mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
e81bcb4995
@ -1,44 +1,45 @@
|
||||
# 像 Linus Torvalds 学习让编出的代码具有“good taste”
|
||||
向 Linus Torvalds 学习让编出的代码具有 “good taste”
|
||||
========
|
||||
|
||||
在[最近关于 Linus Torvalds 的一个采访中][1],这位 Linux 的创始人,在采访过程中大约 14:20 的时候,快速的指出了关于代码的 "good taste"。good taste?采访者请他展示更多的细节,于是,Linus Torvalds 展示了一张提前准备好的插图。
|
||||
在[最近关于 Linus Torvalds 的一个采访中][1],这位 Linux 的创始人,在采访过程中大约 14:20 的时候,提及了关于代码的 “good taste”。good taste?采访者请他展示更多的细节,于是,Linus Torvalds 展示了一张提前准备好的插图。
|
||||
|
||||
这张插图中展示了一个代码片段。但这段代码并没有 “good taste”。这是一个具有 “poor taste” 的代码片段,把它作为例子,以提供一些初步的比较。
|
||||
他展示的是一个代码片段。但这段代码并没有 “good taste”。这是一个具有 “poor taste” 的代码片段,把它作为例子,以提供一些初步的比较。
|
||||
|
||||

|
||||

|
||||
|
||||
这是一个用 C 写的函数,作用是删除链表中的一个对象,它包含有 10 行代码。
|
||||
|
||||
他把注意力集中在底部的 if 语句。正是这个 if 语句受到他的批判。
|
||||
他把注意力集中在底部的 `if` 语句。正是这个 `if` 语句受到他的批判。
|
||||
|
||||
我暂停视频,开始研究幻灯片。我发现我最近有写过和这很像的代码。Linus 不就是在说我的代码品味很差吗?我吞下自尊,继续观看视频。
|
||||
我暂停了这段视频,开始研究幻灯片。我发现我最近有写过和这很像的代码。Linus 不就是在说我的代码品味很差吗?我放下自傲,继续观看视频。
|
||||
|
||||
随后, Linus 向观众解释,正如我们所知道的,当从链表中删除一个对象时,需要考虑两种可能的情况。当所需删除的对象位于链表的表头时,删除过程和位于链表中间的情况不同。这就是这个 if 语句具有 "poor taste" 的原因。
|
||||
随后, Linus 向观众解释,正如我们所知道的,当从链表中删除一个对象时,需要考虑两种可能的情况。当所需删除的对象位于链表的表头时,删除过程和位于链表中间的情况不同。这就是这个 `if` 语句具有 “poor taste” 的原因。
|
||||
|
||||
但既然他承认考虑这两种不同的情况是必要的,那为什么像上面那样写如此糟糕呢?
|
||||
|
||||
接下来,他又向观众展示了第二张幻灯片。这个幻灯片展示的是实现同样功能的一个函数,但这段代码具有 “goog taste” 。
|
||||
|
||||

|
||||

|
||||
|
||||
原先的 10 行代码现在减少为 4 行。
|
||||
|
||||
但代码的行数并不重要,关键是 if 语句,它不见了,因为不再需要了。代码已经被重构,所以,尽管对象的地址还在列表中,但已经运用同样的操作把它删除了。
|
||||
但代码的行数并不重要,关键是 `if` 语句,它不见了,因为不再需要了。代码已经被重构,所以,不用管对象在列表中的位置,都可以运用同样的操作把它删除。
|
||||
|
||||
Linus 解释了一下新的代码,它消除了边缘情况,就是这样。然后采访转入了下一个话题。
|
||||
|
||||
我琢磨了一会这段代码。 Linus 是对的,的确,第二个函数更好。如果这是一个确定代码具有 “good taste” 还是 “bad taste” 的测试,那么很遗憾,我失败了。我从未想到过有可能能够去除条件语句。我写过不止一次这样的 if 语句,因为我经常使用链表。
|
||||
我琢磨了一会这段代码。 Linus 是对的,的确,第二个函数更好。如果这是一个确定代码具有 “good taste” 还是 “bad taste” 的测试,那么很遗憾,我失败了。我从未想到过有可能能够去除条件语句。我写过不止一次这样的 `if` 语句,因为我经常使用链表。
|
||||
|
||||
这个例子的启发,不仅仅是教给了我们一个从链表中删除对象的更好方法,而是启发了我们去考虑自己写的代码。你通过程序实现的一个简单算法,可能还有改进的空间,只是你从来没有考虑过。
|
||||
这个例子的意义,不仅仅是教给了我们一个从链表中删除对象的更好方法,而是启发了我们去思考自己写的代码。你通过程序实现的一个简单算法,可能还有改进的空间,只是你从来没有考虑过。
|
||||
|
||||
以这种方式,我回去审查最近正在做的项目的代码。也许是一个巧合,刚好也是用 C 写的。
|
||||
|
||||
我尽最大的能力去审查代码,“good taste” 的一个基本要求是关于边缘情况的消除方法,通常我们会使用条件语句来消除边缘情况。然而,你的测试使用的条件语句越少,你的代码就会有更好的 “tastes” 。
|
||||
我尽最大的能力去审查代码,“good taste” 的一个基本要求是关于边缘情况的消除方法,通常我们会使用条件语句来消除边缘情况。你的测试使用的条件语句越少,你的代码就会有更好的 “taste” 。
|
||||
|
||||
下面,我将分享一个通过审查代码进行了改进的一个特殊例子。
|
||||
|
||||
这是一个关于初始化网格边缘的算法。
|
||||
|
||||
下面所写的是一个用来初始化 grid 的网格边缘的算法,gird 表示一个二维数组:grid[行][列]
|
||||
下面所写的是一个用来初始化网格边缘的算法,网格 grid 以一个二维数组表示:grid[行][列] 。
|
||||
|
||||
再次说明,这段代码的目的只是用来初始化位于 grid 边缘的点的值,所以,只需要给最上方一行、最下方一行、最左边一列以及最右边一列赋值即可。
|
||||
|
||||
@ -47,27 +48,15 @@ Linus 解释了一下新的代码,它消除了边缘情况,就是这样。
|
||||
```Tr
|
||||
for (r = 0; r < GRID_SIZE; ++r) {
|
||||
for (c = 0; c < GRID_SIZE; ++c) {
|
||||
```
|
||||
|
||||
```
|
||||
// Top Edge
|
||||
if (r == 0)
|
||||
grid[r][c] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Left Edge
|
||||
if (c == 0)
|
||||
grid[r][c] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Right Edge
|
||||
if (c == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Bottom Edge
|
||||
if (r == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
@ -78,84 +67,70 @@ for (r = 0; r < GRID_SIZE; ++r) {
|
||||
虽然这样做是对的,但回过头来看,这个结构存在一些问题。
|
||||
|
||||
1. 复杂性 — 在双层循环里面使用 4 个条件语句似乎过于复杂。
|
||||
2. 高效性 — 假设 GRID_SIZE 的值为 64,那么这个循环需要执行 4096 次,但需要进行赋值的只有位于边缘的 256 个点。
|
||||
2. 高效性 — 假设 `GRID_SIZE` 的值为 64,那么这个循环需要执行 4096 次,但需要进行赋值的只有位于边缘的 256 个点。
|
||||
|
||||
用 Linus 的眼光来看,将会认为这段代码没有 “good taste” 。
|
||||
|
||||
所以,我对上面的问题进行了一下思考。经过一番思考,我把复杂度减少为包含四个条件语句的单层循环。虽然只是稍微改进了一下复杂性,但在性能上也有了极大的提高,因为它只是沿着边缘的点进行了 256 次循环。
|
||||
所以,我对上面的问题进行了一下思考。经过一番思考,我把复杂度减少为包含四个条件语句的单层 `for` 循环。虽然只是稍微改进了一下复杂性,但在性能上也有了极大的提高,因为它只是沿着边缘的点进行了 256 次循环。
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE * 4; ++i) {
|
||||
```
|
||||
|
||||
```
|
||||
// Top Edge
|
||||
if (i < GRID_SIZE)
|
||||
grid[0][i] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Right Edge
|
||||
else if (i < GRID_SIZE * 2)
|
||||
grid[i - GRID_SIZE][GRID_SIZE - 1] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Left Edge
|
||||
else if (i < GRID_SIZE * 3)
|
||||
grid[i - (GRID_SIZE * 2)][0] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Bottom Edge
|
||||
else
|
||||
grid[GRID_SIZE - 1][i - (GRID_SIZE * 3)] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
的确是一个很大的提高。但是它看起来很丑,并不是易于遵循的代码。基于这一点,我并不满意。
|
||||
的确是一个很大的提高。但是它看起来很丑,并不是易于阅读理解的代码。基于这一点,我并不满意。
|
||||
|
||||
我继续思考,是否可以进一步改进呢?事实上,答案是 YES!最后,我想出了一个非常简单且优雅的算法,老实说,我不敢相信我会花了那么长时间才发现这个算法。
|
||||
|
||||
下面是这段代码的最后版本。它只有一层循环并且没有条件语句。另外。循环只执行了 64 次迭代,极大的改善了复杂性和高效性。
|
||||
下面是这段代码的最后版本。它只有一层 `for` 循环并且没有条件语句。另外。循环只执行了 64 次迭代,极大的改善了复杂性和高效性。
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE; ++i) {
|
||||
```
|
||||
|
||||
```
|
||||
// Top Edge
|
||||
grid[0][i] = 0;
|
||||
|
||||
// Bottom Edge
|
||||
grid[GRID_SIZE - 1][i] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Left Edge
|
||||
grid[i][0] = 0;
|
||||
```
|
||||
|
||||
```
|
||||
// Right Edge
|
||||
grid[i][GRID_SIZE - 1] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
这段代码通过单层循环迭代来初始化四条边缘上的点。它并不复杂,而且非常高效,易于阅读。和原始的版本,甚至是第二个版本相比,都有天壤之别。
|
||||
这段代码通过每次循环迭代来初始化四条边缘上的点。它并不复杂,而且非常高效,易于阅读。和原始的版本,甚至是第二个版本相比,都有天壤之别。
|
||||
|
||||
至此,我已经非常满意了。
|
||||
|
||||
那么,我是一个有 “good taste” 的开发者么?
|
||||
|
||||
我觉得我是,但是这并不是因为我上面提供的这个例子,也不是因为我在这篇文章中没有提到的其它代码……而是因为具有 “good taste” 的编码工作远非一段代码所能代表。Linus 自己也说他所提供的这段代码不足以表达他的观点。
|
||||
|
||||
我明白 Linus 的意思,也明白那些具有 “good taste” 的程序员虽各有不同,但是他们都是会将他们之前开发的代码花费时间重构的人。他们明确界定了所开发的组件的边界,以及是如何与其它组件之间的交互。他们试着确保每一样工作都完美、优雅。
|
||||
|
||||
其结果就是类似于 Linus 的 “good taste” 的例子,或者像我的例子一样,不过是千千万万个 “good taste”。
|
||||
|
||||
你会让你的下个项目也具有这种 “good taste” 吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@bartobri/applying-the-linus-tarvolds-good-taste-coding-requirement-99749f37684a
|
||||
|
||||
作者:[Brian Barto][a]
|
||||
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,17 +1,17 @@
|
||||
5 个要了解的开源软件定义网络项目
|
||||
5 个需要知道的开源的软件定义网络(SDN)项目
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
SDN 开始重新定义企业网络。这里有五个应该知道的开源项目。
|
||||
[Creative Commons Zero][1] Pixabay
|
||||
> SDN 开始重新定义企业网络。这里有五个应该知道的开源项目。
|
||||
|
||||
|
||||
纵观整个 2016 年,软件定义网络(SDN)持续快速发展并变得成熟。我们现在已经超出了开源网络的概念阶段,两年前评估这些项目潜力的公司已经开始了企业部署。如几年来所预测的,SDN 正在开始重新定义企业网络。
|
||||
|
||||
这与市场研究人员的观点基本上是一致的。IDC 在今年早些时候公布了 SDN 市场的[一份研究][3],它预计从 2014 年到 2020 年 SDN 的年均复合增长率为 53.9%,届时市场价值将达到 125 亿美元。此外,“<ruby>2016 技术趋势<rt>Technology Trends 2016</rt></ruby>” 报告中将 SDN 列为 2016 年最佳技术投资。
|
||||
|
||||
IDC 网络基础设施副总裁,[Rohit Mehra][4] 说:“云计算和第三方平台推动了 SDN 的需求,这将在 2020 年代表一个价值超过 125 亿美元的市场。毫无疑问的是 SDN 的价值将越来越多地渗透到网络虚拟化软件和 SDN 应用中,包括虚拟化网络和安全服务,大型企业在数据中心实现 SDN 的价值,但它们最终会认识到其在分支机构和校园网络中的广泛应用。“
|
||||
IDC 网络基础设施副总裁,[Rohit Mehra][4] 说:“云计算和第三方平台推动了 SDN 的需求,这预示着 2020 年的一个价值超过 125 亿美元的市场。毫无疑问的是 SDN 的价值将越来越多地渗透到网络虚拟化软件和 SDN 应用中,包括虚拟化网络和安全服务。大型企业现在正在数据中心体现 SDN 的价值,但它们最终会认识到其在分支机构和校园网络中的广泛应用。“
|
||||
|
||||
Linux 基金会最近[发布][5]了其 2016 年度报告[“开放云指南:当前趋势和开源项目”][6]。其中第三份年度报告全面介绍了开放云计算的状态,并包含关于 unikernel 的部分。你现在可以[下载报告][7]了,首先要注意的是汇总和分析研究,说明了容器、unikernel 等的趋势是如何重塑云计算的。该报告提供了对当今开放云环境中心的分类项目的描述和链接。
|
||||
|
||||
@ -19,27 +19,37 @@ Linux 基金会最近[发布][5]了其 2016 年度报告[“开放云指南:
|
||||
|
||||
### 软件定义网络
|
||||
|
||||
[ONOS][8]
|
||||
#### [ONOS][8]
|
||||
|
||||
<ruby>开放网络操作系统<rt>Open Network Operating System </rt></ruby>(ONOS)是一个 Linux 基金会项目,它是一个给服务提供商的软件定义网络操作系统,它具有可扩展性、高可用性、高性能和抽象功能来创建应用程序和服务。[ONOS 的 GitHub 地址][9]。
|
||||
<ruby>开放网络操作系统<rt>Open Network Operating System</rt></ruby>(ONOS)是一个 Linux 基金会项目,它是一个面向服务提供商的软件定义网络操作系统,它具有可扩展性、高可用性、高性能和抽象功能来创建应用程序和服务。
|
||||
|
||||
[OpenContrail][10]
|
||||
[ONOS 的 GitHub 地址][9]。
|
||||
|
||||
OpenContrail 是 Juniper Networks 的云开源网络虚拟化平台。它提供网络虚拟化的所有必要组件:SDN 控制器、虚拟路由器、分析引擎和已发布的上层 API。其 REST API 配置并收集来自系统的操作和分析数据。[OpenContrail 的 GitHub 地址][11]。
|
||||
#### [OpenContrail][10]
|
||||
|
||||
[OpenDaylight][12]
|
||||
OpenContrail 是 Juniper Networks 的云开源网络虚拟化平台。它提供网络虚拟化的所有必要组件:SDN 控制器、虚拟路由器、分析引擎和已发布的上层 API。其 REST API 配置并收集来自系统的操作和分析数据。
|
||||
|
||||
OpenDaylight 是 Linux 基金会的一个 OpenDaylight Foundation 项目,它是一个可编程的、提供给服务提供商和企业的软件定义网络平台。它基于微服务架构,可以在多供应商环境中的一系列硬件上实现网络服务。[OpenDaylight 的 GitHub 地址][13]。
|
||||
[OpenContrail 的 GitHub 地址][11]。
|
||||
|
||||
[Open vSwitch][14]
|
||||
#### [OpenDaylight][12]
|
||||
|
||||
Open vSwitch 是一个 Linux 基金会项目,具有生产级别质量的多层虚拟交换机。它通过程序化扩展设计用于大规模网络自动化,同时还支持标准管理接口和协议,包括 NetFlow、sFlow、IPFIX、RSPAN、CLI、LACP 和 802.1ag。它支持类似 VMware 的分布式 vNetwork 或者 Cisco Nexus 1000V 那样跨越多个物理服务器分发。[OVS 在 GitHub 的地址][15]。
|
||||
OpenDaylight 是 Linux 基金会旗下的 OpenDaylight 基金会项目,它是一个可编程的、提供给服务提供商和企业的软件定义网络平台。它基于微服务架构,可以在多供应商环境中的一系列硬件上实现网络服务。
|
||||
|
||||
[OPNFV][16]
|
||||
[OpenDaylight 的 GitHub 地址][13]。
|
||||
|
||||
<ruby>网络功能虚拟化开放平台<rt>Open Platform for Network Functions Virtualization</rt></ruby>(OPNFV) 是 Linux 基金会项目,它用于企业和服务提供商网络的 NFV 平台。它汇集了计算、存储和网络虚拟化方面的上游组件以创建 NFV 程序的端到端平台。[OPNFV 在 Bitergia 上的地址][17]。
|
||||
#### [Open vSwitch][14]
|
||||
|
||||
_要了解更多关于开源云计算趋势和查看顶级开源云计算项目完整列表,[请下载 Linux 基金会的 “开放云指南”。][18]_
|
||||
Open vSwitch 是一个 Linux 基金会项目,是具有生产级品质的多层虚拟交换机。它通过程序化扩展设计用于大规模网络自动化,同时还支持标准管理接口和协议,包括 NetFlow、sFlow、IPFIX、RSPAN、CLI、LACP 和 802.1ag。它支持类似 VMware 的分布式 vNetwork 或者 Cisco Nexus 1000V 那样跨越多个物理服务器分发。
|
||||
|
||||
[OVS 在 GitHub 的地址][15]。
|
||||
|
||||
#### [OPNFV][16]
|
||||
|
||||
<ruby>网络功能虚拟化开放平台<rt>Open Platform for Network Functions Virtualization</rt></ruby>(OPNFV)是 Linux 基金会项目,它用于企业和服务提供商网络的 NFV 平台。它汇集了计算、存储和网络虚拟化方面的上游组件以创建 NFV 程序的端到端平台。
|
||||
|
||||
[OPNFV 在 Bitergia 上的地址][17]。
|
||||
|
||||
_要了解更多关于开源云计算趋势和查看顶级开源云计算项目完整列表,[请下载 Linux 基金会的 “开放云指南”][18]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1,24 +1,25 @@
|
||||
# 从损坏的 Linux EFI 安装中恢复
|
||||
从损坏的 Linux EFI 安装中恢复
|
||||
=========
|
||||
|
||||
在过去的十多年里,Linux 发行版在安装前、安装过程中、以及安装后偶尔会失败,但我总是有办法恢复系统并继续正常工作。然而,[Solus][1] 损坏了我的笔记本。
|
||||
|
||||
GRUB 恢复。不行,重装。还不行!Ubuntu 拒绝安装,报错目标设备不是这个或那个。哇。我之前还没有遇到过想这样的事情。我的测试机已变成无用的砖块。我们该失望吗?不,绝对不。让我来告诉你怎样你可以修复它吧。
|
||||
GRUB 恢复。不行,重装。还不行!Ubuntu 拒绝安装,目标设备的报错一会这样,一会那样。哇。我之前还没有遇到过像这样的事情。我的测试机已变成无用的砖块。难道我该绝望吗?不,绝对不。让我来告诉你怎样你可以修复它吧。
|
||||
|
||||
### 问题详情
|
||||
|
||||
所有事情都从 Solus 尝试安装它自己的启动引导器 - goofiboot 开始。不知道什么原因、它没有成功完成安装,留给我的就是一个无法启动的系统。BIOS 之后,我有一个 GRUB 恢复终端。
|
||||
所有事情都从 Solus 尝试安装它自己的启动引导器 - goofiboot 开始。不知道什么原因、它没有成功完成安装,留给我的就是一个无法启动的系统。经过 BIOS 引导之后,我进入一个 GRUB 恢复终端。
|
||||
|
||||

|
||||

|
||||
|
||||
我尝试在终端中手动修复,使用类似和我在我的扩展 [GRUB2 指南][2]中介绍的这个或那个命令。但还是不行。然后我尝试按照我在[GRUB2 和 EFI 指南][3]中的建议从 Live CD(译者注:Live CD 是一个完整的计算机可引导安装媒介,它包括在计算机内存中运行的操作系统,而不是从硬盘驱动器加载; CD 本身是只读的。 它允许用户为任何目的运行操作系统,而无需安装它或对计算机的配置进行任何更改)中恢复。我用 efibootmgr 工具创建了一个条目,确保标记它为有效。正如我们之前在指南中做的那样,之前这些是能正常工作的。哎,现在这个方法也不起作用。
|
||||
我尝试在终端中手动修复,使用类似和我在我详实的 [GRUB2 指南][2]中介绍的各种命令。但还是不行。然后我尝试按照我在 [GRUB2 和 EFI 指南][3]中的建议从 Live CD 中恢复(LCTT 译注:Live CD 是一个完整的计算机可引导安装媒介,它包括在计算机内存中运行的操作系统,而不是从硬盘驱动器加载;CD 本身是只读的。 它允许用户为任何目的运行操作系统,而无需安装它或对计算机的配置进行任何更改)。我用 efibootmgr 工具创建了一个引导入口,确保标记它为有效。正如我们之前在指南中做的那样,之前这些是能正常工作的。哎,现在这个方法也不起作用。
|
||||
|
||||
我尝试一次完整的 Ubuntu 安装,把它安装到 Solus 所在的分区,希望安装程序能给我一些有用的信息。但是 Ubuntu 无法按成安装。它报错:failed to install into /target。又回到开始的地方了。怎么办?
