mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
e7be5f33d5
@ -50,6 +50,7 @@ LCTT的组成
|
||||
* 2014/11/04 提升zpl1025为Core Translators成员。
|
||||
* 2014/12/25 提升runningwater为Core Translators成员。
|
||||
* 2015/04/19 发起 LFS-BOOK-7.7-systemd 项目。
|
||||
* 2015/06/09 提升ictlyh和dongfengweixiao为Core Translators成员。
|
||||
|
||||
活跃成员
|
||||
-------------------------------
|
||||
@ -63,6 +64,8 @@ LCTT的组成
|
||||
- CORE @reinoir,
|
||||
- CORE @bazz2,
|
||||
- CORE @zpl1025,
|
||||
- CORE @ictlyh,
|
||||
- CORE @dongfengweixiao
|
||||
- Senior @tinyeyeser,
|
||||
- Senior @vito-L,
|
||||
- Senior @jasminepeng,
|
||||
@ -76,7 +79,6 @@ LCTT的组成
|
||||
- @alim0x,
|
||||
- @2q1w2007,
|
||||
- @theo-l,
|
||||
- @ictlyh,
|
||||
- @FSSlc,
|
||||
- @su-kaiyao,
|
||||
- @blueabysm,
|
||||
@ -167,7 +169,7 @@ LFS 项目活跃成员有:
|
||||
- @KevinSJ
|
||||
- @Yuking-net
|
||||
|
||||
(更新于2015/05/31,以Github contributors列表排名)
|
||||
(更新于2015/06/09,以Github contributors列表排名)
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
|
||||
187
published/20150126 Installing Cisco Packet tracer in Linux.md
Normal file
187
published/20150126 Installing Cisco Packet tracer in Linux.md
Normal file
@ -0,0 +1,187 @@
|
||||
Linux中安装Cisco Packet Tracer
|
||||
================================================================================
|
||||

|
||||
|
||||
### Cisco Packet tracer是什么? ###
|
||||
|
||||
**Cisco Packet Tracer**是一个强大的网络模拟工具,用于进行Cisco认证时的培训。它为我们提供了各个路由器和网络设备的良好的接口视图,这些模拟设备带有很多选项,跟使用物理机一样,我们可以在网络中使用无限的设备。我们能在单个工程中创建多个网络,以获得专业化的训练。Packet Tracer将提供给我们模拟的应用层协议,如**HTTP**,**DNS**,以及像**RIP**,**OSPF**,**EIGRP**等路由协议。
|
||||
|
||||
现在,它发布了包含有**ASA 5505防火墙**命令行配置的版本。Packet Tracer通常用于Windows版本,但没有Linux版本。这里,我们可以下载并安装Cisco Packet Tracer。
|
||||
|
||||
#### 新发布的Cisco Packet Tracer版本: ####
|
||||
|
||||
下一代Cisco Packet Tracer版本将会是Cisco Packet Tracer 6.2,当前还处于开发中。
|
||||
|
||||
### 我的环境设置: ###
|
||||
|
||||
**主机名** : desktop1.unixmen.com
|
||||
|
||||
**IP地址** : 192.168.0.167
|
||||
|
||||
**操作系统** : Ubuntu 14.04 LTS Desktop
|
||||
|
||||
# hostname
|
||||
|
||||
# ifconfig | grep inet
|
||||
|
||||
# lsb_release -a
|
||||
|
||||

|
||||
|
||||
### 步骤 1: 首先,我们需要下载Cisco Packet Tracer。 ###
|
||||
|
||||
要从官方网站下载Packet Tracer,我们需要持有一个令牌,登入Cisco NetSpace,然后从Offering菜单选择CCNA > Cisco Packet Tracer来开始下载。如果我们没有令牌,可以从下面的链接中获得,我已经将它上传到了Droppox。
|
||||
|
||||
官方站点: [https://www.netacad.com/][1]
|
||||
|
||||
大多数人没有下载Packet Tracer的令牌,出于该原因,我已经将它上传到了dropbox,你可以从下面的URL获得Packet Tracer。
|
||||
|
||||
[下载Cisco Packet Tracer 6.1.1][2]
|
||||
|
||||

|
||||
|
||||
### 步骤 2: 安装Java: ###
|
||||
|
||||
要安装Packet Tracer,我们需要安装java。我们可以使用默认的仓库安装java;或者添加PPA仓库,然后更新包缓存来安装java。
|
||||
|
||||
使用以下命令来安装默认的jre
|
||||
|
||||
# sudo apt-get install default-jre
|
||||
|
||||

|
||||
|
||||
(或者)
|
||||
|
||||
使用下面的步骤来安装Java Run-time并设置环境。
|
||||
|
||||
从官方站点下载Java:[下载Java][3]
|
||||
|
||||
# tar -zxvf jre-8u31-linux-x64.tar.gz
|
||||
# sudo mkdir -p /usr/lib/jvm
|
||||
# sudo mv -v jre1.8.0_31 /usr/lib/jvm/
|
||||
# cd /usr/lib/jvm/
|
||||
# sudo update-alternatives --install "/usr/bin/java" "java" "/usr/lib/jvm/jre1.8.0_31/bin/java" 1
|
||||
# sudo update-alternatives --set "java" "/usr/lib/jvm/jre1.8.0_31/bin/java"
|
||||
|
||||
通过编辑用户参数文件来设置Java环境,并添加路径相关的参数。当我们添加进用户参数文件后,我们机器上的每个用户都可以用java了。
|
||||
|
||||
# sudo vi /etc/profile
|
||||
|
||||
将以下条目添加到/etc/profile文件中:
|
||||
|
||||
export JAVA_HOME=/usr/lib/jvm/jre1.8.0_31
|
||||
export PATH=$PATH:/usr/java/jre1.8.0_31/bin
|
||||
|
||||
运行以下命令来立即激活java路径。
|
||||
|
||||
# . /etc/profile
|
||||
|
||||
检查Java版本和环境:
|
||||
|
||||
# echo $JAVA_HOME
|
||||
# java -version
|
||||
|
||||

|
||||
|
||||
### 步骤 3: 启用32位架构支持: ###
|
||||
|
||||
对于Packet Tracer,我们需要一些32位包。要安装32位包,我们需要使用以下命令来安装一些依赖。
|
||||
|
||||
# sudo dpkg --add-architecture i386
|
||||
# sudo apt-get update
|
||||
|
||||

|
||||
|
||||
# sudo apt-get install libc6:i386
|
||||
# sudo apt-get install lib32z1 lib32ncurses5 lib32bz2-1.0
|
||||
# sudo apt-get install libnss3-1d:i386 libqt4-qt3support:i386 libssl1.0.0:i386 libqtwebkit4:i386 libqt4-scripttools:i386
|
||||
|
||||

|
||||
|
||||
### 步骤 4: 解压并安装软件包: ###
|
||||
|
||||
使用tar命令来解压下载的包。
|
||||
|
||||
# mv Cisco\ Packet\ Tracer\ 6.1.1\ Linux.tar.gz\?dl\=0 Cisco_Packet_tracer.tar.gz
|
||||
|
||||
# tar -zxvf Cisco_Packet_tracer.tar.gz
|
||||
|
||||

|
||||
|
||||
导航到解压后的目录
|
||||
|
||||
# cd PacketTracer611Student
|
||||
|
||||
现在,该开始安装了。安装过程很简单,只需几秒钟即可搞定。
|
||||
|
||||
# sudo ./install
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
要使用Packet Tracer工作,我们需要设置环境,Cisco已经提供了环境脚本,我们需要以root用户来运行该脚本以设置环境变量。
|
||||
|
||||
# sudo ./set_ptenv.sh
|
||||
|
||||

|
||||
|
||||
安装到此结束。接下来,我们需要为Packet Tracer创建桌面图标。
|
||||
|
||||
通过创建下面的桌面文件来创建桌面图标。
|
||||
|
||||
# sudo su
|
||||
# cd /usr/share/applications
|
||||
# sudo vim packettracer.desktop
|
||||
|
||||

|
||||
|
||||
使用vim编辑器或你喜爱的那个编辑器来添加以下内容到文件。
|
||||
|
||||
[Desktop Entry]
|
||||
Name= Packettracer
|
||||
Comment=Networking
|
||||
GenericName=Cisco Packettracer
|
||||
Exec=/opt/packettracer/packettracer
|
||||
Icon=/usr/share/icons/packettracer.jpeg
|
||||
StartupNotify=true
|
||||
Terminal=false
|
||||
Type=Application
|
||||
|
||||
使用wq!来保存并退出vim。
|
||||
|
||||

|
||||
|
||||
### 步骤 5: 运行Packet Tracer ###
|
||||
|
||||
# sudo packettracer
|
||||
|
||||
好了,我们已经成功将Packet Tracer安装到Linux中。上述安装步骤适用于所有基于Debian的Linux发行版。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 资源 ###
|
||||
|
||||
主页:[Netacad][4]
|
||||
|
||||
### 尾声: ###
|
||||
|
||||
这里,我们展示了如何安装Packet Tracer到Linux发行版中。希望你们找到了将你们所钟爱的模拟器安装到Linux中的方法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/installing-cisco-packet-tracer-linux/
|
||||
|
||||
作者:[babin][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/babin/
|
||||
[1]:https://www.netacad.com/
|
||||
[2]:https://www.dropbox.com/s/5evz8gyqqvq3o3v/Cisco%20Packet%20Tracer%206.1.1%20Linux.tar.gz?dl=0
|
||||
[3]:http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
|
||||
[4]:https://www.netacad.com/
|
||||
@ -0,0 +1,64 @@
|
||||
iptraf:TCP/UDP网络监控工具
|
||||
================================================================================
|
||||
[iptraf][1]是一个基于ncurses开发的IP局域网监控工具,它可以生成各种网络统计数据,包括TCP信息、UDP统计、ICMP和OSPF信息、以太网负载信息、节点统计、IP校验和错误和其它一些信息。
|
||||
|
||||
它基于ncurses的用户界面也会把使用者从命令行选项的梦靥中拯救出来。
|
||||
|
||||
### 功能 ###
|
||||
|
||||
- 一个用于显示通过网络的IP流量信息的IP流量监控器,包括TCP标识信息、包和字节统计、ICMP详情、OSPF包类型
|
||||
- 显示IP、TCP、UDP、ICMP、非IP和其它IP包计数、IP校验和错误、接口活动、包大小计数的综合详细的接口统计数据
|
||||
- 一个用于计数常用TCP和UDP应用端口的流入和流出包的TCP和UDP服务监控器
|
||||
- 一个用于发现活动主机和显示这些活动主机的数据活动的局域网统计模块
|
||||
- TCP、UDP和其它协议的显示过滤器,允许你查看你做感兴趣的流量
|
||||
- 日志记录
|
||||
- 支持以太网、FDDI、ISDN、SLIP、PPP和回环接口类型
|
||||
- 利用Linux内核内建的原生套接口界面,可以用于大范围支持的网卡
|
||||
- 全屏、菜单驱动操作
|
||||
|
||||
###要安装###
|
||||
|
||||
**Ubuntu及其衍生版**
|
||||
|
||||
sudo apt-get install iptraf
|
||||
|
||||
**Arch Linux及其衍生版**
|
||||
|
||||
sudo pacman -S iptra
|
||||
|
||||
**Fedora及其衍生版**
|
||||
|
||||
sudo yum install iptraf
|
||||
|
||||
### 用法 ###
|
||||
|
||||
如果**iptraf**命令不带任何命令行选项执行,该程序就会以交互模式显现,可以通过主菜单获得各种各样的工具。
|
||||
|
||||

|
||||
|
||||
易于导航的菜单。
|
||||
|
||||

|
||||
|
||||
选择监控的接口。
|
||||
|
||||

|
||||
|
||||
来自**ppp0**接口的流量
|
||||
|
||||

|
||||
|
||||
希望你喜欢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/iptraf-tcpudp-network-monitoring-utility/
|
||||
|
||||
作者:[Enock Seth Nyamador][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/seth/
|
||||
[1]:http://iptraf.seul.org/about.html
|
||||
78
published/20150310 FAQ--BSD.md
Normal file
78
published/20150310 FAQ--BSD.md
Normal file
@ -0,0 +1,78 @@
|
||||
BSD 的那些事
|
||||
================================================================================
|
||||

|
||||
|
||||
### 假如历史稍有不同,今天你将听到的是“FreeBSD之声”... ###
|
||||
(LCTT 译注:本文来自“Linux之声(LinuxVoice)”。)
|
||||
|
||||
#### 那么,这个Birsa Seva Dal是怎么回事呢?难道不是一个印度的政治组织么? ####
|
||||
|
||||
真有趣,您查阅了维基百科上“BSD”的消除分歧页面是为了讲上面这个笑话,对么?这里我们在讨论伯克利软件发行版(Berkeley Software Distribution),一个比您想象中用的更广泛的操作系统家族。
|
||||
|
||||
#### 抱歉,我有点 Hold 不住自己。那么,这些操作系统是怎么回事呢? ####
|
||||
|
||||
今天,主要使用的BSD操作系统有三种。他们都基于Unix,他们都开源,并且大多担任服务器的角色,但也能当作优秀的桌面和工作站。他们运行KDE,Firefox,LibreOffice,Apache,MySQL和许多你能说得出名字的开源软件。它们都很稳定、安全、支持许多不同的硬件。
|
||||
|
||||
#### 真棒!你刚才在描述GNU/Linux吧 ####
|
||||
|
||||
是的,Linux拥有我刚才提到的所有东西,这也是为什么很多人从来不讨论BSD。在日常的使用中,Linux和BSD并没有太多的不同,这主要是因为他们都以Unix为基础,并共用很多软件。您可以登录进远程主机,在Vim中写一些Python代码,使用Mutt检查您的email,您可能并未意识到您在使用BSD。或许您在咖啡馆里正通过网络终端使用它,但不知道他是BSD。
|
||||
|
||||
两者最大的区别在于开发模式和许可证,为了解这些,我们需要回到过去。在BSD中,B代表着加利福尼亚大学伯克利分校(University of California, Berkeley),在1980年代,那里是开源的Unix软件的发源地。到了90年代,基于x86的PC变得流行,许多人对在他们的家庭电脑中安装Unix类操作系统产生了兴趣。1992年,一个叫做386BSD的项目在那时发布,提供了上述功能。
|
||||
|
||||
#### 那么,所有的Linux发行版那个时候在哪里呢? ####
|
||||
|
||||
问得好!您也许知道这一年的前一年(1991),Linus Torvalds已经发布了他的内核,当它与GNU项目结合时,变成了完整的开源操作系统。Linus那时也在关注GNU的内核(Hurd)和386BSD,并且他说过,如果那时两个内核有一个可以正常使用,他可能就不会创造Linux了。所以,90年代的头几年,开源操作系统生机勃勃,没有人知道哪个系统会最终胜出。
|
||||
|
||||
接下来,BSD遇到了一些麻烦。Unix最初的开发方AT&T试图从他们在操作系统方面的付出中获得一些利益,他们声称BSD侵犯了他们的知识产权。此事最终以1992年的一桩诉讼结束,它极大的抑制了BSD的开发进程。其结果就是,许多BSD源码必须重写,与此同时,GNU/Linux已经丰富了功能,变得稳定和流行了。
|
||||
|
||||
在90年代早期,BSD被认为比GNU/Linux更加成熟,如果没有那些法律麻烦,他可能已经成为了x86 PC的标准了。今天,我们可能都在使用它而不是Linux。
|
||||
|
||||
#### 但你提到BSD仍然被广泛的使用,所以它后来有提升么? ####
|
||||
|
||||
是的。386BSD的开发停滞了,但有两只开发团队通过互联网协作并创造了两个独立的成功的项目。FreeBSD成为了使用最广泛的BSD版本,它目前是和Linux最相似的系统,包括桌面和服务器版本。而NetBSD则聚焦于可移植性(今天它可以运行在超过50种不同平台上,均基于同样的代码版本)。另一个版本是OpenBSD,它在NetBSD开始不久就因为开发者的口角而作为NetBSD的分支诞生了,今天,它以专注于安全闻名。多年以来,OpenBSD创建了许多程序,它们都成了Linux的标准部分,比如说OpenSSH - 甚至,现在我们还有了LibreSSL。
|
||||
|
||||
#### 所以,这三种版本的BSD和Linux发行版相似么? ####
|
||||
|
||||
也是也不是,每个BSD版本都有自己的代码库、不同的开发团队。尽管他们间有许多共用的代码(尤其是硬件驱动)。但他们是各自拥有其特色、优点和缺点的相互独立的操作系统。
|
||||
|
||||
我们提到过,BSD的开发模式是他们真正和GNU/Linux区别的重要特点。在GNU/Linux中没有人对其整体进行掌控:一些团队在GNU组件方面工作,一些团队在开发内核,一些在开发启动脚本,一些在写手册,一些在写库等等。这样的开发模式通常被称作缺少中央权利的“荒蛮的美国西部”,由发行版负责将所有的东西各自锲合。
|
||||
|
||||
而BSD则相反,它们从中央化的源代码树中开发并作为一个整体。内核、库、系统组件和文档页都存在一个地方,且以同样的方式使用。许多BSD粉丝声称,这个特点给了操作系统更多的一致性和稳定性。通过我这些年使用BSD的经验来看,我们可以证明手册页已经变得非常完备。
|
||||
|
||||

|
||||
|
||||
#### 难道BSD没有使用GNU/Linux的任何东西么? ####
|
||||
|
||||
是的,但除了GCC。几十年来,GNU Compiler Collection已经成为了实际上的Unix系统标准编译器,但FreeBSD最近已经转而使用LLVM/Clang了。值得注意的是BSD还是用了一些其他的开源项目,但它们并属于GNU或者Linux,比如说X Window System(XFree86和X.org)、Perl等等。并且幸亏有像POSIX一样的标准,许多运行在Linux上的程序可以在BSD的许多版本上编译和运行。
|
||||
|
||||
因此,您可以把LAMP(Linux、Apache、MySQL和PHP)中的L改成FreeBSD,这样可以获得几乎同样的环境,以及一些不同的特性(例如,在文件系统和驱动支持方面)。FreeBSD有一些大型、海量的用户,例如Netflix,每天提供海量的数据。尽管FreeBSD可以做为一个不错的桌面环境,但它的长处在于服务器方面,它拥有超乎寻常的可靠性和网络性能。
|
||||
|
||||
OpenBSD更倾向用于安全性十分必要的场合,如小型Web服务、文件托管、防火墙和网关。NetBSD是BSD主要发行版中最不流行的一个,它能运行在几乎所有平台上,包括古老的Amigas和Acorn boxes,有时您可以在闭源的网络设备中找到它的身影。
|
||||
|
||||
#### 等等,怎么会有人将开源代码闭源呢?那在Linux中是不合适的 ####
|
||||
|
||||
对的,这里我们谈到了它与GNU/Linux的主要不同。BSD版本的许可证(很有趣,就叫做BSD许可证)非常不同于我们所知的GPL。对于新手来说,BSD更简短。BSD许可证主要内容是:对这份代码做你想做的事,但要保留它的初始开发者的荣誉,并且如果它搞坏你的电脑时不要提出诉讼。
|
||||
|
||||
因此,该许可证中没有任何条款强制代码开源,不像GPL,它要求使用这份代码的用户将他们的修改也开源。这一重要的不同引起了互联网上无数的激烈讨论,BSD的粉丝们说他们的许可证更加自由(因为它不那么严格),而GNU/GPL的粉丝说他们的证书才更自由(因为它保留了真正的自由)
|
||||
|
||||
#### 啊呀,不管怎么说,你已经引起了我的兴趣,我在哪里能尝试这些可爱的BSD版本呢? ####
|
||||
|
||||
您大概已经可以猜到这些网站了 – [www.openbsd.org][1]、[www.freebsd.org][2]、[www.netbsd.org][3]。在那里,您可以下载ISO镜像,在VirtualBox中启动它们,然后开始玩耍。如果您已经用了一段时间的Linux,你就会发现这并不难,虽然您需要了解命令行。如果您在寻找一些对新手更加友好的东西,可以试试PC-BSD,PC-BSD([www.pcbsd.org][4])是一个基于FreeBSD的个性化定制版本,它专注于桌面,有美观的图形化安装器和超级简单的软件管理器。
|
||||
|
||||
祝你玩的愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/faq-bsd-2/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
[1]:http://www.openbsd.org/
|
||||
[2]:http://www.freebsd.org/
|
||||
[3]:http://www.netbsd.org/
|
||||
[4]:http://www.pcbsd.org/
|
||||
@ -12,13 +12,13 @@
|
||||
|
||||
|
||||
|
||||
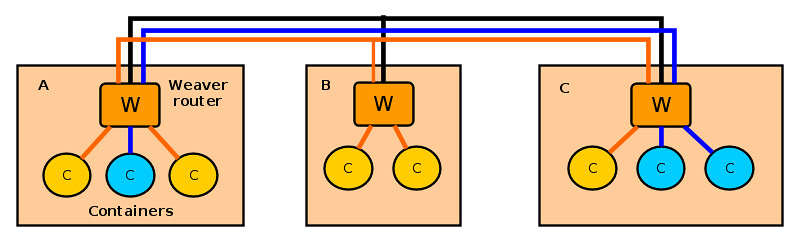
让我们先来看看 weave 怎么工作:先创建一个由多个 peer 组成的对等网络,每个 peer 是一个虚拟路由器容器,叫做“weave 路由器”,它们分布在不同的宿主机上。这个对等网络的每个 peer 之间会维持一个 TCP 链接,用于互相交换拓扑信息,它们也会建立 UDP 链接用于容器间通信。一个 weave 路由器通过桥接技术连接到其他本宿主机上的其他容器。当处于不同宿主机上的两个容器想要通信,一台宿主机上的 weave 路由器通过网桥截获数据包,使用 UDP 协议封装后发给另一台宿主机上的 weave 路由器。
|
||||
让我们先来看看 weave 怎么工作:先创建一个由多个 peer 组成的对等网络,每个 peer 是一个虚拟路由器容器,叫做“weave 路由器”,它们分布在不同的宿主机上。这个对等网络的每个 peer 之间会维持一个 TCP 链接,用于互相交换拓扑信息,它们也会建立 UDP 链接用于容器间通信。一个 weave 路由器通过桥接技术连接到本宿主机上的其他容器。当处于不同宿主机上的两个容器想要通信,一台宿主机上的 weave 路由器通过网桥截获数据包,使用 UDP 协议封装后发给另一台宿主机上的 weave 路由器。
|
||||
|
||||
每个 weave 路由器会刷新整个对等网络的拓扑信息,像容器的 MAC 地址(就像交换机的 MAC 地址学习一样获取其他容器的 MAC 地址),因此它可以决定数据包的下一跳是往哪个容器的。weave 能让两个处于不同宿主机的容器进行通信,只要这两台宿主机在 weave 拓扑结构内连到同一个 weave 路由器。另外,weave 路由器还能使用公钥加密技术将 TCP 和 UDP 数据包进行加密。
|
||||
每个 weave 路由器会刷新整个对等网络的拓扑信息,可以称作容器的 MAC 地址(如同交换机的 MAC 地址学习一样获取其他容器的 MAC 地址),因此它可以决定数据包的下一跳是往哪个容器的。weave 能让两个处于不同宿主机的容器进行通信,只要这两台宿主机在 weave 拓扑结构内连到同一个 weave 路由器。另外,weave 路由器还能使用公钥加密技术将 TCP 和 UDP 数据包进行加密。
|
||||
|
||||
### 准备工作 ###
|
||||
|
||||
在使用 weave 之前,你需要在所有宿主机上安装 Docker[2] 环境,参考[这些][3][教程][4],在 Ubuntu 或 CentOS/Fedora 发行版中安装 Docker。
|
||||
在使用 weave 之前,你需要在所有宿主机上安装 [Docker][2] 环境,参考[这些][3][教程][4],在 Ubuntu 或 CentOS/Fedora 发行版中安装 Docker。
|
||||
|
||||
Docker 环境部署完成后,使用下面的命令安装 weave:
|
||||
|
||||
@ -26,7 +26,7 @@ Docker 环境部署完成后,使用下面的命令安装 weave:
|
||||
$ chmod a+x weave
|
||||
$ sudo cp weave /usr/local/bin
|
||||
|
||||
注意你的 PATH 环境变量要包含 /usr/local/bin 这个路径,请在 /etc/profile 文件中加入一行(LCTT 注:要使环境变量生效,你需要执行这个命令: src /etc/profile):
|
||||
注意你的 PATH 环境变量要包含 /usr/local/bin 这个路径,请在 /etc/profile 文件中加入一行(LCTT 译注:要使环境变量生效,你需要执行这个命令: source /etc/profile):
|
||||
|
||||
export PATH="$PATH:/usr/local/bin"
|
||||
|
||||
@ -34,15 +34,15 @@ Docker 环境部署完成后,使用下面的命令安装 weave:
|
||||
|
||||
Weave 在 TCP 和 UDP 上都使用 6783 端口,如果你的系统开启了防火墙,请确保这两个端口不会被防火墙挡住。
|
||||
|
||||
### 在每台宿主机上开启 Weave 路由器 ###
|
||||
### 在每台宿主机上启动 Weave 路由器 ###
|
||||
|
||||
当你想要让处于在不同宿主机上的容器能够互相通信,第一步要做的就是在每台宿主机上开启 weave 路由器。
|
||||
当你想要让处于在不同宿主机上的容器能够互相通信,第一步要做的就是在每台宿主机上启动 weave 路由器。
|
||||
|
||||
第一台宿主机,运行下面的命令,就会创建并开启一个 weave 路由器容器(LCTT 注:前面说过了,weave 路由器也是一个容器):
|
||||
第一台宿主机,运行下面的命令,就会创建并开启一个 weave 路由器容器(LCTT 译注:前面说过了,weave 路由器也是一个容器):
|
||||
|
||||
$ sudo weave launch
|
||||
|
||||
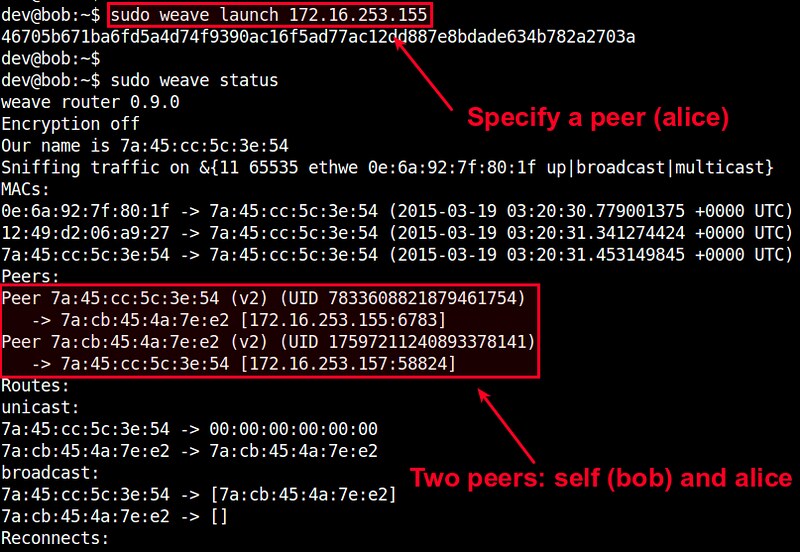
第一次运行这个命令的时候,它会下载一个 weave 镜像,这会花一些时间。下载完成后就会自动运行这个镜像。成功启动后,终端会打印这个 weave 路由器的 ID 号。
|
||||
第一次运行这个命令的时候,它会下载一个 weave 镜像,这会花一些时间。下载完成后就会自动运行这个镜像。成功启动后,终端会输出这个 weave 路由器的 ID 号。
|
||||
|
||||
下面的命令用于查看路由器状态:
|
||||
|
||||
@ -52,7 +52,7 @@ Weave 在 TCP 和 UDP 上都使用 6783 端口,如果你的系统开启了防
|
||||
|
||||
第一个 weave 路由器就绪了,目前为止整个 peer 对等网络中只有一个 peer 成员。
|
||||
|
||||
你也可以使用 doceker 的命令来查看 weave 路由器的状态:
|
||||
你也可以使用 docker 的命令来查看 weave 路由器的状态:
|
||||
|
||||
$ docker ps
|
||||
|
||||
@ -66,7 +66,7 @@ Weave 在 TCP 和 UDP 上都使用 6783 端口,如果你的系统开启了防
|
||||
|
||||
|
||||
|
||||
当你开启更多路由器,这个 peer 成员列表会更长。当你新开一个路由器时,要指定前一个宿主机的 IP 地址,请注意不是第一个宿主机的 IP 地址。
|
||||
当你开启更多路由器,这个 peer 成员列表会更长。当你新开一个路由器时,要指定前一个宿主机的 IP 地址,请注意不是第一个宿主机的 IP 地址(LCTT 译注:链状结构)。
|
||||
|
||||
现在你已经有了一个 weave 网络了,它由位于不同宿主机的 weave 路由器组成。
|
||||
|
||||
@ -82,7 +82,7 @@ Weave 在 TCP 和 UDP 上都使用 6783 端口,如果你的系统开启了防
|
||||
|
||||
hostA:~$ sudo weave run 10.0.0.1/24 -t -i ubuntu
|
||||
|
||||
成功运行后,终端会打印出容器的 ID 号。你可以使用这个 ID 来访问这个容器:
|
||||
成功运行后,终端会显示出容器的 ID 号。你可以使用这个 ID 来访问这个容器:
|
||||
|
||||
hostA:~$ docker attach <container-id>
|
||||
|
||||
@ -124,7 +124,7 @@ weave 提供了一些非常巧妙的特性,我在这里作下简单的介绍
|
||||
|
||||

|
||||
|
||||
现在这个容器可以与 10.10.0.0/24 网络上的其它容器进行通信了。当你要把容器加入一个网络,而这个网络暂时不可用时,上面的步骤就很有帮助了。
|
||||
现在这个容器可以与 10.10.0.0/24 网络上的其它容器进行通信了。这在当你创建一个容器而网络信息还不确定时就很有帮助了。
|
||||
|
||||
#### 将 weave 网络与宿主机网络整合起来 ####
|
||||
|
||||
@ -134,13 +134,13 @@ weave 提供了一些非常巧妙的特性,我在这里作下简单的介绍
|
||||
|
||||
hostA:~$ sudo weave expose 10.0.0.100/24
|
||||
|
||||
这个命令把 IP 地址 10.0.0.100 分配给宿主机 hostA,这样一来 hostA 也连到了 10.0.0.0/24 网络上了。很明显,你在为宿主机选择 IP 地址的时候,需要选一个没有被其他容器使用的地址。
|
||||
这个命令把 IP 地址 10.0.0.100 分配给宿主机 hostA,这样一来宿主机 hostA 也连到了 10.0.0.0/24 网络上了。显然,你在为宿主机选择 IP 地址的时候,需要选一个没有被其他容器使用的地址。
|
||||
|
||||
现在 hostA 就可以访问 10.0.0.0/24 上的所有容器了,不管这些容器是否位于 hostA 上。好巧妙的设定啊,32 个赞!
|
||||
|
||||
### 总结 ###
|
||||
|
||||
如你所见,weave 是一个很有用的 docker 网络配置工具。这个教程只是[它强悍功能][5]的冰山一角。如果你想进一步玩玩,你可以试试它的以下功能:多跳路由功能,这个在 multi-cloud 环境(LCTT 注:多云,企业使用多个不同的云服务提供商的产品,比如 IaaS 和 SaaS,来承载不同的业务)下还是很有用的;动态重路由功能是一个很巧妙的容错技术;或者它的分布式 DNS 服务,它允许你为你的容器命名。如果你决定使用这个好东西,欢迎分享你的使用心得。
|
||||
如你所见,weave 是一个很有用的 docker 网络配置工具。这个教程只是它[强悍功能][5]的冰山一角。如果你想进一步玩玩,你可以试试它的以下功能:多跳路由功能,这个在 multi-cloud 环境(LCTT 译注:多云,企业使用多个不同的云服务提供商的产品,比如 IaaS 和 SaaS,来承载不同的业务)下还是很有用的;动态重路由功能是一个很巧妙的容错技术;或者它的分布式 DNS 服务,它允许你为你的容器命名。如果你决定使用这个好东西,欢迎分享你的使用心得。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1,46 +1,44 @@
|
||||
12个进程管理命令
|
||||
12个进程管理命令介绍
|
||||
================================================================================
|
||||
每个程序在执行时叫进程。当程序是在存储中是可执行文件并且运行的时候,每个进程会被动态得分配系统资源,内存,安全属性和与之相关的状态。可以有多个进程关联同一个程序,并同时执行不会互相干扰。操作系统会有效地管理和追踪所有运行着的进程。
|
||||
执行中的程序在称作进程。当程序以可执行文件存放在存储中,并且运行的时候,每个进程会被动态得分配系统资源、内存、安全属性和与之相关的状态。可以有多个进程关联到同一个程序,并同时执行不会互相干扰。操作系统会有效地管理和追踪所有运行着的进程。
|
||||
|
||||
为了管理这些进程,用户应该能够:
|
||||
|
||||
- 查看所有运行中的进程
|
||||
- 查看进程消耗资源
|
||||
- 定位个别进程并且可以执行指定动作
|
||||
- 定位个别进程并且对其执行指定操作
|
||||
- 改变进程的优先级
|
||||
- 杀死指定进程
|
||||
- 限制进程的有效系统资源
|
||||
- 等
|
||||
- 限制进程可用的系统资源等
|
||||
|
||||
Linux提供了许多命令给用户来高效掌控上述的操作。接下来,一个一个的来讲解下。
|
||||
Linux提供了许多命令来让用户来高效掌控上述的操作。接下来,一个一个的来讲解下。
|
||||
|
||||
### 1. ps ###
|
||||
|
||||
'ps'是最基础浏览系统中的进程的命令。能列出系统中运行的进程,包括进程号,命令,CPU使用量,内存使用量等。下述选项可以得到更多有用的消息。
|
||||
'ps'是Linux 中最基础的浏览系统中的进程的命令。能列出系统中运行的进程,包括进程号、命令、CPU使用量、内存使用量等。下述选项可以得到更多有用的消息。
|
||||
|
||||
ps -a - 列出所有运行中/激活进程
|
||||
|
||||

|
||||
|
||||
ps -ef |grep - 列出需要进程
|
||||
|
||||
ps -aux - 展示进程包括、终端(x)和用户(u)信息,如USER, PID, %CPU, %MEM等
|
||||
ps -aux - 显示进程信息,包括无终端的(x)和针对用户(u)的进程:如USER, PID, %CPU, %MEM等
|
||||
|
||||
### 2. pstree ###
|
||||
|
||||
linux中,每一个进程都是由父进程创建的。此命令帮助可视化进程,通过显示进程树状图表展示进程间关系。如果使用pid了,那么树的根是pid。不然将会是init。
|
||||
linux中,每一个进程都是由其父进程创建的。此命令以可视化方式显示进程,通过显示进程的树状图来展示进程间关系。如果指定了pid了,那么树的根是该pid,不然将会是init(pid: 1)。
|
||||
|
||||

|
||||
|
||||
### 3. top ###
|
||||
|
||||
‘top’是一个更加有用的命令,通过不同的进程所使用的资源可以监视系统。它提供实时的系统状态信息。显示进程的数据包括PID,进程用户,优先值,%CPU,%memory等。可以使用这些显示指示出资源使用量。
|
||||
‘top’是一个更加有用的命令,可以监视系统中不同的进程所使用的资源。它提供实时的系统状态信息。显示进程的数据包括 PID、进程属主、优先级、%CPU、%memory等。可以使用这些显示指示出资源使用量。
|
||||
|
||||

|
||||
|
||||
### 4. htop ###
|
||||
|
||||
htop与top很类似,但是htop是交互式的模式进程查看器。它通过文字图像显示每一个CPU和内存使用量、swap使用量。上下键选择进程,F7和F8改变优先级,F9杀死进程。Htop不是系统默认,所以需要额外安装。
|
||||
htop与top很类似,但是htop是交互式的文本模式的进程查看器。它通过文字图形化地显示每一个进程的CPU和内存使用量、swap使用量。使用上下光标键选择进程,F7和F8改变优先级,F9杀死进程。Htop不是系统默认安装的,所以需要额外安装。
|
||||
|
||||

|
||||
|
||||
@ -48,7 +46,7 @@ htop与top很类似,但是htop是交互式的模式进程查看器。它通过
|
||||
|
||||
通过nice命令的帮助,用户可以设置和改变进程的优先级。提高一个进程的优先级,内核会分配更多CPU时间片给这个进程。默认情况下,进程以0的优先级启动。进程优先级可以通过top命令显示的NI(nice value)列查看。
|
||||
|
||||
进程优先级值的范围从-20到19。值越低,越优先。
|
||||
进程优先级值的范围从-20到19。值越低,优先级越高。
|
||||
|
||||
nice <优先值> <进程名> - 通过给定的优先值启动一个程序
|
||||
|
||||
@ -56,17 +54,17 @@ htop与top很类似,但是htop是交互式的模式进程查看器。它通过
|
||||
|
||||

|
||||
|
||||
上述命令例子,可以看到‘top’命令获得了-3的优先值。
|
||||
上述命令例子中,可以看到‘top’命令获得了-3的优先值。
|
||||
|
||||
### 6. renice ###
|
||||
|
||||
renice命令类似nice命令。使用这个命令可以改变正在运行的进程优先值。注意,用户只能改变属于他们的进程的优先值。
|
||||
renice命令类似nice命令。使用这个命令可以改变正在运行的进程优先值。注意,用户只能改变属于他们自己的进程的优先值。
|
||||
|
||||
renice -n -p - 改变指定进程的优先值
|
||||
|
||||

|
||||
|
||||
优先值初始化为0的3806号进程优先值已经变成了4.
|
||||
初始优先值为0的3806号进程优先值已经变成了4.
|
||||
|
||||
renice -u -g - 通过指定用户和组来改变进程优先值
|
||||
|
||||
@ -76,7 +74,7 @@ renice命令类似nice命令。使用这个命令可以改变正在运行的进
|
||||
|
||||
### 7. kill ###
|
||||
|
||||
这个命令通过发送信号结束进程。如果一个进程没有响应杀死命令,这也许就需要强制杀死,使用-9参数来执行。注意,使用强制杀死的时候一定要小心,因为没有机会确定是否写入完成、是否结束等。如果我们不知道进程PID或者打算用名字杀死进程时候,killall就能派上用场。
|
||||
这个命令用于发送信号来结束进程。如果一个进程没有响应杀死命令,这也许就需要强制杀死,使用-9参数来执行。注意,使用强制杀死的时候一定要小心,因为进程没有时机清理现场,也许写入文件没有完成。如果我们不知道进程PID或者打算用名字杀死进程时候,killall就能派上用场。
|
||||
|
||||
kill <pid>
|
||||
|
||||
@ -84,7 +82,7 @@ renice命令类似nice命令。使用这个命令可以改变正在运行的进
|
||||
|
||||
killall -9 - 杀死所有拥有同样名字的进程
|
||||
|
||||
如果你使用kill,你需要知道进程ID号。pkill是类似的命令但只需要一个模式,如果进程名,进程拥有者等
|
||||
如果你使用kill,你需要知道进程ID号。pkill是类似的命令,但使用模式匹配,如进程名,进程拥有者等。
|
||||
|
||||
pkill <进程名>
|
||||
|
||||
@ -94,17 +92,17 @@ renice命令类似nice命令。使用这个命令可以改变正在运行的进
|
||||
|
||||
### 8. ulimit ###
|
||||
|
||||
命令在控制系统资源在shell和进程上的分配量。对于系统管理员是最有用的,可以管理系统倾向和性能问题。限制资源大小可以确保重要进程持续运行,其他进程不会占用过多资源。
|
||||
该命令用于控制系统资源在shell和进程上的分配量。对于系统管理员是最有用的,可以管理重度使用和存在性能问题的系统。限制资源大小可以确保重要进程持续运行,其他进程不会占用过多资源。
|
||||
|
||||
ulimit -a - 显示当前用户关联的资源限制
|
||||
|
||||

|
||||
|
||||
-f - 最大文件大小
|
||||
-f - 最大文件尺寸大小
|
||||
|
||||
-v - 最大虚拟内存大小(KB)
|
||||
|
||||
-n - 最大文件描述符加1
|
||||
-n - 增加最大文件描述符数量
|
||||
|
||||
-H : 改变和报告硬限制
|
||||
|
||||
@ -114,13 +112,13 @@ renice命令类似nice命令。使用这个命令可以改变正在运行的进
|
||||
|
||||
### 9. w ###
|
||||
|
||||
w提供正确登录的用户和其执行的进程的信息。显示信息头包含信息像现在时间,系统运行时长,登录用户总数,过去1,5,15分钟负载均衡数。
|
||||
w 提供当前登录的用户及其正在执行的进程的信息。显示信息头包含信息,如当前时间、系统运行时长、登录用户总数、过去的1,5,15分钟内的负载均衡数。
|
||||
|
||||
基于这些用户信息,用户可以在终止进程前查看不属于他们的进程。
|
||||
基于这些用户信息,用户在终止不属于他们的进程时要小心。
|
||||
|
||||

|
||||
|
||||
**who**是类似命令,提供列表,包含当前登录用户,系统启动时间,运行级别等。
|
||||
**who**是类似命令,提供当前登录用户列表、系统启动时间、运行级别等。
|
||||
|
||||

|
||||
|
||||
@ -130,7 +128,7 @@ w提供正确登录的用户和其执行的进程的信息。显示信息头包
|
||||
|
||||
### 10. pgrep ###
|
||||
|
||||
pgrep为"进程号全局正则匹配打印"。命令扫描当前运行进程,然后列出选择标准匹配出的进程ID到标准输出。对于通过名字检索进程号是很有用。
|
||||
pgrep的意思是"进程号全局正则匹配输出"。该命令扫描当前运行进程,然后按照命令匹配条件列出匹配结果到标准输出。对于通过名字检索进程号是很有用。
|
||||
|
||||
pgrep -u mint sh
|
||||
|
||||
@ -140,9 +138,9 @@ pgrep为"进程号全局正则匹配打印"。命令扫描当前运行进程,
|
||||
|
||||
### 11. fg , bg ###
|
||||
|
||||
有时,命令需要很长的时间才能执行完成。对于这种情况,我们使用‘bg’命令可以将任务放在后台执行,而是用‘fg’可以调到前台来使用。
|
||||
有时,命令需要很长的时间才能执行完成。对于这种情况,我们使用‘bg’命令可以将任务放在后台执行,而用‘fg’可以调到前台来使用。
|
||||
|
||||
通过‘&’,我们后台启动一个程序:
|
||||
我们可以通过‘&’在后台启动一个程序:
|
||||
|
||||
find . -name *iso > /tmp/res.txt &
|
||||
|
||||
@ -152,7 +150,7 @@ pgrep为"进程号全局正则匹配打印"。命令扫描当前运行进程,
|
||||
|
||||
ctrl+z - 挂起当前执行程序
|
||||
|
||||
bg - 将程序发送到后台运行
|
||||
bg - 将程序放到后台运行
|
||||
|
||||
我们可以使用‘jobs’命令列出所有后台进程。
|
||||
|
||||
@ -160,7 +158,7 @@ pgrep为"进程号全局正则匹配打印"。命令扫描当前运行进程,
|
||||
|
||||
使用‘fg’命令可以将后台程序调到前台执行。
|
||||
|
||||
fg %
|
||||
fg %进程id
|
||||
|
||||

|
||||
|
||||
@ -172,13 +170,13 @@ ipcs命令报告进程间通信设施状态。(共享内存,信号量和消
|
||||
|
||||
ipcs -p -m
|
||||
|
||||
下面屏幕截图列出了共享内存段的创建者ID和进程ID。
|
||||
下面屏幕截图列出了最近访问了共享内存段的进程的创建者的ID和进程ID。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
总之 ,这些命令可以帮助管理员修复问题和改善性能。同样作为一名普通用户也需要解决进程间出现的问题。所以,熟悉如此繁多的命令,从能有效管理进程是行之有效。
|
||||
总之 ,这些命令可以帮助管理员修复问题和改善性能。同样作为一名普通用户也需要解决进程出现的问题。所以,熟悉如此繁多的命令,从能有效管理进程是行之有效。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -186,7 +184,7 @@ via: http://linoxide.com/linux-command/process-management-commands-linux/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,18 +1,18 @@
|
||||
如何在Linux下使用Gitblit工具创建Git仓库服务
|
||||
如何在Linux下使用Gitblit工具创建Git仓库服务
|
||||
================================================================================
|
||||
嗨!朋友,今天我们将学习如何在你的Linux服务器或者PC上安装Gitblit工具。首先,我们看看什么是Git,它的功能以及安装Gitblit的步骤。[Git是分布式版本控制系统][1],它强调速度、数据一致性,并且支持分布式、非线性工作流。它最初由Linus Torvalds在2005年为Linux内核设计和开发,使用GPL2证书,并因此成为软件开发中使用最广泛的版本控制系统。
|
||||
嗨!朋友,今天我们将学习如何在你的Linux服务器或者PC上安装Gitblit工具。首先,我们看看什么是Git,它的功能以及安装Gitblit的步骤。[Git是分布式版本控制系统][1],它强调速度、数据一致性,并且支持分布式、非线性工作流。它最初由Linus Torvalds在2005年为Linux内核设计和开发,使用GPLv2证书,并从此成为软件开发中使用最广泛的版本控制系统。
|
||||
|
||||
[Gitblit是完全开源的软件][2],它基于纯粹的Java堆栈,被设计以在Git仓库速度和效率方面胜任从小型到极大型的项目。它很容易学习和上手,并有着闪电般的性能。它在廉价的本地分支、便于staging、多工作流等方面远胜过一些SCM(版本控制)工具,比如Subversion、CVS、Perforce和ClearCase。
|
||||
[Gitblit是完全开源的软件][2],它基于纯粹的Java堆栈,被设计以在Git仓库速度和效率方面胜任从小型到极大型的项目。它很容易学习和上手,并有着闪电般的性能。它在很多方面远胜 Subversion、CVS、Perforce和ClearCase等SCM(版本控制)工具,比如,如快速本地分支、易于暂存、多工作流等。
|
||||
|
||||
#### Gitblit的功能 ####
|
||||
|
||||
- 它可以做为一个无声的仓库视图,没有管理控制以及用户账户。
|
||||
- 它可以做为完整的Git堆栈,拥有clone, pushing和仓库存取控制。
|
||||
- 它能独立于其他Git工具使用(包括实际的Git),它能和您已创建的工具合作。
|
||||
- 它可以做为一个哑仓库视图,没有管理控制以及用户账户。
|
||||
- 它可以做为完整的Git服务,拥有克隆、推送和仓库访问控制。
|
||||
- 它能独立于其他Git工具使用(包括实际的Git),它能和您已有的工具协作。
|
||||
|
||||
### 1.创建Gitblit安装目录 ###
|
||||
|
||||
首先我们将在我们的服务器上建立一个目录,我们将在该目录下安装最新的Gitblit。
|
||||
首先我们将在我们的服务器上建立一个目录,并在该目录下安装最新的Gitblit。
|
||||
|
||||
$ sudo mkdir -p /opt/gitblit
|
||||
|
||||
@ -28,7 +28,7 @@
|
||||
|
||||

|
||||
|
||||
接下来,我们将解压下载到的tarball压缩包至之前创建的目录 /opt/gitblit/
|
||||
接下来,我们将下载到的tar压缩包解压至之前创建的目录 /opt/gitblit/
|
||||
|
||||
$ sudo tar -zxvf gitblit-1.6.2.tar.gz
|
||||
|
||||
@ -42,7 +42,7 @@
|
||||
|
||||
另一种是将gitblit添加为服务。下面是在linux下将gitblit添加为服务的步骤。
|
||||
|
||||
由于我在使用Ubuntu,下面的命令将是 sudo cp service-ubuntu.sh /etc/init.d/gitblit。所以请根据你的发行版修改文件名service-ubuntu.sh为相应的你运行的发行版。
|
||||
由于我在使用Ubuntu,下面的命令将是 sudo cp service-ubuntu.sh /etc/init.d/gitblit,所以请根据你的发行版修改文件名service-ubuntu.sh为相应的你运行的发行版。
|
||||
|
||||
$ sudo ./install-service-ubuntu.sh
|
||||
|
||||
@ -50,13 +50,13 @@
|
||||
|
||||

|
||||
|
||||
在你的浏览器中打开http://localhost:8080或https://localhost:8443,也可以将localhost根据本地配置替换为IP地址。输入默认的管理员凭证:admin/admin并点击login按钮。
|
||||
在你的浏览器中打开`http://localhost:8080`或`https://localhost:8443`,也可以将localhost根据本地配置替换为IP地址。输入默认的管理员凭证:admin / admin并点击login按钮。
|
||||
|
||||

|
||||
|
||||
现在,我们将添加一个新的用户。首先,你需要以admin用户登录,username = **admin**,password = **admin**。
|
||||
|
||||
然后,点击 user icon > users > (+) new user 来创建一个新用户,如下图所示。
|
||||
然后,点击用户图标 > users > (+) new user 来创建一个新用户,如下图所示。
|
||||
|
||||

|
||||
|
||||
@ -73,7 +73,7 @@
|
||||
git remote add origin ssh://arunlinoxide@localhost:29418/linoxide.com.git
|
||||
git push -u origin master
|
||||
|
||||
请将用户名arunlinoxide替换为你添加的用户名。
|
||||
请将其中的用户名arunlinoxide替换为你添加的用户名。
|
||||
|
||||
#### 在命令行中push一个已存在的仓库 ####
|
||||
|
||||
@ -84,7 +84,7 @@
|
||||
|
||||
### 结论 ###
|
||||
|
||||
欢呼吧!我们已经在Linux电脑中安装好了最新版本的Gitblit。接下来我们便可以在我们的大小工程中享受这样一个优美的版本控制系统。有了Gitblit,版本控制便再容易不过了。它有易于学习、轻量级、高性能的特点。因此,如果你有任何的问题、建议和反馈,请在留言处留言。
|
||||
欢呼吧!我们已经在Linux电脑中安装好了最新版本的Gitblit。接下来我们便可以在我们的大小项目中享受这样一个优美的版本控制系统。有了Gitblit,版本控制便再容易不过了。它有易于学习、轻量级、高性能的特点。因此,如果你有任何的问题、建议和反馈,请在留言处留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -92,7 +92,7 @@ via: http://linoxide.com/linux-how-to/serve-git-repositories-gitblit/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
如何在 Docker 容器里的 Nginx 中安装 WordPress
|
||||
如何在 Docker 容器中架设一个完整的 WordPress 站点
|
||||
================================================================================
|
||||
大家好,今天我们来学习一下如何在 Docker 容器上运行的 Nginx Web 服务器中安装 WordPress。WordPress 是一个很好的免费开源的内容管理系统,全球成千上万的网站都在使用它。[Docker][1] 是一个提供开放平台来打包,分发和运行任何应用的开源轻量级容器项目。它没有语言支持,框架或打包系统的限制,可以在从小的家用电脑到高端服务器的任何地方任何时间运行。这让它们成为可以用于部署和扩展网络应用,数据库和后端服务而不必依赖于特定的栈或者提供商的很好的构建块。
|
||||
|
||||
大家好,今天我们来学习一下如何在 Docker 容器里运行的 Nginx Web 服务器中安装 WordPress。WordPress 是一个很好的免费开源的内容管理系统,全球成千上万的网站都在使用它。[Docker][1] 是一个开源项目,提供了一个可以打包、装载和运行任何应用的轻量级容器的开放平台。它没有语言支持、框架和打包系统的限制,从小型的家用电脑到高端服务器,在何时何地都可以运行。这使它们可以不依赖于特定软件栈和供应商,像一块块积木一样部署和扩展网络应用、数据库和后端服务。
|
||||
|
||||
今天,我们会在 docker 容器上部署最新的 WordPress 软件包,包括需要的前提条件,例如 Nginx Web 服务器、PHP5、MariaDB 服务器等。下面是在运行在 Docker 容器上成功安装 WordPress 的简单步骤。
|
||||
|
||||
@ -14,13 +15,13 @@
|
||||
|
||||
# systemctl restart docker.service
|
||||
|
||||
### 2. 创建 WordPress Docker 文件 ###
|
||||
### 2. 创建 WordPress 的 Dockerfile ###
|
||||
|
||||
我们需要创建用于自动安装 wordpress 以及前提条件的 docker 文件。这个 docker 文件将用于构建 WordPress 的安装镜像。这个 WordPress docker 文件会从 Docker 库中心获取 CentOS 7 镜像并用最新的可用更新升级系统。然后它会安装必要的软件,例如 Nginx Web 服务器、PHP、MariaDB、Open SSH 服务器以及其它保证 Docker 容器正常运行不可缺少的组件。最后它会执行一个初始化 WordPress 安装的脚本。
|
||||
我们需要创建用于自动安装 wordpress 以及其前置需求的 Dockerfile。这个 Dockerfile 将用于构建 WordPress 的安装镜像。这个 WordPress Dockerfile 会从 Docker Registry Hub 获取 CentOS 7 镜像并用最新的可用更新升级系统。然后它会安装必要的软件,例如 Nginx Web 服务器、PHP、MariaDB、Open SSH 服务器,以及其它保证 Docker 容器正常运行不可缺少的组件。最后它会执行一个初始化 WordPress 安装的脚本。
|
||||
|
||||
# nano Dockerfile
|
||||
|
||||
然后,我们需要将下面的配置行添加到 Docker 文件中。
|
||||
然后,我们需要将下面的配置行添加到 Dockerfile中。
|
||||
|
||||
FROM centos:centos7
|
||||
MAINTAINER The CentOS Project <cloud-ops@centos.org>
|
||||
@ -50,9 +51,9 @@
|
||||
|
||||

|
||||
|
||||
### 3. 创建启动 script ###
|
||||
### 3. 创建启动脚本 ###
|
||||
|
||||
我们创建了 docker 文件之后,我们需要创建用于运行和配置 WordPress 安装的脚本,名称为 start.sh。它会为 WordPress 创建并配置数据库和密码。用我们喜欢的文本编辑器打开 start.sh。
|
||||
我们创建了 Dockerfile 之后,我们需要创建用于运行和配置 WordPress 安装的脚本,名称为 start.sh。它会为 WordPress 创建并配置数据库和密码。用我们喜欢的文本编辑器打开 start.sh。
|
||||
|
||||
# nano start.sh
|
||||
|
||||
@ -86,7 +87,7 @@
|
||||
}
|
||||
|
||||
__handle_passwords() {
|
||||
# 在这里我们生成随机密码(感谢 pwgen)。前面两个用于 mysql 用户,最后一个用于 wp-config.php 的随机密钥。
|
||||
# 在这里我们生成随机密码(多亏了 pwgen)。前面两个用于 mysql 用户,最后一个用于 wp-config.php 的随机密钥。
|
||||
WORDPRESS_DB="wordpress"
|
||||
MYSQL_PASSWORD=`pwgen -c -n -1 12`
|
||||
WORDPRESS_PASSWORD=`pwgen -c -n -1 12`
|
||||
@ -292,7 +293,7 @@
|
||||
|
||||
### 5. 构建 WordPress 容器 ###
|
||||
|
||||
现在,完成了创建配置文件和脚本之后,我们终于要使用 docker 文件来创建安装最新的 WordPress CMS(译者注:Content Management System,内容管理系统)所需要的容器,并根据配置文件进行配置。做到这点,我们需要在对应的目录中运行以下命令。
|
||||
现在,完成了创建配置文件和脚本之后,我们终于要使用 Dockerfile 来创建安装最新的 WordPress CMS(译者注:Content Management System,内容管理系统)所需要的容器,并根据配置文件进行配置。做到这点,我们需要在对应的目录中运行以下命令。
|
||||
|
||||
# docker build --rm -t wordpress:centos7 .
|
||||
|
||||
@ -340,7 +341,7 @@ via: http://linoxide.com/linux-how-to/install-wordpress-nginx-docker-container/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,88 @@
|
||||
六种在 Linux 上为你带来 iTunes 般体验的方法
|
||||
================================================================================
|
||||

|
||||
|
||||
随着你对 Linux 的熟悉(也许会成为你首要使用的操作系统),你终将会寻找能在 Linux 上有效管理音乐的工具。你首先想到 iTunes,因为它是近几年最流行的音乐管理工具,但你马上会发现 iTunes 并没有 Linux 版本。而且,现在,你会发现还有比 iTunes 更好的音乐管理工具。
|
||||
|
||||
尽管如此,这并不意味着你就不能使用你喜欢的方式管理音乐。Linux 上有很多方式可以让你整理你的曲库。以下六种,仅供参考:
|
||||
|
||||
### 通过WINE运行iTunes ###
|
||||
|
||||
尽管 iTunes 没有Linux版,你还是可以试试 [使用 WINE 运行 iTunes ][1] 或 PlayOnLinux 的。这些软件给本来只能运行于Windows下的应用程序添加一个兼容层,这样就能让他们运行在Linux上了,但这样的方法效果十有分限。因此,[并非所有 Windows 应用程序都能使用WINE运行][2] - 但这还是一个值得尝试的方法。
|
||||
|
||||
各个版本的iTunes结果可能给你不同的结果,但一般都遵循以下方法:
|
||||
|
||||
1. 安装WINE
|
||||
2. 在WINE里运行iTunes安装程序
|
||||
3. 在网上搜索并解决你遇到的问题。
|
||||
|
||||
如果你在安装时遇到无法解决的问题,比如安装程序错误,或者安装好的程序运行不了,那是没办法的,WINE 就是这样。
|
||||
|
||||
如果你想在 WINE 上运行 iTunes 而且运气很好的跑起来了,那真是很棒。但如果你还想考虑运行一个原生的Linux应用,或者 WINE 不工作的话,还有很多其他选择的。有几个曲库管理软件能让你很方便的管理你的音乐并直接进行播放,还可以制作播放列表。
|
||||
|
||||
### [Amarok][3] ###
|
||||
|
||||

|
||||
|
||||
如果你使用KDE环境,我推荐 Amarok。它具有 [很多管理音乐的特性][4] 而且它还能与KDE桌面环境无缝兼容。它有很多实用的特性如集成了 Last.FM、文件跟踪、动态播放列表及脚本支持。它甚至会自动在你播放曲目时,自动下载艺术家封面。
|
||||
|
||||
### [Banshee][5] ###
|
||||
|
||||

|
||||
|
||||
如果你使用 GNOME 或其他任何基于 GTK 的桌面环境(它们十分常见)的话,我推荐使用使用Bansee作为 [全功能曲库管理工具][6] 。它的功能与Amarok类似,也集成了Last.FM,支持互联网广播,支持podcast等等。选择 Amarok 还是 Bansee 要看你使用的桌面环境(这样才能无缝整合)。
|
||||
|
||||
### [Rhythmbox][7] ###
|
||||
|
||||

|
||||
|
||||
Rhythmbox是一个更好基于GTK的桌面环境的[轻量级的曲库替代品][8]。尽管如此,它也还是有一些自己的特性的。它也支持Last.FM,同时还能无缝播放并与其它如 Nautilus、XChat及Pidgin 等进行整合。
|
||||
|
||||
### [Clementine][9] ###
|
||||
|
||||

|
||||
|
||||
另一款叫 Clementine 的软件也值得我推荐,因为它的界面简洁、易用。它支持非常多的第三方服务例如Spotify,Digtal Imported 及Dropbox。Android系统上还有一款用作 Clementine 遥控的app。[Clementine是跨平台的][10] , 还支持Mac OS X 及 Windows。
|
||||
|
||||
这些程序都能很好的管理并播放你的音乐。唯一的问题是这些程序都不支持与 iOS 设备的整合, 而且目前Linux 上还没有程序能做到这一点。但 iOS 经过很多改进后,已经并不需要再连接到电脑了。
|
||||
|
||||
### [Google Play Music][11] ###
|
||||
|
||||

|
||||
|
||||
最后,如果上面的那些程序还不能满足你的需求的话,你可以试试 Google Play Music。这个在线服务也可以用作播放音乐的曲库管理工具,但它还有几个额外的好处。你可以上传所有的音乐,并且在所有能上网的设备上获取这些音乐。这也意味着你不需要在电脑或者移动设备之间同步你的音乐(无论是 Android 还是 iOS 设备),因为你可以这些设备中使用Google Play Music。 如果你想要扩展你的曲库,你可以订阅 All Access 服务,但这并不是必须的。你不需要支付任何费用也可在你的曲库中储存20,000首
|
||||
|
||||
#### 靠,居然没有 Spotify ?! ####
|
||||
|
||||
尽管 Spotify 也是一款管理和听音乐的方法,我不推荐它的唯一原因是它事实上并不让你管理你的音乐。你不能将曲目上传到 Spotify - 只能它们给你提供的曲目。尽管它们提供了很多,但口味未必一样。
|
||||
|
||||
|
||||
### 你还有其他选择 ###
|
||||
|
||||
以上六个软件应该可以在给你带来类似 iTunes 的功能了。这些软件主要是能让你管理和播放你的曲库,但如果你还需要 iTunes 里的其他特性,其他Linux原生软件或许能满足这类需求。
|
||||
|
||||
**你通常在Linux上使用哪些音乐?**在下方评论与我们分享吧!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/top-6-ways-get-itunes-experience-linux/
|
||||
|
||||
作者:[Danny Stieben][a]
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.makeuseof.com/tag/author/danny/
|
||||
[1]:http://www.makeuseof.com/tag/how-about-some-wine-with-your-linux/
|
||||
[2]:http://www.makeuseof.com/answers/does-wine-runs-all-windows-apps/
|
||||
[3]:https://amarok.kde.org/
|
||||
[4]:http://www.makeuseof.com/tag/control-music-amarok-linux/
|
||||
[5]:http://banshee.fm/
|
||||
[6]:http://www.makeuseof.com/tag/banshee-20-comprehensive-media-player-streamer-podcast-tool-linux/
|
||||
[7]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[8]:http://www.makeuseof.com/tag/play-manage-music-collection-rhythmbox-linux/
|
||||
[9]:https://www.clementine-player.org/
|
||||
[10]:http://www.makeuseof.com/tag/need-a-lightweight-music-player-without-sacrificing-features-clementine-cross-platform/
|
||||
[11]:http://music.google.com/
|
||||
@ -1,6 +1,7 @@
|
||||
如何在Bash Shell脚本中显示对话框以及事例
|
||||
如何在Bash Shell脚本中显示对话框
|
||||
================================================================================
|
||||
这个教程给出几个如何使用类似zenity和whiptail的工具在Bash Shell 脚本中提供消息/对话框的例子。使用这些工具,你的脚本能够告知用户当前程序运行的状态以及有与其交互的能力。这两个工具的不同之处在于显示消息框或者对话框的方式。Zenity用GTK工具包创建图形用户界面,而whiptail在终端内部创建消息框。
|
||||
|
||||
这个教程给出几个如何使用类似zenity和whiptail的工具在Bash Shell 脚本中提供消息/对话框的例子。使用这些工具,你的脚本能够告知用户当前程序运行的状态并能与用户进行交互。这两个工具的不同之处在于显示消息框或者对话框的方式。Zenity用GTK工具包创建图形用户界面,而whiptail则在终端窗口内创建消息框。
|
||||
|
||||
### Zenity 工具 ###
|
||||
|
||||
@ -8,21 +9,21 @@
|
||||
|
||||
sudo apt-get install zenity
|
||||
|
||||
由于用zenity创建消息框或者对话框的命令是相当自解释的,我们会给你提供一些例子。
|
||||
用zenity创建消息框或者对话框的命令是不言自明的,我们会给你提供一些例子来参考。
|
||||
|
||||
### 创建消息框 ###
|
||||
|
||||
zenity --info --title "Information Box" --text "This should be information" --width=300 --height=200
|
||||
zenity --info --title "Information Box" --text "This should be information" --width=300 --height=200
|
||||
|
||||

|
||||
|
||||
创建 Yes/No 对话框
|
||||
创建 Yes/No 询问对话框
|
||||
|
||||
zenity --question --text "Do you want this?" --ok-label "Yeah" --cancel-label="Nope"
|
||||
|
||||

|
||||
|
||||
创建输入框并在变量中保存值
|
||||
创建输入框并将输入值保存到变量中
|
||||
|
||||
a=$(zenity --entry --title "Entry box" --text "Please enter the value" --width=300 --height=200)
|
||||
echo $a
|
||||
@ -75,7 +76,7 @@ zenity --info --title "Information Box" --text "This should be information" --wi
|
||||
|
||||
信息框
|
||||
|
||||
别忘了查看也许能帮助到你的有用的[zenity 选项][1]
|
||||
别忘了查看也许能帮助到你的有用的[zenity 选项][1]。
|
||||
|
||||
### Whiptail 工具 ###
|
||||
|
||||
@ -83,7 +84,7 @@ zenity --info --title "Information Box" --text "This should be information" --wi
|
||||
|
||||
sudo apt-get install whiptail
|
||||
|
||||
用whiptail创建消息框或者对话框的命令也是相当自解释的,我们会给你提供一些基本例子。
|
||||
用whiptail创建消息框或者对话框的命令也是无需解释的,我们会给你提供一些基本例子作为参考。
|
||||
|
||||
### 创建消息框 ###
|
||||
|
||||
@ -103,7 +104,7 @@ zenity --info --title "Information Box" --text "This should be information" --wi
|
||||
|
||||

|
||||
|
||||
尝试使用输入值要注意的一点是whiptail用stdout显示对话框,用stderr输出值。那样的话,如果你用 var=$(...),你不会看到对话框,也不能获得输入的值。解决方法是交换stdout和stderr。在whiptail命令后面添加 **3>&1 1>&2 2>&3** 就可以做到。你想获取输入值的任何whiptail命令也是如此。
|
||||
尝试使用输入值要注意的一点是whiptail用stdout显示对话框,用stderr输出值。这样的话,如果你用 var=$(...),你就根本不会看到对话框,也不能获得输入的值。解决方法是交换stdout和stderr。在whiptail命令后面添加 **3>&1 1>&2 2>&3** 就可以做到。你想获取输入值的任何whiptail命令也是如此。
|
||||
|
||||
### 创建菜单对话框 ###
|
||||
|
||||
@ -157,7 +158,7 @@ zenity --info --title "Information Box" --text "This should be information" --wi
|
||||
|
||||
### 结论 ###
|
||||
|
||||
选择合适的工具显示对话框取决于你期望在桌面机器还是服务器上运行你的脚本。桌面机器用户通常使用窗口环境,更可能用显示的窗口运行脚本和交互。然而,如果你期望用户是在服务器上工作的,你也许会希望安全地显示,并使用whiptail或者任何其它在纯终端窗口显示对话框的工具。
|
||||
选择合适的工具显示对话框取决于你期望在桌面机器还是服务器上运行你的脚本。桌面机器用户通常使用GUI窗口环境,也可能运行脚本并与显示的窗口进行交互。然而,如果你期望用户是在服务器上工作的,(在没有图形界面时,)你也许希望能确保总能显示,那就使用whiptail或者任何其它在纯终端窗口显示对话框的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -165,7 +166,7 @@ via: http://linoxide.com/linux-shell-script/bash-shell-script-show-dialog-box/
|
||||
|
||||
作者:[Ilija Lazarevic][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,176 @@
|
||||
如何使用图形化工具远程管理 Linux上的MySQL
|
||||
================================================================================
|
||||
如果你在一个远程的VPS上运行了MySQL服务器,你会如何管理你的远程数据库主机呢?基于web的数据库管理工具例如[phpMyAdmin][2]或者[Adminer][3]可能会是你第一个想起的。这些基于web的管理工具需要一个正常运行的后端的web服务和PHP引擎。但是,如果你的VPS仅仅用来做数据库服务(例如,数据库与其它服务独立存放的分布式结构),为偶尔的数据库管理提供一整套的LAMP是浪费VPS资源的。更糟的是,LAMP所打开的HTTP端口可能会成为你VPS资源的安全漏洞。
|
||||
|
||||
作为一种选择,你可以使用在一台客户机上运行本地的MySQL客户端,当然,如果没有别的选择,一个纯净的MySQL命令行客户端将是你的默认选择。但是命令行客户端的功能是有限的,因为它没有生产级数据库管理功能,例如:可视化SQL开发、性能调优、模式验证等等。你是否在寻找一个成熟的MySQL管理工具,那么一个MySQL的图形化管理工具将会更好的满足你的需求。
|
||||
|
||||
###什么是MySQL Workbench?
|
||||
|
||||
作为一个由Oracle开发的集成的数据库管理工具,[MySQL Workbench][4]不仅仅是一个简单的MySQL客户端。简而言之,Workbench是一个跨平台的(如:Linux,MacOX,Windows)数据库设计、开发和管理的图形化工具。MySQL Workbench 社区版是遵循GPL协议的。作为一个数据库管理者,你可以使用Workbench去配置MySQL服务、管理MySQL用户、进行数据库的备份与还原、监视数据库的健康状况,所有的都在对用户友好的图形化环境下处理。
|
||||
|
||||
在这个手册里,让我们演示下如何在Linux下安装和使用MySQL Workbench。
|
||||
|
||||
###在Linux上安装MySQL Workbench
|
||||
|
||||
你可以在任何一个桌面linux机器上运行MySQL Workbench来设置你的数据库管理环境。虽然一些Linux发行版(例如:Debian/Ubuntu)在他们的软件源中已经有了MySQL Workbench,但是从官方源中安装是一个好的方法,因为他们提供了最新的版本。这里介绍了如何设置一个官方的Workbench软件源和从中安装它。
|
||||
|
||||
#### 基于 Debian 的桌面 (Debia, Ubuntu, Mint): ####
|
||||
|
||||
到其[官方站点][5],选择一个和你环境匹配的DEB文件,并下载安装:
|
||||
|
||||
例如,对于 Ubuntu 14.10:
|
||||
|
||||
$ wget http://dev.mysql.com/get/mysql-apt-config_0.3.4-2ubuntu14.10_all.deb
|
||||
$ sudo dpkg -i mysql-apt-config_0.3.4-2ubuntu14.10_all.deb
|
||||
|
||||
对于 Debian 7:
|
||||
|
||||
$ wget http://dev.mysql.com/get/mysql-apt-config_0.3.3-1debian7_all.deb
|
||||
$ sudo dpkg -i mysql-apt-config_0.3.3-1debian7_all.deb
|
||||
|
||||
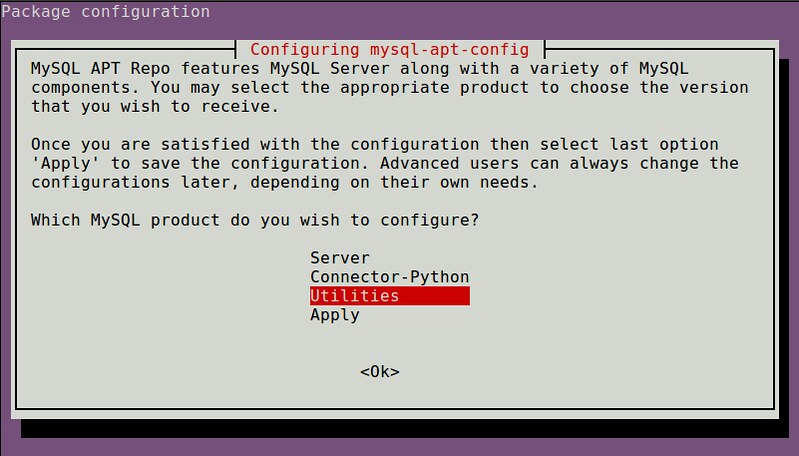
当你安装DEB文件时,你会看到下面的配置菜单,并且选择配置那个MySQL产品
|
||||
|
||||
|
||||
|
||||
选择“Utilities”。完成配置后,选择“Apply”去保存配置。然后,更新包索引,并且安装Workbench。
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install mysql-workbench
|
||||
|
||||
#### 基于 Red Hat 的桌面 (CentOS, Fedora, RHEL): ####
|
||||
|
||||
去官网下载并安装适合你Linux环境的RPM源包。
|
||||
|
||||
例如,对于 CentOS 7:
|
||||
|
||||
$ wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
|
||||
$ sudo yum localinstall mysql-community-release-el7-5.noarch.rpm
|
||||
|
||||
对于 Fedora 21:
|
||||
|
||||
$ wget http://dev.mysql.com/get/mysql-community-release-fc21-6.noarch.rpm
|
||||
$ sudo yum localinstall mysql-community-release-fc21-6.noarch.rpm
|
||||
|
||||
验证"MySQL Tools Community"源是否被安装:
|
||||
|
||||
$ yum repolis enabled
|
||||
|
||||

|
||||
|
||||
安装Workbench
|
||||
|
||||
$ sudo yum install mysql-workbench-community
|
||||
|
||||
###设置远程数据库的安全连接
|
||||
|
||||
接下来是为你运行MySQL服务的VPS设置一个远程连接。当然,你可以直接通过图形化的Workbench连接你的远程MySQL服务器(在数据库开放了远程连接后)。然而,这样做有很大的安全风险,因为有些人很容易窃听你的数据库传输信息,并且一个公开的MySQL端口(默认为3306)会是另外一个攻击入口。
|
||||
|
||||
一个比较好的方法是关掉远程访问数据库服务功能,(仅允许在VPS 上的127.0.0.1访问)。然后在本地客户机和远程VPS之间设置一个SSH隧道,这样的话,和MySQL之间的数据能安全地通过它的本地回环接口上中继。相比较设置一个SSL加密的连接来说,配置SSH隧道需要很少的操作,因为它仅仅需要SSH服务,并且在大多数的VPS上已经部署了。
|
||||
|
||||
让我们来看看如何来为一个MySQL Workbench设置一个SSH隧道。
|
||||
|
||||
在这个设置里,不需要你开放远程访问MySQL服务。
|
||||
|
||||
在一个运行了Workbench的本地客户机上,键入下面的命令,替换'user'(远程 VPS 的用户名)和'remote_vps'(远程 VPS 的地址)为你自己的信息:
|
||||
|
||||
$ ssh user@remote_vps -L 3306:127.0.0.1:3306 -N
|
||||
|
||||
你会被要求输入你VPS的SSH密码,当你成功登陆VPS后,在本地的3306端口和远程VPS的3306端口之间将会建立一个SSH隧道。这里你不会在前台看到任何信息显示。
|
||||
|
||||
或者你可以选择在后台运行SSH隧道,按CTRL+Z停止当前的命令,然后输入bg并且ENTER
|
||||
|
||||

|
||||
|
||||
这样SSH隧道就会在后台运行了。
|
||||
|
||||
###使用MySQL Workbench远程管理MySQL服务
|
||||
|
||||
在建立好SSH隧道后,你可以通过MySQL Workbench去远程连接MySQL服务了。
|
||||
|
||||
输入下面命令启动Workbench:
|
||||
|
||||
$ mysql-workbench
|
||||
|
||||

|
||||
|
||||
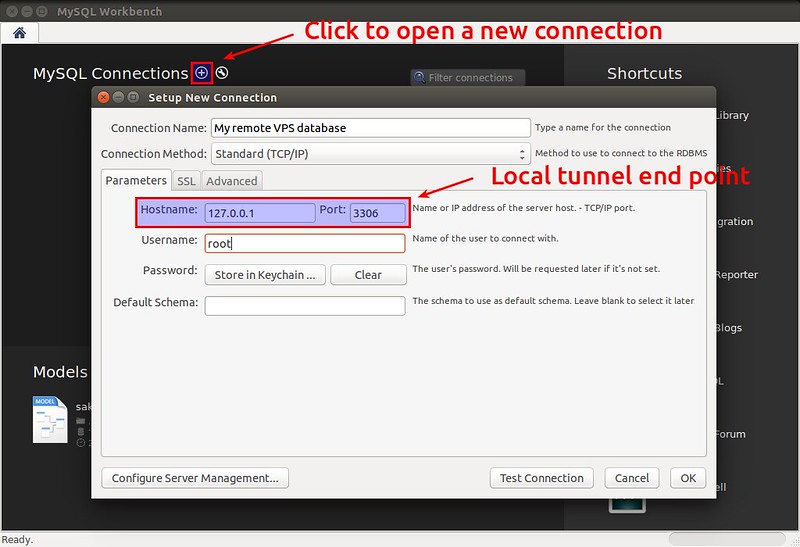
点击Workbench页面上面的“加号”图标去创建一个新的数据库连接,接着会出现下面的连接信息。
|
||||
|
||||
- **Connection Name**: 任意描述 (例如: My remote VPS database)
|
||||
- **Hostname**: 127.0.0.1
|
||||
- **Port**: 3306
|
||||
- **Username**: MySQL 用户名 (例如 root)
|
||||
|
||||
|
||||
|
||||
注意:因为隧道设置的是127.0.0.1:3306,所以主机名字段必须是127.0.0.1,而不能是远程VPS的IP地址或者主机名。
|
||||
|
||||
当你设置好一个新的数据库连接后,你会在Workbench窗口看到一个新的框,点击那个框就会实际去连接远程的MySQL服务了。
|
||||
|
||||

|
||||
|
||||
当你登录到MySQL 服务器后,你可以再左侧面板看到各种管理任务。让我们来看一些常见的管理任务。
|
||||
|
||||
#### MySQL Server Status ####
|
||||
|
||||
该菜单显示了展示数据库服务器的资源使用情况的实时监控面板。(例如:流量、链接、读写)
|
||||
|
||||

|
||||
|
||||
#### Client Connections ####
|
||||
|
||||
客户端连接数是一个极其重要的监控的资源,这个菜单显示了每个连接的详细信息。
|
||||
|
||||

|
||||
|
||||
#### 用户和权限 ####
|
||||
|
||||
这个菜单允许你管理MySQL用户,包括他们的资源限制和权限。
|
||||
|
||||

|
||||
|
||||
#### MySQL Server Administration ####
|
||||
|
||||
你可以启动或关闭MySQL服务,并且检查它的服务日志。
|
||||
|
||||

|
||||
|
||||
#### Database Schema Management ####
|
||||
|
||||
可以可视化的查看、更改、检查数据库结构,在“Schemas”标题下选择任何一个数据库或表,然后右击
|
||||
|
||||
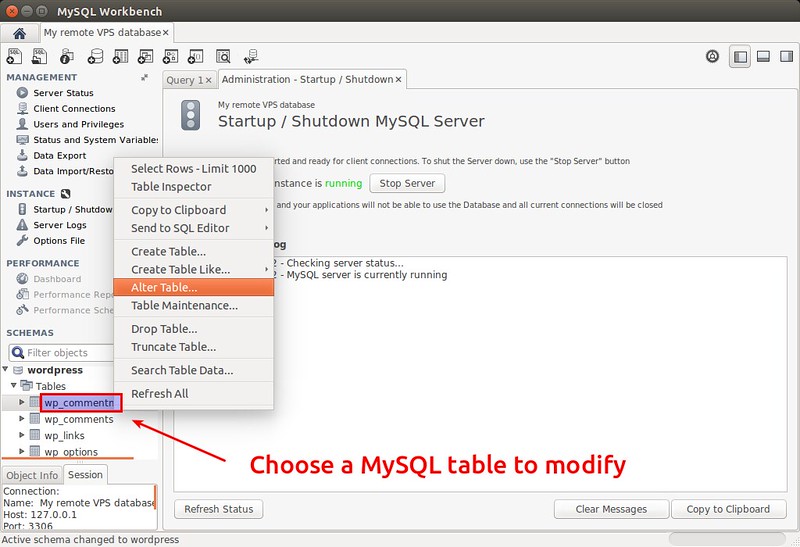
|
||||
|
||||

|
||||
|
||||
#### Database Query ####
|
||||
|
||||
你可以执行任何的语句(只要你的权限允许),并且检查其结果。
|
||||
|
||||
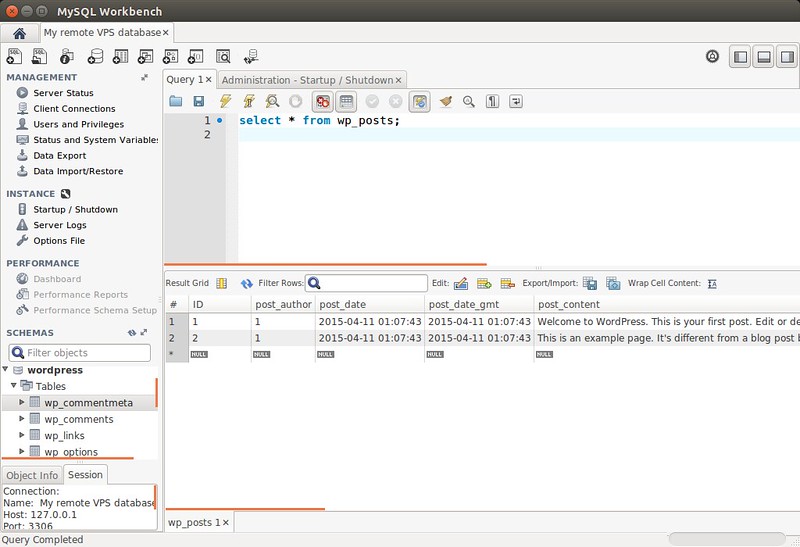
|
||||
|
||||
此外,性能统计数据和报表仅用于MySQL5.6以上的版本。对于5.5及其以下的版本,性能部分会以灰色显示。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
简介且直观的选项卡界面,丰富的特性,开源,使MySQL Workbench成为一个非常好的可视化数据库设计和管理工具。为其减分的是它的性能。我注意到在一台运行繁忙的服务器上,Workbench有时会变得异常缓慢,尽管它的性能差强人意,我依然认为MySQL Workbench是MySQL数据库管理员和设计人员必备的工具之一。
|
||||
|
||||
你曾在你的生产环境中用过Workbench吗?或者你还有别的GUI工具可以推荐?请分享你的经验吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/remote-mysql-databases-gui-tool.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[tyzy313481929](https://github.com/tyzy313481929)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://ask.xmodulo.com/install-phpmyadmin-centos.html
|
||||
[3]:http://xmodulo.com/set-web-based-database-management-system-adminer.html
|
||||
[4]:http://mysqlworkbench.org/
|
||||
[5]:http://dev.mysql.com/downloads/repo/apt/
|
||||
[6]:http://dev.mysql.com/downloads/repo/yum/
|
||||
[7]:http://xmodulo.com/how-to-allow-remote-access-to-mysql.html
|
||||
@ -1,17 +1,14 @@
|
||||
Linux 有问必答 -- 如何在红帽系linux中编译Ixgbe
|
||||
|
||||
Linux 有问必答: 如何在红帽系linux中编译Ixgbe驱动
|
||||
================================================================================
|
||||
> **提问**:我想要安装最新版的ixgbe 10G网卡驱动。在CentOS, Fedora 或 RHEL中,我应该如何编译ixgbe驱动?
|
||||
|
||||
想要在linux使用Intel的PCI Express 10G网卡(例如,82598,82599,x540),需要安装Ixgbe驱动。如今的Linux发行版都会预安装ixgbe的可加载模块,但是预安装的ixgbe驱动不是完整功能版。如果想要开启和定制所有10G网卡的功能(如,RSS、多队列、虚拟化功能、硬件 offload 等),需要从源码编译安装。
|
||||
|
||||
想要在linux使用Intel的PCI Express 10G网卡(例如,82598,82599,x540),需要安装Ixgbe驱动。如今的Linux发行版都会欲安装ixgbe作为可加载模块,但是预安装的ixgbe驱动不是完整功能版。如果想要开启和定制所有10G网卡(如,RSS,多)的功能,需要源码编译安装。
|
||||
|
||||
本文基于红帽系平台(如,CentOS,RHEL或Fedora)。Debian系系统,请看[这篇文章][1]
|
||||
|
||||
本文基于红帽系平台(如,CentOS,RHEL或Fedora)。Debian系平台,请看[这篇文章][1]
|
||||
|
||||
### 第一步: 安装依赖 ###
|
||||
|
||||
首先,安装必要的开发环境和安装匹配的内核头
|
||||
首先,安装必要的开发环境和安装匹配的内核头文件
|
||||
|
||||
$ sudo yum install gcc make
|
||||
$ sudo yum install kernel-devel
|
||||
@ -22,7 +19,7 @@ Linux 有问必答 -- 如何在红帽系linux中编译Ixgbe
|
||||
|
||||
$ wget http://downloads.sourceforge.net/project/e1000/ixgbe%20stable/3.23.2/ixgbe-3.23.2.tar.gz
|
||||
|
||||
确保检查支持内核版本。例如,Ixgbe3.23.2版本支持Linux内核版本2.6.18以上到3.18.1.
|
||||
请检查支持的内核版本。例如,Ixgbe3.23.2版本支持Linux内核版本2.6.18到3.18.1。
|
||||
|
||||
提取压缩包并编译
|
||||
|
||||
@ -30,7 +27,7 @@ Linux 有问必答 -- 如何在红帽系linux中编译Ixgbe
|
||||
$ cd ixgbe-3.23.2/src
|
||||
$ make
|
||||
|
||||
如果成功,编译完成的驱动(ixgbe.ko)可以在当前目录找到。
|
||||
如果成功,可以在当前目录找到编译完成的驱动(ixgbe.ko)。
|
||||
|
||||
可以运行这个命令来查看编译信息:
|
||||
|
||||
@ -44,7 +41,7 @@ Linux 有问必答 -- 如何在红帽系linux中编译Ixgbe
|
||||
|
||||
这步准备加载已经编译好的驱动。
|
||||
|
||||
如果系统已经加载了Ixgbe驱动,首先需要卸载掉老版本。否者,新版本不能够加载。
|
||||
如果系统已经加载了Ixgbe驱动,首先需要卸载掉老版本。否则,新版本不能加载。
|
||||
|
||||
$ sudo rmmod ixgbe.ko
|
||||
|
||||
@ -178,7 +175,7 @@ ixgbe.ko将会安装在下列目录
|
||||
|
||||
/lib/modules/<kernel-version>/kernel/drivers/net/ixgbe
|
||||
|
||||
此时,编译完蛋程序将在启动时自动加载,也可以通过运行命令加载它:
|
||||
此时,编译好的驱动将在启动时自动加载,也可以通过运行命令加载它:
|
||||
|
||||
$ sudo modprobe ixgbe
|
||||
|
||||
@ -190,10 +187,10 @@ via: http://ask.xmodulo.com/compile-ixgbe-driver-centos-rhel-fedora.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Vic020](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/download-install-ixgbe-driver-ubuntu-debian.html
|
||||
[1]:https://linux.cn/article-5149-1.html
|
||||
[2]:http://sourceforge.net/projects/e1000/files/ixgbe%20stable/
|
||||
@ -0,0 +1,55 @@
|
||||
Linux有问必答:如何在虚拟机上配置PCI直通
|
||||
================================================================================
|
||||
> **提问**:我想要分配一块物理网卡到用KVM创建的虚拟机上。我打算为这台虚拟机启用网卡的PCI直通。请问,我如何才能在virt-manager里面通过PCI直通增加一个PCI设备到虚拟机上?
|
||||
|
||||
如今的hypervisor能够高效地在多个虚拟操作系统间共享和模拟硬件资源。然而,虚拟资源共享不是总能使人满意,甚至在虚拟机性能是重点考量时,或者是虚拟机需要硬件DMA的完全控制时,应该避免共享。一项名叫“PCI直通”的技术可以用在一个虚拟机需要独享PCI设备时(例如:网卡、声卡、显卡)。本质上,PCI直通穿透了虚拟层,直接将PCI设备放到虚拟机里,而其他虚拟机则不能访问该设备。
|
||||
|
||||
### 开启“PCI直通”的准备 ###
|
||||
|
||||
如果你想要为一台HVM实例开启PCI直通(例如,一台KVM创建的全虚拟化的虚拟机),你的母系统(包括CPU和主板)必须满足以下条件。如果你的虚拟机是半虚拟化的(由Xen创建),你可以跳过这步。
|
||||
|
||||
为了在 HVM虚拟机上开启PCI直通,系统需要支持**VT-d** (Intel处理器)或者**AMD-Vi** (AMD处理器)。Intel的VT-D(“英特尔直接I/O虚拟化技术”)是适用于最高端的Nehalem处理器和它的后继者(例如,Westmere、Sandy Bridge的,Ivy Bridge)。注意:VT-d和VT-x是两个独立功能。intel/AMD处理器支持VT-D/AMD-VI功能的列表可以[查看这里][1]。
|
||||
|
||||
在确认你的设备支持VT-d/AMD-Vi后,还有两件事情需要做。首先,确保VT-d/AMD-Vi已经在BIOS中开启。然后,在内核启动过程中开启IOMMU。IOMMU服务,是由VT-d/AMD-Vi提供的,可以保护虚拟机访问的主机内存,同时它也是全虚拟化虚拟机支持PCI直通的前提。
|
||||
|
||||
Intel处理器中,通过将“**intel_iommu=on**传给内核启动参数来开启IOMMU。参看[这篇教程][2]了解如何通过GRUB修改内核启动参数。
|
||||
|
||||
配置完启动参数后,重启电脑。
|
||||
|
||||
### 添加PCI设备到虚拟机 ###
|
||||
|
||||
我们已经完成了开启PCI直通的准备。事实上,只需通过virt-manager就可以给虚拟机分配一个PCI设备。
|
||||
|
||||
打开virt-manager的虚拟机设置,在左边工具栏点击‘增加硬件’按钮。
|
||||
|
||||
选择从PCI设备表一个PCI设备来分配,点击“完成”按钮
|
||||
|
||||
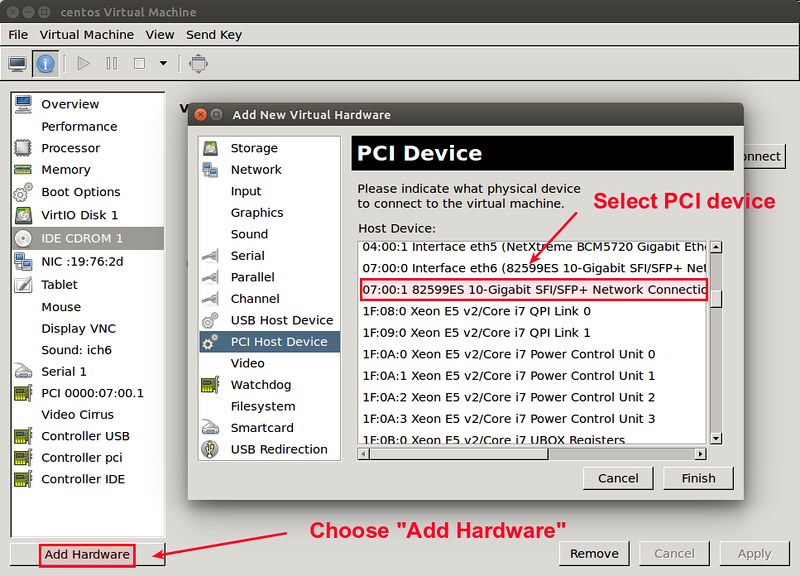
|
||||
|
||||
最后,启动实例。这样,主机的PCI设备已经可以由虚拟机直接访问了。
|
||||
|
||||
### 常见问题 ###
|
||||
|
||||
在虚拟机启动时,如果你看见下列任何一个错误,这个错误有可能由于母机VT-d (或 IOMMU)未开启导致。
|
||||
|
||||
Error starting domain: unsupported configuration: host doesn't support passthrough of host PCI devices
|
||||
|
||||
----------
|
||||
|
||||
Error starting domain: Unable to read from monitor: Connection reset by peer
|
||||
|
||||
请确保"**intel_iommu=on**"启动参数已经按上文叙述开启。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/pci-passthrough-virt-manager.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wiki.xenproject.org/wiki/VTdHowTo
|
||||
[2]:http://xmodulo.com/add-kernel-boot-parameters-via-grub-linux.html
|
||||
@ -72,7 +72,7 @@ Linux网络统计工具/命令
|
||||
|
||||
查看[ss 命令教程][1] 获取更多信息。
|
||||
|
||||
### netstat 命令 : 显示套接字信息的旧的好工具 ###
|
||||
### netstat 命令 : 不错的显示套接字信息的旧工具 ###
|
||||
|
||||
查看所有网络端口以及汇总信息表,输入:
|
||||
|
||||
@ -268,6 +268,7 @@ Linux网络统计工具/命令
|
||||
### sar 命令: 显示网络统计信息 ###
|
||||
|
||||
输入以下命令 (你需要 [通过sysstat包安装并启用sar][3]):
|
||||
|
||||
sar -n DEV
|
||||
|
||||
Linux 2.6.32-220.2.1.el6.x86_64 (www.cyberciti.biz) Tuesday 13 March 2012 _x86_64_ (2 CPU)
|
||||
@ -345,11 +346,11 @@ via: http://www.cyberciti.biz/faq/network-statistics-tools-rhel-centos-debian-li
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
[1]:http://www.cyberciti.biz/tips/linux-investigate-sockets-network-connections.html
|
||||
[2]:http://www.cyberciti.biz/tips/netstat-command-tutorial-examples.html
|
||||
[1]:https://linux.cn/article-4372-1.html
|
||||
[2]:https://linux.cn/article-2434-1.html
|
||||
[3]:http://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html
|
||||
@ -1,8 +1,10 @@
|
||||
如何在一个Docker容器里安装Discourse
|
||||
=============================================================================
|
||||
大家好,今天我们将会学习如何利用Docker平台安装Discourse。Discourse是完全开源的讨论平台,为互联网的下一个十年而搭建,拥有一个邮件列表,一个论坛和一个long-form(此处不明白)聊天室。不管从技术角度还是社会学角度,当你试图去重新想象当今一个现代的,可持续的,完全开源的互联网讨论平台该是什么样子,Discourse都是一个不错的途径。Discourse简洁,直接之于讨论。它确实是一个令人称赞的平台,对于互联网上各种各样的讨论来说,提供了在机器之外如此酷的一个服务。Docker是一个开源平台,提供打包,运输和运行任何应用的平台,如一个轻量级容器。Docker容器技术使得Discourse更加方便和容易去建立应用程序。
|
||||
大家好,今天我们将会学习如何利用Docker平台安装Discourse。Discourse是一个完全开源的讨论平台,以未来十年的互联网理念设计,拥有一个邮件列表,一个论坛和一个长篇聊天室。不管从技术角度还是社会学角度,如今要体验一个现代的、勃勃生机的、完全开源的互联网讨论平台,Discourse都是一个不错的途径。Discourse是一个简单、简明、简易的讨论方式。它确实是一个令人称赞的平台,对于互联网上各种各样的论坛来说,提供了一个上手可用的很酷的服务。
|
||||
|
||||
所以,下面是一些快速且容易的步骤,用来安装Discourse在一个Docker环境里面。
|
||||
Docker是一个开源的、可以将任何应用以轻量级容器的方式打包、传输和运行的开放平台。Docker容器技术使得可以更加方便和容易构建Discourse。
|
||||
|
||||
所以,下面是一些快速且容易的步骤,用来在一个Docker环境里面安装Discourse。
|
||||
|
||||
### 1. 安装Docker ###
|
||||
|
||||
@ -16,7 +18,7 @@ docker安装包在Ubuntu的仓库里面是可用的,所以我们将会使用ap
|
||||
|
||||
#### 在CentOS 7上 ####
|
||||
|
||||
在CentOS 7的主机上,我们使用yum管理器安装docker,因为CentOS的仓库里同样有docker安装包
|
||||
在CentOS 7的主机上,我们使用yum管理器安装docker,因为CentOS的仓库里同样有docker安装包
|
||||
|
||||
# yum install docker
|
||||
|
||||
@ -24,7 +26,7 @@ docker安装包在Ubuntu的仓库里面是可用的,所以我们将会使用ap
|
||||
|
||||
### 2. 设定交换内存 ###
|
||||
|
||||
如果你的RAM容量小于1GB,那么确保升级你的系统达到1GB或者以上,否则Discourse不会在512MB的RAM下安装。如果你现在准备好了安装Discourse,根据下面的步骤为你的VPS(Virtual Private Servers)或者服务器设定交换内存
|
||||
如果你的RAM容量小于1GB,那么确保升级你的系统达到1GB或者以上,Discourse不能在512MB的RAM下安装。如果你现在准备好了安装Discourse,根据下面的步骤为你的VPS(Virtual Private Servers)或者服务器设定交换内存:
|
||||
|
||||
运行下面的命令,创建一个空的交换文件。
|
||||
|
||||
@ -34,7 +36,7 @@ docker安装包在Ubuntu的仓库里面是可用的,所以我们将会使用ap
|
||||
|
||||
# dd if=/dev/zero of=/swapfile bs=1k count=1024k
|
||||
|
||||
如果你想达到2GB,跳过上面的所有步骤,跟着下面做
|
||||
如果你想达到2GB,跳过上一步,跟着下面做
|
||||
|
||||
# dd if=/dev/zero of=/swapfile bs=1k count=2014k
|
||||
|
||||
@ -50,14 +52,14 @@ docker安装包在Ubuntu的仓库里面是可用的,所以我们将会使用ap
|
||||
|
||||
# echo "/swapfile swap swap auto 0 0" | sudo tee -a /etc/fstab
|
||||
|
||||
设置swappiness为10,这样交换内存仅作为一个紧急缓冲区用。
|
||||
设置swappiness参数为10,这样交换内存仅作为一个紧急缓冲区用。
|
||||
|
||||
# sudo sysctl -w vm.swappiness=10
|
||||
# echo vm.swappiness = 10 | sudo tee -a /etc/sysctl.conf
|
||||
|
||||
### 3. 安装Discourse ###
|
||||
|
||||
在我们的主机上安装Docker后,我们将会安装Discourse。现在,我们从官方的Discourse GitHub仓库克隆一份到/var/discourse目录下。我们需要运行下面的命令完成这一步。
|
||||
在我们的主机上安装好Docker后,我们将会安装Discourse。现在,我们从官方的Discourse GitHub仓库克隆一份到`/var/discourse`目录下。我们需要运行下面的命令完成这一步。
|
||||
|
||||
# mkdir /var/discourse/
|
||||
|
||||
@ -65,7 +67,7 @@ docker安装包在Ubuntu的仓库里面是可用的,所以我们将会使用ap
|
||||
|
||||
# git clone https://github.com/discourse/discourse_docker.git /var/discourse/
|
||||
|
||||
克隆好仓库后,我们会为discourse服务器复制配置文件
|
||||
克隆好仓库后,我们给discourse服务器复制配置文件
|
||||
|
||||
# cp samples/standalone.yml containers/app.yml
|
||||
|
||||
@ -77,15 +79,15 @@ docker安装包在Ubuntu的仓库里面是可用的,所以我们将会使用ap
|
||||
|
||||
# nano containers/app.yml
|
||||
|
||||
现在,我们需要设置开发者的邮箱地址为DISCOURSE_DEVELOPER_EMAILS,如下。
|
||||
现在,我们需要将开发者邮箱地址DISCOURSE_DEVELOPER_EMAILS修改为自己的,如下。
|
||||
|
||||
DISCOURSE_DEVELOPER_EMAILS: 'arun@linoxide.com'
|
||||
|
||||
然后,我们会设置主机名为服务器的域名。
|
||||
然后,我们设置主机名为服务器的域名。
|
||||
|
||||
DISCOURSE_HOSTNAME: 'discourse.linoxide.com'
|
||||
|
||||
接着,为每个托管在相同discourse主机或者vps上的SMTP服务器设定邮箱证书。SMTP设置需要从你的Discourse发送邮件
|
||||
接着,设置放在相同的discourse主机或vps上的SMTP服务器的认证信息。这些SMTP设置用于你的Discourse发送邮件。
|
||||
|
||||
DISCOURSE_SMTP_ADDRESS: smtp.linoxide.com
|
||||
DISCOURSE_SMTP_PORT: 587 # (optional)
|
||||
@ -94,11 +96,9 @@ docker安装包在Ubuntu的仓库里面是可用的,所以我们将会使用ap
|
||||
|
||||

