mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
e6f6f0dda6
@ -0,0 +1,230 @@
|
||||
Linux 包管理基础:apt、yum、dnf 和 pkg
|
||||
========================
|
||||
|
||||
![Package_Management_tw_mostov.png-307.8kB][1]
|
||||
|
||||
### 介绍
|
||||
|
||||
大多数现代的类 Unix 操作系统都提供了一种中心化的机制用来搜索和安装软件。软件通常都是存放在存储库中,并通过包的形式进行分发。处理包的工作被称为包管理。包提供了操作系统的基本组件,以及共享的库、应用程序、服务和文档。
|
||||
|
||||
包管理系统除了安装软件外,它还提供了工具来更新已经安装的包。包存储库有助于确保你的系统中使用的代码是经过审查的,并且软件的安装版本已经得到了开发人员和包维护人员的认可。
|
||||
|
||||
在配置服务器或开发环境时,我们最好了解下包在官方存储库之外的情况。某个发行版的稳定版本中的包有可能已经过时了,尤其是那些新的或者快速迭代的软件。然而,包管理无论对于系统管理员还是开发人员来说都是至关重要的技能,而已打包的软件对于主流 Linux 发行版来说也是一笔巨大的财富。
|
||||
|
||||
本指南旨在快速地介绍下在多种 Linux 发行版中查找、安装和升级软件包的基础知识,并帮助您将这些内容在多个系统之间进行交叉对比。
|
||||
|
||||
### 包管理系统:简要概述
|
||||
|
||||
大多数包系统都是围绕包文件的集合构建的。包文件通常是一个存档文件,它包含已编译的二进制文件和软件的其他资源,以及安装脚本。包文件同时也包含有价值的元数据,包括它们的依赖项,以及安装和运行它们所需的其他包的列表。
|
||||
|
||||
虽然这些包管理系统的功能和优点大致相同,但打包格式和工具却因平台而异:
|
||||
|
||||
| 操作系统 | 格式 | 工具 |
|
||||
| --- | --- | --- |
|
||||
| Debian | `.deb` | `apt`, `apt-cache`, `apt-get`, `dpkg` |
|
||||
| Ubuntu | `.deb` | `apt`, `apt-cache`, `apt-get`, `dpkg` |
|
||||
| CentOS | `.rpm` | `yum` |
|
||||
| Fedora | `.rpm` | `dnf` |
|
||||
| FreeBSD | Ports, `.txz` | `make`, `pkg` |
|
||||
|
||||
Debian 及其衍生版,如 Ubuntu、Linux Mint 和 Raspbian,它们的包格式是 `.deb`。APT 这款先进的包管理工具提供了大多数常见的操作命令:搜索存储库、安装软件包及其依赖项,并管理升级。在本地系统中,我们还可以使用 `dpkg` 程序来安装单个的 `deb` 文件,APT 命令作为底层 `dpkg` 的前端,有时也会直接调用它。
|
||||
|
||||
最近发布的 debian 衍生版大多数都包含了 `apt` 命令,它提供了一个简洁统一的接口,可用于通常由 `apt-get` 和 `apt-cache` 命令处理的常见操作。这个命令是可选的,但使用它可以简化一些任务。
|
||||
|
||||
CentOS、Fedora 和其它 Red Hat 家族成员使用 RPM 文件。在 CentOS 中,通过 `yum` 来与单独的包文件和存储库进行交互。
|
||||
|
||||
在最近的 Fedora 版本中,`yum` 已经被 `dnf` 取代,`dnf` 是它的一个现代化的分支,它保留了大部分 `yum` 的接口。
|
||||
|
||||
FreeBSD 的二进制包系统由 `pkg` 命令管理。FreeBSD 还提供了 `Ports` 集合,这是一个存在于本地的目录结构和工具,它允许用户获取源码后使用 Makefile 直接从源码编译和安装包。
|
||||
|
||||
### 更新包列表
|
||||
|
||||
大多数系统在本地都会有一个和远程存储库对应的包数据库,在安装或升级包之前最好更新一下这个数据库。另外,`yum` 和 `dnf` 在执行一些操作之前也会自动检查更新。当然你可以在任何时候对系统进行更新。
|
||||
|
||||
| 系统 | 命令 |
|
||||
| --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get update` |
|
||||
| | `sudo apt update` |
|
||||
| CentOS | `yum check-update` |
|
||||
| Fedora | `dnf check-update` |
|
||||
| FreeBSD Packages | `sudo pkg update` |
|
||||
| FreeBSD Ports | `sudo portsnap fetch update` |
|
||||
|
||||
### 更新已安装的包
|
||||
|
||||
在没有包系统的情况下,想确保机器上所有已安装的软件都保持在最新的状态是一个很艰巨的任务。你将不得不跟踪数百个不同包的上游更改和安全警报。虽然包管理器并不能解决升级软件时遇到的所有问题,但它确实使你能够使用一些命令来维护大多数系统组件。
|
||||
|
||||
在 FreeBSD 上,升级已安装的 ports 可能会引入破坏性的改变,有些步骤还需要进行手动配置,所以在通过 `portmaster` 更新之前最好阅读下 `/usr/ports/UPDATING` 的内容。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get upgrade` | 只更新已安装的包 |
|
||||
| | `sudo apt-get dist-upgrade` | 可能会增加或删除包以满足新的依赖项 |
|
||||
| | `sudo apt upgrade` | 和 `apt-get upgrade` 类似 |
|
||||
| | `sudo apt full-upgrade` | 和 `apt-get dist-upgrade` 类似 |
|
||||
| CentOS | `sudo yum update` | |
|
||||
| Fedora | `sudo dnf upgrade` | |
|
||||
| FreeBSD Packages | `sudo pkg upgrade` | |
|
||||
| FreeBSD Ports | `less /usr/ports/UPDATING` | 使用 `less` 来查看 ports 的更新提示(使用上下光标键滚动,按 q 退出)。 |
|
||||
| | `cd /usr/ports/ports-mgmt/portmaster && sudo make install && sudo portmaster -a` | 安装 `portmaster` 然后使用它更新已安装的 ports |
|
||||
|
||||
### 搜索某个包
|
||||
|
||||
大多数发行版都提供针对包集合的图形化或菜单驱动的工具,我们可以分类浏览软件,这也是一个发现新软件的好方法。然而,查找包最快和最有效的方法是使用命令行工具进行搜索。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `apt-cache search search_string` | |
|
||||
| | `apt search search_string` | |
|
||||
| CentOS | `yum search search_string` | |
|
||||
| | `yum search all search_string` | 搜索所有的字段,包括描述 |
|
||||
| Fedora | `dnf search search_string` | |
|
||||
| | `dnf search all search_string` | 搜索所有的字段,包括描述 |
|
||||
| FreeBSD Packages | `pkg search search_string` | 通过名字进行搜索 |
|
||||
| | `pkg search -f search_string` | 通过名字进行搜索并返回完整的描述 |
|
||||
| | `pkg search -D search_string` | 搜索描述 |
|
||||
| FreeBSD Ports | `cd /usr/ports && make search name=package` | 通过名字进行搜索 |
|
||||
| | `cd /usr/ports && make search key=search_string` | 搜索评论、描述和依赖 |
|
||||
|
||||
### 查看某个软件包的信息
|
||||
|
||||
在安装软件包之前,我们可以通过仔细阅读包的描述来获得很多有用的信息。除了人类可读的文本之外,这些内容通常包括像版本号这样的元数据和包的依赖项列表。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `apt-cache show package` | 显示有关包的本地缓存信息 |
|
||||
| | `apt show package` | |
|
||||
| | `dpkg -s package` | 显示包的当前安装状态 |
|
||||
| CentOS | `yum info package` | |
|
||||
| | `yum deplist package` | 列出包的依赖 |
|
||||
| Fedora | `dnf info package` | |
|
||||
| | `dnf repoquery --requires package` | 列出包的依赖 |
|
||||
| FreeBSD Packages | `pkg info package` | 显示已安装的包的信息 |
|
||||
| FreeBSD Ports | `cd /usr/ports/category/port && cat pkg-descr` | |
|
||||
|
||||
### 从存储库安装包
|
||||
|
||||
知道包名后,通常可以用一个命令来安装它及其依赖。你也可以一次性安装多个包,只需将它们全部列出来即可。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get install package` | |
|
||||
| | `sudo apt-get install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| | `sudo apt-get install -y package` | 在 `apt` 提示是否继续的地方直接默认 `yes` |
|
||||
| | `sudo apt install package` | 显示一个彩色的进度条 |
|
||||
| CentOS | `sudo yum install package` | |
|
||||
| | `sudo yum install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| | `sudo yum install -y package` | 在 `yum` 提示是否继续的地方直接默认 `yes` |
|
||||
| Fedora | `sudo dnf install package` | |
|
||||
| | `sudo dnf install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| | `sudo dnf install -y package` | 在 `dnf` 提示是否继续的地方直接默认 `yes` |
|
||||
| FreeBSD Packages | `sudo pkg install package` | |
|
||||
| | `sudo pkg install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| FreeBSD Ports | `cd /usr/ports/category/port && sudo make install` | 从源码构建安装一个 port |
|
||||
|
||||
### 从本地文件系统安装一个包
|
||||
|
||||
对于一个给定的操作系统,有时有些软件官方并没有提供相应的包,那么开发人员或供应商将需要提供包文件的下载。你通常可以通过 web 浏览器检索这些包,或者通过命令行 `curl` 来检索这些信息。将包下载到目标系统后,我们通常可以通过单个命令来安装它。
|
||||
|
||||
在 Debian 派生的系统上,`dpkg` 用来处理单个的包文件。如果一个包有未满足的依赖项,那么我们可以使用 `gdebi` 从官方存储库中检索它们。
|
||||
|
||||
在 CentOS 和 Fedora 系统上,`yum` 和 `dnf` 用于安装单个的文件,并且会处理需要的依赖。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo dpkg -i package.deb` | |
|
||||
| | `sudo apt-get install -y gdebi && sudo gdebi package.deb` | 安装 `gdebi`,然后使用 `gdebi` 安装 `package.deb` 并处理缺失的依赖|
|
||||
| CentOS | `sudo yum install package.rpm` | |
|
||||
| Fedora | `sudo dnf install package.rpm` | |
|
||||
| FreeBSD Packages | `sudo pkg add package.txz` | |
|
||||
| | `sudo pkg add -f package.txz` | 即使已经安装的包也会重新安装 |
|
||||
|
||||
### 删除一个或多个已安装的包
|
||||
|
||||
由于包管理器知道给定的软件包提供了哪些文件,因此如果某个软件不再需要了,它通常可以干净利落地从系统中清除这些文件。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get remove package` | |
|
||||
| | `sudo apt remove package` | |
|
||||
| | `sudo apt-get autoremove` | 删除不需要的包 |
|
||||
| CentOS | `sudo yum remove package` | |
|
||||
| Fedora | `sudo dnf erase package` | |
|
||||
| FreeBSD Packages | `sudo pkg delete package` | |
|
||||
| | `sudo pkg autoremove` | 删除不需要的包 |
|
||||
| FreeBSD Ports | `sudo pkg delete package` | |
|
||||
| | `cd /usr/ports/path_to_port && make deinstall` | 卸载 port |
|
||||
|
||||
### `apt` 命令
|
||||
|
||||
Debian 家族发行版的管理员通常熟悉 `apt-get` 和 `apt-cache`。较少为人所知的是简化的 `apt` 接口,它是专为交互式使用而设计的。
|
||||
|
||||
| 传统命令 | 等价的 `apt` 命令 |
|
||||
| --- | --- |
|
||||
| `apt-get update` | `apt update` |
|
||||
| `apt-get dist-upgrade` | `apt full-upgrade` |
|
||||
| `apt-cache search string` | `apt search string` |
|
||||
| `apt-get install package` | `apt install package` |
|
||||
| `apt-get remove package` | `apt remove package` |
|
||||
| `apt-get purge package` | `apt purge package` |
|
||||
|
||||
虽然 `apt` 通常是一个特定操作的快捷方式,但它并不能完全替代传统的工具,它的接口可能会随着版本的不同而发生变化,以提高可用性。如果你在脚本或 shell 管道中使用包管理命令,那么最好还是坚持使用 `apt-get` 和 `apt-cache`。
|
||||
|
||||
### 获取帮助
|
||||
|
||||
除了基于 web 的文档,请记住我们可以通过 shell 从 Unix 手册页(通常称为 man 页面)中获得大多数的命令。比如要阅读某页,可以使用 `man`:
|
||||
|
||||
```
|
||||
man page
|
||||
|
||||
```
|
||||
|
||||
在 `man` 中,你可以用箭头键导航。按 `/` 搜索页面内的文本,使用 `q` 退出。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `man apt-get` | 更新本地包数据库以及与包一起工作 |
|
||||
| | `man apt-cache` | 在本地的包数据库中搜索 |
|
||||
| | `man dpkg` | 和单独的包文件一起工作以及能查询已安装的包 |
|
||||
| | `man apt` | 通过更简洁,用户友好的接口进行最基本的操作 |
|
||||
| CentOS | `man yum` | |
|
||||
| Fedora | `man dnf` | |
|
||||
| FreeBSD Packages | `man pkg` | 和预先编译的二进制包一起工作 |
|
||||
| FreeBSD Ports | `man ports` | 和 Ports 集合一起工作 |
|
||||
|
||||
### 结论和进一步的阅读
|
||||
|
||||
本指南通过对多个系统间进行交叉对比概述了一下包管理系统的基本操作,但只涉及了这个复杂主题的表面。对于特定系统更详细的信息,可以参考以下资源:
|
||||
|
||||
* [这份指南][2] 详细介绍了 Ubuntu 和 Debian 的软件包管理。
|
||||
* 这里有一份 CentOS 官方的指南 [使用 yum 管理软件][3]
|
||||
* 这里有一个有关 Fedora 的 `dnf` 的 [wifi 页面][4] 以及一份有关 `dnf` [官方的手册][5]
|
||||
* [这份指南][6] 讲述了如何使用 `pkg` 在 FreeBSD 上进行包管理
|
||||
* 这本 [FreeBSD Handbook][7] 有一节讲述了[如何使用 Ports 集合][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/package-management-basics-apt-yum-dnf-pkg
|
||||
|
||||
译者后记:
|
||||
|
||||
从经典的 `configure` && `make` && `make install` 三部曲到 `dpkg`,从需要手处理依赖关系的 `dpkg` 到全自动化的 `apt-get`,恩~,你有没有想过接下来会是什么?译者只能说可能会是 `Snaps`,如果你还没有听过这个东东,你也许需要关注下这个公众号了:**Snapcraft**
|
||||
|
||||
作者:[Brennen Bearnes][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.digitalocean.com/community/users/bpb
|
||||
|
||||
|
||||
[1]: http://static.zybuluo.com/apollomoon/g9kiere2xuo1511ls1hi9w9w/Package_Management_tw_mostov.png
|
||||
[2]:https://www.digitalocean.com/community/tutorials/ubuntu-and-debian-package-management-essentials
|
||||
[3]: https://www.centos.org/docs/5/html/yum/
|
||||
[4]: https://fedoraproject.org/wiki/Dnf
|
||||
[5]: https://dnf.readthedocs.org/en/latest/index.html
|
||||
[6]: https://www.digitalocean.com/community/tutorials/how-to-manage-packages-on-freebsd-10-1-with-pkg
|
||||
[7]:https://www.freebsd.org/doc/handbook/
|
||||
[8]: https://www.freebsd.org/doc/handbook/ports-using.html
|
||||
[9]:https://www.freebsd.org/doc/handbook/ports-using.html
|
||||
@ -1,20 +1,20 @@
|
||||
响应式编程vs.响应式系统
|
||||
响应式编程与响应式系统
|
||||
============================================================
|
||||
|
||||
>在恒久的迷惑与过多期待的海洋中,登上一组简单响应式设计原则的小岛。
|
||||
> 在恒久的迷惑与过多期待的海洋中,登上一组简单响应式设计原则的小岛。
|
||||
|
||||
>
|
||||
|
||||

|
||||
|
||||
下载 Konrad Malawski 的免费电子书[《为什么选择响应式?企业应用中的基本原则》][5],深入了解更多响应式技术的知识与好处。
|
||||
> 下载 Konrad Malawski 的免费电子书[《为什么选择响应式?企业应用中的基本原则》][5],深入了解更多响应式技术的知识与好处。
|
||||
|
||||
自从2013年一起合作写了[《响应式宣言》][23]之后,我们看着响应式从一种几乎无人知晓的软件构建技术——当时只有少数几个公司的边缘项目使用了这一技术——最后成为中间件领域(middleware field)大佬们全平台战略中的一部分。本文旨在定义和澄清响应式各个方面的概念,方法是比较在_响应式编程_风格下,以及把_响应式系统_视作一个紧密整体的设计方法下写代码的不同。
|
||||
自从 2013 年一起合作写了[《响应式宣言》][23]之后,我们看着响应式从一种几乎无人知晓的软件构建技术——当时只有少数几个公司的边缘项目使用了这一技术——最后成为<ruby>中间件领域<rt>middleware field</rt></ruby>大佬们全平台战略中的一部分。本文旨在定义和澄清响应式各个方面的概念,方法是比较在_响应式编程_风格下和把_响应式系统_视作一个紧密整体的设计方法下编写代码的不同之处。
|
||||
|
||||
### 响应式是一组设计原则
|
||||
响应式技术目前成功的标志之一是“响应式”成为了一个热词,并且跟一些不同的事物与人联系在了一起——常常伴随着像“流(streaming)”,“轻量级(lightweight)”和“实时(real-time)”这样的词。
|
||||
|
||||
举个例子:当我们看到一支运动队时(像棒球队或者篮球队),我们一般会把他们看成一个个单独个体的组合,但是当他们之间碰撞不出火花,无法像一个团队一样高效地协作时,他们就会输给一个“更差劲”的队伍。从这篇文章的角度来看,响应式是一组设计原则,一种关于系统架构与设计的思考方式,一种关于在一个分布式环境下,当实现技术(implementation techniques),工具和设计模式都只是一个更大系统的一部分时如何设计的思考方式。
|
||||
响应式技术目前成功的标志之一是“<ruby>响应式<rt>reactive</rt></ruby>”成为了一个热词,并且跟一些不同的事物与人联系在了一起——常常伴随着像“<ruby>流<rt>streaming</rt></ruby>”、“<ruby>轻量级<rt>lightweight</rt></ruby>”和“<ruby>实时<rt>real-time</rt></ruby>”这样的词。
|
||||
|
||||
举个例子:当我们看到一支运动队时(像棒球队或者篮球队),我们一般会把他们看成一个个单独个体的组合,但是当他们之间碰撞不出火花,无法像一个团队一样高效地协作时,他们就会输给一个“更差劲”的队伍。从这篇文章的角度来看,响应式是一组设计原则,一种关于系统架构与设计的思考方式,一种关于在一个分布式环境下,当实现技术(implementation techniques)、工具和设计模式都只是一个更大系统的一部分时如何设计的思考方式。
|
||||
|
||||
这个例子展示了不经考虑地将一堆软件拼揍在一起——尽管单独来看,这些软件都很优秀——和响应式系统之间的不同。在一个响应式系统中,正是_不同组件(parts)间的相互作用_让响应式系统如此不同,它使得不同组件能够独立地运作,同时又一致协作从而达到最终想要的结果。
|
||||
|
||||
@ -28,62 +28,64 @@ _一个响应式系统_ 是一种架构风格(architectural style),它允许
|
||||
* 响应式编程(基于声明的事件的)
|
||||
* 函数响应式编程(FRP)
|
||||
|
||||
我们将检查这些做法与技术的意思,特别是前两个。更明确地说,我们会在使用它们的时候讨论它们,例如它们是怎么联系在一起的,从它们身上又能到什么样的好处——特别是在为多核、云或移动架构搭建系统的情境下。
|
||||
我们将调查这些做法与技术的意思,特别是前两个。更明确地说,我们会在使用它们的时候讨论它们,例如它们是怎么联系在一起的,从它们身上又能到什么样的好处——特别是在为多核、云或移动架构搭建系统的情境下。
|
||||
|
||||
让我们先来说一说函数响应式编程吧,以及我们在本文后面不再讨论它的原因。
|
||||
|
||||
### 函数响应式编程(FRP)
|
||||
|
||||
_函数响应式编程_,通常被称作_FRP_,是最常被误解的。FRP在二十年前就被Conal Elliott[精确地定义][24]了。但是最近这个术语却被错误地用来描述一些像Elm,Bacon.js的技术以及其它技术中的响应式插件(RxJava, Rx.NET, RxJS)。许多的库(libraries)声称他们支持FRP,事实上他们说的并非_响应式编程_,因此我们不会再进一步讨论它们。
|
||||
<ruby>函数响应式编程<rt>Functional reactive programming</rt></ruby>,通常被称作_FRP_,是最常被误解的。FRP在二十年前就被 Conal Elliott [精确地定义过了][24]了。但是最近这个术语却被错误地^脚注1 用来描述一些像 Elm、Bacon.js 的技术以及其它技术中的响应式插件(RxJava、Rx.NET、 RxJS)。许多的库(libraries)声称他们支持 FRP,事实上他们说的并非_响应式编程_,因此我们不会再进一步讨论它们。
|
||||
|
||||
### 响应式编程
|
||||
|
||||
_响应式编程_,不要把它跟_函数响应式编程_混淆了,它是异步编程下的一个子集,也是一种范式,在这种范式下,由新信息的有效性(availability)推动逻辑的前进,而不是让一条执行线程(a thread-of-execution)去推动控制流(control flow)。
|
||||
<ruby>响应式编程<rt>Reactive programming</rt></ruby>,不要把它跟_函数响应式编程_混淆了,它是异步编程下的一个子集,也是一种范式,在这种范式下,由新信息的有效性(availability)推动逻辑的前进,而不是让一条执行线程(a thread-of-execution)去推动控制流(control flow)。