|
||||
我尝试做一个完整的 Ubuntu 安装,把它安装到 Solus 所在的分区,希望安装程序能给我一些有用的信息。但是 Ubuntu 无法完成安装。它报错:failed to install into /target。又回到开始的地方了。怎么办?
|
||||
|
||||
### 手动清除 EFI 分区
|
||||
|
||||
显然,我们的 EFI 分区出现了严重问题。简单回顾以下,如果你使用的是 UEFI,那么你需要一个单独的 FAT-32 格式化分区。该分区用于存储 EFI 引导镜像。例如,当你安装 Fedora 时,Fedora 引导镜像会被拷贝到 EFI 子目录。每个操作系统都会被存储到一个它自己的目录,一般是 /boot/efi/EFI/<操作系统版本>/。
|
||||
显然,我们的 EFI 分区出现了严重问题。简单回顾以下,如果你使用的是 UEFI,那么你需要一个单独的 FAT-32 格式化的分区。该分区用于存储 EFI 引导镜像。例如,当你安装 Fedora 时,Fedora 引导镜像会被拷贝到 EFI 子目录。每个操作系统都会被存储到一个它自己的目录,一般是 `/boot/efi/EFI/<操作系统版本>/`。
|
||||
|
||||

|
||||

|
||||
|
||||
在我的 [G50][4] 机器上,这里有很多各种发行版测试条目,包括:centos、debian、fedora、mx-15、suse、Ubuntu、zorin 以及其它。这里也有一个 goofiboot 目录。但是,efibootmgr 并没有在它的菜单中显示 goofiboot 条目。显然这里出现了一些问题。
|
||||
|
||||
@ -45,7 +46,7 @@ Boot2003* EFI Network
|
||||
P.S. 上面的输出是在 LIVE 会话中运行命令生成的!
|
||||
|
||||
|
||||
我决定清除所有非默认的以及非微软的条目然后重新开始。显然,有些东西被损坏了,妨碍了新的发行版设置它们自己的启动引导程序。因此我删除了 /boot/efi/EFI 分区下面出 Boot 和 Windows 外的所有目录。同时,我也通过删除所有额外的条目更新了启动管理器。
|
||||
我决定清除所有非默认的以及非微软的条目然后重新开始。显然,有些东西被损坏了,妨碍了新的发行版设置它们自己的启动引导程序。因此我删除了 `/boot/efi/EFI` 分区下面除了 Boot 和 Windows 以外的所有目录。同时,我也通过删除所有额外的条目更新了启动管理器。
|
||||
|
||||
```
|
||||
efibootmgr -b <hex> -B <hex>
|
||||
@ -53,23 +54,20 @@ efibootmgr -b <hex> -B <hex>
|
||||
|
||||
最后,我重新安装了 Ubuntu,并仔细监控 GRUB 安装和配置的过程。这次,成功完成啦。正如预期的那样,几个无效条目出现了一些错误,但整个安装过程完成就好了。
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
### 额外阅读
|
||||
|
||||
如果你不喜欢这种手动修复,你可以阅读:
|
||||
|
||||
```
|
||||
[Boot-Info][5] 手册,里面有帮助你恢复系统的自动化工具
|
||||
|
||||
[Boot-repair-cd][6] 自动恢复工具下载页面
|
||||
```
|
||||
- [Boot-Info][5] 手册,里面有帮助你恢复系统的自动化工具
|
||||
- [Boot-repair-cd][6] 自动恢复工具下载页面
|
||||
|
||||
### 总结
|
||||
|
||||
如果你遇到由于 EFI 分区破坏而导致系统严重瘫痪的情况,那么你可能需要遵循本指南中的建议。 删除所有非默认条目。 如果你使用 Windows 进行多重引导,请确保不要修改任何和 Microsoft 相关的东西。 然后相应地更新引导菜单,以便删除损坏的条目。 重新运行所需发行版的安装设置,或者尝试用之前介绍的比较不严格的修复方法。
|
||||
如果你遇到由于 EFI 分区破坏而导致系统严重瘫痪的情况,那么你可能需要遵循本指南中的建议。 删除所有非默认条目。 如果你使用 Windows 进行多重引导,请确保不要修改任何和 Microsoft 相关的东西。 然后相应地更新引导菜单,以便删除损坏的条目。 重新运行所需发行版的安装设置,或者尝试用之前介绍的比较不严谨的修复方法。
|
||||
|
||||
我希望这篇小文章能帮你节省一些时间。Solus 对我系统的更改使我很懊恼。这些事情本不应该发生,恢复过程也应该更简单。不管怎样,虽然事情似乎很可怕,修复并不是很难。你只需要删除损害的文件然后重新开始。你的数据应该不会受到影响,你也应该能够顺利进入到运行中的系统并继续工作。开始吧。
|
||||
|
||||
@ -84,12 +82,6 @@ efibootmgr -b <hex> -B <hex>
|
||||
|
||||
从 2004 到 2008 年,我通过在医疗图像行业担任物理专家养活自己。我的工作主要关注解决问题和开发算法。为此,我广泛使用 Matlab,主要用于信号和图像处理。另外,我已通过几个主要工程方法的认证,包括 MEDIC Six Sigma Green Belt、实验设计以及统计工程。
|
||||
|
||||
有时候我也会写书,包括 Linux 创新及技术工作。
|
||||
|
||||
往下滚动你可以查看我开源项目的完整列表、发表文章以及专利。
|
||||
|
||||
有关我奖项、提名以及 IT 相关认证的完整列表,稍后也会有。
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
@ -98,7 +90,7 @@ via: http://www.dedoimedo.com/computers/grub2-efi-corrupt-part-recovery.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,123 @@
|
||||
如何通过 OpenELEC 创建你自己的媒体中心
|
||||
======
|
||||
|
||||

|
||||
|
||||
你是否曾经想要创建你自己的家庭影院系统?如果是的话,这里有一个为你准备的指南!在本篇文章中,我们将会介绍如何设置一个由 OpenELEC 以及 Kodi 驱动的家庭娱乐系统。我们将会介绍如何制作安装介质,哪些设备可以运行该软件,如何安装它,以及其他一切需要知道的事情等等。
|
||||
|
||||
### 选择一个设备
|
||||
|
||||
在开始设定媒体中心的软件前,你需要选择一个设备。OpenELEC 支持一系列设备。从一般的桌面设备到树莓派 2/3 等等。选择好设备以后,考虑一下你怎么访问 OpenELEC 系统中的媒体并让其就绪。
|
||||
|
||||
**注意: **OpenELEC 基于 Kodi,有许多方式加载一个可播放的媒体(比如 Samba 网络分享,外设,等等)。
|
||||
|
||||
### 制作安装磁盘
|
||||
|
||||
OpenELEC 安装磁盘需要一个 USB 存储器,且其至少有 1GB 的容量。这是安装该软件的唯一方式,因为开发者没有发布 ISO 文件。取而代之的是需要创建一个 IMG 原始文件。选择与你设备相关的链接并且[下载][10]原始磁盘镜像。当磁盘镜像下载完毕,打开一个终端,并且使用命令将数据从压缩包中解压出来。
|
||||
|
||||
**在Linux/macOS上**
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
gunzip -d OpenELEC*.img.gz
|
||||
```
|
||||
|
||||
**在Windows上**
|
||||
|
||||
下载 [7zip][11],安装它,然后解压压缩文件。
|
||||
|
||||
当原始的 .IMG 文件被解压后,下载 [Etcher USB creation tool][12],并且依据在界面上的指示来安装它并创建 USB 磁盘。
|
||||
|
||||
**注意:** 对于树莓派用户,Etcher 也支持将文件写入到 SD 卡中。
|
||||
|
||||
### 安装 OpenELEC
|
||||
|
||||
OpenELEC 安装进程可能是安装流程最简单的操作系统之一了。将 USB 设备加入,然后配置设备使其以 USB 方式启动。同样,这个过程也可以通过按 DEL 或者 F2 来替代。然而并不是所有的 BIOS 都是一样的,所以最好的方式就是看看手册什么的。
|
||||
|
||||

|
||||
|
||||
一旦进入 BIOS,修改设置使其从 USB 磁盘中直接加载。这将会允许电脑从 USB 磁盘中启动,这将会使你进入到 Syslinux 引导屏幕。在提示符中,键入 `installer`,然后按下回车键。
|
||||
|
||||

|
||||
|
||||
默认情况下,快速安装选项已经是选中的。按回车键来开始安装。这将会使安装器跳转到磁盘选择界面。选择 OpenELEC 要被安装到的地方,然后按下回车键来开始安装过程。
|
||||
|
||||

|
||||
|
||||
一旦完成安装,重启系统并加载 OpenELEC。
|
||||
|
||||
### 配置 OpenELEC
|
||||
|
||||

|
||||
|
||||
在第一次启动时,用户必须配置一些东西。如果你的媒体中心拥有一个无线网卡,OpenELEC 将会提示用户将其连接到一个热点上。选择一个列表中的网络并且输入密码。
|
||||
|
||||

|
||||
|
||||
在下一步“<ruby>欢迎来到 OpenELEC<rt>Welcome to OpenELEC</rt></ruby>”屏上,用户必须配置不同的分享设置(SSH 以及 Samba)。建议你把这些设置开启,因为可以用命令行访问,这将会使得远程传输媒体文件变得很简单。
|
||||
|
||||
### 增加媒体
|
||||
|
||||
在 OpenELEC(Kodi)中增加媒体,首先选择你希望添加的媒体到的部分。以同样的流程,为照片、音乐等添加媒体。在这个指南中,我们将着重讲解添加视频。
|
||||
|
||||

|
||||
|
||||
点击在主页的“<ruby>视频<rt>Video</rt></ruby>”选项来进入视频页面。选择“<ruby>文件<rt>Files</rt></ruby>”选项,在下一个页面点击“<ruby>添加视频...<rt>Add videos…</rt></ruby>”,这将会使得用户进入Kodi 的添加媒体页面。在这个页面,你可以随意的添加媒体源了(包括内部和外部的)。
|
||||
|
||||

|
||||
|
||||
OpenELEC 会自动挂载外部的设备(像是 USB,DVD 碟片,等等),并且它可以通过浏览文件挂载点来挂载。一般情况下,这些设备都会被放在“/run”下,或者,返回你点击“<ruby>添加视频...<rt>Add videos…</rt></ruby>”的页面,在那里选择设备。任何外部设备,包括 DVD/CD,将会直接展示在那里,并可以直接访问。这是一个很好的选择——对于那些不懂如何找到挂载点的用户。
|
||||
|
||||

|
||||
|
||||
现在这个设备在 Kodi 中被选中了,界面将会询问用户去浏览设备上私人文件夹,里面有私人文件——这一切都是在媒体中心文件浏览器工具下执行的。一旦找到了放置文件的文件夹,添加它,给予文件夹一个名字,然后按下 OK 按钮来保存它。
|
||||
|
||||

|
||||
|
||||
当一个用户浏览“<ruby>视频<rt>Videos</rt></ruby>”,他们将会看到可以点击的文件夹,这个文件夹中带有从外部设备添加的媒体。这些文件夹可以很容易地在系统上播放。
|
||||
|
||||
### 使用 OpenELec
|
||||
|
||||
当用户登录他们将会看见一个“主界面”,这个主界面有许多部分,用户可以点击它们并且进入,包括:图片,视频,音乐,程序等等。当悬停在这些部分的时候,子部分就会出现。例如,当悬停在“图片”上时,子部分”文件“以及”插件”就会出现。
|
||||
|
||||

|
||||
|
||||
如果一个用户点击了一个部分中的子部分,例如“插件”,Kodi 插件选择就会出现。这个安装器将会允许用户浏览新的插件内容,来安装到这个子部分(像是图片关联插件,等等)或者启动一个已经存在的图片关联插件,当然,这个插件应该已经安装到系统上了。
|
||||
|
||||
此外,点击任何部分的文件子部分(例如视频)将会直接给显示用户该部分可用的文件。
|
||||
|
||||
### 系统设置
|
||||
|
||||

|
||||
|
||||
Kodi 有丰富的设置区域。为了找到这些设置,使鼠标在右方悬停,目录选择器将会滚动右方并且显示”<ruby>系统<rt>System</rt></ruby>“。点击来打开全局系统设定区。
|
||||
|
||||
用户可以修改任何设置,从安装 Kodi 仓库的插件,到激活各种服务,到改变主题,甚至天气。如果想要退出设定区域并且返回主页面,点击右下方角落中的“home”图标。
|
||||
|
||||
### 结论
|
||||
|
||||
通过 OpenELEC 的安装和配置,你现在可以随意体验使用你自己的 Linux 支持的家庭影院系统。在所有的家庭影院系统 Linux 发行版中,这个是最用户友好的。请记住,尽管这个系统是以“OpenELEC”为名,但它运行着的是 Kodi ,并兼容任何 Kodi 的插件,工具以及程序。
|
||||
|
||||
------
|
||||
|
||||
via: https://www.maketecheasier.com/build-media-center-with-openelec/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[svtter](https://github.com/svtter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]: https://www.maketecheasier.com/author/derrikdiener/
|
||||
[2]: https://www.maketecheasier.com/build-media-center-with-openelec/#comments
|
||||
[3]: https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]: http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F
|
||||
[5]: http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F&text=How+to+Build+Your+Own+Media+Center+with+OpenELEC
|
||||
[6]: mailto:?subject=How%20to%20Build%20Your%20Own%20Media%20Center%20with%20OpenELEC&body=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F
|
||||
[7]: https://www.maketecheasier.com/permanently-disable-windows-defender-windows-10/
|
||||
[8]: https://www.maketecheasier.com/repair-mac-hard-disk-with-fsck/
|
||||
[9]: https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]: http://openelec.tv/get-openelec/category/1-openelec-stable-releases
|
||||
[11]: http://www.7-zip.org/
|
||||
[12]: https://etcher.io/
|
||||
@ -5,40 +5,34 @@
|
||||
|
||||
|
||||

|
||||
>图片提供: opensource.com
|
||||
|
||||
> 图片提供: opensource.com
|
||||
|
||||
当我开始对 [ARM][6]设备,特别是 Raspberry Pi 感兴趣时,我的第一个项目是一个 OpenVPN 服务器。
|
||||
|
||||
通过将 Raspberry Pi 作为家庭网络的安全网关,我可以使用我的手机来控制我的桌面,远程播放 Spotify,打开文档以及一些其他有趣的东西。我在第一个项目中使用了一个现有的教程,因为我害怕自己使用命令行。
|
||||
通过将 Raspberry Pi 作为家庭网络的安全网关,我可以使用我的手机来控制我的桌面,远程播放 Spotify,打开文档以及一些其他有趣的东西。我在第一个项目中使用了一个现有的教程,因为我害怕自己在命令行中拼砌。
|
||||
|
||||
更多关于 Raspberry Pi 的文章:
|
||||
|
||||
* [最新的 Raspberry Pi][1]
|
||||
* [什么是 Raspberry Pi?][2]
|
||||
* [开始使用 Raspberry Pi][3]
|
||||
* [给我们发送你的 Raspberry Pi 项目和教程][4]
|
||||
|
||||
几个月后,这种恐惧消失了。我扩展了我的原始项目,并使用[ Samba 服务器][7]从文件服务器隔离了 OpenVPN 服务器。这是我第一个没有完全按照教程来的项目。不幸的是,在我的 Samba 项目结束后,我意识到我没有记录任何东西,所以我无法复制它。为了重新创建它,我不得不重新参考我曾经用过的那些单独的教程,将项目拼回到一起。
|
||||
几个月后,这种恐惧消失了。我扩展了我的原始项目,并使用 [Samba 服务器][7]从文件服务器分离出了 OpenVPN 服务器。这是我第一个没有完全按照教程来的项目。不幸的是,在我的 Samba 项目结束后,我意识到我没有记录任何东西,所以我无法复制它。为了重新创建它,我不得不重新参考我曾经用过的那些单独的教程,将项目拼回到一起。
|
||||
|
||||
我学到了关于开发人员工作流程的宝贵经验 - 跟踪你所有的更改。我在本地做了一个小的 git 仓库,并记录了我输入的所有命令。
|
||||
|
||||
### 发现 Kubernetes
|
||||
|
||||
2015 年 5 月,我发现了 Linux 容器和 Kubernetes。我觉得 Kubernetes 很有魅力,我可以使用仍在技术上发展的概念 - 并且我实际上可以用它。平台本身及其所呈现的可能性令人兴奋。在此之前,我才刚刚在一块 Raspberry Pi 上运行了一个程序。有了 Kubernetes,我可以做出比以前更高级的配置。
|
||||
2015 年 5 月,我发现了 Linux 容器和 Kubernetes。我觉得 Kubernetes 很有魅力,我可以使用仍然处于技术发展的概念 - 并且我实际上可以用它。平台本身及其所呈现的可能性令人兴奋。在此之前,我才刚刚在一块 Raspberry Pi 上运行了一个程序。而有了 Kubernetes,我可以做出比以前更先进的配置。
|
||||
|
||||
那时候,Docker(v1.6 版本,如果我记得正确的话)在 ARM 上有一个 bug,这意味着在 Raspberry Pi 上运行 Kubernetes 实际上是不可能的。在早期的 0.x 版本中,Kubernetes 的变化很快。每次我在 AMD64 上找到一篇关于如何设置 Kubernetes 的指南时,它针对的还都是一个旧版本,与我当时使用的完全不兼容。
|
||||
|
||||
不管怎样,我用自己的方法在 Raspberry Pi 上创建了一个 Kubernetes 节点,而在 Kubernetes v1.0.1 中,我使用 Docker v1.7.1 [让它工作了][8]。这是第一个将 Kubernetes 全功能部署到 ARM 的方法。
|
||||
|
||||
在 Raspberry Pi 上运行 Kubernetes 的优势在于,由于 ARM 设备非常小巧,因此不会产生大量的功耗。如果程序以正确的方式构建,那么同样可以在 AMD64 上用同样的方法运行程序。有一块小型 IoT 板为教育创造了巨大的机会。用它来做演示也很有用,比如你要出差参加一个会议。携带 Raspberry Pi (通常)比拖着大型英特尔机器要容易得多。
|
||||
在 Raspberry Pi 上运行 Kubernetes 的优势在于,由于 ARM 设备非常小巧,因此不会产生大量的功耗。如果程序以正确的方式构建而成,那么就可以在 AMD64 上用同样的方法运行同一个程序。这样的一块小型 IoT 板为教育创造了巨大的机会。用它来做演示也很有用,比如你要出差参加一个会议。携带 Raspberry Pi (通常)比拖着大型英特尔机器要容易得多。
|
||||
|
||||
现在按照[我建议][9]的 ARM(32 位和 64 位)的支持已被合并到核心中。ARM 的二进制文件会自动与 Kubernetes 一起发布。虽然我们还没有为 ARM 提供自动化的 CI(持续集成)系统,在 PR 合并之前会自动确定它可在 ARM 上工作,它仍然工作得不错。
