mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
e79c83e7c9
@ -1,225 +0,0 @@
|
||||
Translatin by imquanquan
|
||||
|
||||
Here are some amazing advantages of Go that you don’t hear much about
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Artwork from [https://github.com/ashleymcnamara/gophers][1]
|
||||
|
||||
In this article, I discuss why you should give Go a chance and where to start.
|
||||
|
||||
Golang is a programming language you might have heard about a lot during the last couple years. Even though it was created back in 2009, it has started to gain popularity only in recent years.
|
||||
|
||||
|
||||
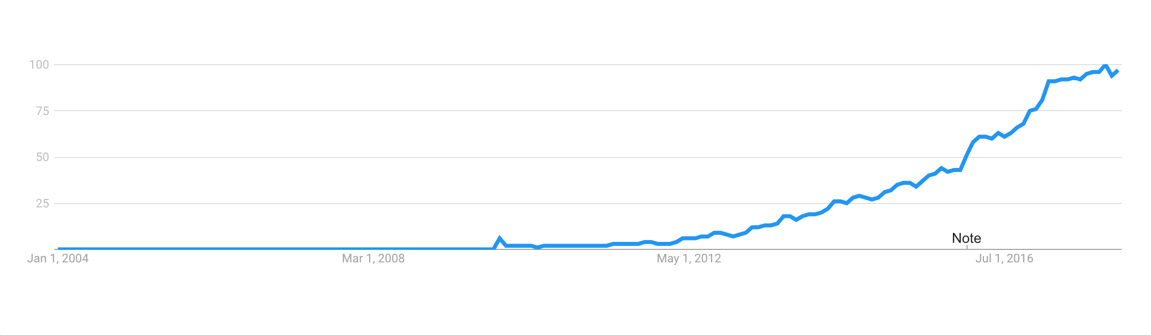
|
||||
Golang popularity according to Google Trends
|
||||
|
||||
This article is not about the main selling points of Go that you usually see.
|
||||
|
||||
Instead, I would like to present to you some rather small but still significant features that you only get to know after you’ve decided to give Go a try.
|
||||
|
||||
These are amazing features that are not laid out on the surface, but they can save you weeks or months of work. They can also make software development more enjoyable.
|
||||
|
||||
Don’t worry if Go is something new for you. This article does not require any prior experience with the language. I have included a few extra links at the bottom, in case you would like to learn a bit more.
|
||||
|
||||
We will go through such topics as:
|
||||
|
||||
* GoDoc
|
||||
|
||||
* Static code analysis
|
||||
|
||||
* Built-in testing and profiling framework
|
||||
|
||||
* Race condition detection
|
||||
|
||||
* Learning curve
|
||||
|
||||
* Reflection
|
||||
|
||||
* Opinionatedness
|
||||
|
||||
* Culture
|
||||
|
||||
Please, note that the list doesn’t follow any particular order. It is also opinionated as hell.
|
||||
|
||||
### GoDoc
|
||||
|
||||
Documentation in code is taken very seriously in Go. So is simplicity.
|
||||
|
||||
[GoDoc][4] is a static code analyzing tool that creates beautiful documentation pages straight out of your code. A remarkable thing about GoDoc is that it doesn’t use any extra languages, like JavaDoc, PHPDoc, or JSDoc to annotate constructions in your code. Just English.
|
||||
|
||||
It uses as much information as it can get from the code to outline, structure, and format the documentation. And it has all the bells and whistles, such as cross-references, code samples, and direct links to your version control system repository.
|
||||
|
||||
All you can do is to add a good old `// MyFunc transforms Foo into Bar` kind of comment which would be reflected in the documentation, too. You can even add [code examples][5] which are actually runnable via the web interface or locally.
|
||||
|
||||
GoDoc is the only documentation engine for Go that is used by the whole community. This means that every library or application written in Go has the same format of documentation. In the long run, it saves you tons of time while browsing those docs.
|
||||
|
||||
Here, for example, is the GoDoc page for my recent pet project: [pullkee — GoDoc][6].
|
||||
|
||||
### Static code analysis
|
||||
|
||||
Go heavily relies on static code analysis. Examples include [godoc][7] for documentation, [gofmt][8] for code formatting, [golint][9] for code style linting, and many others.
|
||||
|
||||
There are so many of them that there’s even an everything-included-kind-of project called [gometalinter][10] to compose them all into a single utility.
|
||||
|
||||
Those tools are commonly implemented as stand-alone command line applications and integrate easily with any coding environment.
|
||||
|
||||
Static code analysis isn’t actually something new to modern programming, but Go sort of brings it to the absolute. I can’t overestimate how much time it saved me. Also, it gives you a feeling of safety, as though someone is covering your back.
|
||||
|
||||
It’s very easy to create your own analyzers, as Go has dedicated built-in packages for parsing and working with Go sources.
|
||||
|
||||
You can learn more from this talk: [GothamGo Kickoff Meetup: Go Static Analysis Tools by Alan Donovan][11].
|
||||
|
||||
### Built-in testing and profiling framework
|
||||
|
||||
Have you ever tried to pick a testing framework for a Javascript project you are starting from scratch? If so, you might understand that struggle of going through such an analysis paralysis. You might have also realized that you were not using like 80% of the framework you have chosen.
|
||||
|
||||
The issue repeats over again once you need to do some reliable profiling.
|
||||
|
||||
Go comes with a built-in testing tool designed for simplicity and efficiency. It provides you the simplest API possible, and makes minimum assumptions. You can use it for different kinds of testing, profiling, and even to provide executable code examples.
|
||||
|
||||
It produces CI-friendly output out-of-box, and the usage is usually as easy as running `go test`. Of course, it also supports advanced features like running tests in parallel, marking them skipped, and many more.
|
||||
|
||||
### Race condition detection
|
||||
|
||||
You might already know about Goroutines, which are used in Go to achieve concurrent code execution. If you don’t, [here’s][12] a really brief explanation.
|
||||
|
||||
Concurrent programming in complex applications is never easy regardless of the specific technique, partly due to the possibility of race conditions.
|
||||
|
||||
Simply put, race conditions happen when several concurrent operations finish in an unpredicted order. It might lead to a huge number of bugs, which are particularly hard to chase down. Ever spent a day debugging an integration test which only worked in about 80% of executions? It probably was a race condition.
|
||||
|
||||
All that said, concurrent programming is taken very seriously in Go and, luckily, we have quite a powerful tool to hunt those race conditions down. It is fully integrated into Go’s toolchain.
|
||||
|
||||
You can read more about it and learn how to use it here: [Introducing the Go Race Detector — The Go Blog][13].
|
||||
|
||||
### Learning curve
|
||||
|
||||
You can learn ALL Go’s language features in one evening. I mean it. Of course, there are also the standard library, and the best practices in different, more specific areas. But two hours would totally be enough time to get you confidently writing a simple HTTP server, or a command-line app.
|
||||
|
||||
The project has [marvelous documentation][14], and most of the advanced topics have already been covered on their blog: [The Go Programming Language Blog][15].
|
||||
|
||||
Go is much easier to bring to your team than Java (and the family), Javascript, Ruby, Python, or even PHP. The environment is easy to setup, and the investment your team needs to make is much smaller before they can complete your first production code.
|
||||
|
||||
### Reflection
|
||||
|
||||
Code reflection is essentially an ability to sneak under the hood and access different kinds of meta-information about your language constructs, such as variables or functions.
|
||||
|
||||
Given that Go is a statically typed language, it’s exposed to a number of various limitations when it comes to more loosely typed abstract programming. Especially compared to languages like Javascript or Python.
|
||||
|
||||
Moreover, Go [doesn’t implement a concept called Generics][16] which makes it even more challenging to work with multiple types in an abstract way. Nevertheless, many people think it’s actually beneficial for the language because of the amount of complexity Generics bring along. And I totally agree.
|
||||
|
||||
According to Go’s philosophy (which is a separate topic itself), you should try hard to not over-engineer your solutions. And this also applies to dynamically-typed programming. Stick to static types as much as possible, and use interfaces when you know exactly what sort of types you’re dealing with. Interfaces are very powerful and ubiquitous in Go.
|
||||
|
||||
However, there are still cases in which you can’t possibly know what sort of data you are facing. A great example is JSON. You convert all the kinds of data back and forth in your applications. Strings, buffers, all sorts of numbers, nested structs and more.
|
||||
|
||||
In order to pull that off, you need a tool to examine all the data in runtime that acts differently depending on its type and structure. Reflection to rescue! Go has a first-class [reflect][17] package to enable your code to be as dynamic as it would be in a language like Javascript.
|
||||
|
||||
An important caveat is to know what price you pay for using it — and only use it when there is no simpler way.
|
||||
|
||||
You can read more about it here: [The Laws of Reflection — The Go Blog][18].
|
||||
|
||||
You can also read some real code from the JSON package sources here: [src/encoding/json/encode.go — Source Code][19]
|
||||
|
||||
### Opinionatedness
|
||||
|
||||
Is there such a word, by the way?
|
||||
|
||||
Coming from the Javascript world, one of the most daunting processes I faced was deciding which conventions and tools I needed to use. How should I style my code? What testing library should I use? How should I go about structure? What programming paradigms and approaches should I rely on?
|
||||
|
||||
Which sometimes basically got me stuck. I was doing this instead of writing the code and satisfying the users.
|
||||
|
||||
To begin with, I should note that I totally get where those conventions should come from. It’s always you and your team. Anyway, even a group of experienced Javascript developers can easily find themselves having most of the experience with entirely different tools and paradigms to achieve kind of the same results.
|
||||
|
||||
This makes the analysis paralysis cloud explode over the whole team, and also makes it harder for the individuals to integrate with each other.
|
||||
|
||||
Well, Go is different. You have only one style guide that everyone follows. You have only one testing framework which is built into the basic toolchain. You have a lot of strong opinions on how to structure and maintain your code. How to pick names. What structuring patterns to follow. How to do concurrency better.
|
||||
|
||||
While this might seem too restrictive, it saves tons of time for you and your team. Being somewhat limited is actually a great thing when you are coding. It gives you a more straightforward way to go when architecting new code, and makes it easier to reason about the existing one.
|
||||
|
||||
As a result, most of the Go projects look pretty alike code-wise.
|
||||
|
||||
### Culture
|
||||
|
||||
People say that every time you learn a new spoken language, you also soak in some part of the culture of the people who speak that language. Thus, the more languages you learn, more personal changes you might experience.
|
||||
|
||||
It’s the same with programming languages. Regardless of how you are going to apply a new programming language in the future, it always gives you a new perspective on programming in general, or on some specific techniques.
|
||||
|
||||
Be it functional programming, pattern matching, or prototypal inheritance. Once you’ve learned it, you carry these approaches with you which broadens the problem-solving toolset that you have as a software developer. It also changes the way you see high-quality programming in general.
|
||||
|
||||
And Go is a terrific investment here. The main pillar of Go’s culture is keeping simple, down-to-earth code without creating many redundant abstractions and putting the maintainability at the top. It’s also a part of the culture to spend the most time actually working on the codebase, instead of tinkering with the tools and the environment. Or choosing between different variations of those.
|
||||
|
||||
Go is also all about “there should be only one way of doing a thing.”
|
||||
|
||||
A little side note. It’s also partially true that Go usually gets in your way when you need to build relatively complex abstractions. Well, I’d say that’s the tradeoff for its simplicity.
|
||||
|
||||
If you really need to write a lot of abstract code with complex relationships, you’d be better off using languages like Java or Python. However, even when it’s not obvious, it’s very rarely the case.
|
||||
|
||||
Always use the best tool for the job!
|
||||
|
||||
### Conclusion
|
||||
|
||||
You might have heard of Go before. Or maybe it’s something that has been staying out of your radar for a while. Either way, chances are, Go can be a very decent choice for you or your team when starting a new project or improving the existing one.
|
||||
|
||||
This is not a complete list of all the amazing things about Go. Just the undervalued ones.
|
||||
|
||||
Please, give Go a try with [A Tour of Go][20] which is an incredible place to start.
|
||||
|
||||
If you wish to learn more about Go’s benefits, you can check out these links:
|
||||
|
||||
* [Why should you learn Go? — Keval Patel — Medium][2]
|
||||
|
||||
* [Farewell Node.js — TJ Holowaychuk — Medium][3]
|
||||
|
||||
Share your observations down in the comments!
|
||||
|
||||
Even if you are not specifically looking for a new language to use, it’s worth it to spend an hour or two getting the feel of it. And maybe it can become quite useful for you in the future.
|
||||
|
||||
Always be looking for the best tools for your craft!
|
||||
|
||||
* * *
|
||||
|
||||
If you like this article, please consider following me for more, and clicking on those funny green little hands right below this text for sharing. 👏👏👏
|
||||
|
||||
Check out my [Github][21] and follow me on [Twitter][22]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Software Engineer and Traveler. Coding for fun. Javascript enthusiast. Tinkering with Golang. A lot into SOA and Docker. Architect at Velvica.
|
||||
|
||||
------------
|
||||
|
||||
|
||||
via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that-you-dont-hear-much-about-1af99de3b23a
|
||||
|
||||
作者:[Kirill Rogovoy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://github.com/ashleymcnamara/gophers
|
||||
[2]:https://medium.com/@kevalpatel2106/why-should-you-learn-go-f607681fad65
|
||||
[3]:https://medium.com/@tjholowaychuk/farewell-node-js-4ba9e7f3e52b
|
||||
[4]:https://godoc.org/
|
||||
[5]:https://blog.golang.org/examples
|
||||
[6]:https://godoc.org/github.com/kirillrogovoy/pullkee
|
||||
[7]:https://godoc.org/
|
||||
[8]:https://golang.org/cmd/gofmt/
|
||||
[9]:https://github.com/golang/lint
|
||||
[10]:https://github.com/alecthomas/gometalinter#supported-linters
|
||||
[11]:https://vimeo.com/114736889
|
||||
[12]:https://gobyexample.com/goroutines
|
||||
[13]:https://blog.golang.org/race-detector
|
||||
[14]:https://golang.org/doc/
|
||||
[15]:https://blog.golang.org/
|
||||
[16]:https://golang.org/doc/faq#generics
|
||||
[17]:https://golang.org/pkg/reflect/
|
||||
[18]:https://blog.golang.org/laws-of-reflection
|
||||
[19]:https://golang.org/src/encoding/json/encode.go
|
||||
[20]:https://tour.golang.org/
|
||||
[21]:https://github.com/kirillrogovoy/
|
||||
[22]:https://twitter.com/krogovoy
|
||||
@ -1,59 +0,0 @@
|
||||
## sober-wang 翻译中
|
||||
Linux Virtual Machines vs Linux Live Images
|
||||
======
|
||||
I'll be the first to admit that I tend to try out new [Linux distros][1] on a far too frequent basis. Yet the method I use to test them, does vary depending on my goals for each instance. In this article, we're going to look at both running Linux virtual machines and running Linux live images. There are advantages to each method, but there are some hurdles with each method as well.
|
||||
|
||||
### Testing out a new Linux distro for the first time
|
||||
|
||||
When I test out a brand new Linux distro for the first time, the method I use depends heavily on the resources of the PC I'm currently on. If I have access to my desktop PC, I'm going to run the distro to be tested in a virtual machine. The reason for this approach is that I can download and test the distro in not only a live environment, but also as an installed product with persistent storage abilities.
|
||||
|
||||
On the other hand, if I am working with much less robust hardware on a PC, then testing out a distro with a virtual machine installation of Linux is counter-productive. I'd be pushing that PC to its limits and honestly would be better off using a live Linux image instead running from a flash drive.
|
||||
|
||||
### Touring software on a new Linux distro
|
||||
|
||||
If you're interested in checking out a distro's desktop environment or the available software, you can't go wrong with a live image of the distro. A live environment provides you with a birds eye view of what to expect in terms of overall layout, applications provided and how the user experience flows overall.
|
||||
|
||||
To be fair, you could do the same thing with a virtual machine installation, but it may be a bit overkill if you would rather avoid filling up hard drive space with yet more data. After all, this is a simple tour of the distro. Remember what I said in the first section – I like to run Linux in a virtual machine to test it. This means I'm going to see how it installs, what the partition options look like and other elements you wouldn't see from using a live image of any given distro.
|
||||
|
||||
Touring usually indicates that you're only looking to take a quick look at a distro, so in this case the method that can be done with the least amount of resistance and time investment is a good course of action.
|
||||
|
||||
### Taking a Linux distro with you
|
||||
|
||||
While it's not as common as it was a few years ago, the ability to take a Linux distro with you may be a consideration for some users. Obviously, virtual machine installations don't necessarily lend themselves favorably to portability. However a live image of a Linux distro is actually quite portable. A live image can be written to a DVD or copied onto a flash drive for easy traveling.
|
||||
|
||||
Expanding on this concept of Linux portability, it's also beneficial to have a live image on a flash drive when showing off how Linux works on a friend's computer. This empowers you to demonstrate how Linux can enrich their life while not relying on running a virtual machine on their PC. It's a bit of a win-win in favor of using a live image.
|
||||
|
||||
### Alternative to dual-booting Linux
|
||||
|
||||
This next item is a huge one. Consider this – perhaps you're a Windows user. You like playing with Linux, but would rather not take the plunge. Dual-booting is out of the question in case something goes wrong or perhaps you're not comfortable identifying individual partitions. Whatever the case may be, both using Linux in a virtual machine or from a live image might be a great option for you.
|
||||
|
||||
Now I'm going to take a rather odd stance on something. I think you'll get far more value in the long term running Linux on a flash drive using a live image than with a virtual machine. There are two reasons for this. First of all, you'll get used to truly running Linux vs running it inside of a virtual machine on top of Windows. Second, you can setup your flash drive to contain user data with persistent storage.
|
||||
|
||||
I'll grant you the same could be said with a virtual machine running Linux, however you will never have an update break anything using the live image approach. Why? Because you're not updating a host OS or the guest OS. Remember there are entire distros that are designed to be nothing more than persistent storage Linux distros. Puppy Linux is one great example. Not only can it run on PCs that would otherwise be recycled or thrown away, it allows you to never be bothered again with tedious system updates thanks to the way the distro handles security. It's not a normal Linux distro and it's walled off in such a way that the persistent live image is free from anything scary.
|
||||
|
||||
### When a Linux virtual machine is absolutely the best option
|
||||
|
||||
As I bring this article to a close, let me leave you with this. There is one instance where using a virtual machine such as Virtual Box is absolutely better than using a live image – recording the desktop environment of any Linux distro.
|
||||
|
||||
For example, I make videos that provide a tour and review of a variety of Linux distros. Doing this with live images would require me to capture the screen with a hardware device or install a software capture device from the live image's repositories. Clearly, a virtual machine is better suited for this job than a live image of a Linux distro.
|
||||
|
||||
Once you toss audio capture into the mix, there is no question that if you're going to use software to capture your review, you really want to have a host OS that has all the basic needs covered for a reasonably decent capture environment. Again, you could do all of this with a hardware device...but that might be cost prohibitive if you're only do video/audio capturing as a part time endeavor.
|
||||
|
||||
### A Linux virtual machine vs a Linux live image
|
||||
|
||||
What is your preferred method of trying out new distros? Perhaps you're someone who is fine with formatting their hard drive and throwing caution to the wind, thus, making the idea of any of this unneeded?