|
||||
|
||||
Discourse 配置
|
||||
|
||||
如果你在使用一个1GB的Discourse,设定UNICORN_WORKERS为2,db_shared_buffers为128MB,这样你会有更多的内存空间。
|
||||
|
||||
运行Discourse需要强制性地创建一个邮件服务器。如果你已经有一个服务器了那就好办多了,我们可以使用它的证书。如果你没有现成的邮件服务器,或者你不知道那是什么。没关系,创建一个免费的帐号在[Mandrill][1] ([Mailgun][2],或者[Mailjet][3]),然后使用面板上提供的证书。
|
||||
运行Discourse需要强制性地创建一个邮件服务器。如果你已经有一个服务器了那就好办多了,我们可以使用它的认证信息。如果你没有现成的邮件服务器,或者你不知道那是什么。没关系,可以在[Mandrill][1] (或[Mailgun][2]和 [Mailjet][3])创建一个免费的帐号,然后使用其提供的认证信息。
|
||||
|
||||
### 5. 启动Discourse应用 ###
|
||||
|
||||
@ -110,35 +110,39 @@ docker安装包在Ubuntu的仓库里面是可用的,所以我们将会使用ap
|
||||
|
||||
上述命令可能会花去几分钟时间,会自动配置我们的Discourse环境。然后,该进程完成后,我们需要运行下面的命令启动Discourse App
|
||||
|
||||
#./launch start app
|
||||
#./launcher start app
|
||||
|
||||

|
||||
|
||||
如果一切都正常,我们就能使用惯用的浏览器来访问我们新鲜出炉的 Discourse 的 Web 界面了: http://ip-address/ or http://discourse.linoxide.com/ 。然后,我们就可以创建一个新账号并成为管理员。
|
||||
|
||||

|
||||
|
||||
### 维护 ###
|
||||
|
||||
这里往下是/var/discourse/目录里加载命令的使用,这使得我们可以承担维护的任务,通过Docker 容器控制Disourse。(这里不太明白原文表达意思)
|
||||
这里往下是/var/discourse/目录里的 launcher 命令的用法,它可以用于我们在Docker 容器里面控制和维护Disourse。
|
||||
|
||||
Usage: launcher COMMAND CONFIG [--skip-prereqs]
|
||||
Commands:
|
||||
start: Start/initialize a container
|
||||
stop: Stop a running container
|
||||
restart: Restart a container
|
||||
destroy: Stop and remove a container
|
||||
enter: Use nsenter to enter a container
|
||||
ssh: Start a bash shell in a running container
|
||||
logs: Docker logs for container
|
||||
mailtest: Test the mail settings in a container
|
||||
bootstrap: Bootstrap a container for the config based on a template
|
||||
rebuild: Rebuild a container (destroy old, bootstrap, start new)
|
||||
cleanup: Remove all containers that have stopped for > 24 hours
|
||||
用法: launcher 命令 配置 [--skip-prereqs]
|
||||
命令:
|
||||
start: 启动/初始化一个容器
|
||||
stop: 停止一个运行的容器
|
||||
restart: 重启一个容器
|
||||
destroy:停止并删除一个容器
|
||||
enter: 使用 nsenter 进入容器
|
||||
ssh: 在一个运行的容器中启动一个 bash shell
|
||||
logs: 容器的 Docker l日志
|
||||
mailtest: 在容器中测试邮件设置
|
||||
bootstrap: 基于配置模版来引导一个容器
|
||||
rebuild: 重建一个容器(摧毁旧的,初始化,启动新的)
|
||||
cleanup: 清理所有停止了24小时以上的容器
|
||||
|
||||
Options:
|
||||
--skip-prereqs Don't check prerequisites
|
||||
--docker-args Extra arguments to pass when running docker
|
||||
选项:
|
||||
--skip-prereqs 不检查前置需求
|
||||
--docker-args 当运行 docker 时,展开并传入参数
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Hurray!我们已经成功使用Docker技术安装了Discourse。Docker技术使得Discourse十分容易安装在任何平台,并且包含所有的要求。我们需要自己的邮件服务器或者邮件服务器的证书来启动它。对于便捷的现代邮件列表,论坛来说,Discourse是一个伟大的平台。(最后这句有些别扭)
|
||||
哈哈!我们已经成功使用Docker技术安装了Discourse。Docker技术使得Discourse十分容易安装在任何平台,并且包含所有的要求。我们需要自己的邮件服务器或者邮件服务器的证书来启动它。对于便捷的现代邮件列表,论坛来说,Discourse是一个伟大的平台。(最后这句有些别扭)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -146,7 +150,7 @@ via: http://linoxide.com/how-tos/install-discourse-docker-container/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,11 @@
|
||||
在Linux中用chattr和lsattr命令管理文件和目录属性
|
||||
================================================================================
|
||||
为了允许添加数据,防止更改或者删除等,文件和文件夹中设定了一定的控制属性。例如,你可以在关键系统文件或者文件夹中启用属性,然后没有用户,包括root,可以删除或者修改它,不允许比如dump命令等备份工具去备份一个特定的文件或者文件夹,等等。这些属性只可以在ext2,ext3或者ext4文件系统中的文件和文件夹上设定。
|
||||
为了允许添加数据,防止更改或者删除等,文件和文件夹可以设定了特定的控制属性。例如,你可以在关键的系统文件或者文件夹中启用属性,然后没有任何用户,包括root,可以删除或者修改它,比如不允许使用像dump这样的命令等备份工具去备份一个特定的文件或者文件夹,等等。这些属性只可以在ext2,ext3或者ext4文件系统中的文件和文件夹上设定。
|
||||
|
||||
有两个命令 **lsattr** 和 **chattr** 用来管理属性。下面是常用属性的列表。
|
||||
|
||||
注:表格代码
|
||||
<table width="482" cellspacing="0" cellpadding="4" style="height: 651px">
|
||||
<table width="482" cellspacing="0" cellpadding="4" border="1">
|
||||
<colgroup>
|
||||
<col width="112">
|
||||
<col width="514"> </colgroup>
|
||||
@ -63,7 +63,7 @@
|
||||
<p align="justify" class="western">e (extent format)</p>
|
||||
</td>
|
||||
<td width="514">
|
||||
<p align="justify" class="western">它表明,该文件使用扩展到映射磁盘上的块</p>
|
||||
<p align="justify" class="western">它表明,该文件使用磁盘上的块的映射扩展</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr valign="top">
|
||||
@ -71,7 +71,7 @@
|
||||
<p align="justify" class="western">i (immutable)</p>
|
||||
</td>
|
||||
<td width="514">
|
||||
<p align="justify" class="western">在文件上启用这个属性时,我们不能更改,重命名或者删除这个文件</p>
|
||||
<p align="justify" class="western">在文件上启用这个属性时,我们不能更改、重命名或者删除这个文件</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr valign="top">
|
||||
@ -96,14 +96,14 @@
|
||||
chattr属性中可以使用的不同选项 :
|
||||
|
||||
- **-R** 递归地修改文件夹和子文件夹的属性
|
||||
- **-V** chattr命令的输出伴随版本信息
|
||||
- **-f** 压缩大部分错误信息
|
||||
- **-V** chattr命令会输出带有版本信息的冗余信息
|
||||
- **-f** 忽略大部分错误信息
|
||||
|
||||
在chattr中用于设置或者取消属性的 **操作符**
|
||||
|
||||
- ‘+’ 符号用来为文件和文件夹设置属性,
|
||||
- ‘-‘ 符号用来移除或者取消属性
|
||||
- ‘=’ 使它们成为文件有的唯一属性。
|
||||
- '+' 符号用来为文件和文件夹设置属性,
|
||||
- '-' 符号用来移除或者取消属性
|
||||
- '=' 使它们成为文件有的唯一属性。
|
||||
|
||||
**chattr** 和 **lsattr** 命令的基本语法 :
|
||||
|
||||
@ -120,7 +120,7 @@ chattr属性中可以使用的不同选项 :
|
||||
现在试着删除或者修改文件
|
||||
|
||||
[root@linuxtechi ~]# rm -f dummy_data
|
||||
rm: cannot remove ‘dummy_data’: Operation not permitted
|
||||
rm: cannot remove 'dummy_data': Operation not permitted
|
||||
|
||||
[root@linuxtechi ~]# echo "test" >> dummy_data
|
||||
-bash: dummy_data: Permission denied
|
||||
@ -193,7 +193,7 @@ via: http://www.linuxtechi.com/file-directory-attributes-in-linux-using-chattr-l
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
20个为桌面用户准备的令人惊叹的Docker容器
|
||||
20个令人惊叹的桌面Docker容器
|
||||
================================================================================
|
||||
大家好,今天我们会列出一些很棒的运行在Docker容器中的桌面软件,我们可以在自己的桌面系统中运行它们。Docker是一个开源的项目,它提供可以将应用程序作为一个轻量级容器来打包、传送和运行的开放平台。它没有语言支持、框架或打包系统的限制,可以运行在任何地方,从小型的家用电脑到高端的服务器。它可以使部署和扩展web应用程序、数据库和后端服务像搭积木一样容易,而不依赖特定技术栈或提供商。它主要是由开发、运维工程师使用的,因为它简单、快速和方便,可以用来测试和辅助开发他们产品,但是我们也可以在桌面环境使用Docker,这样一些桌面程序可以开箱即用。
|
||||
|
||||
大家好,今天我们会列出一些运行在Docker容器中的很棒的桌面软件,我们可以在自己的桌面系统中运行它们。Docker 是一个开源项目,提供了一个可以打包、装载和运行任何应用的轻量级容器的开放平台。它没有语言支持、框架和打包系统的限制,从小型的家用电脑到高端服务器,在何时何地都可以运行。它可以使部署和扩展web应用程序、数据库和后端服务像搭积木一样容易,而不依赖特定技术栈或提供商。它主要是由开发、运维工程师使用的,因为它简单、快速和方便,可以用来测试和辅助开发他们产品,但是我们也可以在桌面环境使用Docker,这样一些桌面程序可以开箱即用。
|
||||
|
||||
下边是20个非常棒的桌面软件docker镜像,我们可以使用Docker来运行。
|
||||
|
||||
### 1. Lynx ###
|
||||
|
||||
Lynx是一个一直以来最受欢迎的文本界面网页浏览器,它对多数Linux用户来说都很熟悉。它应该是现在还在日常和开发环境中被使用的最古老的网页浏览器了。可以使用如下命令运行Lync。
|
||||
Lynx是一个一直以来最受欢迎的文本界面网页浏览器,很多Linux用户都很熟悉它。它应该是现在还在日常和开发环境中被使用的最古老的网页浏览器了。可以使用如下命令运行Lync。
|
||||
|
||||
$ docker run -it \
|
||||
--name lynx \
|
||||
@ -39,7 +40,7 @@ Chrome是一个令人惊叹的图形界面网页浏览器,由Google开发,
|
||||
|
||||
### 4. Tor浏览器 ###
|
||||
|
||||
Tor浏览器是一个支持匿名访问的网页浏览器。它让我们可以自由地在网络世界遨游,或者浏览被特定组织或者网络服务提供商封锁的网站。它会阻止有人通过监视我们的网络连接来窃取我们在网络上的一举一动以及我们的确切位置。运行如下命令运行Tor浏览器。
|
||||
Tor浏览器是一个支持匿名访问的网页浏览器。它让我们可以自由地在网络世界遨游,或者浏览被特定组织或者网络服务提供商封锁的网站。它会阻止别人通过监视我们的网络连接来窃取我们在网络上的一举一动以及我们的确切位置。运行如下命令运行Tor浏览器。
|
||||
|
||||
$ docker run -it \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
@ -50,7 +51,7 @@ Tor浏览器是一个支持匿名访问的网页浏览器。它让我们可以
|
||||
|
||||
### 5. Firefox浏览器 ###
|
||||
|
||||
Firefox浏览器是一个自由并且开源的网页浏览器,它由Mozilla基金会开发。它使用Gecko和SpiderMonkey引擎。Firefox浏览器有很多新特性,并且它以性能和安全性著称。
|
||||
Firefox浏览器是一个自由开源的网页浏览器,它由Mozilla基金会开发。它使用Gecko和SpiderMonkey引擎。Firefox浏览器有很多新特性,并且它以性能和安全性著称。
|
||||
|
||||
$ docker run -d \
|
||||
--name firefox \
|
||||
@ -71,12 +72,12 @@ Rainbow Stream是一个文本界面的Twitter客户端,有实时显示tweetstr
|
||||
|
||||
### 7. Gparted ###
|
||||
|
||||
Gparted是一个用来给磁盘分区的开源软件。现在可以在Docker容器里享受分区的乐趣。可以使用如下命令运行gparted。
|
||||
Gparted是一个用来给磁盘分区的开源软件。现在可以在Docker容器里享受分区的乐趣了。可以使用如下命令运行gparted。
|
||||
|
||||
$ docker run -it \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
-e DISPLAY=unix$DISPLAY \
|
||||
--device /dev/sda:/dev/sda \ # mount the device to partition
|
||||
--device /dev/sda:/dev/sda \ # 将设备挂载为分区
|
||||
--name gparted \
|
||||
jess/gparted
|
||||
|
||||
@ -91,7 +92,7 @@ GIMP(Gnu Image Manipulation Program)是一个令人惊叹的Linux图片编
|
||||
|
||||
### 9. Thunderbird ###
|
||||
|
||||
Thunderbird是一个自由并且开源的电子邮件软件,它由Mozilla基金会开发和维护。它有众多一个电子邮件软件应该具有的功能。Thunderbird非常易于安装和定制。使用如下命令在Docker中运行Thunderbird。
|
||||
Thunderbird是一个自由开源的电子邮件软件,它由Mozilla基金会开发和维护。它有众多一个电子邮件软件应该具有的功能。Thunderbird非常易于安装和定制。使用如下命令在Docker中运行Thunderbird。
|
||||
|
||||
$ docker run -d \
|
||||
-e DISPLAY \
|
||||
@ -102,7 +103,7 @@ Thunderbird是一个自由并且开源的电子邮件软件,它由Mozilla基
|
||||
|
||||
### 10. Mutt ###
|
||||
|
||||
Mutt是一个文本界面的电子邮件客户端,有很多很酷的功能,如颜色支持,IMAP、POP3、SMTP支持,邮件存储支持等。 使用如下命令运行Mutt。
|
||||
Mutt是一个文本界面的电子邮件客户端,有很多很酷的功能,如彩色支持,IMAP、POP3、SMTP支持,邮件存储支持等。 使用如下命令运行Mutt。
|
||||
|
||||
$ docker run -it \
|
||||
-v /etc/localtime:/etc/localtime \
|
||||
@ -114,7 +115,7 @@ Mutt是一个文本界面的电子邮件客户端,有很多很酷的功能,
|
||||
|
||||
### 11. Skype ###
|
||||
|
||||
Skype是一个支持文字、语音和视频的即时通讯软件,它不是开源的,但在Linux下可以很棒地运行。我们同样可以在Docker中运行Skype,使用如下命令。
|
||||
Skype是一个支持文字、语音和视频的即时通讯软件,它不是开源的,但在Linux下可以运行的很好。我们同样可以在Docker中运行Skype,使用如下命令。
|
||||
|
||||
$ docker run -it \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix:ro \
|
||||
@ -124,7 +125,7 @@ Skype是一个支持文字、语音和视频的即时通讯软件,它不是开
|
||||
|
||||
### 12. Cathode ###
|
||||
|
||||
Cathode是一个漂亮并且高度可定制的终端模拟器,灵感来自经典的计算机。使用如下命令运行Cathode。
|
||||
Cathode是一个漂亮并且高度可定制的终端模拟器,灵感来自古典计算机。使用如下命令运行Cathode。
|
||||
|
||||
$ docker run -it \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
@ -134,7 +135,8 @@ Cathode是一个漂亮并且高度可定制的终端模拟器,灵感来自经
|
||||
|
||||
### 13. LibreOffice ###
|
||||
|
||||
LibreOffice是一个功能强大的办公套件,它是自由和开源的,现在由The Document基金会维护。它有干净的界面和强大的功能,让我们释放创造力和提升生产力。LibreOffice将数个应用程序集成在一起,是市面上最强大的自由并且开源的办公套件。
|
||||
LibreOffice是一个功能强大的办公套件,它是自由开源的,现在由The Document基金会维护。它有干净的界面和强大的功能,让我们释放创造力和提升生产力。LibreOffice将数个应用程序集成在一起,是市面上最强大的自由并且开源的办公套件。
|
||||
|
||||
$docker run \
|
||||
-v $HOME/Documents:/home/libreoffice/Documents:rw \
|
||||
-v /tmp/.X11-unix:/tmp/.X11-unix \
|
||||
@ -155,7 +157,7 @@ Spotify可以即时访问数百万的歌曲,从经典老歌到最新单曲。
|
||||
|
||||
### 15. Audacity ###
|
||||
|
||||
Audacity是一个自由并且开源的跨平台软件,用来录制和编辑音频。Audacity可以用来做所有类型音频(例如podcast)的后期处理,如归一化、调整、淡入淡出。使用如下命令来运行Audacity。
|
||||
Audacity是一个自由开源的跨平台软件,用来录制和编辑音频。Audacity可以用来做所有类型音频(例如podcast)的后期处理,如归一化、调整、淡入淡出。使用如下命令来运行Audacity。
|
||||
|
||||
$ docker run --rm \
|
||||
-u $(id -u):$(id -g) \
|
||||
@ -178,7 +180,7 @@ Eclipse是一个集成开发环境。它包含基本的工作区和用来定制
|
||||
|
||||
### 17. VLC媒体播放器 ###
|
||||
|
||||
VLC是一个自由并且开源的跨平台多媒体播放器,可以播放本地文件、DVD、CD、VCD和各种流媒体。VLC由VideoLAN组织开发和维护。使用如下命令运行VLC。
|
||||
VLC是一个自由开源的跨平台多媒体播放器,可以播放本地文件、DVD、CD、VCD和各种流媒体。VLC由VideoLAN组织开发和维护。使用如下命令运行VLC。
|
||||
|
||||
$ docker run -v\
|
||||
$HOME/Documents:/home/vlc/Documents:rw \
|
||||
@ -196,7 +198,7 @@ Vim是一个高度可配置的文本界面文字编辑器,为高效的文本
|
||||
|
||||
### 19. Inkscape ###
|
||||
|
||||
Inkscape是一个自由并且开源的矢量图形编辑器。它可以创建、编辑矢量图形,如插图、图示、线条艺术、图表、徽标以及更复杂的绘画。Inkscape使用的主要矢量图形格式是SVG 1.1版本。它也可以导入和导出一些其他的格式,但实际编辑使用的还是SVG格式。
|
||||
Inkscape是一个自由开源的矢量图形编辑器。它可以创建、编辑矢量图形,如插图、图示、线条艺术、图表、徽标以及更复杂的绘画。Inkscape使用的主要矢量图形格式是SVG 1.1版本。它也可以导入和导出一些其他的格式,但实际编辑使用的还是SVG格式。
|
||||
|
||||
$docker build -t rasch/inkscape --rm .
|
||||
$ docker run --rm -e DISPLAY \
|
||||
@ -207,7 +209,7 @@ Inkscape是一个自由并且开源的矢量图形编辑器。它可以创建、
|
||||
|
||||
### 20. Filezilla ###
|
||||
|
||||
Filezilla是一个自由的FTP解决方案,支持FTP、SFTP、FTPS协议。它的客户端是一个功能强大的文件管理工具。它是一个很棒的高度可靠和易用的开源FTP解决方案。
|
||||
Filezilla是一个免费的FTP解决方案,支持FTP、SFTP、FTPS协议。它的客户端是一个功能强大的文件管理工具。它是一个很棒的高度可靠和易用的开源FTP解决方案。
|
||||
|
||||
$ xhost +si:localuser:$(whoami)
|
||||
$ docker run \
|
||||
@ -229,7 +231,7 @@ via: http://linoxide.com/how-tos/20-docker-containers-desktop-user/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
Linux 上IP转发如何帮助专用接口连接到互联网
|
||||
如何在 Linux 上用 IP转发使内部网络连接到互联网
|
||||
================================================================================
|
||||
大家好,今天我们学习一下在 Linux 上用 iptables 实现从一个网络接口到另一个接口的IP转发或者数据包转发。IP转发的概念是,使 Linux 机器像路由器一样将数据从一个网络发送到另一个网络。所以,它能作为一个**路由器**或者代理服务器,实现从一个连接到多个客户端机器的共享互联网或者网络连接。
|
||||
|
||||
大家好,今天我们学习一下在 Linux 上用 iptables 实现从一个网络接口到另一个接口的IP转发(数据包转发)。IP转发的概念是,使 Linux 机器像路由器一样将数据从一个网络发送到另一个网络。所以,它能作为一个**路由器**或者代理服务器,实现将一个连接的互联网或者网络连接共享给多个客户端机器。
|
||||
|
||||
这是一些启用IP转发或网络包转发方法的简单步骤。
|
||||
|
||||
### 1. 启用 IPv4 转发 ###
|
||||
|
||||
首先,我们打算在我们的 Linux 操作系统上启用 IPv4 转发。要做到这点,我们需要用 sudo 模式在 shell 或终端下执行下面的命令。
|
||||
首先,我们需要在我们的 Linux 操作系统上启用 IPv4 转发。要做到这点,我们需要用 sudo 模式在 shell 或终端下执行下面的命令。
|
||||
|
||||
$ sudo -s
|
||||
|
||||
@ -14,7 +15,7 @@ Linux 上IP转发如何帮助专用接口连接到互联网
|
||||
|
||||

|
||||
|
||||
**注意:上面的命令能马上启用ip转发,但只是临时的,直到下一次重启。要永久启用,我们需要使用我们喜欢的文本编辑器打开 /etc/sysctl.conf 文件。**
|
||||
**注意:上面的命令能马上启用ip转发,但只是临时的,直到下一次重启。要永久启用,我们需要使用我们惯用的文本编辑器打开 /etc/sysctl.conf 文件。**
|
||||
|
||||
# nano /etc/sysctl.conf
|
||||
|
||||
@ -38,13 +39,13 @@ Linux 上IP转发如何帮助专用接口连接到互联网
|
||||
|
||||

|
||||
|
||||
这里,在我们的机器中, eth2 是连接到互联网或者网络的网卡接口, wlan2 是我们要使用 iptables 从 eth2 转发数据包的接口。要做到这点,我们需要运行以下命令。
|
||||
这里,在我们的机器中, eth2 是连接到互联网或者网络的网卡接口, wlan2 是我们要使用 iptables 从 eth2 转发数据包的接口。要实现转发,我们需要运行以下命令。
|
||||
|
||||
# iptables -A FORWARD -i wlan2 -o eth2 -j ACCEPT
|
||||
|
||||
注意:请用你 Linux 机器中的可用设备名称替换 wlan2 和 eth2。
|
||||
|
||||
现在,由于网络过滤器是一个无状态的防火墙,我们要用 iptables 允许已建立的连接通过。要做到这点,我们要运行下面的命令。
|
||||
现在,由于netfilter/iptables是一个无状态的防火墙,我们需要让 iptables 允许已建立的连接通过。要做到这点,我们要运行下面的命令。
|
||||
|
||||
# iptables -A FORWARD -i eth2 -o wlan2 -m state --state ESTABLISHED,RELATED -j ACCEPT
|
||||
|
||||
@ -60,7 +61,7 @@ Linux 上IP转发如何帮助专用接口连接到互联网
|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,用安装的 iptables 作为防火墙解决方案,我们在我们的 Linux 机器上成功的配置了从一个接口到另一个接口的数据包转发。这篇文章允许你的专用接口连接到互联网,你不需要桥接接口,而是路由从一个接口进来的数据包到另一个接口,就是这些。如果你有任何问题、建议、反馈,请写到下面的评论框中,然后我们可以改进或更新我们的内容。非常感谢!享受吧 :-)
|
||||
最后,我们在我们以 iptables 作为防火墙 Linux 机器上成功的配置了从一个接口到另一个接口的数据包转发。这篇文章教给你将你的私有接口连接到互联网,不需要桥接接口,而是将从一个接口进来的数据包路由到另一个接口。就是这些,如果你有任何问题、建议、反馈,请写到下面的评论框中,然后我们可以改进或更新我们的内容。非常感谢!享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -68,7 +69,7 @@ via: http://linoxide.com/firewall/ip-forwarding-connecting-private-interface-int
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -4,19 +4,17 @@ Ubuntu 自带了一些已经预装的默认应用程序,包括非常流行的
|
||||
|
||||

|
||||
|
||||
尽管这两个应用都有它们自己的粉丝,但是没有一个应用能符合每个人的口味和需要。我们经常收到邮件或者推文,询问我们怎样可以在 Ubuntu 上更改默认浏览器或者设置处理邮件链接的不同的电子邮件客户端等。
|
||||
尽管这两个应用都有它们自己的粉丝,但是没有一个应用能符合每个人的口味和需要。我们经常收到邮件或者推文,询问我们可以怎样在 Ubuntu 上更改默认浏览器或者设置处理邮件链接为不同的电子邮件客户端等。
|
||||
|
||||
我们在这里不仅讨论如何安装不同的软件,还包括如何给一个特定的文件,链接或者内容类型设置系统处理应用。
|
||||
我们在这里不仅讨论如何安装不同的软件,还包括如何给一个特定的文件,链接或者内容类型设置其系统处理应用。
|
||||
|
||||
在 Ubuntu 中更改默认应用程序,包括浏览器、电子邮件客户端、文本编辑器、音乐和视频播放器都非常的简单。但并不是每个人都知道更改这些的设置面板在哪里,让我们来快速看一下吧。
|
||||
|
||||
### 如何在 Ubuntu 上更改默认浏览器 ###
|
||||
|
||||

|
||||
Mozilla 火狐浏览器是一扇稳定、开源而且可靠的互联网之窗,但它并不是每个人的选择。这都没关系。
|
||||
|
||||
Mozilla 火狐浏览器是万维网上稳定、开源而且可依赖的窗口,但它并不是每个人的选择。这都没关系。
|
||||
|
||||
在 Ubuntu 上使用不同的默认浏览器,首先,显而易见,你需要安装一个新的浏览器。你该怎么做取决于你想要的浏览器:
|
||||
要在 Ubuntu 上使用不同的默认浏览器,首先,显而易见,你需要安装一个新的浏览器。你该怎么做取决于你想要的浏览器:
|
||||
|
||||
- 开源浏览器,例如 [Epiphany][1], [Chromium][2] 和 [IceWeasel][3],可以从 Ubuntu 软件中心安装。
|
||||
|
||||
@ -24,9 +22,9 @@ Mozilla 火狐浏览器是万维网上稳定、开源而且可依赖的窗口,
|
||||
|
||||
不管你选择哪个浏览器,不管你选择怎样安装,完成之后你就可以继续了。
|
||||
|
||||

|
||||
要更改在点击其它应用(如即时通讯软件、Twitter 客户端、 e-mail 中)中的链接时打开的默认网页浏览器,你需要用到 Ubuntu 系统设置工具。
|
||||
|
||||
点击其它应用上的链接,例如及时通讯软件、Twitter 客户端、 e-mail,要更改打开网页的默认浏览器,你需要用到 Ubuntu 系统设置工具。
|
||||

|
||||
|
||||
你可以用多种方法打开系统设置。其中一种最快的方式是点击右上角(RTL系统是左上角)的 Cog 图标并选择‘系统设置’菜单快捷方式。
|
||||
|
||||
@ -35,25 +33,27 @@ Mozilla 火狐浏览器是万维网上稳定、开源而且可依赖的窗口,
|
||||
1. 在侧边栏选择‘默认应用程序’
|
||||
1. 把 ‘Web’ 条目的 ‘火狐’ 改为你想要的选项
|
||||
|
||||

|
||||
|
||||
就是这样。
|
||||
|
||||
### 如何在 Ubuntu 上更改默认的邮件客户端 ###
|
||||
|
||||
|
||||
|
||||
Ubuntu 用 Thunderbird 作为默认的邮件应用程序。这意味着 当你点击大部分浏览器、 PDF文件、及时通讯软件等上的 **电子邮件地址或者一个 [mailto 链接][7] 的时候会自动打开** 这个应用。
|
||||
Ubuntu 用 Thunderbird 作为默认的邮件应用程序。这意味着当你点击大部分浏览器、 PDF文件、及时通讯软件等上的 **电子邮件地址或者一个 [mailto 链接][7] 的时候会自动打开** 这个应用。
|
||||
|
||||
当然,如果你使用 Thunderbird,这真的很方便。但是我们很多人并非如此; 我们可能**[使用像 Geary 这样的轻量级客户端][8]**,GNOME stalwart Evolution,或者依靠像 Gmail 或者 Outlook 这样的网络邮件服务。
|
||||
|
||||
在 Ubuntu 上从 Thunderbird **更改默认邮件客户端** 到另一个应用程序,打开系统设置 > 详细 > 默认应用程序。点击下拉菜单到 ‘Mail’ 并选择从列表中选择你喜欢的客户端。
|
||||
|
||||
**在 Ubuntu 上设置 Gmail 为默认的邮件客户端**,你首先需要点击下面的按钮安装 ‘gnome-gmail’ 软件包。安装完后打开系统设置 > 详细 > 默认应用程序。点击下拉菜单到 ‘Mail’ 并选择从列表中选择 ‘Gmail’。
|
||||
**在 Ubuntu 上设置 Gmail 为默认的邮件客户端**,你首先需要点击下面的按钮安装 ‘gnome-gmail’ 软件包。安装完后打开系统设置 > 详细 > 默认应用程序。然后点击‘Mail’ 的下拉菜单,并选择从列表中选择 ‘Gmail’。
|
||||
|
||||

|
||||
|
||||
- [在 Ubuntu 上安装 GNOME Gmail][9]
|
||||
|
||||
### 更多 ###
|
||||
|
||||
上述同样的步骤可以用来设置你双击音乐文件时打开你喜欢的音乐播放器,用比如 VLC 应用程序处理 .avi 和 .mp4 文件,等等。
|
||||
上述同样的步骤也可以用来设置你双击音乐文件时打开你喜欢的音乐播放器,用比如 VLC 应用程序处理 .avi 和 .mp4 文件,等等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -61,7 +61,7 @@ via: http://www.omgubuntu.co.uk/2015/04/change-your-default-web-browser-in-ubunt
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -73,5 +73,5 @@ via: http://www.omgubuntu.co.uk/2015/04/change-your-default-web-browser-in-ubunt
|
||||
[5]:http://www.opera.com/computer/linux
|
||||
[6]:https://vivaldi.com/#Download
|
||||
[7]:http://en.wikipedia.org/wiki/Mailto
|
||||
[8]:http://www.omgubuntu.co.uk/2015/03/install-geary-ubuntu-linux-email-update
|
||||
[8]:https://linux.cn/article-5511-1.html
|
||||
[9]:apt://gnome-gmail
|
||||
@ -1,74 +1,87 @@
|
||||
安装完Ubuntu 15.04桌面后要做的15件事
|
||||
================================================================================
|
||||
本教程适用于新手和在自己的电脑上安装好Ubuntu 15.04 “Vivid Vervet” 桌面之后为了自定义自己的系统并安装一些基本程序作为日常使用的已经做了一些准备的人。
|
||||
本教程适用于在自己的电脑上安装了 Ubuntu 15.04 “Vivid Vervet” 桌面的新手,这里会告诉你安装之后应该做哪些事情,来自定义你的系统和安装一些基本程序作为日常使用。
|
||||
|
||||

|
||||
安装完Ubuntu 15.04桌面后要做的15件事
|
||||
|
||||
*安装完Ubuntu 15.04桌面后要做的15件事*
|
||||
|
||||
### 1. 启用Ubuntu额外软件库并更新系统 ###
|
||||
|
||||
在刚装好Ubuntu之后你应该要关心的第一件事是启用官方合作伙伴提供的Ubuntu额外软件库并且通过最近一次的安全补丁和软件更新来保持系统是最新状态。
|
||||
在刚装好Ubuntu之后你应该要关心的第一件事是启用Canonical的官方合作伙伴提供的Ubuntu额外软件库,并且通过最近一次的安全补丁和软件更新来保持系统是最新状态。
|
||||
|
||||
要完成这一步,依次从左边菜单中打开System Settings -> Software and Updates工具并检查所有Ubuntu软件和其他软件库(官方合作伙伴所提供),点击关闭按钮并等待重新加载缓存源树。
|
||||
要完成这一步,依次从左边菜单中打开System Settings -> Software and Updates工具,并检查所有Ubuntu软件和其他软件库(Canonical 的合作伙伴所提供),点击关闭按钮并等待重新加载缓存源树。
|
||||
|
||||

|
||||
Software Updates
|
||||
|
||||
*软件更新*
|
||||
|
||||

|
||||
Other Software (Canonical Partners)
|
||||
|
||||
经过一系列快速平滑的更新过程之后,打开终端并输入以下命令来让系统使用新软件库:
|
||||
*其它软件(Canonical 合作伙伴)*
|
||||
|
||||
为了快速而顺畅的更新,打开终端并输入以下命令来让系统使用新软件库:
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get upgrade
|
||||
|
||||

|
||||
Ubuntu Upgrade
|
||||
|
||||
*Ubuntu 升级*
|
||||
|
||||
### 2. 安装额外驱动 ###
|
||||
|
||||
为了能让系统扫描并安装额外的硬件专有驱动,我们依然从System Settings打开Software and Updates工具,选择Additional Drivers标签并等待该工具扫描驱动。
|
||||
|
||||
如果有驱动匹配到了你的硬件,查看你想要安装的驱动并点击Apply按钮来安装它,以防专有驱动没有如期工作,用Revert按钮就能卸载它们或勾选Do not use the device后点击Apply按钮。
|
||||
如果有驱动匹配到了你的硬件,查看你想要安装的驱动并点击Apply按钮来安装它。如果专有驱动没有如预期的工作,用Revert按钮就能卸载它们或勾选Do not use the device后点击Apply按钮。
|
||||
|
||||

|
||||
Install Drivers
|
||||
|
||||
*安装驱动*
|
||||
|
||||
### 3. 安装Synaptic和Gdebi工具 ###
|
||||
|
||||
除了Ubuntu Software Center,Synaptic是一个apt图形化工具,通过它你能管理、安装、卸载、搜索和升级软件库并配置软件包。同样的,Gdebi在功能上也有相同的地方。在终端上输入以下命令来安装这两个包:
|
||||
除了Ubuntu Software Center之外,Synaptic也是一个apt的图形化工具,通过它你能管理、安装、卸载、搜索和升级软件库并配置软件包。同样的,Gdebi对本地的.deb 包也有类似功能。在终端上输入以下命令来安装这两个包:
|
||||
|
||||
$ sudo apt-get install synaptic gdebi
|
||||
|
||||

|
||||
Install Synaptic and Gdebi
|
||||
|
||||
*安装 Synaptic 和 Gdebi*
|
||||
|
||||

|
||||
Synaptic Package Manager
|
||||
|
||||
### 4. 更改系统外观和运行状态 ###
|
||||
*Synaptic 包管理器*
|
||||
|
||||
如果你想要更改桌面背景或图标大小,依次打开System Settings –> Appearance –> Look并对桌面进行个性化设置,把菜单移动到窗口标题栏,在Behavior标签中启动workspaces和desktop icons或开关auto-hide the Launcher。
|
||||
### 4. 更改系统外观和行为 ###
|
||||
|
||||
如果你想要更改桌面背景或图标大小,依次打开System Settings –> Appearance –> Look,并对桌面进行个性化设置。要把菜单移动到窗口标题栏,在Behavior标签中设置即可。
|
||||
|
||||

|
||||
System Appearances
|
||||
|
||||
*系统外观*
|
||||
|
||||
### 5. 提升系统安全性和隐私性 ###
|
||||
|
||||

|
||||
System Security Enhancement
|
||||
|
||||
*增强系统安全*
|
||||
|
||||

|
||||
System Security Options
|
||||
|
||||
*系统安全选项*
|
||||
|
||||
### 6. 禁用不需要开机自启动的应用程序 ###
|
||||
|
||||
要提高登录系统的速度,通过输入以下命令来显示被隐藏的开机启动应用程序,在Dash中搜索它就能打开Startup Applications工具并反选不需要再登录系统的过程中启动的程序。
|
||||
要提高登录系统的速度,通过输入以下命令来显示被隐藏的开机启动应用程序。
|
||||
|
||||
$ sudo sed -i ‘s/NoDisplay=true/NoDisplay=false/g’ /etc/xdg/autostart/*.desktop
|
||||
$ sudo sed -i 's/NoDisplay=true/NoDisplay=false/g' /etc/xdg/autostart/*.desktop
|
||||
|
||||
在Dash中搜索打开Startup Applications工具,并反选不需要在登录系统的过程中启动的程序。
|
||||
|
||||

|
||||
Disable Unwanted Applications
|
||||
|
||||
*禁用不需要的应用程序*
|
||||
|
||||
### 7. 添加扩展多媒体支持 ###
|
||||
|
||||
@ -88,50 +101,54 @@ Disable Unwanted Applications
|
||||
$ sudo apt-get install vlc smplayer audacious qmmp mixxx xbmc handbrake openshot
|
||||
|
||||

|
||||
Install Media Players
|
||||
|
||||
*安装媒体播放器*
|
||||
|
||||

|
||||
Media Player Playlist
|
||||
|
||||
除了多媒体播放器,安装ubuntu-restricted-extras和Java支持包也可以解码并支持其它受约束的多媒体格式。
|
||||
*媒体播放器的播放列表*
|
||||
|
||||
除了多媒体播放器,安装ubuntu-restricted-extras和Java支持包也可以解码并支持其它受限制的多媒体格式。
|
||||
|
||||
$ sudo apt-get install ubuntu-restricted-extras openjdk-8-jdk
|
||||
|
||||

|
||||
Install Ubuntu Extras
|
||||
|
||||
在终端上输入以下命令来启用DVD Playback和其它多媒体解码器:
|
||||
*安装 Ubuntu Extras*
|
||||
|
||||
在终端上输入以下命令来启用DVD 回放和其它多媒体解码器:
|
||||
|
||||
$ sudo apt-get install ffmpeg gstreamer0.10-plugins-bad lame libavcodec-extra
|
||||
$ sudo /usr/share/doc/libdvdread4/install-css.sh
|
||||
|
||||

|
||||
Enable Video Codes
|
||||
|
||||
### 8. 安装图像处理应用程序 ###
|
||||
*启用视频解码器*
|
||||
|
||||
### 8. 安装图像处理应用程序和安装媒体烧录软件 ###
|
||||
|
||||
如果你是一个摄影爱好者,想在Ubuntu上处理调整图像,或许需要安装一下图像处理程序:
|
||||
|
||||
- GIMP (alternative for Adobe Photoshop)
|
||||
- GIMP (一个 Adobe Photoshop 替代品)
|
||||
- Darktable
|
||||
- Rawtherapee
|
||||
- Pinta
|
||||
- Shotwell
|
||||
- Inkscape (alternative for Adobe Illustrator)
|
||||
- Inkscape (一个 Adobe Illustrator 替代品)
|
||||
- Digikam
|
||||
- Cheese
|
||||
|
||||
这些应用程序能从Ubuntu Software Center中安装或者立刻在终端上使用以下命令:
|
||||
这些应用程序能从Ubuntu Software Center中安装,或者立刻在终端上使用以下命令:
|
||||
|
||||
$ sudo apt-get install gimp gimp-plugin-registry gimp-data-extras darktable rawtherapee pinta shotwell inkscape
|
||||
|
||||

|
||||
Install Image Applications
|
||||
|
||||
*安装图像处理应用程序*
|
||||
|
||||

|
||||
Rawtherapee Tool
|
||||
|
||||
### 9. 安装媒体烧录软件 ###
|
||||
*Rawtherapee Tool*
|
||||
|
||||
如果要挂载ISO镜像或烧录一张CD或DVD,你可以选择并安装以下软件中的一款:
|
||||
|
||||
@ -146,18 +163,20 @@ Rawtherapee Tool
|
||||
$ sudo apt-get install furiusisomount
|
||||
|
||||

|
||||
Install Media Burners
|
||||
|
||||
### 10. 安装压缩应用程序 ###
|
||||
*安装媒体烧录软件*
|
||||
|
||||
### 9. 安装压缩应用程序 ###
|
||||
|
||||
如果要处理大多数归档格式的文件(zip, tar.gz, zip, 7zip rar等等),输入以下命令来安装这些包:
|
||||
|
||||
$ sudo apt-get install unace unrar zip unzip p7zip-full p7zip-rar sharutils rar uudeview mpack arj cabextract file-roller
|
||||
|
||||

|
||||
Install Archive Applications
|
||||
|
||||
### 11. 安装聊天应用程序 ###
|
||||
*安装压缩应用程序*
|
||||
|
||||
### 10. 安装聊天应用程序 ###
|
||||
|
||||
如果你想要和世界各地的人们聊天,这里有一份最流行的Linux聊天应用程序列表:
|
||||
|
||||
@ -179,14 +198,16 @@ Install Archive Applications
|
||||
$ sudo apt-get install telegram
|
||||
|
||||

|
||||
Install Chat Applications
|
||||
|
||||
想要在Ubuntu上安装Viber可以访问[Viber官方网站][1]下载Debian安装包到本地并用Gdebi包管理工具来安装viber.deb应用程序(右击 –> 打开 -> GDebi Package Installer).
|
||||
*安装聊天应用程序*
|
||||
|
||||
想要在Ubuntu上安装Viber可以访问[Viber官方网站][1]下载Debian安装包到本地,并用Gdebi包管理工具来安装viber.deb应用程序(右击 –> 打开 -> GDebi Package Installer).
|
||||
|
||||

|
||||
Install Viber
|
||||
|
||||
### 12. 安装种子软件 ###
|
||||
*安装 Viber*
|
||||
|
||||
### 11. 安装种子软件 ###
|
||||
|
||||
在Ubuntu最流行的种子应用程序和P2P文件共享程序是:
|
||||
|
||||
@ -203,77 +224,90 @@ Install Viber
|
||||
$ sudo apt-get install linuxdcpp
|
||||
|
||||

|
||||
Install Torrent
|
||||
|
||||
### 13. 安装Windows仿真器-Wine和游戏支持平台-Steam ###
|
||||
*安装种子软件*
|
||||
|
||||
Wine仿真器允许你在Linux上安装并运行Window应用程序。在另一方面,Steam是一款Valve开发的流行于Linux系统的游戏平台。想要在你的机器上安装它们,可以输入以下命令或使用Ubuntu Software Center。
|
||||
### 12. 安装Windows仿真器-Wine和游戏支持平台-Steam ###
|
||||
|
||||
Wine仿真器允许你在Linux上安装并运行Window应用程序。在另一方面,Steam是一款Valve开发的基于Linux系统的流行游戏平台。想要在你的机器上安装它们,可以输入以下命令或使用Ubuntu Software Center。
|
||||
|
||||
$ sudo apt-get install steam wine winetricks
|
||||
|
||||

|
||||
Install Wine
|
||||
|
||||
### 14. 安装Cairo-Dock并启用桌面视觉效果 ###
|
||||
*安装 Wine*
|
||||
|
||||
### 13. 安装Cairo-Dock并启用桌面视觉效果 ###
|
||||
|
||||
Cairo-Dock是一款漂亮且灵巧的用于Linux桌面上的启动条,类似于Mac OS X dock。想要在Ubuntu上安装它,可以在终端上运行以下命令:
|
||||
|
||||
$ sudo apt-get install cairo-dock cairo-dock-plug-ins
|
||||
|
||||

|
||||
Install Cairo Dock
|
||||
|
||||
*安装Cairo-Dock*
|
||||
|
||||

|
||||
Add Cairo Dock at Startup
|
||||
|
||||
*让 Cairo Dock 自动启动*
|
||||
|
||||
想要启用某一套桌面效果,例如Cube效果,可以使用以下命令来安装Compiz包:
|
||||
|
||||
$ sudo apt-get install compiz compizconfig-settings-manager compiz-plugins-extra
|
||||
|
||||
想要激活桌面Cube效果,在Dash上查找ccsm,打开CompizConfig Settings Manager,找到General Options – > Desktop Size并设置Horizontal Virtual Size的值为4,Vertical Virtual Size的值为1。然后返回检查Desktop Cube框(禁用Desktop Wall)和Rotate Cube框(解决冲突 -> 禁止切换视图1)并Ctrl+Alt+鼠标左击来查看cube效果。
|
||||
想要激活桌面Cube效果,在Dash上查找ccsm来打开CompizConfig Settings Manager,找到General Options – > Desktop Size并设置Horizontal Virtual Size的值为4,Vertical Virtual Size的值为1。然后返回检查Desktop Cube框(禁用Desktop Wall)和Rotate Cube框(解决冲突 -> 禁止切换视图1)并Ctrl+Alt+鼠标左击来查看cube效果。
|
||||
|
||||

|
||||
Enable Compiz
|
||||
|
||||
*启用Compiz*
|
||||
|
||||

|
||||
Compiz Settings
|
||||
|
||||
*Compiz设置*
|
||||
|
||||

|
||||
Compiz Settings Addons
|
||||
|
||||
*Compiz设置插件*
|
||||
|
||||

|
||||
Desktop Window Rotating
|
||||
|
||||
### 15. 添加额外浏览器支持 ###
|
||||
*桌面窗口旋转*
|
||||
|
||||
### 14. 添加其它浏览器 ###
|
||||
|
||||
Ubuntu 15.04默认浏览器是Mozilla Firefox。想要安装其它浏览器比如Google Chrome或Opera,可以访问它们的官方网站,下载所提供的.deb包并用Gdebi Package Installer在你的系统上安装它们。
|
||||
|
||||

|
||||
Enable Browser Support
|
||||
|
||||
*启用浏览器支持*
|
||||
|
||||

|
||||
Opera Browser Support
|
||||
|
||||
*Opera Browser*
|
||||
|
||||
想要安装Chromium开源浏览器请在终端上输入以下命令:
|
||||
|
||||
$ sudo apt-get install chromium-browser
|
||||
|
||||
### 16. 安装Tweak工具 ###
|
||||
### 15. 安装Tweak工具 ###
|
||||
|
||||
想要用额外的应用程序来自定义Ubuntu吗?在终端上输入以下命令来安装Unity Tweak工具和Gnome Tweak工具:
|
||||
|
||||
$ sudo apt-get install unity-tweak-tool gnome-tweak-tool
|
||||
|
||||

|
||||
Install Tweak Tool
|
||||
|
||||
*安装Tweak Tool*
|
||||
|
||||

|
||||
Tweak Tool Settings
|
||||
|
||||
另一个有趣的tweak工具主要是Ubuntu Tweak包,可以通过访问官方网站来获取并安装: [http://ubuntu-tweak.com/][2].
|
||||
*Tweak Tool 设置*
|
||||
|
||||
另一个有趣的tweak工具主要是Ubuntu Tweak包,可以通过访问官方网站来获取并安装: [http://ubuntu-tweak.com/][2]。
|
||||
|
||||

|
||||
Tweak Tool: System Information
|
||||
|
||||
*Tweak Tool: 系统信息*
|
||||
|
||||
在你安装好这一连串软件之后,你或许想要清理一下你的系统来释放一点硬盘上的空间,输入以下命令即可:
|
||||
|
||||
@ -281,7 +315,7 @@ Tweak Tool: System Information
|
||||
$ sudo apt-get -y autoclean
|
||||
$ sudo apt-get -y clean
|
||||
|
||||
这只是tweaks工具中的其中一些和普通用户日常生活中可能会在Ubuntu 15.04桌面上安装使用的程序。想要了解更多高级的程序,特性和功能,请使用Ubuntu Software Center或查阅Ubuntu Wiki主页。
|
||||
这只是一些普通用户日常使用Ubuntu 15.04桌面是需要调整和安装的程序。想要了解更多高级的程序,特性和功能,请使用Ubuntu Software Center或查阅Ubuntu Wiki主页。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -289,7 +323,7 @@ via: http://www.tecmint.com/things-to-do-after-installing-ubuntu-15-04-desktop/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,30 +1,31 @@
|
||||
如何在 CentOS 中设置 NTP 服务器
|
||||
================================================================================
|
||||
网络时间协议(NTP)用来同步网络上不同主机的系统时间。所有托管的主机都可以和一个指定的被称为 NTP 服务器的时间服务器同步它们的时间。另一方面一个 NTP 服务器将它的时间和任何公共 NTP 服务器,或者你选定的服务器同步。NTP 托管的所有系统时钟都同步精确到毫秒级。
|
||||
|
||||
在一个协作环境中,如果他们不想为 NTP 传输打开防火墙,就有必要设置一个内部 NTP 服务器,然后让员工使用内部服务器而不是公共 NTP 服务器。在这个指南中,我们会介绍如何将一个 CentOS 系统配置为 NTP 服务器。在介绍详细内容之前,让我们先来简单了解一下 NTP 的概念。
|
||||
网络时间协议(NTP)用来同步网络上不同主机的系统时间。你管理的所有主机都可以和一个指定的被称为 NTP 服务器的时间服务器同步它们的时间。而另一方面,一个 NTP 服务器会将它的时间和任意公共 NTP 服务器,或者你选定的服务器同步。由 NTP 管理的所有系统时钟都会同步精确到毫秒级。
|
||||
|
||||
在公司环境中,如果他们不想为 NTP 传输打开防火墙,就有必要设置一个内部 NTP 服务器,然后让员工使用内部服务器而不是公共 NTP 服务器。在这个指南中,我们会介绍如何将一个 CentOS 系统配置为 NTP 服务器。在介绍详细内容之前,让我们先来简单了解一下 NTP 的概念。
|
||||
|
||||
### 为什么我们需要 NTP? ###
|
||||
|
||||
由于制造工艺多种多样,所有的(非原子)时钟并不按照完全一致的速度行走。有一些时钟走的比较快而有一些走的比较慢。因此经过很长一段时间以后,一个时钟的时间慢慢的偏移于其它,导致有名的 “时钟漂移” 或 “时间漂移”。为了最小化时钟漂移的影响,使用 NTP 的主机应该周期性地和指定的 NTP 服务器交互以保持它们的时钟同步。
|
||||
由于制造工艺多种多样,所有的(非原子)时钟并不按照完全一致的速度行走。有一些时钟走的比较快而有一些走的比较慢。因此经过很长一段时间以后,一个时钟的时间慢慢的和其它的发生偏移,这就是常说的 “时钟漂移” 或 “时间漂移”。为了将时钟漂移的影响最小化,使用 NTP 的主机应该周期性地和指定的 NTP 服务器交互以保持它们的时钟同步。
|
||||
|
||||
在不同的主机之间进行时间同步对于计划备份、[干扰检测][1]日志、[分布式任务调度][2]或者事务订单管理来说是很重要的事情。它甚至可能要求作为日常任务的一部分。
|
||||
在不同的主机之间进行时间同步对于计划备份、[入侵检测][1]记录、[分布式任务调度][2]或者事务订单管理来说是很重要的事情。它甚至应该作为日常任务的一部分。
|
||||
|
||||
### NTP 层次 ###
|
||||
### NTP 的层次结构 ###
|
||||
|
||||
NTP 时钟以层次模型组织。层级中的每层被称为一个 *stratum*。stratum 的概念说明了一台机器到授权的时间源有多少 NTP 跳。
|
||||
NTP 时钟以层次模型组织。层级中的每层被称为一个 *stratum(阶层)*。stratum 的概念说明了一台机器到授权的时间源有多少 NTP 跳。
|
||||
|
||||
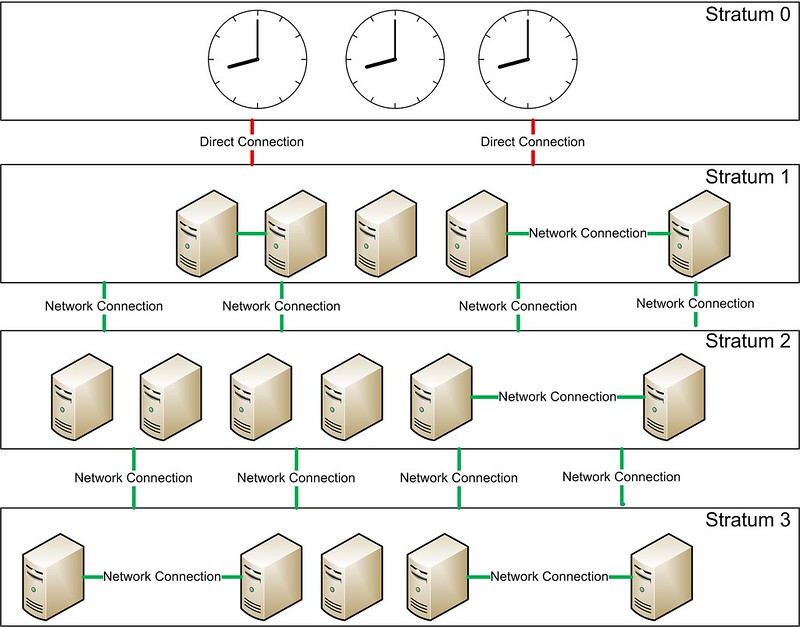
|
||||
|
||||
Stratum 0 由没有时间漂移的时钟组成,例如原子时钟。这种时钟不能在网络上直接使用。Stratum N (N > 1) 层服务器从 Stratum N-1 层服务器同步时间。Stratum N 时钟可能通过网络和彼此互联。
|
||||
Stratum 0 由没有时间漂移的时钟组成,例如原子时钟。这种时钟不能在网络上直接使用。Stratum N (N > 1) 层服务器从 Stratum N-1 层服务器同步时间。Stratum N 时钟能通过网络和彼此互联。
|
||||
|
||||
NTP 支持多达 15 stratums 的层级。Stratum 16 被认为是没有同步不能使用的。
|
||||
NTP 支持多达 15 个 stratum 的层级。Stratum 16 被认为是未同步的,不能使用的。
|
||||
|
||||
### 准备 CentOS 服务器 ###
|
||||
|
||||
现在让我们来开始在 CentOS 上设置 NTP 服务器。
|
||||
|
||||
首先,我们需要保证正确设置了服务器的时区。在 CentOS 7 中,我们可以使用 timedatectl 命令查看和更改服务器的时区(比如,"Australia/Adelaide")
|
||||
首先,我们需要保证正确设置了服务器的时区。在 CentOS 7 中,我们可以使用 timedatectl 命令查看和更改服务器的时区(比如,"Australia/Adelaide",LCTT 译注:中国可设置为 Asia/Shanghai )
|
||||
|
||||
# timedatectl list-timezones | grep Australia
|
||||
# timedatectl set-timezone Australia/Adelaide
|
||||
@ -56,7 +57,7 @@ NTP 支持多达 15 stratums 的层级。Stratum 16 被认为是没有同步不
|
||||
# chown ntp:ntp /var/log/ntpd.log
|
||||
# chcon -t ntpd_log_t /var/log/ntpd.log
|
||||
|
||||
现在初始化 NTP 服务并确保把它添加到了随机启动。
|
||||
现在初始化 NTP 服务并确保把它添加到了开机启动。
|
||||
|
||||
# systemctl restart ntp
|
||||
# systemctl enable ntp
|
||||
@ -69,19 +70,18 @@ NTP 支持多达 15 stratums 的层级。Stratum 16 被认为是没有同步不
|
||||
|
||||
下面的表格解释了输出列。
|
||||
|
||||
注:表格
|
||||
<table id="content">
|
||||
<tbody><tr>
|
||||
<td>remote</td>
|
||||
<td>源在 ntp.conf 中定义。‘*’ 表示当前使用的最好的源;‘+’ 表示可作为 NTP 源的源;‘-’ 标记的源是不可用的。</td>
|
||||
<td>源在 ntp.conf 中定义。‘*’ 表示当前使用的,也是最好的源;‘+’ 表示这些源可作为 NTP 源;‘-’ 标记的源是不可用的。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>refid</td>
|
||||
<td>和远程服务器时钟同步的时钟的 IP 地址。</td>
|
||||
<td>用于和本地时钟同步的远程服务器的 IP 地址。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>st</td>
|
||||
<td>Stratum</td>
|
||||
<td>Stratum(阶层)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>t</td>
|
||||
@ -89,15 +89,15 @@ NTP 支持多达 15 stratums 的层级。Stratum 16 被认为是没有同步不
|
||||
</tr>
|
||||
<tr>
|
||||
<td>when</td>
|
||||
<td>自从上次和服务器交互经过的时间(以秒数计)。</td>
|
||||
<td>自从上次和服务器交互后经过的时间(以秒数计)。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>poll</td>
|
||||
<td>和服务器的轮询频率,以秒数计。</td>
|
||||
<td>和服务器的轮询间隔,以秒数计。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>reach</td>
|
||||
<td>表示和服务器交互是否有任何错误的十进制数。值 337 表示 100% 成功。</td>
|
||||
<td>表示和服务器交互是否有任何错误的八进制数。值 337 表示 100% 成功(即十进制的255)。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>delay</td>
|
||||
@ -109,7 +109,7 @@ NTP 支持多达 15 stratums 的层级。Stratum 16 被认为是没有同步不
|
||||
</tr>
|
||||
<tr>
|
||||
<td>jitter</td>
|
||||
<td>两个例子之间平局时间差异,以毫秒数计。</td>
|
||||
<td>两次取样之间平均时差,以毫秒数计。</td>
|
||||
</tr>
|
||||
</tbody></table>
|
||||
|
||||
@ -120,13 +120,13 @@ NTP 支持多达 15 stratums 的层级。Stratum 16 被认为是没有同步不
|
||||
# iptables -A INPUT -s 192.168.1.0/24 -p udp --dport 123 -j ACCEPT
|
||||
# iptables -A INPUT -p udp --dport 123 -j DROP
|
||||
|
||||
该规则允许从 192.168.1.0/24 来的 NTP 流量(端口 UDP/123),任何其它网络的流量会被截停。你可以根据需要更改规则。
|
||||
该规则允许从 192.168.1.0/24 来的 NTP 流量(端口 UDP/123),任何其它网络的流量会被丢弃。你可以根据需要更改规则。
|
||||
|
||||
### 配置 NTP 客户端 ###
|
||||
|
||||
#### 1. Linux ####
|
||||
|
||||
NTP 客户端主机需要 ntpupdate 软件包和服务器同步时间。可以轻松地使用 yum 或 apt-get 安装这个软件包。安装完软件包之后,用服务器的 IP 地址运行下面的命令。
|
||||
NTP 客户端主机需要 ntpupdate 软件包来和服务器同步时间。可以轻松地使用 yum 或 apt-get 安装这个软件包。安装完软件包之后,用服务器的 IP 地址运行下面的命令。
|
||||
|
||||
# ntpdate <server-IP-address>
|
||||
|
||||
@ -138,17 +138,17 @@ NTP 客户端主机需要 ntpupdate 软件包和服务器同步时间。可以
|
||||
|
||||
#### 3. Cisco 设备 ####
|
||||
|
||||
如果你想和 Cisco 设备同步时间,你可以在全局配置模式下使用下面的命令。
|
||||
如果你想要同步 Cisco 设备的时间,你可以在全局配置模式下使用下面的命令。
|
||||
|
||||
# ntp server <server-IP-address>
|
||||
|
||||
其它有支持 NTP 的卖家有自己的参数用于网络时间。如果你想将设备和 NTP服务器同步时间,请查看设备的说明文档。
|
||||
来自其它厂家的支持 NTP 的设备有自己的用于网络时间的参数。如果你想将设备和 NTP服务器同步时间,请查看设备的说明文档。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
总而言之,NTP 是在你的所有主机上同步时钟的一个协议。我们已经介绍了如何设置 NTP 服务器并使支持 NTP 的设备和服务器同步时间。
|
||||
|
||||
希望能对你有所帮助
|
||||
希望能对你有所帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -156,7 +156,7 @@ via: http://xmodulo.com/setup-ntp-server-centos.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,65 +1,63 @@
|
||||
如何用mod_jk连接器来集成Apache2和Tomcat 7
|
||||
================================================================================
|
||||
Apache是最流行的web服务器。通常用来接收客户端的请求并响应。它得到一个URL并将它翻译成一个文件名(或者静态请求),并将文件从本地磁盘中通过因特网返回,或者将它翻译成程序名执行它,接着将输出返回给请求方。如果web服务器不能处理和完成请求,它会返回一个错误信息。
|
||||
Apache是最流行的web服务器,它通常用来接收客户端的请求并响应。它得到一个URL并将它翻译成一个文件名(或者静态请求),并将文件从本地磁盘中取出,通过因特网返回;或者将它翻译成程序执行它,接着将输出返回给请求方。如果web服务器不能处理和完成请求,它会返回一个错误信息。
|
||||
|
||||
在本篇中,我们会列出Apache的特性以及我们该如何用mod_jk连接器来集成Tomcat7和Tomcat8.
|
||||
在本篇中,我们会列出Apache的特性以及我们该如何用mod\_jk连接器来集成Tomcat 7和Tomcat 8.
|
||||
|
||||
### Apache的特性 ###
|
||||
|
||||
如我们所说Apache是最流行的web服务器。下面是流行背后的原因:
|
||||
|
||||
- 它是自由工具,你可以很简单地下载和安装
|
||||
- 它开放源码因此你可以查看源码,调整它,优化它,并且修复错误和安全漏洞。也可以增加新的功能和模块。
|
||||
- 它开放源码,因此你可以查看源码,调整它,优化它,并且修复错误和安全漏洞。也可以增加新的功能和模块。
|
||||
- 它可以用在只有一两个页面的小网站,或者是有成千上万个页面的大网站,每月处理上百万的常规访问者的请求。它可以同时处理静态和动态内容。
|
||||
- 提高的缓存模块(mod_cache、 mod_disk_cache、 mod_mem_cache)。
|
||||
- 改进的缓存模块(mod\_cache、 mod\_disk\_cache、 mod\_mem\_cache)。
|
||||
- Apache 2 支持 IPv6.
|
||||
|
||||
### Tomcat 目录 ###
|
||||
### Tomcat 的目录 ###
|
||||
|
||||
${tomcat_home} 是tomcat的根目录。你的tomcat安装应该有下面的子目录:
|
||||
|
||||
- ${tomcat_home}\conf – 存放不同配置文件的地方
|
||||
- ${tomcat_home}\webapps – 包含示例程序
|
||||
- ${tomcat_home}\bin – 存放插件的地方
|
||||
- ${tomcat_home}\bin – 存放你的Web服务器的插件的地方
|
||||
|
||||
### Mod_jk 模块 ###
|
||||
|
||||
mod_jk有两种可接受的方式:二进制或者源码。取决于你运行的web服务器的平台,二进制版本的mod_jk也许可以找到。如果有二进制版本的话建议使用这个。
|
||||
mod\_jk有两种可接受的方式:二进制或者源码。取决于你运行的web服务器的平台,也许有符合你的平台的二进制版本的mod\_jk。如果有的话建议使用这个。
|
||||
|
||||
mod_jk模块在这些平台上开发及测试过:
|
||||
mod\_jk模块在这些平台上开发及测试过:
|
||||
|
||||
- Linux、 FreeBSD、 AIX、 HP-UX、 MacOS X、 Solaris ,应该在主流的Unix平台上都支持Apache 1.3 和/或者 2.x。
|
||||
- 0-i386 SP4/SP5/SP6a (应该可以于其他的服务包一起工作), Win2K and WinXP and Win98
|
||||
- Linux、 FreeBSD、 AIX、 HP-UX、 MacOS X、 Solaris ,应该在主流的支持Apache 1.3 和/或者 2.x的Unix平台上都工作。
|
||||
- WinNT 4.0-i386 SP4/SP5/SP6a (应该可以与其他的服务包一起工作), Win2K 和 WinXP 和 Win98
|
||||
- Cygwin (需要你有apache服务器及autoconf/automake支持工具)
|
||||
- Netware
|
||||
- i5/OS V5R4 (System I) 中的 Apache HTTP Server 2.0.58。 确保已经安装了Apache PTF
|
||||
- Tomcat 3.2 到 Tomcat 8.
|
||||
- i5/OS V5R4 (System I) ,带有 Apache HTTP Server 2.0.58。 确保已经安装了最新的 Apache PTF
|
||||
- Tomcat 3.2 到 Tomcat 8
|
||||
|
||||
The mod_jk 需要两个组件:
|
||||
The mod\_jk 需要两个组件:
|
||||
|
||||
- **mod_jk.xxx** – Apache HTTP服务器模块,取决于你的操作系统,它可能是mod_jk.so、mod_jk.nlm或者MOD_JK.SRVPGM。
|
||||
- **workers.properties** - 描述主机以及处理器使用的端口(Tomcat进程)。在下载的源码内可以在conf目录下找到workers.properties文件。
|
||||
- **mod\_jk.xxx** – Apache HTTP服务器模块,取决于你的操作系统,它可能是mod\_jk.so、mod\_jk.nlm或者mod\_jk.SRVPGM。
|
||||
- **workers.properties** - 描述Worker (Tomcat进程)所用的主机以及处理器使用的端口。在下载的源码的conf目录下找到示例的workers.properties文件。
|
||||
|
||||
和Apache HTTP服务器其他的模块一样,mod_jk应该安装在你的Apache服务器下的模块目录下:/usr/lib/apache,你应该更新你的**httpd.conf**文件。
|
||||
和Apache HTTP服务器其他的模块一样,mod\_jk应该安装在你的Apache服务器下的模块目录下:/usr/lib/apache,而且你应该更新你的**httpd.conf**文件。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
它需要非root用户在安装钱使用“sudo”特权。现在我们开始安装,我们将使用下面的命令来安装Apache2和Tomcat:
|
||||
在开始安装前,非root用户需要使用“sudo”特权。现在我们开始安装,我们将使用下面的命令来安装Apache2和Tomcat:
|
||||
|
||||
sudo apt-get install apache2
|
||||
|
||||
sudo apt-get install apache2
|
||||
sudo apt-get install tomcat7
|
||||
|
||||
sudo apt-get install tomcat7-admin
|
||||
|
||||
下面在我们将会使用下面的命令来创建一个测试程序:
|
||||
下面,我们将会使用如下的命令来创建一个测试程序:
|
||||
|
||||
cd /var/lib/tomcat7/webapps
|
||||
sudo mkdir tomcat-demo
|
||||
sudo mkdir tomcat-demo/goodmoring
|
||||
sudo vim tomcat-demo/helloworld/index.jsp
|
||||
|
||||
粘贴下面的代码:
|
||||
并粘贴下面的代码到上述的 index.jsp:
|
||||
|
||||
<HTML>
|
||||
<HEAD>
|
||||
@ -71,19 +69,19 @@ The mod_jk 需要两个组件:
|
||||
</BODY>
|
||||
</HTML>
|
||||
|
||||
一切完毕后,我们将使用下面的命令安装和配置mod_jk:
|
||||
一切完毕后,我们将使用下面的命令安装和配置mod\_jk:
|
||||
|
||||
sudo apt-get install libapache2-mod-jk
|
||||
|
||||
我们将使用下面的命令启用Tomcat的8443转发端口:
|
||||
我们需要使用下面的命令启用Tomcat的8443转发端口:
|
||||
|
||||
sudo vim /etc/tomcat7/server.xml
|
||||
|
||||
我们将解除下面的注释行:
|
||||
解除下面的注释行:
|
||||
|
||||
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
|
||||
|
||||
之后,我们将用下面的命令位Apache创建workers.properties文件:
|
||||
之后,我们将用下面的命令为Apache创建workers.properties文件:
|
||||
|
||||
sudo vim /etc/apache2/workers.properties
|
||||
|
||||
@ -123,7 +121,7 @@ The mod_jk 需要两个组件:
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本篇中我们展示了你该如何使用mod_jk连接器配置和安装Apache2以及Tomcat7。
|
||||
在本篇中我们展示了你该如何使用mod\_jk连接器配置和安装Apache2以及Tomcat7。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -131,7 +129,7 @@ via: http://www.unixmen.com/integrate-apache2-tomcat-7-using-mod_jk-connector/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
|
||||
KDE Plasma 5.3已发布,Kubuntu 15.04升级攻略
|
||||
在 Kubuntu 15.04 中升级 KDE Plasma 5.3
|
||||
================================================================================
|
||||
**KDE[已经宣布][1]Plasma 5.3的稳定版已经准备就绪,它包含了一个新的电源管理方面的稳定特性。**
|
||||
**KDE[已经发布了][1]Plasma 5.3的稳定版,它包含了一个新的电源管理方面的稳定特性。**
|
||||
|
||||
[先前四月份的beta版][2]已经让我们印象深刻,甚至跃跃欲试了,Plasma 5桌面环境的稳定版更新的最新更新已经稳定,并且可以下载了。
|
||||
|
||||
@ -10,7 +9,8 @@ Plasma 5.3继续改善和细化了全新的KDE桌面,它添加了大量的特
|
||||
### Plasma 5.3中的新东西 ###
|
||||
|
||||
|
||||
Plasma 5.3中更好的蓝牙管理
|
||||
|
||||
*Plasma 5.3中更好的蓝牙管理*
|
||||
|
||||
而[在早期关于Plasma 5.3的文章][3]中,我们触及了大量**新特性**,这其中很多都值得反复说道说道。
|
||||
|
||||
@ -18,19 +18,21 @@ Plasma 5.3中更好的蓝牙管理
|
||||
|
||||
在连接了外部监视器的时候合上笔记本盖子时,不会再触发‘挂起’操作。这个新的行为被称之为‘**影院模式**’,并且默认开启。但是,可以通功过电源管理设置中的相关选项禁用。
|
||||
|
||||
**蓝牙功能被改善**,带来了一个全新的面板小程序,使得在连接到并配置配对的蓝牙设备,如只能手机、键盘和扬声器时,比以往更为便捷。
|
||||
**蓝牙功能被改善**,带来了一个全新的面板小程序,使得在连接到并配置配对的蓝牙设备,如智能手机、键盘和扬声器时,比以往更为便捷。
|
||||
|
||||
同样,对于Plasma 5.3,**KDE中的轨迹板配置更为方便**,这多亏了新的安装和设置模块。
|
||||
|
||||
|
||||
轨迹板、触控板。Tomato, Tomayto。
|
||||
|
||||
对于Plasma小部件狂热者,带来了一个**按住并锁定**手势。当启用该功能,会隐藏移动鼠标时出现的设置处理。取而代之的是,它只会在长点击小部件时发生该行为。
|
||||
*轨迹板、触控板。Tomato, Tomayto。*
|
||||
|
||||
谈到widget-y这类事情时,该发布版中**再次引入了几个旧的Plasmoid最受欢迎的东西**,包括一个有用的系统监视器、便利的硬盘驱动器统计和一个漫画阅读器。
|
||||
对于Plasma小部件狂热者,它带来了一个**按住并锁定**手势。当启用该功能,会隐藏移动鼠标时出现的设置处理。取而代之的是,它只会在长点击小部件时发生该行为。
|
||||
|
||||
谈到widget-y这类事情时,该发布版中**再次引入了几个旧的Plasmoid中最受欢迎的东西**,包括一个有用的系统监视器、便利的硬盘驱动器统计和一个漫画阅读器。
|
||||
|
||||
### 了解更多&尝试 ###
|
||||
|
||||

|
||||
|
||||
|
||||
一张全部内容的完整列表——我说全部内容——是指Plasma 5.3中[在官方修改日志中][4]列出的新的和改进的内容。
|
||||
|
||||
@ -40,7 +42,7 @@ Plasma 5.3中更好的蓝牙管理
|
||||
|
||||
如果你需要超级稳定的系统,你可以使用这些镜像来尝试新特性,但是你可以继续使用你的主要计算机上与你的版本对应的KDE版本。
|
||||
|
||||
但是,如果你对实验版满意——请阅:能够处理任何包冲突,或者由尝试升级桌面环境而导致的系统问题——那么你可以安装。
|
||||
不过,如果你对实验版满意——请注意:能够处理任何包冲突,或者由尝试升级桌面环境而导致的系统问题——那么你可以安装。
|
||||
|
||||
### 安装Plasma 5.3到Kubuntu 15.04 ###
|
||||
|
||||
@ -52,20 +54,19 @@ Kubuntu移植PPA可能也会升级除了安装在你系统上的Plasma外的其
|
||||
|
||||
目前为止,使用命令行来升级Kubuntu中的到Plasma 5.3是最快速的方法:
|
||||
|
||||
sudo add-apt-repository ppa:kubuntu-ppa/backports
|
||||
|
||||
sudo add-apt-repository ppa:kubuntu-ppa/backports
|
||||
sudo apt-get update && sudo apt-get dist-upgrade
|
||||
|
||||
在升级过程完成后,如果一切顺利,你应该重启计算机。
|
||||
|
||||
如果你正在使用一个备用桌面环境,比如LXDE、Unity或者GNOME,则你需要在运行完上面的两个命令后安装Kubuntu桌面包(你可以在Ubuntu软件中心找到)。
|
||||
To downgrade to the stock version of Plasma in 15.04 you can use the PPA-Purge tool:
|
||||
|
||||
要降级到15.04中自带的 Plasma 版本的话,你可以使用 PPA-Purge 工具:
|
||||
|
||||
sudo apt-get install ppa-purge
|
||||
|
||||
sudo ppa-purge ppa:kubuntu-ppa/backports
|
||||
|
||||
请在下面的评论中留言,让我们知道你怎么升级/测试过程是怎样的,别忘了告诉我们你在下一个Plasma 5桌面中要看到的特性。
|
||||
请在下面的评论中留言,让我们知道你怎么升级,测试过程是怎样的,别忘了告诉我们你在下一个Plasma 5桌面中要看到的特性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -73,7 +74,7 @@ via: http://www.omgubuntu.co.uk/2015/04/kde-plasma-5-3-released-heres-how-to-upg
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Shell脚本学习初次操作指南
|
||||
Shell脚本编程初体验
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -18,33 +18,33 @@ Linux世界中最为流行的shell脚本语言之一,就是bash。而我认为
|
||||
|
||||
shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象成能帮你做事的那些人,只要你用正确的方式来请求他们去做。比如说,你想要写文档。首先,你需要纸。然后,你需要把内容说给某个人听,让他帮你写。最后,你想要把它存放到某个地方。或者说,你想要造一所房子,因而你需要请合适的人来清空场地。在他们说“事情干完了”,那么另外一些工程师就可以帮你来砌墙。最后,当这些工程师们也告诉你“事情干完了”的时候,你就可以叫油漆工来给房子粉饰了。如果你让油漆工在墙砌好前就来粉饰,会发生什么呢?我想,他们会开始发牢骚了。几乎所有这些像人一样的命令都会说话,如果它们完成了工作而没有发生什么问题,那么它们就会告诉“标准输出”。如果它们不能做你叫它们做的事——它们会告诉“标准错误”。这样,最后,所有的命令都通过“标准输入”来听你的话。
|
||||
|
||||
快速实例——当你打开linux终端并写一些文本时——你正通过“标准输入”和bash说话。那么,让我们来问问bash shell **who am i**吧。
|
||||
快速实例——当你打开linux终端并写一些文本时——你正通过“标准输入”和bash说话。那么,让我们来问问bash shell **who am i(我是谁?)**吧。
|
||||
|
||||
root@localhost ~]# who am i <--- you speaking through the standard input to bash shell
|
||||
root pts/0 2015-04-22 20:17 (192.168.1.123) <--- bash shell answering to you through the standard output
|
||||
root@localhost ~]# who am i <--- 你通过标准输入对 bash shell 说
|
||||
root pts/0 2015-04-22 20:17 (192.168.1.123) <--- bash shell通过标准输出回答你
|
||||
|
||||
现在,让我们说一些bash听不懂的问题:
|
||||
|
||||
[root@localhost ~]# blablabla <--- 哈,你又在和标准输入说话了
|
||||
-bash: blablabla: command not found <--- bash通过标准错误在发牢骚了
|
||||
|
||||
“:”之前的第一个单词通常是向你发牢骚的命令。实际上,这些流中的每一个都有它们自己的索引号:
|
||||
“:”之前的第一个单词通常是向你发牢骚的命令。实际上,这些流中的每一个都有它们自己的索引号(LCTT 译注:文件句柄号):
|
||||
|
||||
- 标准输入(**stdin**) - 0
|
||||
- 标准输出(**stdout**) - 1
|
||||
- 标准错误(**stderr**) - 2
|
||||
|
||||
如果你真的想要知道哪个输出命令说了些什么——你需要重定向(在命令后使用大于号“>”和流索引)那次发言到文件:
|
||||
如果你真的想要知道哪个输出命令说了些什么——你需要将那次发言重定向到(在命令后使用大于号“>”和流索引)文件:
|
||||
|
||||
[root@localhost ~]# blablabla 1> output.txt
|
||||
-bash: blablabla: command not found
|
||||
|
||||
在本例中,我们试着重定向1(**stdout**)流到名为output.txt的文件。让我们来看对该文件内容所做的事情吧,使用cat命令可以做这事:
|
||||
在本例中,我们试着重定向流1(**stdout**)到名为output.txt的文件。让我们来看对该文件内容所做的事情吧,使用cat命令可以做这事:
|
||||
|
||||
[root@localhost ~]# cat output.txt
|
||||
[root@localhost ~]#
|
||||
|
||||
看起来似乎是空的。好吧,现在让我们来重定向2(**stderr**)流:
|
||||
看起来似乎是空的。好吧,现在让我们来重定向流2(**stderr**):
|
||||
|
||||
[root@localhost ~]# blablabla 2> error.txt
|
||||
[root@localhost ~]#
|
||||
@ -77,17 +77,17 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
rm: cannot remove `folder1': Is a directory
|
||||
[root@localhost ~]#
|
||||
|
||||
正如我们所看到的,不同的流被分离到了不同的文件。有时候,这也不似很方便,因为我们想要查看出现错误时,在某些操作前面或后面所连续发生的事情。要实现这一目的,我们可以重定向两个流到同一个文件:
|
||||
正如我们所看到的,不同的流被分离到了不同的文件。有时候,这也不是很方便,因为我们想要查看出现错误时,在某些操作前面或后面所连续发生的事情。要实现这一目的,我们可以重定向两个流到同一个文件:
|
||||
|
||||
command >>out_err.txt 2>>out_err.txt
|
||||
|
||||
注意:请注意,我使用“>>”替代了“>”。它允许我们附加到文件,而不是覆盖文件。
|
||||
|
||||
我们可以重定向一个流到另一个:
|
||||
我们也可以重定向一个流到另一个:
|
||||
|
||||
command >out_err.txt 2>&1
|
||||
|
||||
让我来解释一下吧。所有命令的标准输出将被重定向到out_err.txt,错误输出将被重定向到1-st流(上面已经解释过了),而该流会被重定向到同一个文件。让我们看这个实例:
|
||||
让我来解释一下吧。所有命令的标准输出将被重定向到out_err.txt,错误输出将被重定向到流1(上面已经解释过了),而该流会被重定向到同一个文件。让我们看这个实例:
|
||||
|
||||
[root@localhost ~]# rm -fv folder2 file2 >out_err.txt 2>&1
|
||||
[root@localhost ~]# cat out_err.txt
|
||||
@ -127,7 +127,7 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
|
||||
如果你打算grep一些双引号引起来带有空格的内容呢!
|
||||
|
||||
注意: fdisk命令显示关于Linux操作系统磁盘驱动器的信息
|
||||
注意:fdisk命令显示关于Linux操作系统磁盘驱动器的信息。
|
||||
|
||||
就像我们看到的,这种方式很不方便,因为我们不一会儿就把临时文件空间给搞乱了。要完成该任务,我们可以使用管道。它们允许我们重定向一个命令的**stdout**到另一个命令的**stdin**流:
|
||||
|
||||
@ -147,11 +147,11 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
|
||||
正如我们所知道的,通常,与shell的交流以及shell内的交流是以对话的方式进行的。因此,让我们创建一些真正的脚本吧,这些脚本也会和我们讲话。这会让你学到一些简单的命令,并对脚本的概念有一个更好的理解。
|
||||
|
||||
假设我们是某个公司的总服务台经理,我们想要创建某个shell脚本来注册呼叫信息:电话号码、用户名以及问题的简要描述。我们打算把这些信息存储到普通文本文件data.txt中,以便今后统计。脚本它自己就是以对话的方式工作,这会让总服务台的工作人员的小日子过得轻松点。那么,首先我们需要显示问题。对于现实信息,我们可以用echo和printf命令。这两个都是用来显示信息的,但是printf更为强大,因为我们可以通过它很好地格式化输出,我们可以让它右对齐、左对齐或者为信息留出专门的空间。让我们从一个简单的例子开始吧。要创建文件,请使用你喜欢的文本编辑器(kate,nano,vi,……),然后创建名为note.sh的文件,里面写入这些命令:
|
||||
假设我们是某个公司的总服务台经理,我们想要创建某个shell脚本来注册呼叫信息:电话号码、用户名以及问题的简要描述。我们打算把这些信息存储到普通文本文件data.txt中,以便今后统计。脚本它自己就是以对话的方式工作,这会让总服务台的工作人员的小日子过得轻松点。那么,首先我们需要显示提问。对于显示信息,我们可以用echo和printf命令。这两个都是用来显示信息的,但是printf更为强大,因为我们可以通过它很好地格式化输出,我们可以让它右对齐、左对齐或者为信息留出专门的空间。让我们从一个简单的例子开始吧。要创建文件,请使用你惯用的文本编辑器(kate,nano,vi,……),然后创建名为note.sh的文件,里面写入这些命令:
|
||||
|
||||
echo "Phone number ?"
|
||||
|
||||
### Script执行 ###
|
||||
|
||||
### 如何运行/执行脚本? ###
|
||||
|
||||
在保存文件后,我们可以使用bash命令来运行,把我们的文件作为它的参数:
|
||||
|
||||
@ -176,7 +176,7 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number ?
|
||||
|
||||
在脚本名前,我添加了./组合。.(点)在unix世界中意味着当前位置(当前文件夹),/(斜线)是文件夹分隔符。(在Windows系统中,我们使用\(反斜线)实现同样功能)所以,这整个组合的意思是说:“从当前文件夹执行note.sh脚本”。我想,如果我用完整路径来运行这个脚本的话,你会更加清楚一些:
|
||||
在脚本名前,我添加了 ./ 组合。.(点)在unix世界中意味着当前位置(当前文件夹),/(斜线)是文件夹分隔符。(在Windows系统中,我们使用反斜线 \ 表示同样功能)所以,这整个组合的意思是说:“从当前文件夹执行note.sh脚本”。我想,如果我用完整路径来运行这个脚本的话,你会更加清楚一些:
|
||||
|
||||
[root@localhost ~]# /root/note.sh
|
||||
Phone number ?
|
||||
@ -184,7 +184,7 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
|
||||
它也能工作。
|
||||
|
||||
如果所有linux用户都有相同的默认shell,那就万事OK。如果我们只是执行该脚本,默认的用户shell就会用于解析脚本内容并运行命令。不同的shell有着一丁点不同的语法、内部命令等等,所以,为了保证我们的脚本会使用**bash**,我们应该添加**#!/bin/bash**到文件首行。这样,默认的用户shell将调用**/bin/bash**,而只有在那时候,脚本中的命令才会被执行:
|
||||
如果所有linux用户都有相同的默认shell,那就万事OK。如果我们只是执行该脚本,默认的用户shell就会用于解析脚本内容并运行命令。不同的shell的语法、内部命令等等有着一丁点不同,所以,为了保证我们的脚本会使用**bash**,我们应该添加**#!/bin/bash**到文件首行。这样,默认的用户shell将调用**/bin/bash**,而只有在那时候,脚本中的命令才会被执行:
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
@ -194,13 +194,13 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
|
||||
### 读取输入 ###
|
||||
|
||||
在现实信息后,脚本会等待用户回答。那儿有个**read**命令用来接收用户的回答:
|
||||
在显示信息后,脚本会等待用户回答。有个**read**命令用来接收用户的回答:
|
||||
|
||||
#!/bin/bash
|
||||
echo "Phone number ?"
|
||||
read phone
|
||||
|
||||
在执行后,脚本会等待用户输入,直到用户按[ENTER]键:
|
||||
在执行后,脚本会等待用户输入,直到用户按[ENTER]键结束输入:
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number ?
|
||||
@ -220,7 +220,7 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
You have entered 123456 as a phone number
|
||||
[root@localhost ~]#
|
||||
|
||||
在**bash** shell中,我们使用**$**(美元)符号作为变量标示,除了读入到变量和其它为数不多的时候(将在今后说明)。
|
||||
在**bash** shell中,一般我们使用**$**(美元)符号来表明这是一个变量,除了读入到变量和其它为数不多的时候才不用这个$(将在今后说明)。
|
||||
|
||||
好了,现在我们准备添加剩下的问题了:
|
||||
|
||||
@ -244,7 +244,7 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
|
||||
太完美了!剩下来就是重定向所有东西到文件data.txt了。作为字段分隔符,我们将使用/(斜线)符号。
|
||||
|
||||
**注意** : 你可以选择任何你认为是最好,但是确保文件内容不会包含这些符号在内。它会导致在文本行中产生额外字段。
|
||||
**注意** : 你可以选择任何你认为是最好的分隔符,但是确保文件内容不会包含这些符号在内,否则它会导致在文本行中产生额外字段。
|
||||
|
||||
别忘了使用“>>”来代替“>”,因为我们想要将输出内容附加到文件末!
|
||||
|
||||
@ -262,7 +262,7 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
987/Jimmy/Keybord issue.
|
||||
[root@localhost ~]#
|
||||
|
||||
**注意** : **tail**命令显示了文件的最后**-n**行。
|
||||
**注意** : **tail**命令显示了文件的最后的**n**行。
|
||||
|
||||
搞定。让我们再来运行一次看看:
|
||||
|
||||
@ -285,7 +285,7 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
[root@localhost ~]# date "+%Y.%m.%d %H:%M:%S"
|
||||
2015.04.23 21:33:18 <---- 格式化后的输出
|
||||
|
||||
有几种方式可以读取命令输出到变脸,在这种简单的情况下,我们将使用`(反引号):
|
||||
有几种方式可以读取命令的输出到变量,在这种简单的情况下,我们将使用`(是反引号,不是单引号,和波浪号~在同一个键位):
|
||||
|
||||
[root@localhost ~]# cat note.sh
|
||||
#!/bin/bash
|
||||
@ -320,7 +320,7 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
|
||||
你可以直接从控制台查找到各个命令的大量有趣的信息,只需输入:**man read, man echo, man date, man ……**
|
||||
|
||||
同意吗?它看上去是好多了!
|
||||
同意吗?它看上去是舒服多了!
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number: 321
|
||||
@ -331,9 +331,9 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
2015.04.23 21:43:50/321/Susane/Mouse was stolen
|
||||
[root@localhost ~]#
|
||||
|
||||
光标在消息的后面(不是在新的一行中),这有点意思。
|
||||
光标在消息的后面(不是在新的一行中),这有点意思。(LCTT 译注:如果用 echo 命令输出显示的话,可以用 -n 参数来避免换行。)
|
||||
|
||||
循环
|
||||
### 循环 ###
|
||||
|
||||
是时候来改进我们的脚本了。如果用户一整天都在接电话,如果每次都要去运行,这岂不是很麻烦?让我们让这些活动都永无止境地循环去吧:
|
||||
|
||||
@ -348,7 +348,7 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
echo "$now/$phone/$name/$issue">>data.txt
|
||||
done
|
||||
|
||||
我已经交换了**read phone**和**now=`date`**行。这是因为我想要在输入电话号码后再获得时间。如果我把它放在循环**- the**的首行,变量就会在数据存储到文件中后获得时间。而这并不好,因为下一次呼叫可能在20分钟后,甚至更晚。
|
||||
我已经交换了**read phone**和**now=`date`**行的位置。这是因为我想要在输入电话号码后再获得时间。如果我把它放在循环的首行,那么循环一次后,变量 now 就会在数据存储到文件中后马上获得时间。而这并不好,因为下一次呼叫可能在20分钟后,甚至更晚。
|
||||
|
||||
[root@localhost ~]# ./note.sh
|
||||
Phone number: 123
|
||||
@ -365,11 +365,11 @@ shell脚本语言就跟和几个人聊天类似。你只需把所有命令想象
|
||||
2015.04.23 21:48:16/777/Daniel/I broke my monitor
|
||||
[root@localhost ~]#
|
||||
|
||||
注意: 要从无限循环中退出,你可以按[Ctrl]+[C]键。Shell会显示^表示Ctrl键。
|
||||
注意: 要从无限循环中退出,你可以按[Ctrl]+[C]键。Shell会显示\^表示Ctrl键。
|
||||
|
||||
### 使用管道重定向 ###
|
||||
|
||||
让我们添加更多功能到我们的“弗兰肯斯坦”,我想要脚本在每次呼叫后显示某个统计数据。比如说,我想要查看各个号码呼叫了我几次。对于这个,我们应该cat文件data.txt:
|
||||
让我们添加更多功能到我们的“弗兰肯斯坦(Frankenstein)”,我想要脚本在每次呼叫后显示某个统计数据。比如说,我想要查看各个号码呼叫了我几次。对于这个,我们应该cat文件data.txt:
|
||||
|
||||
[root@localhost ~]# cat data.txt
|
||||
2015.04.23 21:38:56/123/Jim/Script hanging.
|
||||
@ -453,7 +453,7 @@ via: http://linoxide.com/linux-shell-script/guide-start-learning-shell-scripting
|
||||
|
||||
作者:[Petras Liumparas][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
================================================================================
|
||||
各位好,这篇教程关于的是如何在CentOS 7中安装Odoo(就是我们所知的OpenERP)。你是不是在考虑为你的业务安装一个不错的ERP(企业资源规划)软件?那么OpenERP就是你寻找的最好的程序,因为它是一款为你的商务提供杰出特性的自由开源软件。
|
||||
|
||||
[OpenERP][1]是一款自由开源的传统的OpenERP(企业资源规划),它包含了开源CRM、网站构建、电子商务、项目管理、计费账务、销售点、人力资源、市场、生产、采购管理以及其他模块用于提高效率及销售。Odoo可以作为独立程序,但是它可以无缝集成因此你可以在安装数个程序后得到一个全功能的开源ERP。
|
||||
[OpenERP][1]是一款自由开源的传统的OpenERP(企业资源规划),它包含了开源CRM、网站构建、电子商务、项目管理、计费账务、POS、人力资源、市场、生产、采购管理以及其它模块用于提高效率及销售。Odoo中的应用可以作为独立程序使用,它们也可以无缝集成到一起,因此你可以在安装几个程序来得到一个全功能的开源ERP。
|
||||
|
||||
因此,下面是在你的CentOS上安装OpenERP的步骤。
|
||||
|
||||
@ -13,13 +13,13 @@
|
||||
# yum clean all
|
||||
# yum update
|
||||
|
||||
现在我们要安装PostgreSQL,因为OpenERP使用PostgreSQL作为他的数据库。要安装它,我们需要运行下面的命令。
|
||||
现在我们要安装PostgreSQL,因为OpenERP使用PostgreSQL作为它的数据库。要安装它,我们需要运行下面的命令。
|
||||
|
||||
# yum install postgresql postgresql-server postgresql-libs
|
||||
|
||||

|
||||
|
||||
、安装完成后,我们需要用下面的命令初始化数据库。
|
||||
安装完成后,我们需要用下面的命令初始化数据库。
|
||||
|
||||
# postgresql-setup initdb
|
||||
|
||||
@ -42,13 +42,13 @@
|
||||
|
||||
### 2. 设置Odoo仓库 ###
|
||||
|
||||
在初始化数据库初始化完成后,我们要添加EPEL(企业版Linux的额外包)到我们的CentOS中。Odoo(或者OpenERP)依赖于Python运行时以及其他包没有包含在标准仓库中。这样我们要位企业版Linux添加额外的包仓库支持来解决Odoo所需要的依赖。要安装完成,我们需要运行下面的命令。
|
||||
在初始化数据库初始化完成后,我们要添加 EPEL(企业版Linux的额外包)到我们的CentOS中。Odoo(或者OpenERP)依赖的Python运行时环境以及其他包没有包含在标准仓库中。这样我们要为企业版Linux添加额外的包仓库支持来解决Odoo所需要的依赖。要安装完成,我们需要运行下面的命令。
|
||||
|
||||
# yum install epel-release
|
||||
|
||||

|
||||
|
||||
现在,安装EPEL后,我们现在使用yum-config-manager添加Odoo(OpenERp)的仓库。
|
||||
现在,安装EPEL后,我们现在使用yum-config-manager添加Odoo(OpenERP)的仓库。
|
||||
|
||||
# yum install yum-utils
|
||||
|
||||
@ -73,16 +73,16 @@
|
||||
|
||||

|
||||
|
||||
### 4. 防火墙允许 ###
|
||||
### 4. 打开防火墙 ###
|
||||
|
||||
因为Odoo使用8069端口,我们需要在防火墙中允许远程访问。我们使用下面的命令来在防火墙中允许8069防火墙。
|
||||
因为Odoo使用8069端口,我们需要在防火墙中允许远程访问。我们使用下面的命令来在防火墙中允许8069端口访问。
|
||||
|
||||
# firewall-cmd --zone=public --add-port=8069/tcp --permanent
|
||||
# firewall-cmd --reload
|
||||
|
||||

