mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-29 21:41:00 +08:00
Update from LCTT
This commit is contained in:
commit
e8ad08f439
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11066-1.html)
|
||||
[#]: subject: (How To Find The Port Number Of A Service In Linux)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-find-the-port-number-of-a-service-in-linux/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
@ -16,9 +16,9 @@
|
||||
|
||||
### 在 Linux 中查找服务的端口号
|
||||
|
||||
**方法1:使用 [grep][2] 命令**
|
||||
#### 方法1:使用 grep 命令
|
||||
|
||||
要使用 grep 命令在 Linux 中查找指定服务的默认端口号,只需运行:
|
||||
要使用 `grep` 命令在 Linux 中查找指定服务的默认端口号,只需运行:
|
||||
|
||||
```
|
||||
$ grep <port> /etc/services
|
||||
@ -84,11 +84,11 @@ tftp 69/tcp
|
||||
[...]
|
||||
```
|
||||
|
||||
**方法 2:使用 getent 命令**
|
||||
#### 方法 2:使用 getent 命令
|
||||
|
||||
如你所见,上面的命令显示指定搜索词 “ssh”、“http” 和 “ftp” 的所有端口名称和数字。这意味着,你将获得与给定搜索词匹配的所有端口名称的相当长的输出。
|
||||
|
||||
但是,你可以使用 “getent” 命令精确输出结果,如下所示:
|
||||
但是,你可以使用 `getent` 命令精确输出结果,如下所示:
|
||||
|
||||
```
|
||||
$ getent services ssh
|
||||
@ -114,17 +114,15 @@ http 80/tcp
|
||||
$ getent services
|
||||
```
|
||||
|
||||
**方法 3:使用 Whatportis 程序**
|
||||
#### 方法 3:使用 Whatportis 程序
|
||||
|
||||
**Whatportis** 是一个简单的 python 脚本,来用于查找端口名称和端口号。与上述命令不同,此程序以漂亮的表格形式输出。
|
||||
Whatportis 是一个简单的 Python 脚本,来用于查找端口名称和端口号。与上述命令不同,此程序以漂亮的表格形式输出。
|
||||
|
||||
确保已安装 PIP 包管理器。如果没有,请参考以下链接。
|
||||
确保已安装 pip 包管理器。如果没有,请参考以下链接。
|
||||
|
||||
* [**如何使用 Pip 管理 Python 包**][6]
|
||||
- [如何使用 pip 管理 Python 包][6]
|
||||
|
||||
|
||||
|
||||
安装 PIP 后,运行以下命令安装 Whatportis 程序。
|
||||
安装 pip 后,运行以下命令安装 Whatportis 程序。
|
||||
|
||||
```
|
||||
$ pip install whatportis
|
||||
@ -144,9 +142,9 @@ $ whatportis http
|
||||
|
||||
![][7]
|
||||
|
||||
在 Linux 中查找服务的端口号
|
||||
*在 Linux 中查找服务的端口号*
|
||||
|
||||
如果你不知道服务的确切名称,请使用 **–like** 标志来显示相关结果。
|
||||
如果你不知道服务的确切名称,请使用 `–like` 标志来显示相关结果。
|
||||
|
||||
```
|
||||
$ whatportis mysql --like
|
||||
@ -158,7 +156,7 @@ $ whatportis mysql --like
|
||||
$ whatportis 993
|
||||
```
|
||||
|
||||
你甚至可以以 **JSON** 格式显示结果。
|
||||
你甚至可以以 JSON 格式显示结果。
|
||||
|
||||
```
|
||||
$ whatportis 993 --json
|
||||
@ -168,9 +166,7 @@ $ whatportis 993 --json
|
||||
|
||||
有关更多详细信息,请参阅 GitHub 仓库。
|
||||
|
||||
* [**Whatportis GitHub 仓库**][9]
|
||||
|
||||
|
||||
* [Whatportis GitHub 仓库][9]
|
||||
|
||||
就是这些了。你现在知道了如何使用三种简单方法在 Linux 中查找端口名称和端口号。如果你知道任何其他方法/命令,请在下面的评论栏告诉我。我会查看并更相应地更新本指南。
|
||||
|
||||
@ -181,7 +177,7 @@ via: https://www.ostechnix.com/how-to-find-the-port-number-of-a-service-in-linux
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
1208
published/20180629 100 Best Ubuntu Apps.md
Normal file
1208
published/20180629 100 Best Ubuntu Apps.md
Normal file
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11061-1.html)
|
||||
[#]: subject: (Create a Custom System Tray Indicator For Your Tasks on Linux)
|
||||
[#]: via: (https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux)
|
||||
[#]: author: (M.Hanny Sabbagh https://fosspost.org/author/mhsabbagh)
|
||||
|
||||
在 Linux 上为你的任务创建一个自定义的系统托盘指示器
|
||||
======
|
||||
|
||||
系统托盘图标如今仍是一个很神奇的功能。只需要右击图标,然后选择想要的动作,你就可以大幅简化你的生活并且减少日常行为中的大量无用的点击。
|
||||
|
||||
一说到有用的系统托盘图标,我们很容易就想到 Skype、Dropbox 和 VLC:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux][1]
|
||||
|
||||
然而系统托盘图标实际上要更有用得多;你可以根据自己的需求创建自己的系统托盘图标。本指导将会教你通过简单的几个步骤来实现这一目的。
|
||||
|
||||
### 前置条件
|
||||
|
||||
我们将要用 Python 来实现一个自定义的系统托盘指示器。Python 可能已经默安装在所有主流的 Linux 发行版中了,因此你只需要确定一下它已经被安装好了(此处使用版本为 2.7)。另外,我们还需要安装好 `gir1.2-appindicator3` 包。该库能够让我们很容易就能创建系统图标指示器。
|
||||
|
||||
在 Ubuntu/Mint/Debian 上安装:
|
||||
|
||||
```
|
||||
sudo apt-get install gir1.2-appindicator3
|
||||
```
|
||||
|
||||
在 Fedora 上安装:
|
||||
|
||||
```
|
||||
sudo dnf install libappindicator-gtk3
|
||||
```
|
||||
|
||||
对于其他发行版,只需要搜索包含 “appindicator” 的包就行了。
|
||||
|
||||
在 GNOME Shell 3.26 开始,系统托盘图标被删除了。你需要安装 [这个扩展][2](或者其他扩展)来为桌面启用该功能。否则你无法看到我们创建的指示器。
|
||||
|
||||
### 基础代码
|
||||
|
||||
下面是该指示器的基础代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/python
|
||||
import os
|
||||
from gi.repository import Gtk as gtk, AppIndicator3 as appindicator
|
||||
def main():
|
||||
indicator = appindicator.Indicator.new("customtray", "semi-starred-symbolic", appindicator.IndicatorCategory.APPLICATION_STATUS)
|
||||
indicator.set_status(appindicator.IndicatorStatus.ACTIVE)
|
||||
indicator.set_menu(menu())
|
||||
gtk.main()
|
||||
def menu():
|
||||
menu = gtk.Menu()
|
||||
|
||||
command_one = gtk.MenuItem('My Notes')
|
||||
command_one.connect('activate', note)
|
||||
menu.append(command_one)
|
||||
exittray = gtk.MenuItem('Exit Tray')
|
||||
exittray.connect('activate', quit)
|
||||
menu.append(exittray)
|
||||
|
||||
menu.show_all()
|
||||
return menu
|
||||
|
||||
def note(_):
|
||||
os.system("gedit $HOME/Documents/notes.txt")
|
||||
def quit(_):
|
||||
gtk.main_quit()
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
我们待会会解释一下代码是怎么工作的。但是现在,让我们将该文本保存为 `tray.py`,然后使用 Python 运行之:
|
||||
|
||||
```
|
||||
python tray.py
|
||||
```
|
||||
|
||||
我们会看到指示器运行起来了,如下图所示:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 13][3]
|
||||
|
||||
现在,让我们解释一下这个魔法的原理:
|
||||
|
||||
* 前三行代码仅仅用来指明 Python 的路径并且导入需要的库。
|
||||
* `def main()` :此为指示器的主函数。该函数的代码用来初始化并创建指示器。
|
||||
* `indicator = appindicator.Indicator.new("customtray","semi-starred-symbolic",appindicator.IndicatorCategory.APPLICATION_STATUS)` :这里我们指明创建一个名为 `customtray` 的新指示器。这是指示器的唯一名称,这样系统就不会与其他运行中的指示器搞混了。同时我们使用名为 `semi-starred-symbolic` 的图标作为指示器的默认图标。你可以将之改成任何其他值;比如 `firefox` (如果你希望该指示器使用 FireFox 的图标),或任何其他你想用的图标名。最后与 `APPLICATION_STATUS` 相关的部分是指明指示器类别/范围的常规代码。
|
||||
* `indicator.set_status(appindicator.IndicatorStatus.ACTIVE)`:这一行激活指示器。
|
||||
* `indicator.set_menu(menu())`:这里说的是我们想使用 `menu()` 函数(我们会在后面定义) 来为我们的指示器创建菜单项。这很重要,可以让你右击指示器后看到一个可以实施行为的列表。
|
||||
* `gtk.main()`:运行 GTK 主循环。
|
||||
* 在 `menu()` 中我们定义了想要指示器提供的行为或项目。`command_one = gtk.MenuItem('My Notes')` 仅仅使用文本 “My notes” 来初始化第一个菜单项,接下来 `command_one.connect('activate',note)` 将菜单的 `activate` 信号与后面定义的 `note()` 函数相连接;换句话说,我们告诉我们的系统:“当该菜单项被点击,运行 `note()` 函数”。最后,`menu.append(command_one)` 将菜单项添加到列表中。
|
||||
* `exittray` 相关的行是为了创建一个退出的菜单项,以便让你在想要的时候关闭指示器。
|
||||
* `menu.show_all()` 以及 `return menu` 只是返回菜单项给指示器的常规代码。
|
||||
* 在 `note(_)` 下面是点击 “My Notes” 菜单项时需要执行的代码。这里只是 `os.system("gedit $HOME/Documents/notes.txt")` 这一句话;`os.system` 函数允许你在 Python 中运行 shell 命令,因此这里我们写了一行命令来使用 `gedit` 打开家目录下 `Documents` 目录中名为 `notes.txt` 的文件。例如,这个可以称为你今后的日常笔记程序了!
|
||||
|
||||
### 添加你所需要的任务
|
||||
|
||||
你只需要修改代码中的两块地方:
|
||||
|
||||
1. 在 `menu()` 中为你想要的任务定义新的菜单项。
|
||||
2. 创建一个新的函数让给该菜单项被点击时执行特定的行为。
|
||||
|
||||
所以,比如说你想要创建一个新菜单项,在点击后,会使用 VLC 播放硬盘中某个特定的视频/音频文件?要做到这一点,只需要在第 17 行处添加下面三行内容:
|
||||
|
||||
```
|
||||
command_two = gtk.MenuItem('Play video/audio')
|
||||
command_two.connect('activate', play)
|
||||
menu.append(command_two)
|
||||
```
|
||||
|
||||
然后在第 30 行添加下面内容:
|
||||
|
||||
```
|
||||
def play(_):
|
||||
os.system("vlc /home/<username>/Videos/somevideo.mp4")
|
||||
```
|
||||
|
||||
将` `/home/<username>/Videos/somevideo.mp4` 替换成你想要播放的视频/音频文件路径。现在保存该文件然后再次运行该指示器:
|
||||
|
||||
```
|
||||
python tray.py
|
||||
```
|
||||
|
||||
你将会看到:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 15][4]
|
||||
|
||||
而且当你点击新创建的菜单项时,VLC 会开始播放!
|
||||
|
||||
要创建其他项目/任务,只需要重复上面步骤即可。但是要小心,需要用其他命令来替换 `command_two`,比如 `command_three`,这样在变量之间才不会产生冲突。然后定义新函数,就像 `play(_)` 函数那样。
|
||||
|
||||
可能性是无穷的;比如我用这种方法来从网上获取数据(使用 urllib2 库)并显示出来。我也用它来在后台使用 `mpg123` 命令播放 mp3 文件,而且我还定义了另一个菜单项来 `killall mpg123` 以随时停止播放音频。比如 Steam 上的 CS:GO 退出很费时间(窗口并不会自动关闭),因此,作为一个变通的方法,我只是最小化窗口然后点击某个自建的菜单项,它会执行 `killall -9 csgo_linux64` 命令。
|
||||
|
||||
你可以使用这个指示器来做任何事情:升级系统包、运行其他脚本——字面上的任何事情。
|
||||
|
||||
### 自动启动
|
||||
|
||||
我们希望系统托盘指示器能在系统启动后自动启动,而不用每次都手工运行。要做到这一点,只需要在自启动应用程序中添加下面命令即可(但是你需要将 `tray.py` 的路径替换成你自己的路径):
|
||||
|
||||
```
|
||||
nohup python /home/<username>/tray.py &
|
||||
```
|
||||
|
||||
下次重启系统,指示器会在系统启动后自动开始工作了!
|
||||
|
||||
### 结论
|
||||
|
||||
你现在知道了如何为你想要的任务创建自己的系统托盘指示器了。根据每天需要运行的任务的性质和数量,此方法可以节省大量时间。有些人偏爱从命令行创建别名,但是这需要你每次都打开终端窗口或者需要有一个可用的下拉式终端仿真器,而这里,这个系统托盘指示器一直在工作,随时可用。
|
||||
|
||||
你以前用过这个方法来运行你的任务吗?很想听听你的想法。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux
|
||||
|
||||
作者:[M.Hanny Sabbagh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fosspost.org/author/mhsabbagh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Screenshot-at-2019-02-28-0808.png?resize=407%2C345&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 12)
|
||||
[2]: https://extensions.gnome.org/extension/1031/topicons/
|
||||
[3]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1041.png?resize=434%2C140&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 14)
|
||||
[4]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1141.png?resize=440%2C149&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 16)
|
||||
@ -1,30 +1,32 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (luuming)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11067-1.html)
|
||||
[#]: subject: (When to be concerned about memory levels on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3394603/when-to-be-concerned-about-memory-levels-on-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
何时需要关注 linux 的内存层面?
|
||||
何时需要关注 Linux 的内存用量?
|
||||
======
|
||||
Linux 上的内存管理很复杂。尽管使用率高但未必存在问题。你也应当关注一些其他的事情。
|
||||
![Qfamily \(CC BY 2.0\)][1]
|
||||
|
||||
> Linux 上的内存管理很复杂。尽管使用率高但未必存在问题。你也应当关注一些其他的事情。
|
||||
|
||||

|
||||
|
||||
在 Linux 上用光内存通常并不意味着存在严重的问题。为什么?因为健康的 Linux 系统会在内存中缓存磁盘活动,基本上占用掉了未被使用的内存,这显然是一件好事情。
|
||||
|
||||
换句话说,它不让内存浪费掉。使用空闲的内存增加磁盘访问速度,并且不占用运行中应用程序的内存。你也能够想到,使用这种内存缓存比起直接访问硬盘驱动(HDD)快上数百倍,也比明显快于直接访问固态硬盘驱动。内存占满或几乎占满通常意味着系统正在尽可能高效地运行当中——并不是运行中遇到了问题。
|
||||
换句话说,它不让内存浪费掉。使用空闲的内存增加磁盘访问速度,并且不占用运行中应用程序的内存。你也能够想到,使用这种内存缓存比起直接访问硬盘驱动器(HDD)快上数百倍,也比明显快于直接访问固态硬盘驱动。内存占满或几乎占满通常意味着系统正在尽可能高效地运行当中 —— 并不是运行中遇到了问题。
|
||||
|
||||
### 缓存如何工作
|
||||
|
||||
磁盘缓存简单地意味着系统充分利用未使用的资源(空闲内存)来加速磁盘读取与写入。应用程序不会失去任何东西,并且大多数时间里能够按需求获得更多的内存。此外,磁盘缓存不会导致应用程序使用交换分区。反而,用作磁盘缓存的内存空间当被需要时会立即归还,并且磁盘内容会被更新。
|
||||
磁盘缓存简单地意味着系统充分利用未使用的资源(空闲内存)来加速磁盘读取与写入。应用程序不会失去任何东西,并且大多数时间里能够按需求获得更多的内存。此外,磁盘缓存不会导致应用程序转而使用交换分区。反而,用作磁盘缓存的内存空间当被需要时会立即归还,并且磁盘内容会被更新。
|
||||
|
||||
### 主要和次要的页故障
|
||||
|
||||
Linux 系统通过分割物理内存为进程分配空间,将分割成的块称为“页”,并且映射这些页到每个进程的虚拟内存上。不再会用到的页也许会从内存中移除,尽管相关的进程还在运行。当进程需要一个没有被映射或没在内存中页时,故障便会产生。所以,“<ruby>故障<rt>fault</rt></ruby>”并不意味着“<ruby>错误<rt>error</rt></ruby>”而是“<ruby>不可用<rt>unavailables</rt></ruby>”,并且故障在内存管理中扮演者一个重要的角色。
|
||||
Linux 系统通过分割物理内存来为进程分配空间,将分割成的块称为“页”,并且映射这些页到每个进程的虚拟内存上。不再会用到的页也许会从内存中移除,尽管相关的进程还在运行。当进程需要一个没有被映射或没在内存中页时,故障便会产生。所以,这个“<ruby>故障<rt>fault</rt></ruby>”并不意味着“<ruby>错误<rt>error</rt></ruby>”而是“<ruby>不可用<rt>unavailables</rt></ruby>”,并且故障在内存管理中扮演者一个重要的角色。
|
||||
|
||||
次要故障意味着在内存中的页未分配给请求的进程或未在内存管理单元中标记为出现。主要故障意味着页不保留在内存中。
|
||||
次要故障意味着在内存中的页未分配给请求的进程,或未在内存管理单元中标记为出现。主要故障意味着页没有保留在内存中。
|
||||
|
||||
如果你想切身感受一下次要页故障和主要页故障出现的频率,像这样试一下 `ps` 命令。注意我们要的是与页故障和产生它的命令相关的项。输出中省略了很多行。`MINFL` 显示出次要故障的数目,而 `MAJFL` 表示了主要故障的数目。
|
||||
|
||||
@ -45,7 +47,7 @@ $ ps -eo min_flt,maj_flt,cmd
|
||||
927 0 gdm-session-worker [pam/gdm-password]
|
||||
```
|
||||
|
||||
汇报单一进程,你可以尝试这样的命令:
|
||||
汇报单一进程,你可以尝试这样的命令(LCTT 译注:参数里面的 `1` 是要查看的进程的 PID):
|
||||
|
||||
```
|
||||
$ ps -o min_flt,maj_flt 1
|
||||
@ -53,7 +55,7 @@ $ ps -o min_flt,maj_flt 1
|
||||
230064 150
|
||||
```
|
||||
|
||||
你也可以添加其他的项,例如进程所有者的 UID 和 GID。
|
||||
你也可以添加其他的显示字段,例如进程所有者的 UID 和 GID。
|
||||
|
||||
```
|
||||
$ ps -o min_flt,maj_flt,cmd,args,uid,gid 1
|
||||
@ -63,7 +65,7 @@ $ ps -o min_flt,maj_flt,cmd,args,uid,gid 1
|
||||
|
||||
### 多少才算满?
|
||||
|
||||
一种较好的方法来掌握内存究竟使用了多少是用 `free -m` 命令。`-m` 选项指定了数字的单位是 <ruby>MiBs<rt>mebibytes</rt></ruby> 而不是字节。
|
||||
一种较好的方法来掌握内存究竟使用了多少是用 `free -m` 命令。`-m` 选项指定了数字的单位是 <ruby>MiB<rt>mebibyte</rt></ruby> 而不是字节。
|
||||
|
||||
```
|
||||
$ free -m
|
||||
@ -76,7 +78,7 @@ Swap: 3535 0 3535
|
||||
|
||||
### 什么时候要担心
|
||||
|
||||
如果 Linux 系统上的性能表现良好——应用程序响应度高,命令行没有显示出问题——很可能系统状况良好。记住,一些应用也许会出于某种原因而变慢,但它不影响整个系统。
|
||||
如果 Linux 系统上的性能表现良好 —— 应用程序响应度高,命令行没有显示出问题 —— 很可能系统状况良好。记住,一些应用也许会出于某种原因而变慢,但它不影响整个系统。
|
||||
|
||||
过多的硬故障也许表明确实存在问题,但要将其与观察到的性能相比较。
|
||||
|
||||
@ -91,11 +93,10 @@ Swap: 3535 0 3535
|
||||
|
||||
### Linux 性能很复杂
|
||||
|
||||
把所有的放在一边,Linux 系统上的内存可能会变满,并且性能可能会降低。当系统出现问题时不要仅将单一的内存使用报告作为指标。
|
||||
抛开这些不说,Linux 系统上的内存可能会变满,并且性能可能会降低。当系统出现问题时不要仅将单一的内存使用报告作为指标。
|
||||
|
||||
Linux 系统的内存管理很复杂,因为它采取的措施需要确保系统资源得到最好的利用。不要受到一开始内存占满的欺骗,使你认为系统存在问题,但实际上并没有。
|
||||
|
||||
在 [Facebook][4] 和 [LinkedIn][5] 上加入网络研讨会发表你的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -104,7 +105,7 @@ via: https://www.networkworld.com/article/3394603/when-to-be-concerned-about-mem
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11058-1.html)
|
||||
[#]: subject: (Zorin OS Becomes Even More Awesome With Zorin 15 Release)
|
||||
[#]: via: (https://itsfoss.com/zorin-os-15-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
随着 Zorin 15 的发布,Zorin OS 变得更为强大
|
||||
======
|
||||
|
||||

|
||||
|
||||
长久以来 Zorin OS 一直在 [初学者适用的Linux发行版排行][1] 中占有一席之地。的确,它可能不是最受欢迎的,但是对于从 Windows 阵营转向 Linux 的用户而言,它一定是最好的一个发行版。
|
||||
|
||||
我还记得,在几年前,我的一位朋友一直坚持让我安装 [Zorin OS][2]。就我个人而言,当时我并不喜欢它的 UI 风格。但是,现如今 Zorin OS 15 发布了,这也让我有了更多的理由安装并将它作为我日常的操作系统。
|
||||
|
||||
不要担心,在这篇文章里,我会向你介绍你所需要了解的一切。
|
||||
|
||||
### Zorin 15 中的新特性
|
||||
|
||||
让我们来看一下最新版本的 Zorin 有哪些主要的改变。Zorin 15 是基于 Ubuntu 18.04.2 的,因此带来了许多性能上的提升。除此之外,也有许多 UI(用户界面)的改进。
|
||||
|
||||
#### Zorin Connect
|
||||
|
||||
![Zorin Connect][3]
|
||||
|
||||
Zorin OS 15 最主要的一个亮点就是 —— Zorin Connect。如果你使用的是安卓设备,那你一定会喜欢这一功能。类似于 [PushBullet][4](LCTT 译注:PushBullet,子弹推送,一款跨平台推送工具), [Zorin Connect][5] 会提升你的手机和桌面一体化的体验。
|
||||
|
||||
你可以在桌面上同步智能手机的通知,同时还可以回复它。甚至,你可以回复短信并查看对话。
|
||||
|
||||
总的来说,你可以体验到以下功能:
|
||||
|
||||
* 在设备间分享文件或链接
|
||||
* 将你的手机作为电脑的遥控器
|
||||
* 使用手机控制电脑上媒体的播放,并且当有来电接入时自动停止播放
|
||||
|
||||
正如他们在[官方公告][6]中提到的, 数据的传输仅限于本地网络之间,并且不会有数据被上传到云端服务器。通过以下操作体验 Zorin Connect ,找到:Zorin menu (Zorin 菜单) > System Tools (系统工具) > Zorin Connect。
|
||||
|
||||
#### 新的桌面主题(包含夜间模式!)
|
||||
|
||||
![Zorin 夜间模式][7]
|
||||
|
||||
一提到 “夜间模式” 我就毫无抵抗力。对我而言,这是Zorin OS 15 自带的最好的功能。
|
||||
|
||||
当我启用了界面的深色模式时,我的眼睛感到如此舒适,你不想来试试么?
|
||||
|
||||
它不单单是一个深色的主题,而是 UI 更干净直观,并且带有恰到好处的新动画。你可以从 Zorin 内置的外观应用程序里找到所有的相关设置。
|
||||
|
||||
#### 自适应背景调整 & 深色浅色模式
|
||||
|
||||
你可以选择让桌面背景根据一天中每小时的环境亮度进行自动调整。此外,如果你想避免蓝光给眼睛带来伤害,你可以使用夜间模式。
|
||||
|
||||
#### 代办事项应用
|
||||
|
||||
![Todo][9]
|
||||
|
||||
我一直希望支持这个功能,这样我就不必使用其他 Linux 客户端程序来添加任务。很高兴看到内置的应用程序集成并支持谷歌任务和 Todoist。
|
||||
|
||||
#### 还有更多么?
|
||||
|
||||
是的!其他主要的变化包括对 Flatpak 的支持,支持平板笔记本二合一电脑的触摸布局,DND 模式,以及一些重新设计的应用程序(设置、Libre Office),以此来给你更好的用户体验。
|
||||
|
||||
如果你想要了解所有更新和改动的详细信息,你可以查看[官方公告][6]。如果你已经是 Zorin 的用户,你应该已经注意到他们的网站也已经启用了一个全新的外观。
|
||||
|
||||
### 下载 Zorin OS 15
|
||||
|
||||
**注释** : 今年的晚些时候将会推出从 Zorin OS 12 直升 15 版本而不需要重新安装的升级包。
|
||||
|
||||
提示一下,Zorin OS 有三个版本:旗舰版本、核心板和轻量版。
|
||||
|
||||
如果你想支持开发者和项目,同时解锁 Zorin OS 全部的功能,你可以花 39 美元购买旗舰版本。
|
||||
|
||||
如果你只是想要一些基本功能,核心版就可以了(你可以免费下载)。如果是这种情况,比如你有一台旧电脑,那么你可以使用轻量版。
|
||||
|
||||
- [下载 ZORIN OS 15][10]
|
||||
|
||||
你觉得 Zorin 15 怎么样?
