 MPK 来加密。要*解密*这则消息(或者制作签名),我需要访问同一个密钥机构,然后请求一份我的密钥的拷贝。密钥机构将会基于一个秘密保存的<ruby>最高私有密钥<rt>master secret key</rt></ruby>(MSK)来计算我的密钥。
|
||||
|
||||
加上上述所有的算法和参与者,整个系统看起来是这样的:
|
||||
|
||||
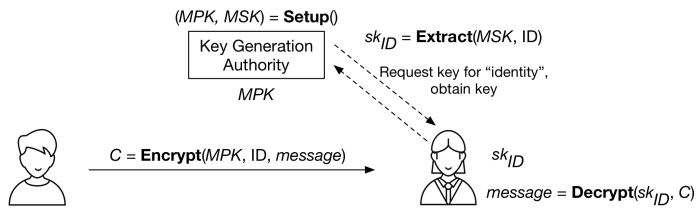
|
||||
|
||||
*一个<ruby>基于身份加密<rt>Identity-Based Encryption</rt></ruby>(IBE)系统的概览。<ruby>密钥生成机构<rt>Key Generation Authority </rt></ruby>的 Setup 算法产生最高公共密钥(MPK)和最高私有密钥(MSK)。该机构可以使用 Extract 算法来根据指定的 ID 生成对应的私钥。加密器(左)仅使用身份和 MPK 来加密。消息的接受者请求对应她身份的私钥,然后用这个私钥解密。(图标由 [Eugen Belyakoff][1] 制作)*
|
||||
|
||||
这个设计有一些重要的优点————并且胜过少数明显的缺点。在好的方面,它*完全*摆脱了任何和你发送消息的对象进行密钥交换的必要。一旦你选择了一个主密钥机构(然后下载了它的 MPK),你就可以加密给整个世界上任何一个人的消息。甚至更酷炫地,在你加密的时候,*你的通讯对象甚至还不需要联系密钥机构*。她可以在你给她发送消息*之后*再取得她的私钥。
|
||||
|
||||
当然,这个“特性”也同时是一个漏洞。因为密钥机构产生所有的私钥,它拥有相当大权力。一个不诚实的机构可以轻易生成你的私钥然后解密你的消息。用更得体的方式来说就是标准的 IBE 系统有效地“包含” [密钥托管机制][12]。^(注2)
|
||||
|
||||
### 基于身份加密(IBE)中的“加密(E)”
|
||||
|
||||
所有这些想法和额外的思考都是萨莫尔在他 1984 年的论文中提出来的。其中有一个小问题:萨莫尔只能解决问题的一半。
|
||||
|
||||
具体地说,萨莫尔提出了一个<ruby>基于身份签名<rt>identity-based signature</rt></ruby>(IBS)的方案—— 一个公共验证密钥是身份、而签名密钥由密钥机构生成的签名方案。他尽力尝试了,但仍然不能找到一个建立基于身份*加密*的解决方案。这成为了一个悬而未决的问题。^(注3)
|
||||
|
||||
到有人能解决萨莫尔的难题等了 16 年。令人惊讶的是,当解答出现的时候,它出现了不只一次,*而是三次*。
|
||||
|
||||
第一个,或许也是最负盛名的 IBE 的实现,是由<ruby>丹·博奈<rt>Dan Boneh</rt></ruby>和<ruby>马太·富兰克林</rt>Matthew Franklin</rt></ruby>在多年以后开发的。博奈和富兰克林的发现的时机十分有意义。<ruby>博奈富兰克林方案<rt>Boneh-Franklin scheme </rt></ruby> 根本上依赖于能支持有效的 “<ruby>[双线性映射][13]<rt>bilinear map</rt></ruby>” (或者“<ruby>配对<rt>pairing</rt></ruby>”)^(注4) 的椭圆曲线。需要计算这些配对的该类 [算法][14] 在萨莫尔撰写他的那篇论文是还不被人知晓,因此没有被*建设性地*使用——即被作为比起 [一种攻击][15] 更有用的东西使用——直至 [2000年][16]。
|
||||
|
||||
*(关于博奈富兰克林 IBE 方案的简短教学,请查看 [这个页面][2])*
|
||||
|
||||
第二个被称为 [Sakai-Kasahara][17] 的方案的情况也大抵类似,这个方案将在与第一个大约同一时间被另外一组学者独立发现。
|
||||
|
||||
第三个 IBE 的实现并不如前二者有效,但却更令人吃惊得多。[这个方案][18] 由<ruby>克利福德·柯克斯<rt>Clifford Cocks</rt></ruby>,一位英国国家通信总局的资深密码学家开发。它因为两个原因而引人注目。第一,柯克斯的 IBE 方案完全不需要用到双线性映射——都是建立在以往的 RSA 的基础上的,这意味着*原则上*这个算法这么多年来仅仅是没有被人们发现(而非在等待相应的理论基础)而已。第二,柯克斯本人近期因为一些甚至更令人惊奇的东西而闻名:在 RSA 算法被提出之前将近 5 年 [发现 RSA 加密系统][19](LCTT 译注:即公钥加密算法)。用再一个在公钥加密领域的重要成就来结束这一成就,实在堪称令人印象深刻的创举。
|
||||
|
||||
自 2001 年起,许多另外的 IBE 构造涌现出来,用到了各种各样的密码学背景知识。尽管如此,博奈和富兰克林早期的实现仍然是这些算法之中最为简单和有效的。
|
||||
|
||||
即使你并不因为 IBE 自身而对它感兴趣,事实证明它的基本元素对密码学家来说在许许多多单纯地加密之外的领域都十分有用。事实上,如果我们把 IBE 看作是一种由单一的主公/私钥对来产生数以亿计的相关联的密钥对的方式,它将会显得意义非凡。这让 IBE 对于诸如<ruby>[选择密文攻击][20]<rt> chosen ciphertext attacks</rt></ruby>, <ruby>[前向安全的公钥加密][21]<rt>forward-secure public key encryption</rt></ruby> 和<ruby>[短签名方案][22]<rt>short signature schemes</rt></ruby> 这样各种各样的应用来说非常有用。
|
||||
|
||||
### 基于特征加密
|
||||
|
||||
当然,如果你给密码学家以一个类似 IBE 的工具,那么首先他们要做的将是找到一种~~让事情更复杂~~改进它的方法。
|
||||
|
||||
最大的改进之一要归功于 [<ruby>阿密特·萨海<rt>Amit Sahai</rt></ruby>和<ruby>布伦特·沃特世<rt>Brent Waters</rt></ruby>][23]。我们称之为<ruby>基于特征加密<rt>Attribute-Based Encryption</rt></ruby>,或者 ABE。
|
||||
|
||||
这个想法最初并不是为了用特征来加密。相反,萨海和沃特世试图开发一种使用生物辨识特征来加密的*基于身份的*加密方案。为了理解这个问题,想象一下我决定使用某种生物辨识特征,比如你的 [虹膜扫描影像][24],来作为你的“身份”来加密一则给你的密文。然后你将向权威机构请求一个对应你的虹膜的解密密钥————如果一切都匹配得上,你就可以解密信息了。
|
||||
|
||||
问题就在于这几乎不能奏效。
|
||||
|
||||
|
||||
|
||||
*告诉我这不会给你带来噩梦*
|
||||
|
||||
因为生物辨识特征的读取(比如虹膜扫描或者指纹模板)本来就是易出错的。这意味着每一次的读取通常都是十分接近的,但却总是会几个对不上的比特。在标准的 IBE 系统中这是灾难性的:如果加密使用的身份和你的密钥身份有哪怕是一个比特的不同,解密都会失效。你就不走运了。
|
||||
|
||||
萨海和沃特世决定通过开发一种包含“阈值门”的 IBE 形式来解决这个问题。在这个背景下,一个身份的每一个字节都被表示为一个不同的“特征”。把每一个这种特征看作是你用于加密的一个元件——譬如“你的虹膜扫描的 5 号字节是 1”和“你的虹膜扫描的 23 号字节是 0”。加密的一方罗列出所有这些字节,然后将它们中的每一个都用于加密中。权威机构生成的解密密钥也嵌入了一连串相似的字节值。根据这个方案的定义,当且仅当(你的身份密钥与密文解密密钥之间)配对的特征数量超过某个预先定义的阈值时,才能顺利解密:*比如*为了能解密,2048 个字节中的(至少) 2024 个要是对应相同的。
|
||||
|
||||
这个想法的优美之处不在于模糊 IBE,而在于一旦你有了一个阈值门和一个“特征”的概念,你就能做更有趣的事情。[主要的观察结论][25] 是阈值门可以拥有实现布尔逻辑的 AND 门和 OR 门(LCTT 译注:译者认为此处应为用 AND 门和
|
||||
OR 门实现, 原文: a threshold gate can be used to implement the boolean AND and OR gates),就像这样:
|
||||
|
||||
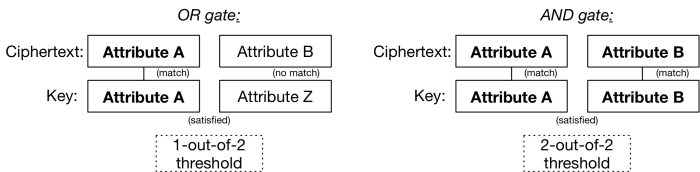
|
||||
|
||||
甚至你还可以将这些逻辑闸门*堆叠*起来,一些在另一些之上,来表示一些相当复杂的布尔表达式——这些表达式本身就用于判定在什么情况下你的密文可以被解密。举个例子,考虑一组更为现实的特征,你可以这样加密一份医学记录,使医院的儿科医生*或者*保险理算员都可以阅读它。你所需要做的只不过是保证人们可以得到正确描述*他们的*特征的密钥(就是一些任意的字符串,如同身份那样)。
|
||||
|
||||
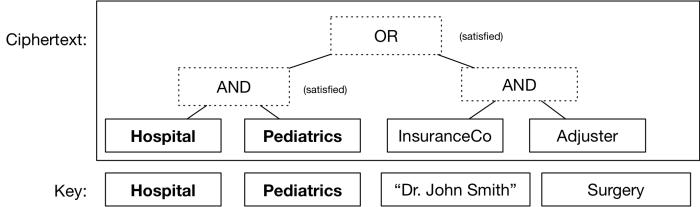
|
||||
|
||||
*一个简单的“密文规定”。在这个规定中当且仅当一个密钥与一组特定的特征匹配时,密文才能被解密。在这个案例中,密钥满足该公式的条件,因此密文将被解密。其余用不到的特征在这里忽略掉。*
|
||||
|
||||
其他的条件判断也能实现。通过一长串特征,比如文件创建时间、文件名,甚至指示文件创建位置的 GPS 坐标, 来加密密文也是有可能的。于是你可以让权威机构分发一部分对应你的数据集的非常精确的密钥————比如说,“该密钥用于解密所有在 11 月 3 号和 12 月 12 号之间在芝加哥被加密的包含‘小儿科’或者‘肿瘤科’标记的放射科文件”。
|
||||
|
||||
### 函数式加密
|
||||
|
||||
一旦拥有一个相关的基础工具,像 IBE 和 ABE,研究人员的本能是去扩充和一般化它。为什么要止步于简单的布尔表达式?我们能不能制作嵌入了*任意的计算机程序*的<ruby>密钥<rt>key</rt></ruby>(或者<ruby>密文<rt>ciphertext</rt></ruby>)?答案被证明是肯定的——尽管不是非常高效。一组 [近几年的][26] [研究][27] 显示可以根据各种各样的<ruby>基于格<rt>lattice-based</rt></ruby>的密码假设,构建在<ruby>任意多项式大小线路<rt> arbitrary polynomial-size circuits</rt></ruby>运作的 ABE。所以这一方向毫无疑问非常有发展潜力。
|
||||
|
||||
这一潜力启发了研究人员将所有以上的想法一般化成为单独一类被称作 <ruby>[“函数式加密”][28]<rt>functional encryption</rt></ruby> 的加密方式。函数式加密更多是一种抽象的概念而没有具体所指——它不过是一种将所有这些系统看作是一个特定的类的实例的方式。它基本的想法是,用一种依赖于(1)明文,和(2)嵌入在密钥中的数据 的任意函数 F 的算法来代表解密过程。
|
||||
|
||||
(LCTT 译注:上面函数 F 的 (1) 原文是“the plaintext inside of a ciphertext”,但译者认为应该是密文,其下的公式同。)
|
||||
|
||||
这个函数大概是这样的:
|
||||
|
||||
输出 = F(密钥数据,密文数据)
|
||||
|
||||
在这一模型中,IBE 可以表达为有一个加密算法 *加密(身份,明文)*并定义了一个这样的函数 F:如果“*密钥输入 == 身份*”,则输出对应明文,否则输出空字符串的系统。相似地,ABE 可以表达为一个稍微更复杂的函数。依照这一范式,我们可以展望在将来,各类有趣的功能都可以由计算不同的函数得到,并在未来的方案中被实现。
|
||||
|
||||
但这些都必须要等到以后了。今天我们谈的已经足够多了。
|
||||
|
||||
### 所以这一切的重点是什么?
|
||||
|
||||
对于我来说,重点不过是证明密码学可以做到一些十分优美惊人的事。当谈及工业与“应用”密码学时,我们鲜有见到这些出现在日常应用中,但我们都可以等待着它们被广泛使用的一天的到来。
|
||||
|
||||
也许完美的应用就在某个地方,也许有一天我们会发现它。
|
||||
|
||||
*注:*
|
||||
|
||||
- 注 1:最初在这片博文里我写的是 “20 世纪 90 年代中期”。在文章的评论里,Tom Ristenpart 提出了异议,并且非常好地论证了很多重要的发展都是在这个时间之后发生的。所以我把时间再推进了大约 5 年,而我也在考虑怎样将这表达得更好一些。
|
||||
- 注 2:我们知道有一种叫作 [“无证书加密”][29] 的加密的中间形式。这个想法由 Al-Riyami 和 Paterson 提出,并且使用到标准公钥加密和 IBE 的结合。基本的思路是用一个(消息接受者生成的)传统密钥和一个 IBE 身份*共同*加密每则消息。然后接受者必须从 IBE 权威机构处获得一份私钥的拷贝来解密。这种方案的优点是两方面的:(1)IBE 密钥机构不能独自解密消息,因为它没有对应的(接受者)私钥,这就解决了“托管”问题(即权威机构完全具备解密消息的能力);(2)发送者不必验证公钥的确属于接收者(LCTT 译注:原文为 sender,但译者认为应该是笔误,应为 recipient),因为 IBE 方面会防止伪装者解密这则消息。但不幸的是,这个系统更像是传统的公钥加密系统,而缺少 IBE 简洁的实用特性。
|
||||
- 注 3:开发 IBE 的一部分挑战在于构建一个面临不同密钥持有者的“勾结”安全的系统。譬如说,想象一个非常简单的只有 2 比特的身份鉴定系统。这个系统只提供四个可能的身份:“00”,“01”,“10”,“11”。如果我分配给你对应 “01” 身份的密钥,分配给 Bob 对应 “10” 的密钥,我需要保证你们不能合谋生成对应 “00” 和 “11” 身份的密钥。一些早期提出的解决方法尝试通过用不同方式将标准公共加密密钥拼接到一起来解决这个问题(比如,为身份的每一个字节保留一个独立的公钥,然后将对应的多个私钥合并成一个分发)。但是,当仅仅只有少量用户合谋(或者他们的密钥被盗)时,这些系统就往往会出现灾难性的失败。因而基本上这个问题的解决就是真正的 IBE 与它的仿造近亲之间的区别。
|
||||
- 注 4: 博奈和富兰克林方案的完整描述可以在 [这里][30] 看到,或者在他们的 [原版论文][31] 中。[这里][32]、[这里][33] 和 [这里][34] 有一部分代码。除了指出这个方案十分高效之外,我不希望在这上面花太多的篇幅。它由 [Voltage Security][35](现属于惠普) 实现并占有专利。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.cryptographyengineering.com/2017/07/02/beyond-public-key-encryption/
|
||||
|
||||
作者:[Matthew Green][a]
|
||||
译者:[Janzen_Liu](https://github.com/JanzenLiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.cryptographyengineering.com/author/matthewdgreen/
|
||||
[1]:https://thenounproject.com/eugen.belyakoff/
|
||||
[2]:https://blog.cryptographyengineering.com/boneh-franklin-ibe/
|
||||
[3]:https://discovery.csc.ncsu.edu/Courses/csc774-S08/reading-assignments/shamir84.pdf
|
||||
[4]:https://en.wikipedia.org/wiki/Diffie%E2%80%93Hellman_key_exchange
|
||||
[5]:https://en.wikipedia.org/wiki/RSA_(cryptosystem)
|
||||
[6]:https://keybase.io/
|
||||
[7]:https://pgp.mit.edu/
|
||||
[8]:https://motherboard.vice.com/en_us/article/bmvdwd/wave-of-spoofed-encryption-keys-shows-weakness-in-pgp
|
||||
[9]:https://motherboard.vice.com/en_us/article/bmvdwd/wave-of-spoofed-encryption-keys-shows-weakness-in-pgp
|
||||
[10]:https://en.wikipedia.org/wiki/Certificate_authority
|
||||
[11]:https://en.wikipedia.org/wiki/Zooko%27s_triangle
|
||||
[12]:https://en.wikipedia.org/wiki/Key_escrow
|
||||
[13]:http://people.csail.mit.edu/alinush/6.857-spring-2015/papers/bilinear-maps.pdf
|
||||
[14]:https://crypto.stanford.edu/miller/
|
||||
[15]:http://ieeexplore.ieee.org/document/259647/
|
||||
[16]:https://pdfs.semanticscholar.org/845e/96c20e5a5ff3b03f4caf72c3cb817a7fa542.pdf
|
||||
[17]:https://en.wikipedia.org/wiki/Sakai%E2%80%93Kasahara_scheme
|
||||
[18]:https://pdfs.semanticscholar.org/8289/821325781e2f0ce83cfbfc1b62c44be799ee.pdf
|
||||
[19]:https://cryptome.org/jya/ellisdoc.htm
|
||||
[20]:https://www.cs.umd.edu/~jkatz/papers/id-cca.pdf
|
||||
[21]:https://eprint.iacr.org/2003/083.pdf
|
||||
[22]:https://en.wikipedia.org/wiki/Boneh%E2%80%93Lynn%E2%80%93Shacham
|
||||
[23]:https://eprint.iacr.org/2004/086.pdf
|
||||
[24]:https://en.wikipedia.org/wiki/Iris_recognition
|
||||
[25]:https://eprint.iacr.org/2006/309.pdf
|
||||
[26]:https://eprint.iacr.org/2013/337.pdf
|
||||
[27]:https://arxiv.org/abs/1210.5287
|
||||
[28]:https://eprint.iacr.org/2010/543.pdf
|
||||
[29]:http://eprint.iacr.org/2003/126.pdf
|
||||
[30]:https://en.wikipedia.org/wiki/Boneh%E2%80%93Franklin_scheme
|
||||
[31]:https://crypto.stanford.edu/~dabo/papers/bfibe.pdf
|
||||
[32]:http://go-search.org/view?id=github.com%2Fvanadium%2Fgo.lib%2Fibe
|
||||
[33]:https://github.com/relic-toolkit/relic
|
||||
[34]:https://github.com/JHUISI/charm
|
||||
[35]:https://www.voltage.com/
|
||||
@ -0,0 +1,117 @@
|
||||
在标准建立之前,软件所存在的问题
|
||||
============================================================
|
||||
|
||||
> 开源项目需要认真对待交付成果中所包含的标准
|
||||
|
||||

|
||||
|
||||
无论以何种标准来衡量,开源软件作为传统的专有软件的替代品而崛起,取得了不错的效果。 如今,仅 Github 中就有着数以千万计的代码仓库,其中重要项目的数量也在快速增长。在本文撰写的时候,[Apache 软件基金会][4] 开展了超过 [300 个项目][5], [Linux 基金会][6] 支持的项目也超过了 60 个。与此同时,[OpenStack 基金会][7] 在 180 多个国家拥有超过 60,000 名成员。
|
||||
|
||||
这样说来,这种情景下有什么问题么?
|
||||
|
||||
开源软件在面对用户的众多需求时,由于缺少足够的意识,而无法独自去解决全部需求。 更糟糕的是,许多开源软件社区的成员(业务主管以及开发者)对利用最合适的工具解决这一问题并不感兴趣。
|
||||
|
||||
让我们开始找出那些有待解决的问题,看看这些问题在过去是如何被处理的。
|
||||
|
||||
问题存在于:通常许多项目都在试图解决一个大问题当中重复的一小部分,而客户希望能够在竞争产品之间做出选择,不满意的话还能够轻松选择其他产品。但是现在看来都是不可能的,在这个问题被解决之前它将会阻碍开源软件的使用。
|
||||
|
||||
这已经不是一个新的问题或者没有传统解决方案的问题了。在一个半世纪以来,用户期望有更多的选择和自由来变换厂商,而这一直是通过标准的制定来实现的。在现实当中,你可以对螺丝钉、灯泡、轮胎、延长线的厂商做出无数多的选择,甚至于对独特形状的红酒杯也可以专注选择。因为标准为这里的每一件物品都提供了物理规格。而在健康和安全领域,我们的幸福也依赖于成千上万的标准,这些标准是由私营行业制定的,以确保在最大化的竞争中能够有完美的结果。
|
||||
|
||||
随着信息与通信技术(ICT)的发展,以同样类似的方式形成了一些重要的组织机构,例如:国际电信联盟(ITU)、国际电工委员会(IEC),以及电气与电子工程师学会标准协会(IEEE-SA)。近千家财团遵循 ICT 标准来进行开发、推广以及测试。
|
||||
|
||||
虽然并非是所有的 ICT 标准都形成了无缝对接,但如今在我们生活的科技世界里,成千上万的基本标准履行着这一承诺,这些标准包含了计算机、移动设备、Wi-Fi 路由器以及其他一切依赖电力来运行的东西。
|
||||
|
||||
关键的一点,在很长的一段时间里,由于客户对拥有种类丰富的产品、避免受制于供应商,并且享受全球范围内的服务的渴望,逐渐演变出了这一体系。
|
||||
|
||||
现在让我们来看看开源软件是如何演进的。
|
||||
|
||||
好消息是伟大的软件已经被创造出来了。坏消息是对于像云计算和虚拟化网络这样的关键领域,没有任何单独的基金会在开发整个堆栈。取而代之的是,单个项目开发单独的一层或者多层,依靠需要时才建立的善意的合作,这些项目最终堆叠成栈。当这一过程运行良好时,结果是好的,但也有可能形成与传统的专有产品同样的锁定。相反,当这一过程运行不良时,坏的结果就是它会浪费开发商、社区成员的时间和努力,同时也会辜负客户的期望。
|
||||
|
||||
最明确的解决方法的创建标准,允许客户避免被锁定,鼓励多个解决方案通过对附加服务和功能进行有益的竞争。当然也存在着例外,但这不是开源世界正在发生的情况。
|
||||
|
||||
这背后的主要原因在于,开源社区的主流观点是:标准意味着限制、落后和多余。对于一个完整的堆栈中的单独一层来说,可能就是这样。但客户想要选择的自由、激烈的竞争,这就导致回到了之前的坏结果上,尽管多个厂商提供相似的集成堆栈,但却被锁定在一个技术上。
|
||||
|
||||
在 Yaron Haviv 于 2017 年 6 月 14 日所写的 “[除非我们协作,否则我们将被困在专有云上][8]” 一文中,就有对这一问题有着很好的描述。
|
||||
|
||||
> 在今天的开源生态系统当中存在一个问题,跨项目整合并不普遍。开源项目能够进行大型合作,构建出分层的模块化的架构,比如说 Linux — 已经一次又一次的证明了它的成功。但是与 Linux 的意识形成鲜明对比的就是如今许多开源社区的日常状态。
|
||||
>
|
||||
> 举个例子:大数据生态系统,就是依赖众多共享组件或通用 API 和层的堆叠来实现的。这一过程同样缺少标准的线路协议,同时,每个处理框架(看看 Spark、Presto 和 Flink)都拥有独立的数据源 API。
|
||||
>
|
||||
> 这种合作的缺乏正在造成担忧。缺少了合作,项目就会变得不通用,结果对客户产生了负面影响。因为每个人都不得不从头开始,重新开发,这基本上就锁定了客户,减缓了项目的发展。
|
||||
|
||||
Haviv 提出了两种解决方法:
|
||||
|
||||
* 项目之间更紧密的合作,联合多个项目消除重叠的部分,使堆栈内的整合更加密切;
|
||||
* 开发 API ,使切换更加容易。
|
||||
|
||||
这两种方法都能达到目的。但除非事情能有所改变,我们将只会看到第一种方法,这就是前边展望中发现的技术锁定。结果会发现工业界,无论是过去 WinTel 的世界,或者纵观苹果的历史,相互竞争的产品都是以牺牲选择来换取紧密整合的。
|
||||
|
||||
同样的事情似乎很有可能发生在新的开源界,如果开源项目继续忽视对标准的需求,那么竞争会存在于层内,甚至是堆栈间。如果现在能够做到的话,这样的问题可能就不会发生了。
|
||||
|
||||
因为如果口惠无实开发软件优先、标准在后的话,对于标准的制定就没有真正的兴趣。主要原因是,大多数的商人和开发者对标准知之甚少。不幸的是,我们能够理解这些使事情变得糟糕的原因。这些原因有几个:
|
||||
|
||||
* 大学几乎很少对标准进行培训;
|
||||
* 过去拥有专业的标准人员的公司遣散了这些部门,现在的部署工程师接受标准组织的培训又远远不够;
|
||||
* 在建立雇主标准工作方面的专业知识方面几乎没有职业价值;
|
||||
* 参与标准活动的工程师可能需要以他们认为是最佳技术解决方案为代价来延长雇主的战略利益;
|
||||
* 在许多公司内部,专业的标准人员与开源开发者之间鲜有交流;
|
||||
* 许多软件工程师将标准视为与 FOSS 定义的“四大自由”有着直接冲突。
|
||||
|
||||
现在,让我们来看看在开源界正在发生什么:
|
||||
|
||||
* 今天大多数的软件工程师鲜有不知道开源的;
|
||||
* 工程师们每天都在享受着开源工具所带来的便利;
|
||||
* 许多令人激动的最前沿的工作正是在开源项目中完成的;
|
||||
* 在热门的开源领域,有经验的开发者广受欢迎,并获得了大量实质性的奖励;
|
||||
* 在备受好评的项目中,开发者在软件开发过程中享受到了空前的自主权;
|
||||
* 事实上,几乎所有的大型 ICT 公司都参与了多个开源项目,最高级别的成员当中,通常每个公司每年的合并成本(会费加上投入的雇员)都超过了一百万美元。
|
||||
|
||||
如果脱离实际的话,这个比喻似乎暗示着标准是走向 ICT 历史的灰烬。但现实却有很大差别。一个被忽视的事实是,开源开发是比常人所认为的更为娇嫩的花朵。这样比喻的原因是:
|
||||
|
||||
* 项目的主要支持者们可以撤回(已经做过的事情),这将导致一个项目的失败;
|
||||
* 社区内的个性和文化冲突会导致社区的瓦解;
|
||||
* 重要项目更加紧密的整合能力有待观察;
|
||||
* 有时专有权在博弈中被削弱,高资助的开源项目在某些情况下会导致失败。
|
||||
* 随着时间的推移,可能个别公司认为其开源策略没能给他们带来预期的回报;
|
||||
* 对关键开源项目的失败引起过多关注,会导致厂商放弃一些投资中的新项目,并说服客户谨慎选择开源方案。
|
||||
|
||||
奇怪的是,最积极解决这些问题的协作单位是标准组织,部分原因是,他们已经感受到了开源合作的崛起所带来的威胁。他们的回应包括更新知识产权策略以允许在此基础上各种类型的合作,开发开源工具,包含开源代码的标准,以及在其他类型的工作项目中开发开源手册。
|
||||
|
||||
结果就是,这些标准组织调整自己成为一个近乎中立的角色,为完整方案的开发提供平台。这些方案能够包含市场上需要的各种类型的合作产品,以及混合工作产品。随着此过程的继续,很有可能使厂商们乐意推行一些包含了标准组织在内的举措,否则他们可能会走向开源基金。
|
||||
|
||||
重要的是,由于这些原因,开源项目开始认真对待项目交付所包含的标准,或者与标准开发商合作,共同为完整的方案做准备。这不仅会有更多的产品选择,对客户更少的限制,而且也给客户在开源方案上更大的信心,同时也对开源产品和服务有更多的需求。
|
||||
|
||||
倘若这一切不发生的话,将会是一个很大的遗憾,因为这是开源所导致的巨大损失。而这取决于如今的项目所做的决定,是供给市场所需,还是甘心于未来日趋下降的影响力,而不是持续的成功。
|
||||
|
||||
_本文源自 ConsortiumInfo.org的 [Standards Blog][2],并已获得出版许可_
|
||||
|
||||
(题图:opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Andy Updegrove - Andy helps 的 CEO,管理团队,由他们的投资者建立的成功的组织。他曾作为一名先驱,自1979年起,就为高科技公司提供商业头脑的法律顾问和策略建议。在全球舞台上,他经常作为代表,帮助推动超过 135 部全球标准的制定,宣传开源,主张联盟,其中包括一些世界上最大,最具影响力的标准制定机构。
|
||||
|
||||
---
|
||||
|
||||
via: https://opensource.com/article/17/7/software-standards
|
||||
|
||||
作者:[Andy Updegrove][a]
|
||||
译者:[softpaopao](https://github.com/softpaopao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andrewupdegrove
|
||||
[1]:https://opensource.com/article/17/7/software-standards?rate=kKK6oD-vGSEdDMj7OHpBMSqASMqbz3ii94q1Kj12lCI
|
||||
[2]:http://www.consortiuminfo.org/standardsblog/article.php?story=20170616133415179
|
||||
[3]:https://opensource.com/user/16796/feed
|
||||
[4]:https://www.apache.org/
|
||||
[5]:https://projects.apache.org/
|
||||
[6]:https://www.linuxfoundation.org/
|
||||
[7]:https://www.linuxfoundation.org/projects/directory
|
||||
[8]:https://www.enterprisetech.com/2017/06/14/well-enslaved-proprietary-clouds-unless-collaborate/
|
||||
[9]:https://opensource.com/users/andrewupdegrove
|
||||
[10]:https://opensource.com/users/andrewupdegrove
|
||||
[11]:https://opensource.com/article/17/7/software-standards#comments
|
||||
@ -1,53 +1,52 @@
|
||||
物联网对 Linux 恶意软件的助长
|
||||
物联网助长了 Linux 恶意软件
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
针对 Linux 系统的恶意软件正在增长,这主要是由于连接到物联网设备的激增。
|
||||
|
||||
这是上周发布的网络安全设备制造商 [WatchGuard Technologies][4] 的一篇报告。
|
||||
这是网络安全设备制造商 [WatchGuard Technologies][4] 上周发布的的一篇报告中所披露的。
|
||||
|
||||
该报告分析了全球 26,000 多件设备收集到的数据,今年第一季度的前 10 中发现了三个针对 Linux 的恶意软件,而上一季度仅有一个。
|
||||
该报告分析了全球 26,000 多件设备收集到的数据,今年第一季度的前 10 名恶意软件中发现了三个针对 Linux 的恶意软件,而上一季度仅有一个。
|
||||
|
||||
WatchGuard 的 CTO Corey Nachreiner 和安全威胁分析师 Marc Laliberte 写道:“Linux 攻击和恶意软件正在兴起。我们相信这是因为 IoT 设备的系统性弱点与其快速增长相结合,它正在将僵尸网络作者转向 Linux 平台。”
|
||||
WatchGuard 的 CTO Corey Nachreiner 和安全威胁分析师 Marc Laliberte 写道:“Linux 上的攻击和恶意软件正在兴起。我们相信这是因为 IoT 设备的系统性弱点与其快速增长相结合的结果,它正在引导僵尸网络的作者们转向 Linux 平台。”
|
||||
|
||||
但是,他们建议“阻止入站 Telnet 和 SSH,以及使用复杂的管理密码,可以防止绝大多数潜在的攻击”。
|
||||
他们建议“阻止入站的 Telnet 和 SSH,以及使用复杂的管理密码,可以防止绝大多数潜在的攻击”。
|
||||
|
||||
### 黑客的新大道
|
||||
|
||||
Laliberte 观察到,Linux 恶意软件在去年年底随着 Mirai 僵尸网络开始增长。Mirai 在九月份曾经用来攻击部分互联网的基础设施,使数百万用户离线。
|
||||
Laliberte 观察到,Linux 恶意软件在去年年底随着 Mirai 僵尸网络开始增长。Mirai 在九月份曾经用来攻击部分互联网的基础设施,迫使数百万用户断线。
|
||||
|
||||
他告诉 LinuxInsider,“现在,随着物联网设备的飞速发展,一条全新的大道正在向攻击者开放。我们相信,随着互联网上新目标的出现,Linux 恶意软件会逐渐增多。”
|
||||
他告诉 LinuxInsider,“现在,随着物联网设备的飞速发展,一条全新的大道正在向攻击者们开放。我们相信,随着互联网上新目标的出现,Linux 恶意软件会逐渐增多。”
|
||||
|
||||
Laliberte 继续说,物联网设备制造商并没有对安全性表现出很大的关注。他们的目标是使他们的设备能够使用、便宜,制造快速。
|
||||
Laliberte 继续说,物联网设备制造商并没有对安全性表现出很大的关注。他们的目标是使他们的设备能够使用、便宜,能够快速制造。
|
||||
|
||||
他说:“他们真的不关心开发过程中的安全。”
|
||||
他说:“开发过程中他们真的不关心安全。”
|
||||
|
||||
### 微不足道的追求
|
||||
### 轻易捕获
|
||||
|
||||
[Alert Logic][5] 的网络安全宣传员 Paul Fletcher说,大多数物联网制造商都使用 Linux 的裁剪版本,因为操作系统需要最少的系统资源来运行。
|
||||
[Alert Logic][5] 的网络安全布道师 Paul Fletcher 说,大多数物联网制造商都使用 Linux 的裁剪版本,因为操作系统需要最少的系统资源来运行。
|
||||
|
||||
他告诉 LinuxInsider,“当你将大量与互联网连接的物联网设备结合在一起时,这相当于在线大量的 Linux 系统,它们可用于攻击。”
|
||||
|
||||
为了使设备易于使用,制造商使用的协议对黑客也是友好的。
|
||||
为了使设备易于使用,制造商使用的协议对黑客来说也是用户友好的。
|
||||
|
||||
Fletcher 说:“攻击者可以访问这些易受攻击的接口,然后上传并执行他们选择的恶意代码。”
|
||||
|
||||
他指出,厂商经常对设备的默认设置很差。
|
||||
他指出,厂商经常给他们的设备很差的默认设置。
|
||||
|
||||
Fletcher说:“通常,管理员帐户是空密码或易于猜测的默认密码,例如‘password123’。”
|
||||
Fletcher 说:“通常,管理员帐户是空密码或易于猜测的默认密码,例如 ‘password123’。”
|
||||
|
||||
[SANS 研究所][6] 首席研究员 Johannes B. Ullrich 表示,安全问题通常是“本身不限定 Linux”。
|
||||
[SANS 研究所][6] 首席研究员 Johannes B. Ullrich 表示,安全问题通常“本身不是 Linux 特有的”。
|
||||
|
||||
他告诉L inuxInsider,“制造商对他们如何配置设备不屑一顾,所以他们使这些设备的利用变得微不足道。”
|
||||
他告诉 LinuxInsider,“制造商对他们如何配置这些设备不屑一顾,所以他们使这些设备的利用变得非常轻易。”
|
||||
|
||||
### 10 大恶意软件
|
||||
|
||||
这些 Linux 恶意软件在 WatchGuard 的第一季度的统计数据中占据了前 10 名:
|
||||
|
||||
* Linux/Exploit,它使用几种木马来扫描可以列入僵尸网络的设备。
|
||||
|
||||
* Linux/Downloader,它使用恶意的 Linux shell 脚本。Linux 运行在许多不同的架构上,如 ARM、MIPS 和传统的 x8 6芯片组。报告解释说,一个根据架构编译的可执行文件不能在不同架构的设备上运行。因此,一些 Linux 攻击利用 dropper shell 脚本下载并安装它们所感染的体系架构的适当恶意组件。
|
||||
这些 Linux 恶意软件在 WatchGuard 的第一季度的统计数据中占据了前 10 名的位置:
|
||||
|
||||
* Linux/Exploit,它使用几种木马来扫描可以加入僵尸网络的设备。
|
||||
* Linux/Downloader,它使用恶意的 Linux shell 脚本。Linux 可以运行在许多不同的架构上,如 ARM、MIPS 和传统的 x86 芯片组。报告解释说,一个为某个架构编译的可执行文件不能在不同架构的设备上运行。因此,一些 Linux 攻击利用 dropper shell 脚本下载并安装适合它们所要感染的体系架构的恶意组件。
|
||||
* Linux/Flooder,它使用了 Linux 分布式拒绝服务工具,如 Tsunami,用于执行 DDoS 放大攻击,以及 Linux 僵尸网络(如 Mirai)使用的 DDoS 工具。报告指出:“正如 Mirai 僵尸网络向我们展示的,基于 Linux 的物联网设备是僵尸网络军队的主要目标。
|
||||
|
||||
### Web 服务器战场
|
||||
@ -56,27 +55,27 @@ WatchGuard 报告指出,敌人攻击网络的方式发生了变化。
|
||||
|
||||
公司发现,到 2016 年底,73% 的 Web 攻击针对客户端 - 浏览器和配套软件。今年头三个月发生了彻底改变,82% 的 Web 攻击集中在 Web 服务器或基于 Web 的服务上。
|
||||
|
||||
报告合著者 Nachreiner 和 Laliberte 写道:“我们不认为下载风格的攻击将会消失,但似乎攻击者已经集中力量和工具来试图利用 Web 服务器攻击。”
|
||||
报告合著者 Nachreiner 和 Laliberte 写道:“我们不认为下载式的攻击将会消失,但似乎攻击者已经集中力量和工具来试图利用 Web 服务器攻击。”
|
||||
|
||||
他们也发现,自 2006 年底以来,杀毒软件的有效性有所下降。
|
||||
|
||||
Nachreiner 和 Laliberte 报道说:“连续的第二季,我们看到使用传统的杀毒软件解决方案漏掉了使用我们更先进的解决方案可以捕获的大量恶意软件,实际上已经从 30% 上升到了 38%。”
|
||||
Nachreiner 和 Laliberte 报道说:“连续的第二个季度,我们看到使用传统的杀毒软件解决方案漏掉了使用我们更先进的解决方案可以捕获的大量恶意软件,实际上已经从 30% 上升到了 38% 漏掉了。”
|
||||
|
||||
他说:“如今网络犯罪分子使用许多精妙的技巧来重新包装恶意软件,从而避免了基于签名的检测。这就是为什么使用基本杀毒的许多网络成为诸如赎金软件之类威胁的受害者。”
|
||||
他说:“如今网络犯罪分子使用许多精妙的技巧来重新包装恶意软件,从而避免了基于签名的检测。这就是为什么使用基本的杀毒软件的许多网络成为诸如赎金软件之类威胁的受害者。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
John P. Mello Jr.自 2003 年以来一直是 ECT 新闻网记者。他的重点领域包括网络安全、IT问题、隐私权、电子商务、社交媒体、人工智能、大数据和消费电子。 他撰写和编辑了众多出版物,包括“波士顿商业杂志”、“波士顿凤凰”、“Megapixel.Net” 和 “政府安全新闻”。给 John 发邮件。
|
||||
John P. Mello Jr.自 2003 年以来一直是 ECT 新闻网记者。他的重点领域包括网络安全、IT问题、隐私权、电子商务、社交媒体、人工智能、大数据和消费电子。 他撰写和编辑了众多出版物,包括“波士顿商业杂志”、“波士顿凤凰”、“Megapixel.Net” 和 “政府安全新闻”。
|
||||
|
||||
-------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84652.html
|
||||
|
||||
作者:[John P. Mello Jr ][a]
|
||||
作者:[John P. Mello Jr][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
183
published/201708/20170706 OpenStack in a Snap.md
Normal file
183
published/201708/20170706 OpenStack in a Snap.md
Normal file
@ -0,0 +1,183 @@
|
||||
在 Snap 中玩转 OpenStack
|
||||
================================
|
||||
|
||||

|
||||
|
||||
OpenStack 非常复杂,许多社区成员都在努力使 OpenStack 的部署和操作更加容易。其中大部分时间都用来改善相关工具,如:Ansible、Puppet、Kolla、Juju、Triple-O 和 Chef (仅举几例)。但是,如果我们降低一下标准,并且还能使包的体验更加简单,将会怎样呢?
|
||||
|
||||
我们正在努力通过 snap 包来实现这一点。snap 包是一种新兴的软件分发方式,这段来自 [snapcraft.io][1] 的介绍很好的总结了它的主要优点:_snap 包可以快速安装、易于创建、安全运行而且能自动地事务化更新,因此你的应用程序总是能保持最新的状态并且永远不会被破坏。_
|
||||
|
||||
### 捆绑软件
|
||||
|
||||
单个 snap 包可以内嵌多个不同来源的软件,从而提供一个能够快速启动和运行的解决方案。当你安装 snap 包时,你会发现安装速度是很快的,这是因为单个 snap 包捆绑了所有它需要的依赖。这和安装 deb 包有些不同,因为它需要下载所有的依赖然后分别进行安装。
|
||||
|
||||
### Snap 包制作简单
|
||||
|
||||
在 Ubuntu 工作的时候,我花了很多时间为 Debian 制作 OpenStack 的安装包。这是一种很特殊技能,需要花很长时间才能理解其中的细微差别。与 snap 包相比,deb 包和 snap 包在复杂性上的差异有天壤之别。snap 包简单易行,并且相当有趣。
|
||||
|
||||
### Snap 包的其它特性
|
||||
|
||||
* 每个 snap 包都安装在其独有的只读 squashfs 文件系统中。
|
||||
* 每个 snap 包都运行在一个由 AppArmor 和 seccomp 策略构建的严格沙箱环境中。
|
||||
* snap 包能事务更新。新版本的 snap 包会安装到一个新的只读 squashfs 文件系统中。如果升级失败,它将回滚到旧版本。
|
||||
* 当有新版本可用时,snap 包将自动更新。
|
||||
* OpenStack 的 snap 包能保证与 OpenStack 的上游约束保持一致。打包的人不需要再为 OpenStack 依赖链维护单独的包。这真是太爽了!
|
||||
|
||||
### OpenStack snap 包介绍
|
||||
|
||||
现在,下面这些项目已经有了相应的 snap 包:
|
||||
|
||||
* `Keystone` —— 这个 snap 包为 OpenStack 提供了身份鉴证服务。
|
||||
* `Glance` —— 这个 snap 包为 OpenStack 提供了镜像服务。
|
||||
* `Neutron` —— 这个 snap 包专门提供了 neutron-server 过程,作为 OpenStack 部署过程的一个 snap 包。
|
||||
* `Nova` —— 这个 snap 包提供 OpenStack 部署过程中的 Nova 控制器组件。
|
||||
* `Nova-hypervisor` —— 这个 snap 包提供 OpenStack 部署过程中的 hypervisor 组件,并且配置使用通过 deb 包安装的 Libvirt/KVM + Open vSwitch 组合。这个 snap 包同时也包含 nava-lxd,这允许我们使用 nova-lxd 而不用 KVM。
|
||||
|
||||
这些 snpa 包已经能让我们部署一个简单可工作的 OpenStack 云。你可以在 [github][2] 上找到所有这些 OpenStack snap 包的源码。有关 OpenStack snap 包更多的细节,请参考上游存储库中各自的 README。在那里,你可以找到更多有关管理 snap 包的信息,比如覆盖默认配置、重启服务、设置别名等等。
|
||||
|
||||
### 想要创建自己的 OpenStack snap 包吗?
|
||||
|
||||
查看 [snap cookie 工具][3]。我很快就会写一篇博文,告诉你如何使用 snap cookie 工具。它非常简单,并且能帮助你在任何时候创建一个新的 OpenStack snap 包。
|
||||
|
||||
### 测试 OpenStack snap 包
|
||||
|
||||
我们已经用简单的脚本初步测试了 OpenStack snap 包。这个脚本会在单个节点上安装 sanp 包,还会在安装后提供额外的配置服务。来尝试下吧:
|
||||
|
||||
```
|
||||
git clone https://github.com/openstack-snaps/snap-test
|
||||
cd snap-test
|
||||
./snap-deploy
|
||||
```
|
||||
|
||||
这样,我们就已经在 Ubuntu Xenial(16.04) 上做了所有的测试。要注意的是,这将在你的系统上安装和配置相当多的软件,因此你最好在可自由使用的机器上运行它。
|
||||
|
||||
### 追踪 OpenStack
|
||||
|
||||
现在,你可以从 snap 商店的边缘通道来安装 snap 包,比如:
|
||||
|
||||
```
|
||||
sudo snap install --edge keystone
|
||||
```
|
||||
|
||||
OpenStack 团队正在努力使 CI/CD 配置到位,以便让 snap 包的发布能够交叉追踪 OpenStack 的发布(比如一个追踪 Ocata,另一个追踪 Pike 等)。每个<ruby>轨道<rt>track</rt></ruby>都有 4 个不同的通道。每个轨道的边缘通道将包含 OpenStack 项目对应分支最近的内容,测试、候选和稳定通道被保留用于已发布的版本。这样我们将看到如下的用法:
|
||||
|
||||
```
|
||||
sudo snap install --channel=ocata/stable keystone
|
||||
sudo snap install --channel=pike/edge keystone
|
||||
```
|
||||
|
||||
### 其它
|
||||
|
||||
我们可以使用多个环境变量来简化 snap 包的制作。[这里][5] 有相关的说明。实际上,你无需深入的研究他们,但是在安装完 snap 包后,你也许会想要了解这些位置:
|
||||
|
||||
#### `$SNAP == /snap/<snap-name>/current`
|
||||
|
||||
这是 snap 包和它所有的文件挂载的位置。所有东西都是只读的。比如我当前安装的 keystone,$SNAP 就是 `/snap/keystone/91`。幸好,你不需要知道当前版本号,因为在 `/snap/keystone/` 中有一个软链接(LCTT 译注:`/snap/keystone/current/`)指向当前正在使用版本对应的文件夹。
|
||||
|
||||
```
|
||||
$ ls /snap/keystone/current/
|
||||
bin etc pysqlite2-doc usr
|
||||
command-manage.wrapper include snap var
|
||||
command-nginx.wrapper lib snap-openstack.yaml
|
||||
command-uwsgi.wrapper meta templates
|
||||
|
||||
$ ls /snap/keystone/current/bin/
|
||||
alembic oslo-messaging-send-notification
|
||||
convert-json oslo-messaging-zmq-broker
|
||||
jsonschema oslo-messaging-zmq-proxy
|
||||
keystone-manage oslopolicy-checker
|
||||
keystone-wsgi-admin oslopolicy-list-redundant
|
||||
keystone-wsgi-public oslopolicy-policy-generator
|
||||
lockutils-wrapper oslopolicy-sample-generator
|
||||
make_metadata.py osprofiler
|
||||
mako-render parse_xsd2.py
|
||||
mdexport.py pbr
|
||||
merge_metadata.py pybabel
|
||||
migrate snap-openstack
|
||||
migrate-repository sqlformat
|
||||
netaddr uwsgi
|
||||
oslo-config-generator
|
||||
|
||||
$ ls /snap/keystone/current/usr/bin/
|
||||
2to3 idle pycompile python2.7-config
|
||||
2to3-2.7 pdb pydoc python2-config
|
||||
cautious-launcher pdb2.7 pydoc2.7 python-config
|
||||
compose pip pygettext pyversions
|
||||
dh_python2 pip2 pygettext2.7 run-mailcap
|
||||
easy_install pip2.7 python see
|
||||
easy_install-2.7 print python2 smtpd.py
|
||||
edit pyclean python2.7
|
||||
|
||||
$ ls /snap/keystone/current/lib/python2.7/site-packages/
|
||||
...
|
||||
```
|
||||
|
||||
#### `$SNAP_COMMON == /var/snap/<snap-name>/common`
|
||||
|
||||
这个目录用于存放系统数据,对于 snap 包的多个修订版本这些数据是共用的。在这里,你可以覆盖默认配置文件和访问日志文件。
|
||||
|
||||
```
|
||||
$ ls /var/snap/keystone/common/
|
||||
etc fernet-keys lib lock log run
|
||||
|
||||
$ sudo ls /var/snap/keystone/common/etc/
|
||||
keystone nginx uwsgi
|
||||
|
||||
$ ls /var/snap/keystone/common/log/
|
||||
keystone.log nginx-access.log nginx-error.log uwsgi.log
|
||||
```
|
||||
|
||||
### 严格限制
|
||||
|
||||
每个 snap 包都是在一个由 seccomp 和 AppArmor 策略构建的严格限制的环境中运行的。更多关于 snap 约束的细节可以在 [这里][7] 查看。
|
||||
|
||||
### snap 包即将到来的新特性和更新
|
||||
|
||||
我正在期待 snap 包一些即将到来的新特性和更新(LCTT 译注:此文发表于 7 月 6 日):
|
||||
|
||||
* 我们正在致力于实现 libvirt AppArmor 策略,这样 nova-hypervisor 的 snap 包就能够访问 qcow2 的<ruby>支持文件<rt>backing files</rt></ruby>。
|
||||
* 现在,作为一种变通方法,你可以将 virt-aa-helper 放在 complain 模式下:`sudo aa-complain /usr/lib/libvirt/virt-aa-helper`。
|
||||
* 我们还在为 snapd 开发额外的接口策略,以便为部署的实例启用网络连接。
|
||||
* 现在你可以在 devmode 模式下安装 nova-hypervisor snap 包,它会禁用安全限制:`snap install -devmode -edge nova-hypervisor`。
|
||||
* 自动连接 nova-hypervisor 的接口。我们正在努力实现在安装时自动定义 nova-hypervisor 接口。
|
||||
* 定义 AppArmor 和 seccomp 策略的接口可以允许 snap 包访问系统的资源。
|
||||
* 现在,你可以手动连接需要接口,在 nova-hypervisor snap 包的 README 中有相关的描述。
|
||||
* 命令自动定义别名。我们正在努力实现 snap 包在安装时为命令自动定义别名。
|
||||
* 这使得我们可以使用传统的命令名。安装 snap 包后,你将可以使用 `nova-manage db sync` 而无需再用 `nova.manage db sync`。
|
||||
* 现在,你可以在安装 snap 包后手动设置别名,比如:`snap alias nova.manage nova-manage`。如想获取更多细节请查看 snap 包的 README 。
|
||||
* 守护进程自动定义别名。当前 snappy 仅支持为命令(非守护进程)定义别名。一旦针对守护进程的别名可用了,我们将设置它们在安装的时候自动配置。
|
||||
* 这使得我们可以使用额外的单元文件名。我们可以使用 `systemctl restart nova-compute` 而无需再用 `systemctl restart snap.nova.nova-compute`。
|
||||
* snap 包资产跟踪。这使得我们可以追踪用来构建 snap 包的版本以便在将来构建时重复使用。
|
||||
|
||||
如果你想多聊一些关于 snap 包的内容,你可以在 freenode 的 #openstack-snaps 这样的 IRC 上找到我们。我们欢迎你的反馈和贡献!感谢并祝你玩得开心!Corey
|
||||
|
||||
------
|
||||
|
||||
作者简介:
|
||||
|
||||
Corey Bryant 是 Ubuntu 的核心开发者和 Canonical 公司 OpenStack 工程团队的软件工程师,他主要专注于为 Ubuntu 提供 OpenStack 的安装包以及为 Juju 进行 OpenStack 的魅力开发。他对开源软件充满热情,喜欢与来自世界各地的人一起工作。
|
||||
|
||||
译者简介:
|
||||
|
||||
> snapcraft.io 的钉子户,对 Ubuntu Core、Snaps 和 Snapcraft 有着浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人的公众号: `Snapcraft`,最近会在上面连载几篇有关 Core snap 发布策略、交付流程和验证流程的文章,欢迎围观 :)
|
||||
|
||||
------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/06/openstack-in-a-snap/
|
||||
|
||||
作者:[Corey Bryant][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/corey-bryant/
|
||||
|
||||
[1]: http://snapcraft.io/
|
||||
[2]:https://github.com/openstack?utf8=%E2%9C%93&q=snap-&type=&language=
|
||||
[3]:https://github.com/openstack-snaps/snap-cookiecutter/blob/master/README.rst
|
||||
[4]:https://snapcraft.io/docs/reference/env
|
||||
[5]: https://snapcraft.io/docs/reference/env
|
||||
[6]:https://snapcraft.io/docs/reference/confinement
|
||||
[7]: https://snapcraft.io/docs/reference/confinement
|
||||
309
published/201708/20170710 How Linux containers have evolved.md
Normal file
309
published/201708/20170710 How Linux containers have evolved.md
Normal file
@ -0,0 +1,309 @@
|
||||
Linux 容器演化史
|
||||
============================================================
|
||||
|
||||
> 容器在过去几年内取得很大的进展。现在我们来回顾它发展的时间线。
|
||||
|
||||

|
||||
|
||||
### Linux 容器是如何演变的
|
||||
|
||||
在过去几年内,容器不仅成为了开发者们热议的话题,还受到了企业的关注。持续增长的关注使得在它的安全性、可扩展性以及互用性等方面的需求也得以增长。满足这些需求需要很大的工程量,下面我们讲讲在红帽这样的企业级这些工程是如何发展的。
|
||||
|
||||
我在 2013 年秋季第一次遇到 Docker 公司(Docker.io)的代表,那时我们在设法使 Red Hat Enterprise Linux (RHEL) 支持 Docker 容器(现在 Docker 项目的一部分已经更名为 _Moby_)的运行。在移植过程中,我们遇到了一些问题。处理容器镜像分层所需的写时拷贝(COW)文件系统成了我们第一个重大阻碍。Red Hat 最终贡献了一些 COW 文件系统实现,包括 [Device Mapper][13]、[btrf][14],以及 [OverlayFS][15] 的第一个版本。在 RHEL 上,我们默认使用 Device Mapper, 但是我们在 OverlayFS 上也已经取得了很大进展。
|
||||
|
||||
我们在用于启动容器的工具上遇到了第二个主要障碍。那时的上游 docker 使用 [LXC][16] 工具来启动容器,然而我们不想在 RHEL 上支持 LXC 工具集。而且在与上游 docker 合作之前,我们已经与 [libvrit][17] 团队携手构建了 [virt-sandbox][18] 工具,它使用 `libvrit-lxc` 来启动容器。
|
||||
|
||||
在那时,红帽里有员工提到一个好办法,换掉 LXC 工具集而添加桥接器,以便 docker 守护进程通过 `libvirt-lxc` 与 libvirt 通讯来启动容器。这个方案也有一些顾虑。考虑下面这个例子,使用 Docker 客户端(`docker-cli`)来启动容器,各层调用会在容器进程(`pid1OfContainer`)之前依次启动:
|
||||
|
||||
> **docker-cli → docker-daemon → libvirt-lxc → pid1OfContainer**
|
||||
|
||||
我不是很喜欢这个方案,因为它在启动容器的工具与最终的容器进程之间有两个守护进程。
|
||||
|
||||
我的团队与上游 docker 开发者合作实现了一个原生的 [Go 编程语言][19] 版本的容器运行时,叫作 [libcontainer][20]。这个库作为 [OCI 运行时规范]的最初版实现与 runc 一同发布。
|
||||
|
||||
> **docker-cli → docker-daemon @ pid1OfContainer**
|
||||
|
||||
大多数人误认为当他们执行一个容器时,容器进程是作为 `docker-cli` 的子进程运行的。实际上他们执行的是一个客户端/服务端请求操作,容器进程是在一个完全单独的环境作为子进程运行的。这个客户端/服务端请求会导致不稳定性和潜在的安全问题,而且会阻碍一些实用特性的实现。举个例子,[systemd][22] 有个叫做套接字唤醒的特性,你可以将一个守护进程设置成仅当相应的套结字被连接时才启动。这意味着你的系统可以节约内存并按需执行服务。套结字唤醒的工作原理是 systemd 代为监听 TCP 套结字,并在数据包到达套结字时启动相应的服务。一旦服务启动完毕,systemd 将套结字交给新启动的守护进程。如果将守护进程运行在基于 docker 的容器中就会出现问题。systemd 的 unit 文件通过 Docker CLI 执行容器,然而这时 systemd 却无法简单地经由 Docker CLI 将套结字转交给 Docker 守护进程。
|
||||
|
||||
类似这样的问题让我们意识到我们需要一个运行容器的替代方案。
|
||||
|
||||
#### 容器编排问题
|
||||
|
||||
上游的 docker 项目简化了容器的使用过程,同时也是一个绝佳的 Linux 容器学习工具。你可以通过一条简单的命令快速地体验如何启动一个容器,例如运行 `docker run -ti fedora sh` 然后你就立即处于一个容器之中。
|
||||
|
||||
当开始把许多容器组织成一个功能更为强大的应用时,你才能体会到容器真正的能力。但是问题在于伴随多容器应用而来的高复杂度使得简单的 Docker 命令无法胜任编排工作。你要如何管理容器应用在有限资源的集群节点间的布局与编排?如何管理它们的生命周期等等?
|
||||
|
||||
在第一届 DockerCon,至少有 7 种不同的公司/开源项目展示了其容器的编排方案。红帽演示了 [OpenShift][23] 的 [geard][24] 项目,它基于 OpenShift v2 的容器(叫作 gears)。红帽觉得我们需要重新审视容器编排,而且可能要与开源社区的其他人合作。
|
||||
|
||||
Google 则演示了 Kubernetes 容器编排工具,它来源于 Google 对其自内部架构进行编排时所积累的知识经验。OpenShift 决定放弃 Gear 项目,开始和 Google 一同开发 Kubernetes。 现在 Kubernetes 是 GitHub 上最大的社区项目之一。
|
||||
|
||||
#### Kubernetes
|
||||
|
||||
Kubernetes 原先被设计成使用 Google 的 [lmctfy][26] 容器运行时环境来完成工作。在 2014 年夏天,lmctfy 兼容了 docker。Kubernetes 还会在 kubernetes 集群的每个节点运行一个 [kubelet][27] 守护进程,这意味着原先使用 docker 1.8 的 kubernetes 工作流看起来是这样的:
|
||||
|
||||
> **kubelet → dockerdaemon @ PID1**
|
||||
|
||||
回退到了双守护进程的模式。
|
||||
|
||||
然而更糟糕的是,每次 docker 的新版本发布都使得 kubernetes 无法工作。Docker 1.10 切换镜像底层存储方案导致所有镜像重建。而 Docker 1.11 开始使用 `runc` 来启动镜像:
|
||||
|
||||
> **kubelet → dockerdaemon @ runc @PID1**
|
||||
|
||||
Docker 1.12 则增加了一个容器守护进程用于启动容器。其主要目的是为了支持 Docker Swarm (Kubernetes 的竞争者之一):
|
||||
|
||||
> **kubelet → dockerdaemon → containerd @runc @ pid1**
|
||||
|
||||
如上所述,_每一次_ docker 发布都破坏了 Kubernetes 的功能,这也是为什么 Kubernetes 和 OpenShift 请求我们为他们提供老版本 Docker 的原因。
|
||||
|
||||
现在我们有了一个三守护进程的系统,只要任何一个出现问题,整个系统都将崩溃。
|
||||
|
||||
### 走向容器标准化
|
||||
|
||||
#### CoreOS、rkt 和其它替代运行时
|
||||
|
||||
因为 docker 运行时带来的问题,几个组织都在寻求一个替代的运行时。CoreOS 就是其中之一。他们提供了一个 docker 容器运行时的替代品,叫 _rkt_ (rocket)。他们同时还引入一个标准容器规范,称作 _appc_ (App Container)。从根本上讲,他们是希望能使得所有人都使用一个标准规范来管理容器镜像中的应用。
|
||||
|
||||
这一行为为标准化工作树立了一面旗帜。当我第一次开始和上游 docker 合作时,我最大的担忧就是最终我们会分裂出多个标准。我不希望类似 RPM 和 DEB 之间的战争影响接下来 20 年的 Linux 软件部署。appc 的一个成果是它说服了上游 docker 与开源社区合作创建了一个称作 [开放容器计划(Open Container Initiative)][28] (OCI) 的标准团体。
|
||||
|
||||
OCI 已经着手制定两个规范:
|
||||
|
||||
[OCI 运行时规范][6]:OCI 运行时规范“旨在规范容器的配置、执行环境以及生命周期”。它定义了容器的磁盘存储,描述容器内运行的应用的 JSON 文件,容器的生成和执行方式。上游 docker 贡献了 libcontainer 并构建了 runc 作为 OCI 运行时规范的默认实现。
|
||||
|
||||
[OCI 镜像文件格式规范][7]:镜像文件格式规范主要基于上游 docker 所使用的镜像格式,定义了容器仓库中实际存储的容器镜像格式。该规范使得应用开发者能为应用使用单一的标准化格式。一些 appc 中描述的概念被加入到 OCI 镜像格式规范中得以保留。这两份规范 1.0 版本的发布已经临近(LCTT 译注:[已经发布](https://linux.cn/article-8778-1.html))。上游 docker 已经同意在 OCI 镜像规范定案后支持该规范。Rkt 现在既支持运行 OCI 镜像也支持传统的上游 docker 镜像。
|
||||
|
||||
OCI 通过为工业界提供容器镜像与运行时标准化的环境,帮助在工具与编排领域解放创新的力量。
|
||||
|
||||
#### 抽象运行时接口
|
||||
|
||||
得益于标准化工作, Kubernetes 编排领域也有所创新。作为 Kubernetes 的一大支持者,CoreOS 提交了一堆补丁,使 Kubernetes 除了 docker 引擎外还能通过 rkt 运行容器并且与容器通讯。Google 和 Kubernetes 上游预见到增加这些补丁和将来可能添加的容器运行时接口将给 Kubernetes 带来的代码复杂度,他们决定实现一个叫作 容器运行时接口(Container Runtime Interface) (CRI) 的 API 协议规范。于是他们将 Kubernetes 由原来的直接调用 docker 引擎改为调用 CRI,这样任何人都可以通过实现服务器端的 CRI 来创建支持
|
||||
Kubernetes 的容器运行时。Kubernetes 上游还为 CRI 开发者们创建了一个大型测试集以验证他们的运行时对 Kubernetes 的支持情况。开发者们还在努力地移除 Kubernetes 对 docker 引擎的调用并将它们隐藏在一个叫作 docker-shim 的薄抽象层后。
|
||||
|
||||
### 容器工具的创新
|
||||
|
||||
#### 伴随 skopeo 而来的容器仓库创新
|
||||
|
||||
几年前我们正与 Atomic 项目团队合作构建 [atomic CLI][29]。我们希望实现一个功能,在镜像还在镜像仓库时查看它的细节。在那时,查看仓库中的容器镜像相关 JSON 文件的唯一方法是将镜像拉取到本地服务器再通过 `docker inspect` 来查看 JSON 文件。这些镜像可能会很大,上至几个 GiB。为了允许用户在不拉取镜像的情况下查看镜像细节,我们希望在 `docker inspect` 接口添加新的 `--remote` 参数。上游 docker 拒绝了我们的代码拉取请求(PR),告知我们他们不希望将 Docker CLI 复杂化,我们可以构建我们自己的工具去实现相同的功能。
|
||||
|
||||
我们的团队在 [Antonio Murdaca][30] 的领导下执行这个提议,构建了 [skopeo][31]。Antonio 没有止步于拉取镜像相关的 JSON 文件,而是决定实现一个完整的协议,用于在容器仓库与本地主机之间拉取与推送容器镜像。
|
||||
|
||||
skopeo 现在被 atomic CLI 大量用于类似检查容器更新的功能以及 [atomic 扫描][32] 当中。Atomic 也使用 skopeo 取代上游 docker 守护进程拉取和推送镜像的功能。
|
||||
|
||||
#### Containers/image
|
||||
|
||||
我们也曾和 CoreOS 讨论过在 rkt 中使用 skopeo 的可能,然而他们表示不希望运行一个外部的协助程序,但是会考虑使用 skopeo 所使用的代码库。于是我们决定将 skopeo 分离为一个代码库和一个可执行程序,创建了 [image][8] 代码库。
|
||||
|
||||
[containers/images][33] 代码库和 skopeo 被几个其它上游项目和云基础设施工具所使用。Skopeo 和 containers/image 已经支持 docker 和多个存储后端,而且能够在容器仓库之间移动容器镜像,还拥有许多酷炫的特性。[skopeo 的一个优点][34]是它不需要任何守护进程的协助来完成任务。Containers/image 代码库的诞生使得类似[容器镜像签名][35]等增强功能得以实现。
|
||||
|
||||
#### 镜像处理与扫描的创新
|
||||
|
||||
我在前文提到 atomic CLI。我们构建这个工具是为了给容器添加不适合 docker CLI 或者我们无法在上游 docker 中实现的特性。我们也希望获得足够灵活性,将其用于开发额外的容器运行时、工具和存储系统。Skopeo 就是一例。
|
||||
|
||||
我们想要在 atomic 实现的一个功能是 `atomic mount`。从根本上讲,我们希望从 Docker 镜像存储(上游 docker 称之为 graph driver)中获取内容,把镜像挂在到某处,以便用工具来查看该镜像。如果你使用上游的 docker,查看镜像内容的唯一方法就是启动该容器。如果其中有不可信的内容,执行容器中的代码来查看它会有潜在危险。通过启动容器查看镜像内容的另一个问题是所需的工具可能没有被包含在容器镜像当中。
|
||||
|
||||
大多数容器镜像扫描器遵循以下流程:它们连接到 Docker 的套结字,执行一个 `docker save` 来创建一个 tar 打包文件,然后在磁盘上分解这个打包文件,最后查看其中的内容。这是一个很慢的过程。
|
||||
|
||||
通过 `atomic mount`,我们希望直接使用 Docker graph driver 挂载镜像。如果 docker 守护进程使用 device mapper,我们将挂载这个设备。如果它使用 overlay,我们会挂载 overlay。这个操作很快而且满足我们的需求。现在你可以执行:
|
||||
|
||||
```
|
||||
# atomic mount fedora /mnt
|
||||
# cd /mnt
|
||||
```
|
||||
|
||||
然后开始探查内容。你完成相应工作后,执行:
|
||||
|
||||
```
|
||||
# atomic umount /mnt
|
||||
```
|
||||
|
||||
我们在 `atomic scan` 中使用了这一特性,实现了一个快速的容器扫描器。
|
||||
|
||||
#### 工具协作的问题
|
||||
|
||||
其中一个严重的问题是 `atomic mount` 隐式地执行这些工作。Docker 守护进程不知道有另一个进程在使用这个镜像。这会导致一些问题(例如,如果你先挂载了 Fedora 镜像,然后某个人执行了 `docker rmi fedora` 命令,docker 守护进程移除镜像时就会产生奇怪的操作失败,同时报告说相应的资源忙碌)。Docker 守护进程可能因此进入一个奇怪的状态。
|
||||
|
||||
#### 容器存储系统
|
||||
|
||||
为了解决这个问题,我们开始尝试将从上游 docker 守护进程剥离出来的 graph driver 代码拉取到我们的代码库中。Docker 守护进程在内存中为 graph driver 完成所有锁的获取。我们想要将这些锁操作转移到文件系统中,这样我们可以支持多个不同的进程来同时操作容器的存储系统,而不用通过单一的守护进程。
|
||||
|
||||
我们创建了 [containers/storage][36] 项目,实现了容器运行、构建、存储所需的所有写时拷贝(COW)特性,同时不再需要一个单一进程来控制和监控这个过程(也就是不需要守护进程)。现在 skopeo 以及其它工具和项目可以直接利用镜像的存储系统。其它开源项目也开始使用 containers/storage,在某些时候,我们也会把这些项目合并回上游 docker 项目。
|
||||
|
||||
### 驶向创新
|
||||
|
||||
当 Kubernetes 在一个节点上使用 docker 守护进程运行容器时会发生什么?首先,Kubernetes 执行一条类似如下的命令:
|
||||
|
||||
```
|
||||
kubelet run nginx -image=nginx
|
||||
```
|
||||
|
||||
这个命令告诉 kubelet 在节点上运行 NGINX 应用程序。kubelet 调用 CRI 请求启动 NGINX 应用程序。在这时,实现了 CRI 规范的容器运行时必须执行以下步骤:
|
||||
|
||||
1. 检查本地是否存在名为 `nginx` 的容器。如果没有,容器运行时会在容器仓库中搜索标准的容器镜像。
|
||||
2. 如果镜像不存在于本地,从容器仓库下载到本地系统。
|
||||
3. 使用容器存储系统(通常是写时拷贝存储系统)解析下载的容器镜像并挂载它。
|
||||
4. 使用标准的容器运行时执行容器。
|
||||
|
||||
让我们看看上述过程使用到的特性:
|
||||
|
||||
1. OCI 镜像格式规范定义了容器仓库存储的标准镜像格式。
|
||||
2. Containers/image 代码库实现了从容器仓库拉取镜像到容器主机所需的所有特性。
|
||||
3. Containers/storage 提供了在写时拷贝的存储系统上探查并处理 OCI 镜像格式的代码库。
|
||||
4. OCI 运行时规范以及 `runc` 提供了执行容器的工具(同时也是 docker 守护进程用来运行容器的工具)。
|
||||
|
||||
这意味着我们可以利用这些工具来使用容器,而无需一个大型的容器守护进程。
|
||||
|
||||
在中等到大规模的基于 DevOps 的持续集成/持续交付环境下,效率、速度和安全性至关重要。只要你的工具遵循 OCI 规范,开发者和执行者就能在持续集成、持续交付到生产环境的自动化中自然地使用最佳的工具。大多数的容器工具被隐藏在容器编排或上层容器平台技术之下。我们预想着有朝一日,运行时和镜像工具的选择会变成容器平台的一个安装选项。
|
||||
|
||||
#### 系统(独立)容器
|
||||
|
||||
在 Atomic 项目中我们引入了<ruby>原子主机<rt>atomic host</rt></ruby>,一种新的操作系统构建方式:所有的软件可以被“原子地”升级并且大多数应用以容器的形式运行在操作系统中。这个平台的目的是证明将来所有的软件都能部署在 OCI 镜像格式中并且使用标准协议从容器仓库中拉取,然后安装到系统上。用容器镜像的形式发布软件允许你以不同的速度升级应用程序和操作系统。传统的 RPM/yum/DNF 包分发方式把应用更新锁定在操作系统的生命周期中。
|
||||
|
||||
在以容器部署基础设施时多数会遇到一个问题——有时一些应用必须在容器运行时执行之前启动。我们看一个使用 docker 的 Kubernetes 的例子:Kubernetes 为了将 pods 或者容器部署在独立的网络中,要求先建立一个网络。现在默认用于创建网络的守护进程是 [flanneld][9],而它必须在 docker 守护进程之前启动,以支持 docker 网络接口来运行 Kubernetes 的 pods。而且,flanneld 使用 [etcd][37] 来存储数据,这个守护进程必须在 flanneld 启动之前运行。
|
||||
|
||||
如果你想把 etcd 和 flanneld 部署到容器镜像中,那就陷入了鸡与鸡蛋的困境中。我们需要容器运行时来启动容器化的应用,但这些应用又需要在容器运行时之前启动。我见过几个取巧的方法尝试解决这个问题,但这些方法都不太干净利落。而且 docker 守护进程当前没有合适的方法来配置容器启动的优先级顺序。我见过一些提议,但它们看起来和 SysVInit 所使用的启动服务的方式相似(我们知道它带来的复杂度)。
|
||||
|
||||
#### systemd
|
||||
|
||||
用 systemd 替代 SysVInit 的原因之一就是为了处理服务启动的优先级和顺序,我们为什么不充分利用这种技术呢?在 Atomic 项目中我们决定在让它在没有容器运行时的情况下也能启动容器,尤其是在系统启动早期。我们增强了 atomic CLI 的功能,让用户可以安装容器镜像。当你执行 `atomic install --system etc`,它将利用 skopeo 从外部的容器仓库拉取 etcd 的 OCI 镜像,然后把它分解(扩展)为 OSTree 底层存储。因为 etcd 运行在生产环境中,我们把镜像处理为只读。接着 `atomic` 命令抓取容器镜像中的 systemd 的 unit 文件模板,用它在磁盘上创建 unit 文件来启动镜像。这个 unit 文件实际上使用 `runc` 来在主机上启动容器(虽然 `runc` 不是必需的)。
|
||||
|
||||
执行 `atomic install --system flanneld` 时会进行相似的过程,但是这时 flanneld 的 unit 文件中会指明它依赖 etcd。
|
||||
|
||||
在系统引导时,systemd 会保证 etcd 先于 flanneld 运行,并且直到 flanneld 启动完毕后再启动容器运行时。这样我们就能把 docker 守护进程和 Kubernetes 部署到系统容器当中。这也意味着你可以启动一台原子主机或者使用传统的基于 rpm 的操作系统,让整个容器编排工具栈运行在容器中。这是一个强大的特性,因为用户往往希望改动容器主机时不受这些组件影响。而且,它保持了主机的操作系统的占用最小化。
|
||||
|
||||
大家甚至讨论把传统的应用程序部署到独立/系统容器或者被编排的容器中。设想一下,可以用 `atomic install --system httpd` 命令安装一个 Apache 容器,这个容器可以和用 RPM 安装的 httpd 服务以相同的方式启动(`systemctl start httpd` ,区别是这个容器 httpd 运行在一个容器中)。存储系统可以是本地的,换言之,`/var/www` 是从宿主机挂载到容器当中的,而容器监听着本地网络的 80 端口。这表明了我们可以在不使用容器守护进程的情况下将传统的负载组件部署到一个容器中。
|
||||
|
||||
### 构建容器镜像
|
||||
|
||||
在我看来,在过去 4 年来容器发展方面最让人失落的是缺少容器镜像构建机制上的创新。容器镜像不过是将一些 tar 包文件与 JSON 文件一起打包形成的文件。基础镜像则是一个 rootfs 与一个描述该基础镜像的 JSON 文件。然后当你增加镜像层时,层与层之间的差异会被打包,同时 JSON 文件会做出相应修改。这些镜像层与基础文件一起被打包,共同构成一个容器镜像。
|
||||
|
||||
现在几乎所有人都使用 `docker build` 与 Dockerfile 格式来构建镜像。上游 docker 已经在几年前停止了接受修改或改进 Dockerfile 格式的拉取请求(PR)了。Dockerfile 在容器的演进过程中扮演了重要角色,开发者和管理员/运维人员可以通过简单直接的方式来构建镜像;然而我觉得 Dockerfile 就像一个简陋的 bash 脚本,还带来了一些尚未解决的问题,例如:
|
||||
|
||||
* 使用 Dockerfile 创建容器镜像要求运行着 Docker 守护进程。
|
||||
* 没有可以独立于 docker 命令的标准工具用于创建 OCI 镜像。
|
||||
* 甚至类似 `ansible-containers` 和 OpenShift S2I (Source2Image) 的工具也在底层使用 `docker-engine`。
|
||||
* Dockerfile 中的每一行都会创建一个新的镜像,这有助于创建容器的开发过程,这是因为构建工具能够识别 Dockerfile 中的未改动行,复用已经存在的镜像从而避免了未改动行的重复执行。但这个特性会产生_大量_的镜像层。
|
||||
* 因此,不少人希望构建机制能压制镜像消除这些镜像层。我猜想上游 docker 最后应该接受了一些提交满足了这个需求。
|
||||
* 要从受保护的站点拉取内容到容器镜像,你往往需要某种密钥。比如你为了添加 RHEL 的内容到镜像中,就需要访问 RHEL 的证书和订阅。
|
||||
* 这些密钥最终会被以层的方式保存在镜像中。开发者要费很大工夫去移除它们。
|
||||
* 为了允许在 docker 构建过程中挂载数据卷,我们在我们维护的 projectatomic/docker 中加入了 `-v volume` 选项,但是这些修改没有被上游 docker 接受。
|
||||
* 构建过程的中间产物最终会保留在容器镜像中,所以尽管 Dockerfile 易于学习,当你想要了解你要构建的镜像时甚至可以在笔记本上构建容器,但它在大规模企业环境下还不够高效。然而在自动化容器平台下,你应该不会关心用于构建 OCI 镜像的方式是否高效。
|
||||
|
||||
### Buildah 起航
|
||||
|
||||
在 DevConf.cz 2017,我让我们团队的 [Nalin Dahyabhai][38] 考虑构建被我称为 `containers-coreutils` 的工具,它基本上就是基于 containers/storage 和 containers/image 库构建的一系列可以使用类似 Dockerfile 语法的命令行工具。Nalin 为了取笑我的波士顿口音,决定把它叫做 [buildah][39]。我们只需要少量的 buildah 原语就可以构建一个容器镜像:
|
||||
|
||||
* 最小化 OS 镜像、消除不必要的工具是主要的安全原则之一。因为黑客在攻击应用时需要一些工具,如果类似 `gcc`,`make`,`dnf` 这样的工具根本不存在,就能阻碍攻击者的行动。
|
||||
* 减小容器的体积总是有益的,因为这些镜像会通过互联网拉取与推送。
|
||||
* 使用 Docker 进行构建的基本原理是在容器构建的根目录下利用命令安装或编译软件。
|
||||
* 执行 `run` 命令要求所有的可执行文件都包含在容器镜像内。只是在容器镜像中使用 `dnf` 就需要完整的 Python 栈,即使在应用中从未使用到 Python。
|
||||
* `ctr=$(buildah from fedora)`:
|
||||
* 使用 containers/image 从容器仓库拉取 Fedora 镜像。
|
||||
* 返回一个容器 ID (`ctr`)。
|
||||
* `mnt=$(buildah mount $ctr)`:
|
||||
* 挂载新建的容器镜像(`$ctr`).
|
||||
* 返回挂载点路径。
|
||||
* 现在你可以使用挂载点来写入内容。
|
||||
* `dnf install httpd –installroot=$mnt`:
|
||||
* 你可以使用主机上的命令把内容重定向到容器中,这样你可以把密钥保留在主机而不导入到容器内,同时构建所用的工具也仅仅存在于主机上。
|
||||
* 容器内不需要包含 `dnf` 或者 Python 栈,除非你的应用用到它们。
|
||||
* `cp foobar $mnt/dir`:
|
||||
* 你可以使用任何 bash 中可用的命令来构造镜像。
|
||||
* `buildah commit $ctr`:
|
||||
* 你可以随时创建一个镜像层,镜像的分层由用户而不是工具来决定。
|
||||
* `buildah config --env container=oci --entrypoint /usr/bin/httpd $ctr`:
|
||||
* Buildah 支持所有 Dockerfile 的命令。
|
||||
* `buildah run $ctr dnf -y install httpd`:
|
||||
* Buildah 支持 `run` 命令,但它是在一个锁定的容器内利用 `runc` 执行命令,而不依赖容器运行时守护进程。
|
||||
* `buildah build-using-dockerfile -f Dockerfile .`:
|
||||
|
||||
我们希望将移植类似 `ansible-containers` 和 OpenShift S2I 这样的工具,改用 `buildah` 以去除对容器运行时守护进程的依赖。
|
||||
|
||||
使用与生产环境相同的容器运行时构建容器镜像会遇到另一个大问题。为了保证安全性,我们需要把权限限制到支持容器构建与运行所需的最小权限。构建容器比起运行容器往往需要更多额外的权限。举个例子,我们默认允许 `mknod` 权限,这会允许进程创建设备节点。有些包的安装会尝试创建设备节点,然而在生产环境中的应用几乎都不会这么做。如果默认移除生产环境中容器的 `mknod` 特权会让系统更为安全。
|
||||
|
||||
另一个例子是,容器镜像默认是可读写的,因为安装过程意味着向 `/usr` 存入软件包。然而在生产环境中,我强烈建议把所有容器设为只读模式,仅仅允许它们写入 tmpfs 或者是挂载了数据卷的目录。通过分离容器的构建与运行环境,我们可以更改这些默认设置,提供一个更为安全的环境。
|
||||
|
||||
* 当然,buildah 可以使用 Dockerfile 构建容器镜像。
|
||||
|
||||
### CRI-O :一个 Kubernetes 的运行时抽象
|
||||
|
||||
Kubernetes 添加了<ruby>容器运行时接口<rt>Container Runtime Interface</rt></ruby>(CRI)接口,使 pod 可以在任何运行时上工作。虽然我不是很喜欢在我的系统上运行太多的守护进程,然而我们还是加了一个。我的团队在 [Mrunal Patel][40] 的领导下于 2016 年后期开始构建 [CRI-O] 守护进程。这是一个用来运行 OCI 应用程序的 OCI 守护进程。理论上,将来我们能够把 CRI-O 的代码直接并入 kubelet 中从而消除这个多余的守护进程。
|
||||
|
||||
不像其它容器运行时,CRI-O 的唯一目的就只是为了满足 Kubernetes 的需求。记得前文描述的 Kubernetes 运行容器的条件。
|
||||
|
||||
Kubernetes 传递消息给 kubelet 告知其运行 NGINX 服务器:
|
||||
|
||||
1. kubelet 唤醒 CRI-O 并告知它运行 NGINX。
|
||||
2. CRI-O 回应 CRI 请求。
|
||||
3. CRI-O 在容器仓库查找 OCI 镜像。
|
||||
4. CRI-O 使用 containers/image 从仓库拉取镜像到主机。
|
||||
5. CRI-O 使用 containers/storage 解压镜像到本地磁盘。
|
||||
6. CRI-O 按照 OCI 运行时规范(通常使用 `runc`)启动容器。如前文所述,Docker 守护进程也同样使用 `runc` 启动它的容器。
|
||||
7. 按照需要,kubelet 也可以使用替代的运行时启动容器,例如 Clear Containers `runcv`。
|
||||
|
||||
CRI-O 旨在成为稳定的 Kubernetes 运行平台。只有通过完整的 Kubernetes 测试集后,新版本的 CRI-O 才会被推出。所有提交到 [https://github.com/Kubernetes-incubator/cri-o][42] 的拉取请求都会运行完整的 Kubernetes 测试集。没有通过测试集的拉取请求都不会被接受。CRI-O 是完全开放的,我们已经收到了来自 Intel、SUSE、IBM、Google、Hyper.sh 等公司的代码贡献。即使不是红帽想要的特性,只要通过一定数量维护者的同意,提交给 CRI-O 的补丁就会被接受。
|
||||
|
||||
### 小结
|
||||
|
||||
我希望这份深入的介绍能够帮助你理解 Linux 容器的演化过程。Linux 容器曾经陷入一种各自为营的困境,Docker 建立起了镜像创建的事实标准,简化了容器的使用工具。OCI 则意味着业界在核心镜像格式与运行时方面的合作,这促进了工具在自动化效率、安全性、高可扩展性、易用性方面的创新。容器使我们能够以一种新奇的方式部署软件——无论是运行于主机上的传统应用还是部署在云端的微服务。而在许多方面,这一切还仅仅是个开始。
|
||||
|
||||
(题图:[Daniel Ramirez][11] [CC BY-SA 4.0][12])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel J Walsh - Daniel 有将近 30 年的计算机安全领域工作经验。他在 2001 年 8 月加入 Red Hat。
|
||||
|
||||
via: https://opensource.com/article/17/7/how-linux-containers-evolved
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
译者:[haoqixu](https://github.com/haoqixu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[2]:https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[4]:https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[5]:https://opensource.com/article/17/7/how-linux-containers-evolved?rate=k1UcW7wzh6axaB_z8ScE-U8cux6fLXXgW_vboB5tIwk
|
||||
[6]:https://github.com/opencontainers/runtime-spec/blob/master/spec.md
|
||||
[7]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[8]:https://github.com/containers/image
|
||||
[9]:https://github.com/coreos/flannel
|
||||
[10]:https://opensource.com/user/16673/feed
|
||||
[11]:https://www.flickr.com/photos/danramarch/
|
||||
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[13]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Logical_Volume_Manager_Administration/device_mapper.html
|
||||
[14]:https://btrfs.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:https://www.kernel.org/doc/Documentation/filesystems/overlayfs.txt
|
||||
[16]:https://linuxcontainers.org/
|
||||
[17]:https://libvirt.org/
|
||||
[18]:http://sandbox.libvirt.org/
|
||||
[19]:https://opensource.com/article/17/6/getting-started-go
|
||||
[20]:https://github.com/opencontainers/runc/tree/master/libcontainer
|
||||
[21]:https://github.com/opencontainers/runtime-spec
|
||||
[22]:https://opensource.com/business/15/10/lisa15-interview-alison-chaiken-mentor-graphics
|
||||
[23]:https://www.openshift.com/
|
||||
[24]:https://openshift.github.io/geard/
|
||||
[25]:https://opensource.com/resources/what-is-kubernetes
|
||||
[26]:https://github.com/google/lmctfy
|
||||
[27]:https://kubernetes.io/docs/admin/kubelet/
|
||||
[28]:https://www.opencontainers.org/
|
||||
[29]:https://github.com/projectatomic/atomic
|
||||
[30]:https://twitter.com/runc0m
|
||||
[31]:https://github.com/projectatomic/skopeo
|
||||
[32]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||
[33]:https://github.com/containers/image
|
||||
[34]:http://rhelblog.redhat.com/2017/05/11/skopeo-copy-to-the-rescue/
|
||||
[35]:https://access.redhat.com/articles/2750891
|
||||
[36]:https://github.com/containers/storage
|
||||
[37]:https://github.com/coreos/etcd
|
||||
[38]:https://twitter.com/nalind
|
||||
[39]:https://github.com/projectatomic/buildah
|
||||
[40]:https://twitter.com/mrunalp
|
||||
[41]:https://github.com/Kubernetes-incubator/cri-o
|
||||
[42]:https://github.com/Kubernetes-incubator/cri-o
|
||||
[43]:https://opensource.com/users/rhatdan
|
||||
[44]:https://opensource.com/users/rhatdan
|
||||
[45]:https://opensource.com/article/17/7/how-linux-containers-evolved#comments
|
||||
@ -0,0 +1,108 @@
|
||||
免费学习 Docker 的最佳方法:Play-with-docker(PWD)
|
||||
============================================================
|
||||
|
||||
去年在柏林的分布式系统峰会上,Docker 的负责人 [Marcos Nils][15] 和 [Jonathan Leibiusky][16] 宣称已经开始研究浏览器内置 Docker 的方案,帮助人们学习 Docker。 几天后,[Play-with-docker][17](PWD)就诞生了。
|
||||
|
||||
PWD 像是一个 Docker 游乐场,用户在几秒钟内就可以运行 Docker 命令。 还可以在浏览器中安装免费的 Alpine Linux 虚拟机,然后在虚拟机里面构建和运行 Docker 容器,甚至可以使用 [Docker 集群模式][18]创建集群。 有了 Docker-in-Docker(DinD)引擎,甚至可以体验到多个虚拟机/个人电脑的效果。 除了 Docker 游乐场外,PWD 还包括一个培训站点 [training.play-with-docker.com][19],该站点提供大量的难度各异的 Docker 实验和测验。
|
||||
|
||||
如果你错过了峰会,Marcos 和 Jonathan 在最后一场 DockerCon Moby Cool Hack 会议中展示了 PWD。 观看下面的视频,深入了解其基础结构和发展路线图。
|
||||
|
||||
|
||||
|
||||
在过去几个月里,Docker 团队与 Marcos、Jonathan,还有 Docker 社区的其他活跃成员展开了密切合作,为项目添加了新功能,为培训部分增加了 Docker 实验室。
|
||||
|
||||
### PWD: 游乐场
|
||||
|
||||
以下快速的概括了游乐场的新功能:
|
||||
|
||||
#### 1、 PWD Docker Machine 驱动和 SSH
|
||||
|
||||
随着 PWD 成功的成长,社区开始问他们是否可以使用 PWD 来运行自己的 Docker 研讨会和培训。 因此,对项目进行的第一次改进之一就是创建 [PWD Docker Machine 驱动][20],从而用户可以通过自己喜爱的终端轻松创建管理 PWD 主机,包括使用 SSH 相关命令的选项。 下面是它的工作原理:
|
||||
|
||||

