mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
e80bbbd082
@ -1,62 +1,63 @@
|
||||
在终端显示世界地图
|
||||
MapSCII:在终端显示世界地图
|
||||
======
|
||||
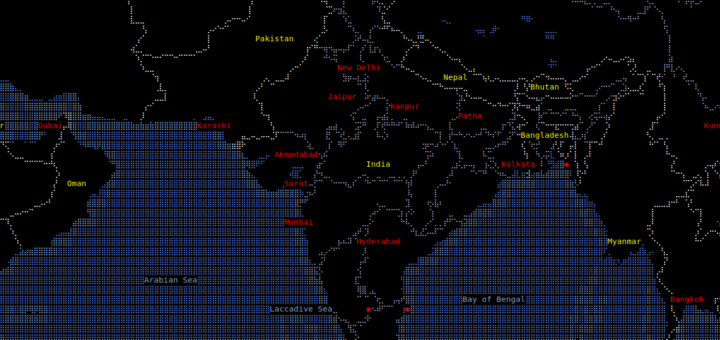
我偶然发现了一个有趣的工具。在终端的世界地图!是的,这太酷了。向 **MapSCII** 问好,这是可在 xterm 兼容终端渲染的盲文和 ASCII 世界地图。它支持 GNU/Linux、Mac OS 和 Windows。我以为这是另一个在 GitHub 上托管的项目。但是我错了!他们做了令人印象深刻的事。我们可以使用我们的鼠标指针在世界地图的任何地方拖拽放大和缩小。其他显著的特性是:
|
||||
|
||||
|
||||
|
||||
我偶然发现了一个有趣的工具。在终端里的世界地图!是的,这太酷了。给 `MapSCII` 打 call,这是可在 xterm 兼容终端上渲染的布莱叶盲文和 ASCII 世界地图。它支持 GNU/Linux、Mac OS 和 Windows。我原以为它只不过是一个在 GitHub 上托管的项目而已,但是我错了!他们做的事令人印象深刻。我们可以使用我们的鼠标指针在世界地图的任何地方拖拽放大和缩小。其他显著的特性是:
|
||||
|
||||
* 发现任何特定地点周围的兴趣点
|
||||
* 高度可定制的图层样式,带有[ Mapbox 样式][1]支持
|
||||
* 连接到任何公共或私有矢量贴片服务器
|
||||
* 高度可定制的图层样式,支持 [Mapbox 样式][1]
|
||||
* 可连接到任何公共或私有的矢量贴片服务器
|
||||
* 或者使用已经提供并已优化的基于 [OSM2VectorTiles][2] 服务器
|
||||
* 离线工作,发现本地 [VectorTile][3]/[MBTiles][4]
|
||||
* 可以离线工作并发现本地的 [VectorTile][3]/[MBTiles][4]
|
||||
* 兼容大多数 Linux 和 OSX 终端
|
||||
* 高度优化算法的流畅体验
|
||||
|
||||
|
||||
|
||||
### 使用 MapSCII 在终端中显示世界地图
|
||||
|
||||
要打开地图,只需从终端运行以下命令:
|
||||
|
||||
```
|
||||
telnet mapscii.me
|
||||
```
|
||||
|
||||
这是我终端上的世界地图。
|
||||
|
||||
[![][5]][6]
|
||||
![][6]
|
||||
|
||||
很酷,是吗?
|
||||
|
||||
要切换到盲文视图,请按 **c**。
|
||||
要切换到布莱叶盲文视图,请按 `c`。
|
||||
|
||||
[![][5]][7]
|
||||
![][7]
|
||||
|
||||
Type **c** again to switch back to the previous format **.**
|
||||
再次输入 **c** 切回以前的格式。
|
||||
再次输入 `c` 切回以前的格式。
|
||||
|
||||
要滚动地图,请使用**向上**、向下**、**向左**、**向右**箭头键。要放大/缩小位置,请使用 **a** 和 **a** 键。另外,你可以使用鼠标的滚轮进行放大或缩小。要退出地图,请按 **q**。
|
||||
要滚动地图,请使用“向上”、“向下”、“向左”、“向右”箭头键。要放大/缩小位置,请使用 `a` 和 `z` 键。另外,你可以使用鼠标的滚轮进行放大或缩小。要退出地图,请按 `q`。
|
||||
|
||||
就像我已经说过的,不要认为这是一个简单的项目。点击地图上的任何位置,然后按 **“a”** 放大。
|
||||
就像我已经说过的,不要认为这是一个简单的项目。点击地图上的任何位置,然后按 `a` 放大。
|
||||
|
||||
放大后,下面是一些示例截图。
|
||||
|
||||
[![][5]][8]
|
||||
![][8]
|
||||
|
||||
我可以放大查看我的国家(印度)的州。
|
||||
|
||||
[![][5]][9]
|
||||
![][9]
|
||||
|
||||
和州内的地区(Tamilnadu):
|
||||
|
||||
[![][5]][10]
|
||||
![][10]
|
||||
|
||||
甚至是地区内的镇 [Taluks][11]:
|
||||
|
||||
[![][5]][12]
|
||||
![][12]
|
||||
|
||||
还有,我完成学业的地方:
|
||||
|
||||
[![][5]][13]
|
||||
![][13]
|
||||
|
||||
即使它只是一个最小的城镇,MapSCII 也能准确地显示出来。 MapSCII 使用 [**OpenStreetMap**][14] 来收集数据。
|
||||
即使它只是一个最小的城镇,MapSCII 也能准确地显示出来。 MapSCII 使用 [OpenStreetMap][14] 来收集数据。
|
||||
|
||||
### 在本地安装 MapSCII
|
||||
|
||||
@ -64,15 +65,16 @@ Type **c** again to switch back to the previous format **.**
|
||||
|
||||
确保你的系统上已经安装了 Node.js。如果还没有,请参阅以下链接。
|
||||
|
||||
[Install NodeJS on Linux][15]
|
||||
- [在 Linux 上安装 NodeJS][15]
|
||||
|
||||
然后,运行以下命令来安装它。
|
||||
|
||||
```
|
||||
sudo npm install -g mapscii
|
||||
|
||||
```
|
||||
|
||||
要启动 MapSCII,请运行:
|
||||
|
||||
```
|
||||
mapscii
|
||||
```
|
||||
@ -81,15 +83,13 @@ mapscii
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/mapscii-world-map-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -99,13 +99,13 @@ via: https://www.ostechnix.com/mapscii-world-map-terminal/
|
||||
[3]:https://github.com/mapbox/vector-tile-spec
|
||||
[4]:https://github.com/mapbox/mbtiles-spec
|
||||
[5]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-1-2.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-2.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-3.png ()
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-4.png ()
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-5.png ()
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-1-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-2.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-3.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-4.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-5.png
|
||||
[11]:https://en.wikipedia.org/wiki/Tehsils_of_India
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-6.png ()
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-7.png ()
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-6.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-7.png
|
||||
[14]:https://www.openstreetmap.org/
|
||||
[15]:https://www.ostechnix.com/install-node-js-linux/
|
||||
@ -0,0 +1,170 @@
|
||||
8 个你不一定全都了解的 rm 命令示例
|
||||
======
|
||||
|
||||
删除文件和复制/移动文件一样,都是很基础的操作。在 Linux 中,有一个专门的命令 `rm`,可用于完成所有删除相关的操作。在本文中,我们将用些容易理解的例子来讨论这个命令的基本使用。
|
||||
|
||||
但在我们开始前,值得指出的是本文所有示例都在 Ubuntu 16.04 LTS 中测试过。
|
||||
|
||||
### Linux rm 命令概述
|
||||
|
||||
通俗的讲,我们可以认为 `rm` 命令是用于删除文件和目录的。下面是此命令的语法:
|
||||
|
||||
```
|
||||
rm [选项]... [要删除的文件/目录]...
|
||||
```
|
||||
|
||||
下面是命令使用说明:
|
||||
|
||||
> GUN 版本 `rm` 命令的手册文档。`rm` 删除每个指定的文件,默认情况下不删除目录。
|
||||
|
||||
> 当删除的文件超过三个或者提供了选项 `-r`、`-R` 或 `--recursive`(LCTT 译注:表示递归删除目录中的文件)时,如果给出 `-I`(LCTT 译注:大写的 I)或 `--interactive=once` 选项(LCTT 译注:表示开启交互一次),则 `rm` 命令会提示用户是否继续整个删除操作,如果用户回应不是确认(LCTT 译注:即没有回复 `y`),则整个命令立刻终止。
|
||||
|
||||
> 另外,如果被删除文件是不可写的,标准输入是终端,这时如果没有提供 `-f` 或 `--force` 选项,或者提供了 `-i`(LCTT 译注:小写的 i) 或 `--interactive=always` 选项,`rm` 会提示用户是否要删除此文件,如果用户回应不是确认(LCTT 译注:即没有回复 `y`),则跳过此文件。
|
||||
|
||||
|
||||
下面这些问答式例子会让你更好的理解这个命令的使用。
|
||||
|
||||
### Q1. 如何用 rm 命令删除文件?
|
||||
|
||||
这是非常简单和直观的。你只需要把文件名(如果文件不是在当前目录中,则还需要添加文件路径)传入给 `rm` 命令即可。
|
||||
|
||||
(LCTT 译注:可以用空格隔开传入多个文件名称。)
|
||||
|
||||
```
|
||||
rm 文件1 文件2 ...
|
||||
```
|
||||
如:
|
||||
|
||||
```
|
||||
rm testfile.txt
|
||||
```
|
||||
|
||||
[![How to remove files using rm command][1]][2]
|
||||
|
||||
### Q2. 如何用 `rm` 命令删除目录?
|
||||
|
||||
如果你试图删除一个目录,你需要提供 `-r` 选项。否则 `rm` 会抛出一个错误告诉你正试图删除一个目录。
|
||||
|
||||
(LCTT 译注:`-r` 表示递归地删除目录下的所有文件和目录。)
|
||||
|
||||
```
|
||||
rm -r [目录名称]
|
||||
```
|
||||
|
||||
如:
|
||||
|
||||
```
|
||||
rm -r testdir
|
||||
```
|
||||
|
||||
[![How to remove directories using rm command][3]][4]
|
||||
|
||||
### Q3. 如何让删除操作前有确认提示?
|
||||
|
||||
如果你希望在每个删除操作完成前都有确认提示,可以使用 `-i` 选项。
|
||||
|
||||
```
|
||||
rm -i [文件/目录]
|
||||
```
|
||||
|
||||
比如,你想要删除一个目录“testdir”,但需要每个删除操作都有确认提示,你可以这么做:
|
||||
|
||||
```
|
||||
rm -r -i testdir
|
||||
```
|
||||
|
||||
[![How to make rm prompt before every removal][5]][6]
|
||||
|
||||
### Q4. 如何让 rm 忽略不存在的文件或目录?
|
||||
|
||||
如果你删除一个不存在的文件或目录时,`rm` 命令会抛出一个错误,如:
|
||||
|
||||
[![Linux rm command example][7]][8]
|
||||
|
||||
然而,如果你愿意,你可以使用 `-f` 选项(LCTT 译注:即 “force”)让此次操作强制执行,忽略错误提示。
|
||||
|
||||
```
|
||||
rm -f [文件...]
|
||||
```
|
||||
|
||||
[![How to force rm to ignore nonexistent files][9]][10]
|
||||
|
||||
### Q5. 如何让 rm 仅在某些场景下确认删除?
|
||||
|
||||
选项 `-I`,可保证在删除超过 3 个文件时或递归删除时(LCTT 译注: 如删除目录)仅提示一次确认。
|
||||
|
||||
比如,下面的截图展示了 `-I` 选项的作用——当两个文件被删除时没有提示,当超过 3 个文件时会有提示。
|
||||
|
||||
[![How to make rm prompt only in some scenarios][11]][12]
|
||||
|
||||
### Q6. 当删除根目录是 rm 是如何工作的?
|
||||
|
||||
当然,删除根目录(`/`)是 Linux 用户最不想要的操作。这也就是为什么默认 `rm` 命令不支持在根目录上执行递归删除操作。(LCTT 译注:早期的 `rm` 命令并无此预防行为。)
|
||||
|
||||
[![How rm works when dealing with root directory][13]][14]
|
||||
|
||||
然而,如果你非得完成这个操作,你需要使用 `--no-preserve-root` 选项。当提供此选项,`rm` 就不会特殊处理根目录(`/`)了。
|
||||
|
||||
假如你想知道在哪些场景下 Linux 用户会删除他们的根目录,点击[这里][15]。
|
||||
|
||||
### Q7. 如何让 rm 仅删除空目录?
|
||||
|
||||
假如你需要 `rm` 在删除目录时仅删除空目录,你可以使用 `-d` 选项。
|
||||
|
||||
```
|
||||
rm -d [目录]
|
||||
```
|
||||
|
||||
下面的截图展示 `-d` 选项的用途——仅空目录被删除了。
|
||||
|
||||
[![How to make rm only remove empty directories][16]][17]
|
||||
|
||||
### Q8. 如何让 rm 显示当前删除操作的详情?
|
||||
|
||||
如果你想 rm 显示当前操作完成时的详细情况,使用 `-v` 选项可以做到。
|
||||
|
||||
```
|
||||
rm -v [文件/目录]
|
||||
```
|
||||
|
||||
如:
|
||||
|
||||
[![How to force rm to emit details of operation it is performing][18]][19]
|
||||
|
||||
### 结论
|
||||
|
||||
考虑到 `rm` 命令提供的功能,可以说其是 Linux 中使用频率最高的命令之一了(就像 [cp][20] 和 `mv` 一样)。在本文中,我们涉及到了其提供的几乎所有主要选项。`rm` 命令有些学习曲线,因此在你日常工作中开始使用此命令之前
|
||||
你将需要花费些时间去练习它的选项。更多的信息,请点击此命令的 [man 手册页][21]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-rm-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/rm-basic-usage.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/rm-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/rm-r.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/rm-r.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/rm-i-option.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/rm-i-option.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/rm-non-ext-error.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/rm-non-ext-error.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/rm-f-option.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/rm-f-option.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/rm-I-option.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/big/rm-I-option.png
|
||||
[13]:https://www.howtoforge.com/images/command-tutorial/rm-root-default.png
|
||||
[14]:https://www.howtoforge.com/images/command-tutorial/big/rm-root-default.png
|
||||
[15]:https://superuser.com/questions/742334/is-there-a-scenario-where-rm-rf-no-preserve-root-is-needed
|
||||
[16]:https://www.howtoforge.com/images/command-tutorial/rm-d-option.png
|
||||
[17]:https://www.howtoforge.com/images/command-tutorial/big/rm-d-option.png
|
||||
[18]:https://www.howtoforge.com/images/command-tutorial/rm-v-option.png
|
||||
[19]:https://www.howtoforge.com/images/command-tutorial/big/rm-v-option.png
|
||||
[20]:https://www.howtoforge.com/linux-cp-command/
|
||||
[21]:https://linux.die.net/man/1/rm
|
||||
@ -0,0 +1,75 @@
|
||||
Building Slack for the Linux community and adopting snaps
|
||||
======
|
||||
![][1]
|
||||
|
||||
Used by millions around the world, [Slack][2] is an enterprise software platform that allows teams and businesses of all sizes to communicate effectively. Slack works seamlessly with other software tools within a single integrated environment, providing an accessible archive of an organisation’s communications, information and projects. Although Slack has grown at a rapid rate in the 4 years since their inception, their desktop engineering team who work across Windows, MacOS and Linux consists of just 4 people currently. We spoke to Felix Rieseberg, Staff Software Engineer, who works on this team following the release of Slack’s first [snap last month][3] to discover more about the company’s attitude to the Linux community and why they decided to build a snap.
|
||||
|
||||
[Install Slack snap][4]
|
||||
|
||||
### Can you tell us about the Slack snap which has been published?
|
||||
|
||||
We launched our first snap last month as a new way to distribute to our Linux community. In the enterprise space, we find that people tend to adopt new technology at a slower pace than consumers, so we will continue to offer a .deb package.
|
||||
|
||||
### What level of interest do you see for Slack from the Linux community?
|
||||
|
||||
I’m excited that interest for Slack is growing across all platforms, so it is hard for us to say whether the interest coming out of the Linux community is different from the one we’re generally seeing. However, it is important for us to meet users wherever they do their work. We have a dedicated QA engineer focusing entirely on Linux and we really do try hard to deliver the best possible experience.
|
||||
|
||||
We generally find it is a little harder to build for Linux, than say Windows, as there is a less predictable base to work from – and this is an area where the Linux community truly shines. We have a fairly large number of users that are quite helpful when it comes to reporting bugs and hunting root causes down.
|
||||
|
||||
### How did you find out about snaps?
|
||||
|
||||
Martin Wimpress at Canonical reached out to me and explained the concept of snaps. Honestly, initially I was hesitant – even though I use Ubuntu – because it seemed like another standard to build and maintain. However, once understanding the benefits I was convinced it was a worthwhile investment.
|
||||
|
||||
### What was the appeal of snaps that made you decide to invest in them?
|
||||
|
||||
Without doubt, the biggest reason we decided to build the snap is the updating feature. We at Slack make heavy use of web technologies, which in turn allows us to offer a wide variety of features – like the integration of YouTube videos or Spotify playlists. Much like a browser, that means that we frequently need to update the application.
|
||||
|
||||
On macOS and Windows, we already had a dedicated auto-updater that doesn’t require the user to even think about updates. We have found that any sort of interruption, even for an update, is an annoyance that we’d like to avoid. Therefore, the automatic updates via snaps seemed far more seamless and easy.
|
||||
|
||||
### How does building snaps compare to other forms of packaging you produce? How easy was it to integrate with your existing infrastructure and process?
|
||||
|
||||
As far as Linux is concerned, we have not tried other “new” packaging formats, but we’ll never say never. Snaps were an easy choice given that the majority of our Linux customers do use Ubuntu. The fact that snaps also run on other distributions was a decent bonus. I think it is really neat how Canonical is making snaps cross-distro rather than focusing on just Ubuntu.
|
||||
|
||||
Building it was surprisingly easy: We have one unified build process that creates installers and packages – and our snap creation simply takes the .deb package and churns out a snap. For other technologies, we sometimes had to build in-house tools to support our buildchain, but the `snapcraft` tool turned out to be just the right thing. The team at Canonical were incredibly helpful to push it through as we did experience a few problems along the way.
|
||||
|
||||
### How do you see the store changing the way users find and install your software?
|
||||
|
||||
What is really unique about Slack is that people don’t just stumble upon it – they know about it from elsewhere and actively try to find it. Therefore, our levels of awareness are already high but having the snap available in the store, I hope, will make installation a lot easier for our users.
|
||||
|
||||
We always try to do the best for our users. The more convinced we become that it is better than other installation options, the more we will recommend the snap to our users.
|
||||
|
||||
### What are your expectations or already seen savings by using snaps instead of having to package for other distros?
|
||||
|
||||
We expect the snap to offer more convenience for our users and ensure they enjoy using Slack more. From our side, the snap will save time on customer support as users won’t be stuck on previous versions which will naturally resolve a lot of issues. Having the snap is an additional bonus for us and something to build on, rather than displacing anything we already have.
|
||||
|
||||
### What release channels (edge/beta/candidate/stable) in the store are you using or plan to use, if any?
|
||||
|
||||
We used the edge channel exclusively in the development to share with the team at Canonical. Slack for Linux as a whole is still in beta, but long-term, having the options for channels is interesting and being able to release versions to interested customers a little earlier will certainly be beneficial.
|
||||
|
||||
### How do you think packaging your software as a snap helps your users? Did you get any feedback from them?
|
||||
|
||||
Installation and updating generally being easier will be the big benefit to our users. Long-term, the question is “Will users that installed the snap experience less problems than other customers?” I have a decent amount of hope that the built-in dependencies in snaps make it likely.
|
||||
|
||||
### What advice or knowledge would you share with developers who are new to snaps?
|
||||
|
||||
I would recommend starting with the Debian package to build your snap – that was shockingly easy. It also starts the scope smaller to avoid being overwhelmed. It is a fairly small time investment and probably worth it. Also if you can, try to find someone at Canonical to work with – they have amazing engineers.
|
||||
|
||||
### Where do you see the biggest opportunity for development?
|
||||
|
||||
We are taking it step by step currently – first get people on the snap, and build from there. People using it will already be more secure as they will benefit from the latest updates.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2018/02/06/building-slack-for-the-linux-community-and-adopting-snaps/
|
||||
|
||||
作者:[Sarah][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sarahfd/
|
||||
[1]:https://insights.ubuntu.com/wp-content/uploads/a115/Slack_linux_screenshot@2x-2.png
|
||||
[2]:https://slack.com/
|
||||
[3]:https://insights.ubuntu.com/2018/01/18/canonical-brings-slack-to-the-snap-ecosystem/
|
||||
[4]:https://snapcraft.io/slack/
|
||||
@ -0,0 +1,49 @@
|
||||
How to start an open source program in your company
|
||||
======
|
||||
|
||||

|
||||
|
||||
Many internet-scale companies, including Google, Facebook, and Twitter, have established formal open source programs (sometimes referred to as open source program offices, or OSPOs for short), a designated place where open source consumption and production is supported inside a company. With such an office in place, any business can execute its open source strategies in clear terms, giving the company tools needed to make open source a success. An open source program office's responsibilities may include establishing policies for code use, distribution, selection, and auditing; engaging with open source communities; training developers; and ensuring legal compliance.
|
||||
|
||||
Internet-scale companies aren't the only ones establishing open source programs; studies show that [65% of companies][1] across industries are using and contributing to open source. In the last couple of years we’ve seen [VMware][2], [Amazon][3], [Microsoft][4], and even the [UK government][5] hire open source leaders and/or create open source programs. Having an open source strategy has become critical for businesses and even governments, and all organizations should be following in their footsteps.
|
||||
|
||||
### How to start an open source program
|
||||
|
||||
Although each open source office will be customized to a specific organization’s needs, there are standard steps that every company goes through. These include:
|
||||
|
||||
* **Finding a leader:** Identifying the right person to lead the open source program is the first step. The [TODO Group][6] maintains a list of [sample job descriptions][7] that may be helpful in finding candidates.
|
||||
* **Deciding on the program structure:** There are a variety of ways to fit an open source program office into an organization's existing structure, depending on its focus. Companies with large intellectual property portfolios may be most comfortable placing the office within the legal department. Engineering-driven organizations may choose to place the office in an engineering department, especially if the focus of the office is to improve developer productivity. Others may want the office to be within the marketing department to support sales of open source products. For inspiration, the TODO Group offers [open source program case studies][8] that can be useful.
|
||||
* **Setting policies and processes:** There needs to be a standardized method for implementing the organization’s open source strategy. The policies, which should require as little oversight as possible, lay out the requirements and rules for working with open source across the organization. They should be clearly defined, easily accessible, and even automated with tooling. Ideally, employees should be able to question policies and provide recommendations for improving or revising them. Numerous organizations active in open source, such as Google, [publish their policies publicly][9], which can be a good place to start. The TODO Group offers examples of other [open source policies][10] organizations can use as resources.
|
||||
|
||||
|
||||
|
||||
### A worthy step
|
||||
|
||||
Opening an open source program office is a big step for most organizations, especially if they are (or are transitioning into) a software company. The benefits to the organization are tremendous and will more than make up for the investment in the long run—not only in employee satisfaction but also in developer efficiency. There are many resources to help on the journey. The TODO Group guides [How to Create an Open Source Program][11], [Measuring Your Open Source Program's Success][12], and [Tools for Managing Open Source Programs][13] are great starting points.
|
||||
|
||||
Open source will truly be sustainable as more companies formalize programs to contribute back to these projects. I hope these resources are useful to you, and I wish you luck on your open source program journey.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-start-open-source-program-your-company
|
||||
|
||||
作者:[Chris Aniszczyk][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/caniszczyk
|
||||
[1]:https://www.blackducksoftware.com/2016-future-of-open-source
|
||||
[2]:http://www.cio.com/article/3095843/open-source-tools/vmware-today-has-a-strong-investment-in-open-source-dirk-hohndel.html
|
||||
[3]:http://fortune.com/2016/12/01/amazon-open-source-guru/
|
||||
[4]:https://opensource.microsoft.com/
|
||||
[5]:https://www.linkedin.com/jobs/view/169669924
|
||||
[6]:http://todogroup.org
|
||||
[7]:https://github.com/todogroup/job-descriptions
|
||||
[8]:https://github.com/todogroup/guides/tree/master/casestudies
|
||||
[9]:https://opensource.google.com/docs/why/
|
||||
[10]:https://github.com/todogroup/policies
|
||||
[11]:https://github.com/todogroup/guides/blob/master/creating-an-open-source-program.md
|
||||
[12]:https://github.com/todogroup/guides/blob/master/measuring-your-open-source-program.md
|
||||
[13]:https://github.com/todogroup/guides/blob/master/tools-for-managing-open-source-programs.md
|
||||
@ -0,0 +1,99 @@
|
||||
UQDS: A software-development process that puts quality first
|
||||
======
|
||||
|
||||

|
||||
|
||||
The Ultimate Quality Development System (UQDS) is a software development process that provides clear guidelines for how to use branches, tickets, and code reviews. It was invented more than a decade ago by Divmod and adopted by [Twisted][1], an event-driven framework for Python that underlies popular commercial platforms like HipChat as well as open source projects like Scrapy (a web scraper).
|
||||
|
||||
Divmod, sadly, is no longer around—it has gone the way of many startups. Luckily, since many of its products were open source, its legacy lives on.
|
||||
|
||||
When Twisted was a young project, there was no clear process for when code was "good enough" to go in. As a result, while some parts were highly polished and reliable, others were alpha quality software—with no way to tell which was which. UQDS was designed as a process to help an existing project with definite quality challenges ramp up its quality while continuing to add features and become more useful.
|
||||
|
||||
UQDS has helped the Twisted project evolve from having frequent regressions and needing multiple release candidates to get a working version, to achieving its current reputation of stability and reliability.
|
||||
|
||||
### UQDS's building blocks
|
||||
|
||||
UQDS was invented by Divmod back in 2006. At that time, Continuous Integration (CI) was in its infancy and modern version control systems, which allow easy branch merging, were barely proofs of concept. Although Divmod did not have today's modern tooling, it put together CI, some ad-hoc tooling to make [Subversion branches][2] work, and a lot of thought into a working process. Thus the UQDS methodology was born.
|
||||
|
||||
UQDS is based upon fundamental building blocks, each with their own carefully considered best practices:
|
||||
|
||||
1. Tickets
|
||||
2. Branches
|
||||
3. Tests
|
||||
4. Reviews
|
||||
5. No exceptions
|
||||
|
||||
|
||||
|
||||
Let's go into each of those in a little more detail.
|
||||
|
||||
#### Tickets
|
||||
|
||||
In a project using the UQDS methodology, no change is allowed to happen if it's not accompanied by a ticket. This creates a written record of what change is needed and—more importantly—why.
|
||||
|
||||
* Tickets should define clear, measurable goals.
|
||||
* Work on a ticket does not begin until the ticket contains goals that are clearly defined.
|
||||
|
||||
|
||||
|
||||
#### Branches
|
||||
|
||||
Branches in UQDS are tightly coupled with tickets. Each branch must solve one complete ticket, no more and no less. If a branch addresses either more or less than a single ticket, it means there was a problem with the ticket definition—or with the branch. Tickets might be split or merged, or a branch split and merged, until congruence is achieved.
|
||||
|
||||
Enforcing that each branch addresses no more nor less than a single ticket—which corresponds to one logical, measurable change—allows a project using UQDS to have fine-grained control over the commits: A single change can be reverted or changes may even be applied in a different order than they were committed. This helps the project maintain a stable and clean codebase.
|
||||
|
||||
#### Tests
|
||||
|
||||
UQDS relies upon automated testing of all sorts, including unit, integration, regression, and static tests. In order for this to work, all relevant tests must pass at all times. Tests that don't pass must either be fixed or, if no longer relevant, be removed entirely.
|
||||
|
||||
Tests are also coupled with tickets. All new work must include tests that demonstrate that the ticket goals are fully met. Without this, the work won't be merged no matter how good it may seem to be.
|
||||
|
||||
A side effect of the focus on tests is that the only platforms that a UQDS-using project can say it supports are those on which the tests run with a CI framework—and where passing the test on the platform is a condition for merging a branch. Without this restriction on supported platforms, the quality of the project is not Ultimate.
|
||||
|
||||
#### Reviews
|
||||
|
||||
While automated tests are important to the quality ensured by UQDS, the methodology never loses sight of the human factor. Every branch commit requires code review, and each review must follow very strict rules:
|
||||
|
||||
1. Each commit must be reviewed by a different person than the author.
|
||||
2. Start with a comment thanking the contributor for their work.
|
||||
3. Make a note of something that the contributor did especially well (e.g., "that's the perfect name for that variable!").
|
||||
4. Make a note of something that could be done better (e.g., "this line could use a comment explaining the choices.").
|
||||
5. Finish with directions for an explicit next step, typically either merge as-is, fix and merge, or fix and submit for re-review.
|
||||
|
||||
|
||||
|
||||
These rules respect the time and effort of the contributor while also increasing the sharing of knowledge and ideas. The explicit next step allows the contributor to have a clear idea on how to make progress.
|
||||
|
||||
#### No exceptions
|
||||
|
||||
In any process, it's easy to come up with reasons why you might need to flex the rules just a little bit to let this thing or that thing slide through the system. The most important fundamental building block of UQDS is that there are no exceptions. The entire community works together to make sure that the rules do not flex, not for any reason whatsoever.
|
||||
|
||||
Knowing that all code has been approved by a different person than the author, that the code has complete test coverage, that each branch corresponds to a single ticket, and that this ticket is well considered and complete brings a piece of mind that is too valuable to risk losing, even for a single small exception. The goal is quality, and quality does not come from compromise.
|
||||
|
||||
### A downside to UQDS
|
||||
|
||||
While UQDS has helped Twisted become a highly stable and reliable project, this reliability hasn't come without cost. We quickly found that the review requirements caused a slowdown and backlog of commits to review, leading to slower development. The answer to this wasn't to compromise on quality by getting rid of UQDS; it was to refocus the community priorities such that reviewing commits became one of the most important ways to contribute to the project.
|
||||
|
||||
To help with this, the community developed a bot in the [Twisted IRC channel][3] that will reply to the command `review tickets` with a list of tickets that still need review. The [Twisted review queue][4] website returns a prioritized list of tickets for review. Finally, the entire community keeps close tabs on the number of tickets that need review. It's become an important metric the community uses to gauge the health of the project.
|
||||
|
||||
### Learn more
|
||||
|
||||
The best way to learn about UQDS is to [join the Twisted Community][5] and see it in action. If you'd like more information about the methodology and how it might help your project reach a high level of reliability and stability, have a look at the [UQDS documentation][6] in the Twisted wiki.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/uqds
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/moshez
|
||||
[1]:https://twistedmatrix.com/trac/
|
||||
[2]:http://structure.usc.edu/svn/svn.branchmerge.html
|
||||
[3]:http://webchat.freenode.net/?channels=%23twisted
|
||||
[4]:https://twisted.reviews
|
||||
[5]:https://twistedmatrix.com/trac/wiki/TwistedCommunity
|
||||
[6]:https://twistedmatrix.com/trac/wiki/UltimateQualityDevelopmentSystem
|
||||
@ -0,0 +1,102 @@
|
||||
Why Linux is better than Windows or macOS for security
|
||||
======
|
||||
|
||||

|
||||
|
||||
Enterprises invest a lot of time, effort and money in keeping their systems secure. The most security-conscious might have a security operations center. They of course use firewalls and antivirus tools. They probably spend a lot of time monitoring their networks, looking for telltale anomalies that could indicate a breach. What with IDS, SIEM and NGFWs, they deploy a veritable alphabet of defenses.
