mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
e7c2b3f674
@ -0,0 +1,199 @@
|
||||
如何在 Linux 系统查询机器最近重启时间
|
||||
======
|
||||
|
||||
在你的 Linux 或类 UNIX 系统中,你是如何查询系统上次重新启动的日期和时间?怎样显示系统关机的日期和时间? `last` 命令不仅可以按照时间从近到远的顺序列出该会话的特定用户、终端和主机名,而且还可以列出指定日期和时间登录的用户。输出到终端的每一行都包括用户名、会话终端、主机名、会话开始和结束的时间、会话持续的时间。要查看 Linux 或类 UNIX 系统重启和关机的时间和日期,可以使用下面的命令。
|
||||
|
||||
- `last` 命令
|
||||
- `who` 命令
|
||||
|
||||
|
||||
### 使用 who 命令来查看系统重新启动的时间/日期
|
||||
|
||||
你需要在终端使用 [who][1] 命令来打印有哪些人登录了系统,`who` 命令同时也会显示上次系统启动的时间。使用 `last` 命令来查看系统重启和关机的日期和时间,运行:
|
||||
|
||||
```
|
||||
$ who -b
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
system boot 2017-06-20 17:41
|
||||
```
|
||||
|
||||
使用 `last` 命令来查询最近登录到系统的用户和系统重启的时间和日期。输入:
|
||||
|
||||
```
|
||||
$ last reboot | less
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
[![Fig.01: last command in action][2]][2]
|
||||
|
||||
或者,尝试输入:
|
||||
|
||||
```
|
||||
$ last reboot | head -1
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
reboot system boot 4.9.0-3-amd64 Sat Jul 15 19:19 still running
|
||||
```
|
||||
|
||||
`last` 命令通过查看文件 `/var/log/wtmp` 来显示自 wtmp 文件被创建时的所有登录(和登出)的用户。每当系统重新启动时,这个伪用户 `reboot` 就会登录。因此,`last reboot` 命令将会显示自该日志文件被创建以来的所有重启信息。
|
||||
|
||||
### 查看系统上次关机的时间和日期
|
||||
|
||||
可以使用下面的命令来显示上次关机的日期和时间:
|
||||
|
||||
```
|
||||
$ last -x|grep shutdown | head -1
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
shutdown system down 2.6.15.4 Sun Apr 30 13:31 - 15:08 (01:37)
|
||||
```
|
||||
|
||||
命令中,
|
||||
|
||||
* `-x`:显示系统关机和运行等级改变信息
|
||||
|
||||
|
||||
这里是 `last` 命令的其它的一些选项:
|
||||
|
||||
```
|
||||
$ last
|
||||
$ last -x
|
||||
$ last -x reboot
|
||||
$ last -x shutdown
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.01: How to view last Linux System Reboot Date/Time ][3]
|
||||
|
||||
### 查看系统正常的运行时间
|
||||
|
||||
评论区的读者建议的另一个命令如下:
|
||||
|
||||
```
|
||||
$ uptime -s
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
2017-06-20 17:41:51
|
||||
```
|
||||
|
||||
### OS X/Unix/FreeBSD 查看最近重启和关机时间的命令示例
|
||||
|
||||
在终端输入下面的命令:
|
||||
|
||||
```
|
||||
$ last reboot
|
||||
```
|
||||
|
||||
在 OS X 示例输出结果如下:
|
||||
|
||||
```
|
||||
reboot ~ Fri Dec 18 23:58
|
||||
reboot ~ Mon Dec 14 09:54
|
||||
reboot ~ Wed Dec 9 23:21
|
||||
reboot ~ Tue Nov 17 21:52
|
||||
reboot ~ Tue Nov 17 06:01
|
||||
reboot ~ Wed Nov 11 12:14
|
||||
reboot ~ Sat Oct 31 13:40
|
||||
reboot ~ Wed Oct 28 15:56
|
||||
reboot ~ Wed Oct 28 11:35
|
||||
reboot ~ Tue Oct 27 00:00
|
||||
reboot ~ Sun Oct 18 17:28
|
||||
reboot ~ Sun Oct 18 17:11
|
||||
reboot ~ Mon Oct 5 09:35
|
||||
reboot ~ Sat Oct 3 18:57
|
||||
|
||||
|
||||
wtmp begins Sat Oct 3 18:57
|
||||
```
|
||||
|
||||
查看关机日期和时间,输入:
|
||||
|
||||
```
|
||||
$ last shutdown
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
shutdown ~ Fri Dec 18 23:57
|
||||
shutdown ~ Mon Dec 14 09:53
|
||||
shutdown ~ Wed Dec 9 23:20
|
||||
shutdown ~ Tue Nov 17 14:24
|
||||
shutdown ~ Mon Nov 16 21:15
|
||||
shutdown ~ Tue Nov 10 13:15
|
||||
shutdown ~ Sat Oct 31 13:40
|
||||
shutdown ~ Wed Oct 28 03:10
|
||||
shutdown ~ Sun Oct 18 17:27
|
||||
shutdown ~ Mon Oct 5 09:23
|
||||
|
||||
|
||||
wtmp begins Sat Oct 3 18:57
|
||||
```
|
||||
|
||||
### 如何查看是谁重启和关闭机器?
|
||||
|
||||
你需要[启用 psacct 服务然后运行下面的命令][4]来查看执行过的命令(包括用户名),在终端输入 [lastcomm][5] 命令查看信息
|
||||
|
||||
```
|
||||
# lastcomm userNameHere
|
||||
# lastcomm commandNameHere
|
||||
# lastcomm | more
|
||||
# lastcomm reboot
|
||||
# lastcomm shutdown
|
||||
### 或者查看重启和关机时间
|
||||
# lastcomm | egrep 'reboot|shutdown'
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
reboot S X root pts/0 0.00 secs Sun Dec 27 23:49
|
||||
shutdown S root pts/1 0.00 secs Sun Dec 27 23:45
|
||||
```
|
||||
|
||||
我们可以看到 root 用户在当地时间 12 月 27 日星期二 23:49 在 pts/0 重新启动了机器。
|
||||
|
||||
### 参见
|
||||
|
||||
* 更多信息可以查看 man 手册(`man last`)和参考文章 [如何在 Linux 服务器上使用 tuptime 命令查看历史和统计的正常的运行时间][6]。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创立者,同时也是一名经验丰富的系统管理员,也是 Linux,类 Unix 操作系统 shell 脚本的培训师。他曾与全球各行各业的客户工作过,包括 IT,教育,国防和空间研究以及非营利部门等等。你可以在 [Twitter][7]、[Facebook][8]、[Google+][9] 关注他。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-last-reboot-time-and-date-find-out.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/unix-linux-who-command-examples-syntax-usage/ "See Linux/Unix who command examples for more info"
|
||||
[2]:https://www.cyberciti.biz/tips/wp-content/uploads/2006/04/last-reboot.jpg
|
||||
[3]:https://www.cyberciti.biz/media/new/tips/2006/04/check-last-time-system-was-rebooted.jpg
|
||||
[4]:https://www.cyberciti.biz/tips/howto-log-user-activity-using-process-accounting.html
|
||||
[5]:https://www.cyberciti.biz/faq/linux-unix-lastcomm-command-examples-usage-syntax/ "See Linux/Unix lastcomm command examples for more info"
|
||||
[6]:https://www.cyberciti.biz/hardware/howto-see-historical-statistical-uptime-on-linux-server/
|
||||
[7]:https://twitter.com/nixcraft
|
||||
[8]:https://facebook.com/nixcraft
|
||||
[9]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,32 +1,35 @@
|
||||
如何在 Linux 或者 UNIX 下调试 Bash Shell 脚本
|
||||
======
|
||||
|
||||
来自我的邮箱:
|
||||
**我写了一个你好世界的小脚本。我如何能调试运行在 Linux 或者类 UNIX 的系统上的 bash shell 脚本呢?**
|
||||
|
||||
> 我写了一个 hello world 小脚本。我如何能调试运行在 Linux 或者类 UNIX 的系统上的 bash shell 脚本呢?
|
||||
|
||||
这是 Linux / Unix 系统管理员或新用户最常问的问题。shell 脚本调试可能是一项繁琐的工作(不容易阅读)。调试 shell 脚本有多种方法。
|
||||
|
||||
您需要传递 -X 或 -V 参数,以在 bash shell 中浏览每行代码。
|
||||
您需要传递 `-x` 或 `-v` 参数,以在 bash shell 中浏览每行代码。
|
||||
|
||||
[![如何在 Linux 或者 UNIX 下调试 Bash Shell 脚本][1]][1]
|
||||
|
||||
让我们看看如何使用各种方法调试 Linux 和 UNIX 上运行的脚本。
|
||||
|
||||
```
|
||||
### -x 选项来调试脚本
|
||||
|
||||
用 -x 选项来运行脚本
|
||||
用 `-x` 选项来运行脚本:
|
||||
|
||||
```
|
||||
$ bash -x script-name
|
||||
$ bash -x domains.sh
|
||||
```
|
||||
|
||||
### 使用 set 内置命令
|
||||
|
||||
bash shell 提供调试选项,可以打开或关闭使用 [set 命令][2]:
|
||||
|
||||
* **set -x** : 显示命令及其执行时的参数。
|
||||
* **set -v** : 显示 shell 输入行作为它们读取的
|
||||
* `set -x` : 显示命令及其执行时的参数。
|
||||
* `set -v` : 显示 shell 输入行作为它们读取的
|
||||
|
||||
可以在 shell 脚本本身中使用上面的两个命令:
|
||||
|
||||
可以在shell脚本本身中使用上面的两个命令:
|
||||
```
|
||||
#!/bin/bash
|
||||
clear
|
||||
@ -43,18 +46,28 @@ ls
|
||||
# more commands
|
||||
```
|
||||
|
||||
你可以代替 [标准 Shebang][3] 行:
|
||||
`#!/bin/bash`
|
||||
用一下代码(用于调试):
|
||||
`#!/bin/bash -xv`
|
||||
你可以代替 [标准释伴][3] 行:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
```
|
||||
|
||||
用以下代码(用于调试):
|
||||
|
||||
```
|
||||
#!/bin/bash -xv
|
||||
```
|
||||
|
||||
### 使用智能调试功能
|
||||
|
||||
首先添加一个叫做 _DEBUG 的特殊变量。当你需要调试脚本的时候,设置 _DEBUG 为 'on':
|
||||
`_DEBUG="on"`
|
||||
首先添加一个叫做 `_DEBUG` 的特殊变量。当你需要调试脚本的时候,设置 `_DEBUG` 为 `on`:
|
||||
|
||||
```
|
||||
_DEBUG="on"
|
||||
```
|
||||
|
||||
在脚本的开头放置以下函数:
|
||||
|
||||
```
|
||||
function DEBUG()
|
||||
{
|
||||
@ -62,11 +75,14 @@ function DEBUG()
|
||||
}
|
||||
```
|
||||
|
||||
function DEBUG() { [ "$_DEBUG" == "on" ] && $@ }
|
||||
现在,只要你需要调试,只需使用 `DEBUG` 函数如下:
|
||||
|
||||
```
|
||||
DEBUG echo "File is $filename"
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
现在,只要你需要调试,只需使用 DEBUG 函数如下:
|
||||
`DEBUG echo "File is $filename"`
|
||||
或者
|
||||
```
|
||||
DEBUG set -x
|
||||
Cmd1
|
||||
@ -74,11 +90,14 @@ Cmd2
|
||||
DEBUG set +x
|
||||
```
|
||||
|
||||
当调试完(在移动你的脚本到生产环境之前)设置 _DEBUG 为 'off'。不需要删除调试行。
|
||||
`_DEBUG="off" # 设置为非 'on' 的任何字符`
|
||||
当调试完(在移动你的脚本到生产环境之前)设置 `_DEBUG` 为 `off`。不需要删除调试行。
|
||||
|
||||
```
|
||||
_DEBUG="off" # 设置为非 'on' 的任何字符
|
||||
```
|
||||
|
||||
示例脚本:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
_DEBUG="on"
|
||||
@ -102,8 +121,13 @@ echo "$a + $b = $c"
|
||||
```
|
||||
|
||||
保存并关闭文件。运行脚本如下:
|
||||
`$ ./script.sh`
|
||||
输出:
|
||||
|
||||
```
|
||||
$ ./script.sh
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
Reading files
|
||||
Found in xyz.txt file
|
||||
@ -114,31 +138,43 @@ Found in xyz.txt file
|
||||
+ '[' on == on ']'
|
||||
+ set +x
|
||||
2 + 3 = 5
|
||||
|
||||
```
|
||||
|
||||
现在设置 DEBUG 为关闭(你需要编辑文件):
|
||||
`_DEBUG="off"`
|
||||
运行脚本:
|
||||
`$ ./script.sh`
|
||||
输出:
|
||||
现在设置 `_DEBUG` 为 `off`(你需要编辑该文件):
|
||||
|
||||
```
|
||||
_DEBUG="off"
|
||||
```
|
||||
|
||||
运行脚本:
|
||||
|
||||
```
|
||||
$ ./script.sh
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
Found in xyz.txt file
|
||||
2 + 3 = 5
|
||||
|
||||
```
|
||||
|
||||
以上是一个简单但非常有效的技术。还可以尝试使用 DEBUG 作为别名替代函数。
|
||||
以上是一个简单但非常有效的技术。还可以尝试使用 `DEBUG` 作为别名而不是函数。
|
||||
|
||||
### 调试 Bash Shell 的常见错误
|
||||
|
||||
Bash 或者 sh 或者 ksh 在屏幕上给出各种错误信息,在很多情况下,错误信息可能不提供详细的信息。
|
||||
|
||||
#### 跳过在文件上应用执行权限
|
||||
When you [write your first hello world bash shell script][4], you might end up getting an error that read as follows:
|
||||
|
||||
当你 [编写你的第一个 hello world 脚本][4],您可能会得到一个错误,如下所示:
|
||||
`bash: ./hello.sh: Permission denied`
|
||||
设置权限使用 chmod 命令:
|
||||
|
||||
```
|
||||
bash: ./hello.sh: Permission denied
|
||||
```
|
||||
|
||||
设置权限使用 `chmod` 命令:
|
||||
|
||||
```
|
||||
$ chmod +x hello.sh
|
||||
$ ./hello.sh
|
||||
@ -147,21 +183,21 @@ $ bash hello.sh
|
||||
|
||||
#### 文件结束时发生意外的错误
|
||||
|
||||
如果您收到文件结束意外错误消息,请打开脚本文件,并确保它有打开和关闭引号。在这个例子中,echo 语句有一个开头引号,但没有结束引号:
|
||||
如果您收到文件结束意外错误消息,请打开脚本文件,并确保它有打开和关闭引号。在这个例子中,`echo` 语句有一个开头引号,但没有结束引号:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
...
|
||||
....
|
||||
|
||||
|
||||
echo 'Error: File not found
|
||||
^^^^^^^
|
||||
missing quote
|
||||
```
|
||||
|
||||
还要确保你检查缺少的括号和大括号 ({}):
|
||||
还要确保你检查缺少的括号和大括号 `{}`:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
.....
|
||||
@ -172,7 +208,9 @@ echo 'Error: File not found
|
||||
```
|
||||
|
||||
#### 丢失像 fi,esac,;; 等关键字。
|
||||
如果你缺少了结尾的关键字,如 fi 或 ;; 你会得到一个错误,如 “XXX 意外”。因此,确保所有嵌套的 if 和 case 语句以适当的关键字结束。有关语法要求的页面。在本例中,缺少 fi:
|
||||
|
||||
如果你缺少了结尾的关键字,如 `fi` 或 `;;` 你会得到一个错误,如 “XXX 意外”。因此,确保所有嵌套的 `if` 和 `case` 语句以适当的关键字结束。有关语法要求的页面。在本例中,缺少 `fi`:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
echo "Starting..."
|
||||
@ -189,16 +227,23 @@ do
|
||||
echo $f
|
||||
done
|
||||
|
||||
# 注意 fi 已经丢失
|
||||
# 注意 fi 丢失了
|
||||
```
|
||||
|
||||
#### 在 Windows 或 UNIX 框中移动或编辑 shell 脚本
|
||||
|
||||
不要在 Linux 上创建脚本并移动到 Windows。另一个问题是编辑 Windows 10上的 shell 脚本并将其移动到 UNIX 服务器上。这将导致一个错误的命令没有发现由于回车返回(DOS CR-LF)。你可以 [将 DOS 换行转换为 CR-LF 的Unix/Linux 格式][5] 使用下列命令:
|
||||
`dos2unix my-script.sh`
|
||||
不要在 Linux 上创建脚本并移动到 Windows。另一个问题是编辑 Windows 10上的 shell 脚本并将其移动到 UNIX 服务器上。这将由于换行符不同而导致命令没有发现的错误。你可以使用下列命令 [将 DOS 换行转换为 CR-LF 的Unix/Linux 格式][5] :
|
||||
|
||||
```
|
||||
dos2unix my-script.sh
|
||||
```
|
||||
|
||||
### 技巧
|
||||
|
||||
#### 技巧 1 - 发送调试信息输出到标准错误
|
||||
|
||||
### 提示1 - 发送调试信息输出到标准错误
|
||||
[标准错误] 是默认错误输出设备,用于写所有系统错误信息。因此,将消息发送到默认的错误设备是个好主意:
|
||||
|
||||
```
|
||||
# 写错误到标准输出
|
||||
echo "Error: $1 file not found"
|
||||
@ -208,17 +253,19 @@ echo "Error: $1 file not found"
|
||||
echo "Error: $1 file not found" 1>&2
|
||||
```
|
||||
|
||||
### 提示2 - 在使用 vim 文本编辑器时,打开语法高亮。
|
||||
大多数现代文本编辑器允许设置语法高亮选项。这对于检测语法和防止常见错误如打开或关闭引号非常有用。你可以在不同的颜色中看到。这个特性简化了 shell 脚本结构中的编写,语法错误在视觉上截然不同。强调不影响文本本身的意义,它只为你编写。在这个例子中,我的脚本使用了 vim 语法高亮:
|
||||
#### 技巧 2 - 在使用 vim 文本编辑器时,打开语法高亮
|
||||
|
||||
大多数现代文本编辑器允许设置语法高亮选项。这对于检测语法和防止常见错误如打开或关闭引号非常有用。你可以在不同的颜色中看到。这个特性简化了 shell 脚本结构中的编写,语法错误在视觉上截然不同。高亮不影响文本本身的意义,它只为你提示而已。在这个例子中,我的脚本使用了 vim 语法高亮:
|
||||
|
||||
[!如何调试 Bash Shell 脚本,在 Linux 或者 UNIX 使用 Vim 语法高亮特性][7]][7]
|
||||
|
||||
### 提示3 - 使用 shellcheck 检查脚本
|
||||
[shellcheck 是一个用于静态分析 shell 脚本的工具][8]。可以使用它来查找 shell 脚本中的错误。这是用 Haskell 编写的。您可以使用这个工具找到警告和建议。让我们看看如何在 Linux 或 类UNIX 系统上安装和使用 shellcheck 来改善你的 shell 脚本,避免错误和高效。
|
||||
#### 技巧 3 - 使用 shellcheck 检查脚本
|
||||
|
||||
### 关于作者
|
||||
发表者:
|
||||
[shellcheck 是一个用于静态分析 shell 脚本的工具][8]。可以使用它来查找 shell 脚本中的错误。这是用 Haskell 编写的。您可以使用这个工具找到警告和建议。你可以看看如何在 Linux 或 类UNIX 系统上安装和使用 shellcheck 来改善你的 shell 脚本,避免错误和高效。
|
||||
|
||||
作者是 nixCraft 创造者,一个经验丰富的系统管理员和一个练习 Linux 操作系统/ UNIX shell 脚本的教练。他曾与全球客户和各种行业,包括 IT,教育,国防和空间研究,以及非营利部门。跟随他 [推特][9],[脸谱网][10],[谷歌+ ][11]。
|
||||
作者:Vivek Gite
|
||||
|
||||
作者是 nixCraft 创造者,一个经验丰富的系统管理员和一个练习 Linux 操作系统/ UNIX shell 脚本的教练。他曾与全球客户和各种行业,包括 IT,教育,国防和空间研究,以及非营利部门。关注他的 [推特][9],[脸谱网][10],[谷歌+ ][11]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -226,7 +273,7 @@ via: https://www.cyberciti.biz/tips/debugging-shell-script.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[zjon](https://github.com/zjon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,158 @@
|
||||
在 Linux 上检测 IDE/SATA SSD 硬盘的传输速度
|
||||
======
|
||||
|
||||
你知道你的硬盘在 Linux 下传输有多快吗?不打开电脑的机箱或者机柜,你知道它运行在 SATA I (150 MB/s) 、 SATA II (300 MB/s) 还是 SATA III (6.0Gb/s) 呢?
|
||||
|
||||
你能够使用 `hdparm` 和 `dd` 命令来检测你的硬盘速度。它为各种硬盘的 ioctls 提供了命令行界面,这是由 Linux 系统的 ATA / IDE / SATA 设备驱动程序子系统所支持的。有些选项只能用最新的内核才能正常工作(请确保安装了最新的内核)。我也推荐使用最新的内核源代码的包含头文件来编译 `hdparm` 命令。
|
||||
|
||||
### 如何使用 hdparm 命令来检测硬盘的传输速度
|
||||
|
||||
以 root 管理员权限登录并执行命令:
|
||||
|
||||
```
|
||||
$ sudo hdparm -tT /dev/sda
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ sudo hdparm -tT /dev/hda
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
/dev/sda:
|
||||
Timing cached reads: 7864 MB in 2.00 seconds = 3935.41 MB/sec
|
||||
Timing buffered disk reads: 204 MB in 3.00 seconds = 67.98 MB/sec
|
||||
```
|
||||
|
||||
为了检测更精准,这个操作应该**重复2-3次** 。这显示了无需访问磁盘,直接从 Linux 缓冲区缓存中读取的速度。这个测量实际上是被测系统的处理器、高速缓存和存储器的吞吐量的指标。这是一个 [for 循环的例子][1],连续运行测试 3 次:
|
||||
|
||||
```
|
||||
for i in 1 2 3; do hdparm -tT /dev/hda; done
|
||||
```
|
||||
|
||||
这里,
|
||||
|
||||
* `-t` :执行设备读取时序
|
||||
* `-T` :执行缓存读取时间
|
||||
* `/dev/sda` :硬盘设备文件
|
||||
|
||||
|
||||
要 [找出 SATA 硬盘的连接速度][2] ,请输入:
|
||||
|
||||
```
|
||||
sudo hdparm -I /dev/sda | grep -i speed
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
* Gen1 signaling speed (1.5Gb/s)
|
||||
* Gen2 signaling speed (3.0Gb/s)
|
||||
* Gen3 signaling speed (6.0Gb/s)
|
||||
|
||||
```
|
||||
|
||||
以上输出表明我的硬盘可以使用 1.5Gb/s、3.0Gb/s 或 6.0Gb/s 的速度。请注意,您的 BIOS/主板必须支持 SATA-II/III 才行:
|
||||
|
||||
```
|
||||
$ dmesg | grep -i sata | grep 'link up'
|
||||
```
|
||||
|
||||
[![Linux Check IDE SATA SSD Hard Disk Transfer Speed][3]][3]
|
||||
|
||||
### dd 命令
|
||||
|
||||
你使用 `dd` 命令也可以获取到相应的速度信息:
|
||||
|
||||
```
|
||||
dd if=/dev/zero of=/tmp/output.img bs=8k count=256k
|
||||
rm /tmp/output.img
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
262144+0 records in
|
||||
262144+0 records out
|
||||
2147483648 bytes (2.1 GB) copied, 23.6472 seconds, `90.8 MB/s`
|
||||
```
|
||||
|
||||
下面是 [推荐的 dd 命令参数][4]:
|
||||
|
||||
```
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
|
||||
## GNU dd syntax ##
|
||||
dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync
|
||||
|
||||
## OR alternate syntax for GNU/dd ##
|
||||
dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync
|
||||
```
|
||||
|
||||
这是上面命令的第三个命令的输出结果:
|
||||
|
||||
```
|
||||
1+0 records in
|
||||
1+0 records out
|
||||
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 4.23889 s, 253 MB/s
|
||||
```
|
||||
|
||||
### “磁盘与存储” - GUI 工具
|
||||
|
||||
您还可以使用位于“系统>管理>磁盘实用程序”菜单中的磁盘实用程序。请注意,在最新版本的 Gnome 中,它简称为“磁盘”。
|
||||
|
||||
#### 如何使用 Linux 上的“磁盘”测试我的硬盘的性能?
|
||||
|
||||
要测试硬盘的速度:
|
||||
|
||||
1. 从“活动概览”中打开“磁盘”(按键盘上的 super 键并键入“disks”)
|
||||
2. 从“左侧窗格”的列表中选择“磁盘”
|
||||
3. 选择菜单按钮并从菜单中选择“测试磁盘性能……”
|
||||
4. 单击“开始性能测试……”并根据需要调整传输速率和访问时间参数。
|
||||
5. 选择“开始性能测试”来测试从磁盘读取数据的速度。需要管理权限请输入密码。
|
||||
|
||||
以上操作的快速视频演示:
|
||||
|
||||
https://www.cyberciti.biz/tips/wp-content/uploads/2007/10/disks-performance.mp4
|
||||
|
||||
#### 只读 Benchmark (安全模式下)
|
||||
|
||||
然后,选择 > 只读:
|
||||
|
||||
![Fig.01: Linux Benchmarking Hard Disk Read Only Test Speed][5]
|
||||
|
||||
上述选项不会销毁任何数据。
|
||||
|
||||
#### 读写的 Benchmark(所有数据将丢失,所以要小心)
|
||||
|
||||
访问“系统>管理>磁盘实用程序菜单>单击性能测试>单击开始读/写性能测试按钮:
|
||||
|
||||
![Fig.02:Linux Measuring read rate, write rate and access time][6]
|
||||
|
||||
### 作者
|
||||
|
||||
作者是 nixCraft 的创造者,是经验丰富的系统管理员,也是 Linux 操作系统/ Unix shell 脚本的培训师。他曾与全球客户以及 IT,教育,国防和空间研究以及非营利部门等多个行业合作。在Twitter,Facebook和Google+上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/how-fast-is-linux-sata-hard-disk.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[2]:https://www.cyberciti.biz/faq/linux-command-to-find-sata-harddisk-link-speed/
|
||||
[3]:https://www.cyberciti.biz/tips/wp-content/uploads/2007/10/Linux-Check-IDE-SATA-SSD-Hard-Disk-Transfer-Speed.jpg
|
||||
[4]:https://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd-command/
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2007/10/Linux-Hard-Disk-Speed-Benchmark.png (Linux Benchmark Hard Disk Speed)
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2007/10/Linux-Hard-Disk-Read-Write-Benchmark.png (Linux Hard Disk Benchmark Read / Write Rate and Access Time)
|
||||
[7]:https://twitter.com/nixcraft
|
||||
[8]:https://facebook.com/nixcraft
|
||||
[9]:https://plus.google.com/+CybercitiBiz
|
||||
89
published/20141029 What does an idle CPU do.md
Normal file
89
published/20141029 What does an idle CPU do.md
Normal file
@ -0,0 +1,89 @@
|
||||
当 CPU 空闲时它都在做什么?
|
||||
============================================================
|
||||
|
||||
在 [上篇文章中][2] 我说了操作系统行为的基本原理是,*在任何一个给定的时刻*,在一个 CPU 上**有且只有一个任务是活动的**。但是,如果 CPU 无事可做的时候,又会是什么样的呢?