|
||||
|
||||
**注意:默认上,只有本地的连接才允许。如果我们要允许PostgreSQL的远程访问,我们需要在pg_hba.conf添加下面图片中一行**
|
||||
**注意:默认情况下只有本地才允许连接数据库。如果我们要允许PostgreSQL的远程访问,我们需要在pg_hba.conf添加下面图片中一行**
|
||||
|
||||
# nano /var/lib/pgsql/data/pg_hba.conf
|
||||
|
||||
@ -90,13 +90,13 @@
|
||||
|
||||
### 5. Web接口 ###
|
||||
|
||||
我们已经在CentOS 7中安装了最新的Odoo 8(OpenERP),我们可以在浏览器中输入http://ip-address:8069来访问Odoo。 接着,我们要做的第一件事就是创建一个新的数据库和新的密码。注意,主密码默认是管理员密码。接着,我们可以在面板中输入用户名和密码。
|
||||
我们已经在CentOS 7中安装了最新的Odoo 8(OpenERP),我们可以在浏览器中输入`http://ip-address:8069`来访问Odoo。 接着,我们要做的第一件事就是创建一个新的数据库和新的密码。注意,主密码默认是‘admin’。接着,我们可以在面板中输入用户名和密码。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
Odoo 8(OpenERP)是世界上最好的开源ERP程序。我们做了一件出色的工作来安装它因为OpenERP是由许多模块组成的针对商务和公司的完整ERP程序。因此,如果你有任何问题、建议、反馈请在下面的评论栏写下。谢谢你!享受OpenERP(Odoo 8)吧 :-)
|
||||
Odoo 8(OpenERP)是世界上最好的开源ERP程序。OpenERP是由许多模块组成的针对商务和公司的完整ERP程序,我们已经把它安装好了。因此,如果你有任何问题、建议、反馈请在下面的评论栏写下。谢谢你!享受OpenERP(Odoo 8)吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -104,7 +104,7 @@ via: http://linoxide.com/linux-how-to/setup-openerp-odoo-centos-7/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
Linux有问必答——Ubuntu桌面上如何禁用默认的密钥环解锁密码输入
|
||||
Linux有问必答:Ubuntu桌面上如何禁用默认的密钥环解锁提示
|
||||
================================================================================
|
||||
>**问题**:当我启动我的Ubuntu桌面时,出现了一个弹出对话框,要求我输入密码来解锁默认的密钥环。我怎样才能禁用这个“解锁默认密钥环”弹出窗口,并自动解锁我的密钥环?
|
||||
|
||||
密钥环被认为是用来以加密方式存储你的登录信息的本地数据库。各种桌面应用(如浏览器、电子邮件客户端)使用密钥环来安全地存储并管理你的登录凭证、机密、密码、证书或密钥。对于那些需要检索存储在密钥环中的信息的应用程序,需要解锁该密钥环。
|
||||
密钥环是一个以加密方式存储你的登录信息的本地数据库。各种桌面应用(如浏览器、电子邮件客户端)使用密钥环来安全地存储并管理你的登录凭证、机密、密码、证书或密钥。对于那些需要检索存储在密钥环中的信息的应用程序,需要解锁该密钥环。
|
||||
|
||||
Ubuntu桌面所使用的GNOME密钥环被整合到了桌面登录中,该密钥环会在你验证进入桌面后自动解锁。但是,如果你设置了自动登录桌面或者是从休眠中唤醒,你默认的密钥环仍然可能“被锁定”的。在这种情况下,你会碰到这一提示:
|
||||
|
||||
>“为密钥环‘默认密钥环’输入密码来解锁。某个应用想要访问密钥环‘默认密钥环’,但它被锁定了。”
|
||||
>“输入密码来解锁密钥环‘默认密钥环’。某个应用想要访问密钥环‘默认密钥环’,但它被锁定了。”
|
||||
>
|
||||
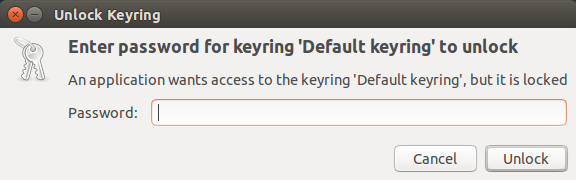
|
||||
|
||||
@ -16,7 +16,7 @@ Ubuntu桌面所使用的GNOME密钥环被整合到了桌面登录中,该密钥
|
||||
|
||||
### 禁用默认密钥环解锁密码 ###
|
||||
|
||||
打开Dash,然后输入“密码”来启动“密码和密钥”应用。
|
||||
打开Dash,然后输入“password”来启动“密码和密钥”应用。
|
||||
|
||||
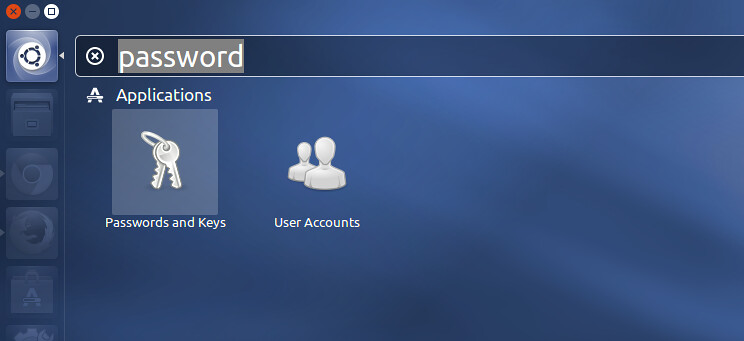
|
||||
|
||||
@ -31,6 +31,7 @@ Ubuntu桌面所使用的GNOME密钥环被整合到了桌面登录中,该密钥
|
||||
输入你的当前登录密码。
|
||||
|
||||
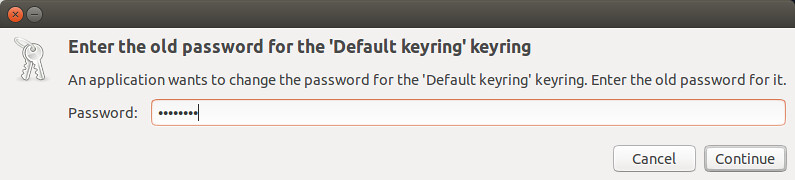
|
||||
|
||||
在设置“默认”密钥环新密码的密码框中留空。
|
||||
|
||||
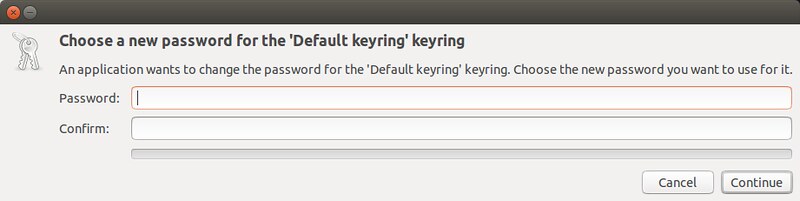
|
||||
@ -47,7 +48,7 @@ via: http://ask.xmodulo.com/disable-entering-password-unlock-default-keyring.htm
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
Linux有问必答——Linux上如何安装Shrew Soft IPsec VPN
|
||||
Linux有问必答:Linux上如何安装Shrew Soft IPsec VPN
|
||||
================================================================================
|
||||
> **Question**: I need to connect to an IPSec VPN gateway. For that, I'm trying to use Shrew Soft VPN client, which is available for free. How can I install Shrew Soft VPN client on [insert your Linux distro]?
|
||||
> **问题**:我需要连接到一个IPSec VPN网关,鉴于此,我尝试使用Shrew Soft VPN客户端,它是一个免费版本。我怎样才能安装Shrew Soft VPN客户端到[插入你的Linux发行版]?
|
||||
|
||||
市面上有许多商业VPN网关,同时附带有他们自己的专有VPN客户端软件。虽然也有许多开源的VPN服务器/客户端备选方案,但它们通常缺乏复杂的IPsec支持,比如互联网密钥交换(IKE),这是一个标准的IPsec协议,用于加固VPN密钥交换和验证安全。Shrew Soft VPN是一个免费的IPsec VPN客户端,它支持多种验证方法、密钥交换、加密以及防火墙穿越选项。
|
||||
> **问题**:我需要连接到一个IPSec VPN网关,鉴于此,我尝试使用Shrew Soft VPN客户端,它是一个免费版本。我怎样才能安装Shrew Soft VPN客户端到[某个Linux发行版]?
|
||||
|
||||
市面上有许多商业VPN网关,同时附带有他们自己的专有VPN客户端软件。虽然也有许多开源的VPN服务器/客户端备选方案,但它们通常缺乏复杂的IPsec支持,比如互联网密钥交换(IKE),这是一个标准的IPsec协议,用于加固VPN密钥交换和验证安全。Shrew Soft VPN是一个免费的IPsec VPN客户端,它支持多种验证方法、密钥交换、加密以及防火墙穿透选项。
|
||||
|
||||
下面介绍如何安装Shrew Soft VPN客户端到Linux平台。
|
||||
|
||||
@ -90,7 +90,7 @@ via: http://ask.xmodulo.com/install-shrew-soft-ipsec-vpn-client-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
修复Ubuntu 14.04中各种更新错误
|
||||
Ubuntu 更新错误修复大全
|
||||
================================================================================
|
||||

|
||||
|
||||
在Ubuntu更新中,谁没有碰见个错误?在Ubuntu和其它基于Ubuntu的Linux发行版中,更新错误很常见,也为数不少。这些错误出现的原因多种多样,修复起来也很简单。在本文中,我们将见到Ubuntu中各种类型频繁发生的更新错误以及它们的修复方法。
|
||||
在Ubuntu更新中,谁没有碰见个错误?在Ubuntu和其它基于Ubuntu的Linux发行版中,更新错误是一个共性的错误,也经常发生。这些错误出现的原因多种多样,修复起来也很简单。在本文中,我们将见到Ubuntu中各种类型频繁发生的更新错误以及它们的修复方法。
|
||||
|
||||
### 合并列表问题 ###
|
||||
|
||||
@ -38,7 +38,7 @@
|
||||
|
||||
下载仓库信息失败的另外一种类型是由于PPA过时导致的。通常,当你运行更新管理器,并看到这样的错误时:
|
||||
|
||||

|
||||

|
||||
|
||||
你可以运行sudo apt-get update来查看哪个PPA更新失败,你可以把它从源列表中删除。你可以按照这个截图指南来[修复下载仓库信息失败错误][3]。
|
||||
|
||||
@ -48,7 +48,7 @@
|
||||
|
||||

|
||||
|
||||
该错误很容易修复,只需修改软件源为主服务器即可。转到软件和更新,在那里你可以修改下载服务器为主服务器:
|
||||
该错误很容易修复,只需修改软件源为主服务器即可。转到“软件和更新”,在那里你可以修改下载服务器为主服务器:
|
||||
|
||||

|
||||
|
||||
@ -78,7 +78,7 @@
|
||||
|
||||
你可以在这里查找到更多详细内容[加载共享库时发生错误][6]。
|
||||
|
||||
### 无法获取锁/var/cache/apt/archives/lock ###
|
||||
### 无法获取锁 /var/cache/apt/archives/lock ###
|
||||
|
||||
在另一个程序在使用APT时,会发生该错误。假定你正在Ubuntu软件中心安装某个东西,然后你又试着在终端中运行apt。
|
||||
|
||||
@ -135,7 +135,7 @@ via: http://itsfoss.com/fix-update-errors-ubuntu-1404/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,21 @@
|
||||
开源旧事:Linux为什么能成功?
|
||||
================================================================================
|
||||
> Linux,这个始于1991年由Lnius Torvalds开发的类Unix操作系统内核已经成为开源世界的中心,人们不禁追问为什么Linux成功了,而包括GNU HURD和BSD在内的那么多相似的项目却失败了?
|
||||
> Linux,这个始于1991年由Linus Torvalds开发的类Unix操作系统内核已经成为开源世界的中心,人们不禁追问为什么Linux成功了,而包括GNU HURD和BSD在内的那么多相似的项目却失败了?
|
||||
|
||||

|
||||
|
||||
自由软件和开源世界的发展史中最令人不解的问题之一是为什么Linux取得了如此辉煌的成功,然而其它同样尝试打造自由开源、类Unix操作系统内核的项目却没能那么成功?这个问题难以回答,但我总结了一些原因,在下面与大家分享。
|
||||
|
||||
不过,首先得明确:当我谈论Linux是一个巨大的成功时所表达的含义。我对Linux成功的定义和对其它类Unix操作系统内核不一样,后者中一些是开源的,一些不是,而且它们繁荣发展的时期是Linux诞生的时期。[GNU][1]的HURD,一个发起于[1991年5月][1]的自由但不是免费的内核,便是其中之一。其它的包括现在大部分人都没听说过的Unix,比如由加州大学伯克利分校开发出来的BSD的各种各样Unix衍生版,由微软主导的Unix系统Xenix,包括Minix在内的学术版本Unix,和在AT&T赞助下开发的最初的Unix。在更早的数十年内,它对于学术界和商业届的计算发展至关重要,但到19世纪90年代就已经几乎已经消失在人们的视野里。
|
||||
不过,首先得明确:当我谈论Linux是一个巨大的成功时所表达的含义。我这样说是相对于其它类Unix操作系统内核的,后者中一些是开源的,一些不是,而且它们繁荣发展的时期是Linux诞生的时期。[GNU][1]的HURD,一个发起于[1991年5月][1]的Free(自由)的内核,便是其中之一。其它的包括现在大部分人都没听说过的Unix,比如由加州大学伯克利分校开发出来的BSD的各种各样Unix衍生版,由微软主导的Unix系统Xenix,包括Minix在内的学术版本Unix,和在AT&T赞助下开发的最初的Unix。在更早的数十年内,它对于学术界和商业界的计算发展至关重要,但到19世纪90年代就已经几乎已经消失在人们的视野里。
|
||||
|
||||
#### 相关阅读 ####
|
||||
|
||||
- [Open Source History: Tracing the Origins of Hacker Culture and the Hacker Ethic][3]
|
||||
- [Unix and Personal Computers: Reinterpreting the Origins of Linux][4]
|
||||
- [开源旧事:黑客文化和黑客伦理的起源追踪][3]
|
||||
- [Unix和个人计算机:重新诠释Linux起源][4]
|
||||
|
||||
因此,得说明的是,我所写的是关于内核,而不是完整的操作系统。在很大程度上,Linux内核的成功归功于GNU整个项目。GNU这个项目产生了一套至关重要的工具,包括编译器、调试器和BASH shell的实现,这些对于构建一个类Unix操作系统是必需的。但是GNU的开发者们从没开发出一个HURD内核的可行版本(尽管他们仍在[不懈努力中][5])。相反,Linux呈现出来的则是一个将GNU各个部分紧密连接在一起的内核,尽管这超出了GNU的初衷。
|
||||
此外,得说明的是,我这里说的是内核,而不是完整的操作系统。在很大程度上,Linux内核的成功归功于GNU整个项目。GNU这个项目产生了一套至关重要的工具,包括编译器、调试器和BASH shell的实现,这些对于构建一个类Unix操作系统是必需的。但是GNU的开发者们从没开发出一个HURD内核的可行版本(尽管他们仍在[不懈努力中][5])。相反,Linux呈现出来的则是一个将GNU各个部分紧密连接在一起的内核,尽管这超出了GNU的初衷。
|
||||
|
||||
因此,值得人们去追问为什么Linux,一个由Linus Torvalds这个芬兰的无名程序员于1991年——和HURD同一年——发起的内核,能够禁受考验并发展壮大?在当时的大环境下,很多拥有强力商业支持的、由当时炙手可热的黑客领头的类Unix内核都没能够发展起来。为了说明这个问题,我找到了一些和这个问题相关的解释。为此我研究了自由软件和开源世界的发展史,和不同解释的优缺点。
|
||||
因此,值得人们去追问为什么Linux,一个由Linus Torvalds这个芬兰的无名程序员于1991年——和HURD同一年——发起的内核,能够经受考验并发展壮大?在当时的大环境下,很多拥有强力商业支持的、由当时炙手可热的黑客领头的类Unix内核都没能够发展起来。为了说明这个问题,我找到了一些和这个问题相关的解释。为此我研究了自由软件和开源世界的发展史,和不同解释的优缺点。
|
||||
|
||||
### Linux采用去中心化的开发方式 ###
|
||||
|
||||
@ -25,7 +25,7 @@
|
||||
|
||||
### Linux是实用型的,而GNU是空想型的 ###
|
||||
|
||||
个人而言,我觉得下面这个说法是最引人注目的,即Linux之所发展得如此迅速是因为它的创建者是一个实用主义者,他起初只是想写一个内核,使其能够在他家里的电脑上运行一个裁剪过的Unix操作系统,而不是成为以改变世界为目标的自由软件的一部分,而后者正是GNU项目的一贯目标。
|
||||
个人而言,我觉得这个说法是最引人注目的,即Linux之所发展得如此迅速是因为它的创建者是一个实用主义者,他起初只是想写一个内核,使其能够在他家里的电脑上运行一个裁剪过的Unix操作系统,而不是成为以改变世界为目标的自由软件的一部分,而后者正是GNU项目的一贯目标。
|
||||
|
||||
然而,这个解释仍然有一些不能完全让人信服的地方。特别是,尽管Torvalds本人信奉实用主义的原则,但无论以前还是现在,并非所有参与到他的项目中的成员都和他一样信奉这一原则。尽管如此,Linux仍然取得了成功。
|
||||
|
||||
@ -37,27 +37,27 @@
|
||||
|
||||
当谈到Linux的成功时,不可忽视的是Linux和其它Unix变体之间的诸多技术差异。Richard Stallman,GNU项目的创始人,在一封给我的电子邮件中解释了为什么HURD的开发进度频频滞后:“GNU Hurd确实不是一次实用上的成功。部分原因是它的基本设计使它像是一个研究项目。(我之所以选择这样的设计,是考虑到这是快速实现一个可用内核的捷径。)”
|
||||
|
||||
就Torvalds独自编写出Linux的所有代码这点而言,Linux也有别于其它Unix变体。当他在1991年8月[第一次发布Linux][7]时他的一个初衷就是拥有一个属于他自己的Unix,免费共享代码。这点特性使得Linux区别于同时期的大部分Unix变体,后者一般是从AT&T Unix或伯克利的BSD中衍生出基础代码。
|
||||
就Torvalds独自编写出Linux的所有代码这点而言,Linux也有别于其它Unix变体。当他在1991年8月[第一次发布Linux][7]时他的一个初衷就是拥有一个属于他自己的Unix,而不用别人的代码。这点特性使得Linux区别于同时期的大部分Unix变体,后者一般是从AT&T Unix或伯克利的BSD中衍生出基础代码。
|
||||
|
||||
我并不是一个计算机科学家,所以我没有资格去评判是否Lunux代码就优于其他Unix代码,以此来解释Linux的成功。虽然这并不能解释Linux和其它Unix内核在文化和人力上的不同,但这个观点对我来说解释得通,因为似乎在理解Linux成功这一点上它比代码更加重要。(译者尽力了+_+)
|
||||
我并不是一个计算机科学家,所以我没有资格去评判是否Linux代码就优于其他Unix代码,以此来解释Linux的成功。虽然这并不能解释Linux和其它Unix内核在文化和人员上的不同,但这个观点对我来说解释得通,因为似乎在理解Linux成功这一点上操作系统设计比代码更加重要。
|
||||
|
||||
### Linux背后的社区提供了有力支持 ###
|
||||
|
||||
Stallman也写到Linux成功的“主要原因”是“Torvalds使Linux成为一个自由软件,所以相比Hurd有更多来自社区的支持涌入Linux的发展中。”但这对于Linux的成长轨迹并非是一个完美的解释,因为它不能说明为什么自由软件的开发者们追随了Torvalds而不是HURD或其它某个Unix。但它仍然突出了这个转变是Linux盛行的很大一部分。(译者尽力了)
|
||||
Stallman也写到Linux成功的“主要原因”是“Torvalds使Linux成为一个自由软件,所以相比Hurd有更多来自社区的支持涌入Linux的发展中。”但这对于Linux的成长轨迹并非是一个完美的解释,因为它不能说明为什么自由软件的开发者们追随了Torvalds而不是HURD或其它某个Unix,但它仍然点明了这种变化是Linux盛行的很大一部分原因。
|
||||
|
||||
对于自由软件社区支持Linux的决定有一个更全面的理由可以用来解释为什么开发者们这么做。起初,Linux只是一个默默无闻的小项目,以任何标准来衡量,它比同时期其它的一些尝试创建一个更加自由的Unix,比如NET BSD和386/BSD,都要显得微不足道。同样,最初并不清楚Linux和自由软件运行目标的亲和力是怎样。创建伊始,Torvalds只是在一份防止Linux不被商业使用的证书下发布了Linux。至于后来他为了保护源代码的开放性转向使用GNU的通用公开证书则是后话了。
|
||||
对于自由软件社区决定支持Linux有一个更全面的理由可以用来解释为什么开发者们这么做。起初,Linux只是一个默默无闻的小项目,以任何标准来衡量,它比同时期其它的一些尝试创建一个更加自由的Unix,比如NET BSD和386/BSD,都要显得微不足道。同样,最初并不清楚Linux和自由软件运动的目标是否一致。创建伊始,Torvalds只是在一份防止Linux不被商业使用的证书下发布了Linux。至于后来他为了保护源代码的开放性转向使用GNU的通用公开证书则是后话了。
|
||||
|
||||
所以,这些就是我所找到的Linux作为一个开源操作系统之所以取得成功的解释,可以肯定Linux的成就在某些方面(但比如桌面版的Linux从未成为它的支持者希望成为的样子)已经是可以衡量的成功。总之,Linux业已以其它任何类Unix操作系统都没有实现的方式成为了计算机世界的基石。也许源于BSD的苹果公司的OS X和iOS系统也很接近这一点,但它们没有在其它方面像Linux影响互联网一样扮演着如此重要的中心角色。
|
||||
所以,这些就是我所找到的Linux作为一个开源操作系统之所以取得成功的解释,可以肯定Linux的成就在某些方面(但比如桌面版的Linux从未成为它的支持者希望成为的样子)已经是可以衡量的成功。总之,Linux业已与其它任何类Unix操作系统不同的方式成为了计算机世界的基石。也许源于BSD的苹果公司的OS X和iOS系统也很接近这一点,但它们没有在其它方面像Linux影响互联网一样扮演着如此重要的中心角色。
|
||||
|
||||
对于为什么Linux能成为它已经成为的样子,或者为什么它在Unix世界的竞争对手们几乎全部变得默默无闻的问题你有其它的想法吗?如果有,我很乐意听到你的想法。(诚然,BSD的变体如今仍有一批追随者,而一些商用的Unix对于[Red Hat][8](RHT)为[他们的用户提供支持][9]来说也仍然十分重要。但这些Unix中没有一个能够像Linux一样几乎征服了从Web服务器到智能手机的每一个领域。)
|
||||
对于为什么Linux能成为现在的样子,或者为什么它在Unix世界的竞争对手们几乎全部变得默默无闻的问题,你有其它的想法吗?如果有,我很乐意听到你的想法。(诚然,BSD的变体如今仍有一批追随者,而一些商用的Unix对于[Red Hat][8](RHT)为[他们的用户提供支持][9]来说也仍然十分重要。但这些Unix中没有一个能够像Linux一样几乎征服了从Web服务器到智能手机的每一个领域。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/050415/open-source-history-why-did-linux-succeed
|
||||
|
||||
作者:[hristopher Tozzi][a]
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
45 个用于 ‘Suse‘ Linux 包管理的 Zypper 命令
|
||||
用于 ‘Suse‘ Linux 包管理的 Zypper 命令大全
|
||||
======================================================================
|
||||
SUSE( Software and System Entwicklung,即软件和系统开发。其中‘entwicklung‘是德语,意为开发)Linux是 Novell 公司在 Linux 内核基础上发布的操作系统。SUSE Linux 有两个发行分支。其中之一名为 OpenSUSE,这是一款自由而且免费的操作系统。该系统由开源社区开发维护,支持一些最新版本的应用软件,其最新的稳定版本为 13.2。
|
||||
SUSE( Software and System Entwicklung,即软件和系统开发。其中‘entwicklung‘是德语,意为开发)Linux 是由 Novell 公司在 Linux 内核基础上建立的操作系统。SUSE Linux 有两个发行分支。其中之一名为 openSUSE,这是一款自由而且免费的操作系统 (free as in speech as well as free as in wine)。该系统由开源社区开发维护,支持一些最新版本的应用软件,其最新的稳定版本为 13.2。
|
||||
|
||||
另外一个分支是SUSE Linux 企业版。该分支是一个为企业及商业化产品设计的 Linux 发行版,包含了大量的企业应用以及适用于商业产品生产环境的特性。其最新的稳定版本为 12。
|
||||
另外一个分支是 SUSE Linux 企业版。该分支是一个为企业及商业化产品设计的 Linux 发行版,包含了大量的企业应用以及适用于商业产品生产环境的特性。其最新的稳定版本为 12。
|
||||
|
||||
以下的链接包含了安装企业版 SUSE Linux 服务器的详细信息。
|
||||
|
||||
- [如何安装企业版 SUSE Linux 12][1]
|
||||
|
||||
Zypper 和 Yast 是 SUSE Linux 平台上的软件包管理工具,他们的底层使用了 RPM(译者注:RPM 最初指 Redhat Pacakge Manager ,现普遍解释为递归短语 RPM Package Manager 的缩写)。
|
||||
Zypper 和 Yast 是 SUSE Linux 平台上的软件包管理工具,他们的底层使用了 RPM(LCTT 译者注:RPM 最初指 Redhat Pacakge Manager ,现普遍解释为递归短语 RPM Package Manager 的缩写)。
|
||||
|
||||
Yast(Yet another Setup Tool )是 OpenSUSE 以及企业版 SUSE 上用于系统管理、设置和配置的工具。
|
||||
|
||||
@ -16,21 +16,21 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
本文将介绍实际应用中常见的一些Zypper命令。这些命令用来进行安装、更新、删除等任何软件包管理器所能够胜任的工作。
|
||||
|
||||
**重要** : 切记所有的这些指令都将在系统全局范围内产生影响,所以必须以 root 身份执行,否则命令将失败。
|
||||
**重要** : 切记所有的这些命令都将在系统全局范围内产生影响,所以必须以 root 身份执行,否则命令将失败。
|
||||
|
||||
### 获取基本的 Zypper 帮助信息 ###
|
||||
|
||||
1. 不带任何选项的执行 zypper, 将输出该命令的全局选项以及子命令列表(译者注:全局选项,global option,控制台命令的输入分为可选参数和位置参数两大类。按照习惯,一般可选参数称为选项'option',而位置参数称为参数 'argument')。
|
||||
1. 不带任何选项的执行 zypper, 将输出该命令的全局选项以及子命令列表(LCTT 译者注:全局选项,global option,控制台命令的输入分为可选参数和位置参数两大类。按照习惯,一般可选参数称为选项'option',而位置参数称为参数 'argument')。
|
||||
|
||||
<pre><code>%> zypper
|
||||
<pre><code># zypper
|
||||
Usage:
|
||||
zypper [--global-options]</code></pre>
|
||||
|
||||
2. 获取一个具体的子命令的帮助信息,比如 'in' (install),可以执行下面的命令
|
||||
|
||||
<pre><code>%> zypper help in</code></pre>
|
||||
<pre><code># zypper help in</code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper help install
|
||||
<pre><code># zypper help install
|
||||
install (in) [options] {capability | rpm_file_uri}
|
||||
|
||||
Install packages with specified capabilities or RPM files with specified
|
||||
@ -96,7 +96,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
4. 获取一个模式包的信息(以 lamp_server 为例)。
|
||||
|
||||
<pre><code>%> zypper info -t pattern lamp_server
|
||||
<pre><code># zypper info -t pattern lamp_server
|
||||
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
@ -136,9 +136,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
5. 开启一个Zypper Shell 的会话。
|
||||
|
||||
<pre><code> %>zypper shell </code></pre>
|
||||
<pre><code># zypper shell </code></pre>
|
||||
或者
|
||||
<pre><code> %>zypper sh </code></pre>
|
||||
<pre><code># zypper sh </code></pre>
|
||||
|
||||
<pre><code>zypper> help
|
||||
Usage:
|
||||
@ -151,9 +151,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
6. 使用 'zypper repos' 或者 'zypper lr' 来列举所有已定以的软件库。
|
||||
|
||||
<pre><code>%> zypper repos</code></pre>
|
||||
<pre><code># zypper repos</code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper lr
|
||||
<pre><code># zypper lr
|
||||
| Alias | Name | Enabled | Refresh
|
||||
--+---------------------------+------------------------------------+---------+--------
|
||||
1 | openSUSE-13.2-0 | openSUSE-13.2-0 | Yes | No
|
||||
@ -183,7 +183,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
8. 根据优先级列举软件库。
|
||||
|
||||
<pre><code>%> zypper lr -P
|
||||
<pre><code># zypper lr -P
|
||||
| Alias | Name | Enabled | Refresh | Priority
|
||||
--+---------------------------+------------------------------------+---------+---------+---------
|
||||
1 | openSUSE-13.2-0 | openSUSE-13.2-0 | Yes | No | 99
|
||||
@ -200,9 +200,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
9. 使用 'zypper refresh' or 'zypper ref' 来刷新 zypper 软件库。
|
||||
|
||||
<pre><code>%> zypper refresh </code></pre>
|
||||
<pre><code># zypper refresh </code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper ref
|
||||
<pre><code># zypper ref
|
||||
Repository 'openSUSE-13.2-0' is up to date.
|
||||
Repository 'openSUSE-13.2-Debug' is up to date.
|
||||
Repository 'openSUSE-13.2-Non-Oss' is up to date.
|
||||
@ -213,13 +213,13 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
10. 刷新一个指定的软件库(以 'repo-non-oss' 为例 )。
|
||||
|
||||
<pre><code>%> zypper refresh repo-non-oss
|
||||
<pre><code># zypper refresh repo-non-oss
|
||||
Repository 'openSUSE-13.2-Non-Oss' is up to date.
|
||||
Specified repositories have been refreshed. </code></pre>
|
||||
|
||||
11. 强制更新一个软件库(以 'repo-non-oss' 为例 )。
|
||||
|
||||
<pre><code>%> zypper ref -f repo-non-oss
|
||||
<pre><code># zypper ref -f repo-non-oss
|
||||
Forcing raw metadata refresh
|
||||
Retrieving repository 'openSUSE-13.2-Non-Oss' metadata ............................................................[done]
|
||||
Forcing building of repository cache
|
||||
@ -230,9 +230,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
本文中我们使用‘zypper modifyrepo‘ 或者 ‘zypper mr‘ 来关闭或者开启 zypper 软件库。
|
||||
|
||||
12. 在关闭一个软件库之前,我们需要知道在 zypper中,每一个软件库有一个唯一的标示数字与之关联,该数字用于打开或者关闭与之相联系的软件库。假设我们需要关闭 'repo-oss' 软件库,那么我们可以通过以下的法来获得该软件库的标志数字。
|
||||
12. 在关闭一个软件库之前,我们需要知道在 zypper 中,每一个软件库有一个唯一的标示数字与之关联,该数字用于打开或者关闭与之相联系的软件库。假设我们需要关闭 'repo-oss' 软件库,那么我们可以通过以下的法来获得该软件库的标志数字。
|
||||
|
||||
<pre><code>%> zypper lr
|
||||
<pre><code># zypper lr
|
||||
| Alias | Name | Enabled | Refresh
|
||||
--+---------------------------+------------------------------------+---------+--------
|
||||
1 | openSUSE-13.2-0 | openSUSE-13.2-0 | Yes | No
|
||||
@ -246,23 +246,23 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
9 | repo-update-non-oss | openSUSE-13.2-Update-Non-Oss | Yes | Yes</code></pre>
|
||||
从以上输出的列表中我们可以看到 'repo-oss' 库的标示数字是 6,因此通过以下的命令来关闭该库。
|
||||
|
||||
<pre><code>%> zypper mr -d 6
|
||||
<pre><code># zypper mr -d 6
|
||||
Repository 'repo-oss' has been successfully disabled.</code></pre>
|
||||
|
||||
13. 如果需要再次开启软件库 ‘repo-oss‘, 接上例,与之相关联的标示数字为 6。
|
||||
|
||||
<pre><code>%> zypper mr -e 6
|
||||
<pre><code># zypper mr -e 6
|
||||
Repository 'repo-oss' has been successfully enabled.</code></pre>
|
||||
|
||||
14. 针对某一个软件库(以 'repo-non-oss' 为例 )开启自动刷新( auto-refresh )和 rpm 缓存,并设置该软件库的优先级,比如85。
|
||||
|
||||
<pre><code>%> zypper mr -rk -p 85 repo-non-oss
|
||||
<pre><code># zypper mr -rk -p 85 repo-non-oss
|
||||
Repository 'repo-non-oss' priority has been left unchanged (85)
|
||||
Nothing to change for repository 'repo-non-oss'.</code></pre>
|
||||
|
||||
15. 对所有的软件库关闭 rpm 文件缓存。
|
||||
|
||||
<pre><code>%> zypper mr -Ka
|
||||
<pre><code># zypper mr -Ka
|
||||
RPM files caching has been disabled for repository 'openSUSE-13.2-0'.
|
||||
RPM files caching has been disabled for repository 'repo-debug'.
|
||||
RPM files caching has been disabled for repository 'repo-debug-update'.
|
||||
@ -274,7 +274,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
RPM files caching has been disabled for repository 'repo-update-non-oss'.</pre></code>
|
||||
|
||||
16. 对所有的软件库开启 rpm 文件缓存。
|
||||
<pre><code> zypper mr -ka
|
||||
<pre><code># zypper mr -ka
|
||||
RPM files caching has been enabled for repository 'openSUSE-13.2-0'.
|
||||
RPM files caching has been enabled for repository 'repo-debug'.
|
||||
RPM files caching has been enabled for repository 'repo-debug-update'.
|
||||
@ -285,8 +285,8 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
RPM files caching has been enabled for repository 'repo-update'.
|
||||
RPM files caching has been enabled for repository 'repo-update-non-oss'.</code></pre>
|
||||
|
||||
17. 关闭远程库的rpm 文件缓存
|
||||
<pre><code>%> zypper mr -Kt
|
||||
17. 关闭远程库的 rpm 文件缓存
|
||||
<pre><code># zypper mr -Kt
|
||||
RPM files caching has been disabled for repository 'repo-debug'.
|
||||
RPM files caching has been disabled for repository 'repo-debug-update'.
|
||||
RPM files caching has been disabled for repository 'repo-debug-update-non-oss'.
|
||||
@ -297,7 +297,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
RPM files caching has been disabled for repository 'repo-update-non-oss'.</code></pre>
|
||||
|
||||
18. 开启远程软件库的 rpm 文件缓存。
|
||||
<pre><code>%> zypper mr -kt
|
||||
<pre><code># zypper mr -kt
|
||||
RPM files caching has been enabled for repository 'repo-debug'.
|
||||
RPM files caching has been enabled for repository 'repo-debug-update'.
|
||||
RPM files caching has been enabled for repository 'repo-debug-update-non-oss'.
|
||||
@ -313,7 +313,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
19. 增加一个新的软件库( 以 “http://download.opensuse.org/update/12.3/” 为例 )。
|
||||
|
||||
<pre><code>%> zypper ar http://download.opensuse.org/update/11.1/ update
|
||||
<pre><code># zypper ar http://download.opensuse.org/update/11.1/ update
|
||||
Adding repository 'update' .............................................................................................................................................................[done]
|
||||
Repository 'update' successfully added
|
||||
Enabled : Yes
|
||||
@ -323,14 +323,14 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
20. 更改一个软件库的名字,这将仅仅改变软件库的别名。 命令 'zypper namerepo' 或者 'zypperr nr' 可以胜任此工作。例如更改标示数字为10的软件库的名字为 'upd8',或者说将标示数字为10的软件库的别名改为 'upd8',可以使用下面的命令。
|
||||
|
||||
<pre><code>%> zypper nr 10 upd8
|
||||
<pre><code># zypper nr 10 upd8
|
||||
Repository 'update' renamed to 'upd8'.</code></pre>
|
||||
|
||||
#### 删除软件库 ####
|
||||
|
||||
21. 删除一个软件库。要从系统删除一个软件库可以使 'zypper removerepo' 或者 'zypper rr'。例如以下的命令可以删除软件库 'upd8'
|
||||
|
||||
<pre><code>%> zypper rr upd8
|
||||
<pre><code># zypper rr upd8
|
||||
# Removing repository 'upd8' .........................................................................................[done]
|
||||
Repository 'upd8' has been removed.</code></pre>
|
||||
|
||||
@ -339,7 +339,8 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
#### 用 zypper 安装一个软件包 ####
|
||||
|
||||
22. 在 zypper 中,我们可以通过软件包的功能名称来安装一个软件包。以 Firefox 为例,以下的命令可以用来安装该软件包。
|
||||
<pre><code>%> zypper in MozillaFirefox
|
||||
|
||||
<pre><code># zypper in MozillaFirefox
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -370,8 +371,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Retrieving: hicolor-icon-theme-0.13-2.1.2.noarch.rpm ...................................................................................................................................[done]
|
||||
Retrieving package sound-theme-freedesktop-0.8-7.1.2.noarch (3/128), 372.6 KiB (460.3 KiB unpacked) </code></pre>
|
||||
|
||||
23. 安装指定版本号的软件包,(以 gcc 5.1 为例)。
|
||||
<pre><code> %>zypper in 'gcc<5.1'
|
||||
23. 安装指定版本号的软件包,(以 gcc 5.1 为例)。
|
||||
|
||||
<pre><code># zypper in 'gcc<5.1'
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -385,7 +387,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
24. 为特定的CPU架构安装软件包(以兼容 i586 的 gcc 为例)。
|
||||
|
||||
<pre><code>%> zypper in gcc.i586
|
||||
<pre><code># zypper in gcc.i586
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -403,7 +405,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
25. 为特定的CPU架构安装指定版本号的软件包(以兼容 i586 且版本低于5.1的 gcc 为例)
|
||||
|
||||
<pre><code>%> zypper in 'gcc.i586<5.1'
|
||||
<pre><code># zypper in 'gcc.i586<5.1'
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -418,8 +420,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
In cache libatomic1-gcc49-4.9.0+r211729-2.1.7.x86_64.rpm (2/13), 14.3 KiB ( 26.1 KiB unpacked)
|
||||
In cache libgomp1-gcc49-4.9.0+r211729-2.1.7.x86_64.rpm (3/13), 41.1 KiB ( 90.7 KiB unpacked) </code></pre>
|
||||
|
||||
26. 从指定的软件库里面安装一个软件包,例如从 amarok 中安装 libxine。
|
||||
<pre><code>%> zypper in amarok upd:libxine1
|
||||
26. 从指定的软件库里面安装一个软件包,例如从 amarok 中安装 libxine。
|
||||
|
||||
<pre><code># zypper in amarok upd:libxine1
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -431,7 +434,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
27. 通过指定软件包的名字安装软件包。
|
||||
|
||||
<pre><code>%> zypper in -n git
|
||||
<pre><code># zypper in -n git
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -451,8 +454,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Overall download size: 15.6 MiB. Already cached: 0 B After the operation, additional 56.7 MiB will be used.
|
||||
Continue? [y/n/? shows all options] (y): y </code></pre>
|
||||
|
||||
28. 通过通配符来安装软件包,例如,安装所有 php5 的软件包。
|
||||
<pre><code>%> zypper in php5*
|
||||
28. 通过通配符来安装软件包,例如,安装所有 php5 的软件包。
|
||||
|
||||
<pre><code># zypper in php5*
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -484,9 +488,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
do not install php5-pear-Horde_Pdf-2.0.1-6.1.3.noarch
|
||||
....</code></pre>
|
||||
|
||||
29. 使用模式名称(模式名称是一类软件包的名字)来批量安装软件包
|
||||
29. 使用模式名称(模式名称是一类软件包的名字)来批量安装软件包。
|
||||
|
||||
<pre><code>%> zypper in -t pattern lamp_server
|
||||
<pre><code># zypper in -t pattern lamp_server
|
||||
ading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -506,7 +510,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Overall download size: 7.2 MiB. Already cached: 1.2 MiB After the operation, additional 34.7 MiB will be used.
|
||||
Continue? [y/n/? shows all options] (y): </code></pre>
|
||||
|
||||
30. 使用一行命令安转一个软件包同时卸载另一个软件包,例如在安装 nano 的同时卸载 vi
|
||||
30. 使用一行命令安装一个软件包同时卸载另一个软件包,例如在安装 nano 的同时卸载 vi
|
||||
|
||||
<pre><code># zypper in nano -vi
|
||||
Loading repository data...
|
||||
@ -530,7 +534,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
31. 使用 zypper 安装 rpm 软件包。
|
||||
|
||||
<pre><code>%> zypper in teamviewer*.rpm
|
||||
<pre><code># zypper in teamviewer*.rpm
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -552,9 +556,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
32. 命令 ‘zypper remove‘ 和 ‘zypper rm‘ 用于卸载软件包。例如卸载 apache2:
|
||||
|
||||
<pre><code>%> zypper remove apache2 </code></pre>
|
||||
<pre><code># zypper remove apache2 </code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper rm apache2
|
||||
<pre><code># zypper rm apache2
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -572,9 +576,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
33. 更新所有的软件包,可以使用 ‘zypper update‘ 或者 ‘zypper up‘。
|
||||
|
||||
<pre><code>%> zypper up </code></pre>
|
||||
<pre><code># zypper up </code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper update
|
||||
<pre><code># zypper update
|
||||
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
@ -591,9 +595,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
Nothing to do.</code></pre>
|
||||
|
||||
35. 安装一个软件库,例如 ariadb,如果该库存在则更新之。
|
||||
35. 安装一个软件库,例如 mariadb,如果该库存在则更新之。
|
||||
|
||||
<pre><code>%> zypper in mariadb
|
||||
<pre><code># zypper in mariadb
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
'mariadb' is already installed.
|
||||
@ -608,7 +612,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
36. 安装某一个软件包的源文件及其依赖关系,例如 mariadb。
|
||||
|
||||
<pre><code>%> zypper si mariadb
|
||||
<pre><code># zypper si mariadb
|
||||
Reading installed packages...
|
||||
Loading repository data...
|
||||
Resolving package dependencies...
|
||||
@ -626,7 +630,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
37. 仅为某一个软件包安装源文件,例如 mariadb
|
||||
|
||||
<pre><code>%> zypper in -D mariadb
|
||||
<pre><code># zypper in -D mariadb
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
'mariadb' is already installed.
|
||||
@ -637,7 +641,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
38. 仅为某一个软件包安装依赖关系,例如 mariadb
|
||||
|
||||
<pre><code>%> zypper si -d mariadb
|
||||
<pre><code># zypper si -d mariadb
|
||||
Reading installed packages...
|
||||
Loading repository data...
|
||||
Resolving package dependencies...
|
||||
@ -653,11 +657,11 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Overall download size: 33.7 MiB. Already cached: 129.5 KiB After the operation, additional 144.3 MiB will be used.
|
||||
Continue? [y/n/? shows all options] (y): y</code></pre>
|
||||
|
||||
#### Zypper in Scripts and Applications ####
|
||||
#### 在脚本和应用中调用 Zypper (非交互式) ####
|
||||
|
||||
39. 安装一个软件包,并且在安装过程中跳过与用户的交互, 例如 mariadb。
|
||||
|
||||
<pre><code>%> zypper --non-interactive in mariadb
|
||||
<pre><code># zypper --non-interactive in mariadb
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
'mariadb' is already installed.
|
||||
@ -668,7 +672,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
40. 卸载一个软件包,并且在卸载过程中跳过与用户的交互,例如 mariadb
|
||||
|
||||
<pre><code>%> zypper --non-interactive rm mariadb
|
||||
<pre><code># zypper --non-interactive rm mariadb
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -681,18 +685,18 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Continue? [y/n/? shows all options] (y): y
|
||||
(1/1) Removing mariadb-10.0.13-2.6.1 .............................................................................[done] </code></pre>
|
||||
|
||||
41. 将 zypper 输出用 XML 格式打印。
|
||||
41. 以 XML 格式显示 zypper 的输出。
|
||||
|
||||
<pre><code>%> zypper --xmlout
|
||||
<pre><code># zypper --xmlout
|
||||
Usage:
|
||||
zypper [--global-options] <command> [--command-options] [arguments]
|
||||
|
||||
Global Options
|
||||
....</code></pre>
|
||||
|
||||
42. 禁止详细信息输出到屏幕。
|
||||
42. 在安装过程中禁止详细信息输出到屏幕。
|
||||
|
||||
<pre><code>%> zypper --quiet in mariadb
|
||||
<pre><code># zypper --quiet in mariadb
|
||||
The following NEW package is going to be installed:
|
||||
mariadb
|
||||
|
||||
@ -703,10 +707,11 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
43. 在卸载过程中禁止详细信息输出到屏幕
|
||||
|
||||
<pre><code>%> zypper --quiet rm mariadb </code></pre>
|
||||
<pre><code># zypper --quiet rm mariadb </code></pre>
|
||||
|
||||
44. 自动地同意版权或者协议。
|
||||
<pre><code>%> zypper patch --auto-agree-with-licenses
|
||||
44. 自动地同意版权或者协议。
|
||||
|
||||
<pre><code># zypper patch --auto-agree-with-licenses
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -717,15 +722,15 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
45. 以下指令可以用来清理Zypper缓存。
|
||||
|
||||
<pre><code>%> zypper clean
|
||||
<pre><code># zypper clean
|
||||
All repositories have been cleaned up.</code></pre>
|
||||
|
||||
如果需要一次性地清理元数据以及软件包缓存,可以通过 -all/-a 选项来达到目的
|
||||
如果需要一次性地清理元数据以及软件包缓存,可以通过 -all 或 -a 选项来达到目的
|
||||
|
||||
<pre><code>%> zypper clean -a
|
||||
<pre><code># zypper clean -a
|
||||
All repositories have been cleaned up.</code></pre>
|
||||
|
||||
46. 查看 Zypper 的历史信息。籍由 Zypper 所有的软件包管理动作,包括安装、更新以及卸载都会在 /var/log/zypp/history中保留历史信息。可以通过 cat 来查看此文件,或者通过过滤器来筛选希望看到的信息。
|
||||
46. 查看 Zypper 的历史信息。任何通过 Zypper 进行的软件包管理动作,包括安装、更新以及卸载都会在 /var/log/zypp/history中保留历史信息。可以通过 cat 来查看此文件,或者通过过滤器来筛选希望看到的信息。
|
||||
|
||||
<pre><code> cat /var/log/zypp/history
|
||||
2015-05-07 15:43:03|install|boost-license1_54_0|1.54.0-10.1.3|noarch||openSUSE-13.2-0|0523b909d2aae5239f9841316dafaf3a37b4f096|
|
||||
@ -742,7 +747,8 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
#### 使用 Zypper 进行SUSE系统升级 ####
|
||||
|
||||
47. 可以使用 Zypper 命令的 'dist-upgrade' 选项来将当前的SUSE Linux升级至最新版本。
|
||||
47. 可以使用 Zypper 命令的 'dist-upgrade' 选项来将当前的 SUSE Linux 升级至最新版本。
|
||||
|
||||
<pre><code># zypper dist-upgrade
|
||||
You are about to do a distribution upgrade with all enabled repositories. Make sure these repositories are compatible before you continue. See 'man zypper' for more information about this command.
|
||||
Building repository 'openSUSE-13.2-0' cache .....................................................................[done]
|
||||
@ -755,11 +761,11 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
原文地址: http://www.tecmint.com/zypper-commands-to-manage-suse-linux-package-management/
|
||||
via: http://www.tecmint.com/zypper-commands-to-manage-suse-linux-package-management/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[张博约](https://github.com/zhangboyue)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,22 @@
|
||||
Linux中用于监控网络、磁盘使用、开机时间、平均负载和内存使用率的shell脚本
|
||||
一个Linux中用于监控的简易shell脚本
|
||||
================================================================================
|
||||
系统管理员的任务真的很艰难,因为他/她必须监控服务器、用户、日志,还得创建备份,等等等等。对于大多数重复性的任务,大多数管理员都会写一个自动化脚本来日复一日重复这些任务。这里,我们已经写了一个shell脚本给大家,用来自动化完成系统管理员所要完成的常规任务,这可能在多数情况下,尤其是对于新手而言十分有用,他们能通过该脚本获取到大多数的他们想要的信息,包括系统、网络、用户、负载、内存、主机、内部IP、外部IP、开机时间等。
|
||||
系统管理员的任务真的很艰难,因为他/她必须监控服务器、用户、日志,还得创建备份,等等等等。对于大多数重复性的任务,大多数管理员都会写一个自动化脚本来日复一日地重复这些任务。这里,我们已经写了一个shell脚本给大家,用来自动化完成系统管理员所要完成的常规任务,这可能在多数情况下,尤其是对于新手而言十分有用,他们能通过该脚本获取到大多数的他们想要的信息,包括系统、网络、用户、负载、内存、主机、内部IP、外部IP、开机时间等。
|
||||
|
||||
我们已经注意并进行了格式化输出(在一定程度上哦)。此脚本不包含任何恶意内容,并且它能以普通用户帐号运行。事实上,我们也推荐你以普通用户运行该脚本,而不是root。
|
||||
|
||||
|
||||
监控Linux系统健康的Shell脚本
|
||||
|
||||
你可以通过给Tecmint和脚本作者合适的积分,获得自由使用/修改/再分发下面代码的权利。我们已经试着在一定程度上自定义了输出结果,除了要求的输出内容外,其它内容都不会生成。我们也已经试着使用了那些Linux系统中通常不使用的变量,这些变量可能也是自由代码。
|
||||
*监控Linux系统健康的Shell脚本*
|
||||
|
||||
在保留Tecmint和脚本作者应得荣誉的前提下,可以自由使用/修改/再分发下面代码。我们已经试着在一定程度上自定义了输出结果,除了要求的输出内容外,其它内容都不会生成。我们也已经试着使用了那些Linux系统中通常不使用的变量,这些变量应该是可以随便用的。
|
||||
|
||||
#### 最小系统要求 ####
|
||||
|
||||
你所需要的一切,就是一台正常运转的Linux盒子。
|
||||
你所需要的一切,就是一台正常运转的Linux机器。
|
||||
|
||||
#### 依赖性 ####
|
||||
|
||||
对于一个标准的Linux发行版,使用此包时没有任何依赖。此外,该脚本不需要root权限来执行。但是,如果你想要安装,则必须输入一次root密码。
|
||||
对于一个标准的Linux发行版,使用此软件包不需任何依赖。此外,该脚本不需要root权限来执行。但是,如果你想要安装,则必须输入一次root密码。
|
||||
|
||||
#### 安全性 ####
|
||||
|
||||
@ -30,16 +31,16 @@ Linux中用于监控网络、磁盘使用、开机时间、平均负载和内存
|
||||
|
||||
强烈建议你以普通用户身份安装该脚本,而不是root。安装过程中会询问root密码,并且在需要的时候安装必要的组件。
|
||||
|
||||
要安装`“tecmint_monitor.sh”`脚本,只需像下面这样使用-i(安装)选项就可以了。
|
||||
要安装“`tecmint_monitor.sh`”脚本,只需像下面这样使用-i(安装)选项就可以了。
|
||||
|
||||
/tecmint_monitor.sh -i
|
||||
./tecmint_monitor.sh -i
|
||||
|
||||
在提示你输入root密码时输入该密码。如果一切顺利,你会看到像下面这样的安装成功信息。
|
||||
|
||||
Password:
|
||||
Congratulations! Script Installed, now run monitor Command
|
||||
|
||||
安装完毕后,你可以通过在任何位置,以任何用户调用命令`‘monitor’`来运行该脚本。如果你不喜欢安装,你需要在每次运行时输入路径。
|
||||
安装完毕后,你可以在任何位置,以任何用户调用命令`‘monitor’`来运行该脚本。如果你不喜欢安装,你需要在每次运行时输入路径。
|
||||
|
||||
# ./Path/to/script/tecmint_monitor.sh
|
||||
|
||||
@ -49,7 +50,7 @@ Linux中用于监控网络、磁盘使用、开机时间、平均负载和内存
|
||||
|
||||
|
||||
|
||||
你一运行命令,就会获得下面这些各种各样和系统相关的信息:
|
||||
你运行命令就会获得下面这些各种各样和系统相关的信息:
|
||||
|
||||
- 互联网连通性
|
||||
- 操作系统类型
|
||||
@ -78,9 +79,9 @@ Linux中用于监控网络、磁盘使用、开机时间、平均负载和内存
|
||||
|
||||
### 小结 ###
|
||||
|
||||
该脚本在一些机器上可以开机即用,这一点我已经检查过。相信对于你而言,它也会正常工作。如果你们发现了什么毛病,可以在评论中告诉我。这个脚本还不是结束,这仅仅是个开始。从这里开始,你可以将它提升到任何等级。如果你想要编辑脚本,将它带入一个更深的层次,尽管随意去做吧,别忘了给我们合适的积分,也别忘了把你更新后的脚本拿出来和我们分享哦,这样,我们也能通过给你合适的积分来更新此文。
|
||||
该脚本在一些机器上可以开机即用,这一点我已经检查过。相信对于你而言,它也会正常工作。如果你们发现了什么毛病,可以在评论中告诉我。这个脚本还不完善,这仅仅是个开始。从这里开始,你可以将它改进到任何程度。如果你想要编辑脚本,将它带入一个更深的层次,尽管随意去做吧,别忘了给我们应的的荣誉,也别忘了把你更新后的脚本拿出来和我们分享哦,这样,我们也会更新此文来给你应得的荣誉。
|
||||
|
||||
别忘了和我们分享你的想法或者脚本,我们会在这儿帮助你。谢谢你们给予的所有挚爱。保持连线,不要走开哦。
|
||||
别忘了和我们分享你的想法或者脚本,我们会在这儿帮助你。谢谢你们给予的所有挚爱。继续浏览,不要走开哦。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -88,7 +89,7 @@ via: http://www.tecmint.com/linux-server-health-monitoring-script/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
如何在 Windows 操作系统中运行 Docker 客户端
|
||||
================================================================================
|
||||
大家好,今天我们来了解一下 Windows 操作系统中的 Docker 以及在其中安装 Docker Windows 客户端的知识。Docker 引擎使用 Linux 特定内核特性,因此不能通过 Windows 内核运行,Docker 引擎创建一个小的虚拟系统运行 Linux 并利用它的资源和内核。Windows Docker 客户端用虚拟化 Docker 引擎构建,运行以及管理 盒子以外的 Docker 容器。这里有个由 Boot2Docker 团队开发的名为 Boot2Docker 的应用程序,它创建运行在基于[Linux 微内核][1]的小型 Linux 系统上的虚拟机,是特意为在 Windows 上运行 [Docker][2] 容器开发的。它完全运行在 RAM 中,需要大约 27M 内存并能在 5s(YMMV,译者注:your mileage may vary,因人而异) 内启动。因此,在用于 Windows 的 Docker 引擎被开发出来之前,我们在 Windows 机器里只能运行 Linux 容器。
|
||||
|
||||
大家好,今天我们来了解一下 Windows 操作系统中的 Docker 以及在其中安装 Docker Windows 客户端的知识。Docker 引擎使用 Linux 特有的内核特性,因此不能通过 Windows 内核运行,所以,(在 Windows 上)Docker 引擎创建了一个小的虚拟系统运行 Linux 并利用它的资源和内核。这样,Windows Docker 客户端就可以用这个虚拟的 Docker 引擎来构建、运行以及管理 Docker 容器。有个叫 Boot2Docker 的团队开发了一个同名的应用程序,它创建了一个虚拟机来运行基于[Tiny Core Linux][1]特制的小型 Linux,来在 Windows 上运行 [Docker][2] 容器。它完全运行在内存中,需要大约 27M 内存并能在 5秒 (因人而异) 内启动。因此,在用于 Windows 的 Docker 引擎被开发出来之前,我们在 Windows 机器里只能运行 Linux 容器。
|
||||
|
||||
下面是安装 Docker 客户端并在上面运行容器的简单步骤。
|
||||
|
||||
@ -12,7 +13,7 @@
|
||||
|
||||
### 2. 安装 Boot2Docker ###
|
||||
|
||||
现在我们运行安装文件,它会安装 Window Docker 客户端、用于 Windows 的 Git(MSYS-git)、VirtualBox、Boot2Docker Linux ISO 以及 Boot2Docker 管理工具,这些对于在盒子之外运行 Docker 引擎都至关重要。
|
||||
现在我们运行安装文件,它会安装 Window Docker 客户端、用于 Windows 的 Git(MSYS-git)、VirtualBox、Boot2Docker Linux ISO 以及 Boot2Docker 管理工具,这些对于开箱即用地运行全功能的 Docker 引擎都至关重要。
|
||||
|
||||

|
||||
|
||||
@ -20,7 +21,7 @@
|
||||
|
||||

|
||||
|
||||
安装完成必要的组件之后,我们从桌面 Boot2Docker 快捷方式启动 Boot2Docker。它会要求你输入以后用于验证的 SSH 密钥。然后会启动一个配置好的用于管理在虚拟机中运行的 Docker 的 unix shell。
|
||||
安装完成必要的组件之后,我们从桌面上的“Boot2Docker Start”快捷方式启动 Boot2Docker。它会要求你输入以后用于验证的 SSH 密钥。然后会启动一个配置好的用于管理在虚拟机中运行的 Docker 的 unix shell。
|
||||
|
||||

|
||||
|
||||
@ -32,7 +33,7 @@
|
||||
|
||||
### 4. 运行 Docker ###
|
||||
|
||||
由于 **Boot2Docker Start** 自动启动了一个已经正确设置好环境变量的 shell,我们可以马上开始使用 Docker。**请注意,如果我们将 Boot2Docker 作为一个远程 Docker 守护进程,那么不要在 docker 命令之前加 sudo。**
|
||||
由于 **Boot2Docker Start** 自动启动了一个已经正确设置好环境变量的 shell,我们可以马上开始使用 Docker。**请注意,如果我们要将 Boot2Docker 作为一个远程 Docker 守护进程,那么不要在 docker 命令之前加 sudo。**
|
||||
|
||||
现在,让我们来试试 **hello-world** 例子镜像,它会下载 hello-world 镜像,运行并输出 "Hello from Docker" 信息。
|
||||
|
||||
@ -56,7 +57,7 @@
|
||||
|
||||
**注意**: 如果你看到 machine does no exist 的错误信息,就运行 **boot2docker init** 命令。
|
||||
|
||||
然后复制控制台中的命令到 cmd.exe 中为控制台窗口设置环境变量,然后我们就可以像平常一样运行 docker 容器了。
|
||||
然后复制上图中控制台标出命令到 cmd.exe 中为控制台窗口设置环境变量,然后我们就可以像平常一样运行 docker 容器了。
|
||||
|
||||
### 6. 使用 PowerShell 运行 Docker ###
|
||||
|
||||
@ -74,7 +75,7 @@
|
||||
|
||||
### 7. 用 PUTTY 登录 ###
|
||||
|
||||
Boot2Docker 在%USERPROFILE%\.ssh 目录生成和使用用于登录的公共和私有密钥,我们也需要使用这个文件夹中的私有密钥。私有密钥需要转换为 PuTTY 的格式。我们可以通过 puttygen.exe 实现。
|
||||
Boot2Docker 会在%USERPROFILE%\.ssh 目录生成和使用用于登录的公共和私有密钥,我们也需要使用这个文件夹中的私有密钥。私有密钥需要转换为 PuTTY 的格式。我们可以通过 puttygen.exe 实现。
|
||||
|
||||
我们需要打开 puttygen.exe 并从 %USERPROFILE%\.ssh\id_boot2docker 中导入("File"->"Load" 菜单)私钥,然后点击 "Save Private Key"。然后用保存的文件通过 PuTTY 用 docker@127.0.0.1:2022 登录。
|
||||
|
||||
@ -88,7 +89,9 @@ Boot2Docker 管理工具提供了一些命令,如下所示。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
通过 Docker Windows 客户端使用 Docker 很有趣。Boot2Docker 管理工具是一个能使任何 Docker 容器能像在 Linux 主机上平稳运行的很棒的应用程序。如果你更仔细的话,你会发现 boot2docker 默认用户的用户名是 docker,密码是 tcuser。最新版本的 boot2docker 设置了一个 host-only 的网络适配器提供访问容器的端口。一般来说是 192.168.59.103,但可以通过 VirtualBox 的 DHCP 实现改变。如果你有任何问题、建议、反馈,请在下面的评论框中写下来然后我们可以改进或者更新我们的内容。非常感谢!Enjoy:-)
|
||||
通过 Docker Windows 客户端使用 Docker 很有趣。Boot2Docker 管理工具是一个能使任何 Docker 容器能像在 Linux 主机上平滑运行的很棒的应用程序。如果你更仔细的话,你会发现 boot2docker 默认用户的用户名是 docker,密码是 tcuser。最新版本的 boot2docker 设置了一个 host-only 的网络适配器提供访问容器的端口。一般来说是 192.168.59.103,但可以通过 VirtualBox 的 DHCP 实现改变。
|
||||
|
||||
如果你有任何问题、建议、反馈,请在下面的评论框中写下来然后我们可以改进或者更新我们的内容。非常感谢!Enjoy:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -96,7 +99,7 @@ via: http://linoxide.com/linux-how-to/run-docker-client-inside-windows-os/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
Linux有问必答——Linux上如何查看torrent文件内容
|
||||
Linux有问必答:Linux上如何查看种子文件的内容
|
||||
================================================================================
|
||||
> **问题**: 我从网站上下载了一个torrent文件。Linux上有没有工具让我查看torrent文件的内容?例如,我想知道torrent里面都有什么文件。
|
||||
> **问题**: 我从网站上下载了一个torrent(种子)文件。Linux上有没有工具让我查看torrent文件的内容?例如,我想知道torrent里面都包含什么文件。
|
||||
|
||||
torrent文件(也就是扩展名为**.torrent**的文件)是BitTorrent元数据文件,里面存储了BitTorrent客户端用来从BitTorrent点对点网络下载共享文件的信息(如,追踪器URL、文件列表、大小、校验和、创建日期等)。在单个torrent文件里面,可以列出一个或多个文件用于共享。
|
||||
|
||||
@ -8,7 +8,7 @@ torrent文件内容由BEncode编码为BitTorrent数据序列化格式,因此
|
||||
|
||||
事实上,任何图形化的BitTorrent客户端(如Transmission或uTorrent)都带有BEncode解码器,所以,你可以用它们直接打开来查看torrent文件的内容。然而,如果你不想要使用BitTorrent客户端来检查torrent文件,你可以试试这个命令行torrent查看器,它叫[dumptorrent][1]。
|
||||
|
||||
**dumptorrent**命令可以使用内建的BEncode解码器打印torrent文件的详细信息(如,文件名、大小、跟踪器URL、创建日期、信息散列等等)。
|
||||
**dumptorrent**命令可以使用内建的BEncode解码器打印出torrent文件的详细信息(如,文件名、大小、跟踪器URL、创建日期、信息散列等等)。
|
||||
|
||||
### 安装DumpTorrent到Linux ###
|
||||
|
||||
@ -32,7 +32,7 @@ torrent文件内容由BEncode编码为BitTorrent数据序列化格式,因此
|
||||
$ make
|
||||
$ sudo cp dumptorrent /usr/local/bin
|
||||
|
||||
确保你的路径中[包含][2]了/usr/local/bin。
|
||||
确保你的搜索路径 PATH 中[包含][2]了/usr/local/bin。
|
||||
|
||||
### 查看torrent的内容 ###
|
||||
|
||||
@ -41,6 +41,7 @@ torrent文件内容由BEncode编码为BitTorrent数据序列化格式,因此
|
||||
$ dumptorrent <torrent-file>
|
||||
|
||||

|
||||
|
||||
要查看torrent的完整内容,请添加“-v”选项。它会打印更多关于torrent的详细信息,包括信息散列、片长度、创建日期、创建者,以及完整的声明列表。
|
||||
|
||||
$ dumptorrent -v <torrent-file>
|
||||
@ -53,7 +54,7 @@ via: http://ask.xmodulo.com/view-torrent-file-content-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
基础的Docker容器网络命令
|
||||
================================================================================
|
||||
各位好,今天我们将学习一些Docker容器的基础命令。Docker 是一个开源项目,提供了一个可以打包、装载和运行任何应用的轻量级容器的开放平台。它没有语言支持、框架和打包系统的限制,从小型的家用电脑到高端服务器,在何时何地都可以运行。它可以使部署和扩展web应用程序、数据库和后端服务像搭积木一样容易,而不依赖特定技术栈或提供商。Docker适用于网络环境,它正应用于数据中心、ISP和越来越多的网络服务。
|
||||
|
||||
因此,这里有一些你在管理Docker容器的时候会用到的一些命令。
|
||||
|
||||
### 1. 找到Docker接口 ###
|
||||
|
||||
Docker默认会创建一个名为docker0的网桥接口作为连接外部世界的基础。运行中的docker容器直接连接到网桥接口docker0。默认上,docker会分配172.17.42.1/16给docker0,它是所有运行中的容器ip地址的子网。找到Docker接口的ip地址非常简单。要找出docker0网桥接口和连接到网桥上的docker容器,我们可以在安装了docker的终端或者shell中运行ip命令。
|
||||
|
||||
# ip a
|
||||
|
||||

|
||||
|
||||
### 2. 得到Docker容器的ip地址 ###
|
||||
|
||||
如我们上面读到的,docker在宿主机中创建了一个叫docker0的网桥接口。在我们创建一个新的docker容器时,它自动被默认分配了一个在该子网范围内的ip地址。因此,要检测运行中的Docker容器的ip地址,我们需要进入一个正在运行的容器并用下面的命令检查ip地址。首先,我们运行一个新的容器并进入其中。如果你已经有一个正在运行的容器,你可以跳过这个步骤。
|
||||
|
||||
# docker run -it ubuntu
|
||||
|
||||
现在,我们可以运行ip a来得到容器的ip地址了。
|
||||
|
||||
# ip a
|
||||
|
||||

|
||||
|
||||
### 3. 映射暴露的端口 ###
|
||||
|
||||
要映射配置在Dockerfile的暴露端口到宿主机的高位端口,我们只需用下面带上-P标志的命令。这会打开docker容器的随机端口并映射到Dockerfile中定义的端口。下面是使用-P来打开/暴露定义的端口的例子。
|
||||
|
||||
# docker run -itd -P httpd
|
||||
|
||||

|
||||
|
||||
上面的命令会映射容器的端口到 httpd 容器的 Dockerfile 中定义的80端口上。我们用下面的命令来查看正在运行的容器暴露的端口。
|
||||
|
||||
# docker ps
|
||||
|
||||
并且可以用下面的curl命令来检查。
|
||||
|
||||
# curl http://localhost:49153
|
||||
|
||||

|
||||
|
||||
### 4. 映射到特定的端口上 ###
|
||||
|
||||
我们也可以映射暴露端口或者docker容器端口到我们指定的端口上。要实现这个,我们用-p标志来定义我们所需的端口。这里是我们的一个例子。
|
||||
|
||||
# docker run -itd -p 8080:80 httpd
|
||||
|
||||
上面的命令会映射(宿主机的)8080端口到(容器的)80上。我们可以运行curl来检查这点。
|
||||
|
||||
# curl http://localhost:8080
|
||||
|
||||

|
||||
|
||||
### 5. 创建自己的网桥 ###
|
||||
|
||||
要给容器创建一个自定义的IP地址,在本篇中我们会创建一个名为br0的新网桥。要分配需要的ip地址,我们需要在运行docker的宿主机中运行下面的命令。
|
||||
|
||||
# stop docker.io
|
||||
# ip link add br0 type bridge
|
||||
# ip addr add 172.30.1.1/20 dev br0
|
||||
# ip link set br0 up
|
||||
# docker -d -b br0
|
||||
|
||||

|
||||
|
||||
创建完docker网桥之后,我们要让docker的守护进程知道它。
|
||||
|
||||
# echo 'DOCKER_OPTS="-b=br0"' >> /etc/default/docker
|
||||
# service docker.io start
|
||||
|
||||

|
||||
|
||||
到这里,桥接后的接口将会分配给容器在桥接子网内的新ip地址。
|
||||
|
||||
### 6. 链接到另外一个容器上 ###
|
||||
|
||||
我们可以用Docker将一个容器连接到另外一个上。我们可以在不同的容器上运行不同的程序,并且相互连接或链接。链接允许容器间相互连接并从一个容器上安全地传输信息给另一个容器。要做到这个,我们可以使用--link标志。首先,我们使用--name标志来标示training/postgres镜像。
|
||||
|
||||
# docker run -d --name db training/postgres
|
||||
|
||||

|
||||
|
||||
完成之后,我们将容器db与training/webapp链接来形成新的叫web的容器。
|
||||
|
||||
# docker run -d -P --name web --link db:db training/webapp python app.py
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
Docker网络很神奇也好玩,我们可以对docker容器做很多事情。我们可以把玩这些简单而基础的docker网络命令。docker的网络是非常先进的,我们可以用它做很多事情。
|
||||
|
||||
如果你有任何的问题、建议、反馈请在下面的评论栏写下来以便于我们我们可以提升或者更新文章的内容。谢谢! 玩得开心!:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/networking-commands-docker-containers/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,14 +1,14 @@
|
||||
70 个可能的 Shell 脚本面试问题及解答
|
||||
Shell 脚本面试问题大全
|
||||
================================================================================
|
||||
我们为你的面试准备选择了 70 个可能的 shell 脚面问题及解答。了解脚本或至少知道基础知识对系统管理员来说至关重要,它也有助于你在工作环境中自动完成很多任务。在过去的几年里,我们注意到所有的 linux 工作职位都要求脚本技能。
|
||||
我们为你的面试准备选择了 70 个你可能遇到的 shell 脚面问题及解答。了解脚本或至少知道基础知识对系统管理员来说至关重要,它也有助于你在工作环境中自动完成很多任务。在过去的几年里,我们注意到所有的 linux 工作职位都要求脚本技能。
|
||||
|
||||
### 1) 如何向脚本传递参数 ? ###
|
||||
|
||||
./script argument
|
||||
./script argument
|
||||
|
||||
**例子** : 显示文件名称脚本
|
||||
|
||||
./show.sh file1.txt
|
||||
./show.sh file1.txt
|
||||
|
||||
cat show.sh
|
||||
#!/bin/bash
|
||||
@ -16,12 +16,11 @@
|
||||
|
||||
### 2) 如何在脚本中使用参数 ? ###
|
||||
|
||||
第一个参数: $1,
|
||||
第二个参数 : $2
|
||||
第一个参数 : $1,第二个参数 : $2
|
||||
|
||||
例子 : 脚本会复制文件(arg1) 到目标地址(arg2)
|
||||
|
||||
./copy.sh file1.txt /tmp/
|
||||
./copy.sh file1.txt /tmp/
|
||||
|
||||
cat copy.sh
|
||||
#!/bin/bash
|
||||
@ -29,127 +28,129 @@
|
||||
|
||||
### 3) 如何计算传递进来的参数 ? ###
|
||||
|
||||
$#
|
||||
$#
|
||||
|
||||
### 4) 如何在脚本中获取脚本名称 ? ###
|
||||
|
||||
$0
|
||||
$0
|
||||
|
||||
### 5) 如何检查之前的命令是否运行成功 ? ###
|
||||
|
||||
$?
|
||||
$?
|
||||
|
||||
### 6) 如何获取文件的最后一行 ? ###
|
||||
|
||||
tail -1
|
||||
tail -1
|
||||
|
||||
### 7) 如何获取文件的第一行 ? ###
|
||||
|
||||
head -1
|
||||
head -1
|
||||
|
||||
### 8) 如何获取一个文件每一行的第三个元素 ? ###
|
||||
|
||||
awk '{print $3}'
|
||||
awk '{print $3}'
|
||||
|
||||
### 9) 假如第一个等于 FIND,如何获取文件中每行的第二个元素 ###
|
||||
### 9) 假如文件中每行第一个元素是 FIND,如何获取第二个元素 ###
|
||||
|
||||
awk '{ if ($1 == "FIND") print $2}'
|
||||
awk '{ if ($1 == "FIND") print $2}'
|
||||
|
||||
### 10) 如何调试 bash 脚本 ###
|
||||
|
||||
Add -xv to #!/bin/bash
|
||||
|
||||
例子
|
||||
将 -xv 参数加到 #!/bin/bash 后
|
||||
|
||||
#!/bin/bash –xv
|
||||
例子:
|
||||
|
||||
#!/bin/bash –xv
|
||||
|
||||
### 11) 举例如何写一个函数 ? ###
|
||||
|
||||
function example {
|
||||
echo "Hello world!"
|
||||
}
|
||||
function example {
|
||||
echo "Hello world!"
|
||||
}
|
||||
|
||||
### 12) 如何向 string 添加 string ? ###
|
||||
### 12) 如何向连接两个字符串 ? ###
|
||||
|
||||
V1="Hello"
|
||||
V2="World"
|
||||
V3=$V1+$V2
|
||||
echo $V3
|
||||
V1="Hello"
|
||||
V2="World"
|
||||
V3=$V1+$V2
|
||||
echo $V3
|
||||
|
||||
Output
|
||||
输出
|
||||
|
||||
Hello+World
|
||||
Hello+World
|
||||
|
||||
### 13) 如何进行两个整数相加 ? ###
|
||||
|
||||
V1=1
|
||||
V2=2
|
||||
V3=$V1+$V2
|
||||
echo $V3
|
||||
V1=1
|
||||
V2=2
|
||||
V3=$V1+$V2
|
||||
echo $V3
|
||||
|
||||
Output
|
||||
3
|
||||
输出
|
||||
|
||||
3
|
||||
|
||||
### 14) 如何检查文件系统中是否存在某个文件 ? ###
|
||||
|
||||
if [ -f /var/log/messages ]
|
||||
then
|
||||
echo "File exists"
|
||||
fi
|
||||
if [ -f /var/log/messages ]
|
||||
then
|
||||
echo "File exists"
|
||||
fi
|
||||
|
||||
### 15) 写出 shell 脚本中所有循环语法 ? ###
|
||||
|
||||
#### for loop : ####
|
||||
#### for 循环 : ####
|
||||
|
||||
for i in $( ls ); do
|
||||
echo item: $i
|
||||
done
|
||||
for i in $( ls ); do
|
||||
echo item: $i
|
||||
done
|
||||
|
||||
#### while loop : ####
|
||||
#### while 循环 : ####
|
||||
|
||||
#!/bin/bash
|
||||
COUNTER=0
|
||||
while [ $COUNTER -lt 10 ]; do
|
||||
echo The counter is $COUNTER
|
||||
let COUNTER=COUNTER+1
|
||||
done
|
||||
#!/bin/bash
|
||||
COUNTER=0
|
||||
while [ $COUNTER -lt 10 ]; do
|
||||
echo The counter is $COUNTER
|
||||
let COUNTER=COUNTER+1
|
||||
done
|
||||
|
||||
#### untill oop : ####
|
||||
#### until 循环 : ####
|
||||
|
||||
#!/bin/bash
|
||||
COUNTER=20
|
||||
until [ $COUNTER -lt 10 ]; do
|
||||
echo COUNTER $COUNTER
|
||||
let COUNTER-=1
|
||||
done
|
||||
#!/bin/bash
|
||||
COUNTER=20
|
||||
until [ $COUNTER -lt 10 ]; do
|
||||
echo COUNTER $COUNTER
|
||||
let COUNTER-=1
|
||||
done
|
||||
|
||||
### 16) 每个脚本开始的 #!/bin/sh 或 #!/bin/bash 表示什么意思 ? ###
|
||||
|
||||
这一行说明要使用的 shell。#!/bin/bash 表示脚本使用 /bin/bash。对于 python 脚本,就是 #!/usr/bin/python
|
||||
这一行说明要使用的 shell。#!/bin/bash 表示脚本使用 /bin/bash。对于 python 脚本,就是 #!/usr/bin/python。(LCTT译注:这一行称之为[释伴行](https://linux.cn/article-3664-1.html)。)
|
||||
|
||||
### 17) 如何获取文本文件的第 10 行 ? ###
|
||||
|
||||
head -10 file|tail -1
|
||||
head -10 file|tail -1
|
||||
|
||||
### 18) bash 脚本文件的第一个符号是什么 ###
|
||||
|
||||
#
|
||||
#
|
||||
|
||||
### 19) 命令:[ -z "" ] && echo 0 || echo 1 的输出是什么 ###
|
||||
|
||||
0
|
||||
0
|
||||
|
||||
### 20) 命令 “export” 有什么用 ? ###
|
||||
|
||||
使变量在子 shell 中公有
|
||||
使变量在子 shell 中可用。
|
||||
|
||||
### 21) 如何在后台运行脚本 ? ###
|
||||
|
||||
在脚本后面添加 “&”
|
||||
在脚本后面添加 “&”。
|
||||
|
||||
### 22) "chmod 500 script" 做什么 ? ###
|
||||
|
||||
使脚本所有者拥有可执行权限
|
||||
使脚本所有者拥有可执行权限。
|
||||
|
||||
### 23) ">" 做什么 ? ###
|
||||
|
||||
@ -157,8 +158,8 @@ head -10 file|tail -1
|
||||
|
||||
### 24) & 和 && 有什么区别 ###
|
||||
|
||||
& - 希望脚本在后台运行的时候使用它
|
||||
&& - 当第一个脚本成功完成才执行命令/脚本的时候使用它
|
||||
- & - 希望脚本在后台运行的时候使用它
|
||||
- && - 当前一个脚本成功完成才执行后面的命令/脚本的时候使用它
|
||||
|
||||
### 25) 什么时候要在 [ condition ] 之前使用 “if” ? ###
|
||||
|
||||
@ -166,81 +167,87 @@ head -10 file|tail -1
|
||||
|
||||
### 26) 命令: name=John && echo 'My name is $name' 的输出是什么 ###
|
||||
|
||||
My name is $name
|
||||
My name is $name
|
||||
|
||||
### 27) bash shell 脚本中哪个符号用于注释 ? ###
|
||||
|
||||
#
|
||||
#
|
||||
|
||||
### 28) 命令: echo ${new:-variable} 的输出是什么 ###
|
||||
|
||||
variable
|
||||
variable
|
||||
|
||||
### 29) ' 和 " 引号有什么区别 ? ###
|
||||
|
||||
' - 当我们不希望把变量转换为值的时候使用它。
|
||||
" - 会计算所有变量的值并用值代替。
|
||||
- ' - 当我们不希望把变量转换为值的时候使用它。
|
||||
- " - 会计算所有变量的值并用值代替。
|
||||
|
||||
### 30) 如何在脚本文件中重定向标准输入输出流到 log.txt 文件 ? ###
|
||||
### 30) 如何在脚本文件中重定向标准输出和标准错误流到 log.txt 文件 ? ###
|
||||
|
||||
在脚本文件中添加 "exec >log.txt 2>&1" 命令
|
||||
在脚本文件中添加 "exec >log.txt 2>&1" 命令。
|
||||
|
||||
### 31) 如何只用 echo 命令获取 string 变量的一部分 ? ###
|
||||
### 31) 如何只用 echo 命令获取字符串变量的一部分 ? ###
|
||||
|
||||
echo ${variable:x:y}
|
||||
x - 起始位置
|
||||
y - 长度
|
||||
|
||||
echo ${variable:x:y}
|
||||
x - 起始位置
|
||||
y - 长度
|
||||
例子:
|
||||
variable="My name is Petras, and I am developer."
|
||||
echo ${variable:11:6} # 会显示 Petras
|
||||
|
||||
### 32) 如果给定字符串 variable="User:123:321:/home/dir" 如何只用 echo 命令获取 home_dir ? ###
|
||||
variable="My name is Petras, and I am developer."
|
||||
echo ${variable:11:6} # 会显示 Petras
|
||||
|
||||
### 32) 如果给定字符串 variable="User:123:321:/home/dir",如何只用 echo 命令获取 home_dir ? ###
|
||||
|
||||
echo ${variable#*:*:*:}
|
||||
|
||||
echo ${variable#*:*:*:}
|
||||
或
|
||||
echo ${variable##*:}
|
||||
|
||||
echo ${variable##*:}
|
||||
|
||||
### 33) 如何从上面的字符串中获取 “User” ? ###
|
||||
|
||||
echo ${variable%:*:*:*}
|
||||
echo ${variable%:*:*:*}
|
||||
|
||||
或
|
||||
echo ${variable%%:*}
|
||||
|
||||
echo ${variable%%:*}
|
||||
|
||||
### 34) 如何使用 awk 列出 UID 小于 100 的用户 ? ###
|
||||
|
||||
awk -F: '$3<100' /etc/passwd
|
||||
awk -F: '$3<100' /etc/passwd
|
||||
|
||||
### 35) 写程序为用户计算主组数目并显示次数和组名 ###
|
||||
|
||||
cat /etc/passwd|cut -d: -f4|sort|uniq -c|while read c g
|
||||
do
|
||||
{ echo $c; grep :$g: /etc/group|cut -d: -f1;}|xargs -n 2
|
||||
done
|
||||
cat /etc/passwd|cut -d: -f4|sort|uniq -c|while read c g
|
||||
do
|
||||
{ echo $c; grep :$g: /etc/group|cut -d: -f1;}|xargs -n 2
|
||||
done
|
||||
|
||||
### 36) 如何在 bash shell 中更改标注域分隔符为 ":" ? ###
|
||||
### 36) 如何在 bash shell 中更改标准的域分隔符为 ":" ? ###
|
||||
|
||||
IFS=":"
|
||||
IFS=":"
|
||||
|
||||
### 37) 如何获取变量长度 ? ###
|
||||
|
||||
${#variable}
|
||||
${#variable}
|
||||
|
||||
### 38) 如何打印变量的最后 5 个字符 ? ###
|
||||
|
||||
echo ${variable: -5}
|
||||
echo ${variable: -5}
|
||||
|
||||
### 39) ${variable:-10} 和 ${variable: -10} 有什么区别? ###
|
||||
|
||||
${variable:-10} - 如果之前没有给 variable 赋值则输出 10
|
||||
${variable: -10} - 输出 variable 的最后 10 个字符
|
||||
- ${variable:-10} - 如果之前没有给 variable 赋值则输出 10
|
||||
- ${variable: -10} - 输出 variable 的最后 10 个字符
|
||||
|
||||
### 40) 如何只用 echo 命令替换字符串的一部分 ? ###
|
||||
|
||||
echo ${variable//pattern/replacement}
|
||||
echo ${variable//pattern/replacement}
|
||||
|
||||
### 41) 哪个命令将命令替换为大写 ? ###
|
||||
|
||||
tr '[:lower:]' '[:upper:]'
|
||||
tr '[:lower:]' '[:upper:]'
|
||||
|
||||
### 42) 如何计算本地用户数目 ? ###
|
||||
|
||||
@ -250,141 +257,151 @@ cat /etc/passwd|wc -l
|
||||
|
||||
### 43) 不用 wc 命令如何计算字符串中的单词数目 ? ###
|
||||
|
||||
set ${string}
|
||||
echo $#
|
||||
set ${string}
|
||||
echo $#
|
||||
|
||||
### 44) "export $variable" 或 "export variable" 哪个正确 ? ###
|
||||
|
||||
export variable
|
||||
export variable
|
||||
|
||||
### 45) 如何列出第二个字母是 a 或 b 的文件 ? ###
|
||||
|
||||
ls -d ?[ab]*
|
||||
ls -d ?[ab]*
|
||||
|
||||
### 46) 如何将整数 a 加到 b 并赋值给 c ? ###
|
||||
|
||||
c=$((a+b))
|
||||
c=$((a+b))
|
||||
|
||||
或
|
||||
c=`expr $a + $b`
|
||||
|
||||
c=`expr $a + $b`
|
||||
|
||||
或
|
||||
c=`echo "$a+$b"|bc`
|
||||
|
||||
c=`echo "$a+$b"|bc`
|
||||
|
||||
### 47) 如何去除字符串中的所有空格 ? ###
|
||||
|
||||
echo $string|tr -d " "
|
||||
echo $string|tr -d " "
|
||||
|
||||
### 48) 重写命令输出变量转换为复数的句子: item="car"; echo "I like $item" ? ###
|
||||
### 48) 重写这个命令,将输出变量转换为复数: item="car"; echo "I like $item" ? ###
|
||||
|
||||
item="car"; echo "I like ${item}s"
|
||||
item="car"; echo "I like ${item}s"
|
||||
|
||||
### 49) 写出输出数字 0 到 100 中 3 的倍数(0 3 6 9 …)的命令 ? ###
|
||||
|
||||
for i in {0..100..3}; do echo $i; done
|
||||
for i in {0..100..3}; do echo $i; done
|
||||
|
||||
或
|
||||
for (( i=0; i<=100; i=i+3 )); do echo "Welcome $i times"; done
|
||||
|
||||
for (( i=0; i<=100; i=i+3 )); do echo "Welcome $i times"; done
|
||||
|
||||
### 50) 如何打印传递给脚本的所有参数 ? ###
|
||||
|
||||
echo $*
|
||||
echo $*
|
||||
|
||||
或
|
||||
echo $@
|
||||
|
||||
echo $@
|
||||
|
||||
### 51) [ $a == $b ] 和 [ $a -eq $b ] 有什么区别 ###
|
||||
|
||||
[ $a == $b ] - 用于字符串比较
|
||||
[ $a -eq $b ] - 用于数字比较
|
||||
- [ $a == $b ] - 用于字符串比较
|
||||
- [ $a -eq $b ] - 用于数字比较
|
||||
|
||||
### 52) = 和 == 有什么区别 ###
|
||||
|
||||
= - 用于为变量复制
|
||||
== - 用于字符串比较
|
||||
- = - 用于为变量复制
|
||||
- == - 用于字符串比较
|
||||
|
||||
### 53) 写出测试 $a 是否大于 12 的命令 ? ###
|
||||
|
||||
[ $a -gt 12 ]
|
||||
[ $a -gt 12 ]
|
||||
|
||||
### 54) 写出测试 $b 是否小于等于 12 的命令 ? ###
|
||||
|
||||
[ $b -le 12 ]
|
||||
[ $b -le 12 ]
|
||||
|
||||
### 55) 如何检查字符串是否以字母 "abc" 开头 ? ###
|
||||
|
||||
[[ $string == abc* ]]
|
||||
[[ $string == abc* ]]
|
||||
|
||||
### 56) [[ $string == abc* ]] 和 [[ $string == "abc*" ]] 有什么区别 ###
|
||||
|
||||
[[ $string == abc* ]] - 检查字符串是否以字母 abc 开头
|
||||
[[ $string == "abc* " ]] - 检查字符串是否完全等于 abc*
|
||||
- [[ $string == abc* ]] - 检查字符串是否以字母 abc 开头
|
||||
- [[ $string == "abc*" ]] - 检查字符串是否完全等于 abc*
|
||||
|
||||
### 57) 如何列出以 ab 或 xy 开头的用户名 ? ###
|
||||
|
||||
egrep "^ab|^xy" /etc/passwd|cut -d: -f1
|
||||
egrep "^ab|^xy" /etc/passwd|cut -d: -f1
|
||||
|
||||
### 58) bash 中 $! 表示什么意思 ? ###
|
||||
|
||||
后台最近命令的 PID
|
||||
后台最近执行命令的 PID.
|
||||
|
||||
### 59) $? 表示什么意思 ? ###
|
||||
|
||||
前台最近命令的结束状态
|
||||
前台最近命令的结束状态。
|
||||
|
||||
### 60) 如何输出当前 shell 的 PID ? ###
|
||||
|
||||
echo $$
|
||||
echo $$
|
||||
|
||||
### 61) 如何获取传递给脚本的参数数目 ? ###
|
||||
|
||||
echo $#
|
||||
echo $#
|
||||
|
||||
(LCTT 译注:和第3题重复了。)
|
||||
|
||||
### 62) $* 和 $@ 有什么区别 ###
|
||||
|
||||
$* - 以一个字符串形式输出所有传递到脚本的参数
|
||||
$@ - 以 $IFS 为分隔符列出所有传递到脚本中的参数
|
||||
- $* - 以一个字符串形式输出所有传递到脚本的参数
|
||||
- $@ - 以 $IFS 为分隔符列出所有传递到脚本中的参数
|
||||
|
||||
### 63) 如何在 bash 中定义数组 ? ###
|
||||
|
||||
array=("Hi" "my" "name" "is")
|
||||
array=("Hi" "my" "name" "is")
|
||||
|
||||
### 64) 如何打印数组的第一个元素 ? ###
|
||||
|
||||
echo ${array[0]}
|
||||
echo ${array[0]}
|
||||
|
||||
### 65) 如何打印数组的所有元素 ? ###
|
||||
|
||||
echo ${array[@]}
|
||||
echo ${array[@]}
|
||||
|
||||
### 66) 如何输出所有数组索引 ? ###
|
||||
|
||||
echo ${!array[@]}
|
||||
echo ${!array[@]}
|
||||
|
||||
### 67) 如何移除数组中索引为 2 的元素 ? ###
|
||||
|
||||
unset array[2]
|
||||
unset array[2]
|
||||
|
||||
### 68) 如何在数组中添加 id 为 333 的元素 ? ###
|
||||
|
||||
array[333]="New_element"
|
||||
array[333]="New_element"
|
||||
|
||||
### 69) shell 脚本如何获取输入的值 ? ###
|
||||
|
||||
a) 通过参数
|
||||
|
||||
./script param1 param2
|
||||
./script param1 param2
|
||||
|
||||
b) 通过 read 命令
|
||||
|
||||
read -p "Destination backup Server : " desthost
|
||||
read -p "Destination backup Server : " desthost
|
||||
|
||||
### 70) 在脚本中如何使用 "expect" ? ###
|
||||
|
||||
/usr/bin/expect << EOD
|
||||
spawn rsync -ar ${line} ${desthost}:${destpath}
|
||||
expect "*?assword:*"
|
||||
send "${password}\r"
|
||||
expect eof
|
||||
EOD
|
||||
/usr/bin/expect << EOD
|
||||
spawn rsync -ar ${line} ${desthost}:${destpath}
|
||||
expect "*?assword:*"
|
||||
send "${password}\r"
|
||||
expect eof
|
||||
EOD
|
||||
|
||||
好运 !! 如果你有任何疑问或者问题需要解答都可以在下面的评论框中写下来。让我们知道这对你的面试有所帮助:-)
|
||||
祝你好运 !! 如果你有任何疑问或者问题需要解答都可以在下面的评论框中写下来。让我们知道这对你的面试有所帮助:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -392,7 +409,7 @@ via: http://linoxide.com/linux-shell-script/shell-scripting-interview-questions-
|
||||
|
||||
作者:[Petras Liumparas][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Linux有问必答——在旧的Ubuntu上如何修复“apt-get update”的“404 Not Found”错误
|
||||
Linux有问必答:如何更新过期版本的Ubuntu
|
||||
================================================================================
|
||||
> **问题**: 我的PC上安装了旧版的Ubuntu 13.04(急切的浣熊)。当我在上面运行“sudo apt-get update”时,它丢给了我一大堆“404 Not Found”错误,结果是我不能使用apt-get或aptitude来安装或更新任何软件包了。由于该错误的原因,我甚至不能将它升级到更新的版本。我怎样才能修复这个问题啊?
|
||||
>
|
||||
@ -20,7 +20,7 @@ Linux有问必答——在旧的Ubuntu上如何修复“apt-get update”的“4
|
||||
|
||||
这里,通过切换到旧版本仓库提供了一个快速修复“404 Not Found”错误的便捷方式。
|
||||
|
||||
首先,使用旧版本仓库替换main/security仓库,就像下面这样。
|
||||
首先,使用old-releases仓库替换main/security仓库,就像下面这样。
|
||||
|
||||
$ sudo sed -i -r 's/([a-z]{2}\.)?archive.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list
|
||||
$ sudo sed -i -r 's/security.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list
|
||||
@ -38,7 +38,7 @@ via: http://ask.xmodulo.com/404-not-found-error-apt-get-update-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
如何使用xkill命令傻点Linux进程/未响应的程序
|
||||
如何使用xkill命令杀掉Linux进程/未响应的程序
|
||||
================================================================================
|
||||
|
||||
我们如何在Linux中杀掉一个资源/进程?很明显我们会找出资源的pid然后用kill命令。
|
||||
|
||||
更准确一点,我们可以找到资源(这里就是terminal)的PID:
|
||||
说的更明白一点,我们可以找到某个资源(比如terminal)的PID:
|
||||
|
||||
$ ps -A | grep -i terminal
|
||||
|
||||
@ -14,7 +15,7 @@
|
||||
|
||||
kill命令会发送一个信号给该pid的进程。
|
||||
|
||||
另外一个方法是我们可以使用pkill命令,它可以基于进程的名字或者其他的属性来杀掉进程。同样我们要杀掉一个叫terminal的进程可以这么做:
|
||||
另外一个方法是我们可以使用pkill命令,它可以基于进程的名字或者其他的属性来杀掉进程。同样我们要杀掉一个叫terminal的进程可以这么做:
|
||||
|
||||
$ pkill terminal
|
||||
|
||||
@ -22,15 +23,15 @@ kill命令会发送一个信号给该pid的进程。
|
||||
|
||||
pkill看上去更加容易上手,因为你你不用找出进程的pid。但是如果你要对系统做更好的控制,那么没有什么可以打败'kill'。使用kill命令可以更好地审视你要杀掉的进程。
|
||||
|
||||
我们已经有一篇覆盖了[kill、pkill和killall命令][1]间细节的指导了。
|
||||
我们已经有一篇覆盖了[kill、pkill和killall命令][1]细节的指导了。
|
||||
|
||||
对于那些运行X Server的人而言,有另外一个工具称为xkill可以将进程从X Window中杀掉而不必传递它的名字或者pid。
|
||||
|
||||
xkill工具强制X server关闭于它客户端之间的联系,这可以让X resource关闭这个客户端。xkill是X11工具集中一个非常容易上手的杀掉无用窗口的工具。
|
||||
xkill工具强制X server关闭与它的客户程序之间的联系,其结果就是X resource关闭了这个客户程序。xkill是X11工具集中一个非常容易上手的杀掉无用窗口的工具。
|
||||
|
||||
它支持的选项如在同时运行多个X Server时使用-display选项后面跟上显示号连接到指定的X server,使用-all(并不建议)杀掉所有在屏幕上的所遇顶层窗口,同时将帧(-frame)也计算在内。
|
||||
它支持的选项如在同时运行多个X Server时使用-display选项后面跟上显示号连接到指定的X server,使用-all(并不建议)杀掉所有在屏幕上的所有顶层窗口,以及帧(-frame)参数。
|
||||
|
||||
要得到所有的客户端你可以运行:
|
||||
要列出所有的客户程序你可以运行:
|
||||
|
||||
$ xlsclients
|
||||
|
||||
@ -46,12 +47,11 @@ xkill工具强制X server关闭于它客户端之间的联系,这可以让X re
|
||||
|
||||
如果后面没有跟上资源id,xkill会将鼠标指针变成一个特殊符号,类似于“X”。只需在你要杀掉的窗口上点击,它就会杀掉它与server端的通信,这个程序就被杀掉了。
|
||||
|
||||
|
||||
$ xkill
|
||||
|
||||

|
||||
|
||||
使用xkill杀掉进程
|
||||
*使用xkill杀掉进程*
|
||||
|
||||
需要注意的是xkill并不能保证它的通信会被成功杀掉/退出。大多数程序会在与服务端的通信被关闭后杀掉。然而仍有少部分会继续运行。
|
||||
|
||||
@ -63,7 +63,7 @@ xkill工具强制X server关闭于它客户端之间的联系,这可以让X re
|
||||
|
||||
**我需要在linux命令行中使用xkill么**
|
||||
|
||||
不是,你不必在命令行中运行xkill。你可以设置一个快捷键,并用它来调用xkill。
|
||||
不是,你不必非在命令行中运行xkill。你可以设置一个快捷键,并用它来调用xkill。
|
||||
|
||||
下面是如何在典型的gnome3桌面中设置键盘快捷键。
|
||||
|
||||
@ -71,13 +71,13 @@ xkill工具强制X server关闭于它客户端之间的联系,这可以让X re
|
||||
|
||||

|
||||
|
||||
Gnome 设置
|
||||
*Gnome 设置*
|
||||
|
||||

|
||||
|
||||
添加快捷键
|
||||
*添加快捷键*
|
||||
|
||||
下次你要杀掉X资源只要用组合键就行了(Ctrl+Alt+Shift+x),你看到你的鼠标变成x了。点击想要杀掉的x资源就行了。
|
||||
下次你要杀掉一个X资源只要用组合键就行了(Ctrl+Alt+Shift+x),你看到你的鼠标变成x了。点击想要杀掉的x资源就行了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -85,9 +85,9 @@ via: http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
[1]:https://linux.cn/article-2116-1.html
|
||||
@ -0,0 +1,29 @@
|
||||
Ubuntu下的Juju现在支持systemd和Google Cloud Platform了
|
||||
================================================================================
|
||||
> Juju已经更新到1.23.3了
|
||||
|
||||
**Cononical旗下的Ubuntu认证公共云总监Udi Nachmany宣布了juju新版本的发布,一个开源的、解决方案驱动的Ubuntu下的协同工具。**
|
||||
|
||||
根据[声明][1]和官方[发布公告][2],Juju 1.23.3是一个主要版本,它打包了那些你想要在云上扩展和管理的包,而不需太多操作。
|
||||
|
||||
Juju 1.23.3显著的功能是包含了对GCE的支持,支持systemd初始化系统,支持Ubuntu 15.04(Vivid Vervet),新的好玩的功能和对受限网络的代理支持。
|
||||
|
||||
另外,juju的发布带来了一个新的样式恢复、新的消息、新的块和实验性地支持Service Leader Elections,还有Ubuntu MAS和AWS上的LXC容器和KVM实例。
|
||||
|
||||
Udi Nachmany说:“在一个相关告示中,如果你正在使用Google云平台,你可能已经注意到了Google最近发布了云启动器。如果你观察的足够仔细,你也会注意到你可以使用这个非常友好的UI来启动你的Ubuntu虚拟机。”
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linux.softpedia.com/blog/Ubuntu-s-Juju-Now-Supports-systemd-and-Google-Cloud-Platform-483279.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://insights.ubuntu.com/2015/06/03/juju-support-for-google-cloud-platform/
|
||||
[2]:https://jujucharms.com/docs/devel/reference-release-notes
|
||||
@ -1,219 +0,0 @@
|
||||
Compact Text Editors Great for Remote Editing and Much More
|
||||
================================================================================
|
||||
A text editor is software used for editing plain text files. This type of software has many different uses including modifying configuration files, writing programming language source code, jotting down thoughts, or even making a grocery list. Given that editors can be used for such a diverse range of activities, it is worth spending the time finding an editor that best suites your preferences.
|
||||
|
||||
Whatever the level of sophistication of the editor, they typically have a common set of functionality, such as searching/replacing text, formatting text, importing files, as well as moving text within the file.
|
||||
|
||||
All of these text editors are console based applications which make them ideal for editing files on remote machines. Textadept also provides a graphical user interface, but remains fast and minimalist.
|
||||
|
||||
Console based applications are also light on system resources (very useful on low spec machines), can be faster and more efficient than their graphical counterparts, they do not stop working when X needs to be restarted, and are great for scripting purposes.
|
||||
|
||||
I have selected my favorite open source text editors that are frugal on system resources.
|
||||
|
||||
----------
|
||||
|
||||
### Textadept ###
|
||||
|
||||

|
||||
|
||||
Textadept is a fast, minimalist, and extensible cross-platform open source text editor for programmers. This open source application is written in a mixture of C and Lua and has been optimized for speed and minimalism over the years.
|
||||
|
||||
Textadept is an ideal editor for programmers who want endless extensibility options without sacrificing speed or succumbing to code bloat and featuritis.
|
||||
|
||||
There is also a version available for the terminal, which only depends on ncurses; great for editing on remote machines.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
|
||||
- Lightweight
|
||||
- Minimal design maximizes screen real estate
|
||||
- Self-contained executable – no installation necessary
|
||||
- Entirely keyboard driven
|
||||
- Unlimited split views (GUI version) split the editor window as many times as you like either horizontally or vertically. Please note that Textadept is not a tabbed editor
|
||||
- Support for over 80 programming languages
|
||||
- Powerful snippets and key commands
|
||||
- Code autocompletion and API lookup
|
||||
- Unparalleled extensibility
|
||||
- Bookmarks
|
||||
- Find and Replace
|
||||
- Find in Files
|
||||
- Buffer-based word completion
|
||||
- Adeptsense autocomplete symbols for programming languages and display API documentation
|
||||
- Themes: light, dark, and term
|
||||
- Uses lexers to assign names to buffer elements like comments, strings, and keywords
|
||||
- Sessions
|
||||
- Snapopen
|
||||
- Available modules include support for Java, Python, Ruby and recent file lists
|
||||
- Conforms with the Gnome HIG Human Interface Guidelines
|
||||
- Modules include support for Java, Python, Ruby and recent file lists
|
||||
- Support for editing Lua code. Syntax autocomplete and LuaDoc is available for many Textadept objects as well as Lua’s standard libraries
|
||||
|
||||
- Website: [foicica.com/textadept][1]
|
||||
- Developer: Mitchell and contributors
|
||||
- License: MIT License
|
||||
- Version Number: 7.7
|
||||
|
||||
----------
|
||||
|
||||
### Vim ###
|
||||
|
||||