|
||||
现在按照[我建议][9]的 ARM(32 位和 64 位)的支持已被合并到 Kubernetes 核心中。ARM 的二进制文件会自动与 Kubernetes 一起发布。虽然我们还没有为 ARM 提供自动化的 CI(持续集成)系统,不过在 PR 合并之前会自动确定它可在 ARM 上工作,现在它运转得不错。
|
||||
|
||||
### Raspberry Pi 上的分布式网络
|
||||
|
||||
我通过 [kubeadm][10] 发现了 Weave Net。[Weave Mesh][11]是一个有趣的分布式网络解决方案,因此我开始阅读更多关于它的内容。在 2016 年 12 月,我在 [Weaveworks][12] 收到了第一份合同工作。我是 Weave Net 中 ARM 支持团队的一员。
|
||||
我通过 [kubeadm][10] 发现了 Weave Net。[Weave Mesh][11] 是一个有趣的分布式网络解决方案,因此我开始了解更多关于它的内容。在 2016 年 12 月,我在 [Weaveworks][12] 收到了第一份合同工作,我成为了 Weave Net 中 ARM 支持团队的一员。
|
||||
|
||||
我很高兴可以在 Raspberry Pi 上运行 Weave Net 的工业案例,比如那些需要更加移动化的工厂。目前,将 Weave Scope 或 Weave Cloud 部署到 Raspberry Pi 可能不太现实(尽管可以考虑使用其他 ARM 设备),因为我猜这个软件需要更多的内存才能运行良好。理想情况下,随着 Raspberry Pi 升级到 2GB 内存,我想我可以在它上面运行 Weave Cloud 了。
|
||||
我很高兴可以在 Raspberry Pi 上运行 Weave Net 的工业案例,比如那些需要设备更加移动化的工厂。目前,将 Weave Scope 或 Weave Cloud 部署到 Raspberry Pi 可能不太现实(尽管可以考虑使用其他 ARM 设备),因为我猜这个软件需要更多的内存才能运行良好。理想情况下,随着 Raspberry Pi 升级到 2GB 内存,我想我可以在它上面运行 Weave Cloud 了。
|
||||
|
||||
在 Weave Net 1.9 中,Weave Net 支持了 ARM。Kubeadm(通常是 Kubernetes)在多个平台上工作。你可以使用 Weave 将 Kubernetes 部署到 ARM,就像在任何 AMD64 设备上一样安装 Docker、kubeadm、kubectl 和 kubelet。然后初始化控制面板组件运行的主机:
|
||||
|
||||
@ -52,7 +46,7 @@ kubeadm init
|
||||
kubectl apply -f https://git.io/weave-kube
|
||||
```
|
||||
|
||||
在此之前在 ARM 上,你只可以用 Flannel 安装一个 pod 网络,但是在 Weave Net 1.9 中已经改变了,它官方支持了 ARM。
|
||||
在此之前在 ARM 上,你只能用 Flannel 安装 pod 网络,但是在 Weave Net 1.9 中已经改变了,它官方支持了 ARM。
|
||||
|
||||
最后,加入你的节点:
|
||||
|
||||
@ -84,7 +78,7 @@ Lucas Käldström - 谢谢你发现我!我是一名来自芬兰的说瑞典语
|
||||
|
||||
via: https://opensource.com/article/17/3/kubernetes-raspberry-pi
|
||||
|
||||
作者:[ Lucas Käldström][a]
|
||||
作者:[Lucas Käldström][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
wyangsun translating
|
||||
|
||||
Apache Spark @Scale: A 60 TB+ production use case
|
||||
===========
|
||||
|
||||
|
||||
@ -1,403 +0,0 @@
|
||||
ictlyh Translating
|
||||
GraphQL In Use: Building a Blogging Engine API with Golang and PostgreSQL
|
||||
============================================================
|
||||
|
||||
### Abstract
|
||||
|
||||
GraphQL appears hard to use in production: the graph interface is flexible in its modeling capabilities but is a poor match for relational storage, both in terms of implementation and performance.
|
||||
|
||||
In this document, we will design and write a simple blogging engine API, with the following specification:
|
||||
|
||||
* three types of resources (users, posts and comments) supporting a varied set of functionality (create a user, create a post, add a comment to a post, follow posts and comments from another user, etc.)
|
||||
* use PostgreSQL as the backing data store (chosen because it’s a popular relational DB)
|
||||
* write the API implementation in Golang (a popular language for writing APIs).
|
||||
|
||||
We will compare a simple GraphQL implementation with a pure REST alternative in terms of implementation complexity and efficiency for a common scenario: rendering a blog post page.
|
||||
|
||||
### Introduction
|
||||
|
||||
GraphQL is an IDL (Interface Definition Language), designers define data types and model information as a graph. Each vertex is an instance of a data type, while edges represent relationships between nodes. This approach is flexible and can accommodate any business domain. However, the problem is that the design process is more complex and traditional data stores don’t map well to the graph model. See _Appendix 1_ for more details on this topic.
|
||||
|
||||
GraphQL has been first proposed in 2014 by the Facebook Engineering Team. Although interesting and compelling in its advantages and features, it hasn’t seen mass adoption. Developers have to trade REST’s simplicity of design, familiarity and rich tooling for GraphQL’s flexibility of not being limited to just CRUD and network efficiency (it optimizes for round-trips to the server).
|
||||
|
||||
Most walkthroughs and tutorials on GraphQL avoid the problem of fetching data from the data store to resolve queries. That is, how to design a database using general-purpose, popular storage solutions (like relational databases) to support efficient data retrieval for a GraphQL API.
|
||||
|
||||
This document goes through building a blog engine GraphQL API. It is moderately complex in its functionality. It is scoped to a familiar business domain to facilitate comparisons with a REST based approach.
|
||||
|
||||
The structure of this document is the following:
|
||||
|
||||
* in the first part we will design a GraphQL schema and explain some of features of the language that are used.
|
||||
* next is the design of the PostgreSQL database in section two.
|
||||
* part three covers the Golang implementation of the GraphQL schema designed in part one.
|
||||
* in part four we compare the task of rendering a blog post page from the perspective of fetching the needed data from the backend.
|
||||
|
||||
### Related
|
||||
|
||||
* The excellent [GraphQL introduction document][1].
|
||||
* The complete and working code for this project is on [github.com/topliceanu/graphql-go-example][2].
|
||||
|
||||
### Modeling a blog engine in GraphQL
|
||||
|
||||
_Listing 1_ contains the entire schema for the blog engine API. It shows the data types of the vertices composing the graph. The relationships between vertices, ie. the edges, are modeled as attributes of a given type.
|
||||
|
||||
```
|
||||
type User {
|
||||
id: ID
|
||||
email: String!
|
||||
post(id: ID!): Post
|
||||
posts: [Post!]!
|
||||
follower(id: ID!): User
|
||||
followers: [User!]!
|
||||
followee(id: ID!): User
|
||||
followees: [User!]!
|
||||
}
|
||||
|
||||
type Post {
|
||||
id: ID
|
||||
user: User!
|
||||
title: String!
|
||||
body: String!
|
||||
comment(id: ID!): Comment
|
||||
comments: [Comment!]!
|
||||
}
|
||||
|
||||
type Comment {
|
||||
id: ID
|
||||
user: User!
|
||||
post: Post!
|
||||
title: String
|
||||
body: String!
|
||||
}
|
||||
|
||||
type Query {
|
||||
user(id: ID!): User
|
||||
}
|
||||
|
||||
type Mutation {
|
||||
createUser(email: String!): User
|
||||
removeUser(id: ID!): Boolean
|
||||
follow(follower: ID!, followee: ID!): Boolean
|
||||
unfollow(follower: ID!, followee: ID!): Boolean
|
||||
createPost(user: ID!, title: String!, body: String!): Post
|
||||
removePost(id: ID!): Boolean
|
||||
createComment(user: ID!, post: ID!, title: String!, body: String!): Comment
|
||||
removeComment(id: ID!): Boolean
|
||||
}
|
||||
```
|
||||
|
||||
_Listing 1_
|
||||
|
||||
The schema is written in the GraphQL DSL, which is used for defining custom data types, such as `User`, `Post` and `Comment`. A set of primitive data types is also provided by the language, such as `String`, `Boolean` and `ID` (which is an alias of `String` with the additional semantics of being the unique identifier of a vertex).
|
||||
|
||||
`Query` and `Mutation` are optional types recognized by the parser and used in querying the graph. Reading data from a GraphQL API is equivalent to traversing the graph. As such a starting vertex needs to be provided; this role is fulfilled by the `Query` type. In this case, all queries to the graph must start with a user specified by id `user(id:ID!)`. For writing data, the `Mutation` vertex type is defined. This exposes a set of operations, modeled as parameterized attributes which traverse (and return) the newly created vertex types. See _Listing 2_ for examples of how these queries might look.
|
||||
|
||||
Vertex attributes can be parameterized, ie. accept arguments. In the context of graph traversal, if a post vertex has multiple comment vertices, you can traverse just one of them by specifying `comment(id: ID)`. All this is by design, the designer can choose not to provide direct paths to individual vertices.
|
||||
|
||||
The `!` character is a type post-fix, works for both primitive or user-defined types and has two semantics:
|
||||
|
||||
* when used for the type of a param in a parametriezed attribute, it means that the param is required.
|
||||
* when used for the return type of an attribute it means that the attribute will not be null when the vertex is retrieved.
|
||||
* combinations are possible, for instance `[Comment!]!` represents a list of non-null Comment vertices, where `[]`, `[Comment]` are valid, but `null, [null], [Comment, null]` are not.
|
||||
|
||||
_Listing 2_ contains a list of _curl_ commands against the blogging API which will populate the graph using mutations and then query it to retrieve data. To run them, follow the instructions in the [topliceanu/graphql-go-example][3] repo to build and run the service.
|
||||
|
||||
```
|
||||
# Mutations to create users 1,2 and 3\. Mutations also work as queries, in these cases we retrieve the ids and emails of the newly created users.
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user1@x.co"){id, email}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user2@x.co"){id, email}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user3@x.co"){id, email}}'
|
||||
# Mutations to add posts for the users. We retrieve their ids to comply with the schema, otherwise we will get an error.
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:1,title:"post1",body:"body1"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:1,title:"post2",body:"body2"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:2,title:"post3",body:"body3"){id}}'
|
||||
# Mutations to all comments to posts. `createComment` expects the user's ID, a title and a body. See the schema in Listing 1.