|
||||
|
||||
事实证明,这种情况是非常普遍的,对于绝大多数的个人电脑来说,这确实是一种常态:大量的睡眠进程,它们都在等待某种情况下被唤醒,差不多在 100% 的 CPU 时间中,都处于虚构的“空闲任务”中。事实上,如果一个普通用户的 CPU 处于持续的繁忙中,它可能意味着有一个错误、bug、或者运行了恶意软件。
|
||||
|
||||
因为我们不能违反我们的原理,*一些任务需要在一个 CPU 上激活*。首先是因为,这是一个良好的设计:持续很长时间去遍历内核,检查是否*有*一个活动任务,这种特殊情况是不明智的做法。最好的设计是*没有任何例外的情况*。无论何时,你写一个 `if` 语句,Nyan Cat 就会喵喵喵。其次,我们需要使用空闲的 CPU 去做*一些事情*,让它们充满活力,你懂得,就是创建天网计划呗。
|
||||
|
||||
因此,保持这种设计的连续性,并领先于那些邪恶计划一步,操作系统开发者创建了一个**空闲任务**,当没有其它任务可做时就调度它去运行。我们可以在 Linux 的 [引导过程][3] 中看到,这个空闲任务就是进程 0,它是由计算机打开电源时运行的第一个指令直接派生出来的。它在 [rest_init][4] 中初始化,在 [init_idle_bootup_task][5] 中初始化空闲<ruby>调度类<rt>scheduling class</rt></ruby>。
|
||||
|
||||
简而言之,Linux 支持像实时进程、普通用户进程等等的不同调度类。当选择一个进程变成活动任务时,这些类按优先级进行查询。通过这种方式,核反应堆的控制代码总是优先于 web 浏览器运行。尽管在通常情况下,这些类返回 `NULL`,意味着它们没有合适的任务需要去运行 —— 它们总是处于睡眠状态。但是空闲调度类,它是持续运行的,从不会失败:它总是返回空闲任务。
|
||||
|
||||
好吧,我们来看一下这个空闲任务*到底做了些什么*。下面是 [cpu_idle_loop][6],感谢开源能让我们看到它的代码:
|
||||
|
||||
```
|
||||
while (1) {
|
||||
while(!need_resched()) {
|
||||
cpuidle_idle_call();
|
||||
}
|
||||
|
||||
/*
|
||||
[Note: Switch to a different task. We will return to this loop when the idle task is again selected to run.]
|
||||
*/
|
||||
schedule_preempt_disabled();
|
||||
}
|
||||
```
|
||||
|
||||
*cpu_idle_loop*
|
||||
|
||||
我省略了很多的细节,稍后我们将去了解任务切换,但是,如果你阅读了这些源代码,你就会找到它的要点:由于这里不需要重新调度(即改变活动任务),它一直处于空闲状态。以所经历的时间来计算,这个循环和其它操作系统中它的“堂兄弟们”相比,在计算的历史上它是运行的最多的代码片段。对于 Intel 处理器来说,处于空闲状态意味着运行着一个 [halt][7] 指令:
|
||||
|
||||
```
|
||||
static inline void native_halt(void)
|
||||
{
|
||||
asm volatile("hlt": : :"memory");
|
||||
}
|
||||
```
|
||||
|
||||
*native_halt*
|
||||
|
||||
`hlt` 指令停止处理器中的代码执行,并将它置于 `halt` 的状态。奇怪的是,全世界各地数以百万计的 Intel 类的 CPU 们花费大量的时间让它们处于 `halt` 的状态,甚至它们在通电的时候也是如此。这并不是高效、节能的做法,这促使芯片制造商们去开发处理器的深度睡眠状态,以带来着更少的功耗和更长休眠时间。内核的 [cpuidle 子系统][8] 是这些节能模式能够产生好处的原因。
|
||||
|
||||
现在,一旦我们告诉 CPU 去 `halt`(睡眠)之后,我们需要以某种方式让它醒来。如果你读过 [上篇文章《你的操作系统什么时候运行?》][9] ,你可能会猜到*中断*会参与其中,而事实确实如此。中断促使 CPU 离开 `halt` 状态返回到激活状态。因此,将这些拼到一起,下图是当你阅读一个完全呈现的 web 网页时,你的系统主要做的事情:
|
||||
|
||||
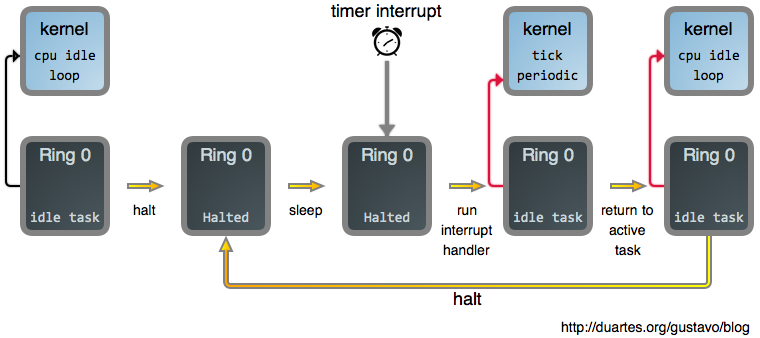
|
||||
|
||||
除定时器中断外的其它中断也会使处理器再次发生变化。如果你再次点击一个 web 页面就会产生这种变化,例如:你的鼠标发出一个中断,它的驱动会处理它,并且因为它产生了一个新的输入,突然进程就可运行了。在那个时刻, `need_resched()` 返回 `true`,然后空闲任务因你的浏览器而被踢出而终止运行。
|
||||
|
||||
如果我们呆呆地看着这篇文章,而不做任何事情。那么随着时间的推移,这个空闲循环就像下图一样:
|
||||
|
||||
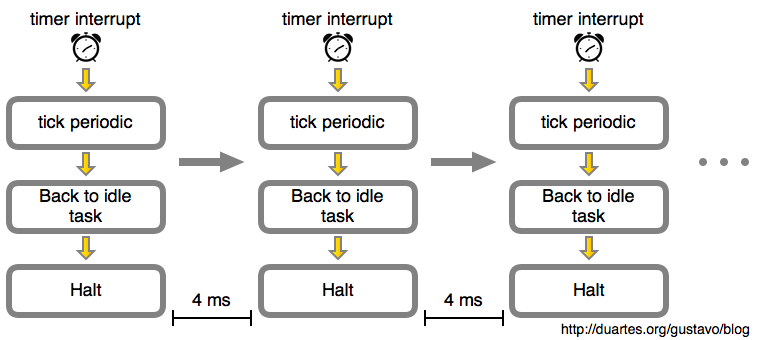
|
||||
|
||||
在这个示例中,由内核计划的定时器中断会每 4 毫秒发生一次。这就是<ruby>滴答<rt>tick</rt></ruby>周期。也就是说每秒钟将有 250 个滴答,因此,这个*滴答速率(频率)*是 250 Hz。这是运行在 Intel 处理器上的 Linux 的典型值,而其它操作系统喜欢使用 100 Hz。这是由你构建内核时在 `CONFIG_HZ` 选项中定义的。
|
||||
|
||||
对于一个*空闲 CPU* 来说,它看起来似乎是个无意义的工作。如果外部世界没有新的输入,在你的笔记本电脑的电池耗尽之前,CPU 将始终处于这种每秒钟被唤醒 250 次的地狱般折磨的小憩中。如果它运行在一个虚拟机中,那我们正在消耗着宿主机 CPU 的性能和宝贵的时钟周期。
|
||||
|
||||
在这里的解决方案是 [动态滴答][10],当 CPU 处于空闲状态时,定时器中断被 [暂停或重计划][11],直到内核*知道*将有事情要做时(例如,一个进程的定时器可能要在 5 秒内过期,因此,我们不能再继续睡眠了),定时器中断才会重新发出。这也被称为*无滴答模式*。
|
||||
|
||||
最后,假设在一个系统中你有一个*活动进程*,例如,一个长时间运行的 CPU 密集型任务。那样几乎就和一个空闲系统是相同的:这些示意图仍然是相同的,只是将空闲任务替换为这个进程,并且相应的描述也是准确的。在那种情况下,每 4 毫秒去中断一次任务仍然是无意义的:它只是操作系统的性能抖动,甚至会使你的工作变得更慢而已。Linux 也可以在这种单一进程的场景中停止这种固定速率的滴答,这被称为 [自适应滴答][12] 模式。最终,这种固定速率的滴答可能会 [完全消失][13]。
|
||||
|
||||
对于阅读一篇文章来说,CPU 基本是无事可做的。内核的这种空闲行为是操作系统难题的一个重要部分,并且它与我们看到的其它情况非常相似,因此,这将帮助我们理解一个运行中的内核。更多的内容将发布在下周的 [RSS][14] 和 [Twitter][15] 上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://manybutfinite.com/post/what-does-an-idle-cpu-do/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/what-does-an-idle-cpu-do/
|
||||
[2]:https://linux.cn/article-9095-1.html
|
||||
[3]:https://manybutfinite.com/post/kernel-boot-process
|
||||
[4]:https://github.com/torvalds/linux/blob/v3.17/init/main.c#L393
|
||||
[5]:https://github.com/torvalds/linux/blob/v3.17/kernel/sched/core.c#L4538
|
||||
[6]:https://github.com/torvalds/linux/blob/v3.17/kernel/sched/idle.c#L183
|
||||
[7]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/include/asm/irqflags.h#L52
|
||||
[8]:http://lwn.net/Articles/384146/
|
||||
[9]:https://linux.cn/article-9095-1.html
|
||||
[10]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/NO_HZ.txt#L17
|
||||
[11]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/highres.txt#L215
|
||||
[12]:https://github.com/torvalds/linux/blob/v3.17/Documentation/timers/NO_HZ.txt#L100
|
||||
[13]:http://lwn.net/Articles/549580/
|
||||
[14]:https://manybutfinite.com/feed.xml
|
||||
[15]:http://twitter.com/manybutfinite
|
||||
@ -1,10 +1,11 @@
|
||||
我在 Twitch 平台直播编程的第一年
|
||||
我在 Twitch 平台直播编程的经验
|
||||
============================================================
|
||||
去年 7 月我进行了第一次直播。不像大多数人那样在 Twitch 上进行游戏直播,我想直播的内容是我利用个人时间进行的开源工作。我对 NodeJS 硬件库有一定的研究(其中大部分是靠我自学的)。考虑到我已经在 Twitch 上有了一个直播间,为什么不再建一个更小更专业的直播间,比如使用 <ruby>JavaScript 驱动硬件<rt>JavaScript powered hardware</rt></ruby> 来建立直播间 :) 我注册了 [我自己的频道][1] ,从那以后我就开始定期直播。
|
||||
|
||||
去年 7 月我进行了第一次直播。不像大多数人那样在 Twitch 上进行游戏直播,我想直播的内容是我利用个人时间进行的开源工作。我对 NodeJS 硬件库有一定的研究(其中大部分是靠我自学的)。考虑到我已经在 Twitch 上有了一个直播间,为什么不再建一个更小更专业的直播间,比如 <ruby>由 JavaScript 驱动的硬件<rt>JavaScript powered hardware</rt></ruby> ;) 我注册了 [我自己的频道][1] ,从那以后我就开始定期直播。
|
||||
|
||||
我当然不是第一个这么做的人。[Handmade Hero][2] 是我最早看到的几个在线直播编程的程序员之一。很快这种直播方式被 Vlambeer 发扬光大,他在 Twitch 的 [Nuclear Throne live][3] 直播间进行直播。我对 Vlambeer 尤其着迷。
|
||||
|
||||
我的朋友 [Nolan Lawson][4] 让我 _真正开始做_ 这件事,而不只是单纯地 _想要做_ 。我看了他 [在周末直播开源工作][5] ,做得棒极了。他解释了他当时做的每一件事。每一件事。回复 GitHub 上的 <ruby>问题<rt>issues</rt></ruby> ,鉴别 bug ,在 <ruby>分支<rt>branches</rt></ruby> 中调试程序,你知道的。这令我着迷,因为 Nolan 使他的开源库得到了广泛的使用。他的开源生活和我的完全不一样。
|
||||
我的朋友 [Nolan Lawson][4] 让我 _真正开始做_ 这件事,而不只是单纯地 _想要做_ 。我看了他 [在周末直播开源工作][5] ,做得棒极了。他解释了他当时做的每一件事。是的,每一件事,包括回复 GitHub 上的 <ruby>问题<rt>issues</rt></ruby> ,鉴别 bug ,在 <ruby>分支<rt>branches</rt></ruby> 中调试程序,你知道的。这令我着迷,因为 Nolan 使他的开源库得到了广泛的使用。他的开源生活和我的完全不一样。
|
||||
|
||||
你甚至可以看到我在他视频下的评论:
|
||||
|
||||
@ -14,27 +15,27 @@
|
||||
|
||||
那个星期六我极少的几个听众给了我很大的鼓舞,因此我坚持了下去。现在我有了超过一千个听众,他们中的一些人形成了一个可爱的小团体,他们会定期观看我的直播,我称呼他们为 “noopkat 家庭” 。
|
||||
|
||||
我们很开心。我想称呼这个即时编程部分为“多玩家在线组队编程”。我真的被他们每个人的热情和才能触动了。一次,一个团体成员指出我的 Arduino 开发板没有连接上软件,因为板子上的芯片丢了。这真是最有趣的时刻之一。
|
||||
我们很开心。我想称呼这个即时编程部分为“多玩家在线组队编程”。我真的被他们每个人的热情和才能触动了。一次,一个团体成员指出我的 Arduino 开发板不能随同我的软件工作,因为板子上的芯片丢了。这真是最有趣的时刻之一。
|
||||
|
||||
我经常暂停直播,检查我的收件箱,看看有没有人对我提过的,不再有时间完成的工作发起 <ruby>拉取请求<rt>pull request</rt></ruby> 。感谢我 Twitch 社区对我的帮助和鼓励。
|
||||
我经常暂停直播,检查我的收件箱,看看有没有人对我提及过但没有时间完成的工作发起 <ruby>拉取请求<rt>pull request</rt></ruby> 。感谢我 Twitch 社区对我的帮助和鼓励。
|
||||
|
||||
我很想聊聊 Twitch 直播给我带来的好处,但它的内容太多了,我应该会在我下一个博客里介绍。我在这里想要分享的,是我学习的关于如何自己实现直播编程的课程。最近几个开发者问我怎么开始自己的直播,因此我在这里想大家展示我给他们的建议!
|
||||
我很想聊聊 Twitch 直播给我带来的好处,但它的内容太多了,我应该会在我下一篇博客里介绍。我在这里想要分享的,是我学习的关于如何自己实现直播编程的课程。最近几个开发者问我怎么开始自己的直播,因此我在这里想大家展示我给他们的建议!
|
||||
|
||||
首先,我在这里贴出一个给过我很大帮助的教程 [“Streaming and Finding Success on Twitch”][7] 。它专注于 Twitch 与游戏直播,但也有很多和我们要做的东西相关的部分。我建议首先阅读这个教程,然后再考虑一些建立直播频道的细节(比如如何选择设备和软件)。
|
||||
|
||||
下面我列出我自己的配置。这些配置是从我多次的错误经验中总结出来的,其中要感谢我的直播同行的智慧与建议(对,你们知道就是你们!)。
|
||||
下面我列出我自己的配置。这些配置是从我多次的错误经验中总结出来的,其中要感谢我的直播同行的智慧与建议。(对,你们知道就是你们!)
|
||||
|
||||
### 软件
|
||||
|
||||
有很多免费的直播软件。我用的是 [Open Broadcaster Software (OBS)][8] 。它适用于大多数的平台。我觉得它十分直观且易于入门,但掌握其他的进阶功能则需要一段时间的学习。学好它你会获得很多好处!这是今天我直播时 OBS 的桌面截图(点击查看大图):
|
||||
有很多免费的直播软件。我用的是 [Open Broadcaster Software (OBS)][8] 。它适用于大多数的平台。我觉得它十分直观且易于入门,但掌握其他的进阶功能则需要一段时间的学习。学好它你会获得很多好处!这是今天我直播时 OBS 的桌面截图:
|
||||
|
||||

|
||||
|
||||
你直播时需要在不用的“场景”中进行切换。一个“场景”是多个“素材”通过堆叠和组合产生的集合。一个“素材”可以是照相机,麦克风,你的桌面,网页,动态文本,图片等等。 OBS 是一个很强大的软件。
|
||||
你直播时需要在不用的“<ruby>场景<rt>scenes</rt></ruby>”中进行切换。一个“场景”是多个“<ruby>素材<rt>sources</rt></ruby>”通过堆叠和组合产生的集合。一个“素材”可以是照相机、麦克风、你的桌面、网页、动态文本、图片等等。 OBS 是一个很强大的软件。
|
||||
|
||||
最上方的桌面场景是我编程的环境,我直播的时候主要停留在这里。我使用 iTerm 和 vim ,同时打开一个可以切换的浏览器窗口来查阅文献或在 GitHub 上分类检索资料。
|
||||
|
||||
底部的黑色长方形是我的网络摄像头,人们可以通过这种个人化的连接方式来观看我工作。
|
||||
底部的黑色长方形是我的网络摄像头,人们可以通过这种更个人化的连接方式来观看我工作。
|
||||
|
||||
我的场景中有一些“标签”,很多都与状态或者顶栏信息有关。顶栏只是添加了个性化信息,它在直播时是一个很好的连续性素材。这是我在 [GIMP][9] 里制作的图片,在你的场景里它会作为一个素材来加载。一些标签是从文本文件里添加的动态内容(例如最新粉丝)。另一个标签是一个 [custom one I made][10] ,它可以展示我直播的房间的动态温度与湿度。
|
||||
|
||||
@ -62,7 +63,7 @@
|
||||
|
||||
### 硬件
|
||||
|
||||
我从使用便宜的器材开始,当我意识到我会长期坚持直播之后,才将他们逐渐换成更好的。开始的时候尽量使用你现有的器材,即使是只用电脑内置的摄像头与麦克风。
|
||||
我从使用便宜的器材开始,当我意识到我会长期坚持直播之后,才将它们逐渐换成更好的。开始的时候尽量使用你现有的器材,即使是只用电脑内置的摄像头与麦克风。
|
||||
|
||||
现在我使用 Logitech Pro C920 网络摄像头,和一个固定有支架的 Blue Yeti 麦克风。花费是值得的。我直播的质量完全不同了。
|
||||
|
||||
@ -116,7 +117,7 @@
|
||||
|
||||
当你即将开始的时候,你会感觉很奇怪,不适应。你会在人们看着你写代码的时候感到紧张。这很正常!尽管我之前有过公共演说的经历,我一开始的时候还是感到陌生而不适应。我感觉我无处可藏,这令我害怕。我想:“大家可能都觉得我的代码很糟糕,我是一个糟糕的开发者。”这是一个困扰了我 _整个职业生涯_ 的想法,对我来说不新鲜了。我知道带着这些想法,我不能在发布到 GitHub 之前仔细地再检查一遍代码,而这样做更有利于我保持我作为开发者的声誉。
|
||||
|
||||
我从 Twitch 直播中发现了很多关于我代码风格的东西。我知道我的风格绝对是“先让它跑起来,然后再考虑可读性,然后再考虑运行速度”。我不再在前一天晚上提前排练好直播的内容(一开始的三四次直播我都是这么做的),所以我在 Twitch 上写的代码是相当粗糙的,我还得保证它们运行起来没问题。当我不看别人的聊天和讨论的时候,我可以写出我最好的代码,这样是没问题的。但我总会忘记我使用过无数遍的方法的名字,而且每次直播的时候都会犯“愚蠢的”错误。一般来说,这不是一个让你能达到你最好状态的生产环境。
|
||||
我从 Twitch 直播中发现了很多关于我代码风格的东西。我知道我的风格绝对是“先让它跑起来,然后再考虑可读性,然后再考虑运行速度”。我不再在前一天晚上提前排练好直播的内容(一开始的三、四次直播我都是这么做的),所以我在 Twitch 上写的代码是相当粗糙的,我还得保证它们运行起来没问题。当我不看别人的聊天和讨论的时候,我可以写出我最好的代码,这样是没问题的。但我总会忘记我使用过无数遍的方法的名字,而且每次直播的时候都会犯“愚蠢的”错误。一般来说,这不是一个让你能达到你最好状态的生产环境。
|
||||
|
||||
我的 Twitch 社区从来不会因为这个苛求我,反而是他们帮了我很多。他们理解我正同时做着几件事,而且真的给了很多务实的意见和建议。有时是他们帮我找到了解决方法,有时是我要向他们解释为什么他们的建议不适合解决这个问题。这真的很像一般意义的组队编程!
|
||||
|
||||
@ -128,7 +129,7 @@
|
||||
|
||||
如果你周日想要加入我的直播,你可以 [订阅我的 Twitch 频道][13] :)
|
||||
|
||||
最后我想说一下,我个人十分感谢 [Mattias Johansson][14] 在我早期开始直播的时候给我的建议和鼓励。他的 [FunFunFunction YouTube channel][15] 也是一个令人激动的定期直播频道。
|
||||
最后我想说一下,我自己十分感谢 [Mattias Johansson][14] 在我早期开始直播的时候给我的建议和鼓励。他的 [FunFunFunction YouTube channel][15] 也是一个令人激动的定期直播频道。
|
||||
|
||||
另:许多人问过我的键盘和其他工作设备是什么样的, [这是我使用的器材的完整列表][16] 。感谢关注!
|
||||
|
||||
@ -136,9 +137,9 @@
|
||||
|
||||
via: https://medium.freecodecamp.org/lessons-from-my-first-year-of-live-coding-on-twitch-41a32e2f41c1
|
||||
|
||||
作者:[ Suz Hinton][a]
|
||||
作者:[Suz Hinton][a]
|
||||
译者:[lonaparte](https://github.com/lonaparte)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
269
published/20170915 How To Install And Setup Vagrant.md
Normal file
269
published/20170915 How To Install And Setup Vagrant.md
Normal file
@ -0,0 +1,269 @@
|
||||
如何安装并设置 Vagrant
|
||||
=============================
|
||||
|
||||
Vagrant 对于虚拟机来说是一个强大的工具,在这里我们将研究如何在 Ubuntu 上设置和使用 Virtualbox 和 Vagrant 来提供可复制的虚拟机。
|
||||
|
||||
### 虚拟机,并不复杂
|
||||
|
||||
多年来,开发人员一直使用虚拟机作为其工作流程的一部分,允许他们交换和更改运行软件的环境,这通常是为了防止项目之间的冲突,例如需要 php 5.3 的项目 A 和需要 php 5.4 的项目 B。
|
||||
|
||||
并且使用虚拟机意味着你只需要你正在使用的计算机就行,而不需要专用硬件来镜像你的生产环境。
|
||||
|
||||
当多个开发人员在一个项目上工作时,它也很方便,他们都可以运行一个包含所有需求的环境,但是维护多台机器并确保所有的需求都具有相同的版本是非常困难的,这时 Vagrant 就能派上用场了。
|
||||
|
||||
#### 使用虚拟机的好处
|
||||
|
||||
- 你的虚拟机与主机环境是分开的
|
||||
- 你可以根据你代码的要求裁剪一个定制虚拟机
|
||||
- 不会影响其他虚拟机
|
||||
- 可以运行在你的主机上无法运行的程序,例如在 Ubuntu 中运行一些只能在 Windows 运行的软件
|
||||
|
||||
### 什么是 Vagrant
|
||||
|
||||
简而言之,这是一个与虚拟机一起工作的工具,可以让你自动创建和删除虚拟机。
|
||||
|
||||
它围绕一个名为 `VagrantFile` 的配置文件而工作,这个配置文件告诉 Vagrant 你想要安装的操作系统,以及一些其他选项,如 IP 和目录同步。 你还可以在虚拟机上添加一个命令的配置脚本。
|
||||
|
||||
通过共享这个 `VagrantFile`,项目的所有开发人员全可以使用完全相同的虚拟机。
|
||||
|
||||
### 安装要求
|
||||
|
||||
#### 安装 VirtualBox
|
||||
|
||||
VirtualBox 是运行虚拟机的程序,它可以从 Ubuntu 仓库中安装。
|
||||
|
||||
```
|
||||
sudo apt-get install virtualbox
|
||||
```
|
||||
|
||||
#### 安装 Vagrant
|
||||
|
||||
对于 Vagrant 本身,你要前往 [https://www.vagrantup.com/downloads.html ](https://www.vagrantup.com/downloads.html) 查看适用于你的操作系统的安装软件包。
|
||||
|
||||
#### 安装增强功能
|
||||
|
||||
如果你打算与虚拟机共享任何文件夹,则需要安装以下插件。
|
||||
|
||||
```
|
||||
vagrant plugin install vagrant-vbguest
|
||||
```
|
||||
|
||||
### 配置 Vagrant
|
||||
|
||||
首先我们需要为 Vagrant 创建一个文件夹。
|
||||
|
||||
```
|
||||
mkdir ~/Vagrant/test-vm
|
||||
cd ~/Vagrant/test-vm
|
||||
```
|
||||
|
||||
创建 VagrantFile:
|
||||
|
||||
```
|
||||
vagrant init
|
||||
```
|
||||
|
||||
开启虚拟机:
|
||||
|
||||
```
|
||||
vagrant up
|
||||
```
|
||||
|
||||
登录机器:
|
||||
|
||||
```
|
||||
vagrant-ssh
|
||||
```
|
||||
|
||||
此时,你将拥有一个基本的 vagrant 机器,以及一个名为 `VagrantFile` 的文件。
|
||||
|
||||
### 定制
|
||||
|
||||
在上面的步骤中创建的 `VagrantFile` 看起来类似于以下内容
|
||||
|
||||
VagrantFile:
|
||||
|
||||
```
|
||||
# -*- mode: ruby -*-
|
||||
# vi: set ft=ruby :
|
||||
# All Vagrant configuration is done below. The "2" in Vagrant.configure
|
||||
# configures the configuration version (we support older styles for
|
||||
# backwards compatibility). Please don't change it unless you know what
|
||||
# you're doing.
|
||||
Vagrant.configure("2") do |config|
|
||||
# The most common configuration options are documented and commented below.
|
||||
# For a complete reference, please see the online documentation at
|
||||
# https://docs.vagrantup.com.
|
||||
|
||||
# Every Vagrant development environment requires a box. You can search for
|
||||
# boxes at https://vagrantcloud.com/search.
|
||||
config.vm.box = "base"
|
||||
|
||||
# Disable automatic box update checking. If you disable this, then
|
||||
# boxes will only be checked for updates when the user runs
|
||||
# `vagrant box outdated`. This is not recommended.
|
||||
# config.vm.box_check_update = false
|
||||
|
||||
# Create a forwarded port mapping which allows access to a specific port
|
||||
# within the machine from a port on the host machine. In the example below,
|
||||
# accessing "localhost:8080" will access port 80 on the guest machine.
|
||||
# NOTE: This will enable public access to the opened port
|
||||
# config.vm.network "forwarded_port", guest: 80, host: 8080
|
||||
|
||||
# Create a forwarded port mapping which allows access to a specific port
|
||||
# within the machine from a port on the host machine and only allow access
|
||||
# via 127.0.0.1 to disable public access
|
||||
# config.vm.network "forwarded_port", guest: 80, host: 8080, host_ip: "127.0.0.1"
|
||||
|
||||
# Create a private network, which allows host-only access to the machine
|
||||
# using a specific IP.
|
||||
# config.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
# Create a public network, which generally matched to bridged network.
|
||||
# Bridged networks make the machine appear as another physical device on
|
||||
# your network.
|
||||
# config.vm.network "public_network"
|
||||
|
||||
# Share an additional folder to the guest VM. The first argument is
|
||||
# the path on the host to the actual folder. The second argument is
|
||||
# the path on the guest to mount the folder. And the optional third
|
||||
# argument is a set of non-required options.
|
||||
# config.vm.synced_folder "../data", "/vagrant_data"
|
||||
|
||||
# Provider-specific configuration so you can fine-tune various
|
||||
# backing providers for Vagrant. These expose provider-specific options.
|
||||
# Example for VirtualBox:
|
||||
#
|
||||
# config.vm.provider "virtualbox" do |vb|
|
||||
# # Display the VirtualBox GUI when booting the machine
|
||||
# vb.gui = true
|
||||
#
|
||||
# # Customize the amount of memory on the VM:
|
||||
# vb.memory = "1024"
|
||||
# end
|
||||
#
|
||||
# View the documentation for the provider you are using for more
|
||||
# information on available options.
|
||||
|
||||
# Enable provisioning with a shell script. Additional provisioners such as
|
||||
# Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
|
||||
# documentation for more information about their specific syntax and use.
|
||||
# config.vm.provision "shell", inline: <<-SHELL
|
||||
# apt-get update
|
||||
# apt-get install -y apache2
|
||||
# SHELL
|
||||
end
|
||||
```
|
||||
|
||||
现在这个 `VagrantFile` 将创建基本的虚拟机。但 Vagrant 背后的理念是让虚拟机为我们的特定任务而配置,所以我们删除注释和调整配置。
|
||||
|
||||
VagrantFile:
|
||||
|
||||
```
|
||||
# -*- mode: ruby -*-
|
||||
# vi: set ft=ruby :
|
||||
|
||||
Vagrant.configure("2") do |config|
|
||||
# Set the Linux Version to Debian Jessie
|
||||
config.vm.box = "debian/jessie64"
|
||||
# Set the IP of the Box
|
||||
config.vm.network "private_network", ip: "192.168.33.10"
|
||||
# Sync Our Projects Directory with the WWW directory
|
||||
config.vm.synced_folder "~/Projects", "/var/www/"
|
||||
# Run the following to Provision
|
||||
config.vm.provision "shell", path: "install.sh"
|
||||
end
|
||||
```
|
||||
|
||||
现在我们有一个简单的 `VagrantFile`,它将 Linux 版本设置为 debian jessie,设置一个 IP 给我们使用,同步我们感兴趣的文件夹,并最后运行 `install.sh`,这是我们可以运行 shell 命令的地方。
|
||||
|
||||
install.sh:
|
||||
|
||||
```
|
||||
#! /usr/bin/env bash
|
||||
# Variables
|
||||
DBHOST=localhost
|
||||
DBNAME=dbname
|
||||
DBUSER=dbuser
|
||||
DBPASSWD=test123
|
||||
|
||||
echo "[ Provisioning machine ]"
|
||||
echo "1) Update APT..."
