mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
Update 20160817 Building a Real-Time Recommendation Engine with Data Science.md
This commit is contained in:
parent
1a4ce623e8
commit
e94405f847
@ -86,7 +86,7 @@ Similarly to our earlier data model, we have users who can like places, but this
|
|||||||
和前面的数据模型相似,用户可以标记“喜欢”的地点,但是这一次他们可以用 1 到 10 的整数给地点评定等级。这是通过前期在 Neo4j 中增加一些属性到关系中建模实现的。
|
和前面的数据模型相似,用户可以标记“喜欢”的地点,但是这一次他们可以用 1 到 10 的整数给地点评定等级。这是通过前期在 Neo4j 中增加一些属性到关系中建模实现的。
|
||||||
|
|
||||||
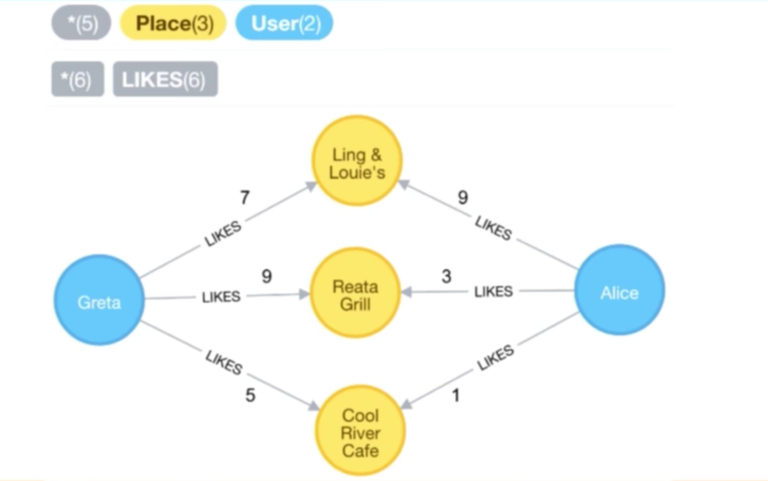
This allows us to find other similar users, like in the example of Greta and Alice. We’ve queried the places they’ve mutually liked, and for each of those places, we can see the weights they have assigned. Presumably, we can use these numbers to determine how similar they are to each other:
|
This allows us to find other similar users, like in the example of Greta and Alice. We’ve queried the places they’ve mutually liked, and for each of those places, we can see the weights they have assigned. Presumably, we can use these numbers to determine how similar they are to each other:
|
||||||
这将允许我们找到其他相似的用户,比如以 Greta 和 Alice 为例,我们都已经查询了他们共同喜欢的地点,并且对于每一个地点,我们可以看到他们给设定的等级。大概地,我们可以通过他们评定的数字等级来确定他们之间的相似性大小。
|
这将允许我们找到其他相似的用户,比如以 Greta 和 Alice 为例,我们都已经查询了他们共同喜欢的地点,并且对于每一个地点,我们可以看到他们给设定的权重。大概地,我们可以通过他们评定的数字等级来确定他们之间的相似性大小。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -128,40 +128,53 @@ Then with their Euclidean distance and themselves, we’re going to create a rel
|
|||||||
通过他们之间的欧几里得距离,我们创建了他们之间的一种关系,叫做“距离”,并且设置了一个欧几里得属性,也叫做“欧几里得”。理论上,我们可以也通过用户间的一些关系来存储其他相似度从而获取不同的相似度,因为在确定的环境下一些相似度可能比其他相似度更有用。
|
通过他们之间的欧几里得距离,我们创建了他们之间的一种关系,叫做“距离”,并且设置了一个欧几里得属性,也叫做“欧几里得”。理论上,我们可以也通过用户间的一些关系来存储其他相似度从而获取不同的相似度,因为在确定的环境下一些相似度可能比其他相似度更有用。
|
||||||
|
|
||||||
And it’s really this ability to model properties on relationships in Neo4j that makes things like this incredibly easy. However, in practice you don’t want to store every single relationship that can possibly exist because you’ll only want to return the top few people of their neighbors.
|
And it’s really this ability to model properties on relationships in Neo4j that makes things like this incredibly easy. However, in practice you don’t want to store every single relationship that can possibly exist because you’ll only want to return the top few people of their neighbors.