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:2,post:1,title:"comment1",body:"comment1"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:1,post:3,title:"comment2",body:"comment2"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:3,post:3,title:"comment3",body:"comment3"){id}}'
|
||||
# Mutations to have the user3 follow users 1 and 2\. Note that the `follow` mutation only returns a boolean which doesn't need to be specified.
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {follow(follower:3, followee:1)}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {follow(follower:3, followee:2)}'
|
||||
|
||||
# Query to fetch all data for user 1
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1)}'
|
||||
# Queries to fetch the followers of user2 and, respectively, user1.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:2){followers{id, email}}}'
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){followers{id, email}}}'
|
||||
# Query to check if user2 is being followed by user1\. If so retrieve user1's email, otherwise return null.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:2){follower(id:1){email}}}'
|
||||
# Query to return ids and emails for all the users being followed by user3.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:3){followees{id, email}}}'
|
||||
# Query to retrieve the email of user3 if it is being followed by user1.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){followee(id:3){email}}}'
|
||||
# Query to fetch user1's post2 and retrieve the title and body. If post2 was not created by user1, null will be returned.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){post(id:2){title,body}}}'
|
||||
# Query to retrieve all data about all the posts of user1.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){posts{id,title,body}}}'
|
||||
# Query to retrieve the user who wrote post2, if post2 was written by user1; a contrived example that displays the flexibility of the language.
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){post(id:2){user{id,email}}}}'
|
||||
```
|
||||
|
||||
_Listing 2_
|
||||
|
||||
By carefully desiging the mutations and type attributes, powerful and expressive queries are possible.
|
||||
|
||||
### Designing the PostgreSQL database
|
||||
|
||||
The relational database design is, as usual, driven by the need to avoid data duplication. This approach was chosen for two reasons: 1\. to show that there is no need for a specialized database technology or to learn and use new design techniques to accommodate a GraphQL API. 2\. to show that a GraphQL API can still be created on top of existing databases, more specifically databases originally designed to power REST endpoints or even traditional server-side rendered HTML websites.
|
||||
|
||||
See _Appendix 1_ for a discussion on differences between relational and graph databases with respect to building a GraphQL API. _Listing 3_ shows the SQL commands to create the new database. The database schema generally matches the GraphQL schema. The `followers` relation needed to be added to support the `follow/unfollow` mutations.
|
||||
|
||||
```
|
||||
CREATE TABLE IF NOT EXISTS users (
|
||||
id SERIAL PRIMARY KEY,
|
||||
email VARCHAR(100) NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS posts (
|
||||
id SERIAL PRIMARY KEY,
|
||||
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
title VARCHAR(200) NOT NULL,
|
||||
body TEXT NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS comments (
|
||||
id SERIAL PRIMARY KEY,
|
||||
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE,
|
||||
title VARCHAR(200) NOT NULL,
|
||||
body TEXT NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS followers (
|
||||
follower_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
followee_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
PRIMARY KEY(follower_id, followee_id)
|
||||
);
|
||||
```
|
||||
|
||||
_Listing 3_
|
||||
|
||||
### Golang API Implementation
|
||||
|
||||
The GraphQL parser implemented in Go and used in this project is `github.com/graphql-go/graphql`. It contains a query parser, but no schema parser. This requires the programmer to build the GraphQL schema in Go using the constructs offered by the library. This is unlike the reference [nodejs implementation][4], which offers a schema parser and exposes hooks for data fetching. As such the schema in `Listing 1` is only useful as a guideline and has to be translated into Golang code. However, this _“limitation”_ offers the opportunity to peer behind the levels of abstraction and see how the schema relates to the graph traversal model for retrieving data. _Listing 4_ shows the implementation of the `Comment` vertex type:
|
||||
|
||||
```
|
||||
var CommentType = graphql.NewObject(graphql.ObjectConfig{
|
||||
Name: "Comment",
|
||||
Fields: graphql.Fields{
|
||||
"id": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.ID, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
"title": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.String),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.Title, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
"body": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.Body, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
},
|
||||
})
|
||||
func init() {
|
||||
CommentType.AddFieldConfig("user", &graphql.Field{
|
||||
Type: UserType,
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return GetUserByID(comment.UserID)
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
})
|
||||
CommentType.AddFieldConfig("post", &graphql.Field{
|
||||
Type: PostType,
|
||||
Args: graphql.FieldConfigArgument{
|
||||
"id": &graphql.ArgumentConfig{
|
||||
Description: "Post ID",
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
},
|
||||
},
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
i := p.Args["id"].(string)
|
||||
id, err := strconv.Atoi(i)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return GetPostByID(id)
|
||||
},
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
_Listing 4_
|
||||
|
||||
Just like in the schema in _Listing 1_, the `Comment` type is a structure with three attributes defined statically; `id`, `title` and `body`. Two other attributes `user` and `post` are defined dynamically to avoid circular dependencies.
|
||||
|
||||
Go does not lend itself well to this kind of dynamic modeling, there is little type-checking support, most of the variables in the code are of type `interface{}` and need to be type asserted before use. `CommentType` itself is a variable of type `graphql.Object` and its attributes are of type `graphql.Field`. So, there’s no direct translation between the GraphQL DSL and the data structures used in Go.
|
||||
|
||||
The `resolve` function for each field exposes the `Source` parameter which is a data type vertex representing the previous node in the traversal. All the attributes of a `Comment` have, as source, the current `CommentType` vertex. Retrieving the `id`, `title` and `body` is a straightforward attribute access, while retrieving the `user` and the `post` requires graph traversals, and thus database queries. The SQL queries are left out of this document because of their simplicity, but they are available in the github repository listed in the _References_ section.
|
||||
|
||||
### Comparison with REST in common scenarios
|
||||
|
||||
In this section we will present a common blog page rendering scenario and compare the REST and the GraphQL implementations. The focus will be on the number of inbound/outbound requests, because these are the biggest contributors to the latency of rendering the page.
|
||||
|
||||
The scenario: render a blog post page. It should contain information about the author (email), about the blog post (title, body), all comments (title, body) and whether the user that made the comment follows the author of the blog post or not. _Figure 1_ and _Figure 2_ show the interaction between the client SPA, the API server and the database, for a REST API and, respectively, for a GraphQL API.
|
||||
|
||||
```
|
||||
+------+ +------+ +--------+
|
||||
|client| |server| |database|
|
||||
+--+---+ +--+---+ +----+---+
|
||||
| GET /blogs/:id | |
|
||||
1\. +-------------------------> SELECT * FROM blogs... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /users/:id | |
|
||||
2\. +-------------------------> SELECT * FROM users... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /blogs/:id/comments | |
|
||||
3\. +-------------------------> SELECT * FROM comments... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /users/:id/followers| |
|
||||
4\. +-------------------------> SELECT * FROM followers.. |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
+ + +
|
||||
```
|
||||
|
||||
_Figure 1_
|
||||
|
||||
```
|
||||
+------+ +------+ +--------+
|
||||
|client| |server| |database|
|
||||
+--+---+ +--+---+ +----+---+
|
||||
| GET /graphql | |
|
||||
1\. +-------------------------> SELECT * FROM blogs... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
2\. | | SELECT * FROM users... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
3\. | | SELECT * FROM comments... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
4\. | | SELECT * FROM followers.. |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
+ + +
|
||||
```
|
||||
|
||||
_Figure 2_
|
||||
|
||||
_Listing 5_ contains the single GraphQL query which will fetch all the data needed to render the blog post.
|
||||
|
||||
```
|
||||
{
|
||||
user(id: 1) {
|
||||
email
|
||||
followers
|
||||
post(id: 1) {
|
||||
title
|
||||
body
|
||||
comments {
|
||||
id
|
||||
title
|
||||
user {
|
||||
id
|
||||
email
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
_Listing 5_
|
||||
|
||||
The number of queries to the database for this scenario is deliberately identical, but the number of HTTP requests to the API server has been reduced to just one. We argue that the HTTP requests over the Internet are the most costly in this type of application.
|
||||
|
||||
The backend doesn’t have to be designed differently to start reaping the benefits of GraphQL, transitioning from REST to GraphQL can be done incrementally. This allows to measure performance improvements and optimize. From this point, the API developer can start to optimize (potentially merge) SQL queries to improve performance. The opportunity for caching is greatly increased, both on the database and API levels.
|
||||
|
||||
Abstractions on top of SQL (for instance ORM layers) usually have to contend with the `n+1` problem. In step `4.` of the REST example, a client could have had to request the follower status for the author of each comment in separate requests. This is because in REST there is no standard way of expressing relationships between more than two resources, whereas GraphQL was designed to prevent this problem by using nested queries. Here, we cheat by fetching all the followers of the user. We defer to the client the logic of determining the users who commented and also followed the author.
|
||||
|
||||
Another difference is fetching more data than the client needs, in order to not break the REST resource abstractions. This is important for bandwidth consumption and battery life spent parsing and storing unneeded data.
|
||||
|
||||
### Conclusions
|
||||
|
||||
GraphQL is a viable alternative to REST because:
|
||||
|
||||
* while it is more difficult to design the API, the process can be done incrementally. Also for this reason, it’s easy to transition from REST to GraphQL, the two paradigms can coexist without issues.
|
||||
* it is more efficient in terms of network requests, even with naive implementations like the one in this document. It also offers more opportunities for query optimization and result caching.
|
||||
* it is more efficient in terms of bandwidth consumption and CPU cycles spent parsing results, because it only returns what is needed to render the page.
|
||||
|
||||
REST remains very useful if:
|
||||
|
||||
* your API is simple, either has a low number of resources or simple relationships between them.
|
||||
* you already work with REST APIs inside your organization and you have the tooling all set up or your clients expect REST APIs from your organization.
|
||||
* you have complex ACL policies. In the blog example, a potential feature could allow users fine-grained control over who can see their email, their posts, their comments on a particular post, whom they follow etc. Optimizing data retrieval while checking complex business rules can be more difficult.
|
||||
|
||||
### Appendix 1: Graph Databases And Efficient Data Storage
|
||||
|
||||
While it is intuitive to think about application domain data as a graph, as this document demonstrates, the question of efficient data storage to support such an interface is still open.
|
||||
|
||||
In recent years graph databases have become more popular. Deferring the complexity of resolving the request by translating the GraphQL query into a specific graph database query language seems like a viable solution.
|
||||
|
||||
The problem is that graphs are not an efficient data structure compared to relational databases. A vertex can have links to any other vertex in the graph and access patterns are less predictable and thus offer less opportunity for optimization.
|
||||
|
||||
For instance, the problem of caching, ie. which vertices need to be kept in memory for fast access? Generic caching algorithms may not be very efficient in the context of graph traversal.
|
||||
|
||||
The problem of database sharding: splitting the database into smaller, non-interacting databases, living on separate hardware. In academia, the problem of splitting a graph on the minimal cut is well understood but it is suboptimal and may potentially result in highly unbalanced cuts due to pathological worst-case scenarios.
|
||||
|
||||
With relational databases, data is modeled in records (or rows, or tuples) and columns, tables and database names are simply namespaces. Most databases are row-oriented, which means that each record is a contiguous chunk of memory, all records in a table are neatly packed one after the other on the disk (usually sorted by some key column). This is efficient because it is optimal for the way physical storage works. The most expensive operation for an HDD is to move the read/write head to another sector on the disk, so minimizing these accesses is critical.
|
||||
|
||||
There is also a high probability that, if the application is interested in a particular record, it will need the whole record, not just a single key from it. There is a high probabilty that if the application is interested in a record, it will be interested in its neighbours as well, for instance a table scan. These two observations make relational databases quite efficient. However, for this reason also, the worst use-case scenario for a relational database is random access across all data all the time. This is exactly what graph databases do.
|
||||
|
||||
With the advent of SSD drives which have faster random access, cheap RAM memory which makes caching large portions of a graph database possible, better techniques to optimize graph caching and partitioning, graph databases have become a viable storage solution. And most large companies use it: Facebook has the Social Graph, Google has the Knowledge Graph.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://alexandrutopliceanu.ro/post/graphql-with-go-and-postgresql
|
||||
|
||||
作者:[Alexandru Topliceanu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/topliceanu
|
||||
[1]:http://graphql.org/learn/
|
||||
[2]:https://github.com/topliceanu/graphql-go-example
|
||||
[3]:https://github.com/topliceanu/graphql-go-example
|
||||
[4]:https://github.com/graphql/graphql-js
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh translating
|
||||
Our guide to a Golang logs world
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
being translated by zhousiyu325
|
||||
|
||||
How to control GPIO pins and operate relays with the Raspberry Pi
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,132 +0,0 @@
|
||||
Containers running Containers
|
||||
============================================================
|
||||
|
||||
Some genuinely exciting news piqued my interest at this year’s DockerCon, that being the new Operating System (OS), LinuxKit, which was announced and is immediately on offer from the undisputed heavyweight container company, Docker.
|
||||
|
||||
The container giant has announced a flexible, extensible Operating System where system services run inside containers for portability. You might be surprised to hear that even includes the Docker runtime daemon itself.
|
||||
|
||||
In this article we’ll have a quick look at what’s promised in LinuxKit, how to try it out for yourself and at ever-shrinking, optimised containers.
|
||||
|
||||
**Less Is More**
|
||||
|
||||
There’s no denying that users have been looking for a stripped-down version of Linux to run their microservices upon. With containerisation you’re trying your hardest to minimise each application so that it becomes a standalone process which sits inside a container of its own. However constantly shifting containers around because you’re patching the host that the containers reside on causes issues. In fact without an orchestrator like Kubernetes or Docker Swarm that container-shuffling is almost always going to cause downtime.
|
||||
|
||||
Needless to say that’s just one reason to keep your OS as miniscule as possible; one of many.
|
||||
|
||||
A favourite quote I’ve repeated on a number of occasions, comes from the talented Dutch programmer, Wietse Zweitze, who brought us the e-mail stalwart Postfix and TCP Wrappers amongst other renowned software.
|
||||
|
||||
The Postfix website ([Postfix TLS_README][10]) states that even if you’re as careful with your coding as Wietse that for “every 1000 lines [you] introduce one additional bug into Postfix.” From my professional DevSecOps perspective by the mention of “bug” I might be forgiven for loosely translating that definition into security issues too.
|
||||
|
||||
From a security perspective it’s precisely for this reason that less-is-more in the world of code. Simply put there’s a number of benefits to using less lines of code; namely security, administration time and performance. For starters there’s less security bugs, less time updating packages and faster boot times.
|
||||
|
||||
**Look deeper inside**
|
||||
|
||||
Think about what runs your application from inside a container.
|
||||
|
||||
A good starting point is Alpine Linux ([https://alpinelinux.org/downloads][1]) which is a low-fat, boiled-down, reduced OS commonly preferred over the more bloated host favourites, such as Ubuntu or CentOS. Alpine also provides a miniroot filesystem (for use within containers) which comes in at a staggering 1.8MB at the last check. Indeed the ISO download for a fully-working Linux Operating System comes in at a remarkable 80MB in size.
|
||||
|
||||
If you decide to utilise a Docker base image from Alpine Linux then you can find one on the Docker Hub ([https://hub.docker.com/_/alpine][2]) where Alpine Linux describes itself as: “A minimal Docker image based on Alpine Linux with a complete package index and only 5 MB in size!”.
|
||||
|
||||
It’s been said, and I won’t attempt to verify this meme, that the ubiquitous Window Start Button is around the same filesize! I’ll refrain from commenting further.
|
||||
|
||||
In all seriousness hopefully that gives you an idea of the power of innovative Unix-type OSs like Alpine Linux.
|
||||
|
||||
**Lock everything up**
|
||||
|
||||
What’s more, it goes on to explain that Alpine Linux is (not surprisingly) based on BusyBox ([BusyBox][3]), the famous set of Linux commands neatly packaged which many people won’t be aware sits inside their broadband router, smart television and of course many IoT devices in their homes as they read this.
|
||||
|
||||
Comments on the the About page ([Alpine Linux][4]) of the Alpine Linux site states:
|
||||
|
||||
“Alpine Linux was designed with security in mind. The kernel is patched with an unofficial port of grsecurity/PaX, and all userland binaries are compiled as Position Independent Executables (PIE) with stack smashing protection. These proactive security features prevent exploitation of entire classes of zero-day and other vulnerabilities.”
|
||||
|
||||
In other words the boiled-down binaries bundled inside the Alpine Linux builds which offers the system its functionality have already been sieved through clever industry-standard security tools in order to help mitigate buffer overflow attacks.
|
||||
|
||||
**Odd socks**
|
||||
|
||||
Why do the innards of containers matter when we’re dealing with Docker’s new OS you may quite rightly ask?
|
||||
|
||||
Well, as you might have guessed, when it comes to containers their construction is all about losing bloat. It’s about not including anything unless it’s absolutely necessary. It’s about having confidence so that you can reap the rewards of decluttering your cupboards, garden shed, garage and sock drawer with total impunity.