|
||||
|
||||
#### 2、 支持文件上传
|
||||
|
||||
Marcos 和 Jonathan 还带来了另一个炫酷的功能就是可以在 PWD 实例中通过拖放文件的方式将 Dockerfile 直接上传到 PWD 窗口。
|
||||
|
||||

|
||||
|
||||
#### 3、 模板会话
|
||||
|
||||
除了文件上传之外,PWD 还有一个功能,可以使用预定义的模板在几秒钟内启动 5 个节点的群集。
|
||||
|
||||

|
||||
|
||||
#### 4、 一键使用 Docker 展示你的应用程序
|
||||
|
||||
PWD 附带的另一个很酷的功能是它的内嵌按钮,你可以在你的站点中使用它来设置 PWD 环境,并快速部署一个构建好的堆栈,另外还有一个 [chrome 扩展][21] ,可以将 “Try in PWD” 按钮添加 DockerHub 最流行的镜像中。 以下是扩展程序的一个简短演示:
|
||||
|
||||

|
||||
|
||||
### PWD 培训站点
|
||||
|
||||
[training.play-with-docker.com][22] 站点提供了大量新的实验。有一些值得注意的两点,包括两个来源于奥斯丁召开的 DockerCon 中的动手实践的实验,还有两个是 Docker 17.06CE 版本中亮眼的新功能:
|
||||
|
||||
* [可以动手实践的 Docker 网络实验][1]
|
||||
* [可以动手实践的 Docker 编排实验][2]
|
||||
* [多阶段构建][3]
|
||||
* [Docker 集群配置文件][4]
|
||||
|
||||
总而言之,现在有 36 个实验,而且一直在增加。 如果你想贡献实验,请从查看 [GitHub 仓库][23]开始。
|
||||
|
||||
### PWD 用例
|
||||
|
||||
根据网站访问量和我们收到的反馈,很可观的说,PWD 现在有很大的吸引力。下面是一些最常见的用例:
|
||||
|
||||
* 紧跟最新开发版本,尝试新功能。
|
||||
* 快速建立集群并启动复制服务。
|
||||
* 通过互动教程学习: [training.play-with-docker.com][5]。
|
||||
* 在会议和集会上做演讲。
|
||||
* 召开需要复杂配置的高级研讨会,例如 Jérôme’的 [Docker 编排高级研讨会][6]。
|
||||
* 和社区成员协作诊断问题检测问题。
|
||||
|
||||
参与 PWD:
|
||||
|
||||
* 通过[向 PWD 提交 PR][7] 做贡献
|
||||
* 向 [PWD 培训站点][8]贡献
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Victor 是 Docker, Inc. 的高级社区营销经理。他喜欢优质的葡萄酒、象棋和足球,上述爱好不分先后顺序。 Victor 的 tweet:@vcoisne 推特。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/best-way-learn-docker-free-play-docker-pwd/
|
||||
|
||||
作者:[Victor][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/victor_c/
|
||||
[1]:http://training.play-with-docker.com/docker-networking-hol/
|
||||
[2]:http://training.play-with-docker.com/orchestration-hol/
|
||||
[3]:http://training.play-with-docker.com/multi-stage/
|
||||
[4]:http://training.play-with-docker.com/swarm-config/
|
||||
[5]:http://training.play-with-docker.com/
|
||||
[6]:https://github.com/docker/labs/tree/master/Docker-Orchestration
|
||||
[7]:https://github.com/play-with-docker/
|
||||
[8]:https://github.com/play-with-docker/training
|
||||
[9]:https://blog.docker.com/author/victor_c/
|
||||
[10]:https://blog.docker.com/tag/docker-labs/
|
||||
[11]:https://blog.docker.com/tag/docker-training/
|
||||
[12]:https://blog.docker.com/tag/docker-workshops/
|
||||
[13]:https://blog.docker.com/tag/play-with-docker/
|
||||
[14]:https://blog.docker.com/tag/pwd/
|
||||
[15]:https://www.twitter.com/marcosnils
|
||||
[16]:https://www.twitter.com/xetorthio
|
||||
[17]:http://play-with-docker.com/
|
||||
[18]:https://docs.docker.com/engine/swarm/
|
||||
[19]:http://training.play-with-docker.com/
|
||||
[20]:https://github.com/play-with-docker/docker-machine-driver-pwd/releases/tag/v0.0.5
|
||||
[21]:https://chrome.google.com/webstore/detail/play-with-docker/kibbhpioncdhmamhflnnmfonadknnoan
|
||||
[22]:http://training.play-with-docker.com/
|
||||
[23]:https://github.com/play-with-docker/play-with-docker.github.io
|
||||
@ -0,0 +1,103 @@
|
||||
混合云的那些事
|
||||
============================================================
|
||||
|
||||
> 了解混合云的细节,包括它是什么以及如何使用它
|
||||
|
||||

|
||||
|
||||
在过去 10 年出现的众多技术中,云计算因其快速发展而引人注目,从一个细分领域的技术而成为了全球热点。就其本身来说,云计算已经造成了许多困惑、争论和辩论,而混合了多种类型的云计算的"混合"云计算也带来了更多的不确定性。阅读下文可以了解有关混合云的一些最常见问题的答案。
|
||||
|
||||
### 什么是混合云
|
||||
|
||||
基本上,混合云是本地基础设施、私有云和公共云(例如,第三方云服务)的灵活和集成的组合。尽管公共云和私有云服务在混合云中是绑定在一起的,但实际上,它们是独立且分开的服务实体,而可以编排在一起服务。使用公共和私有云基础设施的选择基于以下几个因素,包括成本、负载灵活性和数据安全性。
|
||||
|
||||
高级的特性,如<ruby>扩展<rt>scale-up</rt></ruby>和<ruby>延伸scale-out</rt></ruby>,可以快速扩展云应用程序的基础设施,使混合云成为具有季节性或其他可变资源需求的服务的流行选择。(<ruby>扩展<rt>scale-up</rt></ruby>意味着在特定的 Linux 实例上增加计算资源,例如 CPU 内核和内存,而<ruby>延伸scale-out</rt></ruby>则意味着提供具有相似配置的多个实例,并将它们分布到一个集群中)。
|
||||
|
||||
处于混合云解决方案中心的是开源软件,如 [OpenStack][12],它用于部署和管理虚拟机组成的大型网络。自 2010 年 10 月发布以来,OpenStack 一直在全球蓬勃发展。它的一些集成项目和工具处理核心的云计算服务,比如计算、网络、存储和身份识别,而其他数十个项目可以与 OpenStack 捆绑在一起,创建独特的、可部署的混合云解决方案。
|
||||
|
||||
### 混合云的组成部分
|
||||
|
||||
如下图所示,混合云由私有云、公有云注成,并通过内部网络连接,由编排系统、系统管理工具和自动化工具进行管理。
|
||||
|
||||

|
||||
|
||||
*混合云模型*
|
||||
|
||||
#### 公共云基础设施
|
||||
|
||||
* <ruby>基础设施即服务<rt>Infrastructure as a Service</rt></ruby>(IaaS) 从一个远程数据中心提供计算资源、存储、网络、防火墙、入侵预防服务(IPS)等。可以使用图形用户界面(GUI)或命令行接口(CLI)对这些服务进行监视和管理。公共 IaaS 用户不需要购买和构建自己的基础设施,而是根据需要使用这些服务,并根据使用情况付费。
|
||||
* <ruby>平台即服务<rt>Platform as a Service</rt></ruby>(PaaS)允许用户在其上开发、测试、管理和运行应用程序和服务器。这些包括操作系统、中间件、web 服务器、数据库等等。公共 PaaS 以模板形式为用户提供了可以轻松部署和复制的预定义服务,而不是手动实现和配置基础设施。
|
||||
* <ruby>软件即服务<rt>Software as a Service</rt></ruby>(SaaS)通过互联网交付软件。用户可以根据订阅或许可模型或帐户级别使用这些服务,在这些服务中,他们按活跃用户计费。SaaS 软件是低成本、低维护、无痛升级的,并且降低了购买新硬件、软件或带宽以支持增长的负担。
|
||||
|
||||
#### 私有云基础设施
|
||||
|
||||
* 私有 **IaaS** 和 **PaaS** 托管在孤立的数据中心中,并与公共云集成在一起,这些云可以使用远程数据中心中可用的基础设施和服务。这使私有云所有者能够在全球范围内利用公共云基础设施来扩展应用程序,并利用其计算、存储、网络等功能。
|
||||
* **SaaS** 是由公共云提供商完全监控、管理和控制的。SaaS 一般不会在公共云和私有云基础设施之间共享,并且仍然是通过公共云提供的服务。
|
||||
|
||||
#### 云编排和自动化工具
|
||||
|
||||
要规划和协调私有云和公共云实例,云编排工具是必要的。该工具应该具有智能,包括简化流程和自动化重复性任务的能力。此外,集成的自动化工具负责在设置阈值时自动扩展和延伸,以及在发生任何部分损坏或宕机时执行自修复。
|
||||
|
||||
#### 系统和配置管理工具
|
||||
|
||||
在混合云中,系统和配置工具,如 [Foreman][13],管理着私有云和公共云数据中心提供的虚拟机的完整生命周期。这些工具使系统管理员能够轻松地控制用户、角色、部署、升级和实例,并及时地应用补丁、bug 修复和增强功能。包括Foreman 工具中的 [Puppet][14],使管理员能够管理配置,并为所有供给的和注册的主机定义一个完整的结束状态。
|
||||
|
||||
### 混合云的特性
|
||||
|
||||
对于大多数组织来说,混合云是有意义的,因为这些关键特性:
|
||||
|
||||
* **可扩展性:** 在混合云中,集成的私有云和公共云实例共享每个可配置的实例的计算资源池。这意味着每个实例都可以在需要时按需扩展和延伸。
|
||||
* **快速响应:** 当私有云资源超过其阈值时,混合云的弹性支持公共云中的实例快速爆发增长。当需求高峰对运行中的应用程序需要显著的动态提升负载和容量时,这是特别有价值的。(例如,电商在假日购物季期间)
|
||||
* **可靠性:** 组织可以根据需要的成本、效率、安全性、带宽等来选择公共云服务提供商。在混合云中,组织还可以决定存储敏感数据的位置,以及是在私有云中扩展实例,还是通过公共基础设施跨地域进行扩展。另外,混合模型在多个站点上存储数据和配置的能力提供了对备份、灾难恢复和高可用性的支持。
|
||||
* **管理:** 在非集成的云环境中,管理网络、存储、实例和/或数据可能是乏味的。与混合工具相比,传统的编排工具非常有限,因此限制了决策制定和对完整的端到端进程和任务的自动化。使用混合云和有效的管理应用程序,您可以跟踪每个组件的数量增长,并通过定期优化这些组件,使年度费用最小化。
|
||||
* **安全性:** 在评估是否在云中放置应用程序和数据时,安全性和隐私是至关重要的。IT 部门必须验证所有的合规性需求和部署策略。公共云的安全性正在改善,并将继续成熟。而且,在混合云模型中,组织可以将高度敏感的信息存储在私有云中,并将其与存储在公共云中的不敏感数据集成在一起。
|
||||
* **定价:** 云定价通常基于所需的基础设施和服务水平协议(SLA)的要求。在混合云模型中,用户可以在计算资源(CPU/内存)、带宽、存储、网络、公共 IP 地址等粒度上进行比较,价格要么是固定的,要么是可变的,可以按月、小时、甚至每秒钟计量。因此,用户总是可以在公共云提供商中购买最好的价位,并相应地部署实例。
|
||||
|
||||
### 混合云如今的发展
|
||||
|
||||
尽管对公共云服务的需求很大且不断增长,并且从本地到公共云的迁移系统,仍然是大多数大型组织关注的问题。大多数人仍然在企业数据中心和老旧系统中保留关键的应用程序和数据。他们担心在公共基础设施中面临失去控制、安全威胁、数据隐私和数据真实性。因为混合云将这些问题最小化并使收益最大化,对于大多数大型组织来说,这是最好的解决方案。
|
||||
|
||||
### 预测五年后的发展
|
||||
|
||||
我预计混合云模型将在全球范围内被广泛接受,而公司的“无云”政策将在短短几年内变得非常罕见。这是我想我们会看到的:
|
||||
|
||||
* 由于混合云作为一种共担的责任,企业和公共云提供商之间将加强协作,以实施安全措施来遏制网络攻击、恶意软件、数据泄漏和其他威胁。
|
||||
* 实例的爆发性增长将会很快,因此客户可以自发地满足负载需求或进行自我修复。
|
||||
* 此外,编排或自动化工具(如 [Ansible][8])将通过继承用于解决关键问题的能力来发挥重要作用。
|
||||
* 计量和“量入为出”的概念对客户来说是透明的,并且工具将使用户能够通过监控价格波动,安全地销毁现有实例,并提供新的实例以获得最佳的可用定价。
|
||||
|
||||
(题图:[Jason Baker][10]. [CC BY-SA 4.0][11].)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Amit Das 是一名 Red Hat 的工程师,他对 Linux、云计算、DevOps 等充满热情,他坚信新的创新和技术,将以一种开放的方式的让世界更加开放,可以对社会产生积极的影响,改变许多人的生活。
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/7/what-is-hybrid-cloud
|
||||
|
||||
作者:[Amit Das][a]
|
||||
译者:[LHRchina](https://github.com/LHRchina)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/amit-das
|
||||
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||
[6]:https://opensource.com/file/364211
|
||||
[7]:https://opensource.com/article/17/7/what-is-hybrid-cloud?rate=TwB_2KyXM7iqrwDPGZpe6WultoCajdIVgp8xI4oZkTw
|
||||
[8]:https://opensource.com/life/16/8/cloud-ansible-gateway
|
||||
[9]:https://opensource.com/user/157341/feed
|
||||
[10]:https://opensource.com/users/jason-baker
|
||||
[11]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[12]:https://opensource.com/resources/openstack
|
||||
[13]:https://github.com/theforeman
|
||||
[14]:https://github.com/theforeman/puppet-foreman
|
||||
[15]:https://opensource.com/users/amit-das
|
||||
[16]:https://opensource.com/users/amit-das
|
||||
114
published/201708/20170818 How to recover from a git mistake.md
Normal file
114
published/201708/20170818 How to recover from a git mistake.md
Normal file
@ -0,0 +1,114 @@
|
||||
如何恢复丢弃的 git stash 数据
|
||||
============================================================
|
||||
|
||||
> 不要让 git 命令中的错误抹去数天的工作
|
||||
|
||||

|
||||
|
||||
今天我的同事几乎失去了他在四天工作中所做的一切。由于不正确的 `git` 命令,他把保存在 [stash][20] 中的更改删除了。在这悲伤的情节之后,我们试图寻找一种恢复他所做工作的方法,而且我们做到了!
|
||||
|
||||
首先警告一下:当你在实现一个大功能时,请将它分成小块并定期提交。长时间工作而不做提交并不是一个好主意。
|
||||
|
||||
现在我们已经搞定了那个错误,下面就演示一下怎样从 stash 中恢复误删的更改。
|
||||
|
||||
我用作示例的仓库中,只有一个源文件 “main.c”,如下所示:
|
||||
|
||||

|
||||
|
||||
它只有一次提交,即 “Initial commit”:
|
||||
|
||||

|
||||
|
||||
该文件的第一个版本是:
|
||||
|
||||

|
||||
|
||||
我将在文件中写一些代码。对于这个例子,我并不需要做什么大的改动,只需要有什么东西放进 stash 中即可,所以我们仅仅增加一行。“git diff” 的输出如下:
|
||||
|
||||

|
||||
|
||||
现在,假设我想从远程仓库中拉取一些新的更改,当时还不打算提交我自己的更改。于是,我决定先 stash 它,等拉取远程仓库中的更改后,再把我的更改恢复应用到主分支上。我执行下面的命令将我的更改移动到 stash 中:
|
||||
|
||||
```
|
||||
git stash
|
||||
```
|
||||
|
||||
使用命令 `git stash list` 查看 stash,在这里能看到我的更改:
|
||||
|
||||

|
||||
|
||||
我的代码已经在一个安全的地方,而且主分支目前是干净的(使用命令 `git status` 检查)。现在我只需要拉取远程仓库的更改,然后把我的更改恢复应用到主分支上,而且我也应该是这么做的。
|
||||
|
||||
但是我错误地执行了命令:
|
||||
|
||||
```
|
||||
git stash drop
|
||||
```
|
||||
|
||||
它删除了 stash,而不是执行了下面的命令:
|
||||
|
||||
```
|
||||
git stash pop
|
||||
```
|
||||
|
||||
这条命令会在从栈中删除 stash 之前应用它。如果我再次执行命令 `git stash list`,就能看到在没有从栈中将更改恢复到主分支的之前,我就删除了它。OMG!接下来怎么办?
|
||||
|
||||
好消息是:`git` 并没有删除包含了我的更改的对象,它只是移除了对它的引用。为了证明这一点,我使用命令 `git fsck`,它会验证数据库中对象的连接和有效性。这是我对该仓库执行了 `git fsck` 之后的输出:
|
||||
|
||||

|
||||
|
||||
由于使用了参数 `--unreachable`,我让 `git-fsck` 显示出所有不可访问的对象。正如你看到的,它显示并没有不可访问的对象。而当我从 stash 中删除了我的更改之后,再次执行相同的指令,得到了一个不一样的输出:
|
||||
|
||||

|
||||
|
||||
现在有三个不可访问对象。那么哪一个才是我的更改呢?实际上,我不知道。我需要通过执行命令 `git show` 来搜索每一个对象。
|
||||
|
||||

|
||||
|
||||
就是它!ID 号 `95ccbd927ad4cd413ee2a28014c81454f4ede82c` 对应了我的更改。现在我已经找到了丢失的更改,我可以恢复它。其中一种方法是将此 ID 取出来放进一个新的分支,或者直接提交它。如果你得到了你的更改对象的 ID 号,就可以决定以最好的方式,将更改再次恢复应用到主分支上。对于这个例子,我使用 `git stash` 将更改恢复到我的主分支上。
|
||||
|
||||
```
|
||||
git stash apply 95ccbd927ad4cd413ee2a28014c81454f4ede82c
|
||||
```
|
||||
|
||||
另外需要重点记住的是 `git` 会周期性地执行它的垃圾回收程序(`gc`),它执行之后,使用 `git fsck` 就不能再看到不可访问对象了。
|
||||
|
||||
_本文[最初发表][18]于作者的博客,并得到了转载授权。_
|
||||
|
||||
|
||||
(题图:opensource.com,附图:José Guilherme Vanz, [CC BY][1])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/8/recover-dropped-data-stash
|
||||
|
||||
作者:[Jose Guilherme Vanz][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jvanz
|
||||
[1]:https://creativecommons.org/licenses/by/4.0/
|
||||
[2]:https://creativecommons.org/licenses/by/4.0/
|
||||
[3]:https://creativecommons.org/licenses/by/4.0/
|
||||
[4]:https://creativecommons.org/licenses/by/4.0/
|
||||
[5]:https://creativecommons.org/licenses/by/4.0/
|
||||
[6]:https://creativecommons.org/licenses/by/4.0/
|
||||
[7]:https://creativecommons.org/licenses/by/4.0/
|
||||
[8]:https://creativecommons.org/licenses/by/4.0/
|
||||
[9]:https://opensource.com/file/366691
|
||||
[10]:https://opensource.com/file/366696
|
||||
[11]:https://opensource.com/file/366701
|
||||
[12]:https://opensource.com/file/366706
|
||||
[13]:https://opensource.com/file/366711
|
||||
[14]:https://opensource.com/file/366716
|
||||
[15]:https://opensource.com/file/366721
|
||||
[16]:https://opensource.com/file/366726
|
||||
[17]:https://opensource.com/article/17/8/recover-dropped-data-stash?rate=BUOLRB3pka4kgSQFTTEfX7_HJrX6duyjronp9GABnGU
|
||||
[18]:http://jvanz.com/recovering-missed-data-from-stash.html#recovering-missed-data-from-stash
|
||||
[19]:https://opensource.com/user/94726/feed
|
||||
[20]:https://www.git-scm.com/docs/git-stash
|
||||
[21]:https://opensource.com/users/jvanz
|
||||
[22]:https://opensource.com/users/jvanz
|
||||
[23]:https://opensource.com/article/17/8/recover-dropped-data-stash#comments
|
||||
@ -0,0 +1,72 @@
|
||||
Ubuntu Linux 的不同安装类型:服务器 vs 桌面
|
||||
============================================================
|
||||
|
||||
> 内核是任何 Linux 机器的核心
|
||||
|
||||
之前我已经讲了获取与安装 Ubuntu Linux,这次我将讲桌面和服务器的安装。两类安装都满足某些需求。不同的安装包是从 Ubuntu 分开下载的。你可以从 [Ubuntu.com/downloads][1] 选择你需要的。
|
||||
|
||||
无论安装类型如何,都有一些相似之处。
|
||||
|
||||

|
||||
|
||||
*可以从桌面系统图形用户界面或从服务器系统命令行添加安装包。*
|
||||
|
||||
两者都使用相同的内核和包管理器系统。软件包管理器系统是预编译为可在几乎任何 Ubuntu 系统运行的程序的仓库。程序分组成包,然后以安装包进行安装。安装包可以从桌面系统图形用户界面或从服务器系统命令行添加。
|
||||
|
||||
程序安装使用一个名为 `apt-get` 的程序。这是一个包管理器系统或程序管理器系统。最终用户只需输入命令行 `apt-get install (package-name)`,Ubuntu 就会自动获取软件包并进行安装。
|
||||
|
||||
软件包通常安装可以通过手册页访问的文档的命令(这本身就是一个主题)。它们可以通过输入 `man (command)` 来访问。这将打开一个描述该命令详细用法的页面。终端用户还可以 Google 任何的 Linux 命令或安装包,并找到大量关于它的信息。
|
||||
|
||||
例如,在安装网络连接存储套件后,可以通过命令行、GUI 或使用名为 Webmin 的程序进行管理。Webmin 安装了一个基于 Web 的管理界面,用于配置大多数 Linux 软件包,它受到了仅安装服务器版本的人群的欢迎,因为它安装为网页,不需要 GUI。它还允许远程管理服务器。
|
||||
|
||||
大多数(如果不是全部)基于 Linux 的软件包都有专门帮助你如何运行该软件包的视频和网页。只需在 YouTube 上搜索 “Linux Ubuntu NAS”,你就会找到一个指导你如何设置和配置此服务的视频。还有专门指导 Webmin 的设置和操作的视频。
|
||||
|
||||
内核是任何 Linux 安装的核心。由于内核是模块化的,它是非常小的(顾名思义)。我在一个 32MB 的小型闪存上运行 Linux 服务器。我没有打错 - 32MB 的空间!Linux 系统使用的大部分空间都是由安装的软件包使用的。
|
||||
|
||||
|
||||
**服务器**
|
||||
|
||||
服务器安装 ISO 镜像是 Ubuntu 提供的最小的下载。它是针对服务器操作优化的操作系统的精简版本。此版本没有 GUI。默认情况下,它完全从命令行运行。
|
||||
|
||||
移除 GUI 和其他组件可简化系统并最大限度地提高性能。最初没有安装的必要软件包可以稍后通过命令行程序包管理器添加。由于没有 GUI,因此必须从命令行完成所有配置、故障排除和包管理。许多管理员将使用服务器安装来获取一个干净或最小的系统,然后只添加他们需要的某些包。这包括添加桌面 GUI 系统并制作精简桌面系统。
|
||||
|
||||
广播电台可以使用 Linux 服务器作为 Apache Web 服务器或数据库服务器。这些是真实需要消耗处理能力的程序,这就是为什么它们通常使用服务器形式安装以及没有 GUI 的原因。SNORT 和 Cacti 是可以在你的 Linux 服务器上运行的其他程序(这两个应用程序都在上一篇文章中介绍,可以在这里找到:[_http://tinyurl.com/yd8dyegu_][2])。
|
||||
|
||||
|
||||
**桌面**
|
||||
|
||||
桌面安装 ISO 镜像相当大,并且有多个在服务器安装 ISO 镜像上没有的软件包。此安装用于工作站或日常桌面使用。此安装类型允许自定义安装包(程序),或者可以选择默认的桌面配置。
|
||||
|
||||

|
||||
|
||||
*桌面安装 ISO 镜像相当大,并且有多个在服务器安装 ISO 镜像上没有的软件包。此安装包专为工作站或日常桌面使用设计。*
|
||||
|
||||
软件包通过 apt-get 包管理器系统安装,就像服务器安装一样。两者之间的区别在于,在桌面安装中,apt-get 包管理器具有不错的 GUI 前端。这允许通过点击鼠标轻松地从系统安装或删除软件包!桌面安装将设置一个 GUI 以及许多与桌面操作系统相关的软件包。
|
||||
|
||||

|
||||
|
||||
*通过 apt-get 包管理器系统安装软件包,就像服务器安装一样。两者之间的区别在于,在桌面安装中,apt-get 包管理器具有不错的 GUI 前端。**
|
||||
|
||||
这个系统安装后随时可用,可以很好的替代你的 Windows 或 Mac 台式机。它有很多包,包括 Office 套件和 Web 浏览器。
|
||||
|
||||
Linux 是一个成熟而强大的操作系统。无论哪种安装类型,它都可以配置为适合几乎所有需要。从功能强大的数据库服务器到用于网页浏览和写信给奶奶的基本台式机操作系统,天空有极限,而可用的安装包几乎是不竭的。如果你遇到一个需要计算机化解决方案的问题,Linux 可能会提供免费或低成本的软件来解决该问题。
|
||||
|
||||
通过提供两个安装版本,Ubuntu 做得很好,这让人们开始朝着正确的方向前进。
|
||||
|
||||
*Cottingham 是前无线电总工程师,现在从事流媒体工作。*
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.radiomagonline.com/deep-dig/0005/linux-installation-types-server-vs-desktop/39123
|
||||
|
||||
作者:[Chris Cottingham][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.radiomagonline.com/author/chris-cottingham
|
||||
[1]:https://www.ubuntu.com/download
|
||||
[2]:http://tinyurl.com/yd8dyegu
|
||||
[3]:http://www.radiomagonline.com/author/chris-cottingham
|
||||
123
published/201708/20170822 Getting Started With GitHub.md
Normal file
123
published/201708/20170822 Getting Started With GitHub.md
Normal file
@ -0,0 +1,123 @@
|
||||
GitHub 简易入门指南
|
||||
================
|
||||
|
||||
[][1]
|
||||
|
||||
[GitHub][13] 是一个在线平台,旨在促进在一个共同项目上工作的个人之间的代码托管、版本控制和协作。通过该平台,无论何时何地,都可以对项目进行操作(托管和审查代码,管理项目和与世界各地的其他开发者共同开发软件)。**GitHub 平台**为开源项目和私人项目都提供了项目处理功能。
|
||||
|
||||
关于团队项目处理的功能包括:GitHub <ruby>流<rt>Flow></rt></ruby>和 GitHub <ruby>页<rt>Pages</rt></ruby>。这些功能可以让需要定期部署的团队轻松处理工作流程。另一方面,GitHub 页提供了页面用于展示开源项目、展示简历、托管博客等。
|
||||
|
||||
GitHub 也为个人项目提供了必要的工具,使得个人项目可以轻松地处理。它也使得个人可以更轻松地与世界分享他们的项目。
|
||||
|
||||
### 注册 GitHub 并启动一个项目
|
||||
|
||||
在 GitHub 上启动新项目时,您必须先使用您的电子邮件地址创建一个帐户。
|
||||
|
||||
[][2]
|
||||
|
||||
然后,在验证邮箱的时候,用户将自动登录到他们的 GitHub 帐户。
|
||||
|
||||
#### 1、 创建仓库
|
||||
|
||||
之后,我们会被带到一个用于创建<ruby>仓库<rt>repository</rt></ruby>的页面。仓库存储着包括修订历史记录在内的所有项目文件。仓库可以是公开的或者是私有的。公开的仓库可以被任何人查看,但是,只有项目所有者授予权限的人才可以提交修改到这个仓库。另一方面,私有仓库提供了额外的控制,可以将项目设置为对谁可见。因此,公开仓库适用于开源软件项目,而私有仓库主要适用于私有或闭源项目。
|
||||
|
||||
* 填写 “<ruby>仓库名称<rt>Repository Name</rt></ruby>” 和 “<ruby>简短描述<rt>Short Description</rt></ruby>”。
|
||||
* 选中 “<ruby>以一个 README 文件初始化<rt>Initialize this repository with a README</rt></ruby>”。
|
||||
* 最后,点击底部的 “<ruby>创建仓库<rt>Create Repository</rt></ruby>” 按钮。
|
||||
|
||||
[][3]
|
||||
|
||||
#### 2、 添加分支
|
||||
|
||||
在 GitHub 中,<ruby>分支<rt>branch</rt></ruby>是一种同时操作单个仓库的各种版本的方式。默认情况下,任何创建的单个仓库都会被分配一个名为 “MASTER” 的分支,它被认为是最后一个分支。在 GitHub 中,分支在被合并到<ruby>主干<rt>master</rt></ruby>(最后的分支)之前,可以在对仓库进行实验和编辑中发挥作用。
|
||||
|
||||
为了使项目适合每一个人的需求,通常情况下,总是需要添加几个格外的分支来匹配不同的项目。在主分支上创建一个分支和复制主分支时的当前状态是一样的。
|
||||
|
||||
[][4]
|
||||
|
||||
创建分支与在不同版本中保存单个文件是类似的。它通过在特定仓库上执行的任务重命名来实现。
|
||||
|
||||
分支在保持错误修复和功能添加工作中同样被证明是有效。在进行必要的修改后,这些分支会被合并到主分支中。
|
||||
|
||||
在创建仓库后创建一个分支:
|
||||
|
||||
* 在这个例子中,点击仓库名称 “Hello-World” 跳转到你的新仓库。
|
||||
* 点击顶部的 “Branch:Master” 按钮,会看到一个下拉菜单,菜单里有填写分支名称的空白字段。
|
||||
* 输入分支名称,在这个例子中我们输入 “readme-edits“。
|
||||
* 按下回车键或者点击蓝色的 “<ruby>创建分支<rt>create branch</rt></ruby>” 框。
|
||||
|
||||
这样就成功创建了两个分支:master 和 readme-edits。
|
||||
|
||||
#### 3、 修改项目文件并提交
|
||||
|
||||
此步骤提供了关于如何更改仓库并保存修改的指导。在 GitHub 上,<ruby>提交<rt>commit</rt></ruby>被定义为保存的修改的意思。每一次提交都与一个<ruby>提交信息<rt>commit message</rt></ruby>相关联,该提交信息包含了保存的修改的历史记录,以及为何进行这些更改。这使得其他贡献者可以很轻松地知道你做出的更改以及更改的原因。
|
||||
|
||||
要对仓库进行更改和提交更改,请执行以下步骤:
|
||||
|
||||
* 点击仓库名称 “Hello-World”。
|
||||
* 点击右上角的铅笔图标查看和编辑文件。
|
||||
[][5]
|
||||
* 在编辑器中,写一些东西来确定你可以进行更改。
|
||||
* 在<ruby>提交消息<rt>commit message</rt></ruby>字段中做简要的总结,以解释为什么以及如何进行更改。
|
||||
* 点击<ruby>提交更改<rt> commit changes</rt></ruby>按钮保存更改。
|
||||
|
||||
请注意,这些更改仅仅影响到 readme-edits 分支,而不影响主分支。
|
||||
|
||||
[][6]
|
||||
|
||||
#### 4、 开启一个拉取请求
|
||||
|
||||
<ruby>拉取请求<rt>pull request</rt></ruby>是一个允许贡献者提出并请求某人审查和合并某些更改到他们的分支的功能。拉取请求还显示了几个分支的差异(diffs)。更改、添加和删减通常以红色和绿色来表示。一旦提交完成就可以开启拉取请求,即使代码还未完成。
|
||||
|
||||
开启一个拉取请求:
|
||||
|
||||
* 点击<ruby>拉取请求<rt>pull requests</rt></ruby>选项卡。
|
||||
[][7]
|
||||
* 点击<ruby>新建拉取请求<rt>new pull requests</rt></ruby>按钮。
|
||||
* 选择 readme-edits 分支与 master 分支进行比较。
|
||||
[][8]
|
||||
* 确定请求,并确定这是您要提交的内容。
|
||||
* 点击创建拉取请求绿色按钮并输入一个标题。
|
||||
[][9]
|
||||
* 按下回车键。
|
||||
|
||||
用户可以通过尝试创建并保存拉取请求来证实这些操作。
|
||||
|
||||
#### 5、 合并拉取请求
|
||||
|
||||
最后一步是将 readme-edits 分支和 master 分支合并到一起。如果 readme-edits 分支和 master 分支不会产生冲突,则会显示<ruby>merge pull request<rt>合并拉取请求</rt></ruby>的按钮。
|
||||
|
||||
[][10]
|
||||
|
||||
当合并拉取时,有必要确保<ruby>评论<rt>comment</rt></ruby>和其他字段被正确填写。合并拉取:
|
||||
|
||||
* 点击<ruby>merge pull request<rt>合并拉取请求</rt></ruby>的按钮。
|
||||
* 确认合并。
|
||||
* 按下紫色的删除分支按钮,删除 readme-edits 分支,因为它已经被包含在 master 分支中。(LCTT 译注:如果是合并他人提交的拉取请求,则无需也无法删除合并过来的他人的分支。)
|
||||
|
||||
本文提供了 GitHub 平台从注册到使用的基本操作,接下来由大家尽情探索吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/getting-started-with-github
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/getting-started-with-github
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/github-homepage_orig.jpg
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-a-github-repository_orig.jpg
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/add-a-branch-to-github-repository_orig.jpg
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/commit-changes-to-github-repository_orig.jpg
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/commit-branch-to-master_orig.jpg
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/github-pull-request_orig.jpg
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/compare-commit-changes-github_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/open-a-pull-request-in-github-repository_orig.jpg
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/merge-the-pull-request-github_orig.jpg
|
||||
[11]:http://www.linuxandubuntu.com/home/getting-started-with-github
|
||||
[12]:http://www.linuxandubuntu.com/home/getting-started-with-github#comments
|
||||
[13]:https://github.com/
|
||||
@ -0,0 +1,234 @@
|
||||
六个优雅的 Linux 命令行技巧
|
||||
============================================================
|
||||
|
||||
> 一些非常有用的命令能让命令行的生活更满足
|
||||
|
||||

|
||||
|
||||
使用 Linux 命令工作可以获得许多乐趣,但是如果您使用一些命令,它们可以减少您的工作或以有趣的方式显示信息时,您将获得更多的乐趣。在今天的文章中,我们将介绍六个命令,它们可能会使你用在命令行上的时间更加值当。
|
||||
|
||||
### watch
|
||||
|
||||
`watch` 命令会重复运行您给出的任何命令,并显示输出。默认情况下,它每两秒运行一次命令。命令的每次运行都将覆盖上一次运行时显示的内容,因此您始终可以看到最新的数据。
|
||||
|
||||
您可能会在等待某人登录时使用它。在这种情况下,您可以使用 `watch who` 命令或者 `watch -n 15 who` 命令使每 15 秒运行一次,而不是两秒一次。另外终端窗口的右上角会显示日期和时间。
|
||||
|
||||
```
|
||||
$ watch -n 5 who
|
||||
Every 5.0s: who stinkbug: Wed Aug 23 14:52:15 2017
|
||||
|
||||
shs pts/0 2017-08-23 14:45 (192.168.0.11)
|
||||
zoe pts/1 2017-08-23 08:15 (192.168.0.19)
|
||||
```
|
||||
|
||||
您也可以使用它来查看日志文件。如果您显示的数据没有任何变化,则只有窗口角落里的日期和时间会发生变化。
|
||||
|
||||
```
|
||||
$ watch tail /var/log/syslog
|
||||
Every 2.0s: tail /var/log/syslog stinkbug: Wed Aug 23 15:16:37 2017
|
||||
|
||||
Aug 23 14:45:01 stinkbug CRON[7214]: (root) CMD (command -v debian-sa1 > /dev/nu
|
||||
ll && debian-sa1 1 1)
|
||||
Aug 23 14:45:17 stinkbug systemd[1]: Started Session 179 of user shs.
|
||||
Aug 23 14:55:01 stinkbug CRON[7577]: (root) CMD (command -v debian-sa1 > /dev/nu
|
||||
ll && debian-sa1 1 1)
|
||||
Aug 23 15:05:01 stinkbug CRON[7582]: (root) CMD (command -v debian-sa1 > /dev/nu
|
||||
ll && debian-sa1 1 1)
|
||||
Aug 23 15:08:48 stinkbug systemd[1]: Starting Cleanup of Temporary Directories...
|
||||
Aug 23 15:08:48 stinkbug systemd-tmpfiles[7584]: [/usr/lib/tmpfiles.d/var.conf:1
|
||||
4] Duplicate line for path "/var/log", ignoring.
|
||||
Aug 23 15:08:48 stinkbug systemd[1]: Started Cleanup of Temporary Directories.
|
||||
Aug 23 15:13:41 stinkbug systemd[1]: Started Session 182 of user shs.
|
||||
Aug 23 15:14:29 stinkbug systemd[1]: Started Session 183 of user shs.
|
||||
Aug 23 15:15:01 stinkbug CRON[7828]: (root) CMD (command -v debian-sa1 > /dev/nu
|
||||
ll && debian-sa1 1 1)
|
||||
```
|
||||
|
||||
这里的输出和使用命令 `tail -f /var/log/syslog` 的输出相似。
|
||||
|
||||
### look
|
||||
|
||||
这个命令的名字 `look` 可能会让我们以为它和 `watch` 做类似的事情,但其实是不同的。`look` 命令用于搜索以某个特定字符串开头的单词。
|
||||
|
||||
```
|
||||
$ look ecl
|
||||
eclectic
|
||||
eclectic's
|
||||
eclectically
|
||||
eclecticism
|
||||
eclecticism's
|
||||
eclectics
|
||||
eclipse
|
||||
eclipse's
|
||||
eclipsed
|
||||
eclipses
|
||||
eclipsing
|
||||
ecliptic
|
||||
ecliptic's
|
||||
```
|
||||
|
||||
`look` 命令通常有助于单词的拼写,它使用 `/usr/share/dict/words` 文件,除非你使用如下的命令指定了文件名:
|
||||
|
||||
```
|
||||
$ look esac .bashrc
|
||||
esac
|
||||
esac
|
||||
esac
|
||||
```
|
||||
|
||||
在这种情况下,它的作用就像跟在一个 `awk` 命令后面的 `grep` ,只打印匹配行上的第一个单词。
|
||||
|
||||
### man -k
|
||||
|
||||
`man -k` 命令列出包含指定单词的手册页。它的工作基本上和 `apropos` 命令一样。
|
||||
|
||||
```
|
||||
$ man -k logrotate
|
||||
dh_installlogrotate (1) - install logrotate config files
|
||||
logrotate (8) - rotates, compresses, and mails system logs
|
||||
logrotate.conf (5) - rotates, compresses, and mails system logs
|
||||
```
|
||||
|
||||
### help
|
||||
|
||||
当你完全绝望的时候,您可能会试图使用此命令,`help` 命令实际上是显示一个 shell 内置命令的列表。最令人惊讶的是它有相当多的参数变量。你可能会看到这样的东西,然后开始想知道这些内置功能可以为你做些什么:
|
||||
```
|
||||
$ help
|
||||
GNU bash, version 4.4.7(1)-release (i686-pc-linux-gnu)
|
||||
These shell commands are defined internally. Type `help' to see this list.
|
||||
Type `help name' to find out more about the function `name'.
|
||||
Use `info bash' to find out more about the shell in general.
|
||||
Use `man -k' or `info' to find out more about commands not in this list.
|
||||
|
||||
A star (*) next to a name means that the command is disabled.
|
||||
|
||||
job_spec [&] history [-c] [-d offset] [n] or hist>
|
||||
(( expression )) if COMMANDS; then COMMANDS; [ elif C>
|
||||
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs >
|
||||
: kill [-s sigspec | -n signum | -sigs>
|
||||
[ arg... ] let arg [arg ...]
|
||||
[[ expression ]] local [option] name[=value] ...
|
||||
alias [-p] [name[=value] ... ] logout [n]
|
||||
bg [job_spec ...] mapfile [-d delim] [-n count] [-O or>
|
||||
bind [-lpsvPSVX] [-m keymap] [-f file> popd [-n] [+N | -N]
|
||||
break [n] printf [-v var] format [arguments]
|
||||
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
|
||||
caller [expr] pwd [-LP]
|
||||
case WORD in [PATTERN [| PATTERN]...)> read [-ers] [-a array] [-d delim] [->
|
||||
cd [-L|[-P [-e]] [-@]] [dir] readarray [-n count] [-O origin] [-s>
|
||||
command [-pVv] command [arg ...] readonly [-aAf] [name[=value] ...] o>
|
||||
compgen [-abcdefgjksuv] [-o option] [> return [n]
|
||||
complete [-abcdefgjksuv] [-pr] [-DE] > select NAME [in WORDS ... ;] do COMM>
|
||||
compopt [-o|+o option] [-DE] [name ..> set [-abefhkmnptuvxBCHP] [-o option->
|
||||
continue [n] shift [n]
|
||||
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
|
||||
declare [-aAfFgilnrtux] [-p] [name[=v> source filename [arguments]
|
||||
dirs [-clpv] [+N] [-N] suspend [-f]
|
||||
disown [-h] [-ar] [jobspec ... | pid > test [expr]
|
||||
echo [-neE] [arg ...] time [-p] pipeline
|
||||
enable [-a] [-dnps] [-f filename] [na> times
|
||||
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
|
||||
exec [-cl] [-a name] [command [argume> true
|
||||
exit [n] type [-afptP] name [name ...]
|
||||
export [-fn] [name[=value] ...] or ex> typeset [-aAfFgilnrtux] [-p] name[=v>
|
||||
false ulimit [-SHabcdefiklmnpqrstuvxPT] [l>
|
||||
fc [-e ename] [-lnr] [first] [last] o> umask [-p] [-S] [mode]
|
||||
fg [job_spec] unalias [-a] name [name ...]
|
||||
for NAME [in WORDS ... ] ; do COMMAND> unset [-f] [-v] [-n] [name ...]
|
||||
for (( exp1; exp2; exp3 )); do COMMAN> until COMMANDS; do COMMANDS; done
|
||||
function name { COMMANDS ; } or name > variables - Names and meanings of so>
|
||||
getopts optstring name [arg] wait [-n] [id ...]
|
||||
hash [-lr] [-p pathname] [-dt] [name > while COMMANDS; do COMMANDS; done
|
||||
help [-dms] [pattern ...] { COMMANDS ; }
|
||||
```
|
||||
|
||||
### stat -c
|
||||
|
||||
`stat` 命令用于显示文件的大小、所有者、用户组、索引节点号、权限、修改和访问时间等重要的统计信息。这是一个非常有用的命令,可以显示比 `ls -l` 更多的细节。
|
||||
|
||||
```
|
||||
$ stat .bashrc
|
||||
File: .bashrc
|
||||
Size: 4048 Blocks: 8 IO Block: 4096 regular file
|
||||
Device: 806h/2054d Inode: 421481 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
|
||||
Access: 2017-08-23 15:13:41.781809933 -0400
|
||||
Modify: 2017-06-21 17:37:11.875157790 -0400
|
||||
Change: 2017-06-21 17:37:11.899157791 -0400
|
||||
Birth: -
|
||||
```
|
||||
|
||||
使用 `-c` 选项,您可以指定要查看的字段。例如,如果您只想查看一个文件或一系列文件的文件名和访问权限,则可以这样做:
|
||||
|
||||
```
|
||||
$ stat -c '%n %a' .bashrc
|
||||
.bashrc 644
|
||||
```
|
||||
|
||||
在此命令中, `%n` 表示每个文件的名称,而 `%a` 表示访问权限。`%u` 表示数字类型的 UID,而 `%U` 表示用户名。
|
||||
|
||||
```
|
||||
$ stat -c '%n %a' bin/*
|
||||
bin/loop 700
|
||||
bin/move2nohup 700
|
||||
bin/nohup.out 600
|
||||
bin/show_release 700
|
||||
|
||||
$ stat -c '%n %a %U' bin/*
|
||||
bin/loop 700 shs
|
||||
bin/move2nohup 700 shs
|
||||
bin/nohup.out 600 root
|
||||
bin/show_release 700 shs
|
||||
```
|
||||
|
||||
### TAB
|
||||
|
||||
如果你没有使用过 tab 键来补全文件名,你真的错过了一个非常有用的命令行技巧。tab 键提供文件名补全功能(包括使用 `cd` 时的目录)。它在出现歧义之前尽可能多的填充文件名(多个文件以相同的字母开头。如果您有一个名为 `bigplans` 的文件,另一个名为 `bigplans2017` 的文件会发生歧义,你将听到一个声音,然后需要决定是按下回车键还是输入 `2` 之后再按下 tab 键选择第二个文件。
|
||||
|
||||
|
||||
(题图:[Micah Elizabeth Scott][32] [(CC BY 2.0)][33])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3219684/linux/half-a-dozen-clever-linux-command-line-tricks.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.networkworld.com/article/3203369/lan-wan/10-most-important-open-source-networking-projects.html
|
||||
[2]:https://www.networkworld.com/article/3203369/lan-wan/10-most-important-open-source-networking-projects.html#tk.nww_nsdr_ndxprmomod
|
||||
[3]:https://www.networkworld.com/article/3188295/linux/linux-mint-18-1-mostly-smooth-but-some-sharp-edges.html
|
||||
[4]:https://www.networkworld.com/article/3188295/linux/linux-mint-18-1-mostly-smooth-but-some-sharp-edges.html#tk.nww_nsdr_ndxprmomod
|
||||
[5]:https://www.networkworld.com/article/3167272/linux/open-source-users-its-time-for-extreme-vetting.html
|
||||
[6]:https://www.networkworld.com/article/3167272/linux/open-source-users-its-time-for-extreme-vetting.html#tk.nww_nsdr_ndxprmomod
|
||||
[7]:https://www.networkworld.com/article/3218728/linux/how-log-rotation-works-with-logrotate.html
|
||||
[8]:https://www.networkworld.com/article/3194830/linux/10-unix-commands-every-mac-and-linux-user-should-know.html
|
||||
[9]:https://www.networkworld.com/article/3208389/linux/unix-how-random-is-random.html
|
||||
[10]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[11]:https://www.networkworld.com/article/3219826/mobile/prime-members-get-60-off-nucleus-anywhere-intercom-with-amazon-alexa-right-now-deal-alert.html
|
||||
[12]:https://www.networkworld.com/article/3106867/consumer-electronics/32-off-pulse-solo-dimmable-led-light-with-dual-channel-bluetooth-speakers-deal-alert.html
|
||||
[13]:https://www.networkworld.com/article/3219685/mobile/57-off-rockbirds-6-pack-led-mini-super-bright-3-mode-tactical-flashlights-deal-alert.html
|
||||
[14]:https://www.networkworld.com/insider
|
||||
[15]:https://twitter.com/intent/tweet?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html&via=networkworld&text=Half+a+dozen+clever+Linux+command+line+tricks
|
||||
[16]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html
|
||||
[17]:http://www.linkedin.com/shareArticle?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html&title=Half+a+dozen+clever+Linux+command+line+tricks
|
||||
[18]:https://plus.google.com/share?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html
|
||||
[19]:http://reddit.com/submit?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html&title=Half+a+dozen+clever+Linux+command+line+tricks
|
||||
[20]:http://www.stumbleupon.com/submit?url=https%3A%2F%2Fwww.networkworld.com%2Farticle%2F3219684%2Flinux%2Fhalf-a-dozen-clever-linux-command-line-tricks.html
|
||||
[21]:https://www.networkworld.com/article/3219684/linux/half-a-dozen-clever-linux-command-line-tricks.html#email
|
||||
[22]:https://www.networkworld.com/article/3218728/linux/how-log-rotation-works-with-logrotate.html
|
||||
[23]:https://www.networkworld.com/article/3194830/linux/10-unix-commands-every-mac-and-linux-user-should-know.html
|
||||
[24]:https://www.networkworld.com/article/3208389/linux/unix-how-random-is-random.html
|
||||
[25]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[26]:https://www.networkworld.com/video/51206/solo-drone-has-linux-smarts-gopro-mount
|
||||
[27]:https://www.networkworld.com/article/3219826/mobile/prime-members-get-60-off-nucleus-anywhere-intercom-with-amazon-alexa-right-now-deal-alert.html
|
||||
[28]:https://www.networkworld.com/article/3106867/consumer-electronics/32-off-pulse-solo-dimmable-led-light-with-dual-channel-bluetooth-speakers-deal-alert.html
|
||||
[29]:https://www.networkworld.com/article/3219685/mobile/57-off-rockbirds-6-pack-led-mini-super-bright-3-mode-tactical-flashlights-deal-alert.html
|
||||
[30]:https://www.facebook.com/NetworkWorld/
|
||||
[31]:https://www.linkedin.com/company/network-world
|
||||
[32]:https://www.flickr.com/photos/micahdowty/4630801442/in/photolist-84d4Wb-p29iHU-dscgLx-pXKT7a-pXKT7v-azMz3V-azMz7M-4Amp2h-6iyQ51-4nf4VF-5C1gt6-6P4PwG-po6JEA-p6C5Wg-6RcRbH-7GAmbK-dCkRnT-7ETcBp-4Xbhrw-dXrN8w-dXm83Z-dXrNvQ-dXrMZC-dXrMPN-pY4GdS-azMz8X-bfNoF4-azQe61-p1iUtm-87i3vj-7enNsv-6sqvJy-dXm8aD-6smkyX-5CFfGm-dXm8dD-6sqviw-6sqvVU-dXrMVd-6smkXc-dXm7Ug-deuxUg-6smker-Hd15p-6squyf-aGtnxn-6smjRX-5YtTUN-nynqYm-ea5o3c
|
||||
[33]:https://creativecommons.org/licenses/by/2.0/legalcode
|
||||
@ -0,0 +1,211 @@
|
||||
在 Linux 中分割和重组文件
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
非常有用的 `csplit` 命令可以将单个文件分割成多个文件。Carla Schroder 解释说。
|
||||
|
||||
Linux 有几个用于分割文件的工具程序。那么你为什么要分割文件呢?一个用例是将大文件分割成更小的尺寸,以便它适用于比较小的存储介质,比如 U 盘。当您遇到 FAT32(最大文件大小为 4GB),且您的文件大于此时,通过 U 盘传输文件也是一个很好的技巧。另一个用例是加速网络文件传输,因为小文件的并行传输通常更快。
|
||||
|
||||
我们将学习如何使用 `csplit`,`split` 和 `cat` 来重新整理文件,然后再将文件合并在一起。这些操作在任何文件类型下都有用:文本、图片、音频文件、ISO 镜像文件等。
|
||||
|
||||
### 使用 csplit 分割文件
|
||||
|
||||
`csplit` 是这些有趣的小命令中的一个,它永远伴你左右,一旦开始用它就离不开了。`csplit` 将单个文件分割成多个文件。这个示例演示了最简单的使用方法,它将文件 foo.txt 分为三个文件,以行号 17 和 33 作为分割点:
|
||||
|
||||
```
|
||||
$ csplit foo.txt 17 33
|
||||
2591
|
||||
3889
|
||||
2359
|
||||
```
|
||||
|
||||
`csplit` 在当前目录下创建了三个新文件,并以字节为单位打印出新文件的大小。默认情况下,每个新文件名为 `xx_nn`:
|
||||
|
||||
```
|
||||
$ ls
|
||||
xx00
|
||||
xx01
|
||||
xx02
|
||||
```
|
||||
|
||||
您可以使用 `head` 命令查看每个新文件的前十行:
|
||||
|
||||
```
|
||||
$ head xx*
|
||||
|
||||
==> xx00 <==
|
||||
Foo File
|
||||
by Carla Schroder
|
||||
|
||||
Foo text
|
||||
|
||||
Foo subheading
|
||||
|
||||
More foo text
|
||||
|
||||
==> xx01 <==
|
||||
Foo text
|
||||
|
||||
Foo subheading
|
||||
|
||||
More foo text
|
||||
|
||||
==> xx02 <==
|
||||
Foo text
|
||||
|
||||
Foo subheading
|
||||
|
||||
More foo text
|
||||
```
|
||||
|
||||
如果要将文件分割成包含相同行数的多个文件怎么办?可以指定行数,然后将重复次数放在在花括号中。此示例重复分割 4 次,并将剩下的转储到最后一个文件中:
|
||||
|
||||
```
|
||||
$ csplit foo.txt 5 {4}
|
||||
57
|
||||
1488
|
||||
249
|
||||
1866
|
||||
3798
|
||||
```
|
||||
|
||||
您可以使用星号通配符来告诉 `csplit` 尽可能多地重复分割。这听起来很酷,但是如果文件不能等分,则可能会失败(LCTT 译注:低版本的 `csplit` 不支持此参数):
|
||||
|
||||
```
|
||||
$ csplit foo.txt 10 {*}
|
||||
1545
|
||||
2115
|
||||
1848
|
||||
1901
|
||||
csplit: '10': line number out of range on repetition 4
|
||||
1430
|
||||
```
|
||||
|
||||
默认的行为是删除发生错误时的输出文件。你可以用 `-k` 选项来解决这个问题,当有错误时,它就不会删除输出文件。另一个行为是每次运行 `csplit` 时,它将覆盖之前创建的文件,所以你需要使用新的文件名来分别保存它们。使用 `--prefix= _prefix_` 来设置一个不同的文件前缀:
|
||||
|
||||
```
|
||||
$ csplit -k --prefix=mine foo.txt 5 {*}
|
||||
57
|
||||
1488
|
||||
249
|
||||
1866
|
||||
993
|
||||
csplit: '5': line number out of range on repetition 9
|
||||
437
|
||||
|
||||
$ ls
|
||||
mine00
|
||||
mine01
|
||||
mine02
|
||||
mine03
|
||||
mine04
|
||||
mine05
|
||||
```
|
||||
|
||||
选项 `-n` 可用于改变对文件进行编号的数字位数(默认是 2 位):
|
||||
|
||||
```
|
||||
$ csplit -n 3 --prefix=mine foo.txt 5 {4}
|
||||
57
|
||||
1488
|
||||
249
|
||||
1866
|
||||
1381
|
||||
3798
|
||||
|
||||
$ ls
|
||||
mine000
|
||||
mine001
|
||||
mine002
|
||||
mine003
|
||||
mine004
|
||||
mine005
|
||||
```
|
||||
|
||||
`csplit` 中的 “c” 是上下文(context)的意思。这意味着你可以根据任意匹配的方式或者巧妙的正则表达式来分割文件。下面的例子将文件分为两部分。第一个文件在包含第一次出现 “fie” 的前一行处结束,第二个文件则以包含 “fie” 的行开头。
|
||||
|
||||
```
|
||||
$ csplit foo.txt /fie/
|
||||
```
|
||||
|
||||
在每次出现 “fie” 时分割文件:
|
||||
|
||||
```
|
||||
$ csplit foo.txt /fie/ {*}
|
||||
```
|
||||
|
||||
在 “fie” 前五次出现的地方分割文件:
|
||||
|
||||
```
|
||||
$ csplit foo.txt /fie/ {5}
|
||||
```
|
||||
|
||||
仅当内容以包含 “fie” 的行开始时才复制,并且省略前面的所有内容:
|
||||
|
||||
```
|
||||
$ csplit myfile %fie%
|
||||
```
|
||||
|
||||
### 将文件分割成不同大小
|
||||
|
||||
`split` 与 `csplit` 类似。它将文件分割成特定的大小,当您将大文件分割成小的多媒体文件或者使用网络传送时,这就非常棒了。默认的大小为 1000 行:
|
||||
|
||||
```
|
||||
$ split foo.mv
|
||||
$ ls -hl
|
||||
266K Aug 21 16:58 xaa
|
||||
267K Aug 21 16:58 xab
|
||||
315K Aug 21 16:58 xac
|
||||
[...]
|
||||
```
|
||||
|
||||
它们分割出来的大小相似,但你可以指定任何你想要的大小。这个例子中是 20M 字节:
|
||||
|
||||
```
|
||||
$ split -b 20M foo.mv
|
||||
```
|
||||
|
||||
尺寸单位缩写为 K,M,G,T,P,E,Z,Y(1024 的幂)或者 KB,MB,GB 等等(1000 的幂)。
|
||||
|
||||
为文件名选择你自己的前缀和后缀:
|
||||
|
||||
```
|
||||
$ split -a 3 --numeric-suffixes=9 --additional-suffix=mine foo.mv SB
|
||||
240K Aug 21 17:44 SB009mine
|
||||
214K Aug 21 17:44 SB010mine
|
||||
220K Aug 21 17:44 SB011mine
|
||||
```
|
||||
|
||||
`-a` 选项控制编号的数字位置。`--numeric-suffixes` 设置编号的开始值。默认前缀为 `x`,你也可以通过在文件名后输入它来设置一个不同的前缀。
|
||||
|
||||
### 将分割后的文件合并
|
||||
|
||||
你可能想在某个时候重组你的文件。常用的 `cat` 命令就用在这里:
|
||||
|
||||
```
|
||||
$ cat SB0* > foo2.txt
|
||||
```
|
||||
|
||||
示例中的星号通配符将匹配到所有以 SB0 开头的文件,这可能不会得到您想要的结果。您可以使用问号通配符进行更精确的匹配,每个字符使用一个问号:
|
||||
|
||||
```
|
||||
$ cat SB0?????? > foo2.txt
|
||||
```
|
||||
|
||||
和往常一样,请查阅相关的手册和信息页面以获取完整的命令选项。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/8/splitting-and-re-assembling-files-linux
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[2]:https://www.linux.com/files/images/split-filespng
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
53
published/201708/20170824 Understanding OPNFV Starts Here.md
Normal file
53
published/201708/20170824 Understanding OPNFV Starts Here.md
Normal file
@ -0,0 +1,53 @@
|
||||
从这开始了解 OPNFV
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
如果电信运营商或企业今天从头开始构建网络,那么他们可能用软件定义资源的方式构建,这与 Google 或 Facebook 的基础设施类似。这是网络功能虚拟化 (NFV) 的前提。
|
||||
|
||||
NFV 是颠覆的一代,其将彻底改变网络的建设和运营。而且,[OPNFV][3] 是一个领先的开源 NFV 项目,旨在加速这项技术的采用。
|
||||
|
||||
你是想要知道有哪些开源项目可能会帮助你进行 NFV 转换计划的电信运营商或者相关的企业员工么?还是要将你的产品和服务推向新的 NFV 世界的技术提供商?或者,也许是一名想使用开源项目来发展你事业的工程师、网络运维或商业领袖?(例如 2013 年 Rackspace [提到][4] 拥有 OpenStack 技能的网络工程师的平均工资比他们的同行高 13%)?如果这其中任何一个适用于你,那么 _理解 OPNFV_ 一书是你的完美资源。
|
||||
|
||||

|
||||
|
||||
*“理解 OPNFV”一书高屋建瓴地提供了 OPNFV 的理解以及它如何帮助你和你们的组织。*
|
||||
|
||||
本书(由 Mirantis 、 Nick Chase 和我撰写)在 11 个易于阅读的章节和超过 144 页中介绍了从 NFV、NFV 转换、OPNFV 项目的各个方面到 VNF 入门的概述,涵盖了一系列主题。阅读本书后,你将对 OPNFV 是什么有一个高屋建瓴的理解以及它如何帮助你或你们的组织。这本书不是专门面向开发人员的,虽然有开发背景信息很有用。如果你是开发人员,希望作为贡献者参与 OPNFV 项目,那么 [wiki.opnfv.org][5] 仍然是你的最佳资源。
|
||||
|
||||
在本博客系列中,我们会向你展示本书的一部分内容 - 就是有些什么内容,以及你可能会学到的。
|
||||
|
||||
让我们从第一章开始。第 1 章,毫不奇怪,是对 NFV 的介绍。它从业务驱动因素(需要差异化服务、成本压力和敏捷需求)、NFV 是什么,以及你可从 NFV 可以获得什么好处的角度做了简要概述。
|
||||
|
||||
简而言之,NFV 可以在数据中心的计算节点上执行复杂的网络功能。在计算节点上执行的网络功能称为虚拟网络功能 (VNF)。因此,VNF 可以作为网络运行,NFV 还会添加机制来确定如何将它们链接在一起,以提供对网络中流量的控制。
|
||||
|
||||
虽然大多数人认为它用在电信,但 NFV 涵盖了广泛的使用场景,从基于应用或流量类型的按角色访问控制 (RBAC) 到用于管理网络内容的内容分发网络 (CDN) 网络(通常需要的地方),更明显的电信相关用例如演进分组核心 (EPC) 和 IP 多媒体系统(IMS)。
|
||||
|
||||
此外,一些主要收益包括增加收入、改善客户体验、减少运营支出 (OPEX)、减少资本支出 (CAPEX)和为新项目腾出资源。本节还提供了具体的 NFV 总体拥有成本 (TCO) 分析。这些话题的处理很简单,因为我们假设你有一些 NFV 背景。然而,如果你刚接触 NFV ,不要担心 - 介绍材料足以理解本书的其余部分。
|
||||
|
||||
本章总结了 NFV 要求 - 安全性、性能、互操作性、易操作性以及某些具体要求,如服务保证和服务功能链。不符合这些要求,没有 NFV 架构或技术可以真正成功。
|
||||
|
||||
阅读本章后,你将对为什么 NFV 非常重要、NFV是什么,以及 NFV 成功的技术要求有一个很好的概念。我们将在今后的博客文章中浏览下面的章节。
|
||||
|
||||
这本书已被证明是行业活动上最受欢迎的赠品,中文版正在进行之中!但是你现在可以[下载 PDF 格式的电子书][6],或者在亚马逊上下载[打印版本][7]。
|
||||
|
||||
(题图:[Creative Commons Zero][1]Pixabay)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/opnfv/2017/8/understanding-opnfv-starts-here
|
||||
|
||||
作者:[AMAR KAPADIA][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/akapadia
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/network-transformationpng
|
||||
[3]:https://www.opnfv.org/
|
||||
[4]:https://blog.rackspace.com/solving-the-openstack-talent-gap
|
||||
[5]:https://wiki.opnfv.org/
|
||||
[6]:https://www.opnfv.org/resources/download-understanding-opnfv-ebook
|
||||
[7]:https://www.amazon.com/dp/B071LQY724/ref=cm_sw_r_cp_ep_dp_pgFMzbM8YHJA9
|
||||
@ -0,0 +1,40 @@
|
||||
OpenStack 上的 OpenShift:更好地交付应用程序
|
||||
============================================================
|
||||
|
||||
你有没有问过自己,我应该在哪里运行 OpenShift?答案是任何地方 - 它可以在裸机、虚拟机、私有云或公共云中很好地运行。但是,这里有一些为什么人们正迁移到围绕全栈和资源消耗自动化相关的私有云和公有云的原因。传统的操作系统一直是关于[硬件资源的展示和消耗][2] - 硬件提供资源,应用程序消耗它们,操作系统一直是交通警察。但传统的操作系统一直局限于单机^注1 。
|
||||
|
||||
那么,在原生云的世界里,现在意味着这个概念扩展到包括多个操作系统实例。这就是 OpenStack 和 OpenShift 所在。在原生云世界,虚拟机、存储卷和网段都成为动态配置的构建块。我们从这些构建块构建我们的应用程序。它们通常按小时或分钟付费,并在不再需要时被取消配置。但是,你需要将它们视为应用程序的动态配置能力。 OpenStack 在动态配置能力(展示)方面非常擅长,OpenShift 在动态配置应用程序(消费)方面做的很好,但是我们如何将它们结合在一起来提供一个动态的、高度可编程的多节点操作系统呢?
|
||||
|
||||
要理解这个,让我们来看看如果我们在传统的环境中安装 OpenShift 会发生什么 - 想像我们想要为开发者提供动态访问来创建新的应用程序,或者想象我们想要提供业务线,使其能够访问现有应用程序的新副本以满足合同义务。每个应用程序都需要访问持久存储。持久存储不是临时的,在传统的环境中,这通过提交一张工单实现。没关系,我们可以连到 OpenShift,每次需要存储时都会提交一张工单。存储管理员可以登录企业存储阵列并根据需要删除卷,然后将其移回 OpenShift 以满足应用程序。但这将是一个非常慢的手动过程,而且你可能会遇到存储管理员辞职。
|
||||
|
||||

|
||||
|
||||
在原生云的世界里,我们应该将其视为一个策略驱动的自动化流程。存储管理员变得更加战略性、设置策略、配额和服务级别(银、黄金等),但实际配置变得动态。
|
||||
|
||||

|
||||
|
||||
动态过程可扩展到多个应用程序 - 这可能是开发者测试的业务线甚至新应用程序。从 10 多个应用程序到 1000 个应用程序,动态配置提供原生云体验。
|
||||
|
||||

|
||||
|
||||
下面的演示视频展示了动态存储配置如何与 Red Hat OpenStack 平台(Cinder 卷)以及 Red Hat OpenShift 容器平台配合使用,但动态配置并不限于存储。想象一下,随着 OpenShift 的一个实例需要更多的容量、节点自动扩展的环境。想象一下,推送一个敏感的程序更改前,将网段划分为负载测试 OpenShift 的特定实例。这些是你为何需要动态配置 IT 构建块的原因。OpenStack 实际上是以 API 驱动的方式实现的。
|
||||
|
||||
[YOUTUBE VIDEO](https://youtu.be/PfWmAS9Fc7I)
|
||||
|
||||
OpenShift 和 OpenStack 一起更好地交付应用程序。OpenStack 动态提供资源,而 OpenShift 会动态地消耗它们。它们一起为你所有的容器和虚拟机需求提供灵活的原生云解决方案。
|
||||
|
||||
注1:高可用性集群和一些专门的操作系统在一定程度上弥合了这一差距,但在计算中通常是一个边缘情况。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.openshift.com/openshift-on-openstack-delivering-applications-better-together/
|
||||
|
||||
作者:[SCOTT MCCARTY][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.openshift.com/author/smccartyredhat-com/
|
||||
[1]:https://blog.openshift.com/author/smccartyredhat-com/
|
||||
[2]:https://docs.google.com/presentation/d/139_dxpiYc5JR8yKAP8pl-FcZmOFQCuV8RyDxZqOOcVE/edit
|
||||
108
published/20170821 Manage your finances with LibreOffice Calc.md
Normal file
108
published/20170821 Manage your finances with LibreOffice Calc.md
Normal file
@ -0,0 +1,108 @@
|
||||
使用 LibreOffice Calc 管理你的财务
|
||||
============================================================
|
||||
|
||||
> 你想知道你的钱花在哪里?这个精心设计的电子表格可以一目了然地回答这个问题。
|
||||
|
||||

|
||||
|
||||
|
||||
如果你像大多数人一样,没有一个无底般的银行帐户。你可能需要仔细观察你的每月支出。
|
||||
|
||||
有很多方法可以做到这一点,但是最快最简单的方法是使用电子表格。许多人创建一个非常基本的电子表格来完成这项工作,它由两长列组成,总计位于底部。这是可行的,但这有点傻。
|
||||
|
||||
我将通过使用 LibreOffice Calc 创建一个更便于细查的(我认为)以及更具视觉吸引力的个人消费电子表格。
|
||||
|
||||
你说不用 LibreOffice?没关系。你可以使用 [Gnumeric][7]、[Calligra Sheets][8] 或 [EtherCalc][9] 等电子表格工具使用本文中的信息。
|
||||
|
||||
### 首先列出你的费用
|
||||
|
||||
先别费心 LibreOffice 了。坐下来用笔和纸,列出你的每月日常开支。花时间,翻遍你的记录,记下所有的事情,无论它多么渺小。不要担心你花了多少钱。重点放在你把钱花在哪里。
|
||||
|
||||
完成之后,将你的费用分组到最有意义的标题下。例如,将你的燃气、电气和水费放在“水电费”下。你也可能想要为我们每个月都会遇到的意外费用,使用一组名为“种种”。
|
||||
|
||||
### 创建电子表格
|
||||
|
||||
启动 LibreOffice Calc 并创建一个空的电子表格。在电子表格的顶部留下三个空白行。之后我们会回来。
|
||||
|
||||
你把你的费用归类是有原因的:这些组将成为电子表格上的块。我们首先将最重要的花费组(例如 “家庭”)放在电子表格的顶部。
|
||||
|
||||
在工作表顶部第四行的第一个单元格中输入该花费组的名称。将它放大(可以是 12 号字体)、加粗使得它显眼。
|
||||
|
||||
在该标题下方的行中,添加以下三列:
|
||||
|
||||
* 花费
|
||||
* 日期
|
||||
* 金额
|
||||
|
||||
在“花费”列下的单元格中输入该组内花费的名称。
|
||||
|
||||
接下来,选择日期标题下的单元格。单击 **Format** 菜单,然后选择 **Number Format > Date**。对“金额”标题下的单元格重复此操作,然后选择 **Number Format > Currency**。
|
||||
|
||||
你会看到这样:
|
||||
|
||||

|
||||
|
||||
这是一组开支的方式。不要为每个花费组创建新块, 而是复制你创建的内容并将其粘贴到第一个块旁边。我建议一行放三块, 在它们之间有一个空列。
|
||||
|
||||
你会看到这样:
|
||||
|
||||

|
||||
|
||||
对所有你的花费组做重复操作。
|
||||
|
||||
### 总计所有
|
||||
|
||||
查看所有个人费用是一回事,但你也可以一起查看每组费用的总额和所有费用。
|
||||
|
||||
我们首先总计每个费用组的金额。你可以让 LibreOffice Calc 自动做这些。高亮显示“金额”列底部的单元格,然后单击 “Formula” 工具栏上的 “Sum” 按钮。
|
||||
|
||||

|
||||
|
||||
单击金额列中的第一个单元格,然后将光标拖动到列中的最后一个单元格。然后按下 Enter。
|
||||
|
||||

|
||||
|
||||
现在让我们用你顶部留下的两三行空白行做一些事。这就是你所有费用的总和。我建议把它放在那里,这样无论何时你打开文件时它都是可见的。
|
||||
|
||||
在表格左上角的其中一个单元格中,输入类似“月总计”。然后,在它旁边的单元格中,输入 `=SUM()`。这是 LibreOffice Calc 函数,它可以在电子表格中添加特定单元格的值。
|
||||
|
||||
不要手动输入要添加的单元格的名称,请按住键盘上的 Ctrl。然后在电子表格上单击你在每组费用中总计的单元格。
|
||||
|
||||
### 完成
|
||||
|
||||
你有一张追踪一个月花费的表。拥有单个月花费的电子表格有点浪费。为什么不用它跟踪全年的每月支出呢?
|
||||
|
||||
右键单击电子表格底部的选项卡,然后选择 **Move or Copy Sheet**。在弹出的窗口中,单击 **-move to end position-**,然后按下 Enter 键。一直重复到你有 12 张表 - 每月一张。以月份重命名表格,然后使用像 _Monthly Expenses 2017.ods_ 这样的描述性名称保存电子表格。
|
||||
|
||||
现在设置完成了,你可以使用电子表格了。使用电子表格跟踪你的花费本身不会坚实你的财务基础,但它可以帮助你控制每个月的花费。
|
||||
|
||||
(题图: opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Scott Nesbitt - 我是一名长期使用自由/开源软件的用户,并为了乐趣和收益写了各种软件。我不会太严肃。你可以在网上这些地方找到我:Twitter、Mastodon、GitHub。
|
||||
|
||||
----------------
|
||||
|
||||
via: https://opensource.com/article/17/8/budget-libreoffice-calc
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/file/366811
|
||||
[2]:https://opensource.com/file/366831
|
||||
[3]:https://opensource.com/file/366821
|
||||
[4]:https://opensource.com/file/366826
|
||||
[5]:https://opensource.com/article/17/8/budget-libreoffice-calc?rate=C87fXAfGoIpA1OuF-Zx1nv-98UN9GgbFUz4tl_bKug4
|
||||
[6]:https://opensource.com/user/14925/feed
|
||||
[7]:http://www.gnumeric.org/
|
||||
[8]:https://www.calligra.org/sheets/
|
||||
[9]:https://ethercalc.net/
|
||||
[10]:https://opensource.com/users/scottnesbitt
|
||||
[11]:https://opensource.com/users/scottnesbitt
|
||||
[12]:https://opensource.com/article/17/8/budget-libreoffice-calc#comments
|
||||
@ -1,73 +0,0 @@
|
||||
How to Manage the Security Vulnerabilities of Your Open Source Product
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
In his upcoming talk at ELC + OpenIoT Summit, Ryan Ware, Security Architect at Intel, will explain how you can navigate the flood of vulnerabilities and manage the security of your product.[Creative Commons Zero][2]Pixabay
|
||||
|
||||
The security vulnerabilities that you need to consider when developing open source software can be overwhelming. Common Vulnerability Enumeration (CVE) IDs, zero-day, and other vulnerabilities are seemingly announced every day. With this flood of information, how can you stay up to date?
|
||||
|
||||
“If you shipped a product that was built on top of Linux kernel 4.4.1, between the release of that kernel and now, there have been nine CVEs against that kernel version,” says Ryan Ware, Security Architect at Intel, in the Q&A below. “These all would affect your product despite the fact they were not known at the time you shipped.”
|
||||
|
||||
|
||||