|
||||
|
||||
我肯定会尝试一下,将 Zorin OS 作为我的主要操作系统 -(手动狗头)。你呢?你觉得最新的版本怎么样?欢迎在下面的评论中告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/zorin-os-15-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-beginners/
|
||||
[2]: https://zorinos.com/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-connect.jpg
|
||||
[4]: https://www.pushbullet.com/
|
||||
[5]: https://play.google.com/store/apps/details?id=com.zorinos.zorin_connect&hl=en_IN
|
||||
[6]: https://zoringroup.com/blog/2019/06/05/zorin-os-15-is-here-faster-easier-more-connected/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-dark-mode.jpg
|
||||
[8]: https://itsfoss.com/necunos-linux-smartphone/
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/Todo.jpg
|
||||
[10]: https://zorinos.com/download/
|
||||
[11]: https://itsfoss.com/ubuntu-1404-codenamed-trusty-tahr/
|
||||
@ -1,36 +1,37 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11063-1.html)
|
||||
[#]: subject: (Free and Open Source Trello Alternative OpenProject 9 Released)
|
||||
[#]: via: (https://itsfoss.com/openproject-9-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
替代 Trello 的免费开源 OpenProject 9 发布了
|
||||
替代 Trello 的 OpenProject 9 发布了
|
||||
======
|
||||
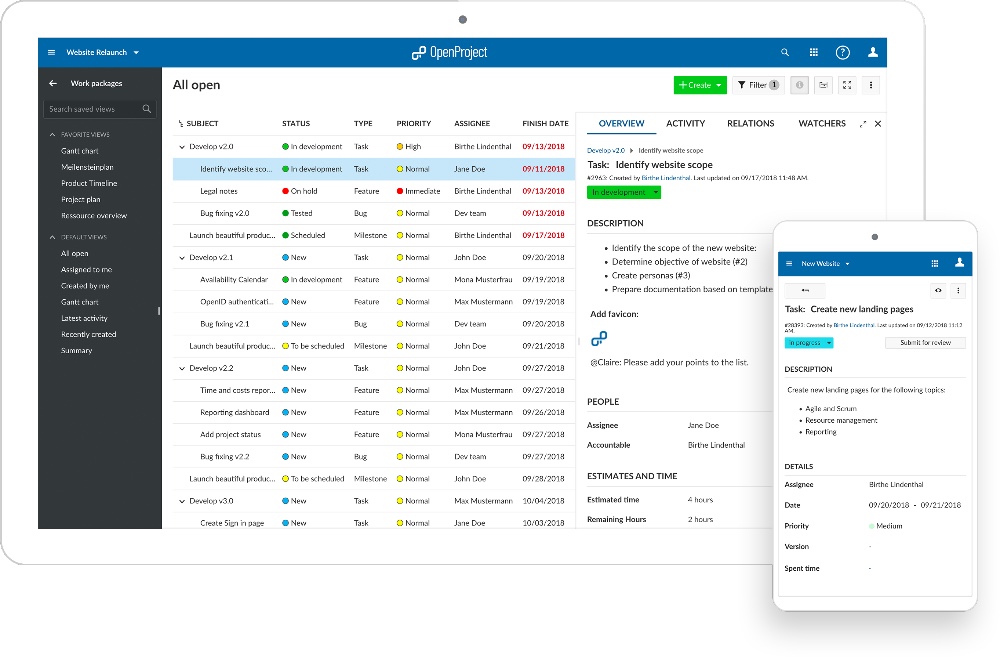
|
||||
|
||||
[OpenProject][1] 是一个开源项目协作管理软件。它是 [Trello][2] 和 [Jira][3] 等专有方案的替代品。
|
||||
|
||||
如果个人使用,你可以免费使用它,并在你自己的服务器上进行设置(并托管它)。这样,你就可以控制数据。
|
||||
|
||||
当然,如果你是[云或企业版用户][4],那么你可以使用高级功能和更优先的帮助。
|
||||
当然,如果你是[企业云版的用户][4],那么你可以使用高级功能和更优先的帮助。
|
||||
|
||||
OpenProject 9 的重点是新的看板试图,包列表视图和工作模板。
|
||||
OpenProject 9 的重点是新的面板视图,包列表视图和工作模板。
|
||||
|
||||
如果你对此不了解,可以尝试一下。但是,如果你是现有用户 - 在迁移到 OpenProject 9 之前,你应该知道这些新功能。
|
||||
如果你对此不了解,可以尝试一下。但是,如果你是已有用户 —— 在迁移到 OpenProject 9 之前,你应该知道这些新功能。
|
||||
|
||||
### OpenProject 9 有什么新功能?
|
||||
|
||||
以下是最新版 OpenProjec t的一些主要更改。
|
||||
以下是最新版 OpenProject 的一些主要更改。
|
||||
|
||||
#### Scrum 和敏捷看板
|
||||
#### Scrum 和敏捷面板
|
||||
|
||||
![][5]
|
||||
|
||||
对于云和企业版,有一个新的 [scrum][6] 和[敏捷][7]看板视图。你还可以 [kanban 风格][8]方式展示你的工作,从而更轻松地支持你的敏捷和 scrum 团队。
|
||||
对于企业云版,有了一个新的 [scrum][6] 和[敏捷][7]面板视图。你还可以[看板风格][8]方式展示你的工作,从而更轻松地支持你的敏捷和 scrum 团队。
|
||||
|
||||
新的看板视图使你可以轻松了解为该任务分配的人员并快速更新状态。你还有不同的看板视图选项,如基本看板、状态看板和版本看板。
|
||||
新的面板视图使你可以轻松了解为该任务分配的人员并快速更新状态。你还有不同的面板视图选项,如基本面板、状态面板和版本面板。
|
||||
|
||||
#### 工作包模板
|
||||
|
||||
@ -46,9 +47,9 @@ OpenProject 9 的重点是新的看板试图,包列表视图和工作模板。
|
||||
|
||||
#### “我的”页面的可自定义工作包视图
|
||||
|
||||
“我的”页面显示你正在处理的内容(以及进度),它不应该一直很无聊。因此,现在你可以自定义它,甚至可以添加甘特图来可视化你的工作。
|
||||
“我的”页面显示你正在处理的内容(以及进度),它不应该一直那么呆板。因此,现在你可以自定义它,甚至可以添加甘特图来可视化你的工作。
|
||||
|
||||
**总结**
|
||||
### 总结
|
||||
|
||||
有关迁移和安装的详细说明,请参阅[官方的公告帖][12],其中包含了必要的细节。
|
||||
|
||||
@ -61,7 +62,7 @@ via: https://itsfoss.com/openproject-9-release/
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,18 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11064-1.html)
|
||||
[#]: subject: (IPython is still the heart of Jupyter Notebooks for Python developers)
|
||||
[#]: via: (https://opensource.com/article/19/6/ipython-still-heart-jupyterlab)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg/users/marcobravo)
|
||||
|
||||
对 Python 开发者而言,IPython 仍然是 Jupyter Notebook 的核心
|
||||
======
|
||||
Jupyter 项目提供的魔法般的开发体验很大程度上得益于它的 IPython 基因。
|
||||
![I love Free Software FSFE celebration][1]
|
||||
|
||||
> Jupyter 项目提供的魔法般的开发体验很大程度上得益于它的 IPython 基因。
|
||||
|
||||

|
||||
|
||||
最近刚刚写过我为什么觉得觉得 Jupyter 项目(特别是 JupyterLab)提供了一种 [魔法般的 Python 开发体验][2]。在研究这些不同项目之间的关联的时候,我回顾了一下 Jupyter 最初从 IPython 分支出来的这段历史。正如 Jupyter 项目的 [大拆分™ 声明][3] 所说:
|
||||
|
||||
@ -34,7 +36,7 @@ Jupyter 项目提供的魔法般的开发体验很大程度上得益于它的 IP
|
||||
|
||||
### IPython 如今的作用
|
||||
|
||||
IPython 提供了一个强大的、交互性的 Python shell,以及 Jupyter 的内核。安装完成之后,我可以在任何命令行运行 **ipython** 本身,将它当作一个(比默认 Python shell 好太多的)Python shell 来使用:
|
||||
IPython 提供了一个强大的、交互性的 Python shell,以及 Jupyter 的内核。安装完成之后,我可以在任何命令行运行 `ipython` 本身,将它当作一个(比默认 Python shell 好太多的)Python shell 来使用:
|
||||
|
||||
|
||||
```
|
||||
@ -50,15 +52,15 @@ In [4]: print(average)
|
||||
6.571428571428571
|
||||
```
|
||||
|
||||
这就让我们发现了一个更为重要的问题:是IPython 让 JupyterLab 可以在项目中执行代码,并且支持了一系列被称为 *magic*的功能(感谢 Nicholas Reith 在我上一篇文章的评论里提到这点)。
|
||||
这就让我们发现了一个更为重要的问题:是 IPython 让 JupyterLab 可以在项目中执行代码,并且支持了一系列被称为 *Magic* 的功能(感谢 Nicholas Reith 在我上一篇文章的评论里提到这点)。
|
||||
|
||||
### IPython 让魔法成为现实
|
||||
|
||||
JupyterLab 和其它使用 IPython 的前端工具可以让你感觉像是在最喜欢的 IDE 或者是终端模拟器的环境下工作。我非常喜欢 [dotfiles][5] 快捷键功能,magic 也有类似 dotfile 的特征。比如说,可以试一下 **[%bookmark][6]** 这个命令。我把默认开发文件夹 **~/Develop** 关联到了一个可以在任何时候直接跳转的快捷方式上。
|
||||
JupyterLab 和其它使用 IPython 的前端工具可以让你感觉像是在最喜欢的 IDE 或者是终端模拟器的环境下工作。我非常喜欢 [点文件][5] 快捷键功能,Magic 也有类似点文件的特征。比如说,可以试一下 [%bookmark][6] 这个命令。我把默认开发文件夹 `~/Develop` 关联到了一个可以在任何时候直接跳转的快捷方式上。
|
||||
|
||||
![Screenshot of commands from JupyterLab][7]
|
||||
|
||||
**%bookmark**、**%cd**,以及我在前一篇文章里介绍过的 **!** 操作符,都是由 IPython 支持的。正如这篇 [文档][8] 所说:
|
||||
`%bookmark`、`%cd`,以及我在前一篇文章里介绍过的 `!` 操作符,都是由 IPython 支持的。正如这篇 [文档][8] 所说:
|
||||
|
||||
> Jupyter 用户你们好:Magic 功能是 IPython 内核提供的专属功能。一个内核是否支持 Magic 功能是由该内核的开发者针对该内核所决定的。
|
||||
|
||||
@ -66,7 +68,7 @@ JupyterLab 和其它使用 IPython 的前端工具可以让你感觉像是在最
|
||||
|
||||
作为一个好奇的新手,我之前并不是特别确定 IPython 是否仍然和 Jupyter 生态还有任何联系。现在我对 IPython 的持续开发有了新的认识和,并且意识到它正是 JupyterLab 强大的用户体验的来源。这也是相当有才华的一批贡献者进行最前沿研究的成果,所以如果你在学术论文中使用到了 Jupyter 项目的话别忘了引用他们。为了方便引用,他们还提供了一个 [现成的引文][9]。
|
||||
|
||||
如果你在考虑参与哪个开源项目的贡献的话,一定不要忘了 IPython 哦。记得看看 [最新发布说明][10],在这里可以找到 magic 功能的完整列表。
|
||||
如果你在考虑参与哪个开源项目的贡献的话,一定不要忘了 IPython 哦。记得看看 [最新发布说明][10],在这里可以找到 Magic 功能的完整列表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -74,8 +76,8 @@ via: https://opensource.com/article/19/6/ipython-still-heart-jupyterlab
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,24 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11056-1.html)
|
||||
[#]: subject: (A beginner's guide to Linux permissions)
|
||||
[#]: via: (https://opensource.com/article/19/6/understanding-linux-permissions)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brson/users/greg-p/users/tj)
|
||||
|
||||
Linux 权限入门指南
|
||||
======
|
||||
Linux安全权限能够指定谁可以对文件或目录执行什么操作。
|
||||
![Hand putting a Linux file folder into a drawer][1]
|
||||
|
||||
与其他系统相比而言 Linux 系统的众多优点中最为主要一个便是Linux 系统有着更少的安全漏洞和被攻击的隐患。Linux无疑为用户提供了更为灵活和精细化的文件系统安全权限控制。这可能意味着Linux用户理解安全权限是至关重要的。虽然这并不一定是必要的,但是对于初学者来说,理解Linux权限的基本知识仍是一个明智之选。
|
||||
> Linux 安全权限能够指定谁可以对文件或目录执行什么操作。
|
||||
|
||||

|
||||
|
||||
与其他系统相比而言 Linux 系统的众多优点中最为主要一个便是 Linux 系统有着更少的安全漏洞和被攻击的隐患。Linux 无疑为用户提供了更为灵活和精细化的文件系统安全权限控制。这可能意味着 Linux 用户理解安全权限是至关重要的。虽然这并不一定是必要的,但是对于初学者来说,理解 Linux 权限的基本知识仍是一个明智之选。
|
||||
|
||||
### 查看 Linux 安全权限
|
||||
|
||||
在开始 Linux 权限的相关学习之前,假设我们新建了一个名为 **PermissionDemo**的目录。使用 **cd** 命令进入这个目录,然后使用 **ls -l** 命令查看 Linux 安全管理权限信息。如果你想以时间为序排列,加上 **-t** 选项
|
||||
在开始 Linux 权限的相关学习之前,假设我们新建了一个名为 `PermissionDemo` 的目录。使用 `cd` 命令进入这个目录,然后使用 `ls -l` 命令查看 Linux 安全管理权限信息。如果你想以时间为序排列,加上 `-t` 选项
|
||||
|
||||
|
||||
```
|
||||
@ -27,11 +29,11 @@ Linux安全权限能够指定谁可以对文件或目录执行什么操作。
|
||||
|
||||
![No output from ls -l command][2]
|
||||
|
||||
要了解关于 **ls** 命令的更多信息,请通过在命令行中输入 **man ls** 来查看命令手册。
|
||||
要了解关于 `ls` 命令的更多信息,请通过在命令行中输入 `man ls` 来查看命令手册。
|
||||
|
||||
![ls man page][3]
|
||||
|
||||
现在,让我们创建两个名为 **cat.txt** 和 **dog.txt** 的空白文件;这一步使用 **touch** 命令将更为简便。然后继续使用 **mkdir** 命令创建一个名为 **Pets** 的空目录。我们可以再次使用**ls -l**命令查看这些新文件的权限。
|
||||
现在,让我们创建两个名为 `cat.txt` 和 `dog.txt` 的空白文件;这一步使用 `touch` 命令将更为简便。然后继续使用 `mkdir` 命令创建一个名为 `Pets` 的空目录。我们可以再次使用`ls -l`命令查看这些新文件的权限。
|
||||
|
||||
![Creating new files and directory][4]
|
||||
|
||||
@ -39,42 +41,43 @@ Linux安全权限能够指定谁可以对文件或目录执行什么操作。
|
||||
|
||||
### 谁拥有权限?
|
||||
|
||||
首先要注意的是 _who_ 具有访问文件/目录的权限。请注意下面红色框中突出显示的部分。第一列是指具有访问权限的 _user(用户)_ ,而第二列是指具有访问权限的 _group(组)_ 。
|
||||
首先要注意的是*谁*具有访问文件/目录的权限。请注意下面红色框中突出显示的部分。第一列是指具有访问权限的*用户*,而第二列是指具有访问权限的*组*。
|
||||
|
||||
![Output from -ls command][5]
|
||||
|
||||
用户的类型主要有三种:**user**、**group**;和**other**(本质上既不是用户也不是组)。还有一个**all**,意思是几乎所有人。
|
||||
用户的类型主要有三种:用户、组和其他人(本质上既不是用户也不是组)。还有一个*全部*,意思是几乎所有人。
|
||||
|
||||
![User types][6]
|
||||
|
||||
由于我们使用 **root** 作为当前用户,所以我们可以访问任何文件或目录,因为 **root** 是超级用户。然而,通常情况并非如此,您可能会被限定使用您的普通用户登录。所有的用户都存储在 **/etc/passwd** 文件中。
|
||||
由于我们使用 `root` 作为当前用户,所以我们可以访问任何文件或目录,因为 `root` 是超级用户。然而,通常情况并非如此,你可能会被限定使用你的普通用户登录。所有的用户都存储在 `/etc/passwd` 文件中。
|
||||
|
||||
![/etc/passwd file][7]
|
||||
|
||||
“组“的相关信息保存在 **/etc/group** 文件中。
|
||||
“组“的相关信息保存在 `/etc/group` 文件中。
|
||||
|
||||
![/etc/passwd file][8]
|
||||
|
||||
### 他们有什么权限?
|
||||
|
||||
我们需要注意的是 **ls -l** 命令输出结果的另一部分与执行权限有关。以上,我们查看了创建的dog.txt 和 cat.txt文件以及Pets目录的所有者和组权限都属于 **root** 用户。我们可以通过这一信息了解到不同用户组所拥有的相应权限,如下面的红色框中的标示。
|
||||
我们需要注意的是 `ls -l` 命令输出结果的另一部分与执行权限有关。以上,我们查看了创建的 `dog.txt` 和 `cat.txt` 文件以及 `Pets` 目录的所有者和组权限都属于 `root` 用户。我们可以通过这一信息了解到不同用户组所拥有的相应权限,如下面的红色框中的标示。
|
||||
|
||||
![Enforcing permissions for different user ownership types][9]
|
||||
|
||||
我们可以把每一行分解成五部分。第一部分标志着它是文件还是目录;文件用 **-** (连字符)标记,目录用 **d** 来标记。接下来的三个部分分别是**user**、**group**和**other**的对应权限。最后一部分是[**access-control list**][10] (ACL)(访问控制列表)的标志,是记录着特定用户或者用户组对该文件的操作权限的列表。
|
||||
我们可以把每一行分解成五部分。第一部分标志着它是文件还是目录:文件用 `-`(连字符)标记,目录用 `d` 来标记。接下来的三个部分分别是用户、组和其他人的对应权限。最后一部分是[访问控制列表][10] (ACL)的标志,是记录着特定用户或者用户组对该文件的操作权限的列表。
|
||||
|
||||
![Different Linux permissions][11]
|
||||
|
||||
Linux 的权限级别可以用字母或数字标识。有三种权限类型:
|
||||
|
||||
* **read(读):** r or 4
|
||||
* **write(写):** w or 2
|
||||
* **executable(可执行):** x or 1
|
||||
(LCTT译注:原文此处对应的字母标示 **x** 误写为 **e** 已更正)
|
||||
* 可读取:`r` 或 `4`
|
||||
* 可写入:`w` 或 `2`
|
||||
* 可执行:`x` 或 `1`
|
||||
|
||||
(LCTT 译注:原文此处对应的字母标示 `x` 误写为 `e`,已更正)
|
||||
|
||||
![Privilege types][12]
|
||||
|
||||
每个字母符号(**r**、**w**或**x**)表示有该项权限,而 **-** 表示无该项权限。在下面的示例中,文件的所有者可读可写,用户组成员仅可读,其他人可读可执行。转换成数字表示法,对应的是645(如何计算,请参见下图的图示)。
|
||||
每个字母符号(`r`、`w` 或 `x`)表示有该项权限,而 `-` 表示无该项权限。在下面的示例中,文件的所有者可读可写,用户组成员仅可读,其他人可读可执行。转换成数字表示法,对应的是 `645`(如何计算,请参见下图的图示)。
|
||||
|
||||
![Permission type example][13]
|
||||
|
||||
@ -93,7 +96,7 @@ via: https://opensource.com/article/19/6/understanding-linux-permissions
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
202
published/20190627 How to use Tig to browse Git logs.md
Normal file
202
published/20190627 How to use Tig to browse Git logs.md
Normal file
@ -0,0 +1,202 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11069-1.html)
|
||||
[#]: subject: (How to use Tig to browse Git logs)
|
||||
[#]: via: (https://opensource.com/article/19/6/what-tig)
|
||||
[#]: author: (Olaf Alders https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo)
|
||||
|
||||
如何使用 Tig 浏览 Git 日志
|
||||
======
|
||||
|
||||
> Tig 可不仅仅是 Git 的文本界面。以下是它如何增强你的日常工作流程。
|
||||
|
||||

|
||||
|
||||
如果你使用 Git 作为你的版本控制系统,你可能已经让自己接受了 Git 是一个复杂的野兽的事实。它是一个很棒的工具,但浏览 Git 仓库可能很麻烦。因此像 [Tig][2] 这样的工具出现了。
|
||||
|
||||
来自 [Tig 手册页][3]:
|
||||
|
||||
> Tig 是 `git`(1) 的基于 ncurses 的文本界面。它主要用作 Git 仓库浏览器,但也有助于在块级别暂存提交更改,并作为各种 Git 命令的输出分页器。
|
||||
|
||||
这基本上意味着 Tig 提供了一个可以在终端中运行的基于文本的用户界面。Tig 可以让你轻松浏览你的 Git 日志,但它可以做的远不止让你从最后的提交跳到前一个提交。
|
||||
|
||||
![Tig screenshot][4]
|
||||
|
||||
这篇快速入门的 Tig 中的许多例子都是直接从其出色的手册页中拿出来的。我强烈建议你阅读它以了解更多信息。
|
||||
|
||||
### 安装 Tig
|
||||
|
||||
* Fedora 和 RHEL: `sudo dnf install tig`
|
||||
* Ubuntu 和 Debian: `sudo apt install tig`
|
||||
* MacOS: `:brew install tig`
|
||||
|
||||
有关更多方式,请参阅官方[安装说明][5]。
|
||||
|
||||
### 浏览当前分支中的提交
|
||||
|
||||
如果要浏览分支中的最新提交,请输入:
|
||||
|
||||
```
|
||||
tig
|
||||
```
|
||||
|
||||
就是这样。这个三字符命令将启动一个浏览器,你可以在其中浏览当前分支中的提交。你可以将其视为 `git log` 的封装器。
|
||||
|
||||
要浏览这些输出,可以使用向上和向下箭头键从一个提交移动到另一个提交。按回车键将会垂直分割窗口,右侧包含所选提交的内容。你可以继续在左侧的提交历史记录中上下浏览,你的更改将显示在右侧。使用 `k` 和 `j` 可以逐行上下浏览,`-` 和空格键可以在右侧上下翻页。使用 `q` 退出右侧窗格。
|
||||
|
||||
搜索 `tig` 输出也很简单。使用 `/` (向前)或 `?` (向后)在左右窗格中搜索。
|
||||
|
||||
![Searching Tig][6]
|
||||
|
||||
这些就足以让你浏览你的提交信息了。这里有很多的键绑定,但单击 `h` 将显示“帮助”菜单,你可以在其中发现其导航和命令选项。你还可以使用 `/` 和 `?` 来搜索“帮助”菜单。使用 `q` 退出帮助。
|
||||
|
||||
![Tig Help][7]
|
||||
|
||||
### 浏览单个文件的修改
|
||||
|
||||
由于 Tig 是 `git log` 的封装器,它可以方便地接受可以传递给 `git log` 的相同参数。例如,要浏览单个文件的提交历史记录,请输入:
|
||||
|
||||
```
|
||||
tig README.md
|
||||
```
|
||||
|
||||
将其与被封装的 Git 命令的输出进行比较,以便更清楚地了解 Tig 如何增强输出。
|
||||
|
||||
```
|
||||
git log README.md
|
||||
```
|
||||
|
||||
要在原始 Git 输出中包含补丁,你可以添加 `-p` 选项:
|
||||
|
||||
```
|
||||
git log -p README.md
|
||||
```
|
||||
|
||||
如果要将提交范围缩小到特定日期范围,请尝试以下操作:
|
||||
|
||||
```
|
||||
tig --after="2017-01-01" --before="2018-05-16" -- README.md
|
||||
```
|
||||
|
||||
再一次,你可以将其与原始的 Git 版本进行比较:
|
||||
|
||||
|
||||
```
|
||||
git log --after="2017-01-01" --before="2018-05-16" -- README.md
|
||||
```
|
||||
|
||||
### 浏览谁更改了文件
|
||||
|
||||
有时你想知道谁对文件进行了更改以及原因。命令:
|
||||
|
||||
```
|
||||
tig blame README.md
|
||||
```
|
||||
|
||||
器本质上是 `git blame` 的封装。正如你所期望的那样,它允许你查看谁是编辑指定行的最后一人,它还允许你查看到引入该行的提交。这有点像 vim 的 `vim-fugitive` 插件提供的 `:Gblame` 命令。
|
||||
|
||||
### 浏览你的暂存区
|
||||
|
||||
如果你像我一样,你可能会在你的暂存区做了许多修改。你很容易忘记它们。你可以通过以下方式查看暂存处中的最新项目:
|
||||
|
||||
```
|
||||
git stash show -p stash@{0}
|
||||
```
|
||||
|
||||
你可以通过以下方式找到第二个最新项目:
|
||||
|
||||
```
|
||||
git stash show -p stash@{1}
|
||||
```
|
||||
|
||||
以此类推。如果你在需要它们时调用这些命令,那么你会有比我更清晰的记忆。
|
||||
|
||||
与上面的 Git 命令一样,Tig 可以通过简单的调用轻松增强你的 Git 输出:
|
||||
|
||||
```
|
||||
tig stash
|
||||
```
|
||||
|
||||
尝试在有暂存的仓库中执行此命令。你将能够浏览*并搜索*你的暂存项,快速浏览你的那些修改。
|
||||
|
||||
### 浏览你的引用
|
||||
|
||||
Git ref 是指你提交的东西的哈希值。这包括文件和分支。使用 `tig refs` 命令可以浏览所有的 ref 并深入查看特定提交。
|
||||
|
||||
```
|
||||
tig refs
|
||||
```
|
||||
|
||||
完成后,使用 `q` 回到前面的菜单。
|
||||
|
||||
### 浏览 git 状态
|
||||
|
||||
如果要查看哪些文件已被暂存,哪些文件未被跟踪,请使用 `tig status`,它是 `git status` 的封装。
|
||||
|
||||
![Tig status][8]
|
||||
|
||||
### 浏览 git grep
|
||||
|
||||
你可以使用 `grep` 命令在文本文件中搜索表达式。命令 `tig grep` 允许你浏览 `git grep` 的输出。例如:
|
||||
|
||||
```
|
||||
tig grep -i foo lib/Bar
|
||||
```
|
||||
|
||||
它会让你浏览 `lib/Bar` 目录中以大小写敏感的方式搜索 `foo` 的输出。
|
||||
|
||||
### 通过标准输入管道输出给 Tig
|
||||
|
||||
如果要将提交 ID 列表传递给 Tig,那么必须使用 `--stdin` 标志,以便 `tig show` 从标准输入读取。否则,`tig show` 会在没有输入的情况下启动(出现空白屏幕)。
|
||||
|
||||
```
|
||||
git rev-list --author=olaf HEAD | tig show --stdin
|
||||
```
|
||||
|
||||
### 添加自定义绑定
|
||||
|
||||
你可以使用 [rc][9] 文件自定义 Tig。以下是如何根据自己的喜好添加一些有用的自定义键绑定的示例。
|
||||
|
||||
在主目录中创建一个名为 `.tigrc` 的文件。在你喜欢的编辑器中打开 `~/.tigrc` 并添加:
|
||||
|
||||
```
|
||||
# 应用选定的暂存内容
|
||||
bind stash a !?git stash apply %(stash)
|
||||
|
||||
# 丢弃选定的暂存内容
|
||||
bind stash x !?git stash drop %(stash)
|
||||
```
|
||||
|
||||
如上所述,运行 `tig stash` 以浏览你的暂存。但是,通过这些绑定,你可以按 `a` 将暂存中的项目应用到仓库,并按 `x` 从暂存中删除项目。请记住,你要在浏览暂存*列表*时,才能执行这些命令。如果你正在浏览暂存*项*,请输入 `q` 退出该视图,然后按 `a` 或 `x` 以获得所需效果。
|
||||
|
||||
有关更多信息,你可以阅读有关 [Tig 键绑定][10]。
|
||||
|
||||
### 总结
|
||||
|
||||
我希望这有助于演示 Tig 如何增强你的日常工作流程。Tig 可以做更强大的事情(比如暂存代码行),但这超出了这篇介绍性文章的范围。这里有足够的让你置身于危险的信息,但还有更多值得探索的地方。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/what-tig
|
||||
|
||||
作者:[Olaf Alders][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb (A person programming)
|
||||
[2]: https://jonas.github.io/tig/
|
||||
[3]: http://manpages.ubuntu.com/manpages/bionic/man1/tig.1.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/tig.jpg (Tig screenshot)
|
||||
[5]: https://jonas.github.io/tig/INSTALL.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/tig-search.png (Searching Tig)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/tig-help.png (Tig Help)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/tig-status.png (Tig status)
|
||||
[9]: https://en.wikipedia.org/wiki/Run_commands
|
||||
[10]: https://github.com/jonas/tig/wiki/Bindings
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11059-1.html)
|
||||
[#]: subject: (Ubuntu or Fedora: Which One Should You Use and Why)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-vs-fedora/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -10,9 +10,9 @@
|
||||
你应该选择 Ubuntu 还是 Fedora?
