mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
e7da8a74ec
@ -1,42 +1,42 @@
|
||||
Ubuntu每日贴士——保护你的Home文件夹
|
||||
================================================================================
|
||||
几天之前,我们向大家展示了如何在Ubuntu中改变您的home文件夹,以便只有授权用户才能够看到您文件夹中的内容。我们说过,“adduser”命令创建的用户目录,目录里面内容是所有人可读的。这意味着:默认情况下,您的机器上所有有帐号的用户,都能够浏览您home文件夹里面的内容。
|
||||
Ubuntu每日小技巧——保护你的Home文件夹
|
||||
=================================
|
||||
|
||||
几天之前,我们向大家展示了如何在Ubuntu中改变您的home文件夹,以便只有授权用户才能够看到您文件夹中的内容。我们说过,“adduser”命令创建的用户目录,目录里面内容是所有人可读的。这意味着:默认情况下,您的机器上所有有帐号的用户,都能够浏览您home文件夹里面的内容。
|
||||
|
||||
要想阅读之前的文章,[请点击这里][2].在那篇文章中,我们还介绍了如何设置权限,可以让您的home文件夹不被任何人浏览。
|
||||
这篇博客中提到,还可以通过加密文件目录的方式来获得同样的效果。当home文件夹被加密后,未经授权的用户将既不能看到也不能访问该目录。
|
||||
|
||||
在这篇博客里,还可以看到如何通过加密文件目录的方式来获得同样的效果。当home文件夹被加密后,未经授权的用户将既不能看到也不能访问该目录。
|
||||
|
||||
加密home文件夹并不是在每个环境中对每个人都适用,所以在实际使用该功能之前,请确信自己真的需要它。
|
||||
要加密home目录,请登录到Ubuntu并运行以下命令。
|
||||
|
||||
要使用加密home目录的功能,请登录到Ubuntu并运行以下命令。
|
||||
|
||||
sudo apt-get install ecryptfs-utils
|
||||
|
||||
当加密当前home文件夹时,你是无法进行系统登录的,必须创建一个临时账户并登录进去。之后再运行下面这些命令,来加密你的home文件夹。
|
||||
使用你当前的账户名代替USERNAME。
|
||||
你是无法在登录后加密当前home文件夹的,必须创建一个临时账户并登录进去。之后再运行下面这些命令,来加密你的home文件夹。
|
||||
|
||||
使用你当前的账户名代替下面的USERNAME。
|
||||
|
||||
sudo ecryptfs-migrate-home -u USERNAME
|
||||
|
||||
当以临时用户的身份登录时,由于你的帐号拥有root或admin权限,就需要运行**su**+用户名,以自己的身份运行命令。系统会提示你输入密码。
|
||||
当以临时用户的身份登录后,为使你的帐号拥有root或admin权限,就需要以自己的身份运行 **su**+用户名的命令。系统会提示你输入密码。
|
||||
|
||||
su USERNAME
|
||||
|
||||
使用具有root或admin权限的帐号代替USERNAME。
|
||||
使用具有使用root或admin权限的帐号(译注:即拥有su权限的账号)代替USERNAME。
|
||||
|
||||
在这之后,运行**ecryptfs-migrate-home –u USERNAME**命令加密home文件夹。
|
||||
在这之后,运行 **ecryptfs-migrate-home –u USERNAME** 命令加密home文件夹。
|
||||
|
||||
要想在Ubuntu创建一个用户,运行下面的命令。
|
||||
|
||||
sudo adduser USERNAME
|
||||
|
||||
要想在Ubuntu中删除的用户,运行下面的命令。
|
||||
|
||||
sudo deluser USERNAME
|
||||
|
||||
登录后,你将会看到如下截图的界面,包含更多关于加密home文件夹的信息。
|
||||
使用被加密的账号第一次登录后,你将会看到如下截图的界面,包含更多关于加密home文件夹的信息。
|
||||
|
||||

|
||||
|
||||
要创建带有加密home目录的用户,运行下面的命令:
|
||||
要创建带有加密home目录的用户,运行下面的命令:
|
||||
|
||||
adduser –encrypt-home USERNAME
|
||||
|
||||
试试看吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.liberiangeek.net/2013/09/daily-ubuntu-tips-protect-home-folders/
|
||||
@ -8,13 +8,13 @@ Gnome Control Center允许用户使用大量的工具应用程序来对他们的
|
||||
|
||||
**GNOME Control Center 3.10.1的功能亮点:**
|
||||
|
||||
- 修正了一些内存泄露;
|
||||
- 修正了一些内存泄露问题;
|
||||
- 创建目录时使用一致的权限;
|
||||
- 鼠标移动速度设置不会再复位;
|
||||
- 没有启用远程控制功能时屏幕共享可正常使用;
|
||||
- 相同名字的文件夹不会再被选定为媒体共享文件夹;
|
||||
- 当要启用DLNA,必须使MediaExport插件启用;
|
||||
- 在“标题栏”的按钮图标已经对齐。
|
||||
- 顶栏的按钮图标已经对齐。
|
||||
|
||||
有关变更、更新及Bug修复等情况的完整列表信息可以在官网[变更日志][1]中查看。
|
||||
|
||||
@ -0,0 +1,33 @@
|
||||
Mark Shuttleworth将出席下月5~8号香港OpenStack峰会并演讲
|
||||
================================================================================
|
||||
|
||||
通过分析[Canonical][1],调查者不难发现几个改变,其中包括愿景、奋斗目标和行动准则等,都已经逐渐地将Canonical定位到业界之巅,通过在所有相关业绩和计算环境方面的成绩,它成为了领导创新发展的非常重要的部分。
|
||||
|
||||
Ubuntu桌面环境为那些追求稳定、快速、安全而优美的个人用户、公司企业和国家部门支撑了3000万台计算机的运行,这是一个巨大的成功,然而,这个桌面系统只是Canonical跨过层层困难到达IT世界之巅的蓬勃运动的一部分。
|
||||
|
||||
在云计算方面,Canonical已经深入而积极参与到OpenStack的创建上。作为最流行、可靠的、快速的开源云平台,Ubuntu正是OpenStack所基于的操作系统,这个云平台是汇集了NASA、HP和世界上的专家们,通力合作的所开发的开放云平台。
|
||||
|
||||
Ubuntu是公司和开发者所渴望使用的强大的OpenStack[原生的][2]操作系统,Ubuntu提供了众多优势和优点:Ubuntu和OpenStack发布时间是同步的,同步的发行使得OpenStack能在最新的Utuntu下运行,Canonical提供支持,包括产品、服务等,来支持最佳的OpenStack的管理和操作等。
|
||||
|
||||
**OpenStack峰会**是一个专家们的重要集会,在这里讨论、提出和分析OpenStack各个方面的内容,也包括丰富的展览、案例研究,以来自创新开发者的基调为特色,也有开发者集会和工作分享,最主要的是专家们会讨论关于目前和将来的OpenStack和云计算的格局。
|
||||
|
||||

|
||||
|
||||
这次OpenStack峰会将会于11月5号到8号在香港举行,可以[在此注册参会][3]。
|
||||
|
||||
Canonical的**Mark Shuttleworth**已经确定会出席在香港举行的OpenStack峰会,他将做一个讲演,围绕交互性,进一步加强Ubuntu和OpenStack的结合等,并揭示关于未来的创新目标的新细节、计划和Canonical为Ubuntu所做的成就。
|
||||
|
||||
更多细节请点击 [https://www.openstack.org/summit/hk][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://iloveubuntu.net/mark-shuttleworth-attend-and-conduct-keynote-openstack-summit-hong-kong-november-5th-8th-2013
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
译者:[Vic___](http://blog.csdn.net/Vic___) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
[1]:http://www.canonical.com/
|
||||
[2]:http://www.ubuntu.com/cloud/tools/openstack
|
||||
[3]:https://www.eventbrite.com/event/6786581849/o21
|
||||
[4]:https://www.openstack.org/summit/hk
|
||||
@ -1,14 +1,13 @@
|
||||
现在可以预订System 76 Ubuntu触摸笔记本了!!!
|
||||
|
||||
================================================================================
|
||||
现在可以预订System 76的Ubuntu触摸笔记本了!!!
|
||||
===================================
|
||||
|
||||

|
||||
|
||||
**Ubuntu PC 制造商 System 76 已经公布了一款搭载Ubuntu 13.10的触摸笔记本.**
|
||||
|
||||
Darter Ultra Thin 14.1寸高清**搭载Ubuntu多点触摸显示**,0.9''的厚度,地盘重4.60英镑(约2kg),电池大约能支持5个小时 - 受Linux电池管理的影响,这是令人震撼的.
|
||||
Darter Ultra Thin 14.1寸高清笔记本 **搭载了Ubuntu多点触摸显示**,0.9英寸的厚度,约重4.60磅(大约2公斤)。令人吃惊的是,虽然受到了Linux电池管理缺陷的影响,电池居然能支持5个小时。
|
||||
|
||||
在笔记本的触摸屏附近也提供很多传统的输入设备,也就是多点的触摸板和巧克力键盘.
|
||||
除了触摸屏外,也提供了传统的输入设备,如多点触摸板和巧克力式的键盘。
|
||||
|
||||

|
||||
|
||||
@ -16,30 +15,30 @@ Darter Ultra Thin 14.1寸高清**搭载Ubuntu多点触摸显示**,0.9''的厚度
|
||||
|
||||

|
||||
|
||||
普通版**定价在899美元左右**,它带有:
|
||||
普通版 **定价在899美元左右**,它带有:
|
||||
|
||||
- Inel i5-4200U @ 1.5Ghz (双核)
|
||||
- 4GB DDR3 RAM
|
||||
- Intel HD 4400 显卡
|
||||
- 500 GB 5400 RPM HDD
|
||||
- 集成WIFI和蓝牙
|
||||
- 1MP 网络摄像头
|
||||
- 一百万像素的网络摄像头
|
||||
|
||||
对于所有System 76电脑来说,你可以通过提高规格和添加可选的额外设备来定制你的神机。Dater提供的可选项包括有:
|
||||
|
||||
对于所有System 76电脑来说,你可以通过提高规格和添加可选的额外设备来精饰你的梦幻机.Dater提供的可选项包括有:
|
||||
-
|
||||
- Inter 酷睿i5和i7 CPU
|
||||
- 能扩展到16GB的DDR3 RAM
|
||||
- 双储存,包括SSD + HDD的联合体.
|
||||
|
||||
提供所有必要的端口:
|
||||
|
||||
提供所有必要的端口:
|
||||
- HDMI 输出
|
||||
- 以太网
|
||||
- 2个USB3.0插口
|
||||
- 分开的耳机和麦克风插孔
|
||||
- SD 读卡器
|
||||
|
||||
更多关于Dater Thin的信息请转向System 76站点,到10月28号后,你可以预订Dater Thin,只需5美元在美国的快递费.
|
||||
更多关于Dater Thin的信息请访问System 76站点,到10月28号前,你都可以预订Dater Thin。
|
||||
|
||||
- [System76 Darter UltraThin 笔记本][1]
|
||||
|
||||
@ -49,6 +48,6 @@ via: http://www.omgubuntu.co.uk/2013/10/system76-touchscreen-ubuntu-laptop-avail
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
译者:[Luoxcat](https://github.com/Luoxcat) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Luoxcat](https://github.com/Luoxcat) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
[1]:https://www.system76.com/laptops/model/daru4
|
||||
@ -1,8 +1,9 @@
|
||||
Ubuntu 13.10 发布 - 升级是否是必须的 ?
|
||||
================================================================================
|
||||
Ubuntu 13.10 发布 - 值得升级吗 ?
|
||||
===================================
|
||||
|
||||

|
||||
|
||||
**今天是Ubuntu 13.10 发布的日子。经过6个月紧锣密鼓地开发,‘Saucy Salamander’ 终于可供下载了。**
|
||||
**经过6个月紧锣密鼓地开发,‘Saucy Salamander’ 终于发布了。**
|
||||
|
||||
拥有超过两千万的用户基础,Ubuntu的每次更新,无论最终变动的结果多么得琐碎、细小,都能引起关注。这次发布也不例外。
|
||||
|
||||
@ -12,60 +13,61 @@ Ubuntu 13.10 发布 - 升级是否是必须的 ?
|
||||
|
||||
**下载 Ubuntu 13.10**:[http://releases.ubuntu.com/13.10/][1]
|
||||
|
||||
## “Ubuntu 13.10 令人厌烦的” - 网络 ##
|
||||
## “Ubuntu 13.10 令人厌烦的” - 来自互联网
|
||||
|
||||
我见过许多人-科技记者,博主,还有评论家,用“令人讨厌的”字眼来形容Ubuntu 13.10。
|
||||
我见过许多人,有科技记者、博主,还有评论家,用“令人讨厌的”字眼来形容Ubuntu 13.10。
|
||||
|
||||
诚然,Saucy Salamander比之先前的版本并没有为桌面版添加多少新的特色,但是新的版本确实变动了,也改善了,只不过大多数变动相较而言很小。
|
||||
诚然,Saucy Salamander比之先前的版本并没有为桌面用户添加多少新的特色,但是新的版本确实变化了,也改善了,只不过 **大多数** 变动相较而言很小。
|
||||
|
||||
强调一下这里的‘most’。
|
||||
强调一下这里的‘大多数’。
|
||||
|
||||
**工具箱花样繁多**
|
||||

|
||||
|
||||

|
||||
*这些东西究竟有多大用处呢?*
|
||||
|
||||
Unity的新的 搜索建议 功能是新版本中大的亮点。你的每一次搜索,都会把大范围在线资源的相关信息整合到一起,然后利用语义智能把筛选出来的东西放到工具箱。
|
||||
Unity的新的_搜索建议_功能是新版本中大的亮点。你的每一次搜索,都会把大范围的在线资源的相关信息整合到一起,然后利用语义智能把筛选出来的东西放到Dash中。
|
||||
|
||||
*Amazon, eBay, Etsy, Wikipedia, Weather Channel, SoundCloud* - 信息来源超过50个网站
|
||||
|
||||
> ‘…莫名其妙,乱七八糟。’
|
||||
|
||||
字面上貌似这个功能挺有用的:按下tab键,,你就可以绕过浏览器找到任何你想搜寻的东西,随便一些东西,然后从桌面上就可以浏览结果。
|
||||
|
||||
事实上,帮助挺少,阻碍倒是不小。那么多的web服务都给一个搜索的关键字条目提供结果 - 无论看起来有多无碍 -
|
||||
都导致工具箱充斥着莫名其妙、乱七八糟、不相关的东西。
|
||||
事实上,帮助挺少,阻碍倒是不小。那么多的web服务都给一个搜索的关键字条目提供结果 - 无论看起来有多无碍 - 都导致工具箱充斥着莫名其妙、乱七八糟、不相关的东西。
|
||||
|
||||
> ‘以当前这种形式,该功能还超越不了浏览器体验’
|
||||
|
||||
也不是没有尝试过结束这种混乱,代之以秩序井然。给查找结果分门别类,比如,购物,音乐,视频。由结果过滤器来控制泛滥的信息。
|
||||
|
||||
但是,坦白说,以当前这种形式,该功能还超越不了浏览器体验。谷歌就比较聪明,知道自己要找什么,把结果以一种易于浏览,易于过滤的形式呈现出来。
|
||||
|
||||
Ubuntu开发者称**搜索结果会变得越来越相关的**,因为该服务可以从用户那里自主学习。让我们拭目以待。
|
||||
Ubuntu开发者称 **搜索结果会变得越来越相关的**,因为该服务可以从用户那里自主学习。让我们拭目以待。
|
||||
|
||||
**关闭搜索建议功能**
|
||||
|
||||
关闭范围建议功能
|
||||

|
||||
|
||||
*每一个范围都可以单独关闭*
|
||||
*每一个搜索范围都可以单独关闭*
|
||||
|
||||
关闭“搜索建议”功能很简单,听从我的建议,就可以单独关闭给你带来混乱结果的范围。这样你就能够继续使用该功能,同时又过滤掉不相干的东西。
|
||||
|
||||
## Ubuntu 13.10 桌面 ##
|
||||
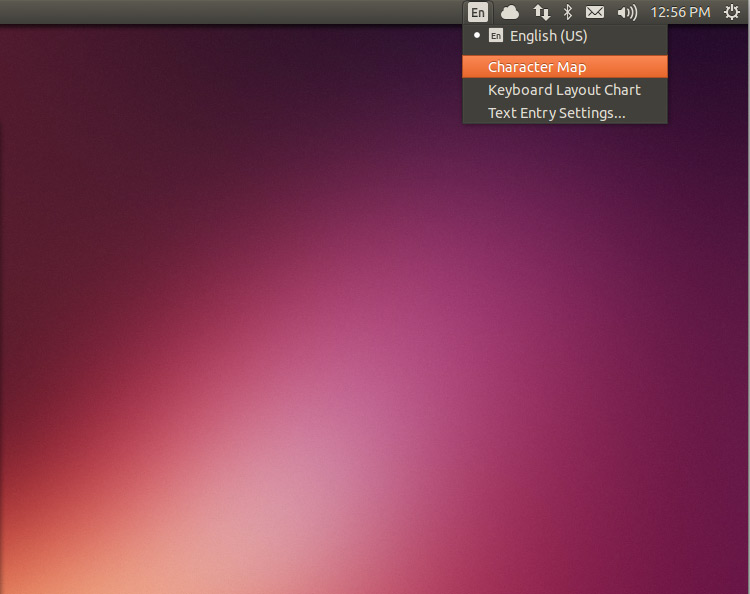
**Indicator Keyboard**
|
||||
**指示灯键盘**
|
||||
|
||||
**键盘指示器**
|
||||
|
||||
|
||||
无论你需要与否,新的‘指示灯键盘’已经添加到Ubuntu中,该功能使得在多种语言之间的切换更容易。
|
||||
无论你需要与否,新的‘键盘指示器’已经添加到Ubuntu中,该功能使得在多种语言之间的切换更容易。
|
||||
|
||||
可以在Text Entry Settings上面找到该功能入口,关闭它,然后取消紧挨着‘Show Current Input Source in Menu Bar’勾选框。
|
||||
|
||||
**Ubuntu 登陆**
|
||||
**Ubuntu 登录**
|
||||