|
||||
|
||||
Docker certainly deserve some credit for their foresight. Reportedly, early 2016 Docker hired a key driving force behind Alpine Linux, Nathaniel Copa, who helped switch the default, official image library away from Ubuntu to Alpine. The bandwidth that Docker Hub saved from the newly-streamlined image downloads alone must have been welcomed.
|
||||
|
||||
And, bringing us up-to-date, that work will stand arm-in-arm with the latest container-based OS work; Docker’s LinuxKit.
|
||||
|
||||
For clarity LinuxKit is not ever-likely destined to replace Alpine but rather to sit underneath the containers and act as a stripped-down OS that you can happily spin up your runtime daemon (in this case the Docker daemon which spawns your containers) upon.
|
||||
|
||||
**Blondie's Atomic**
|
||||
|
||||
A finely-tuned host is by no means a new thing (I mentioned the household devices embedded with Linux previously) and the evil geniuses who have been optimising Linux for the last couple of decades realised sometime ago that the underlying OS was key to churning out a server estate fulls of hosts brimming with containers.
|
||||
|
||||
For example the mighty Red Hat have long been touting Red Hat Atomic ([https://www.redhat.com/en/resources/red-hat-enterprise-linux-atomic-host][5]) having contributed to Project Atomic ([Project Atomic][6]). The latter goes on to explain:
|
||||
|
||||
“Based on proven technology either from Red Hat Enterprise Linux or the CentOS and Fedora projects, Atomic Host is a lightweight, immutable platform, designed with the sole purpose of running containerized applications.”
|
||||
|
||||
There’s good reason that the underlying, immutable Atomic OS is forwarded as the recommended choice with Red Hat’s OpenShift PaaS (Platform as a Service) product. It’s minimal, performant and sophisticated.
|
||||
|
||||
**Features**
|
||||
|
||||
The mantra that less-is-more was evident throughout Docker’s announcement regarding LinuxKit. The project to realise the vision of LinuxKit was apparently no small undertaking and with the guiding hand of expert Justin Cormack, a Docker veteran and master with unikernels ([https://en.wikipedia.org/wiki/Unikernel][7]), and in partnership with HPE, Intel, ARM, IBM and Microsoft LinuxKit can run on mainframes as well as IoT-based fridge freezers.
|
||||
|
||||
The configurable, pluggable and extensible nature of LinuxKit will appeal to many projects looking for a baseline upon which to build their services. By open-sourcing the project Docker are wisely inviting input from every man and their dog to contribute to its functionality which will mature like a good cheese undoubtedly over time.
|
||||
|
||||
**Proof of the pudding**
|
||||
|
||||
Having promised to point those eager to get going with this new OS, let us wait no longer. If you want to get your hands on LinuxKit you can do so from the GitHub page here: [LinuxKit][11]
|
||||
|
||||
On the GitHub page there’s instructions on how to get up and running along with some features.
|
||||
|
||||
Time permitting I plan to get my hands much dirtier with LinuxKit. The somewhat-contentious Kubernetes versus Docker Swarm orchestration capabilities will be interesting to try out. I’d like to see memory footprints, boot times and diskspace-usage benchmarking too.
|
||||
|
||||
If the promises are true then pluggable system services which run as containers is a fascinating way to build an OS. Docker blogged ([https://blog.docker.com/2017/04/introducing-linuxkit-container-os-toolkit][12]) the following on its tiny footprint: “Because LinuxKit is container-native, it has a very minimal size – 35MB with a very minimal boot time. All system services are containers, which means that everything can be removed or replaced.”
|
||||
|
||||
I don’t know about you but that certainly whets my appetite.
|
||||
|
||||
**Call the cops**
|
||||
|
||||
Features aside with my DevSecOps hat on I will be in seeing how the promise of security looks in reality.
|
||||
|
||||
Docker quotes from NIST (the National Institute of Standards and Technology: [https://www.nist.gov][8]) and claims on their blog that:
|
||||
|
||||
“Security is a top-level objective and aligns with NIST stating, in their draft Application Container Security Guide: “Use container-specific OSes instead of general-purpose ones to reduce attack surfaces. When using a container-specific OS, attack surfaces are typically much smaller than they would be with a general-purpose OS, so there are fewer opportunities to attack and compromise a container-specific OS.”
|
||||
|
||||
Possibly the most important container-to-host and host-to-container security innovation will be the fact that system containers (system services) are apparently heavily sandboxed into their own unprivileged space, given just the external access that they need.
|
||||
|
||||
Couple that functionality with the collaboration of the Kernel Self Protection Project (KSPP) ([https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project][9]) and with a resounding thumbs-up from me it looks like Docker have focussed on something very worthwhile. For those unfamiliar KSPP’s raison d’etre is as follows:
|
||||
|
||||
“This project starts with the premise that kernel bugs have a very long lifetime, and that the kernel must be designed in ways to protect against these flaws.”
|
||||
|
||||
The KSPP site goes on to state admirably that:
|
||||
|
||||
“Those efforts are important and on-going, but if we want to protect our billion Android phones, our cars, the International Space Station, and everything else running Linux, we must get proactive defensive technologies built into the upstream Linux kernel. We need the kernel to fail safely, instead of just running safely.”
|
||||
|
||||
And, initially, if Docker only take baby steps with LinuxKit the benefit that it will bring over time through maturity will likely make great strides in the container space.
|
||||
|
||||
**The End is far from nigh**
|
||||
|
||||
As the powerhouse that is Docker continues to grow arms and legs there’s no doubt whatsoever that these giant-sized leaps in the direction of solid progress will benefit users and other software projects alike.
|
||||
|
||||
I would encourage all with an interest in Linux to closely watch this (name)space...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.devsecops.cc/devsecops/containers.html
|
||||
|
||||
作者:[Chris Binnie ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.devsecops.cc/
|
||||
[1]:https://alpinelinux.org/downloads/
|
||||
[2]:https://hub.docker.com/_/alpine
|
||||
[3]:https://busybox.net/
|
||||
[4]:https://www.alpinelinux.org/about/
|
||||
[5]:https://www.redhat.com/en/resources/red-hat-enterprise-linux-atomic-host
|
||||
[6]:http://www.projectatomic.io/
|
||||
[7]:https://en.wikipedia.org/wiki/Unikernel
|
||||
[8]:https://www.nist.gov/
|
||||
[9]:https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project
|
||||
[10]:http://www.postfix.org/TLS_README.html
|
||||
[11]:https://github.com/linuxkit/linuxkit
|
||||
[12]:https://blog.docker.com/2017/04/introducing-linuxkit-container-os-toolkit
|
||||
@ -1,153 +0,0 @@
|
||||
Installing Google TensorFlow Neural Network Software for CPU and GPU on Ubuntu 16.04
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [1 Install CUDA][1]
|
||||
2. [2 Install the CuDNN library][2]
|
||||
3. [3 Add the installation location to Bashrc file][3]
|
||||
4. [4 Install TensorFlow with GPU support][4]
|
||||
5. [5 Install TensorFlow with only CPU support][5]
|
||||
|
||||
TensorFlow is an open source software for performing machine learning tasks. Google, its creator wanted to expose a powerful tool to help developers explore and build machine learning based applications and so they released this as an open source project. TensorFlow is an extremely powerful tool specializing in a type of neural network called the deep neural network.
|
||||
|
||||
Deep neural networks are used to perform complex machine learning tasks such as image recognition, handwriting recognition, Natural language processing, chatbots, and more. These neural networks are trained to learn the tasks it is supposed to perform. As the computations required for training is extremely huge, most of the time, a GPU support is required and this is where TensorFlow comes to the rescue. It is GPU enabled and thus by installing the software with GPU support, the training time required can be significantly reduced.
|
||||
|
||||
This tutorial helps you to install TensorFlow for CPU only and also with GPU support. So, to get TensorFlow with GPU support, you must have a Nvidia GPU with CUDA support. Installation of CUDA and CuDNN ( Nvidia computation libraries) are a bit tricky and this guide provides a step by step approach to installing them before actually coming to the installation of TensorFlow itself.
|
||||
|
||||
The Nvidia CUDA is a GPU-accelerated library that has highly tuned implementations for standard routines used in neural networks. the CuDNN is a tuning library for the GPU which takes care of GPU performance tuning automatically. TensorFlow relies on both these for training and running deep neural networks and hence they have to be installed before TensorFlow is installed.
|
||||
|
||||
It is very important to note that, those who DO NOT wish to install TensorFlow with GPU support, then you can skip all these following steps and jump straight to "Step 5: Install TensorFlow with only CPU support" section of this guide.
|
||||
|
||||
An introduction to TensorFlow can be found [here][10].
|
||||
|
||||
### 1 Install CUDA
|
||||
|
||||
Firstly, download CUDA for Ubuntu 16.04 from [here.][11] This file is pretty big (2GB) so, it might take sometime to get downloaded.
|
||||
|
||||
The downloaded file is ".deb" package. To install it, run the following commands:
|
||||
|
||||
sudo dpkg -i cuda-repo-ubuntu1604-8-0-local_8.0.44-1_amd64.deb
|
||||
|
||||
[
|
||||
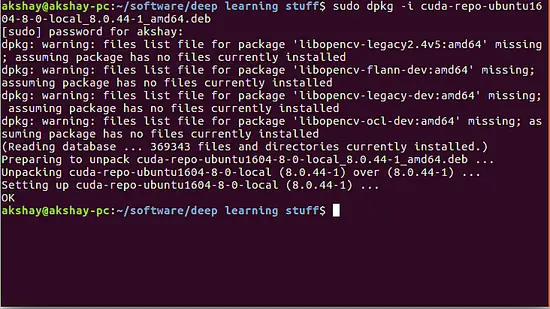
|
||||
][12]
|
||||
|
||||
the following commands install any dependencies that have been missed and finally install the cuda toolkit:
|
||||
|
||||
sudo apt install -f
|
||||
|
||||
sudo apt update
|
||||
|
||||
sudo apt install cuda
|
||||
|
||||
If it successfully installed, you will get a message saying it's "successfully installed". If it's already installed, then you will get output similar to the image below:
|
||||
|
||||
[
|
||||
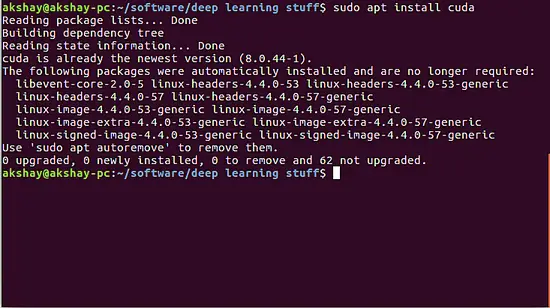
|
||||
][13]
|
||||
|
||||
### 2 Install the CuDNN library
|
||||
|
||||
CuDNN downloading requires a bit of work sadly. Nvidia does not directly give you the files to download (It's free however). Follow the steps to get your CuDNN files.
|
||||
|
||||
1. click [here][8] to goto Nvidia's register page and create an account. First page asks you to enter your personal details and the second page asks you to answer a few survey questions. It's alright if you do not know answers to all, you can just select an option at random.
|
||||
2. The previous step would have lead to Nvidia sending you an activation link to your mail-Id. Once you have activated, head over to the CuDNN download link [here][9].
|
||||
3. Once you login to that page, you will have to fill out another smaller survey. Randomly click on the checkboxes and then click on "proceed to Download" button at the bottom of the survey and in the next page click on agree to terms of use.
|
||||
4. Finally, in the drop down, click on "Download cuDNN v5.1 (Jan 20, 2017), for CUDA 8.0", and within that drop down, you need to download two files by clicking on it:
|
||||
* [cuDNN v5.1 Runtime Library for Ubuntu14.04 (Deb)][6]
|
||||
* [cuDNN v5.1 Developer Library for Ubuntu14.04 (Deb)][7]
|
||||
|
||||
NOTE: even though the library says it's for Ubuntu 14.04, use that link only. it works for 16.04 as well
|
||||
|
||||
Now that you finally have both the CuDNN files, it's time to install them!! Use the following commands from the folder which contains this downloaded files:
|
||||
|
||||
sudo dpkg -i libcudnn5_5.1.5-1+cuda8.0_amd64.deb
|
||||
|
||||
sudo dpkg -i libcudnn5-dev_5.1.5-1+cuda8.0_amd64.deb
|
||||
|
||||
Following image shows the output of running these commands:
|
||||
|
||||
[
|
||||
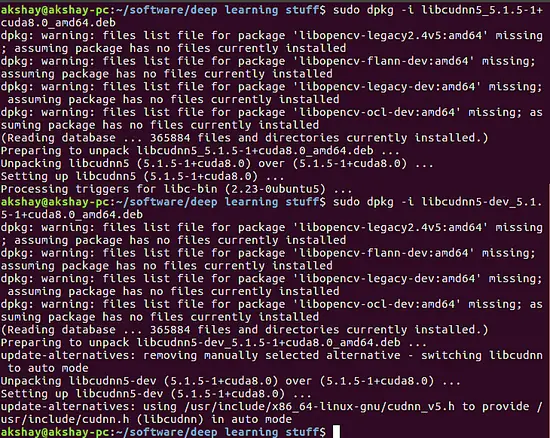
|
||||
][14]
|
||||
|
||||
### 3 Add the installation location to Bashrc file
|
||||
|
||||
the installation location should be added to the bashrc file so that from the next time onward, the system should know where to find the installed directory for CUDA. use the following command to open the bashrc file:
|
||||
|
||||
sudo gedit ~/.bashrc
|
||||
|
||||
once the file opens, add the following two lines at the end of that file:
|
||||
|
||||
```
|
||||
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
|
||||
export CUDA_HOME=/usr/local/cuda
|
||||
```
|
||||
|
||||
### 4 Install TensorFlow with GPU support
|
||||
|
||||
this step we install TensorFlow with GPU support. Run the following command if you are using python 2.7:
|
||||
|
||||
pip install TensorFlow-gpu
|
||||
|
||||
if you have python 3.x instead of the above command, use the following:
|
||||
|
||||
pip3 install TensorFlow-gpu
|
||||
|
||||
You will get a "successfully installed" message once the command finishes execution. Now, all that remains to test is whether it has installed correctly. To test this, open a command prompt and type the following commands:
|
||||
|
||||
python
|
||||
|
||||
import TensorFlow as tf
|
||||
|
||||
You should get an output similar to the image below. From the image you can observe that the CUDA libraries have been successfully opened. Now, if there were errors, messages saying failure to open CUDA and even modules not being found will appear. In that case you might have missed one of the step above and re-doing this tutorial carefully will be the way to go.
|
||||
|
||||
[
|
||||
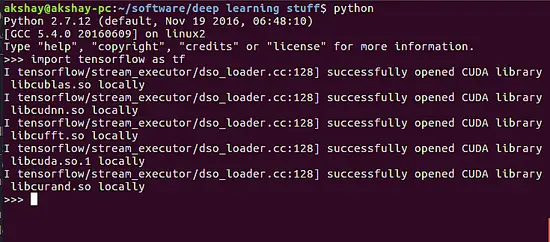
|
||||
][15]
|
||||
|
||||
### 5 Install TensorFlow with only CPU support
|
||||
|
||||
NOTE : This step has to be executed by people who do not have a GPU or people who do not have a Nvidia GPU. Others, please ignore this step!!
|
||||
|
||||
installing TensorFlow for CPU only is extremely easy. Use the following two commands :
|
||||
|
||||
pip install TensorFlow
|
||||
|
||||
if you have python 3.x instead of the above command, use the following:
|
||||
|
||||
pip3 install TensorFlow
|
||||
|
||||
Yes, it's that simple!