|
||||
|
||||
But how many have given much thought to one of the cornerstones of their digital operations: the operating systems deployed on the workforce’s PCs? Was security even a factor when the desktop OS was selected?
|
||||
|
||||
This raises a question that every IT person should be able to answer: Which operating system is the most secure for general deployment?
|
||||
|
||||
We asked some experts what they think of the security of these three choices: Windows, the ever-more-complex platform that’s easily the most popular desktop system; macOS X, the FreeBSD Unix-based operating system that powers Apple Macintosh systems; and Linux, by which we mean all the various Linux distributions and related Unix-based systems.
|
||||
|
||||
### How we got here
|
||||
|
||||
One reason enterprises might not have evaluated the security of the OS they deployed to the workforce is that they made the choice years ago. Go back far enough and all operating systems were reasonably safe, because the business of hacking into them and stealing data or installing malware was in its infancy. And once an OS choice is made, it’s hard to consider a change. Few IT organizations would want the headache of moving a globally dispersed workforce to an entirely new OS. Heck, they get enough pushback when they move users to a new version of their OS of choice.
|
||||
|
||||
Still, would it be wise to reconsider? Are the three leading desktop OSes different enough in their approach to security to make a change worthwhile?
|
||||
|
||||
Certainly the threats confronting enterprise systems have changed in the last few years. Attacks have become far more sophisticated. The lone teen hacker that once dominated the public imagination has been supplanted by well-organized networks of criminals and shadowy, government-funded organizations with vast computing resources.
|
||||
|
||||
Like many of you, I have firsthand experience of the threats that are out there: I have been infected by malware and viruses on numerous Windows computers, and I even had macro viruses that infected files on my Mac. More recently, a widespread automated hack circumvented the security on my website and infected it with malware. The effects of such malware were always initially subtle, something you wouldn’t even notice, until the malware ended up so deeply embedded in the system that performance started to suffer noticeably. One striking thing about the infestations was that I was never specifically targeted by the miscreants; nowadays, it’s as easy to attack 100,000 computers with a botnet as it is to attack a dozen.
|
||||
|
||||
### Does the OS really matter?
|
||||
|
||||
The OS you deploy to your users does make a difference for your security stance, but it isn’t a sure safeguard. For one thing, a breach these days is more likely to come about because an attacker probed your users, not your systems. A [survey][1] of hackers who attended a recent DEFCON conference revealed that “84 percent use social engineering as part of their attack strategy.” Deploying a secure operating system is an important starting point, but without user education, strong firewalls and constant vigilance, even the most secure networks can be invaded. And of course there’s always the risk of user-downloaded software, extensions, utilities, plug-ins and other software that appears benign but becomes a path for malware to appear on the system.
|
||||
|
||||
And no matter which platform you choose, one of the best ways to keep your system secure is to ensure that you apply software updates promptly. Once a patch is in the wild, after all, the hackers can reverse engineer it and find a new exploit they can use in their next wave of attacks.
|
||||
|
||||
And don’t forget the basics. Don’t use root, and don’t grant guest access to even older servers on the network. Teach your users how to pick really good passwords and arm them with tools such as [1Password][2] that make it easier for them to have different passwords on every account and website they use.
|
||||
|
||||
Because the bottom line is that every decision you make regarding your systems will affect your security, even the operating system your users do their work on.
|
||||
|
||||
**[ To comment on this story, visit[Computerworld's Facebook page][3]. ]**
|
||||
|
||||
### Windows, the popular choice
|
||||
|
||||
If you’re a security manager, it is extremely likely that the questions raised by this article could be rephrased like so: Would we be more secure if we moved away from Microsoft Windows? To say that Windows dominates the enterprise market is to understate the case. [NetMarketShare][4] estimates that a staggering 88% of all computers on the internet are running a version of Windows.
|
||||
|
||||
If your systems fall within that 88%, you’re probably aware that Microsoft has continued to beef up security in the Windows system. Among its improvements have been rewriting and re-rewriting its operating system codebase, adding its own antivirus software system, improving firewalls and implementing a sandbox architecture, where programs can’t access the memory space of the OS or other applications.
|
||||
|
||||
But the popularity of Windows is a problem in itself. The security of an operating system can depend to a large degree on the size of its installed base. For malware authors, Windows provides a massive playing field. Concentrating on it gives them the most bang for their efforts.
|
||||
As Troy Wilkinson, CEO of Axiom Cyber Solutions, explains, “Windows always comes in last in the security world for a number of reasons, mainly because of the adoption rate of consumers. With a large number of Windows-based personal computers on the market, hackers historically have targeted these systems the most.”
|
||||
|
||||
It’s certainly true that, from Melissa to WannaCry and beyond, much of the malware the world has seen has been aimed at Windows systems.
|
||||
|
||||
### macOS X and security through obscurity
|
||||
|
||||
If the most popular OS is always going to be the biggest target, then can using a less popular option ensure security? That idea is a new take on the old — and entirely discredited — concept of “security through obscurity,” which held that keeping the inner workings of software proprietary and therefore secret was the best way to defend against attacks.
|
||||
|
||||
Wilkinson flatly states that macOS X “is more secure than Windows,” but he hastens to add that “macOS used to be considered a fully secure operating system with little chance of security flaws, but in recent years we have seen hackers crafting additional exploits against macOS.”
|
||||
|
||||
In other words, the attackers are branching out and not ignoring the Mac universe.
|
||||
|
||||
Security researcher Lee Muson of Comparitech says that “macOS is likely to be the pick of the bunch” when it comes to choosing a more secure OS, but he cautions that it is not impenetrable, as once thought. Its advantage is that “it still benefits from a touch of security through obscurity versus the still much larger target presented by Microsoft’s offering.”
|
||||
|
||||
Joe Moore of Wolf Solutions gives Apple a bit more credit, saying that “off the shelf, macOS X has a great track record when it comes to security, in part because it isn’t as widely targeted as Windows and in part because Apple does a pretty good job of staying on top of security issues.”
|
||||
|
||||
### And the winner is …
|
||||
|
||||
You probably knew this from the beginning: The clear consensus among experts is that Linux is the most secure operating system. But while it’s the OS of choice for servers, enterprises deploying it on the desktop are few and far between.
|
||||
|
||||
And if you did decide that Linux was the way to go, you would still have to decide which distribution of the Linux system to choose, and things get a bit more complicated there. Users are going to want a UI that seems familiar, and you are going to want the most secure OS.
|
||||
|
||||
As Moore explains, “Linux has the potential to be the most secure, but requires the user be something of a power user.” So, not for everyone.
|
||||
|
||||
Linux distros that target security as a primary feature include [Parrot Linux][5], a Debian-based distro that Moore says provides numerous security-related tools right out of the box.
|
||||
|
||||
Of course, an important differentiator is that Linux is open source. The fact that coders can read and comment upon each other’s work might seem like a security nightmare, but it actually turns out to be an important reason why Linux is so secure, says Igor Bidenko, CISO of Simplex Solutions. “Linux is the most secure OS, as its source is open. Anyone can review it and make sure there are no bugs or back doors.”
|
||||
|
||||
Wilkinson elaborates that “Linux and Unix-based operating systems have less exploitable security flaws known to the information security world. Linux code is reviewed by the tech community, which lends itself to security: By having that much oversight, there are fewer vulnerabilities, bugs and threats.”
|
||||
|
||||
That’s a subtle and perhaps counterintuitive explanation, but by having dozens — or sometimes hundreds — of people read through every line of code in the operating system, the code is actually more robust and the chance of flaws slipping into the wild is diminished. That had a lot to do with why PC World came right out and said Linux is more secure. As Katherine Noyes [explains][6], “Microsoft may tout its large team of paid developers, but it’s unlikely that team can compare with a global base of Linux user-developers around the globe. Security can only benefit through all those extra eyeballs.”
|
||||
|
||||
Another factor cited by PC World is Linux’s better user privileges model: Windows users “are generally given administrator access by default, which means they pretty much have access to everything on the system,” according to Noyes’ article. Linux, in contrast, greatly restricts “root.”
|
||||
|
||||
Noyes also noted that the diversity possible within Linux environments is a better hedge against attacks than the typical Windows monoculture: There are simply a lot of different distributions of Linux available. And some of them are differentiated in ways that specifically address security concerns. Security Researcher Lee Muson of Comparitech offers this suggestion for a Linux distro: “The[Qubes OS][7] is as good a starting point with Linux as you can find right now, with an [endorsement from Edward Snowden][8] massively overshadowing its own extremely humble claims.” Other security experts point to specialized secure Linux distributions such as [Tails Linux][9], designed to run securely and anonymously directly from a USB flash drive or similar external device.
|
||||
|
||||
### Building security momentum
|
||||
|
||||
Inertia is a powerful force. Although there is clear consensus that Linux is the safest choice for the desktop, there has been no stampede to dump Windows and Mac machines in favor of it. Nonetheless, a small but significant increase in Linux adoption would probably result in safer computing for everyone, because in market share loss is one sure way to get Microsoft’s and Apple’s attention. In other words, if enough users switch to Linux on the desktop, Windows and Mac PCs are very likely to become more secure platforms.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.computerworld.com/article/3252823/linux/why-linux-is-better-than-windows-or-macos-for-security.html
|
||||
|
||||
作者:[Dave Taylor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.computerworld.com/author/Dave-Taylor/
|
||||
[1]:https://www.esecurityplanet.com/hackers/fully-84-percent-of-hackers-leverage-social-engineering-in-attacks.html
|
||||
[2]:http://www.1password.com
|
||||
[3]:https://www.facebook.com/Computerworld/posts/10156160917029680
|
||||
[4]:https://www.netmarketshare.com/operating-system-market-share.aspx?options=%7B%22filter%22%3A%7B%22%24and%22%3A%5B%7B%22deviceType%22%3A%7B%22%24in%22%3A%5B%22Desktop%2Flaptop%22%5D%7D%7D%5D%7D%2C%22dateLabel%22%3A%22Trend%22%2C%22attributes%22%3A%22share%22%2C%22group%22%3A%22platform%22%2C%22sort%22%3A%7B%22share%22%3A-1%7D%2C%22id%22%3A%22platformsDesktop%22%2C%22dateInterval%22%3A%22Monthly%22%2C%22dateStart%22%3A%222017-02%22%2C%22dateEnd%22%3A%222018-01%22%2C%22segments%22%3A%22-1000%22%7D
|
||||
[5]:https://www.parrotsec.org/
|
||||
[6]:https://www.pcworld.com/article/202452/why_linux_is_more_secure_than_windows.html
|
||||
[7]:https://www.qubes-os.org/
|
||||
[8]:https://twitter.com/snowden/status/781493632293605376?lang=en
|
||||
[9]:https://tails.boum.org/about/index.en.html
|
||||
@ -0,0 +1,295 @@
|
||||
Prevent Files And Folders From Accidental Deletion Or Modification In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Some times, I accidentally “SHIFT+DELETE” my data. Yes, I am an idiot who don’t double check what I am exactly going to delete. And, I am too dumb or lazy to backup the data. Result? Data loss! They are gone in a fraction of second. I do it every now and then. If you’re anything like me, I’ve got a good news. There is a simple, yet useful commandline utility called **“chattr”** (abbreviation of **Ch** ange **Attr** ibute) which can be used to prevent files and folders from accidental deletion or modification in Unix-like distributions. It applies/removes certain attributes to a file or folder in your Linux system. So the users can’t delete or modify the files and folders either accidentally or intentionally, even as root user. Sounds useful, isn’t it?
|
||||
|
||||
In this brief tutorial, we are going to see how to use chattr in real time in-order to prevent files and folders from accidental deletion in Linux.
|
||||
|
||||
### Prevent Files And Folders From Accidental Deletion Or Modification In Linux
|
||||
|
||||
By default, Chattr is available in most modern Linux operating systems. Let us see some examples.
|
||||
|
||||
The default syntax of chattr command is:
|
||||
```
|
||||
chattr [operator] [switch] [filename]
|
||||
|
||||
```
|
||||
|
||||
chattr has the following operators.
|
||||
|
||||
* The operator **‘+’** causes the selected attributes to be added to the existing attributes of the files;
|
||||
* The operator **‘-‘** causes them to be removed;
|
||||
* The operator **‘=’** causes them to be the only attributes that the files have.
|
||||
|
||||
|
||||
|
||||
Chattr has different attributes namely – **aAcCdDeijsStTu**. Each letter applies a particular attributes to a file.
|
||||
|
||||
* **a** – append only,
|
||||
* **A** – no atime updates,
|
||||
* **c** – compressed,
|
||||
* **C** – no copy on write,
|
||||
* **d** – no dump,
|
||||
* **D** – synchronous directory updates,
|
||||
* **e** – extent format,
|
||||
* **i** – immutable,
|
||||
* **j** – data journalling,
|
||||
* **P** – project hierarchy,
|
||||
* **s** – secure deletion,
|
||||
* **S** – synchronous updates,
|
||||
* **t** – no tail-merging,
|
||||
* **T** – top of directory hierarchy,
|
||||
* **u** – undeletable.
|
||||
|
||||
|
||||
|
||||
In this tutorial, we are going to discuss the usage of two attributes, namely **a** , **i** which are used to prevent the deletion of files and folders. That’s what our topic today, isn’t? Indeed!
|
||||
|
||||
### Prevent files from accidental deletion
|
||||
|
||||
Let me create a file called **file.txt** in my current directory.
|
||||
```
|
||||
$ touch file.txt
|
||||
|
||||
```
|
||||
|
||||
Now, I am going to apply **“i”** attribute which makes the file immutable. It means you can’t delete, modify the file, even if you’re the file owner and the root user.
|
||||
```
|
||||
$ sudo chattr +i file.txt
|
||||
|
||||
```
|
||||
|
||||
You can check the file attributes using command:
|
||||
```
|
||||
$ lsattr file.txt
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
----i---------e---- file.txt
|
||||
|
||||
```
|
||||
|
||||
Now, try to remove the file either as a normal user or with sudo privileges.
|
||||
```
|
||||
$ rm file.txt
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
rm: cannot remove 'file.txt': Operation not permitted
|
||||
|
||||
```
|
||||
|
||||
Let me try with sudo command:
|
||||
```
|
||||
$ sudo rm file.txt
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
rm: cannot remove 'file.txt': Operation not permitted
|
||||
|
||||
```
|
||||
|
||||
Let us try to append some contents in the text file.
|
||||
```
|
||||
$ echo 'Hello World!' >> file.txt
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
bash: file.txt: Operation not permitted
|
||||
|
||||
```
|
||||
|
||||
Try with **sudo** privilege:
|
||||
```
|
||||
$ sudo echo 'Hello World!' >> file.txt
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
bash: file.txt: Operation not permitted
|
||||
|
||||
```
|
||||
|
||||
As you noticed in the above outputs, We can’t delete or modify the file even as root user or the file owner.
|
||||
|
||||
To revoke attributes, just use **“-i”** switch as shown below.
|
||||
```
|
||||
$ sudo chattr -i file.txt
|
||||
|
||||
```
|
||||
|
||||
Now, the immutable attribute has been removed. You can now delete or modify the file.
|
||||
```
|
||||
$ rm file.txt
|
||||
|
||||
```
|
||||
|
||||
Similarly, you can restrict the directories from accidental deletion or modification as described in the next section.
|
||||
|
||||
### Prevent folders from accidental deletion and modification
|
||||
|
||||
Create a directory called dir1 and a file called file.txt inside this directory.
|
||||
```
|
||||
$ mkdir dir1 && touch dir1/file.txt
|
||||
|
||||
```
|
||||
|
||||
Now, make this directory and its contents (file.txt) immutable using command:
|
||||
```
|
||||
$ sudo chattr -R +i dir1
|
||||
|
||||
```
|
||||
|
||||
Where,
|
||||
|
||||
* **-R** – will make the dir1 and its contents immutable recursively.
|
||||
* **+i** – makes the directory immutable.
|
||||
|
||||
|
||||
|
||||
Now, try to delete the directory either as normal user or using sudo user.
|
||||
```
|
||||
$ rm -fr dir1
|
||||
|
||||
$ sudo rm -fr dir1
|
||||
|
||||
```
|
||||
|
||||
You will get the following output:
|
||||
```
|
||||
rm: cannot remove 'dir1/file.txt': Operation not permitted
|
||||
|
||||
```
|
||||
|
||||
Try to append some contents in the file using “echo” command. Did you make it? Of course, you couldn’t!
|
||||
|
||||
To revoke the attributes back, run:
|
||||
```
|
||||
$ sudo chattr -R -i dir1
|
||||
|
||||
```
|
||||
|
||||
Now, you can delete or modify the contents of this directory as usual.
|
||||
|
||||
### Prevent files and folders from accidental deletion, but allow append operation
|
||||
|
||||
We know now how to prevent files and folders from accidental deletion and modification. Next, we are going to prevent files and folders from deletion, but allow the file for writing in append mode only. That means you can’t edit, modify the existing data in the file, rename the file, and delete the file. You can only open the file for writing in append mode.
|
||||
|
||||
To set append mode attribution to a file/directory, we do the following.
|
||||
|
||||
**For files:**
|
||||
```
|
||||
$ sudo chattr +a file.txt
|
||||
|
||||
```
|
||||
|
||||
**For directories: **
|
||||
```
|
||||
$ sudo chattr -R +a dir1
|
||||
|
||||
```
|
||||
|
||||
A file/folder with the ‘a’ attribute set can only be open in append mode for writing.
|
||||
|
||||
Add some contents to the file(s) to check whether it works or not.
|
||||
```
|
||||
$ echo 'Hello World!' >> file.txt
|
||||
|
||||
$ echo 'Hello World!' >> dir1/file.txt
|
||||
|
||||
```
|
||||
|
||||
Check the file contents using cat command:
|
||||
```
|
||||
$ cat file.txt
|
||||
|
||||
$ cat dir1/file.txt
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Hello World!
|
||||
|
||||
```
|
||||
|
||||
You will see that you can now be able to append the contents. It means we can modify the files and folders.
|
||||
|
||||
Let us try to delete the file or folder now.
|
||||
```
|
||||
$ rm file.txt
|
||||
|
||||
```
|
||||
|
||||
**Output:**
|
||||
```
|
||||
rm: cannot remove 'file.txt': Operation not permitted
|
||||
|
||||
```
|
||||
|
||||
Let us try to delete the folder:
|
||||
```
|
||||
$ rm -fr dir1/
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
rm: cannot remove 'dir1/file.txt': Operation not permitted
|
||||
|
||||
```
|
||||
|
||||
To remove the attributes, run the following commands:
|
||||
|
||||
**For files:**
|
||||
```
|
||||
$ sudo chattr -R -a file.txt
|
||||
|
||||
```
|
||||
|
||||
**For directories: **
|
||||
```
|
||||
$ sudo chattr -R -a dir1/
|
||||
|
||||
```
|
||||
|
||||
Now, you can delete or modify the files and folders as usual.
|
||||
|
||||
For more details, refer the man pages.
|
||||
```
|
||||
man chattr
|
||||
|
||||
```
|
||||
|
||||
### Wrapping up
|
||||
|
||||
Data protection is one of the main job of a System administrator. There are numerous free and commercial data protection software are available on the market. Luckily, we’ve got this built-in tool that helps us to protect the data from accidental deletion or modification. Chattr can be used as additional tool to protect the important system files and data in your Linux system.
|
||||
|
||||
And, that’s all for today. Hope this helps. I will be soon here with another useful article. Until then, stay tuned with OSTechNix!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,97 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Monitoring network bandwidth with iftop command
|
||||
======
|
||||
System Admins are required to monitor IT infrastructure to make sure that everything is up & running. We have to monitor performance of hardware i.e memory, hdds & CPUs etc & so does we have to monitor our network. We need to make sure that our network is not being over utilised or our applications, websites might not work. In this tutorial, we are going to learn to use IFTOP utility.
|
||||
|
||||
( **Recommended read** :[ **Resource monitoring using Nagios**][1], [**Tools for checking system info**,][2] [**Important logs to monitor**][3])
|
||||
|
||||
Iftop is network monitoring utility that provides real time real time bandwidth monitoring. Iftop measures total data moving in & out of the individual socket connections i.e. it captures packets moving in and out via network adapter & than sums those up to find the bandwidth being utilized.
|
||||
|
||||
## Installation on Debian/Ubuntu
|
||||
|
||||
Iftop is available with default repositories of Debian/Ubuntu & can be simply installed using the command below,
|
||||
|
||||
```
|
||||
$ sudo apt-get install iftop
|
||||
```
|
||||
|
||||
## Installation on RHEL/Centos using yum
|
||||
|
||||
For installing iftop on CentOS or RHEL, we need to enable EPEL repository. To enable repository, run the following on your terminal,
|
||||
|
||||
### RHEL/CentOS 7
|
||||
|
||||
```
|
||||
$ rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-10.noarch.rpm
|
||||
```
|
||||
|
||||
### RHEL/CentOS 6 (64 Bit)
|
||||
|
||||
```
|
||||
$ rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
### RHEL/CentOS 6 (32 Bit)
|
||||
|
||||
```
|
||||
$ rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
After epel repository has been installed, we can now install iftop by running,
|
||||
|
||||
```
|
||||
$ yum install iftop
|
||||
```
|
||||
|
||||
This will install iftop utility on your system. We will now use it to monitor our network,
|
||||
|
||||
## Using IFTOP
|
||||
|
||||
You can start using iftop by opening your terminal windown & type,
|
||||
|
||||
```
|
||||
$ iftop
|
||||
```
|
||||
|
||||
![network monitoring][5]
|
||||
|
||||
You will now be presented with network activity happening on your machine. You can also use
|
||||
|
||||
```
|
||||
$ iftop -n
|
||||
```
|
||||
|
||||
Which will present the network information on your screen but with '-n' , you will not be presented with the names related to IP addresses but only ip addresses. This option allows for some bandwidth to be saved, which goes into resolving IP addresses to names.
|
||||
|
||||
Now we can also see all the commands that can be used with iftop. Once you have ran iftop, press 'h' button on the keyboard to see all the commands that can be used with iftop.
|
||||
|
||||
![network monitoring][7]
|
||||
|
||||
To monitor a particular network interface, we can mention interface with iftop,
|
||||
|
||||
```
|
||||
$ iftop -I enp0s3
|
||||
```
|
||||
|
||||
You can check further options that are used with iftop using help, as mentioned above. But these mentioned examples are only what you might to monitor network.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/monitoring-network-bandwidth-iftop-command/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/installing-configuring-nagios-server/
|
||||
[2]:http://linuxtechlab.com/commands-system-hardware-info/
|
||||
[3]:http://linuxtechlab.com/important-logs-monitor-identify-issues/
|
||||
[4]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=661%2C424
|
||||
[5]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/04/iftop-1.jpg?resize=661%2C424
|
||||
[6]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=663%2C416
|
||||
[7]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/04/iftop-help.jpg?resize=663%2C416
|
||||
193
sources/tech/20180123 Migrating to Linux- The Command Line.md
Normal file
193
sources/tech/20180123 Migrating to Linux- The Command Line.md
Normal file
@ -0,0 +1,193 @@
|
||||
Migrating to Linux: The Command Line
|
||||
======
|
||||
|
||||

|
||||
|
||||
This is the fourth article in our series on migrating to Linux. If you missed the previous installments, we've covered [Linux for new users][1], [files and filesystems][2], and [graphical environments][3]. Linux is everywhere. It's used to run most Internet services like web servers, email servers, and others. It's also used in your cell phone, your car console, and a whole lot more. So, you might be curious to try out Linux and learn more about how it works.
|
||||
|
||||
Under Linux, the command line is very useful. On desktop Linux systems, although the command line is optional, you will often see people have a command line window open alongside other application windows. On Internet servers, and when Linux is running in a device, the command line is often the only way to interact directly with the system. So, it's good to know at least some command line basics.
|
||||
|
||||
In the command line (often called a shell in Linux), everything is done by entering commands. You can list files, move files, display the contents of files, edit files, and more, even display web pages, all from the command line.
|
||||
|
||||
If you are already familiar with using the command line in Windows (either CMD.EXE or PowerShell), you may want to jump down to the section titled Familiar with Windows Command Line? and read that first.
|
||||
|
||||
### Navigating
|
||||
|
||||
In the command line, there is the concept of the current working directory (Note: A folder and a directory are synonymous, and in Linux they're usually called directories). Many commands will look in this directory by default if no other directory path is specified. For example, typing ls to list files, will list files in this working directory. For example:
|
||||
```
|
||||
$ ls
|
||||
Desktop Documents Downloads Music Pictures README.txt Videos
|
||||
```
|
||||
|
||||
The command, ls Documents, will instead list files in the Documents directory:
|
||||
```
|
||||
$ ls Documents
|
||||
report.txt todo.txt EmailHowTo.pdf
|
||||
```
|
||||
|
||||
You can display the current working directory by typing pwd. For example:
|
||||
```
|
||||
$ pwd
|
||||
/home/student
|
||||
```
|
||||
|
||||
You can change the current directory by typing cd and then the directory you want to change to. For example:
|
||||
```
|
||||
$ pwd
|
||||
/home/student
|
||||
$ cd Downloads
|
||||
$ pwd
|
||||
/home/student/Downloads
|
||||
```
|
||||
|
||||
A directory path is a list of directories separated by a / (slash) character. The directories in a path have an implied hierarchy, for example, where the path /home/student expects there to be a directory named home in the top directory, and a directory named student to be in that directory home.
|
||||
|
||||
Directory paths are either absolute or relative. Absolute directory paths start with the / character.
|
||||
|
||||
Relative paths start with either . (dot) or .. (dot dot). In a path, a . (dot) means the current directory, and .. (dot dot) means one directory up from the current one. For example, ls ../Documents means look in the directory up one from the current one and show the contents of the directory named Documents in there:
|
||||
```
|
||||
$ pwd
|
||||
/home/student
|
||||
$ ls
|
||||
Desktop Documents Downloads Music Pictures README.txt Videos
|
||||
$ cd Downloads
|
||||
$ pwd
|
||||
/home/student/Downloads
|
||||
$ ls ../Documents
|
||||
report.txt todo.txt EmailHowTo.pdf
|
||||
```
|
||||
|
||||
When you first open a command line window on a Linux system, your current working directory is set to your home directory, usually: /home/<your login name here>. Your home directory is dedicated to your login where you can store your own files.
|
||||
|
||||
The environment variable $HOME expands to the directory path to your home directory. For example:
|
||||
```
|
||||
$ echo $HOME
|
||||
/home/student
|
||||
```
|
||||
|
||||
The following table shows a summary of some of the common commands used to navigate directories and manage simple text files.
|
||||
|
||||
### Searching
|
||||
|
||||
Sometimes I forget where a file resides, or I forget the name of the file I am looking for. There are a couple of commands in the Linux command line that you can use to help you find files and search the contents of files.
|
||||
|
||||
The first command is find. You can use find to search for files and directories by name or other attribute. For example, if I forgot where I kept my todo.txt file, I can run the following:
|
||||
```
|
||||
$ find $HOME -name todo.txt
|
||||
/home/student/Documents/todo.txt
|
||||
```
|
||||
|
||||
The find program has a lot of features and options. A simple form of the command is:
|
||||
find <directory to search> -name <filename>
|
||||
|
||||
If there is more than one file named todo.txt from the example above, it will show me all the places where it found a file by that name. The find command has many options to search by type (file, directory, or other), by date, newer than date, by size, and more. You can type:
|
||||
```
|
||||
man find
|
||||
```
|
||||
|
||||
to get help on how to use the find command.
|
||||
|
||||
You can also use a command called grep to search inside files for specific contents. For example:
|
||||
```
|
||||
grep "01/02/2018" todo.txt
|
||||
```
|
||||
|
||||
will show me all the lines that have the January 2, 2018 date in them.
|
||||
|
||||
### Getting Help
|
||||
|
||||
There are a lot of commands in Linux, and it would be too much to describe all of them here. So the next best step to show how to get help on commands.
|
||||
|
||||
The command apropos helps you find commands that do certain things. Maybe you want to find out all the commands that operate on directories or get a list of open files, but you don't know what command to run. So, you can try:
|
||||
```
|
||||
apropos directory
|
||||
```
|
||||
|
||||
which will give a list of commands and have the word "directory" in their help text. Or, you can do:
|
||||
```
|
||||
apropos "list open files"
|
||||
```
|
||||
|
||||
which will show one command, lsof, that you can use to list open files.
|
||||
|
||||
If you know the command you need to use but aren't sure which options to use to get it to behave the way you want, you can use the command called man, which is short for manual. You would use man <command>, for example:
|
||||
```
|
||||
man ls
|
||||
```
|
||||
|
||||
You can try man ls on your own. It will give several pages of information.
|
||||
|
||||
The man command explains all the options and parameters you can give to a command, and often will even give an example.
|
||||
|
||||
Many commands often also have a help option (e.g., ls --help), which will give information on how to use a command. The man pages are usually more detailed, while the --help option is useful for a quick lookup.
|
||||
|
||||
### Scripts
|
||||
|
||||
One of the best things about the Linux command line is that the commands that are typed in can be scripted, and run over and over again. Commands can be placed as separate lines in a file. You can put #!/bin/sh as the first line in the file, followed by the commands. Then, once the file is marked as executable, you can run the script as if it were its own command. For example,
|
||||
```
|
||||
--- contents of get_todays_todos.sh ---
|
||||
#!/bin/sh
|
||||
todays_date=`date +"%m/%d/%y"`
|
||||
grep $todays_date $HOME/todos.txt
|
||||
```
|
||||
|
||||
Scripts help automate certain tasks in a set of repeatable steps. Scripts can also get very sophisticated if needed, with loops, conditional statements, routines, and more. There's not space here to go into detail, but you can find more information about Linux bash scripting online.
|
||||
|
||||
Familiar with Windows Command Line?
|
||||
|
||||
If you are familiar with the Windows CMD or PowerShell program, typing commands at a command prompt should feel familiar. However, several things work differently in Linux and if you don't understand those differences, it may be confusing.
|
||||
|
||||
First, under Linux, the PATH environment variable works different than it does under Windows. In Windows, the current directory is assumed to be the first directory on the path, even though it's not listed in the list of directories in PATH. Under Linux, the current directory is not assumed to be on the path, and it is not explicitly put on the path either. Putting . in the PATH environment variable is considered to be a security risk under Linux. In Linux, to run a program in the current directory, you need to prefix it with ./ (which is the file's relative path from the current directory). This trips up a lot of CMD users. For example:
|
||||
```
|
||||
./my_program
|
||||
```
|
||||
|
||||
rather than
|
||||
```
|
||||
my_program
|
||||
```
|
||||
|
||||
In addition, in Windows paths are separated by a ; (semicolon) character in the PATH environment variable. On Linux, in PATH, directories are separated by a : (colon) character. Also in Linux, directories in a single path are separated by a / (slash) character while under Windows directories in a single path are separated by a \ (backslash) character. So a typical PATH environment variable in Windows might look like:
|
||||
```
|
||||
PATH="C:\Program Files;C:\Program Files\Firefox;"
|
||||
while on Linux it might look like:
|
||||
PATH="/usr/bin:/opt/mozilla/firefox"
|
||||
```
|
||||
|
||||
Also note that environment variables are expanded with a $ on Linux, so $PATH expands to the contents of the PATH environment variable whereas in Windows you need to enclose the variable in percent symbols (e.g., %PATH%).