|
||||
|
||||
登陆、注册页面也加到了Ubuntu安装程序里头,安装后就不需要再配置账号了。
|
||||
登录、注册页面也加到了Ubuntu安装程序里头,安装后就不需要再配置账号了。
|
||||
|
||||
**性能**
|
||||
|
||||
Unity 7正常运行远远超出原先预定的时间(14.04 LTS默认情况下,在4月到期),其中一些急需维修了。
|
||||
Unity 7的使用已经远超原先预定的时间(14.04 LTS默认情况下,在4月到期),其中一些急需改进了。
|
||||
|
||||
我自己并没有切身体验一下,但是那些体验过的人们都注意到该发行版性能有显著提升。
|
||||
|
||||
@ -78,10 +80,10 @@ Shotwell都已经预安装好了。
|
||||
|
||||
Ubuntu仓库也包含一些其他的流行的应用,比如[Geary mail client][2] 和比较受欢迎的图片编辑器 GIMP。
|
||||
|
||||
Finally, [GTK3 apps now look better under Ubuntu’s default theme][3].
|
||||
最后, [使用Ubuntu默认主题,GTK3 应用看起来好多了][3].
|
||||
|
||||
## 总结 ##
|
||||
|
||||
> 一个健壮、可靠的发行版,与其说是崭新的开始,不如说是一个脚注。
|
||||
|
||||
Ubuntu 13.10是一个健壮、可靠的发行版, 巩固了其作为“走出去”的Linux发行版的地位,对新用户和丰富的专业人员均适用。
|
||||
@ -94,8 +96,8 @@ via: http://www.omgubuntu.co.uk/2013/10/ubuntu-13-10-review-available-for-downlo
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
译者:[译者ID](https://github.com/l3b2w1) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[l3b2w1](https://github.com/l3b2w1) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
[1]:http://releases.ubuntu.com/13.10/
|
||||
[2]:http://www.omgubuntu.co.uk/2013/10/geary-0-4-released-with-new-look-new-features
|
||||
[3]:http://www.omgubuntu.co.uk/2013/08/ub untu-themes-fix-coming-to-saucy
|
||||
[3]:http://www.omgubuntu.co.uk/2013/08/ubuntu-themes-fix-coming-to-saucy
|
||||
@ -1,37 +0,0 @@
|
||||
crowner翻译
|
||||
Daily Ubuntu Tips – Understanding The App Menus And Buttons
|
||||
================================================================================
|
||||
Ubuntu is a decent operating system. It can do almost anything a modern OS can do and sometimes, even better. If you’re new to Ubuntu, there are some things you won’t know right away. Things that are common to power users may not be so common to you and this series called ‘Daily Ubuntu Tips’ is here to help you, the new users learn how to configure and manage Ubuntu easily.
|
||||
|
||||
Ubuntu comes with a menu bar. The main menu bar is the dark strip at the top of your screen which contains the status menu or indicator with (Date/Time, volume button), the App menus and Windows management buttons.
|
||||
|
||||
Windows management buttons are at the top left corner of the main menu (dark strip). When you open an application, the buttons on the main menu at the top left corner with close, minimize, maximize and restore is called Windows management buttons.
|
||||
|
||||
The App menus is located at the right of the Windows management button. It shows application menus when they are opened.
|
||||
|
||||
By default, Ubuntu hides the app menus and windows management buttons unless you move your mouse to the left corner, you wouldn’t be able to see them. If you open an application and can’t find the menu, just move your mouse to the left corner of your screen to show it.
|
||||
|
||||
If this is confusing and you want to disable the app menus so that each application can have its own menu, then continue below.
|
||||
|
||||
To uninstall or remove the app menus, run the commands below.
|
||||
|
||||
sudo apt-get autoremove indicator-appmenu
|
||||
|
||||
Running the command above will remove the app menu also known as global-menu. Now for the change to take effect, log out and log back in.
|
||||
|
||||
Now when you open applications in Ubuntu, each application will show its own menus instead of hiding it on the global menu or main menu.
|
||||
|
||||

|
||||
|
||||
That’s it! To go back to what it was, run the commands below
|
||||
|
||||
sudo apt-get install indicator-appmenu
|
||||
|
||||
Enjoy!
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.liberiangeek.net/2013/09/daily-ubuntu-tips-understanding-app-menus-buttons/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
@ -1,3 +1,4 @@
|
||||
翻译 hello world
|
||||
Install Apache With SSL in Ubuntu 13.10
|
||||
================================================================================
|
||||
In this short tutorial let me show you how to install Apache with SSL support. My testbox details are given below:
|
||||
@ -93,4 +94,4 @@ via: http://www.unixmen.com/install-apache-ssl-ubuntu-13-10/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,292 +0,0 @@
|
||||
coolpigs is translating this article
|
||||
|
||||
Installing a Desktop Algorithmic Trading Research Environment using Ubuntu Linux and Python
|
||||
================================================================================
|
||||
In this article I want to discuss how to set up a robust, efficient and interactive development environment for algorithmic trading strategy research making use of Ubuntu Desktop Linux and the Python programming language. We will utilise this environment for nearly all subsequent algorithmic trading articles.
|
||||
|
||||
To create the research environment we will install the following software tools, all of which are open-source and free to download:
|
||||
|
||||
- [Oracle VirtualBox][1] - For virtualisation of the operating system
|
||||
- [Ubuntu Desktop Linux][2] - As our virtual operating system
|
||||
- [Python][3] - The core programming environment
|
||||
- [NumPy][4]/[SciPy][5] - For fast, efficient array/matrix calculation
|
||||
- [IPython][6] - For visual interactive development with Python
|
||||
- [matplotlib][7] - For graphical visualisation of data
|
||||
- [pandas][8] - For data "wrangling" and time series analysis
|
||||
- [scikit-learn][9] - For machine learning and artificial intelligence algorithms
|
||||
|
||||
These tools (coupled with a suitable [securities master database][10]) will allow us to create a rapid interactive strategy research environment. Pandas is designed for "data wrangling" and can import and cleanse time series data very efficiently. NumPy/SciPy running underneath keeps the system extremely well optimised. IPython/matplotlib (and the qtconsole described below) allow interactive visualisation of results and rapid iteration. scikit-learn allows us to apply machine learning techniques to our strategies to further enhance performance.
|
||||
|
||||
Note that I've written the tutorial so that Windows or Mac OSX users who are unwilling or unable to install Ubuntu Linux directly can still follow along by using VirtualBox. VirtualBox allows us to create a "Virtual Machine" inside the host system that can emulate a guest operating system without affecting the host in any way. This allows experimentation with Ubuntu and the Python tools before committing to a full installation. For those who already have Ubuntu Desktop installed, you can skip to the section on "Installing the Python Research Environment Packages on Ubuntu".
|
||||
|
||||
## Installing VirtualBox and Ubuntu Linux ##
|
||||
|
||||
This section of the tutorial regarding VirtualBox installation has been written for a Mac OSX system, but will easily translate to a Windows host environment. Once VirtualBox has been installed the procedure will be the same for any underlying host operating system.
|
||||
|
||||
Before we begin installing the software we need to go ahead and download both Ubuntu and VirtualBox.
|
||||
|
||||
**Downloading the Ubuntu Desktop disk image**
|
||||
|
||||
Open up your favourite web browser and navigate to the [Ubuntu Desktop][11] homepage then select Ubuntu 13.04:
|
||||
|
||||

|
||||
|
||||
*Download Ubuntu 13.04 (64-bit if appropriate)*
|
||||
|
||||
You will be asked to contribute a donation although this is optional. Once you have reached the download page make sure to select Ubuntu 13.04. You'll need to choose whether you want the 32-bit or 64-bit version. It is likely you'll have a 64-bit system, but if you're in doubt, then choose 32-bit. On a Mac OSX system the Ubuntu Desktop ISO disk image will be stored in your Downloads directory. We will make use of it later once we have installed VirtualBox.
|
||||
|
||||
**Downloading and Installing VirtualBox**
|
||||
|
||||
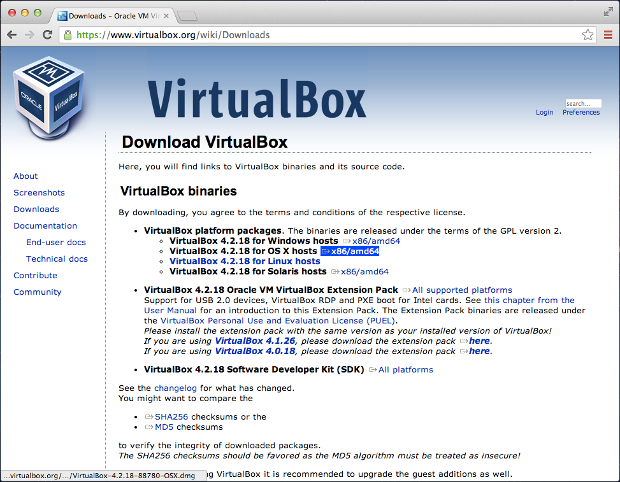
Now that we've downloaded Ubuntu we need to go and obtain the latest version of Oracle's VirtualBox software. Click [here][12] to visit the website and select the version for your particular host (for the purposes of this tutorial we need Mac OSX):
|
||||
|
||||
|
||||
|
||||
*Oracle VirtualBox download page*
|
||||
|
||||
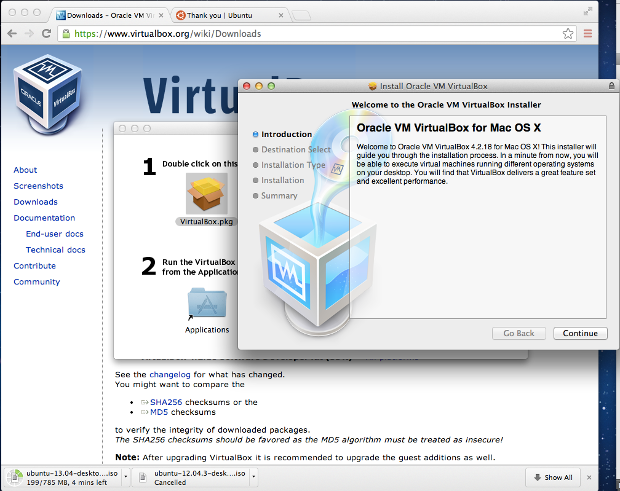
Once the file has been downloaded we need to run it and click on the package icon (this will vary somewhat in Windows but will be a similar process):
|
||||
|
||||
|
||||
|
||||
*Double-click the package icon to install VirtualBox*
|
||||
|
||||
Once the package has opened, we follow the installation instructions, keeping the defaults as they are (unless you feel the need to change them!). Now that VirtualBox has been installed we can open it from the Applications folder (which can be found with Finder). It puts VirtualBox on the icon dock while running, so you may wish to keep it there permanently if you want to examine Ubuntu Linux more closely in the future before committing to a full install:
|
||||
|
||||

|
||||
|
||||
*VirtualBox with no disk images yet*
|
||||
|
||||
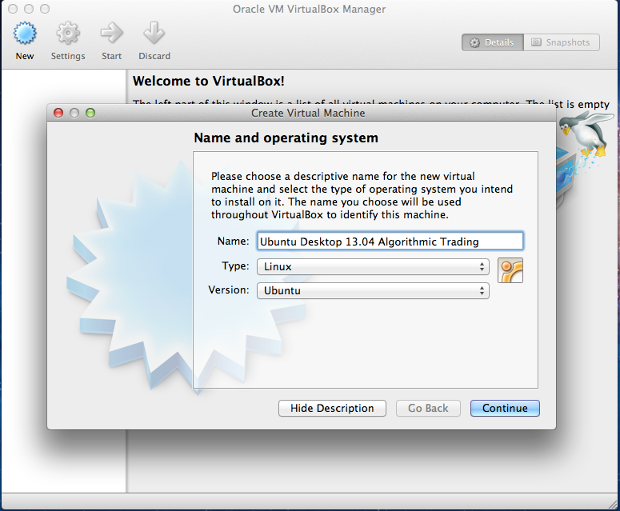
We are now going to create a new 'virtual box' (i.e. virtualised operating system) by clicking on the New icon, which looks like a cog. I've called mine "Ubuntu Desktop 13.04 Algorithmic Trading" (so you may wish to use something similarly descriptive!):
|
||||
|
||||
|
||||
|
||||
*Naming our new virtual environment*
|
||||
|
||||
Choose the amount of RAM you wish to allocate to the virtual system. I've kept it at 512Mb since this is only a "test" system. A 'real' backtesting engine would likely use a native installation (and thus allocate significantly more memory) for efficiency reasons:
|
||||
|
||||

|
||||
|
||||
*Choose the amount of RAM for the virtual disk*
|
||||
|
||||
Create a virtual hard drive and use the recommended 8Gb, with a VirtualBox Disk Image, dynamically allocated, with the same name as the VirtualBox Image above:
|
||||
|
||||

|
||||
|
||||
*Choosing the type of hard disk used by the image*
|
||||
|
||||
You will now see a complete system with listed details:
|
||||
|
||||

|
||||
|
||||
*The virtual image has been created*
|
||||
|
||||
We now need to tell VirtualBox to include a virtual 'CD drive' for the new disk image so that we can pretend to boot our new Ubuntu disk image from this CD drive. Head to the Settings section, click on the "Storage" tab and add a Disk. You will need to navigate to the Ubuntu Disk image ISO file stored in your Downloads directly (or wherever you downloaded Ubuntu to). Select it and then save the settings:
|
||||
|
||||

|
||||
|
||||
*Choosing the Ubuntu Desktop ISO on first boot*
|
||||
|
||||
Now we are ready to boot up our Ubuntu image and get it installed. Click on "Start" and then on "OK" when you see the message about Host Capture of the Mouse/Keyboard. Note that on my Mac OSX, the host capture key is the Left Cmd key (i.e. Left Apple key). You will now be presented with the Ubuntu Desktop installation screen. Click on "Install Ubuntu":
|
||||
|
||||

|
||||
|
||||
*Click on Install Ubuntu to get started*
|
||||
|
||||
Make sure to tick both boxes to install the proprietary MP3 and Wi-Fi drivers:
|
||||
|
||||

|
||||
|
||||
*Install the proprietary drivers for MP3 and Wi-Fi*
|
||||
|
||||
You will now see a screen asking how you would like to store the data created for the operating system. Don't panic about the "Erase Disk and Install Ubuntu" option. It does NOT mean that it will erase your normal hard disk! It actually refers to the virtual disk it is using to run Ubuntu in, which is safe to erase (there isn't anything on there anyway, as we've just created it). Carry on with the install and you will be presented with a screen asking for your location and subsequently, your keyboard layout:
|
||||
|
||||

|
||||
|
||||
*Select your geographical location*
|
||||
|
||||
Enter in your user credentials, making sure to remember your password as you'll need it later on for installing packages:
|
||||
|
||||

|
||||
|
||||
*Enter your username and password (this password is the administrator password)*
|
||||
|
||||
Ubuntu will now install the files. It should be relatively quick as it is just copying from the hard disk to the hard disk! Eventually it will complete and the VirtualBox will restart. If it doesn't restart on its own, you can go to the menu and force a Shutdown. You will be brought back to the Ubuntu Login Screen:
|
||||
|
||||

|
||||
|
||||
*The Ubuntu Desktop login screen*
|
||||
|
||||
Login with your username and password from above and you will see your shiny new Ubuntu desktop:
|
||||
|
||||

|
||||
|
||||
*The Unity interface to the Ubuntu Desktop after logging in*
|
||||
|
||||
The last thing to do is click on the Firefox icon to test that the internet/networking functionality is correct by visiting a website (I picked QuantStart.com, funnily enough!):
|
||||
|
||||

|
||||
|
||||
The Ubuntu Desktop login screen
|
||||
|
||||
Now that the Ubuntu Desktop is installed we can begin installing the algorithmic trading research environment packages.
|
||||
|
||||
## Installing the Python Research Environment Packages on Ubuntu ##
|
||||
|
||||
Click on the search button at the top-left of the screen and type "Terminal" into the box to bring up the command-line interface. Double-click the terminal icon to launch the Terminal:
|
||||
|
||||