|
||||
|
||||
它能够把问题分解为多个独立的步骤,这些独立的步骤可以以异步且非阻塞(non-blocking)的方式被执行,最后再组合在一起产生一条工作流(workflow)——它的输入和输出可能是非绑定的(unbounded)。
|
||||
|
||||
[“异步地(Asynchronous)”][25]被牛津词典定义为“不在同一时刻存在或发生”,在我们的语境下,它意味着一条消息或者一个事件可发生在任何时刻,有可能是在未来。这在响应式编程中是非常重要的一项技术,因为响应式编程允许[非阻塞式(non-blocking)]的执行方式——执行线程在竞争一块共享资源时不会因为阻塞(blocking)而陷入等待(防止执行线程在当前的工作完成之前执行任何其它操作),而是在共享资源被占用的期间转而去做其它工作。阿姆达尔定律(Amdahl's Law)[2][9]告诉我们,竞争是可伸缩性(scalability)最大的敌人,所以一个响应式系统应当在极少数的情况下才不得不做阻塞工作。
|
||||
[“异步地(Asynchronous)”][25]被牛津词典定义为“不在同一时刻存在或发生”,在我们的语境下,它意味着一条消息或者一个事件可发生在任何时刻,也有可能是在未来。这在响应式编程中是非常重要的一项技术,因为响应式编程允许[非阻塞式(non-blocking)]的执行方式——执行线程在竞争一块共享资源时不会因为阻塞(blocking)而陷入等待(为了防止执行线程在当前的工作完成之前执行任何其它操作),而是在共享资源被占用的期间转而去做其它工作。阿姆达尔定律(Amdahl's Law) ^脚注2 告诉我们,竞争是可伸缩性(scalability)最大的敌人,所以一个响应式系统应当在极少数的情况下才不得不做阻塞工作。
|
||||
|
||||
响应式编程一般是_事件驱动(event-driven)_ ,相比之下,响应式系统则是_消息驱动(message-driven)_ 的——事件驱动与消息驱动之间的差别会在文章后面阐明。
|
||||
|
||||
响应式编程库的应用程序接口(API)一般是以下二者之一:
|
||||
|
||||
* 基于回调的(Callback-based)——匿名的间接作用(side-effecting)回调函数被绑定在事件源(event sources)上,当事件被放入数据流(dataflow chain)中时,回调函数被调用。
|
||||
* 声明式的(Declarative)——通过函数的组合,通常是使用一些固定的函数,像 _map_, _filter_, _fold_ 等等。
|
||||
* 声明式的(Declarative)——通过函数的组合,通常是使用一些固定的函数,像 _map_、 _filter_、 _fold_ 等等。
|
||||
|
||||
大部分的库会混合这两种风格,一般还带有基于流(stream-based)的操作符(operators),像windowing, counts, triggers。
|
||||
大部分的库会混合这两种风格,一般还带有基于流(stream-based)的操作符(operators),像 windowing、 counts、 triggers。
|
||||
|
||||
说响应式编程跟[数据流编程(dataflow programming)][27]有关是很合理的,因为它强调的是_数据流_而不是_控制流_。
|
||||
|
||||
举几个为这种编程技术提供支持的的编程抽象概念:
|
||||
|
||||
* [Futures/Promises][10]——一个值的容器,具有读共享/写独占(many-read/single-write)的语义,即使变量尚不可用也能够添加异步的值转换操作。
|
||||
* 流(streams)-[响应式流][11]——无限制的数据处理流,支持异步,非阻塞式,支持多个源与目的的反压转换管道(back-pressured transformation pipelines)。
|
||||
* [数据流变量][12]——依赖于输入,过程(procedures)或者其它单元的单赋值变量(存储单元)(single assignment variables),它能够自动更新值的改变。其中一个应用例子是表格软件——一个单元的值的改变会像涟漪一样荡开,影响到所有依赖于它的函数,顺流而下地使它们产生新的值。
|
||||
* 流(streams) - [响应式流][11]——无限制的数据处理流,支持异步,非阻塞式,支持多个源与目的的反压转换管道(back-pressured transformation pipelines)。
|
||||
* [数据流变量][12]——依赖于输入、过程(procedures)或者其它单元的单赋值变量(single assignment variables)(存储单元),它能够自动更新值的改变。其中一个应用例子是表格软件——一个单元的值的改变会像涟漪一样荡开,影响到所有依赖于它的函数,顺流而下地使它们产生新的值。
|
||||
|
||||
在JVM中,支持响应式编程的流行库有Akka Streams、Ratpack、Reactor、RxJava和Vert.x等等。这些库实现了响应式编程的规范,成为JVM上响应式编程库之间的互通标准(standard for interoperability),并且根据它自身的叙述是“……一个为如何处理非阻塞式反压异步流提供标准的倡议”
|
||||
在 JVM 中,支持响应式编程的流行库有 Akka Streams、Ratpack、Reactor、RxJava 和 Vert.x 等等。这些库实现了响应式编程的规范,成为 JVM 上响应式编程库之间的互通标准(standard for interoperability),并且根据它自身的叙述是“……一个为如何处理非阻塞式反压异步流提供标准的倡议”。
|
||||
|
||||
响应式编程的基本好处是:提高多核和多CPU硬件的计算资源利用率;根据阿姆达尔定律以及引申的Günther的通用可伸缩性定律[3][13](Günther’s Universal Scalability Law),通过减少序列化点(serialization points)来提高性能。
|
||||
响应式编程的基本好处是:提高多核和多 CPU 硬件的计算资源利用率;根据阿姆达尔定律以及引申的 Günther 的通用可伸缩性定律(Günther’s Universal Scalability Law) ^脚注3 ,通过减少序列化点(serialization points)来提高性能。
|
||||
|
||||
另一个好处是开发者生产效率,传统的编程范式都尽力想提供一个简单直接的可持续的方法来处理异步非阻塞式计算和I/O。在响应式编程中,因活动(active)组件之间通常不需要明确的协作,从而也就解决了其中大部分的挑战。
|
||||
另一个好处是开发者生产效率,传统的编程范式都尽力想提供一个简单直接的可持续的方法来处理异步非阻塞式计算和 I/O。在响应式编程中,因活动(active)组件之间通常不需要明确的协作,从而也就解决了其中大部分的挑战。
|
||||
|
||||
响应式编程真正的发光点在于组件的创建跟工作流的组合。为了在异步执行上取得最大的优势,把[反压(back-pressure)][28]加进来是很重要,这样能避免过度使用,或者确切地说,无限度的消耗资源。
|
||||
响应式编程真正的发光点在于组件的创建跟工作流的组合。为了在异步执行上取得最大的优势,把[反压(back-pressure)][28]加进来是很重要,这样能避免过度使用,或者确切地说,避免无限度的消耗资源。
|
||||
|
||||
尽管如此,响应式编程在搭建现代软件上仍然非常有用,为了在更高层次上理解(reason about)一个系统,那么必须要使用到另一个工具:_响应式架构_——设计响应式系统的方法。此外,要记住编程范式有很多,而响应式编程仅仅只是其中一个,所以如同其它工具一样,响应式编程并不是万金油,它不意图适用于任何情况。
|
||||
尽管如此,响应式编程在搭建现代软件上仍然非常有用,为了在更高层次上理解(reason about)一个系统,那么必须要使用到另一个工具:<ruby>响应式架构<rt>reactive architecture</rt></ruby>——设计响应式系统的方法。此外,要记住编程范式有很多,而响应式编程仅仅只是其中一个,所以如同其它工具一样,响应式编程并不是万金油,它不意图适用于任何情况。
|
||||
|
||||
### 事件驱动 vs. 消息驱动
|
||||
如上面提到的,响应式编程——专注于短时间的数据流链条上的计算——因此倾向于_事件驱动_,而响应式系统——关注于通过分布式系统的通信和协作所得到的弹性和韧性——则是[_消息驱动的_][29][4][14](或者称之为 _消息式(messaging)_ 的)。
|
||||
|
||||
如上面提到的,响应式编程——专注于短时间的数据流链条上的计算——因此倾向于_事件驱动_,而响应式系统——关注于通过分布式系统的通信和协作所得到的弹性和韧性——则是[_消息驱动的_][29] ^脚注4(或者称之为 _消息式(messaging)_ 的)。
|
||||
|
||||
一个拥有长期存活的可寻址(long-lived addressable)组件的消息驱动系统跟一个事件驱动的数据流驱动模型的不同在于,消息具有固定的导向,而事件则没有。消息会有明确的(一个)去向,而事件则只是一段等着被观察(observe)的信息。另外,消息式(messaging)更适用于异步,因为消息的发送与接收和发送者和接收者是分离的。
|
||||
|
||||
响应式宣言中的术语表定义了两者之间[概念上的不同][30]:
|
||||
|
||||
> 一条消息就是一则被送往一个明确目的地的数据。一个事件则是达到某个给定状态的组件发出的一个信号。在一个消息驱动系统中,可寻址到的接收者等待消息的到来然后响应它,否则保持休眠状态。在一个事件驱动系统中,通知的监听者被绑定到消息源上,这样当消息被发出时它就会被调用。这意味着一个事件驱动系统专注于可寻址的事件源而消息驱动系统专注于可寻址的接收者。
|
||||
|
||||
分布式系统需要通过消息在网络上传输进行交流,以实现其沟通基础,与之相反,事件的发出则是本地的。在底层通过发送包裹着事件的消息来搭建跨网络的事件驱动系统的做法很常见。这样能够维持在分布式环境下事件驱动编程模型的相对简易性并且在某些特殊的和合理范围内的使用案例上工作得很好。
|
||||
分布式系统需要通过消息在网络上传输进行交流,以实现其沟通基础,与之相反,事件的发出则是本地的。在底层通过发送包裹着事件的消息来搭建跨网络的事件驱动系统的做法很常见。这样能够维持在分布式环境下事件驱动编程模型的相对简易性,并且在某些特殊的和合理的范围内的使用案例上工作得很好。
|
||||
|
||||
然而,这是有利有弊的:在编程模型的抽象性和简易性上得一分,在控制上就减一分。消息强迫我们去拥抱分布式系统的真实性和一致性——像局部错误(partial failures),错误侦测(failure detection),丢弃/复制/重排序 消息(dropped/duplicated/reordered messages),最后还有一致性,管理多个并发真实性等等——然后直面它们,去处理它们,而不是像过去无数次一样,藏在一个蹩脚的抽象面罩后——假装网络并不存在(例如EJB, [RPC][31], [CORBA][32], 和 [XA][33])。
|
||||
然而,这是有利有弊的:在编程模型的抽象性和简易性上得一分,在控制上就减一分。消息强迫我们去拥抱分布式系统的真实性和一致性——像局部错误(partial failures),错误侦测(failure detection),丢弃/复制/重排序 (dropped/duplicated/reordered )消息,最后还有一致性,管理多个并发真实性等等——然后直面它们,去处理它们,而不是像过去无数次一样,藏在一个蹩脚的抽象面罩后——假装网络并不存在(例如EJB、 [RPC][31]、 [CORBA][32] 和 [XA][33])。
|
||||
|
||||
这些在语义学和适用性上的不同在应用设计中有着深刻的含义,包括分布式系统的复杂性(complexity)中的 _弹性(resilience)_, _韧性(elasticity)_,_移动性(mobility)_,_位置透明性(location transparency)_ 和 _管理(management)_,这些在文章后面再进行介绍。
|
||||
这些在语义学和适用性上的不同在应用设计中有着深刻的含义,包括分布式系统的复杂性(complexity)中的 _弹性(resilience)_、 _韧性(elasticity)_、_移动性(mobility)_、_位置透明性(location transparency)_ 和 _管理(management)_,这些在文章后面再进行介绍。
|
||||
|
||||
在一个响应式系统中,特别是使用了响应式编程技术的,这样的系统中就即有事件也有消息——一个是用于沟通的强大工具(消息),而另一个则呈现现实(事件)。
|
||||
|
||||
@ -91,17 +93,17 @@ _响应式编程_,不要把它跟_函数响应式编程_混淆了,它是异
|
||||
|
||||
_响应式系统_ —— 如同在《响应式宣言》中定义的那样——是一组用于搭建现代系统——已充分准备好满足如今应用程序所面对的不断增长的需求的现代系统——的架构设计原则。
|
||||
|
||||
响应式系统的原则决对不是什么新东西,它可以被追溯到70和80年代Jim Gray和Pat Helland在[串级系统(Tandem System)][34]上和Joe aomstrong和Robert Virding在[Erland][35]上做出的重大工作。然而,这些人在当时都超越了时代,只有到了最近5-10年,技术行业才被不得不反思当前企业系统最好的开发实践活动并且学习如何将来之不易的响应式原则应用到今天这个多核、云计算和物联网的世界中。
|
||||
响应式系统的原则决对不是什么新东西,它可以被追溯到 70 和 80 年代 Jim Gray 和 Pat Helland 在[串级系统(Tandem System)][34] 上和 Joe aomstrong 和 Robert Virding 在 [Erland][35] 上做出的重大工作。然而,这些人在当时都超越了时代,只有到了最近 5 - 10 年,技术行业才被不得不反思当前企业系统最好的开发实践活动并且学习如何将来之不易的响应式原则应用到今天这个多核、云计算和物联网的世界中。
|
||||
|
||||
响应式系统的基石是_消息传递(message-passing)_ ,消息传递为两个组件之间创建一条暂时的边界,使得他们能够在 _时间_ 上分离——实现并发性——和 _空间(space)_ ——实现分布式(distribution)与移动性(mobility)。这种分离是两个组件完全[隔离(isolation)][36]以及实现 _弹性(resilience)_ 和 _韧性(elasticity)_ 基础的必需条件。
|
||||
响应式系统的基石是_消息传递(message-passing)_ ,消息传递为两个组件之间创建一条暂时的边界,使得它们能够在 _时间_ 上分离——实现并发性——和 _空间(space)_ ——实现分布式(distribution)与移动性(mobility)。这种分离是两个组件完全[隔离(isolation)][36]以及实现 _弹性(resilience)_ 和 _韧性(elasticity)_ 基础的必需条件。
|
||||
|
||||
### 从程序到系统
|
||||
|
||||
这个世界的连通性正在变得越来越高。我们构建 _程序_ ——为单个操作子计算某些东西的端到端逻辑——已经不如我们构建 _系统_ 来得多了。
|
||||
这个世界的连通性正在变得越来越高。我们不再构建 _程序_ ——为单个操作子来计算某些东西的端到端逻辑——而更多地在构建 _系统_ 了。
|
||||
|
||||
系统从定义上来说是复杂的——每一部分都包含多个组件,每个组件的自身或其子组件也可以是一个系统——这意味着软件要正常工作已经越来越依赖于其它软件。
|
||||
|
||||
我们今天构建的系统会在多个计算机上被操作,小型的或大型的,数量少的或数量多的,相近的或远隔半个地球的。同时,由于人们的生活正变得越来越依赖于系统顺畅运行的有效性,用户的期望也变得越得越来越难以满足。
|
||||
我们今天构建的系统会在多个计算机上操作,小型的或大型的,或少或多,相近的或远隔半个地球的。同时,由于人们的生活正变得越来越依赖于系统顺畅运行的有效性,用户的期望也变得越得越来越难以满足。
|
||||
|
||||
为了实现用户——和企业——能够依赖的系统,这些系统必须是 _灵敏的(responsive)_ ,这样无论是某个东西提供了一个正确的响应,还是当需要一个响应时响应无法使用,都不会有影响。为了达到这一点,我们必须保证在错误( _弹性_ )和欠载( _韧性_ )下,系统仍然能够保持灵敏性。为了实现这一点,我们把系统设计为 _消息驱动的_ ,我们称其为 _响应式系统_ 。
|
||||
|
||||
@ -109,36 +111,32 @@ _响应式系统_ —— 如同在《响应式宣言》中定义的那样——
|
||||
|
||||
弹性是与 _错误下_ 的灵敏性(responsiveness)有关的,它是系统内在的功能特性,是需要被设计的东西,而不是能够被动的加入系统中的东西。弹性是大于容错性的——弹性无关于故障退化(graceful degradation)——虽然故障退化对于系统来说是很有用的一种特性——与弹性相关的是与从错误中完全恢复达到 _自愈_ 的能力。这就需要组件的隔离以及组件对错误的包容,以免错误散播到其相邻组件中去——否则,通常会导致灾难性的连锁故障。
|
||||
|
||||
因此构建一个弹性的,自愈(self-healing)系统的关键是允许错误被:容纳,具体化为消息,发送给其他的(担当监管者的(supervisors))组件,从而在错误组件之外修复出一个安全环境。在这,消息驱动是其促成因素:远离高度耦合的、脆弱的深层嵌套的同步调用链,大家长期要么学会忍受其煎熬或直接忽略。解决的想法是将调用链中的错误管理分离,将客户端从处理服务端错误的责任中解放出来。
|
||||
因此构建一个弹性的、自愈(self-healing)系统的关键是允许错误被:容纳、具体化为消息,发送给其他的(担当监管者的(supervisors))组件,从而在错误组件之外修复出一个安全环境。在这,消息驱动是其促成因素:远离高度耦合的、脆弱的深层嵌套的同步调用链,大家长期要么学会忍受其煎熬或直接忽略。解决的想法是将调用链中的错误管理分离,将客户端从处理服务端错误的责任中解放出来。
|
||||
|
||||
### 响应式系统的韧性
|
||||
|
||||
[韧性(Elasticity)][37]是关于 _欠载下的灵敏性(responsiveness)_ 的——意味着一个系统的吞吐量在资源增加或减少时能够自动地相应增加或减少(scales up or down)(同样能够向内或外扩展(scales in or out))以满足不同的需求。这是利用云计算承诺的特性所必需的因素:使系统利用资源更加有效,成本效益更佳,对环境友好以及实现按次付费。
|
||||
|
||||
系统必须能够在不重写甚至不重新设置的情况下,适应性地——即无需介入自动伸缩——响应状态及行为,沟通负载均衡,故障转移(failover),以及升级。实现这些的就是 _位置透明性(location transparency)_ :使用同一个方法,同样的编程抽象,同样的语义,在所有向度中伸缩(scaling)系统的能力——从CPU核心到数据中心。
|
||||
系统必须能够在不重写甚至不重新设置的情况下,适应性地——即无需介入自动伸缩——响应状态及行为,沟通负载均衡,故障转移(failover),以及升级。实现这些的就是 _位置透明性(location transparency)_ :使用同一个方法,同样的编程抽象,同样的语义,在所有向度中伸缩(scaling)系统的能力——从 CPU 核心到数据中心。
|
||||
|
||||
如同《响应式宣言》所述:
|
||||
|
||||
> 一个极大地简化问题的关键洞见在于意识到我们都在使用分布式计算。无论我们的操作系统是运行在一个单一结点上(拥有多个独立的CPU,并通过QPI链接进行交流),还是在一个节点集群(cluster of nodes,独立的机器,通过网络进行交流)上。拥抱这个事实意味着在垂直方向上多核的伸缩与在水平方面上集群的伸缩并无概念上的差异。在空间上的解耦 [...],是通过异步消息传送以及运行时实例与其引用解耦从而实现的,这就是我们所说的位置透明性。
|
||||
> 一个极大地简化问题的关键洞见在于意识到我们都在使用分布式计算。无论我们的操作系统是运行在一个单一结点上(拥有多个独立的 CPU,并通过 QPI 链接进行交流),还是在一个节点集群(cluster of nodes)(独立的机器,通过网络进行交流)上。拥抱这个事实意味着在垂直方向上多核的伸缩与在水平方面上集群的伸缩并无概念上的差异。在空间上的解耦 [...],是通过异步消息传送以及运行时实例与其引用解耦从而实现的,这就是我们所说的位置透明性。
|
||||
|
||||
因此,不论接收者在哪里,我们都以同样的方式与它交流。唯一能够在语义上等同实现的方式是消息传送。
|
||||
|
||||
### 响应式系统的生产效率
|
||||
|
||||
既然大多数的系统生来即是复杂的,那么其中一个最重要的点即是保证一个系统架构在开发和维护组件时,最小程度地减低生产效率,同时将操作的 _偶发复杂性(accidental complexity_ 降到最低。
|
||||
既然大多数的系统生来即是复杂的,那么其中一个最重要的点即是保证一个系统架构在开发和维护组件时,最小程度地减低生产效率,同时将操作的 _偶发复杂性(accidental complexity)_ 降到最低。
|
||||
|
||||
这一点很重要,因为在一个系统的生命周期中——如果系统的设计不正确——系统的维护会变得越来越困难,理解、定位和解决问题所需要花费时间和精力会不断地上涨。
|
||||
|
||||
响应式系统是我们所知的最具 _生产效率_ 的系统架构(在多核、云及移动架构的背景下):
|
||||
|
||||
* 错误的隔离为组件与组件之间裹上[舱壁][15](译者注:当船遭到损坏进水时,舱壁能够防止水从损坏的船舱流入其他船舱),防止引发连锁错误,从而限制住错误的波及范围以及严重性。
|
||||
|
||||
* 错误的隔离为组件与组件之间裹上[舱壁][15](LCTT 译注:当船遭到损坏进水时,舱壁能够防止水从损坏的船舱流入其他船舱),防止引发连锁错误,从而限制住错误的波及范围以及严重性。
|
||||
* 监管者的层级制度提供了多个等级的防护,搭配以自我修复能力,避免了许多曾经在侦查(inverstigate)时引发的操作代价(cost)——大量的瞬时故障(transient failures)。
|
||||
|
||||
* 消息传送和位置透明性允许组件被卸载下线、代替或重新布线(rerouted)同时不影响终端用户的使用体验,并降低中断的代价、它们的相对紧迫性以及诊断和修正所需的资源。
|
||||
|
||||
* 复制减少了数据丢失的风险,减轻了数据检索(retrieval)和存储的有效性错误的影响。
|
||||
|
||||
* 韧性允许在使用率波动时保存资源,允许在负载很低时,最小化操作开销,并且允许在负载增加时,最小化运行中断(outgae)或紧急投入(urgent investment)伸缩性的风险。
|
||||
|
||||
因此,响应式系统使生成系统(creation systems)很好的应对错误、随时间变化的负载——同时还能保持低运营成本。
|
||||
@ -173,19 +171,19 @@ _响应式系统_ —— 如同在《响应式宣言》中定义的那样——
|
||||
|
||||
响应式编程在内部逻辑及数据流转换的组件层次上为开发者提高了生产率——通过性能与资源的有效利用实现。而响应式系统在构建 _原生云(cloud native)_ 和其它大型分布式系统的系统层次上为架构师及DevOps从业者提高了生产率——通过弹性与韧性。我们建议在响应式系统设计原则中结合响应式编程技术。
|
||||
|
||||
```
|
||||
1 参考Conal Elliott,FRP的发明者,见[这个演示][16][↩][17]
|
||||
2 [Amdahl 定律][18]揭示了系统理论上的加速会被一系列的子部件限制,这意味着系统在新的资源加入后会出现收益递减(diminishing returns)。 [↩][19]
|
||||
3 Neil Günter的[通用可伸缩性定律(Universal Scalability Law)][20]是理解并发与分布式系统的竞争与协作的重要工具,它揭示了当新资源加入到系统中时,保持一致性的开销会导致不好的结果。
|
||||
4 消息可以是同步的(要求发送者和接受者同时存在),也可以是异步的(允许他们在时间上解耦)。其语义上的区别超出本文的讨论范围。[↩][22]
|
||||
```
|
||||
|
||||
> 1. 参考Conal Elliott,FRP的发明者,见[这个演示][16]
|
||||
> 2. [Amdahl 定律][18]揭示了系统理论上的加速会被一系列的子部件限制,这意味着系统在新的资源加入后会出现收益递减(diminishing returns)。
|
||||
> 3. Neil Günter的[通用可伸缩性定律(Universal Scalability Law)][20]是理解并发与分布式系统的竞争与协作的重要工具,它揭示了当新资源加入到系统中时,保持一致性的开销会导致不好的结果。
|
||||
> 4. 消息可以是同步的(要求发送者和接受者同时存在),也可以是异步的(允许他们在时间上解耦)。其语义上的区别超出本文的讨论范围。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems
|
||||
|
||||
作者:[Jonas Bonér][a] , [Viktor Klang][b]
|
||||
作者:[Jonas Bonér][a], [Viktor Klang][b]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
399
published/20161220 TypeScript the missing introduction.md
Normal file
399
published/20161220 TypeScript the missing introduction.md
Normal file
@ -0,0 +1,399 @@
|
||||
一篇缺失的 TypeScript 介绍
|
||||
=============================================================
|
||||
|
||||
**下文是 James Henry([@MrJamesHenry][8])所提交的内容。我是 ESLint 核心团队的一员,也是 TypeScript 布道师。我正在和 Todd 在 [UltimateAngular][9] 平台上合作发布 Angular 和 TypeScript 的精品课程。**
|
||||
|
||||
> 本文的主旨是为了介绍我们是如何看待 TypeScript 的以及它在加强 JavaScript 开发中所起的作用。
|
||||
>
|
||||
> 我们也将尽可能地给出那些类型和编译方面的那些时髦词汇的准确定义。
|
||||
|
||||
TypeScript 强大之处远远不止这些,本篇文章无法涵盖,想要了解更多请阅读[官方文档][15],或者学习 [UltimateAngular 上的 TypeScript 课程][16] ,从初学者成为一位 TypeScript 高手。
|
||||
|
||||
### 背景
|
||||
|
||||
TypeScript 是个出乎意料强大的工具,而且它真的很容易掌握。
|
||||
|
||||
然而,TypeScript 可能比 JavaScript 要更为复杂一些,因为 TypeScript 可能向我们同时引入了一系列以前没有考虑过的 JavaScript 程序相关的技术概念。
|
||||
|
||||
每当我们谈论到类型、编译器等这些概念的时候,你会发现很快会变的不知所云起来。
|
||||
|
||||
这篇文章就是一篇为了解答你需要知道的许许多多不知所云的概念,来帮助你 TypeScript 快速入门的教程,可以让你轻松自如的应对这些概念。
|
||||
|
||||
### 关键知识的掌握
|
||||
|
||||
在 Web 浏览器中运行我们的代码这件事或许使我们对它是如何工作的产生一些误解,“它不用经过编译,是吗?”,“我敢肯定这里面是没有类型的...”