|
||||
|
||||
Ryan Ware, Security Architect at Intel[Used with permission][1]
|
||||
|
||||
In his upcoming presentation at[ ELC][6] + [OpenIoT Summit,][7] Ryan Ware, Security Architect at Intel, will present strategies for how you can navigate these waters and successfully manage the security of your product. In this preview of his talk, Ware discusses the most common developer mistakes, strategies to stay on top of vulnerabilities, and more.
|
||||
|
||||
**Linux.com: Let's start from the beginning. Can you tell readers briefly about the Common Vulnerabilities and Exposures (CVE), 0-day, and other vulnerabilities? What are they, and why are they important?**
|
||||
|
||||
Ryan Ware: Excellent questions. Common Vulnerabilities and Exposures (CVE) is a database maintained by the MITRE Corporation (a not-for-profit organization) at the behest of the United States government. It’s currently funded under the US Department of Homeland Security. It was created in 1999 to house information about all publicly known security vulnerabilities. Each of these vulnerabilities has its own identifier (a CVE-ID) and can be referenced by that. This is how the term CVE, which really applies to the whole database, has morphed into meaning an individual security vulnerability: a CVE.
|
||||
|
||||
Many of the vulnerabilities that end up in the CVE database started out life as 0-day vulnerabilities. These are vulnerabilities that for whatever reason haven’t followed a more ordered disclosure process such as Responsible Disclosure. The key is that they’ve become public and exploitable without the software vendor being able to respond with a remediation of some type -- usually a software patch. These and other unpatched software vulnerabilities are critically important because until they are patched, the vulnerability is exploitable. In many ways, the release of a CVE or a 0-Day is like a starting gun going off. Until you reach the end of the race, your customers are vulnerable.
|
||||
|
||||
**Linux.com: How many are there? How do you determine which are pertinent to your product?**
|
||||
|
||||
Ryan: Before going into how many, everyone shipping software of any kind needs to keep something in mind. Even if you take all possible efforts to ensure that the software you ship doesn’t have known vulnerabilities in it, your software *does* have vulnerabilities. They are just not known. For example, if you shipped a product that was built on top of Linux kernel 4.4.1, between the release of that kernel and now, there have been nine CVEs against that kernel version. These all would affect your product despite the fact they were not known at the time you shipped.
|
||||
|
||||
At this point in time, the CVE database contains 80,957 entries (January 30, 2017) and includes entries going all the way back to 1999 when there were 894 documented issues. The largest number in a year to date was 2014 when 7,946 issues were documented. That said, I believe that the decrease in numbers over the last two years isn’t due to there being fewer security vulnerabilities. This is something I’ll touch on in my talk.
|
||||
|
||||
**Linux.com: What are some strategies that developers can use to stay on top of all this information?**
|
||||
|
||||
Ryan: There are various ways a developer can float on top of the flood of vulnerability information. One of my favorite tools for doing so is [CVE Details][8]. They present the information from MITRE in a very digestible way. The best feature they have is the ability to create custom RSS feeds so you can follow vulnerabilities for the components you care about. Those with more complex tracking problems may want to start by downloading the MITRE CVE database (freely available) and pulling regular updates. Other excellent tools, such as cvechecker, allow you to check for known vulnerabilities in your software.
|
||||
|
||||
For key portions of your software stack, I also recommend one amazingly effective tool: Get involved with the upstream community. These are the people who understand the software you are shipping best. There are no better experts in the world. Work with them.
|
||||
|
||||
**Linux.com: How can you know whether your product has all the vulnerabilities covered? Are there tools that you recommend?**
|
||||
|
||||
Ryan: Unfortunately, as I said above, you will never have all vulnerabilities removed from your product. Some of the tools I mentioned above are key. However, there is one piece of software I haven’t mentioned yet that is absolutely critical to any product you ship: a software update mechanism. If you do not have the ability to update the product software out in the field, you have no ability to address security concerns when your customers are affected. You must be able to update, and the easier the update process, the better your customers will be protected.
|
||||
|
||||
**Linux.com: What else do developers need to know to successfully manage security vulnerabilities?**
|
||||
|
||||
Ryan: There is one mistake that I see over and over. Developers always need to keep in mind the idea of minimizing their attackable surface area. What does this mean? In practice, it means only including the things in your product that your product actually needs! This not only includes ensuring you do not incorporate extraneous software packages into your product, but that you also compile projects with configurations that turn off features you don’t need.
|
||||
|
||||
How does this help? Imagine it’s 2014\. You’ve just gone into work to see that the tech news is all Heartbleed all the time. You know you include OpenSSL in your product because you need to do some basic cryptographic functionality but you don’t use TLS heartbeat, the feature with the vulnerability in question. Would you rather:
|
||||
|
||||
a. Spend the rest of your work working with customers and partners handholding them through a critical software update fixing a highly visible security issue?
|
||||
|
||||
b. Be able to tell customers and partners simply that you compiled your products OpenSSL with the “–DOPENSSL_NO_HEARTBEATS” flag and they aren’t vulnerable, allowing you to focus on new features and other productive activities.
|
||||
|
||||
The easiest vulnerability to address is the one you don’t include.
|
||||
|
||||
_Embedded Linux Conference + OpenIoT Summit North America will be held on February 21-23, 2017 in Portland, Oregon. [Check out over 130 sessions][5] on the Linux kernel, embedded development & systems, and the latest on the open Internet of Things._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/event/elcna/2017/2/how-manage-security-vulnerabilities-your-open-source-product
|
||||
|
||||
作者:[AMBER ANKERHOLZ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/aankerholz
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/ryan-ware01jpg
|
||||
[4]:https://www.linux.com/files/images/security-software-vulnerabilitiesjpg
|
||||
[5]:http://events.linuxfoundation.org/events/embedded-linux-conference/program/schedule?utm_source=linux&utm_campaign=elc17&utm_medium=blog&utm_content=video-blog
|
||||
[6]:http://events.linuxfoundation.org/events/embedded-linux-conference
|
||||
[7]:http://events.linuxfoundation.org/events/openiot-summit
|
||||
[8]:http://www.cvedetails.com/
|
||||
@ -1,67 +0,0 @@
|
||||
Open Source First: A manifesto for private companies
|
||||
============================================================
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
This is a manifesto that any private organization can use to frame their collaboration transformation. Take a read and let me know what you think.
|
||||
|
||||
I presented [a talk at the Linux TODO group][3] using this article as my material. For those of you who are not familiar with the TODO group, they support open source leadership at commercial companies. It is important to lean on each other because legal, security, and other shared knowledge is so important for the open source community to move forward. This is especially true because we need to represent both the commercial and public community best interests.
|
||||
|
||||
"Open source first" means that we look to open source before we consider vendor-based products to meet our needs. To use open source technology correctly, you need to do more than just consume, you need to participate to ensure the open source technology survives long term. To participate in open source requires your engineer's time be split between working for your company and the open source project. We expect to bring the open source contribution intent and collaboration internal to our private company. We need to define, build, and maintain a culture of contribution, collaboration, and merit-based work.
|
||||
|
||||
### Open garden development
|
||||
|
||||
Our private company strives to be a leader in technology through its contributions to the technology community. This requires more than just the use of open source code. To be a leader requires participation. To be a leader also requires various types of participation with groups (communities) outside of the company. These communities are organized around a specific R&D project. Participation in each of these communities is much like working for a company. Substantial results require substantial participation.
|
||||
|
||||
### Code more, live better
|
||||
|
||||
We must be generous with computing resources, stingy with space, and encourage the messy, creative stew that results from this. Allowing people access to the tools of their business will transform them. We must have spontaneous interactions. We must build the online and physical spaces that encourage creativity through collaboration. Collaboration doesn't happen without access to each other in real time.
|
||||
|
||||
### Innovation through meritocracy
|
||||
|
||||
We must create a meritocracy. The quality of ideas has to overcome the group structure and tenure of those in it. Promotion by merit encourages everyone to be better people and employees. While we are being the best badasses we can be, hardy debates between passionate people will happen. Our culture should encourage the obligation to dissent. Strong opinions and ideas lead to a passionate work ethic. The ideas and opinions can and should come from all. It shouldn't make difference who you are, rather it should matter what you do. As meritocracy takes hold, we need to invest in teams that are going to do the right thing without permission.
|
||||
|
||||
### Project to product
|
||||
|
||||
As our private company embraces open source contribution, we must also create clearer separation between working upstream on an R&D project and implementing the resulting product in production. A project is R&D where failing fast and developing features is the status quo. A product is what you put into production, has SLAs, and is using the results of the R&D project. The separation requires at least separate repositories for projects and products. Normal separation consists of different communities working on the projects and products. Each of the communities require substantial contribution and participation. In order to keep these activities separate, there needs to be a workflow of customer feature and bug fix requests from project to product.
|
||||
|
||||
Next, we highlight the major steps in creating, supporting, and expanding open source at our private company.
|
||||
|
||||
### A school for the technically gifted
|
||||
|
||||
The seniors must mentor the inexperienced. As you learn new skills, you pass them on to the next person. As you train the next person, you move on to new challenges. Never expect to stay in one position for very long. Get skills, become awesome, pass learning on, and move on.
|
||||
|
||||
### Find the best people for your family
|
||||
|
||||
We love our work. We love it so much that we want to work with our friends. We are part of a community that is larger than our company. Recruiting the best people to work with us, should always be on our mind. We will find awesome jobs for the people around us, even if that isn't with our company. Thinking this way makes hiring great people a way of life. As hiring becomes common, then reviewing and helping new hires becomes easy.
|
||||
|
||||
### More to come
|
||||
|
||||
I will be posting [more details][4] about each tenet on my blog, stay tuned.
|
||||
|
||||
_This article was originally posted on [Sean Robert's blog][1]. Licensed CC BY._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Sean A Roberts - Lead with empathy while focusing on results. I practice meritocracy. Intelligent things found here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/open-source-first
|
||||
|
||||
作者:[ ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sarob
|
||||
[1]:https://sarob.com/2017/01/open-source-first/
|
||||
[2]:https://opensource.com/article/17/2/open-source-first?rate=CKF77ZVh5e_DpnmSlOKTH-MuFBumAp-tIw-Rza94iEI
|
||||
[3]:https://sarob.com/2017/01/todo-open-source-presentation-17-january-2017/
|
||||
[4]:https://sarob.com/2017/02/open-source-first-project-product/
|
||||
[5]:https://opensource.com/user/117441/feed
|
||||
[6]:https://opensource.com/users/sarob
|
||||
@ -1,3 +1,5 @@
|
||||
translating by @explosic4
|
||||
|
||||
Why working openly is hard when you just want to get stuff done
|
||||
============================================================
|
||||
|
||||
@ -85,7 +87,7 @@ So perhaps I should reconsider my GSD mentality and expand it to GMD: Get **mor
|
||||
|
||||
作者简介:
|
||||
|
||||
Jason Hibbets - Jason Hibbets is a senior community evangelist in Corporate Marketing at Red Hat where he is a community manager for Opensource.com. He has been with Red Hat since 2003 and is the author of The foundation for an open source city. Prior roles include senior marketing specialist, project manager, Red Hat Knowledgebase maintainer, and support engineer. Follow him on Twitter:
|
||||
Jason Hibbets - Jason Hibbets is a senior community evangelist in Corporate Marketing at Red Hat where he is a community manager for Opensource.com. He has been with Red Hat since 2003 and is the author of The foundation for an open source city. Prior roles include senior marketing specialist, project manager, Red Hat Knowledgebase maintainer, and support engineer. Follow him on Twitter:
|
||||
|
||||
-----------
|
||||
|
||||
|
||||
@ -1,168 +0,0 @@
|
||||
【Translating by JanzenLiu】
|
||||
Beyond public key encryption
|
||||
============================================================
|
||||
|
||||
One of the saddest and most fascinating things about applied cryptography is _how
|
||||

|
||||
little cryptography we actually use. _ This is not to say that cryptography isn’t widely used in industry — it is. Rather, what I mean is that cryptographic researchers have developed so many useful technologies, and yet industry on a day to day basis barely uses any of them. In fact, with a few minor exceptions, the vast majority of the cryptography we use was settled by the early-2000s.*
|
||||
|
||||
Most people don’t sweat this, but as a cryptographer who works on the boundary of research and deployed cryptography it makes me unhappy. So while I can’t solve the problem entirely, what I _can_ do is talk about some of these newer technologies. And over the course of this summer that’s what I intend to do: talk. Specifically, in the next few weeks I’m going to write a series of posts that describe some of the advanced cryptography that we _don’t_ generally see used.
|
||||
|
||||
Today I’m going to start with a very simple question: what lies beyond public key cryptography? Specifically, I’m going to talk about a handful of technologies that were developed in the past 20 years, each of which allows us to go beyond the traditional notion of public keys.
|
||||
|
||||
This is a wonky post, but it won’t be mathematically-intense. For actual definitions of the schemes, I’ll provide links to the original papers, and references to cover some of the background. The point here is to explain what these new schemes do — and how they can be useful in practice.
|
||||
|
||||
### Identity Based Cryptography
|
||||
|
||||
In the mid-1980s, a cryptographer named Adi Shamir proposed a [radical new idea.][3]The idea, put simply, was _to get rid of public keys_ .
|
||||
|
||||
To understand where Shamir was coming from, it helps to understand a bit about public key encryption. You see, prior to the invention of public key crypto, all cryptography involved secret keys. Dealing with such keys was a huge drag. Before you could communicate securely, you needed to exchange a secret with your partner. This process was fraught with difficulty and didn’t scale well.
|
||||
|
||||
Public key encryption (beginning with [Diffie-Hellman][4] and Shamir’s [RSA][5]cryptosystem) hugely revolutionized cryptography by dramatically simplifying this key distribution process. Rather than sharing secret keys, users could now transmit their _public_ key to other parties. This public key allowed the recipient to encrypt to you (or verify your signature) but it could not be used to perform the corresponding decryption (or signature generation) operations. That part would be done with a secret key you kept to yourself.
|
||||
|
||||
While the use of public keys improved many aspects of using cryptography, it also gave rise to a set of new challenges. In practice, it turns out that having public keys is only half the battle — people still need to use distribute them securely.
|
||||
|
||||
For example, imagine that I want to send you a PGP-encrypted email. Before I can do this, I need to obtain a copy of your public key. How do I get this? Obviously we could meet in person and exchange that key on physical media — but nobody wants to do this. It would much more desirable to obtain your public key electronically. In practice this means either _(1)_ we have to exchange public keys by email, or _(2)_ I have to obtain your key from a third piece of infrastructure, such as a [website][6] or [key server][7]. And now we come to the problem: if that email or key server is _untrustworthy _ (or simply allows anyone to [upload a key in y][8][our name][9]),I might end up downloading a malicious party’s key by accident. When I send a message to “you”, I’d actually be encrypting it to Mallory.
|
||||
|
||||

|
||||
Mallory.
|
||||
|
||||
Solving this problem — of exchanging public keys and verifying their provenance — has motivated a _huge_ amount of practical cryptographic engineering, including the entire [web PKI.][10] In most cases, these systems work well. But Shamir wasn’t satisfied. What if, he asked, we could do it better? More specifically, he asked: _could we replace those pesky public keys with something better?_
|
||||
|
||||
Shamir’s idea was exciting. What he proposed was a new form of public key cryptography in which the user’s “public key” could simply be their _identity_ . This identity could be a name (e.g., “Matt Green”) or something more precise like an email address. Actually, it didn’t realy matter. What did matter was that the public key would be some arbitrary string — and _not_ a big meaningless jumble of characters like “7cN5K4pspQy3ExZV43F6pQ6nEKiQVg6sBkYPg1FG56Not”.
|
||||
|
||||
Of course, using an arbitrary string as a public key raises a big problem. Meaningful identities sound great — but I don’t own them. If my public key is “Matt Green”, how do I get the corresponding private key? And if _I_ can get out that private key, what stops _some other Matt Green_ from doing the same, and thus reading my messages? And ok, now that I think about this, what stops some random person who _isn’t_ named Matt Green from obtaining it? Yikes. We’re headed straight into [Zooko’s triangle][11].
|
||||
|
||||
Shamir’s idea thus requires a bit more finesse. Rather than expecting identities to be global, he proposed a special server called a “key generation authority” that would be responsible for generating the private keys. At setup time, this authority would generate a single _master public key (MPK), _ which it would publish to the world. If you wanted to encrypt a message to “Matt Green” (or verify my signature), then you could do so using my identity and the single MPK of an authority we’d both agree to use. To _decrypt _ that message (or sign one), I would have to visit the same key authority and ask for a copy of my secret key. The key authority would compute my key based on a _master secret key (MSK)_ , which it would keep very secret.
|
||||
|
||||
With all algorithms and players specified, whole system looks like this:
|
||||
|
||||

|
||||
Overview of an Identity-Based Encryption (IBE) system. The Setup algorithm of the Key Generation Authority generates the master public key (MPK) and master secret key (MSK). The authority can use the Extract algorithm to derive the secret key corresponding to a specific ID. The encryptor (left) encrypts using only the identity and MPK. The recipient requests the secret key for her identity, and then uses it to decrypt. (Icons by [Eugen Belyakoff][1])
|
||||
|
||||
This design has some important advantages — and more than a few obvious drawbacks. On the plus side, it removes the need for any key exchange _at all_ with the person you’re sending the message to. Once you’ve chosen a master key authority (and downloaded its MPK), you can encrypt to anyone in the entire world. Even cooler: at the time you encrypt, _your recipient doesn’t even need to have contacted the key authority yet_ . She can obtain her secret key _after_ I send her a message.
|
||||
|
||||
Of course, this “feature” is also a bug. Because the key authority generates all the secret keys, it has an awful lot of power. A dishonest authority could easily generate your secret key and decrypt your messages. The polite way to say this is that standard IBE systems effectively “bake in” [key escrow][12].**
|
||||
|
||||
### Putting the “E” in IBE
|
||||
|
||||
All of these ideas and more were laid out by Shamir in his 1984 paper. There was just one small problem: Shamir could only figure out half the problem.
|
||||
|
||||
Specifically, Shamir’s proposed a scheme for _identity-based signature_ (IBS) — a signature scheme where the public verification key is an identity, but the signing key is generated by the key authority. Try as he might, he could not find a solution to the problem of building identity-based _ encryption _ (IBE). This was left as an open problem.***
|
||||
|
||||
It would take more than 16 years before someone answered Shamir’s challenge. Surprisingly, when the answer came it came not once _but three times_ .
|
||||
|
||||
The first, and probably most famous realization of IBE was developed by Dan Boneh and Matthew Franklin much later — in 2001\. The timing of Boneh and Franklin’s discovery makes a great deal of sense. The Boneh-Franklin scheme relies fundamentally on elliptic curves that support an efficient “[bilinear map][13]” (or “pairing”).**** The [algorithms][14] needed to compute such pairings were not known when Shamir wrote his paper, and weren’t employed _constructively_ — that is, as a useful thing rather than [an attack][15] — until about [2000][16]. The same can be said about a second scheme called [Sakai-Kasahara][17], which would be independently discovered around the same time.
|
||||
|
||||
_(For a brief tutorial on the Boneh-Franklin IBE scheme, see [this page][2].)_
|
||||
|
||||
The third realization of IBE was not as efficient as the others, but was much more surprising. [This scheme][18] was developed by Clifford Cocks, a senior cryptologist at Britain’s GCHQ. It’s noteworthy for two reasons. First, Cocks’ IBE scheme does not require bilinear pairings at all — it is based in the much older RSA setting, which means _in principle _ it spent all those years just waiting to be found. Second, Cocks himself had recently become known for something even more surprising: [discovering the RSA cryptosystem,][19] nearly five years before RSA did. To bookend that accomplishment with a second major advance in public key cryptography was a pretty impressive accomplishment.
|
||||
|
||||
In the years since 2001, a number of additional IBE constructions have been developed, using all sorts of cryptographic settings. Nonetheless, Boneh and Franklin’s early construction remains among the simplest and most efficient.
|
||||
|
||||
Even if you’re not interested in IBE for its own sake, it turns out that this primitive is really useful to cryptographers for many things beyond simple encryption. In fact, it’s more helpful to think of IBE as a way of “pluralizing” a single public/secret master keypair into billions of related keypairs. This makes it useful for applications as diverse as blocking [chosen ciphertext attacks,][20] [forward-secure public key encryption][21], and short [signature schemes][22].
|
||||
|
||||
Attribute Based Encryption
|
||||
|
||||
Of course, if you leave cryptographers alone with a tool like IBE, the first thing they’re going to do is find a way to ~~make things more complicated~~ improve on it.
|
||||
|
||||
One of the biggest such improvements is due to [Sahai and Waters][23]. It’s called Attribute-Based Encryption, or ABE.
|
||||
|
||||
The origin of this idea was not actually to encrypt with attributes. Instead Sahai and Waters were attempting to develop an _Identity-Based_ encryption scheme that could encrypt using biometrics. To understand the problem, imagine I decide to use a biometric like your [iris scan][24] as the “identity” to encrypt you a ciphertext. Later on you’ll ask the authority for a decryption key that corresponds to your own iris scan — and if everything matches up and you’ll be able to decrypt.
|
||||
|
||||
The problem is that this will almost never work.
|
||||
|
||||
The issue here is that biometric readings (like iris scans or fingerprint templates) are inherently error-prone. This means every scan will typically be very _close_ , but often there will be a few bits that disagree. With standard IBE
|
||||
|
||||

|
||||
Tell me this isn’t giving you nightmares.
|
||||
|
||||
this is _fatal_ : if the encryption identity differs from your key identity by even a single bit, decryption will not work. You’re out of luck.
|
||||
|
||||
Sahai and Waters decided that the solution to this problem was to develop a form of IBE with a “threshold gate”. In this setting, each bit of the identity is represented as a different “attribute”. Think of each of these as components you’d encrypt under — something like “bit 5 of your iris scan is a 1” and “bit 23 of your iris scan is a 0”. The encrypting party lists all of these bits and encrypts under each one. The decryption key generated by the authority embeds a similar list of bit values. The scheme is defined so that decryption will work if and only if the number of matching attributes (between your key and the ciphertext) exceeds some pre-defined threshold: _e.g.,_ any 2024 out of 2048 bits must be identical in order to decrypt.
|
||||
|
||||
The beautiful thing about this idea is not fuzzy IBE. It’s that once you have a threshold gate and a concept of “attributes”, you can more interesting things. The [main observation][25] is that a threshold gate can be used to implement the boolean AND and OR gates, like so:
|
||||
|
||||

|
||||
|
||||
Even better, you can _stack_ these gates on top of one another to assign a fairly complex boolean formula — which will itself determine what conditions your ciphertext can be decrypted under. For example, switching to a more realistic set of attributes, you could encrypt a medical record so that either a pediatrician in a hospital could read it, _or_ an insurance adjuster could. All you’d need is to make sure people received keys that correctly described _their_ attributes (which are just arbitrary strings, like identities).
|
||||
|
||||

|
||||
A simple “ciphertext policy”, in which the ciphertext can be decrypted if and only if a key matches an appropriate set of attributes. In this case, the key satisfies the formula and thus the ciphertext decrypts. The remaining key attributes are ignored.
|
||||
|
||||
The other direction can be implemented as well. It’s possible to encrypt a ciphertext under a long list of attributes, such as creation time, file name, and even GPS coordinates indicating where the file was created. You can then have the authority hand out keys that correspond to a very precise slice of your dataset — for example, “this key decrypts any radiology file encrypted in Chicago between November 3rd and December 12th that is tagged with ‘pediatrics’ or ‘oncology'”.
|
||||
|
||||
### Functional Encryption
|
||||
|
||||
Once you have a related of primitives like IBE and ABE, the researchers’ instinct is to both extend and generalize. Why stop at simple boolean formulae? Can we make keys (or ciphertexts) that embed _arbitrary computer programs? _ The answer, it turns out, is yes — though not terribly efficiently. A set of [recent][26] [works][27] show that it is possible to build ABE that works over arbitrary polynomial-size circuits, using various lattice-based assumptions. So there is certainly a lot of potential here.
|
||||
|
||||
This potential has inspired researchers to generalize all of the above ideas into a single class of encryption called “[functional encryption][28]“. Functional encryption is more conceptual than concrete — it’s just a way to look at all of these systems as instances of a specific class. The basic idea is to represent the decryption procedure as an algorithm that computes an arbitary function _F_ over (1) the plaintext inside of a ciphertext, and (2) the data embedded in the key. This function has the following profile:
|
||||
|
||||
_output = F(key data, plaintext data)_
|
||||
|
||||
In this model _IBE_ can be expressed by having the encryption algorithm encrypt _ (identity, plaintext) _ and defining the function _F _ such that, if “ _key input == identity”, it _ outputs the plaintext, and outputs an empty string otherwise. Similarly, ABE can be expressed by a slightly more complex function. Following this paradigm, once can envision all sorts of interesting functions that might be computed by different functions and realized by future schemes.
|
||||
|
||||
But those will have to wait for another time. We’ve gone far enough for today.
|
||||
|
||||
### So what’s the point of all this?
|
||||
|
||||
For me, the point is just to show that cryptography can do some pretty amazing things. We rarely see this on a day-to-day basis when it comes to industry and “applied” cryptography, but it’s all there waiting to be used.
|
||||
|
||||
Perhaps the perfect application is out there. Maybe you’ll find it.
|
||||
|
||||
_Notes:_
|
||||
|
||||
* An earlier version of this post said “mid-1990s”. In comments below, Tom Ristenpart takes issue with that and makes the excellent point that many important developments post-date that. So I’ve moved the date forward about five years, and I’m thinking about how to say this in a nicer way.
|
||||
|
||||
** There is also an intermediate form of encryption known as “[certificateless encryption][29]“. Proposed by Al-Riyami and Paterson, this idea uses a _combination_ of standard public key encryption and IBE. The basic idea is to encrypt each message using _both_ a traditional public key (generated by the recipient) and an IBE identity. The recipient must then obtain a copy of the secret key from the IBE authority to decrypt. The advantages here are twofold: (1) the IBE key authority can’t decrypt the message by itself, since it does not have the corresponding secret key, which solves the “escrow” problem. And (2) the sender does not need to verify that the public key really belongs to the sender (e.g., by checking a certificate), since the IBE portion prevents imposters from decrypting the resulting message. Unfortunately this system is more like traditional public key cryptography than IBE, and does not have the neat usability features of IBE.
|
||||
|
||||
*** A part of the challenge of developing IBE is the need to make a system that is secure against “collusion” between different key holders. For example, imagine a very simple system that has only 2-bit identities. This gives four possible identities: “00”, “01”, “10”, “11”. If I give you a key for the identity “01” and I give Bob a key for “10”, we need to ensure that you two cannot collude to produce a key for identities “00” and “11”. Many earlier proposed solutions have tried to solve this problem by gluing together standard public encryption keys in various ways (e.g., by having a separate public key for each bit of the identity and giving out the secret keys as a single “key”). However these systems tend to fail catastrophically when just a few users collude (or their keys are stolen). Solving the collusion problem is fundamentally what separates real IBE from its faux cousins.
|
||||
|
||||
**** A full description of Boneh and Franklin’s scheme can be found [here][30], or in the [original paper][31]. Some code is [here][32] and [here][33] and [here][34]. I won’t spend more time on it, except to note that the scheme is very efficient. It was patented and implemented by [Voltage Security][35], now part of HPE.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/LCTT/TranslateProject/tree/master/sources/tech
|
||||
|
||||
作者:[Matthew Green][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.cryptographyengineering.com/author/matthewdgreen/
|
||||
[1]:https://thenounproject.com/eugen.belyakoff/
|
||||
[2]:https://blog.cryptographyengineering.com/boneh-franklin-ibe/
|
||||
[3]:https://discovery.csc.ncsu.edu/Courses/csc774-S08/reading-assignments/shamir84.pdf
|
||||
[4]:https://en.wikipedia.org/wiki/Diffie%E2%80%93Hellman_key_exchange
|
||||
[5]:https://en.wikipedia.org/wiki/RSA_(cryptosystem)
|
||||
[6]:https://keybase.io/
|
||||
[7]:https://pgp.mit.edu/
|
||||
[8]:https://motherboard.vice.com/en_us/article/bmvdwd/wave-of-spoofed-encryption-keys-shows-weakness-in-pgp
|
||||
[9]:https://motherboard.vice.com/en_us/article/bmvdwd/wave-of-spoofed-encryption-keys-shows-weakness-in-pgp
|
||||
[10]:https://en.wikipedia.org/wiki/Certificate_authority
|
||||
[11]:https://en.wikipedia.org/wiki/Zooko%27s_triangle
|
||||
[12]:https://en.wikipedia.org/wiki/Key_escrow
|
||||
[13]:http://people.csail.mit.edu/alinush/6.857-spring-2015/papers/bilinear-maps.pdf
|
||||
[14]:https://crypto.stanford.edu/miller/
|
||||
[15]:http://ieeexplore.ieee.org/document/259647/
|
||||
[16]:https://pdfs.semanticscholar.org/845e/96c20e5a5ff3b03f4caf72c3cb817a7fa542.pdf
|
||||
[17]:https://en.wikipedia.org/wiki/Sakai%E2%80%93Kasahara_scheme
|
||||
[18]:https://pdfs.semanticscholar.org/8289/821325781e2f0ce83cfbfc1b62c44be799ee.pdf
|
||||
[19]:https://cryptome.org/jya/ellisdoc.htm
|
||||
[20]:https://www.cs.umd.edu/~jkatz/papers/id-cca.pdf
|
||||
[21]:https://eprint.iacr.org/2003/083.pdf
|
||||
[22]:https://en.wikipedia.org/wiki/Boneh%E2%80%93Lynn%E2%80%93Shacham
|
||||
[23]:https://eprint.iacr.org/2004/086.pdf
|
||||
[24]:https://en.wikipedia.org/wiki/Iris_recognition
|
||||
[25]:https://eprint.iacr.org/2006/309.pdf
|
||||
[26]:https://eprint.iacr.org/2013/337.pdf
|
||||
[27]:https://arxiv.org/abs/1210.5287
|
||||
[28]:https://eprint.iacr.org/2010/543.pdf
|
||||
[29]:http://eprint.iacr.org/2003/126.pdf
|
||||
[30]:https://en.wikipedia.org/wiki/Boneh%E2%80%93Franklin_scheme
|
||||
[31]:https://crypto.stanford.edu/~dabo/papers/bfibe.pdf
|
||||
[32]:http://go-search.org/view?id=github.com%2Fvanadium%2Fgo.lib%2Fibe
|
||||
[33]:https://github.com/relic-toolkit/relic
|
||||
[34]:https://github.com/JHUISI/charm
|
||||
[35]:https://www.voltage.com/
|
||||
@ -1,136 +0,0 @@
|
||||
Translating by softpaopao
|
||||
|
||||
The problem with software before standards
|
||||
============================================================
|
||||
|
||||
### Open source projects need to get serious about including standards in their deliverables.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
By any measure, the rise of open source software as an alternative to the old, proprietary ways has been remarkable. Today, there are tens of millions of libraries hosted at GitHub alone, and the number of major projects is growing rapidly. As of this writing, the [Apache Software Foundation][4] hosts over [300 projects][5], while the [Linux Foundation][6] supports over 60. Meanwhile, the more narrowly focused [OpenStack Foundation][7] boasts 60,000 members living in more than 180 countries.
|
||||
|
||||
So, what could possibly be wrong with this picture?
|
||||
|
||||
What's missing is enough awareness that, while open source software can meet the great majority of user demands, standing alone it can't meet all of them. Worse yet, too many members of the open source community (business leads as well as developers) have no interest in making use of the most appropriate tools available to close the gap.
|
||||
|
||||
Let's start by identifying the problem that needs to be solved, and then see how that problem used to be solved in the past.
|
||||
|
||||
The problem is that there are often many projects trying to solve the same small piece of a larger problem. Customers want to be able to have a choice among competing products and to easily switch among products if they're not satisfied. That's not possible right now, and until this problem is solved, it will hold back open source adoption.
|
||||
|
||||
It's also not a new problem or a problem without traditional solutions. Over the course of a century and a half, user expectations of broad choice and freedom to switch vendors were satisfied through the development of standards. In the physical world, you can choose between myriad vendors of screws, light bulbs, tires, extension cords, and even of the proper shape wine glass for the pour of your choice, because standards provide the physical specifications for each of these goods. In the world of health and safety, our well-being relies on thousands of standards developed by the private sector that ensure proper results while maximizing competition.
|
||||
|
||||
When information and communications technology (ICT) came along, the same approach was taken with the formation of major organizations such as the International Telecommunication Union (ITU), International Electrotechnical Commission (IEC), and the Standards Association of the Institute of Electrical and Electronics Engineers (IEEE-SA). Close to 1,000 consortia followed to develop, promote, or test compliance with ICT standards.
|
||||
|
||||
While not all ICT standards resulted in seamless interoperability, the technology world we live in today exists courtesy of the tens of thousands of essential standards that fulfill that promise, as implemented in computers, mobile devices, Wi-Fi routers, and indeed everything else that runs on electricity.
|
||||
|
||||
The point here is that, over a very long time, a system evolved that could meet customers' desires to have broad product offerings, avoid vendor lock-in, and enjoy services on a global basis.
|
||||
|
||||
Now let's look at how open software is evolving.
|
||||
|
||||
The good news is that great software is being created. The bad news is that in many key areas, like cloud computing and network virtualization, no single foundation is developing the entire stack. Instead, discrete projects develop individual layers, or parts of layers, and then rely on real-time, goodwill-based collaboration up and down the stack among peer projects. When this process works well, the results are good but have the potential to create lock-in the same way that traditional, proprietary products could. When the process works badly, it can result in much wasted time and effort for vendors and community members, as well as disappointed customer expectations.
|
||||
|
||||
The clear way to provide a solution is to create standards that allow customers to avoid lock-in, along with encouraging the availability of multiple solutions competing through value-added features and services. But, with rare exceptions, that's not what's happening in the world of open source.
|
||||
|
||||
The main reason behind this is the prevailing opinion in the open source community is that standards are limiting, irrelevant, and unnecessary. Within a single, well-integrated stack, that may be the case. But for customers that want freedom of choice and ongoing, robust competition, the result could be a return to the bad old days of being locked into a technology, albeit with multiple vendors offering similarly integrated stacks.
|
||||
|
||||
A good description of the problem can be found in a June 14, 2017, article written by Yaron Haviv, "[We'll Be Enslaved to Proprietary Clouds Unless We Collaborate][8]":
|
||||
|
||||
> _Cross-project integration is not exactly prevalent in today's open source ecosystem, and it's a problem. Open source projects that enable large-scale collaboration and are built on a layered and modular architecture—such as Linux_ — _have proven their success time and again. But the Linux ideology stands in stark contrast to the general state of much of today's open source community._
|
||||
>
|
||||
> _Case in point: big data ecosystems, where numerous overlapping implementations rarely share components or use common APIs and layers. They also tend to lack standard wire protocols, and each processing framework (think Spark, Presto, and Flink) has its own data source API._
|
||||
>
|
||||
> _This lack of collaboration is causing angst. Without it, projects are not interchangeable, resulting in negative repercussions for customers by essentially locking them in and slowing down the evolution of projects because each one has to start from scratch and re-invent the wheel._
|
||||
|
||||
Haviv proposes two ways to resolve the situation:
|
||||
|
||||
* Closer collaboration among projects, leading to consolidation, the elimination of overlaps between multiple projects, and tighter integration within a stack;
|
||||
|
||||
* The development of APIs to make switching easier.
|
||||
|
||||
Both these approaches make sense. But unless something changes, we'll see only the first, and that's where the prospect for lock-in is found. The result would be where the industry found itself in the WinTel world of the past or throughout Apple's history, where competing product choice is sacrificed in exchange for tight integration.
|
||||
|
||||
The same thing can, and likely will, happen in the new open source world if open source projects continue to ignore the need for standards so that competition can exist within layers, and even between stacks. Where things stand today, there's almost no chance of that happening.
|
||||
|
||||
The reason is that while some projects pay lip service to develop software first and standards later, there is no real interest in following through with the standards. The main reason is that most business people and developers don't know much about standards. Unfortunately, that's all too understandable and likely to get worse. The reasons are several:
|
||||
|
||||
* Universities dedicate almost no training time to standards;
|
||||
|
||||
* Companies that used to have staffs of standards professionals have disbanded those departments and now deploy engineers with far less training to participate in standards organizations;
|
||||
|
||||
* There is little career value in establishing expertise in representing an employer in standards work;
|
||||
|
||||
* Engineers participating in standards activities may be required to further the strategic interests of their employer at the cost of what they believe to be the best technical solution;
|
||||
|
||||
* There is little to no communication between open source developers and standards professionals within many companies;
|
||||
|
||||
* Many software engineers view standards as being in direct conflict with the "four freedoms" underlying the FOSS definition.
|
||||
|
||||
Now let's look at what's going on in the world of open source:
|
||||
|
||||
* It would be difficult for any software engineer today to not know about open source;
|
||||
|
||||
* It's a tool engineers are comfortable with and often use on a daily basis;
|
||||
|
||||
* Much of the sexiest, most cutting-edge work is being done in open source projects;
|
||||
|
||||
* Developers with expertise in hot open source areas are much sought after and command substantial compensation premiums;
|
||||
|
||||
* Developers enjoy unprecedented autonomy in developing software within well-respected projects;
|
||||
|
||||
* Virtually all of the major ICT companies participate in multiple open source projects, often with a combined cost (dues plus dedicated employees) of over $1 million per year per company at the highest membership level.
|
||||
|
||||
When viewed in a vacuum, this comparison would seem to indicate that standards are headed for the ash heap of history in ICT. But the reality is more nuanced. It also ignores the reality that open source development can be a more delicate flower than many might assume. The reasons include the following:
|
||||
|
||||
* Major supporters of projects can decommit (and sometimes have done so), leading to the failure of a project;
|
||||
|
||||
* Personality and cultural conflicts within communities can lead to disruptions;
|
||||
|
||||
* The ability of key projects to more tightly integrate remains to be seen;
|
||||
|
||||
* Proprietary game playing has sometimes undercut, and in some cases caused the failure of, highly funded open source projects;
|
||||
|
||||
* Over time, individual companies may decide that their open source strategies have failed to bring the rewards they anticipated;
|
||||
|
||||
* A few well-publicized failures of key open source projects could lead vendors to back off from investing in new projects and persuade customers to be wary of committing to open source solutions.
|
||||
|
||||
Curiously enough, the collaborative entities that are addressing these issues most aggressively are standards organizations, in part because they feel (rightly) threatened by the rise of open source collaboration. Their responses include upgrading their intellectual property rights policies to allow all types of collaboration to occur under the same umbrella, including development of open source tools, inclusion of open source code in standards, and development of open source reference implementations of standards, among other types of work projects.
|
||||
|
||||
The result is that standards organizations are retooling themselves to provide an approach-neutral venue for the development of complete solutions. Those solutions can incorporate whatever type of collaborative work product, or hybrid work product, the marketplace may need. As this process continues, it is likely that vendors will begin to pursue some initiatives within standards organizations that might otherwise have made their way to open source foundations.
|
||||
|
||||
For all these reasons, it's crucial that open source projects get serious about including standards in their deliverables or otherwise partner with appropriate standards-developers to jointly provide complete solutions. The result will not only be greater product choice and less customer lock-in, but far greater confidence by customers in open source solutions, and therefore far greater demand for and use of open source products and services.
|
||||
|
||||
If that doesn't happen it will be a great shame, because the open source cause has the most to lose. It's up to the projects now to decide whether to give the market what it wants and needs or reconcile themselves to a future of decreasing influence, rather than continuing success.
|
||||
|
||||
_This was originally published on ConsortiumInfo.org's [Standards Blog][2] and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Andy Updegrove - Andy helps CEOs, management teams, and their investors build successful organizations. Regionally, he’s been a pioneer in providing business-minded legal counsel and strategic advice to high-tech companies since 1979. On the global stage, he’s represented, and usually helped launch, more than 135 worldwide standard setting, open source, promotional and advocacy consortia, including some of the largest and most influential standard setting organizations in the world.
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/7/software-standards
|
||||
|
||||
作者:[ Andy Updegrove][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andrewupdegrove
|
||||
[1]:https://opensource.com/article/17/7/software-standards?rate=kKK6oD-vGSEdDMj7OHpBMSqASMqbz3ii94q1Kj12lCI
|
||||
[2]:http://www.consortiuminfo.org/standardsblog/article.php?story=20170616133415179
|
||||
[3]:https://opensource.com/user/16796/feed
|
||||
[4]:https://www.apache.org/
|
||||
[5]:https://projects.apache.org/
|
||||
[6]:https://www.linuxfoundation.org/
|
||||
[7]:https://www.linuxfoundation.org/projects/directory
|
||||
[8]:https://www.enterprisetech.com/2017/06/14/well-enslaved-proprietary-clouds-unless-collaborate/
|
||||
[9]:https://opensource.com/users/andrewupdegrove
|
||||
[10]:https://opensource.com/users/andrewupdegrove
|
||||
[11]:https://opensource.com/article/17/7/software-standards#comments
|
||||
@ -0,0 +1,140 @@
|
||||
Running MongoDB as a Microservice with Docker and Kubernetes
|
||||
===================
|
||||
|
||||
### Introduction
|
||||
|
||||
Want to try out MongoDB on your laptop? Execute a single command and you have a lightweight, self-contained sandbox; another command removes all traces when you're done.
|
||||
|
||||
Need an identical copy of your application stack in multiple environments? Build your own container image and let your development, test, operations, and support teams launch an identical clone of your environment.
|
||||
|
||||
Containers are revolutionizing the entire software lifecycle: from the earliest technical experiments and proofs of concept through development, test, deployment, and support.
|
||||
|
||||
#### [Read the Enabling Microservices: Containers & Orchestration Explained white paper][6].
|
||||
|
||||
Orchestration tools manage how multiple containers are created, upgraded and made highly available. Orchestration also controls how containers are connected to build sophisticated applications from multiple, microservice containers.
|
||||
|
||||
The rich functionality, simple tools, and powerful APIs make container and orchestration functionality a favorite for DevOps teams who integrate them into Continuous Integration (CI) and Continuous Delivery (CD) workflows.
|
||||
|
||||
This post delves into the extra challenges you face when attempting to run and orchestrate MongoDB in containers and illustrates how these challenges can be overcome.
|
||||
|
||||
### Considerations for MongoDB
|
||||
|
||||
Running MongoDB with containers and orchestration introduces some additional considerations:
|
||||
|
||||
* MongoDB database nodes are stateful. In the event that a container fails, and is rescheduled, it's undesirable for the data to be lost (it could be recovered from other nodes in the replica set, but that takes time). To solve this, features such as the _Volume_ abstraction in Kubernetes can be used to map what would otherwise be an ephemeral MongoDB data directory in the container to a persistent location where the data survives container failure and rescheduling.
|
||||
|
||||
* MongoDB database nodes within a replica set must communicate with each other – including after rescheduling. All of the nodes within a replica set must know the addresses of all of their peers, but when a container is rescheduled, it is likely to be restarted with a different IP address. For example, all containers within a Kubernetes Pod share a single IP address, which changes when the pod is rescheduled. With Kubernetes, this can be handled by associating a Kubernetes Service with each MongoDB node, which uses the Kubernetes DNS service to provide a `hostname` for the service that remains constant through rescheduling.
|
||||
|
||||
* Once each of the individual MongoDB nodes is running (each within its own container), the replica set must be initialized and each node added. This is likely to require some additional logic beyond that offered by off the shelf orchestration tools. Specifically, one MongoDB node within the intended replica set must be used to execute the `rs.initiate` and `rs.add` commands.
|
||||
|
||||
* If the orchestration framework provides automated rescheduling of containers (as Kubernetes does) then this can increase MongoDB's resiliency since a failed replica set member can be automatically recreated, thus restoring full redundancy levels without human intervention.
|
||||
|
||||
* It should be noted that while the orchestration framework might monitor the state of the containers, it is unlikely to monitor the applications running within the containers, or backup their data. That means it's important to use a strong monitoring and backup solution such as [MongoDB Cloud Manager][1], included with [MongoDB Enterprise Advanced][2] and [MongoDB Professional][3]. Consider creating your own image that contains both your preferred version of MongoDB and the [MongoDB Automation Agent][4].
|
||||
|
||||
### Implementing a MongoDB Replica Set using Docker and Kubernetes
|
||||
|
||||
As described in the previous section, distributed databases such as MongoDB require a little extra attention when being deployed with orchestration frameworks such as Kubernetes. This section goes to the next level of detail, showing how this can actually be implemented.
|
||||
|
||||
We start by creating the entire MongoDB replica set in a single Kubernetes cluster (which would normally be within a single data center – that clearly doesn't provide geographic redundancy). In reality, little has to be changed to run across multiple clusters and those steps are described later.
|
||||
|
||||
Each member of the replica set will be run as its own pod with a service exposing an external IP address and port. This 'fixed' IP address is important as both external applications and other replica set members can rely on it remaining constant in the event that a pod is rescheduled.
|
||||
|
||||
The following diagram illustrates one of these pods and the associated Replication Controller and service.
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
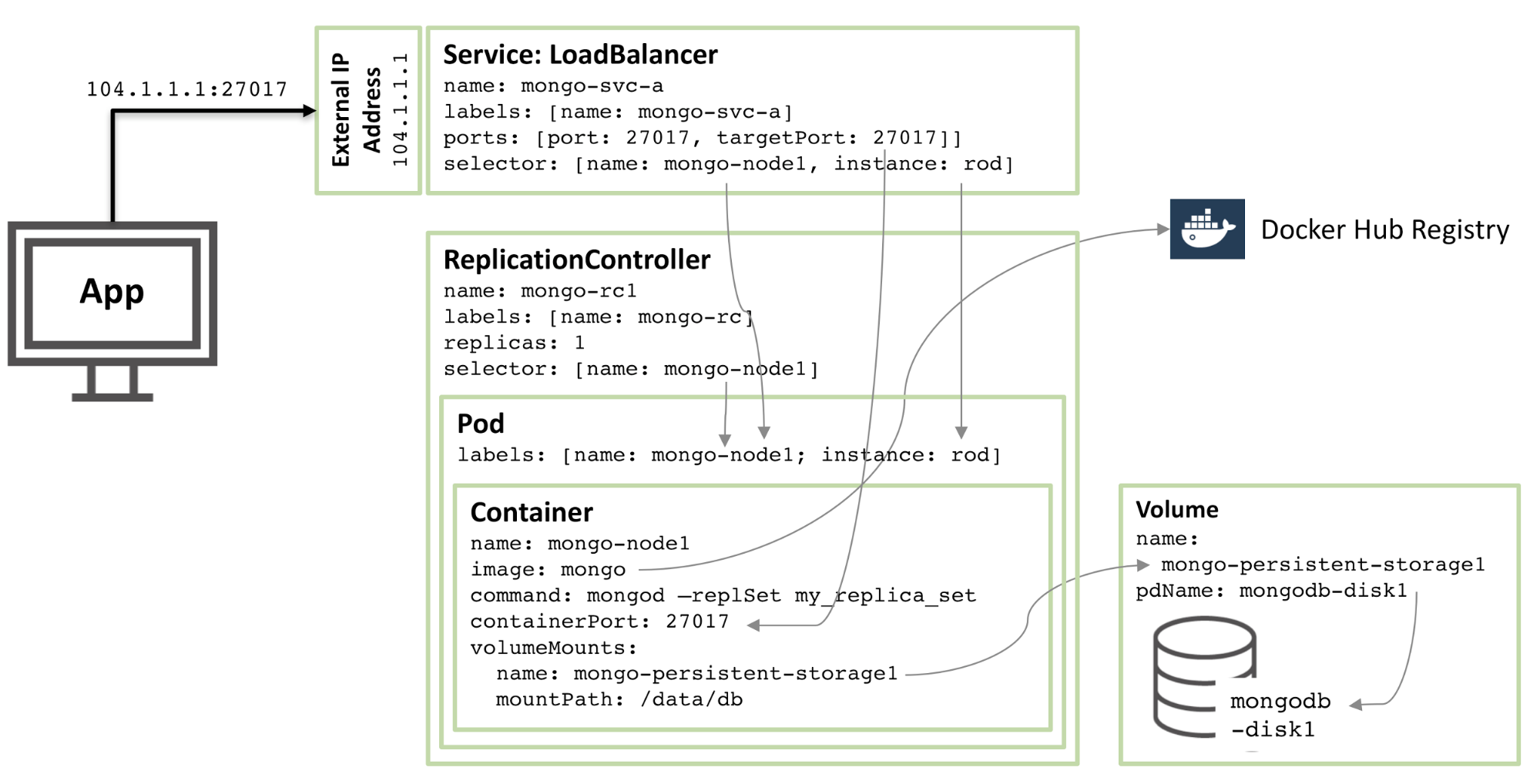
|
||||
</center>
|
||||
|
||||
Figure 1: MongoDB Replica Set member configured as a Kubernetes Pod and exposed as a service
|
||||
|
||||
Stepping through the resources described in that configuration we have:
|
||||
|
||||
* Starting at the core there is a single container named `mongo-node1`. `mongo-node1`includes an image called `mongo` which is a publicly available MongoDB container image hosted on [Docker Hub][5]. The container exposes port `27107` within the cluster.
|
||||
|
||||
* The Kubernetes _volumes_ feature is used to map the `/data/db` directory within the connector to the persistent storage element named `mongo-persistent-storage1`; which in turn is mapped to a disk named `mongodb-disk1` created in the Google Cloud. This is where MongoDB would store its data so that it is persisted over container rescheduling.
|
||||
|
||||
* The container is held within a pod which has the labels to name the pod `mongo-node`and provide an (arbitrary) instance name of `rod`.
|
||||
|
||||
* A Replication Controller named `mongo-rc1` is configured to ensure that a single instance of the `mongo-node1` pod is always running.
|
||||
|
||||
* The `LoadBalancer` service named `mongo-svc-a` exposes an IP address to the outside world together with the port of `27017` which is mapped to the same port number in the container. The service identifies the correct pod using a selector that matches the pod's labels. That external IP address and port will be used by both an application and for communication between the replica set members. There are also local IP addresses for each container, but those change when containers are moved or restarted, and so aren't of use for the replica set.
|
||||
|
||||
The next diagram shows the configuration for a second member of the replica set.
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
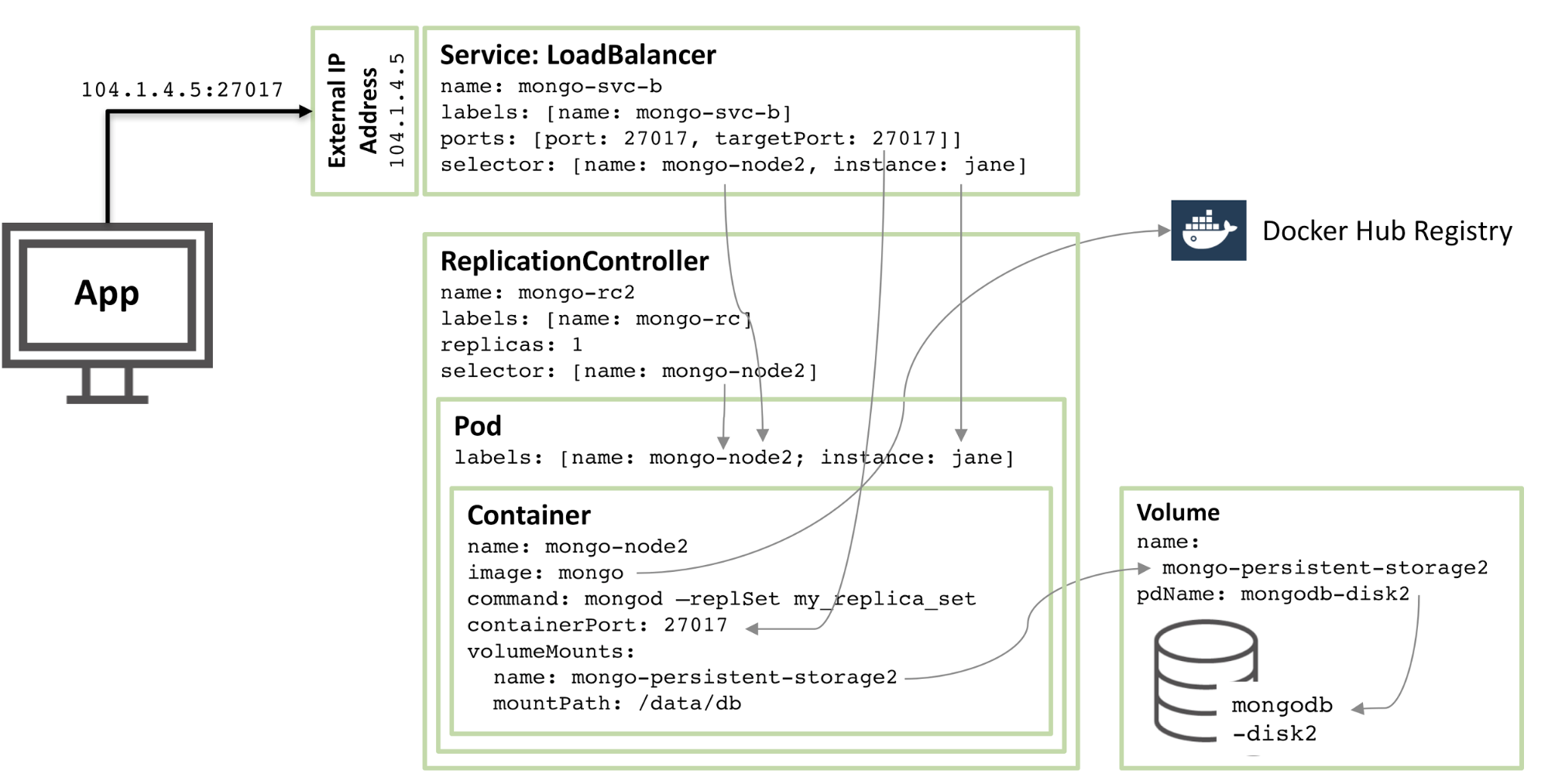
|
||||
</center>
|
||||
|
||||
Figure 2: Second MongoDB Replica Set member configured as a Kubernetes Pod
|
||||
|
||||
90% of the configuration is the same, with just these changes:
|
||||
|
||||
* The disk and volume names must be unique and so `mongodb-disk2` and `mongo-persistent-storage2` are used
|
||||
|
||||
* The Pod is assigned a label of `instance: jane` and `name: mongo-node2` so that the new service can distinguish it (using a selector) from the `rod` Pod used in Figure 1.
|
||||
|
||||
* The Replication Controller is named `mongo-rc2`
|
||||
|
||||
* The Service is named `mongo-svc-b` and gets a unique, external IP address (in this instance, Kubernetes has assigned `104.1.4.5`)
|
||||
|
||||
The configuration of the third replica set member follows the same pattern and the following figure shows the complete replica set:
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
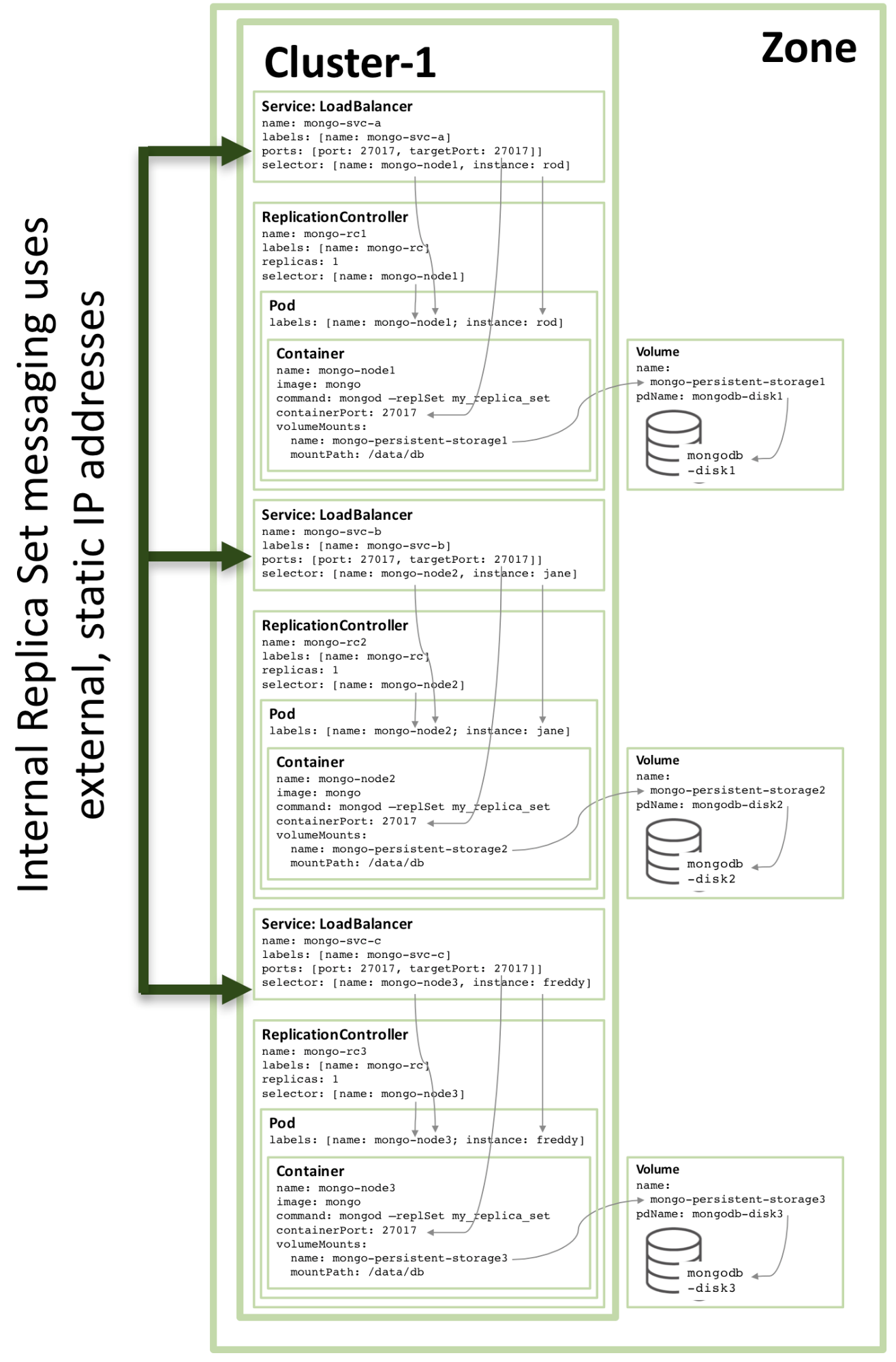
|
||||
</center>
|
||||
|
||||
Figure 3: Full Replica Set member configured as a Kubernetes Service
|
||||
|
||||
Note that even if running the configuration shown in Figure 3 on a Kubernetes cluster of three or more nodes, Kubernetes may (and often will) schedule two or more MongoDB replica set members on the same host. This is because Kubernetes views the three pods as belonging to three independent services.
|
||||
|
||||
To increase redundancy (within the zone), an additional _headless_ service can be created. The new service provides no capabilities to the outside world (and will not even have an IP address) but it serves to inform Kubernetes that the three MongoDB pods form a service and so Kubernetes will attempt to schedule them on different nodes.
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
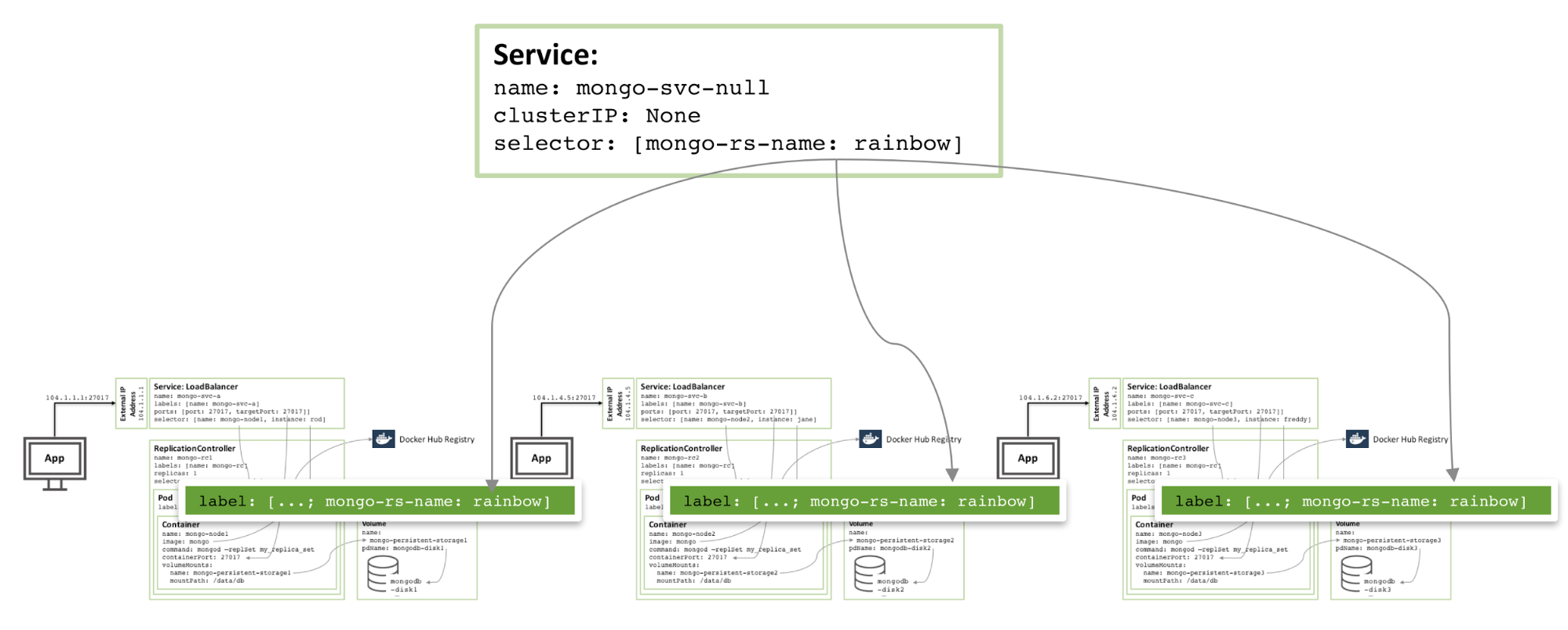
|
||||
</center>
|
||||
|
||||
Figure 4: Headless service to avoid co-locating of MongoDB replica set members
|
||||
|
||||
The actual configuration files and the commands needed to orchestrate and start the MongoDB replica set can be found in the [Enabling Microservices: Containers & Orchestration Explained white paper][7]. In particular, there are some special steps required to combine the three MongoDB instances into a functioning, robust replica set which are described in the paper.
|
||||
|
||||
#### Multiple Availability Zone MongoDB Replica Set
|
||||
|
||||
There is risk associated with the replica set created above in that everything is running in the same GCE cluster, and hence in the same availability zone. If there were a major incident that took the availability zone offline, then the MongoDB replica set would be unavailable. If geographic redundancy is required, then the three pods should be run in three different availability zones or regions.
|
||||
|
||||
Surprisingly little needs to change in order to create a similar replica set that is split between three zones – which requires three clusters. Each cluster requires its own Kubernetes YAML file that defines just the pod, Replication Controller and service for one member of the replica set. It is then a simple matter to create a cluster, persistent storage, and MongoDB node for each zone.
|
||||
|
||||
<center style="-webkit-font-smoothing: subpixel-antialiased; color: rgb(66, 66, 66); font-family: "Akzidenz Grotesk BQ Light", Helvetica; font-size: 16px; position: relative;">
|
||||
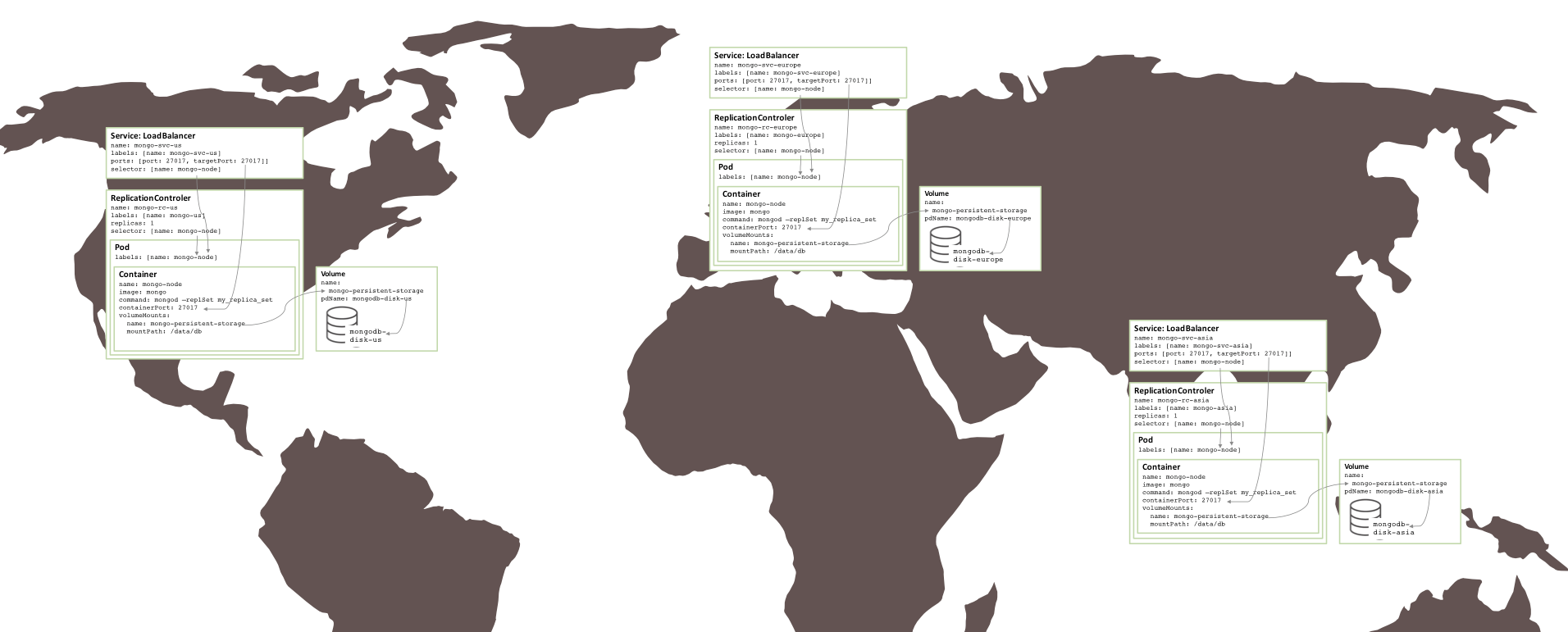
|
||||
</center>
|
||||
|
||||
Figure 5: Replica set running over multiple availability zones
|
||||
|
||||
### Next Steps
|
||||
|
||||
To learn more about containers and orchestration – both the technologies involved and the business benefits they deliver – read the [Enabling Microservices: Containers & Orchestration Explained white paper][8]. The same paper provides the complete instructions to get the replica set described in this post up and running on Docker and Kubernetes in the Google Container Engine.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Andrew is a Principal Product Marketing Manager working for MongoDB. He joined at the start last summer from Oracle where he spent 6+ years in product management, focused on High Availability. He can be contacted @andrewmorgan or through comments on his blog (clusterdb.com).
|
||||
|
||||
-------
|
||||
|
||||
via: https://www.mongodb.com/blog/post/running-mongodb-as-a-microservice-with-docker-and-kubernetes
|
||||
|
||||
作者:[Andrew Morgan ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.clusterdb.com/
|
||||
[1]:https://www.mongodb.com/cloud/
|
||||
[2]:https://www.mongodb.com/products/mongodb-enterprise-advanced
|
||||
[3]:https://www.mongodb.com/products/mongodb-professional
|
||||
[4]:https://docs.cloud.mongodb.com/tutorial/nav/install-automation-agent/
|
||||
[5]:https://hub.docker.com/_/mongo/
|
||||
[6]:https://www.mongodb.com/collateral/microservices-containers-and-orchestration-explained?jmp=inline
|
||||
[7]:https://www.mongodb.com/collateral/microservices-containers-and-orchestration-explained
|
||||
[8]:https://www.mongodb.com/collateral/microservices-containers-and-orchestration-explained
|
||||
@ -1,96 +0,0 @@
|
||||
XYenChi is Translating
|
||||
LEDE and OpenWrt
|
||||
===================
|
||||
|
||||
The [OpenWrt][1] project is perhaps the most widely known Linux-based distribution for home WiFi routers and access points; it was spawned from the source code of the now-famous Linksys WRT54G router more than 12 years ago. In early May, the OpenWrt user community was thrown into a fair amount of confusion when a group of core OpenWrt developers [announced][2] that they were starting a spin-off (or, perhaps, a fork) of OpenWrt to be named the [Linux Embedded Development Environment][3] (LEDE). It was not entirely clear to the public why the split was taking place—and the fact that the LEDE announcement surprised a few other OpenWrt developers suggested trouble within the team.
|
||||
|
||||
The LEDE announcement was sent on May 3 by Jo-Philipp Wich to both the OpenWrt development list and the new LEDE development list. It describes LEDE as "a reboot of the OpenWrt community" and as "a spin-off of the OpenWrt project" seeking to create an embedded-Linux development community "with a strong focus on transparency, collaboration and decentralisation."
|
||||
|
||||
The rationale given for the reboot was that OpenWrt suffered from longstanding issues that could not be fixed from within—namely, regarding internal processes and policies. For instance, the announcement said, the number of developers is at an all-time low, but there is no process for on-boarding new developers (and, it seems, no process for granting commit access to new developers). The project infrastructure is unreliable (evidently, server outages over the past year have caused considerable strife within the project), the announcement said, but internal disagreements and single points of failure prevented fixing it. There is also a general lack of "communication, transparency and coordination" internally and from the project to the outside world. Finally, a few technical shortcomings were cited: inadequate testing, lack of regular builds, and poor stability and documentation.
|
||||
|
||||
The announcement goes on to describe how the LEDE reboot will address these issues. All communication channels will be made available for public consumption, decisions will be made by project-wide votes, the merge policy will be more relaxed, and so forth. A more detailed explanation of the new project's policies can be found on the [rules][4] page at the LEDE site. Among other specifics, it says that there will be only one class of committer (that is, no "core developer" group with additional privileges), that simple majority votes will settle decisions, and that any infrastructure managed by the project must have at least three operators with administrative access. On the LEDE mailing list, Hauke Mehrtens [added][5] that the project will make an effort to have patches sent upstream—a point on which OpenWrt has been criticized in the past, especially where the kernel is concerned.
|
||||
|
||||
In addition to Wich, the announcement was co-signed by OpenWrt contributors John Crispin, Daniel Golle, Felix Fietkau, Mehrtens, Matthias Schiffer, and Steven Barth. It ends with an invitation for others interested in participating to visit the LEDE site.
|
||||
|
||||
#### Reactions and questions
|
||||
|
||||
One might presume that the LEDE organizers expected their announcement to be met with some mixture of positive and negative reactions. After all, a close reading of the criticisms of the OpenWrt project in the announcement suggests that there were some OpenWrt project members that the LEDE camp found difficult to work with (the "single points of failure" or "internal disagreements" that prevented infrastructure fixes, for instance).
|
||||
|
||||
And, indeed, there were negative responses. OpenWrt co-founder Mike Baker [responded][6] with some alarm, disagreeing with all of the LEDE announcement's conclusions and saying "phrases such as a 'reboot' are both vague and misleading and the LEDE project failed to identify its true nature." Around the same time, someone disabled the @openwrt.org email aliases of those developers who signed the LEDE announcement; when Fietkau [objected][7], Baker [replied][8] that the accounts were "temporarily disabled" because "it's unclear if LEDE still represents OpenWrt." Imre Kaloz, another core OpenWrt member, [wrote][9]that "the LEDE team created most of that [broken] status quo" in OpenWrt that it was now complaining about.
|
||||
|
||||
But the majority of the responses on the OpenWrt list expressed confusion about the announcement. List members were not clear whether the LEDE team was going to [continue contributing][10] to OpenWrt or not, nor what the [exact nature][11] of the infrastructure and internal problems were that led to the split. Baker's initial response lamented the lack of public debate over the issues cited in the announcement: "We recognize the current OpenWrt project suffers from a number of issues," but "we hoped we had an opportunity to discuss and attempt to fix" them. Baker concluded:
|
||||
|
||||
We would like to stress that we do want to have an open discussion and resolve matters at hand. Our goal is to work with all parties who can and want to contribute to OpenWrt, including the LEDE team.
|
||||
|
||||
In addition to the questions over the rationale of the new project, some list subscribers expressed confusion as to whether LEDE was targeting the same uses cases as OpenWrt, given the more generic-sounding name of the new project. Furthermore, a number of people, such as Roman Yeryomin, [expressed confusion][12] as to why the issues demanded the departure of the LEDE team, particularly given that, together, the LEDE group constituted a majority of the active core OpenWrt developers. Some list subscribers, like Michael Richardson, were even unclear on [who would still be developing][13] OpenWrt.
|
||||
|
||||
#### Clarifications
|
||||
|
||||
The LEDE team made a few attempts to further clarify their position. In Fietkau's reply to Baker, he said that discussions about proposed changes within the OpenWrt project tended to quickly turn "toxic," thus resulting in no progress. Furthermore:
|
||||
|
||||
A critical part of many of these debates was the fact that people who were controlling critical pieces of the infrastructure flat out refused to allow other people to step up and help, even in the face of being unable to deal with important issues themselves in a timely manner.
|
||||
|
||||
This kind of single-point-of-failure thing has been going on for years, with no significant progress on resolving it.
|
||||
|
||||
Neither Wich nor Fietkau pointed fingers at specific individuals, although others on the list seemed to think that the infrastructure and internal decision-making problems in OpenWrt came down to a few people. Daniel Dickinson [stated][14] that:
|
||||
|
||||
My impression is that Kaloz (at least) holds infrastructure hostage to maintain control, and that the fundamental problem here is that OpenWrt is *not* democratic and ignores what people who were ones visibly working on openwrt want and overrides their wishes because he/they has/have the keys.
|
||||
|
||||
On the other hand, Luka Perkov [countered][15] that many OpenWrt developers wanted to switch from Subversion to Git, but that Fietkau was responsible for blocking that change.
|
||||
|
||||
What does seem clear is that the OpenWrt project has been operating with a governance structure that was not functioning as desired and, as a result, personality conflicts were erupting and individuals were able to disrupt or block proposed changes simply by virtue of there being no well-defined process. Clearly, that is not a model that works well in the long run.
|
||||
|
||||
On May 6, Crispin [wrote][16] to the OpenWrt list in a new thread, attempting to reframe the LEDE project announcement. It was not, he said, meant as a "hostile or disruptive" act, but to make a clean break from the dysfunctional structures of OpenWrt and start fresh. The matter "does not boil down to one single event, one single person or one single flamewar," he said. "We wanted to split with the errors we have done ourselves in the past and the wrong management decision that were made at times." Crispin also admitted that the announcement had not been handled well, saying that the LEDE team "messed up the politics of the launch."
|
||||
|
||||
Crispin's email did not seem to satisfy Kaloz, who [insisted][17] that Crispin (as release manager) and Fietkau (as lead developer) could simply have made any desirable changes within the OpenWrt project. But the discussion thread has subsequently gone silent; whatever happens next on either the LEDE or OpenWrt side remains to be seen.
|
||||
|
||||
#### Intent
|
||||
|
||||
For those still seeking further detail on what the LEDE team regarded as problematic within OpenWrt, there is one more source of information that can shed light on the issues. Prior to the public announcement, the LEDE organizers spent several weeks hashing out their plan, and IRC logs of the meetings have now been [published][18]. Of particular interest is the March 30 [meeting][19] that includes a detailed discussion of the project's goals.
|
||||
|
||||
Several specific complaints about OpenWrt's infrastructure are included, such as the shortcomings of the project's Trac issue tracker. It is swamped with incomplete bug reports and "me too" comments, Wich said, and as a result, few committers make use of it. In addition, people seem confused by the fact that bugs are also being tracked on GitHub, making it unclear where issues ought to be discussed.
|
||||
|
||||
The IRC discussion also tackles the development process itself. The LEDE team would like to implement several changes, starting with the use of staging trees that get merged into the trunk during a formal merge window, rather than the commit-directly-to-master approach employed by OpenWrt. The project would also commit to time-based releases and encourage user testing by only releasing binary modules that have successfully been tested, by the community rather than the core developers, on actual hardware.
|
||||
|
||||
Finally, the IRC discussion does make it clear that the LEDE team's intent was not to take OpenWrt by surprise with its announcement. Crispin suggested that LEDE be "semi public" at first and gradually be made more public. Wich noted that he wanted LEDE to be "neutral, professional and welcoming to OpenWrt to keep the door open for a future reintegration." The launch does not seem to have gone well on that front, which is unfortunate.
|
||||
|
||||
In an email, Fietkau added that the core OpenWrt developers had been suffering from bottlenecks on tasks like patch review and maintenance work that were preventing them from getting other work done—such as setting up download mirrors or improving the build system. In just the first few days after the LEDE announcement, he said, the team had managed to tackle the mirror and build-system tasks, which had languished for years.
|
||||
|
||||
A lot of what we did in LEDE was based on the experience with decentralizing the development of packages by moving it to GitHub and giving up a lot of control over how packages should be maintained. This ended up reducing our workload significantly and we got quite a few more active developers this way.
|
||||
|
||||
We really wanted to do something similar with the core development, but based on our experience with trying to make bigger changes we felt that we couldn't do this from within the OpenWrt project.
|
||||
|
||||
Fixing the infrastructure will reap other dividends, too, he said, such as an improved system for managing the keys used to sign releases. The team is considering a rule that imposes some conditions on non-upstream patches, such as requiring a description of the patch and an explanation of why it has not yet been sent upstream. He also noted that many of the remaining OpenWrt developers have expressed interest in joining LEDE, and that the parties involved are trying to figure out if they will re-merge the projects.
|
||||
|
||||
One would hope that LEDE's flatter governance model and commitment to better transparency will help it to find success in areas where OpenWrt has struggled. For the time being, sorting out the communication issues that plagued the initial announcement may prove to be a major hurdle. If that process goes well, though, LEDE and OpenWrt may find common ground and work together in the future. If not, then the two teams may each be forced to move forward with fewer resources than they had before, which may not be what developers or users want to see.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/686767/
|
||||
|
||||
作者:[Nathan Willis ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://lwn.net/Articles/686767/
|
||||
[1]:https://openwrt.org/
|
||||
[2]:https://lwn.net/Articles/686180/
|
||||
[3]:https://www.lede-project.org/
|
||||
[4]:https://www.lede-project.org/rules.html
|
||||
[5]:http://lists.infradead.org/pipermail/lede-dev/2016-May/000080.html
|
||||
[6]:https://lwn.net/Articles/686988/
|
||||
[7]:https://lwn.net/Articles/686989/
|
||||
[8]:https://lwn.net/Articles/686990/
|
||||
[9]:https://lwn.net/Articles/686991/
|
||||
[10]:https://lwn.net/Articles/686995/
|
||||
[11]:https://lwn.net/Articles/686996/
|
||||
[12]:https://lwn.net/Articles/686992/
|
||||
[13]:https://lwn.net/Articles/686993/
|
||||
[14]:https://lwn.net/Articles/686998/
|
||||
[15]:https://lwn.net/Articles/687001/
|
||||
[16]:https://lwn.net/Articles/687003/
|
||||
[17]:https://lwn.net/Articles/687004/
|
||||
[18]:http://meetings.lede-project.org/lede-adm/2016/?C=M;O=A
|
||||
[19]:http://meetings.lede-project.org/lede-adm/2016/lede-adm.2016-03-30-11.05.log.html
|
||||
166
sources/tech/20160518 Cleaning Up Your Linux Startup Process.md
Normal file
166
sources/tech/20160518 Cleaning Up Your Linux Startup Process.md
Normal file
@ -0,0 +1,166 @@
|
||||
penghuster apply for it
|
||||
|
||||
Cleaning Up Your Linux Startup Process
|
||||
============================================================
|
||||
|
||||