|
||||||
|
在 Neo4j 中,的确是关于关系的模型性能力使得完成像这样的事情无比简单。然而,实际上,你不会希望存入每一个可能存在的单一关系,因为你仅仅希望返回离他们“最近”的一些人。
|
||||||
|
|
||||||
So you can just store the top in according to some threshold so you don’t have this fully connected graph. This allows you to perform graph database queries like the below in real time, because we’ve pre-computed it and stored it on the relationship, and in Cypher we’ll be able to grab that very quickly:
|
So you can just store the top in according to some threshold so you don’t have this fully connected graph. This allows you to perform graph database queries like the below in real time, because we’ve pre-computed it and stored it on the relationship, and in Cypher we’ll be able to grab that very quickly:
|
||||||
|
因此你可以根据一些临界值来存入顶端关系从而你不需要有完整的连通图。这允许你完成一些像下面这样的实时数据库请求,因为我们已经预先计算好了“距离”并存储在了关系中,在 Cypher 中,我们能够很快的攫取出数据。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
In this query, we’re matching on places and categories:
|
In this query, we’re matching on places and categories:
|
||||||
|
在这个请求中,我们依据地点和目录来进行匹配:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Again, the first three lines are the same, except that for the logged-in user, we’re getting users who have a :DISTANCE relationship to them. This is where what we went over earlier comes into play – in practice you should only store the top :DISTANCE relationships to users who are similar to them so you’re not grabbing a huge volume of users in this MATCH clause. Instead, we’re grabbing users who have a :DISTANCE relationship to them where those users like that place.
|
Again, the first three lines are the same, except that for the logged-in user, we’re getting users who have a :DISTANCE relationship to them. This is where what we went over earlier comes into play – in practice you should only store the top :DISTANCE relationships to users who are similar to them so you’re not grabbing a huge volume of users in this MATCH clause. Instead, we’re grabbing users who have a :DISTANCE relationship to them where those users like that place.
|
||||||
|
再次说明,前三行是相同的,除了登录登录用户以外,我们找出了有距离关系的用户。我们这是前面查看的关系产生的作用 - 实际上,你只需要存储处于顶端的相似用户“距离”关系,因此你不需要在匹配项目中攫取大量用户。相反,我们只攫取和那些用户“喜欢”的地方有“距离”关系的用户。
|
||||||
|
|
||||||
This has allowed us to express a somewhat complicated pattern in just a few lines. We’re also grabbing the :LIKES relationship and putting it on a variable because we’re going to use those weights later to apply a rating.
|
This has allowed us to express a somewhat complicated pattern in just a few lines. We’re also grabbing the :LIKES relationship and putting it on a variable because we’re going to use those weights later to apply a rating.
|
||||||
|
这允许我们用少许几行内容表达有些复杂的模型。我们也可以攫取“喜欢”关系并把它放入到变量中,因为后面我们将使用这些权重来评级。
|
||||||
|
|
||||||
What’s important here is that we’re ordering those users by their distance ascending, because it is a distance metric, and we want the lowest distances because that indicates they are the most similar.
|
What’s important here is that we’re ordering those users by their distance ascending, because it is a distance metric, and we want the lowest distances because that indicates they are the most similar.
|
||||||
|
在这儿重要的是,我们可以依据“距离”大小将用户按照升序进行排序,这是因为一个距离测度,我们想找到用户间的最小距离因为这表明他们的相似度最大。
|
||||||
|
|
||||||
With those other users ordered by the Euclidean distance, we’re going to collect the top three users’ ratings and use those as our average score to recommend these places. In other words, we’ve taken an active user, found users who are most similar to them based on the places they’ve liked, and then averaged the scores those similar users have given to rank those places in a result set.
|
With those other users ordered by the Euclidean distance, we’re going to collect the top three users’ ratings and use those as our average score to recommend these places. In other words, we’ve taken an active user, found users who are most similar to them based on the places they’ve liked, and then averaged the scores those similar users have given to rank those places in a result set.
|
||||||
|
通过其他按照欧几里得距离排序好的用户,我们得到用户评分最高的三个地点并使用它们作为平均得分来推荐这些地点。用其他的话来说,我们先找出一个积极用户,然后依据其他用户“喜欢”的地方找出和他最相似的其他用户,在然后按照这些相似用户评分的平均值把那些地点排序在结果的集合中。
|
||||||
|
|
||||||
We’re essentially taking an average here by adding it up and dividing by the number of elements in the collection, and we’re ordering by that average ascending. Then secondarily, we’re ordering by the gate distance. Hypothetically, there could be ties I suppose, and then you order by the gate distance and then returning the name, category, gate and terminal.
|
We’re essentially taking an average here by adding it up and dividing by the number of elements in the collection, and we’re ordering by that average ascending. Then secondarily, we’re ordering by the gate distance. Hypothetically, there could be ties I suppose, and then you order by the gate distance and then returning the name, category, gate and terminal.