|
||||
|
||||
Most people I've interacted with online tend to follow much of the methodology I've touched on above, but I'd love to hear what approach works best for you. Hit the comments, let me know which method you prefer when checking out the greatest and latest from the Linux distro world.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datamation.com/open-source/linux-virtual-machines-vs-linux-live-images.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:https://www.datamation.com/open-source/best-linux-distro.html
|
||||
@ -1,162 +0,0 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
Installing and using Git and GitHub on Ubuntu Linux: A beginner's guide
|
||||
======
|
||||
|
||||
GitHub is a treasure trove of some of the world's best projects, built by the contributions of developers all across the globe. This simple, yet extremely powerful platform helps every individual interested in building or developing something big to contribute and get recognized in the open source community.
|
||||
|
||||
This tutorial is a quick setup guide for installing and using GitHub and how to perform its various functions of creating a repository locally, connecting this repo to the remote host that contains your project (where everyone can see), committing the changes and finally pushing all the content in the local system to GitHub.
|
||||
|
||||
Please note that this tutorial assumes that you have a basic knowledge of the terms used in Git such as push, pull requests, commit, repository, etc. It also requires you to register to GitHub [here][1] and make a note of your GitHub username. So let's begin:
|
||||
|
||||
### 1 Installing Git for Linux
|
||||
|
||||
Download and install Git for Linux:
|
||||
|
||||
```
|
||||
sudo apt-get install git
|
||||
```
|
||||
|
||||
The above command is for Ubuntu and works on all Recent Ubuntu versions, tested from Ubuntu 16.04 to Ubuntu 18.04 LTS (Bionic Beaver) and it's likely to work the same way on future versions.
|
||||
|
||||
### 2 Configuring GitHub
|
||||
|
||||
Once the installation has successfully completed, the next thing to do is to set up the configuration details of the GitHub user. To do this use the following two commands by replacing "user_name" with your GitHub username and replacing "email_id" with your email-id you used to create your GitHub account.
|
||||
|
||||
```
|
||||
git config --global user.name "user_name"
|
||||
|
||||
git config --global user.email "email_id"
|
||||
```
|
||||
|
||||
The following image shows an example of my configuration with my "user_name" being "akshaypai" and my "email_id" being "[[email protected]][2]"
|
||||
|
||||
[![Git config][3]][4]
|
||||
|
||||
### 3 Creating a local repository
|
||||
|
||||
Create a folder on your system. This will serve as a local repository which will later be pushed onto the GitHub website. Use the following command:
|
||||
|
||||
```
|
||||
git init Mytest
|
||||
```
|
||||
|
||||
If the repository is created successfully, then you will get the following line:
|
||||
|
||||
Initialized empty Git repository in /home/akshay/Mytest/.git/
|
||||
|
||||
This line may vary depending on your system.
|
||||
|
||||
So here, Mytest is the folder that is created and "init" makes the folder a GitHub repository. Change the directory to this newly created folder:
|
||||
|
||||
```
|
||||
cd Mytest
|
||||
```
|
||||
|
||||
### 4 Creating a README file to describe the repository
|
||||
|
||||
Now create a README file and enter some text like "this is a git setup on Linux". The README file is generally used to describe what the repository contains or what the project is all about. Example:
|
||||
|
||||
```
|
||||
gedit README
|
||||
```
|
||||
|
||||
You can use any other text editors. I use gedit. The content of the README file will be:
|
||||
|
||||
This is a git repo
|
||||
|
||||
### 5 Adding repository files to an index
|
||||
|
||||
This is an important step. Here we add all the things that need to be pushed onto the website into an index. These things might be the text files or programs that you might add for the first time into the repository or it could be adding a file that already exists but with some changes (a newer version/updated version).
|
||||
|
||||
Here we already have the README file. So, let's create another file which contains a simple C program and call it sample.c. The contents of it will be:
|
||||
```
|
||||
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
{
|
||||
printf("hello world");
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
So, now that we have 2 files
|
||||
|
||||
README and sample.c
|
||||
|
||||
add it to the index by using the following 2 commands:
|
||||
|
||||
```
|
||||
git add README
|
||||
|
||||
git add smaple.c
|
||||
```
|
||||
|
||||
Note that the "git add" command can be used to add any number of files and folders to the index. Here, when I say index, what I am referring to is a buffer like space that stores the files/folders that have to be added into the Git repository.
|
||||
|
||||
### 6 Committing changes made to the index
|
||||
|
||||
Once all the files are added, we can commit it. This means that we have finalized what additions and/or changes have to be made and they are now ready to be uploaded to our repository. Use the command :
|
||||
|
||||
```
|
||||
git commit -m "some_message"
|
||||
```
|
||||
|
||||
"some_message" in the above command can be any simple message like "my first commit" or "edit in readme", etc.
|
||||
|
||||
### 7 Creating a repository on GitHub
|
||||
|
||||
Create a repository on GitHub. Notice that the name of the repository should be the same as the repository's on the local system. In this case, it will be "Mytest". To do this login to your account on <https://github.com>. Then click on the "plus(+)" symbol at the top right corner of the page and select "create new repository". Fill the details as shown in the image below and click on "create repository" button.
|
||||
|
||||
[![Creating a repository on GitHub][5]][6]
|
||||
|
||||
Once this is created, we can push the contents of the local repository onto the GitHub repository in your profile. Connect to the repository on GitHub using the command:
|
||||
|
||||
Important Note: Make sure you replace 'user_name' and 'Mytest' in the path with your Github username and folder before running the command!
|
||||
|
||||
```
|
||||
git remote add origin <https://github.com/user\_name/Mytest.git>
|
||||
```
|
||||
|
||||
### 8 Pushing files in local repository to GitHub repository
|
||||
|
||||
The final step is to push the local repository contents into the remote host repository (GitHub), by using the command:
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
|
||||
Enter the login credentials [user_name and password].
|
||||
|
||||
The following image shows the procedure from step 5 to step 8
|
||||
|
||||
[![Pushing files in local repository to GitHub repository][7]][8]
|
||||
|
||||
So this adds all the contents of the 'Mytest' folder (my local repository) to GitHub. For subsequent projects or for creating repositories, you can start off with step 3 directly. Finally, if you log in to your GitHub account and click on your Mytest repository, you can see that the 2 files README and sample.c have been uploaded and are visible to all as shown in the following image.
|
||||
|
||||
[![Content uploaded to Github][9]][10]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-git-and-github-on-ubuntu/
|
||||
|
||||
作者:[Akshay Pai][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
[1]:https://github.com/
|
||||
[2]:https://www.howtoforge.com/cdn-cgi/l/email-protection
|
||||
[3]:https://www.howtoforge.com/images/ubuntu_github_getting_started/config.png
|
||||
[4]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/config.png
|
||||
[5]:https://www.howtoforge.com/images/ubuntu_github_getting_started/details.png
|
||||
[6]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/details.png
|
||||
[7]:https://www.howtoforge.com/images/ubuntu_github_getting_started/steps.png
|
||||
[8]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/steps.png
|
||||
[9]:https://www.howtoforge.com/images/ubuntu_github_getting_started/final.png
|
||||
[10]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/final.png
|
||||
@ -1,3 +1,5 @@
|
||||
translating----geekpi
|
||||
|
||||
How to install software from the Linux command line
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,201 @@
|
||||
Linux for Beginners: Moving Things Around
|
||||
======
|
||||
|
||||

|
||||
|
||||
In previous installments of this series, [you learned about directories][1] and how [permissions to access directories work][2]. Most of what you learned in those articles can be applied to files, except how to make a file executable.
|
||||
|
||||
So let's deal with that before moving on.
|
||||
|
||||
### No _.exe_ Needed
|
||||
|
||||
In other operating systems, the nature of a file is often determined by its extension. If a file has a _.jpg_ extension, the OS guesses it is an image; if it ends in _.wav_ , it is an audio file; and if it has an _.exe_ tacked onto the end of the file name, it is a program you can execute.
|
||||
|
||||
This leads to serious problems, like trojans posing as documents. Fortunately, that is not how things work in Linux. Sure, you may see occasional executable file endings in _.sh_ that indicate they are runnable shell scripts, but this is mostly for the benefit of humans eyeballing files, the same way when you use `ls --color`, the names of executable files show up in bright green.
|
||||
|
||||
The fact is most applications have no extension at all. What determines whether a file is really program is the _x_ (for _executable_ ) bit. You can make any file executable by running
|
||||
```
|
||||
chmod a+x some_program
|
||||
|
||||
```
|
||||
|
||||
regardless of its extension or lack thereof. The `x` in the command above sets the _x_ bit and the `a` says you are setting it for _all_ users. You could also set it only for the group of users that own the file (`g+x`), or for only one user, the owner (`u+x`).
|
||||
|
||||
Although we will be covering creating and running scripts from the command line later in this series, know that you can run a program by writing the path to it and then tacking on the name of the program on the end:
|
||||
```
|
||||
path/to/directory/some_program
|
||||
|
||||
```
|
||||
|
||||
Or, if you are currently in the same directory, you can use:
|
||||
```
|
||||
./some_program
|
||||
|
||||
```
|
||||
|
||||
There are other ways of making your program available from anywhere in the directory tree (hint: look up the `$PATH` environment variable), but you will be reading about those when we talk about shell scripting.
|
||||
|
||||
### Copying, Moving, Linking
|
||||
|
||||
Obviously, there are more ways of modifying and handling files from the command line than just playing around with their permissions. Most applications will create a new file if you still try to open a file that doesn't exist. Both
|
||||
```
|
||||
nano test.txt
|
||||
|
||||
```
|
||||
|
||||
and
|
||||
```
|
||||
vim test.txt
|
||||
|
||||
```
|
||||
|
||||
([nano][3] and [vim][4] being to popular command line text editors) will create an empty _test.txt_ file for you to edit if _test.txt_ didn't exist beforehand.
|
||||
|
||||
You can also create an empty file by _touching_ it:
|
||||
```
|
||||
touch test.txt
|
||||
|
||||
```
|
||||
|
||||
Will create a file, but not open it in any application.
|
||||
|
||||
You can use `cp` to make a copy of a file in another location or under a new name:
|
||||
```
|
||||
cp test.txt copy_of_test.txt
|
||||
|
||||
```
|
||||
|
||||
You can also copy a whole bunch of files:
|
||||
```
|
||||
cp *.png /home/images
|
||||
|
||||
```
|
||||
|
||||
The instruction above copies all the PNG files in the current directory into an _images/_ directory hanging off of your home directory. The _images/_ directory has to exist before you try this, or `cp` will show an error. Also, be warned that, if you copy a file to a directory that contains another file with the same name, `cp` will silently overwrite the old file with the new one.
|
||||
|
||||
You can use
|
||||
```
|
||||
cp -i *.png /home/images
|
||||
|
||||
```
|
||||
|
||||
If you want `cp` to warn you of any dangers (the `-i` options stands for _interactive_ ).
|
||||
|
||||
You can also copy whole directories, but you need the `-r` option for that:
|
||||
```
|
||||
cp -rv directory_a/ directory_b
|
||||
|
||||
```
|
||||
|
||||
The `-r` option stands for _recursive_ , meaning that `cp` will drill down into _directory_a_ , copying over all the files and subdirectories contained within. I personally like to include the `-v` option, as it makes `cp` _verbose_ , meaning that it will show you what it is doing instead of just copying silently and then exiting.
|
||||
|
||||
The `mv` command moves stuff. That is, it changes files from one location to another. In its simplest form, `mv` looks a lot like `cp`:
|
||||
```
|
||||
mv test.txt new_test.txt
|
||||
|
||||
```
|
||||
|
||||
The command above makes _new_test.txt_ appear and _test.txt_ disappear.
|
||||
```
|
||||
mv *.png /home/images
|
||||
|
||||
```
|
||||
|
||||
Moves all the PNG files in the current directory to a directory called _images/_ hanging of your home directory. Again you have to be careful you do not overwrite existing files by accident. Use
|
||||
```
|
||||
mv -i *.png /home/images
|
||||
|
||||
```
|
||||
|
||||
the same way you would with `cp` if you want to be on the safe side.
|
||||
|
||||
Apart from moving versus copying, another difference between `mv` and `cp`is when you move a directory:
|
||||
```
|
||||
mv directory_a/ directory_b
|
||||
|
||||
```
|
||||
|
||||
No need for a recursive flag here. This is because what you are really doing is renaming the directory, the same way in the first example, you were renaming the file*. In fact, even when you "move" a file from one directory to another, as long as both directories are on the same storage device and partition, you are renaming the file.
|
||||
|
||||
You can do an experiment to prove it. `time` is a tool that lets you measure how long a command takes to execute. Look for a hefty file, something that weighs several hundred MBs or even some GBs (say, something like a long video) and try copying it from one directory to another like this:
|
||||
```
|
||||
$ time cp hefty_file.mkv another_directory/
|
||||
real 0m3,868s
|
||||
user 0m0,016s
|
||||
sys 0m0,887s
|
||||
|
||||
```
|
||||
|
||||
In bold is what you have to type into the terminal and below what `time` outputs. The number to focus on is the one on the first line, _real_ time. It takes nearly 4 seconds to copy the 355 MBs of _hefty_file.mkv_ to _another_directory/_.
|
||||
|
||||
Now let's try moving it:
|
||||
```
|
||||
$ time mv hefty_file.mkv another_directory/
|
||||
real 0m0,004s
|
||||
user 0m0,000s
|
||||
sys 0m0,003s
|
||||
|
||||
```
|
||||
|
||||
Moving is nearly instantaneous! This is counterintuitive, since it would seem that `mv` would have to copy the file and then delete the original. That is two things `mv` has to do versus `cp`'s one. But, somehow, `mv` is 1000 times faster.
|
||||
|
||||
That is because the file system's structure, with all its tree of directories, only exists for the users convenience. At the beginning of each partition there is something called a _partition table_ that tells the operating system where to find each file on the actual physical disk. On the disk, data is not split up into directories or even files. [There are tracks, sectors and clusters instead][5]. When you "move" a file within the same partition, what the operating system does is just change the entry for that file in the partition table, but it still points to the same cluster of information on the disk.
|
||||
|
||||
Yes! Moving is a lie! At least within the same partition that is. If you try and move a file to a different partition or a different device, `mv` is still fast, but is noticeably slower than moving stuff around within the same partition. That is because this time there is actually copying and erasing of data going on.
|
||||
|
||||
### Renaming
|
||||
|
||||
There are several distinct command line `rename` utilities around. None are fixtures like `cp` or `mv` and they can work in slightly different ways. What they all have in common is that they are used to change _parts_ of the names of files.
|
||||
|
||||
In Debian and Ubuntu, the default `rename` utility uses [regular expressions][6] (patterns of strings of characters) to mass change files in a directory. The instruction:
|
||||
```
|
||||
rename 's/\.JPEG$/.jpg/' *
|
||||
|
||||
```
|
||||
|
||||
will change all the extensions of files with the extension _JPEG_ to _jpg_. The file _IMG001.JPEG_ becomes _IMG001.jpg_ , _my_pic.JPEG_ becomes _my_pic.jpg_ , and so on.
|
||||
|
||||
Another version of `rename` available by default in Manjaro, a derivative of Arch, is much simpler, but arguably less powerful:
|
||||
```
|
||||
rename .JPEG .jpg *
|
||||
|
||||
```
|
||||
|
||||
This does the same renaming as you saw above. In this version, `.JPEG` is the string of characters you want to change, `.jpg` is what you want to change it to, and `*` represents all the files in the current directory.
|
||||
|
||||
The bottom line is that you are better off using `mv` if all you want to do is rename one file or directory, and that's because `mv` is realiably the same in all distributions everywhere.
|
||||
|
||||
### Learning more
|
||||
|
||||
Check out the both `mv` and `cp`'s _man_ pages to learn more. Run
|
||||
```
|
||||
man cp
|
||||
|
||||
```
|
||||
|
||||
or
|
||||
```
|
||||
man mv
|
||||
|
||||
```
|
||||
|
||||
to read about all the options these commands come with and which make them more powerful and safer to use.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/8/linux-beginners-moving-things-around
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[1]: https://www.linux.com/blog/learn/2018/5/manipulating-directories-linux
|
||||
[2]: https://www.linux.com/blog/learn/intro-to-linux/2018/7/users-groups-and-other-linux-beasts-part-2
|
||||
[3]: https://www.nano-editor.org/
|
||||
[4]: https://www.vim.org/
|
||||
[5]: https://en.wikipedia.org/wiki/Disk_sector
|
||||
[6]: https://en.wikipedia.org/wiki/Regular_expression
|
||||
@ -0,0 +1,57 @@
|
||||
6 places to host your git repository
|
||||
======
|
||||
|
||||

|
||||
|
||||
Perhaps you're one of the few people who didn't notice, but a few months back, [Microsoft bought GitHub][1]. Nothing against either company. Microsoft has become a vocal supporter of open source in recent years, and GitHub has been the de facto code repository for a heaping large number of open source projects almost since its inception.
|
||||
|
||||
However, the recent(-ish) purchase may have gotten you a little itchy. After all, there's nothing quite like a corporate buy-out to make you realize you've had your open source code sitting on a commercial platform. Maybe you're not quite ready to jump ship just yet, but it would at least be helpful to know your options. Let's have a look around the web and see what's available.
|
||||
|
||||
### Option 1: GitHub
|
||||
|
||||
Seriously, this is a valid option. [GitHub][2] doesn't have a history of acting in bad faith, and Microsoft certainly has been smiling on open source of late. There's nothing wrong with keeping your project on GitHub and taking a wait-and-see perspective. It's still the largest community website for software development, and it still has some of the best tools for issue tracking, code review, continuous integration, and general code management. And its underpinnings are still on Git, everyone's favorite open source distributed version control system. Your code is still your code. There's nothing wrong with leaving things where they are if nothing is broken.
|
||||
|
||||
### Option 2: GitLab
|
||||
|
||||
[GitLab][3] is probably the leading contender when it comes to alternative code platforms. It's fully open source. You can host your code right on GitLab's site much like you would on GitHub, but you can also choose to self-host a GitLab instance of your own on your own server and have full control over who has access to everything there and how things are managed. GitLab pretty much has feature parity with GitHub, and some folks might even say its continuous integration and testing tools are superior. Although the community of developers on GitLab is certainly smaller than the one on GitHub, it's still nothing to sneeze at. And it's possible that you'll find more like-minded developers among the population there.
|
||||
|
||||
### Option 3: Bitbucket
|
||||
|
||||
[Bitbucket][4] has been around for many years. In some ways, it could serve as a looking glass into the future of GitHub. Bitbucket was acquired by a larger corporation (Atlassian) eight years ago and has already been through some of that change-over process. It's still a commercial platform like GitHub, but it's far from being a startup, and it's on pretty stable footing, organizationally speaking. Bitbucket shares most of the features available on GitHub and GitLab, plus a few novel features of its own, like native support for [Mercurial][5] repositories.
|
||||
|
||||
### Option 4: SourceForge
|
||||
|
||||
The granddaddy of open source code repository sites is [SourceForge][6]. It used to be that if you had an open source project, SourceForge was the place to host your code and share your releases. It took a little while to migrate to Git for version control, and it had its own rash of commercial acquiring and re-acquiring events, coupled with a few unfortunate bundling decisions for a few open source projects. That said, SourceForge seems to have recovered since then, and the site is still a place where quite a few open source projects live. A lot of folks still feel a bit burned, though, and some people aren't huge fans of its various attempts to monetize the platform, so be sure you go in with open eyes.