|
||||
Learn how to clean up your Linux startup process.[Used with permission][1]
|
||||
|
||||
The average general-purpose Linux distribution launches all kinds of stuff at startup, including a lot of services that don't need to be running. Bluetooth, Avahi, ModemManager, ppp-dns… What are these things, and who needs them?
|
||||
|
||||
Systemd provides a lot of good tools for seeing what happens during your system startup, and controlling what starts at boot. In this article, I’ll show how to turn off startup cruft on Systemd distributions.
|
||||
|
||||
### View Boot Services
|
||||
|
||||
In the olden days, you could easily see which services were set to launch at boot by looking in /etc/init.d. Systemd does things differently. You can use the following incantation to list enabled boot services:
|
||||
|
||||
```
|
||||
systemctl list-unit-files --type=service | grep enabled
|
||||
accounts-daemon.service enabled
|
||||
anacron-resume.service enabled
|
||||
anacron.service enabled
|
||||
bluetooth.service enabled
|
||||
brltty.service enabled
|
||||
[...]
|
||||
```
|
||||
|
||||
And, there near the top is my personal nemesis: Bluetooth. I don't use it on my PC, and I don't need it running. The following commands stop it and then disable it from starting at boot:
|
||||
|
||||
```
|
||||
$ sudo systemctl stop bluetooth.service
|
||||
$ sudo systemctl disable bluetooth.service
|
||||
```
|
||||
|
||||
You can confirm by checking the status:
|
||||
|
||||
```
|
||||
$ systemctl status bluetooth.service
|
||||
bluetooth.service - Bluetooth service
|
||||
Loaded: loaded (/lib/systemd/system/bluetooth.service; disabled; vendor preset: enabled)
|
||||
Active: inactive (dead)
|
||||
Docs: man:bluetoothd(8)
|
||||
```
|
||||
|
||||
A disabled service can be started by another service. If you really want it dead, without uninstalling it, then you can mask it to prevent it from starting under any circumstances:
|
||||
|
||||
```
|
||||
$ sudo systemctl mask bluetooth.service
|
||||
Created symlink from /etc/systemd/system/bluetooth.service to /dev/null.
|
||||
```
|
||||
|
||||
Once you are satisfied that disabling a service has no bad side effects, you may elect to uninstall it.
|
||||
|
||||
You can generate a list of all services:
|
||||
|
||||
```
|
||||
$ systemctl list-unit-files --type=service
|
||||
UNIT FILE STATE
|
||||
accounts-daemon.service enabled
|
||||
acpid.service disabled
|
||||
alsa-restore.service static
|
||||
alsa-utils.service masked
|
||||
```
|
||||
|
||||
You cannot enable or disable static services, because these are dependencies of other systemd services and are not meant to run by themselves.
|
||||
|
||||
### Can I Get Rid of These Services?
|
||||
|
||||
How do you know what you need, and what you can safely disable? As always, that depends on your particular setup.
|
||||
|
||||
Here is a sampling of services and what they are for. Many services are distro-specific, so have your distribution documentation handy (i.e., Google and Stack Overflow).
|
||||
|
||||
* **accounts-daemon.service** is a potential security risk. It is part of AccountsService, which allows programs to get and manipulate user account information. I can't think of a good reason to allow this kind of behind-my-back operations, so I mask it.
|
||||
|
||||
* **avahi-daemon.service** is supposed to provide zero-configuration network discovery, and make it super-easy to find printers and other hosts on your network. I always disable it and don't miss it.
|
||||
|
||||
* **brltty.service** provides Braille device support, for example, Braille displays.
|
||||
|
||||
* **debug-shell.service** opens a giant security hole and should never be enabled except when you are using it. This provides a password-less root shell to help with debugging systemd problems.
|
||||
|
||||
* **ModemManager.service** is a DBus-activated daemon that controls mobile broadband (2G/3G/4G) interfaces. If you don't have a mobile broadband interface -- built-in, paired with a mobile phone via Bluetooth, or USB dongle -- you don't need this.
|
||||
|
||||
* **pppd-dns.service** is a relic of the dim past. If you use dial-up Internet, keep it. Otherwise, you don't need it.
|
||||
|
||||
* **rtkit-daemon.service** sounds scary, like rootkit, but you need it because it is the real-time kernel scheduler.
|
||||
|
||||
* **whoopsie.service** is the Ubuntu error reporting service. It collects crash reports and sends them to [https://daisy.ubuntu.com][2]. You may safely disable it, or you can remove it permanently by uninstalling apport.
|
||||
|
||||
* **wpa_supplicant.service** is necessary only if you use a Wi-Fi network interface.
|
||||
|
||||
### What Happens During Bootup
|
||||
|
||||
Systemd has some commands to help debug boot issues. This command replays all of your boot messages:
|
||||
|
||||
```
|
||||
$ journalctl -b
|
||||
|
||||
-- Logs begin at Mon 2016-05-09 06:18:11 PDT,
|
||||
end at Mon 2016-05-09 10:17:01 PDT. --
|
||||
May 16 06:18:11 studio systemd-journal[289]:
|
||||
Runtime journal (/run/log/journal/) is currently using 8.0M.
|
||||
Maximum allowed usage is set to 157.2M.
|
||||
Leaving at least 235.9M free (of currently available 1.5G of space).
|
||||
Enforced usage limit is thus 157.2M.
|
||||
[...]
|
||||
```
|
||||
|
||||
You can review previous boots with **journalctl -b -1**, which displays the previous startup;**journalctl -b -2** shows two boots ago, and so on.
|
||||
|
||||
This spits out a giant amount of output, which is interesting but maybe not all that useful. It has several filters to help you find what you want. Let's look at PID 1, which is the parent process for all other processes:
|
||||
|
||||
```
|
||||
$ journalctl _PID=1
|
||||
|
||||
May 08 06:18:17 studio systemd[1]: Starting LSB: Raise network interfaces....
|
||||
May 08 06:18:17 studio systemd[1]: Started LSB: Raise network interfaces..
|
||||
May 08 06:18:17 studio systemd[1]: Reached target System Initialization.
|
||||
May 08 06:18:17 studio systemd[1]: Started CUPS Scheduler.
|
||||
May 08 06:18:17 studio systemd[1]: Listening on D-Bus System Message Bus Socket
|
||||
May 08 06:18:17 studio systemd[1]: Listening on CUPS Scheduler.
|
||||
[...]
|
||||
```
|
||||
|
||||
This shows what was started -- or attempted to start.
|
||||
|
||||
One of the most useful tools is **systemd-analyze blame**, which shows which services are taking the longest to start up.
|
||||
|
||||
```
|
||||
$ systemd-analyze blame
|
||||
8.708s gpu-manager.service
|
||||
8.002s NetworkManager-wait-online.service
|
||||
5.791s mysql.service
|
||||
2.975s dev-sda3.device
|
||||
1.810s alsa-restore.service
|
||||
1.806s systemd-logind.service
|
||||
1.803s irqbalance.service
|
||||
1.800s lm-sensors.service
|
||||
1.800s grub-common.service
|
||||
```
|
||||
|
||||
This particular example doesn't show anything unusual, but if there is startup bottleneck, this command will find it.
|
||||
|
||||
You may also find these previous Systemd how-tos useful:
|
||||
|
||||
* [Understanding and Using Systemd][3]
|
||||
|
||||
* [Intro to Systemd Runlevels and Service Management Commands][4]
|
||||
|
||||
* [Here We Go Again, Another Linux Init: Intro to systemd][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/cleaning-your-linux-startup-process
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://daisy.ubuntu.com/
|
||||
[3]:https://www.linux.com/learn/understanding-and-using-systemd
|
||||
[4]:https://www.linux.com/learn/intro-systemd-runlevels-and-service-management-commands
|
||||
[5]:https://www.linux.com/learn/here-we-go-again-another-linux-init-intro-systemd
|
||||
[6]:https://www.linux.com/files/images/banner-cleanup-startuppng
|
||||
@ -0,0 +1,214 @@
|
||||
translating by firmianay
|
||||
|
||||
Here are all the Git commands I used last week, and what they do.
|
||||
============================================================
|
||||
|
||||
Image credit: [GitHub Octodex][6]
|
||||
|
||||
Like most newbies, I started out searching StackOverflow for Git commands, then copy-pasting answers, without really understanding what they did.
|
||||
|
||||
|
||||
|
||||
Image credit: [XKCD][7]
|
||||
|
||||
I remember thinking,“Wouldn’t it be nice if there were a list of the most common Git commands along with an explanation as to why they are useful?”
|
||||
|
||||
Well, here I am years later to compile such a list, and lay out some best practices that even intermediate-advanced developers should find useful.
|
||||
|
||||
To keep things practical, I’m basing this list off of the actual Git commands I used over the past week.
|
||||
|
||||
Almost every developer uses Git, and most likely GitHub. But the average developer probably only uses these three commands 99% of the time:
|
||||
|
||||
```
|
||||
git add --all
|
||||
git commit -am "<message>"
|
||||
git push origin master
|
||||
```
|
||||
|
||||
That’s all well and good when you’re working on a one-person team, a hackathon, or a throw-away app, but when stability and maintenance start to become a priority, cleaning up commits, sticking to a branching strategy, and writing coherent commit messages becomes important.
|
||||
|
||||
I’ll start with the list of commonly used commands to make it easier for newbies to understand what is possible with Git, then move into the more advanced functionality and best practices.
|
||||
|
||||
#### Regularly used commands
|
||||
|
||||
To initialize Git in a repository (repo), you just need to type the following command. If you don’t initialize Git, you cannot run any other Git commands within that repo.
|
||||
|
||||
```
|
||||
git init
|
||||
```
|
||||
|
||||
If you’re using GitHub and you’re pushing code to a GitHub repo that’s stored online, you’re using a remote repo. The default name (also known as an alias) for that remote repo is origin. If you’ve copied a project from Github, it already has an origin. You can view that origin with the command git remote -v, which will list the URL of the remote repo.
|
||||
|
||||
If you initialized your own Git repo and want to associate it with a GitHub repo, you’ll have to create one on GitHub, copy the URL provided, and use the command git remote add origin <URL>, with the URL provided by GitHub replacing “<URL>”. From there, you can add, commit, and push to your remote repo.
|
||||
|
||||
The last one is used when you need to change the remote repository. Let’s say you copied a repo from someone else and want to change the remote repository from the original owner’s to your own GitHub account. Follow the same process as git remote add origin, except use set-url instead to change the remote repo.
|
||||
|
||||
```
|
||||
git remote -v
|
||||
git remote add origin <url>
|
||||
git remote set-url origin <url>
|
||||
```
|
||||
|
||||
The most common way to copy a repo is to use git clone, followed by the URL of the repo.
|
||||
|
||||
Keep in mind that the remote repository will be linked to the account from which you cloned the repo. So if you cloned a repo that belongs to someone else, you will not be able to push to GitHub until you change the originusing the commands above.
|
||||
|
||||
```
|
||||
git clone <url>
|
||||
```
|
||||
|
||||
You’ll quickly find yourself using branches. If you don’t understand what branches are, there are other tutorials that are much more in-depth, and you should read those before proceeding ([here’s one][8]).
|
||||
|
||||
The command git branch lists all branches on your local machine. If you want to create a new branch, you can use git branch <name>, with <name> representing the name of the branch, such as “master”.
|
||||
|
||||
The git checkout <name> command switches to an existing branch. You can also use the git checkout -b <name> command to create a new branch and immediately switch to it. Most people use this instead of separate branch and checkout commands.
|
||||
|
||||
```
|
||||
git branch
|
||||
git branch <name>
|
||||
git checkout <name>
|
||||
git checkout -b <name>
|
||||
```
|
||||
|
||||
If you’ve made a bunch of changes to a branch, let’s call it “develop”, and you want to merge that branch back into your master branch, you use the git merge <branch> command. You’ll want to checkout the master branch, then run git merge develop to merge develop into the master branch.
|
||||
|
||||
```
|
||||
git merge <branch>
|
||||
```
|
||||
|
||||
If you’re working with multiple people, you’ll find yourself in a position where a repo was updated on GitHub, but you don’t have the changes locally. If that’s the case, you can use git pull origin <branch> to pull the most recent changes from that remote branch.
|
||||
|
||||
```
|
||||
git pull origin <branch>
|
||||
```
|
||||
|
||||
If you’re curious to see what files have been changed and what’s being tracked, you can use git status. If you want to see _how much_ each file has been changed, you can use git diff to see the number of lines changed in each file.
|
||||
|
||||
```
|
||||
git status
|
||||
git diff --stat
|
||||
```
|
||||
|
||||
### Advanced commands and best practices
|
||||
|
||||
Soon you reach a point where you want your commits to look nice and stay consistent. You might also have to fiddle around with your commit history to make your commits easier to comprehend or to revert an accidental breaking change.
|
||||
|
||||
The git log command lets you see the commit history. You’ll want to use this to see the history of your commits.
|
||||
|
||||
Your commits will come with messages and a hash, which is random series of numbers and letters. An example hash might look like this: c3d882aa1aa4e3d5f18b3890132670fbeac912f7
|
||||
|
||||
```
|
||||
git log
|
||||
```
|
||||
|
||||
Let’s say you pushed something that broke your app. Rather than fix it and push something new, you’d rather just go back one commit and try again.
|
||||
|
||||
If you want to go back in time and checkout your app from a previous commit, you can do this directly by using the hash as the branch name. This will detach your app from the current version (because you’re editing a historical record, rather than the current version).
|
||||
|
||||
```
|
||||
git checkout c3d88eaa1aa4e4d5f
|
||||
```
|
||||
|
||||
Then, if you make changes from that historical branch and you want to push again, you’d have to do a force push.
|
||||
|
||||
Caution: Force pushing is dangerous and should only be done if you absolutely must. It will overwrite the history of your app and you will lose whatever came after.
|
||||
|
||||
```
|
||||
git push -f origin master
|
||||
```
|
||||
|
||||
Other times it’s just not practical to keep everything in one commit. Perhaps you want to save your progress before trying something potentially risky, or perhaps you made a mistake and want to spare yourself the embarrassment of having an error in your version history. For that, we have git rebase.
|
||||
|
||||
Let’s say you have 4 commits in your local history (not pushed to GitHub) in which you’ve gone back and forth. Your commits look sloppy and indecisive. You can use rebase to combine all of those commits into a single, concise commit.
|
||||
|
||||
```
|
||||
git rebase -i HEAD~4
|
||||
```
|
||||
|
||||
The above command will open up your computer’s default editor (which is Vim unless you’ve set it to something else), with several options for how you can change your commits. It will look something like the code below:
|
||||
|
||||
```
|
||||
pick 130deo9 oldest commit message
|
||||
pick 4209fei second oldest commit message
|
||||
pick 4390gne third oldest commit message
|
||||
pick bmo0dne newest commit message
|
||||
```
|
||||
|
||||
In order to combine these, we need to change the “pick” option to “fixup” (as the documentation below the code says) to meld the commits and discard the commit messages. Note that in vim, you need to press “a” or “i” to be able to edit the text, and to save and exit, you need to type the escapekey followed by “shift + z + z”. Don’t ask me why, it just is.
|
||||
|
||||
```
|
||||
pick 130deo9 oldest commit message
|
||||
fixup 4209fei second oldest commit message
|
||||
fixup 4390gne third oldest commit message
|
||||
fixup bmo0dne newest commit message
|
||||
```
|
||||
|
||||
This will merge all of your commits into the commit with the message “oldest commit message”.
|
||||
|
||||
The next step is to rename your commit message. This is entirely a matter of opinion, but so long as you follow a consistent pattern, anything you do is fine. I recommend using the [commit guidelines put out by Google for Angular.js][9].
|
||||
|
||||
In order to change the commit message, use the amend flag.
|
||||
|
||||
```
|
||||
git commit --amend
|
||||
```
|
||||
|
||||
This will also open vim, and the text editing and saving rules are the same as above. To give an example of a good commit message, here’s one following the rules from the guideline:
|
||||
|
||||
```
|
||||
feat: add stripe checkout button to payments page
|
||||
```
|
||||
|
||||
```
|
||||
- add stripe checkout button
|
||||
- write tests for checkout
|
||||
```
|
||||
|
||||
One advantage to keeping with the types listed in the guideline is that it makes writing change logs easier. You can also include information in the footer (again, specified in the guideline) that references issues.
|
||||
|
||||
Note: you should avoid rebasing and squashing your commits if you are collaborating on a project, and have code pushed to GitHub. If you start changing version history under people’s noses, you could end up making everyone’s lives more difficult with bugs that are difficult to track.
|
||||
|
||||
There are an almost endless number of possible commands with Git, but these commands are probably the only ones you’ll need to know for your first few years of programming.
|
||||
|
||||
* * *
|
||||
|
||||
_Sam Corcos is the lead developer and co-founder of _ [_Sightline Maps_][10] _, the most intuitive platform for 3D printing topographical maps, as well as _ [_LearnPhoenix.io_][11] _, an intermediate-advanced tutorial site for building scalable production apps with Phoenix and React. Get $20 off of LearnPhoenix with the coupon code: _ _free_code_camp_
|
||||
|
||||
|
||||
* [Git][1]
|
||||
|
||||
* [Github][2]
|
||||
|
||||
* [Programming][3]
|
||||
|
||||
* [Software Development][4]
|
||||
|
||||
* [Web Development][5]
|
||||
|
||||
Show your support
|
||||
|
||||
Clapping shows how much you appreciated Sam Corcos’s story.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/git-cheat-sheet-and-best-practices-c6ce5321f52
|
||||
|
||||
作者:[Sam Corcos][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@SamCorcos?source=post_header_lockup
|
||||
[1]:https://medium.freecodecamp.org/tagged/git?source=post
|
||||
[2]:https://medium.freecodecamp.org/tagged/github?source=post
|
||||
[3]:https://medium.freecodecamp.org/tagged/programming?source=post
|
||||
[4]:https://medium.freecodecamp.org/tagged/software-development?source=post
|
||||
[5]:https://medium.freecodecamp.org/tagged/web-development?source=post
|
||||
[6]:https://octodex.github.com/
|
||||
[7]:https://xkcd.com/1597/
|
||||
[8]:https://guides.github.com/introduction/flow/
|
||||
[9]:https://github.com/angular/angular.js/blob/master/CONTRIBUTING.md#-git-commit-guidelines
|
||||
[10]:http://sightlinemaps.com/
|
||||
[11]:http://learnphoenix.io/
|
||||
@ -1,3 +1,4 @@
|
||||
yzca Translating
|
||||
Docker Engine swarm mode - Intro tutorial
|
||||
============================
|
||||
|
||||
|
||||
@ -1,177 +0,0 @@
|
||||
[Translating by Snapcrafter]
|
||||
Making your snaps available to the store using snapcraft
|
||||
============================================================
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
Now that Ubuntu Core has been officially released, it might be a good time to get your snaps into the Store!
|
||||
|
||||
**Delivery and Store Concepts **
|
||||
So let’s start with a refresher on what we have available on the Store side to manage your snaps.
|
||||
|
||||
Every time you push a snap to the store, the store will assign it a revision, this revision is unique in the store for this particular snap.
|
||||
|
||||
However to be able to push a snap for the first time, the name needs to be registered which is pretty easy to do given the name is not already taken.
|
||||
|
||||
Any revision on the store can be released to a number of channels which are defined conceptually to give your users the idea of a stability or risk level, these channel names are:
|
||||
|
||||
* stable
|
||||
|
||||
* candidate
|
||||
|
||||
* beta
|
||||
|
||||
* edge
|
||||
|
||||
Ideally anyone with a CI/CD process would push daily or on every source update to the edge channel. During this process there are two things to take into account.
|
||||
|
||||
The first thing to take into account is that at the beginning of the snapping process you will likely get started with a non confined snap as this is where the bulk of the work needs to happen to adapt to this new paradigm. With that in mind, your project gets started with a confinement set to devmode. This makes it possible to get going on the early phases of development and still get your snap into the store. Once everything is fully supported with the security model snaps work in, this confinement entry can be switched to strict. Given the confinement level of devmode this snap is only releasable on the edge and beta channels which hints your users on how much risk they are taking by going there.
|
||||
|
||||
So let’s say you are good to go on the confinement side and you start a CI/CD process against edge but you also want to make sure in some cases that early releases of a new iteration against master never make it to stable or candidate and for this we have a grade entry. If the grade of the snap is set to devel the store will never allow you to release to the most stable channels (stable and candidate). not be possible.
|
||||
|
||||
Somewhere along the way we might want to release a revision into beta which some users are more likely want to track on their side (which given good release management process should be to some level more usable than a random daily build). When that stage in the process is over but want people to keep getting updates we can choose to close the beta channel as we only plan to release to candidate and stable from a certain point in time, by closing this beta channel we will make that channel track the following open channel in the stability list, in this case it is candidate, if candidate is tracking stable whatever is in stable is what we will get.
|
||||
|
||||
**Enter Snapcraft**
|
||||
|
||||
So given all these concepts how do we get going with snapcraft, first of all we need to login:
|
||||
|
||||
```
|
||||
$ snapcraft login
|
||||
Enter your Ubuntu One SSO credentials.
|
||||
Email: sxxxxx.sxxxxxx@canonical.com
|
||||
Password: **************
|
||||
Second-factor auth: 123456
|
||||
```
|
||||
|
||||
After logging in we are ready to get our snap registered, for examples sake let’s say we wanted to register awesome-database, a fantasy snap we want to get started with:
|
||||
|
||||
```
|
||||
$ snapcraft register awesome-database
|
||||
We always want to ensure that users get the software they expect
|
||||
for a particular name.
|
||||
|
||||
If needed, we will rename snaps to ensure that a particular name
|
||||
reflects the software most widely expected by our community.
|
||||
|
||||
For example, most people would expect ‘thunderbird’ to be published by
|
||||
Mozilla. They would also expect to be able to get other snaps of
|
||||
Thunderbird as 'thunderbird-sergiusens'.
|
||||
|
||||
Would you say that MOST users will expect 'a' to come from
|
||||
you, and be the software you intend to publish there? [y/N]: y
|
||||
|
||||
You are now the publisher for 'awesome-database'
|
||||
```
|
||||
|
||||
So assuming we have the snap built already, all we have to do is push it to the store. Let’s take advantage of a shortcut and –release in the same command:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap --release edge
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 1 of 'awesome-database' created.
|
||||
|
||||
Channel Version Revision
|
||||
stable - -
|
||||
candidate - -
|
||||
beta - -
|
||||
edge 0.1 1
|
||||
|
||||
The edge channel is now open.
|
||||
```
|
||||
|
||||
If we try to release this to stable the store will block us:
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 1 stable
|
||||
Revision 1 (devmode) cannot target a stable channel (stable, grade: devel)
|
||||
```
|
||||
|
||||
We are safe from messing up and making this available to our faithful users. Now eventually we will push a revision worthy of releasing to the stable channel:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 10 of 'awesome-database' created.
|
||||
```
|
||||
|
||||
```
|
||||
Notice that the version is just a friendly identifier and what really matters is the revision number the store generates for us. Now let’s go ahead and release this to stable:
|
||||
```
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 10 stable
|
||||
Channel Version Revision
|
||||
stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge 0.1 10
|
||||
|
||||
The 'stable' channel is now open.
|
||||
```
|
||||
|
||||
In this last channel map view for the architecture we are working with, we can see that edge is going to be stuck on revision 10, and that beta and candidate will be following stable which is on revision 10\. For some reason we decide that we will focus on stability and make our CI/CD push to beta instead. This means that our edge channel will slightly fall out of date, in order to avoid things like this we can decide to close the channel:
|
||||
|
||||
```
|
||||
$ snapcraft close awesome-database edge
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
|
||||
The edge channel is now closed.
|
||||
```
|
||||
|
||||
In this current state, all channels are following the stable channel so people subscribed to candidate, beta and edge would be tracking changes to that channel. If revision 11 is ever pushed to stable only, people on the other channels would also see it.
|
||||
|
||||
This listing also provides us with a full architecture view, in this case we have only been working with amd64.
|
||||
|
||||
**Getting more information**
|
||||
|
||||
So some time passed and we want to know what was the history and status of our snap in the store. There are two commands for this, the straightforward one is to run status which will give us a familiar result:
|
||||
|
||||
```
|
||||
$ snapcraft status awesome-database
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
```
|
||||
|
||||
We can also get the full history:
|
||||
|
||||
```
|
||||
$ snapcraft history awesome-database
|
||||
Rev. Uploaded Arch Version Channels
|
||||
3 2016-09-30T12:46:21Z amd64 0.1 stable*
|
||||
...
|
||||
...
|
||||
...
|
||||
2 2016-09-30T12:38:20Z amd64 0.1 -
|
||||
1 2016-09-30T12:33:55Z amd64 0.1 -
|
||||
```
|
||||
|
||||
**Closing remarks**
|
||||
|
||||
I hope this gives an overview of the things you can do with the store and more people start taking advantage of it!
|
||||
|
||||
[Publish a snap][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2016/11/15/making-your-snaps-available-to-the-store-using-snapcraft/
|
||||
|
||||
作者:[Sergio Schvezov ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[1]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[2]:http://snapcraft.io/docs/build-snaps/publish
|
||||
@ -1,198 +0,0 @@
|
||||
What is Kubernetes?
|
||||
============================================================
|
||||
|
||||
This page is an overview of Kubernetes.
|
||||
|
||||
* [Kubernetes is][6]
|
||||
|
||||
* [Why containers?][7]
|
||||
* [Why do I need Kubernetes and what can it do?][1]
|
||||
|
||||
* [How is Kubernetes a platform?][2]
|
||||
|
||||
* [What Kubernetes is not][3]
|
||||
|
||||
* [What does _Kubernetes_ mean? K8s?][4]
|
||||
|
||||
* [What’s next][8]
|
||||
|
||||
Kubernetes is an [open-source platform for automating deployment, scaling, and operations of application containers][25] across clusters of hosts, providing container-centric infrastructure.
|
||||
|
||||
With Kubernetes, you are able to quickly and efficiently respond to customer demand:
|
||||
|
||||
* Deploy your applications quickly and predictably.
|
||||
|
||||
* Scale your applications on the fly.
|
||||
|
||||
* Roll out new features seamlessly.
|
||||
|
||||
* Limit hardware usage to required resources only.
|
||||
|
||||
Our goal is to foster an ecosystem of components and tools that relieve the burden of running applications in public and private clouds.
|
||||
|
||||
#### Kubernetes is
|
||||
|
||||
* **Portable**: public, private, hybrid, multi-cloud
|
||||
|
||||
* **Extensible**: modular, pluggable, hookable, composable
|
||||
|
||||
* **Self-healing**: auto-placement, auto-restart, auto-replication, auto-scaling
|
||||
|
||||
Google started the Kubernetes project in 2014\. Kubernetes builds upon a [decade and a half of experience that Google has with running production workloads at scale][26], combined with best-of-breed ideas and practices from the community.
|
||||
|
||||
### Why containers?
|
||||
|
||||
Looking for reasons why you should be using [containers][27]?
|
||||
|
||||

|
||||
|
||||
The _Old Way_ to deploy applications was to install the applications on a host using the operating system package manager. This had the disadvantage of entangling the applications’ executables, configuration, libraries, and lifecycles with each other and with the host OS. One could build immutable virtual-machine images in order to achieve predictable rollouts and rollbacks, but VMs are heavyweight and non-portable.
|
||||
|
||||
The _New Way_ is to deploy containers based on operating-system-level virtualization rather than hardware virtualization. These containers are isolated from each other and from the host: they have their own filesystems, they can’t see each others’ processes, and their computational resource usage can be bounded. They are easier to build than VMs, and because they are decoupled from the underlying infrastructure and from the host filesystem, they are portable across clouds and OS distributions.
|
||||
|
||||
Because containers are small and fast, one application can be packed in each container image. This one-to-one application-to-image relationship unlocks the full benefits of containers. With containers, immutable container images can be created at build/release time rather than deployment time, since each application doesn’t need to be composed with the rest of the application stack, nor married to the production infrastructure environment. Generating container images at build/release time enables a consistent environment to be carried from development into production. Similarly, containers are vastly more transparent than VMs, which facilitates monitoring and management. This is especially true when the containers’ process lifecycles are managed by the infrastructure rather than hidden by a process supervisor inside the container. Finally, with a single application per container, managing the containers becomes tantamount to managing deployment of the application.
|
||||
|
||||
Summary of container benefits:
|
||||
|
||||
* **Agile application creation and deployment**: Increased ease and efficiency of container image creation compared to VM image use.
|
||||
|
||||
* **Continuous development, integration, and deployment**: Provides for reliable and frequent container image build and deployment with quick and easy rollbacks (due to image immutability).
|
||||
|
||||
* **Dev and Ops separation of concerns**: Create application container images at build/release time rather than deployment time, thereby decoupling applications from infrastructure.
|
||||
|
||||
* **Environmental consistency across development, testing, and production**: Runs the same on a laptop as it does in the cloud.
|
||||
|
||||
* **Cloud and OS distribution portability**: Runs on Ubuntu, RHEL, CoreOS, on-prem, Google Container Engine, and anywhere else.
|
||||
|
||||
* **Application-centric management**: Raises the level of abstraction from running an OS on virtual hardware to run an application on an OS using logical resources.
|
||||
|
||||
* **Loosely coupled, distributed, elastic, liberated [micro-services][5]**: Applications are broken into smaller, independent pieces and can be deployed and managed dynamically – not a fat monolithic stack running on one big single-purpose machine.
|
||||
|
||||
* **Resource isolation**: Predictable application performance.
|
||||
|
||||
* **Resource utilization**: High efficiency and density.
|
||||
|
||||
#### Why do I need Kubernetes and what can it do?
|
||||
|
||||
At a minimum, Kubernetes can schedule and run application containers on clusters of physical or virtual machines. However, Kubernetes also allows developers to ‘cut the cord’ to physical and virtual machines, moving from a **host-centric** infrastructure to a **container-centric** infrastructure, which provides the full advantages and benefits inherent to containers. Kubernetes provides the infrastructure to build a truly **container-centric** development environment.
|
||||
|
||||
Kubernetes satisfies a number of common needs of applications running in production, such as:
|
||||
|
||||
* [Co-locating helper processes][9], facilitating composite applications and preserving the one-application-per-container model
|
||||
|
||||
* [Mounting storage systems][10]
|
||||
|
||||
* [Distributing secrets][11]
|
||||
|
||||
* [Checking application health][12]
|
||||
|
||||
* [Replicating application instances][13]
|
||||
|
||||
* [Using Horizontal Pod Autoscaling][14]
|
||||
|
||||
* [Naming and discovering][15]
|
||||
|
||||
* [Balancing loads][16]
|
||||
|
||||
* [Rolling updates][17]
|
||||
|
||||
* [Monitoring resources][18]
|
||||
|
||||
* [Accessing and ingesting logs][19]
|
||||
|
||||
* [Debugging applications][20]
|
||||
|
||||
* [Providing authentication and authorization][21]
|
||||
|
||||
This provides the simplicity of Platform as a Service (PaaS) with the flexibility of Infrastructure as a Service (IaaS), and facilitates portability across infrastructure providers.
|
||||
|
||||
#### How is Kubernetes a platform?
|
||||
|
||||
Even though Kubernetes provides a lot of functionality, there are always new scenarios that would benefit from new features. Application-specific workflows can be streamlined to accelerate developer velocity. Ad hoc orchestration that is acceptable initially often requires robust automation at scale. This is why Kubernetes was also designed to serve as a platform for building an ecosystem of components and tools to make it easier to deploy, scale, and manage applications.
|
||||
|
||||
[Labels][28] empower users to organize their resources however they please. [Annotations][29]enable users to decorate resources with custom information to facilitate their workflows and provide an easy way for management tools to checkpoint state.
|
||||
|
||||
Additionally, the [Kubernetes control plane][30] is built upon the same [APIs][31] that are available to developers and users. Users can write their own controllers, such as [schedulers][32], with [their own APIs][33] that can be targeted by a general-purpose [command-line tool][34].
|
||||
|
||||
This [design][35] has enabled a number of other systems to build atop Kubernetes.
|
||||
|
||||
#### What Kubernetes is not
|
||||
|
||||
Kubernetes is not a traditional, all-inclusive PaaS (Platform as a Service) system. It preserves user choice where it is important.
|
||||
|
||||
Kubernetes:
|
||||
|
||||
* Does not limit the types of applications supported. It does not dictate application frameworks (e.g., [Wildfly][22]), restrict the set of supported language runtimes (for example, Java, Python, Ruby), cater to only [12-factor applications][23], nor distinguish _apps_ from _services_ . Kubernetes aims to support an extremely diverse variety of workloads, including stateless, stateful, and data-processing workloads. If an application can run in a container, it should run great on Kubernetes.
|
||||
|
||||
* Does not provide middleware (e.g., message buses), data-processing frameworks (for example, Spark), databases (e.g., mysql), nor cluster storage systems (e.g., Ceph) as built-in services. Such applications run on Kubernetes.
|
||||
|
||||
* Does not have a click-to-deploy service marketplace.
|
||||
|
||||
* Does not deploy source code and does not build your application. Continuous Integration (CI) workflow is an area where different users and projects have their own requirements and preferences, so it supports layering CI workflows on Kubernetes but doesn’t dictate how layering should work.
|
||||
|
||||
* Allows users to choose their logging, monitoring, and alerting systems. (It provides some integrations as proof of concept.)
|
||||
|
||||
* Does not provide nor mandate a comprehensive application configuration language/system (for example, [jsonnet][24]).
|
||||
|
||||
* Does not provide nor adopt any comprehensive machine configuration, maintenance, management, or self-healing systems.
|
||||
|
||||
On the other hand, a number of PaaS systems run _on_ Kubernetes, such as [Openshift][36], [Deis][37], and [Eldarion][38]. You can also roll your own custom PaaS, integrate with a CI system of your choice, or use only Kubernetes by deploying your container images on Kubernetes.
|
||||
|
||||
Since Kubernetes operates at the application level rather than at the hardware level, it provides some generally applicable features common to PaaS offerings, such as deployment, scaling, load balancing, logging, and monitoring. However, Kubernetes is not monolithic, and these default solutions are optional and pluggable.
|
||||
|
||||
Additionally, Kubernetes is not a mere _orchestration system_ . In fact, it eliminates the need for orchestration. The technical definition of _orchestration_ is execution of a defined workflow: first do A, then B, then C. In contrast, Kubernetes is comprised of a set of independent, composable control processes that continuously drive the current state towards the provided desired state. It shouldn’t matter how you get from A to C. Centralized control is also not required; the approach is more akin to _choreography_ . This results in a system that is easier to use and more powerful, robust, resilient, and extensible.
|
||||
|
||||
#### What does _Kubernetes_ mean? K8s?
|
||||
|
||||
The name **Kubernetes** originates from Greek, meaning _helmsman_ or _pilot_ , and is the root of _governor_ and [cybernetic][39]. _K8s_ is an abbreviation derived by replacing the 8 letters “ubernete” with “8”.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
|
||||
|
||||
作者:[kubernetes.io][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kubernetes.io/
|
||||
[1]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-do-i-need-kubernetes-and-what-can-it-do
|
||||
[2]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#how-is-kubernetes-a-platform
|
||||
[3]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-kubernetes-is-not
|
||||
[4]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#what-does-kubernetes-mean-k8s
|
||||
[5]:https://martinfowler.com/articles/microservices.html
|
||||
[6]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#kubernetes-is
|
||||
[7]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#why-containers
|
||||
[8]:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/#whats-next
|
||||
[9]:https://kubernetes.io/docs/concepts/workloads/pods/pod/
|
||||
[10]:https://kubernetes.io/docs/concepts/storage/volumes/
|
||||
[11]:https://kubernetes.io/docs/concepts/configuration/secret/
|
||||
[12]:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
|
||||
[13]:https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
|
||||
[14]:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
||||
[15]:https://kubernetes.io/docs/concepts/services-networking/connect-applications-service/
|
||||
[16]:https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[17]:https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller/
|
||||
[18]:https://kubernetes.io/docs/tasks/debug-application-cluster/resource-usage-monitoring/
|
||||
[19]:https://kubernetes.io/docs/concepts/cluster-administration/logging/
|
||||
[20]:https://kubernetes.io/docs/tasks/debug-application-cluster/debug-application-introspection/
|
||||
[21]:https://kubernetes.io/docs/admin/authorization/
|
||||
[22]:http://wildfly.org/
|
||||
[23]:https://12factor.net/
|
||||
[24]:https://github.com/google/jsonnet
|
||||
[25]:http://www.slideshare.net/BrianGrant11/wso2con-us-2015-kubernetes-a-platform-for-automating-deployment-scaling-and-operations
|
||||
[26]:https://research.google.com/pubs/pub43438.html
|
||||
[27]:https://aucouranton.com/2014/06/13/linux-containers-parallels-lxc-openvz-docker-and-more/
|
||||
[28]:https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
|
||||
[29]:https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/
|
||||
[30]:https://kubernetes.io/docs/concepts/overview/components/
|
||||
[31]:https://kubernetes.io/docs/reference/api-overview/
|
||||
[32]:https://git.k8s.io/community/contributors/devel/scheduler.md
|
||||
[33]:https://git.k8s.io/community/contributors/design-proposals/extending-api.md
|
||||
[34]:https://kubernetes.io/docs/user-guide/kubectl-overview/
|
||||
[35]:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/principles.md
|
||||
[36]:https://www.openshift.org/
|
||||
[37]:http://deis.io/
|
||||
[38]:http://eldarion.cloud/
|
||||
[39]:http://www.etymonline.com/index.php?term=cybernetics
|
||||
@ -1,141 +0,0 @@
|
||||
### What is Kubernetes?
|
||||
|
||||
Kubernetes, or k8s ( _k, 8 characters, s...get it?_ ), or “kube” if you’re into brevity, is an open source platform that automates [Linux container][3] operations. It eliminates many of the manual processes involved in deploying and scaling containerized applications. In other words, you can cluster together groups of hosts running Linux containers, and Kubernetes helps you easily and efficiently manage those clusters. These clusters can span hosts across [public][4], [private][5], or hybrid clouds.
|
||||
|
||||
Kubernetes was originally developed and designed by engineers at Google. Google was one of the [early contributors to Linux container technology][6] and has talked publicly about how [everything at Google runs in containers][7]. (This is the technology behind Google’s cloud services.) Google generates more than 2 billion container deployments a week—all powered by an internal platform: [Borg][8]. Borg was the predecessor to Kubernetes and the lessons learned from developing Borg over the years became the primary influence behind much of the Kubernetes technology.
|
||||
|
||||
_Fun fact: The seven spokes in the Kubernetes logo refer to the project’s original name, “[Project Seven of Nine][1].”_
|
||||
|
||||
Red Hat was one of the first companies to work with Google on Kubernetes, even prior to launch, and has become the [2nd leading contributor][9] to Kubernetes upstream project. Google [donated][10] the Kubernetes project to the newly formed [Cloud Native Computing Foundation][11] in 2015.
|
||||
|
||||
* * *
|
||||
|
||||
### Why do you need Kubernetes?
|
||||
|
||||
Real production apps span multiple containers. Those containers must be deployed across multiple server hosts. Kubernetes gives you the orchestration and management capabilities required to deploy containers, at scale, for these workloads. Kubernetes orchestration allows you to build application services that span multiple containers, schedule those containers across a cluster, scale those containers, and manage the health of those containers over time.
|
||||
|
||||
Kubernetes also needs to integrate with networking, storage, security, telemetry and other services to provide a comprehensive container infrastructure.
|
||||
|
||||

|
||||
|
||||
Of course, this depends on how you’re using containers in your environment. A rudimentary application of Linux containers treats them as efficient, fast virtual machines. Once you scale this to a production environment and multiple applications, it's clear that you need multiple, colocated containers working together to deliver the individual services. This significantly multiplies the number of containers in your environment and as those containers accumulate, the complexity also grows.
|
||||
|
||||
Kubernetes fixes a lot of common problems with container proliferation—sorting containers together into a ”pod.” Pods add a layer of abstraction to grouped containers, which helps you schedule workloads and provide necessary services—like networking and storage—to those containers. Other parts of Kubernetes help you load balance across these pods and ensure you have the right number of containers running to support your workloads.
|
||||
|
||||
With the right implementation of Kubernetes—and with the help of other open source projects like [Atomic Registry][12], [Open vSwitch][13], [heapster][14], [OAuth][15], and [SELinux][16]— you can orchestrate all parts of your container infrastructure.
|
||||
|
||||
* * *
|
||||
|
||||
### What can you do with Kubernetes?
|
||||
|
||||
The primary advantage of using Kubernetes in your environment is that it gives you the platform to schedule and run containers on clusters of physical or virtual machines. More broadly, it helps you fully implement and rely on a container-based infrastructure in production environments. And because Kubernetes is all about automation of operational tasks, you can do many of the same things that other application platforms or management systems let you do, but for your containers.
|
||||
|
||||
With Kubernetes you can:
|
||||
|
||||
* Orchestrate containers across multiple hosts.
|
||||
|
||||
* Make better use of hardware to maximize resources needed to run your enterprise apps.
|
||||
|
||||
* Control and automate application deployments and updates.
|
||||
|
||||
* Mount and add storage to run stateful apps.
|
||||
|
||||
* Scale containerized applications and their resources on the fly.
|
||||
|
||||
* Declaratively manage services, which guarantees the deployed applications are always running how you deployed them.
|
||||
|
||||
* Health-check and self-heal your apps with autoplacement, autorestart, autoreplication, and autoscaling.
|
||||
|
||||
Kubernetes, however, relies on other projects to fully provide these orchestrated services. With the addition of other open source projects, you can fully realize the power of Kubernetes. These necessary pieces include (among others):
|
||||
|
||||
* Registry, through projects like Atomic Registry or Docker Registry.
|
||||
|
||||
* Networking, through projects like OpenvSwitch and intelligent edge routing.
|
||||
|
||||
* Telemetry, through projects such as heapster, kibana, hawkular, and elastic.
|
||||
|
||||
* Security, through projects like LDAP, SELinux, RBAC, and OAUTH with multi-tenancy layers.
|
||||
|
||||
* Automation, with the addition of Ansible playbooks for installation and cluster life-cycle management.
|
||||
|
||||
* Services, through a rich catalog of precreated content of popular app patterns.
|
||||
|
||||
[Get all of this, prebuilt and ready to deploy, with Red Hat OpenShift][17]
|
||||
|
||||
* * *
|
||||
|
||||
### Learn to speak Kubernetes
|
||||
|
||||
Like any technology, there are a lot of words specific to the technology that can be a barrier to entry. Let's break down some of the more common terms to help you understand Kubernetes.
|
||||
|
||||
**Master:** The machine that controls Kubernetes nodes. This is where all task assignments originate.
|
||||
|
||||
**Node:** These machines perform the requested, assigned tasks. The Kubernetes master controls them.
|
||||
|
||||
**Pod:** A group of one or more containers deployed to a single node. All containers in a pod share an IP address, IPC, hostname, and other resources. Pods abstract network and storage away from the underlying container. This lets you move containers around the cluster more easily.
|
||||
|
||||
**Replication controller: ** This controls how many identical copies of a pod should be running somewhere on the cluster.
|
||||
|
||||
**Service:** This decouples work definitions from the pods. Kubernetes service proxies automatically get service requests to the right pod—no matter where it moves to in the cluster or even if it’s been replaced.
|
||||
|
||||
**Kubelet:** This service runs on nodes and reads the container manifests and ensures the defined containers are started and running.
|
||||
|
||||
**kubectl:** This is the command line configuration tool for Kubernetes.
|
||||
|
||||
[Had enough? No? Check out the Kubernetes glossary.][18]
|
||||
|
||||
* * *
|
||||
|
||||
### Using Kubernetes in production
|
||||
|
||||
Kubernetes is open source. And, as such, there’s not a formalized support structure around that technology—at least not one you’d trust your business on. If you had an issue with your implementation of Kubernetes, while running in production, you’re not going to be very happy. And your customers probably won’t, either.
|
||||
|
||||
That’s where [Red Hat OpenShift][2] comes in. OpenShift is Kubernetes for the enterprise—and a lot more. OpenShift includes all of the extra pieces of technology that makes Kubernetes powerful and viable for the enterprise, including: registry, networking, telemetry, security, automation, and services. With OpenShift, your developers can make new containerized apps, host them, and deploy them in the cloud with the scalability, control, and orchestration that can turn a good idea into new business quickly and easily.
|
||||
|
||||
Best of all, OpenShift is supported and developed by the #1 leader in open source, Red Hat.
|
||||
|
||||
* * *
|
||||
|
||||
### A look at how Kubernetes fits into your infrastructure
|
||||
|
||||

|
||||
|
||||
Kubernetes runs on top of an operating system ([Red Hat Enterprise Linux Atomic Host][19], for example) and interacts with pods of containers running on the nodes. The Kubernetes master takes the commands from an administrator (or DevOps team) and relays those instructions to the subservient nodes. This handoff works with a multitude of services to automatically decide which node is best suited for the task. It then allocates resources and assigns the pods in that node to fulfill the requested work.
|
||||
|
||||
So, from an infrastructure point of view, there is little change to how you’ve been managing containers. Your control over those containers happens at a higher level, giving you better control without the need to micromanage each separate container or node. Some work is necessary, but it’s mostly a question of assigning a Kubernetes master, defining nodes, and defining pods.
|
||||
|
||||
### What about docker?
|
||||
|
||||
The [docker][20] technology still does what it's meant to do. When kubernetes schedules a pod to a node, the kubelet on that node will instruct docker to launch the specified containers. The kubelet then continuously collects the status of those containers from docker and aggregates that information in the master. Docker pulls containers onto that node and starts and stops those containers as normal. The difference is that an automated system asks docker to do those things instead of the admin doing so by hand on all nodes for all containers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.redhat.com/en/containers/what-is-kubernetes
|
||||
|
||||
作者:[www.redhat.com ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.redhat.com/
|
||||
[1]:https://cloudplatform.googleblog.com/2016/07/from-Google-to-the-world-the-Kubernetes-origin-story.html
|
||||
[2]:https://www.redhat.com/en/technologies/cloud-computing/openshift
|
||||
[3]:https://www.redhat.com/en/containers/whats-a-linux-container
|
||||
[4]:https://www.redhat.com/en/topics/cloud-computing/what-is-public-cloud
|
||||
[5]:https://www.redhat.com/en/topics/cloud-computing/what-is-private-cloud
|
||||
[6]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[7]:https://speakerdeck.com/jbeda/containers-at-scale
|
||||
[8]:http://blog.kubernetes.io/2015/04/borg-predecessor-to-kubernetes.html
|
||||
[9]:http://stackalytics.com/?project_type=kubernetes-group&metric=commits
|
||||
[10]:https://techcrunch.com/2015/07/21/as-kubernetes-hits-1-0-google-donates-technology-to-newly-formed-cloud-native-computing-foundation-with-ibm-intel-twitter-and-others/
|
||||
[11]:https://www.cncf.io/
|
||||
[12]:http://www.projectatomic.io/registry/
|
||||
[13]:http://openvswitch.org/
|
||||
[14]:https://github.com/kubernetes/heapster
|
||||
[15]:https://oauth.net/
|
||||
[16]:https://selinuxproject.org/page/Main_Page
|
||||
[17]:https://www.redhat.com/en/technologies/cloud-computing/openshift
|
||||
[18]:https://kubernetes.io/docs/reference/
|
||||
[19]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux/options
|
||||
[20]:https://www.redhat.com/en/containers/what-is-docker
|
||||
@ -1,205 +0,0 @@
|
||||
MonkeyDEcho translating
|
||||
|
||||
The End Of An Era: A Look Back At The Most Popular Solaris Milestones & News
|
||||
=================================
|
||||
|
||||

|
||||
With it looking certain now that [Oracle is ending Solaris feature development][42]with the cancelling of Solaris 12, here's a look back at the most popular Solaris news and milestones for the project over the years on Phoronix.
|
||||
|
||||
There were many great/fun Solaris memories.
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
During the Sun Microsystems days, I was genuinely interested in Solaris. There were frequent Solaris articles on Phoronix while Linux was always our main focus. Solaris was fun to play around with, OpenSolaris / SXCE was great, I ported the Phoronix Test Suite to Solaris, we had great relations with the Sun Microsystems folks, was at many Sun events, etc.
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
_Sun had some rather unique events back in the day..._
|
||||
|
||||
Unfortunately since Oracle acquired Sun, Solaris basically went downhill. The biggest blow was arguably when Oracle ended OpenSolaris and moved all their Solaris efforts back to a proprietary model...
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Lots of great memories for Solaris during the Sun days, so given Oracle wiping "Solaris 12" off their roadmap, I figured it would be fun to look back at the most-viewed Solaris stories on Phoronix while waiting to hear from Oracle about "Solaris 11.next" as their final step to likely winding down the operating system development.
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Though in a post-Solaris world it will be interesting to see what Oracle does with ZFS and if they double down on their RHEL-based Oracle Enterprise Linux. Time will tell.
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Anyhow, here's a look back at our most-viewed Solaris stories since 2004:
|
||||
|
||||
**[ATI R500/600 Driver For Solaris Coming?][6]**
|
||||
_While no ATI fglrx driver is available for Solaris/OpenSolaris or *BSD, now that AMD will be offering up specifications to X.Org developers and an open-source driver, it certainly is promising for any Solaris user depending upon ATI's Radeon X1000 "R500" or HD 2000 "R600" series. The open-source X.Org driver that will be released next week is far from mature, but it should be able to be ported to Solaris and other operating systems using X.Org with relative ease. What AMD announced today is targeted for the Linux community, but it can certainly help out Solaris/OpenSolaris users that use ATI hardware. Especially with "Project Indiana" coming out soon, it's only a matter of time before the open-source R500/600 driver is ported. Tell us what you think in our Solaris forum._
|
||||
|
||||
**[Solaris Express Community Build 71][7]**
|
||||
_Build 71 of Solaris Express Community Edition (SXCE) is now available. You can find out more about Solaris Express Community Build 71 at OpenSolaris.org. On a side note, with news at the Linux Kernel Summit that AMD will be providing GPU specifications, the resulting X.Org driver could lead to an improved state for Solaris/OpenSolaris on ATI hardware in the future._
|
||||
|
||||
**[Farewell To OpenSolaris. Oracle Just Killed It Off.][8]**
|
||||
_Oracle has finally announced their plans for Solaris operating system and OpenSolaris platform and it's not good. OpenSolaris is now effectively dead and there will not be anymore OpenSolaris releases -- including the long-delayed 2010 release. Solaris will still live-on and Oracle is busy working on Solaris 11 for a release next year and there will be a "Solaris 11 Express" as being a similar product to OpenSolaris, but it will only ship after Oracle's enterprise release._
|
||||
|
||||
**[Solaris Express Community Build 72][9]**
|
||||
_For those of you wanting to try out the latest and greatest in OpenSolaris software right now prior to the release of "Project Indiana", build 72 of Solaris Express Community Edition is now available. Solaris Express Community Edition (SXCE) Build 72 can be downloaded from OpenSolaris.org. Meanwhile, the preview release of Sun's Project Indiana is expected next month._
|
||||
|
||||
**[OpenSolaris Developer Summit][10]**
|
||||
_Announced earlier today on the OpenSolaris Forums was the first-ever OpenSolaris Developer Summit. This summit is taking place in October at the University of California, Santa Cruz. Sara Dornsife describes this summit as "not a conference with presentations or exhibitors, but an in-person, collaborative working session to plan the next release of Project Indiana." Ian Murdock will be keynoting at this Project Indiana fest, but beyond that the schedule is still being planned. Phoronix may be covering this event and you can discuss this summit in our Solaris forums._
|
||||
|
||||
**[Solaris Containers For Linux][11]**
|
||||
_Sun Microsystems has announced that they will soon be supporting Solaris Containers for Linux applications. This will make it possible to run Linux applications under Solaris without any modifications to the binary package. The Solaris Containers for Linux will allow for a smoother migration from Linux to Solaris, assist in cross-platform development,and other benefits. As far as when the support will arrive, it's "coming soon"._
|
||||
|
||||
**[Oracle Still To Make OpenSolaris Changes][12]**
|
||||
_Since Oracle finished its acquisition of Sun Microsystems, there have been many changes to the open-source projects that were once supported under Sun now being discontinued by Oracle and significant changes being made to the remaining open-source products. One of the open-source projects that Oracle hasn't been too open about their intentions with has been OpenSolaris. Solaris Express Community Edition (SXCE) already closed up last month and there hasn't been too much information flowing out about the next OpenSolaris release, which is supposed to be known as OpenSolaris 2010.03 with a release date sometime in March._
|
||||
|
||||
**[Xen For Solaris Updated][13]**
|
||||
_It's been a while, but Xen for Solaris has finally been updated. John Levon poimts out that this latest build is based upon Xen 3.0.4 and Solaris "Nevada" Build 66\. Some of the improvements in this latest build include PAE support, HVM support, new virt-manager tools, improved debugging support, and last but not least is managed domain support. The download for the July 2007 Solaris Xen update can be found over at Sun's website._
|
||||
|
||||
**[IBM To Distribute Sun's Solaris][14]**
|
||||
_Sun Microsystems and IBM are holding a teleconference right now where they have just announced IBM will begin distributing Sun's Solaris operating system on select servers. These IBM servers include the x86-based system X servers as well as Blade Center Servers. The official press release has just been issued and can be read at the Sun news room._
|
||||
|
||||
**[Oracle Solaris 11 Kernel Source-Code Leaked][15]**
|
||||
_It appears that the kernel source-code to Solaris 11 was leaked onto the Internet this past weekend._
|
||||
|
||||
**[Solaris 12 Might Finally Bring Radeon KMS Driver][16]**
|
||||
_It looks like Oracle may be preparing to release their own AMD Radeon kernel mode-setting (KMS) driver for introducing into Oracle Solaris 12._
|
||||
|
||||
**[OpenSXCE 2013.05 Revives The Solaris Community][17]**
|
||||
_OpenSXCE 2013.05 is out in the wild as the community revival of the Solaris Express Community Edition._
|
||||
|
||||
**[OpenSolaris Will Not Merge With Linux][18]**
|
||||
_At LinuxWorld 2007 in San Francisco, Andrew Morton said during his keynote that no key components of OpenSolaris will appear in the Linux kernel. In fact, Morton had even stated that "It’s a great shame that OpenSolaris still exists." Some of these key OpenSolaris components include Zones, ZFS, and DTrace. Though there is the possibility that Project Indiana could turn these into GPLv3 projects... More information is available at ZDNET._
|
||||
|
||||
**[Oracle Has Yet To Clarify Solaris 11 Kernel Source][19]**
|
||||
_It was one month ago that Phoronix was the first to note the Solaris 11 kernel source-code was leaked onto the Internet via Torrent sites. One month later, Oracle still hasn't officially commented on the situation._
|
||||
|
||||
**[Oracle Might Be Canning Solaris][20]**
|
||||
_Oracle might be pulling the plug on the Solaris operating system, at least according to some new rumors._
|
||||
|
||||
**[Solaris Express Community Build 70][21]**
|
||||
_Build 70 for Solaris Express Community Edition "Nevada" (SXCE snv_70) is now available. The announcement with download links can be found in the OpenSolaris Forums. Also announced was the 71st build of their Network Storage that includes source-code from Qlogic for the fibre channel HBA driver._
|
||||
|
||||
**[Solaris 10 7/07 HW Release][22]**
|
||||
_The documentation is now online for the Solaris 10 7/07 HW Release. As noted on the Solaris Releases page, Solaris 10 7/07 is only for SPARC Enterprise M4000-M9000 servers and no x86/x64 version is available. The latest Solaris update for all platforms is Solaris 10 11/06\. You can discuss Solaris 7/07 in the Phoronix Forums._
|
||||
|
||||
**[Solaris Telecom Servers From Intel][23]**
|
||||
_Intel has announced today the availability of Intel-powered Sun Solaris telecommunications rack and blade servers that meet NEBS, ETSI, and ATCA compliance. Of these new carrier grade platforms, the Intel Carrier Grade Rack Mount Server TIGW1U supports both Linux and Solaris 10 and the Intel NetStructure MPCBL0050 SBC will support both operating systems as well. Today's press release can be read here._
|
||||
|
||||
**[The Sad State Of GPU Drivers For BSD, Solaris][24]**
|
||||
_Yesterday a discussion arose on the mailing list about killing off all the old Mesa drivers. These old drivers aren't actively maintained, support vintage graphics processors, and aren't updated to support new Mesa functionality. They're now also getting in the way as Intel and other developers work to clean up the core of Mesa as they bolster this open-source graphics library for the future. There's also some implications for BSD and Solaris users by this move to clean-up Mesa._
|
||||
|
||||
**[Oracle Solaris 11.1 Brings 300+ Enhancements][25]**
|
||||
_Oracle released Solaris 11.1 from their Oracle OpenWorld conference yesterday in San Francisco._
|
||||
|
||||
[
|
||||

|
||||
][26]
|
||||
|
||||
And then of the most-viewed featured articles with Solaris:
|
||||
|
||||
**[Ubuntu vs. OpenSolaris vs. FreeBSD Benchmarks][27]**
|
||||
_Over the past few weeks we have been providing several in-depth articles looking at the performance of Ubuntu Linux. We had begun by providing Ubuntu 7.04 to 8.10 benchmarks and had found the performance of this popular Linux distribution to become slower with time and that article was followed up with Mac OS X 10.5 vs. Ubuntu 8.10 benchmarks and other articles looking at the state of Ubuntu's performance. In this article, we are now comparing the 64-bit performance of Ubuntu 8.10 against the latest test releases of OpenSolaris 2008.11 and FreeBSD 7.1._
|
||||
|
||||
**[NVIDIA Performance: Windows vs. Linux vs. Solaris][28]**
|
||||
_Earlier this week we previewed the Quadro FX1700, which is one of NVIDIA's mid-range workstation graphics cards that is based upon the G84GL core that in turn is derived from the consumer-class GeForce 8600 series. This PCI Express graphics card offers 512MB of video memory with two dual-link DVI connections and support for OpenGL 2.1 while maintaining a maximum power consumption of just 42 Watts. As we mentioned in the preview article, we would be looking at this graphics card's performance not only under Linux but also testing this workstation solution in both Microsoft Windows and Sun's Solaris. In this article today, we are doing just that as we test the NVIDIA Quadro FX1700 512MB with each of these operating systems and their respective binary display drivers._
|
||||
|
||||
**[FreeBSD 8.0 Benchmarked Against Linux, OpenSolaris][29]**
|
||||
_With the stable release of FreeBSD 8.0 arriving last week we finally were able to put it up on the test bench and give it a thorough look over with the Phoronix Test Suite. We compared the FreeBSD 8.0 performance between it and the earlier FreeBSD 7.2 release along with Fedora 12 and Ubuntu 9.10 on the Linux side and then the OpenSolaris 2010.02 b127 snapshot on the Sun OS side._
|
||||
|
||||
**[Fedora, Debian, FreeBSD, OpenBSD, OpenSolaris Benchmarks][30]**
|
||||
_Last week we published the first Debian GNU/kFreeBSD benchmarks that compared the 32-bit and 64-bit performance of this Debian port -- that straps the FreeBSD kernel underneath a Debian GNU user-land -- to Debian GNU/Linux. We have now extended that comparison to put many other operating systems in a direct performance comparison
|
||||
to these Debian GNU/Linux and Debian GNU/kFreeBSD snapshots of 6.0 Squeeze to Fedora 12, FreeBSD 7.2, FreeBSD 8.0, OpenBSD 4.6, and OpenSolaris 2009.06._
|
||||
|
||||
**[AMD Shanghai Opteron: Linux vs. OpenSolaris Benchmarks][31]**
|
||||
_In January we published a review of the AMD Shanghai Opteron CPUs on Linux when we looked at four of the Opteron 2384 models. The performance of these 45nm quad-core workstation/server processors were great when compared to the earlier AMD Barcelona processors on Ubuntu Linux, but how is their performance when running Sun's OpenSolaris operating system? Up for viewing today are dual AMD Shanghai benchmarks when running OpenSolaris 2008.11, Ubuntu 8.10, and a daily build of the forthcoming Ubuntu 9.04 release._
|
||||
|
||||
**[OpenSolaris vs. Linux Kernel Benchmarks][32]**
|
||||
_Earlier this week we delivered benchmarks of Ubuntu 9.04 versus Mac OS X 10.5.6 and found that the Leopard operating system had performed better than the Jaunty Jackalope in a majority of the tests, at least when it came to Ubuntu 32-bit. We are back with more operating system benchmarks today, but this time we are comparing the performance of the Linux and Sun OpenSolaris kernels. We had used the Nexenta Core Platform 2 operating system that combines the OpenSolaris kernel with a GNU/Ubuntu user-land to that of the same Ubuntu package set but with the Linux kernel. Testing was done with both 32-bit and 64-bit Ubuntu server installations._
|
||||
|
||||
**[Netbook Performance: Ubuntu vs. OpenSolaris][33]**
|
||||
_In the past we have published OpenSolaris vs. Linux Kernel benchmarks and similar articles looking at the performance of Sun's OpenSolaris up against popular Linux distributions. We have looked at the performance on high-end AMD workstations, but we have never compared the OpenSolaris and Linux performance on netbooks. Well, not until today. In this article we have results comparing OpenSolaris 2009.06 and Ubuntu 9.04 on the Dell Inspiron Mini 9 netbook._
|
||||
|
||||
**[NVIDIA Graphics: Linux vs. Solaris][34]**
|
||||
_At Phoronix we are constantly exploring the different display drivers under Linux, and while we have reviewed Sun's Check Tool and test motherboards with Solaris in addition to covering a few other areas, we have yet to perform a graphics driver comparison between Linux and Solaris. That is until today. With interest in Solaris on the rise thanks to Project Indiana, we have decided to finally offer our first quantitative graphics comparison between Linux and Solaris with the NVIDIA proprietary drivers._
|
||||
|
||||
**[OpenSolaris 2008.05 Gives A New Face To Solaris][35]**
|
||||
_In early February, Sun Microsystems had released a second preview release of Project Indiana. For those out of the loop, Project Indiana is the codename for the project led by Ian Murdock at Sun that aims to push OpenSolaris on more desktop and notebook computers by addressing the long-standing usability problems of Solaris. We were far from being impressed by Preview 2 as it hadn't possessed any serious advantages over a GNU/Linux desktop that would interest normal users. However, with the release of OpenSolaris 2008.05 "Project Indiana" coming up in May, Sun Microsystems has today released a final test copy of this operating system. Our initial experience with this new OpenSolaris release is vastly better than what we had encountered less than three months ago when last looking at Project Indiana._
|
||||
|
||||
**[A Quick Tour Of Oracle Solaris 11][36]**
|
||||
_Solaris 11 was released on Wednesday as the first major update to the former Sun operating system in seven years. A lot has changed in the Solaris stack in the past seven years, and OpenSolaris has come and gone in that time, but in this article is a brief look through the brand new Oracle Solaris 11 release._
|
||||
|
||||
**[New Benchmarks Of OpenSolaris, BSD & Linux][37]**
|
||||
_Earlier today we put out benchmarks of ZFS on Linux via a native kernel module that will be made publicly available to bring this Sun/Oracle file-system over to more Linux users. Now though as a bonus we happen to have new benchmarks of the latest OpenSolaris-based distributions, including OpenSolaris, OpenIndiana, and Augustiner-Schweinshaxe, compared to PC-BSD, Fedora, and Ubuntu._
|
||||
|
||||
**[FreeBSD/PC-BSD 9.1 Benchmarked Against Linux, Solaris, BSD][38]**
|
||||
_While FreeBSD 9.1 has yet to be officially released, the FreeBSD-based PC-BSD 9.1 "Isotope" release has already been made available this month. In this article are performance benchmarks comparing the 64-bit release of PC-BSD 9.1 against DragonFlyBSD 3.0.3, Oracle Solaris Express 11.1, CentOS 6.3, Ubuntu 12.10, and a development snapshot of Ubuntu 13.04._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Michael Larabel is the principal author of Phoronix.com and founded the site in 2004 with a focus on enriching the Linux hardware experience. Michael has written more than 10,000 articles covering the state of Linux hardware support, Linux performance, graphics drivers, and other topics. Michael is also the lead developer of the Phoronix Test Suite, Phoromatic, and OpenBenchmarking.org automated benchmarking software. He can be followed via Twitter or contacted via MichaelLarabel.com.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.phoronix.com/scan.php?page=news_item&px=Solaris-2017-Look-Back
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://www.phoronix.com/image-viewer.php?id=982&image=sun_sxce81_03_lrg
|
||||
[2]:http://www.phoronix.com/image-viewer.php?id=711&image=java7_bash_13_lrg
|
||||
[3]:http://www.phoronix.com/image-viewer.php?id=sun_sxce_farewell&image=sun_sxce_07_lrg
|
||||
[4]:http://www.phoronix.com/image-viewer.php?id=solaris_200805&image=opensolaris_indiana_03b_lrg
|
||||
[5]:http://www.phoronix.com/image-viewer.php?id=oracle_solaris_11&image=oracle_solaris11_02_lrg
|
||||
[6]:http://www.phoronix.com/scan.php?page=news_item&px=NjA0Mg
|
||||
[7]:http://www.phoronix.com/scan.php?page=news_item&px=NjAzNQ
|
||||
[8]:http://www.phoronix.com/scan.php?page=news_item&px=ODUwNQ
|
||||
[9]:http://www.phoronix.com/scan.php?page=news_item&px=NjA0Nw
|
||||
[10]:http://www.phoronix.com/scan.php?page=news_item&px=NjAwNA
|
||||
[11]:http://www.phoronix.com/scan.php?page=news_item&px=NjAxMQ
|
||||
[12]:http://www.phoronix.com/scan.php?page=news_item&px=ODAwNg
|
||||
[13]:http://www.phoronix.com/scan.php?page=news_item&px=NTkzMQ
|
||||
[14]:http://www.phoronix.com/scan.php?page=news_item&px=NTk4NA
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=MTAzMDE
|
||||
[16]:http://www.phoronix.com/scan.php?page=news_item&px=MTI5MTU
|
||||
[17]:http://www.phoronix.com/scan.php?page=news_item&px=MTM4Njc
|
||||
[18]:http://www.phoronix.com/scan.php?page=news_item&px=NTk2Ng
|
||||
[19]:http://www.phoronix.com/scan.php?page=news_item&px=MTAzOTc
|
||||
[20]:http://www.phoronix.com/scan.php?page=news_item&px=Oracle-Solaris-Demise-Rumors
|
||||
[21]:http://www.phoronix.com/scan.php?page=news_item&px=NTk4Nw
|
||||
[22]:http://www.phoronix.com/scan.php?page=news_item&px=NTkyMA
|
||||
[23]:http://www.phoronix.com/scan.php?page=news_item&px=NTg5Nw
|
||||
[24]:http://www.phoronix.com/scan.php?page=news_item&px=OTgzNA
|
||||
[25]:http://www.phoronix.com/scan.php?page=news_item&px=MTE5OTQ
|
||||
[26]:http://www.phoronix.com/image-viewer.php?id=opensolaris_200906&image=opensolaris_200906_06_lrg
|
||||
[27]:http://www.phoronix.com/vr.php?view=13149
|
||||
[28]:http://www.phoronix.com/vr.php?view=11968
|
||||
[29]:http://www.phoronix.com/vr.php?view=14407
|
||||
[30]:http://www.phoronix.com/vr.php?view=14533
|
||||
[31]:http://www.phoronix.com/vr.php?view=13475
|
||||
[32]:http://www.phoronix.com/vr.php?view=13826
|
||||
[33]:http://www.phoronix.com/vr.php?view=14039
|
||||
[34]:http://www.phoronix.com/vr.php?view=10301
|
||||
[35]:http://www.phoronix.com/vr.php?view=12269
|
||||
[36]:http://www.phoronix.com/vr.php?view=16681
|
||||
[37]:http://www.phoronix.com/vr.php?view=15476
|
||||
[38]:http://www.phoronix.com/vr.php?view=18291
|
||||
[39]:http://www.michaellarabel.com/
|
||||
[40]:https://www.phoronix.com/scan.php?page=news_topic&q=Oracle
|
||||
[41]:https://www.phoronix.com/forums/node/925794
|
||||
[42]:http://www.phoronix.com/scan.php?page=news_item&px=No-Solaris-12
|
||||
@ -1,134 +0,0 @@
|
||||
Useful Meld tips/tricks for intermediate users
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [1\. Navigation][1]
|
||||
2. [2\. Things you can do with changes][2]
|
||||
3. [4\. Filtering text][3]
|
||||
|
||||
* [Conclusion][4]
|
||||
|
||||
Meld is a feature-rich visual comparison and merging tool available for Linux. If you're new to the tool, you can head to our [beginner's guide][5] to get a quick know-how of how the utility works. However, if you've already read that, or are already using Meld for basic comparison/merging tasks, you'll be glad to know that in this tutorial, we will be discussing some really useful tips/tricks that will make your experience with the tool even better.
|
||||
|
||||
_But before we jump onto the installation and explanation part, it'd be worth sharing that all the instructions and examples presented in this tutorial have been tested on Ubuntu 14.04 and the Meld version we've used is 3.14.2_.
|
||||
|
||||
### Meld tips/tricks for intermediate users
|
||||
|
||||
### 1\. Navigation
|
||||
|
||||
As you might already know (and we've also mentioned this in our beginner's guide), standard scrolling is not the only way to navigate between changes while using Meld - you can easily switch from one change to another using the up and down arrow keys located in the pane that sits above the edit area:
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
However, this requires you to move your mouse pointer to these arrows and then click one of them (depending on where you want to go - up or down) repeatedly. You'll be glad to know that there exists an even easier way to jump between changes: just use your mouse's scroll wheel to perform scrolling when mouse pointer is on the central change bar.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
This way, you can navigate between changes without taking your eyes off them, or getting distracted.
|
||||
|
||||
### 2\. Things you can do with changes
|
||||
|
||||
Just look at the last screenshot in the previous section. You know what those black arrows do, right? By default, they let you perform the merge/change operation - merge when there's no confliction, and change when there's a conflict in the same line.
|
||||
|
||||
But do you know you can delete individual changes if you want. Yes, that's possible. For this, all you have to do is to press the Shift key when dealing with changes. You'll observe that arrows get converted into crosses.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Just click any of them, and the corresponding change will get deleted.
|
||||
|
||||
Not only delete, you can also make sure that conflicting changes do not change the lines when merged. For example, here's an example of a conflicting change:
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Now, if you click any the two black arrows, the line where the arrow points will get changed, and will become similar to the corresponding line of other file. That's fine as long as you want this to happen. But what if you don't want any of the lines to get changed? Instead, the aim is to insert the changed line above or below the corresponding line in other file.
|
||||
|
||||
What I am trying to say is that, for example, in the screenshot above, the need is to add 'test 2' above or below 'test23', rather than changing 'test23' to 'test2'. You'll be glad to know that even that's possible with Meld. Just like you press the Shift key to delete comments, in this case, you'll have to press the Ctrl key.
|
||||
|
||||
And you'll observe that the current action will be changed to insert - the dual arrow icons will confirm this.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
As clear from the direction of arrows, this action helps users to insert the current change above or below (as selected) the corresponding change in other file.
|
||||
|
||||
### 3\. Customize the way files are displayed in Meld's editor area
|
||||
|
||||
There might be times when you would want the text size in Meld's editor area to be a bit large (for better or more comfortable viewing), or you would want the text lines to wrap instead of going out of visual area (meaning you don't want to use the horizontal scroll bar at the bottom).
|
||||
|
||||
Meld provides some display- and font-related customization options in its _Preferences_ menu under the _Editor_ tab (_Edit->Preferences->Editor_) where you'll be able to make these kind of tweaks:
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
So here you can see that, by default, Meld uses the system defined font width. Just uncheck that box under the _Font_ category, and you'll have a plethora of font type and size options to select from.
|
||||
|
||||
Then in the _Display_ section, you'll see all the customization options we were talking about: you can set Tab width, tell the tool whether or not to insert spaces instead of tabs, enable/disable text wrapping, make Meld show line numbers and whitespaces (very useful in some cases) as well as use syntax highlighting.
|
||||
|
||||
### 4\. Filtering text
|
||||
|
||||
There are times when not all the changes that Meld shows are important to you. For example, while comparing two C programming files, you may not want changes in comments to be shown by Meld as you only want to focus on code-related changes. So, in that case, you can tell Meld to filter (or ignore) comment-related changes.
|
||||
|
||||
For example, here's a Meld comparison where comment-related changes are highlighted by the tool:
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
And here's the case where Meld has ignored the same changes, focusing only on the code-related changes:
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Cool, isn't it? So, how did that happen? Well, for this, what I did was, I enabled the 'C comments' text filter in _Edit->Preferences->Text Filters_ tab:
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
As you can see, aside from 'C comments', you can also filter out C++ comments, Script comments, leading or all whitespaces, and more. What more, you can also define custom text filters for any specific case you are dealing with. For example, if you are dealing with log-files and don't want changes in lines that begin with a particular pattern to be highlighted by Meld, then you can define a custom text filter for that case.
|
||||
|
||||
However, keep in mind that in order to define a new text filter, you need to know Python language as well as how to create regular expressions in that language.
|
||||
|
||||
### Conclusion
|
||||
|
||||
All the four tips/tricks discussed here aren't very difficult to understand and use (except, of course, if you want to create custom text filters right away), and once you start using them, you'll agree that they are really beneficial. The key here is to keep practicing, otherwise any tip/trick you learn will slip out of your mind in no time.
|
||||
|
||||
Do you know or use any other intermediate level Meld tip or trick? If yes, then you are welcome to share that in comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/
|
||||
|
||||
作者:[Ansh ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/
|
||||
[1]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-navigation
|
||||
[2]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-things-you-can-do-with-changes
|
||||
[3]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#-filtering-text
|
||||
[4]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/#conclusion
|
||||
[5]:https://www.howtoforge.com/tutorial/beginners-guide-to-visual-merge-tool-meld-on-linux/
|
||||
[6]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-go-next-prev-9.png
|
||||
[7]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-center-area-scrolling.png
|
||||
[8]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-delete-changes.png
|
||||
[9]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-conflicting-change.png
|
||||
[10]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-ctrl-insert.png
|
||||
[11]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-editor-tab.png
|
||||
[12]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-changes-with-comments.png
|
||||
[13]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-changes-without-comments.png
|
||||
[14]:https://www.howtoforge.com/images/beginners-guide-to-visual-merge-tool-meld-on-linux-part-2/big/meld-text-filters.png
|
||||
@ -0,0 +1,412 @@
|
||||
Understanding Firewalld in Multi-Zone Configurations
|
||||
============================================================
|
||||
|
||||
Stories of compromised servers and data theft fill today's news. It isn't difficult for someone who has read an informative blog post to access a system via a misconfigured service, take advantage of a recently exposed vulnerability or gain control using a stolen password. Any of the many internet services found on a typical Linux server could harbor a vulnerability that grants unauthorized access to the system.
|
||||
|
||||
Since it's an impossible task to harden a system at the application level against every possible threat, firewalls provide security by limiting access to a system. Firewalls filter incoming packets based on their IP of origin, their destination port and their protocol. This way, only a few IP/port/protocol combinations interact with the system, and the rest do not.
|
||||
|
||||
Linux firewalls are handled by netfilter, which is a kernel-level framework. For more than a decade, iptables has provided the userland abstraction layer for netfilter. iptables subjects packets to a gauntlet of rules, and if the IP/port/protocol combination of the rule matches the packet, the rule is applied causing the packet to be accepted, rejected or dropped.
|
||||
|
||||
Firewalld is a newer userland abstraction layer for netfilter. Unfortunately, its power and flexibility are underappreciated due to a lack of documentation describing multi-zoned configurations. This article provides examples to remedy this situation.
|
||||
|
||||
### Firewalld Design Goals
|
||||
|
||||
#
|
||||
|
||||
The designers of firewalld realized that most iptables usage cases involve only a few unique IP sources, for each of which a whitelist of services is allowed and the rest are denied. To take advantage of this pattern, firewalld categorizes incoming traffic into zones defined by the source IP and/or network interface. Each zone has its own configuration to accept or deny packets based on specified criteria.
|
||||
|
||||
Another improvement over iptables is a simplified syntax. Firewalld makes it easier to specify services by using the name of the service rather than its port(s) and protocol(s)—for example, samba rather than UDP ports 137 and 138 and TCP ports 139 and 445\. It further simplifies syntax by removing the dependence on the order of statements as was the case for iptables.
|
||||
|
||||
Finally, firewalld enables the interactive modification of netfilter, allowing a change in the firewall to occur independently of the permanent configuration stored in XML. Thus, the following is a temporary modification that will be overwritten by the next reload:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd <some modification>
|
||||
|
||||
```
|
||||
|
||||
And, the following is a permanent change that persists across reboots:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent <some modification>
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
### Zones
|
||||
|
||||
The top layer of organization in firewalld is zones. A packet is part of a zone if it matches that zone's associated network interface or IP/mask source. Several predefined zones are available:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --get-zones
|
||||
block dmz drop external home internal public trusted work
|
||||
|
||||
```
|
||||
|
||||
An active zone is any zone that is configured with an interface and/or a source. To list active zones:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --get-active-zones
|
||||
public
|
||||
interfaces: eno1 eno2
|
||||
|
||||
```
|
||||
|
||||
**Interfaces** are the system's names for hardware and virtual network adapters, as you can see in the above example. All active interfaces will be assigned to zones, either to the default zone or to a user-specified one. However, an interface cannot be assigned to more than one zone.
|
||||
|
||||
In its default configuration, firewalld pairs all interfaces with the public zone and doesn't set up sources for any zones. As a result, public is the only active zone.
|
||||
|
||||
**Sources** are incoming IP address ranges, which also can be assigned to zones. A source (or overlapping sources) cannot be assigned to multiple zones. Doing so results in undefined behavior, as it would not be clear which rules should be applied to that source.
|
||||
|
||||
Since specifying a source is not required, for every packet there will be a zone with a matching interface, but there won't necessarily be a zone with a matching source. This indicates some form of precedence with priority going to the more specific source zones, but more on that later. First, let's inspect how the public zone is configured:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services: dhcpv6-client ssh
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
default
|
||||
|
||||
```
|
||||
|
||||
Going line by line through the output:
|
||||
|
||||
* `public (default, active)` indicates that the public zone is the default zone (interfaces default to it when they come up), and it is active because it has at least one interface or source associated with it.
|
||||
|
||||
* `interfaces: eno1 eno2` lists the interfaces associated with the zone.
|
||||
|
||||
* `sources:` lists the sources for the zone. There aren't any now, but if there were, they would be of the form xxx.xxx.xxx.xxx/xx.
|
||||
|
||||
* `services: dhcpv6-client ssh` lists the services allowed through the firewall. You can get an exhaustive list of firewalld's defined services by executing `firewall-cmd --get-services`.
|
||||
|
||||
* `ports:` lists port destinations allowed through the firewall. This is useful if you need to allow a service that isn't defined in firewalld.
|
||||
|
||||
* `masquerade: no` indicates that IP masquerading is disabled for this zone. If enabled, this would allow IP forwarding, with your computer acting as a router.
|
||||
|
||||
* `forward-ports:` lists ports that are forwarded.
|
||||
|
||||
* `icmp-blocks:` a blacklist of blocked icmp traffic.
|
||||
|
||||
* `rich rules:` advanced configurations, processed first in a zone.
|
||||
|
||||
* `default` is the target of the zone, which determines the action taken on a packet that matches the zone yet isn't explicitly handled by one of the above settings.
|
||||
|
||||
### A Simple Single-Zoned Example
|
||||
|
||||
Say you just want to lock down your firewall. Simply remove the services currently allowed by the public zone and reload:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=public --remove-service=dhcpv6-client
|
||||
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
These commands result in the following firewall:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services:
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
default
|
||||
|
||||
```
|
||||
|
||||
In the spirit of keeping security as tight as possible, if a situation arises where you need to open a temporary hole in your firewall (perhaps for ssh), you can add the service to just the current session (omit `--permanent`) and instruct firewalld to revert the modification after a specified amount of time:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --add-service=ssh --timeout=5m
|
||||
|
||||
```
|
||||
|
||||
The timeout option takes time values in seconds (s), minutes (m) or hours (h).
|
||||
|
||||
### Targets
|
||||
|
||||
When a zone processes a packet due to its source or interface, but there is no rule that explicitly handles the packet, the target of the zone determines the behavior:
|
||||
|
||||
* `ACCEPT`: accept the packet.
|
||||
|
||||
* `%%REJECT%%`: reject the packet, returning a reject reply.
|
||||
|
||||
* `DROP`: drop the packet, returning no reply.
|
||||
|
||||
* `default`: don't do anything. The zone washes its hands of the problem, and kicks it "upstairs".
|
||||
|
||||
There was a bug present in firewalld 0.3.9 (fixed in 0.3.10) for source zones with targets other than `default` in which the target was applied regardless of allowed services. For example, a source zone with the target `DROP` would drop all packets, even if they were whitelisted. Unfortunately, this version of firewalld was packaged for RHEL7 and its derivatives, causing it to be a fairly common bug. The examples in this article avoid situations that would manifest this behavior.
|
||||
|
||||
### Precedence
|
||||
|
||||
Active zones fulfill two different roles. Zones with associated interface(s) act as interface zones, and zones with associated source(s) act as source zones (a zone could fulfill both roles). Firewalld handles a packet in the following order:
|
||||
|
||||
1. The corresponding source zone. Zero or one such zones may exist. If the source zone deals with the packet because the packet satisfies a rich rule, the service is whitelisted, or the target is not default, we end here. Otherwise, we pass the packet on.
|
||||
|
||||
2. The corresponding interface zone. Exactly one such zone will always exist. If the interface zone deals with the packet, we end here. Otherwise, we pass the packet on.
|
||||
|
||||
3. The firewalld default action. Accept icmp packets and reject everything else.
|
||||
|
||||
The take-away message is that source zones have precedence over interface zones. Therefore, the general design pattern for multi-zoned firewalld configurations is to create a privileged source zone to allow specific IP's elevated access to system services and a restrictive interface zone to limit the access of everyone else.
|
||||
|
||||
### A Simple Multi-Zoned Example
|
||||
|
||||
To demonstrate precedence, let's swap ssh for http in the public zone and set up the default internal zone for our favorite IP address, 1.1.1.1\. The following commands accomplish this task:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=internal --add-source=1.1.1.1
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
which results in the following configuration:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services: dhcpv6-client http
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
default
|
||||
# firewall-cmd --zone=internal --list-all
|
||||
internal (active)
|
||||
interfaces:
|
||||
sources: 1.1.1.1
|
||||
services: dhcpv6-client mdns samba-client ssh
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=internal --get-target
|
||||
default
|
||||
|
||||
```
|
||||
|
||||
With the above configuration, if someone attempts to `ssh` in from 1.1.1.1, the request would succeed because the source zone (internal) is applied first, and it allows ssh access.
|
||||
|
||||
If someone attempts to `ssh` from somewhere else, say 2.2.2.2, there wouldn't be a source zone, because no zones match that source. Therefore, the request would pass directly to the interface zone (public), which does not explicitly handle ssh. Since public's target is `default`, the request passes to the firewalld default action, which is to reject it.
|
||||
|
||||
What if 1.1.1.1 attempts http access? The source zone (internal) doesn't allow it, but the target is `default`, so the request passes to the interface zone (public), which grants access.
|
||||
|
||||
Now let's suppose someone from 3.3.3.3 is trolling your website. To restrict access for that IP, simply add it to the preconfigured drop zone, aptly named because it drops all connections:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=drop --add-source=3.3.3.3
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
The next time 3.3.3.3 attempts to access your website, firewalld will send the request first to the source zone (drop). Since the target is `DROP`, the request will be denied and won't make it to the interface zone (public) to be accepted.
|
||||
|
||||
### A Practical Multi-Zoned Example
|
||||
|
||||
Suppose you are setting up a firewall for a server at your organization. You want the entire world to have http and https access, your organization (1.1.0.0/16) and workgroup (1.1.1.0/8) to have ssh access, and your workgroup to have samba access. Using zones in firewalld, you can set up this configuration in an intuitive manner.
|
||||
|
||||
Given the naming, it seems logical to commandeer the public zone for your world-wide purposes and the internal zone for local use. Start by replacing the dhcpv6-client and ssh services in the public zone with http and https:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=public --remove-service=dhcpv6-client
|
||||
# firewall-cmd --permanent --zone=public --remove-service=ssh
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=public --add-service=https
|
||||
|
||||
```
|
||||
|
||||
Then trim mdns, samba-client and dhcpv6-client out of the internal zone (leaving only ssh) and add your organization as the source:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=internal --remove-service=mdns
|
||||
# firewall-cmd --permanent --zone=internal --remove-service=samba-client
|
||||
# firewall-cmd --permanent --zone=internal --remove-service=dhcpv6-client
|
||||
# firewall-cmd --permanent --zone=internal --add-source=1.1.0.0/16
|
||||
|
||||
```
|
||||
|
||||
To accommodate your elevated workgroup samba privileges, add a rich rule:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=internal --add-rich-rule='rule
|
||||
↪family=ipv4 source address="1.1.1.0/8" service name="samba"
|
||||
↪accept'
|
||||
|
||||
```
|
||||
|
||||
Finally, reload, pulling the changes into the active session:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
Only a few more details remain. Attempting to `ssh` in to your server from an IP outside the internal zone results in a reject message, which is the firewalld default. It is more secure to exhibit the behavior of an inactive IP and instead drop the connection. Change the public zone's target to `DROP`rather than `default` to accomplish this:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=public --set-target=DROP
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
But wait, you no longer can ping, even from the internal zone! And icmp (the protocol ping goes over) isn't on the list of services that firewalld can whitelist. That's because icmp is an IP layer 3 protocol and has no concept of a port, unlike services that are tied to ports. Before setting the public zone to `DROP`, pinging could pass through the firewall because both of your `default` targets passed it on to the firewalld default, which allowed it. Now it's dropped.
|
||||
|
||||
To restore pinging to the internal network, use a rich rule:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --permanent --zone=internal --add-rich-rule='rule
|
||||
↪protocol value="icmp" accept'
|
||||
# firewall-cmd --reload
|
||||
|
||||
```
|
||||
|
||||
In summary, here's the configuration for the two active zones:
|
||||
|
||||
```
|
||||
|
||||
# firewall-cmd --zone=public --list-all
|
||||
public (default, active)
|
||||
interfaces: eno1 eno2
|
||||
sources:
|
||||
services: http https
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
# firewall-cmd --permanent --zone=public --get-target
|
||||
DROP
|
||||
# firewall-cmd --zone=internal --list-all
|
||||
internal (active)
|
||||
interfaces:
|
||||
sources: 1.1.0.0/16
|
||||
services: ssh
|
||||
ports:
|
||||
masquerade: no
|
||||
forward-ports:
|
||||
icmp-blocks:
|
||||
rich rules:
|
||||
rule family=ipv4 source address="1.1.1.0/8"
|
||||
↪service name="samba" accept
|
||||
rule protocol value="icmp" accept
|
||||
# firewall-cmd --permanent --zone=internal --get-target
|
||||
default
|
||||
|
||||
```
|
||||
|
||||
This setup demonstrates a three-layer nested firewall. The outermost layer, public, is an interface zone and spans the entire world. The next layer, internal, is a source zone and spans your organization, which is a subset of public. Finally, a rich rule adds the innermost layer spanning your workgroup, which is a subset of internal.
|
||||
|
||||
The take-away message here is that when a scenario can be broken into nested layers, the broadest layer should use an interface zone, the next layer should use a source zone, and additional layers should use rich rules within the source zone.
|
||||
|
||||
### Debugging
|
||||
|
||||
Firewalld employs intuitive paradigms for designing a firewall, yet gives rise to ambiguity much more easily than its predecessor, iptables. Should unexpected behavior occur, or to understand better how firewalld works, it can be useful to obtain an iptables description of how netfilter has been configured to operate. Output for the previous example follows, with forward, output and logging lines trimmed for simplicity:
|
||||
|
||||
```
|
||||
|
||||
# iptables -S
|
||||
-P INPUT ACCEPT
|
||||
... (forward and output lines) ...
|
||||
-N INPUT_ZONES
|
||||
-N INPUT_ZONES_SOURCE
|
||||
-N INPUT_direct
|
||||
-N IN_internal
|
||||
-N IN_internal_allow
|
||||
-N IN_internal_deny
|
||||
-N IN_public
|
||||
-N IN_public_allow
|
||||
-N IN_public_deny
|
||||
-A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
|
||||
-A INPUT -i lo -j ACCEPT
|
||||
-A INPUT -j INPUT_ZONES_SOURCE
|
||||
-A INPUT -j INPUT_ZONES
|
||||
-A INPUT -p icmp -j ACCEPT
|
||||
-A INPUT -m conntrack --ctstate INVALID -j DROP
|
||||
-A INPUT -j REJECT --reject-with icmp-host-prohibited
|
||||
... (forward and output lines) ...
|
||||
-A INPUT_ZONES -i eno1 -j IN_public
|
||||
-A INPUT_ZONES -i eno2 -j IN_public
|
||||
-A INPUT_ZONES -j IN_public
|
||||
-A INPUT_ZONES_SOURCE -s 1.1.0.0/16 -g IN_internal
|
||||
-A IN_internal -j IN_internal_deny
|
||||
-A IN_internal -j IN_internal_allow
|
||||
-A IN_internal_allow -p tcp -m tcp --dport 22 -m conntrack
|
||||
↪--ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p udp -m udp --dport 137
|
||||
↪-m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p udp -m udp --dport 138
|
||||
↪-m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p tcp -m tcp --dport 139
|
||||
↪-m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -s 1.1.1.0/8 -p tcp -m tcp --dport 445
|
||||
↪-m conntrack --ctstate NEW -j ACCEPT
|
||||
-A IN_internal_allow -p icmp -m conntrack --ctstate NEW
|
||||
↪-j ACCEPT
|
||||
-A IN_public -j IN_public_deny
|
||||
-A IN_public -j IN_public_allow
|
||||
-A IN_public -j DROP
|
||||
-A IN_public_allow -p tcp -m tcp --dport 80 -m conntrack
|
||||
↪--ctstate NEW -j ACCEPT
|
||||
-A IN_public_allow -p tcp -m tcp --dport 443 -m conntrack
|
||||
↪--ctstate NEW -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
In the above iptables output, new chains (lines starting with `-N`) are first declared. The rest are rules appended (starting with `-A`) to iptables. Established connections and local traffic are accepted, and incoming packets go to the `INPUT_ZONES_SOURCE` chain, at which point IPs are sent to the corresponding zone, if one exists. After that, traffic goes to the `INPUT_ZONES` chain, at which point it is routed to an interface zone. If it isn't handled there, icmp is accepted, invalids are dropped, and everything else is rejected.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Firewalld is an under-documented firewall configuration tool with more potential than many people realize. With its innovative paradigm of zones, firewalld allows the system administrator to break up traffic into categories where each receives a unique treatment, simplifying the configuration process. Because of its intuitive design and syntax, it is practical for both simple single-zoned and complex multi-zoned configurations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/understanding-firewalld-multi-zone-configurations?page=0,0
|
||||
|
||||
作者:[ Nathan Vance][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxjournal.com/users/nathan-vance
|
||||
[1]:https://www.linuxjournal.com/tag/firewalls
|
||||
[2]:https://www.linuxjournal.com/tag/howtos
|
||||
[3]:https://www.linuxjournal.com/tag/networking
|
||||
[4]:https://www.linuxjournal.com/tag/security
|
||||
[5]:https://www.linuxjournal.com/tag/sysadmin
|
||||
[6]:https://www.linuxjournal.com/users/william-f-polik
|
||||
[7]:https://www.linuxjournal.com/users/nathan-vance
|
||||
@ -1,3 +1,5 @@
|
||||
翻译中 by zionfuo
|
||||
|
||||
How to take screenshots on Linux using Scrot
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,119 +0,0 @@
|
||||
ucasFL translating
|
||||
Know your Times Tables, but... do you know your "Hash Tables"?
|
||||
============================================================
|
||||
|
||||
Diving into the world of Hash Tables and understanding the underlying mechanics is _extremely_ interesting, and very rewarding. So lets get into it and get started from the beginning.
|
||||
|
||||
A Hash Table is a common data structure used in many modern day Software applications. It provides a dictionary-like functionality, giving you the ability to perform opertations such as inserting, removing and deleting items inside it. Let’s just say I want to find what the definition of what “Apple” is, and I know the defintion is stored in my defined Hash Table. I will query my Hash Table to give me a defintion. The _entry_ inside my Hash Table might look something like this `"Apple" => "A green fruit of fruity goodness"`. So, “Apple” is my _key_ and “A green fruit of fruity goodness” is my associated _value_ .
|
||||
|
||||
One more example just so we’re clear, take below the contents of a Hash Table:
|
||||
|
||||
|
||||
```
|
||||
1234
|
||||
```
|
||||
|
||||
```
|
||||
"bread" => "solid""water" => "liquid""soup" => "liquid""corn chips" => "solid"
|
||||
```
|
||||
|
||||
|
||||
I want to look up if _bread_ is a solid or liquid, So I will query the Hash Table to give me the associated value, and the table will return to me with “solid”. Ok so we got the generally gist of how it functions. Another important concept to note with Hash Tables is the fact that every key is unique. Let’s say tomorrow, I feel like having a bread milkshake (which is a _liquid_ ), we now need to update the Hash Table to reflect its change from solid to liquid! So we add the entry into the dictionary, the key : “bread” and the value : “liquid”. Can you spot what has changed in the table below?
|
||||
|
||||
|
||||
```
|
||||
1234
|
||||
```
|
||||
|
||||
```
|
||||
"bread" => "liquid""water" => "liquid""soup" => "liquid""corn chips" => "solid"
|
||||
```
|
||||
|
||||
|
||||
That’s right, bread has been updated to have the value “liquid”.
|
||||
|
||||
**Keys are unique**, my bread can’t be both a liquid and a solid. But what makes this data structure so special from the rest? Why not just use an [Array][1] instead? It depends on the nature of the problem. You may very well be better off using a Array for a particular problem, and that also brings me to the point, **choose the data structure that is most suited to your problem**. Example, If all you need to do is store a simple grocery list, an Array would do just fine. Consider the two problems below, each problem is very different in nature.
|
||||
|
||||
1. I need a grocery list of fruit
|
||||
|
||||
2. I need a grocery list of fruit and how much each it will cost me (per kilogram).
|
||||
|
||||
As you can see below, an Array might be a better choice for storing the fruit for the grocery list. But a Hash Table looks like a better choice for looking up the cost of each item.
|
||||
|
||||
|
||||
```
|
||||
123456789
|
||||
```
|
||||
|
||||
```
|
||||
//Example Array ["apple, "orange", "pear", "grape"] //Example Hash Table { "apple" : 3.05, "orange" : 5.5, "pear" : 8.4, "grape" : 12.4 }
|
||||
```
|
||||
|
||||
|
||||
There are literally so many oppurtunities to [use][2] Hash Tables.
|
||||
|
||||
### Time and what that means to you
|
||||
|
||||
[A brush up on time and space complexity][3].
|
||||
|
||||
On average it takes a Hash Table O(1) to search, insert and delete entries in the Hash Table. For the unaware, O(1) is spoken as “Big O 1” and represents constant time. Meaning that the running time to perform each operation is not dependent on the amount of data in the dataset. We can also _promise_ that for searching, inserting and deleting items will take constant time, “IF AND ONLY” IF the implementation of the Hash Table is done right. If it’s not, then it can be really slow _O(n)_ , especially if everything hashes to the same position/slot in the Hash Table.
|
||||
|
||||
### Building a good Hash Table
|
||||
|
||||
So far we now understand how to use a Hash Table, but what if we wanted to **build** one? Essentially what we need to do is map a string (eg. “dog”) to a **hash code** (a generated number), which maps to an index of an Array. You might ask, why not just go straight to using indexes? Why bother? Well this way it allows us to find out immediately where “dog” is located by quering directly for “dog”, `String name = Array["dog"] //name is "Lassy"`. But with using an index to look up the name, we could be in the likely situation that we do not know the index where the name is located. For example, `String name = Array[10] // name is now "Bob"` - that’s not my dog’s name! And that is the benefit of mapping the string to a hash code (which corresponds to an index of an Array). We can get the index of the Array by using the modulo operator with the size of the Hash Table, `index = hash_code % table_size`.
|
||||
|
||||
Another situation that we want to avoid is having two keys mapping to the same index, this is called a **hash collision** and they’re very likely to happen if the hash function is not properly implemented. But the truth is that every hash function _with more inputs than outputs_ there is some chance of collision. To demonstrate a simple collision take the following two function outputs below:
|
||||
|
||||
`int cat_idx = hashCode("cat") % table_size; //cat_idx is now equal to 1`
|
||||
|
||||
`int dog_idx = hashCode("dog") % table_size; //dog_idx is now also equal 1`
|
||||
|
||||
We can see that both Array indexes are now 1! And as such the values will overwrite each other because they are being written to the same index. Like if we tried to look up the value for “cat” it would then return “Lassy”. Not what we wanted after all. There are various methods of [resolving hash collisions][4], the more popular one is called **Chaining**. The idea with chaining is that there is a Linked List for each index of an Array. If a collision occurs, the value will be stored inside that Linked List. Thus in the previous example, we would get the value we requested, but it we would need to search a Linked List attached to the index 1 of the Array. Hashing with Chaining achieves O(1 + α) time where α is the load factor which can be represented as n/k, n being the number of entries in the Hash Table and k being the number of slots available in the Hash Table. But remember this only holds true if the keys that you give are particularly random (relying on [SUHA][5])).
|
||||
|
||||
This is a big assumption to make, as there is always a possibility that non-equal keys will hash to the same slot. One solution to this is to take the reliance of randomness away from what keys are given to the Hash Table, and put the randomness on how the keys will be hashed to increase the likeliness of _very few conflicts_ occuring. And this is known as…
|
||||
|
||||
### Universal Hashing
|
||||
|
||||
The concept is pretty simple, select _at random_ a hash function h from the set universal hash family to compute the hash code. So in other words, choose any random hash function to hash the key! And by following this method it provides a _very low_ probability that the hashes of two distinct keys will not be the same. I will keep this one short, but if you don’t trust me then trust [Mathematics][6] instead. Also another thing to watch out for is when implementing this method be careful of having a bad universal hash family. It can blow out the time and space complexity to O(U) where U is the size of the family. And where the challenge lies is finding a Hash family that does not take too much time to compute, and too much space to store.
|
||||
|
||||
### A Hash function of the Gods
|
||||
|
||||
The search for perfection is inevitable. What if we could construct a _Perfect hash function_ where we could just map things to a set of integers with absolutely _no collisions_ . Good news is we can do this, Well kind of.. but our data has to be static (which means no insertions/deletes/updates can assured constant time). One approach to achieve a perfect hash function is to use _2-Level Hashing_ , it is basically a combination of the last two ideas we previously discussed. It uses _Universal Hashing_ to select which hash function to use, and then combines it with _Chaining_ , but this time instead of using a Linked List data structure we use another Hash Table! Let’s see how this looks visually below:
|
||||
|
||||
[][8]
|
||||
|
||||
**But how does this work and how can we ensure no lookup collisions?**
|
||||
|
||||
Well it works in reverse to the [Birthday paradox][7]. It states that in a set of N randomly chosen people, some pair will have the same birthday. But if the number of days in a year far outwighs the number of people (squared) then there is a damn good possibility that no pair of people will share the same birthday. So how it relates is, for each chained Hash Table is the size of the first-level Hash Table _squared_ . That is if 2 elements happen to hash to the same slot, then the size of the chained Hash Table will be of size 4\. Most of the time the chained Tables will be very sparse/empty.
|
||||
|
||||
Repeat the following two steps to ensure no look up collisions,
|
||||
|
||||
* Select a hash from the universal hash family
|
||||
|
||||
* If we get a collision, then select another hash from the universal hash family.
|
||||
|
||||
Literally that is it, (Well.. for an O(N^2) space solution anyway). If space is a concern, then a different approach is obviously needed. But the great thing is that we will only ever have to do this process on average **twice**.
|
||||
|
||||
### Summing up
|
||||
|
||||
A Hash Table is only as good as it’s _Hash function_ . Deriving a _Perfect hash function_ is much harder to achieve without losing in particular areas such as functionality, time and space. I invite you to always consider Hash Tables when solving a problem as they offer great performance benefits and they can make a noticeable difference in the usability of your application. Hash Tables and Perfect hash functions are often used in Real-time programming applications. And have been widely implemented in algorithms around the world. Hash Tables are here to stay.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zeroequalsfalse.press/2017/02/20/hashtables/
|
||||
|
||||
作者:[Marty Jacobs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zeroequalsfalse.press/about
|
||||
[1]:https://en.wikipedia.org/wiki/Array_data_type
|
||||
[2]:https://en.wikipedia.org/wiki/Hash_table#Uses
|
||||
[3]:https://www.hackerearth.com/practice/basic-programming/complexity-analysis/time-and-space-complexity/tutorial/
|
||||
[4]:https://en.wikipedia.org/wiki/Hash_table#Collision_resolution
|
||||
[5]:https://en.wikipedia.org/wiki/SUHA_(computer_science
|
||||
[6]:https://en.wikipedia.org/wiki/Universal_hashing#Mathematical_guarantees
|
||||
[7]:https://en.wikipedia.org/wiki/Birthday_problem
|
||||
[8]:http://www.zeroequalsfalse.press/2017/02/20/hashtables/Diagram.png
|
||||
@ -1,76 +0,0 @@
|
||||
Developer-defined application delivery
|
||||
============================================================
|
||||
|
||||
How load balancers help you manage the complexity of distributed systems.
|
||||
|
||||
|
||||