|
||||
|
||||
Vim is an advanced text editor that seeks to provide the power of the editor 'Vi', with a more complete feature set.
|
||||
|
||||
This editor is very useful for editing programs and other plain ASCII files. All commands are given with normal keyboard characters, so those who can type with ten fingers can work very fast. Additionally, function keys can be defined by the user, and the mouse can be used.
|
||||
|
||||
Vim is often called a "programmer's editor," and is so useful for programming that many consider it to be an entire Integrated Development Environment. However, this application is not only intended for programmers. Vim is highly regarded for all kinds of text editing, from composing email to editing configuration files.
|
||||
|
||||
Vim's interface is based on commands given in a text user interface. Although its graphical user interface, gVim, adds menus and toolbars for commonly used commands, the software's entire functionality is still reliant on its command line mode.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
|
||||
- 3 modes:
|
||||
- - Command mode
|
||||
- - Insert mode
|
||||
- - Command line mode
|
||||
- Unlimited undo
|
||||
- Multiple windows and buffers
|
||||
- Flexible insert mode
|
||||
- Syntax highlighting highlight portions of the buffer in different colors or styles, based on the type of file being edited
|
||||
- Interactive commands
|
||||
- - Marking a line
|
||||
- - vi line buffers
|
||||
- - Shift a block of code
|
||||
- Block operators
|
||||
- Command line history
|
||||
- Extended regular expressions
|
||||
- Edit compressed/archive files (gzip, bzip2, zip, tar)
|
||||
- Filename completion
|
||||
- Block operations
|
||||
- Jump tags
|
||||
- Folding text
|
||||
- Indenting
|
||||
- ctags and cscope intergration
|
||||
- 100% vi compatibility mode
|
||||
- Plugins to add/extend functionality
|
||||
- Macros
|
||||
- vimscript, Vim's internal scripting language
|
||||
- Unicode support
|
||||
- Multi-language support
|
||||
- Integrated On-line help
|
||||
|
||||
- Website: [www.vim.org][2]
|
||||
- Developer: Bram Moolenaar
|
||||
- License: GNU GPL compatible (charityware)
|
||||
- Version Number: 7.4
|
||||
|
||||
----------
|
||||
|
||||
### ne ###
|
||||
|
||||

|
||||
|
||||
ne is a full screen open source text editor. It is intended to be an easier to learn alternative to vi, yet still portable across POSIX-compliant operating systems.
|
||||
|
||||
ne is easy to use for the beginner, but powerful and fully configurable for the wizard, and most sparing in its resource usage.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
|
||||
- Three user interfaces: control keystrokes, command line, and menus; keystrokes and menus are completely configurable
|
||||
- Syntax highlighting
|
||||
- Full support for UTF-8 files, including multiple-column characters
|
||||
- The number of documents and clips, the dimensions of the display, and the file/line lengths are limited only by the integer size of the machine
|
||||
- Simple scripting language where scripts can be generated via an idiotproof record/play method
|
||||
- Unlimited undo/redo capability (can be disabled with a command)
|
||||
- Automatic preferences system based on the extension of the file name being edited
|
||||
- Automatic completion of prefixes using words in your documents as dictionary
|
||||
- File requester with completion features for easy file retrieval;
|
||||
- Extended regular expression search and replace à la emacs and vi
|
||||
- A very compact memory model easily load and modify very large files
|
||||
- Editing of binary files
|
||||
|
||||
- Website: [ne.di.unimi.it][3]
|
||||
- Developer: Sebastiano Vigna (original developer). Additional features added by Todd M. Lewis
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 2.5
|
||||
|
||||
----------
|
||||
|
||||
### Zile ###
|
||||
|
||||

|
||||
|
||||
Zile Is Lossy Emacs (Zile) is a small Emacs clone. Zile is a customizable, self-documenting real-time display editor. Zile was written to be as similar as possible to Emacs; every Emacs user should feel comfortable with Zile.
|
||||
|
||||
Zile is distinguished by a very small RAM memory footprint, of approximately 130kB, and quick editing sessions. It is 8-bit clean, allowing it to be used on any sort of file.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Small but fast and powerful
|
||||
- Multi buffer editing with multi level undo
|
||||
- Multi window
|
||||
- Killing, yanking and registers
|
||||
- Minibuffer completion
|
||||
- Auto fill (word wrap)
|
||||
- Registers
|
||||
- Looks like Emacs. Key sequences, function and variable names are identical with Emacs's
|
||||
- Killing
|
||||
- Yanking
|
||||
- Auto line ending detection
|
||||
|
||||
- Website: [www.gnu.org/software/zile][4]
|
||||
- Developer: Reuben Thomas, Sandro Sigala, David A. Capello
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 2.4.11
|
||||
|
||||
----------
|
||||
|
||||
### nano ###
|
||||
|
||||

|
||||
|
||||
nano is a curses-based text editor. It is a clone of Pico, the editor of the Pine email client.
|
||||
|
||||
The nano project was started in 1999 due to licensing issues with the Pine suite (Pine was not distributed under a free software license), and also because Pico lacked some essential features.
|
||||
|
||||
nano aims to emulate the functionality and easy-to-use interface of Pico, while offering additional functionality, but without the tight mailer integration of the Pine/Pico package.
|
||||
|
||||
nano, like Pico, is keyboard-oriented, controlled with control keys.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Interactive search and replace
|
||||
- Color syntax highlighting
|
||||
- Go to line and column number
|
||||
- Auto-indentation
|
||||
- Feature toggles
|
||||
- UTF-8 support
|
||||
- Mixed file format auto-conversion
|
||||
- Verbatim input mode
|
||||
- Multiple file buffers
|
||||
- Smooth scrolling
|
||||
- Bracket matching
|
||||
- Customizable quoting string
|
||||
- Backup files
|
||||
- Internationalization support
|
||||
- Filename tab completion
|
||||
|
||||
- Website: [nano-editor.org][5]
|
||||
- Developer: Chris Allegretta, David Lawrence, Jordi Mallach, Adam Rogoyski, Robert Siemborski, Rocco Corsi, David Benbennick, Mike Frysinger
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 2.2.6
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20141011073917230/TextEditors.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://foicica.com/textadept/
|
||||
[2]:http://www.vim.org/
|
||||
[3]:http://ne.di.unimi.it/
|
||||
[4]:http://www.gnu.org/software/zile/
|
||||
[5]:http://nano-editor.org/
|
||||
@ -0,0 +1,95 @@
|
||||
Tickr Is An Open-Source RSS News Ticker for Linux Desktops
|
||||
================================================================================
|
||||

|
||||
|
||||
**Latest! Latest! Read all about it!**
|
||||
|
||||
Alright, so the app we’re highlighting today isn’t quite the binary version of an old newspaper seller — but it is a great way to have the latest news brought to you, on your desktop.
|
||||
|
||||
Tick is a GTK-based news ticker for the Linux desktop that scrolls the latest headlines and article titles from your favourite RSS feeds in horizontal strip that you can place anywhere on your desktop.
|
||||
|
||||
Call me Joey Calamezzo; I put mine on the bottom TV news station style.
|
||||
|
||||
“Over to you, sub-heading.”
|
||||
|
||||
### RSS — Remember That? ###
|
||||
|
||||
“Thanks paragraph ending.”
|
||||
|
||||
In an era of push notifications, social media, and clickbait, cajoling us into reading the latest mind-blowing, humanity saving listicle ASAP, RSS can seem a bit old hat.
|
||||
|
||||
For me? Well, RSS lives up to its name of Really Simple Syndication. It’s the easiest, most manageable way to have news come to me. I can manage and read stuff when I want; there’s no urgency to view lest the tweet vanish into the stream or the push notification vanish.
|
||||
|
||||
The beauty of Tickr is in its utility. You can have a constant stream of news trundling along the bottom of your screen, which you can passively glance at from time to time.
|
||||
|
||||

|
||||
|
||||
There’s no pressure to ‘read’ or ‘mark all read’ or any of that. When you see something you want to read you just click it to open it in a web browser.
|
||||
|
||||
### Setting it Up ###
|
||||
|
||||

|
||||
|
||||
Although Tickr is available to install from the Ubuntu Software Centre it hasn’t been updated for a long time. Nowhere is this sense of abandonment more keenly felt than when opening the unwieldy and unintuitive configuration panel.
|
||||
|
||||
To open it:
|
||||
|
||||
1. Right click on the Tickr bar
|
||||
1. Go to Edit > Preferences
|
||||
1. Adjust the various settings
|
||||
|
||||
Row after row of options and settings, few of which seem to make sense at first. But poke and prod around and you’ll controls for pretty much everything, including:
|
||||
|
||||
- Set scrolling speed
|
||||
- Choose behaviour when mousing over
|
||||
- Feed update frequency
|
||||
- Font, including font sizes and color
|
||||
- Separator character (‘delineator’)
|
||||
- Position of Tickr on screen
|
||||
- Color and opacity of Tickr bar
|
||||
- Choose how many articles each feed displays
|
||||
|
||||
One ‘quirk’ worth mentioning is that pressing the ‘Apply’ only updates the on-screen Tickr to preview changes. For changes to take effect when you exit the Preferences window you need to click ‘OK’.
|
||||
|
||||
Getting the bar to sit flush on your display can also take a fair bit of tweaking, especially on Unity.
|
||||
|
||||
Press the “full width button” to have the app auto-detect your screen width. By default when placed at the top or bottom it leaves a 25px gap (the app was created back in the days of GNOME 2.x desktops). After hitting the top or bottom buttons just add an extra 25 pixels to the input box compensate for this.
|
||||
|
||||
Other options available include: choose which browser articles open in; whether Tickr appears within a regular window frame; whether a clock is shown; and how often the app checks feed for articles.
|
||||
|
||||
#### Adding Feeds ####
|
||||
|
||||
Tickr comes with a built-in list of over 30 different feeds, ranging from technology blogs to mainstream news services.
|
||||
|
||||

|
||||
|
||||
You can select as many of these as you like to show headlines in the on screen ticker. If you want to add your own feeds you can: –
|
||||
|
||||
1. Right click on the Tickr bar
|
||||
1. Go to File > Open Feed
|
||||
1. Enter Feed URL
|
||||
1. Click ‘Add/Upd’ button
|
||||
1. Click ‘OK (select)’
|
||||
|
||||
To set how many items from each feed shows in the ticker change the “Read N items max per feed” in the other preferences window.
|
||||
|
||||
### Install Tickr in Ubuntu 14.04 LTS and Up ###
|
||||
|
||||
So that’s Tickr. It’s not going to change the world but it will keep you abreast of what’s happening in it.
|
||||
|
||||
To install it in Ubuntu 14.04 LTS or later head to the Ubuntu Software Centre but clicking the button below.
|
||||
|
||||
- [Click to install Tickr form the Ubuntu Software Center][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticker
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:apt://tickr
|
||||
@ -1,3 +1,5 @@
|
||||
fyh 翻译中。。。
|
||||
|
||||
Open source all over the world
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,58 +0,0 @@
|
||||
translating wi-cuckoo
|
||||
Is Linux Better than OS X? GNU, Open Source and Apple in History
|
||||
================================================================================
|
||||
> Tensions between the free software/open source community and Apple date back to the 1980s, Linux's founder called the core of Mac OS X "a piece of crap" and other anecdotes from software history.
|
||||
|
||||

|
||||
|
||||
Open source fans have long had a rocky relationship with Microsoft. Everyone knows that. But, in many ways, the tension between Apple and supporters of free or open source software is even starker—even if it receives much less attention in the press.
|
||||
|
||||
To be sure, not all open source advocates have an aversion to Apple. Anecdotally, I've seen plenty of Linux hackers sporting iPhones and iPads. In fact, some Linux users like Apple's OS X so much that they've [created a number of Linux distributions][1] designed to look just like it. (So has the [North Korean government][2], incidentally.)
|
||||
|
||||
But relations between the Cult of Mac and the Cult of Tux—that is, the Linux community (not to mention the other, smaller segments of the free and open source software world)—have not always been completely peaceable. And that's by no means a new phenomenon, as I'm discovering as I research the history of Linux and the Free Software Foundation.
|
||||
|
||||
### GNU vs. Apple ###
|
||||
|
||||
The ill will dates to at least the late 1980s. By June 1988, [GNU][3], the project launched by Richard Stallman to build a completely free Unix-like operating system whose source code would be freely shared, was [strongly criticizing][4] Apple's lawsuit against [Hewlett-Packard][5] (HPQ) and [Microsoft][6] (MSFT) over what Apple claimed was improper copying of the "look and feel" of the Macintosh operating system. If Apple prevailed, GNU warned, the company "will use this new power over the public to put an end to free software that could substitute for commercial software."
|
||||
|
||||
At the time, GNU fought against the lawsuit (which meant, ironically, that GNU was supporting Microsoft, though those were different times) by distributing "[Keep Your Lawyers Off My Computer" buttons][7]. It also urged GNU supporters to boycott Apple, warning that, even if Macintoshes seemed like good computers, Apple's success in the lawsuit could provide the company with a monopoly in the market that would greatly increase the price of computers.
|
||||
|
||||
Apple eventually [lost the lawsuit][8], but not until 1994, after which GNU [dropped its Apple boycott][9]. In the interim, GNU remained critical of the company. In the early 1990s, even after it began promoting GNU software programs for use on other personal computing platforms, including MS-DOS PCs, [GNU affirmed][10] that, until Apple ceased pursuing a "monopoly" over computers with user interfaces similar to those of the Macintosh, "we will not provide any support for Apple machines." (It's therefore ironic that a fair amount of the software that made it into OS X, the Unix-like operating system that Apple introduced later in the 1990s, came from GNU. But that's another story.)
|
||||
|
||||
### Torvalds on Jobs ###
|
||||
|
||||
Despite his more laissez-faire attitude toward most issues, Linus Torvalds, the creator of the Linux kernel, was no less charitable in his attitudes toward Apple than Stallman and GNU had been. In his 2001 book "Just for Fun: The Story of an Accidental Revolutionary," Torvalds described meeting with Steve Jobs circa 1997, at the latter's invitation, to discuss Mac OS X, which Apple was then developing but had not yet released publicly.
|
||||
|
||||
"Basically, Jobs started off by trying to tell me that on the desktop there were just two players, Microsoft and Apple, and that he thought that the best thing I could do for Linux was to get in bed with Apple and try to get the open source people behind Mac OS X," Torvalds wrote.
|
||||
|
||||
This courting apparently turned Torvalds off quite a bit. One point of disagreement centered on Torvalds's technical disdain for Mach, the kernel on which Apple was then building its new OS X operating system, which Torvalds called "a piece of crap. It contains all the design mistakes you can make, and managed to even make up a few of its own."
|
||||
|
||||
But more off-putting, apparently, was the way Jobs was approaching open source in developing OS X (which had many open source programs at its core): "He sort of played down the flaw in the setup: Who cares if the basic operating system, the real low-core stuff, is open source if you then have the Mac layer on top, which is not open source?"
|
||||
|
||||
All in all, Torvalds concluded, Jobs "didn't use very many arguments. He just basically took it for granted that I would be interested" in collaborating with Apple. "He was clueless, unable to imagine that there could be entire segments of the human race who weren't the least bit concerned about increasing the Mac's market share. I think he was truly surprised at how little I cared about how big a market the Mac had—or how big a market Microsoft has."
|
||||
|
||||
Torvalds doesn't speak for all Linux users, of course. And his views on OS X and Apple may have softened since 2001. But the fact that, in the early 2000s, the Linux community's leading figure exhibited so much disdain for Apple and the hubris of its chief says something significant about how deeply seated tensions between the Apple world and the open source/free software world are.
|
||||
|
||||
Both of these historical tidbits offer insight into the great debate regarding the actual value of Apple's products—whether the company thrives on the quality of the hardware and software it creates, or merely benefits from exceptional marketing acumen that allows it to sell products for much more than their non-Apple functional equivalents are worth. But I'll stay out of that debate, for now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/051815/linux-better-os-x-gnu-open-source-and-apple-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:https://www.linux.com/news/software/applications/773516-the-mac-ifying-of-the-linux-desktop/
|
||||
[2]:http://thevarguy.com/open-source-application-software-companies/010615/north-koreas-red-star-linux-os-made-apples-image
|
||||
[3]:http://gnu.org/
|
||||
[4]:https://www.gnu.org/bulletins/bull5.html
|
||||
[5]:http://www.hp.com/
|
||||
[6]:http://www.microsoft.com/
|
||||
[7]:http://www.duntemann.com/AppleSnakeButton.jpg
|
||||
[8]:http://www.freibrun.com/articles/articl12.htm
|
||||
[9]:https://www.gnu.org/bulletins/bull18.html#SEC6
|
||||
[10]:https://www.gnu.org/bulletins/bull12.html
|
||||
@ -1,197 +0,0 @@
|
||||
Installing Cisco Packet tracer in Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
### What is Cisco Packet tracer ? ###
|
||||
|
||||
**Cisco Packet tracer** is a powerful network simulator tool which used to trained while we do some Cisco certifications. It provide us good Interface view for every router’s, and networking devices which with many options same as using the physical machines we can use unlimited devices in a network. We can create multiple network in single project to get trained like a professionals. packet tracer will provide us with simulated application layer protocols such as **HTTP**, **DNS**, Routing with **RIP**, **OSPF**, **EIGRP** etc.
|
||||
|
||||
Now it has been released including **ASA 5505 firewall** with command line configurations. Packet tracer available commonly for Windows, but not for Linux distributions. Here we can download and get install Cisco package tracer.
|
||||
|
||||
#### Newly released version of Cisco packet tracer: ####
|
||||
|
||||
The next Cisco Packet Tracer version will be Cisco Packet Tracer 6.2 currently it’s under development.
|
||||
|
||||
### My Environment Setup: ###
|
||||
|
||||
**Hostname** : desktop1.unixmen.com
|
||||
|
||||
**IP address** : 192.168.0.167
|
||||
|
||||
**Operating system** : Ubuntu 14.04 LTS Desktop
|
||||
|
||||
# hostname
|
||||
|
||||
# ifconfig | grep inet
|
||||
|
||||
# lsb_release -a
|
||||
|
||||

|
||||
|
||||
### Step 1: First we need to download the Cisco Packet tracer. ###
|
||||
|
||||
To download Packet Tracer from official website we need to have a token, sign into Cisco NetSpace and select CCNA > Cisco Packet Tracer from the Offerings menu to start the download. If we don’t have a token you can get from below link which i have uploaded in Dropbox.
|
||||
|
||||
Official Website: [https://www.netacad.com/][1]
|
||||
|
||||
Many of them don’t have a token to download packet tracer. For that i have uploaded it in dropbox you can get packet tracer from below URL.
|
||||
|
||||
[Download Cisco Packet Tracer 6.1.1][2]
|
||||
|
||||

|
||||
|
||||
### Step 2: Install Java: ###
|
||||
|
||||
To get install packet tracer we need to have install Java, To get install java we can use the default or add the PPA repository and update the package cache to get install java.
|
||||
|
||||
Install the default jre using
|
||||
|
||||
# sudo apt-get install default-jre
|
||||
|
||||

|
||||
|
||||
(or)
|
||||
|
||||
Use the below step to get install Java Run-time and set the Environment.
|
||||
|
||||
Download Java from official website : [Download Java][3]
|
||||
|
||||
# tar -zxvf jre-8u31-linux-x64.tar.gz
|
||||
|
||||
# sudo mkdir -p /usr/lib/jvm
|
||||
|
||||
# sudo mv -v jre1.8.0_31 /usr/lib/jvm/
|
||||
|
||||
# cd /usr/lib/jvm/
|
||||
|
||||
# sudo update-alternatives --install "/usr/bin/java" "java" "/usr/lib/jvm/jre1.8.0_31/bin/java" 1
|
||||
|
||||
# sudo update-alternatives --set "java" "/usr/lib/jvm/jre1.8.0_31/bin/java"
|
||||
|
||||
Set the environment for java by editing the profile file and add the location. While we adding in profile file java will available for every user’s in our machine.
|
||||
|
||||
# sudo vi /etc/profile
|
||||
|
||||
Add the following entries to the bottom of your /etc/profile file:
|
||||
|
||||
export JAVA_HOME=/usr/lib/jvm/jre1.8.0_31
|
||||
export PATH=$PATH:/usr/java/jre1.8.0_31/bin
|
||||
|
||||
Run the below command to activate java path immediately.
|
||||
|
||||
# . /etc/profile
|
||||
|
||||
Check for the Java version and Environment:
|
||||
|
||||
# echo $JAVA_HOME
|
||||
|
||||
# java -version
|
||||
|
||||

|
||||
|
||||
### Step 3: Enable 32bit architecture support: ###
|
||||
|
||||
For Packet tracer we need some of 32bit packages. To get install 32bit packages we need to install some of dependencies using below commands.
|
||||
|
||||
# sudo dpkg --add-architecture i386
|
||||
# sudo apt-get update
|
||||
|
||||

|
||||
|
||||
# sudo apt-get install libc6:i386
|
||||
|
||||
# sudo apt-get install lib32z1 lib32ncurses5 lib32bz2-1.0
|
||||
|
||||
# sudo apt-get install libnss3-1d:i386 libqt4-qt3support:i386 libssl1.0.0:i386 libqtwebkit4:i386 libqt4-scripttools:i386
|
||||
|
||||

|
||||
|
||||
### Step 4: Extract and install the package: ###
|
||||
|
||||
Extract the downloaded package using tar command.
|
||||
|
||||
# mv Cisco\ Packet\ Tracer\ 6.1.1\ Linux.tar.gz\?dl\=0 Cisco_Packet_tracer.tar.gz
|
||||
|
||||
# tar -zxvf Cisco_Packet_tracer.tar.gz
|
||||
|
||||

|
||||
|
||||
Navigate to the extracted directory
|
||||
|
||||
# cd PacketTracer611Student
|
||||
|
||||
Now it’s time to start the installation , Installation is very simple and just take few seconds.
|
||||
|
||||
# sudo ./install
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
To working with Package tracer we need to set the environment for that Cisco have provided the environment script, We need to run the script using root user to set the environment variable.
|
||||
|
||||
# sudo ./set_ptenv.sh
|
||||
|
||||

|
||||
|
||||
That’s it for installation step’s. next we need to create a Desktop Icon for Packet tracer.
|
||||
|
||||
Create the Desktop Icon by creating desktop file under.
|
||||
|
||||
# sudo su
|
||||
|
||||
# cd /usr/share/applications
|
||||
|
||||
# sudo vim packettracer.desktop
|
||||
|
||||

|
||||
|
||||
Append the Below content to the file using vim editor or your favourite one.
|
||||
|
||||
[Desktop Entry]
|
||||
Name= Packettracer
|
||||
Comment=Networking
|
||||
GenericName=Cisco Packettracer
|
||||
Exec=/opt/packettracer/packettracer
|
||||
Icon=/usr/share/icons/packettracer.jpeg
|
||||
StartupNotify=true
|
||||
Terminal=false
|
||||
Type=Application
|
||||
|
||||
Save and quit using wq!
|
||||
|
||||

|
||||
|
||||
### Step 5: Run the packet tracer ###
|
||||
|
||||
# sudo packettracer
|
||||
|
||||
That’s it we have successfully installed the packet tracer in Linux, These above steps are suitable for every debian based Linux distributions.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Resources ###
|
||||
|
||||
Home page:[Netacad][4]
|
||||
|
||||
### Conclusion: ###
|
||||
|
||||
Here we have seen how to install packet tracer in Linux distribution, Hope you have find a way to get install your favorite Simulator in Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/installing-cisco-packet-tracer-linux/
|
||||
|
||||
作者:[babin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/babin/
|
||||
[1]:https://www.netacad.com/
|
||||
[2]:https://www.dropbox.com/s/5evz8gyqqvq3o3v/Cisco%20Packet%20Tracer%206.1.1%20Linux.tar.gz?dl=0
|
||||
[3]:http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
|
||||
[4]:https://www.netacad.com/
|
||||
@ -1,64 +0,0 @@
|
||||
iptraf: A TCP/UDP Network Monitoring Utility
|
||||
================================================================================
|
||||
[iptraf][1] is an ncurses-based IP LAN monitor that generates various network statistics including TCP info, UDP counts, ICMP and OSPF information, Ethernet load info, node stats, IP checksum errors, and others.
|
||||
|
||||
Its ncurses-based user interface also saves users from remembering command line switches.
|
||||
|
||||
### Features ###
|
||||
|
||||
- An IP traffic monitor that shows information on the IP traffic passing over your network. Includes TCP flag information, packet and byte counts, ICMP details, OSPF packet types.
|
||||
- General and detailed interface statistics showing IP, TCP, UDP, ICMP, non-IP and other IP packet counts, IP checksum errors, interface activity, packet size counts.
|
||||
- A TCP and UDP service monitor showing counts of incoming and outgoing packets for common TCP and UDP application ports
|
||||
- A LAN statistics module that discovers active hosts and shows statistics showing the data activity on them
|
||||
- TCP, UDP, and other protocol display filters, allowing you to view only traffic you’re interested in.
|
||||
- Logging
|
||||
- Supports Ethernet, FDDI, ISDN, SLIP, PPP, and loopback interface types.
|
||||
- Utilizes the built-in raw socket interface of the Linux kernel, allowing it to be used over a wide range of supported network cards.
|
||||
- Full-screen, menu-driven operation.
|
||||
|
||||
To install
|
||||
|
||||
### Ubuntu and it’s derivatives ###
|
||||
|
||||
sudo apt-get install iptraf
|
||||
|
||||
### Arch Linux and Its derivatives ###
|
||||
|
||||
sudo pacman -S iptra
|
||||
|
||||
### Fedora and its derivatives ###
|
||||
|
||||
sudo yum install iptraf
|
||||
|
||||
### Usage ###
|
||||
|
||||
If the **iptraf** command is issued without any command-line options, the program comes up in interactive mode, with the various facilities accessed through the main menu.
|
||||
|
||||

|
||||
|
||||
Menu for easy navigation.
|
||||
|
||||

|
||||
|
||||
Selecting interfaces to monitor.
|
||||
|
||||

|
||||
|
||||
Traffic from interface **ppp0**
|
||||
|
||||

|
||||
|
||||
Enjoy!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/iptraf-tcpudp-network-monitoring-utility/
|
||||
|
||||
作者:[Enock Seth Nyamador][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/seth/
|
||||
[1]:http://iptraf.seul.org/about.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating by chenzhijun
|
||||
|
||||
How to access Feedly RSS feed from the command line on Linux
|
||||
================================================================================
|
||||
In case you didn't know, [Feedly][1] is one of the most popular online news aggregation services. It offers seamlessly unified news reading experience across desktops, Android and iOS devices via browser extensions and mobile apps. Feedly took on the demise of Google Reader in 2013, quickly gaining a lot of then Google Reader users. I was one of them, and Feedly has remained my default RSS reader since then.
|
||||
@ -103,4 +105,4 @@ via: http://xmodulo.com/feedly-rss-feed-command-line-linux.html
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://feedly.com/
|
||||
[2]:https://github.com/Jarkore/Feednix
|
||||
[3]:https://aur.archlinux.org/packages/feednix/
|
||||
[3]:https://aur.archlinux.org/packages/feednix/
|
||||
|
||||
@ -1,270 +0,0 @@
|
||||
Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules
|
||||
================================================================================
|
||||
For those of you in the hosting business, or if you’re hosting your own servers and exposing them to the Internet, securing your systems against attackers must be a high priority.
|
||||
|
||||
mod_security (an open source intrusion detection and prevention engine for web applications that integrates seamlessly with the web server) and mod_evasive are two very important tools that can be used to protect a web server against brute force or (D)DoS attacks.
|
||||
|
||||
mod_evasive, as its name suggests, provides evasive capabilities while under attack, acting as an umbrella that shields web servers from such threats.
|
||||
|
||||

|
||||
Install Mod_Security and Mod_Evasive to Protect Apache
|
||||
|
||||
In this article we will discuss how to install, configure, and put them into play along with Apache on RHEL/CentOS 6 and 7 as well as Fedora 21-15. In addition, we will simulate attacks in order to verify that the server reacts accordingly.
|
||||
|
||||
This assumes that you have a LAMP server installed on your system. If not, please check this article before proceeding further.
|
||||
|
||||
- [Install LAMP stack in RHEL/CentOS 7][1]
|
||||
|
||||
You will also need to setup iptables as the default [firewall][2] front-end instead of firewalld if you’re running RHEL/CentOS 7 or Fedora 21. We do this in order to use the same tool in both RHEL/CentOS 7/6 and Fedora 21.
|
||||
|
||||
### Step 1: Installing Iptables Firewall on RHEL/CentOS 7 and Fedora 21 ###
|
||||
|
||||
To begin, stop and disable firewalld:
|
||||
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
|
||||

|
||||
Disable Firewalld Service
|
||||
|
||||
Then install the iptables-services package before enabling iptables:
|
||||
|
||||
# yum update && yum install iptables-services
|
||||
# systemctl enable iptables
|
||||
# systemctl start iptables
|
||||
# systemctl status iptables
|
||||
|
||||

|
||||
Install Iptables Firewall
|
||||
|
||||
### Step 2: Installing Mod_Security and Mod_evasive ###
|
||||
|
||||
In addition to having a LAMP setup already in place, you will also have to [enable the EPEL repository][3] in RHEL/CentOS 7/6 in order to install both packages. Fedora users don’t need to enable any repo, because epel is a already part of Fedora project.
|
||||
|
||||
# yum update && yum install mod_security mod_evasive
|
||||
|
||||
When the installation is complete, you will find the configuration files for both tools in /etc/httpd/conf.d.
|
||||
|
||||
# ls -l /etc/httpd/conf.d
|
||||
|
||||

|
||||
mod_security + mod_evasive Configurations
|
||||
|
||||
Now, in order to integrate these two modules with Apache and have it load them when it starts, make sure the following lines appear in the top level section of mod_evasive.conf and mod_security.conf, respectively:
|
||||
|
||||
LoadModule evasive20_module modules/mod_evasive24.so
|
||||
LoadModule security2_module modules/mod_security2.so
|
||||
|
||||
Note that modules/mod_security2.so and modules/mod_evasive24.so are the relative paths, from the /etc/httpd directory to the source file of the module. You can verify this (and change it, if needed) by listing the contents of the /etc/httpd/modules directory:
|
||||
|
||||
# cd /etc/httpd/modules
|
||||
# pwd
|
||||
# ls -l | grep -Ei '(evasive|security)'
|
||||
|
||||
|
||||
Verify mod_security + mod_evasive Modules
|
||||
|
||||
Then restart Apache and verify that it loads mod_evasive and mod_security:
|
||||
|
||||
# service httpd restart [On RHEL/CentOS 6 and Fedora 20-18]
|
||||
# systemctl restart httpd [On RHEL/CentOS 7 and Fedora 21]
|
||||
|
||||
----------
|
||||
|
||||
[Dump a list of loaded Static and Shared Modules]
|
||||
|
||||
# httpd -M | grep -Ei '(evasive|security)'
|
||||
|
||||
|
||||
Check mod_security + mod_evasive Modules Loaded
|
||||
|
||||
### Step 3: Installing A Core Rule Set and Configuring Mod_Security ###
|
||||
|
||||
In few words, a Core Rule Set (aka CRS) provides the web server with instructions on how to behave under certain conditions. The developer firm of mod_security provide a free CRS called OWASP ([Open Web Application Security Project][4]) ModSecurity CRS that can be downloaded and installed as follows.
|
||||
|
||||
1. Download the OWASP CRS to a directory created for that purpose.
|
||||
|
||||
# mkdir /etc/httpd/crs-tecmint
|
||||
# cd /etc/httpd/crs-tecmint
|
||||
# wget https://github.com/SpiderLabs/owasp-modsecurity-crs/tarball/master
|
||||
|
||||

|
||||
Download mod_security Core Rules
|
||||
|
||||
2. Untar the CRS file and change the name of the directory for one of our convenience.
|
||||
|
||||
# tar xzf master
|
||||
# mv SpiderLabs-owasp-modsecurity-crs-ebe8790 owasp-modsecurity-crs
|
||||
|
||||

|
||||
Extract mod_security Core Rules
|
||||
|
||||
3. Now it’s time to configure mod_security. Copy the sample file with rules (owasp-modsecurity-crs/modsecurity_crs_10_setup.conf.example) into another file without the .example extension:
|
||||
|
||||
# cp modsecurity_crs_10_setup.conf.example modsecurity_crs_10_setup.conf
|
||||
|
||||
and tell Apache to use this file along with the module by inserting the following lines in the web server’s main configuration file /etc/httpd/conf/httpd.conf file. If you chose to unpack the tarball in another directory you will need to edit the paths following the Include directives:
|
||||
|
||||
<IfModule security2_module>
|
||||
Include crs-tecmint/owasp-modsecurity-crs/modsecurity_crs_10_setup.conf
|
||||
Include crs-tecmint/owasp-modsecurity-crs/base_rules/*.conf
|
||||
</IfModule>
|
||||
|
||||
Finally, it is recommended that we create our own configuration file within the /etc/httpd/modsecurity.d directory where we will place our customized directives (we will name it tecmint.conf in the following example) instead of modifying the CRS files directly. Doing so will allow for easier upgrading the CRSs as new versions are released.
|
||||
|
||||
<IfModule mod_security2.c>
|
||||
SecRuleEngine On
|
||||
SecRequestBodyAccess On
|
||||
SecResponseBodyAccess On
|
||||
SecResponseBodyMimeType text/plain text/html text/xml application/octet-stream
|
||||
SecDataDir /tmp
|
||||
</IfModule>
|
||||
|
||||
You can refer to the [SpiderLabs’ ModSecurity GitHub][5] repository for a complete explanatory guide of mod_security configuration directives.
|
||||
|
||||
### Step 4: Configuring Mod_Evasive ###
|
||||
|
||||
mod_evasive is configured using directives in /etc/httpd/conf.d/mod_evasive.conf. Since there are no rules to update during a package upgrade, we don’t need a separate file to add customized directives, as opposed to mod_security.
|
||||
|
||||
The default mod_evasive.conf file has the following directives enabled (note that this file is heavily commented, so we have stripped out the comments to highlight the configuration directives below):
|
||||
|
||||
<IfModule mod_evasive24.c>
|
||||
DOSHashTableSize 3097
|
||||
DOSPageCount 2
|
||||
DOSSiteCount 50
|
||||
DOSPageInterval 1
|
||||
DOSSiteInterval 1
|
||||
DOSBlockingPeriod 10
|
||||
</IfModule>
|
||||
|
||||
Explanation of the directives:
|
||||
|
||||
- DOSHashTableSize: This directive specifies the size of the hash table that is used to keep track of activity on a per-IP address basis. Increasing this number will provide a faster look up of the sites that the client has visited in the past, but may impact overall performance if it is set too high.
|
||||
- DOSPageCount: Legitimate number of identical requests to a specific URI (for example, any file that is being served by Apache) that can be made by a visitor over the DOSPageInterval interval.
|
||||
- DOSSiteCount: Similar to DOSPageCount, but refers to how many overall requests can be made to the entire site over the DOSSiteInterval interval.
|
||||
- DOSBlockingPeriod: If a visitor exceeds the limits set by DOSSPageCount or DOSSiteCount, his source IP address will be blacklisted during the DOSBlockingPeriod amount of time. During DOSBlockingPeriod, any requests coming from that IP address will encounter a 403 Forbidden error.
|
||||
|
||||
Feel free to experiment with these values so that your web server will be able to handle the required amount and type of traffic.
|
||||
|
||||
**Only a small caveat**: if these values are not set properly, you run the risk of ending up blocking legitimate visitors.
|
||||
|
||||
You may also want to consider other useful directives:
|
||||
|
||||
#### DOSEmailNotify ####
|
||||
|
||||
If you have a mail server up and running, you can send out warning messages via Apache. Note that you will need to grant the apache user SELinux permission to send emails if SELinux is set to enforcing. You can do so by running
|
||||
|
||||
# setsebool -P httpd_can_sendmail 1
|
||||
|
||||
Next, add this directive in the mod_evasive.conf file with the rest of the other directives:
|
||||
|
||||
DOSEmailNotify you@yourdomain.com
|
||||
|
||||
If this value is set and your mail server is working properly, an email will be sent to the address specified whenever an IP address becomes blacklisted.
|
||||
|
||||
#### DOSSystemCommand ####
|
||||
|
||||
This needs a valid system command as argument,
|
||||
|
||||
DOSSystemCommand </command>
|
||||
|
||||
This directive specifies a command to be executed whenever an IP address becomes blacklisted. It is often used in conjunction with a shell script that adds a firewall rule to block further connections coming from that IP address.
|
||||
|
||||
**Write a shell script that handles IP blacklisting at the firewall level**
|
||||
|
||||
When an IP address becomes blacklisted, we need to block future connections coming from it. We will use the following shell script that performs this job. Create a directory named scripts-tecmint (or whatever name of your choice) in /usr/local/bin and a file called ban_ip.sh in that directory.
|
||||
|
||||
#!/bin/sh
|
||||
# IP that will be blocked, as detected by mod_evasive
|
||||
IP=$1
|
||||
# Full path to iptables
|
||||
IPTABLES="/sbin/iptables"
|
||||
# mod_evasive lock directory
|
||||
MOD_EVASIVE_LOGDIR=/var/log/mod_evasive
|
||||
# Add the following firewall rule (block all traffic coming from $IP)
|
||||
$IPTABLES -I INPUT -s $IP -j DROP
|
||||
# Remove lock file for future checks
|
||||
rm -f "$MOD_EVASIVE_LOGDIR"/dos-"$IP"
|
||||
|
||||
Our DOSSystemCommand directive should read as follows:
|
||||
|
||||
DOSSystemCommand "sudo /usr/local/bin/scripts-tecmint/ban_ip.sh %s"
|
||||
|
||||
In the line above, %s represents the offending IP as detected by mod_evasive.
|
||||
|
||||
**Add the apache user to the sudoers file**
|
||||
|
||||
Note that all of this just won’t work unless you to give permissions to user apache to run our script (and that script only!) without a terminal and password. As usual, you can just type visudo as root to access the /etc/sudoers file and then add the following 2 lines as shown in the image below:
|
||||
|
||||
apache ALL=NOPASSWD: /usr/local/bin/scripts-tecmint/ban_ip.sh
|
||||
Defaults:apache !requiretty
|
||||
|
||||

|
||||
Add Apache User to Sudoers
|
||||
|
||||
**IMPORTANT**: As a default security policy, you can only run sudo in a terminal. Since in this case we need to use sudo without a tty, we have to comment out the line that is highlighted in the following image:
|
||||
|
||||
#Defaults requiretty
|
||||
|
||||
|
||||
Disable tty for Sudo
|
||||
|
||||
Finally, restart the web server:
|
||||
|
||||
# service httpd restart [On RHEL/CentOS 6 and Fedora 20-18]
|
||||
# systemctl restart httpd [On RHEL/CentOS 7 and Fedora 21]
|
||||
|
||||
### Step 4: Simulating an DDoS Attacks on Apache ###
|
||||
|
||||
There are several tools that you can use to simulate an external attack on your server. You can just google for “tools for simulating ddos attacks” to find several of them.
|
||||
|
||||
Note that you, and only you, will be held responsible for the results of your simulation. Do not even think of launching a simulated attack to a server that you’re not hosting within your own network.
|
||||
|
||||
Should you want to do the same with a VPS that is hosted by someone else, you need to appropriately warn your hosting provider or ask permission for such a traffic flood to go through their networks. Tecmint.com is not, by any means, responsible for your acts!
|
||||
|
||||
In addition, launching a simulated DoS attack from only one host does not represent a real life attack. To simulate such, you would need to target your server from several clients at the same time.
|
||||
|
||||
Our test environment is composed of a CentOS 7 server [IP 192.168.0.17] and a Windows host from which we will launch the attack [IP 192.168.0.103]:
|
||||
|
||||

|
||||
Confirm Host IPAddress
|
||||
|
||||
Please play the video below and follow the steps outlined in the indicated order to simulate a simple DoS attack:
|
||||
|
||||
注:youtube视频,发布的时候不行做个链接吧
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/-U_mdet06Jk"></iframe>
|
||||
|
||||
Then the offending IP is blocked by iptables:
|
||||
|
||||

|
||||
Blocked Attacker IP
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
With mod_security and mod_evasive enabled, the simulated attack causes the CPU and RAM to experiment a temporary usage peak for only a couple of seconds before the source IPs are blacklisted and blocked by the firewall. Without these tools, the simulation will surely knock down the server very fast and render it unusable during the duration of the attack.
|
||||
|
||||
We would love to hear if you’re planning on using (or have used in the past) these tools. We always look forward to hearing from you, so don’t hesitate to leave your comments and questions, if any, using the form below.
|
||||
|
||||
### Reference Links ###
|
||||
|
||||
- [https://www.modsecurity.org/][6]
|
||||
- [http://www.zdziarski.com/blog/?page_id=442][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[2]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
[3]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[4]:https://www.owasp.org/index.php/Category:OWASP_ModSecurity_Core_Rule_Set_Project
|
||||
[5]:https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual#Configuration_Directives
|
||||
[6]:https://www.modsecurity.org/
|
||||
[7]:http://www.zdziarski.com/blog/?page_id=442
|
||||
@ -1,152 +0,0 @@
|
||||
7 Command Line Tools for Browsing Websites and Downloading Files in Linux
|
||||
================================================================================
|
||||
In the last article, we have covered few useful tools like ‘rTorrent‘, ‘wget‘, ‘cURL‘, ‘w3m‘, and ‘Elinks‘. We got lots of response to cover few other tools of same genre, if you’ve missed the first part you can go through it..
|
||||
|
||||
- [5 Command Line Tools for Downloading Files and Browsing Websites][1]
|
||||
|
||||
This article aims at making you aware of several other Linux command Line browsing and downloading applications, which will help you to browse and download files within the Linux shell.
|
||||
|
||||
### 1. links ###
|
||||
|
||||
Links is an open source web browser written in C programming Language. It is available for all major platforms viz., Linux, Windows, OS X and OS/2. This browser is text based as well as graphical. The text based links web browser is shipped by most of the standard Linux distributions by default. If links is not installed in your system by default you may install it from the repo. Elinks is a fork of links.
|
||||
|
||||
# apt-get install links
|
||||
# yum install links
|
||||
|
||||
After installing links, you can browse any websites within the terminal as shown below in the screen cast..
|
||||
|
||||
# links www.tecmint.com
|
||||
|
||||
Use UP and DOWN arrow keys to navigate. Right arrow Key on a link will redirect you to that link and Left arrow key will bring you back to the last page. To QUIT press q.
|
||||
|
||||
Here is how it seems to access Tecmint using links tool.
|
||||
|
||||

|
||||
|
||||
If you are interested in installing GUI of links, you may need to download latest source tarball (i.e. version 2.9) from [http://links.twibright.com/download/][2].
|
||||
|
||||
Alternatively, you may use following wget command to download and install as suggested below.
|
||||
|
||||
# wget http://links.twibright.com/download/links-2.9.tar.gz
|
||||
# tar -xvf links-2.9.tar.gz
|
||||
# cd links-2.9
|
||||
# ./configure –enable-graphics
|
||||
# make
|
||||
# make install
|
||||
|
||||
**Note**: You need to install packages (libpng, libjpeg, TIFF library, SVGAlib, XFree86, C Compiler and make), if not already installed to successfully compile the package.
|
||||
|
||||
### 2. links2 ###
|
||||
|
||||
Links2 is a graphical web browser version of Twibright Labs Links web browser. This browser has support for mouse and clicks. Designed specially for speed without any CSS support, fairly good HTML and JavaScript support with limitations.
|
||||
|
||||
To install links2.
|
||||
|
||||
# apt-get install links2
|
||||
# yum install links2
|
||||
|
||||
### 3. lynx ###
|
||||
|
||||
A text based web browser released under GNU GPLv2 license and written in ISO C. lynx is highly configurable web browser and Savior for many SYSAdmin. It has the reputation of being the oldest web browser that is being used and still actively developed.
|
||||
|
||||
To install lynx.
|
||||
|
||||
# apt-get install lynx
|
||||
# yum install lynx
|
||||
|
||||
After installing lynx, type the following command to browse the website as shown below in the screen cast..
|
||||
|
||||
# lynx www.tecmint.com
|
||||
|
||||

|
||||
|
||||
If you are interested in knowing a bit more about links and lynx web browser, you may like to visit the below link:
|
||||
|
||||
- [Web Browsing with Lynx and Links Command Line Tools][3]
|
||||
|
||||
### 4. youtube-dl ###
|
||||
|
||||
youtube-dl is a platform independent application which can be used to download videos from youtube and a few other sites. Written primarily in python and released under GNU GPL License, the application works out of the box. (Since youtube don’t allow you to download videos, it may be illegal to use it. Check the laws before you start using this.)
|
||||
|
||||
To install youtube-dl.
|
||||
|
||||
# apt-get install youtube-dl
|
||||
# yum install youtube-dl
|
||||
|
||||
After installing, try to download files from the Youtube site, as shown in the below screen cast.
|
||||
|
||||
# youtube-dl https://www.youtube.com/watch?v=ql4SEy_4xws
|
||||
|
||||

|
||||
|
||||
If you are interested in knowing more about youtube-dl you may like to visit the below link:
|
||||
|
||||
- [YouTube-DL – A Command Line Youtube Video Downloader for Linux][4]
|
||||
|
||||
### 5. fetch ###
|
||||
|
||||
It is a command utility for unix-like operating system that is used for URL retrieval. It supports a lot of options like fetching ipv4 only address, ipv6 only address, no redirect, exit after successful file retrieval request, retry, etc.
|
||||
|
||||
Fetch can be Downloaded and installed from the link below
|
||||
|
||||
- [http://sourceforge.net/projects/fetch/?source=typ_redirect][5]
|
||||
|
||||
But before you compile and run it, you should install HTTP Fetcher. Download HTTP Fetcher from the link below.
|
||||
|
||||
- [http://sourceforge.net/projects/http-fetcher/?source=typ_redirect][6]
|
||||
|
||||
### 6. Axel ###
|
||||
|
||||
Axel is a command-line based download accelerator for Linux. Axel makes it possible to download a file at much faster speed through single connection request for multiple copies of files in small chunks through multiple http and ftp connections.
|
||||
|
||||
To install Axel.
|
||||
|
||||
# apt-get install axel
|
||||
# yum install axel
|
||||
|
||||
After axel installed, you may use following command to download any given file, as shown in the screen cast.
|
||||
|
||||
# axel http://mirror.cse.iitk.ac.in/archlinux/iso/2015.04.01/archlinux-2015.04.01-dual.iso
|
||||
|
||||

|
||||
|
||||
### 7. aria2 ###
|
||||
|
||||
aria2 is a command-line based download utility that is lightweight and support multi-protocol (HTTP, HTTPS, FTP, BitTorrent and Metalink). It can use metalinks files to simultaneously download ISO files from more than one server. It can serve as a Bit torrent client as well.
|
||||
|
||||
To install aria2.
|
||||
|
||||
# apt-get install aria2
|
||||
# yum install aria2
|
||||
|
||||
Once aria2 installed, you can fire up the following command to download any given file…
|
||||
|
||||
# aria2c http://cdimage.debian.org/debian-cd/7.8.0/multi-arch/iso-cd/debian-7.8.0-amd64-i386-netinst.iso
|
||||
|
||||
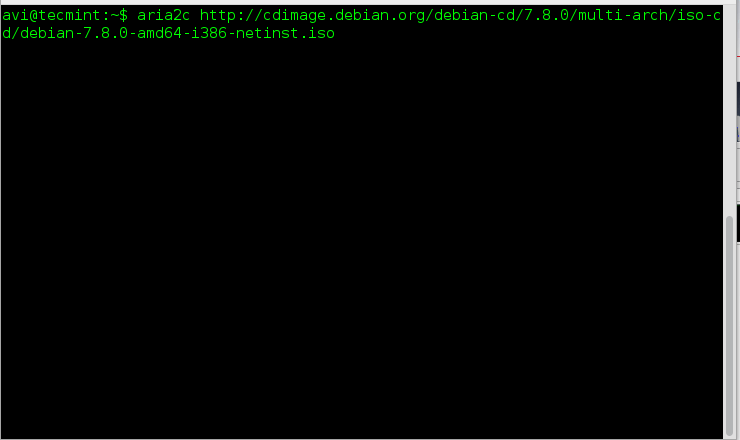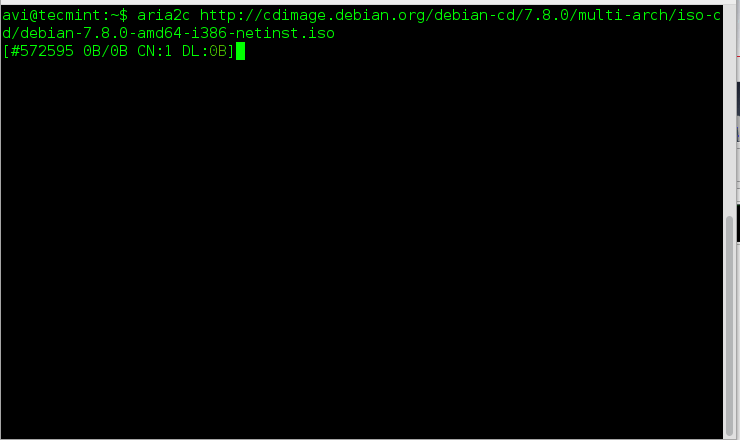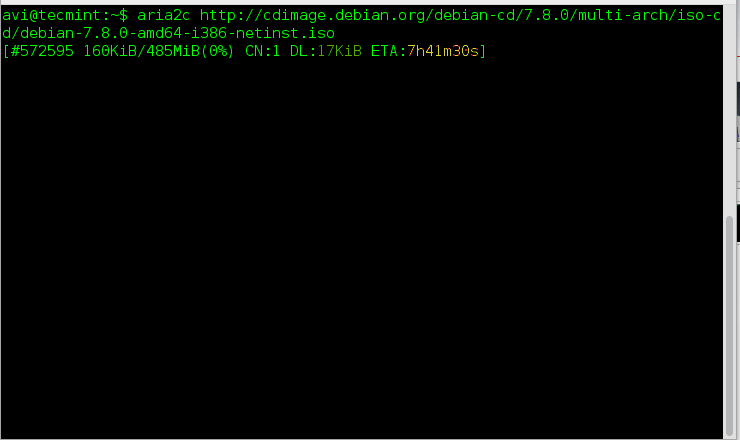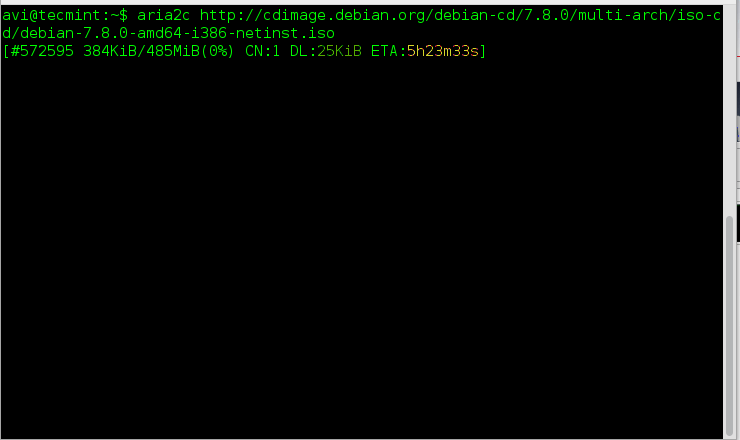
|
||||
Aria2: Command Line Download Manager for Linux
|
||||
|
||||
If you’re interested to know more at aria2 and their switches, read the following article.
|
||||
|
||||
- [Aria2 – A Multi-Protocol Command-Line Download Manager for Linux][7]
|
||||
|
||||
That’s all for now. I’ll be here again with another interesting topic you people will love to read. Till then stay tuned and connected to Tecmint. Don’t forget to provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/command-line-web-browser-download-file-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wangjiezhe](https://github.com/wangjiezhe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/linux-command-line-tools-for-downloading-files/
|
||||
[2]:http://links.twibright.com/download/
|
||||
[3]:http://www.tecmint.com/command-line-web-browsers/
|
||||
[4]:http://www.tecmint.com/install-youtube-dl-command-line-video-download-tool/
|
||||
[5]:http://sourceforge.net/projects/fetch/?source=typ_redirect
|
||||
[6]:http://sourceforge.net/projects/http-fetcher/?source=typ_redirect
|
||||
[7]:http://www.tecmint.com/install-aria2-a-multi-protocol-command-line-download-manager-in-rhel-centos-fedora/
|
||||
@ -1,3 +1,4 @@
|
||||
2q1w2007申领
|
||||
How to access a Linux server behind NAT via reverse SSH tunnel
|
||||
================================================================================
|
||||
You are running a Linux server at home, which is behind a NAT router or restrictive firewall. Now you want to SSH to the home server while you are away from home. How would you set that up? SSH port forwarding will certainly be an option. However, port forwarding can become tricky if you are dealing with multiple nested NAT environment. Besides, it can be interfered with under various ISP-specific conditions, such as restrictive ISP firewalls which block forwarded ports, or carrier-grade NAT which shares IPv4 addresses among users.
|
||||
|
||||
@ -1,181 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
Install ‘Tails 1.4′ Linux Operating System to Preserve Privacy and Anonymity
|
||||
================================================================================
|
||||
In this Internet world and the world of Internet we perform most of our task online be it Ticket booking, Money transfer, Studies, Business, Entertainment, Social Networking and what not. We spend a major part of our time online daily. It has been getting hard to remain anonymous with each passing day specially when backdoors are being planted by organizations like NSA (National Security Agency) who are putting their nose in between every thing that we come across online. We have least or no privacy online. All the searches are logged upon the basis of user Internet surfing activity and machine activity.
|
||||
|
||||
A wonderful browser from Tor project is used by millions which help us surfing the web anonymously however it is not difficult to trace your browsing habits and hence tor alone is not the guarantee of your safety online. You may like to check Tor features and installation instructions here:
|
||||
|
||||
- [Anonymous Web Browsing using Tor][1]
|
||||
|
||||
There is a operating system named Tails by Tor Projects. Tails (The Amnesic Incognito Live System) is a live operating system, based on Debian Linux distribution, which mainly focused on preserving privacy and anonymity on the web while browsing internet, means all it’s outgoing connection are forced to pass through the Tor and direct (non-anonymous) requests are blocked. The system is designed to run from any boot-able media be it USB stick or DVD.
|
||||
|
||||
The latest stable release of Tails OS is 1.4 which was released on May 12, 2015. Powered by open source Monolithic Linux Kernel and built on top of Debian GNU/Linux Tails aims at Personal Computer Market and includes GNOME 3 as default user Interface.
|
||||
|
||||
#### Features of Tails OS 1.4 ####
|
||||
|
||||
- Tails is a free operating system, free as in beer and free as in speech.
|
||||
- Built on top of Debian/GNU Linux. The most widely used OS that is Universal.
|
||||
- Security Focused Distribution.
|
||||
- Windows 8 camouflage.
|
||||
- Need not to be installed and browse Internet anonymously using Live Tails CD/DVD.
|
||||
- Leave no trace on the computer, while tails is running.
|
||||
- Advanced cryptographic tools used to encrypt everything that concerns viz., files, emails, etc.
|
||||
- Sends and Receive traffic through tor network.
|
||||
- In true sense it provides privacy for anyone, anywhere.
|
||||
- Comes with several applications ready to be used from Live Environment.
|
||||
- All the softwares comes per-configured to connect to INTERNET only through Tor network.
|
||||
- Any application that tries to connect to Internet without Tor Network is blocked, automatically.
|
||||
- Restricts someone who is watching what sites you visit and restricts sites to learn your geographical location.
|
||||
- Connect to websites that are blocked and/or censored.
|
||||
- Designed specially not to use space used by parent OS even when there is free swap space.
|
||||
- The whole OS loads on RAM and is flushed when we reboot/shutdown. Hence no trace of running.
|
||||
- Advanced security implementation by encrypting USB disk, HTTPS ans Encrypt and sign emails and documents.
|
||||
|
||||
#### What can you expect in Tails 1.4 ####
|
||||
|
||||
- Tor Browser 4.5 with a security Slider.
|
||||
- Tor Upgraded to version 0.2.6.7.
|
||||
- Several Security holes fixed.
|
||||
- Many of the bug fixed and patches applied to Applications like curl, OpenJDK 7, tor Network, openldap, etc.
|
||||
|
||||
To get a complete list of change logs you may visit [HERE][2]
|
||||
|
||||
**Note**: It is strongly recommended to upgrade to Tails 1.4, if you’re using any older version of Tails.
|
||||
|
||||
#### Why should I use Tails Operating System ####
|
||||
|
||||
You need Tails because you need:
|
||||
|
||||
- Freedom from network surveillance
|
||||
- Defend freedom, privacy and confidentiality
|
||||
- Security aka traffic analysis
|
||||
|
||||
This tutorial will walk through the installation of Tails 1.4 OS with a short review.
|
||||
|
||||
### Tails 1.4 Installation Guide ###
|
||||
|
||||
1. To download the latest Tails OS 1.4, you may use wget command to download directly.
|
||||
|
||||
$ wget http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
|
||||
|
||||
Alternatively you may download Tails 1.4 Direct ISO image or use a Torrent Client to pull the iso image file for you. Here is the link to both downloads:
|
||||
|
||||
- [tails-i386-1.4.iso][3]
|
||||
- [tails-i386-1.4.torrent][4]
|
||||
|
||||
2. After downloading, verify ISO Integrity by matching SHA256 checksum with the SHA256SUM provided on the official website..
|
||||
|
||||
$ sha256sum tails-i386-1.4.iso
|
||||
|
||||
339c8712768c831e59c4b1523002b83ccb98a4fe62f6a221fee3a15e779ca65d
|
||||
|
||||
If you are interested in knowing OpenPGP, checking Tails signing key against Debian keyring and anything related to Tails cryptographic signature, you may like to point your browser [HERE][5].
|
||||
|
||||
3. Next you need to write the image to USB stick or DVD ROM. You may like to check the article, [How to Create Live Bootable USB][6] for details on how to make a flash drive bootable and write ISO to it.
|
||||
|
||||
4. Insert the Tails OS Bootable flash drive or DVD ROM in the disk and boot from it (select from BIOS to boot). The first screen – two options to select from ‘Live‘ and ‘Live (failsafe)‘. Select ‘Live‘ and press Enter.
|
||||
|
||||

|
||||
Tails Boot Menu
|
||||
|
||||
5. Just before login. You have two options. Click ‘More Options‘ if you want to configure and set advanced options else click ‘No‘.
|
||||
|
||||

|
||||
Tails Welcome Screen
|
||||
|
||||
6. After clicking Advanced option, you need to setup root password. This is important if you want to upgrade it. This root password is valid till you shutdown/reboot the machine.
|
||||
|
||||
Also you may enable Windows Camouflage, if you want to run this OS on a public place, so that it seems as you are running Windows 8 operating system. Good option indeed! Is not it? Also you have a option to configure Network and Mac Address. Click ‘Login‘ when done!.
|
||||
|
||||

|
||||
Tails OS Configuration
|
||||
|
||||
7. This is Tails GNU/Linux OS camouflaged by Windows Skin.
|
||||
|
||||

|
||||
Tails Windows Look
|
||||
|
||||
8. It will start Tor Network in the background. Check the Notification on the top-right corner of the screen – Tor is Ready / You are now connected to the Internet.
|
||||
|
||||
Also check what it contains under Internet Menu. Notice – It has Tor Browser (safe) and Unsafe Web Browser (Where incoming and outgoing data don’t pass through TOR Network) along with other applications.
|
||||
|
||||
|
||||
Tails Menu and Tools
|
||||
|
||||
9. Click Tor and check your IP Address. It confirms my physical location is not shared and my privacy is intact.
|
||||
|
||||

|
||||
Check Privacy on Tails
|
||||
|
||||
10. You may Invoke Tails Installer to clone & Install, Clone & Upgrade and Upgrade from ISO.
|
||||
|
||||

|
||||
Tails Installer Options
|
||||
|
||||
11. The other option was to select Tor without any advanced option, just before login (Check step #5 above).
|
||||
|
||||

|
||||
Tails Without Advance Option
|
||||
|
||||
12. You will get log-in to Gnome3 Desktop Environment.
|
||||
|
||||

|
||||
Tails Gnome Desktop
|
||||
|
||||
13. If you click to Launch Unsafe browser in Camouflage or without Camouflage, you will be notified.
|
||||
|
||||

|
||||
Tails Browsing Notification
|
||||
|
||||
If you do, this is what you get in a Browser.
|
||||
|
||||

|
||||
Tails Browsing Alert
|
||||
|
||||
#### Is Tails for me? ####
|
||||
|
||||
To get the above question answered, first answer a few question.
|
||||
|
||||
- Do you need your privacy to be intact while you are online?
|
||||
- Do you want to remain hidden from Identity thieves?
|
||||
- Do you want somebody to put your nose in between your private chat online?
|
||||
- Do you really want to show your geographical location to anybody there?
|
||||
- Do you carry out banking transactions online?
|
||||
- Are you happy with the censorship by government and ISP?
|
||||
|
||||
If the answer to any of the above question is ‘YES‘ you preferably need Tails. If answer to all the above question is ‘NO‘ you perhaps don’t need it.
|
||||
|
||||
To know more about Tails? Point your browser to user Documentation : [https://tails.boum.org/doc/index.en.html][7]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Tails is an OS which is must for those who work in an unsafe environment. An OS focused on security yet contains bundles of Application – Gnome Desktop, Tor, Firefox (Iceweasel), Network Manager, Pidgin, Claws mail, Liferea feed addregator, Gobby, Aircrack-ng, I2P.
|
||||
|
||||
It also contain several tools for Encryption and Privacy Under the Hood, viz., LUKS, GNUPG, PWGen, Shamir’s Secret Sharing, Virtual Keyboard (against Hardware Keylogging), MAT, KeePassX Password Manager, etc.
|
||||
|
||||
That’s all for now. Keep Connected to Tecmint. Share your thoughts on Tails GNU/Linux Operating System. What do you think about the future of the Project? Also test it Locally and let us know your experience.
|
||||
|
||||
You may run it in [Virtualbox][8] as well. Remember Tails loads the whole OS in RAM hence give enough RAM to run Tails in VM.
|
||||
|
||||
I tested in 1GB Environment and it worked without lagging. Thanks to all our readers for their Support. In making Tecmint a one place for all Linux related stuffs your co-operation is needed. Kudos!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-tails-1-4-linux-operating-system-to-preserve-privacy-and-anonymity/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
[2]:https://tails.boum.org/news/version_1.4/index.en.html
|
||||
[3]:http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
|
||||
[4]:https://tails.boum.org/torrents/files/tails-i386-1.4.torrent
|
||||
[5]:https://tails.boum.org/download/index.en.html#verify
|
||||
[6]:http://www.tecmint.com/install-linux-from-usb-device/
|
||||
[7]:https://tails.boum.org/doc/index.en.html
|
||||
[8]:http://www.tecmint.com/install-virtualbox-on-redhat-centos-fedora/
|
||||
@ -1,3 +1,4 @@
|
||||
wyangsun翻译中
|
||||
How to Create Own Online Shopping Store Using “OpenCart” in Linux
|
||||
================================================================================
|
||||
In the Internet world we are doing everything using a computer. Electronic Commerce aka e-commerce is one one of them. E-Commerce is nothing new and it started in the early days of ARPANET, where ARPANET used to arrange sale between students of Massachusetts Institute of Technology and Stanford Artificial Intelligence Laboratory.
|
||||
@ -222,4 +223,4 @@ via: http://www.tecmint.com/create-e-commerce-online-shopping-store-using-openca
|
||||
[1]:http://demo.opencart.com/
|
||||
[2]:http://demo.opencart.com/admin/
|
||||
[3]:http://www.opencart.com/index.php?route=download/download/
|
||||
[4]:http://secure.hostgator.com/%7Eaffiliat/cgi-bin/affiliates/clickthru.cgi?id=tecmint
|
||||
[4]:http://secure.hostgator.com/%7Eaffiliat/cgi-bin/affiliates/clickthru.cgi?id=tecmint
|
||||
|
||||
@ -1,289 +0,0 @@
|
||||
translating by wwy-hust
|
||||
|
||||
27 ‘DNF’ (Fork of Yum) Commands for RPM Package Management in Linux
|
||||
================================================================================
|
||||
DNF aka Dandified YUM is a next generation Package Manager for RPM based Distribution. It was first introduced in Fedora 18 and it is replaced [YUM utility][1] in recent release of Fedora 22.
|
||||
|
||||

|
||||
|
||||
DNF aims at improving the bottlenecks of YUM viz., Performance, Memory Usages, Dependency Resolution, Speed and lots of other factors. DNF does Package Management using RPM, libsolv and hawkey library. Though it does not come per-installed in CentOS and RHEL 7 you can yum, dnf and use it alongside the yum.
|
||||
|
||||
You may like to read more about DNF here:
|
||||
|
||||
- [Reasons Behind Replacing Yum with DNF][2]
|
||||
|
||||
The latest stable release of DNF is 1.0 (at the time of writing of post) which was released on May 11, 2015. It (and all previous version of DNF) is mostly written in Python and is released under GPL v2 License.
|
||||
|
||||
### Installation of DNF ###
|
||||
|
||||
DNF in not available in the default repository of RHEL/CentOS 7. However Fedora 22 ships with DNF implemented officially.
|
||||
|
||||
To install DNF on RHEL/CentOS systems, you need to first install and enable epel-release repository.
|
||||
|
||||
# yum install epel-release
|
||||
OR
|
||||
# yum install epel-release -y
|
||||
|
||||
Though it is not ethical to use ‘-y‘ with yum as it is recommended to see what is being installed in your system. However if this does not matter you much you may use ‘-y’ with yum to install everything automatically without user’s intervention.
|
||||
|
||||
Next, install DNS package using yum command from epel-release repository.
|
||||
|
||||
# yum install dnf
|
||||
|
||||
After dnf installed successfully, it’s time to show you 27 practical usage of dnf commands with examples that will help you to manage packages in RPM based distribution easily and effectively.
|
||||
|
||||
### 1. Check DNF Version ###
|
||||
|
||||
Check the version of DNF installed on your System.
|
||||
|
||||
# dnf --version
|
||||
|
||||
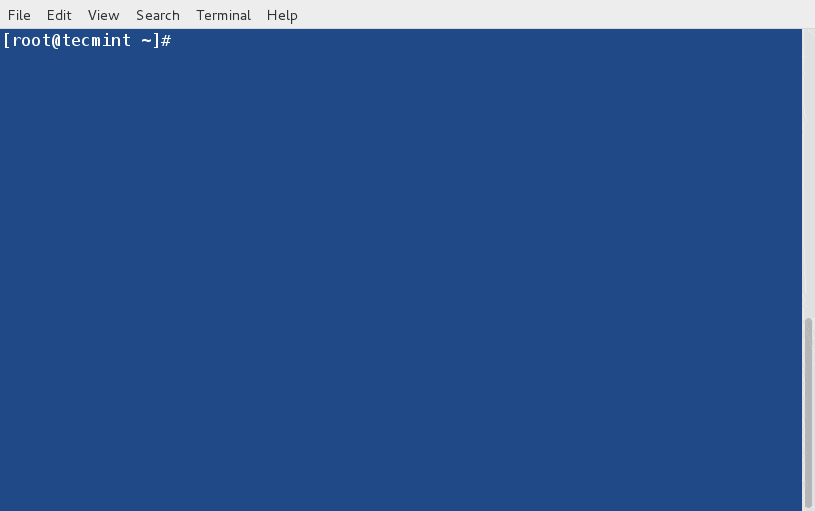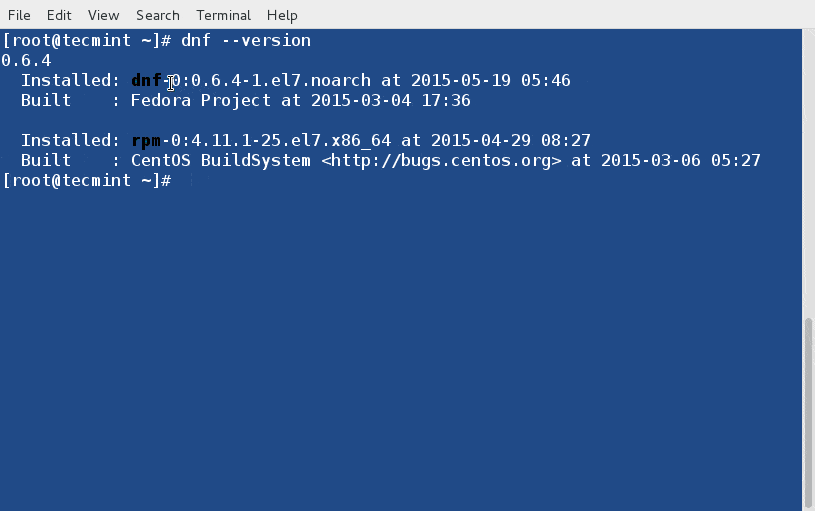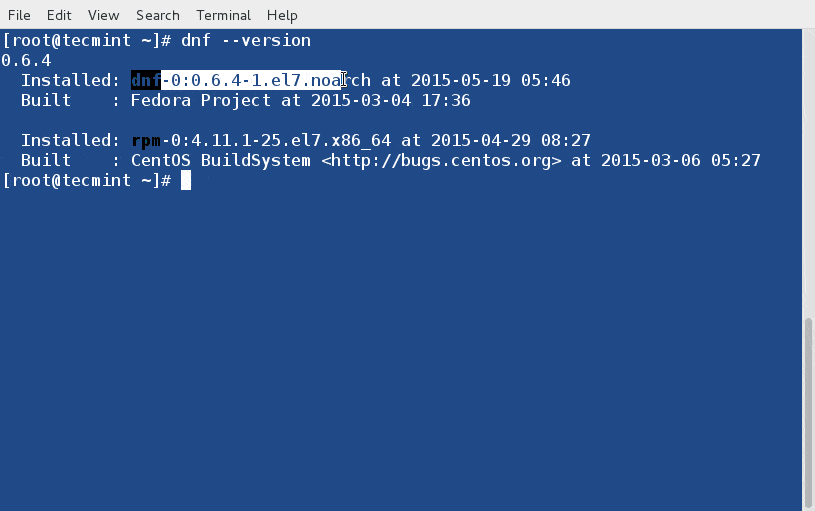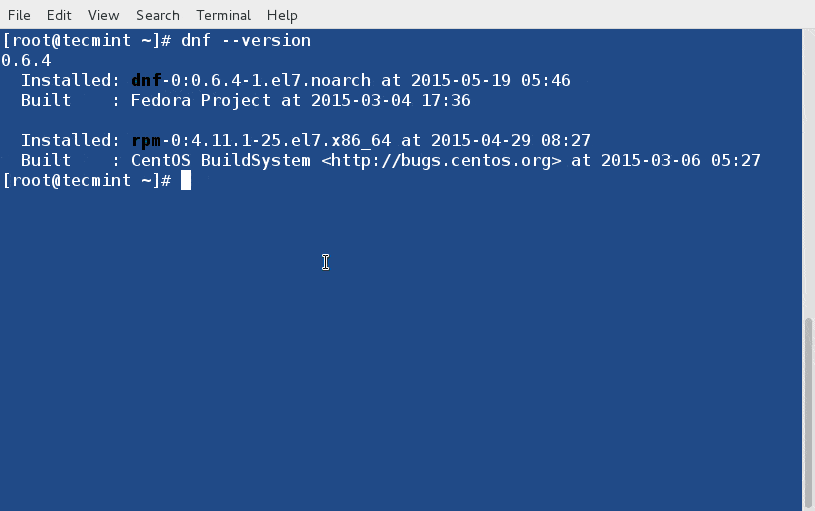
|
||||
|
||||
### 2. List Enabled DNF Repositories ###
|
||||
|
||||
The option ‘repolist‘ with dnf command, will display all enabled repositories under your system.
|
||||
|
||||
# dnf repolist
|
||||
|
||||

|
||||
|
||||
### 3. List all Enabled and Disabled DNF Repositories ###
|
||||
|
||||
The option ‘repolist all‘ will print all the enabled/disabled repositories under your system.
|
||||
|
||||
# dnf repolist all
|
||||
|
||||
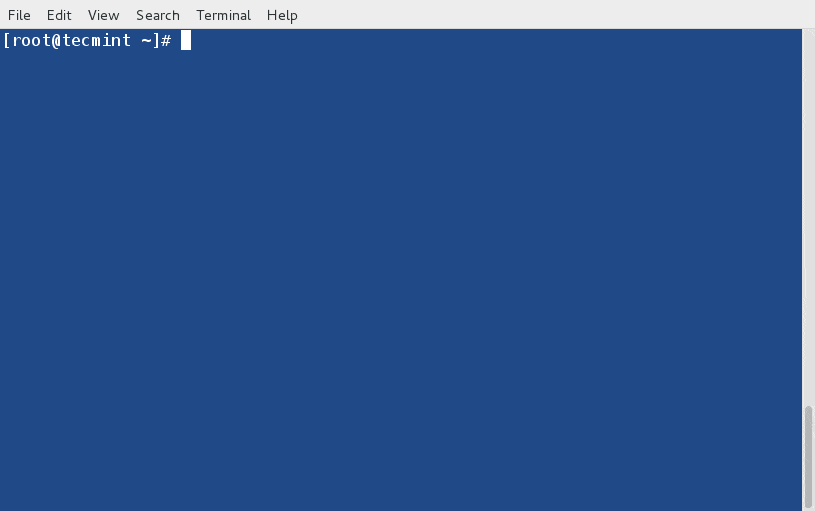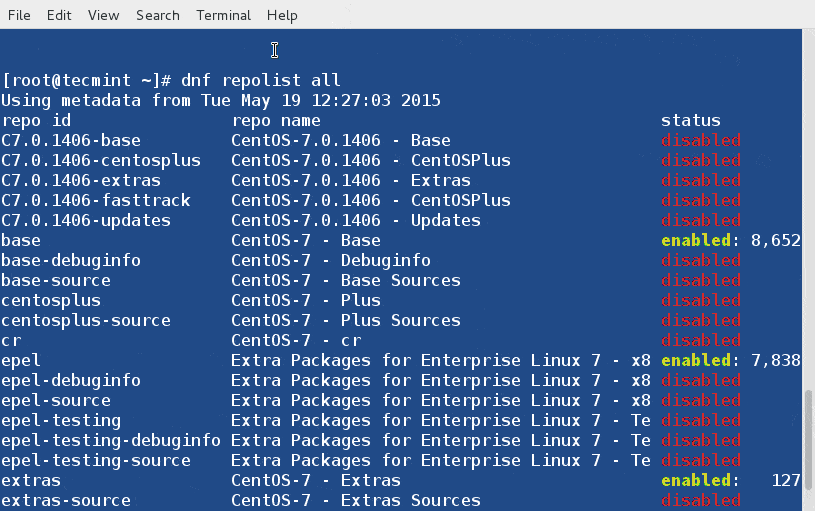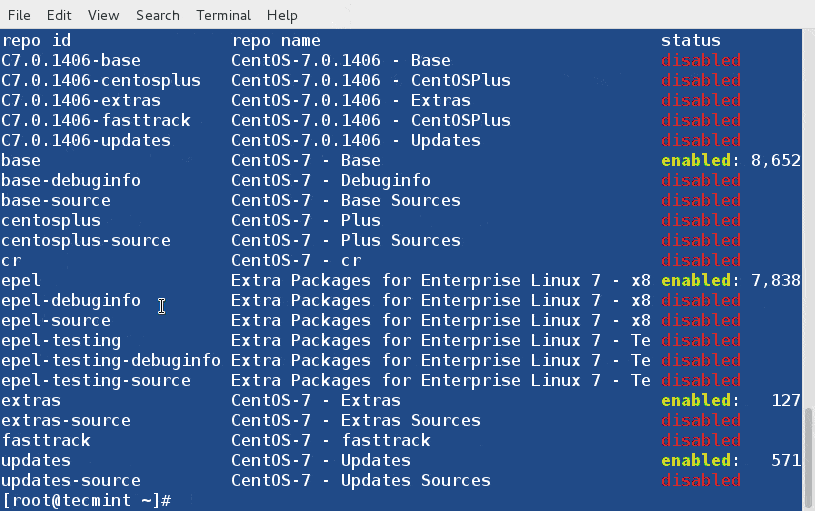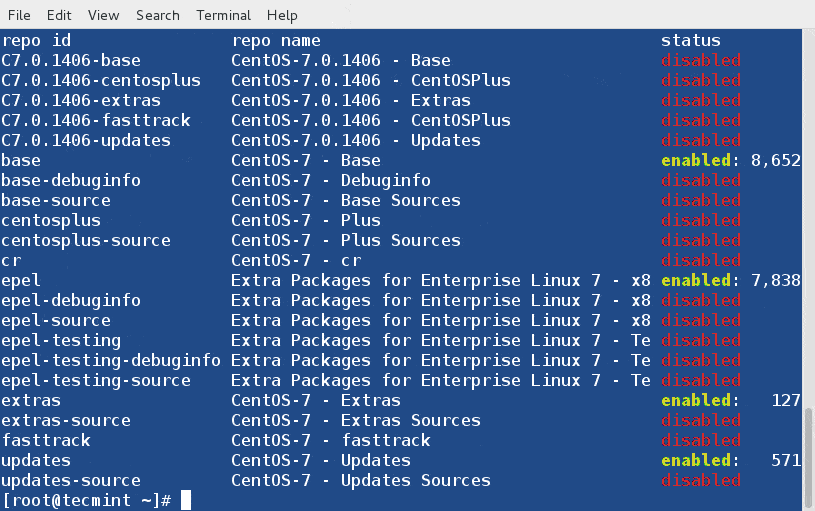
|
||||
|
||||
### 4. List all Available and Installed Packages using DNF ###
|
||||
|
||||
The command “dnf list” will list all the available packages from all the repositories and installed packages on your Linux system.
|
||||
|
||||
# dnf list
|
||||
|
||||

|
||||
|
||||
### 5. List all Installed Packages using DNF ###
|
||||
|
||||
While the “dnf list” command shows all the available/installed packages from all the repositories. However, you have the option to list only the installed packages using option “list installed” as shown below.
|
||||
|
||||
# dnf list installed
|
||||
|
||||

|
||||
|
||||
### 6. List all Available Packages using DNF ###
|
||||
|
||||
Similarly, the “list available” option, will list all the packages available to be installed from all the enabled repositories.
|
||||
|
||||
# dnf list available
|
||||
|
||||
|
||||
|
||||
### 7. Search for a Package using DNF ###
|
||||
|
||||
If incase, you’ve no idea about the package that you want install, in such situation you may use ‘search‘ option with dnf command to search for the package that matches the word or string (say nano).
|
||||
|
||||
# dnf search nano
|
||||
|
||||

|
||||
|
||||
### 8. See what Provides a file/sub-package? ###
|
||||
|
||||
The dnf option “provides” find the name of the package that provides specific file/sub-package. For example, if you would like to find what provides ‘/bin/bash‘ on your system?
|
||||
|
||||
# dnf provides /bin/bash
|
||||
|
||||
|
||||
|
||||
### 9. Get Details of a Package using DNF ###
|
||||
|
||||
Let’s assume you want to know the information of a package before installing it on the system, you may use “info” switch to get a detailed information about a package (say nano) as below.
|
||||
|
||||
# dnf info nano
|
||||
|
||||
|
||||
|
||||
### 10. Install a Package with DNF ###
|
||||
|
||||
To install a package called nano, just run the below command it will automatically resolve and install all required dependencies for package nano.
|
||||
|
||||
# dnf install nano
|
||||
|
||||

|
||||
|
||||
### 11. Updating a Package using DNF ###
|
||||
|
||||
You may update only a specific package (say systemd) and leave everything on the system untouched.
|
||||
|
||||
# dnf update systemd
|
||||
|
||||

|
||||
|
||||
### 12. Check for System Updates using DNF ###
|
||||
|
||||
Check updates for all the system packages installed into the system simply as.
|
||||
|
||||
# dnf check-update
|
||||
|
||||
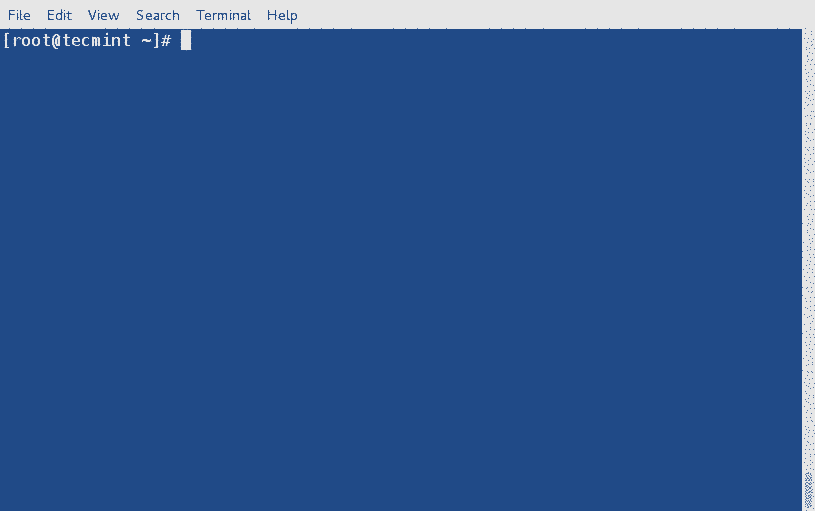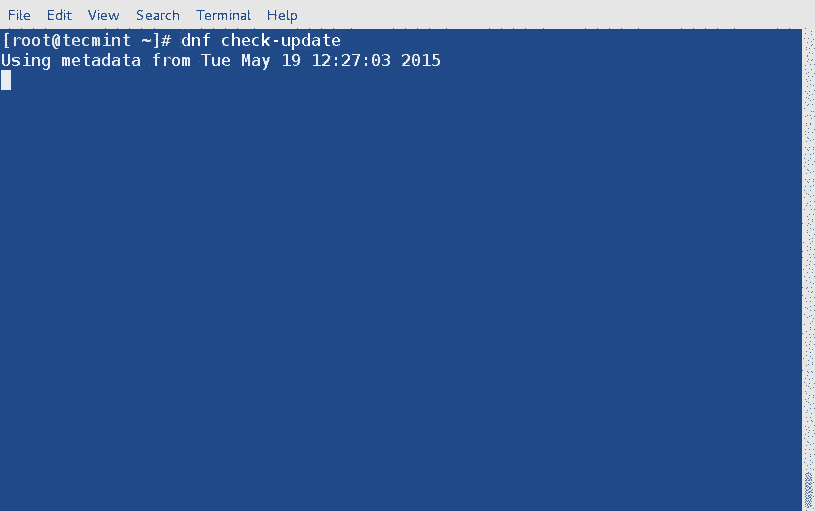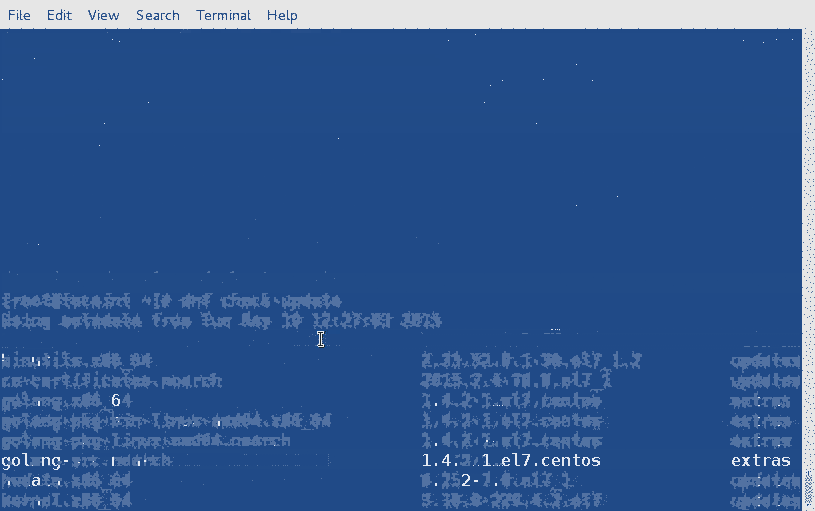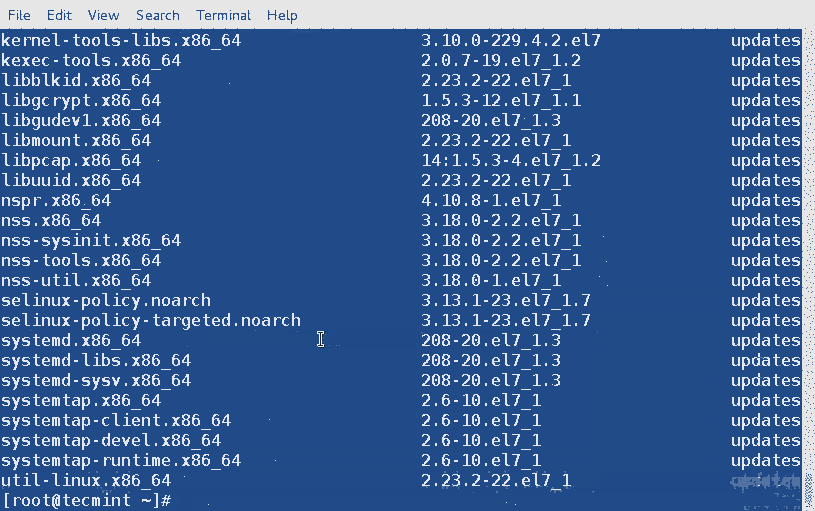
|
||||
|
||||
### 13. Update All System Packages using DNF ###
|
||||
|
||||
You may update the whole system including all the installed packages with following commands.
|
||||
|
||||
# dnf update
|
||||
OR
|
||||
# dnf upgrade
|
||||
|
||||

|
||||
|
||||
### 14. Remove/Erase a Package using DNF ###
|
||||
|
||||
To remove or erase any unwanted package (say nano), you may use “remove” or “erase” switch with dnf command to remove it.
|
||||
|
||||
# dnf remove nano
|
||||
OR
|
||||
# dnf erase nano
|
||||
|
||||
|
||||
|
||||
### 15. Remove Orphan Packages using DNF ###
|
||||
|
||||
Those packages that were installed to satisfy dependency may be useless if not being used by other applications. To remove those orphan packages execute the below command.
|
||||
|
||||
# dnf autoremove
|
||||
|
||||

|
||||
|
||||
### 16. Remove Cached Packages using DNF ###
|
||||
|
||||
A lot of time we encounter out-of-date headers and unfinished transactions which results into error while executing dnf. We may clean all the cached packages and headers containing remote package information simply by executing.
|
||||
|
||||
# dnf clean all
|
||||
|
||||
|
||||
|
||||
### 17. Get Help on Specific DNF Command ###
|
||||
|
||||
You may get help of any specific dnf command (say clean) just by executing the below command.
|
||||
|
||||
# dnf help clean
|
||||
|
||||
|
||||
|
||||
### 18. List all DNF Commands and Options ###
|
||||
|
||||
To list help on all available dnf commands and option simply type.
|
||||
|
||||
# dnf help
|
||||
|
||||

|
||||
|
||||
### 19. View History of DNF ###
|
||||
|
||||
You may call dnf history to look at the list of already executed dnf commands. This way you can be aware of what was installed/removed with time stamp.
|
||||
|
||||
# dnf history
|
||||
|
||||
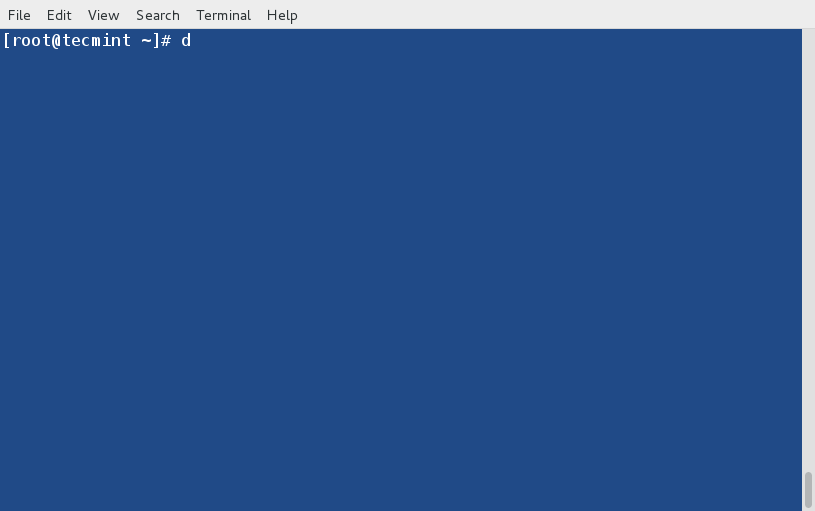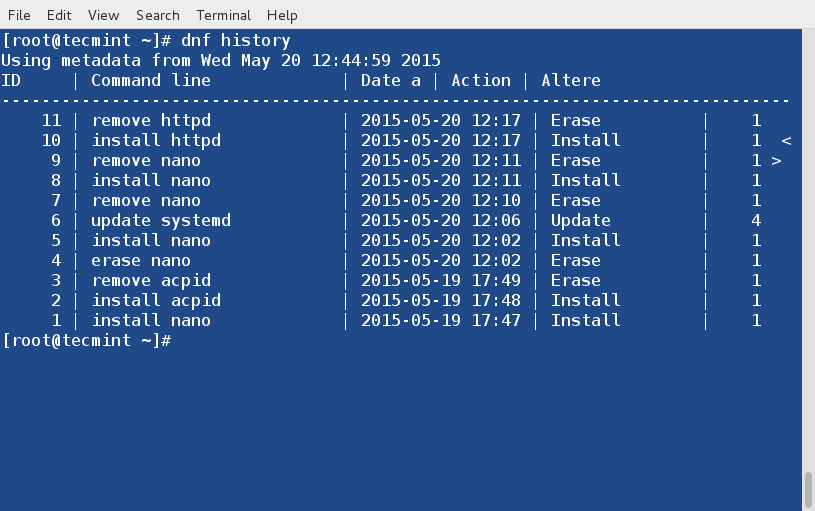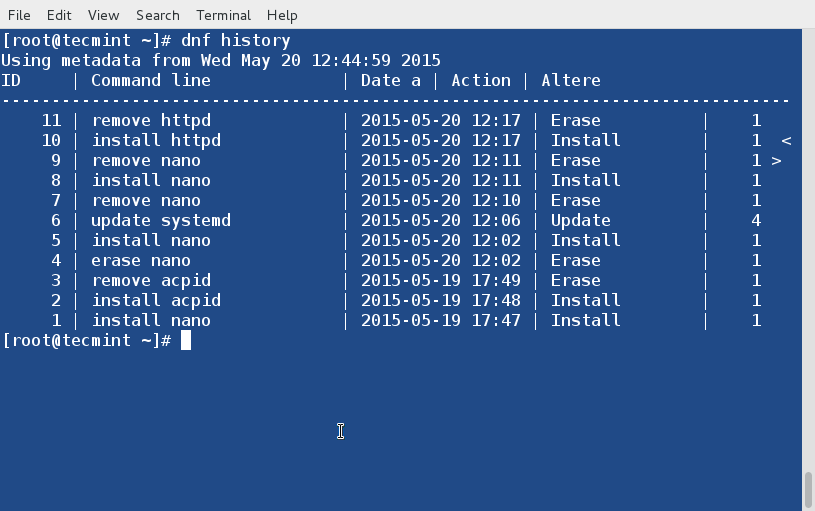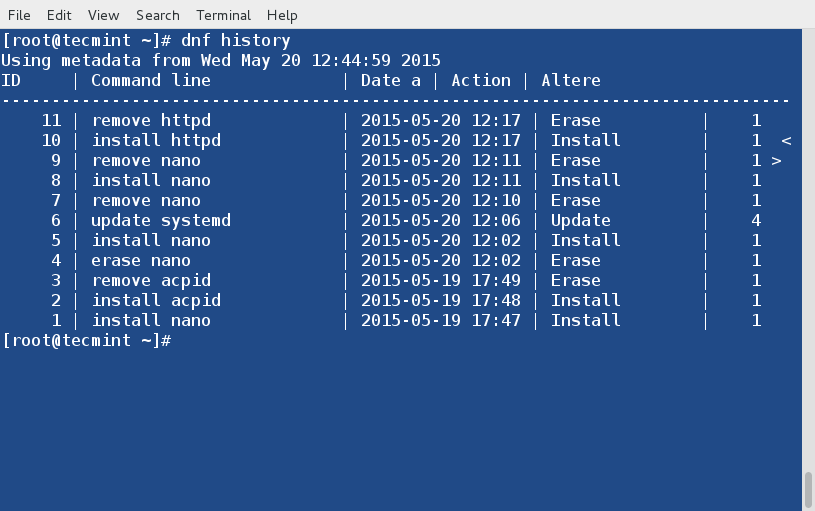
|
||||
|
||||
### 20. List all Group Packages ###
|
||||
|
||||
The command “dnf grouplist” will print all available or installed packages, if nothing is mentioned, it will list all known groups.
|
||||
|
||||
# dnf grouplist
|
||||
|
||||

|
||||
|
||||
### 21. Install a Group Package using DNF ###
|
||||
|
||||
To install a Group of packages bundled together as group package (say Educational Software) simply as.
|
||||
|
||||
# dnf groupinstall 'Educational Software'
|
||||
|
||||

|
||||
|
||||
### 22. Update a Group Package ###
|
||||
|
||||
Let’s update a Group Package (say Educational Software) by executing the below command.
|
||||
|
||||
# dnf groupupdate 'Educational Software'
|
||||
|
||||
|
||||
|
||||
### 23. Remove a Group Package ###
|
||||
|
||||
We can remove the group Package (say Educational Software) as.
|
||||
|
||||
# dnf groupremove 'Educational Software'
|
||||
|
||||
|
||||
|
||||
### 24. Install a Package from Specific Repository ###
|
||||
|
||||
DNF makes it possible to install any specific package (say phpmyadmin) from a repo (epel) as simply as,
|
||||
|
||||
# dnf --enablerepo=epel install phpmyadmin
|
||||
|
||||

|
||||
|
||||
### 25. Synchronize Installed Packages to Stable Release ###
|
||||
|
||||
The command “dnf distro-sync” will provides necessary options to synchronize all installed packages to most recent stable version available from any enabled repository. If no package is selected, all installed packages are synchronized.
|
||||
|
||||
# dnf distro-sync
|
||||
|
||||

|
||||
|
||||
### 26. Reinstall a Package ###
|
||||
|
||||
The command “dnf reinstall nano” will reinstall an already installed package (say nano).
|
||||
|
||||
# dnf reinstall nano
|
||||
|
||||

|
||||
|
||||
### 27. Downgrade a Package ###
|
||||
|
||||
The option “downgrade” will downgrades the named package (say acpid) to lower version if possible.
|
||||
|
||||
# dnf downgrade acpid
|
||||
|
||||
Sample Output
|
||||
|
||||
Using metadata from Wed May 20 12:44:59 2015
|
||||
No match for available package: acpid-2.0.19-5.el7.x86_64
|
||||
Error: Nothing to do.
|
||||
|
||||
**My observation**: DNF does not downgraded the package as it is supposed to. It has also been reported as bug.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
DNF is the upper state of the end of the art Package Manager YUM. It tends to do a lot of processing automatically which is not going to be praised by many experienced Linux System Administrator, as I believe. As a matter of example:
|
||||
|
||||
- `--skip-broken` is not recognized by DNF and there is no alternative.
|
||||
- There is nothing like ‘resolvedep‘ command however you may run dnf provides.
|
||||
- There is no ‘deplist‘ command to find package dependency.
|
||||
- You exclude a repo, means the exclusion apply on all operations, unlike yum which excludes those repos only at the time of install and updates, etc.
|
||||
|
||||
Several Linux users are not happy the way Linux Ecosystem is moving. First [Systemd removed init system][3] v and now DNF will be replacing YUM sooner in Fedora 22 and later in RHEL and CentOS.
|
||||
|
||||
What do you think? are distributions and the whole Linux ecosystem is not valuing it’s users and moving against their will. Also it is often said in IT industry – “Why fix, If not broken?”, and neither init System V is broken nor YUM.
|
||||
|
||||
That’s all for now. Please let me know your valuable thoughts in the comments below. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-next-generation-package-management-utility-for-linux/
|
||||
[3]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
@ -1,115 +0,0 @@
|
||||
Translating by GOLinux!
|
||||
Things To Do After Installing Fedora 22
|
||||
================================================================================
|
||||
Fedora 22 the latest entrant in the community developed line of Red hat operating systems is released on the 26th of May 2015. A lot of speculation and anticipation has been associated with this release of the venerable fedora. Well there are some major changes that are being proposed for Fedora 22.
|
||||
|
||||
Systemd is the new kid in the block when it comes to initialization daemons, it is poised to replace the venerable sysvinit module that has long been a part of the Linux ecosystem. Another major change that users will come across in the base python version. Its just that python in available in two different flavors the 2.x and 3.x lines. Each has its fair share of quirks and benefits. So users who might prefer the 2.x flavor might want to install their favorite python. The dandified Yum installer that has been around since Fedora 18 is all set to replace the age old YUM installer. Fedora has finally decided that it is time that DNF replace YUM.
|
||||
|
||||
### 1) Install VLC media player ###
|
||||
|
||||
Fedora 22 comes with a default media player viz. gnome videos (previously known as totem). If that is fine by you we can skip this step and move ahead. However if you like me prefer the most widely used VLC you can go ahead and install it from the RPMFusion repos. You can do that with :
|
||||
|
||||
sudo dnf install vlc -y
|
||||
|
||||
### 2) Configure RPMFusion Repos ###
|
||||
|
||||
As I already mentioned Fedora is very strict with its ideologies, it does not ship with any non-free components with it. The official repositories does not provide some essential software containing non-free components like multimedia codes. So it is necessary to install some 3rd party repositories which will provide us some essential software. Luckily RPMFusion repositories come to the rescue.
|
||||
|
||||
$ sudo dnf install --nogpgcheck http://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-22.noarch.rpm
|
||||
|
||||
### 3) Install Multimedia Codecs ###
|
||||
|
||||
As is said some multimedia codecs and plugins don't ship with fedora. Now who would like to miss out on their favorite shows and movies just because the codes are proprietary. Try this:
|
||||
|
||||
$ sudo dnf install gstreamer-plugins-bad gstreamer-plugins-bad-free-extras gstreamer-plugins-ugly gstreamer-ffmpeg gstreamer1-libav gstreamer1-plugins-bad-free-extras gstreamer1-plugins-bad-freeworld gstreamer-plugins-base-tools gstreamer1-plugins-good-extras gstreamer1-plugins-ugly gstreamer1-plugins-bad-free gstreamer1-plugins-good gstreamer1-plugins-base gstreamer1
|
||||
|
||||
### 4) Update your system ###
|
||||
|
||||
Fedora is a bleeding edge distribution and hence it releases updates which will fix bugs and loopholes present in your system continuously. Hence it is a good practice to keep your system up to date.
|
||||
|
||||
$ sudo dnf update -y
|
||||
|
||||
### 5) Uninstall software you may not need ###
|
||||
|
||||
Fedora comes with a set of pre-chosen packages that most users can utilize, however for more advanced users, you may recognize that you do not need all of it. It's easy enough to remove any packages you don't need using the following command - I chose to uninstall rhythmbox because I know I won't use it:
|
||||
|
||||
$ sudo dnf remove rhythmbox
|
||||
|
||||
### 6) Install Adobe Flash ###
|
||||
|
||||
We all wish Adobe Flash didn't exist anymore since it is not always know for being the most secure or resource efficient, but for awhile it's here to stay. The only way to install Adobe Flash for Fedora 22 is to install the official RPM from Adobe, as shown below.
|
||||
|
||||
You can download the RPM [here][1]. After downloading the file, you can right click and open it like this:
|
||||
|
||||