|
||||
|
||||
### Option 5: Roll your own
|
||||
|
||||
If you want full control of your project's destiny (and no one to blame but yourself), then doing it all yourself may be the best option for you. It is a good alternative for both large and small projects. Git is open source, so it's easily self-hosted. If you want issue tracking and code review, you can run an instance of GitLab or [Phabricator][7]. For continuous integration, you can set up your own instance of the [Jenkins][8] automation server. Yes, you'll need to take responsibility for your own infrastructure overhead and the associated security requirements. However, it's not that hard to get yourself set up. And if you want a sure-fire way to avoid being beholden to the whims of anyone else's platform, this is the way to do it.
|
||||
|
||||
### Option 6: All of the above
|
||||
|
||||
Here's the beauty of all of this: Despite the proprietary drapery strewn over some of these platforms, they're still built on top of solid open source technology. And not just open source, but explicitly designed to be distributed across multiple nodes on a large network (like the internet). You're not required to use just one. You can use a couple… or all of them. Roll your own setup as a guaranteed home base using GitLab and have clone repositories on GitHub and Bitbucket for issue tracking and continuous integration. Keep your main codebase on GitHub but have "backup" clones sitting on GitLab for your own piece of mind.
|
||||
|
||||
The key thing is you have options. And we have those options thanks to open source licensing on very useful and powerful projects. The future is bright.
|
||||
|
||||
Of course, I'm bound to have missed some of the open source options available out there. Feel free to pipe up with your favorites. Are you using multiple platforms? What's your setup? Let everyone know in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/github-alternatives
|
||||
|
||||
作者:[Jason van Gumster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mairin
|
||||
[1]: https://www.theverge.com/2018/6/4/17422788/microsoft-github-acquisition-official-deal
|
||||
[2]: https://github.com/
|
||||
[3]: https://gitlab.com
|
||||
[4]: https://bitbucket.org
|
||||
[5]: https://www.mercurial-scm.org/wiki/Repository
|
||||
[6]: https://sourceforge.net
|
||||
[7]: https://phacility.com/phabricator/
|
||||
[8]: https://jenkins.io
|
||||
131
sources/tech/20180830 A quick guide to DNF for yum users.md
Normal file
131
sources/tech/20180830 A quick guide to DNF for yum users.md
Normal file
@ -0,0 +1,131 @@
|
||||
A quick guide to DNF for yum users
|
||||
======
|
||||
|
||||

|
||||
|
||||
Dandified yum, better known as [DNF][1], is a software package manager for RPM-based Linux distributions that installs, updates, and removes packages. It was first introduced in Fedora 18 in a testable state (i.e., tech preview), but it's been Fedora's default package manager since Fedora 22.
|
||||
|
||||
* Dependency calculation based on modern dependency-solving technology
|
||||
* Optimized memory-intensive operations
|
||||
* The ability to run in Python 2 and Python 3
|
||||
* Complete documentation available for Python APIs
|
||||
|
||||
|
||||
|
||||
Since it is the next-generation version of the traditional yum package manager, it has more advanced and robust features than you'll find in yum. Some of the features that distinguish DNF from yum are:
|
||||
|
||||
DNF uses [hawkey][2] libraries, which resolve RPM dependencies for running queries on client machines. These are built on top of libsolv, a package-dependency solver that uses a satisfiability algorithm. You can find more details on the algorithm in [libsolv's GitHub][3] repository.
|
||||
|
||||
### CLI commands that differ in DNF and yum
|
||||
|
||||
Following are some of the changes to yum's command-line interface (CLI) you will find in DNF.
|
||||
|
||||
**dnf update** or **dnf upgrade:** Executing either dnf update or dnf upgrade has the same effect in the system: both update installed packages. However, dnf upgrade is preferred since it works exactly like **yum --obsoletes update**.
|
||||
|
||||
**resolvedep:** This command doesn't exist in DNF. Instead, execute **dnf provides** to find out which package provides a particular file.
|
||||
|
||||
**deplist:** Yum's deplist command, which lists RPM dependencies, was removed in DNF because it uses the package-dependency solver algorithm to solve the dependency query.
|
||||
|
||||
**dnf remove <package>:** You must specify concrete versions of whatever you want to remove. For example, **dnf remove kernel** will delete all packages called "kernel," so make sure to use something like **dnf remove kernel-4.16.x**.
|
||||
|
||||
**dnf history rollback:** This check, which undoes transactions after the one you specifiy, was dropped since not all the possible changes in the RPM Database Tool are stored in the history of the transaction.
|
||||
|
||||
**--skip-broken:** This install command, which checks packages for dependency problems, is triggered in yum with --skip-broken. However, now it is part of dnf update by default, so there is no longer any need for it.
|
||||
|
||||
**-b, --best:** These switches select the best available package versions in transactions. During dnf upgrade, which by default skips over updates that cannot be installed for dependency reasons, this switch forces DNF to consider only the latest packages. Use **dnf upgrade --best**.
|
||||
|
||||
**--allowerasing:** Allows erasing of installed packages to resolve dependencies. This option could be used as an alternative to the **yum swap X Y** command, in which the packages to remove are not explicitly defined.
|
||||
|
||||
For example: **dnf --allowerasing install Y**.
|
||||
|
||||
**\--enableplugin:** This switch is not recognized and has been dropped.
|
||||
|
||||
### DNF Automatic
|
||||
|
||||
The [DNF Automatic][4] tool is an alternative CLI to dnf upgrade. It can execute automatically and regularly from systemd timers, cron jobs, etc. for auto-notification, downloads, or updates.
|
||||
|
||||
To start, install dnf-automatic rpm and enable the systemd timer unit (dnf-automatic.timer). It behaves as specified by the default configuration file (which is /etc/dnf/automatic.conf).
|
||||
```
|
||||
# yum install dnf-automatic
|
||||
# systemctl enable dnf-automatic.timer
|
||||
# systemctl start dnf-automatic.timer
|
||||
# systemctl status dnf-automatic.timer
|
||||
```
|
||||
|
||||

|
||||
|
||||
Other timer units that override the default configuration are listed below. Select the one that meets your system requirements.
|
||||
|
||||
* **dnf-automatic-notifyonly.timer:** Notifies the available updates
|
||||
* **dnf-automatic-download.timer:** Downloads packages, but doesn't install them
|
||||
* **dnf-automatic-install.timer:** Downloads and installs updates
|
||||
|
||||
|
||||
|
||||
### Basic DNF commands useful for package management
|
||||
|
||||
**# yum install dnf:** This installs DNF RPM from the yum package manager.
|
||||
|
||||

|
||||
|
||||
**# dnf –version:** This specifies the DNF version.
|
||||
|
||||

|
||||
|
||||
**# dnf list all** or **# dnf list <package-name>:** This lists all or specific packages; this example lists the kernel RPM available in the system.
|
||||
|
||||

|
||||
|
||||
**# dnf check-update** or **# dnf check-update kernel:** This views updates in the system.
|
||||
|
||||

|
||||
|
||||
**# dnf search <package-name>:** When you search for a specific package via DNF, it will search for an exact match as well as all wildcard searches available in the repository.
|
||||
|
||||

|
||||
|
||||
**# dnf repolist all:** This downloads and lists all enabled repositories in the system.
|
||||
|
||||

|
||||
|
||||
**# dnf list --recent** or **# dnf list --recent <package-name>:** The **\--recent** option dumps all recently added packages in the system. Other list options are **\--extras** , **\--upgrades** , and **\--obsoletes**.
|
||||
|
||||

|
||||
|
||||
**# dnf updateinfo list available** or **# dnf updateinfo list available sec:** These list all the advisories available in the system; including the sec option will list all advisories labeled "security fix."
|
||||
|
||||

|
||||
|
||||
**# dnf updateinfo list available sec --sec-severity Critical:** This lists all the security advisories in the system marked "critical."
|
||||
|
||||

|
||||
|
||||
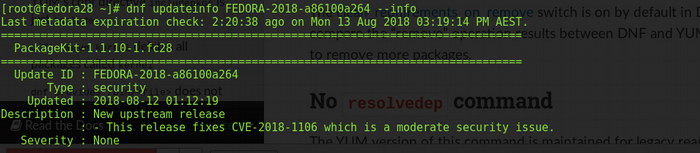
**# dnf updateinfo FEDORA-2018-a86100a264 –info:** This verifies the information of any advisory via the **\--info** switch.
|
||||
|
||||
|
||||
|
||||
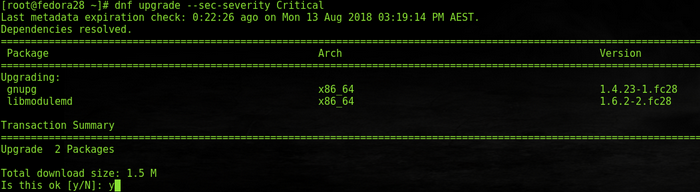
**# dnf upgrade --security** or **# dnf upgrade --sec-severity Critical:** This applies all the security advisories available in the system. With the **\--sec-severity** option, you can include the packages with severity marked either Critical, Important, Moderate, or Low.
|
||||
|
||||
|
||||
|
||||
### Summary
|
||||
|
||||
These are just a small number of DNF's features, changes, and commands. For complete information about DNF's CLI, new plugins, and hook APIs, refer to the [DNF guide][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/guide-yum-dnf
|
||||
|
||||
作者:[Amit Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/amit-das
|
||||
[1]: https://fedoraproject.org/wiki/DNF?rd=Dnf
|
||||
[2]: https://fedoraproject.org/wiki/Features/Hawkey
|
||||
[3]: https://github.com/openSUSE/libsolv
|
||||
[4]: https://dnf.readthedocs.io/en/latest/automatic.html
|
||||
[5]: https://dnf.readthedocs.io/en/latest/index.html
|
||||
@ -0,0 +1,98 @@
|
||||
How To Reset MySQL Or MariaDB Root Password
|
||||
======
|
||||
|
||||

|
||||
|
||||
Few months ago, I had [**setup LAMP stack in Ubuntu 18.04**][1] server. Today, I tried to login as root user in my database server, but I completely forgot the password. After couple Google searches and going through some blog posts, I successfully reset the password. For those wondering how to do this, this brief tutorial explains how can we reset MySQL or MariaDB Root password in Unix-like operating systems.
|
||||
|
||||
### Reset MySQL or MariaDB Root password
|
||||
|
||||
First, stop the database server.
|
||||
|
||||
If you use MySQL, type the following command and hit ENTER key.
|
||||
```
|
||||
$ sudo systemctl stop mysql
|
||||
|
||||
```
|
||||
|
||||
For MariaDB:
|
||||
```
|
||||
$ sudo systemctl stop mariadb
|
||||
|
||||
```
|
||||
|
||||
Next, restart the database server without permission checking using the following command:
|
||||
```
|
||||
$ sudo mysqld_safe --skip-grant-tables &
|
||||
|
||||
```
|
||||
|
||||
Here, the **`--skip-grant-tables`**option allows you to connect without a password and with all privileges. If you start your server with this option, it also enables `--skip-networking`option which is used to prevent the other clients from connecting to the database server. And, the ampersand **( &)** symbol is used to run the command in background, so you could type the other commands in the following steps. Please be mindful that the above command is dangerous and your database server becomes insecure. You should run this command only for a brief period to reset the password.
|
||||
|
||||
Next, login to your MySQL/MariaDB server as root user:
|
||||
```
|
||||
$ mysql
|
||||
|
||||
```
|
||||
|
||||
At the **mysql >** or **MariaDB [(none)] >** prompt, run the following command to reset the root user password:
|
||||
```
|
||||
UPDATE mysql.user SET Password=PASSWORD('NEW-PASSWORD') WHERE User='root';
|
||||
|
||||
```
|
||||
|
||||
Replace **NEW-PASSWORD** in the above command with your own password.
|
||||
|
||||
Then, type following commands to exit from the mysql console.
|
||||
```
|
||||
FLUSH PRIVILEGES;
|
||||
|
||||
exit
|
||||
|
||||
```
|
||||
|
||||
Finally, shutdown the running database server that you started earlier with `--skip-grant-tables`option. To do so, run:
|
||||
```
|
||||
$ sudo mysqladmin -u root -p shutdown
|
||||
|
||||
```
|
||||
|
||||
You will be asked to enter your mysql/mariadb root user password that you set in the previous step.
|
||||
|
||||
Now, start mysql/mariadb service normally using command:
|
||||
```
|
||||
$ sudo systemctl start mysql
|
||||
|
||||
```
|
||||
|
||||
For MariaDB:
|
||||
```
|
||||
$ sudo systemctl start mariadb
|
||||
|
||||
```
|
||||
|
||||
Verify if the password has really been changed using the following command:
|
||||
```
|
||||
$ mysql -u root -p
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for today. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-reset-mysql-or-mariadb-root-password/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/install-apache-mariadb-php-lamp-stack-ubuntu-16-04/
|
||||
@ -0,0 +1,97 @@
|
||||
How to Update Firmware on Ubuntu 18.04
|
||||
======
|
||||
Usually, the default software center in Ubuntu and other Linux handle the update of the firmware of your system. But if you encounter errors with it, you can use fwupd command line tool for updating the firmware of your system.
|
||||
|
||||
I use [Dell XPS 13 Ubuntu edition][1] as my main operating system. I have done a fresh [installation of Ubuntu 18.04][2] on it and I cannot be happier with the hardware compatibility. Bluetooth, external USB headsets and speakers, multi-monitor, everything works out of the box.
|
||||
|
||||
The one thing that troubled me was one of the [firmware][3] updates that appeared in the Software Center.
|
||||
|
||||
![Updating firmware in Ubuntu][4]
|
||||
|
||||
Clicking on the Update button resulted in an error a few seconds later.
|
||||
|
||||
![Updating firmware in Ubuntu][5]
|
||||
|
||||
The error message was:
|
||||
|
||||
**Unable to update “Thunderbolt NVM for Xps Notebook 9360”: could not detect device after update: timed out while waiting for device**
|
||||
|
||||
In this quick tip, I’ll show you how to update the firmware of your system in [Ubuntu][6].
|
||||
|
||||
### Updating firmware in Ubuntu 18.04
|
||||
|
||||
![How to update firmware in Ubuntu][7]
|
||||
|
||||
One thing you should know that GNOME Software i.e. the software center in Ubuntu 18.04 is also capable of updating the firmware. But in situations when it fails for some reason, you can use the command line tool fwupd.
|
||||
|
||||
[fwupd][8] is an open source daemon that handles firmware upgrades in Linux based systems. It is created by GNOME developer [Richard Hughes][9]. Developers from Dell also contributed to the development of this open source tool.
|
||||
|
||||
Basically, it utilizes the LVFS, Linux Vendor Firmware Service. Hardware vendors upload redistributable firmware to the LVFS site and thanks to fwupd, you can upgrade those firmware from inside the operating system itself. fwupd is supported by major Linux distributions like Ubuntu and Fedora.
|
||||
|
||||
Open a terminal and update your system first:
|
||||
```
|
||||
sudo apt update && sudo apt upgrade -y
|
||||
|
||||
```
|
||||
|
||||
After that you can use the following commands one by one to start the daemon, refresh the list of available firmware updates and install the firmware updates.
|
||||
```
|
||||
sudo service fwupd start
|
||||
|
||||
```
|
||||
|
||||
Once the daemon is running, check if there are any firmware updates available.
|
||||
```
|
||||
sudo fwupdmgr refresh
|
||||
|
||||
```
|
||||
|
||||
The output should look like this:
|
||||
|
||||
Fetching metadata <https://cdn.fwupd.org/downloads/firmware.xml.gz>
|
||||
Downloading… [****************************]
|
||||
Fetching signature <https://cdn.fwupd.org/downloads/firmware.xml.gz.asc>
|
||||
|
||||
After this, run the firmware update:
|
||||
```
|
||||
sudo fwupdmgr update
|
||||
|
||||
```
|
||||
|
||||
The output of the firmware update could be similar to this:
|
||||
|
||||
```
|
||||
No upgrades for XPS 13 9360 TPM 2.0, current is 1.3.1.0: 1.3.1.0=same
|
||||
No upgrades for XPS 13 9360 System Firmware, current is 0.2.8.1: 0.2.8.1=same, 0.2.7.1=older, 0.2.6.2=older, 0.2.5.1=older, 0.2.4.2=older, 0.2.3.1=older, 0.2.2.1=older, 0.2.1.0=older, 0.1.3.7=older, 0.1.3.5=older, 0.1.3.2=older, 0.1.2.3=older
|
||||
Downloading 21.00 for XPS13 9360 Thunderbolt Controller…
|
||||
Updating 21.00 on XPS13 9360 Thunderbolt Controller…
|
||||
Decompressing… [***********]
|
||||
Authenticating… [***********]
|
||||
Restarting device… [***********]
|
||||
```
|
||||
|
||||
This should handle the firmware update in Ubuntu 18.04. I hope this quick tip helped you with firmware updates in Linux.
|
||||
|
||||
If you have questions or suggestions, please feel free to use the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/update-firmware-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://itsfoss.com/dell-xps-13-ubuntu-review/
|
||||
[2]: https://itsfoss.com/install-ubuntu-dual-boot-mode-windows/
|
||||
[3]: https://en.wikipedia.org/wiki/Firmware
|
||||
[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/ubuntu-firmware-update-error-1.png
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/ubuntu-firmware-update-error-2.jpg
|
||||
[6]: https://www.ubuntu.com/
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/update-firmware-ubuntu.png
|
||||
[8]: https://fwupd.org/
|
||||
[9]: https://github.com/hughsie/fwupd
|
||||
@ -0,0 +1,59 @@
|
||||
3 innovative open source projects for the new school year
|
||||
======
|
||||
|
||||

|
||||
|
||||
I first wrote about open source learning software for educators in the fall of 2013. Fast-forward five years—today, open source software and principles have moved from outsiders in the education industry to the popular crowd.
|
||||
|
||||
Since Penn Manor School District has [adopted open software][1] and cultivated a learning community built on trust, we've watched student creativity, ingenuity, and engagement soar. Here are three free and open source software tools we’ve used during the past school year. All three have enabled great student projects and may spark cool classroom ideas for open-minded educators.
|
||||
|
||||
### Catch a wave: Software-defined radio
|
||||
|
||||
Students may love the modern sounds of Spotify and Soundcloud, but there's an old-school charm to snatching noise from the atmosphere. Penn Manor help desk student apprentices had serious fun with [software-defined radio][2] (SDR). With an inexpensive software-defined radio kit, students can capture much more than humdrum FM radio stations. One of our help desk apprentices, JR, discovered everything from local emergency radio chatter to unencrypted pager messages.
|
||||
|
||||
Our basic setup involved a student’s Linux laptop running [gqrx software][3] paired with a [USB RTL-SDR tuner and a simple antenna][4]. It was light enough to fit in a student backpack for SDR on the go. And the kit was great for creative hacking, which JR demonstrated when he improvised all manner of antennas, including a frying pan, in an attempt to capture signals from the U.S. weather satellite [NOAA-18][5].
|
||||
|
||||
Former Penn Manor IT specialist Tom Swartz maintains an excellent [quick-start resource for SDR][6].
|
||||
|
||||
### Stream far for a middle school crowd: OBS Studio
|
||||
|
||||
Remember live morning TV announcements in school? Amateur weather reports, daily news updates, middle school puns... In-house video studios are an excellent opportunity for fun collaboration and technical learning. But many schools are stuck running proprietary broadcast and video mixing software, and many more are unable to afford costly production hardware such as [NewTek’s TriCaster][7].
|
||||
|
||||
Cue [OBS Studio][8], a free, open source, real-time broadcasting program ideally suited for school projects as well as professional video streaming. During the past six months, several Penn Manor schools successfully upgraded to OBS Studio running on Linux. OBS handles our multi-source video and audio mixing, chroma key compositing, transitions, and just about anything else students need to run a surprising polished video broadcast.
