-
- | Regex operator |
- Meaning |
-
-
- | . |
- Matches any single character. |
-
-
- | ? |
- The preceding item is optional and will be matched, at most, once. |
-
-
- | * |
- The preceding item will be matched zero or more times. |
-
-
- | + |
- The preceding item will be matched one or more times. |
-
-
- | {N} |
- The preceding item is matched exactly N times. |
-
-
- | {N,} |
- The preceding item is matched N or more times. |
-
-
- | {N,M} |
- The preceding item is matched at least N times, but not more than M times. |
-
-
- | - |
- Represents the range if it's not first or last in a list or the ending point of a range in a list. |
-
-
- | ^ |
- Matches the empty string at the beginning of a line; also represents the characters not in the range of a list. |
-
-
- | $ |
- Matches the empty string at the end of a line. |
-
-
- | \b |
- Matches the empty string at the edge of a word. |
-
-
- | \B |
- Matches the empty string provided it's not at the edge of a word. |
-
-
- | \< |
- Match the empty string at the beginning of word. |
-
-
- | \> |
- Match the empty string at the end of word. |
-
-
-
-#### grep vs egrep ####
-
-egrep is the same as **grep -E**. It interpret PATTERN as an extended regular expression. From the grep man page:
-
- In basic regular expressions the meta-characters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{,
- \|, \(, and \).
- Traditional egrep did not support the { meta-character, and some egrep implementations support \{ instead, so portable scripts should avoid { in
- grep -E patterns and should use [{] to match a literal {.
- GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification.
- For example, the command grep -E '{1' searches for the two-character string {1 instead of reporting a syntax error in the regular expression.
- POSIX.2 allows this behavior as an extension, but portable scripts should avoid it.
-
-References:
-
-- man page grep and regex(7)
-- info page grep`
-
---------------------------------------------------------------------------------
-
-via: http://www.cyberciti.biz/faq/grep-regular-expressions/
-
-šĹúŤÄÖÔľöVivek Gite
-ŤĮĎŤÄÖÔľö[ŤĮĎŤÄÖID](https://github.com/ŤĮĎŤÄÖID)
-ś†°ŚĮĻÔľö[ś†°ŚĮĻŤÄÖID](https://github.com/ś†°ŚĮĻŤÄÖID)
-
-śú¨śĖáÁĒĪ [LCTT](https://github.com/LCTT/TranslateProject) ŚéüŚąõÁľĖŤĮĎÔľĆ[Linuxšł≠ŚõĹ](https://linux.cn/) Ťć£Ť™Čśé®Śáļ
\ No newline at end of file
diff --git a/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 3--Search Multiple Words or String Pattern Using grep Command.md b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 3--Search Multiple Words or String Pattern Using grep Command.md
index bb12d2e1b3..bd58e78535 100644
--- a/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 3--Search Multiple Words or String Pattern Using grep Command.md
+++ b/sources/tech/Linux or UNIX grep Command Tutorial series/20151127 Linux or UNIX grep Command Tutorial series 3--Search Multiple Words or String Pattern Using grep Command.md
@@ -1,4 +1,4 @@
-Search Multiple Words / String Pattern Using grep Command
+(ÁŅĽŤĮĎšł≠ by runningwater)Search Multiple Words / String Pattern Using grep Command
================================================================================
How do I search multiple strings or words using the grep command? For example I'd like to search word1, word2, word3 and so on within /path/to/file. How do I force grep to search multiple words?
@@ -33,7 +33,7 @@ Fig.01: Linux / Unix egrep Command Search Multiple Words Demo Output
via: http://www.cyberciti.biz/faq/searching-multiple-words-string-using-grep/
šĹúŤÄÖÔľöVivek Gite
-ŤĮĎŤÄÖÔľö[ŤĮĎŤÄÖID](https://github.com/ŤĮĎŤÄÖID)
+ŤĮĎŤÄÖÔľö[runningwater](https://github.com/runningwater)
ś†°ŚĮĻÔľö[ś†°ŚĮĻŤÄÖID](https://github.com/ś†°ŚĮĻŤÄÖID)
śú¨śĖáÁĒĪ [LCTT](https://github.com/LCTT/TranslateProject) ŚéüŚąõÁľĖŤĮĎÔľĆ[Linuxšł≠ŚõĹ](https://linux.cn/) Ťć£Ť™Čśé®Śáļ
diff --git a/translated/news/20151208 Apple Swift Programming Language Comes To Linux.md b/translated/news/20151208 Apple Swift Programming Language Comes To Linux.md
new file mode 100644
index 0000000000..fe2089345d
--- /dev/null
+++ b/translated/news/20151208 Apple Swift Programming Language Comes To Linux.md
@@ -0,0 +1,43 @@
+
+ŤčĻśěúÁľĖÁ®čŤĮ≠Ť®ÄSwiftŚľÄŚßčśĒĮśĆĀLinux
+================================================================================
+
+
+ŤčĻśěúšĻüŚľÄśļźšļÜÔľüśėĮÁöĄÔľĆŤčĻśěúÁľĖÁ®čŤĮ≠Ť®ÄSwiftŚ∑≤ÁĽŹŚľÄśļźšļÜ„ÄāŚÖ∂Śģ윹ϚĽ¨ŚĻ∂šłćŚļĒŤĮ•śĄüŚąįśĄŹŚ§ĖԾƌõ†šłļ[Śú®ŚÖ≠šł™śúąšĽ•ŚČćŤčĻśěúŚįĪŚ∑≤ÁĽŹŚģ£ŚłÉšļÜŤŅôšł™ś∂ąśĀĮ][1]„Äā
+
+ŤčĻśěúŚģ£ŚłÉŤŅôŚĎ®Śįܜ鮌áļŚľÄśļźSwiftÁ§ĺŚĆļ„ÄāšłÄšł™šłďÁĒ®šļ錾ĜļźSwiftÁ§ĺŚĆļÁöĄ[śĖįÁĹĎÁęô][2]Ś∑≤ÁĽŹŚįĪšĹćÔľĆÁĹĎÁęôť¶Ėť°ĶśėĺÁ§ļšĽ•šłčšŅ°śĀĮÔľö
+
+> śąĎšĽ¨ŚĮĻSwiftŚľÄśļźśĄüŚąįŚÖīŚ•č„ÄāŚú®ŤčĻśěúśé®ŚáļšļÜÁľĖÁ®čŤĮ≠Ť®ÄSwiftšĻ茟éԾƌģɌ幌ŅęśąźšłļŚéÜŚŹ≤šłäŚĘěťēŅśúÄŚŅęÁöĄŤĮ≠Ť®ÄšĻ蚳ĄÄāSwiftŚŹĮšĽ•ÁľĖŚÜôŚáļťö嚼•ÁĹģšŅ°ÁöĄŚŹąŚŅꌏąŚģČŚÖ®ÁöĄŤĹĮšĽ∂„ÄāÁõģŚČćÔľĆSwiftśėĮŚľÄśļźÁöĄÔľĆšĹ†ŤÉĹŚłģŚä©ŚĀöŚáļťöŹŚ§ĄŚŹĮÁĒ®ÁöĄśúÄŚ•ĹÁöĄťÄöÁĒ®ÁľĖÁ®čŤĮ≠Ť®Ä„Äā
+
+[swift.org][2]ŤŅôšł™ÁĹĎÁęôŚįÜšľöšĹúšłļšłÄÁęôŚľŹÁĹĎÁęôԾƌģÉšľöśŹźšĺõŚźĄÁßćŤĶĄśĖôÁöĄšłčŤĹĹԾƌĆ֜訌źĄÁßćŚĻ≥ŚŹįÔľĆÁ§ĺŚĆļśĆáŚćóԾƜúÄśĖįś∂ąśĀĮԾƌ֕ťó®śēôÁ®čԾƍī°ÁĆģŚľÄśļźSwiftÁöĄŤĮīśėéԾƜĖᚼ∂ŚíĆšłÄšļõŚÖ∂šĽĖÁöĄśĆáŚćó„Äā Ś¶āśěúšĹ†ś≠£śúüŚĺÖÁĚÄŚ≠¶šĻ†SwiftԾƝā£šĻąŚŅÖť°ĽśĒ∂ŤóŹŤŅôšł™ÁĹĎÁęô„Äā
+
+Śú®ŤčĻśěúÁöĄŤŅôś¨°Śģ£ŚłÉšł≠ԾƚłÄšł™ÁĒ®šļéśĖĻšĺŅŚąÜšļęŚíƜ쥌ĽļšĽ£Á†ĀÁöĄŚĆÖÁģ°ÁźÜŚô®Ś∑≤ÁĽŹŚŹĮÁĒ®šļÜ„Äā
+
+ŚĮĻšļéśČÄśúČÁöĄLinuxšĹŅÁĒ®ŤÄ֜̕ŤĮīԾƜúÄťá捶ĀÁöĄśėĮԾƜļźšĽ£Á†ĀŚ∑≤ÁĽŹŚŹĮšĽ•šĽé[Github][3]Ťé∑ŚĺóšļÜ.šĹ†ŚŹĮšĽ•šĽéšĽ•šłčťďĺśé•CheckoutŚģÉÔľö
+Most important of all for Linux users, the source code is now available at [Github][3]. You can check it out from the link below:
+
+- [ŤčĻśěúSwiftśļźšĽ£Á†Ā][3]
+
+ťô§ś≠§šĻ茧ĖԾƌĮĻšļéubuntu 14.04ŚíĆ15.10ÁČąśú¨ŤŅėśúȝʥÁľĖŤĮĎÁöĄšļĆŤŅõŚą∂śĖᚼ∂„Äā
+
+- [ubuntuÁ≥ĽÁĽüÁöĄSwiftšļĆŤŅõŚą∂śĖᚼ∂][4]
+
+šłćŤ¶ĀśÄ•ÁĚČ鼚ĹŅÁĒ®ŚģÉšĽ¨ÔľĆŚõ†šłļŤŅôšļõťÉĹśėĮŚŹĎŚĪēŚąÜśĒĮŤÄĆšłĒšłćťÄāŚźąšļéšłďÁĒ®śúļŚô®„ÄāŚõ†ś≠§ÁéįŚú®ťĀŅŚÖćšĹŅÁĒ®ÔľĆšłÄśó¶ŚŹĎŚłÉšļÜLinuxšłčSwiftÁöĄÁ®≥ŚģöÁČąśú¨ÔľĆśąĎŚłĆśúõubuntušľöśääŚģÉŚĆÖŚźęŚú®[umake][5]šł≠ťĚ†ŤŅĎ[Visual Studio][6]ÁöĄŚúįśĖĻ„Äā
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/swift-open-source-linux/
+
+šĹúŤÄÖÔľö[Abhishek][a]
+ŤĮĎŤÄÖÔľö[Flowsnow](https://github.com/Flowsnow)
+ś†°ŚĮĻÔľö[ś†°ŚĮĻŤÄÖID](https://github.com/ś†°ŚĮĻŤÄÖID)
+
+śú¨śĖáÁĒĪ [LCTT](https://github.com/LCTT/TranslateProject) ŚéüŚąõÁľĖŤĮĎÔľĆ[Linuxšł≠ŚõĹ](https://linux.cn/) Ťć£Ť™Čśé®Śáļ
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://itsfoss.com/apple-open-sources-swift-programming-language-linux/
+[2]:https://swift.org/
+[3]:https://github.com/apple
+[4]:https://swift.org/download/#latest-development-snapshots
+[5]:https://wiki.ubuntu.com/ubuntu-make
+[6]:http://itsfoss.com/install-visual-studio-code-ubuntu/
diff --git a/translated/share/20151030 80 Linux Monitoring Tools for SysAdmins.md b/translated/share/20151030 80 Linux Monitoring Tools for SysAdmins.md
new file mode 100644
index 0000000000..7c16ca9fc8
--- /dev/null
+++ b/translated/share/20151030 80 Linux Monitoring Tools for SysAdmins.md
@@ -0,0 +1,604 @@
+
+šłļ Linux Á≥ĽÁĽüÁģ°ÁźÜŚĎėŚáÜŚ§áÁöĄ80šł™ÁõĎśéߌ∑•ŚÖ∑
+================================================================================
+
+
+ťöŹÁĚÄŤ°ĆšłöÁöĄšłćśĖ≠ŚŹĎŚĪēԾƜúČŤģłŚ§öśĮĒšĹ†śÉ≥ŤĪ°šł≠śõīś£íÁöĄŚ∑•ŚÖ∑„ÄāŤŅôťáĆŚąóÁĚÄÁĹĎšłäśúÄŚÖ®ÁöĄÔľąŚ∑•ŚÖ∑ԾȄÄāśč•śúČŤ∂ÖŤŅá80ÁßćśĖĻŚľŹśĚ•Áģ°ÁźÜšĹ†ÁöĄśúļŚô®„ÄāŚú®śú¨śĖášł≠ԾƜąĎšĽ¨šłĽŤ¶ĀŤģ≤ŤŅįšĽ•šłčśĖĻťĚĘÔľö
+
+- ŚĎĹšĽ§Ť°ĆŚ∑•ŚÖ∑
+- šłéÁĹĎÁĽúÁõłŚÖ≥ÁöĄ
+- Á≥ĽÁĽüÁõłŚÖ≥ÁöĄÁõĎśéߌ∑•ŚÖ∑
+- śó•ŚŅóÁõĎśéߌ∑•ŚÖ∑
+- ŚüļÁ°ÄŤģĺśĖĹÁõĎśéߌ∑•ŚÖ∑
+
+ÁõĎśéߌíĆŤįÉŤĮēśÄߍÉĹťóģťĘėťĚ쌳łŚõįťöĺԾƚĹÜÁĒ®ŚĮĻšļÜś≠£Á°ģÁöĄŚ∑•ŚÖ∑śúČśó∂šĻüśėĮŚĺąŚģĻśėďÁöĄ„ÄāšłčťĚĘśėĮšłÄšļõšĹ†ŚŹĮŤÉĹŚź¨ŤĮīŤŅáÁöĄŚ∑•ŚÖ∑ԾƌĹďšĹ†šĹŅÁĒ®ŚģÉšĽ¨śó∂ŚŹĮŤÉĹŚ≠ėŚú®šłÄšļõťóģťĘėÔľö
+
+### ŚćĀŚ§ßÁ≥ĽÁĽüÁõĎśéߌ∑•ŚÖ∑ ###
+
+#### 1. Top ####
+
+
+
+ŤŅôśėĮšłÄšł™ŤĘęťĘĄŚģČŤ£ÖŚú®ŤģłŚ§ö UNIX Á≥ĽÁĽüšł≠ÁöĄŚįŹŚ∑•ŚÖ∑„ÄāŚĹďšĹ†śÉ≥Ť¶Āśü•ÁúčŚú®Á≥ĽÁĽüšł≠ŤŅźŤ°ĆÁöĄŤŅõÁ®čśąĖÁļŅÁ®čśó∂Ôľötop śėĮšłÄšł™ŚĺąŚ•ĹÁöĄŚ∑•ŚÖ∑„ÄāšĹ†ŚŹĮšĽ•ŚĮĻŤŅôšļõŤŅõÁ®čšĽ•šłćŚźĆÁöĄś†áŚáÜŤŅõŤ°ĆśéíŚļŹÔľĆťĽėŤģ§śėĮšĽ• CPU ŤŅõŤ°ĆśéíŚļŹÁöĄ„Äā
+
+#### 2. [htop][1] ####
+
+
+
+HTOP ŚģěŤī®šłäśėĮ top ÁöĄŚĘ쌾ļÁČąśú¨„ÄāŚģÉśõīŚģĻśėďŚĮĻŤŅõÁ®čśéíŚļŹ„ÄāŚģÉŚú®ŤßÜŤßČšłäśõīŚģĻśėďÁźÜŤß£ŚĻ∂šłĒŚ∑≤ÁĽŹŚÜÖŚĽļšļÜŤģłŚ§öťÄöÁĒ®ÁöĄŚĎĹšĽ§„ÄāŚģÉšĻüśėĮŚģĆŚÖ®šļ§šļíÁöĄ„Äā
+
+#### 3. [atop][2] ####
+
+Atop ŚíĆ topÔľĆhtop ťĚ쌳łÁõłšľľÔľĆŚģÉšĻüŤÉĹÁõĎśéßśČÄśúČŤŅõÁ®čԾƚĹÜšłćŚźĆšļé top ŚíĆ htop ÁöĄśėĮԾƌģÉšľöŤģįŚĹēŤŅõÁ®čÁöĄśó•ŚŅóšĺõšĽ•ŚźéŚąÜśěź„ÄāŚģÉšĻüŤÉĹśėĺÁ§ļśČÄśúČŤŅõÁ®čÁöĄŤĶĄśļźś∂ąŤÄó„ÄāŚģÉŤŅėšľöťęėšļģśėĺÁ§ļŚ∑≤ÁĽŹŤĺ匹įšłīÁēĆŤīüŤĹĹÁöĄŤĶĄśļź„Äā
+
+#### 4. [apachetop][3] ####
+
+Apachetop šľöÁõĎŤßÜ apache ÁĹĎÁĽúśúćŚä°Śô®ÁöĄśēīšĹďśÄߍÉĹ„ÄāŚģÉšłĽŤ¶ĀśėĮŚüļšļé mytop„ÄāŚģÉšľöśėĺÁ§ļŚĹďŚČć reads, writes ÁöĄśēįťáŹšĽ•ŚŹä requests ŤŅõÁ®čÁöĄśÄĽśēį„Äā
+
+#### 5. [ftptop][4] ####
+
+ftptop ÁĽôšĹ†śŹźšĺõšļÜŚĹďŚČćśČÄśúČŤŅěśé•Śąį ftp śúćŚä°Śô®ÁöĄŚüļśú¨šŅ°śĀĮԾƌ¶āšľöŤĮ̜ļśēįԾƜ≠£Śú®šłäšľ†ŚíĆšłčŤĹĹÁöĄŚģĘśą∑ÁęĮśēįťáŹšĽ•ŚŹäŚģĘśą∑ÁęĮšŅ°śĀĮ„Äā
+
+#### 6. [mytop][5] ####
+
+
+
+mytop śėĮšłÄšł™ŚĺąśĖĻšĺŅÁöĄŚ∑•ŚÖ∑ÔľĆÁĒ®šļéÁõĎśéßÁļŅÁ®čŚíĆ mysql ÁöĄśÄߍÉĹ„ÄāŚģÉÁĽôšļܚņšłÄšł™Śģěśó∂ÁöĄśēįśćģŚļďśü•ŤĮĘŚ§ĄÁźÜÁĽďśěú„Äā
+
+#### 7. [powertop][6] ####
+
+
+