|
||||
|
||||
Right click and select "Open With Software Install"
|
||||
|
||||
Then, simply click install on the window that pops up:
|
||||
|
||||

|
||||
|
||||
Click on "Install" to complete the process of installing the custom RPM from Adobe
|
||||
|
||||
Once the process completes, the "Install" button will change to "Remove" and the installation should have finished. If your browser is open during the process, it may ask you to close it first or restart it after the install for the changes to take effect.
|
||||
|
||||
### 7) Spin Up a VM with Gnome Boxes ###
|
||||
|
||||
So you just installed Fedora and you're loving it, but maybe you need Windows still for something proprietary, or maybe you just want to play with another Linux distro. In any situation, you can use Gnome Boxes, provided with Fedora 22, to easily create a VM or use a live distribution. Follow the steps below to get started using an ISO of your choice! Who knows, maybe you can even check out a [Fedora Spin][2].
|
||||
|
||||
First open Gnome Boxes and select "New" in the top left:
|
||||
|
||||

|
||||
|
||||
Click "New" to start the process of adding a new virtual machine.
|
||||
|
||||
Next, click to open a file and choose an ISO:
|
||||
|
||||

|
||||
|
||||
After choosing to select a file or ISO, select your ISO. In this case, I had a Debian ISO I installed
|
||||
|
||||
Finally, customize the VM settings or use the defaults and click "Create." The VM will start by default and the available VMs will be available in Gnome Boxes as little thumbnails.
|
||||
|
||||

|
||||
|
||||
Customize the settings to whatever you choose, or keep the defaults. Click "Create" when you are done and the VM will be ready to go.
|
||||
|
||||
### 8) Install Google Chrome ###
|
||||
|
||||
Firefox is included with Fedora 22, but as with most software, everyone has their browser of choice. If yours happens to be Google Chrome, you can follow the instructions above for Adobe Flash player, however, obviously use the RPM from Google for whichever version of Chrome you download. The latest version can usually be found [here][3].
|
||||
|
||||
### 9) Add Social Media and Other Online Accounts ###
|
||||
|
||||
Gnome has some nice built in functionality to accommodate accounts for things like Facebook, Google, and other online accounts. You can access the Online Accounts settings through the main Gnome Settings application. You can access the settings by right clicking on the desktop or by finding it in the applications. Then, simply click on Online Accounts and add the accounts of your choosing. If you add an account like Google, for example, you can use it as the default for things like sending email, calendar appointments, interacting with photos and documents, and more.
|
||||
|
||||
### 10) Install KDE or another Desktop Environment ###
|
||||
|
||||
Some of us just don't like Gnome, and that's okay. Run the following command in Terminal to install everything necessary to use KDE instead. The same instructions can be applied to xfce, lxde, or other desktop environments as well.
|
||||
|
||||
$ sudo dnf install @kde-desktop
|
||||
|
||||
After the install finishes, log out. When you click on your username, notice the little gear wheel that indicates settings. Click it and select "Plasma." When you log in again, you will be greeted by a fresh KDE desktop.
|
||||
|
||||

|
||||
|
||||
The Plasma environment after just installing it on Fedora 22
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
That’s it you are all set to go. Use the system and try out things. If you don't find something according to your liking, linux gives you the freedom to change them. Fedora comes with the latest Gnome shell as its desktop environment, too heavy for you and don't like it. Try KDE or some light weight DE like cinnamon, xfce etc. Wish you a very happy and hassle free Fedora experience. !!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/things-do-after-installing-fedora-22/
|
||||
|
||||
作者:[Jonathan DeMasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/jonathande/
|
||||
[1]:https://get.adobe.com/flashplayer/
|
||||
[2]:http://spins.fedoraproject.org/
|
||||
[3]:https://www.google.com/intl/en/chrome/browser/desktop/index.html
|
||||
@ -0,0 +1,209 @@
|
||||
translating by wwy-hust
|
||||
|
||||
Nishita Agarwal Shares Her Interview Experience on Linux ‘iptables’ Firewall
|
||||
================================================================================
|
||||
Nishita Agarwal, a frequent Tecmint Visitor shared her experience (Question and Answer) with us regarding the job interview she had just given in a privately owned hosting company in Pune, India. She was asked a lot of questions on a variety of topics however she is an expert in iptables and she wanted to share those questions and their answer (she gave) related to iptables to others who may be going to give interview in near future.
|
||||
|
||||

|
||||
|
||||
All the questions and their Answer are rewritten based upon the memory of Nishita Agarwal.
|
||||
|
||||
> “Hello Friends! My name is **Nishita Agarwal**. I have Pursued Bachelor Degree in Technology. My area of Specialization is UNIX and Variants of UNIX (BSD, Linux) fascinates me since the time I heard it. I have 1+ years of experience in storage. I was looking for a job change which ended with a hosting company in Pune, India.”
|
||||
|
||||
Here is the collection of what I was asked during the Interview. I’ve documented only those questions and their answer that were related to iptables based upon my memory. Hope this will help you in cracking your Interview.
|
||||
|
||||
### 1. Have you heard of iptables and firewall in Linux? Any idea of what they are and for what it is used? ###
|
||||
|
||||
> **Answer** : I’ve been using iptables for quite long time and I am aware of both iptables and firewall. Iptables is an application program mostly written in C Programming Language and is released under GNU General Public License. Written for System administration point of view, the latest stable release if iptables 1.4.21.iptables may be considered as firewall for UNIX like operating system which can be called as iptables/netfilter, more accurately. The Administrator interact with iptables via console/GUI front end tools to add and define firewall rules into predefined tables. Netfilter is a module built inside of kernel that do the job of filtering.
|
||||
>
|
||||
> Firewalld is the latest implementation of filtering rules in RHEL/CentOS 7 (may be implemented in other distributions which I may not be aware of). It has replaced iptables interface and connects to netfilter.
|
||||
|
||||
### 2. Have you used some kind of GUI based front end tool for iptables or the Linux Command Line? ###
|
||||
|
||||
> **Answer** : Though I have used both the GUI based front end tools for iptables like Shorewall in conjugation of [Webmin][1] in GUI and Direct access to iptables via console.And I must admit that direct access to iptables via Linux console gives a user immense power in the form of higher degree of flexibility and better understanding of what is going on in the background, if not anything other. GUI is for novice administrator while console is for experienced.
|
||||
|
||||
### 3. What are the basic differences between between iptables and firewalld? ###
|
||||
|
||||
> **Answer** : iptables and firewalld serves the same purpose (Packet Filtering) but with different approach. iptables flush the entire rules set each time a change is made unlike firewalld. Typically the location of iptables configuration lies at ‘/etc/sysconfig/iptables‘ whereas firewalld configuration lies at ‘/etc/firewalld/‘, which is a set of XML files.Configuring a XML based firewalld is easier as compared to configuration of iptables, however same task can be achieved using both the packet filtering application ie., iptables and firewalld. Firewalld runs iptables under its hood along with it’s own command line interface and configuration file that is XML based and said above.
|
||||
|
||||
### 4. Would you replace iptables with firewalld on all your servers, if given a chance? ###
|
||||
|
||||
> **Answer** : I am familiar with iptables and it’s working and if there is nothing that requires dynamic aspect of firewalld, there seems no reason to migrate all my configuration from iptables to firewalld.In most of the cases, so far I have never seen iptables creating an issue. Also the general rule of Information technology says “why fix if it is not broken”. However this is my personal thought and I would never mind implementing firewalld if the Organization is going to replace iptables with firewalld.
|
||||
|
||||
### 5. You seems confident with iptables and the plus point is even we are using iptables on our server. ###
|
||||
|
||||
What are the tables used in iptables? Give a brief description of the tables used in iptables and the chains they support.
|
||||
|
||||
> **Answer** : Thanks for the recognition. Moving to question part, There are four tables used in iptables, namely they are:
|
||||
>
|
||||
> Nat Table
|
||||
> Mangle Table
|
||||
> Filter Table
|
||||
> Raw Table
|
||||
>
|
||||
> Nat Table : Nat table is primarily used for Network Address Translation. Masqueraded packets get their IP address altered as per the rules in the table. Packets in the stream traverse Nat Table only once. ie., If a packet from a jet of Packets is masqueraded they rest of the packages in the stream will not traverse through this table again. It is recommended not to filter in this table. Chains Supported by NAT Table are PREROUTING Chain, POSTROUTING Chain and OUTPUT Chain.
|
||||
>
|
||||
> Mangle Table : As the name suggests, this table serves for mangling the packets. It is used for Special package alteration. It can be used to alter the content of different packets and their headers. Mangle table can’t be used for Masquerading. Supported chains are PREROUTING Chain, OUTPUT Chain, Forward Chain, INPUT Chain, POSTROUTING Chain.
|
||||
>
|
||||
> Filter Table : Filter Table is the default table used in iptables. It is used for filtering Packets. If no rules are defined, Filter Table is taken as default table and filtering is done on the basis of this table. Supported Chains are INPUT Chain, OUTPUT Chain, FORWARD Chain.
|
||||
>
|
||||
> Raw Table : Raw table comes into action when we want to configure packages that were exempted earlier. It supports PREROUTING Chain and OUTPUT Chain.
|
||||
|
||||
### 6. What are the target values (that can be specified in target) in iptables and what they do, be brief! ###
|
||||
|
||||
> **Answer** : Following are the target values that we can specify in target in iptables:
|
||||
>
|
||||
> ACCEPT : Accept Packets
|
||||
> QUEUE : Paas Package to user space (place where application and drivers reside)
|
||||
> DROP : Drop Packets
|
||||
> RETURN : Return Control to calling chain and stop executing next set of rules for the current Packets in the chain.
|
||||
|
||||
|
||||
### 7. Lets move to the technical aspects of iptables, by technical I means practical. ###
|
||||
|
||||
How will you Check iptables rpm that is required to install iptables in CentOS?.
|
||||
|
||||
> **Answer** : iptables rpm are included in standard CentOS installation and we do not need to install it separately. We can check the rpm as:
|
||||
>
|
||||
> # rpm -qa iptables
|
||||
>
|
||||
> iptables-1.4.21-13.el7.x86_64
|
||||
>
|
||||
> If you need to install it, you may do yum to get it.
|
||||
>
|
||||
> # yum install iptables-services
|
||||
|
||||
### 8. How to Check and ensure if iptables service is running? ###
|
||||
|
||||
> **Answer** : To check the status of iptables, you may run the following command on the terminal.
|
||||
>
|
||||
> # service status iptables [On CentOS 6/5]
|
||||
> # systemctl status iptables [On CentOS 7]
|
||||
>
|
||||
> If it is not running, the below command may be executed.
|
||||
>
|
||||
> ---------------- On CentOS 6/5 ----------------
|
||||
> # chkconfig --level 35 iptables on
|
||||
> # service iptables start
|
||||
>
|
||||
> ---------------- On CentOS 7 ----------------
|
||||
> # systemctl enable iptables
|
||||
> # systemctl start iptables
|
||||
>
|
||||
> We may also check if the iptables module is loaded or not, as:
|
||||
>
|
||||
> # lsmod | grep ip_tables
|
||||
|
||||
### 9. How will you review the current Rules defined in iptables? ###
|
||||
|
||||
> **Answer** : The current rules in iptables can be review as simple as:
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Sample Output
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
### 10. How will you flush all iptables rules or a particular chain? ###
|
||||
|
||||
> **Answer** : To flush a particular iptables chain, you may use following commands.
|
||||
>
|
||||
>
|
||||
> # iptables --flush OUTPUT
|
||||
>
|
||||
> To Flush all the iptables rules.
|
||||
>
|
||||
> # iptables --flush
|
||||
|
||||
### 11. Add a rule in iptables to accept packets from a trusted IP Address (say 192.168.0.7) ###
|
||||
|
||||
> **Answer** : The above scenario can be achieved simply by running the below command.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
>
|
||||
> We may include standard slash or subnet mask in the source as:
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
> # iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
### 12. How to add rules to ACCEPT, REJECT, DENY and DROP ssh service in iptables. ###
|
||||
|
||||
> **Answer** : Hoping ssh is running on port 22, which is also the default port for ssh, we can add rule to iptables as:To ACCEPT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j ACCEPT
|
||||
>
|
||||
> To REJECT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j REJECT
|
||||
>
|
||||
> To DENY tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j DENY
|
||||
>
|
||||
> To DROP tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j DROP
|
||||
|
||||
### 13. Let me give you a scenario. Say there is a machine the local ip address of which is 192.168.0.6. You need to block connections on port 21, 22, 23, and 80 to your machine. What will you do? ###
|
||||
|
||||
> **Answer** : Well all I need to use is the ‘multiport‘ option with iptables followed by port numbers to be blocked and the above scenario can be achieved in a single go as.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
|
||||
>
|
||||
> The written rules can be checked using the below command.
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
> DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**Interviewer** : That’s all I wanted to ask. You are a valuable employee we won’t like to miss. I will recommend your name to the HR. If you have any question you may ask me.
|
||||
|
||||
As a candidate I don’t wanted to kill the conversation hence keep asking about the projects I would be handling if selected and what are the other openings in the company. Not to mention HR round was not difficult to crack and I got the opportunity.
|
||||
|
||||
Also I would like to thank Avishek and Ravi (whom I am a friend since long) for taking the time to document my interview.
|
||||
|
||||
Friends! If you had given any such interview and you would like to share your interview experience to millions of Tecmint readers around the globe? then send your questions and answers to admin@tecmint.com.
|
||||
|
||||
Thank you! Keep Connected. Also let me know if I could have answered a question more correctly than what I did.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
@ -0,0 +1,99 @@
|
||||
How to Clear RAM Memory Cache, Buffer and Swap Space on Linux
|
||||
================================================================================
|
||||
Like any other operating system, GNU/Linux has implemented a memory management efficiently and even more than that. But if any process is eating away your memory and you want to clear it, Linux provides a way to flush or clear ram cache.
|
||||
|
||||

|
||||
|
||||
### How to Clear Cache in Linux? ###
|
||||
|
||||
Every Linux System has three options to clear cache without interrupting any processes or services.
|
||||
|
||||
1. Clear PageCache only.
|
||||
|
||||
# sync; echo 1 > /proc/sys/vm/drop_caches
|
||||
|
||||
2. Clear dentries and inodes.
|
||||
|
||||
# sync; echo 2 > /proc/sys/vm/drop_caches
|
||||
|
||||
3. Clear PageCache, dentries and inodes.
|
||||
|
||||
# sync; echo 3 > /proc/sys/vm/drop_caches
|
||||
|
||||
Explanation of above command.
|
||||
|
||||
sync will flush the file system buffer. Command Separated by `“;”` run sequentially. The shell wait for each command to terminate before executing the next command in the sequence. As mentioned in kernel documentation, writing to drop_cache will clean cache without killing any application/service, [command echo][1] is doing the job of writing to file.
|
||||
|
||||
If you have to clear the disk cache, the first command is safest in enterprise and production as `“...echo 1 > ….”` will clear the PageCache only. It is not recommended to use third option above `“...echo 3 >”` in production until you know what you are doing, as it will clear PageCache, dentries and inodes.
|
||||
|
||||
**Is it a good idea to free Buffer and Cache in Linux that might be used by Linux Kernel?**
|
||||
|
||||
When you are applying various settings and want to check, if it is actually implemented specially on I/O-extensive benchmark, then you may need to clear buffer cache. You can drop cache as explained above without rebooting the System i.e., no downtime required.
|
||||
|
||||
Linux is designed in such a way that it looks into disk cache before looking onto the disk. If it finds the resource in the cache, then the request doesn’t reach the disk. If we clean the cache, the disk cache will be less useful as the OS will look for the resource on the disk.
|
||||
|
||||
Moreover it will also slow the system for a few seconds while the cache is cleaned and every resource required by OS is loaded again in the disk-cache.
|
||||
|
||||
Now we will be creating a shell script to auto clear RAM cache daily at 2PM via a cron scheduler task. Create a shell script clearcache.sh and add the following lines.
|
||||
|
||||
#!/bin/bash
|
||||
# Note, we are using "echo 3", but it is not recommended in production instead use "echo 1"
|
||||
echo "echo 3 > /proc/sys/vm/drop_caches"
|
||||
|
||||
Set execute permission on the clearcache.sh file.
|
||||
|
||||
# chmod 755 clearcache.sh
|
||||
|
||||
Now you may call the script whenever you required to clear ram cache.
|
||||
|
||||
Now set a cron to clear RAM cache everyday at 2PM. Open crontab for editing.
|
||||
|
||||
# crontab -e
|
||||
|
||||
Append the below line, save and exit to run it at 2PM daily.
|
||||
|
||||
0 3 * * * /path/to/clearcache.sh
|
||||
|
||||
For more details on how to cron a job you may like to check our article on [11 Cron Scheduling Jobs][2].
|
||||
|
||||
**Is it good idea to auto clear RAM cache on production server?**
|
||||
|
||||
No! it is not. Think of a situation when you have scheduled the script to clear ram cache everyday at 2PM. Everyday at 2PM the script is executed and it flushes your RAM cache. One day for whatsoever reason, may be more than expected users are online on your website and seeking resource from your server.
|
||||
|
||||
At the same time scheduled script run and clears everything in cache. Now all the user are fetching data from disk. It will result in server crash and corrupt the database. So clear ram-cache only when required,and known your foot steps, else you are a Cargo Cult System Administrator.
|
||||
|
||||
#### How to Clear Swap Space in Linux? ####
|
||||
|
||||
If you want to clear Swap space, you may like to run the below command.
|
||||
|
||||
# swapoff -a && swapon -a
|
||||
|
||||
Also you may add above command to a cron script above, after understanding all the associated risk.
|
||||
|
||||
Now we will be combining both above commands into one single command to make a proper script to clear RAM Cache and Swap Space.
|
||||
|
||||
# echo 3 > /proc/sys/vm/drop_caches && swapoff -a && swapon -a && printf '\n%s\n' 'Ram-cache and Swap Cleared'
|
||||
|
||||
OR
|
||||
|
||||
su -c 'echo 3 >/proc/sys/vm/drop_caches' && swapoff -a && swapon -a && printf '\n%s\n' 'Ram-cache and Swap Cleared'
|
||||
|
||||
After testing both above command, we will run command “free -h” before and after running the script and will check cache.
|
||||
|
||||
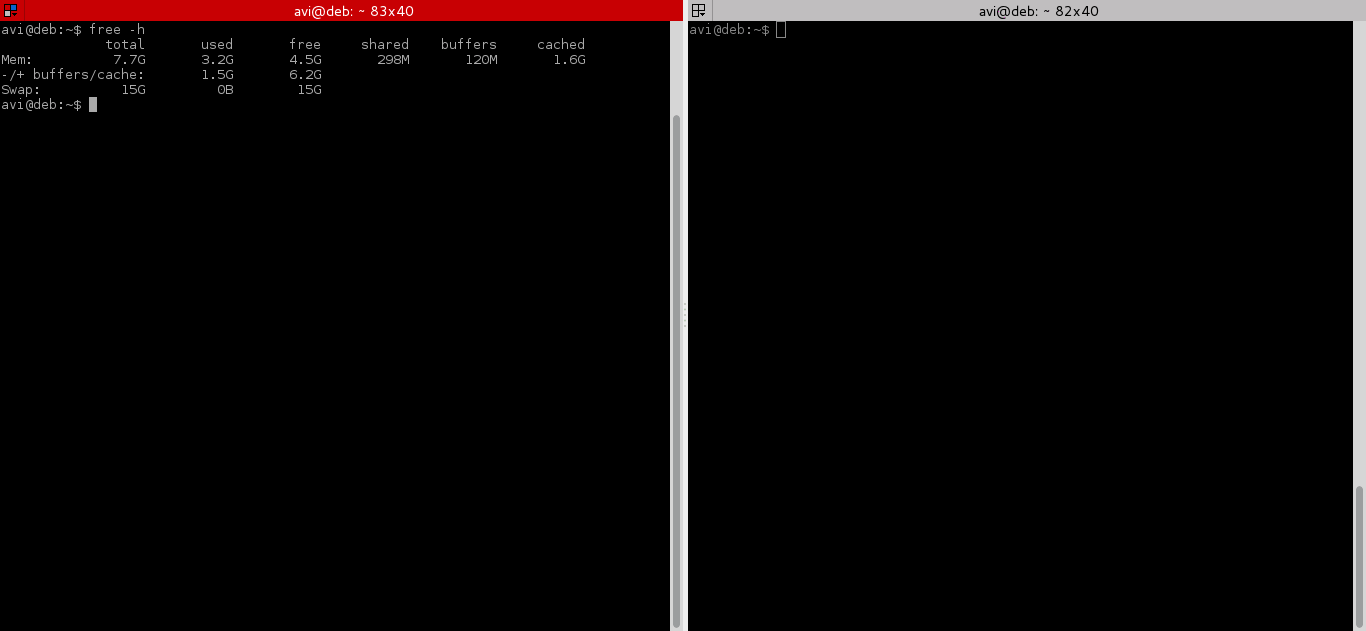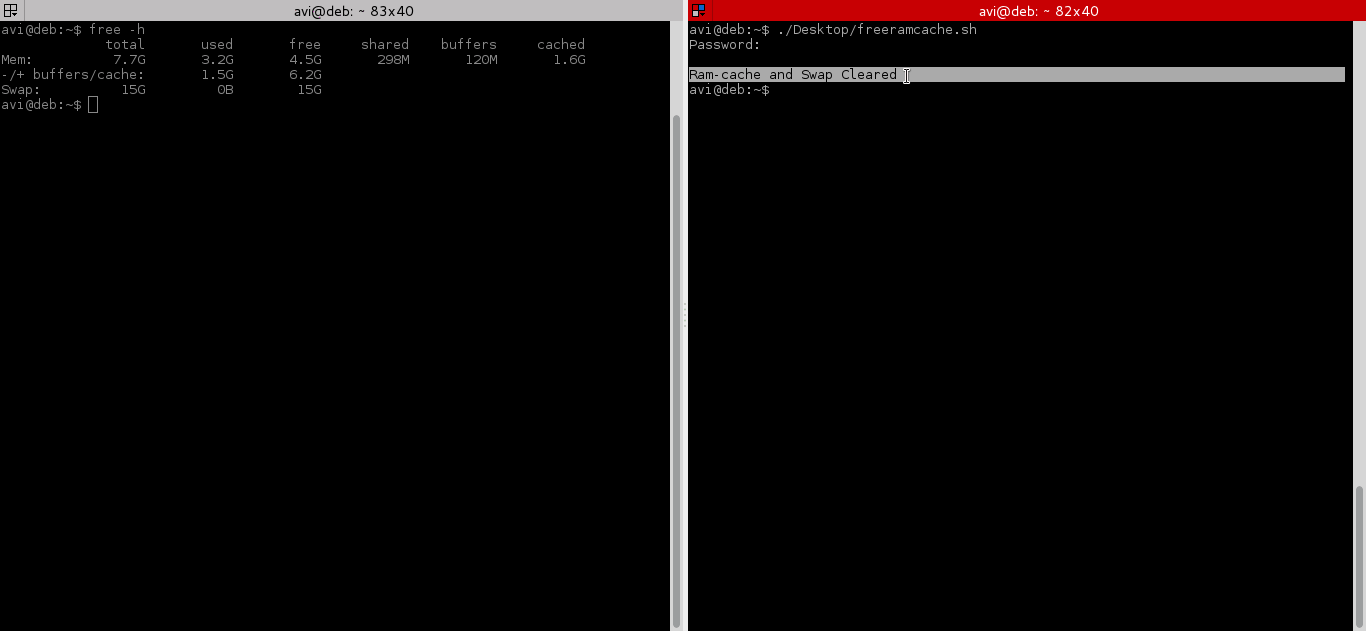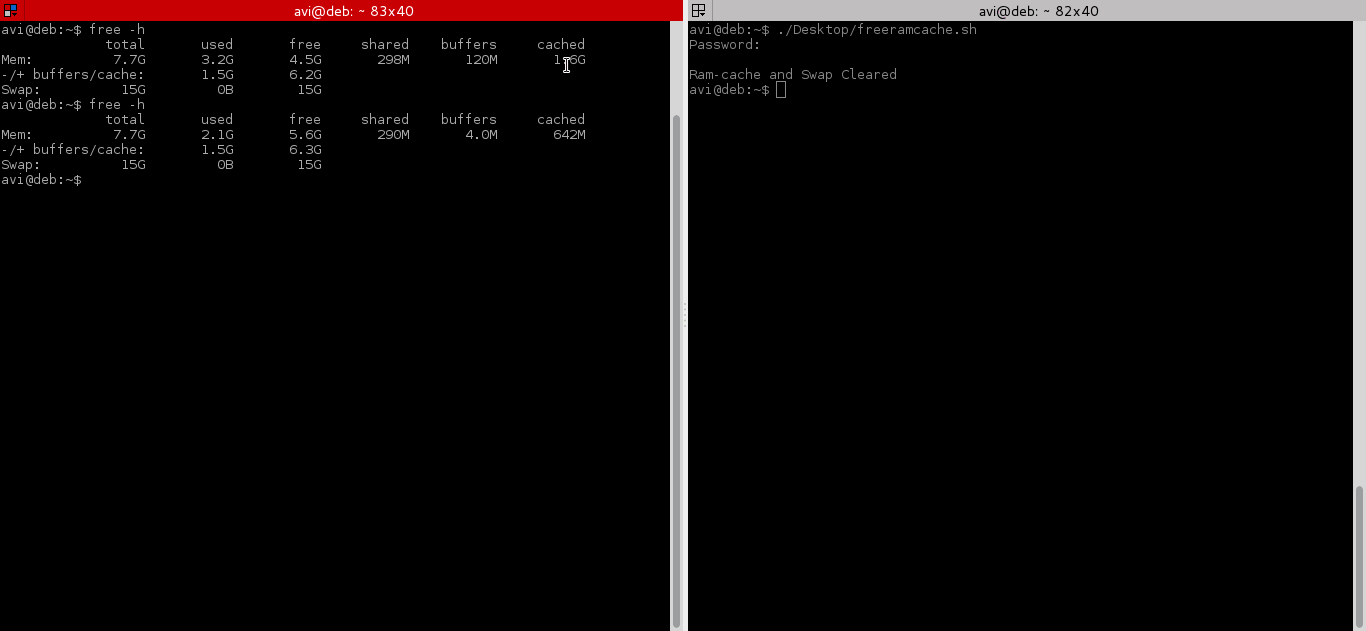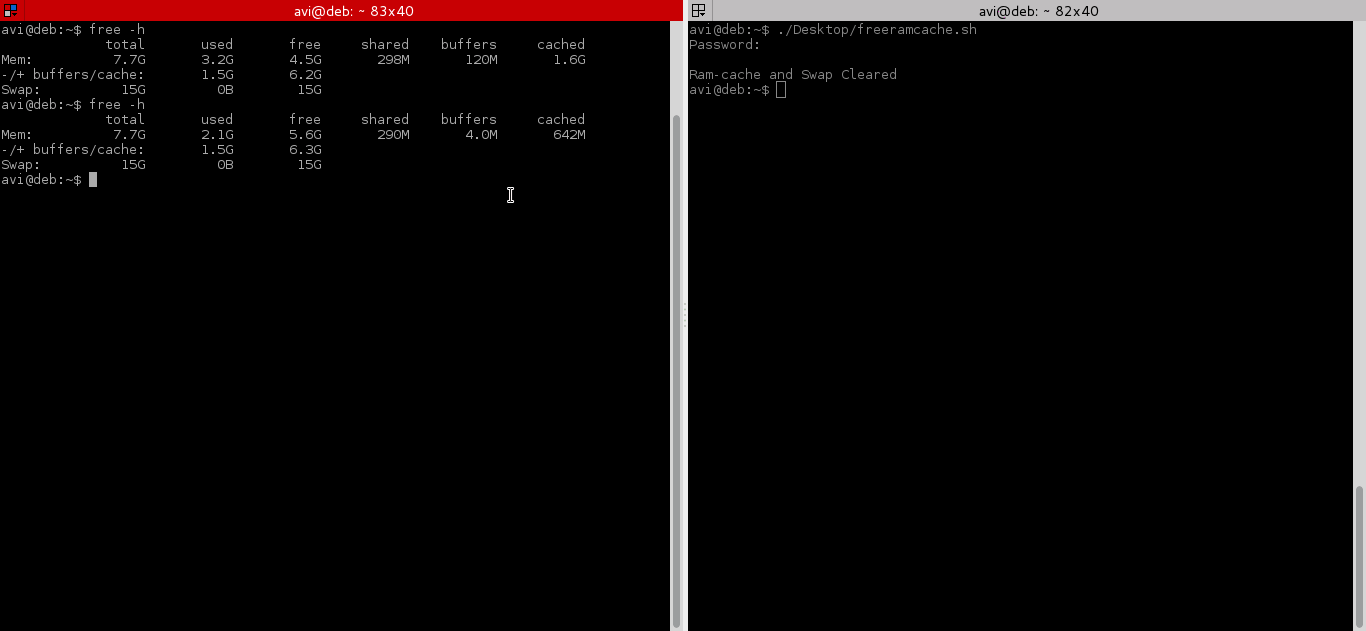
|
||||
|
||||
That’s all for now, if you liked the article, don’t forget to provide us with your valuable feedback in the comments to let us know, what you think is it a good idea to clear ram cache and buffer in production and Enterprise?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/clear-ram-memory-cache-buffer-and-swap-space-on-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
@ -0,0 +1,131 @@
|
||||
translating----geekpi
|
||||
|
||||
How to Install nginx and google pagespeed on Ubuntu 15.04 (Vivid Vervet)
|
||||
================================================================================
|
||||
Nginx (engine-x) is a open source and high performance HTTP server, reverse proxy and IMAP/POP3 proxy server. The outstanding features of Nginx are: stability, rich feature set, simple configuration and low resource consumption. Nginx is being used by some of the largest websites on the internet and is gaining more and more popularity in the webmaster community. This tutorials shows how to build a nginx .deb package for Ubuntu 15.04 from source that has Google pagespeed module compiled in.
|
||||
|
||||
|
||||
Pagespeed is a web server module developed by Google to speed up a website response times, optimize html and reduce the page load time. ngx_pagespeed features include :
|
||||
|
||||
- Image optimization: stripping meta-data, dynamic resizing, recompression.
|
||||
- CSS & JavaScript minification, concatenation, inlining, and outlining.
|
||||
- Small resource inlining.
|
||||
- Deferring image and JavaScript loading.
|
||||
- HTML rewriting.
|
||||
- Cache lifetime extension.
|
||||
|
||||
see more [https://developers.google.com/speed/pagespeed/module/][1].
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
Ubuntu Server 15.04 64 bit
|
||||
root privileges
|
||||
|
||||
What we will do in this tutorial :
|
||||
|
||||
- Install the prerequisite packages.
|
||||
- Installing nginx with ngx_pagespeed.
|
||||
- Testing.
|
||||
|
||||
#### Install the prerequisite packages ####
|
||||
|
||||
sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
|
||||
#### Installing nginx with ngx_pagespeed ####
|
||||
|
||||
**Step 1 - Adding nginx repository**
|
||||
|
||||
vim /etc/apt/sources.list.d/nginx.list
|
||||
|
||||
add the line:
|
||||
|
||||
deb http://nginx.org/packages/ubuntu/ trusty nginx
|
||||
deb-src http://nginx.org/packages/ubuntu/ trusty nginx
|
||||
|
||||
Update your repository:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
note : if you get the messege : GPG error [...] NO_PUBKEY [...] bla bla
|
||||
|
||||
please add the the key:
|
||||
|
||||
sudo sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys KEYNUMBER
|
||||
sudo apt-get update
|
||||
|
||||
**Step 2 - Download nginx 1.8 from ubuntu repository**
|
||||
|
||||
sudo su
|
||||
cd ~
|
||||
mkdir -p ~/new/nginx_source/
|
||||
cd ~/new/nginx_source/
|
||||
apt-get source nginx
|
||||
apt-get build-dep nginx
|
||||
|
||||
**Step 3 - Download Pagespeed**
|
||||
|
||||
cd ~
|
||||
mkdir -p ~/new/ngx_pagespeed/
|
||||
cd ~/new/ngx_pagespeed/
|
||||
ngx_version=1.9.32.3
|
||||
wget https://github.com/pagespeed/ngx_pagespeed/archive/release-${ngx_version}-beta.zip
|
||||
unzip release-${ngx_version}-beta.zip
|
||||
|
||||
cd ngx_pagespeed-release-1.9.32.3-beta/
|
||||
wget https://dl.google.com/dl/page-speed/psol/${ngx_version}.tar.gz
|
||||
tar -xzf 1.9.32.3.tar.gz
|
||||
|
||||
**Step 4 - Configure nginx to build with Pagespeed**
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/debin/
|
||||
vim rules
|
||||
|
||||
add the module under CFLAGS `.configure` :
|
||||
|
||||
--add-module=../../ngx_pagespeed/ngx_pagespeed-release-1.9.32.3-beta \
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**Step 5 - Build nginx package and Install**
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/
|
||||
dpkg-buildpackage -b
|
||||
|
||||
The dpkg-buildpackage command will build the nginx.deb under ~/new/ngix_source/ Once package building is complete, please look in the directory:
|
||||
|
||||
cd ~/new/ngix_source/
|
||||
ls
|
||||
|
||||
|
||||
|
||||
And then install nginx.
|
||||
|
||||
dpkg -i nginx_1.8.0-1~trusty_amd64.deb
|
||||
|
||||
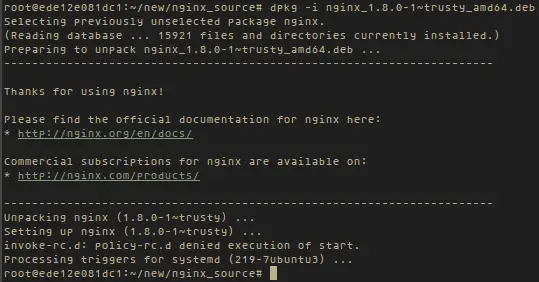
|
||||
|
||||
#### Testing ####
|
||||
|
||||
Run nginx -V to see the ngx_pagespeed was builted with nginx.
|
||||
|
||||
nginx -V
|
||||
|
||||
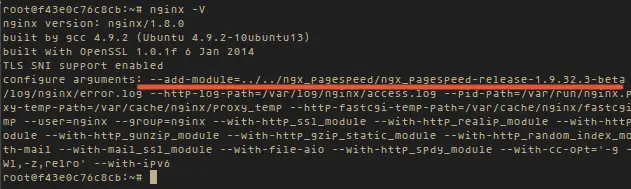
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The nginx web server there is a stable and fast open source http server that supports a variety of modules for optimization. One of these modules is the 'PageSpeed module' which is developed by google. Unlike apache, nginx modules are not dynamically loadable, so you have to select the desired modules before you build the nginx package.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-nginx-and-google-pagespeed-on-ubuntu-15-04/#step-build-nginx-package-and-install
|
||||
|
||||
作者:Muhammad Arul
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://developers.google.com/speed/pagespeed/module/
|
||||
@ -0,0 +1,435 @@
|
||||
How to Manipulate Filenames Having Spaces and Special Characters in Linux
|
||||
================================================================================
|
||||
We come across files and folders name very regularly. In most of the cases file/folder name are related to the content of the file/folder and starts with number and characters. Alpha-Numeric file name are pretty common and very widely used, but this is not the case when we have to deal with file/folder name that has special characters in them.
|
||||
|
||||
**Note**: We can have files of any type but for simplicity and easy implementation we will be dealing with Text file (.txt), throughout the article.
|
||||
|
||||
Example of most common file names are:
|
||||
|
||||
abc.txt
|
||||
avi.txt
|
||||
debian.txt
|
||||
...
|
||||
|
||||
Example of numeric file names are:
|
||||
|
||||
121.txt
|
||||
3221.txt
|
||||
674659.txt
|
||||
...
|
||||
|
||||
Example of Alpha-Numeric file names are:
|
||||
|
||||
eg84235.txt
|
||||
3kf43nl2.txt
|
||||
2323ddw.txt
|
||||
...
|
||||
|
||||
Examples of file names that has special character and is not very common:
|
||||
|
||||
#232.txt
|
||||
#bkf.txt
|
||||
#bjsd3469.txt
|
||||
#121nkfd.txt
|
||||
-2232.txt
|
||||
-fbjdew.txt
|
||||
-gi32kj.txt
|
||||
--321.txt
|
||||
--bk34.txt
|
||||
...
|
||||
|
||||
One of the most obvious question here is – who on earth create/deal with files/folders name having a Hash `(#)`, a semi-colon `(;)`, a dash `(-)` or any other special character.
|
||||
|
||||
I Agree to you, that such file names are not common still your shell should not break/give up when you have to deal with any such file names. Also speaking technically every thing be it folder, driver or anything else is treated as file in Linux.
|
||||
|
||||
### Dealing with file that has dash (-) in it’s name ###
|
||||
|
||||
Create a file that starts with a dash `(-)`, say -abx.txt.
|
||||
|
||||
$ touch -abc.txt
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
touch: invalid option -- 'b'
|
||||
Try 'touch --help' for more information.
|
||||
|
||||
The reason for above error, that shell interprets anything after a dash `(-)`, as option, and obviously there is no such option, hence is the error.
|
||||
|
||||
To resolve such error, we have to tell the Bash shell (yup this and most of the other examples in the article is for BASH) not to interpret anything after special character (here dash), as option.
|
||||
|
||||
There are two ways to resolve this error as:
|
||||
|
||||
$ touch -- -abc.txt [Option #1]
|
||||
$ touch ./-abc.txt [Option #2]
|
||||
|
||||
You may verify the file thus created by both the above ways by running commands ls or [ls -l][1] for long listing.
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 11:05 -abc.txt
|
||||
|
||||
To edit the above file you may do:
|
||||
|
||||
$ nano -- -abc.txt
|
||||
or
|
||||
$ nano ./-abc.txt
|
||||
|
||||
**Note**: You may replace nano with any other editor of your choice say vim as:
|
||||
|
||||
$ vim -- -abc.txt
|
||||
or
|
||||
$ vim ./-abc.txt
|
||||
|
||||
Similarly to move such file you have to do:
|
||||
|
||||
$ mv -- -abc.txt -a.txt
|
||||
or
|
||||
$ mv -- -a.txt -abc.txt
|
||||
|
||||
and to Delete this file, you have to do:
|
||||
|
||||
$ rm -- -abc.txt
|
||||
or
|
||||
$ rm ./-abc.txt
|
||||
|
||||
If you have lots of files in a folder the name of which contains dash, and you want to delete all of them at once, do as:
|
||||
|
||||
$ rm ./-*
|
||||
|
||||
**Important to Note:**
|
||||
|
||||
1. The same rule as discussed above follows for any number of hypen in the name of the file and their occurrence. Viz., -a-b-c.txt, ab-c.txt, abc-.txt, etc.
|
||||
|
||||
2. The same rule as discussed above follows for the name of the folder having any number of hypen and their occurrence, except the fact that for deleting the folder you have to use ‘rm -rf‘ as:
|
||||
|
||||
$ rm -rf -- -abc
|
||||
or
|
||||
$ rm -rf ./-abc
|
||||
|
||||
### Dealing with files having HASH (#) in the name ###
|
||||
|
||||
The symbol `#` has a very different meaning in BASH. Anything after a `#` is interpreted as comment and hence neglected by BASH.
|
||||
|
||||
**Understand it using examples:**
|
||||
|
||||
create a file #abc.txt.
|
||||
|
||||
$ touch #abc.txt
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
touch: missing file operand
|
||||
Try 'touch --help' for more information.
|
||||
|
||||
The reason for above error, that Bash is interpreting #abc.txt a comment and hence ignoring. So the [command touch][2] has been passed without any file Operand, and hence is the error.
|
||||
|
||||
To resolve such error, you may ask BASH not to interpret # as comment.
|
||||
|
||||
$ touch ./#abc.txt
|
||||
or
|
||||
$ touch '#abc.txt'
|
||||
|
||||
and verify the file just created as:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:14 #abc.txt
|
||||
|
||||
Now create a file the name of which contains # anywhere except at the begging.
|
||||
|
||||
$ touch ./a#bc.txt
|
||||
$ touch ./abc#.txt
|
||||
|
||||
or
|
||||
$ touch 'a#bc.txt'
|
||||
$ touch 'abc#.txt'
|
||||
|
||||
Run ‘ls -l‘ to verify it:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:16 a#bc.txt
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:16 abc#.txt
|
||||
|
||||
What happens when you create two files (say a and #bc) at once:
|
||||
|
||||
$ touch a.txt #bc.txt
|
||||
|
||||
Verify the file just created:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:18 a.txt
|
||||
|
||||
Obvious from the above example it only created file ‘a‘ and file ‘#bc‘ has been ignored. To execute the above situation successfully we can do,
|
||||
|
||||
$ touch a.txt ./#bc.txt
|
||||
or
|
||||
$ touch a.txt '#bc.txt'
|
||||
|
||||
and verify it as:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:20 a.txt
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 12:20 #bc.txt
|
||||
|
||||
You can move the file as:
|
||||
|
||||
$ mv ./#bc.txt ./#cd.txt
|
||||
or
|
||||
$ mv '#bc.txt' '#cd.txt'
|
||||
|
||||
Copy it as:
|
||||
|
||||
$ cp ./#cd.txt ./#de.txt
|
||||
or
|
||||
$ cp '#cd.txt' '#de.txt'
|
||||
|
||||
You may edit it as using your choice of editor as:
|
||||
|
||||
$ vi ./#cd.txt
|
||||
or
|
||||
$ vi '#cd.txt'
|
||||
|
||||
----------
|
||||
|
||||
$ nano ./#cd.txt
|
||||
or
|
||||
$ nano '#cd.txt'
|
||||
|
||||
And Delete it as:
|
||||
|
||||
$ rm ./#bc.txt
|
||||
or
|
||||
$ rm '#bc.txt'
|
||||
|
||||
To delete all the files that has hash (#) in the file name, you may use:
|
||||
|
||||
# rm ./#*
|
||||
|
||||
### Dealing with files having semicolon (;) in its name ###
|
||||
|
||||
In case you are not aware, semicolon acts as a command separator in BASH and perhaps other shell as well. Semicolon lets you execute several command in one go and acts as separator. Have you ever deal with any file name having semicolon in it? If not here you will.
|
||||
|
||||
Create a file having semi-colon in it.
|
||||
|
||||
$ touch ;abc.txt
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
touch: missing file operand
|
||||
Try 'touch --help' for more information.
|
||||
bash: abc.txt: command not found
|
||||
|
||||
The reason for above error, that when you run the above command BASH interpret touch as a command but could not find any file operand before semicolon and hence it reports error. It also reports another error that ‘abc.txt‘ command not found, only because after semicolon BASH was expecting another command and ‘abc.txt‘, is not a command.
|
||||
|
||||
To resolve such error, tell BASH not to interpret semicolon as command separator, as:
|
||||
|
||||
$ touch ./';abc.txt'
|
||||
or
|
||||
$ touch ';abc.txt'
|
||||
|
||||
**Note**: We have enclosed the file name with single quote ''. It tells BASH that ; is a part of file name and not command separator.
|
||||
|
||||
Rest of the action (viz., copy, move, delete) on the file and folder having semicolon in its name can be carried out straight forward by enclosing the name in single quote.
|
||||
|
||||
### Dealing with other special characters in file/folder name ###
|
||||
|
||||
#### Plus Sign (+) in file name ####
|
||||
|
||||
Don’t requires anything extra, just do it normal way, as simple file name as shown below.
|
||||
|
||||
$ touch +12.txt
|
||||
|
||||
#### Dollar sign ($) in file name ####
|
||||
|
||||
You have to enclose file name in single quote, as we did in the case of semicolon. Rest of the things are straight forward..
|
||||
|
||||
$ touch '$12.txt'
|
||||
|
||||
#### Percent (%) in file name ####
|
||||
|
||||
You don’t need to do anything differently, treat it as normal file.
|
||||
|
||||
$ touch %12.txt
|
||||
|
||||
#### Asterisk (*) in file name ####
|
||||
|
||||
Having Asterisk in file name don’t change anything and you can continue using it as normal file.
|
||||
|
||||
$ touch *12.txt
|
||||
|
||||
Note: When you have to delete a file that starts with *, Never use following commands to delete such files.
|
||||
|
||||
$ rm *
|
||||
or
|
||||
$ rm -rf *
|
||||
|
||||
Instead use,
|
||||
|
||||
$ rm ./*.txt
|
||||
|
||||
#### Exclamation mark (!) in file name ####
|
||||
|
||||
Just Enclose the file name in single quote and rest of the things are same.
|
||||
|
||||
$ touch '!12.txt'
|
||||
|
||||
#### At Sign (@) in file name ####
|
||||
|
||||
Nothing extra, treat a filename having At Sign as nonrmal file.
|
||||
|
||||
$ touch '@12.txt'
|
||||
|
||||
#### ^ in file name ####
|
||||
|
||||
No extra attention required. Use a file having ^ in filename as normal file.
|
||||
|
||||
$ touch ^12.txt
|
||||
|
||||
#### Ampersand (&) in file name ####
|
||||
|
||||
Filename should be enclosed in single quotes and you are ready to go.
|
||||
|
||||
$ touch '&12.txt'
|
||||
|
||||
#### Parentheses () in file name ####
|
||||
|
||||
If the file name has Parenthesis, you need to enclose filename with single quotes.
|
||||
|
||||
$ touch '(12.txt)'
|
||||
|
||||
#### Braces {} in file name ####
|
||||
|
||||
No Extra Care needed. Just treat it as just another file.
|
||||
|
||||
$ touch {12.txt}
|
||||
|
||||
#### Chevrons <> in file name ####
|
||||
|
||||
A file name having Chevrons must be enclosed in single quotes.
|
||||
|
||||
$ touch '<12.txt>'
|
||||
|
||||
#### Square Brackets [ ] in file name ####
|
||||
|
||||
Treat file name having Square Brackets as normal files and you need not take extra care of it.
|
||||
|
||||
$ touch [12.txt]
|
||||
|
||||
#### Under score (_) in file name ####
|
||||
|
||||
They are very common and don’t require anything extra. Just do what you would have done with a normal file.
|
||||
|
||||
$ touch _12.txt
|
||||
|
||||
#### Equal-to (=) in File name ####
|
||||
|
||||
Having an Equal-to sign do not change anything, you can use it as normal file.
|
||||
|
||||
$ touch =12.txt
|
||||
|
||||
#### Dealing with back slash (\) ####
|
||||
|
||||
Backslash tells shell to ignore the next character. You have to enclose file name in single quote, as we did in the case of semicolon. Rest of the things are straight forward.
|
||||
|
||||
$ touch '\12.txt'
|
||||
|
||||
#### The Special Case of Forward Slash ####
|
||||
|
||||
You cannot create a file the name of which includes a forward slash (/), until your file system has bug. There is no way to escape a forward slash.
|
||||
|
||||
So if you can create a file such as ‘/12.txt’ or ‘b/c.txt’ then either your File System has bug or you have Unicode support, which lets you create a file with forward slash. In this case the forward slash is not a real forward slash but a Unicode character that looks alike a forward slash.
|
||||
|
||||
#### Question Mark (?) in file name ####
|
||||
|
||||
Again, an example where you don’t need to put any special attempt. A file name having Question mark can be treated in the most general way.
|
||||
|
||||
$ touch ?12.txt
|
||||
|
||||
#### Dot Mark (.) in file name ####
|
||||
|
||||
The files starting with dot `(.)` are very special in Linux and are called dot files. They are hidden files generally a configuration or system files. You have to use switch ‘-a‘ or ‘-A‘ with ls command to view such files.
|
||||
|
||||
Creating, editing, renaming and deleting of such files are straight forward.
|
||||
|
||||
$ touch .12.txt
|
||||
|
||||
Note: In Linux you may have as many dots `(.)` as you need in a file name. Unlike other system dots in file name don’t means to separate name and extension. You can create a file having multiple dots as:
|
||||
|
||||
$ touch 1.2.3.4.5.6.7.8.9.10.txt
|
||||
|
||||
and check it as:
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 0
|
||||
-rw-r--r-- 1 avi avi 0 Jun 8 14:32 1.2.3.4.5.6.7.8.9.10.txt
|
||||
|
||||
#### Comma (,) in file name ####
|
||||
|
||||
You can have comma in a file name, as many as you want and you Don’t requires anything extra. Just do it normal way, as simple file name.
|
||||
|
||||
$ touch ,12.txt
|
||||
or
|
||||
$ touch ,12,.txt
|
||||
|
||||
#### Colon (:) in File name ####
|
||||
|
||||
You can have colon in a file name, as many as you want and you Don’t requires anything extra. Just do it normal way, as simple file name.
|
||||
|
||||
$ touch :12.txt
|
||||
or
|
||||
$ touch :12:.txt
|
||||
|
||||
#### Having Quotes (single and Double) in file name ####
|
||||
|
||||
To have quotes in file name, we have to use the rule of exchange. I.e, if you need to have single quote in file name, enclose the file name with double quotes and if you need to have double quote in file name, enclose it with single quote.
|
||||
|
||||
$ touch "15'.txt"
|
||||
|
||||
and
|
||||
|
||||
$ touch '15”.txt'
|
||||
|
||||
#### Tilde (~) in file name ####
|
||||
|
||||
Some Editors in Linux like emacs create a backup file of the file being edited. The backup file has the name of the original file plus a tilde at the end of the file name. You can have a file that name of which includes tilde, at any location simply as:
|
||||
|
||||
$ touch ~1a.txt
|
||||
or
|
||||
$touch 2b~.txt
|
||||
|
||||
#### White Space in file name ####
|
||||
|
||||
Create a file the name of which has space between character/word, say “hi my name is avishek.txt”.
|
||||
|
||||
It is not a good idea to have file name with spaces and if you have to distinct readable name, you should use, underscore or dash. However if you have to create such a file, you have to use backward slash which ignores the next character to it. To create above file we have to do it this way..
|
||||
|
||||
$ touch hi\ my\ name\ is\ avishek.txt
|
||||
|
||||
hi my name is avishek.txt
|
||||
|
||||
I have tried covering all the scenario you may come across. Most of the above implementation are explicitly for BASH Shell and may not work in other shell.
|
||||
|
||||
If you feel that I missed something (that is very common and human nature), you may include your suggestion in the comments below. Keep Connected, Keep Commenting. Stay Tuned and connected! Like and share us and help us get spread!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
233
sources/tech/20150610 How to secure your Linux server.md
Normal file
233
sources/tech/20150610 How to secure your Linux server.md
Normal file
@ -0,0 +1,233 @@
|
||||
How to secure your Linux server
|
||||
================================================================================
|
||||
> A server is made up of so many different components that makes it hard to offer one solution for everyone's needs. This articles tries to cover some useful tips and tricks to help you keep your server and users protected.
|
||||
|
||||
No doubt improving server security is one of the most important things system administrators should always look for. This of course has been a topic of many different articles, blogs and forum threads.
|
||||
|
||||
A server is made up of so many different components that makes it hard to offer one solution for everyone’s needs. This articles tries to cover some useful tips and tricks to help you keep your server and users protected.
|
||||
|
||||
There are a few things that every system administrator should know and there is no way to talk about security without mentioning:
|
||||
|
||||
- Keep your system **up to date**
|
||||
- Change passwords frequently – use numeric, alphabetical and non-alphabetical symbols
|
||||
- Give users the **minimum** permissions they need to do their job.
|
||||
- Install only packages that you really need
|
||||
|
||||
Here comes the more interesting part:
|
||||
|
||||
### Change default SSH port ###
|
||||
|
||||
The first thing that I would like to change when setting up a new server is the default SSH port. This simple change can save your server from thousands of brute force attempts.
|
||||
|
||||
To change the default SSH port, open your sshd_config:
|
||||
|
||||
sudo vim /etc/ssh/sshd_config
|
||||
|
||||
Find the following line:
|
||||
|
||||
#Port 22
|
||||
|
||||
The “#” symbol means that this line is a comment. Remove the # symbol then change the port to a number of your choice. The port number should not be larger than 65535. Make sure not to use any port already used by your system or other services. You can see a list of commonly used ports in [Wikipedia][1]. For the purpose of this article I will use:
|
||||
|
||||
Port 16543
|
||||
|
||||
Now save the file and close it for a moment.
|
||||
|
||||
Next important step is to:
|
||||
|
||||
### Use SSH Keys ###
|
||||
|
||||
It is extremely important to use SSH keys when accessing the server over SSH. This adds additional protection and ensure that only people who have the key can access the server.
|
||||
|
||||
To generate SSH key on your local computer run:
|
||||
|
||||
ssh-keygen -t rsa
|
||||
|
||||
You will receive an output asking you to setup the file name where the key should be written as well as setup a password:
|
||||
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/root/.ssh/id_rsa): my_key
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in my_key.
|
||||
Your public key has been saved in my_key.pub.
|
||||
The key fingerprint is:
|
||||
SHA256:MqD/pzzTRsCjZb6mpfjyrr5v1pJLBcgprR5tjNoI20A
|
||||
|
||||
When compete, you will have two files:
|
||||
|
||||
my_key
|
||||
|
||||
my_key.pub
|
||||
|
||||
Now copy the my_key.pub to ~/.ssh/authorized_keys
|
||||
|
||||
cp my_key.pub ~/.ssh/authorized_keys
|
||||
|
||||
Now upload your key on the server by using:
|
||||
|
||||
scp -P16543 authorized_keys user@yourserver-ip:/home/user/.ssh/
|
||||
|
||||
Now you can access the server from the same local machine without having to enter any password.
|
||||
|
||||
### Disable password authentication for SSH ###
|
||||
|
||||
Now that we have SSH keys, it is safe to disable the password authentication for SSH. Open again the sshd_config file and set the following changes:
|
||||
|
||||
ChallengeResponseAuthentication no
|
||||
PasswordAuthentication no
|
||||
UsePAM no
|
||||
|
||||
### Disable Root login ###
|
||||
|
||||
The next important step is to disable direct access with root user. Instead you should use sudo or su to perform administrative jobs. To do this you will need to add a new user that has root privileges. To do this you will need to edit the sudoers file located in:
|
||||
|
||||
/etc/sudoers/
|
||||
|
||||
You may edit that file with command such as **visudo**. I would recommend you using this command as it will check the file for any syntax errors prior closing the file. This is useful if you have wrongly edited the file.
|
||||
|
||||
Now to give root privileges to a user. For the purpose of this tutorial I will use user **sysadmin**. Make sure you are using an existing user on your system when you edit your own file. Now find the following line:
|
||||
|
||||
root ALL=(ALL) ALL
|
||||
|
||||
Copy that line and paste it below. In the new line change “root” with “sysadmin”. You should now have these two lines:
|
||||
|
||||
root ALL=(ALL) ALL
|
||||
sysadmin ALL=(ALL) ALL
|
||||
|
||||
I would like to explain what each of the options in the above line represents:
|
||||
|
||||
(1) root (2)ALL=(3)(ALL) (4)ALL
|
||||
|
||||
(1) User
|
||||
|
||||
(2) Terminal from which user can use sudo
|
||||
|
||||
(3) Which users User may act as
|
||||
|
||||
(4) Which commands he may use
|
||||
|
||||
|
||||
You can use this settings to give access to users to some of the system tools.
|
||||
|
||||
At this point it is safe to save your file.
|
||||
|
||||
To disable direct root access over SSH open again the **sshd_config** file and find the following line:
|
||||
|
||||
#PermitRootLogin yes
|
||||
|
||||
and change it to:
|
||||
|
||||
PermitRootLogin no
|
||||
|
||||
Now save the file and restart the sshd daemon so the changes can take effect. Simply run the following command:
|
||||
|
||||
sudo /etc/init.d/sshd restart
|
||||
|
||||
### Setup firewall ###
|
||||
|
||||
A firewall can help you block incoming and outgoing ports as well as block brute force login attempts. I like using SCF (Config Server Firewall) as it a powerful solution that uses iptables, it’s easy to manage and has a web interface for people who don’t like typing too many commands.
|
||||
|
||||
To install CSF access your server and navigate to:
|
||||
|
||||
cd /usr/local/src/
|
||||
|
||||
Then execute the following commands as root:
|
||||
|
||||
wget https://download.configserver.com/csf.tgz
|
||||
tar -xzf csf.tgz
|
||||
csf
|
||||
sh install.sh
|
||||
|
||||
You will need to wait for the installer to finish its job. We will edit CSF configuration by editing:
|
||||
|
||||
/etc/csf/csf.conf
|
||||
|
||||
By default CSF will be started in testing mode. You will need to set it to product by changing the “TESTING” value to 0
|
||||
|
||||
TESTING = "0"
|
||||
|
||||
Next thing you can edit are the allowed ports on your server. For that purpose find the following section of the csf.conf file and modify the ports per your needs:
|
||||
|
||||
# Allow incoming TCP ports
|
||||
TCP_IN = "20,21,25,53,80,110,143,443,465,587,993,995,16543"
|
||||
# Allow outgoing TCP ports
|
||||
TCP_OUT = "20,21,22,25,53,80,110,113,443,587,993,995,16543"
|
||||
# Allow incoming UDP ports
|
||||
UDP_IN = "20,21,53"
|
||||
# Allow outgoing UDP ports
|
||||
# To allow outgoing traceroute add 33434:33523 to this list
|
||||
UDP_OUT = "20,21,53,113,123"
|
||||
|
||||
Setup these per your requirements. I would recommend you using only the ports you need and avoiding allowing huge ranges of ports. Additionally you can avoid using the unsecured services unsecured ports. For example instead of allowing the default SMTP port 25 you can only allow ports 465 and 587 for outgoing emails.
|
||||
|
||||
**IMPORTANT**: Do not forget to allow your customized SSH port.
|
||||
|
||||
It is important to allow your IP address so it will never get blocked. Such IP addresses can be defined in:
|
||||
|
||||
/etc/csf/csf.ignore
|
||||
|
||||
The blocked IP address will appear in:
|
||||
|
||||
/etc/csf/csf.deny
|
||||
|
||||
When you have finished making changes – restart csf with:
|
||||
|
||||
sudo /etc/init.d/csf restart
|
||||
|
||||
Just to show you how useful CSF is I will show you part of csf.deny on one of my servers:
|
||||
|
||||
211.216.48.205 # lfd: (sshd) Failed SSH login from 211.216.48.205 (KR/Korea, Republic of/-): 5 in the last 3600 secs - Fri Mar 6 00:30:35 2015
|
||||
103.41.124.53 # lfd: (sshd) Failed SSH login from 103.41.124.53 (HK/Hong Kong/-): 5 in the last 3600 secs - Fri Mar 6 01:06:46 2015
|
||||
103.41.124.42 # lfd: (sshd) Failed SSH login from 103.41.124.42 (HK/Hong Kong/-): 5 in the last 3600 secs - Fri Mar 6 01:59:04 2015
|
||||
103.41.124.26 # lfd: (sshd) Failed SSH login from 103.41.124.26 (HK/Hong Kong/-): 5 in the last 3600 secs - Fri Mar 6 02:48:26 2015
|
||||
109.169.74.58 # lfd: (sshd) Failed SSH login from 109.169.74.58 (GB/United Kingdom/mail2.algeos.com): 5 in the last 3600 secs - Fri Mar 6 03:49:03 2015
|
||||
|
||||
The IP addresses that performed the brute force login attempt got blocked and they will not bother me again.
|
||||
|
||||
#### Lock accounts ####
|
||||
|
||||
In case an account is not going to be used for a long period of time you can lock it in order to prevent access to it. You can do this with:
|
||||
|
||||
passwd -l accountName
|
||||
|
||||
Account can still be used by the root user.
|
||||
|
||||
### Know your services ###
|
||||
|
||||
The whole idea of a server is to provide access to different services. Limit those to only the ones you need and disable the unused ones. This will not only free some resources, but will make your server a little bit more secured. For example if you are running a headless server you will definitely not need X display or a desktop environment. If there are no Windows network shares, you can safely disable Samba.
|
||||
|
||||
You can use the commands below to see which services are started upon system boot:
|
||||
|
||||
chkconfig --list | grep "3:on"
|
||||
|
||||
If your system runs with **systemd**:
|
||||
|
||||
systemctl list-unit-files --type=service | grep enabled
|
||||
|
||||
To disable a service you can use commands such as:
|
||||
|
||||
chkconfig service off
|
||||
systemctl disable service
|
||||
|
||||
In the above example change “service” with the name of the actual service you wish to stop. Here is an example:
|
||||
|
||||
chkconfig httpd off
|
||||
systemctl disable httpd
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
This article was meant to cover some of the general security steps you can take to start securing your server. You can always take additional actions to increase the server protection. Remember that it is your responsibility to keep your server secured and make the wise decision while doing it. Unfortunately there is no easy way to do this and the “perfect” setup requires lots of time and tests until you achieve the desired result.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxveda.com/2015/06/03/secure-linux-server/
|
||||
|
||||
作者:[Marin Todorow][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxveda.com/author/marin_todorov/
|
||||
[1]:http://en.wikipedia.org/wiki/Port_%28computer_networking%29#Common_port_numbers
|
||||
@ -0,0 +1,212 @@
|
||||
Nishita Agarwal Shares Her Interview Experience on Linux ‘iptables’ Firewall
|
||||
================================================================================
|
||||
Nishita Agarwal, a frequent Tecmint Visitor shared her experience (Question and Answer) with us regarding the job interview she had just given in a privately owned hosting company in Pune, India. She was asked a lot of questions on a variety of topics however she is an expert in iptables and she wanted to share those questions and their answer (she gave) related to iptables to others who may be going to give interview in near future.
|
||||
|
||||

|
||||
|
||||
All the questions and their Answer are rewritten based upon the memory of Nishita Agarwal.
|
||||
|
||||
> “Hello Friends! My name is **Nishita Agarwal**. I have Pursued Bachelor Degree in Technology. My area of Specialization is UNIX and Variants of UNIX (BSD, Linux) fascinates me since the time I heard it. I have 1+ years of experience in storage. I was looking for a job change which ended with a hosting company in Pune, India.”
|
||||
|
||||
Here is the collection of what I was asked during the Interview. I’ve documented only those questions and their answer that were related to iptables based upon my memory. Hope this will help you in cracking your Interview.
|
||||
|
||||
**1. Have you heard of iptables and firewall in Linux? Any idea of what they are and for what it is used?**
|
||||
|
||||
> **Answer** : I’ve been using iptables for quite long time and I am aware of both iptables and firewall. Iptables is an application program mostly written in C Programming Language and is released under GNU General Public License. Written for System administration point of view, the latest stable release if iptables 1.4.21.iptables may be considered as firewall for UNIX like operating system which can be called as iptables/netfilter, more accurately. The Administrator interact with iptables via console/GUI front end tools to add and define firewall rules into predefined tables. Netfilter is a module built inside of kernel that do the job of filtering.
|
||||
>
|
||||
> Firewalld is the latest implementation of filtering rules in RHEL/CentOS 7 (may be implemented in other distributions which I may not be aware of). It has replaced iptables interface and connects to netfilter.
|
||||
|
||||
**2. Have you used some kind of GUI based front end tool for iptables or the Linux Command Line?**
|
||||
|
||||
> **Answer** : Though I have used both the GUI based front end tools for iptables like Shorewall in conjugation of [Webmin][1] in GUI and Direct access to iptables via console.And I must admit that direct access to iptables via Linux console gives a user immense power in the form of higher degree of flexibility and better understanding of what is going on in the background, if not anything other. GUI is for novice administrator while console is for experienced.
|
||||
|
||||
**3. What are the basic differences between between iptables and firewalld?**
|
||||
|
||||
> **Answer** : iptables and firewalld serves the same purpose (Packet Filtering) but with different approach. iptables flush the entire rules set each time a change is made unlike firewalld. Typically the location of iptables configuration lies at ‘/etc/sysconfig/iptables‘ whereas firewalld configuration lies at ‘/etc/firewalld/‘, which is a set of XML files.Configuring a XML based firewalld is easier as compared to configuration of iptables, however same task can be achieved using both the packet filtering application ie., iptables and firewalld. Firewalld runs iptables under its hood along with it’s own command line interface and configuration file that is XML based and said above.
|
||||
|
||||
**4. Would you replace iptables with firewalld on all your servers, if given a chance?**
|
||||
|
||||
> **Answer** : I am familiar with iptables and it’s working and if there is nothing that requires dynamic aspect of firewalld, there seems no reason to migrate all my configuration from iptables to firewalld.In most of the cases, so far I have never seen iptables creating an issue. Also the general rule of Information technology says “why fix if it is not broken”. However this is my personal thought and I would never mind implementing firewalld if the Organization is going to replace iptables with firewalld.
|
||||
|
||||
**5. You seems confident with iptables and the plus point is even we are using iptables on our server.**
|
||||
|
||||
What are the tables used in iptables? Give a brief description of the tables used in iptables and the chains they support.
|
||||
|
||||
> **Answer** : Thanks for the recognition. Moving to question part, There are four tables used in iptables, namely they are:
|
||||
>
|
||||
> - Nat Table
|
||||
> - Mangle Table
|
||||
> - Filter Table
|
||||
> - Raw Table
|
||||
>
|
||||
> Nat Table : Nat table is primarily used for Network Address Translation. Masqueraded packets get their IP address altered as per the rules in the table. Packets in the stream traverse Nat Table only once. ie., If a packet from a jet of Packets is masqueraded they rest of the packages in the stream will not traverse through this table again. It is recommended not to filter in this table. Chains Supported by NAT Table are PREROUTING Chain, POSTROUTING Chain and OUTPUT Chain.
|
||||
>
|
||||
> Mangle Table : As the name suggests, this table serves for mangling the packets. It is used for Special package alteration. It can be used to alter the content of different packets and their headers. Mangle table can’t be used for Masquerading. Supported chains are PREROUTING Chain, OUTPUT Chain, Forward Chain, INPUT Chain, POSTROUTING Chain.
|
||||
>
|
||||
> Filter Table : Filter Table is the default table used in iptables. It is used for filtering Packets. If no rules are defined, Filter Table is taken as default table and filtering is done on the basis of this table. Supported Chains are INPUT Chain, OUTPUT Chain, FORWARD Chain.
|
||||
>
|
||||
> Raw Table : Raw table comes into action when we want to configure packages that were exempted earlier. It supports PREROUTING Chain and OUTPUT Chain.
|
||||
|
||||
**6. What are the target values (that can be specified in target) in iptables and what they do, be brief!**
|
||||
|
||||
> **Answer** : Following are the target values that we can specify in target in iptables:
|
||||
>
|
||||
> - ACCEPT : Accept Packets
|
||||
> - QUEUE : Paas Package to user space (place where application and drivers reside)
|
||||
> - DROP : Drop Packets
|
||||
> - RETURN : Return Control to calling chain and stop executing next set of rules for the current Packets in the chain.
|
||||
|
||||
|
||||
**7. Lets move to the technical aspects of iptables, by technical I means practical.**
|
||||
|
||||
How will you Check iptables rpm that is required to install iptables in CentOS?.
|
||||
|
||||
> **Answer** : iptables rpm are included in standard CentOS installation and we do not need to install it separately. We can check the rpm as:
|
||||
>
|
||||
> # rpm -qa iptables
|
||||
>
|
||||
> iptables-1.4.21-13.el7.x86_64
|
||||
>
|
||||
> If you need to install it, you may do yum to get it.
|
||||
>
|
||||
> # yum install iptables-services
|
||||
|
||||
**8. How to Check and ensure if iptables service is running?**
|
||||
|
||||
> **Answer** : To check the status of iptables, you may run the following command on the terminal.
|
||||
>
|
||||
> # service status iptables [On CentOS 6/5]
|
||||
> # systemctl status iptables [On CentOS 7]
|
||||
>
|
||||
> If it is not running, the below command may be executed.
|
||||
>
|
||||
> ---------------- On CentOS 6/5 ----------------
|
||||
> # chkconfig --level 35 iptables on
|
||||
> # service iptables start
|
||||
>
|
||||
> ---------------- On CentOS 7 ----------------
|
||||
> # systemctl enable iptables
|
||||
> # systemctl start iptables
|
||||
>
|
||||
> We may also check if the iptables module is loaded or not, as:
|
||||
>
|
||||
> # lsmod | grep ip_tables
|
||||
|
||||
**9. How will you review the current Rules defined in iptables?**
|
||||
|
||||
> **Answer** : The current rules in iptables can be review as simple as:
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Sample Output
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**10. How will you flush all iptables rules or a particular chain?**
|
||||
|
||||
> **Answer** : To flush a particular iptables chain, you may use following commands.
|
||||
>
|
||||
>
|
||||
> # iptables --flush OUTPUT
|
||||
>
|
||||
> To Flush all the iptables rules.
|
||||
>
|
||||
> # iptables --flush
|
||||
|
||||
**11. Add a rule in iptables to accept packets from a trusted IP Address (say 192.168.0.7)**
|
||||
|
||||
> **Answer** : The above scenario can be achieved simply by running the below command.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
>
|
||||
> We may include standard slash or subnet mask in the source as:
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
> # iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
**12. How to add rules to ACCEPT, REJECT, DENY and DROP ssh service in iptables.**
|
||||
|
||||
> **Answer** : Hoping ssh is running on port 22, which is also the default port for ssh, we can add rule to iptables as:
|
||||
>
|
||||
> To ACCEPT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j ACCEPT
|
||||
>
|
||||
> To REJECT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j REJECT
|
||||
>
|
||||
> To DENY tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j DENY
|
||||
>
|
||||
> To DROP tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j DROP
|
||||
|
||||
**13. Let me give you a scenario. Say there is a machine the local ip address of which is 192.168.0.6. You need to block connections on port 21, 22, 23, and 80 to your machine. What will you do?**
|
||||
|
||||
> **Answer** : Well all I need to use is the ‘multiport‘ option with iptables followed by port numbers to be blocked and the above scenario can be achieved in a single go as.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 21,22,23,80 -j DROP
|
||||
>
|
||||
> The written rules can be checked using the below command.
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
> DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**Interviewer** : That’s all I wanted to ask. You are a valuable employee we won’t like to miss. I will recommend your name to the HR. If you have any question you may ask me.
|
||||
|
||||
As a candidate I don’t wanted to kill the conversation hence keep asking about the projects I would be handling if selected and what are the other openings in the company. Not to mention HR round was not difficult to crack and I got the opportunity.
|
||||
|
||||
Also I would like to thank Avishek and Ravi (whom I am a friend since long) for taking the time to document my interview.
|
||||
|
||||
Friends! If you had given any such interview and you would like to share your interview experience to millions of Tecmint readers around the globe? then send your questions and answers to admin@tecmint.com or you may submit your interview experience using following form.
|
||||
|
||||
- [Share Your Interview Experience][2]
|
||||
|
||||
Thank you! Keep Connected. Also let me know if I could have answered a question more correctly than what I did.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
[2]:https://docs.google.com/a/tecmint.com/forms/d/1jfu1Kg8_qToqvyi6pOT1HQb0dAFvRE-Yc_aOkj0RoSg/viewform
|
||||
@ -0,0 +1,133 @@
|
||||
watch - Repeat Linux / Unix Commands Regular Intervals
|
||||
================================================================================
|
||||
A server administrator needs to maintain the system and keep it updated and safe. A number of intrusion attempts may happen every day. There are some other activities that maintain their log. These logs are updated regularly. In order to check these updates, the commands are executed repeatedly. For example, for simply reading a file, commands like head, tail, cat etc are used. These commands need to be executed repeatedly. The watch command can be used to repeat a command at regular intervals.
|
||||
|
||||
### Watch Command ###
|
||||
|
||||
Watch is a simple command, with a few options. The basic syntax of watch command is:
|
||||
|
||||
watch [-dhvt] [-n <seconds>] [--differences[=cumulative]] [--help] [--interval=<seconds>] [--no-title] [--version] <command>
|
||||
|
||||
Watch command runs the command specified to it after every 2 seconds by default. This time is counted between the completion of command and beginning of next execution. As a simple example, watch command can be used to watch the log updates, The updates are appended at the end of the file, so tail command can be used with watch to see the updates to the file. This command continues to run until you hit CTRL + C to return to the prompt.
|
||||
|
||||
### Examples ###
|
||||
|
||||
> Keep an eye on errors/notices/warning being generated at run time every couple of seconds.
|
||||
|
||||
watch tail /var/log/messages
|
||||
|
||||

|
||||
|
||||
> Keep an eye on disk usage after specified time interval.
|
||||
|
||||
watch df -h
|
||||
|
||||

|
||||
|
||||
> It is very important for administrators to keep an eye on high I/O wait causing disk operations especially the Mysql transactions.
|
||||
|
||||
watch mysqladmin processlist
|
||||
|
||||

|
||||
|
||||
> Keep an eye on server load and uptime at runtime.
|
||||
|
||||
watch uptime
|
||||
|
||||

|
||||
|
||||
> Keep an eye on queue size for Exim at the time a cron is run to send notices to subscribers.
|
||||
|
||||
watch exim -bpc
|
||||
|
||||

|
||||
|
||||
### 1) Iteration delay ###
|
||||
|
||||
watch [-n <seconds>] <command>
|
||||
|
||||
The default interval between the commands can be changed with -n switch. The following command will run the tail command after 5 seconds:
|
||||
|
||||
watch -n 5 date
|
||||
|
||||

|
||||
|
||||
### 2) Successive output comparison ###
|
||||
|
||||
If you use -d option with watch command, it will highlight the differences between the first command output to every next command output cumulatively.
|
||||
|
||||
watch [-d or --differences[=cumulative]] <command>
|
||||
|
||||
#### Example1 ####
|
||||
|
||||
Let’s see the successive time outputs extracted using following watch command and observe how the difference is highlighted.
|
||||
|
||||
watch -n 15 -d date
|
||||
|
||||
First time date is capture when command is executed, the next iteration will be repeated after 15 seconds.
|
||||
|
||||

|
||||
|
||||
Upon the execution of next iteration, it can be seen that all output is exactly same except the seconds have increased from 14 to 29 which is highlighted.
|
||||
|
||||

|
||||
|
||||
#### Example 2 ####
|
||||
|
||||
Let’s experience in difference between two successive outputs of “uptime” command repeated by watch.
|
||||
|
||||
watch -n 20 -d uptime
|
||||
|
||||

|
||||
|
||||
Now the difference between the time is highlighted as well as the three load snapshots as well.
|
||||
|
||||

|
||||
|
||||
### 3) Output without title ###
|
||||
|
||||
If you don’t want to display extra details about the iteration delay and actual command run by watch then –t switch can be used.
|
||||
|
||||
watch [-t or --no-title] <command>
|
||||
|
||||
Let’s see the output of following command as an example.
|
||||
|
||||
watch -t date
|
||||
|
||||

|
||||
|
||||
### Watch help ###
|
||||
|
||||
Brief details of the watch command can be found by typing the following command in SSH.
|
||||
|
||||
watch -h [or --help]
|
||||
|
||||

|
||||
|
||||
### Watch version ###
|
||||
|
||||
Run the following command in SSH terminal to check the version of watch.
|
||||
|
||||
watch -v [--version]
|
||||
|
||||

|
||||
|
||||
**BUGS**
|
||||
|
||||
Unfortunately, upon terminal resize, the screen will not be correctly repainted until the next scheduled update. All --differences highlight-ing is lost on that update as well.
|
||||
|
||||
### Summary ###
|
||||
|
||||
Watch is a very powerful utility for system administrators because it can be used to monitor, logs, operations, performance and throughput of the system at run time. One can easily format and delay the output of watch utility. Any Linux command / utility or script and be supplied to watch for desired and continuous output.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/linux-watch-command/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
@ -0,0 +1,315 @@
|
||||
[translating by xiqingongzi]
|
||||
|
||||
RHCSA Series: Reviewing Essential Commands & System Documentation – Part 1
|
||||
================================================================================
|
||||
RHCSA (Red Hat Certified System Administrator) is a certification exam from Red Hat company, which provides an open source operating system and software to the enterprise community, It also provides support, training and consulting services for the organizations.
|
||||
|
||||

|
||||
|
||||
RHCSA Exam Preparation Guide
|
||||
|
||||
RHCSA exam is the certification obtained from Red Hat Inc, after passing the exam (codename EX200). RHCSA exam is an upgrade to the RHCT (Red Hat Certified Technician) exam, and this upgrade is compulsory as the Red Hat Enterprise Linux was upgraded. The main variation between RHCT and RHCSA is that RHCT exam based on RHEL 5, whereas RHCSA certification is based on RHEL 6 and 7, the courseware of these two certifications are also vary to a certain level.
|
||||
|
||||
This Red Hat Certified System Administrator (RHCSA) is essential to perform the following core system administration tasks needed in Red Hat Enterprise Linux environments:
|
||||
|
||||
- Understand and use necessary tools for handling files, directories, command-environments line, and system-wide / packages documentation.
|
||||
- Operate running systems, even in different run levels, identify and control processes, start and stop virtual machines.
|
||||
- Set up local storage using partitions and logical volumes.
|
||||
- Create and configure local and network file systems and its attributes (permissions, encryption, and ACLs).
|
||||
- Setup, configure, and control systems, including installing, updating and removing software.
|
||||
- Manage system users and groups, along with use of a centralized LDAP directory for authentication.
|
||||
- Ensure system security, including basic firewall and SELinux configuration.
|
||||
|
||||
To view fees and register for an exam in your country, check the [RHCSA Certification page][1].
|
||||
|
||||
To view fees and register for an exam in your country, check the RHCSA Certification page.
|
||||
|
||||
In this 15-article RHCSA series, titled Preparation for the RHCSA (Red Hat Certified System Administrator) exam, we will going to cover the following topics on the latest releases of Red Hat Enterprise Linux 7.
|
||||
|
||||
- Part 1: Reviewing Essential Commands & System Documentation
|
||||
- Part 2: How to Perform File and Directory Management in RHEL 7
|
||||
- Part 3: How to Manage Users and Groups in RHEL 7
|
||||
- Part 4: Editing Text Files with Nano and Vim / Analyzing text with grep and regexps
|
||||
- Part 5: Process Management in RHEL 7: boot, shutdown, and everything in between
|
||||
- Part 6: Using ‘Parted’ and ‘SSM’ to Configure and Encrypt System Storage
|
||||
- Part 7: Using ACLs (Access Control Lists) and Mounting Samba / NFS Shares
|
||||
- Part 8: Securing SSH, Setting Hostname and Enabling Network Services
|
||||
- Part 9: Installing, Configuring and Securing a Web and FTP Server
|
||||
- Part 10: Yum Package Management, Automating Tasks with Cron and Monitoring System Logs
|
||||
- Part 11: Firewall Essentials and Control Network Traffic Using FirewallD and Iptables
|
||||
- Part 12: Automate RHEL 7 Installations Using ‘Kickstart’
|
||||
- Part 13: RHEL 7: What is SELinux and how it works?
|
||||
- Part 14: Use LDAP-based authentication in RHEL 7
|
||||
- Part 15: Virtualization in RHEL 7: KVM and Virtual machine management
|
||||
|
||||
In this Part 1 of the RHCSA series, we will explain how to enter and execute commands with the correct syntax in a shell prompt or terminal, and explained how to find, inspect, and use system documentation.
|
||||
|
||||

|
||||
|
||||
RHCSA: Reviewing Essential Linux Commands – Part 1
|
||||
|
||||
#### Prerequisites: ####
|
||||
|
||||
At least a slight degree of familiarity with basic Linux commands such as:
|
||||
|
||||
- [cd command][2] (change directory)
|
||||
- [ls command][3] (list directory)
|
||||
- [cp command][4] (copy files)
|
||||
- [mv command][5] (move or rename files)
|
||||
- [touch command][6] (create empty files or update the timestamp of existing ones)
|
||||
- rm command (delete files)
|
||||
- mkdir command (make directory)
|
||||
|
||||
The correct usage of some of them are anyway exemplified in this article, and you can find further information about each of them using the suggested methods in this article.
|
||||
|
||||
Though not strictly required to start, as we will be discussing general commands and methods for information search in a Linux system, you should try to install RHEL 7 as explained in the following article. It will make things easier down the road.
|
||||
|
||||
- [Red Hat Enterprise Linux (RHEL) 7 Installation Guide][7]
|
||||
|
||||
### Interacting with the Linux Shell ###
|
||||
|
||||
If we log into a Linux box using a text-mode login screen, chances are we will be dropped directly into our default shell. On the other hand, if we login using a graphical user interface (GUI), we will have to open a shell manually by starting a terminal. Either way, we will be presented with the user prompt and we can start typing and executing commands (a command is executed by pressing the Enter key after we have typed it).
|
||||
|
||||
Commands are composed of two parts:
|
||||
|
||||
- the name of the command itself, and
|
||||
- arguments
|
||||
|
||||
Certain arguments, called options (usually preceded by a hyphen), alter the behavior of the command in a particular way while other arguments specify the objects upon which the command operates.
|
||||
|
||||
The type command can help us identify whether another certain command is built into the shell or if it is provided by a separate package. The need to make this distinction lies in the place where we will find more information about the command. For shell built-ins we need to look in the shell’s man page, whereas for other binaries we can refer to its own man page.
|
||||
|
||||
|
||||
|
||||
Check Shell built in Commands
|
||||
|
||||
In the examples above, cd and type are shell built-ins, while top and less are binaries external to the shell itself (in this case, the location of the command executable is returned by type).
|
||||
|
||||
Other well-known shell built-ins include:
|
||||
|
||||
- [echo command][8]: Displays strings of text.
|
||||
- [pwd command][9]: Prints the current working directory.
|
||||
|
||||

|
||||
|
||||
More Built in Shell Commands
|
||||
|
||||
**exec command**
|
||||
|
||||
Runs an external program that we specify. Note that in most cases, this is better accomplished by just typing the name of the program we want to run, but the exec command has one special feature: rather than create a new process that runs alongside the shell, the new process replaces the shell, as can verified by subsequent.
|
||||
|
||||
# ps -ef | grep [original PID of the shell process]
|
||||
|
||||
When the new process terminates, the shell terminates with it. Run exec top and then hit the q key to quit top. You will notice that the shell session ends when you do, as shown in the following screencast:
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/f02w4WT73LE"></iframe>
|
||||
|
||||
**export command**
|
||||
|
||||
Exports variables to the environment of subsequently executed commands.
|
||||
|
||||
**history Command**
|
||||
|
||||
Displays the command history list with line numbers. A command in the history list can be repeated by typing the command number preceded by an exclamation sign. If we need to edit a command in history list before executing it, we can press Ctrl + r and start typing the first letters associated with the command. When we see the command completed automatically, we can edit it as per our current need:
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/69vafdSMfU4"></iframe>
|
||||
|
||||
This list of commands is kept in our home directory in a file called .bash_history. The history facility is a useful resource for reducing the amount of typing, especially when combined with command line editing. By default, bash stores the last 500 commands you have entered, but this limit can be extended by using the HISTSIZE environment variable:
|
||||
|
||||

|
||||
|
||||
Linux history Command
|
||||
|
||||
But this change as performed above, will not be persistent on our next boot. In order to preserve the change in the HISTSIZE variable, we need to edit the .bashrc file by hand:
|
||||
|
||||
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
|
||||
HISTSIZE=1000
|
||||
|
||||
**Important**: Keep in mind that these changes will not take effect until we restart our shell session.
|
||||
|
||||
**alias command**
|
||||
|
||||
With no arguments or with the -p option prints the list of aliases in the form alias name=value on standard output. When arguments are provided, an alias is defined for each name whose value is given.
|
||||
|
||||
With alias, we can make up our own commands or modify existing ones by including desired options. For example, suppose we want to alias ls to ls –color=auto so that the output will display regular files, directories, symlinks, and so on, in different colors:
|
||||
|
||||
# alias ls='ls --color=auto'
|
||||
|
||||
|
||||
|
||||
Linux alias Command
|
||||
|
||||
**Note**: That you can assign any name to your “new command” and enclose as many commands as desired between single quotes, but in that case you need to separate them by semicolons, as follows:
|
||||
|
||||
# alias myNewCommand='cd /usr/bin; ls; cd; clear'
|
||||
|
||||
**exit command**
|
||||
|
||||
The exit and logout commands both terminate the shell. The exit command terminates any shell, but the logout command terminates only login shells—that is, those that are launched automatically when you initiate a text-mode login.
|
||||
|
||||
If we are ever in doubt as to what a program does, we can refer to its man page, which can be invoked using the man command. In addition, there are also man pages for important files (inittab, fstab, hosts, to name a few), library functions, shells, devices, and other features.
|
||||
|
||||
#### Examples: ####
|
||||
|
||||
- man uname (print system information, such as kernel name, processor, operating system type, architecture, and so on).
|
||||
- man inittab (init daemon configuration).
|
||||
|
||||
Another important source of information is provided by the info command, which is used to read info documents. These documents often provide more information than the man page. It is invoked by using the info keyword followed by a command name, such as:
|
||||
|
||||
# info ls
|
||||
# info cut
|
||||
|
||||
In addition, the /usr/share/doc directory contains several subdirectories where further documentation can be found. They either contain plain-text files or other friendly formats.
|
||||
|
||||
Make sure you make it a habit to use these three methods to look up information for commands. Pay special and careful attention to the syntax of each of them, which is explained in detail in the documentation.
|
||||
|
||||
**Converting Tabs into Spaces with expand Command**
|
||||
|
||||
Sometimes text files contain tabs but programs that need to process the files don’t cope well with tabs. Or maybe we just want to convert tabs into spaces. That’s where the expand tool (provided by the GNU coreutils package) comes in handy.
|
||||
|
||||
For example, given the file NumbersList.txt, let’s run expand against it, changing tabs to one space, and display on standard output.
|
||||
|
||||
# expand --tabs=1 NumbersList.txt
|
||||
|
||||

|
||||
|
||||
Linux expand Command
|
||||
|
||||
The unexpand command performs the reverse operation (converts spaces into tabs).
|
||||
|
||||
**Display the first lines of a file with head and the last lines with tail**
|
||||
|
||||
By default, the head command followed by a filename, will display the first 10 lines of the said file. This behavior can be changed using the -n option and specifying a certain number of lines.
|
||||
|
||||
# head -n3 /etc/passwd
|
||||
# tail -n3 /etc/passwd
|
||||
|
||||

|
||||
|
||||
Linux head and tail Command
|
||||
|
||||
One of the most interesting features of tail is the possibility of displaying data (last lines) as the input file grows (tail -f my.log, where my.log is the file under observation). This is particularly useful when monitoring a log to which data is being continually added.
|
||||
|
||||
Read More: [Manage Files Effectively using head and tail Commands][10]
|
||||
|
||||
**Merging Lines with paste**
|
||||
|
||||
The paste command merges files line by line, separating the lines from each file with tabs (by default), or another delimiter that can be specified (in the following example the fields in the output are separated by an equal sign).
|
||||
|
||||
# paste -d= file1 file2
|
||||
|
||||
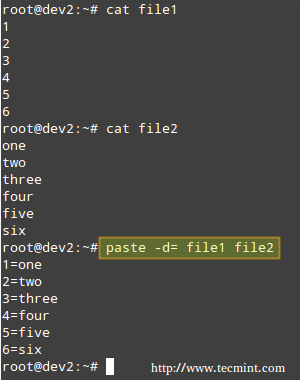
|
||||
|
||||
Merge Files in Linux
|
||||
|
||||
**Breaking a file into pieces using split command**
|
||||
|
||||
The split command is used split a file into two (or more) separate files, which are named according to a prefix of our choosing. The splitting can be defined by size, chunks, or number of lines, and the resulting files can have a numeric or alphabetic suffixes. In the following example, we will split bash.pdf into files of size 50 KB (-b 50KB), using numeric suffixes (-d):
|
||||
|
||||
# split -b 50KB -d bash.pdf bash_
|
||||
|
||||

|
||||
|
||||
Split Files in Linux
|
||||
|
||||
You can merge the files to recreate the original file with the following command:
|
||||
|
||||
# cat bash_00 bash_01 bash_02 bash_03 bash_04 bash_05 > bash.pdf
|
||||
|
||||
**Translating characters with tr command**
|
||||
|
||||
The tr command can be used to translate (change) characters on a one-by-one basis or using character ranges. In the following example we will use the same file2 as previously, and we will change:
|
||||
|
||||
- lowercase o’s to uppercase,
|
||||
- and all lowercase to uppercase
|
||||
|
||||
# cat file2 | tr o O
|
||||
# cat file2 | tr [a-z] [A-Z]
|
||||
|
||||
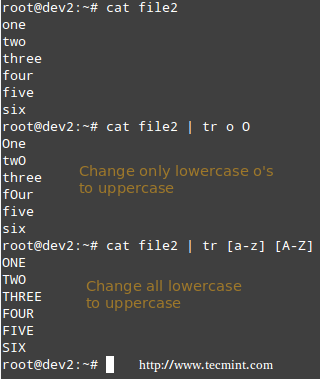
|
||||
|
||||
Translate Characters in Linux
|
||||
|
||||
**Reporting or deleting duplicate lines with uniq and sort command**
|
||||
|
||||
The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default. We must note that uniq does not detect repeated lines unless they are adjacent. Thus, uniq is commonly used along with a preceding sort (which is used to sort lines of text files).
|
||||
|
||||
By default, sort takes the first field (separated by spaces) as key field. To specify a different key field, we need to use the -k option. Please note how the output returned by sort and uniq change as we change the key field in the following example:
|
||||
|
||||
# cat file3
|
||||
# sort file3 | uniq
|
||||
# sort -k2 file3 | uniq
|
||||
# sort -k3 file3 | uniq
|
||||
|
||||

|
||||
|
||||
Remove Duplicate Lines in Linux
|
||||
|
||||
**Extracting text with cut command**
|
||||
|
||||
The cut command extracts portions of input lines (from stdin or files) and displays the result on standard output, based on number of bytes (-b), characters (-c), or fields (-f).
|
||||
|
||||
When using cut based on fields, the default field separator is a tab, but a different separator can be specified by using the -d option.
|
||||
|
||||
# cut -d: -f1,3 /etc/passwd # Extract specific fields: 1 and 3 in this case
|
||||
# cut -d: -f2-4 /etc/passwd # Extract range of fields: 2 through 4 in this example
|
||||
|
||||

|
||||
|
||||
Extract Text From a File in Linux
|
||||
|
||||
Note that the output of the two examples above was truncated for brevity.
|
||||
|
||||
**Reformatting files with fmt command**
|
||||
|
||||
fmt is used to “clean up” files with a great amount of content or lines, or with varying degrees of indentation. The new paragraph formatting defaults to no more than 75 characters wide. You can change this with the -w (width) option, which set the line length to the specified number of characters.
|
||||
|
||||
For example, let’s see what happens when we use fmt to display the /etc/passwd file setting the width of each line to 100 characters. Once again, output has been truncated for brevity.
|
||||
|
||||
# fmt -w100 /etc/passwd
|
||||
|
||||

|
||||
|
||||
File Reformatting in Linux
|
||||
|
||||
**Formatting content for printing with pr command**
|
||||
|
||||
pr paginates and displays in columns one or more files for printing. In other words, pr formats a file to make it look better when printed. For example, the following command:
|
||||
|
||||
# ls -a /etc | pr -n --columns=3 -h "Files in /etc"
|
||||
|
||||
Shows a listing of all the files found in /etc in a printer-friendly format (3 columns) with a custom header (indicated by the -h option), and numbered lines (-n).
|
||||
|
||||

|
||||
|
||||
File Formatting in Linux
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have discussed how to enter and execute commands with the correct syntax in a shell prompt or terminal, and explained how to find, inspect, and use system documentation. As simple as it seems, it’s a large first step in your way to becoming a RHCSA.
|
||||
|
||||
If you would like to add other commands that you use on a periodic basis and that have proven useful to fulfill your daily responsibilities, feel free to share them with the world by using the comment form below. Questions are also welcome. We look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://www.redhat.com/en/services/certification/rhcsa
|
||||
[2]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[3]:http://www.tecmint.com/ls-command-interview-questions/
|
||||
[4]:http://www.tecmint.com/advanced-copy-command-shows-progress-bar-while-copying-files/
|
||||
[5]:http://www.tecmint.com/rename-multiple-files-in-linux/
|
||||
[6]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[7]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[8]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[9]:http://www.tecmint.com/pwd-command-examples/
|
||||
[10]:http://www.tecmint.com/view-contents-of-file-in-linux/
|
||||
@ -0,0 +1,322 @@
|
||||
RHCSA Series: How to Perform File and Directory Management – Part 2
|
||||
================================================================================
|
||||
In this article, RHCSA Part 2: File and directory management, we will review some essential skills that are required in the day-to-day tasks of a system administrator.
|
||||
|
||||

|
||||
|
||||
RHCSA: Perform File and Directory Management – Part 2
|
||||
|
||||
### Create, Delete, Copy, and Move Files and Directories ###
|
||||
|
||||
File and directory management is a critical competence that every system administrator should possess. This includes the ability to create / delete text files from scratch (the core of each program’s configuration) and directories (where you will organize files and other directories), and to find out the type of existing files.
|
||||
|
||||
The [touch command][1] can be used not only to create empty files, but also to update the access and modification times of existing files.
|
||||
|
||||

|
||||
|
||||
touch command example
|
||||
|
||||
You can use `file [filename]` to determine a file’s type (this will come in handy before launching your preferred text editor to edit it).
|
||||
|
||||
|
||||
|
||||
file command example
|
||||
|
||||
and `rm [filename]` to delete it.
|
||||
|
||||

|
||||
|
||||
rm command example
|
||||
|
||||
As for directories, you can create directories inside existing paths with `mkdir [directory]` or create a full path with `mkdir -p [/full/path/to/directory].`
|
||||
|
||||

|
||||
|
||||
mkdir command example
|
||||
|
||||
When it comes to removing directories, you need to make sure that they’re empty before issuing the `rmdir [directory]` command, or use the more powerful (handle with care!) `rm -rf [directory]`. This last option will force remove recursively the `[directory]` and all its contents – so use it at your own risk.
|
||||
|
||||
### Input and Output Redirection and Pipelining ###
|
||||
|
||||
The command line environment provides two very useful features that allows to redirect the input and output of commands from and to files, and to send the output of a command to another, called redirection and pipelining, respectively.
|
||||
|
||||
To understand those two important concepts, we must first understand the three most important types of I/O (Input and Output) streams (or sequences) of characters, which are in fact special files, in the *nix sense of the word.
|
||||
|
||||
- Standard input (aka stdin) is by default attached to the keyboard. In other words, the keyboard is the standard input device to enter commands to the command line.
|
||||
- Standard output (aka stdout) is by default attached to the screen, the device that “receives” the output of commands and display them on the screen.
|
||||
- Standard error (aka stderr), is where the status messages of a command is sent to by default, which is also the screen.
|
||||
|
||||
In the following example, the output of `ls /var` is sent to stdout (the screen), as well as the result of ls /tecmint. But in the latter case, it is stderr that is shown.
|
||||
|
||||

|
||||
|
||||
Input and Output Example
|
||||
|
||||
To more easily identify these special files, they are each assigned a file descriptor, an abstract representation that is used to access them. The essential thing to understand is that these files, just like others, can be redirected. What this means is that you can capture the output from a file or script and send it as input to another file, command, or script. This will allow you to store on disk, for example, the output of commands for later processing or analysis.
|
||||
|
||||
To redirect stdin (fd 0), stdout (fd 1), or stderr (fd 2), the following operators are available.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="226"></colgroup>
|
||||
<colgroup width="743"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Redirection Operator</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Effect</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Redirects standard output to a file containing standard output. If the destination file exists, it will be overwritten.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends standard output to a file.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Redirects standard error to a file containing standard output. If the destination file exists, it will be overwritten.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">2>></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends standard error to the existing file.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;">&></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Redirects both standard output and standard error to a file; if the specified file exists, it will be overwritten.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><</span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Uses the specified file as standard input.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="CENTER" height="18" style="border: 1px solid #000000;"><b><span style="font-family: Courier New;"><></span></b></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">The specified file is used for both standard input and standard output.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
As opposed to redirection, pipelining is performed by adding a vertical bar `(|)` after a command and before another one.
|
||||
|
||||
Remember:
|
||||
|
||||
- Redirection is used to send the output of a command to a file, or to send a file as input to a command.
|
||||
- Pipelining is used to send the output of a command to another command as input.
|
||||
|
||||
#### Examples Of Redirection and Pipelining ####
|
||||
|
||||
**Example 1: Redirecting the output of a command to a file**
|
||||
|
||||
There will be times when you will need to iterate over a list of files. To do that, you can first save that list to a file and then read that file line by line. While it is true that you can iterate over the output of ls directly, this example serves to illustrate redirection.
|
||||
|
||||
# ls -1 /var/mail > mail.txt
|
||||
|
||||
|
||||
|
||||
Redirect output of command tot a file
|
||||
|
||||
**Example 2: Redirecting both stdout and stderr to /dev/null**
|
||||
|
||||
In case we want to prevent both stdout and stderr to be displayed on the screen, we can redirect both file descriptors to `/dev/null`. Note how the output changes when the redirection is implemented for the same command.
|
||||
|
||||
# ls /var /tecmint
|
||||
# ls /var/ /tecmint &> /dev/null
|
||||
|
||||

|
||||
|
||||
Redirecting stdout and stderr ouput to /dev/null
|
||||
|
||||
#### Example 3: Using a file as input to a command ####
|
||||
|
||||
While the classic syntax of the [cat command][2] is as follows.
|
||||
|
||||
# cat [file(s)]
|
||||
|
||||
You can also send a file as input, using the correct redirection operator.
|
||||
|
||||
# cat < mail.txt
|
||||
|
||||
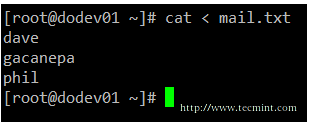
|
||||
|
||||
cat command example
|
||||
|
||||
#### Example 4: Sending the output of a command as input to another ####
|
||||
|
||||
If you have a large directory or process listing and want to be able to locate a certain file or process at a glance, you will want to pipeline the listing to grep.
|
||||
|
||||
Note that we use to pipelines in the following example. The first one looks for the required keyword, while the second one will eliminate the actual `grep command` from the results. This example lists all the processes associated with the apache user.
|
||||
|
||||
# ps -ef | grep apache | grep -v grep
|
||||
|
||||