|
||||
|
||||
更有意思的是,上述的说法既是正确的也是不正确的,这取决于上下文环境和我们是如何定义这些概念的。
|
||||
|
||||
首先,我们要作的是明确这些。
|
||||
|
||||
#### JavaScript 是解释型语言还是编译型语言?
|
||||
|
||||
传统意义上,程序员经常将自己的程序编译之后运行出结果就认为这种语言是编译型语言。
|
||||
|
||||
> 从初学者的角度来说,编译的过程就是将我们自己编辑好的高级语言程序转换成机器实际运行的格式。
|
||||
|
||||
就像 Go 语言,可以使用 `go build` 的命令行工具编译 .go 的文件,将其编译成代码的低级形式,它可以直接执行、运行。
|
||||
|
||||
```
|
||||
# We manually compile our .go file into something we can run
|
||||
# using the command line tool "go build"
|
||||
go build ultimate-angular.go
|
||||
# ...then we execute it!
|
||||
./ultimate-angular
|
||||
```
|
||||
|
||||
作为一个 JavaScript 程序员(这一刻,请先忽略我们对新一代构建工具和模块加载程序的热爱),我们在日常的 JavaScript 开发中并没有编译的这一基本步骤,
|
||||
|
||||
我们写一些 JavaScript 代码,把它放在浏览器的 `<script>` 标签中,它就能运行了(或者在服务端环境运行,比如:node.js)。
|
||||
|
||||
**好吧,因此 JavaScript 没有进行过编译,那它一定是解释型语言了,是吗?**
|
||||
|
||||
实际上,我们能够确定的一点是,JavaScript 不是我们自己编译的,现在让我们简单的回顾一个简单的解释型语言的例子,再来谈 JavaScript 的编译问题。
|
||||
|
||||
> 解释型计算机语言的执行的过程就像人们看书一样,从上到下、一行一行的阅读。
|
||||
|
||||
我们所熟知的解释型语言的典型例子是 bash 脚本。我们终端中的 bash 解释器逐行读取我们的命令并且执行它。
|
||||
|
||||
现在我们回到 JavaScript 是解释执行还是编译执行的讨论中,我们要将逐行读取和逐行执行程序分开理解(对“解释型”的简单理解),不要混在一起。
|
||||
|
||||
以此代码为例:
|
||||
|
||||
```
|
||||
hello();
|
||||
function hello(){
|
||||
console.log("Hello")
|
||||
}
|
||||
```
|
||||
|
||||
这是真正意义上 JavaScript 输出 Hello 单词的程序代码,但是,在 `hello()` 在我们定义它之前就已经使用了这个函数,这是简单的逐行执行办不到的,因为 `hello()` 在第一行没有任何意义的,直到我们在第二行声明了它。
|
||||
|
||||
像这样在 JavaScript 是存在的,因为我们的代码实际上在执行之前就被所谓的“JavaScript 引擎”或者是“特定的编译环境”编译过,这个编译的过程取决于具体的实现(比如,使用 V8 引擎的 node.js 和 Chome 就和使用 SpiderMonkey 的 FireFox 就有所不同)。
|
||||
|
||||
在这里,我们不会在进一步的讲解编译型执行和解释型执行微妙之处(这里的定义已经很好了)。
|
||||
|
||||
> 请务必记住,我们编写的 JavaScript 代码已经不是我们的用户实际执行的代码了,即使是我们简单地将其放在 HTML 中的 `<script>` ,也是不一样的。
|
||||
|
||||
#### 运行时间 VS 编译时间
|
||||
|
||||
现在我们已经正确理解了编译和运行是两个不同的阶段,那“<ruby>运行阶段<rt>Run Time</rt></ruby>”和“<ruby>编译阶段<rt>Compile Time</rt></ruby>”理解起来也就容易多了。
|
||||
|
||||
编译阶段,就是我们在我们的编辑器或者 IDE 当中的代码转换成其它格式的代码的阶段。
|
||||
|
||||
运行阶段,就是我们程序实际执行的阶段,例如:上面的 `hello()` 函数就执行在“运行阶段”。
|
||||
|
||||
#### TypeScript 编译器
|
||||
|
||||
现在我们了解了程序的生命周期中的关键阶段,接下来我们可以介绍 TypeScript 编译器了。
|
||||
|
||||
TypeScript 编译器是帮助我们编写代码的关键。比如,我们不需将 JavaScript 代码包含到 `<script>` 标签当中,只需要通过 TypeScript 编译器传递它,就可以在运行程序之前得到改进程序的建议。
|
||||
|
||||
> 我们可以将这个新的步骤作为我们自己的个人“编译阶段”,这将在我们的程序抵达 JavaScript 主引擎之前,确保我们的程序是以我们预期的方式编写的。
|
||||
|
||||
它与上面 Go 语言的实例类似,但是 TypeScript 编译器只是基于我们编写程序的方式提供提示信息,并不会将其转换成低级的可执行文件,它只会生成纯 JavaScript 代码。
|
||||
|
||||
```
|
||||
# One option for passing our source .ts file through the TypeScript
|
||||
# compiler is to use the command line tool "tsc"
|
||||
tsc ultimate-angular.ts
|
||||
|
||||
# ...this will produce a .js file of the same name
|
||||
# i.e. ultimate-angular.js
|
||||
```
|
||||
|
||||
在[官方文档][23]中,有许多关于将 TypeScript 编译器以各种方式融入到你的现有工作流程中的文章。这些已经超出本文范围。
|
||||
|
||||
#### 动态类型与静态类型
|
||||
|
||||
就像对比编译程序与解释程序一样,动态类型与静态类型的对比在现有的资料中也是极其模棱两可的。
|
||||
|
||||
让我们先回顾一下我们在 JavaScript 中对于类型的理解。
|
||||
|
||||
我们的代码如下:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
```
|
||||
|
||||
我们如何给别人描述这段代码?
|
||||
|
||||
“我们声明了一个变量 `name`,它被分配了一个 “James” 的**字符串**,然后我们又申请了一个变量 `sum`,它被分配了一个**数字** 1 和**数字** 2 的求和的数值结果。”
|
||||
|
||||
即使在这样一个简单的程序中,我们也使用了两个 JavaScript 的基本类型:`String` 和 `Number`。
|
||||
|
||||
就像上面我们讲编译一样,我们不会陷入编程语言类型的学术细节当中,关键是要理解在 JavaScript 中类型表示的是什么,并扩展到 TypeScript 的类型的理解上。
|
||||
|
||||
从每夜拜读的最新 ECMAScript 规范中我们可以学到(LOL, JK - “wat’s an ECMA?”),它大量引用了 JavaScript 的类型及其用法。
|
||||
|
||||
直接引自官方规范:
|
||||
|
||||
> ECMAScript 语言的类型取决于使用 ECMAScript 语言的 ECMAScript 程序员所直接操作的值。
|
||||
>
|
||||
> ECMAScript 语言的类型有 Undefined、Null、Boolean、String、Symbol、Number 和 Object。
|
||||
|
||||
我们可以看到,JavaScript 语言有 7 种正式类型,其中我们在我们现在程序中使用了 6 种(Symbol 首次在 ES2015 中引入,也就是 ES6)。
|
||||
|
||||
现在我们来深入一点看上面的 JavaScript 代码中的 “name 和 sum”。
|
||||
|
||||
我们可以把我们当前被分配了字符串“James”的变量 `name` 重新赋值为我们的第二个变量 sum 的当前值,目前是数字 3。
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
该 `name` 变量开始“存有”一个字符串,但现在它“存有”一个数字。这凸显了 JavaScript 中变量和类型的基本特性:
|
||||
|
||||
“James” 值一直是字符串类型,而 `name` 变量可以分配任何类型的值。和 `sum` 赋值的情况相同,1 是一个数字类型,`sum` 变量可以分配任何可能的值。
|
||||
|
||||
> 在 JavaScript 中,值是具有类型的,而变量是可以随时保存任何类型的值。
|
||||
|
||||
这也恰好是一个“动态类型语言”的定义。
|
||||
|
||||
相比之下,我们可以将“静态类型语言”视为我们可以(也必须)将类型信息与特定变量相关联的语言:
|
||||
|
||||
```
|
||||
var name: string = ‘James’;
|
||||
```
|
||||
|
||||
在这段代码中,我们能够更好地显式声明我们对变量 `name` 的意图,我们希望它总是用作一个字符串。
|
||||
|
||||
你猜怎么着?我们刚刚看到我们的第一个 TypeScript 程序。
|
||||
|
||||
当我们<ruby>反思</rt>reflect</rt></ruby>我们自己的代码(非编程方面的双关语“反射”)时,我们可以得出的结论,即使我们使用动态语言(如 JavaScript),在几乎所有的情况下,当我们初次定义变量和函数参数时,我们应该有非常明确的使用意图。如果这些变量和参数被重新赋值为与我们原先赋值不同类型的值,那么有可能某些东西并不是我们预期的那样工作的。
|
||||
|
||||
> 作为 JavaScript 开发者,TypeScript 的静态类型注释给我们的一个巨大的帮助,它能够清楚地表达我们对变量的意图。
|
||||
|
||||
> 这种改进不仅有益于 TypeScript 编译器,还可以让我们的同事和将来的自己明白我们的代码。代码是用来读的。
|
||||
|
||||
### TypeScript 在我们的 JavaScript 工作流程中的作用
|
||||
|
||||
我们已经开始看到“为什么经常说 TypeScript 只是 JavaScript + 静态类型”的说法了。`: string` 对于我们的 `name` 变量就是我们所谓的“类型注释”,在编译时被使用(换句话说,当我们让代码通过 TypeScript 编译器时),以确保其余的代码符合我们原来的意图。
|
||||
|
||||
我们再来看看我们的程序,并添加显式注释,这次是我们的 `sum` 变量:
|
||||
|
||||
```
|
||||
var name: string = 'James';
|
||||
var sum: number = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
如果我们使用 TypeScript 编译器编译这个代码,我们现在就会收到一个在 `name = sum` 这行的错误: `Type 'number' is not assignable to type 'string'`,我们的这种“偷渡”被警告,我们执行的代码可能有问题。
|
||||
|
||||
> 重要的是,如果我们想要继续执行,我们可以选择忽略 TypeScript 编译器的错误,因为它只是在将 JavaScript 代码发送给我们的用户之前给我们反馈的工具。
|
||||
|
||||
TypeScript 编译器为我们输出的最终 JavaScript 代码将与上述原始源代码完全相同:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
类型注释全部为我们自动删除了,现在我们可以运行我们的代码了。
|
||||
|
||||
> 注意:在此示例中,即使我们没有提供显式类型注释的 `: string` 和 `: number` ,TypeScript 编译器也可以为我们提供完全相同的错误 。
|
||||
|
||||
> TypeScript 通常能够从我们使用它的方式推断变量的类型!
|
||||
|
||||
#### 我们的源文件是我们的文档,TypeScript 是我们的拼写检查
|
||||
|
||||
对于 TypeScript 与我们的源代码的关系来说,一个很好的类比,就是拼写检查与我们在 Microsoft Word 中写的文档的关系。
|
||||
|
||||
这两个例子有三个关键的共同点:
|
||||
|
||||
1. **它能告诉我们写的东西的客观的、直接的错误:**
|
||||
* _拼写检查_:“我们已经写了字典中不存在的字”
|
||||
* _TypeScript_:“我们引用了一个符号(例如一个变量),它没有在我们的程序中声明”
|
||||
2. **它可以提醒我们写的可能是错误的:**
|
||||
* _拼写检查_:“该工具无法完全推断特定语句的含义,并建议重写”
|
||||
* _TypeScript_:“该工具不能完全推断特定变量的类型,并警告不要这样使用它”
|
||||
3. **我们的来源可以用于其原始目的,无论工具是否存在错误:**
|
||||
* _拼写检查_:“即使您的文档有很多拼写错误,您仍然可以打印出来,并把它当成文档使用”
|
||||
* _TypeScript_:“即使您的源代码具有 TypeScript 错误,它仍然会生成您可以执行的 JavaScript 代码”
|
||||
|
||||
### TypeScript 是一种可以启用其它工具的工具
|
||||
|
||||
TypeScript 编译器由几个不同的部分或阶段组成。我们将通过查看这些部分之一 The Parser(语法分析程序)来结束这篇文章,除了 TypeScript 已经为我们做的以外,它为我们提供了在其上构建其它开发工具的机会。
|
||||
|
||||
编译过程的“解析器步骤”的结果是所谓的抽象语法树,简称为 AST。
|
||||
|
||||
#### 什么是抽象语法树(AST)?
|
||||
|
||||
我们以普通文本形式编写我们的程序,因为这是我们人类与计算机交互的最好方式,让它们能够做我们想要的东西。我们并不是很擅长于手工编写复杂的数据结构!
|
||||
|
||||
然而,不管在哪种情况下,普通文本在编译器里面实际上是一个非常棘手的事情。它可能包含程序运作不必要的东西,例如空格,或者可能存在有歧义的部分。
|
||||
|
||||
因此,我们希望将我们的程序转换成数据结构,将数据结构全部映射为我们所使用的所谓“标记”,并将其插入到我们的程序中。
|
||||
|
||||
这个数据结构正是 AST!
|
||||
|
||||
AST 可以通过多种不同的方式表示,我使用 JSON 来看一看。
|
||||
|
||||
我们从这个极其简单的基本源代码来看:
|
||||
|
||||
```
|
||||
var a = 1;
|
||||
```
|
||||
|
||||
TypeScript 编译器的 Parser(语法分析程序)阶段的(简化后的)输出将是以下 AST:
|
||||
|
||||
```
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 256,
|
||||
"text": "var a = 1;",
|
||||
"statements": [
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 200,
|
||||
"declarationList": {
|
||||
"pos": 0,
|
||||
"end": 9,
|
||||
"kind": 219,
|
||||
"declarations": [
|
||||
{
|
||||
"pos": 3,
|
||||
"end": 9,
|
||||
"kind": 218,
|
||||
"name": {
|
||||
"pos": 3,
|
||||
"end": 5,
|
||||
"text": "a"
|
||||
},
|
||||
"initializer": {
|
||||
"pos": 7,
|
||||
"end": 9,
|
||||
"kind": 8,
|
||||
"text": "1"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
我们的 AST 中的对象称为节点。
|
||||
|
||||
#### 示例:在 VS Code 中重命名符号
|
||||
|
||||
在内部,TypeScript 编译器将使用 Parser 生成的 AST 来提供一些非常重要的事情,例如,发生在编译程序时的类型检查。
|
||||
|
||||
但它不止于此!
|
||||
|
||||
> 我们可以使用 AST 在 TypeScript 之上开发自己的工具,如代码美化工具、代码格式化工具和分析工具。
|
||||
|
||||
建立在这个 AST 代码之上的工具的一个很好的例子是:<ruby>语言服务器<rt>Language Server</rt></ruby>。
|
||||
|
||||
深入了解语言服务器的工作原理超出了本文的范围,但是当我们编写程序时,它能为我们提供一个绝对重量级别功能,就是“重命名符号”。
|
||||
|
||||
假设我们有以下源代码:
|
||||
|
||||
```
|
||||
// The name of the author is James
|
||||
var first_name = 'James';
|
||||
console.log(first_name);
|
||||
```
|
||||
|
||||
经过代码审查和对完美的适当追求,我们决定应该改换我们的变量命名惯例;使用驼峰式命名方式,而不是我们当前正在使用这种蛇式命名。
|
||||
|
||||
在我们的代码编辑器中,我们一直以来可以选择多个相同的文本,并使用多个光标来一次更改它们。
|
||||
|
||||

|
||||
|
||||
当我们把程序也视作文本这样继续操作时,我们已经陷入了一个典型的陷阱中。
|
||||
|
||||
那个注释中我们不想修改的“name”单词,在我们的手动匹配中却被误选中了。我们可以看到在现实世界的应用程序中这样更改代码是有多危险。
|
||||
|
||||
正如我们在上面学到的那样,像 TypeScript 这样的东西在幕后生成一个 AST 的时候,与我们的程序不再像普通文本那样可以交互,每个标记在 AST 中都有自己的位置,而且它有很清晰的映射关系。
|
||||
|
||||
当我们右键单击我们的 `first_name` 变量时,我们可以在 VS Code 中直接“重命名符号”(TypeScript 语言服务器插件也可用于其他编辑器)。
|
||||
|
||||

|
||||
|
||||
非常好!现在我们的 `first_name` 变量是唯一需要改变的东西,如果需要的话,这个改变甚至会发生在我们项目中的多个文件中(与导出和导入的值一样)!