|
||||
|
||||
Cloud-native applications are designed to draw upon the performance, scalability, and reliability benefits of distributed systems. Unfortunately, distributed systems often come at the cost of added complexity. As individual components of your application are distributed across networks, and those networks have communication gaps or experience degraded performance, your distributed application components need to continue to function independently.
|
||||
|
||||
To avoid inconsistencies in application state, distributed systems should be designed with an understanding that components will fail. Nowhere is this more prominent than in the network. Consequently, at their core, distributed systems rely heavily on load balancing—the distribution of requests across two or more systems—in order to be resilient in the face of network disruption and horizontally scale as system load fluctuates.
|
||||
|
||||
Get O'Reilly's weekly Systems Engineering and Operations newsletter[
|
||||

|
||||
][5]
|
||||
|
||||
As distributed systems become more and more prevalent in the design and delivery of cloud-native applications, load balancers saturate infrastructure design at every level of modern application architecture. In their most commonly thought-of configuration, load balancers are deployed in front of the application, handling requests from the outside world. However, the emergence of microservices means that load balancers play a critical role behind the scenes: i.e. managing the flow between _services_ .
|
||||
|
||||
Therefore, when you work with cloud-native applications and distributed systems, your load balancer takes on other role(s):
|
||||
|
||||
* As a reverse proxy to provide caching and increased security as it becomes the go-between for external clients.
|
||||
* As an API gateway by providing protocol translation (e.g. REST to AMQP).
|
||||
* It may handle security (i.e. running a web application firewall).
|
||||
* It may take on application management tasks such as rate limiting and HTTP/2 support.
|
||||
|
||||
Given their clearly expanded capabilities beyond that of balancing traffic, load balancers can be more broadly referred to as Application Delivery Controllers (ADCs).
|
||||
|
||||
### Developers defining infrastructure
|
||||
|
||||
Historically, ADCs were purchased, deployed, and managed by IT professionals most commonly to run enterprise-architected applications. For physical load balancer equipment (e.g. F5, Citrix, Brocade, etc.), this largely remains the case. Cloud-native applications with their distributed systems design and ephemeral infrastructure require load balancers to be as dynamic as the infrastructure (e.g. containers) upon which they run. These are often software load balancers (e.g. NGINX and load balancers from public cloud providers). Cloud-native applications are typically developer-led initiatives, which means that developers are creating the application (e.g. microservices) and the infrastructure (Kubernetes and NGINX). Developers are increasingly making or heavily influencing decisions for load balancing (and other) infrastructure.
|
||||
|
||||
As a decision maker, the developer of cloud-native applications generally isn't aware of, or influenced by, enterprise infrastructure requirements or existing deployments, both considering that these deployments are often new and often deployments within a public or private cloud environment. Because cloud technologies have abstracted infrastructure into programmable APIs, developers are defining the way that applications are built at each layer of that infrastructure. In the case of the load balancer, developers choose which type to use, how it gets deployed, and which functions to enable. They programmatically encode how the load balancer behaves—how it dynamically responds to the needs of the application as the application grows, shrinks and evolves in functionality over the lifetime of application deployments. Developers are defining infrastructure as code—both infrastructure configuration and its operation as code.
|
||||
|
||||
### Why developers are defining infrastructure
|
||||
|
||||
The practice of writing this code— _how applications are built and deployed_ —has undergone a fundamental shift, which can be characterized in many ways. Stated pithily, this fundamental shift has been driven by two factors: the time it takes to bring new application functionality to market ( _time to market_ ) and the time it takes for an application user to derive value from the offering ( _time to value_ ). As a result, new applications are written to be continuously delivered (as a service), not downloaded and installed.
|
||||
|
||||
Time-to-market and time-to-value pressures aren’t new, but they are joined by other factors that are increasing the decisioning-making power developers have:
|
||||
|
||||
* Cloud: the ability to define infrastructure as code via API.
|
||||
* Scale: the need to run operations efficiently in large environments.
|
||||
* Speed: the need to deliver application functionality now; for businesses to be competitive.
|
||||
* Microservices: abstraction of framework and tool choice, further empowering developers to make infrastructure decisions.
|
||||
|
||||
In addition to the above factors, it’s worth noting the impact of open source. With the prevalence and power of open source software, developers have a plethora of application infrastructure—languages, runtimes, frameworks, databases, load balancers, managed services, etc.—at their fingertips. The rise of microservices has democratized the selection of application infrastructure, allowing developers to choose best-for-purpose tooling. In the case of choice of load balancer, those that tightly integrate with and respond to the dynamic nature of cloud-native applications rise to the top of the heap.
|
||||
|
||||
### Conclusion
|
||||
|
||||
As you are mulling over your cloud-native application design, join me for a discussion on _[Load Balancing in the Cloud with NGINX and Kubernetes][8]_ . We'll examine the load balancing capabilities of different public clouds and container platforms and walk through a case study involving a bloat-a-lith—an overstuffed monolithic application. We'll look at how it was broken into smaller, independent services and how capabilities of NGINX and Kubernetes came to its rescue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Lee Calcote is an innovative thought leader, passionate about developer platforms and management software for clouds, containers, infrastructure and applications. Advanced and emerging technologies have been a consistent focus through Calcote’s tenure at SolarWinds, Seagate, Cisco and Pelco. An organizer of technology meetups and conferences, a writer, author, speaker, he is active in the tech community.
|
||||
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://www.oreilly.com/learning/developer-defined-application-delivery
|
||||
|
||||
作者:[Lee Calcote][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/7f693-lee-calcote
|
||||
[1]:https://pixabay.com/en/ship-containers-products-shipping-84139/
|
||||
[2]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[3]:https://www.oreilly.com/people/7f693-lee-calcote
|
||||
[4]:http://www.oreilly.com/pub/e/3864?intcmp=il-webops-webcast-reg-webcast_new_site_developer_defined_application_delivery_text_cta
|
||||
[5]:https://www.oreilly.com/learning/developer-defined-application-delivery?imm_mid=0ee8c5&cmp=em-webops-na-na-newsltr_20170310
|
||||
[6]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[7]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[8]:http://www.oreilly.com/pub/e/3864?intcmp=il-webops-webcast-reg-webcast_new_site_developer_defined_application_delivery_body_text_cta
|
||||
@ -1,181 +0,0 @@
|
||||
翻译中++++++++++++++
|
||||
++++++++++++++
|
||||
Getting started with Perl on the Raspberry Pi
|
||||
============================================================
|
||||
|
||||
> We're all free to pick what we want to run on our Raspberry Pi.
|
||||
|
||||
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
When I spoke recently at SVPerl (Silicon Valley Perl) about Perl on the Raspberry Pi, someone asked, "I heard the Raspberry Pi is supposed to use Python. Is that right?" I was glad he asked because it's a common misconception. The Raspberry Pi can run any language. Perl, Python, and others are part of the initial installation of Raspbian Linux, the official software for the board.
|
||||
|
||||
The origin of the myth is simple. The Raspberry Pi's creator, UK Computer Science professor Eben Upton, has told the story that the "Pi" part of the name was intended to sound like Python because he likes the language. He chose it as his emphasis for kids to learn coding. But he and his team made a general-purpose computer. The open source software on the Raspberry Pi places no restrictions on us. We're all free to pick what we want to run and make each Raspberry Pi our own.
|
||||
|
||||
More on Raspberry Pi
|
||||
|
||||
* [Our latest on Raspberry Pi][1]
|
||||
* [What is Raspberry Pi?][2]
|
||||
* [Getting started with Raspberry Pi][3]
|
||||
* [Send us your Raspberry Pi projects and tutorials][4]
|
||||
|
||||
The second point to my presentation at SVPerl and this article is to introduce my "PiFlash" script. It was written in Perl, but it doesn't require any knowledge of Perl to automate your task of flashing SD cards for a Raspberry Pi from a Linux system. It provides safety for beginners, so they won't accidentally erase a hard drive while trying to flash an SD card. It offers automation and convenience for power users, which includes me and is why I wrote it. Similar tools already existed for Windows and Macs, but the instructions on the Raspberry Pi website oddly have no automated tools for Linux users. Now one exists.
|
||||
|
||||
Open source software has a long tradition of new projects starting because an author wanted to "scratch their own itch," or to solve their own problems. That's the way Eric S. Raymond described it in his 1997 paper and 1999 book "[The Cathedral and the Bazaar][8]," which defined the open source software development methodology. I wrote PiFlash to fill a need for Linux users like myself.
|
||||
|
||||
### Downloadable system images
|
||||
|
||||
When setting up a Raspberry Pi, you first need to download an operating system for it. We call it a "system image" file. Once you download it to your desktop, laptop, or even another Raspberry Pi, you have to write or "flash" it to an SD card. The details are covered online already. It can be a bit tricky to do manually because getting the system image on the whole SD card and not on a partition matters. The system image will actually contain at least one partition of its own because the Raspberry Pi's boot procedure needs a FAT32 filesystem partition from which to start. Other partitions after the boot partition can be any filesystem type supported by the OS kernel.
|
||||
|
||||
In most cases on the Raspberry Pi, we're running some distribution with a Linux kernel. Here's a list of common system images that you can download for the Raspberry Pi (but there's nothing to stop you from building your own from scratch).
|
||||
|
||||
The ["NOOBS"][9] system from the Raspberry Pi Foundation is their recommended system for new users. It stands for "New Out of the Box System." It's obviously intended to sound like the term "noob," short for "newbie." NOOBS starts a Raspbian-based Linux system, which presents a menu that you can use to automatically download and install several other system images on your Raspberry Pi.
|
||||
|
||||
[Raspbian ][10][Linux][11] is Debian Linux specialized for the Raspberry Pi. It's the official Linux distribution for the Raspberry Pi and is maintained by the Raspberry Pi Foundation. Nearly all Raspberry Pi software and drivers start with Raspbian before going to other Linux distributions. It runs on all models of the Raspberry Pi. The default installation includes Perl.
|
||||
|
||||
Ubuntu Linux (and the community edition Ubuntu MATE) includes the Raspberry Pi as one of its supported platforms for the ARM (Advanced RISC Machines) processor. [RISC (Reduced Instruction Set Computer) architecture] Ubuntu is a commercially supported open source variant of Debian Linux, so its software comes as DEB packages. Perl is included. It only works on the Raspberry Pi 2 and 3 models with their 32-bit ARM7 and 64-bit ARM8 processors. The ARM6 processor of the Raspberry Pi 1 and Zero was never supported by Ubuntu's build process.
|
||||
|
||||
[Fedora Linux][12] supports the Raspberry Pi 2 and 3 as of Fedora 25\. Fedora is the open source project affiliated with Red Hat. Fedora serves as the base that the commercial RHEL (Red Hat Enterprise Linux) adds commercial packages and support to, so its software comes as RPM (Red Hat Package Manager) packages like all Red Hat-compatible Linux distributions. Like the others, it includes Perl.
|
||||
|
||||
[RISC OS][13] is a single-user operating system made specifically for the ARM processor. If you want to experiment with a small desktop that is more compact than Linux (due to fewer features), it's an option. Perl runs on RISC OS.
|
||||
|
||||
[RaspBSD][14] is the Raspberry Pi distribution of FreeBSD. It's a Unix-based system, but isn't Linux. As an open source Unix, form follows function and it has many similarities to Linux, including that the operating system environment is made from a similar set of open source packages, including Perl.
|
||||
|
||||
[OSMC][15], the Open Source Media Center, and [LibreElec][16] are TV entertainment center systems. They are both based on the Kodi entertainment center, which runs on a Linux kernel. It's a really compact and specialized Linux system, so don't expect to find Perl on it.
|
||||
|
||||
[Microsoft ][17][Windows IoT Core][18] is a new entrant that runs only on the Raspberry Pi 3\. You need Microsoft developer access to download it, so as a Linux geek, that deterred me from looking at it. My PiFlash script doesn't support it, but if that's what you're looking for, it's there.
|
||||
|
||||
### The PiFlash script
|
||||
|
||||
If you look at the Raspberry Pi 's [SD card flashing][19][ instructions][20], you'll see the instructions to do that from Windows or Mac involve downloading a tool to write to the SD card. But for Linux systems, it's a set of instructions to do manually. I've done that manual procedure so many times that it triggered my software-developer instinct to automate the process, and that's where the PiFlash script came from. It's tricky because there are many ways a Linux system can be set up, but they are all based on the Linux kernel.
|
||||
|
||||
I always imagined one of the biggest potential errors of the manual procedure is accidentally erasing the wrong device, instead of the SD card, and destroying the data on a hard drive that I wanted to keep. In my presentation at SVPerl, I was surprised to find someone in the audience who has made that mistake (and wasn't afraid to admit it). Therefore, one of the purposes of the PiFlash script, to provide safety for new users by refusing to erase a device that isn't an SD card, is even more needed than I expected. PiFlash will also refuse to overwrite a device that contains a mounted filesystem.
|
||||
|
||||
For experienced users, including me, the PiFlash script offers the convenience of automation. After downloading the system image, I don't have to uncompress it or extract the system image from a zip archive. PiFlash will extract it from whichever format it's in and directly flash the SD card.
|
||||
|
||||
I posted [PiFlash and its instructions][21] on GitHub.
|
||||
|
||||
It's a command-line tool with the following usages:
|
||||
|
||||
**piflash [--verbose] input-file output-device**
|
||||
|
||||
**piflash [--verbose] --SDsearch**
|
||||
|
||||
The **input-file** parameter is the system image file, whatever you downloaded from the Raspberry Pi software distribution sites. The **output-device** parameter is the path of the block device for the SD card you want to write to.
|
||||
|
||||
Alternatively, use **--SDsearch** to print a list of the device names of SD cards on the system.
|
||||
|
||||
The optional **--verbose** parameter is useful for printing out all of the program's state data in case you need to ask for help, submit a bug report, or troubleshoot a problem yourself. That's what I used for developing it.
|
||||
|
||||
This example of using the script writes a Raspbian image, still in its zip archive, to the SD card at **/dev/mmcblk0**:
|
||||
|
||||
**piflash 2016-11-25-raspbian-jessie.img.zip /dev/mmcblk0**
|
||||
|
||||
If you had specified **/dev/mmcblk0p1** (the first partition on the SD card), it would have recognized that a partition is not the correct location and refused to write to it.
|
||||
|
||||
One tricky aspect is recognizing which devices are SD cards on various Linux systems. The example with **mmcblk0** is from the PCI-based SD card interface on my laptop. If I used a USB SD card interface, it would be **/dev/sdb**, which is harder to distinguish from hard drives present on many systems. However, there are only a few Linux block drivers that support SD cards. PiFlash checks the parameters of the block devices in both those cases. If all else fails, it will accept USB drives which are writable, removable and have the right physical sector count for an SD card.
|
||||
|
||||
I think that covers most cases. However, what if you have another SD card interface I haven't seen? I'd like to hear from you. Please include the **--verbose**** --SDsearch** output, so I can see what environment was present on your system when it tried. Ideally, if the PiFlash script becomes widely used, we should build up an open source community around maintaining it for as many Raspberry Pi users as we can.
|
||||
|
||||
### CPAN modules for Raspberry Pi
|
||||
|
||||
CPAN is the [Comprehensive Perl Archive Network][22], a worldwide network of download mirrors containing a wealth of Perl modules. All of them are open source. The vast quantity of modules on CPAN has been a huge strength of Perl over the years. For many thousands of tasks, there is no need to re-invent the wheel, you can just use the code someone else already posted, then submit your own once you have something new.
|
||||
|
||||
As Raspberry Pi is a full-fledged Linux system, most CPAN modules will run normally on it, but I'll focus on some that are specifically for the Raspberry Pi's hardware. These would usually be for embedded systems projects like measurement, control, or robotics. You can connect your Raspberry Pi to external electronics via its GPIO (General-Purpose Input/Output) pins.
|
||||
|
||||
Modules specifically for accessing the Raspberry Pi's GPIO pins include [Device::SMBus][23], [Device::I2C][24], [Rpi::PIGPIO][25], [Rpi::SPI][26], [Rpi::WiringPi][27], [Device::WebIO::RaspberryPi][28] and [Device::PiGlow][29]. Modules for other embedded systems with Raspberry Pi support include [UAV::Pilot::Wumpus::Server::Backend::RaspberryPiI2C][30], [RPi::DHT11][31] (temperature/humidity), [RPi::HCSR04][32] (ultrasonic), [App::RPi::EnvUI][33] (lights for growing plants), [RPi::DigiPot::MCP4XXXX][34] (potentiometer), [RPi::ADC::ADS][35] (A/D conversion), [Device::PaPiRus][36] and [Device::BCM2835::Timer][37] (the on-board timer chip).
|
||||
|
||||
### Examples
|
||||
|
||||
Here are some examples of what you can do with Perl on a Raspberry Pi.
|
||||
|
||||
### Example 1: Flash OSMC with PiFlash and play a video
|
||||
|
||||
For this example, you'll practice setting up and running a Raspberry Pi using the OSMC (Open Source Media Center).
|
||||
|
||||
* Go to [RaspberryPi.Org][5]. In the downloads area, get the latest version of OSMC.
|
||||
* Insert a blank SD card in your Linux desktop or laptop. The Raspberry Pi 1 uses a full-size SD card. Everything else uses a microSD, which may require a common adapter to insert it.
|
||||
* Check "cat /proc/partitions" before and after inserting the SD card to see which device name it was assigned by the system. It could be something like **/dev/mmcblk0** or **/dev/sdb**. Substitute your correct system image file and output device in a command that looks like this:
|
||||
|
||||
** piflash OSMC_TGT_rbp2_20170210.img.gz /dev/mmcblk0**
|
||||
|
||||
* Eject the SD card. Put it in the Raspberry Pi and boot it connected to an HDMI monitor.
|
||||
* While OSMC is setting up, get a USB stick and put some videos on it. For purposes of the demonstration, I suggest using the "youtube-dl" program to download two videos. Run "youtube-dl OHF2xDrq8dY" (The Bloomberg "Hello World" episode about UK tech including Raspberry Pi) and "youtube-dl nAvZMgXbE9c" (CNet's Top 5 Raspberry Pi projects). Move them to the USB stick, then unmount and remove it.
|
||||
* Insert the USB stick in the OSMC Raspberry Pi. Follow the Videos menu to the external device.
|
||||
* When you can play the videos on the Raspberry Pi, you have completed the exercise. Have fun.
|
||||
|
||||
### Example 2: A script to play random videos from a directory
|
||||
|
||||
This example uses a script to shuffle-play videos from a directory on the Raspberry Pi. Depending on the videos and where it's installed, this could be a kiosk display. I wrote it to display videos while using indoor exercise equipment.
|
||||
|
||||
* Set up a Raspberry Pi to boot Raspbian Linux. Connect it to an HDMI monitor.
|
||||
* Download my ["do-video" script][6] from GitHub and put it on the Raspberry Pi.
|
||||
* Follow the installation instructions on the page. The main thing is to install the **omxplayer** package, which plays videos smoothly using the Raspberry Pi's hardware video acceleration.
|
||||
* Put some videos in a directory called Videos under the home directory.
|
||||
* Run "do-video" and videos should start playing.
|
||||
|
||||
### Example 3: A script to read GPS data
|
||||
|
||||
This example is more advanced and optional, but it shows how Perl can read from external devices. At my "Perl on Pi" page on GitHub from the previous example, there is also a **gps-read.pl** script. It reads NMEA (National Marine Electronics Association) data from a GPS via the serial port. Instructions are on the page, including parts I used from AdaFruit Industries to build it, but any GPS that outputs NMEA data could be used.
|
||||
|
||||
With these tasks, I've made the case that you really can use Perl as well as any other language on a Raspberry Pi. I hope you enjoy it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ian Kluft - Ian has had parallel interests since grade school in computing and flight. He was coding on Unix before there was Linux, and started on Linux 6 months after the kernel was posted. He has a masters degree in Computer Science and is a CSSLP (Certified Secure Software Lifecycle Professional). On the side he's a pilot and a certified flight instructor. As a licensed Ham Radio operator for over 25 years, experimentation with electronics has evolved in recent years to include the Raspberry Pi
|
||||
|
||||
------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/perl-raspberry-pi
|
||||
|
||||
作者:[Ian Kluft ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ikluft
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:http://raspberrypi.org/
|
||||
[6]:https://github.com/ikluft/ikluft-tools/tree/master/perl-on-pi
|
||||
[7]:https://opensource.com/article/17/3/perl-raspberry-pi?rate=OsZH1-H_xMfLtSFqZw4SC-_nyV4yo_sgKKBJGjUsbfM
|
||||
[8]:http://www.catb.org/~esr/writings/cathedral-bazaar/
|
||||
[9]:https://www.raspberrypi.org/downloads/noobs/
|
||||
[10]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[11]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[12]:https://fedoraproject.org/wiki/Raspberry_Pi#Downloading_the_Fedora_ARM_image
|
||||
[13]:https://www.riscosopen.org/content/downloads/raspberry-pi
|
||||
[14]:http://www.raspbsd.org/raspberrypi.html
|
||||
[15]:https://osmc.tv/
|
||||
[16]:https://libreelec.tv/
|
||||
[17]:http://ms-iot.github.io/content/en-US/Downloads.htm
|
||||
[18]:http://ms-iot.github.io/content/en-US/Downloads.htm
|
||||
[19]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[20]:https://www.raspberrypi.org/documentation/installation/installing-images/README.md
|
||||
[21]:https://github.com/ikluft/ikluft-tools/tree/master/piflash
|
||||
[22]:http://www.cpan.org/
|
||||
[23]:https://metacpan.org/pod/Device::SMBus
|
||||
[24]:https://metacpan.org/pod/Device::I2C
|
||||
[25]:https://metacpan.org/pod/RPi::PIGPIO
|
||||
[26]:https://metacpan.org/pod/RPi::SPI
|
||||
[27]:https://metacpan.org/pod/RPi::WiringPi
|
||||
[28]:https://metacpan.org/pod/Device::WebIO::RaspberryPi
|
||||
[29]:https://metacpan.org/pod/Device::PiGlow
|
||||
[30]:https://metacpan.org/pod/UAV::Pilot::Wumpus::Server::Backend::RaspberryPiI2C
|
||||
[31]:https://metacpan.org/pod/RPi::DHT11
|
||||
[32]:https://metacpan.org/pod/RPi::HCSR04
|
||||
[33]:https://metacpan.org/pod/App::RPi::EnvUI
|
||||
[34]:https://metacpan.org/pod/RPi::DigiPot::MCP4XXXX
|
||||
[35]:https://metacpan.org/pod/RPi::ADC::ADS
|
||||
[36]:https://metacpan.org/pod/Device::PaPiRus
|
||||
[37]:https://metacpan.org/pod/Device::BCM2835::Timer
|
||||
[38]:https://opensource.com/user/120171/feed
|
||||
[39]:https://opensource.com/article/17/3/perl-raspberry-pi#comments
|
||||
[40]:https://opensource.com/users/ikluft
|
||||
@ -1,3 +1,5 @@
|
||||
MonkeyDEcho translating
|
||||
|
||||
Introduction to functional programming
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Writing a Time Series Database from Scratch
|
||||
Translating by Torival Writing a Time Series Database from Scratch
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
@ -1,101 +0,0 @@
|
||||
translating-----geekpi
|
||||
|
||||
11 reasons to use the GNOME 3 desktop environment for Linux
|
||||
============================================================
|
||||
|
||||
### The GNOME 3 desktop was designed with the goals of being simple, easy to access, and reliable. GNOME's popularity attests to the achievement of those goals.
|
||||
|
||||
|
||||

|
||||
>Image by : [Gunnar Wortmann][8] via [Pixabay][9]. Modified by Opensource.com. [CC BY-SA 4.0][10].
|
||||
|
||||
Late last year, an upgrade to Fedora 25 caused issues with the new version of [KDE][11] Plasma that made it difficult for me to get any work done. So I decided to try other Linux desktop environments for two reasons. First, I needed to get my work done. Second, having been using KDE exclusively for many years, I thought it might be time to try some different desktops.
|
||||
|
||||
The first alternate desktop I tried for several weeks was [Cinnamon][12] which I wrote about in January, and then I wrote about [LXDE][13] which I used for about eight weeks and I have found many things about it that I like. I have used [GNOME 3][14] for a few weeks to research this article.
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
Like almost everything else in the cyberworld, GNOME is an acronym; it stands for GNU Network Object Model. The GNOME 3 desktop was designed with the goals of being simple, easy to access, and reliable. GNOME's popularity attests to the achievement of those goals.
|
||||
|
||||
GNOME 3 is useful in environments where lots of screen real-estate is needed. That means both large screens with high resolution, and minimizing the amount of space needed by the desktop widgets, panels, and icons to allow access to tasks like launching new programs. The GNOME project has a set of Human Interface Guidelines (HIG) that are used to define the GNOME philosophy for how humans should interface with the computer.
|
||||
|
||||
### My eleven reasons for using GNOME 3
|
||||
|
||||
1. **Choice:** GNOME is available in many forms on some distributions like my personal favorite, Fedora. The login options for your desktop of choice are GNOME Classic, GNOME on Xorg, GNOME, and GNOME (Wayland). On the surface, these all look the same once they are launched but they use different X servers or are built with different toolkits. Wayland provides more functionality for the little niceties of the desktop such as kinetic scrolling, drag-and-drop, and paste with middle click.
|
||||
|
||||
2. **Getting started tutorial:** The getting started tutorial is displayed the first time a user logs into the desktop. It shows how to perform common tasks and provides a link to more extensive help. The tutorial is also easily accessible after it is dismissed on first boot so it can be accessed at any time. It is very simple and straightforward and provides users new to GNOME an easy and obvious starting point. To return to the tutorial later, click on **Activities**, then click on the square of nine dots which displays the applications. Then find and click on the life preserver icon labeled, **Help**.
|
||||
|
||||
3. **Clean deskto****p:** With a minimalist approach to a desktop environment in order to reduce clutter, GNOME is designed to present only the minimum necessary to have a functional environment. You should see only the top bar (yes, that is what it is called) and all else is hidden until needed. The intention is to allow the user to focus on the task at hand and to minimize the distractions caused by other stuff on the desktop.
|
||||
|
||||
4. **The top bar:** The top bar is always the place to start, no matter what you want to do. You can launch applications, log out, power off, start or stop the network, and more. This makes life simple when you want to do anything. Aside from the current application, the top bar is usually the only other object on the desktop.
|
||||
|
||||
5. **The dash:** The dash contains three icons by default, as shown below. As you start using applications, they are added to the dash so that your most frequently used applications are displayed there. You can also add application icons to the dash yourself from the application viewer.
|
||||
|
||||

|
||||
|
||||
6. **A****pplication ****v****iewer:** I really like the application viewer that is accessible from the vertical bar on the left side of the GNOME desktop,, above. The GNOME desktop normally has nothing on it unless there is a running program so you must click on the **Activities** selection on the top bar, click on the square consisting of nine dots at the bottom of the dash, which is the icon for the viewer.
|
||||
|
||||

|
||||
|
||||
The viewer itself is a matrix consisting of the icons of the installed applications as shown above. There is a pair of mutually exclusive buttons below the matrix, **Frequent **and **All**. By default, the application viewer shows all installed applications. Click on the **Frequent** button and it shows only the applications used most frequently. Scroll up and down to locate the application you want to launch. The applications are displayed in alphabetical order by name.
|
||||
|
||||
The [GNOME][6] website and the built-in help have more detail on the viewer.
|
||||
|
||||
7. **Application ready n****otification****s:** GNOME has a neat notifier that appears at top of screen when the window for a newly launched app is open and ready. Simply click on the notification to switch to that window. This saved me some time compared to searching for the newly opened application window on some other desktops.
|
||||
|
||||
8. **A****pplication ****display****:** In order to access a different running application that is not visible you click on the activity menu. This displays all of the running applications in a matrix on the desktop. Click on the desired application to bring it to the foreground. Although the current application is displayed in the Top Bar, other running applications are not.
|
||||
|
||||
9. **Minimal w****indow decorations:** Open windows on the desktop are also quite simple. The only button apparent on the title bar is the "**X**" button to close a window. All other functions such as minimize, maximize, move to another desktop, and so on, are accessible with a right-click on the title bar.
|
||||
|
||||
10. **New d****esktops are automatically created: **New empty desktops created automatically when the next empty one down is used. This means that there will always be one empty desktop and available when needed. All of the other desktops I have used allow you to set the number of desktops while the desktop is active, too, but it must be done manually using the system settings.
|
||||
|
||||
11. **Compatibility:** As with all of the other desktops I have used, applications created for other desktops will work correctly on GNOME. This is one of the features that has made it possible for me to test all of these desktops so that I can write about them.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
GNOME is a desktop unlike any other I have used. Its prime directive is "simplicity." Everything else takes a back seat to simplicity and ease of use. It takes very little time to learn how to use GNOME if you start with the getting started tutorial. That does not mean that GNOME is deficient in any way. It is a powerful and flexible desktop that stays out of the way at all times.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||
|
||||
---------------
|
||||
|
||||
via: https://opensource.com/article/17/5/reasons-gnome
|
||||
|
||||
作者:[David Both ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?src=linux_resource_menu&intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://www.gnome.org/gnome-3/
|
||||
[7]:https://opensource.com/article/17/5/reasons-gnome?rate=MbGLV210A21ONuGAP8_Qa4REL7cKFvcllqUddib0qMs
|
||||
[8]:https://pixabay.com/en/users/karpartenhund-3077375/
|
||||
[9]:https://pixabay.com/en/garden-gnome-black-and-white-f%C3%B6hr-1584401/
|
||||
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]:https://opensource.com/life/15/4/9-reasons-to-use-kde
|
||||
[12]:https://opensource.com/article/17/1/cinnamon-desktop-environment
|
||||
[13]:https://opensource.com/article/17/3/8-reasons-use-lxde
|
||||
[14]:https://www.gnome.org/gnome-3/
|
||||
[15]:https://opensource.com/user/14106/feed
|
||||
[16]:https://opensource.com/article/17/5/reasons-gnome#comments
|
||||
[17]:https://opensource.com/users/dboth
|
||||
82
sources/tech/20170531 DNS Infrastructure at GitHub.md
Normal file
82
sources/tech/20170531 DNS Infrastructure at GitHub.md
Normal file
@ -0,0 +1,82 @@
|
||||
[DNS Infrastructure at GitHub][1]
|
||||
============================================================
|
||||
|
||||
|
||||
At GitHub we recently revamped how we do DNS from the ground up. This included both how we [interact with external DNS providers][4] and how we serve records internally to our hosts. To do this, we had to design and build a new DNS infrastructure that could scale with GitHub’s growth and across many data centers.
|
||||
|
||||
Previously GitHub’s DNS infrastructure was fairly simple and straightforward. It included a local, forwarding only DNS cache on every server and a pair of hosts that acted as both caches and authorities used by all these hosts. These hosts were available both on the internal network as well as public internet. We configured zone stubs in the caching daemon to direct queries locally rather than recurse on the internet. We also had NS records set up at our DNS providers that pointed specific internal zones to the public IPs of this pair of hosts for queries external to our network.
|
||||
|
||||
This configuration worked for many years but was not without its downsides. Many applications are highly sensitive to resolving DNS queries and any performance or availability issues we ran into would cause queuing and degraded performance at best and customer impacting outages at worst. Configuration and code changes can cause large unexpected changes in query rates. As such scaling beyond these two hosts became an issue. Due to the network configuration of these hosts we would just need to keep adding IPs and hosts which has its own problems. While attempting to fire fight and remediate these issues, the old system made it difficult to identify causes due to a lack of metrics and visibility. In many cases we resorted to `tcpdump` to identify traffic and queries in question. Another issue was running on public DNS servers we run the risk of leaking internal network information. As a result we decided to build something better and began to identify our requirements for the new system.
|
||||
|
||||
We set out to design a new DNS infrastructure that would improve the aforementioned operational issues including scaling and visibility, as well as introducing some additional requirements. We wanted to continue to run our public DNS zones via external DNS providers so whatever system we build needed to be vendor agnostic. Additionally, we wanted this system to be capable of serving both our internal and external zones, meaning internal zones were only available on our internal network unless specifically configured otherwise and external zones are resolvable without leaving our internal network. We wanted the new DNS architecture to allow both a [deploy-based workflow for making changes][5] as well as API access to our records for automated changes via our inventory and provisioning systems. The new system could not have any external dependencies; too much relies on DNS functioning for it to get caught in a cascading failure. This includes connectivity to other data centers and DNS services that may reside there. Our old system mixed the use of caches and authorities on the same host; we wanted to move to a tiered design with isolated roles. Lastly, we wanted a system that could support many data center environments whether it be EC2 or bare metal.
|
||||
|
||||
### Implementation
|
||||
|
||||
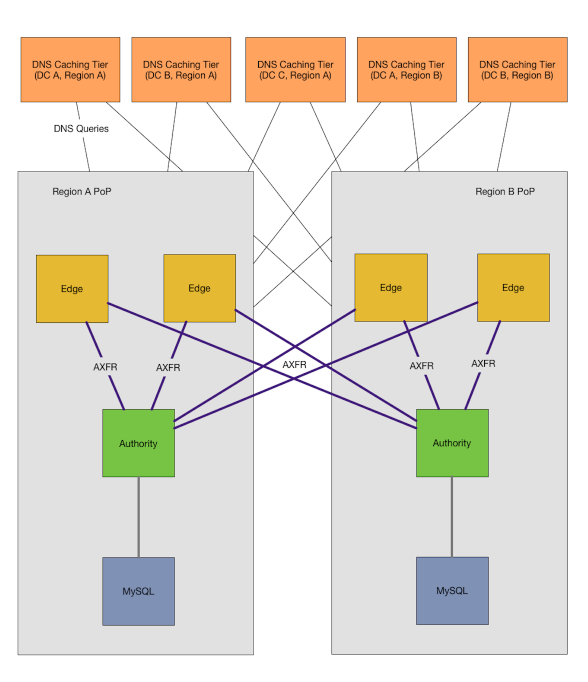
|
||||
|
||||
To build this system we identified three classes of hosts: caches, edges, and authorities. Caches serve as recursive resolvers and DNS “routers” caching responses from the edge tier. The edge tier, running a DNS authority daemon, responds to queries from the caching tier for zones it is configured to zone transfer from the authority tier. The authority tier serve as hidden DNS masters as our canonical source for DNS data, servicing zone transfers from the edge hosts as well as providing an HTTP API for creating, modifying or deleting records.
|
||||
|
||||
In our new configuration, caches live in each data center meaning application hosts don’t need to traverse a data center boundary to retrieve a record. The caches are configured to map zones to the edge hosts within their region in order to route our internal zones to our own hosts. Any zone that is not explicitly configured will recurse on the internet to resolve an answer.
|
||||
|
||||
The edge hosts are regional hosts, living in our network edge PoPs (Point of Presence). Our PoPs have one or more data centers that rely on them for external connectivity, without the PoP the data center can’t get to the internet and the internet can’t get to them. The edges perform zone transfers with all authorities regardless of what region or location they exist in and store those zones locally on their disk.
|
||||
|
||||
Our authorities are also regional hosts, only containing zones applicable to the region it is contained in. Our inventory and provisioning systems determine which regional authority a zone lives in and will create and delete records via an HTTP API as servers come and go. OctoDNS maps zones to regional authorities and uses the same API to create static records and to ensure dynamic sources are in sync. We have an additional separate authority for external domains, such as github.com, to allow us to query our external domains during a disruption to connectivity. All records are stored in MySQL.
|
||||
|
||||
### Operability
|
||||
|
||||
|
||||
|
||||
One huge benefit of moving to a more modern DNS infrastructure is observability. Our old DNS system had little to no metrics and limited logging. A large factor in deciding which DNS servers to use was the breadth and depth of metrics they produce. We finalized on [Unbound][6] for the caches, [NSD][7] for the edge hosts and [PowerDNS][8] for the authorities, all of which have been proven in DNS infrastructures much larger than at GitHub.
|
||||
|
||||
When running in our bare metal data centers, caches are accessed via a private [anycast][9] IP resulting in it reaching the nearest available cache host. The caches have been deployed in a rack aware manner that provides some level of balanced load between them and isolation against some power and network failure modes. When a cache host fails, servers that would normally use it for lookups will now automatically be routed to the next closest cache, keeping latency low as well as providing tolerance to some failure modes. Anycast allows us to scale the number of caches behind a single IP address unlike our previous configuration, giving us the ability to run as many caching hosts as DNS demand requires.
|
||||
|
||||
Edge hosts perform zone transfers with the authority tier, regardless of region or location. Our zones are not large enough that keeping a copy of all of them in every region is a problem. This means for every zone, all caches will have access to a local edge server with a local copy of all zones even when a region is offline or upstream providers are having connectivity issues. This change alone has proven to be quite resilient in the face of connectivity issues and has helped keep GitHub available during failures that not long ago would have caused customer facing outages.
|
||||
|
||||
These zone transfers include both our internal and external zones from their respective authorities. As you might guess zones like github.com are external and zones like github.net are generally internal. The difference between them is only the types of use and data stored in them. Knowing which zones are internal and external gives us some flexibility in our configuration.
|
||||
|
||||
```
|
||||
$ dig +short github.com
|
||||
192.30.253.112
|
||||
192.30.253.113
|
||||
|
||||
```
|
||||
|
||||
Public zones are [sync’d][10] to external DNS providers and are records GitHub users use everyday. Addtionally, public zones are completely resolvable within our network without needing to communicate with our external providers. This means any service that needs to look up `api.github.com` can do so without needing to rely on external network connectivity. We also use the stub-first configuration option of Unbound which gives a lookup a second chance if our internal DNS service is down for some reason by looking it up externally when it fails.
|
||||
|
||||
```
|
||||
$ dig +short time.github.net
|
||||
10.127.6.10
|
||||
|
||||
```
|
||||
|
||||
Most of the `github.net` zone is completely private, inaccessible from the internet and only contains [RFC 1918][11] IP addresses. Private zones are split up per region and site. Each region and/or site has a set of sub-zones applicable to that location, sub-zones for management network, service discovery, specific service records and yet to be provisioned hosts that are in our inventory. Private zones also include reverse lookup zones for PTRs.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Replacing an old system with a new one that is ready to serve millions of customers is never easy. Using a pragmatic, requirements based approach to designing and implementing our new DNS system resulted in a DNS infrastructure that was able to hit the ground running and will hopefully grow with GitHub into the future.
|
||||
|
||||
Want to help the GitHub SRE team solve interesting problems like this? We’d love for you to join us. [Apply Here][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://githubengineering.com/dns-infrastructure-at-github/
|
||||
|
||||
作者:[Joe Williams ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/joewilliams
|
||||
[1]:https://githubengineering.com/dns-infrastructure-at-github/
|
||||
[2]:https://github.com/joewilliams
|
||||
[3]:https://github.com/joewilliams
|
||||
[4]:https://githubengineering.com/enabling-split-authority-dns-with-octodns/
|
||||
[5]:https://githubengineering.com/enabling-split-authority-dns-with-octodns/
|
||||
[6]:https://unbound.net/
|
||||
[7]:https://www.nlnetlabs.nl/projects/nsd/
|
||||
[8]:https://powerdns.com/
|
||||
[9]:https://en.wikipedia.org/wiki/Anycast
|
||||
[10]:https://githubengineering.com/enabling-split-authority-dns-with-octodns/
|
||||
[11]:http://www.faqs.org/rfcs/rfc1918.html
|
||||
[12]:https://boards.greenhouse.io/github/jobs/669805#.WPVqJlPyvUI
|
||||
@ -1,4 +1,4 @@
|
||||
(翻译中 by runningwater)
|
||||
Translating by Snapcrafter
|
||||
A user's guide to links in the Linux filesystem
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,310 @@
|
||||
[MySQL infrastructure testing automation at GitHub][31]
|
||||
============================================================
|
||||
|
||||
Our MySQL infrastructure is a critical component to GitHub. MySQL serves GitHub.com, GitHub’s API, authentication and more. Every `git` request touches MySQL in some way. We are tasked with keeping the data available, and maintaining its integrity. Even while our MySQL clusters serve traffic, we need to be able to perform tasks such as heavy duty cleanups, ad-hoc updates, online schema migrations, cluster topology refactoring, pooling and load balancing and more. We have the infrastructure to automate away such operations; in this post we share a few examples of how we build trust in our infrastructure through continuous testing. It is essentially how we sleep well at night.
|
||||
|
||||
### Backups[][36]
|
||||
|
||||
It is incredibly important to take backups of your data. If you are not taking backups of your database, it is likely a matter of time before this will become an issue. Percona [Xtrabackup][37]is the tool we have been using for issuing full backups for our MySQL databases. If there is data that we need to be certain is saved, we have a server that is backing up the data.
|
||||
|
||||
In addition to the full binary backups, we run logical backups several times a day. These backups allow our engineers to get a copy of recent data. There are times that they would like a complete set of data from a table so they can test an index change on a production sized table or see data from a certain point of time. Hubot allows us to restore a backed up table and will ping us when the table is ready to use.
|
||||
|
||||

|
||||
**tomkrouper**.mysql backup-list locations
|
||||

|
||||
**Hubot**
|
||||
```
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
| Backup ID | Table Name | Donor Host | Backup Start | Backup End | File Name |
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
| 1699494 | locations | db-mysql-0903 | 2017-07-01 22:09:17 | 2017-07-01 22:09:17 | backup-mycluster-locations-1498593122.sql.gz |
|
||||
| 1699133 | locations | db-mysql-0903 | 2017-07-01 16:11:37 | 2017-07-01 16:11:39 | backup-mycluster-locations-1498571521.sql.gz |
|
||||
| 1698772 | locations | db-mysql-0903 | 2017-07-01 10:09:21 | 2017-07-01 10:09:22 | backup-mycluster-locations-1498549921.sql.gz |
|
||||
| 1698411 | locations | db-mysql-0903 | 2017-07-01 04:12:32 | 2017-07-01 04:12:32 | backup-mycluster-locations-1498528321.sql.gz |
|
||||
| 1698050 | locations | db-mysql-0903 | 2017-06-30 22:18:23 | 2017-06-30 22:18:23 | backup-mycluster-locations-1498506721.sql.gz |
|
||||
| ...
|
||||
| 1262253 | locations | db-mysql-0088 | 2016-08-01 01:58:51 | 2016-08-01 01:58:54 | backup-mycluster-locations-1470034801.sql.gz |
|
||||
| 1064984 | locations | db-mysql-0088 | 2016-04-04 13:07:40 | 2016-04-04 13:07:43 | backup-mycluster-locations-1459494001.sql.gz |
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
|
||||
```
|
||||
|
||||

|
||||
**tomkrouper**.mysql restore 1699133
|
||||

|
||||
**Hubot**A restore job has been created for the backup job 1699133\. You will be notified in #database-ops when the restore is complete.
|
||||

|
||||
**Hubot**[@tomkrouper][1]: the locations table has been restored as locations_2017_07_01_16_11 in the restores database on db-mysql-0482
|
||||
|
||||
The data is loaded onto a non-production database which is accessible to the engineer requesting the restore.
|
||||
|
||||
The last way we keep a “backup” of data around is we use [delayed replicas][38]. This is less of a backup and more of a safeguard. For each production cluster we have a host that has replication delayed by 4 hours. If a query is run that shouldn’t have, we can run `mysql panic` in chatops. This will cause all of our delayed replicas to stop replication immediately. This will also page the on-call DBA. From there we can use delayed replica to verify there is an issue, and then fast forward the binary logs to the point right before the error. We can then restore this data to the master, thus recovering data to that point.
|
||||
|
||||
Backups are great, however they are worthless if some unknown or uncaught error occurs corrupting the backup. A benefit of having a script to restore backups is it allows us to automate the verification of backups via cron. We have set up a dedicated host for each cluster that runs a restore of the latest backup. This ensures that the backup ran correctly and that we are able to retrieve the data from the backup.
|
||||
|
||||
Depending on dataset size, we run several restores per day. Restored servers are expected to join the replication stream and to be able to catch up with replication. This tests not only that we took a restorable backup, but also that we correctly identified the point in time at which it was taken and can further apply changes from that point in time. We are alerted if anything goes wrong in the restore process.
|
||||
|
||||
We furthermore track the time the restore takes, so we have a good idea of how long it will take to build a new replica or restore in cases of emergency.
|
||||
|
||||
The following is an output from an automated restore process, written by Hubot in our robots chat room.
|
||||
|
||||

|
||||
**Hubot**gh-mysql-backup-restore: db-mysql-0752: restore_log.id = 4447
|
||||
gh-mysql-backup-restore: db-mysql-0752: Determining backup to restore for cluster 'prodcluster'.
|
||||
gh-mysql-backup-restore: db-mysql-0752: Enabling maintenance mode
|
||||
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
|
||||
gh-mysql-backup-restore: db-mysql-0752: Disabling Puppet
|
||||
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Removing MySQL files
|
||||
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-restore
|
||||
gh-mysql-backup-restore: db-mysql-0752: Restore file: xtrabackup-notify-2017-07-02_0000.xbstream
|
||||
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-prepare
|
||||
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Update file ownership
|
||||
gh-mysql-backup-restore: db-mysql-0752: Upgrade MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Backup Host: db-mysql-0034
|
||||
gh-mysql-backup-restore: db-mysql-0752: Setting up replication
|
||||
gh-mysql-backup-restore: db-mysql-0752: Starting replication
|
||||
gh-mysql-backup-restore: db-mysql-0752: Replication catch-up
|
||||
gh-mysql-backup-restore: db-mysql-0752: Restore complete (replication running)
|
||||
gh-mysql-backup-restore: db-mysql-0752: Enabling Puppet
|
||||
gh-mysql-backup-restore: db-mysql-0752: Disabling maintenance mode
|
||||
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
|
||||
gh-mysql-backup-restore: db-mysql-0752: Restore process complete.
|
||||
|
||||
One thing we use backups for is adding a new replica to an existing set of MySQL servers. We will initiate the build of a new server, and once we are notified it is ready, we can start a restore of the latest backup for that particular cluster. We have a script in place that runs all of the restore commands that we would otherwise have to do by hand. Our automated restore system essentially uses the same script. This simplifies the system build process and allows us to have a host up and running with a handful of chat commands opposed to dozens of manual processes. Shown below is a restore kicked manually in chat:
|
||||
|
||||

|
||||
**jessbreckenridge**.mysql backup-restore -H db-mysql-0007 -o -r magic_word=daily_rotating_word
|
||||

|
||||
**Hubot**[@jessbreckenridge][2] gh-mysql-backup-restore: db-mysql-0007: Determining backup to restore for cluster 'mycluster'.
|
||||
[@jessbreckenridge][3] gh-mysql-backup-restore: db-mysql-0007: restore_log.id = 4449
|
||||
[@jessbreckenridge][4] gh-mysql-backup-restore: db-mysql-0007: Enabling maintenance mode
|
||||
[@jessbreckenridge][5] gh-mysql-backup-restore: db-mysql-0007: Setting orchestrator downtime
|
||||
[@jessbreckenridge][6] gh-mysql-backup-restore: db-mysql-0007: Disabling Puppet
|
||||
[@jessbreckenridge][7] gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
|
||||
[@jessbreckenridge][8] gh-mysql-backup-restore: db-mysql-0007: Removing MySQL files
|
||||
[@jessbreckenridge][9] gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-restore
|
||||
[@jessbreckenridge][10] gh-mysql-backup-restore: db-mysql-0007: Restore file: xtrabackup-mycluster-2017-07-02_0015.xbstream
|
||||
[@jessbreckenridge][11] gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-prepare
|
||||
[@jessbreckenridge][12] gh-mysql-backup-restore: db-mysql-0007: Update file ownership
|
||||
[@jessbreckenridge][13] gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
|
||||
[@jessbreckenridge][14] gh-mysql-backup-restore: db-mysql-0007: Upgrade MySQL
|
||||
[@jessbreckenridge][15] gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
|
||||
[@jessbreckenridge][16] gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
|
||||
[@jessbreckenridge][17] gh-mysql-backup-restore: db-mysql-0007: Setting up replication
|
||||
[@jessbreckenridge][18] gh-mysql-backup-restore: db-mysql-0007: Starting replication
|
||||
[@jessbreckenridge][19] gh-mysql-backup-restore: db-mysql-0007: Backup Host: db-mysql-0201
|
||||
[@jessbreckenridge][20] gh-mysql-backup-restore: db-mysql-0007: Replication catch-up
|
||||
[@jessbreckenridge][21] gh-mysql-backup-restore: db-mysql-0007: Replication behind by 4589 seconds, waiting 1800 seconds before next check.
|
||||
[@jessbreckenridge][22] gh-mysql-backup-restore: db-mysql-0007: Restore complete (replication running)
|
||||
[@jessbreckenridge][23] gh-mysql-backup-restore: db-mysql-0007: Enabling puppet
|
||||
[@jessbreckenridge][24] gh-mysql-backup-restore: db-mysql-0007: Disabling maintenance mode
|
||||
|
||||
### Failovers[][39]
|
||||
|
||||
[We use orchestrator][40] to perform automated failovers for masters and intermediate masters. We expect `orchestrator` to correctly detect master failure, designate a replica for promotion, heal the topology under said designated replica, make the promotion. We expect VIPs to change, pools to change, clients to reconnect, `puppet` to run essential components on promoted master, and more. A failover is a complex task that touches many aspects of our infrastructure.
|
||||
|
||||
To build trust in our failovers we set up a _production-like_ , test cluster, and we continuously crash it to observe failovers.
|
||||
|
||||
The _production-like_ cluster is a replication setup that is identical in all aspects to our production clusters: types of hardware, operating systems, MySQL versions, network environments, VIP, `puppet` configurations, [haproxy setup][41], etc. The only thing different to this cluster is that it doesn’t send/receive production traffic.
|
||||
|
||||
We emulate a write load on the test cluster, while avoiding replication lag. The write load is not too heavy, but has queries that are intentionally contending to write on same datasets. This isn’t too interesting in normal times, but proves to be useful upon failovers, as we will shortly describe.
|
||||
|
||||
Our test cluster has representative servers from three data centers. We would _like_ the failover to promote a replacement replica from within the same data center. We would _like_ to be able to salvage as many replicas as possible under such constraint. We _require_ that both apply whenever possible. `orchestrator` has no prior assumption on the topology; it must react on whatever the state was at time of the crash.
|
||||
|
||||
We, however, are interested in creating complex and varying scenarios for failovers. Our failover testing script prepares the grounds for the failover:
|
||||
|
||||
* It identifies existing master
|
||||
|
||||
* It refactors the topology to have representatives of all three data centers under the master. Different DCs have different network latencies and are expected to react in different timing to master’s crash.
|
||||
|
||||
* It chooses a crash method. We choose from shooting the master (`kill -9`) or network partitioning it: `iptables -j REJECT` (nice-ish) or `iptables -j DROP`(unresponsive).
|
||||
|
||||
The script proceeds to crash the master by chosen method, and waits for `orchestrator` to reliably detect the crash and to perform failover. While we expect detection and promotion to both complete within `30` seconds, the script relaxes this expectation a bit, and sleeps for a designated time before looking into failover results. It will then:
|
||||
|
||||
* Check that a new (different) master is in place
|
||||
|
||||
* There is a good number of replicas in the cluster
|
||||
|
||||
* The master is writable
|
||||
|
||||
* Writes to the master are visible on the replicas
|
||||
|
||||
* Internal service discovery entries are updated (identity of new master is as expected; old master removed)
|
||||
|
||||
* Other internal checks
|
||||
|
||||
These tests confirm that the failover was successful, not only MySQL-wise but also on our larger infrastructure scope. A VIP has been assumed; specific services have been started; information got to where it was supposed to go.
|
||||
|
||||
The script further proceeds to restore the failed server:
|
||||
|
||||
* Restoring it from backup, thereby implicitly testing our backup/restore procedure
|
||||
|
||||
* Verifying server configuration is as expected (the server no longer believes it’s the master)
|
||||
|
||||
* Returning it to the replication cluster, expecting to find data written on the master
|
||||
|
||||
Consider the following visualization of a scheduled failover test: from having a well-running cluster, to seeing problems on some replicas, to diagnosing the master (`7136`) is dead, to choosing a server to promote (`a79d`), refactoring the topology below that server, to promoting it (failover successful), to restoring the dead master and placing it back into the cluster.
|
||||
|
||||
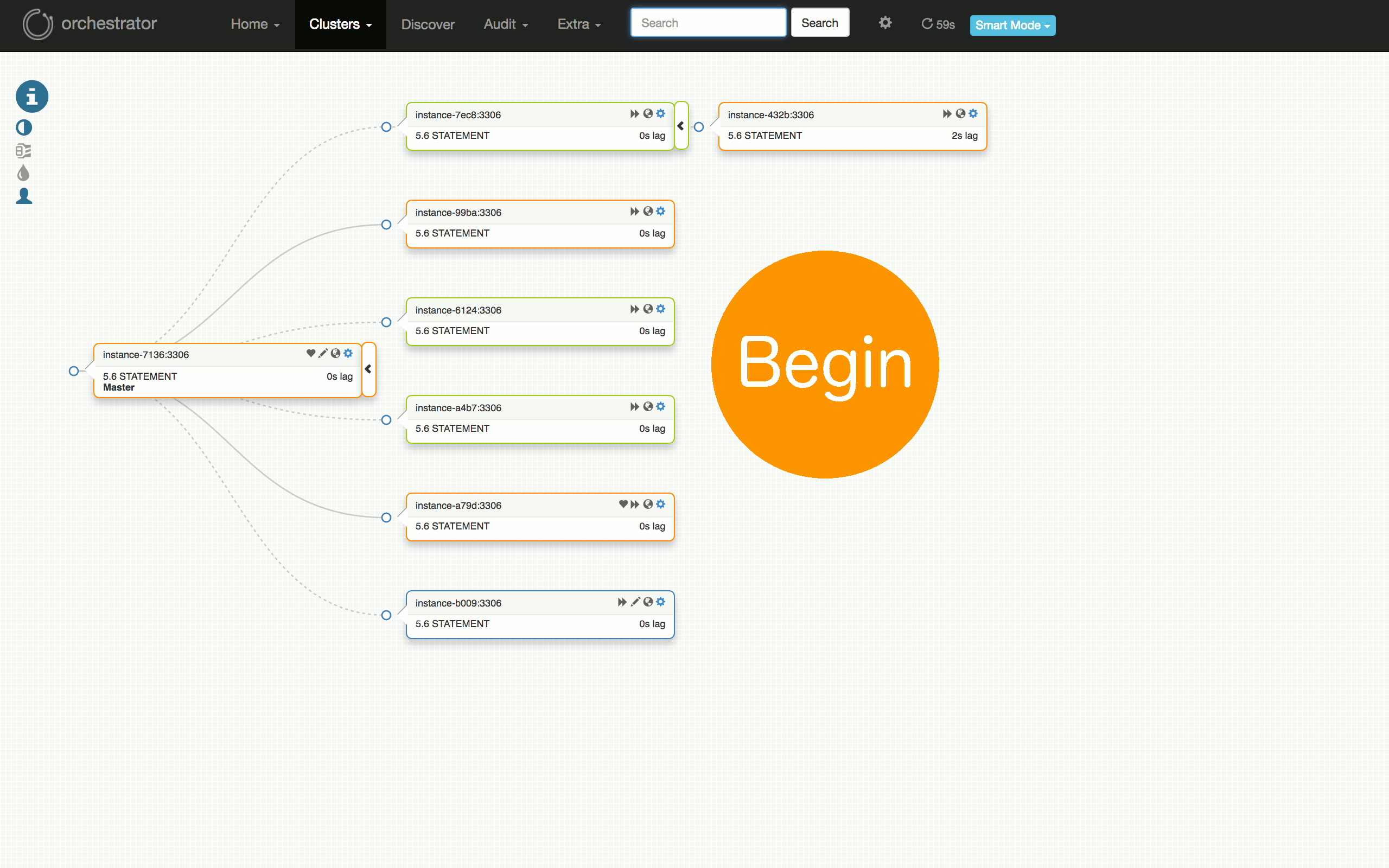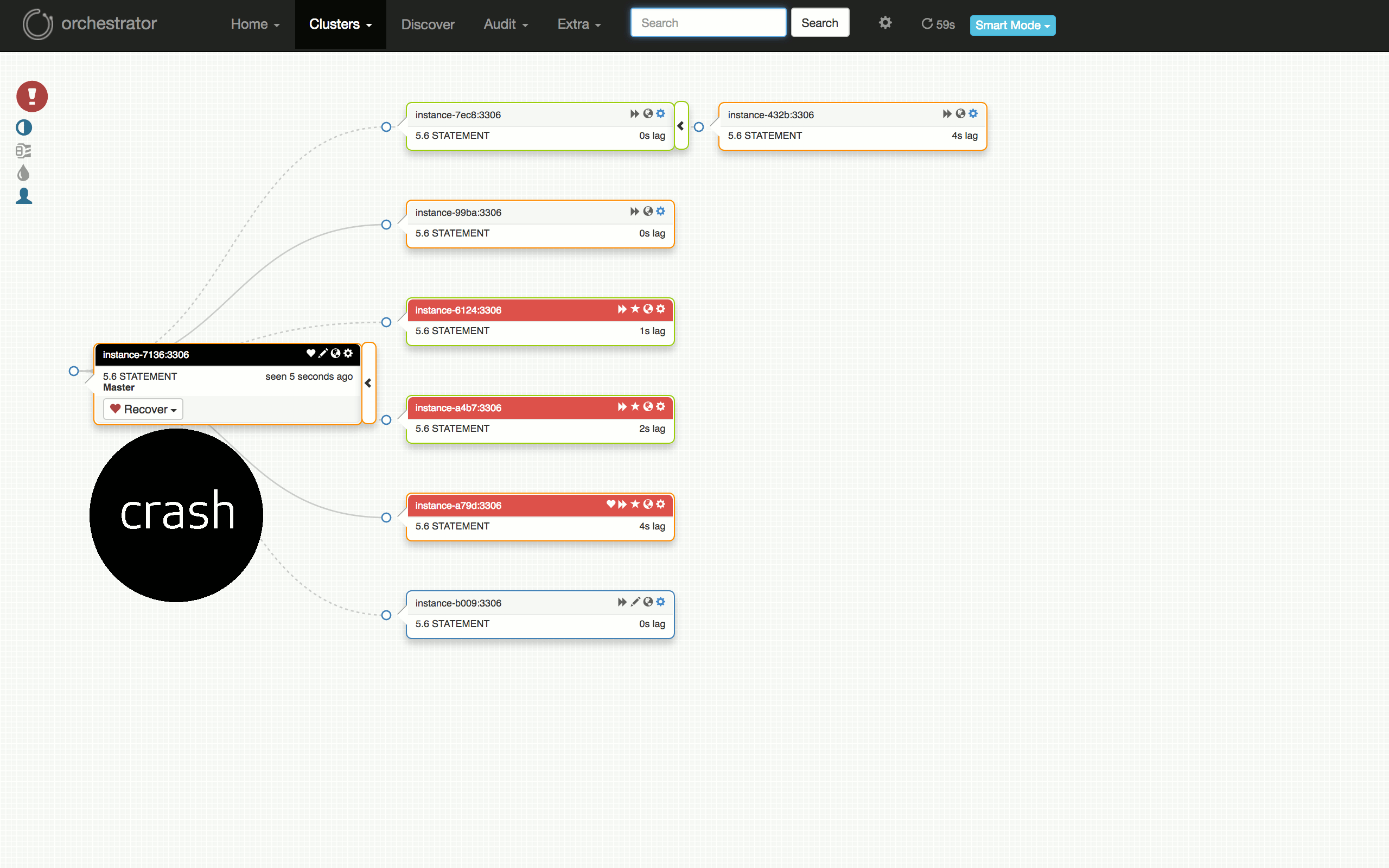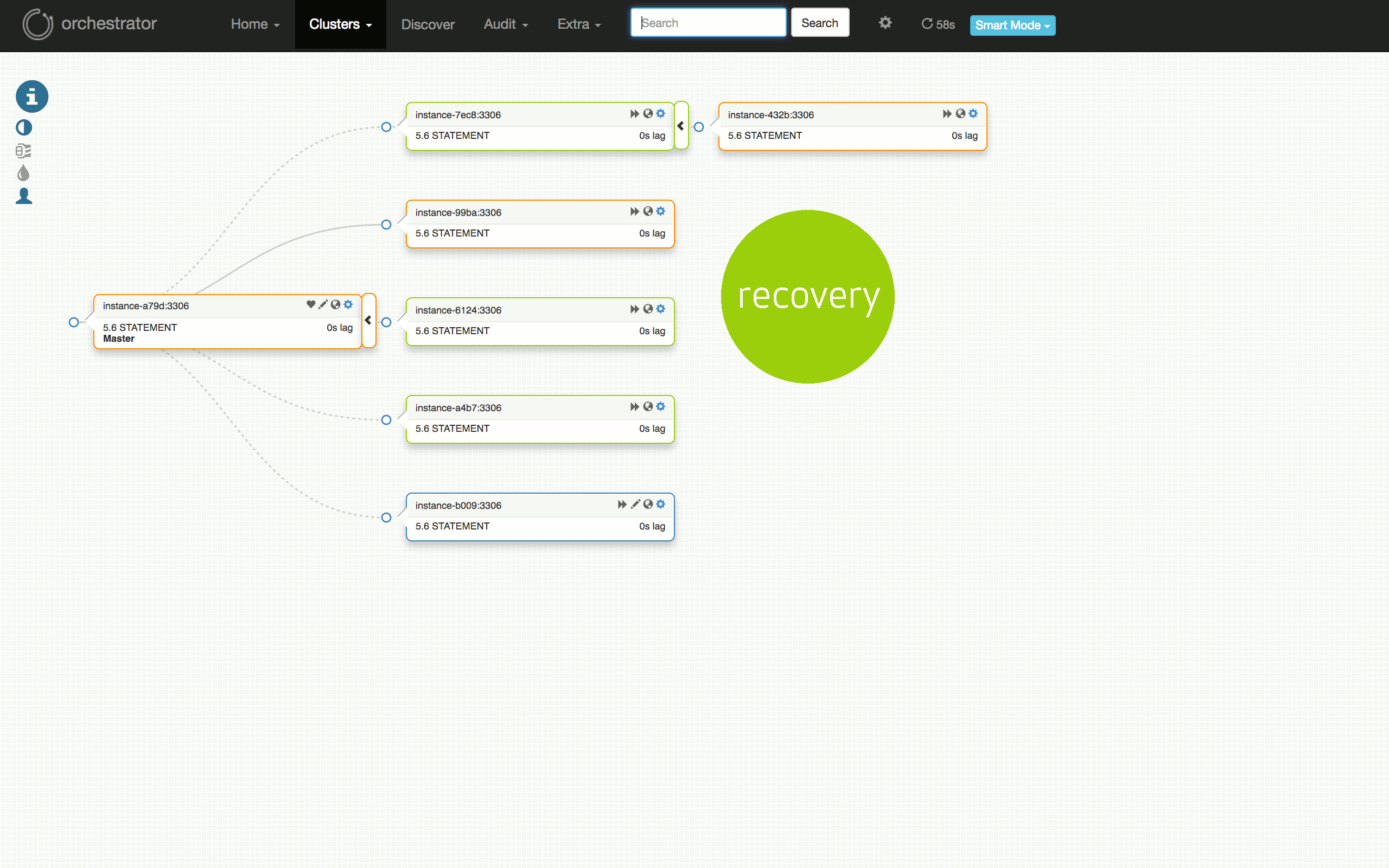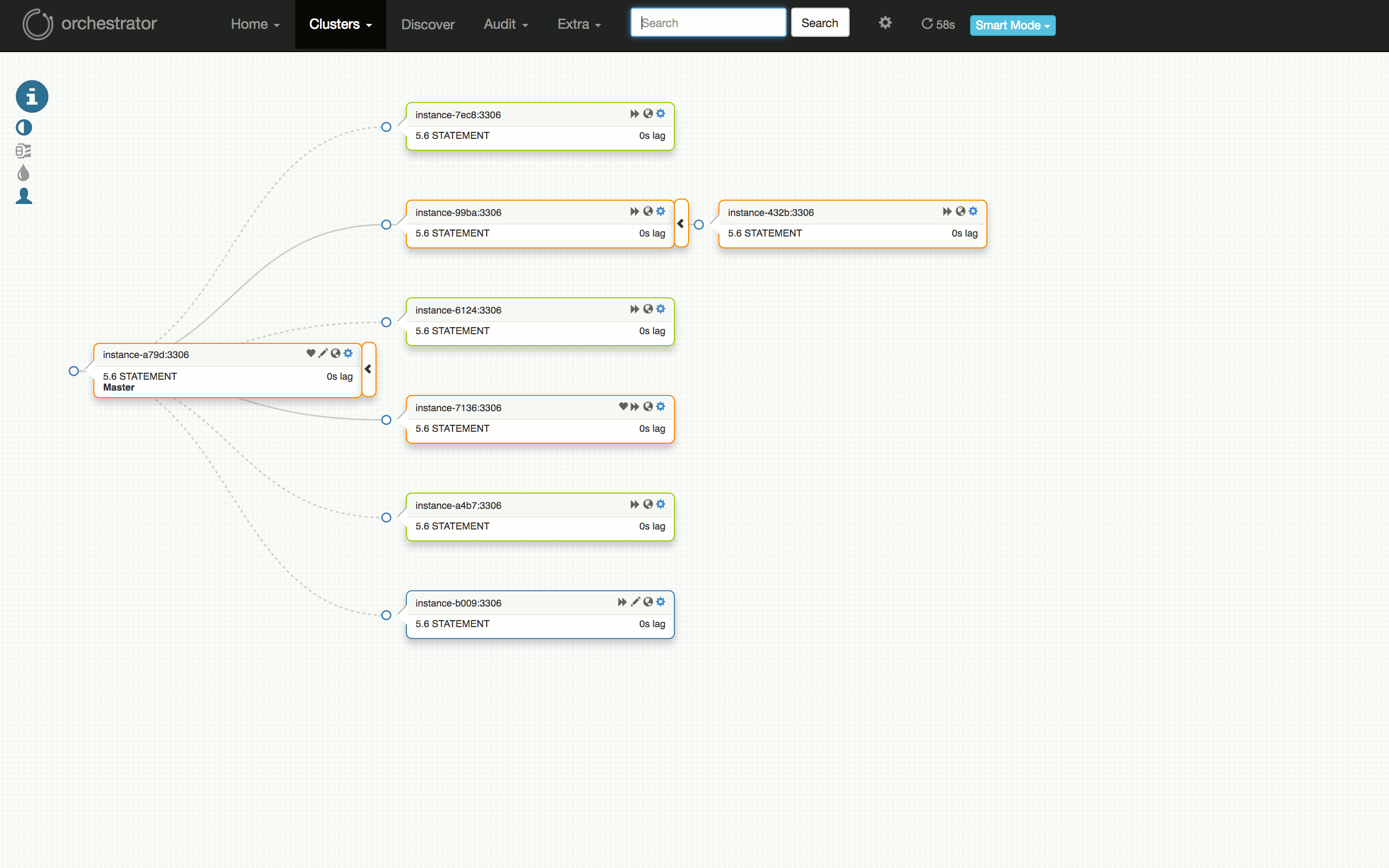
|
||||
|
||||
#### What would a test failure look like?
|
||||
|
||||
Our testing script uses a stop-the-world approach. A single failure in any of the failover components fails the entire test, disabling any future automated tests until a human resolves the matter. We get alerted and proceed to check the status and logs.
|
||||
|
||||
The script would fail on an unacceptable detection or failover time; on backup/restore issues; on losing too many servers; on unexpected configuration following the failover; etc.
|
||||
|
||||
We need to be certain `orchestrator` connects the servers correctly. This is where the contending write load comes useful: if set up incorrectly, replication is easily susceptible to break. We would get `DUPLICATE KEY` or other errors to suggest something went wrong.
|
||||
|
||||
This is particularly important as we make improvements and introduce new behavior to `orchestrator`, and allows us to test such changes in a safe environment.
|
||||
|
||||
#### Coming up: chaos testing
|
||||
|
||||
The testing procedure illustrated above will catch (and has caught) problems on many parts of our infrastructure. Is it enough?
|
||||
|
||||
In a production environment there’s always something else. Something about the particular test method that won’t apply to our production clusters. They don’t share the same traffic and traffic manipulation, nor the exact same set of servers. The types of failure can vary.
|
||||
|
||||
We are designing chaos testing for our production clusters. Chaos testing would literally destroy pieces in our production, but on expected schedule and under sufficiently controlled manner. Chaos testing introduces a higher level of trust in the recovery mechanism and affects (thus tests) larger parts of our infrastructure and application.
|
||||
|
||||
This is delicate work: while we acknowledge the need for chaos testing, we also wish to avoid unnecessary impact to our service. Different tests will differ in risk level and impact, and we will work to ensure availability of our service.
|
||||
|
||||
### Schema migrations[][42]
|
||||
|
||||
[We use gh-ost][43] to run live schema migrations. `gh-ost` is stable, but also under active developments, with major new features being added or planned.
|
||||
|
||||
`gh-ost` migrates tables by copying data onto a _ghost_ table, applying ongoing changes intercepted by the binary logs onto the _ghost_ table, even as the original table is being written to. It then swaps the _ghost_ table in place of the original table. At migration completion GitHub proceeds to work with a table generated and populated by `gh-ost`.
|
||||
|
||||
At this time almost all of GitHub’s MySQL data has been recreated by `gh-ost`, and most of it multiple times. We must have high trust in `gh-ost` to let it tamper with our data over and over again, even in face of active development. Here’s how we gain this trust.
|
||||
|
||||
`gh-ost` provides a testing-in-production capability. It supports running a migration on a replica, in much the same way as it would run on the master: `gh-ost` would connect to the replica and treat it as if it were the master. It would parse its binary logs the same way it would for a real master migration. However it would copy rows and apply binlog events to the replica, and avoid making writes onto the master.
|
||||
|
||||
We run `gh-ost`-dedicated replicas in production. These replicas do not serve production traffic. Each such replica retrieves the current list of production tables and iterates them in random order. One by one it picks a table and performs a replica-migration on that table. The migration doesn’t actually modify table structure, but instead runs a trivial `ENGINE=InnoDB`. The test runs the migration even as the table is being used in production, thus copying real production data and applying true production traffic off the binary logs.
|
||||
|
||||
These migrations can be audited. Here’s how we can inspect status of running tests from chat:
|
||||
|
||||