|
||||
|
||||
Send output of command as input to another
|
||||
|
||||
### Archiving, Compressing, Unpacking, and Uncompressing Files ###
|
||||
|
||||
If you need to transport, backup, or send via email a group of files, you will use an archiving (or grouping) tool such as [tar][3], typically used with a compression utility like gzip, bzip2, or xz.
|
||||
|
||||
Your choice of a compression tool will be likely defined by the compression speed and rate of each one. Of these three compression tools, gzip is the oldest and provides the least compression, bzip2 provides improved compression, and xz is the newest and provides the best compression. Typically, files compressed with these utilities have .gz, .bz2, or .xz extensions, respectively.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="165"></colgroup>
|
||||
<colgroup width="137"></colgroup>
|
||||
<colgroup width="366"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Command</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Abbreviation</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000000;"><b><span style="font-size: medium;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –create</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">c</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Creates a tar archive</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –concatenate</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">A</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends tar files to an archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –append</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">r</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends non-tar files to an archive</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –update</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">u</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Appends files that are newer than those in an archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –diff or –compare</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">d</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Compares an archive to files on disk</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="20" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –list</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">t</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Lists the contents of a tarball</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="18" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> –extract or –get</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">x</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;">Extracts files from an archive</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="258"></colgroup>
|
||||
<colgroup width="152"></colgroup>
|
||||
<colgroup width="803"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="CENTER" height="24" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">Operation modifier</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">Abbreviation</span></b></td>
|
||||
<td align="CENTER" bgcolor="#999999" style="border: 1px solid #000001;"><b><span style="font-size: medium;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>directory dir</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> C</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Changes to directory dir before performing operations</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>same-permissions and <span style="font-family: Courier New;">—</span>same-owner</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> p</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Preserves permissions and ownership information, respectively.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –verbose</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> v</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Lists all files as they are read or extracted; if combined with –list, it also displays file sizes, ownership, and timestamps</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>exclude file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> —</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Excludes file from the archive. In this case, file can be an actual file or a pattern.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;">—</span>gzip or <span style="font-family: Courier New;">—</span>gunzip</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> z</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Compresses an archive through gzip</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –bzip2</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> j</span></td>
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;">Compresses an archive through bzip2</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="LEFT" height="24" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> –xz</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Courier New;"> J</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;">Compresses an archive through xz</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### Example 5: Creating a tarball and then compressing it using the three compression utilities ####
|
||||
|
||||
You may want to compare the effectiveness of each tool before deciding to use one or another. Note that while compressing small files, or a few files, the results may not show much differences, but may give you a glimpse of what they have to offer.
|
||||
|
||||
# tar cf ApacheLogs-$(date +%Y%m%d).tar /var/log/httpd/* # Create an ordinary tarball
|
||||
# tar czf ApacheLogs-$(date +%Y%m%d).tar.gz /var/log/httpd/* # Create a tarball and compress with gzip
|
||||
# tar cjf ApacheLogs-$(date +%Y%m%d).tar.bz2 /var/log/httpd/* # Create a tarball and compress with bzip2
|
||||
# tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* # Create a tarball and compress with xz
|
||||
|
||||

|
||||
|
||||
tar command examples
|
||||
|
||||
#### Example 6: Preserving original permissions and ownership while archiving and when ####
|
||||
|
||||
If you are creating backups from users’ home directories, you will want to store the individual files with the original permissions and ownership instead of changing them to that of the user account or daemon performing the backup. The following example preserves these attributes while taking the backup of the contents in the `/var/log/httpd` directory:
|
||||
|
||||
# tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* --same-permissions --same-owner
|
||||
|
||||
### Create Hard and Soft Links ###
|
||||
|
||||
In Linux, there are two types of links to files: hard links and soft (aka symbolic) links. Since a hard link represents another name for an existing file and is identified by the same inode, it then points to the actual data, as opposed to symbolic links, which point to filenames instead.
|
||||
|
||||
In addition, hard links do not occupy space on disk, while symbolic links do take a small amount of space to store the text of the link itself. The downside of hard links is that they can only be used to reference files within the filesystem where they are located because inodes are unique inside a filesystem. Symbolic links save the day, in that they point to another file or directory by name rather than by inode, and therefore can cross filesystem boundaries.
|
||||
|
||||
The basic syntax to create links is similar in both cases:
|
||||
|
||||
# ln TARGET LINK_NAME # Hard link named LINK_NAME to file named TARGET
|
||||
# ln -s TARGET LINK_NAME # Soft link named LINK_NAME to file named TARGET
|
||||
|
||||
#### Example 7: Creating hard and soft links ####
|
||||
|
||||
There is no better way to visualize the relation between a file and a hard or symbolic link that point to it, than to create those links. In the following screenshot you will see that the file and the hard link that points to it share the same inode and both are identified by the same disk usage of 466 bytes.
|
||||
|
||||
On the other hand, creating a hard link results in an extra disk usage of 5 bytes. Not that you’re going to run out of storage capacity, but this example is enough to illustrate the difference between a hard link and a soft link.
|
||||
|
||||

|
||||
|
||||
Difference between a hard link and a soft link
|
||||
|
||||
A typical usage of symbolic links is to reference a versioned file in a Linux system. Suppose there are several programs that need access to file fooX.Y, which is subject to frequent version updates (think of a library, for example). Instead of updating every single reference to fooX.Y every time there’s a version update, it is wiser, safer, and faster, to have programs look to a symbolic link named just foo, which in turn points to the actual fooX.Y.
|
||||
|
||||
Thus, when X and Y change, you only need to edit the symbolic link foo with a new destination name instead of tracking every usage of the destination file and updating it.
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have reviewed some essential file and directory management skills that must be a part of every system administrator’s tool-set. Make sure to review other parts of this series as well in order to integrate these topics with the content covered in this tutorial.
|
||||
|
||||
Feel free to let us know if you have any questions or comments. We are always more than glad to hear from our readers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[2]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
@ -0,0 +1,248 @@
|
||||
RHCSA Series: How to Manage Users and Groups in RHEL 7 – Part 3
|
||||
================================================================================
|
||||
Managing a RHEL 7 server, as it is the case with any other Linux server, will require that you know how to add, edit, suspend, or delete user accounts, and grant users the necessary permissions to files, directories, and other system resources to perform their assigned tasks.
|
||||
|
||||

|
||||
|
||||
RHCSA: User and Group Management – Part 3
|
||||
|
||||
### Managing User Accounts ###
|
||||
|
||||
To add a new user account to a RHEL 7 server, you can run either of the following two commands as root:
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
When a new user account is added, by default the following operations are performed.
|
||||
|
||||
- His/her home directory is created (`/home/username` unless specified otherwise).
|
||||
- These `.bash_logout`, `.bash_profile` and `.bashrc` hidden files are copied inside the user’s home directory, and will be used to provide environment variables for his/her user session. You can explore each of them for further details.
|
||||
- A mail spool directory is created for the added user account.
|
||||
- A group is created with the same name as the new user account.
|
||||
|
||||
The full account summary is stored in the `/etc/passwd `file. This file holds a record per system user account and has the following format (fields are separated by a colon):
|
||||
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- These two fields `[username]` and `[Comment]` are self explanatory.
|
||||
- The second filed ‘x’ indicates that the account is secured by a shadowed password (in `/etc/shadow`), which is used to logon as `[username]`.
|
||||
- The fields `[UID]` and `[GID]` are integers that shows the User IDentification and the primary Group IDentification to which `[username]` belongs, equally.
|
||||
|
||||
Finally,
|
||||
|
||||
- The `[Home directory]` shows the absolute location of `[username]’s` home directory, and
|
||||
- `[Default shell]` is the shell that is commit to this user when he/she logins into the system.
|
||||
|
||||
Another important file that you must become familiar with is `/etc/group`, where group information is stored. As it is the case with `/etc/passwd`, there is one record per line and its fields are also delimited by a colon:
|
||||
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
where,
|
||||
|
||||
- `[Group name]` is the name of group.
|
||||
- Does this group use a group password? (An “x” means no).
|
||||
- `[GID]`: same as in `/etc/passwd`.
|
||||
- `[Group members]`: a list of users, separated by commas, that are members of each group.
|
||||
|
||||
After adding an account, at anytime, you can edit the user’s account information using usermod, whose basic syntax is:
|
||||
|
||||
# usermod [options] [username]
|
||||
|
||||
Read Also:
|
||||
|
||||
- [15 ‘useradd’ Command Examples][1]
|
||||
- [15 ‘usermod’ Command Examples][2]
|
||||
|
||||
#### EXAMPLE 1: Setting the expiry date for an account ####
|
||||
|
||||
If you work for a company that has some kind of policy to enable account for a certain interval of time, or if you want to grant access to a limited period of time, you can use the `--expiredate` flag followed by a date in YYYY-MM-DD format. To verify that the change has been applied, you can compare the output of
|
||||
|
||||
# chage -l [username]
|
||||
|
||||
before and after updating the account expiry date, as shown in the following image.
|
||||
|
||||
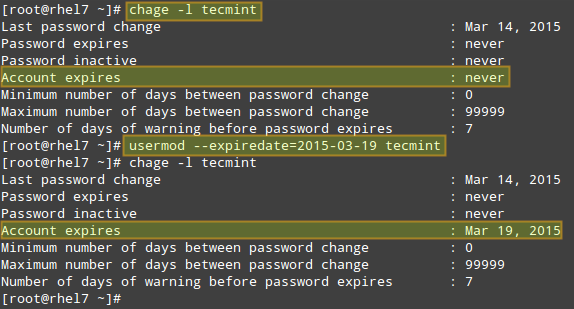
|
||||
|
||||
Change User Account Information
|
||||
|
||||
#### EXAMPLE 2: Adding the user to supplementary groups ####
|
||||
|
||||
Besides the primary group that is created when a new user account is added to the system, a user can be added to supplementary groups using the combined -aG, or –append –groups options, followed by a comma separated list of groups.
|
||||
|
||||
#### EXAMPLE 3: Changing the default location of the user’s home directory and / or changing its shell ####
|
||||
|
||||
If for some reason you need to change the default location of the user’s home directory (other than /home/username), you will need to use the -d, or –home options, followed by the absolute path to the new home directory.
|
||||
|
||||
If a user wants to use another shell other than bash (for example, sh), which gets assigned by default, use usermod with the –shell flag, followed by the path to the new shell.
|
||||
|
||||
#### EXAMPLE 4: Displaying the groups an user is a member of ####
|
||||
|
||||
After adding the user to a supplementary group, you can verify that it now actually belongs to such group(s):
|
||||
|
||||
# groups [username]
|
||||
# id [username]
|
||||
|
||||
The following image depicts Examples 2 through 4:
|
||||
|
||||

|
||||
|
||||
Adding User to Supplementary Group
|
||||
|
||||
In the example above:
|
||||
|
||||
# usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||
To remove a user from a group, omit the `--append` switch in the command above and list the groups you want the user to belong to following the `--groups` flag.
|
||||
|
||||
#### EXAMPLE 5: Disabling account by locking password ####
|
||||
|
||||
To disable an account, you will need to use either the -l (lowercase L) or the –lock option to lock a user’s password. This will prevent the user from being able to log on.
|
||||
|
||||
#### EXAMPLE 6: Unlocking password ####
|
||||
|
||||
When you need to re-enable the user so that he can log on to the server again, use the -u or the –unlock option to unlock a user’s password that was previously blocked, as explained in Example 5 above.
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
The following image illustrates Examples 5 and 6:
|
||||
|
||||

|
||||
|
||||
Lock Unlock User Account
|
||||
|
||||
#### EXAMPLE 7: Deleting a group or an user account ####
|
||||
|
||||
To delete a group, you’ll want to use groupdel, whereas to delete a user account you will use userdel (add the –r switch if you also want to delete the contents of its home directory and mail spool):
|
||||
|
||||
# groupdel [group_name] # Delete a group
|
||||
# userdel -r [user_name] # Remove user_name from the system, along with his/her home directory and mail spool
|
||||
|
||||
If there are files owned by group_name, they will not be deleted, but the group owner will be set to the GID of the group that was deleted.
|
||||
|
||||
### Listing, Setting and Changing Standard ugo/rwx Permissions ###
|
||||
|
||||
The well-known [ls command][3] is one of the best friends of any system administrator. When used with the -l flag, this tool allows you to view a list a directory’s contents in long (or detailed) format.
|
||||
|
||||
However, this command can also be applied to a single file. Either way, the first 10 characters in the output of `ls -l` represent each file’s attributes.
|
||||
|
||||
The first char of this 10-character sequence is used to indicate the file type:
|
||||
|
||||
- – (hyphen): a regular file
|
||||
- d: a directory
|
||||
- l: a symbolic link
|
||||
- c: a character device (which treats data as a stream of bytes, i.e. a terminal)
|
||||
- b: a block device (which handles data in blocks, i.e. storage devices)
|
||||
|
||||
The next nine characters of the file attributes, divided in groups of three from left to right, are called the file mode and indicate the read (r), write(w), and execute (x) permissions granted to the file’s owner, the file’s group owner, and the rest of the users (commonly referred to as “the world”), respectively.
|
||||
|
||||
While the read permission on a file allows the same to be opened and read, the same permission on a directory allows its contents to be listed if the execute permission is also set. In addition, the execute permission in a file allows it to be handled as a program and run.
|
||||
|
||||
File permissions are changed with the chmod command, whose basic syntax is as follows:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
where new_mode is either an octal number or an expression that specifies the new permissions. Feel free to use the mode that works best for you in each case. Or perhaps you already have a preferred way to set a file’s permissions – so feel free to use the method that works best for you.
|
||||
|
||||
The octal number can be calculated based on the binary equivalent, which can in turn be obtained from the desired file permissions for the owner of the file, the owner group, and the world.The presence of a certain permission equals a power of 2 (r=22, w=21, x=20), while its absence means 0. For example:
|
||||
|
||||

|
||||
|
||||
File Permissions
|
||||
|
||||
To set the file’s permissions as indicated above in octal form, type:
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
Please take a minute to compare our previous calculation to the actual output of `ls -l` after changing the file’s permissions:
|
||||
|
||||
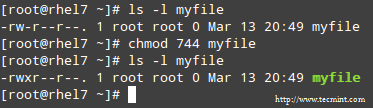
|
||||
|
||||
Long List Format
|
||||
|
||||
#### EXAMPLE 8: Searching for files with 777 permissions ####
|
||||
|
||||
As a security measure, you should make sure that files with 777 permissions (read, write, and execute for everyone) are avoided like the plague under normal circumstances. Although we will explain in a later tutorial how to more effectively locate all the files in your system with a certain permission set, you can -by now- combine ls with grep to obtain such information.
|
||||
|
||||
In the following example, we will look for file with 777 permissions in the /etc directory only. Note that we will use pipelining as explained in [Part 2: File and Directory Management][4] of this RHCSA series:
|
||||
|
||||
# ls -l /etc | grep rwxrwxrwx
|
||||
|
||||

|
||||
|
||||
Find All Files with 777 Permission
|
||||
|
||||
#### EXAMPLE 9: Assigning a specific permission to all users ####
|
||||
|
||||
Shell scripts, along with some binaries that all users should have access to (not just their corresponding owner and group), should have the execute bit set accordingly (please note that we will discuss a special case later):
|
||||
|
||||
# chmod a+x script.sh
|
||||
|
||||
**Note**: That we can also set a file’s mode using an expression that indicates the owner’s rights with the letter `u`, the group owner’s rights with the letter `g`, and the rest with `o`. All of these rights can be represented at the same time with the letter `a`. Permissions are granted (or revoked) with the `+` or `-` signs, respectively.
|
||||
|
||||

|
||||
|
||||
Set Execute Permission on File
|
||||
|
||||
A long directory listing also shows the file’s owner and its group owner in the first and second columns, respectively. This feature serves as a first-level access control method to files in a system:
|
||||
|
||||
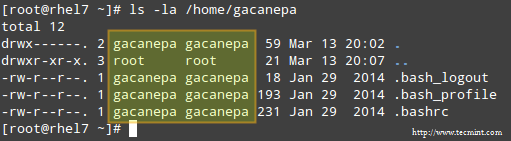
|
||||
|
||||
Check File Owner and Group
|
||||
|
||||
To change file ownership, you will use the chown command. Note that you can change the file and group ownership at the same time or separately:
|
||||
|
||||
# chown user:group file
|
||||
|
||||
**Note**: That you can change the user or group, or the two attributes at the same time, as long as you don’t forget the colon, leaving user or group blank if you want to update the other attribute, for example:
|
||||
|
||||
# chown :group file # Change group ownership only
|
||||
# chown user: file # Change user ownership only
|
||||
|
||||
#### EXAMPLE 10: Cloning permissions from one file to another ####
|
||||
|
||||
If you would like to “clone” ownership from one file to another, you can do so using the –reference flag, as follows:
|
||||
|
||||
# chown --reference=ref_file file
|
||||
|
||||
where the owner and group of ref_file will be assigned to file as well:
|
||||
|
||||

|
||||
|
||||
Clone File Ownership
|
||||
|
||||
### Setting Up SETGID Directories for Collaboration ###
|
||||
|
||||
Should you need to grant access to all the files owned by a certain group inside a specific directory, you will most likely use the approach of setting the setgid bit for such directory. When the setgid bit is set, the effective GID of the real user becomes that of the group owner.
|
||||
|
||||
Thus, any user can access a file under the privileges granted to the group owner of such file. In addition, when the setgid bit is set on a directory, newly created files inherit the same group as the directory, and newly created subdirectories will also inherit the setgid bit of the parent directory.
|
||||
|
||||
# chmod g+s [filename]
|
||||
|
||||
To set the setgid in octal form, prepend the number 2 to the current (or desired) basic permissions.
|
||||
|
||||
# chmod 2755 [directory]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
A solid knowledge of user and group management, along with standard and special Linux permissions, when coupled with practice, will allow you to quickly identify and troubleshoot issues with file permissions in your RHEL 7 server.
|
||||
|
||||
I assure you that as you follow the steps outlined in this article and use the system documentation (as explained in [Part 1: Reviewing Essential Commands & System Documentation][5] of this series) you will master this essential competence of system administration.
|
||||
|
||||
Feel free to let us know if you have any questions or comments using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://www.tecmint.com/ls-interview-questions/
|
||||
[4]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
@ -0,0 +1,254 @@
|
||||
RHCSA Series: Editing Text Files with Nano and Vim / Analyzing text with grep and regexps – Part 4
|
||||
================================================================================
|
||||
Every system administrator has to deal with text files as part of his daily responsibilities. That includes editing existing files (most likely configuration files), or creating new ones. It has been said that if you want to start a holy war in the Linux world, you can ask sysadmins what their favorite text editor is and why. We are not going to do that in this article, but will present a few tips that will be helpful to use two of the most widely used text editors in RHEL 7: nano (due to its simplicity and easiness of use, specially to new users), and vi/m (due to its several features that convert it into more than a simple editor). I am sure that you can find many more reasons to use one or the other, or perhaps some other editor such as emacs or pico. It’s entirely up to you.
|
||||
|
||||

|
||||
|
||||
RHCSA: Editing Text Files with Nano and Vim – Part 4
|
||||
|
||||
### Editing Files with Nano Editor ###
|
||||
|
||||
To launch nano, you can either just type nano at the command prompt, optionally followed by a filename (in this case, if the file exists, it will be opened in edition mode). If the file does not exist, or if we omit the filename, nano will also be opened in edition mode but will present a blank screen for us to start typing:
|
||||
|
||||

|
||||
|
||||
Nano Editor
|
||||
|
||||
As you can see in the previous image, nano displays at the bottom of the screen several functions that are available via the indicated shortcuts (^, aka caret, indicates the Ctrl key). To name a few of them:
|
||||
|
||||
- Ctrl + G: brings up the help menu with a complete list of functions and descriptions:Ctrl + X: exits the current file. If changes have not been saved, they are discarded.
|
||||
- Ctrl + R: lets you choose a file to insert its contents into the present file by specifying a full path.
|
||||
|
||||
|
||||
|
||||
Nano Editor Help Menu
|
||||
|
||||
- Ctrl + O: saves changes made to a file. It will let you save the file with the same name or a different one. Then press Enter to confirm.
|
||||
|
||||

|
||||
|
||||
Nano Editor Save Changes Mode
|
||||
|
||||
- Ctrl + X: exits the current file. If changes have not been saved, they are discarded.
|
||||
- Ctrl + R: lets you choose a file to insert its contents into the present file by specifying a full path.
|
||||
|
||||
|
||||
|
||||
Nano: Insert File Content to Parent File
|
||||
|
||||
will insert the contents of /etc/passwd into the current file.
|
||||
|
||||
- Ctrl + K: cuts the current line.
|
||||
- Ctrl + U: paste.
|
||||
- Ctrl + C: cancels the current operation and places you at the previous screen.
|
||||
|
||||
To easily navigate the opened file, nano provides the following features:
|
||||
|
||||
- Ctrl + F and Ctrl + B move the cursor forward or backward, whereas Ctrl + P and Ctrl + N move it up or down one line at a time, respectively, just like the arrow keys.
|
||||
- Ctrl + space and Alt + space move the cursor forward and backward one word at a time.
|
||||
|
||||
Finally,
|
||||
|
||||
- Ctrl + _ (underscore) and then entering X,Y will take you precisely to Line X, column Y, if you want to place the cursor at a specific place in the document.
|
||||
|
||||

|
||||
|
||||
Navigate to Line Numbers in Nano
|
||||
|
||||
The example above will take you to line 15, column 14 in the current document.
|
||||
|
||||
If you can recall your early Linux days, specially if you came from Windows, you will probably agree that starting off with nano is the best way to go for a new user.
|
||||
|
||||
### Editing Files with Vim Editor ###
|
||||
|
||||
Vim is an improved version of vi, a famous text editor in Linux that is available on all POSIX-compliant *nix systems, such as RHEL 7. If you have the chance and can install vim, go ahead; if not, most (if not all) the tips given in this article should also work.
|
||||
|
||||
One of vim’s distinguishing features is the different modes in which it operates:
|
||||
|
||||
|
||||
- Command mode will allow you to browse through the file and enter commands, which are brief and case-sensitive combinations of one or more letters. If you need to repeat one of them a certain number of times, you can prefix it with a number (there are only a few exceptions to this rule). For example, yy (or Y, short for yank) copies the entire current line, whereas 4yy (or 4Y) copies the entire current line along with the next three lines (4 lines in total).
|
||||
- In ex mode, you can manipulate files (including saving a current file and running outside programs or commands). To enter ex mode, we must type a colon (:) starting from command mode (or in other words, Esc + :), directly followed by the name of the ex-mode command that you want to use.
|
||||
- In insert mode, which is accessed by typing the letter i, we simply enter text. Most keystrokes result in text appearing on the screen.
|
||||
- We can always enter command mode (regardless of the mode we’re working on) by pressing the Esc key.
|
||||
|
||||
Let’s see how we can perform the same operations that we outlined for nano in the previous section, but now with vim. Don’t forget to hit the Enter key to confirm the vim command!
|
||||
|
||||
To access vim’s full manual from the command line, type :help while in command mode and then press Enter:
|
||||
|
||||
|
||||
|
||||
vim Edito Help Menu
|
||||
|
||||
The upper section presents an index list of contents, with defined sections dedicated to specific topics about vim. To navigate to a section, place the cursor over it and press Ctrl + ] (closing square bracket). Note that the bottom section displays the current file.
|
||||
|
||||
1. To save changes made to a file, run any of the following commands from command mode and it will do the trick:
|
||||
|
||||
:wq!
|
||||
:x!
|
||||
ZZ (yes, double Z without the colon at the beginning)
|
||||
|
||||
2. To exit discarding changes, use :q!. This command will also allow you to exit the help menu described above, and return to the current file in command mode.
|
||||
|
||||
3. Cut N number of lines: type Ndd while in command mode.
|
||||
|
||||
4. Copy M number of lines: type Myy while in command mode.
|
||||
|
||||
5. Paste lines that were previously cutted or copied: press the P key while in command mode.
|
||||
|
||||
6. To insert the contents of another file into the current one:
|
||||
|
||||
:r filename
|
||||
|
||||
For example, to insert the contents of `/etc/fstab`, do:
|
||||
|
||||
|
||||
|
||||
Insert Content of File in vi Editor
|
||||
|
||||
7. To insert the output of a command into the current document:
|
||||
|
||||
:r! command
|
||||
|
||||
For example, to insert the date and time in the line below the current position of the cursor:
|
||||
|
||||
|
||||
|
||||
Insert Time an Date in vi Editor
|
||||
|
||||
In another article that I wrote for, ([Part 2 of the LFCS series][1]), I explained in greater detail the keyboard shortcuts and functions available in vim. You may want to refer to that tutorial for further examples on how to use this powerful text editor.
|
||||
|
||||
### Analyzing Text with Grep and Regular Expressions ###
|
||||
|
||||
By now you have learned how to create and edit files using nano or vim. Say you become a text editor ninja, so to speak – now what? Among other things, you will also need how to search for regular expressions inside text.
|
||||
|
||||
A regular expression (also known as “regex” or “regexp“) is a way of identifying a text string or pattern so that a program can compare the pattern against arbitrary text strings. Although the use of regular expressions along with grep would deserve an entire article on its own, let us review the basics here:
|
||||
|
||||
**1. The simplest regular expression is an alphanumeric string (i.e., the word “svm”) or two (when two are present, you can use the | (OR) operator):**
|
||||
|
||||
# grep -Ei 'svm|vmx' /proc/cpuinfo
|
||||
|
||||
The presence of either of those two strings indicate that your processor supports virtualization:
|
||||
|
||||

|
||||
|
||||
Regular Expression Example
|
||||
|
||||
**2. A second kind of a regular expression is a range list, enclosed between square brackets.**
|
||||
|
||||
For example, `c[aeiou]t` matches the strings cat, cet, cit, cot, and cut, whereas `[a-z]` and `[0-9]` match any lowercase letter or decimal digit, respectively. If you want to repeat the regular expression X certain number of times, type `{X}` immediately following the regexp.
|
||||
|
||||
For example, let’s extract the UUIDs of storage devices from `/etc/fstab`:
|
||||
|
||||
# grep -Ei '[0-9a-f]{8}-([0-9a-f]{4}-){3}[0-9a-f]{12}' -o /etc/fstab
|
||||
|
||||

|
||||
|
||||
Extract String from a File
|
||||
|
||||
The first expression in brackets `[0-9a-f]` is used to denote lowercase hexadecimal characters, and `{8}` is a quantifier that indicates the number of times that the preceding match should be repeated (the first sequence of characters in an UUID is a 8-character long hexadecimal string).
|
||||
|
||||
The parentheses, the `{4}` quantifier, and the hyphen indicate that the next sequence is a 4-character long hexadecimal string, and the quantifier that follows `({3})` denote that the expression should be repeated 3 times.
|
||||
|
||||
Finally, the last sequence of 12-character long hexadecimal string in the UUID is retrieved with `[0-9a-f]{12}`, and the -o option prints only the matched (non-empty) parts of the matching line in /etc/fstab.
|
||||
|
||||
**3. POSIX character classes.**
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="201"></colgroup>
|
||||
<colgroup width="440"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center" height="25" bgcolor="#999999" style="border: 1px solid #000000;"><b>Character Class</b></td>
|
||||
<td align="center" bgcolor="#999999" style="border: 1px solid #000000;"><b>Matches…</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:alnum:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any alphanumeric [a-zA-Z0-9] character</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:alpha:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any alphabetic [a-zA-Z] character</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:blank:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Spaces or tabs</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:cntrl:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any control characters (ASCII 0 to 32)</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:digit:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any numeric digits [0-9]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:graph:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any visible characters</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:lower:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any lowercase [a-z] character</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:print:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any non-control characters</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:space:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any whitespace</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:punct:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any punctuation marks</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:upper:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any uppercase [A-Z] character</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:xdigit:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any hex digits [0-9a-fA-F]</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [:word:]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> Any letters, numbers, and underscores [a-zA-Z0-9_]</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
For example, we may be interested in finding out what the used UIDs and GIDs (refer to [Part 2][2] of this series to refresh your memory) are for real users that have been added to our system. Thus, we will search for sequences of 4 digits in /etc/passwd:
|
||||
|
||||
# grep -Ei [[:digit:]]{4} /etc/passwd
|
||||
|
||||

|
||||
|
||||
Search For a String in File
|
||||
|
||||
The above example may not be the best case of use of regular expressions in the real world, but it clearly illustrates how to use POSIX character classes to analyze text along with grep.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have provided some tips to make the most of nano and vim, two text editors for the command-line users. Both tools are supported by extensive documentation, which you can consult in their respective official web sites (links given below) and using the suggestions given in [Part 1][3] of this series.
|
||||
|
||||
#### Reference Links ####
|
||||
|
||||
- [http://www.nano-editor.org/][4]
|
||||
- [http://www.vim.org/][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-how-to-use-nano-vi-editors/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/vi-editor-usage/
|
||||
[2]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[3]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[4]:http://www.nano-editor.org/
|
||||
[5]:http://www.vim.org/
|
||||
@ -0,0 +1,216 @@
|
||||
RHCSA Series: Process Management in RHEL 7: Boot, Shutdown, and Everything in Between – Part 5
|
||||
================================================================================
|
||||
We will start this article with an overall and brief revision of what happens since the moment you press the Power button to turn on your RHEL 7 server until you are presented with the login screen in a command line interface.
|
||||
|
||||

|
||||
|
||||
Linux Boot Process
|
||||
|
||||
**Please note that:**
|
||||
|
||||
1. the same basic principles apply, with perhaps minor modifications, to other Linux distributions as well, and
|
||||
2. the following description is not intended to represent an exhaustive explanation of the boot process, but only the fundamentals.
|
||||
|
||||
### Linux Boot Process ###
|
||||
|
||||
1. The POST (Power On Self Test) initializes and performs hardware checks.
|
||||
|
||||
2. When the POST finishes, the system control is passed to the first stage boot loader, which is stored on either the boot sector of one of the hard disks (for older systems using BIOS and MBR), or a dedicated (U)EFI partition.
|
||||
|
||||
3. The first stage boot loader then loads the second stage boot loader, most usually GRUB (GRand Unified Boot Loader), which resides inside /boot, which in turn loads the kernel and the initial RAM–based file system (also known as initramfs, which contains programs and binary files that perform the necessary actions needed to ultimately mount the actual root filesystem).
|
||||
|
||||
4. We are presented with a splash screen that allows us to choose an operating system and kernel to boot:
|
||||
|
||||

|
||||
|
||||
Boot Menu Screen
|
||||
|
||||
5. The kernel sets up the hardware attached to the system and once the root filesystem has been mounted, launches process with PID 1, which in turn will initialize other processes and present us with a login prompt.
|
||||
|
||||
Note: That if we wish to do so at a later time, we can examine the specifics of this process using the [dmesg command][1] and filtering its output using the tools that we have explained in previous articles of this series.
|
||||
|
||||

|
||||
|
||||
Login Screen and Process PID
|
||||
|
||||
In the example above, we used the well-known ps command to display a list of current processes whose parent process (or in other words, the process that started them) is systemd (the system and service manager that most modern Linux distributions have switched to) during system startup:
|
||||
|
||||
# ps -o ppid,pid,uname,comm --ppid=1
|
||||
|
||||
Remember that the -o flag (short for –format) allows you to present the output of ps in a customized format to suit your needs using the keywords specified in the STANDARD FORMAT SPECIFIERS section in man ps.
|
||||
|
||||
Another case in which you will want to define the output of ps instead of going with the default is when you need to find processes that are causing a significant CPU and / or memory load, and sort them accordingly:
|
||||
|
||||
# ps aux --sort=+pcpu # Sort by %CPU (ascending)
|
||||
# ps aux --sort=-pcpu # Sort by %CPU (descending)
|
||||
# ps aux --sort=+pmem # Sort by %MEM (ascending)
|
||||
# ps aux --sort=-pmem # Sort by %MEM (descending)
|
||||
# ps aux --sort=+pcpu,-pmem # Combine sort by %CPU (ascending) and %MEM (descending)
|
||||
|
||||

|
||||
|
||||
Customize ps Command Output
|
||||
|
||||
### An Introduction to SystemD ###
|
||||
|
||||
Few decisions in the Linux world have caused more controversies than the adoption of systemd by major Linux distributions. Systemd’s advocates name as its main advantages the following facts:
|
||||
|
||||
Read Also: [The Story Behind ‘init’ and ‘systemd’][2]
|
||||
|
||||
1. Systemd allows more processing to be done in parallel during system startup (as opposed to older SysVinit, which always tends to be slower because it starts processes one by one, checks if one depends on another, and then waits for daemons to launch so more services can start), and
|
||||
|
||||
2. It works as a dynamic resource management in a running system. Thus, services are started when needed (to avoid consuming system resources if they are not being used) instead of being launched without a valid reason during boot.
|
||||
|
||||
3. Backwards compatibility with SysVinit scripts.
|
||||
|
||||
Systemd is controlled by the systemctl utility. If you come from a SysVinit background, chances are you will be familiar with:
|
||||
|
||||
- the service tool, which -in those older systems- was used to manage SysVinit scripts, and
|
||||
- the chkconfig utility, which served the purpose of updating and querying runlevel information for system services.
|
||||
- shutdown, which you must have used several times to either restart or halt a running system.
|
||||
|
||||
The following table shows the similarities between the use of these legacy tools and systemctl:
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="237"></colgroup>
|
||||
<colgroup width="256"></colgroup>
|
||||
<colgroup width="1945"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="left" height="25" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Legacy tool</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Systemctl equivalent</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name start</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl start name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Start name (where name is a service)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name stop</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl stop name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Stop name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name condrestart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl try-restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name (if it’s already running)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name restart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name reload</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reload name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Reloads the configuration for name</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name status</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl status name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Displays the current status of name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service –status-all</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays the status of all current services</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name on</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl enable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Enable name to run on startup as specified in the unit file (the file to which the symlink points). The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links inside the /etc/systemd/system directory.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name off</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl disable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Disables name to run on startup as specified in the unit file (the file to which the symlink points)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl is-enabled name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Verify whether name (a specific service) is currently enabled</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl –type=service</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays all services and tells whether they are enabled or disabled</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -h now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl poweroff</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Power-off the machine (halt)</span></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -r now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reboot</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Reboot the system</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Systemd also introduced the concepts of units (which can be either a service, a mount point, a device, or a network socket) and targets (which is how systemd manages to start several related process at the same time, and can be considered -though not equal- as the equivalent of runlevels in SysVinit-based systems.
|
||||
|
||||
### Summing Up ###
|
||||
|
||||
Other tasks related with process management include, but may not be limited to, the ability to:
|
||||
|
||||
**1. Adjust the execution priority as far as the use of system resources is concerned of a process:**
|
||||
|
||||
This is accomplished through the renice utility, which alters the scheduling priority of one or more running processes. In simple terms, the scheduling priority is a feature that allows the kernel (present in versions => 2.6) to allocate system resources as per the assigned execution priority (aka niceness, in a range from -20 through 19) of a given process.
|
||||
|
||||
The basic syntax of renice is as follows:
|
||||
|
||||
# renice [-n] priority [-gpu] identifier
|
||||
|
||||
In the generic command above, the first argument is the priority value to be used, whereas the other argument can be interpreted as process IDs (which is the default setting), process group IDs, user IDs, or user names. A normal user (other than root) can only modify the scheduling priority of a process he or she owns, and only increase the niceness level (which means taking up less system resources).
|
||||
|
||||

|
||||
|
||||
Process Scheduling Priority
|
||||
|
||||
**2. Kill (or interrupt the normal execution) of a process as needed:**
|
||||
|
||||
In more precise terms, killing a process entitles sending it a signal to either finish its execution gracefully (SIGTERM=15) or immediately (SIGKILL=9) through the [kill or pkill commands][3].
|
||||
|
||||
The difference between these two tools is that the former is used to terminate a specific process or a process group altogether, while the latter allows you to do the same based on name and other attributes.
|
||||
|
||||
In addition, pkill comes bundled with pgrep, which shows you the PIDs that will be affected should pkill be used. For example, before running:
|
||||
|
||||
# pkill -u gacanepa
|
||||
|
||||
It may be useful to view at a glance which are the PIDs owned by gacanepa:
|
||||
|
||||
# pgrep -l -u gacanepa
|
||||
|
||||
|
||||
|
||||
Find PIDs of User
|
||||
|
||||
By default, both kill and pkill send the SIGTERM signal to the process. As we mentioned above, this signal can be ignored (while the process finishes its execution or for good), so when you seriously need to stop a running process with a valid reason, you will need to specify the SIGKILL signal on the command line:
|
||||
|
||||
# kill -9 identifier # Kill a process or a process group
|
||||
# kill -s SIGNAL identifier # Idem
|
||||
# pkill -s SIGNAL identifier # Kill a process by name or other attributes
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have explained the basics of the boot process in a RHEL 7 system, and analyzed some of the tools that are available to help you with managing processes using common utilities and systemd-specific commands.
|
||||
|
||||
Note that this list is not intended to cover all the bells and whistles of this topic, so feel free to add your own preferred tools and commands to this article using the comment form below. Questions and other comments are also welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dmesg-commands/
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -0,0 +1,269 @@
|
||||
RHCSA Series: Using ‘Parted’ and ‘SSM’ to Configure and Encrypt System Storage – Part 6
|
||||
================================================================================
|
||||
In this article we will discuss how to set up and configure local system storage in Red Hat Enterprise Linux 7 using classic tools and introducing the System Storage Manager (also known as SSM), which greatly simplifies this task.
|
||||
|
||||

|
||||
|
||||
RHCSA: Configure and Encrypt System Storage – Part 6
|
||||
|
||||
Please note that we will present this topic in this article but will continue its description and usage on the next one (Part 7) due to vastness of the subject.
|
||||
|
||||
### Creating and Modifying Partitions in RHEL 7 ###
|
||||
|
||||
In RHEL 7, parted is the default utility to work with partitions, and will allow you to:
|
||||
|
||||
- Display the current partition table
|
||||
- Manipulate (increase or decrease the size of) existing partitions
|
||||
- Create partitions using free space or additional physical storage devices
|
||||
|
||||
It is recommended that before attempting the creation of a new partition or the modification of an existing one, you should ensure that none of the partitions on the device are in use (`umount /dev/partition`), and if you’re using part of the device as swap you need to disable it (`swapoff -v /dev/partition`) during the process.
|
||||
|
||||
The easiest way to do this is to boot RHEL in rescue mode using an installation media such as a RHEL 7 installation DVD or USB (Troubleshooting → Rescue a Red Hat Enterprise Linux system) and Select Skip when you’re prompted to choose an option to mount the existing Linux installation, and you will be presented with a command prompt where you can start typing the same commands as shown as follows during the creation of an ordinary partition in a physical device that is not being used.
|
||||
|
||||

|
||||
|
||||
RHEL 7 Rescue Mode
|
||||
|
||||
To start parted, simply type.
|
||||
|
||||
# parted /dev/sdb
|
||||
|
||||
Where `/dev/sdb` is the device where you will create the new partition; next, type print to display the current drive’s partition table:
|
||||
|
||||
|
||||
|
||||
Creat New Partition
|
||||
|
||||
As you can see, in this example we are using a virtual drive of 5 GB. We will now proceed to create a 4 GB primary partition and then format it with the xfs filesystem, which is the default in RHEL 7.
|
||||
|
||||
You can choose from a variety of file systems. You will need to manually create the partition with mkpart and then format it with mkfs.fstype as usual because mkpart does not support many modern filesystems out-of-the-box.
|
||||
|
||||
In the following example we will set a label for the device and then create a primary partition `(p)` on `/dev/sdb`, which starts at the 0% percentage of the device and ends at 4000 MB (4 GB):
|
||||
|
||||
|
||||
|
||||
Label Partition Name
|
||||
|
||||
Next, we will format the partition as xfs and print the partition table again to verify that changes were applied:
|
||||
|
||||
# mkfs.xfs /dev/sdb1
|
||||
# parted /dev/sdb print
|
||||
|
||||

|
||||
|
||||
Format Partition as XFS Filesystem
|
||||
|
||||
For older filesystems, you could use the resize command in parted to resize a partition. Unfortunately, this only applies to ext2, fat16, fat32, hfs, linux-swap, and reiserfs (if libreiserfs is installed).
|
||||
|
||||
Thus, the only way to resize a partition is by deleting it and creating it again (so make sure you have a good backup of your data!). No wonder the default partitioning scheme in RHEL 7 is based on LVM.
|
||||
|
||||
To remove a partition with parted:
|
||||
|
||||
# parted /dev/sdb print
|
||||
# parted /dev/sdb rm 1
|
||||
|
||||

|
||||
|
||||
Remove or Delete Partition
|
||||
|
||||
### The Logical Volume Manager (LVM) ###
|
||||
|
||||
Once a disk has been partitioned, it can be difficult or risky to change the partition sizes. For that reason, if we plan on resizing the partitions on our system, we should consider the possibility of using LVM instead of the classic partitioning system, where several physical devices can form a volume group that will host a defined number of logical volumes, which can be expanded or reduced without any hassle.
|
||||
|
||||
In simple terms, you may find the following diagram useful to remember the basic architecture of LVM.
|
||||
|
||||

|
||||
|
||||
Basic Architecture of LVM
|
||||
|
||||
#### Creating Physical Volumes, Volume Group and Logical Volumes ####
|
||||
|
||||
Follow these steps in order to set up LVM using classic volume management tools. Since you can expand this topic reading the [LVM series on this site][1], I will only outline the basic steps to set up LVM, and then compare them to implementing the same functionality with SSM.
|
||||
|
||||
**Note**: That we will use the whole disks `/dev/sdb` and `/dev/sdc` as PVs (Physical Volumes) but it’s entirely up to you if you want to do the same.
|
||||
|
||||
**1. Create partitions `/dev/sdb1` and `/dev/sdc1` using 100% of the available disk space in /dev/sdb and /dev/sdc:**
|
||||
|
||||
# parted /dev/sdb print
|
||||
# parted /dev/sdc print
|
||||
|
||||
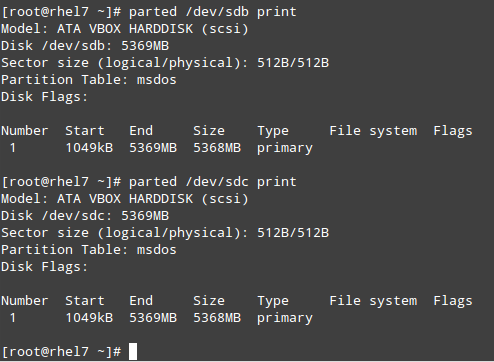
|
||||
|
||||
Create New Partitions
|
||||
|
||||
**2. Create 2 physical volumes on top of /dev/sdb1 and /dev/sdc1, respectively.**
|
||||
|
||||
# pvcreate /dev/sdb1
|
||||
# pvcreate /dev/sdc1
|
||||
|
||||

|
||||
|
||||
Create Two Physical Volumes
|
||||
|
||||
Remember that you can use pvdisplay /dev/sd{b,c}1 to show information about the newly created PVs.
|
||||
|
||||
**3. Create a VG on top of the PV that you created in the previous step:**
|
||||
|
||||
# vgcreate tecmint_vg /dev/sd{b,c}1
|
||||
|
||||

|
||||
|
||||
Create Volume Group
|
||||
|
||||
Remember that you can use vgdisplay tecmint_vg to show information about the newly created VG.
|
||||
|
||||
**4. Create three logical volumes on top of VG tecmint_vg, as follows:**
|
||||
|
||||
# lvcreate -L 3G -n vol01_docs tecmint_vg [vol01_docs → 3 GB]
|
||||
# lvcreate -L 1G -n vol02_logs tecmint_vg [vol02_logs → 1 GB]
|
||||
# lvcreate -l 100%FREE -n vol03_homes tecmint_vg [vol03_homes → 6 GB]
|
||||
|
||||

|
||||
|
||||
Create Logical Volumes
|
||||
|
||||
Remember that you can use lvdisplay tecmint_vg to show information about the newly created LVs on top of VG tecmint_vg.
|
||||
|
||||
**5. Format each of the logical volumes with xfs (do NOT use xfs if you’re planning on shrinking volumes later!):**
|
||||
|
||||
# mkfs.xfs /dev/tecmint_vg/vol01_docs
|
||||
# mkfs.xfs /dev/tecmint_vg/vol02_logs
|
||||
# mkfs.xfs /dev/tecmint_vg/vol03_homes
|
||||
|
||||
**6. Finally, mount them:**
|
||||
|
||||
# mount /dev/tecmint_vg/vol01_docs /mnt/docs
|
||||
# mount /dev/tecmint_vg/vol02_logs /mnt/logs
|
||||
# mount /dev/tecmint_vg/vol03_homes /mnt/homes
|
||||
|
||||
#### Removing Logical Volumes, Volume Group and Physical Volumes ####
|
||||
|
||||
**7. Now we will reverse the LVM implementation and remove the LVs, the VG, and the PVs:**
|
||||
|
||||
# lvremove /dev/tecmint_vg/vol01_docs
|
||||
# lvremove /dev/tecmint_vg/vol02_logs
|
||||
# lvremove /dev/tecmint_vg/vol03_homes
|
||||
# vgremove /dev/tecmint_vg
|
||||
# pvremove /dev/sd{b,c}1
|
||||
|
||||
**8. Now let’s install SSM and we will see how to perform the above in ONLY 1 STEP!**
|
||||
|
||||
# yum update && yum install system-storage-manager
|
||||
|
||||
We will use the same names and sizes as before:
|
||||
|
||||
# ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 /mnt/docs /dev/sd{b,c}1
|
||||
# ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 /mnt/logs /dev/sd{b,c}1
|
||||
# ssm create -n vol03_homes -p tecmint_vg --fstype ext4 /mnt/homes /dev/sd{b,c}1
|
||||
|
||||
Yes! SSM will let you:
|
||||
|
||||
- initialize block devices as physical volumes
|
||||
- create a volume group
|
||||
- create logical volumes
|
||||
- format LVs, and
|
||||
- mount them using only one command
|
||||
|
||||
**9. We can now display the information about PVs, VGs, or LVs, respectively, as follows:**
|
||||
|
||||
# ssm list dev
|
||||
# ssm list pool
|
||||
# ssm list vol
|
||||
|
||||

|
||||
|
||||
Check Information of PVs, VGs, or LVs
|
||||
|
||||
**10. As we already know, one of the distinguishing features of LVM is the possibility to resize (expand or decrease) logical volumes without downtime.**
|
||||
|
||||
Say we are running out of space in vol02_logs but have plenty of space in vol03_homes. We will resize vol03_homes to 4 GB and expand vol02_logs to use the remaining space:
|
||||
|
||||
# ssm resize -s 4G /dev/tecmint_vg/vol03_homes
|
||||
|
||||
Run ssm list pool again and take note of the free space in tecmint_vg:
|
||||
|
||||
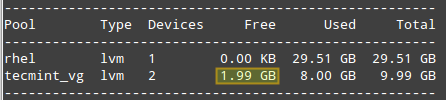
|
||||
|
||||
Check Volume Size
|
||||
|
||||
Then do:
|
||||
|
||||
# ssm resize -s+1.99 /dev/tecmint_vg/vol02_logs
|
||||
|
||||
**Note**: that the plus sign after the -s flag indicates that the specified value should be added to the present value.
|
||||
|
||||
**11. Removing logical volumes and volume groups is much easier with ssm as well. A simple,**
|
||||
|
||||
# ssm remove tecmint_vg
|
||||
|
||||
will return a prompt asking you to confirm the deletion of the VG and the LVs it contains:
|
||||
|
||||

|
||||
|
||||
Remove Logical Volume and Volume Group
|
||||
|
||||
### Managing Encrypted Volumes ###
|
||||
|
||||
SSM also provides system administrators with the capability of managing encryption for new or existing volumes. You will need the cryptsetup package installed first:
|
||||
|
||||
# yum update && yum install cryptsetup
|
||||
|
||||
Then issue the following command to create an encrypted volume. You will be prompted to enter a passphrase to maximize security:
|
||||
|
||||
# ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/docs /dev/sd{b,c}1
|
||||
# ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/logs /dev/sd{b,c}1
|
||||
# ssm create -n vol03_homes -p tecmint_vg --fstype ext4 --encrypt luks /mnt/homes /dev/sd{b,c}1
|
||||
|
||||
Our next task consists in adding the corresponding entries in /etc/fstab in order for those logical volumes to be available on boot. Rather than using the device identifier (/dev/something).
|
||||
|
||||
We will use each LV’s UUID (so that our devices will still be uniquely identified should we add other logical volumes or devices), which we can find out with the blkid utility:
|
||||
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol01_docs
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol02_logs
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol03_homes
|
||||
|
||||
In our case:
|
||||
|
||||

|
||||
|
||||
Find Logical Volume UUID
|
||||
|
||||
Next, create the /etc/crypttab file with the following contents (change the UUIDs for the ones that apply to your setup):
|
||||
|
||||
docs UUID=ba77d113-f849-4ddf-8048-13860399fca8 none
|
||||
logs UUID=58f89c5a-f694-4443-83d6-2e83878e30e4 none
|
||||
homes UUID=92245af6-3f38-4e07-8dd8-787f4690d7ac none
|
||||
|
||||
And insert the following entries in /etc/fstab. Note that device_name (/dev/mapper/device_name) is the mapper identifier that appears in the first column of /etc/crypttab.
|
||||
|
||||
# Logical volume vol01_docs:
|
||||
/dev/mapper/docs /mnt/docs ext4 defaults 0 2
|
||||
# Logical volume vol02_logs
|
||||
/dev/mapper/logs /mnt/logs ext4 defaults 0 2
|
||||
# Logical volume vol03_homes
|
||||
/dev/mapper/homes /mnt/homes ext4 defaults 0 2
|
||||
|
||||
Now reboot (systemctl reboot) and you will be prompted to enter the passphrase for each LV. Afterwards you can confirm that the mount operation was successful by checking the corresponding mount points:
|
||||
|
||||

|
||||
|
||||
Verify Logical Volume Mount Points
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial we have started to explore how to set up and configure system storage using classic volume management tools and SSM, which also integrates filesystem and encryption capabilities in one package. This makes SSM an invaluable tool for any sysadmin.
|
||||
|
||||
Let us know if you have any questions or comments – feel free to use the form below to get in touch with us!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-partitions-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
@ -0,0 +1,212 @@
|
||||
RHCSA Series: Using ACLs (Access Control Lists) and Mounting Samba / NFS Shares – Part 7
|
||||
================================================================================
|
||||
In the last article ([RHCSA series Part 6][1]) we started explaining how to set up and configure local system storage using parted and ssm.
|
||||
|
||||

|
||||
|
||||
RHCSA Series:: Configure ACL’s and Mounting NFS / Samba Shares – Part 7
|
||||
|
||||
We also discussed how to create and mount encrypted volumes with a password during system boot. In addition, we warned you to avoid performing critical storage management operations on mounted filesystems. With that in mind we will now review the most used file system formats in Red Hat Enterprise Linux 7 and then proceed to cover the topics of mounting, using, and unmounting both manually and automatically network filesystems (CIFS and NFS), along with the implementation of access control lists for your system.
|
||||
|
||||
#### Prerequisites ####
|
||||
|
||||
Before proceeding further, please make sure you have a Samba server and a NFS server available (note that NFSv2 is no longer supported in RHEL 7).
|
||||
|
||||
During this guide we will use a machine with IP 192.168.0.10 with both services running in it as server, and a RHEL 7 box as client with IP address 192.168.0.18. Later in the article we will tell you which packages you need to install on the client.
|
||||
|
||||
### File System Formats in RHEL 7 ###
|
||||
|
||||
Beginning with RHEL 7, XFS has been introduced as the default file system for all architectures due to its high performance and scalability. It currently supports a maximum filesystem size of 500 TB as per the latest tests performed by Red Hat and its partners for mainstream hardware.
|
||||
|
||||
Also, XFS enables user_xattr (extended user attributes) and acl (POSIX access control lists) as default mount options, unlike ext3 or ext4 (ext2 is considered deprecated as of RHEL 7), which means that you don’t need to specify those options explicitly either on the command line or in /etc/fstab when mounting a XFS filesystem (if you want to disable such options in this last case, you have to explicitly use no_acl and no_user_xattr).
|
||||
|
||||
Keep in mind that the extended user attributes can be assigned to files and directories for storing arbitrary additional information such as the mime type, character set or encoding of a file, whereas the access permissions for user attributes are defined by the regular file permission bits.
|
||||
|
||||
#### Access Control Lists ####
|
||||
|
||||
As every system administrator, either beginner or expert, is well acquainted with regular access permissions on files and directories, which specify certain privileges (read, write, and execute) for the owner, the group, and “the world” (all others). However, feel free to refer to [Part 3 of the RHCSA series][2] if you need to refresh your memory a little bit.
|
||||
|
||||
However, since the standard ugo/rwx set does not allow to configure different permissions for different users, ACLs were introduced in order to define more detailed access rights for files and directories than those specified by regular permissions.
|
||||
|
||||
In fact, ACL-defined permissions are a superset of the permissions specified by the file permission bits. Let’s see how all of this translates is applied in the real world.
|
||||
|
||||
1. There are two types of ACLs: access ACLs, which can be applied to either a specific file or a directory), and default ACLs, which can only be applied to a directory. If files contained therein do not have a ACL set, they inherit the default ACL of their parent directory.
|
||||
|
||||
2. To begin, ACLs can be configured per user, per group, or per an user not in the owning group of a file.
|
||||
|
||||
3. ACLs are set (and removed) using setfacl, with either the -m or -x options, respectively.
|
||||
|
||||
For example, let us create a group named tecmint and add users johndoe and davenull to it:
|
||||
|
||||
# groupadd tecmint
|
||||
# useradd johndoe
|
||||
# useradd davenull
|
||||
# usermod -a -G tecmint johndoe
|
||||
# usermod -a -G tecmint davenull
|
||||
|
||||
And let’s verify that both users belong to supplementary group tecmint:
|
||||
|
||||
# id johndoe
|
||||
# id davenull
|
||||
|
||||

|
||||
|
||||
Verify Users
|
||||
|
||||
Let’s now create a directory called playground within /mnt, and a file named testfile.txt inside. We will set the group owner to tecmint and change its default ugo/rwx permissions to 770 (read, write, and execute permissions granted to both the owner and the group owner of the file):
|
||||
|
||||
# mkdir /mnt/playground
|
||||
# touch /mnt/playground/testfile.txt
|
||||
# chmod 770 /mnt/playground/testfile.txt
|
||||
|
||||
Then switch user to johndoe and davenull, in that order, and write to the file:
|
||||
|
||||
echo "My name is John Doe" > /mnt/playground/testfile.txt
|
||||
echo "My name is Dave Null" >> /mnt/playground/testfile.txt
|
||||
|
||||
So far so good. Now let’s have user gacanepa write to the file – and the write operation will, which was to be expected.
|
||||
|
||||
But what if we actually need user gacanepa (who is not a member of group tecmint) to have write permissions on /mnt/playground/testfile.txt? The first thing that may come to your mind is adding that user account to group tecmint. But that will give him write permissions on ALL files were the write bit is set for the group, and we don’t want that. We only want him to be able to write to /mnt/playground/testfile.txt.
|
||||
|
||||
# touch /mnt/playground/testfile.txt
|
||||
# chown :tecmint /mnt/playground/testfile.txt
|
||||
# chmod 777 /mnt/playground/testfile.txt
|
||||
# su johndoe
|
||||
$ echo "My name is John Doe" > /mnt/playground/testfile.txt
|
||||
$ su davenull
|
||||
$ echo "My name is Dave Null" >> /mnt/playground/testfile.txt
|
||||
$ su gacanepa
|
||||
$ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt
|
||||
|
||||

|
||||
|
||||
Manage User Permissions
|
||||
|
||||
Let’s give user gacanepa read and write access to /mnt/playground/testfile.txt.
|
||||
|
||||
Run as root,
|
||||
|
||||
# setfacl -R -m u:gacanepa:rwx /mnt/playground
|
||||
|
||||
and you’ll have successfully added an ACL that allows gacanepa to write to the test file. Then switch to user gacanepa and try to write to the file again:
|
||||
|
||||
$ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt
|
||||
|
||||
To view the ACLs for a specific file or directory, use getfacl:
|
||||
|
||||
# getfacl /mnt/playground/testfile.txt
|
||||
|
||||

|
||||
|
||||
Check ACLs of Files
|
||||
|
||||
To set a default ACL to a directory (which its contents will inherit unless overwritten otherwise), add d: before the rule and specify a directory instead of a file name:
|
||||
|
||||
# setfacl -m d:o:r /mnt/playground
|
||||
|
||||
The ACL above will allow users not in the owner group to have read access to the future contents of the /mnt/playground directory. Note the difference in the output of getfacl /mnt/playground before and after the change:
|
||||
|
||||

|
||||
|
||||
Set Default ACL in Linux
|
||||
|
||||
[Chapter 20 in the official RHEL 7 Storage Administration Guide][3] provides more ACL examples, and I highly recommend you take a look at it and have it handy as reference.
|
||||
|
||||
#### Mounting NFS Network Shares ####
|
||||
|
||||
To show the list of NFS shares available in your server, you can use the showmount command with the -e option, followed by the machine name or its IP address. This tool is included in the nfs-utils package:
|
||||
|
||||
# yum update && yum install nfs-utils
|
||||
|
||||
Then do:
|
||||
|
||||
# showmount -e 192.168.0.10
|
||||
|
||||
and you will get a list of the available NFS shares on 192.168.0.10:
|
||||
|
||||
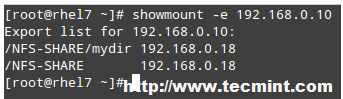
|
||||
|
||||
Check Available NFS Shares
|
||||
|
||||
To mount NFS network shares on the local client using the command line on demand, use the following syntax:
|
||||
|
||||
# mount -t nfs -o [options] remote_host:/remote/directory /local/directory
|
||||
|
||||
which, in our case, translates to:
|
||||
|
||||
# mount -t nfs 192.168.0.10:/NFS-SHARE /mnt/nfs
|
||||
|
||||
If you get the following error message: “Job for rpc-statd.service failed. See “systemctl status rpc-statd.service” and “journalctl -xn” for details.”, make sure the rpcbind service is enabled and started in your system first:
|
||||
|
||||
# systemctl enable rpcbind.socket
|
||||
# systemctl restart rpcbind.service
|
||||
|
||||
and then reboot. That should do the trick and you will be able to mount your NFS share as explained earlier. If you need to mount the NFS share automatically on system boot, add a valid entry to the /etc/fstab file:
|
||||
|
||||
remote_host:/remote/directory /local/directory nfs options 0 0
|
||||
|
||||
The variables remote_host, /remote/directory, /local/directory, and options (which is optional) are the same ones used when manually mounting an NFS share from the command line. As per our previous example:
|
||||
|
||||
192.168.0.10:/NFS-SHARE /mnt/nfs nfs defaults 0 0
|
||||
|
||||
#### Mounting CIFS (Samba) Network Shares ####
|
||||
|
||||
Samba represents the tool of choice to make a network share available in a network with *nix and Windows machines. To show the Samba shares that are available, use the smbclient command with the -L flag, followed by the machine name or its IP address. This tool is included in the samba-client package:
|
||||
|
||||
You will be prompted for root’s password in the remote host:
|
||||
|
||||
# smbclient -L 192.168.0.10
|
||||
|
||||

|
||||
|
||||
Check Samba Shares
|
||||
|
||||
To mount Samba network shares on the local client you will need to install first the cifs-utils package:
|
||||
|
||||
# yum update && yum install cifs-utils
|
||||
|
||||
Then use the following syntax on the command line:
|
||||
|
||||
# mount -t cifs -o credentials=/path/to/credentials/file //remote_host/samba_share /local/directory
|
||||
|
||||
which, in our case, translates to:
|
||||
|
||||
# mount -t cifs -o credentials=~/.smbcredentials //192.168.0.10/gacanepa /mnt/samba
|
||||
|
||||
where smbcredentials:
|
||||
|
||||
username=gacanepa
|
||||
password=XXXXXX
|
||||
|
||||
is a hidden file inside root’s home (/root/) with permissions set to 600, so that no one else but the owner of the file can read or write to it.
|
||||
|
||||
Please note that the samba_share is the name of the Samba share as returned by smbclient -L remote_host as shown above.
|
||||
|
||||
Now, if you need the Samba share to be available automatically on system boot, add a valid entry to the /etc/fstab file as follows:
|
||||
|
||||
//remote_host:/samba_share /local/directory cifs options 0 0
|
||||
|
||||
The variables remote_host, /samba_share, /local/directory, and options (which is optional) are the same ones used when manually mounting a Samba share from the command line. Following the definitions given in our previous example:
|
||||
|
||||
//192.168.0.10/gacanepa /mnt/samba cifs credentials=/root/smbcredentials,defaults 0 0
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have explained how to set up ACLs in Linux, and discussed how to mount CIFS and NFS network shares in a RHEL 7 client.
|
||||
|
||||
I recommend you to practice these concepts and even mix them (go ahead and try to set ACLs in mounted network shares) until you feel comfortable. If you have questions or comments feel free to use the form below to contact us anytime. Also, feel free to share this article through your social networks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-partitions-in-linux/
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
[3]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Storage_Administration_Guide/ch-acls.html
|
||||
@ -0,0 +1,215 @@
|
||||
RHCSA Series: Securing SSH, Setting Hostname and Enabling Network Services – Part 8
|
||||
================================================================================
|
||||
As a system administrator you will often have to log on to remote systems to perform a variety of administration tasks using a terminal emulator. You will rarely sit in front of a real (physical) terminal, so you need to set up a way to log on remotely to the machines that you will be asked to manage.
|
||||
|
||||
In fact, that may be the last thing that you will have to do in front of a physical terminal. For security reasons, using Telnet for this purpose is not a good idea, as all traffic goes through the wire in unencrypted, plain text.
|
||||
|
||||
In addition, in this article we will also review how to configure network services to start automatically at boot and learn how to set up network and hostname resolution statically or dynamically.
|
||||
|
||||

|
||||
|
||||
RHCSA: Secure SSH and Enable Network Services – Part 8
|
||||
|
||||
### Installing and Securing SSH Communication ###
|
||||
|
||||
For you to be able to log on remotely to a RHEL 7 box using SSH, you will have to install the openssh, openssh-clients and openssh-servers packages. The following command not only will install the remote login program, but also the secure file transfer tool, as well as the remote file copy utility:
|
||||
|
||||
# yum update && yum install openssh openssh-clients openssh-servers
|
||||
|
||||
Note that it’s a good idea to install the server counterparts as you may want to use the same machine as both client and server at some point or another.
|
||||
|
||||
After installation, there is a couple of basic things that you need to take into account if you want to secure remote access to your SSH server. The following settings should be present in the `/etc/ssh/sshd_config` file.
|
||||
|
||||
1. Change the port where the sshd daemon will listen on from 22 (the default value) to a high port (2000 or greater), but first make sure the chosen port is not being used.
|
||||
|
||||
For example, let’s suppose you choose port 2500. Use [netstat][1] in order to check whether the chosen port is being used or not:
|
||||
|
||||
# netstat -npltu | grep 2500
|
||||
|
||||
If netstat does not return anything, you can safely use port 2500 for sshd, and you should change the Port setting in the configuration file as follows:
|
||||
|
||||
Port 2500
|
||||
|
||||
2. Only allow protocol 2:
|
||||
|
||||
Protocol 2
|
||||
|
||||
3. Configure the authentication timeout to 2 minutes, do not allow root logins, and restrict to a minimum the list of users which are allowed to login via ssh:
|
||||
|
||||
LoginGraceTime 2m
|
||||
PermitRootLogin no
|
||||
AllowUsers gacanepa
|
||||
|
||||
4. If possible, use key-based instead of password authentication:
|
||||
|
||||
PasswordAuthentication no
|
||||
RSAAuthentication yes
|
||||
PubkeyAuthentication yes
|
||||
|
||||
This assumes that you have already created a key pair with your user name on your client machine and copied it to your server as explained here.
|
||||
|
||||
- [Enable SSH Passwordless Login][2]
|
||||
|
||||
### Configuring Networking and Name Resolution ###
|
||||
|
||||
1. Every system administrator should be well acquainted with the following system-wide configuration files:
|
||||
|
||||
- /etc/hosts is used to resolve names <---> IPs in small networks.
|
||||
|
||||
Every line in the `/etc/hosts` file has the following structure:
|
||||
|
||||
IP address - Hostname - FQDN
|
||||
|
||||
For example,
|
||||
|
||||
192.168.0.10 laptop laptop.gabrielcanepa.com.ar
|
||||
|
||||
2. `/etc/resolv.conf` specifies the IP addresses of DNS servers and the search domain, which is used for completing a given query name to a fully qualified domain name when no domain suffix is supplied.
|
||||
|
||||
Under normal circumstances, you don’t need to edit this file as it is managed by the system. However, should you want to change DNS servers, be advised that you need to stick to the following structure in each line:
|
||||
|
||||
nameserver - IP address
|
||||
|
||||
For example,
|
||||
|
||||
nameserver 8.8.8.8
|
||||
|
||||
3. 3. `/etc/host.conf` specifies the methods and the order by which hostnames are resolved within a network. In other words, tells the name resolver which services to use, and in what order.
|
||||
|
||||
Although this file has several options, the most common and basic setup includes a line as follows:
|
||||
|
||||
order bind,hosts
|
||||
|
||||
Which indicates that the resolver should first look in the nameservers specified in `resolv.conf` and then to the `/etc/hosts` file for name resolution.
|
||||
|
||||
4. `/etc/sysconfig/network` contains routing and global host information for all network interfaces. The following values may be used:
|
||||
|
||||
NETWORKING=yes|no
|
||||
HOSTNAME=value
|
||||
|
||||
Where value should be the Fully Qualified Domain Name (FQDN).
|
||||
|
||||
GATEWAY=XXX.XXX.XXX.XXX
|
||||
|
||||
Where XXX.XXX.XXX.XXX is the IP address of the network’s gateway.
|
||||
|
||||
GATEWAYDEV=value
|
||||
|
||||
In a machine with multiple NICs, value is the gateway device, such as enp0s3.
|
||||
|
||||
5. Files inside `/etc/sysconfig/network-scripts` (network adapters configuration files).
|
||||
|
||||
Inside the directory mentioned previously, you will find several plain text files named.
|
||||
|
||||
ifcfg-name
|
||||
|
||||
Where name is the name of the NIC as returned by ip link show:
|
||||
|
||||

|
||||
|
||||
Check Network Link Status
|
||||
|
||||
For example:
|
||||
|
||||
|
||||
|
||||
Network Files
|
||||
|
||||
Other than for the loopback interface, you can expect a similar configuration for your NICs. Note that some variables, if set, will override those present in `/etc/sysconfig/network` for this particular interface. Each line is commented for clarification in this article but in the actual file you should avoid comments:
|
||||
|
||||
HWADDR=08:00:27:4E:59:37 # The MAC address of the NIC
|
||||
TYPE=Ethernet # Type of connection
|
||||
BOOTPROTO=static # This indicates that this NIC has been assigned a static IP. If this variable was set to dhcp, the NIC will be assigned an IP address by a DHCP server and thus the next two lines should not be present in that case.
|
||||
IPADDR=192.168.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NM_CONTROLLED=no # Should be added to the Ethernet interface to prevent NetworkManager from changing the file.
|
||||
NAME=enp0s3
|
||||
UUID=14033805-98ef-4049-bc7b-d4bea76ed2eb
|
||||
ONBOOT=yes # The operating system should bring up this NIC during boot
|
||||
|
||||
### Setting Hostnames ###
|
||||
|
||||
In Red Hat Enterprise Linux 7, the hostnamectl command is used to both query and set the system’s hostname.
|
||||
|
||||
To display the current hostname, type:
|
||||
|
||||
# hostnamectl status
|
||||
|
||||
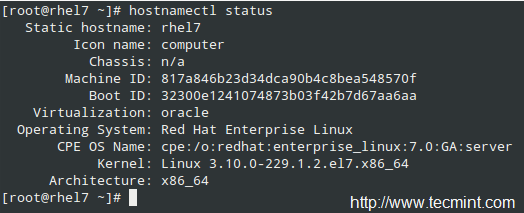
|
||||
|
||||
Check System Hostname
|
||||
|
||||
To change the hostname, use
|
||||
|
||||
# hostnamectl set-hostname [new hostname]
|
||||
|
||||
For example,
|
||||
|
||||
# hostnamectl set-hostname cinderella
|
||||
|
||||
For the changes to take effect you will need to restart the hostnamed daemon (that way you will not have to log off and on again in order to apply the change):
|
||||
|
||||
# systemctl restart systemd-hostnamed
|
||||
|
||||

|
||||
|
||||
Set System Hostname
|
||||
|
||||
In addition, RHEL 7 also includes the nmcli utility that can be used for the same purpose. To display the hostname, run:
|
||||
|
||||
# nmcli general hostname
|
||||
|
||||
and to change it:
|
||||
|
||||
# nmcli general hostname [new hostname]
|
||||
|
||||
For example,
|
||||
|
||||
# nmcli general hostname rhel7
|
||||
|
||||

|
||||
|
||||
Set Hostname Using nmcli Command
|
||||
|
||||
### Starting Network Services on Boot ###
|
||||
|
||||
To wrap up, let us see how we can ensure that network services are started automatically on boot. In simple terms, this is done by creating symlinks to certain files specified in the [Install] section of the service configuration files.
|
||||
|
||||
In the case of firewalld (/usr/lib/systemd/system/firewalld.service):
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
Alias=dbus-org.fedoraproject.FirewallD1.service
|
||||
|
||||
To enable the service:
|
||||
|
||||
# systemctl enable firewalld
|
||||
|
||||
On the other hand, disabling firewalld entitles removing the symlinks:
|
||||
|
||||
# systemctl disable firewalld
|
||||
|
||||

|
||||
|
||||
Enable Service at System Boot
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have summarized how to install and secure connections via SSH to a RHEL server, how to change its name, and finally how to ensure that network services are started on boot. If you notice that a certain service has failed to start properly, you can use systemctl status -l [service] and journalctl -xn to troubleshoot it.
|
||||
|
||||
Feel free to let us know what you think about this article using the comment form below. Questions are also welcome. We look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-series-secure-ssh-set-hostname-enable-network-services-in-rhel-7/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/20-netstat-commands-for-linux-network-management/
|
||||
[2]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
@ -0,0 +1,176 @@
|
||||
RHCSA Series: Installing, Configuring and Securing a Web and FTP Server – Part 9
|
||||
================================================================================
|
||||
A web server (also known as a HTTP server) is a service that handles content (most commonly web pages, but other types of documents as well) over to a client in a network.
|
||||
|
||||
A FTP server is one of the oldest and most commonly used resources (even to this day) to make files available to clients on a network in cases where no authentication is necessary since FTP uses username and password without encryption.
|
||||
|
||||
The web server available in RHEL 7 is version 2.4 of the Apache HTTP Server. As for the FTP server, we will use the Very Secure Ftp Daemon (aka vsftpd) to establish connections secured by TLS.
|
||||
|
||||

|
||||
|
||||
RHCSA: Installing, Configuring and Securing Apache and FTP – Part 9
|
||||
|
||||
In this article we will explain how to install, configure, and secure a web server and a FTP server in RHEL 7.
|
||||
|
||||
### Installing Apache and FTP Server ###
|
||||
|
||||
In this guide we will use a RHEL 7 server with a static IP address of 192.168.0.18/24. To install Apache and VSFTPD, run the following command:
|
||||
|
||||
# yum update && yum install httpd vsftpd
|
||||
|
||||
When the installation completes, both services will be disabled initially, so we need to start them manually for the time being and enable them to start automatically beginning with the next boot:
|
||||
|
||||
# systemctl start httpd
|
||||
# systemctl enable httpd
|
||||
# systemctl start vsftpd
|
||||
# systemctl enable vsftpd
|
||||
|
||||
In addition, we have to open ports 80 and 21, where the web and ftp daemons are listening, respectively, in order to allow access to those services from the outside:
|
||||
|
||||
# firewall-cmd --zone=public --add-port=80/tcp --permanent
|
||||
# firewall-cmd --zone=public --add-service=ftp --permanent
|
||||
# firewall-cmd --reload
|
||||
|
||||
To confirm that the web server is working properly, fire up your browser and enter the IP of the server. You should see the test page:
|
||||
|
||||

|
||||
|
||||
Confirm Apache Web Server
|
||||
|
||||
As for the ftp server, we will have to configure it further, which we will do in a minute, before confirming that it’s working as expected.
|
||||
|
||||
### Configuring and Securing Apache Web Server ###
|
||||
|
||||
The main configuration file for Apache is located in `/etc/httpd/conf/httpd.conf`, but it may rely on other files present inside `/etc/httpd/conf.d`.
|
||||
|
||||
Although the default configuration should be sufficient for most cases, it’s a good idea to become familiar with all the available options as described in the [official documentation][1].
|
||||
|
||||
As always, make a backup copy of the main configuration file before editing it:
|
||||
|
||||
# cp /etc/httpd/conf/httpd.conf /etc/httpd/conf/httpd.conf.$(date +%Y%m%d)
|
||||
|
||||
Then open it with your preferred text editor and look for the following variables:
|
||||
|
||||
- ServerRoot: the directory where the server’s configuration, error, and log files are kept.
|
||||
- Listen: instructs Apache to listen on specific IP address and / or ports.
|
||||
- Include: allows the inclusion of other configuration files, which must exist. Otherwise, the server will fail, as opposed to the IncludeOptional directive, which is silently ignored if the specified configuration files do not exist.
|
||||
- User and Group: the name of the user/group to run the httpd service as.
|
||||
- DocumentRoot: The directory out of which Apache will serve your documents. By default, all requests are taken from this directory, but symbolic links and aliases may be used to point to other locations.
|
||||
- ServerName: this directive sets the hostname (or IP address) and port that the server uses to identify itself.
|
||||
|
||||
The first security measure will consist of creating a dedicated user and group (i.e. tecmint/tecmint) to run the web server as and changing the default port to a higher one (9000 in this case):
|
||||
|
||||
ServerRoot "/etc/httpd"
|
||||
Listen 192.168.0.18:9000
|
||||
User tecmint
|
||||
Group tecmint
|
||||
DocumentRoot "/var/www/html"
|
||||
ServerName 192.168.0.18:9000
|
||||
|
||||
You can test the configuration file with.
|
||||
|
||||
# apachectl configtest
|
||||
|
||||
and if everything is OK, then restart the web server.
|
||||
|
||||
# systemctl restart httpd
|
||||
|
||||
and don’t forget to enable the new port (and disable the old one) in the firewall:
|
||||
|
||||
# firewall-cmd --zone=public --remove-port=80/tcp --permanent
|
||||
# firewall-cmd --zone=public --add-port=9000/tcp --permanent
|
||||
# firewall-cmd --reload
|
||||
|
||||
Note that, due to SELinux policies, you can only use the ports returned by
|
||||
|
||||
# semanage port -l | grep -w '^http_port_t'
|
||||
|
||||
for the web server.
|
||||
|
||||
If you want to use another port (i.e. TCP port 8100), you will have to add it to SELinux port context for the httpd service:
|
||||
|
||||
# semanage port -a -t http_port_t -p tcp 8100
|
||||
|
||||

|
||||
|
||||
Add Apache Port to SELinux Policies
|
||||
|
||||
To further secure your Apache installation, follow these steps:
|
||||
|
||||
1. The user Apache is running as should not have access to a shell:
|
||||
|
||||
# usermod -s /sbin/nologin tecmint
|
||||
|
||||
2. Disable directory listing in order to prevent the browser from displaying the contents of a directory if there is no index.html present in that directory.
|
||||
|
||||
Edit `/etc/httpd/conf/httpd.conf` (and the configuration files for virtual hosts, if any) and make sure that the Options directive, both at the top and at Directory block levels, is set to None:
|
||||
|
||||
Options None
|
||||
|
||||
3. Hide information about the web server and the operating system in HTTP responses. Edit /etc/httpd/conf/httpd.conf as follows:
|
||||
|
||||
ServerTokens Prod
|
||||
ServerSignature Off
|
||||
|
||||
Now you are ready to start serving content from your /var/www/html directory.
|
||||
|
||||
### Configuring and Securing FTP Server ###
|
||||
|
||||
As in the case of Apache, the main configuration file for Vsftpd `(/etc/vsftpd/vsftpd.conf)` is well commented and while the default configuration should suffice for most applications, you should become acquainted with the documentation and the man page `(man vsftpd.conf)` in order to operate the ftp server more efficiently (I can’t emphasize that enough!).
|
||||
|
||||
In our case, these are the directives used:
|
||||
|
||||
anonymous_enable=NO
|
||||
local_enable=YES
|
||||
write_enable=YES
|
||||
local_umask=022
|
||||
dirmessage_enable=YES
|
||||
xferlog_enable=YES
|
||||
connect_from_port_20=YES
|
||||
xferlog_std_format=YES
|
||||
chroot_local_user=YES
|
||||
allow_writeable_chroot=YES
|
||||
listen=NO
|
||||
listen_ipv6=YES
|
||||
pam_service_name=vsftpd
|
||||
userlist_enable=YES
|
||||
tcp_wrappers=YES
|
||||
|
||||
By using `chroot_local_user=YES`, local users will be (by default) placed in a chroot’ed jail in their home directory right after login. This means that local users will not be able to access any files outside their corresponding home directories.
|
||||
|
||||
Finally, to allow ftp to read files in the user’s home directory, set the following SELinux boolean:
|
||||
|
||||
# setsebool -P ftp_home_dir on
|
||||
|
||||
You can now connect to the ftp server using a client such as Filezilla:
|
||||
|
||||

|
||||
|
||||
Check FTP Connection
|
||||
|
||||
Note that the `/var/log/xferlo`g log records downloads and uploads, which concur with the above directory listing:
|
||||
|
||||

|
||||
|
||||
Monitor FTP Download and Upload
|
||||
|
||||
Read Also: [Limit FTP Network Bandwidth Used by Applications in a Linux System with Trickle][2]
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this tutorial we have explained how to set up a web and a ftp server. Due to the vastness of the subject, it is not possible to cover all the aspects of these topics (i.e. virtual web hosts). Thus, I recommend you also check other excellent articles in this website about [Apache][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-series-install-and-secure-apache-web-server-and-ftp-in-rhel/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://httpd.apache.org/docs/2.4/
|
||||
[2]:http://www.tecmint.com/manage-and-limit-downloadupload-bandwidth-with-trickle-in-linux/
|
||||
[3]:http://www.google.com/cse?cx=partner-pub-2601749019656699:2173448976&ie=UTF-8&q=virtual+hosts&sa=Search&gws_rd=cr&ei=Dy9EVbb0IdHisASnroG4Bw#gsc.tab=0&gsc.q=apache
|
||||
@ -0,0 +1,197 @@
|
||||
RHCSA Series: Yum Package Management, Automating Tasks with Cron and Monitoring System Logs – Part 10
|
||||
================================================================================
|
||||
In this article we will review how to install, update, and remove packages in Red Hat Enterprise Linux 7. We will also cover how to automate tasks using cron, and will finish this guide explaining how to locate and interpret system logs files with the focus of teaching you why all of these are essential skills for every system administrator.
|
||||
|
||||

|
||||
|
||||
RHCSA: Yum Package Management, Cron Job Scheduling and Log Monitoring – Part 10
|
||||
|
||||
### Managing Packages Via Yum ###
|
||||
|
||||
To install a package along with all its dependencies that are not already installed, you will use:
|
||||
|
||||
# yum -y install package_name(s)
|
||||
|
||||
Where package_name(s) represent at least one real package name.
|
||||
|
||||
For example, to install httpd and mlocate (in that order), type.
|
||||
|
||||
# yum -y install httpd mlocate
|
||||
|
||||
**Note**: That the letter y in the example above bypasses the confirmation prompts that yum presents before performing the actual download and installation of the requested programs. You can leave it out if you want.
|
||||
|
||||
By default, yum will install the package with the architecture that matches the OS architecture, unless overridden by appending the package architecture to its name.
|
||||
|
||||
For example, on a 64 bit system, yum install package will install the x86_64 version of package, whereas yum install package.x86 (if available) will install the 32-bit one.
|
||||
|
||||
There will be times when you want to install a package but don’t know its exact name. The search all or search options can search the currently enabled repositories for a certain keyword in the package name and/or in its description as well, respectively.
|
||||
|
||||
For example,
|
||||
|
||||
# yum search log
|
||||
|
||||
will search the installed repositories for packages with the word log in their names and summaries, whereas
|
||||
|
||||
# yum search all log
|
||||
|
||||
will look for the same keyword in the package description and url fields as well.
|
||||
|
||||
Once the search returns a package listing, you may want to display further information about some of them before installing. That is when the info option will come in handy:
|
||||
|
||||
# yum info logwatch
|
||||
|
||||

|
||||
|
||||
Search Package Information
|
||||
|
||||
You can regularly check for updates with the following command:
|
||||
|
||||
# yum check-update
|
||||
|
||||
The above command will return all the installed packages for which an update is available. In the example shown in the image below, only rhel-7-server-rpms has an update available:
|
||||
|
||||

|
||||
|
||||
Check For Package Updates
|
||||
|
||||
You can then update that package alone with,
|
||||
|
||||
# yum update rhel-7-server-rpms
|
||||
|
||||
If there are several packages that can be updated, yum update will update all of them at once.
|
||||
|
||||
Now what happens when you know the name of an executable, such as ps2pdf, but don’t know which package provides it? You can find out with `yum whatprovides “*/[executable]”`:
|
||||
|
||||
# yum whatprovides “*/ps2pdf”
|
||||
|
||||
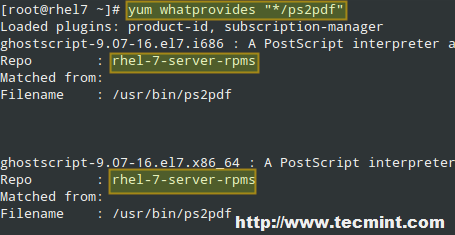
|
||||
|
||||
Find Package Belongs to Which Package
|
||||
|
||||
Now, when it comes to removing a package, you can do so with yum remove package. Easy, huh? This goes to show that yum is a complete and powerful package manager.
|
||||
|
||||
# yum remove httpd
|
||||
|
||||
Read Also: [20 Yum Commands to Manage RHEL 7 Package Management][1]
|
||||
|
||||
### Good Old Plain RPM ###
|
||||
|
||||
RPM (aka RPM Package Manager, or originally RedHat Package Manager) can also be used to install or update packages when they come in form of standalone `.rpm` packages.
|
||||
|
||||
It is often utilized with the `-Uvh` flags to indicate that it should install the package if it’s not already present or attempt to update it if it’s installed `(-U)`, producing a verbose output `(-v)` and a progress bar with hash marks `(-h)` while the operation is being performed. For example,
|
||||
|
||||
# rpm -Uvh package.rpm
|
||||
|
||||
Another typical use of rpm is to produce a list of currently installed packages with code>rpm -qa (short for query all):
|
||||
|
||||
# rpm -qa
|
||||
|
||||

|
||||
|
||||
Query All RPM Packages
|
||||
|
||||
Read Also: [20 RPM Commands to Install Packages in RHEL 7][2]
|
||||
|
||||
### Scheduling Tasks using Cron ###
|
||||
|
||||
Linux and other Unix-like operating systems include a tool called cron that allows you to schedule tasks (i.e. commands or shell scripts) to run on a periodic basis. Cron checks every minute the /var/spool/cron directory for files which are named after accounts in /etc/passwd.
|
||||
|
||||
When executing commands, any output is mailed to the owner of the crontab (or to the user specified in the MAILTO environment variable in the /etc/crontab, if it exists).
|
||||
|
||||
Crontab files (which are created by typing crontab -e and pressing Enter) have the following format:
|
||||
|
||||

|
||||
|
||||
Crontab Entries
|
||||
|
||||
Thus, if we want to update the local file database (which is used by locate to find files by name or pattern) every second day of the month at 2:15 am, we need to add the following crontab entry:
|
||||
|
||||
15 02 2 * * /bin/updatedb
|
||||
|
||||
The above crontab entry reads, “Run /bin/updatedb on the second day of the month, every month of the year, regardless of the day of the week, at 2:15 am”. As I’m sure you already guessed, the star symbol is used as a wildcard character.
|
||||
|
||||
After adding a cron job, you can see that a file named root was added inside /var/spool/cron, as we mentioned earlier. That file lists all the tasks that the crond daemon should run:
|
||||
|
||||
# ls -l /var/spool/cron
|
||||
|
||||

|
||||
|
||||
Check All Cron Jobs
|
||||
|
||||
In the above image, the current user’s crontab can be displayed either using cat /var/spool/cron/root or,
|
||||
|
||||
# crontab -l
|
||||
|
||||
If you need to run a task on a more fine-grained basis (for example, twice a day or three times each month), cron can also help you to do that.
|
||||
|
||||
For example, to run /my/script on the 1st and 15th of each month and send any output to /dev/null, you can add two crontab entries as follows:
|
||||
|
||||
01 00 1 * * /myscript > /dev/null 2>&1
|
||||
01 00 15 * * /my/script > /dev/null 2>&1
|
||||
|
||||
But in order for the task to be easier to maintain, you can combine both entries into one:
|
||||
|
||||
01 00 1,15 * * /my/script > /dev/null 2>&1
|
||||
|
||||
Following the previous example, we can run /my/other/script at 1:30 am on the first day of the month every three months:
|
||||
|
||||
30 01 1 1,4,7,10 * /my/other/script > /dev/null 2>&1
|
||||
|
||||
But when you have to repeat a certain task every “x” minutes, hours, days, or months, you can divide the right position by the desired frequency. The following crontab entry has the exact same meaning as the previous one:
|
||||
|
||||
30 01 1 */3 * /my/other/script > /dev/null 2>&1
|
||||
|
||||
Or perhaps you need to run a certain job on a fixed frequency or after the system boots, for example. You can use one of the following string instead of the five fields to indicate the exact time when you want your job to run:
|
||||
|
||||
@reboot Run when the system boots.
|
||||
@yearly Run once a year, same as 00 00 1 1 *.
|
||||
@monthly Run once a month, same as 00 00 1 * *.
|
||||
@weekly Run once a week, same as 00 00 * * 0.
|
||||
@daily Run once a day, same as 00 00 * * *.
|
||||
@hourly Run once an hour, same as 00 * * * *.
|
||||
|
||||
Read Also: [11 Commands to Schedule Cron Jobs in RHEL 7][3]
|
||||
|
||||
### Locating and Checking Logs ###
|
||||
|
||||
System logs are located (and rotated) inside the /var/log directory. According to the Linux Filesystem Hierarchy Standard, this directory contains miscellaneous log files, which are written to it or an appropriate subdirectory (such as audit, httpd, or samba in the image below) by the corresponding daemons during system operation:
|
||||
|
||||
# ls /var/log
|
||||
|
||||

|
||||
|
||||
Linux Log Files Location
|
||||
|
||||
Other interesting logs are [dmesg][4] (contains all messages from kernel ring buffer), secure (logs connection attempts that require user authentication), messages (system-wide messages) and wtmp (records of all user logins and logouts).
|
||||
|
||||
Logs are very important in that they allow you to have a glimpse of what is going on at all times in your system, and what has happened in the past. They represent a priceless tool to troubleshoot and monitor a Linux server, and thus are often used with the `tail -f command` to display events, in real time, as they happen and are recorded in a log.
|
||||
|
||||
For example, if you want to display kernel-related events, type the following command:
|
||||
|
||||
# tail -f /var/log/dmesg
|
||||
|
||||
Same if you want to view access to your web server:
|
||||
|
||||
# tail -f /var/log/httpd/access.log
|
||||
|
||||
### Summary ###
|
||||
|
||||
If you know how to efficiently manage packages, schedule tasks, and where to look for information about the current and past operation of your system you can rest assure that you will not run into surprises very often. I hope this article has helped you learn or refresh your knowledge about these basic skills.
|
||||
|
||||
Don’t hesitate to drop us a line using the contact form below if you have any questions or comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/yum-package-management-cron-job-scheduling-monitoring-linux-logs/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[3]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/dmesg-commands/
|
||||
@ -0,0 +1,191 @@
|
||||
RHCSA Series: Firewall Essentials and Network Traffic Control Using FirewallD and Iptables – Part 11
|
||||
================================================================================
|
||||
In simple words, a firewall is a security system that controls the incoming and outgoing traffic in a network based on a set of predefined rules (such as the packet destination / source or type of traffic, for example).
|
||||
|
||||

|
||||
|
||||
RHCSA: Control Network Traffic with FirewallD and Iptables – Part 11
|
||||
|
||||
In this article we will review the basics of firewalld, the default dynamic firewall daemon in Red Hat Enterprise Linux 7, and iptables service, the legacy firewall service for Linux, with which most system and network administrators are well acquainted, and which is also available in RHEL 7.
|
||||
|
||||
### A Comparison Between FirewallD and Iptables ###
|
||||
|
||||
Under the hood, both firewalld and the iptables service talk to the netfilter framework in the kernel through the same interface, not surprisingly, the iptables command. However, as opposed to the iptables service, firewalld can change the settings during normal system operation without existing connections being lost.
|
||||
|
||||
Firewalld should be installed by default in your RHEL system, though it may not be running. You can verify with the following commands (firewall-config is the user interface configuration tool):
|
||||
|
||||
# yum info firewalld firewall-config
|
||||
|
||||

|
||||
|
||||
Check FirewallD Information
|
||||
|
||||
and,
|
||||
|
||||
# systemctl status -l firewalld.service
|
||||
|
||||

|
||||
|
||||
Check FirewallD Status
|
||||
|
||||
On the other hand, the iptables service is not included by default, but can be installed through.
|
||||
|
||||
# yum update && yum install iptables-services
|
||||
|
||||
Both daemons can be started and enabled to start on boot with the usual systemd commands:
|
||||
|
||||
# systemctl start firewalld.service | iptables-service.service
|
||||
# systemctl enable firewalld.service | iptables-service.service
|
||||
|
||||
Read Also: [Useful Commands to Manage Systemd Services][1]
|
||||
|
||||
As for the configuration files, the iptables service uses `/etc/sysconfig/iptables` (which will not exist if the package is not installed in your system). On a RHEL 7 box used as a cluster node, this file looks as follows:
|
||||
|
||||

|
||||
|
||||
Iptables Firewall Configuration
|
||||
|
||||
Whereas firewalld store its configuration across two directories, `/usr/lib/firewalld` and `/etc/firewalld`:
|
||||
|
||||
# ls /usr/lib/firewalld /etc/firewalld
|
||||
|
||||

|
||||
|
||||
FirewallD Configuration
|
||||
|
||||
We will examine these configuration files further later in this article, after we add a few rules here and there. By now it will suffice to remind you that you can always find more information about both tools with.
|
||||
|
||||
# man firewalld.conf
|
||||
# man firewall-cmd
|
||||
# man iptables
|
||||
|
||||
Other than that, remember to take a look at [Reviewing Essential Commands & System Documentation – Part 1][2] of the current series, where I described several sources where you can get information about the packages installed on your RHEL 7 system.
|
||||
|
||||
### Using Iptables to Control Network Traffic ###
|
||||
|
||||
You may want to refer to [Configure Iptables Firewall – Part 8][3] of the Linux Foundation Certified Engineer (LFCE) series to refresh your memory about iptables internals before proceeding further. Thus, we will be able to jump in right into the examples.
|
||||
|
||||
**Example 1: Allowing both incoming and outgoing web traffic**
|
||||
|
||||
TCP ports 80 and 443 are the default ports used by the Apache web server to handle normal (HTTP) and secure (HTTPS) web traffic. You can allow incoming and outgoing web traffic through both ports on the enp0s3 interface as follows:
|
||||
|
||||
# iptables -A INPUT -i enp0s3 -p tcp --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
|
||||
# iptables -A OUTPUT -o enp0s3 -p tcp --sport 80 -m state --state ESTABLISHED -j ACCEPT
|
||||
# iptables -A INPUT -i enp0s3 -p tcp --dport 443 -m state --state NEW,ESTABLISHED -j ACCEPT
|
||||
# iptables -A OUTPUT -o enp0s3 -p tcp --sport 443 -m state --state ESTABLISHED -j ACCEPT
|
||||
|
||||
**Example 2: Block all (or some) incoming connections from a specific network**
|
||||
|
||||
There may be times when you need to block all (or some) type of traffic originating from a specific network, say 192.168.1.0/24 for example:
|
||||
|
||||
# iptables -I INPUT -s 192.168.1.0/24 -j DROP
|
||||
|
||||
will drop all packages coming from the 192.168.1.0/24 network, whereas,
|
||||
|
||||
# iptables -A INPUT -s 192.168.1.0/24 --dport 22 -j ACCEPT
|
||||
|
||||
will only allow incoming traffic through port 22.
|
||||
|
||||
**Example 3: Redirect incoming traffic to another destination**
|
||||
|
||||
If you use your RHEL 7 box not only as a software firewall, but also as the actual hardware-based one, so that it sits between two distinct networks, IP forwarding must have been already enabled in your system. If not, you need to edit `/etc/sysctl.conf` and set the value of net.ipv4.ip_forward to 1, as follows:
|
||||
|
||||
net.ipv4.ip_forward = 1
|
||||
|
||||
then save the change, close your text editor and finally run the following command to apply the change:
|
||||
|
||||
# sysctl -p /etc/sysctl.conf
|
||||
|
||||
For example, you may have a printer installed at an internal box with IP 192.168.0.10, with the CUPS service listening on port 631 (both on the print server and on your firewall). In order to forward print requests from clients on the other side of the firewall, you should add the following iptables rule:
|
||||
|
||||
# iptables -t nat -A PREROUTING -i enp0s3 -p tcp --dport 631 -j DNAT --to 192.168.0.10:631
|
||||
|
||||
Please keep in mind that iptables reads its rules sequentially, so make sure the default policies or later rules do not override those outlined in the examples above.
|
||||
|
||||
### Getting Started with FirewallD ###
|
||||
|
||||
One of the changes introduced with firewalld are zones. This concept allows to separate networks into different zones level of trust the user has decided to place on the devices and traffic within that network.
|
||||
|
||||
To list the active zones:
|
||||
|
||||
# firewall-cmd --get-active-zones
|
||||
|
||||
In the example below, the public zone is active, and the enp0s3 interface has been assigned to it automatically. To view all the information about a particular zone:
|
||||
|
||||
# firewall-cmd --zone=public --list-all
|
||||
|
||||
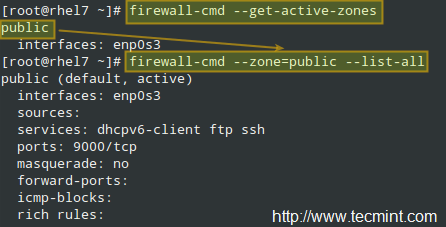
|
||||
|
||||
List all FirewallD Zones
|
||||
|
||||
Since you can read more about zones in the [RHEL 7 Security guide][4], we will only list some specific examples here.
|
||||
|
||||
**Example 4: Allowing services through the firewall**
|
||||
|
||||
To get a list of the supported services, use.
|
||||
|
||||
# firewall-cmd --get-services
|
||||
|
||||

|
||||
|
||||
List All Supported Services
|
||||
|
||||
To allow http and https web traffic through the firewall, effective immediately and on subsequent boots:
|
||||
|
||||
# firewall-cmd --zone=MyZone --add-service=http
|
||||
# firewall-cmd --zone=MyZone --permanent --add-service=http
|
||||
# firewall-cmd --zone=MyZone --add-service=https
|
||||
# firewall-cmd --zone=MyZone --permanent --add-service=https
|
||||
# firewall-cmd --reload
|
||||
|
||||
If code>–zone is omitted, the default zone (you can check with firewall-cmd –get-default-zone) is used.
|
||||
|
||||
To remove the rule, replace the word add with remove in the above commands.
|
||||
|
||||
**Example 5: IP / Port forwarding**
|
||||
|
||||
First off, you need to find out if masquerading is enabled for the desired zone:
|
||||
|
||||
# firewall-cmd --zone=MyZone --query-masquerade
|
||||
|
||||
In the image below, we can see that masquerading is enabled for the external zone, but not for public:
|
||||
|
||||

|
||||
|
||||
Check Masquerading Status
|
||||
|
||||
You can either enable masquerading for public:
|
||||
|
||||
# firewall-cmd --zone=public --add-masquerade
|
||||
|
||||
or use masquerading in external. Here’s what we would do to replicate Example 3 with firewalld:
|
||||
|
||||
# firewall-cmd --zone=external --add-forward-port=port=631:proto=tcp:toport=631:toaddr=192.168.0.10
|
||||
|
||||
And don’t forget to reload the firewall.
|
||||
|
||||
You can find further examples on [Part 9][5] of the RHCSA series, where we explained how to allow or disable the ports that are usually used by a web server and a ftp server, and how to change the corresponding rule when the default port for those services are changed. In addition, you may want to refer to the firewalld wiki for further examples.
|
||||
|
||||
Read Also: [Useful FirewallD Examples to Configure Firewall in RHEL 7][6]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have explained what a firewall is, what are the available services to implement one in RHEL 7, and provided a few examples that can help you get started with this task. If you have any comments, suggestions, or questions, feel free to let us know using the form below. Thank you in advance!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/firewalld-vs-iptables-and-control-network-traffic-in-firewall/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/manage-services-using-systemd-and-systemctl-in-linux/
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[3]:http://www.tecmint.com/configure-iptables-firewall/
|
||||
[4]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Security_Guide/sec-Using_Firewalls.html
|
||||
[5]:http://www.tecmint.com/rhcsa-series-install-and-secure-apache-web-server-and-ftp-in-rhel/
|
||||
[6]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
@ -0,0 +1,142 @@
|
||||
RHCSA Series: Automate RHEL 7 Installations Using ‘Kickstart’ – Part 12
|
||||
================================================================================
|
||||
Linux servers are rarely standalone boxes. Whether it is in a datacenter or in a lab environment, chances are that you have had to install several machines that will interact one with another in some way. If you multiply the time that it takes to install Red Hat Enterprise Linux 7 manually on a single server by the number of boxes that you need to set up, this can lead to a rather lengthy effort that can be avoided through the use of an unattended installation tool known as kickstart.
|
||||
|
||||
In this article we will show what you need to use kickstart utility so that you can forget about babysitting servers during the installation process.
|
||||
|
||||