|
||||
|
||||
### 总结
|
||||
|
||||
哦,我们在这篇文章中已经讲了很多的内容。
|
||||
|
||||
我们把有关学术方面的规避开,围绕编译器和类型还有很多专业术语给出了通俗的定义。
|
||||
|
||||
我们对比了编译语言与解释语言、运行阶段与编译阶段、动态类型与静态类型,以及抽象语法树(AST)如何为我们的程序构建工具提供了更为优化的方法。
|
||||
|
||||
重要的是,我们提供了 TypeScript 作为我们 JavaScript 开发工具的一种思路,以及如何在其上构建更棒的工具,比如说作为重构代码的一种方式的重命名符号。
|
||||
|
||||
快来 UltimateAngular 平台上学习从初学者到 TypeScript 高手的课程吧,开启你的学习之旅!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://toddmotto.com/typescript-the-missing-introduction
|
||||
|
||||
作者:James Henry
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[2]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[3]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[4]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[5]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[6]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[7]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[8]:https://twitter.com/MrJamesHenry
|
||||
[9]:https://ultimateangular.com/courses
|
||||
[10]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[11]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[12]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[13]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[14]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[15]:http://www.typescriptlang.org/docs
|
||||
[16]:https://ultimateangular.com/courses#typescript
|
||||
[17]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#table-of-contents
|
||||
[18]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[19]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[20]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[21]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[22]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[23]:http://www.typescriptlang.org/docs
|
||||
[24]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[25]:http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-262.pdf
|
||||
[26]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[27]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[28]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[29]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[30]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[31]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[32]:https://ultimateangular.com/courses#typescript
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,234 @@
|
||||
学习用 Python 编程时要避免的 3 个错误
|
||||
============================================================
|
||||
|
||||
> 这些错误会造成很麻烦的问题,需要数小时才能解决。
|
||||
|
||||

|
||||
|
||||
当你做错事时,承认错误并不是一件容易的事,但是犯错是任何学习过程中的一部分,无论是学习走路,还是学习一种新的编程语言都是这样,比如学习 Python。
|
||||
|
||||
为了让初学 Python 的程序员避免犯同样的错误,以下列出了我学习 Python 时犯的三种错误。这些错误要么是我长期以来经常犯的,要么是造成了需要几个小时解决的麻烦。
|
||||
|
||||
年轻的程序员们可要注意了,这些错误是会浪费一下午的!
|
||||
|
||||
### 1、 可变数据类型作为函数定义中的默认参数
|
||||
|
||||
这似乎是对的?你写了一个小函数,比如,搜索当前页面上的链接,并可选将其附加到另一个提供的列表中。
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=[]):
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
从表面看,这像是十分正常的 Python 代码,事实上它也是,而且是可以运行的。但是,这里有个问题。如果我们给 `add_to` 参数提供了一个列表,它将按照我们预期的那样工作。但是,如果我们让它使用默认值,就会出现一些神奇的事情。
|
||||
|
||||
试试下面的代码:
|
||||
|
||||
```
|
||||
def fn(var1, var2=[]):
|
||||
var2.append(var1)
|
||||
print var2
|
||||
|
||||
fn(3)
|
||||
fn(4)
|
||||
fn(5)
|
||||
```
|
||||
|
||||
可能你认为我们将看到:
|
||||
|
||||
```
|
||||
[3]
|
||||
[4]
|
||||
[5]
|
||||
```
|
||||
|
||||
但实际上,我们看到的却是:
|
||||
|
||||
```
|
||||
[3]
|
||||
[3, 4]
|
||||
[3, 4, 5]
|
||||
```
|
||||
|
||||
为什么呢?如你所见,每次都使用的是同一个列表,输出为什么会是这样?在 Python 中,当我们编写这样的函数时,这个列表被实例化为函数定义的一部分。当函数运行时,它并不是每次都被实例化。这意味着,这个函数会一直使用完全一样的列表对象,除非我们提供一个新的对象:
|
||||
|
||||
```
|
||||
fn(3, [4])
|
||||
```
|
||||
|
||||
```
|
||||
[4, 3]
|
||||
```
|
||||
|
||||
答案正如我们所想的那样。要想得到这种结果,正确的方法是:
|
||||
|
||||
```
|
||||
def fn(var1, var2=None):
|
||||
if not var2:
|
||||
var2 = []
|
||||
var2.append(var1)
|
||||
```
|
||||
|
||||
或是在第一个例子中:
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=None):
|
||||
if not add_to:
|
||||
add_to = []
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
这将在模块加载的时候移走实例化的内容,以便每次运行函数时都会发生列表实例化。请注意,对于不可变数据类型,比如[**元组**][7]、[**字符串**][8]、[**整型**][9],是不需要考虑这种情况的。这意味着,像下面这样的代码是非常可行的:
|
||||
|
||||
```
|
||||
def func(message="my message"):
|
||||
print message
|
||||
```
|
||||
|
||||
### 2、 可变数据类型作为类变量
|
||||
|
||||
这和上面提到的最后一个错误很相像。思考以下代码:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
这段代码看起来非常正常。我们有一个储存 URL 的对象。当我们调用 add_url 方法时,它会添加一个给定的 URL 到存储中。看起来非常正确吧?让我们看看实际是怎样的:
|
||||
|
||||
```
|
||||
a = URLCatcher()
|
||||
a.add_url('http://www.google.com')
|
||||
b = URLCatcher()
|
||||
b.add_url('http://www.bbc.co.hk')
|
||||
```
|
||||
|
||||
b.urls:
|
||||
|
||||
```
|
||||
['http://www.google.com', 'http://www.bbc.co.uk']
|
||||
```
|
||||
|
||||
a.urls:
|
||||
|
||||
```
|
||||
['http://www.google.com', 'http://www.bbc.co.uk']
|
||||
```
|
||||
|
||||
等等,怎么回事?!我们想的不是这样啊。我们实例化了两个单独的对象 `a` 和 `b`。把一个 URL 给了 `a`,另一个给了 `b`。这两个对象怎么会都有这两个 URL 呢?
|
||||
|
||||
这和第一个错例是同样的问题。创建类定义时,URL 列表将被实例化。该类所有的实例使用相同的列表。在有些时候这种情况是有用的,但大多数时候你并不想这样做。你希望每个对象有一个单独的储存。为此,我们修改代码为:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
def __init__(self):
|
||||
self.urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
现在,当创建对象时,URL 列表被实例化。当我们实例化两个单独的对象时,它们将分别使用两个单独的列表。
|
||||
|
||||
### 3、 可变的分配错误
|
||||
|
||||
这个问题困扰了我一段时间。让我们做出一些改变,并使用另一种可变数据类型 - [**字典**][10]。
|
||||
|
||||
```
|
||||
a = {'1': "one", '2': 'two'}
|
||||
```
|
||||
|
||||
现在,假设我们想把这个字典用在别的地方,且保持它的初始数据完整。
|
||||
|
||||
```
|
||||
b = a
|
||||
|
||||
b['3'] = 'three'
|
||||
```
|
||||
|
||||
简单吧?
|
||||
|
||||
现在,让我们看看原来那个我们不想改变的字典 `a`:
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
哇等一下,我们再看看 **b**?
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
等等,什么?有点乱……让我们回想一下,看看其它不可变类型在这种情况下会发生什么,例如一个**元组**:
|
||||
|
||||
```
|
||||
c = (2, 3)
|
||||
d = c
|
||||
d = (4, 5)
|
||||
```
|
||||
|
||||
现在 `c` 是 `(2, 3)`,而 `d` 是 `(4, 5)`。
|
||||
|
||||
这个函数结果如我们所料。那么,在之前的例子中到底发生了什么?当使用可变类型时,其行为有点像 **C** 语言的一个指针。在上面的代码中,我们令 `b = a`,我们真正表达的意思是:`b` 成为 `a` 的一个引用。它们都指向 Python 内存中的同一个对象。听起来有些熟悉?那是因为这个问题与先前的相似。其实,这篇文章应该被称为「可变引发的麻烦」。
|
||||
|
||||
列表也会发生同样的事吗?是的。那么我们如何解决呢?这必须非常小心。如果我们真的需要复制一个列表进行处理,我们可以这样做:
|
||||
|
||||
```
|
||||
b = a[:]
|
||||
```
|
||||
|
||||
这将遍历并复制列表中的每个对象的引用,并且把它放在一个新的列表中。但是要注意:如果列表中的每个对象都是可变的,我们将再次获得它们的引用,而不是完整的副本。
|
||||
|
||||
假设在一张纸上列清单。在原来的例子中相当于,A 某和 B 某正在看着同一张纸。如果有个人修改了这个清单,两个人都将看到相同的变化。当我们复制引用时,每个人现在有了他们自己的清单。但是,我们假设这个清单包括寻找食物的地方。如果“冰箱”是列表中的第一个,即使它被复制,两个列表中的条目也都指向同一个冰箱。所以,如果冰箱被 A 修改,吃掉了里面的大蛋糕,B 也将看到这个蛋糕的消失。这里没有简单的方法解决它。只要你记住它,并编写代码的时候,使用不会造成这个问题的方式。
|
||||
|
||||
字典以相同的方式工作,并且你可以通过以下方式创建一个昂贵副本:
|
||||
|
||||
```
|
||||
b = a.copy()
|
||||
```
|
||||
|
||||
再次说明,这只会创建一个新的字典,指向原来存在的相同的条目。因此,如果我们有两个相同的列表,并且我们修改字典 `a` 的一个键指向的可变对象,那么在字典 b 中也将看到这些变化。
|
||||
|
||||
可变数据类型的麻烦也是它们强大的地方。以上都不是实际中的问题;它们是一些要注意防止出现的问题。在第三个项目中使用昂贵复制操作作为解决方案在 99% 的时候是没有必要的。你的程序或许应该被改改,所以在第一个例子中,这些副本甚至是不需要的。
|
||||
|
||||
_编程快乐!在评论中可以随时提问。_
|
||||
|
||||
(题图: opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Pete Savage - Peter 是一位充满激情的开源爱好者,在过去十年里一直在推广和使用开源产品。他从 Ubuntu 社区开始,在许多不同的领域自愿参与音频制作领域的研究工作。在职业经历方面,他起初作为公司的系统管理员,大部分时间在管理和建立数据中心,之后在 Red Hat 担任 CloudForms 产品的主要测试工程师。
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python
|
||||
|
||||
作者:[Pete Savage][a]
|
||||
译者:[polebug](https://github.com/polebug)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psav
|
||||
[1]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python?rate=SfClhaQ6tQsJdKM8-YTNG00w53fsncvsNWafwuJbtqs
|
||||
[2]:http://www.google.com/
|
||||
[3]:http://www.bbc.co.uk/
|
||||
[4]:http://www.google.com/
|
||||
[5]:http://www.bbc.co.uk/
|
||||
[6]:https://opensource.com/user/36026/feed
|
||||
[7]:https://docs.python.org/2/library/functions.html?highlight=tuple#tuple
|
||||
[8]:https://docs.python.org/2/library/string.html
|
||||
[9]:https://docs.python.org/2/library/functions.html#int
|
||||
[10]:https://docs.python.org/2/library/stdtypes.html?highlight=dict#dict
|
||||
[11]:https://opensource.com/users/psav
|
||||
[12]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python#comments
|
||||
@ -0,0 +1,124 @@
|
||||
4 个 Linux 桌面上的轻量级图像浏览器
|
||||
============================================================
|
||||
|
||||
> 当你需要的不仅仅是一个基本的图像浏览器,而是一个完整的图像编辑器,请查看这些程序。
|
||||
|
||||

|
||||
|
||||
像大多数人一样,你计算机上可能有些照片和其他图像。而且,像大多数人一样,你可能想要经常查看那些图像和照片。
|
||||
|
||||
而启动一个 [GIMP][18] 或者 [Pinta][19] 这样的图片编辑器对于简单的浏览图片来说太笨重了。
|
||||
|
||||
另一方面,大多数 Linux 桌面环境中包含的基本图像查看器可能不足以满足你的需要。如果你想要一些更多的功能,但仍然希望它是轻量级的,那么看看这四个 Linux 桌面中的图像查看器,如果还不能满足你的需要,还有额外的选择。
|
||||
|
||||
### Feh
|
||||
|
||||
[Feh][20] 是我以前在老旧计算机上最喜欢的软件。它简单、朴实、用起来很好。
|
||||
|
||||
你可以从命令行启动 Feh:只将其指向图像或者包含图像的文件夹之后就行了。Feh 会快速加载,你可以通过鼠标点击或使用键盘上的向左和向右箭头键滚动图像。不能更简单了。
|
||||
|
||||
Feh 可能很轻量级,但它提供了一些选项。例如,你可以控制 Feh 的窗口是否具有边框,设置要查看的图像的最小和最大尺寸,并告诉 Feh 你想要从文件夹中的哪个图像开始浏览。
|
||||
|
||||

|
||||
|
||||
*Feh 的使用*
|
||||
|
||||
### Ristretto
|
||||
|
||||
如果你将 Xfce 作为桌面环境,那么你会熟悉 [Ristretto][21]。它很小、简单、并且非常有用。
|
||||
|
||||
怎么简单?你打开包含图像的文件夹,单击左侧的缩略图之一,然后单击窗口顶部的导航键浏览图像。Ristretto 甚至有幻灯片功能。
|
||||
|
||||
Ristretto 也可以做更多的事情。你可以使用它来保存你正在浏览的图像的副本,将该图像设置为桌面壁纸,甚至在另一个应用程序中打开它,例如,当你需要修改一下的时候。
|
||||
|
||||

|
||||
|
||||
*在 Ristretto 中浏览照片 *
|
||||
|
||||
### Mirage
|
||||
|
||||
表面上,[Mirage][22]有点平常,没什么特色,但它做着和其他优秀图片浏览器一样的事:打开图像,将它们缩放到窗口的宽度,并且可以使用键盘滚动浏览图像。它甚至可以使用幻灯片。
|
||||
|
||||
不过,Mirage 将让需要更多功能的人感到惊喜。除了其核心功能,Mirage 还可以调整图像大小和裁剪图像、截取屏幕截图、重命名图像,甚至生成文件夹中图像的 150 像素宽的缩略图。
|
||||
|
||||
如果这还不够,Mirage 还可以显示 [SVG 文件][23]。你甚至可以从[命令行][24]中运行。
|
||||
|
||||
|
||||

|
||||
|
||||
*使用 Mirage*
|
||||
|
||||
### Nomacs
|
||||
|
||||
[Nomacs][25] 显然是本文中最重量级的图像浏览器。它所呈现的那么多功能让人忽视了它的速度。它快捷而易用。
|
||||
|
||||
Nomacs 不仅仅可以显示图像。你还可以查看和编辑图像的[元数据][26],向图像添加注释,并进行一些基本的编辑,包括裁剪、调整大小、并将图像转换为灰度。Nomacs 甚至可以截图。
|
||||
|
||||
一个有趣的功能是你可以在桌面上运行程序的两个实例,并在这些实例之间同步图像。当需要比较两个图像时,[Nomacs 文档][27]中推荐这样做。你甚至可以通过局域网同步图像。我没有尝试通过网络进行同步,如果你做过可以分享下你的经验。
|
||||
|
||||
|
||||

|
||||
|
||||
*Nomacs 中的照片及其元数据*
|
||||
|
||||
### 其他一些值得一看的浏览器
|
||||
|
||||
如果这四个图像浏览器不符合你的需求,这里还有其他一些你可能感兴趣的。
|
||||
|
||||
**[Viewnior][11]** 自称是 “GNU/Linux 中的快速简单的图像查看器”,它很适合这个用途。它的界面干净整洁,Viewnior 甚至可以进行一些基本的图像处理。
|
||||
|
||||
如果你喜欢在命令行中使用,那么 **display** 可能是你需要的浏览器。 **[ImageMagick][12]** 和 **[GraphicsMagick][13]** 这两个图像处理软件包都有一个名为 display 的应用程序,这两个版本都有查看图像的基本和高级选项。
|
||||
|
||||
**[Geeqie][14]** 是更轻和更快的图像浏览器之一。但是,不要让它的简单误导你。它包含的功能有元数据编辑功能和其它浏览器所缺乏的查看相机 RAW 图像格式的功能。
|
||||
|
||||
**[Shotwell][15]** 是 GNOME 桌面的照片管理器。然而它不仅仅能浏览图像,而且 Shotwell 非常快速,并且非常适合显示照片和其他图形。
|
||||
|
||||
_在 Linux 桌面中你有最喜欢的一款轻量级图片浏览器么?请在评论区随意分享你的喜欢的浏览器_
|
||||
|
||||
(题图:[互联网存档图书图片][17]. 由 Opensource.com 修改。 CC BY-SA 4.0)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我是一名长期使用自由/开源软件的用户,并因为乐趣和收获写各种东西。我不会很严肃。你可以在这些网站上找到我:Twitter、Mastodon、GitHub。
|
||||
|
||||
via: https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/361216
|
||||
[7]:https://opensource.com/file/361231
|
||||
[8]:https://opensource.com/file/361221
|
||||
[9]:https://opensource.com/file/361226
|
||||
[10]:https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop?rate=UcKbaJQJAbLScWVu8qm9bqii7JMsIswjfcBHt3aRnEU
|
||||
[11]:http://siyanpanayotov.com/project/viewnior/
|
||||
[12]:https://www.imagemagick.org/script/display.php
|
||||
[13]:http://www.graphicsmagick.org/display.html
|
||||
[14]:http://geeqie.org/
|
||||
[15]:https://wiki.gnome.org/Apps/Shotwell
|
||||
[16]:https://opensource.com/user/14925/feed
|
||||
[17]:https://www.flickr.com/photos/internetarchivebookimages/14758810172/in/photolist-oubL5m-ocu2ck-odJwF4-oeq1na-odgZbe-odcugD-w7KHtd-owgcWd-oucGPe-oud585-rgBDNf-obLoQH-oePNvs-osVgEq-othPLM-obHcKo-wQR3KN-oumGqG-odnCyR-owgLg3-x2Zeyq-hMMxbq-oeRzu1-oeY49i-odumMM-xH4oJo-odrT31-oduJr8-odX8B3-obKG8S-of1hTN-ovhHWY-ow7Scj-ovfm7B-ouu1Hj-ods7Sg-qwgw5G-oeYz5D-oeXqFZ-orx8d5-hKPN4Q-ouNKch-our8E1-odvGSH-oweGTn-ouJNQQ-ormX8L-od9XZ1-roZJPJ-ot7Wf4
|
||||
[18]:https://www.gimp.org/
|
||||
[19]:https://pinta-project.com/pintaproject/pinta/
|
||||
[20]:https://feh.finalrewind.org/
|
||||
[21]:https://docs.xfce.org/apps/ristretto/start
|
||||
[22]:http://mirageiv.sourceforge.net/
|
||||
[23]:https://en.wikipedia.org/wiki/Scalable_Vector_Graphics
|
||||
[24]:http://mirageiv.sourceforge.net/docs-advanced.html#cli
|
||||
[25]:http://nomacs.org/
|
||||
[26]:https://iptc.org/standards/photo-metadata/photo-metadata/
|
||||
[27]:http://nomacs.org/synchronization/
|
||||
[28]:https://opensource.com/users/scottnesbitt
|
||||
[29]:https://opensource.com/users/scottnesbitt
|
||||
[30]:https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop#comments
|
||||
@ -3,17 +3,14 @@
|
||||
|
||||
[][2]
|
||||
|
||||
**Apache Hadoop** 软件库是一个框架,它允许使用简单的编程模型在计算机集群上对大型数据集进行分布式处理。Apache™ Hadoop® 是可靠、可扩展、分布式计算的开源软件。
|
||||
Apache Hadoop 软件库是一个框架,它允许使用简单的编程模型在计算机集群上对大型数据集进行分布式处理。Apache™ Hadoop® 是可靠、可扩展、分布式计算的开源软件。
|
||||
|
||||
该项目包括以下模块:
|
||||
|
||||
* **Hadoop Common**:支持其他 Hadoop 模块的常用工具
|
||||
|
||||
* **Hadoop 分布式文件系统 (HDFS™)**:分布式文件系统,可提供对应用程序数据的高吞吐量访问
|
||||
|
||||
* **Hadoop YARN**:作业调度和集群资源管理框架。
|
||||
|
||||
* **Hadoop MapReduce**:一个基于 YARN 的大型数据集并行处理系统。
|
||||
* Hadoop Common:支持其他 Hadoop 模块的常用工具。
|
||||
* Hadoop 分布式文件系统 (HDFS™):分布式文件系统,可提供对应用程序数据的高吞吐量访问支持。
|
||||
* Hadoop YARN:作业调度和集群资源管理框架。
|
||||
* Hadoop MapReduce:一个基于 YARN 的大型数据集并行处理系统。
|
||||
|
||||
本文将帮助你逐步在 CentOS 上安装 hadoop 并配置单节点 hadoop 集群。
|
||||
|
||||
@ -30,7 +27,7 @@ Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)
|
||||
|
||||
要安装或更新 Java,请参考下面逐步的说明。
|
||||
|
||||
第一步是从[ Oracle 官方网站][3]下载最新版本的 java。
|
||||
第一步是从 [Oracle 官方网站][3]下载最新版本的 java。
|
||||
|
||||
```
|
||||
cd /opt/
|
||||
@ -58,7 +55,7 @@ There are 3 programs which provide 'java'.