|
||||
apt-get -qq update
|
||||
|
||||
echo "1) Install Utilities..."
|
||||
apt-get install -y tidy pdftk curl xpdf imagemagick openssl vim git
|
||||
|
||||
echo "2) Installing Apache..."
|
||||
apt-get install -y apache2
|
||||
|
||||
echo "3) Installing PHP and packages..."
|
||||
apt-get install -y php5 libapache2-mod-php5 libssh2-php php-pear php5-cli php5-common php5-curl php5-dev php5-gd php5-imagick php5-imap php5-intl php5-mcrypt php5-memcached php5-mysql php5-pspell php5-xdebug php5-xmlrpc
|
||||
#php5-suhosin-extension, php5-mysqlnd
|
||||
|
||||
echo "4) Installing MySQL..."
|
||||
debconf-set-selections <<< "mysql-server mysql-server/root_password password secret"
|
||||
debconf-set-selections <<< "mysql-server mysql-server/root_password_again password secret"
|
||||
apt-get install -y mysql-server
|
||||
mysql -uroot -p$DBPASSWD -e "CREATE DATABASE $DBNAME"
|
||||
mysql -uroot -p$DBPASSWD -e "grant all privileges on $DBNAME.* to '$DBUSER'@'localhost' identified by '$DBPASSWD'"
|
||||
|
||||
echo "5) Generating self signed certificate..."
|
||||
mkdir -p /etc/ssl/localcerts
|
||||
openssl req -new -x509 -days 365 -nodes -subj "/C=US/ST=Denial/L=Springfield/O=Dis/CN=www.example.com" -out /etc/ssl/localcerts/apache.pem -keyout /etc/ssl/localcerts/apache.key
|
||||
chmod 600 /etc/ssl/localcerts/apache*
|
||||
|
||||
echo "6) Setup Apache..."
|
||||
a2enmod rewrite
|
||||
> /etc/apache2/sites-enabled/000-default.conf
|
||||
echo "
|
||||
<VirtualHost *:80>
|
||||
ServerAdmin webmaster@localhost
|
||||
DocumentRoot /var/www/
|
||||
ErrorLog ${APACHE_LOG_DIR}/error.log
|
||||
CustomLog ${APACHE_LOG_DIR}/access.log combined
|
||||
</VirtualHost>
|
||||
|
||||
" >> /etc/apache2/sites-enabled/000-default.conf
|
||||
service apache2 restart
|
||||
|
||||
echo "7) Composer Install..."
|
||||
curl --silent https://getcomposer.org/installer | php
|
||||
mv composer.phar /usr/local/bin/composer
|
||||
|
||||
echo "8) Install NodeJS..."
|
||||
curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -
|
||||
apt-get -qq update
|
||||
apt-get -y install nodejs
|
||||
|
||||
echo "9) Install NPM Packages..."
|
||||
npm install -g gulp gulp-cli
|
||||
|
||||
echo "Provisioning Completed"
|
||||
```
|
||||
|
||||
通过上面的步骤,在你的目录中会有 `VagrantFile` 和 `install.sh`,运行 vagrant 会做下面的事情:
|
||||
|
||||
- 采用 Debian Jessie 来创建虚拟机
|
||||
- 将机器的 IP 设置为 192.168.33.10
|
||||
- 同步 `~/Projects` 和 `/var/www/` 目录
|
||||
- 安装并设置 Apache、Mysql、PHP、Git、Vim
|
||||
- 安装并运行 Composer
|
||||
- 安装 Nodejs 和 gulp
|
||||
- 创建一个 MySQL 数据库
|
||||
- 创建自签名证书
|
||||
|
||||
通过与其他人共享 `VagrantFile` 和 `install.sh`,你可以在两台不同的机器上使用完全相同的环境。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.chris-shaw.com/blog/how-to-install-and-setup-vagrant
|
||||
|
||||
作者:[Christopher Shaw][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.chris-shaw.com
|
||||
[1]:/cdn-cgi/l/email-protection
|
||||
134
published/20171005 Reasons Kubernetes is cool.md
Normal file
134
published/20171005 Reasons Kubernetes is cool.md
Normal file
@ -0,0 +1,134 @@
|
||||
为什么 Kubernetes 很酷
|
||||
============================================================
|
||||
|
||||
在我刚开始学习 Kubernetes(大约是一年半以前吧?)时,我真的不明白为什么应该去关注它。
|
||||
|
||||
在我使用 Kubernetes 全职工作了三个多月后,我才逐渐明白了为什么我应该使用它。(我距离成为一个 Kubernetes 专家还很远!)希望这篇文章对你理解 Kubernetes 能做什么会有帮助!
|
||||
|
||||
我将尝试去解释我对 Kubernetes 感兴趣的一些原因,而不去使用 “<ruby>原生云<rt>cloud native</rt></ruby>”、“<ruby>编排系统<rt>orchestration</rt></ruby>”、“<ruby>容器<rt>container</rt></ruby>”,或者任何 Kubernetes 专用的术语 :)。我去解释的这些观点主要来自一位 Kubernetes 操作者/基础设施工程师,因为,我现在的工作就是去配置 Kubernetes 和让它工作的更好。
|
||||
|
||||
我不会去尝试解决一些如 “你应该在你的生产系统中使用 Kubernetes 吗?”这样的问题。那是非常复杂的问题。(不仅是因为“生产系统”根据你的用途而总是有不同的要求)
|
||||
|
||||
### Kubernetes 可以让你无需设置一台新的服务器即可在生产系统中运行代码
|
||||
|
||||
我首次被说教使用 Kubernetes 是与我的伙伴 Kamal 的下面的谈话:
|
||||
|
||||
大致是这样的:
|
||||
|
||||
* Kamal: 使用 Kubernetes 你可以通过一条命令就能设置一台新的服务器。
|
||||
* Julia: 我觉得不太可能吧。
|
||||
* Kamal: 像这样,你写一个配置文件,然后应用它,这时候,你就在生产系统中运行了一个 HTTP 服务。
|
||||
* Julia: 但是,现在我需要去创建一个新的 AWS 实例,明确地写一个 Puppet 清单,设置服务发现,配置负载均衡,配置我们的部署软件,并且确保 DNS 正常工作,如果没有什么问题的话,至少在 4 小时后才能投入使用。
|
||||
* Kamal: 是的,使用 Kubernetes 你不需要做那么多事情,你可以在 5 分钟内设置一台新的 HTTP 服务,并且它将自动运行。只要你的集群中有空闲的资源它就能正常工作!
|
||||
* Julia: 这儿一定是一个“坑”。
|
||||
|
||||
这里有一种陷阱,设置一个生产用 Kubernetes 集群(在我的经险中)确实并不容易。(查看 [Kubernetes 艰难之旅][3] 中去开始使用时有哪些复杂的东西)但是,我们现在并不深入讨论它。
|
||||
|
||||
因此,Kubernetes 第一个很酷的事情是,它可能使那些想在生产系统中部署新开发的软件的方式变得更容易。那是很酷的事,而且它真的是这样,因此,一旦你使用一个运作中的 Kubernetes 集群,你真的可以仅使用一个配置文件就在生产系统中设置一台 HTTP 服务(在 5 分钟内运行这个应用程序,设置一个负载均衡,给它一个 DNS 名字,等等)。看起来真的很有趣。
|
||||
|
||||
### 对于运行在生产系统中的代码,Kubernetes 可以提供更好的可见性和可管理性
|
||||
|
||||
在我看来,在理解 etcd 之前,你可能不会理解 Kubernetes 的。因此,让我们先讨论 etcd!
|
||||
|
||||
想像一下,如果现在我这样问你,“告诉我你运行在生产系统中的每个应用程序,它运行在哪台主机上?它是否状态很好?是否为它分配了一个 DNS 名字?”我并不知道这些,但是,我可能需要到很多不同的地方去查询来回答这些问题,并且,我需要花很长的时间才能搞定。我现在可以很确定地说不需要查询,仅一个 API 就可以搞定它们。
|
||||
|
||||
在 Kubernetes 中,你的集群的所有状态 – 运行中的应用程序 (“pod”)、节点、DNS 名字、 cron 任务、 等等 —— 都保存在一个单一的数据库中(etcd)。每个 Kubernetes 组件是无状态的,并且基本是通过下列方式工作的:
|
||||
|
||||
* 从 etcd 中读取状态(比如,“分配给节点 1 的 pod 列表”)
|
||||
* 产生变化(比如,“在节点 1 上运行 pod A”)
|
||||
* 更新 etcd 中的状态(比如,“设置 pod A 的状态为 ‘running’”)
|
||||
|
||||
这意味着,如果你想去回答诸如 “在那个可用区中有多少台运行着 nginx 的 pod?” 这样的问题时,你可以通过查询一个统一的 API(Kubernetes API)去回答它。并且,你可以在每个其它 Kubernetes 组件上运行那个 API 去进行同样的访问。
|
||||
|
||||
这也意味着,你可以很容易地去管理每个运行在 Kubernetes 中的任何东西。比如说,如果你想要:
|
||||
|
||||
* 部署实现一个复杂的定制的部署策略(部署一个东西,等待 2 分钟,部署 5 个以上,等待 3.7 分钟,等等)
|
||||
* 每当推送到 github 上一个分支,自动化 [启动一个新的 web 服务器][1]
|
||||
* 监视所有你的运行的应用程序,确保它们有一个合理的内存使用限制。
|
||||
|
||||
这些你只需要写一个程序与 Kubernetes API(“controller”)通讯就可以了。
|
||||
|
||||
另一个关于 Kubernetes API 的令人激动的事情是,你不会局限于 Kubernetes 所提供的现有功能!如果对于你要部署/创建/监视的软件有你自己的方案,那么,你可以使用 Kubernetes API 去写一些代码去达到你的目的!它可以让你做到你想做的任何事情。
|
||||
|
||||
### 即便每个 Kubernetes 组件都“挂了”,你的代码将仍然保持运行
|
||||
|
||||
关于 Kubernetes 我(在各种博客文章中 :))承诺的一件事情是,“如果 Kubernetes API 服务和其它组件‘挂了’也没事,你的代码将一直保持运行状态”。我认为理论上这听起来很酷,但是我不确定它是否真是这样的。
|
||||
|
||||
到目前为止,这似乎是真的!
|
||||
|
||||
我已经断开了一些正在运行的 etcd,发生了这些情况:
|
||||
|
||||
1. 所有的代码继续保持运行状态
|
||||
2. 不能做 _新的_ 事情(你不能部署新的代码或者生成变更,cron 作业将停止工作)
|
||||
3. 当它恢复时,集群将赶上这期间它错过的内容
|
||||
|
||||
这样做意味着如果 etcd 宕掉,并且你的应用程序的其中之一崩溃或者发生其它事情,在 etcd 恢复之前,它不能够恢复。
|
||||
|
||||
### Kubernetes 的设计对 bug 很有弹性
|
||||
|
||||
与任何软件一样,Kubernetes 也会有 bug。例如,到目前为止,我们的集群控制管理器有内存泄漏,并且,调度器经常崩溃。bug 当然不好,但是,我发现 Kubernetes 的设计可以帮助减轻它的许多核心组件中的错误的影响。
|
||||
|
||||
如果你重启动任何组件,将会发生:
|
||||
|
||||
* 从 etcd 中读取所有的与它相关的状态
|
||||
* 基于那些状态(调度 pod、回收完成的 pod、调度 cron 作业、按需部署等等),它会去做那些它认为必须要做的事情
|
||||
|
||||
因为,所有的组件并不会在内存中保持状态,你在任何时候都可以重启它们,这可以帮助你减轻各种 bug 的影响。
|
||||
|
||||
例如,如果在你的控制管理器中有内存泄露。因为,控制管理器是无状态的,你可以每小时定期去重启它,或者,在感觉到可能导致任何不一致的问题发生时重启它。又或者,在调度器中遇到了一个 bug,它有时忘记了某个 pod,从来不去调度它们。你可以每隔 10 分钟来重启调度器来缓减这种情况。(我们并不会这么做,而是去修复这个 bug,但是,你_可以这样做_ :))
|
||||
|
||||
因此,我觉得即使在它的核心组件中有 bug,我仍然可以信任 Kubernetes 的设计可以让我确保集群状态的一致性。并且,总在来说,随着时间的推移软件质量会提高。唯一你必须去操作的有状态的东西就是 etcd。
|
||||
|
||||
不用过多地讨论“状态”这个东西 —— 而我认为在 Kubernetes 中很酷的一件事情是,唯一需要去做备份/恢复计划的东西是 etcd (除非为你的 pod 使用了持久化存储的卷)。我认为这样可以使 Kubernetes 运维比你想的更容易一些。
|
||||
|
||||
### 在 Kubernetes 之上实现新的分布式系统是非常容易的
|
||||
|
||||
假设你想去实现一个分布式 cron 作业调度系统!从零开始做工作量非常大。但是,在 Kubernetes 里面实现一个分布式 cron 作业调度系统是非常容易的!(仍然没那么简单,毕竟它是一个分布式系统)
|
||||
|
||||
我第一次读到 Kubernetes 的 cron 作业控制器的代码时,我对它是如此的简单感到由衷高兴。去读读看,其主要的逻辑大约是 400 行的 Go 代码。去读它吧! => [cronjob_controller.go][4] <=
|
||||
|
||||
cron 作业控制器基本上做的是:
|
||||
|
||||
* 每 10 秒钟:
|
||||
* 列出所有已存在的 cron 作业
|
||||
* 检查是否有需要现在去运行的任务
|
||||
* 如果有,创建一个新的作业对象去调度,并通过其它的 Kubernetes 控制器实际运行它
|
||||
* 清理已完成的作业
|
||||
* 重复以上工作
|
||||
|
||||
Kubernetes 模型是很受限制的(它有定义在 etcd 中的资源模式,控制器读取这个资源并更新 etcd),我认为这种相关的固有的/受限制的模型,可以使它更容易地在 Kubernetes 框架中开发你自己的分布式系统。
|
||||
|
||||
Kamal 给我说的是 “Kubernetes 是一个写你自己的分布式系统的很好的平台” ,而不是“ Kubernetes 是一个你可以使用的分布式系统”,并且,我觉得它真的很有意思。他做了一个 [为你推送到 GitHub 的每个分支运行一个 HTTP 服务的系统][5] 的原型。这花了他一个周末的时间,大约 800 行 Go 代码,我认为它真不可思议!
|
||||
|
||||
### Kubernetes 可以使你做一些非常神奇的事情(但并不容易)
|
||||
|
||||
我一开始就说 “kubernetes 可以让你做一些很神奇的事情,你可以用一个配置文件来做这么多的基础设施,它太神奇了”。这是真的!
|
||||
|
||||
为什么说 “Kubernetes 并不容易”呢?是因为 Kubernetes 有很多部分,学习怎么去成功地运营一个高可用的 Kubernetes 集群要做很多的工作。就像我发现它给我了许多抽象的东西,我需要去理解这些抽象的东西才能调试问题和正确地配置它们。我喜欢学习新东西,因此,它并不会使我发狂或者生气,但是我认为了解这一点很重要 :)
|
||||
|
||||
对于 “我不能仅依靠抽象概念” 的一个具体的例子是,我努力学习了许多 [Linux 上网络是如何工作的][6],才让我对设置 Kubernetes 网络稍有信心,这比我以前学过的关于网络的知识要多很多。这种方式很有意思但是非常费时间。在以后的某个时间,我或许写更多的关于设置 Kubernetes 网络的困难/有趣的事情。
|
||||
|
||||
或者,为了成功设置我的 Kubernetes CA,我写了一篇 [2000 字的博客文章][7],述及了我不得不学习 Kubernetes 不同方式的 CA 的各种细节。
|
||||
|
||||
我觉得,像 GKE (Google 的 Kubernetes 产品) 这样的一些监管的 Kubernetes 的系统可能更简单,因为,他们为你做了许多的决定,但是,我没有尝试过它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/10/05/reasons-kubernetes-is-cool/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:https://github.com/kamalmarhubi/kubereview
|
||||
[2]:https://jvns.ca/categories/kubernetes
|
||||
[3]:https://github.com/kelseyhightower/kubernetes-the-hard-way
|
||||
[4]:https://github.com/kubernetes/kubernetes/blob/e4551d50e57c089aab6f67333412d3ca64bc09ae/pkg/controller/cronjob/cronjob_controller.go
|
||||
[5]:https://github.com/kamalmarhubi/kubereview
|
||||
[6]:https://jvns.ca/blog/2016/12/22/container-networking/
|
||||
[7]:https://jvns.ca/blog/2017/08/05/how-kubernetes-certificates-work/
|
||||
|
||||
|
||||
@ -0,0 +1,127 @@
|
||||
怎样完整地离线更新并升级基于 Debian 的操作系统
|
||||
======
|
||||
|
||||

|
||||
|
||||
不久之前我已经向你展示了如何在任意离线的 [Ubuntu][1] 和 [Arch Linux][2] 操作系统上安装软件。 今天,我们将会看看如何完整地离线更新并升级基于 Debian 的操作系统。 和之前所述方法的不同之处在于,这次我们将会升级整个操作系统,而不是单个的软件包。这个方法在你没有网络链接或拥有的网络速度很慢的时候十分有用。
|
||||
|
||||
### 完整地离线更新并升级基于 Debian 的操作系统
|
||||
|
||||
首先假设,你在单位拥有正在运行并配置有高速互联网链接的系统(Windows 或者 Linux),而在家有一个没有网络链接或网络很慢(例如拨号网络)的 Debian 或其衍生的操作系统。现在如果你想要离线更新你家里的操作系统怎么办?购买一个更加高速的网络链接?不,根本不需要!你仍然可以通过互联网离线更新升级你的操作系统。这正是 **Apt-Offline**工具可以帮助你做到的。
|
||||
|
||||
正如其名,apt-offline 是一个为 Debian 及其衍生发行版(诸如 Ubuntu、Linux Mint 这样基于 APT 的操作系统)提供的离线 APT 包管理器。使用 apt-offline,我们可以完整地更新/升级我们的 Debian 系统而不需要网络链接。这个程序是由 Python 编程语言写成的兼具 CLI 和图形界面的跨平台工具。
|
||||
|
||||
#### 准备工作
|
||||
|
||||
* 一个已经联网的操作系统(Windows 或者 Linux)。在这份指南中,为了便于理解,我们将之称为在线操作系统。
|
||||
* 一个离线操作系统(Debian 及其衍生版本)。我们称之为离线操作系统。
|
||||
* 有足够空间容纳所有更新包的 USB 驱动器或者外接硬盘。
|
||||
|
||||
#### 安装
|
||||
|
||||
Apt-Offline 可以在 Debian 及其衍生版本的默认仓库中获得。如果你的在线操作系统是运行的 Debian、Ubuntu、Linux Mint,及其它基于 DEB 的操作系统,你可以通过下面的命令安装 Apt-Offline:
|
||||
|
||||
```
|
||||
sudo apt-get install apt-offline
|
||||
```
|
||||
|
||||
如果你的在线操作系统运行的是非 Debian 类的发行版,使用 `git clone` 获取 Apt-Offline 仓库:
|
||||
|
||||
```
|
||||
git clone https://github.com/rickysarraf/apt-offline.git
|
||||
```
|
||||
|
||||
切换到克隆的目录下并在此处运行:
|
||||
|
||||
```
|
||||
cd apt-offline/
|
||||
sudo ./apt-offline
|
||||
```
|
||||
|
||||
#### 在离线操作系统(没有联网的操作系统)上的步骤
|
||||
|
||||
到你的离线操作系统上创建一个你想存储签名文件的目录:
|
||||
|
||||
```
|
||||
mkdir ~/tmp
|
||||
cd ~/tmp/
|
||||
```
|
||||
|
||||
你可以自己选择使用任何目录。接下来,运行下面的命令生成签名文件:
|
||||
|
||||
```
|
||||
sudo apt-offline set apt-offline.sig
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
Generating database of files that are needed for an update.
|
||||
Generating database of file that are needed for operation upgrade
|
||||
```
|
||||
|
||||
默认条件下,apt-offline 将会生成需要更新和升级的相关文件的数据库。你可以使用 `--update` 或者 `--upgrade` 选项相应创建。
|
||||
|
||||
拷贝完整的 `tmp` 目录到你的 USB 驱动器或者或者外接硬盘上,然后换到你的在线操作系统(有网络链接的操作系统)。
|
||||
|
||||
#### 在在线操作系统上的步骤
|
||||
|
||||
插入你的 USB 驱动器然后进入 `tmp` 文件夹:
|
||||
|
||||
```
|
||||
cd tmp/
|
||||
```
|
||||
|
||||
然后,运行如下命令:
|
||||
|
||||
```
|
||||
sudo apt-offline get apt-offline.sig --threads 5 --bundle apt-offline-bundle.zip
|
||||
```
|
||||
|
||||
在这里的 `-threads 5` 代表着(并发连接的) APT 仓库的数目。如果你想要从更多的仓库下载软件包,你可以增加这里的数值。然后 `-bundle apt-offline-bundle.zip` 选项表示所有的软件包将会打包到一个叫做 `apt-offline-bundle.zip` 的单独存档中。这个存档文件将会被保存在你的当前工作目录中(LCTT 译注:即 `tmp` 目录)。
|
||||
|
||||
上面的命令将会按照之前在离线操作系统上生成的签名文件下载数据。
|
||||
|
||||
![][4]
|
||||
|
||||
根据你的网络状况,这个操作将会花费几分钟左右的时间。请记住,apt-offline 是跨平台的,所以你可以在任何操作系统上使用它下载包。
|
||||
|
||||
一旦下载完成,拷贝 `tmp` 文件夹到你的 USB 或者外接硬盘上并且返回你的离线操作系统(LCTT 译注:此处的复制操作似不必要,因为我们一直在 USB 存储器的 `tmp` 目录中操作)。千万保证你的 USB 驱动器上有足够的空闲空间存储所有的下载文件,因为所有的包都放在 `tmp` 文件夹里了。
|
||||
|
||||
#### 离线操作系统上的步骤
|
||||
|
||||
把你的设备插入你的离线操作系统,然后切换到你之前下载了所有包的 `tmp`目录下。
|
||||
|
||||
```
|
||||
cd tmp
|
||||
```
|
||||
|
||||
然后,运行下面的命令来安装所有下载好的包。
|
||||
|
||||
```
|
||||
sudo apt-offline install apt-offline-bundle.zip
|
||||
```
|
||||
|
||||
这个命令将会更新 APT 数据库,所以 APT 将会在 APT 缓冲里找所有需要的包。
|
||||
|
||||
**注意事项:** 如果在线和离线操作系统都在同一个局域网中,你可以通过 `scp` 或者其他传输应用程序将 `tmp` 文件传到离线操作系统中。如果两个操作系统在不同的位置(LCTT 译注:意指在不同的局域网),那就使用 USB 设备来拷贝。
|
||||
|
||||
好了大伙儿,现在就这么多了。 希望这篇指南对你有用。还有更多好东西正在路上。敬请关注!