|
||||
======
|
||||
|
||||
_**摘要:选择 Ubuntu 还是 Fedora?它们的区别是什么?哪一个更好?你应该使用哪一个?看看这篇对比 Ubuntu 和 Fedora 的文章吧。**_
|
||||
> 选择 Ubuntu 还是 Fedora?它们的区别是什么?哪一个更好?你应该使用哪一个?看看这篇对比 Ubuntu 和 Fedora 的文章吧。
|
||||
|
||||
Ubuntu 和 Fedora 都是最流行的 Linux 发行版之一,在两者之间做出选择实非易事。在这篇文章里,我会对比一下 Ubuntu 和 Fedora 的不同特点,帮助你进行决策。
|
||||
[Ubuntu][1] 和 [Fedora][2] 都是最流行的 Linux 发行版之一,在两者之间做出选择实非易事。在这篇文章里,我会对比一下 Ubuntu 和 Fedora 的不同特点,帮助你进行决策。
|
||||
|
||||
请注意,这篇文章主要是从桌面版的角度进行对比的。Fedora 或者 Ubuntu 针对容器的特殊版本不会被考虑在内。
|
||||
|
||||
@ -57,7 +57,7 @@ Ubuntu 和 Fedora 默认都使用 GNOME 桌面环境。
|
||||
|
||||
![GNOME Desktop in Fedora][6]
|
||||
|
||||
Fedora 使用的是 stock GNOME 桌面,而 Ubuntu 则在此基础上做了个性化调整,让它看起来就像 Ubuntu 之前使用的 Unity 桌面环境。
|
||||
Fedora 使用的是原装的 GNOME 桌面,而 Ubuntu 则在此基础上做了个性化调整,让它看起来就像 Ubuntu 之前使用的 Unity 桌面环境。
|
||||
|
||||
![GNOME desktop customized by Ubuntu][7]
|
||||
|
||||
@ -69,15 +69,13 @@ Fedora 通过 [Fedora Spins][8] 的方式提供了一些不同桌面环境的版
|
||||
|
||||
#### 软件包管理和可用软件数量
|
||||
|
||||
Ubuntu 使用 APT 软件包管理器提供软件并进行管理(包括应用程序、库,以及其它所需代码),而 Fedora 使用 DNF 软件包管理器。
|
||||
|
||||
[][9]
|
||||
Ubuntu 使用 APT 软件包管理器提供软件并进行管理(包括应用程序、库,以及其它所需编解码器),而 Fedora 使用 DNF 软件包管理器。
|
||||
|
||||
[Ubuntu 拥有庞大的软件仓库][10],能够让你轻松安装数以千计的程序,包括 FOSS(LCTT 译注:Free and Open-Source Software 的缩写,自由开源软件)和非 FOSS 的软件。Fedora 则只专注于提供开源软件。虽然这一点在最近的版本里有所转变,但是 Fedora 的软件仓库在规模上仍然比 Ubuntu 的要逊色一些。
|
||||
|
||||
一些第三方软件开发者为 Linux 提供像 .exe 文件一样可以点击安装的软件包。在 Ubuntu 里这些软件包是 .deb 格式的,在 Fedora 里是 .rpm 格式的。
|
||||
|
||||
大多数软件供应商都为 Linux 用户提供 DEM 和 RPM 文件,但是我也经历过供应商只提供 DEB 文件的情况。比如说 SEO 工具 [Screaming Frog][11] 就只提供 DEB 软件包。反过来,一个软件只有 RPM 格式但是没有 DEB 格式这种情况就极其罕见了。
|
||||
大多数软件供应商都为 Linux 用户提供 DEB 和 RPM 文件,但是我也经历过供应商只提供 DEB 文件的情况。比如说 SEO 工具 [Screaming Frog][11] 就只提供 DEB 软件包。反过来,一个软件只有 RPM 格式但是没有 DEB 格式这种情况就极其罕见了。
|
||||
|
||||
#### 硬件支持
|
||||
|
||||
@ -113,9 +111,9 @@ Fedora 则是红帽公司的一个社区项目。红帽公司是一个专注于
|
||||
|
||||
#### 在背后支持的企业
|
||||
|
||||
Ubuntu 和 Fedora 都有来自母公司的支持。Ubuntu 源自 [Canonical][21] 公司,而 Fedora 源自 [红帽公司][22](现在是 [IBM 的一部分][23])。背后企业的支持非常重要,因为可以确保 Linux 发行版良好的维护。
|
||||
Ubuntu 和 Fedora 都有来自母公司的支持。Ubuntu 源自 [Canonical][21] 公司,而 Fedora 源自 [红帽公司][22](现在是 [IBM 的一部分][23])。背后企业的支持非常重要,因为可以确保 Linux 发行版良好的维护。
|
||||
|
||||
有一些发行版是由一群独立的业余爱好者们共同创建的,但是在工作负荷之下经常会崩溃。你也许见过一些还算比较流行的发行版项目仅仅是因为这个原因而终止了。很多这样的发行版由于开发者没有足够的业余时间可以投入到项目上而不得不终止,比如 [Antergos][24] 和 Korora。
|
||||
有一些发行版是由一群独立的业余爱好者们共同创建的,但是在工作压力之下经常会结束。你也许见过一些还算比较流行的发行版项目仅仅是因为这个原因而终止了。很多这样的发行版由于开发者没有足够的业余时间可以投入到项目上而不得不终止,比如 [Antergos][24] 和 Korora。
|
||||
|
||||
Ubuntu 和 Fedora 的背后都有基于 Linux 的企业的支持,这让它们比其它独立的发行版更胜一筹。
|
||||
|
||||
@ -131,7 +129,7 @@ Fedora 同样有服务端版本,并且也有人在使用。但是大多数系
|
||||
|
||||
学习 Fedora 可以更好地帮助你使用红帽企业级 Linux(RHEL)。RHEL 是一个付费产品,你需要购买订阅才可以使用。如果你希望在服务器上运行一个和 Fedora 或者红帽类似的操作系统,我推荐使用 CentOS。[CentOS][26] 同样是红帽公司附属的一个社区项目,但是专注于服务端。
|
||||
|
||||
#### 结论
|
||||
### 结论
|
||||
|
||||
你可以看到,Ubuntu 和 Fedora 有很多相似之处。不过就可用软件数量、驱动安装和线上支持来说,Ubuntu 的确更有优势。**Ubuntu 也因此成为了一个更好的选择,尤其是对于没有经验的 Linux 新手而言。**
|
||||
|
||||
@ -147,8 +145,8 @@ via: https://itsfoss.com/ubuntu-vs-fedora/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11068-1.html)
|
||||
[#]: subject: (Say WHAAAT? Mozilla has Been Nominated for the “Internet Villain” Award in the UK)
|
||||
[#]: via: (https://itsfoss.com/mozilla-internet-villain/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
什么?!Mozilla 被提名英国“互联网恶棍”奖
|
||||
======
|
||||
|
||||
Mozilla Firefox 是目前最流行的浏览器之一。很多用户喜欢它胜过 Chrome 就是因为它鼓励隐私保护,并且可以通过一些选项设置让你的互联网活动尽可能地私密。
|
||||
|
||||
不过最近推出的功能之一 —— 仍然处于测试阶段的 [DoH (DNS-over-HTTPS)][1] 功能却受到了英国互联网服务提供商行业协会的负面评价。
|
||||
|
||||
英国<ruby>互联网服务提供商行业协会<rt>Internet Services Providers Association</rt></ruby>(ISPA)决定将 Mozilla 列入 2019 年“互联网恶棍”奖的最终入围者名单。该奖项将在 ISPA 于 7 月 11 日在伦敦举行的颁奖典礼上进行颁发。
|
||||
|
||||
![][3]
|
||||
|
||||
### 为什么说 “Mozilla” 是 “互联网恶棍”?
|
||||
|
||||
ISPA 在他们的声明中表示,Mozilla 因为支持了 DoH(DNS-over-HTTPS)而被视为“互联网恶棍”。
|
||||
|
||||
> [@mozilla][4] 被提名为 [#ISPA][5] 的 [#互联网恶棍][6] 是因为他们试图推行 DNS-over-HTTPS 以绕开英国的内容过滤系统和家长监护模式,破坏了英国 [#互联网][7] 安全准则。 <https://t.co/d9NaiaJYnk> [pic.twitter.com/WeZhLq2uvi][8]
|
||||
>
|
||||
> — 英国互联网提供商行业协会 (ISPAUK) (@ISPAUK) [2019 年 7 月 4 日][9]
|
||||
|
||||

|
||||
|
||||
和 Mozilla 一同被列入最终入围者名单的还有欧盟《版权法第 13 条》和美国总统特朗普。ISPA 在他们的声明里是这样解释的:
|
||||
|
||||
**Mozilla**:因为试图推行 DNS-over-HTTPS 以绕开英国的内容过滤系统和家长监护模式,破坏了英国互联网安全准则。
|
||||
|
||||
**欧盟《版权法第 13 条》**:因为要求各平台使用“内容识别技术”,威胁到了线上言论自由。
|
||||
|
||||
**美国总统特朗普**:因为在试图保护其国家安全的过程中,为复杂的全球通信供应链带来了巨大的不确定性。
|
||||
|
||||
### 什么是 DNS-over-HTTPS?
|
||||
|
||||
你可以将 DoH 理解为,域名解析服务(DNS)的请求通过 HTTPS 连接加密传输。
|
||||
|
||||
传统意义上的 DNS 请求是不会被加密的,因此你的 DNS 提供商或者是互联网服务提供商(ISP)可以监视或者是控制你的浏览行为。如果没有 DoH,你很容易被 DNS 提供商强制拦截和进行内容过滤,并且你的互联网服务提供商也同样可以做到。
|
||||
|
||||
然而 DoH 颠覆了这一点,可以让你得到一个私密的浏览体验。
|
||||
|
||||
你可以研究一下 [Mozilla 是如何开展和 Cloudflare 的合作的][11],并且可以自己配置一下 DoH(如果需要的话)。
|
||||
|
||||
### DoH 有用吗?
|
||||
|
||||
既有用又没有用。
|
||||
|
||||
当然了,从事情的一方面来看,DoH 可以帮助用户绕过 DNS 或者互联网服务提供商强制的内容过滤系统。如果说 DoH 有助于满足我们避开互联网审查的需求,那么它是一件好事情。
|
||||
|
||||
不过从事情的另一方面来看,如果你是一位家长,而你的孩子在 Mozilla Firefox 上使用了 DoH 的话,你就无法 [设置内容过滤器][12] 了。这取决于 [防火墙配置][13] 的好坏。
|
||||
|
||||
DoH 可能会成为一些人绕过家长监护的手段,这可能不是一件好事。
|
||||
|
||||
如果我这样的说法有问题,你可以在下面的评论区纠正我。
|
||||
|
||||
并且,使用 DoH 就意味着你没办法使用本地 host 文件了(如果你正用它作为广告拦截或者是其它用途的话)。
|
||||
|
||||
### 总结
|
||||
|
||||
你是如何看待 DoH 的呢?它足够好吗?
|
||||
|
||||
你又是如何看待 ISPA 的决定的呢?你觉得他们这样的声明是不是在鼓励互联网审查和政府对网民的监控呢?
|
||||
|
||||
我个人觉得这个提名决定非常可笑。即使 DoH 并不是所有人都需要的那个终极功能,能够有一种保护个人隐私的选择也总不是件坏事。
|
||||
|
||||
在下面的评论区里发表你的看法吧。最后我想引用这么一句话:
|
||||
|
||||
> 在谎言遍地的时代,说真话是一种革命行为。(LCTT 译注:引自乔治奥威尔)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mozilla-internet-villain/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/DNS_over_HTTPS
|
||||
[2]: https://www.ispa.org.uk/ispa-announces-finalists-for-2019-internet-heroes-and-villains-trump-and-mozilla-lead-the-way-as-villain-nominees/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/mozilla-internet-villain.jpg?resize=800%2C450&ssl=1
|
||||
[4]: https://twitter.com/mozilla?ref_src=twsrc%5Etfw
|
||||
[5]: https://twitter.com/hashtag/ISPAs?src=hash&ref_src=twsrc%5Etfw
|
||||
[6]: https://twitter.com/hashtag/InternetVillain?src=hash&ref_src=twsrc%5Etfw
|
||||
[7]: https://twitter.com/hashtag/internet?src=hash&ref_src=twsrc%5Etfw
|
||||
[8]: https://t.co/WeZhLq2uvi
|
||||
[9]: https://twitter.com/ISPAUK/status/1146725374455373824?ref_src=twsrc%5Etfw
|
||||
[10]: https://itsfoss.com/why-firefox/
|
||||
[11]: https://blog.nightly.mozilla.org/2018/06/01/improving-dns-privacy-in-firefox/
|
||||
[12]: https://itsfoss.com/how-to-block-porn-by-content-filtering-on-ubuntu/
|
||||
[13]: https://itsfoss.com/set-up-firewall-gufw/
|
||||
@ -1,116 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Zorin OS Becomes Even More Awesome With Zorin 15 Release)
|
||||
[#]: via: (https://itsfoss.com/zorin-os-15-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Zorin OS Becomes Even More Awesome With Zorin 15 Release
|
||||
======
|
||||
|
||||
Zorin OS has always been known as one of the [beginner-focused Linux distros][1] out there. Yes, it may not be the most popular – but it sure is a good distribution specially for Windows migrants.
|
||||
|
||||
A few years back, I remember, a friend of mine always insisted me to install [Zorin OS][2]. Personally, I didn’t like the UI back then. But, now that Zorin OS 15 is here – I have more reasons to get it installed as my primary OS.
|
||||
|
||||
Fret not, in this article, we’ll talk about everything that you need to know.
|
||||
|
||||
### New Features in Zorin 15
|
||||
|
||||
Let’s see the major changes in the latest release of Zorin. Zorin 15 is based on Ubuntu 18.04.2 and thus it brings the performance improvement under the hood. Other than that, there are several UI (User Interface) improvements.
|
||||
|
||||
#### Zorin Connect
|
||||
|
||||
![Zorin Connect][3]
|
||||
|
||||
Zorin OS 15’s main highlight is – Zorin Connect. If you have an Android device, you are in for a treat. Similar to [PushBullet][4], [Zorin Connect][5] integrates your phone with the desktop experience.
|
||||
|
||||
You get to sync your smartphone’s notifications on your desktop while also being able to reply to it. Heck, you can also reply to the SMS messages and view those conversations.
|
||||
|
||||
In addition to these, you get the following abilities:
|
||||
|
||||
* Share files and web links between devices
|
||||
* Use your phone as a remote control for your computer
|
||||
* Control media playback on your computer from your phone, and pause playback automatically when a phone call arrives
|
||||
|
||||
|
||||
|
||||
As mentioned in their [official announcement post][6], the data transmission will be on your local network and no data will be transmitted to the cloud. To access Zorin Connect, navigate your way through – Zorin menu > System Tools > Zorin Connect.
|
||||
|
||||
[Get ZORIN CONNECT ON PLAY STORE][5]
|
||||
|
||||
#### New Desktop Theme (with dark mode!)
|
||||
|
||||
![Zorin Dark Mode][7]
|
||||
|
||||
I’m all in when someone mentions “Dark Mode” or “Dark Theme”. For me, this is the best thing that comes baked in with Zorin OS 15.
|
||||
|
||||
[][8]
|
||||
|
||||
Suggested read Necuno is a New Open Source Smartphone Running KDE
|
||||
|
||||
It’s so pleasing to my eyes when I enable the dark mode on anything, you with me?
|
||||
|
||||
Not just a dark theme, the UI is a lot cleaner and intuitive with subtle new animations. You can find all the settings from the Zorin Appearance app built-in.
|
||||
|
||||
#### Adaptive Background & Night Light
|
||||
|
||||
You get an option to let the background adapt according to the brightness of the environment every hour of the day. Also, you can find the night mode if you don’t want the blue light to stress your eyes.
|
||||
|
||||
#### To do app
|
||||
|
||||
![Todo][9]
|
||||
|
||||
I always wanted this to happen so that I don’t have to use a separate service that offers a Linux client to add my tasks. It’s good to see a built-in app with integration support for Google Tasks and Todoist.
|
||||
|
||||
#### There’s More?
|
||||
|
||||
Yes! Other major changes include the support for Flatpak, a touch layout for convertible laptops, a DND mode, and some redesigned apps (Settings, Libre Office) to give you better user experience.
|
||||
|
||||
If you want the detailed list of changes along with the minor improvements, you can follow the [announcement post][6]. If you are already a Zorin user, you would notice that they have refreshed their website with a new look as well.
|
||||
|
||||
### Download Zorin OS 15
|
||||
|
||||
**Note** : _Direct upgrades from Zorin OS 12 to 15 – without needing to re-install the operating system – will be available later this year._
|
||||
|
||||
In case you didn’t know, there are three versions of Zorin OS – Ultimate, Core, and the Lite version.
|
||||
|
||||
If you want to support the devs and the project while unlocking the full potential of Zorin OS, you should get the ultimate edition for $39.
|
||||
|
||||
If you just want the essentials, the core edition will do just fine (which you can download for free). In either case, if you have an old computer, the lite version is the one to go with.
|
||||
|
||||
[DOWNLOAD ZORIN OS 15][10]
|
||||
|
||||
**What do you think of Zorin 15?**
|
||||
|
||||
[][11]
|
||||
|
||||
Suggested read Ubuntu 14.04 Codenamed Trusty Tahr
|
||||
|
||||
I’m definitely going to give it a try as my primary OS – fingers crossed. What about you? What do you think about the latest release? Feel free to let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/zorin-os-15-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-beginners/
|
||||
[2]: https://zorinos.com/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-connect.jpg?fit=800%2C473&ssl=1
|
||||
[4]: https://www.pushbullet.com/
|
||||
[5]: https://play.google.com/store/apps/details?id=com.zorinos.zorin_connect&hl=en_IN
|
||||
[6]: https://zoringroup.com/blog/2019/06/05/zorin-os-15-is-here-faster-easier-more-connected/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-dark-mode.jpg?fit=722%2C800&ssl=1
|
||||
[8]: https://itsfoss.com/necunos-linux-smartphone/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/Todo.jpg?fit=800%2C652&ssl=1
|
||||
[10]: https://zorinos.com/download/
|
||||
[11]: https://itsfoss.com/ubuntu-1404-codenamed-trusty-tahr/
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,49 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Donald Trump Now Wants to Ban End-to-End Encryption)
|
||||
[#]: via: (https://news.softpedia.com/news/donald-trump-now-wants-to-ban-end-to-end-encryption-526567.shtml)
|
||||
[#]: author: (Bogdan Popa https://news.softpedia.com/editors/browse/bogdan-popa)
|
||||
|
||||
Donald Trump Now Wants to Ban End-to-End Encryption
|
||||
======
|
||||
|
||||
**After[banning][1] and [unbanning][2] Huawei, United States President Donald Trump is now planning to go after end-to-end encryption, with a new report claiming that senior White House officials met this week to discuss the first step the administration could make in this regard.**
|
||||
|
||||
[Politico][3] notes, citing three people familiar with the matter, that number two officials from several key agencies discussed a potential offensive against end-to-end encryption.
|
||||
|
||||
“The two paths were to either put out a statement or a general position on encryption, and [say] that they would continue to work on a solution, or to ask Congress for legislation,” one source was quoted as saying by the cited publication.
|
||||
|
||||
While the White House administration wants to kill off end-to-end encryption in software developed by American companies, this proposal was received with mixed reactions from representatives of various agencies in the country.
|
||||
|
||||
For example, the DHS “is internally divided,” Politico notes, as the agency is aware of the security implications that banning end-to-end encryption could generate.
|
||||
|
||||
### The encryption dispute
|
||||
|
||||
Pushing for regulations against end-to-end encryption is described as a decisive step in the efforts of intelligence agencies and law enforcement in the United States to access devices and data belonging to criminals and terrorists.
|
||||
|
||||
The encryption, which the majority of American companies have already bundled into their products, including here Apple and Google, blocks investigators from accessing suspects’ data. Tech companies position end-to-end encryption as a key privacy feature, and several of them have warned that any regulation against it could even affect national security.
|
||||
|
||||
Apple, in particular, is one of the biggest companies fighting against anti-encryption regulation. The company [**refused to unlock an iPhone used by the San Bernardino terrorist**][4], explaining that breaking into the device would have compromised the security of all customers.
|
||||
|
||||
The FBI eventually unlocked the device using software developed by a third-party.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.softpedia.com/news/donald-trump-now-wants-to-ban-end-to-end-encryption-526567.shtml
|
||||
|
||||
作者:[Bogdan Popa;Jun][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://news.softpedia.com/editors/browse/bogdan-popa
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://news.softpedia.com/news/google-bans-huawei-from-using-android-google-play-gmail-other-services-526083.shtml
|
||||
[2]: https://news.softpedia.com/news/breaking-donald-trump-says-huawei-can-buy-american-products-again-526564.shtml
|
||||
[3]: https://www.politico.com/story/2019/06/27/trump-officials-weigh-encryption-crackdown-1385306
|
||||
[4]: https://news.softpedia.com/news/judge-orders-apple-to-help-the-fbi-hack-san-bernardino-shooter-s-iphone-500517.shtml
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Lessons in Vendor Lock-in: Google and Huawei)
|
||||
[#]: via: (https://www.linuxjournal.com/content/lessons-vendor-lock-google-and-huawei)
|
||||
[#]: author: (Kyle Rankin https://www.linuxjournal.com/users/kyle-rankin)
|
||||
|
||||
Lessons in Vendor Lock-in: Google and Huawei
|
||||
======
|
||||

|
||||
|
||||
What happens when you're locked in to a vendor that's too big to fail, but is on the opposite end of a trade war?
|
||||
|
||||
The story of Google no longer giving Huawei access to Android updates is still developing, so by the time you read this, the situation may have changed. At the moment, Google has granted Huawei a 90-day window whereby it will have access to Android OS updates, the Google Play store and other Google-owned Android assets. After that point, due to trade negotiations between the US and China, Huawei no longer will have that access.
|
||||
|
||||
Whether or not this new policy between Google and Huawei is still in place when this article is published, this article isn't about trade policy or politics. Instead, I'm going to examine this as a new lesson in vendor lock-in that I don't think many have considered before: what happens when the vendor you rely on is forced by its government to stop you from being a customer?
|
||||
|
||||
### Too Big to Fail
|
||||
|
||||
Vendor lock-in isn't new, but until the last decade or so, it generally was thought of by engineers as a bad thing. Companies would take advantage the fact that you used one of their products that was legitimately good to use the rest of their products that may or may not be as good as those from their competitors. People felt the pain of being stuck with inferior products and rebelled.
|
||||
|
||||
These days, a lot of engineers have entered the industry in a world where the new giants of lock-in are still growing and have only flexed their lock-in powers a bit. Many engineers shrug off worries about choosing a solution that requires you to use only products from one vendor, in particular if that vendor is a large enough company. There is an assumption that those companies are too big ever to fail, so why would it matter that you rely on them (as many companies in the cloud do) for every aspect of their technology stack?
|
||||
|
||||
Many people who justify lock-in with companies who are too big to fail point to all of the even more important companies who use that vendor who would have even bigger problems should that vendor have a major bug, outage or go out of business. It would take so much effort to use cross-platform technologies, the thinking goes, when the risk of going all-in with a single vendor seems so small.
|
||||
|
||||
Huawei also probably figured (rightly) that Google and Android were too big to fail. Why worry about the risks of being beholden to a single vendor for your OS when that vendor was used by other large companies and would have even bigger problems if the vendor went away?
|
||||
|
||||
### The Power of Updates
|
||||
|
||||
Google held a particularly interesting and subtle bit of lock-in power over Huawei (and any phone manufacturer who uses Android)—the power of software updates. This form of lock-in isn't new. Microsoft famously used the fact that software updates in Microsoft Office cost money (naturally, as it was selling that software) along with the fact that new versions of Office had this tendency to break backward compatibility with older document formats to encourage everyone to upgrade. The common scenario was that the upper-level folks in the office would get brand-new, cutting-edge computers with the latest version of Office on them. They would start saving new documents and sharing them, and everyone else wouldn't be able to open them. It ended up being easier to upgrade everyone's version of Office than to have the bosses remember to save new documents in old formats every time.
|
||||
|
||||
The main difference with Android is that updates are critical not because of compatibility, but for security. Without OS updates, your phone ultimately will become vulnerable to exploits that attackers continue to find in your software. The Android OS that ships on phones is proprietary and therefore requires permission from Google to get those updates.
|
||||
|
||||
Many people still don't think of the Android OS as proprietary software. Although people talk about the FOSS underpinnings in Android, only people who go to the extra effort of getting a pure-FOSS version of Android, like LineageOS, on their phones actually experience it. The version of Android most people tend to use has a bit of FOSS in the center, surrounded by proprietary Google Apps code.
|
||||
|
||||
It's this Google Apps code that gives Google the kind of powerful leverage over a company like Huawei. With traditional Android releases, Google controls access to OS updates including security updates. All of this software is signed with Google's signing keys. This system is built with security in mind—attackers can't easily build their own OS update to install on your phone—but it also has a convenient side effect of giving Google control over the updates.
|
||||
|
||||
What's more, the Google Apps suite isn't just a convenient way to load Gmail or Google Docs, it also includes the tight integration with your Google account and the Google Play store. Without those hooks, you don't have access to the giant library of applications that everyone expects to use on their phones. As anyone with a LineageOS phone that uses F-Droid can attest, while a large number of applications are available in the F-Droid market, you can't expect to see those same apps as on Google Play. Although you can side-load some Google Play apps, many applications, such as Google Maps, behave differently without a Google account. Note that this control isn't unique to Google. Apple uses similar code-signing features with similar restrictions on its own phones and app updates.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Without access to these OS updates, Huawei now will have to decide whether to create its own LineageOS-style Android fork or a whole new phone OS of its own. In either case, it will have to abandon the Google Play Store ecosystem and use F-Droid-style app repositories, or if it goes 100% alone, it will need to create a completely new app ecosystem. If its engineers planned for this situation, then they likely are working on this plan right now; otherwise, they are all presumably scrambling to address an event that "should never happen". Here's hoping that if you find yourself in a similar case of vendor lock-in with an overseas company that's too big to fail, you never get caught in the middle of a trade war.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxjournal.com/content/lessons-vendor-lock-google-and-huawei
|
||||
|
||||
作者:[Kyle Rankin][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxjournal.com/users/kyle-rankin
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,85 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is DevSecOps?)
|
||||
[#]: via: (https://opensource.com/article/19/1/what-devsecops)
|
||||
[#]: author: (Brett Hunoldt https://opensource.com/users/bretthunoldtcom)
|
||||
|
||||
What is DevSecOps?
|
||||
======
|
||||
The journey to DevSecOps begins with empowerment, enablement, and education. Here's how to get started.
|
||||

|
||||
|
||||
> “DevSecOps enables organizations to deliver inherently secure software at DevOps speed.” -Stefan Streichsbier
|
||||
|
||||
DevSecOps as a practice or an art form is an evolution on the concept of DevOps. To better understand DevSecOps, you should first have an understanding of what DevOps means.
|
||||
|
||||
DevOps was born from merging the practices of development and operations, removing the silos, aligning the focus, and improving efficiency and performance of both the teams and the product. A new synergy was formed, with DevOps focused on building products and services that are easy to maintain and that automate typical operations functions.
|
||||
|
||||
Security is a common silo in many organizations. Security’s core focus is protecting the organization, and sometimes this means creating barriers or policies that slow down the execution of new services or products to ensure that everything is well understood and done safely and that nothing introduces unnecessary risk to the organization.
|
||||
|
||||
**[[Download the Getting started with DevSecOps guide]][1]**
|
||||
|
||||
Because of the distinct nature of the security silo and the friction it can introduce, development and operations sometimes bypass or work around security to meet their objectives. At some firms, the silo creates an expectation that security is entirely the responsibility of the security team and it is up to them to figure out what security defects or issues may be introduced as a result of a product.
|
||||
|
||||
DevSecOps looks at merging the security discipline within DevOps. By enhancing or building security into the developer and/or operational role, or including a security role within the product engineering team, security naturally finds itself in the product by design.
|
||||
|
||||
This allows companies to release new products and updates more quickly and with full confidence that security is embedded into the product.
|
||||
|
||||
### Where does rugged software fit into DevSecOps?
|
||||
|
||||
Building rugged software is more an aspect of the DevOps culture than a distinct practice, and it complements and enhances a DevSecOps practice. Think of a rugged product as something that has been battle-hardened through experimentation or experience.
|
||||
|
||||
It’s important to note that rugged software is not necessarily 100% secure (although it may have been at some point in time). However, it has been designed to handle most of what is thrown at it.
|
||||
|
||||
The key tenets of a rugged software practice are fostering competition, experimentation, controlled failure, and cooperation.
|
||||
|
||||
### How do you get started in DevSecOps?
|
||||
|
||||
Gettings started with DevSecOps involves shifting security requirements and execution to the earliest possible stage in the development process. It ultimately creates a shift in culture where security becomes everyone’s responsibility, not only the security team’s.
|
||||
|
||||
You may have heard teams talking about a "shift left." If you flatten the development pipeline into a horizontal line to include the key stages of the product evolution—from initiation to design, building, testing, and finally to operating—the goal of a security is to be involved as early as possible. This allows the risks to be better evaluated, socialized, and mitigated by design. The "shift-left" mentality is about moving this engagement far left in this pipeline.
|
||||
|
||||
This journey begins with three key elements:
|
||||
|
||||
* empowerment
|
||||
* enablement
|
||||
* education
|
||||
|
||||
|
||||
|
||||
Empowerment, in my view, is about releasing control and allowing teams to make independent decisions without fear of failure or repercussion (within reason). The only caveat in this process is that information is critical to making informed decisions (more on that below).
|
||||
|
||||
To achieve empowerment, business and executive support (which can be created through internal sales, presentations, and establishing metrics to show the return on this investment) is critical to break down the historic barriers and siloed teams. Integrating security into the development and operations teams and increasing both communication and transparency can help you begin the journey to DevSecOps.
|
||||
|
||||
This integration and mobilization allows teams to focus on a single outcome: Building a product for which they share responsibility and collaborate on development and security in a reliable way. This will take you most of the way towards empowerment. It places the shared responsibility for the product with the teams building it and ensures that any part of the product can be taken apart and maintain its security.
|
||||
|
||||
Enablement involves placing the right tools and resources in the hands of the teams. It’s about creating a culture of knowledge-sharing through forums, wikis, and informal gatherings.
|
||||
|
||||
Creating a culture that focuses on automation and the concept that repetitive tasks should be coded will likely reduce operational overhead and strengthen security. This scenario is about more than providing knowledge; it is about making this knowledge highly accessible through multiple channels and mediums (which are enabled through tools) so that it can be consumed and shared in whatever way teams or individuals prefer. One medium might work best when team members are coding and another when they are on the road. Make the tools accessible and simple and let the team play with them.
|
||||
|
||||
Different DevSecOp teams will have different preferences, so allow them to be independent whenever possible. This is a delicate balancing exercise because you do want economies of scale and the ability to share among products. Collaboration and involvement in the selection and renewal of these tools will help lower the barriers of adoption.
|
||||
|
||||
Finally, and perhaps most importantly, DevSecOps is about training and awareness building. Meetups, social gatherings, or formal presentations within the organization are great ways for peers to teach and share their learnings. Sometimes these highlight shared challenges, concerns, or risks others may not have considered. Sharing and teaching are also effective ways to learn and to mentor teams.
|
||||
|
||||
In my experience, each organization's culture is unique, so you can’t take a “one-size-fits-all” approach. Reach out to your teams and find out what tools they want to use. Test different forums and gatherings and see what works best for your culture. Seek feedback and ask the teams what is working, what they like, and why. Adapt and learn, be positive, and never stop trying, and you’ll almost always succeed.
|
||||
|
||||
[Download the Getting started with DevSecOps guide][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/what-devsecops
|
||||
|
||||
作者:[Brett Hunoldt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bretthunoldtcom
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/downloads/devsecops
|
||||
@ -1,3 +1,5 @@
|
||||
translating by qfzy1233
|
||||
|
||||
MX Linux: A Mid-Weight Distro Focused on Simplicity
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhang5788)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
206
sources/tech/20190518 Best Linux Distributions for Beginners.md
Normal file
206
sources/tech/20190518 Best Linux Distributions for Beginners.md
Normal file
@ -0,0 +1,206 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Best Linux Distributions for Beginners)
|
||||
[#]: via: (https://itsfoss.com/best-linux-beginners/)
|
||||
[#]: author: (Aquil Roshan https://itsfoss.com/author/aquil/)
|
||||
|
||||
Best Linux Distributions for Beginners
|
||||
======
|
||||
|
||||
_**Brief** : In this article, we will see the **best Linux distro for beginners**_. This will help new Linux users to pick their first distribution.
|
||||
|
||||
Let’s face it, [Linux][1] can pose an overwhelming complexity to new users. But then, it’s not Linux itself that brings this complexity. Rather, it’s the “newness” factor that causes this. Not getting nostalgic, but remembering my first time with Linux, I didn’t even know what to expect. I liked it. But it was an upstream swim for me initially.