|
||||
Enter to keep the current selection[+], or type selection number: 3 [Press Enter]
|
||||
```
|
||||
|
||||
现在你可能还需要使用alternatives 命令设置 javac 和 jar 命令路径。
|
||||
现在你可能还需要使用 `alternatives` 命令设置 `javac` 和 `jar` 命令路径。
|
||||
|
||||
```
|
||||
alternatives --install /usr/bin/jar jar /opt/jdk1.7.0_79/bin/jar 2
|
||||
@ -69,27 +66,27 @@ alternatives --set javac /opt/jdk1.7.0_79/bin/javac
|
||||
|
||||
下一步是配置环境变量。使用以下命令正确设置这些变量。
|
||||
|
||||
* 设置 **JAVA_HOME** 变量
|
||||
设置 `JAVA_HOME` 变量:
|
||||
|
||||
```
|
||||
export JAVA_HOME=/opt/jdk1.7.0_79
|
||||
```
|
||||
|
||||
* 设置 **JRE_HOME** 变量
|
||||
设置 `JRE_HOME` 变量:
|
||||
|
||||
```
|
||||
export JRE_HOME=/opt/jdk1.7.0_79/jre
|
||||
```
|
||||
|
||||
* 设置 **PATH** 变量
|
||||
设置 `PATH` 变量:
|
||||
|
||||
```
|
||||
export PATH=$PATH:/opt/jdk1.7.0_79/bin:/opt/jdk1.7.0_79/jre/bin
|
||||
```
|
||||
|
||||
### 安装 **Apache Hadoop**
|
||||
### 安装 Apache Hadoop
|
||||
|
||||
设置好 java 环境后。开始安装 **Apache Hadoop**。
|
||||
设置好 java 环境后。开始安装 Apache Hadoop。
|
||||
|
||||
第一步是创建用于 hadoop 安装的系统用户帐户。
|
||||
|
||||
@ -98,7 +95,7 @@ useradd hadoop
|
||||
passwd hadoop
|
||||
```
|
||||
|
||||
现在你需要配置用户 hadoop 的 ssh 密钥。使用以下命令启用无需密码的 ssh 登录。
|
||||
现在你需要配置用户 `hadoop` 的 ssh 密钥。使用以下命令启用无需密码的 ssh 登录。
|
||||
|
||||
```
|
||||
su - hadoop
|
||||
@ -119,7 +116,7 @@ mv hadoop-2.6.0 hadoop
|
||||
|
||||
下一步是设置 hadoop 使用的环境变量。
|
||||
|
||||
编辑 **~/.bashrc**,并在文件末尾添加以下这些值。
|
||||
编辑 `~/.bashrc`,并在文件末尾添加以下这些值。
|
||||
|
||||
```
|
||||
export HADOOP_HOME=/home/hadoop/hadoop
|
||||
@ -138,7 +135,7 @@ export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
编辑 **$HADOOP_HOME/etc/hadoop/hadoop-env.sh** 并设置 **JAVA_HOME** 环境变量。
|
||||
编辑 `$HADOOP_HOME/etc/hadoop/hadoop-env.sh` 并设置 `JAVA_HOME` 环境变量。
|
||||
|
||||
```
|
||||
export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
@ -149,10 +146,10 @@ export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
首先编辑 hadoop 配置文件并进行以下更改。
|
||||
|
||||
```
|
||||
cd /home/hadoop/hadoop/etc/hadoop
|
||||
cd /home/hadoop/hadoop/etc/hadoop
|
||||
```
|
||||
|
||||
让我们编辑 core-site.xml。
|
||||
让我们编辑 `core-site.xml`。
|
||||
|
||||
```
|
||||
<configuration>
|
||||
@ -163,7 +160,7 @@ export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
</configuration>
|
||||
```
|
||||
|
||||
接着编辑 hdfs-site.xml:
|
||||
接着编辑 `hdfs-site.xml`:
|
||||
|
||||
```
|
||||
<configuration>
|
||||
@ -184,7 +181,7 @@ export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
</configuration>
|
||||
```
|
||||
|
||||
并编辑 mapred-site.xml:
|
||||
并编辑 `mapred-site.xml`:
|
||||
|
||||
```
|
||||
<configuration>
|
||||
@ -195,7 +192,7 @@ export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
</configuration>
|
||||
```
|
||||
|
||||
最后编辑 yarn-site.xml:
|
||||
最后编辑 `yarn-site.xml`:
|
||||
|
||||
```
|
||||
<configuration>
|
||||
@ -220,7 +217,7 @@ start-dfs.sh
|
||||
start-yarn.sh
|
||||
```
|
||||
|
||||
要检查所有服务是否正常启动,请使用 “jps” 命令:
|
||||
要检查所有服务是否正常启动,请使用 `jps` 命令:
|
||||
|
||||
```
|
||||
jps
|
||||
@ -237,19 +234,19 @@ jps
|
||||
25807 NameNode
|
||||
```
|
||||
|
||||
现在,你可以在浏览器中访问 Hadoop 服务:**http://your-ip-address:8088/**。
|
||||
现在,你可以在浏览器中访问 Hadoop 服务:http://your-ip-address:8088/ 。
|
||||
|
||||
[][5]
|
||||
|
||||
谢谢!!!
|
||||
谢谢阅读!!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/setup-apache-hadoop-centos/
|
||||
|
||||
作者:[anismaj ][a]
|
||||
作者:[anismaj][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,41 +1,41 @@
|
||||
Samba 系列(十四):在命令行中将 CentOS 7 与 Samba4 AD 集成
|
||||
============================================================
|
||||
|
||||
本指南将向你介绍如何使用 Authconfig 在命令行中将无图形界面的 CentOS 7 服务器集成到[ Samba4 AD 域控制器][3]中。
|
||||
本指南将向你介绍如何使用 Authconfig 在命令行中将无图形界面的 CentOS 7 服务器集成到 [Samba4 AD 域控制器][3]中。
|
||||
|
||||
这类设置提供了由 Samba 持有的单一集中式帐户数据库,允许 AD 用户通过网络基础设施对 CentOS 服务器进行身份验证。
|
||||
|
||||
#### 要求
|
||||
|
||||
1. [在 Ubuntu 上使用 Samba4 创建 AD 基础架构][1]
|
||||
|
||||
2. [CentOS 7.3 安装指南][2]
|
||||
|
||||
### 步骤 1:为 Samba4 AD DC 配置 CentOS
|
||||
|
||||
1. 在开始将 CentOS 7 服务器加入 Samba4 DC 之前,你需要确保网络接口被正确配置为通过 DNS 服务查询域。
|
||||
1、 在开始将 CentOS 7 服务器加入 Samba4 DC 之前,你需要确保网络接口被正确配置为通过 DNS 服务查询域。
|
||||
|
||||
运行 [ip address][4] 命令列出你机器网络接口,选择要编辑的特定网卡,通过针对接口名称运行 nmtui-edit 命令(如本例中的 ens33),如下所示。
|
||||
运行 `ip address` 命令列出你机器网络接口,选择要编辑的特定网卡,通过针对接口名称运行 `nmtui-edit` 命令(如本例中的 ens33),如下所示。
|
||||
|
||||
```
|
||||
# ip address
|
||||
# nmtui-edit ens33
|
||||
```
|
||||
[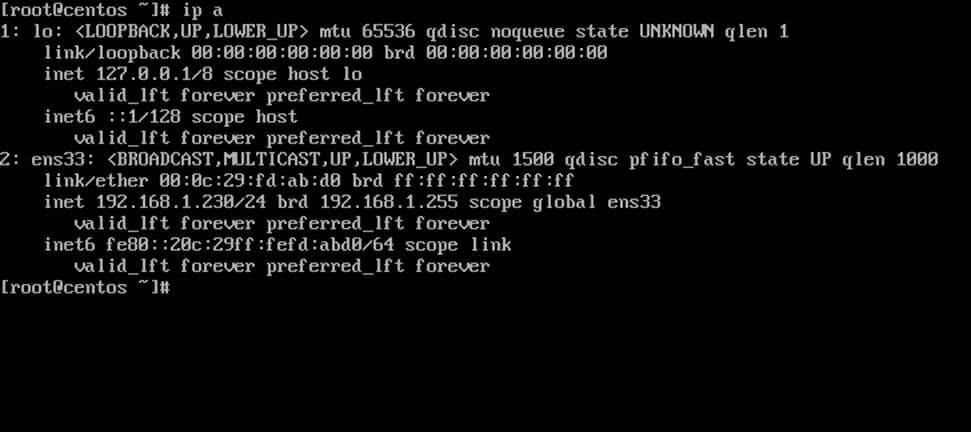][5]
|
||||
|
||||
列出网络接口
|
||||
[][5]
|
||||
|
||||
2. 打开网络接口进行编辑后,添加最适合 LAN 的静态 IPv4 配置,并确保为 DNS 服务器设置 Samba AD 域控制器 IP 地址。
|
||||
*列出网络接口*
|
||||
|
||||
2、 打开网络接口进行编辑后,添加最适合 LAN 的静态 IPv4 配置,并确保为 DNS 服务器设置 Samba AD 域控制器 IP 地址。
|
||||
|
||||
另外,在搜索域中追加你的域的名称,并使用 [TAB] 键跳到确定按钮来应用更改。
|
||||
|
||||
当你仅对域 dns 记录使用短名称时, 已提交的搜索域保证域对应项会自动追加到 dns 解析 (FQDN) 中。
|
||||
|
||||
[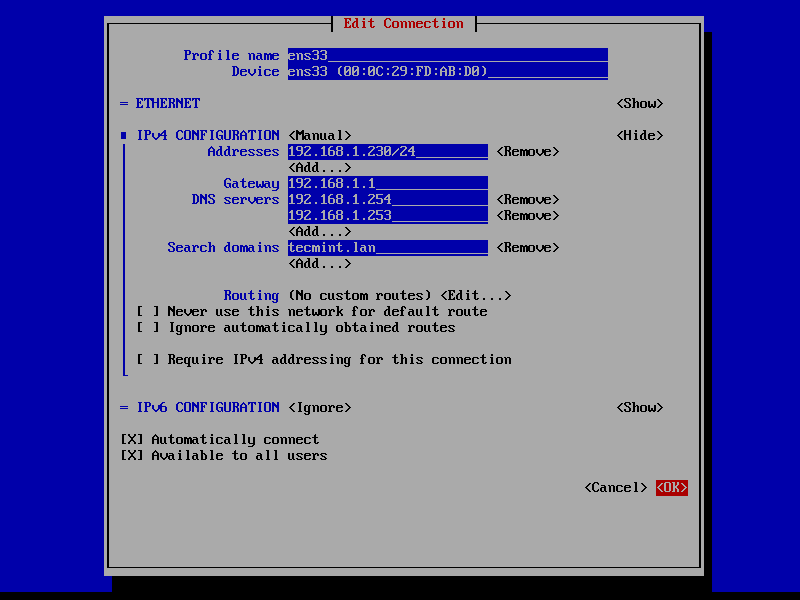][6]
|
||||
[][6]
|
||||
|
||||
配置网络接口
|
||||
*配置网络接口*
|
||||
|
||||
3.最后,重启网络守护进程以应用更改,并通过对域名和域控制器 ping 来测试 DNS 解析是否正确配置,如下所示。
|
||||
3、最后,重启网络守护进程以应用更改,并通过对域名和域控制器 ping 来测试 DNS 解析是否正确配置,如下所示。
|
||||
|
||||
```
|
||||
# systemctl restart network.service
|
||||
@ -43,11 +43,12 @@ Samba 系列(十四):在命令行中将 CentOS 7 与 Samba4 AD 集成
|
||||
# ping -c2 adc1
|
||||
# ping -c2 adc2
|
||||
```
|
||||
[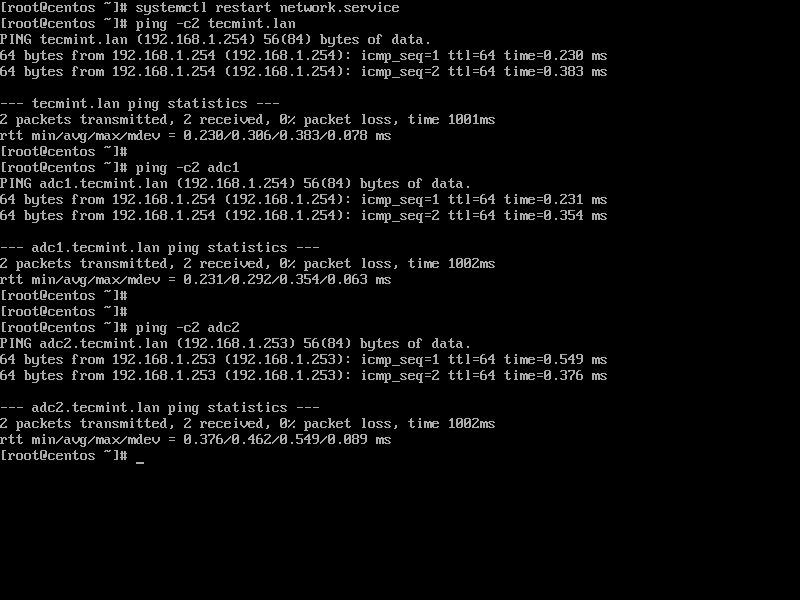][7]
|
||||
|
||||
验证域上的 DNS 解析
|
||||
[][7]
|
||||
|
||||
4. 另外,使用下面的命令配置你的计算机主机名并重启机器应用更改。
|
||||
*验证域上的 DNS 解析*
|
||||
|
||||
4、 另外,使用下面的命令配置你的计算机主机名并重启机器应用更改。
|
||||
|
||||
```
|
||||
# hostnamectl set-hostname your_hostname
|
||||
@ -61,25 +62,26 @@ Samba 系列(十四):在命令行中将 CentOS 7 与 Samba4 AD 集成
|
||||
# hostname
|
||||
```
|
||||
|
||||
5. 最后,使用 root 权限运行以下命令,与 Samba4 AD DC 同步本地时间。
|
||||
5、 最后,使用 root 权限运行以下命令,与 Samba4 AD DC 同步本地时间。
|
||||
|
||||
```
|
||||
# yum install ntpdate
|
||||
# ntpdate domain.tld
|
||||
```
|
||||
[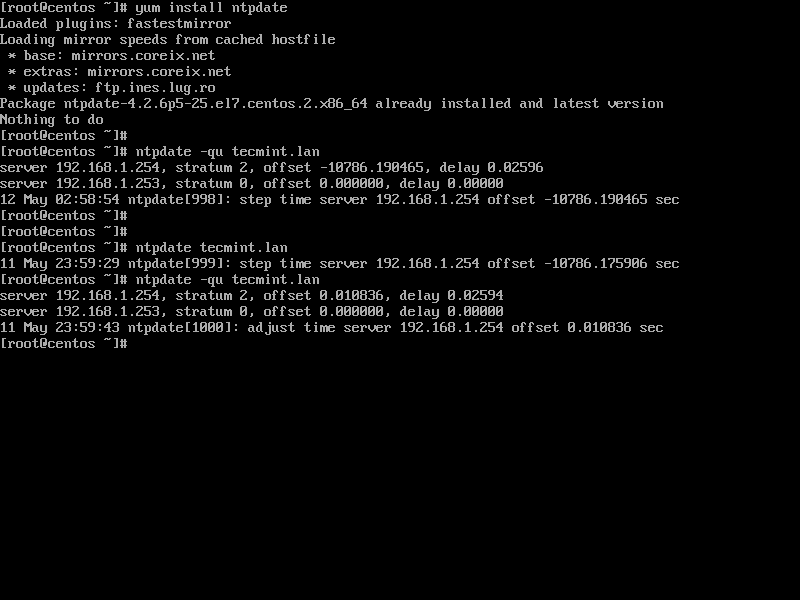][8]
|
||||
|
||||
与 Samba4 AD DC 同步时间
|
||||
[][8]
|
||||
|
||||
*与 Samba4 AD DC 同步时间*
|
||||
|
||||
### 步骤 2:将 CentOS 7 服务器加入到 Samba4 AD DC
|
||||
|
||||
6. 要将 CentOS 7 服务器加入到 Samba4 AD 中,请先用具有 root 权限的帐户在计算机上安装以下软件包。
|
||||
6、 要将 CentOS 7 服务器加入到 Samba4 AD 中,请先用具有 root 权限的帐户在计算机上安装以下软件包。
|
||||
|
||||
```
|
||||
# yum install authconfig samba-winbind samba-client samba-winbind-clients
|
||||
```
|
||||
|
||||
7. 为了将 CentOS 7 服务器与域控制器集成,可以使用 root 权限运行 authconfig-tui,并使用下面的配置。
|
||||
7、 为了将 CentOS 7 服务器与域控制器集成,可以使用 root 权限运行 `authconfig-tui`,并使用下面的配置。
|
||||
|
||||
```
|
||||
# authconfig-tui
|
||||
@ -89,53 +91,46 @@ Samba 系列(十四):在命令行中将 CentOS 7 与 Samba4 AD 集成
|
||||
|
||||
* 在 User Information 中:
|
||||
* Use Winbind
|
||||
|
||||
* 在 Authentication 中使用[空格键]选择:
|
||||
* Use Shadow Password
|
||||
|
||||
* Use Winbind Authentication
|
||||
|
||||
* Local authorization is sufficient
|
||||
|
||||
[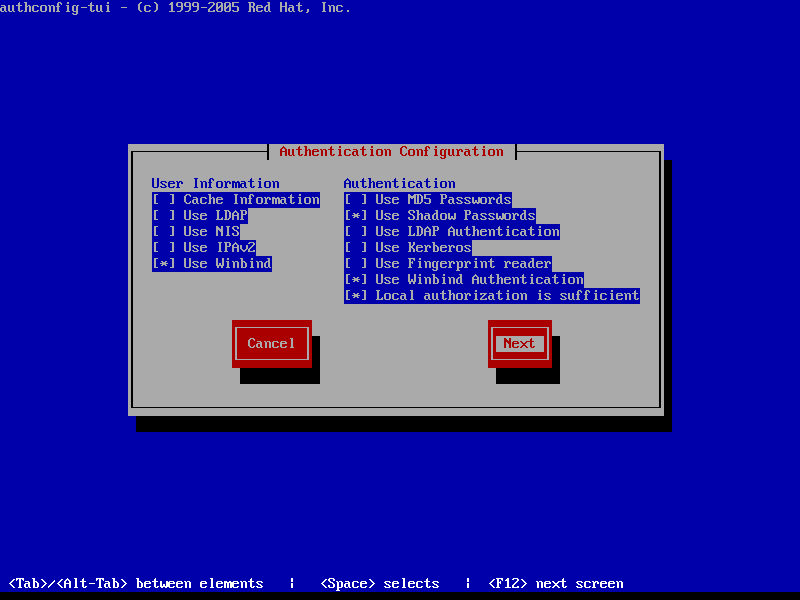][9]
|
||||
[][9]
|
||||
|
||||
验证配置
|
||||
*验证配置*
|
||||
|
||||
8. 点击 Next 进入 Winbind 设置界面并配置如下:
|
||||
8、 点击 Next 进入 Winbind 设置界面并配置如下:
|
||||
|
||||
* Security Model: ads
|
||||
|
||||
* Domain = YOUR_DOMAIN (use upper case)
|
||||
|
||||
* Domain Controllers = domain machines FQDN (comma separated if more than one)
|
||||
|
||||
* ADS Realm = YOUR_DOMAIN.TLD
|
||||
|
||||
* Template Shell = /bin/bash
|
||||
|
||||
[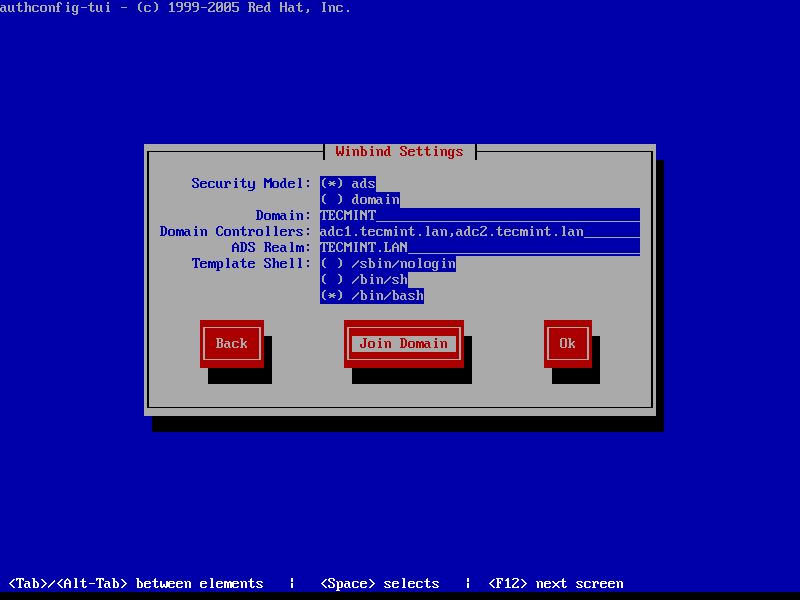][10]
|
||||
[][10]
|
||||
|
||||
Winbind 设置
|
||||
*Winbind 设置*
|
||||
|
||||
9. 要加入域,使用 [tab] 键跳到 “Join Domain” 按钮,然后按[回车]键加入域。
|
||||
9、 要加入域,使用 [tab] 键跳到 “Join Domain” 按钮,然后按[回车]键加入域。
|
||||
|
||||
在下一个页面,添加具有提升权限的 Samba4 AD 帐户的凭据,以将计算机帐户加入 AD,然后单击 “OK” 应用设置并关闭提示。
|
||||
|
||||
请注意,当你输入用户密码时,凭据将不会显示在屏幕中。在下面再次点击 OK,完成 CentOS 7 的域集成。
|
||||
|
||||
[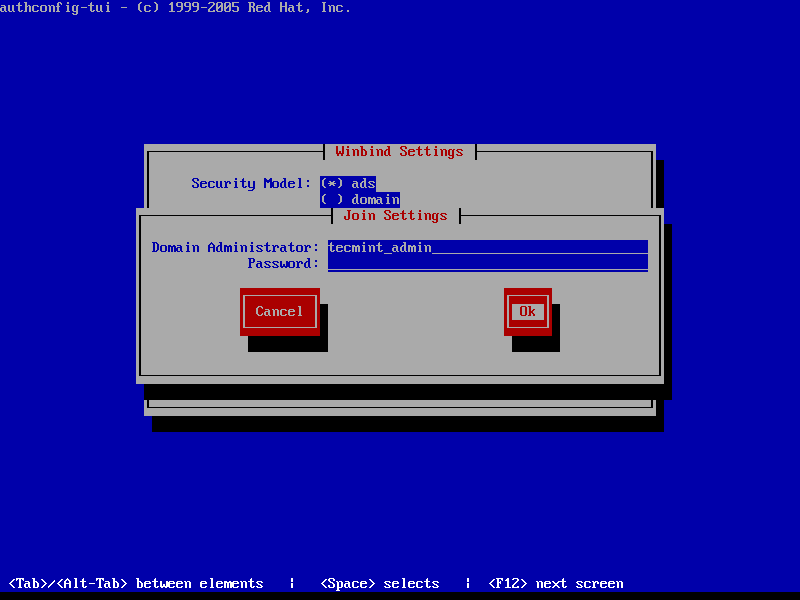][11]
|
||||
[][11]
|
||||
|
||||
加入域到 Samba4 AD DC
|
||||
*加入域到 Samba4 AD DC*
|
||||
|
||||
[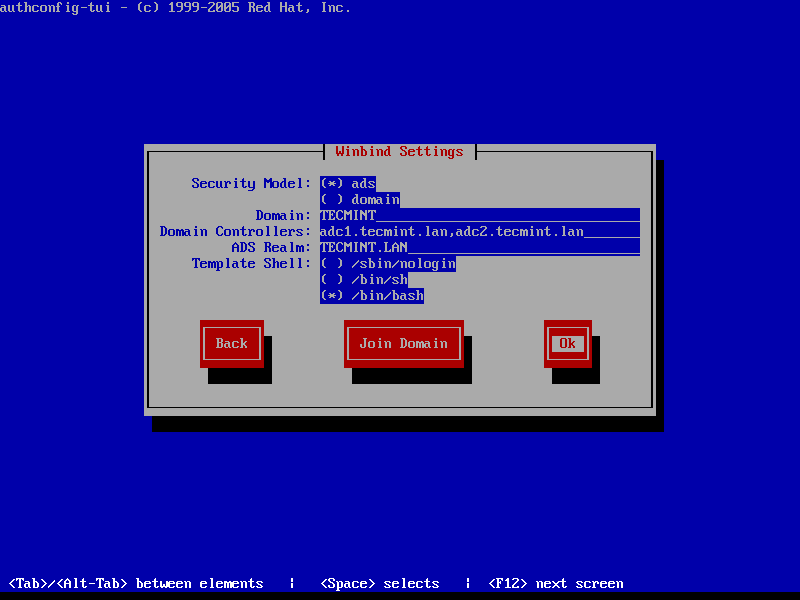][12]
|
||||
[][12]
|
||||
|
||||
确认 Winbind 设置
|
||||
*确认 Winbind 设置*
|
||||
|
||||
要强制将机器添加到特定的 Samba AD OU 中,请使用 hostname 命令获取计算机的完整名称,并使用机器名称在该 OU 中创建一个新的计算机对象。