+powertop ŚŹĮšĽ•ŚłģŚä©šĹ†ŤĮäśĖ≠šłéÁĒĶťáŹś∂ąŤÄóŚíĆÁĒĶśļźÁģ°ÁźÜÁõłŚÖ≥ÁöĄťóģťĘė„ÄāŚģÉšĻüŚŹĮšĽ•ŚłģšĹ†ŤŅõŤ°ĆÁĒĶśļźÁģ°ÁźÜŤģĺÁĹģԾƚĽ•ŚģěÁéįŚĮĻšĹ†śúćŚä°Śô®śúÄśúČśēąÁöĄťÖćÁĹģ„ÄāšĹ†ŚŹĮšĽ•šĹŅÁĒ® tab ťĒģŤŅõŤ°ĆťÄČť°ĻŚąáśćĘ„Äā
+
+#### 8. [iotop][7] ####
+
+
+
+iotop ÁĒ®šļéś£Äśü• I/O ÁöĄšĹŅÁĒ®śÉÖŚÜĶԾƌĻ∂šłļšĹ†śŹźšĺõšļÜšłÄšł™ÁĪĽšľľ top ÁöĄÁēĆťĚʜ̕śėĺÁ§ļ„ÄāŚģÉśĮŹŚąóśėĺÁ§ļŤĮĽŚíĆŚÜôÁöĄťÄüÁéáԾƜĮŹŤ°ĆšĽ£Ť°®šłÄšł™ŤŅõÁ®č„ÄāŚĹďŚáļÁéįÁ≠ČŚĺÖ I/O šļ§śćĘśó∂ԾƌģÉšĻüśėĺÁ§ļŤŅõÁ®čś∂ąŤÄóśó∂ťóīÁöĄÁô匹ܜĮĒ„Äā
+
+### šłéÁĹĎÁĽúÁõłŚÖ≥ÁöĄÁõĎśéß ###
+
+#### 9. [ntopng][8] ####
+
+
+
+ntopng śėĮ ntop ÁöĄŚćáÁļßÁȹԾƌģÉśŹźšĺõšļÜšłÄšł™ŤÉĹšĹŅÁĒ®śĶŹŤßąŚô®ŤŅõŤ°ĆÁĹĎÁĽúÁõĎśéßÁöĄŚõĺŚĹĘÁĒ®śą∑ÁēĆťĚĘ„ÄāŚģÉŤŅėśúČŚÖ∂šĽĖÁĒ®ťÄĒԾƌ¶āÔľöŚģöšĹćšłĽśúļԾƜėĺÁ§ļÁĹĎÁĽúśĶĀťáŹŚíĆ ip śĶĀťáŹŚąÜŚłÉŚĻ∂ŤÉĹŤŅõŤ°ĆŚąÜśěź„Äā
+
+#### 10. [iftop][9] ####
+
+
+
+iftop ÁĪĽšľľšļé topԾƚĹÜŚģÉšłĽŤ¶ĀšłćśėĮś£Äśü• cpu ÁöĄšĹŅÁĒ®ÁéáŤÄĆśėĮÁõĎŚź¨ÁĹĎŚć°ÁöĄśĶĀťáŹÔľĆŚĻ∂šĽ•Ť°®ś†ľÁöĄŚĹĘŚľŹśėĺÁ§ļŚĹďŚČćÁöĄšĹŅÁĒ®ťáŹ„ÄāŚÉŹ‚ÄúšłļšĽÄšĻąśąĎÁöĄÁĹĎťÄüŤŅôšĻąśÖĘŚĎĘÔľüÔľĀ‚ÄĚŤŅôś†∑ÁöĄťóģťĘėŚģÉŚŹĮšĽ•Áõīśé•ŚõěÁ≠Ē„Äā
+
+#### 11. [jnettop][10] ####
+
+
+
+jnettop šĽ•ÁõłŚźĆÁöĄśĖĻŚľŹśĚ•ÁõĎśĶčÁĹĎÁĽúśĶĀťáŹšĹÜśĮĒ iftop śõīŚĹĘŤĪ°„ÄāŚģÉŤŅėśĒĮśĆĀŤá™ŚģöšĻČÁöĄśĖáśú¨ŤĺďŚáļŚĻ∂ŤÉĹšĽ•ŚŹčŚ•ĹÁöĄšļ§šļíśĖĻŚľŹśĚ•ŚŅęťÄüŚąÜśěźśó•ŚŅó„Äā
+
+#### 12. [bandwidthd][11] ####
+
+
+
+bandwidthd ŚŹĮšĽ•Ť∑üŤł™ TCP/IP ÁĹĎÁĽúŚ≠źÁĹĎÁöĄšĹŅÁĒ®śÉÖŚÜĶŚĻ∂ŤÉĹŚú®śĶŹŤßąŚô®šł≠ťÄöŤŅá png ŚõĺÁČáŚĹĘŤĪ°ŚĆĖÁöĄśěĄŚĽļšłÄšł™ HTML ť°ĶťĚĘ„ÄāŚģÉśúČšłÄšł™śēįśćģŚļďť©ĪŚä®Á≥ĽÁĽüԾƜĒĮśĆĀśźúÁīĘԾƍŅ᜼§ÔľĆŚ§öšľ†śĄüŚô®ŚíƍᙌģöšĻČśä•Ť°®„Äā
+
+#### 13. [EtherApe][12] ####
+
+EtherApe šĽ•ŚõĺŚĹĘŚĆĖśėĺÁ§ļÁĹĎÁĽúśĶĀťáŹÔľĆŚŹĮšĽ•śĒĮśĆĀśõīŚ§öÁöĄŤäāÁāĻ„ÄāŚģÉŚŹĮšĽ•śćēŤé∑Śģěśó∂śĶĀťáŹšŅ°śĀĮԾƚĻüŚŹĮšĽ•šĽé tcpdump ŤŅõŤ°ĆŤĮĽŚŹĖ„ÄāšĻüŚŹĮšĽ•šĹŅÁĒ®ŚÖ∑śúČ pcap ŤĮ≠ś≥ēÁöĄÁĹĎÁĽúŤŅ᜼§śėĺÁ§ļÁČĻŚģöšŅ°śĀĮ„Äā
+
+#### 14. [ethtool][13] ####
+
+
+
+ethtool ÁĒ®šļéśėĺÁ§ļŚíĆšŅģśĒĻÁĹĎÁĽúśé•ŚŹ£śéߌą∂Śô®ÁöĄšłÄšļõŚŹāśēį„ÄāŚģÉšĻüŚŹĮšĽ•ÁĒ®śĚ•ŤĮäśĖ≠šĽ•Ś§™ÁĹĎŤģ匧áԾƌĻ∂Ťé∑ŚĺóśõīŚ§öÁöĄÁĽüŤģ°śēįśćģ„Äā
+
+#### 15. [NetHogs][14] ####
+
+
+
+NetHogs śČďÁ†īšļÜÁĹĎÁĽúśĶĀťáŹśĆȌ揍ģģśąĖŚ≠źÁĹĎŤŅõŤ°ĆÁĽüŤģ°ÁöĄŚéüÁźÜ„ÄāŚģÉšĽ•ŤŅõÁ®čÁĽĄśĚ•Ťģ°Áģó„ÄāśČÄšĽ•ÔľĆŚĹďÁĹĎÁĽúśĶĀťáŹÁĆõŚĘěśó∂ԾƚņŚŹĮšĽ•šĹŅÁĒ® NetHogs śü•ÁúčśėĮÁĒĪŚď™šł™ŤŅõÁ®čťÄ†śąźÁöĄ„Äā
+
+#### 16. [iptraf][15] ####
+
+
+
+iptraf śĒ∂ťõÜÁöĄŚźĄÁßćśĆᜆáԾƌ¶ā TCP ŤŅěśé•śēįśćģŚĆÖŚíĆŚ≠óŤäāśēįԾƜ镌Ź£ÁēĆťĚĘŚíĆśīĽŚä®śĆᜆáÔľĆTCP/UDP ťÄöšŅ°śēÖťöúÔľĆÁęôŚÜÖśēįśćģŚĆÖŚíĆŚ≠óŤäāśēį„Äā
+
+#### 17. [ngrep][16] ####
+
+
+
+ngrep ŚįĪśėĮ grep šĹÜśėĮÁõłŚĮĻšļéÁĹĎÁĽúŚĪāÁöĄ„Äāpcap śĄŹŤĮÜŚąįŚźéŚÖĀŤģłŚÖ∂śĆáŚģöśČ©ŚĪēŤßĄŚąôśąĖŚćĀŚÖ≠ŤŅõŚą∂Ť°®Ťĺ匾ŹśĚ•ŚĆĻťÖćśēįśćģŚĆÖ„Äā
+
+#### 18. [MRTG][17] ####
+
+
+
+MRTG śúÄŚąĚŤĘꌾȏϜ̕ÁõĎśéߍ∑ĮÁĒĪŚô®ÁöĄśĶĀťáŹÔľĆšĹÜÁéįŚú®ŚģÉšĻüŤÉĹŚ§üÁõĎśéßÁĹĎÁĽúÁõłŚÖ≥ÁöĄšłúŤ•Ņ„ÄāŚģÉśĮŹšļĒŚąÜťíüśĒ∂ťõÜšłÄś¨°ÔľĆÁĄ∂ŚźéšļßÁĒüšłÄšł™ HTML ť°ĶťĚĘ„ÄāŚģÉŤŅėŚÖ∑śúČŚŹĎťÄĀťāģšĽ∂śä•Ť≠¶ÁöĄŤÉĹŚäõ„Äā
+
+#### 19. [bmon][18] ####
+
+
+
+Bmon ŤÉĹÁõĎśéߌĻ∂ŚłģŚä©šĹ†ŤįÉŤĮēÁĹĎÁĽú„ÄāŚģÉŤÉĹśćēŤé∑ÁĹĎÁĽúÁõłŚÖ≥ÁöĄÁĽüŤģ°śēįśćģԾƌĻ∂šĽ•ŚŹčŚ•ĹÁöĄśĖĻŚľŹŤŅõŤ°ĆŚĪēÁ§ļ„ÄāšĹ†ŤŅėŚŹĮšĽ•šłé bmon ťÄöŤŅ፥öśú¨ŤŅõŤ°Ćšļ§šļí„Äā
+
+#### 20. traceroute ####
+
+
+
+Traceroute šłÄšł™ŚÜÖÁĹģŚ∑•ŚÖ∑ԾƍÉĹśĶčŤĮēŤ∑ĮÁĒĪŚíĆśēįśćģŚĆÖŚú®ÁĹĎÁĽúšł≠ÁöĄŚĽ∂ŤŅü„Äā
+
+#### 21. [IPTState][19] ####
+
+IPTState ŚŹĮšĽ•Ťģ©šĹ†Ť∑®Ť∂ä iptables śĚ•ÁõĎśéßśĶĀťáŹÔľĆŚĻ∂ťÄöŤŅášĹ†śĆáŚģöÁöĄśĚ°šĽ∂śĚ•ŤŅõŤ°ĆśéíŚļŹ„ÄāŤĮ•Ś∑•ŚÖ∑ŤŅėŚÖĀŤģłšĹ†šĽéŤ°®šł≠Śą†ťô§Áä∂śÄĀšŅ°śĀĮ„Äā
+
+#### 22. [darkstat][20] ####
+
+
+
+Darkstat ŤÉĹśćēŤé∑ÁĹĎÁĽúśĶĀťáŹŚĻ∂Ťģ°ÁģóÁĽüŤģ°ÁöĄśēįśćģ„ÄāŤĮ•śä•ŚĎäťúÄŤ¶ĀŚú®śĶŹŤßąŚô®šł≠ŤŅõŤ°Ćśü•ÁúčԾƌģÉšłļšĹ†śŹźšĺõšļÜšłÄšł™ťĚ쌳łś£íÁöĄŚõĺŚĹĘÁĒ®śą∑ÁēĆťĚĘ„Äā
+
+#### 23. [vnStat][21] ####
+
+
+
+vnStat śėĮšłÄšł™ÁĹĎÁĽúśĶĀťáŹÁõĎśéߌ∑•ŚÖ∑ԾƌģÉÁöĄśēįśćģÁĽüŤģ°śėĮÁĒĪŚÜÖś†łŤŅõŤ°ĆśŹźšĺõÁöĄÔľĆŚÖ∂ś∂ąŤÄóÁöĄÁ≥ĽÁĽüŤĶĄśļźťĚ쌳łŚįĎ„ÄāÁ≥ĽÁĽüťáćśĖįŚźĮŚä®ŚźéԾƌģÉśĒ∂ťõÜÁöĄśēįśćģšĽćÁĄ∂Ś≠ėŚú®„ÄāŚģÉŚÖ∑śúČťĘúŤČ≤ťÄČť°ĻšĺõÁ≥ĽÁĽüÁģ°ÁźÜŚĎėšĹŅÁĒ®„Äā
+
+#### 24. netstat ####
+
+
+
+netstat śėĮšłÄšł™ŚÜÖÁĹģÁöĄŚ∑•ŚÖ∑ԾƌģÉŤÉĹśėĺÁ§ļ TCP ÁĹĎÁĽúŤŅěśé•ÔľĆŤ∑ĮÁĒĪŤ°®ŚíĆÁĹĎÁĽúśé•ŚŹ£śēįťáŹÔľĆŤĘęÁĒ®śĚ•Śú®ÁĹĎÁĽúšł≠śü•śČĺťóģťĘė„Äā
+
+#### 25. ss ####
+
+ŚĻ∂ťĚě netstatԾƜúÄŚ•ĹšĹŅÁĒ® ss„Äāss ŚĎĹšĽ§ŤÉĹŚ§üśėĺÁ§ļÁöĄšŅ°śĀĮśĮĒ netstat śõīŚ§öԾƚĻüśõīŚŅę„ÄāŚ¶āśěúšĹ†śÉ≥śü•ÁúčÁĽüŤģ°ÁĽďśěúÁöĄśÄĽšŅ°śĀĮԾƚņŚŹĮšĽ•šĹŅÁĒ®ŚĎĹšĽ§ `ss -s`„Äā
+
+#### 26. [nmap][22] ####
+
+
+
+Nmap ŚŹĮšĽ•śČ꜏ŹšĹ†śúćŚä°Śô®ŚľÄśĒĺÁöĄÁęĮŚŹ£ŚĻ∂šłĒŚŹĮšĽ•ś£ÄśĶčś≠£Śú®šĹŅÁĒ®Śď™šł™śďćšĹúÁ≥ĽÁĽü„ÄāšĹܚņšĻüŚŹĮšĽ•šĹŅÁĒ® SQL ś≥®ŚÖ•śľŹśīěÔľĆÁĹĎÁĽúŚŹĎÁéįŚíĆśłóťÄŹśĶčŤĮēÁõłŚÖ≥ÁöĄŚÖ∂šĽĖśČčśģĶ„Äā
+
+#### 27. [MTR][23] ####
+
+
+
+MTR ÁĽďŚźąšļÜ traceroute ŚíĆ ping ÁöĄŚäüŤÉĹŚąįšłÄšł™ÁĹĎÁĽúŤĮäśĖ≠Ś∑•ŚÖ∑šłä„ÄāŚĹďšĹŅÁĒ®ŤĮ•Ś∑•ŚÖ∑śó∂ԾƌģÉšľöťôźŚą∂Śćēšł™śēįśćģŚĆÖÁöĄŤ∑≥śēįԾƌźĆśó∂šĻüÁõĎŤßÜŚģÉšĽ¨ÁöĄŚąįśúüśó∂ťóī„ÄāÁĄ∂ŚźéśĮŹÁßíŤŅõŤ°Ćťá挧ć„Äā
+
+#### 28. [Tcpdump][24] ####
+
+
+
+Tcpdump ŚįÜŤĺďŚáļšłÄšł™šĹ†Śú®ŚĎĹšĽ§šł≠ŚĆĻťÖćŚĻ∂śćēŤé∑ŚąįÁöĄśēįśćģŚĆÖÁöĄšŅ°śĀĮ„ÄāšĹ†ŤŅėŚŹĮšĽ•ŚįÜś≠§śēįśćģšŅĚŚ≠ėŚĻ∂ŤŅõšłÄś≠•ŚąÜśěź„Äā
+
+#### 29. [Justniffer][25] ####
+
+
+
+Justniffer śėĮ tcp śēįśćģŚĆÖŚóÖśéĘŚô®„ÄāšĹŅÁĒ®ś≠§ŚóÖśéĘŚô®šĹ†ŚŹĮšĽ•ťÄČśč©śĒ∂ťõÜšĹéÁļߌąęÁöĄśēįśćģŤŅėśėĮťęėÁļߌąęÁöĄśēįśćģ„ÄāŚģÉšĻüŚŹĮšĽ•Ťģ©šĹ†šĽ•Ťá™ŚģöšĻČśĖĻŚľŹÁĒüśąźśó•ŚŅó„ÄāśĮĒŚ¶āś®°šĽŅ Apache ÁöĄŤģŅťóģśó•ŚŅó„Äā
+
+### šłéÁ≥ĽÁĽüśúČŚÖ≥ÁöĄÁõĎśéß ###
+
+#### 30. [nmon][26] ####
+
+
+
+nmon ŚįÜśēįśćģŤĺďŚáļŚąįŚĪŹŚĻēšłäÁöĄÔľĆśąĖŚįÜŚÖ∂šŅĚŚ≠ėŚú®šłÄšł™šĽ•ťÄóŚŹ∑ŚąÜťöĒÁöĄśĖᚼ∂šł≠„ÄāšĹ†ŚŹĮšĽ•śü•Áúč CPUԾƌÜÖŚ≠ėÔľĆÁĹĎÁĽúԾƜĖᚼ∂Á≥ĽÁĽüÔľĆtop ŤŅõÁ®č„ÄāśēįśćģšĻüŚŹĮšĽ•ŤĘęś∑ĽŚä†Śąį RRD śēįśćģŚļďšł≠ÁĒ®šļéŤŅõšłÄś≠•ŚąÜśěź„Äā
+
+#### 31. [conky][27] ####
+
+
+
+Conky ŤÉĹÁõĎŤßÜšłćŚźĆśďćšĹúÁ≥ĽÁĽüŚĻ∂ÁĽüŤģ°śēįśćģ„ÄāŚģÉśĒĮśĆĀ IMAP ŚíĆ POP3ÔľĆ ÁĒöŤá≥ŤģłŚ§öśĶĀŤ°ĆÁöĄťü≥šĻźśí≠śĒĺŚô®ÔľĀŚáļšļéśĖĻšĺŅšłćŚźĆÁöĄšļļԾƚņŚŹĮšĽ•šĹŅÁĒ®Ťá™Ś∑ĪÁöĄ Lua ŤĄöśú¨śąĖÁ®čŚļŹśĚ•ŤŅõŤ°ĆśČ©ŚĪē„Äā
+
+#### 32. [Glances][28] ####
+
+
+
+šĹŅÁĒ® Glances ÁõĎśéߚņÁöĄÁ≥ĽÁĽüԾƌÖ∂śó®Śú®šĹŅÁĒ®śúÄŚįŹÁöĄÁ©ļťóīšłļšĹ†ŚĎąÁéįśúÄŚ§öÁöĄšŅ°śĀĮ„ÄāŚģÉŚŹĮšĽ•Śú®ŚģĘśą∑ÁęĮ/śúćŚä°Śô®ÁęĮś®°ŚľŹšłčŤŅźŤ°ĆԾƚĻüśúČŤŅúÁ®čÁõĎśéßÁöĄŤÉĹŚäõ„ÄāŚģÉšĻüśúČšłÄšł™ Web ÁēĆťĚĘ„Äā
+
+#### 33. [saidar][29] ####
+
+
+
+Saidar śėĮšłÄšł™ťĚ쌳łŚįŹÁöĄŚ∑•ŚÖ∑ԾƚłļšĹ†śŹźšĺõśúČŚÖ≥Á≥ĽÁĽüŤĶĄśļźÁöĄŚüļÁ°ÄšŅ°śĀĮ„ÄāŚģÉŚįÜÁ≥ĽÁĽüŤĶĄśļźŚú®ŚÖ®ŚĪŹŤŅõŤ°ĆśėĺÁ§ļ„ÄāťáćÁāĻśėĮ saidar šľöŚįĹŚŹĮŤÉĹÁöĄÁģÄŚĆĖ„Äā
+
+#### 34. [RRDtool][30] ####
+
+
+
+RRDtool śėĮÁĒ®śĚ•Ś§ĄÁźÜ RRD śēįśćģŚļďÁöĄŚ∑•ŚÖ∑„ÄāRRDtool śó®Śú®Ś§ĄÁźÜśó∂ťóīŚļŹŚąóśēįśćģԾƌ¶ā CPU ŤīüŤĹĹԾƜł©Śļ¶Á≠Č„ÄāŤĮ•Ś∑•ŚÖ∑śŹźšĺõšļÜšłÄÁßćśĖĻś≥ēśĚ•śŹźŚŹĖ RRD śēįśćģŚĻ∂šĽ•ŚõĺŚĹĘÁēĆťĚĘśėĺÁ§ļ„Äā
+
+#### 35. [monit][31] ####
+
+
+
+Ś¶āśěúŚáļÁéįśēÖťöúśó∂ÔľĆmonit śúČŚŹĎťÄĀŤ≠¶śä•šĽ•ŚŹäťáćśĖįŚźĮŚä®śúćŚä°ÁöĄŚäüŤÉĹ„ÄāŚģÉŚŹĮšĽ•ŚĮĻšĽĽšĹēÁĪĽŚěčŤŅõŤ°Ćś£Äśü•ÔľĆšĹ†ŚŹĮšĽ•šłļ monit ŚÜôšłÄšł™ŤĄöśú¨ÔľĆŚģÉśúČšłÄšł™ Web ÁĒ®śą∑ÁēĆťĚʜ̕ŚąÜśč֚ņÁúľÁĚõÁöĄŚéčŚäõ„Äā
+
+#### 36. [Linux process explorer][32] ####
+
+
+
+Linux process explorer śėĮÁĪĽšľľ OSX śąĖ Windows ÁöĄŚú®ÁļŅÁõĎŤßÜŚô®„ÄāŚģÉśĮĒ top śąĖ ps ÁöĄšĹŅÁĒ®ŤĆÉŚõīśõīŚĻŅ„ÄāšĹ†ŚŹĮšĽ•śü•ÁúčśĮŹšł™ŤŅõÁ®čÁöĄŚÜÖŚ≠ėś∂ąŤÄ󚼕ŚŹä CPU ÁöĄšĹŅÁĒ®śÉÖŚÜĶ„Äā
+
+#### 37. df ####
+
+
+
+df śėĮ disk free ÁöĄÁľ©ŚÜôԾƌģÉśėĮśČÄśúČ UNIX Á≥ĽÁĽüťĘĄŤ£ÖÁöĄÁ®čŚļŹÔľĆÁĒ®śĚ•śėĺÁ§ļÁĒ®śą∑śúČŤģŅťóģśĚÉťôźÁöĄśĖᚼ∂Á≥ĽÁĽüÁöĄŚŹĮÁĒ®Á£ĀÁõėÁ©ļťóī„Äā
+
+#### 38. [discus][33] ####
+
+
+
+Discus ÁĪĽšľľšļé dfԾƌģÉÁöĄÁõģÁöĄśėĮťÄöŤŅášĹŅÁĒ®śõīŚźłŚľēšļļÁöĄÁČĻśÄßԾƌ¶āťĘúŤČ≤ԾƌõĺŚĹĘŚíĆśēįŚ≠óśĚ•ŚĮĻ df ŤŅõŤ°ĆśĒĻŤŅõ„Äā
+
+#### 39. [xosview][34] ####
+
+
+
+xosview śėĮšłÄś¨ĺÁĽŹŚÖłÁöĄÁ≥ĽÁĽüÁõĎśéߌ∑•ŚÖ∑ԾƌģÉÁĽôšĹ†śŹźšĺõŚĆÖśč¨ IRQ ÁöĄŚźĄšł™šłćŚźĆťÉ®ŚąÜÁöĄśÄĽŤßą„Äā
+
+#### 40. [Dstat][35] ####
+
+
+
+Dstat śó®Śú®śõŅšĽ£ vmstatÔľĆiostatÔľĆnetstat ŚíĆ ifstat„ÄāŚģÉŚŹĮšĽ•Ťģ©šĹ†śü•Śģěśó∂śü•ÁúčśČÄśúČÁöĄÁ≥ĽÁĽüŤĶĄśļź„ÄāŤŅôšļõśēįśćģŚŹĮšĽ•ŚĮľŚáļšłļ CSV„ÄāśúÄťá捶ĀÁöĄśėĮ dstat ŚÖĀŤģłšĹŅÁĒ®śŹíšĽ∂Ծƌõ†ś≠§ŚÖ∂ŚŹĮšĽ•śČ©ŚĪēŚąįśõīŚ§öťĘÜŚüü„Äā
+
+#### 41. [Net-SNMP][36] ####
+
+SNMP śėĮ‚ÄúÁģÄŚćēÁĹĎÁĽúÁģ°ÁźÜŚćŹŤģģ‚ÄĚÔľĆNet-SNMP Ś∑•ŚÖ∑Ś•óšĽ∂šĹŅÁĒ®ŤĮ•ŚćŹŤģģŚŹĮŚłģŚä©šĹ†śĒ∂ťõÜśúćŚä°Śô®ÁöĄŚáÜÁ°ģšŅ°śĀĮ„Äā
+
+#### 42. [incron][37] ####
+
+Incron ŚÖĀŤģłšĹ†ÁõĎśéßšłÄšł™ÁõģŚĹēś†ĎÔľĆÁĄ∂ŚźéŚĮĻŤŅôšļõŚŹėŚĆĖťáጏĖśé™śĖĹ„ÄāŚ¶āśěúšĹ†śÉ≥ŚįÜÁõģŚĹē‚Äėa‚Äôšł≠ÁöĄśĖįśĖᚼ∂Ś§ćŚą∂ŚąįÁõģŚĹē‚Äėb‚ÄôԾƍŅôś≠£śėĮ incron ŤÉĹŚĀöÁöĄ„Äā
+
+#### 43. [monitorix][38] ####
+
+Monitorix śėĮŤĹĽťáŹÁļßÁöĄÁ≥ĽÁĽüÁõĎśéߌ∑•ŚÖ∑„ÄāŚģÉŚŹĮšĽ•ŚłģŚä©šĹ†ÁõĎśéßšłÄŚŹįśúļŚô®ÔľĆŚĻ∂šłļšĹ†śŹźšĺõšłįŚĮĆÁöĄśĆᜆá„ÄāŚģÉšĻüśúČšłÄšł™ŚÜÖÁĹģÁöĄ HTTP śúćŚä°Śô®ÔľĆśĚ•śü•ÁúčŚõ印®ŚíĆśČÄśúČśĆᜆáÁöĄśä•ŚĎä„Äā
+
+#### 44. vmstat ####
+
+
+
+vmstatÔľąvirtual memory statisticsԾȜėĮšłÄšł™ŚįŹÁöĄŚÜÖÁĹģŚ∑•ŚÖ∑ԾƍÉĹÁõĎśéߌíĆśėĺÁ§ļśúļŚô®ÁöĄŚÜÖŚ≠ė„Äā
+
+#### 45. uptime ####
+
+ŤŅôšł™ŚįŹÁ®čŚļŹŤÉĹŚŅęťÄüśėĺÁ§ļšĹ†śúļŚô®ŤŅźŤ°ĆšļÜŚ§öšĻÖÔľĆÁõģŚČćśúČŚ§öŚįĎÁĒ®śą∑ÁôĽŚĹēŚíĆÁ≥ĽÁĽüŤŅáŚéĽ1ŚąÜťíüÔľĆ5ŚąÜťíüŚíĆ15ŚąÜťíüÁöĄŚĻ≥ŚĚáŤīüŤĹĹ„Äā
+
+#### 46. mpstat ####
+
+
+
+mpstat śėĮšłÄšł™ŚÜÖÁĹģÁöĄŚ∑•ŚÖ∑ԾƍÉĹÁõĎŤßÜ cpu ÁöĄšĹŅÁĒ®śÉÖŚÜĶ„ÄāśúÄŚłłŤßĀÁöĄšĹŅÁĒ®śĖĻś≥ēśėĮ `mpstat -P ALL`ԾƌģÉÁĽôšĹ†śŹźšĺõ cpu ÁöĄšĹŅÁĒ®śÉÖŚÜĶ„ÄāšĹ†šĻüŚŹĮšĽ•ťóīťöĒśõīśĖį cpu ÁöĄšĹŅÁĒ®śÉÖŚÜĶ„Äā
+
+#### 47. pmap ####
+
+
+
+pmap śėĮšłÄšł™ŚÜÖÁĹģÁöĄŚ∑•ŚÖ∑ԾƜ䕌Ď䚳Ěł™ŤŅõÁ®čÁöĄŚÜÖŚ≠ėśė†ŚįĄ„ÄāšĹ†ŚŹĮšĽ•šĹŅÁĒ®ŤŅôšł™ŚĎĹšĽ§śĚ•śČĺŚáļŚÜÖŚ≠ėÁď∂ťĘąÁöĄŚéüŚõ†„Äā
+
+#### 48. ps ####
+
+
+
+ŤĮ•ŚĎĹšĽ§ŚįÜÁĽôšĹ†ŚĹďŚČćśČÄśúČŤŅõÁ®čÁöĄś¶āŤŅį„ÄāšĹ†ŚŹĮšĽ•šĹŅÁĒ® `ps -A` ŚĎĹšĽ§śü•ÁúčśČÄśúČŤŅõÁ®č„Äā
+
+#### 49. [sar][39] ####
+
+
+
+sar śėĮ sysstat ŚĆÖÁöĄšłÄťÉ®ŚąÜԾƌŹĮšĽ•ŚłģŚä©šĹ†śĒ∂ťõÜԾƜ䕌ĎäŚíĆšŅĚŚ≠ėšłćŚźĆÁ≥ĽÁĽüÁöĄśĆᜆá„ÄāšĹŅÁĒ®šłćŚźĆÁöĄŚŹāśēįԾƌģÉšľöÁĽôšĹ†śŹźšĺõ CPU, ŚÜÖŚ≠ė ŚíĆ I/O šĹŅÁĒ®śÉÖŚÜĶŚŹäŚÖ∂šĽĖšłúŤ•Ņ„Äā
+
+#### 50. [collectl][40] ####
+
+
+