|
||||
|
||||
Penn Manor students stream a live morning show via UDP multicast to staff and students tuned in via the [mpv][9] media player. OBS also supports live streaming to YouTube, Facebook Live, and Twitch, which means students can broadcast daily school lunch menus and other vital updates to the world.
|
||||
|
||||
### Self-drive by light: TurtleBot3 and Lidar
|
||||
|
||||
Of course, robots are cool, but robots with lasers are ace. The newest star of the Penn Manor student help desk is Patch, a petite educational robot built with the [TurtleBot3][10] open hardware and software kit. The Turtlebot platform is extensible and great for hardware hacking, but we were most interested in creating a self-driving gadget.
|
||||
|
||||
We used the Turtlebot3 Burger, the entry-level kit powered by a Raspberry PI and loaded with a laser distance sensor. New student tech apprentices Aiden, Alex, and Tristen were challenged to make the robot autonomously navigate down one Penn Manor High School hallway and back to the technology center. It was a tall order: The team spent several months building the bot, and then working through the [ROS][11]-based programming, [rviz][12] (a 3D environment visualizer) and mapping for simultaneous localization and mapping (SLAM).
|
||||
|
||||
Building the robot was a joy, but without a doubt, the programming challenged the students, none of whom had previously touched any of the ROS software tools. However, after much persistence, trial and error, and tenacity, Aiden and Tristen succeeded in achieving both the hallway navigation goal and in confusing fellow students with a tiny robot transversing school corridors and magically avoiding objects and people in its path.
|
||||
|
||||
I recommend the TurtleBot3, but educators should be aware of the cost (approximately US$ 500) and the complexity. However, the kit is an outstanding resource for students aspiring to technology careers or those who want to build something amazing.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/back-school-project-ideas
|
||||
|
||||
作者:[Charlie Reisinger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/charlie
|
||||
[1]: https://opensource.com/education/14/9/interview-charlie-reisinger-penn-manor
|
||||
[2]: https://en.wikipedia.org/wiki/Software-defined_radio
|
||||
[3]: http://gqrx.dk/
|
||||
[4]: https://www.amazon.com/JahyShow%C2%AE-RTL2832U-RTL-SDR-Receiver-Compatible/dp/B01H830YQ6
|
||||
[5]: https://en.wikipedia.org/wiki/NOAA-18
|
||||
[6]: https://github.com/tomswartz07/CPOSC2017
|
||||
[7]: https://www.newtek.com/tricaster/
|
||||
[8]: https://obsproject.com/
|
||||
[9]: https://mpv.io/
|
||||
[10]: https://www.turtlebot.com/
|
||||
[11]: http://www.ros.org/
|
||||
[12]: http://wiki.ros.org/rviz
|
||||
@ -0,0 +1,108 @@
|
||||
6 open source tools for making your own VPN
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you want to try your hand at building your own VPN but aren’t sure where to start, you’ve come to the right place. I’ll compare six of the best free and open source tools to set up and use a VPN on your own server. These VPNs work whether you want to set up a site-to-site VPN for your business or just create a remote access proxy to unblock websites and hide your internet traffic from ISPs.
|
||||
|
||||
Which is best depends on your needs and limitations, so take into consideration your own technical expertise, environment, and what you want to achieve with your VPN. In particular, consider the following factors:
|
||||
|
||||
* VPN protocol
|
||||
* Number of clients and types of devices
|
||||
* Server distro compatibility
|
||||
* Technical expertise required
|
||||
|
||||
|
||||
|
||||
### Algo
|
||||
|
||||
[Algo][1] was designed from the bottom up to create VPNs for corporate travelers who need a secure proxy to the internet. It “includes only the minimal software you need,” meaning you sacrifice extensibility for simplicity. Algo is based on StrongSwan but cuts out all the things that you don’t need, which has the added benefit of removing security holes that a novice might otherwise not notice.
|
||||
|
||||
As an added bonus, it even blocks ads!
|
||||
|
||||
Algo supports only the IKEv2 protocol and Wireguard. Because IKEv2 support is built into most devices these days, it doesn’t require a client app like OpenVPN. Algo can be deployed using Ansible on Ubuntu (the preferred option), Windows, RedHat, CentOS, and FreeBSD. Setup is automated using Ansible, which configures the server based on your answers to a short set of questions. It’s also very easy to tear down and re-deploy on demand.
|
||||
|
||||
Algo is probably the easiest and fastest VPN to set up and deploy on this list. It’s extremely tidy and well thought out. If you don’t need any of the more advanced features offered by other tools and just need a secure proxy, it’s a great option. Note that Algo explicitly states it’s not meant for geo-unblocking or evading censorship, and was primarily designed for confidentiality.
|
||||
|
||||
### Streisand
|
||||
|
||||
[Streisand][2] can be installed on any Ubuntu 16.04 server using a single command; the process takes about 10 minutes. It supports L2TP, OpenConnect, OpenSSH, OpenVPN, Shadowsocks, Stunnel, Tor bridge, and WireGuard. Depending on which protocol you choose, you may need to install a client app.
|
||||
|
||||
In many ways, Streisand is similar to Algo, but it offers more protocols and customization. This takes a bit more effort to manage and secure but is also more flexible. Note Streisand does not support IKEv2. I would say Streisand is more effective for bypassing censorship in places like China and Turkey due to its versatility, but Algo is easier and faster to set up.
|
||||
|
||||
The setup is automated using Ansible, so there’s not much technical expertise required. You can easily add more users by sending them custom-generated connection instructions, which include an embedded copy of the server’s SSL certificate.
|
||||
|
||||
Tearing down Streisand is a quick and painless process, and you can re-deploy on demand.
|
||||
|
||||
### OpenVPN
|
||||
|
||||
[OpenVPN][3] requires both client and server applications to set up VPN connections using the protocol of the same name. OpenVPN can be tweaked and customized to fit your needs, but it also requires the most technical expertise of the tools covered here. Both remote access and site-to-site configurations are supported; the former is what you’ll need if you plan on using your VPN as a proxy to the internet. Because client apps are required to use OpenVPN on most devices, the end user must keep them updated.
|
||||
|
||||
Server-side, you can opt to deploy in the cloud or on your Linux server. Compatible distros include CentOS, Ubuntu, Debian, and openSUSE. Client apps are available for Windows, MacOS, iOS, and Android, and there are unofficial apps for other devices. Enterprises can opt to set up an OpenVPN Access Server, but that’s probably overkill for individuals, who will want the Community Edition.
|
||||
|
||||
OpenVPN is relatively easy to configure with static key encryption, but it isn’t all that secure. Instead, I recommend setting it up with [easy-rsa][4], a key management package you can use to set up a public key infrastructure. This allows you to connect multiple devices at a time and protect them with perfect forward secrecy, among other benefits. OpenVPN uses SSL/TLS for encryption, and you can specify DNS servers in your configuration.
|
||||
|
||||
OpenVPN can traverse firewalls and NAT firewalls, which means you can use it to bypass gateways and firewalls that might otherwise block the connection. It supports both TCP and UDP transports.
|
||||
|
||||
### StrongSwan
|
||||
|
||||
You might have come across a few different VPN tools with “Swan” in the name. FreeS/WAN, OpenSwan, LibreSwan, and [strongSwan][5] are all forks of the same project, and the lattermost is my personal favorite. Server-side, strongSwan runs on Linux 2.6, 3.x, and 4x kernels, Android, FreeBSD, macOS, iOS, and Windows.
|
||||
|
||||
StrongSwan uses the IKEv2 protocol and IPSec. Compared to OpenVPN, IKEv2 connects much faster while offering comparable speed and security. This is useful if you prefer a protocol that doesn’t require installing an additional app on the client, as most newer devices manufactured today natively support IKEv2, including Windows, MacOS, iOS, and Android.
|
||||
|
||||
StrongSwan is not particularly easy to use, and despite decent documentation, it uses a different vocabulary than most other tools, which can be confusing. Its modular design makes it great for enterprises, but that also means it’s not the most streamlined. It’s certainly not as straightforward as Algo or Streisand.
|
||||
|
||||
Access control can be based on group memberships using X.509 attribute certificates, a feature unique to strongSwan. It supports EAP authentication methods for integration into other environments like Windows Active Directory. StrongSwan can traverse NAT firewalls.
|
||||
|
||||
### SoftEther
|
||||
|
||||
[SoftEther][6] started out as a project by a graduate student at the University of Tsukuba in Japan. SoftEther VPN Server and VPN Bridge run on Windows, Linux, OSX, FreeBSD, and Solaris, while the client app works on Windows, Linux, and MacOS. VPN Bridge is mainly for enterprises that need to set up site-to-site VPNs, so individual users will just need the server and client programs to set up remote access.
|
||||
|
||||
SoftEther supports the OpenVPN, L2TP, SSTP, and EtherIP protocols, but its own SoftEther protocol claims to be able to be immunized against deep packet inspection thanks to “Ethernet over HTTPS” camouflage. SoftEther also makes a few tweaks to reduce latency and increase throughput. Additionally, SoftEther includes a clone function that allows you to easily transition from OpenVPN to SoftEther.
|
||||
|
||||
SoftEther can traverse NAT firewalls and bypass firewalls. On restricted networks that permit only ICMP and DNS packets, you can utilize SoftEther’s VPN over ICMP or VPN over DNS options to penetrate the firewall. SoftEther works with both IPv4 and IPv6.
|
||||
|
||||
SoftEther is easier to set up than OpenVPN and strongSwan but is a bit more complicated than Streisand and Algo.
|
||||
|
||||
### WireGuard
|
||||
|
||||
[WireGuard][7] is the newest tool on this list; it's so new that it’s not even finished yet. That being said, it offers a fast and easy way to deploy a VPN. It aims to improve on IPSec by making it simpler and leaner like SSH.
|
||||
|
||||
Like OpenVPN, WireGuard is both a protocol and a software tool used to deploy a VPN that uses said protocol. A key feature is “crypto key routing,” which associates public keys with a list of IP addresses allowed inside the tunnel.
|
||||
|
||||
WireGuard is available for Ubuntu, Debian, Fedora, CentOS, MacOS, Windows, and Android. WireGuard works on both IPv4 and IPv6.
|
||||
|
||||
WireGuard is much lighter than most other VPN protocols, and it transmits packets only when data needs to be sent.
|
||||
|
||||
The developers say WireGuard should not yet be trusted because it hasn’t been fully audited yet, but you’re welcome to give it a spin. It could be the next big thing!
|
||||
|
||||
### Homemade VPN vs. commercial VPN
|
||||
|
||||
Making your own VPN adds a layer of privacy and security to your internet connection, but if you’re the only one using it, then it would be relatively easy for a well-equipped third party, such as a government agency, to trace activity back to you.
|
||||
|
||||
Furthermore, if you plan to use your VPN to unblock geo-locked content, a homemade VPN may not be the best option. Since you’ll only be connecting from a single IP address, your VPN server is fairly easy to block.
|
||||
|
||||
Good commercial VPNs don’t have these issues. With a provider like [ExpressVPN][8], you share the server’s IP address with dozens or even hundreds of other users, making it nigh-impossible to track a single user’s activity. You also get a huge range of hundreds or thousands of servers to choose from, so if one has been blacklisted, you can just switch to another.
|
||||
|
||||
The tradeoff of a commercial VPN, however, is that you must trust the provider not to snoop on your internet traffic. Be sure to choose a reputable provider with a clear no-logs policy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/open-source-tools-vpn
|
||||
|
||||
作者:[Paul Bischoff][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]: https://blog.trailofbits.com/2016/12/12/meet-algo-the-vpn-that-works/
|
||||
[2]: https://github.com/StreisandEffect/streisand
|
||||
[3]: https://openvpn.net/
|
||||
[4]: https://github.com/OpenVPN/easy-rsa
|
||||
[5]: https://www.strongswan.org/
|
||||
[6]: https://www.softether.org/
|
||||
[7]: https://www.wireguard.com/
|
||||
[8]: https://www.comparitech.com/vpn/reviews/expressvpn/
|
||||
@ -0,0 +1,73 @@
|
||||
Publishing Markdown to HTML with MDwiki
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are plenty of reasons to like Markdown, a simple language with an easy-to-learn syntax that can be used with any text editor. Using tools like [Pandoc][1], you can convert Markdown text to [a variety of popular formats][2], including HTML. You can also automate that conversion process in a web server. An HTML5 and JavaScript application called [MDwiki][3], created by Timo Dörr, can take a stack of Markdown files and turn them into a website when requested from a browser. The MDwiki site includes a how-to guide and other information to help you get started:
|
||||
|
||||
![MDwiki site getting started][5]
|
||||
|
||||
What an Mdwiki site looks like.
|
||||
|
||||
Inside the web server, a basic MDwiki site looks like this:
|
||||
|
||||
![MDwiki site inside web server][7]
|
||||
|
||||
What the webserver folder for that site looks like.
|
||||
|
||||
I renamed the MDwiki HTML file `START.HTML` for this project. There is also one Markdown file that deals with navigation and a JSON file to hold a few configuration settings. Everything else is site content.
|
||||
|
||||
While the overall website design is pretty much fixed by MDwiki, the content, styling, and number of pages are not. You can view a selection of different sites generated by MDwiki at [the MDwiki site][8]. It is fair to say that MDwiki sites lack the visual appeal that a web designer could achieve—but they are functional, and users should balance their simple appearance against the speed and ease of creating and editing them.
|
||||
|
||||
Markdown comes in various flavors that extend a stable core functionality for different specific purposes. MDwiki uses GitHub flavor [Markdown][9], which adds features such as formatted code blocks and syntax highlighting for popular programming languages, making it well-suited for producing program documentation and tutorials.
|
||||
|
||||
MDwiki also supports what it calls "gimmicks," which add extra functionality such as embedding YouTube video content and displaying mathematical formulas. These are worth exploring if you need them for specific projects. I find MDwiki an ideal tool for creating technical documentation and educational resources. I have also discovered some tricks and hacks that might not be immediately apparent.
|
||||
|
||||
MDwiki works with any modern web browser when deployed in a web server; however, you do not need a web server if you access MDwiki with Mozilla Firefox. Most MDwiki users will opt to deploy completed projects on a web server to avoid excluding potential users, but development and testing can be done with just a text editor and Firefox. Completed MDwiki projects that are loaded into a Moodle Virtual Learning Environment (VLE) can be read by any modern browser, which could be useful in educational contexts. (This is probably also true for other VLE software, but you should test that.)
|
||||
|
||||
MDwiki's default color scheme is not ideal for all projects, but you can replace it with another theme downloaded from [Bootswatch.com][10]. To do this, simply open the MDwiki HTML file in an editor, take out the `extlib/css/bootstrap-3.0.0.min.css` code, and insert the downloaded Bootswatch theme. There is also an MDwiki gimmick that lets users choose a Bootswatch theme to replace the default after MDwiki loads in their browser. I often work with users who have visual impairments, and they tend to prefer high-contrast themes, with white text on a dark background.
|
||||
|
||||
![MDwiki screen with Bootswatch Superhero theme][12]
|
||||
|
||||
MDwiki screen using the Bootswatch Superhero theme
|
||||
|
||||
MDwiki, Markdown files, and static images are fine for many purposes. However, you might sometimes want to include, say, a JavaScript slideshow or a feedback form. Markdown files can include HTML code, but mixing Markdown with HTML can get confusing. One solution is to create the feature you want in a separate HTML file and display it inside a Markdown file with an iframe tag. I took this idea from the [Twine Cookbook][13], a support site for the Twine interactive fiction engine. The Twine Cookbook doesn’t actually use MDwiki, but combining Markdown and iframe tags opens up a wide range of creative possibilities.
|
||||
|
||||
Here is an example:
|
||||
|
||||
This HTML will display an HTML page created by the Twine interactive fiction engine inside a Markdown file.
|
||||
```
|
||||
<iframe height="400" src="sugarcube_dungeonmoving_example.html" width="90%"></iframe>
|
||||
```
|
||||
|
||||
The result in an MDwiki-generated site looks like this:
|
||||
|
||||
|
||||
|
||||
In short, MDwiki is an excellent small application that achieves its purpose extremely well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/markdown-html-publishing
|
||||
|
||||
作者:[Peter Cheer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/petercheer
|
||||
[1]: https://pandoc.org/
|
||||
[2]: https://opensource.com/downloads/pandoc-cheat-sheet
|
||||
[3]: http://dynalon.github.io/mdwiki/#!index.md
|
||||
[4]: https://opensource.com/file/407306
|
||||
[5]: https://opensource.com/sites/default/files/uploads/1_-_mdwiki_screenshot.png (MDwiki site getting started)
|
||||
[6]: https://opensource.com/file/407311
|
||||
[7]: https://opensource.com/sites/default/files/uploads/2_-_mdwiki_inside_web_server.png (MDwiki site inside web server)
|
||||
[8]: http://dynalon.github.io/mdwiki/#!examples.md
|
||||
[9]: https://guides.github.com/features/mastering-markdown/
|
||||
[10]: https://bootswatch.com/
|
||||
[11]: https://opensource.com/file/407316
|
||||
[12]: https://opensource.com/sites/default/files/uploads/3_-_mdwiki_bootswatch_superhero.png (MDwiki screen with Bootswatch Superhero theme)
|
||||
[13]: https://github.com/iftechfoundation/twine-cookbook
|
||||
164
sources/tech/20180831 Test containers with Python and Conu.md
Normal file
164
sources/tech/20180831 Test containers with Python and Conu.md
Normal file
@ -0,0 +1,164 @@
|
||||
Test containers with Python and Conu
|
||||
======
|
||||
|
||||

|
||||
|
||||
More and more developers are using containers to develop and deploy their applications. This means that easily testing containers is also becoming important. [Conu][1] (short for container utilities) is a Python library that makes it easy to write tests for your containers. This article shows you how to use it to test your containers.
|
||||
|
||||
### Getting started
|
||||
|
||||
First you need a container application to test. For that, the following commands create a new directory with a container Dockerfile, and a Flask application to be served by the container.
|
||||
```
|
||||
$ mkdir container_test
|
||||
$ cd container_test
|
||||
$ touch Dockerfile
|
||||
$ touch app.py
|
||||
|
||||
```
|
||||
|
||||
Copy the following code inside the app.py file. This is the customary basic Flask application that returns the string “Hello Container World!”
|
||||
```
|
||||
from flask import Flask
|
||||
app = Flask(__name__)
|
||||
|
||||
@app.route('/')
|
||||
def hello_world():
|
||||
return 'Hello Container World!'