|
||||
|
||||
将新对象添加到 Samba4 AD 中的最佳方法是已经集成到[安装了 RSAT 工具][13]的域的 Wubdows 机器上使用 ADUC 工具。
|
||||
将新对象添加到 Samba4 AD 中的最佳方法是已经集成到[安装了 RSAT 工具][13]的域的 Windows 机器上使用 ADUC 工具。
|
||||
|
||||
重要:加入域的另一种方法是使用 authconfig 命令行,它可以对集成过程进行广泛的控制。
|
||||
重要:加入域的另一种方法是使用 `authconfig` 命令行,它可以对集成过程进行广泛的控制。
|
||||
|
||||
但是,这种方法很容易因为其众多参数造成错误,如下所示。该命令必须输入一条长命令行。
|
||||
|
||||
@ -143,92 +138,97 @@ Winbind 设置
|
||||
# authconfig --enablewinbind --enablewinbindauth --smbsecurity ads --smbworkgroup=YOUR_DOMAIN --smbrealm YOUR_DOMAIN.TLD --smbservers=adc1.yourdomain.tld --krb5realm=YOUR_DOMAIN.TLD --enablewinbindoffline --enablewinbindkrb5 --winbindtemplateshell=/bin/bash--winbindjoin=domain_admin_user --update --enablelocauthorize --savebackup=/backups
|
||||
```
|
||||
|
||||
10. 机器加入域后,通过使用以下命令验证 winbind 服务是否正常运行。
|
||||
10、 机器加入域后,通过使用以下命令验证 winbind 服务是否正常运行。
|
||||
|
||||
```
|
||||
# systemctl status winbind.service
|
||||
```
|
||||
|
||||
11. 接着检查是否在 Samba4 AD 中成功创建了 CentOS 机器对象。从安装了 RSAT 工具的 Windows 机器使用 AD 用户和计算机工具,并进入到你的域计算机容器。一个名为 CentOS 7 Server 的新 AD 计算机帐户对象应该在右边的列表中。
|
||||
11、 接着检查是否在 Samba4 AD 中成功创建了 CentOS 机器对象。从安装了 RSAT 工具的 Windows 机器使用 AD 用户和计算机工具,并进入到你的域计算机容器。一个名为 CentOS 7 Server 的新 AD 计算机帐户对象应该在右边的列表中。
|
||||
|
||||
12. 最后,使用文本编辑器打开 samba 主配置文件(/etc/samba/smb.conf)来调整配置,并在 [global] 配置块的末尾附加以下行,如下所示:
|
||||
12、 最后,使用文本编辑器打开 samba 主配置文件(`/etc/samba/smb.conf`)来调整配置,并在 `[global]` 配置块的末尾附加以下行,如下所示:
|
||||
|
||||
```
|
||||
winbind use default domain = true
|
||||
winbind offline logon = true
|
||||
```
|
||||
[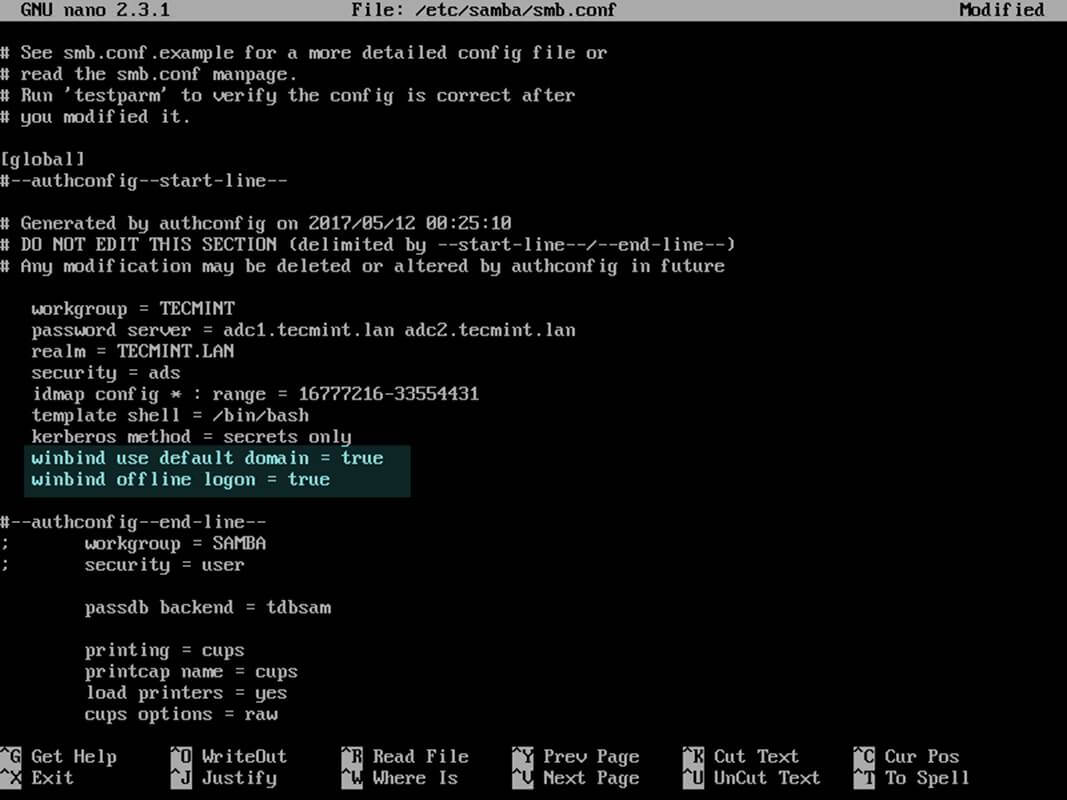][14]
|
||||
|
||||
配置 Samba
|
||||
[][14]
|
||||
|
||||
13. 为了在 AD 帐户首次登录时在机器上创建本地家目录,请运行以下命令
|
||||
*配置 Samba*
|
||||
|
||||
13、 为了在 AD 帐户首次登录时在机器上创建本地家目录,请运行以下命令:
|
||||
|
||||
```
|
||||
# authconfig --enablemkhomedir --update
|
||||
```
|
||||
|
||||
14. 最后,重启 Samba 守护进程使更改生效,并使用一个 AD 账户登陆验证域加入。AD 帐户的家目录应该会自动创建。
|
||||
14、 最后,重启 Samba 守护进程使更改生效,并使用一个 AD 账户登陆验证域加入。AD 帐户的家目录应该会自动创建。
|
||||
|
||||
```
|
||||
# systemctl restart winbind
|
||||
# su - domain_account
|
||||
```
|
||||
[][15]
|
||||
|
||||
验证域加入
|
||||
[][15]
|
||||
|
||||
15. 通过以下命令之一列出域用户或域组。
|
||||
*验证域加入*
|
||||
|
||||
15、 通过以下命令之一列出域用户或域组。
|
||||
|
||||
```
|
||||
# wbinfo -u
|
||||
# wbinfo -g
|
||||
```
|
||||
[][16]
|
||||
|
||||
列出域用户和组
|
||||
[][16]
|
||||
|
||||
16. 要获取有关域用户的信息,请运行以下命令。
|
||||
*列出域用户和组*
|
||||
|
||||
16、 要获取有关域用户的信息,请运行以下命令。
|
||||
|
||||
```
|
||||
# wbinfo -i domain_user
|
||||
```
|
||||
[][17]
|
||||
|
||||
列出域用户信息
|
||||
[][17]
|
||||
|
||||
17. 要显示域摘要信息,请使用以下命令。
|
||||
*列出域用户信息*
|
||||
|
||||
17、 要显示域摘要信息,请使用以下命令。
|
||||
|
||||
```
|
||||
# net ads info
|
||||
```
|
||||
[][18]
|
||||
|
||||
列出域摘要
|
||||
[][18]
|
||||
|
||||
*列出域摘要*
|
||||
|
||||
### 步骤 3:使用 Samba4 AD DC 帐号登录CentOS
|
||||
|
||||
18. 要在 CentOS 中与域用户进行身份验证,请使用以下命令语法之一。
|
||||
18、 要在 CentOS 中与域用户进行身份验证,请使用以下命令语法之一。
|
||||
|
||||
```
|
||||
# su - ‘domain\domain_user’
|
||||
# su - domain\\domain_user
|
||||
```
|
||||
|
||||
或者使用下面的语法来防止 winbind 使用 default domain = true 参数来设置 samba 配置文件。
|
||||
或者在 samba 配置文件中设置了 `winbind use default domain = true` 参数的情况下,使用下面的语法。
|
||||
|
||||
```
|
||||
# su - domain_user
|
||||
# su - domain_user@domain.tld
|
||||
```
|
||||
|
||||
19. 要为域用户或组添加 root 权限,请使用 visudocommand 编辑 sudoers 文件,并添加以下截图所示的行。
|
||||
19、 要为域用户或组添加 root 权限,请使用 `visudocommand` 编辑 `sudoers` 文件,并添加以下截图所示的行。
|
||||
|
||||
```
|
||||
YOUR_DOMAIN\\domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
%YOUR_DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||
```
|
||||
|
||||
如果 winbind 使用 default domain = true 参数设置 samba 配置文件,那么使用下面的配置。
|
||||
或者在 samba 配置文件中设置了 `winbind use default domain = true` 参数的情况下,使用下面的语法。
|
||||
|
||||
```
|
||||
domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
@ -236,9 +236,9 @@ domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
```
|
||||
[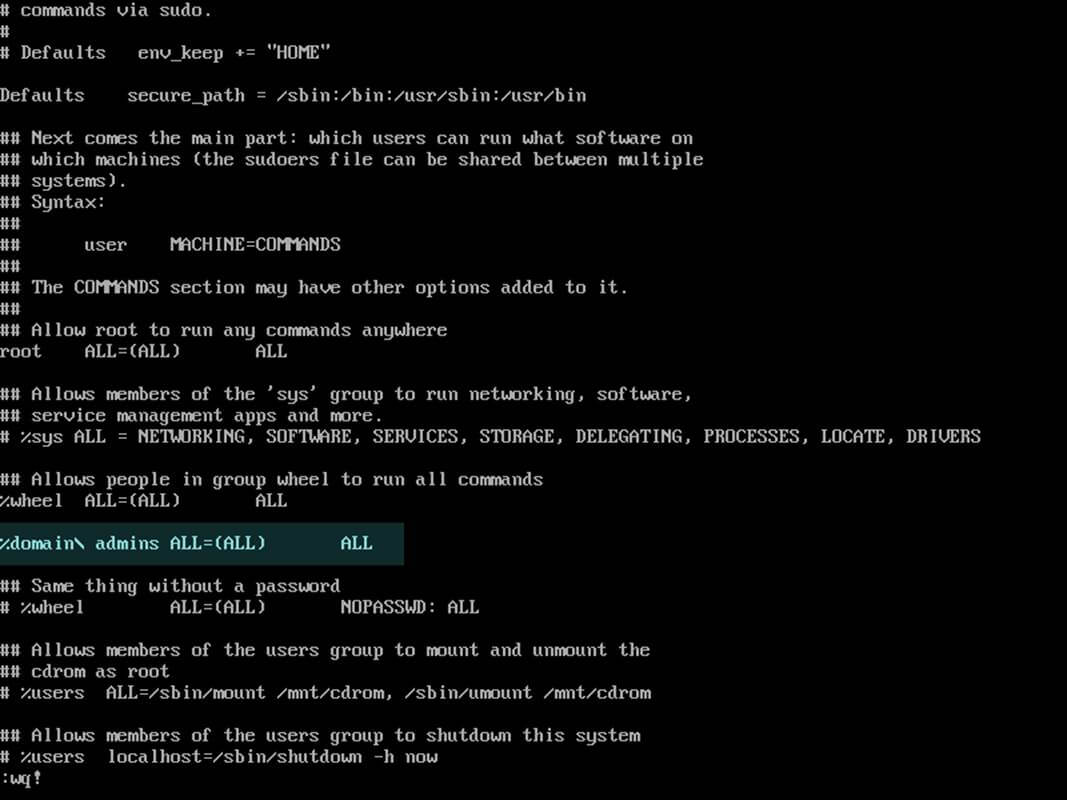][19]
|
||||
|
||||
授予域用户 root 权限
|
||||
*授予域用户 root 权限*
|
||||
|
||||
20. 针对 Samba4 AD DC 的以下一系列命令也可用于故障排除:
|
||||
20、 针对 Samba4 AD DC 的以下一系列命令也可用于故障排除:
|
||||
|
||||
```
|
||||
# wbinfo -p #Ping domain
|
||||
@ -246,7 +246,7 @@ domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
# wbinfo -t #Check trust relationship
|
||||
```
|
||||
|
||||
21. 要离开该域, 请使用具有提升权限的域帐户对你的域名运行以下命令。从 AD 中删除计算机帐户后, 重启计算机以在集成进程之前还原更改。
|
||||
21、 要离开该域, 请使用具有提升权限的域帐户对你的域名运行以下命令。从 AD 中删除计算机帐户后, 重启计算机以在集成进程之前还原更改。
|
||||
|
||||
```
|
||||
# net ads leave -w DOMAIN -U domain_admin
|
||||
@ -259,23 +259,22 @@ domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
|
||||
作者简介:
|
||||
|
||||
Matei Cezar
|
||||
我是一个电脑上瘾的家伙,开源和基于 linux 的系统软件的粉丝,在 Linux 发行版桌面、服务器和 bash 脚本方面拥有大约 4 年的经验。
|
||||
Matei Cezar - 我是一个电脑上瘾的家伙,开源和基于 linux 的系统软件的粉丝,在 Linux 发行版桌面、服务器和 bash 脚本方面拥有大约 4 年的经验。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/integrate-centos-7-to-samba4-active-directory/
|
||||
|
||||
作者:[Matei Cezar ][a]
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:https://www.tecmint.com/centos-7-3-installation-guide/
|
||||
[3]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[1]:https://linux.cn/article-8065-1.html
|
||||
[2]:https://linux.cn/article-8048-1.html
|
||||
[3]:https://linux.cn/article-8065-1.html
|
||||
[4]:https://www.tecmint.com/ip-command-examples/
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Network-Interfaces.jpg
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Network-Interface.png
|
||||
@ -285,7 +284,7 @@ via: https://www.tecmint.com/integrate-centos-7-to-samba4-active-directory/
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/07/Winbind-Settings.png
|
||||
[11]:https://www.tecmint.com/wp-content/uploads/2017/07/Join-Domain-to-Samba4-AD-DC.png
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/07/Confirm-Winbind-Settings.png
|
||||
[13]:https://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[13]:https://linux.cn/article-8097-1.html
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Samba.jpg
|
||||
[15]:https://www.tecmint.com/wp-content/uploads/2017/07/Verify-Domain-Joining.jpg
|
||||
[16]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Users-and-Groups.png
|
||||
@ -1,33 +1,30 @@
|
||||
如何建模可以帮助你避免在 OpenStack 中遇到问题
|
||||
============================================================
|
||||
|
||||
|
||||
### 分享或保存
|
||||
|
||||

|
||||
|
||||
_乐高的空客 A380-800模型。空客运行 OpenStack_
|
||||
|
||||
“StuckStack” 是 OpenStack 的一种部署方式,通常由于技术上但有时是商业上的原因,它无法在没有明显中断、时间和费用的情况下升级。在关于这个话题的最后一篇文章中,我们讨论了这些云中有多少陷入僵局,当时的决定与当今大部分的智慧是一致的。现在 OpenStack 已经有 7 年了,最近随着容器编排系统的增长以及更多企业开始利用公共和私有的云平台,OpenStack 正面临着压力。
|
||||
OpenStack 部署完就是一个 “<ruby>僵栈<rt>StuckStack</rt></ruby>”,一般出于技术原因,但有时是商业上的原因,它是无法在没有明显中断,也不花费时间和成本的情况下升级的。在关于这个话题的最后一篇文章中,我们讨论了这些云中有多少陷入僵局,以及当时是怎么决定的与如今的大部分常识相符。现在 OpenStack 已经有 7 年了,最近随着容器编排系统的增长以及更多企业开始利用公共和私有的云平台,OpenStack 正面临着压力。
|
||||
|
||||
|
||||
### 没有魔法解决方案
|
||||
|
||||
如果你仍在寻找一个解决方案来没有任何问题地升级你现有的 StuckStack, 那么我有坏消息给你: 有没有魔法解决方案, 你最好集中精力建立一个标准化的平台, 它可以有效地操作和升级。
|
||||
如果你仍在寻找一个可以没有任何问题地升级你现有的 <ruby>僵栈<rt>StuckStack</rt></ruby> 的解决方案,那么我有坏消息给你:没有魔法解决方案,你最好集中精力建立一个标准化的平台,它可以有效地运营和轻松地升级。
|
||||
|
||||
低成本航空业已经表明, 虽然乘客可能渴望最好的体验, 可以坐在头等舱或者商务舱喝香槟, 有足够的空间放松, 但是大多数人会选择乘坐最便宜的, 最终价值等式不保证他们付出更多的代价。工作负载是相同的。长期而言, 工作负载将运行在最经济的平台上, 因为在高价硬件或软件上运行的业务实际上并没有受益。
|
||||
廉价航空业已经表明,虽然乘客可能渴望最好的体验,可以坐在头等舱或者商务舱喝香槟,有足够的空间放松,但是大多数人会选择乘坐最便宜的,最终价值等式不要让他们付出更多的代价。工作负载是相同的。长期而言,工作负载将运行在最经济的平台上,因为在高价硬件或软件上运行的业务实际上并没有受益。
|
||||
|
||||
Amazon、Microsoft、Google 等大型公共云企业都知道,这就是为什么他们建立了高效的数据中心, 并使用模型来构建、操作和扩展基础设施。长期以来,企业一直奉行以设计、制造、市场、定价、销售,实施为一体的最优秀的硬件和软件基础设施。现实可能并不总是符合承诺,但由于成本模式在当今世界无法生存,所以现在还不重要。一些组织试图通过改用免费软件替代, 而不改变自己的行为来解决这一问题。因此, 他们发现, 他们只是将成本从软件获取变到软件操作。好消息是,那些高效运营的大型运营商使用的技术,现在可用于所有类型的组织。
|
||||
Amazon、Microsoft、Google 等大型公共云企业都知道,这就是为什么他们建立了高效的数据中心,并使用模型来构建、操作和扩展基础设施。长期以来,企业一直奉行以设计、制造、市场、定价、销售、实施为一体的最优秀的硬件和软件基础设施。现实可能并不总是符合承诺,但它现在还不重要,因为<ruby>成本模式<rt>cost model</rt></ruby>在当今世界无法生存。一些组织试图通过改用免费软件替代,而不改变自己的行为来解决这一问题。因此,他们发现,他们只是将成本从获取软件变到运营软件上。好消息是,那些高效运营的大型运营商使用的技术,现在可用于所有类型的组织。