+ÁĪĽšľľšļé sarÔľĆcollectl śĒ∂ťõܚņśúļŚô®ÁöĄśÄߍÉĹśĆᜆá„ÄāťĽėŤģ§śÉÖŚÜĶšłčԾƜėĺÁ§ļ cpuÔľĆÁĹĎÁĽúŚíĆÁ£ĀÁõėÁĽüŤģ°śēįśćģԾƚĹÜŚģÉŚģěťôÖśĒ∂ťõÜšļ܌幌§öšŅ°śĀĮ„Äāšłé sar šłćŚźĆÁöĄśėĮÔľĆcollectl ŤÉĹŚ§üŚ§ĄÁźÜśĮĒÁßíśõīŚįŹÁöĄŚćēšĹćԾƌģÉŚŹĮšĽ•ŤĘęÁõīśé•ťÄĀŚÖ•ÁĽėŚõĺŚ∑•ŚÖ∑ŚĻ∂šłĒ collectl ÁöĄÁõĎśéߍŅáÁ®čśõīŚĻŅś≥õ„Äā
+
+#### 51. [iostat][41] ####
+
+
+
+iostat šĻüśėĮ sysstat ŚĆÖÁöĄšłÄťÉ®ŚąÜ„Äāś≠§ŚĎĹšĽ§ÁĒ®šļéÁõĎśéßÁ≥ĽÁĽüÁöĄŤĺďŚÖ•/ŤĺďŚáļ„ÄāŚÖ∂śä•ŚĎ䌏ĮšĽ•ÁĒ®śĚ•ŤŅõŤ°ĆÁ≥ĽÁĽüŤįÉšľėԾƚĽ•śõīŚ•ĹŚúįŤįÉŤäāšĹ†śúļŚô®šłäÁ°¨ÁõėÁöĄŤĺďŚÖ•/ŤĺďŚáļŤīüŤĹĹ„Äā
+
+#### 52. free ####
+
+
+
+ŤŅôśėĮšłÄšł™ŚÜÖÁĹģÁöĄŚĎĹšĽ§ÁĒ®šļéśėĺÁ§ļšĹ†śúļŚô®šłäŚŹĮÁĒ®ÁöĄŚÜÖŚ≠ėŚ§ßŚįŹšĽ•ŚŹäŚ∑≤šĹŅÁĒ®ÁöĄŚÜÖŚ≠ėŚ§ßŚįŹ„ÄāŚģÉŤŅėŚŹĮšĽ•śėĺÁ§ļśüźśó∂ŚąĽŚÜÖś†łśČÄšĹŅÁĒ®ÁöĄÁľďŚÜ≤ŚĆļŚ§ßŚįŹ„Äā
+
+#### 53. /Proc śĖᚼ∂Á≥ĽÁĽü ####
+
+
+
+proc śĖᚼ∂Á≥ĽÁĽüŚŹĮšĽ•Ťģ©šĹ†śü•ÁúčŚÜÖś†łÁöĄÁĽüŤģ°šŅ°śĀĮ„ÄāšĽéŤŅôšļõÁĽüŤģ°śēįśćģŚŹĮšĽ•ŚĺóŚąįšĹ†śúļŚô®šłäšłćŚźĆÁ°¨šĽ∂Ťģ匧áÁöĄŤĮ¶ÁĽÜšŅ°śĀĮ„ÄāÁúčÁúčŤŅôšł™ [ procśĖᚼ∂ÁĽüŤģ°ÁöĄŚģĆśēīŚąóŤ°® ][42]„Äā
+
+#### 54. [GKrellM][43] ####
+
+GKrellm śėĮšłÄšł™ŚõĺŚĹĘŚļĒÁĒ®Á®čŚļŹśĚ•ÁõĎśéߚņÁ°¨šĽ∂ÁöĄÁä∂śÄĀšŅ°śĀĮԾƌɏCPUԾƌÜÖŚ≠ėÔľĆÁ°¨ÁõėÔľĆÁĹĎÁĽúśé•ŚŹ£šĽ•ŚŹäŚÖ∂šĽĖÁöĄ„ÄāŚģÉšĻüŚŹĮšĽ•ÁõĎŤßÜŚĻ∂ŚźĮŚä®šĹ†śČÄťÄČśč©ÁöĄťāģšĽ∂ťėÖŤĮĽŚô®„Äā
+
+#### 55. [Gnome Á≥ĽÁĽüÁõĎśéߌô®][44] ####
+
+
+
+Gnome Á≥ĽÁĽüÁõĎśéߌô®śėĮšłÄšł™Śüļśú¨ÁöĄÁ≥ĽÁĽüÁõĎśéߌ∑•ŚÖ∑ԾƌÖ∂ŤÉĹťÄöŤŅᚳĚł™ś†ĎÁä∂ÁĽďśěĄśĚ•śü•ÁúčŤŅõÁ®čÁöĄšĺĚŤĶĖŚÖ≥Á≥ĽÔľĆŤÉĹśĚÄś≠ĽŚŹäŤįÉśēīŤŅõÁ®čšľėŚÖąÁļßԾƍŅėŤÉĹšĽ•Śõ印®ŚĹĘŚľŹśėĺÁ§ļśČÄśúČśúćŚä°Śô®ÁöĄśĆᜆá„Äā
+
+### śó•ŚŅóÁõĎśéߌ∑•ŚÖ∑ ###
+
+#### 56. [GoAccess][45] ####
+
+
+
+GoAccess śėĮšłÄšł™Śģěśó∂ÁöĄÁĹĎÁĽúśó•ŚŅóŚąÜśěźŚô®ÔľĆŚģÉŤÉĹŚąÜśěź apache, nginx ŚíĆ amazon cloudfront ÁöĄŤģŅťóģśó•ŚŅó„ÄāŚģÉšĻüŚŹĮšĽ•ŚįÜśēįśćģŤĺďŚáļśąź HTMLÔľĆJSON śąĖ CSV ś†ľŚľŹ„ÄāŚģÉšľöÁĽôšĹ†šłÄšł™Śüļśú¨ÁöĄÁĽüŤģ°šŅ°śĀĮԾƍģŅťóģťáŹÔľĆ404ť°ĶťĚĘԾƍģŅŚģĘšĹćÁĹģŚíĆŚÖ∂šĽĖšłúŤ•Ņ„Äā
+
+#### 57. [Logwatch][46] ####
+
+Logwatch śėĮšłÄšł™śó•ŚŅóŚąÜśěźÁ≥ĽÁĽü„ÄāŚģÉťÄöŤŅጹܜěźÁ≥ĽÁĽüÁöĄśó•ŚŅóԾƌĻ∂šłļšĹ†śČÄśĆáŚģöÁöĄŚĆļŚüüŚąõŚĽļšłÄšł™ŚąÜśěźśä•ŚĎä„ÄāŚģÉśĮŹŚ§©ÁĽôšĹ†šłÄšł™śä•ŚĎ䌏ĮšĽ•Ťģ©šĹ†ŤäĪŤīĻśõīŚįĎÁöĄśó∂ťóīśĚ•ŚąÜśěźśó•ŚŅó„Äā
+
+#### 58. [Swatch][47] ####
+
+
+
+ŚÉŹ Logwatch šłÄś†∑ÔľĆSwatch šĻüÁõĎśéߚņÁöĄśó•ŚŅóԾƚĹÜšłćśėĮÁĽôšĹ†šłÄšł™śä•ŚĎäԾƌģÉšľöŚĆĻťÖćšĹ†ŚģöšĻČÁöĄś≠£ŚąôŤ°®Ťĺ匾ŹÔľĆŚĹďŚĆĻťÖ挹įŚźéšľöťÄöŤŅáťāģšĽ∂śąĖśéߌą∂ŚŹįťÄöÁü•šĹ†„ÄāŚģÉŚŹĮÁĒ®šļéś£ÄśĶčŚÖ•šĺĶŤÄÖ„Äā
+
+#### 59. [MultiTail][48] ####
+
+
+
+MultiTail ŚŹĮŚłģŚä©šĹ†Śú®Ś§öÁ™óŚŹ£šłčÁõĎśéßśó•ŚŅóśĖᚼ∂„ÄāšĹ†ŚŹĮšĽ•ŚįÜŤŅôšļõśó•ŚŅóśĖᚼ∂ŚźąŚĻ∂śąźšłÄšł™„ÄāŚģÉšĻüŚÉŹś≠£ŚąôŤ°®Ťĺ匾ŹšłÄś†∑šĹŅÁĒ®šłćŚźĆÁöĄťĘúŤČ≤śĚ•śėĺÁ§ļśó•ŚŅóśĖᚼ∂šĽ•śĖĻšĺŅšĹ†ťėÖŤĮĽ„Äā
+
+#### Á≥ĽÁĽüŚ∑•ŚÖ∑ ####
+
+#### 60. [acct or psacct][49] ####
+
+acct šĻüÁßį psacctÔľąŚŹĖŚÜ≥šļ錶āśěúšĹ†šĹŅÁĒ® apt-get ŤŅėśėĮ yumԾȌŹĮšĽ•ÁõĎśéßśČÄśúČÁĒ®śą∑śČߍ°ĆÁöĄŚĎĹšĽ§ÔľĆŚĆÖśč¨ CPU ŚíĆŚÜÖŚ≠ėŚú®Á≥ĽÁĽüŚÜÖśČÄšĹŅÁĒ®ÁöĄśó∂ťóī„ÄāšłÄśó¶ŚģČŤ£ÖŚģĆśąźŚźéšĹ†ŚŹĮšĽ•šĹŅÁĒ®ŚĎĹšĽ§ ‚Äėsa‚Äô śĚ•śü•Áúč„Äā
+
+#### 61. [whowatch][50] ####
+
+ÁĪĽšľľ acctԾƍŅôšł™Ś∑•ŚÖ∑ÁõĎśéßÁ≥ĽÁĽüšłäśČÄśúČÁöĄÁĒ®śą∑ԾƌĻ∂ŚÖĀŤģłšĹ†Śģěśó∂śü•Áú蚼ĖšĽ¨ś≠£Śú®śČߍ°ĆÁöĄŚĎĹšĽ§ŚŹäŤŅźŤ°ĆÁöĄŤŅõÁ®č„ÄāŚģÉŚįÜśČÄśúČŤŅõÁ®čšĽ•ś†ĎÁä∂ÁĽďśěĄŤĺďŚáļԾƍŅôś†∑šĹ†ŚįĪŚŹĮšĽ•śłÖś•öŚúįÁú茹įŚąįŚļēŚŹĎÁĒüšļÜšĽÄšĻą„Äā
+
+#### 62. [strace][51] ####
+
+
+
+strace ŤĘęÁĒ®šļéŤĮäśĖ≠ԾƍįÉŤĮēŚíĆÁõĎśéßÁ®čŚļŹšĻčťóīÁöĄÁõłšļíŤįÉÁĒ®ŤŅáÁ®č„ÄāśúÄŚłłŤßĀÁöĄŚĀöś≥ēśėĮÁĒ® strace śČďŚćįÁ≥ĽÁĽüŤįÉÁĒ®ÁöĄÁ®čŚļŹŚąóŤ°®ÔľĆŚÖ∂ŚŹĮšĽ•ÁúčŚáļÁ®čŚļŹśėĮŚź¶ŚÉŹťĘĄśúüťā£ś†∑ŤĘęśČߍ°ĆšļÜ„Äā
+
+#### 63. [DTrace][52] ####
+
+
+
+DTrace ŚŹĮšĽ•ŤĮīśėĮ strace ÁöĄŚ§ßŚď•„ÄāŚģɌ䮜ÄĀŚúįŤ∑üŤł™šłéś£ÄśĶ蚼£Á†ĀŚģěśó∂ŤŅźŤ°ĆÁöĄśĆᚼ§„ÄāŚģÉŚÖĀŤģłšĹ†ś∑ĪŚÖ•ŚąÜśěźŚÖ∂śÄߍÉĹŚíĆŤĮäśĖ≠śēÖťöú„ÄāšĹÜśėĮԾƌģÉŚĻ∂šłćÁģÄŚćēԾƌ§ßÁļ¶śúČ1200śú¨šĻ¶šł≠śŹźŚąįŤŅáŚģÉ„Äā
+
+#### 64. [webmin][53] ####
+
+
+
+Webmin śėĮšłÄšł™Śüļšļé Web ÁöĄÁ≥ĽÁĽüÁģ°ÁźÜŚ∑•ŚÖ∑„ÄāŚģÉšłćťúÄŤ¶ĀśČčŚä®ÁľĖŤĺĎ UNIX ťÖćÁĹģśĖᚼ∂ԾƌĻ∂ŚÖĀŤģłšĹ†ŤŅúÁ®čÁģ°ÁźÜÁ≥ĽÁĽü„ÄāŚģÉśúČšłÄŚĮĻÁõĎśéßś®°ŚĚóÁĒ®šļéŤŅěśé•ŚģÉ„Äā
+
+#### 65. stat ####
+
+
+
+Stat śėĮšłÄšł™ŚÜÖÁĹģÁöĄŚ∑•ŚÖ∑ÔľĆÁĒ®šļéśėĺÁ§ļśĖᚼ∂ŚíĆśĖᚼ∂Á≥ĽÁĽüÁöĄÁä∂śÄĀšŅ°śĀĮ„ÄāŚģÉšľöśėĺÁ§ļśĖᚼ∂ŤĘęšŅģśĒĻԾƍģŅťóģśąĖśõīśĒĻÁöĄšŅ°śĀĮ„Äā
+
+#### 66. ifconfig ####
+
+
+
+ifconfig śėĮšłÄšł™ŚÜÖÁĹģÁöĄŚ∑•ŚÖ∑ÁĒ®šļéťÖćÁĹģÁĹĎÁĽúśé•ŚŹ£„ÄāŚ§ßŚ§öśēįÁĹĎÁĽúÁõĎśéߌ∑•ŚÖ∑ŤÉĆŚźéťÉĹšĹŅÁĒ® ifconfig ŚįÜŚÖ∂ŤģĺÁĹģśąźś∑∑šĻĪś®°ŚľŹśĚ•śćēŤé∑śČÄśúČÁöĄśēįśćģŚĆÖ„ÄāšĹ†ŚŹĮšĽ•śČčŚä®śČߍ°Ć `ifconfig eth0 promisc` ŚĻ∂šĹŅÁĒ® `ifconfig eth0 -promisc` ŤŅĒŚõěś≠£Śłłś®°ŚľŹ„Äā
+
+#### 67. [ulimit][54] ####
+
+
+
+ulimit śėĮšłÄšł™ŚÜÖÁĹģÁöĄŚ∑•ŚÖ∑ԾƌŹĮÁõĎśéßÁ≥ĽÁĽüŤĶĄśļźÔľĆŚĻ∂ŚŹĮšĽ•ťôźŚą∂šĽĽšĹēÁõĎśéߍĶĄśļźšłćŚĺóŤ∂Öś†á„ÄāśĮĒŚ¶āŚĀöšłÄšł™ fork ÁāłŚľĻԾƌ¶āśěúšĹŅÁĒ® ulimit ś≠£Á°ģťÖćÁĹģšļÜŚįÜŚģĆŚÖ®šłćŚŹóŚĹĪŚďć„Äā
+
+#### 68. [cpulimit][55] ####
+
+CPULimit śėĮšłÄšł™ŚįŹŚ∑•ŚÖ∑ÁĒ®šļéÁõĎśéߌĻ∂ťôźŚą∂ŤŅõÁ®čŚĮĻ CPU ÁöĄšĹŅÁĒ®Áéá„ÄāŚÖ∂ÁČĻŚąęśúČÁĒ®ÔľĆŤÉĹťôźŚą∂śČĻŚ§ĄÁźÜšĹúšłöŚĮĻ CPU ÁöĄšĹŅÁĒ®ÁéášŅĚśĆĀŚú®šłÄŚģöŤĆÉŚõī„Äā
+
+#### 69. lshw ####
+
+
+
+lshw śėĮšłÄšł™ŚįŹÁöĄŚÜÖÁĹģŚ∑•ŚÖ∑ŤÉĹśŹźŚŹĖŚÖ≥šļéśú¨śúļÁ°¨šĽ∂ťÖćÁĹģÁöĄŤĮ¶ÁĽÜšŅ°śĀĮ„ÄāŚģÉŚŹĮšĽ•ŤĺďŚáļ CPU ÁČąśú¨ŚíĆšłĽśĚŅťÖćÁĹģ„Äā
+
+#### 70. w ####
+
+w śėĮšłÄšł™ŚÜÖÁĹģŚĎĹšĽ§ÁĒ®šļéśėĺÁ§ļŚĹďŚČćÁôĽŚĹēÁĒ®śą∑ÁöĄšŅ°śĀĮŚŹäšĽĖšĽ¨śČÄŤŅźŤ°ĆÁöĄŤŅõÁ®č„Äā
+
+#### 71. lsof ####
+
+
+
+lsof śėĮšłÄšł™ŚÜÖÁĹģÁöĄŚ∑•ŚÖ∑ŚŹĮŤģ©šĹ†ŚąóŚáļśČÄśúČśČÄÁöĄśĖᚼ∂ŚíĆÁĹĎÁĽúŤŅěśé•„ÄāšĽéťā£ťáƚņŚŹĮšĽ•Áú茹įśĖᚼ∂śėĮÁĒĪŚď™šł™ŤŅõÁ®čśČÄÁöĄÔľĆŚüļšļéŤŅõÁ®čŚźćԾƌŹĮťÄöŤŅᚳĚł™ÁČĻŚģöÁöĄÁĒ®śą∑śĚ•śĚÄś≠ĽŚĪěšļéśüźšł™ÁĒ®śą∑ÁöĄśČÄśúČŤŅõÁ®č„Äā
+
+### ŚüļÁ°Äśě∂śěĄÁõĎśéߌ∑•ŚÖ∑ ###
+
+#### 72. Server Density ####
+
+
+
+śąĎšĽ¨ÁöĄ [śúćŚä°Śô®ÁõĎśéߌ∑•ŚÖ∑][56]ÔľĀŚģÉśúČšłÄšł™ web ÁēĆťĚĘԾƚĹŅšĹ†ŚŹĮšĽ•ŤŅõŤ°Ćśä•Ť≠¶ŤģĺÁĹģŚĻ∂ŚŹĮšĽ•ťÄöŤŅáŚõ印®śĚ•śü•ÁúčśČÄśúČÁ≥ĽÁĽüÁöĄÁĹĎÁĽúśĆᜆá„ÄāšĹ†ŤŅėŚŹĮšĽ•ŤģĺÁĹģÁõĎśéßÁöĄÁĹĎÁęôԾƜó†ŤģļśėĮŚź¶Śú®ÁļŅ„ÄāServer Density ŚÖĀŤģłšĹ†ŤģĺÁĹģÁĒ®śą∑ÁöĄśĚÉťôźÔľĆšĹ†ŚŹĮšĽ•ś†ĻśćģśąĎšĽ¨ÁöĄśŹíšĽ∂śąĖ api śĚ•śČ©ŚĪēšĹ†ÁöĄÁõĎśéß„ÄāŤĮ•śúćŚä°Ś∑≤ÁĽŹśĒĮśĆĀ Nagios ÁöĄśŹíšĽ∂šļÜ„Äā
+
+#### 73. [OpenNMS][57] ####
+
+
+
+OpenNMS šłĽŤ¶ĀśúČŚõõšł™ŚäüŤÉĹŚĆļÔľöšļ蚼∂Áģ°ÁźÜŚíĆťÄöÁü•;ŚŹĎÁéįŚíĆťÖćÁĹģ;śúćŚä°ÁõĎśéߌíĆśēįśćģśĒ∂ťõÜ„ÄāŚÖ∂ŤģĺŤģ°ŚŹĮŤĘęŚú®Ś§öÁßćÁĹĎÁĽúÁéĮŚĘÉšł≠ŚģöŚą∂„Äā
+
+#### 74. [SysUsage][58] ####
+
+
+
+SysUsage ťÄöŤŅá Sar ŚíĆŚÖ∂šĽĖÁ≥ĽÁĽüŚĎĹšĽ§śĆĀÁĽ≠ÁõĎśéߚņÁöĄÁ≥ĽÁĽü„ÄāšłÄśó¶Ťĺ匹įťėąŚÄľŚģÉšĻüŚŹĮšĽ•ŤŅõŤ°Ćśä•Ť≠¶ťÄöÁü•„ÄāSysUsage śú¨ŤļęšĻüŚŹĮšĽ•śĒ∂ťõÜśČÄśúČÁöĄÁĽüŤģ°šŅ°śĀĮŚĻ∂Ś≠ėŚā®Śú®šłÄšł™ŚúįśĖĻ„ÄāŚģÉśúČšłÄšł™ Web ÁēĆťĚĘŚŹĮšĽ•Ťģ©šĹ†śü•ÁúčśČÄśúČÁöĄÁĽüŤģ°śēįśćģ„Äā
+
+#### 75. [brainypdm][59] ####
+
+
+
+brainypdm śėĮšłÄšł™śēįśćģÁģ°ÁźÜŚíĆÁõĎśéߌ∑•ŚÖ∑ԾƌģÉŤÉĹśĒ∂ťõܜ̕Ťá™ nagios śąĖŚÖ∂ŚģÉŚÖ¨ŚÖĪŤĶĄśļźÁöĄśēįśćģŚĻ∂šĽ•Śõ印®śėĺÁ§ļ„ÄāŚģÉśėĮŤ∑®ŚĻ≥ŚŹįÁöĄÔľĆŚÖ∂Śüļšļé Web ŚĻ∂ŚŹĮŤá™ŚģöšĻČŚõĺŚĹĘ„Äā
+
+#### 76. [PCP][60] ####
+
+
+
+PCP ŚŹĮšĽ•śĒ∂ťõܜ̕Ťá™Ś§öšł™šłĽśúļÁöĄśĆᜆáԾƌĻ∂šłĒśēąÁéáŚĺąťęė„ÄāŚģÉšĻüśúČšłÄšł™śŹíšĽ∂ś°Üśě∂ԾƜČÄšĽ•šĹ†ŚŹĮšĽ•śääŚģÉśĒ∂ťõÜÁöĄŚĮĻšĹ†Śĺąťá捶ĀÁöĄśĆᜆášĹŅÁĒ®śŹíšĽ∂śĚ•Áģ°ÁźÜ„ÄāšĹ†ŚŹĮšĽ•ťÄöŤŅᚼĽšĹēšłÄšł™ Web ÁēĆťĚĘśąĖ GUI ŤģŅťóģŚõĺŚĹĘśēįśćģ„ÄāŚģÉśĮĒŤĺÉťÄāŚźąŚ§ßŚěčÁõĎśéßÁ≥ĽÁĽü„Äā
+
+#### 77. [KDE Á≥ĽÁĽüšŅĚśä§][61] ####
+
+
+
+ŤŅôšł™Ś∑•ŚÖ∑śóĘśėĮšłÄšł™Á≥ĽÁĽüÁõĎśéߌô®šĻüśėĮšłÄšł™šĽĽŚä°Áģ°ÁźÜŚô®„ÄāšĹ†ŚŹĮšĽ•ťÄöŤŅáŚ∑•šĹúŤ°®śĚ•śü•Áú茧öŚŹįśúļŚô®ÁöĄśúćŚä°śĆᜆáԾƌ¶āśěúšłÄšł™ŤŅõÁ®čťúÄŤ¶ĀŤĘęśĚÄś≠ĽśąĖŤÄ֚ņťúÄŤ¶ĀŚźĮŚä®šłÄšł™ŤŅõÁ®čԾƌģÉŚŹĮšĽ•Śú® KDE Á≥ĽÁĽüšŅ̜䧚ł≠śĚ•ŚģĆśąź„Äā
+
+#### 78. [Munin][62] ####
+
+
+
+Munin śóĘśėĮšłÄšł™ÁĹĎÁĽúšĻüśėĮÁ≥ĽÁĽüÁõĎśéߌ∑•ŚÖ∑ԾƌĹĚł™śĆᜆáŤ∂ÖŚáļÁĽôŚģöÁöĄťėąŚÄľśó∂ŚģÉšľöśŹźšĺõśä•Ť≠¶śúļŚą∂„ÄāŚģÉŤŅźÁĒ® RRDtool ŚąõŚĽļŚõ印®ÔľĆŚĻ∂šłĒŚģÉšĻüśúČ Web ÁēĆťĚʜ̕śėĺÁ§ļŤŅôšļõŚõ印®„ÄāŚģÉśõīŚľļŤįÉÁöĄśėĮŚć≥śŹíŚć≥ÁĒ®ÁöĄŚäüŤÉĹŚĻ∂šłĒśúČŤģłŚ§öŚŹĮÁĒ®ÁöĄśŹíšĽ∂„Äā
+
+#### 79. [Nagios][63] ####
+
+
+
+Nagios śėĮÁ≥ĽÁĽüŚíĆÁĹĎÁĽúÁõĎśéߌ∑•ŚÖ∑ԾƌŹĮŚłģŚä©šĹ†ÁõĎśéߌ§öŚŹįśúćŚä°Śô®„ÄāŚĹĎÁĒüťĒôŤĮĮśó∂ŚģÉšĻüśúČśä•Ť≠¶ŚäüŤÉĹ„ÄāŚģÉÁöĄŚĻ≥ŚŹįšĻüśúȌ幌§öÁöĄśŹíšĽ∂„Äā
+
+#### 80. [Zenoss][64] ####
+
+
+
+Zenoss śŹźšĺõšļÜšłÄšł™ Web ÁēĆťĚĘԾƚĹŅšĹ†ŚŹĮšĽ•ÁõĎśéßśČÄśúČÁöĄÁ≥ĽÁĽüŚíĆÁĹĎÁĽúśĆᜆá„Äāś≠§Ś§ĖԾƌģÉŤÉōᙌ䮌ŹĎÁéįÁĹĎÁĽúŤĶĄśļźŚíĆšŅģśĒĻÁĹĎÁĽúťÖćÁĹģ„ÄāŚĻ∂šłĒšľöśŹźťÜíšĹ†ťáጏĖŤ°ĆŚä®ÔľĆŚģÉšĻüśĒĮśĆĀ Nagios ÁöĄśŹíšĽ∂„Äā
+
+#### 81. [Cacti][65] ####
+
+
+
+(ŚíĆšłäšłÄšł™šłÄś†∑!) Cacti śėĮšłÄšł™ÁĹĎÁĽúŚõĺŚĹĘŤß£ŚÜ≥śĖĻś°ąÔľĆŚÖ∂šĹŅÁĒ® RRDtool ŤŅõŤ°ĆśēįśćģŚ≠ėŚā®„ÄāŚģÉŚÖĀŤģłÁĒ®śą∑Śú®ťĘĄŚģöÁöĄśó∂ťóīťóīťöĒŤŅõŤ°ĆśäēÁ•®śúćŚä°ŚĻ∂ŚįÜÁĽďśěúšĽ•ŚõĺŚĹĘśėĺÁ§ļ„ÄāCacti ŚŹĮšĽ•ťÄöŤŅá shell ŤĄöśú¨śČ©ŚĪēśĚ•ÁõĎśéߚņśČÄťÄČśč©ÁöĄśĚ•śļź„Äā
+
+#### 82. [Zabbix][66] ####
+
+
+
+Zabbix śėĮšłÄšł™ŚľÄśļźÁöĄŚüļÁ°ÄŤģĺśĖĹÁõĎśéßŤß£ŚÜ≥śĖĻś°ą„ÄāŚģÉšĹŅÁĒ®šļÜŤģłŚ§öśēįśćģŚļďśĚ•Ś≠ėśĒĺÁõĎśéßÁĽüŤģ°šŅ°śĀĮ„ÄāŚÖ∂ś†łŚŅÉśėĮÁĒ® C ŤĮ≠Ť®ÄÁľĖŚÜôԾƌĻ∂Śú®ŚČćÁęĮšł≠šĹŅÁĒ® PHP„ÄāŚ¶āśěúšĹ†šłćŚĖúś¨ĘŚģČŤ£ÖšĽ£ÁźÜÔľĆZabbix ŚŹĮŤÉĹśėĮšłÄšł™śúÄŚ•ĹťÄČśč©„Äā
+
+### ťôĄŚä†ťÉ®ŚąÜÔľö ###
+
+śĄüŤįĘśā®ÁöĄŚĽļŤģģ„ÄāŤŅôśėĮśąĎšĽ¨ÁöĄšłÄšł™ťôĄŚä†ťÉ®ŚąÜÔľĆÁĒĪšļ霹ϚĽ¨ťúÄŤ¶ĀťáćśĖįÁľĖśéíśČÄśúČÁöĄś†áťĘėԾƝČīšļéś≠§ÔľĆŤŅôśėĮŚú®śúÄŚźéÁöĄšłÄšł™ÁģÄÁü≠ťÉ®ŚąÜԾƜ†Ļśćģśā®ÁöĄŚĽļŤģģś∑ĽŚä†ÁöĄšłÄšļõ Linux ÁõĎśéߌ∑•ŚÖ∑Ôľö
+
+#### 83. [collectd][67] ####
+
+Collectd śėĮšłÄšł™ Unix Śģąśä§ŤŅõÁ®čśĚ•śĒ∂ťõÜśČÄśúČÁöĄÁõĎśéßśēįśćģ„ÄāŚģÉťááÁĒ®šļÜś®°ŚĚóŚĆĖŤģĺŤģ°ŚĻ∂šĹŅÁĒ®śŹíšĽ∂śĚ•Ś°ęŤ°•šłÄšļõÁľļťô∑„ÄāŤŅôś†∑ŤÉĹšĹŅ collectd šŅĚśĆĀŤĹĽťáŹÁļߌĻ∂ŚŹĮŤŅõŤ°ĆŚģöŚą∂„Äā
+
+#### 84. [Observium][68] ####
+
+Observium śėĮšłÄšł™Ťá™Śä®ŚŹĎÁéįÁĹĎÁĽúÁöĄÁõĎśéߌĻ≥ŚŹįԾƜĒĮśĆĀśôģťÄöÁöĄÁ°¨šĽ∂ŚĻ≥ŚŹįŚíĆśďćšĹúÁ≥ĽÁĽü„ÄāObservium šłďś≥®šļ霏źšĺõšłÄšł™šľėÁĺéԾƌäüŤÉĹŚľļŚ§ßÔľĆÁģÄŚćēÁõīŤßāÁöĄÁēĆťĚʜ̕śėĺÁ§ļÁĹĎÁĽúÁöĄŚĀ•Śļ∑ŚíĆÁä∂śÄĀ„Äā
+
+#### 85. Nload ####
+
+ŤŅôśėĮšłÄšł™ŚĎĹšĽ§Ť°ĆŚ∑•ŚÖ∑śĚ•ÁõĎśéßÁĹĎÁĽúÁöĄŚźěŚźźťáŹ„ÄāŚģÉŚĺąśēīśīĀԾƌõ†šłļŚģÉšĹŅÁĒ®šł§šł™Śõ印®ŚíĆŚÖ∂šĽĖšłÄšļõśúČÁĒ®ÁöĄśēįśćģÁĪĽšľľšľ†ŤĺďÁöĄśēįśćģśÄĽťáŹśĚ•ŚĮĻŤŅõŚáļÁęôśĶĀťáŹŤŅõŤ°ĆŚŹĮŤßÜŚĆĖ„ÄāšĹ†ŚŹĮšĽ•šĹŅÁĒ®Ś¶āšłčśĖĻś≥ēŚģČŤ£ÖŚģÉÔľö
+
+ yum install nload
+
+śąĖŤÄÖ
+
+ sudo apt-get install nload
+
+#### 86. [SmokePing][69] ####
+