|
||||
|
||||
祝你愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/fully-update-upgrade-offline-debian-based-systems/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[leemeans](https://github.com/leemeans)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/install-softwares-offline-ubuntu-16-04/
|
||||
[2]:https://www.ostechnix.com/install-packages-offline-arch-linux/
|
||||
[3]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/11/apt-offline.png
|
||||
@ -1,27 +1,26 @@
|
||||
一步一步学习如何在 MariaDB 中配置主从复制
|
||||
循序渐进学习如何在 MariaDB 中配置主从复制
|
||||
======
|
||||
在我们前面的教程中,我们已经学习了 [**如何安装和配置 MariaDB**][1],也学习了 [**管理 MariaDB 的一些基础命令**][2]。现在我们来学习,如何在 MariaDB 服务器上配置一个主从复制。
|
||||
|
||||
复制是用于为我们的数据库去创建多个副本,这些副本可以在其它数据库上用于运行查询,像一些非常繁重的查询可能会影响主数据库服务器的性能,或者我们可以使用它来做数据冗余,或者兼具以上两个目的。我们可以将这个过程自动化,即主服务器到从服务器的复制过程自动进行。执行备份而不影响在主服务器上的写操作。
|
||||
在我们前面的教程中,我们已经学习了 [如何安装和配置 MariaDB][1],也学习了 [管理 MariaDB 的一些基础命令][2]。现在我们来学习,如何在 MariaDB 服务器上配置一个主从复制。
|
||||
|
||||
复制是用于为我们的数据库创 建多个副本,这些副本可以在其它数据库上用于运行查询,像一些非常繁重的查询可能会影响主数据库服务器的性能,或者我们可以使用它来做数据冗余,或者兼具以上两个目的。我们可以将这个过程自动化,即主服务器到从服务器的复制过程自动进行。执行备份而不影响在主服务器上的写操作。
|
||||
|
||||
因此,我们现在去配置我们的主-从复制,它需要两台安装了 MariaDB 的机器。它们的 IP 地址如下:
|
||||
|
||||
**主服务器 -** 192.168.1.120 **主机名** master.ltechlab.com
|
||||
- **主服务器 -** 192.168.1.120 **主机名 -** master.ltechlab.com
|
||||
- **从服务器 -** 192.168.1.130 **主机名 -** slave.ltechlab.com
|
||||
|
||||
**从服务器 -** 192.168.1.130 **主机名 -** slave.ltechlab.com
|
||||
MariaDB 安装到这些机器上之后,我们继续进行本教程。如果你需要安装和配置 MariaDB 的教程,请查看[**这个教程**][1]。
|
||||
|
||||
MariaDB 安装到这些机器上之后,我们继续进行本教程。如果你需要安装和配置 MariaDB 的教程,请查看[ **这个教程**][1]。
|
||||
### 第 1 步 - 主服务器配置
|
||||
|
||||
|
||||
### **第 1 步 - 主服务器配置**
|
||||
|
||||
我们现在进入到 MariaDB 中的一个命名为 ' **important '** 的数据库,它将被复制到我们的从服务器。为开始这个过程,我们编辑名为 ' **/etc/my.cnf** ' 的文件,它是 MariaDB 的配置文件。
|
||||
我们现在进入到 MariaDB 中的一个命名为 `important` 的数据库,它将被复制到我们的从服务器。为开始这个过程,我们编辑名为 `/etc/my.cnf` 的文件,它是 MariaDB 的配置文件。
|
||||
|
||||
```
|
||||
$ vi /etc/my.cnf
|
||||
```
|
||||
|
||||
在这个文件中找到 [mysqld] 节,然后输入如下内容:
|
||||
在这个文件中找到 `[mysqld]` 节,然后输入如下内容:
|
||||
|
||||
```
|
||||
[mysqld]
|
||||
@ -43,7 +42,7 @@ $ systemctl restart mariadb
|
||||
$ mysql -u root -p
|
||||
```
|
||||
|
||||
在它上面创建一个命名为 'slaveuser' 的为主从复制使用的新用户,然后运行如下的命令为它分配所需要的权限:
|
||||
在它上面创建一个命名为 `slaveuser` 的为主从复制使用的新用户,然后运行如下的命令为它分配所需要的权限:
|
||||
|
||||
```
|
||||
STOP SLAVE;
|
||||
@ -53,19 +52,19 @@ FLUSH TABLES WITH READ LOCK;
|
||||
SHOW MASTER STATUS;
|
||||
```
|
||||
|
||||
**注意: ** 我们配置主从复制需要 **MASTER_LOG_FILE 和 MASTER_LOG_POS ** 的值,它可以通过 'show master status' 来获得,因此,你一定要确保你记下了它们的值。
|
||||
**注意:** 我们配置主从复制需要 `MASTER_LOG_FILE` 和 `MASTER_LOG_POS` 的值,它可以通过 `show master status` 来获得,因此,你一定要确保你记下了它们的值。
|
||||
|
||||
这些命令运行完成之后,输入 'exit' 退出这个会话。
|
||||
这些命令运行完成之后,输入 `exit` 退出这个会话。
|
||||
|
||||
### 第 2 步 - 创建一个数据库备份,并将它移动到从服务器上
|
||||
|
||||
现在,我们需要去为我们的数据库 'important' 创建一个备份,可以使用 'mysqldump' 命令去备份。
|
||||
现在,我们需要去为我们的数据库 `important` 创建一个备份,可以使用 `mysqldump` 命令去备份。
|
||||
|
||||
```
|
||||
$ mysqldump -u root -p important > important_backup.sql
|
||||
```
|
||||
|
||||
备份完成后,我们需要重新登陆到 MariaDB 数据库,并解锁我们的表。
|
||||
备份完成后,我们需要重新登录到 MariaDB 数据库,并解锁我们的表。
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
@ -78,7 +77,7 @@ $ UNLOCK TABLES;
|
||||
|
||||
### 第 3 步:配置从服务器
|
||||
|
||||
我们再次去编辑 '/etc/my.cnf' 文件,找到配置文件中的 [mysqld] 节,然后输入如下内容:
|
||||
我们再次去编辑(从服务器上的) `/etc/my.cnf` 文件,找到配置文件中的 `[mysqld]` 节,然后输入如下内容:
|
||||
|
||||
```
|
||||
[mysqld]
|
||||
@ -93,7 +92,7 @@ replicate-do-db=important
|
||||
$ mysql -u root -p < /data/ important_backup.sql
|
||||
```
|
||||
|
||||
当这个恢复过程结束之后,我们将通过登入到从服务器上的 MariaDB,为数据库 'important' 上的用户 'slaveuser' 授权。
|
||||
当这个恢复过程结束之后,我们将通过登入到从服务器上的 MariaDB,为数据库 `important` 上的用户 'slaveuser' 授权。
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
@ -110,9 +109,9 @@ FLUSH PRIVILEGES;
|
||||
$ systemctl restart mariadb
|
||||
```
|
||||
|
||||
### **第 4 步:启动复制**
|
||||
### 第 4 步:启动复制
|
||||
|
||||
记住,我们需要 **MASTER_LOG_FILE 和 MASTER_LOG_POS** 变量的值,它可以通过在主服务器上运行 'SHOW MASTER STATUS' 获得。现在登入到从服务器上的 MariaDB,然后通过运行下列命令,告诉我们的从服务器它应该去哪里找主服务器。
|
||||
记住,我们需要 `MASTER_LOG_FILE` 和 `MASTER_LOG_POS` 变量的值,它可以通过在主服务器上运行 `SHOW MASTER STATUS` 获得。现在登入到从服务器上的 MariaDB,然后通过运行下列命令,告诉我们的从服务器它应该去哪里找主服务器。
|
||||
|
||||
```
|
||||
STOP SLAVE;
|
||||
@ -131,13 +130,13 @@ SHOW SLAVE STATUS\G;
|
||||
$ mysql -u root -p
|
||||
```
|
||||
|
||||
选择数据库为 'important':
|
||||
选择数据库为 `important`:
|
||||
|
||||
```
|
||||
use important;
|
||||
```
|
||||
|
||||
在这个数据库上创建一个名为 ‘test’ 的表:
|
||||
在这个数据库上创建一个名为 `test` 的表:
|
||||
|
||||
```
|
||||
create table test (c int);
|
||||
@ -175,10 +174,10 @@ via: http://linuxtechlab.com/creating-master-slave-replication-mariadb/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/installing-configuring-mariadb-rhelcentos/
|
||||
[2]:http://linuxtechlab.com/mariadb-administration-commands-beginners/
|
||||
[1]:https://linux.cn/article-8320-1.html
|
||||
[2]:https://linux.cn/article-9306-1.html
|
||||
@ -1,12 +1,12 @@
|
||||
用 mod 保护您的网站免受应用层 DOS 攻击
|
||||
用 Apache 服务器模块保护您的网站免受应用层 DOS 攻击
|
||||
======
|
||||
|
||||
有多种恶意攻击网站的方法,比较复杂的方法要涉及数据库和编程方面的技术知识。一个更简单的方法被称为“拒绝服务”或“DOS”攻击。这个攻击方法的名字来源于它的意图:使普通客户或网站访问者的正常服务请求被拒绝。
|
||||
有多种可以导致网站下线的攻击方法,比较复杂的方法要涉及数据库和编程方面的技术知识。一个更简单的方法被称为“<ruby>拒绝服务<rt>Denial Of Service</rt></ruby>”(DOS)攻击。这个攻击方法的名字来源于它的意图:使普通客户或网站访问者的正常服务请求被拒绝。
|
||||
|
||||
一般来说,有两种形式的 DOS 攻击:
|
||||
|
||||
1. OSI 模型的三、四层,即网络层攻击
|
||||
2. OSI 模型的七层,即应用层攻击
|
||||
1. OSI 模型的三、四层,即网络层攻击
|
||||
2. OSI 模型的七层,即应用层攻击
|
||||
|
||||
第一种类型的 DOS 攻击——网络层,发生于当大量的垃圾流量流向网页服务器时。当垃圾流量超过网络的处理能力时,网站就会宕机。
|
||||
|
||||
@ -14,174 +14,172 @@
|
||||
|
||||
本文将着眼于缓解应用层攻击,因为减轻网络层攻击需要大量的可用带宽和上游提供商的合作,这通常不是通过配置网络服务器就可以做到的。
|
||||
|
||||
通过配置普通的网页服务器,可以保护网页免受应用层攻击,至少是适度的防护。防止这种形式的攻击是非常重要的,因为 [Cloudflare][1] 最近 [报道][2] 了网络层攻击的数量正在减少,而应用层攻击的数量则在增加。
|
||||
通过配置普通的网页服务器,可以保护网页免受应用层攻击,至少是适度的防护。防止这种形式的攻击是非常重要的,因为 [Cloudflare][1] 最近 [报告称][2] 网络层攻击的数量正在减少,而应用层攻击的数量则在增加。
|
||||
|
||||
本文将根据 [zdziarski 的博客][4] 来解释如何使用 Apache2 的模块 [mod_evasive][3]。
|
||||
本文将介绍如何使用 [zdziarski][4] 开发的 Apache2 的模块 [mod_evasive][3]。
|
||||
|
||||
另外,mod_evasive 会阻止攻击者试图通过尝试数百个组合来猜测用户名和密码,即暴力攻击。
|
||||
另外,mod_evasive 会阻止攻击者通过尝试数百个用户名和密码的组合来进行猜测(即暴力攻击)的企图。
|
||||
|
||||
Mod_evasive 会记录来自每个 IP 地址的请求的数量。当这个数字超过相应 IP 地址的几个阈值之一时,会出现一个错误页面。错误页面所需的资源要比一个能够响应合法访问的在线网站少得多。
|
||||
mod_evasive 会记录来自每个 IP 地址的请求的数量。当这个数字超过相应 IP 地址的几个阈值之一时,会出现一个错误页面。错误页面所需的资源要比一个能够响应合法访问的在线网站少得多。
|
||||
|
||||
### 在 Ubuntu 16.04 上安装 mod_evasive
|
||||
|
||||
Ubuntu 16.04 默认的软件库中包含了 mod_evasive,名称为“libapache2-mod-evasive”。您可以使用 `apt-get` 来完成安装:
|
||||
Ubuntu 16.04 默认的软件库中包含了 mod_evasive,名称为 “libapache2-mod-evasive”。您可以使用 `apt-get` 来完成安装:
|
||||
|
||||
```
|
||||
apt-get update
|
||||
apt-get upgrade
|
||||
apt-get install libapache2-mod-evasive
|
||||
|
||||
```
|
||||
|
||||
现在我们需要配置 mod_evasive。
|
||||
|
||||
它的配置文件位于 `/etc/apache2/mods-available/evasive.conf`。默认情况下,所有模块的设置在安装后都会被注释掉。因此,在修改配置文件之前,模块不会干扰到网站流量。
|
||||
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
#DOSHashTableSize 3097
|
||||
#DOSPageCount 2
|
||||
#DOSSiteCount 50
|
||||
#DOSPageInterval 1
|
||||
#DOSSiteInterval 1
|
||||
#DOSBlockingPeriod 10
|
||||
|
||||
#DOSEmailNotify you@yourdomain.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
#DOSLogDir "/var/log/mod_evasive"
|
||||
<IfModule mod_evasive20.c>
|
||||
#DOSHashTableSize 3097
|
||||
#DOSPageCount 2
|
||||
#DOSSiteCount 50
|
||||
#DOSPageInterval 1
|
||||
#DOSSiteInterval 1
|
||||
#DOSBlockingPeriod 10
|
||||
|
||||
#DOSEmailNotify you@yourdomain.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
#DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
第一部分的参数的含义如下:
|
||||
|
||||
* **DOSHashTableSize** - 正在访问网站的 IP 地址列表及其请求数。
|
||||
* **DOSPageCount** - 在一定的时间间隔内,每个的页面的请求次数。时间间隔由 DOSPageInterval 定义。
|
||||
* **DOSPageInterval** - mod_evasive 统计页面请求次数的时间间隔。
|
||||
* **DOSSiteCount** - 与 DOSPageCount 相同,但统计的是网站内任何页面的来自相同 IP 地址的请求数量。
|
||||
* **DOSSiteInterval** - mod_evasive 统计网站请求次数的时间间隔。
|
||||
* **DOSBlockingPeriod** - 某个 IP 地址被加入黑名单的时长(以秒为单位)。
|
||||
|
||||
* `DOSHashTableSize` - 正在访问网站的 IP 地址列表及其请求数的当前列表。
|
||||
* `DOSPageCount` - 在一定的时间间隔内,每个页面的请求次数。时间间隔由 DOSPageInterval 定义。
|
||||
* `DOSPageInterval` - mod_evasive 统计页面请求次数的时间间隔。
|
||||
* `DOSSiteCount` - 与 `DOSPageCount` 相同,但统计的是来自相同 IP 地址对网站内任何页面的请求数量。
|
||||
* `DOSSiteInterval` - mod_evasive 统计网站请求次数的时间间隔。
|
||||
* `DOSBlockingPeriod` - 某个 IP 地址被加入黑名单的时长(以秒为单位)。
|
||||
|
||||
如果使用上面显示的默认配置,则在如下情况下,一个 IP 地址会被加入黑名单:
|
||||
|
||||
* 每秒请求同一页面超过两次。
|
||||
* 每秒请求 50 个以上不同页面。
|
||||
|
||||
|
||||
如果某个 IP 地址超过了这些阈值,则被加入黑名单 10 秒钟。
|
||||
|
||||
这看起来可能不算久,但是,mod_evasive 将一直监视页面请求,包括在黑名单中的 IP 地址,并重置其加入黑名单的起始时间。只要一个 IP 地址一直尝试使用 DOS 攻击该网站,它将始终在黑名单中。
|
||||
|
||||
其余的参数是:
|
||||
|
||||
* **DOSEmailNotify** - 用于接收 DOS 攻击信息和 IP 地址黑名单的电子邮件地址。
|
||||
* **DOSSystemCommand** - 检测到 DOS 攻击时运行的命令。
|
||||
* **DOSLogDir** - 用于存放 mod_evasive 的临时文件的目录。
|
||||
|
||||
* `DOSEmailNotify` - 用于接收 DOS 攻击信息和 IP 地址黑名单的电子邮件地址。
|
||||
* `DOSSystemCommand` - 检测到 DOS 攻击时运行的命令。
|
||||
* `DOSLogDir` - 用于存放 mod_evasive 的临时文件的目录。
|
||||
|
||||
### 配置 mod_evasive
|
||||
|
||||
默认的配置是一个很好的开始,因为它的黑名单里不该有任何合法的用户。取消配置文件中的所有参数(DOSSystemCommand 除外)的注释,如下所示:
|
||||
默认的配置是一个很好的开始,因为它不会阻塞任何合法的用户。取消配置文件中的所有参数(`DOSSystemCommand` 除外)的注释,如下所示:
|
||||
|
||||
```
|
||||
<IfModule mod_evasive20.c>
|
||||
DOSHashTableSize 3097
|
||||
DOSPageCount 2
|
||||
DOSSiteCount 50
|
||||
DOSPageInterval 1
|
||||
DOSSiteInterval 1
|
||||
DOSBlockingPeriod 10
|
||||
|
||||
DOSEmailNotify JohnW@example.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
DOSLogDir "/var/log/mod_evasive"
|
||||
<IfModule mod_evasive20.c>
|
||||
DOSHashTableSize 3097
|
||||
DOSPageCount 2
|
||||
DOSSiteCount 50
|
||||
DOSPageInterval 1
|
||||
DOSSiteInterval 1
|
||||
DOSBlockingPeriod 10
|
||||
|
||||
DOSEmailNotify JohnW@example.com
|
||||
#DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
|
||||
DOSLogDir "/var/log/mod_evasive"
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
必须要创建日志目录并且要赋予其与 apache 进程相同的所有者。这里创建的目录是 `/var/log/mod_evasive` ,并且在 Ubuntu 上将该目录的所有者和组设置为 `www-data` ,与 Apache 服务器相同:
|
||||
必须要创建日志目录并且要赋予其与 apache 进程相同的所有者。这里创建的目录是 `/var/log/mod_evasive` ,并且在 Ubuntu 上将该目录的所有者和组设置为 `www-data` ,与 Apache 服务器相同:
|
||||
|
||||
```
|
||||
mkdir /var/log/mod_evasive
|
||||
chown www-data:www-data /var/log/mod_evasive
|
||||
|
||||
```
|
||||
|
||||
在编辑了 Apache 的配置之后,特别是在正在运行的网站上,在重新启动或重新加载之前,最好检查一下语法,因为语法错误将影响 Apache 的启动从而使网站宕机。
|
||||
|
||||
Apache 包含一个辅助命令,是一个配置语法检查器。只需运行以下命令来检查您的语法:
|
||||
|
||||
```
|
||||
apachectl configtest
|
||||
|
||||
```
|
||||
|
||||
如果您的配置是正确的,会得到如下结果:
|
||||
|
||||
```
|
||||
Syntax OK
|
||||
|
||||
```
|
||||
|
||||
但是,如果出现问题,您会被告知在哪部分发生了什么错误,例如:
|
||||
|
||||
```
|
||||
AH00526: Syntax error on line 6 of /etc/apache2/mods-enabled/evasive.conf:
|
||||
DOSSiteInterval takes one argument, Set site interval
|
||||
Action 'configtest' failed.
|
||||
The Apache error log may have more information.
|
||||
|
||||
```
|
||||
|
||||
如果您的配置通过了 configtest 的测试,那么这个模块可以安全地被启用并且 Apache 可以重新加载:
|
||||
|
||||
```
|
||||
a2enmod evasive
|
||||
systemctl reload apache2.service
|
||||
|
||||
```
|
||||
|
||||
Mod_evasive 现在已配置好并正在运行了。
|
||||
mod_evasive 现在已配置好并正在运行了。
|
||||
|
||||
### 测试
|
||||
|
||||
为了测试 mod_evasive,我们只需要向服务器提出足够的网页访问请求,以使其超出阈值,并记录来自 Apache 的响应代码。
|
||||
|
||||
一个正常并成功的页面请求将收到如下响应:
|
||||
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
```
|
||||
|
||||
但是,被 mod_evasive 拒绝的将返回以下内容:
|
||||
|
||||
```
|
||||
HTTP/1.1 403 Forbidden
|
||||
|
||||
```
|
||||
|
||||
以下脚本会尽可能迅速地向本地主机(127.0.0.1,localhost)的 80 端口发送 HTTP 请求,并打印出每个请求的响应代码。
|
||||
|
||||
你所要做的就是把下面的 bash 脚本复制到一个文件中,例如 `mod_evasive_test.sh`:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
for i in {1..50}; do
|
||||
curl -s -I 127.0.0.1 | head -n 1
|
||||
#!/bin/bash
|
||||
set -e
|
||||
|
||||
for i in {1..50}; do
|
||||
curl -s -I 127.0.0.1 | head -n 1
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
这个脚本的部分含义如下:
|
||||
|
||||
* curl - 这是一个发出网络请求的命令。
|
||||
* -s - 隐藏进度表。
|
||||
* -I - 仅显示响应头部信息。
|
||||
* head - 打印文件的第一部分。
|
||||
* -n 1 - 只显示第一行。
|
||||
* `curl` - 这是一个发出网络请求的命令。
|
||||
* `-s` - 隐藏进度表。
|
||||
* `-I` - 仅显示响应头部信息。
|
||||
* `head` - 打印文件的第一部分。
|
||||
* `-n 1` - 只显示第一行。
|
||||
|
||||
然后赋予其执行权限:
|
||||
|
||||
```
|
||||
chmod 755 mod_evasive_test.sh
|
||||
|
||||
```
|
||||
|
||||
在启用 mod_evasive **之前**,脚本运行时,将会看到 50 行“HTTP / 1.1 200 OK”的返回值。
|
||||
在启用 mod_evasive **之前**,脚本运行时,将会看到 50 行 “HTTP / 1.1 200 OK” 的返回值。
|
||||
|
||||
但是,启用 mod_evasive 后,您将看到以下内容:
|
||||
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
HTTP/1.1 200 OK
|
||||
@ -191,13 +189,11 @@ HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
HTTP/1.1 403 Forbidden
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
前两个请求被允许,但是在同一秒内第三个请求发出时,mod_evasive 拒绝了任何进一步的请求。您还将收到一封电子邮件(邮件地址在选项 `DOSEmailNotify` 中设置),通知您有 DOS 攻击被检测到。
|
||||
|
||||
Mod_evasive 现在已经在保护您的网站啦!
|
||||
|
||||
mod_evasive 现在已经在保护您的网站啦!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -205,7 +201,7 @@ via: https://bash-prompt.net/guides/mod_proxy/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,174 @@
|
||||
为初学者准备的 MariaDB 管理命令
|
||||
======
|
||||
|
||||
之前我们学过了[在 Centos/RHEL 7 上安装 MariaDB 服务器并保证其安全][1],使之成为了 RHEL/CentOS 7 的默认数据库。现在我们再来看看一些有用的 MariaDB 管理命令。这些都是使用 MariaDB 最基础的命令,而且它们对 MySQL 也同样适合,因为 Mariadb 就是 MySQL 的一个分支而已。
|
||||
|
||||
**(推荐阅读:[在 RHEL/CentOS 上安装并配置 MongoDB][2])**
|
||||
|
||||
### MariaDB 管理命令
|
||||
|
||||
#### 1、查看 MariaDB 安装的版本
|
||||
|
||||
要查看所安装数据库的当前版本,在终端中输入下面命令:
|
||||
|
||||
```
|
||||
$ mysql -version
|
||||
```
|
||||
|
||||
该命令会告诉你数据库的当前版本。此外你也可以运行下面命令来查看版本的详细信息:
|
||||
|
||||
```
|
||||
$ mysqladmin -u root -p version
|
||||
```
|
||||
|
||||
#### 2、登录 MariaDB
|
||||
|
||||
要登录 MariaDB 服务器,运行:
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
```
|
||||
|
||||
然后输入密码登录。
|
||||
|
||||
#### 3、列出所有的数据库
|
||||
|
||||
要列出 MariaDB 当前拥有的所有数据库,在你登录到 MariaDB 中后运行:
|
||||
|
||||
```
|
||||
> show databases;
|
||||
```
|
||||
|
||||
(LCTT 译注:`$` 这里代表 shell 的提示符,`>` 这里代表 MariaDB shell 的提示符。)
|
||||
|
||||
#### 4、创建新数据库
|
||||
|
||||
在 MariaDB 中创建新数据库,登录 MariaDB 后运行:
|
||||
|
||||
```
|
||||
> create database dan;
|
||||
```
|
||||
|
||||
若想直接在终端创建数据库,则运行:
|
||||
|
||||
```
|
||||
$ mysqladmin -u user -p create dan
|
||||
```
|
||||
|
||||
这里,`dan` 就是新数据库的名称。
|
||||
|
||||
#### 5、删除数据库
|
||||
|
||||
要删除数据库,在已登录的 MariaDB 会话中运行:
|
||||
|
||||
```
|
||||
> drop database dan;
|
||||
```
|
||||
|
||||
此外你也可以运行,
|
||||
|
||||
```
|
||||
$ mysqladmin -u root -p drop dan
|
||||
```
|
||||
|
||||
**注意:** 若在运行 `mysqladmin` 命令时提示 “access denied” 错误,这应该是由于我们没有给 root 授权。要对 root 授权,请参照第 7 点方法,只是要将用户改成 root。
|
||||
|
||||
#### 6、创建新用户
|
||||
|
||||
为数据库创建新用户,运行:
|
||||
|
||||
```
|
||||
> CREATE USER 'dan'@'localhost' IDENTIFIED BY 'password';
|
||||
```
|
||||
|
||||
#### 7、授权用户访问某个数据库
|
||||
|
||||
授权用户访问某个数据库,运行:
|
||||
|
||||
```
|
||||
> GRANT ALL PRIVILEGES ON test.* to 'dan'@'localhost';
|
||||
```
|
||||
|
||||
这会赋予用户 `dan` 对名为 `test` 的数据库完全操作的权限。我们也可以限定为用户只赋予 `SELECT`、`INSERT`、`DELETE` 权限。
|
||||
|
||||
要赋予访问所有数据库的权限,将 `test` 替换成 `*` 。像这样:
|
||||
|
||||
```
|
||||
> GRANT ALL PRIVILEGES ON *.* to 'dan'@'localhost';
|
||||
```
|
||||
|
||||
#### 8、备份/导出数据库
|
||||
|
||||
要创建单个数据库的备份,在终端窗口中运行下列命令,
|
||||
|
||||
```
|
||||
$ mysqldump -u root -p database_name>db_backup.sql
|
||||
```
|
||||
|
||||
若要一次性创建多个数据库的备份则运行:
|
||||
|
||||
```
|
||||
$ mysqldump -u root -p --databases db1 db2 > db12_backup.sql
|
||||
```
|
||||
|
||||
要一次性导出多个数据库,则运行:
|
||||
|
||||
```
|
||||
$ mysqldump -u root -p --all-databases > all_dbs.sql
|
||||
```
|
||||
|
||||
#### 9、从备份中恢复数据库
|
||||
|
||||
要从备份中恢复数据库,运行:
|
||||
|
||||
```
|
||||
$ mysql -u root -p database_name < db_backup.sql
|
||||
```
|
||||
|
||||
但这条命令成功的前提是预先没有存在同名的数据库。如果想要恢复数据库数据到已经存在的数据库中,则需要用到 `mysqlimport` 命令:
|
||||
|
||||
```
|
||||
$ mysqlimport -u root -p database_name < db_backup.sql
|
||||
```
|
||||
|
||||
#### 10、更改 mariadb 用户的密码
|
||||
|
||||
本例中我们会修改 `root` 的密码,但修改其他用户的密码也是一样的过程。
|
||||
|
||||
登录 mariadb 并切换到 'mysql' 数据库:
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
> use mysql;
|
||||
```
|
||||
|
||||
然后运行下面命令:
|
||||
|
||||
```
|
||||
> update user set password=PASSWORD('your_new_password_here') where User='root';
|
||||
```
|
||||
|
||||
下一步,重新加载权限:
|
||||
|
||||
```
|
||||
> flush privileges;
|
||||
```
|
||||
|
||||
然后退出会话。
|
||||
|
||||
我们的教程至此就结束了,在本教程中我们学习了一些有用的 MariaDB 管理命令。欢迎您的留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/mariadb-administration-commands-beginners/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/installing-configuring-mariadb-rhelcentos/
|
||||
[2]:http://linuxtechlab.com/mongodb-installation-configuration-rhelcentos/
|
||||
@ -0,0 +1,201 @@
|
||||
如何统计 Linux 中文件和文件夹/目录的数量
|
||||
======
|
||||
|
||||
嗨,伙计们,今天我们再次带来一系列可以多方面帮助到你的复杂的命令。 通过操作命令,可以帮助您计数当前目录中的文件和目录、递归计数,统计特定用户创建的文件列表等。
|
||||
|
||||
在本教程中,我们将向您展示如何使用多个命令,并使用 `ls`、`egrep`、`wc` 和 `find` 命令执行一些高级操作。 下面的命令将可用在多个方面。
|
||||
|
||||
为了实验,我打算总共创建 7 个文件和 2 个文件夹(5 个常规文件和 2 个隐藏文件)。 下面的 `tree` 命令的输出清楚的展示了文件和文件夹列表。
|
||||
|
||||
```
|
||||
# tree -a /opt
|
||||
/opt
|
||||
├── magi
|
||||
│ └── 2g
|
||||
│ ├── test5.txt
|
||||
│ └── .test6.txt
|
||||
├── test1.txt
|
||||
├── test2.txt
|
||||
├── test3.txt
|
||||
├── .test4.txt
|
||||
└── test.txt
|
||||
|
||||
2 directories, 7 files
|
||||
```
|
||||
|
||||
### 示例-1
|
||||
|
||||
统计当前目录的文件(不包括隐藏文件)。 运行以下命令以确定当前目录中有多少个文件,并且不计算点文件(LCTT 译注:点文件即以“.” 开头的文件,它们在 Linux 默认是隐藏的)。
|
||||
|
||||
```
|
||||
# ls -l . | egrep -c '^-'
|
||||
4
|
||||
```
|
||||
|
||||
**细节:**
|
||||
|
||||
* `ls` : 列出目录内容
|
||||
* `-l` : 使用长列表格式
|
||||
* `.` : 列出有关文件的信息(默认为当前目录)
|
||||
* `|` : 将一个程序的输出发送到另一个程序进行进一步处理的控制操作符
|
||||
* `egrep` : 打印符合模式的行
|
||||
* `-c` : 通用输出控制
|
||||
* `'^-'` : 以“-”开头的行(`ls -l` 列出长列表时,行首的 “-” 代表普通文件)
|
||||
|
||||
### 示例-2
|
||||
|
||||
统计当前目录包含隐藏文件在内的文件。 包括当前目录中的点文件。
|
||||
|
||||
```
|
||||
# ls -la . | egrep -c '^-'
|
||||
5
|
||||
```
|
||||
|
||||
### 示例-3
|
||||
|
||||
运行以下命令来计数当前目录的文件和文件夹。 它会计算所有的文件和目录。
|
||||
|
||||
```
|
||||
# ls -l | wc -l
|
||||
5
|
||||
```
|
||||
|
||||
**细节:**
|
||||
|
||||
* `ls` : 列出目录内容
|
||||
* `-l` : 使用长列表格式
|
||||
* `|` : 将一个程序的输出发送到另一个程序进行进一步处理的控制操作符
|
||||
* `wc` : 这是一个统计每个文件的换行符、单词和字节数的命令
|
||||
* `-l` : 输出换行符的数量
|
||||
|
||||
### 示例-4
|
||||
|
||||
统计当前目录包含隐藏文件和目录在内的文件和文件夹。
|
||||
|
||||
```
|
||||
# ls -la | wc -l
|
||||
8
|
||||
```
|
||||
|
||||
### 示例-5
|
||||
|
||||
递归计算当前目录的文件,包括隐藏文件。
|
||||
|
||||
```
|
||||
# find . -type f | wc -l
|
||||
7
|
||||
```
|
||||
|
||||
**细节 :**
|
||||
|
||||
* `find` : 搜索目录结构中的文件
|
||||
* `-type` : 文件类型
|
||||
* `f` : 常规文件
|
||||
* `wc` : 这是一个统计每个文件的换行符、单词和字节数的命令
|
||||
* `-l` : 输出换行符的数量
|
||||
|
||||
### 示例-6
|
||||
|
||||
使用 `tree` 命令输出目录和文件数(不包括隐藏文件)。
|
||||
|
||||
```
|
||||
# tree | tail -1
|
||||
2 directories, 5 files
|
||||
```
|
||||
|
||||
### 示例-7
|
||||
|
||||
使用包含隐藏文件的 `tree` 命令输出目录和文件计数。
|
||||
|
||||
```
|
||||
# tree -a | tail -1
|
||||
2 directories, 7 files
|
||||
```
|
||||
|
||||
### 示例-8
|
||||
|
||||
运行下面的命令递归计算包含隐藏目录在内的目录数。
|
||||
|
||||
```
|
||||
# find . -type d | wc -l
|
||||
3
|
||||
```
|
||||
|
||||
### 示例-9
|
||||
|
||||
根据文件扩展名计数文件数量。 这里我们要计算 `.txt` 文件。
|
||||
|
||||
```
|
||||
# find . -name "*.txt" | wc -l
|
||||
7
|
||||
```
|
||||
|
||||
### 示例-10
|
||||
|
||||
组合使用 `echo` 命令和 `wc` 命令统计当前目录中的所有文件。 `4` 表示当前目录中的文件数量。
|
||||
|
||||
```
|
||||
# echo *.* | wc
|
||||
1 4 39
|
||||
```
|
||||
|
||||
### 示例-11
|
||||
|
||||
组合使用 `echo` 命令和 `wc` 命令来统计当前目录中的所有目录。 第二个 `1` 表示当前目录中的目录数量。
|
||||
|
||||
```
|
||||
# echo */ | wc
|
||||
1 1 6
|
||||
```
|
||||
|
||||
### 示例-12
|
||||
|
||||
组合使用 `echo` 命令和 `wc` 命令来统计当前目录中的所有文件和目录。 `5` 表示当前目录中的目录和文件的数量。
|
||||
|
||||
```
|
||||
# echo * | wc
|
||||
1 5 44
|
||||
```
|
||||
|
||||
### 示例-13
|
||||
|
||||
统计系统(整个系统)中的文件数。
|
||||
|
||||
```
|
||||
# find / -type f | wc -l
|
||||
69769
|
||||
```
|
||||
|
||||
### 示例-14
|
||||
|
||||
统计系统(整个系统)中的文件夹数。
|
||||
|
||||
```
|
||||
# find / -type d | wc -l
|
||||
8819
|
||||
```
|
||||
|
||||
### 示例-15
|
||||
|
||||
运行以下命令来计算系统(整个系统)中的文件、文件夹、硬链接和符号链接数。
|
||||
|
||||
```
|
||||
# find / -type d -exec echo dirs \; -o -type l -exec echo symlinks \; -o -type f -links +1 -exec echo hardlinks \; -o -type f -exec echo files \; | sort | uniq -c
|
||||
8779 dirs
|
||||
69343 files
|
||||
20 hardlinks
|
||||
11646 symlinks
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-count-the-number-of-files-and-folders-directories-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/empty-a-file-delete-contents-lines-from-a-file-remove-matching-string-from-a-file-remove-empty-blank-lines-from-a-file/
|
||||
70
published/20171215 Linux Vs Unix.md
Normal file
70
published/20171215 Linux Vs Unix.md
Normal file
@ -0,0 +1,70 @@
|
||||
Linux 与 Unix 之差异
|
||||
==============
|
||||
|
||||
[][1]