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(debug=True,host='0.0.0.0')
|
||||
|
||||
```
|
||||
|
||||
### Create and Build a Test Container
|
||||
|
||||
To build the test container, add the following instructions to the Dockerfile.
|
||||
```
|
||||
FROM registry.fedoraproject.org/fedora-minimal:latest
|
||||
RUN microdnf -y install python3-flask && microdnf clean all
|
||||
ADD ./app.py /srv
|
||||
CMD ["python3", "/srv/app.py"]
|
||||
|
||||
```
|
||||
|
||||
Then build the container using the Docker CLI tool.
|
||||
```
|
||||
$ sudo dnf -y install docker
|
||||
$ sudo systemctl start docker
|
||||
$ sudo docker build . -t flaskapp_container
|
||||
|
||||
```
|
||||
|
||||
Note : The first two commands are only needed if Docker is not installed on your system.
|
||||
|
||||
After the build use the following command to run the container.
|
||||
```
|
||||
$ sudo docker run -p 5000:5000 --rm flaskapp_container
|
||||
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
|
||||
* Restarting with stat
|
||||
* Debugger is active!
|
||||
* Debugger PIN: 473-505-51
|
||||
|
||||
```
|
||||
|
||||
Finally, use curl to check that the Flask application is correctly running inside the container:
|
||||
```
|
||||
$ curl http://127.0.0.1:5000
|
||||
Hello Container World!
|
||||
|
||||
```
|
||||
|
||||
With the flaskapp_container now running and ready for testing, you can stop it using **Ctrl+C**.
|
||||
|
||||
### Create a test script
|
||||
|
||||
Before you write the test script, you must install conu. Inside the previously created container_test directory run the following commands.
|
||||
```
|
||||
$ python3 -m venv .venv
|
||||
$ source .venv/bin/activate
|
||||
(.venv)$ pip install --upgrade pip
|
||||
(.venv)$ pip install conu
|
||||
|
||||
$ touch test_container.py
|
||||
|
||||
```
|
||||
|
||||
Then copy and save the following script in the test_container.py file.
|
||||
```
|
||||
import conu
|
||||
|
||||
PORT = 5000
|
||||
|
||||
with conu.DockerBackend() as backend:
|
||||
image = backend.ImageClass("flaskapp_container")
|
||||
options = ["-p", "5000:5000"]
|
||||
container = image.run_via_binary(additional_opts=options)
|
||||
|
||||
try:
|
||||
# Check that the container is running and wait for the flask application to start.
|
||||
assert container.is_running()
|
||||
container.wait_for_port(PORT)
|
||||
|
||||
# Run a GET request on / port 5000.
|
||||
http_response = container.http_request(path="/", port=PORT)
|
||||
|
||||
# Check the response status code is 200
|
||||
assert http_response.ok
|
||||
|
||||
# Get the response content
|
||||
response_content = http_response.content.decode("utf-8")
|
||||
|
||||
# Check that the "Hello Container World!" string is served.
|
||||
assert "Hello Container World!" in response_content
|
||||
|
||||
# Get the logs from the container
|
||||
logs = [line for line in container.logs()]
|
||||
# Check the the Flask application saw the GET request.
|
||||
assert b'"GET / HTTP/1.1" 200 -' in logs[-1]
|
||||
|
||||
finally:
|
||||
container.stop()
|
||||
container.delete()
|
||||
|
||||
```
|
||||
|
||||
#### Test Setup
|
||||
|
||||
The script starts by setting conu to use Docker as a backend to run the container. Then it sets the container image to use the flaskapp_container you built in the first part of this tutorial.
|
||||
|
||||
The next step is to configure the options needed to run the container. In this example, the Flask application serves the content on port 5000. Therefore you need to expose this port and map it to the same port on the host.
|
||||
|
||||
Finally, the script starts the container, and it’s now ready to be tested.
|
||||
|
||||
#### Testing methods
|
||||
|
||||
Before testing a container, check that the container is running and ready. The example script is using container.is_running and container.wait_for_port. These methods ensure the container is running and the service is available on the expected port.
|
||||
|
||||
The container.http_request is a wrapper around the [requests][2] library which makes it convenient to send HTTP requests during the tests. This method returns a [requests.Response][3]object, so it’s easy to access the content of the response for testing.
|
||||
|
||||
Conu also gives access to the container logs. Once again, this can be useful during testing. In the example above, the container.logs method returns the container logs. You can use them to assert that a specific log was printed, or for example that no exceptions were raised during testing.
|
||||
|
||||
Conu provides many other useful methods to interface with containers. A full list of the APIs is available in the [documentation][4]. You can also consult the examples available on [GitHub][5].
|
||||
|
||||
All the code and files needed to run this tutorial are available on [GitHub][6] as well. For readers who want to take this example further, you can look at using [pytest][7] to run the tests and build a container test suite.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/test-containers-python-conu/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/cverna/
|
||||
[1]: https://github.com/user-cont/conu
|
||||
[2]: http://docs.python-requests.org/en/master/
|
||||
[3]: http://docs.python-requests.org/en/master/api/#requests.Response
|
||||
[4]: https://conu.readthedocs.io/en/latest/index.html
|
||||
[5]: https://github.com/user-cont/conu/tree/master/docs/source/examples
|
||||
[6]: https://github.com/cverna/container_test_script
|
||||
[7]: https://docs.pytest.org/en/latest/
|
||||
@ -0,0 +1,222 @@
|
||||
5 Ways to Take Screenshot in Linux [GUI and Terminal]
|
||||
======
|
||||
Here are several ways you can take screenshots and edit the screenshots by adding text, arrows etc. Instructions and mentioned screenshot tools are valid for Ubuntu and other major Linux distributions.
|
||||
|
||||
![How to take screenshots in Ubuntu Linux][1]
|
||||
|
||||
When I switched from Windows to Ubuntu as my primary OS, the first thing I was worried about was the availability of screenshot tools. Well, it is easy to utilize the default keyboard shortcuts in order to take screenshots but with a standalone tool, I get to annotate/edit the image while taking the screenshot.
|
||||
|
||||
In this article, we will introduce you to the default methods/tools (without a 3rd party screenshot tool) to take a screenshot while also covering the list of best screenshot tools available for Linux.
|
||||
|
||||
### Method 1: The default way to take screenshot in Linux
|
||||
|
||||
Do you want to capture the image of your entire screen? A specific region? A specific window?
|
||||
|
||||
If you just want a simple screenshot without any annotations/fancy editing capabilities, the default keyboard shortcuts will do the trick. These are not specific to Ubuntu. Almost all Linux distributions and desktop environments support these keyboard shortcuts.
|
||||
|
||||
Let’s take a look at the list of keyboard shortcuts you can utilize:
|
||||
|
||||
**PrtSc** – Save a screenshot of the entire screen to the “Pictures” directory.
|
||||
**Shift + PrtSc** – Save a screenshot of a specific region to Pictures.
|
||||
**Alt + PrtSc** – Save a screenshot of the current window to Pictures.
|
||||
**Ctrl + PrtSc** – Copy the screenshot of the entire screen to the clipboard.
|
||||
**Shift + Ctrl + PrtSc** – Copy the screenshot of a specific region to the clipboard.
|
||||
**Ctrl + Alt + PrtSc** – Copy the screenshot of the current window to the clipboard.
|
||||
|
||||
As you can see, taking screenshots in Linux is absolutely simple with the default screenshot tool. However, if you want to immediately annotate (or other editing features) without importing the screenshot to another application, you can use a dedicated screenshot tool.
|
||||
|
||||
#### **Method 2: Take and edit screenshots in Linux with Flameshot**
|
||||
|
||||
![flameshot][2]
|
||||
|
||||
Feature Overview
|
||||
|
||||
* Annotate (highlight, point, add text, box in)
|
||||
* Blur part of an image
|
||||
* Crop part of an image
|
||||
* Upload to Imgur
|
||||
* Open screenshot with another app
|
||||
|
||||
|
||||
|
||||
Flameshot is a quite impressive screenshot tool which arrived on [GitHub][3] last year.
|
||||
|
||||
If you have been searching for a screenshot tool that helps you annotate, blur, mark, and upload to imgur while being actively maintained unlike some outdated screenshot tools, Flameshot should be the one to have installed.
|
||||
|
||||
Fret not, we will guide you how to install it and configure it as per your preferences.
|
||||
|
||||
To install it on Ubuntu, you just need to search for it on Ubuntu Software center and get it installed. In case you want to use the terminal, here’s the command for it:
|
||||
```
|
||||
sudo apt install flameshot
|
||||
|
||||
```
|
||||
|
||||
If you face any trouble installing, you can follow their [official installation instructions][4]. After installation, you need to configure it. Well, you can always search for it and launch it, but if you want to trigger the Flameshot screenshot tool by using **PrtSc** key, you need to assign a custom keyboard shortcut.
|
||||
|
||||
Here’s how you can do that:
|
||||
|
||||
* Head to the system settings and navigate your way to the Keyboard settings.
|
||||
* You will find all the keyboard shortcuts listed there, ignore them and scroll down to the bottom. Now, you will find a **+** button.
|
||||
* Click the “+” button to add a custom shortcut. You need to enter the following in the fields you get:
|
||||
**Name:** Anything You Want
|
||||
**Command:** /usr/bin/flameshot gui
|
||||
* Finally, set the shortcut to **PrtSc** – which will warn you that the default screenshot functionality will be disabled – so proceed doing it.
|
||||
|
||||
|
||||
|
||||
For reference, your custom keyboard shortcut field should look like this after configuration:
|
||||
|
||||
![][5]
|
||||
Map keyboard shortcut with Flameshot
|
||||
|
||||
### **Method 3: Take and edit screenshots in Linux with Shutter**
|
||||
|
||||
![][6]
|
||||
|
||||
Feature Overview:
|
||||
|
||||
* Annotate (highlight, point, add text, box in)
|
||||
* Blur part of an image
|
||||
* Crop part of an image
|
||||
* Upload to image hosting sites
|
||||
|
||||
|
||||
|
||||
[Shutter][7] is a popular screenshot tool available for all major Linux distributions. Though it seems to be no more being actively developed, it is still an excellent choice for handling screenshots.
|
||||
|
||||
You might encounter certain bugs/errors. The most common problem with Shutter on any latest Linux distro releases is that the ability to edit the screenshots is disabled by default along with the missing applet indicator. But, fret not, we have a solution to that. You just need to follow our guide to[fix the disabled edit option in Shutter and bring back the applet indicator][8].
|
||||
|
||||
After you’re done fixing the problem, you can utilize it to edit the screenshots in a jiffy.
|
||||
|
||||
To install shutter, you can browse the software center and get it from there. Alternatively, you can use the following command in the terminal to install Shutter in Ubuntu-based distributions:
|
||||
```
|
||||
sudo apt install shutter
|
||||
|
||||
```
|
||||
|
||||
As we saw with Flameshot, you can either choose to use the app launcher to search for Shutter and manually launch the application, or you can follow the same set of instructions (with a different command) to set a custom shortcut to trigger Shutter when you press the **PrtSc** key.
|
||||
|
||||
If you are going to assign a custom keyboard shortcut, you just need to use the following in the command field:
|
||||
```
|
||||
shutter -f
|
||||
|
||||
```
|
||||
|
||||
### Method 4: Use GIMP for taking screenshots in Linux
|
||||
|
||||
![][9]
|
||||
|
||||
Feature Overview:
|
||||
|
||||
* Advanced Image Editing Capabilities (Scaling, Adding filters, color correction, Add layers, Crop, and so on.)
|
||||
* Take a screenshot of the selected area
|
||||
|
||||
|
||||
|
||||
If you happen to use GIMP a lot and you probably want some advance edits on your screenshots, GIMP would be a good choice for that.
|
||||
|
||||
You should already have it installed, if not, you can always head to your software center to install it. If you have trouble installing, you can always refer to their [official website for installation instructions][10].
|
||||
|
||||
To take a screenshot with GIMP, you need to first launch it, and then navigate your way through **File- >Create->Screenshot**.
|
||||
|
||||
After you click on the screenshot option, you will be greeted with a couple of tweaks to control the screenshot. That’s just it. Click “ **Snap** ” to take the screenshot and the image will automatically appear within GIMP, ready for you to edit.
|
||||
|
||||
### Method 5: Taking screenshot in Linux using command line tools
|
||||
|
||||
This section is strictly for terminal lovers. If you like using the terminal, you can utilize the **GNOME screenshot** tool or **ImageMagick** or **Deepin Scrot** – which comes baked in on most of the popular Linux distributions.
|
||||
|
||||
To take a screenshot instantly, enter the following command:
|
||||
|
||||
#### GNOME Screenshot (for GNOME desktop users)
|
||||
```
|
||||
gnome-screenshot
|
||||
|
||||
```
|
||||
|
||||
To take a screenshot with a delay, enter the following command (here, **5** – is the number of seconds you want to delay)
|
||||
|
||||
GNOME screenshot is one of the default tools that exists in all distributions with GNOME desktop.
|
||||
```
|
||||
gnome-screenshot -d -5
|
||||
|
||||
```
|
||||
|
||||
#### ImageMagick
|
||||
|
||||
[ImageMagick][11] should be already pre-installed on your system if you are using Ubuntu, Mint, or any other popular Linux distribution. In case, it isn’t there, you can always install it by following the [official installation instructions (from source)][12]. In either case, you can enter the following in the terminal:
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
|
||||
```
|
||||
|
||||
After you have it installed, you can type in the following commands to take a screenshot:
|
||||
|
||||
To take the screenshot of your entire screen:
|
||||
```
|
||||
import -window root image.png
|
||||
|
||||
```
|
||||
|
||||
Here, “image.png” is your desired name for the screenshot.
|
||||
|
||||
To take the screenshot of a specific area:
|
||||
```
|
||||
import image.png
|
||||
|
||||
```
|
||||
|
||||
#### Deepin Scrot
|
||||
|
||||
Deepin Scrot is a slightly advanced terminal-based screenshot tool. Similar to the others, you should already have it installed. If not, get it installed through the terminal by typing:
|
||||
```
|
||||
sudo apt-get install scrot
|
||||
|
||||
```
|
||||
|
||||
After having it installed, follow the instructions below to take a screenshot:
|
||||
|
||||
To take a screenshot of the entire screen:
|
||||
```
|
||||
scrot myimage.png
|
||||
|
||||
```
|
||||
|
||||
To take a screenshot of the selected aread:
|
||||
```
|
||||
scrot -s myimage.png
|
||||
|
||||
```
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
So, these are the best screenshot tools available for Linux. Yes, there are a few more tools available (like [Spectacle][13] for KDE-based distros), but if you end up comparing them, the above-mentioned tools will outshine them.
|
||||
|
||||
In case you find a better screenshot tool than the ones mentioned in our article, feel free to let us know about it in the comments below.
|
||||
|
||||
Also, do tell us about your favorite screenshot tool!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/take-screenshot-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Taking-Screenshots-in-Linux.png
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/flameshot-pic.png
|
||||
[3]: https://github.com/lupoDharkael/flameshot
|
||||
[4]: https://github.com/lupoDharkael/flameshot#installation
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/flameshot-config-default.png
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/shutter-screenshot.jpg
|
||||
[7]: http://shutter-project.org/
|
||||
[8]: https://itsfoss.com/shutter-edit-button-disabled/
|
||||
[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/gimp-screenshot.jpg
|
||||
[10]: https://www.gimp.org/downloads/
|
||||
[11]: https://www.imagemagick.org/script/index.php
|
||||
[12]: https://www.imagemagick.org/script/install-source.php
|
||||
[13]: https://www.kde.org/applications/graphics/spectacle/
|
||||
@ -0,0 +1,168 @@
|
||||
Flameshot – A Simple, Yet Powerful Feature-rich Screenshot Tool
|
||||
======
|
||||
|
||||

|
||||
|
||||
Capturing screenshots is part of my job. I have been using Deepin-screenshot tool for taking screenshots. It’s a simple, light-weight and quite neat screenshot tool. It comes with all options such as mart window identification, shortcuts supporting, image editing, delay screenshot, social sharing, smart saving, and image resolution adjusting etc. Today, I stumbled upon yet another screenshot tool that ships with many features. Say hello to **Flameshot** , a simple and powerful, feature-rich screenshot tool for Unix-like operating systems. It is easy to use, customizable and has an option to upload your screenshots to **imgur** , an online image sharing website. And also, Flameshot has a CLI version, so you can take screenshots from commandline as well. Flameshot is completely free and open source tool. In this guide, we will see how to install Flameshot and how to take screenshots using it.
|
||||
|
||||
### Install Flameshot
|
||||
|
||||
**On Arch Linux:**
|
||||
|
||||
Flameshot is available [community] repository in Arch Linux. Make sure you have enabled community repository and install Flameshot using pacman as shown below.
|
||||
```
|
||||
$ sudo pacman -S flameshot
|
||||
|
||||
```
|
||||
|
||||
It is also available in [**AUR**][1], so you can install it using any AUR helper programs, for example [**Yay**][2], in Arch-based systems.
|
||||
```
|
||||
$ yay -S flameshot-git
|
||||
|
||||
```
|
||||
|
||||
**On Fedora:**
|
||||
```
|
||||
$ sudo dnf install flameshot
|
||||
|
||||
```
|
||||
|
||||
On **Debian 10+** and **Ubuntu 18.04+** , install it using APT package manager.
|
||||
```
|
||||
$ sudo apt install flameshot
|
||||
|
||||
```
|
||||
|
||||
**On openSUSE:**
|
||||
```
|
||||
$ sudo zypper install flameshot
|
||||
|
||||
```
|
||||
|
||||
On other distributions, compile and install it from source code. The compilation requires **Qt version 5.3** or higher and **GCC 4.9.2** or higher.
|
||||
|
||||
### Usage
|
||||
|
||||
Launch Flameshot from menu or application launcher. On MATE desktop environment, It usually found under **Applications - > Graphics**.
|
||||
|
||||
Once you opened it, you will see Flameshot systray icon in your system’s panel.
|
||||
|
||||
**Note:**
|
||||
|
||||
If you are using Gnome you need to install the [TopIcons][3] extension in order to see the systemtray icon.
|
||||
|
||||
Right click on the tray icon and you’ll see some menu items to open the configuration window and the information window or quit the application.
|
||||
|
||||
To capture screenshot, just click on the tray icon. You will see help window that says how to use Flameshot. Choose an area to capture and hit **ENTER** key to capture the screen. Press right click to show the color picker, hit spacebar to view the side panel. You can use increase or decrease the pointer’s thickness by using the Mouse scroll button.
|
||||
|
||||
Flameshot comes with quite good set of features, such as,
|
||||
|
||||
* Free hand writing
|
||||
* Line drawing
|
||||
* Rectangle / Circle drawing
|
||||
* Rectangle selection
|
||||
* Arrows
|
||||
* Marker to highlight important points
|
||||
* Add text
|
||||
* Blur the image/text
|
||||
* Show the dimension of the image
|
||||
* Undo/Redo the changes while editing images
|
||||
* Copy the selection to the clipboard
|
||||
* Save the selection
|
||||
* Leave the capture screen
|
||||
* Choose an app to open images
|
||||
* Upload the selection to imgur site
|
||||
* Pin image to desktop
|
||||
|
||||
|
||||
|
||||
Here is a sample demo:
|
||||
|
||||
<http://www.ostechnix.com/wp-content/uploads/2018/09/Flameshot-demo.mp4>
|
||||
|
||||
**Keyboard shortcuts**
|
||||
|
||||
Frameshot supports keyboard shortcuts. Right click on Flameshot tray icon and click **Information** window to see all the available shortcuts in the graphical capture mode. Here is the list of available keyboard shortcuts in GUI mode.
|
||||
|
||||
| Keys | Description |
|
||||
|------------------------|------------------------------|
|
||||
| ←, ↓, ↑, → | Move selection 1px |
|
||||
| Shift + ←, ↓, ↑, → | Resize selection 1px |
|
||||
| Esc | Quit capture |
|
||||
| Ctrl + C | Copy to clipboard |
|
||||
| Ctrl + S | Save selection as a file |
|
||||
| Ctrl + Z | Undo the last modification |
|
||||
| Right Click | Show color picker |
|
||||
| Mouse Wheel | Change the tool’s thickness |
|
||||
|
||||
Shift + drag a handler of the selection area: mirror redimension in the opposite handler.