|
||||||
|
本质上,我们通过把所有得分加起来然后除以收集的元素数目来计算出平均分,然后按照平均分的升序排序。其次,我们按照出入口距离排序。假想地,我猜测应该会有交接点,因此你可以通过出入口距离排序然后再返回名字、目录、出入口和终点。
|
||||||
|
|
||||||
### Cluster Recommendations
|
### Cluster Recommendations
|
||||||
|
### 集群推荐
|
||||||
|
|
||||||
Our final example is going to be a cluster recommendation, which can be thought of as a workflow of offline computing that may be required as a workaround in Cypher. This may now be obsolete based on the new procedures announced at GraphConnect Europe, but sometimes you have to do certain algorithmic approaches that Cypher version 2.3 doesn’t expose.
|
Our final example is going to be a cluster recommendation, which can be thought of as a workflow of offline computing that may be required as a workaround in Cypher. This may now be obsolete based on the new procedures announced at GraphConnect Europe, but sometimes you have to do certain algorithmic approaches that Cypher version 2.3 doesn’t expose.
|
||||||
|
我们最后要讲的一个例子是集群推荐,在 Cyphe 中,这可以被想像成一个作为工作区的离线工作流。这可能完全基于在欧洲 GraphConnect 上宣布的新程序,但是有时你必须进行一些 Cypher 2.3 版本没有显示的算法逼近。
|
||||||
|
|
||||||
This is where you can use some form of statistical software, pull data out of Neo4j into a software such as Apache Spark, R or Python. Below is an example of R code for pulling data out of Neo4j, running an algorithm, and then – if appropriate – writing the results of that algorithm back into Neo4j as either a property, node, relationship or a new label.
|
This is where you can use some form of statistical software, pull data out of Neo4j into a software such as Apache Spark, R or Python. Below is an example of R code for pulling data out of Neo4j, running an algorithm, and then – if appropriate – writing the results of that algorithm back into Neo4j as either a property, node, relationship or a new label.
|
||||||
|
你这儿可以使用一些统计软件,把数据从 Neo4j 取出然后放入像 Apache Spark, R 或者 Python 这样的软件中。下面是一个把数据从 Neo4j 中取出的 R 源代码,运行算法程序,如果正确,写下算法程序返回给 Neo4j 的结果,比如一个属性、节点、关系或者一个新的标签。
|
||||||
|
|
||||||
By persisting the results of that algorithm into the graph, you can use it in real-time with queries similar to the ones we just went over:
|
By persisting the results of that algorithm into the graph, you can use it in real-time with queries similar to the ones we just went over:
|
||||||
|
通过持续把算法程序运行结果放入到图表中,你可以在一个和我们刚刚看到的询问相似的实时询问中使用它:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Below is some example code for how you do this in R, but you can easily do the same thing with whatever software you’re most comfortable with, such as Python or Spark. All you have to do is log in and connect to the graph.
|
Below is some example code for how you do this in R, but you can easily do the same thing with whatever software you’re most comfortable with, such as Python or Spark. All you have to do is log in and connect to the graph.
|
||||||
|
下面是用 R 来完成这件事的一些示例代码,但是你可以使用任何你最喜欢的软件来做相同的事,比如 Python 或 Spark。你需要做的只是登录并连接到图表。
|
||||||
|
|
||||||
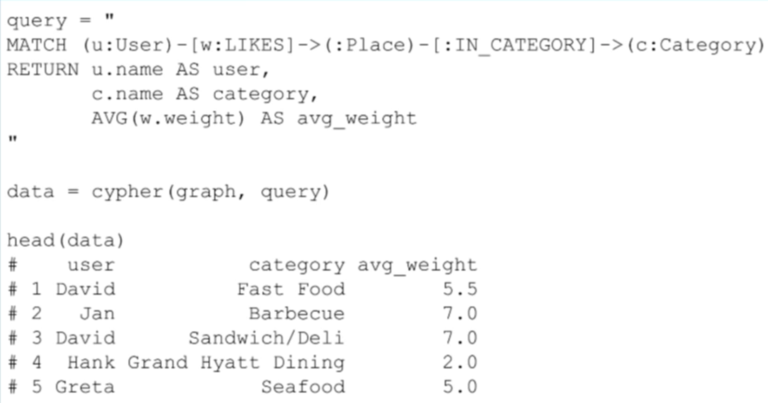
In the following example, I’ve clustered users together based on their similarities. Each user is represented as an observation, and I want to get the average rating that they’ve given each category:
|
In the following example, I’ve clustered users together based on their similarities. Each user is represented as an observation, and I want to get the average rating that they’ve given each category:
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
Presumably, users who rate the bar category in similar ways are similar in general. Here I’m grabbing the names of users who like places in the same category, the category name, and the average weight of the “likes” relationships, as average weight, and that’s going to give me a table like this:
|
Presumably, users who rate the bar category in similar ways are similar in general. Here I’m grabbing the names of users who like places in the same category, the category name, and the average weight of the “likes” relationships, as average weight, and that’s going to give me a table like this:
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user