|
||||
|
||||
在计算机时代,相当一部分的人错误地认为 **Unix** 和 **Linux** 操作系统是一样的。然而,事实恰好相反。让我们仔细看看。
|
||||
|
||||
### 什么是 Unix?
|
||||
|
||||
[][2]
|
||||
|
||||
在 IT 领域,以操作系统而为人所知的 Unix,是 1969 年 AT&T 公司在美国新泽西所开发的(目前它的商标权由国际开放标准组织所拥有)。大多数的操作系统都受到了 Unix 的启发,而 Unix 也受到了未完成的 Multics 系统的启发。Unix 的另一版本是来自贝尔实验室的 Play 9。
|
||||
|
||||
#### Unix 被用于哪里?
|
||||
|
||||
作为一个操作系统,Unix 大多被用在服务器、工作站,现在也有用在个人计算机上。它在创建互联网、计算机网络或客户端/服务器模型方面发挥着非常重要的作用。
|
||||
|
||||
#### Unix 系统的特点
|
||||
|
||||
* 支持多任务
|
||||
* 相比 Multics 操作更加简单
|
||||
* 所有数据以纯文本形式存储
|
||||
* 采用单一根文件的树状存储
|
||||
* 能够同时访问多用户账户
|
||||
|
||||
#### Unix 操作系统的组成
|
||||
|
||||
**a)** 单核操作系统,负责低级操作以及由用户发起的操作,内核之间的通信通过系统调用进行。
|
||||
**b)** 系统工具
|
||||
**c)** 其他应用程序
|
||||
|
||||
### 什么是 Linux?
|
||||
|
||||
[][4]
|
||||
|
||||
这是一个基于 Unix 操作系统原理的开源操作系统。正如开源的含义一样,它是一个可以自由下载的系统。它也可以通过编辑、添加及扩充其源代码而定制该系统。这是它最大的好处之一,而不像今天的其它操作系统(Windows、Mac OS X 等)需要付费。Unix 系统不是创建新系统的唯一模版,另外一个重要的因素是 MINIX 系统,不像 Linus,此版本被其缔造者(Andrew Tanenbaum)用于商业系统。
|
||||
|
||||
Linux 由 Linus Torvalds 开发于 1991 年,这是一个其作为个人兴趣的操作系统。为什么 Linux 借鉴 Unix 的一个主要原因是因为其简洁性。Linux 第一个官方版本(0.01)发布于 1991 年 9 月 17 日。虽然这个系统并不是很完美和完善,但 Linus 对它产生很大的兴趣,并在几天内,Linus 发出了一些关于 Linux 源代码扩展以及其他想法的电子邮件。
|
||||
|
||||
#### Linux 的特点
|
||||
|
||||
Linux 的基石是 Unix 内核,其基于 Unix 的基本特点以及 **POSIX** 和单独的 **UNIX 规范标准**。看起来,该操作系统官方名字取自于 **Linus**,其中其操作系统名称的尾部的 “x” 和 **Unix 系统**相联系。
|
||||
|
||||
#### 主要功能
|
||||
|
||||
* 同时运行多任务(多任务)
|
||||
* 程序可以包含一个或多个进程(多用途系统),且每个进程可能有一个或多个线程。
|
||||
* 多用户,因此它可以运行多个用户程序。
|
||||
* 个人帐户受适当授权的保护。
|
||||
* 因此账户准确地定义了系统控制权。
|
||||
|
||||
**企鹅 Tux** 的 Logo 作者是 Larry Ewing,他选择这个企鹅作为他的开源 **Linux 操作系统**的吉祥物。**Linux Torvalds** 最初提出这个新的操作系统的名字为 “Freax” ,即为 “自由(free)” + “奇异(freak)” + x(UNIX 系统)的结合字,而不像存放它的首个版本的 FTP 服务器上所起的名字(Linux)。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/linux-vs-unix
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[HardworkFish](https://github.com/HardworkFish)
|
||||
校对:[imquanquan](https://github.com/imquanquan), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/linux-vs-unix
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/unix_orig.png
|
||||
[3]:http://www.unix.org/what_is_unix.html
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/linux_orig.png
|
||||
[5]:https://www.linux.com
|
||||
76
published/20171218 Internet Chemotherapy.md
Normal file
76
published/20171218 Internet Chemotherapy.md
Normal file
@ -0,0 +1,76 @@
|
||||
互联网化疗
|
||||
======
|
||||
|
||||
> LCTT 译注:本文作者 janit0r 被认为是 BrickerBot 病毒的作者。此病毒会攻击物联网上安全性不足的设备并使其断开和其他网络设备的连接。janit0r 宣称他使用这个病毒的目的是保护互联网的安全,避免这些设备被入侵者用于入侵网络上的其他设备。janit0r 称此项目为“互联网化疗”。janit0r 决定在 2017 年 12 月终止这个项目,并在网络上发表了这篇文章。
|
||||
|
||||
> —— 12/10 2017
|
||||
|
||||
### --[ 1 互联网化疗
|
||||
|
||||
<ruby>互联网化疗<rt>Internet Chemotherapy</rt></ruby>是在 2016 年 11 月 到 2017 年 12 月之间的一个为期 13 个月的项目。它曾被称为 “BrickerBot”、“错误的固件升级”、“勒索软件”、“大规模网络瘫痪”,甚至 “前所未有的恐怖行为”。最后一个有点伤人了,费尔南德斯(LCTT 译注:委内瑞拉电信公司 CANTV 的光纤网络曾在 2017 年 8 月受到病毒攻击,公司董事长曼努埃尔·费尔南德斯称这次攻击为[“前所未有的恐怖行为”][1]),但我想我大概不能让所有人都满意吧。
|
||||
|
||||
你可以从 http://91.215.104.140/mod_plaintext.py 下载我的代码模块,它可以基于 http 和 telnet 发送恶意请求(LCTT 译注:这个链接已经失效,不过在 [Github][2] 上有备份)。因为平台的限制,模块里是代码混淆过的单线程 Python 代码,但<ruby>载荷<rt>payload</rd></ruby>(LCTT 译注:payload,指实质的攻击/利用代码)依然是明文,任何合格的程序员应该都能看得懂。看看这里面有多少载荷、0-day 漏洞和入侵技巧,花点时间让自己接受现实。然后想象一下,如果我是一个黑客,致力于创造出强大的 DDoS 生成器来勒索那些最大的互联网服务提供商(ISP)和公司的话,互联网在 2017 年会受到怎样的打击。我完全可以让他们全部陷入混乱,并同时对整个互联网造成巨大的伤害。
|
||||
|
||||
我的 ssh 爬虫太危险了,不能发布出来。它包含很多层面的自动化,可以只利用一个被入侵的路由器就能够在设计有缺陷的 ISP 的网络上平行移动并加以入侵。正是因为我可以征用数以万计的 ISP 的路由器,而这些路由器让我知晓网络上发生的事情并给我提供源源不断的节点用来进行入侵行动,我才得以进行我的反物联网僵尸网络项目。我于 2015 年开始了我的非破坏性的 ISP 的网络清理项目,于是当 Mirai 病毒入侵时我已经做好了准备来做出回应。主动破坏其他人的设备仍然是一个困难的决定,但无比危险的 CVE-2016-10372 漏洞让我别无选择。从那时起我就决定一不做二不休。
|
||||
|
||||
(LCTT 译注:上一段中提到的 Mirai 病毒首次出现在 2016 年 8 月。它可以远程入侵运行 Linux 系统的网络设备并利用这些设备构建僵尸网络。本文作者 janit0r 宣称当 Mirai 入侵时他利用自己的 BrickerBot 病毒强制将数以万计的设备从网络上断开,从而减少 Mirai 病毒可以利用的设备数量。)
|
||||
|
||||
我在此警告你们,我所做的只是权宜之计,它并不足以在未来继续拯救互联网。坏人们正变得更加聪明,潜在存在漏洞的设备数量在持续增加,发生大规模的、能使网络瘫痪的事件只是时间问题。如果你愿意相信,我曾经在一个持续 13 个月的项目中使上千万有漏洞的设备变得无法使用,那么不过分地说,如此严重的事件本已经在 2017 年发生了。
|
||||
|
||||
__你们应该意识到,只需要再有一两个严重的物联网漏洞,我们的网络就会严重瘫痪。__ 考虑到我们的社会现在是多么依赖数字网络,而计算机安全应急响应组(CERT)、ISP 们和政府们又是多么地忽视这种问题的严重性,这种事件造成的伤害是无法估计的。ISP 在持续地部署暴露了控制端口的设备,而且即使像 Shodan 这样的服务可以轻而易举地发现这些问题,国家 CERT 还是似乎并不在意。而很多国家甚至都没有自己的 CERT 。世界上许多最大的 ISP 都没有雇佣任何熟知计算机安全问题的人,而是在出现问题的时候依赖于外来的专家来解决。我曾见识过大型 ISP 在我的僵尸网络的调节之下连续多个月持续受损,但他们还是不能完全解决漏洞(几个好的例子是 BSNL、Telkom ZA、PLDT、某些时候的 PT Telkom,以及南半球大部分的大型 ISP )。只要看看 Telkom ZA 解决他们的 Aztech 调制解调器问题的速度有多慢,你就会开始理解现状有多么令人绝望。在 99% 的情况下,要解决这个问题只需要 ISP 部署合理的访问控制列表,并把部署在用户端的设备(CPE)单独分段就行,但是几个月过去之后他们的技术人员依然没有弄明白。如果 ISP 在经历了几周到几个月的针对他们设备的蓄意攻击之后仍然无法解决问题,我们又怎么能期望他们会注意到并解决 Mirai 在他们网络上造成的问题呢?世界上许多最大的 ISP 对这些事情无知得令人发指,而这毫无疑问是最大的危险,但奇怪的是,这应该也是最容易解决的问题。
|
||||
|
||||
我已经尽自己的责任试着去让互联网多坚持一段时间,但我已经尽力了。接下来要交给你们了。即使很小的行动也是非常重要的。你们能做的事情有:
|
||||
|
||||
* 使用像 Shodan 之类的服务来检查你的 ISP 的安全性,并驱使他们去解决他们网络上开放的 telnet、http、httpd、ssh 和 tr069 等端口。如果需要的话,可以把这篇文章给他们看。从来不存在什么好的理由来让这些端口可以从外界访问。暴露控制端口是业余人士的错误。如果有足够的客户抱怨,他们也许真的会采取行动!
|
||||
* 用你的钱包投票!拒绝购买或使用任何“智能”产品,除非制造商保证这个产品能够而且将会收到及时的安全更新。在把你辛苦赚的钱交给提供商之前,先去查看他们的安全记录。为了更好的安全性,可以多花一些钱。
|
||||
* 游说你本地的政治家和政府官员,让他们改进法案来规范物联网设备,包括路由器、IP 照相机和各种“智能”设备。不论私有还是公有的公司目前都没有足够的动机去在短期内解决该问题。这件事情和汽车或者通用电器的安全标准一样重要。
|
||||
* 考虑给像 GDI 基金会或者 Shadowserver 基金会这种缺少支持的白帽黑客组织贡献你的时间或者其他资源。这些组织和人能产生巨大的影响,并且他们可以很好地发挥你的能力来帮助互联网。
|
||||
* 最后,虽然希望不大,但可以考虑通过设立法律先例来让物联网设备成为一种“<ruby>诱惑性危险品<rt>attractive nuisance</rt></ruby>”(LCTT 译注:attractive nuisance 是美国法律中的一个原则,意思是如果儿童在私人领地上因为某些对儿童有吸引力的危险物品而受伤,领地的主人需要负责,无论受伤的儿童是否是合法进入领地)。如果一个房主可以因为小偷或者侵入者受伤而被追责,我不清楚为什么设备的主人(或者 ISP 和设备制造商)不应该因为他们的危险的设备被远程入侵所造成的伤害而被追责。连带责任原则应该适用于对设备应用层的入侵。如果任何有钱的大型 ISP 不愿意为设立这样的先例而出钱(他们也许的确不会,因为他们害怕这样的先例会反过来让自己吃亏),我们甚至可以在这里还有在欧洲为这个行动而进行众筹。 ISP 们:把你们在用来应对 DDoS 的带宽上省下的可观的成本当做我为这个目标的间接投资,也当做它的好处的证明吧。
|
||||
|
||||
### --[ 2 时间线
|
||||
|
||||
下面是这个项目中一些值得纪念的事件:
|
||||
|
||||
* 2016 年 11 月底的德国电信 Mirai 事故。我匆忙写出的最初的 TR069/64 请求只执行了 `route del default`,不过这已经足够引起 ISP 去注意这个问题,而它引发的新闻头条警告了全球的其他 ISP 来注意这个迫近的危机。
|
||||
* 大约 1 月 11 日 到 12 日,一些位于华盛顿特区的开放了 6789 控制端口的硬盘录像机被 Mirai 入侵并瘫痪,这上了很多头条新闻。我要给 Vemulapalli 点赞,她居然认为 Mirai 加上 `/dev/urandom` 一定是“非常复杂的勒索软件”(LCTT 译注:Archana Vemulapalli 当时是华盛顿市政府的 CTO)。欧洲的那两个可怜人又怎么样了呢?
|
||||
* 2017 年 1 月底发生了第一起真正的大规模 ISP 下线事件。Rogers Canada 的提供商 Hitron 非常粗心地推送了一个在 2323 端口上监听的无验证的 root shell(这可能是一个他们忘记关闭的 debug 接口)。这个惊天的失误很快被 Mirai 的僵尸网络所发现,造成大量设备瘫痪。
|
||||
* 在 2017 年 2 月,我注意到 Mirai 在这一年里的第一次扩张,Netcore/Netis 以及 Broadcom 的基于 CLI (命令行接口)的调制解调器都遭受了攻击。BCM CLI 后来成为了 Mirai 在 2017 年的主要战场,黑客们和我自己都在这一年的余下时间里花大量时间寻找无数 ISP 和设备制造商设置的默认密码。前面代码中的“broadcom” 载荷也许看上去有点奇怪,但它们是统计角度上最可能禁用那些大量的有问题的 BCM CLI 固件的序列。
|
||||
* 在 2017 年 3 月,我大幅提升了我的僵尸网络的节点数量并开始加入更多的网络载荷。这是为了应对包括 Imeij、Amnesia 和 Persirai 在内的僵尸网络的威胁。大规模地禁用这些被入侵的设备也带来了新的一些问题。比如在 Avtech 和 Wificam 设备所泄露的登录信息当中,有一些用户名和密码非常像是用于机场和其他重要设施的,而英国政府官员大概在 2017 年 4 月 1 日关于针对机场和核设施的“实际存在的网络威胁”做出过警告。哎呀。
|
||||
* 这种更加激进的扫描还引起了民间安全研究者的注意,安全公司 Radware 在 2017 年 4 月 6 日发表了一篇关于我的项目的文章。这个公司把它叫做“BrickerBot”。显然,如果我要继续增加我的物联网防御措施的规模,我必须想出更好的网络映射与检测方法来应对蜜罐或者其他有风险的目标。
|
||||
* 2017 年 4 月 11 日左右的时候发生了一件非常不寻常的事情。一开始这看上去和许多其他的 ISP 下线事件相似,一个叫 Sierra Tel 的半本地 ISP 在一些 Zyxel 设备上使用了默认的 telnet 用户名密码 supervisor/zyad1234。一个 Mirai 运行器发现了这些有漏洞的设备,我的僵尸网络紧随其后,2017 年精彩绝伦的 BCM CLI 战争又开启了新的一场战斗。这场战斗并没有持续很久。它本来会和 2017 年的其他数百起 ISP 下线事件一样,如果不是在尘埃落定之后发生的那件非常不寻常的事情的话。令人惊奇的是,这家 ISP 并没有试着把这次网络中断掩盖成某种网络故障、电力超额或错误的固件升级。他们完全没有对客户说谎。相反,他们很快发表了新闻公告,说他们的调制解调器有漏洞,这让他们的客户们得以评估自己可能遭受的风险。这家全世界最诚实的 ISP 为他们值得赞扬的公开行为而收获了什么呢?悲哀的是,它得到的只是批评和不好的名声。这依然是我记忆中最令人沮丧的“为什么我们得不到好东西”的例子,这很有可能也是为什么 99% 的安全错误都被掩盖而真正的受害者被蒙在鼓里的最主要原因。太多时候,“有责任心的信息公开”会直接变成“粉饰太平”的委婉说法。
|
||||
* 在 2017 年 4 月 14 日,国土安全部关于“BrickerBot 对物联网的威胁”做出了警告,我自己的政府把我作为一个网络威胁这件事让我觉得他们很不公平而且目光短浅。跟我相比,对美国人民威胁最大的难道不应该是那些部署缺乏安全性的网络设备的提供商和贩卖不成熟的安全方案的物联网设备制造商吗?如果没有我,数以百万计的人们可能还在用被入侵的设备和网络来处理银行业务和其他需要保密的交易。如果国土安全部里有人读到这篇文章,我强烈建议你重新考虑一下保护国家和公民究竟是什么意思。
|
||||
* 在 2017 年 4 月底,我花了一些时间改进我的 TR069/64 攻击方法,然后在 2017 年 5 月初,一个叫 Wordfence 的公司(现在叫 Defiant)报道称一个曾给 Wordpress 网站造成威胁的基于入侵 TR069 的僵尸网络很明显地衰减了。值得注意的是,同一个僵尸网络在几星期后使用了一个不同的入侵方式暂时回归了(不过这最终也同样被化解了)。
|
||||
* 在 2017 年 5 月,主机托管公司 Akamai 在它的 2017 年第一季度互联网现状报告中写道,相比于 2016 年第一季度,大型(超过 100 Gbps)DDoS 攻击数减少了 89%,而总体 DDoS 攻击数减少了 30%。鉴于大型 DDoS 攻击是 Mirai 的主要手段,我觉得这给这些月来我在物联网领域的辛苦劳动提供了实际的支持。
|
||||
* 在夏天我持续地改进我的入侵技术军火库,然后在 7 月底我针对亚太互联网络信息中心(APNIC)的 ISP 进行了一些测试。测试结果非常令人吃惊。造成的影响之一是数十万的 BSNL 和 MTNL 调制解调器被禁用,而这次中断事故在印度成为了头条新闻。考虑到当时在印度和中国之间持续升级的地缘政治压力,我觉得这个事故有很大的风险会被归咎于中国所为,于是我很罕见地决定公开承认是我所做。Catalin,我很抱歉你在报道这条新闻之后突然被迫放的“两天的假期”。
|
||||
* 在处理过亚太互联网络信息中心(APNIC)和非洲互联网络信息中心(AfriNIC)的之后,在 2017 年 8 月 9 日我又针对拉丁美洲与加勒比地区互联网络信息中心(LACNIC)进行了大规模的清理,给这个大洲的许多提供商造成了问题。在数百万的 Movilnet 的手机用户失去连接之后,这次攻击在委内瑞拉被大幅报道。虽然我个人反对政府监管互联网,委内瑞拉的这次情况值得注意。许多拉美与加勒比地区的提供商与网络曾在我的僵尸网络的持续调节之下连续数个月逐渐衰弱,但委内瑞拉的提供商很快加强了他们的网络防护并确保了他们的网络设施的安全。我认为这是由于委内瑞拉相比于该地区的其他国家来说进行了更具侵入性的深度包检测。值得思考一下。
|
||||
* F5 实验室在 2017 年 8 月发布了一个题为“狩猎物联网:僵尸物联网的崛起”的报告,研究者们在其中对近期 telnet 活动的平静表达了困惑。研究者们猜测这种活动的减少也许证实了一个或多个非常大型的网络武器正在成型(我想这大概确实是真的)。这篇报告是在我印象中对我的项目的规模最准确的评估,但神奇的是,这些研究者们什么都推断不出来,尽管他们把所有相关的线索都集中到了一页纸上。
|
||||
* 2017 年 8 月,Akamai 的 2017 年第二季度互联网现状报告宣布这是三年以来首个该提供商没有发现任何大规模(超过 100 Gbps)攻击的季度,而且 DDoS 攻击总数相比 2017 年第一季度减少了 28%。这看上去给我的清理工作提供了更多的支持。这个出奇的好消息被主流媒体所完全忽视了,这些媒体有着“流血的才是好新闻”的心态,即使是在信息安全领域。这是我们为什么不能得到好东西的又一个原因。
|
||||
* 在 CVE-2017-7921 和 7923 于 2017 年 9 月公布之后,我决定更密切地关注海康威视公司的设备,然后我惊恐地发现有一个黑客们还没有发现的方法可以用来入侵有漏洞的固件。于是我在 9 月中旬开启了一个全球范围的清理行动。超过一百万台硬盘录像机和摄像机(主要是海康威视和大华出品)在三周内被禁用,然后包括 IPVM.com 在内的媒体为这些攻击写了多篇报道。大华和海康威视在新闻公告中提到或暗示了这些攻击。大量的设备总算得到了固件升级。看到这次清理活动造成的困惑,我决定给这些闭路电视制造商写一篇[简短的总结][3](请原谅在这个粘贴板网站上的不和谐的语言)。这令人震惊的有漏洞而且在关键的安全补丁发布之后仍然在线的设备数量应该能够唤醒所有人,让他们知道现今的物联网补丁升级过程有多么无力。
|
||||
* 2017 年 9 月 28 日左右,Verisign 发表了报告称 2017 年第二季度的 DDoS 攻击数相比第一季度减少了 55%,而且攻击峰值大幅减少了 81%。
|
||||
* 2017 年 11 月 23 日,CDN 供应商 Cloudflare 报道称“近几个月来,Cloudflare 看到试图用垃圾流量挤满我们的网络的简单进攻尝试有了大幅减少”。Cloudflare 推测这可能和他们的政策变化有一定关系,但这些减少也和物联网清理行动有着明显的重合。
|
||||
* 2017 年 11 月底,Akamai 的 2017 年第三季度互联网现状报告称 DDoS 攻击数较前一季度小幅增加了 8%。虽然这相比 2016 年的第三季度已经减少了很多,但这次小幅上涨提醒我们危险仍然存在。
|
||||
* 作为潜在危险的更进一步的提醒,一个叫做“Satori”的新的 Mirai 变种于 2017 年 11 月至 12 月开始冒头。这个僵尸网络仅仅通过一个 0-day 漏洞而达成的增长速度非常值得注意。这起事件凸显了互联网的危险现状,以及我们为什么距离大规模的事故只差一两起物联网入侵。当下一次威胁发生而且没人阻止的时候,会发生什么?Sinkholing 和其他的白帽或“合法”的缓解措施在 2018 年不会有效,就像它们在 2016 年也不曾有效一样。也许未来各国政府可以合作创建一个国际范围的反黑客特别部队来应对特别严重的会影响互联网存续的威胁,但我并不抱太大期望。
|
||||
* 在年末出现了一些危言耸听的新闻报道,有关被一个被称作“Reaper”和“IoTroop”的新的僵尸网络。我知道你们中有些人最终会去嘲笑那些把它的规模估算为一两百万的人,但你们应该理解这些网络安全研究者们对网络上发生的事情以及不由他们掌控的硬件的事情都是一知半解。实际来说,研究者们不可能知道或甚至猜测到大部分有漏洞的设备在僵尸网络出现时已经被禁用了。给“Reaper”一两个新的未经处理的 0-day 漏洞的话,它就会变得和我们最担心的事情一样可怕。
|
||||
|
||||
### --[ 3 临别赠言
|
||||
|
||||
我很抱歉把你们留在这种境况当中,但我的人身安全受到的威胁已经不允许我再继续下去。我树了很多敌人。如果你想要帮忙,请看前面列举的该做的事情。祝你好运。
|
||||
|
||||
也会有人批评我,说我不负责任,但这完全找错了重点。真正的重点是如果一个像我一样没有黑客背景的人可以做到我所做到的事情,那么一个比我厉害的人可以在 2017 年对互联网做比这要可怕太多的事情。我并不是问题本身,我也不是来遵循任何人制定的规则的。我只是报信的人。你越早意识到这点越好。
|
||||
|
||||
-Dr Cyborkian 又名 janit0r,“病入膏肓”的设备的调节者。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://ghostbin.com/paste/q2vq2
|
||||
|
||||
作者:janit0r
|
||||
译者:[yixunx](https://github.com/yixunx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,
|
||||
[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.telecompaper.com/news/venezuelan-operators-hit-by-unprecedented-cyberattack--1208384
|
||||
[2]:https://github.com/JeremyNGalloway/mod_plaintext.py
|
||||
[3]:http://depastedihrn3jtw.onion.link/show.php?md5=62d1d87f67a8bf485d43a05ec32b1e6f
|
||||
@ -0,0 +1,243 @@
|
||||
如何在 Linux/Unix/Windows 中发现隐藏的进程和端口
|
||||
==============
|
||||
|
||||
`unhide` 是一个小巧的网络取证工具,能够发现那些借助 rootkit、LKM 及其它技术隐藏的进程和 TCP/UDP 端口。这个工具在 Linux、UNIX 类、MS-Windows 等操作系统下都可以工作。根据其 man 页面的说明:
|
||||
|
||||
> Unhide 通过下述三项技术来发现隐藏的进程。
|
||||
> 1. 进程相关的技术,包括将 `/proc` 目录与 [/bin/ps][1] 命令的输出进行比较。
|
||||
> 2. 系统相关的技术,包括将 [/bin/ps][1] 命令的输出结果同从系统调用方面得到的信息进行比较。
|
||||
> 3. 穷举法相关的技术,包括对所有的进程 ID 进行暴力求解,该技术仅限于在基于 Linux2.6 内核的系统中使用。
|
||||
|
||||
绝大多数的 Rootkit 工具或者恶意软件借助内核来实现进程隐藏,这些进程只在内核内部可见。你可以使用 `unhide` 或者诸如 [rkhunter 等工具,扫描 rootkit 程序 、后门程序以及一些可能存在的本地漏洞][2]。
|
||||
|
||||
![本文讲解如何在多个操作系统下安装和使用unhide][3]
|
||||
|
||||
这篇文章描述了如何安装 unhide 并搜索隐藏的进程和 TCP/UDP 端口。
|
||||
|
||||
### 如何安装 unhide
|
||||
|
||||
首先建议你在只读介质上运行这个工具。如果使用的是 Ubuntu 或者 Debian 发行版,输入下述的 [apt-get][4]/[apt][5] 命令以安装 Unhide:
|
||||
|
||||
```
|
||||
$ sudo apt-get install unhide
|
||||
```
|
||||
|
||||
一切顺利的话你的命令行会输出以下内容:
|
||||
|
||||
```
|
||||
[sudo] password for vivek:
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
Suggested packages:
|
||||
rkhunter
|
||||
The following NEW packages will be installed:
|
||||
unhide
|
||||
0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 46.6 kB of archives.
|
||||
After this operation, 136 kB of additional disk space will be used.