|
||||
|
||||
RHCSA: Automatic Kickstart Installation of RHEL 7
|
||||
|
||||
#### Introducing Kickstart and Automated Installations ####
|
||||
|
||||
Kickstart is an automated installation method used primarily by Red Hat Enterprise Linux (and other Fedora spin-offs, such as CentOS, Oracle Linux, etc.) to execute unattended operating system installation and configuration. Thus, kickstart installations allow system administrators to have identical systems, as far as installed package groups and system configuration are concerned, while sparing them the hassle of having to manually install each of them.
|
||||
|
||||
### Preparing for a Kickstart Installation ###
|
||||
|
||||
To perform a kickstart installation, we need to follow these steps:
|
||||
|
||||
1. Create a Kickstart file, a plain text file with several predefined configuration options.
|
||||
|
||||
2. Make the Kickstart file available on removable media, a hard drive or a network location. The client will use the rhel-server-7.0-x86_64-boot.iso file, whereas you will need to make the full ISO image (rhel-server-7.0-x86_64-dvd.iso) available from a network resource, such as a HTTP of FTP server (in our present case, we will use another RHEL 7 box with IP 192.168.0.18).
|
||||
|
||||
3. Start the Kickstart installation
|
||||
|
||||
To create a kickstart file, login to your Red Hat Customer Portal account, and use the [Kickstart configuration tool][1] to choose the desired installation options. Read each one of them carefully before scrolling down, and choose what best fits your needs:
|
||||
|
||||

|
||||
|
||||
Kickstart Configuration Tool
|
||||
|
||||
If you specify that the installation should be performed either through HTTP, FTP, or NFS, make sure the firewall on the server allows those services.
|
||||
|
||||
Although you can use the Red Hat online tool to create a kickstart file, you can also create it manually using the following lines as reference. You will notice, for example, that the installation process will be in English, using the latin american keyboard layout and the America/Argentina/San_Luis time zone:
|
||||
|
||||
lang en_US
|
||||
keyboard la-latin1
|
||||
timezone America/Argentina/San_Luis --isUtc
|
||||
rootpw $1$5sOtDvRo$In4KTmX7OmcOW9HUvWtfn0 --iscrypted
|
||||
#platform x86, AMD64, or Intel EM64T
|
||||
text
|
||||
url --url=http://192.168.0.18//kickstart/media
|
||||
bootloader --location=mbr --append="rhgb quiet crashkernel=auto"
|
||||
zerombr
|
||||
clearpart --all --initlabel
|
||||
autopart
|
||||
auth --passalgo=sha512 --useshadow
|
||||
selinux --enforcing
|
||||
firewall --enabled
|
||||
firstboot --disable
|
||||
%packages
|
||||
@base
|
||||
@backup-server
|
||||
@print-server
|
||||
%end
|
||||
|
||||
In the online configuration tool, use 192.168.0.18 for HTTP Server and `/kickstart/tecmint.bin` for HTTP Directory in the Installation section after selecting HTTP as installation source. Finally, click the Download button at the right top corner to download the kickstart file.
|
||||
|
||||
In the kickstart sample file above, you need to pay careful attention to.
|
||||
|
||||
url --url=http://192.168.0.18//kickstart/media
|
||||
|
||||
That directory is where you need to extract the contents of the DVD or ISO installation media. Before doing that, we will mount the ISO installation file in /media/rhel as a loop device:
|
||||
|
||||
# mount -o loop /var/www/html/kickstart/rhel-server-7.0-x86_64-dvd.iso /media/rhel
|
||||
|
||||

|
||||
|
||||
Mount RHEL ISO Image
|
||||
|
||||
Next, copy all the contents of /media/rhel to /var/www/html/kickstart/media:
|
||||
|
||||
# cp -R /media/rhel /var/www/html/kickstart/media
|
||||
|
||||
When you’re done, the directory listing and disk usage of /var/www/html/kickstart/media should look as follows:
|
||||
|
||||

|
||||
|
||||
Kickstart Media Files
|
||||
|
||||
Now we’re ready to kick off the kickstart installation.
|
||||
|
||||
Regardless of how you choose to create the kickstart file, it’s always a good idea to check its syntax before proceeding with the installation. To do that, install the pykickstart package.
|
||||
|
||||
# yum update && yum install pykickstart
|
||||
|
||||
And then use the ksvalidator utility to check the file:
|
||||
|
||||
# ksvalidator /var/www/html/kickstart/tecmint.bin
|
||||
|
||||
If the syntax is correct, you will not get any output, whereas if there’s an error in the file, you will get a warning notice indicating the line where the syntax is not correct or unknown.
|
||||
|
||||
### Performing a Kickstart Installation ###
|
||||
|
||||
To start, boot your client using the rhel-server-7.0-x86_64-boot.iso file. When the initial screen appears, select Install Red Hat Enterprise Linux 7.0 and press the Tab key to append the following stanza and press Enter:
|
||||
|
||||
# inst.ks=http://192.168.0.18/kickstart/tecmint.bin
|
||||
|
||||

|
||||
|
||||
RHEL Kickstart Installation
|
||||
|
||||
Where tecmint.bin is the kickstart file created earlier.
|
||||
|
||||
When you press Enter, the automated installation will begin, and you will see the list of packages that are being installed (the number and the names will differ depending on your choice of programs and package groups):
|
||||
|
||||
|
||||
|
||||
Automatic Kickstart Installation of RHEL 7
|
||||
|
||||
When the automated process ends, you will be prompted to remove the installation media and then you will be able to boot into your newly installed system:
|
||||
|
||||

|
||||
|
||||
RHEL 7 Boot Screen
|
||||
|
||||
Although you can create your kickstart files manually as we mentioned earlier, you should consider using the recommended approach whenever possible. You can either use the online configuration tool, or the anaconda-ks.cfg file that is created by the installation process in root’s home directory.
|
||||
|
||||
This file actually is a kickstart file, so you may want to install the first box manually with all the desired options (maybe modify the logical volumes layout or the file system on top of each one) and then use the resulting anaconda-ks.cfg file to automate the installation of the rest.
|
||||
|
||||
In addition, using the online configuration tool or the anaconda-ks.cfg file to guide future installations will allow you to perform them using an encrypted root password out-of-the-box.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Now that you know how to create kickstart files and how to use them to automate the installation of Red Hat Enterprise Linux 7 servers, you can forget about babysitting the installation process. This will give you time to do other things, or perhaps some leisure time if you’re lucky.
|
||||
|
||||
Either way, let us know what you think about this article using the form below. Questions are also welcome!
|
||||
|
||||
Read Also: [Automated Installations of Multiple RHEL/CentOS 7 Distributions using PXE and Kickstart][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/automatic-rhel-installations-using-kickstart/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://access.redhat.com/labs/kickstartconfig/
|
||||
[2]:http://www.tecmint.com/multiple-centos-installations-using-kickstart/
|
||||
@ -0,0 +1,176 @@
|
||||
RHCSA Series: Mandatory Access Control Essentials with SELinux in RHEL 7 – Part 13
|
||||
================================================================================
|
||||
During this series we have explored in detail at least two access control methods: standard ugo/rwx permissions ([Manage Users and Groups – Part 3][1]) and access control lists ([Configure ACL’s on File Systems – Part 7][2]).
|
||||
|
||||

|
||||
|
||||
RHCSA Exam: SELinux Essentials and Control FileSystem Access
|
||||
|
||||
Although necessary as first level permissions and access control mechanisms, they have some limitations that are addressed by Security Enhanced Linux (aka SELinux for short).
|
||||
|
||||
One of such limitations is that a user can expose a file or directory to a security breach through a poorly elaborated chmod command and thus cause an unexpected propagation of access rights. As a result, any process started by that user can do as it pleases with the files owned by the user, where finally a malicious or otherwise compromised software can achieve root-level access to the entire system.
|
||||
|
||||
With those limitations in mind, the United States National Security Agency (NSA) first devised SELinux, a flexible mandatory access control method, to restrict the ability of processes to access or perform other operations on system objects (such as files, directories, network ports, etc) to the least permission model, which can be modified later as needed. In few words, each element of the system is given only the access required to function.
|
||||
|
||||
In RHEL 7, SELinux is incorporated into the kernel itself and is enabled in Enforcing mode by default. In this article we will explain briefly the basic concepts associated with SELinux and its operation.
|
||||
|
||||
### SELinux Modes ###
|
||||
|
||||
SELinux can operate in three different ways:
|
||||
|
||||
- Enforcing: SELinux denies access based on SELinux policy rules, a set of guidelines that control the security engine.
|
||||
- Permissive: SELinux does not deny access, but denials are logged for actions that would have been denied if running in enforcing mode.
|
||||
- Disabled (self-explanatory).
|
||||
|
||||
The `getenforce` command displays the current mode of SELinux, whereas `setenforce` (followed by a 1 or a 0) is used to change the mode to Enforcing or Permissive, respectively, during the current session only.
|
||||
|
||||
In order to achieve persistence across logouts and reboots, you will need to edit the `/etc/selinux/config` file and set the SELINUX variable to either enforcing, permissive, or disabled:
|
||||
|
||||
# getenforce
|
||||
# setenforce 0
|
||||
# getenforce
|
||||
# setenforce 1
|
||||
# getenforce
|
||||
# cat /etc/selinux/config
|
||||
|
||||

|
||||
|
||||
Set SELinux Mode
|
||||
|
||||
Typically you will use setenforce to toggle between SELinux modes (enforcing to permissive and back) as a first troubleshooting step. If SELinux is currently set to enforcing while you’re experiencing a certain problem, and the same goes away when you set it to permissive, you can be confident you’re looking at a SELinux permissions issue.
|
||||
|
||||
### SELinux Contexts ###
|
||||
|
||||
A SELinux context consists of an access control environment where decisions are made based on SELinux user, role, and type (and optionally a level):
|
||||
|
||||
- A SELinux user complements a regular Linux user account by mapping it to a SELinux user account, which in turn is used in the SELinux context for processes in that session, in order to explicitly define their allowed roles and levels.
|
||||
- The concept of role acts as an intermediary between domains and SELinux users in that it defines which process domains and file types can be accessed. This will shield your system against vulnerability to privilege escalation attacks.
|
||||
- A type defines an SELinux file type or an SELinux process domain. Under normal circumstances, processes are prevented from accessing files that other processes use, and and from accessing other processes, thus access is only allowed if a specific SELinux policy rule exists that allows it.
|
||||
|
||||
Let’s see how all of that works through the following examples.
|
||||
|
||||
**EXAMPLE 1: Changing the default port for the sshd daemon**
|
||||
|
||||
In [Securing SSH – Part 8][3] we explained that changing the default port where sshd listens on is one of the first security measures to secure your server against external attacks. Let’s edit the `/etc/ssh/sshd_config` file and set the port to 9999:
|
||||
|
||||
Port 9999
|
||||
|
||||
Save the changes, and restart sshd:
|
||||
|
||||
# systemctl restart sshd
|
||||
# systemctl status sshd
|
||||
|
||||

|
||||
|
||||
Restart SSH Service
|
||||
|
||||
As you can see, sshd has failed to start. But what happened?
|
||||
|
||||
A quick inspection of `/var/log/audit/audit.log` indicates that sshd has been denied permissions to start on port 9999 (SELinux log messages include the word “AVC” so that they might be easily identified from other messages) because that is a reserved port for the JBoss Management service:
|
||||
|
||||
# cat /var/log/audit/audit.log | grep AVC | tail -1
|
||||
|
||||

|
||||
|
||||
Inspect SSH Logs
|
||||
|
||||
At this point you could disable SELinux (but don’t!) as explained earlier and try to start sshd again, and it should work. However, the semanage utility can tell us what we need to change in order for us to be able to start sshd in whatever port we choose without issues.
|
||||
|
||||
Run,
|
||||
|
||||
# semanage port -l | grep ssh
|
||||
|
||||
to get a list of the ports where SELinux allows sshd to listen on.
|
||||
|
||||

|
||||
|
||||
Semanage Tool
|
||||
|
||||
So let’s change the port in /etc/ssh/sshd_config to Port 9998, add the port to the ssh_port_t context, and then restart the service:
|
||||
|
||||
# semanage port -a -t ssh_port_t -p tcp 9998
|
||||
# systemctl restart sshd
|
||||
# systemctl is-active sshd
|
||||
|
||||

|
||||
|
||||
Semanage Add Port
|
||||
|
||||
As you can see, the service was started successfully this time. This example illustrates the fact that SELinux controls the TCP port number to its own port type internal definitions.
|
||||
|
||||
**EXAMPLE 2: Allowing httpd to send access sendmail**
|
||||
|
||||
This is an example of SELinux managing a process accessing another process. If you were to implement mod_security and mod_evasive along with Apache in your RHEL 7 server, you need to allow httpd to access sendmail in order to send a mail notification in the wake of a (D)DoS attack. In the following command, omit the -P flag if you do not want the change to be persistent across reboots.
|
||||
|
||||
# semanage boolean -1 | grep httpd_can_sendmail
|
||||
# setsebool -P httpd_can_sendmail 1
|
||||
# semanage boolean -1 | grep httpd_can_sendmail
|
||||
|
||||

|
||||
|
||||
Allow Apache to Send Mails
|
||||
|
||||
As you can tell from the above example, SELinux boolean settings (or just booleans) are true / false rules embedded into SELinux policies. You can list all the booleans with `semanage boolean -l`, and alternatively pipe it to grep in order to filter the output.
|
||||
|
||||
**EXAMPLE 3: Serving a static site from a directory other than the default one**
|
||||
|
||||
Suppose you are serving a static website using a different directory than the default one (`/var/www/html`), say /websites (this could be the case if you’re storing your web files in a shared network drive, for example, and need to mount it at /websites).
|
||||
|
||||
a). Create an index.html file inside /websites with the following contents:
|
||||
|
||||
<html>
|
||||
<h2>SELinux test</h2>
|
||||
</html>
|
||||
|
||||
If you do,
|
||||
|
||||
# ls -lZ /websites/index.html
|
||||
|
||||
you will see that the index.html file has been labeled with the default_t SELinux type, which Apache can’t access:
|
||||
|
||||

|
||||
|
||||
Check SELinux File Permission
|
||||
|
||||
b). Change the DocumentRoot directive in `/etc/httpd/conf/httpd.conf` to /websites and don’t forget to update the corresponding Directory block. Then, restart Apache.
|
||||
|
||||
c). Browse to `http://<web server IP address>`, and you should get a 503 Forbidden HTTP response.
|
||||
|
||||
d). Next, change the label of /websites, recursively, to the httpd_sys_content_t type in order to grant Apache read-only access to that directory and its contents:
|
||||
|
||||
# semanage fcontext -a -t httpd_sys_content_t "/websites(/.*)?"
|
||||
|
||||
e). Finally, apply the SELinux policy created in d):
|
||||
|
||||
# restorecon -R -v /websites
|
||||
|
||||
Now restart Apache and browse to `http://<web server IP address>` again and you will see the html file displayed correctly:
|
||||
|
||||

|
||||
|
||||
Verify Apache Page
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have gone through the basics of SELinux. Note that due to the vastness of the subject, a full detailed explanation is not possible in a single article, but we believe that the principles outlined in this guide will help you to move on to more advanced topics should you wish to do so.
|
||||
|
||||
If I may, let me recommend two essential resources to start with: the [NSA SELinux page][4] and the [RHEL 7 SELinux User’s and Administrator’s][5] guide.
|
||||
|
||||
Don’t hesitate to let us know if you have any questions or comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-manage-users-and-groups
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares/
|
||||
[3]:http://www.tecmint.com/rhcsa-series-secure-ssh-set-hostname-enable-network-services-in-rhel-7/
|
||||
[4]:https://www.nsa.gov/research/selinux/index.shtml
|
||||
[5]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/SELinux_Users_and_Administrators_Guide/part_I-SELinux.html
|
||||
@ -0,0 +1,214 @@
|
||||
适合于远程编辑以及更多环境的简洁文本编辑器
|
||||
================================================================================
|
||||
文本编辑器是用来编辑纯文本的软件。这种软件有许多用处,包括修改配置文件,编写程序源代码,记下一些想法或者甚至写一份购物列表。由于这种编辑器能都用于许多不同的活动,因此值得花些时间找一个最适合您喜好的编辑器。
|
||||
|
||||
不论编辑器有多么复杂,它们通常有一个共同的功能集,包括查找/替换文本,格式化文本,导入文件以及在文件中移动文本。
|
||||
|
||||
所有这些文本编辑器都是基于终端的应用,因此他们很适合在远程主机上编辑文件。文本编辑器通常也会提供一个图形化的用户界面,但依旧会保证快速和最小化。
|
||||
|
||||
基于终端的应用程序在系统资源方面也是轻量级的(在低配置机器上很有用),比起它的图形化版本来也会更快、更高效,由于它们在X需要重启时也不会停止工作,因此非常适合编写脚本。
|
||||
|
||||
我选择了一些我最喜欢的开源文本编辑器,他们在使用系统资源方面都非常节俭。
|
||||
|
||||
----------
|
||||
|
||||
### Textadept ###
|
||||
|
||||

|
||||
|
||||
Textadept是一款适合程序员的,快速、最小化、可扩展、跨平台的开源文本编辑器。这个开源程序由C和Lua写就,并且于这些年间在速度和最小化方面进行了优化。
|
||||
|
||||
Textadept是那些想要无限的扩展性且不愿牺牲速度或屈服于代码膨胀的程序员们的理想编辑器。
|
||||
|
||||
它也有一个用于终端的版本,仅仅依赖ncurses,适合在远程主机上进行编辑。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 轻量级
|
||||
- 最小化设计以最大化屏幕
|
||||
- 自包含的执行文件 - 无需安装
|
||||
- 全键盘驱动
|
||||
- 无限制的分割视图(GUI版本),以您所好任意水平或垂直的分割编辑器窗口。请注意Textadept没有打开文件标签。
|
||||
- 支持多于80种的编程语言
|
||||
- 强大的片段快捷命令
|
||||
- 代码自动补全和API查询
|
||||
- 无与伦比的扩展性
|
||||
- 书签
|
||||
- 查找和替换
|
||||
- 在文件中查找
|
||||
- 基于缓存的单词补全
|
||||
- 成熟的编程语言符号自动补全,以及显示API文档的功能
|
||||
- 主题:明亮、黑暗、终端
|
||||
- 使用词法分析器将名称分配给缓冲元素,如评论、字符串、关键词
|
||||
- 远程会话
|
||||
- 快速打开
|
||||
- 许多可用的模块,包括对Java、Python、Ruby和近期打开文件列表的支持
|
||||
- 符合Gnome HIG用户接口的指导
|
||||
- 支持编辑Lua代码。语法自动补全,LuaDoc,许多Textadept对象和Lua的标准库。
|
||||
|
||||
- 网址: [foicica.com/textadept][1]
|
||||
- 开发者: Mitchell and contributors
|
||||
- 许可证: MIT License
|
||||
- 版本号: 7.7
|
||||
|
||||
----------
|
||||
|
||||
### Vim ###
|
||||
|
||||

|
||||
|
||||
vim是一个高级的文本编辑器,它基于'vi'的强大,并拥有更全面的功能集。
|
||||
|
||||
这个编辑器对编程和编辑其他纯ASCII的文件十分有用。所有的命令都由普通的键盘字符提供,能够使用十指来输入,因而十分快捷。另外,功能键可以由用户来定义,并且可也以使用鼠标。
|
||||
|
||||
Vim通常被称作"程序员的编辑器",它十分适合于编程,并被认为可以作为完整的集成开发环境。然而,这个软件并不是仅仅面向程序员。Vim高度重视各种文本编辑,从编写email到修改配置文件。
|
||||
|
||||
Vim的接口基于文本界面下的命令行。尽管它的图形化版本gVim为常用的命令添加了菜单和工具栏,但这个软件的整个功能依旧依赖于它的命令行模式。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 3 种模式:
|
||||
- - Command 模式
|
||||
- - Insert 模式
|
||||
- - Command line 模式
|
||||
- 无限制的撤销
|
||||
- 多个窗口和缓冲区
|
||||
- 平滑的输入模式
|
||||
- 根据所编辑的文件的类型使用不同的颜色或风格进行语法高亮
|
||||
- 交互命令
|
||||
- - 标记一行
|
||||
- - vi 行缓冲
|
||||
- - 移动代码块
|
||||
- 块操作
|
||||
- 命令历史
|
||||
- 扩展的正则表达式
|
||||
- 编辑压缩/打包文件 (gzip, bzip2, zip, tar)
|
||||
- 文件名补全
|
||||
- 标记跳转
|
||||
- 折叠文本
|
||||
- 缩进
|
||||
- ctags和cscope整合
|
||||
- 100%与vi的模式兼容
|
||||
- 插件用于添加/扩展功能
|
||||
- 宏
|
||||
- vimscript, Vim的内部脚本
|
||||
- Unicode支持
|
||||
- 多语言支持
|
||||
- 在线帮助支持
|
||||
|
||||
- 网址: [www.vim.org][2]
|
||||
- 开发者: Bram Moolenaar
|
||||
- 许可证: GNU GPL compatible (charityware)
|
||||
- 版本号: 7.4
|
||||
|
||||
----------
|
||||
|
||||
### ne ###
|
||||
|
||||

|
||||
|
||||
ne是一款全屏幕的开源文本编辑器。它像是一个比vi更容易学习的vi替代物,并且可以在POSIX-兼容的系统中便携使用。
|
||||
|
||||
ne对于新手来说易于使用,但也非常强大并有完全可配置的引导程序,并且在资源使用上十分节约。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 三种用户接口: 控制击键,命令行和菜单;击键和菜单都可配置
|
||||
- 语法高亮
|
||||
- 对于UTF-8文件的完全支持,包括多列字符
|
||||
- 文档,剪切,显示的维度和文件/行号长度都有编号,并且仅受制于机器的整型字长
|
||||
- 简单的脚本语言,脚本可以用简单易理解的录制/播放的方式制作
|
||||
- 无限制的撤销/重做功能(可以通过命令禁用)
|
||||
- 基于被编辑的文件扩展的自动个性化配置系统
|
||||
- 使用您文档中的词语做字典来进行自动前缀补全
|
||||
- 易用的文件存取功能
|
||||
- 扩展的正则表达式可用于查找和替换,类似emacs和vi
|
||||
- 非常紧凑的内存模型,在加载和修改大型文件时十分快速
|
||||
- 可编辑二进制文件
|
||||
|
||||
- 网址: [ne.di.unimi.it][3]
|
||||
- 开发者: Sebastiano Vigna (original developer). Additional features added by Todd M. Lewis
|
||||
- 许可证: GNU GPL v3
|
||||
- 版本号: 2.5
|
||||
|
||||
----------
|
||||
|
||||
### Zile ###
|
||||
|
||||

|
||||
|
||||
Zile是Lossy Emacs(Emacs精简版),它是一个小型的Emacs的克隆版。Zile是一个可定制的,自文档化,实时显示的编辑器,在编写Zile时像Emacs一样尽可能的小,每个Emacs用户都会对Zile感到亲切。
|
||||
|
||||
Zile以它极小的RAM用量,大约130KB,以及快速开始编辑而闻名。它是8比特清洁的,允许用于编写任何种类的文件。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 小型但快速、强大
|
||||
- 多个缓冲区,允许多级的撤销
|
||||
- 多窗口
|
||||
- 好用,有力【不太清楚怎么翻译】
|
||||
- 以最小的缓冲区完成补全
|
||||
- 自动填充 (自动换行)
|
||||
- 寄存器视图
|
||||
- 看起来像Emacs,键序列、功能和变量名都与Emacs相同
|
||||
- Killing
|
||||
- Yanking
|
||||
- 自动行末检测
|
||||
|
||||
- 网址: [www.gnu.org/software/zile][4]
|
||||
- 开发者: Reuben Thomas, Sandro Sigala, David A. Capello
|
||||
- 许可证: GNU GPL v2
|
||||
- 版本号: 2.4.11
|
||||
|
||||
----------
|
||||
|
||||
### nano ###
|
||||
|
||||

|
||||
|
||||
nano是基于curses库的文本编辑器。它是Pico(Pine电子邮件客户端编辑器)的一个复刻版。
|
||||
|
||||
由于Pine的许可证问题诉讼案(Pine并未以开源许可证发布),并且也因为Pine缺少一些重要的功能,nano项目于1999年开始。
|
||||
|
||||
nano致力于赶上Pico的功能和其易用性,与此同时提供更多的功能,但不集成Pine/Pico的邮件客户端。
|
||||
|
||||
nano像Pico一样是以键盘为导向的设计,可以用控制键来控制。
|
||||
|
||||
#### 功能包括: ####
|
||||
|
||||
- 交互式的查找和替换
|
||||
- 彩色语法高亮
|
||||
- 转到行号和列号处
|
||||
- 自动缩进
|
||||
- 功能开关
|
||||
- 支持UTF-8
|
||||
- 混合型的文件类型自动转换
|
||||
- 逐字输入模式
|
||||
- 多个文件缓冲区
|
||||
- 平滑滚动
|
||||
- 括号匹配
|
||||
- 自定义引用字符串
|
||||
- 备份文件
|
||||
- 国际化支持
|
||||
- tab补全文件名
|
||||
|
||||
- 网址: [nano-editor.org][5]
|
||||
- 开发者: Chris Allegretta, David Lawrence, Jordi Mallach, Adam Rogoyski, Robert Siemborski, Rocco Corsi, David Benbennick, Mike Frysinger
|
||||
- 许可证: GNU GPL v3
|
||||
- 版本号: 2.2.6
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20141011073917230/TextEditors.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://foicica.com/textadept/
|
||||
[2]:http://www.vim.org/
|
||||
[3]:http://ne.di.unimi.it/
|
||||
[4]:http://www.gnu.org/software/zile/
|
||||
[5]:http://nano-editor.org/
|
||||
@ -1,115 +0,0 @@
|
||||
六种在 Linux 上带来 iTunes 体验的方法
|
||||
Top 6 Ways To Get Your iTunes Experience On Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
随着你对 Linux 的熟悉(也许会成为你首要使用的操作系统),你最终会寻找能在Linux上有效管理音乐的工具。你首先想到了 iTunes,因为它是近几年最流行的音乐管理工具,但你马上会发现iTunes并没有Linux版本。而且,你会发现还有比 iTunes 更好的音乐管理工具。
|
||||
As you’re getting used to Linux (potentially as your new main operating system), you’ll eventually try to find a way to efficiently manage your music. iTunes comes to mind because it’s been the most popular way to manage music over the years, but you’ll quickly find out that iTunes isn’t available natively on Linux. Plus, better ways exist to manage your music now that it’s 2015.
|
||||
|
||||
尽管如此,这并不意味着你就不能使用你喜欢的方式管理音乐。Linux 上有很多方式可以让你整理你的音乐库。以下六种,仅供参考:
|
||||
However, that doesn’t automatically mean that you won’t be able to manage your music the way you want to. There’s plenty of other ways to keep tabs on your music library. Here’s six great ways to get it done.
|
||||
|
||||
### 在WINE上运行iTunes ###
|
||||
### iTunes via WINE ###
|
||||
|
||||
尽管 iTunes 没有Linux版,你还是可以试试 [使用 WINE 运行 iTunes ][1] 或 PlayOnLinux 的。这些软件给本来只能运行于Windows下的应用程序添加了一个兼容层,这样就能让他们运行在Linux上了,但这样的方法效果十有分限。因此 [并非所有 Windows 应用程序都能使用WINE运行][2] - 但这还是一个值得尝试的方法。
|
||||
Even if iTunes isn’t available in Linux as a native application, you can still try to [get it to work under WINE][1] or PlayOnLinux. These pieces of software try to add a compatibility layer so that Windows applications work on Linux, but the results are far from perfect. Therefore, [not all Windows applications will run with WINE][2] — but it’s still worth a try.
|
||||
|
||||
各个版本的iTunes结果可能给你不同的结果,但一般都遵循以下方法:
|
||||
1. 安装WINE
|
||||
1. 在WINE里运行iTunes安装程序
|
||||
1. 在网上搜索并解决你遇到的问题。
|
||||
|
||||
如果你在安装时遇到无法解决的问题,比如安装程序错误,或者安装好的程序运行不了,那是没办法的,WINE 就是这样
|
||||
|
||||
如果你想在 WINE 上运行 iTunes 但恰好运行不了的话,没问题。但如果你还想考虑运行一个原生的Linux的话,还有很多其他选择的。这些音乐管理软件狗能让你很方便的管理你的音乐并直接进行播放,还可以制作播放列表。
|
||||
|
||||
Each version of iTunes can give you different results, but the general process is as follows:
|
||||
|
||||
1. Install WINE
|
||||
1. Run the iTunes installer via WINE
|
||||
1. Google and try to solve any problems you come across.
|
||||
|
||||
Again, you might come across issues somewhere along the way which cannot be solved, such as the installer failing or the installed application refusing to run. That’s just how it is with WINE.
|
||||
|
||||
If you really want to use iTunes and you happen to luck out with WINE, then that’s great. However, if you’d rather use a native Linux application or WINE didn’t work for you, then there are options here as well. Several “music library manager” programs are available to give you a quick oversight of your music and play it directly in the application, as well as make playlists.
|
||||
|
||||
### [Amarok][3] ###
|
||||
|
||||

|
||||
|
||||
如果你使用KDE环境,我推荐 Amarok。它具有 [很多管理音乐的特性][4] 而且他还能与KDE桌面环境无缝兼容。它很有很多实用的特性如无缝兼容 Last.FM,文件跟踪,动态播放列表及个吃支持。它甚至会自动在你播放曲目时,自动下载艺术家封面。
|
||||
|
||||
If you use KDE, then I’d recommend Amarok. It has [plenty of features to manage your music][4] and tight desktop integration with KDE. It also has useful features such as Last.FM integration, file tracking, dynamic playlists, and script support. It can even pull up biographies of artists as you play their songs.
|
||||
|
||||
### [Banshee][5] ###
|
||||
|
||||

|
||||
|
||||
如果你使用 GNOME 或其他任何基于 GTK 的桌面环境(他们十分常见)的话,我推荐使用使用Bansee作为 [全功能音乐库管理工具][6] 。它的功能与Amarok类似,也与Last.FM无缝兼容,支持网络广播,支持podcast,还有很多其他功能。选择 Amarok 还是 Bansee 要看你使用的桌面环境(这样才能无缝整合)。
|
||||
|
||||
If you use GNOME or any GTK-based desktop environment (they’re quite common), then I’d recommend Banshee as a [full-featured music library][6] manager. It has a very similar feature set as Amarok, including Last.FM integration, Internet radio support, podcast support, and much more. Amarok and Banshee are really among the top two choices, so which one you choose should depend on which desktop environment you’re using (for integration’s sake).
|
||||
|
||||
### [Rhythmbox][7] ###
|
||||
|
||||

|
||||
|
||||
Rhythmbox是一个 基于GTK的桌环境下更 [轻量级的音乐库替代品][8]。尽管如此,它也还是有一些特性的。它也支持Last.FM,同时还能无缝播放并与其他如 Nautilus, XChat,及Pidgin 等进行整合。
|
||||
Rhythmbox as a more [lightweight music library alternative][8] that is best used on GTK-based desktop environments. However, it still has quite a few features. You also get Last.FM support here, plus gapless playback and integration with various other applications such as Nautilus, XChat, and Pidgin.
|
||||
|
||||
### [Clementine][9] ###
|
||||
|
||||

|
||||
|
||||
另一款叫 Clementine 的软件也值得我推荐,因为它的见面简洁、易用。它支持非常多的第三方服务例如Spotify,Digtal Imported 及Dropbox。Android系统上还有一款用作 Clementine 遥控的app。[Clementine是一个跨平台的][10] , 还支持Mac OS X 及 Windows。
|
||||
Another application called Clementine also gets my recommendation with its clean and intuitive interface. It has tons of support for third-party services such as Spotify, Digitally Imported, and Dropbox. There’s also an Android app you can use as a remote control for Clementine. [Clementine is cross-platform][10] and available for Windows and Mac OS X.
|
||||
|
||||
这些程序都能很好的管理并播放你的音乐。唯一的问题是这些程序都不支持与 iOS 设备的整合, 而且目前还没有程序能做到这一点。但 iOS 经过很多改进后,已经足以不需要再连接到电脑了。
|
||||
They all are excellent at managing and playing your music. The only downside to all of these is that there is no iOS device integration, and there’s currently no modern application that can do that. However, iOS has received enough improvements that it’s virtually unnecessary to connect it to a computer anymore.
|
||||
|
||||
### [Google Play Music][11] ###
|
||||
|
||||

|
||||
|
||||
最后,如果上面的那些程序还不能满足你的需求的花,你可以试试 Google Play Music。这个在线服务也可以用作能播放音乐的音乐库管理工具,但他还有几个额外的好处。你可以上传所有的音乐,并且在所有能上网的设备上获取这些音乐。这也意味着你不需要在电脑或者移动设备之间同步你的音乐(无论是 Android 还是 iOS 设备),因为你可以这些设备中使用Google Play Music。 如果你想要扩展你的去库,你可以订阅 All Access,但这并不是必须的。你不需要支付任何费用也可在你的曲库中储存20,000首
|
||||
Lastly, if none of those applications satisfy your needs, you can take a look at Google Play Music. This online service acts as a music library manager that can play your music, but it also has some extra benefits. You can upload all your music to it and have access on any device connected to the Internet. That also means that you won’t have to sync your music between your computer and your mobile device (no matter if Android or iOS) because you have access to Google Play Music from both. If you want to expand your library you can get the All Access subscription, but it’s not a requirement. You can use it simply as a music library completely free for up to 20,000 songs.
|
||||
|
||||
#### 靠,居然没有 Spotify ?! ####
|
||||
#### Wot, no Spotify?! ####
|
||||
|
||||
尽管 Spotify 也是一款管理和听音乐的方法,我不推荐它的唯一原因是它事实上并不让你管理你的音乐。你不能将曲目上传到 Spotify - 只能它们给你提供的曲目。尽管它们提供了很多,但原理都不尽相同。
|
||||
The only reason why I don’t mention Spotify is that, although it’s also a great way to access and listen to music, it doesn’t really let you manage your own music. You can’t upload trakcs to Spotify — you have to listen to what they give you. Albeit they give you a lot, but it’s nonetheless a different mechanism.
|
||||
|
||||
### 你还有其他选择 ###
|
||||
### You Have Options ###
|
||||
|
||||
以上六个软件应该可以在给你带来类似 iTunes 的功能了。这些软件主要是能让你管理和播放你的音乐库,但如果你还需要 iTunes 里的其他特性,其他Linux原生软件或许能满足这类需求。
|
||||
|
||||
With these six options, you should be able to get iTunes-like functionality on your desktop. These options focused mainly on managing and playing your music library, but if there are any other features that you need from iTunes, other Linux-native applications can take care of those needs.
|
||||
|
||||
**你通常在Linux上使用哪些音乐?**在下方评论与我们分享吧!
|
||||
**What music applications do you regularly use on Linux?** Let us know in the comments!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/top-6-ways-get-itunes-experience-linux/
|
||||
|
||||
作者:[Danny Stieben][a]
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.makeuseof.com/tag/author/danny/
|
||||
[1]:http://www.makeuseof.com/tag/how-about-some-wine-with-your-linux/
|
||||
[2]:http://www.makeuseof.com/answers/does-wine-runs-all-windows-apps/
|
||||
[3]:https://amarok.kde.org/
|
||||
[4]:http://www.makeuseof.com/tag/control-music-amarok-linux/
|
||||
[5]:http://banshee.fm/
|
||||
[6]:http://www.makeuseof.com/tag/banshee-20-comprehensive-media-player-streamer-podcast-tool-linux/
|
||||
[7]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[8]:http://www.makeuseof.com/tag/play-manage-music-collection-rhythmbox-linux/
|
||||
[9]:https://www.clementine-player.org/
|
||||
[10]:http://www.makeuseof.com/tag/need-a-lightweight-music-player-without-sacrificing-features-clementine-cross-platform/
|
||||
[11]:http://music.google.com/
|
||||
@ -0,0 +1,55 @@
|
||||
Arc是一个很棒的Linux桌面的GTK主题
|
||||
================================================================================
|
||||
|
||||
|
||||
距离本站上次推荐的GTK主题已经过了很久了。
|
||||
|
||||
但是看到上面的Arc后,需要纠正这点了。
|
||||
|
||||
我们不能不提到它。
|
||||
|
||||
### Arc GTK主题 ###
|
||||
|
||||

|
||||
|
||||
Transparency. Not to everyones’ taste.
|
||||
透明并不符合每个人的口味
|
||||
|
||||
Arc是一个扁平化主题并有微妙的配色并部分选中的窗口透明,就像GTK的顶拦和Nautilus的侧边栏。
|
||||
|
||||
|
||||
它的效果不像我们之前的主题那样将程序渲染的像躲猫猫那样混乱。像OSX Yosemite,效果用的不变多但是很好。
|
||||
|
||||
随之的图标集(称为Vertex)同样可用。
|
||||
|
||||
**是的它支持Unity**
|
||||
|
||||
Arc主题支持基于GTK3和GTK2桌面环境,包含Gnome Shell(当然)和标准的Ubuntu Unity。
|
||||
|
||||
它也可以很好地与轻量级的Budgie和elementary的Pantheon桌面以及也可以工作在Cinnamon上。
|
||||
|
||||

|
||||
|
||||
Arc中的开关、滑块和小挂件。
|
||||
|
||||
它并不容易下载与安装- *understatement klaxon* - 因为它还在密集开发中。
|
||||
|
||||
|
||||
安装包需要GTK 3.14或者更新,这意味着Ubuntu 14.04 LTS和14.10的用户无法使用了。
|
||||
|
||||
那些使用Ubuntu 15.04的用户可以使用这个主题。你还不能添加ppa或者双击.deb包。如果你喜欢你看见的你需要卷起你的袖子并查看github上的编译指导。
|
||||
|
||||
- [Github中Arc安装指导][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/arc-gtk-theme
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://github.com/horst3180/Arc-theme
|
||||
@ -0,0 +1,61 @@
|
||||
如何在Linux中安装漂亮的扁平化Arc GTK+主题
|
||||
================================================================================
|
||||
> 易于看懂的每步都有的教程
|
||||
|
||||
**今天我们将向你介绍最新发布的GTK+主题,它拥有透明和扁平元素,并且与多个桌面环境和Linux发行版见荣发。[这个主题叫Arc][1]。**
|
||||
|
||||
开始讲细节之前,我建议你快速地看一下下面的图,这样你有会对这个主题就会有一个基本的概念了。同样你应该意识到它目前可以工作在GTK+ 2.x、GTK+ 3.x、GNOME-Shell、 Budgie、 Unity和Pantheon用户界面,它们都使用了GNOME栈。
|
||||
|
||||
同样、Arc主题的开发者提醒我们它已经成功地在Ubuntu 15.04(Vivid Vervet)、 Arch Linux、 elementary OS 0.3 Freya、 Fedora 21、 Fedora 22、 Debian GNU/Linux 8.0 (Jessie)、 Debian Testing、 Debian Unstable、 openSUSE 13.2、 openSUSE Tumbleweed和Gentoo测试过了。
|
||||
|
||||
### 要求和安装指导 ###
|
||||
|
||||
要构建Arc主题,你需要先安装一些包,比如autoconf、 automake、 pkg-config (对Fedora的pkgconfig)、基于Debian/Ubuntu-based发行版的libgtk-3-dev或者基于RPM的gtk3-devel、 git、 gtk2-engines-pixbuf和gtk-engine-murrine (对Fedora的gtk-murrine-engine)。
|
||||
|
||||
Arc主题还没有二进制包,因此你需要从git仓库中取下最新的源码并编译。这样,打开终端并运行下面的命令,一行行地,并在每行的末尾按下回车键并等待上一步完成来继续一步。
|
||||
|
||||
git clone https://github.com/horst3180/arc-theme --depth 1 && cd arc-theme
|
||||
git fetch --tags
|
||||
git checkout $(git describe --tags `git rev-list --tags --max-count=1`)
|
||||
./autogen.sh --prefix=/usr
|
||||
sudo make install
|
||||
|
||||
就是这样!此时你已经在你的GNU/Linux发行版中安装了Arc主题,如果你使用GNOME可以使用GONME Tweak工具或者如果你使用Unity可以使用Unity Tweak工具来激活主题。玩得开心也不要忘了在下面的评论栏里留下你的截图。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Here-s-How-to-Install-the-Beautiful-Arc-GTK-plus-Flat-Theme-on-Linux-483143.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:https://github.com/horst3180/Arc-theme
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -0,0 +1,172 @@
|
||||
12个全球认可的Linux认证
|
||||
================================================================================
|
||||
大家好,今天我们将会认识一些非常有价值的全球认可的Linux认证。Linux认证是不同Linux专业机构在全球范围内进行的认证程序。Linux认证可以让Linux专业人才很容易获得Linux相关的工作,在服务器或者公司等等这些地方。Linux认证评估一个人在Linux的各个领域里的专业程度。有很多不错的Linux专业机构提供不同的Linux认证。但是全球仅有少数被十分认可的Linux认证,在公司谋取一份工作时含金量很高,这些工作包括管理服务器,虚拟化,安装系统与软件,配置程序,应用支持和其他Linux操作系统相关的东西。随着全球使用Linux操作系统的服务器的增长,拉动了对于Linux专业人才的需求。为了更好的证明Linux专业技术,公司进行的著名的认证一直有着更高的优先级,在全球看来。
|
||||
|
||||
这里是一些全球认可的Linux认证,我们接下来将会一一讨论。
|
||||
|
||||
### 1. CompTIA Linxu+ ###
|
||||
|
||||
CompTIA Linux+ 是LPI“Linux Professional Institute”主办的一个Linux认证,在全世界范围内提供培训。其提供的Linux相关知识,使得产生了一大批Linux相关专业的工作,如Linux管理员,高级网络管理员,系统管理员,Linux数据库管理员和网页管理员。如果任何人想从事安装和维护Linux操作系统,该课程会帮助达到认证要求,并且通过提供对Linux系统更宽阔的认识,能够为考试做好准备。LPI的CompTIA Linux+认证的主要目的就是,提供给证书持有者足够扎实的知识,关于安装软件,操作,管理和设备排障的。我们可以用一定的费用,时间和努力,,完成CompTIA Linux+,赢得三个业内认可的证书,我们可以自动收到**LPI LPIC-1**和**SUSE Certified Linux Administrator (CLA)**证书。
|
||||
|
||||
- ** 认证代码** : LX0-103和LX0-104 (2015年三月30日启动)或者LX0-101和LX0-102
|
||||
- 题目数量:一次考试60道题
|
||||
- 题目类型:多选
|
||||
- 考试时长:90分钟
|
||||
- 要求:A+,Network+,并且有至少12个月的Linux管理经历
|
||||
- 分数线:500 (对于200-800的范围来说)
|
||||
- 语言:英语,将来会有德语,葡萄牙语,汉语,西班牙。
|
||||
- 有效期:认证后三年有效
|
||||
|
||||
**注意**:不同系列的考试不能交叉。如果你考的是LX0-101,那么你必须考LX0-102完成认证。同样的,你必须考完LX0-103和LX0-104。LX0-103和LX0-104是LX0-101和LX0-102的升级版。
|
||||
|
||||
### 2. LPIC ###
|
||||
|
||||
LPIC,全称Linux专业委员会认证,是Linux专业委员会的一个Linux认证程序。这是一个多层次的认证程序,要求在每个级别通过一系列(通常是两个)的认证考试。该认证有三个层次,包括初级水平认证 **LPIC-1** ,高级水平认证 **LPIC-2**和最高水平认证 **LPIC-3**。前两个认证侧重于 **Linux系统管理**,而最后一个认证侧重一些专业技能,包括虚拟化和安全。为了得到 **LPIC-3** 认证,一个持有 **LPIC-1** 与**LPIC-2** 的考生必须通过300复杂环境测试,303安全测试,304虚拟化测试和高可用性的其中一个。**LPIC-1**认证按照证书持有者可以通过运行Linux,使用命令行界面和基本的网络知识安装,维护,配置任务而设计,LPIC-2验证考生很少的管理知识,主要是中型混合网络方面。LPIC-3认证按照企业级别的Linux专业技能设计,代表了最高的专业水平(==最后这句不知道如何翻译==)
|
||||
|
||||
- **认证代码**:LPIC-1(101和102),LPIC-2(201和202)和LPIC-3(300,303或者304)
|
||||
- 题目类型:60个多项选择
|
||||
- 考试时长:90分钟
|
||||
- 要求:Linux基础
|
||||
- 分数线:500(在200-800的范围内)
|
||||
- 语言:LPIC-1:英语,德语,意大利语,葡萄牙语,西班牙语(现代),汉语(简体),汉语(繁体),日语
|
||||
- LPIC-2:英语,德语,葡萄牙语,日语
|
||||
- LPIC-3:英语,日语
|
||||
- 有效期:退休之后五年内仍然有效
|
||||
|
||||
### 3.Oracle Linux OCA ###
|
||||
|
||||
Oracle联合认证(OCA)为个人而定制,那些对部署和管理Oracle Linux操作系统且想证明知识牢固感兴趣的人。该认证专业知识仅仅是在Oracle Linux发行版上,这个系统完全是为Oracle产品特别剪裁的,为了运行在Oracle设计的系统上面,包括Oracle Exadata数据库机器,Oracle Exalytics 内存中机器,Oracle Exalogic 均衡云,和Oracle数据库应用。Oracle Linux稳定的企业级内核对于企业应用表现突出,高扩展性和稳定性。OCA认证覆盖如管理本地磁盘设备,文件系统,安装和移除Solaris包与补丁,协调系统启动过程和系统进程方面。这是达到OCP证书佼佼者的第一步。OCA认证以其前身为Sun Certified Solaris Associate(SCSAS)而为人所知。
|
||||
|
||||
- **认证代码**:OCA
|
||||
- 题目类型:75道多项选择
|
||||
- 考试时长:120分钟
|
||||
- 要求:无
|
||||
- 分数线:64%
|
||||
- 有效期:永远有效
|
||||
|
||||
### 4. Oracle Linux OCP ###
|
||||
|
||||
Oracle Certified Professional(OCP),时Oracle公司为Oracle Linux提供的一个认证,覆盖更多的进阶知识和技能,对于一个Oracle Linux管理员来说。它囊括的知识有配置网络接口,映射交换配置,清理垃圾,管理软件、数据库和核心文件。OCP认证是技术性专业知识和专业技能的基准测试,这些知识与技能需要在公司里广泛用于开发,部署和管理应用,中间设备和数据库。Oracle Linux OCP的工作机会在增长,得益于工作市场和经济。根据考试纲领,证书持有者有能力胜任安全管理,为Oracle 数据库准备Oracle Linux系统,排除故障,安装软件包,安装和配置内核模块,维护交换空间,完成用户和组管理,创建文件系统,配置逻辑卷管理(LVM)、文件分享服务等等。
|
||||
|
||||
- **认证代码**:OCP
|
||||
- 题目类型:60至80道多项选择题
|
||||
- 考试时长:120分钟
|
||||
- 要求:Oracle Linux OCA
|
||||
- 分数线:64%
|
||||
- 有效期:永远有效
|
||||
|
||||
### 5. RHCSA ###
|
||||
|
||||
RHCSA是红帽公司作为红帽认证系统工程师推出的一个认证程序。RHCSAs指一些拥有技能和能力在著名的红帽Linux环境下完成核心系统管理的人。这是一个入门级的认证程序,关注在系统管理上的实际胜任能力,包括安装、配置一个红帽Linux系统,接入一个可用的网络运行网络服务。一个红帽认证的系统管理员可以理解和使用基本的工具,用以处理文件,目录,命令行环境和文档,操作运行中的系统,包括以不同的启动级别启动,标记进程,开启和停止虚拟机和控制服务,使用分区和逻辑卷配置本地存储,部署配置和维护系统,包括软件安装、更新和核心服务,管理用户和组,包括使用一个中心的目录用于验证,安全性工作,包括基本的基本防火墙和SELinux配置。要获得RHCE和其他认证,首先得认证过RHCSA。
|
||||
|
||||
- **认证代码**:RHCSA
|
||||
- 课程代码:RH124,RH134和RH199
|
||||
- 考试代码:EX200
|
||||
- 考试时长:21-22小时,取决于选择的课程
|
||||
- 要求:无。有一些Linux基础知识更好
|
||||
- 分数线:300总分,210过(70%)
|
||||
- 有效期:3年
|
||||
|
||||
### 6. RHCE ###
|
||||
|
||||
RHCE,也叫做红帽认证工程师,是一个中到高级水平的认证程序,为一些红帽认证系统管理员(RHCSA),想学习一个负责红帽企业Linux的高级系统管理员要求的额外技能和知识而开设的,RHCE有能力,知识和技能配置静态的路由,包过滤,网络地址转换(NAT),设定内核运行参数,配置一个互联网小型计算机系统接口(ISCSI)初始化程序,产生并推送系统使用的报告,使用shell脚本自动完成系统维护任务,配置系统登入,包括远程登录,提供网络服务如HTTP/HTTPS,文件传输协议(FTP),网络文件系统(NFS),服务信息块(SMB),简单邮件传输协议(SMTP),安全shell(SSH)和网络时间协议(NTP)等等。RHCSAs希望获得更多高级水平的认证,并且已经完成系统管理员I,II和III,或者RHCE认证建议的RHCE快速跟进课程。
|
||||
|
||||
- **认证代码**:RHCE
|
||||
- 课程代码:RH124,RH134,RH254和RH199
|
||||
- 考试代码:EX200和EX300
|
||||
- 考试时长:21-22个小时,取决于所选课程
|
||||
- 要求:一个RHCSA证书
|
||||
- 分数线:300总分,210过(70%)
|
||||
- 有效期:3年
|
||||
|
||||
### 7. RHCA ###
|
||||
|
||||
RHCA就是红帽认证架构师,是红帽公司的一个认证程序。它的关注点在系统管理的实际能力,包括安装和配置一个红帽Linux系统,并加入到一个可用网络中运行网络服务。RHCA是所有红帽认证中最高水平的认证。考生需要选择他们希望关注的集合,或者选择合格的红帽认证的任意组合,以此来创建一个他们自己的集合。这里有三个主要的集合,数据中心,云和应用平台。精通数据中心集合的RHCA能够运行,管理数据中心,而熟悉云的可以创建,配置和管理私有的,混合的云,云应用平台以及使用红帽企业Linux平台的灵活存储方案。精通应用平台集合的RHCA拥有技能如安装,配置和管理红帽JBoss企业应用平台和应用,云应用平台和混合云环境,借助红帽的OpenShift企业版,使用红帽JBoss数据虚拟化技术从多个资源里组合数据。
|
||||
|
||||
- **认证代码**:RHCA
|
||||
- 课程代码:CL210,CL220.CL280,RH236,RH318,RH413,RH436,RH442,JB248和JB450
|
||||
- 考试代码:EX333,EX401,EX423或者EX318,EX436和EX442
|
||||
- 考试时长:21-22个小时,取决于所选课程
|
||||
- 要求:未过期的RHCE证书
|
||||
- 分数线:300总分,210过(70%)
|
||||
- 有效期:3年
|
||||
|
||||
### 8. SUSE CLA ###
|
||||
|
||||
SUSE认证Linux管理员(SUSE CLA)是SUSE推出的一个初级认证,关注点在SUSE Linux企业服务器环境下的日常任务管理。为了获得SUSE CLA认证,完成课程任务不是必须的,你不得不通过考试获得认证。SUSE CLA有能力,也有技术去使用Linux桌面,定位并利用帮助资源,管理Linux文件系统,用Linux Shell和命令行工作,安装SLE 11 SP22,管理系统安装,硬件,备份和恢复,用YaST管理Linux,Linux进程和服务,存储,配置网络,远程接入,SLE 11 SP2模拟器,任务自动化和管理用户访问和安全工作。我们可以同时获得LPI的SUSE CLA,LPIC-1和CompTIA Linux,因为SUSE,Linux Professional Institute和CompATI合作提供给你这个机会,去获得三个Linux认证。
|
||||
|
||||
- **认证代码**:SUSE CLA
|
||||
- 课程代码:3115,3116
|
||||
- 考试代码:050-720,050-710
|
||||
- 问题类型:多项选择
|
||||
- 考试时长:90分钟
|
||||
- 要求:无
|
||||
- 分数线:512
|
||||
|
||||
### 9. SUSE CLP ###
|
||||
|
||||
SUSE认证Linux专业人员(CLP)是一个认证程序,为那些希望获得关于SUSE Linux企业服务器更多高级且专业的知识的人而服务。SUSE CLP是通过SUSE CLA认证后的下一步。一个人应该通过CLA的考试并拥有证书,然后才能获得CLP的认证,通过完成CLP的考试。通过SUSE CLP认证的人员有能力完成安装和配置SUSE Linux企业服务器11系统,维护文件系统,管理软件包,进程,打印,使用IPv6配置基础网络服务,samba,网页服务器,创建和运行bash shell脚本。
|
||||
|
||||
- **认证代码**:SUSE CLP
|
||||
- 课程代码:3115,3116和3117
|
||||
- 考试代码:050-721,050-697
|
||||
- 考试类型:手写
|
||||
- 考试时长:180分钟
|
||||
- 要求:SUSE CLA 认证
|
||||
|
||||
### 10. SUSE CLE ###
|
||||
|
||||
SUSE认证Linux工程师(CLE)是一个工程师级别的高级认证,为那些已经通过CLE考试的人准备。为了获得CLE认证,人们需要获得SUSE CLA和CLP的认证。获得CLE认证的人员拥有架设复杂SUSE Linux企业服务器环境的技能。CLE认证过的人可以配置基本的网络服务,管理打印,配置和使用Open LDAP,samba,IPv6,完成健康检测和(这里不知道),创建和执行shell脚本,部署SUSE Linux企业板,通过Xen实现虚拟化等等。
|
||||
|
||||
- **认证代码**:SUSE CLE
|
||||
- 课程代码:3107
|
||||
- 考试代码:050-723
|
||||
- 考试类型:手写
|
||||
- 考试时长:120分钟
|
||||
- 要求:SUSE CLP 10或者11证书
|
||||
|
||||
### 11. LFCS ###
|
||||
|
||||
Linux基金会认证系统管理员(LFCS)认证考生Linux使用中拥有的知识和通过终端环境使用Linux。LFCS是Linux基金会的一个认证程序,为使用Linux操作系统工作的系统管理员和工程师准备。Linux基金会联合工业级专家,Linux内核社区,测试考生扎实的技能,知识和应用能力。通过LFCS认证的人员拥有一些技能,知识和能力,包括在命令行下编辑和操作文件,管理和处理文件系统与存储的错误,聚合分区作为LVM设备,配置SWAP分区,管理网络文件系统,管理用户帐号,权限和属组,创建并执行bash shell脚本,安装,升级,移除软件包等等。
|
||||
|
||||
- **认证代码**:LFCS
|
||||
- 课程代码:LFCS201,LFCS220(可选)
|
||||
- 考试代码:LFCS 考试
|
||||
- 考试时长:2小时
|
||||
- 要求:无
|
||||
- 分数线:74%
|
||||
- 语言:英语
|
||||
- 有效期:两年
|
||||
|
||||
### 12. LFCE ###
|
||||
|
||||
Linux基金会认证工程师(LFCE),是Linux基金会为Linux工程师推出的认证。通过LFCE认证的人员拥有一个对于Linux较宽范围的技能,相比于LFCS。这是一个工程师级别的高级认证程序。LFCE认证的人具备一些网络管理方面的技能和能力,如配置网络服务,包过滤,网络运行模拟器,IP连通,配置文件系统和文件服务,网络文件系统,从仓库安装,升级软件包,管理网络安全,配置iptables,http服务,代理服务,邮件服务等等。由于其为高级工程级别的认证程序,所以普遍认为相比LFCS,学习和通过的难度更大些。
|
||||
|
||||
- **认证代码**:LFCE
|
||||
- 课程代码:LFS230
|
||||
- 考试代码:LFCE 考试
|
||||
- 考试时长:2小时
|
||||
- 要求:认证过LFCS
|
||||
- 分数线:72%
|
||||
- 语言:英语
|
||||
- 有效期:2年
|
||||
|
||||
### 我们发现的情况(这仅仅是我们的观点)###
|
||||
|
||||
最近的调查表明,在不同的高端招聘代理中,称80%的Linux工作描述更倾向于红帽的认证。如果你是一个学生/新手,并且想学习Linux,那么我们建议选择越来越流行的Linux基金会认证,或者CompTIA Linux也可以是一个选择。如果你已经知道了oracle或suse,或者在他们的产品上工作,那oracle/suse的认证会更好些,如果你在一个公司工作了,这些认证会对你的职业生涯成长有帮助:-)
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这个世界上,成千上万的大公司正在运行跑着Linux操作系统的服务器和主框架,为了在这些服务器上管理,配置和工作,总是存在对Linux技术/专业知识高度认证的需求。这些国际上承认的认证对某些人在Linux的职业生涯扮演很重要的角色。全世界范围内的这些公司运行着Linux,需要Linux工程师,系统管理员和已经获得认证且在Linux相关领域干得不错的有热情的人员。全球认可的Linux认证,对于专业知识和职业生涯的辉煌都是很基础的,所以好好准备考试并获得认证,对于在Linux建立职业生涯是一个很好的选择。如果你有任何问题,想法,反馈,请写在下方的评论框里,让我们好知道哪些东西需要添加或者改进。谢谢!:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/12-globally-recognized-linux-certifications/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,35 @@
|
||||
sevenot translated
|
||||
下载年度报告,了解The Document Foundation2014年的成果
|
||||
================================================================================
|
||||

|
||||
|
||||
|
||||
TDF ReportThe Document Foundation (TDF)郑重地发布了2014年度报告,你可以点击这里下载: [http://tdf.io/report2014][1] (3.2 MB PDF)。高清质量的可以点击这里下载 [http://tdf.io/report2014hq][2] (15.9 MB PDF)。
|
||||
|
||||
TDF年度报告中,以回顾2014年开始了这篇报告,其中包括了TDF和LibreOffice的精彩集锦,并且总结了财务情况和预算。
|
||||
|
||||
该报告涉及到项目和活动的会议包括:2014年在伯尔尼的LibreOffice大会,在布鲁塞尔、大加那利岛、巴黎、波士顿和土鲁斯的认证项目,网站与质量保证,Hackfests项目,本土语言项目,基础设施,文档项目,市场设计与营销。
|
||||
|
||||
该报告涉及到的软件开发活动和代码包括:工程指导委员会的活动,LibreOffice的开发,文档解放项目,LibreOffice的安卓移植。
|
||||
|
||||
报告的最后一部分则把焦点对准了那些做出了极大贡献的人们,他们是TDF的工作人员,董事会成员,委员会成员,委托组织成员,TDF的核心成员和咨询委员会成员。
|
||||
|
||||
TDF 2014年度报告的编辑工作由Sophie Gautier, Alexander Werner, Christian Lohmaier, Florian Effenberger, Italo Vignoli 和 Robinson Tryon完成,由Barak Paz设计样式,Libreoffice社区协助完成。
|
||||
|
||||
|
||||
为了使该文档分布达到最大程度的分布,采用了CC3 认证发布,除非特殊标注,TDF成员和自由软件基金会拥有其所有权。
|
||||
[德语版年度报告下载请点击[http://tdf.io/bericht2014][3]].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.documentfoundation.org/2015/06/03/read-about-the-document-foundation-achievements-in-2014-download-the-annual-report/
|
||||
|
||||
作者:italovignoli
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://wiki.documentfoundation.org/File:TDF2014AnnualReport.pdf
|
||||
[2]:https://wiki.documentfoundation.org/File:TDF2014AnnualReportHQ.pdf
|
||||
[3]:https://wiki.documentfoundation.org/File:TDF2014AnnualReportDE.pdf
|
||||
@ -1,75 +0,0 @@
|
||||
BSD常见问题
|
||||
================================================================================
|
||||

|
||||
|
||||
### 假如历史稍有不同,您将在今天听到FreeBSD的声音... ###
|
||||
|
||||
#### 那么,这个Birsa Seva Dal是怎么回事呢?难道不是一个印度的政治组织么? ####
|
||||
|
||||
真有趣,您查阅了维基百科上“BSD”的消除分歧页面是为了讲上面这个笑话,对么?这里我们在讨论伯克利软件发行版(Berkeley Software Distribution),一个比您想象中用的更广泛的操作系统家族。
|
||||
|
||||
#### 抱歉,我控制不住自己。那么,这些操作系统是怎么回事呢? ####
|
||||
|
||||
今天,主要使用的BSD操作系统有三种。他们都基于Unix,他们都开源,并且大多担任服务器的角色,但也能当作优秀的桌面和工作站。他们运行KDE,Firefox,LibreOffice,Apache,MySQL和许多你能说得出名字的开源软件。它们都很稳定、安全、支持许多不同的硬件。
|
||||
|
||||
#### 恭喜你!你刚才在描述GNU/Linux吧 ####
|
||||
|
||||
是的,Linux拥有我刚才提到的所有东西,这也是为什么很多人从来不讨论BSD。在日常的使用中,Linux和BSD并没有太多的不同,这主要是因为他们都以Unix为基础,并共用很多软件。您可以登录进远程主机,在Vim中写一些Python代码,使用Mutt检查您的email,您可能并未意识到您在使用BSD。或许您在咖啡馆里正通过网络终端使用它,但不知道他是BSD。
|
||||
|
||||
两者最大的区别在于开发模型和许可证,为了解这些,我们需要回到过去。在BSD中,B代表着加利福尼亚大学伯克利分校(University of California, Berkeley),在1980年代,那里是开源Unix软件的发源地。到了90年代,基于x86的PC变得流行,许多人对在他们的家庭电脑中安装Unix类操作系统产生了兴趣。一个叫做386BSD的项目在那时发布并可以提供上述的功能。
|
||||
|
||||
#### 那么,所有的Linux发行版那个时候在哪里呢? ####
|
||||
|
||||
问得好!您也许知道一年前,Linus Torvalds已经发布了他的内核,当与GNU项目结合时,变成了完整的开源操作系统。Linus那时已经在跟进GNU的内核(Hurd)和386BSD,并且谈到,如果那时两个内核有一个可以被用于日常生活,他可能就不会创造Linux了。所以,90年代的头几年,开源操作系统生机勃勃,没有人知道哪个系统会最终胜出。
|
||||
|
||||
接下来,BSD遇到了一些麻烦。Unix最初的开发方AT&T试图从他们的工作中获得一些利益,他们声称BSD侵犯了他们的知识产权。此事最终以1992年的一桩诉讼结束,它极大的抑制了BSD的开发进程。最后,许多BSD源码的分支必须被重写,而在这时,GNU/Linux已经丰富了功能,变得稳定和流行了。
|
||||
|
||||
在90年代,BSD被论证比GNU/Linux更加成熟,如果没有那些法律麻烦,他可能已经成为了x86 PC的标准了。今天,我们可能都在使用它而不是Linux。
|
||||
|
||||
#### 但你提到BSD仍然被广泛的使用,所以它后来有提升么? ####
|
||||
|
||||
是的。386BSD的开发停滞了,但有两只开发团队以网络的方式工作并创造了两个独立的成功的项目。FreeBSD成为了使用最广泛的BSD版本,它目前是和Linux最相似的系统,包括桌面和服务器版本。然而NetBSD聚焦于可移植性(今天它可以运行在超过50种不同平台上,均基于同样的代码版本)。另一个版本是OpenBSD,它在NetBSD开始不久就因为开发者的口角而作为NetBSD的分支诞生了,今天,它以专注于安全闻名。多年以来,OpenBSD创建了许多程序,它们都成了Linux的标准,比如说OpenSSH - 所以,现在我们有了LibreSSL。
|
||||
|
||||
#### 所以,这三种版本的BSD和Linux发行版相似么? ####
|
||||
|
||||
也是也不是,每个BSD版本都有自己的代码库、不同的开发团队。尽管他们间有许多共用的代码(尤其是硬件驱动)。但他们是各自拥有其特色、优点和缺点的相互独立的操作系统。
|
||||
|
||||
我们提到过,BSD的开发模型是他们真正和GNU/Linux区别的重要特点。在GNU/Linux中没有人对其整体进行负责:一些团队在GNU组件方面工作,一些团队在开发内核,一些在开发启动脚本,一些在写手册,一些在写库等等。这样的开发模型通常被称作缺少中央权利的“荒蛮的美国西部”,由发行版负责用使所有东西各自锲合。
|
||||
|
||||
而BSD则相反,它们从中央化的源代码树中开发并作为一个整体。内核、库、系统组件和文档页都存在一个地方,且以同样的方式使用。许多BSD粉丝声称,这个特点给了操作系统更多的一致性和稳定性。通过我这些年使用BSD的经验来看,我们可以证明手册页已经变得非常完备。
|
||||
|
||||

|
||||
|
||||
#### 难道BSD没有使用GNU/Linux的任何东西么? ####
|
||||
|
||||
是的,但除了GCC。几十年来,GNU Compiler Collection已经成为了实际上的Unix系统标准编译器,但FreeBSD最近已经转而使用LLVM/Clang了。值得注意的是BSD还是用了一些其他的开源项目,但它们并不是GNU或者Linux,比如说X Window System(XFree86和X.org)、Perl等等。并且幸亏有像POSIX一样的标准,许多运行在Linux上的程序可以在BSD的许多版本上编译和运行。
|
||||
|
||||
因此,您可以把LAMP(Linux、Apache、MySQL和PHP)中的L改成FreeBSD,这样可以获得几乎同样的环境,以及一些不同的特性(例如,在文件系统和驱动支持方面)。FreeBSD有大量的用户,例如Netflix,每天提供极大量的数据。尽管FreeBSD可以做一个好的桌面环境,但他的长处在于服务器方面,它拥有超乎寻常的可靠性和网络性能。
|
||||
|
||||
OpenBSD更倾向用于安全性十分必要的场合,如小型Web服务、文件托管、防火墙和网关。NetBSD是BSD主要发行版中最不流行的一个,它能运行在几乎所有平台上,包括古老的Amigas和Acorn boxes,有时您可以在闭源的网络设备中找到它的身影。
|
||||
|
||||
#### 等等,怎么会有人将开源代码闭源呢?那在Linux中是不合适的 ####
|
||||
|
||||
对的,这里我们谈到了它与GNU/Linux的主要不同。BSD版本的许可证(很有趣,叫做BSD许可证)非常不同于我们所知的GPL。对于新手来说,BSD更短。BSD许可证主要内容是:对这份代码,做你想做的事,但给它最初的开发人员开发的权利,并且在它搞坏你的电脑时不要提出诉讼。
|
||||
|
||||
因此,该许可证中没有任何条款强制代码开源,不像GPL,它要求使用这份代码的用户将他们的修改也开源。这一重要的不同引起了互联网上无数的激烈讨论,BSD的粉丝们说他们的许可证更加自由(因为它不那么严格),而GNU/GPL的粉丝说他们的证书才更自由(因为它保留了真正的自由)
|
||||
|
||||
#### 啊呀,不管怎么说,你已经引起了我的兴趣,我在哪里能尝试这些可爱的BSD版本呢? ####
|
||||
|
||||
您大概已经可以猜到这些网站了 – [www.openbsd.org][1]、[www.freebsd.org][2]、[www.netbsd.org][3]。在那里,您可以下载ISO镜像,在VirtualBox中启动它们,然后开始玩耍。如果您已经用了一段时间的Linux,尽管您需要了解那些命令,但这不会太难。如果您在寻找一些对新手更加友好的东西,可以试试PC-BSD,PC-BSD([www.pcbsd.org][4])是一个基于FreeBSD的个性化定制版本,它专注于桌面,有美观的图形化安装器和超级简单的软件管理器。祝你玩的愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/faq-bsd-2/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
[1]:http://www.openbsd.org/
|
||||
[2]:http://www.freebsd.org/
|
||||
[3]:http://www.netbsd.org/
|
||||
[4]:http://www.pcbsd.org/
|
||||
@ -0,0 +1,57 @@
|
||||
Linux比Mac OS X更好吗?历史中的GNU,开源和Apple
|
||||
==============================================================================
|
||||
> 自由软件/开源社区与Apple之间的争论可以回溯到上世纪80年代,当时Linux的创始人称Mac OS X的核心就是"一个废物",还有其他一些软件历史上的轶事。
|
||||
|
||||

|
||||
|
||||
开源拥护者们与微软之间有着很长,而且摇摆的关系。每个人都知道这个。但是,在许多方面,自由或者开源软件的支持者们与Apple之间的紧张关系则更加突出——尽管这很少受到媒体的关注。
|
||||
|
||||
需要说明的是,并不是所有的开源拥护者都厌恶苹果。Anecdotally(待译),我已经见过很多Linux的黑客玩弄iPhones和iPads。实际上,许多Linux用户是十分喜欢Apple的OS X系统的,以至于他们[创造了很多Linux的发行版][1],都设计得看起来像OS X。(顺便说下,[北朝鲜政府][2]就这样做了。)
|
||||
|
||||
但是Mac的信徒与企鹅——即Linux社区(未提及自由与开源软件世界的小众群体)的信徒之间的关系,并不一直是完全的和谐。并且这绝不是一个新的现象,在我研究Linux历史和开源基金会的时候就发现了。
|
||||
|
||||
### GNU vs. Apple ###
|
||||
|
||||
这场战争将回溯到至少上世界80年代后期。1988年6月,Richard Stallman发起了[GNU][3]项目,希望建立一个完全自由的类Unix操作系统,其源代码讲会免费共享,[[强烈指责][4]Apple对[Hewlett-Packard][5](HPQ)和[Microsoft][6](MSFT)的诉讼,称Apple的声明中,说别人对Macintosh操作系统的界面和体验的抄袭是不正确。如果Apple流行,GNU警告到,这家公司“将会借助大众的新力量终结掉自由软件,而自由软件可以成为商业软件的替代品。”
|
||||
|
||||
那个时候,GNU对抗Apple的诉讼(这意味着,十分讽刺的是,GNU正在支持Microsoft,尽管当时的情况不一样),通过发布["让你的律师远离我的电脑”按钮][7]。同时呼吁GNU的支持者们抵制Apple,警告如果Macintoshes看起来是不错的计算机,但Apple一旦赢得了诉讼就会给市场带来垄断,这会极大地提高计算机的售价。
|
||||
|
||||
Apple最终[输掉了诉讼][8],但是直到1994年之后,GNU才[撤销对Apple的抵制][9]。这期间,GNU一直不断指责Apple。在上世纪90年代早期甚至之后,GNU开始发展GNU软件项目,可以在其他个人电脑平台包括MS-DOS上使用。[GNU 宣称][10],除非Apple停止在计算机领域垄断的野心,让用户界面可以模仿Macintosh的一些东西,否则“我们不会提供任何对Apple机器的支持。”(因此讽刺的是一大堆软件都开发了OS X和类Unix系统的版本,于是Apple在90年代后期介绍这些软件来自GNU。但是那是另外的故事了。)
|
||||
|
||||
### Trovalds on Jobs ###
|
||||
|
||||
除去他对大多数发行版比较自由放任的态度,Liuns Trovalds,Linux内核的创造者,相较于Stallman和GNU过去对Apple的态度没有多一点仁慈。在他2001年出版的书"Just For Fun: The Story of an Accidental Revolutionary"中,Trovalds描述到与Steve Jobs的一个会面,大约是1997年收到后者的邀请去讨论Mac OS X,Apple正在开发,但还没有公开发布。
|
||||
|
||||
"基本上,Jobs一开始就试图告诉我在桌面上的玩家就两个,Microsoft和Apple,而且他认为我能为Linux做的最好的事,就是从了Apple,努力让开源用户站到Mac OS X后面去"Trovalds写道。
|
||||
|
||||
这次谈判显然让Trovalds很不爽。争吵的一点集中在Trovalds对Mach技术上的藐视,对于Apple正在用于构建新的OS X操作系统的内核,Trovalds称其“一推废物。它包含了所有你能做到的设计错误,并且甚至打算只弥补一小部分。”
|
||||
|
||||
但是更令人不快的是,显然是Jobs在开发OS X时入侵开源的方式(OS X的核心里上有很多开源程序):“他有点贬低了结构的瑕疵:谁在乎基础操作系统,真正的low-core东西是不是开源,如果你有Mac层在最上面,这不是开源?”
|
||||
|
||||
一切的一切,Trovalds总结到,Jobs“并没有使用太多争论。他仅仅很简单地说着,胸有成竹地认为我会对与Apple合作感兴趣”。“他没有任何线索,不能去想像还会有人并不关心Mac市场份额的增长。我认为他真的感到惊讶了,当我表现出对Mac的市场有多大,或者Microsoft市场有多大的可怜的关心时。”
|
||||
|
||||
当然,Trovalds并没有对所有Linux用户说起。他对于OS X和Apple的看法从2001年开始就渐渐软化了。但实际上,早在2000年,Linux社区的领导角色表现出对Apple和其高层的傲慢的深深的鄙视,可以看出一些重要的东西,关于Apple和开源/自由软件世界的矛盾是多么的根深蒂固。
|
||||
|
||||
从以上两则历史上的花边新闻中,可以看到关于Apple产品价值的重大争议,即是否该公司致力于提升软硬件的质量,或者仅仅是借市场的小聪明获利,后者会让Apple产品卖出更多的钱,**********(该处不知如何翻译)。但是不管怎样,我会暂时置身讨论之外。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/051815/linux-better-os-x-gnu-open-source-and-apple-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:https://www.linux.com/news/software/applications/773516-the-mac-ifying-of-the-linux-desktop/
|
||||
[2]:http://thevarguy.com/open-source-application-software-companies/010615/north-koreas-red-star-linux-os-made-apples-image
|
||||
[3]:http://gnu.org/
|
||||
[4]:https://www.gnu.org/bulletins/bull5.html
|
||||
[5]:http://www.hp.com/
|
||||
[6]:http://www.microsoft.com/
|
||||
[7]:http://www.duntemann.com/AppleSnakeButton.jpg
|
||||
[8]:http://www.freibrun.com/articles/articl12.htm
|
||||
[9]:https://www.gnu.org/bulletins/bull18.html#SEC6
|
||||
[10]:https://www.gnu.org/bulletins/bull12.html
|
||||
@ -0,0 +1,271 @@
|
||||
在Apache中使用Mod_Security和Mod_evasive来抵御暴力破解和DDos攻击
|
||||
================================================================================
|
||||
对于那些托管主机或者需要将您的主机暴露在因特网中的人来说,保证您的系统在面对攻击时安全是一个重要的事情。
|
||||
|
||||
mod_security(一个开源的可以无缝接入Web服务器的用于Web应用入侵检测和防护的引擎)和mod_evasive是两个在服务器端对抗暴力破解和(D)Dos攻击的非常重要的工具。
|
||||
|
||||
mod_evasive,如它的名字一样,在受攻击时提供避实就虚的功能,它像一个雨伞一样保护Web服务器免受那些威胁。
|
||||
|
||||

|
||||
|
||||
安装Mod_Security和Mod_Evasive来保护Apache
|
||||
|
||||
在这篇文章中我们将讨论如何安装、配置以及在RHEL/CentOS6、7和Fedora 21-15上将它们整合到Apache。另外,我们会模拟攻击以便验证服务器做出了正确的反应。
|
||||
|
||||
以上以您的系统中安装有LAMP服务器为基础,所以,如果您没有安装,请先阅读下面链接的文章再开始阅读本文。
|
||||
|
||||
- [在RHEL/CentOS 7中安装LAMP][1]
|
||||
|
||||
如果您在运行RHEL/CentOS 7或Fedora 21,您还需要安装iptables作为默认[防火墙][2]前端以取代firewalld。这样做是为了在RHEL/CentOS 7或Fedora 21中使用同样的工具。
|
||||
|
||||
### 步骤 1: 在RHEL/CentOS 7和Fedora 21上安装Iptables防火墙 ###
|
||||
|
||||
用下面的命令停止和禁用firewalld:
|
||||
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
|
||||

|
||||
禁用firewalld服务
|
||||
|
||||
接下来在使能iptables之前安装iptables-services包:
|
||||
|
||||
# yum update && yum install iptables-services
|
||||
# systemctl enable iptables
|
||||
# systemctl start iptables
|
||||
# systemctl status iptables
|
||||
|
||||

|
||||
安装Iptables防火墙
|
||||
|
||||
### 步骤 2: 安装Mod_Security和Mod_evasive ###
|
||||
|
||||
另外,在安装LAMP后,您还需要在RHEL/CentOS 7/6中[开启EPEL仓库][3]来安装这两个包。Fedora用户不需要开启这个仓库,因为epel已经是Fedora项目的一部分了。
|
||||
|
||||
# yum update && yum install mod_security mod_evasive
|
||||
|
||||
当安装结束后,您会在/etc/httpd/conf.d下找到两个工具的配置文件。
|
||||
|
||||
# ls -l /etc/httpd/conf.d
|
||||
|
||||

|
||||
mod_security + mod_evasive 配置文件
|
||||
|
||||
现在,为了整合这两个模块到Apache,并在启动时加载它们。请确保下面几行出现在mod_evasive.conf和mod_security.conf的顶层部分,它们分别为:
|
||||
|
||||
LoadModule evasive20_module modules/mod_evasive24.so
|
||||
LoadModule security2_module modules/mod_security2.so
|
||||
|
||||
请注意modules/mod_security2.so和modules/mod_evasive24.so都是从/etc/httpd到模块源文件的相对路径。您可以通过列出/etc/httpd/modules的内容来验证(如果需要的话,修改它):
|
||||
|
||||
# cd /etc/httpd/modules
|
||||
# pwd
|
||||
# ls -l | grep -Ei '(evasive|security)'
|
||||
|
||||

|
||||
验证mod_security + mod_evasive模块
|
||||
|
||||
接下来重启Apache并且核实它已加载了mod_evasive和mod_security:
|
||||
|
||||
# service httpd restart [在RHEL/CentOS 6和Fedora 20-18上]
|
||||
# systemctl restart httpd [在RHEL/CentOS 7和Fedora 21上]
|
||||
|
||||
----------
|
||||
|
||||
[输出已加载的静态模块和动态模块列表]
|
||||
|
||||
# httpd -M | grep -Ei '(evasive|security)'
|
||||
|
||||

|
||||
检查mod_security + mod_evasive模块已加载
|
||||
|
||||
### 步骤 3: 安装一个核心规则集并且配置Mod_Security ###
|
||||
|
||||
简单来说,一个核心规则集(即CRS)为web服务器提供特定状况下如何反应的指令。mod_security的开发者们提供了一个免费的CRS,叫做OWASP([开放Web应用安全项目])ModSecurity CRS,可以从下面的地址下载和安装。
|
||||
|
||||
1. 下载OWASP CRS到为之创建的目录
|
||||
|
||||
# mkdir /etc/httpd/crs-tecmint
|
||||
# cd /etc/httpd/crs-tecmint
|
||||
# wget https://github.com/SpiderLabs/owasp-modsecurity-crs/tarball/master
|
||||
|
||||

|
||||
下载mod_security核心规则
|
||||
|
||||
2. 解压CRS文件并修改文件夹名称
|
||||
|
||||
# tar xzf master
|
||||
# mv SpiderLabs-owasp-modsecurity-crs-ebe8790 owasp-modsecurity-crs
|
||||
|
||||

|
||||
解压mod_security核心规则
|
||||
|
||||
3. 现在,是时候配置mod_security了。将同样的规则文件(owasp-modsecurity-crs/modsecurity_crs_10_setup.conf.example)拷贝至另一个没有.example扩展的文件。
|
||||
|
||||
# cp modsecurity_crs_10_setup.conf.example modsecurity_crs_10_setup.conf
|
||||
|
||||
并通过将下面的几行插入到web服务器的主配置文件/etc/httpd/conf/httpd.conf来告诉Apache将这个文件和该模块放在一起使用。如果您选择解压打包文件到另一个文件夹,那么您需要修改Include的路径:
|
||||
|
||||
<IfModule security2_module>
|
||||
Include crs-tecmint/owasp-modsecurity-crs/modsecurity_crs_10_setup.conf
|
||||
Include crs-tecmint/owasp-modsecurity-crs/base_rules/*.conf
|
||||
</IfModule>
|
||||
|
||||
最后,建议您在/etc/httpd/modsecurity.d目录下创建自己的配置文件,在那里我们可以用我们自定义的文件夹(接下来的示例中,我们会将其命名为tecmint.conf)而无需修改CRS文件的目录。这样做能够在CRSs发布新版本时更加容易的升级。
|
||||
|
||||
<IfModule mod_security2.c>
|
||||
SecRuleEngine On
|
||||
SecRequestBodyAccess On
|
||||
SecResponseBodyAccess On
|
||||
SecResponseBodyMimeType text/plain text/html text/xml application/octet-stream
|
||||
SecDataDir /tmp
|
||||
</IfModule>
|
||||
|
||||
您可以在[SpiderLabs的ModSecurity GitHub][5]仓库中参考关于mod_security目录的更完整的解释。
|
||||
|
||||
### 步骤 4: 配置Mod_Evasive ###
|
||||
|
||||
mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。与mod_security不同,由于在包升级时没有规则来更新,因此我们不需要独立的文件来添加自定义指令。
|
||||
|
||||
默认的mod_evasive.conf开启了下列的目录(注意这个文件被详细的注释了,因此我们剔掉了注释以重点显示配置指令):
|
||||
|
||||
<IfModule mod_evasive24.c>
|
||||
DOSHashTableSize 3097
|
||||
DOSPageCount 2
|
||||
DOSSiteCount 50
|
||||
DOSPageInterval 1
|
||||
DOSSiteInterval 1
|
||||
DOSBlockingPeriod 10
|
||||
</IfModule>
|
||||
|
||||
这些指令的解释:
|
||||
|
||||
- DOSHashTableSize: 这个指令指明了哈希表的大小,它用来追踪基于IP地址的活动。增加这个数字将使查询站点访问历史变得更快,但如果被设置的太高则会影响整体性能。
|
||||
- DOSPageCount: 在DOSPageInterval间隔内可由一个用户发起的面向特定的URI(例如,一个Apache托管的文件)的同一个请求的数量。
|
||||
- DOSSiteCount: 类似DOSPageCount,但涉及到整个站点总共有多少的请求可以在DOSSiteInterval间隔内被发起。
|
||||
- DOSBlockingPeriod: 如果一个用户超过了DOSSPageCount的限制或者DOSSiteCount,他的源IP地址将会在DOSBlockingPeriod期间内被加入黑名单。在DOSBlockingPeriod期间,任何从这个IP地址发起的请求将会遭遇一个403禁止错误。
|
||||
|
||||
尽可能的试验这些值,以使您的web服务器有能力处理特定大小的负载。
|
||||
|
||||
**一个小警告**: 如果这些值设置的不合适,则您会蒙受阻挡合法用户的风险。
|
||||
|
||||
您也许想考虑下其他有用的指令:
|
||||
|
||||
#### DOSEmailNotify ####
|
||||
|
||||
如果您运行有一个邮件服务器,您可以通过Apache发送警告消息。注意,如果SELinux已开启,您需要授权apache用户SELinux的权限来发送email。您可以通过下面的命令来授予权限:
|
||||
|
||||
# setsebool -P httpd_can_sendmail 1
|
||||
|
||||
接下来,将这个指令和其他指令一起加入到mod_evasive.conf文件。
|
||||
|
||||
DOSEmailNotify you@yourdomain.com
|
||||
|
||||
如果这个值被合适的设置并且您的邮件服务器在正常的运行,则当一个IP地址被加入黑名单时,会有一封邮件被发送到相应的地址。
|
||||
|
||||
#### DOSSystemCommand ####
|
||||
|
||||
它需要一个有效的系统命令作为参数,
|
||||
|
||||
DOSSystemCommand </command>
|
||||
|
||||
这个指令指定当一个IP地址被加入黑名单时执行的命令。它通常结合shell脚本来使用,在脚本中添加一条防火墙规则来阻挡某个IP进一步的连接。
|
||||
|
||||
**写一个shell脚本在防火墙阶段处理IP黑名单**
|
||||
|
||||
当一个IP地址被加入黑名单,我们需要阻挡它进一步的连接。我们需要下面的shell脚本来执行这个任务。在/usr/local/bin下创建一个叫做scripts-tecmint的文件夹(或其他的名字),以及一个叫做ban_ip.sh的文件。
|
||||
|
||||
#!/bin/sh
|
||||
# 由mod_evasive检测出,将被阻挡的IP地址
|
||||
IP=$1
|
||||
# iptables的完整路径
|
||||
IPTABLES="/sbin/iptables"
|
||||
# mod_evasive锁文件夹
|
||||
MOD_EVASIVE_LOGDIR=/var/log/mod_evasive
|
||||
# 添加下面的防火墙规则 (阻止所有从$IP流入的流量)
|
||||
$IPTABLES -I INPUT -s $IP -j DROP
|
||||
# 为了未来的检测,移除锁文件
|
||||
rm -f "$MOD_EVASIVE_LOGDIR"/dos-"$IP"
|
||||
|
||||
我们的DOSSystemCommand指令应该是这样的:
|
||||
|
||||
DOSSystemCommand "sudo /usr/local/bin/scripts-tecmint/ban_ip.sh %s"
|
||||
|
||||
上面一行的%s代表了由mod_evasive检测到的攻击IP地址。
|
||||
|
||||
**将apache用户添加到sudoers文件**
|
||||
|
||||
请注意,如果您不给予apache用户以无需终端和密码的方式运行我们脚本(关键就是这个脚本)的权限,则这一切都不起作用。通常,您只需要以root权限键入visudo来存取/etc/sudoers文件,接下来添加下面的两行即可:
|
||||
|
||||
apache ALL=NOPASSWD: /usr/local/bin/scripts-tecmint/ban_ip.sh
|
||||
Defaults:apache !requiretty
|
||||
|
||||

|
||||
添加Apache用户到Sudoers
|
||||
|
||||
**重要**: 作为默认的安全策略,您只能在终端中运行sudo。由于这个时候我们需要在没有tty的时候运行sudo,我们像下面图片中那样必须注释掉下面这一行:
|
||||
|
||||
#Defaults requiretty
|
||||
|
||||

|
||||
为Sudo禁用tty
|
||||
|
||||
最后,重启web服务器:
|
||||
|
||||
# service httpd restart [在RHEL/CentOS 6和Fedora 20-18上]
|
||||
# systemctl restart httpd [在RHEL/CentOS 7和Fedora 21上]
|
||||
|
||||
### 步骤4: 在Apache上模拟DDos攻击 ###
|
||||
|
||||
有许多工具可以在您的服务器上模拟外部的攻击。您可以google下“tools for simulating ddos attacks”来找一找相关的工具。
|
||||
|
||||
注意,您(也只有您)将负责您模拟所造成的结果。请不要考虑向不在您网络中的服务器发起模拟攻击。
|
||||
|
||||
假如您想对一个由别人托管的VPS做这些事情,您需要向您的托管商发送适当的警告或就那样的流量通过他们的网络获得允许。Tecmint.com不会为您的行为负责!
|
||||
|
||||
另外,仅从一个主机发起一个Dos攻击的模拟无法代表真实的攻击。为了模拟真实的攻击,您需要使用许多客户端在同一时间将您的服务器作为目标。
|
||||
|
||||
我们的测试环境由一个CentOS 7服务器[IP 192.168.0.17]和一个Windows组成,在Windows[IP 192.168.0.103]上我们发起攻击:
|
||||
|
||||

|
||||
确认主机IP地址
|
||||
|
||||
请播放下面的视频,并跟从列出的步骤来模拟一个Dos攻击:
|
||||
|
||||
注:youtube视频,发布的时候不行做个链接吧
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/-U_mdet06Jk"></iframe>
|
||||
|
||||
然后攻击者的IP将被iptables阻挡:
|
||||
|
||||

|
||||
阻挡攻击者的IP地址
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在开启mod_security和mod_evasive的情况下,模拟攻击会导致CPU和RAM用量在源IP地址被加入黑名单之前出现短暂几秒的使用峰值。如果没有这些模块,模拟攻击绝对会很快将服务器击溃,并使服务器在攻击期间无法提供服务。
|
||||
|
||||
我们很高兴听见您打算使用(或已经使用过)这些工具。我们期望得到您的反馈,所以,请在留言处留下您的评价和问题,谢谢!
|
||||
|
||||
### 参考链接 ###
|
||||
|
||||
- [https://www.modsecurity.org/][6]
|
||||
- [http://www.zdziarski.com/blog/?page_id=442][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[2]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
[3]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[4]:https://www.owasp.org/index.php/Category:OWASP_ModSecurity_Core_Rule_Set_Project
|
||||
[5]:https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual#Configuration_Directives
|
||||
[6]:https://www.modsecurity.org/
|
||||
[7]:http://www.zdziarski.com/blog/?page_id=442
|
||||
@ -0,0 +1,149 @@
|
||||
Linux中7个用来浏览网页和下载文件的命令
|
||||
================================================================================
|
||||
上一篇文章中,我们提到了`rTorrent`、`wget`、`cURL`、`w3m`、`Elinks`等几个有用的工具,很多人回信说还有其它几个类似的工具也值得讨论,所以就有了这篇文章。如果错过了第一部分的讨论,可以通过下面的链接来回顾。
|
||||
|
||||
- [5个下载文件和浏览网页的命令行工具][1]
|
||||
|
||||
这篇文章介绍了Linux下用于浏览网页和下载文件的其它几个命令行工具。
|
||||
|
||||
### 1. links ###
|
||||
|
||||
Links是用C语言写的一个开源web浏览器,支持包括Linux、Windows、OS X和OS/2在内的所有主流平台。它提供了基于文本和图形界面两种版本。大多数标准的Linux发行版都默认包含了基于文本的版本。如果您的发行版中默认没有安装links,可以通过包管理工具进行安装。Elinks是links的一个衍生版本。
|
||||
|
||||
# apt-get install links
|
||||
# yum install links
|
||||
|
||||
安装完成后,您可以像下图中那样使用命令浏览任意网页。
|
||||
|
||||
# links www.tecmint.com
|
||||
|
||||
在links中,可以使用键盘上的上下箭头键进行浏览。在超链接上按下右箭头会打开它,按下左箭头会返回到上一页面,按q键退出。
|
||||
|
||||
下图展示了如何使用links访问Tecmint的网站。
|
||||
|
||||

|
||||
|
||||
如何你想安装links的图形界面版本,可能需要从[http://links.twibright.com/download/][2]下载最新的版本tarball(version 2.9)的源代码。
|
||||
|
||||
同样,也可以像下面那样使用wget下载安装。
|
||||
|
||||
# wget http://links.twibright.com/download/links-2.9.tar.gz
|
||||
# tar -xvf links-2.9.tar.gz
|
||||
# cd links-2.9
|
||||
# ./configure –enable-graphics
|
||||
# make
|
||||
# make install
|
||||
|
||||
**注意**:links源代码的编译需要安装libpng, libjpeg, TIFF library, SVGAlib, XFree86, C Compiler and make这几个包。
|
||||
|
||||
### 2. links2 ###
|
||||
|
||||
Links是Twibright实验室编写的web浏览器,而Links2是基于它的一个图形化版本。Links2支持鼠标点击,设计强调速度,不支持任何CSS,在一定程度上很好地支持了HTML和JavaScript。
|
||||
|
||||
通过下面的命令安装Links2。
|
||||
|
||||
# apt-get install links2
|
||||
# yum install links2
|
||||
|
||||
### 3. lynx ###
|
||||
|
||||
lynx是一个基于文本的web浏览器,使用GNU GPLv2协议发布,用ISO C编写。lynx是一个可高度配置的web浏览器,是许多系统管理员的救世主,有最悠久的web浏览器之称,并且至今仍然处在积极开发中。
|
||||
|
||||
通过下面的命令安装lyns。
|
||||
|
||||
# apt-get install lynx
|
||||
# yum install lynx
|
||||
|
||||
安装完成后,可以像下图中那样使用这个命令浏览网页。
|
||||
|
||||
# lynx www.tecmint.com
|
||||
|
||||

|
||||
|
||||
如果你想对links和lyns了解更多,可以访问下面的链接。
|
||||
|
||||
- [使用Lynx和Links命令浏览网页][3]
|
||||
|
||||
### 4. youtube-dl ###
|
||||
|
||||
youtube-dl是一个跨平台的应用,可以用来下载youtube和另外几个网站上的视频。它主要使用python开发,使用GNU GPL协议发布,并且超越了法律约束。(youtube不允许用户下载视频,因此使用youtube-dl可能会导致违法。使用该工具之前请您仔细阅读相关法律。)
|
||||
|
||||
使用如下命令安装youtube-dl。
|
||||
|
||||
# apt-get install youtube-dl
|
||||
# yum install youtube-dl
|
||||
|
||||
安装完成后,可以用如下命令像图中那样从youtube网站下载视频。
|
||||
|
||||
# youtube-dl https://www.youtube.com/watch?v=ql4SEy_4xws
|
||||
|
||||

|
||||
|
||||
如果你想对youtube-dl了解更多,可以访问如下链接。
|
||||
|
||||
- [YouTube-DL – Linux下的youtube视频下载工具][4]
|
||||
|
||||
### 5. fetch ###
|
||||
|
||||
fetch是类unix系统下的一个检索URL的命令,支持许多选项,例如只检索ipv4或ipv6地址,无重定向,检索请求成功时退出,自动重试等。
|
||||
|
||||
fetch可以从通过下面的链接下载和安装。
|
||||
|
||||
- [http://sourceforge.net/projects/fetch/?source=typ_redirect][5]
|
||||
|
||||
编译安装之前,需要安装HTTP Fetcher,可以通过下面的链接下载。
|
||||
|
||||
- [http://sourceforge.net/projects/http-fetcher/?source=typ_redirect][6]
|
||||
|
||||
### 6. Axel ###
|
||||
|
||||
Axel是Linux下的一个基于命令行的下载加速器,可以对请求使用多线程和多个http和ftp连接加速。
|
||||
|
||||
使用下面的命令安装Axel。
|
||||
|
||||
# apt-get install axel
|
||||
# yum install axel
|
||||
|
||||
Axel安装完成后,可以像下图那样使用这个命令下载任意文件。
|
||||
|
||||
# axel http://mirror.cse.iitk.ac.in/archlinux/iso/2015.04.01/archlinux-2015.04.01-dual.iso
|
||||
|
||||

|
||||
|
||||
### 7. aria2 ###
|
||||
|
||||
aria2是一个轻量级的基于命令行的下载工具,并且支持多种协议((HTTP, HTTPS, FTP, BitTorrent以及Metalink)。它可以使用.metalinks文件从多台服务器同时下载ISO文件。
|
||||
|
||||
使用下面的命令安装aria2。
|
||||
|
||||
# apt-get install aria2
|
||||
# yum install aria2
|
||||
|
||||
aria2安装完成后,可以像下图那样运行这个命令下载任意文件。
|
||||
|
||||
# aria2c http://cdimage.debian.org/debian-cd/7.8.0/multi-arch/iso-cd/debian-7.8.0-amd64-i386-netinst.iso
|
||||
|
||||

|
||||
|
||||
Aria2: Linux命令行下载工具
|
||||
|
||||
目前就这么多了。稍后咱们讨论另一个有意思的话题。请保持联系,常来Tecmint逛逛。别忘了在评论中给我们提供您的宝贵反馈,您的喜爱和分享帮助我们不断前行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/command-line-web-browser-download-file-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[fyh](https://github.com/fyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/linux-command-line-tools-for-downloading-files/
|
||||
[2]:http://links.twibright.com/download/
|
||||
[3]:http://www.tecmint.com/command-line-web-browsers/
|
||||
[4]:http://www.tecmint.com/install-youtube-dl-command-line-video-download-tool/
|
||||
[5]:http://sourceforge.net/projects/fetch/?source=typ_redirect
|
||||
[6]:http://sourceforge.net/projects/http-fetcher/?source=typ_redirect
|
||||
[7]:http://www.tecmint.com/install-aria2-a-multi-protocol-command-line-download-manager-in-rhel-centos-fedora/
|
||||
@ -1,171 +0,0 @@
|
||||
Translating by demon
|
||||
如何使用图形化工具远程管理Linux Vps上的MySql
|
||||
================================================================================
|
||||
如果你在一个远程的VPS上运行了MYSQL server,你会如何管理你的远程数据库主机呢?基于web的数据库管理工具例如phpMyAdmin或者Adminer可能会是你一个想起的。这些基于web的管理工具需要一个后端的web服务和PHP引擎在正常运行。但是,如果你的VPS仅仅用来做数据库服务(e.g., for a multi-tier app),为临时的数据库管理提供一整套的LAMP是浪费VPS资源的。更糟的是,LAMP带有的HTTP端口可能会成为你VPS资源的安全漏洞。
|
||||
|
||||
作为一种选择,你可以使用在一台客户机上运行本地的Mysql客户端,当然,如果没有别的选择,一个纯净的命令行mysql客户端将是你的默认选择。但是命令行客户端的功能是有限的,因此它不适合在生产环境中使用,例如:sql开发,性能调优,模式验证等等。你是否在寻找一个成熟的MYSQL管理工具,那么一个MYSQL的图形化管理工具将会更好的满足你的需求。
|
||||
|
||||
什么是MySQL Workbench?
|
||||
|
||||
作为一个由Oracle开发的成熟数据库管理工具,mysql workbench不仅仅是一个MySQL客户端。简而言之,Workbench是一个跨平台的(eg:Linux,MacOX,Windows)数据库设计,开发和管理图形工具。社区版本的Msyql Workbench是遵循GPL协议的。作为一个数据库管理者,你可以使用Workbench去配置Mysql服务,管理Mysql用户,完成数据库的备份与还原,监视数据库的健康状况,所有的都在对用户友好的图形化环境下处理。
|
||||
|
||||
在这个手册里,让我们演示下如何在Linux下安装和使用Mysql Workbench.
|
||||
|
||||
在Linux上安装MySQL Workbench
|
||||
|
||||
你可以在任何一个桌面linux机器上运行Mysql Workbench去设置你的数据库管理环境。然而一些Linux发行版(例如:Debian/Ubuntu)在他们的软件源中已经有了Mysql Workbench.从官方源中安装是一个好的方法,因为他们提供了最新的版本。这里介绍了如何设置一个官方的Workbench源和从中安装它。
|
||||
|
||||
#### Debian-based Desktop (Debia, Ubuntu, Mint): ####
|
||||
|
||||
到其官方站点,选择一个和你环境匹配的DEB file源,并下载安装
|
||||
|
||||
For example, on Ubuntu 14.10:
|
||||
|
||||
$ wget http://dev.mysql.com/get/mysql-apt-config_0.3.4-2ubuntu14.10_all.deb
|
||||
$ sudo dpkg -i mysql-apt-config_0.3.4-2ubuntu14.10_all.deb
|
||||
|
||||
on Debian 7:
|
||||
|
||||
$ wget http://dev.mysql.com/get/mysql-apt-config_0.3.3-1debian7_all.deb
|
||||
$ sudo dpkg -i mysql-apt-config_0.3.3-1debian7_all.deb
|
||||
|
||||
当你安装DEB文件时,你会看到下面的配置菜单,并且选择配置那个Mysql产品
|
||||
|
||||