|
||||
|
||||
### 什么是软件模型?
|
||||
|
||||
虽然许多年来, 软件程序由许多对象、进程和服务组成, 但近年来, 程序是普遍由许多单独的服务组成, 它们高度分布式地分布在数据中心的不同服务器以及跨越数据中心的服务器上。
|
||||
虽然许多年来,软件程序由许多对象、进程和服务而组成,但近年来,程序是普遍由许多单独的服务组成,它们高度分布在数据中心的不同服务器以及跨越数据中心的服务器上。
|
||||
|
||||

|
||||
|
||||
_OpenStack 服务的简单演示_
|
||||
|
||||
许多服务意味着许多软件需要配置、管理并跟踪许多物理机器。以成本效益的方式规模化地进行这一工作需要一个模型,即所有组件如何连接以及它们如何映射到物理资源。为了构建模型,我们需要有一个软件组件库,这是一种定义它们如何彼此连接以及将其部署到平台上的方法,无论是物理还是虚拟。在 Canonical 公司,我们几年前就认识到这一点,并建立了一个通用的软件建模工具 [Juju][2],使得运营商能够从 100 个通用软件服务目录中组合灵活的拓扑结构、架构和部署目标。
|
||||
许多服务意味着许多软件需要配置、管理并跟踪许多物理机器。以成本效益的方式规模化地进行这一工作需要一个模型,即所有组件如何连接以及它们如何映射到物理资源。为了构建模型,我们需要有一个软件组件库,这是一种定义它们如何彼此连接以及将其部署到平台上的方法,无论是物理的还是虚拟的。在 Canonical 公司,我们几年前就认识到这一点,并建立了一个通用的软件建模工具 [Juju][2],使得运营商能够从 100 个通用软件服务目录中组合灵活的拓扑结构、架构和部署目标。
|
||||
|
||||

|
||||
|
||||
@ -35,13 +32,13 @@ Amazon、Microsoft、Google 等大型公共云企业都知道,这就是为什
|
||||
|
||||
在 Juju 中,软件服务被定义为一种叫做 Charm 的东西。 Charms 是代码片段,它通常用 python 或 bash 编写,其中提供有关服务的信息 - 声明的接口、服务的安装方式、可连接的其他服务等。
|
||||
|
||||
Charms 可以简单或者复杂,具体取决于你想要赋予的功能。对于 OpenStack,Canonical 在上游 OpenStack 社区的帮助下,为主要 OpenStack 服务开发了一套完整的 Charms。Charms 代表了模型的说明,使其可以轻松地部署、操作扩展和复制。Charms 还定义了如何升级自身,包括在需要时执行升级的顺序以及如何在需要时优雅地暂停和恢复服务。通过将 Juju 连接到诸如[裸机即服务(MAAS)][3]这样的裸机配置系统,其中 OpenStack 的逻辑模型可以部署到物理硬件上。默认情况下,Charms 将在 LXC 容器中部署服务,从而根据云行为的需要, 提供更大的灵活性来重新定位服务。配置在 Charms 中定义,或者在部署时由第三方工具(如 Puppet 或 Chef)注入。
|
||||
Charms 可以简单或者复杂,具体取决于你想要赋予的功能。对于 OpenStack,Canonical 在上游 OpenStack 社区的帮助下,为主要 OpenStack 服务开发了一套完整的 Charms。Charms 代表了模型的说明,使其可以轻松地部署、操作扩展和复制。Charms 还定义了如何升级自身,包括在需要时执行升级的顺序以及如何在需要时优雅地暂停和恢复服务。通过将 Juju 连接到诸如 [裸机即服务(MAAS)][3] 这样的裸机配置系统,其中 OpenStack 的逻辑模型可以部署到物理硬件上。默认情况下,Charms 将在 LXC 容器中部署服务,从而根据云行为的需要,提供更大的灵活性来重新定位服务。配置在 Charms 中定义,或者在部署时由第三方工具(如 Puppet 或 Chef)注入。
|
||||
|
||||
这种方法有两个不同的好处:1 - 通过创建一个模型,我们从底层硬件抽象出每个云服务。2 - 使用已知来源的标准化组件,通过迭代组合新的架构。这种一致性使我们能够使用相同的工具部署非常不同的云架构,运行和升级这些工具是安全的。
|
||||
|
||||
通过全面自动化的配置工具和软件程序来管理硬件库存,运营商可以比使用传统企业技术或构建偏离核心的定制系统更有效地扩展基础架构。有价值的开发资源可以集中在创新应用领域,使新的软件服务更快上线,而不是改变标准的商品基础设施, 这将会导致进一步的兼容性问题。
|
||||
通过全面自动化的配置工具和软件程序来管理硬件库存,运营商可以比使用传统企业技术或构建偏离核心的定制系统更有效地扩展基础架构。有价值的开发资源可以集中在创新应用领域,使新的软件服务更快上线,而不是改变标准的商品基础设施,这将会导致进一步的兼容性问题。
|
||||
|
||||
在下一篇文章中,我将介绍部署完全建模的 OpenStack 的一些最佳实践,以及如何快速地进行操作。如果你有一个现有的 StuckStack, 那么虽然我们不能很容易地拯救它, 但是与公有云相比,我们将能够让你走上一条完全支持的、高效的基础架构以及运营成本的道路。
|
||||
在下一篇文章中,我将介绍部署完全建模的 OpenStack 的一些最佳实践,以及如何快速地进行操作。如果你有一个现有的 <ruby>僵栈<rt>StuckStack</rt></ruby>,那么虽然我们不能很容易地拯救它,但是与公有云相比,我们将能够让你走上一条完全支持的、高效的基础架构以及运营成本的道路。
|
||||
|
||||
### 即将举行的网络研讨会
|
||||
|
||||
@ -62,9 +59,9 @@ Charms 可以简单或者复杂,具体取决于你想要赋予的功能。对
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/18/stuckstack-how-modelling-helps-you-avoid-getting-a-stuck-openstack/
|
||||
|
||||
作者:[Mark Baker ][a]
|
||||
作者:[Mark Baker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,62 +1,56 @@
|
||||
Docker 领导 OCI 发布容器运行时和镜像格式规范 V1.0
|
||||
OCI 发布容器运行时和镜像格式规范 V1.0
|
||||
============================================================
|
||||
|
||||
今天是开放容器计划(OCI)的一个重要里程碑,OCI 发布了容器运行时和镜像规范的 1.0 版本,而Docker 在这过去两年中一直充当着驱动和领航的核心角色。我们的目标是为社区、客户以及更广泛的容器行业提供底层的标准。要了解这一里程碑的意义,我们先来看看 Docker 在开发容器技术行业标准方面的成长和发展历史。
|
||||
7 月 19 日是<ruby>开放容器计划<rt>Open Container Initiative</rt></ruby>(OCI)的一个重要里程碑,OCI 发布了容器运行时和镜像规范的 1.0 版本,而 Docker 在这过去两年中一直充当着推动和引领的核心角色。我们的目标是为社区、客户以及更广泛的容器行业提供底层的标准。要了解这一里程碑的意义,我们先来看看 Docker 在开发容器技术行业标准方面的成长和发展历史。
|
||||
|
||||
**Docker 将运行时和镜像捐赠给 OCI 的历史**
|
||||
### Docker 将运行时和镜像捐赠给 OCI 的历史回顾
|
||||
|
||||
Docker 的镜像格式和容器运行时在 2013 年作为开源项目发布后,迅速成为事实上的标准。我们认识到将其转交给中立管理机构管理,以加强创新和防止行业碎片化的重要性。我们与广泛的容器技术人员和行业领导者合作,成立了开放容器项目(Open Container Project)来制定了一套容器标准,并在 Linux 基金会的支持下,于 2015 年 6 月在 Docker 大会(DockerCon)上推出。最终在那个夏天演变成为开放容器计划(Open Container Initiative ,OCI)。
|
||||
Docker 的镜像格式和容器运行时在 2013 年作为开源项目发布后,迅速成为事实上的标准。我们认识到将其转交给中立管理机构管理,以加强创新和防止行业碎片化的重要性。我们与广泛的容器技术人员和行业领导者合作,成立了<ruby>开放容器项目<rt>Open Container Project</rt></ruby>来制定了一套容器标准,并在 Linux 基金会的支持下,于 2015 年 6 月在 Docker 大会(DockerCon)上推出。最终在那个夏天演变成为<ruby>开放容器计划<rt>Open Container Initiative</rt></ruby> (OCI)。
|
||||
|
||||
Docker 贡献了 runc ,这是从 Docker 员工 [Michael Crosby][17] 的 libcontainer 项目中发展而来的容器运行时参考实现。 runc 是描述容器生命周期和运行时行为的运行时规范的基础。runc 被用在数千万个节点的生产环境中,这比任何其他代码库都要大一个数量级。runc 已经成为运行时规范的参考实现,并且随着项目的进展而不断发展。
|
||||
Docker 贡献了 runc ,这是从 Docker 员工 [Michael Crosby][17] 的 libcontainer 项目中发展而来的容器运行时参考实现。 runc 是描述容器生命周期和运行时行为的运行时规范的基础。runc 被用在数千万个节点的生产环境中,这比任何其它代码库都要大一个数量级。runc 已经成为运行时规范的参考实现,并且随着项目的进展而不断发展。
|
||||
|
||||
在运行时规范制定工作开始近一年后,我们组建了一个新的工作组来制定镜像格式的规范。 Docker 将 Docker V2 镜像格式捐赠给 OCI 作为镜像规范的基础。通过这次捐赠,OCI 定义了构成容器镜像的数据结构(原始镜像)。定义容器镜像格式是一个至关重要的步骤,但它需要一个像 Docker 这样的平台通过定义和提供构建、管理和发布镜像的工具来实现它的价值。 例如,Dockerfile 等内容并不包括在 OCI 规范中。
|
||||
|
||||
**标题:Docker 为 OCI 贡献的历史**
|
||||

|
||||
|
||||

|
||||
### 开放容器标准化之旅
|
||||
|
||||
**开放容器标准化之旅**
|
||||
这个规范已经持续开发了两年。随着代码的重构,更小型的项目已经从 runc 参考实现中脱颖而出,并支持即将发布的认证测试工具。
|
||||
|
||||
这个规范已经持续开发了两年。随着代码的重构,小型项目已经从 runc 参考实现中脱颖而出,并支持即将发布的认证测试工具。
|
||||
有关 Docker 参与塑造 OCI 的详细信息,请参阅上面的时间轴,其中包括:创建 runc ,和社区一起更新、迭代运行时规范,创建 containerd 以便于将 runc 集成到 Docker 1.11 中,将 Docker V2 镜像格式贡献给 OCI 作为镜像格式规范的基础,并在 [containerd][18] 中实现该规范,使得该核心容器运行时同时涵盖了运行时和镜像格式标准,最后将 containerd 捐赠给了<ruby>云计算基金会<rt>Cloud Native Computing Foundation</rt></ruby>(CNCF),并于本月发布了更新的 1.0 alpha 版本。
|
||||
|
||||
有关 Docker 参与塑造 OCI 的详细信息,请参阅上面的时间轴,其中包括:创建 runc ,和社区一起更新迭代运行时规范,创建 containerd 以便于将 runc 集成到 Docker 1.11 中,将 Docker V2 镜像格式贡献给 OCI 作为其础镜像格式规范的基础,并在 [containerd][18] 中实现该规范,使得该核心容器运行时同时涵盖了运行时和镜像格式标准,最后将 containerd 捐赠给了云计算基金会(CNCF),并将其更新到 1.0 alpha 版本于本月发布。
|
||||
|
||||
维护者 [Michael Crosby][19] 和 [Stephen Day][20] 引导了这些规范的发展,并且为 v1.0 版本的实现提供了极大的帮助,以及 Alexander Morozov,Josh Hawn,Derek McGown 和 Aaron Lehmann 也贡献了代码,以及Stephen Walli 参加了认证工作组。
|
||||
维护者 [Michael Crosby][19] 和 [Stephen Day][20] 引导了这些规范的发展,并且为 v1.0 版本的实现提供了极大的帮助,另外 Alexander Morozov,Josh Hawn,Derek McGown 和 Aaron Lehmann 也贡献了代码,以及 Stephen Walli 参加了认证工作组。
|
||||
|
||||
Docker 仍然致力于推动容器标准化进程,在每个人都认可的层面建立起坚实的基础,使整个容器行业能够在依旧十分差异化的层面上进行创新。
|
||||
|
||||
**开放标准只是一小块拼图**
|
||||
### 开放标准只是一小块拼图
|
||||
|
||||
Docker 是一个完整的平台,用于创建、管理、保护和编排容器以及镜像。该项目的愿景始终是致力于成为支持开源组件的行业规范的基石,或着是容器解决方案的校准铅锤。Docker 平台正位于此层之上 -- 为客户提供从开发到生产的安全的容器管理解决方案。
|
||||
|
||||
OCI 运行时和镜像规范成为一个可靠的标准基础,允许和鼓励多样化的容器解决方案,同时它们不限制产品创新或遏制主要开发者。打一个比方,TCP/IP,HTTP 和 HTML 成为过去25年来建立万维网的可靠标准,其他公司可以继续通过这些标准的新工具、技术和浏览器进行创新。 OCI 规范也为容器解决方案提供了类似的规范基础。
|
||||
OCI 运行时和镜像规范成为一个可靠的标准基础,允许和鼓励多样化的容器解决方案,同时它们不限制产品创新或遏制主要开发者。打一个比方,TCP/IP、HTTP 和 HTML 成为过去 25 年来建立万维网的可靠标准,其他公司可以继续通过这些标准的新工具、技术和浏览器进行创新。 OCI 规范也为容器解决方案提供了类似的规范基础。
|
||||
|
||||
开源项目也在为产品开发提供组件方面发挥着作用。containerd 项目就使用 OCI 的 runc 参考实现,负责镜像的传输和存储,容器运行和监控,以及支持存储和网络附件的等底层功能。containerd 项目已经被 Docker 捐赠给了 CNCF ,与其他重要项目一起支持云计算解决方案。
|
||||
开源项目也在为产品开发提供组件方面发挥着作用。containerd 项目就使用了 OCI 的 runc 参考实现,它负责镜像的传输和存储,容器运行和监控,以及支持存储和网络附件的等底层功能。containerd 项目已经被 Docker 捐赠给了 CNCF ,与其他重要项目一起支持云计算解决方案。
|
||||
|
||||
Docker 使用了 containerd 和其他自己的核心开源基础设施组件,如 LinuxKit,InfraKit 和 Notary 等项目来构建和保护 Docker 社区版容器解决方案。正在寻找一个完整的容器平台,能提供容器管理、安全性、编排、网络和更多功能的用户和组织可以查看 Docker Enterprise Edition 。
|
||||
Docker 使用了 containerd 和其它自己的核心开源基础设施组件,如 LinuxKit,InfraKit 和 Notary 等项目来构建和保护 Docker 社区版容器解决方案。正在寻找一个能提供容器管理、安全性、编排、网络和更多功能的完整容器平台的用户和组织可以了解下 Docker Enterprise Edition 。
|
||||
|
||||

|
||||
|
||||
> 这张图强调了 OCI 规范提供了一个由容器运行时实现的标准层:containerd 和 runc。 要组装一个完整的、具有完整容器生命周期和工作流程的容器平台,如 Docker,需要和许多其他的组件集成在一起:管理基础架构的 InfraKit,提供操作系统的 LinuxKit,交付编排的 SwarmKit,确保安全性的 Notary。
|
||||
> 这张图强调了 OCI 规范提供了一个由容器运行时实现的标准层:containerd 和 runc。 要组装一个完整的像 Docker 这样具有完整容器生命周期和工作流程的容器平台,需要和许多其他的组件集成在一起:管理基础架构的 InfraKit,提供操作系统的 LinuxKit,交付编排的 SwarmKit,确保安全性的 Notary。
|
||||
|
||||
**OCI 下一步该干什么**
|
||||
### OCI 下一步该干什么
|
||||
|
||||
随着运行时和镜像规范的发布,我们应该庆祝开发者的努力。开放容器计划的下一个关键工作是提供认证计划,以验证实现者的产品和项目确实符合运行时和镜像规范。[认证工作组][21] 已经组织了一个程序,结合了开发套件(developing suite)的[运行时][22]和[镜像][23]规范测试工具将展示产品应该如何参照标准进行实现。
|
||||
|
||||
同时,目前规范的开发者们正在考虑下一个最重要的容器技术领域。云计算基金会的通用容器网络接口开发工作已经正在进行中,支持镜像签署和分发的工作正也在 OCI 的考虑之中。
|
||||
同时,当前规范的开发者们正在考虑下一个最重要的容器技术领域。云计算基金会的通用容器网络接口开发工作已经正在进行中,支持镜像签署和分发的工作正也在 OCI 的考虑之中。
|
||||
|
||||
除了 OCI 及其成员,Docker 仍然致力于推进容器技术的标准化。 OCI 的使命是为用户和公司提供在开发人工具、镜像分发、容器编排、安全、监控和管理等方面进行创新的基准。Docker 将继续引领创新,不仅提供提高生产力和效率的工具,而且还通过授权用户,合作伙伴和客户进行创新。
|
||||
除了 OCI 及其成员,Docker 仍然致力于推进容器技术的标准化。 OCI 的使命是为用户和公司提供在开发者工具、镜像分发、容器编排、安全、监控和管理等方面进行创新的基准。Docker 将继续引领创新,不仅提供提高生产力和效率的工具,而且还通过授权用户,合作伙伴和客户进行创新。
|
||||
|
||||
**在 Docker 学习更过关于 OCI 和开源的信息:**
|
||||
|
||||
* 阅读 [OCI 规范的误区][1]
|
||||
|
||||
* 访问 [开放容器计划的网站][2]
|
||||
|
||||
* 访问 [Moby 项目网站 ][3]
|
||||
|
||||
* 访问 [Moby 项目网站][3]
|
||||
* 参加 [DockerCon Europe 2017][4]
|
||||
|
||||
* 参加 [Moby Summit LA][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -69,14 +63,14 @@ Patrick Chanezon是Docker Inc.技术人员。他的工作是帮助构建 Docker
|
||||
|
||||
via: https://blog.docker.com/2017/07/oci-release-of-v1-0-runtime-and-image-format-specifications/
|
||||
|
||||
作者:[Patrick Chanezon ][a]
|
||||
作者:[Patrick Chanezon][a]
|
||||
译者:[rieonke](https://github.com/rieonke)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/chanezon/
|
||||
[1]:https://blog.docker.com/2017/07/demystifying-open-container-initiative-oci-specifications/
|
||||
[1]:https://linux.cn/article-8763-1.html
|
||||
[2]:https://www.opencontainers.org/join
|
||||
[3]:http://mobyproject.org/
|
||||
[4]:https://europe-2017.dockercon.com/
|
||||
@ -1,3 +1,4 @@
|
||||
【Translating by JanzenLiu】
|
||||
Beyond public key encryption
|
||||
============================================================
|
||||
|
||||
|
||||
95
sources/tech/20160511 LEDE and OpenWrt.md
Normal file
95
sources/tech/20160511 LEDE and OpenWrt.md
Normal file
@ -0,0 +1,95 @@
|
||||
LEDE and OpenWrt
|
||||
===================
|
||||
|
||||
The [OpenWrt][1] project is perhaps the most widely known Linux-based distribution for home WiFi routers and access points; it was spawned from the source code of the now-famous Linksys WRT54G router more than 12 years ago. In early May, the OpenWrt user community was thrown into a fair amount of confusion when a group of core OpenWrt developers [announced][2] that they were starting a spin-off (or, perhaps, a fork) of OpenWrt to be named the [Linux Embedded Development Environment][3] (LEDE). It was not entirely clear to the public why the split was taking place—and the fact that the LEDE announcement surprised a few other OpenWrt developers suggested trouble within the team.
|
||||
|
||||
The LEDE announcement was sent on May 3 by Jo-Philipp Wich to both the OpenWrt development list and the new LEDE development list. It describes LEDE as "a reboot of the OpenWrt community" and as "a spin-off of the OpenWrt project" seeking to create an embedded-Linux development community "with a strong focus on transparency, collaboration and decentralisation."
|
||||
|
||||
The rationale given for the reboot was that OpenWrt suffered from longstanding issues that could not be fixed from within—namely, regarding internal processes and policies. For instance, the announcement said, the number of developers is at an all-time low, but there is no process for on-boarding new developers (and, it seems, no process for granting commit access to new developers). The project infrastructure is unreliable (evidently, server outages over the past year have caused considerable strife within the project), the announcement said, but internal disagreements and single points of failure prevented fixing it. There is also a general lack of "communication, transparency and coordination" internally and from the project to the outside world. Finally, a few technical shortcomings were cited: inadequate testing, lack of regular builds, and poor stability and documentation.
|
||||
|
||||
The announcement goes on to describe how the LEDE reboot will address these issues. All communication channels will be made available for public consumption, decisions will be made by project-wide votes, the merge policy will be more relaxed, and so forth. A more detailed explanation of the new project's policies can be found on the [rules][4] page at the LEDE site. Among other specifics, it says that there will be only one class of committer (that is, no "core developer" group with additional privileges), that simple majority votes will settle decisions, and that any infrastructure managed by the project must have at least three operators with administrative access. On the LEDE mailing list, Hauke Mehrtens [added][5] that the project will make an effort to have patches sent upstream—a point on which OpenWrt has been criticized in the past, especially where the kernel is concerned.
|
||||
|
||||
In addition to Wich, the announcement was co-signed by OpenWrt contributors John Crispin, Daniel Golle, Felix Fietkau, Mehrtens, Matthias Schiffer, and Steven Barth. It ends with an invitation for others interested in participating to visit the LEDE site.
|
||||
|
||||
#### Reactions and questions
|
||||
|
||||
One might presume that the LEDE organizers expected their announcement to be met with some mixture of positive and negative reactions. After all, a close reading of the criticisms of the OpenWrt project in the announcement suggests that there were some OpenWrt project members that the LEDE camp found difficult to work with (the "single points of failure" or "internal disagreements" that prevented infrastructure fixes, for instance).