+SmokePing ŚŹĮšĽ•Ť∑üŤł™šĹ†ÁĹĎÁĽúŚĽ∂ŤŅüԾƌĻ∂ŚĮĻšĽĖšĽ¨ŤŅõŤ°ĆŚŹĮŤßÜŚĆĖ„ÄāSmokePing śúČšłÄšł™śĶĀŤ°ĆÁöĄŚĽ∂ŤŅüśĶčťáŹśŹíšĽ∂„ÄāŚ¶āśěúŚõĺŚĹĘÁĒ®śą∑ÁēĆťĚĘŚĮĻšĹ†śĚ•ŤĮīťĚ쌳łťá捶ĀÔľĆÁéįŚú®śúČšłÄšł™ś≠£Śú®ŚľÄŚŹĎšł≠ÁöĄśŹíšĽ∂śĚ•ŚģěÁéįś≠§ŚäüŤÉĹ„Äā
+
+#### 87. [MobaXterm][70] ####
+
+Ś¶āśěúšĹ†śēīŚ§©Śú® windows ÁéĮŚĘÉšłčŚ∑•šĹú„ÄāšĹ†ŚŹĮŤÉĹšľöŤßČŚĺó Windows šłčŚŹóÁĽąÁęĮÁ™óŚŹ£ÁöĄťôźŚą∂„ÄāMobaXterm ś≠£śėĮÁĒĪś≠§ŤÄƜ̕ÁöĄÔľĆŚģÉŚÖĀŤģłšĹ†šĹŅÁĒ®Ś§öšł™Śú® Linux šł≠ÁõłšľľÁöĄÁĽąÁęĮ„ÄāŤŅôŚįÜšľöśěĀŚ§ßŚúįŚłģŚä©šĹ†Śú®ÁõĎśéßśĖĻťĚĘÁöĄťúÄśĪāÔľĀ
+
+#### 88. [Shinken monitoring][71] ####
+
+Shinken śėĮšłÄšł™ÁõĎśéßś°Üśě∂ԾƌÖ∂śėĮÁĒĪ python ŚĮĻ Nagios ŤŅõŤ°ĆŚģĆŚÖ®ťáćŚÜôÁöĄ„ÄāŚģÉÁöĄÁõģÁöĄśėĮŚĘ쌾ļÁĀĶśīĽśÄߌíĆÁģ°ÁźÜśõīŚ§ßÁéĮŚĘÉ„ÄāšĹÜšĽćšŅĚśĆĀśČÄśúČÁöĄ nagios ťÖćÁĹģŚíĆśŹíšĽ∂„Äā
+
+--------------------------------------------------------------------------------
+
+via: https://blog.serverdensity.com/80-linux-monitoring-tools-know/
+
+šĹúŤÄÖÔľö[Jonathan Sundqvist][a]
+ŤĮĎŤÄÖÔľö[strugglingyouth](https://github.com/strugglingyouth)
+ś†°ŚĮĻÔľö[ś†°ŚĮĻŤÄÖID](https://github.com/ś†°ŚĮĻŤÄÖID)
+
+śú¨śĖáÁĒĪ [LCTT](https://github.com/LCTT/TranslateProject) ŚéüŚąõÁľĖŤĮĎÔľĆ[Linuxšł≠ŚõĹ](https://linux.cn/) Ťć£Ť™Čśé®Śáļ
+
+
+[a]:https://www.serverdensity.com/
+[1]:http://hisham.hm/htop/
+[2]:http://www.atoptool.nl/
+[3]:https://github.com/JeremyJones/Apachetop
+[4]:http://www.proftpd.org/docs/howto/Scoreboard.html
+[5]:http://jeremy.zawodny.com/mysql/mytop/
+[6]:https://01.org/powertop
+[7]:http://guichaz.free.fr/iotop/
+[8]:http://www.ntop.org/products/ntop/
+[9]:http://www.ex-parrot.com/pdw/iftop/
+[10]:http://jnettop.kubs.info/wiki/
+[11]:http://bandwidthd.sourceforge.net/
+[12]:http://etherape.sourceforge.net/
+[13]:https://www.kernel.org/pub/software/network/ethtool/
+[14]:http://nethogs.sourceforge.net/
+[15]:http://iptraf.seul.org/
+[16]:http://ngrep.sourceforge.net/
+[17]:http://oss.oetiker.ch/mrtg/
+[18]:https://github.com/tgraf/bmon/
+[19]:http://www.phildev.net/iptstate/index.shtml
+[20]:https://unix4lyfe.org/darkstat/
+[21]:http://humdi.net/vnstat/
+[22]:http://nmap.org/
+[23]:http://www.bitwizard.nl/mtr/
+[24]:http://www.tcpdump.org/
+[25]:http://justniffer.sourceforge.net/
+[26]:http://nmon.sourceforge.net/pmwiki.php
+[27]:http://conky.sourceforge.net/
+[28]:https://github.com/nicolargo/glances
+[29]:https://packages.debian.org/sid/utils/saidar
+[30]:http://oss.oetiker.ch/rrdtool/
+[31]:http://mmonit.com/monit
+[32]:http://sourceforge.net/projects/procexp/
+[33]:http://packages.ubuntu.com/lucid/utils/discus
+[34]:http://www.pogo.org.uk/~mark/xosview/
+[35]:http://dag.wiee.rs/home-made/dstat/
+[36]:http://www.net-snmp.org/
+[37]:http://inotify.aiken.cz/?section=incron&page=about&lang=en
+[38]:http://www.monitorix.org/
+[39]:http://sebastien.godard.pagesperso-orange.fr/
+[40]:http://collectl.sourceforge.net/
+[41]:http://sebastien.godard.pagesperso-orange.fr/
+[42]:http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/proc.html
+[43]:http://members.dslextreme.com/users/billw/gkrellm/gkrellm.html
+[44]:http://freecode.com/projects/gnome-system-monitor
+[45]:http://goaccess.io/
+[46]:http://sourceforge.net/projects/logwatch/
+[47]:http://sourceforge.net/projects/swatch/
+[48]:http://www.vanheusden.com/multitail/
+[49]:http://www.gnu.org/software/acct/
+[50]:http://whowatch.sourceforge.net/
+[51]:http://sourceforge.net/projects/strace/
+[52]:http://dtrace.org/blogs/about/
+[53]:http://www.webmin.com/
+[54]:http://ss64.com/bash/ulimit.html
+[55]:https://github.com/opsengine/cpulimit
+[56]:https://www.serverdensity.com/server-monitoring/
+[57]:http://www.opennms.org/
+[58]:http://sysusage.darold.net/
+[59]:http://sourceforge.net/projects/brainypdm/
+[60]:http://www.pcp.io/
+[61]:https://userbase.kde.org/KSysGuard
+[62]:http://munin-monitoring.org/
+[63]:http://www.nagios.org/
+[64]:http://www.zenoss.com/
+[65]:http://www.cacti.net/
+[66]:http://www.zabbix.com/
+[67]:https://collectd.org/
+[68]:http://www.observium.org/
+[69]:http://oss.oetiker.ch/smokeping/
+[70]:http://mobaxterm.mobatek.net/
+[71]:http://www.shinken-monitoring.org/
diff --git a/translated/share/20151130 eSpeak--Text To Speech Tool For Linux.md b/translated/share/20151130 eSpeak--Text To Speech Tool For Linux.md
new file mode 100644
index 0000000000..271866ff47
--- /dev/null
+++ b/translated/share/20151130 eSpeak--Text To Speech Tool For Linux.md
@@ -0,0 +1,64 @@
+eSpeak: LinuxśĖáśú¨ŤĹ¨ŤĮ≠ťü≥Ś∑•ŚÖ∑
+================================================================================
+
+
+[eSpeak][1]śėĮLinuxÁöĄŚĎĹšĽ§Ť°ĆŚ∑•ŚÖ∑ԾƍÉĹśääśĖáśú¨ŤĹ¨ŚŹėśąźŤĮ≠ťü≥„ÄāŤŅôśėĮšłÄś¨ĺÁĒ®CŤĮ≠Ť®ÄŚÜôŚįĪÁöĄÁ≤ĺŤáīÁöĄŤĮ≠ťü≥ŚźąśąźŚô®ÔľĆśŹźšĺõŤčĪŤĮ≠ŚíĆŚÖ∂ŚģÉŚ§öÁßćŤĮ≠Ť®ÄśĒĮśĆĀ„Äā
+
+eSpeakšĽéś†áŚáÜŤĺďŚÖ•śąĖŤÄÖŤĺďŚÖ•śĖᚼ∂šł≠ŤĮĽŚŹĖśĖáśú¨„ÄāŤôĹÁĄ∂ŤĮ≠ťü≥ŤĺďŚáļšłéÁúüšļļŚ£įťü≥ÁõłŚéĽÁĒöŤŅúԾƚĹÜśėĮԾƌú®šĹ†ť°ĻÁõģśúČÁĒ®ŚĺóŚąįÁöĄŚúįśĖĻÔľĆeSpeakšĽćšłćŚ§ĪšłļšłÄšł™Á≤ĺŤáīŚŅęść∑ÁöĄŚ∑•ŚÖ∑„Äā
+
+eSpeakťÉ®ŚąÜšłĽŤ¶ĀÁČĻśÄߌ¶āšłčÔľö
+
+- šłļLinuxŚíĆWindowsŚáÜŚ§áÁöĄŚĎĹšĽ§Ť°ĆŚ∑•ŚÖ∑
+- šĽéśĖᚼ∂śąĖŤÄÖś†áŚáÜŤĺďŚÖ•šł≠śääśĖáśú¨ŤĮĽŚáļśĚ•
+- śŹźšĺõÁĽôŚÖ∂ŚģÉÁ®čŚļŹšĹŅÁĒ®ÁöĄŚÖĪšļęŚļďÁČąśú¨
+- šłļWindowsśŹźšĺõSAPI5ÁČąśú¨ÔľĆŚú®screen-readersśąĖŤÄÖŚÖ∂ŚģÉśĒĮśĆĀWindows SAPI5śé•ŚŹ£Á®čŚļŹÁöĄśĒĮśĆĀšłčÔľĆeSpeakšĽćÁĄ∂ŤÉĹś≠£ŚłłšĹŅÁĒ®
+- ŚŹĮÁ߼ś§ćŚąįŚÖ∂ŚģÉŚĻ≥ŚŹįԾƌĆ֜訌ģČŚćďÔľĆOSXÁ≠Č
+- Ś§öÁßćÁČĻŤČ≤Ś£įťü≥śŹźšĺõťÄČśč©
+- ŤĮ≠ťü≥ŤĺďŚáļŚŹĮšŅĚŚ≠ėšłļ[.WAV][2]ś†ľŚľŹÁöĄśĖᚼ∂
+- ťÉ®ŚąÜSSML([Speech Synthesis Markup Language][3])ŤÉĹšłļHTMLśČÄśĒĮśĆĀ
+- šĹďÁßĮŚįŹŚ∑ßԾƜēīšł™Á®čŚļŹŚĆ֜訍Į≠Ť®ÄśĒĮśĆĀÁ≠ČŚć†ÁĒ®šłćŤ∂≥2MB
+- ŚŹĮšĽ•ŚģěÁéįśĖáśú¨Śąįťü≥Áī†ÁľĖÁ†ĀÁöĄŤĹ¨ŚĆĖԾƍÉĹŤĘęŚÖ∂ŚģÉŤĮ≠ťü≥ŚźąśąźŚľēśď錟łÁļ≥šłļŚČćÁęĮŚ∑•ŚÖ∑
+- ŚŹĮšĹúšłļÁĒüśąźŚíĆŤįÉŚą∂ťü≥Áī†śēįśćģÁöĄŚľÄŚŹĎŚ∑•ŚÖ∑
+
+### ŚģČŤ£ÖeSpeak ###
+
+ŚüļšļéUbuntuÁöĄÁ≥ĽÁĽüšł≠Ծƌú®ÁĽąÁęĮŤŅźŤ°ĆšĽ•šłčŚĎĹšĽ§ŚģČŤ£ÖeSpeakÔľö
+
+ sudo apt-get install espeak
+
+eSpeak is an old tool and I presume that it should be available in the repositories of other Linux distributions such as Arch Linux, Fedora etc. You can install eSpeak easily using dnf, pacman etc.eSpeakśėĮšłÄšł™ŚŹ§ŤÄĀÁöĄŚ∑•ŚÖ∑ԾƜąĎśé®śĶčŚģÉŚļĒŤĮ•ŤÉĹŚú®ŚÖ∂ŚģÉšľóŚ§öLinuxŚŹĎŤ°ĆÁČąŚ¶āArchÔľĆFedorašł≠ŤŅźŤ°Ć„ÄāšĹŅÁĒ®dnfÔľĆpacmanÁ≠ČŚĎĹšĽ§ŚįĪŤÉĹŤĹĽśėďŚģČŤ£Ö„Äā
+
+eSpeakÁĒ®ś≥ēŚ¶āšłčÔľöŤĺďŚÖ•espeakśĆČenterťĒģŤŅźŤ°ĆÁ®čŚļŹ„ÄāŤĺďŚÖ•Ś≠óÁ¨¶śĆČenterŤĹ¨śćĘšłļŤĮ≠ťü≥ŤĺďŚáļÔľąŤĮĎŤ°•ÔľČ„ÄāšĹŅÁĒ®Ctrl+CśĚ•ŚÖ≥ťó≠ŤŅźŤ°Ćšł≠ÁöĄÁ®čŚļŹ„Äā
+
+
+
+ŤŅėśúČŚÖ∂ŚģÉŚŹĮšĽ•ÁöĄťÄČť°ĻԾƌŹĮšĽ•ťÄöŤŅáÁ®čŚļŹŚłģŚä©ŤŅõŤ°Ćśü•Áúč„Äā
+
+### GUIÁČąśú¨ÔľöGespeaker ###
+
+Ś¶āśěúšĹ†śõīŚÄ匟ϚļéšĹŅÁĒ®GUIÁČąśú¨ÔľĆŚŹĮšĽ•ŚģČŤ£ÖGespeakerԾƌģÉšłļeSpeakśŹźšĺõšļÜGTKÁēĆťĚĘ„Äā
+
+šĹŅÁĒ®šĽ•šłčŚĎĹšĽ§śĚ•ŚģČŤ£ÖGespeakerÔľö
+
+ sudo apt-get install gespeaker
+
+śďćšĹúśé•ŚŹ£ÁģÄśėéśėďÁĒ®ÔľĆšĹ†ŚģĆŚÖ®ŚŹĮšĽ•Ťá™Ť°ĆśéĘÁīĘ„Äā
+
+
+
+ŤôĹÁĄ∂ŤŅôšł™Ś∑•ŚÖ∑šłćŤÉĹšłļŚ§ßťÉ®ŚąÜŤģ°ÁģóśČÄÁĒ®ÔľĆšĹÜśėĮŚĹďšĹ†ÁöĄť°ĻÁõģťúÄŤ¶ĀśääśĖáśú¨ŤĹ¨śćĘśąźŤĮ≠ťü≥ÔľĆespeakŤŅėśėĮśĆļśĖĻšĺŅšĹŅÁĒ®ÁöĄ„ÄāťúÄŚąôÁĒ®šĻ茟ß~
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/espeak-text-speech-linux/
+
+šĹúŤÄÖÔľö[Abhishek][a]
+ŤĮĎŤÄÖÔľö[ŤĮĎŤÄÖID](https://github.com/soooogreen)
+ś†°ŚĮĻÔľö[ś†°ŚĮĻŤÄÖID](https://github.com/ś†°ŚĮĻŤÄÖID)
+
+śú¨śĖáÁĒĪ [LCTT](https://github.com/LCTT/TranslateProject) ŚéüŚąõÁľĖŤĮĎÔľĆ[Linuxšł≠ŚõĹ](https://linux.cn/) Ťć£Ť™Čśé®Śáļ
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://espeak.sourceforge.net/
+[2]:http://en.wikipedia.org/wiki/WAV
+[3]:http://en.wikipedia.org/wiki/Speech_Synthesis_Markup_Language
diff --git a/translated/talk/20150820 Why did you start using Linux.md b/translated/talk/20150820 Why did you start using Linux.md
new file mode 100644
index 0000000000..aa48db697c
--- /dev/null
+++ b/translated/talk/20150820 Why did you start using Linux.md
@@ -0,0 +1,144 @@
+ŚĻīŤĹĽšļļԾƚņšłļŚē•šĹŅÁĒ® linux
+================================================================================
+> šĽäŚ§©ÁöĄŚľÄśļźÁĽľŤŅįÔľöśėĮšĽÄšĻąŚł¶šĹ†ŤŅõŚÖ• linux ÁöĄšłĖÁēĆÔľüŚŹ∑Ś§ĖÔľöIBM Śüļšļé Linux ÁöĄŚ§ßŚěčśúļ„ÄāšĽ•ŚŹäԾƚņŚļĒŤĮ•śäõŚľÉ win10 ťÄČśč© Linux ÁöĄŚéüŚõ†„Äā
+
+### ŚĹ̚ņšłļšĹēšĹŅÁĒ® LinuxÔľü ###
+
+Linux Ť∂äśĚ•Ť∂äśĶĀŤ°ĆԾƌ幌§ö OS X śąĖ Windows ÁĒ®śą∑ťÉōŨÁ߼Śąį Linux ťėĶŤź•šļÜ„ÄāšĹÜśėĮšĹ†Áü•ťĀďśėĮšĽÄšĻąŤģ©šĽĖšĽ¨ŚľÄŚßčšĹŅÁĒ® Linux ÁöĄŚźóÔľüšłÄšł™ Reddit ÁĒ®śą∑Śú®ÁĹĎÁęôšłäťóģšļÜŤŅôšł™ťóģťĘėԾƌĻ∂šłĒŚĺóŚąįšļ܌幌§öśúČŤ∂£ÁöĄŚõěÁ≠Ē„Äā
+
+šłÄšł™Śźćšłļ SilverKnight ÁöĄÁĒ®śą∑Śú® Reddit ÁöĄ Linux śĚŅŚĚóšłäťóģšļÜŚ¶āšłčťóģťĘėÔľö
+
+> śąĎÁü•ťĀďŤŅôšł™ťóģťĘėŤāĮŚģöŤĘęťóģŤŅášļÜԾƚĹÜśąĎŤŅėśėĮśÉ≥Śź¨Śź¨ŚĻīŤĹĽšłÄšĽ£šĹŅÁĒ® Linux ÁöĄŚéüŚõ†ÔľĆšĽ•ŚŹäśėĮšĽÄšĻąŤģ©šĽĖšĽ¨ŚĚöŚģöŚúįśąźšłļ Linux ÁĒ®śą∑„Äā
+>
+> śąĎśó†śĄŹťėĽś≠ĘŚ§ßŚģ∂Ťģ≤ŚáļšĹ†šĽ¨ťā£šļõÁ≤ĺŚĹ©ÁöĄ Linux śēÖšļčԾƚĹÜśėĮśąĎŤŅėśėĮŚĮĻťā£šļõś≤°śúČÁĽŹŚéÜŤŅᚼĚĻąÁ≤ĺŚĹ©śēÖšļčÁöĄśĖįšļļÁöĄśÉ≥ś≥ēśĮĒŤĺÉśĄüŚÖīŤ∂£„Äā
+>
+> śąĎ27Ś≤ĀԾƌć䌟äŚ≠ź Linux ÁĒ®śą∑ԾƍŅôšļõŚĻīŤ£ÖŤŅášłćŚįĎŚŹĎŤ°ĆÁȹԾƚĹÜś≤°śúČśäēŚÖ•ŚÖ®ťÉ®Á≤ĺŚäõŚéĽÁé© Linux„ÄāśąĎś≠£Śú®śČĺśõīŚ§öÁöĄ„ÄĀŤÉĹŤģ©śąĎŚÖ®ŤļęŚŅÉśäēŚÖ•Śąį Linux śĹģśĶĀÁöĄÁźÜÁĒĪԾƜąĖŤÄÖŤĮīśŅÄŚäĪ„Äā
+>
+> [ŤĮ¶ŤßĀ Reddit][1]
+
+šĽ•šłčśėĮÁĹĎÁęôšłäÁöĄŚõ쌧ćÔľö
+
+> **DoublePlusGood**ÔľöśąĎ12Ś≤ĀŚľÄŚßčšĹŅÁĒ® BacktrackÔľąÁéįŚú®śĒĻŚźćšłļ KaliÔľČԾƌõ†šłļśąĎśÉ≥śąźšłļšłÄŚźćťĽĎŚģĘÔľąLCTT ŤĮĎś≥®ÔľöŚéüśĖá1337 haxorÔľĆ1337 śėĮ leet ÁöĄÁĀęśėüśĖáŚÜôś≥ēԾƜĄŹšłļ'ÁĀęśėüśĖá'ÔľĆhaxor šłļ hackor ÁöĄÁĀęśėüśĖáŚÜôś≥ēԾƜĄŹšłļ'ťĽĎŚģĘ'ԾƌŹ¶šłÄÁßćŚÜôś≥ēśėĮ 1377 h4x0rԾƜĽ°śĽ°ÁöĄÁĀęśėüśĖáśĖáŚĆĖԾȄÄāśąĎÁéįŚú®šłÄÁõīšĹŅÁĒ® ArchLinuxԾƌõ†šłļŚģÉÁĽôśąĎśó†ťôźŤá™ÁĒĪԾƍģ©śąĎŚĮĻśąĎÁöĄÁĒĶŤĄĎŚŹĮšĽ•šłļśČÄś¨≤šłļ„Äā