|
||||
**ggunson**.migration test-status
|
||||

|
||||
**Hubot**
|
||||
```
|
||||
# Migrating `prod`.`pull_requests`; Ghost table is `prod`.`_pull_requests_gho`
|
||||
# Migrating ghost-db-mysql-0007:3306; inspecting ghost-db-mysql-0007:3306; executing on ghost-db-mysql-0007
|
||||
# Migration started at Mon Jan 30 02:13:39 -0800 2017
|
||||
# chunk-size: 2500; max-lag-millis: 1500ms; max-load: Threads_running=30; critical-load: Threads_running=1000; nice-ratio: 0.000000
|
||||
# throttle-additional-flag-file: /tmp/gh-ost.throttle
|
||||
# panic-flag-file: /tmp/ghost-test-panic.flag
|
||||
# Serving on unix socket: /tmp/gh-ost.test.sock
|
||||
Copy: 57992500/86684838 66.9%; Applied: 57708; Backlog: 1/100; Time: 3h28m38s(total), 3h28m36s(copy); streamer: mysql-bin.000576:142993938; State: migrating; ETA: 1h43m12s
|
||||
```
|
||||
|
||||
When a test migration completes copying of table data it stops replication and performs the cut-over, replacing the original table with the _ghost_ table, and then swaps back. We’re not interested in actually replacing the data. Instead we are left with both the original table and the _ghost_ table, which should both be identical. We verify that by checksumming the entire table data for both tables.
|
||||
|
||||
A test can complete with:
|
||||
|
||||
* _success_ : All went well and checksum is identical. We expect to see this.
|
||||
|
||||
* _failure_ : Execution problem. This can occasionally happen due to the migration process being killed, a replication issue etc., and is typically unrelated to `gh-ost` itself.
|
||||
|
||||
* _checksum failure_ : table data inconsistency. For a tested branch, this call for fixes. For an ongoing `master` branch test, this would imply immediate blocking of production migrations. We don’t get the latter.
|
||||
|
||||
Test results are audited, sent to robot chatrooms, sent as events to our metrics systems. Each vertical line in the following graph represents a successful migration test:
|
||||
|
||||
|
||||
|
||||
These tests run continuously. We are notified by alerts in case of failures. And of course we can always visit the robots chatroom to know what’s going on.
|
||||
|
||||
#### Testing new versions
|
||||
|
||||
We continuously improve `gh-ost`. Our development flow is based on `git` branches, which we then offer to merge via [pull requests][44].
|
||||
|
||||
A submitted `gh-ost` pull request goes through Continuous Integration (CI) which runs basic compilation and unit tests. Once past this, the PR is technically eligible for merging, but even more interestingly it is [eligible for deployment via Heaven][45]. Being the sensitive component in our infrastructure that it is, we take care to deploy `gh-ost` branches for intensive testing before merging into `master`.
|
||||
|
||||

|
||||
**shlomi-noach**.deploy gh-ost/fix-reappearing-throttled-reasons to prod/ghost-db-mysql-0007
|
||||

|
||||
**Hubot**[@shlomi-noach][25] is deploying gh-ost/fix-reappearing-throttled-reasons (baee4f6) to production (ghost-db-mysql-0007).
|
||||
[@shlomi-noach][26]'s production deployment of gh-ost/fix-reappearing-throttled-reasons (baee4f6) is done! (2s)
|
||||
[@shlomi-noach][27], make sure you watch for exceptions in haystack
|
||||

|
||||
**jonahberquist**.deploy gh-ost/interactive-command-question to prod/ghost-db-mysql-0012
|
||||

|
||||
**Hubot**[@jonahberquist][28] is deploying gh-ost/interactive-command-question (be1ab17) to production (ghost-db-mysql-0012).
|
||||
[@jonahberquist][29]'s production deployment of gh-ost/interactive-command-question (be1ab17) is done! (2s)
|
||||
[@jonahberquist][30], make sure you watch for exceptions in haystack
|
||||

|
||||
**shlomi-noach**.wcid gh-ost
|
||||

|
||||
**Hubot**shlomi-noach testing fix-reappearing-throttled-reasons 41 seconds ago: ghost-db-mysql-0007
|
||||
jonahberquist testing interactive-command-question 7 seconds ago: ghost-db-mysql-0012
|
||||
|
||||
Nobody is in the queue.
|
||||
|
||||
Some PRs are small and do not affect the data itself. Changes to status messages, interactive commands etc. are of lesser impact to the `gh-ost` app. Others pose significant changes to the migration logic and operation. We would tests these rigorously, running through our production tables fleet until satisfied these changes do not pose data corruption threat.
|
||||
|
||||
### Summary[][46]
|
||||
|
||||
Throughout testing we build trust in our systems. By automating these tests, in production, we get repetitive confirmation that everything is working as expected. As we continue to develop our infrastructure we also follow up by adapting tests to cover the newest changes.
|
||||
|
||||
Production always surprises with scenarios not covered by tests. The more we test on production environment, the more input we get on our app’s expectations and our infrastructure’s capabilities.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://githubengineering.com/mysql-testing-automation-at-github/
|
||||
|
||||
作者:[tomkrouper ][a], [Shlomi Noach][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/tomkrouper
|
||||
[b]:https://github.com/shlomi-noach
|
||||
[1]:https://github.com/tomkrouper
|
||||
[2]:https://github.com/jessbreckenridge
|
||||
[3]:https://github.com/jessbreckenridge
|
||||
[4]:https://github.com/jessbreckenridge
|
||||
[5]:https://github.com/jessbreckenridge
|
||||
[6]:https://github.com/jessbreckenridge
|
||||
[7]:https://github.com/jessbreckenridge
|
||||
[8]:https://github.com/jessbreckenridge
|
||||
[9]:https://github.com/jessbreckenridge
|
||||
[10]:https://github.com/jessbreckenridge
|
||||
[11]:https://github.com/jessbreckenridge
|
||||
[12]:https://github.com/jessbreckenridge
|
||||
[13]:https://github.com/jessbreckenridge
|
||||
[14]:https://github.com/jessbreckenridge
|
||||
[15]:https://github.com/jessbreckenridge
|
||||
[16]:https://github.com/jessbreckenridge
|
||||
[17]:https://github.com/jessbreckenridge
|
||||
[18]:https://github.com/jessbreckenridge
|
||||
[19]:https://github.com/jessbreckenridge
|
||||
[20]:https://github.com/jessbreckenridge
|
||||
[21]:https://github.com/jessbreckenridge
|
||||
[22]:https://github.com/jessbreckenridge
|
||||
[23]:https://github.com/jessbreckenridge
|
||||
[24]:https://github.com/jessbreckenridge
|
||||
[25]:https://github.com/shlomi-noach
|
||||
[26]:https://github.com/shlomi-noach
|
||||
[27]:https://github.com/shlomi-noach
|
||||
[28]:https://github.com/jonahberquist
|
||||
[29]:https://github.com/jonahberquist
|
||||
[30]:https://github.com/jonahberquist
|
||||
[31]:https://githubengineering.com/mysql-testing-automation-at-github/
|
||||
[32]:https://github.com/tomkrouper
|
||||
[33]:https://github.com/tomkrouper
|
||||
[34]:https://github.com/shlomi-noach
|
||||
[35]:https://github.com/shlomi-noach
|
||||
[36]:https://githubengineering.com/mysql-testing-automation-at-github/#backups
|
||||
[37]:https://www.percona.com/software/mysql-database/percona-xtrabackup
|
||||
[38]:https://dev.mysql.com/doc/refman/5.6/en/replication-delayed.html
|
||||
[39]:https://githubengineering.com/mysql-testing-automation-at-github/#failovers
|
||||
[40]:http://githubengineering.com/orchestrator-github/
|
||||
[41]:https://githubengineering.com/context-aware-mysql-pools-via-haproxy/
|
||||
[42]:https://githubengineering.com/mysql-testing-automation-at-github/#schema-migrations
|
||||
[43]:http://githubengineering.com/gh-ost-github-s-online-migration-tool-for-mysql/
|
||||
[44]:https://github.com/github/gh-ost/pulls
|
||||
[45]:https://githubengineering.com/deploying-branches-to-github-com/
|
||||
[46]:https://githubengineering.com/mysql-testing-automation-at-github/#summary
|
||||
@ -1,199 +0,0 @@
|
||||
cygmris is translating
|
||||
|
||||
OpenStack in a Snap
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
OpenStack is complex and many of the community members are working hard to make the deployment and operation of OpenStack easier. Much of this time is focused on tools such as Ansible, Puppet, Kolla, Juju, Triple-O, Chef (to name a few). But what if we step down a level and also make the package experience easier?
|
||||
|
||||
With snaps we’re working on doing just that. Snaps are a new way of delivering software. The following description from [snapcraft.io][2] provides a good summary of the core benefits of snaps: _“Snaps are quick to install, easy to create, safe to run, and they update automatically and transactionally so your app is always fresh and never broken.”_
|
||||
|
||||
### Bundled software
|
||||
|
||||
A single snap can deliver multiple pieces of software from different sources to provide a solution that gets you up and running fast. You’ll notice that installing a snap is quick. That’s because when you install a snap, that single snap bundles all of its dependencies. That’s a bit different from installing a deb, where all of the dependencies get pulled down and installed separately.
|
||||
|
||||
### Snaps are easy to create
|
||||
|
||||
In my time working on Ubuntu, I’ve spent much of it working on Debian packaging for OpenStack. It’s a niche skill that takes quite a bit of time to understand the nuances of. When compared with snaps, the difference in complexity between deb packages and snaps is like night and day. Snaps are just plain simple to work on, and even quite fun!
|
||||
|
||||
### A few more features of snaps
|
||||
|
||||
* Each snap is installed in it’s own read-only squashfs filesystem.
|
||||
|
||||
* Each snap is run in a strict environment sandboxed by AppArmor and seccomp policy.
|
||||
|
||||
* Snaps are transactional. New versions of a snap install to a new read-only squashfs filesystem. If an upgrade fails, it will roll-back to the old version.
|
||||
|
||||
* Snaps will auto-refresh when new versions are available.
|
||||
|
||||
* OpenStack Snaps are guaranteed to be aligned with OpenStack’s upper-constraints. Packagers no longer need to maintain separate packages for the OpenStack dependency chain. Woo-hoo!
|
||||
|
||||
### Introducing the OpenStack Snaps!
|
||||
|
||||
We currently have the following projects snapped:
|
||||
|
||||
* **Keystone** – This snap provides the OpenStack identity service.
|
||||
|
||||
* **Glance** – This snap provides the OpenStack image service.
|
||||
|
||||
* **Neutron** – This snap specifically provides the ‘neutron-server’ process as part of a snap based OpenStack deployment.
|
||||
|
||||
* **Nova** – This snap provides the Nova controller component of an OpenStack deployment.
|
||||
|
||||
* **Nova-hypervisor** – This snap provides the hypervisor component of an OpenStack deployment, configured to use Libvirt/KVM + Open vSwitch which are installed using deb packages. This snap also includes nova-lxd, allowing for use of nova-lxd instead of KVM.
|
||||
|
||||
This is enough to get a minimal working OpenStack cloud. You can find the source for all of the OpenStack snaps on [github][3]. For more details on the OpenStack snaps please refer to the individual READMEs in the upstream repositories. There you can find more details for managing the snaps, such as overriding default configs, restarting services, setting up aliases, and more.
|
||||
|
||||
### Want to create your own OpenStack snap?
|
||||
|
||||
Check out the [snap cookie cutter][4]. I’ll be writing a blog post soon that walks you through using the snap cookie cutter. It’s really simple and will help get the creation of a new OpenStack snap bootstrapped in no time.
|
||||
|
||||
### Testing the OpenStack snaps
|
||||
|
||||
We’ve been using a simple script for initial testing of the OpenStack snaps. The script installs the snaps on a single node and provides additional post-install configuration for services. To try it out:
|
||||
|
||||
```
|
||||
git clone https://github.com/openstack-snaps/snap-test
|
||||
cd snap-test
|
||||
./snap-deploy
|
||||
```
|
||||
|
||||
At this point we’ve been doing all of our testing on Ubuntu Xenial (16.04). Also note that this will install and configure quite a bit of software on your system so you’ll likely want to run it on a disposable machine.
|
||||
|
||||
### Tracking OpenStack
|
||||
|
||||
Today you can install snaps from the edge channel of the snap store. For example:
|
||||
|
||||
```
|
||||
sudo snap install --edge keystone
|
||||
```
|
||||
|
||||
The OpenStack team is working toward getting CI/CD in place to enable publishing snaps across tracks for OpenStack releases (Ie. a track for ocata, another track for pike, etc). Within each track will be 4 different channels. The edge channel for each track will contain the tip of the OpenStack project’s corresponding branch, with the beta, candidate and release channels being reserved for released versions. This should result in an experience such as:
|
||||
|
||||
```
|
||||
sudo snap install --channel=ocata/stable keystone
|
||||
sudo snap install --channel=pike/edge keystone
|
||||
```
|
||||
|
||||
### Poking around
|
||||
|
||||
Snaps have various environment variables available to them that simplify the creation of the snap. They’re all documented [here][6]. You probably won’t need to know much about them to be honest, however there are a few locations that you’ll want to be familiar with once you’ve installed a snap:
|
||||
|
||||
### _$SNAP == /snap/<snap-name>/current_
|
||||
|
||||
This is where the snap and all of it’s files are mounted. Everything here is read-only. In my current install of keystone, $SNAP is /snap/keystone/91\. Fortunately you don’t need to know the current version number as there’s a symlink to that directory at /snap/keystone/current.
|
||||
|
||||
```
|
||||
$ ls /snap/keystone/current/
|
||||
bin etc pysqlite2-doc usr
|
||||
command-manage.wrapper include snap var
|
||||
command-nginx.wrapper lib snap-openstack.yaml
|
||||
command-uwsgi.wrapper meta templates
|
||||
|
||||
$ ls /snap/keystone/current/bin/
|
||||
alembic oslo-messaging-send-notification
|
||||
convert-json oslo-messaging-zmq-broker
|
||||
jsonschema oslo-messaging-zmq-proxy
|
||||
keystone-manage oslopolicy-checker
|
||||
keystone-wsgi-admin oslopolicy-list-redundant
|
||||
keystone-wsgi-public oslopolicy-policy-generator
|
||||
lockutils-wrapper oslopolicy-sample-generator
|
||||
make_metadata.py osprofiler
|
||||
mako-render parse_xsd2.py
|
||||
mdexport.py pbr
|
||||
merge_metadata.py pybabel
|
||||
migrate snap-openstack
|
||||
migrate-repository sqlformat
|
||||
netaddr uwsgi
|
||||
oslo-config-generator
|
||||
|
||||
$ ls /snap/keystone/current/usr/bin/
|
||||
2to3 idle pycompile python2.7-config
|
||||
2to3-2.7 pdb pydoc python2-config
|
||||
cautious-launcher pdb2.7 pydoc2.7 python-config
|
||||
compose pip pygettext pyversions
|
||||
dh_python2 pip2 pygettext2.7 run-mailcap
|
||||
easy_install pip2.7 python see
|
||||
easy_install-2.7 print python2 smtpd.py
|
||||
edit pyclean python2.7
|
||||
|
||||
$ ls /snap/keystone/current/lib/python2.7/site-packages/
|
||||
...
|
||||
```
|
||||
|
||||
### _$SNAP_COMMON == /var/snap/<snap-name>/common_
|
||||
|
||||
This directory is used for system data that is common across revisions of a snap. This is where you’ll override default config files and access log files.
|
||||
|
||||
```
|
||||
$ ls /var/snap/keystone/common/
|
||||
etc fernet-keys lib lock log run
|
||||
|
||||
$ sudo ls /var/snap/keystone/common/etc/
|
||||
keystone nginx uwsgi
|
||||
|
||||
$ ls /var/snap/keystone/common/log/
|
||||
keystone.log nginx-access.log nginx-error.log uwsgi.log
|
||||
```
|
||||
|
||||
### Strict confinement
|
||||
|
||||
The snaps all run under strict confinement, where each snap is run in a restricted environment that is sandboxed with seccomp and AppArmor policy. More details on snap confinement can be viewed [here][7].
|
||||
|
||||
### New features/updates coming for snaps
|
||||
|
||||
There are a few features and updates coming for snaps that I’m looking forward to:
|
||||
|
||||
* We’re working on getting libvirt AppArmor policy in place so that the nova-hypervisor snap can access qcow2 backing files.
|
||||
* For now, as a work-around, you can put virt-aa-helper in complain mode: sudo aa-complain /usr/lib/libvirt/virt-aa-helper
|
||||
|
||||
* We’re also working on getting additional snapd interface policy in place that will enable network connectivity for deployed instances.
|
||||
* For now you can install the nova-hypervisor snap in devmode, which disables security confinement: snap install –devmode –edge nova-hypervisor
|
||||
|
||||
* Auto-connecting nova-hypervisor interfaces. We’re working on getting the interfaces for the nova-hypervisor defined automatically at install time.
|
||||
* Interfaces define the AppArmor and seccomp policy that enables a snap to access resources on the system.
|
||||
|
||||
* For now you can manually connect the required interfaces as described in the nova-hypervisor snap’s README.
|
||||
|
||||
* Auto-alias support for commands. We’re working on getting auto-alias support defined for commands across the snaps, where aliases will be defined automatically at install time.
|
||||
* This enables use of the traditional command names. Instead of ‘nova.manage db sync‘ you’ll be able to issue ‘nova-manage db sync’ right after installing the snap.
|
||||
|
||||
* For now you can manually enable aliases after the snap is installed, such as ‘snap alias nova.manage nova-manage’. See the snap READMEs for more details.
|
||||
|
||||
* Auto-alias support for daemons. Currently snappy only supports aliases for commands (not daemons). Once alias support is available for daemons, we’ll set them up to be automatically configured at install time.
|
||||
* This enables use of the traditional unit file names. Instead of ‘systemctl restart snap.nova.nova-compute’ you’ll be able to issue ‘systemctl restart nova-compute’.
|
||||
|
||||
* Asset tracking for snaps. This will enables tracking of versions used to build the snap which can be re-used in future builds.
|
||||
|
||||
If you’d like to chat more about snaps you can find us on IRC in #openstack-snaps on freenode. We welcome your feedback and contributions! Thanks and have fun! Corey
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Corey Bryant is an Ubuntu core developer and software engineer at Canonical on the OpenStack Engineering team, primarily focusing on OpenStack packaging for Ubuntu and OpenStack charm development for Juju. He's passionate about open-source software and enjoys working with people from all over the world on a common cause.
|
||||
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: 网址
|
||||
|
||||
作者:[ Corey Bryant ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/corey-bryant/
|
||||
[1]:https://insights.ubuntu.com/author/corey-bryant/
|
||||
[2]:http://snapcraft.io/
|
||||
[3]:https://github.com/openstack?utf8=%E2%9C%93&q=snap-&type=&language=
|
||||
[4]:https://github.com/openstack-snaps/snap-cookiecutter/blob/master/README.rst
|
||||
[5]:https://github.com/openstack-snaps/snap-test
|
||||
[6]:https://snapcraft.io/docs/reference/env
|
||||
[7]:https://snapcraft.io/docs/reference/confinement
|
||||
@ -1,4 +1,5 @@
|
||||
The changing face of the hybrid cloud
|
||||
Translating by ZH1122
|
||||
The changing face of the hybrid cloud
|
||||
============================================================
|
||||
|
||||
### Terms and concepts around cloud computing are still new, but evolving.
|
||||
|
||||
@ -1,350 +0,0 @@
|
||||
【haoqixu翻译中】How Linux containers have evolved
|
||||
============================================================
|
||||
|
||||
### Containers have come a long way in the past few years. We walk through the timeline.
|
||||
|
||||
|
||||

|
||||
Image credits :
|
||||
|
||||
[Daniel Ramirez][11]. [CC BY-SA 4.0][12]
|
||||
|
||||
In the past few years, containers have become a hot topic among not just developers, but also enterprises. This growing interest has caused an increased need for security improvements and hardening, and preparing for scaleability and interoperability. This has necessitated a lot of engineering, and here's the story of how much of that engineering has happened at an enterprise level at Red Hat.
|
||||
|
||||
When I first met up with representatives from Docker Inc. (Docker.io) in the fall of 2013, we were looking at how to make Red Hat Enterprise Linux (RHEL) use Docker containers. (Part of the Docker project has since been rebranded as _Moby_ .) We had several problems getting this technology into RHEL. The first big hurdle was getting a supported Copy On Write (COW) file system to handle container image layering. Red Hat ended up contributing a few COW implementations, including [Device Mapper][13], [btrfs][14], and the first version of [OverlayFS][15]. For RHEL, we defaulted to Device Mapper, although we are getting a lot closer on OverlayFS support.
|
||||
|
||||
Linux Containers
|
||||
|
||||
* [What are Linux containers?][1]
|
||||
|
||||
* [What is Docker?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [An introduction to container terminology][4]
|
||||
|
||||
The next major hurdle was on the tooling to launch the container. At that time, upstream docker was using [LXC][16]tools for launching containers, and we did not want to support LXC tools set in RHEL. Prior to working with upstream docker, I had been working with the [libvirt][17] team on a tool called [virt-sandbox][18], which used **libvirt-lxc** for launching containers.
|
||||
|
||||
At the time, some people at Red Hat thought swapping out the LXC tools and adding a bridge so the Docker daemon would communicate with libvirt using **libvirt-lxc** to launch containers was a good idea. There were serious concerns with this approach. Consider the following example of starting a container with the Docker client (**docker-cli**) and the layers of calls before the container process (**pid1OfContainer**) is started:
|
||||
|
||||
**docker-cli → docker-daemon → libvirt-lxc → pid1OfContainer**
|
||||
|
||||
I did not like the idea of having two daemons between your tool to launch containers and the final running container.
|
||||
|
||||
My team worked hard with the upstream docker developers on a native [Go programming language][19] implementation of the container runtime, called [libcontainer][20]. This library eventually got released as the initial implementation of the [OCI Runtime Specification][21]along with runc.
|
||||
|
||||
**docker- ****cli**** → docker-daemon @ pid1OfContainer**
|
||||
|
||||
Although most people mistakenly think that when they execute a container, the container process is a child of the **docker-cli**, they actually have executed a client/server operation and the container process is running as a child of a totally separate environment. This client/server operation can lead to instability and potential security concerns, and it blocks useful features. For example, [systemd][22] has a feature called socket activation, where you can set up a daemon to run only when a process connects to a socket. This means your system uses less memory and only has services executing when they are needed. The way socket activation works is systemd listens at a TCP socket, and when a packet arrives for the socket, systemd activates the service that normally listens on the socket. Once the service is activated, systemd hands the socket to the newly started daemon. Moving this daemon into a Docker-based container causes issues. The unit file would start the container using the Docker CLI and there was no easy way for systemd to pass the connected socket to the Docker daemon through the Docker CLI.
|
||||
|
||||
Problems like this made us realize that we needed alternate ways to run containers.
|
||||
|
||||
### The container orchestration problem
|
||||
|
||||
The upstream docker project made using containers easy, and it continues to be a great tool for learning about Linux containers. You can quickly experience launching a container by running a simple command like **docker run -ti fedora sh** and instantly you are in a container.
|
||||
|
||||
The real power of containers comes about when you start to run many containers simultaneously and hook them together into a more powerful application. The problem with setting up a multi-container application is the complexity quickly grows and wiring it up using simple Docker commands falls apart. How do you manage the placement or orchestration of container applications across a cluster of nodes with limited resources? How does one manage their lifecycle, and so on?
|
||||
|
||||
At the first DockerCon, at least seven different companies/open source projects showed how you could orchestrate containers. Red Hat's [OpenShift][23] had a project called [geard][24], loosely based on OpenShift v2 containers (called "gears"), which we were demonstrating. Red Hat decided that we needed to re-look at orchestration and maybe partner with others in the open source community.
|
||||
|
||||
Google was demonstrating [Kubernetes][25] container orchestration based on all of the knowledge Google had developed in orchestrating their own internal architecture. OpenShift decided to drop our Gear project and start working with Google on Kubernetes. Kubernetes is now one of the largest community projects on GitHub.
|
||||
|
||||
#### Kubernetes
|
||||
|
||||
Kubernetes was developed to use Google's [lmctfy][26] container runtime. Lmctfy was ported to work with Docker during the summer of 2014\. Kubernetes runs a daemon on each node in the Kubernetes cluster called a [kubelet][27]. This means the original Kubernetes with Docker 1.8 workflow looked something like:
|
||||
|
||||
**kubelet → dockerdaemon @ PID1**
|
||||
|
||||
Back to the two-daemon system.
|
||||
|
||||
But it gets worse. With every release of Docker, Kubernetes broke.Docker 1.10 Switched the backing store causing a rebuilding of all images.Docker 1.11 started using **runc** to launch containers:
|
||||
|
||||
**kubelet → dockerdaemon @ runc @PID1**
|
||||
|
||||
Docker 1.12 added a container daemon to launch containers. Its main purpose was to satisfy Docker Swarm (a Kubernetes competitor):
|
||||
|
||||
**kubelet → dockerdaemon → containerd @runc @ pid1**
|
||||
|
||||
As was stated previously, _every_ Docker release has broken Kubernetes functionality, which is why Kubernetes and OpenShift require us to ship older versions of Docker for their workloads.
|
||||
|
||||
Now we have a three-daemon system, where if anything goes wrong on any of the daemons, the entire house of cards falls apart.
|
||||
|
||||
### Toward container standardization
|
||||
|
||||
### CoreOS, rkt, and the alternate runtime
|
||||
|
||||
Due to the issues with the Docker runtime, several organizations were looking at alternative runtimes. One such organization was CoreOS. CoreOS had offered an alternative container runtime to upstream docker, called _rkt_ (rocket). They also introduced a standard container specification called _appc_ (App Container). Basically, they wanted to get everyone to use a standard specification for how you store applications in a container image bundle.
|
||||
|
||||
This threw up red flags. When I first started working on containers with upstream docker, my biggest fear is that we would end up with multiple specifications. I did not want an RPM vs. Debian-like war to affect the next 20 years of shipping Linux software. One good outcome from the appc introduction was that it convinced upstream docker to work with the open source community to create a standards body called the [Open Container Initiative][28] (OCI).
|
||||
|
||||
The OCI has been working on two specifications:
|
||||
|
||||
**[OCI Runtime Specification][6]**: The OCI Runtime Specification "aims to specify the configuration, execution environment, and lifecycle of a container." It defines what a container looks like on disk, the JSON file that describes the application(s) that will run within the container, and how to spawn and execute the container. Upstream docker contributed the libcontainer work and built runc as a default implementation of the OCI Runtime Specification.
|
||||
|
||||
**[OCI Image Format Specification][7]**: The Image Format Specification is based mainly on the upstream docker image format and defines the actual container image bundle that sits at container registries. This specification allows application developers to standardize on a single format for their applications. Some of the ideas described in appc, although it still exists, have been added to the OCI Image Format Specification. Both of these OCI specifications are nearing 1.0 release. Upstream docker has agreed to support the OCI Image Specification once it is finalized. Rkt now supports running OCI images as well as traditional upstream docker images.
|
||||
|
||||
The Open Container Initiative, by providing a place for the industry to standardize around the container image and the runtime, has helped free up innovation in the areas of tooling and orchestration.
|
||||
|
||||
### Abstracting the runtime interface
|
||||
|
||||
One of the innovations taking advantage of this standardization is in the area of Kubernetes orchestration. As a big supporter of the Kubernetes effort, CoreOS submitted a bunch of patches to Kubernetes to add support for communicating and running containers via rkt in addition to the upstream docker engine. Google and upstream Kubernetes saw that adding these patches and possibly adding new container runtime interfaces in the future was going to complicate the Kubernetes code too much. The upstream Kubernetes team decided to implement an API protocol specification called the Container Runtime Interface (CRI). Then they would rework Kubernetes to call into CRI rather than to the Docker engine, so anyone who wants to build a container runtime interface could just implement the server side of the CRI and they could support Kubernetes. Upstream Kubernetes created a large test suite for CRI developers to test against to prove they could service Kubernetes. There is an ongoing effort to remove all of Docker-engine calls from Kubernetes and put them behind a shim called the docker-shim.
|
||||
|
||||
### Innovations in container tooling
|
||||
|
||||
### Container registry innovations with skopeo
|
||||
|
||||
A few years ago, we were working with the Project Atomic team on the [atomic CLI][29] . We wanted the ability to examine a container image when it sat on a container registry. At that time, the only way to look at the JSON data associated with a container image at a container registry was to pull the image to the local server and then you could use **docker inspect** to read the JSON files. These images can be huge, up to multiple gigabytes. Because we wanted to allow users to examine the images and decide not to pull them, we wanted to add a new **--remote** interface to **docker inspect**. Upstream docker rejected the pull request, telling us that they did not want to complicate the Docker CLI, and that we could easily build our own tooling to do the same.
|
||||
|
||||
My team, led by [Antonio Murdaca][30], ran with the idea and created [skopeo][31]. Antonio did not stop at just pulling the JSON file associated with the image—he decided to implement the entire protocol for pulling and pushing container images from container registries to/from the local host.
|
||||
|
||||
Skopeo is now used heavily within the atomic CLI for things such as checking for new updates for containers and inside of [atomic scan][32]. Atomic also uses skopeo for pulling and pushing images, instead of using the upstream docker daemon.
|
||||
|
||||
### Containers/image
|
||||
|
||||
We had been talking to CoreOS about potentially using skopeo with rkt, and they said that they did not want to **exec** out to a helper application, but would consider using the library that skopeo used. We decided to split skopeo apart into a library and executable and created **[image][8]**.
|
||||
|
||||
The [containers/image][33] library and skopeo are used in several other upstream projects and cloud infrastructure tools. Skopeo and containers/image have evolved to support multiple storage backends in addition to Docker, and it has the ability to move container images between container registries and many cool features. A [nice thing about skopeo][34]is it does not require any daemons to do its job. The breakout of containers/image library has also allowed us to add enhancements such as [container image signing][35].
|
||||
|
||||
### Innovations in image handling and scanning
|
||||
|
||||
I mentioned the **atomic** CLI command earlier in this article. We built this tool to add features to containers that did not fit in with the Docker CLI, and things that we did not feel we could get into the upstream docker. We also wanted to allow flexibility to support additional container runtimes, tools, and storage as they developed. Skopeo is an example of this.
|
||||
|
||||
One feature we wanted to add to atomic was **atomic mount**. Basically we wanted to take content that was stored in the Docker image store (upstream docker calls this a graph driver), and mount the image somewhere, so that tools could examine the image. Currently if you use upstream docker, the only way to look at an image is to start the container. If you have untrusted content, executing code inside of the container to look at the image could be dangerous. The second problem with examining an image by starting it is that the tools to examine the container are probably not in the container image.
|
||||
|
||||
Most container image scanners seem to have the following pattern: They connect to the Docker socket, do a **docker save** to create a tarball, then explode the tarball on disk, and finally examine the contents. This is a slow operation.
|
||||
|
||||
With **atomic mount**, we wanted to go into the Docker graph driver and mount the image. If the Docker daemon was using device mapper, we would mount the device. If it was using overlay, we would mount the overlay. This is an incredibly quick operation and satisfies our needs. You can now do:
|
||||
|
||||
```
|
||||
# atomic mount fedora /mnt
|
||||
# cd /mnt
|
||||
```
|
||||
|
||||
And start examining the content. When you are done, do a:
|
||||
|
||||
```
|
||||
# atomic umount /mnt
|
||||
```
|
||||
|
||||
We use this feature inside of **atomic scan**, which allows you to have some of the fastest container scanners around.
|
||||
|
||||
#### **Issues with tool coordination**
|
||||
|
||||
One big problem is that **atomic mount** is doing this under the covers. The Docker daemon does not know that another process is using the image. This could cause problems (for example, if you mounted the Fedora image above and then someone went and executed **docker rmi fedora**, the Docker daemon would fail weirdly when trying to remove the Fedora image saying it was busy). The Docker daemon could get into a weird state.
|
||||
|
||||
### Containers storage
|
||||
|
||||
To solve this issue, we started looking at pulling the graph driver code out of the upstream docker daemon into its own repository. The Docker daemon did all of its locking in memory for the graph driver. We wanted to move this locking into the file system so that we could have multiple distinct processes able to manipulate the container storage at the same time, without having to go through a single daemon process.
|
||||
|
||||
We created a project called [container/storage][36], which can do all of the COW features required for running, building, and storing containers, without requiring one process to control and monitor it (i.e., no daemon required). Now skopeo and other tools and projects can take advantage of the storage. Other open source projects have begun to use containers/storage, and at some point we would like to merge this project back into the upstream docker project.
|
||||
|
||||
### Undock and let's innovate
|
||||
|
||||
If you think about what happens when Kubernetes runs a container on a node with the Docker daemon, first Kubernetes executes a command like:
|
||||
|
||||
```
|
||||
kubelet run nginx –image=nginx
|
||||
```
|
||||
|
||||
This command tells the kubelet to run the NGINX application on the node. The kubelet calls into the CRI and asks it to start the NGINX application. At this point, the container runtime that implemented the CRI must do the following steps:
|
||||
|
||||
1. Check local storage for a container named **nginx**. If not local, the container runtime will search for a standardized container image at a container registry.
|
||||
|
||||
2. If the image is not in local storage, download it from the container registry to the local system.
|
||||
|
||||
3. Explode the the download container image on top of container storage—usually a COW storage—and mount it up.
|
||||
|
||||
4. Execute the container using a standardized container runtime.
|
||||
|
||||
Let's look at the features described above:
|
||||
|
||||
1. OCI Image Format Specification defines the standard image format for images stored at container registries.
|
||||
|
||||
2. Containers/image is the library that implements all features needed to pull a container image from a container registry to a container host.
|
||||
|
||||
3. Containers/storage provides a library to exploding OCI Image Formats onto COW storage and allows you to work with the image.
|
||||
|
||||
4. OCI Runtime Specification and **runc** provide tools for executing the containers (the same tool that the Docker daemon uses for running containers).
|
||||
|
||||
This means we can use these tools to implement the ability to use containers without requiring a big container daemon.
|
||||
|
||||
In a moderate- to large-scale DevOps-based CI/CD environment, efficiency, speed, and security are important. And as long as your tools conform to the OCI specifications, then a developer or an operator should be using the best tools for automation through the CI/CD pipeline and into production. Most of the container tooling is hidden beneath orchestration or higher-up container platform technology. We envision a time in which runtime or image bundle tool selection perhaps becomes an installation option of the container platform.
|
||||
|
||||
### System (standalone) containers
|
||||
|
||||
On Project Atomic we introduced the **atomic host**, a new way of building an operating system in which the software can be "atomicly" updated and most of the applications that run on it will be run as containers. Our goal with this platform is to prove that most software can be shipped in the future in OCI Image Format, and use standard protocols to get images from container registries and install them on your system. Providing software as container images allows you to update the host operating system at a different pace than the applications that run on it. The traditional RPM/yum/DNF way of distributing packages locks the applications to the live cycle of the host operating systems.
|
||||
|
||||
One problem we see with shipping most of the infrastructure as containers is that sometimes you must run an application before the container runtime daemon is executing. Let's look at our Kubernetes example running with the Docker daemon: Kubernetes requires a network to be set up so that it can put its pods/containers into isolated networks. The default daemon we use for this currently is **[flanneld][9]**, which must be running before the Docker daemon is started in order to hand the Docker daemon the network interfaces to run the Kubernetes pods. Also, flanneld uses [**etcd**][37] for its data store. This daemon is required to be run before flanneld is started.
|
||||
|
||||
If we want to ship etcd and flanneld as container images, we have a chicken and egg situation. We need the container runtime daemon to start the containerized applications, but these applications need to be running before the container runtime daemon is started. I have seen several hacky setups to try to handle this situation, but none of them are clean. Also, the Docker daemon currently has no decent way to configure the priority order that containers start. I have seen suggestions on this, but they all look like the old SysVInit way of starting services (and we know the complexities that caused).
|
||||
|
||||
### systemd
|
||||
|
||||
One reason for replacing SysVInit with systemd was to handle the priority and ordering of starting services, so why not take advantage of this technology? In Project Atomic, we decided that we wanted to run containers on the host without requiring a container runtime daemon, especially for early boot. We enhanced the atomic CLI to allow you to install container images. If you execute** atomic install --system etcd**, it uses skopeo to go out to a container registries and pulls down the etcd OCI Image. Then it explodes (or expands) the image onto an OSTree backing store. Because we are running etcd in production, we treat the image as read-only. Next the **atomic** command grabs the systemd unit file template from the container image and creates a unit file on disk to start the image. The unit file actually uses **runc** to start the container on the host (although **runc** is not necessary).
|
||||
|
||||
Similar things happen if you execute **atomic install --system flanneld**, except this time the flanneld unit file specifies that it needs etcd unit running before it starts.
|
||||
|
||||
When the system boots up, systemd ensures that etcd is running before flanneld, and that the container runtime is not started until after flanneld is started. This allows you to move the Docker daemon and Kubernetes into system containers. This means you can boot up an atomic host or a traditional rpm-based operating system that runs the entire container orchestration stack as containers. This is powerful because we know customers want to continue to patch their container hosts independently of these components. Furthermore, it keeps the host's operating system footprint to a minimum.
|
||||
|
||||
There even has been discussion about putting traditional applications into containers that can run either as standalone/system containers or as an orchestrated container. Consider an Apache container that you could install with the **atomic install --system httpd** command. This container image would be started the same way you start an rpm-based httpd service (**systemctl start httpd** except httpd will be started in a container). The storage could be local, meaning /var/www from the host gets mounted into the container, and the container listens on the local network at port 80\. This shows that you could run traditional workloads on a host inside of a container without requiring a container runtime daemon.
|
||||
|
||||
### Building container images
|
||||
|
||||
From my perspective, one of the saddest things about container innovation over the past four years has been the lack of innovation on mechanisms to build container images. A container image is nothing more than a tarball of tarballs and some JSON files. The base image of a container is a rootfs along with an JSON file describing the base image. Then as you add layers, the difference between the layers gets tar’d up along with changes to the JSON file. These layers and the base file get tar'd up together to form the container image.
|
||||
|
||||
Almost everyone is building with the **docker build** and the Dockerfile format. Upstream docker stopped accepting pull requests to modify or improve Dockerfile format and builds a couple of years ago. The Dockerfile played an important part in the evolution of containers. Developers or administrators/operators could build containers in a simple and straightforward manner; however, in my opinion, the Dockerfile is really just a poor man’s bash script and creates several problems that have never been solved. For example:
|
||||
|
||||
* To build a container image, Dockerfile requires a Docker daemon to be running.
|
||||
* No one has built standard tooling to create the OCI image outside of executing Docker commands.
|
||||
|
||||
* Even tools such as **ansible-containers** and OpenShift S2I (Source2Image) use **docker-engine** under the covers.
|
||||
|
||||
* Each line in a Dockerfile creates a new image, which helps in the development process of creating the container because the tooling is smart enough to know that the lines in the Dockerfile have not changed, so the existing images can be used and the lines do not need to be reprocessed. This can lead to a _huge_ number of layers.
|
||||
* Because of these, several people have requested mechanisms to squash the images eliminating the layers. I think upstream docker finally has accepted something to satisfy the need.
|
||||
|
||||
* To pull content from secured sites to put into your container image, often you need some form of secrets. For example you need access to the RHEL certificates and subscriptions in order to add RHEL content to an image.
|
||||
* These secrets can end up in layers stored in the image. And the developer needs to jump through hoops to remove the secrets.
|
||||
|
||||
* To allow volumes to be mounted in during Docker build, we have added a **-v** volume switch to the projectatomic/docker package that we ship, but upstream docker has not accepted these patches.
|
||||
|
||||
* Build artifacts end up inside of the container image. So although Dockerfiles are great for getting started or building containers on a laptop while trying to understand the image you may want to build, they really are not an effective or efficient means to build images in a high-scaled enterprise environment. And behind an automated container platform, you shouldn't care if you are using a more efficient means to build OCI-compliant images.
|
||||
|
||||
### Undock with Buildah
|
||||
|
||||
At DevConf.cz 2017, I asked [Nalin Dahyabhai][38] on my team to look at building what I called **containers-coreutils**, basically, to use the containers/storage and containers/image libraries and build a series of command-line tools that could mimic the syntax of the Dockerfile. Nalin decided to call it [buildah][39], making fun of my Boston accent. With a few buildah primitives, you can build a container image:
|
||||
|
||||
* One of the main concepts of security is to keep the amount of content inside of an OS image as small as possible to eliminate unwanted tools. The idea is that a hacker might need tools to break through an application, and if the tools such as **gcc**, **make**, **dnf** are not present, the attacker can be stopped or confined.
|
||||
|
||||
* Because these images are being pulled and pushed over the internet, shrinking the size of the container is always a good idea.
|
||||
|
||||
* How Docker build works is commands to install software or compile software have to be in the **uildroot** of the container.
|
||||
|
||||
* Executing the **run** command requires all of the executables to be inside of the container image. Just using **dnf** inside of the container image requires that the entire Python stack be present, even if you never use Python in the application.
|
||||
|
||||
* **ctr=$(buildah from fedora)**:
|
||||
* Uses containers/image to pull the Fedora image from a container registry.
|
||||
|
||||
* Returns a container ID (**ctr**).
|
||||
|
||||
* **mnt=$(buildah mount $ctr)**:
|
||||
* Mounts up the newly created container image (**$ctr**).
|
||||
|
||||
* Returns the path to the mount point.
|
||||
|
||||
* You can now use this mount point to write content.
|
||||
|
||||
* **dnf install httpd –installroot=$mnt**:
|
||||
* You can use commands on the host to redirect content into the container, which means you can keep your secrets on the host, you don't have to put them inside of the container, and your build tools can be kept on the host.
|
||||
|
||||
* You don't need **dnf** inside of the container or the Python stack unless your application is going to use it.
|
||||
|
||||
* **cp foobar $mnt/dir**:
|
||||
* You can use any command available in bash to populate the container.
|
||||
|
||||
* **buildah commit $ctr**:
|
||||
* You can create a layer whenever you decide. You control the layers rather than the tool.
|
||||
|
||||
* **buildah config --env container=oci --entrypoint /usr/bin/httpd $ctr**:
|
||||
* All of the commands available inside of Dockerfile can be specified.
|
||||
|
||||
* **buildah run $ctr dnf -y install httpd**:
|
||||
* Buildah **run** is supported, but instead of relying on a container runtime daemon, buildah executes **runc** to run the command inside of a locked down container.
|
||||
|
||||
* **buildah build-using-dockerfile -f Dockerfile .**:
|
||||
|
||||
We want to move tools like **ansible-containers** and OpenShift S2I to use **buildah**rather than requiring a container runtime daemon.
|
||||
|
||||
Another big issue with building in the same container runtime that is used to run containers in production is that you end up with the lowest common denominator when it comes to security. Building containers tends to require a lot more privileges than running containers. For example, we allow the **mknod** capability by default. The **mknod** capability allows processes to create device nodes. Some package installs attempt to create device nodes, yet in production almost no applications do. Removing the **mknod** capability from your containers in production would make your systems more secure.
|
||||
|
||||
Another example is that we default container images to read/write because the install process means writing packages to **/usr**. Yet in production, I argue that you really should run all of your containers in read-only mode. Only allow the containers to write to **tmpfs** or directories that have been volume mounted into the container. By splitting the running of containers from the building, we could change the defaults and make for a much more secure environment.
|
||||
|
||||
* And yes, buildah can build a container image using a Dockerfile.
|
||||
|
||||
### CRI-O a runtime abstraction for Kubernetes
|
||||
|
||||
Kubernetes added an API to plug in any runtime for the pods called Container Runtime Interface (CRI). I am not a big fan of having lots of daemons running on my system, but we have added another. My team led by [Mrunal Patel][40] started working on [CRI-O][41] daemon in late 2016\. This is a Container Runtime Interface daemon for running OCI-based applications. Theoretically, in the future we could compile in the CRI-O code directly into the kubelet to eliminate the second daemon.
|
||||
|
||||
Unlike other container runtimes, CRI-O's only purpose in life is satisfying Kubernetes' needs. Remember the steps described above for what Kubernetes need to run a container.
|
||||
|
||||
Kubernetes sends a message to the kubelet that it wants it to run the NGINX server:
|
||||
|
||||
1. The kubelet calls out to the CRI-O to tell it to run NGINX.
|
||||
|
||||
2. CRI-O answers the CRI request.
|
||||
|
||||
3. CRI-O finds an OCI Image at a container registry.
|
||||
|
||||
4. CRI-O uses containers/image to pull the image from the registry to the host.
|
||||
|
||||
5. CRI-O unpacks the image onto local storage using containers/storage.
|
||||
|
||||
6. CRI-O launches a OCI Runtime Specification, usually **runc**, and starts the container. As I stated previously, the Docker daemon launches its containers using **runc**, in exactly the same way.
|
||||
|
||||
7. If desired, the kubelet could also launch the container using an alternate runtime, such as Clear Containers **runv**.
|
||||
|
||||
CRI-O is intended to be a stable platform for running Kubernetes, and we will not ship a new version of CRI-O unless it passes the entire Kubernetes test suite. All pull requests that go to [https://github.com/Kubernetes-incubator/cri-o][42] run against the entire Kubernetes test suite. You can not get a pull request into CRI-O without passing the tests. CRI-O is fully open, and we have had contributors from several different companies, including Intel, SUSE, IBM, Google, Hyper.sh. As long as a majority of maintainers agree to a patch to CRI-O, it will get accepted, even if the patch is not something that Red Hat wants.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I hope this deep dive helps you understand how Linux containers have evolved. At one point, Linux containers were an every-vendor-for-themselves situation. Docker helped focus on a de facto standard for image creation and simplifying the tools used to work with containers. The Open Container Initiative now means that the industry is working around a core image format and runtime, which fosters innovation around making tooling more efficient for automation, more secure, highly scalable, and easier to use. Containers allow us to examine installing software in new and novel ways—whether they are traditional applications running on a host, or orchestrated micro-services running in the cloud. In many ways, this is just the beginning.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel J Walsh - Daniel Walsh has worked in the computer security field for almost 30 years. Dan joined Red Hat in August 2001.
|
||||
|
||||
via: https://opensource.com/article/17/7/how-linux-containers-evolved
|
||||
|
||||
作者:[ Daniel J Walsh (Red Hat)][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://opensource.com/resources/what-are-linux-containers?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[2]:https://opensource.com/resources/what-docker?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[4]:https://developers.redhat.com/blog/2016/01/13/a-practical-introduction-to-docker-container-terminology/utm_campaign=containers&intcmp=70160000000h1s6AAA
|
||||
[5]:https://opensource.com/article/17/7/how-linux-containers-evolved?rate=k1UcW7wzh6axaB_z8ScE-U8cux6fLXXgW_vboB5tIwk
|
||||
[6]:https://github.com/opencontainers/runtime-spec/blob/master/spec.md
|
||||
[7]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[8]:https://github.com/containers/imagehttps://github.com/containers/image
|
||||
[9]:https://github.com/coreos/flannel
|
||||
[10]:https://opensource.com/user/16673/feed
|
||||
[11]:https://www.flickr.com/photos/danramarch/
|
||||
[12]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[13]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Logical_Volume_Manager_Administration/device_mapper.html
|
||||
[14]:https://btrfs.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:https://www.kernel.org/doc/Documentation/filesystems/overlayfs.txt
|
||||
[16]:https://linuxcontainers.org/
|
||||
[17]:https://libvirt.org/
|
||||
[18]:http://sandbox.libvirt.org/
|
||||
[19]:https://opensource.com/article/17/6/getting-started-go
|
||||
[20]:https://github.com/opencontainers/runc/tree/master/libcontainer
|
||||
[21]:https://github.com/opencontainers/runtime-spec
|
||||
[22]:https://opensource.com/business/15/10/lisa15-interview-alison-chaiken-mentor-graphics
|
||||
[23]:https://www.openshift.com/
|
||||
[24]:https://openshift.github.io/geard/
|
||||
[25]:https://opensource.com/resources/what-is-kubernetes
|
||||
[26]:https://github.com/google/lmctfy
|
||||
[27]:https://kubernetes.io/docs/admin/kubelet/
|
||||
[28]:https://www.opencontainers.org/
|
||||
[29]:https://github.com/projectatomic/atomic
|
||||
[30]:https://twitter.com/runc0m
|
||||
[31]:https://github.com/projectatomic/skopeohttps://github.com/projectatomic/skopeo
|
||||
[32]:https://developers.redhat.com/blog/2016/05/02/introducing-atomic-scan-container-vulnerability-detection/
|
||||
[33]:https://github.com/containers/image
|
||||
[34]:http://rhelblog.redhat.com/2017/05/11/skopeo-copy-to-the-rescue/
|
||||
[35]:https://access.redhat.com/articles/2750891
|
||||
[36]:https://github.com/containers/storage
|
||||
[37]:https://github.com/coreos/etcd
|
||||
[38]:https://twitter.com/nalind
|
||||
[39]:https://github.com/projectatomic/buildah
|
||||
[40]:https://twitter.com/mrunalp
|
||||
[41]:https://github.com/Kubernetes-incubator/cri-o
|
||||
[42]:https://github.com/Kubernetes-incubator/cri-o
|
||||
[43]:https://opensource.com/users/rhatdan
|
||||
[44]:https://opensource.com/users/rhatdan
|
||||
[45]:https://opensource.com/article/17/7/how-linux-containers-evolved#comments
|
||||
@ -0,0 +1,335 @@
|
||||
Writing a Linux Debugger Part 9: Handling variables
|
||||
============================================================
|
||||
|
||||
Variables are sneaky. At one moment they’ll be happily sitting in registers, but as soon as you turn your head they’re spilled to the stack. Maybe the compiler completely throws them out of the window for the sake of optimization. Regardless of how often variables move around in memory, we need some way to track and manipulate them in our debugger. This post will teach you more about handling variables in your debugger and demonstrate a simple implementation using `libelfin`.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
1. [Setup][1]
|
||||
|
||||
2. [Breakpoints][2]
|
||||
|
||||
3. [Registers and memory][3]
|
||||
|
||||
4. [Elves and dwarves][4]
|
||||
|
||||
5. [Source and signals][5]
|
||||
|
||||
6. [Source-level stepping][6]
|
||||
|
||||
7. [Source-level breakpoints][7]
|
||||
|
||||
8. [Stack unwinding][8]
|
||||
|
||||
9. [Handling variables][9]
|
||||
|
||||
10. [Advanced topics][10]
|
||||
|
||||
* * *
|
||||
|
||||
Before you get started, make sure that the version of `libelfin` you are using is the [`fbreg` branch of my fork][11]. This contains some hacks to support getting the base of the current stack frame and evaluating location lists, neither of which are supported by vanilla `libelfin`. You might need to pass `-gdwarf-2` to GCC to get it to generate compatible DWARF information. But before we get into the implementation, I’ll give a more detailed description of how locations are encoded in DWARF 5, which is the most recent specification. If you want more information than what I write here, then you can grab the standard from [here][12].
|
||||
|
||||
### DWARF locations
|
||||
|
||||
The location of a variable in memory at a given moment is encoded in the DWARF information using the `DW_AT_location`attribute. Location descriptions can be either single location descriptions, composite location descriptions, or location lists.
|
||||
|
||||
* Simple location descriptions describe the location of one contiguous piece (usually all) of an object. A simple location description may describe a location in addressable memory, or in a register, or the lack of a location (with or without a known value).
|
||||
* Example:
|
||||
* `DW_OP_fbreg -32`
|
||||
|
||||
* A variable which is entirely stored -32 bytes from the stack frame base
|
||||
|
||||
* Composite location descriptions describe an object in terms of pieces, each of which may be contained in part of a register or stored in a memory location unrelated to other pieces.
|
||||
* Example:
|
||||
* `DW_OP_reg3 DW_OP_piece 4 DW_OP_reg10 DW_OP_piece 2`
|
||||
|
||||
* A variable whose first four bytes reside in register 3 and whose next two bytes reside in register 10.
|
||||
|
||||
* Location lists describe objects which have a limited lifetime or change location during their lifetime.
|
||||
* Example:
|
||||
* `<loclist with 3 entries follows>`
|
||||
* `[ 0]<lowpc=0x2e00><highpc=0x2e19>DW_OP_reg0`
|
||||
|
||||
* `[ 1]<lowpc=0x2e19><highpc=0x2e3f>DW_OP_reg3`
|
||||
|
||||
* `[ 2]<lowpc=0x2ec4><highpc=0x2ec7>DW_OP_reg2`
|
||||
|
||||
* A variable whose location moves between registers depending on the current value of the program counter
|
||||
|
||||
The `DW_AT_location` is encoded in one of three different ways, depending on the kind of location description. `exprloc`s encode simple and composite location descriptions. They consist of a byte length followed by a DWARF expression or location description. `loclist`s and `loclistptr`s encode location lists. They give indexes or offsets into the `.debug_loclists` section, which describes the actual location lists.
|
||||
|
||||
### DWARF Expressions
|
||||
|
||||
The actual location of the variables is computed using DWARF expressions. These consist of a series of operations which operate on a stack of values. There are an impressive number of DWARF operations available, so I won’t explain them all in detail. Instead I’ll give a few examples from each class of expression to give you a taste of what is available. Also, don’t get scared off by these; `libelfin` will take care off all of this complexity for us.
|
||||
|
||||
* Literal encodings
|
||||
* `DW_OP_lit0`, `DW_OP_lit1`, …, `DW_OP_lit31`
|
||||
* Push the literal value on to the stack
|
||||
|
||||
* `DW_OP_addr <addr>`
|
||||
* Pushes the address operand on to the stack
|
||||
|
||||
* `DW_OP_constu <unsigned>`
|
||||
* Pushes the unsigned value on to the stack
|
||||
|
||||
* Register values
|
||||
* `DW_OP_fbreg <offset>`
|
||||
* Pushes the value found at the base of the stack frame, offset by the given value
|
||||
|
||||
* `DW_OP_breg0`, `DW_OP_breg1`, …, `DW_OP_breg31 <offset>`
|
||||
* Pushes the contents of the given register plus the given offset to the stack
|
||||
|
||||
* Stack operations
|
||||
* `DW_OP_dup`
|
||||
* Duplicate the value at the top of the stack
|
||||
|
||||
* `DW_OP_deref`
|
||||
* Treats the top of the stack as a memory address, and replaces it with the contents of that address
|
||||
|
||||
* Arithmetic and logical operations
|
||||
* `DW_OP_and`
|
||||
* Pops the top two values from the stack and pushes back the logical `AND` of them
|
||||
|
||||
* `DW_OP_plus`
|
||||
* Same as `DW_OP_and`, but adds the values
|
||||
|
||||
* Control flow operations
|
||||
* `DW_OP_le`, `DW_OP_eq`, `DW_OP_gt`, etc.
|
||||
* Pops the top two values, compares them, and pushes `1` if the condition is true and `0`otherwise
|
||||
|
||||
* `DW_OP_bra <offset>`
|
||||
* Conditional branch: if the top of the stack is not `0`, skips back or forward in the expression by `offset`
|
||||
|
||||
* Type conversions
|
||||
* `DW_OP_convert <DIE offset>`
|
||||
* Converts value on the top of the stack to a different type, which is described by the DWARF information entry at the given offset
|
||||
|
||||
* Special operations
|
||||
* `DW_OP_nop`
|
||||
* Do nothing!
|
||||
|
||||
### DWARF types
|
||||
|
||||
DWARF’s representation of types needs to be strong enough to give debugger users useful variable representations. Users most often want to be able to debug at the level of their application rather than at the level of their machine, and they need a good idea of what their variables are doing to achieve that.
|
||||
|
||||
DWARF types are encoded in DIEs along with the majority of the other debug information. They can have attributes to indicate their name, encoding, size, endianness, etc. A myriad of type tags are available to express pointers, arrays, structures, typedefs, anything else you could see in a C or C++ program.
|
||||
|
||||
Take this simple structure as an example:
|
||||
|
||||
```
|
||||
struct test{
|
||||
int i;
|
||||
float j;
|
||||
int k[42];
|
||||
test* next;
|
||||
};
|
||||
```
|
||||
|
||||
The parent DIE for this struct is this:
|
||||
|
||||
```
|
||||
< 1><0x0000002a> DW_TAG_structure_type
|
||||
DW_AT_name "test"
|
||||
DW_AT_byte_size 0x000000b8
|
||||
DW_AT_decl_file 0x00000001 test.cpp
|
||||
DW_AT_decl_line 0x00000001
|
||||
|
||||
```
|
||||
|
||||
The above says that we have a structure called `test` of size `0xb8`, declared at line `1` of `test.cpp`. All there are then many children DIEs which describe the members.
|
||||
|
||||
```
|
||||
< 2><0x00000032> DW_TAG_member
|
||||
DW_AT_name "i"
|
||||
DW_AT_type <0x00000063>
|
||||
DW_AT_decl_file 0x00000001 test.cpp
|
||||
DW_AT_decl_line 0x00000002
|
||||
DW_AT_data_member_location 0
|
||||
< 2><0x0000003e> DW_TAG_member
|
||||
DW_AT_name "j"
|
||||
DW_AT_type <0x0000006a>
|
||||
DW_AT_decl_file 0x00000001 test.cpp
|
||||
DW_AT_decl_line 0x00000003
|
||||
DW_AT_data_member_location 4
|
||||
< 2><0x0000004a> DW_TAG_member
|
||||
DW_AT_name "k"
|
||||
DW_AT_type <0x00000071>
|
||||
DW_AT_decl_file 0x00000001 test.cpp
|
||||
DW_AT_decl_line 0x00000004
|
||||
DW_AT_data_member_location 8
|
||||
< 2><0x00000056> DW_TAG_member
|
||||
DW_AT_name "next"
|
||||
DW_AT_type <0x00000084>
|
||||
DW_AT_decl_file 0x00000001 test.cpp
|
||||
DW_AT_decl_line 0x00000005
|
||||
DW_AT_data_member_location 176(as signed = -80)
|
||||
|
||||
```
|
||||
|
||||
Each member has a name, a type (which is a DIE offset), a declaration file and line, and a byte offset into the structure where the member is located. The types which are pointed to come next.
|
||||
|
||||
```
|
||||
< 1><0x00000063> DW_TAG_base_type
|
||||
DW_AT_name "int"
|
||||
DW_AT_encoding DW_ATE_signed
|
||||
DW_AT_byte_size 0x00000004
|
||||
< 1><0x0000006a> DW_TAG_base_type
|
||||
DW_AT_name "float"
|
||||
DW_AT_encoding DW_ATE_float
|
||||
DW_AT_byte_size 0x00000004
|
||||
< 1><0x00000071> DW_TAG_array_type
|
||||
DW_AT_type <0x00000063>
|
||||
< 2><0x00000076> DW_TAG_subrange_type
|
||||
DW_AT_type <0x0000007d>
|
||||
DW_AT_count 0x0000002a
|
||||
< 1><0x0000007d> DW_TAG_base_type
|
||||
DW_AT_name "sizetype"
|
||||
DW_AT_byte_size 0x00000008
|
||||
DW_AT_encoding DW_ATE_unsigned
|
||||
< 1><0x00000084> DW_TAG_pointer_type
|
||||
DW_AT_type <0x0000002a>
|
||||
|
||||
```
|
||||
|
||||
As you can see, `int` on my laptop is a 4-byte signed integer type, and `float` is a 4-byte float. The integer array type is defined by pointing to the `int` type as its element type, a `sizetype` (think `size_t`) as the index type, with `2a` elements. The `test*` type is a `DW_TAG_pointer_type` which references the `test` DIE.
|
||||
|
||||
* * *
|
||||
|
||||
### Implementing a simple variable reader
|
||||
|
||||
As mentioned, `libelfin` will deal with most of the complexity for us. However, it doesn’t implement all of the different methods for representing variable locations, and handling a lot of them in our code would get pretty complex. As such, I’ve chosen to only support `exprloc`s for now. Feel free to add support for more types of expression. If you’re really feeling brave, submit some patches to `libelfin` to help complete the necessary support!
|
||||
|
||||
Handling variables is mostly down to locating the different parts in memory or registers, then reading or writing is the same as you’ve seen before. I’ll only show you how to implement reading for the sake of simplicity.
|
||||
|
||||
First we need to tell `libelfin` how to read registers from our process. We do this by creating a class which inherits from `expr_context` and uses `ptrace` to handle everything:
|
||||
|
||||
```
|
||||
class ptrace_expr_context : public dwarf::expr_context {
|
||||
public:
|
||||
ptrace_expr_context (pid_t pid) : m_pid{pid} {}
|
||||
|
||||
dwarf::taddr reg (unsigned regnum) override {
|
||||
return get_register_value_from_dwarf_register(m_pid, regnum);
|
||||
}
|
||||
|
||||
dwarf::taddr pc() override {
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, m_pid, nullptr, ®s);
|
||||
return regs.rip;
|
||||
}
|
||||
|
||||
dwarf::taddr deref_size (dwarf::taddr address, unsigned size) override {
|
||||
//TODO take into account size
|
||||
return ptrace(PTRACE_PEEKDATA, m_pid, address, nullptr);
|
||||
}
|
||||
|
||||
private:
|
||||
pid_t m_pid;
|
||||
};
|
||||
```
|
||||
|
||||
The reading will be handled by a `read_variables` function in our `debugger` class:
|
||||
|
||||
```
|
||||
void debugger::read_variables() {
|
||||
using namespace dwarf;
|
||||
|
||||
auto func = get_function_from_pc(get_pc());
|
||||
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
The first thing we do above is find the function which we’re currently in. Then we need to loop through the entries in that function, looking for variables:
|
||||
|
||||
```
|
||||
for (const auto& die : func) {
|
||||
if (die.tag == DW_TAG::variable) {
|
||||
//...
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We get the location information by looking up the `DW_AT_location` entry in the DIE:
|
||||
|
||||
```
|
||||
auto loc_val = die[DW_AT::location];
|
||||
```
|
||||
|
||||
Then we ensure that it’s an `exprloc` and ask `libelfin` to evaluate the expression for us:
|
||||
|
||||
```
|
||||
if (loc_val.get_type() == value::type::exprloc) {
|
||||
ptrace_expr_context context {m_pid};
|
||||
auto result = loc_val.as_exprloc().evaluate(&context);
|
||||
```
|
||||
|
||||
Now that we’ve evaluated the expression, we need to read the contents of the variable. It could be in memory or a register, so we’ll handle both cases:
|
||||
|
||||
```
|
||||
switch (result.location_type) {
|
||||
case expr_result::type::address:
|
||||
{
|
||||
auto value = read_memory(result.value);
|
||||
std::cout << at_name(die) << " (0x" << std::hex << result.value << ") = "
|
||||
<< value << std::endl;
|
||||
break;
|
||||
}
|
||||
|
||||
case expr_result::type::reg:
|
||||
{
|
||||
auto value = get_register_value_from_dwarf_register(m_pid, result.value);
|
||||
std::cout << at_name(die) << " (reg " << result.value << ") = "
|
||||
<< value << std::endl;
|
||||
break;
|
||||
}
|
||||
|
||||
default:
|
||||
throw std::runtime_error{"Unhandled variable location"};
|
||||
}
|
||||
```
|
||||
|
||||
As you can see I’ve simply printed out the value without interpreting it based on the type of the variable. Hopefully from this code you can see how you could support writing variables, or searching for variables with a given name.
|
||||
|
||||
Finally we can add this to our command parser:
|
||||
|
||||
```
|
||||
else if(is_prefix(command, "variables")) {
|
||||
read_variables();
|
||||
}
|
||||
```
|
||||
|
||||
### Testing it out
|
||||
|
||||
Write a few small functions which have some variables, compile it without optimizations and with debug info, then see if you can read the values of your variables. Try writing to the memory address where a variable is stored and see the behaviour of the program change.
|
||||
|
||||
* * *
|
||||
|
||||
Nine posts down, one to go! Next time I’ll be talking about some more advanced concepts which might interest you. For now you can find the code for this post [here][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/
|
||||
|
||||
作者:[ Simon Brand][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-break/
|
||||
[8]:https://blog.tartanllama.xyz/writing-a-linux-debugger-unwinding/
|
||||
[9]:https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/
|
||||
[10]:https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
||||
[11]:https://github.com/TartanLlama/libelfin/tree/fbreg
|
||||
[12]:http://dwarfstd.org/
|
||||
[13]:https://github.com/TartanLlama/minidbg/tree/tut_variable
|
||||
@ -0,0 +1,149 @@
|
||||
Writing a Linux Debugger Part 10: Advanced topics
|
||||
============================================================
|
||||
|
||||
We’re finally here at the last post of the series! This time I’ll be giving a high-level overview of some more advanced concepts in debugging: remote debugging, shared library support, expression evaluation, and multi-threaded support. These ideas are more complex to implement, so I won’t walk through how to do so in detail, but I’m happy to answer questions about these concepts if you have any.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
1. [Setup][1]
|
||||
|
||||
2. [Breakpoints][2]
|
||||
|
||||
3. [Registers and memory][3]
|
||||
|
||||
4. [Elves and dwarves][4]
|
||||
|
||||
5. [Source and signals][5]
|
||||
|
||||
6. [Source-level stepping][6]
|
||||
|
||||
7. [Source-level breakpoints][7]
|
||||
|
||||
8. [Stack unwinding][8]
|
||||
|
||||
9. [Handling variables][9]
|
||||
|
||||
10. [Advanced topics][10]
|
||||
|
||||
* * *
|
||||
|
||||
### Remote debugging
|
||||
|
||||
Remote debugging is very useful for embedded systems or debugging the effects of environment differences. It also sets a nice divide between the high-level debugger operations and the interaction with the operating system and hardware. In fact, debuggers like GDB and LLDB operate as remote debuggers even when debugging local programs. The general architecture is this:
|
||||
|
||||