|
||||
|
||||
*The Ubuntu Desktop login screen*
|
||||
|
||||
All subsequent commands will need to be typed into this terminal.
|
||||
|
||||
The first thing to do on any brand new Ubuntu Linux system is to update and upgrade the packages. The former tells Ubuntu about new packages that are available, while the latter actually performs the process of replacing older packages with newer versions. Run the following commands (you will be prompted for your passwords):
|
||||
|
||||
sudo apt-get -y update
|
||||
sudo apt-get -y upgrade
|
||||
|
||||
*Note that the -y prefix tells Ubuntu that you want to accept 'yes' to all yes/no questions. "sudo" is a Ubuntu/Debian Linux command that allows other commands to be executed with administrator privileges. Since we are installing our packages sitewide, we need 'root access' to the machine and thus must make use of 'sudo'.*
|
||||
|
||||
You may get an error message here:
|
||||
|
||||
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
|
||||
|
||||
To remedy it just run "sudo apt-get -y update" again or take a look at this site for additional commands to run in case the first does not work ([http://penreturns.rc.my/2012/02/could-not-get-lock-varlibaptlistslock.html][13]).
|
||||
|
||||
Once both of those updating commands have been successfully executed we now need to install Python, NumPy/SciPy, matplotlib, pandas, scikit-learn and IPython. We will start by installing the Python development packages and compilers needed to compile all of the software:
|
||||
|
||||
sudo apt-get install python-pip python-dev python2.7-dev build-essential liblapack-dev libblas-dev
|
||||
|
||||
Once the necessary packages are installed we can go ahead and install NumPy via pip, the Python package manager. Pip will download a zip file of the package and then compile it from the source code for us. Bear in mind that it will take some time to compile, probably 10-20 minutes!
|
||||
|
||||
sudo pip install numpy
|
||||
|
||||
Once NumPy has been installed we need to check that it works before proceeding. If you look in the terminal you'll see your username followed by your computer name. In my case it is `mhallsmoore@algobox`, which is followed by the prompt. At the prompt type `python` and then try importing NumPy. We will test that it works by calculating the mean average of a list:
|
||||
|
||||
mhallsmoore@algobox:~$ python
|
||||
Python 2.7.4 (default, Sep 26 2013, 03:20:26)
|
||||
[GCC 4.7.3] on linux2
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> import numpy
|
||||
>>> from numpy import mean
|
||||
>>> mean([1,2,3])
|
||||
2.0
|
||||
>>> exit()
|
||||
|
||||
Now that NumPy has been successfully installed we want to install the Python Scientific library known as SciPy. However it has a few package dependencies of its own including the ATLAS library and the GNU Fortran compiler:
|
||||
|
||||
sudo apt-get install libatlas-base-dev gfortran
|
||||
|
||||
We are ready to install SciPy now, with pip. This will take quite a long time (approx 20 minutes, depending upon your computer) so it might be worth going and grabbing a coffee:
|
||||
|
||||
sudo pip install scipy
|
||||
|
||||
Phew! SciPy has now been installed. Let's test it out by calculating the standard deviation of a list of integers:
|
||||
|
||||
mhallsmoore@algobox:~$ python
|
||||
Python 2.7.4 (default, Sep 26 2013, 03:20:26)
|
||||
[GCC 4.7.3] on linux2
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> import scipy
|
||||
>>> from scipy import std
|
||||
>>> std([1,2,3])
|
||||
0.81649658092772603
|
||||
>>> exit()
|
||||
|
||||
Next we need to install the dependency packages for matplotlib, the Python graphing library. Since matplotlib is a Python package, we cannot use pip to install the underlying libraries for working with PNGs, JPEGs and freetype fonts, so we need Ubuntu to install them for us:
|
||||
|
||||
sudo apt-get install libpng-dev libjpeg8-dev libfreetype6-dev
|
||||
|
||||
Now we can install matplotlib:
|
||||
|
||||
sudo pip install matplotlib
|
||||
|
||||
We're now going to install the data analysis and machine learning libraries pandas and scikit-learn. We don't need any additional dependencies at this stage as they're covered by NumPy and SciPy:
|
||||
|
||||
sudo pip install -U scikit-learn
|
||||
sudo pip install pandas
|
||||
|
||||
We should test scikit-learn:
|
||||
|
||||
mhallsmoore@algobox:~$ python
|
||||
Python 2.7.4 (default, Sep 26 2013, 03:20:26)
|
||||
[GCC 4.7.3] on linux2
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> from sklearn load datasets
|
||||
>>> iris = datasets.load_iris()
|
||||
>>> iris
|
||||
..
|
||||
..
|
||||
'petal width (cm)']}
|
||||
>>>
|
||||
|
||||
In addition, we should also test pandas:
|
||||
|
||||
>>> from pandas import DataFrame
|
||||
>>> pd = DataFrame()
|
||||
>>> pd
|
||||
Empty DataFrame
|
||||
Columns: []
|
||||
Index: []
|
||||
>>> exit()
|
||||
|
||||
Finally, we want to instal IPython. This is an interactive Python interpreter that provides a significantly more streamlined workflow compared to using the standard Python console. In later tutorials I will outline the full usefulness of IPython for algorithmic trading development:
|
||||
|
||||
sudo pip install ipython
|
||||
|
||||
While IPython is sufficiently useful on its own, it can be made even more powerful by including the qtconsole, which provides the ability to inline matplotlib visualisations. However, it takes a little bit more work to get this up and running.
|
||||
|
||||
First, we need to install the the [Qt library][14]. For this you may need to update your packages again (I did!):
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
Now we can install Qt:
|
||||
|
||||
sudo apt-get install libqt4-core libqt4-gui libqt4-dev
|
||||
|
||||
The qtconsole has a few additional packages, namely the ZMQ and Pygments libraries:
|
||||
|
||||
sudo apt-get install libzmq-dev
|
||||
sudo pip install pyzmq
|
||||
sudo pip install pygments
|
||||
|
||||
Finally we are ready to launch IPython with the qtconsole:
|
||||
|
||||
ipython qtconsole --pylab=inline
|
||||
|
||||
Then we can make a (rather simple!) plot by typing the following commands (I've included the IPython numbered input/outut which you do not need to type):
|
||||
|
||||
In [1]: x=np.array([1,2,3])
|
||||
|
||||
In [2]: plot(x)
|
||||
Out[2]: [<matplotlib.lines.Line2D at 0x392a1d0>]
|
||||
|
||||
This produces the following inline chart:
|
||||
|
||||
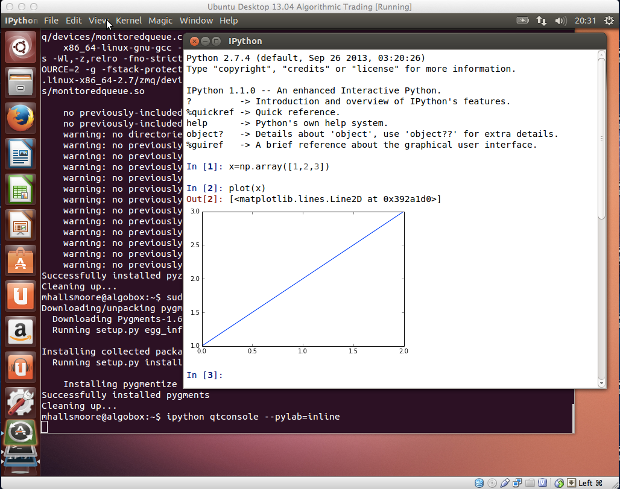
|
||||
|
||||
*IPython with qtconsole displaying an inline chart*
|
||||
|
||||
That's it for the installation procedure. We now have an extremely robust, efficient and interactive algorithmic trading research environment at our fingertips. In subsequent articles I will be detailing how IPython, matplotlib, pandas and scikit-learn can be combined to successfully research and backtest quantitative trading strategies in a straightforward manner.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://quantstart.com/articles/Installing-a-Desktop-Algorithmic-Trading-Research-Environment-using-Ubuntu-Linux-and-Python
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[1]:https://www.virtualbox.org/
|
||||
[2]:http://www.ubuntu.com/desktop
|
||||
[3]:http://python.org/
|
||||
[4]:http://www.numpy.org/
|
||||
[5]:http://www.scipy.org/
|
||||
[6]:http://ipython.org/
|
||||
[7]:http://matplotlib.org/
|
||||
[8]:http://pandas.pydata.org/
|
||||
[9]:http://scikit-learn.org/
|
||||
[10]:http://quantstart.com/articles/Securities-Master-Database-with-MySQL-and-Python
|
||||
[11]:http://www.ubuntu.com/desktop
|
||||
[12]:https://www.virtualbox.org/
|
||||
[13]:http://penreturns.rc.my/2012/02/could-not-get-lock-varlibaptlistslock.html
|
||||
[14]:http://qt-project.org/downloads
|
||||
@ -1,403 +0,0 @@
|
||||
[这篇我领了]
|
||||
NoSQL comparison
|
||||
================
|
||||
|
||||
While SQL databases are insanely useful tools, their monopoly in the last decades is coming to an end. And it's just time: I can't even count the things that were forced into relational databases, but never really fitted them. (That being said, relational databases will always be the best for the stuff that has relations.)
|
||||
|
||||
But, the differences between NoSQL databases are much bigger than ever was between one SQL database and another. This means that it is a bigger responsibility on software architects to choose the appropriate one for a project right at the beginning.
|
||||
|
||||
In this light, here is a comparison of [Cassandra][], [Mongodb][], [CouchDB][], [Redis][], [Riak][], [Couchbase (ex-Membase)][], [Hypertable][], [ElasticSearch][], [Accumulo][], [VoltDB][], [Kyoto Tycoon][], [Scalaris][], [Neo4j][] and [HBase][]:
|
||||
|
||||
##The most popular ones
|
||||
|
||||
###MongoDB (2.2)
|
||||
|
||||
**Written in:** C++
|
||||
|
||||
**Main point:** Retains some friendly properties of SQL. (Query, index)
|
||||
|
||||
**License:** AGPL (Drivers: Apache)
|
||||
|
||||
**Protocol:** Custom, binary (BSON)
|
||||
|
||||
- Master/slave replication (auto failover with replica sets)
|
||||
- Sharding built-in
|
||||
- Queries are javascript expressions
|
||||
- Run arbitrary javascript functions server-side
|
||||
- Better update-in-place than CouchDB
|
||||
- Uses memory mapped files for data storage
|
||||
- Performance over features
|
||||
- Journaling (with --journal) is best turned on
|
||||
- On 32bit systems, limited to ~2.5Gb
|
||||
- An empty database takes up 192Mb
|
||||
- GridFS to store big data + metadata (not actually an FS)
|
||||
- Has geospatial indexing
|
||||
- Data center aware
|
||||
|
||||
**Best used:** If you need dynamic queries. If you prefer to define indexes, not map/reduce functions. If you need good performance on a big DB. If you wanted CouchDB, but your data changes too much, filling up disks.
|
||||
|
||||
**For example:** For most things that you would do with MySQL or PostgreSQL, but having predefined columns really holds you back.
|
||||
|
||||
|
||||
###Riak (V1.2)
|
||||
|
||||
**Written in:** Erlang & C, some JavaScript
|
||||
|
||||
**Main point:** Fault tolerance
|
||||
|
||||
**License:** Apache
|
||||
|
||||
**Protocol:** HTTP/REST or custom binary
|
||||
|
||||
- Stores blobs
|
||||
- Tunable trade-offs for distribution and replication
|
||||
- Pre- and post-commit hooks in JavaScript or Erlang, for validation and security.
|
||||
- Map/reduce in JavaScript or Erlang
|
||||
- Links & link walking: use it as a graph database
|
||||
- Secondary indices: but only one at once
|
||||
- Large object support (Luwak)
|
||||
- Comes in "open source" and "enterprise" editions
|
||||
- Full-text search, indexing, querying with Riak Search
|
||||
- In the process of migrating the storing backend from "Bitcask" to Google's "LevelDB"
|
||||
- Masterless multi-site replication replication and SNMP monitoring are commercially licensed
|
||||
|
||||
**Best used:** If you want something Dynamo-like data storage, but no way you're gonna deal with the bloat and complexity. If you need very good single-site scalability, availability and fault-tolerance, but you're ready to pay for multi-site replication.
|
||||
|
||||
**For example:** Point-of-sales data collection. Factory control systems. Places where even seconds of downtime hurt. Could be used as a well-update-able web server.
|
||||
|
||||
###CouchDB (V1.2)
|
||||
|
||||
**Written in:** Erlang
|
||||
|
||||
**Main point:** DB consistency, ease of use
|
||||
|
||||
**License:** Apache
|
||||
|
||||
**Protocol:** HTTP/REST
|
||||
|
||||
- Bi-directional (!) replication,
|
||||
- continuous or ad-hoc,
|
||||
- with conflict detection,
|
||||
- thus, master-master replication. (!)
|
||||
- MVCC - write operations do not block reads
|
||||
- Previous versions of documents are available
|
||||
- Crash-only (reliable) design
|
||||
- Needs compacting from time to time
|
||||
- Views: embedded map/reduce
|
||||
- Formatting views: lists & shows
|
||||
- Server-side document validation possible
|
||||
- Authentication possible
|
||||
- Real-time updates via '_changes' (!)
|
||||
- Attachment handling
|
||||
- thus, CouchApps (standalone js apps)
|
||||
|
||||
**Best used:** For accumulating, occasionally changing data, on which pre-defined queries are to be run. Places where versioning is important.
|
||||
|
||||
**For example:** CRM, CMS systems. Master-master replication is an especially interesting feature, allowing easy multi-site deployments.
|
||||
|
||||
###Redis (V2.4)
|
||||
|
||||
**Written in:** C/C++
|
||||
|
||||
**Main point:** Blazing fast
|
||||
|
||||
**License:** BSD
|
||||
|
||||
**Protocol:** Telnet-like
|
||||
|
||||
- Disk-backed in-memory database,
|
||||
- Currently without disk-swap (VM and Diskstore were abandoned)
|
||||
- Master-slave replication
|
||||
- Simple values or hash tables by keys,
|
||||
- but complex operations like ZREVRANGEBYSCORE.
|
||||
- INCR & co (good for rate limiting or statistics)
|
||||
- Has sets (also union/diff/inter)
|
||||
- Has lists (also a queue; blocking pop)
|
||||
- Has hashes (objects of multiple fields)
|
||||
- Sorted sets (high score table, good for range queries)
|
||||
- Redis has transactions (!)
|
||||
- Values can be set to expire (as in a cache)
|
||||
- Pub/Sub lets one implement messaging (!)
|
||||
|
||||
**Best used:** For rapidly changing data with a foreseeable database size (should fit mostly in memory).
|
||||
|
||||
**For example:** Stock prices. Analytics. Real-time data collection. Real-time communication. And wherever you used memcached before.
|
||||
|
||||
##Clones of Google's Bigtable
|
||||
|
||||
###HBase (V0.92.0)
|
||||
|
||||
**Written in:** Java
|
||||
|
||||
**Main point:** Billions of rows X millions of columns
|
||||
|
||||
**License:** Apache
|
||||
|
||||
**Protocol:** HTTP/REST (also Thrift)
|
||||
|
||||
- Modeled after Google's BigTable
|
||||
- Uses Hadoop's HDFS as storage
|
||||
- Map/reduce with Hadoop
|
||||
- Query predicate push down via server side scan and get filters
|
||||
- Optimizations for real time queries
|
||||
- A high performance Thrift gateway
|
||||
- HTTP supports XML, Protobuf, and binary
|
||||
- Jruby-based (JIRB) shell
|
||||
- Rolling restart for configuration changes and minor upgrades
|
||||
- Random access performance is like MySQL
|
||||
- A cluster consists of several different types of nodes
|
||||
|
||||
**Best used:** Hadoop is probably still the best way to run Map/Reduce jobs on huge datasets. Best if you use the Hadoop/HDFS stack already.
|
||||
|
||||
**For example:** Search engines. Analysing log data. Any place where scanning huge, two-dimensional join-less tables are a requirement.
|
||||
|
||||
###Cassandra (1.2)
|
||||
|
||||
**Written in:** Java
|
||||
|
||||
**Main point:** Best of BigTable and Dynamo
|
||||
|
||||
**License:** Apache
|
||||
|
||||
**Protocol:** Thrift & custom binary CQL3
|
||||
|
||||
- Tunable trade-offs for distribution and replication (N, R, W)
|
||||
- Querying by column, range of keys (Requires indices on anything that you want to search on)
|
||||
- BigTable-like features: columns, column families
|
||||
- Can be used as a distributed hash-table, with an "SQL-like" language, CQL (but no JOIN!)
|
||||
- Data can have expiration (set on INSERT)
|
||||
- Writes can be much faster than reads (when reads are disk-bound)
|
||||
- Map/reduce possible with Apache Hadoop
|
||||
- All nodes are similar, as opposed to Hadoop/HBase
|
||||
- Very good and reliable cross-datacenter replication
|
||||
|
||||
**Best used:** When you write more than you read (logging). If every component of the system must be in Java. ("No one gets fired for choosing Apache's stuff.")
|
||||
|
||||
**For example:** Banking, financial industry (though not necessarily for financial transactions, but these industries are much bigger than that.) Writes are faster than reads, so one natural niche is data analysis.
|
||||
|
||||
###Hypertable (0.9.6.5)
|
||||
|
||||
**Written in:** C++
|
||||
|
||||
**Main point:** A faster, smaller HBase
|
||||
|
||||
**License:** GPL 2.0
|
||||
|
||||
**Protocol:** Thrift, C++ library, or HQL shell
|
||||
|
||||
- Implements Google's BigTable design
|
||||
- Run on Hadoop's HDFS
|
||||
- Uses its own, "SQL-like" language, HQL
|
||||
- Can search by key, by cell, or for values in column families.
|
||||
- Search can be limited to key/column ranges.
|
||||
- Sponsored by Baidu
|
||||
- Retains the last N historical values
|
||||
- Tables are in namespaces
|
||||
- Map/reduce with Hadoop
|
||||
|
||||
**Best used:** If you need a better HBase.
|
||||
|
||||
**For example:** Same as HBase, since it's basically a replacement: Search engines. Analysing log data. Any place where scanning huge, two-dimensional join-less tables are a requirement.
|
||||
|
||||
###Accumulo (1.4)
|
||||
|
||||
**Written in:** Java and C++
|
||||
|
||||
**Main point:** A BigTable with Cell-level security
|
||||
|
||||
**License:** Apache
|
||||
|
||||
**Protocol:** Thrift
|
||||
|
||||
- Another BigTable clone, also runs of top of Hadoop
|
||||
- Cell-level security
|
||||
- Bigger rows than memory are allowed
|
||||
- Keeps a memory map outside Java, in C++ STL
|
||||
- Map/reduce using Hadoop's facitlities (ZooKeeper & co)
|
||||
- Some server-side programming
|
||||
|
||||
**Best used:** If you need a different HBase.
|
||||
|
||||
**For example:** Same as HBase, since it's basically a replacement: Search engines. Analysing log data. Any place where scanning huge, two-dimensional join-less tables are a requirement.
|
||||
|
||||
##Special-purpose
|
||||
|
||||
###Neo4j (V1.5M02)
|
||||
|
||||
**Written in:** Java
|
||||
|
||||
**Main point:** Graph database - connected data
|
||||
|
||||
**License:** GPL, some features AGPL/commercial
|
||||
|
||||
**Protocol:** HTTP/REST (or embedding in Java)
|
||||
|
||||
- Standalone, or embeddable into Java applications
|
||||
- Full ACID conformity (including durable data)
|
||||
- Both nodes and relationships can have metadata
|
||||
- Integrated pattern-matching-based query language ("Cypher")
|
||||
- Also the "Gremlin" graph traversal language can be used
|
||||
- Indexing of nodes and relationships
|
||||
- Nice self-contained web admin
|
||||
- Advanced path-finding with multiple algorithms
|
||||
- Indexing of keys and relationships
|
||||
- Optimized for reads
|
||||
- Has transactions (in the Java API)
|
||||
- Scriptable in Groovy
|
||||
- Online backup, advanced monitoring and High Availability is AGPL/commercial licensed
|
||||
|
||||
**Best used:** For graph-style, rich or complex, interconnected data. Neo4j is quite different from the others in this sense.
|
||||
|
||||
**For example:** For searching routes in social relations, public transport links, road maps, or network topologies.
|
||||
|
||||
###ElasticSearch (0.20.1)
|
||||
|
||||
**Written in:** Java
|
||||
|
||||
**Main point:** Advanced Search
|
||||
|
||||
**License:** Apache
|
||||
|
||||
**Protocol:** JSON over HTTP (Plugins: Thrift, memcached)
|
||||
|
||||
- Stores JSON documents
|
||||
- Has versioning
|
||||
- Parent and children documents
|
||||
- Documents can time out
|
||||
- Very versatile and sophisticated querying, scriptable
|
||||
- Write consistency: one, quorum or all
|
||||
- Sorting by score (!)
|
||||
- Geo distance sorting
|
||||
- Fuzzy searches (approximate date, etc) (!)
|
||||
- Asynchronous replication
|
||||
- Atomic, scripted updates (good for counters, etc)
|
||||
- Can maintain automatic "stats groups" (good for debugging)
|
||||
- Still depends very much on only one developer (kimchy).
|
||||
|
||||
**Best used:** When you have objects with (flexible) fields, and you need "advanced search" functionality.
|
||||
|
||||
**For example:** A dating service that handles age difference, geographic location, tastes and dislikes, etc. Or a leaderboard system that depends on many variables.
|
||||
|
||||
##The "long tail"
|
||||
|
||||
(Not widely known, but definitely worthy ones)
|
||||
|
||||
###Couchbase (ex-Membase) (2.0)
|
||||
|
||||
**Written in:** Erlang & C
|
||||
|
||||
**Main point:** Memcache compatible, but with persistence and clustering
|
||||
|
||||
**License:** Apache
|
||||
|
||||
**Protocol:** memcached + extensions
|
||||
|
||||
- Very fast (200k+/sec) access of data by key
|
||||
- Persistence to disk
|
||||
- All nodes are identical (master-master replication)
|
||||
- Provides memcached-style in-memory caching buckets, too
|
||||
- Write de-duplication to reduce IO
|
||||
- Friendly cluster-management web GUI
|
||||
- Connection proxy for connection pooling and multiplexing (Moxi)
|
||||
- Incremental map/reduce
|
||||
- Cross-datacenter replication
|
||||
|
||||
**Best used:** Any application where low-latency data access, high concurrency support and high availability is a requirement.
|
||||
|
||||
**For example:** Low-latency use-cases like ad targeting or highly-concurrent web apps like online gaming (e.g. Zynga).
|
||||
|
||||
###VoltDB (2.8.4.1)
|
||||
|
||||
**Written in:** Java
|
||||
|
||||
**Main point:** Fast transactions and rapidly changing data
|
||||
|
||||
**License:** GPL 3
|
||||
|
||||
**Protocol:** Proprietary
|
||||
|
||||
- In-memory relational database.
|
||||
- Can export data into Hadoop
|
||||
- Supports ANSI SQL
|
||||
- Stored procedures in Java
|
||||
- Cross-datacenter replication
|
||||
|
||||
**Best used:** Where you need to act fast on massive amounts of incoming data.
|
||||
|
||||
**For example:** Point-of-sales data analysis. Factory control systems.
|
||||
|
||||
###Scalaris (0.5)
|
||||
|
||||
**Written in:** Erlang
|
||||
|
||||
**Main point:** Distributed P2P key-value store
|
||||
|
||||
**License:** Apache
|
||||
|
||||
**Protocol:** Proprietary & JSON-RPC
|
||||
|
||||
- In-memory (disk when using Tokyo Cabinet as a backend)
|
||||
- Uses YAWS as a web server
|
||||
- Has transactions (an adapted Paxos commit)
|
||||
- Consistent, distributed write operations
|
||||
- From CAP, values Consistency over Availability (in case of network partitioning, only the bigger partition - works)
|
||||
|
||||
**Best used:** If you like Erlang and wanted to use Mnesia or DETS or ETS, but you need something that is accessible from more languages (and scales much better than ETS or DETS).
|
||||
|
||||
**For example:** In an Erlang-based system when you want to give access to the DB to Python, Ruby or Java programmers.
|
||||
|
||||
###Kyoto Tycoon (0.9.56)
|
||||
|
||||
**Written in:** C++
|
||||
|
||||
**Main point:** A lightweight network DBM
|
||||
|
||||
**License:** GPL
|
||||
|
||||
**Protocol:** HTTP (TSV-RPC or REST)
|
||||
|
||||
- Based on Kyoto Cabinet, Tokyo Cabinet's successor
|
||||
- Multitudes of storage backends: Hash, Tree, Dir, etc (everything from Kyoto Cabinet)
|
||||
- Kyoto Cabinet can do 1M+ insert/select operations per sec (but Tycoon does less because of overhead)
|
||||
- Lua on the server side
|
||||
- Language bindings for C, Java, Python, Ruby, Perl, Lua, etc
|
||||
- Uses the "visitor" pattern
|
||||
- Hot backup, asynchronous replication
|
||||
- background snapshot of in-memory databases
|
||||
- Auto expiration (can be used as a cache server)
|
||||
|
||||
**Best used:** When you want to choose the backend storage algorithm engine very precisely. When speed is of the essence.
|
||||
|
||||
**For example:** Caching server. Stock prices. Analytics. Real-time data collection. Real-time communication. And wherever you used memcached before.
|
||||
|
||||
Of course, all these systems have much more features than what's listed here. I only wanted to list the key points that I base my decisions on. Also, development of all are very fast, so things are bound to change.
|
||||
|
||||
P.s.: And no, there's no date on this review. There are version numbers, since I update the databases one by one, not at the same time. And believe me, the basic properties of databases don't change that much.
|
||||
|
||||
---
|
||||
|
||||
via: http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
|
||||
|
||||
本文由 [LCTT][] 原创翻译,[Linux中国][] 荣誉推出
|
||||
|
||||
译者:[译者ID][] 校对:[校对者ID][]
|
||||
|
||||
[LCTT]:https://github.com/LCTT/TranslateProject
|
||||
[Linux中国]:http://linux.cn/portal.php
|
||||
[译者ID]:http://linux.cn/space/译者ID
|
||||
[校对者ID]:http://linux.cn/space/校对者ID
|
||||
|
||||
[Cassandra]:http://cassandra.apache.org/
|
||||
[Mongodb]:http://www.mongodb.org/
|
||||
[CouchDB]:http://couchdb.apache.org/
|
||||
[Redis]:http://redis.io/
|
||||
[Riak]:http://basho.com/riak/
|
||||
[Couchbase (ex-Membase)]:http://www.couchbase.org/membase
|
||||
[Hypertable]:http://hypertable.org/
|
||||
[ElasticSearch]:http://www.elasticsearch.org/
|
||||
[Accumulo]:http://accumulo.apache.org/
|
||||
[VoltDB]:http://voltdb.com/
|
||||
[Kyoto Tycoon]:http://fallabs.com/kyototycoon/
|
||||
[Scalaris]:https://code.google.com/p/scalaris/
|
||||
[Neo4j]:http://neo4j.org/
|
||||
[HBase]:http://hbase.apache.org/
|
||||
@ -1,68 +0,0 @@
|
||||
00 About the author
|
||||
================================================================================
|
||||
[][1]
|
||||
|
||||
Feel free to post or email me (DevynCJohnson@Gmail.com) suggestions for this series, both on topics for future articles in the series and on how the series can be made better and more interesting.
|
||||
|
||||
I write two articles a week for Linux.org. One is the Linux kernel series and the other is any random Linux topic. Feel free to email suggestions on what you would like to read about in the "random article". I would like to write something that will draw numerous readers to the site. My goal is to write an article that has 10,000+ readers in one week.
|
||||
|
||||
Soon, I will also write tutorials on how to install some of the popular Linux distros, so if there is a particular one you want to read about, email me.
|
||||
|
||||
Check out my wallpapers on [http://gnome-look.org/usermanager/search.php?username=DevynCJohnson&action=contents&PHPSESSID=32424677ef4d9dffed020d06ef2522ac][2]
|
||||
|
||||
My AI project:
|
||||
|
||||
- [https://launchpad.net/neobot][3]
|
||||
|
||||
Ubuntu 13.10 (AMD64)
|
||||
|
||||
- [https://launchpad.net/~devyncjohnson-d][4]
|
||||
- [DevynCJohnson@Gmail.com][5]
|
||||
|
||||
|
||||
|
||||
**Gender**:Male
|
||||
|
||||
**Birthday**:Aug 31, 1994 (Age: 19)
|
||||
|
||||
**Home page**:https://launchpad.net/~devyncjohnson-d
|
||||
|
||||
**Location**:United States
|
||||
|
||||
Devyn Collier Johnson was home-schooled by his two wonderful parents and has graduated one university and is now attending another. His father, Jarret Wayne Buse, has many computer certifications, and Jarret has written and published many books on computers. He also does some programming, and he has given Devyn help and ideas for his artificial intelligence program. His mother, Cassandra Ann Johnson, is a stay-at-home mother, home-schooling his many siblings. Devyn Collier Johnson lives in Indiana with his parents and focuses his time on college and personal computer programming.
|
||||
|
||||
Devyn Collier Johnson graduated high-school at age sixteen. He attends college as a commuting student maintaining the Dean's list. He majors in electrical technology engineering. Devyn Collier Johnson has learned many computer languages. Some he taught himself while others his father taught him and helped him understand. Some of the languages he knows include Xaiml, AIML, Unix Shell, Python3, VPython, PyQT, PyGTK, Coffeescript, GEL, SED, HTML4/5, CSS3, SVG, and XML. Devyn knows bits and pieces of some other languages. He earned four computer certifications in April 2012 and those four being NCLA, Linux+, LPIC-1, and DCTS. His Linux Professional ID is LPI000254694.
|
||||
|
||||
In July 2012, Devyn Collier Johnson decided to make his chatterbot from scratch. He designed his own markup language (Xaiml) and AI engine (ProgramPY-SH or Pysh). On March 3, 2013, Devyn published his new chatterbot on Launchpad.net. The bot is named Neo which is from the Proto-Indo European word for "new".
|
||||
|
||||
Devyn maintains a few other projects. He makes Opera and Firefox themes ([https://addons.mozilla.org/en-US/firefox/user/DevynCJohnson/][6]) ([https://my.opera.com/devyncjohnson/account/][7]); he also has many other graphic design projects. Most of his programming projects are hosted on [https://launchpad.net/~devyncjohnson-d][4], and some are mirrored on Sourceforge.net. Some other miscellaneous projects can be found in the links below.
|
||||
|
||||
- [http://askubuntu.com/users/158340/devyn-collier-johnson][8]
|
||||
- [http://unix.stackexchange.com/users/40770/devyn-collier-johnson][9]
|
||||
- [http://stackoverflow.com/users/2354783/devyn-collier-johnson][10]
|
||||
- [http://www.linux.org/members/devyncjohnson.4843/][1]
|
||||
- [http://gnome-look.org/usermanager/search.php?username=DevynCJohnson][11]
|
||||
- [http://www.creatity.com/?user=1449&action=detailUser][12]
|
||||
- [http://openclipart.org/user-detail/DevynCJohnson][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.org/members/devyncjohnson.4843/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.linux.org/members/devyncjohnson.4843/
|
||||
[2]:http://gnome-look.org/usermanager/search.php?username=DevynCJohnson&action=contents&PHPSESSID=32424677ef4d9dffed020d06ef2522ac
|
||||
[3]:https://launchpad.net/neobot
|
||||
[4]:https://launchpad.net/~devyncjohnson-d
|
||||
[5]:DevynCJohnson@Gmail.com
|
||||
[6]:https://addons.mozilla.org/en-US/firefox/user/DevynCJohnson/
|
||||
[7]:https://my.opera.com/devyncjohnson/account/
|
||||
[8]:http://askubuntu.com/users/158340/devyn-collier-johnson
|
||||
[9]:http://unix.stackexchange.com/users/40770/devyn-collier-johnson
|
||||
[10]:http://stackoverflow.com/users/2354783/devyn-collier-johnson
|
||||
[11]:http://gnome-look.org/usermanager/search.php?username=DevynCJohnson
|
||||
[12]:http://www.creatity.com/?user=1449&action=detailUser
|
||||
[13]:http://openclipart.org/user-detail/DevynCJohnson
|
||||
@ -1,37 +0,0 @@
|
||||
Translating----------geekpi
|
||||
|
||||
01 The Linux Kernel: Introduction
|
||||
================================================================================
|
||||
In 1991, a Finnish student named Linus Benedict Torvalds made the kernel of a now popular operating system. He released Linux version 0.01 on September 1991, and on February 1992, he licensed the kernel under the GPL license. The GNU General Public License (GPL) allows people to use, own, modify, and distribute the source code legally and free of charge. This permits the kernel to become very popular because anyone may download it for free. Now that anyone can make their own kernel, it may be helpful to know how to obtain, edit, configure, compile, and install the Linux kernel.
|
||||
|
||||
A kernel is the core of an operating system. The operating system is all of the programs that manages the hardware and allows users to run applications on a computer. The kernel controls the hardware and applications. Applications do not communicate with the hardware directly, instead they go to the kernel. In summary, software runs on the kernel and the kernel operates the hardware. Without a kernel, a computer is a useless object.
|
||||
|
||||