+>
+> **Zack**ÔľöśąĎŤģįŚĺóśėĮ12„ÄĀ3Ś≤ĀÁöĄśó∂ŚÄôšĹŅÁĒ® LinuxÔľĆÁéįŚú®15Ś≤ĀšļÜ„Äā
+>
+> śąĎ11Ś≤ĀÁöĄśó∂ŚÄôŚįĪŚĮĻ Windows XP śĄüŚąįšłćŤÄźÁɶԾƚłÄšł™ÁģÄŚćēÁöĄŚäüŤÉĹԾƜĮĒŚ¶āŚÖ≥śúļÔľĆTMD ťÉĹŤ¶ĀŤģ©śąĎŤÄźŚŅÉÁ≠ČÁĚÄŚģÉśÖĘśÖĘŚģĆśąź„Äā
+>
+> Śú®ťā£šĻčŚČćŚá†šł™śúąÔľĆśąĎŚú® freenode IRC ŤĀ䌧©Śģ§ŚŹāšłéŤģ®ŤģļšļÜšłÄšł™śłłśąŹÔľĆŚģÉśėĮšłÄšł™ŚľÄśļźť°ĻÁõģԾƌ§ßŚ§öśēįÁĒ®śą∑šĹŅÁĒ® Linux„Äā
+>
+> śąĎšłćśĖ≠Śź¨Śąį Linux šĹÜŚĹďśó∂ŚĮĻŚģÉŤŅėś≤°śúČŚÖīŤ∂£„ÄāÁĄ∂ŤÄĆÁĒĪšļéŤŅôšļõŤĀ䌧©ťĘĎťĀďÔľąŚ§ßťÉ®ŚąÜŚú® freenode šłäԾȍįąŤģļšļ܌幌§öÁľĖÁ®čŤĮĚťĘėԾƜąĎŚįĪŚľÄŚßčŚ≠¶šĻ† python šļÜ„Äā
+>
+> šłÄŚĻīŚźéśąĎŚįĚŤĮēÁĚÄŚģČŤ£Ö GNU/Linux ÔľąšłĽŤ¶ĀśėĮ ubuntuԾȌąįśąĎÁöĄśĖįÁĒĶŤĄĎÔľąŚÖ∂ŚģěšłćśĖįԾƚĹÜŚģÉśėĮšĹúšłļśąĎÁöĄÁĒüśó•Á§ľÁČ©ŤĘꜹόĺóŚąįÁöĄÔľČ„ÄāšłćŚĻłÁöĄśėĮŚģɜļśėĮšłćŤÉĹś≠£ŚłłŚ∑•šĹúԾƌéüŚõ†śú™Áü•ÔľĆšĻüŤģłÁ°¨ÁõėŚĚŹšļÜԾƚĻüŤģłÁĀįŚįėŚ§™Ś§öšļÜ„Äā
+>
+> ťā£śó∂śąĎśĒ匾ɍᙌ∑ĪŤß£ŚÜ≥ŤŅôšł™ťóģťĘėÔľĆÁĄ∂ŚźéÁľ†ÁĚÄŤÄĀÁąłÁĽôśąĎÁöĄÁĒĶŤĄĎŤ£Öšłä UbuntuԾƚĽĖšĻüśó†ŤÉĹšłļŚäõԾƌéüŚõ†ŚźĆšłä„Äā
+>
+> Śú®ŤŅĹśĪā Linux šłÄśģĶśó∂ťóīŚźéԾƜąĎśČďÁģóśäõŚľÉ WindowsԾƚĹŅÁĒ® Linux Mint šĽ£śõŅ UbuntuԾƜú¨śĚ•ś≤°śäĪšĽÄšĻąŚłĆśúõԾƚĹÜ Linux Mint ÁęüÁĄ∂ŤÉĹŤ∑ĎŤĶ∑śĚ•ÔľĀ
+>
+> šļéśėĮŤŅôšł™Á≥ĽÁĽüśąĎÁĒ®šļÜ6šł™śúą„Äā
+>
+> ťā£śģĶśó∂ťóīśąĎÁöĄšłÄšł™śú茏čÁĽôšļÜśąĎšłÄŚŹįŤôöśčüśúļԾƍ∑Ď Ubuntu ÁöĄÔľĆśąĎÁĒ®šļÜšłÄŚĻīÔľĆÁõīŚąįśąĎÁąłÁĽôšļÜśąĎšłÄŚŹįśúćŚä°Śô®„Äā
+>
+> 6šł™śúąŚźéśąĎŚĺóŚąįšłÄŚŹįśĖį PCÔľąÁéįŚú®ŤŅėŚú®ÁĒ®ÔľČ„ÄāšļéśėĮŤĶ∑śÉ≥śäėŤÖĺÁāĻšłćšłÄś†∑ÁöĄšłúŤ•Ņ„Äā
+>
+> śąĎśČďÁģóŤ£Ö openSUSE„Äā
+>
+> śąĎŚĺąŚĖúś¨ĘŤŅôšł™Á≥ĽÁĽü„ÄāÁĄ∂ŚźéŚú®Śú£ŤĮěŤäāÁöĄśó∂ŚÄôśąĎŚĺóŚąįś†ĎŤéďśīĺԾƚłäťĚĘŚŹ™ŤÉĹŤ∑Ď DebianԾƍŅėšłćŤÉĹśĒĮśĆĀŚÖ∂ŚģÉŚŹĎŤ°ĆÁČą„Äā
+>
+> **Cqz**ÔľöśąĎ9Ś≤ĀÁöĄśó∂ŚÄôśúČšłÄś¨°Áé© Windows 98ÔľĆÁĽďśěúŤŅôŤīߌĹďśúļšļÜԾƌéüŚõ†śú™Áü•„ÄāśąĎś≤°śúČ Windows ŚģČŤ£ÖÁõėԾƚĹÜśąĎÁąłÁöĄšłÄśú¨šĽčÁĽćÁľĖÁ®čÁöĄśĚāŚŅóšłäśúČšłÄŚľ†ťöŹšĻ¶ťôĄŤĶ†ÁöĄŚÖČÁõėԾƍŅôŚľ†ŚÖČÁõėšłäŚąöŚ•ĹśúČ Mandrake Linux ÁöĄŚģČŤ£ÖŤĹĮšĽ∂ԾƚļéśėĮśąĎÁ쨝óīŚįĪśąźšłļšļÜ Linux ÁĒ®śą∑„ÄāśąĎŚĹďśó∂ŤŅėšłćÁü•ťĀďŤá™Ś∑ĪŚú®Áé©šĽÄšĻąÔľĆšĹÜśėĮÁé©ŚĺóŚĺąŚó®Áöģ„ÄāŤŅôšļõŚĻīśąĎŤôĹÁĄ∂Śú®ÁĒĶŤĄĎšłäŤ£ÖšļÜŚ§öÁßć Windows ÁČąśú¨ÔľĆšĹÜśėĮ FLOSS šłĖÁēĆśČćśėĮśąĎÁöĄŚģ∂„ÄāÁéįŚú®śąĎŚŹ™śää Windows Ť£ÖŚú®ŤôöśčüśúļšłäÔľĆÁĒ®śĚ•Áé©śłłśąŹ„Äā
+>
+> **Tosmarcel**Ôľö15Ś≤Āťā£ŚĻīŚĮĻ'ÁľĖÁ®č'ŤŅôšł™ś¶āŚŅĶŚĺąŚ•ĹŚ•áÔľĆÁĄ∂ŚźéśąĎŚľÄŚßčšļÜŚďąšĹõŤĮĺÁ®č'CS50'ԾƍŅôšł™ŤĮĺÁ®čŤ¶ĀśąĎšĽ¨ŚģČŤ£Ö Linux ŤôöśčüśúļÁĒ®śĚ•śČߍ°ĆšłÄšļõŚĎĹšĽ§„ÄāŚĹďśó∂śąĎťóģŤá™Ś∑ĪšłļšĽÄšĻą Windows ś≤°śúČŤŅôšļõŚĎĹšĽ§ÔľüšļéśėĮśąĎ Google šļÜ LinuxԾƜźúÁīĘÁĽďśěúŚáļÁéįšļÜ UbuntuԾƌú®ŚģČŤ£Ö Ubuntu„ÄāÁöĄśó∂ŚÄôšłćŚįŹŚŅÉśää Windows ŚąÜŚĆļÁĽôŚą†šļÜ„Äā„Äā„ÄāŚĹďśó∂ŚĮĻ Linux śĮęśó†śČÄÁü•ÔľĆťÄāŚļĒŤŅôšł™Á≥ĽÁĽüťĚ쌳łŚõįťöĺ„ÄāśąĎÁéįŚú®16Ś≤ĀÔľĆÁĒ® ArchLinuxԾƚłćśÉ≥ÁĒ®Śõě WindowsԾƜąĎÁąĪ ArchLinux„Äā
+>
+> **Micioonthet**ÔľöÁ¨¨šłÄś¨°Śź¨ŤĮī Linux śėĮŚú®śąĎ5ŚĻīÁļßÁöĄśó∂ŚÄôԾƌĹďśó∂ŚéĽśąĎšłÄśú茏čŚģ∂ԾƚĽĖÁöĄÁ¨ĒŤģįśú¨Ť£ÖÁöĄŚįĪśėĮ MEPISÔľąDebianÁöĄšłÄšł™śĮĒŤĺÉŤÄĀÁöĄŤ°ćÁĒüÁČąÔľČԾƍÄĆšłćśėĮ XP„Äā
+>
+> ŚéüśĚ•śėĮšĽĖÁąłÁąłśėĮšł™ÁĺéŚõĹÁöĄÁ§ĺšľöŚ≠¶Śģ∂ԾƍÄĆšĽĖŚÖ®Śģ∂ťÉĹšłćšŅ°šĽĽŚĺģŤĹĮ„ÄāśąĎŚĮĻŤŅôšļõšłúŤ•ŅŚģĆŚÖ®ťôĆÁĒüԾƍŅôÁ≥ĽÁĽüŚģĆŚÖ®ś≤°śúČśąĎÁÜüśāČÁöĄŤĹĮšĽ∂ԾƜąĎŚĺąÁĖĎśÉĎšĽĖśÄéšĻąŤÉĹšĹŅÁĒ®„Äā
+>
+> śąĎ13Ś≤Āťā£ŚĻīŤŅėś≤°śúȍᙌ∑ĪÁöĄÁ¨ĒŤģįśú¨ÁĒĶŤĄĎԾƍÄĆśąĎŚŹ¶šłÄšĹćśú茏čśÄĽśėĮśäĪśÄ®šĽĖÁöĄÁĒĶŤĄĎśúČŚ§öśÖĘԾƜČÄšĽ•śąĎśČďÁģóśääŚģÉšĻįšłčśĚ•ŚĻ∂šŅģŚ•ĹŚģÉ„ÄāśąĎŤäĪšļÜ20ÁĺéŚÖÉšĻįšłčšļÜŤŅôŚŹįŤ£ÖÁĚÄ Windows Vista Á≥ĽÁĽü„ÄĀŤ∑ĎśĽ°ÁóÖśĮí„ÄĀŚģĆŚÖ®śó†ś≥ēšĹŅÁĒ®ÁöĄśÉ†śôģÁ¨ĒŤģįśú¨„ÄāśąĎšłćśÉ≥ťáćŤ£ÖŤģ®ŚéĆÁöĄ Windows Á≥ĽÁĽüԾƍģįŚĺó Linux śėĮŚÖćŤīĻÁöĄÔľĆśČÄšĽ•śąĎŚąĽšļÜšłÄŚľ† Ubuntu 14.04 ŚÖČÁõėԾƝ©¨šłäśääŚģÉŤ£ÖŤĶ∑śĚ•ÔľĆÁĄ∂ŚźéśąĎŤĘęŚģÉÁöĄťęėśÄߍÉĹÁĽôťúáÁ≤ĺšļÜ„Äā
+>
+> śąĎÁöĄšłĖÁēĆÔľąÁĒĪšļéŚģÉŚÖĀŤŅźŤ°ĆŚú® JAVA šłäԾƜČÄšĽ•ŚĹďśó∂ŚģÉśėĮ Linux šłčšłļśēįšłćŚ§öÁöĄŚá†šł™śłłśąŹšĻčšłÄԾȌú® Vista šłäŚŹ™ŤÉĹŤ∑Ď5ŚłßśĮŹÁßíԾƍÄĆŚú® Ubuntu šłäŤÉĹŤ∑ĎŚąį25Śłß„Äā
+>
+> śąĎŚąįÁéįŚú®ŤŅėšľöŚĀ∂ŚįĒšĹŅÁĒ®šłÄšłčťā£ŚŹįÁ¨ĒŤģįśú¨ÔľĆLinux ŚŹĮšłćšľöŚú®šĻéšĹ†ÁöĄÁ°¨šĽ∂Ťģ匧áśúČŚ§öŤÄĀ„Äā
+>
+> šĻ茟霹ϜääśąĎÁąłšĻüśčČŚÖ• Linux Ť°ĆŚąóԾƜąĎšĽ¨šľöšĽ•ŚĺąšĹéÁöĄšĽ∑ś†ľšĻįŤÄĀÁĒĶŤĄĎԾƍ£Öšłä Linux Mint śąĖŚÖ∂šĽĖŤĹĽťáŹÁļߌŹĎŤ°ĆÁȹԾƍŅôÁúĀšļÜŚ•ĹŚ§öťíĪ„Äā
+>
+> **Webtm**ÔľöśąĎÁąĻśĮŹŚŹįÁĒĶŤĄĎťÉĹšľöŤ£ÖŚ§öšł™ŚŹĎŤ°ĆÁȹԾƜúȌᆌŹįśėĮ opensuse ŚíĆ DebianԾƚĽĖÁöĄšł™šļļÁĒĶŤĄĎŤ£ÖÁöĄśėĮ Slackware„ÄāśČÄšĽ•śąĎŤģįŚĺóŚĺąŚįŹÁöĄśó∂ŚÄôšłÄÁõīŚú®Áé© debianԾƚĹÜś≤°śúČśäēŚÖ•ŚĺąŚ§öÁ≤ĺŚäõԾƜąĎÁĒ®šļ܌ᆌĻīÁöĄ WindowsÔľĆÁĄ∂ŚźéśąĎÁąĻťóģśąĎśúČś≤°śúČŚÖīŤ∂£ŤĮēŤĮē debian„ÄāŤŅôśėĮšł™śúČŤ∂£ÁöĄÁĽŹŚéÜԾƌú®ťā£šĻ茟霹ϚłÄÁõīšĹŅÁĒ® debian„ÄāŤÄĆÁéįŚú®śąĎšłćÁĒ® LinuxԾƍŨśäē freeBSDÔľĆ5šł™śúąšļÜÔľĆÁĒ®ŚĺóŚĺąŚľÄŚŅÉ„Äā
+>
+> ŚģĆŚÖ®śéߌą∂Ťá™Ś∑ĪÁöĄÁ≥ĽÁĽüśėĮšł™ŚĺąŚ•áŚ¶ôÁöĄšĹƄÄāŚľÄśļźŚĪäśúČŚ•ĹŚ§öťÖ∑ťÖ∑ÁöĄŤĹĮšĽ∂ԾƜąĎŤģ§šłļŚú®Ťá™Ś∑ĪŤß£ŚÜ≥šłÄšļõťóģťĘėŚĻ∂šłĒŚą©ÁĒ®ŤŅôšļõŚ∑•ŚÖ∑Ťß£ŚÜ≥ŚÖ∂šĽĖšļčśÉÖÁöĄŤŅáÁ®čśėĮśúÄśúČŤ∂£ÁöĄ„ÄāŚĹďÁĄ∂Á®≥ŚģöŚíĆťęėśēąšĻüśėĮŚźłŚľēśąĎÁöĄŚúįśĖĻ„ÄāśõīšłćÁĒ®ŤĮīŚģÉÁöĄšŅĚŚĮÜÁļߌąęšļÜ„Äā
+>
+> **Wyronaut**ÔľöśąĎšĽäŚĻī18ÔľĆÁ¨¨šłÄś¨°Áé© Linux śėĮ13Ś≤ĀԾƌĹďśó∂Áé©ÁöĄ UbuntuԾƚłļŚē•Ť¶ĀÁĘį LinuxÔľüŚõ†šłļśąĎśÉ≥śź≠šłÄšł™'śąĎÁöĄšłĖÁēĆ'ÁöĄśúćŚä°Śô®śĚ•ŚíĆŚįŹšľôšľīÁé©śłłśąŹÔľĆŚĹďśó∂'śąĎÁöĄšłĖÁēĆ'ŚŹĮśėĮšł™śĖįť≤úÁé©śĄŹŚĄŅ„ÄāŤÄĆśź≠šł™ÁßĀśúćťúÄŤ¶ĀÁĒ® Linux Á≥ĽÁĽü„Äā
+>
+> ŚĹďśó∂śąĎŤŅėśėĮšł™śĖįśČčԾƌĮĻÁĚÄ Linux ÁöĄŚĎĹšĽ§Ť°ĆśúČšļõŚāĽÁúľÔľĆŚõ†šłļŚĺąŚ§öšłúŤ•ŅťÉĹŤ¶ĀśąĎŤá™Ś∑ĪŚ§ĄÁźÜ„ÄāŤŅėśėĮŚ§öšļŹšļÜ Google ŚíĆÁĽīŚüļԾƜąĎśąźŚäüŚúįŚú®Ś§öŚŹįŤÄĀ PC šłäťÉ®ÁĹ≤šļÜšłÄšļõÁģÄŚćēÁöĄśúćŚä°Śô®ÔľĆťā£šļõśó©Ś∑≤śó†šļļťóģśī•ÁöĄŤÄĀŚŹ§ŤĎ£śúļŚô®ŚŹąŤÉĹŚŹĎśĆ•šĹôÁÉ≠šļÜ„Äā
+>
+> Ť∑ĎŤŅáśłłśąŹśúćŚä°Śô®ŚźéԾƜąĎŚŹąŚľÄŚßčŤ∑Ď web śúćŚä°Śô®ÔľĆŚÖąśėĮŤ∑Ďšļ܌ᆌĻī HTMLÔľĆCSS ŚíĆ PHPԾƚĻ茟錏ó TheNewBoston ŤßÜťĘĎÁöĄŤĮĮŚĮľŤĹ¨ŚąįšļÜ JAVA„Äā
+>
+> šłÄŚĎ®ŚźéśĒĺŚľÉ JAVA śĒĻÁĒ® PythonԾƌĹďśó∂Ś≠¶šĻ† Python ÁĒ®ÁöĄšĻ¶ŚźćŚŹę„ÄäLearn Python The Hard Way„ÄčԾƚĹúŤÄÖśėĮ Zed A. Shaw„ÄāśąĎŤäĪšļÜšł§ŚĎ®Ś≠¶ŚģĆ PythonÔľĆÁĄ∂ŚźéŚľÄŚßčÁúč„ÄäC++ Primer„ÄčԾƌõ†šłļśąĎśÉ≥ŚĀöśłłśąŹŚľÄŚŹĎ„ÄāÁú茹įšłÄŚćäÔľąŚ§ßś¶ā500ť°ĶÔľČÁöĄśó∂ŚÄôśąĎśĒ匾ɚļÜ„Äāťā£šł™śó∂ŚÄôśąĎśúČÁāĻŤģ®ŚéĆÁé©ÁĒĶŤĄĎšļÜ„Äā
+>
+> ŤŅôś†∑šł≠śĖ≠šļÜšłÄśģĶśó∂ťóīšĻ茟éԾƜąĎŚÜ≥ŚģöŚ≠¶šĻ† JavaScriptԾƍĮĽšļÜ2śú¨šĻ¶ÔľĆŤĮēšļÜ4šł™ŚĻ≥ŚŹįÔľĆÁĄ∂ŚźéŚŹąšłćÁé©šļÜ„Äā
+>
+> ÁéįŚú®ŚąįšļÜšłćŚĺóšłćśČ嚳ĜČÄŚ≠¶ś†°ŚĻ∂ŚÜ≥ŚģöśĮēšłöŚźéśČ嚼ĚĻąś†∑Ś∑•šĹúÁöĄÁ≥üÁ≥ēśó∂ŚąĽ„ÄāśąĎšłćśÉ≥Áé©ŚõĺŚĹĘÁēĆťĚĘÁľĖÁ®čԾƜČÄšĽ•śąĎšłćšľöŤŅõśłłśąŹŤ°Ćšłö„ÄāśąĎšĻüšłćŚĖúś¨ĘÁĒĽÁĒĽŚíĆŚĽļś®°„ÄāÁĄ∂ŚźéśąĎŚŹĎÁéįšļÜšłÄšł™ś∂ČŚŹäÁĹĎÁĽúŚģČŚÖ®ÁöĄšłďšłöԾƚļéśėĮśąĎÁę茹ĽÁąĪšłäŚģÉšļÜ„ÄāśąĎśĆĎšļ܌幌§ö C ŤĮ≠Ť®ÄÁöĄšĻ¶śĚ•Śļ¶ŤŅáŤŅôšł™ŚĀáśúüԾƌĻ∂šłĒŚ§ćšĻ†šļÜšłÄšłčśēįŚ≠¶śĚ•ŤŅéśé•śĖįÁöĄś†°Śõ≠ÁĒüśīĽ„Äā
+>
+> ÁõģŚČćśąĎÁé© archlinuxԾƚłćŚźĆ PC šłäŤ∑ĎÁĚÄšłćŚźĆšĽĽŚä°ÔľĆŚģÉšĽ¨ŤŅźŤ°ĆŚĺąÁ®≥Śģö„Äā
+>
+> ŚŹĮšĽ•ŤĮī Linux Śł¶śąĎŤŅõŚÖ•ÁľĖÁ®čÁöĄšłĖÁēĆԾƍÄĆŚŹćŤŅáśĚ•ÔľĆśąĎśúÄÁĽąŚú®Ś≠¶ś†°Ť¶ĀŚ≠¶ÁöĄŚįĪśėĮ Linux„ÄāśąĎšľįŤģ°šľöÁĽąÁĒüśĄüŤįĘ Linux„Äā
+>
+> **Linuxllc**ÔľöšĹ†šĽ¨ŚŹĮšĽ•Ś≠¶Ś≠¶ŚÉŹśąĎŤŅôś†∑ÁöĄŤÄĀŚ§ī„Äā
+>
+> śČĒśéČ WindowsÔľĀśČĒśéČ WindowsÔľĀśČĒśéČ WindowsÔľĀÁĽôŤá™Ś∑ĪšłÄšł™ŚĚöśĆĀšĹŅÁĒ® Linux ÁöĄÁźÜÁĒĪԾƝā£ŚįĪśėĮŚģƌ֮ԾƌżŚļēԾƍŅúÁ¶ĽÔľĆWindows„Äā
+>
+> śąĎŚú® 2003 ŚĻīśĒĺŚľÉ WindowsԾƌŹ™ÁĒ®šļÜ5Ś§©ŚįĪśääśČÄśúČÁĒĶŤĄĎŤ∑Ďśąź LinuxԾƌĆ֜訜ČÄśúČÁöĄŚ§ĖŚõīŤģ匧áÔľąLCTT ŤĮĎś≥®ÔľöśĮĒŚ¶āśČďŚćįśúļÔľüԾȄÄāśąĎšłćÁé© Windows ťáĆÁöĄśłłśąŹÔľĆŚŹ™Áé© Linux ťáĆÁöĄ„Äā
+>
+> **Highclass**ÔľöśąĎ28Ś≤ĀԾƚłćÁü•ťĀďŤŅėśėĮšłćśėĮšĹ†Ť¶ĀśČĺÁöĄŚĻīŤĹĽšļļÁĪĽŚěč„Äā
+>
+> ŤÄĀŚģěŤĮīśąĎŚĮĻÁĒĶŤĄĎśĆļśĄüŚÖīŤ∂£ÁöĄÔľĆŚĹύŅėś≤°śé•Ťß¶'Ťá™ÁĒĪŤĹĮšĽ∂Śď≤Ś≠¶'ÁöĄśó∂ŚÄôԾƜąĎŤģ§šłļ free śėĮŚÖćŤīĻÁöĄśĄŹśÄĚ„ÄāśąĎšĻüšłćŤģ§šłļŚĎĹšĽ§Ť°ĆÁēĆťĚʌ幍ģ©šļļťö嚼•śé•ŚŹóԾƌõ†šłļśąĎŚįŹśó∂ŚÄôŚįĪśé•Ťß¶ŤŅá DOS Á≥ĽÁĽü„Äā
+>
+> śąĎÁ¨¨šłÄšł™ŚŹĎŤ°ĆÁČąśėĮ MandrakeԾƌú®śąĎ11Ś≤ĀŤŅėśėĮ12Ś≤Āťā£ŚĻīśąĎśääŚģ∂ťáĆÁöĄÁĒĶŤĄĎŚľĄŚĺóšĻĪšłÉŚÖęÁ≥üÔľĆÁĄ∂ŚźéśąĎšłÄÁõīśäėŤÖĺťā£ŚŹįÁĒĶŤĄĎԾƍĮēÁĚÄŤģ©śąĎśäÄÁöĄśäÄŤÉĹśŹźŚćᚳĚł™ŚŹįťė∂„ÄāÁéįŚú®śąĎŚú®šłÄŚģ∂ŚÖ¨ŚŹłŚÖ®ŤĀĆšĹŅÁĒ® Linux„ÄāÔľąŤĮ∑ŚÖĀŤģłśąĎŤÄłšł™Ťā©ÔľČ„Äā
+>
+> **Matto**ÔľöśąĎÁöĄÁĒĶŤĄĎśėĮśóߍīߌłāŚúļś∑ėŚõěśĚ•ÁöĄÔľĆŤ£Ö XPԾƍ∑ĎŚĺóśÖĘԾƚļéśėĮśąĎśÉ≥śćĘšł™Á≥ĽÁĽü„ÄāGoogle šļÜšłÄšłčԾƌŹĎÁéį Ubuntu„ÄāŚĹďŚĻīśąĎ15„ÄĀ6Ś≤ĀÔľĆÁéįŚú®23šļÜԾƌįĪŤĀĆÁöĄŚÖ¨ŚŹłŚÜ֝ɮšĹŅÁĒ® Linux„Äā
+>
+> [śõīŚ§öŤĮĄŤģļÁ߼ś≠• Reddit][2]
+
+### IBM ÁöĄ Linux Ś§ßŚěčśúļ ###
+
+IBM ŚĺąšĻÖŚČćŚįĪÁĒ® Linux šļÜ„ÄāÁéįŚú®ŤŅôŚģ∂ŚÖ¨ŚŹłťÄĜ鮌áļšłÄś¨ĺśúļŚô®šłďťó®šĹŅÁĒ® UbuntuԾƜúļŚô®ŚźćŚŹę LinuxOne„Äā
+
+Ron Miller Śú® TecchCrunch ŚćöŚģĘšłäŤĮīÔľö
+
+> śĖįÁöĄŚ§ßŚěčśúļŚĆ֜訚ł§ś¨ĺśúļŚěčԾƝÉĹśėĮšĽ•šľĀťĻÖŚźćÁßįŚĎĹŚźćÁöĄÔľąLinux ÁöĄŚźČÁ••ÁČ©ŚįĪśėĮšłÄŚŹ™šľĀťĻÖԾƜáā18śĎłÁöĄŚĎĹŚźćÁĒ®śĄŹšļÜś≤°ÔľüÔľČÁ¨¨šłÄś¨ĺŚŹęŚłĚšľĀťĻÖԾƚĹŅÁĒ® IBM z13 śúļŚěčԾƜąĎšĽ¨śó©Śú®1śúąšĽĹŚįĪšĽčÁĽćŤŅášļÜ„ÄāŚŹ¶šłÄś¨ĺÁ®ćŚĺģŚįŹšłÄÁāĻԾƌźćŚŹęŤ∑≥Ś≤©šľĀťĻÖԾƚĺõŚÖ•ťó®ÁļßšĻįŚģ∂šĹŅÁĒ®„Äā
+>
+> šĻüŤģłšĹ†šľöšĽ•šłļŚ§ßŚěčśúļŚįĪŚÉŹśĀźťĺôšłÄś†∑śó©ŚįĪÁĀ≠ÁĽĚšļÜԾƚĹÜšłĖÁēĆšłäŤģłŚ§öŚ§ßŚěčśúļśěĄšł≠ťÉĹŤŅėŚú®šĹŅÁĒ®ŚģÉšĽ¨ÔľĆŚģÉšĽ¨ŤŅėŚĀ•Śú®„ÄāšĹúšłļŚŹĎŚĪēšļĎśäÄśúĮśąėÁē•ÁöĄšłÄťÉ®ŚąÜԾƜēįśćģŚąÜśěźšłéŚģČŚÖ®śúČśúõšļ霏źŚćá Ubuntu Ś§ßŚěčśúļÁöĄŚłāŚúļԾƍŅôÁß挧ߌěčśúļŤÉĹśŹźšĺõšłÄÁ≥ĽŚąóŚľÄśļźÁöĄšľĀšłöÁļߍĹĮšĽ∂ԾƜĮĒŚ¶ā Apache SparkÔľĆNode.jsÔľĆMongoDBÔľĆMariaDBÔľĆPostgreSQL ŚíĆ Chef„Äā
+>
+> Ś§ßŚěčśúļŤŅėšľöŚ≠ėŚú®šļéŚģĘśą∑ťĘĄÁĹģÁöĄśēįśćģšł≠ŚŅÉšł≠ԾƚĹÜśėĮŚłāŚúļÁöĄŚ§ßŚįŹŚŹĖŚÜ≥šļéšľöśúČŚ§öŚįĎŚģĘśą∑šĹŅÁĒ®ŤŅôÁßćÁĪĽšľľšļéšļĎśúćŚä°ÁöĄÁ≥ĽÁĽü„ÄāMauri Ťß£ťáäťĀďÔľĆIBM ś≠£Śú®ŚĮĽśĪāŚĘěŚä†Ś§ßŚěčśúļťĒÄťáŹÁöĄťÄĒŚĺĄÔľĆšłé Canonical ŚÖ¨ŚŹłŚźąšĹúԾƝľďŚäĪšĹŅÁĒ®ŚľÄśļźŚ∑•ŚÖ∑ԾƝÉĹŤÉĹšłļŚ§ßŚěčśúļśČ̳Ěł™ŚįŹÁöĄÔľĆŚćīŤÉĹŤĶöťíĪÁöĄŚłāŚúļ„Äā
+>
+>
+> [ŤĮ¶śÉÖÁ߼ś≠• TechCrunch][3]
+
+### šĹ†šłļšĽÄšĻąŤ¶ĀśĒĺŚľÉ Windows10 ŤÄĆťÄČśč© Linux ###
+
+Ťá™šĽé Windows10 ŚáļśĚ•šĽ•ŚźéԾƌźĄÁß挙íšĹďťÉĹśä•ťĀďŤŅáŚģÉÁöĄťöźŤóŹťóīŤįćŚäüŤÉĹ„ÄāZDNet ŚąóŚáļšļÜšłÄšļõśĒĺŚľÉ Windows10 ÁöĄÁźÜÁĒĪ„Äā
+
+SJVN Śú® ZDNet ÁöĄśä•ŚĎäÔľö
+
+> šĹ†ŤĮēŤĮēŚÖ≥śéČ Windows10 ÁöĄśēįśćģŚąÜšļęŚäüŤÉĹԾƌ̏ś∂ąśĀĮśĚ•šļÜÔľöwindow10 šľöÁĽßÁĽ≠śääšĹ†ÁöĄśēįśćģŚąÜšļęÁĽôŚĺģŤĹĮŚÖ¨ŚŹł„ÄāŤĮ∑ťÄČśč© Linux Śźß„Äā