|
||||
|
||||
Not knowing where to start can be a downer. Especially for someone who does not have the concept of something else running on their PC in place of Windows.
|
||||
|
||||
Linux is more than an OS. It’s an idea where everybody grows together and there’s something for everybody. We have already covered:
|
||||
|
||||
* [Best Linux distributions for Windows users][2]
|
||||
* [Best lightweight Linux distros][3]
|
||||
* [Best Linux distributions for hacking][4]
|
||||
* [Best Linux distributions for gaming][5]
|
||||
* [Best Linux distributions for privacy and anonymity][6]
|
||||
* [Best Linux distributions that look like MacOS][7]
|
||||
|
||||
|
||||
|
||||
In addition to that, there are distributions that cater to the needs of newcomers especially. So here are a few such Linux distros for beginners. You can watch it in a video and [subscribe to our YouTube channel][8] for more Linux related videos.
|
||||
|
||||
### Best Linux Distros for Beginners
|
||||
|
||||
Please remember that this list is no particular order. The main criteria for compiling this list is ease of installation, out of the box hardware software, ease of use and availability of software packages.
|
||||
|
||||
#### 1\. Ubuntu
|
||||
|
||||
If you’ve researched Linux on the internet, it’s highly probable that you have come across Ubuntu. Ubuntu is one of the leading Linux distributions. It is also the perfect path to begin your Linux journey.
|
||||
|
||||
![][9]
|
||||
|
||||
Ubuntu has been tagged as Linux for human beings. Now, this is because Ubuntu has put in a lot of effort on universal usability. Ubuntu does not require you to be technically sound for you to use it. It breaks the notion of Linux=Command line hassle. This is one of the major plus points that rocketed Ubuntu to where it is today.
|
||||
|
||||
Ubuntu offers a very convenient installation procedure. The installer speaks plain English (or any major language you want). You can even try out Ubuntu before actually going through the installation procedure. The installer provides simple options to:
|
||||
|
||||
* Install Ubuntu removing the older OS
|
||||
* [Install Ubuntu alongside Windows][10] or any other existing OS (A choice is given at every startup to select the OS to boot).
|
||||
* Configure partitions for users who know what they are doing.
|
||||
|
||||
|
||||
|
||||
_Beginner tip: Select the second option if you are not sure about what to do._
|
||||
|
||||
Ubuntu’s user interface is called GNOME. It is as simple as well as productive as it gets. You can search anything from applications to files by pressing the Windows key. Is there any way you can make this simpler?
|
||||
|
||||
There are no driver installation issues as Ubuntu comes with a hardware detector which detects, downloads and installs optimal drivers for your PC. Also, the installation comes with all the basic software like a music player, video player, an office suite and games for some time killing.
|
||||
|
||||
Ubuntu has a great documentation and community support. [Ubuntu forums ][11]and [Ask Ubuntu][12] provide an appreciable quality support in almost all aspects regarding Ubuntu. It’s highly probable that any question you might have will already be answered. And the answers are beginner friendly.
|
||||
|
||||
Do check out and download [Ubuntu][13] at the [official site.][13]
|
||||
|
||||
#### 2\. Linux Mint Cinnamon
|
||||
|
||||
For years, Linux Mint has been the **number one** Linux distribution on [Distrowatch][14]. Well deserved throne I must say. Linux mint is one of my personal favorites. It is elegant, graceful and provides a superior computing experience (out of the box).
|
||||
|
||||
![][15]
|
||||
|
||||
Linux Mint features the Cinnamon desktop environment. New Linux users who are still in the process of familiarizing themselves with Linux software will find Cinnamon very useful. All the software are very accessibly grouped under categories. Although this is nothing of a mind-blowing feature, to new users who do not know the names of Linux software, this is a huge bonus.
|
||||
|
||||
[][16]
|
||||
|
||||
Suggested read Installing Microsoft Visual Studio Code on Linux
|
||||
|
||||
Linux Mint is fast. Runs fine on older computers. Linux Mint is built upon the rock-solid Ubuntu base. It uses the same software repository as Ubuntu. About the Ubuntu software repository, Ubuntu pushes software for general only use after extensive testing. This means users will not have to deal with unexpected crashes and glitches that some new software are prone to, which can be a real no-no for new Linux users.
|
||||
|
||||
![][17]
|
||||
|
||||
Windows 7 lovers who are really not into where Microsoft if heading with Windows 10 will find Linux Mint lovable. Linux Mint desktop is pretty similar to Windows 7 desktop. Similar toolbar, similar menu, similar tray icons are all set to make Windows users feel absolutely at home.
|
||||
|
||||
Personally, I’m more likely to suggest Linux Mint to someone who is new to Linux world as Linux Mint does impress users enough for them to accept it. To me, Linux Mint should be the first among the list of Linux for beginners.
|
||||
|
||||
Do check out [Linux Mint here][18]. Go for the Cinnamon version.
|
||||
|
||||
#### 3\. Zorin OS
|
||||
|
||||
A majority of computer users are Windows users. And when a [Windows user gets a Linux][2], there’s a fair amount of ‘unlearning process’ that user must go through. A huge amount of operations have been fixed in our muscle memory. For example, the mouse reaching to the lower left corner of the screen (Start) everytime you want to launch an application. So if we could find something that eases these issues on Linux, it’s half a battle won. Enter Zorin OS.
|
||||
|
||||
![][19]
|
||||
|
||||
Zorin OS is an Ubuntu-based, highly polished Linux distribution, entirely made for Windows refugees. Although pretty much every Linux distro is usable by everybody, some people might tend to be reluctant when the desktop looks too alien. Zorin OS dodges past this obstacle because of its similarities with Windows appearance wise.
|
||||
|
||||
Package managers are something of a new concept to Linux newcomers. That’s why Zorin OS comes with a huge (I mean really huge) list of pre-installed software. Anything you need, there’s good chance it’s already installed on Zorin OS. As if that was not enough, [Wine and PlayOnLinux][20] come pre-installed so you can run your loved Windows software and [games][21] here too.
|
||||
|
||||
![][22]
|
||||
|
||||
Zorin OS comes with an amazing theme engine called the ‘Zorin look changer’. It offers some heavy customization options with presets to make your OS look like Windows 7, XP, 2000 or even a Mac for that matter. You’re going to feel home.
|
||||
|
||||
![][23]
|
||||
|
||||
These features make Zorin OS the _**best Linux distro for beginners**_ , isn’t it? Do check out the [Zorin OS website][24] to know more and download the OS.
|
||||
|
||||
#### 4\. Elementary OS
|
||||
|
||||
Since we have taken a look at Linux distros for Windows users, let’s swing by something for MacOS users too. Elementary OS very quickly rose to fame and now is always included in the list of top distros, all thanks to its aesthetic essence. Inspired by MacOS looks, Elementary OS is one of the most beautiful Linux distros.
|
||||
|
||||
![][25]
|
||||
|
||||
Elementary OS is another Ubuntu-based operating system which means the operating system itself is unquestionably stable. Elementary OS features the Pantheon desktop environment. You can immediately notice the resemblance to MacOS desktop. This is an advantage to MacOS users switching to Linux as they will much comfortable with the desktop and this really eases the process of coping to this change.
|
||||
|
||||
![][26]
|
||||
|
||||
The menu is simple and customizable according to user preferences. The operating system is zero intrusive so you can really focus on your work. It comes with a very small number of pre-installed software. So, any new user will not be repulsed by huge bloat. But hey, it’s got everything you need out of the box. For more software, Elementary OS provides a neat AppCenter. It is highly accessible and simple. Everything at one place. You can get all the software you want and perform upgrades in clicks.
|
||||
|
||||
[][27]
|
||||
|
||||
Suggested read How to Install and Use Slack in Linux
|
||||
|
||||
Experience wise, [Elementary OS][28] is really a great piece of software. Definitely give [it a try.][28]
|
||||
|
||||
#### 5\. Linux Mint Mate
|
||||
|
||||
A good number of people who come to Linux are looking to revive older computers. With Windows 10, many computers that had decent specs just some years ago have become incompetent. A quick google will suggest you install Linux on such computers. In that way, you can keep them running up to the mark for the near future. Linux Mint Mate is a great Linux distro if you are looking for something to run your older computers.
|
||||
|
||||
![][29]
|
||||
|
||||
Linux Mint Mate is very light, resource efficient but still a polished distro. It can run smoothly on computers with less muscle power. The desktop environment does not come with bells and jingles. But in no way is it functionally inferior to any other desktop environments. The operating system is non-intrusive and allows you to have a productive computing experience without getting in your way.
|
||||
|
||||
Again, the Linux Mint Mate is based on Ubuntu and has the advantage of huge base solid Ubuntu software repository. It comes with a minimum number of necessities pre-installed. Easy driver installation and setting management are made available.
|
||||
|
||||
You can run Linux Mint Mate even if you have 512 MB RAM and 9 GB hard disk space (the more the merrier).
|
||||
|
||||
The Mate desktop environment is really simple to use with no twists in the tale. This is really a huge plus point for Linux beginners. All the more reason to [try out Linux Mint Mate][30].
|
||||
|
||||
#### 6\. Manjaro Linux
|
||||
|
||||
Ok. Any long time Linux user will say guiding a newcomer even in the general direction of Arch Linux is a sin. But hear me out.
|
||||
|
||||
Arch is considered experts-only Linux because of it’s highly complex installation procedure. Manajro and Arch Linux have a common origin. But they differ extensively in everything else.
|
||||
|
||||
![][31]
|
||||
|
||||
Manajro Linux has an extremely beginner friendly installation procedure. A lot of things are automated like driver installation using ‘Hardware detection’. Manjaro hugely negates the hardware driver hassles that torments a lot of other Linux distros. And even if you face any issues, Manjaro has an amazing community support.
|
||||
|
||||
Manjaro has its own software repository which maintains the latest of software. While providing up to date software to users is a priority, guaranteed stability is not at all compromised. This is one of the prime differences between Arch and Manjaro. Manjaro delays package releases to make sure they are absolutely stable and no regression will be caused. You can also access the Arch User Repository on Manjaro, so anything and everything you need, is always available.
|
||||
|
||||
If you want to know more about Manjaro features, do read my colleague [John’s experience with Manjaro Linux and why he is hooked][32] to it.
|
||||
|
||||
![][33]
|
||||
|
||||
Manjaro Linux comes in XFCE, KDE, Gnome, Cinnamon and a host of more desktop environments. Do check out the [official website][34].
|
||||
|
||||
To install any of the above 6 operating systems, you need to create a bootable USB stick. If you are currently using Windows [use this guide to do so][35]. Mac OS users may [follow this guide][36].
|
||||
|
||||
**Your choice for the best Linux distro for beginners?**
|
||||
|
||||
Linux might come with a learning curve, but that’s not something anybody ever regretted. Go ahead get an ISO and check out Linux. If you are already a Linux user, do share this article and help someone fall in love with Linux in this season of love. Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-linux-beginners/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/aquil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/what-is-linux
|
||||
[2]: https://itsfoss.com/windows-like-linux-distributions/
|
||||
[3]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[4]: https://itsfoss.com/linux-hacking-penetration-testing/
|
||||
[5]: https://itsfoss.com/linux-gaming-distributions/
|
||||
[6]: https://itsfoss.com/privacy-focused-linux-distributions/
|
||||
[7]: https://itsfoss.com/macos-like-linux-distros/
|
||||
[8]: https://www.youtube.com/c/itsfoss
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/06/ubuntu-18-04-desktop.jpeg?resize=800%2C450&ssl=1
|
||||
[10]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[11]: https://ubuntuforums.org/
|
||||
[12]: http://askubuntu.com/
|
||||
[13]: https://www.ubuntu.com/
|
||||
[14]: https://distrowatch.com/
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/LM_Home.jpg?ssl=1
|
||||
[16]: https://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/LM_SS.jpg?ssl=1
|
||||
[18]: https://linuxmint.com/
|
||||
[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/Zorin.jpg?ssl=1
|
||||
[20]: https://itsfoss.com/use-windows-applications-linux/
|
||||
[21]: https://itsfoss.com/linux-gaming-guide/
|
||||
[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/Zorin-office.jpg?ssl=1
|
||||
[23]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/OSX.jpg?ssl=1
|
||||
[24]: https://zorinos.com/
|
||||
[25]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2017/02/Pantheon-Desktop.jpg?resize=800%2C500&ssl=1
|
||||
[26]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/Application-Menu.jpg?ssl=1
|
||||
[27]: https://itsfoss.com/slack-use-linux/
|
||||
[28]: https://elementary.io/
|
||||
[29]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/mate.jpg?ssl=1
|
||||
[30]: http://blog.linuxmint.com/?p=3182
|
||||
[31]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/02/manajro.jpg?ssl=1
|
||||
[32]: https://itsfoss.com/why-use-manjaro-linux/
|
||||
[33]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/manjaro-kde.jpg?ssl=1
|
||||
[34]: https://manjaro.org/
|
||||
[35]: https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-windows
|
||||
[36]: https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-macos
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (QiaoN)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -213,7 +213,7 @@ via: https://opensource.com/article/19/5/run-your-blog-github-pages-python
|
||||
|
||||
作者:[Erik O'Shaughnessy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[QiaoN](https://github.com/QiaoN)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,215 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to use Tig to browse Git logs)
|
||||
[#]: via: (https://opensource.com/article/19/6/what-tig)
|
||||
[#]: author: (Olaf Alders https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo)
|
||||
|
||||
How to use Tig to browse Git logs
|
||||
======
|
||||
Tig is more than just a text-mode interface for Git. Here's how it can enhance your daily workflow.
|
||||
![A person programming][1]
|
||||
|
||||
If you work with Git as your version control system, you've likely already resigned yourself to the fact that Git is a complicated beast. It is a fantastic tool, but it can be cumbersome to navigate Git repositories. That's where a tool like [Tig][2] comes in.
|
||||
|
||||
From the [Tig man page][3]:
|
||||
|
||||
> Tig is an ncurses-based text-mode interface for git(1). It functions mainly as a Git repository browser, but can also assist in staging changes for commit at chunk level and act as a pager for output from various Git commands.
|
||||
|
||||
This basically means that Tig provides a text-based user interface you can run in your terminal. Tig makes it easy to browse your Git logs, but it can do much more than just bounce you around from your last commit to a previous one.
|
||||
|
||||
![Tig screenshot][4]
|
||||
|
||||
Many of the examples in this quick introduction to Tig have been poached directly from its excellent man page. I highly recommend reading it to learn more.
|
||||
|
||||
### Install Tig
|
||||
|
||||
* Fedora and RHEL: **sudo dnf install tig**
|
||||
* Ubuntu and Debian: **sudo apt install tig**
|
||||
* MacOS: **brew install tig**
|
||||
|
||||
|
||||
|
||||
See the official [installation instructions][5] for even more options.
|
||||
|
||||
### Browse commits in your current branch
|
||||
|
||||
If you want to browse the latest commits in your branch, enter:
|
||||
|
||||
|
||||
```
|
||||
`tig`
|
||||
```
|
||||
|
||||
That's it. This three-character command will launch a browser where you can navigate the commits in your current branch. You can think of it as a wrapper around **git log**.
|
||||
|
||||
To navigate the output, you can use the Up and Down arrow keys to move from one commit to another. Pressing the Return/Enter key will open a vertical split with the contents of the chosen commit on the right-hand side. You can continue to browse up and down in your commit history on the left-hand side, and your changes will appear on the right. Use **k** and **j** to navigate up and down by line and **-** and the Space Bar to page up and down on the right-hand side. Use **q** to exit the right-hand pane.
|
||||
|
||||
Searching on **tig** output is simple as well. Use **/** to search forward and **?** to search backward on both the left and right panes.
|
||||
|
||||
![Searching Tig][6]
|
||||
|
||||
That's enough to get you started navigating your commits. There are too many key bindings to cover here, but clicking **h** will display a Help menu where you can discover its navigation and command options. You can also use **/** and **?** to search the Help menu. Use **q** to exit Help.
|
||||
|
||||
![Tig Help][7]
|
||||
|
||||
### Browse revisions for a single file
|
||||
|
||||
Since Tig is a wrapper around **git log**, it conveniently accepts the same arguments that can be passed to **git log**. For instance, to browse the commit history for a single file, enter:
|
||||
|
||||
|
||||
```
|
||||
`tig README.md`
|
||||
```
|
||||
|
||||
Compare this with the output of the Git command being wrapped to get a clearer view of how Tig enhances the output.
|
||||
|
||||
|
||||
```
|
||||
`git log README.md`
|
||||
```
|
||||
|
||||
To include the patches in the raw Git output, you can add a **-p** option:
|
||||
|
||||
|
||||
```
|
||||
`git log -p README.md`
|
||||
```
|
||||
|
||||
If you want to narrow the commits down to a specific date range, try something like this:
|
||||
|
||||
|
||||
```
|
||||
`tig --after="2017-01-01" --before="2018-05-16" -- README.md`
|
||||
```
|
||||
|
||||
Again, you can compare this with the raw Git version:
|
||||
|
||||
|
||||
```
|
||||
`git log --after="2017-01-01" --before="2018-05-16" -- README.md`
|
||||
```
|
||||
|
||||
### Browse who changed a file
|
||||
|
||||
Sometimes you want to find out who made a change to a file and why. The command:
|
||||
|
||||
|
||||
```
|
||||
`tig blame README.md`
|
||||
```
|
||||
|
||||
is essentially a wrapper around **git blame**. As you would expect, it allows you to see who the last person was to edit a given line, and it also allows you to navigate to the commit that introduced the line. This is somewhat like the **:Gblame** command Vim's **vim-fugitive** plugin provides.
|
||||
|
||||
### Browse your stash
|
||||
|
||||
If you're like me, you may have a pile of edits in your stash. It's easy to lose track of them. You can view the latest item in your stash via:
|
||||
|
||||
|
||||
```
|
||||
`git stash show -p stash@{0}`
|
||||
```
|
||||
|
||||
You can find the second most recent item via:
|
||||
|
||||
|
||||
```
|
||||
`git stash show -p stash@{1}`
|
||||
```
|
||||
|
||||
and so on. If you can recall these commands whenever you need them, you have a much sharper memory than I do.
|
||||
|
||||
As with the Git commands above, Tig makes it easy to enhance your Git output with a simple invocation:
|
||||
|
||||
|
||||
```
|
||||
`tig stash`
|
||||
```
|
||||
|
||||
Try issuing this command in a repository with a populated stash. You'll be able to browse _and search_ your stash items, giving you a quick overview of everything you saved for a rainy day.
|
||||
|
||||
### Browse your refs
|
||||
|
||||
A Git ref is the hash of something you have committed. This includes files as well as branches. Using the **tig refs** command allows you to browse all of your refs and drill down to specific commits.
|
||||
|
||||
|
||||
```
|
||||
`tig refs`
|
||||
```
|
||||
|
||||
When you're finished, use **q** to return to a previous menu.
|
||||
|
||||
### Browse git status
|
||||
|
||||
If you want to view which files have been staged and which are untracked, use **tig status**, a wrapper around **git status**.
|
||||
|
||||
![Tig status][8]
|
||||
|
||||
### Browse git grep
|
||||
|
||||
You can use the **grep** command to search for expressions in text files. The command **tig grep** allows you to navigate the output of **git grep**. For example:
|
||||
|
||||
|
||||
```
|
||||
`tig grep -i foo lib/Bar`
|
||||
```
|
||||
|
||||
will navigate the output of a case-insensitive search for **foo** in the **lib/Bar** directory.
|
||||
|
||||
### Pipe output to Tig via STDIN
|
||||
|
||||
If you are piping a list of commit IDs to Tig, you must use the **\--stdin** flag so that **tig show** reads from stdin. Otherwise, **tig show** launches without input (rendering an empty screen).
|
||||
|
||||
|
||||
```
|
||||
`git rev-list --author=olaf HEAD | tig show --stdin`
|
||||
```
|
||||
|
||||
### Add custom bindings
|
||||
|
||||
You can customize Tig with an [rc][9] file. Here's how you can configure Tig to your liking, using the example of adding some helpful custom key bindings.
|
||||
|
||||
Create a file in your home directory called **.tigrc**. Open **~/.tigrc** in your favorite editor and add:
|
||||
|
||||
|
||||
```
|
||||
# Apply the selected stash
|
||||
bind stash a !?git stash apply %(stash)
|
||||
|
||||
# Drop the selected stash item
|
||||
bind stash x !?git stash drop %(stash)
|
||||
```
|
||||
|
||||
Run **tig stash** to browse your stash, as above. However, with these bindings in place, you can press **a** to apply an item from the stash to your repository and **x** to drop an item from the stash. Keep in mind that you'll need to perform these commands when browsing the stash _list_. If you're browsing a stash _item_, enter **q** to exit that view and press **a** or **x** to get the effect you want.
|
||||
|
||||
For more information, you can read more about [Tig key bindings][10].
|
||||
|
||||
### Wrapping up
|
||||
|
||||
I hope this has been a helpful demonstration of how Tig can enhance your daily workflow. Tig can do even more powerful things (such as staging lines of code), but that's outside the scope of this introductory article. There's enough information here to make you dangerous, but there's still more to explore.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/what-tig
|
||||
|
||||
作者:[Olaf Alders][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/oalders/users/mbbroberg/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_keyboard_laptop_development_code_woman.png?itok=vbYz6jjb (A person programming)
|
||||
[2]: https://jonas.github.io/tig/
|
||||
[3]: http://manpages.ubuntu.com/manpages/bionic/man1/tig.1.html
|
||||
[4]: https://opensource.com/sites/default/files/uploads/tig.jpg (Tig screenshot)
|
||||
[5]: https://jonas.github.io/tig/INSTALL.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/tig-search.png (Searching Tig)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/tig-help.png (Tig Help)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/tig-status.png (Tig status)
|
||||
[9]: https://en.wikipedia.org/wiki/Run_commands
|
||||
[10]: https://github.com/jonas/tig/wiki/Bindings
|
||||
@ -1,276 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Make Linux stronger with firewalls)
|
||||
[#]: via: (https://opensource.com/article/19/7/make-linux-stronger-firewalls)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Make Linux stronger with firewalls
|
||||
======
|
||||
Learn how firewalls work and which settings to tweak for better Linux
|
||||
security.
|
||||
![People working together to build ][1]
|
||||
|
||||
Everyone's heard of firewalls, even if only as a plot device in a TV cybercrime drama. Many people also know that their computer is (likely) running a firewall, but fewer people understand how to take control of their firewall when necessary.
|
||||
|
||||
Firewalls block unwanted network traffic, but different networks have different threat levels. For instance, if you're at home, you probably trust the other computers and devices on your network a lot more than when you're out at the local café using public WiFi. You can hope your computer differentiates between a trusted network and an untrusted one, or you can learn to manage, or at least verify, your security settings yourself.
|
||||
|
||||
### How firewalls work
|
||||
|
||||
Communication between devices on a network happens through gateways called _ports_. Port, in this context, doesn't mean a physical connection like a USB port or an HDMI port. In network lingo, a port is an entirely virtual concept representing pathways for a specific type of data to either arrive at or depart from a computer. This system could have been called anything, like "connections" or "doorways," but they were named ports at least [as early as 1981][2], and that's the name in use today. The point is, there's nothing special about any port; they're just a way to designate an address where data transference may happen.
|
||||
|
||||
Back in 1972, [a list of port numbers][3] (then called "sockets") was published, and this has since evolved into a set of well-known standard port numbers that help manage specific kinds of traffic. For instance, you access ports 80 and 443 on a daily basis when you visit a website, because most everyone on the internet has agreed, implicitly or explicitly, that data is transferred from web servers over those ports. You can test this theory by opening a web browser and navigating to a website with a nonstandard port appended to the URL. For instance, if you navigate to **example.com:42**, your request is denied because example.com does not serve a website at port 42.
|
||||
|
||||
![Navigating to a nonstandard port produces an error][4]
|
||||
|
||||
If you revisit the same website at port 80, you get a website, as expected. You can specify port 80 with **:80** at the end of the URL, but because port 80 is the standard port for HTTP traffic, your web browser assumes port 80 by default.
|
||||
|
||||
When a computer, like a web server, expects traffic at a specific port, it's acceptable (and necessary) to have the port open for traffic. The danger is leaving ports open that you have no reason to expect traffic on, and that's exactly what a firewall is for.
|
||||
|
||||
### Install firewalld
|
||||
|
||||
There are many interfaces for firewall configuration. This article covers [**firewalld**][5], which integrates with Network Manager on the desktop and **firewall-cmd** in the terminal. Many Linux distributions ship with these tools installed. If yours doesn't, you can either take this article as general advice for firewall management and apply it to what you use, or you can install **firewalld**.
|
||||
|
||||
On Ubuntu, for instance, you must enable the **universe** repository, deactivate the default **ufw** firewall, and then install **firewalld**:
|
||||
|
||||
|
||||
```
|
||||
$ sudo systemctl disable ufw
|
||||
$ sudo add-apt-repository universe
|
||||
$ sudo apt install firewalld
|
||||
```
|
||||
|
||||
Fedora, CentOS, RHEL, OpenSUSE, and many others include **firewalld** by default.
|
||||
|
||||
Regardless of your distribution, for a firewall to be effective, it must be active and set to be loaded at boot. The less you have to think about firewall maintenance, the better.
|
||||
|
||||
|
||||
```
|
||||
`$ sudo systemctl enable --now firewalld`
|
||||
```
|
||||
|
||||
### Choose your zone with Network Manager
|
||||
|
||||
You probably connect to many different networks every day. You're on one network at work, another at the café, and yet another at home. Your computer can detect which network you use more frequently than others, but it doesn't know which you trust.
|
||||
|
||||
A firewall _zone_ contains presets deciding what ports to open and close. Using zones, you can choose a policy that makes the most sense for the network you're currently on.
|
||||
|
||||
To see a list of available zones, open the Network Manager Connection Editor, found in your Applications menu, or with the **nm-connection-editor &** command.
|
||||
|
||||
![Network Manager Connection Editor][6]
|
||||
|
||||
From the list of network connections, double-click on your current network.
|
||||
|
||||
In the network configuration window that appears, click the General tab.
|
||||
|
||||
In the General panel, click the drop-down menu next to Firewall Zone for a list of all available zones.
|
||||
|
||||
![Firewall zones][7]
|
||||
|
||||
You can get this same list with this terminal command:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --get-zones`
|
||||
```
|
||||
|
||||
The zone titles indicate what their designers had in mind when creating them, but you can get the specifics of any zone with this terminal command:
|
||||
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --zone work --list-all
|
||||
work
|
||||
target: default
|
||||
icmp-block-inversion: no
|
||||
interfaces:
|
||||
sources:
|
||||
services: ssh dhcpv6-client
|
||||
ports:
|
||||
protocols:
|
||||
[...]
|
||||
```
|
||||
|
||||
In this example, the **work** zone is configured to permit SSH and DHCPv6-client incoming traffic but drops any other incoming traffic not explicitly requested by the user. (In other words, the **work** zone doesn't block HTTP response traffic when you visit a website, but it _does_ deny an HTTP request on your port 80.)
|
||||
|
||||
View each zone to get familiar with the traffic each one allows. The most common ones are:
|
||||
|
||||
* **Work:** Use this one when on a network you mostly trust. SSH, DHCPv6, and mDNS are permitted, and you can add more as needed. This zone is meant to be a starting point for a custom work environment based on your daily office requirements.
|
||||
* **Public:** For networks you do not trust. This zone is the same as the work zone, but presumably, you would not add the same exceptions as your work zone.
|
||||
* **Drop:** All incoming connections are dropped with no response given. This is as close to a stealth mode as you can get without shutting off networking entirely because only outgoing network connections are possible (even a casual port scanner could detect your computer from outgoing traffic, though, so don't mistake this zone for a cloaking device). This is arguably the safest zone when on public WiFi, and definitely the best when you have reason to believe a network is hostile.
|
||||
* **Block:** All incoming connections are rejected with a message declaring that the requested port is prohibited. Only network connections you initiate are possible. This is a "friendly" version of the drop zone because, even though no port is open for incoming traffic, a port verbosely declines an uninitiated connection.
|
||||
* **Home:** Use this when you trust other computers on the network. Only selected incoming connections are accepted, and you can add more as needed.
|
||||
* **Internal:** Similar to the work zone, this is intended for internal networks where you mostly trust the other computers. You can open more ports and services as needed but still maintain a different rule set than you have on your work zone.
|
||||
* **Trusted:** All network connections are accepted. Good for troubleshooting or on networks you absolutely trust.
|
||||
|
||||
|
||||
|
||||
### Assigning a zone to a network
|
||||
|
||||
You can assign a zone to any network connection you make. Furthermore, you can assign a different zone to each network interface (Ethernet cable, WiFi, and so on) that attaches to each network.
|
||||
|
||||
Select the zone you want and click the Save button to commit the change.
|
||||
|
||||
![Setting a new zone][8]
|
||||
|
||||
The easiest way to get into the habit of assigning a zone to a network interface is to tend to the networks you use most often. Assign the home zone to your home network, the work zone to your work network, and the public network to your favorite library or café network.
|
||||
|
||||
Once you have assigned a zone to all your usual networks, make an effort to assign a zone to the next new network you join, whether it's a new café or your mate's home network. Assigning zones is the best way to reinforce your own awareness that networks are not all equal and that you're not any more secure than anybody else just because you run Linux.