There are many reasons for a user to want to make their own kernel. Many users may want to make a kernel that only contains the code needed to run on their system. For instance, my kernel contains drivers for FireWire devices, but my computer lacks these ports. When the system boots up, time and RAM space is wasted on drivers for devices that my system does not have installed. If I wanted to streamline my kernel, I could make my own kernel that does not have FireWire drivers. As for another reason, a user may own a device with a special piece of hardware, but the kernel that came with their latest version of Ubuntu lacks the needed driver. This user could download the latest kernel (which is a few versions ahead of Ubuntu's Linux kernels) and make their own kernel that has the needed driver. However, these are two of the most common reasons for users wanting to make their own Linux kernels.
|
||||
|
||||
Before we download a kernel, we should discuss some important definitions and facts. The Linux kernel is a monolithic kernel. This means that the whole operating system is on the RAM reserved as kernel space. To clarify, the kernel is put on the RAM. The space used by the kernel is reserved for the kernel. Only the kernel may use the reserved kernel space. The kernel owns that space on the RAM until the system is shutdown. In contrast to kernel space, there is user space. User space is the space on the RAM that the user's programs own. Applications like web browsers, video games, word processors, media players, the wallpaper, themes, etc. are all on the user space of the RAM. When an application is closed, any program may use the newly freed space. With kernel space, once the RAM space is taken, nothing else can have that space.
|
||||
|
||||
The Linux kernel is also a preemptive multitasking kernel. This means that the kernel will pause some tasks to ensure that every application gets a chance to use the CPU. For instance, if an application is running but is waiting for some data, the kernel will put that application on hold and allow another program to use the newly freed CPU resources until the data arrives. Otherwise, the system would be wasting resources for tasks that are waiting for data or another program to execute. The kernel will force programs to wait for the CPU or stop using the CPU. Applications cannot unpause or use the CPU without the kernel allowing them to do so.
|
||||
|
||||
The Linux kernel makes devices appear as files in the folder /dev. USB ports, for instance, are located in /dev/bus/usb. The hard-drive partitions are seen in /dev/disk/by-label. It is because of this feature that many people say "On Linux, everything is a file.". If a user wanted to access data on their memory card, for example, they cannot access the data through these device files.
|
||||
|
||||
The Linux kernel is portable. Portability is one of the best features that makes Linux popular. Portability is the ability for the kernel to work on a wide variety of processors and systems. Some of the processor types that the kernel supports include Alpha, AMD, ARM, C6X, Intel, x86, Microblaze, MIPS, PowerPC, SPARC, UltraSPARC, etc. This is not a complete list.
|
||||
|
||||
In the boot folder (/boot), users will see a "vmlinux" or a "vmlinuz" file. Both are compiled Linux kernels. The one that ends in a "z" is compressed. The "vm" stands for virtual memory. On systems with SPARC processors, users will see a zImage file instead. A small number of users may find a bzImage file; this is also a compressed Linux kernel. No matter which one a user owns, they are all bootable files that should not be changed unless the user knows what they are doing. Otherwise, their system can be made unbootable - the system will not turn on.
|
||||
|
||||
Source code is the coding of the program. With source code, programmers can make changes to the kernel and see how the kernel works.
|
||||
|
||||
### Downloading the Kernel: ###
|
||||
|
||||
Now, that we understand more about the kernel, it is time to download the source code. Go to [kernel.org][1] and click the large download button. Once the download is finished, uncompress the downloaded file.
|
||||
|
||||
For this article, I am using the source code for Linux kernel 3.9.4. All of the instructions in this article series are the same (or nearly the same) for all versions of the kernel.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.org/threads/%EF%BB%BFthe-linux-kernel-introduction.4203/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.kernel.org/
|
||||
@ -1,134 +0,0 @@
|
||||
02 The Linux Kernel: The Source Code
|
||||
================================================================================
|
||||
After the kernel source code is downloaded and uncompressed, users will see many folders and files. It may be a challenge trying to find a particular file. Thankfully, the source code is sorted in a specific way. This enables developers to find any given file or part of the kernel.
|
||||
|
||||
The root of the kernel source code contains the folders listed below.
|
||||
|
||||
arch
|
||||
block
|
||||
crypto
|
||||
Documentation
|
||||
drivers
|
||||
firmware
|
||||
fs
|
||||
include
|
||||
init
|
||||
ipc
|
||||
kernel
|
||||
lib
|
||||
mm
|
||||
net
|
||||
samples
|
||||
scripts
|
||||
security
|
||||
sound
|
||||
tools
|
||||
usr
|
||||
virt
|
||||
|
||||
There are also some files that are located in the root of the source code. They are listed in the table below.
|
||||
|
||||
**COPYING** - Information about licensing and rights. The Linux kernel is licensed under the GPLv2 license. This license grants anyone the right to use, modify, distribute, and share the source code and compiled code for free. However, no one can sell the source code.
|
||||
|
||||
**CREDITS** - List of contributors
|
||||
|
||||
**Kbuild** - This is a script that sets up some settings for making the kernel. For example, this script sets up a ARCH variable where ARCH is the processor type that a developer wants the kernel to support.
|
||||
|
||||
**Kconfig** - This script is used when developer configure the kernel which will be discussed in a later article.
|
||||
|
||||
**MAINTAINERS** - This is a list of the current maintainers, their email addresses, website, and the specific file or part of the kernel that they specialize in developing and fixing. This is useful for when a developer finds a bug in the kernel and they wish to report the bug to the maintainer that can handle the issue.
|
||||
|
||||
**Makefile** - This script is the main file that is used to compile the kernel. This file passes parameters to the compiler as well as the list of files to compile and any other necessary information.
|
||||
|
||||
**README** - This text file provides information to developers that want to know how to compile the kernel.
|
||||
|
||||
**REPORTING-BUGS** - This text document provides information on reporting bugs.
|
||||
|
||||
The coding for the kernel will be in files with the extension ".c", or ".h". The “.c” extension indicates that the kernel is written in C, one of many programming languages. The “.h” files are Header files, and they are also written in C. The header files contain code that many of the “.c” files use. This saves programmers' time because they can use the contained code instead of writing new code. Otherwise, a group of code that performs the same action would be in many or all of the “.c” files. That would also consume and waste hard drive space.
|
||||
|
||||
All of the files in the above listed folders are well organized. The folder names help developers to at least have a good guess on the contents of the folders. A directory tree and descriptions are provided below.
|
||||
|
||||
**arch** - This folder contains a Kconfig which sets up some settings for compiling the source code that belongs in this folder. Each supported processor architecture is in the corresponding folder. So, the source code for Alpha processors belong in the alpha folder. Keep in mind that as time goes on, some new processors will be supported, or some may be dropped. For Linux Kernel v3.9.4, these are the folders under arch:
|
||||
|
||||
alpha
|
||||
arc
|
||||
arm
|
||||
arm64
|
||||
avr32
|
||||
blackfin
|
||||
c6x
|
||||
cris
|
||||
frv
|
||||
h8300
|
||||
hexagon
|
||||
ia64
|
||||
m32r
|
||||
m68k
|
||||
metag
|
||||
microblaze
|
||||
mips
|
||||
mn10300
|
||||
openrisc
|
||||
parisc
|
||||
powerpc
|
||||
s390
|
||||
score
|
||||
sh
|
||||
sparc
|
||||
tile
|
||||
um
|
||||
unicore32
|
||||
x86
|
||||
xtensa
|
||||
|
||||
**block** – This folder holds code for block-device drivers. Block devices are devices that accept and send data in blocks. Data blocks are chunks of data instead of a continual stream.
|
||||
|
||||
**crypto** - This folder contains the source code for many encryption algorithms. For example, “sha1_generic.c” is the file that contains the code for the sha1 encryption algorithm.
|
||||
|
||||
**Documentation** - This folder contains plain-text documents that provide information on the kernel and many of the files. If a developer needs information, they may be able to find the needed information in here.
|
||||
|
||||
**drivers** - This directory contains the code for the drivers. A driver is software that controls a piece of hardware. For example, for a computer to understand the keyboard and make it usable, a keyboard driver is needed. Many folders exist in this folder. Each folder is named after each piece or type of hardware. For example, the bluetooth folder holds the code for bluetooth drivers. Other obvious drivers are scsi, usb, and firewire. Some drivers may be more difficult to find. For instance, joystick drivers are not in a joystick folder. Instead, they are under ./drivers/input/joystick. Keyboard and mouse drivers are also located in the input folder. The Macintosh folder contains code for hardware made by Apple. The xen folder contains code for the Xen hypervisor. A hypervisor is software or hardware that allows users to run multiple operating systems on a single computer. This means that the xen code would allow users to have two or more Linux system running on one computer at the same time. Users could also run Windows, Solaris, FreeBSD, or some other operating system on the Linux system. There are many other folders under drivers, but they are too numerous to mention in this article, but they will in a later article.
|
||||
|
||||
**firmware** - The firmware folder contains code that allows the computer to read and understand signals from devices. For illustration, a webcam manages its own hardware, but the computer must understand the signals that the webcam is sending the computer. The Linux system will then use the vicam firmware to understand the webcam. Otherwise, without firmware, the Linux system does not know how to process the information that the webcam is sending. Also, the firmware helps the Linux system to send messages to the device. The Linux system could then tell the webcam to refocus or turnoff.
|
||||
|
||||
**fs** - This is the FileSystem folder. All of the code needed to understand and use filesystems is here. Inside this folder, each filesystem's code is in its own folder. For instance, the ext4 filesystem's code is in the ext4 folder. Within the fs folder, developers will see some files not in folders. These files handle filesystems overall. For example, mount.h would contain code for mounting filesystems. A filesystem is a structured way to store and manage files and directories on a storage device. Each filesystem has its own advantages and disadvantages. These are due to the programming of the filesystem. For illustration, the NTFS filesystem supports transparent compression (when enabled, files are automatically compressed without the user noticing). Most filesystems lack this feature, but they could only possess this ability if it is programmed into the files in the fs folder.
|
||||
|
||||
**include** - The include folder contains miscellaneous header files that the kernel uses. The name for the folder comes from the C command "include" that is used to import a header into C code upon compilation.
|
||||
|
||||
**init** - The init folder has code that deals with the startup of the kernel (INITiation). The main.c file is the core of the kernel. This is the main source code file the connects all of the other files.
|
||||
|
||||
**ipc** - IPC stands for Inter-Process Communication. This folder has the code that handles the communication layer between the kernel and processes. The kernel controls the hardware and programs can only ask the kernel to perform a task. Assume a user has a program that opens the DVD tray. The program does not open the tray directly. Instead, the program informs the kernel that the tray should be opened. Then, the kernel opens the tray by sending a signal to the hardware. This code also manages the kill signals. For illustration, when a system administrator opens a process manager to close a program that has locked-up, the signal to close the program is called a kill signal. The kernel receives the signal and then the kernel (depending on which type of kill signal) will ask the program to stop or the kernel will simply take the process out of the memory and CPU. Pipes used in the command-line are also used by the IPC. The pipes tell the kernel to place the output data on a physical page on in memory. The program or command receiving the data is given a pointer to the page on memory.
|
||||
|
||||
**kernel** - The code in this folder controls the kernel itself. For instance, if a debugger needed to trace an issue, the kernel would use code that originated from source files in this folder to inform the debugger of all of the actions that the kernel performs. There is also code here for keeping track of time. In the kernel folder is a directory titled "power". Some code in this folder provide the abilities for the computer to restart, power-off, and suspend.
|
||||
|
||||
**lib** - the library folder has the code for the kernel's library which is a set of files that that the kernel will need to reference.
|
||||
|
||||
**mm** - The Memory Management folder contains the code for managing the memory. Memory is not randomly placed on the RAM. Instead, the kernel places the data on the RAM carefully. The kernel does not overwrite any memory that is being used or that holds important data.
|
||||
|
||||
**net** - The network folder contains the code for network protocols. This includes code for IPv6 and Appletalk as well as protocols for Ethernet, wifi, bluetooth, etc. Also, the code for handling network bridges and DNS name resolution is in the net directory.
|
||||
|
||||
**samples** - This folder contains programming examples and modules that are being started. Assume a new module with a helpful feature is wanted, but no programmer has announced that they would work on the project. Well, these modules go here. This gives new kernel programmers a chance to help by going through this folder and picking a module they would like to help develop.
|
||||
|
||||
**scripts** - This folder has the scripts needed for compiling the kernel. It is best to not change anything in this folder. Otherwise, you may not be able to configure or make a kernel.
|
||||
|
||||
**security** - This folder has the code for the security of the kernel. It is important to protect the kernel from computer viruses and hackers. Otherwise, the Linux system can be damaged. Kernel security will be discussed in a later article.
|
||||
|
||||
**sound** - This directory has sound driver code for sound/audio cards.
|
||||
|
||||
**tools** - This directory contains tools that interact with the kernel.
|
||||
|
||||
**usr** - Remember the vmlinuz file and similar files mentioned in the previous article? The code in this folder creates those files after the kernel is compiled.
|
||||
|
||||
**virt** - This folder contains code for virtualization which allows users to run multiple operating systems at once. This is different from Xen (mentioned previously). With virtualization, the guest operating system is acting like any other application within the Linux operating system (host system). With a hypervisor like Xen, the two operating systems are managing the hardware together and the same time. In virtualization, the guest OS runs on top of the Linux kernel while in a hypervisor, there is no guest OS and all of the operating systems do not depend on each other.
|
||||
|
||||
Tip: Never move a file in the kernel source unless you know what you are doing. Otherwise, the compilation with fail due to a "missing" file.
|
||||
|
||||
The Linux kernel folder structure has remained relatively constant. The kernel developers have made some modifications, but overall, this setup is the same throughout all kernel versions. The driver folder's layout also remains about the same.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.org/threads/the-linux-kernel-the-source-code.4204/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
4
sources/The Linux Kernel/03 The Linux Kernel--Drivers.md
Normal file → Executable file
4
sources/The Linux Kernel/03 The Linux Kernel--Drivers.md
Normal file → Executable file
@ -1,3 +1,5 @@
|
||||
translating-------------------geekpi
|
||||
|
||||
03 The Linux Kernel: Drivers
|
||||
================================================================================
|
||||
Drivers are small programs that enable the kernel to communicate and handle hardware or protocols (rules and standards). Without a driver, the kernel does not know how to communicate with the hardware or handle protocols (the kernel actually hands the commands to the BIOS and the BIOS passes them on the the hardware). The Linux Kernel source code contains many drivers (in the form of source code) in the drivers folder. Each folder within the drivers folder will be explained. When configuring and compiling the kernel, it helps to understand the drivers. Otherwise, a user may add drivers to the kernel that they do not need or leave out important drivers. The driver source code usually includes a commented line that states the purpose of the driver. For example, the source code for the tc driver has a single commented line that says the driver is for TURBOchannel buses. Because of the documentation, users should be able to look at the first few commented lines of future drivers to learn their purpose.
|
||||
@ -232,4 +234,4 @@ via: http://www.linux.org/threads/the-linux-kernel-drivers.4205/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
68
translated/00 About the author.md
Normal file
68
translated/00 About the author.md
Normal file
@ -0,0 +1,68 @@
|
||||
00 关于作者
|
||||
================================================================================
|
||||
[][1]
|
||||
|
||||
随时可以给我写信或者发邮件(DevynCJohnson@Gmail.com)提出对本系列的建议,无论是本系列后续的文章还是如何使这个系列更好和有趣
|
||||
|
||||
我每周为Linux.org写两篇文章。一篇是Linux内核系列而另一篇是任何随机的Linux话题。随时可以发邮件建议你想看到的“随机文章”。我乐意在站上写一些能够吸引大量读者的东西。我的目标是每周写一篇拥有1万以上读者的文章。
|
||||
|
||||
很快我会写一些关于如何安装流行Linux发行版的文章,因此,如果你想要阅读某个特定发行版文章,请给我发邮件。
|
||||
|
||||
看看我的壁纸: [http://gnome-look.org/usermanager/search.php?username=DevynCJohnson&action=contents&PHPSESSID=32424677ef4d9dffed020d06ef2522ac][2]
|
||||
|
||||
我的人工智能项目:
|
||||
|
||||
- [https://launchpad.net/neobot][3]
|
||||
|
||||
Ubuntu 13.10 (AMD64)
|
||||
|
||||
- [https://launchpad.net/~devyncjohnson-d][4]
|
||||
- [DevynCJohnson@Gmail.com][5]
|
||||
|
||||
|
||||
|
||||
**性别**:性别:男
|
||||
|
||||
**生日**:Aug 31, 1994 (Age: 19)
|
||||
|
||||
**主页**:https://launchpad.net/~devyncjohnson-d
|
||||
|
||||
**位置**:United States
|
||||
|
||||
戴文.科利尔.约翰逊(Devyn Collier Johnson)在家接受他伟大的父母教育并已从一所大学毕业,现在已加入了另外一所大学。他的父亲,杰瑞特.韦恩.布斯(Jarret Wayne Buse)拥有很多的计算机证书,并且他已经撰写并出版了许多关于计算机的书籍。他也做一些编程,并给了戴文的人工智能程序提供过一些帮助和点子。他的妈妈,卡桑德拉.安.约翰逊(Cassandra Ann Johnson),是一名家庭主妇,在家教育了许多他的许多兄弟姐妹。戴文.科利尔.约翰逊和他的父母住在印第安纳并把他的时间集中在大学和个人的电脑编程上。
|
||||
|
||||
戴文.科利尔.约翰逊十六岁毕业于一所高中。他作为一名走读生进入大学并一直保持在优秀学生名单上。他的专业是电气技术工程。戴文.科利尔.约翰逊已经学习了很多计算机语言。一些是他自学的而有的则是他父亲教导并且帮助他理解的。一些他了解的语言包括Xaiml、AIML、Unix Shell、Python3、VPython、PyQT、PyGTK、Coffeescript、GEL、SED、HTML4/5、CSS3、SVG和XML。戴文另外还了解一点其他的语言。他在2012年4月获取了4项计算机证书他们是NCLA、Linux+、LPIC-1、和DCTS。 他的Linux专业ID是LPI000254694。
|
||||
|
||||
在2012年7月,戴文.科利尔.约翰逊决定从头开始做他的聊天机器人。他设计了自己的标记语言(Xaiml)和AI引擎(ProgramPY-SH 或者 Pysh)。在2013年3月,戴文在Launchpad.net上发布了他的机器人。这个机器人名为Neo,取自原始印欧语中单词的“new”
|
||||
|
||||
戴文还维护了其他几个项目。他制作Opera和Firebox的主题 ([https://addons.mozilla.org/en-US/firefox/user/DevynCJohnson/][6]) ([https://my.opera.com/devyncjohnson/account/][7]); 他还有许多其他的图形设计项目。他的大多数编程项目托管在 [https://launchpad.net/~devyncjohnson-d][4], 另外在Sourceforge.net上也有镜像,其他的一些杂项可以通过下面的链接找到。
|
||||
|
||||
- [http://askubuntu.com/users/158340/devyn-collier-johnson][8]
|
||||
- [http://unix.stackexchange.com/users/40770/devyn-collier-johnson][9]
|
||||
- [http://stackoverflow.com/users/2354783/devyn-collier-johnson][10]
|
||||
- [http://www.linux.org/members/devyncjohnson.4843/][1]
|
||||
- [http://gnome-look.org/usermanager/search.php?username=DevynCJohnson][11]
|
||||
- [http://www.creatity.com/?user=1449&action=detailUser][12]
|
||||
- [http://openclipart.org/user-detail/DevynCJohnson][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.org/members/devyncjohnson.4843/
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.linux.org/members/devyncjohnson.4843/
|
||||
[2]:http://gnome-look.org/usermanager/search.php?username=DevynCJohnson&action=contents&PHPSESSID=32424677ef4d9dffed020d06ef2522ac
|
||||
[3]:https://launchpad.net/neobot
|
||||
[4]:https://launchpad.net/~devyncjohnson-d
|
||||
[5]:DevynCJohnson@Gmail.com
|
||||
[6]:https://addons.mozilla.org/en-US/firefox/user/DevynCJohnson/
|
||||
[7]:https://my.opera.com/devyncjohnson/account/
|
||||
[8]:http://askubuntu.com/users/158340/devyn-collier-johnson
|
||||
[9]:http://unix.stackexchange.com/users/40770/devyn-collier-johnson
|
||||
[10]:http://stackoverflow.com/users/2354783/devyn-collier-johnson
|
||||
[11]:http://gnome-look.org/usermanager/search.php?username=DevynCJohnson
|
||||
[12]:http://www.creatity.com/?user=1449&action=detailUser
|
||||
[13]:http://openclipart.org/user-detail/DevynCJohnson
|
||||
36
translated/01 The Linux Kernel--Introduction.md
Normal file
36
translated/01 The Linux Kernel--Introduction.md
Normal file
@ -0,0 +1,36 @@
|
||||
01 Linux 内核: 介绍
|
||||
================================================================================
|
||||
在1991年,一个叫林纳斯·本纳第克特·托瓦兹的芬兰学生制作了一个现在非常流行的操作系统内核。他于1991年9月发布了Linux 0.01并且于1992年以GPL许可证的方式授权了该内核。GNU通用许可证(GPL)允许人们使用、拥有、修改以及合法和免费的分发源代码。这使得内核变得非常流行因为任何人都可以免费地下载。现在任何人都可以制作他们自己的内核,这对于了解如何获取、编辑、配置、编译并且安装Linux内核或许是有帮助的。
|
||||
|
||||
内核是操作系统的核心。操作系统是一系列管理硬件和允许用户在一台电脑上运行应用的程序。内核控制着硬件和应用。应用并不直接和硬件打交道,而是先进入内核。总之,软件运行在内核上而内核操作着硬件。没有内核,电脑就是一个没用的物件。
|
||||
|
||||
有很多理由用户想制作他们自己的内核。许多用户也许想要一个只包含需要的代码来运行他们的系统的内核。比如说我的内核包含了火线设备驱动,但是我的电脑缺乏这些端口。当系统启动的时,时间和内存就会浪费在那些我系统上并没有安装的设备上。如果我想要简化我的内核,我会制作自己不包含火线驱动的内核。至于另外一个理由,某个用户可能拥有一台有特殊硬件的设备,但是最新的Ubuntu版本中的内核缺乏所需的驱动。这个用户可以下载最新的内核(比当前Ununtud的Linux内核更新几个版本)并制作他们自己的有相应驱动的内核。不管怎样,这两个是用户想要制作自己的Linux内核的普遍原因。
|
||||
|
||||
在下载内核前,我们应该讨论一些重要的术语和事实。Linux内核是一个宏内核,这意味着整个操作系统是作为内核空间保留在内存上。说的更新出一些,内核是放在内存上。内核使用的空间是预留给内核的。只有内核可以使用预留的内核空间。内核拥有这些内存上的空间直到系统关闭。与内核空间相对应的还是用户空间。用户空间是内存上用户程序拥有的空间。比如浏览器、电子游戏、文字处理器、媒体播放器、壁纸、主题等都是内存上的用户空间。当一个程序关闭的时候,任何程序都可能使用新释放的空间。在内核空间,一旦内存被占用,没有任何其他程序可以使用这块空间。
|
||||
|
||||
Linux内核也是一个抢占式多任务内核。这意味这内核可以暂停一些任务来保证任何应用有机会来使用CPU。举个例子,如果一个应用正在运行但是正在等待一些数据,内核会把这个应用暂停并允许其他的程序使用新释放的CPU资源知道数据到来。否则,系统将会浪费资源给那些正在等待数据或者其他程序执行的的任务。内核将会强制程序去等待或者停止使用CPU。没有内核的允许,应用程序不能不暂停或者使用CPU。
|
||||
|
||||
Linux内核使得设备作为文件显示在/dev文件夹下。举个例子,USB端口位于/dev/bus/usb。硬盘分区则位于/dev/disk/by-label。这是这个特性许多人说:“在Linux上,一切皆文件”。举个例子,如果一个用户想要访问在存储卡上的数据,他们不能通过设备文件访问这些数据。
|
||||
|
||||
Linux内核是可移植的。可移植性是使Linux流行其中一个最好的特性。可移植性使得内核可以工作在广泛的处理器和系统上。一些内核支持的处理器的型号包括:Alpha、AMD、ARM、C6X、Intel、x86、Microblaze、MIPS、PowerPC、SPARC、UltraSPARC等等。这还不是全部的列表。
|
||||
|
||||
在引导文件夹(/boot),用户会看到诸如“vmlinux”或者“vmlinuz”的文件。这两者都是已编译的Linux内核。以“z”结尾的是已压缩的。“vm”代表虚拟内存。在SPARC处理器的系统上,用户可以看见一个zImage文件。一小部分用户可以发现一个bzImage文件,这也是一个已压缩的Linux内核。无论用户有哪个文件,他们都是不可以被更改除非用户知道他们正在做什么的引导文件。否则系统会变成无法引导---系统无法开启。
|
||||
|
||||
源代码是程序的编码。有了源代码,程序员可以修改内核并能看到内核是如何工作的。
|
||||
|
||||
### 下载内核: ###
|
||||
|
||||
现在我们更多地了解了内核,是时候下载内核源代码了。进入kernel.org并点击那个巨大的下载按钮。一旦下载完成,解压下载的文件。
|
||||
|
||||
对于本文,我使用的源代码是Linux kernel 3.9.4.这个文章系列的所有指导对于所有的内核版本是相同的(或者非常相似的)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.org/threads/%EF%BB%BFthe-linux-kernel-introduction.4203/
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.kernel.org/
|
||||
|
||||
136
translated/02 The Linux Kernel--The Source Code.md
Executable file
136
translated/02 The Linux Kernel--The Source Code.md
Executable file
@ -0,0 +1,136 @@
|
||||
02 Linux 内核: 源代码
|
||||
================================================================================
|
||||
在下载并解压内核源代码后,用户可以看到许多文件夹和文件。尝试去找一个特定的文件或许是一个挑战。谢天谢地,源代码以一个特定的方式排序。这使开发者能够轻松找到任何文件或者内核的一部分
|
||||
|
||||
内核源代码的根目录下包含了以下文件夹
|
||||
|
||||
arch
|
||||
block
|
||||
crypto
|
||||
Documentation
|
||||
drivers
|
||||
firmware
|
||||
fs
|
||||
include
|
||||
init
|
||||
ipc
|
||||
kernel
|
||||
lib
|
||||
mm
|
||||
net
|
||||
samples
|
||||
scripts
|
||||
security
|
||||
sound
|
||||
tools
|
||||
usr
|
||||
virt
|
||||
|
||||
这里另外还有一些文件在源代码的根目录下。它们在下表中列出。
|
||||
|
||||
**COPYING** -许可和授权信息。Linux内核在GPLv2许可证下授权。该许可证授予任何人有权免费去使用、修改、分发和共享源代码和编译代码。然而,没有人可以出售源代码。
|
||||
|
||||
**CREDITS** - 贡献者列表
|
||||
|
||||
**Kbuild** - 这是一个设置一些内核设定的脚本。打个比方,这个脚本设定一个ARCH变量,ARCH是处理器的类型,这是一个开发者想要内核支持的类型。
|
||||
|
||||
**Kconfig** - 这个脚本会在开发人员配置内核的时候用到,这会在以后的文章中讨论。
|
||||
|
||||
**MAINTAINERS** - 这是一个目前维护者列表,他们的电子邮件地址,主页,和特定的文件或者他们正在从事的开发和修复的内核的一部分。这对当一个开发者在内核中发现一个问题并希望能够报告这个问题给能够处理这个问题的维护者时是很有用的。
|
||||
|
||||
**Makefile** - This script is the main file that is used to compile the kernel. This file passes parameters to the compiler as well as the list of files to compile and any other necessary information.
|
||||
这个脚本是编译内核主文件。这个文件将编译参数和编译所需的文件和必要的信息传给编译器
|
||||
|
||||
**README** - 这个文档提供给开发者想要知道的如何编译内核的信息。
|
||||
|
||||
**REPORTING-BUGS** - 这个文档提供如何报告问题的信息。
|
||||
|
||||
为内核的代码是以“.c”或“.h”为扩展名的文件。 “.c”的扩展名表明内核是用众多的编程语言之一C写的, “h”的文件是头文件,而他们也是用C写成。头文件包含了许多“.c”文件需要使用的代码。,因为他们可以使用已经存在的代码而不是编写新的代码,这节省了程序员的时间。否则,一组执行相同的动作的代码,将存在许多或全部都是“c”文件。这也会消耗和浪费硬盘空间。
|
||||
|
||||
所有上面列出的文件夹中的文件都有良好的组织。文件夹名称至少可以帮助开发人员很好地猜测文件夹中的内容。下面提供了一个目录树和描述。
|
||||
|
||||
**arch** - This folder contains a Kconfig which sets up some settings for compiling the source code that belongs in this folder. Each supported processor architecture is in the corresponding folder. So, the source code for Alpha processors belong in the alpha folder. Keep in mind that as time goes on, some new processors will be supported, or some may be dropped. For Linux Kernel v3.9.4, these are the folders under arch:
|
||||
此文件夹包含了编译代码所需的一系列设定的Kconfig文件。每个支持的处理器架构都在它相应的文件夹中。所以,Alpha处理器的源代码在alpha文件夹中。请记住,随着时间的推移,一些新的处理器将被支持,有些会被放弃。对于Linux v3.9.4,arch下有以下文件夹:
|
||||
alpha
|
||||
arc
|
||||
arm
|
||||
arm64
|
||||
avr32
|
||||
blackfin
|
||||
c6x
|
||||
cris
|
||||
frv
|
||||
h8300
|
||||
hexagon
|
||||
ia64
|
||||
m32r
|
||||
m68k
|
||||
metag
|
||||
microblaze
|
||||
mips
|
||||
mn10300
|
||||
openrisc
|
||||
parisc
|
||||
powerpc
|
||||
s390
|
||||
score
|
||||
sh
|
||||
sparc
|
||||
tile
|
||||
um
|
||||
unicore32
|
||||
x86
|
||||
xtensa
|
||||
|
||||
**block** – 此文件夹包含块设备驱动程序的代码。块设备是以块接收和发送的数据的设备。数据块都是大块的数据而不是持续的数据流。
|
||||
|
||||
**crypto** - 这个文件夹包含许多加密算法的源代码。例如,“sha1_generic.c”这个文件包含了SHA1加密算法的代码。
|
||||
|
||||
**Documentation** - 此文件夹包含了内核信息和其他许多文件信息的纯文本文档。如果开发者需要一些信息,他们可以在这里找到所需要的信息。
|
||||
|
||||
**drivers** - 该目录包含了驱动代码。驱动是一块控制硬件的软件。例如,要让计算机知道键盘并使其可用,键盘驱动器是必要的。这个文件夹中存在许多文件夹。每个文件夹都以硬件的种类或者型号命名。例如,'bluetooth'包含了蓝牙驱动程序的代码。还有其他明显驱动器像SCSI,USB和火线。有些驱动程序可能会比较难找到。例如,操纵杆驱动不在'joystick'文件夹中。相反,它们在./drivers/input/joystick。同样键盘和鼠标驱动也在这个文件夹中。 'Macintosh'包含了苹果的硬件代码。 'Xen'包含了Xen hypervisor代码。hypervisor是一种允许用户在一台计算机上运行多个操作系统的软件或硬件。这意味着在Xen允许用户在一台计算机上同时运行的两个或两个以上的Linux系统。用户还可以运行Windows,Solaris,FreeBSD或其他操作系统在Linux系统上。driver文件夹下还有许多其他的文件夹,但他们在这篇文章中无法一一列举,他们将在以后的文章中提到。
|
||||
|
||||
**firmware** - fireware中包含了让计算机读取和理解从设备发来的信号的代码。举例来说,一个摄像头管理它自己的硬件,但计算机必须了解摄像头给计算机发送的信号。Linux系统会使用vicam固件了解摄像头。否则,没有了固件,Linux系统将不知道如何处理摄像头发来的信息。另外,固件同样有助于将Linux系统发送消息给该设备。这样Linux系统可以告诉摄像头重新调整或关闭摄像头。
|
||||
|
||||
**fs** - 这是文件系统的文件夹。理解和使用的文件系统所需要的所有的代码就在这里。在这个文件夹里,每种文件系统都有自己的文件夹。例如,ext4文件系统的代码在ext4文件夹内。 在fs文件夹内,开发者会看到一些不在文件夹中的文件。这些文件用来处理文件系统整体。例如,mount.h中会包含挂载文件系统的代码。文件系统是以结构化的方式来存储和管理的存储设备上的文件和目录。每个文件系统都有自己的优点和缺点。这是由文件系统的编写决定的。举例来说,NTFS文件系统支持的透明压缩(当启用时,会在用户没注意的情况下自动压缩文件)。大多数文件系统缺乏此功能,但如果在fs文件夹里编入相应的文件,它们也有这种能力。
|
||||
|
||||
**include** - include包含了内核所需的各种头文件.这个名字来自于C语言用"incluide"来在编译时导入头文件.
|
||||
|
||||
**init** - init文件夹包含了内核启动处理代码(INITiation).main.c是内核的核心文件.这是用来链接其他文件的主要源代码文件.
|
||||
|
||||
**ipc** - IPC代表进程间通讯。此文件夹中的代码是作为内核与进程之间的通信层。内核控制着硬件因此程序只能请求内核来执行任务。假设用户有一个打开DVD托盘的程序。程序不直接打开托盘。相反,该程序通知内核托盘应该被打开。然后,内核给硬件发送一个信号去打开托盘。这些代码同样管理kill信号。举例来说,当系统管理员打开进程管理器去关闭一个已经锁死的程序,这个关闭程序的信号被称为kill信号。内核接收到信号,然后会要求程序停止(取决于kill的类型)或内核直接把进程从内存和CPU中移除。命令行中的管道同样用于进程间通信 。管道会告诉内核在某个内存页上写入输出数据。程序或者命令得到的数据是来自内存页上的某个给定指针.
|
||||
|
||||
**kernel** - 这个文件夹中的代码控制内核本身。例如,如果一个调试器需要跟踪问题,内核将使用这个文件夹中代码来将内核指令通知调试器。这里还有踪时间的代码。内核文件夹下有个"power"文件夹 。这个文件夹中的代码可以使计算机重新启动,关机,挂起。
|
||||
|
||||
**lib** - 这个文件夹包含了内核需要引用的一系列内核库文件代码
|
||||
|
||||
**mm** - mm文件夹中包含了内存管理代码。内存并不是随机放置在RAM上 。相反,内核小心地将数据放在RAM上。内核不会覆盖任何正在使用或保存重要数据的内存区域。
|
||||
|
||||
**net** - net文件夹中包含了网络协议代码。这包括IPv6,AppleTalk,以太网, WiFi,蓝牙等的代码,此外,处理网桥和DNS解析的代码也在net目录。
|
||||
|
||||
**samples** -此文件夹包含了程序示例和正在编写中的模块代码。假设一个新的模块引入了一个希望的功能,但没有程序员声明可以正常运行在内核上。那么,这些模块就会移到这里。这给了新内核程序员一个机会通过这个文件夹获得帮助并选择一个他们想要帮助开发的模块。
|
||||
|
||||
**scripts** -这个文件夹有内核编译所需的脚本。最好不要改变这个文件夹内的任何东西。否则,您可能无法配置或编译内核。
|
||||
|
||||
|
||||
**security** - 这个文件夹是有关内核安全的代码。它对计算机免于受到病毒和黑客的侵害很重要。否则,Linux系统可能会遭到损坏。关于内核的安全性,将在以后的文章中讨论。
|
||||
|
||||
**sound** - 这个文件夹中包含了声卡驱动。
|
||||
|
||||
**tools** - 这个文件夹中包含了和内核交互的文件。
|
||||
|
||||
**usr** - 还记得在以前的文章中提到vmlinuz和其他类似的文件么?这个文件夹中的代码在内核编译完成后创建这些文件。
|
||||
|
||||
**virt** -此文件夹包含了虚拟化代码,它允许用户一次运行多个操作系统。 这与先前提到的Xen是不同的。通过虚拟化,客户机操作系统就像任何其他运行在Linux主机的应用程序一样运行。通过hypervisor(注:虚拟机管理程序)如Xen,这两个操作系统同时管理硬件。在虚拟化中,在客户机操作系统上运行在Linux内核上,而在hypervisor中,它没有客户系统并且所有的系统不互相依赖。
|
||||
|
||||
提示: 决不在内核源代码内动文件,除非你知道你在做什么。否则,编译会由于缺失文件失败。
|
||||
|
||||
Linux内核的文件夹结构保持相对稳定。内核开发者已经做了一些修改,但总体来说,这种设置对整个内核版本相同。驱动程序文件夹的布局也保持基本相同。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.org/threads/the-linux-kernel-the-source-code.4204/
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,36 @@
|
||||
Ubuntu每日贴士 – 深入理解应用菜单和按钮
|
||||
================================================================================
|
||||
Ubuntu是一款很不错的操作系统。它基本上可以做到任何现代操作系统能做的事情,甚至有时候能做的更好。如果你是一个ubuntu新手,那么你现在还有很多不知道的事情。对于那些专家级用户来说十分普通的事情课能对你来说可能就不太普通了,因此这个“ubuntu每日贴士”系列旨在帮助你和新用户轻松设置管理ubuntu。
|
||||
|
||||
Ubuntu有一个菜单栏。主菜单栏是在屏幕的顶端黑色条状栏,其包含了状态菜单或指示器和时间日期,音量键,应用菜单和窗口管理按钮。
|
||||
|
||||
窗口管理按钮在主菜单(黑色条状栏)的左上角。当年你打开一个程序的时候,主菜单左上角的按钮包括关闭,最小化,最大化,和保存按钮叫做窗口管理按钮。
|
||||
|
||||
应用按钮位于窗口管理按钮的右侧。当它打开时显示应用菜单。
|
||||
|
||||
默认情况下,ubuntu隐藏了窗口应用菜单和管理按钮,只有当你把鼠标放在左侧角里的时候才能看到。如果你打开一个程序但是找不到菜单,只需要把你的鼠标移动到屏幕左上角就可以使它显示出来。
|
||||
|
||||
如果这让你很困惑,而且你想关闭应用菜单而使每个程序都有自己的菜单的话,继续向下看。
|
||||
|
||||
运行以下命令以安装或删除应用菜单:
|
||||
|
||||
sudo apt-get autoremove indicator-appmenu
|
||||
|
||||
运行上面的命令将会删除应用菜单即全局菜单。现在,为了使改变生效,先退出然后再登陆回来。
|
||||
|
||||
现在,当你打开一个ubuntu里面的程序的时候,每个程序就会用显示自己的菜单代替把它隐藏在全局菜单或主菜单里。
|
||||
|
||||