+>
+> šĹ†ŚŹĮšĽ•śúȌ幌§öśĖĻś≥ēšłćŤģ© Windows10 ś≥Ąťú≤šĹ†ÁöĄÁßėŚĮÜԾƚĹܚņšłćŤÉĹťėĽś≠ĘŚģÉšļ§Ťįą„ÄāCortanaÔľĆwin10 ŚįŹŚ®úԾƍĮ≠ťü≥Śä©śČčԾƌįĪÁģóšĹ†śä䌕ĻŚÖ≥šļÜԾƌ•ĻšĻüšľöśääśēįśćģŚŹĎÁĽôŚĺģŤĹĮŚÖ¨ŚŹł„ÄāŤŅôšļõśēįśćģŚĆ֜訚ņÁöĄÁĒĶŤĄĎ IDԾƌĺģŤĹĮÁĒ®Śģɜ̕ŤĮÜŚąęšĹ†ÁöĄ PC śúļ„Äā
+>
+> śČÄšĽ•Ś¶āśěúŤŅôšļõś≥ĄŚĮÜÁĽôšĹ†Śł¶śĚ•šļÜÁɶśĀľÔľĆšĹ†ŚŹĮšĽ•šĹŅÁĒ®ŤÄĀÁČąśú¨ Windows7ԾƜąĖŤÄÖśćĘŚąį Linux„ÄāÁĄ∂ŤÄĆԾƌĹď Windows7 šłćŚÜ朏źšĺõśäÄśúĮśĒĮśĆĀÁöĄťā£Ś§©ŚąįśĚ•ÔľĆŚ¶āśěúšĹ†ŤŅėśÉ≥šŅĚÁēôťöźÁßĀԾƜúÄÁĽąšĹ†ŤŅėśėĮŚŹ™ŤÉĹťÄČśč© Linux„Äā
+>
+> ŤŅôťáĆŤŅėśúČšļõŚįŹšľóÁöĄś°ĆťĚĘÁ≥ĽÁĽüŤÉĹšŅ̜䧚ņÁöĄťöźÁßĀԾƜĮĒŚ¶ā BSD Śģ∂śóŹÁöĄ FreeBSDÔľĆPCBSDÔľĆNetBSDÔľĆeComStationÔľĆOS/2„ÄāšĹÜśėĮԾƜúÄŚ•ĹÁöĄťÄČśč©ŤŅėśėĮ LinuxԾƌģÉśŹźšĺõśúÄšĹéÁöĄŚ≠¶šĻ†śõ≤ÁļŅ„Äā
+>
+> [ŤĮ¶śÉÖÁ߼ś≠• ZDNet][4]
+
+--------------------------------------------------------------------------------
+
+via: http://www.itworld.com/article/2972587/linux/why-did-you-start-using-linux.html
+
+šĹúŤÄÖÔľö[Jim Lynch][a]
+ŤĮĎŤÄÖÔľö[bazz2](https://github.com/bazz2)
+ś†°ŚĮĻÔľö[ś†°ŚĮĻŤÄÖID](https://github.com/ś†°ŚĮĻŤÄÖID)
+
+śú¨śĖáÁĒĪ [LCTT](https://github.com/LCTT/TranslateProject) ŚéüŚąõÁŅĽŤĮĎÔľĆ[Linuxšł≠ŚõĹ](https://linux.cn/) Ťć£Ť™Čśé®Śáļ
+
+[a]:http://www.itworld.com/author/Jim-Lynch/
+[1]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
+[2]:https://www.reddit.com/r/linux/comments/3hb2sr/question_for_younger_users_why_did_you_start/
+[3]:http://techcrunch.com/2015/08/16/ibm-teams-with-canonical-on-linux-mainframe/
+[4]:http://www.zdnet.com/article/sick-of-windows-spying-on-you-go-linux/
diff --git a/translated/talk/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md b/translated/talk/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md
deleted file mode 100644
index 921f1a57aa..0000000000
--- a/translated/talk/20151012 The Brief History Of Aix HP-UX Solaris BSD And LINUX.md
+++ /dev/null
@@ -1,101 +0,0 @@
-Aix, HP-UX, Solaris, BSD, ŚíĆ LINUX ÁģÄŚŹ≤
-================================================================================
-
-
-Ť¶ĀŤģįšĹŹÔľĆŚĹĜČáťó®Śú®šĹ†ťĚĘŚČćŚÖ≥ťó≠ÁöĄśó∂ŚÄôԾƌŹ¶šłÄśČáťó®ŚįĪšľöśČĄÄā[Ken Thompson][1] ŚíĆ [Dennis Richie][2] šł§šł™šļļŚįĪśėĮŤŅôŚŹ•ŚźćŤ®ÄŚĺąŚ•ĹÁöĄŚģěšĺč„ÄāšĽĖšĽ¨šŅ©śėĮ **20šłĖÁļ™** śúÄšľėÁßÄÁöĄšŅ°śĀĮśäÄśúĮšłďŚģ∂Ծƌõ†šłļšĽĖšĽ¨ŚąõťÄ†šļÜ **UNIX**ԾƜúÄŚÖ∑ŚĹĪŚďćŚäõŚíĆŚąõśĖįśÄßÁöĄŤĹĮšĽ∂šĻ蚳ĄÄā
-
-### UNIX Á≥ĽÁĽüŤĮěÁĒüšļéŤīĚŚįĒŚģ읙ƌģ§ ###
-
-**UNIX** śúÄŚľÄŚßčÁöĄŚźćŚ≠óśėĮ **UNICS** (**UN**iplexed **I**nformation and **C**omputing **S**ervice)ԾƌģÉśúČšłÄšł™Ś§ßŚģ∂Śļ≠ԾƌĻ∂šłćśėĮšĽéÁü≥Ś§īÁľĚťáĆŤĻ¶ŚáļśĚ•ÁöĄ„ÄāUNIXÁöĄÁ•ĖÁą∂śėĮ **CTSS** (**C**ompatible **T**ime **S**haring **S**ystem)ԾƌģÉÁöĄÁą∂šļ≤śėĮ **Multics** (**MULT**iplexed **I**nformation and **C**omputing **S**ervice)ԾƍŅôšł™Á≥ĽÁĽüŤÉĹśĒĮśĆĀŚ§ßťáŹÁĒ®śą∑ťÄöŤŅášļ§šļ팾ŹŚąÜśó∂šĹŅÁĒ®Ś§ßŚěčśúļ„Äā
-
-UNIX ŤĮěÁĒüšļé **1969** ŚĻīÔľĆÁĒĪ **Ken Thompson** šĽ•ŚŹäŚźéśĚ•Śä†ŚÖ•ÁöĄ **Dennis Richie** ŚÖĪŚźĆŚģĆśąź„ÄāŤŅôšł§šĹćšľėÁßÄÁöĄÁ†ĒÁ©∂ŚĎėŚíĆÁßĎŚ≠¶Śģ∂šłÄŤĶ∑Śú®šłÄšł™**ťÄöÁĒ®ÁĒĶŚ≠ź**ŚíĆ**ťļĽÁúĀÁźÜŚ∑•Ś≠¶ťôĘ**ÁöĄŚźąšĹúť°ĻÁõģťáĆŚ∑•šĹúԾƝ°ĻÁõģÁõģś†áśėĮŚľÄŚŹĎšłÄšł™ŚŹę Multics ÁöĄšļ§šļ팾ŹŚąÜśó∂Á≥ĽÁĽü„Äā
-
-Multics ÁöĄÁõģś†áśėĮśēīŚźąŚąÜśó∂ŚÖĪšļꚼ•ŚŹäŚĹďśó∂ŚÖ∂šĽĖŚÖąŤŅõśäÄśúĮԾƌÖĀŤģłÁĒ®śą∑Śú®ŤŅúÁ®čÁĽąÁęĮťÄöŤŅáÁĒĶŤĮĚÁôĽŚĹēŚąįšłĽśúļÔľĆÁĄ∂ŚźéŚŹĮšĽ•ÁľĖŤĺĎśĖáś°£ÔľĆťėÖŤĮĽÁĒĶŚ≠źťāģšĽ∂ԾƍŅźŤ°ĆŤģ°ÁģóŚô®ÔľĆÁ≠ČÁ≠Č„Äā
-
-Śú®šĻ茟éÁöĄšļĒŚĻīťáĆÔľĆAT&T ŚÖ¨ŚŹłšłļ Multics ť°ĻÁõģśäēŚÖ•šļÜśēįÁôĺšłáÁĺéŚÖÉ„ÄāšĽĖšĽ¨Ťī≠šĻįšļÜ GE-645 Ś§ßŚěčśúļԾƍĀöťõÜšļÜŤīĚŚįĒŚģ읙ƌģ§ÁöĄť°∂ÁļßÁ†ĒÁ©∂šļļŚĎėԾƚĺ茶ā Ken Thompson, Stuart Feldman, Dennis Ritchie, M. Douglas McIlroy, Joseph F. Ossanna, šĽ•ŚŹä Robert Morris„ÄāšĹÜśėĮť°ĻÁõģÁõģś†áŚ§™ŤŅáśŅÄŤŅõԾƍŅõŚļ¶šł•ťá朼쌟é„ÄāśúÄŚźéÔľĆAT&T ťęėŚĪāŚÜ≥ŚģöśĒ匾ɍŅôšł™ť°ĻÁõģ„Äā
-
-ŤīĚŚįĒŚģ읙ƌģ§ÁöĄÁģ°ÁźÜŚĪāŚÜ≥ŚģöŚĀúś≠ĘŤŅôšł™Ťģ©ŤģłŚ§öÁ†ĒÁ©∂šļļŚĎėśó†śĮĒÁļ†ÁĽďÁöĄśďćšĹúÁ≥ĽÁĽüšłäÁöĄśČÄśúČťĀóÁēôŚ∑•šĹú„ÄāšłćŤŅ፶ĀśĄüŤįĘ ThompsonÔľĆRichie ŚíĆšłÄšļõŚÖ∂šĽĖÁ†ĒÁ©∂ŚĎėԾƚĽĖšĽ¨śääŤÄĀśĚŅÁöĄŚĎĹšĽ§šłĘŚąįšłÄŤĺĻԾƌĻ∂ÁĽßÁĽ≠Śú®Śģ읙ƌģ§ťáĆśĽ°śÄÄÁÉ≠ŚŅÉŚúįŚŅėśąĎŚ∑•šĹúԾƜúÄÁĽąŚ≠ĶŚĆĖŚáļŚČćśó†ŚŹ§šļļŚźéśó†śĚ•ŤÄÖÁöĄ UNIX„Äā
-
-UNIX ÁöĄÁ¨¨šłÄŚ£įŚēľŚď≠śėĮŚú®šłÄŚŹį PDP-7 ŚĺģŚěčśúļšłäԾƌģÉśėĮ Thompson śĶčŤĮēŤá™Ś∑ĪŚú®śďćšĹúÁ≥ĽÁĽüŤģĺŤģ°šłäÁöĄÁāĻŚ≠źÁöĄśúļŚô®ÔľĆšĻüśėĮ Thompson ŚíĆ Richie šłÄŤĶ∑Áé© Space and Travel śłłśąŹÁöĄś®°śčüŚô®„Äā
-
-> ‚ÄúśąĎšĽ¨śÉ≥Ť¶ĀÁöĄšłćšĽÖśėĮšłÄšł™šľėÁßÄÁöĄÁľĖÁ®čÁéĮŚĘÉԾƍÄĆśėĮŤÉĹŚõīÁĽēŤŅôšł™Á≥ĽÁĽüŚĹĘśąźŚõĘšĹď„ÄāśĆČśąĎšĽ¨Ťá™Ś∑ĪÁöĄÁĽŹť™ĆԾƝÄöŤŅáŤŅúÁ®čŤģŅťóģŚíĆŚąÜśó∂ŚÖĪšļęšłĽśúļŚģěÁéįÁöĄŚÖ¨ŚÖĪŤģ°ÁģóԾƜú¨Ťī®šłäšłćŚŹ™śėĮÁĒ®ÁĽąÁęĮŤĺďŚÖ•Á®čŚļŹšĽ£śõŅśČďŚ≠ĒśúļŤÄĆŚ∑≤ԾƍÄĆśėĮťľďŚäĪŚĮÜŚąáś≤üťÄö„Äā‚ÄĚDennis Richie ŤĮī„Äā
-
-UNIX śėĮÁ¨¨šłÄšł™ťĚ†ŤŅĎÁźÜśÉ≥ÁöĄÁ≥ĽÁĽüԾƌú®ŤŅôťáĆÁ®čŚļŹŚĎėŚŹĮšĽ•ŚĚźŚú®śúļŚô®ŚČćŤá™ÁĒĪśĎÜŚľĄÁ®čŚļŹÔľĆśéĘÁīĘŚźĄÁß挏ĮŤÉĹśÄߌĻ∂ťöŹśČčśĶčŤĮē„ÄāŚú® UNIX śēīšł™ÁĒüŚĎĹŚĎ®śúüťáĆԾƌģÉŚźłŚľēšļÜŚ§ßťáŹŚõ†ŚÖ∂šĽĖśďćšĹúÁ≥ĽÁĽüťôźŚą∂ŤÄĆśäēŤļęŤŅáśĚ•ÁöĄťęėśČčŚĀöŚáļśó†ÁßĀŤī°ÁĆģԾƌõ†ś≠§ŚģÉÁöĄŚäüŤÉĹś®°ŚěčšłÄÁõīšŅĚśĆĀšłäŚćáŤ∂čŚäŅ„Äā
-
-UNIX Śú® 1970 ŚĻīŚõ†šłļ PDP-11/20 Ťé∑ŚĺóšļÜť¶Ėś¨°ŤĶĄťáĎś≥®ŚÖ•ÔľĆšĻ茟éś≠£ŚľŹśõīŚźćšłļ UNIX ŚĻ∂śĒĮśĆĀŚú® PDP-11/20 šłäŤŅźŤ°Ć„ÄāUNIX Śł¶śĚ•ÁöĄÁ¨¨šłÄś¨°śĒ∂Ťé∑śėĮŚú® 1971 ŚĻīԾƍīĚŚįĒŚģ읙ƌģ§ÁöĄšłďŚą©ťÉ®ťó®ťÖ挧áśĚ•ŚĀöśĖáŚ≠󌧥ÁźÜ„Äā
-
-### UNIX šłäÁöĄ C ŤĮ≠Ť®ÄťĚ©ŚĎĹ ###
-
-Dennis Richie Śú® 1972 ŚĻīŚŹĎśėéšļÜšłÄÁßćŚŹę ‚Äú**C**‚ÄĚ ÁöĄťęėÁļßÁľĖÁ®čŤĮ≠Ť®Ä ԾƚĻ茟隼ĖŚíĆ Ken Thompson ŚÜ≥ŚģöÁĒ® ‚ÄúC‚ÄĚ ťáćŚÜô UNIX Á≥ĽÁĽüԾƜ̕śĒĮśĆĀśõīŚ•ĹÁöĄÁ߼ś§ćśÄß„ÄāšĽĖšĽ¨Śú®ťā£šłÄŚĻīťáĆÁľĖŚÜôŚíĆŤįÉŤĮēšļÜŚ∑ģšłćŚ§ö 100,000 Ť°ĆšĽ£Á†Ā„ÄāŚú®šĹŅÁĒ®šļÜ ‚ÄúC‚ÄĚ ŤĮ≠Ť®ÄŚźéÔľĆÁ≥ĽÁĽüŚŹĮÁ߼ś§ćśÄßťĚ쌳łŚ•ĹԾƌŹ™ťúÄŤ¶ĀšŅģśĒĻšłÄŚįŹťÉ®ŚąÜśúļŚô®ÁõłŚÖ≥ÁöĄšĽ£Á†ĀŚįĪŚŹĮšĽ•ŚįÜ UNIX Á߼ś§ćŚąįŚÖ∂šĽĖŤģ°ÁģóśúļŚĻ≥ŚŹįšłä„Äā
-
-UNIX Á¨¨šłÄś¨°ŚÖ¨ŚľÄťú≤ťĚĘśėĮ 1973 ŚĻī Dennis Ritchie ŚíĆ Ken Thompson Śú®śďćšĹúÁ≥ĽÁĽüŚéüÁźÜšłäŚŹĎŤ°®ÁöĄšłÄÁĮáŤģļśĖáÔľĆÁĄ∂Śźé AT&T ŚŹĎŚłÉšļÜ UNIX Á≥ĽÁĽüÁ¨¨ 5 ÁȹԾƌĻ∂śéąśĚÉÁĽôśēôŤā≤śúļśěĄšĹŅÁĒ®ÔľĆÁĄ∂ŚźéŚú® 1976 ŚĻīÁ¨¨šłÄś¨°šĽ• **$20.000** ÁöĄšĽ∑ś†ľśéąśĚÉšľĀšłöšĹŅÁĒ® UNIX Á¨¨ 6 ÁČą„ÄāŚļĒÁĒ®śúÄŚĻŅś≥õÁöĄśėĮ 1980 ŚĻīŚŹĎŚłÉÁöĄ UNIX Á¨¨ 7 ÁȹԾƚĽĽšĹēšļļťÉĹŚŹĮšĽ•Ťī≠šĻįśéąśĚÉԾƌŹ™śėĮśéąśĚɜ̰ś¨ĺťĚ쌳łśúČťôź„ÄāśéąśĚÉŚÜÖŚģĻŚĆ֜訜ļźšĽ£Á†ĀԾƚĽ•ŚŹäÁĒ® PDP-11 śĪáÁľĖŤĮ≠Ť®ÄŚÜôÁöĄŚŹäŚÖ∂ÁõłŚÖ≥ŚÜÖś†ł„ÄāŚŹćś≠£ÔľĆŚźĄÁßćÁČąśú¨ UNIX Á≥ĽÁĽüŚģĆŚÖ®ÁĒĪŚģÉÁöĄÁĒ®śą∑śČčŚÜĆÁ°ģŚģö„Äā
-
-### AIX Á≥ĽÁĽü ###
-
-Śú® **1983** ŚĻīÔľĆ**Microsoft** Ťģ°ŚąíŚľÄŚŹĎ **Xenix** šĹúšłļ MS-DOS ÁöĄŚ§öÁĒ®śą∑ÁČąÁĽßšĽĽŤÄÖԾƚĽĖšĽ¨Śú®ťā£šłÄŚĻīŤäĪšļÜ $8,000 śź≠ŚĽļšļÜšłÄŚŹįśč•śúČ **512 KB** ŚÜÖŚ≠ėšĽ•ŚŹä **10 MB**Á°¨ÁõėŚĻ∂ŤŅźŤ°Ć Xenix ÁöĄ Altos 586„ÄāŤÄĆŚąį 1984 ŚĻīšłļś≠ĘԾƌ֮šłĖÁēĆ UNIX System V Á¨¨šļĆÁČąÁöĄŚģČŤ£ÖśēįťáŹŚ∑≤ÁĽŹŤ∂ÖŤŅášļÜ 100,000 „ÄāŚú® 1986 ŚĻīŚŹĎŚłÉšļÜŚĆÖŚźęŚõ†ÁČĻÁĹĎŚüüŚźćśúćŚä°ÁöĄ 4.3BSDԾƍÄĆšłĒ **IBM** Śģ£ŚłÉ **AIX Á≥ĽÁĽü**ÁöĄŚģČŤ£ÖśēįŚ∑≤ÁĽŹŤ∂ÖŤŅá 250,000„ÄāAIX Śüļšļé Unix System V ŚľÄŚŹĎԾƍŅôŚ•óÁ≥ĽÁĽüśč•śúČ BSD ť£éś†ľÁöĄś†ĻśĖᚼ∂Á≥ĽÁĽüԾƜėĮšł§ŤÄÖÁöĄÁĽďŚźą„Äā
-
-AIX Á¨¨šłÄś¨°ŚľēŚÖ•šļÜ **śó•ŚŅóśĖᚼ∂Á≥ĽÁĽü (JFS)** šĽ•ŚŹäťõÜśąźťÄĽŤĺĎŚć∑Áģ°ÁźÜŚô® (LVM)„ÄāIBM Śú® 1989 ŚĻīŚįÜ AIX Á߼ś§ćŚąįŤá™Ś∑ĪÁöĄ RS/6000 ŚĻ≥ŚŹį„Äā2001 ŚĻīŚŹĎŚłÉÁöĄ 5L ÁČąśėĮšłÄšł™Á™ĀÁ†īśÄßÁöĄÁČąśú¨ÔľĆśŹźšĺõšļÜ Linux ŚŹčŚ•ĹśÄßšĽ•ŚŹäśĒĮśĆĀ Power4 śúćŚä°Śô®ÁöĄťÄĽŤĺĎŚąÜŚĆļ„Äā
-
-Śú® 2004 ŚĻīŚŹĎŚłÉÁöĄ AIX 5.3 ŚľēŚÖ•šļÜśĒĮśĆĀ Advanced Power Virtualization (APV) ÁöĄŤôöśčüŚĆĖśäÄśúĮԾƜĒĮśĆĀŚĮĻÁßįŚ§öÁļŅÁ®čԾƌĺģŚąÜŚĆļԾƚĽ•ŚŹäŚŹĮŚąÜšļęÁöĄŚ§ĄÁźÜŚô®śĪ†„Äā
-
-Śú® 2007 ŚĻīÔľĆIBM ŚźĆśó∂ŚŹĎŚłÉ AIX 6.1 ŚíĆ Power6 śě∂śěĄÔľĆŚľÄŚßčŚä†ŚľļŤá™Ś∑ĪÁöĄŤôöśčüŚĆĖšļߌďĀ„ÄāšĽĖšĽ¨ŤŅėŚįÜ Advanced Power Virtualization ťáćśĖįŚĆÖŤ£Öśąź PowerVM„Äā
-
-ŤŅôś¨°śĒĻŤŅõŚĆ֜訍ĘęÁßįšłļ WPARs ÁöĄŤīüŤĹĹŚąÜŚĆļŚĹĘŚľŹÔľĆÁĪĽšľľšļé Solaris ÁöĄ zones/ContainersԾƚĹÜśėĮŚäüŤÉĹśõīŚľļ„Äā
-
-### HP-UX Á≥ĽÁĽü ###
-
-**śÉ†śôģ UNIX (HP-UX)** śļźšļé System V Á¨¨ 3 ÁČą„ÄāŤŅôŚ•óÁ≥ĽÁĽüšłÄŚľÄŚß茏™śĒĮśĆĀ PA-RISC HP 9000 ŚĻ≥ŚŹį„ÄāHP-UX Á¨¨ 1 ÁČąŚŹĎŚłÉšļé 1984 ŚĻī„Äā
-
-HP-UX Á¨¨ 9 ÁČąŚľēŚÖ•šļÜ SAMԾƚłÄšł™ŚüļšļéŚ≠óÁ¨¶ÁöĄŚõĺŚĹĘÁĒ®śą∑ÁēĆťĚĘ (GUI)ÔľĆÁĒ®śą∑ŚŹĮšĽ•ÁĒ®śĚ•Áģ°ÁźÜśēīšł™Á≥ĽÁĽü„ÄāŚú® 1995 ŚĻīŚŹĎŚłÉÁöĄÁ¨¨ 10 ÁȹԾƍįÉśēīšļÜÁ≥ĽÁĽüśĖᚼ∂ŚąÜŚłÉšĽ•ŚŹäÁõģŚĹēÁĽďśěĄÔľĆŚŹėŚĺóśúČÁāĻÁĪĽšľľ AT&T SVR4„Äā
-
-Á¨¨ 11 ÁČąŚŹĎŚłÉšļé 1997 ŚĻī„ÄāŤŅôśėĮ HP Á¨¨šłÄšł™śĒĮśĆĀ 64 šĹćŚĮĽŚĚÄÁöĄÁČąśú¨„ÄāšłćŤŅáŚú® 2000 ŚĻīťáćśĖįŚŹĎŚłÉśąź 11iԾƌõ†šłļ HP šłļÁČĻŚģöÁöĄšŅ°śĀĮśäÄśúĮÁõģÁöĄÔľĆŚľēŚÖ•šļÜśďćšĹúÁéĮŚĘÉŚíĆŚąÜÁļߌļĒÁĒ®ÁöĄśćÜÁĽĎÁĽĄ„Äā
-
-Śú® 2001 ŚĻīŚŹĎŚłÉÁöĄ 11.20 ÁČąŚģ£ÁßįśĒĮśĆĀ Itanium Á≥ĽÁĽü„ÄāHP-UX śėĮÁ¨¨šłÄšł™šĹŅÁĒ® ACLsÔľąŤģŅťóģśéߌą∂ŚąóŤ°®ÔľČÁģ°ÁźÜśĖᚼ∂śĚÉťôźÁöĄ UNIX Á≥ĽÁĽüԾƚĻüśėĮť¶ĖŚÖąśĒĮśĆĀŚÜÖŚĽļťÄĽŤĺĎŚć∑Áģ°ÁźÜŚô®ÁöĄÁ≥ĽÁĽüšĻ蚳ĄÄā
-
-Ś¶āšĽäÔľĆHP-UX Śõ†šłļ HP ŚíĆ Veritas ÁöĄŚźąšĹúŚÖ≥Á≥ĽšĹŅÁĒ®šļÜ Veritas šĹúšłļšłĽśĖᚼ∂Á≥ĽÁĽü„Äā
-
-HP-UX ÁõģŚČćÁöĄśúÄśĖįÁČąśú¨śėĮ 11iv3, update 4„Äā
-
-### Solaris Á≥ĽÁĽü ###
-
-Sun ÁöĄ UNIX ÁČąśú¨śėĮ **Solaris**ÔľĆÁĒ®śĚ•śé•śõŅ 1992 ŚĻīŚąõŚĽļÁöĄ **SunOS**„ÄāSunOS šłÄŚľÄŚßčŚüļšļé BSDÔľąšľĮŚÖ茹©ŤĹĮšĽ∂ŚŹĎŤ°ĆÁȹԾȝ£éś†ľÁöĄ UNIXԾƚĹÜśėĮ SunOS 5.0 ÁČąšĽ•ŚŹäšĻ茟éÁöĄÁČąśú¨ťÉĹśėĮŚüļšļéťáćśĖįŚĆÖŤ£Öśąź Solaris ÁöĄ Unix System V Á¨¨ 4 ÁČą„Äā
-
-SunOS 1.0 ÁČąšļé 1983 ŚĻīŚŹĎŚłÉÔľĆÁĒ®šļéśĒĮśĆĀ Sun-1 ŚíĆ Sun-2 ŚĻ≥ŚŹį„ÄāťöŹŚźéŚú® 1985 ŚĻīŚŹĎŚłÉšļÜ 2.0 ÁČą„ÄāŚú® 1987 ŚĻīÔľĆSun ŚíĆ AT&T Śģ£ŚłÉŚźąšĹúšłÄšł™ť°ĻÁõģšĽ• SVR4 šłļŚüļÁ°ÄŚįÜ System V ŚíĆ BSD ŚźąŚĻ∂śąźšłÄšł™ÁČąśú¨„Äā
-
-Solaris 2.4 śėĮ Sun ŚŹĎŚłÉÁöĄÁ¨¨šłÄšł™ Sparc/x86 ÁČąśú¨„Äā1994 ŚĻī 11 śúąšĽĹŚŹĎŚłÉÁöĄ SunOS 4.1.4 ÁČąśėĮśúÄŚźéšłÄšł™ÁČąśú¨„ÄāSolaris 7 śėĮť¶Ėšł™ 64 šĹć Ultra Sparc ÁČąśú¨ÔľĆŚä†ŚÖ•šļÜŚĮĻśĖᚼ∂Á≥ĽÁĽüŚÖÉśēįśćģŤģįŚĹēÁöĄŚéüÁĒüśĒĮśĆĀ„Äā
-