|
||||
|
||||
In Linux, options are commonly passed to programs using a - (dash) character in front of the option, while under Windows options are passed by preceding options with a / (slash) character. So, under Linux, you would do:
|
||||
```
|
||||
a_prog -h
|
||||
```
|
||||
|
||||
rather than
|
||||
```
|
||||
a_prog /h
|
||||
```
|
||||
|
||||
Under Linux, file extensions generally don't signify anything. For example, renaming myscript to myscript.bat doesn't make it executable. Instead to make a file executable, the file's executable permission flag needs to be set. File permissions are covered in more detail next time.
|
||||
|
||||
Under Linux when file and directory names start with a . (dot) character they are hidden. So, for example, if you're told to edit the file, .bashrc, and you don't see it in your home directory, it probably really is there. It's just hidden. In the command line, you can use option -a on the command ls to see hidden files. For example:
|
||||
```
|
||||
ls -a
|
||||
```
|
||||
|
||||
Under Linux, common commands are also different from those in the Windows command line. The following table that shows a mapping from common items used under CMD and the alternative used under Linux.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
[3]:https://www.linux.com/blog/learn/2017/12/migrating-linux-graphical-environments
|
||||
@ -1,133 +0,0 @@
|
||||
Custom Embedded Linux Distributions
|
||||
======
|
||||
### Why Go Custom?
|
||||
|
||||
In the past, many embedded projects used off-the-shelf distributions and stripped them down to bare essentials for a number of reasons. First, removing unused packages reduced storage requirements. Embedded systems are typically shy of large amounts of storage at boot time, and the storage available, in non-volatile memory, can require copying large amounts of the OS to memory to run. Second, removing unused packages reduced possible attack vectors. There is no sense hanging on to potentially vulnerable packages if you don't need them. Finally, removing unused packages reduced distribution management overhead. Having dependencies between packages means keeping them in sync if any one package requires an update from the upstream distribution. That can be a validation nightmare.
|
||||
|
||||
Yet, starting with an existing distribution and removing packages isn't as easy as it sounds. Removing one package might break dependencies held by a variety of other packages, and dependencies can change in the upstream distribution management. Additionally, some packages simply cannot be removed without great pain due to their integrated nature within the boot or runtime process. All of this takes control of the platform outside the project and can lead to unexpected delays in development.
|
||||
|
||||
A popular alternative is to build a custom distribution using build tools available from an upstream distribution provider. Both Gentoo and Debian provide options for this type of bottom-up build. The most popular of these is probably the Debian debootstrap utility. It retrieves prebuilt core components and allows users to cherry-pick the packages of interest in building their platforms. But, debootstrap originally was only for x86 platforms. Although there are ARM (and possibly other) options now, debootstrap and Gentoo's catalyst still take dependency management away from the local project.
|
||||
|
||||
Some people will argue that letting someone else manage the platform software (like Android) is much easier than doing it yourself. But, those distributions are general-purpose, and when you're sitting on a lightweight, resource-limited IoT device, you may think twice about any any advantage that is taken out of your hands.
|
||||
|
||||
### System Bring-Up Primer
|
||||
|
||||
A custom Linux distribution requires a number of software components. The first is the toolchain. A toolchain is a collection of tools for compiling software, including (but not limited to) a compiler, linker, binary manipulation tools and standard C library. Toolchains are built specifically for a target hardware device. A toolchain built on an x86 system that is intended for use with a Raspberry Pi is called a cross-toolchain. When working with small embedded devices with limited memory and storage, it's always best to use a cross-toolchain. Note that even applications written for a specific purpose in a scripted language like JavaScript will need to run on a software platform that needs to be compiled with a cross-toolchain.
|
||||
|
||||

|
||||
|
||||
Figure 1\. Compile Dependencies and Boot Order
|
||||
|
||||
The cross-toolchain is used to build software components for the target hardware. The first component needed is a bootloader. When power is applied to a board, the processor (depending on design) attempts to jump to a specific memory location to start running software. That memory location is where a bootloader is stored. Hardware can have a built-in bootloader that can be run directly from its storage location or it may be copied into memory first before it is run. There also can be multiple bootloaders. A first-stage bootloader would reside on the hardware in NAND or NOR flash, for example. Its sole purpose would be to set up the hardware so a second-stage bootloader, such as one stored on an SD card, can be loaded and run.
|
||||
|
||||
Bootloaders have enough knowledge to get the hardware to the point where it can load Linux into memory and jump to it, effectively handing control over to Linux. Linux is an operating system. This means that, by design, it doesn't actually do anything other than monitor the hardware and provide services to higher layer software—aka applications. The [Linux kernel][1] often is accompanied by a variety of firmware blobs. These are software objects that have been precompiled, often containing proprietary IP (intellectual property) for devices used with the hardware platform. When building a custom distribution, it may be necessary to acquire any firmware blobs not provided by the Linux kernel source tree before beginning compilation of the kernel.
|
||||
|
||||
Applications are stored in the root filesystem. The root filesystem is constructed by compiling and collecting a variety of software libraries, tools, scripts and configuration files. Collectively, these all provide the services, such as network configuration and USB device mounting, required by applications the project will run.
|
||||
|
||||
In summary, a complete system build requires the following components:
|
||||
|
||||
1. A cross-toolchain.
|
||||
|
||||
2. One or more bootloaders.
|
||||
|
||||
3. The Linux kernel and associated firmware blobs.
|
||||
|
||||
4. A root filesystem populated with libraries, tools and utilities.
|
||||
|
||||
5. Custom applications.
|
||||
|
||||
### Start with the Right Tools
|
||||
|
||||
The components of the cross-toolchain can be built manually, but it's a complex process. Fortunately, tools exist that make this process easier. The best of them is probably [Crosstool-NG][2]. This project utilizes the same kconfig menu system used by the Linux kernel to configure the bits and pieces of the toolchain. The key to using this tool is finding the correct configuration items for the target platform. This typically includes the following items:
|
||||
|
||||
1. The target architecture, such as ARM or x86.
|
||||
|
||||
2. Endianness: little (typically Intel) or big (typically ARM or others).
|
||||
|
||||
3. CPU type as it's known to the compiler, such as GCC's use of either -mcpu or --with-cpu.
|
||||
|
||||
4. The floating point type supported, if any, by the CPU, such as GCC's use of either -mfpu or --with-fpu.
|
||||
|
||||
5. Specific version information for the binutils package, the C library and the C compiler.
|
||||
|
||||

|
||||
|
||||
Figure 2. Crosstool-NG Configuration Menu
|
||||
|
||||
The first four are typically available from the processor maker's documentation. It can be hard to find these for relatively new processors, but for the Raspberry Pi or BeagleBoards (and their offspring and off-shoots), you can find the information online at places like the [Embedded Linux Wiki][3].
|
||||
|
||||
The versions of the binutils, C library and C compiler are what will separate the toolchain from any others that might be provided from third parties. First, there are multiple providers of each of these things. Linaro provides bleeding-edge versions for newer processor types, while working to merge support into upstream projects like the GNU C Library. Although you can use a variety of providers, you may want to stick to the stock GNU toolchain or the Linaro versions of the same.
|
||||
|
||||
Another important selection in Crosstool-NG is the version of the Linux kernel. This selection gets headers for use with various toolchain components, but it is does not have to be the same as the Linux kernel you will boot on the target hardware. It's important to choose a kernel that is not newer than the target hardware's kernel. When possible, pick a long-term support kernel that is older than the kernel that will be used on the target hardware.
|
||||
|
||||
For most developers new to custom distribution builds, the toolchain build is the most complex process. Fortunately, binary toolchains are available for many target hardware platforms. If building a custom toolchain becomes problematic, search online at places like the [Embedded Linux Wiki][4] for links to prebuilt toolchains.
|
||||
|
||||
### Booting Options
|
||||
|
||||
The next component to focus on after the toolchain is the bootloader. A bootloader sets up hardware so it can be used by ever more complex software. A first-stage bootloader is often provided by the target platform maker, burned into on-hardware storage like an EEPROM or NOR flash. The first-stage bootloader will make it possible to boot from, for example, an SD card. The Raspberry Pi has such a bootloader, which makes creating a custom bootloader unnecessary.
|
||||
|
||||
Despite that, many projects add a secondary bootloader to perform a variety of tasks. One such task could be to provide a splash animation without using the Linux kernel or userspace tools like plymouth. A more common secondary bootloader task is to make network-based boot or PCI-connected disks available. In those cases, a tertiary bootloader, such as GRUB, may be necessary to get the system running.
|
||||
|
||||
Most important, bootloaders load the Linux kernel and start it running. If the first-stage bootloader doesn't provide a mechanism for passing kernel arguments at boot time, a second-stage bootloader may be necessary.
|
||||
|
||||
A number of open-source bootloaders are available. The [U-Boot project][5] often is used for ARM platforms like the Raspberry Pi. CoreBoot typically is used for x86 platform like the Chromebook. Bootloaders can be very specific to target hardware. The choice of bootloader will depend on overall project requirements and target hardware (search for lists of open-source bootloaders be online).
|
||||
|
||||
### Now Bring the Penguin
|
||||
|
||||
The bootloader will load the Linux kernel into memory and start it running. Linux is like an extended bootloader: it continues hardware setup and prepares to load higher-level software. The core of the kernel will set up and prepare memory for sharing between applications and hardware, prepare task management to allow multiple applications to run at the same time, initialize hardware components that were not configured by the bootloader or were configured incompletely and begin interfaces for human interaction. The kernel may not be configured to do this on its own, however. It may include an embedded lightweight filesystem, known as the initramfs or initrd, that can be created separately from the kernel to assist in hardware setup.
|
||||
|
||||
Another thing the kernel handles is downloading binary blobs, known generically as firmware, to hardware devices. Firmware is pre-compiled object files in formats specific to a particular device that is used to initialize hardware in places that the bootloader and kernel cannot access. Many such firmware objects are available from the Linux kernel source repositories, but many others are available only from specific hardware vendors. Examples of devices that often provide their own firmware include digital TV tuners or WiFi network cards.
|
||||
|
||||
Firmware may be loaded from the initramfs or may be loaded after the kernel starts the init process from the root filesystem. However, creating the kernel often will be the process where obtaining firmware will occur when creating a custom Linux distribution.
|
||||
|
||||
### Lightweight Core Platforms
|
||||
|
||||
The last thing the Linux kernel does is to attempt to run a specific program called the init process. This can be named init or linuxrc or the name of the program can be passed to the kernel by the bootloader. The init process is stored in a file system that the kernel can access. In the case of the initramfs, the file system is stored in memory (either by the kernel itself or by the bootloader placing it there). But the initramfs is not typically complete enough to run more complex applications. So another file system, known as the root file system, is required.
|
||||
|
||||

|
||||
|
||||
Figure 3\. Buildroot Configuration Menu
|
||||
|
||||
The initramfs filesystem can be built using the Linux kernel itself, but more commonly, it is created using a project called [BusyBox][6]. BusyBox combines a collection of GNU utilities, such as grep or awk, into a single binary in order to reduce the size of the filesystem itself. BusyBox often is used to jump-start the root filesystem's creation.
|
||||
|
||||
But, BusyBox is purposely lightweight. It isn't intended to provide every tool that a target platform will need, and even those it does provide can be feature-reduced. BusyBox has a sister project known as [Buildroot][7], which can be used to get a complete root filesystem, providing a variety of libraries, utilities and scripting languages. Like Crosstool-NG and the Linux kernel, both BusyBox and Buildroot allow custom configuration using the kconfig menu system. More important, the Buildroot system handles dependencies automatically, so selection of a given utility will guarantee that any software it requires also will be built and installed in the root filesystem.
|
||||
|
||||
Buildroot can generate a root filesystem archive in a variety of formats. However, it is important to note that the filesystem only is archived. Individual utilities and libraries are not packaged in either Debian or RPM formats. Using Buildroot will generate a root filesystem image, but its contents are not managed packages. Despite this, Buildroot does provide support for both the opkg and rpm package managers. This means custom applications that will be installed on the root filesystem can be package-managed, even if the root filesystem itself is not.
|
||||
|
||||
### Cross-Compiling and Scripting
|
||||
|
||||
One of Buildroot's features is the ability to generate a staging tree. This directory contains libraries and utilities that can be used to cross-compile other applications. With a staging tree and the cross toolchain, it becomes possible to compile additional applications outside Buildroot on the host system instead of on the target platform. Using rpm or opkg, those applications then can be installed to the root filesystem on the target at runtime using package management software.
|
||||
|
||||
Most custom systems are built around the idea of building applications with scripting languages. If scripting is required on the target platform, a variety of choices are available from Buildroot, including Python, PHP, Lua and JavaScript via Node.js. Support also exists for applications requiring encryption using OpenSSL.
|
||||
|
||||
### What's Next
|
||||
|
||||
The Linux kernel and bootloaders are compiled like most applications. Their build systems are designed to build a specific bit of software. Crosstool-NG and Buildroot are metabuilds. A metabuild is a wrapper build system around a collection of software, each with their own build systems. Alternatives to these include [Yocto][8] and [OpenEmbedded][9]. The benefit of Buildroot is the ease with which it can be wrapped by an even higher-level metabuild to automate customized Linux distribution builds. Doing this opens the option of pointing Buildroot to project-specific cache repositories. Using cache repositories can speed development and offers snapshot builds without worrying about changes to upstream repositories.
|
||||
|
||||
An example implementation of a higher-level build system is [PiBox][10]. PiBox is a metabuild wrapped around all of the tools discussed in this article. Its purpose is to add a common GNU Make target construction around all the tools in order to produce a core platform on which additional software can be built and distributed. The PiBox Media Center and kiosk projects are implementations of application-layer software installed on top of the core platform to produce a purpose-built platform. The [Iron Man project][11] is intended to extend these applications for home automation, integrated with voice control and IoT management.
|
||||
|
||||
But PiBox is nothing without these core software tools and could never run without an in-depth understanding of a complete custom distribution build process. And, PiBox could not exist without the long-term dedication of the teams of developers for these projects who have made custom-distribution-building a task for the masses.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/custom-embedded-linux-distributions
|
||||
|
||||
作者:[Michael J.Hammel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/1000879
|
||||
[1]:https://www.kernel.org
|
||||
[2]:http://crosstool-ng.github.io
|
||||
[3]:https://elinux.org/Main_Page
|
||||
[4]:https://elinux.org/Main_Page
|
||||
[5]:https://www.denx.de/wiki/U-Boot
|
||||
[6]:https://busybox.net
|
||||
[7]:https://buildroot.org
|
||||
[8]:https://www.yoctoproject.org
|
||||
[9]:https://www.openembedded.org/wiki/Main_Page
|
||||
[10]:https://www.piboxproject.com
|
||||
[11]:http://redmine.graphics-muse.org/projects/ironman/wiki/Getting_Started
|
||||
@ -0,0 +1,90 @@
|
||||
How to Check if Your Computer Uses UEFI or BIOS
|
||||
======
|
||||
**Brief: A quick tutorial to tell you if your system uses the modern UEFI or the legacy BIOS. Instructions for both Windows and Linux have been provided.**
|
||||
|
||||
When you are trying to [dual boot Linux with Windows][1], you would want to know if you have UEFI or BIOS boot mode on your system. It helps you decide in partition making for installing Linux.
|
||||
|
||||
I am not going to discuss [what is BIOS][2] here. However, I would like to tell you a few advantages of [UEFI][3] over BIOS.
|
||||
|
||||
UEFI or Unified Extensible Firmware Interface was designed to overcome some of the limitations of BIOS. It added the ability to use larger than 2 TB disks and had a CPU independent architecture and drivers. With a modular design, it supported remote diagnostics and repairing even with no operating system installed and a flexible without-OS environment including networking capability.
|
||||
|
||||
### Advantage of UEFI over BIOS
|
||||
|
||||
* UEFI is faster in initializing your hardware.
|
||||
* Offer Secure Boot which means everything you load before an OS is loaded has to be signed. This gives your system an added layer of protection from running malware.
|
||||
* BIOS do not support a partition of over 2TB.
|
||||
* Most importantly, if you are dual booting it’s always advisable to install both the OS in the same booting mode.
|
||||
|
||||
|
||||
|
||||
![How to check if system has UEFI or BIOS][4]
|
||||
|
||||
If you are trying to find out whether your system runs UEFI or BIOS, it’s not that difficult. Let me start with Windows first and afterward, we’ll see how to check UEFI or BIOS on Linux systems.
|
||||
|
||||
### Check if you are using UEFI or BIOS on Windows
|
||||
|
||||
On Windows, “System Information” in Start panel and under BIOS Mode, you can find the boot mode. If it says Legacy, your system has BIOS. If it says UEFI, well it’s UEFI.
|
||||
|
||||
![][5]
|
||||
|
||||
**Alternative** : If you using Windows 10, you can check whether you are using UEFI or BIOS by opening File Explorer and navigating to C:\Windows\Panther. Open file setupact.log and search for the below string.
|
||||
```
|
||||
Detected boot environment
|
||||
|
||||
```
|
||||
|
||||
I would advise opening this file in notepad++, since its a huge text file and notepad may hang (at least it did for me with 6GB RAM).
|
||||
|
||||
You will find a couple of lines which will give you the information.
|
||||
```
|
||||
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect:FirmwareType 1.
|
||||
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect: Detected boot environment: BIOS
|
||||
|
||||
```
|
||||
|
||||
### Check if you are using UEFI or BIOS on Linux
|
||||
|
||||
The easiest way to find out if you are running UEFI or BIOS is to look for a folder /sys/firmware/efi. The folder will be missing if your system is using BIOS.
|
||||
|
||||
![Find if system uses UEFI or BIOS on Ubuntu Linux][6]
|
||||
|
||||
**Alternative** : The other method is to install a package called efibootmgr.
|
||||
|
||||
On Debian and Ubuntu based distributions, you can install the efibootmgr package using the command below:
|
||||
```
|
||||
sudo apt install efibootmgr
|
||||
|
||||
```
|
||||
|
||||
Once done, type the below command:
|
||||
```
|
||||
sudo efibootmgr
|
||||
|
||||
```
|
||||
|
||||
If your system supports UEFI, it will output different variables. If not you will see a message saying EFI variables are not supported.
|
||||
|
||||
![][7]
|
||||
|
||||
### Final Words
|
||||
|
||||
Finding whether your system is using UEFI or BIOS is easy. On one hand, features like faster and secure boot provide an upper hand to UEFI, there is not much that should bother you if you are using BIOS – unless you are planning to use a 2TB hard disk to boot.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/check-uefi-or-bios/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1]:https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
[2]:https://www.lifewire.com/bios-basic-input-output-system-2625820
|
||||
[3]:https://www.howtogeek.com/56958/htg-explains-how-uefi-will-replace-the-bios/
|
||||
[4]:https://itsfoss.com/wp-content/uploads/2018/02/uefi-or-bios-800x450.png
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2018/01/BIOS-800x491.png
|
||||
[6]:https://itsfoss.com/wp-content/uploads/2018/02/uefi-bios.png
|
||||
[7]:https://itsfoss.com/wp-content/uploads/2018/01/bootmanager.jpg
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Python Hello World and String Manipulation
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
A File Transfer Utility To Download Only The New Parts Of A File
|
||||
======
|
||||
|
||||

|
||||
|
||||
Just because Internet plans are getting cheaper every day, you shouldn’t waste your data by repeatedly downloading the same stuff over and over. The one fine example is downloading development version of Ubuntu or any Linux images. As you may know, Ubuntu developers releases daily builds, alpha, beta ISO images every few months for testing. In the past, I used to download those images whenever they are available to test and review each edition. Not anymore! Thanks to **Zsync** file transfer program. Now it is possible to download only the new parts of the ISO image. This will save you a lot of time and Internet bandwidth. Not just time and bandwidth, it will save you the resources on server side and client side.
|
||||
|
||||
Zsync uses the same algorithm as **Rsync** , but it only download the new parts of a file that you have a copy of an older version of the file on your computer already. Rsync is mainly for synchronizing data between computers, whereas Zsync is for distributing data. To put this simply, the one file on a central location can be distributed to thousands of downloaders using Zsync. It is completely free and open source released under the Artistic License V2.
|
||||
|
||||
### Installing Zsync
|
||||
|
||||
Zsync is available in the default repositories of most Linux distributions.
|
||||
|
||||
On **Arch Linux** and derivatives, install it using command:
|
||||
```
|
||||
$ sudo pacman -S zsync
|
||||
|
||||
```
|
||||
|
||||
On **Fedora** :
|
||||
|
||||
Enable Zsync repository:
|
||||
```
|
||||
$ sudo dnf copr enable ngompa/zsync
|
||||
|
||||
```
|
||||
|
||||
And install it using command:
|
||||
```
|
||||
$ sudo dnf install zsync
|
||||
|
||||
```
|
||||
|
||||
On **Debian, Ubuntu, Linux Mint** :
|
||||
```
|
||||
$ sudo apt-get install zsync
|
||||
|
||||
```
|
||||
|
||||
For other distributions, you can download the binary from the [**Zsync download page**][1] and manually compile and install it as shown below.
|
||||
```
|
||||
$ wget http://zsync.moria.org.uk/download/zsync-0.6.2.tar.bz2
|
||||
$ tar xjf zsync-0.6.2.tar.bz2
|
||||
$ cd zsync-0.6.2/
|
||||
$ configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Please be mindful that **zsync is only useful if people offer zsync downloads**. Currently, Debian, Ubuntu (all flavours) ISO images are available as .zsync downloads. For example, visit the following link.
|
||||
|
||||
As you may noticed, Ubuntu 18.04 LTS daily build is available as direct ISO and .zsync file. If you download .ISO file, you have to download the full ISO whenever the ISO gets new updates. But, if you download .zsync file, the Zsync will download only the new changes in future. You don’t need to download the whole ISO image each time.
|
||||
|
||||
A .zsync file contains a meta-data needed by zsync program. This file contains the pre-calculated checksums for the rsync algorithm; it is generated on the server, once, and is then used by any number of downloaders. To download a .zsync file using Zsync client program, all you have to do:
|
||||
```
|
||||
$ zsync <.zsync-file-URL>
|
||||
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
$ zsync http://cdimage.ubuntu.com/ubuntu/daily-live/current/bionic-desktop-amd64.iso.zsync
|
||||
|
||||
```
|
||||
|
||||
If you already have the old image file on your system, Zsync will calculate the difference between the old and new file in the remote server and download only the new parts. You will see the calculation process as a series of dots or stars on your Terminal.
|
||||
|
||||
If there is an old version of the file you’re just downloading is available in the current working directory, Zsync will download only the new parts. Once the download is finished, you will get two images, the one you just downloaded and the old image with **.iso.zs-old** extension on its filename.
|
||||
|
||||
If there is no relevent local data found, Zsync will download the whole file.
|
||||
|
||||
|
||||
|
||||
You can cancel the download process at any time by pressing **CTRL-C**.
|
||||
|
||||
Just imagine if you use the direct .ISO file or torrent, you will lose around 1.4GB bandwidth whenever you download new image. So, instead of downloading entire alpha, beta and daily build images, Zsync just downloads the new parts of the ISO file that you already have a copy of an older version of it on your system.
|
||||
|
||||
And, that’s all for today. Hope this helps. I will be soon here with another useful guide. Until then stay tuned with OSTechNix!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/zsync-file-transfer-utility-download-new-parts-file/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://zsync.moria.org.uk/downloads
|
||||
@ -0,0 +1,102 @@
|
||||
Block ads on your network with Raspberry Pi and pi-hole
|
||||
======
|
||||
|
||||

|
||||
|
||||
Got an old Raspberry Pi lying around? Hate seeing ads while browsing the web? [Pi-hole][1] is an open source software project that blocks ads for all devices on your home network by routing all advertising servers into nowhere. What's best is it takes just a few minutes to set up.
|
||||
|
||||
Pi-hole blocks over 100,000 ad-serving domains, blocks advertisements on any device (including mobiles, tablets, and PCs), and because it completely blocks ads rather than just hiding them, this improves overall network performance (because ads are never downloaded). You can monitor performance and statistics in a web interface, and there's even an API you can use.
|
||||
|
||||
### What you will need
|
||||
|
||||
* Raspberry Pi + SD card
|
||||
* USB power cable
|
||||
* Ethernet cable
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
You don't need a recent Raspberry Pi model—an older one will do the job, as long as it's got at least 512MB RAM—so a Pi 1 Model B (rev 2), a Model B+, or a Pi 2 or 3 would do. You could use a Pi Zero, but you'll need a USB micro Ethernet adapter too. You could use a Pi Zero W with WiFi rather than Ethernet, but as it's part of your network infrastructure, I'd recommend a good, solid, wired connection instead.
|
||||
|
||||
### Prepare the SD card
|
||||
|
||||
First of all, you'll probably want to install Raspbian Stretch Lite onto an SD card. The card should be at least 4GB (the full desktop Raspbian image requires at least 8GB but the Lite image is, well, lighter). You can use the full Raspbian desktop image if you prefer, but as this is going to be running as a headless application, you don't need anything more.
|
||||
|
||||
|
||||
|
||||
Using your main PC, download the Raspbian Stretch Lite image from the Raspberry Pi website. Now unzip it to extract the `.img` file within, and you'll write this image to your SD card. It doesn't matter if the SD card is blank or not, as everything on it will be wiped.
|
||||
|
||||
If you're using Linux, the easiest way to write the image is using the command-line tool `dd`. Alternatively, you can use cross-platform software [Etcher][2] (follow the guide "[How to write SD cards for the Raspberry Pi][3]" by Les Pounder).
|
||||
|
||||
|
||||
|
||||
Once your SD card image has burned, you can insert it into your Raspberry Pi, connect a keyboard, monitor, and Ethernet cable, and then plug in the power. After the initial setup, the Pi won't need the keyboard or monitor. If you're experienced in working with the Pi headless, you can [enable SSH][4] and set it up [remotely][5].
|
||||
|
||||
### Install Pi-hole
|
||||
|
||||
Once your Raspberry Pi boots up, log in with the default username (`pi`) and password (`raspberry`). Now you're at the command line, and you're ready to install Pi-hole. Simply type the following command and press Enter:
|
||||
```
|
||||
curl -sSL https://install.pi-hole.net | bash
|
||||
|
||||
```
|
||||
|
||||
This command downloads the Pi-hole installer script and executes it. You can take a look at the contents by browsing `https://install.pi-hole.net` in your browser and see what it's doing. It will generate an admin password for you, and print it to the screen along with other installer information.
|
||||
|
||||
That's it! In just a few minutes, your Pi will be ready to start blocking ads.
|
||||
|
||||
Before you disconnect the Pi, you need to know its IP address and your router's IP address (if you don't already know it). Just type `hostname -I` in the terminal for the Pi's IP address, and `ip route | grep default` to locate your router. It will look something like `192.168.1.1`.
|
||||
|
||||
### Configure your router
|
||||
|
||||
Your Raspberry Pi is now running a DNS server, and you can tell your router to use Pi-hole as its DNS server instead of your ISP's default. Log into your router's management console web interface. This can usually be found by typing your router's IP address into your web browser's address bar.
|
||||
|
||||
Look for DHCP/DNS settings under LAN settings and set your primary DNS server to the IP address of the Pi-hole. It should look something like this:
|
||||
|
||||
|
||||
|
||||
See the [Pi-hole discourse][6] for more information on this step.
|
||||
|
||||
You'll also want to make sure your Pi-hole maintains the same IP address, so also look for DHCP IP reservations and add an entry for your Pi.
|
||||
|
||||
### Test it out
|
||||
|
||||
Now shut down the Pi by running the command `sudo halt` and disconnecting the power. You can remove the monitor cable and the keyboard and place the Pi-hole in its permanent location—probably plugged in near your router. Ensure the Ethernet is connected and boot it back up by reconnecting the power.
|
||||
|
||||
Navigate to a website on your PC or a device on your WiFi (I highly recommend [Opensource.com][7]) to check that your internet access is working correctly (if not, you may have misconfigured your DNS settings). If web browsing seems to work as expected, it's set up correctly. Now, when you browse the web, it should be ad-free! Even ads served within apps on your mobile devices won't get through! Happy surfing!
|
||||
|
||||
If you really want to flex your new ad-blocking muscles, you can try browsing some of the ad-ridden websites listed on this [test page][8].
|
||||
|
||||
Now access the Pi-hole's web interface by entering its IP address into your web browser's address bar (e.g. <http://192.168.1.4/admin> \- or `http://pi.hole/admin` should work too). You should see the Pi-hole dashboard and some statistics (they will be very low at this stage). Once you login using the password you were given during installation, you'll see some pretty graphs too:
|
||||
|
||||
|
||||
|
||||
You can also tweak your Pi-hole's settings, like whitelist and blacklist domains, disable permanently or temporarily, access the stats for blocked queries, and more.
|
||||
|
||||
Occasionally, you'll want to upgrade your Pi-hole installation. The web interface includes an update notification when one is available. If you have enabled SSH, you can log in remotely, otherwise you'll have to reconnect the monitor and keyboard. When logged in, simply run the command `pihole -up`.
|
||||
|
||||
|
||||
|
||||
Have you used Pi-hole or another open source ad blocker? Please share your experience in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/block-ads-raspberry-pi
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://pi-hole.net/
|
||||
[2]:https://etcher.io/
|
||||
[3]:https://opensource.com/article/17/3/how-write-sd-cards-raspberry-pi
|
||||
[4]:https://www.raspberrypi.org/blog/a-security-update-for-raspbian-pixel/
|
||||
[5]:https://www.raspberrypi.org/documentation/remote-access/ssh/README.md
|
||||
[6]:https://discourse.pi-hole.net/t/how-do-i-configure-my-devices-to-use-pi-hole-as-their-dns-server/245
|
||||
[7]:https://opensource.com/
|
||||
[8]:https://pi-hole.net/pages-to-test-ad-blocking-performance/
|
||||
@ -0,0 +1,130 @@
|
||||
How to Create, Revert and Delete KVM Virtual machine snapshot with virsh command
|
||||
======
|
||||
[![KVM-VirtualMachine-Snapshot][1]![KVM-VirtualMachine-Snapshot][2]][2]
|
||||
|
||||
While working on the virtualization platform system administrators usually take the snapshot of virtual machine before doing any major activity like deploying the latest patch and code.
|
||||
|
||||
Virtual machine **snapshot** is a copy of virtual machine’s disk at the specific point of time. In other words we can say snapshot keeps or preserve the state and data of a virtual machine at given point of time.
|
||||
|
||||
### Where we can use VM snapshots ..?
|
||||
|
||||
If you are working on **KVM** based **hypervisors** we can take virtual machines or domain snapshot using the virsh command. Snapshot becomes very helpful in a situation where you have installed or apply the latest patches on the VM but due to some reasons, application hosted in the VMs becomes unstable and application team wants to revert all the changes or patches. If you had taken the snapshot of the VM before applying patches then we can restore or revert the VM to its previous state using snapshot.
