mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
Translating: How to create a cloud-based encrypted file system on Linux (去除命令行尾的空格)
This commit is contained in:
parent
f330eb51cc
commit
e7688df88b
@ -32,7 +32,7 @@
|
||||
|
||||
#### 对于 Fedora:####
|
||||
|
||||
$ sudo yum install s3ql
|
||||
$ sudo yum install s3ql
|
||||
|
||||
对于 Arch Linux,使用 [AUR][6]。
|
||||
|
||||
@ -41,7 +41,7 @@
|
||||
在 ~/.s3ql 目录中创建 autoinfo2 文件,它是 S3QL 的一个默认的配置文件。这个文件里的信息包括必须的 AWS access key,S3 bucket 名,以及加密口令。这个加密口令将被用来加密一个随机生成的主密钥,而主密钥将被用来实际地加密 S3QL 文件系统数据。
|
||||
|
||||
$ mkdir ~/.s3ql
|
||||
$ vi ~/.s3ql/authinfo2
|
||||
$ vi ~/.s3ql/authinfo2
|
||||
|
||||
----------
|
||||
|
||||
@ -55,7 +55,7 @@
|
||||
|
||||
为了安全起见,让 authinfo2 文件仅对你可访问。
|
||||
|
||||
$ chmod 600 ~/.s3ql/authinfo2
|
||||
$ chmod 600 ~/.s3ql/authinfo2
|
||||
|
||||
### 创建 S3QL 文件系统 ###
|
||||
|
||||
@ -63,7 +63,7 @@
|
||||
|
||||
使用 mkfs.s3ql 工具来创建一个新的 S3QL 文件系统。这个命令中的 bucket 名应该与 authinfo2 文件中所指定的相符。使用“--ssl”参数将强制使用 SSL 连接到后端存储服务器。默认情况下,mkfs.s3ql 命令会在 S3QL 文件系统中启用压缩和加密。
|
||||
|
||||
$ mkfs.s3ql s3://[bucket-name] --ssl
|
||||
$ mkfs.s3ql s3://[bucket-name] --ssl
|
||||
|
||||
你会被要求输入一个加密口令。请输入你在 ~/.s3ql/autoinfo2 中通过“fs-passphrase”指定的那个口令。
|
||||
|
||||
@ -78,13 +78,13 @@
|
||||
首先创建一个本地的挂载点,然后使用 mount.s3ql 命令来挂载 S3QL 文件系统。
|
||||
|
||||
$ mkdir ~/mnt_s3ql
|
||||
$ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
|
||||
$ mount.s3ql s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
挂载一个 S3QL 文件系统不需要特权用户,只要确定你对该挂载点有写权限即可。
|
||||
|
||||
视情况,你可以使用“--compress”参数来指定一个压缩算法(如 lzma、bzip2、zlib)。在不指定的情况下,lzma 将被默认使用。注意如果你指定了一个自定义的压缩算法,它将只会应用到新创建的数据对象上,并不会影响已经存在的数据对象。
|
||||
|
||||
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
|
||||
$ mount.s3ql --compress bzip2 s3://[bucket-name] ~/mnt_s3ql
|
||||
|
||||
因为性能原因,S3QL 文件系统维护了一份本地文件缓存,里面包括了最近访问的(部分或全部的)文件。你可以通过“--cachesize”和“--max-cache-entries”选项来自定义文件缓存的大小。
|
||||
|
||||
@ -95,7 +95,7 @@
|
||||
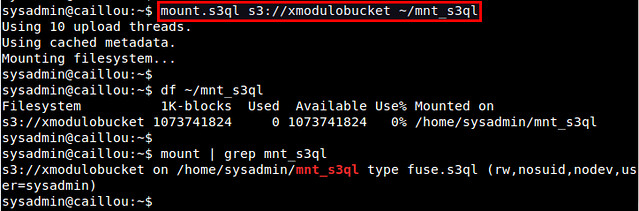
运行 mount.s3ql 之后,检查 S3QL 文件系统是否被成功挂载了:
|
||||
|
||||
$ df ~/mnt_s3ql
|
||||
$ mount | grep s3ql
|
||||
$ mount | grep s3ql
|
||||
|
||||
|
||||
|
||||
@ -103,31 +103,31 @@
|
||||
|
||||
To unmount an S3QL file system (with potentially uncommitted data) safely, use umount.s3ql command. It will wait until all data (including the one in local file system cache) has been successfully transferred and written to backend servers. Depending on the amount of write-pending data, this process can take some time.
|
||||
|
||||
$ umount.s3ql ~/mnt_s3ql
|
||||
$ umount.s3ql ~/mnt_s3ql
|
||||
|
||||
View S3QL File System Statistics and Repair an S3QL File System
|
||||
|
||||
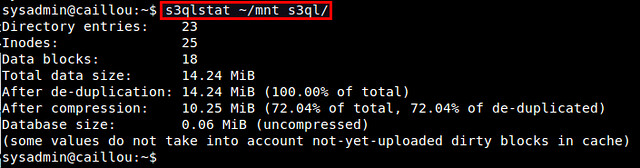
To view S3QL file system statistics, you can use s3qlstat command, which shows information such as total data/metadata size, de-duplication and compression ratio.
|
||||
|
||||
$ s3qlstat ~/mnt_s3ql
|
||||
$ s3qlstat ~/mnt_s3ql
|
||||
|
||||
|
||||
|
||||
You can check and repair an S3QL file system with fsck.s3ql command. Similar to fsck command, the file system being checked needs to be unmounted first.
|
||||
|
||||
$ fsck.s3ql s3://[bucket-name]
|
||||
$ fsck.s3ql s3://[bucket-name]
|
||||
|
||||
### S3QL Use Case: Rsync Backup ###
|
||||
|
||||
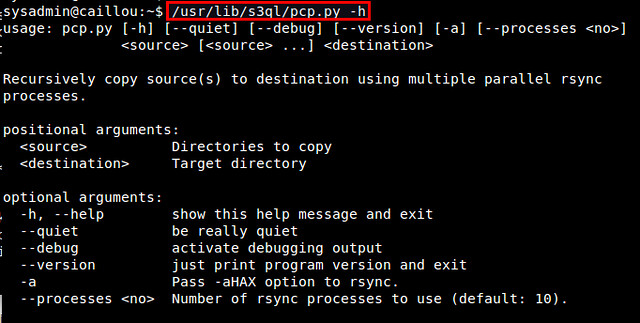
Let me conclude this tutorial with one popular use case of S3QL: local file system backup. For this, I recommend using rsync incremental backup tool especially because S3QL comes with a rsync wrapper script (/usr/lib/s3ql/pcp.py). This script allows you to recursively copy a source tree to a S3QL destination using multiple rsync processes.
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -h
|
||||
$ /usr/lib/s3ql/pcp.py -h
|
||||
|
||||
|
||||
|
||||
The following command will back up everything in ~/Documents to an S3QL file system via four concurrent rsync connections.
|
||||
|
||||
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
|
||||
$ /usr/lib/s3ql/pcp.py -a --quiet --processes=4 ~/Documents ~/mnt_s3ql
|
||||
|
||||
The files will first be copied to the local file cache, and then gradually flushed to the backend servers over time in the background.
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user