|
||||
|
||||
### Default zone
|
||||
|
||||
Rather than prompting you for a zone every time you join a new network, firewalld assigns any unknown network a default zone. Open a terminal and type this command to get your default zone:
|
||||
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --get-default
|
||||
public
|
||||
```
|
||||
|
||||
In this example, the public zone is the default. It's expected that you will keep the public zone highly restrictive, so it's a pretty safe zone to assign unknown networks. However, you can set your own default instead.
|
||||
|
||||
For instance, if you're more paranoid than most, or if you know that you frequent networks you have reason to distrust, you can assign a highly restrictive zone as default:
|
||||
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --set-default-zone drop
|
||||
success
|
||||
$ sudo firewall-cmd --get-default
|
||||
drop
|
||||
```
|
||||
|
||||
Now any new network you join will be subject to the drop zone rules unless you manually change it to something less restrictive.
|
||||
|
||||
### Customizing zones by opening ports and services
|
||||
|
||||
Firewalld's developers don't intend for their zone definitions to satisfy the needs of all the different networks and levels of trust in existence. They're just starting points for you to use and customize.
|
||||
|
||||
You don't have to know much about firewalls to be able to open and close ports based on the kinds of network activity you know you generate.
|
||||
|
||||
#### Predefined services
|
||||
|
||||
The simplest way to add permissions to your firewall is to add a predefined service. Strictly speaking, there's no such thing as a "service" as far as your firewall knows, because firewalls understand port numbers and protocol types. However, firewalld provides collections of ports and protocols based on standards and conventions.
|
||||
|
||||
For example, if you're a web developer and want to open your computer up on your local network so your colleagues can see the website you're building, you would add the **http** and **https** services. If you're a gamer and you're running the open source [murmur][9] voice-chat server for your guild, then you'd add the **murmur** service. There are many other services available, which you can view with this command:
|
||||
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --get-services
|
||||
amanda-client amanda-k5-client bacula bacula-client \
|
||||
bgp bitcoin bitcoin-rpc ceph cfengine condor-collector \
|
||||
ctdb dhcp dhcpv6 dhcpv6-client dns elasticsearch \
|
||||
freeipa-ldap freeipa-ldaps ftp [...]
|
||||
```
|
||||
|
||||
If you see a service you need, add it to your current firewall configuration, for example:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-service murmur`
|
||||
```
|
||||
|
||||
This command opens all the ports and protocols needed for a particular service _within your default zone_, but only until you reboot your computer or restart your firewall. To make your changes permanent, use the **\--permanent** flag:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-service murmur --permanent`
|
||||
```
|
||||
|
||||
You can also issue the command for a zone other than your default:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-service murmur --permanent --zone home`
|
||||
```
|
||||
|
||||
#### Ports
|
||||
|
||||
Sometimes you want to allow traffic for something that just isn't defined by firewalld's services. Maybe you're setting up a nonstandard port for a common service or you need to open an arbitrary port.
|
||||
|
||||
For example, maybe you're running the open source [virtual tabletop][10] software [MapTool][11]. Since you're running the MapTool server and there's no industry standard governing which port MapTool runs on, you can decide what port it uses and then "poke a hole" in your firewall to allow traffic on that port.
|
||||
|
||||
The process is basically the same as for services:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-port 51234/tcp`
|
||||
```
|
||||
|
||||
This command opens port 51234 to incoming TCP connections _in your default zone_, but only until you reboot your computer or restart your firewall. To make your changes permanent, use the **\--permanent** flag:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-port 51234/tcp --permanent`
|
||||
```
|
||||
|
||||
You can also issue the command for a zone other than your default:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-port 51234/tcp --permanent --zone home`
|
||||
```
|
||||
|
||||
Allowing traffic through your computer is different from letting traffic through your router"s firewall. Your router probably has a different interface for its own embeded firewall (though the principle is the same), which is outside the scope of this article.
|
||||
|
||||
### Removing ports and services
|
||||
|
||||
If you decide a service or a port is no longer needed, you can restart your firewall to clear your changes, unless you use the **\--permanent** flag.
|
||||
|
||||
If you made your changes permanent, use the **\--remove-port** or **\--remove-service** flag:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --remove-port 51234/tcp --permanent`
|
||||
```
|
||||
|
||||
You can remove ports and services from a zone other than your default zone by specifying a zone in your command:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --remove-service murmur --permanent --zone home`
|
||||
```
|
||||
|
||||
### Custom zones
|
||||
|
||||
You can use and abuse the default zones provided by firewalld, but you also have the freedom to create your own. For instance, if it makes sense for you to have a zone specific to gaming, then you can create one and switch over to it only while gaming.
|
||||
|
||||
To create a new, empty zone, create a new zone called **game** and reload the firewall rules so that your new zone becomes active:
|
||||
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --new-zone game --permanent
|
||||
success
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
Once it's created and active, you can customize it with all the services and ports you need to have open for game night.
|
||||
|
||||
### Diligence
|
||||
|
||||
Start thinking about your firewall strategy today. Start slow, and build up some sane defaults that make sense for you. It may take time before you make it a habit to think about your firewall and understand which network services you use, but with a little exploration, you can strengthen your Linux workstation no matter what your environment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/make-linux-stronger-firewalls
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_buildtogether.png?itok=9Tvz64K5 (People working together to build )
|
||||
[2]: https://tools.ietf.org/html/rfc793
|
||||
[3]: https://tools.ietf.org/html/rfc433
|
||||
[4]: https://opensource.com/sites/default/files/uploads/web-port-nonstandard.png (Navigating to a nonstandard port produces an error)
|
||||
[5]: https://firewalld.org/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/nm-connection-editor.png (Network Manager Connection Editor)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/nm-zone.png (Firewall zones)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/nm-set.png (Setting a new zone)
|
||||
[9]: https://www.mumble.com/
|
||||
[10]: https://opensource.com/article/18/5/maptool
|
||||
[11]: https://github.com/RPTools
|
||||
@ -0,0 +1,262 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Newsboat – A Command line RSS/Atom Feed Reader For Text Consoles)
|
||||
[#]: via: (https://www.ostechnix.com/newsbeuter-command-line-rssatom-feed-reader-unix-like-systems/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Newsboat – A Command line RSS/Atom Feed Reader For Text Consoles
|
||||
======
|
||||
|
||||
![Newsboat RSS/Atom Feed reader][1]
|
||||
|
||||
**Newsboat** , a fork of Newsbeuter, is a free, open source RSS/Atom feed reader for text consoles. It supports GNU/Linux, FreeBSD, Mac OS X, and other Unix-like operating systems. Compared to other slow and huge amount of memory consumed RSS feed readers, Newsboat is the best choice for anyone who are looking for a simple, slick and fast feed reader that can be completely managed via keyboard.
|
||||
|
||||
Concerning about the features, we can list the following:
|
||||
|
||||
* Subscribe to RSS 0.9x, 1.0, 2.0 and Atom feeds.
|
||||
* Download podcasts.
|
||||
* Configure your keyboard shortcuts as per your wish.
|
||||
* Search through all downloaded articles.
|
||||
* Categorize and query your subscriptions with a flexible tag system.
|
||||
* Integrate any data source through a flexible filter and plugin system.
|
||||
* Automatically remove unwanted articles through a “killfile”.
|
||||
* Define “meta feeds” using a powerful query language.
|
||||
* Synchronize newsboatr with your bloglines.com account.
|
||||
* Import and exporting your subscriptions with the widely used OPML format.
|
||||
* Customize the look and feel of Newsboat as per your liking.
|
||||
* Keep all your feeds in sync with Google Reader.
|
||||
* And many.
|
||||
|
||||
|
||||
|
||||
In this brief guide, let us see how to install and use Newsboat in Linux.
|
||||
|
||||
### Newsboat – A Command line RSS/Atom Feed Reader
|
||||
|
||||
##### Installation
|
||||
|
||||
**On Arch Linux and derivatives:**
|
||||
|
||||
Newsboat is available in the [Community] repository of Arch Linux. So, you can install it using [**Pacman**][2] command as shown below.
|
||||
|
||||
```
|
||||
$ sudo pacman -S newsboat
|
||||
```
|
||||
|
||||
**On Debian, Ubuntu, Linux Mint:**
|
||||
|
||||
It is also available in the default repositories of DEB based systems such as Ubuntu, Linux Mint. To install it, run the following command:
|
||||
|
||||
```
|
||||
$ sudo apt-get install newsboat
|
||||
```
|
||||
|
||||
**On Fedora:**
|
||||
|
||||
Newsboat is available in the official repositories of Fedora. To install it, run:
|
||||
|
||||
```
|
||||
$ sudo dnf install newsboat
|
||||
```
|
||||
|
||||
Newsboat is also available as [**Snap**][3], so you can install it using command:
|
||||
|
||||
```
|
||||
$ sudo snap install newsboat
|
||||
```
|
||||
|
||||
Once installed, launch it using command:
|
||||
|
||||
```
|
||||
$ newsboat
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
Starting newsboat 2.10.2...
|
||||
Loading configuration...done.
|
||||
Opening cache...done.
|
||||
Loading URLs from /home/sk/.newsboat/urls...done.
|
||||
Error: no URLs configured. Please fill the file /home/sk/.newsboat/urls with RSS feed URLs or import an OPML file.
|
||||
|
||||
newsboat 2.10.2
|
||||
usage: newsboat [-i <file>|-e] [-u <urlfile>] [-c <cachefile>] [-x <command> ...] [-h]
|
||||
-e, --export-to-opml export OPML feed to stdout
|
||||
-r, --refresh-on-start refresh feeds on start
|
||||
-i, --import-from-opml=<file> import OPML file
|
||||
-u, --url-file=<urlfile> read RSS feed URLs from <urlfile>
|
||||
-c, --cache-file=<cachefile> use <cachefile> as cache file
|
||||
-C, --config-file=<configfile> read configuration from <configfile>
|
||||
-X, --vacuum compact the cache
|
||||
-x, --execute=<command>... execute list of commands
|
||||
-q, --quiet quiet startup
|
||||
-v, --version get version information
|
||||
-l, --log-level=<loglevel> write a log with a certain loglevel (valid values: 1 to 6)
|
||||
-d, --log-file=<logfile> use <logfile> as output log file
|
||||
-E, --export-to-file=<file> export list of read articles to <file>
|
||||
-I, --import-from-file=<file> import list of read articles from <file>
|
||||
-h, --help this help
|
||||
```
|
||||
|
||||
As you see in the above screenshot, we haven’t added any URLs yet in Newsboat.
|
||||
|
||||
##### Managing Feeds
|
||||
|
||||
We can add, edit, tag, and delete feeds by editing the **urls** file. The default urls file is **~/.newsboat/urls**. If it is not available, just create it.
|
||||
|
||||
**Add feeds**
|
||||
|
||||
To add a feed, edit this file
|
||||
|
||||
```
|
||||
$ vi ~/.newsboat/urls
|
||||
```
|
||||
|
||||
Then, add the feed URLs one by one.
|
||||
|
||||
```
|
||||
http://feeds.feedburner.com/Ostechnix
|
||||
```
|
||||
|
||||
If the feed URL has protected with user name and password, you need to mention the username and password as shown below.
|
||||
|
||||
```
|
||||
http://username:[email protected]/feed.rss
|
||||
```
|
||||
|
||||
After adding all urls, save and close the file.
|
||||
|
||||
**Add tags to the feeds**
|
||||
|
||||
You can add one or more tags to categorize the feeds as per your liking. Specify the tags separated by space if you want to add more than one tags to a single feed. If you want to specify a single tag that contains a space, just mention it within double quotes like below.
|
||||
|
||||
```
|
||||
http://feeds.feedburner.com/Ostechnix "All Linux news"
|
||||
https://www.archlinux.org/feeds/packages/ "Only Arch Linux related news"
|
||||
```
|
||||
|
||||
**Read feeds**
|
||||
|
||||
To read feeds, just launch the Newsboat utility from the Terminal using command:
|
||||
|
||||
```
|
||||
$ newsboat
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
![][4]
|
||||
|
||||
Newsboat Rss feed reader
|
||||
|
||||
As you see in the above screenshot, I have added two RSS feeds. You can now start downloading the feeds, either by pressing **“R”** to download all feeds, or by pressing **“r”** to download the currently selected feed.
|
||||
|
||||
Now, you will see the list of recent items in each feed.
|
||||
|
||||
![][5]
|
||||
|
||||
Alternatively, you can run the following command to refresh feeds on start:
|
||||
|
||||
```
|
||||
$ newsboat -r
|
||||
```
|
||||
|
||||
Use **Up/Down** arrows to choose a feed and hit **ENTER** key to open the currently selected feed.
|
||||
|
||||
![][6]
|
||||
|
||||
Press ENTER key to open the selected entry:
|
||||
|
||||
![][7]
|
||||
|
||||
To open the entry in your default web browser, simply press **o**.
|
||||
|
||||
Here is the list of keyboard controls to manage your feeds.
|
||||
|
||||
* Press **n** to go the next unread entry.
|
||||
* Press **o** to open the selected entry in default web browser.
|
||||
* Press **r** (small letter) to reload the currently selected feed.
|
||||
* Press **R** (capital) to reload all feeds.
|
||||
* Press **A** to mark as read.
|
||||
* Press **/** to search for a specific entry.
|
||||
* Press **s** to save single entry or all entries.
|
||||
* Press **e** to enqueue.
|
||||
* Press **?** (question mark) to open the help window at any time.
|
||||
* And press **q** to go back and exit.
|
||||
|
||||
|
||||
|
||||
**Remove feeds**
|
||||
|
||||
To remove the feeds, just delete the URL in the urls file.
|
||||
|
||||
**Useful tip for Arch Linux users**
|
||||
|
||||
If you’re using a Arch based Linux distribution, I know a good way to read the Arch news page before updating your system. The reason for doing this is you can read the Arch news about current updating issues before actually updating your Arch Linux.
|
||||
|
||||
Add the Arch news link in **~/.newsboat/urls** file:
|
||||
|
||||
```
|
||||
$ https://www.archlinux.org/feeds/news/
|
||||
```
|
||||
|
||||
Open your **~/.bashrc** file and add the following line:
|
||||
|
||||
```
|
||||
alias update='newsboat -r && sudo pacman -Syu'
|
||||
```
|
||||
|
||||
Replace ‘update’ with any alias name of your choice.
|
||||
|
||||
Now, run the following command to update your Arch Linux system.
|
||||
|
||||
```
|
||||
$ update
|
||||
```
|
||||
|
||||
Whenever you run the above command, it will load the Arch news feed in your Terminal. You can simply read about current issues and then update the Arch Linux system.
|
||||
|
||||
For more details, refer the Newsboat help section using command:
|
||||
|
||||
```
|
||||
$ newsboat -h
|
||||
```
|
||||
|
||||
Also, refer the [**official documentation**][8] page for more detailed information.
|
||||
|
||||
And, that’s all. Hope this helps. I will be soon here with another useful guide. If you find this article helpful, please take a moment to share it on your social, professional networks and support OSTechNix.
|
||||
|
||||
**Resources:**
|
||||
|
||||
* [**Newsboat website**][9]
|
||||
* [**Newsboat GtiHub Repository**][10]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/newsbeuter-command-line-rssatom-feed-reader-unix-like-systems/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2017/07/Newsboat-RSS-Atom-Feed-reader-720x340.png
|
||||
[2]: https://www.ostechnix.com/getting-started-pacman/
|
||||
[3]: https://www.ostechnix.com/introduction-ubuntus-snap-packages/
|
||||
[4]: https://www.ostechnix.com/wp-content/uploads/2017/07/Newsboat.png
|
||||
[5]: https://www.ostechnix.com/wp-content/uploads/2017/07/Load-new-feeds.png
|
||||
[6]: https://www.ostechnix.com/wp-content/uploads/2017/07/Newboat1.png
|
||||
[7]: https://www.ostechnix.com/wp-content/uploads/2017/07/Open-Rss-feed-entry.png
|
||||
[8]: https://newsboat.org/releases/2.16.1/docs/newsboat.html
|
||||
[9]: https://newsboat.org/
|
||||
[10]: https://github.com/newsboat/newsboat
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to be good at creating and maintaining systems at-large)
|
||||
[#]: via: (https://opensource.com/article/19/7/book-review-building-evolutionary-architectures)
|
||||
[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
|
||||
|
||||
How to be good at creating and maintaining systems at-large
|
||||
======
|
||||
A book review of "Building Evolutionary Architectures: Support Constant
|
||||
Change" for open source and security folks
|
||||
![An open book][1]
|
||||
|
||||
Initially, this article was simply a review of the book, but as I got into it, I realised that I wanted to talk about how the approach it describes is applicable to a couple of different groups (security folks and open source projects), and so I’ve gone with it.
|
||||
|
||||
How, then, did I come across the book? I was attending a conference a few months ago (DeveloperWeek San Diego), and decided to go to one of the sessions because it looked interesting. The speaker was Dr. Rebecca Parsons, and I liked what she was talking about so much that I ordered this book, whose subject was the topic of her talk, to arrive at home by the time I would return a couple of days later.
|
||||
|
||||
![Building Evolutionary Architectures: Support Constant Change][2]
|
||||
|
||||
[_Building Evolutionary Architectures: Support Constant Change_][3] is not a book about securitym, and I'm a security guy, but it deals with security as one application of its approach, and very convincingly. The central issue that the authors—all employees of ThoughtWorks—identify is, simplified, that although we’re good at creating features for applications, we’re less good at creating, and then maintaining, broader properties of systems. This problem is compounded, they suggest, by the fast and ever-changing nature of modern development practices, where "enterprise architects can no longer rely on static planning".
|
||||
|
||||
The alternative that they propose is to consider "fitness functions", "objectives you want your architecture to exhibit or move towards". Crucially, these are properties of the architecture—or system—rather than features or specific functionality. Tests should be created to monitor the specific functions, but they won’t be your standard unit tests, nor will they necessarily be "point in time" tests. Instead, they will measure a variety of issues, possibly over a period of time, to let you know whether your system is meeting the particular fitness functions you are measuring. There’s a lot of discussion of how to measure these fitness functions, but I would have liked even more. From my point of view, it was one of the most valuable topics covered.
|
||||
|
||||
Frankly, the above might be enough to recommend the book, but there’s more. They advocate strongly for creating incremental change to meet your requirements (gradual, rather than major changes) and "evolvable architectures", encouraging you to realise that:
|
||||
|
||||
1. you may not meet all your fitness functions at the beginning;
|
||||
2. applications which may have met the fitness functions at one point may _cease_ to meet them later on, for various reasons;
|
||||
3. your architecture is likely to change over time;
|
||||
4. your requirements, and therefore the priority that you give to each fitness function, will change over time;
|
||||
5. even if your fitness functions remain the same, the ways in which you need to monitor them may change.
|
||||
|
||||
|
||||
|
||||
All of these are, in my view, extremely useful insights for anybody designing and building a system. Combining them with architectural thinking is even more valuable.
|
||||
|
||||
As is standard for modern O’Reilly books, there are examples throughout, including a worked fake consultancy journey of a particular company with specific needs, leading you through some of the practices in the book. At times, this felt a little contrived, but the mechanism is generally helpful. There were times when the book seemed to stray from its core approach—which is architectural, as per the title—into explanations through pseudo code, but these support one of the useful aspects of the book, which is giving examples of what architectures are more or less suited to the principles expounded in the more theoretical parts. Some readers may feel more at home with the theoretical, others with the more example-based approach (I lean towards the former), but all in all, it seems like an appropriate balance. Relating these to the impact of "architectural coupling" was particularly helpful, in my view.
|
||||
|
||||
There is a useful grounding in some of the advice in Conway’s Law ("Organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations.") which led me to wonder how we could model open source projects—and their architectures—based on this perspective. There are also (as is also standard these days) patterns and anti-patterns: I would generally consider these a useful part of any book on design and architecture.
|
||||
|
||||
### Why is this a book for security folks?
|
||||
|
||||
The most important thing about this book, from my point of view as a security systems architect, is that it _isn’t_ about security. Security is mentioned, but is not considered core enough to the book to merit a mention in the appendix. The point, though, is that the security of a system—an embodiment of an architecture—is a perfect example of a fitness function. Taking this as a starting point for a project will help you do two things.
|
||||
|
||||
First, you will avoid focussing on features and functionality, and look at the bigger picture. Second, you will consider what you _really_ need from security in the system, and how that translates into issues such as the security posture to be adopted, and the measurements you will take to validate it through the lifecycle.
|
||||
|
||||
Possibly even more important than those two points is that it will force you to consider the priority of security in relation to other fitness functions (resilience, maybe, or ease of use?) and how the relative priorities will—and should—change over time. A realisation that we don’t live in a bubble, and that our priorities are not always that same as those of other stakeholders in a project, is always useful.
|
||||
|
||||
### Why is this a book for open source folks?
|
||||
|
||||
Very often—and for quite understandable and forgiveable reasons—the architectures of open source projects grow organically at first, needing major overhauls and refactoring at various stages of their lifecycles. This is not to say that this doesn’t happen in proprietary software projects as well, of course, but the sometimes frequent changes in open source projects' emphasis and requirements, the ebb and flow of contributors and contributions and the sometimes, um, reduced levels of documentation aimed at end users can mean that features are significantly prioritised over what we could think of as the core vision of the project. One way to remedy this would be to consider the appropriate fitness functions of the project, to state them upfront, and to have a regular cadence of review by the community, to ensure that they are:
|
||||
|
||||
* still relevant;
|
||||
* correctly prioritised at this stage in the project;
|
||||
* actually being met.
|
||||
|
||||
|
||||
|
||||
If any of the above come into question, it’s a good time to consider a wider review by the community, and maybe a refactoring or partial redesign of the project.
|
||||
|
||||
Open source projects have—quite rightly—various different models of use and intended users. One of the happenstances that can negatively affect a project is when it is identified as a possible fit for a use case for which it was not originally intended. Academic software which is designed for accuracy over performance might not be a good fit for corporate research, for instance, in the same way that a project aimed at home users which prioritises minimal computing resources might not be appropriate for a high-availability enterprise roll-out. One of the ways of making this clear is by being very clear up-front about the fitness functions that you expect your project to meet—and, vice versa, about the fitness functions you are looking to fulfil when you are looking to select a project. It is easy to focus on features and functionality, and to overlook the more non-functional aspects of a system, and fitness functions allow us to make some informed choices about how to balance these decisions.
|
||||
|
||||
_This article was originally posted on [Alice, Eve and Bob - a security blog][4]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/book-review-building-evolutionary-architectures
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mikecamel
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/open_book_color.jpg?itok=I-8tNQOP (An open book)
|
||||
[2]: https://opensource.com/sites/default/files/styles/medium/public/uploads/building-evolutionary-architectures.jpg?itok=UlyKLSxV (Building Evolutionary Architectures: Support Constant Change)
|
||||
[3]: https://www.oreilly.com/library/view/building-evolutionary-architectures/9781491986356/
|
||||
[4]: https://aliceevebob.com/2019/06/25/building-evolutionary-architectures-for-security-and-for-open-source/
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Bash Script to Monitor Messages Log (Warning, Error and Critical) on Linux
|
||||
======
|
||||
|
||||
There are many open source monitoring tools are currently available in market to monitor Linux systems performance.
|
||||
|
||||
It will send an email alert when the system reaches the specified threshold limit.
|
||||
|
||||
It monitors everything such as CPU utilization, Memory utilization, swap utilization, disk space utilization and much more.
|
||||
|
||||
If you only have few systems and want to monitor them then writing a small shell script can make your task very easy.
|
||||
|
||||
In this tutorial we have added a shell script to monitor Messages Log on Linux system.
|
||||
|
||||
We had added many useful shell scripts in the past. If you want to check those, navigate to the below link.
|
||||
|
||||
* **[How to automate day to day activities using shell scripts?][1]**
|
||||
|
||||
|
||||
|
||||
This script will check **“warning, error and critical”** in the `/var/log/messages` file and trigger a mail to given email id, if it’s found anything related it.
|
||||
|
||||
We can’t run this script frequently that may fill up your inbox if the server has many matching strings, instead we can run once in a day.
|
||||
|
||||
To overcome this issue, i made the script to trigger an email in a different manner.
|
||||
|
||||
If any given strings are found in the **“/var/log/messages”** file for yesterday’s date then the script will send an email alert to given email id.
|
||||
|
||||
**Note:** You need to change the email id instead of ours. Also, you can change the Memory utilization threshold value as per your requirement.
|
||||
|
||||
```
|
||||
# vi /opt/scripts/os-log-alert.sh
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
#Set the variable which equal to zero
|
||||
|
||||
prev_count=0
|
||||
|
||||
count=$(grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | egrep -wi 'warning|error|critical' | wc -l)
|
||||
|
||||
if [ "$prev_count" -lt "$count" ] ; then
|
||||
|
||||
# Send a mail to given email id when errors found in log
|
||||
|
||||
SUBJECT="WARNING: Errors found in log on "`date --date='yesterday' '+%b %e'`""
|
||||
|
||||
# This is a temp file, which is created to store the email message.
|
||||
|
||||
MESSAGE="/tmp/logs.txt"
|
||||
|
||||
TO="[email protected]"
|
||||
|
||||
echo "ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin." >> $MESSAGE
|
||||
|
||||
echo "Hostname: `hostname`" >> $MESSAGE
|
||||
|
||||
echo -e "\n" >> $MESSAGE
|
||||
|
||||
echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
|
||||
|
||||
echo "Error messages in the log file as below" >> $MESSAGE
|
||||
|
||||
echo "+------------------------------------------------------------------------------------+" >> $MESSAGE
|
||||
|
||||
grep -i "`date --date='yesterday' '+%b %e'`" /var/log/messages | awk '{ $3=""; print}' | egrep -wi 'warning|error|critical' >> $MESSAGE
|
||||
|
||||
mail -s "$SUBJECT" "$TO" < $MESSAGE
|
||||
|
||||
#rm $MESSAGE
|
||||
|
||||
fi
|
||||
```
|
||||
|
||||
Set an executable permission to `os-log-alert.sh` file.
|
||||
|
||||
```
|
||||
$ chmod +x /opt/scripts/os-log-alert.sh
|
||||
```
|
||||
|
||||
Finally add a cronjob to automate this. It will run everyday at 7'o clock.
|
||||
|
||||
```
|
||||
# crontab -e
|
||||
0 7 * * * /bin/bash /opt/scripts/os-log-alert.sh
|
||||
```
|
||||
|
||||
**Note:** You will be getting an email alert everyday at 7 o'clock, which is for yesterday's log.
|
||||
|
||||
**Output:** You will be getting an email alert similar to below.
|
||||
|
||||
```
|
||||
ATTENTION: Errors are found in /var/log/messages. Please Check with Linux admin.
|
||||
|
||||
+-----------------------------------------------------+
|
||||
Error messages in the log file as below
|
||||
+-----------------------------------------------------+
|
||||
Jul 3 02:40:11 ns1 kernel: php-fpm[3175]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||
Jul 3 02:50:14 ns1 kernel: lmtp[8249]: segfault at 20 ip 00007f9cc05295e4 sp 00007ffc57bca1a0 error 4 in libdovecot-storage.so.0.0.0[7f9cc04df000+148000]
|
||||
Jul 3 15:36:09 ns1 kernel: php-fpm[17846]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||
Jul 3 15:45:54 ns1 pure-ftpd: ([email protected]) [WARNING] Authentication failed for user [daygeek]
|
||||
Jul 3 16:25:36 ns1 pure-ftpd: ([email protected]) [WARNING] Sorry, cleartext sessions and weak ciphers are not accepted on this server.#012Please reconnect using TLS security mechanisms.
|
||||
Jul 3 16:44:20 ns1 kernel: php-fpm[8979]: segfault at 299 ip 000055dfe7cc7e25 sp 00007ffd799d7d38 error 4 in php-fpm[55dfe7a89000+3a7000]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-bash-script-to-monitor-messages-log-warning-error-critical-send-email/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/shell-script/
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Copy and paste at the Linux command line with xclip)
|
||||
[#]: via: (https://opensource.com/article/19/7/xclip)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
Copy and paste at the Linux command line with xclip
|
||||
======
|
||||
Learn how to get started with the Linux xclip utility.
|
||||
![Green paperclips][1]
|
||||
|
||||
How do you usually copy all or part of a text file when working on the Linux desktop? Chances are you open the file in a text editor, select all or just the text you want to copy, and paste it somewhere else.
|
||||
|
||||
That works. But you can do the job a bit more efficiently at the command line using the [xclip][2] utility. xclip provides a conduit between commands you run in a terminal window and the clipboard in a Linux graphical desktop environment.
|
||||
|
||||
### Installing xclip
|
||||
|
||||
xclip isn't standard kit with many Linux distributions. To see if it's installed on your computer, open a terminal window and type **which xclip**. If that command returns output like _/usr/bin/xclip_, then you're ready to go. Otherwise, you need to install xclip.
|
||||
|
||||
To do that, use your distribution's package manager. Or, if you're adventurous, [grab the source code][2] from GitHub and compile it yourself.
|
||||
|
||||
### Doing the basics
|
||||
|
||||
Let's say you want to copy the contents of a file to the clipboard. There are two ways to do that with xclip. Type either:
|
||||
|
||||
|
||||
```
|
||||
`xclip file_name`
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
|
||||
```
|
||||
`xclip -sel clip file_name`
|
||||
```
|
||||
|
||||
What's the difference between the two commands (aside from the second one being longer)? The first command works if you use the middle button on the mouse to paste text. However, not everyone does. Many people are conditioned to use a right-click menu or to press Ctrl+V to paste text. If you're one of those people (I am!), using the **-sel clip** option ensures you can paste what you want to paste.