|
||||
|
||||
**Note:** We can only take the snapshot of the VMs whose disk format is **Qcow2** and raw disk format is not supported by kvm virsh command, Use below command to convert the raw disk format to qcow2
|
||||
```
|
||||
# qemu-img convert -f raw -O qcow2 image-name.img image-name.qcow2
|
||||
|
||||
```
|
||||
|
||||
### Create KVM Virtual Machine (domain) Snapshot
|
||||
|
||||
I am assuming KVM hypervisor is already configured on CentOS 7 / RHEL 7 box and VMs are running on it. We can list the all the VMs on hypervisor using below virsh command,
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh list --all
|
||||
Id Name State
|
||||
----------------------------------------------------
|
||||
94 centos7.0 running
|
||||
101 overcloud-controller running
|
||||
102 overcloud-compute2 running
|
||||
103 overcloud-compute1 running
|
||||
114 webserver running
|
||||
115 Test-MTN running
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
Let’s suppose we want to create the snapshot of ‘ **webserver** ‘ VM, run the below command,
|
||||
|
||||
**Syntax :**
|
||||
|
||||
```
|
||||
# virsh snapshot-create-as –domain {vm_name} –name {snapshot_name} –description “enter description here”
|
||||
```
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-create-as --domain webserver --name webserver_snap --description "snap before patch on 4Feb2018"
|
||||
Domain snapshot webserver_snap created
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
Once the snapshot is created then we can list snapshots related to the VM using below command,
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-list webserver
|
||||
Name Creation Time State
|
||||
------------------------------------------------------------
|
||||
webserver_snap 2018-02-04 15:05:05 +0530 running
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
To list the detailed info of VM’s snapshot, run the beneath virsh command,
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-info --domain webserver --snapshotname webserver_snap
|
||||
Name: webserver_snap
|
||||
Domain: webserver
|
||||
Current: yes
|
||||
State: running
|
||||
Location: internal
|
||||
Parent: -
|
||||
Children: 0
|
||||
Descendants: 0
|
||||
Metadata: yes
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
We can view the size of snapshot using below qemu-img command,
|
||||
```
|
||||
[root@kvm-hypervisor ~]# qemu-img info /var/lib/libvirt/images/snaptestvm.img
|
||||
|
||||
```
|
||||
|
||||
[![qemu-img-command-output-kvm][1]![qemu-img-command-output-kvm][3]][3]
|
||||
|
||||
### Revert / Restore KVM virtual Machine to Snapshot
|
||||
|
||||
Let’s assume we want to revert or restore webserver VM to the snapshot that we have created in above step. Use below virsh command to restore Webserver VM to its snapshot “ **webserver_snap** ”
|
||||
|
||||
**Syntax :**
|
||||
|
||||
```
|
||||
# virsh snapshot-revert {vm_name} {snapshot_name}
|
||||
```
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-revert webserver webserver_snap
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
### Delete KVM virtual Machine Snapshots
|
||||
|
||||
To delete KVM virtual machine snapshots, first get the VM’s snapshot details using “ **virsh snapshot-list** ” command and then use “ **virsh snapshot-delete** ” command to delete the snapshot. Example is shown below:
|
||||
```
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-list --domain webserver
|
||||
Name Creation Time State
|
||||
------------------------------------------------------------
|
||||
webserver_snap 2018-02-04 15:05:05 +0530 running
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
[root@kvm-hypervisor ~]# virsh snapshot-delete --domain webserver --snapshotname webserver_snap
|
||||
Domain snapshot webserver_snap deleted
|
||||
[root@kvm-hypervisor ~]#
|
||||
|
||||
```
|
||||
|
||||
That’s all from this article, I hope you guys get an idea on how to manage KVM virtual machine snapshots using virsh command. Please do share your feedback and don’t hesitate to share it among your technical friends 🙂
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/create-revert-delete-kvm-virtual-machine-snapshot-virsh-command/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/plugins/lazy-load/images/1x1.trans.gif
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2018/02/KVM-VirtualMachine-Snapshot.jpg
|
||||
[3]:https://www.linuxtechi.com/wp-content/uploads/2018/02/qemu-img-command-output-kvm.jpg
|
||||
@ -0,0 +1,191 @@
|
||||
Linux md5sum Command Explained For Beginners (5 Examples)
|
||||
======
|
||||
|
||||
When downloading files, particularly installation files from websites, it is a good idea to verify that the download is valid. A website will often display a hash value for each file so that you can make sure the download completed correctly. In this article, we will be discussing the md5sum tool that you can use to validate the download. Two other utilities, sha256sum and sha512sum, work the same way as md5sum.
|
||||
|
||||
### Linux md5sum command
|
||||
|
||||
The md5sum command prints a 32-character (128-bit) checksum of the given file, using the MD5 algorithm. Following is the command syntax of this command line tool:
|
||||
|
||||
```
|
||||
md5sum [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
And here's how md5sum's man page explains it:
|
||||
```
|
||||
Print or check MD5 (128-bit) checksums.
|
||||
|
||||
```
|
||||
|
||||
The following Q&A-styled examples will give you an even better idea of the basic usage of md5sum.
|
||||
|
||||
Note: We'll be using three files named file1.txt, file2.txt, and file3.txt as the input files in our examples. The text in each file is listed below.
|
||||
|
||||
file1.txt:
|
||||
```
|
||||
hi
|
||||
hello
|
||||
how are you
|
||||
thanks.
|
||||
|
||||
```
|
||||
|
||||
file2.txt:
|
||||
```
|
||||
hi
|
||||
hello to you
|
||||
I am fine
|
||||
Your welcome!
|
||||
|
||||
```
|
||||
|
||||
file3.txt:
|
||||
```
|
||||
hallo
|
||||
Guten Tag
|
||||
Wie geht es dir
|
||||
Danke.
|
||||
|
||||
```
|
||||
|
||||
### Q1. How to display the hash value?
|
||||
|
||||
Use the command without any options to display the hash value and the filename.
|
||||
|
||||
```
|
||||
md5sum file1.txt
|
||||
```
|
||||
|
||||
Here's the output this command produced on our system:
|
||||
```
|
||||
[Documents]$ md5sum file1.txt
|
||||
1ff38cc592c4c5d0c8e3ca38be8f1eb1 file1.txt
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
The output can also be displayed in a BSD-style format using the --tag option.
|
||||
|
||||
md5sum --tag file1.txt
|
||||
```
|
||||
[Documents]$ md5sum --tag file1.txt
|
||||
MD5 (file1.txt) = 1ff38cc592c4c5d0c8e3ca38be8f1eb1
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
### Q2. How to validate multiple files?
|
||||
|
||||
The md5sum command can validate multiple files at one time. We will add file2.txt and file3.txt to demonstrate the capabilities.
|
||||
|
||||
If you write the hashes to a file, you can use that file to check whether any of the files have changed. Here we are writing the hashes of the files to the file hashes, and then using that to validate that none of the files have changed.
|
||||
|
||||
```
|
||||
md5sum file1.txt file2.txt file3.txt > hashes
|
||||
md5sum --check hashes
|
||||
```
|
||||
|
||||
```
|
||||
[Documents]$ md5sum file1.txt file2.txt file3.txt > hashes
|
||||
[Documents]$ md5sum --check hashes
|
||||
file1.txt: OK
|
||||
file2.txt: OK
|
||||
file3.txt: OK
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
Now we will change file3.txt, adding a single exclamation mark to the end of the file, and rerun the command.
|
||||
|
||||
```
|
||||
echo "!" >> file3.txt
|
||||
md5sum --check hashes
|
||||
```
|
||||
|
||||
```
|
||||
[Documents]$ md5sum --check hashes
|
||||
file1.txt: OK
|
||||
file2.txt: OK
|
||||
file3.txt: FAILED
|
||||
md5sum: WARNING: 1 computed checksum did NOT match
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
You can see that file3.txt has changed.
|
||||
|
||||
### Q3. How to display only modified files?
|
||||
|
||||
If you have many files to check, you may want to display only the files that have changed. Using the "\--quiet" option, md5sum will only list the files that have changed.
|
||||
|
||||
```
|
||||
md5sum --quiet --check hashes
|
||||
```
|
||||
|
||||
```
|
||||
[Documents]$ md5sum --quiet --check hashes
|
||||
file3.txt: FAILED
|
||||
md5sum: WARNING: 1 computed checksum did NOT match
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
### Q4. How to detect changes in a script?
|
||||
|
||||
You may want to use md5sum in a script. Using the "\--status" option, md5sum won't print any output. Instead, the status code returns 0 if there are no changes, and 1 if the files don't match. The following script hashes.sh will return a 1 in the status code, because the files have changed. The script file is below:
|
||||
|
||||
```
|
||||
sh hashes.sh
|
||||
```
|
||||
|
||||
```
|
||||
hashes.sh:
|
||||
#!/bin/bash
|
||||
md5sum --status --check hashes
|
||||
Result=$?
|
||||
echo "File check status is: $Result"
|
||||
exit $Result
|
||||
|
||||
[Documents]$ sh hashes.sh
|
||||
File check status is: 1
|
||||
[[email protected] Documents]$
|
||||
|
||||
```
|
||||
|
||||
### Q5. How to identify invalid hash values?
|
||||
|
||||
md5sum can let you know if you have invalid hashes when you compare files. To warn you if any hash values are incorrect, you can use the --warn option. For this last example, we will use sed to insert an extra character at the beginning of the third line. This will change the hash value in the file hashes, making it invalid.
|
||||
|
||||
```
|
||||
sed -i '3s/.*/a&/' hashes
|
||||
md5sum --warn --check hashes
|
||||
```
|
||||
|
||||
This shows that the third line has an invalid hash.
|
||||
```
|
||||
[Documents]$ sed -i '3s/.*/a&/' hashes
|
||||
[Documents]$ md5sum --warn --check hashes
|
||||
file1.txt: OK
|
||||
file2.txt: OK
|
||||
md5sum: hashes: 3: improperly formatted MD5 checksum line
|
||||
md5sum: WARNING: 1 line is improperly formatted
|
||||
[Documents]$
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
The md5sum is a simple command which can quickly validate one or multiple files to determine whether any of them have changed from the original file. For more information on md5sum, see it's [man page.][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-md5sum-command/
|
||||
|
||||
作者:[David Paige][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/
|
||||
[1]:https://linux.die.net/man/1/md5sum
|
||||
@ -0,0 +1,97 @@
|
||||
New Linux User? Try These 8 Great Essential Linux Apps
|
||||
======
|
||||
|
||||

|
||||
|
||||
When you are new to Linux, even if you are not new to computers in general, one of the problems you will face is which apps to use. With millions of Linux apps, the choice is certainly not easy. Below you will find eight (out of millions) essential Linux apps to get you settled in quickly.
|
||||
|
||||
Most of these apps are not exclusive to Linux. If you have used Windows/Mac before, chances are you are familiar with some of them. Depending on what your needs and interests are, you might not need all these apps, but in my opinion, most or all of the apps on this list are useful for newbies who are just starting out on Linux.
|
||||
|
||||
**Related** : [11 Portable Apps Every Linux User Should Use][1]
|
||||
|
||||
### 1. Chromium Web Browser
|
||||
|
||||
![linux-apps-01-chromium][2]
|
||||
|
||||
There is hardly a user who doesn’t need a web browser. While you can find good old Firefox for almost any Linux distro, and there is also a bunch of other [Linux browsers][3], a browser you should definitely try is [Chromium][4]. It’s the open source counterpart of Google’s Chrome browser. The main advantages of Chromium is that it is secure and fast. There are also tons of add-ons for it.
|
||||
|
||||
### 2. LibreOffice
|
||||
|
||||
![linux-apps-02-libreoffice][5]
|
||||
|
||||
[LibreOffice][6] is an open source Office suite that comes with word processor (Writer), spreadsheet (Calc), presentation (Impress), database (Base), formula editor (Math), and vector graphics and flowcharts (Draw) applications. It’s compatible with Microsoft Office documents, and there are even [LibreOffice extensions][7] if the default functionality isn’t enough for you.
|
||||
|
||||
LibreOffice is definitely one essential Linux app that you should have on your Linux computer.
|
||||
|
||||
### 3. GIMP
|
||||
|
||||
![linux-apps-03-gimp][8]
|
||||
|
||||
[GIMP][9] is a very powerful open-source image editor. It’s similar to Photoshop. With GIMP you can edit photos and create and edit raster images for the Web and print. It’s true there are simpler image editors for Linux, so if you have no idea about image processing at all, GIMP might look too complicated to you. GIMP goes way beyond simple image crop and resize – it offers layers, filters, masks, paths, etc.
|
||||
|
||||
### 4. VLC Media Player
|
||||
|
||||
![linux-apps-04-vlc][10]
|
||||
|
||||
[VLC][11] is probably the best movie player. It’s cross-platform, so you might know it from Windows. What’s really special about VLC is that it comes with lots of codecs (not all of which are open source, though), so it will play (almost) any music or video file.
|
||||
|
||||
### 5. Jitsy
|
||||
|
||||
![linux-apps-05-jitsi][12]
|
||||
|
||||
[Jitsy][13] is all about communication. You can use it for Google Talk, Facebook chat, Yahoo, ICQ and XMPP. It’s a multi-user tool for audio and video calls (including conference calls), as well as desktop streaming and group chats. Conversations are encrypted. With Jitsy you can also transfer files and record your calls.
|
||||
|
||||
### 6. Synaptic
|
||||
|
||||
![linux-apps-06-synaptic][14]
|
||||
|
||||
[Synaptic][15] is an alternative app installer for Debian-based distros. It comes with some distros but not all, so if you are using a Debian-based Linux, but there is no Synaptic in it, you might want to give it a try. Synaptic is a GUI tool for adding and removing apps from your system, and typically veteran Linux users favor it over the [Software Center package manager][16] that comes with many distros as a default.
|
||||
|
||||
**Related** : [10 Free Linux Productivity Apps You Haven’t Heard Of][17]
|
||||
|
||||
### 7. VirtualBox
|
||||
|
||||
![linux-apps-07-virtualbox][18]
|
||||
|
||||
[VirtualBox][19] allows you to run a virtual machine on your computer. A virtual machine comes in handy when you want to install another Linux distro or operating system from within your current Linux distro. You can use it to run Windows apps as well. Performance will be slower, but if you have a powerful computer, it won’t be that bad.
|
||||
|
||||
### 8. AisleRiot Solitaire
|
||||
|
||||
![linux-apps-08-aisleriot][20]
|
||||
|
||||
A solitaire pack is hardly an absolute necessity for a new Linux user, but since it’s so fun. If you are into solitaire games, this is a great solitaire pack. [AisleRiot][21] is one of the emblematic Linux apps, and this is for a reason – it comes with more than eighty solitaire games, including the popular Klondike, Bakers Dozen, Camelot, etc. Just be warned – it’s addictive and you might end up spending long hours playing with it!
|
||||
|
||||
Depending on the distro you are using, the way to install these apps is not the same. However, most, if not all, of these apps will be available for install with a package manager for your distro, or even come pre-installed with your distro. The best thing is, you can install and try them out and easily remove them if you don’t like them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/essential-linux-apps/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[1]:https://www.maketecheasier.com/portable-apps-for-linux/ (11 Portable Apps Every Linux User Should Use)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/01/Linux-apps-01-Chromium.jpg (linux-apps-01-chromium)
|
||||
[3]:https://www.maketecheasier.com/linux-browsers-you-probably-havent-heard-of/
|
||||
[4]:http://www.chromium.org/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2018/01/Linux-apps-02-LibreOffice.jpg (linux-apps-02-libreoffice)
|
||||
[6]:https://www.libreoffice.org/
|
||||
[7]:https://www.maketecheasier.com/best-libreoffice-extensions/
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2018/01/Linux-apps-03-GIMP.jpg (linux-apps-03-gimp)
|
||||
[9]:https://www.gimp.org/
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/01/Linux-apps-04-VLC.jpg (linux-apps-04-vlc)
|
||||
[11]:http://www.videolan.org/
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2018/01/Linux-apps-05-Jitsi.jpg (linux-apps-05-jitsi)
|
||||
[13]:https://jitsi.org/
|
||||
[14]:https://www.maketecheasier.com/assets/uploads/2018/01/Linux-apps-06-Synaptic.jpg (linux-apps-06-synaptic)
|
||||
[15]:http://www.nongnu.org/synaptic/
|
||||
[16]:https://www.maketecheasier.com/are-linux-gui-software-centers-any-good/
|
||||
[17]:https://www.maketecheasier.com/free-linux-productivity-apps-you-havent-heard-of/ (10 Free Linux Productivity Apps You Haven’t Heard Of)
|
||||
[18]:https://www.maketecheasier.com/assets/uploads/2018/01/Linux-apps-07-VirtualBox.jpg (linux-apps-07-virtualbox)
|
||||
[19]:https://www.virtualbox.org/
|
||||
[20]:https://www.maketecheasier.com/assets/uploads/2018/01/Linux-apps-08-AisleRiot.jpg (linux-apps-08-aisleriot)
|
||||
[21]:https://wiki.gnome.org/Aisleriot
|
||||
535
sources/tech/20180206 Manage printers and printing.md
Normal file
535
sources/tech/20180206 Manage printers and printing.md
Normal file
@ -0,0 +1,535 @@
|
||||
Manage printers and printing
|
||||
======
|
||||
|
||||
|
||||
### Printing in Linux
|
||||
|
||||
Although much of our communication today is electronic and paperless, we still have considerable need to print material from our computers. Bank statements, utility bills, financial and other reports, and benefits statements are just some of the items that we still print. This tutorial introduces you to printing in Linux using CUPS.
|
||||
|
||||
CUPS, formerly an acronym for Common UNIX Printing System, is the printer and print job manager for Linux. Early computer printers typically printed lines of text in a particular character set and font size. Today's graphical printers are capable of printing both graphics and text in a variety of sizes and fonts. Nevertheless, some of the commands you use today have their history in the older line printer daemon (LPD) technology.
|
||||
|
||||
This tutorial helps you prepare for Objective 108.4 in Topic 108 of the Linux Server Professional (LPIC-1) exam 102. The objective has a weight of 2.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
To get the most from the tutorials in this series, you need a basic knowledge of Linux and a working Linux system on which you can practice the commands covered in this tutorial. You should be familiar with GNU and UNIX® commands. Sometimes different versions of a program format output differently, so your results might not always look exactly like the listings shown here.
|
||||
|
||||
In this tutorial, I use Fedora 27 for examples.
|
||||
|
||||
### Some printing history
|
||||
|
||||
This small history is not part of the LPI objectives but may help you with context for this objective.
|
||||
|
||||
Early computers mostly used line printers. These were impact printers that printed a line of text at a time using fixed-pitch characters and a single font. To speed up overall system performance, early mainframe computers interleaved work for slow peripherals such as card readers, card punches, and line printers with other work. Thus was born Simultaneous Peripheral Operation On Line or spooling, a term that is still commonly used when talking about computer printing.
|
||||
|
||||
In UNIX and Linux systems, printing initially used the Berkeley Software Distribution (BSD) printing subsystem, consisting of a line printer daemon (lpd) running as a server, and client commands such as `lpr` to submit jobs for printing. This protocol was later standardized by the IETF as RFC 1179, **Line Printer Daemon Protocol**.
|
||||
|
||||
System also had a printing daemon. It was functionally similar to the Berkeley LPD, but had a different command set. You will frequently see two commands with different options that accomplish the same task. For example, `lpr` from the Berkeley implementation and `lp` from the System V implementation each print files.
|
||||
|
||||
Advances in printer technology made it possible to mix different fonts on a page and to print images as well as words. Variable pitch fonts, and more advanced printing techniques such as kerning and ligatures, are now standard. Several improvements to the basic lpd/lpr approach to printing were devised, such as LPRng, the next generation LPR, and CUPS.
|
||||
|
||||
Many printers capable of graphical printing initially used the Adobe PostScript language. A PostScript printer has an engine that interprets the commands in a print job and produces finished pages from these commands. PostScript is often used as an intermediate form between an original file, such as a text or an image file, and a final form suitable for a particular printer that does not have PostScript capability. Conversion of a print job, such as an ASCII text file or a JPEG image to PostScript, and conversion from PostScript to the final raster form required for a non-PostScript printer is done using filters.
|
||||
|
||||
Today, Portable Document Format (PDF), which is based on PostScript, has largely replaced raw PostScript. PDF is designed to be independent of hardware and software and to encapsulate a full description of the pages to be printed. You can view PDF files as well as print them.
|
||||
|
||||
### Manage print queues
|
||||
|
||||
Users direct print jobs to a logical entity called a print queue. In single-user systems, a print queue and a printer are usually equivalent. However, CUPS allows a system without an attached printer to queue print jobs for eventual printing on a remote system, and, through the use of classes to allow a print job directed to a class to be printed on the first available printer of that class.
|
||||
|
||||
You can inspect and manipulate print queues. Some of the commands to do so are new for CUPS. Others are compatibility commands that have their roots in LPD commands, although the current options are usually a limited subset of the original LPD printing system options.
|
||||
|
||||
You can check the queues known to the system using the CUPS `lpstat` command. Some common options are shown in Table 1.
|
||||
|
||||
###### Table 1. Options for lpstat
|
||||
| Option | Purpose |
|
||||
| -a | Display accepting status of printers. |
|
||||
| -c | Display print classes. |
|
||||
| -p | Display print status: enabled or disabled. |
|
||||
| -s | Display default printer, printers, and classes. Equivalent to -d -c -v. Note that multiple options must be separated as values can be specified for many. |
|
||||
| -s | Display printers and their devices. |
|
||||
|
||||
|
||||
You may also use the LPD `lpc` command, found in /usr/sbin, with the `status` option. If you do not specify a printer name, all queues are listed. Listing 1 shows some examples of both commands.
|
||||
|
||||
###### Listing 1. Displaying available print queues
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -d
|
||||
system default destination: HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -v HL-2280DW
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
[ian@atticf27 ~]$ lpstat -s
|
||||
system default destination: HL-2280DW
|
||||
members of class anyprint:
|
||||
HL-2280DW
|
||||
XP-610
|
||||
device for anyprint: ///dev/null
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
device for XP-610: dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
[ian@atticf27 ~]$ lpstat -a XP-610
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
[ian@atticf27 ~]$ /usr/sbin/lpc status HL-2280DW
|
||||
HL-2280DW:
|
||||
printer is on device 'dnssd' speed -1
|
||||
queuing is disabled
|
||||
printing is enabled
|
||||
no entries
|
||||
daemon present
|
||||
|
||||
```
|
||||
|
||||
This example shows two printers, HL-2280DW and XP-610, and a class, `anyprint`, which allows print jobs to be directed to the first available of these two printers.
|
||||
|
||||
In this example, queuing of print jobs to HL-2280DW is currently disabled, although printing is enabled, as might be done in order to drain the queue before taking the printer offline for maintenance. Whether queuing is enabled or disabled is controlled by the `cupsaccept` and `cupsreject` commands. Formerly, these were `accept` and `reject`, but you will probably find these commands in /usr/sbin are now just links to the newer commands. Similarly, whether printing is enabled or disabled is controlled by the `cupsenable` and `cupsdisable` commands. In earlier versions of CUPS, these were called `enable` and `disable`, which allowed confusion with the builtin bash shell `enable`. Listing 2 shows how to enable queuing on printer HL-2280DW while disabling printing. Several of the CUPS commands support a `-r` option to give a reason for the action. This reason is displayed when you use `lpstat`, but not if you use `lpc`.
|
||||
|
||||
###### Listing 2. Enabling queuing and disabling printing
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -a -p HL-2280DW
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW not accepting requests since Thu 27 Apr 2017 05:52:27 PM EDT -
|
||||
Maintenance scheduled
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
printer HL-2280DW is idle. enabled since Thu 27 Apr 2017 05:52:27 PM EDT
|
||||
Maintenance scheduled
|
||||
[ian@atticf27 ~]$ accept HL-2280DW
|
||||
[ian@atticf27 ~]$ cupsdisable -r "waiting for toner delivery" HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -p -a
|
||||
printer anyprint is idle. enabled since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
printer HL-2280DW disabled since Mon 29 Jan 2018 04:03:50 PM EST -
|
||||
waiting for toner delivery
|
||||
printer XP-610 is idle. enabled since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Mon 29 Jan 2018 04:03:50 PM EST
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
|
||||
```
|
||||
|
||||
Note that an authorized user must perform these tasks. This may be root or another authorized user. See the SystemGroup entry in /etc/cups/cups-files.conf and the man page for cups-files.conf for more information on authorizing user groups.
|
||||
|
||||
### Manage user print jobs
|
||||
|
||||
Now that you have seen a little of how to check on print queues and classes, I will show you how to manage jobs on printer queues. The first thing you might want to do is find out whether any jobs are queued for a particular printer or for all printers. You do this with the `lpq` command. If no option is specified, `lpq` displays the queue for the default printer. Use the `-P` option with a printer name to specify a particular printer or the `-a` option to specify all printers, as shown in Listing 3.
|
||||
|
||||
###### Listing 3. Checking print queues with lpq
|
||||
```
|
||||
[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st unknown 4 unknown 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th unknown 8 unknown 1024 bytes
|
||||
5th unknown 9 unknown 1024 bytes
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lpq -P xp-610
|
||||
xp-610 is ready
|
||||
no entries
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 8 .bashrc 1024 bytes
|
||||
5th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
In this example, five jobs, 4, 6, 7, 8, and 9, are queued for the printer named HL-2280DW and none for XP-610. Using the `-P` option in this case simply shows that the printer is ready but has no queued hobs. Note that CUPS printer names are not case-sensitive. Note also that user ian submitted a job twice, a common user action when a job does not print the first time.
|
||||
|
||||
In general, you can view or manipulate your own print jobs, but root or another authorized user is usually required to manipulate the jobs of others. Most CUPS commands also encrypted communication between the CUPS client command and CUPS server using a `-E` option
|
||||
|
||||
Use the `lprm` command to remove one of the .bashrc jobs from the queue. With no options, the current job is removed. With the `-` option, all jobs are removed. Otherwise, specify a list of jobs to be removed as shown in Listing 4.
|
||||
|
||||
###### Listing 4. Deleting print jobs with lprm
|
||||
```
|
||||
[[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lprm
|
||||
lprm: Forbidden
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lprm 8
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
Note that user pat was not able to remove the first job on the queue, because it was for user ian. However, ian was able to remove his own job number 8.
|
||||
|
||||
Another command that will help you manipulate jobs on print queues is the `lp` command. Use it to alter attributes of jobs, such as priority or number of copies. Let us assume user ian wants his job 9 to print before those of user pat, and he really did want two copies of it. The job priority ranges from a lowest priority of 1 to a highest priority of 100 with a default of 50. User ian could use the `-i`, `-n`, and `-q` options to specify a job to alter and a new number of copies and priority as shown in Listing 5. Note the use of the `-l` option of the `lpq` command, which provides more verbose output.
|
||||
|
||||
###### Listing 5. Changing the number of copies and priority with lp
|
||||
```
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
[ian@atticf27 ~]$ lp -i 9 -q 60 -n 2
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 9 .bashrc 1024 bytes
|
||||
2nd ian 4 permutation.C 6144 bytes
|
||||
3rd pat 6 bitlib.h 6144 bytes
|
||||
4th pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
Finally, the `lpmove` command allows jobs to be moved from one queue to another. For example, we might want to do this because printer HL-2280DW is not currently printing. You can specify just a hob number, such as 9, or you can qualify it with the queue name and a hyphen, such as HL-2280DW-0. The `lpmove` command requires an authorized user. Listing 6 shows how to move these jobs to another queue, specifying first by printer and job ID, then all jobs for a given printer. By the time we check the queues again, one of the jobs is already printing.
|
||||
|
||||
###### Listing 6. Moving jobs to another print queue with lpmove
|
||||
```
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW-9 anyprint
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW xp-610
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active ian 9 .bashrc 1024 bytes
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
[ian@atticf27 ~]$ # A few minutes later
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active pat 6 bitlib.h 6144 bytes
|
||||
1st pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
If you happen to use a print server that is not CUPS, such as LPD or LPRng, many of the queue administration functions are handled as subcommands of the `lpc` command. For example, you might use `lpc topq` to move a job to the top of a queue. Other `lpc` subcommands include `disable`, `down`, `enable`, `hold`, `move`, `redirect`, `release`, and `start`. These subcommands are not implemented in the CUPS `lpc` compatibility command.
|
||||
|
||||
#### Printing files
|
||||
|
||||
How are print jobs erected? Many graphical programs provide a method of printing, usually under the **File** menu option. These programs provide graphical tools for choosing a printer, margin sizes, color or black-and-white printing, number of copies, selecting 2-up printing (which is 2 pages per sheet, often used for handouts), and so on. Here I show you the command-line tools for controlling such features, and then a graphical implementation for comparison.
|
||||
|
||||
The simplest way to print any file is to use the `lpr` command and provide the file name. This prints the file on the default printer. The `lp` command can print files as well as modify print jobs. Listing 7 shows a simple example using both commands. Note that `lpr` quietly spools the job, but `lp` displays the job number of the spooled job.
|
||||
|
||||
###### Listing 7. Printing with lpr and lp
|
||||
```
|
||||
[ian@atticf27 ~]$ echo "Print this text" > printexample.txt
|
||||
[ian@atticf27 ~]$ lpr printexample.txt
|
||||
[ian@atticf27 ~]$ lp printexample.txt
|
||||
request id is HL-2280DW-12 (1 file(s))
|
||||
|
||||
```
|
||||
|
||||
Table 2 shows some options that you may use with `lpr`. Note that `lp` has similar options to `lpr`, but names may differ; for example, `-#` on `lpr` is equivalent to `-n` on `lp`. Check the man pages for more information.
|
||||
|
||||
###### Table 2. Options for lpr
|
||||
|
||||
| Option | Purpose |
|
||||
| -C, -J, or -T | Set a job name. |
|
||||
| -P | Select a particular printer. |
|
||||
| -# | Specify number of copies. Note this is different from the -n option you saw with the lp command. |
|
||||
| -m | Send email upon job completion. |
|
||||
| -l | Indicate that the print file is already formatted for printing. Equivalent to -o raw. |
|
||||
| -o | Set a job option. |
|
||||
| -p | Format a text file with a shaded header. Equivalent to -o prettyprint. |
|
||||
| -q | Hold (or queue) the job for later printing. |
|
||||
| -r | Remove the file after it has been spooled for printing. |
|
||||
|
||||
Listing 8 shows some of these options in action. I request an email confirmation after printing, that the job be held and that the file be deleted after printing.
|
||||
|
||||
###### Listing 8. Printing with lpr
|
||||
```
|
||||
[ian@atticf27 ~]$ lpr -P HL-2280DW -J "Ian's text file" -#2 -m -p -q -r printexample.txt
|
||||
[[ian@atticf27 ~]$ lpq -l
|
||||
HL-2280DW is ready
|
||||
|
||||
|
||||
ian: 1st [job 13 localhost]
|
||||
2 copies of Ian's text file 1024 bytes
|
||||
[ian@atticf27 ~]$ ls printexample.txt
|
||||
ls: cannot access 'printexample.txt': No such file or directory
|
||||
|
||||
```
|
||||
|
||||
I now have a held job in the HL-2280DW print queue. What to do? The `lp` command has options to hold and release jobs, using various values with the `-H` option. Listing 9 shows how to release the held job. Check the `lp` man page for information on other options.