-Solaris 9 ŚŹĎŚłÉšļé 2002 ŚĻīԾƜĒĮśĆĀ Linux ÁČĻśÄßšĽ•ŚŹä Solaris Ść∑Áģ°ÁźÜŚô®„ÄāšĻ茟éÔľĆ2005 ŚĻīŚŹĎŚłÉšļÜ Solaris 10Ծƌł¶śĚ•ŤģłŚ§öŚąõśĖįԾƜĮĒŚ¶āśĒĮśĆĀ Solaris ContainersԾƜĖįÁöĄ ZFS śĖᚼ∂Á≥ĽÁĽüԾƚĽ•ŚŹäťÄĽŤĺĎŚüü„Äā
-
-ÁõģŚČć Solaris śúÄśĖįÁöĄÁČąśú¨śėĮ Á¨¨ 10 ÁȹԾƜúÄŚźéÁöĄśõīśĖįŚŹĎŚłÉšļé 2008 ŚĻī„Äā
-
-### Linux ###
-
-ŚąįšļÜ 1991 ŚĻīÔľĆÁĒ®śĚ•śõŅšĽ£ŚēÜšłöśďćšĹúÁ≥ĽÁĽüÁöĄŚÖćŤīĻÁ≥ĽÁĽüÁöĄťúÄśĪāśó•śłźťęėś∂®„ÄāŚõ†ś≠§ **Linus Torvalds** ŚľÄŚßčśěĄŚĽļšłÄšł™ŚÖćŤīĻÁöĄśďćšĹúÁ≥ĽÁĽüԾƜúÄÁĽąśąźšłļ **Linux**„ÄāLinux śúÄŚľÄŚß茏™śúČšłÄšļõ ‚ÄúC‚ÄĚ śĖᚼ∂ԾƌĻ∂šłĒšĹŅÁĒ®šļÜťėĽś≠ĘŚēÜšłöŚŹĎŤ°ĆÁöĄśéąśĚÉ„ÄāLinux śėĮšłÄšł™ÁĪĽ UNIX Á≥ĽÁĽüšĹÜŚŹąšłćŚįĹÁõłŚźĆ„Äā
-
-2015 ŚĻī ŚŹĎŚłÉšļÜŚüļšļé GNU Public License śéąśĚÉÁöĄ 3.18 ÁČą„ÄāIBM Ś£įÁßįśúČŤ∂ÖŤŅá 1800 šłáŤ°ĆŚľÄśļźšĽ£Á†ĀŚľÄśĒĺÁĽôŚľÄŚŹĎŤÄÖ„Äā
-
-Ś¶āšĽä GNU Public License śėĮŚļĒÁĒ®śúÄŚĻŅś≥õÁöĄŚÖćŤīĻŤĹĮšĽ∂śéąśĚÉśĖĻŚľŹ„Äāś†ĻśćģŚľÄśļźŤĹĮšĽ∂ŚéüŚąôԾƍŅôšĽĹśéąśĚÉŚÖĀŤģłšł™šļļŚíĆšľĀšłöŤá™ÁĒĪŚąÜŚŹĎ„ÄĀŤŅźŤ°Ć„ÄĀťÄöŤŅáśč∑ŤīĚŚÖĪšļę„ÄĀŚ≠¶šĻ†ÔľĆšĽ•ŚŹäšŅģśĒĻŤĹĮšĽ∂śļźÁ†Ā„Äā
-
-### UNIX vs. Linux: śäÄśúĮś¶āŤ¶Ā ###
-
-- Linux ťľďŚäĪŚ§öś†∑śÄßÔľĆLinux ÁöĄŚľÄŚŹĎšļļŚĎėśúČśõīŚĻŅťėĒÁöĄŤÉĆśôĮԾƜúČśõīŚ§öšłćŚźĆÁĽŹť™ĆŚíĆśĄŹŤßĀ„Äā
-- Linux śĮĒ UNIX śĒĮśĆĀśõīŚ§öÁöĄŚĻ≥ŚŹįŚíĆśě∂śěĄ„Äā
-- UNIX ŚēÜšłöÁČąśú¨ÁöĄŚľÄŚŹĎšļļŚĎėšľöšłļšĽĖšĽ¨ÁöĄśďćšĹúÁ≥ĽÁĽüŤÄÉŤôĎÁČĻŚģöÁõģś†áŚĻ≥ŚŹįšĽ•ŚŹäÁĒ®śą∑„Äā
-- **Linux śĮĒ UNIX śúČśõīŚ•ĹÁöĄŚģČŚÖ®śÄß**ԾƜõīŚįĎŚŹóÁóÖśĮíśąĖśĀ∂śĄŹŤĹĮšĽ∂śĒĽŚáĽ„ÄāLinux šłäŚ§ßÁļ¶śúČ 60-100 ÁßćÁóÖśĮíԾƚĹÜśėĮś≤°śúČšĽĽšĹēšłÄÁßćŤŅėŚú®šľ†śí≠„ÄāŚŹ¶šłÄśĖĻťĚĘÔľĆUNIX šłäŚ§ßÁļ¶śúČ 85-120 ÁßćÁóÖśĮíԾƚĹÜśėĮŚÖ∂šł≠śúČšłÄšļõŤŅėŚú®šľ†śí≠šł≠„Äā
-- ťÄöŤŅá UNIX ŚĎĹšĽ§ÔľĆÁ≥ĽÁĽüšłäÁöĄŚ∑•ŚÖ∑ŚíĆŚÖÉÁī†ŚĺąŚįĎśĒĻŚŹėÔľĆÁĒöŤá≥ŚĺąŚ§öśé•ŚŹ£ŚíĆŚĎĹšĽ§Ť°ĆŚŹāśēįŚú®ŚźéÁĽ≠ UNIX ÁČąśú¨šł≠šłÄÁõīś≤ŅÁĒ®„Äā
-- śúČšļõ Linux ŚľÄŚŹĎť°ĻÁõģšĽ•Ťá™śĄŅšłļŚüļÁ°ÄŤŅõŤ°ĆŤĶĄŚä©ÔľĆśĮĒŚ¶ā Debian„ÄāŚÖ∂šĽĖť°ĻÁõģšľöÁĽīśä§šłÄšł™ŚíĆŚēÜšłö Linux ÁöĄÁ§ĺŚĆļÁȹԾƜĮĒŚ¶ā SUSE ÁöĄ openSUSE šĽ•ŚŹäÁļĘŚłĹÁöĄ Fedora„Äā
-- šľ†ÁĽü UNIX śėĮÁļĶŚźĎśČ©ŚĪēԾƍÄĆŚŹ¶šłÄśĖĻťĚĘ Linux śėĮś®™ŚźĎśČ©ŚĪē„Äā
-
---------------------------------------------------------------------------------
-
-via: http://www.unixmen.com/brief-history-aix-hp-ux-solaris-bsd-linux/
-
-šĹúŤÄÖÔľö[M.el Khamlichi][a]
-ŤĮĎŤÄÖÔľö[zpl1025](https://github.com/zpl1025)
-ś†°ŚĮĻÔľö[Caroline](https://github.com/carolinewuyan)
-
-śú¨śĖáÁĒĪ [LCTT](https://github.com/LCTT/TranslateProject) ŚéüŚąõÁľĖŤĮĎÔľĆ[Linuxšł≠ŚõĹ](https://linux.cn/) Ťć£Ť™Čśé®Śáļ
-
-[a]:http://www.unixmen.com/author/pirat9/
-[1]:http://www.unixmen.com/ken-thompson-unix-systems-father/
-[2]:http://www.unixmen.com/dennis-m-ritchie-father-c-programming-language/
diff --git a/translated/talk/20151124 Review--5 memory debuggers for Linux coding.md b/translated/talk/20151124 Review--5 memory debuggers for Linux coding.md
new file mode 100644
index 0000000000..b49ba9e40a
--- /dev/null
+++ b/translated/talk/20151124 Review--5 memory debuggers for Linux coding.md
@@ -0,0 +1,299 @@
+ÁāĻŤĮĄÔľöLinuxÁľĖÁ®čšł≠šļĒś¨ĺŚÜÖŚ≠ėŤįÉŤĮēŚô®
+================================================================================
+
+Credit: [Moini][1]
+
+šĹúšłļšłÄšł™Á®čŚļŹŚĎėԾƜąĎÁü•ťĀϜļŚú®ÁäĮťĒôŤĮĮ‚ÄĒ‚ÄĒšļčŚģěśėĮԾƜÄéšĻąŚŹĮŤÉĹšľöšłćÁäĮťĒôÁöĄÔľĀÁ®čŚļŹŚĎėšĻüśėĮšļļŚēä„ÄāśúČÁöĄťĒôŤĮĮŤÉĹŚú®ÁľĖÁ†ĀŤŅáÁ®čšł≠ŚŹäśó∂ŚŹĎÁéįԾƍÄĆśúČšļõŚćīŚĺóÁ≠ČŚąįŤĹĮšĽ∂śĶčŤĮēśČćśėĺťú≤ŚáļśĚ•„ÄāÁĄ∂ŤÄĆԾƜúČšłÄÁĪĽťĒôŤĮĮŚĻ∂šłćŤÉĹŚú®ŤŅôšł§šł™śó∂śúüŤĘęśéíťô§ÔľĆšĽéŤÄĆŚĮľŤáīŤĹĮšĽ∂šłćŤÉĹś≠£ŚłłŤŅźŤ°ĆÔľĆÁĒöŤá≥śėĮśŹźŚČćšł≠ś≠Ę„Äā
+
+śÉ≥ŚąįšļÜŚźóÔľüśąĎŤĮīÁöĄŚįĪśėĮŚÜÖŚ≠ėÁõłŚÖ≥ÁöĄťĒôŤĮĮ„ÄāśČčŚä®ŤįÉŤĮēŤŅôšļõťĒôŤĮĮšłćšĽÖŤÄóśó∂ԾƍÄĆšłĒŚĺąťö匏ĎÁéįŚĻ∂Áļ†ś≠£„ÄāŚÄľŚĺóšłÄśŹźÁöĄśėĮԾƍŅôÁßćťĒôŤĮĮťĚ쌳łŚúįŚłłŤßĀÔľĆÁČĻŚąęśėĮŚú®šłÄšļõŤĹĮšĽ∂ťáĆԾƍŅôšļõŤĹĮšĽ∂śėĮÁĒ®C/C++ŤŅôÁĪĽŚÖĀŤģł[śČčŚä®Áģ°ÁźÜŚÜÖŚ≠ė][2]ÁöĄŤĮ≠Ť®ÄÁľĖŚÜôÁöĄ„Äā
+
+ŚĻłŤŅźÁöĄśėĮÔľĆÁéįŤ°ĆśúČšłÄšļõÁľĖÁ®čŚ∑•ŚÖ∑ŤÉĹŚ§üŚłģšĹ†śČ匹įŤĹĮšĽ∂Á®čŚļŹšł≠ŤŅôšļõŚÜÖŚ≠ėÁõłŚÖ≥ÁöĄťĒôŤĮĮ„ÄāŚú®ŤŅôšļõŚ∑•ŚÖ∑ťõÜšł≠ԾƜąĎŤĮĄŚģöšļÜšļĒś¨ĺLinuxŚŹĮÁĒ®ÁöĄÔľĆśĶĀŤ°Ć„ÄĀŚÖćŤīĻŚĻ∂šłĒŚľÄśļźÁöĄŚÜÖŚ≠ėŤįÉŤĮēŚô®ÔľöDmalloc„ÄĀElectric Fence„ÄĀ Memcheck„ÄĀ MemwatchšĽ•ŚŹäMtrace„Äāśó•ŚłłÁľĖÁ†ĀŤŅáÁ®čšł≠śąĎŚ∑≤ÁĽŹśääŤŅôšļĒšł™ŤįÉŤĮēŚô®ÁĒ®šļÜšł™ťĀćԾƜČÄšĽ•ŤŅôšļõÁāĻŤĮĄśėĮŚĽļÁęčŚú®śąĎÁöĄŚģěťôÖšĹƚĻčšłäÁöĄ„Äā
+
+### [Dmalloc][3] ###
+
+**ŚľÄŚŹĎŤÄÖ**ÔľöGray Watson
+
+**ÁāĻŤĮĄÁČąśú¨**Ôľö5.5.2
+
+**LinuxśĒĮśĆĀ**ÔľöśČÄśúČÁßćÁĪĽ
+
+**ŤģłŚŹĮ**ÔľöÁü•ŤĮÜŚÖĪšļęÁĹ≤Śźć-ÁõłŚźĆśĖĻŚľŹŚÖĪšļęŤģłŚŹĮŤĮĀ3.0
+
+DmallocśėĮGray WatsonŚľÄŚŹĎÁöĄšłÄś¨ĺŚÜÖŚ≠ėŤįÉŤĮēŚ∑•ŚÖ∑„ÄāŚģÉŚģěÁéįśąźŚļďԾƌįĀŤ£ÖšļÜś†áŚáÜŚÜÖŚ≠ėÁģ°ÁźÜŚáĹśēįŚ¶ā**malloc(), calloc(), free()**Á≠ČԾƚĹŅŚĺóÁ®čŚļŹŚĎėŚĺ󚼕ś£ÄśĶčŚáļśúČťóģťĘėÁöĄšĽ£Á†Ā„Äā
+
+
+Dmalloc
+
+Ś¶āŚźĆŚ∑•ŚÖ∑ÁöĄÁĹĎť°ĶśČÄŚąóԾƍŅôšł™ŤįÉŤĮēŚô®śŹźšĺõÁöĄÁČĻśÄߌĆ֜訌ÜÖŚ≠ėś≥ĄśľŹŤ∑üŤł™„ÄĀ[ťá挧ćťáäśĒĺ(double free)][4]ťĒôŤĮĮŤ∑üŤł™„ÄĀšĽ•ŚŹä[Ť∂äÁēĆŚÜôŚÖ•(fence-post write)][5]ś£ÄśĶč„ÄāŚÖ∂ŚģÉÁČĻśÄߌĆ֜訜Ėᚼ∂/Ť°ĆŚŹ∑śä•ŚĎä„ÄĀśôģťÄöÁĽüŤģ°ŤģįŚĹē„Äā
+
+#### śõīśĖįŚÜÖŚģĻ ####
+
+5.5.2ÁČąśú¨śėĮšłÄšł™[bugšŅģŚ§ćŚŹĎŤ°ĆÁČą][6]ԾƌźĆśó∂šŅģŚ§ćšļܜ쥌ĽļŚíĆŚģČŤ£ÖÁöĄťóģťĘė„Äā
+
+#### śúČšĹēšľėÁāĻ ####
+
+DmallocśúÄŚ§ßÁöĄšľėÁāĻśėĮŚŹĮšĽ•ŤŅõŤ°ĆšĽĽśĄŹťÖćÁĹģ„ÄāśĮĒŚ¶āŤĮīԾƚņŚŹĮšĽ•ťÖćÁĹģšĽ•śĒĮśĆĀC++Á®čŚļŹŚíĆŚ§öÁļŅÁ®čŚļĒÁĒ®„ÄāDmallocŤŅėśŹźšĺõšłÄšł™śúČÁĒ®ÁöĄŚäüŤÉĹÔľöŤŅźŤ°Ćśó∂ŚŹĮťÖćÁĹģԾƍŅôŤ°®Á§ļŚú®DmallocśČߍ°Ćśó∂ԾƌŹĮšĽ•ŤĹĽśėďŚúįšĹŅŤÉĹśąĖŤÄÖÁ¶ĀŤÉĹŚģÉśŹźšĺõÁöĄÁČĻśÄß„Äā
+
+šĹ†ŤŅėŚŹĮšĽ•ťÖ挟ą[GNU Project Debugger (GDB)][7]śĚ•šĹŅÁĒ®DmallocԾƌŹ™ťúÄŤ¶ĀŚįÜdmalloc.gdbśĖᚼ∂ÔľąšĹćšļéDmallocśļźÁ†ĀŚĆÖšł≠ÁöĄcontribŚ≠źÁõģŚĹēťáĆÔľČÁöĄŚÜÖŚģĻś∑ĽŚä†ŚąįšĹ†ÁöĄšłĽÁõģŚĹēšł≠ÁöĄ.gdbinitśĖᚼ∂ťáĆŚć≥ŚŹĮ„Äā
+
+ŚŹ¶Ś§ĖšłÄšł™šľėÁāĻŤģ©śąĎŚĮĻDmallocÁąĪšłćťáäśČčÁöĄśėĮŚģÉśúČŚ§ßťáŹÁöĄŤĶĄśĖôśĖáÁĆģ„ÄāŚČćŚĺÄŚģėÁĹĎÁöĄ[Documentationś†áÁ≠ĺ][8]ԾƌŹĮšĽ•Ťé∑ŚŹĖšĽĽšĹēŚÜÖŚģĻԾƜúČŚÖ≥šļ錶āšĹēšłčŤĹĹ„ÄĀŚģČŤ£Ö„ÄĀŤŅźŤ°ĆԾƜÄ霆∑šĹŅÁĒ®ŚļďԾƌíĆDmallocśČÄśŹźšĺõÁČĻśÄßÁöĄÁĽÜŤäāśŹŹŤŅįԾƌŹäŚÖ∂ŤĺďŚÖ•śĖᚼ∂ÁöĄŤß£ťáä„ÄāťáĆťĚĘŤŅėśúČšłÄšł™ÁꆍäāšĽčÁĽćšļÜšłÄŤą¨ťóģťĘėÁöĄŤß£ŚÜ≥śĖĻś≥ē„Äā
+
+#### ś≥®śĄŹšļčť°Ļ ####
+
+Ť∑üMtracešłÄś†∑ÔľĆDmallocťúÄŤ¶ĀÁ®čŚļŹŚĎėśĒĻŚä®šĽĖšĽ¨ÁöĄśļźšĽ£Á†Ā„ÄāśĮĒŚ¶āŤĮīšĹ†ŚŹĮšĽ•ÔľąŚŅÖť°ĽÁöĄÔľČś∑ĽŚä†Ś§īśĖᚼ∂**dmalloc.h**Ծƌ∑•ŚÖ∑ŚįĪŤÉĹśĪáśä•šļßÁĒüťóģťĘėÁöĄŤįÉÁĒ®ÁöĄśĖᚼ∂śąĖŤ°ĆŚŹ∑„ÄāŤŅôšł™ŚäüŤÉĹťĚ쌳łśúČÁĒ®ÔľĆŚõ†šłļŚģÉŤäāÁúĀšļÜŤįÉŤĮēÁöĄśó∂ťóī„Äā
+
+ťô§ś≠§šĻ茧ĖԾƍŅėťúÄŤ¶ĀŚú®ÁľĖŤĮϚņÁöĄÁ®čŚļŹśó∂ԾƜääDmallocŚļďÔľąÁľĖŤĮĎśļźÁ†ĀŚĆÖśó∂šļßÁĒüÁöĄÔľČťďĺśé•ŤŅõŚéĽ„Äā
+
+ÁĄ∂ŤÄĆԾƍŅėśúČÁāĻśõīťļĽÁɶÁöĄšļčԾƝúÄŤ¶ĀŤģĺÁĹģšłÄšł™ÁéĮŚĘÉŚŹėťáŹÔľĆŚĎĹŚźćšłļ**DMALLOC_OPTION**ԾƚĽ•šĺõŚ∑•ŚÖ∑Śú®ŤŅźŤ°Ćśó∂ťÖćÁĹģŚÜÖŚ≠ėŤįÉŤĮēÁČĻśÄßԾƚĽ•ŚŹäŤĺďŚáļśĖᚼ∂ÁöĄŤ∑ĮŚĺĄ„ÄāŚŹĮšĽ•śČčŚä®šłļŤĮ•ÁéĮŚĘÉŚŹėťáŹŚąÜťÖ暳Ěł™ŚÄľÔľĆšłćŤŅጹ̌≠¶ŤÄÖŚŹĮŤÉĹšľöŤßČŚĺóŤŅôšł™ŤŅáÁ®čśúČÁāĻŚõįťöĺԾƌõ†šłļšĹ†śÉ≥šĹŅŤÉĹÁöĄDmallocÁČĻśÄßśėĮŚ≠ėŚú®šļéŤŅôšł™ŚÄľšĻčšł≠ÁöĄ‚ÄĒ‚ÄĒŤ°®Á§ļšłļŚźĄŤá™ÁöĄŚćĀŚÖ≠ŤŅõŚą∂ŚÄľÁöĄÁīĮŚä†„Äā[ŤŅôťáĆ][9]śúČŤĮ¶ÁĽÜšĽčÁĽć„Äā
+
+šłÄšł™śĮĒŤĺÉÁģÄŚćēśĖĻś≥ēŤģĺÁĹģŤŅôšł™ÁéĮŚĘÉŚŹėťáŹśėĮšĹŅÁĒ®[DmallocŚģěÁĒ®śĆᚼ§][10]ԾƍŅôśėĮšłďšłļŤŅôšł™ÁõģÁöĄŤģĺŤģ°ÁöĄśĖĻś≥ē„Äā
+
+#### śÄĽÁĽď ####
+
+DmallocÁúüś≠£ÁöĄšľėŚäŅŚú®šļéŚģÉÁöĄŚŹĮťÖćÁĹģťÄČť°Ļ„ÄāŤÄĆšłĒťęėŚļ¶ŚŹĮÁ߼ś§ćԾƜõĺÁĽŹśąźŚäüÁ߼ś§ćŚąįŚ§öÁßćśďćšĹúÁ≥ĽÁĽüŚ¶āAIX„ÄĀBSD/OS„ÄĀDG/UX„ÄĀFree/Net/OpenBSD„ÄĀGNU/Hurd„ÄĀHPUX„ÄĀIrix„ÄĀLinux„ÄĀMS-DOG„ÄĀNeXT„ÄĀOSF„ÄĀSCO„ÄĀSolaris„ÄĀSunOS„ÄĀUltrix„ÄĀUnixwareÁĒöŤá≥UnicosÔľąŤŅźŤ°ĆŚú®Cray T3EšłĽśúļšłäԾȄÄāŤôĹÁĄ∂DmallocśúȌ幌§öšłúŤ•ŅťúÄŤ¶ĀŚ≠¶šĻ†ÔľĆšĹÜśėĮŚģÉśČÄśŹźšĺõÁöĄÁČĻśÄߌľŚĺóšłļšĻ蚼ėŚáļ„Äā
+
+### [Electric Fence][15] ###
+
+**ŚľÄŚŹĎŤÄÖ**ÔľöBruce Perens
+
+**ÁāĻŤĮĄÁČąśú¨**Ôľö2.2.3
+
+**LinuxśĒĮśĆĀ**ÔľöśČÄśúČÁßćÁĪĽ
+
+**ŤģłŚŹĮ**ÔľöGNU ťÄöÁĒ®ŚÖ¨ŚÖĪŤģłŚŹĮŤĮĀ (Á¨¨šļĆÁČą)
+
+Electric FenceśėĮBruce PerensŚľÄŚŹĎÁöĄšłÄś¨ĺŚÜÖŚ≠ėŤįÉŤĮēŚ∑•ŚÖ∑ԾƌģÉšĽ•ŚļďÁöĄŚĹĘŚľŹŚģěÁéįԾƚņÁöĄÁ®čŚļŹťúÄŤ¶Āťďĺśé•ŚģÉ„ÄāElectric FenceŤÉĹś£ÄśĶčŚáļ[ś†ą][11]ŚÜÖŚ≠ėśļĘŚáļŚíĆŤģŅťóģŚ∑≤ÁĽŹťáäśĒĺÁöĄŚÜÖŚ≠ė„Äā
+
+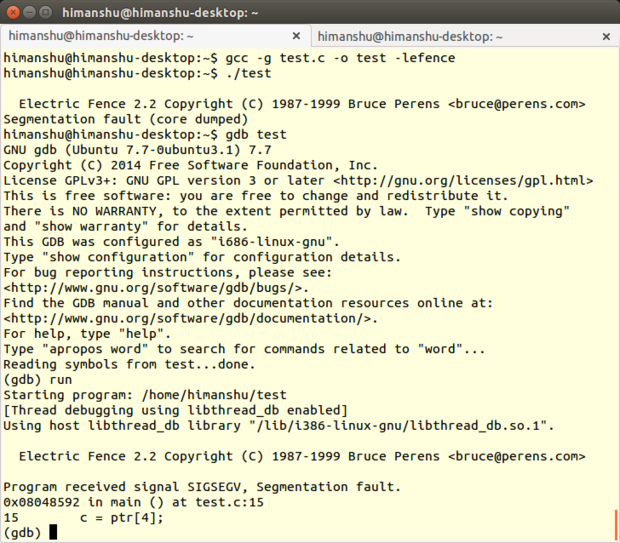
+Electric Fence
+
+ť°ĺŚźćśÄĚšĻČÔľĆElectric FenceŚú®śĮŹšł™ÁĒ≥ŤĮ∑ÁöĄÁľďŚ≠ėŤĺĻÁēĆŚĽļÁęčšļÜfenceÔľąťė≤śä§ÔľČԾƚĽĽšĹēťĚěś≥ēŚÜÖŚ≠ėŤģŅťóģťÉĹšľöŚĮľŤáī[śģĶťĒôŤĮĮ][12]„ÄāŤŅôšł™ŤįÉŤĮēŚ∑•ŚÖ∑ŚźĆśó∂śĒĮśĆĀCŚíĆC++ÁľĖÁ®č„Äā
+
+
+#### śõīśĖįŚÜÖŚģĻ ####
+
+2.2.3ÁČąśú¨šŅģŚ§ćšļÜŚ∑•ŚÖ∑ÁöĄśěĄŚĽļÁ≥ĽÁĽüԾƚĹŅŚĺó-fno-builtin-mallocťÄČť°ĻŤÉĹÁúüś≠£šľ†ÁĽô[GNU Compiler Collection (GCC)][13]„Äā
+
+#### śúČšĹēšľėÁāĻ ####
+
+śąĎŚĖúś¨ĘElectric Fenceť¶ĖŤ¶ĀÁöĄšłÄÁāĻśėĮÔľąMemwatch„ÄĀDmallocŚíĆMtraceśČÄšłćŚÖ∑śúČÁöĄÔľČԾƍŅôšł™ŤįÉŤĮēŚ∑•ŚÖ∑šłćťúÄŤ¶ĀšĹ†ÁöĄśļźÁ†ĀŚĀöšĽĽšĹēÁöĄśĒĻŚä®ÔľĆšĹ†ŚŹ™ťúÄŤ¶ĀŚú®ÁľĖŤĮĎÁöĄśó∂ŚÄôśääŚģÉÁöĄŚļďťďĺśé•ŤŅõšĹ†ÁöĄÁ®čŚļŹŚć≥ŚŹĮ„Äā
+
+ŚÖ∂ś¨°ÔľĆElectric FenceŚģěÁéįšłÄšł™śĖĻś≥ēÔľĆÁ°ģŤģ§ŚĮľŤáīŤ∂äÁēĆŤģŅťóģ(a bounds violation)ÁöĄÁ¨¨šłÄšł™śĆᚼ§ŚįĪśėĮŚľēŤĶ∑śģĶťĒôŤĮĮÁöĄŚéüŚõ†„ÄāŤŅôśĮĒŚú®ŚźéťĚĘŚÜ挏ĎÁéįťóģťĘėŤ¶ĀŚ•ĹŚ§öšļÜ„Äā
+
+šłćÁģ°śėĮŚź¶śúČś£ÄśĶčŚáļťĒôŤĮĮÔľĆElectric FenceÁĽŹŚłłšľöŚú®ŤĺďŚáļšļßÁĒüÁČąśĚÉšŅ°śĀĮ„ÄāŤŅôšłÄÁāĻťĚ쌳łśúČÁĒ®ÔľĆÁĒĪś≠§ŚŹĮšĽ•Á°ģŚģöšĹ†śČÄŤŅźŤ°ĆÁöĄÁ®čŚļŹŚ∑≤ÁĽŹŚźĮÁĒ®šļÜElectric Fence„Äā
+
+#### ś≥®śĄŹšļčť°Ļ ####
+
+ŚŹ¶šłÄśĖĻťĚĘԾƜąĎŚĮĻElectric FenceÁúüś≠£ŚŅĶŚŅĶšłćŚŅėÁöĄśėĮŚģÉś£ÄśĶčŚÜÖŚ≠ėś≥ĄśľŹÁöĄŤÉĹŚäõ„ÄāŚÜÖŚ≠ėś≥ĄśľŹśėĮC/C++ŤĹĮšĽ∂śúÄŚłłŤßĀšĻüśėĮśúÄťöĺťöźÁßėÁöĄťóģťĘėšĻ蚳ĄÄāšłćŤŅáÔľĆElectric FencešłćŤÉĹś£ÄśĶčŚáļŚ†ÜŚÜÖŚ≠ėśļĘŚáļԾƍÄĆšłĒšĻüšłćśėĮÁļŅÁ®čŚģČŚÖ®ÁöĄ„Äā
+
+ŚüļšļéElectric FencešľöŚú®ÁĒ®śą∑ŚąÜťÖćŚÜÖŚ≠ėŚĆļÁöĄŚČ挟錹ܝÖćÁ¶Āś≠ĘŤģŅťóģÁöĄŤôöśčüŚÜÖŚ≠ėť°ĶԾƌ¶āśěúšĹ†ŤŅጧöÁöĄŤŅõŤ°ĆŚä®śÄĀŚÜÖŚ≠ėŚąÜťÖćԾƌįÜšľöŚĮľŤáīšĹ†ÁöĄÁ®čŚļŹś∂ąŤÄóŚ§ßťáŹÁöĄťĘĚŚ§ĖŚÜÖŚ≠ė„Äā
+
+Electric FenceŤŅėśúČšłÄšł™ŚĪÄťôźśėĮšłćŤÉĹśėéÁ°ģśĆáŚáļťĒôŤĮĮšĽ£Á†ĀśČÄŚú®ÁöĄŤ°ĆŚŹ∑„ÄāŚģÉśČÄŤÉĹŚĀöŚŹ™śėĮŚú®ÁõĎśĶ茹įŚÜÖŚ≠ėÁõłŚÖ≥ťĒôŤĮĮśó∂šļßÁĒüśģĶťĒôŤĮĮ„ÄāśÉ≥Ť¶ĀŚģöšĹ捰ƌŹ∑ԾƝúÄŤ¶ĀŚÄüŚä©[The Gnu Project Debugger (GDB)][14]ŤŅôś†∑ÁöĄŤįÉŤĮēŚ∑•ŚÖ∑śĚ•ŤįÉŤĮēšĹ†ŚźĮÁĒ®šļÜElectric FenceÁöĄÁ®čŚļŹ„Äā
+