|
||||
|
||||
This concludes, the installation guide, you can now start to build your deep learning applications. If you are just starting out, then you can look at the official tutorial for beginners [here][16]. If you are looking for more advanced tutorials, then you can learn how to setup an image recognition system/tool which capable of identifying thousands of objects with high accuracy from [here][17].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
|
||||
作者:[Akshay Pai ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
[1]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-install-cuda
|
||||
[2]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-install-the-cudnn-library
|
||||
[3]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-add-the-installation-location-to-bashrc-file
|
||||
[4]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-install-tensorflow-with-gpu-support
|
||||
[5]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-install-tensorflow-with-only-cpu-support
|
||||
[6]:https://developer.nvidia.com/compute/machine-learning/cudnn/secure/v5.1/prod_20161129/8.0/libcudnn5_5.1.10-1+cuda8.0_amd64-deb
|
||||
[7]:https://developer.nvidia.com/compute/machine-learning/cudnn/secure/v5.1/prod_20161129/8.0/libcudnn5-dev_5.1.10-1+cuda8.0_amd64-deb
|
||||
[8]:https://developer.nvidia.com/group/node/873374/subscribe/og_user_node
|
||||
[9]:https://developer.nvidia.com/rdp/form/cudnn-download-survey
|
||||
[10]:http://sourcedexter.com/what-is-tensorflow/
|
||||
[11]:https://developer.nvidia.com/compute/cuda/8.0/Prod2/local_installers/cuda-repo-ubuntu1604-8-0-local-ga2_8.0.61-1_amd64-deb
|
||||
[12]:https://www.howtoforge.com/images/installing_tensorflow_machine_learning_software_for_cpu_and_gpu_on_ubuntu_1604/big/image1.png
|
||||
[13]:https://www.howtoforge.com/images/installing_tensorflow_machine_learning_software_for_cpu_and_gpu_on_ubuntu_1604/big/image2.png
|
||||
[14]:https://www.howtoforge.com/images/installing_tensorflow_machine_learning_software_for_cpu_and_gpu_on_ubuntu_1604/big/image3.png
|
||||
[15]:https://www.howtoforge.com/images/installing_tensorflow_machine_learning_software_for_cpu_and_gpu_on_ubuntu_1604/big/image4.png
|
||||
[16]:https://www.tensorflow.org/get_started/mnist/beginners
|
||||
[17]:https://www.tensorflow.org/tutorials/image_recognition
|
||||
@ -0,0 +1,402 @@
|
||||
GraphQL 用例:使用 Golang 和 PostgreSQL 构建一个博客引擎 API
|
||||
============================================================
|
||||
|
||||
### 摘要
|
||||
|
||||
GraphQL 在生产环境中似乎难以使用:虽然对于建模功能来说图接口非常灵活,但是并不适用于关系型存储,不管是在实现还是性能方面。
|
||||
|
||||
在这篇博客中,我们会设计并实现一个简单的博客引擎 API,它支持以下功能:
|
||||
|
||||
* 三种类型的资源(用户、博文以及评论)支持多种功能(创建用户、创建博文、给博文添加评论、关注其它用户的博文和评论,等等。)
|
||||
* 使用 PostgreSQL 作为后端数据存储(选择它因为它是一个流行的关系型数据库)。
|
||||
* 使用 Golang(开发 API 的一个流行语言)进行 API 实现。
|
||||
|
||||
我们会比较简单的 GraphQL 实现和纯 REST 替代方案,在一种普通场景(呈现博客文章页面)下对比它们的实现复杂性和效率。
|
||||
|
||||
### 介绍
|
||||
|
||||
GraphQL 是一种 IDL(Interface Definition Language,接口定义语言),设计者定义数据类型和并把数据建模为一个图。每个顶点都是一种数据类型的一个实例,边代表了节点之间的关系。这种方式非常灵活,能适应任何业务领域。然而,问题是设计过程更加复杂,而且传统的数据存储不能很好地映射到图模型。阅读_附录1_了解更多关于这个问题的详细信息。
|
||||
|
||||
GraphQL 在 2014 年由 Facebook 的工程师团队首次提出。尽管它的优点和功能非常有趣而且引人注目,它并没有得到大规模应用。开发者需要权衡 REST 的设计简单性、熟悉性、丰富的工具和 GraphQL 不会受限于 CRUD(LCTT 译注:Create、Read、Update、Delete) 以及网络性能(它优化了往返服务器的网络)的灵活性。
|
||||
|
||||
大部分关于 GraphQL 的教程和指南都跳过了从数据存储获取数据以便解决查询的问题。也就是,如何使用通用目的、流行存储方案(例如关系型数据库)为 GraphQL API 设计一个支持高效数据提取的数据库。
|
||||
|
||||
这篇博客介绍构建一个博客引擎 GraphQL API 的流程。它的功能相当复杂。为了和基于 REST 的方法进行比较,它的范围被限制为一个熟悉的业务领域。
|
||||
|
||||
这篇博客的文章结构如下:
|
||||
|
||||
* 第一部分我们会设计一个 GraphQL 模式并介绍所使用语言的一些功能。
|
||||
* 第二部分是 PostgreSQL 数据库的设计。
|
||||
* 第三部分介绍了使用 Golang 实现第一部分设计的 GraphQL 模式。
|
||||
* 第四部分我们以从后端获取所需数据的角度来比较呈现博客文章页面的任务。
|
||||
|
||||
### 相关阅读
|
||||
|
||||
* 很棒的 [GraphQL 介绍文档][1]。
|
||||
* 该项目的完整实现代码在 [github.com/topliceanu/graphql-go-example][2]。
|
||||
|
||||
### 在 GraphQL 中建模一个博客引擎
|
||||
|
||||
_列表1_包括了博客引擎 API 的全部模式。它显示了组成图的顶点的数据类型。顶点之间的关系,也就是边,被建模为指定类型的属性。
|
||||
|
||||
```
|
||||
type User {
|
||||
id: ID
|
||||
email: String!
|
||||
post(id: ID!): Post
|
||||
posts: [Post!]!
|
||||
follower(id: ID!): User
|
||||
followers: [User!]!
|
||||
followee(id: ID!): User
|
||||
followees: [User!]!
|
||||
}
|
||||
|
||||
type Post {
|
||||
id: ID
|
||||
user: User!
|
||||
title: String!
|
||||
body: String!
|
||||
comment(id: ID!): Comment
|
||||
comments: [Comment!]!
|
||||
}
|
||||
|
||||
type Comment {
|
||||
id: ID
|
||||
user: User!
|
||||
post: Post!
|
||||
title: String
|
||||
body: String!
|
||||
}
|
||||
|
||||
type Query {
|
||||
user(id: ID!): User
|
||||
}
|
||||
|
||||
type Mutation {
|
||||
createUser(email: String!): User
|
||||
removeUser(id: ID!): Boolean
|
||||
follow(follower: ID!, followee: ID!): Boolean
|
||||
unfollow(follower: ID!, followee: ID!): Boolean
|
||||
createPost(user: ID!, title: String!, body: String!): Post
|
||||
removePost(id: ID!): Boolean
|
||||
createComment(user: ID!, post: ID!, title: String!, body: String!): Comment
|
||||
removeComment(id: ID!): Boolean
|
||||
}
|
||||
```
|
||||
|
||||
_列表1_
|
||||
|
||||
模式使用 GraphQL DSL 编写,它用于定义自定义数据类型,例如 `User`、`Post` 和 `Comment`。该语言也提供了一系列原始数据类型,例如 `String`、`Boolean` 和 `ID`(是`String` 的别名,但是有顶点唯一标识符的额外语义)。
|
||||
|
||||
`Query` 和 `Mutation` 是语法解析器能识别并用于查询图的可选类型。从 GraphQL API 读取数据等同于遍历图。需要提供这样一个起始顶点;该角色通过 `Query` 类型来实现。在这种情况中,所有图的查询都要从一个由 id `user(id:ID!)` 指定的用户开始。对于写数据,定义了 `Mutation` 顶点。它提供了一系列操作,建模为能遍历(并返回)新创建顶点类型的参数化属性。_列表2_是这些查询的一些例子。
|
||||
|
||||
顶点属性能被参数化,也就是能接受参数。在图遍历场景中,如果一个博文顶点有多个评论顶点,你可以通过指定 `comment(id: ID)` 只遍历其中的一个。所有这些都取决于设计,设计者可以选择不提供到每个独立顶点的直接路径。
|
||||
|
||||
`!` 字符是一个类型后缀,适用于原始类型和用户定义类型,它有两种语义:
|
||||
|
||||
* 当被用于参数化属性的参数类型时,表示这个参数是必须的。
|
||||
* 当被用于一个属性的返回类型时,表示当顶点被获取时该属性不会为空。
|
||||
* 也可以把它们组合起来,例如 `[Comment!]!` 表示一个非空 Comment 顶点链表,其中 `[]`、`[Comment]` 是有效的,但 `null, [null], [Comment, null]` 就不是。
|
||||
|
||||
|
||||
_列表2_ 包括一系列用于博客 API 的 _curl_ 命令,它们会使用 mutation 填充图然后查询图以便获取数据。要运行它们,按照 [topliceanu/graphql-go-example][3] 仓库中的指令编译并运行服务。
|
||||
|
||||
```
|
||||
# 创建用户 1、2 和 3 的更改。更改和查询类似,在该情景中我们检索新创建用户的 id 和 email。
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user1@x.co"){id, email}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user2@x.co"){id, email}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createUser(email:"user3@x.co"){id, email}}'
|
||||
# 为用户添加博文的更改。为了和模式匹配我们需要检索他们的 id,否则会出现错误。
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:1,title:"post1",body:"body1"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:1,title:"post2",body:"body2"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createPost(user:2,title:"post3",body:"body3"){id}}'
|
||||
# 博文所有评论的更改。`createComment` 需要用户 id,标题和正文。看列表 1 的模式。
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:2,post:1,title:"comment1",body:"comment1"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:1,post:3,title:"comment2",body:"comment2"){id}}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {createComment(user:3,post:3,title:"comment3",body:"comment3"){id}}'
|
||||
# 让用户 3 关注用户 1 和用户 2 的更改。注意 `follow` 更改只返回一个布尔值而不需要指定。
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {follow(follower:3, followee:1)}'
|
||||
curl -XPOST http://vm:8080/graphql -d 'mutation {follow(follower:3, followee:2)}'
|
||||
|
||||
# 用户获取用户 1 所有数据的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1)}'
|
||||
# 用户获取用户 2 和用户 1 的关注者的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:2){followers{id, email}}}'
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){followers{id, email}}}'
|
||||
# 检测用户 2 是否被用户 1 关注的查询。如果是,检索用户 1 的 email,否则返回空。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:2){follower(id:1){email}}}'
|
||||
# 返回用户 3 关注的所有用户 id 和 email 的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:3){followees{id, email}}}'
|
||||
# 如果用户 3 被用户 1 关注,就获取用户 3 email 的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){followee(id:3){email}}}'
|
||||
# 获取用户 1 的第二篇博文的查询,检索它的标题和正文。如果博文 2 不是由用户 1 创建的,就会返回空。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){post(id:2){title,body}}}'
|
||||
# 获取用户 1 的所有博文的所有数据的查询。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){posts{id,title,body}}}'
|
||||
# 获取写博文 2 用户的查询,如果博文 2 是由 用户 1 撰写;一个现实语言灵活性的例证。
|
||||
curl -XPOST http://vm:8080/graphql -d '{user(id:1){post(id:2){user{id,email}}}}'
|
||||
```
|
||||
|
||||
_列表2_
|
||||
|
||||
通过仔细设计 mutation 和类型属性,可以实现强大而富有表达力的查询。
|
||||
|
||||
### 设计 PostgreSQL 数据库
|
||||
|
||||
关系型数据库的设计,一如以往,由避免数据冗余的需求驱动。选择该方式有两个原因:1\. 表明实现 GraphQL API 不需要定制化的数据库技术或者学习和使用新的设计技巧。2\. 表明 GraphQL API 能在现有的数据库之上创建,更具体地说,最初设计用于 REST 后端甚至传统的呈现 HTML 站点的服务器端数据库。
|
||||
|
||||
阅读 _附录1_ 了解关于关系型和图数据库在构建 GraphQL API 方面的区别。_列表3_ 显示了用于创建新数据库的 SQL 命令。数据库模式和 GraphQL 模式相对应。为了支持 `follow/unfollow` 更改,需要添加 `followers` 关系。
|
||||
|
||||
```
|
||||
CREATE TABLE IF NOT EXISTS users (
|
||||
id SERIAL PRIMARY KEY,
|
||||
email VARCHAR(100) NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS posts (
|
||||
id SERIAL PRIMARY KEY,
|
||||
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
title VARCHAR(200) NOT NULL,
|
||||
body TEXT NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS comments (
|
||||
id SERIAL PRIMARY KEY,
|
||||
user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
post_id INTEGER NOT NULL REFERENCES posts(id) ON DELETE CASCADE,
|
||||
title VARCHAR(200) NOT NULL,
|
||||
body TEXT NOT NULL
|
||||
);
|
||||
CREATE TABLE IF NOT EXISTS followers (
|
||||
follower_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
followee_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE,
|
||||
PRIMARY KEY(follower_id, followee_id)
|
||||
);
|
||||
```
|
||||
|
||||
_列表3_
|
||||
|
||||
### Golang API 实现
|
||||
|
||||
本项目使用的用 Go 实现的 GraphQL 语法解析器是 `github.com/graphql-go/graphql`。它包括一个查询解析器,但不包括模式解析器。这要求开发者利用库提供的结构使用 Go 构建 GraphQL 模式。这和 [nodejs 实现][3] 不同,后者提供了一个模式解析器并为数据获取暴露了钩子。因此 `列表1` 中的模式只是作为指导使用,需要转化为 Golang 代码。然而,这个_“限制”_提供了与抽象级别对等的机会,并且了解模式如何和用于检索数据的图遍历模型相关。_列表4_ 显示了 `Comment` 顶点类型的实现:
|
||||
|
||||
```
|
||||
var CommentType = graphql.NewObject(graphql.ObjectConfig{
|
||||
Name: "Comment",
|
||||
Fields: graphql.Fields{
|
||||
"id": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.ID, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
"title": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.String),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.Title, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
"body": &graphql.Field{
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return comment.Body, nil
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
},
|
||||
},
|
||||
})
|
||||
func init() {
|
||||
CommentType.AddFieldConfig("user", &graphql.Field{
|
||||
Type: UserType,
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
if comment, ok := p.Source.(*Comment); ok == true {
|
||||
return GetUserByID(comment.UserID)
|
||||
}
|
||||
return nil, nil
|
||||
},
|
||||
})
|
||||
CommentType.AddFieldConfig("post", &graphql.Field{
|
||||
Type: PostType,
|
||||
Args: graphql.FieldConfigArgument{
|
||||
"id": &graphql.ArgumentConfig{
|
||||
Description: "Post ID",
|
||||
Type: graphql.NewNonNull(graphql.ID),
|
||||
},
|
||||
},
|
||||
Resolve: func(p graphql.ResolveParams) (interface{}, error) {