|
||||
|
||||
**Command line options**
|
||||
|
||||
Flameshot also has a set of command line options to delay the screenshots and save images in custom paths.
|
||||
|
||||
To capture screen with Flameshot GUI, run:
|
||||
```
|
||||
$ flameshot gui
|
||||
|
||||
```
|
||||
|
||||
To capture screen with GUI and save it in a custom path of your choice:
|
||||
```
|
||||
$ flameshot gui -p ~/myStuff/captures
|
||||
|
||||
```
|
||||
|
||||
To open GUI with a delay of 2 seconds:
|
||||
```
|
||||
$ flameshot gui -d 2000
|
||||
|
||||
```
|
||||
|
||||
To capture fullscreen with custom save path (no GUI) with a delay of 2 seconds:
|
||||
```
|
||||
$ flameshot full -p ~/myStuff/captures -d 2000
|
||||
|
||||
```
|
||||
|
||||
To capture fullscreen with custom save path copying to clipboard:
|
||||
```
|
||||
$ flameshot full -c -p ~/myStuff/captures
|
||||
|
||||
```
|
||||
|
||||
To capture the screen containing the mouse and print the image (bytes) in **PNG** format:
|
||||
```
|
||||
$ flameshot screen -r
|
||||
|
||||
```
|
||||
|
||||
To capture the screen number 1 and copy it to the clipboard:
|
||||
```
|
||||
$ flameshot screen -n 1 -c
|
||||
|
||||
```
|
||||
|
||||
What do you need? Flameshot has almost all features for capturing pictures, adding annotations, editing images, blur or highlight important points and a lot more. I think I will stick with Flameshot for a while as find it best replacement for my current screenshot tool. Give it a try and you won’t be disappointed.
|
||||
|
||||
And, that’s all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/flameshot-a-simple-yet-powerful-feature-rich-screenshot-tool/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://aur.archlinux.org/packages/flameshot-git
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[3]: https://extensions.gnome.org/extension/1031/topicons/
|
||||
@ -0,0 +1,118 @@
|
||||
Getting started with the i3 window manager on Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
In my article [5 reasons the i3 window manager makes Linux better][1], I shared the top five reasons I use and recommend the [i3 window manager][2] as an alternative Linux desktop experience.
|
||||
|
||||
In this post, I will walk through the installation and basic configuration of i3 on Fedora 28 Linux.
|
||||
|
||||
### 1\. Installation
|
||||
|
||||
Log into a Fedora workstation and open up a terminal. Use `dnf` to install the required package, like this:
|
||||
```
|
||||
[ricardo@f28i3 ~]$ sudo dnf install -y i3 i3-ipc i3status i3lock dmenu terminator --exclude=rxvt-unicode
|
||||
Last metadata expiration check: 1:36:15 ago on Wed 08 Aug 2018 12:04:31 PM EDT.
|
||||
Dependencies resolved.
|
||||
================================================================================================
|
||||
Package Arch Version Repository Size
|
||||
================================================================================================
|
||||
Installing:
|
||||
dmenu x86_64 4.8-1.fc28 fedora 33 k
|
||||
i3 x86_64 4.15-1.fc28 fedora 323 k
|
||||
i3-ipc noarch 0.1.4-12.fc28 fedora 14 k
|
||||
i3lock x86_64 2.9.1-2.fc28 fedora 33 k
|
||||
i3status x86_64 2.12-1.fc28 updates 62 k
|
||||
terminator noarch 1.91-4.fc28 fedora 570 k
|
||||
Installing dependencies:
|
||||
dzen2 x86_64 0.8.5-21.20100104svn.fc28 fedora 60 k
|
||||
|
||||
... Skipping dependencies/install messages
|
||||
|
||||
Complete!
|
||||
[ricardo@f28i3 ~]$
|
||||
```
|
||||
|
||||
**Note:** In this command, I'm explicitly excluding the package `rxvt-unicode` because I prefer `terminator` as my terminal emulator.
|
||||
|
||||
Depending on the status of your system, it may install many dependencies. Wait for the installation to complete successfully and then reboot your machine.
|
||||
|
||||
### 2. First login and initial setup
|
||||
|
||||
After your machine restarts, you're ready to log into i3 for the first time. In the GNOME Display Manager (GDM) screen, click on your username but—before typing the password to log in—click on the small gear icon and change the session to i3 instead of GNOME, like this:
|
||||
|
||||
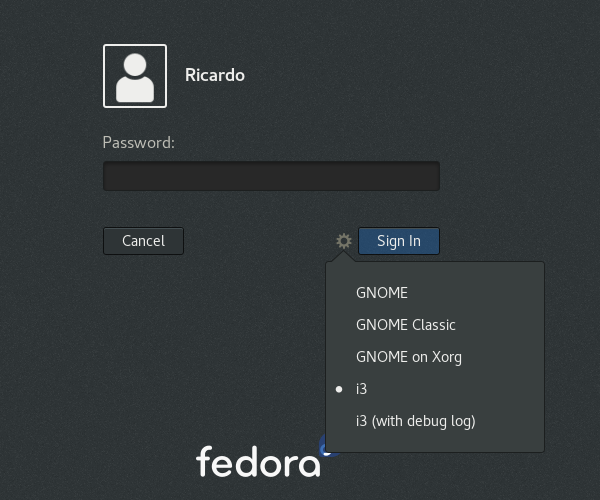
|
||||
|
||||
Type your password and click `Sign In`. On your first login, you are presented with the i3 configuration screen:
|
||||
|
||||
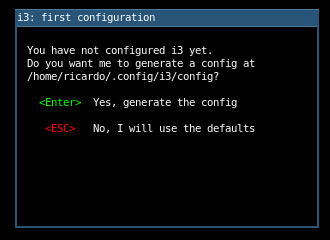
|
||||
|
||||
Press `ENTER` to generate a config file in your `$HOME/.config/i3` directory. Later you can use this config file to further customize i3's behavior.
|
||||
|
||||
On the next screen, you need to select your `Mod` key. This is important, as the `Mod` key is used to trigger most of i3's keyboard shortcuts. Press `ENTER` to use the default `Win` key as the `Mod` key. If you don't have a `Win` key on your keyboard or prefer to use `Alt` instead, use the arrow key to select it and press `ENTER` to confirm.
|
||||
|
||||
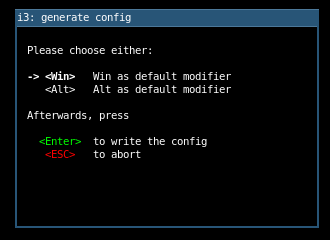
|
||||
|
||||
You're now logged into your i3 session. Because i3 is a minimalist window manager, you see a black screen with the status bar on the bottom:
|
||||
|
||||

|
||||
|
||||
Next, let's look at navigating in i3.
|
||||
|
||||
### 3\. Basic shortcuts
|
||||
|
||||
Now that you're logged into an i3 session, you'll need a few basic keyboard shortcuts to get around.
|
||||
|
||||
The majority of i3 shortcuts use the `Mod` key you defined during the initial configuration. When I refer to `Mod` in the following examples, press the key you defined. This will usually be the `Win` key, but it can also be the `Alt` key.
|
||||
|
||||
First, to open up a terminal, use `Mod+ENTER`. Open more than one terminal and notice how i3 automatically tiles them to occupy all available space. By default, i3 splits the screen horizontally; use `Mod+v` to split vertically and press `Mod+h` to go back to the horizontal split.
|
||||
|
||||
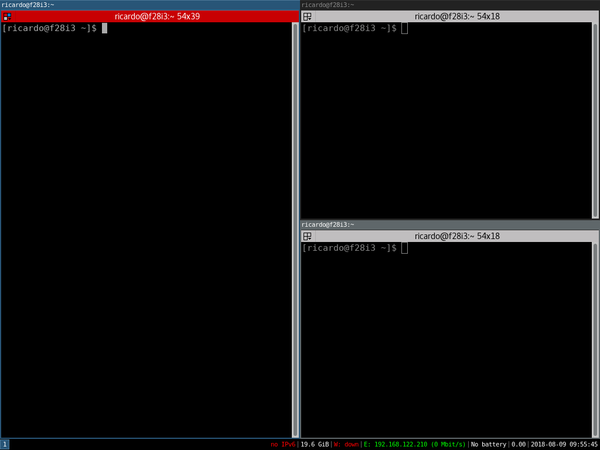
|
||||
|
||||
To start other applications, press `Mod+d` to open `dmenu`, a simple text-based application menu. By default, `dmenu` presents a list of all applications available on your `$PATH`. Select the application you want to start by using the arrow keys or narrow down the search by typing parts of the application's name. Press `ENTER` to start the selected application.
|
||||
|
||||

|
||||
|
||||
If your application does not provide a way to close it, you can use i3 to kill a window by pressing `Mod+Shift+q`. Be careful, as you may lose unsaved work—this behavior depends on each application.
|
||||
|
||||
Finally, to end your session and exit i3, press `Mod+Shift+e`. You are presented with a confirmation message at the top of your screen. Click on `Yes, exit i3` to exit or `X` to cancel.
|
||||
|
||||

|
||||
|
||||
This is just an initial list of shortcuts you can use to get around i3. For many more, consult i3's official [documentation][3].
|
||||
|
||||
### 4\. Replacing GDM
|
||||
|
||||
Using i3 window manager reduces the memory utilization on your system; however, Fedora still uses the default GDM as its login screen. GDM loads several GNOME-related libraries and applications that consume memory.
|
||||
|
||||
If you want to further reduce your system's memory utilization, you can replace GDM with a more lightweight display manager, such as `lightdm`, like this:
|
||||
```
|
||||
[ricardo@f28i3 ~]$ sudo dnf install -y lightdm
|
||||
[ricardo@f28i3 ~]$ sudo systemctl disable gdm
|
||||
Removed /etc/systemd/system/display-manager.service.
|
||||
[ricardo@f28i3 ~]$ sudo systemctl enable lightdm
|
||||
Created symlink /etc/systemd/system/display-manager.service -> /usr/lib/systemd/system/lightdm.service.
|
||||
[ricardo@f28i3 ~]$
|
||||
```
|
||||
|
||||
Restart your machine to see the Lightdm login screen.
|
||||
|
||||
Now you're ready to log in and use i3.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-i3-window-manager
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rgerardi
|
||||
[1]: https://opensource.com/article/18/8/i3-tiling-window-manager
|
||||
[2]: https://i3wm.org
|
||||
[3]: https://i3wm.org/docs/userguide.html#_default_keybindings
|
||||
@ -0,0 +1,223 @@
|
||||
你没听说过的 Go 语言惊人优点
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
来自 [https://github.com/ashleymcnamara/gophers][1] 的图稿
|
||||
|
||||
在这篇文章中,我将讨论为什么你需要尝试一下 Go,以及应该从哪里学起。
|
||||
|
||||
Golang 是可能是最近几年里你经常听人说起的编程语言。尽管它在 2009 年已经发布,但它最近才开始流行起来。
|
||||
|
||||

|
||||
|
||||
根据 Google 趋势,Golang 语言非常流行。
|
||||
|
||||
这篇文章不会讨论一些你经常看到的 Golang 的主要特性。
|
||||
|
||||
相反,我想向您介绍一些相当小众但仍然很重要的功能。在您决定尝试Go后,您才会知道这些功能。
|
||||
|
||||
这些都是表面上没有体现出来的惊人特性,但它们可以为您节省数周或数月的工作量。而且这些特性还可以使软件开发更加愉快。
|
||||
|
||||
阅读本文不需要任何语言经验,所以不比担心 Golang 对你来说是新的事物。如果你想了解更多,可以看看我在底部列出的一些额外的链接,。
|
||||
|
||||
我们将讨论以下主题:
|
||||
|
||||
* GoDoc
|
||||
|
||||
* 静态代码分析
|
||||
|
||||
* 内置的测试和分析框架
|
||||
|
||||
* 竞争条件检测
|
||||
|
||||
* 学习曲线
|
||||
|
||||
* 反射(Reflection)
|
||||
|
||||
* Opinionatedness(专制独裁的 Go)
|
||||
|
||||
* 文化
|
||||
|
||||
请注意,这个列表不遵循任何特定顺序来讨论。
|
||||
|
||||
### GoDoc
|
||||
|
||||
Golang 非常重视代码中的文档,简洁也是如此。
|
||||
|
||||
[GoDoc][4] 是一个静态代码分析工具,可以直接从代码中创建漂亮的文档页面。GoDoc 的一个显着特点是它不使用任何其他的语言,如 JavaDoc,PHPDoc 或 JSDoc 来注释代码中的结构,只需要用英语。
|
||||
|
||||
它使用从代码中获取的尽可能多的信息来概述、构造和格式化文档。它有多而全的功能,比如:交叉引用,代码示例以及一个指向版本控制系统仓库的链接。
|
||||
|
||||
而你需要做的只有添加一些好的,像 `// MyFunc transforms Foo into Bar` 这样子的注释,而这些注释也会反映在的文档中。你甚至可以添加一些通过网络接口或者在本地可以实际运行的 [代码示例][5]。
|
||||
|
||||
GoDoc 是 Go 的唯一文档引擎,供整个社区使用。这意味着用 Go 编写的每个库或应用程序都具有相同的文档格式。从长远来看,它可以帮你在浏览这些文档时节省大量时间。
|
||||
|
||||
例如,这是我最近一个小项目的 GoDoc 页面:[pullkee — GoDoc][6]。
|
||||
|
||||
### 静态代码分析
|
||||
|
||||
Go 严重依赖于静态代码分析。例子包括 godoc 文档,gofmt 代码格式化,golint 代码风格统一,等等。
|
||||
|
||||
其中有很多甚至全部包含在类似 [gometalinter][10] 的项目中,这些将它们全部组合成一个实用程序。
|
||||
|
||||
这些工具通常作为独立的命令行应用程序实现,并可轻松与任何编码环境集成。
|
||||
|
||||
静态代码分析实际上并不是现代编程的新概念,但是 Go 将其带入了绝对的范畴。我无法估量它为我节省了多少时间。此外,它给你一种安全感,就像有人在你背后支持你一样。
|
||||
|
||||
创建自己的分析器非常简单,因为 Go 有专门的内置包来解析和加工 Go 源码。
|
||||
|
||||
你可以从这个链接中了解到更多相关内容: [GothamGo Kickoff Meetup: Go Static Analysis Tools by Alan Donovan][11].
|
||||
|
||||
### 内置的测试和分析框架
|
||||
|
||||
您是否曾尝试为一个从头开始的 Javascript 项目选择测试框架?如果是这样,你可能会明白经历这种分析瘫痪的斗争。您可能也意识到您没有使用其中 80% 的框架。
|
||||
|
||||
一旦您需要进行一些可靠的分析,问题就会重复出现。
|
||||
|
||||
Go 附带内置测试工具,旨在简化和提高效率。它为您提供了最简单的 API,并做出最小的假设。您可以将它用于不同类型的测试,分析,甚至可以提供可执行代码示例。
|
||||
|
||||
它可以开箱即用地生成持续集成友好的输出,而且它的用法很简单,只需运行 `go test`。当然,它还支持高级功能,如并行运行测试,跳过标记代码,以及其他更多功能。
|
||||
|
||||
### 竞争条件检测
|
||||
|
||||
您可能已经了解了 Goroutines,它们在 Go 中用于实现并发代码执行。如果你未曾了解过,[这里][12]有一个非常简短的解释。
|
||||
|
||||
无论具体技术如何,复杂应用中的并发编程都不容易,部分原因在于竞争条件的可能性。
|
||||
|
||||
简单地说,当几个并发操作以不可预测的顺序完成时,竞争条件就会发生。它可能会导致大量的错误,特别难以追查。如果你曾经花了一天时间调试集成测试,该测试仅在大约 80% 的执行中起作用?这可能是竞争条件引起的。
|
||||
|
||||
总而言之,在 Go 中非常重视并发编程,幸运的是,我们有一个强大的工具来捕捉这些竞争条件。它完全集成到 Go 的工具链中。
|
||||
|
||||
您可以在这里阅读更多相关信息并了解如何使用它:[介绍 Go 中的竞争条件检测 - Go Blog][13]。
|
||||
|
||||
### 学习曲线
|
||||
|
||||
您可以在一个晚上学习所有 Go 的语言功能。我是认真的。当然,还有标准库,以及不同,更具体领域的最佳实践。但是两个小时就足以让你自信地编写一个简单的 HTTP 服务器或命令行应用程序。
|
||||
|
||||
Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进行了介绍:[The Go Programming Language Blog][15]。
|
||||
|
||||
比起 Java(以及 Java 家族的语言),Javascript,Ruby,Python 甚至 PHP,你可以更轻松地把 Go 语言带到你的团队中。由于环境易于设置,您的团队在完成第一个生产代码之前需要进行的投资要小得多。
|
||||
|
||||
### 反射(Reflection)
|
||||
|
||||
代码反射本质上是一种隐藏在编译器下并访问有关语言结构的各种元信息的能力,例如变量或函数。
|
||||
|
||||
鉴于 Go 是一种静态类型语言,当涉及更松散类型的抽象编程时,它会受到许多各种限制。特别是与 Javascript 或 Python 等语言相比。
|
||||
|
||||
此外,Go [没有实现一个名为泛型的概念][16],这使得以抽象方式处理多种类型更具挑战性。然而,由于泛型带来的复杂程度,许多人认为不实现泛型对语言实际上是有益的。我完全同意。
|
||||
|
||||
根据 Go 的理念(这是一个单独的主题),您应该努力不要过度设计您的解决方案。这也适用于动态类型编程。尽可能坚持使用静态类型,并在确切知道要处理的类型时使用接口(interfaces)。接口在 Go 中非常强大且无处不在。
|
||||
|
||||
但是,仍然存在一些情况,你无法知道你处理的数据类型。一个很好的例子是 JSON。您可以在应用程序中来回转换所有类型的数据。字符串,缓冲区,各种数字,嵌套结构等。
|
||||
|
||||
为了解决这个问题,您需要一个工具来检查运行时的数据并根据其类型和结构采取不同行为。反射(Reflect)可以帮到你。Go 拥有一流的反射包,使您的代码能够像 Javascript 这样的语言一样动态。
|
||||
|
||||
一个重要的警告是知道你使用它所带来的代价 - 并且只有知道在没有更简单的方法时才使用它。
|
||||
|
||||
你可以在这里阅读更多相关信息: [反射的法则 — Go 博客][18].
|
||||
|
||||
您还可以在此处阅读 JSON 包源码中的一些实际代码: [src/encoding/json/encode.go — Source Code][19]
|
||||
|
||||
### Opinionatedness
|
||||
|
||||
顺便问一下,有这样一个单词吗?
|
||||
|
||||
来自 Javascript 世界,我面临的最艰巨的困难之一是决定我需要使用哪些约定和工具。我应该如何设计代码?我应该使用什么测试库?我该怎么设计结构?我应该依赖哪些编程范例和方法?