|
||||
|
||||
选择“Utilities”.完成配置后,选择“Apply”去保存配置。然后,更新包索引,并且安装Workbench
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install mysql-workbench
|
||||
|
||||
#### Red Hat-based Desktop (CentOS, Fedora, RHEL): ####
|
||||
|
||||
去官网下载并安装适合你Linux环境的RPM源包
|
||||
For example, on CentOS 7:
|
||||
|
||||
$ wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
|
||||
$ sudo yum localinstall mysql-community-release-el7-5.noarch.rpm
|
||||
|
||||
on Fedora 21:
|
||||
|
||||
$ wget http://dev.mysql.com/get/mysql-community-release-fc21-6.noarch.rpm
|
||||
$ sudo yum localinstall mysql-community-release-fc21-6.noarch.rpm
|
||||
|
||||
验证"MySQL Tools Community"源是否被安装
|
||||
$ yum repolis enabled
|
||||
|
||||

|
||||
|
||||
安装Workbench
|
||||
|
||||
$ sudo yum install mysql-workbench-community
|
||||
|
||||
设置远程数据库的安全连接
|
||||
|
||||
接下来是为你运行Mysql服务的VPS设置一个远程连接,当然你可以直接通过图形化的Workbench连接你的远程Mysql服务器(在数据库开放了远程连接后)。然而,这样做有很大的安全风险,因为有些人很容易窃听你的数据库传输信息,并且一个公开的Mysql端口(默认为3306)被作为攻击入口。
|
||||
|
||||
一个比较好的方法是关掉远程访问数据库服务功能,(仅允许在127.0.0.1访问)。然后在本地客户机和远程Vps直接设置一个SSH隧道,这样的话,和mysql之间的数据能被安全的传输,仅在它的本地回环接口上。相比较设置一个SSL加密的连接来说,配置SSH隧道需要很少的操作,因为他仅仅需要SSH服务,并且在大多数的VPS上已经部署了。
|
||||
|
||||
让我们来看看如何来为一个Mysql Workbench设置一个SSH隧道,这里的设置,不需要你开放远程访问Mysql服务。
|
||||
在一个运行了Workbench的本地客户机上,键入下面的命令,替换'user' and 'remote_vps'为你自己的信息
|
||||
|
||||
$ ssh user@remote_vps -L 3306:127.0.0.1:3306 -N
|
||||
|
||||
你会被要求输入你VPS的SSH密码,当你成功登陆VPS后,一个SSH隧道将会在本地的3306端口和远程VPS的3306端口将会被建立。这里你不会看到任何信息。
|
||||
|
||||
或者你可以选择在后台运行SSH隧道,按CTRL+Z停止当前的命令,然后输入bg并且ENTER
|
||||
|
||||

|
||||
|
||||
这样SSH隧道就会在后台运行了。
|
||||
|
||||
使用MySQL Workbench远程管理MySQL服务
|
||||
|
||||
在建立好SSH隧道后,你可以通过MySQL Workbench去远程连接Mysql服务了。
|
||||
|
||||
输入下面命令启动Workbench
|
||||
|
||||
$ mysql-workbench
|
||||
|
||||

|
||||
|
||||
点击Workbench页面上面的加号图标去创建一个新的数据库连接,接着会出现下面的连接信息。
|
||||
|
||||
- **Connection Name**: any description (e.g., My remote VPS database)
|
||||
- **Hostname**: 127.0.0.1
|
||||
- **Port**: 3306
|
||||
- **Username**: MySQL username (e.g., root)
|
||||
|
||||

|
||||
|
||||
注意:因为隧道设置的是127.0.0.1:3306,所以主机名哪里必须是127.0.0.1,而不能是远程VPS的IP地址或者主机名
|
||||
|
||||
当你设置好一个新的数据库连接后,你会在Workbench窗口看到一个新的框,点击那个框就会实际去连接远程的MySQL服务了。
|
||||
|
||||

|
||||
|
||||
当你设置好一个新的数据库连接后,你会在Workbench窗口看到一个新的框,点击那个框就会实际去连接远程的MySQL服务了。
|
||||
|
||||
#### MySQL Server Status ####
|
||||
|
||||
当你设置好一个新的数据库连接后,你会在Workbench窗口看到一个新的框,点击那个框就会实际去连接远程的MySQL服务了。
|
||||
|
||||

|
||||
|
||||
#### Client Connections ####
|
||||
|
||||
连接数是一个极其重要的监视资源,这个菜单显示了每个连接的详细信息。
|
||||
|
||||

|
||||
|
||||
#### 用户和权限 ####
|
||||
|
||||
这个菜单允许你管理MySQL用户,包括他们的资源限制和权限。
|
||||
|
||||

|
||||
|
||||
#### MySQL Server Administration ####
|
||||
|
||||
你可以启动或关闭MySQL服务,并且检查它的服务日志。
|
||||
|
||||

|
||||
|
||||
#### Database Schema Management ####
|
||||
|
||||
可以可视化的查看,更改,检查数据库结构,在“Schemas”标题下选择任何一个数据库或表,然后右击
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
#### Database Query ####
|
||||
|
||||
你可以执行任何的语句(只要你的权限允许),并且检查他的结果。
|
||||
|
||||

|
||||
|
||||
此外,性能统计数据和报表仅用于MySQL5.6以上的版本。对于5.5及其以下的版本,性能部分会以灰色显示。
|
||||
### 结论 ###
|
||||
|
||||
简介且直观的选项卡界面,丰富的特性,开源,使MySQL Workbench成为一个非常好的可视化数据库设计和管理工具。为其减分的是它的性能。我注意到在一台运行繁忙的服务器上,Workbench优势会变得异常缓慢,尽管它的性能差强人意,我依然认为MySQL Workbench是MySQL数据库管理员和设计人员必备的工具之一。
|
||||
|
||||
你曾在你的生产环境中用过Workbench吗?或者你还有别的GUI工具可以推荐?请分享你的经验吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/remote-mysql-databases-gui-tool.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/tyzy313481929译者demon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://ask.xmodulo.com/install-phpmyadmin-centos.html
|
||||
[3]:http://xmodulo.com/set-web-based-database-management-system-adminer.html
|
||||
[4]:http://mysqlworkbench.org/
|
||||
[5]:http://dev.mysql.com/downloads/repo/apt/
|
||||
[6]:http://dev.mysql.com/downloads/repo/yum/
|
||||
[7]:http://xmodulo.com/how-to-allow-remote-access-to-mysql.html
|
||||
@ -1,56 +0,0 @@
|
||||
Linux有问必答:如何在虚拟机上配置PCI-passthrough
|
||||
================================================================================
|
||||
> **提问**:我想要设置一块物理网卡到用KVM创建的虚拟机上。我打算开启网卡的PCI passthrough给这台虚拟机。请问,我如何才能增加一个PCI设备通过PCI直通到虚拟机上?
|
||||
|
||||
如今的hypervisor能够高效地在多个虚拟操作系统分享和模拟硬件资源。然而,虚拟资源分享,虚拟机的性能,或者是虚拟机需要硬件DMA的完全控制,不是总能使人满意。一项名叫“PCI passthrough”的技术可以用在一个虚拟机需要独享PCI设备时(例如:network/sound/video card)。本质上,PCI passthrough越过了虚拟层,直接扩展PCI设备到虚拟机。但是其他虚拟机不能同时共享。
|
||||
|
||||
|
||||
### 开启“PCI Passthrough”的准备 ###
|
||||
|
||||
如果你想要为一台HVM实例开启PCI passthrough(例如,一台KVM创建的full虚拟机),你的母系统(包括CPU和主板)必须满足以下条件。但是如果你的虚拟机是para-V(由Xen创建),你可以挑过这步。
|
||||
|
||||
为了开启PCI passthrough,系统需要支持**VT-d** (Intel处理器)或者**AMD-Vi** (AMD处理器)。Intel的VT-D(“英特尔虚拟化技术支持直接I/ O”)是适用于最高端的Nehalem处理器和它的后继者(例如,Westmere、Sandy Bridge的,Ivy Bridge)。注意:VT-d和VT-x是两个独立功能。intel/AMD处理器支持VT-D/AMD-VI功能的列表可以[点击这里][1]。
|
||||
|
||||
完成验证你的设备支持VT-d/AMD-Vi后,还有两件事情需要做。首先,确保VT-d/AMD-Vi已经在BIOS中开启。然后,在内核启动过程中开启IOMMU。IOMMU服务,是VT-d,/AMD-Vi提供,可以保护虚拟机访问的主机内存,同时它也是full虚拟机支持PCI passthrough的前提。
|
||||
|
||||
Intel处理器中,内核开启IOMMU通过在启动参数中修改“**intel_iommu=on**”。参看[这篇教程][2]获得如何通过GRUB修改内核启动参数。
|
||||
|
||||
配置完成启动参数后,重启电脑。
|
||||
|
||||
### 添加PCI设备到虚拟机 ###
|
||||
|
||||
我们已经完成了开启PCI Passthrough的准备。事实上,只需通过虚拟机管理就可以给虚拟机分配一个PCI设备。
|
||||
|
||||
打开虚拟机设置,在左边工具栏点击‘增加硬件’按钮。
|
||||
|
||||
选择从PCI设备表一个PCI设备来分配,点击“完成”按钮
|
||||
|
||||

|
||||
|
||||
最后,开启实例。目前为止,主机的PCI设备已经可以由虚拟机直接访问了。
|
||||
|
||||
### 常见问题 ###
|
||||
|
||||
在虚拟机启动时,如果你看见下列任何一个错误,这个错误有可能由于母机VT-d (或 IOMMU)未开启导致。
|
||||
|
||||
Error starting domain: unsupported configuration: host doesn't support passthrough of host PCI devices
|
||||
|
||||
----------
|
||||
|
||||
Error starting domain: Unable to read from monitor: Connection reset by peer
|
||||
|
||||
请确保"**intel_iommu=on**"启动参数已经按上文叙述开启。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/pci-passthrough-virt-manager.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wiki.xenproject.org/wiki/VTdHowTo
|
||||
[2]:http://xmodulo.com/add-kernel-boot-parameters-via-grub-linux.html
|
||||
@ -1,106 +0,0 @@
|
||||
关于Docker容器的基础网络命令
|
||||
================================================================================
|
||||
各位好,今天我们将学习一些Docker容器的基础命令。Docker是一个提供了开放平台来打包、发布并以一个轻量级容器运行任意程序的开放平台。它没有语言支持、框架或者打包系统的限制,可在任何时间、任何地方在小到家用电脑大到高端服务器上运行。这使得在部署和扩展网络应用、数据库和终端服务时不依赖于特定的栈或者提供商。Docker注定是用于网络的如它正应用于数据中心、ISP和越来越多的网络服务。
|
||||
|
||||
因此,这里有一些你在管理Docker容器的时候会用到的一些命令。
|
||||
|
||||
### 1. 找到Docker接口 ###
|
||||
|
||||
Docker默认会创建一个名为docker0的网桥接口来连接外部的世界。docker容器运行时直接连接到网桥接口docker0。默认上,docker会分配172.17.42.1/16给docker0,它是所有运行容器ip地址的子网。得到Docker接口的ip地址非常简单。要找出docker0网桥接口和连接到网桥上的docker容器,我们可以在终端或者安装了docker的shell中运行ip命令。
|
||||
|
||||
# ip a
|
||||
|
||||

|
||||
|
||||
### 2. 得到Docker容器的ip地址 ###
|
||||
|
||||
如我们上面读到的,docker在主机中创建了一个叫docker0的网桥接口。如我们创建一个心的docker容器一样,它自动被默认分配了一个在子网范围内的ip地址。因此,要检测运行中的Docker容器的ip地址,我们需要进入一个正在运行的容器并用下面的命令检查ip地址。首先,我们运行一个新的容器并进入。如果你已经有一个正在运行的容器,你可以跳过这个步骤。
|
||||
|
||||
# docker run -it ubuntu
|
||||
|
||||
现在,我们可以运行ip a来得到容器的ip地址了。
|
||||
|
||||
# ip a
|
||||
|
||||

|
||||
|
||||
### 3. 映射暴露的端口 ###
|
||||
|
||||
要映射配置在Dockerfile的暴露端口,我们只需用下面带上-P标志的命令。这会打开docker容器的随机端口并映射到Dockerfile中定义的端口。下面是使用-P来打开/映射定义的端口的例子。
|
||||
|
||||
# docker run -itd -P httpd
|
||||
|
||||

|
||||
|
||||
上面的命令会映射Dockerfile中定义的httpd 80端口到容器的端口上。我们用下面的命令来查看正在运行的容器暴露的端口。
|
||||
|
||||
# docker ps
|
||||
|
||||
并且可以用下面的curl命令来检查。
|
||||
|
||||
# curl http://localhost:49153
|
||||
|
||||

|
||||
|
||||
### 4. 映射到特定的端口上 ###
|
||||
|
||||
我们也可以映射暴露端口或者docker容器端口到我们指定的端口上。要实现这个,我们用-p标志来定义我们的需要。这里是我们的一个例子。
|
||||
|
||||
# docker run -itd -p 8080:80 httpd
|
||||
|
||||
上面的命令会映射8080端口到80上。我们可以运行curl来检查这点。
|
||||
|
||||
# curl http://localhost:8080
|
||||
|
||||

|
||||
|
||||
### 5. 创建自己的网桥 ###
|
||||
|
||||
要给容器创建一个自定义的IP地址,在本篇中我们会创建一个名为bro的新网桥。要分配需要的ip地址,我们需要在运行docker的主机中运行下面的命令。
|
||||
|
||||
# stop docker.io
|
||||
# ip link add br0 type bridge
|
||||
# ip addr add 172.30.1.1/20 dev br0
|
||||
# ip link set br0 up
|
||||
# docker -d -b br0
|
||||
|
||||

|
||||
|
||||
创建完docker网桥之后,我们要让docker的守护进程知道它。
|
||||
|
||||
# echo 'DOCKER_OPTS="-b=br0"' >> /etc/default/docker
|
||||
# service docker.io start
|
||||
|
||||

|
||||
|
||||
到这里,桥接后的接口将会分配给容器新的在桥接子网内的ip地址。
|
||||
|
||||
### 6. 链接到另外一个容器上 ###
|
||||
|
||||
我们可以用Dokcer连接一个容器到另外一个上。我们可以在不容的容器上运行不同的程序,并且相互连接或链接。链接允许容器间相互连接并安全地从一个容器上传输信息给另一个容器。要做到这个,我们可以使用--link标志。首先,我们使用--name标志来表示training/postgres镜像。
|
||||
|
||||
# docker run -d --name db training/postgres
|
||||
|
||||

|
||||
|
||||
完成之后,我们将容器db与training/webapp链接来形成新的叫web的容器。
|
||||
|
||||
# docker run -d -P --name web --link db:db training/webapp python app.py
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
Docker网络很神奇也好玩,因为有我们可以对docker容器做很多事情。这里有些简单和基础的我们可以把玩docker网络命令。docker的网络是非常高级的。我们可以用它做很多事情。如果你有任何的问题、建议、反馈请在下面的评论栏写下来以便于我们我们可以提升或者更新文章的内容。谢谢! 玩得开心!:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/networking-commands-docker-containers/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,180 @@
|
||||
安装 Tails 1.4 Linux 操作系统来保护隐私和保持匿名
|
||||
================================================================================
|
||||
在这个互联网世界和互联网的世界中,我们在线执行我们的大多数任务,无论是订票,汇款,研究,商务,娱乐,社交网络,还是其他。每天我们花费大部分时间在网络上。在每个逝去的日子里,在网络中保持匿名变得越来越难,尤其是在被某些机构例如 NSA (National Security Agency,国安局) 植入后门的情况下,这些机构嗅探着我们在网络中的所有动作。在网络中,我们有着极少,或者说根本就没有隐私。基于用户浏览网络的活动和机器的活动的搜索都被记录了下来。
|
||||
|
||||
一个来自于 Tor 项目的绝妙浏览器正被上百万人使用,它帮助我们匿名地浏览网络,即使这样,跟踪你的浏览习惯也并不难,所以只使用 Tor 并不能保证你的网络安全。你可以从下面的链接中查看 Tor 的特点及安装指南。
|
||||
|
||||
- [使用 Tor 来进行匿名网络浏览][1]
|
||||
|
||||
Tor 项目中有一个名为 Tails 的操作系统。Tails (The Amnesic Incognito Live System) 是一个 live 操作系统,基于 Debian Linux 发行版本,主要着眼于在浏览网络时在网络中保护隐私和匿名,这意味着所有的外向连接都强制通过 Tor 来连接,直接的(非匿名的) 连接请求都会被阻挡。该系统被设计为可在任何可启动介质上运行,例如 USB 或 DVD。
|
||||
|
||||
Tails OS 的最新稳定发行版本为 1.4 , 于 2015 年 5 月 12 日发行。Tails 由开源单片 Linux 内核支持,构建在 Debian GNU/Linux 之上,着眼于个人电脑市场, 使用 GNOME 3 作为其默认的用户界面。
|
||||
|
||||
#### Tails OS 1.4 的特点 ####
|
||||
|
||||
- Tails 是一个 free 的操作系统, free 的意义正如 免费(free)啤酒和言论自由(free) 中的 free
|
||||
- 构建在 Debian/GNU Linux 操作系统之上, Debian 是使用最广泛的通用操作系统
|
||||
- 着眼于安全的发行版本
|
||||
- 有 Windows 8 外观作为其伪装
|
||||
- 不必安装就可以使用 Live Tails CD/DVD 来匿名浏览网络
|
||||
- 当 Tails 运行时,不留下任何痕迹
|
||||
- 使用先进的加密工具来加密任何相关文件,邮件等内容
|
||||
- 通过 Tor 网络来发送和接收流量
|
||||
- 在真正意义上为任何人在任何地方保护隐私
|
||||
- 在 Live 环境中带有一些可用的应用
|
||||
- 系统自带的所有软件都预先配置好只通过 Tor 网络来连接到互联网
|
||||
- 任何不通过 Tor 网络而尝试连接网络的应用都将被自动阻拦。
|
||||
- 限制那些想查看你正在浏览什么网站的人的行动,并限制网站获取你的地理位置
|
||||
- 连接到那些被墙或被审查的网站
|
||||
- 特别设计不使用主操作系统的空间,即使在 swap 空间还有空余的情况下
|
||||
- 整个操作系统加载在 RAM 中,在每次重启或关机后会自动擦除掉,所以不会留下任何运行的痕迹。
|
||||
- 先进的安全实现,通过加密 USB 磁盘, HTTPS 应答加密和对邮件,文档进行签名。
|
||||
|
||||
#### 在 Tails 1.4 中可期待的东西 ####
|
||||
|
||||
- 带有安全滑块的 Tor 浏览器 4.5
|
||||
- Tor 被升级到版本 0.2.6.7
|
||||
- 修补了几个安全漏洞
|
||||
- 针对诸如 curl, OpenJDK 7, tor Network, openldap 等应用, 许多漏洞被修复并打上了补丁
|
||||
|
||||
要得到完整的更改记录,你需要访问 [这里][2]
|
||||
|
||||
**注意**: 假如你使用 Tails 的任何旧版本,强烈建议升级到 Tails 1.4 。
|
||||
|
||||
#### 为什么我应该使用 Tails 操作系统 ####
|
||||
|
||||
你需要 Tails 因为你想:
|
||||
|
||||
- 在网络监控下保持自由
|
||||
- 捍卫自由,隐私和秘密
|
||||
- 流量分析下保持安全
|
||||
|
||||
这个教程将带你了解 Tails 1.4 操作系统的安装并给出一个简短的评论。
|
||||
|
||||
### Tails 1.4 安装指南 ###
|
||||
|
||||
1. 为了下载最新的 Tails OS 1.4,你可以使用 wget 命令来直接下载它
|
||||
|
||||
$ wget http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
|
||||
|
||||
或者你可以直接下载 Tails 1.4 的 ISO 镜像文件,或使用一个 Torrent 客户端来为你获取 ISO 镜像文件:
|
||||
|
||||
- [tails-i386-1.4.iso][3]
|
||||
- [tails-i386-1.4.torrent][4]
|
||||
|
||||
2. 下载后,可使用 SHA256SUM 来获取 ISO 文件的哈希值并与官方提供的值相比较,以核实 ISO 文件的完整性
|
||||
|
||||
$ sha256sum tails-i386-1.4.iso
|
||||
|
||||
339c8712768c831e59c4b1523002b83ccb98a4fe62f6a221fee3a15e779ca65d
|
||||
|
||||
假如你熟悉 OpenPGP ,将 Tails 的签名密钥与 Debian 的 keyring 相比较以验证其签名,若想了解任何有关 Tails 的加密签名,请将浏览器指向 [这里][5]
|
||||
|
||||
3. 下一步,你需要将镜像写入 USB 或 DVD ROM 中。或许你需要看看这篇文章 [如何创建一个 Live 可启动的 USB][6] 以了解如何使得一个闪存驱动器变得可启动并向它写入 ISO 镜像文件。
|
||||
|
||||
4. 插入 Tails OS 可启动闪存驱动器或 DVD ROM,并从那里启动 (在 BIOS 中选择该介质来启动)。第一个屏幕中会有两个选项 'Live' 和 'Live (failsafe)' 让你选择。选择 'Live' 并确定。
|
||||
|
||||

|
||||
Tails 启动菜单
|
||||
|
||||
5. 在登录之前,你有两个选项, 假如你想配置并设定高级选项,点击 '更多选项' 否则点击 'NO'。
|
||||
|
||||

|
||||
Tails 欢迎界面
|
||||
|
||||
6. 在点击高级选项后,你需要设置 root 密码。假如你想升级它,这是非常重要的。这个 root 密码将会一直有效,知道你关机或重启。
|
||||
|
||||
另外,若你想开启 Windows 伪装,假如你想在一个公共场所运行这个操作系统,这将使得看起来你正在运行 Windows 8 操作系统。这真是一个好的选项!不是吗?另外,你还有一个选项来配置 网络和 Mac 地址,当一切准备完毕后,点击 '登录' !
|
||||
|
||||

|
||||
Tails OS 的配置
|
||||
|
||||
7. 这是使用 Windows 皮肤伪装的 Tails GNU/Linux OS:
|
||||
|
||||

|
||||
Tails 的 Windows 伪装
|
||||
|
||||
8. 系统将在后台启动 Tor 网络。在屏幕的右上角查看通知 – Tor 已经准备好了 或现在你已经连接上了互联网。
|
||||
|
||||
你也可以在 Internet 菜单下查看它包含了哪些东西。 注意 – 它包含有 Tor 浏览器(安全的) 和 不安全的网络浏览器(其中的向内和向外数据不通过 Tor 网络) 和其他应用。
|
||||
|
||||

|
||||
Tails 菜单和工具
|
||||
|
||||
9. 点击 Tor 并检查你的 IP 地址。 它确认我的物理位置没有被分享以及我的隐私未被触动。
|
||||
|
||||

|
||||
在 Tails 上检查隐私
|
||||
|
||||
10. 你还可以激活 Tails 安装器来从 ISO 镜像文件中 克隆和安装, 克隆和升级以及升级系统。
|
||||
|
||||

|
||||
Tails 安装器选项
|
||||
|
||||
11. 其他选项为选择 Tor 不带有高级选项,就在登录之前。(查看上面的第 5 步).
|
||||
|
||||

|
||||
Tails 未带有高级选项
|
||||
|
||||
12. 你将登录到 Gnome3 桌面环境。
|
||||
|
||||

|
||||
Tails Gnome 桌面
|
||||
|
||||
13. 假如你点击启动不安全的浏览器,无论在带有伪装,还是没有带有伪装的情况下,你都将会收到弹窗通知。
|
||||
|
||||

|
||||
Tails 浏览通知
|
||||
|
||||
假如你仍启动不安全的浏览器,你将在浏览器中看到如下网页:
|
||||
|
||||

|
||||
Tails 浏览警告
|
||||
|
||||
#### Tails 适合我吗?####
|
||||
|
||||
要想得到上面问题的答案,首先回答如下的问题:
|
||||
|
||||
- 在上网时,你想你的隐私未被触动吗?
|
||||
- 你想在身份信息窃取者的眼皮底下保持隐身吗?
|
||||
- 你想在你的网上私人聊天过程中被他人嗅探吗?
|
||||
- 你真的想向任何人展示你的地理位置吗?
|
||||
- 你开展银行网上交易吗?
|
||||
- 你愿意受政府和 ISP(注:网络提供商) 的审查吗?
|
||||
|
||||
假如以上问题中,任意一个问题的答案为 'YES',则你最好需要 Tails。假如上面所有的问题的答案都是 'NO',则或许你不需要它。
|
||||
|
||||
想对 Tails 了解更多?请将你的浏览器指向它的用户文档页面:
|
||||
|
||||
文档: [https://tails.boum.org/doc/index.en.html][7]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
对于那些工作在不安全环境中的人来说,Tails 是一个必需的操作系统。Tails 还是一个着眼于安全的操作系统,现在为止,包含一大批应用 – Gnome 桌面, Tor, Firefox (Iceweasel), Network Manager, Pidgin, Claws mail, Liferea feed addregator, Gobby, Aircrack-ng, I2P。
|
||||
|
||||
同时,它含有一些有关加密和隐私的工具,即 UKS, GNUPG, PWGen, Shamir’s Secret Sharing, Virtual Keyboard (against Hardware Keylogging), MAT, KeePassX Password Manager 等。
|
||||
|
||||
这就是全部了。关注 Tecmint。请分享你的有关 Tails GNU/Linux 操作系统的想法。对于这个项目的未来,你怎么看?同时在实际中测试它,并让我们获知你的体验感受。
|
||||
|
||||
你也可以在 [Virtualbox][8] 中运行它。 Tails 在 RAM 中加载整个操作系统,所以在 VM 中你需要给定足够的 RAM 来运行 Tails。
|
||||
|
||||
我在 1GB 的环境中测试了 Tails,它工作起来毫无滞后感。谢谢我们的所有用户的支持。使 Tecmint 成为一个包含所有 Linux 相关信息的地方,你的合作是必需的。 Kudos!
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-tails-1-4-linux-operating-system-to-preserve-privacy-and-anonymity/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
[2]:https://tails.boum.org/news/version_1.4/index.en.html
|
||||
[3]:http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
|
||||
[4]:https://tails.boum.org/torrents/files/tails-i386-1.4.torrent
|
||||
[5]:https://tails.boum.org/download/index.en.html#verify
|
||||
[6]:http://www.tecmint.com/install-linux-from-usb-device/
|
||||
[7]:https://tails.boum.org/doc/index.en.html
|
||||
[8]:http://www.tecmint.com/install-virtualbox-on-redhat-centos-fedora/
|
||||
@ -0,0 +1,287 @@
|
||||
27个Linux下软件包管理工具‘DNF’(Yum的分支)的命令
|
||||
================================================================================
|
||||
DNF即Dandified YUM是基于RPM的发行版的下一代软件包管理工具。它首先在Fedora 18中出现,并且在最近发行的Fedora 22中替代了[YUM工具集][1]。
|
||||
|
||||

|
||||
|
||||
DNF致力于改善YUM的瓶颈,即性能、内存占用、依赖解决、速度和许多其他方面。DNF使用RPM、libsolv和hawkey库进行包管理。尽管它并未预装在CentOS和RHEL 7中,但您可以通过yum安装,并同时使用二者。
|
||||
|
||||
您也许想阅读更多关于DNF的信息:
|
||||
|
||||
- [使用DNF取代Yum背后的原因][2]
|
||||
|
||||
最新的DNF稳定版本是2015年5月11日发布的1.0(在写这篇文章之前)。它(以及所有DNF之前版本)主要由Python编写,并以GPL v2许可证发布。
|
||||
|
||||
### 安装DNF ###
|
||||
|
||||
尽管Fedora 22官方已经过渡到了DNF,但DNF并不在RHEL/CentOS 7的默认仓库中。
|
||||
|
||||
为了在RHEL/CentOS系统中安装DNF,您需要首先安装和开启epel-release仓库。
|
||||
|
||||
# yum install epel-release
|
||||
或
|
||||
# yum install epel-release -y
|
||||
|
||||
尽管并不建议在使用yum时添上'-y'选项,因为最好还是看看什么将安装在您的系统中。但如果您对此并不在意,则您可以使用'-y'选项以自动化的安装而无需用户干预。
|
||||
|
||||
接下来,使用yum命令从epel-realease仓库安装DNF包。
|
||||
|
||||
# yum install dnf
|
||||
|
||||
在您装完dnf后,我会向您展示27个实用的dnf命令和例子,以便帮您更容易和高效的管理基于RPM包的发行版。
|
||||
|
||||
### 1. 检查DNF版本 ###
|
||||
|
||||
检查您的系统上安装的DNF版本。
|
||||
|
||||
# dnf --version
|
||||
|
||||

|
||||
|
||||
### 2. 列出开启的DNF仓库 ###
|
||||
|
||||
dnf命令中的'repolist'选项将显示您系统中所有开启的仓库。
|
||||
|
||||
# dnf repolist
|
||||
|
||||

|
||||
|
||||
### 3. 列出所有开启和关闭的DNF仓库 ###
|
||||
|
||||
'repolist all'选项将显示您系统中所有开启/关闭的仓库。
|
||||
|
||||
# dnf repolist all
|
||||
|
||||

|
||||
|
||||
### 4. 用DNF列出所有可用的且已安装的软件包 ###
|
||||
|
||||
'dnf list'命令将列出所有仓库中所有可用的软件包和您Linux系统中已安装的软件包。
|
||||
|
||||
# dnf list
|
||||
|
||||

|
||||
|
||||
### 5. 用DNF列出所有已安装的软件包 ###
|
||||
|
||||
尽管'dnf list'命令将列出所有仓库中所有可用的软件包和已安装的软件包。然而像下面一样使用'list installed'选项将只列出已安装的软件包。
|
||||
|
||||
# dnf list installed
|
||||
|
||||

|
||||
|
||||
### 6. 用DNF列出所有可用的软件包 ###
|
||||
|
||||
类似的,可以用'list available'选项列出所有开启的仓库中所有可用的软件包。
|
||||
|
||||
# dnf list available
|
||||
|
||||

|
||||
|
||||
### 7. 使用DNF查找软件包 ###
|
||||
|
||||
如果您不太清楚您想安装的软件包的名字,这种情况下,您可以使用'search'选项来搜索匹配该字符(例如,nano)和字符串的软件包。
|
||||
|
||||
# dnf search nano
|
||||
|
||||

|
||||
|
||||
### 8. 查看哪个软件包提供了某个文件/子软件软件包? ###
|
||||
|
||||
dnf的选项'provides'能查找提供了某个文件/子软件包的软件包名。例如,如果您想找找那个软件包提供了您系统中的'/bin/bash'文件,可以使用下面的命令
|
||||
|
||||
# dnf provides /bin/bash
|
||||
|
||||

|
||||
|
||||
### 9. 使用DNF获得一个软件包的详细信息 ###
|
||||
|
||||
如果您想在安装一个软件包前知道它的详细信息,您可以使用'info'来获得一个软件包的详细信息,例如:
|
||||
|
||||
# dnf info nano
|
||||
|
||||

|
||||
|
||||
### 10. 使用DNF安装软件包 ###
|
||||
|
||||
想安装一个叫nano的软件包,只需运行下面的命令,它会为nano自动的解决和安装所有的依赖。
|
||||
|
||||
# dnf install nano
|
||||
|
||||

|
||||
|
||||
### 11. 使用DNF更新一个软件包 ###
|
||||
|
||||
您可能只想更新一个特定的包(例如,systemd)并且保留系统内剩余软件包不变。
|
||||
|
||||
# dnf update systemd
|
||||
|
||||

|
||||
|
||||
### 12. 使用DNF检查系统更新 ###
|
||||
|
||||
检查系统中安装的所有软件包的更新可以简单的使用dnf进行:
|
||||
|
||||
# dnf check-update
|
||||
|
||||

|
||||
|
||||
### 13. 使用DNF安装系统中所有的软件包 ###
|
||||
|
||||
您可以使用下面的命令来更新整个系统中所有已安装的软件包。
|
||||
|
||||
# dnf update
|
||||
或
|
||||
# dnf upgrade
|
||||
|
||||

|
||||
|
||||
### 14. 使用DNF来移除/删除一个软件包 ###
|
||||
|
||||
您可以在dnf命令中使用'remove'或'erase'选项来移除任何不想要的软件包。
|
||||
|
||||
# dnf remove nano
|
||||
或
|
||||
# dnf erase nano
|
||||
|
||||

|
||||
|
||||
### 15. 使用DNF移除于依赖无用的软件包(Orphan Packages) ###
|
||||
|
||||
这些为了满足依赖安装的软件包在相应的程序删除后便不再需要了。可以用过下面的命令来将它们删除。
|
||||
|
||||
# dnf autoremove
|
||||
|
||||

|
||||
|
||||
### 16. 使用DNF移除缓存的软件包 ###
|
||||
|
||||
我们在使用dnf时经常会碰到过期的头部和不完整的事务,它们会导致错误。我们可以使用下面的语句清理缓存的软件包和包含远程包信息的头部。
|
||||
|
||||
# dnf clean all
|
||||
|
||||

|
||||
|
||||
### 17. 获得特定DNF命令的帮助 ###
|
||||
|
||||
您可能需要特定的DNF命令的帮助(例如,clean),可以通过下面的命令来得到:
|
||||
|
||||
# dnf help clean
|
||||
|
||||

|
||||
|
||||
### 18. 列出所有DNF的命令和选项 ###
|
||||
|
||||
要显示所有dnf的命令和选项,只需要:
|
||||
|
||||
# dnf help
|
||||
|
||||

|
||||
|
||||
### 19. 查看DNF的历史记录 ###
|
||||
|
||||
您可以调用'dnf history'来查看已经执行过的dnf命令的列表。这样您便可以知道什么被安装/移除以及时间戳。
|
||||
|
||||
# dnf history
|
||||
|
||||

|
||||
|
||||
### 20. 显示所有软件包组 ###
|
||||
|
||||
'dnf grouplist'命令可以打印所有可用的或已安装的软件包,如果没有什么输出,则它会列出所有已知的软件包组。
|
||||
|
||||
# dnf grouplist
|
||||
|
||||

|
||||
|
||||
### 21. 使用DNF安装一个软件包组 ###
|
||||
|
||||
要安装一组由许多软件打包在一起的软件包组(例如,Educational Softaware),只需要执行:
|
||||
|
||||
# dnf groupinstall 'Educational Software'
|
||||
|
||||

|
||||
|
||||
### 22. 更新一个软件包组 ###
|
||||
|
||||
可以通过下面的命令来更新一个软件包组(例如,Educational Software):
|
||||
|
||||
# dnf groupupdate 'Educational Software'
|
||||
|
||||

|
||||
|
||||
### 23. 移除一个软件包组 ###
|
||||
|
||||
可以使用下面的命令来移除一个软件包组(例如,Educational Software):
|
||||
|
||||
# dnf groupremove 'Educational Software'
|
||||
|
||||

|
||||
|
||||
### 24. 从某个特定的仓库安装一个软件包 ###
|
||||
|
||||
DNF可以从任何特定的仓库安装一个软件包(例如,phpmyadmin):
|
||||
|
||||
# dnf --enablerepo=epel install phpmyadmin
|
||||
|
||||

|
||||
|
||||
### 25. 将已安装的软件包同步到稳定发行版 ###
|
||||
|
||||
'dnf distro-sync'将同步所有已安装的软件包到所有开启的仓库中最近的稳定版本。如果没有软件包被选择,则会同步所有已安装的软件包。
|
||||
|
||||
# dnf distro-sync
|
||||
|
||||

|
||||
|
||||
### 26. 重新安装一个软件包 ###
|
||||
|
||||
'dnf reinstall nano'命令将重新安装一个已经安装的软件包(例如,nano):
|
||||
|
||||
# dnf reinstall nano
|
||||
|
||||

|
||||
|
||||
### 27. 降级一个软件包 ###
|
||||
|
||||
选项'downgrade'将会使一个软件包(例如,acpid)回退到低版本。
|
||||
|
||||
# dnf downgrade acpid
|
||||
|
||||
示例输出
|
||||
|
||||
Using metadata from Wed May 20 12:44:59 2015
|
||||
No match for available package: acpid-2.0.19-5.el7.x86_64
|
||||
Error: Nothing to do.
|
||||
|
||||
**我的观察**:dnf不会按预想的那样降级一个软件包。这已做为一个bug被提交。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
DNF是YUM管理器的优秀替代品。它倾向于自动做许多有经验的Linux系统管理员不建议做的工作。例如:
|
||||
|
||||
- `--skip-broken`不被DNF识别,并且DNF中没有其替代命令。
|
||||
- 尽管您可能会运行dnf provides,但再也没有'resolvedep'命令了。
|
||||
- 没有'deplist'命令用来发现软件包依赖。
|
||||
- 您排除一个仓库意味着在所有操作上排除该仓库,而在yum中,排除一个仓库只在安装和升级等时刻排除他们。
|
||||
|
||||
许多Linux用户对于Linux生态系统的走向不甚满意。首先[Systemd替换了init system][3]v,现在DNF将于不久后替换YUM,首先是Fedora 22,接下来是RHEL和CentOS。
|
||||
|
||||
您怎么看呢?是不是发行版和整个Linux生态系统并不注重用户并且在朝着与用户愿望相悖的方向前进呢?IT行业里有这样一句话 - “如果没有坏,为什么要修呢?”,System V和YUM都没有坏。
|
||||
|
||||
上面便是这篇文章的全部了。请在下方留言以让我了解您的宝贵想法。点赞和分享以帮助我们传播。谢谢!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-next-generation-package-management-utility-for-linux/
|
||||
[3]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
@ -0,0 +1,113 @@
|
||||
安装Fedora 22后要做的事
|
||||
================================================================================
|
||||
Fedora 22,Red Hat操作系统的社区开发版的最新成员,已经于2015年5月26日发布了。这个令人神圣的Fedora发行版充斥着各种炒作和预期,Fedora 22推出了大量的重大变化。
|
||||
|
||||
就初始化进程而言,Systemd还是个新生儿,但它已经准备好替换脆弱的sysvinit这个一直是Linux生态系统一部分的模块。另外一个用户会碰到的重大改变存在于基本仓库的python版本中,这里提供了两种不同口味的python版本2.x和3.x分线,各个都有其不同的癖好和优点。所以,那些偏好2.x口味的用户可能想要安装他们喜爱的python版本。自从Fedora 18开始被打扮得更加时髦的Yum安装器也被设置来替换过时陈旧的YUM安装器后。Fedora也已最后决定,现在是时候用DNF来替换YUM了。
|
||||
### 1) 安装VLC媒体播放器 ###
|
||||
|
||||
Fedora 22默认自带了媒体播放器viz gnome视频播放器(前身是totem)。如果你对此不感冒,那么我们可以跳过这一步继续往前走。但是,如果你像我一样,偏好使用最广泛的VLC,那么就去从RPMFusion仓库安装吧。安装方法如下:
|
||||
|
||||
sudo dnf install vlc -y
|
||||
|
||||
### 2) 配置RPMFusion仓库 ###
|
||||
|
||||
正如我已经提到过的,Fedora的意识形态很是严谨,它不会自带任何非自由组件。官方仓库不会提供一些包含有非自由组件的基本软件,比如像多媒体编码。因此,安装一些第三方仓库很有必要,这些仓库会为我们提供一些基本的软件。幸运的是,RPMFusion仓库前来拯救我们了。
|
||||
|
||||
$ sudo dnf install --nogpgcheck http://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-22.noarch.rpm
|
||||
|
||||
### 3) 安装多媒体编码 ###
|
||||
|
||||
刚刚我们说过,一些多媒体编码和插件不会随Fedora一起发送。现在,有谁想仅仅是因为专有编码而错过他们最爱的节目和电影?试试这个吧:
|
||||
|
||||
$ sudo dnf install gstreamer-plugins-bad gstreamer-plugins-bad-free-extras gstreamer-plugins-ugly gstreamer-ffmpeg gstreamer1-libav gstreamer1-plugins-bad-free-extras gstreamer1-plugins-bad-freeworld gstreamer-plugins-base-tools gstreamer1-plugins-good-extras gstreamer1-plugins-ugly gstreamer1-plugins-bad-free gstreamer1-plugins-good gstreamer1-plugins-base gstreamer1
|
||||
|
||||
### 4) 更新系统 ###
|
||||
|
||||
Fedora是一个尖端的发行版,因此它会持续发布更新用以修复系统中出现的错误和漏洞。因而,保持系统更新到最新,是个不错的做法。
|
||||
|
||||
$ sudo dnf update -y
|
||||
|
||||
### 5) 卸载你不需要的软件 ###
|
||||
|
||||
Fedora预装了一些大多数用户可以利用的包,但是对于更高级的用户,你可能意识到你并不需要它。要移除你不需要的包相当容易,只需使用以下命令——我选择卸载rhythmbox,因为我知道我不会用到它:
|
||||
|
||||
$ sudo dnf remove rhythmbox
|
||||
|
||||
### 6) 安装Adobe Flash ###
|
||||
|
||||
我们都希望Adobe Flash不要再存在了,因为它并不被认为是最安全的,或者资源利用最好的,但是暂时先让它待着吧。Fedora 22安装Adobe Flash的唯一途径是从Adobe安装官方RPM,就像下面这样。
|
||||
|
||||
你可以从[这里][1]下载RPM。下载完后,你可以直接右击并像下面这样打开:
|
||||
|
||||

|
||||
|
||||
右击并选择“用软件安装打开”
|
||||
|
||||
然后,只需在弹出窗口中点击安装:
|
||||
|
||||

|
||||
|
||||
点击“安装”来完成从Adobe安装自定义RPM的过程
|
||||
|
||||
该过程完成后,“安装”按钮会变成“移除”,而此时安装也完成了。如果在此过程中你的浏览器开着,会提示你先把它关掉或在安装完成后重启以使修改生效。
|
||||
|
||||
### 7) 用Gnome Boxes加速虚拟机 ###
|
||||
|
||||
你刚刚安装了Fedora,你也很是喜欢,但是出于某些私人原因,你也许仍然需要Windows,或者你只是想玩玩另外一个Linux发行版。不管哪种情况,你都可以使用Gnome Boxes来简单地创建一个虚拟机或使用一个live发行版,Fedora 22提供了该软件。遵循以下步骤,使用你所选的ISO来开始吧!谁知道呢,也许你可以检验一下某个[Fedora Spin][2]。
|
||||
|
||||
首先,打开Gnome Boxes,然后在顶部左边选择“新建”:
|
||||
|
||||

|
||||
|
||||
点击“新建”来开始添加一个新虚拟机的进程吧。
|
||||
|
||||
接下来,点击打开文件并选择一个ISO:
|
||||
|
||||

|
||||
|
||||
在选择选择了选择文件或ISO后,选择你的ISO。这里,我已经安装了一个Debian ISO。
|
||||
|
||||
最后,自定义VM设置或使用默认,然后点击“创建”。VM会以默认方式启动,可用的VM会在Gnome Boxes以小缩略图的方式显示。
|
||||
|
||||

|
||||
|
||||
自定义设置为你所选择的,或者也可以保持默认。完成后,点击“创建”,VM就一切就绪了。
|
||||
|
||||
### 8) 安装Google Chrome ###
|
||||
|
||||
Firefox被包含在Fedora 22中,但是就跟大多数软件一样,每个人都有他们自己的选择。如果你所喜爱的浏览器恰好是Google Chrome,你可以使用和上面安装Adobe Flash Player类似的指令。然而,很明显,你得使用来自Google的任何你所下载的版本的RPM。最新的版本通常可以在[这里][3]找到。
|
||||
|
||||
### 9) 添加社交媒体和其它在线帐号 ###
|
||||
|
||||
Gnome自带有不错的内建功能用于容纳帐号相关的东西,像Facebook,Google以及其它在线帐号。你可以通过主Gnome设置应用访问在线帐号设置。然后,只需点击在线帐号,并添加你所选择的帐号。如果你要添加一个帐号,比如像Google,你可以用它来作为默认帐号,用来完成诸如发送邮件、日历提醒、相片和文档交互,以及诸如此类的更多事情。
|
||||
|
||||
### 10) 安装KDE或另一个桌面环境 ###
|
||||
|
||||
我们中的某些人不喜欢Gnome,那也没问题。在终端中运行以下命令来安装KDE所需的一切来替换它。这些指令也可以用以安装xfce、lxde或其它桌面环境。
|
||||
|
||||
$ sudo dnf install @kde-desktop
|
||||
|
||||
安装完成后,登出。当你点击你的用户名时,注意那个表示设置的小齿轮。点击它,然后选择“Plasma”。当你再次登录时,一个全新的KDE桌面就会欢迎你。
|
||||
|
||||

|
||||
|
||||
刚刚安装到Fedora 22上的Plasma环境
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
就是这样了,一切就绪。使用新系统吧,试试新东西。如果你找不到与你喜好相关的东西,linux赋予你自由修改它的权利。Fedora自带有最新的Gnome Shell作为其桌面环境,如果你觉得太臃肿而不喜欢,那么试试KDE或一些轻量级的DE,像Cinnamon、xfce之类。愿你的Fedora之旅十分开心并且没有困扰。!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/things-do-after-installing-fedora-22/
|
||||
|
||||
作者:[Jonathan DeMasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/jonathande/
|
||||
[1]:https://get.adobe.com/flashplayer/
|
||||
[2]:http://spins.fedoraproject.org/
|
||||
[3]:https://www.google.com/intl/en/chrome/browser/desktop/index.html
|
||||
@ -0,0 +1,181 @@
|
||||
使用SNMP和Cacti监控Linux服务器
|
||||
================================================================================
|
||||
SNMP(或者叫简单网络管理协议)用于收集设备内部发生的数据,如负载、磁盘状态、带宽之类。像Cacti这样的网络监控工具用这些数据来生成图标以达到监控的目的。
|
||||
|
||||
在一个典型的Cacti和SNMP部署中,会有一台或多台启用了SNMP的设备,以及一台独立的用来从那些设备收集SNMP回馈的监控服务器。请记住,所有需要监控的设备必须启用SNMP。在本教程中,出于演示目的,我们将在同一台Linux服务器上配置Cacti和SNMP。
|
||||
|
||||
### 在Debian或Ubuntu上配置SNMP ###
|
||||
|
||||
要安装SNMP代理(snmpd)到基于Debian的系统,请运行以下命令:
|
||||
|
||||
root@server:~# apt-get install snmpd
|
||||
|
||||
然后,如下编辑配置文件。
|
||||
|
||||
root@server:~# vim /etc/snmp/snmpd.conf
|
||||
|
||||
----------
|
||||
|
||||
# this will make snmpd listen on all interfaces
|
||||
agentAddress udp:161
|
||||
|
||||
# a read only community 'myCommunity' and the source network is defined
|
||||
rocommunity myCommunity 172.17.1.0/24
|
||||
|
||||
sysLocation Earth
|
||||
sysContact email@domain.tld
|
||||
|
||||
在编辑完配置文件后,重启snmpd。
|
||||
|
||||
root@server:~# service snmpd restart
|
||||
|
||||
### 在CentOS或RHEL上配置SNMP ###
|
||||
|
||||
要安装SNMP工具和库,请运行以下命令。
|
||||
|
||||
root@server:~# sudo yum install net-snmp
|
||||
|
||||
然后,如下编辑SNMP配置文件。
|
||||
|
||||
root@server:~# vim /etc/snmp/snmpd.conf
|
||||
|
||||
----------
|
||||
|
||||
# A user 'myUser' is being defined with the community string 'myCommunity' and source network 172.17.1.0/24
|
||||
com2sec myUser 172.17.1.0/24 myCommunity
|
||||
|
||||
# myUser is added into the group 'myGroup' and the permission of the group is defined
|
||||
group myGroup v1 myUser
|
||||
group myGroup v2c myUser
|
||||
view all included .1
|
||||
access myGroup "" any noauth exact all all none
|
||||
|
||||
----------
|
||||
|
||||
root@server:~# service snmpd restart
|
||||
root@server:~# chkconfig snmpd on
|
||||
|
||||
重启snmpd服务,然后添加到启动服务列表。
|
||||
|
||||
### 测试SNMP ###
|
||||
|
||||
SNMP可以通过运行snmpwalk命令进行测试。如果SNMP已经配置成功,该命令会生成大量输出。
|
||||
|
||||
root@server:~# snmpwalk -c myCommunity 172.17.1.44 -v1
|
||||
|
||||
----------
|
||||
|
||||
iso.3.6.1.2.1.1.1.0 = STRING: "Linux mrtg 3.5.0-17-generic #28-Ubuntu SMP Tue Oct 9 19:31:23 UTC 2012 x86_64"
|
||||
iso.3.6.1.2.1.1.2.0 = OID: iso.3.6.1.4.1.8072.3.2.10
|
||||
iso.3.6.1.2.1.1.3.0 = Timeticks: (2097) 0:00:20.97
|
||||
|
||||
~~ OUTPUT TRUNCATED ~~
|
||||
|
||||
iso.3.6.1.2.1.92.1.1.2.0 = Gauge32: 1440
|
||||
iso.3.6.1.2.1.92.1.2.1.0 = Counter32: 1
|
||||
iso.3.6.1.2.1.92.1.2.2.0 = Counter32: 0
|
||||
iso.3.6.1.2.1.92.1.3.1.1.2.7.100.101.102.97.117.108.116.1 = Timeticks: (1) 0:00:00.01
|
||||
iso.3.6.1.2.1.92.1.3.1.1.3.7.100.101.102.97.117.108.116.1 = Hex-STRING: 07 DD 0B 12 00 39 27 00 2B 06 00
|
||||
|
||||
### 配置带有SNMP的Cacti ###
|
||||
|
||||
在本教程中,我们将在同一台Linux服务器上设置Cacti和SNMP。所以,去[安装Cacti][2]到刚刚配置SNMP的Linux服务器上吧。
|
||||
|
||||
安装完后,Cacti网页接口可以通过“http://172.17.1.44/cacti”来访问,当然,在你的环境中,请将IP地址换成你的服务器的地址。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
安装过程中Cacti的路径一般都是正确的,但是如有必要,请再次检查以下。
|
||||
|
||||
|
||||
|
||||
在首次安装过程中,Cacti默认的用户名和密码是“admin”和“admin”。在首次登录后会强制你修改密码。
|
||||
|
||||
|
||||
|
||||
### 添加设备到Cacti并管理 ###
|
||||
|
||||
Cacti将根据先前配置的SNMP字符串注册设备。在本教程中,我们将只添加启用了SNMP的本地服务器。
|
||||
|
||||
要添加设备,我们必须以管理员登录,然后转到Cacti管理员面板中的控制台。点击控制台 > 设备。
|
||||
|
||||

|
||||
|
||||
那里可能已经有一个名为‘localhost’的设备。我们不需要它,因为我们要创建全新的图表。我们可以将该设备从列表中删除,使用“添加”按钮来添加新设备。
|
||||
|
||||

|
||||
|
||||
接下来,我们设置设备参数。
|
||||
|
||||

|
||||
|
||||
由于设备已经添加,我们来指定想要创建的图表模板。你可以在该页的最后章节中找到本节内容。
|
||||
|
||||
|
||||
|
||||
然后,我们继续来创建图表。
|
||||
|
||||
|
||||
|
||||
这里,我们创建用于平均负载、RAM和硬盘、处理器的图表。
|
||||
|
||||
|
||||
|
||||
### 接口图表和64位计数器 ###
|
||||
|
||||
默认情况下,Cacti在SNMP查询中使用32位计数器。32位计数器对于大多数带宽图表而言已经足够了,但是对于超过100Mbps的带宽,它就无能为力了。如果已经知道带宽会超过100Mbps,建议你使用64位计数器。使用64位计数器一点也不麻烦。
|
||||
|
||||
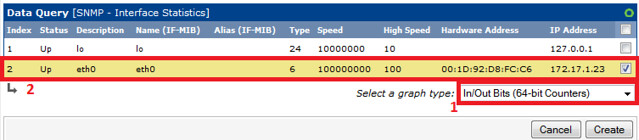
|
||||
|
||||
**注意**: Cacti会花费大约15分钟来产生新图表,除了耐心等待,你别无选择。
|
||||
|
||||
### 创建图表树 ###
|
||||
|
||||
这些截图展示了如何创建图表树,以及如何添加图表到这些树中。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
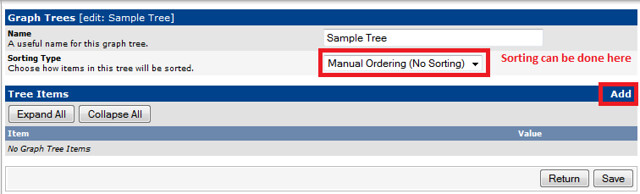
|
||||
|
||||
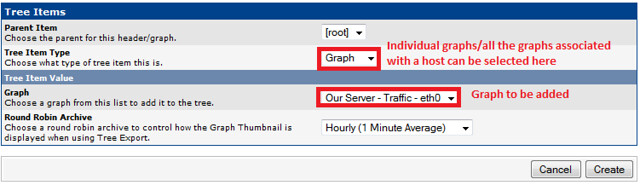
|
||||
|
||||
我们可以验证图表树中的图表。
|
||||
|
||||

|
||||
|
||||
### 用户管理 ###
|
||||
|
||||
最后,我们创建一个只具有查看我们刚创建的图表权限的用户。Cacti内建了用户管理系统,而且是高度可定制的。
|
||||
|
||||
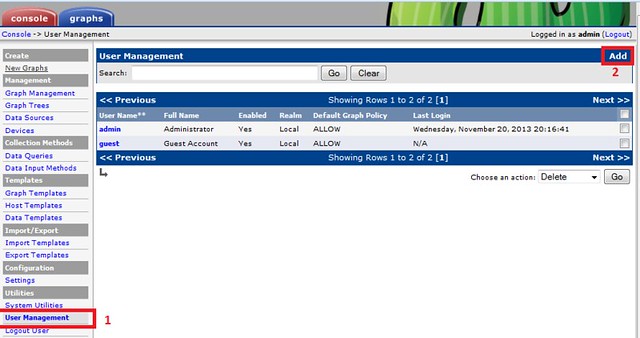
|
||||
|
||||
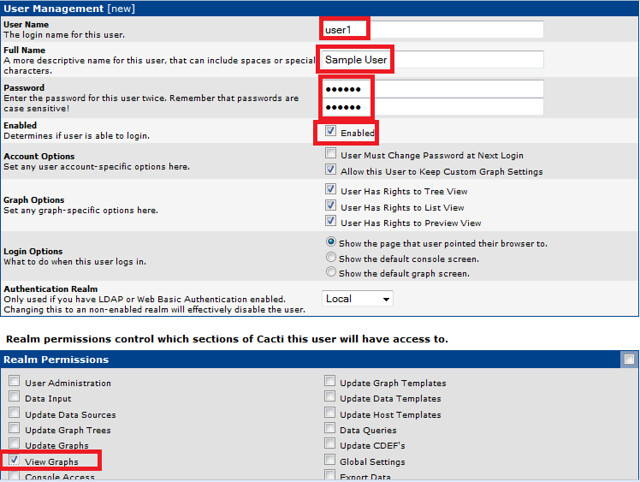
|
||||
|
||||
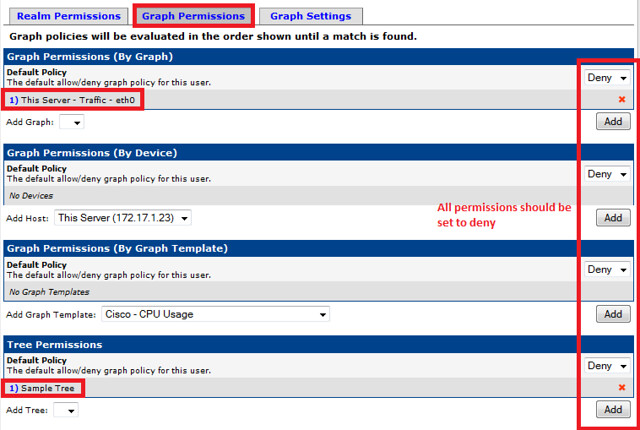
|
||||
|
||||
在完成这些步骤后,我们可以使用‘user1’来登录进去,并验证只有该用户可以查看该图表。
|
||||
|
||||
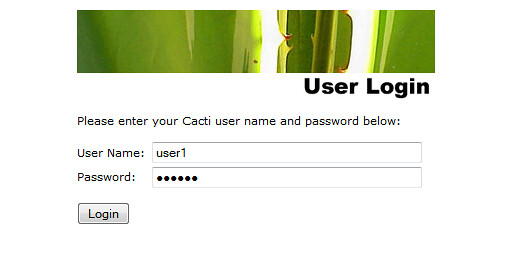
|
||||
|
||||
|
||||
|
||||
至此,我们在网络监控系统中部署了一台Cacti服务器。Cacti服务器比较稳定,可以处理大量图表而不会出问题。
|
||||
|
||||
希望本文对你有所帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/monitor-linux-servers-snmp-cacti.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/install-configure-cacti-linux.html
|
||||
@ -0,0 +1,269 @@
|
||||
如何用Nagios监控服务
|
||||
================================================================================
|
||||
Nagios内置了很多脚本来监控服务。本篇会使用其中一些来检查通用服务如MySql、Apache、DNS等等。
|
||||
|
||||
为了保证本篇集中在系统监控,我们不会配置hostgroup或者模板,它们已经在 [前面的教程][1]中覆盖了,它们可以满足这些条件了。
|
||||
|
||||
### 在命令行中运行Nagios ###
|
||||
|
||||
通常建议在添加到Nagios前现在命令行中运行Nagios服务检测脚本。它会给出执行是否成功以及脚本的输出将会看上去的样子。
|
||||
|
||||
这些脚本存储在 /etc/nagios-plugins/config/ ,可执行文件在 /usr/lib/nagios/plugins/。
|
||||
|
||||
下面就是该怎么做
|
||||
|
||||
root@nagios:~# cd /etc/nagios-plugins/config/
|
||||
|
||||
提供的脚本包含了语法帮助。示例包含了部分输出。
|
||||
|
||||
root@nagios:~# cat /etc/nagios-plugins/config/tcp_udp.cfg
|
||||
|
||||
----------
|
||||
|
||||
# 'check_tcp' command definition
|
||||
define command{
|
||||
command_name check_tcp
|
||||
command_line /usr/lib/nagios/plugins/check_tcp -H '$HOSTADDRESS$' -p '$ARG1$'
|
||||
|
||||
了解了语法,TCP 80端口可以用下面的方法检查。
|
||||
|
||||
root@nagios:~# /usr/lib/nagios/plugins/check_tcp -H 10.10.10.1 -p 80
|
||||
|
||||
----------
|
||||
|
||||
TCP OK - 0.000 second response time on port 80|time=0.000222s;;;0.000000;10.000000
|
||||
|
||||
### 示例拓扑 ###
|
||||
|
||||
本片中使用下面三台服务器。每台服务器运行多个通用服务。Nagios服务器现在运行的是Ubuntu。
|
||||
|
||||
- Server 1 (10.10.10.1) : MySQL, Apache2
|
||||
- Server 2 (10.10.10.2) : Postfix, Apache2
|
||||
- Server 3 (10.10.10.3): DNS
|
||||
|
||||
首先,服务器被定义在了Nagios中。
|
||||
|
||||
root@nagios:~# vim /etc/nagios3/conf.d/example.cfg
|
||||
|
||||
----------
|
||||
|
||||
define host{
|
||||
use generic-host
|
||||
host_name test-server-1
|
||||
alias test-server-1
|
||||
address 10.10.10.1
|
||||
}
|
||||
|
||||
define host{
|
||||
use generic-host
|
||||
host_name test-server-2
|
||||
alias test-server-2
|
||||
address 10.10.10.2
|
||||
}
|
||||
|
||||
define host{
|
||||
use generic-host
|
||||
host_name test-server-3
|
||||
alias test-server-3
|
||||
address 10.10.10.3
|
||||
}
|
||||
|
||||
### 监控MySQL服务 ###
|
||||
|
||||
#### MySQL 监控需要 ####
|
||||
|
||||
- 通过检查3306端口来检测MySQL是否运行中。
|
||||
- 检测特定的数据库'testDB'是否可用。
|
||||
|
||||
#### MySQL 服务器设置 ####
|
||||
|
||||
开始检测MySQL时,需要记住MySQL默认只监听回环接口127.0.0.1。这增加了数据库的安全。手动调节需要告诉MySQL该监听什么其他接口。下面是该怎么做。
|
||||
|
||||
这个设置在所有的MySQL服务器上已经做了。
|
||||
|
||||
root@nagios:~# vim /etc/mysql/my.cnf
|
||||
|
||||
下面这行被注释掉了来监听所有接口。
|
||||
|
||||
#bind-address = 127.0.0.1
|
||||
|
||||
同样,MySQL将不会运行任何主机来连接到它。在本机和任意主机都创建了用户‘nagios’。这个用户接着在所有的数据库中被授予所有的权限,这将在会用在监控中。
|
||||
|
||||
下面的设置对所有的MySQL服务器都已经设置。
|
||||
|
||||
root@nagios:~# mysql -u root –p
|
||||
## MySQL root password here ##
|
||||
|
||||
'nagios@localhost'用户在MySQL服务器中创建了。
|
||||
|
||||
mysql> CREATE USER 'nagios'@'localhost' IDENTIFIED BY 'nagios-pass';
|
||||
mysql> GRANT ALL PRIVILEGES ON *.* TO 'nagios'@'localhost';
|
||||
|
||||
'nagios@any-host'用户创建了。
|
||||
|
||||
mysql> CREATE USER 'nagios'@'%' IDENTIFIED BY 'nagios-pass';
|
||||
mysql> GRANT ALL PRIVILEGES ON *.* TO 'nagios'@'%';
|
||||
|
||||
mysql> FLUSH PRIVILEGES;
|
||||
|
||||
这使MySQL监听所有的接口,同样接受来自用户'nagios'的进入链接。
|
||||
|
||||
请注意,这种变化可能有安全隐患,所以需要说几句话:
|
||||
|
||||
- 这个设置将会暴露MySQL给所有的接口,包括WAN。确保只有合法的网络访问是非常重要的。应该使用防火墙和TCP封装器等过滤器。
|
||||
- MySQL用户‘nagios’的密码应该非常强。如果只有几台Nagios服务器,那么应该创建'nagios@servername'用户而不是任意用户的'nagios@%'。
|
||||
|
||||
#### 对MySQL的NAgios配置 ####
|
||||
|
||||
用下面的来做一些调整。
|
||||
|
||||
root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use generic-service
|
||||
host_name test-server-1
|
||||
;hostgroup can be used instead as well
|
||||
|
||||
service_description Check MYSQL via TCP port
|
||||
check_command check_tcp!3306
|
||||
}
|
||||
|
||||
define service{
|
||||
use generic-service
|
||||
host_name test-server-1
|
||||
;hostgroup can be used instead as well
|
||||
|
||||
service_description Check availability of database 'testDB'
|
||||
check_command check_mysql_database!nagios!nagios-pass!testDB
|
||||
;check_mysql!userName!userPassword!databaseName
|
||||
}
|
||||
|
||||
这样,Nagios就可以同时监控MySQL服务器和数据库的可用性。
|
||||
|
||||
### 监控Apache服务器 ###
|
||||
|
||||
Nagios同样也可以监控Apache服务。
|
||||
|
||||
#### Apache监控需要 ####
|
||||
|
||||
- 监控apache是否可用
|
||||
|
||||
这个任务非常简单因为Nagios有一个内置命令。
|
||||
|
||||
root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use generic-service
|
||||
host_name test-server-1, test-server-2
|
||||
service_description Check Apache Web Server
|
||||
check_command check_http
|
||||
}
|
||||
|
||||
现在就非常简单了。
|
||||
|
||||
### 监控DNS服务 ###
|
||||
|
||||
Nagios通过向DNS服务器查询一个完全合格域名(FQDN),或者使用dig工具来查询。默认用于FQDN的是www.google.com,但是这个可以按需改变。按照下面的文件修改来完成这个任务。
|
||||
|
||||
root@nagios:~# vim /etc/nagios-plugins/config/dns.cfg
|
||||
|
||||
----------
|
||||
|
||||
## The -H portion can be modified to replace Google ##
|
||||
define command{
|
||||
command_name check_dns
|
||||
command_line /usr/lib/nagios/plugins/check_dns -H www.google.com -s '$HOSTADDRESS$'
|
||||
}
|
||||
|
||||
编辑下面的行。
|
||||
|
||||
root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
|
||||
|
||||
----------
|
||||
|
||||
## Nagios asks server-3 to resolve the IP for google.com ##
|
||||
define service{
|
||||
use generic-service
|
||||
host_name test-server-3
|
||||
service_description Check DNS
|
||||
check_command check_dns
|
||||
}
|
||||
|
||||
## Nagios asks server-3 to dig google.com ##
|
||||
define service{
|
||||
use generic-service
|
||||
host_name test-server-3
|
||||
service_description Check DNS via dig
|
||||
check_command check_dig!www.google.com
|
||||
}
|
||||
|
||||
### 监控邮件服务器 ###
|
||||
|
||||
Nagios可以监控不同的邮件服务组件如SMTP、POP、IMAP和mailq。之前提过,server-2设置了后缀邮件服务。Nagios将被配置来监控SMTP和邮件队列。
|
||||
|
||||
|
||||
root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use generic-service
|
||||
host_name test-server-2
|
||||
service_description Check SMTP
|
||||
check_command check_smtp
|
||||
}
|
||||
|
||||
define service{
|
||||
use generic-service
|
||||
host_name test-server-2
|
||||
service_description Check Mail Queue
|
||||
check_command check_mailq_postfix!50!100
|
||||
;warning at 50, critical at 100
|
||||
}
|
||||
|
||||
下面的截屏显示了目前配置监控服务的概览。
|
||||
|
||||

|
||||
|
||||
### 基于端口自定义监控程序 ###
|
||||
|
||||
让我们假设下面的自定义程序同样运行在网络中,监听一个特定的端口。
|
||||
|
||||
- 测试1号服务器:自定义程序(TCP端口 12345)
|
||||
|
||||
过一些小的调整,Nagios也可以帮助监控这个程序。
|
||||
|
||||
root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
|
||||
|
||||
----------
|
||||
|
||||
define service{
|
||||
use generic-service
|
||||
host_name test-server-1
|
||||
service_description Check server 1 custom application
|
||||
check_command check_tcp!12345
|
||||
}
|
||||
|
||||
在完结之前,Nagios可以监控网络很多其他的方面。存储在/etc/nagios-plugins/config/中的脚本为Nagios很棒的能力。
|
||||
|
||||
|
||||
一些Nagios提供的脚本被限制在本地服务器。例子包含服务负载、进程并发数量、登录用户数量。这些检查可以提供Nagios服务器内有用的信息。
|
||||
|
||||
希望这篇有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/monitor-common-services-nagios.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/install-configure-nagios-linux.html
|
||||
@ -0,0 +1,305 @@
|
||||
Ubuntu 15.04上配置OpenVPN服务器-客户端
|
||||
================================================================================
|
||||
虚拟专用网(VPN)是几种用于建立与其它网络连接的网络技术中常见的一个名称。它被称为虚拟网,因为各个节点的连接不是通过物理线路实现的。而由于没有网络所有者的正确授权是不能通过公共线路访问到网络,所以它是专用的。
|
||||
|
||||

|
||||
|
||||
[OpenVPN][1]软件通过TUN/TAP驱动的帮助,使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提额外提供了灵活的配置,可以帮助你避免防火墙限制。
|
||||
|
||||
OpenVPN中,由OpenSSL库和传输层安全协议(TLS)提供了安全和加密。TLS是SSL协议的一个改进版本。
|
||||
|
||||
OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何预备使用带有公共密钥非对称加密和TLS协议基础结构(PKI)。
|
||||
|
||||
### 服务器端配置 ###
|
||||
|
||||
首先,我们必须安装OpenVPN。在Ubuntu 15.04和其它带有‘apt’报管理器的Unix系统中,可以通过如下命令安装:
|
||||
|
||||
sudo apt-get install openvpn
|
||||
|
||||
然后,我们必须配置一个密钥对,这可以通过默认的“openssl”工具完成。但是,这种方式十分难。这也是我们使用“easy-rsa”来实现此目的的原因。接下来的命令会将“easy-rsa”安装到系统中。
|
||||
|
||||
sudo apt-get unstall easy-rsa
|
||||
|
||||
**注意**: 所有接下来的命令要以超级用户权限执行,如在“sudo -i”命令后;此外,你可以使用“sudo -E”作为接下来所有命令的前缀。
|
||||
|
||||
开始之前,我们需要拷贝“easy-rsa”到openvpn文件夹。
|
||||
|
||||
mkdir /etc/openvpn/easy-rsa
|
||||
cp -r /usr/share/easy-rsa /etc/openvpn/easy-rsa
|
||||
mv /etc/openvpn/easy-rsa/easy-rsa /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
然后进入到该目录
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
这里,我们开启了一个密钥生成进程。
|
||||
|
||||
首先,我们编辑一个“var”文件。为了简化生成过程,我们需要在里面指定数据。这里是“var”文件的一个样例:
|
||||
|
||||
export KEY_COUNTRY="US"
|
||||
export KEY_PROVINCE="CA"
|
||||
export KEY_CITY="SanFrancisco"
|
||||
export KEY_ORG="Fort-Funston"
|
||||
export KEY_EMAIL="my@myhost.mydomain"
|
||||
export KEY_OU=server
|
||||
|
||||
希望这些字段名称对你而言已经很清楚,不需要进一步说明了。
|
||||
|
||||
其次,我们需要拷贝openssl配置。另外一个版本已经有现成的配置文件,如果你没有特定要求,你可以使用它的上一个版本。这里是1.0.0版本。
|
||||
|
||||
cp openssl-1.0.0.cnf openssl.cnf
|
||||
|
||||
第三,我们需要加载环境变量,这些变量已经在前面一步中编辑好了。
|
||||
|
||||
source ./vars
|
||||
|
||||
生成密钥的最后一步准备工作是清空旧的证书和密钥,以及生成新密钥的序列号和索引文件。可以通过以下命令完成。
|
||||
|
||||
./clean-all
|
||||
|
||||
现在,我们完成了准备工作,准备好启动生成进程了。让我们先来生成证书。
|
||||
|
||||
./build-ca
|
||||
|
||||
在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查以下,如有必要进行编辑,然后按回车几次。对话如下
|
||||
|
||||
Generating a 2048 bit RSA private key
|
||||
.............................................+++
|
||||
...................................................................................................+++
|
||||
writing new private key to 'ca.key'
|
||||
-----
|
||||
You are about to be asked to enter information that will be incorporated
|
||||
into your certificate request.
|
||||
What you are about to enter is what is called a Distinguished Name or a DN.
|
||||
There are quite a few fields but you can leave some blank
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [Fort-Funston CA]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
|
||||
接下来,我们需要生成一个服务器密钥
|
||||
|
||||
./build-key-server server
|
||||
|
||||
该命令的对话如下:
|
||||
|
||||
Generating a 2048 bit RSA private key
|
||||
........................................................................+++
|
||||
............................+++
|
||||
writing new private key to 'server.key'
|
||||
-----
|
||||
You are about to be asked to enter information that will be incorporated
|
||||
into your certificate request.
|
||||
What you are about to enter is what is called a Distinguished Name or a DN.
|
||||
There are quite a few fields but you can leave some blank
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [server]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
|
||||
Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
A challenge password []:
|
||||
An optional company name []:
|
||||
Using configuration from /etc/openvpn/easy-rsa/2.0/openssl-1.0.0.cnf
|
||||
Check that the request matches the signature
|
||||
Signature ok
|
||||
The Subject's Distinguished Name is as follows
|
||||
countryName :PRINTABLE:'US'
|
||||
stateOrProvinceName :PRINTABLE:'CA'
|
||||
localityName :PRINTABLE:'SanFrancisco'
|
||||
organizationName :PRINTABLE:'Fort-Funston'
|
||||
organizationalUnitName:PRINTABLE:'MyOrganizationalUnit'
|
||||
commonName :PRINTABLE:'server'
|
||||
name :PRINTABLE:'EasyRSA'
|
||||
emailAddress :IA5STRING:'me@myhost.mydomain'
|
||||
Certificate is to be certified until May 22 19:00:25 2025 GMT (3650 days)
|
||||
Sign the certificate? [y/n]:y
|
||||
1 out of 1 certificate requests certified, commit? [y/n]y
|
||||
Write out database with 1 new entries
|
||||
Data Base Updated
|
||||
|
||||
这里,最后两个关于“签署证书”和“提交”的问题,我们必须回答“yes”。
|
||||
|
||||
现在,我们已经有了证书和服务器密钥。下一步,就是去省城Diffie-Hellman密钥。执行以下命令,耐心等待。在接下来的几分钟内,我们将看到许多点和加号。
|
||||
|
||||
./build-dh
|
||||
|
||||
该命令的输出样例如下
|
||||
|
||||
Generating DH parameters, 2048 bit long safe prime, generator 2
|
||||
This is going to take a long time
|
||||
................................+................<and many many dots>
|
||||
|
||||
在漫长的等待之后,我们可以继续生成最后的密钥了,该密钥用于TLS验证。命令如下:
|
||||
|
||||
openvpn --genkey --secret keys/ta.key
|
||||
|
||||
现在,生成完毕,我们可以移动所有生成的文件到最后的位置中。
|
||||
|
||||
cp -r /etc/openvpn/easy-rsa/2.0/keys/ /etc/openvpn/
|
||||
|
||||
最后,我们来创建OpenVPN配置文件。让我们从样例中拷贝过来吧:
|
||||
|
||||
cp /usr/share/doc/openvpn/examples/sample-config-files/server.conf.gz /etc/openvpn/
|
||||
cd /etc/openvpn
|
||||
gunzip -d /etc/openvpn/server.conf.gz
|
||||
|
||||
然后编辑
|
||||
|
||||
vim /etc/openvpn/server.conf
|
||||
|
||||
我们需要指定密钥的自定义路径
|
||||
|
||||
ca /etc/openvpn/keys/ca.crt
|
||||
cert /etc/openvpn/keys/server.crt
|
||||
key /etc/openvpn/keys/server.key # This file should be kept secret
|
||||
dh /etc/openvpn/keys/dh2048.pem
|
||||
|
||||
一切就绪。在重启OpenVPN后,服务器端配置就完成了。
|
||||
|
||||
service openvpn restart
|
||||
|
||||
### Unix的客户端配置 ###
|
||||
|
||||
假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要从先前的部分连接到OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的目录中:
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
加载环境变量
|
||||
|
||||
source vars
|
||||
|
||||
然后创建客户端密钥
|
||||
|
||||
./build-key client
|
||||
|
||||
我们将看到一个与先前关于服务器密钥生成部分的章节描述一样的对话,填入客户端的实际信息。
|
||||
|
||||
如果需要密码保护密钥,你需要运行另外一个命令,命令如下
|
||||
|
||||
./build-key-pass client
|
||||
|
||||
在此种情况下,在建立VPN连接时,会提示你输入密码。
|
||||
|
||||
现在,我们需要将以下文件从服务器拷贝到客户端/etc/openvpn/keys/文件夹。
|
||||
|
||||
服务器文件列表:
|
||||
|
||||
- ca.crt,
|
||||
- dh2048.pem,
|
||||
- client.crt,
|
||||
- client.key,
|
||||
- ta.key.
|
||||
|
||||
在此之后,我们转到客户端,准备配置文件。配置文件位于/etc/openvpn/client.conf,内容如下
|
||||
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
|
||||
ca /etc/openvpn/keys/ca.crt
|
||||
cert /etc/openvpn/keys/client.crt
|
||||
key /etc/openvpn/keys/client.key
|
||||
tls-client
|
||||
tls-auth /etc/openvpn/keys/ta.key 1
|
||||
auth SHA1
|
||||
cipher BF-CBC
|
||||
remote-cert-tls server
|
||||
comp-lzo
|
||||
persist-key
|
||||
persist-tun
|
||||
|
||||
status openvpn-status.log
|
||||
log /var/log/openvpn.log
|
||||
verb 3
|
||||
mute 20
|
||||
|
||||
在此之后,我们需要重启OpenVPN以接受新配置。
|
||||
|
||||
service openvpn restart
|
||||
|
||||
好了,客户端配置完成。
|
||||
|
||||
### 安卓客户端配置 ###
|
||||
|
||||
安卓设备上的OpenVPN配置和Unix系统上的十分类似,我们需要一个含有配置文件、密钥和证书的包。文件列表如下:
|
||||
|
||||
- configuration file (.ovpn),
|
||||
- ca.crt,
|
||||
- dh2048.pem,
|
||||
- client.crt,
|
||||
- client.key.
|
||||
|
||||
客户端密钥生成方式和先前章节所述的一样。
|
||||
|
||||
配置文件内容如下
|
||||
|
||||
client tls-client
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
nobind
|
||||
ca ca.crt
|
||||
cert client.crt
|
||||
key client.key
|
||||
dh dh2048.pem
|
||||
persist-tun
|
||||
persist-key
|
||||
|
||||
verb 3
|
||||
mute 20
|
||||
|
||||
所有这些文件我们必须移动我们设备的SD卡上。
|
||||
|
||||
然后,我们需要安装[OpenVPN连接][2]。
|
||||
|
||||
接下来,配置过程很是简单:
|
||||
|
||||
open setting of OpenVPN and select Import options
|
||||
select Import Profile from SD card option
|
||||
in opened window go to folder with prepared files and select .ovpn file
|
||||
application offered us to create a new profile
|
||||
tap on the Connect button and wait a second
|
||||
|
||||
搞定。现在,我们的安卓设备已经通过安全的VPN连接连接到我们的专用网。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
虽然OpenVPN初始配置花费不少时间,但是简易客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和在企业中使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/configure-openvpn-server-client-ubuntu-15-04/
|
||||
|
||||
作者:[Ivan Zabrovskiy][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/ivanz/
|
||||
[1]:https://openvpn.net/
|
||||
[2]:https://play.google.com/store/apps/details?id=net.openvpn.openvpn
|
||||
@ -0,0 +1,151 @@
|
||||
在Ubuntu 15.04中安装RUby on Rails
|
||||
================================================================================
|
||||
本篇我们会学习如何用rbenv在Ubuntu 15.04中安装Ruby on Rails。我们选择Ubuntu作为操作系统因为Ubuntu是Linux发行版中自带很多包和完整文档的操作系统,因此我认为这是正确的选择。如果你不想安装最新的Ubuntu,你可以从[下载iso文件][1]开始。
|
||||
|
||||
### 安装 Ruby ###
|
||||
|
||||
我们要做的第一件事是更新Ubuntu包并且为Ruby安装一些依赖。
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get install git-core curl zlib1g-dev build-essential libssl-dev libreadline-dev libyaml-dev libsqlite3-dev sqlite3 libxml2-dev libxslt1-dev libcurl4-openssl-dev python-software-properties libffi-dev
|
||||
|
||||
有三种方法来安装Ruby比如rbenv,rvm和从源码安装。每种都有各自的好处,但是这些天开发者们更倾向使用rbenv而不是rvm和源码来安装。我们将安装最新的Ruby版本,2.2.2。
|
||||
|
||||
用rbenv来安装只有简单的两步。第一步安装rbenv接着是ruby-build:
|
||||
|
||||
cd
|
||||
git clone git://github.com/sstephenson/rbenv.git .rbenv
|
||||
echo 'eval "$(rbenv init -)"' >> ~/.bashrc
|
||||
exec $SHELL
|
||||
|
||||
git clone git://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build
|
||||
echo 'export PATH="$HOME/.rbenv/plugins/ruby-build/bin:$PATH"' >> ~/.bashrc
|
||||
exec $SHELL
|
||||
|
||||
git clone https://github.com/sstephenson/rbenv-gem-rehash.git ~/.rbenv/plugins/rbenv-gem-rehash
|
||||
|
||||
rbenv install 2.2.2
|
||||
rbenv global 2.2.2
|
||||
ruby -v
|
||||
|
||||
我们需要安装Bundler但是我们要在安装之前告诉rubygems不要为每个包本地安装文档。
|
||||
|
||||
echo "gem: --no-ri --no-rdoc" > ~/.gemrc
|
||||
gem install bundler
|
||||
|
||||
### 配置 GIT ###
|
||||
|
||||
配置git之前,你要创建一个github账号,你可以注册[git][2]。我们需要git作为版本控制系统,因此我们要设置来匹配github账号。
|
||||
|
||||
用户的github账号来代替下面的**Name** 和 **Email address** 。
|
||||
|
||||
git config --global color.ui true
|
||||
git config --global user.name "YOUR NAME"
|
||||
git config --global user.email "YOUR@EMAIL.com"
|
||||
ssh-keygen -t rsa -C "YOUR@EMAIL.com"
|
||||
|
||||
接下来用新生成的ssh key添加到github账号中。这样你需要复制下面命令的输出并[粘贴在这][3]。
|
||||
|
||||
cat ~/.ssh/id_rsa.pub
|
||||
|
||||
如果你做完了,检查是否已经成功。
|
||||
|
||||
ssh -T git@github.com
|
||||
|
||||
你应该得到下面这样的信息。
|
||||
|
||||
Hi excid3! You've successfully authenticated, but GitHub does not provide shell access.
|
||||
|
||||
### 安装 Rails ###
|
||||
|
||||
我们需要安装javascript运行时,像NodeJS因为这些天Rails带来很多依赖。这样我们可以结合并缩小你的javascript来提供一个更快的生产环境。
|
||||
|
||||
我们需要添加PPA来安装nodeJS。
|
||||
|
||||
sudo add-apt-repository ppa:chris-lea/node.js
|
||||
sudo apt-get update
|
||||
sudo apt-get install nodejs
|
||||
|
||||
如果在更新是晕倒了问题,你可以试试这个命令:
|
||||
|
||||
# Note the new setup script name for Node.js v0.12
|
||||
curl -sL https://deb.nodesource.com/setup_0.12 | sudo bash -
|
||||
|
||||
# Then install with:
|
||||
sudo apt-get install -y nodejs
|
||||
|
||||
下一步,用这个命令:
|
||||
|
||||
gem install rails -v 4.2.1
|
||||
|
||||
因为我们正在使用rbenv,用下面的命令来安装rails。
|
||||
|
||||
rbenv rehash
|
||||
|
||||
要确保rails已经正确安炸u哪个,你可以运行rails -v,显示如下:
|
||||
|
||||
rails -v
|
||||
# Rails 4.2.1
|
||||
|
||||
如果你得到的是不同的结果可能是环境没有设置正确。
|
||||
|
||||
### 设置 MySQL ###
|
||||
|
||||
或许你已经熟悉MySQL了,你可以从Ubuntu的仓库中安装MySQL的客户端与服务端。你可以在安装时设置root用户密码。这个信息将来会进入你rails程序的database.yml文件中、用下面的命令来安装mysql。
|
||||
|
||||
sudo apt-get install mysql-server mysql-client libmysqlclient-dev
|
||||
|
||||
安装libmysqlclient-dev用于提供在设置rails程序时,rails在连接mysql所需要用到的用于编译mysql2 gem的文件。
|
||||
|
||||
### 最后一步 ###
|
||||
|
||||
让我们尝试创建你的第一个rails程序:
|
||||
|
||||
# Use MySQL
|
||||
|
||||
rails new myapp -d mysql
|
||||
|
||||
# Move into the application directory
|
||||
|
||||
cd myapp
|
||||
|
||||
# Create Database
|
||||
|
||||
rake db:create
|
||||
|
||||
rails server
|
||||
|
||||
访问http://localhost:3000来访问你的新网站。现在你的电脑上已经可以构建rails程序了。
|
||||
|
||||

|
||||
|
||||
如果你在创建数据库时遇到了“Access denied for user 'root'@'localhost' (Using password: NO)”这个错误信息,你需要更新你的config/database.yml文件来匹配数据库的**用户名**和**密码**。
|
||||
|
||||
# Edit your database.yml in config folder
|
||||
|
||||
nano config/database.yml
|
||||
|
||||
接着输入MySql root用户的密码。
|
||||
|
||||

|
||||
|
||||
退出 (Ctrl+X)并保存。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Rails是用Ruby写的, 也就是随着rails一起使用的编程语言。在Ubuntu 15.04中Ruby on Rails可以用rbenv、 rvm和源码的方式来安装。本篇我们使用的是rbenv方式并用了MySQL作为数据库。有任何的问题或建议,请在评论栏指出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/installing-ruby-rails-using-rbenv-ubuntu-15-04/
|
||||
|
||||
作者:[Obet][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/obetp/
|
||||
[1]:http://release.ubuntu.com/15.04
|
||||
[2]:http://github.com
|
||||
[3]:https://github.com/settings/ssh
|
||||
@ -0,0 +1,77 @@
|
||||
Ubuntu中安装Unity 8桌面预览版
|
||||
================================================================================
|
||||

|
||||
|
||||
如果你一直关注新闻,那么Ubuntu将会切换到[Mir显示服务器][1],并随同发布[Unity 8][2]桌面。然而,在尚未确定Unity 8是否会在[Ubuntu 15.10 Willy Werewolf][3]中部署到Mir上之前,提供了一个Unity 8的预览版本供你体验和测试。通过官方PPA,可以很容地**安装Unity 8到Ubuntu 14.04,14.10和15.04中**。
|
||||
|
||||
到目前为止,开发者已经可以通过[ISO][4]获得该Unity 8预览来进行测试。但是Canonical已经通过[LXC容器][5]发布了。通过该方法,你可以获取Unity 8桌面会话,让它作为任何一个桌面环境运行在Mir显示服务器上。就像你[在Ubuntu中安装Mate桌面][6],然后从LightDm登录屏幕选择桌面会话一样。
|
||||
|
||||
好奇?想要试试Unity 8?让我们来看怎样安装它吧。
|
||||
|
||||
**注意: 它是一个实验性预览,可能不是所有人都可以让它正确工作的。**
|
||||
|
||||
### 安装Unity 8桌面到Ubuntu ###
|
||||
|
||||
下面是安装并使用Unity 8的步骤:
|
||||
|
||||
#### 步骤 1: 安装Unity 8到Ubuntu 12.04和14.04 ####
|
||||
|
||||
如果你真运行着Ubuntu 12.04和14.04,那么你必须使用官方PPA来安装Unity 8。使用以下命令进行安装:
|
||||
|
||||
sudo apt-add-repository ppa:unity8-desktop-session-team/unity8-preview-lxc
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
sudo apt-get install unity8-lxc
|
||||
|
||||
#### 步骤 1: 安装Unity 8到Ubuntu 14.10和15.04 ####
|
||||
|
||||
如果你真运行着Ubuntu 14.10或15.04,那么Unity 8 LXC已经在源中准备好。你只需要运行以下命令:
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get install unity8-lxc
|
||||
|
||||
#### 步骤 2: 设置Unity 8桌面预览LXC ####
|
||||
|
||||
安装Unity 8 LXC后,该对它进行设置,下面的命令就可达到目的:
|
||||
|
||||
sudo unity8-lxc-setup
|
||||
|
||||
它将花费一些时间来设置,所以,给点耐心吧。它会下载ISO,然后解压缩,接着完整最后一些必要的设置来让它工作。它也会安装一个LightDM的轻度修改版本。这一切都搞定后,需要重启。
|
||||
|
||||
#### 步骤 3: 选择Unity 8 ####
|
||||
|
||||
重启后,在登录屏幕,点击你的登录旁边的Ubuntu图标:
|
||||
|
||||

|
||||
|
||||
你应该可以在这看到Unity 8的选项,选择它:
|
||||
|
||||

|
||||
|
||||
### 卸载Unity 8 LXC ###
|
||||
|
||||
如果你发现Unity 8毛病太多,或者你不喜欢它,那么你可以以相同的方式切换会默认Unity版本。此外,你也可以通过下面的命令移除Unity 8:
|
||||
|
||||
sudo apt-get remove unity8-lxc
|
||||
|
||||
该命令会将Unity 8选项从LightDM屏幕移除,但是配置仍然保留着。
|
||||
|
||||
以上就是你在Ubuntu中安装嗲有Mir的Unity 8的全部过程,试玩后请分享你关于Unity 8的想法哦!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-unity-8-desktop-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://en.wikipedia.org/wiki/Mir_%28software%29
|
||||
[2]:https://wiki.ubuntu.com/Unity8Desktop
|
||||
[3]:http://itsfoss.com/ubuntu-15-10-codename/
|
||||
[4]:https://wiki.ubuntu.com/Unity8DesktopIso
|
||||
[5]:https://wiki.ubuntu.com/Unity8inLXC
|
||||
[6]:http://itsfoss.com/install-mate-desktop-ubuntu-14-04/
|
||||
@ -0,0 +1,171 @@
|
||||
如何用Perl访问SQLite数据库
|
||||
================================================================================
|
||||
SQLite是一个零配置,无服务端,基于文件的事务文件系统。由于它的轻量级,自包含和紧凑的设计,所以当你想要集成数据库到你的程序中时,SQLite是一个非常流行的选择。在这篇文章中,我会展示如何用Perl脚本来创建和访问SQLite数据库。我演示的Perl代码片段是完整的,所以你可以很简单地修改并集成到你的项目中。
|
||||
|
||||

|
||||
|
||||
### 访问SQLite的准备 ###
|
||||
|
||||
我会使用SQLite DBI Perl驱动来连接到SQLite3。因此你需要在Linux中安装它(和SQLite3一起)。
|
||||
|
||||
**Debian、 Ubuntu 或者 Linux Mint**
|
||||
|
||||
$ sudo apt-get install sqlite3 libdbd-sqlite3-perl
|
||||
|
||||
**CentOS、 Fedora 或者 RHEL**
|
||||
|
||||
$ sudo yum install sqlite perl-DBD-SQLite
|
||||
|
||||
安装后,你可以检查SQLite驱动可以通过下面的脚本访问到。
|
||||
|
||||
#!/usr/bin/perl
|
||||
|
||||
my @drv = DBI->available_drivers();
|
||||
print join("\n", @drv), "\n";
|
||||
|
||||
如果你运行脚本,你应该会看见下面的输出。
|
||||
|
||||
DBM
|
||||
ExampleP
|
||||
File
|
||||
Gofer
|
||||
Proxy
|
||||
SQLite
|
||||
Sponge
|
||||
|
||||
### Perl SQLite 访问示例 ###
|
||||
|
||||
下面就是Perl访问SQLite的示例。这个Perl脚本会演示下面这些SQLite数据库的常规管理。
|
||||
|
||||
- 创建和连接SQLite数据库
|
||||
- 在SQLite数据库中创建新表
|
||||
- 在表中插入行
|
||||
- 在表中搜索和迭代行
|
||||
- 在表中更新行
|
||||
- 在表中删除行
|
||||
|
||||
use DBI;
|
||||
use strict;
|
||||
|
||||
# define database name and driver
|
||||
my $driver = "SQLite";
|
||||
my $db_name = "xmodulo.db";
|
||||
my $dbd = "DBI:$driver:dbname=$db_name";
|
||||
|
||||
# sqlite does not have a notion of username/password
|
||||
my $username = "";
|
||||
my $password = "";
|
||||
|
||||
# create and connect to a database.
|
||||
# this will create a file named xmodulo.db
|
||||
my $dbh = DBI->connect($dbd, $username, $password, { RaiseError => 1 })
|
||||
or die $DBI::errstr;
|
||||
print STDERR "Database opened successfully\n";
|
||||
|
||||
# create a table
|
||||
my $stmt = qq(CREATE TABLE IF NOT EXISTS NETWORK
|
||||
(ID INTEGER PRIMARY KEY AUTOINCREMENT,
|
||||
HOSTNAME TEXT NOT NULL,
|
||||
IPADDRESS INT NOT NULL,
|
||||
OS CHAR(50),
|
||||
CPULOAD REAL););
|
||||
my $ret = $dbh->do($stmt);
|
||||
if($ret < 0) {
|
||||
print STDERR $DBI::errstr;
|
||||
} else {
|
||||
print STDERR "Table created successfully\n";
|
||||
}
|
||||
|
||||
# insert three rows into the table
|
||||
$stmt = qq(INSERT INTO NETWORK (HOSTNAME,IPADDRESS,OS,CPULOAD)
|
||||
VALUES ('xmodulo', 16843009, 'Ubuntu 14.10', 0.0));
|
||||
$ret = $dbh->do($stmt) or die $DBI::errstr;
|
||||
|
||||
$stmt = qq(INSERT INTO NETWORK (HOSTNAME,IPADDRESS,OS,CPULOAD)
|
||||
VALUES ('bert', 16843010, 'CentOS 7', 0.0));
|
||||
$ret = $dbh->do($stmt) or die $DBI::errstr;
|
||||
|
||||
$stmt = qq(INSERT INTO NETWORK (HOSTNAME,IPADDRESS,OS,CPULOAD)
|
||||
VALUES ('puppy', 16843011, 'Ubuntu 14.10', 0.0));
|
||||
$ret = $dbh->do($stmt) or die $DBI::errstr;
|
||||
|
||||
# search and iterate row(s) in the table
|
||||
$stmt = qq(SELECT id, hostname, os, cpuload from NETWORK;);
|
||||
my $obj = $dbh->prepare($stmt);
|
||||
$ret = $obj->execute() or die $DBI::errstr;
|
||||
|
||||
if($ret < 0) {
|
||||
print STDERR $DBI::errstr;
|
||||
}
|
||||
while(my @row = $obj->fetchrow_array()) {
|
||||
print "ID: ". $row[0] . "\n";
|
||||
print "HOSTNAME: ". $row[1] ."\n";
|
||||
print "OS: ". $row[2] ."\n";
|
||||
print "CPULOAD: ". $row[3] ."\n\n";
|
||||
}
|
||||
|
||||
# update specific row(s) in the table
|
||||
$stmt = qq(UPDATE NETWORK set CPULOAD = 50 where OS='Ubuntu 14.10';);
|
||||
$ret = $dbh->do($stmt) or die $DBI::errstr;
|
||||
|
||||
if( $ret < 0 ) {
|
||||
print STDERR $DBI::errstr;
|
||||
} else {
|
||||
print STDERR "A total of $ret rows updated\n";
|
||||
}
|
||||
|
||||
# delete specific row(s) from the table
|
||||
$stmt = qq(DELETE from NETWORK where ID=2;);
|
||||
$ret = $dbh->do($stmt) or die $DBI::errstr;
|
||||
|
||||
if($ret < 0) {
|
||||
print STDERR $DBI::errstr;
|
||||
} else {
|
||||
print STDERR "A total of $ret rows deleted\n";
|
||||
}
|
||||
|
||||
# quit the database
|
||||
$dbh->disconnect();
|
||||
print STDERR "Exit the database\n";
|
||||
|
||||
上面的Perl脚本运行成功后会创建一个叫“xmodulo.db”的数据库文件,并会有下面的输出。
|
||||
|
||||
Database opened successfully
|
||||
Table created successfully
|
||||
ID: 1
|
||||
HOSTNAME: xmodulo
|
||||
OS: Ubuntu 14.10
|
||||
CPULOAD: 0
|
||||
|
||||
ID: 2
|
||||
HOSTNAME: bert
|
||||
OS: CentOS 7
|
||||
CPULOAD: 0
|
||||
|
||||
ID: 3
|
||||
HOSTNAME: puppy
|
||||
OS: Ubuntu 14.10
|
||||
CPULOAD: 0
|
||||
|
||||
A total of 2 rows updated
|
||||
A total of 1 rows deleted
|
||||
Exit the database
|
||||
|
||||
### 错误定位 ###
|
||||
|
||||
如果你尝试没有安装SQLite DBI驱动的情况下使用Perl访问SQLite的话,你会遇到下面的错误。你必须按开始说的安装DBI驱动。
|
||||
|
||||
Can't locate DBI.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at ./script.pl line 3.
|
||||
BEGIN failed--compilation aborted at ./script.pl line 3.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/access-sqlite-database-perl.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
@ -0,0 +1,67 @@
|
||||
|
||||
在Ubuntu 15.04下安装Android Studio
|
||||
PS 原MD文件有大段重复并且排版错误,译者已修复
|
||||
================================================================================
|
||||
|
||||
Android Studio是官方为了Android应用开发者而发布的IDE,它基于IntelliJ的IDEA。
|
||||
|
||||
### Android Studio的功能 ###
|
||||
|
||||
灵活的基于Gradle的建构系统
|
||||
|
||||
针对不同手机编译多个版本的apk
|
||||
|
||||
代码模板功能构建出各种常用的应用
|
||||
|
||||
支持拖动编辑主题的富布局编辑器
|
||||
|
||||
lint工具可以捕捉到应用的性能、可用性、版本冲突或者其他问题
|
||||
|
||||
代码混淆和应用签名功能
|
||||
|
||||
内置 Google Cloud Platform 的支持,可以轻易的融入Google Cloud Messaging 和 App Engine支持
|
||||
|
||||
还有更多
|
||||
|
||||
|
||||
|
||||
### 在 Ubuntu 15.04 上安装 Android Studio ###
|
||||
|
||||
打开terminal,输入以下命令
|
||||
|
||||
sudo apt-add-repository ppa:paolorotolo/android-studio
|
||||
sudo apt-get update
|
||||
sudo apt-get install android-studio
|
||||
|
||||
|
||||
如果要把Android Studio添加到启动栏,你需要如下操作
|
||||
|
||||
打开Android Studio,点击Configure选择Create Desktop Entry,这样Android Studio应该在dash中创建快捷方式了。
|
||||
|
||||
### 截图 ###
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-android-studio-on-ubuntu-15-04.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[NearTan](https://github.com/NearTan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
Loading…
Reference in New Issue
Block a user