+śúÄŚźéšłÄÁāĻÔľĆElectric FenceŤôĹÁĄ∂ŤÉĹś£ÄśĶčŚáļŚ§ßťÉ®ŚąÜÁöĄÁľďŚÜ≤ŚĆļśļĘŚáļԾƜúČšłÄšł™šĺ茧ĖśėĮԾƌ¶āśěúśČÄÁĒ≥ŤĮ∑ÁöĄÁľďŚÜ≤ŚĆļŚ§ßŚįŹšłćśėĮÁ≥ĽÁĽüŚ≠óťēŅÁöĄŚÄćśēįԾƍŅôśó∂ŚÄôśļĘŚáļÔľąŚć≥šĹŅŚŹ™śúȌᆚł™Ś≠óŤäāԾȌįĪšłćŤÉĹŤĘęś£ÄśĶčŚáļśĚ•„Äā
+
+#### śÄĽÁĽď ####
+
+ŚįĹÁģ°śúČťā£šĻąŚ§öÁöĄŚĪÄťôźÔľĆšĹÜśėĮElectric FenceÁöĄšľėÁāĻŚćīŚú®šļéŚģÉÁöĄśėďÁĒ®śÄß„ÄāÁ®čŚļŹŚŹ™Ť¶Āťďĺśé•Ś∑•ŚÖ∑šłÄś¨°ÔľĆElectric FenceŚįĪŚŹĮšĽ•Śú®ÁõĎśĶčŚáļŚÜÖŚ≠ėÁõłŚÖ≥ťóģťĘėÁöĄśó∂ŚÄôśä•Ť≠¶„ÄāšłćŤŅáԾƌ¶āŚźĆŚČćťĚĘśČÄŤĮīÔľĆElectric FenceťúÄŤ¶ĀťÖ挟ąŚÉŹGDBŤŅôś†∑ÁöĄśļźÁ†ĀŤįÉŤĮēŚô®šĹŅÁĒ®„Äā
+
+
+### [Memcheck][16] ###
+
+**ŚľÄŚŹĎŤÄÖ**Ôľö[ValgrindŚľÄŚŹĎŚõĘťėü][17]
+
+**ÁāĻŤĮĄÁČąśú¨**Ôľö3.10.1
+
+**LinuxśĒĮśĆĀ**ÔľöśČÄśúČÁßćÁĪĽ
+
+**ŤģłŚŹĮ**ÔľöťÄöÁĒ®ŚÖ¨ŚÖĪŤģłŚŹĮŤĮĀ
+
+[Valgrind][18]śėĮšłÄšł™śŹźšĺõŚ•ĹŚá†ś¨ĺŤįÉŤĮēŚíĆLinuxÁ®čŚļŹśÄߍÉĹŚąÜśěźŚ∑•ŚÖ∑ÁöĄŚ•óšĽ∂„ÄāŤôĹÁĄ∂ValgrindŚíĆÁľĖŚÜôŤĮ≠Ť®ÄŚźĄšłćÁõłŚźĆÔľąśúČJava„ÄĀPerl„ÄĀPython„ÄĀAssembly code„ÄĀortran„ÄĀAdaÁ≠ČÁ≠ČÔľČÁöĄÁ®čŚļŹťÖ挟ąŚ∑•šĹúԾƚĹÜśėĮŚģÉśČÄśŹźšĺõÁöĄŚ∑•ŚÖ∑Ś§ßťÉ®ŚąÜťÉĹśĄŹŚú®śĒĮśĆĀC/C++śČÄÁľĖŚÜôÁöĄÁ®čŚļŹ„Äā
+
+MemcheckšĹúšłļŚÜÖŚ≠ėťĒôŤĮĮś£ÄśĶčŚô®ÔľĆśėĮšłÄś¨ĺśúÄŚŹóś¨ĘŤŅéÁöĄMemcheckŚ∑•ŚÖ∑„ÄāŚģÉŤÉĹŚ§üś£ÄśĶčŚáļŤĮłŚ§öťóģťĘėŤĮłŚ¶āŚÜÖŚ≠ėś≥ĄśľŹ„ÄĀśó†śēąÁöĄŚÜÖŚ≠ėŤģŅťóģ„ÄĀśú™ŚģöšĻČŚŹėťáŹÁöĄšĹŅÁĒ®šĽ•ŚŹäś†ąŚÜÖŚ≠ėŚąÜťÖćŚíĆťáäśĒĺÁõłŚÖ≥ÁöĄťóģťĘėÁ≠Č„Äā
+
+#### śõīśĖįŚÜÖŚģĻ ####
+
+Ś∑•ŚÖ∑Ś•óšĽ∂(3.10.1)ÁöĄ[ŚŹĎŤ°ĆÁČą][19]śėĮšłÄšł™ŚČĮÁČąśú¨ÔľĆšłĽŤ¶ĀšŅģŚ§ćšļÜ3.10.0ÁČąśú¨ŚŹĎÁéįÁöĄbug„Äāťô§ś≠§šĻ茧ĖԾƚĽéšłĽÁČąśú¨backportšłÄšļõŚĆÖԾƚŅģŚ§ćšļÜÁľļŚ§ĪÁöĄAArch64 ARMv8śĆᚼ§ŚíĆÁ≥ĽÁĽüŤįÉÁĒ®„Äā
+
+#### śúČšĹēšľėÁāĻ ####
+
+ŚźĆŚÖ∂ŚģÉśČÄśúČValgrindŚ∑•ŚÖ∑šłÄś†∑ÔľĆMemcheckšĻüśėĮŚüļśú¨ÁöĄŚĎĹšĽ§Ť°ĆŚģěÁĒ®Á®čŚļŹ„ÄāŚģÉÁöĄśďćšĹúťĚ쌳łÁģÄŚćēÔľöťÄöŚłłśąĎšĽ¨šľöšĹŅÁĒ®ŤĮłŚ¶āprog arg1 arg2ś†ľŚľŹÁöĄŚĎĹšĽ§śĚ•ŤŅźŤ°ĆÁ®čŚļŹÔľĆŤÄĆMemcheckŚŹ™Ť¶ĀśĪāšĹ†Ś§öŚä†Śá†šł™ŚÄľŚć≥ŚŹĮԾƌįĪŚÉŹvalgrind --leak-check=full prog arg1 arg2„Äā
+
+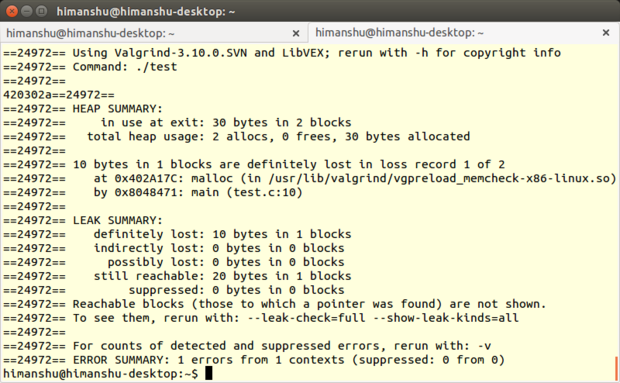
+Memcheck
+
+Ôľąś≥®śĄŹÔľöŚõ†šłļMemcheckśėĮValgrindÁöĄťĽėŤģ§Ś∑•ŚÖ∑śČÄšĽ•śó†ťúÄśŹźŚŹäMemcheck„ÄāšĹÜśėĮԾƝúÄŤ¶ĀŚú®ÁľĖŤĮĎÁ®čŚļŹšĻ茹̌ł¶šłä-gŚŹāśēįťÄČť°ĻԾƍŅôšłÄś≠•šľöś∑ĽŚä†ŤįÉŤĮēšŅ°śĀĮԾƚĹŅŚĺóMemcheckÁöĄťĒôŤĮĮšŅ°śĀĮšľöŚĆÖŚźęś≠£Á°ģÁöĄŤ°ĆŚŹ∑„ÄāÔľČ
+
+śąĎÁúüś≠£ŚÄĺŚŅÉšļéMemcheckÁöĄśėĮŚģÉśŹźšĺõšļ܌幌§öŚĎĹšĽ§Ť°ĆťÄČť°ĻÔľąŚ¶āšłäśČÄŤŅįÁöĄ--leak-checkťÄČť°ĻÔľČԾƌ¶āś≠§šłćšĽÖŤÉĹśéߌą∂Ś∑•ŚÖ∑ŤŅźŤĹ¨ŤŅėŚŹĮšĽ•śéߌą∂ŚģÉÁöĄŤĺďŚáļ„Äā
+
+šłĺšł™šĺčŚ≠źÔľĆŚŹĮšĽ•ŚľÄŚźĮ--track-originsťÄČť°ĻԾƚĽ•śü•ÁúčÁ®čŚļŹśļźÁ†Āšł≠śú™ŚąĚŚßčŚĆĖÁöĄśēįśćģ„ÄāŚŹĮšĽ•ŚľÄŚźĮ--show-mismatched-freesťÄČť°ĻŤģ©MemcheckŚĆĻťÖćŚÜÖŚ≠ėÁöĄŚąÜťÖćŚíĆťáäśĒĺśäÄśúĮ„ÄāŚĮĻšļéCŤĮ≠Ť®ÄśČÄŚÜôÁöĄšĽ£Á†ĀÔľĆMemcheckšľöÁ°ģšŅĚŚŹ™ŤÉĹšĹŅÁĒ®free()ŚáĹśēįśĚ•ťáäśĒĺŚÜÖŚ≠ėÔľĆmalloc()ŚáĹśēįśĚ•ÁĒ≥ŤĮ∑ŚÜÖŚ≠ė„ÄāŤÄĆŚĮĻC++śČÄŚÜôÁöĄśļźÁ†ĀÔľĆMemcheckšľöś£Äśü•śėĮŚź¶šĹŅÁĒ®šļÜdeleteśąĖdelete[]śďćšĹúÁ¨¶śĚ•ťáäśĒĺŚÜÖŚ≠ėԾƚĽ•ŚŹänewśąĖŤÄÖnew[]śĚ•ÁĒ≥ŤĮ∑ŚÜÖŚ≠ė„Äā
+
+MemcheckśúÄŚ•ĹÁöĄÁČĻÁāĻԾƌį§ŚÖ∂śėĮŚĮĻšļ錹̌≠¶ŤÄ֜̕ŤĮīÁöĄÔľĆśėĮŚģÉšľöÁĽôÁĒ®śą∑ŚĽļŤģģšĹŅÁĒ®ťā£šł™ŚĎĹšĽ§Ť°ĆťÄČť°ĻŤÉĹŤģ©ŤĺďŚáļśõīŚä†śúČśĄŹšĻČ„ÄāśĮĒŚ¶āŤĮīԾƌ¶āśěúšĹ†šłćšĹŅÁĒ®Śüļśú¨ÁöĄ--leak-checkťÄČť°ĻÔľĆMemcheckšľöŚú®ŤĺďŚáļśó∂ŚĽļŤģģ‚ÄúšĹŅÁĒ®--leak-check=fullťáćśĖįŤŅźŤ°ĆԾƜü•ÁúčśõīŚ§öś≥ĄśľŹŚÜÖŚ≠ėÁĽÜŤäā‚ÄĚ„ÄāŚ¶āśěúÁ®čŚļŹśúČśú™ŚąĚŚßčŚĆĖÁöĄŚŹėťáŹÔľĆMemcheckšľöšļßÁĒüšŅ°śĀĮ‚ÄúšĹŅÁĒ®--track-origins=yesԾƜü•Áúčśú™ŚąĚŚßčŚĆĖŚŹėťáŹÁöĄŚģöšĹć‚ÄĚ„Äā
+
+MemcheckŚŹ¶Ś§ĖšłÄšł™śúČÁĒ®ÁöĄÁČĻśÄßśėĮŚģÉŚŹĮšĽ•[ŚąõŚĽļśäĎŚą∂śĖᚼ∂(suppression files)][20]ÔľĆÁĒĪś≠§ŚŹĮšĽ•ŚŅĹÁē•ÁČĻŚģöšłćŤÉĹšŅģś≠£ÁöĄťĒôŤĮĮԾƍŅôś†∑MemcheckŤŅźŤ°Ćśó∂ŚįĪšłćšľöśĮŹś¨°ťÉĹśä•Ť≠¶šļÜ„ÄāŚÄľŚĺóšłÄśŹźÁöĄśėĮÔľĆMemcheckšľöŚéĽŤĮĽŚŹĖťĽėŤģ§śäĎŚą∂śĖᚼ∂śĚ•ŚŅĹÁē•Á≥ĽÁĽüŚļďÔľąśĮĒŚ¶āCŚļďԾȚł≠ÁöĄśä•ťĒôԾƍŅôšļõťĒôŤĮĮŚú®Á≥ĽÁĽüŚąõŚĽļšĻčŚČćŚįĪŚ∑≤ÁĽŹŚ≠ėŚú®šļÜ„ÄāŚŹĮšĽ•ťÄČśč©ŚąõŚĽļšłÄšł™śĖįÁöĄśäĎŚą∂śĖᚼ∂ԾƜąĖśėĮÁľĖŤĺĎÁéįśúČÁöĄ(ťÄöŚłłśėĮ/usr/lib/valgrind/default.supp)„Äā
+
+MemcheckŤŅėśúČťęėÁļߌäüŤÉĹԾƜĮĒŚ¶āŚŹĮšĽ•šĹŅÁĒ®[ŚģöŚą∂ŚÜÖŚ≠ėŚąÜťÖćŚô®][22]śĚ•[ś£ÄśĶčŚÜÖŚ≠ėťĒôŤĮĮ][21]„Äāťô§ś≠§šĻ茧ĖÔľĆMemcheckśŹźšĺõ[ÁõĎśéߌĎĹšĽ§][23]ԾƌĹďÁĒ®ŚąįValgrindÁöĄŚÜÖÁĹģgdbserverԾƚĽ•ŚŹä[ŚģĘśą∑ÁęĮŤĮ∑śĪā][24]śúļŚą∂ÔľąšłćšĽÖŤÉĹśääÁ®čŚļŹÁöĄŤ°ĆšłļŚĎäÁü•MemcheckԾƍŅėŚŹĮšĽ•ŤŅõŤ°Ćśü•ŤĮĘԾȜó∂ŚŹĮšĽ•šĹŅÁĒ®„Äā
+
+#### ś≥®śĄŹšļčť°Ļ ####
+
+śĮęśó†ÁĖĎťóģÔľĆMemcheckŚŹĮšĽ•ŤäāÁúĀŚĺąŚ§öŤįÉŤĮēśó∂ťóīšĽ•ŚŹäÁúĀŚéĽŚĺąŚ§öťļĽÁɶ„ÄāšĹÜśėĮŚģÉšĹŅÁĒ®šļ܌幌§öŚÜÖŚ≠ėԾƌĮľŤáīÁ®čŚļŹśČߍ°ĆŚŹėśÖĘÔľą[ÁĒĪŤĶĄśĖôŚŹĮÁü•][25]Ծƌ§ßś¶āŤäĪšłä20Ťá≥30ŚÄćśó∂ťóīԾȄÄā
+
+ťô§ś≠§šĻ茧ĖÔľĆMemcheckŤŅėśúČŚÖ∂ŚģÉŚĪÄťôź„Äāś†ĻśćģÁĒ®śą∑ŤĮĄŤģļÔľĆMemcheckśėéśėĺšłćśėĮ[ÁļŅÁ®čŚģČŚÖ®][26]ÁöĄÔľõŚģÉšłćŤÉĹś£ÄśĶčŚáļ [ťĚôśÄĀÁľďŚÜ≤ŚĆļśļĘŚáļ][27]ÔľõŤŅėśúČŚįĪśėĮԾƚłÄšļõLinuxÁ®čŚļŹŚ¶ā[GNU Emacs][28]ÔľĆÁõģŚČćŤŅėšłćŤÉĹšĹŅÁĒ®Memcheck„Äā
+
+Ś¶āśěúśúČŚÖīŤ∂£ÔľĆŚŹĮšĽ•Śú®[ŤŅôťáĆ][29]śü•ÁúčValgrindŤĮ¶ŚįĹÁöĄŚĪÄťôźśÄߍĮīśėé„Äā
+
+#### śÄĽÁĽď ####
+
+śó†ŤģļśėĮŚĮĻšļ錹̌≠¶ŤÄÖŤŅėśėĮťā£šļõťúÄŤ¶ĀťęėÁļßÁČĻśÄßÁöĄšļļśĚ•ŤĮīÔľĆMemcheckťÉĹśėĮšłÄś¨ĺšĺŅść∑ÁöĄŚÜÖŚ≠ėŤįÉŤĮēŚ∑•ŚÖ∑„ÄāŚ¶āśěúšĹ†šĽÖťúÄŤ¶ĀŚüļśú¨ŤįÉŤĮēŚíĆťĒôŤĮĮś†łśü•ÔľĆMemcheckšľöťĚ쌳łŚģĻśėďšłäśČč„ÄāŤÄĆŚĹďšĹ†śÉ≥Ť¶ĀšĹŅÁĒ®ŚÉŹśäĎŚą∂śĖᚼ∂śąĖŤÄÖÁõĎśéßśĆᚼ§ŤŅôś†∑ÁöĄÁČĻśÄßԾƌįĪťúÄŤ¶ĀŤäĪšłÄšļõŚäüŚ§ęŚ≠¶šĻ†šļÜ„Äā
+
+ŤôĹÁĄ∂ÁĹóŚąóšļÜŚ§ßťáŹÁöĄŚĪÄťôźśÄßԾƚĹÜśėĮValgrindÔľąŚĆÖśč¨MemcheckԾȌú®ŚģÉÁöĄÁĹĎÁęôšłäŚ£įÁßįŚÖ®ÁźÉśúČ[śąźŚćÉšłäšłáÁ®čŚļŹŚĎė][30]šĹŅÁĒ®šļÜś≠§Ś∑•ŚÖ∑„ÄāŚľÄŚŹĎŚõĘťėüÁßįśĒ∂ŚąįśĚ•Ťá™Ť∂ÖŤŅá30šł™ŚõĹŚģ∂ÁöĄÁĒ®śą∑ŚŹćť¶ąÔľĆŤÄĆŤŅôšļõÁĒ®śą∑ÁöĄŚ∑•Á®čšĽ£Á†ĀśúČÁöĄťęėŤĺĺ2.5ŚćÉšłáŤ°Ć„Äā
+
+### [Memwatch][31] ###
+
+**ŚľÄŚŹĎŤÄÖ**ÔľöJohan Lindh
+
+**ÁāĻŤĮĄÁČąśú¨**Ôľö2.71
+
+**LinuxśĒĮśĆĀ**ÔľöśČÄśúČÁßćÁĪĽ
+
+**ŤģłŚŹĮ**ÔľöGNUťÄöÁĒ®ŚÖ¨ŚÖĪŤģłŚŹĮŤĮĀ
+
+MemwatchśėĮÁĒĪJohan LindhŚľÄŚŹĎÁöĄŚÜÖŚ≠ėŤįÉŤĮēŚ∑•ŚÖ∑ԾƍôĹÁĄ∂ŚģÉšłĽŤ¶ĀśČģśľĒŚÜÖŚ≠ėś≥ĄśľŹś£ÄśĶčŚô®ÁöĄŤßíŤČ≤ԾƚĹÜśėĮŚģÉšĻüŚÖ∑śúČś£ÄśĶčŚÖ∂ŚģÉŚ¶ā[ťá挧ćťáäśĒĺŤ∑üŤł™ŚíĆŚÜÖŚ≠ėťĒôŤĮĮťáäśĒĺ][32]„ÄĀÁľďŚÜ≤ŚĆļśļĘŚáļŚíĆšłčśļĘ„ÄĀ[ťáéśĆáťíą][33]ŚÜôŚÖ•Á≠ČÁ≠ČŚÜÖŚ≠ėÁõłŚÖ≥ťóģťĘėÁöĄŤÉĹŚäõÔľąś†ĻśćģÁĹĎť°ĶšĽčÁĽćśČÄÁü•ÔľČ„Äā
+
+MemwatchśĒĮśĆĀÁĒ®CŤĮ≠Ť®ÄśČÄÁľĖŚÜôÁöĄÁ®čŚļŹ„ÄāŚŹĮšĽ•Śú®C++Á®čŚļŹšł≠šĹŅÁĒ®ŚģÉԾƚĹÜśėĮŤŅôÁßćŚĀöś≥ēŚĻ∂šłćśŹźŚÄ°ÔľąÁĒĪMemwatchśļźÁ†ĀŚĆÖťöŹťôĄÁöĄQ&AśĖᚼ∂šł≠ŚŹĮÁü•ÔľČ„Äā
+
+#### śõīśĖįŚÜÖŚģĻ ####
+
+ŤŅôšł™ÁČąśú¨ś∑ĽŚä†šļÜULONG_LONG_MAXšĽ•ŚĆļŚąÜ32šĹćŚíĆ64šĹćÁ®čŚļŹ„Äā
+
+#### śúČšĹēšľėÁāĻ ####
+
+Ť∑üDmallocšłÄś†∑ÔľĆMemwatchšĻüśúČšľėÁßÄÁöĄśĖáÁĆģŤĶĄśĖô„ÄāŚŹāŤÄÉUSINGśĖᚼ∂ԾƌŹĮšĽ•Ś≠¶šĻ†Ś¶āšĹēšĹŅÁĒ®MemwatchԾƌŹĮšĽ•šļÜŤß£MemwatchśėĮŚ¶āšĹēŚąĚŚßčŚĆĖ„ÄĀŚ¶āšĹēśłÖÁźÜšĽ•ŚŹäŚ¶āšĹēŤŅõŤ°ĆI/OśďćšĹúÁöĄÔľĆÁ≠ČÁ≠ČšłćšłÄŤÄĆŤ∂≥„ÄāŤŅėśúČšłÄšł™FAQśĖᚼ∂ԾƜó®Śú®ŚłģŚä©ÁĒ®śą∑Ťß£ŚÜ≥šĹŅÁĒ®ŤŅáÁ®čťĀጹįÁöĄšłÄŤą¨ťóģťĘė„ÄāśúÄŚźéŤŅėśúČšłÄšł™test.cśĖᚼ∂śŹźšĺõŚ∑•šĹúś°ąšĺ茏āŤÄÉ„Äā
+
+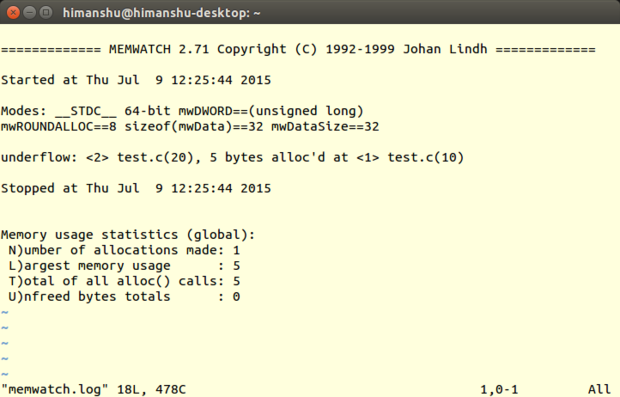
+Memwatch
+
+šłćŚźĆšļéMtraceÔľĆMemwatchÁöĄŤĺďŚáļšļßÁĒüÁöĄśó•ŚŅóśĖᚼ∂ÔľąťÄöŚłłśėĮmemwatch.logԾȜėĮšļļÁĪĽŚŹĮťėÖŤĮĽś†ľŚľŹ„ÄāŤÄĆšłĒÔľĆMemwatchśĮŹś¨°ŤŅźŤ°Ćśó∂śÄĽšľöśčľśé•ŚÜÖŚ≠ėŤįÉŤĮēŤĺďŚáļŚąįś≠§śĖᚼ∂śúęŚįĺԾƍÄĆšłćśėĮŤŅõŤ°ĆŤ¶ÜÁõĖÔľąŤĮĎśĒĻԾȄÄāŚ¶āś≠§šĺŅŚŹĮŚú®ťúÄŤ¶ĀšĻčśó∂ԾƍżśĚĺśü•ÁúčšĻčŚČćÁöĄŤĺďŚáļšŅ°śĀĮ„Äā
+
+ŚźĆś†∑ŚÄľŚĺóšłÄśŹźÁöĄśėĮŚĹďšĹ†śČߍ°ĆšļÜŚźĮÁĒ®MemwatchÁöĄÁ®čŚļŹÔľĆMemwatchšľöŚú®[ś†áŚáÜŤĺďŚáļ][34]šł≠šļßÁĒüšłÄšł™ŚćēŤ°ĆŤĺďŚáļԾƌĎäÁü•ŚŹĎÁéįšļÜťĒôŤĮĮÔľĆÁĄ∂ŚźéšĹ†ŚŹĮšĽ•Śú®śó•ŚŅóśĖᚼ∂šł≠śü•ÁúčŤĺďŚáļÁĽÜŤäā„ÄāŚ¶āśěúś≤°śúČšļßÁĒüťĒôŤĮĮšŅ°śĀĮԾƌįĪŚŹĮšĽ•Á°ģšŅĚśó•ŚŅóśĖᚼ∂šłćšľöŚÜôŚÖ•šĽĽšĹēťĒôŤĮĮԾƌ§öś¨°ŤŅźŤ°ĆÁöĄŤĮĚŤÉĹŚģěťôÖŤäāÁúĀśó∂ťóī„Äā
+
+ŚŹ¶šłÄšł™śąĎŚĖúś¨ĘÁöĄšľėÁāĻśėĮMemwatchŚźĆś†∑Śú®śļźÁ†Āšł≠śŹźšĺõšłÄšł™śĖĻś≥ēԾƚņŚŹĮšĽ•śćģś≠§Ťé∑ŚŹĖMemwatchÁöĄŤĺďŚáļšŅ°śĀĮÔľĆÁĄ∂ŚźéšĽĽÁĒĪšĹ†ŤŅõŤ°ĆŚ§ĄÁźÜÔľąŚŹāŤÄÉMemwatchśļźÁ†Āšł≠ÁöĄmwSetOutFunc()ŚáĹśēįŤé∑ŚŹĖśõīŚ§öśúČŚÖ≥ÁöĄšŅ°śĀĮԾȄÄā
+
+#### ś≥®śĄŹšļčť°Ļ ####
+
+Ť∑üMtraceŚíĆDmallocšłÄś†∑ÔľĆMemwatchšĻüťúÄŤ¶ĀšĹ†ŚĺĚņÁöĄśļźśĖᚼ∂ťáĆŚĘěŚä†šĽ£Á†ĀÔľöšĹ†ťúÄŤ¶Āśäämemwatch.hŤŅôšł™Ś§īśĖᚼ∂ŚĆÖŚźęŤŅõšĹ†ÁöĄšĽ£Á†Ā„ÄāŤÄĆšłĒÔľĆÁľĖŤĮĎÁ®čŚļŹÁöĄśó∂ŚÄôԾƚņťúÄŤ¶ĀŤŅ쌟Ćmemwatch.cšłÄŚĚóÁľĖŤĮĎÔľõśąĖŤÄ֚ņŚŹĮšĽ•śääŚ∑≤ÁĽŹÁľĖŤĮĎŚ•ĹÁöĄÁõģś†áś®°ŚĚóŚĆÖŚźęŤĶ∑śĚ•ÔľĆÁĄ∂ŚźéŚú®ŚĎĹšĽ§Ť°ĆŚģöšĻČMEMWATCHŚíĆMW_STDIOŚŹėťáŹ„ÄāšłćÁĒ®ŤĮīԾƜÉ≥Ť¶ĀŚú®ŤĺďŚáļšł≠ŚģöšĹ捰ƌŹ∑ÔľĆ-gÁľĖŤĮĎŚô®ťÄČť°ĻšĻüŚįĎšłćšļÜ„Äā
+
+ŤŅėśúČšłÄšļõś≤°śúČŚÖ∑Ś§áÁöĄÁČĻśÄß„ÄāśĮĒŚ¶āMemwatchšłćŤÉĹś£ÄśĶčŚáļŚĺÄšłÄŚĚóŚ∑≤ÁĽŹŤĘęťáäśĒĺÁöĄŚÜÖŚ≠ėŚÜôŚÖ•śďćšĹúԾƜąĖśėĮŚú®ŚąÜťÖćÁöĄŚÜÖŚ≠ėŚĚóšĻ茧ĖÁöĄŤĮĽŚŹĖśďćšĹú„ÄāŤÄĆšłĒÔľĆMemwatchšĻüšłćśėĮÁļŅÁ®čŚģČŚÖ®ÁöĄ„ÄāŤŅėśúČšłÄÁāĻԾƜ≠£Ś¶āśąĎŚú®ŚľÄŚßčśó∂śĆáŚáļԾƌú®C++Á®čŚļŹšłäŤŅźŤ°ĆMemwatchÁöĄÁĽďśěúśėĮšłćŤÉŝʥśĖôÁöĄ„Äā
+
+#### śÄĽÁĽď ####
+
+MemcheckŚŹĮšĽ•ś£ÄśĶčŚĺąŚ§öŚÜÖŚ≠ėÁõłŚÖ≥ÁöĄťóģťĘėԾƌú®Ś§ĄÁźÜCÁ®čŚļŹśó∂śėĮťĚ쌳łšĺŅść∑ÁöĄŤįÉŤĮēŚ∑•ŚÖ∑„ÄāŚõ†šłļśļźÁ†ĀŚįŹŚ∑ßԾƜČÄšĽ•ŚŹĮšĽ•šĽéšł≠šļÜŤß£MemcheckŚ¶āšĹēŤŅźŤĹ¨ÔľĆśúČťúÄŤ¶ĀÁöĄŤĮĚŚŹĮšĽ•ŤįÉŤĮēŚģÉÔľĆÁĒöŤá≥ŚŹĮšĽ•ś†ĻśćģŤá™ŤļęťúÄśĪāśČ©ŚĪēŚćáÁļߌģÉÁöĄŚäüŤÉĹ„Äā
+
+### [Mtrace][35] ###
+
+**ŚľÄŚŹĎŤÄÖ**: Roland McGrath and Ulrich Drepper
+
+**ÁāĻŤĮĄÁČąśú¨**: 2.21
+
+**LinuxśĒĮśĆĀ**ÔľöśČÄśúČÁßćÁĪĽ
+
+**ŤģłŚŹĮ**ÔľöGNUťÄöÁĒ®ŚÖ¨ŚÖĪŤģłŚŹĮŤĮĀ
+
+MtraceśėĮ[GNU CŚļď][36]šł≠ÁöĄšłÄś¨ĺŚÜÖŚ≠ėŤįÉŤĮēŚ∑•ŚÖ∑ԾƌźĆśó∂śĒĮśĆĀLinux CŚíĆC++Á®čŚļŹÔľĆś£ÄśĶčÁĒĪmalloc()ŚíĆfree()ŚáĹśēįÁöĄšłćŚĮĻÁ≠ČŤįÉÁĒ®śČÄŚľēŤĶ∑ÁöĄŚÜÖŚ≠ėś≥ĄśľŹťóģťĘė„Äā
+
+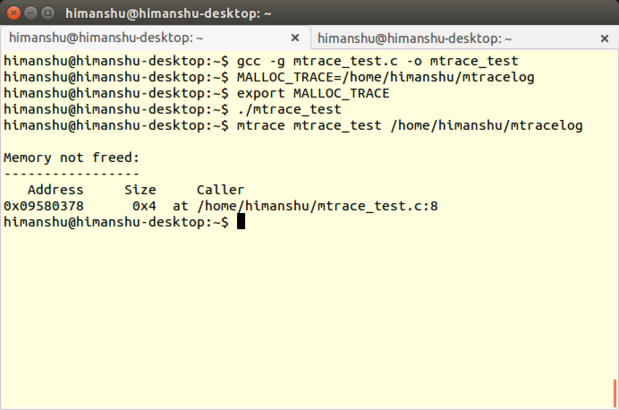
+Mtrace
+
+MtraceŚģěÁéįšłļŚĮĻmtrace()ŚáĹśēįÁöĄŤįÉÁĒ®ÔľĆŤ∑üŤł™Á®čŚļŹšł≠śČÄśúČmalloc/freeŤįÉÁĒ®ÔľĆŚú®ÁĒ®śą∑śĆáŚģöÁöĄśĖᚼ∂šł≠ŤģįŚĹēÁõłŚÖ≥šŅ°śĀĮ„ÄāśĖᚼ∂šĽ•šłÄÁßćśúļŚô®ŚŹĮŤĮĽÁöĄś†ľŚľŹŤģįŚĹēśēįśćģԾƜČÄšĽ•śúČšłÄšł™PerlŤĄöśú¨ÔľąŚźĆś†∑ŚĎĹŚźćšłļmtraceÔľČÁĒ®śĚ•śääśĖᚼ∂ŤĹ¨śćĘŚĻ∂ŚĪēÁ§ļšłļšļļÁĪĽŚŹĮŤĮĽś†ľŚľŹ„Äā
+
+#### śõīśĖįŚÜÖŚģĻ ####
+
+[MtraceśļźÁ†Ā][37]ŚíĆ[PerlśĖᚼ∂][38]ŚźĆGNU CŚļď(2.21ÁČąśú¨)šłÄŤĶ∑ťáäŚáļԾƝô§šļÜśõīśĖįÁČąśĚÉśó•śúüԾƌÖ∂ŚģÉŚąęśó†śĒĻŚä®„Äā
+
+#### śúČšĹēšľėÁāĻ ####
+
+MtraceśúÄšľėÁßÄÁöĄÁČĻÁāĻśėĮťĚ쌳łÁģÄŚćēśėďŚ≠¶„ÄāšĹ†ŚŹ™ťúÄŤ¶ĀšļÜŤß£Śú®šĹ†ÁöĄśļźÁ†Āšł≠Ś¶āšĹēšĽ•ŚŹäšĹēŚ§Ąś∑ĽŚä†mtrace()ŚŹäŚÖ∂ŚĮĻÁęčÁöĄmuntrace()ŚáĹśēįԾƍŅėśúČŚ¶āšĹēšĹŅÁĒ®MtraceÁöĄPerlŤĄöśú¨„ÄāŚźéŤÄÖťĚ쌳łÁģÄŚćēԾƌŹ™ťúÄŤ¶ĀŤŅźŤ°ĆśĆᚼ§mtrace