|
||||
|
||||
这有时候基本上让我卡住了。我需要花时间思考这些事情而不是编写代码并满足用户。
|
||||
|
||||
首先,我应该注意到我完全可以得到这些惯例的来源,它总是来源于你或者你的团队。无论如何,即使是一群经验丰富的 Javascript 开发人员也可以轻松地发现自己拥有完全不同的工具和范例的大部分经验,以实现相同的结果。
|
||||
|
||||
这导致整个团队中分析的瘫痪,并且使得个体之间更难以相互协作。
|
||||
|
||||
嗯,Go 是不同的。即使您对如何构建和维护代码有很多强烈的意见,例如:如何命名,要遵循哪些结构模式,如何更好地实现并发。但你只有一个每个人都遵循的风格指南。你只有一个内置在基本工具链中的测试框架。
|
||||
|
||||
虽然这似乎过于严格,但它为您和您的团队节省了大量时间。当你写代码时,受一点限制实际上是一件好事。在构建新代码时,它为您提供了一种更直接的方法,并且可以更容易地调试现有代码。
|
||||
|
||||
因此,大多数 Go 项目在代码方面看起来非常相似。
|
||||
|
||||
### 文化
|
||||
|
||||
人们说,每当你学习一门新的口语时,你也会沉浸在说这种语言的人的某些文化中。因此,您学习的语言越多,您可能会有更多的变化。
|
||||
|
||||
编程语言也是如此。无论您将来如何应用新的编程语言,它总能给的带来新的编程视角或某些特别的技术。
|
||||
|
||||
无论是函数式编程,模式匹配(pattern matching)还是原型继承(prototypal inheritance)。一旦你学会了它们,你就可以随身携带这些编程思想,这扩展了你作为软件开发人员所拥有的问题解决工具集。它们也改变了你阅读高质量代码的方式。
|
||||
|
||||
而 Go 在方面有一项了不起的财富。Go 文化的主要支柱是保持简单,脚踏实地的代码,而不会产生许多冗余的抽象概念,并将可维护性放在首位。大部分时间花费在代码的编写工作上,而不是在修补工具和环境或者选择不同的实现方式上,这也是 Go文化的一部分。
|
||||
|
||||
Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
一点注意事项。当你需要构建相对复杂的抽象代码时,Go 通常会妨碍你。好吧,我会说这是简单的权衡。
|
||||
|
||||
如果你真的需要编写大量具有复杂关系的抽象代码,那么最好使用 Java 或 Python 等语言。然而,这种情况却很少。
|
||||
|
||||
在工作时始终使用最好的工具!
|
||||
|
||||
### 总结
|
||||
|
||||
你或许之前听说过 Go,或者它暂时在你圈子以外的地方。但无论怎样,在开始新项目或改进现有项目时,Go 可能是您或您团队的一个非常不错的选择。
|
||||
|
||||
这不是 Go 的所有惊人的优点的完整列表,只是一些被人低估的特性。
|
||||
|
||||
请尝试一下从 [Go 之旅(A Tour of Go)][20]来开始学习 Go,这将是一个令人惊叹的开始。
|
||||
|
||||
如果您想了解有关 Go 的优点的更多信息,可以查看以下链接:
|
||||
|
||||
* [你为什么要学习 Go? - Keval Patel][2]
|
||||
|
||||
* [告别Node.js - TJ Holowaychuk][3]
|
||||
|
||||
并在评论中分享您的阅读感悟!
|
||||
|
||||
即使您不是为了专门寻找新的编程语言语言,也值得花一两个小时来感受它。也许它对你来说可能会变得非常有用。
|
||||
|
||||
不断为您的工作寻找最好的工具!
|
||||
|
||||
* * *
|
||||
|
||||
If you like this article, please consider following me for more, and clicking on those funny green little hands right below this text for sharing. 👏👏👏
|
||||
|
||||
Check out my [Github][21] and follow me on [Twitter][22]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Software Engineer and Traveler. Coding for fun. Javascript enthusiast. Tinkering with Golang. A lot into SOA and Docker. Architect at Velvica.
|
||||
|
||||
------------
|
||||
|
||||
|
||||
via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that-you-dont-hear-much-about-1af99de3b23a
|
||||
|
||||
作者:[Kirill Rogovoy][a]
|
||||
译者:[译者ID](https://github.com/imquanquan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://github.com/ashleymcnamara/gophers
|
||||
[2]:https://medium.com/@kevalpatel2106/why-should-you-learn-go-f607681fad65
|
||||
[3]:https://medium.com/@tjholowaychuk/farewell-node-js-4ba9e7f3e52b
|
||||
[4]:https://godoc.org/
|
||||
[5]:https://blog.golang.org/examples
|
||||
[6]:https://godoc.org/github.com/kirillrogovoy/pullkee
|
||||
[7]:https://godoc.org/
|
||||
[8]:https://golang.org/cmd/gofmt/
|
||||
[9]:https://github.com/golang/lint
|
||||
[10]:https://github.com/alecthomas/gometalinter#supported-linters
|
||||
[11]:https://vimeo.com/114736889
|
||||
[12]:https://gobyexample.com/goroutines
|
||||
[13]:https://blog.golang.org/race-detector
|
||||
[14]:https://golang.org/doc/
|
||||
[15]:https://blog.golang.org/
|
||||
[16]:https://golang.org/doc/faq#generics
|
||||
[17]:https://golang.org/pkg/reflect/
|
||||
[18]:https://blog.golang.org/laws-of-reflection
|
||||
[19]:https://golang.org/src/encoding/json/encode.go
|
||||
[20]:https://tour.golang.org/
|
||||
[21]:https://github.com/kirillrogovoy/
|
||||
[22]:https://twitter.com/krogovoy
|
||||
@ -1,63 +1,55 @@
|
||||
## sober-wang 翻译中
|
||||
|
||||
Linux Virtual Machines vs Linux Live Images
|
||||
Linxu 虚拟机 vs Linux 实体机
|
||||
======
|
||||
I'll be the first to admit(认可) that I tend(照顾) to try out new [Linux distros(发行版本)][1] on a far(远) too frequent(频繁) basis. Yet the method(方法) I use to test them, does vary depending(依赖) on my goals(目标) for each instance(每一个). In this article(文章), we're going to look at both(两个) running Linux virtual machines and running Linux live images. There are advantages(优势/促进/有利于) to each method(方法), but there are some hurdles(障碍) with each method(方法/函数) as well(同样的).
|
||||
|
||||
首先我得承认,我非常倾向于频繁尝试新的[ linux 发行版本 ][1],我的目标是为了解决每一个 Linux 发行版的依赖,所以我用一些方法来测试它们。在一些文章中,我们将会看到两种运行 Linux 的模式,虚拟机或实体机。每一种方式都存在优势,但是有一些障碍会伴随着这两种方式。
|
||||
|
||||
### Testing out a new Linux distro for the first time
|
||||
### 第一时间测试一个新的 Linux 发行版
|
||||
|
||||
When I test out a brand new Linux distro for the first time, the method I use depends heavily(沉重的) on the resources(资源) of the PC I'm currently(目前的) on. If I have access to my desktop PC, I'm going to run the distro to be tested in a virtual machine. The reason(理由) for this approach(靠近) is that I can download and test the distro in not only a live environment(环境), but also(也) as an installed product with persistent(稳定的) storage abilities(能力).
|
||||
为了第一时间去做 Linux 发型版本的依赖测试,我把它们运行在我目前所拥有的所有类型的 PC 上。如果我用我的台式机,我将运行一个 Linux 虚拟机做测试。使用这种方法的原因是,不仅仅是生活环境下我可以下载测并测试发行版,但也会用稳定的生产环境安装。
|
||||
|
||||
为了第一时间去做 Linux 发型版本的依赖测试,我把它们运行在我目前所拥有的所有类型的 PC 上。如果我用我的台式机,我将运行一个 Linux 虚拟机做测试。
|
||||
在另一方面,如果我在工作中我的PC不具备强力的硬件条件的,在一个虚拟机上测试 Linux 发型版本的时候将会产生相反的效果。老实的讲,我会将电脑性能压榨到极限,如果在经济条件服务的情况下我会使用实体机运行 Linux 镜像替代虚拟机
|
||||
|
||||
On the other hand, if I am working with much less robust hardware on a PC, then testing out a distro with a virtual machine installation of Linux is counter-productive. I'd be pushing that PC to its limits and honestly would be better off using a live Linux image instead running from a flash drive.
|
||||
### 在一个新的 Linux 发行版本上运行旅游软件
|
||||
|
||||
### Touring software on a new Linux distro
|
||||
如果你有兴趣查看发行版本的桌面环境或购买软件,你不能因为发行版本的一个实时图片而诽谤它。一个生活环境提供给你希望的鸟瞰全局的视角,如何使用户体验更好是由应用程序提供的。
|
||||
|
||||
If you're interested in checking out a distro's desktop environment or the available software, you can't go wrong with a live image of the distro. A live environment provides you with a birds eye view of what to expect in terms of overall layout, applications provided and how the user experience flows overall.
|
||||
公平的说,一个虚拟化安装你也可以做同样的事,但是它有点不好,如果这么做你将要消除硬件上的许多数据。毕竟这是一个简单的发行版。记得我说过在第一部分-我做测试喜欢在虚拟机上运行 Linux 。这个方式我就能看见如何去安装它,使用镜像安装时你讲看不见有区别的操作和其他工作原理。
|
||||
|
||||
To be fair, you could do the same thing with a virtual machine installation, but it may be a bit overkill if you would rather avoid filling up hard drive space with yet more data. After all, this is a simple tour of the distro. Remember what I said in the first section – I like to run Linux in a virtual machine to test it. This means I'm going to see how it installs, what the partition options look like and other elements you wouldn't see from using a live image of any given distro.
|
||||
通常你仅能看见一个关于发行版本的简短介绍,关于功能用最少的阻力和时间投入,是解决这个问题的好办法。
|
||||
|
||||
Touring usually indicates that you're only looking to take a quick look at a distro, so in this case the method that can be done with the least amount of resistance and time investment is a good course of action.
|
||||
### 随身携带一个
|
||||
|
||||
### Taking a Linux distro with you
|
||||
这个话题虽然不像几年前那样普遍,使用 Linux 发行版的能力可能是许多用户所顾虑的。明显,适合他们自己携带的系统,虚拟机是无法提供的。无论如何,一个 Linux 发行版本的镜像是具有可移植性的。一个镜像能够轻松的写入到 DVD 或者 Flash 存储设备中。
|
||||
|
||||
While it's not as common as it was a few years ago, the ability to take a Linux distro with you may be a consideration for some users. Obviously, virtual machine installations don't necessarily lend themselves favorably to portability. However a live image of a Linux distro is actually quite portable. A live image can be written to a DVD or copied onto a flash drive for easy traveling.
|
||||
在 Linux 可移植性的概念上花费时间,这有益于在一个朋友的电脑上使用 Flash 存储设备安装镜像版 Linux 。这个授权使你能证明 Linux 能充实他们的生活,虽然在他们的 PC 上运行一个虚拟机是不可靠的。在喜爱使用镜像的用户哪里,它是双赢的。
|
||||
|
||||
Expanding on this concept of Linux portability, it's also beneficial to have a live image on a flash drive when showing off how Linux works on a friend's computer. This empowers you to demonstrate how Linux can enrich their life while not relying on running a virtual machine on their PC. It's a bit of a win-win in favor of using a live image.
|
||||
### 选择做双系统 Linux
|
||||
|
||||
### Alternative to dual-booting Linux
|
||||
这是一个巨大的项目。考虑一些事,例如你在使用 Windows .你喜欢玩 Linux ,但是宁可不获取插件。在一些出状况或考虑你不是拥有单独分区,双系统将是一个问题。不管什么样的情况,同时使用 Linux 虚拟机和镜像系统都对于你是一个很好的选择。
|
||||
|
||||
This next item is a huge one. Consider this – perhaps you're a Windows user. You like playing with Linux, but would rather not take the plunge. Dual-booting is out of the question in case something goes wrong or perhaps you're not comfortable identifying individual partitions. Whatever the case may be, both using Linux in a virtual machine or from a live image might be a great option for you.
|
||||
现在,我在一些事物上采取奇怪的立场。长期运行 Linux 镜像在 Flash 存储或虚拟机,我知道你将为了更多的价值走更远。对于这个说法有两个原因。第一个,在 Windows 中安装一个虚拟机 VS 真正的运行的 Linux 。第二,用一个持续的存储设备你的 Flash 存储,安装 Linux 和你的数据。
|
||||
|
||||
Now I'm going to take a rather odd stance on something. I think you'll get far more value in the long term running Linux on a flash drive using a live image than with a virtual machine. There are two reasons for this. First of all, you'll get used to truly running Linux vs running it inside of a virtual machine on top of Windows. Second, you can setup your flash drive to contain user data with persistent storage.
|
||||
我知道你会说用一个虚拟机运行 Linux 也是如此,无论如何你都无法升级到用镜像安装的地步。为什么?你不会更新你的宿主系统或者客户系统。记住,有一些发行 Linux 发行版本被设定为只能在持久存储中运行。Puppy Linux 就是一个非常好的例子。它仅能运行在个人 PC 上,否则它将进入死循环或被丢弃,它允许你永远不被单调的系统省级困扰,由于发行版会安全的处理这些更新。它不是一个正常的 Linux 发行版,有一个持久的免费镜像这样的方式用一堵墙个离开,多么可怕。
|
||||
|
||||
I'll grant you the same could be said with a virtual machine running Linux, however you will never have an update break anything using the live image approach. Why? Because you're not updating a host OS or the guest OS. Remember there are entire distros that are designed to be nothing more than persistent storage Linux distros. Puppy Linux is one great example. Not only can it run on PCs that would otherwise be recycled or thrown away, it allows you to never be bothered again with tedious system updates thanks to the way the distro handles security. It's not a normal Linux distro and it's walled off in such a way that the persistent live image is free from anything scary.
|
||||
### Linux 虚拟机是一个绝好的选择
|
||||
|
||||
### When a Linux virtual machine is absolutely the best option
|
||||
我就讲到这里,这篇文章是时候结束了。Virtual Box 绝对是一个非常不错的运行 Linux 虚拟机的虚拟化产品。
|
||||
|
||||
As I bring this article to a close, let me leave you with this. There is one instance where using a virtual machine such as Virtual Box is absolutely better than using a live image – recording the desktop environment of any Linux distro.
|
||||
例如,我制作了一个录像,里面介绍和评论了许多 Linux 发行版。硬件安装或者虚拟机安装一个从 Linux 发行版镜像库获得的镜像,一个实时的操作我们需要通过屏幕去捕获它。很明显,虚拟机运行 Linux 和 镜像安装更适合。
|
||||
|
||||
For example, I make videos that provide a tour and review of a variety of Linux distros. Doing this with live images would require me to capture the screen with a hardware device or install a software capture device from the live image's repositories. Clearly, a virtual machine is better suited for this job than a live image of a Linux distro.
|
||||
一旦你需要在音频资料中采集到混音,这没有问题,那如果你用软件去采集你的信息,为了一个合理的采集环境,你将需要一个本地安装的系统,这里面包含了所有的基本要求。在一次,用一个硬件安装方式,但是这开销可能很大,如果你仅仅是用与视频和音频操作,这需要花费一部分时间。
|
||||
|
||||
Once you toss audio capture into the mix, there is no question that if you're going to use software to capture your review, you really want to have a host OS that has all the basic needs covered for a reasonably decent capture environment. Again, you could do all of this with a hardware device...but that might be cost prohibitive if you're only do video/audio capturing as a part time endeavor.
|
||||
### Linux 虚拟机 VS Linux 镜像
|
||||
|
||||
### A Linux virtual machine vs a Linux live image
|
||||
你最喜欢尝试新发行版的方式是那些?也许,你会格式化磁盘,然后豁出去了,因此,不需要任何理由
|
||||
|
||||
What is your preferred method of trying out new distros? Perhaps you're someone who is fine with formatting their hard drive and throwing caution to the wind, thus, making the idea of any of this unneeded?
|
||||
|
||||
Most people I've interacted with online tend to follow much of the methodology I've touched on above, but I'd love to hear what approach works best for you. Hit the comments, let me know which method you prefer when checking out the greatest and latest from the Linux distro world.
|
||||
大多数人告诉我他们喜欢上面的方法,但是我很像知道哪种方式更加适合你。点击评论,让我知道在 Linux 发行世界最伟大和最新的版本时,您更喜欢哪种方法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datamation.com/open-source/linux-virtual-machines-vs-linux-live-images.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[sober-wang](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,147 @@
|
||||
在Ubuntu Linux上安装和使用Git和GitHub:初学者指南
|
||||
======
|
||||
|
||||
Github是一个存放着世界上最棒的一些软件项目的宝藏,这些软件项目由全世界的开发者无私贡献。这个看似简单,实则非常强大的平台因为大大帮助了那些对开发大规模软件感兴趣的开发者而被开源社区所称道。
|
||||
|
||||
这篇向导是对于安装和使用GitHub的的一个快速说明,本文还将涉及诸如创建本地仓库,如何链接这个本地仓库到包含你的项目的远程仓库(这样每个人都能看到你的项目了), 以及如何提交改变并最终推送所有的本地内容到Github。
|
||||
|
||||
请注意这篇向导假设你对Git术语有基本的了解,如推送,拉取请求,提交,仓库等等。并且希望你在GitHub上已注册成功并记下了你的GitHub用户名,那么我们这就进入正题吧:
|
||||
|
||||
### 1 在Linux上安装Git
|
||||
|
||||
下载并安装Git:
|
||||
|
||||
```
|
||||
sudo apt-get install git
|
||||
```
|
||||
|
||||
上面的命令适用于Ubuntu并且应该在所有最新版的Ubuntu上都能工作,它们在Ubuntu 16.04和Ubuntu 18.04 LTS (Bionic Beaver)上都测试过,在将来的版本上应该也能工作。
|
||||
|
||||
|
||||
### 2 配置GitHub
|
||||
|
||||
一旦安装完成,接下去就是配置GitHub用户的详细配置信息。请使用下面的两条命令并确保用你自己的GitHub用户名替换"user_name",用你创建GitHub账户的电子邮件替换“email_id”。
|
||||
|
||||
```
|
||||
git config --global user.name "user_name"
|
||||
|
||||
git config --global user.email "email_id"
|
||||
|
||||
```
|
||||
|
||||
下面的图片显示的例子是如何用我的 GitHub “用户名”:“akshaypai”和我的"邮件地址"[[email protected]][2]来配置上面的命令。
|
||||
|
||||
[![Git config][3]][4]
|
||||
|
||||
### 3 创建本地仓库
|
||||
在你的系统上创建一个目录。它将会被作为本地仓库使用,稍后它会被推送到 GitHub 的远程仓库。请使用如下命令:
|
||||
|
||||
```
|
||||
git init Mytest
|
||||
```
|
||||
如果目录被成功创建,你会看到如下信息:
|
||||
|
||||
Initialized empty Git repository in /home/akshay/Mytest/.git/
|
||||
|
||||
这行信息可能随你的系统不同而变化。
|
||||
这里,Mytest 是创建的目录而“init” 将其转化为一个 GitHub 仓库。将当前目录改为这个新创建的目录。
|
||||
|
||||
```
|
||||
cd Mytest
|
||||
```
|
||||
|
||||
### 4 新建一个 REAME 文件来描述仓库
|
||||
现在创建一个 README 文件并输入一些文本,如“this is git setup on linux”。REAME 文件一般用于描述这个仓库用来放置什么内容或这个项目是关于什么的。例如:
|
||||
|
||||
```
|
||||
gedit README
|
||||
```
|
||||
你可以使用任何文本编辑器。我喜欢使用gedit。README文件的内容可以为:
|
||||
|
||||
This is a git repo
|
||||
|
||||
### 5 将仓库里的文件加入一个索引
|
||||
这是很重要的一步。这里我们会将所有需要推送到 GitHub 的内容都加入一个索引。这些内容可能包括你第一次加入仓库的文本文件或者应用程序,也有可能是对已存在文件的一些编辑(文件的一个更新版本)。
|
||||
既然我们已经有了 README 文件,那么让我们创建一个别的文件吧,如一个简单的 C 程序,我们叫它sample.c。文件内容是:
|
||||
|
||||
```
|
||||
|
||||
#include<stdio.h>
|
||||
int main()
|
||||
{
|
||||
printf("hello world");
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
现在我们有两个文件了。
|
||||
README 和 sample.c
|
||||
用下面的命令将他们加入索引:
|
||||
|
||||
```
|
||||
git add README
|
||||
|
||||
git add smaple.c
|
||||
```
|
||||
|
||||
请注意“git add” 命令能将任意数量的文件和目录加入到索引。这里,当我说“ 索引” 的时候,我是指一个有一定空间的缓冲区,这个缓冲区存储了所有已经被加入到 Git 仓库的文件或目录。
|
||||
|
||||
### 6 将所作的改动加入索引
|
||||
所有的文件都加好以后,你就可以提交了。这意味着你已经确定了最终的文件改动( 或增加),现在他们已经准备好被上传到我们自己的仓库了。请使用命令:
|
||||
|
||||
```
|
||||
git commit -m "some_message"
|
||||
```
|
||||
“some_message”在上面的命令里可以是一些简单的信息如“我的第一次提交”或者“ 编辑了readme 文件”,等等。
|
||||
|
||||
### 7 在GitHub上创建一个仓库
|
||||
在 GitHub 上创建一个仓库。请注意仓库的名字必须和你本地创建的仓库的名字严格一致。在这个例子里是'Mytest'。请首先登陆你的 GitHub 账户<https://github.com>。点击页面右上角 的"plus(+)"符号,并选择"create nw repository"。如下图所示填入详细信息,点击“create repository”。
|
||||
|
||||
[![Creating a repository on GitHub][5]][6]
|
||||
一旦创建完成,我们就能将本地的仓库推送到 GitHub 你名下的仓库,用下列命令连接 GitHub 上的仓库:
|
||||
请注意:请确保在运行下列命令前替换了路径中的“user_name” 和“Mytest”为你的 GitHub 用户名和目录名!