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 unhide amd64 20130526-1 [46.6 kB]
|
||||
Fetched 46.6 kB in 0s (49.0 kB/s)
|
||||
Selecting previously unselected package unhide.
|
||||
(Reading database ... 205367 files and directories currently installed.)
|
||||
Preparing to unpack .../unhide_20130526-1_amd64.deb ...
|
||||
Unpacking unhide (20130526-1) ...
|
||||
Setting up unhide (20130526-1) ...
|
||||
Processing triggers for man-db (2.7.6.1-2) ...
|
||||
```
|
||||
|
||||
### 如何在 RHEL/CentOS/Oracle/Scientific/Fedora 上安装 unhide
|
||||
|
||||
输入下列 yum Type the following yum command (first turn on EPLE repo on a CentOS/RHEL version 6.x or version 7.x):
|
||||
|
||||
输入以下的 [yum][6] 命令(CentOS/RHEL [6.x][7] 或 [7.x][8] 上首先打开 EPEL 仓库):
|
||||
|
||||
```
|
||||
$ sudo yum install unhide
|
||||
```
|
||||
|
||||
在 Fedora 上则使用以下 dnf 命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install unhide
|
||||
```
|
||||
|
||||
### 如何在 Arch 上安装 unhide
|
||||
|
||||
键入以下 pacman 命令安装:
|
||||
|
||||
```
|
||||
$ sudo pacman -S unhide
|
||||
```
|
||||
|
||||
### 如何在 FreeBSD 上安装 unhide
|
||||
|
||||
可以通过以下的命令使用 port 来安装 unhide:
|
||||
|
||||
```
|
||||
# cd /usr/ports/security/unhide/
|
||||
# make install clean
|
||||
```
|
||||
|
||||
或者可以通过二进制文件安装 hide,使用 pkg 命令安装:
|
||||
|
||||
```
|
||||
# pkg install unhide
|
||||
```
|
||||
|
||||
### 如何使用 unhide 工具?
|
||||
|
||||
unhide 的语法是:
|
||||
|
||||
```
|
||||
unhide [options] test_list
|
||||
```
|
||||
|
||||
`test_list` 参数可以是以下测试列表中的一个或者多个标准测试:
|
||||
|
||||
|
||||
1. brute
|
||||
2. proc
|
||||
3. procall
|
||||
4. procfs
|
||||
5. quick
|
||||
6. reverse
|
||||
7. sys
|
||||
|
||||
或基本测试:
|
||||
|
||||
1. checkbrute
|
||||
2. checkchdir
|
||||
3. checkgetaffinity
|
||||
4. checkgetparam
|
||||
5. checkgetpgid
|
||||
6. checkgetprio
|
||||
7. checkRRgetinterval
|
||||
8. checkgetsched
|
||||
9. checkgetsid
|
||||
10. checkkill
|
||||
11. checknoprocps
|
||||
12. checkopendir
|
||||
13. checkproc
|
||||
14. checkquick
|
||||
15. checkreaddir
|
||||
16. checkreverse
|
||||
17. checksysinfo
|
||||
18. checksysinfo2
|
||||
19. checksysinfo3
|
||||
|
||||
你可以通过以下示例命令使用 `unhide`:
|
||||
|
||||
```
|
||||
# unhide proc
|
||||
# unhide sys
|
||||
# unhide quick
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Unhide 20130526
|
||||
Copyright © 2013 Yago Jesus & Patrick Gouin
|
||||
License GPLv3+ : GNU GPL version 3 or later
|
||||
http://www.unhide-forensics.info
|
||||
|
||||
NOTE : This version of unhide is for systems using Linux >= 2.6
|
||||
|
||||
Used options:
|
||||
[*]Searching for Hidden processes through comparison of results of system calls, proc, dir and ps
|
||||
```
|
||||
|
||||
### 如何使用 unhide-tcp 工具辨明 TCP/UDP 端口的身份
|
||||
|
||||
以下是来自 man 页面的介绍:
|
||||
|
||||
> `unhide-tcp` 取证工具通过对所有可用的 TCP/IP 端口进行暴力求解的方式,辨别所有正在监听,却没有列入 [/bin/netstat][9] 或者 [/bin/ss][10] 命令输出的 TCP/IP 端口身份。
|
||||
|
||||
> 注一:对于 FreeBSD、OpenBSD系统,一般使用 netstat 命令取代在这些操作系统上不存在的 iproute2,此外,sockstat 命令也用于替代 fuser。
|
||||
|
||||
> 注二:如果操作系统不支持 iproute2 命令,在使用 `unhide` 时需要在命令上加上 `-n` 或者 `-s` 选项。
|
||||
|
||||
```
|
||||
# unhide-tcp
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Unhide 20100201
|
||||
http://www.security-projects.com/?Unhide
|
||||
|
||||
Starting TCP checking
|
||||
|
||||
Starting UDP checking
|
||||
```
|
||||
|
||||
上述操作中,没有发现隐藏的端口。
|
||||
|
||||
但在下述示例中,我展示了一些有趣的事。
|
||||
|
||||
```
|
||||
# unhide-tcp
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Unhide 20100201
|
||||
http://www.security-projects.com/?Unhide
|
||||
|
||||
|
||||
Starting TCP checking
|
||||
|
||||
Found Hidden port that not appears in netstat: 1048
|
||||
Found Hidden port that not appears in netstat: 1049
|
||||
Found Hidden port that not appears in netstat: 1050
|
||||
Starting UDP checking
|
||||
```
|
||||
|
||||
可以看到 `netstat -tulpn` 和 `ss` 命令确实没有反映出这三个隐藏的端口:
|
||||
|
||||
```
|
||||
# netstat -tulpn | grep 1048
|
||||
# ss -lp
|
||||
# ss -l | grep 1048
|
||||
```
|
||||
|
||||
通过下述的 man 命令可以更多地了解 `unhide`:
|
||||
|
||||
```
|
||||
$ man unhide
|
||||
$ man unhide-tcp
|
||||
```
|
||||
|
||||
### Windows 用户如何安装使用 unhide
|
||||
|
||||
你可以通过这个[页面][13]获取 Windows 版本的 unhide。
|
||||
|
||||
----
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-windows-find-hidden-processes-tcp-udp-ports.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[ljgibbslf](https://github.com/ljgibbslf)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/ (Linux / Unix ps command)
|
||||
[2]:https://www.cyberciti.biz/faq/howto-check-linux-rootkist-with-detectors-software/
|
||||
[3]:https://www.cyberciti.biz/tips/wp-content/uploads/2011/11/Linux-FreeBSD-Unix-Windows-Find-Hidden-Process-Ports.jpg
|
||||
[4]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[5]://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[6]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[7]:https://www.cyberciti.biz/faq/fedora-sl-centos-redhat6-enable-epel-repo/
|
||||
[8]:https://www.cyberciti.biz/faq/installing-rhel-epel-repo-on-centos-redhat-7-x/
|
||||
[9]:https://www.cyberciti.biz/tips/linux-display-open-ports-owner.html (Linux netstat command)
|
||||
[10]:https://www.cyberciti.biz/tips/linux-investigate-sockets-network-connections.html
|
||||
[11]:https://www.cyberciti.biz/tips/netstat-command-tutorial-examples.html
|
||||
[12]:https://www.cyberciti.biz/tips/linux-investigate-sockets-network-connections.html
|
||||
[13]:http://www.unhide-forensics.info/?Windows:Download
|
||||
@ -1,36 +1,40 @@
|
||||
Python 版的 Nmon 分析器:让你远离 excel 宏
|
||||
======
|
||||
[Nigel's monitor][1],也叫做 "Nmon",是一个很好的监控,记录和分析 Linux/*nix 系统性能随时间变化的工具。Nmon 最初由 IBM 开发并于 2009 年夏天开源。时至今日 Nmon 已经在所有 linux 平台和架构上都可用了。它提供了大量的实时工具来可视化当前系统统计信息,这些统计信息包括 CPU,RAM,网络和磁盘 I/O。然而,Nmon 最棒的特性是可以随着时间的推移记录系统性能快照。
|
||||
比如:`nmon -f -s 1`。
|
||||
![nmon CPU and Disk utilization][2]
|
||||
会创建一个日志文件,该日志文件最开头是一些系统的元数据 T( 章节 AAA - BBBV),后面是定时抓取的监控系统属性的快照,比如 CPU 和内存的使用情况。这个文件很难直接由电子表格应用来处理,因此诞生了 [Nmon_Analyzer][3] excel 宏。如果你用的是 Windows/Mac 并安装了 Microsoft Office,那么这个工具非常不错。如果没有这个环境那也可以使用 Nmon2rrd 工具,这个工具能将日志文件转换 RRD 输入文件,进而生成图形。这个过程很死板而且有点麻烦。现在出现了一个更灵活的工具,像你们介绍一下 pyNmonAnalyzer,它一个可定制化的解决方案来生成结构化的 CSV 文件和基于 [matplotlib][4] 生成图片的简单 HTML 报告。
|
||||
|
||||
### 入门介绍:
|
||||
[Nigel's monitor][1],也叫做 “Nmon”,是一个很好的监控、记录和分析 Linux/*nix 系统性能随时间变化的工具。Nmon 最初由 IBM 开发并于 2009 年夏天开源。时至今日 Nmon 已经在所有 Linux 平台和架构上都可用了。它提供了很棒的当前系统统计信息的基于命令行的实时可视化报告,这些统计信息包括 CPU、RAM、网络和磁盘 I/O。然而,Nmon 最棒的特性是可以随着时间的推移记录系统性能快照。
|
||||
|
||||
比如:`nmon -f -s 1`。
|
||||
|
||||
![nmon CPU and Disk utilization][2]
|
||||
|
||||
会创建一个日志文件,该日志文件最开头是一些系统的元数据(AAA - BBBV 部分),后面是所监控的系统属性的定时快照,比如 CPU 和内存的使用情况。这个输出的文件很难直接由电子表格应用来处理,因此诞生了 [Nmon_Analyzer][3] excel 宏。如果你用的是 Windows/Mac 并安装了 Microsoft Office,那么这个工具非常不错。如果没有这个环境那也可以使用 Nmon2rrd 工具,这个工具能将日志文件转换 RRD 输入文件,进而生成图形。这个过程很死板而且有点麻烦。现在出现了一个更灵活的工具,我向你们介绍一下 pyNmonAnalyzer,它提供了一个可定制化的解决方案来生成结构化的 CSV 文件和带有用 [matplotlib][4] 生成的图片的简单 HTML 报告。
|
||||
|
||||
### 入门介绍
|
||||
|
||||
系统需求:
|
||||
|
||||
从名字中就能看出我们需要有 python。此外 pyNmonAnalyzer 还依赖于 matplotlib 和 numpy。若你使用的是 debian 衍生的系统,则你需要先安装这些包:
|
||||
```
|
||||
$> sudo apt-get install python-numpy python-matplotlib
|
||||
|
||||
```
|
||||
|
||||
##### 获取 pyNmonAnalyzer:
|
||||
|
||||
你可页克隆 git 仓库:
|
||||
```
|
||||
$> git clone git@github.com:madmaze/pyNmonAnalyzer.git
|
||||
|
||||
$ sudo apt-get install python-numpy python-matplotlib
|
||||
```
|
||||
|
||||
或者
|
||||
#### 获取 pyNmonAnalyzer:
|
||||
|
||||
直接从这里下载:[pyNmonAnalyzer-0.1.zip][5]
|
||||
你可以克隆 git 仓库:
|
||||
|
||||
接下来我们需要一个 Nmon 文件,如果没有的话,可以使用发行版中提供的实例或者自己录制一个样本:`nmon -F test.nmon -s 1 -c 120`,会录制每个 1 秒录制一次,供录制 120 个快照道 test.nmon 文件中 .nmon。
|
||||
```
|
||||
$ git clone git@github.com:madmaze/pyNmonAnalyzer.git
|
||||
```
|
||||
|
||||
或者,直接从这里下载:[pyNmonAnalyzer-0.1.zip][5] 。
|
||||
|
||||
接下来我们需要一个 Nmon 文件,如果没有的话,可以使用发行版中提供的实例或者自己录制一个样本:`nmon -F test.nmon -s 1 -c 120`,会录制 120 个快照,每秒一个,存储到 test.nmon 文件中。
|
||||
|
||||
让我们来看看基本的帮助信息:
|
||||
|
||||
```
|
||||
$> ./pyNmonAnalyzer.py -h
|
||||
$ ./pyNmonAnalyzer.py -h
|
||||
usage: pyNmonAnalyzer.py [-h] [-x] [-d] [-o OUTDIR] [-c] [-b] [-r CONFFNAME]
|
||||
input_file
|
||||
|
||||
@ -53,30 +57,29 @@ optional arguments:
|
||||
-r CONFFNAME, --reportConfig CONFFNAME
|
||||
Report config file, if none exists: we will write the
|
||||
default config file out (Default: ./report.config)
|
||||
|
||||
```
|
||||
|
||||
该工具有两个主要的选项
|
||||
|
||||
1。将 nmon 文件传唤成一系列独立的 CSV 文件
|
||||
2。使用 matplotlib 生成带图形的 HTML 报告
|
||||
|
||||
1. 将 nmon 文件传唤成一系列独立的 CSV 文件
|
||||
2. 使用 matplotlib 生成带图形的 HTML 报告
|
||||
|
||||
|
||||
下面命令既会生成 CSV 文件,也会生成 HTML 报告:
|
||||
```
|
||||
$> ./pyNmonAnalyzer.py -c -b test.nmon
|
||||
|
||||
```
|
||||
$ ./pyNmonAnalyzer.py -c -b test.nmon
|
||||
```
|
||||
|
||||
这会常见一个 `。/data` 目录,其中有一个存放 CSV 文件的目录 ("。/data/csv/"),一个存放 PNG 图片的目录 ("。/data/img/") 以及一个 HTML 报告 ("。/data/report.html")。
|
||||
这会创建一个 `./data` 目录,其中有一个存放 CSV 文件的目录 (`./data/csv/`),一个存放 PNG 图片的目录 (`./data/img/`) 以及一个 HTML 报告 (`./data/report.html`)。
|
||||
|
||||
默认情况下,HTML 报告中会用图片展示 CPU,磁盘繁忙度,内存使用情况和网络传输情况。所有这些都定义在一个自解释的配置文件中 ("report.config")。目前这个工具 h 那不是特别的灵活,因为 CPU 和 MEM 除了 on 和 off 外,无法做其他的配置。不过下一步将会改进作图的方法并允许用户灵活地指定针对哪些数据使用哪种作图方法。
|
||||
默认情况下,HTML 报告中会用图片展示 CPU、磁盘繁忙程度、内存使用情况和网络传输情况。所有这些都定义在一个不言自明的配置文件中 (`report.config`)。目前这个工具还不是特别的灵活,因为 CPU 和 MEM 除了 `on` 和 `off` 外,无法做其他的配置。不过下一步将会改进作图的方法并允许用户灵活地指定针对哪些数据使用哪种作图方法。
|
||||
|
||||
### 报告的例子:
|
||||
### 报告的例子
|
||||
|
||||
[![pyNmonAnalyzer Graph output][6]
|
||||
**Click to see the full Report**][7]
|
||||
![pyNmonAnalyzer Graph output][6]
|
||||
|
||||
[点击查看完整报告][7]
|
||||
|
||||
目前这些报告还十分的枯燥而且只能打印出基本的几种标记图表,不过它的功能还在不断的完善中。目前在开发的是一个向导来让配置调整变得更容易。如果有任何建议,找到任何 bug 或者有任何功能需求,欢迎与我交流。
|
||||
|
||||
@ -86,7 +89,7 @@ via: https://matthiaslee.com/python-nmon-analyzer-moving-away-from-excel-macros/
|
||||
|
||||
作者:[Matthias Lee][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,18 +1,18 @@
|
||||
从 ISO 和在线仓库创建一个 YUM 仓库
|
||||
从 ISO 和在线仓库创建一个 Yum 仓库
|
||||
======
|
||||
|
||||
YUM 是 Centos/RHEL/Fedora 中最重要的工具之一。尽管在 Fedora 的最新版本中,它已经被 DNF 所取代,但这并不意味着它已经成功了。它仍然被广泛用于安装 rpm 包,我们已经在前面的教程([**在这里阅读**] [1])中用示例讨论了 YUM。
|
||||
Yum 是 Centos/RHEL/Fedora 中最重要的工具之一。尽管在 Fedora 的最新版本中,它已经被 DNF 所取代,但这并不意味着它自生自灭了。它仍然被广泛用于安装 rpm 包,我们已经在前面的教程([**在这里阅读**] [1])中用示例讨论了 Yum。
|
||||
|
||||
在本教程中,我们将学习创建一个本地 YUM 仓库,首先使用系统的 ISO 镜像,然后创建一个在线 yum 仓库的镜像。
|
||||
在本教程中,我们将学习创建一个本地 Yum 仓库,首先使用系统的 ISO 镜像,然后创建一个在线 Yum 仓库的镜像。
|
||||
|
||||
### 用 DVD ISO 创建 YUM
|
||||
### 用 DVD ISO 创建 Yum
|
||||
|
||||
我们在本教程中使用 Centos 7 dvd,同样的过程也应该可以用在 RHEL 7 上。
|
||||
|
||||
首先在根文件夹中创建一个名为 YUM 的目录
|
||||
首先在根文件夹中创建一个名为 Yum 的目录
|
||||
|
||||
```
|
||||
$ mkdir /YUM-
|
||||
$ mkdir /YUM
|
||||
```
|
||||
|
||||
然后挂载 Centos 7 ISO:
|
||||
@ -21,7 +21,7 @@ $ mkdir /YUM-
|
||||
$ mount -t iso9660 -o loop /home/dan/Centos-7-x86_x64-DVD.iso /mnt/iso/
|
||||
```
|
||||
|
||||
接下来,从挂载的 ISO 中复制软件包到 /YUM 中。当所有的软件包都被复制到系统中后,我们将安装创建 YUM 所需的软件包。打开 /YUM 并安装以下 RPM 包:
|
||||
接下来,从挂载的 ISO 中复制软件包到 `/YUM` 中。当所有的软件包都被复制到系统中后,我们将安装创建 Yum 所需的软件包。打开 `/YUM` 并安装以下 RPM 包:
|
||||
|
||||
```
|
||||
$ rpm -ivh deltarpm
|
||||
@ -29,7 +29,7 @@ $ rpm -ivh python-deltarpm
|
||||
$ rpm -ivh createrepo
|
||||
```
|
||||
|
||||
安装完成后,我们将在 **/etc/yum.repos.d** 中创建一个名 为 **“local.repo”** 的文件,其中包含所有的 yum 信息。
|
||||
安装完成后,我们将在 `/etc/yum.repos.d` 中创建一个名 为 `local.repo` 的文件,其中包含所有的 Yum 信息。
|
||||
|
||||
```
|
||||
$ vi /etc/yum.repos.d/local.repo
|
||||
@ -49,28 +49,28 @@ enabled=1
|
||||
$ createrepo -v /YUM
|
||||
```
|
||||
|
||||
创建仓库数据需要一些时间。一切完成后,请运行
|
||||
创建仓库数据需要一些时间。一切完成后,请运行:
|
||||
|
||||
```
|
||||
$ yum clean all
|
||||
```
|
||||
|
||||
清理缓存,然后运行
|
||||
清理缓存,然后运行:
|
||||
|
||||
```
|
||||
$ yum repolist
|
||||
```
|
||||
|
||||
检查所有仓库列表。你应该在列表中看到 “local.repo”。
|
||||
检查所有仓库列表。你应该在列表中看到 `local.repo`。
|
||||
|
||||
|
||||
### 使用在线仓库创建镜像 YUM 仓库
|
||||
### 使用在线仓库创建镜像 Yum 仓库
|
||||
|
||||
创建在线 yum 的过程与使用 ISO 镜像创建 yum 类似,只是我们将从在线仓库而不是 ISO 中获取 rpm 软件包。
|
||||
创建在线 Yum 的过程与使用 ISO 镜像创建 Yum 类似,只是我们将从在线仓库而不是 ISO 中获取 rpm 软件包。
|
||||
|
||||
首先,我们需要找到一个在线仓库来获取最新的软件包。建议你找一个离你位置最近的在线 yum 仓库,以优化下载速度。我们将使用下面的镜像,你可以从[ CENTOS 镜像列表][2]中选择一个离你最近的镜像。
|
||||
首先,我们需要找到一个在线仓库来获取最新的软件包。建议你找一个离你位置最近的在线 Yum 仓库,以优化下载速度。我们将使用下面的镜像,你可以从 [CENTOS 镜像列表][2]中选择一个离你最近的镜像。
|
||||
|
||||
选择镜像之后,我们将使用 rsync 将该镜像与我们的系统同步,但在此之前,请确保你服务器上有足够的空间。
|
||||
选择镜像之后,我们将使用 `rsync` 将该镜像与我们的系统同步,但在此之前,请确保你服务器上有足够的空间。
|
||||
|
||||
```
|
||||
$ rsync -avz rsync://mirror.fibergrid.in/centos/7.2/os/x86_64/Packages/s/ /YUM
|
||||
@ -96,9 +96,9 @@ $ crontab -e
|
||||
30 12 * * * rsync -avz http://mirror.centos.org/centos/7/os/x86_64/Packages/ /YUM
|
||||
```
|
||||
|
||||
这会在每晚 12:30 同步 yum。还请记住在 /etc/yum.repos.d 中创建仓库配置文件,就像我们上面所做的一样。
|
||||
这会在每晚 12:30 同步 Yum。还请记住在 `/etc/yum.repos.d` 中创建仓库配置文件,就像我们上面所做的一样。
|
||||
|
||||
就是这样,你现在有你自己的 yum 仓库来使用。如果你喜欢它,请分享这篇文章,并在下面的评论栏留下你的意见/疑问。
|
||||
就是这样,你现在使用你自己的 Yum 仓库了。如果你喜欢它,请分享这篇文章,并在下面的评论栏留下你的意见/疑问。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -107,7 +107,7 @@ via: http://linuxtechlab.com/creating-yum-repository-iso-online-repo/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -7,52 +7,49 @@
|
||||
|
||||
* 快速搜索
|
||||
* 更复杂的搜索条件
|
||||
* 连接条件
|
||||
* 组合条件
|
||||
* 反转条件
|
||||
* 简单和详细的回应
|
||||
* 寻找重复的文件
|
||||
|
||||
有很多有用的命令可以搜索文件,**find** 命令可能是其中最有名的,但它不是唯一的命令,也不一定总是找到目标文件的最快方法。
|
||||
有很多有用的命令可以搜索文件,`find` 命令可能是其中最有名的,但它不是唯一的命令,也不一定总是找到目标文件的最快方法。
|
||||
|
||||
### 快速搜索命令:which 和 locate
|
||||
|
||||
搜索文件的最简单的命令可能就是 **which** 和 **locate** 了,但二者都有一些局限性。**which** 命令只会在系统定义的搜索路径中,查找可执行的文件,通常用于识别命令。如果您对输入 which 时会运行的命令感到好奇,您可以使用命令 which which,它会指向对应的可执行文件。
|
||||
搜索文件的最简单的命令可能就是 `which` 和 `locate` 了,但二者都有一些局限性。`which` 命令只会在系统定义的搜索路径中,查找可执行的文件,通常用于识别命令。如果您对输入 `which` 时会运行哪个命令感到好奇,您可以使用命令 `which which`,它会指出对应的可执行文件。
|
||||
|
||||
```
|
||||
$ which which
|
||||
/usr/bin/which
|
||||
|
||||
```
|
||||
|
||||
**which** 命令会显示它找到的第一个以相应名称命名的可执行文件(也就是使用该命令时将运行的那个文件),然后停止。
|
||||
`which` 命令会显示它找到的第一个以相应名称命名的可执行文件(也就是使用该命令时将运行的那个文件),然后停止。
|
||||
|
||||
**locate** 命令更大方一点,它可以查找任意数量的文件,但它也有一个限制:仅当文件名被包含在由 **updatedb** 命令准备的数据库时才有效。该文件可能会存储在某个位置,如 /var/lib/mlocate/mlocate.db,但不能用 locate 以外的任何命令读取。这个文件的更新通常是通过每天通过 cron 运行的 updatedb 进行的。
|