|
||||
|
||||
### Using xclip with other applications
|
||||
|
||||
Copying the contents of a file directly to the clipboard is a neat parlor trick. Chances are, you won't be doing that very often. There are other ways you can use xclip, and those involve pairing it with another command-line application.
|
||||
|
||||
That pairing is done with a _pipe_ (|). The pipe redirects the output of one command line application to another. Doing that opens several possibilities. Let's take a look at three of them.
|
||||
|
||||
Say you're a system administrator and you need to copy the last 30 lines of a log file into a bug report. Opening the file in a text editor, scrolling down to the end, and copying and pasting is a bit of work. Why not use xclip and the [tail][3] utility to quickly and easily do the deed? Run this command to copy those last 30 lines:
|
||||
|
||||
|
||||
```
|
||||
`tail -n 30 logfile.log | xclip -sel clip`
|
||||
```
|
||||
|
||||
Quite a bit of my writing goes into some content management system (CMS) or another for publishing on the web. However, I never use a CMS's WYSIWYG editor to write—I write offline in [plain text][4] formatted with [Markdown][5]. That said, many of those editors have an HTML mode. By using this command, I can convert a Markdown-formatted file to HTML using [Pandoc][6] and copy it to the clipboard in one fell swoop:
|
||||
|
||||
|
||||
```
|
||||
`pandoc -t html file.md | xclip -sel clip`
|
||||
```
|
||||
|
||||
From there, I paste away.
|
||||
|
||||
Two of my websites are hosted using [GitLab Pages][7]. I generate the HTTPS certificates for those sites using a tool called [Certbot][8], and I need to copy the certificate for each site to GitLab whenever I renew it. Combining the [cat][9] command and xclip is faster and more efficient than using an editor. For example:
|
||||
|
||||
|
||||
```
|
||||
`cat /etc/letsencrypt/live/website/fullchain.pem | xclip -sel clip`
|
||||
```
|
||||
|
||||
Is that all you can do with xclip? Definitely not. I'm sure you can find more uses to fit your needs.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Not everyone will use xclip. That's fine. It is, however, one of those little utilities that really comes in handy when you need it. And, as I've discovered on a few occasions, you don't know when you'll need it. When that time comes, you'll be glad xclip is there.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/xclip
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life_paperclips.png?itok=j48op49T (Green paperclips)
|
||||
[2]: https://github.com/astrand/xclip
|
||||
[3]: https://en.wikipedia.org/wiki/Tail_(Unix)
|
||||
[4]: https://plaintextproject.online
|
||||
[5]: https://gumroad.com/l/learnmarkdown
|
||||
[6]: https://pandoc.org
|
||||
[7]: https://docs.gitlab.com/ee/user/project/pages/
|
||||
[8]: https://certbot.eff.org/
|
||||
[9]: https://en.wikipedia.org/wiki/Cat_(Unix)
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Enable ‘Tap to click’ on Ubuntu Login Screen [Quick Tip])
|
||||
[#]: via: (https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Enable ‘Tap to click’ on Ubuntu Login Screen [Quick Tip]
|
||||
======
|
||||
|
||||
_**Brief: The tap to click option doesn’t work on the login screen in Ubuntu 18.04 GNOME desktop. In this tutorial, you’ll learn to enable the ‘tap to click’ on the Ubuntu login screen.**_
|
||||
|
||||
One of the first few things I do after installing Ubuntu is to make sure that tap to click has been enabled. As a laptop user, I prefer to tap the touchpad for making a left click. This is more convenient than using the left click button on the touchpad all the time.
|
||||
|
||||
This is what happens when I have logged in and using the operating system. But if you are at the login screen, the tap to click doesn’t work and that’s an annoyance.
|
||||
|
||||
On the [GDM login screen][1] in Ubuntu (or other distributions using GNOME desktop), you have to click the username in order to bring the password field. Now if you are habitual of tap to click, it doesn’t work on the login screen even if you have it enabled and use it after logging into the system.
|
||||
|
||||
This is a minor annoyance but an annoyance nonetheless. The good news is that you can fix this annoyance.Let me show you how to do that in this quick tip.
|
||||
|
||||
### Enabling tap to click on Ubuntu login screen
|
||||
|
||||
![][2]
|
||||
|
||||
You’ll have to use the terminal and a few commands here. I hope you are comfortable with it.
|
||||
|
||||
[Open a terminal using Ctrl+Alt+T shortcut in Ubuntu][3]. Since Ubuntu 18.04 is still using X server, you need to enable it to connect to the [x server][4]. For that, you can add gdm to access control list.
|
||||
|
||||
Switch to root user first. It’s required because you have to switch as gdm user later and you cannot do that as a non-root user.
|
||||
|
||||
```
|
||||
sudo -i
|
||||
```
|
||||
|
||||
[There is no password set for root user in Ubuntu][5]. You access it with your admin user account. So when asked for password, use your own password. You won’t see anything being typed on the screen when you type in your password.
|
||||
|
||||
```
|
||||
xhost +SI:localuser:gdm
|
||||
```
|
||||
|
||||
Here’s the output for me:
|
||||
|
||||
```
|
||||
xhost +SI:localuser:gdm
|
||||
localuser:gdm being added to access control list
|
||||
```
|
||||
|
||||
Now run this command so that the the ‘user gdm’ has the correct tap to click setting.
|
||||
|
||||
```
|
||||
gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click true
|
||||
```
|
||||
|
||||
If you see a warning like this: (process:6339): dconf-WARNING **: 19:52:21.217: Unable to open /root/.local/share/flatpak/exports/share/dconf/profile/user: Permission denied . Don’t worry. Just ignore it.
|
||||
|
||||
[][6]
|
||||
|
||||
Suggested read How To Change Hostname on Ubuntu & Other Linux Distributions
|
||||
|
||||
This will enable you to perform a tap to click on the login screen. Why were you not able to use tap to click when you made the changes in the system settings before? It’s because at the login screen, you haven’t selected your username yet. You get to use your account only when you select the user on the screen. This is why you had to use the user gdm and add the correct settings with it.
|
||||
|
||||
Restart Ubuntu and you’ll see that you can now use the tap to select your user account now.
|
||||
|
||||
#### Revert the changes
|
||||
|
||||
If you are not happy with the tap to click on the Ubuntu login screen for some reason, you can revert the changes.
|
||||
|
||||
You’ll have to perform all the steps you did in the previous section: switch to root, connect gdm with x server, switch to gdm user. But instead of the last command, you need to run this command:
|
||||
|
||||
```
|
||||
gsettings set org.gnome.desktop.peripherals.touchpad tap-to-click false
|
||||
```
|
||||
|
||||
That’s it.
|
||||
|
||||
As I said, it’s a tiny thing. I mean you can easily do a left click instead of the tap to click. It’s just a matter of one single click.However, it breaks the ‘continuity’ when you are forced to use the left click after a few taps.
|
||||
|
||||
I hope you liked this quick little tweak. If you know some other cool tweaks, do share it with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/enable-tap-to-click-on-ubuntu-login-screen/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://wiki.archlinux.org/index.php/GDM
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/tap-to-click-on-ubuntu-login.jpg?ssl=1
|
||||
[3]: https://itsfoss.com/ubuntu-shortcuts/
|
||||
[4]: https://en.wikipedia.org/wiki/X.Org_Server
|
||||
[5]: https://itsfoss.com/change-password-ubuntu/
|
||||
[6]: https://itsfoss.com/change-hostname-ubuntu/
|
||||
@ -0,0 +1,311 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Learn object-oriented programming with Python)
|
||||
[#]: via: (https://opensource.com/article/19/7/get-modular-python-classes)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Learn object-oriented programming with Python
|
||||
======
|
||||
Make your code more modular with Python classes.
|
||||
![Developing code.][1]
|
||||
|
||||
In my previous article, I explained how to [make Python modular][2] by using functions, creating modules, or both. Functions are invaluable to avoid repeating code you intend to use several times, and modules ensure that you can use your code across different projects. But there's another component to modularity: the class.
|
||||
|
||||
If you've heard the term _object-oriented programming_, then you may have some notion of the purpose classes serve. Programmers tend to consider a class as a virtual object, sometimes with a direct correlation to something in the physical world, and other times as a manifestation of some programming concept. Either way, the idea is that you can create a class when you want to create "objects" within a program for you or other parts of the program to interact with.
|
||||
|
||||
### Templates without classes
|
||||
|
||||
Assume you're writing a game set in a fantasy world, and you need this application to be able to drum up a variety of baddies to bring some excitement into your players' lives. Knowing quite a lot about functions, you might think this sounds like a textbook case for functions: code that needs to be repeated often but is written once with allowance for variations when called.
|
||||
|
||||
Here's an example of a purely function-based implementation of an enemy generator:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
def enemy(ancestry,gear):
|
||||
enemy=ancestry
|
||||
weapon=gear
|
||||
hp=random.randrange(0,20)
|
||||
ac=random.randrange(0,20)
|
||||
return [enemy,weapon,hp,ac]
|
||||
|
||||
def fight(tgt):
|
||||
print("You take a swing at the " + tgt[0] + ".")
|
||||
hit=random.randrange(0,20)
|
||||
if hit > tgt[3]:
|
||||
print("You hit the " + tgt[0] + " for " + str(hit) + " damage!")
|
||||
tgt[2] = tgt[2] - hit
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
foe=enemy("troll","great axe")
|
||||
print("You meet a " + foe[0] + " wielding a " + foe[1])
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
while True:
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
fight(foe)
|
||||
|
||||
if foe[2] < 1:
|
||||
print("You killed your foe!")
|
||||
else:
|
||||
print("The " + foe[0] + " has " + str(foe[2]) + " HP remaining")
|
||||
```
|
||||
|
||||
The **enemy** function creates an enemy with several attributes, such as ancestry, a weapon, health points, and a defense rating. It returns a list of each attribute, representing the sum total of the enemy.
|
||||
|
||||
In a sense, this code has created an object, even though it's not using a class yet. Programmers call this "enemy" an _object_ because the result (a list of strings and integers, in this case) of the function represents a singular but complex _thing_ in the game. That is, the strings and integers in the list aren't arbitrary: together, they describe a virtual object.
|
||||
|
||||
When writing a collection of descriptors, you use variables so you can use them any time you want to generate an enemy. It's a little like a template.
|
||||
|
||||
In the example code, when an attribute of the object is needed, the corresponding list item is retrieved. For instance, to get the ancestry of an enemy, the code looks at **foe[0]**, for health points, it looks at **foe[2]** for health points, and so on.
|
||||
|
||||
There's nothing necessarily wrong with this approach. The code runs as expected. You could add more enemies of different types, you could create a list of enemy types and randomly select from the list during enemy creation, and so on. It works well enough, and in fact [Lua][3] uses this principle very effectively to approximate an object-oriented model.
|
||||
|
||||
However, there's sometimes more to an object than just a list of attributes.
|
||||
|
||||
### The way of the object
|
||||
|
||||
In Python, everything is an object. Anything you create in Python is an _instance_ of some predefined template. Even basic strings and integers are derivatives of the Python **type** class. You can witness this for yourself an interactive Python shell:
|
||||
|
||||
|
||||
```
|
||||
>>> foo=3
|
||||
>>> type(foo)
|
||||
<class 'int'>
|
||||
>>> foo="bar"
|
||||
>>> type(foo)
|
||||
<class 'str'>
|
||||
```
|
||||
|
||||
When an object is defined by a class, it is more than just a collection of attributes. Python classes have functions all their own. This is convenient, logically, because actions that pertain only to a certain class of objects are contained within that object's class.
|
||||
|
||||
In the example code, the fight code is a function of the main application. That works fine for a simple game, but in a complex one, there would be more than just players and enemies in the game world. There might be townsfolk, livestock, buildings, forests, and so on, and none of them ever need access to a fight function. Placing code for combat in an enemy class means your code is better organized; and in a complex application, that's a significant advantage.
|
||||
|
||||
Furthermore, each class has privileged access to its own local variables. An enemy's health points, for instance, isn't data that should ever change except by some function of the enemy class. A random butterfly in the game should not accidentally reduce an enemy's health to 0. Ideally, even without classes, that would never happen, but in a complex application with lots of moving parts, it's a powerful trick of the trade to ensure that parts that don't need to interact with one another never do.
|
||||
|
||||
Python classes are also subject to garbage collection. When an instance of a class is no longer used, it is moved out of memory. You may never know when this happens, but you tend to notice when it doesn't happen because your application takes up more memory and runs slower than it should. Isolating data sets into classes helps Python track what is in use and what is no longer needed.
|
||||
|
||||
### Classy Python
|
||||
|
||||
Here's the same simple combat game using a class for the enemy:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.ac=random.randrange(12,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
|
||||
# game start
|
||||
foe=Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
This version of the game handles the enemy as an object containing the same attributes (ancestry, weapon, health, and defense), plus a new attribute measuring whether the enemy has been vanquished yet, as well as a function for combat.
|
||||
|
||||
The first function of a class is a special function called (in Python) an _init_, or initialization, function. This is similar to a [constructor][4] in other languages; it creates an instance of the class, which is identifiable to you by its attributes and to whatever variable you use when invoking the class (**foe** in the example code).
|
||||
|
||||
### Self and class instances
|
||||
|
||||
The class' functions accept a new form of input you don't see outside of classes: **self**. If you don't include **self**, then Python has no way of knowing _which_ instance of the class to use when you call a class function. It's like challenging a single orc to a duel by saying "I'll fight the orc" in a room full of orcs; nobody knows which one you're referring to, and so bad things happen.
|
||||
|
||||
![Image of an Orc, CC-BY-SA by Buch on opengameart.org][5]
|
||||
|
||||
CC-BY-SA by Buch on opengameart.org
|
||||
|
||||
Each attribute created within a class is prepended with the **self** notation, which identifies that variable as an attribute of the class. Once an instance of a class is spawned, you swap out the **self** prefix with the variable representing that instance. Using this technique, you could challenge just one orc to a duel in a room full of orcs by saying "I'll fight the gorblar.orc"; when Gorblar the Orc hears **gorblar.orc**, he knows which orc you're referring to (him_self_), and so you get a fair fight instead of a brawl. In Python:
|
||||
|
||||
|
||||
```
|
||||
gorblar=Enemy("orc","sword")
|
||||
print("The " + gorblar.enemy + " has " + str(gorblar.hp) + " remaining.")
|
||||
```
|
||||
|
||||
Instead of looking to **foe[0]** (as in the functional example) or **gorblar[0]** for the enemy type, you retrieve the class attribute (**gorblar.enemy** or **gorblar.hp** or whatever value for whatever object you need).
|
||||
|
||||
### Local variables
|
||||
|
||||
If a variable in a class is not prepended with the **self** keyword, then it is a local variable, just as in any function. For instance, no matter what you do, you cannot access the **hit** variable outside the **Enemy.fight** class:
|
||||
|
||||
|
||||
```
|
||||
>>> print(foe.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.hit)
|
||||
AttributeError: 'Enemy' object has no attribute 'hit'
|
||||
|
||||
>>> print(foe.fight.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.fight.hit)
|
||||
AttributeError: 'function' object has no attribute 'hit'
|
||||
```
|
||||
|
||||
The **hit** variable is contained within the Enemy class, and only "lives" long enough to serve its purpose in combat.
|
||||
|
||||
### More modularity
|
||||
|
||||
This example uses a class in the same text document as your main application. In a complex game, it's easier to treat each class almost as if it were its own self-standing application. You see this when multiple developers work on the same application: one developer works on a class, and the other works on the main program, and as long as they communicate with one another about what attributes the class must have, the two code bases can be developed in parallel.
|
||||
|
||||
To make this example game modular, split it into two files: one for the main application and one for the class. Were it a more complex application, you might have one file per class, or one file per logical groups of classes (for instance, a file for buildings, a file for natural surroundings, a file for enemies and NPCs, and so on).
|
||||
|
||||
Save one file containing just the Enemy class as **enemy.py** and another file containing everything else as **main.py**.
|
||||
|
||||
Here's **enemy.py**:
|
||||
|
||||
|
||||
```
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.stg=random.randrange(0,20)
|
||||
self.ac=random.randrange(0,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
```
|
||||
|
||||
Here's **main.py**:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import enemy as en
|
||||
|
||||
# game start
|
||||
foe=en.Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
Importing the module **enemy.py** is done very specifically with a statement that refers to the file of classes as its name without the **.py** extension, followed by a namespace designator of your choosing (for example, **import enemy as en**). This designator is what you use in the code when invoking a class. Instead of just using **Enemy()**, you preface the class with the designator of what you imported, such as **en.Enemy**.
|
||||
|
||||
All of these file names are entirely arbitrary, although not uncommon in principle. It's a common convention to name the part of the application that serves as the central hub **main.py**, and a file full of classes is often named in lowercase with the classes inside it, each beginning with a capital letter. Whether you follow these conventions doesn't affect how the application runs, but it does make it easier for experienced Python programmers to quickly decipher how your application works.
|
||||
|
||||
There's some flexibility in how you structure your code. For instance, using the code sample, both files must be in the same directory. If you want to package just your classes as a module, then you must create a directory called, for instance, **mybad** and move your classes into it. In **main.py**, your import statement changes a little:
|
||||
|
||||
|
||||
```
|
||||
`from mybad import enemy as en`
|
||||
```
|
||||
|
||||
Both systems produce the same results, but the latter is best if the classes you have created are generic enough that you think other developers could use them in their projects.
|
||||
|
||||
Regardless of which you choose, launch the modular version of the game:
|
||||
|
||||
|
||||
```
|
||||
$ python3 ./main.py
|
||||
You meet a troll wielding a great axe
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You missed.
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 8 damage!
|
||||
The troll has 4 HP remaining
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 11 damage!
|
||||
The troll has -7 HP remaining
|
||||
You have won...this time.
|
||||
```
|
||||
|
||||
The game works. It's modular. And now you know what it means for an application to be object-oriented. But most importantly, you know to be specific when challenging an orc to a duel.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
|
||||
[2]: https://opensource.com/article/19/6/get-modular-python-functions
|
||||
[3]: https://opensource.com/article/17/4/how-program-games-raspberry-pi
|
||||
[4]: https://opensource.com/article/19/6/what-java-constructor
|
||||
[5]: https://opensource.com/sites/default/files/images/orc-buch-opengameart_cc-by-sa.jpg (CC-BY-SA by Buch on opengameart.org)
|
||||
121
sources/tech/20190705 Manage your shell environment.md
Normal file
121
sources/tech/20190705 Manage your shell environment.md
Normal file
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Manage your shell environment)
|
||||
[#]: via: (https://fedoramagazine.org/manage-your-shell-environment/)
|
||||
[#]: author: (Eduard Lucena https://fedoramagazine.org/author/x3mboy/)
|
||||
|
||||
Manage your shell environment
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Some time ago, the Fedora Magazine has published an [article introducing ZSH][2] — an alternative shell to Fedora’s default, bash. This time, we’re going to look into customizing it to use it in a more effective way. All of the concepts shown in this article also work in other shells such as bash.
|
||||
|
||||
### Alias
|
||||
|
||||
Aliases are shortcuts for commands. This is useful for creating short commands for actions that are performed often, but require a long command that would take too much time to type. The syntax is:
|
||||
|
||||
```
|
||||
$ alias yourAlias='complex command with arguments'
|
||||
```
|
||||
|
||||
They don’t always need to be used for shortening long commands. Important is that you use them for tasks that you do often. An example could be:
|
||||
|
||||
```
|
||||
$ alias dnfUpgrade='dnf -y upgrade'
|
||||
```
|
||||
|
||||
That way, to do a system upgrade, I just type dnfUpgrade instead of the whole dnf command.
|
||||
|
||||
The problem of setting aliases right in the console is that once the terminal session is closed, the alias would be lost. To set them permanently, resource files are used.
|
||||
|
||||
### Resource Files
|
||||
|
||||
Resource files (or rc files) are configuration files that are loaded per user in the beginning of a session or a process (when a new terminal window is opened, or a new program like vim is started). In the case of ZSH, the resource file is _.zshrc_, and for bash it’s _.bashrc_.
|
||||
|
||||
To make the aliases permanent, you can either put them in your resource. You can edit your resource file with a text editor of your choice. This example uses vim:
|
||||
|
||||
```
|
||||
$ vim $HOME/.zshrc
|
||||
```
|
||||
|
||||
Or for bash:
|
||||
|
||||
```
|
||||
$ vim $HOME/.bashrc
|
||||
```
|
||||
|
||||
Note that the location of the resource file is specified relatively to a home directory — and that’s where ZSH (or bash) are going to look for the file by default for each user.
|
||||
|
||||
Other option is to put your configuration in any other file, and then source it:
|
||||
|
||||
```
|
||||
$ source /path/to/your/rc/file
|
||||
```
|
||||
|
||||
Again, sourcing it right in your session will only apply it to the session, so to make it permanent, add the source command to your resource file. The advantage of having your source file in a different location is that you can source it any time. Or anywhere which is especially useful in shared environments.
|
||||
|
||||
### Environment Variables
|
||||
|
||||
Environment variables are values assigned to a specific name which can be then called in scripts and commands. They start with the $ dollar sign. One of the most common is $HOME that references the home directory.
|
||||
|
||||
As the name suggests, environment variables are a part of your environment. Set a variable using the following syntax:
|
||||
|
||||
```
|
||||
$ http_proxy="http://your.proxy"
|
||||
```
|
||||
|
||||
And to make it an environment variable, export it with the following command:
|
||||
|
||||
```
|
||||
$ export $http_proxy
|
||||
```
|
||||
|
||||
To see all the environment variables that are currently set, use the _env_ command:
|
||||
|
||||
```
|
||||
$ env
|
||||
```
|
||||
|
||||
The command outputs all the variables available in your session. To demonstrate how to use them in a command, try running the following echo commands:
|
||||
|
||||
```
|
||||
$ echo $PWD
|
||||
/home/fedora
|
||||
$ echo $USER
|
||||
fedora
|
||||
```
|
||||
|
||||
What happens here is variable expansion — the value stored in the variable is used in your command.
|
||||
|
||||
Another useful variable is _$PATH_, that defines directories that your shell uses to look for binaries.
|
||||
|
||||
### The $PATH variable
|
||||
|
||||
There are many directories, or folders (the way they are called in graphical environments) that are important to the OS. Some directories are set to hold binaries you can use directly in your shell. And these directories are defined in the $PATH variable.
|
||||
|
||||
```
|
||||
$ echo $PATH
|
||||
/usr/lib64/qt-3.3/bin:/usr/share/Modules/bin:/usr/lib64/ccache:/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/usr/libexec/sdcc:/usr/libexec/sdcc:/usr/bin:/bin:/sbin:/usr/sbin:/opt/FortiClient
|
||||
```
|
||||
|
||||
This will help you when you want to have your own binaries (or scripts) accessible in the shell.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/manage-your-shell-environment/
|
||||
|
||||
作者:[Eduard Lucena][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/x3mboy/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2018/05/manage-shell-env-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/set-zsh-fedora-system/
|
||||
@ -0,0 +1,134 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Delete A Repository And GPG Key In Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-delete-a-repository-and-gpg-key-in-ubuntu/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Delete A Repository And GPG Key In Ubuntu
|
||||
======
|
||||
|
||||
![Delete A Repository And GPG Key In Ubuntu][1]
|
||||
|
||||
The other day we discussed how to [**list the installed repositories**][2] in RPM and DEB-based systems. Today, we are going to learn how to delete a repository along with its GPG key in Ubuntu. For those wondering, a repository (shortly **repo** ) is a central place where the developers keep the software packages. The packages in the repositories are thoroughly tested and built specifically for each version by Ubuntu developers. The users can download and install these packages on their Ubuntu system using **Apt** **package manager**. Ubuntu has four official repositories namely **Main** , **Universe** , **Restricted** and **Multiverse**.
|
||||
|
||||
Apart from the official repositories, there are many unofficial repositories maintained by developers (or package maintainers). The unofficial repositories usually have the packages which are not available in the official repositories. All packages are signed with pair of keys, a public and private key, by the package maintainer. As you already know, the public key is given out to the users and the private must be kept secret. Whenever you add a new repository in the sources list, you should also add the repository key if Apt package manager wants to trust the newly added repository. Using the repository keys, you can ensure that you’re getting the packages from the right person. Hope you got a basic idea about software repositories and repository keys. Now let us go ahead and see how to delete the repository and its key if it is no longer necessary in Ubuntu systems.
|
||||
|
||||
### Delete A Repository In Ubuntu
|
||||
|
||||
Whenever you add a repository using “add-apt-repository” command, it will be stored in **/etc/apt/sources.list** file.
|
||||
|
||||
To delete a software repository from Ubuntu and its derivatives, just open the /etc/apt/sources.list file and look for the repository entry and delete it.
|
||||
|
||||
```
|
||||
$ sudo nano /etc/apt/sources.list
|
||||
```
|
||||
|
||||
As you can see in the below screenshot, I have added [**Oracle Virtualbox**][3] repository in my Ubuntu system.
|
||||
|
||||
![][4]
|
||||
|
||||
virtualbox repository
|
||||
|
||||
To delete this repository, simply remove the entry. Save and close the file.
|
||||
|
||||
If you have added PPA repositories, look into **/etc/apt/sources.list.d/** directory and delete the respective entry.
|
||||
|
||||
Alternatively, you can delete the repository using “add-apt-repository” command. For example, I am deleting the [**Systemback**][5] repository like below.