|
||||
|
||||
就是这样! 想返回原来的状态的话,运行下面的命令:
|
||||
|
||||
sudo apt-get install indicator-appmenu
|
||||
|
||||
使用愉快!
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.liberiangeek.net/2013/09/daily-ubuntu-tips-understanding-app-menus-buttons/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
译者:[crowner](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
@ -0,0 +1,301 @@
|
||||
在Ubuntu下用Python搭建桌面算法交易研究环境
|
||||
================================================================================
|
||||
这篇文章将讨论在ubuntu下,使用Python编程语言,来搭建一个强大,高效和易交互的算法交易策略研究环境.几乎所有的后续的算法交易文章都将利用此环境.
|
||||
|
||||
搭建此环境需要安装以下软件,它们都是开源的或免费下载的:
|
||||
|
||||
- [Oracle VirtualBox][1] - 虚拟机
|
||||
- [Ubuntu Desktop Linux][2] - 作为我们的虚拟操作系统
|
||||
- [Python][3] - 核心编程环境
|
||||
- [NumPy][4]/[SciPy][5] - 快速、高效的数组和矩阵运算
|
||||
- [IPython][6] - Python的可视化交互环境
|
||||
- [matplotlib][7] - 图形化的虚拟数据
|
||||
- [pandas][8] - 数据“冲突”和时间序列分析
|
||||
- [scikit-learn][9] - 机器学习和人工智能算法
|
||||
|
||||
这些工具(配合合适的 [证券master数据库][10]),将使我们能够创建一个快速可交互的策略研究环境。Pandas是专为数据“冲突”设计的,它可以高效地导入和清洗时间序列数据。NumPy/SciPy在底层运行,使得系统被很好的优化。IPython/matplotlib (和qtconsole,详见下文)使结果可视化可交互并快速迭代。scikit-learn可让我们将机器学习技术应用到我们的策略中,以进一步提高性能。
|
||||
|
||||
请注意,我写这篇教程是为了那些无法或不愿意直接安装ubuntu系统的windows或Mac OSX用户,通过VirtualBox来搭建此环境。VirtualBox使我们可在host操作系统中创建一个虚拟机,可模拟guest操作系统,而丝毫不影响host操作系统。由此我们可以在完整安装Ubuntu前练习Ubuntu和Python工具。如果已经安装Ubuntu桌面系统,可跳过“在Ubuntu下安装Python研究环境包”这一节。
|
||||
|
||||
##安装VirtualBoX和Ubuntu##
|
||||
|
||||
Mac OSX操作系统上关于VirtualBox安装的部分已经写过了,这里将简单的移到Windows环境中。一旦各种host操作系统下的VirtualBox安装完毕,其它过程就都一样了。
|
||||
|
||||
开始安装前,我们需要先下载Ubuntu和VirtualBox。
|
||||
|
||||
**下载Ubuntu桌面磁盘镜像**
|
||||
|
||||
打开收藏夹,导航到[Ubuntu 桌面][11]主页,然后选择Ubuntu 13.04:
|
||||
|
||||