|
||||
i := p.Args["id"].(string)
|
||||
id, err := strconv.Atoi(i)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return GetPostByID(id)
|
||||
},
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
_列表4_
|
||||
|
||||
正如 _列表1_ 中的模式,`Comment` 类型是静态定义的一个有三个属性的结构体:`id`、`title` 和 `body`。为了避免循环依赖,动态定义了 `user` 和 `post` 两个其它属性。
|
||||
|
||||
Go 并不适用于这种动态建模,它只支持一些类型检查,代码中大部分变量都是 `interface{}` 类型,在使用之前都需要进行类型断言。`CommentType` 是一个 `graphql.Object` 类型的变量,它的属性是 `graphql.Field` 类型。因此,GraphQL DSL 和 Go 中使用的数据结构并没有直接的转换。
|
||||
|
||||
每个字段的 `resolve` 函数暴露了 `Source` 参数,它是表示遍历时前一个节点的数据类型顶点。`Comment` 的所有属性都有作为 source 的当前 `CommentType` 顶点。检索`id`、`title` 和 `body` 是一个直接属性访问,而检索 `user` 和 `post` 要求图遍历,也需要数据库查询。由于它们非常简单,这篇文章并没有介绍这些 SQL 查询,但在_参考文献_部分列出的 github 仓库中有。
|
||||
|
||||
### 普通场景下和 REST 的对比
|
||||
|
||||
在这一部分,我们会展示一个普通的博客文章呈现场景,并比较 REST 和 GraphQL 的实现。关注重点会放在入站/出站请求数量,因为这些是造成页面呈现延迟的最主要原因。
|
||||
|
||||
场景:呈现一个博客文章页面。它应该包含关于作者(email)、博客文章(标题、正文)、所有评论(标题、正文)以及评论人是否关注博客文章作者的信息。_图1_ 和 _图2_ 显示了客户端 SPA、API 服务器以及数据库之间的交互,一个是 REST API、另一个对应是 GraphQL API。
|
||||
|
||||
```
|
||||
+------+ +------+ +--------+
|
||||
|client| |server| |database|
|
||||
+--+---+ +--+---+ +----+---+
|
||||
| GET /blogs/:id | |
|
||||
1\. +-------------------------> SELECT * FROM blogs... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /users/:id | |
|
||||
2\. +-------------------------> SELECT * FROM users... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /blogs/:id/comments | |
|
||||
3\. +-------------------------> SELECT * FROM comments... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
| GET /users/:id/followers| |
|
||||
4\. +-------------------------> SELECT * FROM followers.. |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
+ + +
|
||||
```
|
||||
|
||||
_图1_
|
||||
|
||||
```
|
||||
+------+ +------+ +--------+
|
||||
|client| |server| |database|
|
||||
+--+---+ +--+---+ +----+---+
|
||||
| GET /graphql | |
|
||||
1\. +-------------------------> SELECT * FROM blogs... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
2\. | | SELECT * FROM users... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
3\. | | SELECT * FROM comments... |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
| | |
|
||||
| | |
|
||||
| | |
|
||||
4\. | | SELECT * FROM followers.. |
|
||||
| +--------------------------->
|
||||
| <---------------------------+
|
||||
<-------------------------+ |
|
||||
| | |
|
||||
+ + +
|
||||
```
|
||||
|
||||
_图2_
|
||||
|
||||
_列表5_ 是一条用于获取所有呈现博文所需数据的简单 GraphQL 查询。
|
||||
|
||||
```
|
||||
{
|
||||
user(id: 1) {
|
||||
email
|
||||
followers
|
||||
post(id: 1) {
|
||||
title
|
||||
body
|
||||
comments {
|
||||
id
|
||||
title
|
||||
user {
|
||||
id
|
||||
email
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
_列表5_
|
||||
|
||||
对于这种情况,对数据库的查询次数是故意相同的,但是到 API 服务器的 HTTP 请求已经减少到只有一个。我们认为在这种类型的应用程序中通过互联网的 HTTP 请求是最昂贵的。
|
||||
|
||||
为了获取 GraphQL 的优势,后端并不需要进行特别设计,从 REST 到 GraphQL 的转换可以逐步完成。这使得可以测量性能提升和优化。从这一点,API 设计者可以开始优化(潜在的合并) SQL 查询从而提高性能。缓存的机会在数据库和 API 级别都大大增加。
|
||||
|
||||
SQL 之上的抽象(例如 ORM 层)通常会和 `n+1` 问题想抵触。在 REST 事例的步骤 4 中,客户端可能不得不在单独的请求中为每个评论的作者请求关注状态。这是因为在 REST 中没有标准的方式来表达两个以上资源之间的关系,而 GraphQL 旨在通过使用嵌套查询来防止这类问题。这里我们通过获取用户的所有关注者进行欺骗。我们向客户推荐确定评论和关注作者用户的逻辑。
|
||||
|
||||
另一个区别是获取比客户端所需更多的数据,以免破坏 REST 资源抽象。这对于用于解析和存储不需要数据的带宽消耗和电池寿命非常重要。
|
||||
|
||||
### 总结
|
||||
|
||||
GraphQL 是 REST 的一个可用替代方案,因为:
|
||||
|
||||
* 尽管设计 API 更加困难,该过程可以逐步完成。也是由于这个原因,从 REST 转换到 GraphQL 非常容易,两个流程可以没有任何问题地共存。
|
||||
* 在网络请求方面更加高效,即使是类似本博客中的简单实现。它还提供了更多查询优化和结果缓存的机会。
|
||||
* 在用于解析结果的带宽消耗和 CPU 周期方面它更加高效,因为它只返回呈现页面所需的数据。
|
||||
|
||||
REST 仍然非常有用,如果:
|
||||
|
||||
* 你的 API 非常简单,只有少量的资源或者资源之间关系简单。
|
||||
* 在你的组织中已经在使用 REST API,而且你已经配置好了所有工具,或者你的客户希望获取 REST API。
|
||||
* 你有复杂的 ACL(LCTT 译注:Access Control List) 策略。在博客例子中,可能的功能是允许用户良好地控制谁能查看他们的电子邮箱、博客、特定博客的评论、他们关注了谁,等等。优化数据获取同时检查复杂的业务规则可能会更加困难。
|
||||
|
||||
### 附录1:图数据库和高效数据存储
|
||||
|
||||
尽管将应用领域数据想象为一个图非常直观,正如这篇博文介绍的那样,但是支持这种接口的高效数据存储问题仍然没有解决。
|
||||
|
||||
近年来图数据库变得越来越流行。通过将 GraphQL 查询转换为特定的图数据库查询语言从而延迟解决请求的复杂性似乎是一种可行的方案。
|
||||
|
||||
问题是和关系型数据库相比图并不是一种高效的数据结构。图中一个顶点可能有到任何其它顶点的连接,访问模式比较难以预测因此提供了较少的优化机会。
|
||||
|
||||
例如缓存的问题,为了快速访问需要将哪些顶点保存在内存中?通用缓存算法在图遍历场景中可能没那么高效。
|
||||
|
||||
数据库分片问题:把数据库切分为更小、没有交叉的数据库并保存到独立的硬件。在学术上,最小切割的图划分问题已经得到了很好的理解,但可能是次优的而且由于病态的最坏情况可能导致高度不平衡切割。
|
||||
|
||||
在关系型数据库中,数据被建模为记录(行或者元组)和列,表和数据库名称都只是简单的命名空间。大部分数据库都是面向行的,意味着每个记录都是一个连续的内存块,一个表中的所有记录在磁盘上一个接一个地整齐地打包(通常按照某个关键列排序)。这非常高效,因为这是物理存储最优的工作方式。HDD 最昂贵的操作是将磁头移动到磁盘上的另一个扇区,因此最小化此类访问非常重要。
|
||||
|
||||
很有可能如果应用程序对一条特定记录感兴趣,它需要获取整条记录,而不仅仅是记录中的其中一列。也很有可能如果应用程序对一条记录感兴趣,它也会对该记录周围的记录感兴趣,例如全表扫描。这两点使得关系型数据库相当高效。然而,也是因为这个原因,关系型数据库的最差使用场景就是总是随机访问所有数据。图数据库正是如此。
|
||||
|
||||
随着支持更快随机访问的 SSD 驱动器的出现,更便宜的内存使得缓存大部分图数据库成为可能,更好的优化图缓存和分区的技术,图数据库开始成为可选的存储解决方案。大部分大公司也使用它:Facebook 有 Social Graph,Google 有 Knowledge Graph。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://alexandrutopliceanu.ro/post/graphql-with-go-and-postgresql
|
||||
|
||||
作者:[Alexandru Topliceanu][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/topliceanu
|
||||
[1]:http://graphql.org/learn/
|
||||
[2]:https://github.com/topliceanu/graphql-go-example
|
||||
[3]:https://github.com/graphql/graphql-js
|
||||
@ -1,123 +0,0 @@
|
||||
# 如何通过OpenELEC创建你自己的媒体中心
|
||||
|
||||

|
||||
|
||||
你是否曾经想要创建你自己的家庭影院系统?如果是的话,这里有一个为你准备的指南!在本篇文章中,我们将会介绍如何设置一个由OpenELEC以及Kodi驱动的家庭娱乐系统。我们将会介绍如何合适的安装,哪些设备可以运行软件,如何安装它,以及其他一切需要知道的事情。
|
||||
|
||||
### 选择一个设备
|
||||
|
||||
在开始设定媒体中心的软件前,你需要选择一个设备。OpenELEC支持一系列设备。从一般的桌面设备到树莓派2/3等等。选择好设备以后,考虑一下你怎么访问OpenELEC系统中的媒体,以及准备好使用
|
||||
|
||||
**注意: **OpenELEC基于Okdi,有许多方式加载一个可以运行的媒体(像是Samba网络分享,额外的设备,等等)。
|
||||
|
||||
### 制作安装磁盘
|
||||
|
||||
OpenELEC安装磁盘需要一个USB存储器,且其至少1GB的容量。这是安装软件的唯一方式,因为开发者没有发布ISO文件。取而代之的是一个需要被创建的IMG原始文件。选择与你设备相关的链接并且[下载][10]原始的磁盘镜像。当磁盘镜像下载完毕,打开一个终端,并且使用命令将数据从压缩包中解压出来。
|
||||
|
||||
**在Linux/macOS上**
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
gunzip -d OpenELEC*.img.gz
|
||||
```
|
||||
|
||||
**在Windows上**
|
||||
|
||||
下载[7zip][11],安装它,然后解压压缩文件。
|
||||
|
||||
当原始的 .IMG 文件被解压后,下载[Etcher USB creation tool][12],并且依据在界面上的指南来安装它,以及创建USB磁盘。
|
||||
|
||||
**注意:** 对于树莓派用户, Etcher也支持将文件写入到SD卡中。
|
||||
|
||||
### 安装OpenElEC
|
||||
|
||||
OpenELEC安装进程可能是安装流程中最简单的操作系统之一了。将USB设备加入,然后配置设备使其以USB方式启动作为开始。同样,这个过程也可以通过按DEL或者F2来替代。然而并不是所有的BIOS都是一样的, 所以最好的方式就是看看手册什么的。
|
||||
|
||||

|
||||
|
||||
一旦进入BIOS,修改设置使其从USB磁盘中直接加载。这将会允许电脑从USB磁盘中启动,这将会使你从Syslinux boot屏幕中启动。在提示中,进入”installer“,然后按下Enter按键。
|
||||
|
||||

|
||||
|
||||
通常,快速安装选项是被选中的。按Enter来开始安装。这将会使安装器跳转到磁盘选择界面。选择硬盘——那个OpenELEC应该被安装的地方,然后按下Enter按键来开始安装过程。
|
||||
|
||||

|
||||
|
||||
一旦完成安装,重启系统,并且加载OpenELEC。
|
||||
|
||||
### 配置 OpenELEC
|
||||
|
||||

|
||||
|
||||
在第一次启动时,用户必须配置一些东西。如果你的媒体中心拥有一个无线网卡,OpenELEC将会提示用户将其连接到一个热点上。选择一个列表中的网络并且输入密码。
|
||||
|
||||

|
||||
|
||||
在下一步”欢迎来到OpenELEC“屏上,用户必须配置不同的分享设置(SSH以及Samba)。它将会建议你把这些设置开启,因为拥有命令行权限,这将会使得远程传输媒体文件变得很简单。
|
||||
|
||||
## 增加媒体
|
||||
|
||||
在OpenELEC(Kodi)中增加媒体,首先选择你希望添加的媒体的部分。为照片音乐等添加媒体,是同一个过程。在这个指南中,我们将着重讲解添加视频。
|
||||
|
||||

|
||||
|
||||
点击在主页的”视频“选项来进入视频页面。选择”文件“选项,在下一个页面点击“添加视频...",这将会使得用户进入Kodi的添加媒体页面。在这个页面,你可以随意的添加媒体源了(包括内部和外部的)。
|
||||
|
||||

|
||||
|
||||
OpenELEC自动挂载外部的设备(像是USB,DVD信息碟片,等等),并且他可以被添加到浏览文件挂载点。一般情况下,这些设备都会被放在”/run“下,或者,返回你点击”添加视频..."的页面,在那里选择设备。任何外部设备,包括 DVD/CD,将会直接展示那些可以展示的部分。这是一个很好的选择——对于那些不懂如何找到挂载点的用户。
|
||||
|
||||

|
||||
|
||||
现在这个设备在Kodi中被选中了,界面将会询问用户去浏览设备上私人文件夹,里面有私人文件——这一切都是在媒体中心文件浏览器工具下执行的。一旦有文件的文件夹被找到阿勒,添加它,给予文件夹一个名字,然后按下OK按钮来保存它。
|
||||
|
||||

|
||||
|
||||
当一个用户浏览“视频”,他们将会看到可以点击的文件夹,这个文件夹中带有从外部设备添加的媒体。这些文件夹可以在系统上很简单的播放。
|
||||
|
||||
### 使用 OpenELec
|
||||
|
||||
当用户登录他们将会看见一个“主界面”,这个主界面有许多部分,用户可以点击他们并且进入,包括:图片,视频,音乐,程序等等。当悬停在这些部分的时候,子部分就会出现。例如,当悬停在“图片”上时,子部分”文件“以及”插件”就会出现。
|
||||
|
||||

|
||||
|
||||
Additionally, clicking the files subsection of any section (e.g. Videos) takes the user directly to any available files in that section.
|
||||
如果一个用户点击了一个部分中的子部分,例如“插件”,Kodi 插件选择就会出现。这个安装器将会允许用户浏览新的插件内容,来安装到这个子部分(像是图片关联插件,等等)或者启动一个已经存在的图片关联插件,当然,这个插件应该已经安装到系统上了。
|
||||
|
||||
此外,点击任何部分的文件子部分(例如 视频)将会直接带领用户到任何可用的文件的那个部分。
|
||||
|
||||
### 系统设置
|
||||
|
||||

|
||||
|
||||
Kodi有许多扩展设置区域。为了获得这些设置,使鼠标在右方悬停,目录选择器将会滚动右方并且显示”系统“。点他来打开全局系统设定区。
|
||||
|
||||
任何设置都可以被用户修改,安装插件从Kodi仓库到激活额外的服务,到改变他们,甚至天气。如果想要退出设定区域并且返回主页面,点击右下方角落中的”home“图标。
|
||||
|
||||
### 结论
|
||||
|
||||
通过OpenELEC的安装和配置,你现在可以随意离开或者使用你自己的Linux支持的家庭影院系统。在所有的家庭影院系统Linux发行版中,这个是最用户有好的。请记住,尽管这个系统是以”OpenELEC“来被熟知的,它运行着Kodi以及它适应任何Kodi的插件,工具以及程序。
|
||||
|
||||
------
|
||||
|
||||
via: https://www.maketecheasier.com/build-media-center-with-openelec/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[svtter](https://github.com/svtter)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]: https://www.maketecheasier.com/author/derrikdiener/
|
||||
[2]: https://www.maketecheasier.com/build-media-center-with-openelec/#comments
|
||||
[3]: https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]: http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F
|
||||
[5]: http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F&text=How+to+Build+Your+Own+Media+Center+with+OpenELEC
|
||||
[6]: mailto:?subject=How%20to%20Build%20Your%20Own%20Media%20Center%20with%20OpenELEC&body=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F
|
||||
[7]: https://www.maketecheasier.com/permanently-disable-windows-defender-windows-10/
|
||||
[8]: https://www.maketecheasier.com/repair-mac-hard-disk-with-fsck/
|
||||
[9]: https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]: http://openelec.tv/get-openelec/category/1-openelec-stable-releases
|
||||
[11]: http://www.7-zip.org/
|
||||
[12]: https://etcher.io/
|
||||
132
translated/tech/20170501 Containers running Containers.md
Normal file
132
translated/tech/20170501 Containers running Containers.md
Normal file
@ -0,0 +1,132 @@
|
||||
容器中运行容器
|
||||
============================================================
|
||||
|
||||
一些令人振奋的消息引发了我对今年 DockerCon 的兴趣,在会议中宣布了一个新的操作系统(OS)LinuxKit,并由无可争议的容器巨头公司 Docker 提供。
|
||||
|
||||
容器巨头已经宣布了一个灵活的、可扩展的操作系统,为了可移植性系统服务在其内运行。当你听到包括 Docker 运行时也在内时,你可能会感到惊讶。
|
||||
|
||||
在本文中,我们将简要介绍一下 LinuxKit 中承诺的内容,以及如何自己尝试并不断缩小优化容器。
|
||||
|
||||
**少即是多**
|
||||
|
||||
不可否认的是,用户一直在寻找一个被剥离版本的 Linux 来运行他们的微服务。通过容器化,你会尽可能地减少每个应用程序,使其成为一个位于其自身容器内的独立进程。但是,由于你对那些驻留容器主机的修补导致的问题,因此你不断地移动容器。实际上如果没有像 Kubernetes 或 Docker Swarm 这样的协调者,容器编排几乎总是会导致停机。
|
||||
|
||||
不用说,这只是让你保持操作系统尽可能小的原因之一。
|
||||
|
||||
我曾多次在不同场合重复过的最喜爱的名言,来自荷兰的天才程序员 Wietse Zweitze,他为我们提供了 email 中的 Postfix 和 TCP Wrappers 等知名软件。
|
||||
|
||||
Postfix 网站([Postfix TLS_README][10])指出,即使你编码和 Wietse 一样小心,“每 1000 行[你]就会在 Postfix 中引入一个额外的错误”。从我的专业的 DevSecOps 角度提到我可以被原谅的 “bug” 可以不严谨地说成安全问题。
|
||||
|
||||
从安全的角度来看,正是由于这个原因,代码世界中“少即是多”。简单地说,使用较少的代码行有很多好处,即安全性、管理时间和性能。对于初学者来说,安全漏洞较少,更新软件包的时间更短,启动时间更快。
|
||||
|
||||
**深入观察**
|
||||
|
||||
考虑下从容器内部运行你的程序。
|
||||
|
||||
一个好的起点是 Alpine Linux([https://alpinelin.org.org/downloads][1]),它是一个精简化的操作系统,通常比那些笨重的系统更受喜欢,如 Ubuntu 或 CentOS 等。Alpine 还提供了一个 miniroot 文件系统(用于容器内),最后一次检测是惊人的 1.8M。事实上,完整的 Linux 操作系统下载后有 80M。
|
||||
|
||||
如果你决定使用 Alpine Linux 作为 Docker 基础镜像,那么你可以在Docker Hub([https://hub.docker.com/_/alpine][2])上找到一个,其中 Alpine Linux 将自己描述为:“一个基于 Alpine Linux 的最小 Docker 镜像,具有完整的包索引,大小只有5 MB!”