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository -r ppa:nemh/systemback
|
||||
```
|
||||
|
||||
Finally, update the software sources list using command:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
### Delete Repository keys
|
||||
|
||||
We use “apt-key” command to add the repository keys. First, let us list the added keys using command:
|
||||
|
||||
```
|
||||
$ sudo apt-key list
|
||||
```
|
||||
|
||||
This command will list all added repository keys.
|
||||
|
||||
```
|
||||
/etc/apt/trusted.gpg
|
||||
--------------------
|
||||
pub rsa1024 2010-10-31 [SC]
|
||||
3820 03C2 C8B7 B4AB 813E 915B 14E4 9429 73C6 2A1B
|
||||
uid [ unknown] Launchpad PPA for Kendek
|
||||
|
||||
pub rsa4096 2016-04-22 [SC]
|
||||
B9F8 D658 297A F3EF C18D 5CDF A2F6 83C5 2980 AECF
|
||||
uid [ unknown] Oracle Corporation (VirtualBox archive signing key) <[email protected]>
|
||||
sub rsa4096 2016-04-22 [E]
|
||||
|
||||
/etc/apt/trusted.gpg.d/ubuntu-keyring-2012-archive.gpg
|
||||
------------------------------------------------------
|
||||
pub rsa4096 2012-05-11 [SC]
|
||||
790B C727 7767 219C 42C8 6F93 3B4F E6AC C0B2 1F32
|
||||
uid [ unknown] Ubuntu Archive Automatic Signing Key (2012) <[email protected]>
|
||||
|
||||
/etc/apt/trusted.gpg.d/ubuntu-keyring-2012-cdimage.gpg
|
||||
------------------------------------------------------
|
||||
pub rsa4096 2012-05-11 [SC]
|
||||
8439 38DF 228D 22F7 B374 2BC0 D94A A3F0 EFE2 1092
|
||||
uid [ unknown] Ubuntu CD Image Automatic Signing Key (2012) <[email protected]>
|
||||
|
||||
/etc/apt/trusted.gpg.d/ubuntu-keyring-2018-archive.gpg
|
||||
------------------------------------------------------
|
||||
pub rsa4096 2018-09-17 [SC]
|
||||
F6EC B376 2474 EDA9 D21B 7022 8719 20D1 991B C93C
|
||||
uid [ unknown] Ubuntu Archive Automatic Signing Key (2018) <[email protected]>
|
||||
```
|
||||
|
||||
As you can see in the above output, the long (40 characters) hex value is the repository key. If you want APT package manager to stop trusting the key, simply delete it using command:
|
||||
|
||||
```
|
||||
$ sudo apt-key del "3820 03C2 C8B7 B4AB 813E 915B 14E4 9429 73C6 2A1B"
|
||||
```
|
||||
|
||||
Or, specify the last 8 characters only:
|
||||
|
||||
```
|
||||
$ sudo apt-key del 73C62A1B
|
||||
```
|
||||
|
||||
Done! The repository key has been deleted. Run the following command to update the repository lists:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
**Resource:**
|
||||
|
||||
* [**Software repositories – Ubuntu Community Wiki**][6]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-delete-a-repository-and-gpg-key-in-ubuntu/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Delete-a-repository-in-ubuntu-720x340.png
|
||||
[2]: https://www.ostechnix.com/find-list-installed-repositories-commandline-linux/
|
||||
[3]: https://www.ostechnix.com/install-oracle-virtualbox-ubuntu-16-04-headless-server/
|
||||
[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/virtualbox-repository.png
|
||||
[5]: https://www.ostechnix.com/systemback-restore-ubuntu-desktop-and-server-to-previous-state/
|
||||
[6]: https://help.ubuntu.com/community/Repositories/Ubuntu
|
||||
@ -0,0 +1,312 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Install NetData Performance Monitoring Tool On Linux)
|
||||
[#]: via: (https://www.ostechnix.com/netdata-real-time-performance-monitoring-tool-linux/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Install NetData Performance Monitoring Tool On Linux
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
**NetData** is a distributed, real-time, performance and health monitoring tool for systems and applications. It provides unparalleled insights of everything happening on a system in real-time. You can view the results in a highly interactive web-dashboard. Using Netdata, you can get a clear idea of what is happening now, and what happened before in your systems and applications. You don’t need to be an expert to deploy this tool in your Linux systems. NetData just works fine out of the box with zero configuration, and zero dependencies. Just install this utility and sit back, NetData will take care of the rest.
|
||||
|
||||
It has its own built-in webserver to display the result in graphical format. NetData is quite fast and efficient, and it will immediately start to analyze the performance of your system in no time after installing it. It is written using **C** programming language, so it is extremely light weight. It consumes less than 3% of a single core CPU usage and a 10-15MB of RAM. We can easily embed the charts on any existing web pages, and also it has a plugin API, so that you can monitor any application.
|
||||
|
||||
Here is the list of things that will be monitored by NetData utility in your Linux system.
|
||||
|
||||
* CPU usage,
|
||||
* RAM Usage,
|
||||
* Swap memory usage,
|
||||
* Kernel memory usage,
|
||||
* Hard disks and its usage,
|
||||
* Network interfaces,
|
||||
* IPtables,
|
||||
* Netfilter,
|
||||
* DDoS protection,
|
||||
* Processes,
|
||||
* Applications,
|
||||
* NFS server,
|
||||
* Web server (Apache & Nginx),
|
||||
* Database servers (MySQL),
|
||||
* DHCP server,
|
||||
* DNS server,
|
||||
* Email serve,r
|
||||
* Proxy server,
|
||||
* Tomcat,
|
||||
* PHP,
|
||||
* SNP devices,
|
||||
* And many more.
|
||||
|
||||
|
||||
|
||||
NetData is free, open source tool and it supports Linux, FreeBSD and Mac OS.
|
||||
|
||||
### Install NetData On Linux
|
||||
|
||||
Netdata can be installed on any Linux distributions that have **Bash** installed.
|
||||
|
||||
The easiest way to install Netdata is to run the following one-liner command from the Terminal:
|
||||
|
||||
```
|
||||
$ bash <(curl -Ss https://my-netdata.io/kickstart-static64.sh)
|
||||
```
|
||||
|
||||
This will download and install everything needed to up and run Netdata.
|
||||
|
||||
Some users may not want to inject something directly into Bash without investigating it. If you don’t like this method, you can follow the steps below to install it on your system.
|
||||
|
||||
**On Arch Linux:**
|
||||
|
||||
The latest version is available in the Arch Linux default repositories. So, we can install it with [**pacman**][2] using command:
|
||||
|
||||
```
|
||||
$ sudo pacman -S netdata
|
||||
```
|
||||
|
||||
**On DEB and RPM-based systems**
|
||||
|
||||
NetData is not available in the default repositories of DEB based (Ubuntu / Debian) or RPM based (RHEL / CentOS / Fedora) systems. We need to install NetData manually from its Git repository.
|
||||
|
||||
First install the required dependencies:
|
||||
|
||||
```
|
||||
# Debian / Ubuntu
|
||||
$ sudo apt-get install zlib1g-dev uuid-dev libuv1-dev liblz4-dev libjudy-dev libssl-dev libmnl-dev gcc make git autoconf autoconf-archive autogen automake pkg-config curl
|
||||
|
||||
# Fedora
|
||||
$ sudo dnf install zlib-devel libuuid-devel libuv-devel lz4-devel Judy-devel openssl-devel libmnl-devel gcc make git autoconf autoconf-archive autogen automake pkgconfig curl findutils
|
||||
|
||||
# CentOS / Red Hat Enterprise Linux
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum install autoconf automake curl gcc git libmnl-devel libuuid-devel openssl-devel libuv-devel lz4-devel Judy-devel lm_sensors make MySQL-python nc pkgconfig python python-psycopg2 PyYAML zlib-devel
|
||||
|
||||
# openSUSE
|
||||
$ sudo zypper install zlib-devel libuuid-devel libuv-devel liblz4-devel judy-devel openssl-devel libmnl-devel gcc make git autoconf autoconf-archive autogen automake pkgconfig curl findutils
|
||||
```
|
||||
|
||||
After installing the required dependencies, install NetData on DEB or RPM based systems as shown below.
|
||||
|
||||
Git clone the NetData repository:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/netdata/netdata.git --depth=100
|
||||
```
|
||||
|
||||
The above command will create a directory called **‘netdata’** in the current working directory.
|
||||
|
||||
Change to the ‘netdata’ directory:
|
||||
|
||||
```
|
||||
$ cd netdata/
|
||||
```
|
||||
|
||||
Finally, install and start NetData using command:
|
||||
|
||||
```
|
||||
$ sudo ./netdata-installer.sh
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
```
|
||||
Welcome to netdata!
|
||||
Nice to see you are giving it a try!
|
||||
|
||||
You are about to build and install netdata to your system.
|
||||
|
||||
It will be installed at these locations:
|
||||
|
||||
- the daemon at /usr/sbin/netdata
|
||||
- config files at /etc/netdata
|
||||
- web files at /usr/share/netdata
|
||||
- plugins at /usr/libexec/netdata
|
||||
- cache files at /var/cache/netdata
|
||||
- db files at /var/lib/netdata
|
||||
- log files at /var/log/netdata
|
||||
- pid file at /var/run
|
||||
|
||||
This installer allows you to change the installation path.
|
||||
Press Control-C and run the same command with --help for help.
|
||||
|
||||
Press ENTER to build and install netdata to your system > ## Press ENTER key
|
||||
```
|
||||
|
||||
After installing NetData, you will see the following output at the end:
|
||||
|
||||
```
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
OK. NetData is installed and it is running (listening to *:19999).
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
INFO: Command line options changed. -pidfile, -nd and -ch are deprecated.
|
||||
If you use custom startup scripts, please run netdata -h to see the
|
||||
corresponding options and update your scripts.
|
||||
|
||||
Hit http://localhost:19999/ from your browser.
|
||||
|
||||
To stop netdata, just kill it, with:
|
||||
|
||||
killall netdata
|
||||
|
||||
To start it, just run it:
|
||||
|
||||
/usr/sbin/netdata
|
||||
|
||||
|
||||
Enjoy!
|
||||
|
||||
Uninstall script generated: ./netdata-uninstaller.sh
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
Install NetData
|
||||
|
||||
NetData has been installed and started.
|
||||
|
||||
To install Netdata on other Linux distributions, refer the [**official installation instructions page**][4].
|
||||
|
||||
##### Allow NetData default port via Firewall or Router
|
||||
|
||||
If your system stays behind any firewall or router, you must allow the default port **19999** to access the NetData web interface from any remote systems on the network,.
|
||||
|
||||
**On Ubuntu / Debian:**
|
||||
|
||||
```
|
||||
$ sudo ufw allow 19999
|
||||
```
|
||||
|
||||
**On CentOS / RHEL / Fedora:**
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --permanent --add-port=19999/tcp
|
||||
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
### Starting / Stopping NetData
|
||||
|
||||
To enable and start Netdata service on systems that use **Systemd** , run:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable netdata
|
||||
|
||||
$ sudo systemctl start netdata
|
||||
```
|
||||
|
||||
To stop:
|
||||
|
||||
```
|
||||
$ sudo systemctl stop netdata
|
||||
```
|
||||
|
||||
To enable and start Netdata service on systems that use **Init** , run:
|
||||
|
||||
```
|
||||
$ sudo service netdata start
|
||||
|
||||
$ sudo chkconfig netdata on
|
||||
```
|
||||
|
||||
To stop it:
|
||||
|
||||
```
|
||||
$ sudo service netdata stop
|
||||
```
|
||||
|
||||
### Access NetData via Web browser
|
||||
|
||||
Open your web browser, and navigate to **<http://127.0.0.1:19999>** or **<http://localhost:19999/>** or **<http://ip-address:19999>**. You should see a screen something like below.
|
||||
|
||||
![][5]
|
||||
|
||||
Netdata dashboard
|
||||
|
||||
From the dashboard, you will find the complete statistics of your Linux system. Scroll down to view each section.
|
||||
|
||||
You can download and/or view NetData default configuration file at any time by simply navigating to **<http://localhost:19999/netdata.conf>**.
|
||||
|
||||
![][6]
|
||||
|
||||
Netdata configuration file
|
||||
|
||||
### Updating NetData
|
||||
|
||||
In Arch Linux, just run the following command to update NetData. If the updated version is available in the repository, it will be automatically installed.
|
||||
|
||||
```
|
||||
$ sudo pacman -Syyu
|
||||
```
|
||||
|
||||
In DEB or RPM based systems, just go to the directory where you have cloned it (In our case it’s netdata).
|
||||
|
||||
```
|
||||
$ cd netdata
|
||||
```
|
||||
|
||||
Pull the latest update:
|
||||
|
||||
```
|
||||
$ git pull
|
||||
```
|
||||
|
||||
Then, rebuild and update it using command:
|
||||
|
||||
```
|
||||
$ sudo ./netdata-installer.sh
|
||||
```
|
||||
|
||||
### Uninstalling NetData
|
||||
|
||||
Go to the location where you have cloned NetData.
|
||||
|
||||
```
|
||||
$ cd netdata
|
||||
```
|
||||
|
||||
Then, uninstall it using command:
|
||||
|
||||
```
|
||||
$ sudo ./netdata-uninstaller.sh --force
|
||||
```
|
||||
|
||||
In Arch Linux, the following command will uninstall it.
|
||||
|
||||
```
|
||||
$ sudo pacman -Rns netdata
|
||||
```
|
||||
|
||||
**Resources:**
|
||||
|
||||
* [**NetData website**][7]
|
||||
* [**NetData GitHub page**][8]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/netdata-real-time-performance-monitoring-tool-linux/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2016/06/Install-netdata-720x340.png
|
||||
[2]: https://www.ostechnix.com/getting-started-pacman/
|
||||
[3]: https://www.ostechnix.com/wp-content/uploads/2016/06/Deepin-Terminal_002-6.png
|
||||
[4]: https://docs.netdata.cloud/packaging/installer/
|
||||
[5]: https://www.ostechnix.com/wp-content/uploads/2016/06/Netdata-dashboard.png
|
||||
[6]: https://www.ostechnix.com/wp-content/uploads/2016/06/Netdata-config-file.png
|
||||
[7]: http://netdata.firehol.org/
|
||||
[8]: https://github.com/firehol/netdata
|
||||
@ -0,0 +1,446 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Youtube-dl Tutorial With Examples For Beginners)
|
||||
[#]: via: (https://www.ostechnix.com/youtube-dl-tutorial-with-examples-for-beginners/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Youtube-dl Tutorial With Examples For Beginners
|
||||
======
|
||||
|
||||
![Youtube-dl Tutorial With Examples For Beginners][1]
|
||||
|
||||
There are numerous applications available to Download Youtube videos. We have covered such applications, namely [**ClipGrab**][2], and [**Mps-youtube**][3] etc., in the past. Today, we are going to learn about yet another Youtube downloader called **Youtube-dl**. Like Mps-youtube, Youtube-dl is also a command line program to download videos from Youtube and a lot of other websites listed [**here**][4]. Youtube-dl can be able to download a single track or entire playlist in one go. It is a free and open source command line program written in **Python**. It supports GNU/Linux, Mac OS X and Microsoft Windows.
|
||||
|
||||
### Installing Youtube-dl
|
||||
|
||||
The easiest and officially recommended way to install Youtube-dl is just download it, save it in your PATH, make it executable and start using it right away.
|
||||
|
||||
```
|
||||
$ sudo curl -L https://yt-dl.org/downloads/latest/youtube-dl -o /usr/local/bin/youtube-dl
|
||||
```
|
||||
|
||||
If you don’t have curl, use **wget** instead:
|
||||
|
||||
```
|
||||
$ sudo wget https://yt-dl.org/downloads/latest/youtube-dl -O /usr/local/bin/youtube-dl
|
||||
|
||||
$ sudo chmod a+rx /usr/local/bin/youtube-dl
|
||||
```
|
||||
|
||||
Alternatively, you can install it using [**Pip**][5] as shown below.
|
||||
|
||||
```
|
||||
$ sudo -H pip install --upgrade youtube-dl
|
||||
```
|
||||
|
||||
Youtube-dl is also available in the official repositories of some Linux distributions. For example, you can install it in Arch Linux using command:
|
||||
|
||||
```
|
||||
$ sudo pacman -S youtube-dl
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux mint:
|
||||
|
||||
```
|
||||
$ sudo apt install youtube-dl
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install youtube-dl
|
||||
```
|
||||
|
||||
FFmpeg is also required to download 720p videos from YouTube and convert videos to other formats. To install FFmpeg, refer the following guide.
|
||||
|
||||
* [**How to install FFmpeg on Linux**][6]
|
||||
|
||||
|
||||
|
||||
### Update Youtube-dl
|
||||
|
||||
If you’ve manually installed Youtube-dl using curl or wget, run the following command to update it:
|
||||
|
||||
```
|
||||
$ sudo youtube-dl -U
|
||||
```
|
||||
|
||||
If you installed it using pip, do:
|
||||
|
||||
```
|
||||
$ sudo pip install -U youtube-dl
|
||||
```
|
||||
|
||||
Those who installed Youtube-dl using the distribution’s package manager, just use the appropriate update command. For example, on Arch Linux, you can update Youtube-dl by simply running the following command:
|
||||
|
||||
```
|
||||
$ sudo pacman -Syu
|
||||
```
|
||||
|
||||
On Debian, Ubuntu:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
Now, let us see some examples to learn to use Youtube-dl.
|
||||
|
||||
### Youtube-dl Tutorial With Examples
|
||||
|
||||
Here, I have compiled most commonly used Youtube-dl commands to download a video or playlist from youtube.
|
||||
|
||||
####### **1\. Download video or playlist**
|
||||
|
||||
To download a video or the entire playlist from Youtube, just mention the URL like below:
|
||||
|
||||
```
|
||||
$ youtube-dl https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
If you want to download video or playlist with a custom name of your choice, the command would be:
|
||||
|
||||
```
|
||||
$ youtube-dl -o 'abdul kalam inspirational speech' https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
Replace “abdul kalam inspirational speech” with your own name.
|
||||
|
||||
You can also include additional details, such as the title, the uploader name (channel name) and upload date etc., in the file name by using the following command:
|
||||
|
||||
```
|
||||
$ youtube-dl -o '%(title)s by %(uploader)s on %(upload_date)s in %(playlist)s.%(ext)s' https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
####### **2\. Download multiple videos**
|
||||
|
||||
Sometimes, you might want to download multiple videos from or any other site. If so, just mention the URL of the videos with space-separated like below:
|
||||
|
||||
```
|
||||
$ youtube-dl <url1> <url2>
|
||||
```
|
||||
|
||||
Alternatively, you can put them all in a text file and pass it to Youtube-dl as an argument like below.
|
||||
|
||||
```
|
||||
$ youtube-dl -a url.txt
|
||||
```
|
||||
|
||||
This command will download all videos mentioned in the url.txt file.
|
||||
|
||||
####### **3\. Download audio-only from a video**
|
||||
|
||||
Youtube-dl allows us to download audio only from a Youtube video. If you ever been in a situation to download only the audio, run:
|
||||
|
||||
```
|
||||
$ youtube-dl -x https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
By default, Youtube-dl will save the audio in **Ogg** (opus) format.
|
||||
|
||||
If you prefer to download any other formats, for example **mp3** , run:
|
||||
|
||||
```
|
||||
$ youtube-dl -x --audio-format mp3 https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
This command will download the audio from the given video/playlist, convert it to an MP3 and save it in the current directory. Please note that you should install either [**ffmpeg**][7] or **avconv** to convert the file to mp3 format.
|
||||
|
||||
####### **4\. Download video with description, metadata, annotations, subtitles and thumbnail**
|
||||
|
||||
To download a video along with its other details such as description, metadata, annotations, subtitles, and thumbnail etc., use the following command:
|
||||
|
||||
```
|
||||
$ youtube-dl --write-description --write-info-json --write-annotations --write-sub --write-thumbnail https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
####### **5\. List all available formats of video or playlist**
|
||||
|
||||
To list all available formats that a video or playlist is available in, use the following command:
|
||||
|
||||
```
|
||||
$ youtube-dl --list-formats https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
Or
|
||||
|
||||
```
|
||||
$ youtube-dl -F https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
![][8]
|
||||
|
||||
List all available formats of a youtube video using youtube-dl
|
||||
|
||||
As you can see in the above screenshot, Youtube-dl lists all available formats of the given video. From left to right, it displays the video format code, extension and resolution note of the respective video. This can be helpful when you want to download a video at a specific quality or format.
|
||||
|
||||
####### **6\. Download videos in certain quality and/or format**
|
||||
|
||||
By default, Youtube-dl will download the best available quality video. However, it is also possible to download a video or playlist at a specific quality or format.
|
||||
|
||||
Youtube is capable of downloading videos in the following qualities:
|
||||
|
||||
* **best** – Select the best quality format of the given file with video and audio.
|
||||
* **worst** – Select the worst quality format (both video and audio).
|
||||
* **bestvideo** – Select the best quality video-only format (e.g. DASH video). Please note that it may not be available.
|
||||
* **worstvideo** – Select the worst quality video-only format. May not be available.
|
||||
* **bestaudio** – Select the best quality audio only-format. May not be available.
|
||||
* **worstaudio** – Select the worst quality audio only-format. May not be available.
|
||||
|
||||
|
||||
|
||||
For example, if you want to download **best quality** format (both audio and video), just use the following command:
|
||||
|
||||
```
|
||||
$ youtube-dl -f best https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
Similarly, to download audio-only with best quality:
|
||||
|
||||
```
|
||||
$ youtube-dl -f bestaudio https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
To download worst quality video-only format, use the following command:
|
||||
|
||||
```
|
||||
$ youtube-dl -f worstvideo https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
You also combine different format options like below.
|
||||
|
||||
```
|
||||
$ youtube-dl -f bestvideo+bestaudio https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
The above command will download best quality video-only and best quality audio-only formats and merge them together with ffmpeg or avconv. Make sure you have installed any one of these tools on your system.
|
||||
|
||||
If you don’t want to merge, replace **+** (plus) operator with **,** (comma) like below:
|
||||
|
||||
```
|
||||
$ youtube-dl -f 'bestvideo,bestaudio' https://www.youtube.com/watch?v=7E-cwdnsiow -o '%(title)s.f%(format_id)s.%(ext)s'
|
||||
```
|
||||
|
||||
This command will download best quality video and best quality audio and **will not mix them**. In this case, you will get two files, one is audio and another is video. In this example, an output template ( **-o** option) is recommended as bestvideo and bestaudio may have the same file name.
|
||||
|
||||
We can even download a video or playlist at a specific quality with **specific resolution**.
|
||||
|
||||
For instance, the following command will download the **best quality** video in **480 pixel resolution** (less than or equal to 480p).
|
||||
|
||||
```
|
||||
$ youtube-dl -f "best[height<=480]" https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
Like already said, we can group the format selectors to get a specific quality video. The following command will download best format available(both audio and video) but **no better than 480p**.
|
||||
|
||||
```
|
||||
$ youtube-dl -f 'bestvideo[height<=480]+bestaudio/best[height<=480]' https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
####### **7. Download videos using format code
|
||||
|
||||
**
|
||||
|
||||
All videos have format codes which we can use to download a video at specific quality. To find the format code, just list the available formats using any one of the following commands:
|
||||
|
||||
```
|
||||
$ youtube-dl --list-formats https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
Or
|
||||
|
||||
```
|
||||
$ youtube-dl -F https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
As you can see in the above screenshot, all format codes of the given video are listed in the first column. The best quality format is given at the end (the format code is **22** ). So, the command to download best quality format is:
|
||||
|
||||
```
|
||||
$ youtube-dl -f 22 https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
Some videos may not have the same formats available while you download videos from playlist. In such cases, you can specify multiple format codes in any preferred order of your choice. Take a look at the following example:
|
||||
|
||||
```
|
||||
$ youtube-dl -f 22/17/18 <playlist_url>
|
||||
```
|
||||
|
||||
As per the above example, Youtube-dl will download the videos in format 22 if it is available. If the format 22 is not available, it will then download format 17 if it is available. If both 22 and 17 formats are not available, it will finally try to download format 18. If none of the specified formats are available, Youtube-dl will complain that no suitable formats are available for download.
|
||||
|
||||
Please note that that slash is left-associative, i.e. formats on the left hand side are preferred.
|
||||
|
||||
####### **8. Download videos by file extension
|
||||
|
||||
**
|
||||
|
||||
Download video(s) in your preferred format, say for example MP4, just run:
|
||||
|
||||
```
|
||||
$ youtube-dl --format mp4 https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
Or,
|
||||
|
||||
```
|
||||
$ youtube-dl -f mp4 https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
Like I already mentioned in the previous section, some videos may not available in your preferred formats. In such cases, Youtube-dl will download any other best available formats. For instance, this command will download best quality MP4 format file. If MP4 format is not available, then it will download any other best available format.
|
||||
|
||||
```
|
||||
$ youtube-dl -f 'bestvideo[ext=mp4]+bestaudio[ext=m4a]/best[ext=mp4]/best' https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
If you want to download them with custom filename, do:
|
||||
|
||||
```
|
||||
$ youtube-dl -f mp4 -o '%(title)s.f%(format_id)s.%(ext)s' https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
####### **9. Set size limit for videos
|
||||
|
||||
**
|
||||
|
||||
When you download multiple videos from a playlist, you might want to download videos within a certain size only.
|
||||
|
||||
For example, this command will not download any videos smaller than the given size, say **100MB** :
|
||||
|
||||
```
|
||||
$ youtube-dl --min-filesize 100M <playlist_url>
|
||||
```
|
||||
|
||||
If you don’t want to download videos larger than the given size, do:
|
||||
|
||||
```
|
||||
$ youtube-dl --max-filesize 100M <playlist_url>
|
||||
```
|
||||
|
||||
We can also combine format selection operators to download certain size videos.
|
||||
|
||||
The following command will download best video-only format but **not bigger than 100 MB**.
|
||||
|
||||
```
|
||||
$ youtube-dl -f 'best[filesize<100M]' https://www.youtube.com/watch?v=7E-cwdnsiow
|
||||
```
|
||||
|
||||
####### **10. Download videos by date-wise
|
||||
|
||||
**
|
||||
|
||||
Youtube-dl allows us to filter and download video or playlist by their upload date. This will be very helpful when you want to download videos from a playlist that contains 100s of videos.
|
||||
|
||||
For instance, to download videos uploaded at an exact date, for example October 01, 2018, the command would be:
|
||||
|
||||
```
|
||||
$ youtube-dl --date 20181001 <URL>
|
||||
```
|
||||
|
||||
Download videos uploaded on or before a specific date:
|
||||
|
||||
```
|
||||
$ youtube-dl --datebefore 20180101 <URL>
|
||||
```
|
||||
|
||||
Download videos uploaded on or after a specific date:
|
||||
|
||||
```
|
||||
$ youtube-dl --dateafter 20180101 <URL>
|
||||
```
|
||||
|
||||
Download only the videos uploaded in the last 6 months:
|
||||
|
||||
```
|
||||
$ youtube-dl --dateafter now-6months <URL>
|
||||
```
|
||||
|
||||
To download videos between a specific date, for example January 01, 2018 to January 01, 2019, use the following command:
|
||||
|
||||
```
|
||||
$ youtube-dl --dateafter 20180101 --datebefore 20190101 <URL>
|
||||
```
|
||||
|
||||
####### **11. Download specific videos from playlist
|
||||
|
||||
**
|
||||
|
||||
This is yet another useful feature of Youtube-dl. It allows us to download a specific song(s) from a playlist that contains 100s of songs.
|
||||
|
||||
For example, to download the 10th file from a playlist, run:
|
||||
|
||||
```
|
||||
$ youtube-dl --playlist-items 10 <playlist_url>
|
||||
```
|
||||
|
||||
Similarly, to download multiple random files, just specify indices of the videos in the playlist separated by commas like below::
|
||||
|
||||
```
|
||||
$ youtube-dl --playlist-items 2,3,7,10 <playlist_url>
|
||||
```
|
||||
|
||||
You can also specify the range of songs. To download a video playlist starting from a certain video, say 10, to end:
|
||||
|
||||
```
|
||||
$ youtube-dl --playlist-start 10 <playlist_url>
|
||||
```
|
||||
|
||||
To download only the files starting from 2nd to 5th in a playlist, use:
|
||||
|
||||
```
|
||||
$ youtube-dl --playlist-start 2 --playlist-end 5 <playlist_url>
|
||||
```
|
||||
|
||||
####### 12\. Download only videos suitable for specific age
|
||||
|
||||
This is another notable feature of Youtube-dl. It allows us to download only videos suitable for the given age.
|
||||
|
||||
Say for example, to download all “Let’s Play” videos that aren’t marked “NSFW” or age-restricted for 7 year-olds from a playlist, run:
|
||||
|
||||
```
|
||||
$ youtube-dl --match-title "let's play" --age-limit 7 --reject-title "nsfw" <playlist_url>
|
||||
```
|
||||
|
||||
Youtube-dl has a lot more options. I guess these 12 examples are just enough to use Youtube-dl to download videos from online. For more details, refer Youtube-dl help section.
|
||||
|
||||
```
|
||||
$ youtube-dl --help
|
||||
```
|
||||
|
||||
**Resources:**
|
||||
|
||||
* [**Youtube-dl website**][10]
|
||||
* [**Youtube-dl GitHub Repository**][11]
|
||||
* [**https://jonlabelle.com/snippets/view/shell/youtube-dl-command**][12]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/youtube-dl-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/06/youtube-dl-720x340.png
|
||||
[2]: https://www.ostechnix.com/clipgrab-youtube-downloader-converter/
|
||||
[3]: https://www.ostechnix.com/mps-youtube-commandline-youtube-player-downloader/
|
||||
[4]: https://ytdl-org.github.io/youtube-dl/supportedsites.html
|
||||
[5]: https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
[6]: https://www.ostechnix.com/install-ffmpeg-linux/
|
||||
[7]: https://www.ostechnix.com/20-ffmpeg-commands-beginners/
|
||||
[8]: https://www.ostechnix.com/wp-content/uploads/2019/06/List-all-available-formats-youtube-dl.png
|
||||
[9]: https://www.ostechnix.com/wp-content/uploads/2019/06/List-all-available-formats-youtube-dl-1.png
|
||||
[10]: https://ytdl-org.github.io/youtube-dl/index.html
|
||||
[11]: https://github.com/ytdl-org/youtube-dl
|
||||
[12]: https://jonlabelle.com/snippets/view/shell/youtube-dl-command
|
||||
85
translated/talk/20191110 What is DevSecOps.md
Normal file
85
translated/talk/20191110 What is DevSecOps.md
Normal file
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (PandaWizard)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is DevSecOps?)
|
||||
[#]: via: (https://opensource.com/article/19/1/what-devsecops)
|
||||
[#]: author: (Brett Hunoldt https://opensource.com/users/bretthunoldtcom)
|
||||
|
||||
什么是 DevSecOps?