||||
`locate` 命令更大方一点,它可以查找任意数量的文件,但它也有一个限制:仅当文件名被包含在由 `updatedb` 命令构建的数据库时才有效。该文件可能会存储在某个位置,如 `/var/lib/mlocate/mlocate.db`,但不能用 `locate` 以外的任何命令读取。这个文件的更新通常是通过每天通过 cron 运行的 `updatedb` 进行的。
|
||||
|
||||
简单的 **find** 命令不需要太多限制,不过它需要搜索的起点和指定搜索条件。最简单的 find 命令:按文件名搜索文件。如下所示:
|
||||
简单的 `find` 命令没有太多限制,不过它需要指定搜索的起点和搜索条件。最简单的 `find` 命令:按文件名搜索文件。如下所示:
|
||||
|
||||
```
|
||||
$ find . -name runme
|
||||
./bin/runme
|
||||
|
||||
```
|
||||
|
||||
如上所示,通过文件名搜索文件系统的当前位置将会搜索所有子目录,除非您指定了搜索深度。
|
||||
|
||||
### 不仅仅是文件名
|
||||
|
||||
**find** 命令允许您搜索除文件名以外的多种条件,包括文件所有者、组、权限、大小、修改时间、缺少所有者或组和文件类型等。除了查找文件外,您还可以删除文件、对其进行重命名、更改所有者、更改权限和对文件运行几乎任何命令。
|
||||
`find` 命令允许您搜索除文件名以外的多种条件,包括文件所有者、组、权限、大小、修改时间、缺少所有者或组,和文件类型等。除了查找文件外,您还可以删除文件、对其进行重命名、更改所有者、更改权限和对找到的文件运行几乎任何命令。
|
||||
|
||||
下面两条命令会查找:在当前目录中 root 用户拥有的文件,以及非指定用户(在本例中为 shs)拥有的文件。在这个例子中,两个输出是一样的,但并不总是如此。
|
||||
下面两条命令会查找:在当前目录中 root 用户拥有的文件,以及不被指定用户(在本例中为 shs)所拥有的文件。在这个例子中,两个输出是一样的,但并不总是如此。
|
||||
|
||||
```
|
||||
$ find . -user root -ls
|
||||
396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./xyz -> /home/peanut/xyz
|
||||
$ find . ! -user shs -ls
|
||||
396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./xyz -> /home/peanut/xyz
|
||||
|
||||
```
|
||||
|
||||
感叹号“!”字符代表“非”:反转跟随其后的条件。
|
||||
感叹号 `!` 字符代表“非”:反转跟随其后的条件。
|
||||
|
||||
下面的命令将查找具有特定权限的文件:
|
||||
|
||||
@ -61,7 +58,6 @@ $ find . -perm 750 -ls
|
||||
397176 4 -rwxr-x--- 1 shs shs 115 Sep 14 13:52 ./ll
|
||||
398209 4 -rwxr-x--- 1 shs shs 117 Sep 21 08:55 ./get-updates
|
||||
397145 4 drwxr-x--- 2 shs shs 4096 Sep 14 15:42 ./newdir
|
||||
|
||||
```
|
||||
|
||||
接下来的命令显示具有 777 权限的非符号链接文件:
|
||||
@ -70,19 +66,17 @@ $ find . -perm 750 -ls
|
||||
$ sudo find /home -perm 777 ! -type l -ls
|
||||
397132 4 -rwxrwxrwx 1 shs shs 18 Sep 15 16:06 /home/shs/bin/runme
|
||||
396949 4 -rwxrwxrwx 1 root root 558 Sep 21 11:21 /home/oops
|
||||
|
||||
```
|
||||
|
||||
以下命令将查找大小超过千兆字节的文件。请注意,我们找到了一个非常有趣的文件。它在 ELF 核心文件格式中代表该系统的物理内存。
|
||||
以下命令将查找大小超过千兆字节的文件。请注意,我们找到了一个非常有趣的文件。它以 ELF core 文件格式表示了该系统的物理内存。
|
||||
|
||||
```
|
||||
$ sudo find / -size +1G -ls
|
||||
4026531994 0 -r-------- 1 root root 140737477881856 Sep 21 11:23 /proc/kcore
|
||||
1444722 15332 -rw-rw-r-- 1 shs shs 1609039872 Sep 13 15:55 /home/shs/Downloads/ubuntu-17.04-desktop-amd64.iso
|
||||
|
||||
```
|
||||
|
||||
只要您知道 find 命令是如何描述文件类型的,就可以通过文件类型来查找文件。
|
||||
只要您知道 `find` 命令是如何描述文件类型的,就可以通过文件类型来查找文件。
|
||||
|
||||
```
|
||||
b = 块设备文件
|
||||
@ -93,7 +87,6 @@ f = 常规文件
|
||||
l = 符号链接
|
||||
s = 套接字
|
||||
D = 门(仅限 Solaris)
|
||||
|
||||
```
|
||||
|
||||
在下面的命令中,我们要寻找符号链接和套接字:
|
||||
@ -103,28 +96,25 @@ $ find . -type l -ls
|
||||
396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./whatever -> /home/peanut/whatever
|
||||
$ find . -type s -ls
|
||||
395256 0 srwxrwxr-x 1 shs shs 0 Sep 21 08:50 ./.gnupg/S.gpg-agent
|
||||
|
||||
```
|
||||
|
||||
您还可以根据 inode 数字来搜索文件:
|
||||
您还可以根据 inode 号来搜索文件:
|
||||
|
||||
```
|
||||
$ find . -inum 397132 -ls
|
||||
397132 4 -rwx------ 1 shs shs 18 Sep 15 16:06 ./bin/runme
|
||||
|
||||
```
|
||||
|
||||
另一种通过 inode 搜索文件的方法是使用 **debugfs** 命令。在大的文件系统上,这个命令可能比 find 快得多,您可能需要安装 icheck。
|
||||
另一种通过 inode 搜索文件的方法是使用 `debugfs` 命令。在大的文件系统上,这个命令可能比 `find` 快得多,您可能需要安装 icheck。
|
||||
|
||||
```
|
||||
$ sudo debugfs -R 'ncheck 397132' /dev/sda1
|
||||
debugfs 1.42.13 (17-May-2015)
|
||||
Inode Pathname
|
||||
397132 /home/shs/bin/runme
|
||||
|
||||
```
|
||||
|
||||
在下面的命令中,我们从主目录(〜)开始,限制搜索的深度(是我们将搜索子目录的层数),并只查看在最近一天内创建或修改的文件(mtime 设置)。
|
||||
在下面的命令中,我们从主目录(`~`)开始,限制搜索的深度(即我们将搜索子目录的层数),并只查看在最近一天内创建或修改的文件(`mtime` 设置)。
|
||||
|
||||
```
|
||||
$ find ~ -maxdepth 2 -mtime -1 -ls
|
||||
@ -132,29 +122,28 @@ $ find ~ -maxdepth 2 -mtime -1 -ls
|
||||
394006 8 -rw------- 1 shs shs 5909 Sep 21 08:18 /home/shs/.bash_history
|
||||
399612 4 -rw------- 1 shs shs 53 Sep 21 08:50 /home/shs/.Xauthority
|
||||
399615 4 drwxr-xr-x 2 shs shs 4096 Sep 21 09:32 /home/shs/Downloads
|
||||
|
||||
```
|
||||
|
||||
### 不仅仅是列出文件
|
||||
|
||||
使用 **-exec** 选项,在您使用 find 命令找到文件后可以以某种方式更改文件。您只需参照 -exec 选项即可运行相应的命令。
|
||||
使用 `-exec` 选项,在您使用 `find` 命令找到文件后可以以某种方式更改文件。您只需参照 `-exec` 选项即可运行相应的命令。
|
||||
|
||||
```
|
||||
$ find . -name runme -exec chmod 700 {} \;
|
||||
$ find . -name runme -ls
|
||||
397132 4 -rwx------ 1 shs shs 18 Sep 15 16:06 ./bin/runme
|
||||
|
||||
```
|
||||
|
||||
在这条命令中,“{}”代表文件名。此命令将更改当前目录和子目录中任何名为“runme”的文件的权限。
|
||||
在这条命令中,`{}` 代表文件名。此命令将更改当前目录和子目录中任何名为 `runme` 的文件的权限。
|
||||
|
||||
把您想运行的任何命令放在 -exec 选项之后,并使用类似于上面命令的语法即可。
|
||||
把您想运行的任何命令放在 `-exec` 选项之后,并使用类似于上面命令的语法即可。
|
||||
|
||||
### 其他搜索条件
|
||||
|
||||
如上面的例子所示,您还可以通过其他条件进行搜索:文件的修改时间、所有者、权限等。以下是一些示例。
|
||||
|
||||
#### 根据用户查找文件
|
||||
|
||||
```
|
||||
$ sudo find /home -user peanut
|
||||
/home/peanut
|
||||
@ -162,23 +151,22 @@ $ sudo find /home -user peanut
|
||||
/home/peanut/.bash_logout
|
||||
/home/peanut/.profile
|
||||
/home/peanut/examples.desktop
|
||||
|
||||
```
|
||||
|
||||
#### 根据权限查找文件
|
||||
#### 根据权限查找文件
|
||||
|
||||
```
|
||||
$ sudo find /home -perm 777
|
||||
/home/shs/whatever
|
||||
/home/oops
|
||||
|
||||
```
|
||||
|
||||
#### 根据修改时间查找文件
|
||||
|
||||
```
|
||||
$ sudo find /home -mtime +100
|
||||
/home/shs/.mozilla/firefox/krsw3giq.default/gmp-gmpopenh264/1.6/gmpopenh264.info
|
||||
/home/shs/.mozilla/firefox/krsw3giq.default/gmp-gmpopenh264/1.6/libgmpopenh264.so
|
||||
|
||||
```
|
||||
|
||||
#### 通过比较修改时间查找文件
|
||||
@ -188,12 +176,11 @@ $ sudo find /home -mtime +100
|
||||
```
|
||||
$ sudo find /var/log -newer /var/log/syslog
|
||||
/var/log/auth.log
|
||||
|
||||
```
|
||||
|
||||
### 寻找重复的文件
|
||||
|
||||
如果您正在清理磁盘空间,则可能需要删除较大的重复文件。确定文件是否真正重复的最好方法是使用 **fdupes** 命令。此命令使用 md5 校验和来确定文件是否具有相同的内容。使用 -r(递归)选项,fdupes 将在一个目录下并查找具有相同校验和而被确定为内容相同的文件。
|
||||
如果您正在清理磁盘空间,则可能需要删除较大的重复文件。确定文件是否真正重复的最好方法是使用 `fdupes` 命令。此命令使用 md5 校验和来确定文件是否具有相同的内容。使用 `-r`(递归)选项,`fdupes` 将在一个目录下并查找具有相同校验和而被确定为内容相同的文件。
|
||||
|
||||
如果以 root 身份运行这样的命令,您可能会发现很多重复的文件,但是很多文件都是创建时被添加到主目录的启动文件。
|
||||
|
||||
@ -209,25 +196,23 @@ $ sudo find /var/log -newer /var/log/syslog
|
||||
/home/tsmith/.bashrc
|
||||
/home/peanut/.bashrc
|
||||
/home/rocket/.bashrc
|
||||
|
||||
```
|
||||
|
||||
同样,您可能会在 /usr 中发现很多重复的但不该删除的配置文件。所以,请谨慎利用 fdupes 的输出。
|
||||
同样,您可能会在 `/usr` 中发现很多重复的但不该删除的配置文件。所以,请谨慎利用 `fdupes` 的输出。
|
||||
|
||||
fdupes 命令并不总是很快,但是要记住,它正在对许多文件运行校验和来做比较,你可能会意识到它的有效性。
|
||||
`fdupes` 命令并不总是很快,但是要记住,它正在对许多文件运行校验和来做比较,你可能会意识到它是多么有效。
|
||||
|
||||
### 总结
|
||||
|
||||
有很多方法可以在 Linux 系统上查找文件。如果您可以描述清楚您正在寻找什么,上面的命令将帮助您找到目标。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3227075/linux/mastering-file-searches-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,64 +1,65 @@
|
||||
如何在Linux上用Fail2ban保护服务器免受暴力攻击
|
||||
如何在 Linux 上用 Fail2Ban 保护服务器免受暴力攻击
|
||||
======
|
||||
|
||||
Linux管理员的一个重要任务是保护服务器免受非法攻击或访问。 默认情况下,Linux系统带有配置良好的防火墙,比如Iptables,Uncomplicated Firewall(UFW),ConfigServer Security Firewall(CSF)等,可以防止多种攻击。
|
||||
Linux 管理员的一个重要任务是保护服务器免受非法攻击或访问。 默认情况下,Linux 系统带有配置良好的防火墙,比如iptables、Uncomplicated Firewall(UFW),ConfigServer Security Firewall(CSF)等,可以防止多种攻击。
|
||||
|
||||
任何连接到互联网的机器都是恶意攻击的潜在目标。 有一个名为fail2ban的工具可用来缓解服务器上的非法访问。
|
||||
任何连接到互联网的机器都是恶意攻击的潜在目标。 有一个名为 Fail2Ban 的工具可用来缓解服务器上的非法访问。
|
||||
|
||||
### 什么是Fail2ban?
|
||||
### 什么是 Fail2Ban?
|
||||
|
||||
[Fail2ban][1]是一款入侵防御软件,可以保护服务器免受暴力攻击。 它是用Python编程语言编写的。 Fail2ban基于auth日志文件工作,默认情况下它会扫描所有auth日志文件,如`/var/log/auth.log`,`/var/log/apache/access.log`等,并禁止带有恶意标志的IP,比如密码失败太多,寻找漏洞等等标志。
|
||||
[Fail2Ban][1] 是一款入侵防御软件,可以保护服务器免受暴力攻击。 它是用 Python 编程语言编写的。 Fail2Ban 基于auth 日志文件工作,默认情况下它会扫描所有 auth 日志文件,如 `/var/log/auth.log`、`/var/log/apache/access.log` 等,并禁止带有恶意标志的IP,比如密码失败太多,寻找漏洞等等标志。
|
||||
|
||||
通常,fail2Ban用于更新防火墙规则,用于在指定的时间内拒绝IP地址。 它也会发送邮件通知。 Fail2Ban为各种服务提供了许多过滤器,如ssh,apache,nginx,squid,named,mysql,nagios等。
|
||||
通常,Fail2Ban 用于更新防火墙规则,用于在指定的时间内拒绝 IP 地址。 它也会发送邮件通知。 Fail2Ban 为各种服务提供了许多过滤器,如 ssh、apache、nginx、squid、named、mysql、nagios 等。
|
||||
|
||||
Fail2Ban能够降低错误认证尝试的速度,但是它不能消除弱认证带来的风险。 这只是服务器防止暴力攻击的安全手段之一。
|
||||
Fail2Ban 能够降低错误认证尝试的速度,但是它不能消除弱认证带来的风险。 这只是服务器防止暴力攻击的安全手段之一。
|
||||
|
||||
### 如何在Linux中安装Fail2ban
|
||||
### 如何在 Linux 中安装 Fail2Ban
|
||||
|
||||
Fail2ban已经与大部分Linux发行版打包在一起了,所以只需使用你的发行包版的包管理器来安装它。
|
||||
Fail2Ban 已经与大部分 Linux 发行版打包在一起了,所以只需使用你的发行包版的包管理器来安装它。
|
||||
|
||||
对于**`Debian / Ubuntu`**,使用[APT-GET命令][2]或[APT命令][3]安装。
|
||||
对于 Debian / Ubuntu,使用 [APT-GET 命令][2]或 [APT 命令][3]安装。
|
||||
|
||||
```
|
||||
$ sudo apt install fail2ban
|
||||
```
|
||||
|
||||
对于**`Fedora`**,使用[DNF命令][4]安装。
|
||||
对于 Fedora,使用 [DNF 命令][4]安装。
|
||||
|
||||
```
|
||||
$ sudo dnf install fail2ban
|
||||
```
|
||||
|
||||
对于 **`CentOS/RHEL`**,启用[EPEL库][5]或[RPMForge][6]库,使用[YUM命令][7]安装。
|
||||
对于 CentOS/RHEL,启用 [EPEL 库][5]或 [RPMForge][6] 库,使用 [YUM 命令][7]安装。
|
||||
|
||||
```
|
||||
$ sudo yum install fail2ban
|
||||
```
|
||||
|
||||
对于**`Arch Linux`**,使用[Pacman命令][8]安装。
|
||||
对于 Arch Linux,使用 [Pacman 命令][8]安装。
|
||||
|
||||
```
|
||||
$ sudo pacman -S fail2ban
|
||||
```
|
||||
|
||||
对于 **`openSUSE`** , 使用[Zypper命令][9]安装.
|
||||
对于 openSUSE , 使用 [Zypper命令][9]安装。
|
||||
|
||||
```
|
||||
$ sudo zypper in fail2ban
|
||||
```
|
||||
|
||||
### 如何配置Fail2ban
|
||||
### 如何配置 Fail2Ban
|
||||
|
||||
默认情况下,Fail2ban将所有配置文件保存在`/etc/fail2ban/` 目录中。 主配置文件是`jail.conf`,它包含一组预定义的过滤器。 所以,不要编辑文件,这是不可取的,因为只要有新的更新配置就会重置为默认值。
|
||||
默认情况下,Fail2Ban 将所有配置文件保存在 `/etc/fail2ban/` 目录中。 主配置文件是 `jail.conf`,它包含一组预定义的过滤器。 所以,不要编辑该文件,这是不可取的,因为只要有新的更新,配置就会重置为默认值。
|
||||
|
||||
只需在同一目录下创建一个名为`jail.local`的新配置文件,并根据您的意愿进行修改。
|
||||
只需在同一目录下创建一个名为 `jail.local` 的新配置文件,并根据您的意愿进行修改。
|
||||
|
||||
```
|
||||
# cp /etc/fail2ban/jail.conf /etc/fail2ban/jail.local
|
||||
```
|
||||
|
||||
默认情况下,大多数选项都已经配置的很完美了,如果要启用对任何特定IP的访问,则可以将IP地址添加到`ignoreip` 区域,对于多个ip的情况,用空格隔开ip地址。
|
||||
默认情况下,大多数选项都已经配置的很完美了,如果要启用对任何特定 IP 的访问,则可以将 IP 地址添加到 `ignoreip` 区域,对于多个 IP 的情况,用空格隔开 IP 地址。
|
||||
|
||||
配置文件中的`DEFAULT`部分包含Fail2Ban遵循的基本规则集,您可以根据自己的意愿调整任何参数。
|
||||
配置文件中的 `DEFAULT` 部分包含 Fail2Ban 遵循的基本规则集,您可以根据自己的意愿调整任何参数。
|
||||
|
||||
```
|
||||
# nano /etc/fail2ban/jail.local
|
||||
@ -71,16 +72,14 @@ maxretry = 3
|
||||
destemail = 2daygeek@gmail.com
|
||||
```
|
||||
|
||||
* **ignoreip:**本部分允许我们列出IP地址列表,Fail2ban不会禁止与列表中的地址匹配的主机
|
||||
* **bantime:**主机被禁止的秒数
|
||||
* **findtime:**如果在上次“findtime”秒期间已经发生了“maxretry”次重试,则主机会被禁止
|
||||
* **maxretry:**“maxretry”是主机被禁止之前的失败次数
|
||||
|
||||
|
||||
* `ignoreip`:本部分允许我们列出 IP 地址列表,Fail2Ban 不会禁止与列表中的地址匹配的主机
|
||||
* `bantime`:主机被禁止的秒数
|
||||
* `findtime`:如果在最近 `findtime` 秒期间已经发生了 `maxretry` 次重试,则主机会被禁止
|
||||
* `maxretry`:是主机被禁止之前的失败次数
|
||||
|
||||
### 如何配置服务
|
||||
|
||||
Fail2ban带有一组预定义的过滤器,用于各种服务,如ssh,apache,nginx,squid,named,mysql,nagios等。 我们不希望对配置文件进行任何更改,只需在服务区域中添加`enabled = true`这一行就可以启用任何服务。 禁用服务时将true改为false即可。
|
||||
Fail2Ban 带有一组预定义的过滤器,用于各种服务,如 ssh、apache、nginx、squid、named、mysql、nagios 等。 我们不希望对配置文件进行任何更改,只需在服务区域中添加 `enabled = true` 这一行就可以启用任何服务。 禁用服务时将 `true` 改为 `false` 即可。
|
||||
|
||||
```
|
||||
# SSH servers
|
||||
@ -91,16 +90,15 @@ logpath = %(sshd_log)s
|
||||
backend = %(sshd_backend)s
|
||||
```
|
||||
|
||||
* **enabled:** 确定服务是打开还是关闭。
|
||||
* **port :**指的是特定的服务。 如果使用默认端口,则服务名称可以放在这里。 如果使用非传统端口,则应该是端口号。
|
||||
* **logpath:**提供服务日志的位置
|
||||
* **backend:**“后端”指定用于获取文件修改的后端。
|
||||
* `enabled`: 确定服务是打开还是关闭。
|
||||
* `port`:指明特定的服务。 如果使用默认端口,则服务名称可以放在这里。 如果使用非传统端口,则应该是端口号。
|
||||
* `logpath`:提供服务日志的位置
|
||||
* `backend`:指定用于获取文件修改的后端。
|
||||
|
||||
### 重启 Fail2Ban
|
||||
|
||||
进行更改后,重新启动 Fail2Ban 才能生效。
|
||||
|
||||
### 重启Fail2Ban
|
||||
|
||||
进行更改后,重新启动Fail2Ban才能生效。
|
||||
```
|
||||
[For SysVinit Systems]
|
||||
# service fail2ban restart
|
||||
@ -109,9 +107,10 @@ backend = %(sshd_backend)s
|
||||
# systemctl restart fail2ban.service
|
||||
```
|
||||
|
||||
### 验证Fail2Ban iptables规则
|
||||
### 验证 Fail2Ban iptables 规则
|
||||
|
||||
你可以使用下面的命令来确认是否在防火墙中成功添加了Fail2Ban iptables 规则。
|
||||
|
||||
你可以使用下面的命令来确认是否在防火墙中成功添加了Fail2Ban iptables规则。
|
||||
```
|
||||
# iptables -L
|
||||
Chain INPUT (policy ACCEPT)
|
||||
@ -135,9 +134,9 @@ target prot opt source destination
|
||||
RETURN all -- anywhere anywhere
|
||||
```
|
||||
|
||||
### 如何测试Fail2ban
|
||||
### 如何测试 Fail2Ban
|
||||
|
||||
我做了一些失败的尝试来测试这个。 为了证实这一点,我要验证`/var/log/fail2ban.log` 文件。
|
||||
我做了一些失败的尝试来测试这个。 为了证实这一点,我要验证 `/var/log/fail2ban.log` 文件。
|
||||
|
||||
```
|
||||
2017-11-05 14:43:22,901 fail2ban.server [7141]: INFO Changed logging target to /var/log/fail2ban.log for Fail2ban v0.9.6
|
||||
@ -184,6 +183,7 @@ RETURN all -- anywhere anywhere
|
||||
```
|
||||
|
||||
要查看启用的监狱列表,请运行以下命令。
|
||||
|
||||
```
|
||||
# fail2ban-client status
|
||||
Status
|
||||
@ -191,7 +191,8 @@ Status
|
||||
`- Jail list: apache-auth, sshd
|
||||
```
|
||||
|
||||
通过运行以下命令来获取禁止的IP地址。
|
||||
通过运行以下命令来获取禁止的 IP 地址。
|
||||
|
||||
```
|
||||
# fail2ban-client status ssh
|
||||
Status for the jail: ssh
|
||||
@ -205,18 +206,19 @@ Status for the jail: ssh
|
||||
`- Total banned: 1
|
||||
```
|
||||
|
||||
要从Fail2Ban中删除禁止的IP地址,请运行以下命令。
|
||||
要从 Fail2Ban 中删除禁止的 IP 地址,请运行以下命令。
|
||||
|
||||
```
|
||||
# fail2ban-client set ssh unbanip 192.168.1.115
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-install-setup-configure-fail2ban-on-linux/#
|
||||
via: https://www.2daygeek.com/how-to-install-setup-configure-fail2ban-on-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -15,19 +15,17 @@
|
||||
|
||||
好,让我们直接来看第一个 bug。这是我在 Dropbox 工作时遇到的一个 bug。你们或许听说过,Dropbox 是一个将你的文件从一个电脑上同步到云端和其他电脑上的应用。
|
||||
|
||||
|
||||
|
||||
```
|
||||
+--------------+ +---------------+
|
||||
| | | |
|
||||
| METASERVER | | BLOCKSERVER |
|
||||
| 元数据服务器 | | 块服务器 |
|
||||
| | | |
|
||||
+-+--+---------+ +---------+-----+
|
||||
^ | ^
|
||||
| | |
|
||||
| | +----------+ |
|
||||
| +---> | | |
|
||||
| | CLIENT +--------+
|
||||
| | 客户端 +--------+
|
||||
+--------+ |
|
||||
+----------+
|
||||
```
|
||||
@ -79,7 +77,7 @@
|
||||
l \x0c < $ ( . -
|
||||
```
|
||||
|
||||
英文逗号的 ASCII 码是44。`l` 的 ASCII 码是 108。它们的二进制表示如下:
|
||||
英文逗号的 ASCII 码是 44。`l` 的 ASCII 码是 108。它们的二进制表示如下:
|
||||
|
||||
```
|
||||
bin(ord(',')): 0101100
|
||||
@ -101,8 +99,7 @@ $ : 0100100
|
||||
- : 0101101
|
||||
```
|
||||
|
||||
|
||||
### 位反转是真的!
|
||||
#### 位反转是真的!
|
||||
|
||||
我爱这个 bug 因为它证明了位反转是可能真实发生的事情,而不只是一个理论上的问题。实际上,它在某些情况下会比平时更容易发生。其中一种情况是用户使用的是低配或者老旧的硬件,而运行 Dropbox 的电脑很多都是这样。另外一种会造成很多位反转的地方是外太空——在太空中没有大气层来保护你的内存不受高能粒子和辐射的影响,所以位反转会十分常见。
|
||||
|
||||
@ -110,31 +107,31 @@ $ : 0100100
|
||||
|
||||
在刚才那种情况下,Dropbox 并不需要处理位反转。出现内存损坏的是用户的电脑,所以即使我们可以检测到逗号字符的位反转,但如果这发生在其他字符上我们就不一定能检测到了,而且如果从硬盘中读取的文件本身发生了位反转,那我们根本无从得知。我们能改进的地方很少,于是我们决定无视这个异常并继续程序的运行。这种 bug 一般都会在客户端重启之后自动解决。
|
||||
|
||||
### 不常见的 bug 并非不可能发生
|
||||
#### 不常见的 bug 并非不可能发生
|
||||
|
||||
这是我最喜欢的 bug 之一,有几个原因。第一,它提醒我注意不常见和不可能之间的区别。当规模足够大的时候,不常见的现象会以值得注意的频率发生。
|
||||
|
||||
### 覆盖面广的 bug
|
||||
#### 覆盖面广的 bug
|
||||
|
||||
这个 bug 第二个让我喜欢的地方是它覆盖面非常广。每当桌面客户端和服务器交流的时候,这个 bug 都可能悄然出现,而这可能会发生在系统里很多不同的端点和组件当中。这意味着许多不同的 Dropbox 工程师会看到这个 bug 的各种版本。你第一次看到它的时候,你 _真的_ 会满头雾水,但在那之后诊断这个 bug 就变得很容易了,而调查过程也非常简短:你只需找到中间的字母,看它是不是个 `l`。
|
||||
|
||||
### 文化差异
|
||||
#### 文化差异
|
||||
|
||||
这个 bug 的一个有趣的副作用是它展示了服务器组和客户端组之间的文化差异。有时候这个 bug 会被服务器组的成员发现并展开调查。如果你的 _服务器_ 上发生了位反转,那应该不是个偶然——这很可能是内存损坏,你需要找到受影响的主机并尽快把它从集群中移除,不然就会有损坏大量用户数据的风险。这是个事故,而你必须迅速做出反应。但如果是用户的电脑在破坏数据,你并没有什么可以做的。
|
||||
|
||||
### 分享你的 bug
|
||||
#### 分享你的 bug
|
||||
|
||||
如果你在调试一个难搞的 bug,特别是在大型系统中,不要忘记跟别人讨论。也许你的同事以前就遇到过类似的 bug。若是如此,你可能会节省很多时间。就算他们没有见过,也不要忘记在你解决了问题之后告诉他们解决方法——写下来或者在组会中分享。这样下次你们组遇到类似的问题时,你们都会早有准备。
|
||||
|
||||
### Bug 如何帮助你进步
|
||||
|
||||
### Recurse Center
|
||||
#### Recurse Center
|
||||
|
||||
在加入 Dropbox 之前,我曾在 Recurse Center 工作。它的理念是建立一个社区让正在自学的程序员们聚到一起来提高能力。这就是 Recurse Center 的全部了:我们没有大纲、作业、截止日期等等。唯一的前提条件是我们都想要成为更好的程序员。参与者中有的人有计算机学位但对自己的实际编程能力不够自信,有的人已经写了十年 Java 但想学 Clojure 或者 Haskell,还有各式各样有着其他的背景的参与者。
|
||||
|
||||
我在那里是一位导师,帮助人们更好地利用这个自由的环境,并参考我们从以前的参与者那里学到的东西来提供指导。所以我的同事们和我本人都非常热衷于寻找对成年自学者最有帮助的学习方法。
|
||||
|
||||
### 刻意练习
|
||||
#### 刻意练习
|
||||
|
||||
在学习方法这个领域有很多不同的研究,其中我觉得最有意思的研究之一是刻意练习的概念。刻意练习理论意在解释专业人士和业余爱好者的表现的差距。它的基本思想是如果你只看内在的特征——不论先天与否——它们都无法非常好地解释这种差距。于是研究者们,包括最初的 Ericsson、Krampe 和 Tesch-Romer,开始寻找能够解释这种差距的理论。他们最终的答案是在刻意练习上所花的时间。
|
||||
|
||||
@ -189,18 +186,15 @@ $ : 0100100
|
||||
|
||||
所有这些 bug 都很容易修复。前两个 bug 出在客户端上,所以我们在 alpha 版本修复了它们,但大部分的客户端还没有获得这些改动。我们在服务器代码中修复了第三个 bug 并部署了新版的服务器。
|
||||
|
||||
### 📈
|
||||
#### 激增
|
||||
|
||||
突然日志服务器集群的流量开始激增。客服团队找到我们并问我们是否知道原因。我花了点时间把所有的部分拼到一起。
|
||||
|
||||
在修复之前,这四件事情会发生:
|
||||
|
||||
1. 日志文件从最早的开始发送
|
||||
|
||||
2. 日志文件从最新的开始删除
|
||||
|
||||
3. 如果服务器无法解码日志文件,它会返回 500
|
||||
|
||||
4. 如果客户端收到 500,它会停止发送日志
|
||||
|
||||
一个存有损坏的日志文件的客户端会试着发送这个文件,服务器会返回 500,客户端会放弃发送日志。在下一次运行时,它会尝试再次发送同样的文件,再次失败,并再次放弃。最终日志目录会被填满,然后客户端会开始删除最新的日志文件,而把损坏的文件继续保留在硬盘上。
|
||||
@ -209,27 +203,27 @@ $ : 0100100
|
||||
|
||||
问题是,处于这种状态的客户端比我们想象的要多很多。任何有一个损坏文件的客户端都会像被关在堤坝里一样,无法再发送日志。现在这个堤坝被清除了,所有这些客户端都开始发送它们的日志目录的剩余内容。
|
||||
|
||||
### 我们的选择
|
||||
#### 我们的选择
|
||||
|
||||
好的,现在文件从世界各地的电脑如洪水般涌来。我们能做什么?(当你在一个有 Dropbox 这种规模,尤其是这种桌面客户端的规模的公司工作时,会遇到这种有趣的事情:你可以非常轻易地对自己造成 DDOS 攻击)。
|
||||
好的,现在文件从世界各地的电脑如洪水般涌来。我们能做什么?(当你在一个有 Dropbox 这种规模,尤其是这种桌面客户端的规模的公司工作时,会遇到这种有趣的事情:你可以非常轻易地对自己造成 DDoS 攻击)。
|
||||
|
||||
当你部署的新版本发生问题时,第一个选项是回滚。这是非常合理的选择,但对于这个问题,它无法帮助我们。我们改变的不是服务器的状态而是客户端的——我们删除了那些出错文件。将服务器回滚可以防止更多客户端进入这种状态,但它并不能解决根本问题。
|
||||
|
||||
那扩大日志集群的规模呢?我们试过了——然后因为处理能力增加了,我们开始收到更多的请求。我们又扩大了一次,但你不可能一直这么下去。为什么不能?因为这个集群并不是独立的。它会向另一个集群发送请求,在这里是为了处理异常。如果你的一个集群正在被 DDOS,而你持续扩大那个集群,你最终会把它依赖的集群也弄坏,然后你就有两个问题了。
|
||||
那扩大日志集群的规模呢?我们试过了——然后因为处理能力增加了,我们开始收到更多的请求。我们又扩大了一次,但你不可能一直这么下去。为什么不能?因为这个集群并不是独立的。它会向另一个集群发送请求,在这里是为了处理异常。如果你的一个集群正在被 DDoS,而你持续扩大那个集群,你最终会把它依赖的集群也弄坏,然后你就有两个问题了。
|
||||
|
||||
我们考虑过的另一个选择是减低负载——你不需要每一个日志文件,所以我们可以直接无视一些请求。一个难点是我们并没有一个很好的方法来区分好的请求和坏的请求。我们无法快速地判断哪些日志文件是旧的,哪些是新的。
|
||||
|
||||
我们最终使用的是一个 Dropbox 里许多不同场合都用过的一个解决方法:我们有一个自定义的头字段,`chillout`,全世界所有的客户端都遵守它。如果客户端收到一个有这个头字段的响应,它将在字段所标注的时间内不再发送任何请求。很早以前一个英明的程序员把它加到了 Dropbox 客户端里,在之后这些年中它已经不止一次地起了作用。
|
||||
|
||||
### 了解你的系统
|
||||
#### 了解你的系统
|
||||
|
||||
这个 bug 的第一个教训是要了解你的系统。我对于客户端和服务器之间的交互有不错的理解,但我并没有考虑到当服务器和所有这些客户端同时交互的时候会发生什么。这是一个我没有完全搞懂的层面。
|
||||
|
||||
### 了解你的工具
|
||||
#### 了解你的工具
|
||||
|
||||
第二个教训是要了解你的工具。如果出了差错,你有哪些选项?你能撤销你做的迁移吗?你如何知道事情出了差错,你又如何发现更多信息?所有这些事情都应该在危机发生之前就了解好——但如果你没有,你会在危机发生时学到它们并不会再忘记。
|
||||
|
||||
### 功能开关 & 服务器端功能控制
|
||||
#### 功能开关 & 服务器端功能控制
|
||||
|
||||
第三个教训是专门针对移动端和桌面应用开发者的:_你需要服务器端功能控制和功能开关_。当你发现一个问题时如果你没有服务器端的功能控制,你可能需要几天或几星期来推送新版本或者提交新版本到应用商店中,然后问题才能得到解决。这是个很糟糕的处境。Dropbox 桌面客户端不需要经过应用商店的审查过程,但光是把一个版本推送给上千万的用户就已经要花很多时间。相比之下,如果你能在新功能遇到问题的时候在服务器上翻转一个开关:十分钟之后你的问题就已经解决了。
|
||||
|
||||
@ -237,7 +231,7 @@ $ : 0100100
|
||||
|
||||
但是它的好处——啊,当你需要它的时候,你真的是很需要它。
|
||||
|
||||
# 如何去爱 bug
|
||||
### 如何去爱 bug
|
||||
|
||||
我讲了几个我爱的 bug,也讲了为什么要爱 bug。现在我想告诉你如何去爱 bug。如果你现在还不爱 bug,我知道唯一一种改变的方法,那就是要有成长型心态。
|
||||
|
||||
@ -261,7 +255,7 @@ Dweck 发现一个人看待智力的方式——固定型还是成长型心态
|
||||
|
||||
这些发现表明成长型心态对 debug 至关重要。我们必须从从困惑中重整旗鼓,诚实地面对我们理解上的不足,并时不时地在寻找答案的路上努力奋斗——成长型心态会让这些都变得更简单而且不那么痛苦。
|
||||
|
||||
### 热爱你的 bug
|
||||
#### 热爱你的 bug
|
||||
|
||||
我在 Recurse Center 工作时会直白地欢迎挑战,我就是这样学会热爱我的 bug 的。有时参与者会坐到我身边说“唉,我觉得我遇到了个奇怪的 Python bug”,然后我会说“太棒了,我 _爱_ 奇怪的 Python bug!” 首先,这百分之百是真的,但更重要的是,我这样是在对参与者强调,找到让自己觉得困难的事情是一种成就,而他们做到了这一点,这是件好事。
|
||||
|
||||
@ -274,22 +268,18 @@ Dweck 发现一个人看待智力的方式——固定型还是成长型心态
|
||||
在此向给我的演讲提出反馈以及给我的演讲提供其他帮助的人士表示感谢:
|
||||
|
||||
* Sasha Laundy
|
||||
|
||||
* Amy Hanlon
|
||||
|
||||
* Julia Evans
|
||||
|
||||
* Julian Cooper
|
||||
|
||||
* Raphael Passini Diniz 以及其他的 Python Brasil 组织团队成员
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://akaptur.com/blog/2017/11/12/love-your-bugs/
|
||||
|
||||
作者:[Allison Kaptur ][a]
|
||||
作者:[Allison Kaptur][a]
|
||||
译者:[yixunx](https://github.com/yixunx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,6 @@
|
||||
在 Linux 上恢复一个损坏的 USB 设备至初始状态
|
||||
======
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
很多时候我们诸如 SD 卡和 U 盘这样的储存器可能会被损坏,并且因此或其他原因不能继续使用。
|
||||
@ -13,56 +11,52 @@
|
||||
|
||||
[][1]
|
||||
|
||||
警告:接下来的操作会将你设备上的所有数据格式化
|
||||
**警告:接下来的操作会将你设备上的所有数据格式化。**
|
||||
|
||||
无论是上面提及的什么原因,最终的结果是我们无法继续使用这个设备。
|
||||
|
||||
|
||||
无论什么原因,最终的结果是我们无法继续使用这个设备。
|
||||
|
||||
所以这里是一个恢复一个 USB 设备或者是 SD 卡到出厂状态的方法。
|
||||
所以这里有一个恢复 USB 设备或者是 SD 卡到出厂状态的方法。
|
||||
|
||||
大多数时候通过文件浏览器进行一次简单格式化可以解决问题,但是在一些极端情况下,比如文件管理器没有作用,而你又需要你的设备可以继续工作时,你可以使用下面的指导:
|
||||
|
||||
我们将会使用一个叫做 mkusb 的小工具来实现目标,这个工具的安装非常简单。
|
||||
我们将会使用一个叫做 `mkusb` 的小工具来实现目标,这个工具的安装非常简单。
|
||||
|
||||
添加 mkusb 的仓库:
|
||||
|
||||
```
|
||||
sudo apt add repository ppa:mkusb/ppa
|
||||
```
|
||||
|
||||
现在更新你的包列表:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
1. 添加 mkusb 的仓库
|
||||
安装 `mkusb:
|
||||
|
||||
`sudo apt add repository ppa:mkusb/ppa`
|
||||
```
|
||||
sudo apt-get install mkusb
|
||||
```
|
||||
|
||||
2. 现在更新你的包列表
|
||||
|
||||
`sudo apt-get update`
|
||||
|
||||
3. 安装 mkusb
|
||||
|
||||
`sudo apt-get install mkusb`
|
||||
|
||||
现在运行 mkusb 你将会看到这个提示,点击 ‘Yes’。
|
||||
现在运行 `mkusb` 你将会看到这个提示,点击 ‘Yes’。
|
||||
|
||||
[][2]
|
||||
|
||||
现在 mkusb 将会最后一次询问你是否希望继续格式化你的数据,‘Stop’是被默认选择的,你现在选择 ‘Go’并点击‘OK’。
|
||||
现在 `mkusb` 将会最后一次询问你是否希望继续格式化你的数据,‘Stop’是被默认选择的,你现在选择 ‘Go’ 并点击 ‘OK’。
|
||||
|
||||
[][3]
|
||||
|
||||
窗口将会关闭,摒弃人此时你的终端看起来是这样的。
|
||||
窗口将会关闭,此时你的终端看起来是这样的。
|
||||
|
||||
[][4]
|
||||
|
||||
在几秒钟之后,整个过程将会完成,并且你将看到一个这样的弹出窗口。
|
||||
|
||||
|
||||
|
||||
[][5]
|
||||
|
||||
你现在需要把你的设备从系统推出,然后再重新插进去。你的设备将被恢复成为一个普通设备而且还能像原来一样的工作。
|
||||
|
||||
|
||||
|
||||
[][6]
|
||||
|
||||
我们现在所做的操作本可以通过终端命令或是 gparted 或者其他的软件来完成,但是那将会需要一些关于分区管理的知识。
|
||||
@ -71,23 +65,19 @@
|
||||
|
||||
### 结论
|
||||
|
||||
**mkusb**
|
||||
|
||||
是一个很容易使用的程序,它可以修复你的 USB 储存设备和 SD 卡。mkusb通过 mkusb 的 PPA 来下载。所有在 mkusb 上的操作都需要超级管理员的权限,并且你在这个设备上的所有数据将会被格式化。
|
||||
`mkusb` 是一个很容易使用的程序,它可以修复你的 USB 储存设备和 SD 卡。`mkusb` 通过 mkusb 的 PPA 来下载。所有在 `mkusb` 上的操作都需要超级管理员的权限,并且你在这个设备上的所有数据将会被格式化。
|
||||
|
||||
一旦操作完成,你将会重置这个设备并让它继续工作。
|
||||
|
||||
如果你感到任何疑惑,你可以在下面的评论栏里免费发表。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/restore-corrupted-usb-drive-to-original-state-in-linux
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[Drshu](https://github.com/Drshu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,16 @@
|
||||
从命令行查看加密货币价格
|
||||
用命令行查看比特币等加密货币的价格
|
||||
======
|
||||
|
||||

|
||||
前段时间,我们发布了一个关于 **[Cli-Fyi][1] ** 的指南 - 一个潜在有用的命令行查询工具。使用 Cli-Fyi,我们可以很容易地了解加密货币的最新价格和许多其他有用的细节。今天,我们将看到另一个名为 **“Coinmon”** 的加密货币价格查看工具。不像 Cli.Fyi,Coinmon 只能用来查看不同加密货币的价格。没有其他功能!Coinmon 会检查加密货币的价格,并立即直接从你的终端修改价格。它将从 [coinmarketcap.com][2] API 获取所有详细信息。对于那些 **加密货币投资者**和**工程师**来说是非常有用的。
|
||||
|
||||
前段时间,我们发布了一个关于 [Cli-Fyi][1] 的指南 - 一个可能有用的命令行查询工具。使用 Cli-Fyi,我们可以很容易地了解加密货币的最新价格和许多其他有用的细节。今天,我们将看到另一个名为 “Coinmon” 的加密货币价格查看工具。不像 Cli.Fyi,Coinmon 只能用来查看不同加密货币的价格。没有其他功能!Coinmon 会在终端上检查加密货币的价格。它将从 [coinmarketcap.com][2] API 获取所有详细信息。对于那些 **加密货币投资者**和**工程师**来说是非常有用的。
|
||||
|
||||
### 安装 Coinmon
|
||||
|
||||
确保你的系统上安装了 Node.js 和 Npm。如果你的机器上没有安装 Node.js 和/或 npm,请参考以下链接进行安装。
|
||||
|
||||
安装完 Node.js 和 Npm 后,从终端运行以下命令安装 Coinmon。
|
||||
|
||||
```
|
||||
sudo npm install -g coinmon
|
||||
```
|
||||
@ -15,38 +18,42 @@ sudo npm install -g coinmon
|
||||
### 从命令行查看加密货币价格
|
||||
|
||||
运行以下命令查看市值排名的前 10 位的加密货币:
|
||||
|
||||
```
|
||||
coinmon
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
[![][3]][4]
|
||||
![][4]
|
||||
|
||||
如我所说,如果你不带任何参数运行 Coinmon,它将显示前 10 位加密货币。你还可以使用 `-t` 标志查看最高的 n 位加密货币,例如 20。
|
||||
|
||||
如我所说,如果你不带任何参数运行 coinmon,它将显示前 10 位加密货币。你还可以使用 “-t” 标志查看最高的 n 位加密货币,例如 20。
|
||||
```
|
||||
coinmon -t 20
|
||||
```
|
||||
|
||||
所有价格默认以美元显示。你还可以使用 “-c” 标志将价格从美元转换为另一种货币。
|
||||
所有价格默认以美元显示。你还可以使用 `-c` 标志将价格从美元转换为另一种货币。
|
||||
|
||||
例如,要将价格转换为 INR(印度卢比),运行:
|
||||
|
||||
```
|
||||
coinmon -c inr
|
||||
```
|
||||
|
||||
[![][3]][5]
|
||||
![][5]
|
||||
|
||||
目前,Coinmon 支持 AUD、BRL、CAD、CHF、CLP、CNY、CZK、DKK、EUR、GBP、HKD、HUF、IDR、ILS、INR、JPY、KRW、MXN、MYR、NOK、NZD、PHP、PKR、PLN、RUB、SEK、SGD、THB、TRY、TWD、ZAR 这些货币。
|
||||
|
||||
也可以使用加密货币的符号来搜索价格。
|
||||
|
||||
```
|
||||
coinmon -f btc
|
||||
```
|
||||
|
||||
这里,**btc** 是比特币的符号。你可以在[**这**][6]查看所有可用的加密货币的符号。
|
||||
这里,`btc` 是比特币的符号。你可以在[**这里**][6]查看所有可用的加密货币的符号。
|
||||
|
||||
有关更多详情,请参阅coinmon的帮助部分:
|
||||
有关更多详情,请参阅 coinmon 的帮助部分:
|
||||
|
||||
```
|
||||
$ coinmon -h
|
||||
@ -67,15 +74,13 @@ Options:
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/coinmon-check-cryptocurrency-prices-commandline/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -83,6 +88,6 @@ via: https://www.ostechnix.com/coinmon-check-cryptocurrency-prices-commandline/
|
||||
[1]:https://www.ostechnix.com/cli-fyi-quick-easy-way-fetch-information-ips-emails-domains-lots/
|
||||
[2]:https://coinmarketcap.com/
|
||||
[3]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/11/coinmon-1.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/11/coinmon-2.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/11/coinmon-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/11/coinmon-2.png
|
||||
[6]:https://en.wikipedia.org/wiki/List_of_cryptocurrencies
|
||||
@ -0,0 +1,118 @@
|
||||
迁移到 Linux:图形操作环境
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 这篇文章对 Linux 图形环境做了一番介绍,展示了在不同的 Linux 发行版上的各种选择。
|
||||
|
||||
这是我们迁移到 Linux 系统系列的第三篇文章。如果你错过了先前的两篇,这里有两文的链接《[入门介绍][1]》 和 《[磁盘、文件、和文件系统][2]》。本文中,我们将讨论图形操作环境。在 Linux 系统中,你可以依照喜好选择并且定制一个图形界面,你有很大的选择余地,这也是 Linux 优越的体验之一。
|
||||
|
||||
一些主流的 Linux 图形界面包括:Cinnamon、Gnome、KDE Plasma、Xfce 和 MATE,总之这里有很多选择。
|
||||
|
||||
有一点经常混淆 Linux 新手,虽然某个 Linux 系统分配了一个缺省的图形环境,但是一般你可以随时更换这个图形界面。这和 Windows 或 Mac OS 的惯用者的定势思维不同。安装图形环境是一件独立的事情,很多时候,Linux 和其图形环境的连接并不紧密。此外,你在一个图形环境构建运行的程序同样适用于另一个图形环境。比如说一个为 KDE Plasma 图形环境编写的应用程序完全适用于 Gnome 桌面图形环境。
|
||||
|
||||
由于人们熟悉 Windows 和 MacOS 系统,部分 Linux 操作系统的图形环境在一定程度上尝试着去模仿它们,但另一些 Linux 图形界面则是独特的。
|
||||
|
||||
下面,我将就一些不同的 Linux 发行版,展示几个 Linux 图形环境。如果你不确定应该采用那个 Linux 发行版,那我建议你从 [Ubuntu][3] 开始,获取其长期支持(LTS)的版本(Ubuntu 16.04.3 LTS 正在开发)。Ubuntu 稳定且真的非常好用。
|
||||
|
||||
### 由 Mac 过渡
|
||||
|
||||
Elementary OS 发行版提供了和 Mac 系统风格很接近的界面。它的默认图形环境被称作 Pantheon,是一款很适合 Mac 用户过渡使用的图形环境。这款图形界面发行版的屏幕底部有一个停靠栏,专为极简者使用而设计。为了保持简约的风格,很多默认的应用程序甚至都不会有自己的菜单。相反,它们的按钮和控件在应用程序的标题栏上(图 1)。
|
||||
|
||||
![Elementary OS][5]
|
||||
|
||||
*图 1: Elementary OS Pantheon.*
|
||||
|
||||
Ubuntu 发行版提供的一个默认的图形界面,也和 Mac 相似。Ubuntu 17.04 或者更老的版本都使用 Unity 图形环境,Unity 停靠栏的默认位置在屏幕的左边,屏幕顶部有一个全局应用程序共享的菜单栏。
|
||||
|
||||
### 由 Windows 过渡
|
||||
|
||||
ChaletOS 亦步亦趋模仿 Windows 界面,可以帮助 Windows 用户轻松的过渡到 Linux。ChaletOS 使用的图形环境是 Xfce(图 2)。在屏幕的左下角有一个开始(主)菜单和搜索栏。屏幕的右下角是一个桌面图标和一些通知信息。这看起来和 Windows 非常像,乍一看,可能都会以为桌面跑的是 Windows。
|
||||
|
||||
![ChaletOS][6]
|
||||
|
||||
*图 2: ChaletOS with Xfce.*
|
||||
|
||||
Zorin OS 发行版同样尝试模仿 Windows。 Zorin OS 使用的 Gnome 的改进桌面,工作起来和 Windows 的图形界面很相似。左下角的开始按钮、右下角的通知栏和信息通知栏。开始按钮会弹出一个和 Windows 无异的应用程序列表和搜索框。
|
||||
|
||||
### 独有的图形环境
|
||||
|
||||
Gnome 桌面(图 3)是最常用的图形环境之一。许多发行版将 Gnome 作为默认的图形环境。Gnome 并不打算模仿 Windows 或是 MacOS,而是以其自身的优雅和易用为目标。
|
||||
|
||||
![][7]
|
||||
|
||||
*图 3:openSUSE with Gnome.*
|
||||
|
||||
Gnome 桌面环境从版本 2 到 版本 3 发生了巨变,Cinnamon 环境为消除该改变带来的不利影响而创造。尽管 Cinnamon 和前辈 Gnome 2 外观不相似,但是它依旧尝试提供一个简约的界面,而且它的功能和 Windows XP 类似。
|
||||
|
||||
MATE 图形环境直接模仿于 Gnome 2,在它的屏幕顶部有一个用作设置和存放应用的菜单栏,底部提供了一个应用程序运行选项卡和一些其他组件。
|
||||
|
||||
KDE plasma 围绕组件界面而构建,组件可以安装在桌面或是面板上(图 4)。
|
||||
|
||||
![KDE Plasma][8]
|
||||
|
||||
*图 4: 安装了 KDE Plasma 的 Kubuntu 操作系统。*
|
||||
|
||||
没有那个图形环境比另外一个更好。不同的风格适用不同的用户风格。另外,如果选择太多无从下手,那就从 [Ubuntu][3] 开始吧。
|
||||
|
||||
### 相似与不同
|
||||
|
||||
不同的操作系统处理方式不同,这会给使用者的过渡带来挑战。比如说,菜单栏可能出现在不同的位置,然后设置有可能用不同的选项入口路径。我列举了一些相似或不同地方来帮助减少 Linux 调整。
|
||||
|
||||
#### 鼠标
|
||||
|
||||
Linux 的鼠标通常和 Windows 与 MacOS 的工作方式有所差异。在 Windows 或 Mac,双击标签,你几乎可以打开任何事物,而这在 Linux 图形界面中很多都被设置为单击。
|
||||
|
||||
此外在 Windows 系统中,你通常通过单击窗口获取焦点。在 Linux,很多窗口的焦点获取方式被设置为鼠标悬停,即便鼠标悬停下的窗口并不在屏幕顶端。这种微妙的差异有时候会让人很吃惊。比如说,在 Windows 中,假如有一个后台应用(不在屏幕顶层),你移动鼠标到它的上面,不点击鼠标仅仅转动鼠标滚轮,顶层窗口会滚动。而在 Linux 中,后台窗口(鼠标悬停的那个窗口)会滚动。
|
||||
|
||||
#### 菜单
|
||||
|
||||
应用菜单是电脑程序的一个主要集中位置,最近似乎可以调整移动菜单栏到不碍事的地方,甚至干脆完全删除。大概,当你迁移到 Linux,你可能找不到你期待的菜单。应用程序菜单会像 MacOS一样出现在全局共享菜单栏内。和很多移动应用程序一样,该菜单可能在“更多选项”的图标里。或者,这个菜单干脆被完全移除被一个按钮取代,正如在 Elementary OS Pantheon 环境里的一些程序一样。
|
||||
|
||||
#### 工作空间
|
||||
|
||||
很多 Linux 图形环境提供了多个工作空间。一个工作空间包含的正在运行的程序窗口充盈了整个屏幕。切换到不同的工作空间将会改变程序的可见性。这个概念是把当前项目运行使用的全部应用程序分组到一个工作空间,而一些为另一个项目使用的应用程序会被分组到不同的工作空间。
|
||||
|
||||
不是每一个人都需要甚至是喜欢工作空间,但是我提到它是因为,作为一个新手,你可能无意间通过一个组合键切换了工作空间,然后,“喂!我的应用程序哪去了?” 如果你看到的还是你熟悉的桌面壁纸,那你可能只是切换了工作空间,你所有的应用程序还在一个工作空间运行,只是现在不可见而已。在很多 Linux 环境中,通过敲击 `Alt+Ctrl` 和一个箭头(上、下、左或右)可以切换工作空间。很有可能发现你的应用程序一直都在另一个工作空间里运行。
|
||||
|
||||
当然,如果你刚好喜欢工作空间(很多人都喜欢),然后你就发现了一个 Linux 很有用的默认功能。
|
||||
|
||||
#### 设置
|
||||
|
||||
许多 Linux 图形环境提供一些类型的设置程序或是面板让你在机器上配置设置。值得注意的是类似 Windows 和 MacOS,Linux 可以配置好很多细节,但不是所有的详细设置都可以在设置程序上找到。但是这些设置项已经足够满足大部分典型的桌面系统,比如选择桌面壁纸,改变熄屏时间,连接打印机等其他一些设置。
|
||||
|
||||
和 Windows 或者 MacOS 相比,Linux 的应用程序设置的分组或是命名都有不同的方式。甚至同是 Linux 系统,不同的图形界面也会出现不同的设置,这可能需要时间适应。当然,在你的图形环境中设置配置的问题可以通过在线查询这样不错的方法解决。
|
||||
|
||||
#### 应用程序
|
||||
|
||||
最后,Linux 的应用程序也可能不同。你可能会发现一些熟悉的应用程序,但是对你来说更多的将会是崭新的应用。比如说,你能在 Linux 上找到 Firefox、Chrome 和 Skype。如果不能找到特定的应用程序,通常你能使用一些替代程序。如果还是不能,那你可以使用 WINE 这样的兼容层来运行 Windows 的应用程序。
|
||||
|
||||
在很多 Linux 图形环境中,你可以通过敲击 Windows 的标志键来打开应用程序菜单栏。在其他一些情况中,你不得不点击开始(主)按钮或应用程序菜单。很多图形环境中,你可以通过分类搜索到应用程序而不一定需要它的特定程序名。比如说,你要使用一个你不清楚名字的编辑器程序,这时候,你可以在应用程序菜单栏键的搜索框中键入“editor”字样,它将为你展示一个甚至更多的被认为是编辑器类的应用程序。
|
||||
|
||||
为帮你起步,这里列举了一点可能成为 Linux 系统使用的替代程序。
|
||||
|
||||
![linux][10]
|
||||
|
||||
请注意,Linux 提供了大量的满足你需求的选择,这张表里列举的一点也不完整。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2017/12/migrating-linux-graphical-environments
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://linux.cn/article-9212-1.html
|
||||
[2]:https://linux.cn/article-9213-1.html
|
||||
[3]:https://www.evernote.com/OutboundRedirect.action?dest=https%3A%2F%2Fwww.ubuntu.com%2Fdownload%2Fdesktop
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/elementaryos.png?itok=kJk2-BsL (Elementary OS)
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/chaletos.png?itok=Zdm2rRgu
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/opensuse.png?itok=TM0Q9AyH
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kubuntu.png?itok=a2E7ttaa (KDE Plasma)
|
||||
[9]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
|
||||
[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/linux-options.png?itok=lkqD1UMj
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user