|
||||
|
||||
###### Listing 9. Resuming printing of a held print job
|
||||
```
|
||||
[ian@atticf27 ~]$ lp -i 13 -H resume
|
||||
|
||||
```
|
||||
|
||||
Not all of the vast array of available printers support the same set of options. Use the `lpoptions` command to see the general options that are set for a printer. Add the `-l` option to display printer-specific options. Listing 10 shows two examples. Many common options relate to portrait/landscape printing, page dimensions, and placement of the output on the pages. See the man pages for details.
|
||||
|
||||
###### Listing 10. Checking printer options
|
||||
```
|
||||
[ian@atticf27 ~]$ lpoptions -p HL-2280DW
|
||||
copies=1 device-uri=dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
finishings=3 job-cancel-after=10800 job-hold-until=no-hold job-priority=50
|
||||
job-sheets=none,none marker-change-time=1517325288 marker-colors=#000000,#000000
|
||||
marker-levels=-1,92 marker-names='Black\ Toner\ Cartridge,Drum\ Unit'
|
||||
marker-types=toner,opc number-up=1 printer-commands=none
|
||||
printer-info='Brother HL-2280DW' printer-is-accepting-jobs=true
|
||||
printer-is-shared=true printer-is-temporary=false printer-location
|
||||
printer-make-and-model='Brother HL-2250DN - CUPS+Gutenprint v5.2.13 Simplified'
|
||||
printer-state=3 printer-state-change-time=1517325288 printer-state-reasons=none
|
||||
printer-type=135188 printer-uri-supported=ipp://localhost/printers/HL-2280DW
|
||||
sides=one-sided
|
||||
|
||||
[ian@atticf27 ~]$ lpoptions -l -p xp-610
|
||||
PageSize/Media Size: *Letter Legal Executive Statement A4
|
||||
ColorModel/Color Model: *Gray Black
|
||||
InputSlot/Media Source: *Standard ManualAdj Manual MultiPurposeAdj MultiPurpose
|
||||
UpperAdj Upper LowerAdj Lower LargeCapacityAdj LargeCapacity
|
||||
StpQuality/Print Quality: None Draft *Standard High
|
||||
Resolution/Resolution: *301x300dpi 150dpi 300dpi 600dpi
|
||||
Duplex/2-Sided Printing: *None DuplexNoTumble DuplexTumble
|
||||
StpiShrinkOutput/Shrink Page If Necessary to Fit Borders: *Shrink Crop Expand
|
||||
StpColorCorrection/Color Correction: *None Accurate Bright Hue Uncorrected
|
||||
Desaturated Threshold Density Raw Predithered
|
||||
StpBrightness/Brightness: 0 100 200 300 400 500 600 700 800 900 *None 1100
|
||||
1200 1300 1400 1500 1600 1700 1800 1900 2000 Custom.REAL
|
||||
StpContrast/Contrast: 0 100 200 300 400 500 600 700 800 900 *None 1100 1200
|
||||
1300 1400 1500 1600 1700 1800 1900 2000 2100 2200 2300 2400 2500 2600 2700
|
||||
2800 2900 3000 3100 3200 3300 3400 3500 3600 3700 3800 3900 4000 Custom.REAL
|
||||
StpImageType/Image Type: None Text Graphics *TextGraphics Photo LineArt
|
||||
|
||||
```
|
||||
|
||||
Most GUI applications have a print dialog, often using the **File >Print** menu choice. Figure 1 shows an example in GIMP, an image manipulation program.
|
||||
|
||||
###### Figure 1. Printing from the GIMP
|
||||
|
||||
![Printing from the GIMP][3]
|
||||
|
||||
So far, all our commands have been implicitly directed to the local CUPS print server. You can also direct most commands to the server on another system, by specifying the `-h` option along with a port number if it is not the CUPS default of 631.
|
||||
|
||||
### CUPS and the CUPS server
|
||||
|
||||
At the heart of the CUPS printing system is the `cupsd` print server which runs as a daemon process. The CUPS configuration file is normally located in /etc/cups/cupsd.conf. The /etc/cups directory also contains other configuration files related to CUPS. CUPS is usually started during system initialization, but may be controlled by the CUPS script located in /etc/rc.d/init.d or /etc/init.d, according to your distribution. For newer systems using systemd initialization, the CUPS service script is likely in /usr/lib/systemd/system/cups.service. As with most such scripts, you can stop, start, or restart the daemon. See our tutorial [Learn Linux, 101: Runlevels, boot targets, shutdown, and reboot][4] for more information on using initialization scripts.
|
||||
|
||||
The configuration file, /etc/cups/cupsd.conf, contains parameters that control things such as access to the printing system, whether remote printing is allowed, the location of spool files, and so on. On some systems, a second part describes individual print queues and is usually generated automatically by configuration tools. Listing 11 shows some entries for a default cupsd.conf file. Note that comments start with a # character. Defaults are usually shown as comments and entries that are changed from the default have the leading # character removed.
|
||||
|
||||
###### Listing 11. Parts of a default /etc/cups/cupsd.conf file
|
||||
```
|
||||
# Only listen for connections from the local machine.
|
||||
Listen localhost:631
|
||||
Listen /var/run/cups/cups.sock
|
||||
|
||||
# Show shared printers on the local network.
|
||||
Browsing On
|
||||
BrowseLocalProtocols dnssd
|
||||
|
||||
# Default authentication type, when authentication is required...
|
||||
DefaultAuthType Basic
|
||||
|
||||
# Web interface setting...
|
||||
WebInterface Yes
|
||||
|
||||
# Set the default printer/job policies...
|
||||
<Policy default>
|
||||
# Job/subscription privacy...
|
||||
JobPrivateAccess default
|
||||
JobPrivateValues default
|
||||
SubscriptionPrivateAccess default
|
||||
SubscriptionPrivateValues default
|
||||
|
||||
# Job-related operations must be done by the owner or an administrator...
|
||||
<Limit Create-Job Print-Job Print-URI Validate-Job>
|
||||
Order deny,allow
|
||||
</Limit>
|
||||
|
||||
```
|
||||
|
||||
File, directory, and user configuration directives that used to be allowed in cupsd.conf are now stored in cups-files.conf instead. This is to prevent certain types of privilege escalation attacks. Listing 12 shows some entries from cups-files.conf. Note that spool files are stored by default in the /var/spool file system as you would expect from the Filesystem Hierarchy Standard (FHS). See the man pages for cupsd.conf and cups-files.conf for more details on these configuration files.
|
||||
|
||||
###### Listing 12. Parts of a default /etc/cups/cups-files.conf
|
||||
```
|
||||
# Location of the file listing all of the local printers...
|
||||
#Printcap /etc/printcap
|
||||
|
||||
# Format of the Printcap file...
|
||||
#PrintcapFormat bsd
|
||||
#PrintcapFormat plist
|
||||
#PrintcapFormat solaris
|
||||
|
||||
# Location of all spool files...
|
||||
#RequestRoot /var/spool/cups
|
||||
|
||||
# Location of helper programs...
|
||||
#ServerBin /usr/lib/cups
|
||||
|
||||
# SSL/TLS keychain for the scheduler...
|
||||
#ServerKeychain ssl
|
||||
|
||||
# Location of other configuration files...
|
||||
#ServerRoot /etc/cups
|
||||
|
||||
```
|
||||
|
||||
Listing 12 refers to the /etc/printcap file. This was the name of the configuration file for LPD print servers, and some applications still use it to determine available printers and their properties. It is usually generated automatically in a CUPS system, so you will probably not modify it yourself. However, you may need to check it if you are diagnosing user printing problems. Listing 13 shows an example.
|
||||
|
||||
###### Listing 13. Automatically generated /etc/printcap
|
||||
```
|
||||
# This file was automatically generated by cupsd(8) from the
|
||||
# /etc/cups/printers.conf file. All changes to this file
|
||||
# will be lost.
|
||||
HL-2280DW|Brother HL-2280DW:rm=atticf27:rp=HL-2280DW:
|
||||
anyprint|Any available printer:rm=atticf27:rp=anyprint:
|
||||
XP-610|EPSON XP-610 Series:rm=atticf27:rp=XP-610:
|
||||
|
||||
```
|
||||
|
||||
Each line here has a printer name and printer description as well as the name of the remote machine (rm) and remote printer (rp) on that machine. Older /etc/printcap file also described the printer capabilities.
|
||||
|
||||
#### File conversion filters
|
||||
|
||||
You can print many types of files using CUPS, including plain text, PDF, PostScript, and a variety of image formats without needing to tell the `lpr` or `lp` command anything more than the file name. This magic feat is accomplished through the use of filters. Indeed, a popular filter for many years was named magicfilter.
|
||||
|
||||
CUPS uses Multipurpose Internet Mail Extensions (MIME) types to determine the appropriate conversion filter when printing a file. Other printing packages might use the magic number mechanism as used by the `file` command. See the man pages for `file` or `magic` for more details.
|
||||
|
||||
Input files are converted to an intermediate raster or PostScript format using filters. Job information such as number of copies is added. The data is finally sent through a beckend to the destination printer. There are some filters (such as `a2ps` or `dvips`) that you can use to manually filter input. You might do this to obtain special formatting results, or to handle a file format that CUPS does not support natively.
|
||||
|
||||
#### Adding printers
|
||||
|
||||
CUPS supports a variety of printers, including:
|
||||
|
||||
* Locally attached parallel and USB printers
|
||||
* Internet Printing Protocol (IPP) printers
|
||||
* Remote LPD printers
|
||||
* Microsoft® Windows® printers using SAMBA
|
||||
* Novell printers using NCP
|
||||
* HP Jetdirect attached printers
|
||||
|
||||
|
||||
|
||||
Most systems today attempt to autodetect and autoconfigure local hardware when the system starts or when the device is attached. Similarly, many network printers can be autodetected. Use the CUPS web administration tool ((<http://localhost:631> or <http://127.0.0.1:631>) to search for or add printers. Many distributions include their own configuration tools, for example YaST on SUSE systems. Figure 2 shows the CUPS interface using localhost:631 and Figure 3 shows the GNOME printer settings dialog on Fedora 27.
|
||||
|
||||
###### Figure 2. Using the CUPS web interface
|
||||
|
||||
|
||||
![Using the CUPS web interface][5]
|
||||
|
||||
###### Figure 3. Using printer settings on Fedora 27
|
||||
|
||||
|
||||
![Using printer settings on Fedora 27][6]
|
||||
|
||||
You can also configure printers from a command line. Before you configure a printer, you need some basic information about the printer and about how it is connected. If a remote system needs a user ID or password, you will also need that information.
|
||||
|
||||
You need to know what driver to use for your printer. Not all printers are fully supported on Linux and some may not work at all, or only with limitations. Check at OpenPrinting.org (see Related topics) to see if there is a driver for your particular printer. The `lpinfo` command can also help you identify the available device types and drivers. Use the `-v` option to list supported devices and the `-m` option to list drivers, as shown in Listing 14.
|
||||
|
||||
###### Listing 14. Available printer drivers
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i xp-610
|
||||
lsb/usr/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
EPSON XP-610 Series, Epson Inkjet Printer Driver (ESC/P-R) for Linux
|
||||
[ian@atticf27 ~]$ locate "Epson-XP-610_Series-epson-escpr-en.ppd.gz"
|
||||
/usr/share/ppd/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
[ian@atticf27 ~]$ lpinfo -v
|
||||
network socket
|
||||
network ipps
|
||||
network lpd
|
||||
network beh
|
||||
network ipp
|
||||
network http
|
||||
network https
|
||||
direct hp
|
||||
serial serial:/dev/ttyS0?baud=115200
|
||||
direct parallel:/dev/lp0
|
||||
network smb
|
||||
direct hpfax
|
||||
network dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
network dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
network lpd://BRN001BA98A1891/BINARY_P1
|
||||
network lpd://192.168.1.38:515/PASSTHRU
|
||||
|
||||
```
|
||||
|
||||
The Epson-XP-610_Series-epson-escpr-en.ppd.gz driver is located in the /usr/share/ppd/Epson/epson-inkjet-printer-escpr/ directory on my system.
|
||||
|
||||
Is you don't find a driver, check the printer manufacturer's website in case a proprietary driver is available. For example, at the time of writing Brother has a driver for my HL-2280DW printer, but this driver is not listed at OpenPrinting.org.
|
||||
|
||||
Once you have the basic information, you can configure a printer using the `lpadmin` command as shown in Listing 15. For this purpose, I will create another instance of my HL-2280DW printer for duplex printing.
|
||||
|
||||
###### Listing 15. Configuring a printer
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i "hl.*2280"
|
||||
HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
lsb/usr/HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW-duplex -E -m HL2280DW.ppd \
|
||||
> -v dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/ \
|
||||
> -D "Brother 1" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Tue 30 Jan 2018 10:56:10 AM EST
|
||||
HL-2280DW-duplex accepting requests since Wed 31 Jan 2018 11:41:16 AM EST
|
||||
HXP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
Rather than creating a copy of the printer for duplex printing, you can just create a new class for duplex printing using `lpadmin` with the `-c` option .
|
||||
|
||||
If you need to remove a printer, use `lpadmin` with the `-x` option.
|
||||
|
||||
Listing 16 shows how to remove the printer and create a class instead.
|
||||
|
||||
###### Listing 16. Removing a printer and creating a class
|
||||
```
|
||||
[ian@atticf27 ~]$ lpadmin -x HL-2280DW-duplex
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW -c duplex -E -D "Duplex printing" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ cupsenable duplex
|
||||
[ian@atticf27 ~]$ cupsaccept duplex
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
duplex accepting requests since Wed 31 Jan 2018 12:12:05 PM EST
|
||||
HL-2280DW accepting requests since Wed 31 Jan 2018 11:51:16 AM EST
|
||||
XP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
You can also set various printer options using the `lpadmin` or `lpoptions` commands. See the man pages for more details.
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
If you are having trouble printing, try these tips:
|
||||
|
||||
* Ensure that the CUPS server is running. You can use the `lpstat` command, which will report an error if it is unable to connect to the cupsd daemon. Alternatively, you might use the `ps -ef` command and check for cupsd in the output.
|
||||
* If you try to queue a job for printing and get an error message indicating that the printer is not accepting jobs results, use `lpstat -a` or `lpc status` to check that the printer is accepting jobs.
|
||||
* If a queued job does not print, use `lpstat -p` or `lpc status` to check that the printer is accepting jobs. You may need to move the job to another printer as discussed earlier.
|
||||
* If the printer is remote, check that it still exists on the remote system and that it is operational.
|
||||
* Check the configuration file to ensure that a particular user or remote system is allowed to print on the printer.
|
||||
* Ensure that your firewall allows remote printing requests, either from another system to your system, or from your system to another, as appropriate.
|
||||
* Verify that you have the right driver.
|
||||
|
||||
|
||||
|
||||
As you can see, printing involves the correct functioning of several components of your system and possibly network. In a tutorial of this length, we can only give you starting points for diagnosis. Most CUPS systems also have a graphical interface to the command-line functions that we discuss here. Generally, this interface is accessible from the local host using a browser pointed to port 631 (<http://localhost:631> or <http://127.0.0.1:631>), as shown earlier in Figure 2.
|
||||
|
||||
You can debug CUPS by running it in the foreground rather than as a daemon process. You can also test alternate configuration files if necessary. Run `cupsd -h` for more information, or see the man pages.
|
||||
|
||||
CUPS also maintains an access log and an error log. You can change the level of logging using the LogLevel statement in cupsd.conf. By default, logs are stored in the /var/log/cups directory. They may be viewed from the **Administration** tab on the browser interface (<http://localhost:631>). Use the `cupsctl` command without any options to display logging options. Either edit cupsd.conf, or use `cupsctl` to adjust various logging parameters. See the `cupsctl` man page for more details.
|
||||
|
||||
The Ubuntu Wiki also has a good page on [Debugging Printing Problems][7].
|
||||
|
||||
This concludes your introduction to printing and CUPS.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-4/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
[3]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/gimp-print.jpg
|
||||
[4]:https://www.ibm.com/developerworks/library/l-lpic1-101-3/
|
||||
[5]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-cups-web.jpg
|
||||
[6]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-settings.jpg
|
||||
[7]:https://wiki.ubuntu.com/DebuggingPrintingProblems
|
||||
@ -0,0 +1,504 @@
|
||||
Modern Web Automation With Python and Selenium – Real Python
|
||||
======
|
||||
|
||||
In this tutorial you’ll learn advanced Python web automation techniques: Using Selenium with a “headless” browser, exporting the scraped data to CSV files, and wrapping your scraping code in a Python class.
|
||||
|
||||
### Motivation: Tracking Listening Habits
|
||||
|
||||
Suppose that you have been listening to music on [bandcamp][4] for a while now, and you find yourself wishing you could remember a song you heard a few months back.
|
||||
|
||||
Sure you could dig through your browser history and check each song, but that might be a pain… All you remember is that you heard the song a few months ago and that it was in the electronic genre.
|
||||
|
||||
“Wouldn’t it be great,” you think to yourself, “if I had a record of my listening history? I could just look up the electronic songs from two months ago and I’d surely find it.”
|
||||
|
||||
**Today, you will build a basic Python class, called`BandLeader` that connects to [bandcamp.com][4], streams music from the “discovery” section of the front page, and keeps track of your listening history.**
|
||||
|
||||
The listening history will be saved to disk in a [CSV][5] file. You can then explore that CSV file in your favorite spreadsheet application or even with Python.
|
||||
|
||||
If you have had some experience with [web scraping in Python][6], you are familiar with making HTTP requests and using Pythonic APIs to navigate the DOM. You will do more of the same today, except with one difference.
|
||||
|
||||
**Today you will use a full-fledged browser running in headless mode to do the HTTP requests for you.**
|
||||
|
||||
A [headless browser][7] is just a regular web browser, except that it contains no visible UI element. Just like you’d expect, it can do more than make requests: it can also render HTML (though you cannot see it), keep session information, and even perform asynchronous network communications by running JavaScript code.
|
||||
|
||||
If you want to automate the modern web, headless browsers are essential.
|
||||
|
||||
**Free Bonus:** [Click here to download a "Python + Selenium" project skeleton with full source code][1] that you can use as a foundation for your own Python web scraping and automation apps.
|
||||
|
||||
### Setup
|
||||
|
||||
Your first step, before writing a single line of Python, is to install a [Selenium][8] supported [WebDriver][9] for your favorite web browser. In what follows, you will be working with [Firefox][10], but [Chrome][11] could easily work too.
|
||||
|
||||
So, assuming that the path `~/.local/bin` is in your execution `PATH`, here’s how you would install the Firefox webdriver, called `geckodriver`, on a Linux machine:
|
||||
```
|
||||
$ wget https://github.com/mozilla/geckodriver/releases/download/v0.19.1/geckodriver-v0.19.1-linux64.tar.gz
|
||||
$ tar xvfz geckodriver-v0.19.1-linux64.tar.gz
|
||||
$ mv geckodriver ~/.local/bin
|
||||
|
||||
```
|
||||
|
||||
Next, you install the [selenium][12] package, using `pip` or however else you like. If you made a [virtual environment][13] for this project, you just type:
|
||||
```
|
||||
$ pip install selenium
|
||||
|
||||
```
|
||||
|
||||
[ If you ever feel lost during the course of this tutorial, the full code demo can be found [on GitHub][14]. ]
|
||||
|
||||
Now it’s time for a test drive:
|
||||
|
||||
### Test Driving a Headless Browser
|
||||
|
||||
To test that everything is working, you decide to try out a basic web search via [DuckDuckGo][15]. You fire up your preferred Python interpreter and type:
|
||||
```
|
||||
>>> from selenium.webdriver import Firefox
|
||||
>>> from selenium.webdriver.firefox.options import Options
|
||||
>>> opts = Options()
|
||||
>>> opts.set_headless()
|
||||
>>> assert options.headless # operating in headless mode
|
||||
>>> browser = Firefox(options=opts)
|
||||
>>> browser.get('https://duckduckgo.com')
|
||||
|
||||
```
|
||||
|
||||
So far you have created a headless Firefox browser navigated to `https://duckduckgo.com`. You made an `Options` instance and used it to activate headless mode when you passed it to the `Firefox` constructor. This is akin to typing `firefox -headless` at the command line.
|
||||
|
||||
|
||||
|
||||
Now that a page is loaded you can query the DOM using methods defined on your newly minted `browser` object. But how do you know what to query? The best way is to open your web browser and use its developer tools to inspect the contents of the page. Right now you want to get ahold of the search form so you can submit a query. By inspecting DuckDuckGo’s home page you find that the search form `<input>` element has an `id` attribute `"search_form_input_homepage"`. That’s just what you needed:
|
||||
```
|
||||
>>> search_form = browser.find_element_by_id('search_form_input_homepage')
|
||||
>>> search_form.send_keys('real python')
|
||||
>>> search_form.submit()
|
||||
|
||||
```
|
||||
|
||||
You found the search form, used the `send_keys` method to fill it out, and then the `submit` method to perform your search for `"Real Python"`. You can checkout the top result:
|
||||
```
|
||||
>>> results = browser.find_elements_by_class_name('result')
|
||||
>>> print(results[0].text)
|
||||
|
||||
Real Python - Real Python
|
||||
Get Real Python and get your hands dirty quickly so you spend more time making real applications. Real Python teaches Python and web development from the ground up ...
|
||||
https://realpython.com
|
||||
|
||||
```
|
||||
|
||||
Everything seems to be working. In order to prevent invisible headless browser instances from piling up on your machine, you close the browser object before exiting your python session:
|
||||
```
|
||||
>>> browser.close()
|
||||
>>> quit()
|
||||
|
||||
```
|
||||
|
||||
### Groovin on Tunes
|
||||
|
||||
You’ve tested that you can drive a headless browser using Python, now to put it to use.
|
||||
|
||||
1. You want to play music
|
||||
2. You want to browse and explore music
|
||||
3. You want information about what music is playing.
|
||||
|
||||
|
||||
|
||||
To start, you navigate to <https://bandcamp.com> and start to poke around in your browser’s developer tools. You discover a big shiny play button towards the bottom of the screen with a `class` attribute that contains the value`"playbutton"`. You check that it works:
|
||||
|
||||
<https://files.realpython.com/media/web-scraping-bandcamp-discovery-section.84a10034f564.jpg>
|
||||
```
|
||||
>>> opts = Option()
|
||||
>>> opts.set_headless()
|
||||
>>> browser = Firefox(options=opts)
|
||||
>>> browser.get('https://bandcamp.com')
|
||||
>>> browser.find_element_by_class('playbutton').click()
|
||||
|
||||
```
|
||||
|
||||
You should hear music! Leave it playing and move back to your web browser. Just to the side of the play button is the discovery section. Again, you inspect this section and find that each of the currently visible available tracks has a `class` value of `"discover-item"`, and that each item seems to be clickable. In Python, you check this out:
|
||||
```
|
||||
>>> tracks = browser.find_elements_by_class_name('discover-item')
|
||||
>>> len(tracks) # 8
|
||||
>>> tracks[3].click()
|
||||
|
||||
```
|
||||
|
||||
A new track should be playing! This is the first step to exploring bandcamp using Python! You spend a few minutes clicking on different tracks in your Python environment but soon grow tired of the meagre library of 8 songs.
|
||||
|
||||
### Exploring the Catalogue
|
||||
|
||||
Looking a back at your browser, you see the buttons for exploring all of the tracks featured in bandcamp’s music discovery section. By now this feels familiar: each button has a `class` value of `"item-page"`. The very last button is the “next” button that will display the next eight tracks in the catalogue. You go to work:
|
||||
```
|
||||
>>> next_button = [e for e in browser.find_elements_by_class_name('item-page')
|
||||
if e.text.lower().find('next') > -1]
|
||||
>>> next_button.click()
|
||||
|
||||
```
|
||||
|
||||
Great! Now you want to look at the new tracks, so you think “I’ll just repopulate my `tracks` variable like I did a few minutes ago”. But this is where things start to get tricky.
|
||||
|
||||
First, bandcamp designed their site for humans to enjoy using, not for Python scripts to access programmatically. When you call `next_button.click()` the real web browser responds by executing some JavaScript code. If you try it out in your browser, you see that some time elapses as the catalogue of songs scrolls with a smooth animation effect. If you try to repopulate your `tracks` variable before the animation finishes, you may not get all the tracks and you may get some that you don’t want.
|
||||
|
||||
The solution? You can just sleep for a second or, if you are just running all this in a Python shell, you probably wont even notice - after all it takes time for you to type too.
|
||||
|
||||
Another slight kink is something that can only be discovered through experimentation. You try to run the same code again:
|
||||
```
|
||||
>>> tracks = browser.find_elements_by_class_name('discover-item')
|
||||
>>> assert(len(tracks) == 8)
|
||||
AssertionError
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
But you notice something strange. `len(tracks)` is not equal to `8` even though only the next batch of `8` should be displayed. Digging a little further you find that your list contains some tracks that were displayed before. To get only the tracks that are actually visible in the browser, you need to filter the results a little.
|
||||
|
||||
After trying a few things, you decide to keep a track only if its `x` coordinate on the page fall within the bounding box of the containing element. The catalogue’s container has a `class` value of `"discover-results"`. Here’s how you proceed:
|
||||
```
|
||||
>>> discover_section = self.browser.find_element_by_class_name('discover-results')
|
||||
>>> left_x = discover_section.location['x']
|
||||
>>> right_x = left_x + discover_section.size['width']
|
||||
>>> discover_items = browser.find_element_by_class_name('discover_items')
|
||||
>>> tracks = [t for t in discover_items
|
||||
if t.location['x'] >= left_x and t.location['x'] < right_x]
|
||||
>>> assert len(tracks) == 8
|
||||
|
||||
```
|
||||
|
||||
### Building a Class
|
||||
|
||||
If you are growing weary of retyping the same commands over and over again in your Python environment, you should dump some of it into a module. A basic class for your bandcamp manipulation should do the following:
|
||||
|
||||
1. Initialize a headless browser and navigate to bandcamp
|
||||
2. Keep a list of available tracks
|
||||
3. Support finding more tracks
|
||||
4. Play, pause, and skip tracks
|
||||
|
||||
|
||||
|
||||
All in one go, here’s the basic code:
|
||||
```
|
||||
from selenium.webdriver import Firefox
|
||||
from selenium.webdriver.firefox.options import Options
|
||||
from time import sleep, ctime
|
||||
from collections import namedtuple
|
||||
from threading import Thread
|
||||
from os.path import isfile
|
||||
import csv
|
||||
|
||||
|
||||
BANDCAMP_FRONTPAGE='https://bandcamp.com/'
|
||||
|
||||
class BandLeader():
|
||||
def __init__(self):
|
||||
# create a headless browser
|
||||
opts = Options()
|
||||
opts.set_headless()
|
||||
self.browser = Firefox(options=opts)
|
||||
self.browser.get(BANDCAMP_FRONTPAGE)
|
||||
|
||||
# track list related state
|
||||
self._current_track_number = 1
|
||||
self.track_list = []
|
||||
self.tracks()
|
||||
|
||||
def tracks(self):
|
||||
'''
|
||||
query the page to populate a list of available tracks
|
||||
'''
|
||||
|
||||
# sleep to give the browser time to render and finish any animations
|
||||
sleep(1)
|
||||
|
||||
# get the container for the visible track list
|
||||
discover_section = self.browser.find_element_by_class_name('discover-results')
|
||||
left_x = discover_section.location['x']
|
||||
right_x = left_x + discover_section.size['width']
|
||||
|
||||
# filter the items in the list to include only those we can click
|
||||
discover_items = self.browser.find_elements_by_class_name('discover-item')
|
||||
self.track_list = [t for t in discover_items
|
||||
if t.location['x'] >= left_x and t.location['x'] < right_x]
|
||||
|
||||
# print the available tracks to the screen
|
||||
for (i,track) in enumerate(self.track_list):
|
||||
print('[{}]'.format(i+1))
|
||||
lines = track.text.split('\n')
|
||||
print('Album : {}'.format(lines[0]))
|
||||
print('Artist : {}'.format(lines[1]))
|
||||
if len(lines) > 2:
|
||||
print('Genre : {}'.format(lines[2]))
|
||||
|
||||
def catalogue_pages(self):
|
||||
'''
|
||||
print the available pages in the catalogue that are presently
|
||||
accessible
|
||||
'''
|
||||
print('PAGES')
|
||||
for e in self.browser.find_elements_by_class_name('item-page'):
|
||||
print(e.text)
|
||||
print('')
|
||||
|
||||
|
||||
def more_tracks(self,page='next'):
|
||||
'''
|
||||
advances the catalog and repopulates the track list, we can pass in a number
|
||||
to advance any of hte available pages
|
||||
'''
|
||||
|
||||
next_btn = [e for e in self.browser.find_elements_by_class_name('item-page')
|
||||
if e.text.lower().strip() == str(page)]
|
||||
|
||||
if next_btn:
|
||||
next_btn[0].click()
|
||||
self.tracks()
|
||||
|
||||
def play(self,track=None):
|
||||
'''
|
||||
play a track. If no track number is supplied, the presently selected track
|
||||
will play
|
||||
'''
|
||||
|
||||
if track is None:
|
||||
self.browser.find_element_by_class_name('playbutton').click()
|
||||
elif type(track) is int and track <= len(self.track_list) and track >= 1:
|
||||
self._current_track_number = track
|
||||
self.track_list[self._current_track_number - 1].click()
|
||||
|
||||
|
||||
def play_next(self):
|
||||
'''
|
||||
plays the next available track
|
||||
'''
|
||||
if self._current_track_number < len(self.track_list):
|
||||
self.play(self._current_track_number+1)
|
||||
else:
|
||||
self.more_tracks()
|
||||
self.play(1)
|
||||
|
||||
|
||||
def pause(self):
|
||||
'''
|
||||
pauses the playback
|
||||
'''
|
||||
self.play()
|
||||
```
|
||||
|
||||
Pretty neat. You can import this into your Python environment and run bandcamp programmatically! But wait, didn’t you start this whole thing because you wanted to keep track of information about your listening history?
|
||||
|
||||
### Collecting Structured Data
|
||||
|
||||
Your final task is to keep track of the songs that you actually listened to. How might you do this? What does it mean to actually listen to something anyway? If you are perusing the catalogue, stopping for a few seconds on each song, do each of those songs count? Probably not. You are going to allow some ‘exploration’ time to factor in to your data collection.
|
||||
|
||||
Your goals are now to:
|
||||
|
||||
1. Collect structured information about the currently playing track
|
||||
2. Keep a “database” of tracks
|
||||
3. Save and restore that “database” to and from disk
|
||||
|
||||
|
||||
|
||||
You decide to use a [namedtuple][16] to store the information that you track. Named tuples are good for representing bundles of attributes with no functionality tied to them, a bit like a database record.