|
||||
|
||||
The debugger is the component which we interact with through the command line. Maybe if you’re using an IDE there’ll be another layer on top which communicates with the debugger through the _machine interface_ . On the target machine (which may be the same as the host) there will be a _debug stub_ , which in theory is a very small wrapper around the OS debug library which carries out all of your low-level debugging tasks like setting breakpoints on addresses. I say “in theory” because stubs are getting larger and larger these days. The LLDB debug stub on my machine is 7.6MB, for example. The debug stub communicates with the debugee process using some OS-specific features (in our case, `ptrace`), and with the debugger though some remote protocol.
|
||||
|
||||
The most common remote protocol for debugging is the GDB remote protocol. This is a text-based packet format for communicating commands and information between the debugger and debug stub. I won’t go into detail about it, but you can read all you could want to know about it [here][11]. If you launch LLDB and execute the command `log enable gdb-remote packets` then you’ll get a trace of all packets sent through the remote protocol. On GDB you can write `set remotelogfile <file>` to do the same.
|
||||
|
||||
As a simple example, here’s the packet to set a breakpoint:
|
||||
|
||||
```
|
||||
$Z0,400570,1#43
|
||||
|
||||
```
|
||||
|
||||
`$` marks the start of the packet. `Z0` is the command to insert a memory breakpoint. `400570` and `1` are the argumets, where the former is the address to set a breakpoint on and the latter is a target-specific breakpoint kind specifier. Finally, the `#43` is a checksum to ensure that there was no data corruption.
|
||||
|
||||
The GDB remote protocol is very easy to extend for custom packets, which is very useful for implementing platform- or language-specific functionality.
|
||||
|
||||
* * *
|
||||
|
||||
### Shared library and dynamic loading support
|
||||
|
||||
The debugger needs to know what shared libraries have been loaded by the debuggee so that it can set breakpoints, get source-level information and symbols, etc. As well as finding libraries which have been dynamically linked against, the debugger must track libraries which are loaded at runtime through `dlopen`. To facilitate this, the dynamic linker maintains a _rendezvous structure_ . This structure maintains a linked list of shared library descriptors, along with a pointer to a function which is called whenever the linked list is updated. This structure is stored where the `.dynamic` section of the ELF file is loaded, and is initialized before program execution.
|
||||
|
||||
A simple tracing algorithm is this:
|
||||
|
||||
* The tracer looks up the entry point of the program in the ELF header (or it could use the auxillary vector stored in `/proc/<pid>/aux`)
|
||||
|
||||
* The tracer places a breakpoint on the entry point of the program and begins execution.
|
||||
|
||||
* When the breakpoint is hit, the address of the rendezvous structure is found by looking up the load address of `.dynamic` in the ELF file.
|
||||
|
||||
* The rendezvous structure is examined to get the list of currently loaded libraries.
|
||||
|
||||
* A breakpoint is set on the linker update function.
|
||||
|
||||
* Whenever the breakpoint is hit, the list is updated.
|
||||
|
||||
* The tracer infinitely loops, continuing the program and waiting for a signal until the tracee signals that it has exited.
|
||||
|
||||
I’ve written a small demonstration of these concepts, which you can find [here][12]. I can do a more detailed write up of this in the future if anyone is interested.
|
||||
|
||||
* * *
|
||||
|
||||
### Expression evaluation
|
||||
|
||||
Expression evaluation is a feature which lets users evaluate expressions in the original source language while debugging their application. For example, in LLDB or GDB you could execute `print foo()` to call the `foo` function and print the result.
|
||||
|
||||
Depending on how complex the expression is, there are a few different ways of evaluating it. If the expression is a simple identifier, then the debugger can look at the debug information, locate the variable and print out the value, just like we did in the last part of this series. If the expression is a bit more complex, then it may be possible to compile the code to an intermediate representation (IR) and interpret that to get the result. For example, for some expressions LLDB will use Clang to compile the expression to LLVM IR and interpret that. If the expression is even more complex, or requires calling some function, then the code might need to be JITted to the target and executed in the address space of the debuggee. This involves calling `mmap` to allocate some executable memory, then the compiled code is copied to this block and is executed. LLDB does this by using LLVM’s JIT functionality.
|
||||
|
||||
If you want to know more about JIT compilation, I’d highly recommend [Eli Bendersky’s posts on the subject][13].
|
||||
|
||||
* * *
|
||||
|
||||
### Multi-threaded debugging support
|
||||
|
||||
The debugger shown in this series only supports single threaded applications, but to debug most real-world applications, multi-threaded support is highly desirable. The simplest way to support this is to trace thread creation and parse the procfs to get the information you want.
|
||||
|
||||
The Linux threading library is called `pthreads`. When `pthread_create` is called, the library creates a new thread using the `clone` syscall, and we can trace this syscall with `ptrace` (assuming your kernel is older than 2.5.46). To do this, you’ll need to set some `ptrace` options after attaching to the debuggee:
|
||||
|
||||
```
|
||||
ptrace(PTRACE_SETOPTIONS, m_pid, nullptr, PTRACE_O_TRACECLONE);
|
||||
```
|
||||
|
||||
Now when `clone` is called, the process will be signaled with our old friend `SIGTRAP`. For the debugger in this series, you can add a case to `handle_sigtrap` which can handle the creation of the new thread:
|
||||
|
||||
```
|
||||
case (SIGTRAP | (PTRACE_EVENT_CLONE << 8)):
|
||||
//get the new thread ID
|
||||
unsigned long event_message = 0;
|
||||
ptrace(PTRACE_GETEVENTMSG, pid, nullptr, message);
|
||||
|
||||
//handle creation
|
||||
//...
|
||||
```
|
||||
|
||||
Once you’ve got that, you can look in `/proc/<pid>/task/` and read the memory maps and suchlike to get all the information you need.
|
||||
|
||||
GDB uses `libthread_db`, which provides a bunch of helper functions so that you don’t need to do all the parsing and processing yourself. Setting up this library is pretty weird and I won’t show how it works here, but you can go and read [this tutorial][14] if you’d like to use it.
|
||||
|
||||
The most complex part of multithreaded support is modelling the thread state in the debugger, particularly if you want to support [non-stop mode][15] or some kind of heterogeneous debugging where you have more than just a CPU involved in your computation.
|
||||
|
||||
* * *
|
||||
|
||||
### The end!
|
||||
|
||||
Whew! This series took a long time to write, but I learned a lot in the process and I hope it was helpful. Get in touch on Twitter [@TartanLlama][16] or in the comments section if you want to chat about debugging or have any questions about the series. If there are any other debugging topics you’d like to see covered then let me know and I might do a bonus post.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
||||
|
||||
作者:[Simon Brand ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-break/
|
||||
[8]:https://blog.tartanllama.xyz/writing-a-linux-debugger-unwinding/
|
||||
[9]:https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/
|
||||
[10]:https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
||||
[11]:https://sourceware.org/gdb/onlinedocs/gdb/Remote-Protocol.html
|
||||
[12]:https://github.com/TartanLlama/dltrace
|
||||
[13]:http://eli.thegreenplace.net/tag/code-generation
|
||||
[14]:http://timetobleed.com/notes-about-an-odd-esoteric-yet-incredibly-useful-library-libthread_db/
|
||||
[15]:https://sourceware.org/gdb/onlinedocs/gdb/Non_002dStop-Mode.html
|
||||
[16]:https://twitter.com/TartanLlama
|
||||
@ -0,0 +1,213 @@
|
||||
Designing a Microservices Architecture for Failure
|
||||
============================================================
|
||||
|
||||
|
||||
A Microservices architecture makes it possible to **isolate failures**through well-defined service boundaries. But like in every distributed system, there is a **higher chance** for network, hardware or application level issues. As a consequence of service dependencies, any component can be temporarily unavailable for their consumers. To minimize the impact of partial outages we need to build fault tolerant services that can **gracefully** respond to certain types of outages.
|
||||
|
||||
This article introduces the most common techniques and architecture patterns to build and operate a **highly available microservices** system based on [RisingStack’s Node.js Consulting & Development experience][3].
|
||||
|
||||
_If you are not familiar with the patterns in this article, it doesn’t necessarily mean that you do something wrong. Building a reliable system always comes with an extra cost._
|
||||
|
||||
### The Risk of the Microservices Architecture
|
||||
|
||||
The microservices architecture moves application logic to services and uses a network layer to communicate between them. Communicating over a network instead of in-memory calls brings extra latency and complexity to the system which requires cooperation between multiple physical and logical components. The increased complexity of the distributed system leads to a higher chance of particular **network failures**.
|
||||
|
||||
One of the biggest advantage of a microservices architecture over a monolithic one is that teams can independently design, develop and deploy their services. They have full ownership over their service's lifecycle. It also means that teams have no control over their service dependencies as it's more likely managed by a different team. With a microservices architecture, we need to keep in mind that provider **services can be temporarily unavailable** by broken releases, configurations, and other changes as they are controlled by someone else and components move independently from each other.
|
||||
|
||||
### Graceful Service Degradation
|
||||
|
||||
One of the best advantages of a microservices architecture is that you can isolate failures and achieve graceful service degradation as components fail separately. For example, during an outage customers in a photo sharing application maybe cannot upload a new picture, but they can still browse, edit and share their existing photos.
|
||||
|
||||

|
||||
|
||||
_Microservices fail separately (in theory)_
|
||||
|
||||
In most of the cases, it's hard to implement this kind of graceful service degradation as applications in a distributed system depend on each other, and you need to apply several failover logics _(some of them will be covered by this article later)_ to prepare for temporary glitches and outages.
|
||||
|
||||

|
||||
|
||||
_Services depend on each other and fail together without failover logics._
|
||||
|
||||
### Change management
|
||||
|
||||
Google’s site reliability team has found that roughly **70% of the outages are caused by changes** in a live system. When you change something in your service - you deploy a new version of your code or change some configuration - there is always a chance for failure or the introduction of a new bug.
|
||||
|
||||
In a microservices architecture, services depend on each other. This is why you should minimize failures and limit their negative effect. To deal with issues from changes, you can implement change management strategies and **automatic rollouts**.
|
||||
|
||||
For example, when you deploy new code, or you change some configuration, you should apply these changes to a subset of your instances gradually, monitor them and even automatically revert the deployment if you see that it has a negative effect on your key metrics.
|
||||
|
||||

|
||||
|
||||
_Change Management - Rolling Deployment_
|
||||
|
||||
Another solution could be that you run two production environments. You always deploy to only one of them, and you only point your load balancer to the new one after you verified that the new version works as it is expected. This is called blue-green, or red-black deployment.
|
||||
|
||||
**Reverting code is not a bad thing.** You shouldn’t leave broken code in production and then think about what went wrong. Always revert your changes when it’s necessary. The sooner the better.
|
||||
|
||||
#### Want to learn more about building reliable mircoservices architectures?
|
||||
|
||||
##### Check out our upcoming trainings!
|
||||
|
||||
[MICROSERVICES TRAININGS ][4]
|
||||
|
||||
### Health-check and Load Balancing
|
||||
|
||||
Instances continuously start, restart and stop because of failures, deployments or autoscaling. It makes them temporarily or permanently unavailable. To avoid issues, your load balancer should **skip unhealthy instances** from the routing as they cannot serve your customers' or sub-systems' need.
|
||||
|
||||
Application instance health can be determined via external observation. You can do it with repeatedly calling a `GET /health`endpoint or via self-reporting. Modern **service discovery** solutions continuously collect health information from instances and configure the load-balancer to route traffic only to healthy components.
|
||||
|
||||
### Self-healing
|
||||
|
||||
Self-healing can help to recover an application. We can talk about self-healing when an application can **do the necessary steps** to recover from a broken state. In most of the cases, it is implemented by an external system that watches the instances health and restarts them when they are in a broken state for a longer period. Self-healing can be very useful in most of the cases, however, in certain situations it **can cause trouble** by continuously restarting the application. This might happen when your application cannot give positive health status because it is overloaded or its database connection times out.
|
||||
|
||||
Implementing an advanced self-healing solution which is prepared for a delicate situation - like a lost database connection - can be tricky. In this case, you need to add extra logic to your application to handle edge cases and let the external system know that the instance is not needed to restart immediately.
|
||||
|
||||
### Failover Caching
|
||||
|
||||
Services usually fail because of network issues and changes in our system. However, most of these outages are temporary thanks to self-healing and advanced load-balancing we should find a solution to make our service work during these glitches. This is where **failover caching** can help and provide the necessary data to our application.
|
||||
|
||||
Failover caches usually use **two different expiration dates**; a shorter that tells how long you can use the cache in a normal situation, and a longer one that says how long can you use the cached data during failure.
|
||||
|
||||
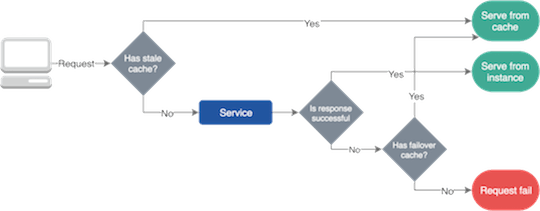
|
||||
|
||||
_Failover Caching_
|
||||
|
||||
It’s important to mention that you can only use failover caching when it serves **the outdated data better than nothing**.
|
||||
|
||||
To set cache and failover cache, you can use standard response headers in HTTP.
|
||||
|
||||
For example, with the `max-age` header you can specify the maximum amount of time a resource will be considered fresh. With the `stale-if-error` header, you can determine how long should the resource be served from a cache in the case of a failure.
|
||||
|
||||
Modern CDNs and load balancers provide various caching and failover behaviors, but you can also create a shared library for your company that contains standard reliability solutions.
|
||||
|
||||
### Retry Logic
|
||||
|
||||
There are certain situations when we cannot cache our data or we want to make changes to it, but our operations eventually fail. In these cases, we can **retry our action** as we can expect that the resource will recover after some time or our load-balancer sends our request to a healthy instance.
|
||||
|
||||
You should be careful with adding retry logic to your applications and clients, as a larger amount of **retries can make things even worse** or even prevent the application from recovering.
|
||||
|
||||
In distributed system, a microservices system retry can trigger multiple other requests or retries and start a **cascading effect**. To minimize the impact of retries, you should limit the number of them and use an exponential backoff algorithm to continually increase the delay between retries until you reach the maximum limit.
|
||||
|
||||
As a retry is initiated by the client _(browser, other microservices, etc.)_ and the client doesn't know that the operation failed before or after handling the request, you should prepare your application to handle **idempotency**. For example, when you retry a purchase operation, you shouldn't double charge the customer. Using a unique **idempotency-key** for each of your transactions can help to handle retries.
|
||||
|
||||
### Rate Limiters and Load Shedders
|
||||
|
||||
Rate limiting is the technique of defining how many requests can be received or processed by a particular customer or application during a timeframe. With rate limiting, for example, you can filter out customers and microservices who are responsible for **traffic peaks**, or you can ensure that your application doesn’t overload until autoscaling can’t come to rescue.
|
||||
|
||||
You can also hold back lower-priority traffic to give enough resources to critical transactions.
|
||||
|
||||

|
||||
|
||||
_A rate limiter can hold back traffic peaks_
|
||||
|
||||
A different type of rate limiter is called the _concurrent request limiter_ . It can be useful when you have expensive endpoints that shouldn’t be called more than a specified times, while you still want to serve traffic.
|
||||
|
||||
A _fleet usage load shedder_ can ensure that there are always enough resources available to **serve critical transactions**. It keeps some resources for high priority requests and doesn’t allow for low priority transactions to use all of them. A load shedder makes its decisions based on the whole state of the system, rather than based on a single user’s request bucket size. Load shedders **help your system to recover**, since they keep the core functionalities working while you have an ongoing incident.
|
||||
|
||||
To read more about rate limiters and load shredders, I recommend checking out [Stripe’s article][5].
|
||||
|
||||
### Fail Fast and Independently
|
||||
|
||||
In a microservices architecture we want to prepare our services **to fail fast and separately**. To isolate issues on service level, we can use the _bulkhead pattern_ . You can read more about bulkheads later in this blog post.
|
||||
|
||||
We also want our components to **fail fast** as we don't want to wait for broken instances until they timeout. Nothing is more disappointing than a hanging request and an unresponsive UI. It's not just wasting resources but also screwing up the user experience. Our services are calling each other in a chain, so we should pay an extra attention to prevent hanging operations before these delays sum up.
|
||||
|
||||
The first idea that would come to your mind would be applying fine grade timeouts for each service calls. The problem with this approach is that you cannot really know what's a good timeout value as there are certain situations when network glitches and other issues happen that only affect one-two operations. In this case, you probably don’t want to reject those requests if there’s only a few of them timeouts.
|
||||
|
||||
We can say that achieving the fail fast paradigm in microservices by **using timeouts is an anti-pattern** and you should avoid it. Instead of timeouts, you can apply the _circuit-breaker_ pattern that depends on the success / fail statistics of operations.
|
||||
|
||||
#### Want to learn more about building reliable mircoservices architectures?
|
||||
|
||||
##### Check out our upcoming trainings!
|
||||
|
||||
[MICROSERVICES TRAININGS ][6]
|
||||
|
||||
### Bulkheads
|
||||
|
||||
Bulkhead is used in the industry to **partition** a ship **into sections**, so that sections can be sealed off if there is a hull breach.
|
||||
|
||||
The concept of bulkheads can be applied in software development to **segregate resources**.
|
||||
|
||||
By applying the bulkheads pattern, we can **protect limited resources** from being exhausted. For example, we can use two connection pools instead of a shared on if we have two kinds of operations that communicate with the same database instance where we have limited number of connections. As a result of this client - resource separation, the operation that timeouts or overuses the pool won't bring all of the other operations down.
|
||||
|
||||
One of the main reasons why Titanic sunk was that its bulkheads had a design failure, and the water could pour over the top of the bulkheads via the deck above and flood the entire hull.
|
||||
|
||||

|
||||
|
||||
_Bulkheads in Titanic (they didn't work)_
|
||||
|
||||
### Circuit Breakers
|
||||
|
||||
To limit the duration of operations, we can use timeouts. Timeouts can prevent hanging operations and keep the system responsive. However, using static, fine tuned timeouts in microservices communication is an **anti-pattern** as we’re in a highly dynamic environment where it's almost impossible to come up with the right timing limitations that work well in every case.
|
||||
|
||||
Instead of using small and transaction-specific static timeouts, we can use circuit breakers to deal with errors. Circuit breakers are named after the real world electronic component because their behavior is identical. You can **protect resources** and **help them to recover** with circuit breakers. They can be very useful in a distributed system where a repetitive failure can lead to a snowball effect and bring the whole system down.
|
||||
|
||||
A circuit breaker opens when a particular type of **error occurs multiple times** in a short period. An open circuit breaker prevents further requests to be made - like the real one prevents electrons from flowing. Circuit breakers usually close after a certain amount of time, giving enough space for underlying services to recover.
|
||||
|
||||
Keep in mind that not all errors should trigger a circuit breaker. For example, you probably want to skip client side issues like requests with `4xx` response codes, but include `5xx` server-side failures. Some circuit breakers can have a half-open state as well. In this state, the service sends the first request to check system availability, while letting the other requests to fail. If this first request succeeds, it restores the circuit breaker to a closed state and lets the traffic flow. Otherwise, it keeps it open.
|
||||
|
||||

|
||||
|
||||
_Circuit Breaker_
|
||||
|
||||
### Testing for Failures
|
||||
|
||||
You should continually **test your system against common issues** to make sure that your services can **survive various failures**. You should test for failures frequently to keep your team prepared for incidents.
|
||||
|
||||
For testing, you can use an external service that identifies groups of instances and randomly terminates one of the instances in this group. With this, you can prepare for a single instance failure, but you can even shut down entire regions to simulate a cloud provider outage.
|
||||
|
||||
One of the most popular testing solutions is the [ChaosMonkey][7]resiliency tool by Netflix.
|
||||
|
||||
### Outro
|
||||
|
||||
Implementing and running a reliable service is not easy. It takes a lot of effort from your side and also costs money to your company.
|
||||
|
||||
Reliability has many levels and aspects, so it is important to find the best solution for your team. You should make reliability a factor in your business decision processes and allocate enough budget and time for it.
|
||||
|
||||
### Key Takeways
|
||||
|
||||
* Dynamic environments and distributed systems - like microservices - lead to a higher chance of failures.
|
||||
|
||||
* Services should fail separately, achieve graceful degradation to improve user experience.
|
||||
|
||||
* 70% of the outages are caused by changes, reverting code is not a bad thing.
|
||||
|
||||
* Fail fast and independently. Teams have no control over their service dependencies.
|
||||
|
||||
* Architectural patterns and techniques like caching, bulkheads, circuit breakers and rate-limiters help to build reliable microservices.
|
||||
|
||||
To learn more about running a reliable service check out our free [Node.js Monitoring, Alerting & Reliability 101 e-book][8]. In case you need help with implementing a microservices system, reach out to us at [@RisingStack][9] on Twitter, or enroll in our upcoming [Building Microservices with Node.js][10].
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
作者简介
|
||||
|
||||
[Péter Márton][2]
|
||||
|
||||
CTO at RisingStack, microservices and brewing beer with Node.js
|
||||
|
||||
[https://twitter.com/slashdotpeter][1]</footer>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.risingstack.com/designing-microservices-architecture-for-failure/
|
||||
|
||||
作者:[ Péter Márton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.risingstack.com/author/peter-marton/
|
||||
[1]:https://twitter.com/slashdotpeter
|
||||
[2]:https://blog.risingstack.com/author/peter-marton/
|
||||
[3]:https://risingstack.com/
|
||||
[4]:https://blog.risingstack.com/training-building-microservices-node-js/?utm_source=rsblog&utm_medium=roadblock-new&utm_content=/designing-microservices-architecture-for-failure/
|
||||
[5]:https://stripe.com/blog/rate-limiters
|
||||
[6]:https://blog.risingstack.com/training-building-microservices-node-js/?utm_source=rsblog&utm_medium=roadblock-new
|
||||
[7]:https://github.com/Netflix/chaosmonkey
|
||||
[8]:https://trace.risingstack.com/monitoring-ebook
|
||||
[9]:https://twitter.com/RisingStack
|
||||
[10]:https://blog.risingstack.com/training-building-microservices-node-js/
|
||||
[11]:https://blog.risingstack.com/author/peter-marton/
|
||||
@ -0,0 +1,201 @@
|
||||
The user’s home dashboard in our app, AlignHow we built our first full-stack JavaScript web app in three weeks
|
||||
============================================================
|
||||
|
||||
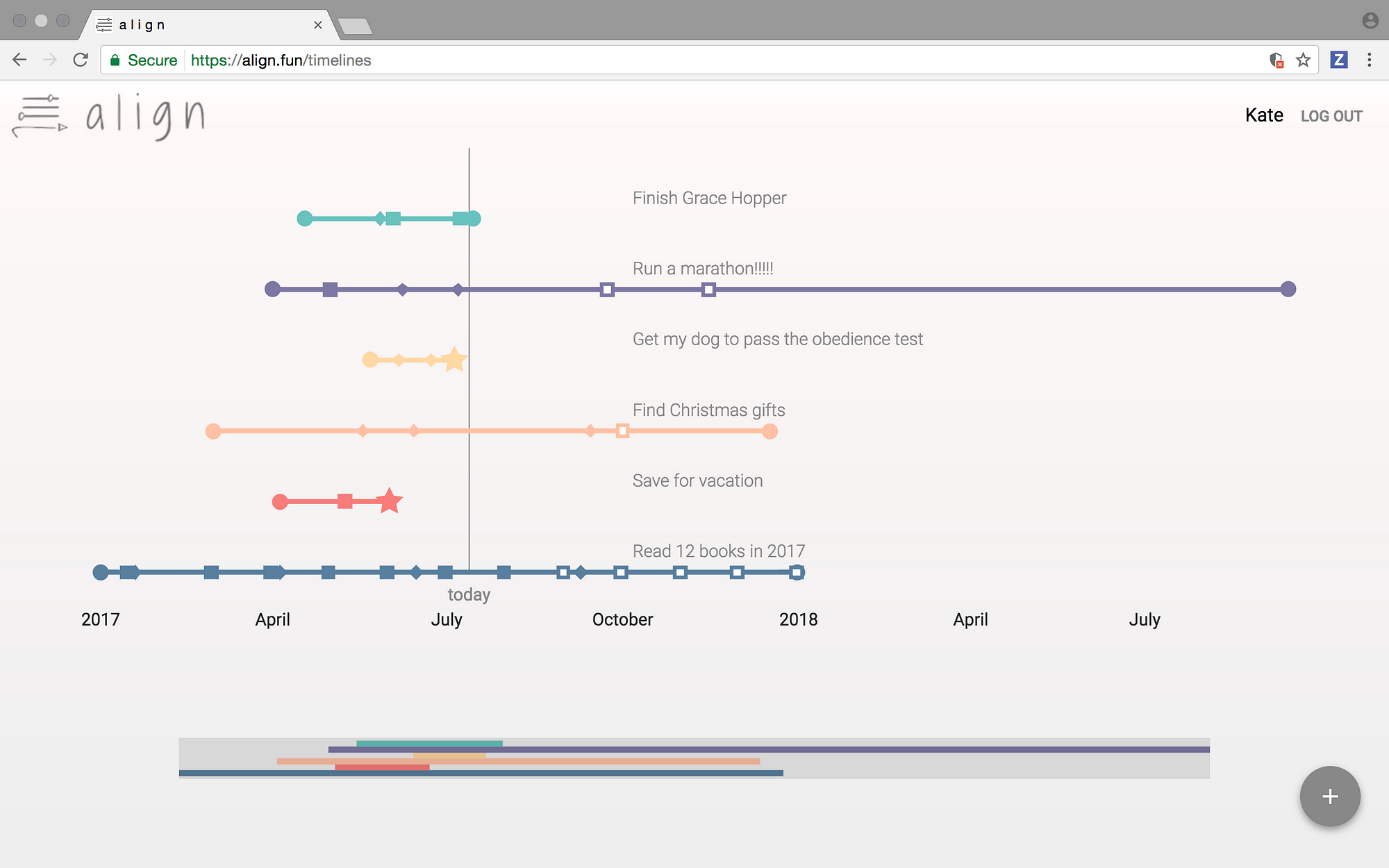
|
||||
|
||||
### A simple step-by-step guide to go from idea to deployed app
|
||||
|
||||
My three months of coding bootcamp at the Grace Hopper Program have come to a close, and the title of this article is actually not quite true — I’ve now built _three_ full-stack apps: [an e-commerce store from scratch][3], a [personal hackathon project][4] of my choice, and finally, a three-week capstone project. That capstone project was by far the most intensive— a three week journey with two teammates — and it is my proudest achievement from bootcamp. It is the first robust, complex app I have ever fully built and designed.
|
||||
|
||||
As most developers know, even when you “know how to code”, it can be really overwhelming to embark on the creation of your first full-stack app. The JavaScript ecosystem is incredibly vast: with package managers, modules, build tools, transpilers, databases, libraries, and decisions to be made about all of them, it’s no wonder that so many budding coders never build anything beyond Codecademy tutorials. That’s why I want to walk you through a step-by-step guide of the decisions and steps my team took to create our live app, Align.
|
||||
|
||||
* * *
|
||||
|
||||
First, some context. Align is a web app that uses an intuitive timeline interface to help users set long-term goals and manage them over time.Our stack includes Firebase for back-end services and React on the front end. My teammates and I explain more in this short video:
|
||||
|
||||
[video](https://youtu.be/YacM6uYP2Jo)
|
||||
|
||||
Demoing Align @ Demo Day Live // July 10, 2017
|
||||
|
||||
So how did we go from Day 1, when we were assigned our teams, to the final live app? Here’s a rundown of the steps we took:
|
||||
|
||||
* * *
|
||||
|
||||
### Step 1: Ideate
|
||||
|
||||
The first step was to figure out what exactly we wanted to build. In my past life as a consultant at IBM, I led ideation workshops with corporate leaders. Pulling from that, I suggested to my group the classic post-it brainstorming strategy, in which we all scribble out as many ideas as we can — even ‘stupid ones’ — so that people’s brains keep moving and no one avoids voicing ideas out of fear.
|
||||
|
||||

|
||||
|
||||
After generating a few dozen app ideas, we sorted them into categories to gain a better understanding of what themes we were collectively excited about. In our group, we saw a clear trend towards ideas surrounding self-improvement, goal-setting, nostalgia, and personal development. From that, we eventually honed in on a specific idea: a personal dashboard for setting and managing long-term goals, with elements of memory-keeping and data visualization over time.
|
||||
|
||||
From there, we created a set of user stories — descriptions of features we wanted to have, from an end-user perspective — to elucidate what exactly we wanted our app to do.
|
||||
|
||||
### Step 2: Wireframe UX/UI
|
||||
|
||||
Next, on a white board, we drew out the basic views we envisioned in our app. We incorporated our set of user stories to understand how these views would work in a skeletal app framework.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
These sketches ensured we were all on the same page, and provided a visual blueprint going forward of what exactly we were all working towards.
|
||||
|
||||
### Step 3: Choose a data structure and type of database
|
||||
|
||||
It was now time to design our data structure. Based on our wireframes and user stories, we created a list in a Google doc of the models we would need and what attributes each should include. We knew we needed a ‘goal’ model, a ‘user’ model, a ‘milestone’ model, and a ‘checkin’ model, as well as eventually a ‘resource’ model, and an ‘upload’ model.
|
||||
|
||||
|
||||

|
||||
Our initial sketch of our data models
|
||||
|
||||
After informally sketching the models out, we needed to choose a _type _ of database: ‘relational’ vs. ‘non-relational’ (a.k.a. ‘SQL’ vs. ‘NoSQL’). Whereas SQL databases are table-based and need predefined schema, NoSQL databases are document-based and have dynamic schema for unstructured data.
|
||||
|
||||
For our use case, it didn’t matter much whether we used a SQL or a No-SQL database, so we ultimately chose Google’s cloud NoSQL database Firebasefor other reasons:
|
||||
|
||||
1. It could hold user image uploads in its cloud storage
|
||||
|
||||
2. It included WebSocket integration for real-time updating
|
||||
|
||||
3. It could handle our user authentication and offer easy OAuth integration
|
||||
|
||||
Once we chose a database, it was time to understand the relations between our data models. Since Firebase is NoSQL, we couldn’t create join tables or set up formal relations like _“Checkins belongTo Goals”_ . Instead, we needed to figure out what the JSON tree would look like, and how the objects would be nested (or not). Ultimately, we structured our model like this:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||

|
||||
Our final Firebase data scheme for the Goal object. Note that Milestones & Checkins are nested under Goals.
|
||||
|
||||
_(Note: Firebase prefers shallow, normalized data structures for efficiency, but for our use case, it made most sense to nest it, since we would never be pulling a Goal from the database without its child Milestones and Checkins.)_
|
||||
|
||||
### Step 4: Set up Github and an agile workflow
|
||||
|
||||
We knew from the start that staying organized and practicing agile development would serve us well. We set up a Github repo, on which weprevented merging to master to force ourselves to review each other’s code.
|
||||
|
||||
|
||||
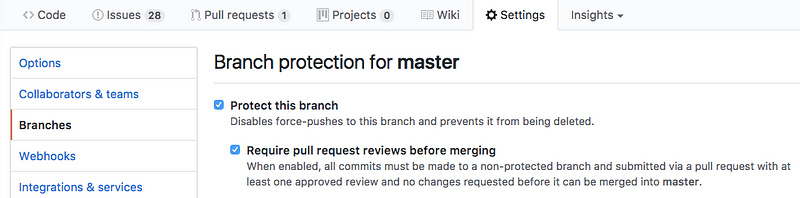
|
||||
|
||||
We also created an agile board on [Waffle.io][5], which is free and has easy integration with Github. On the Waffle board, we listed our user stories as well as bugs we knew we needed to fix. Later, when we started coding, we would each create git branches for the user story we were currently working on, moving it from swim lane to swim lane as we made progress.
|
||||
|
||||
|
||||
|
||||
|
||||
We also began holding “stand-up” meetings each morning to discuss the previous day’s progress and any blockers each of us were encountering. This meeting often decided the day’s flow — who would be pair programming, and who would work on an issue solo.
|
||||
|
||||
I highly recommend some sort of structured workflow like this, as it allowed us to clearly define our priorities and make efficient progress without any interpersonal conflict.
|
||||
|
||||
### Step 5: Choose & download a boilerplate
|
||||
|
||||
Because the JavaScript ecosystem is so complicated, we opted not to build our app from absolute ground zero. It felt unnecessary to spend valuable time wiring up our Webpack build scripts and loaders, and our symlink that pointed to our project directory. My team chose the [Firebones][6] skeleton because it fit our use case, but there are many open-source skeleton options available to choose from.
|
||||
|
||||
### Step 6: Write back-end API routes (or Firebase listeners)
|
||||
|
||||
If we weren’t using a cloud-based database, this would have been the time to start writing our back-end Express routes to make requests to our database. But since we were using Firebase, which is already in the cloud and has a different way of communicating with code, we just worked to set up our first successful database listener.
|
||||
|
||||
To ensure our listener was working, we coded out a basic user form for creating a Goal, and saw that, indeed, when we filled out the form, our database was live-updating. We were connected!
|
||||
|
||||
### Step 7: Build a “Proof Of Concept”
|
||||
|
||||
Our next step was to create a “proof of concept” for our app, or a prototype of the most difficult fundamental features to implement, demonstrating that our app _could _ eventuallyexist. For us, this meant finding a front-end library to satisfactorily render timelines, and connecting it to Firebase successfully to display some seed data in our database.
|
||||
|
||||
|
||||

|
||||
Basic Victory.JS timelines
|
||||
|
||||
We found Victory.JS, a React library built on D3, and spent a day reading the documentation and putting together a very basic example of a _VictoryLine_ component and a _VictoryScatter_ component to visually display data from the database. Indeed, it worked! We were ready to build.
|
||||
|
||||
### Step 8: Code out the features
|
||||
|
||||
Finally, it was time to build out all the exciting functionality of our app. This is a giant step that will obviously vary widely depending on the app you’re personally building. We looked at our wireframes and started coding out the individual user stories in our Waffle. This often included touching both front-end and back-end code (for example, creating a front-end form and also connecting it to the database). Our features ranged from major to minor, and included things like:
|
||||
|
||||
* ability to create new goals, milestones, and checkins
|
||||
|
||||
* ability to delete goals, milestones, and checkins
|
||||
|
||||
* ability to change a timeline’s name, color, and details
|
||||
|
||||
* ability to zoom in on timelines
|
||||
|
||||
* ability to add links to resources
|
||||
|
||||
* ability to upload media
|
||||
|
||||
* ability to bubble up resources and media from milestones and checkins to their associated goals
|
||||
|
||||
* rich text editor integration
|
||||
|
||||
* user signup / authentication / OAuth
|
||||
|
||||
* popover to view timeline options
|
||||
|
||||
* loading screens
|
||||
|
||||
For obvious reasons, this step took up the bulk of our time — this phase is where most of the meaty code happened, and each time we finished a feature, there were always more to build out!
|
||||
|
||||
### Step 9: Choose and code the design scheme
|
||||
|
||||
Once we had an MVP of the functionality we desired in our app, it was time to clean it up and make it pretty. My team used Material-UI for components like form fields, menus, and login tabs, which ensured everything looked sleek, polished, and coherent without much in-depth design knowledge.
|
||||
|
||||
|
||||
|
||||
This was one of my favorite features to code out. Its beauty is so satisfying!
|
||||
|
||||
We spent a while choosing a color scheme and editing the CSS, which provided us a nice break from in-the-trenches coding. We also designed alogo and uploaded a favicon.
|
||||
|
||||
### Step 10: Find and squash bugs
|
||||
|
||||
While we should have been using test-driven development from the beginning, time constraints left us with precious little time for anything but features. This meant that we spent the final two days simulating every user flow we could think of and hunting our app for bugs.
|
||||
|
||||
|
||||

|
||||
|
||||
This process was not the most systematic, but we found plenty of bugs to keep us busy, including a bug in which the loading screen would last indefinitely in certain situations, and one in which the resource component had stopped working entirely. Fixing bugs can be annoying, but when it finally works, it’s extremely satisfying.
|
||||
|
||||
### Step 11: Deploy the live app
|
||||
|
||||
The final step was to deploy our app so it would be available live! Because we were using Firebase to store our data, we deployed to Firebase Hosting, which was intuitive and simple. If your back end uses a different database, you can use Heroku or DigitalOcean. Generally, deployment directions are readily available on the hosting site.
|
||||
|
||||
We also bought a cheap domain name on Namecheap.com to make our app more polished and easy to find.
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
And that was it — we were suddenly the co-creators of a real live full-stack app that someone could use! If we had a longer runway, Step 12 would have been to run A/B testing on users, so we could better understand how actual users interact with our app and what they’d like to see in a V2.
|
||||
|
||||
For now, however, we’re happy with the final product, and with the immeasurable knowledge and understanding we gained throughout this process. Check out Align [here][7]!
|
||||
|
||||
|
||||

|
||||
Team Align: Sara Kladky (left), Melanie Mohn (center), and myself.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/ladies-storm-hackathons/how-we-built-our-first-full-stack-javascript-web-app-in-three-weeks-8a4668dbd67c?imm_mid=0f581a&cmp=em-web-na-na-newsltr_20170816
|
||||
|
||||
作者:[Sophia Ciocca ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@sophiaciocca?source=post_header_lockup
|
||||
[1]:https://medium.com/@sophiaciocca?source=post_header_lockup
|
||||
[2]:https://medium.com/@sophiaciocca?source=post_header_lockup
|
||||
[3]:https://github.com/limitless-leggings/limitless-leggings
|
||||
[4]:https://www.youtube.com/watch?v=qyLoInHNjoc
|
||||
[5]:http://www.waffle.io/
|
||||
[6]:https://github.com/FullstackAcademy/firebones
|
||||
[7]:https://align.fun/
|
||||
[8]:https://github.com/align-capstone/align
|
||||
[9]:https://github.com/sophiaciocca
|
||||
[10]:https://github.com/Kladky
|
||||
[11]:https://github.com/melaniemohn
|
||||
537
sources/tech/20170811 UP – deploy serverless apps in seconds.md
Normal file
537
sources/tech/20170811 UP – deploy serverless apps in seconds.md
Normal file
@ -0,0 +1,537 @@
|
||||
UP – deploy serverless apps in seconds
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Last year I wrote [Blueprints for Up][1], describing how most of the building blocks are available to create a great serverless experience on AWS with minimal effort. This post talks about the initial alpha release of [Up][2].
|
||||
|
||||
Why focus on serverless? For starters it’s cost-effective since you pay on-demand, only for what you use. Serverless options are self-healing, as each request is isolated and considered to be “stateless.” And finally it scales indefinitely with ease — there are no machines or clusters to manage. Deploy your code and you’re done.
|
||||
|
||||
Roughly a month ago I decided to start working on it over at [apex/up][3], and wrote the first small serverless sample application [tj/gh-polls][4] for live SVG GitHub user polls. It worked well and costs less than $1/month to serve millions of polls, so I thought I’d go ahead with the project and see if I can offer open-source and commercial variants.
|
||||
|
||||
The long-term goal is to provide a “Bring your own Heroku” of sorts, supporting many platforms. While Platform-as-a-Service is nothing new, the serverless ecosystem is making this kind of program increasingly trivial. This said, AWS and others often suffer in terms of UX due to the flexibility they provide. Up abstracts the complexity away, while still providing you with a virtually ops-free solution.
|
||||
|
||||
### Installation
|
||||
|
||||
You can install Up with the following command, and view the [temporary documentation][5] to get started. Or if you’re sketched out by install scripts, grab a [binary release][6]. (Keep in mind that this project is still early on.)
|
||||
|
||||
```
|
||||
curl -sfL https://raw.githubusercontent.com/apex/up/master/install.sh | sh
|
||||
```
|
||||
|
||||
To upgrade to the latest version at any time just run:
|
||||
|
||||
```
|
||||
up upgrade
|
||||
```
|
||||
|
||||
You may also install via NPM:
|
||||
|
||||
```
|
||||
npm install -g up
|
||||
```
|
||||
|
||||
### Features
|
||||
|
||||
What features does the early alpha provide? Let’s take a look! Keep in mind that Up is not a hosted service, so you’ll need an AWS account and [AWS credentials][8]. If you’re not familiar at all with AWS you may want to hold off until that process is streamlined.
|
||||
|
||||
The first question I always get is: how does up(1) differ from [apex(1)][9]? Apex focuses on deploying functions, for pipelines and event processing, while Up focuses on apps, apis, and static sites, aka single deployable units. Apex does not provision API Gateway, SSL certs, or DNS for you, nor does it provide URL rewriting, script injection and so on.
|
||||
|
||||
#### Single command serverless apps
|
||||
|
||||
Up lets you deploy apps, apis, and static sites with a single command. To create an application all you need is a single file, in the case of Node.js, an `./app.js` listening on `PORT` which is provided by Up. Note that if you’re using a `package.json` Up will detect and utilize the `start` and `build`scripts.
|
||||
|
||||
```
|
||||
const http = require('http')
|
||||
const { PORT = 3000 } = process.env
|
||||
```
|
||||
|
||||
```
|
||||
http.createServer((req, res) => {
|
||||
res.end('Hello World\n')
|
||||
}).listen(PORT)
|
||||
```
|
||||
|
||||
Additional [runtimes][10] are supported out of the box, such as `main.go` for Golang, so you can deploy Golang, Python, Crystal, or Node.js applications in seconds.
|
||||
|
||||
```
|
||||
package main
|
||||
```
|
||||
|
||||
```
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"net/http"
|
||||
"os"
|
||||
)
|
||||
```
|
||||
|
||||
```
|
||||
func main() {
|
||||
addr := ":" + os.Getenv("PORT")
|
||||
http.HandleFunc("/", hello)
|
||||
log.Fatal(http.ListenAndServe(addr, nil))
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
func hello(w http.ResponseWriter, r *http.Request) {
|
||||
fmt.Fprintln(w, "Hello World from Go")
|
||||
}
|
||||
```
|
||||
|
||||
To deploy the application type `up` to create the resources required, and deploy the application itself. There are no smoke and mirrors here, once it says “complete”, you’re done, the app is immediately available — there is no remote build process.
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
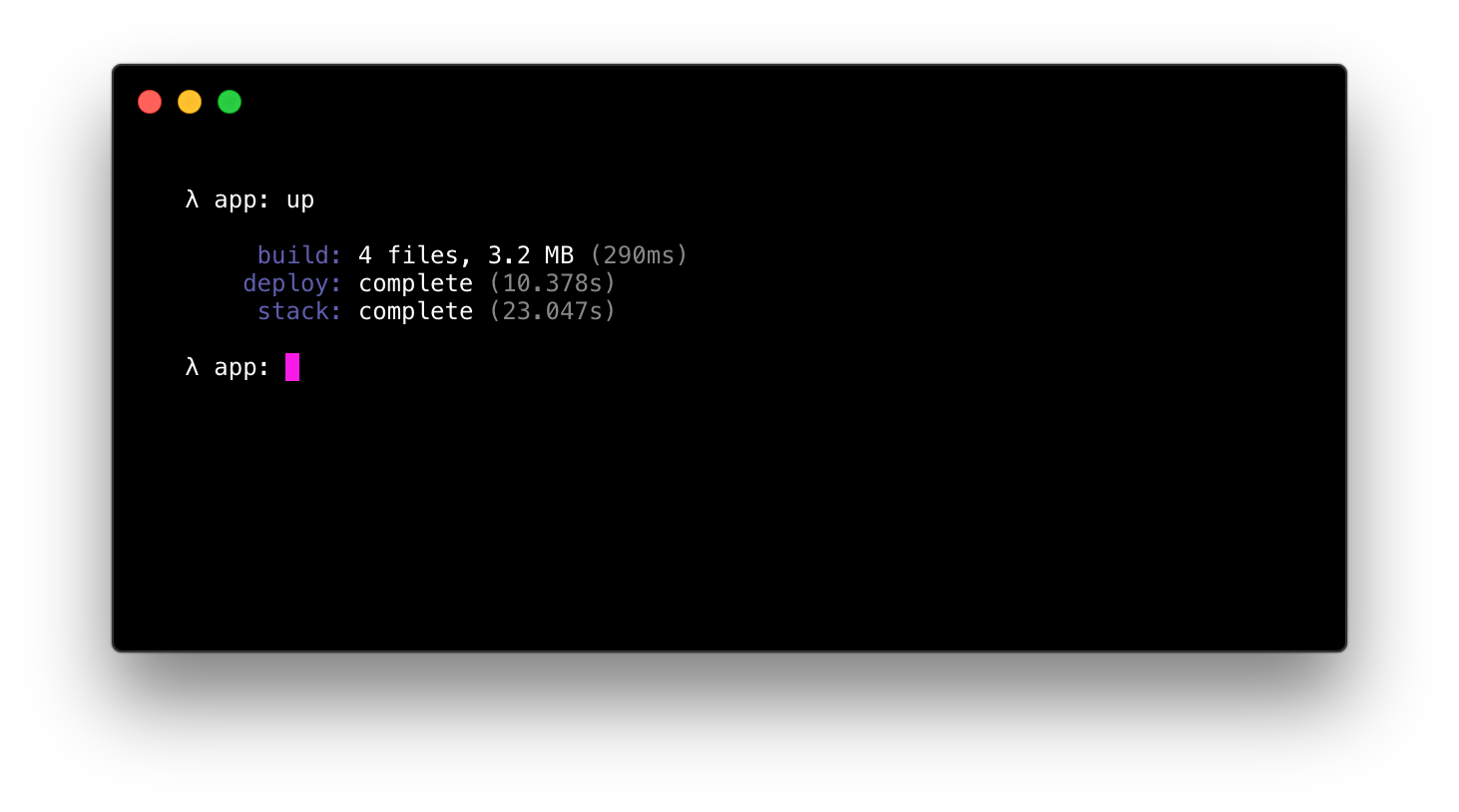
|
||||
|
||||
The subsequent deploys will be even quicker since the stack is already provisioned:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
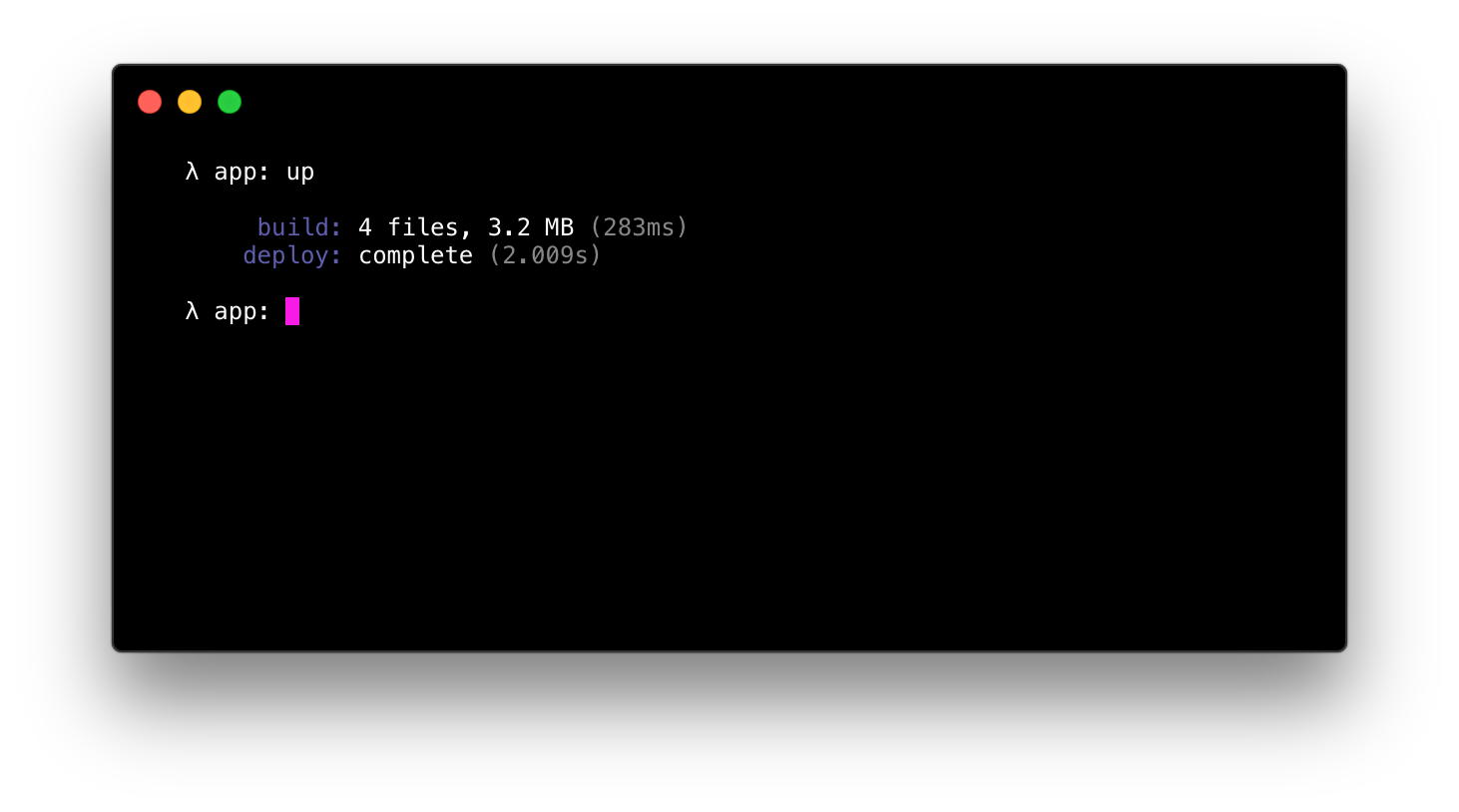
|
||||
|
||||
Test out your app with `up url --open` to view it in the browser, `up url --copy` to save the URL to the clipboard, or try it with curl:
|
||||
|
||||
```
|
||||
curl `up url`
|
||||
Hello World
|
||||
```
|
||||
|
||||
To delete the app and its resources just type `up stack delete`:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
Deploy to the staging or production environments using `up staging` or `up production` , and `up url --open production` for example. Note that custom domains are not yet available, [they will be shortly][11]. Later you’ll also be able to “promote” a release to other stages.
|
||||
|
||||
#### Reverse proxy
|
||||
|
||||
One feature which makes Up unique is that it doesn’t just simply deploy your code, it places a Golang reverse proxy in front of your application. This provides many features such as URL rewriting, redirection, script injection and more, which we’ll look at further in the post.
|
||||
|
||||
#### Infrastructure as code
|
||||
|
||||
Up follows modern best practices in terms of configuration, as all changes to the infrastructure can be previewed before applying, and the use of IAM policies can also restrict developer access to prevent mishaps. A side benefit is that it helps self-document your infrastructure as well.
|
||||
|
||||
Here’s an example of configuring some (dummy) DNS records and free SSL certificates via AWS ACM which utilizes LetsEncrypt.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"dns": {
|
||||
"myapp.com": [
|
||||
{
|
||||
"name": "myapp.com",
|
||||
"type": "A",
|
||||
"ttl": 300,
|
||||
"value": ["35.161.83.243"]
|
||||
},
|
||||
{
|
||||
"name": "blog.myapp.com",
|
||||
"type": "CNAME",
|
||||
"ttl": 300,
|
||||
"value": ["34.209.172.67"]
|
||||
},
|
||||
{
|
||||
"name": "api.myapp.com",
|
||||
"type": "A",
|
||||
"ttl": 300,
|
||||
"value": ["54.187.185.18"]
|
||||
}
|
||||
]
|
||||
},
|
||||
"certs": [
|
||||
{
|
||||
"domains": ["myapp.com", "*.myapp.com"]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
When you deploy the application the first time via `up` all the permissions required, API Gateway, Lambda function, ACM certs, Route53 DNS records and others are created for you.
|
||||
|
||||
[ChangeSets][12] are not yet implemented but you will be able to preview further changes with `up stack plan` and commit them with `up stack apply`, much like you would with Terraform.
|
||||
|
||||
Check out the [configuration documentation][13] for more information.
|
||||
|
||||
#### Global deploys
|
||||
|
||||
The `regions` array allows you to specify target regions for your app. For example if you’re only interested in a single region you’d use:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["us-west-2"]
|
||||
}
|
||||
```
|
||||
|
||||
If your customers are concentrated in North America, you may want to use all of the US and CA regions:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["us-*", "ca-*"]
|
||||
}
|
||||
```
|
||||
|
||||
Lastly of course you can target all 14 regions currently supported:
|
||||
|
||||
```
|
||||
{
|
||||
"regions": ["*"]
|
||||
}
|
||||
```
|
||||
|
||||
Multi-region support is still a work-in-progress as a few new AWS features are required to tie things together.
|
||||
|
||||
#### Static file serving
|
||||
|
||||
Up supports static file serving out of the box, with HTTP cache support, so you can use CloudFront or any other CDN in front of your application to dramatically reduce latency.
|
||||
|
||||
By default the working directory is served (`.`) when `type` is “static”, however you may provide a `static.dir` as well:
|
||||
|
||||
```
|
||||
{ "name": "app", "type": "static", "static": { "dir": "public" }}
|
||||
```
|
||||
|
||||
#### Build hooks
|
||||
|
||||
The build hooks allow you to define custom actions when deploying or performing other operations. A common example would be to bundle Node.js apps using Webpack or Browserify, greatly reducing the file size, as node_modules is _huge_ .
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"hooks": {
|
||||
"build": "browserify --node server.js > app.js",
|
||||
"clean": "rm app.js"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Script and stylesheet injection
|
||||
|
||||
Up allows you to inject scripts and styles, either inline or paths in a declarative manner. It even supports a number of “canned” scripts for Google Analytics and [Segment][14], just copy & paste your write key.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "site",
|
||||
"type": "static",
|
||||
"inject": {
|
||||
"head": [
|
||||
{
|
||||
"type": "segment",
|
||||
"value": "API_KEY"
|
||||
},
|
||||
{
|
||||
"type": "inline style",
|
||||
"file": "/css/primer.css"
|
||||
}
|
||||
],
|
||||
"body": [
|
||||
{
|
||||
"type": "script",
|
||||
"value": "/app.js"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Rewrites and redirects
|
||||
|
||||
Up supports redirects and URL rewriting via the `redirects` object, which maps path patterns to a new location. If `status` is omitted (or 200) then it is a rewrite, otherwise it is a redirect.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"type": "static",
|
||||
"redirects": {
|
||||
"/blog": {
|
||||
"location": "https://blog.apex.sh/",
|
||||
"status": 301
|
||||
},
|
||||
"/docs/:section/guides/:guide": {
|
||||
"location": "/help/:section/:guide",
|
||||
"status": 302
|
||||
},
|
||||
"/store/*": {
|
||||
"location": "/shop/:splat"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
A common use-case for rewrites is for SPAs (Single Page Apps), where you want to serve the `index.html` file regardless of the path. Unless of course the file exists.
|
||||
|
||||
```
|
||||
{
|
||||
"name": "app",
|
||||
"type": "static",
|
||||
"redirects": {
|
||||
"/*": {
|
||||
"location": "/",
|
||||
"status": 200
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
If you want to force the rule regardless of a file existing, just add `"force": true` .
|
||||
|
||||
#### Environment variables
|
||||
|
||||
Secrets will be in the next release, however for now plain-text environment variables are supported:
|
||||
|
||||
```
|
||||
{
|
||||
"name": "api",
|
||||
"environment": {
|
||||
"API_FEATURE_FOO": "1",
|
||||
"API_FEATURE_BAR": "0"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### CORS support
|
||||
|
||||
The [CORS][16] support allows you to to specify which (if any) domains can access your API from the browser. If you wish to allow any site to access your API, just enable it:
|
||||
|
||||
```
|
||||
{
|
||||
"cors": {
|
||||
"enable": true
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You can also customize access, for example restricting API access to your front-end or SPA only.
|
||||
|
||||
```
|
||||
{
|
||||
"cors": {
|
||||
"allowed_origins": ["https://myapp.com"],
|
||||
"allowed_methods": ["HEAD", "GET", "POST", "PUT", "DELETE"],
|
||||
"allowed_headers": ["Content-Type", "Authorization"]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### Logging
|
||||
|
||||
For the low price of $0.5/GB you can utilize CloudWatch logs for structured log querying and tailing. Up implements a custom [query language][18] used to improve upon what CloudWatch provides, purpose-built for querying structured JSON logs.
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
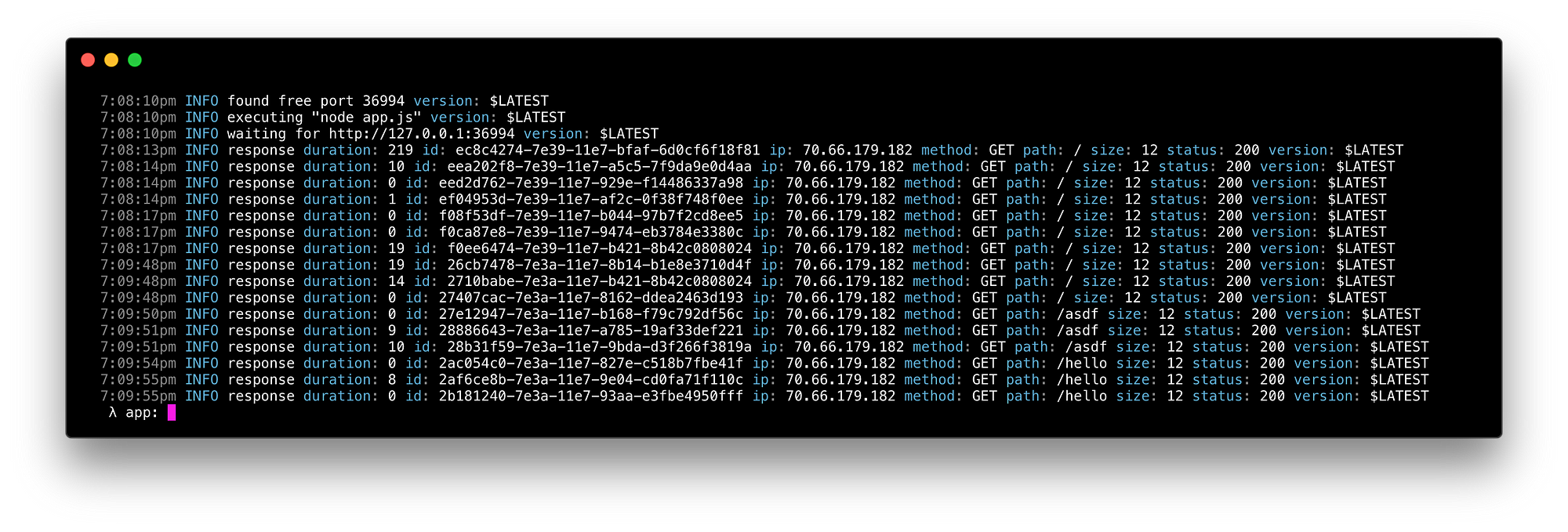
|
||||
|
||||
You can query existing logs:
|
||||
|
||||
```
|
||||
up logs
|
||||
```
|
||||
|
||||
Tail live logs:
|
||||
|
||||
```
|
||||
up logs -f
|
||||
```
|
||||
|
||||
Or filter on either of them, for example only showing 200 GET / HEAD requests that take more than 5 milliseconds to complete:
|
||||
|
||||
```
|
||||
up logs 'method in ("GET", "HEAD") status = 200 duration >= 5'
|
||||
```
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
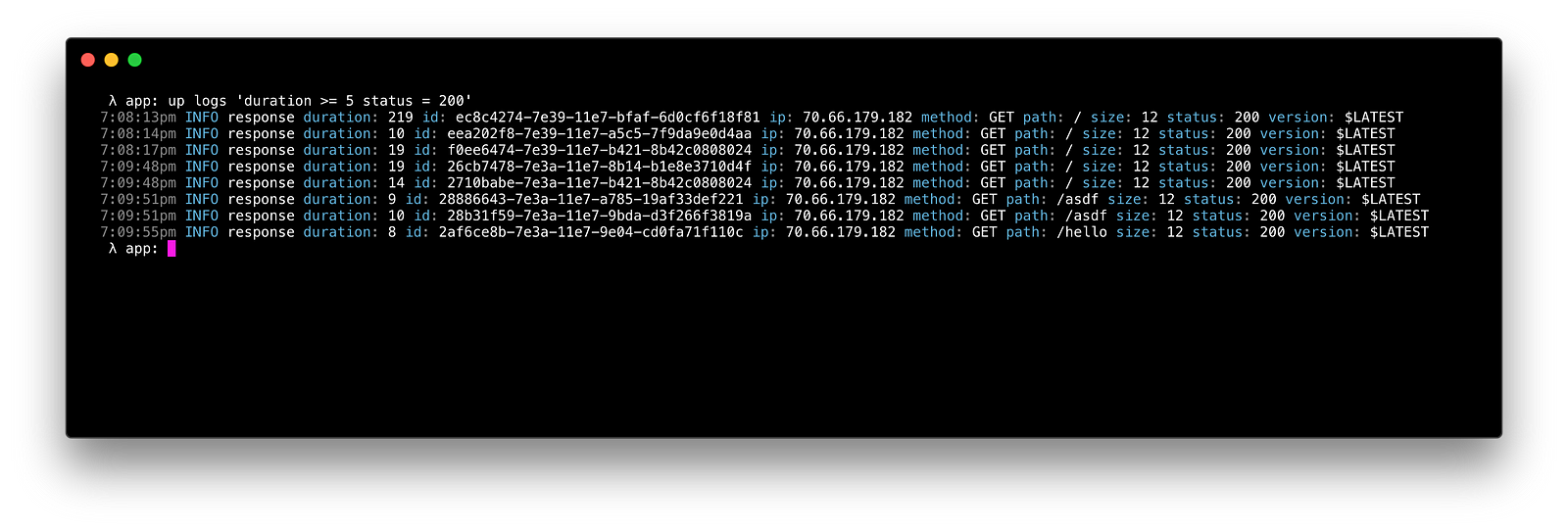
|
||||
|
||||
The query language is quite flexible, here are some more examples from `up help logs`
|
||||
|
||||
```
|
||||
Show logs from the past 5 minutes.
|
||||
$ up logs
|
||||
```
|
||||
|
||||
```
|
||||
Show logs from the past 30 minutes.
|
||||
$ up logs -s 30m
|
||||
```
|
||||
|
||||
```
|
||||
Show logs from the past 5 hours.
|
||||
$ up logs -s 5h
|
||||
```
|
||||
|
||||
```
|
||||
Show live log output.
|
||||
$ up logs -f
|
||||
```
|
||||
|
||||
```
|
||||
Show error logs.
|
||||
$ up logs error
|
||||
```
|
||||
|
||||
```
|
||||
Show error and fatal logs.
|
||||
$ up logs 'error or fatal'
|
||||
```
|
||||
|
||||
```
|
||||
Show non-info logs.
|
||||
$ up logs 'not info'
|
||||
```
|
||||
|
||||
```
|
||||
Show logs with a specific message.
|
||||
$ up logs 'message = "user login"'
|
||||
```
|
||||
|
||||
```
|
||||
Show 200 responses with latency above 150ms.
|
||||
$ up logs 'status = 200 duration > 150'
|
||||
```
|
||||
|
||||
```
|
||||
Show 4xx and 5xx responses.
|
||||
$ up logs 'status >= 400'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails containing @apex.sh.
|
||||
$ up logs 'user.email contains "@apex.sh"'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails ending with @apex.sh.
|
||||
$ up logs 'user.email = "*@apex.sh"'
|
||||
```
|
||||
|
||||
```
|
||||
Show emails starting with tj@.
|
||||
$ up logs 'user.email = "tj@*"'
|
||||
```
|
||||
|
||||
```
|
||||
Show errors from /tobi and /loki
|
||||
$ up logs 'error and (path = "/tobi" or path = "/loki")'
|
||||
```
|
||||
|
||||
```
|
||||
Show the same as above with 'in'
|
||||
$ up logs 'error and path in ("/tobi", "/loki")'
|
||||
```
|
||||
|
||||
```
|
||||
Show logs with a more complex query.
|
||||
$ up logs 'method in ("POST", "PUT") ip = "207.*" status = 200 duration >= 50'
|
||||
```
|
||||
|
||||
```
|
||||
Pipe JSON error logs to the jq tool.
|
||||
$ up logs error | jq
|
||||
```
|
||||
|
||||
Note that the `and` keyword is implied, though you can use it if you prefer.
|
||||
|
||||
#### Cold start times
|
||||
|
||||
This is a property of AWS Lambda as a platform, but the cold start times are typically well below 1 second, and in the future I plan on providing an option to keep them warm.
|
||||
|
||||
#### Config validation
|
||||
|
||||
The `up config` command outputs the resolved configuration, complete with defaults and inferred runtime settings – it also serves the dual purpose of validating configuration, as any error will result in exit > 0.
|
||||
|
||||
#### Crash recovery
|
||||
|
||||
Another benefit of using Up as a reverse proxy is performing crash recovery — restarting your server upon crashes and re-attempting the request before responding to the client with an error.
|
||||
|
||||
For example suppose your Node.js application crashes with an uncaught exception due to an intermittent database issue, Up can retry this request before ever responding to the client. Later this behaviour will be more customizable.
|
||||
|
||||
#### Continuous integration friendly
|
||||
|
||||
It’s hard to call this a feature, but thanks to Golang’s relatively small and isolated binaries, you can install Up in a CI in a second or two.
|
||||
|
||||
#### HTTP/2
|
||||
|
||||
Up supports HTTP/2 out of the box via API Gateway, reducing the latency for serving apps and sites with with many assets. I’ll do more comprehensive testing against many platforms in the future, but Up’s latency is already favourable:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
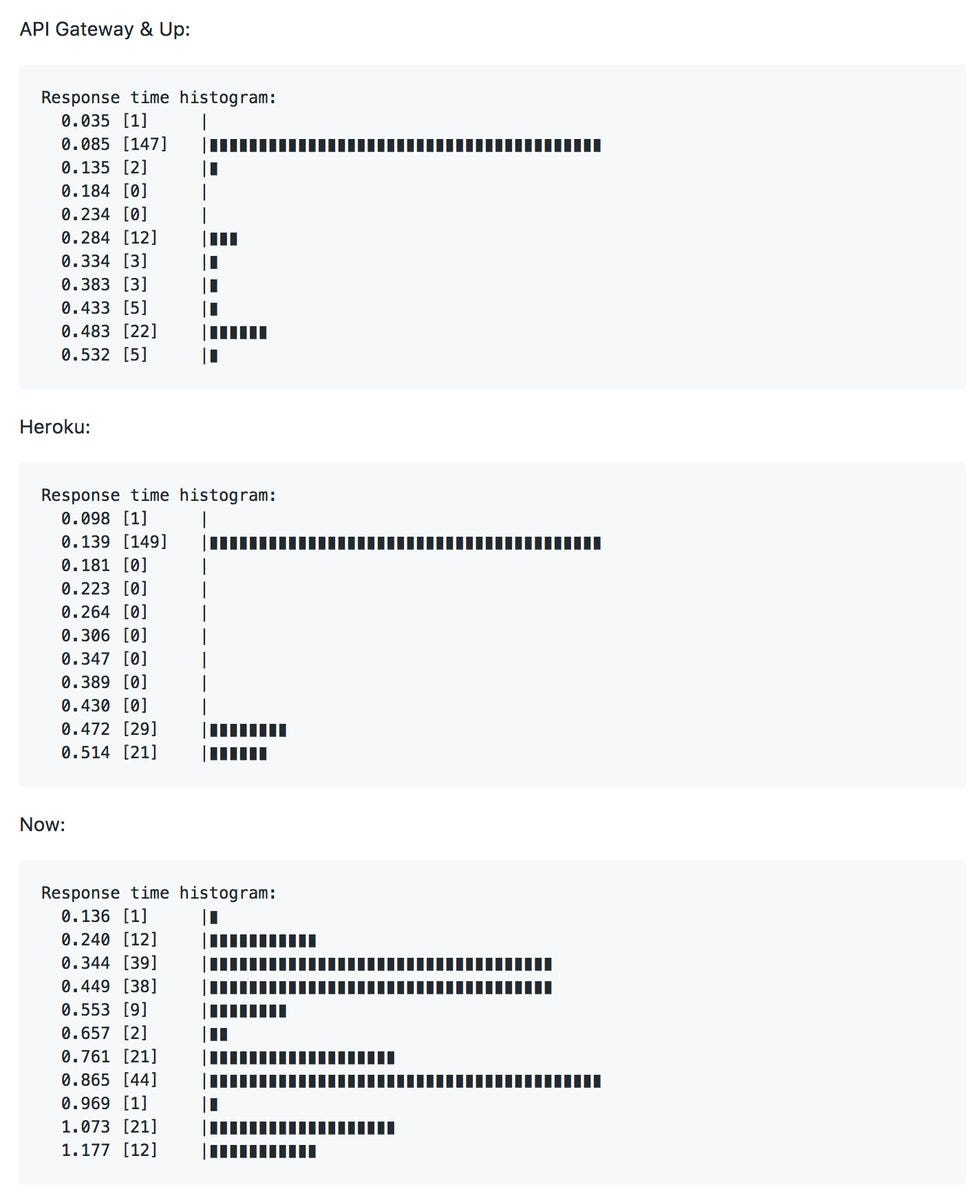
|
||||
|
||||
#### Error pages
|
||||
|
||||
Up provides a default error page which you may customize with `error_pages` if you’d like to provide a support email or tweak the color.
|
||||
|
||||
```
|
||||
{ "name": "site", "type": "static", "error_pages": { "variables": { "support_email": "support@apex.sh", "color": "#228ae6" } }}
|
||||
```
|
||||
|
||||
By default it looks like this:
|
||||
|
||||
** 此处有Canvas,请手动处理 **
|
||||
|
||||
|
||||
|
||||
If you’d like to provide custom templates you may create one or more of the following files. The most specific file takes precedence.
|
||||
|
||||
* `error.html` – Matches any 4xx or 5xx
|
||||
|
||||
* `5xx.html` – Matches any 5xx error
|
||||
|
||||
* `4xx.html` – Matches any 4xx error
|
||||
|
||||
* `CODE.html` – Matches a specific code such as 404.html
|
||||
|
||||
Check out the [docs][22] to read more about templating.
|
||||
|
||||
### Scaling and cost
|
||||
|
||||
So you’ve made it this far, but how well does Up scale? Currently API Gateway and AWS are the target platform, so you’re not required to make any changes in order to scale, just deploy your code and it’s done. You pay only for what you actually use, on-demand, and no manual intervention is required for scaling.
|
||||
|
||||
AWS offers 1,000,000 requests per month for free, but you can use [http://serverlesscalc.com][23] to plug in your expected traffic. In the future Up will provide additional platforms, so that if one becomes prohibitively expensive, you can migrate to another!
|
||||
|
||||
### The Future
|
||||
|
||||
That’s all for now! It may not look like much, but it’s clocking-in above 10,000 lines of code already, and I’ve just begun development. Take a look at the issue queue for a small look at what to expect in the future, assuming the project becomes sustainable.
|
||||
|
||||
If you find the free version useful please consider donating on [OpenCollective][24], as I do not make any money working on it. I will be working on early access to the Pro version shortly, with a discounted annual price for early adopters. Either the Pro or Enterprise editions will provide the source as well, so internal hotfixes and customizations can be made.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.freecodecamp.org/up-b3db1ca930ee
|
||||
|
||||
作者:[TJ Holowaychuk ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@tjholowaychuk?source=post_header_lockup
|
||||
[1]:https://medium.com/@tjholowaychuk/blueprints-for-up-1-5f8197179275
|
||||
[2]:https://github.com/apex/up
|
||||
[3]:https://github.com/apex/up
|
||||
[4]:https://github.com/tj/gh-polls
|
||||
[5]:https://github.com/apex/up/tree/master/docs
|
||||
[6]:https://github.com/apex/up/releases
|
||||
[7]:https://raw.githubusercontent.com/apex/up/master/install.sh
|
||||
[8]:https://github.com/apex/up/blob/master/docs/aws-credentials.md
|
||||
[9]:https://github.com/apex/apex
|
||||
[10]:https://github.com/apex/up/blob/master/docs/runtimes.md
|
||||
[11]:https://github.com/apex/up/issues/166
|
||||
[12]:https://github.com/apex/up/issues/115
|
||||
[13]:https://github.com/apex/up/blob/master/docs/configuration.md
|
||||
[14]:https://segment.com/
|
||||
[15]:https://blog.apex.sh/
|
||||
[16]:https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS
|
||||
[17]:https://myapp.com/
|
||||
[18]:https://github.com/apex/up/blob/master/internal/logs/parser/grammar.peg
|
||||
[19]:http://twitter.com/apex
|
||||
[20]:http://twitter.com/apex
|
||||
[21]:http://twitter.com/apex
|
||||
[22]:https://github.com/apex/up/blob/master/docs/configuration.md#error-pages
|
||||
[23]:http://serverlesscalc.com/
|
||||
[24]:https://opencollective.com/apex-up
|
||||
540
sources/tech/20170815 Getting Started with Headless Chrome.md
Normal file
540
sources/tech/20170815 Getting Started with Headless Chrome.md
Normal file
@ -0,0 +1,540 @@
|
||||
Getting Started with Headless Chrome
|
||||
============================================================
|
||||
|
||||
|
||||
### TL;DR
|
||||
|
||||
[Headless Chrome][9] is shipping in Chrome 59\. It's a way to run the Chrome browser in a headless environment. Essentially, running Chrome without chrome! It brings **all modern web platform features** provided by Chromium and the Blink rendering engine to the command line.
|
||||
|
||||
Why is that useful?
|
||||
|
||||
A headless browser is a great tool for automated testing and server environments where you don't need a visible UI shell. For example, you may want to run some tests against a real web page, create a PDF of it, or just inspect how the browser renders an URL.
|
||||
|
||||
<aside class="caution" style="box-sizing: inherit; font-size: 14px; margin-top: 16px; margin-bottom: 16px; padding: 12px 24px 12px 60px; background: rgb(255, 243, 224); color: rgb(221, 44, 0);">**Caution:** Headless mode is available on Mac and Linux in **Chrome 59**. [Windows support][2] is coming in Chrome 60\. To check what version of Chrome you have, open `chrome://version`.</aside>
|
||||
|
||||
### Starting Headless (CLI)
|
||||
|
||||
The easiest way to get started with headless mode is to open the Chrome binary from the command line. If you've got Chrome 59+ installed, start Chrome with the `--headless` flag:
|
||||
|
||||
```
|
||||
chrome \
|
||||
--headless \ # Runs Chrome in headless mode.
|
||||
--disable-gpu \ # Temporarily needed for now.
|
||||
--remote-debugging-port=9222 \
|
||||
https://www.chromestatus.com # URL to open. Defaults to about:blank.
|
||||
```
|
||||
|
||||
<aside class="note" style="box-sizing: inherit; font-size: 14px; margin-top: 16px; margin-bottom: 16px; padding: 12px 24px 12px 60px; background: rgb(225, 245, 254); color: rgb(2, 136, 209);">**Note:** Right now, you'll also want to include the `--disable-gpu` flag. That will eventually go away.</aside>
|
||||
|
||||
`chrome` should point to your installation of Chrome. The exact location will vary from platform to platform. Since I'm on Mac, I created convenient aliases for each version of Chrome that I have installed.
|
||||
|
||||
If you're on the stable channel of Chrome and cannot get the Beta, I recommend using `chrome-canary`:
|
||||
|
||||
```
|
||||
alias chrome="/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome"
|
||||
alias chrome-canary="/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary"
|
||||
alias chromium="/Applications/Chromium.app/Contents/MacOS/Chromium"
|
||||
```
|
||||
|
||||
Download Chrome Canary [here][10].
|
||||
|
||||
### Command line features
|
||||
|
||||
In some cases, you may not need to [programmatically script][11] Headless Chrome. There are some [useful command line flags][12] to perform common tasks.
|
||||
|
||||
### Printing the DOM
|
||||
|
||||
The `--dump-dom` flag prints `document.body.innerHTML` to stdout:
|
||||
|
||||
```
|
||||
chrome --headless --disable-gpu --dump-dom https://www.chromestatus.com/
|
||||
```
|
||||
|
||||
### Create a PDF
|
||||
|
||||
The `--print-to-pdf` flag creates a PDF of the page:
|
||||
|
||||
```
|
||||
chrome --headless --disable-gpu --print-to-pdf https://www.chromestatus.com/
|
||||
```
|
||||
|
||||
### Taking screenshots
|
||||
|
||||
To capture a screenshot of a page, use the `--screenshot` flag:
|
||||
|
||||
```
|
||||
chrome --headless --disable-gpu --screenshot https://www.chromestatus.com/
|
||||
|
||||
# Size of a standard letterhead.
|
||||
chrome --headless --disable-gpu --screenshot --window-size=1280,1696 https://www.chromestatus.com/
|
||||
|
||||
# Nexus 5x
|
||||
chrome --headless --disable-gpu --screenshot --window-size=412,732 https://www.chromestatus.com/
|
||||
```
|
||||
|
||||
Running with `--screenshot` will produce a file named `screenshot.png` in the current working directory. If you're looking for full page screenshots, things are a tad more involved. There's a great blog post from David Schnurr that has you covered. Check out [Using headless Chrome as an automated screenshot tool ][13].
|
||||
|
||||
### REPL mode (read-eval-print loop)
|
||||
|
||||
The `--repl` flag runs Headless in a mode where you can evaluate JS expressions in the browser, right from the command line:
|
||||
|
||||
```
|
||||
$ chrome --headless --disable-gpu --repl https://www.chromestatus.com/
|
||||
[0608/112805.245285:INFO:headless_shell.cc(278)] Type a Javascript expression to evaluate or "quit" to exit.
|
||||
>>> location.href
|
||||
{"result":{"type":"string","value":"https://www.chromestatus.com/features"}}
|
||||
>>> quit
|
||||
$
|
||||
```
|
||||
|
||||
### Debugging Chrome without a browser UI?
|
||||
|
||||
When you run Chrome with `--remote-debugging-port=9222`, it starts an instance with the [DevTools protocol][14] enabled. The protocol is used to communicate with Chrome and drive the headless browser instance. It's also what tools like Sublime, VS Code, and Node use for remote debugging an application. #synergy
|
||||
|
||||
Since you don't have browser UI to see the page, navigate to `http://localhost:9222` in another browser to check that everything is working. You'll see a list of inspectable pages where you can click through and see what Headless is rendering:
|
||||
|
||||