|
||||
|
||||
*下载Ubuntu13.04(64位(如适用))*
|
||||
|
||||
你会被问及是否愿意捐赠一些money,不过这个是可选的。进入下载页面后选择Ubuntu 13.04。你需要选择是否要下载32位或64位版本。很可能你是64位系统,但如果你有疑问,那么选择32位。在Mac OSX系统上,Ubuntu桌面ISO磁盘镜像将保存到下载目录下。安装VirtualBox后我们就要用到它了。
|
||||
|
||||
|
||||
**下载和安装VirtualBox**
|
||||
|
||||
现在,我们已经下载了Ubuntu ,接下来需要去获取最新版本的Oracle的VirtualBox软件。点击[这里][12]访问该网站,选择你的特定主机的版本(本教程要求Mac OSX版本)
|
||||
|
||||

|
||||
|
||||
*Oracle VirtualBox下载页面*
|
||||
|
||||
一旦文件下载完毕,我们点击安装包图标运行(Windows上会有些不同,但是类似):
|
||||
|
||||
|
||||

|
||||
|
||||
*双击安装包图标,安装VirtualBox*
|
||||
|
||||
打开后,按照安装说明操作,保持默认(除非你觉得有必要修改他们!)。VirtualBox安装完毕后,可从Applications文件夹中打开(可通过Finder搜索到)。VirtualBox运行过程中它的图标将出现在Dock栏里,如果你以后想经常以虚拟机方式使用Ubuntu,你可以将VirtualBox图标永久保存在Dock栏中:
|
||||
|
||||
|
||||

|
||||
|
||||
*还没有磁盘镜像的VirtualBox*
|
||||
|
||||
点击类似齿轮的图标,创建一个新的虚拟盒子(也就是虚拟机),命名为"Ubuntu Desktop 13.04 Algorithmic Trading"(你可以使用别的类似的描述):
|
||||
|
||||

|
||||
|
||||
*命名我们的新虚拟环境*
|
||||
|
||||
分配虚拟机内存.因为是测试系统,所以我只分配了512Mb.一个实际的回溯引擎因为效率原因需要一个本地安装(这样才能明显分配到更多内存):
|
||||
|
||||

|
||||
|
||||
*选择虚拟磁盘的RAM量*
|
||||
|
||||
创建虚拟硬盘,大小为推荐的8Gb,动态生成VirtualBox磁盘镜像,名字同上:
|
||||
|
||||

|
||||
|
||||
*选择镜像所使用的硬盘类型*
|
||||
|
||||
You will now see a complete system with listed details:
|
||||
完整系统的详细信息如下:
|
||||
|
||||

|
||||
|
||||
*已经创建的虚拟镜像*
|
||||
|
||||
现在我们需要在VirtualBox中为新的磁盘镜像包含一个虚拟的'CD驱动器',这样就可以假装从这张光盘驱动器引导我们的Ubuntu磁盘镜像。在Settings里点击“Storage”选项卡,并添加一个磁盘。选择Downloads目录下的Ubuntu磁盘镜像ISO文件(或者其他你下载Ubuntu的目录),选择Ubuntu ISO镜像,并保存设置。
|
||||
|
||||

|
||||
|
||||
*在第一次启动时选择Ubuntu桌面ISO*
|
||||
|
||||
一切就绪,准备启动Ubuntu镜像并安装。点击“Start”,当出现主机捕获鼠标或键盘消息时点击“Ok”。在我的Mac OSX系统中,主机捕获键是左边的Cmd键(即左Apple键)。现在出现在你眼前的就是Ubuntu桌面安装界面,点击“Install Ubuntu”:
|
||||
|
||||
|
||||

|
||||
|
||||
*点击 "Install Ubuntu "开始安装*
|
||||
|
||||
确保勾选两个框,安装专有的MP3和Wi-Fi驱动程序:
|
||||
|
||||

|
||||
|
||||
*安装MP3和Wi-Fi的专用驱动程序*
|
||||
|
||||
现在,您将看到一个界面,询问你想如何保存操作系统创建过程中的的数据。不要惊慌于“Erase Disk and Install Ubuntu”的选项。这并不意味着它会删除你的普通硬盘!它实际上指的是运行Ubuntu的虚拟磁盘,这是安全擦除(反正里面没有什么内容,因为是我们刚刚创建的)。继续进行安装,将出现询问位置的界面,随后,又将出现选择键盘布局的界面:
|
||||
|
||||
|
||||

|
||||
|
||||
*选择您所在的地理位置*
|
||||
|
||||
输入您的用户凭据,请务必记住您的密码,以后安装软件包的时候需要它:
|
||||
|
||||
|
||||

|
||||
|
||||
*输入您的用户名和密码(此密码是管理员密码)*
|
||||
|
||||
现在, Ubuntu将安装文件。它应该是比较快的,因为它是从硬盘复制到硬盘!完成后VirtualBox将重启。如果不自行重启,你可以去菜单强制关机。接下来将回到Ubuntu的登录界面:
|
||||
|
||||
|
||||

|
||||
|
||||
*Ubuntu桌面登录界面*
|
||||
|
||||
用您的用户名和密码登录,你将看到闪亮的新的Ubuntu桌面:
|
||||
|
||||
|
||||

|
||||
|
||||
*Ubuntu桌面登录后的整体界面*
|
||||
|
||||
最后需要做的事是点击火狐图标,通过访问一个网站(我选择QuantStart.com,有意思吧!),来测试互联网/网络功能是正确的:
|
||||
|
||||
|
||||

|
||||
|
||||
*Ubuntu中的火狐浏览器(注:原文此处为"The Ubuntu Desktop login screen")*
|
||||
|
||||
现在Ubuntu桌面已经安装完毕,接下来,我们就可以开始安装的算法交易研究环境软件包。
|
||||
|
||||
## Installing the Python Research Environment Packages on Ubuntu ## 在Ubuntu上安装Python研究环境软件包
|
||||
|
||||
点击左上角的搜索按钮,在输入框里输入“Terminal”,弹出命令行界面。双击终端图标启动终端:
|
||||
|
||||