|
||||
```
|
||||
TrackRec = namedtuple('TrackRec', [
|
||||
'title',
|
||||
'artist',
|
||||
'artist_url',
|
||||
'album',
|
||||
'album_url',
|
||||
'timestamp' # When you played it
|
||||
])
|
||||
|
||||
```
|
||||
|
||||
In order to collect this information, you add a method to the `BandLeader` class. Checking back in with the browser’s developer tools, you find the right HTML elements and attributes to select all the information you need. Also, you only want to get information about the currently playing track if there music is actually playing at the time. Luckily, the page player adds a `"playing"` class to the play button whenever music is playing and removes it when the music stops. With these considerations in mind, you write a couple of methods:
|
||||
```
|
||||
def is_playing(self):
|
||||
'''
|
||||
returns `True` if a track is presently playing
|
||||
'''
|
||||
playbtn = self.browser.find_element_by_class_name('playbutton')
|
||||
return playbtn.get_attribute('class').find('playing') > -1
|
||||
|
||||
|
||||
def currently_playing(self):
|
||||
'''
|
||||
Returns the record for the currently playing track,
|
||||
or None if nothing is playing
|
||||
'''
|
||||
try:
|
||||
if self.is_playing():
|
||||
title = self.browser.find_element_by_class_name('title').text
|
||||
album_detail = self.browser.find_element_by_css_selector('.detail-album > a')
|
||||
album_title = album_detail.text
|
||||
album_url = album_detail.get_attribute('href').split('?')[0]
|
||||
artist_detail = self.browser.find_element_by_css_selector('.detail-artist > a')
|
||||
artist = artist_detail.text
|
||||
artist_url = artist_detail.get_attribute('href').split('?')[0]
|
||||
return TrackRec(title, artist, artist_url, album_title, album_url, ctime())
|
||||
|
||||
except Exception as e:
|
||||
print('there was an error: {}'.format(e))
|
||||
|
||||
return None
|
||||
```
|
||||
|
||||
For good measure, you also modify the `play` method to keep track of the currently playing track:
|
||||
```
|
||||
def play(self, track=None):
|
||||
'''
|
||||
play a track. If no track number is supplied, the presently selected track
|
||||
will play
|
||||
'''
|
||||
|
||||
if track is None:
|
||||
self.browser.find_element_by_class_name('playbutton').click()
|
||||
elif type(track) is int and track <= len(self.track_list) and track >= 1:
|
||||
self._current_track_number = track
|
||||
self.track_list[self._current_track_number - 1].click()
|
||||
|
||||
sleep(0.5)
|
||||
if self.is_playing():
|
||||
self._current_track_record = self.currently_playing()
|
||||
```
|
||||
|
||||
Next, you’ve got to keep a database of some kind. Though it may not scale well in the long run, you can go far with a simple list. You add `self.database = []` to `BandCamp`‘s `__init__` method. Because you want to allow for time to pass before entering a `TrackRec` object into the database, you decide to use Python’s [threading tools][17] to run a separate process that maintains the database in the background.
|
||||
|
||||
You’ll supply a `_maintain()` method to `BandLeader` instances that will run it a separate thread. The new method will periodically check the value of `self._current_track_record` and add it to the database if it is new.
|
||||
|
||||
You will start the thread when the class is instantiated by adding some code to `__init__`.
|
||||
```
|
||||
# the new init
|
||||
def __init__(self):
|
||||
# create a headless browser
|
||||
opts = Options()
|
||||
opts.set_headless()
|
||||
self.browser = Firefox(options=opts)
|
||||
self.browser.get(BANDCAMP_FRONTPAGE)
|
||||
|
||||
# track list related state
|
||||
self._current_track_number = 1
|
||||
self.track_list = []
|
||||
self.tracks()
|
||||
|
||||
# state for the database
|
||||
self.database = []
|
||||
self._current_track_record = None
|
||||
|
||||
# the database maintenance thread
|
||||
self.thread = Thread(target=self._maintain)
|
||||
self.thread.daemon = True # kills the thread with the main process dies
|
||||
self.thread.start()
|
||||
|
||||
self.tracks()
|
||||
|
||||
|
||||
def _maintain(self):
|
||||
while True:
|
||||
self._update_db()
|
||||
sleep(20) # check every 20 seconds
|
||||
|
||||
|
||||
def _update_db(self):
|
||||
try:
|
||||
check = (self._current_track_record is not None
|
||||
and (len(self.database) == 0
|
||||
or self.database[-1] != self._current_track_record)
|
||||
and self.is_playing())
|
||||
if check:
|
||||
self.database.append(self._current_track_record)
|
||||
|
||||
except Exception as e:
|
||||
print('error while updating the db: {}'.format(e)
|
||||
|
||||
```
|
||||
|
||||
If you’ve never worked with multithreaded programming in Python, [you should read up on it!][18] For your present purpose, you can think of thread as a loop that runs in the background of the main Python process (the one you interact with directly). Every twenty seconds, the loop checks a few things to see if the database needs to be updated, and if it does, appends a new record. Pretty cool.
|
||||
|
||||
The very last step is saving the database and restoring from saved states. Using the [csv][19] package you can ensure your database resides in a highly portable format, and remains usable even if you abandon your wonderful `BandLeader` class ;)
|
||||
|
||||
The `__init__` method should be yet again altered, this time to accept a file path where you’d like to save the database. You’d like to load this database if it is available, and you’d like to save it periodically, whenever it is updated. The updates look like so:
|
||||
```
|
||||
def __init__(self,csvpath=None):
|
||||
self.database_path=csvpath
|
||||
self.database = []
|
||||
|
||||
# load database from disk if possible
|
||||
if isfile(self.database_path):
|
||||
with open(self.database_path, newline='') as dbfile:
|
||||
dbreader = csv.reader(dbfile)
|
||||
next(dbreader) # to ignore the header line
|
||||
self.database = [TrackRec._make(rec) for rec in dbreader]
|
||||
|
||||
# .... the rest of the __init__ method is unchanged ....
|
||||
|
||||
|
||||
# a new save_db method
|
||||
def save_db(self):
|
||||
with open(self.database_path,'w',newline='') as dbfile:
|
||||
dbwriter = csv.writer(dbfile)
|
||||
dbwriter.writerow(list(TrackRec._fields))
|
||||
for entry in self.database:
|
||||
dbwriter.writerow(list(entry))
|
||||
|
||||
|
||||
# finally add a call to save_db to your database maintenance method
|
||||
def _update_db(self):
|
||||
try:
|
||||
check = (self._current_track_record is not None
|
||||
and self._current_track_record is not None
|
||||
and (len(self.database) == 0
|
||||
or self.database[-1] != self._current_track_record)
|
||||
and self.is_playing())
|
||||
if check:
|
||||
self.database.append(self._current_track_record)
|
||||
self.save_db()
|
||||
|
||||
except Exception as e:
|
||||
print('error while updating the db: {}'.format(e)
|
||||
```
|
||||
|
||||
And voilà! You can listen to music and keep a record of what you hear! Amazing.
|
||||
|
||||
Something interesting about the above is that [using a `namedtuple`][16] really begins to pay off. When converting to and from CSV format, you take advantage of the ordering of the rows in the CSV file to fill in the rows in the `TrackRec` objects. Likewise, you can create the header row of the CSV file by referencing the `TrackRec._fields` attribute. This is one of the reasons using a tuple ends up making sense for columnar data.
|
||||
|
||||
### What’s Next and What Have You Learned?
|
||||
|
||||
From here you could do loads more! Here are a few quick ideas that would leverage the mild superpower that is Python + Selenium:
|
||||
|
||||
* You could extend the `BandLeader` class to navigate to album pages and play the tracks you find there
|
||||
* You might decide to create playlists based on your favorite or most frequently heard tracks
|
||||
* Perhaps you want to add an autoplay feature
|
||||
* Maybe you’d like to query songs by date or title or artist and build playlists that way
|
||||
|
||||
|
||||
|
||||
**Free Bonus:** [Click here to download a "Python + Selenium" project skeleton with full source code][1] that you can use as a foundation for your own Python web scraping and automation apps.
|
||||
|
||||
You have learned that Python can do everything that a web browser can do, and a bit more. You could easily write scripts to control virtual browser instances that run in the cloud, create bots that interact with real users, or that mindlessly fill out forms! Go forth, and automate!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://realpython.com/blog/python/modern-web-automation-with-python-and-selenium/
|
||||
|
||||
作者:[Colin OKeefe][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://realpython.com/team/cokeefe/
|
||||
[1]:https://realpython.com/blog/python/modern-web-automation-with-python-and-selenium/#
|
||||
[4]:https://bandcamp.com
|
||||
[5]:https://en.wikipedia.org/wiki/Comma-separated_values
|
||||
[6]:https://realpython.com/blog/python/python-web-scraping-practical-introduction/
|
||||
[7]:https://en.wikipedia.org/wiki/Headless_browser
|
||||
[8]:http://www.seleniumhq.org/docs/
|
||||
[9]:https://en.wikipedia.org/wiki/Selenium_(software)#Selenium_WebDriver
|
||||
[10]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[11]:https://www.google.com/chrome/index.html
|
||||
[12]:http://seleniumhq.github.io/selenium/docs/api/py/
|
||||
[13]:https://realpython.com/blog/python/python-virtual-environments-a-primer/
|
||||
[14]:https://github.com/realpython/python-web-scraping-examples
|
||||
[15]:https://duckduckgo.com
|
||||
[16]:https://dbader.org/blog/writing-clean-python-with-namedtuples
|
||||
[17]:https://docs.python.org/3.6/library/threading.html#threading.Thread
|
||||
[18]:https://dbader.org/blog/python-parallel-computing-in-60-seconds
|
||||
[19]:https://docs.python.org/3.6/library/csv.html
|
||||
156
sources/tech/20180206 Power(Shell) to the people.md
Normal file
156
sources/tech/20180206 Power(Shell) to the people.md
Normal file
@ -0,0 +1,156 @@
|
||||
Power(Shell) to the people
|
||||
======
|
||||
|
||||

|
||||
|
||||
Earlier this year, [PowerShell Core][1] [became generally available][2] under an Open Source ([MIT][3]) license. PowerShell is hardly a new technology. From its first release for Windows in 2006, PowerShell's creators [sought][4] to incorporate the power and flexibility of Unix shells while remedying their perceived deficiencies, particularly the need for text manipulation to derive value from combining commands.
|
||||
|
||||
Five major releases later, PowerShell Core allows the same innovative shell and command environment to run natively on all major operating systems, including OS X and Linux. Some (read: almost everyone) may still scoff at the audacity and/or the temerity of this Windows-born interloper to offer itself to platforms that have had strong shell environments since time immemorial (at least as defined by a millennial). In this post, I hope to make the case that PowerShell can provide advantages to even seasoned users.
|
||||
|
||||
### Consistency across platforms
|
||||
|
||||
If you plan to port your scripts from one execution environment to another, you need to make sure you use only the commands and syntaxes that work. For example, on GNU systems, you would obtain yesterday's date as follows:
|
||||
```
|
||||
date --date="1 day ago"
|
||||
|
||||
```
|
||||
|
||||
On BSD systems (such as OS X), the above syntax wouldn't work, as the BSD date utility requires the following syntax:
|
||||
```
|
||||
date -v -1d
|
||||
|
||||
```
|
||||
|
||||
Because PowerShell is licensed under a permissive license and built for all platforms, you can ship it with your application. Thus, when your scripts run in the target environment, they'll be running on the same shell using the same command implementations as the environment in which you tested your scripts.
|
||||
|
||||
### Objects and structured data
|
||||
|
||||
*nix commands and utilities rely on your ability to consume and manipulate unstructured data. Those who have lived for years with `sed` `grep` and `awk` may be unbothered by this statement, but there is a better way.
|
||||
|
||||
Let's redo the yesterday's date example in PowerShell. To get the current date, run the `Get-Date` cmdlet (pronounced "commandlet"):
|
||||
```
|
||||
> Get-Date
|
||||
|
||||
|
||||
|
||||
Sunday, January 21, 2018 8:12:41 PM
|
||||
|
||||
```
|
||||
|
||||
The output you see isn't really a string of text. Rather, it is a string representation of a .Net Core object. Just like any other object in any other OOP environment, it has a type and most often, methods you can call.
|
||||
|
||||
Let's prove this:
|
||||
```
|
||||
> $(Get-Date).GetType().FullName
|
||||
|
||||
System.DateTime
|
||||
|
||||
```
|
||||
|
||||
The `$(...)` syntax behaves exactly as you'd expect from POSIX shells—the result of the evaluation of the command in parentheses is substituted for the entire expression. In PowerShell, however, the $ is strictly optional in such expressions. And, most importantly, the result is a .Net object, not text. So we can call the `GetType()` method on that object to get its type object (similar to `Class` object in Java), and the `FullName` [property][5] to get the full name of the type.
|
||||
|
||||
So, how does this object-orientedness make your life easier?
|
||||
|
||||
First, you can pipe any object to the `Get-Member` cmdlet to see all the methods and properties it has to offer.
|
||||
```
|
||||
> (Get-Date) | Get-Member
|
||||
PS /home/yevster/Documents/ArticlesInProgress> $(Get-Date) | Get-Member
|
||||
|
||||
|
||||
TypeName: System.DateTime
|
||||
|
||||
|
||||
Name MemberType Definition
|
||||
---- ---------- ----------
|
||||
Add Method datetime Add(timespan value)
|
||||
AddDays Method datetime AddDays(double value)
|
||||
AddHours Method datetime AddHours(double value)
|
||||
AddMilliseconds Method datetime AddMilliseconds(double value)
|
||||
AddMinutes Method datetime AddMinutes(double value)
|
||||
AddMonths Method datetime AddMonths(int months)
|
||||
AddSeconds Method datetime AddSeconds(double value)
|
||||
AddTicks Method datetime AddTicks(long value)
|
||||
AddYears Method datetime AddYears(int value)
|
||||
CompareTo Method int CompareTo(System.Object value), int ...
|
||||
```
|
||||
|
||||
You can quickly see that the DateTime object has an `AddDays` that you can quickly use to get yesterday's date:
|
||||
```
|
||||
> (Get-Date).AddDays(-1)
|
||||
|
||||
|
||||
Saturday, January 20, 2018 8:24:42 PM
|
||||
```
|
||||
|
||||
To do something slightly more exciting, let's call Yahoo's weather service (because it doesn't require an API token) and get your local weather.
|
||||
```
|
||||
$city="Boston"
|
||||
$state="MA"
|
||||
$url="https://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20weather.forecast%20where%20woeid%20in%20(select%20woeid%20from%20geo.places(1)%20where%20text%3D%22${city}%2C%20${state}%22)&format=json&env=store%3A%2F%2Fdatatables.org%2Falltableswithkeys"
|
||||
```
|
||||
|
||||
Now, we could do things the old-fashioned way and just run `curl $url` to get a giant blob of JSON, or...
|
||||
```
|
||||
$weather=(Invoke-RestMethod $url)
|
||||
```
|
||||
|
||||
If you look at the type of `$weather` (by running `echo $weather.GetType().FullName`), you will see that it's a `PSCustomObject`. It's a dynamic object that reflects the structure of the JSON.
|
||||
|
||||
And PowerShell will be thrilled to help you navigate through it with its tab completion. Just type `$weather.` (making sure to include the ".") and press Tab. You will see all the root-level JSON keys. Type one, followed by a "`.`", press Tab again, and you'll see its children (if any).
|
||||
|
||||
Thus, you can easily navigate to the data you want:
|
||||
```
|
||||
> echo $weather.query.results.channel.atmosphere.pressure
|
||||
1019.0
|
||||
|
||||
|
||||
> echo $weather.query.results.channel.wind.chill
|
||||
41
|
||||
```
|
||||
|
||||
And if you have JSON or CSV lying around (or returned by an outside command) as unstructured data, just pipe it into the `ConvertFrom-Json` or `ConvertFrom-CSV` cmdlet, respectively, and you can have your data in nice clean objects.
|
||||
|
||||
### Computing vs. automation
|
||||
|
||||
We use shells for two purposes. One is for computing, to run individual commands and to manually respond to their output. The other is automation, to write scripts that execute multiple commands and respond to their output programmatically.
|
||||
|
||||
A problem that most of us have learned to overlook is that these two purposes place different and conflicting requirements on the shell. Computing requires the shell to be laconic. The fewer keystrokes a user can get away with, the better. It's unimportant if what the user has typed is barely legible to another human being. Scripts, on the other hand, are code. Readability and maintainability are key. And here, POSIX utilities often fail us. While some commands do offer both laconic and readable syntaxes (e.g. `-f` and `--force`) for some of their parameters, the command names themselves err on the side of brevity, not readability.
|
||||
|
||||
PowerShell includes several mechanisms to eliminate that Faustian tradeoff.
|
||||
|
||||
First, tab completion eliminates typing of argument names. For instance, type `Get-Random -Mi`, press Tab and PowerShell will complete the argument for you: `Get-Random -Minimum`. But if you really want to be laconic, you don't even need to press Tab. For instance, PowerShell will understand
|
||||
```
|
||||
Get-Random -Mi 1 -Ma 10
|
||||
```
|
||||
|
||||
because `Mi` and `Ma` each have unique completions.
|
||||
|
||||
You may have noticed that all PowerShell cmdlet names have a verb-noun structure. This can help script readability, but you probably don't want to keep typing `Get-` over and over in the command line. So don't! If you type a noun without a verb, PowerShell will look for a `Get-` command with that noun.
|
||||
|
||||
Caution: although PowerShell is not case-sensitive, it's a good practice to capitalize the first letter of the noun when you intend to use a PowerShell command. For example, typing `date` will call your system's `date` utility. Typing `Date` will call PowerShell's `Get-Date` cmdlet.
|
||||
|
||||
And if that's not enough, PowerShell has aliases to create simple names. For example, if you type `alias -name cd`, you will discover the `cd` command in PowerShell is itself an alias for the `Set-Location` command.
|
||||
|
||||
So to review—you get powerful tab completion, aliases, and noun completions to keep your command names short, automatic and consistent parameter name truncation, while still enjoying a rich, readable syntax for scripting.
|
||||
|
||||
### So... friends?
|
||||
|
||||
There are just some of the advantages of PowerShell. There are more features and cmdlets I haven't discussed (check out [Where-Object][6] or its alias `?` if you want to make `grep` cry). And hey, if you really feel homesick, PowerShell will be happy to launch your old native utilities for you. But give yourself enough time to get acclimated in PowerShell's object-oriented cmdlet world, and you may find yourself choosing to forget the way back.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/powershell-people
|
||||
|
||||
作者:[Yev Bronshteyn][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/yevster
|
||||
[1]:https://github.com/PowerShell/PowerShell/blob/master/README.md
|
||||
[2]:https://blogs.msdn.microsoft.com/powershell/2018/01/10/powershell-core-6-0-generally-available-ga-and-supported/
|
||||
[3]:https://spdx.org/licenses/MIT
|
||||
[4]:http://www.jsnover.com/Docs/MonadManifesto.pdf
|
||||
[5]:https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/classes-and-structs/properties
|
||||
[6]:https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.core/where-object?view=powershell-6
|
||||
398
sources/tech/20180206 Programming in Color with ncurses.md
Normal file
398
sources/tech/20180206 Programming in Color with ncurses.md
Normal file
@ -0,0 +1,398 @@
|
||||
Programming in Color with ncurses
|
||||
======
|
||||
In parts [one][1] and [two][2] of my article series about programming with the ncurses library, I introduced a few curses functions to draw text on the screen, query characters from the screen and read from the keyboard. To demonstrate several of these functions, I created a simple adventure game in curses that drew a game map and player character using simple characters. In this follow-up article, I show how to add color to a curses program.
|
||||
|
||||
Drawing on the screen is all very well and good, but if it's all white-on-black text, your program might seem dull. Colors can help convey more information—for example, if your program needs to indicate success or failure. In such a case, you could display text in green or red to help emphasize the outcome. Or, maybe you simply want to use colors to "snazz" up your program to make it look prettier.
|
||||
|
||||
In this article, I use a simple example to demonstrate color manipulation via the curses functions. In my previous article, I wrote a basic adventure-style game that lets you move a player character around a crudely drawn map. However, the map was entirely black and white text, relying on shapes to suggest water (~) or mountains (^), so let's update the game to use colors.
|
||||
|
||||
### Color Essentials
|
||||
|
||||
Before you can use colors, your program needs to know if it can rely on the terminal to display the colors correctly. On modern systems, this always should be true. But in the classic days of computing, some terminals were monochromatic, such as the venerable VT52 and VT100 terminals, usually providing white-on-black or green-on-black text.
|
||||
|
||||
To query the terminal capability for colors, use the has_colors() function. This will return a true value if the terminal can display color, and a false value if not. It is usually used to start an if block, like this:
|
||||
|
||||
```
|
||||
|
||||
if (has_colors() == FALSE) {
|
||||
endwin();
|
||||
printf("Your terminal does not support color\n");
|
||||
exit(1);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Having determined that the terminal can display color, you then can set up curses to use colors with the start_color() function. Now you're ready to define the colors your program will use.
|
||||
|
||||
In curses, you define colors in pairs: a foreground color on a background color. This allows curses to set both color attributes at once, which often is what you want to do. To establish a color pair, use init_pair() to define a foreground and background color, and associate it to an index number. The general syntax is:
|
||||
|
||||
```
|
||||
|
||||
init_pair(index, foreground, background);
|
||||
|
||||
```
|
||||
|
||||
Consoles support only eight basic colors: black, red, green, yellow, blue, magenta, cyan and white. These colors are defined for you with the following names:
|
||||
|
||||
* COLOR_BLACK
|
||||
|
||||
* COLOR_RED
|
||||
|
||||
* COLOR_GREEN
|
||||
|
||||
* COLOR_YELLOW
|
||||
|
||||
* COLOR_BLUE
|
||||
|
||||
* COLOR_MAGENTA
|
||||
|
||||
* COLOR_CYAN
|
||||
|
||||
* COLOR_WHITE
|
||||
|
||||
### Applying the Colors
|
||||
|
||||
In my adventure game, I'd like the grassy areas to be green and the player's "trail" to be a subtle yellow-on-green dotted path. Water should be blue, with the tildes in the similar cyan color. I'd like mountains to be grey, but black text on a white background should make for a reasonable compromise. To make the player's character more visible, I'd like to use a garish red-on-magenta scheme. I can define these colors pairs like so:
|
||||
|
||||
```
|
||||
|
||||
start_color();
|
||||
init_pair(1, COLOR_YELLOW, COLOR_GREEN);
|
||||
init_pair(2, COLOR_CYAN, COLOR_BLUE);
|
||||
init_pair(3, COLOR_BLACK, COLOR_WHITE);
|
||||
init_pair(4, COLOR_RED, COLOR_MAGENTA);
|
||||
|
||||
```
|
||||
|
||||
To make my color pairs easy to remember, my program defines a few symbolic constants:
|
||||
|
||||
```
|
||||
|
||||
#define GRASS_PAIR 1
|
||||
#define EMPTY_PAIR 1
|
||||
#define WATER_PAIR 2
|
||||
#define MOUNTAIN_PAIR 3
|
||||
#define PLAYER_PAIR 4
|
||||
|
||||
```
|
||||
|
||||
With these constants, my color definitions become:
|
||||
|
||||
```
|
||||
|
||||
start_color();
|
||||
init_pair(GRASS_PAIR, COLOR_YELLOW, COLOR_GREEN);
|
||||
init_pair(WATER_PAIR, COLOR_CYAN, COLOR_BLUE);
|
||||
init_pair(MOUNTAIN_PAIR, COLOR_BLACK, COLOR_WHITE);
|
||||
init_pair(PLAYER_PAIR, COLOR_RED, COLOR_MAGENTA);
|
||||
|
||||
```
|
||||
|
||||
Whenever you want to display text using a color, you just need to tell curses to set that color attribute. For good programming practice, you also should tell curses to undo the color combination when you're done using the colors. To set the color, use attron() before calling functions like mvaddch(), and then turn off the color attributes with attroff() afterward. For example, when I draw the player's character, I might do this:
|
||||
|
||||
```
|
||||
|
||||
attron(COLOR_PAIR(PLAYER_PAIR));
|
||||
mvaddch(y, x, PLAYER);
|
||||
attroff(COLOR_PAIR(PLAYER_PAIR));
|
||||
|
||||
```
|
||||
|
||||
Note that applying colors to your programs adds a subtle change to how you query the screen. Normally, the value returned by mvinch() is of type chtype Without color attributes, this is basically an integer and can be used as such. But, colors add extra attributes to the characters on the screen, so chtype carries extra color information in an extended bit pattern. If you use mvinch(), the returned value will contain this extra color value. To extract just the "text" value, such as in the is_move_okay() function, you need to apply a bitwise & with the A_CHARTEXT bit mask:
|
||||
|
||||
```
|
||||
|
||||
int is_move_okay(int y, int x)
|
||||
{
|
||||
int testch;
|
||||
|
||||
/* return true if the space is okay to move into */
|
||||
|
||||
testch = mvinch(y, x);
|
||||
return (((testch & A_CHARTEXT) == GRASS)
|
||||
|| ((testch & A_CHARTEXT) == EMPTY));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
With these changes, I can update the adventure game to use colors:
|
||||
|
||||
```
|
||||
|
||||
/* quest.c */
|
||||
|
||||
#include
|
||||
#include
|
||||
|
||||
#define GRASS ' '
|
||||
#define EMPTY '.'
|
||||
#define WATER '~'
|
||||
#define MOUNTAIN '^'
|
||||
#define PLAYER '*'
|
||||
|
||||
#define GRASS_PAIR 1
|
||||
#define EMPTY_PAIR 1
|
||||
#define WATER_PAIR 2
|
||||
#define MOUNTAIN_PAIR 3
|
||||
#define PLAYER_PAIR 4
|
||||
|
||||
int is_move_okay(int y, int x);
|
||||
void draw_map(void);
|
||||
|
||||
int main(void)
|
||||
{
|
||||
int y, x;
|
||||
int ch;
|
||||
|
||||
/* initialize curses */
|
||||
|
||||
initscr();
|
||||
keypad(stdscr, TRUE);
|
||||
cbreak();
|
||||
noecho();
|
||||
|
||||
/* initialize colors */
|
||||
|
||||
if (has_colors() == FALSE) {
|
||||
endwin();
|
||||
printf("Your terminal does not support color\n");
|
||||
exit(1);
|
||||
}
|
||||
|
||||
start_color();
|
||||
init_pair(GRASS_PAIR, COLOR_YELLOW, COLOR_GREEN);
|
||||
init_pair(WATER_PAIR, COLOR_CYAN, COLOR_BLUE);
|
||||
init_pair(MOUNTAIN_PAIR, COLOR_BLACK, COLOR_WHITE);
|
||||
init_pair(PLAYER_PAIR, COLOR_RED, COLOR_MAGENTA);
|
||||
|
||||
clear();
|
||||
|
||||
/* initialize the quest map */
|
||||
|
||||
draw_map();
|
||||
|
||||
/* start player at lower-left */
|
||||
|
||||
y = LINES - 1;
|
||||
x = 0;
|
||||
|
||||
do {
|
||||
|
||||
/* by default, you get a blinking cursor - use it to
|
||||
indicate player * */
|
||||
|
||||
attron(COLOR_PAIR(PLAYER_PAIR));
|
||||
mvaddch(y, x, PLAYER);
|
||||
attroff(COLOR_PAIR(PLAYER_PAIR));
|
||||
move(y, x);
|
||||
refresh();
|
||||
|
||||
ch = getch();
|
||||
|
||||
/* test inputted key and determine direction */
|
||||
|
||||
switch (ch) {
|
||||
case KEY_UP:
|
||||
case 'w':
|
||||
case 'W':
|
||||
if ((y > 0) && is_move_okay(y - 1, x)) {
|
||||
attron(COLOR_PAIR(EMPTY_PAIR));
|
||||
mvaddch(y, x, EMPTY);
|
||||
attroff(COLOR_PAIR(EMPTY_PAIR));
|
||||
y = y - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_DOWN:
|
||||
case 's':
|
||||
case 'S':
|
||||
if ((y < LINES - 1) && is_move_okay(y + 1, x)) {
|
||||
attron(COLOR_PAIR(EMPTY_PAIR));
|
||||
mvaddch(y, x, EMPTY);
|
||||
attroff(COLOR_PAIR(EMPTY_PAIR));
|
||||
y = y + 1;
|
||||
}
|
||||
break;
|
||||
case KEY_LEFT:
|
||||
case 'a':
|
||||
case 'A':
|
||||
if ((x > 0) && is_move_okay(y, x - 1)) {
|
||||
attron(COLOR_PAIR(EMPTY_PAIR));
|
||||
mvaddch(y, x, EMPTY);
|
||||
attroff(COLOR_PAIR(EMPTY_PAIR));
|
||||
x = x - 1;
|
||||
}
|
||||
break;
|
||||
case KEY_RIGHT:
|
||||
case 'd':
|
||||
case 'D':
|
||||
if ((x < COLS - 1) && is_move_okay(y, x + 1)) {
|
||||
attron(COLOR_PAIR(EMPTY_PAIR));
|
||||
mvaddch(y, x, EMPTY);
|
||||
attroff(COLOR_PAIR(EMPTY_PAIR));
|
||||
x = x + 1;
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
while ((ch != 'q') && (ch != 'Q'));
|
||||
|
||||
endwin();
|
||||
|
||||
exit(0);
|
||||
}
|
||||
|
||||
int is_move_okay(int y, int x)
|
||||
{
|
||||
int testch;
|
||||
|
||||
/* return true if the space is okay to move into */
|
||||
|
||||
testch = mvinch(y, x);
|
||||
return (((testch & A_CHARTEXT) == GRASS)
|
||||
|| ((testch & A_CHARTEXT) == EMPTY));
|
||||
}
|
||||
|
||||
void draw_map(void)
|
||||
{
|
||||
int y, x;
|
||||
|
||||
/* draw the quest map */
|
||||
|
||||
/* background */
|
||||
|
||||
attron(COLOR_PAIR(GRASS_PAIR));
|
||||
for (y = 0; y < LINES; y++) {
|
||||
mvhline(y, 0, GRASS, COLS);
|
||||
}
|
||||
attroff(COLOR_PAIR(GRASS_PAIR));
|
||||
|
||||
/* mountains, and mountain path */
|
||||
|
||||
attron(COLOR_PAIR(MOUNTAIN_PAIR));
|
||||
for (x = COLS / 2; x < COLS * 3 / 4; x++) {
|
||||
mvvline(0, x, MOUNTAIN, LINES);
|
||||
}
|
||||
attroff(COLOR_PAIR(MOUNTAIN_PAIR));
|
||||
|
||||
attron(COLOR_PAIR(GRASS_PAIR));
|
||||
mvhline(LINES / 4, 0, GRASS, COLS);
|
||||
attroff(COLOR_PAIR(GRASS_PAIR));
|
||||
|
||||
/* lake */
|
||||
|
||||
attron(COLOR_PAIR(WATER_PAIR));
|
||||
for (y = 1; y < LINES / 2; y++) {
|
||||
mvhline(y, 1, WATER, COLS / 3);
|
||||
}
|
||||
attroff(COLOR_PAIR(WATER_PAIR));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Unless you have a keen eye, you may not be able to spot all of the changes necessary to support color in the adventure game. The diff tool shows all the instances where functions were added or code was changed to support colors:
|
||||
|
||||
```
|
||||
|
||||
$ diff quest-color/quest.c quest/quest.c
|
||||
12,17d11
|
||||
< #define GRASS_PAIR 1
|
||||
< #define EMPTY_PAIR 1
|
||||
< #define WATER_PAIR 2
|
||||
< #define MOUNTAIN_PAIR 3
|
||||
< #define PLAYER_PAIR 4
|
||||
<
|
||||
33,46d26
|
||||
< /* initialize colors */
|
||||
<
|
||||
< if (has_colors() == FALSE) {
|
||||
< endwin();
|
||||
< printf("Your terminal does not support color\n");
|
||||
< exit(1);
|
||||
< }
|
||||
<
|
||||
< start_color();
|
||||
< init_pair(GRASS_PAIR, COLOR_YELLOW, COLOR_GREEN);
|
||||
< init_pair(WATER_PAIR, COLOR_CYAN, COLOR_BLUE);
|
||||
< init_pair(MOUNTAIN_PAIR, COLOR_BLACK, COLOR_WHITE);
|
||||
< init_pair(PLAYER_PAIR, COLOR_RED, COLOR_MAGENTA);
|
||||
<
|
||||
61d40
|
||||
< attron(COLOR_PAIR(PLAYER_PAIR));
|
||||
63d41
|
||||
< attroff(COLOR_PAIR(PLAYER_PAIR));
|
||||
76d53
|
||||
< attron(COLOR_PAIR(EMPTY_PAIR));
|
||||
78d54
|
||||
< attroff(COLOR_PAIR(EMPTY_PAIR));
|
||||
86d61
|
||||
< attron(COLOR_PAIR(EMPTY_PAIR));
|
||||
88d62
|
||||
< attroff(COLOR_PAIR(EMPTY_PAIR));
|
||||
96d69
|
||||
< attron(COLOR_PAIR(EMPTY_PAIR));
|
||||
98d70
|
||||
< attroff(COLOR_PAIR(EMPTY_PAIR));
|
||||
106d77
|
||||
< attron(COLOR_PAIR(EMPTY_PAIR));
|
||||
108d78
|
||||
< attroff(COLOR_PAIR(EMPTY_PAIR));
|
||||
128,129c98
|
||||
< return (((testch & A_CHARTEXT) == GRASS)
|
||||
< || ((testch & A_CHARTEXT) == EMPTY));
|
||||
---
|
||||
> return ((testch == GRASS) || (testch == EMPTY));
|
||||
140d108
|
||||
< attron(COLOR_PAIR(GRASS_PAIR));
|
||||
144d111
|
||||
< attroff(COLOR_PAIR(GRASS_PAIR));
|
||||
148d114
|
||||
< attron(COLOR_PAIR(MOUNTAIN_PAIR));
|
||||
152d117
|
||||
< attroff(COLOR_PAIR(MOUNTAIN_PAIR));
|
||||
154d118
|
||||
< attron(COLOR_PAIR(GRASS_PAIR));
|
||||
156d119
|
||||
< attroff(COLOR_PAIR(GRASS_PAIR));
|
||||
160d122
|
||||
< attron(COLOR_PAIR(WATER_PAIR));
|
||||
164d125
|
||||
< attroff(COLOR_PAIR(WATER_PAIR));
|
||||
|
||||
```
|
||||
|
||||
### Let's Play—Now in Color
|
||||
|
||||
The program now has a more pleasant color scheme, more closely matching the original tabletop gaming map, with green fields, blue lake and imposing gray mountains. The hero clearly stands out in red and magenta livery.