|
||||
|
||||
据说无处不在的 “Window Start Button” 也是大致相同的大小!我不会尝试去验证,也不会进一步评论。
|
||||
|
||||
严肃地希望能让你了解创新的类 Unix 操作系统(如 Alpine Linux)的强大功能。
|
||||
|
||||
**锁定一切**
|
||||
|
||||
再说一点,Alpine Linux 是(并不惊人)基于 BusyBox([BusyBox][3]),一套著名的打包了 Linux 命令的集合,许多人不会意识到他们的宽带路由器、智能电视,当然还有他们家庭中的物联网设备就有它。
|
||||
|
||||
Alpine Linux 站点的“关于”页面([Alpine Linux][4])的评论中指出:
|
||||
|
||||
“Alpine Linux 的设计考虑到安全性。内核使用非官方的 grsecurity/PaX 移植进行修补,所有用户态二进制文件都编译为具有堆栈保护的地址无关可执行文件(PIE)。 这些主动安全特性可以防止所有类别的零日和其他漏洞利用”
|
||||
|
||||
换句话说,Alpine Linux 中的二进制文件捆绑在一起,提供了那些通过行业安全工具筛选的功能,以帮助缓解缓冲区溢出攻击。
|
||||
|
||||
**奇怪的袜子**
|
||||
|
||||
你可能会问,为什么当我们处理 Docker 的新操作系统时,容器的内部结构很重要?
|
||||
|
||||
那么,你可能已经猜到,当涉及容器时,他们的目标是精简。除非绝对必要,否则不包括任何东西。所以有信心的是,你可以在清理橱柜、花园棚子、车库和袜子抽屉后获得回报而没有惩罚。
|
||||
|
||||
Docker 的确因为它们的先见而获得声望。据报道,2 月初,Docker 聘请了 Alpine Linux 的主要推动者 Nathaniel Copa,他帮助将默认的官方镜像库从 Ubuntu 切换到 Alpine。Docker Hub 从新近精简镜像节省的带宽受到了欢迎。
|
||||
|
||||
并且最新的情况是,这项工作将与最新的基于容器的操作系统相结合:Docker 的 LinuxKit。
|
||||
|
||||
要说清楚的是 LinuxKit 不会注定代替 Alpine,而是位于容器下层,并作为一个完整的操作系统,你可以高兴地启动你的运行时守护程序(在这种情况下,在容器中产生 Docker 守护程序)。
|
||||
|
||||
**Blondie Atomic **
|
||||
|
||||
经过精心调试的主机绝对不是一件新事物(以前提到过嵌入式 Linux 的家用设备)。在过去几十年中一直在优化 Linux 的天才在某个时候意识到底层的操作系统是快速生产含有大量容器主机的关键。
|
||||
|
||||
例如,强大的红帽长期以来一直在出售已经贡献给 Project Atomic ([Project Atomic][6]) 的 Red Hat Atomic([https://www.redhat.com/en/resources/red-hat-enterprise-linux-atomic-host][5])。后者继续解释:
|
||||
|
||||
“基于 Red Hat Enterprise Linux 或 CentOS 和 Fedora 项目的成熟技术,Atomic Host 是一个轻量级的、不可变的平台,其设计目的仅在于运行容器化应用程序。
|
||||
|
||||
有一个很好理由将底层的、不可变的 Atomic OS 作为 Red Hat OpenShift PaaS(平台即服务)产品推荐。它最小化、高性能、尖端。
|
||||
|
||||
**特性**
|
||||
|
||||
在 Docker 关于 LinuxKit 的公告中,少即是多的口号是显而易见的。实现 LinuxKit 愿景的项目显然是不小的事业,它由 Docker 老将和 Unikernels([https://en.wikipedia.org/wiki/Unikernel][7])的主管 Justin Cormack 指导,并与 HPE、Intel、ARM、IBM 和 Microsoft LinuxKit 合作,可以在大型机以及基于物联网的冰柜中运行。
|
||||
|
||||
LinuxKit 的可配置、可插拔和可扩展性质将吸引许多项目寻找建立其服务的基准。通过开源项目,Docker 明智地邀请每个男人和他们的狗投入其功能开发,随着时间的推移,它会像好的奶酪那样成熟。
|
||||
|
||||
**布丁的证明**
|
||||
|
||||
有承诺称那些急于使用新系统的人不用再等待了。如果你准备着手 LinuxKit,你可以从 GitHub 中开始:[LinuxKit][11]
|
||||
|
||||
在 GitHub 页面上有关于如何启动和运行一些功能的指导。
|
||||
|
||||
时间允许的话我准备更加深入 LinuxKit。有争议的 Kubernetes 与 Docker Swarm 编排功能对比会是有趣的尝试。我还想看到内存占用、启动时间和磁盘空间使用率的基准测试。
|
||||
|
||||
如果承诺是真实的,则作为容器运行的可插拔系统服务是构建操作系统的迷人方式。Docker 在博客([https://blog.docker.com/2017/04/introducing-linuxkit-container-os-toolkit][12])中提到:“因为 LinuxKit 是原生容器,它有一个非常小的尺寸 - 35MB,引导时间非常小。所有系统服务都是容器,这意味着可以删除或替换所有的内容。“
|
||||
|
||||
我不知道你怎么样,但这非常符合我的胃口。
|
||||
|
||||
**呼叫警察**
|
||||
|
||||
除了站在我 DevSecOps 角度看到的功能,我将看到承诺的安全在现实中的面貌。
|
||||
|
||||
Docker 引用来自 NIST(国家标准与技术研究所:[https://www.nist.gov] [8]),并在他们的博客上声称:
|
||||
|
||||
安全性是最高目标,这与 NIST 在其“应用程序容器安全指南”草案中说明的保持一致:“使用容器专用操作系统而不是通用操作系统来减少攻击面。当使用专用容器操作系统时,攻击面通常比通用操作系统小得多,因此攻击和危及专用容器操作系统的机会较少。”
|
||||
|
||||
可能最重要的容器到主机和主机到容器的安全创新将是系统容器(系统服务)被完全地沙箱化到自己的非特权空间中,而只给它们需要的外部访问。
|
||||
|
||||
通过内核自我保护项目(KSPP)([https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project][9])的协作来实现这一功能,我很满意 Docker 开始专注于一些非常值得的东西上。对于那些不熟悉的 KSPP 的人而言,它存在理由如下:
|
||||
|
||||
“启动这个项目的的假设是内核 bug 的存在时间很长,内核必须设计成防止这些缺陷。”
|
||||
|
||||
KSPP 网站继续表态:
|
||||
|
||||
“这些努力非常重要并还在进行,但如果我们要保护我们的十亿 Android 手机、我们的汽车、国际空间站,还有其他运行 Linux 的产品,我们必须在上游的 Linux 内核中建立积极的防御性技术。我们需要内核安全地错误,而不只是安全地运行。”
|
||||
|
||||
而且,如果 Docker 最初只能在 LinuxKit 前进一小步,那么随着时间的推移,成熟度带来的好处可能会在容器领域中取得长足的进步。
|
||||
|
||||
**离终点还远**
|
||||
|
||||
像 Docker 这样不断发展壮大的集团无论在哪个方向上取得巨大的飞跃都将会用户和其他软件带来益处。
|
||||
|
||||
我鼓励所有对 Linux 感兴趣的人密切关注这个领域。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.devsecops.cc/devsecops/containers.html
|
||||
|
||||
作者:[Chris Binnie ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.devsecops.cc/
|
||||
[1]:https://alpinelinux.org/downloads/
|
||||
[2]:https://hub.docker.com/_/alpine
|
||||
[3]:https://busybox.net/
|
||||
[4]:https://www.alpinelinux.org/about/
|
||||
[5]:https://www.redhat.com/en/resources/red-hat-enterprise-linux-atomic-host
|
||||
[6]:http://www.projectatomic.io/
|
||||
[7]:https://en.wikipedia.org/wiki/Unikernel
|
||||
[8]:https://www.nist.gov/
|
||||
[9]:https://kernsec.org/wiki/index.php/Kernel_Self_Protection_Project
|
||||
[10]:http://www.postfix.org/TLS_README.html
|
||||
[11]:https://github.com/linuxkit/linuxkit
|
||||
[12]:https://blog.docker.com/2017/04/introducing-linuxkit-container-os-toolkit
|
||||
@ -0,0 +1,154 @@
|
||||
在 Ubuntu 16.04 中安装支持 CPU 和 GPU 的 Google TensorFlow 神经网络软件
|
||||
============================================================
|
||||
|
||||
### 在本页中
|
||||
|
||||
1. [1 安装 CUDA][1]
|
||||
2. [2 安装 CuDNN 库][2]
|
||||
3. [3 在 .bashrc 中添加安装位置][3]
|
||||
4. [4 安装带有 GPU 支持的 TensorFlow][4]
|
||||
5. [5 安装只支持 CPU 的 TensorFlow][5]
|
||||
|
||||
TensorFlow 是用于机器学习任务的开源软件。它的创建者 Google 希望发布一个强大的工具帮助开发者探索和建立基于机器学习的程序,所以他们在今年作为开源项目发布了它。TensorFlow 是一个非常强大的工具,专注于一种称为深层神经网络的神经网络。
|
||||
|
||||
深层神经网络被用来执行复杂的机器学习任务,例如图像识别、手写识别、自然语言处理、聊天机器人等等。这些神经网络被训练学习它应该执行的任务。至于训练所需的计算是非常巨大的,在大多数情况下需要 CPU 支持,这时 TensorFlow 就派上用场了。启用了 GPU 并安装了支持 GPU 的软件,那么训练所需的时间就可以大大减少。
|
||||
|
||||
本教程可以帮助你安装只支持 CPU 和支持 GPU 的 TensorFlow。因此,要获得带有 GPU 支持的 TensorFLow,你必须要有一块支持 CUDA 的 Nvidia GPU。CUDA 和 CuDNN(Nvidia 的计算库)的安装有点棘手,本指南提供在实际安装 TensorFlow 之前一步步安装它们的方法。
|
||||
|
||||
Nvidia CUDA 是一个 GPU 加速库,它已经为标准神经网络程序调整过。CuDNN 是一个用于 GPU 的调整库,它负责 GPU 性能的自动调整。TensorFlow 同时依赖这两者用于训练并运行深层神经网络,因此它们必须在 TensorFlow 之前安装。
|
||||
|
||||
需要指出的是,那些不希望安装支持 GPU 的 TensorFlow 的人,你可以跳过以下所有的步骤并直接跳到:“步骤 5:安装只支持 CPU 的 TensorFlow”。
|
||||
|
||||
关于 TensorFlow 的介绍可以在[这里][10]找到。
|
||||
|
||||
|
||||
### 1 安装 CUDA
|
||||
|
||||
首先,在[这里][11]下载用于 Ubuntu 16.04 的 CUDA。此文件非常大(2GB),因此也许会花费一些时间下载。
|
||||
|
||||
下载的文件是 “.deb” 包。要安装它,运行下面的命令:
|
||||
|
||||
sudo dpkg -i cuda-repo-ubuntu1604-8-0-local_8.0.44-1_amd64.deb
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
下面的的命令会安装所有的依赖,并最后安装 cuda 工具包:
|
||||
|
||||
sudo apt install -f
|
||||
|
||||
sudo apt update
|
||||
|
||||
sudo apt install cuda
|
||||
|
||||
如果成功安装,你会看到一条消息说:“successfully installed”。如果已经安装了,接着你可以看到类似下面的输出:
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
### 2 successfully installed
|
||||
|
||||
CuDNN 下载需要花费一些功夫。Nvidia 没有直接提供下载文件(虽然它是免费的)。通过下面的步骤获取 CuDNN。
|
||||
|
||||
1.点击[此处][8]进入 Nvidia 的注册页面并创建一个帐户。第一页要求你输入你的个人资料,第二页会要求你回答几个调查问题。如果你不知道所有答案也没问题,你可以随机选择一个选项。
|
||||
2.通过前面的步骤,Nvidia 会向你的邮箱发送一个激活链接。在你激活之后,直接进入[这里][9]的 CuDNN 下载链接。
|
||||
3.登录之后,你需要填写另外一份类似的调查。随机点击复选框,然后点击调查底部的 “proceed to Download”,在下一页我们点击同意使用条款。
|
||||
4.最后,在下拉中点击 “Download cuDNN v5.1 (Jan 20, 2017), for CUDA 8.0”,最后,你需要下载这两个文件:
|
||||
* [cuDNN v5.1 Runtime Library for Ubuntu14.04 (Deb)][6]
|
||||
* [cuDNN v5.1 Developer Library for Ubuntu14.04 (Deb)][7]
|
||||
|
||||
注意:即使说的是用于 Ubuntu 14.04 的库。它也适用于 16.04。
|
||||
|
||||
现在你已经同时有 CuDNN 的两个文件了,是时候安装它们了!在包含这些文件的文件夹内运行下面的命令:
|
||||
|
||||
sudo dpkg -i libcudnn5_5.1.5-1+cuda8.0_amd64.deb
|
||||
|
||||
sudo dpkg -i libcudnn5-dev_5.1.5-1+cuda8.0_amd64.deb
|
||||
|
||||
下面的图片展示了这些命令的输出:
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
### 3 在 bashrc 中添加安装位置
|
||||
|
||||
安装位置应该被添加到 bashrc 中,以便系统下一次知道如何找到这些用于 CUDA 的文件。使用下面的命令打开 bashrc 文件:
|
||||
|
||||
sudo gedit ~/.bashrc
|
||||
|
||||
文件打开后,添加下面两行到文件的末尾:
|
||||
|
||||
```
|
||||
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
|
||||
export CUDA_HOME=/usr/local/cuda
|
||||
```
|
||||
|
||||
### 4 安装带有 GPU 支持的 TensorFlow
|
||||
|
||||
这步我们将安装带有 GPU 支持的 TensorFlow。如果你使用的是 Python 2.7,运行下面的命令:
|
||||
|
||||
pip install TensorFlow-gpu
|
||||
|
||||
如果安装了 Python 3.x,使用下面的命令:
|
||||
|
||||
pip3 install TensorFlow-gpu
|
||||
|
||||
安装完后,你会看到一条 “successfully installed” 的消息。现在,剩下要测试的是是否已经正确安装。打开终端并输入下面的命令测试:
|
||||
|
||||
python
|
||||
|
||||
import TensorFlow as tf
|
||||
|
||||
你应该会看到类似下面图片的输出。在图片中你可以观察到 CUDA 库已经成功打开了。如果有任何错误,消息会提示说无法打开 CUDA 甚至无法找到模块。为防你或许遗漏了上面的某步,仔细重做教程的每一步就行了。
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
### 5 安装只支持 CPU 的 TensorFlow
|
||||
|
||||
注意:这步是对那些没有 GPU 或者没有 Nvidia GPU 的人而言的。其他人请忽略这步!!
|
||||
|
||||
安装只支持 CPU 的 TensorFlow 非常简单。使用下面两个命令:
|
||||
|
||||
pip install TensorFlow
|
||||
|
||||
如果你有 python 3.x,使用下面的命令:
|
||||
|
||||
pip3 install TensorFlow
|
||||
|
||||
是的,就是这么简单!
|
||||
|
||||
安装指南至此结束,你现在可以开始构建深度学习应用了。如果你刚刚起步,你可以在[这里][16]看下适合初学者的官方教程。如果你正在寻找更多的高级教程,你可以在[这里][17]学习了解如何设置可以高精度识别上千个物体的图片识别系统/工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
|
||||
作者:[Akshay Pai ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
[1]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-install-cuda
|
||||
[2]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-install-the-cudnn-library
|
||||
[3]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-add-the-installation-location-to-bashrc-file
|
||||
[4]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-install-tensorflow-with-gpu-support
|
||||
[5]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/#-install-tensorflow-with-only-cpu-support
|
||||
[6]:https://developer.nvidia.com/compute/machine-learning/cudnn/secure/v5.1/prod_20161129/8.0/libcudnn5_5.1.10-1+cuda8.0_amd64-deb
|
||||
[7]:https://developer.nvidia.com/compute/machine-learning/cudnn/secure/v5.1/prod_20161129/8.0/libcudnn5-dev_5.1.10-1+cuda8.0_amd64-deb
|
||||
[8]:https://developer.nvidia.com/group/node/873374/subscribe/og_user_node
|
||||
[9]:https://developer.nvidia.com/rdp/form/cudnn-download-survey
|
||||
[10]:http://sourcedexter.com/what-is-tensorflow/
|
||||
[11]:https://developer.nvidia.com/compute/cuda/8.0/Prod2/local_installers/cuda-repo-ubuntu1604-8-0-local-ga2_8.0.61-1_amd64-deb
|
||||
[12]:https://www.howtoforge.com/images/installing_tensorflow_machine_learning_software_for_cpu_and_gpu_on_ubuntu_1604/big/image1.png
|
||||
[13]:https://www.howtoforge.com/images/installing_tensorflow_machine_learning_software_for_cpu_and_gpu_on_ubuntu_1604/big/image2.png
|
||||
[14]:https://www.howtoforge.com/images/installing_tensorflow_machine_learning_software_for_cpu_and_gpu_on_ubuntu_1604/big/image3.png
|
||||
[15]:https://www.howtoforge.com/images/installing_tensorflow_machine_learning_software_for_cpu_and_gpu_on_ubuntu_1604/big/image4.png
|
||||
[16]:https://www.tensorflow.org/get_started/mnist/beginners
|
||||
[17]:https://www.tensorflow.org/tutorials/image_recognition
|
||||
Loading…
Reference in New Issue
Block a user