|
||||
|
||||
**Ubuntu中的终端界面(注:原文此处为"Ubuntu Desktop login screen")*
|
||||
|
||||
所有后续的命令都在此终端输入。
|
||||
|
||||
任何崭新的Ubuntu Linux系统上做的第一件事就是更新和升级软件包。前者告诉Ubuntu可用的新软件包有哪些,后者用新版的软件包替换旧版的。运行下列命令(你将被提示输入您的密码) :
|
||||
|
||||
|
||||
sudo apt-get -y update
|
||||
sudo apt-get -y upgrade
|
||||
|
||||
*-y前缀告诉Ubuntu接受所有回答“是/否”的问题为'是'。 “sudo”是一个Ubuntu/Debian Linux的命令,允许以管理员权限执行其他命令。由于我们将在站点范围安装软件包,我们需要机器的root权限,因此必须使用'sudo'*
|
||||
|
||||
你可能会在这里得到一个错误消息:
|
||||
|
||||
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
|
||||
|
||||
为了解决这个问题,你只需再次运行"sudo apt-get -y update"或者万一第一种方式不起作用,你可以在该站点([http://penreturns.rc.my/2012/02/could-not-get-lock-varlibaptlistslock.html][13])上查看是否有其他的命令。
|
||||
|
||||
一旦这些更新命令成功执行,接下来我们需要安装Python,NumPy/SciPy,matplotlib,pandas,scikit-learn和IPython。我们将开始安装Python开发包和编译器,编译器将在编译所有软件的时候用到:
|
||||
|
||||
sudo apt-get install python-pip python-dev python2.7-dev build-essential liblapack-dev libblas-dev
|
||||
|
||||
一旦安装必要的软件包,我们就可以通过pip,即Python包管理器,安装NumPy的。pip将下载NumPy的zip包,然后从源代码编译。请记住,编译需要花费一些时间,大概10-20分钟!
|
||||
|
||||
sudo pip install numpy
|
||||
|
||||
NumPy安装完了后,我们需要在继续之前检查它是否可用。如果你仔细看终端,你会发现计算机名后面跟了你的用户名。比如我的是`mhallsmoore@algobox`,随后是提示符。在提示符下键入`python`,然后试着导入NumPy。我们将计算一个列表的平均值,以测试NumPy是否可用:
|
||||
|
||||
mhallsmoore@algobox:~$ python
|
||||
Python 2.7.4 (default, Sep 26 2013, 03:20:26)
|
||||
[GCC 4.7.3] on linux2
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> import numpy
|
||||
>>> from numpy import mean
|
||||
>>> mean([1,2,3])
|
||||
2.0
|
||||
>>> exit()
|
||||
|
||||
现在,我们已成功安装NumPy,接下来要安装Python的科学库,即SciPy。然而,它有一些依赖的软件包,包括ATLAS库和GNU Fortran编译器:
|
||||
|
||||
sudo apt-get install libatlas-base-dev gfortran
|
||||
|
||||
现在,我们将通过pip安装SciPy.这将需要相当长的时间(约20分钟,这取决于你的电脑),所以也许你可以去喝杯咖啡先:
|
||||
|
||||
sudo pip install scipy
|
||||
|
||||
唷!现在已安装SciPy。让我们通过计算一个整数列表的标准差来测试SciPy是否可以正常使用:
|
||||
|
||||
mhallsmoore@algobox:~$ python
|
||||
Python 2.7.4 (default, Sep 26 2013, 03:20:26)
|
||||
[GCC 4.7.3] on linux2
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> import scipy
|
||||
>>> from scipy import std
|
||||
>>> std([1,2,3])
|
||||
0.81649658092772603
|
||||
>>> exit()
|
||||
|
||||
接下来我们需要安装matplotlib的依赖包,Python的图形库。 由于matplotlib是一个Python包,无法使用pip去安装以下PNG,JPEG文件和FreeType字体库相关的库,所以我们需要Ubuntu为我们安装:
|
||||
|
||||
sudo apt-get install libpng-dev libjpeg8-dev libfreetype6-dev
|
||||
|
||||
现在我们可以安装matplotlib了:
|
||||
|
||||
sudo pip install matplotlib
|
||||
|
||||
我们将安装数据分析和机器学习库,pandas和scikit-learn.这步不需要安装额外的依赖库, 因为NumPy和SciPy已经将依赖都覆盖了.
|
||||
|
||||
sudo pip install -U scikit-learn
|
||||
sudo pip install pandas
|
||||
|
||||
我需要测试scikit-learn:
|
||||
|
||||
mhallsmoore@algobox:~$ python
|
||||
Python 2.7.4 (default, Sep 26 2013, 03:20:26)
|
||||
[GCC 4.7.3] on linux2
|
||||
Type "help", "copyright", "credits" or "license" for more information.
|
||||
>>> from sklearn load datasets
|
||||
>>> iris = datasets.load_iris()
|
||||
>>> iris
|
||||
..
|
||||
..
|
||||
'petal width (cm)']}
|
||||
>>>
|
||||
|
||||
另外,我们需要测试pandas:
|
||||
|
||||
>>> from pandas import DataFrame
|
||||
>>> pd = DataFrame()
|
||||
>>> pd
|
||||
Empty DataFrame
|
||||
Columns: []
|
||||
Index: []
|
||||
>>> exit()
|
||||
|
||||
最后, 我们需要安装IPython.这是一个交互式的Python解释器,它提供了一个更精简的工作流相比标准的Python控制台。在以后的教程中,我将讲述IPython在算法交易开发中的充分的用处:
|
||||
|
||||
sudo pip install ipython
|
||||
|
||||
虽然IPython本身已经相当有用,但它通过包含qtconsole可以有更强大的能力,qtconsole提供了内联matplotlib可视化的能力。尽管如此,它需要多一点点的工作以使它启动和运行。
|
||||
|
||||
首先,我们需要安装[Qt库][14]。对于这一点,你可能需要更新你的软件包(我做了!):
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
现在我们可以安装Qt了:
|
||||
|
||||
sudo apt-get install libqt4-core libqt4-gui libqt4-dev
|
||||
|
||||
qtconsole有一些附加的包,即ZMQ和Pygments库:
|
||||
|
||||
sudo apt-get install libzmq-dev
|
||||
sudo pip install pyzmq
|
||||
sudo pip install pygments
|
||||
|
||||
最后我们准备启动带有qtconsole的IPython:
|
||||
|
||||
ipython qtconsole --pylab=inline
|
||||
|
||||
然后我们可以做一个图(非常简单的!), 键入下列命令(我已经包含了IPython编号的输入/输出,你不需要再输入):
|
||||
|
||||
In [1]: x=np.array([1,2,3])
|
||||
|
||||
In [2]: plot(x)
|
||||
Out[2]: [<matplotlib.lines.Line2D at 0x392a1d0>]
|
||||
|
||||
这将产生以下内嵌图表:
|
||||
|
||||

|
||||
|
||||
*带有qtconsole的IPython显示一幅内嵌的图表*
|
||||
|
||||
这就是它的安装过程。现在,我们手头就有一个非常强大的,高效和互动的算法交易的科研环境。我会在后续的文章中详细介绍如何结合IPython,matplotlib,pandas和scikit-learn,以一种直观的方式, 成功地研究和回溯测试量化交易策略。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
来源于: http://quantstart.com/articles/Installing-a-Desktop-Algorithmic-Trading-Research-Environment-using-Ubuntu-Linux-and-Python
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
译者:[coolpigs](https://github.com/coolpigs) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[1]:https://www.virtualbox.org/
|
||||
[2]:http://www.ubuntu.com/desktop
|
||||
[3]:http://python.org/
|
||||
[4]:http://www.numpy.org/
|
||||
[5]:http://www.scipy.org/
|
||||
[6]:http://ipython.org/
|
||||
[7]:http://matplotlib.org/
|
||||
[8]:http://pandas.pydata.org/
|
||||
[9]:http://scikit-learn.org/
|
||||
[10]:http://quantstart.com/articles/Securities-Master-Database-with-MySQL-and-Python
|
||||
[11]:http://www.ubuntu.com/desktop
|
||||
[12]:https://www.virtualbox.org/
|
||||
[13]:http://penreturns.rc.my/2012/02/could-not-get-lock-varlibaptlistslock.html
|
||||
[14]:http://qt-project.org/downloads
|
||||
@ -1,34 +0,0 @@
|
||||
Mark Shuttleworth 将出席今年香港的OpenStack最高峰会并发表主题演讲
|
||||
================================================================================
|
||||
Mark Shuttleworth将出席今年11月5日到8日在香港的OpenStack最高峰会并发表主题演讲
|
||||
|
||||
通过分析[Canonical.com][1],调查者不难发现几个改变,其中包括眼界,奋斗目标和行动准则等,都已经逐渐地规范定位为计算机世界之巅,通过所有相关的因素和计算环境,它成为了领导创新发展非常重要的部分。
|
||||
|
||||
Ubuntu,--桌面操作系统--,通电了3000万为了追求稳定、快速、安全还漂亮的个人用户、公司企业和国家部门,是一个巨大的成功,然而,这个桌面系统只是Canonical跨过层层困难到达IT世界之巅的蓬勃运动的一部分。
|
||||
|
||||
在云计算方面,Canonical已经深度并积极参与到OpenStack,作为最流行、可靠的、快速的开源云平台,Ubuntu正是OpenStack的使用操作系统,云平台云集了NASA,HP和世界上专家们,通力合作的发开开放云平台。
|
||||
|
||||
Ubuntu是给公司和开发者渴望利用的给力的OpenStack[默认的][2]操作系统,Ubuntu提供了众多优势和好处:Ubuntu和OpenStack发布时间是同步的,同步的发行使得OpenStack能在最新的Utuntu下运行,Canonical提供支持,--产品,服务,等等--,为最佳的OpenStack的管理和操作等。
|
||||
|
||||
|
||||
**OpenStack峰会**是一个有趣的专家们集会的事件,为了讨论,提出和分析各个方面的OpenStack,以有趣的展会,个案研究,来自创新开发者的基调为特色,也有开发者集会和工作分享,本质上,专家们会讨论关于现在和明天的OpenStack和云计算的格局。
|
||||
|
||||

|
||||
|
||||
下一次的OpenStack峰会将会于11月5号到8号在香港举行,参加注册[registrations][3]。
|
||||
|
||||
Canonical的**Mark Shuttleworth**将会坚定地出席在香港举行的OpenStack峰会,他将展开一个主题,围绕交互性,进一步加强Ubuntu和OpenStack的效应等,并揭示新的细节关于未来的创新目标,计划和Canonical为Ubuntu所做的成就。
|
||||
|
||||
更多细节和优惠(有效日期:10月26前)请点击 [https://www.openstack.org/summit/hk][4]
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://iloveubuntu.net/mark-shuttleworth-attend-and-conduct-keynote-openstack-summit-hong-kong-november-5th-8th-2013
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
译者:[Vic___](http://blog.csdn.net/Vic___) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[1]:http://www.canonical.com/
|
||||
[2]:http://www.ubuntu.com/cloud/tools/openstack
|
||||
[3]:https://www.eventbrite.com/event/6786581849/o21
|
||||
[4]:https://www.openstack.org/summit/hk
|
||||
@ -1,18 +1,20 @@
|
||||
Metal Backup and Recovery Is Now Possible with Debian-Based Clonezilla Live 2.2.0-13
|
||||
现在可以通过基于Debian的Clonezilla(再生龙) Live 2.2.0-13 备份和恢复设备
|
||||
|
||||
================================================================================
|
||||
Clonezilla Live 2.2.0-13, a Linux distribution based on DRBL, Partclone, and udpcast that allows users to do bare metal backup and recovery, is now available for testing.
|
||||
|
||||
Clonezilla Live 2.2.0-13,一个基于DRBL,Partclone,和udpcast的Linux发行版,允许用户完成一些裸金属的备份和还原,目前还只是测试版.
|
||||
|
||||