|
||||
|
||||
```
|
||||
git remote add origin https://github.com/user\_name/Mytest.git>
|
||||
```
|
||||
|
||||
### 8 将本地仓库里的文件推送的GitHub仓库
|
||||
最后一步是用下列的命令将本地仓库的内容推送到远程仓库(GitHub)
|
||||
|
||||
|
||||
```
|
||||
git push origin master
|
||||
```
|
||||
当提示登陆名和密码时键入登陆名和密码。
|
||||
下面的图片显示了步骤5到步骤8的流程
|
||||
|
||||
[![Pushing files in local repository to GitHub repository][7]][8]
|
||||
|
||||
上述将 Mytest 目录里的所有内容(文件) 推送到了GitHub。对于以后的项目或者创建新的仓库,你可以直接从步骤3开始。最后,如果你登陆你的 GitHub 账户并点击你的Mytest 仓库,你会看到这两个文件:README 和sample.c 已经被上传并像如下 图片显示:
|
||||
|
||||
[![Content uploaded to Github][9]][10]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-git-and-github-on-ubuntu/
|
||||
|
||||
作者:[Akshay Pai][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
[1]:https://github.com/
|
||||
[2]:https://www.howtoforge.com/cdn-cgi/l/email-protection
|
||||
[3]:https://www.howtoforge.com/images/ubuntu_github_getting_started/config.png
|
||||
[4]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/config.png
|
||||
[5]:https://www.howtoforge.com/images/ubuntu_github_getting_started/details.png
|
||||
[6]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/details.png
|
||||
[7]:https://www.howtoforge.com/images/ubuntu_github_getting_started/steps.png
|
||||
[8]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/steps.png
|
||||
[9]:https://www.howtoforge.com/images/ubuntu_github_getting_started/final.png
|
||||
[10]:https://www.howtoforge.com/images/ubuntu_github_getting_started/big/final.png
|
||||
@ -1,38 +1,37 @@
|
||||
translating by ypingcn
|
||||
|
||||
How to capture and analyze packets with tcpdump command on Linux
|
||||
如何在 Linux 上使用 tcpdump 命令捕获和分析数据包
|
||||
======
|
||||
tcpdump is a well known command line **packet analyzer** tool. Using tcpdump command we can capture the live TCP/IP packets and these packets can also be saved to a file. Later on these captured packets can be analyzed via tcpdump command. tcpdump command becomes very handy when it comes to troubleshooting on network level.
|
||||
tcpdump 是一个有名的命令行**数据包分析**工具。我们可以使用 tcpdump 命令捕获实时 TCP/IP 数据包,这些数据包也可以保存到文件中。之后这些捕获的数据包可以通过 tcpdump 命令进行分析。tcpdump 命令在网络级故障排除时变得非常方便。
|
||||
|
||||

|
||||
|
||||
tcpdump is available in most of the Linux distributions, for Debian based Linux, it be can be installed using apt command,
|
||||
tcpdump 在大多数 Linux 发行版中都能用,对于基于 Debian 的Linux,可以使用 apt 命令安装它
|
||||
|
||||
```
|
||||
# apt install tcpdump -y
|
||||
|
||||
```
|
||||
|
||||
On RPM based Linux OS, tcpdump can be installed using below yum command
|
||||
在基于 RPM 的 Linux 操作系统上,可以使用下面的 yum 命令安装 tcpdump
|
||||
|
||||
```
|
||||
# yum install tcpdump -y
|
||||
|
||||
```
|
||||
|
||||
When we run the tcpdump command without any options then it will capture packets of all the interfaces. So to stop or cancel the tcpdump command, type “ **ctrl+c** ” . In this tutorial we will discuss how to capture and analyze packets using different practical examples,
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口的数据包。因此,要停止或取消 tcpdump 命令,请输入 '**ctrl+c**'。在本教程中,我们将使用不同的实例来讨论如何捕获和分析数据包,
|
||||
|
||||
### Example:1) Capturing packets from a specific interface
|
||||
### 示例: 1) 从特定接口捕获数据包
|
||||
|
||||
When we run the tcpdump command without any options, it will capture packets on the all interfaces, so to capture the packets from a specific interface use the option ‘ **-i** ‘ followed by the interface name.
|
||||
当我们在没用任何选项的情况下运行 tcpdump 命令时,它将捕获所有接口上的数据包,因此,要从特定接口捕获数据包,请使用选项 '**-i**',后跟接口名称。
|
||||
|
||||
Syntax :
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -i {interface-name}
|
||||
# tcpdump -i {接口名}
|
||||
```
|
||||
|
||||
Let’s assume, i want to capture packets from interface “enp0s3”
|
||||
假设我想从接口“enp0s3”捕获数据包
|
||||
|
||||
输出将如下所示,
|
||||
|
||||
Output would be something like below,
|
||||
```
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
@ -46,25 +45,26 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
109930 packets captured
|
||||
110065 packets received by filter
|
||||
133 packets dropped by kernel
|
||||
[[email protected] ~]#
|
||||
[[email protected] ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:2) Capturing specific number number of packet from a specific interface
|
||||
### 示例: 2) 从特定接口捕获特定数量数据包
|
||||
|
||||
假设我们想从特定接口(如“enp0s3”)捕获12个数据包,这可以使用选项 '**-c {数量} -I {接口名称}**' 轻松实现
|
||||
|
||||
Let’s assume we want to capture 12 packets from the specific interface like “enp0s3”, this can be easily achieved using the options “ **-c {number} -i {interface-name}** ”
|
||||
```
|
||||
root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
|
||||
```
|
||||
|
||||
Above command will generate the output something like below
|
||||
上面的命令将生成如下所示的输出
|
||||
|
||||
[![N-Number-Packsets-tcpdump-interface][1]][2]
|
||||
|
||||
### Example:3) Display all the available Interfaces for tcpdump
|
||||
### 示例: 3) 显示 tcpdump 的所有可用接口
|
||||
|
||||
使用 '**-D**' 选项显示 tcpdump 命令的所有可用接口,
|
||||
|
||||
Use ‘ **-D** ‘ option to display all the available interfaces for tcpdump command,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -D
|
||||
1.enp0s3
|
||||
@ -83,17 +83,17 @@ Use ‘ **-D** ‘ option to display all the available interfaces for tcpdump co
|
||||
14.vxlan_sys_4789
|
||||
15.any (Pseudo-device that captures on all interfaces)
|
||||
16.lo [Loopback]
|
||||
[[email protected] ~]#
|
||||
|
||||
[[email protected] ~]#
|
||||
```
|
||||
|
||||
I am running the tcpdump command on one of my openstack compute node, that’s why in the output you have seen number interfaces, tab interface, bridges and vxlan interface.
|
||||
我正在我的一个openstack计算节点上运行tcpdump命令,这就是为什么在输出中你会看到数字接口、标签接口、网桥和vxlan接口
|
||||
|
||||
### Example:4) Capturing packets with human readable timestamp (-tttt option)
|
||||
### 示例: 4) 捕获带有可读时间戳(-tttt 选项)的数据包
|
||||
|
||||
默认情况下,在tcpdump命令输出中,没有显示可读性好的时间戳,如果您想将可读性好的时间戳与每个捕获的数据包相关联,那么使用 '**-tttt**'选项,示例如下所示,
|
||||
|
||||
By default in tcpdump command output, there is no proper human readable timestamp, if you want to associate human readable timestamp to each captured packet then use ‘ **-tttt** ‘ option, example is shown below,
|
||||
```
|
||||
[[email protected] ~]# tcpdump -c 8 -tttt -i enp0s3
|
||||
[[email protected] ~]# tcpdump -c 8 -tttt -i enp0s3
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
2018-08-25 23:23:36.954883 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 1449206247:1449206435, ack 3062020950, win 291, options [nop,nop,TS val 86178422 ecr 21583714], length 188
|
||||
@ -107,29 +107,30 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
8 packets captured
|
||||
134 packets received by filter
|
||||
69 packets dropped by kernel
|
||||
[[email protected] ~]#
|
||||
[[email protected] ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:5) Capturing and saving packets to a file (-w option)
|
||||
### 示例: 5) 捕获数据包并将其保存到文件( -w 选项)
|
||||
|
||||
Use “ **-w** ” option in tcpdump command to save the capture TCP/IP packet to a file, so that we can analyze those packets in the future for further analysis.
|
||||
使用 tcpdump 命令中的 '**-w**' 选项将捕获的 TCP/IP 数据包保存到一个文件中,以便我们可以在将来分析这些数据包以供进一步分析。
|
||||
|
||||
Syntax :
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -w file_name.pcap -i {interface-name}
|
||||
# tcpdump -w 文件名.pcap -i {接口名}
|
||||
```
|
||||
|
||||
Note: Extension of file must be **.pcap**
|
||||
注意:文件扩展名必须为 **.pcap**
|
||||
|
||||
Let’s assume i want to save the captured packets of interface “ **enp0s3** ” to a file name **enp0s3-26082018.pcap**
|
||||
假设我要把 '**enp0s3**' 接口捕获到的包保存到文件名为 **enp0s3-26082018.pcap**
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018.pcap -i enp0s3
|
||||
```
|
||||
|
||||
Above command will generate the output something like below,
|
||||
上述命令将生成如下所示的输出,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018.pcap -i enp0s3
|
||||
tcpdump: listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
@ -142,27 +143,28 @@ anaconda-ks.cfg enp0s3-26082018.pcap
|
||||
|
||||
```
|
||||
|
||||
Capturing and Saving the packets whose size **greater** than **N bytes**
|
||||
捕获并保存大小**大于 N 字节**的数据包
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-2.pcap greater 1024
|
||||
|
||||
```
|
||||
|
||||
Capturing and Saving the packets whose size **less** than **N bytes**
|
||||
捕获并保存大小**小于 N 字节**的数据包
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-3.pcap less 1024
|
||||
|
||||
```
|
||||
|
||||
### Example:6) Reading packets from the saved file ( -r option)
|
||||
### 示例: 6) 从保存的文件中读取数据包( -r 选项)
|
||||
|
||||
In the above example we have saved the captured packets to a file, we can read those packets from the file using the option ‘ **-r** ‘, example is shown below,
|
||||
在上面的例子中,我们已经将捕获的数据包保存到文件中,我们可以使用选项 '**-r**' 从文件中读取这些数据包,例子如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -r enp0s3-26082018.pcap
|
||||
```
|
||||
|
||||
Reading the packets with human readable timestamp,
|
||||
用可读性高的时间戳读取包内容,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -tttt -r enp0s3-26082018.pcap
|
||||
reading from file enp0s3-26082018.pcap, link-type EN10MB (Ethernet)
|
||||
@ -184,15 +186,16 @@ p,TS val 81359114 ecr 81350901], length 508
|
||||
|
||||
```
|
||||
|
||||
### Example:7) Capturing only IP address packets on a specific Interface (-n option)
|
||||
### 示例: 7) 仅捕获特定接口上的 IP 地址数据包( -n 选项)
|
||||
|
||||
Using -n option in tcpdum command we can capture only IP address packets on specific interface, example is shown below,
|
||||
使用 tcpdump 命令中的 -n 选项,我们能只捕获特定接口上的 IP 地址数据包,示例如下所示,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3
|
||||
```
|
||||
|
||||
Output of above command would be something like below,
|
||||
上述命令输出如下,
|
||||
|
||||
```
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
@ -211,15 +214,17 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
|
||||
```
|
||||
|
||||
You can also capture N number of IP address packets using -c and -n option in tcpdump command,
|
||||
您还可以使用 tcpdump 命令中的 -c 和 -N 选项捕获 N 个 IP 地址包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 25 -n -i enp0s3
|
||||
|
||||
```
|
||||
|
||||
### Example:8) Capturing only TCP packets on a specific interface
|
||||
|
||||
In tcpdump command we can capture only tcp packets using the ‘ **tcp** ‘ option,
|
||||
### 示例: 8) 仅捕获特定接口上的TCP数据包
|
||||
|
||||
在 tcpdump 命令中,我们能使用 '**tcp**' 选项来只捕获TCP数据包,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -i enp0s3 tcp
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
@ -234,14 +239,13 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:36:54.523461 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 1232, win 9086, options [nop,nop,TS val 20883110 ecr 83375990], length 0
|
||||
22:36:54.523604 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1232:1572, ack 1, win 291, options [nop,nop,TS val 83375991 ecr 20883110], length 340
|
||||
...................................................................................................................................................
|
||||
|
||||
```
|
||||
|
||||
### Example:9) Capturing packets from a specific port on a specific interface
|
||||
### 示例: 9) 从特定接口上的特定端口捕获数据包
|
||||
|
||||
Using tcpdump command we can capture packet from a specific port (e.g 22) on a specific interface enp0s3
|
||||
使用 tcpdump 命令,我们可以从特定接口 enp0s3 上的特定端口(例如 22 )捕获数据包
|
||||
|
||||
Syntax :
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -i {interface-name} port {Port_Number}
|
||||
@ -259,20 +263,21 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:54:55.038708 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 940:1304, ack 1, win 291, options [nop,nop,TS val 84456506 ecr 21153238], length 364
|
||||
............................................................................................................................
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:10) Capturing the packets from a Specific Source IP on a Specific Interface
|
||||
|
||||
Using “ **src** ” keyword followed by “ **ip address** ” in tcpdump command we can capture the packets from a specific Source IP,
|
||||
### 示例: 10) 在特定接口上捕获来自特定来源 IP 的数据包
|
||||
|
||||
syntax :
|
||||
在tcpdump命令中,使用 '**src**' 关键字后跟 '**IP 地址**',我们可以捕获来自特定来源 IP 的数据包,
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -n -i {interface-name} src {ip-address}
|
||||
# tcpdump -n -i {接口名} src {IP 地址}
|
||||
```
|
||||
|
||||
Example is shown below,
|
||||
例子如下,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3 src 169.144.0.10
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
@ -295,12 +300,12 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
|
||||
```
|
||||
|
||||
### Example:11) Capturing packets from a specific destination IP on a specific Interface
|
||||
### 示例: 11) 在特定接口上捕获来自特定目的IP的数据包
|
||||
|
||||
Syntax :
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -n -i {interface-name} dst {IP-address}
|
||||
# tcpdump -n -i {接口名} dst {IP 地址}
|
||||
```
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3 dst 169.144.0.1
|
||||
@ -316,23 +321,25 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
|
||||
```
|
||||
|
||||
### Example:12) Capturing TCP packet communication between two Hosts
|
||||
### 示例: 12) 捕获两台主机之间的 TCP 数据包通信
|
||||
|
||||
假设我想捕获两台主机 169.144.0.1 和 169.144.0.20 之间的 TCP 数据包,示例如下所示,
|
||||
|
||||
Let’s assume i want to capture tcp packets between two hosts 169.144.0.1 & 169.144.0.20, example is shown below,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-tcp-comm.pcap -i enp0s3 tcp and \(host 169.144.0.1 or host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
Capturing only SSH packet flow between two hosts using tcpdump command,
|
||||
使用 tcpdump 命令只捕获两台主机之间的 SSH 数据包流,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w ssh-comm-two-hosts.pcap -i enp0s3 src 169.144.0.1 and port 22 and dst 169.144.0.20 and port 22
|
||||
|
||||
```
|
||||
|
||||
### Example:13) Capturing the udp network packets (to & fro) between two hosts
|
||||
示例: 13) 捕获两台主机之间的 UDP 网络数据包(来回)
|
||||
|
||||
Syntax :
|
||||
语法:
|
||||
|
||||
```
|
||||
# tcpdump -w -s -i udp and \(host and host \)
|
||||
@ -342,11 +349,12 @@ Syntax :
|
||||
|
||||
```
|
||||
|
||||
### Example:14) Capturing packets in HEX and ASCII Format
|
||||
### 示例: 14) 捕获十六进制和ASCII格式的数据包
|
||||
|
||||
Using tcpdump command, we can capture tcp/ip packet in ASCII and HEX format,
|
||||
使用 tcpdump 命令,我们可以以 ASCII 和十六进制格式捕获 TCP/IP 数据包,
|
||||
|
||||
要使用** -A **选项捕获ASCII格式的数据包,示例如下所示:
|
||||
|
||||
To capture the packets in ASCII format use **-A** option, example is shown below,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -A -i enp0s3
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
@ -366,10 +374,10 @@ root@compute-0-1 @..........
|
||||
...(.c.$g.......Se.....
|
||||
.fW..e..
|
||||
..................................................................................................................................................
|
||||
|
||||
```
|
||||
|
||||
To Capture the packets both in HEX and ASCII format use **-XX** option
|
||||
要同时以十六进制和 ASCII 格式捕获数据包,请使用** -XX **选项
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -XX -i enp0s3
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
@ -401,7 +409,7 @@ listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
|
||||
```
|
||||
|
||||
That’s all from this article, i hope you got an idea how to capture and analyze tcp/ip packets using tcpdump command. Please do share your feedback and comments.
|
||||
这就是本文的全部内容,我希望您能了解如何使用 tcpdump 命令捕获和分析 TCP/IP 数据包。请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -409,11 +417,11 @@ via: https://www.linuxtechi.com/capture-analyze-packets-tcpdump-command-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/uploads/2018/08/N-Number-Packsets-tcpdump-interface-1024x422.jpg
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2018/08/N-Number-Packsets-tcpdump-interface.jpg
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
[1]: https://www.linuxtechi.com/wp-content/uploads/2018/08/N-Number-Packsets-tcpdump-interface-1024x422.jpg
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2018/08/N-Number-Packsets-tcpdump-interface.jpg
|
||||
Loading…
Reference in New Issue
Block a user