|
||||
|
||||

|
||||
|
||||
Figure 1\. A Simple Tabletop Game Map, with a Lake and Mountains
|
||||
|
||||

|
||||
|
||||
Figure 2\. The player starts the game in the lower-left corner.
|
||||
|
||||

|
||||
|
||||
Figure 3\. The player can move around the play area, such as around the lake, through the mountain pass and into unknown regions.
|
||||
|
||||
With colors, you can represent information more clearly. This simple example uses colors to indicate playable areas (green) versus impassable regions (blue or gray). I hope you will use this example game as a starting point or reference for your own programs. You can do so much more with curses, depending on what you need your program to do.
|
||||
|
||||
In a follow-up article, I plan to demonstrate other features of the ncurses library, such as how to create windows and frames. In the meantime, if you are interested in learning more about curses, I encourage you to read Pradeep Padala's [NCURSES Programming HOWTO][3], at the Linux Documentation Project.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/programming-color-ncurses
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/jim-hall
|
||||
[1]:http://www.linuxjournal.com/content/getting-started-ncurses
|
||||
[2]:http://www.linuxjournal.com/content/creating-adventure-game-terminal-ncurses
|
||||
[3]:http://tldp.org/HOWTO/NCURSES-Programming-HOWTO
|
||||
@ -0,0 +1,61 @@
|
||||
translating by lujun9972
|
||||
Save Some Battery On Our Linux Machines With TLP
|
||||
======
|
||||

|
||||
|
||||
I have always found battery life with Linux to be relatively lesser than windows. Nevertheless, this is [Linux][1] and we always have something up our sleeves.
|
||||
|
||||
Now talking about this small utility called TLP, that can actually save some juice on your device.
|
||||
|
||||
|
||||
|
||||
**TLP - Linux Advanced Power Management** is a small command line utility that can genuinely help extend battery life by performing several tweaks on your Linux system.
|
||||
|
||||
```
|
||||
sudo apt install tlp
|
||||
```
|
||||
|
||||
[][2]
|
||||
|
||||
For other distributions, you can read the instructions from the [official website][3] .
|
||||
|
||||
|
||||
|
||||
After installation is complete, you will have to run the following command to start tlp for the first time only. TLP will automatically start the next time you boot your system.
|
||||
|
||||
[][4]
|
||||
|
||||
Now TLP has started and it has already made the default configurations needed to save battery. We will now see the configurations file. It is located in **/etc/default/tlp**. We need to edit this file to change various configurations.
|
||||
|
||||
There are many options in this file and to enable an option just remove the leading **#** character from that line. There will be instructions about each option and the values that you can allot to it. Some of the things that you will be able to do are -
|
||||
|
||||
* Autosuspend USB devices
|
||||
|
||||
* Define wireless devices to enable/disable at startup
|
||||
|
||||
* Spin down hard drives
|
||||
|
||||
* Switch off wireless devices
|
||||
|
||||
* Set CPU for performance or power savings
|
||||
|
||||
### Conclusion
|
||||
|
||||
TLP is an amazing utility that can help save battery life on Linux systems. I have personally found at least 30-40% of extended battery life when using TLP.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/save-some-battery-on-our-linux-machines-with-tlp
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/linux
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/install-tlp-in-linux.jpeg
|
||||
[3]:http://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/start-tlp-on-linux.jpeg
|
||||
340
sources/tech/20180206 Simple TensorFlow Examples.md
Normal file
340
sources/tech/20180206 Simple TensorFlow Examples.md
Normal file
@ -0,0 +1,340 @@
|
||||
Translating by ghsgz | Simple TensorFlow Examples
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this post, we are going to see some TensorFlow examples and see how it’s easy to define tensors, perform math operations using tensors, and other machine learning examples.
|
||||
|
||||
## What is TensorFlow?
|
||||
|
||||
TensorFlow is a library which was developed by Google for solving complicated mathematical problems which takes much time.
|
||||
|
||||
Actually, TensorFlow can do many things like:
|
||||
|
||||
* Solving complex mathematical expressions.
|
||||
* Machine learning techniques, where you give it a sample of data for training, then you give another sample of data to predict the result based on the training data. This is the artificial intelligence!!
|
||||
* GPU support. You can use GPU (Graphical Processing Unit) instead of CPU for faster processing. There are two versions of TensorFlow, CPU version and GPU version.
|
||||
|
||||
|
||||
|
||||
Before we start working with TensorFlow examples, we need to know some basics.
|
||||
|
||||
## What is a Tensor?
|
||||
|
||||
The tensor is the main blocks of data that TensorFlow uses, it’s like the variables that TensorFlow uses to work with data. Each tensor has a dimension and a type.
|
||||
|
||||
The dimension is the rows and columns of the tensor, you can define one-dimensional tensor, two-dimensional tensor, and three-dimensional tensor as we will see later.
|
||||
|
||||
The type is the data type for the elements of the tensor.
|
||||
|
||||
## Define one-dimensional Tensor
|
||||
|
||||
To define a tensor, we will create a NumPy array or a [Python list][1] and convert it to a tensor using the tf_convert_to_tensor function.
|
||||
|
||||
We will use NumPy to create an array like this:
|
||||
```
|
||||
import numpy as np arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
```
|
||||
|
||||
You can see from the results the dimension and shape of the array.
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
print(arr)
|
||||
|
||||
print (arr.ndim)
|
||||
|
||||
print (arr.shape)
|
||||
|
||||
print (arr.dtype)
|
||||
|
||||
```
|
||||
|
||||
It looks like the Python list but here there is no comma between the items.
|
||||
|
||||
Now we will convert this array to a tensor using tf_convert_to_tensor function.
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
tensor = tf.convert_to_tensor(arr,tf.float64)
|
||||
|
||||
print(tensor)
|
||||
|
||||
```
|
||||
|
||||
From the results, you can see the tensor definition, but you can’t see the tensor elements.
|
||||
|
||||
Well, to see the tensor elements, you can run a session like this:
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr = np.array([1, 5.5, 3, 15, 20])
|
||||
|
||||
tensor = tf.convert_to_tensor(arr,tf.float64)
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
print(sess.run(tensor))
|
||||
|
||||
print(sess.run(tensor[1]))
|
||||
|
||||
```
|
||||
|
||||
## Define Two-dimensional Tensor
|
||||
|
||||
The same way as the one-dimensional array, but this time we will define the array like this:
|
||||
|
||||
```
|
||||
arr = np.array([(1, 5.5, 3, 15, 20),(10, 20, 30, 40, 50), (60, 70, 80, 90, 100)])
|
||||
```
|
||||
|
||||
And you can convert it to a tensor like this:
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr = np.array([(1, 5.5, 3, 15, 20),(10, 20, 30, 40, 50), (60, 70, 80, 90, 100)])
|
||||
|
||||
tensor = tf.convert_to_tensor(arr)
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
print(sess.run(tensor))
|
||||
|
||||
```
|
||||
|
||||
Now you know how to define tensors, what about performing some math operations between them?
|
||||
|
||||
## Performing Math on Tensors
|
||||
|
||||
Suppose that we have 2 arrays like this:
|
||||
```
|
||||
arr1 = np.array([(1,2,3),(4,5,6)])
|
||||
|
||||
arr2 = np.array([(7,8,9),(10,11,12)])
|
||||
|
||||
```
|
||||
|
||||
We need to get the sum of them. You can perform many math operations using TensorFlow.
|
||||
|
||||
You can use the add function like this:
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr1 = np.array([(1,2,3),(4,5,6)])
|
||||
|
||||
arr2 = np.array([(7,8,9),(10,11,12)])
|
||||
|
||||
arr3 = tf.add(arr1,arr2)
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
tensor = sess.run(arr3)
|
||||
|
||||
print(tensor)
|
||||
|
||||
```
|
||||
|
||||
You can multiply arrays like this:
|
||||
```
|
||||
import numpy as np
|
||||
|
||||
import tensorflow as tf
|
||||
|
||||
arr1 = np.array([(1,2,3),(4,5,6)])
|
||||
|
||||
arr2 = np.array([(7,8,9),(10,11,12)])
|
||||
|
||||
arr3 = tf.multiply(arr1,arr2)
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
tensor = sess.run(arr3)
|
||||
|
||||
print(tensor)
|
||||
|
||||
```
|
||||
|
||||
Now you got the idea.
|
||||
|
||||
## Three-dimensional Tensor
|
||||
|
||||
We saw how to work with one and two-dimensional tensors, now we will see the three-dimensional tensors, but this time we won’t use numbers, we will use an RGB image where each piece of the image is specified by x, y, and z coordinates.
|
||||
|
||||
These coordinates are the width, height, and color depth.
|
||||
|
||||
First, let’s import the image using matplotlib. You can install matplotlib [using pip][2] if it’s not installed on your system.
|
||||
|
||||
Now, put your file in the same directory with your Python file and import the image using matplotlib like this:
|
||||
```
|
||||
import matplotlib.image as img
|
||||
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
print(myimage.ndim)
|
||||
|
||||
print(myimage.shape)
|
||||
|
||||
```
|
||||
|
||||
As you can see, it’s a three-dimensional image where the width is 150 and the height is 150 and the color depth is 3.
|
||||
|
||||
You can view the image like this:
|
||||
```
|
||||
import matplotlib.image as img
|
||||
|
||||
import matplotlib.pyplot as plot
|
||||
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
plot.imshow(myimage)
|
||||
|
||||
plot.show()
|
||||
|
||||
```
|
||||
|
||||
Cool!!
|
||||
|
||||
What about manipulating the image using TensorFlow? Super easy.
|
||||
|
||||
## Crop Or Slice Image Using TensorFlow
|
||||
|
||||
First, we put the values on a placeholder like this:
|
||||
```
|
||||
myimage = tf.placeholder("int32",[None,None,3])
|
||||
|
||||
```
|
||||
|
||||
To slice the image, we will use the slice operator like this:
|
||||
```
|
||||
cropped = tf.slice(myimage,[10,0,0],[16,-1,-1])
|
||||
|
||||
```
|
||||
|
||||
Finally, run the session:
|
||||
```
|
||||
result = sess.run(cropped, feed\_dict={slice: myimage})
|
||||
|
||||
```
|
||||
|
||||
Then you can see the result image using matplotlib.
|
||||
|
||||
So the whole code will be like this:
|
||||
```
|
||||
import tensorflow as tf
|
||||
|
||||
import matplotlib.image as img
|
||||
|
||||
import matplotlib.pyplot as plot
|
||||
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
slice = tf.placeholder("int32",[None,None,3])
|
||||
|
||||
cropped = tf.slice(myimage,[10,0,0],[16,-1,-1])
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
result = sess.run(cropped, feed_dict={slice: myimage})
|
||||
|
||||
plot.imshow(result)
|
||||
|
||||
plot.show()
|
||||
|
||||
```
|
||||
|
||||
Awesome!!
|
||||
|
||||
## Transpose Images using TensorFlow
|
||||
|
||||
In this TensorFlow example, we will do a simple transformation using TensorFlow.
|
||||
|
||||
First, specify the input image and initialize TensorFlow variables:
|
||||
```
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
image = tf.Variable(myimage,name='image')
|
||||
|
||||
vars = tf.global_variables_initializer()
|
||||
|
||||
```
|
||||
|
||||
Then we will use the transpose function which flips the 0 and 1 axes of the input grid:
|
||||
```
|
||||
sess = tf.Session()
|
||||
|
||||
flipped = tf.transpose(image, perm=[1,0,2])
|
||||
|
||||
sess.run(vars)
|
||||
|
||||
result=sess.run(flipped)
|
||||
|
||||
```
|
||||
|
||||
Then you can show the resulting image using matplotlib.
|
||||
```
|
||||
import tensorflow as tf
|
||||
|
||||
import matplotlib.image as img
|
||||
|
||||
import matplotlib.pyplot as plot
|
||||
|
||||
myfile = "likegeeks.png"
|
||||
|
||||
myimage = img.imread(myfile)
|
||||
|
||||
image = tf.Variable(myimage,name='image')
|
||||
|
||||
vars = tf.global_variables_initializer()
|
||||
|
||||
sess = tf.Session()
|
||||
|
||||
flipped = tf.transpose(image, perm=[1,0,2])
|
||||
|
||||
sess.run(vars)
|
||||
|
||||
result=sess.run(flipped)
|
||||
|
||||
plot.imshow(result)
|
||||
|
||||
plot.show()
|
||||
|
||||
```
|
||||
|
||||
All these TensorFlow examples show you how easy it’s to work with TensorFlow.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/likegeeks/define-and-use-tensors-using-simple-tensorflow-examples-ggdgwoy4u
|
||||
|
||||
作者:[LikeGeeks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/likegeeks
|
||||
[1]:https://likegeeks.com/python-list-functions/
|
||||
[2]:https://likegeeks.com/import-create-install-reload-alias-python-modules/#Install-Python-Modules-Using-pip
|
||||
186
sources/tech/20180207 Python Global Keyword (With Examples).md
Normal file
186
sources/tech/20180207 Python Global Keyword (With Examples).md
Normal file
@ -0,0 +1,186 @@
|
||||
Python Global Keyword (With Examples)
|
||||
======
|
||||
Before reading this article, make sure you have got some basics of [Python Global, Local and Nonlocal Variables][1].
|
||||
|
||||
### Introduction to global Keyword
|
||||
|
||||
In Python, `global` keyword allows you to modify the variable outside of the current scope. It is used to create a global variable and make changes to the variable in a local context.
|
||||
|
||||
#### Rules of global Keyword
|
||||
|
||||
The basic rules for `global` keyword in Python are:
|
||||
|
||||
* When we create a variable inside a function, it’s local by default.
|
||||
* When we define a variable outside of a function, it’s global by default. You don’t have to use `global` keyword.
|
||||
* We use `global` keyword to read and write a global variable inside a function.
|
||||
* Use of `global` keyword outside a function has no effect
|
||||
|
||||
|
||||
|
||||
#### Use of global Keyword (With Example)
|
||||
|
||||
Let’s take an example.
|
||||
|
||||
##### Example 1: Accessing global Variable From Inside a Function
|
||||
```
|
||||
c = 1 # global variable
|
||||
|
||||
def add():
|
||||
print(c)
|
||||
|
||||
add()
|
||||
|
||||
```
|
||||
|
||||
When we run above program, the output will be:
|
||||
```
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
However, we may have some scenarios where we need to modify the global variable from inside a function.
|
||||
|
||||
##### Example 2: Modifying Global Variable From Inside the Function
|
||||
```
|
||||
c = 1 # global variable
|
||||
|
||||
def add():
|
||||
c = c + 2 # increment c by 2
|
||||
print(c)
|
||||
|
||||
add()
|
||||
|
||||
```
|
||||
|
||||
When we run above program, the output shows an error:
|
||||
```
|
||||
UnboundLocalError: local variable 'c' referenced before assignment
|
||||
|
||||
```
|
||||
|
||||
This is because we can only access the global variable but cannot modify it from inside the function.
|
||||
|
||||
The solution for this is to use the `global` keyword.
|
||||
|
||||
##### Example 3: Changing Global Variable From Inside a Function using global
|
||||
```
|
||||
c = 0 # global variable
|
||||
|
||||
def add():
|
||||
global c
|
||||
c = c + 2 # increment by 2
|
||||
print("Inside add():", c)
|
||||
|
||||
add()
|
||||
print("In main:", c)
|
||||
|
||||
```
|
||||
|
||||
When we run above program, the output will be:
|
||||
```
|
||||
Inside add(): 2
|
||||
In main: 2
|
||||
|
||||
```
|
||||
|
||||
In the above program, we define c as a global keyword inside the `add()` function.
|
||||
|
||||
Then, we increment the variable c by `1`, i.e `c = c + 2`. After that, we call the `add()` function. Finally, we print global variable c.
|
||||
|
||||
As we can see, change also occured on the global variable outside the function, `c = 2`.
|
||||
|
||||
### Global Variables Across Python Modules
|
||||
|
||||
In Python, we create a single module `config.py` to hold global variables and share information across Python modules within the same program.
|
||||
|
||||
Here is how we can share global variable across the python modules.
|
||||
|
||||
##### Example 4 : Share a global Variable Across Python Modules
|
||||
|
||||
Create a `config.py` file, to store global variables
|
||||
```
|
||||
a = 0
|
||||
b = "empty"
|
||||
|
||||
```
|
||||
|
||||
Create a `update.py` file, to change global variables
|
||||
```
|
||||
import config
|
||||
|
||||
config.a = 10
|
||||
config.b = "alphabet"
|
||||
|
||||
```
|
||||
|
||||
Create a `main.py` file, to test changes in value
|
||||
```
|
||||
import config
|
||||
import update
|
||||
|
||||
print(config.a)
|
||||
print(config.b)
|
||||
|
||||
```
|
||||
|
||||
When we run the `main.py` file, the output will be
|
||||
```
|
||||
10
|
||||
alphabet
|
||||
|
||||
```
|
||||
|
||||
In the above, we create three files: `config.py`, `update.py` and `main.py`.
|
||||
|
||||
The module `config.py` stores global variables of a and b. In `update.py` file, we import the `config.py` module and modify the values of a and b. Similarly, in `main.py` file we import both `config.py` and `update.py` module. Finally, we print and test the values of global variables whether they are changed or not.
|
||||
|
||||
### Global in Nested Functions
|
||||
|
||||
Here is how you can use a global variable in nested function.
|
||||
|
||||
##### Example 5: Using a Global Variable in Nested Function
|
||||
```
|
||||
def foo():
|
||||
x = 20
|
||||
|
||||
def bar():
|
||||
global x
|
||||
x = 25
|
||||
|
||||
print("Before calling bar: ", x)
|
||||
print("Calling bar now")
|
||||
bar()
|
||||
print("After calling bar: ", x)
|
||||
|
||||
foo()
|
||||
print("x in main : ", x)
|
||||
|
||||
```
|
||||
|
||||
The output is :
|
||||
```
|
||||
Before calling bar: 20
|
||||
Calling bar now
|
||||
After calling bar: 20
|
||||
x in main : 25
|
||||
|
||||
```
|
||||
|
||||
In the above program, we declare global variable inside the nested function `bar()`. Inside `foo()` function, x has no effect of global keyword.
|
||||
|
||||
Before and after calling `bar()`, the variable x takes the value of local variable i.e `x = 20`. Outside of the `foo()` function, the variable x will take value defined in the `bar()` function i.e `x = 25`. This is because we have used `global` keyword in x to create global variable inside the `bar()` function (local scope).
|
||||
|
||||
If we make any changes inside the `bar()` function, the changes appears outside the local scope, i.e. `foo()`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.programiz.com/python-programming/global-keyword
|
||||
|
||||
作者:[programiz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.programiz.com
|
||||
[1]:https://www.programiz.com/python-programming/global-local-nonlocal-variables
|
||||
@ -0,0 +1,198 @@
|
||||
Python Global, Local and Nonlocal variables (With Examples)
|
||||
======
|
||||
### Global Variables
|
||||
|
||||
In Python, a variable declared outside of the function or in global scope is known as global variable. This means, global variable can be accessed inside or outside of the function.
|
||||
|
||||
Let's see an example on how a global variable is created in Python.
|
||||
|
||||
#### Example 1: Create a Global Variable
|
||||
```
|
||||
x = "global"
|
||||
|
||||
def foo():
|
||||
print("x inside :", x)
|
||||
|
||||
foo()
|
||||
print("x outside:", x)
|
||||
|
||||
```
|
||||
|
||||
When we run the code, the will output be:
|
||||
```
|
||||
x inside : global
|
||||
x outside: global
|
||||
|
||||
```
|
||||
|
||||
In above code, we created x as a global variable and defined a `foo()` to print the global variable x. Finally, we call the `foo()` which will print the value of x.
|
||||
|
||||
What if you want to change value of x inside a function?
|
||||
```
|
||||
x = "global"
|
||||
|
||||
def foo():
|
||||
x = x * 2
|
||||
print(x)
|
||||
foo()
|
||||
|
||||
```
|
||||
|
||||
When we run the code, the will output be:
|
||||
```
|
||||
UnboundLocalError: local variable 'x' referenced before assignment
|
||||
|
||||
```
|
||||
|
||||
The output shows an error because Python treats x as a local variable and x is also not defined inside `foo()`.
|
||||
|
||||
To make this work we use `global` keyword, to learn more visit [Python Global Keyword][1].
|
||||
|
||||
### Local Variables
|
||||
|
||||
A variable declared inside the function's body or in the local scope is known as local variable.
|
||||
|
||||
#### Example 2: Accessing local variable outside the scope
|
||||
```
|
||||
def foo():
|
||||
y = "local"
|
||||
|
||||
foo()
|
||||
print(y)
|
||||
|
||||
```
|
||||
|
||||
When we run the code, the will output be:
|
||||
```
|
||||
NameError: name 'y' is not defined
|
||||
|
||||
```
|
||||
|
||||
The output shows an error, because we are trying to access a local variable y in a global scope whereas the local variable only works inside `foo() `or local scope.
|
||||
|
||||
Let's see an example on how a local variable is created in Python.
|
||||
|
||||
#### Example 3: Create a Local Variable
|
||||
|
||||
Normally, we declare a variable inside the function to create a local variable.
|
||||
```
|
||||
def foo():
|
||||
y = "local"
|
||||
print(y)
|
||||
|
||||
foo()
|
||||
|
||||
```
|
||||
|
||||
When we run the code, it will output:
|
||||
```
|
||||
local
|
||||
|
||||
```
|
||||
|
||||
Let's take a look to the earlier problem where x was a global variable and we wanted to modify x inside `foo()`.
|
||||
|
||||
### Global and local variables
|
||||
|
||||
Here, we will show how to use global variables and local variables in the same code.
|
||||
|
||||
#### Example 4: Using Global and Local variables in same code
|
||||
```
|
||||
x = "global"
|
||||
|
||||
def foo():
|
||||
global x
|
||||
y = "local"
|
||||
x = x * 2
|
||||
print(x)
|
||||
print(y)
|
||||
|
||||
foo()
|
||||
|
||||
```
|
||||
|
||||
When we run the code, the will output be:
|
||||
```
|
||||
global global
|
||||
local
|
||||
|
||||
```
|
||||
|
||||
In the above code, we declare x as a global and y as a local variable in the `foo()`. Then, we use multiplication operator `*` to modify the global variable x and we print both x and y.
|
||||
|
||||
After calling the `foo()`, the value of x becomes `global global` because we used the `x * 2` to print two times `global`. After that, we print the value of local variable y i.e `local`.
|
||||
|
||||
#### Example 5: Global variable and Local variable with same name
|
||||
```
|
||||
x = 5
|
||||
|
||||
def foo():
|
||||
x = 10
|
||||
print("local x:", x)
|
||||
|
||||
foo()
|
||||
print("global x:", x)
|
||||
|
||||
```
|
||||
|
||||
When we run the code, the will output be:
|
||||
```
|
||||
local x: 10
|
||||
global x: 5
|
||||
|
||||
```
|
||||
|
||||
In above code, we used same name x for both global variable and local variable. We get different result when we print same variable because the variable is declared in both scopes, i.e. the local scope inside `foo()` and global scope outside `foo()`.
|
||||
|
||||
When we print the variable inside the `foo()` it outputs `local x: 10`, this is called local scope of variable.
|
||||
|
||||
Similarly, when we print the variable outside the `foo()`, it outputs `global x: 5`, this is called global scope of variable.
|
||||
|
||||
### Nonlocal Variables
|
||||
|
||||
Nonlocal variable are used in nested function whose local scope is not defined. This means, the variable can be neither in the local nor the global scope.
|
||||
|
||||
Let's see an example on how a global variable is created in Python.
|
||||
|
||||
We use `nonlocal` keyword to create nonlocal variable.
|
||||
|
||||
#### Example 6: Create a nonlocal variable
|
||||
```
|
||||
def outer():
|
||||
x = "local"
|
||||
|
||||
def inner():
|
||||
nonlocal x
|
||||
x = "nonlocal"
|
||||
print("inner:", x)
|
||||
|
||||
inner()
|
||||
print("outer:", x)
|
||||
|
||||
outer()
|
||||
|
||||
```
|
||||
|
||||
When we run the code, the will output be:
|
||||
```
|
||||
inner: nonlocal
|
||||
outer: nonlocal
|
||||
|
||||
```
|
||||
|
||||
In the above code there is a nested function `inner()`. We use `nonlocal` keyword to create nonlocal variable. The `inner()` function is defined in the scope of another function `outer()`.
|
||||
|
||||
Note : If we change value of nonlocal variable, the changes appears in the local variable.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.programiz.com/python-programming/global-local-nonlocal-variables
|
||||
|
||||
作者:[programiz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.programiz.com/
|
||||
[1]:https://www.programiz.com/python-programming/global-keyword
|
||||
@ -0,0 +1,95 @@
|
||||
使用 iftop 命令监控网络带宽
|
||||
======
|
||||
系统管理员需要监控 IT 基础设施来确保一切正常运行。我们需要监控硬件也就是内存、硬盘和 CPU 等的性能,我们也必须监控我们的网络。我们需要确保我们的网络不被过度使用,或者我们的程序,网站可能无法正常工作。在本教程中,我们将学习使用 IFTOP。
|
||||
|
||||
(**推荐阅读**:[**使用 Nagios** 进行资源监控][1]、[**用于检查系统信息的工具**][2] 、[**要监控的重要日志**][3] )
|
||||
|
||||
Iftop 是网络监控工具,它提供实时带宽监控。 Iftop 测量进出各个套接字连接的总数据量,即它捕获通过网络适配器收到或发出的数据包,然后将这些数据相加以得到使用的带宽。
|
||||
|
||||
## 在 Debian/Ubuntu 上安装
|
||||
|
||||
Iftop 存在于 Debian/Ubuntu 的默认仓库中,可以使用下面的命令安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install iftop
|
||||
```
|
||||
|
||||
## 使用 yum 在 RHEL/Centos 上安装
|
||||
|
||||
要在 CentOS 或 RHEL 上安装 iftop,我们需要启用 EPEL 仓库。要启用仓库,请在终端上运行以下命令:
|
||||
|
||||
### RHEL/CentOS 7
|
||||
|
||||
```
|
||||
$ rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-10.noarch.rpm
|
||||
```
|
||||
|
||||
### RHEL/CentOS 6(64位)
|
||||
|
||||
```
|
||||
$ rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
### RHEL/CentOS 6 (64位)
|
||||
|
||||
```
|
||||
$ rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
epel 仓库安装完成后,我们可以用下面的命令安装 iftop:
|
||||
|
||||
```
|
||||
$ yum install iftop
|
||||
```
|
||||
|
||||
这将在你的系统上安装 iftop。我们现在将用它来监控我们的网络。
|
||||
|
||||
## 使用 IFTOP
|
||||
|
||||
可以打开终端窗口,并输入下面的命令使用 iftop:
|
||||
|
||||
```
|
||||
$ iftop
|
||||
```
|
||||
|
||||
![network monitoring][5]
|
||||
|
||||
现在你将看到计算机上发生的网络活动。你也可以使用:
|
||||
|
||||
```
|
||||
$ iftop -n
|
||||
```
|
||||
|
||||
这将在屏幕上显示网络信息,但使用 “-n”,则不会显示与 IP 地址相关的名称,只会显示 IP 地址。这个选项能节省一些将 IP 地址解析为名称的带宽。
|
||||
|
||||
我们也可以看到 iftop 可以使用的所有命令。运行 iftop 后,按下键盘上的 “h” 查看 iftop 可以使用的所有命令。
|
||||
|
||||
![network monitoring][7]
|
||||
|
||||
要监控特定的网络接口,我们可以在 iftop 后加上接口名:
|
||||
|
||||
```
|
||||
$ iftop -I enp0s3
|
||||
```
|
||||
|
||||
如上所述,你可以使用帮助来查看 iftop 可以使用的更多选项。但是这些提到的例子只是可能只是监控网络。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/monitoring-network-bandwidth-iftop-command/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/installing-configuring-nagios-server/
|
||||
[2]:http://linuxtechlab.com/commands-system-hardware-info/
|
||||
[3]:http://linuxtechlab.com/important-logs-monitor-identify-issues/
|
||||
[4]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=661%2C424
|
||||
[5]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/04/iftop-1.jpg?resize=661%2C424
|
||||
[6]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=663%2C416
|
||||
[7]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/04/iftop-help.jpg?resize=663%2C416
|
||||
@ -1,142 +1,142 @@
|
||||
如何使用 VI 编辑器:基础篇
|
||||
====
|
||||
|
||||
# 如何使用 VI 编辑器:基础篇
|
||||
|
||||
|
||||
VI 是一个基于命令行,功能强大的文本编辑器,最早为 Unix 系统开发,后来也被移植到许多的 Unix 和 Linux 发行版上。
|
||||
|
||||
在 linux 上还存在着另一个,VI编辑器的高阶版本 —— VIM(也被称作 VI IMproved)。VIM 在 VI 已经很强的功能上添加了更多的功能,这些功能有:
|
||||
在 linux 上还存在着另一个,VI编辑器的高阶版本 —— VIM(也被称作 VI IMproved)。VIM 只是在 VI 已经很强的功能上添加了更多的功能,这些功能有:
|
||||
|
||||
- 支持更多 Linux 发行版。
|
||||
- 支持多种编程语言,包括 python,c++,perl 等语言的代码块折叠,语法高亮。
|
||||
- 支持通过多种网络协议,包括 http,ssh等;支持在压缩格式下编辑文件
|
||||
- 支持分屏同时编辑多个文件
|
||||
- 支持更多 Linux 发行版,
|
||||
- 支持多种编程语言,包括 python,c++,perl 等语言的代码块折叠,语法高亮,
|
||||
- 支持通过多种网络协议,包括 http,ssh等编辑文件,
|
||||
- 支持在压缩格式下编辑文件,
|
||||
- 支持分屏同时编辑多个文件。
|
||||
|
||||
接下里我们来讨论 VI/VIM 的命令以及选项。本文出于教学的目的,我们使用 VI 来举例,但所有的命令都可以被用于 VIM。首先我们先介绍 VI 编辑器的两种模式。
|
||||
接下来我们会讨论 VI/VIM 的命令以及选项。本文出于教学的目的,我们使用 VI 来举例,但所有的命令都可以被用于 VIM。首先我们先介绍 VI 编辑器的两种模式。
|
||||
|
||||
## **命令模式**
|
||||
|
||||
命令模式
|
||||
----
|
||||
|
||||
命令模式下,我们可以保存文件,在 VI 内运行命令,复制/剪切/粘贴操作,以及查找/替换等任务。当我们处于输入模式时,我们可以按下 escape(Esc)键返回命令模式
|
||||
|
||||
输入模式
|
||||
----
|
||||
## **输入模式**
|
||||
|
||||
|
||||
在输入模式下,我们可以键入文件内容。在命令模式下按下 i 进入输入模式
|
||||
|
||||
我们可以通过下述命令建立一个文件(如果该文件存在,则编辑已有文件)
|
||||
|
||||
$ vi filename
|
||||
**$ vi filename**
|
||||
|
||||
|
||||
一旦该文件被创立或者打开,我们首先进入命令模式,我们需要进入输入模式以在文件中输入内容。我们通过前文已经大致上了解这两种模式。
|
||||
|
||||
退出 Vi
|
||||
-----
|
||||
### **退出 Vi**
|
||||
|
||||
|
||||
|
||||
如果是想从输入模式中退出,我们首先需要按下 'ESC' 进入命令模式。接下来我们可以根据不同的需要分别使用两种命令退出 Vi
|
||||
|
||||
- 不保存退出 - 在命令模式中输入 :q!