|
||||
|
||||
[Clonezilla Live 2.2.0-13][1] is a new development version for this distribution and the developers have chosen to move a little faster with the numbering systems. There are no major differences, but some packages have been updated.
|
||||
[Clonezilla Live 2.2.0-13][1] 是这个放行版的最新开发版本,开发人员已经选择添加了一些快一点的编号系统,没有太大的差异,但是一些包已经更新了.
|
||||
|
||||
“The underlying GNU/Linux operating system was upgraded. This release is based on the Debian Sid repository (as of 2013/Oct/14). Package drbl has been updated to 2.5.12-drbl1, and clonezilla has been updated to 3.7.15-drbl1,” reads the announcement.
|
||||
“底层的GNU/Linux操作系统已经升级,这次放行版基于Debian Sid库(2013-10-14).DRBL包已经更新到2.5.12-drbl1,clonezilla更新到了3.7.15-drbl1,” 从公告中摘取.
|
||||
|
||||
The developers also integrated Samba 4.0.10, which isn't exactly the last stable one released, but it's still recently new.
|
||||
开发者还集成了Samba 4.0.10,这不是最后的稳定释放版本,但它仍然是最新的.
|
||||
|
||||
Remember that this is a development version and it should NOT be installed on production machines. It is intended for testing purposes only.
|
||||
请注意这是个开发版本,请不要安装在生产机上.这只用于测试的目的.
|
||||
|
||||
**Download Clonezilla Live 2.2.0-13**
|
||||
**下载 Clonezilla Live 2.2.0-13**
|
||||
|
||||
- [Clonezilla LiveCD 2.1.2-53 (ISO) i486 Stable][2][iso] [120 MB]
|
||||
- [Clonezilla LiveCD 2.1.2-53 (ISO) i686 PAE Stable][3][iso] [121 MB]
|
||||
@ -27,7 +29,7 @@ via: http://news.softpedia.com/news/Metal-Backup-and-Recovery-Is-Now-Possible-wi
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Luoxcat](https://github.com/Luoxcat) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[1]:http://free.nchc.org.tw/clonezilla-live/testing/ChangeLog-Clonezilla-live.txt
|
||||
[2]:http://downloads.sourceforge.net/clonezilla/clonezilla-live-2.1.2-53-i486.iso
|
||||
@ -35,4 +37,4 @@ via: http://news.softpedia.com/news/Metal-Backup-and-Recovery-Is-Now-Possible-wi
|
||||
[4]:http://downloads.sourceforge.net/clonezilla/clonezilla-live-2.1.2-53-amd64.iso
|
||||
[5]:http://sourceforge.net/projects/clonezilla/files/clonezilla_live_testing/2.2.0-8/clonezilla-live-2.2.0-13-i486.iso/download
|
||||
[6]:http://sourceforge.net/projects/clonezilla/files/clonezilla_live_testing/2.2.0-8/clonezilla-live-2.2.0-13-i686-pae.iso/download
|
||||
[7]:http://sourceforge.net/projects/clonezilla/files/clonezilla_live_testing/2.2.0-8/clonezilla-live-2.2.0-13-amd64.iso/download
|
||||
[7]:http://sourceforge.net/projects/clonezilla/files/clonezilla_live_testing/2.2.0-8/clonezilla-live-2.2.0-13-amd64.iso/download
|
||||
402
translated/NoSQL comparison.md
Normal file
402
translated/NoSQL comparison.md
Normal file
@ -0,0 +1,402 @@
|
||||
各种 NoSQL 的比较
|
||||
================
|
||||
|
||||
即使关系型数据库依然是非常有用的工具,它们持续几十年的垄断地位就要走到头了。现在已经存在无数能撼动关系型数据库地位的 NoSQL,当然,这些 NoSQL 还无法完全取代它们。(也就是说,关系型数据库还是处理关系型事务的最佳方式。)
|
||||
|
||||
NoSQL 与 NoSQL 之间的区别,要远大于 SQL 与 SQL 之间的区别。所以软件架构师必须要在项目一开始就选好一款合适的 NoSQL。
|
||||
|
||||
考虑到这种情况,本文为大家介绍以下几种 NoSQL 之间的区别:[Cassandra][], [Mongodb][], [CouchDB][], [Redis][], [Riak][], [Couchbase (ex-Membase)][], [Hypertable][], [ElasticSearch][], [Accumulo][], [VoltDB][], [Kyoto Tycoon][], [Scalaris][], [Neo4j][]和[HBase][]:
|
||||
|
||||
##最流行的 NoSQL
|
||||
|
||||
###MongoDB 2.2版
|
||||
|
||||
**开发语言:** C++
|
||||
|
||||
**主要特性:** 保留 SQL 中一些用户友好的特性(查询、索引等)
|
||||
|
||||
**许可证:** AGPL (发起者: Apache)
|
||||
|
||||
**数据传输、存储的格式:** 自定义,二进制( BSON 文档格式)
|
||||
|
||||
- 主/从备份(支持自动故障切换功能)
|
||||
- 自带数据分片功能
|
||||
- 通过 javascript 表达式提供数据查询
|
||||
- 服务器端完全支持 javascript 脚本
|
||||
- 比 CouchDB 更好的升级功能
|
||||
- 数据存储使用内存映射文件技术
|
||||
- 功能丰富,性能不俗
|
||||
- 最好开启日志功能(使用 --journal 参数)
|
||||
- 在 32 位系统中,内存限制在 2.5GB
|
||||
- 空数据库占用 192MB 空间
|
||||
- 使用 GridFS(不是真正的文件系统)来保存大数据和元数据
|
||||
- 支持对数据建立索引
|
||||
- 数据中心意识
|
||||
|
||||
**应用场景:** 动态查询;需要定义索引而不是 map/reduce 功能;提高大数据库性能;想使用 CouchDB 但数据的 IO 吞吐量太大,CouchDB 无法满足要求。MongoDB 可以满足你的需求
|
||||
|
||||
**使用案例:** 想布署 MySQL 或 PostgreSQL,但它们存在的预定义处理语句和预定义变量让你望而却步。这个时候,MongoDB 是你可以考虑的选项
|
||||
|
||||
###Riak 1.2版
|
||||
|
||||
**开发语言:** Erlang、C、以及一些 JavaScript
|
||||
|
||||
**主要特性:** 容错机制(当一份数据失效,服务会自动切换到备份数据,保证服务一直在线 —— 译者注)
|
||||
|
||||
**许可证:** Apache
|
||||
|
||||
**数据传输、存储的格式:** HTTP/REST 架构,自定义二进制格式
|
||||
|
||||
- 可存储 BLOB(binary large object,二进制大对象,比如一张图片、一个声音文件 —— 译者注)
|
||||
- 可在分部式存储和备份存储之间作协调
|
||||
- 为了保证可验证性和安全性,Riak 在 JS 和 Erlaing 中提供提交前(pre-commit)和提交后(post-commit)钩子(hook)函数(你可以在提交数据前执行一个 hook,或者在提交数据后执行一个 hook —— 译者注)
|
||||
- JS 和 Erlang 提供映射和简化(map/reduce)编程模型
|
||||
- 使用 links 和 link walking 图形化数据库(link 用于描述对象之间的关系,link walking 是一个用于查询对象关系的进程 —— 译者注)
|
||||
- 次要标记(secondaty indeces,开发者在写数据时可用多个名称来标记一个对象 —— 译者注),一次只能用一个
|
||||
- 支持大数据对象(Luwak)(Luwak 是 Riak 中的一个服务层,为大数据量对象提供简单的、面向文档的抽象,弥补了 Riak 的 Key/Value 存储格式在处理大数据对象方面的不足 —— 译者注)
|
||||
- 提供“开源”和“企业”两个版本
|
||||
- 提供“全文搜索”(可能就是允许用户在不提供 table/volume 等信息,对一个表进行文本字段的搜索,瞎猜的,望指正 —— 译者注)
|
||||
- 正在将存储后端从“Bitcask”迁移到 Google 的“LevelDB”上
|
||||
- 企业版本提供多点备份(各点地位平等,非主从架构)和SNMP监控功能
|
||||
|
||||
**应用场景:** 假如你想要类似 Dynamo 的数据库,但不想要它的庞大和复杂;假如你需要良好的单点可扩展性、可用性和容错能力,但不想为多点备份买单。 Riak 能满足你的需求
|
||||
|
||||
**使用案例:** 销售点数据收集;工厂控制系统;必须实时在线的系统;需要易于升级的网站服务器
|
||||
|
||||
###CouchDB 1.2版
|
||||
|
||||
**开发语言:** Erlang
|
||||
|
||||
**主要特性:** 数据一致性;易于使用
|
||||
|
||||
**许可证:** Apache
|
||||
|
||||
**数据传输格式:** HTTP/REST
|
||||
|
||||
- 双向复制(一种同步技术,每个备份点都有一份它们自己的拷贝,允许用户在存储点断线的情况下修改数据,当存储节点重新上线时,CouchDB 会对所有节点同步这些修改 —— 译者注)
|
||||
- 支持持续同步或者点对点同步
|
||||
- 支持冲突检测
|
||||
- 支持主主互备(多个数据库时时同步数据,起到备份和分摊用户并行访问量的作用 —— 译者注)
|
||||
- 多版本并发控制(MVCC),写操作时不需要阻塞读操作(或者说不需要锁住数据库)
|
||||
- 向下兼容
|
||||
- 可靠的 crash-only 设计(所谓 crash-only,就是程序出错时,只需重启下程序,丢弃内存的所有数据,不需要执行复杂的数据恢复操作 —— 译者注)
|
||||
- 需要实时压缩数据
|
||||
- 视图(文档是 CouchDB 的核心概念,CouchDB 中的视图声明了如何从文档中提取数据,以及如何对提取出来的数据进行处理 —— 译者注):内嵌映射和简化(map/reduce)编程模型
|
||||
- 格式化的views字段:lists(包含把视图运行结果转换成非 JSON 格式的方法)和 shows(包含把文档转换成非 JSON 格式的方法)(在 CouchDB 中,一个 Web 应用是与一个设计文档相对应的。在设计文档中可以包含一些特殊的字段,views 字段包含永久的视图定义 —— 译者注)
|
||||
- 可能会提供服务器端文档验证的功能
|
||||
- 可能提供身份认证功能
|
||||
- 通过 _changes 函数实时更新数据
|
||||
- 链接处理(attachment:couchDB 的每份文档都可以有一个 attachment,就像一份 email 有它的网址 —— 译者注)
|
||||
- 有个 CouchApps(第三方JS的应用)
|
||||
|
||||
**应用场景:** 用于随机数据量多、需要预定义查询的地方;用于版本控制比较重要的地方
|
||||
|
||||
**使用案例:** 可用于客户关系管理(CRM),内容管理系统(CMS);可用于主主互备甚至多机互备
|
||||
|
||||
###Redis 2.4版
|
||||
|
||||
**开发语言:** C/C++
|
||||
|
||||
**主要特性:** 快到掉渣
|
||||
|
||||
**许可证:** BSD
|
||||
|
||||
**数据传输方式:** 类似 Telnet
|
||||
|
||||
- Redis 是一个内存数据库(in-memory database,简称 IMDB,将数据放在内存进行读写,这才是“快到掉渣”的真正原因 —— 译者注),磁盘只是提供数据持久化(即将内存的数据写到磁盘)的功能(这类数据库被称为“disk backed”数据库)
|
||||
- 当前不支持将磁盘作为 swap 分区,虚拟内存(VM)和 Diskstore 方式都没加到此版本(Redis 的数据持久化共有4种方式:定时快照、基于语句追加、虚拟内存、diskstore。其中 VM 方式由于性能不好以及不稳定的问题,已经被作者放弃,而 diskstore 方式还在实验阶段 —— 译者注)
|
||||
- 主从备份
|
||||
- 存储结构为简单的 key/value 或 hash 表
|
||||
- 但是操作比较复杂,比如:ZREVRANGEBYSCORE
|
||||
- 支持 INCR(INCR key 就是将key中存储的数值加一 —— 译者注)命令(对限速和统计有帮助)
|
||||
- 支持sets数据类型(以及 union/diff/inter)
|
||||
- 支持 lists (以及 queue/blocking pop)
|
||||
- 支持 hash sets (多级对象)
|
||||
- 支持 sorted sets(高效率的表,在范围查找方面有优势)
|
||||
- 支持事务处理
|
||||
- 缓存中的数据可被标记为过期
|
||||
- Pub/Sub 操作能让用户发送信息
|
||||
|
||||
**应用场景:** 适合布署快速多变的小规模数据(可以完全运行在存在中)
|
||||
|
||||
**使用案例:** 股价系统、分析系统、实时数据收集系统、实时通信系统、以及取代 memcached
|
||||
|
||||
##Google Bigtable 的衍生品
|
||||
|
||||
###HBase 0.92.0 版
|
||||
|
||||
**开发语言:** Java
|
||||
|
||||
**主要特性:** 支持几十亿行*几百万列的大表
|
||||
|
||||
**许可证:** Apache
|
||||
|
||||
**数据传输方式:** HTTP/REST (也支持 Thrift 开发框架)
|
||||
|
||||
- 仿造 Google 的 BigTable
|
||||
- 使用 Hadoop 的 HDFS 文件系统作为存储
|
||||
- 使用 Hadoop 的映射和简化(map/reduce)编程模型
|
||||
- 查询条件被推送到服务器端,由服务器端执行扫描和过滤
|
||||
- 对实时查询进行优化
|
||||
- 高性能的 Thrift gateway(访问 HBase 的接口之一,特点是利用 Thrift 序列化支持多种语言,可用于异构系统在线访问 HBase 表数据 —— 译者注)
|
||||
- 使用 HTTP 通信协议,支持 XML、Protobuf 以及一些二进制文档结构
|
||||
- 支持基于 Jruby(JIRB)的shell
|
||||
- 当配置信息有更改时,支持 rolling restart(轮流重启数据节点)
|
||||
- 随机读写性能与 MySQL 一样
|
||||
- 一个集群可由不同类型的结点组成
|
||||
|
||||
**应用场景:** Hadoop 可能是在大数据上跑 Map/Reduce 业务的最佳选择;如果你已经搭建了 Hadoop/HDFS 架构,HBase 也是你最佳的选择。
|
||||
|
||||
**使用案例:** 搜索引擎;日志分析系统;扫描大型二维非关系型数据表。
|
||||
|
||||
###Cassandra 1.2版
|
||||
|
||||
**开发语言:** Java
|
||||
|
||||
**主要特性:** BigTable 和 Dynamo的完美结合(Cassandra 以 Amazon 专有的完全分布式的 Dynamo 为基础,结合了Google BigTable基于 Column Family 的数据模型 —— 译者注)
|
||||
|
||||
**许可证:** Apache
|
||||
|
||||
**数据传输和存储方式:** Thrift 和自定义二进制 CQL3(即 Cassandra 查询语言第3版 —— 译者注)
|
||||
|
||||
- 可以灵活调整对数据的分布式或备份式存储(通过设置N,R,W之间的关系)(NRW是数据库布署模型中的概念,N是存储网络中复制数据的节点数,R是网络中读数据的节点数,W是网络中写数据的节点数。一个环境中N值是固定的,设置不同的WR值组合能在数据可用性和数据一致性之间取得不同的平衡,可参考 CAP 定理 —— 译者注)
|
||||
- 按列查询,按keys值排序后存储(需要包含你想要搜索的任何信息)(Cassandra 的数据模型借鉴自 BigTable 的列式存储,列式存储可以理解成这样,将行ID、列簇号,列号以及时间戳一起,组成一个Key,然后将Value按Key的顺序进行存储 —— 译者注)
|
||||
- 类似 BigTable 的特性:列、列簇
|
||||
- 支持分布式 hash 表,使用“类 SQL” 语言 —— CQL(但没有 SQL 中的 JOIN 语句)
|
||||
- 可以为数据设置一个过期时间(使用 INSERT 指令)
|
||||
- 写性能远高于读性能(读性能的瓶颈是磁盘 IO)
|
||||
- 可使用 Hadoop 的映射和简化(map/reduce)编程模型
|
||||
- 所有节点都相似,这点与 Hadop/HBase 架构不同
|
||||
- 可靠的跨数据中心备份解决方案
|
||||
|
||||
**应用场景:** 写操作多于读操作的环境(比如日志系统);如果系统全部由 JAVA 组成(“没人会因为使用了 Apache 许可下的产品而被炒鱿鱼”(此句貌似是网上有人针对“Apache considered harmful”一文所作的回应 —— 译者注))
|
||||
|
||||
**使用案例:** 银行、金融机构;写性能强于读性能,所以 Cassandra 天生就是用来作数据分析的。
|
||||
|
||||
###Hypertable 0.9.6.5版
|
||||
|
||||
**开发语言:** C++
|
||||
|
||||
**主要特性:** HBase 的精简版,但比 HBase 更快
|
||||
|
||||
**许可证:** GPL 2.0
|
||||
|
||||
**数据传输和存储的方式:** Thrift,C++库,或者 HQL shell
|
||||
|
||||
- 采用与 Google BigTable 相似的设计
|
||||
- 运行在 Hadoop HDFS 之上
|
||||
- 使用自己的“类 SQL”语言 —— HQL
|
||||
- 可以根据 key 值、单元(cell)进行查找,可以在列簇上查找
|
||||
- 查询数据可以指定 key 或者列的范围
|
||||
- 由百度公司赞助(百度早在2009年就成为这个项目的赞助商了 —— 好吧译者表示有点大惊小怪了:P)
|
||||
- 能保留一个值的 N 个历史版本
|
||||
- 表在命名空间内定义
|
||||
- 使用 Hadoop 的 Map/reduce 模型
|
||||
|
||||
**应用场景:** 假如你需要一个更好的HBase,就用Hypertable吧。
|
||||
|
||||
**使用案例:** 与HBase一样,就是搜索引擎被换了下;分析日志数据的系统;适用于浏览大规模二维非关系型数据表。
|
||||
|
||||
###Accumulo 1.4版
|
||||
|
||||
**开发语言:** Java 和 C++
|
||||
|
||||
**主要特性:** 一个有着单元级安全的 BigTable
|
||||
|
||||
**许可证:** Apache
|
||||
|
||||
**数据传输和存储的方式:** Thrift
|
||||
|
||||
- 另一个 BigTable 的复制品,也是跑在 Hadoop 的上层
|
||||
- 单元级安全保证
|
||||
- 允许使用比内存容量更大的数据列
|
||||
- 通过 C++ 的 STL 可保持数据从 JAVA 环境的内存映射出来
|
||||
- 使用 Hadoop 的 Map/reduce 模型
|
||||
- 支持在服务器端编程
|
||||
|
||||
**应用场景:** HBase的替代品
|
||||
|
||||
**使用案例:** 与HBase一样,就是搜索引擎被换了下;分析日志数据的系统;适用于浏览大规模二维非关系型数据表。
|
||||
|
||||
##特殊用途
|
||||
|
||||
###Neo4j V1.5M02 版
|
||||
|
||||
**开发语言:** Java
|
||||
|
||||
**主要特性:** 图形化数据库
|
||||
|
||||
**许可证:** GPL,AGPL(商业用途)
|
||||
|
||||
**数据传输和存储的方式:** HTTP/REST(或内嵌在 Java 中)
|
||||
|
||||
- 可独立存在,或内嵌在 JAVA 的应用中
|
||||
- 完全的 ACID 保证(包括正在处理的数据)
|
||||
- 节点和节点的关系都可以拥有原数据
|
||||
- 集成基于“模式匹配”的查询语言(Cypher)
|
||||
- 支持“Gremlin”图形转化语言
|
||||
- 可对节点与节点关系进行索引
|
||||
- 良好的自包含网页管理技术
|
||||
- 多个算法实现高级文件查找功能
|
||||
- 可对 key 与 key 的关系进行索引
|
||||
- 优化读性能
|
||||
- 在 JAVA API 中实现事务处理
|
||||
- 可运行脚本 Groovy 脚本
|
||||
- 在商用版本中提供在线备份,高级监控和高可用性功能
|
||||
|
||||
**应用场景:** 适用于用图形显示复杂的交互型数据。
|
||||
|
||||
**使用案例:** 搜寻社交关系网、公共传输链、公路路线图、或网络拓扑结构
|
||||
|
||||
###ElasticSearch 0.20.1 版
|
||||
|
||||
**开发语言:** Java
|
||||
|
||||
**主要特性:** 高级搜索
|
||||
|
||||
**许可证:** Apache
|
||||
|
||||
**数据传输和存储的方式:** 通过 HTTP 使用 JSON 进行数据索引(插件:Thrift, memcached)
|
||||
|
||||
- 以 JSON 形式保存数据
|
||||
- 提供版本升级功能
|
||||
- 有父文档和子文档功能
|
||||
- 文档有过期时间
|
||||
- 提供复杂多样的查询指令,可使用脚本
|
||||
- 支持写操作一致性的三个级别:ONE、QUORUM、ALL
|
||||
- 支持通过分数排序
|
||||
- 支持通过地理位置排序
|
||||
- 支持模糊查询(通过近似数据查询等方式实现)
|
||||
- 支持异步复制
|
||||
- 自动升级,也可通过设置脚本升级
|
||||
- 可以维持自动的“统计组”(对调试很有帮助)
|
||||
- 只有一个开发者(kimchy)
|
||||
|
||||
**应用场景:** 当你有可伸缩性很强的项目并且想拥有“高级搜索”功能。
|
||||
|
||||
**使用案例:** 可布署一个约会服务,提供不同年龄、不同地理位置、不同品味的客户的交友需求。或者可以布署一个基于多项参数的排行榜。
|
||||
|
||||
##其他
|
||||
|
||||
(不怎么有名,但值得在这里介绍一下)
|
||||
|
||||
###Couchbase (ex-Membase) 2.0 版
|
||||
|
||||
**开发语言:** Erlang 和 C
|
||||
|
||||
**主要特性:** 兼容 Memcache,但数据是持久化的,并且支持集群
|
||||
|
||||
**许可证:** Apache
|
||||
|
||||
**数据传输和存储的方式:** 缓存和扩展(memcached + extensions)
|
||||
|
||||
- 通过 key 访问数据非常快(20万以上IOPS)
|
||||
- 数据保存在磁盘(不像 Memcache 保存在内存中 —— 译者注)
|
||||
- 在主主互备中,所有节点数据是一致的
|
||||
- 提供类似 Memcache 将数据保存在内存的功能
|
||||
- 支持重复数据删除功能
|
||||
- 友好的集群管理 Web 界面
|
||||
- 支持池和多丛结构的代理(利用 Moxi 项目)
|
||||
- 支持 Map/reduce 模式
|
||||
- 支持跨数据中心备份
|
||||
|
||||
**应用场景:** 适用于低延迟数据访问系统,高并发和高可用系统。
|
||||
|
||||
**使用案例:** 低延迟可用于广告定投;高并发可用于在线游戏(如星佳公司)。
|
||||
|
||||
###VoltDB 2.8.4.1版
|
||||
|
||||
**开发语言:** Java
|
||||
|
||||
**主要特性:** 快速的事务处理和数据变更
|
||||
|
||||
**许可证:** GPL 3
|
||||
|
||||
**数据传输和存储的方式:** 专有方式
|
||||
|
||||
- 运行在内存的关系型数据库
|
||||
- 可以将数据导入到 Hadoop
|
||||
- 支持 ANSI SQL
|
||||
- 在 JAVA 环境中保存操作过程
|
||||
- 支持跨数据中心备份
|
||||
|
||||
**应用场景:** 适用于在大量传入数据中保证快速反应能力的场合。
|
||||
|
||||
**使用案例:** 销售点数据分析系统;工厂控制系统。
|
||||
|
||||
###Scalaris 0.5版
|
||||
|
||||
**开发语言:** Erlang
|
||||
|
||||
**主要特性:** 分布式 P2P 键值存储
|
||||
|
||||
**许可证:** Apache
|
||||
|
||||
**数据传输和存储的方式:** 自有方式和 基于JSON的远程过程调用协议
|
||||
|
||||
- 数据保存在内存中(使用 Tokyo Cabinet 作为后台时,数据可以持久化到磁盘中)
|
||||
- 使用 YAWS 作为 Web 服务器
|
||||
- Has transactions (an adapted Paxos commit)
|
||||
- 支持事务处理(基于 Paxos 提交)(Paxos 是一种基于消息传递模型的一致性算法 —— 译者注)
|
||||
- 支持分布式数据的一致性写操作
|
||||
- 根据 CAP 定理,数据一致性要求高于数据可用性(前提是在一个比较大的网络分区环境下工作)(CAP 定理:数据一致性consistency、数据可用性availability、分隔容忍partition tolerance是分布式计算系统的三个属性,一个分布式计算系统不可能同时满足全部三项)
|
||||
|
||||
**应用场景:** 如果你喜欢 Erlang 并且想要使用 Mnesia 或 DETS 或 ETS,但你需要一个能使用多种语言(并且可扩展性强于 ETS 和 DETS)的技术,那就选它吧。
|
||||
|
||||
**使用案例:** 使用基于 Erlang 的系统,但是想通过 Python、Ruby 或 JAVA 访问数据库
|
||||
|
||||
###Kyoto Tycoon 0.9.56版
|
||||
|
||||
**开发语言:** C++
|
||||
|
||||
**主要特性:** 轻量级网络数据库管理系统
|
||||
|
||||
**许可证:** GPL
|
||||
|
||||
**数据传输和存储的方式:** HTTP (TSV-RPC or REST)
|
||||
|
||||
- 基于 Kyoto Cabinet, 是 Tokyo Cabinet 的成功案例
|
||||
- 支持多种存储后端:Hash,树、目录等等(所有概念都是从 Kyoto Cabinet 那里来的)
|
||||
- Kyoto Cabinet 可以达到每秒100万次插入/查询操作(但是 Tycoon 由于瓶颈问题,性能比 Cabinet 要差点)
|
||||
- 服务器端支持 Lua 脚本语言
|
||||
- 支持 C、JAVA、Python、Ruby、Perl、Lua 等语言
|
||||
- 使用访问者模式开发(visitor patten:让开发者能在不修改类层次结构的前提下,定义该类层次结构的操作 —— 不明白就算了,译者也不明白)
|
||||
- 支持热备、异步备份
|
||||
- 支持内存数据库在后端执行快照
|
||||
- 自动过期处理(可用来布署一个缓存服务器)
|
||||
|
||||
**应用场景:** 当你想要一个很精准的后端存储算法引擎,并且速度是刚需的时候,玩玩 Kyoto Tycoon 吧。
|
||||
|
||||
**使用案例:** 缓存服务器;股价查询系统;数据分析系统;实时数据控制系统;实时交互系统;memcached的替代品。
|
||||
|
||||
当然,上述系统的特点肯定不止列出来这么点。我只是列出了我认为很关键的信息。另外科技发展迅猛,技术改变得非常快。
|
||||
|
||||
附:现在下定论比较孰优孰劣还为时过早。上述数据库的版本号以及特性我会一个一个慢慢更新。相信我,这些数据库的特性不会变得很快。
|
||||
|
||||
---
|
||||
|
||||
via: http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
|
||||
|
||||
本文由 [LCTT][] 原创翻译,[Linux中国][] 荣誉推出
|
||||
|
||||
译者:[译者ID][] 校对:[校对者ID][]
|
||||
|
||||
[LCTT]:https://github.com/LCTT/TranslateProject
|
||||
[Linux中国]:http://linux.cn/portal.php
|
||||
[chenjintao]:http://linux.cn/space/chenjintao
|
||||
[校对者ID]:http://linux.cn/space/校对者ID
|
||||
|
||||
[Cassandra]:http://cassandra.apache.org/
|
||||
[Mongodb]:http://www.mongodb.org/
|
||||
[CouchDB]:http://couchdb.apache.org/
|
||||
[Redis]:http://redis.io/
|
||||
[Riak]:http://basho.com/riak/
|
||||
[Couchbase (ex-Membase)]:http://www.couchbase.org/membase
|
||||
[Hypertable]:http://hypertable.org/
|
||||
[ElasticSearch]:http://www.elasticsearch.org/
|
||||
[Accumulo]:http://accumulo.apache.org/
|
||||
[VoltDB]:http://voltdb.com/
|
||||
[Kyoto Tycoon]:http://fallabs.com/kyototycoon/
|
||||
[Scalaris]:https://code.google.com/p/scalaris/
|
||||
[Neo4j]:http://neo4j.org/
|
||||
[HBase]:http://hbase.apache.org/
|
||||
Loading…
Reference in New Issue
Block a user