|
||||
======
|
||||
DevSecOps 的实践之旅开始于 DevSecOps 授权,启用和培养。下面就介绍如何开始学习使用 DevSecOps。
|
||||

|
||||
|
||||
> Stephen Streichsbier 说过: DevSecOps 使得组织可以用 DevOps 的速度发布内在安全的软件。
|
||||
|
||||
DevSecOps 是一场关于 DevOps 概念实践或艺术形式的变革。为了更好理解 DevSecOps,你应该首先理解 DevOps 的含义。
|
||||
|
||||
DevOps 起源于通过合并开发和运维实践,消除隔离,统一关注点,提升团队和产品的效率和性能。它是一种注重构建容易维持和易于平常自动运营维护产品和服务的新型协作方式。
|
||||
|
||||
安全在很多团队中都是常见的隔离点。安全的核心关注点是保护团队,而有时这也意味着生成延缓新服务或是新产品发布的障碍或是策略,用于保障任何事都能被很好的理解和安全的执行,并且没有给团队带来不必要的风险。
|
||||
|
||||
**[[点击下载 DevSecOps 的引导手册]][1]**
|
||||
|
||||
因为安全方面的明显特征和它可能带来的摩擦,开发和运维有时会避开或是满足客观的安全要求。在一些公司,这种隔离形成了一种产品安全完全是安全团队责任的期望,并取决于安全团队去寻找产品的安全缺陷或是可能带来的问题。
|
||||
|
||||
DevSecOps 看起来是通过给开发或是运维角色加强或是建立安全意识,或是在产品团队中引入一个安全工程师角色,在产品设计中找到安全问题,从而把安全要求汇聚在 Devops 中。
|
||||
|
||||
这样使得公司能更快发布和更新产品,并且充分相信安全已经嵌入产品中。
|
||||
|
||||
### 坚固的软件哪里适用 DevSecOps?
|
||||
|
||||
建造坚固的软件是 DevOps 文化的一个层面而不是一个特别的实践,它完善和增强了 DevSecops 的实践。想想一款坚固的软件就像是某些经历过残酷战斗过程的事物。
|
||||
|
||||
有必要指出坚固的软件并不是 100% 安全可靠的(虽然它可能最终是在某些方面)。然而,它被设计成可以处理大部分被抛过来的问题。
|
||||
|
||||
践行坚固软件最重要的原则是促进竞争,实践,可控的失败与合作。
|
||||
|
||||
### 你如何开始学习 DevSecOps ?
|
||||
|
||||
开始实践 DevSecOps 涉及提升安全需求和在开发过程中最早期可能的阶段实践。它最终在公司文化上提升了安全的重要性,使得安全成为所有人的责任,而并不只是安全团队的责任。
|
||||
|
||||
你可能在团队中听说过“左上升”这个词,如果你把开发周期包括产品变革的的关键时期线放平在一条横线上,从初始化到设计,建造,测试以及最终的运行。安全的目的就是今早的参与进来。这使得风险可以在设计中能更好的评估、交流和减轻。“左提升”的含义是指促使安全能在开发周期线上更往左走。
|
||||
|
||||
这篇入门文章有三个关键要素:
|
||||
|
||||
* 授权
|
||||
* 启用
|
||||
* 培养
|
||||
|
||||
|
||||
|
||||
授权,在我看来,是关于释放控制权以及使得团队做出独立决定而不用害怕失败或影响(理性分析)。这个过程的唯一告诫信息就是要严格的做出明智的决定(不要比这更低要求)。
|
||||
|
||||
为了实现授权,商务和行政支持(通过内部销售,展示来建立,通过建立矩阵来 展示这项投资的回报)是打破历史障碍和分割的团队的关键。合并安全人员到开发和运维团队中,提升交流和透明度透明度有助于 DevSecOps 的开始之旅。
|
||||
|
||||
这次整合和移动使得团队只关注单一的结果:打造一个他们共同负责的产品,让开发和安全人员相互依赖合作。这将引领你们共同走向授权。这是产品研发团队的共同责任,并保证每个可分割的产品都保持其安全性。
|
||||
|
||||
启用涉及正确的使用掌握在团队手中的工具和资源。这是准备建立一种通过论坛、维基、信息聚合的知识分享文化。
|
||||
|
||||
打造一种注重自动化、重复任务应该编码来尽可能减少以后的操作并增强安全性。这种场景不仅仅是提供知识,而是让这种知识能够通过多种渠道和媒介(通过某些工具)可获取,以便它可以被团队或是个人以他喜欢的方式去消化和分享。一种工具可以更好的实现当团队成员正在编码而另一组成员正在来的路上。让工具简单可用和让团队可以使用它们。
|
||||
|
||||
不同的 DevSecOps 团队有不同的喜好,因此允许它们尽可能的保持独立。这是一种微笑平衡的练习,因为你真的很想在经济规模和能力中分享产品。在选择中协作参与并更新工具方法有助于减少使用中的障碍。
|
||||
|
||||
最后,也可能是最重要的, DevSecOps 是有关训练和兴趣打造。聚会、社交或是组织中通常的报告会都是很棒的方式让同事们教学和分享他们的知识。有时,这些高光的被分享的挑战、关注点或是一些其他人没有关注到的风险。分享和教学也是一种高效的学习和指导团队的方法。
|
||||
|
||||
在我个人经验中,每个团队的文化都是独一无二的,因此你不能用“一种尺寸适合所有”的方法。走进你的团队并找到他们想要使用的工具方法。尝试不同的论坛和聚会并找出最适用于你们文化的方式。寻找反馈并询问团队如何工作,他们喜欢什么以及对应的原因。适应和学习,保持乐观,不要停止尝试,你们将会有所收获。
|
||||
|
||||
[下载 DevSecOps 的入门手册][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/what-devsecops
|
||||
|
||||
作者:[Brett Hunoldt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[PandaWizard](https://github.com/PandaWizard)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bretthunoldtcom
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/downloads/devsecops
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,187 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create a Custom System Tray Indicator For Your Tasks on Linux)
|
||||
[#]: via: (https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux)
|
||||
[#]: author: (M.Hanny Sabbagh https://fosspost.org/author/mhsabbagh)
|
||||
|
||||
在 Linux 上为你的任务创建一个自定义的系统托盘指示器
|
||||
======
|
||||
|
||||
时至今日系统托盘图标依然很有用。只需要右击图标,然后选择想要的动作即可,你可以大幅简化你的生活并且减少日常行为中的大量无用的点击。
|
||||
|
||||
一说到有用的系统托盘图标,我们很容易就想到 Skype,Dropbox 和 VLC:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 11][1]
|
||||
|
||||
然而系统托盘图标实际上要更有用得多; 你可以根据自己的需求创建自己的系统托盘图标。本指导将会教你通过简单的几个步骤来实现这一目的。
|
||||
|
||||
### 前置条件
|
||||
|
||||
我们将要用 Python 来实现一个自定义的系统托盘指示器。Python 默认在所有主流的 Linux 发行版中都有安装,因此你只需要确定一下它已经确实被安装好了(版本为 2.7)。另外,我们还需要安装好 gir1.2-appindicator3 包。该库能够让我们很容易就能创建系统图标指示器。
|
||||
|
||||
在 Ubuntu/Mint/Debian 上安装:
|
||||
|
||||
```
|
||||
sudo apt-get install gir1.2-appindicator3
|
||||
```
|
||||
|
||||
在 Fedora 上安装:
|
||||
|
||||
```
|
||||
sudo dnf install libappindicator-gtk3
|
||||
```
|
||||
|
||||
对于其他发行版,只需要搜索包含 appindicator 的包就行了。
|
||||
|
||||
在 GNOME Shell 3.26 开始,系统托盘图标被删除了。你需要安装 [这个扩展 ][2] (或者其他扩展) 来为桌面启用该功能。否则你无法看到我们创建的指示器。
|
||||
|
||||
### 基础代码
|
||||
|
||||
下面是指示器的基础代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/python
|
||||
import os
|
||||
from gi.repository import Gtk as gtk, AppIndicator3 as appindicator
|
||||
|
||||
def main():
|
||||
indicator = appindicator.Indicator.new("customtray", "semi-starred-symbolic", appindicator.IndicatorCategory.APPLICATION_STATUS)
|
||||
indicator.set_status(appindicator.IndicatorStatus.ACTIVE)
|
||||
indicator.set_menu(menu())
|
||||
gtk.main()
|
||||
|
||||
def menu():
|
||||
menu = gtk.Menu()
|
||||
|
||||
command_one = gtk.MenuItem('My Notes')
|
||||
command_one.connect('activate', note)
|
||||
menu.append(command_one)
|
||||
|
||||
exittray = gtk.MenuItem('Exit Tray')
|
||||
exittray.connect('activate', quit)
|
||||
menu.append(exittray)
|
||||
|
||||
menu.show_all()
|
||||
return menu
|
||||
|
||||
def note(_):
|
||||
os.system("gedit $HOME/Documents/notes.txt")
|
||||
|
||||
def quit(_):
|
||||
gtk.main_quit()
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
我们待会会解释一下代码是怎么工作的。但是现在,让我们将该文本保存为 tray.py,然后使用 Python 运行之:
|
||||
|
||||
```
|
||||
python tray.py
|
||||
```
|
||||
|
||||
我们会看到指示器运行起来了,如下图所示:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 13][3]
|
||||
|
||||
现在,让我们解释一下魔术的原理:
|
||||
|
||||
* 前三行代码仅仅用来指明 Python 的路径并且导入需要的库。
|
||||
|
||||
* def main() : 此为指示器的主函数。该函数的代码用来初始化并创建指示器。
|
||||
|
||||
* indicator = appindicator.Indicator.new(“customtray”,“semi-starred-symbolic”,appindicator.IndicatorCategory.APPLICATION_STATUS) : 这里我们指明创建一个名为 `customtray` 的指示器。这是指示器的唯一名称这样系统就不会与其他运行中的指示器搞混了。同时我们使用名为 `semi-starred-symbolic` 的图标作为指示器的默认图标。你可以将之改成任何其他值; 比如 `firefox` (如果你希望该指示器使用 FireFox 的图标),或任何其他希望的图标名。最后与 `APPLICATION_STATUS` 相关的部分是指明指示器类别/范围的常规代码。
|
||||
|
||||
* `indicator.set_status(appindicator.IndicatorStatus.ACTIVE)` : 这一行激活指示器。
|
||||
|
||||
* `indicator.set_menu(menu())` : 这里我的是我们想使用 `menu()` 函数 (我们会在后面定义) 来为我们的指示器创建菜单项。这很重要,可以让你右击指示器后看到一个可以实施行为的列别。
|
||||
|
||||
* `gtk.main()` : 运行 GTK 主循环。
|
||||
|
||||
* 在 `menu()` 中我们定义了想要指示器提供的行为或项目。`command_one = gtk.MenuItem(‘My Notes’)` 仅仅使用文本 “My notes” 来初始化第一个菜单项,接下来 `command_one.connect(‘activate’,note)` 将菜单的 `activate` 信号与后面定义的 `note()` 函数相连接; 换句话说,我们告诉我们的系统:“当该菜单项被点击,运行 note() 函数”。最后,`menu.append(command_one)` 将菜单项添加到列表中。
|
||||
|
||||
* `exittray` 相关的行是为了创建一个退出的菜单项让你在想要的时候关闭指示器。
|
||||
|
||||
* `menu.show_all()` 以及 `return menu` 只是返回菜单项给指示器的常规代码。
|
||||
|
||||
* 在 `note(_)` 下面是点击 “My Notes” 菜单项时需要执行的代码。这里只是 `os.system(“gedit $HOME/Documents/notes.txt”)` 这一句话; `os.system` 函数允许你在 Python 中运行 shell 命令,因此这里我们写了一行命令来使用 `gedit` 打开 home 目录下 `Documents` 目录中名为 `notes.txt` 的文件。例如,这个可以称为你今后的日常笔记程序了!
|
||||
|
||||
### 添加你所需要的任务
|
||||
|
||||
你只需要修改代码中的两块地方:
|
||||
|
||||
1。在 `menu()` 中为你想要的任务定义新的菜单项。
|
||||
|
||||
2。创建一个新的函数让给该菜单项被点击时执行特定的行为。
|
||||
|
||||
|
||||
所以,比如说你想要创建一个新菜单项,在点击后,会使用 VLC 播放硬盘中某个特定的视频/音频文件?要做到这一点,只需要在地 17 行处添加下面三行内容:
|
||||
|
||||
```
|
||||
command_two = gtk.MenuItem('Play video/audio')
|
||||
command_two.connect('activate', play)
|
||||
menu.append(command_two)
|
||||
```
|
||||
|
||||
然后在地 30 行添加下面内容:
|
||||
|
||||
```
|
||||
def play(_):
|
||||
os.system("vlc /home/<username>/Videos/somevideo.mp4")
|
||||
```
|
||||
|
||||
将 /home/<username>/Videos/somevideo.mp4 替换成你想要播放的视频/音频文件路径。现在保存该文件然后再次运行该指示器:
|
||||
|
||||
```
|
||||
python tray.py
|
||||
```
|
||||
|
||||
你将会看到:
|
||||
|
||||
![Create a Custom System Tray Indicator For Your Tasks on Linux 15][4]
|
||||
|
||||
而且当你点击新创建的菜单项时,VLC 会开始播放!
|
||||
|
||||
要创建其他项目/任务,只需要重复上面步骤即可。但是要小心,需要用其他命令来为 command_two 改名,比如 command_three,这样在变量之间才不会产生冲突。然后定义新函数,就像 play(_) 函数那样。
|
||||
|
||||
从这里开始的可能性是无穷的; 比如我用这种方法来从网上获取数据(使用 urllib2 库) 并显示出来。我也用它来在后台使用 mpg123 命令播放 mp3 文件,而且我还定义了另一个菜单项来杀掉所有的 mpg123 来随时停止播放音频。比如 Steam 上的 CS:GO 退出很费时间(窗口并不会自动关闭),因此,作为一个变通的方法,我只是最小化窗口然后点击某个自建的菜单项,它会执行 killall -9 csgo_linux64 命令。
|
||||
|
||||
你可以使用这个指示器来做任何事情:升级系统包,运行其他脚本。字面上的任何事情。
|
||||
|
||||
### 自动启动
|
||||
|
||||
我们希望系统托盘指示器能在系统启动后自动启动,而不用每次都手工运行。要做到这一点,只需要在自启动应用程序中添加下面命令即可(但是你需要将 tray.py 的路径替换成你自己的路径):
|
||||
|
||||
```
|
||||
nohup python /home/<username>/tray.py &
|
||||
```
|
||||
|
||||
下次重启系统,指示器会在系统启动后自动开始工作了!
|
||||
|
||||
### 结论
|
||||
|
||||
你现在知道了如何为你想要的任务创建自己的系统托盘指示器了。根据每天需要运行的任务的性质和数量,此方法可以节省大量时间。有些人偏爱从命令行创建别名,但是这需要你每次都打开终端窗口或者需要有一个可用的下拉式终端仿真器,而这里,这个系统托盘指示器一直在工作,随时可用。
|
||||
|
||||
你以前用过这个方法来运行你的任务吗?很想听听你的想法。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fosspost.org/tutorials/custom-system-tray-icon-indicator-linux
|
||||
|
||||
作者:[M.Hanny Sabbagh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fosspost.org/author/mhsabbagh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/02/Screenshot-at-2019-02-28-0808.png?resize=407%2C345&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 12)
|
||||
[2]: https://extensions.gnome.org/extension/1031/topicons/
|
||||
[3]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1041.png?resize=434%2C140&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 14)
|
||||
[4]: https://i2.wp.com/fosspost.org/wp-content/uploads/2019/03/Screenshot-at-2019-03-02-1141.png?resize=440%2C149&ssl=1 (Create a Custom System Tray Indicator For Your Tasks on Linux 16)
|
||||
@ -214,7 +214,7 @@ via: https://fedoramagazine.org/jupyter-and-data-science-in-fedora/
|
||||
|
||||
作者:[Avi Alkalay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
261
translated/tech/20190702 Make Linux stronger with firewalls.md
Normal file
261
translated/tech/20190702 Make Linux stronger with firewalls.md
Normal file
@ -0,0 +1,261 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Make Linux stronger with firewalls)
|
||||
[#]: via: (https://opensource.com/article/19/7/make-linux-stronger-firewalls)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用防火墙让你的 Linux 更加强大
|
||||
======
|
||||
掌握防火墙的工作原理,以及如何设置防火墙来提高 Linux 的安全性
|
||||
![People working together to build ][1]
|
||||
|
||||
所有人都听说过防火墙(哪怕仅仅是在网络犯罪片里看到过相关的情节设定),很多人也知道他们的计算机里很可能正运行着防火墙,但是很少有人明白在必要的时候如何驾驭防火墙。
|
||||
|
||||
防火墙被用来拦截那些不请自来的网络流量,然而不同网络需要的安全级别也不尽相同。比如说,和在外面一家咖啡馆里使用公共 WiFi 相比,你在家里的时候可以更加信任网络里的其它计算机和设备。你或许希望计算机能够区分可以信任和不可信任的网络,不过最好还是应该学会自己去管理(或者至少是核实)你的安全设置。
|
||||
|
||||
### 防火墙的工作原理
|
||||
|
||||
网络里不同设备之间的通信是通过一种叫做 **端口** 的网关实现的。这里的端口指的并不是像 USB 端口 或者 HDMI 端口这样的物理连接。在网络术语中,端口是一个纯粹的虚拟概念,用来表示某种类型的数据到达或离开一台计算机时候所走的路径。其实也可以换个名字来称呼,比如叫“连接”或者“门道”,不过 [早在 1981 年的时候][2] 它们就被称作端口了,这个叫法也沿用至今。其实端口这个东西没有任何特别之处,只是一种用来指代一个可能会发生数据传输的地址的方式。
|
||||
|
||||
1972 年,一份 [端口数字清单][3](那时候的端口被称为“套接字”)被发布了,并且从此演化为一组众所周知的标准端口号,帮助管理特定类型的网络流量。比如说,你每天访问网站的时候都会使用 80 和 443 端口,因为互联网上的绝大多数人都同意(或者是默认)数据从 web 服务器上传输的时候是通过这两个端口的。如果想要验证这一点,你可以在使用浏览器访问网站的时候在 URL 后面加上一个非标准的端口号码。比如说,访问 **example.com:42** 的请求会被拒绝,因为 example.com 在 42 端口上并不提供网站服务。
|
||||
|
||||
|
||||
![Navigating to a nonstandard port produces an error][4]
|
||||
|
||||
如果你是通过 80 端口访问同一个网站,就可以(不出所料地)正常访问了。你可以在 URL 后面加上 **:80** 来指定使用 80 端口,不过由于 80 端口是 HTTP 访问的标准端口,所以你的浏览器其实已经默认在使用 80 端口了。
|
||||
|
||||
当一台计算机(比如说 web 服务器)准备在指定端口接收网络流量的时候,保持该端口向网络流量开放是一种可以接受的(也是必要的)行为。但是不需要接收流量的端口如果也处在开放状态就比较危险了,这就是需要用防火墙解决的问题。
|
||||
|
||||
#### 安装 firewalld
|
||||
|
||||
有很多种配置防火墙的方式,这篇文章介绍 [**firewalld**][5]。在桌面环境下它被集成在网络管理器(Network Manager)里,在终端里则是集成在 **firewall-cmd** 里。很多 Linux 发行版都预装了这些工具。如果你的发行版里没有,你可以把这篇文章当成是管理防火墙的通用性建议,在你所使用的防火墙软件里使用类似的方法,或者你也可以选择安装 **firewalld**。
|
||||
|
||||
比如说在 Ubuntu 上,你必须启用 **universe** 软件仓库,关闭默认的 **ufw** 防火墙,然后再安装 **firewalld**:
|
||||
|
||||
|
||||
```
|
||||
$ sudo systemctl disable ufw
|
||||
$ sudo add-apt-repository universe
|
||||
$ sudo apt install firewalld
|
||||
```
|
||||
|
||||
Fedora、CentOS、RHEL、OpenSUSE,以及其它很多发行版默认就包含了 **firewalld**。
|
||||
|
||||
无论你使用哪个发行版,如果希望防火墙发挥作用,就必须保持它在开启状态,并且设置成开机自动加载。你应该尽可能减少在防火墙维护工作上所花费的精力。
|
||||
|
||||
```
|
||||
`$ sudo systemctl enable --now firewalld`
|
||||
```
|
||||
|
||||
### 使用网络管理器选择区域
|
||||
|
||||
或许你每天都会连接到很多不同的网络。在工作的时候使用的是一个网络,在咖啡馆里是另一个,在家里又是另一个。你的计算机可以判断出哪一个网络的使用频率比较高,但是它并不知道哪一个是你信任的网络。
|
||||
|
||||
一个防火墙的 **区域** 里包含了端口开放和关闭的预设规则。你可以通过使用区域来选择一个对当前网络最适用的策略。
|
||||
|
||||
你可以打开网络管理器里的连接编辑器(可以在应用菜单里找到),或者是使用 **nm-connection-editor &** 命令以获取所有可用区域的列表。
|
||||
|
||||
![Network Manager Connection Editor][6]
|
||||
|
||||
在网络连接列表中,双击你现在所使用的网络。
|
||||
|
||||
在出现的网络配置窗口中,点击“通用”标签页。
|
||||
|
||||
在“通用”面板中,点击“防火墙区域”旁边的下拉菜单以获取所有可用区域的列表。
|
||||
|
||||
![Firewall zones][7]
|
||||
|
||||
也可以使用下面的终端命令以获取同样的列表:
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --get-zones`
|
||||
```
|
||||
|
||||
每个区域的名称已经可以透露出设计者创建这个区域的意图,不过你也可以使用下面这个终端命令获取任何一个区域的详细信息:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --zone work --list-all
|
||||
work
|
||||
target: default
|
||||
icmp-block-inversion: no
|
||||
interfaces:
|
||||
sources:
|
||||
services: ssh dhcpv6-client
|
||||
ports:
|
||||
protocols:
|
||||
[...]
|
||||
```
|
||||
|
||||
在这个例子中,**工作**区域的配置是允许接收 SSH 和 DHCPv6-client 的流量,但是拒绝接收其他任何用户没有明确请求的流量。(换句话说,**工作**区域并不会在你浏览网站的时候拦截 HTTP 响应流量,但是 **会** 拦截一个针对你计算机上 80 端口的 HTTP 请求。)
|
||||
|
||||
你可以依次查看每一个区域,弄清楚它们分别都允许什么样的流量。比较常见的有:
|
||||
|
||||
* **工作:** 这个区域应该在你非常信任的网络上使用。它允许 SSH、DHCPv6 和 mDNS,并且还可以添加更多允许的项目。该区域非常适合作为一个基础配置,然后在此之上根据日常办公的需求自定义一个工作环境。
|
||||
* **公共:** 用在你不信任的网络上。这个区域的配置和工作区域是一样的,但是你不应该再继续添加其它任何允许项目。
|
||||
* **丢弃:** 所有传入连接都会被丢弃,并且不会有任何响应。在不彻底关闭网络的条件下,这已经是最接近隐形模式的配置了,因为只允许传出网络连接(不过随便一个端口扫描器就可以通过传出流量检测到你的计算机,所以这个区域并不是一个隐形装置)。如果你在使用公共 WiFi,这个区域可以说是最安全的选择;如果你觉得当前的网络比较危险,这个区域也一定是最好的选择。
|
||||
* **拦截:** 所有传入连接都会被拒绝,但是会返回一个消息说明所请求的端口被禁用了。只有你主动发起的网络连接是被允许的。这是一个友好版的 **丢弃** 区域,因为虽然还是没有任何一个端口允许传入流量,但是说明了会拒绝接收任何不是本机主动发起的连接。
|
||||
* **家庭:** 在你信任网络里的其它计算机的情况下使用这个区域。该区域只会允许你所选择的传入连接,但是你可以根据需求添加更多的允许项目。
|
||||
* **内部:** 和工作区域类似,该区域适用于内部网络,你应该在基本信任网络里的计算机的情况下使用。你可以根据需求开放更多的端口和服务,同时保持和工作区域不同的一套规则。
|
||||
* **信任:** 接受所有的网络连接。适合在故障排除的情况下或者是在你绝对信任的网络上使用。
|
||||
|
||||
|
||||
### 为网络指定一个区域
|
||||
|
||||
你可以为你的任何一个网络连接都指定一个区域,并且对于同一个网络的不同连接方式(比如以太网、WiFi 等等)也可以指定不同的区域。
|
||||
|
||||
选择你想要的区域,点击“保存”按钮提交修改。
|
||||
|
||||
![Setting a new zone][8]
|
||||
|
||||
养成为网络连接指定区域的习惯的最好办法是从你最常用的网络开始。为你的家庭网络指定家庭区域,为工作网络指定工作区域,为你最喜欢的图书馆或者咖啡馆的网络指定公关区域。
|
||||
|
||||
一旦你为所有常用的网络都指定了一个区域,在之后加入新的网络的时候(无论是一个新的咖啡馆还是你朋友家的网络),试图也为它指定一个区域吧。这样可以很好地让你意识到不同的网络的安全性是不一样的,你并不会仅仅因为使用了 Linux 而比任何人更加安全。
|
||||
|
||||
### 默认区域
|
||||
|
||||
每次你加入一个新的网络的时候,firewalld 并不会提示你进行选择,而是会指定一个默认区域。你可以在终端里输入下面这个命令来获取你的默认区域:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --get-default
|
||||
public
|
||||
```
|
||||
|
||||
在这个例子里,默认区域是公共区域。你应该保证公共区域有非常严格的限制规则,这样在将它指定到未知网络中的时候才比较安全。或者你也可以设置你自己的默认区域。
|
||||
|
||||
比如说,如果你是一个比较多疑的人,或者需要经常接触不可信任的网络的话,你可以设置一个非常严格的默认区域:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --set-default-zone drop
|
||||
success
|
||||
$ sudo firewall-cmd --get-default
|
||||
drop
|
||||
```
|
||||
|
||||
这样一来,任何你新加入的网络都会被指定使用丢弃区域,除非你手动将它制定为另一个没有这么严格的区域。
|
||||
|
||||
### 通过开放端口和服务实现自定义区域
|
||||
|
||||
Firewalld 的开发者们并不是想让他们设定的区域能够适应世界上所有不同的网络和所有级别的信任程度。你可以直接使用这些区域,也可以在它们基础上进行个性化配置。
|
||||
|
||||
你可以根据自己所需要进行的网络活动决定开放或关闭哪些端口,这并不需要对防火墙有多深的理解。
|
||||
|
||||
#### 预设服务
|
||||
|
||||
在你的防火墙上添加许可的最简单的方式就是添加预设服务。严格来讲,你的防火墙并不懂什么是“服务”,因为它只知道端口号码和使用协议的类型。不过在标准和传统的基础之上,防火墙可以为你提供一套端口和协议的组合。
|
||||
|
||||
比如说,如果你是一个 web 开发者并且希望你的计算机对本地网络开放(这样你的同事就可以看到你正在搭建的网站了),可以添加 **http** 和 **https** 服务。如果你是一名游戏玩家,并且在为你的游戏公会运行开源的 [murmur][9] 语音聊天服务器,那么你可以添加 **murmur** 服务。还有其它很多可用的服务,你可以使用下面这个命令查看:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --get-services
|
||||
amanda-client amanda-k5-client bacula bacula-client \
|
||||
bgp bitcoin bitcoin-rpc ceph cfengine condor-collector \
|
||||
ctdb dhcp dhcpv6 dhcpv6-client dns elasticsearch \
|
||||
freeipa-ldap freeipa-ldaps ftp [...]
|
||||
```
|
||||
|
||||
如果你找到了一个自己需要的服务,可以将它添加到当前的防火墙配置中,比如说:
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-service murmur`
|
||||
```
|
||||
|
||||
这个命令 **在你的默认区域里** 添加了指定服务所需要的所有端口和协议,不过在重启计算机或者防火墙之后就会失效。如果想让你的修改永久有效,可以使用 **\--permanent** 标志:
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-service murmur --permanent`
|
||||
```
|
||||
|
||||
你也可以将这个命令用于一个非默认区域:
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-service murmur --permanent --zone home`
|
||||
```
|
||||
|
||||
#### 端口
|
||||
|
||||
有时候你希望允许的流量并不在 firewalld 定义的服务之中。也许你想在一个非标准的端口上运行一个常规服务,或者就是想随意开放一个端口。
|
||||
|
||||
举例来说,也许你正在运行开源的 [虚拟桌游][10] 软件 [MapTool][11]。由于 MapTool 服务器应该使用哪个端口这件事情并没有一个行业标准,所以你可以自行决定使用哪个端口,然后在防火墙上“开一个洞”,让它允许该端口上的流量。
|
||||
|
||||
实现方式和添加服务差不多:
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-port 51234/tcp`
|
||||
```
|
||||
|
||||
这个命令 **在你的默认区域** 里将 51234 端口向 TCP 传入连接开放,不过在重启计算机或者防火墙之后就会失效。如果想让你的修改永久有效,可以使用 **\--permanent** 标志:
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-port 51234/tcp --permanent`
|
||||
```
|
||||
|
||||
你也可以将这个命令用于一个非默认区域:
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --add-port 51234/tcp --permanent --zone home`
|
||||
```
|
||||
|
||||
在路由器的防火墙上设置允许流量和在本机上设置的方式是不同的。你的路由器可能会为它的内嵌防火墙提供一个不同的配置界面(原理上是相同的),不过这就超出本文范围了。
|
||||
|
||||
### 移除端口和服务
|
||||
|
||||
如果你不再需要某项服务或者某个端口了,并且设置的时候没有使用 **\--permanent** 标志的话,那么可以通过重启防火墙来清除修改。
|
||||
|
||||
如果你已经将修改设置为永久生效了,可以使用 **\--remove-port** 或者 **\--remove-service** 标志来清除:
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --remove-port 51234/tcp --permanent`
|
||||
```
|
||||
|
||||
你可以通过在命令中指定一个区域以将端口或者服务从一个非默认区域中移除。
|
||||
|
||||
```
|
||||
`$ sudo firewall-cmd --remove-service murmur --permanent --zone home`
|
||||
```
|
||||
|
||||
### 自定义区域
|
||||
|
||||
你可以随意使用 firewalld 默认提供的这些区域,不过也完全可以创建自己的区域。比如如果希望有一个针对游戏的特别区域,你可以创建一个,然后只有在玩儿游戏的时候切换到该区域。
|
||||
|
||||
如果想要创建一个新的空白区域,你可以创建一个名为 **game** 的新区域,然后重新加载 firewall 规则,这样你的新区域就启用了:
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --new-zone game --permanent
|
||||
success
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
一旦创建好并且处于启用状态,你就可以通过添加玩游戏时所需要的服务和端口来实现个性化定制了。
|
||||
|
||||
### 勤勉
|
||||
|
||||
从今天起开始思考你的防火墙策略吧。不用着急,可以试着慢慢搭建一些合理的默认规则。你也许需要花上一段时间才能习惯于思考防火墙的配置问题,以及弄清楚你使用了哪些网络服务,不过无论是处在什么样的环境里,只要稍加探索你就可以让自己的 Linux 工作站变得更为强大。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/make-linux-stronger-firewalls
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUSINESS_buildtogether.png?itok=9Tvz64K5 (People working together to build )
|
||||
[2]: https://tools.ietf.org/html/rfc793
|
||||
[3]: https://tools.ietf.org/html/rfc433
|
||||
[4]: https://opensource.com/sites/default/files/uploads/web-port-nonstandard.png (Navigating to a nonstandard port produces an error)
|
||||
[5]: https://firewalld.org/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/nm-connection-editor.png (Network Manager Connection Editor)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/nm-zone.png (Firewall zones)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/nm-set.png (Setting a new zone)
|
||||
[9]: https://www.mumble.com/
|
||||
[10]: https://opensource.com/article/18/5/maptool
|
||||
[11]: https://github.com/RPTools
|
||||
Loading…
Reference in New Issue
Block a user