|
||||
- 保存并退出 - 在命令模式中输入 :wq
|
||||
1. 不保存退出 - 在命令模式中输入 **':q!'**
|
||||
2. 保存并退出 - 在命令模式中输入 **':wq'**
|
||||
|
||||
移动光标
|
||||
### **移动光标**
|
||||
----
|
||||
|
||||
下面我们来讨论下那些在命令模式中移动光标的命令和选项
|
||||
|
||||
|
||||
- k 将光标上移一行
|
||||
1. **k** 将光标上移一行
|
||||
|
||||
- j 将光标下移一行
|
||||
2. **j** 将光标下移一行
|
||||
|
||||
- h 将光标左移一个字母
|
||||
3. **h** 将光标左移一个字母
|
||||
|
||||
- i 将光标右移一个字母
|
||||
4. **i** 将光标右移一个字母
|
||||
|
||||
注意:如果你想通过一个命令上移下移多行,或者左移右移多个字母,你可以使用 4k 或者 5j,这两条命令会分别上移 4 行或者右移 5 个字母。
|
||||
|
||||
- 0 将光标移动到该行行首
|
||||
1. **0** 将光标移动到该行行首
|
||||
|
||||
- $ 将光标移动到该行行尾
|
||||
2. **$** 将光标移动到该行行尾
|
||||
|
||||
- nG 将光标移动到第 n 行
|
||||
3. **nG** 将光标移动到第 n 行
|
||||
|
||||
- G 将光标移动到文件的最后一行
|
||||
4. **G** 将光标移动到文件的最后一行
|
||||
|
||||
- { 将光标移动到上一段
|
||||
5. **{** 将光标移动到上一段
|
||||
|
||||
- } 将光标移动到下一段
|
||||
6. **}** 将光标移动到下一段
|
||||
|
||||
除此之外还有一些命令可以用于控制光标的移动,但上述列出的这些命令应该就能应付日常工作所需。
|
||||
|
||||
|
||||
编辑文本
|
||||
----
|
||||
## **编辑文本**
|
||||
|
||||
|
||||
这部分会列出一些用于命令模式的命令,可以进入插入模式来编辑当前文件
|
||||
|
||||
|
||||
- i 在光标所在行的行首插入内容
|
||||
1. **i** 在光标所在行的行首插入内容
|
||||
|
||||
|
||||
|
||||
- I 在光标所在行的行尾插入内容
|
||||
2. **I** 在光标所在行的行尾插入内容
|
||||
|
||||
|
||||
|
||||
- a 在当前光标之前插入内容
|
||||
3. **a** 在当前光标之前插入内容
|
||||
|
||||
|
||||
|
||||
- A 在当前光标之后插入内容
|
||||
4. **A** 在当前光标之后插入内容
|
||||
|
||||
|
||||
|
||||
- o 在当前光标所在行之前添加一行
|
||||
5. **o** 在当前光标所在行之前添加一行
|
||||
|
||||
|
||||
|
||||
- O 在当前光标所在行之后添加一行
|
||||
6. **O** 在当前光标所在行之后添加一行
|
||||
|
||||
|
||||
删除文本
|
||||
----
|
||||
## **删除文本**
|
||||
|
||||
|
||||
以下的这些命令都只能在命令模式下使用,所以首先需要按下 'ESC' 进入命令模式,如果你正处于插入模式
|
||||
|
||||
|
||||
- dd 删除光标所在的整行内容,可以在 dd 前增加数字,比如 2dd可以删除从光标所在行开始的两行
|
||||
1. **dd** 删除光标所在的整行内容,可以在 dd 前增加数字,比如 2dd可以删除从光标所在行开始的两行
|
||||
|
||||
|
||||
|
||||
- d$ 删除从光标所在行开始的所有行
|
||||
2. **d$** 删除从光标所在行开始的所有行
|
||||
|
||||
|
||||
|
||||
- d^ 删除从文件开始直到光标所在行的所有行
|
||||
3. **d^** 删除从文件开始直到光标所在行的所有行
|
||||
|
||||
|
||||
|
||||
- dw 删除从光标所在位置直到下一个词开始的所有内容
|
||||
4 **dw** 删除从光标所在位置直到下一个词开始的所有内容
|
||||
|
||||
|
||||
|
||||
|
||||
复制黏贴命令
|
||||
------
|
||||
### **复制黏贴命令**
|
||||
|
||||
|
||||
|
||||
|
||||
- yy 复制当前行,在yy前添加数字可以复制多行
|
||||
1. **yy**复制当前行,在yy前添加数字可以复制多行
|
||||
|
||||
|
||||
|
||||
- p 在光标之后粘贴复制行
|
||||
2. **p** 在光标之后粘贴复制行
|
||||
|
||||
|
||||
|
||||
- P 在光标之前粘贴复制行
|
||||
3. **P** 在光标之前粘贴复制行
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,176 +0,0 @@
|
||||
#给Linux初学者的rm命令说明(8个例子)
|
||||
|
||||
======
|
||||
|
||||
删除文件和复制/移动文件一样,都是很基础操作。在Linux中,有一个专门的命令**`rm`**,可用于完成所有删除相关的操作。在本文中,我们将用些容易理解的例子来讨论这个命令的基本使用。
|
||||
|
||||
|
||||
但在我们开始前,值得指出的是本文所有示例都在**Ubuntu 16.04 LTS**
|
||||
中测试过。
|
||||
|
||||
## Linux rm 命令概述
|
||||
|
||||
通俗的讲,我们可以认为**`rm`**命令是用于删除文件和目录的。下面是此命令的语法:
|
||||
|
||||
```
|
||||
rm [选项]... [要删除的文件/目录]...
|
||||
```
|
||||
下面是命令使用说明:
|
||||
|
||||
```
|
||||
GUN版本rm命令的手册文档。
|
||||
rm删除每个指定的文件,默认是不删除目录。
|
||||
|
||||
当删除的文件超过三个或者提供了选项-r/-R/--recursive(译者注:表示递归删除目录中的文件)时,如果提供`-I`(译者注:大写的I)或者`--interactive=once`选项(译者注:表示开启交互一次),则rm命令会提示用户是否继续整个删除操作,如果用户回应是否,则整个命令立刻终止。
|
||||
|
||||
另外,如果被删除文件是不可写的,标准输入是终端,这时如果没有提供-f/--force选项,或者提供了-i(译者注:小写的i)/--interactive=always选项,rm会提示用户是否要删除此文件,如果用户回应否,则跳过此文件。
|
||||
```
|
||||
|
||||
下面这些问答式例子会让你更好的理解这个命令的使用。
|
||||
|
||||
#### Q1. 如何用rm命令删除文件?
|
||||
|
||||
这是非常简单和直观的。你只需要把文件名(如果文件不是在当前目录中,则还需要添加文件路径)传入给rm命令即可。
|
||||
|
||||
*译者注:可以用空格隔开传入多个文件名称*
|
||||
|
||||
```
|
||||
rm 文件1 文件2 ...
|
||||
```
|
||||
如:
|
||||
```
|
||||
rm testfile.txt
|
||||
```
|
||||
|
||||
[![How to remove files using rm command][1]][2]
|
||||
|
||||
|
||||
#### Q2. 如何用rm命令删除目录?
|
||||
|
||||
如果你试图删除一个目录,你需要提供-r选项。否则rm会抛出一个错误告诉你正试图删除一个目录。
|
||||
*译者注:-r表示递归的删除目录下的所有文件和目录*
|
||||
```
|
||||
rm -r [目录名称]
|
||||
```
|
||||
|
||||
如:
|
||||
|
||||
```
|
||||
rm -r testdir
|
||||
```
|
||||
|
||||
[![How to remove directories using rm command][3]][4]
|
||||
|
||||
|
||||
#### Q3. 如何让删除操作前有确认提示?
|
||||
|
||||
如果你希望在每个删除操作完成前都有确认提示,可以使用**-i**选项。
|
||||
|
||||
```
|
||||
rm -i [文件/目录]
|
||||
```
|
||||
|
||||
比如,你想要删除一个目录'testdir',但需要每个删除操作都有确认提示,你可以这么做:
|
||||
```
|
||||
rm -r -i testdir
|
||||
```
|
||||
|
||||
[![How to make rm prompt before every removal][5]][6]
|
||||
|
||||
#### Q4. 如何让rm忽略不存在的文件或目录?
|
||||
|
||||
如果你删除一个不存在的文件或目录时,rm命令会抛出一个错误,如:
|
||||
|
||||
[![Linux rm command example][7]][8]
|
||||
|
||||
然而,如果你愿意,你可以使用**-f**选项(译者注:force)让此次操作强制执行,忽略错误提示。
|
||||
|
||||
```
|
||||
rm -f [文件...]
|
||||
```
|
||||
|
||||
[![How to force rm to ignore nonexistent files][9]][10]
|
||||
|
||||
|
||||
#### Q5. 如何让rm在某些场景下仅提示一次删除确认?
|
||||
|
||||
选项**-I**,可保证在删除超过3个文件时或递归删除时(如删除目录,译者注)仅提示一次确认。
|
||||
比如,下面的截图展示了**-I**选择的作用-当两个文件被删除时没有提示,当超过3个文件时会仅有一次提示。
|
||||
[![How to make rm prompt only in some scenarios][11]][12]
|
||||
|
||||
|
||||
#### Q6. 当删除根目录是rm是如何工作的?
|
||||
当然,删除根目录(/)是Linux用户最不想要的操作。这也就是为什么默认**rm**命令不支持在根目录上执行递归删除操作。
|
||||
|
||||
[![How rm works when dealing with root directory][13]][14]
|
||||
|
||||
然而,如果你非得完成这个操作,你需要使用**\--no-preserve-root**选项。当提供此选项,rm就不会特殊处理根目录(/)了。
|
||||
|
||||
假如你想知道在哪些场景下Linux用户会删除他们的根目录,点击[这里][15]。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### Q7. 如何让rm仅删除空目录?
|
||||
|
||||
假如你需要rm在删除目录时仅删除空目录,你可以使用**-d**选项。
|
||||
|
||||
|
||||
```
|
||||
rm -d [目录]
|
||||
```
|
||||
下面的截图展示**-d**选项的用途-仅空目录被删除了。
|
||||
|
||||
[![How to make rm only remove empty directories][16]][17]
|
||||
|
||||
|
||||
#### Q8. 如何让rm显示当前删除操作的详情?
|
||||
|
||||
如果你想rm显示当前操作完成时的详细情况,使用**-v**选项可以做到。
|
||||
|
||||
```
|
||||
rm -v [文件/目录]
|
||||
```
|
||||
|
||||
如:
|
||||
|
||||
[![How to force rm to emit details of operation it is performing][18]][19]
|
||||
|
||||
#### 结论
|
||||
|
||||
考虑到**rm**命令提供的功能,可以说其是Linux中使用频率最高的命令之一了(就像cp和mv一样)。在本文中,我们涉及到了其提供的几乎所有主要选项。rm命令有些学习曲线,因此在你日常工作中开始使用此命令之前
|
||||
你将需要花费些时间去练习它的选项。更多的信息,请点击此命令的[man page][21]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-rm-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/rm-basic-usage.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/rm-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/rm-r.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/rm-r.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/rm-i-option.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/rm-i-option.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/rm-non-ext-error.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/rm-non-ext-error.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/rm-f-option.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/rm-f-option.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/rm-I-option.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/big/rm-I-option.png
|
||||
[13]:https://www.howtoforge.com/images/command-tutorial/rm-root-default.png
|
||||
[14]:https://www.howtoforge.com/images/command-tutorial/big/rm-root-default.png
|
||||
[15]:https://superuser.com/questions/742334/is-there-a-scenario-where-rm-rf-no-preserve-root-is-needed
|
||||
[16]:https://www.howtoforge.com/images/command-tutorial/rm-d-option.png
|
||||
[17]:https://www.howtoforge.com/images/command-tutorial/big/rm-d-option.png
|
||||
[18]:https://www.howtoforge.com/images/command-tutorial/rm-v-option.png
|
||||
[19]:https://www.howtoforge.com/images/command-tutorial/big/rm-v-option.png
|
||||
[20]:https://www.howtoforge.com/linux-cp-command/
|
||||
[21]:https://linux.die.net/man/1/rm
|
||||
132
translated/tech/20180201 Custom Embedded Linux Distributions.md
Normal file
132
translated/tech/20180201 Custom Embedded Linux Distributions.md
Normal file
@ -0,0 +1,132 @@
|
||||
定制嵌入式 Linux 发行版
|
||||
======
|
||||
### 为什么要定制?
|
||||
|
||||
以前,许多嵌入式项目都使用现成的发行版,然后出于种种原因,再将它们剥离到只剩下基本的必需的东西。首先,移除不需要的包以减少占用的存储空间。在启动时,嵌入式系统一般不需要大量的存储空间以及可用存储空间。在嵌入式系统运行时,可能从非易失性内存中拷贝大量的操作系统文件到内存中。第二,移除用不到的包可以降低可能的攻击面。如果你不需要它们就没有必要把这些可能有漏洞的包挂在上面。最后,移除用不到包可以降低发行管理的开销。如果在包之间有依赖关系,意味着任何一个包请求从上游更新,那么它们都必须保持同步。那样可能就会出现验证噩梦。
|
||||
|
||||
然而,从现在的发行版开始去移除包并不像说的那样容易。移除一个包可能会打破与其它包保持的各种依赖关系,以及可能在上游的发行管理中改变依赖。另外,由于在引导或者运行时进程中的集成特性,一些包并不能轻易地简单地移除。所有这些都是项目之外的平台的管理,并且有可能会导致意外的开发延迟。
|
||||
|
||||
一个普通的选择是从上游发行版供应商处使用有效的构建工具去构建一个定制的发行版。无论是 Gentoo 还是 Debian 都提供这种自下而上的构建方式。这些构建工具中最为流行的可能是 Debian 的 debootstrap 实用程序。它取出预构建的核心组件并允许用户去精选出它们感兴趣的包来构建用户自己的平台。但是,debootstrap 最初仅在 x86 平台上可用,虽然,现在有了 ARM(也有可能会有其它的平台)选项。debootstrap 和 Gentoo 的 catalyst 仍然从本地项目中将依赖管理移除。
|
||||
|
||||
一些人认为让别人去管理平台软件(像 Android 一样)要比自己亲自管理容易的多。但是,那些发行版都是多用途的,当你在一个轻量级的、资源有限的物联网设备上使用它时,你可能会再三考虑从你手中被拿走的任何益处。
|
||||
|
||||
### 系统 Bring-Up Primer
|
||||
|
||||
一个定制的 Linux 发行版要求许多软件组件。其中第一个就是工具链。一个工具链是编译软件的一个工具集合。包括(但不限于)一个编译器、链接器、二进制操作工具以及标准的 C 库。工具链是为一个特定的目标硬件设备专门构建的。如果一个构建在 x86 系统上的工具链想要使用在树莓派上,那么这个工具链就被称为交叉编译工具链。当在内存和存储都十分有限的小型嵌入式设备上工作时,最好是使用一个交叉编译工具链。需要注意的是,即便是使用像 JavaScript 这样的脚本语言编写的应用程序,也需要使用交叉编译工具链编译的一个软件平台上去运行。
|
||||
|
||||

|
||||
|
||||
图 1\. 编译依赖和引导顺序
|
||||
|
||||
交叉编译工具链用于为目标硬件构建软件组件。需要的第一个组件是引导加载程序。当计算机主板加电之后,处理器(可能有差异,取决于设计)尝试去跳转到一个特定的内存位置去开始运行软件。那个内存位置就是保存引导加载程序的地方。硬件可能有内置的引导加载程序,它可能直接从它的存储位置或者它可能拷贝到内存中它首次运行的位置。那里也可能会有多个引导加载程序。例如,一个第一阶段的引导加载程序可能位于硬件的 NAND 或者 NOR 闪存中。它唯一的功能是设置硬件以便于执行第二阶段的引导加载程序,比如,存储在 SD 卡中的可以被加载并运行的引导加载程序。
|
||||
|
||||
引导加载程序能够从硬件中取得足够的信息,将 Linux 加载到内存中并跳转到正确的位置,将控制权有效地移交到 Linux,Linux 是一个操作系统。这意味着,在这种设计中,它除了监控硬件和向上层软件(也就是应用程序)提供服务外,它实际上什么都不做。[Linux 内核][1] 中通常是各种各样的固件块。那些预编译的软件对象,通常包含硬件平台使用的设备的专用 IP(知识资产),当构建一个定制发行版时,在开始编译内核之前,它可能会要求获得一些 Linux 内核源树没有提供的必需的固件块。
|
||||
|
||||
应用程序保存在 root 文件系统中,这个 root 文件系统是通过编译构建的,它集合了各种软件库、工具、脚本以及配置文件。总的来说,它们都提供服务,比如,网络配置和 USB 驱动加载,这些都是将要运行的项目应用程序所需要的。
|
||||
|
||||
总的来说,一个完整的系统构建要求下列的组件:
|
||||
|
||||
1. 一个交叉编译工具链
|
||||
|
||||
2. 一个或多个引导加载程序
|
||||
|
||||
3. Linux 内核和相关的固件块
|
||||
|
||||
4. 一个包含库、工具以及实用程序的 root 文件系统
|
||||
|
||||
5. 定制的应用程序
|
||||
|
||||
### 使用适当的工具开始构建
|
||||
|
||||
交叉编译工具链的组件可以手工构建,但这是一个很复杂的过程。幸运的是,现有的工具可以很容易地完成这一过程。构建交叉编译工具链的最好工具可能是 [Crosstool-NG][2],这个工具使用了与 Linux 内核相同的 kconfig 菜单系统来构建工具链的位和片断。使用这个芽的关键是,为目标平台找到正确的配置项。配置项通常包含下列内容:
|
||||
|
||||
1. 目标架构,比如,是 ARM 还是 x86。
|
||||
|
||||
2. 字节顺序:小字节顺序(一般情况下,Intel 采用这种顺序)还是大字节顺序(一般情况下,ARM 或者其它的平台采用这种顺序)。
|
||||
|
||||
3. 编译器已知的 CPU 类型,比如,GCC 既可以使用 -mcpu 也可以使用 --with-cpu。
|
||||
|
||||
4. 支持的浮点类型,如果有的话,比如,GCC 既可以使用 -mfpu 也可以使用 --with-fpu。
|
||||
|
||||
5. 二进制工具包、C 库以及 C 编译器的特定版本信息。
|
||||
|
||||

|
||||
|
||||
图 2. Crosstool-NG 配置菜单
|
||||
|
||||
前四个一般情况下可以从处理器制造商的文档中获得。对于较新的处理器,它们可能不容易找到,但是,像树莓派或者 BeagleBoards(以及它们的后代和分支),你可以在像 [嵌入式 Linux Wiki][3] 这样的地方找到相关信息。
|
||||
|
||||
二进制实用工具、C 库、以及 C 编译器的版本,将与任何第三方提供的其它工具链分开。首先,它们中的每一个都有多个提供者。Linaro 为最新的处理器类型提供了最先进的版本,同时致力于将支持合并到像 GNU C 库这样的上游项目中。尽管你可以使用各种提供者的工具,你可能想去使用现成的 GNU 工具链或者相同版本的 Linaro。
|
||||
|
||||
在 Crosstool-NG 中的另外的重要选择是 Linux 内核的版本。这个选择将得到用于各种工具链组件的头,但是它没有必要一定与你在目标硬件上将要引导的 Linux 内核相同。选择一个不比目标硬件的内核更新的 Linux 内核是很重要的。如果可能的话,尽量选择一个比目标硬件使用的内核更老的长周期支持的内核。
|
||||
|
||||
对于大多数不熟悉构建定制发行版的开发者来说,工具链的构建是最为复杂的过程。幸运的是,大多数硬件平台的二进制工具链都可以想办法得到。如果构建一个定制的工具链有问题,可以去在线搜索像 [嵌入式 Linux Wiki][4] 这样的地方去查找预构建工具链。
|
||||
|
||||
### 引导选项
|
||||
|
||||
在构建完工具链之后,接下来的工作是引导加载程序。引导加载程序用于设置硬件,以便于越来越复杂的软件能够使用这些硬件。第一阶段的引导加载程序通常由目标平台制造商提供,它通常被烧录到类似于 EEPROM 或者 NOR 闪存这类的在硬件上的存储中。第一阶段的引导加载程序将使设备从这里开始引导,比如,一个 SD 存储卡。树莓派的引导加载程序就是这样的,它样做也就没有必要再去创建一个定制引导加载程序。
|
||||
|
||||
尽管如此,许多项目还是增加了第二阶段的引导加载程序,以便于去执行一个多样化的任务。在无需使用 Linux 内核或者像 plymouth 这样的用户空间工具的情况下提供一个启动动画,就是其中一个这样的任务。一个更常见的第二阶段引导加载程序的任务是去提供基于网络的引导或者使连接到 PCI 上的磁盘可用。在那种情况下,一个第三阶段的引导加载程序,比如 GRUB,可能才是让系统运行起来所必需的。
|
||||
|
||||
最重要的是,引导加载程序加载 Linux 内核并使它开始运行。如果第一阶段引导加载程序没有提供一个在启动时传递内核参数的机制,那么,在第二阶段的引导加载程序中就必须要提供。
|
||||
|
||||
有许多的开源引导加载程序可以使用。[U-Boot 项目][5] 通常是用于像树莓派这样的 ARM 平台。CoreBoot 一般是用于像 Chromebook 这样的 x86 平台。引导加载程序是目标硬件专用的。引导加载程序的选择总体上取决于项目的需求以及目标硬件(可以去网络上在线搜索开源引导加载程序的列表)。
|
||||
|
||||
### Now Bring the Penguin
|
||||
|
||||
引导加载程序将加载 Linux 内核到内存中,然后去运行它。Linux 就像一个扩展的引导加载程序:它包含了硬件设置以及加载高级软件的预处理工作。内核的核心将设置和预处理应用程序和硬件之间共享使用的内存;预处理任务管理器以允许多个应用程序同时运行;初始化没有被引导加载程序配置的或者是已经配置了但是没有完成的硬件组件;以及开启人机交互界面。内核可以并不会配置为它自己去做这些工作,但是,它可以包含一个嵌入的、轻量级的文件系统,这类文件系统大家熟知的有 initramfs 或者 initrd,它们可以独立于内核而创建,用于去辅助设置硬件。
|
||||
|
||||
内核操作的另外的事情是去下载二进制块(通常称为固件)到硬件设备。固件是用特定格式预编译的对象文件,用于在引导加载程序或者内核不能访问的地方去初始化特定硬件。许多的这种固件对象可以从 Linux 内核源仓库中获取,但是,还有很多其它的固件只能从特定的硬件供应商处获得。例如,经常由它们自己提供固件的设备有数字电视调谐器或者 WiFi 网卡。
|
||||
|
||||
固件可以从 initramfs 中加载,也或者是在内核从 root 文件系统中启动 init 进程之后加载。但是,当你去创建一个定制的 Linux 发行版时,创建内核的过程常常就是获取各种固件的过程。
|
||||
|
||||
### 轻量级核心平台
|
||||
|
||||
Linux 内核做的最后一件事情是尝试去运行一个被称为 init 进程的专用程序。这个专用程序的名字可能是 init 或者 linuxrc 或者是由加载程序传递给内核的名字。init 进程保存在一个能够被内核访问的文件系统中。在 initramfs 的示例中,这个文件系统保存在内存中(它可能是被内核自己放置到那里,也可能是被引导加载程序放置在那里)。但是,对于运行更复杂的应用程序,initramfs 通常并不够完整。因此需要另外一个文件系统,这就是众所周知的 root 文件系统。
|
||||
|
||||

|
||||
|
||||
图 3\. 构建 root 配置菜单
|
||||
|
||||
initramfs 文件系统可以使用 Linux 内核自己去构建,但是更常用的作法是,使用一个被称为 [BusyBox][6] 的项目去创建。BusyBox 组合许多 GNU 实用程序(比如,grep 或者 awk)到一个单个的二进制文件中,以便于减小文件系统自身的大小。BusyBox 通常用于去启动 root 文件系统的创建过程。
|
||||
|
||||
但是,BusyBox 是特意轻量化设计的。它并不打算提供目标平台所需要的所有工具,甚至提供的工具也是经过功能简化的。BusyBox 有一个“妹妹”项目叫做 [Buildroot][7],它可以用于去得到一个完整的 root 文件系统,提供了各种库、实用程序、以及脚本语言。像 Crosstool-NG 和 Linux 内核一样,BusyBox 和 Buildroot 也都允许使用 kconfig 菜单系统去定制配置。更重要的是,Buildroot 系统自动处理依赖关系,因此,选定实用程序将会保证该程序所需要的软件也会被构建并安装到 root 文件系统。
|
||||
|
||||
Buildroot 可以用多种格式去生成一个 root 文件系统包。但是,需要重点注意的是,这个文件系统是被打包的。单个的实用程序和库并不是以 Debian 或者 RPM 格式打包进去的。使用 Buildroot 将生成一个 root 文件系统镜像,但是它的内容不是管理包。即使如此,Buildroot 还是提供对 opkg 和 rpm 包管理器的支持的。这意味着,虽然 root 文件系统自身并不支持包管理,但是,安装在 root 文件系统上的定制应用程序能够进行包管理。
|
||||
|
||||
### 交叉编译和脚本化
|
||||
|
||||
Buildroot 的其中一个特性是能够生成一个临时树。这个目录包含库和实用程序,它可以被用于去交叉编译其它应用程序。使用一个临时树和交叉编译工具链,在主机系统上而不是目标平台上对 Buildroot 之外的其它应用程序编译成为可能。使用 rpm 或者 opkg 包管理软件之后,这些应用程序可以在运行时被安装在目标平台的 root 文件系统上。
|
||||
|
||||
大多数定制系统的构建都是围绕着用脚本语言构建应用程序的想法去构建的。如果需求在目标平台上运行脚本,在 Buildroot 上有多种可用的选择,包括 Python、PHP、Lua 以及基于 Node.js 的 JavaScript。对于需要使用 OpenSSL 加密的应用程序也提供支持。
|
||||
|
||||
### 接下来做什么
|
||||
|
||||
Linux 内核和引导加载程序的编译过程与大多数应用程序是一样的。它们的构建系统被设计为去构建一个专用的软件位。Crosstool-NG 和 Buildroot 是元构建。一个元构建是将一系列有自己构建系统的软件集合封装为一个构建系统。可靠的元构建包括 [Yocto][8] 和 [OpenEmbedded][9]。Buildroot 的好处是可以将更高级别的元构建进行轻松的封装,以便于将定制 Linux 发行版的构建过程自动化。这样做之后,将会打开 Buildroot 指向到项目专用的缓存仓库的选项。使用缓存仓库可以加速开发过程,并且可以在无需担心上游仓库变化的情况下提供构建快照。
|
||||
|
||||
一个实现高级构建系统的示例是 [PiBox][10]。PiBox 就是封装了在本文中讨论的各种工具的一个元构建。它的目的是黑围绕所有工具去增加一个通用的 GNU Make 目标架构,为了生成一个核心平台,这个平台可以构建或分发其它软件。PiBox 媒体中心和 kiosk 项目是安装在核心平台之上的应用层软件的实现,目的是用于去产生一个构建平台。[Iron Man 项目][11] 是为了家庭自动化的目的而扩展了这种应用程序,它集成了语音管理和物联网设备的管理。
|
||||
|
||||
但是,PiBox 如果没有这些核心的软件工具,它什么也做不了。并且,如果不去深入了解一个完整的定制发行版的构建过程,那么你将无法正确运行 PiBox。而且,如果没有 PiBox 开发团队对这个项目的长期奉献,也就没有 PiBox 项目,它完成了定制发行版构建中的大量任务。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/custom-embedded-linux-distributions
|
||||
|
||||
作者:[Michael J.Hammel][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/1000879
|
||||
[1]:https://www.kernel.org
|
||||
[2]:http://crosstool-ng.github.io
|
||||
[3]:https://elinux.org/Main_Page
|
||||
[4]:https://elinux.org/Main_Page
|
||||
[5]:https://www.denx.de/wiki/U-Boot
|
||||
[6]:https://busybox.net
|
||||
[7]:https://buildroot.org
|
||||
[8]:https://www.yoctoproject.org
|
||||
[9]:https://www.openembedded.org/wiki/Main_Page
|
||||
[10]:https://www.piboxproject.com
|
||||
[11]:http://redmine.graphics-muse.org/projects/ironman/wiki/Getting_Started
|
||||
Loading…
Reference in New Issue
Block a user