|
||||
DevTools remote debugging UI
|
||||
|
||||
From here, you can use the familiar DevTools features to inspect, debug, and tweak the page as you normally would. If you're using Headless programmatically, this page is also a powerful debugging tool for seeing all the raw DevTools protocol commands going across the wire, communicating with the browser.
|
||||
|
||||
### Using programmatically (Node)
|
||||
|
||||
### The Puppeteer API
|
||||
|
||||
[Puppeteer][15] is a Node library developed by the Chrome team. It provides a high-level API to control headless (or full) Chrome. It's similar to other automated testing libraries like Phantom and NightmareJS, but it only works with the latest versions of Chrome.
|
||||
|
||||
Among other things, Puppeteer can be used to easily take screenshots, create PDFs, navigate pages, and fetch information about those pages. I recommend the library if you want to quickly automate browser testing. It hides away the complexities of the DevTools protocol and takes care of redundant tasks like launching a debug instance of Chrome.
|
||||
|
||||
Install it:
|
||||
|
||||
```
|
||||
yarn add puppeteer
|
||||
```
|
||||
|
||||
**Example** - print the user agent
|
||||
|
||||
```
|
||||
const puppeteer = require('puppeteer');
|
||||
|
||||
(async() => {
|
||||
const browser = await puppeteer.launch();
|
||||
console.log(await browser.version());
|
||||
browser.close();
|
||||
})();
|
||||
```
|
||||
|
||||
**Example** - taking a screenshot of the page
|
||||
|
||||
```
|
||||
const puppeteer = require('puppeteer');
|
||||
|
||||
(async() => {
|
||||
|
||||
const browser = await puppeteer.launch();
|
||||
const page = await browser.newPage();
|
||||
await page.goto('https://www.chromestatus.com', {waitUntil: 'networkidle'});
|
||||
await page.pdf({path: 'page.pdf', format: 'A4'});
|
||||
|
||||
browser.close();
|
||||
})();
|
||||
```
|
||||
|
||||
Check out [Puppeteer's documentation][16] to learn more about the full API.
|
||||
|
||||
### The CRI library
|
||||
|
||||
[chrome-remote-interface][17] is a lower-level library than Puppeteer's API. I recommend it if you want to be close to the metal and use the [DevTools protocol][18] directly.
|
||||
|
||||
#### Launching Chrome
|
||||
|
||||
chrome-remote-interface doesn't launch Chrome for you, so you'll have to take care of that yourself.
|
||||
|
||||
In the CLI section, we [started Chrome manually][19] using `--headless --remote-debugging-port=9222`. However, to fully automate tests, you'll probably want to spawn Chrome _from_ your application.
|
||||
|
||||
One way is to use `child_process`:
|
||||
|
||||
```
|
||||
const execFile = require('child_process').execFile;
|
||||
|
||||
function launchHeadlessChrome(url, callback) {
|
||||
// Assuming MacOSx.
|
||||
const CHROME = '/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome';
|
||||
execFile(CHROME, ['--headless', '--disable-gpu', '--remote-debugging-port=9222', url], callback);
|
||||
}
|
||||
|
||||
launchHeadlessChrome('https://www.chromestatus.com', (err, stdout, stderr) => {
|
||||
...
|
||||
});
|
||||
```
|
||||
|
||||
But things get tricky if you want a portable solution that works across multiple platforms. Just look at that hard-coded path to Chrome :(
|
||||
|
||||
##### Using ChromeLauncher
|
||||
|
||||
[Lighthouse][20] is a marvelous tool for testing the quality of your web apps. A robust module for launching Chrome was developed within Lighthouse and is now extracted for standalone use. The [`chrome-launcher` NPM module][21] will find where Chrome is installed, set up a debug instance, launch the browser, and kill it when your program is done. Best part is that it works cross-platform thanks to Node!
|
||||
|
||||
By default, **`chrome-launcher` will try to launch Chrome Canary** (if it's installed), but you can change that to manually select which Chrome to use. To use it, first install from npm:
|
||||
|
||||
```
|
||||
yarn add chrome-launcher
|
||||
```
|
||||
|
||||
**Example** - using `chrome-launcher` to launch Headless
|
||||
|
||||
```
|
||||
const chromeLauncher = require('chrome-launcher');
|
||||
|
||||
// Optional: set logging level of launcher to see its output.
|
||||
// Install it using: yarn add lighthouse-logger
|
||||
// const log = require('lighthouse-logger');
|
||||
// log.setLevel('info');
|
||||
|
||||
/**
|
||||
* Launches a debugging instance of Chrome.
|
||||
* @param {boolean=} headless True (default) launches Chrome in headless mode.
|
||||
* False launches a full version of Chrome.
|
||||
* @return {Promise<ChromeLauncher>}
|
||||
*/
|
||||
function launchChrome(headless=true) {
|
||||
return chromeLauncher.launch({
|
||||
// port: 9222, // Uncomment to force a specific port of your choice.
|
||||
chromeFlags: [
|
||||
'--window-size=412,732',
|
||||
'--disable-gpu',
|
||||
headless ? '--headless' : ''
|
||||
]
|
||||
});
|
||||
}
|
||||
|
||||
launchChrome().then(chrome => {
|
||||
console.log(`Chrome debuggable on port: ${chrome.port}`);
|
||||
...
|
||||
// chrome.kill();
|
||||
});
|
||||
```
|
||||
|
||||
Running this script doesn't do much, but you should see an instance of Chrome fire up in the task manager that loaded `about:blank`. Remember, there won't be any browser UI. We're headless.
|
||||
|
||||
To control the browser, we need the DevTools protocol!
|
||||
|
||||
#### Retrieving information about the page
|
||||
|
||||
<aside class="warning" style="box-sizing: inherit; font-size: 14px; margin-top: 16px; margin-bottom: 16px; padding: 12px 24px 12px 60px; background: rgb(251, 233, 231); color: rgb(213, 0, 0);">**Warning:** The DevTools protocol can do a ton of interesting stuff, but it can be a bit daunting at first. I recommend spending a bit of time browsing the [DevTools Protocol Viewer][3], first. Then, move on to the `chrome-remote-interface` API docs to see how it wraps the raw protocol.</aside>
|
||||
|
||||
Let's install the library:
|
||||
|
||||
```
|
||||
yarn add chrome-remote-interface
|
||||
```
|
||||
|
||||
##### Examples
|
||||
|
||||
**Example** - print the user agent
|
||||
|
||||
```
|
||||
const CDP = require('chrome-remote-interface');
|
||||
|
||||
...
|
||||
|
||||
launchChrome().then(async chrome => {
|
||||
const version = await CDP.Version({port: chrome.port});
|
||||
console.log(version['User-Agent']);
|
||||
});
|
||||
```
|
||||
|
||||
Results in something like: `HeadlessChrome/60.0.3082.0`
|
||||
|
||||
**Example** - check if the site has a [web app manifest][22]
|
||||
|
||||
```
|
||||
const CDP = require('chrome-remote-interface');
|
||||
|
||||
...
|
||||
|
||||
(async function() {
|
||||
|
||||
const chrome = await launchChrome();
|
||||
const protocol = await CDP({port: chrome.port});
|
||||
|
||||
// Extract the DevTools protocol domains we need and enable them.
|
||||
// See API docs: https://chromedevtools.github.io/devtools-protocol/
|
||||
const {Page} = protocol;
|
||||
await Page.enable();
|
||||
|
||||
Page.navigate({url: 'https://www.chromestatus.com/'});
|
||||
|
||||
// Wait for window.onload before doing stuff.
|
||||
Page.loadEventFired(async () => {
|
||||
const manifest = await Page.getAppManifest();
|
||||
|
||||
if (manifest.url) {
|
||||
console.log('Manifest: ' + manifest.url);
|
||||
console.log(manifest.data);
|
||||
} else {
|
||||
console.log('Site has no app manifest');
|
||||
}
|
||||
|
||||
protocol.close();
|
||||
chrome.kill(); // Kill Chrome.
|
||||
});
|
||||
|
||||
})();
|
||||
```
|
||||
|
||||
**Example** - extract the `<title>` of the page using DOM APIs.
|
||||
|
||||
```
|
||||
const CDP = require('chrome-remote-interface');
|
||||
|
||||
...
|
||||
|
||||
(async function() {
|
||||
|
||||
const chrome = await launchChrome();
|
||||
const protocol = await CDP({port: chrome.port});
|
||||
|
||||
// Extract the DevTools protocol domains we need and enable them.
|
||||
// See API docs: https://chromedevtools.github.io/devtools-protocol/
|
||||
const {Page, Runtime} = protocol;
|
||||
await Promise.all([Page.enable(), Runtime.enable()]);
|
||||
|
||||
Page.navigate({url: 'https://www.chromestatus.com/'});
|
||||
|
||||
// Wait for window.onload before doing stuff.
|
||||
Page.loadEventFired(async () => {
|
||||
const js = "document.querySelector('title').textContent";
|
||||
// Evaluate the JS expression in the page.
|
||||
const result = await Runtime.evaluate({expression: js});
|
||||
|
||||
console.log('Title of page: ' + result.result.value);
|
||||
|
||||
protocol.close();
|
||||
chrome.kill(); // Kill Chrome.
|
||||
});
|
||||
|
||||
})();
|
||||
```
|
||||
|
||||
### Using Selenium, WebDriver, and ChromeDriver
|
||||
|
||||
Right now, Selenium opens a full instance of Chrome. In other words, it's an automated solution but not completely headless. However, Selenium can be configured to run headless Chrome with a little work. I recommend [Running Selenium with Headless Chrome][23] if you want the full instructions on how to set things up yourself, but I've dropped in some examples below to get you started.
|
||||
|
||||
#### Using ChromeDriver
|
||||
|
||||
[ChromeDriver][24] 2.3.0 supports Chrome 59 and later and works with headless Chrome. In some cases, you may need Chrome 60 to work around bugs. For example, there are known issues with taking screenshots in Chrome 59.
|
||||
|
||||
Install:
|
||||
|
||||
```
|
||||
yarn add selenium-webdriver chromedriver
|
||||
```
|
||||
|
||||
Example:
|
||||
|
||||
```
|
||||
const fs = require('fs');
|
||||
const webdriver = require('selenium-webdriver');
|
||||
const chromedriver = require('chromedriver');
|
||||
|
||||
// This should be the path to your Canary installation.
|
||||
// I'm assuming Mac for the example.
|
||||
const PATH_TO_CANARY = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary';
|
||||
|
||||
const chromeCapabilities = webdriver.Capabilities.chrome();
|
||||
chromeCapabilities.set('chromeOptions', {
|
||||
binary: PATH_TO_CANARY // Screenshots require Chrome 60\. Force Canary.
|
||||
'args': [
|
||||
'--headless',
|
||||
]
|
||||
});
|
||||
|
||||
const driver = new webdriver.Builder()
|
||||
.forBrowser('chrome')
|
||||
.withCapabilities(chromeCapabilities)
|
||||
.build();
|
||||
|
||||
// Navigate to google.com, enter a search.
|
||||
driver.get('https://www.google.com/');
|
||||
driver.findElement({name: 'q'}).sendKeys('webdriver');
|
||||
driver.findElement({name: 'btnG'}).click();
|
||||
driver.wait(webdriver.until.titleIs('webdriver - Google Search'), 1000);
|
||||
|
||||
// Take screenshot of results page. Save to disk.
|
||||
driver.takeScreenshot().then(base64png => {
|
||||
fs.writeFileSync('screenshot.png', new Buffer(base64png, 'base64'));
|
||||
});
|
||||
|
||||
driver.quit();
|
||||
```
|
||||
|
||||
#### Using WebDriverIO
|
||||
|
||||
[WebDriverIO][25] is a higher level API on top of Selenium WebDriver.
|
||||
|
||||
Install:
|
||||
|
||||
```
|
||||
yarn add webdriverio chromedriver
|
||||
```
|
||||
|
||||
Example: filter CSS features on chromestatus.com
|
||||
|
||||
```
|
||||
const webdriverio = require('webdriverio');
|
||||
const chromedriver = require('chromedriver');
|
||||
|
||||
// This should be the path to your Canary installation.
|
||||
// I'm assuming Mac for the example.
|
||||
const PATH_TO_CANARY = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary';
|
||||
const PORT = 9515;
|
||||
|
||||
chromedriver.start([
|
||||
'--url-base=wd/hub',
|
||||
`--port=${PORT}`,
|
||||
'--verbose'
|
||||
]);
|
||||
|
||||
(async () => {
|
||||
|
||||
const opts = {
|
||||
port: PORT,
|
||||
desiredCapabilities: {
|
||||
browserName: 'chrome',
|
||||
chromeOptions: {
|
||||
binary: PATH_TO_CANARY // Screenshots require Chrome 60\. Force Canary.
|
||||
args: ['--headless']
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
const browser = webdriverio.remote(opts).init();
|
||||
|
||||
await browser.url('https://www.chromestatus.com/features');
|
||||
|
||||
const title = await browser.getTitle();
|
||||
console.log(`Title: ${title}`);
|
||||
|
||||
await browser.waitForText('.num-features', 3000);
|
||||
let numFeatures = await browser.getText('.num-features');
|
||||
console.log(`Chrome has ${numFeatures} total features`);
|
||||
|
||||
await browser.setValue('input[type="search"]', 'CSS');
|
||||
console.log('Filtering features...');
|
||||
await browser.pause(1000);
|
||||
|
||||
numFeatures = await browser.getText('.num-features');
|
||||
console.log(`Chrome has ${numFeatures} CSS features`);
|
||||
|
||||
const buffer = await browser.saveScreenshot('screenshot.png');
|
||||
console.log('Saved screenshot...');
|
||||
|
||||
chromedriver.stop();
|
||||
browser.end();
|
||||
|
||||
})();
|
||||
```
|
||||
|
||||
### Further resources
|
||||
|
||||
Here are some useful resources to get you started:
|
||||
|
||||
Docs
|
||||
|
||||
* [DevTools Protocol Viewer][4] - API reference docs
|
||||
|
||||
Tools
|
||||
|
||||
* [chrome-remote-interface][5] - node module that wraps the DevTools protocol
|
||||
|
||||
* [Lighthouse][6] - automated tool for testing web app quality; makes heavy use of the protocol
|
||||
|
||||
* [chrome-launcher][7] - node module for launching Chrome, ready for automation
|
||||
|
||||
Demos
|
||||
|
||||
* "[The Headless Web][8]" - Paul Kinlan's great blog post on using Headless with api.ai.
|
||||
|
||||
### FAQ
|
||||
|
||||
**Do I need the `--disable-gpu` flag?**
|
||||
|
||||
Yes, for now. The `--disable-gpu` flag is a temporary requirement to work around a few bugs. You won't need this flag in future versions of Chrome. See [https://crbug.com/546953#c152][26] and [https://crbug.com/695212][27] for more information.
|
||||
|
||||
**So I still need Xvfb?**
|
||||
|
||||
No. Headless Chrome doesn't use a window so a display server like Xvfb is no longer needed. You can happily run your automated tests without it.
|
||||
|
||||
What is Xvfb? Xvfb is an in-memory display server for Unix-like systems that enables you to run graphical applications (like Chrome) without an attached physical display. Many people use Xvfb to run earlier versions of Chrome to do "headless" testing.
|
||||
|
||||
**How do I create a Docker container that runs Headless Chrome?**
|
||||
|
||||
Check out [lighthouse-ci][28]. It has an [example Dockerfile][29] that uses Ubuntu as a base image, and installs + runs Lighthouse in an App Engine Flexible container.
|
||||
|
||||
**Can I use this with Selenium / WebDriver / ChromeDriver**?
|
||||
|
||||
Yes. See [Using Selenium, WebDrive, or ChromeDriver][30].
|
||||
|
||||
**How is this related to PhantomJS?**
|
||||
|
||||
Headless Chrome is similar to tools like [PhantomJS][31]. Both can be used for automated testing in a headless environment. The main difference between the two is that Phantom uses an older version of WebKit as its rendering engine while Headless Chrome uses the latest version of Blink.
|
||||
|
||||
At the moment, Phantom also provides a higher level API than the [DevTools protocol][32].
|
||||
|
||||
**Where do I report bugs?**
|
||||
|
||||
For bugs against Headless Chrome, file them on [crbug.com][33].
|
||||
|
||||
For bugs in the DevTools protocol, file them at [github.com/ChromeDevTools/devtools-protocol][34].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介
|
||||
|
||||
[Eric Bidelman][1]Engineer @ Google working on Lighthouse, Web Components, Chrome, and the web
|
||||
|
||||
-----------------------------------
|
||||
|
||||
via: https://developers.google.com/web/updates/2017/04/headless-chrome
|
||||
|
||||
作者:[Eric Bidelman ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://developers.google.com/web/resources/contributors#ericbidelman
|
||||
[1]:https://developers.google.com/web/resources/contributors#ericbidelman
|
||||
[2]:https://bugs.chromium.org/p/chromium/issues/detail?id=686608
|
||||
[3]:https://chromedevtools.github.io/devtools-protocol/
|
||||
[4]:https://chromedevtools.github.io/devtools-protocol/
|
||||
[5]:https://www.npmjs.com/package/chrome-remote-interface
|
||||
[6]:https://github.com/GoogleChrome/lighthouse
|
||||
[7]:https://github.com/GoogleChrome/lighthouse/tree/master/chrome-launcher
|
||||
[8]:https://paul.kinlan.me/the-headless-web/
|
||||
[9]:https://chromium.googlesource.com/chromium/src/+/lkgr/headless/README.md
|
||||
[10]:https://www.google.com/chrome/browser/canary.html
|
||||
[11]:https://developers.google.com/web/updates/2017/04/headless-chrome#node
|
||||
[12]:https://cs.chromium.org/chromium/src/headless/app/headless_shell_switches.cc
|
||||
[13]:https://medium.com/@dschnr/using-headless-chrome-as-an-automated-screenshot-tool-4b07dffba79a
|
||||
[14]:https://chromedevtools.github.io/devtools-protocol/
|
||||
[15]:https://github.com/GoogleChrome/puppeteer
|
||||
[16]:https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
|
||||
[17]:https://www.npmjs.com/package/chrome-remote-interface
|
||||
[18]:https://chromedevtools.github.io/devtools-protocol/
|
||||
[19]:https://developers.google.com/web/updates/2017/04/headless-chrome#cli
|
||||
[20]:https://developers.google.com/web/tools/lighthouse/
|
||||
[21]:https://www.npmjs.com/package/chrome-launcher
|
||||
[22]:https://developers.google.com/web/fundamentals/engage-and-retain/web-app-manifest/
|
||||
[23]:https://intoli.com/blog/running-selenium-with-headless-chrome/
|
||||
[24]:https://sites.google.com/a/chromium.org/chromedriver/
|
||||
[25]:http://webdriver.io/
|
||||
[26]:https://bugs.chromium.org/p/chromium/issues/detail?id=546953#c152
|
||||
[27]:https://bugs.chromium.org/p/chromium/issues/detail?id=695212
|
||||
[28]:https://github.com/ebidel/lighthouse-ci
|
||||
[29]:https://github.com/ebidel/lighthouse-ci/blob/master/builder/Dockerfile.headless
|
||||
[30]:https://developers.google.com/web/updates/2017/04/headless-chrome#drivers
|
||||
[31]:http://phantomjs.org/
|
||||
[32]:https://chromedevtools.github.io/devtools-protocol/
|
||||
[33]:https://bugs.chromium.org/p/chromium/issues/entry?components=Blink&blocking=705916&cc=skyostil%40chromium.org&Proj=Headless
|
||||
[34]:https://github.com/ChromeDevTools/devtools-protocol/issues/new
|
||||
170
sources/tech/20170815 Automated testing with Headless Chrome.md
Normal file
170
sources/tech/20170815 Automated testing with Headless Chrome.md
Normal file
@ -0,0 +1,170 @@
|
||||
Automated testing with Headless Chrome
|
||||
============================================================
|
||||
|
||||
|
||||
If you want to run automated tests using Headless Chrome, look no further! This article will get you all set up using Karma as a runner and Mocha+Chai for authoring tests.
|
||||
|
||||
**What are these things?**
|
||||
|
||||
Karma, Mocha, Chai, Headless Chrome, oh my!
|
||||
|
||||
[Karma][2] is a testing harness that works with any of the the most popular testing frameworks ([Jasmine][3], [Mocha][4], [QUnit][5]).
|
||||
|
||||
[Chai][6] is an assertion library that works with Node and in the browser. We need the latter.
|
||||
|
||||
[Headless Chrome][7] is a way to run the Chrome browser in a headless environment without the full browser UI. One of the benefits of using Headless Chrome (as opposed to testing directly in Node) is that your JavaScript tests will be executed in the same environment as users of your site. Headless Chrome gives you a real browser context without the memory overhead of running a full version of Chrome.
|
||||
|
||||
### Setup
|
||||
|
||||
### Installation
|
||||
|
||||
Install Karma, the relevant, plugins, and the test runners using `yarn`:
|
||||
|
||||
```
|
||||
yarn add --dev karma karma-chrome-launcher karma-mocha karma-chai
|
||||
yarn add --dev mocha chai
|
||||
```
|
||||
|
||||
or use `npm`:
|
||||
|
||||
```
|
||||
npm i --save-dev karma karma-chrome-launcher karma-mocha karma-chai
|
||||
npm i --save-dev mocha chai
|
||||
```
|
||||
|
||||
I'm using [Mocha][8] and [Chai][9] in this post, but if you're not a fan, choose your favorite assertion library that works in the browser.
|
||||
|
||||
### Configure Karma
|
||||
|
||||
Create a `karma.config.js` file that uses the `ChromeHeadless` launcher.
|
||||
|
||||
**karma.conf.js**
|
||||
|
||||
```
|
||||
module.exports = function(config) {
|
||||
config.set({
|
||||
frameworks: ['mocha', 'chai'],
|
||||
files: ['test/**/*.js'],
|
||||
reporters: ['progress'],
|
||||
port: 9876, // karma web server port
|
||||
colors: true,
|
||||
logLevel: config.LOG_INFO,
|
||||
browsers: ['ChromeHeadless'],
|
||||
autoWatch: false,
|
||||
// singleRun: false, // Karma captures browsers, runs the tests and exits
|
||||
concurrency: Infinity
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
<aside class="note" style="box-sizing: inherit; font-size: 14px; margin-top: 16px; margin-bottom: 16px; padding: 12px 24px 12px 60px; background: rgb(225, 245, 254); color: rgb(2, 136, 209);">**Note:** Run `./node_modules/karma/bin/ init karma.conf.js` to generate the Karma configuration file.</aside>
|
||||
|
||||
### Write a test
|
||||
|
||||
Create a test in `/test/test.js`.
|
||||
|
||||
**/test/test.js**
|
||||
|
||||
```
|
||||
describe('Array', () => {
|
||||
describe('#indexOf()', () => {
|
||||
it('should return -1 when the value is not present', () => {
|
||||
assert.equal(-1, [1,2,3].indexOf(4));
|
||||
});
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
### Run your tests
|
||||
|
||||
Add a `test` script in `package.json` that runs Karma with our settings.
|
||||
|
||||
**package.json**
|
||||
|
||||
```
|
||||
"scripts": {
|
||||
"test": "karma start --single-run --browsers ChromeHeadless karma.conf.js"
|
||||
}
|
||||
```
|
||||
|
||||
When you run your tests (`yarn test`), Headless Chrome should fire up and output the results to the terminal:
|
||||
|
||||

|
||||
|
||||
### Creating your own Headless Chrome launcher
|
||||
|
||||
The `ChromeHeadless` launcher is great because it works out of the box for testing on Headless Chrome. It includes the appropriate Chrome flags for you and launches a remote debugging version of Chrome on port `9222`.
|
||||
|
||||
However, sometimes you may want to pass custom flags to Chrome or change the remote debugging port the launcher uses. To do that, create a `customLaunchers` field that extends the base `ChromeHeadless` launcher:
|
||||
|
||||
**karma.conf.js**
|
||||
|
||||
```
|
||||
module.exports = function(config) {
|
||||
...
|
||||
|
||||
config.set({
|
||||
browsers: ['Chrome', 'ChromeHeadless', 'MyHeadlessChrome'],
|
||||
|
||||
customLaunchers: {
|
||||
MyHeadlessChrome: {
|
||||
base: 'ChromeHeadless',
|
||||
flags: ['--disable-translate', '--disable-extensions', '--remote-debugging-port=9223']
|
||||
}
|
||||
},
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
### Running it all on Travis CI
|
||||
|
||||
Configuring Karma to run your tests in Headless Chrome is the hard part. Continuous integration in Travis is just a few lines away!
|
||||
|
||||
To run your tests in Travis, use `dist: trusty` and install the Chrome stable addon:
|
||||
|
||||
**.travis.yml**
|
||||
|
||||
```
|
||||
language: node_js
|
||||
node_js:
|
||||
- "7"
|
||||
dist: trusty # needs Ubuntu Trusty
|
||||
sudo: false # no need for virtualization.
|
||||
addons:
|
||||
chrome: stable # have Travis install chrome stable.
|
||||
cache:
|
||||
yarn: true
|
||||
directories:
|
||||
- node_modules
|
||||
install:
|
||||
- yarn
|
||||
script:
|
||||
- yarn test
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介
|
||||
|
||||
[Eric Bidelman][1]Engineer @ Google working on Lighthouse, Web Components, Chrome, and the web
|
||||
|
||||
----------------
|
||||
|
||||
via: https://developers.google.com/web/updates/2017/06/headless-karma-mocha-chai
|
||||
|
||||
作者:[ Eric Bidelman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://developers.google.com/web/resources/contributors#ericbidelman
|
||||
[1]:https://developers.google.com/web/resources/contributors#ericbidelman
|
||||
[2]:https://karma-runner.github.io/
|
||||
[3]:https://jasmine.github.io/
|
||||
[4]:https://mochajs.org/
|
||||
[5]:https://qunitjs.com/
|
||||
[6]:http://chaijs.com/
|
||||
[7]:https://developers.google.com/web/updates/2017/04/headless-chrome
|
||||
[8]:https://mochajs.org/
|
||||
[9]:http://chaijs.com/
|
||||
@ -0,0 +1,93 @@
|
||||
Creating better disaster recovery plans
|
||||
============================================================
|
||||
|
||||
Five questions for Tanya Reilly: How service interdependencies make recovery harder and why it’s a good idea to deliberately and preemptively manage dependencies.
|
||||
|
||||
[Register for the O'Reilly Velocity Conference][5] to join Tanya Reilly and other industry experts. Use code ORM20 to save 20% on your conference pass (Gold, Silver, and Bronze passes).
|
||||
|
||||
I recently asked Tanya Reilly, Site Reliability Engineer at Google, to share her thoughts on how to make better disaster recovery plans. Tanya is presenting a session titled [_Have you tried turning it off and turning it on again?_][9] at the O’Reilly Velocity Conference, taking place Oct. 1-4 in New York.
|
||||
|
||||
### 1\. What are the most common mistakes people make when planning their backup systems strategy?
|
||||
|
||||
The classic line is "you don't need a backup strategy, you need a restore strategy." If you have backups, but you haven't tested restoring them, you don't really have backups. Testing doesn't just mean knowing you can get the data back; it means knowing how to put it back into the database, how to handle incremental changes, how to reinstall the whole thing if you need to. It means being sure that your recovery path doesn't rely on some system that could be lost at the same time as the data.
|
||||
|
||||
But testing restores is tedious. It's the sort of thing that people will cut corners on if they're busy. It's worth taking the time to make it as simple and painless and automated as possible; never rely on human willpower for anything! At the same time, you have to be sure that the people involved know what to do, so it's good to plan regular wide-scale disaster tests. Recovery exercises are a great way to find out that the documentation for the process is missing or out of date, or that you don't have enough resources (disk, network, etc.) to transfer and reinsert the data.
|
||||
|
||||
### 2\. What are the most common challenges in creating a disaster recovery (DR) plan?
|
||||
|
||||
I think a lot of DR is an afterthought: "We have this great system, and our business relies on it ... I guess we should do DR for it?" And by that point, the system is extremely complex, full of interdependencies and hard to duplicate.
|
||||
|
||||
The first time something is installed, it's often hand-crafted by a human who is tweaking things and getting it right, and sometimes that's the version that sticks around. When you build the _second_ one, it's hard to be sure it's exactly the same. Even in sites with serious config management, you can leave something out, or let it get out of date.
|
||||
|
||||
Encrypted backups aren't much use if you've lost access to the decryption key, for example. And any parts that are only used in a disaster may have bit-rotted since you last checked in on them. The only way to be sure you've covered everything is to fail over in earnest. Plan your disaster for a time when you're ready for it!
|
||||
|
||||
It's better if you can design the system so that the disaster recovery modes are part of normal operation. If your service is designed from the start to be replicated, adding more replicas is a regular operation and probably automated. There are no new pathways; it's just a capacity problem. But there can still be some forgotten components of the system that only run in one or two places. An occasional scheduled fake disaster is good for shaking those out.
|
||||
|
||||
By the way, those forgotten components could include information that's only in one person's brain, so if you find yourself saying, "We can't do our DR failover test until X is back from vacation," then that person is a dangerous single point of failure.
|
||||
|
||||
Parts of the system that are only used in disasters need the most testing, or they'll fail you when you need them. The fewer of those you have, the safer you are and the less toilsome testing you have to do.
|
||||
|
||||
### 3\. Why do service interdependencies make recovery harder after a disaster?
|
||||
|
||||
If you've got just one binary, then recovering it is relatively easy: you start that binary back up. But we increasingly break out common functionality into separate services. Microservices mean we have more flexibility and less reinvention of wheels: if we need a backend to do something and one already exists, great, we can just use that. But someone needs to keep a big picture of what depends on what, because it can get very tangled very fast.
|
||||
|
||||
#### MANAGE, GROW, AND EVOLVE YOUR SYSTEMS
|
||||
|
||||
|
||||
You may know what backends you use directly, but you might not notice when new ones are added into libraries you use. You might depend on something that also indirectly depends on you. After an outage, you can end up with a deadlock: two systems that each can't start until the other is running and providing some functionality. It's a hard situation to recover from!
|
||||
|
||||
You can even end up with things that indirectly depend on themselves—for example, a device that you need to configure to bring up the network, but you can't get to it while the network is down. Often people have thought about these circular dependencies in advance and have some sort of fallback plan, but those are inherently the road less traveled: they're only intended to be used in extreme cases, and they follow a different path through your systems or processes or code. This means they're more likely to have a bug that won't be uncovered until you really, really need them to work.
|
||||
|
||||
### 4\. You advise people to start deliberately managing their dependencies long before they think they need to in order to ward off potentially catastrophic system failure. Why is this important and what’s your advice for doing it effectively?
|
||||
|
||||
Managing your dependencies is essential for being sure you can recover from a disaster. It makes operating the systems easier too. If your dependencies aren't reliable, you can't be reliable, so you need to know what they are.
|
||||
|
||||
It's possible to start managing dependencies after they've become chaotic, but it's much, much easier if you start early. You can set policies on the use of various services—for example, you must be this high in the stack to depend on this set of systems. You can introduce a culture of thinking about dependencies by making it a regular part of design document review. But bear in mind that lists of dependencies will quickly become stale; it's best if you have programmatic dependency discovery, and even dependency enforcement. [My Velocity talk][10] covers more about how we do that.
|
||||
|
||||
The other advantage of starting early is that you can split up your services into vertical "strata," where the functionality in each stratum must be able to come completely online before the next one begins. So, for example, you could say that the network has to be able to completely start up without using any other services. Then, say, your storage systems should depend on nothing but the network, the application backends should only depend on network and storage, and so on. Different strata will make sense for different architectures.
|
||||
|
||||
If you plan this in advance, it's much easier for new services to choose dependencies. Each one should only depend on services lower in the stack. You can still end up with cycles—things in the same stratum depending on each other—but they're more tightly contained and easier to deal with on a case-by-case basis.
|
||||
|
||||
### 5\. What other parts of the program for Velocity NY are of interest to you?
|
||||
|
||||
I've got my whole Tuesday and Wednesday schedule completely worked out! As you might have gathered, I care a lot about making huge interdependent systems manageable, so I'm looking forward to hearing [Carin Meier's thoughts on managing system complexity][11], [Sarah Wells on microservices][12] and [Baron Schwartz on observability][13]. I'm fascinated to hear [Jon Moore's story][14] on how Comcast went from yearly release cycles to releasing daily. And as an ex-sysadmin, I'm looking forward to hearing [where Bryan Liles sees that role going][15].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Nikki McDonald
|
||||
|
||||
Nikki McDonald is a content director at O'Reilly Media, Inc. She lives in Ann Arbor, Michigan.
|
||||
|
||||
Tanya Reilly
|
||||
|
||||
Tanya Reilly has been a Systems Administrator and Site Reliability Engineer at Google since 2005, working on low-level infrastructure like distributed locking, load balancing, and bootstrapping. Before Google, she was a Systems Administrator at eircom.net, Ireland’s largest ISP, and before that she was the entire IT Department for a small software house.
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/creating-better-disaster-recovery-plans
|
||||
|
||||
作者:[ Nikki McDonald][a],[Tanya Reilly][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/nikki-mcdonald
|
||||
[b]:https://www.oreilly.com/people/5c97a-tanya-reilly
|
||||
[1]:https://pixabay.com/en/crane-baukran-load-crane-crane-arm-2436704/
|
||||
[2]:https://conferences.oreilly.com/velocity/vl-ny?intcmp=il-webops-confreg-reg-vlny17_new_site_right_rail_cta
|
||||
[3]:https://www.oreilly.com/people/nikki-mcdonald
|
||||
[4]:https://www.oreilly.com/people/5c97a-tanya-reilly
|
||||
[5]:https://conferences.oreilly.com/velocity/vl-ny?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_text_cta
|
||||
[6]:https://www.oreilly.com/ideas/creating-better-disaster-recovery-plans
|
||||
[7]:https://conferences.oreilly.com/velocity/vl-ny?intcmp=il-webops-confreg-reg-vlny17_new_site_right_rail_cta
|
||||
[8]:https://conferences.oreilly.com/velocity/vl-ny?intcmp=il-webops-confreg-reg-vlny17_new_site_right_rail_cta
|
||||
[9]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/61400?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[10]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/61400?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[11]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/62779?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[12]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/61597?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[13]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/61630?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[14]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/62733?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
[15]:https://conferences.oreilly.com/velocity/vl-ny/public/schedule/detail/62893?intcmp=il-webops-confreg-reg-vlny17_new_site_creating_better_disaster_recovery_plans_body_text_cta
|
||||
@ -0,0 +1,728 @@
|
||||
Go vs .NET Core in terms of HTTP performance
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Hello Friends!
|
||||
|
||||
Lately I’ve heard a lot of discussion around the new .NET Core and its performance especially on web servers.
|
||||
|
||||
I didn’t want to start comparing two different things, so I did patience for quite long for a more stable version.
|
||||
|
||||
This Monday, Microsoft [announced the .NET Core version 2.0][7], so I feel ready to do it! Do you?
|
||||
|
||||
As we already mentioned, we will compare two identical things here, in terms of application, the expected response and the stability of their run times, so we will not try to put more things in the game like `JSON` or `XML`encoders and decoders, just a simple text message. To achieve a fair comparison we will use the [MVC architecture pattern][8] on both sides, Go and .NET Core.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
[Go][9] (or Golang): is a [rapidly growing][10] open source programming language designed for building simple, fast, and reliable software.
|
||||
|
||||
There are not lot of web frameworks for Go with MVC support but, luckily for us Iris does the job.
|
||||
|
||||
[Iris][11]: A fast, simple and efficient micro web framework for Go. It provides a beautifully expressive and easy to use foundation for your next website, API, or distributed app.
|
||||
|
||||
[C#][12]: is a general-purpose, object-oriented programming language. Its development team is led by [Anders Hejlsberg][13].
|
||||
|
||||
[.NET Core][14]: Develop high performance applications in less time, on any platform.
|
||||
|
||||
Download Go from [https://golang.org/dl][15] and .NET Core from [https://www.microsoft.com/net/core][16].
|
||||
|
||||
After you’ve download and install these, you will need Iris from Go’s side. Installation is very easy, just open your terminal and execute:
|
||||
|
||||
```
|
||||
go get -u github.com/kataras/iris
|
||||
```
|
||||
|
||||
### Benchmarking
|
||||
|
||||
#### Hardware
|
||||
|
||||
* Processor: Intel(R) Core(TM) i7–4710HQ CPU @ 2.50GHz 2.50GHz
|
||||
|
||||
* RAM: 8.00 GB
|
||||
|
||||
#### Software
|
||||
|
||||
* OS: Microsoft Windows [Version 10.0.15063], power plan is “High performance”
|
||||
|
||||
* HTTP Benchmark Tool: [https://github.com/codesenberg/bombardier][1], latest version 1.1
|
||||
|
||||
* .NET Core: [https://www.microsoft.com/net/core][2], latest version 2.0
|
||||
|
||||
* Iris: [https://github.com/kataras/iris][3], latest version 8.3 built with [go1.8.3][4]
|
||||
|
||||
Both of the applications will just return the text “value” on request path “api/values/{id}”.
|
||||
|
||||
.NET Core MVC
|
||||
|
||||
|
||||

|
||||
Logo designed by [Pablo Iglesias][5].
|
||||
|
||||
Created using `dotnet new webapi` . That `webapi`template will generate the code for you, including the `return “value” `on `GET `method requests.
|
||||
|
||||
_Source Code_
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.IO;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore;
|
||||
using Microsoft.AspNetCore.Hosting;
|
||||
using Microsoft.Extensions.Configuration;
|
||||
using Microsoft.Extensions.Logging;
|
||||
|
||||
namespace netcore_mvc
|
||||
{
|
||||
public class Program
|
||||
{
|
||||
public static void Main(string[] args)
|
||||
{
|
||||
BuildWebHost(args).Run();
|
||||
}
|
||||
|
||||
public static IWebHost BuildWebHost(string[] args) =>
|
||||
WebHost.CreateDefaultBuilder(args)
|
||||
.UseStartup<Startup>()
|
||||
.Build();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore.Builder;
|
||||
using Microsoft.AspNetCore.Hosting;
|
||||
using Microsoft.Extensions.Configuration;
|
||||
using Microsoft.Extensions.DependencyInjection;
|
||||
using Microsoft.Extensions.Logging;
|
||||
using Microsoft.Extensions.Options;
|
||||
|
||||
namespace netcore_mvc
|
||||
{
|
||||
public class Startup
|
||||
{
|
||||
public Startup(IConfiguration configuration)
|
||||
{
|
||||
Configuration = configuration;
|
||||
}
|
||||
|
||||
public IConfiguration Configuration { get; }
|
||||
|
||||
// This method gets called by the runtime. Use this method to add services to the container.
|
||||
public void ConfigureServices(IServiceCollection services)
|
||||
{
|
||||
services.AddMvcCore();
|
||||
}
|
||||
|
||||
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
|
||||
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
|
||||
{
|
||||
app.UseMvc();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore.Mvc;
|
||||
|
||||
namespace netcore_mvc.Controllers
|
||||
{
|
||||
// ValuesController is the equivalent
|
||||
// `ValuesController` of the Iris 8.3 mvc application.
|
||||
[Route("api/[controller]")]
|
||||
public class ValuesController : Controller
|
||||
{
|
||||
// Get handles "GET" requests to "api/values/{id}".
|
||||
[HttpGet("{id}")]
|
||||
public string Get(int id)
|
||||
{
|
||||
return "value";
|
||||
}
|
||||
|
||||
// Put handles "PUT" requests to "api/values/{id}".
|
||||
[HttpPut("{id}")]
|
||||
public void Put(int id, [FromBody]string value)
|
||||
{
|
||||
}
|
||||
|
||||
// Delete handles "DELETE" requests to "api/values/{id}".
|
||||
[HttpDelete("{id}")]
|
||||
public void Delete(int id)
|
||||
{
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
_Start the .NET Core web server_
|
||||
|
||||
```
|
||||
$ cd netcore-mvc
|
||||
$ dotnet run -c Release
|
||||
Hosting environment: Production
|
||||
Content root path: C:\mygopath\src\github.com\kataras\iris\_benchmarks\netcore-mvc
|
||||
Now listening on: http://localhost:5000
|
||||
Application started. Press Ctrl+C to shut down.
|
||||
```
|
||||
|
||||
_Target and run the HTTP benchmark tool_
|
||||
|
||||
```
|
||||
$ bombardier -c 125 -n 5000000 http://localhost:5000/api/values/5
|
||||
Bombarding http://localhost:5000/api/values/5 with 5000000 requests using 125 connections
|
||||
5000000 / 5000000 [=====================================================] 100.00% 2m3s
|
||||
Done!
|
||||
Statistics Avg Stdev Max
|
||||
Reqs/sec 40226.03 8724.30 161919
|
||||
Latency 3.09ms 1.40ms 169.12ms
|
||||
HTTP codes:
|
||||
1xx - 0, 2xx - 5000000, 3xx - 0, 4xx - 0, 5xx - 0
|
||||
others - 0
|
||||
Throughput: 8.91MB/s
|
||||
```
|
||||
|
||||
Iris MVC
|
||||
|
||||
|
||||

|
||||
Logo designed by [Santosh Anand][6].
|
||||
|
||||
_Source Code_
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"github.com/kataras/iris"
|
||||
"github.com/kataras/iris/_benchmarks/iris-mvc/controllers"
|
||||
)
|
||||
|
||||
func main() {
|
||||
app := iris.New()
|
||||
app.Controller("/api/values/{id}", new(controllers.ValuesController))
|
||||
app.Run(iris.Addr(":5000"), iris.WithoutVersionChecker)
|
||||
}
|
||||
view raw
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
package controllers
|
||||
|
||||
import "github.com/kataras/iris/mvc"
|
||||
|
||||
// ValuesController is the equivalent
|
||||
// `ValuesController` of the .net core 2.0 mvc application.
|
||||
type ValuesController struct {
|
||||
mvc.Controller
|
||||
}
|
||||
|
||||
// Get handles "GET" requests to "api/values/{id}".
|
||||
func (vc *ValuesController) Get() {
|
||||
// id,_ := vc.Params.GetInt("id")
|
||||
vc.Ctx.WriteString("value")
|
||||
}
|
||||
|
||||
// Put handles "PUT" requests to "api/values/{id}".
|
||||
func (vc *ValuesController) Put() {}
|
||||
|
||||
// Delete handles "DELETE" requests to "api/values/{id}".
|
||||
func (vc *ValuesController) Delete() {}
|
||||
```
|
||||
|
||||
|
||||
_Start the Go web server_
|
||||
|
||||
```
|
||||
$ cd iris-mvc
|
||||
$ go run main.go
|
||||
Now listening on: http://localhost:5000
|
||||
Application started. Press CTRL+C to shut down.
|
||||
```
|
||||
|
||||
_Target and run the HTTP benchmark tool_
|
||||
|
||||
```
|
||||
$ bombardier -c 125 -n 5000000 http://localhost:5000/api/values/5
|
||||
Bombarding http://localhost:5000/api/values/5 with 5000000 requests using 125 connections
|
||||
5000000 / 5000000 [======================================================] 100.00% 47s
|
||||
Done!
|
||||
Statistics Avg Stdev Max
|
||||
Reqs/sec 105643.81 7687.79 122564
|
||||
Latency 1.18ms 366.55us 22.01ms
|
||||
HTTP codes:
|
||||
1xx - 0, 2xx - 5000000, 3xx - 0, 4xx - 0, 5xx - 0
|
||||
others - 0
|
||||
Throughput: 19.65MB/s
|
||||
```
|
||||
|
||||
For those who understand better by images, I did print my screen too!
|
||||
|
||||
Click [here][23] to see these screenshots.
|
||||
|
||||
#### Summary
|
||||
|
||||
* Time to complete the `5000000 requests` - smaller is better.
|
||||
|
||||
* Reqs/sec — bigger is better.
|
||||
|
||||
* Latency — smaller is better
|
||||
|
||||
* Throughput — bigger is better.
|
||||
|
||||
* Memory usage — smaller is better.
|
||||
|
||||
* LOC (Lines Of Code) — smaller is better.
|
||||
|
||||
.NET Core MVC Application, written using 86 lines of code, ran for 2 minutes and 8 seconds serving 39311.56 requests per second within 3.19mslatency in average and 229.73ms max, the memory usage of all these was ~126MB (without the dotnet host).
|
||||
|
||||
Iris MVC Application, written using 27 lines of code, ran for 47 secondsserving 105643.71 requests per second within 1.18ms latency in average and 22.01ms max, the memory usage of all these was ~12MB.
|
||||
|
||||
> There is also another benchmark with templates, scroll to the bottom.
|
||||
|
||||
Update 20 August 2017
|
||||
|
||||
As [Josh Clark][24] and [Scott Hanselman][25] pointed out on this [re-twee][26]t , on .NET Core `Startup.cs` file the line with `services.AddMvc();` can be replaced with `services.AddMvcCore();` . I followed their helpful instructions and re-run the benchmarks. The article now contains the latest benchmark output for the .NET Core application with the change both Josh and Scott noted.
|
||||
|
||||
|
||||
@topdawgevh @shanselman they also used AddMvc() instead of AddMvcCore()... doesn't one include more middleware?
|
||||
|
||||
— @clarkis117
|
||||
|
||||
@clarkis117 @topdawgevh Cool @MakisMaropoulos we'll take a look. @ben_a_adams @davidfowl. Good learnings on how to make easier performant defaults.
|
||||
|
||||
— @shanselman
|
||||
|
||||
@shanselman @clarkis117 @topdawgevh @ben_a_adams @davidfowl @shanselman @ben_a_adams @davidfowl Thank you for your feedback! I did update the results, no difference. I'm open for any other suggestion
|
||||
|
||||
— @MakisMaropoulos
|
||||
|
||||
>It had a small difference but not as huge (8.91MB/s from 8.61MB/s)
|
||||
|
||||
|
||||
|
||||
For those who want to compare with the standard `services.AddMvc(); `you can see the old output by pressing [here][27].
|
||||
|
||||
* * *
|
||||
|
||||
### Can you stay a bit longer for one more?
|
||||
|
||||
Let’s run one more benchmark, spawn `1000000 requests` but this time we expect `HTML` generated by templates via the view engine.
|
||||
|
||||
#### .NET Core MVC with Templates
|
||||
|
||||
|
||||
```
|
||||
using System;
|
||||
|
||||
namespace netcore_mvc_templates.Models
|
||||
{
|
||||
public class ErrorViewModel
|
||||
{
|
||||
public string Title { get; set; }
|
||||
public int Code { get; set; }
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Diagnostics;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore.Mvc;
|
||||
using netcore_mvc_templates.Models;
|
||||
|
||||
namespace netcore_mvc_templates.Controllers
|
||||
{
|
||||
public class HomeController : Controller
|
||||
{
|
||||
public IActionResult Index()
|
||||
{
|
||||
return View();
|
||||
}
|
||||
|
||||
public IActionResult About()
|
||||
{
|
||||
ViewData["Message"] = "Your application description page.";
|
||||
|
||||
return View();
|
||||
}
|
||||
|
||||
public IActionResult Contact()
|
||||
{
|
||||
ViewData["Message"] = "Your contact page.";
|
||||
|
||||
return View();
|
||||
}
|
||||
|
||||
public IActionResult Error()
|
||||
{
|
||||
return View(new ErrorViewModel { Title = "Error", Code = 500});
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.IO;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore;
|
||||
using Microsoft.AspNetCore.Hosting;
|
||||
using Microsoft.Extensions.Configuration;
|
||||
using Microsoft.Extensions.Logging;
|
||||
|
||||
namespace netcore_mvc_templates
|
||||
{
|
||||
public class Program
|
||||
{
|
||||
public static void Main(string[] args)
|
||||
{
|
||||
BuildWebHost(args).Run();
|
||||
}
|
||||
|
||||
public static IWebHost BuildWebHost(string[] args) =>
|
||||
WebHost.CreateDefaultBuilder(args)
|
||||
.UseStartup<Startup>()
|
||||
.Build();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
using System;
|
||||
using System.Collections.Generic;
|
||||
using System.Linq;
|
||||
using System.Threading.Tasks;
|
||||
using Microsoft.AspNetCore.Builder;
|
||||
using Microsoft.AspNetCore.Hosting;
|
||||
using Microsoft.Extensions.Configuration;
|
||||
using Microsoft.Extensions.DependencyInjection;
|
||||
|
||||
namespace netcore_mvc_templates
|
||||
{
|
||||
public class Startup
|
||||
{
|
||||
public Startup(IConfiguration configuration)
|
||||
{
|
||||
Configuration = configuration;
|
||||
}
|
||||
|
||||
public IConfiguration Configuration { get; }
|
||||
|
||||
// This method gets called by the runtime. Use this method to add services to the container.
|
||||
public void ConfigureServices(IServiceCollection services)
|
||||
{
|
||||
/* An unhandled exception was thrown by the application.
|
||||
System.InvalidOperationException: No service for type
|
||||
'Microsoft.AspNetCore.Mvc.ViewFeatures.ITempDataDictionaryFactory' has been registered.
|
||||
Solution: Use AddMvc() instead of AddMvcCore() in Startup.cs and it will work.
|
||||
*/
|
||||
// services.AddMvcCore();
|
||||
services.AddMvc();
|
||||
}
|
||||
|
||||
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
|
||||
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
|
||||
{
|
||||
app.UseStaticFiles();
|
||||
|
||||
app.UseMvc(routes =>
|
||||
{
|
||||
routes.MapRoute(
|
||||
name: "default",
|
||||
template: "{controller=Home}/{action=Index}/{id?}");
|
||||
});
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
/*
|
||||
wwwroot/css
|
||||
wwwroot/images
|
||||
wwwroot/js
|
||||
wwwroot/lib
|
||||
wwwroot/favicon.ico
|
||||
|
||||
|
||||
Views/Shared/_Layout.cshtml
|
||||
Views/Shared/Error.cshtml
|
||||
|
||||
Views/Home/About.cshtml
|
||||
Views/Home/Contact.cshtml
|
||||
Views/Home/Index.cshtml
|
||||
|
||||
These files are quite long to be shown in this article but you can view them at:
|
||||
https://github.com/kataras/iris/tree/master/_benchmarks/netcore-mvc-templates
|
||||
```
|
||||
|
||||
|
||||
_Start the .NET Core web server_
|
||||
|
||||
```
|
||||
$ cd netcore-mvc-templates
|
||||
$ dotnet run -c Release
|
||||
Hosting environment: Production
|
||||
Content root path: C:\mygopath\src\github.com\kataras\iris\_benchmarks\netcore-mvc-templates
|
||||
Now listening on: http://localhost:5000
|
||||
Application started. Press Ctrl+C to shut down.
|
||||
```
|
||||
|
||||
_Target and run the HTTP benchmark tool_
|
||||
|
||||
```
|
||||
Bombarding http://localhost:5000 with 1000000 requests using 125 connections
|
||||
1000000 / 1000000 [====================================================] 100.00% 1m20s
|
||||
Done!
|
||||
Statistics Avg Stdev Max
|
||||
Reqs/sec 11738.60 7741.36 125887
|
||||
Latency 10.10ms 22.10ms 1.97s
|
||||
HTTP codes:
|
||||
1xx — 0, 2xx — 1000000, 3xx — 0, 4xx — 0, 5xx — 0
|
||||
others — 0
|
||||
Throughput: 89.03MB/s
|
||||
```
|
||||
|
||||
#### Iris MVC with Templates
|
||||
|
||||
```
|
||||
package controllers
|
||||
|
||||
import "github.com/kataras/iris/mvc"
|
||||
|
||||
type AboutController struct{ mvc.Controller }
|
||||
|
||||
func (c *AboutController) Get() {
|
||||
c.Data["Title"] = "About"
|
||||
c.Data["Message"] = "Your application description page."
|
||||
c.Tmpl = "about.html"
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
package controllers
|
||||
|
||||
import "github.com/kataras/iris/mvc"
|
||||
|
||||
type ContactController struct{ mvc.Controller }
|
||||
|
||||
func (c *ContactController) Get() {
|
||||
c.Data["Title"] = "Contact"
|
||||
c.Data["Message"] = "Your contact page."
|
||||
c.Tmpl = "contact.html"
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
package models
|
||||
|
||||
// HTTPError a silly structure to keep our error page data.
|
||||
type HTTPError struct {
|
||||
Title string
|
||||
Code int
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
package controllers
|
||||
|
||||
import "github.com/kataras/iris/mvc"
|
||||
|
||||
type IndexController struct{ mvc.Controller }
|
||||
|
||||
func (c *IndexController) Get() {
|
||||
c.Data["Title"] = "Home Page"
|
||||
c.Tmpl = "index.html"
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"github.com/kataras/iris/_benchmarks/iris-mvc-templates/controllers"
|
||||
|
||||
"github.com/kataras/iris"
|
||||
"github.com/kataras/iris/context"
|
||||
)
|
||||
|
||||
const (
|
||||
// templatesDir is the exactly the same path that .NET Core is using for its templates,
|
||||
// in order to reduce the size in the repository.
|
||||
// Change the "C\\mygopath" to your own GOPATH.
|
||||
templatesDir = "C:\\mygopath\\src\\github.com\\kataras\\iris\\_benchmarks\\netcore-mvc-templates\\wwwroot"
|
||||
)
|
||||
|
||||
func main() {
|
||||
app := iris.New()
|
||||
app.Configure(configure)
|
||||
|
||||
app.Controller("/", new(controllers.IndexController))
|
||||
app.Controller("/about", new(controllers.AboutController))
|
||||
app.Controller("/contact", new(controllers.ContactController))
|
||||
|
||||
app.Run(iris.Addr(":5000"), iris.WithoutVersionChecker)
|
||||
}
|
||||
|
||||
func configure(app *iris.Application) {
|
||||
app.RegisterView(iris.HTML("./views", ".html").Layout("shared/layout.html"))
|
||||
app.StaticWeb("/public", templatesDir)
|
||||
app.OnAnyErrorCode(onError)
|
||||
}
|
||||
|
||||
type err struct {
|
||||
Title string
|
||||
Code int
|
||||
}
|
||||
|
||||
func onError(ctx context.Context) {
|
||||
ctx.ViewData("", err{"Error", ctx.GetStatusCode()})
|
||||
ctx.View("shared/error.html")
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
/*
|
||||
../netcore-mvc-templates/wwwroot/css
|
||||
../netcore-mvc-templates/wwwroot/images
|
||||
../netcore-mvc-templates/wwwroot/js
|
||||
../netcore-mvc-templates/wwwroot/lib
|
||||
../netcore-mvc-templates/wwwroot/favicon.ico
|
||||
views/shared/layout.html
|
||||
views/shared/error.html
|
||||
views/about.html
|
||||
views/contact.html
|
||||
views/index.html
|
||||
These files are quite long to be shown in this article but you can view them at:
|
||||
https://github.com/kataras/iris/tree/master/_benchmarks/iris-mvc-templates
|
||||
*/
|
||||
```
|
||||
|
||||
|
||||
|
||||
_Start the Go web server_
|
||||
|
||||
```
|
||||
$ cd iris-mvc-templates
|
||||
$ go run main.go
|
||||
Now listening on: http://localhost:5000
|
||||
Application started. Press CTRL+C to shut down.
|
||||
|
||||
```
|
||||
|
||||
_Target and run the HTTP benchmark tool_
|
||||
|
||||
```
|
||||
Bombarding http://localhost:5000 with 1000000 requests using 125 connections
|
||||
1000000 / 1000000 [======================================================] 100.00% 37s
|
||||
Done!
|
||||
Statistics Avg Stdev Max
|
||||
Reqs/sec 26656.76 1944.73 31188
|
||||
Latency 4.69ms 1.20ms 22.52ms
|
||||
HTTP codes:
|
||||
1xx — 0, 2xx — 1000000, 3xx — 0, 4xx — 0, 5xx — 0
|
||||
others — 0
|
||||
Throughput: 192.51MB/s
|
||||
```
|
||||
|
||||
Summary
|
||||
|
||||
* Time to complete the `1000000 requests` — smaller is better.
|
||||
|
||||
* Reqs/sec — bigger is better.
|
||||
|
||||
* Latency — smaller is better
|
||||
|
||||
* Memory usage — smaller is better.
|
||||
|
||||
* Throughput — bigger is better.
|
||||
|
||||
.NET Core MVC with Templates Application ran for 1 minute and 20 seconds serving 11738.60 requests per second with 89.03MB/s within 10.10ms latency in average and 1.97s max, the memory usage of all these was ~193MB (without the dotnet host).
|
||||
|
||||
Iris MVC with Templates Application ran for 37 seconds serving 26656.76requests per second with 192.51MB/s within 1.18ms latency in average and 22.52ms max, the memory usage of all these was ~17MB.
|
||||
|
||||
### What next?
|
||||
|
||||
Download the example source code from [there ][32]and run the same benchmarks from your machine, then come back here and share your results with the rest of us!
|
||||
|
||||
For those who want to add other go or c# .net core web frameworks to the list please push a PR to the `_benchmarks` folder inside [this repository][33].
|
||||
|
||||
I need to personally thanks the [dev.to][34] team for sharing my article at their twitter account, as well.
|
||||
|
||||
Go vs .NET Core in terms of HTTP performance { author: @MakisMaropoulos } https://t.co/IXL5LSpnjX
|
||||
|
||||
— @ThePracticalDev
|
||||
|
||||
|
||||
Thank you all for the 100% green feedback, have fun!
|
||||
|
||||
#### Update: Monday, 21 August 2017
|
||||
|
||||
A lot of people reached me saying that want to see a new benchmarking article based on the .NET Core’s lower level Kestrel this time.
|
||||
|
||||
So I did, follow the below link to learn the performance difference between Kestrel and Iris, it contains a sessions storage management benchmark too!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/go-vs-net-core-in-terms-of-http-performance-7535a61b67b8
|
||||
|
||||
作者:[ Gerasimos Maropoulos][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@kataras?source=post_header_lockup
|
||||
[1]:https://github.com/codesenberg/bombardier
|
||||
[2]:https://www.microsoft.com/net/core
|
||||
[3]:https://github.com/kataras/iris
|
||||
[4]:https://golang.org/
|
||||
[5]:https://github.com/campusMVP/dotnetCoreLogoPack
|
||||
[6]:https://github.com/santoshanand
|
||||
[7]:https://blogs.msdn.microsoft.com/dotnet/2017/08/14/announcing-net-core-2-0/
|
||||
[8]:https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller
|
||||
[9]:https://golang.org/
|
||||
[10]:http://www.tiobe.com/tiobe-index/
|
||||
[11]:http://iris-go.com/
|
||||
[12]:https://en.wikipedia.org/wiki/C_Sharp_%28programming_language%29
|
||||
[13]:https://twitter.com/ahejlsberg
|
||||
[14]:https://www.microsoft.com/net/
|
||||
[15]:https://golang.org/dl
|
||||
[16]:https://www.microsoft.com/net/core
|
||||
[17]:http://localhost:5000/
|
||||
[18]:http://localhost:5000/api/values/5
|
||||
[19]:http://localhost:5000/api/values/5
|
||||
[20]:http://localhost:5000/
|
||||
[21]:http://localhost:5000/api/values/5
|
||||
[22]:http://localhost:5000/api/values/5
|
||||
[23]:https://github.com/kataras/iris/tree/master/_benchmarks/screens
|
||||
[24]:https://twitter.com/clarkis117
|
||||
[25]:https://twitter.com/shanselman
|
||||
[26]:https://twitter.com/shanselman/status/899005786826788865
|
||||
[27]:https://github.com/kataras/iris/blob/master/_benchmarks/screens/5m_requests_netcore-mvc.png
|
||||
[28]:http://localhost:5000/
|
||||
[29]:http://localhost:5000/
|
||||
[30]:http://localhost:5000/
|
||||
[31]:http://localhost:5000/
|
||||
[32]:https://github.com/kataras/iris/tree/master/_benchmarks
|
||||
[33]:https://github.com/kataras/iris
|
||||
[34]:https://dev.to/kataras/go-vsnet-core-in-terms-of-http-performance
|
||||
@ -0,0 +1,420 @@
|
||||
【翻译中 @haoqixu】Your Serverless Raspberry Pi cluster with Docker
|
||||
============================================================
|
||||
|
||||
|
||||
This blog post will show you how to create your own Serverless Raspberry Pi cluster with Docker and the [OpenFaaS][33] framework. People often ask me what they should do with their cluster and this application is perfect for the credit-card sized device - want more compute power? Scale by adding more RPis.
|
||||
|
||||
> "Serverless" is a design pattern for event-driven architectures just like "bridge", "facade", "factory" and "cloud" are also abstract concepts - [so is "serverless"][21].
|
||||
|
||||
Here's my cluster for the blog post - with brass stand-offs used to separate each device.
|
||||
|
||||
|
||||
|
||||
### What is Serverless and why does it matter to you?
|
||||
|
||||
> As an industry we have some explaining to do regarding what the term "serverless" means. For the sake of this blog post let us assume that it is a new architectural pattern for event-driven architectures and that it lets you write tiny, reusable functions in whatever language you like. [Read more on Serverless here][22].
|
||||
|
||||
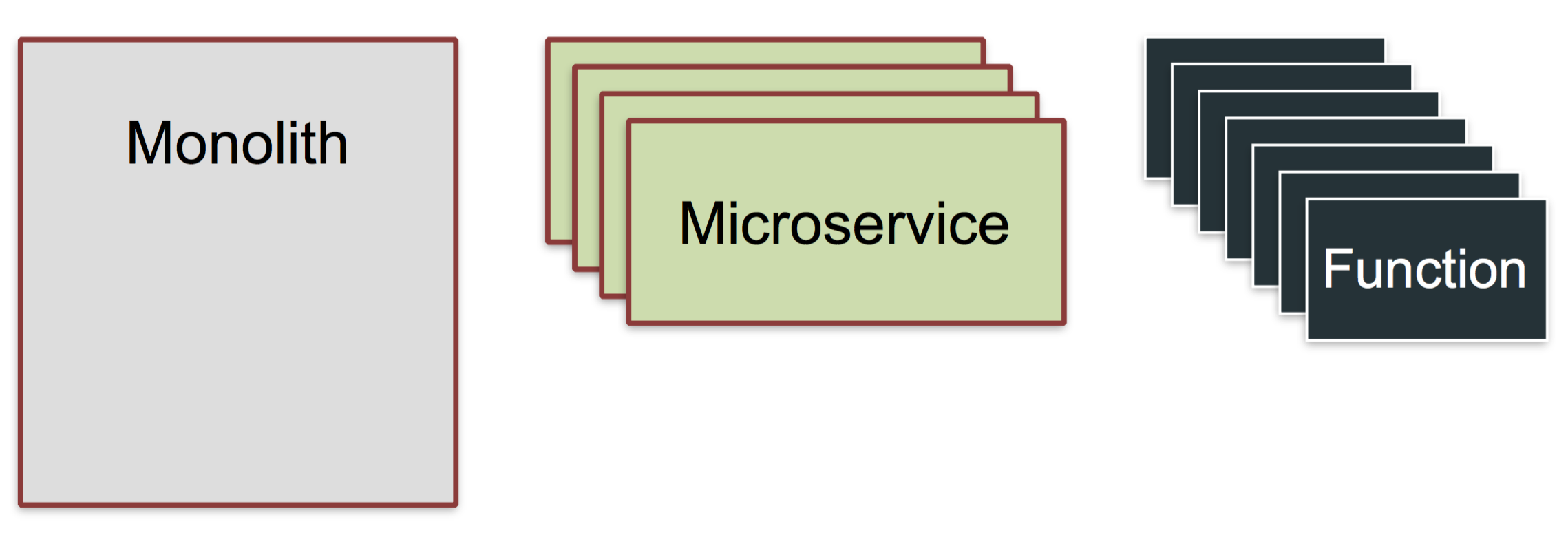
|
||||
_Serverless is an architectural pattern resulting in: Functions as a Service, or FaaS_
|
||||
|
||||
Serverless functions can do anything, but usually work on a given input - such as an event from GitHub, Twitter, PayPal, Slack, your Jenkins CI pipeline - or in the case of a Raspberry Pi - maybe a real-world sensor input such as a PIR motion sensor, laser tripwire or even a temperature gauge.
|
||||
|
||||

|
||||
|
||||
Let's also assume that serverless functions tend to make use of third-party back-end services to become greater than the sum of their parts.
|
||||
|
||||
For more background information checkout my latest blog post - [Introducing Functions as a Service (FaaS)][34]
|
||||
|
||||
### Overview
|
||||
|
||||
We'll be using [OpenFaaS][35] which lets you turn any single host or cluster into a back-end to run serverless functions. Any binary, script or programming language that can be deployed with Docker will work on [OpenFaaS][36] and you can chose on a scale between speed and flexibility. The good news is a UI and metrics are also built-in.
|
||||
|
||||
Here's what we'll do:
|
||||
|
||||
* Set up Docker on one or more hosts (Raspberry Pi 2/3)
|
||||
|
||||
* Join them together in a Docker Swarm
|
||||
|
||||
* Deploy [OpenFaaS][23]
|
||||
|
||||
* Write our first function in Python
|
||||
|
||||
### Docker Swarm
|
||||
|
||||
Docker is a technology for packaging and deploying applications, it also has clustering built-in which is secure by default and only takes one line to set up. OpenFaaS uses Docker and Swarm to spread your serverless functions across all your available RPis.
|
||||
|
||||

|
||||
_Pictured: 3x Raspberry Pi Zero_
|
||||
|
||||
I recommend using Raspberry Pi 2 or 3 for this project along with an Ethernet switch and a [powerful USB multi-adapter][37].
|
||||
|
||||
### Prepare Raspbian
|
||||
|
||||
Flash [Raspbian Jessie Lite][38] to an SD card, 8GB will do but 16GB is recommended.
|
||||
|
||||
_Note: do not download Raspbian Stretch_
|
||||
|
||||
> The community is helping the Docker team to ready support for Raspbian Stretch, but it's not yet seamless. Please download Jessie Lite from the [RPi foundation's archive here][24]
|
||||
|
||||
I recommend using [Etcher.io][39] to flash the image.
|
||||
|
||||
> Before booting the RPi you'll need to create a file in the boot partition called "ssh". Just keep the file blank. This enables remote logins.
|
||||
|
||||
* Power up and change the hostname
|
||||
|
||||
Now power up the RPi and connect with `ssh`
|
||||
|
||||
```
|
||||
$ ssh pi@raspberrypi.local
|
||||
|
||||
```
|
||||
|
||||
> The password is `raspberry`.
|
||||
|
||||
Use the `raspi-config` utility to change the hostname to `swarm-1` or similar and then reboot.
|
||||
|
||||
While you're here you can also change the memory split between the GPU (graphics) and the system to 16mb.
|
||||
|
||||
* Now install Docker
|
||||
|
||||
We can use a utility script for this:
|
||||
|
||||
```
|
||||
$ curl -sSL https://get.docker.com | sh
|
||||
|
||||
```
|
||||
|
||||
> This installation method may change in the future. As noted above you need to be running Jessie so we have a known configuration.
|
||||
|
||||
You may see a warning like this, but you can ignore it and you should end up with Docker CE 17.05:
|
||||
|
||||
```
|
||||
WARNING: raspbian is no longer updated @ https://get.docker.com/
|
||||
Installing the legacy docker-engine package...
|
||||
|
||||
```
|
||||
|
||||
After, make sure your user account can access the Docker client with this command:
|
||||
|
||||
```
|
||||
$ usermod pi -aG docker
|
||||
|
||||
```
|
||||
|
||||
> If your username isn't `pi` then replace `pi` with `alex` for instance.
|
||||
|
||||
* Change the default password
|
||||
|
||||
Type in `$sudo passwd pi` and enter a new password, please don't skip this step!
|
||||
|
||||
* Repeat
|
||||
|
||||
Now repeat the above for each of the RPis.
|
||||
|
||||
### Create your Swarm cluster
|
||||
|
||||
Log into the first RPi and type in the following:
|
||||
|
||||
```
|
||||
$ docker swarm init
|
||||
Swarm initialized: current node (3ra7i5ldijsffjnmubmsfh767) is now a manager.
|
||||
|
||||
To add a worker to this swarm, run the following command:
|
||||
|
||||
docker swarm join \
|
||||
--token SWMTKN-1-496mv9itb7584pzcddzj4zvzzfltgud8k75rvujopw15n3ehzu-af445b08359golnzhncbdj9o3 \
|
||||
192.168.0.79:2377
|
||||
|
||||
```
|
||||
|
||||
You'll see the output with your join token and the command to type into the other RPis. So log into each one with `ssh` and paste in the command.
|
||||
|
||||
Give this a few seconds to connect then on the first RPi check all your nodes are listed:
|
||||
|
||||
```
|
||||
$ docker node ls
|
||||
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
|
||||
3ra7i5ldijsffjnmubmsfh767 * swarm1 Ready Active Leader
|
||||
k9mom28s2kqxocfq1fo6ywu63 swarm3 Ready Active
|
||||
y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
|
||||
|
||||
```
|
||||
|
||||
Congratulations! You have a Raspberry Pi cluster!
|
||||
|
||||
_*More on clusters_
|
||||
|
||||
You can see my three hosts up and running. Only one is a manager at this point. If our manager were to go _down_ then we'd be in an unrecoverable situation. The way around this is to add redundancy by promoting more of the nodes to managers - they will still run workloads, unless you specifically set up your services to only be placed on workers.
|
||||
|
||||
To upgrade a worker to a manager, just type in `docker node promote <node_name>`from one of your managers.
|
||||
|
||||
> Note: Swarm commands such as `docker service ls` or `docker node ls` can only be done on the manager.
|
||||
|
||||
For a deeper dive into how managers and workers keep "quorum" head over to the [Docker Swarm admin guide][40].
|
||||
|
||||
### OpenFaaS
|
||||
|
||||
Now let's move on to deploying a real application to enable Serverless functions to run on our cluster. [OpenFaaS][41] is a framework for Docker that lets any process or container become a serverless function - at scale and on any hardware or cloud. Thanks to Docker and Golang's portability it also runs very well on a Raspberry Pi.
|
||||
|
||||

|
||||
|
||||
> Please show your support and **star** the [OpenFaaS][25] repository on GitHub.
|
||||
|
||||
Log into the first RPi (where we ran `docker swarm init`) and clone/deploy the project:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas/
|
||||
$ cd faas
|
||||
$ ./deploy_stack.armhf.sh
|
||||
Creating network func_functions
|
||||
Creating service func_gateway
|
||||
Creating service func_prometheus
|
||||
Creating service func_alertmanager
|
||||
Creating service func_nodeinfo
|
||||
Creating service func_markdown
|
||||
Creating service func_wordcount
|
||||
Creating service func_echoit
|
||||
|
||||
```
|
||||
|
||||
Your other RPis will now be instructed by Docker Swarm to start pulling the Docker images from the internet and extracting them to the SD card. The work will be spread across all the RPis so that none of them are overworked.
|
||||
|
||||
This could take a couple of minutes, so you can check when it's done by typing in:
|
||||
|
||||
```
|
||||
$ watch 'docker service ls'
|
||||
ID NAME MODE REPLICAS IMAGE PORTS
|
||||
57ine9c10xhp func_wordcount replicated 1/1 functions/alpine:latest-armhf
|
||||
d979zipx1gld func_prometheus replicated 1/1 alexellis2/prometheus-armhf:1.5.2 *:9090->9090/tcp
|
||||
f9yvm0dddn47 func_echoit replicated 1/1 functions/alpine:latest-armhf
|
||||
lhbk1fc2lobq func_markdown replicated 1/1 functions/markdownrender:latest-armhf
|
||||
pj814yluzyyo func_alertmanager replicated 1/1 alexellis2/alertmanager-armhf:0.5.1 *:9093->9093/tcp
|
||||
q4bet4xs10pk func_gateway replicated 1/1 functions/gateway-armhf:0.6.0 *:8080->8080/tcp
|
||||
v9vsvx73pszz func_nodeinfo replicated 1/1 functions/nodeinfo:latest-armhf
|
||||
|
||||
```
|
||||
|
||||
We want to see 1/1 listed on all of our services.
|
||||
|
||||
Given any service name you can type in the following to see which RPi it was scheduled to:
|
||||
|
||||
```
|
||||
$ docker service ps func_markdown
|
||||
ID IMAGE NODE STATE
|
||||
func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
|
||||
|
||||
```
|
||||
|
||||
The state should be `Running` - if it says `Pending` then the image could still be on its way down from the internet.
|
||||
|
||||
At that point, find the IP address of your RPi and open that in a web-browser on port 8080:
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
|
||||
```
|
||||
|
||||
For example if your IP was: 192.168.0.100 - then go to [http://192.168.0.100:8080][42]
|
||||
|
||||
At this point you should see the FaaS UI also called the API Gateway. This is where you can define, test and invoke your functions.
|
||||
|
||||
Click on the Markdown conversion function called func_markdown and type in some Markdown (this is what Wikipedia uses to write its content).
|
||||
|
||||
Then hit invoke. You'll see the invocation count go up and the bottom half of the screen shows the result of your function:
|
||||
|
||||
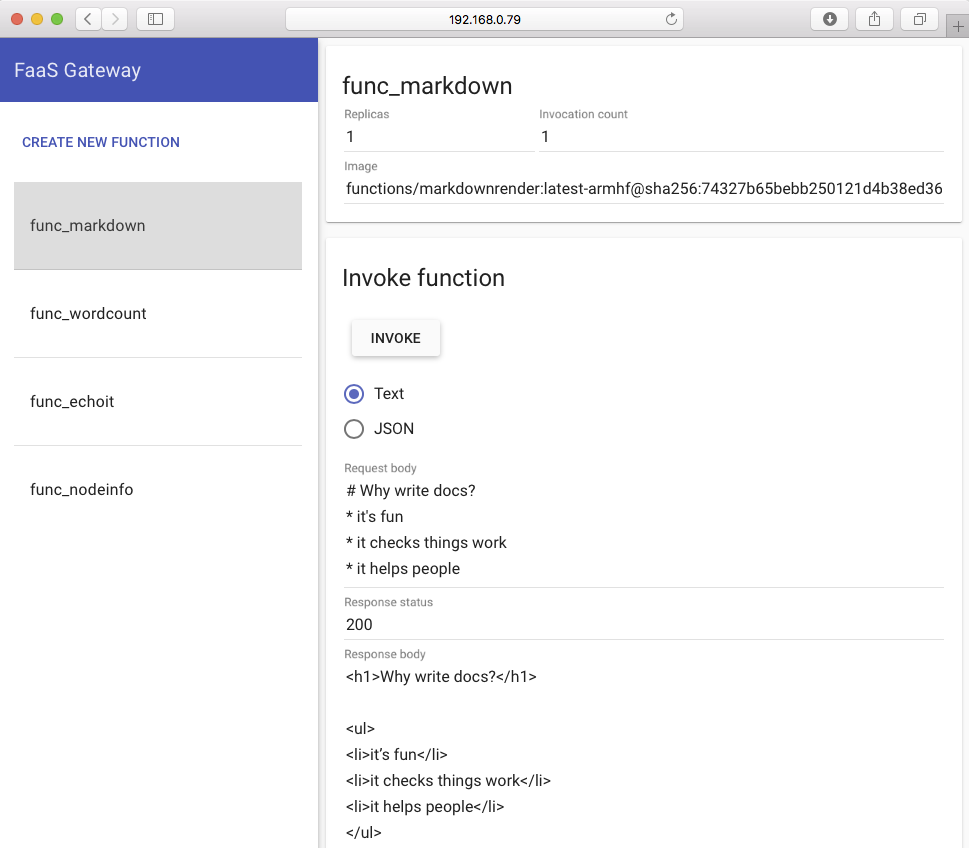
|
||||
|
||||
### Deploy your first serverless function:
|
||||
|
||||
There is already a tutorial written for this section, but we'll need to get the RPi set up with a couple of custom steps first.
|
||||
|
||||
* Get the FaaS-CLI
|
||||
|
||||
```
|
||||
$ curl -sSL cli.openfaas.com | sudo sh
|
||||
armv7l
|
||||
Getting package https://github.com/alexellis/faas-cli/releases/download/0.4.5-b/faas-cli-armhf
|
||||
|
||||
```
|
||||
|
||||
* Clone the samples:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas-cli
|
||||
$ cd faas-cli
|
||||
|
||||
```
|
||||
|
||||
* Patch the samples for Raspberry Pi
|
||||
|
||||
We'll temporarily update our templates so they work with the Raspberry Pi:
|
||||
|
||||
```
|
||||
$ cp template/node-armhf/Dockerfile template/node/
|
||||
$ cp template/python-armhf/Dockerfile template/python/
|
||||
|
||||
```
|
||||
|
||||
The reason for doing this is that the Raspberry Pi has a different processor to most computers we interact with on a daily basis.
|
||||
|
||||
> Get up to speed on Docker on the Raspberry Pi - read: [5 Things you need to know][26]
|
||||
|
||||
Now you can follow the same tutorial written for PC, Laptop and Cloud available below, but we are going to run a couple of commands first for the Raspberry Pi.
|
||||
|
||||
* [Your first serverless Python function with OpenFaaS][27]
|
||||
|
||||
Pick it up at step 3:
|
||||
|
||||
* Instead of placing your functions in `~/functions/hello-python` - place them inside the `faas-cli` folder we just cloned from GitHub.
|
||||
|
||||
* Also replace "localhost" for the IP address of your first RPi in the `stack.yml`file.
|
||||
|
||||
Note that the Raspberry Pi may take a few minutes to download your serverless function to the relevant RPi. You can check on your services to make sure you have 1/1 replicas showing up with this command:
|
||||
|
||||
```
|
||||
$ watch 'docker service ls'
|
||||
pv27thj5lftz hello-python replicated 1/1 alexellis2/faas-hello-python-armhf:latest
|
||||
|
||||
```
|
||||
|
||||
**Continue the tutorial:** [Your first serverless Python function with OpenFaaS][43]
|
||||
|
||||
For more information on working with Node.js or other languages head over to the main [FaaS repo][44]
|
||||
|
||||
### Check your function metrics
|
||||
|
||||
With a Serverless experience, you don't want to spend all your time managing your functions. Fortunately [Prometheus][45] metrics are built into OpenFaaS meaning you can keep track of how long each functions takes to run and how often it's being called.
|
||||
|
||||
_Metrics drive auto-scaling_
|
||||
|
||||
If you generate enough load on any of of the functions then OpenFaaS will auto-scale your function and when the demand eases off you'll get back to a single replica again.
|
||||
|
||||
Here is a sample query you can paste into Safari, Chrome etc:
|
||||
|
||||
Just change the IP address to your own.
|
||||
|
||||
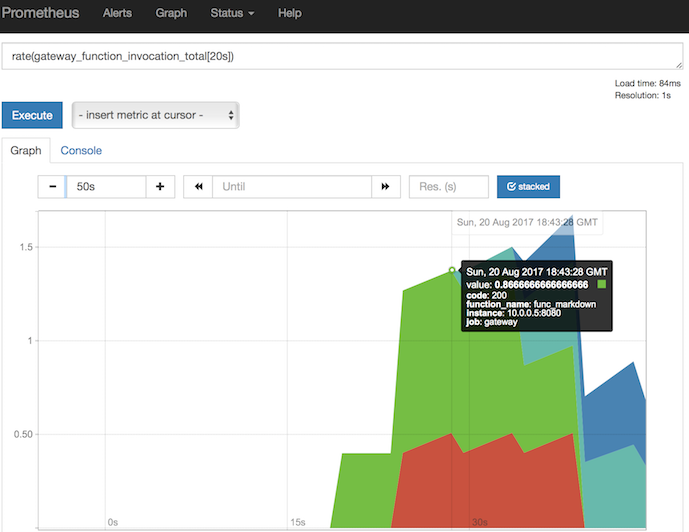
|
||||
|
||||
```
|
||||
http://192.168.0.25:9090/graph?g0.range_input=15m&g0.stacked=1&g0.expr=rate(gateway_function_invocation_total%5B20s%5D)&g0.tab=0&g1.range_input=1h&g1.expr=gateway_service_count&g1.tab=0
|
||||
|
||||
```
|
||||
|
||||
The queries are written in PromQL - Prometheus query language. The first one shows us how often the function is being called:
|
||||
|
||||
```
|
||||
rate(gateway_function_invocation_total[20s])
|
||||
|
||||
```
|
||||
|
||||
The second query shows us how many replicas we have of each function, there should be only one of each at the start:
|
||||
|
||||
```
|
||||
gateway_service_count
|
||||
|
||||
```
|
||||
|
||||
If you want to trigger auto-scaling you could try the following on the RPi:
|
||||
|
||||
```
|
||||
$ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello world" ; done
|
||||
|
||||
```
|
||||
|
||||
Check the Prometheus "alerts" page, and see if you are generating enough load for the auto-scaling to trigger, if you're not then run the command in a few additional Terminal windows too.
|
||||
|
||||
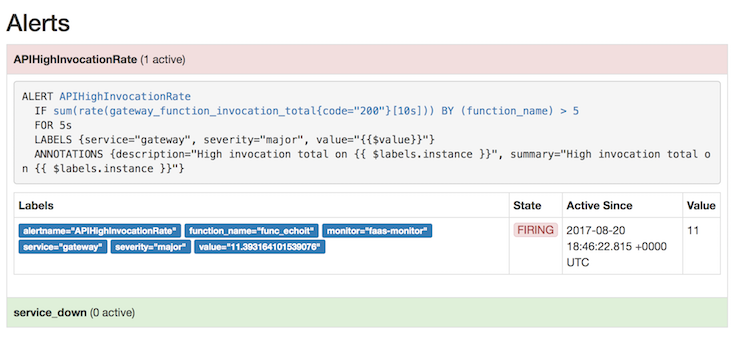
|
||||
|
||||
After you reduce the load, the replica count shown in your second graph and the `gateway_service_count` metric will go back to 1 again.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
We've now set up Docker, Swarm and run OpenFaaS - which let us treat our Raspberry Pi like one giant computer - ready to crunch through code.
|
||||
|
||||
> Please show support for the project and **Star** the [FaaS GitHub repository][28]
|
||||
|
||||
How did you find setting up your Docker Swarm first cluster and running OpenFaaS? Please share a picture or a Tweet on Twitter [@alexellisuk][46]
|
||||
|
||||
**Watch my Dockercon video of OpenFaaS**
|
||||
|
||||
I presented OpenFaaS (then called FaaS) [at Dockercon in Austin][47] - watch this video for a high-level introduction and some really interactive demos Alexa and GitHub.
|
||||
|
||||
** 此处有iframe,请手动处理 **
|
||||
|
||||
Got questions? Ask in the comments below - or send your email over to me for an invite to my Raspberry Pi, Docker and Serverless Slack channel where you can chat with like-minded people about what you're working on.
|
||||
|
||||
**Want to learn more about Docker on the Raspberry Pi?**
|
||||
|
||||
I'd suggest starting with [5 Things you need to know][48] which covers things like security and and the subtle differences between RPi and a regular PC.
|
||||
|
||||
* [Dockercon tips: Docker & Raspberry Pi][18]
|
||||
|
||||
* [Control GPIO with Docker Swarm][19]
|
||||
|
||||
* [Is that a Docker Engine in your pocket??][20]
|
||||
|
||||
_Share on Twitter_
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.alexellis.io/your-serverless-raspberry-pi-cluster/
|
||||
|
||||
作者:[Alex Ellis ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/alexellisuk
|
||||
[1]:https://twitter.com/alexellisuk
|
||||
[2]:https://twitter.com/intent/tweet?in_reply_to=898978596773138436
|
||||
[3]:https://twitter.com/intent/retweet?tweet_id=898978596773138436
|
||||
[4]:https://twitter.com/intent/like?tweet_id=898978596773138436
|
||||
[5]:https://twitter.com/alexellisuk
|
||||
[6]:https://twitter.com/alexellisuk
|
||||
[7]:https://twitter.com/Docker
|
||||
[8]:https://twitter.com/Raspberry_Pi
|
||||
[9]:https://twitter.com/alexellisuk/status/898978596773138436
|
||||
[10]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||
[11]:https://twitter.com/alexellisuk
|
||||
[12]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[13]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[14]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[15]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[16]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||
[17]:https://support.twitter.com/articles/20175256
|
||||
[18]:https://blog.alexellis.io/dockercon-tips-docker-raspberry-pi/
|
||||
[19]:https://blog.alexellis.io/gpio-on-swarm/
|
||||
[20]:https://blog.alexellis.io/docker-engine-in-your-pocket/
|
||||
[21]:https://news.ycombinator.com/item?id=15052192
|
||||
[22]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||
[23]:https://github.com/alexellis/faas
|
||||
[24]:http://downloads.raspberrypi.org/raspbian_lite/images/raspbian_lite-2017-07-05/
|
||||
[25]:https://github.com/alexellis/faas
|
||||
[26]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||
[27]:https://blog.alexellis.io/first-faas-python-function
|
||||
[28]:https://github.com/alexellis/faas
|
||||
[29]:https://blog.alexellis.io/tag/docker/
|
||||
[30]:https://blog.alexellis.io/tag/raspberry-pi/
|
||||
[31]:https://blog.alexellis.io/tag/openfaas/
|
||||
[32]:https://blog.alexellis.io/tag/faas/
|
||||
[33]:https://github.com/alexellis/faas
|
||||
[34]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||
[35]:https://github.com/alexellis/faas
|
||||
[36]:https://github.com/alexellis/faas
|
||||
[37]:https://www.amazon.co.uk/Anker-PowerPort-Family-Sized-Technology-Smartphones/dp/B00PK1IIJY
|
||||
[38]:http://downloads.raspberrypi.org/raspbian/images/raspbian-2017-07-05/
|
||||
[39]:https://etcher.io/
|
||||
[40]:https://docs.docker.com/engine/swarm/admin_guide/
|
||||
[41]:https://github.com/alexellis/faas
|
||||
[42]:http://192.168.0.100:8080/
|
||||
[43]:https://blog.alexellis.io/first-faas-python-function
|
||||
[44]:https://github.com/alexellis/faas
|
||||
[45]:https://prometheus.io/
|
||||
[46]:https://twitter.com/alexellisuk
|
||||
[47]:https://blog.alexellis.io/dockercon-2017-captains-log/
|
||||
[48]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user