|
||||
|
||||
And, indeed, there were negative responses. OpenWrt co-founder Mike Baker [responded][6] with some alarm, disagreeing with all of the LEDE announcement's conclusions and saying "phrases such as a 'reboot' are both vague and misleading and the LEDE project failed to identify its true nature." Around the same time, someone disabled the @openwrt.org email aliases of those developers who signed the LEDE announcement; when Fietkau [objected][7], Baker [replied][8] that the accounts were "temporarily disabled" because "it's unclear if LEDE still represents OpenWrt." Imre Kaloz, another core OpenWrt member, [wrote][9]that "the LEDE team created most of that [broken] status quo" in OpenWrt that it was now complaining about.
|
||||
|
||||
But the majority of the responses on the OpenWrt list expressed confusion about the announcement. List members were not clear whether the LEDE team was going to [continue contributing][10] to OpenWrt or not, nor what the [exact nature][11] of the infrastructure and internal problems were that led to the split. Baker's initial response lamented the lack of public debate over the issues cited in the announcement: "We recognize the current OpenWrt project suffers from a number of issues," but "we hoped we had an opportunity to discuss and attempt to fix" them. Baker concluded:
|
||||
|
||||
We would like to stress that we do want to have an open discussion and resolve matters at hand. Our goal is to work with all parties who can and want to contribute to OpenWrt, including the LEDE team.
|
||||
|
||||
In addition to the questions over the rationale of the new project, some list subscribers expressed confusion as to whether LEDE was targeting the same uses cases as OpenWrt, given the more generic-sounding name of the new project. Furthermore, a number of people, such as Roman Yeryomin, [expressed confusion][12] as to why the issues demanded the departure of the LEDE team, particularly given that, together, the LEDE group constituted a majority of the active core OpenWrt developers. Some list subscribers, like Michael Richardson, were even unclear on [who would still be developing][13] OpenWrt.
|
||||
|
||||
#### Clarifications
|
||||
|
||||
The LEDE team made a few attempts to further clarify their position. In Fietkau's reply to Baker, he said that discussions about proposed changes within the OpenWrt project tended to quickly turn "toxic," thus resulting in no progress. Furthermore:
|
||||
|
||||
A critical part of many of these debates was the fact that people who were controlling critical pieces of the infrastructure flat out refused to allow other people to step up and help, even in the face of being unable to deal with important issues themselves in a timely manner.
|
||||
|
||||
This kind of single-point-of-failure thing has been going on for years, with no significant progress on resolving it.
|
||||
|
||||
Neither Wich nor Fietkau pointed fingers at specific individuals, although others on the list seemed to think that the infrastructure and internal decision-making problems in OpenWrt came down to a few people. Daniel Dickinson [stated][14] that:
|
||||
|
||||
My impression is that Kaloz (at least) holds infrastructure hostage to maintain control, and that the fundamental problem here is that OpenWrt is *not* democratic and ignores what people who were ones visibly working on openwrt want and overrides their wishes because he/they has/have the keys.
|
||||
|
||||
On the other hand, Luka Perkov [countered][15] that many OpenWrt developers wanted to switch from Subversion to Git, but that Fietkau was responsible for blocking that change.
|
||||
|
||||
What does seem clear is that the OpenWrt project has been operating with a governance structure that was not functioning as desired and, as a result, personality conflicts were erupting and individuals were able to disrupt or block proposed changes simply by virtue of there being no well-defined process. Clearly, that is not a model that works well in the long run.
|
||||
|
||||
On May 6, Crispin [wrote][16] to the OpenWrt list in a new thread, attempting to reframe the LEDE project announcement. It was not, he said, meant as a "hostile or disruptive" act, but to make a clean break from the dysfunctional structures of OpenWrt and start fresh. The matter "does not boil down to one single event, one single person or one single flamewar," he said. "We wanted to split with the errors we have done ourselves in the past and the wrong management decision that were made at times." Crispin also admitted that the announcement had not been handled well, saying that the LEDE team "messed up the politics of the launch."
|
||||
|
||||
Crispin's email did not seem to satisfy Kaloz, who [insisted][17] that Crispin (as release manager) and Fietkau (as lead developer) could simply have made any desirable changes within the OpenWrt project. But the discussion thread has subsequently gone silent; whatever happens next on either the LEDE or OpenWrt side remains to be seen.
|
||||
|
||||
#### Intent
|
||||
|
||||
For those still seeking further detail on what the LEDE team regarded as problematic within OpenWrt, there is one more source of information that can shed light on the issues. Prior to the public announcement, the LEDE organizers spent several weeks hashing out their plan, and IRC logs of the meetings have now been [published][18]. Of particular interest is the March 30 [meeting][19] that includes a detailed discussion of the project's goals.
|
||||
|
||||
Several specific complaints about OpenWrt's infrastructure are included, such as the shortcomings of the project's Trac issue tracker. It is swamped with incomplete bug reports and "me too" comments, Wich said, and as a result, few committers make use of it. In addition, people seem confused by the fact that bugs are also being tracked on GitHub, making it unclear where issues ought to be discussed.
|
||||
|
||||
The IRC discussion also tackles the development process itself. The LEDE team would like to implement several changes, starting with the use of staging trees that get merged into the trunk during a formal merge window, rather than the commit-directly-to-master approach employed by OpenWrt. The project would also commit to time-based releases and encourage user testing by only releasing binary modules that have successfully been tested, by the community rather than the core developers, on actual hardware.
|
||||
|
||||
Finally, the IRC discussion does make it clear that the LEDE team's intent was not to take OpenWrt by surprise with its announcement. Crispin suggested that LEDE be "semi public" at first and gradually be made more public. Wich noted that he wanted LEDE to be "neutral, professional and welcoming to OpenWrt to keep the door open for a future reintegration." The launch does not seem to have gone well on that front, which is unfortunate.
|
||||
|
||||
In an email, Fietkau added that the core OpenWrt developers had been suffering from bottlenecks on tasks like patch review and maintenance work that were preventing them from getting other work done—such as setting up download mirrors or improving the build system. In just the first few days after the LEDE announcement, he said, the team had managed to tackle the mirror and build-system tasks, which had languished for years.
|
||||
|
||||
A lot of what we did in LEDE was based on the experience with decentralizing the development of packages by moving it to GitHub and giving up a lot of control over how packages should be maintained. This ended up reducing our workload significantly and we got quite a few more active developers this way.
|
||||
|
||||
We really wanted to do something similar with the core development, but based on our experience with trying to make bigger changes we felt that we couldn't do this from within the OpenWrt project.
|
||||
|
||||
Fixing the infrastructure will reap other dividends, too, he said, such as an improved system for managing the keys used to sign releases. The team is considering a rule that imposes some conditions on non-upstream patches, such as requiring a description of the patch and an explanation of why it has not yet been sent upstream. He also noted that many of the remaining OpenWrt developers have expressed interest in joining LEDE, and that the parties involved are trying to figure out if they will re-merge the projects.
|
||||
|
||||
One would hope that LEDE's flatter governance model and commitment to better transparency will help it to find success in areas where OpenWrt has struggled. For the time being, sorting out the communication issues that plagued the initial announcement may prove to be a major hurdle. If that process goes well, though, LEDE and OpenWrt may find common ground and work together in the future. If not, then the two teams may each be forced to move forward with fewer resources than they had before, which may not be what developers or users want to see.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/686767/
|
||||
|
||||
作者:[Nathan Willis ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://lwn.net/Articles/686767/
|
||||
[1]:https://openwrt.org/
|
||||
[2]:https://lwn.net/Articles/686180/
|
||||
[3]:https://www.lede-project.org/
|
||||
[4]:https://www.lede-project.org/rules.html
|
||||
[5]:http://lists.infradead.org/pipermail/lede-dev/2016-May/000080.html
|
||||
[6]:https://lwn.net/Articles/686988/
|
||||
[7]:https://lwn.net/Articles/686989/
|
||||
[8]:https://lwn.net/Articles/686990/
|
||||
[9]:https://lwn.net/Articles/686991/
|
||||
[10]:https://lwn.net/Articles/686995/
|
||||
[11]:https://lwn.net/Articles/686996/
|
||||
[12]:https://lwn.net/Articles/686992/
|
||||
[13]:https://lwn.net/Articles/686993/
|
||||
[14]:https://lwn.net/Articles/686998/
|
||||
[15]:https://lwn.net/Articles/687001/
|
||||
[16]:https://lwn.net/Articles/687003/
|
||||
[17]:https://lwn.net/Articles/687004/
|
||||
[18]:http://meetings.lede-project.org/lede-adm/2016/?C=M;O=A
|
||||
[19]:http://meetings.lede-project.org/lede-adm/2016/lede-adm.2016-03-30-11.05.log.html
|
||||
@ -1,68 +0,0 @@
|
||||
Performance made easy with Linux containers
|
||||
============================================================
|
||||
|
||||

|
||||
Image credits : CC0 Public Domain
|
||||
|
||||
Performance for an application determines how quickly your software can complete the intended task. It answers questions about the application, such as:
|
||||
|
||||
* Response time under peak load
|
||||
* Ease of use, supported functionality, and use cases compared to an alternative
|
||||
* Operational costs (CPU usage, memory needs, data throughput, bandwidth, etc.)
|
||||
|
||||
The value of this performance analysis extends beyond the estimation of the compute resources needed to serve the load or the number of application instances needed to meet the peak demand. Performance is clearly tied to the fundamentals of a successful business. It informs the overall user experience, including identifying what slows down customer-expected response times, improving customer stickiness by designing content delivery optimized to their bandwidth, choosing the best device, and ultimately helping enterprises grow their business.
|
||||
|
||||
### The problem
|
||||
|
||||
Of course, this is an oversimplification of the value of performance engineering for business services. To understand the challenges behind accomplishing what I've just described, let's make this real and just a little bit complicated.
|
||||
|
||||

|
||||
|
||||
Real-world applications are likely hosted on the cloud. An application could avail to very large (or conceptually infinite) amounts of compute resources. Its needs in terms of both hardware and software would be met via the cloud. The developers working on it would use the cloud-offered features for enabling faster coding and deployment. Cloud hosting doesn't come free, but the cost overhead is proportional to the resource needs of the application.
|
||||
|
||||
Outside of Search as a Service (SaaS), Platform as a Service (PaaS), Infrastructure as a Service (IaaS), and Load Balancing as a Service (LBaaS), which is when the cloud takes care of traffic management for this hosted app, a developer probably may also use one or more of these fast-growing cloud services:
|
||||
|
||||
* Security as a Service (SECaaS), which meets security needs for software and the user
|
||||
* Data as a Service (DaaS), which provides a user's data on demand for application
|
||||
* Logging as a Service (LaaS), DaaS's close cousin, which provides analytic metrics on delivery and usage of logs
|
||||
* Search as a Service (SaaS), which is for the analytics and big data needs of the app
|
||||
* Network as a Service (NaaS), which is for sending and receiving data across public networks
|
||||
|
||||
Cloud-powered services are also growing exponentially because they make writing complex apps easier for developers. In addition to the software complexity, the interplay of all these distributed components becomes more involved. The user base becomes more diverse. The list of requirements for the software becomes longer. The dependencies on other services becomes larger. Because of these factors, the flaws in this ecosystem can trigger a domino effect of performance problems.
|
||||
|
||||
For example, assume you have a well-written application that follows secure coding practices, is designed to meet varying load requirements, and is thoroughly tested. Assume also that you have the infrastructure and analytics work in tandem to support the basic performance requirements. What does it take to build performance standards into the implementation, design, and architecture of your system? How can the software keep up with evolving market needs and emerging technologies? How do you measure the key parameters to tune a system for optimal performance as it ages? How can the system be made resilient and self-recovering? How can you identify any underlying performance problems faster and resolved them sooner?
|
||||
|
||||
### Enter containers
|
||||
|
||||
Software [containers][2] backed with the merits of [microservices][3] design, or Service-oriented Architecture (SoA), improves performance because a system comprising of smaller, self-sufficient code blocks is easier to code and has cleaner, well-defined dependencies on other system components. It is easier to test and problems, including those around resource utilization and memory over-consumption, are more easily identified than in a giant monolithic architecture.
|
||||
|
||||
When scaling the system to serve increased load, the containerized applications replicate fast and easy. Security flaws are better isolated. Patches can be versioned independently and deployed fast. Performance monitoring is more targeted and the measurements are more reliable. You can also rewrite and "facelift" resource-intensive code pieces to meet evolving performance requirements.
|
||||
|
||||
Containers start fast and stop fast. They enable efficient resource utilization and far better process isolation than Virtual Machines (VMs). Containers do not have idle memory and CPU overhead. They allow for multiple applications to share a machine without the loss of data or performance. Containers make applications portable, so developers can build and ship apps to any server running Linux that has support for container technology, without worrying about performance penalties. Containers live within their means and abide by the quotas (examples include storage, compute, and object count quotas) as imposed by their cluster manager, such as Cloud Foundry's Diego, [Kubernetes][4], Apache Mesos, and Docker Swarm.
|
||||
|
||||
While containers show merit in performance, the coming wave of "serverless" computing, also known as Function as a Service (FaaS), is set to extend the benefits of containers. In the FaaS era, these ephemeral or short-lived containers will drive the benefits beyond application performance and translate directly to savings in overhead costs of hosting in the cloud. If the container does its job faster, then it lives for a shorter time, and the computation overload is purely on demand.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Garima is a Engineering Manager at Red Hat focussed on OpenShift Container Platform. Prior to Red Hat, Garima helped fuel innovation at Akamai Technologies & MathWorks Inc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/performance-container-world
|
||||
|
||||
作者:[Garima][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/garimavsharma
|
||||
[1]:https://opensource.com/article/17/2/performance-container-world?rate=RozKaIY39AZNxbayqFkUmtkkhoGdctOVuGOAJqVJII8
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers
|
||||
[3]:https://opensource.com/resources/what-are-microservices
|
||||
[4]:https://opensource.com/resources/what-is-kubernetes
|
||||
[5]:https://opensource.com/user/109286/feed
|
||||
[6]:https://opensource.com/article/17/2/performance-container-world#comments
|
||||
[7]:https://opensource.com/users/garimavsharma
|
||||
@ -1,74 +0,0 @@
|
||||
# Filtering Packets In Wireshark on Kali Linux
|
||||
|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Introduction][1]
|
||||
|
||||
* [2. Boolean Expressions and Comparison Operators][2]
|
||||
|
||||
* [3. Filtering Capture][3]
|
||||
|
||||
* [4. Filtering Results][4]
|
||||
|
||||
* [5. Closing Thoughts][5]
|
||||
|
||||
### Introduction
|
||||
|
||||
Filtering allows you to focus on the exact sets of data that you are interested in reading. As you have seen, Wireshark collects _everything_ by default. That can get in the way of the specific data that you are looking for. Wireshark provides two powerful filtering tools to make targeting the exact data you need simple and painless.
|
||||
|
||||
There are two way that Wireshark can filter packets. It can filter an only collect certain packets, or the packet results can be filtered after they are collected. Of course, these can be used in conjunction with one another, and their respective usefulness is dependent on which and how much data is being collected.
|
||||
|
||||
### Boolean Expressions and Comparison Operators
|
||||
|
||||
Wireshark has plenty of built-in filters which work just great. Start typing in either of the filter fields, and you will see them autocomplete in. Most correspond to the more common distinctions that a user would make between packets. Filtering only HTTP requests would be a good example.
|
||||
|
||||
For everything else, Wireshark uses Boolean expressions and/or comparison operators. If you've ever done any kind of programming, you should be familiar with Boolean expressions. They are expressions that use "and," "or," and "not" to verify the truthfulness of a statement or expression. Comparison operators are much simpler. They just determine if two or more things are equal, greater, or less than one another.
|
||||
|
||||
### Filtering Capture
|
||||
|
||||
Before diving in to custom capture filters, take a look at the ones Wireshark already has built in. Click on the "Capture" tab on the top menu, and go to "Options." Below the available interfaces is the line where you can write your capture filters. Directly to its left is a button labeled "Capture Filter." Click on it, and you will see a new dialog box with a listing of pre-built capture filters. Look around and see what's there.
|
||||
|
||||

|
||||
|
||||
|
||||
At the bottom of that box, there is a small form for creating and saving hew capture filters. Press the "New" button to the left. It will create a new capture filter populated with filler data. To save the new filter, just replace the filler with the actual name and expression that you want and click "Ok." The filter will be saved and applied. Using this tool, you can write and save multiple different filters and have them ready to use again in the future.
|
||||
|
||||
Capture has it's own syntax for filtering. For comparison, it omits and equals symbol and uses `>` and for greater and less than. For Booleans, it relies on the words "and," "or," and "not."
|
||||
|
||||
If, for example, you only wanted to listen to traffic on port 80, you could use and expressions like this: `port 80`. If you only wanted to listen on port 80 from a specific IP, you would add that on. `port 80 and host 192.168.1.20` As you can see, capture filters have specific keywords. These keywords are used to tell Wireshark how to monitor packets and which ones to look at. For example, `host` is used to look at all traffic from an IP. `src` is used to look at traffic originating from that IP. `dst` in contrast, only watches incoming traffic to an IP. To watch traffic on a set of IPs or a network, use `net`.
|
||||
|
||||
### Filtering Results
|
||||
|
||||
The bottom menu bar on your layout is the one dedicated to filtering results. This filter doesn't change the data that Wireshark has collected, it just allows you to sort through it more easily. There is a text field for entering a new filter expression with a drop down arrow to review previously entered filters. Next to that is a button marked "Expression" and a few others for clearing and saving your current expression.
|
||||
|
||||
Click on the "Expression" button. You will see a small window with several boxes with options in them. To the left is the largest box with a huge list of items, each with additional collapsed sub-lists. These are all of the different protocols, fields, and information that you can filter by. There's no way to go through all of it, so the best thing to do is look around. You should notice some familiar options like HTTP, SSL, and TCP.
|
||||
|
||||

|
||||
|
||||
The sub-lists contain the different parts and methods that you can filter by. This would be where you'd find the methods for filtering HTTP requests by GET and POST.
|
||||
|
||||
You can also see a list of operators in the middle boxes. By selecting items from each column, you can use this window to create filters without memorizing every item that Wireshark can filter by. For filtering results, comparison operators use a specific set of symbols. `==` determines if two things are equal. `>`determines if one thing is greater than another, `<` finds if something is less. `>=` and `<=` are for greater than or equal to and less than or equal to respectively. They can be used to determine if packets contain the right values or filter by size. An example of using `==` to filter only HTTP GET requests like this: `http.request.method == "GET"`.
|
||||
|
||||
Boolean operators can chain smaller expressions together to evaluate based on multiple conditions. Instead of words like with capture, they use three basic symbols to do this. `&&` stands for "and." When used, both statements on either side of `&&` must be true in order for Wireshark to filter those packages. `||`signifies "or." With `||` as long as either expression is true, it will be filtered. If you were looking for all GET and POST requests, you could use `||` like this: `(http.request.method == "GET") || (http.request.method == "POST")`. `!` is the "not" operator. It will look for everything but the thing that is specified. For example, `!http` will give you everything but HTTP requests.
|
||||
|
||||
### Closing Thoughts
|
||||
|
||||
Filtering Wireshark really allows you to efficiently monitor your network traffic. It takes some time to familiarize yourself with the options available and become used to the powerful expressions that you can create with filters. Once you do, though, you will be able to quickly collect and find exactly the network data the you are looking for without having to comb through long lists of packets or do a whole lot of work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
|
||||
作者:[Nick Congleton ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
[1]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h1-introduction
|
||||
[2]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h2-boolean-expressions-and-comparison-operators
|
||||
[3]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h3-filtering-capture
|
||||
[4]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h4-filtering-results
|
||||
[5]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h5-closing-thoughts
|
||||
@ -1,3 +1,4 @@
|
||||
penghuster is translating
|
||||
An introduction to the Linux boot and startup processes
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
# How to work around video and subtitle embed errors
|
||||
|
||||
|
||||
|
||||
@ -1,228 +0,0 @@
|
||||
|
||||
polebug is translating
|
||||
|
||||
3 mistakes to avoid when learning to code in Python
|
||||
============================================================
|
||||
|
||||
### These errors created big problems that took hours to solve.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
It's never easy to admit when you do things wrong, but making errors is part of any learning process, from learning to walk to learning a new programming language, such as Python.
|
||||
|
||||
Here's a list of three things I got wrong when I was learning Python, presented so that newer Python programmers can avoid making the same mistakes. These are errors that either I got away with for a long time or that that created big problems that took hours to solve.
|
||||
|
||||
Take heed young coders, some of these mistakes are afternoon wasters!
|
||||
|
||||
### 1\. Mutable data types as default arguments in function definitions
|
||||
|
||||
It makes sense right? You have a little function that, let's say, searches for links on a current page and optionally appends it to another supplied list.
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=[]):
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
On the face of it, this looks like perfectly normal Python, and indeed it is. It works. But there are issues with it. If we supply a list for the **add_to** parameter, it works as expected. If, however, we let it use the default, something interesting happens.
|
||||
|
||||
Try the following code:
|
||||
|
||||
```
|
||||
def fn(var1, var2=[]):
|
||||
var2.append(var1)
|
||||
print var2
|
||||
|
||||
fn(3)
|
||||
fn(4)
|
||||
fn(5)
|
||||
```
|
||||
|
||||
You may expect that we would see:
|
||||
|
||||
**[3]
|
||||
[4]
|
||||
[5]**
|
||||
|
||||
But we actually see this:
|
||||
|
||||
**[3]
|
||||
[3, 4]
|
||||
[3, 4, 5]**
|
||||
|
||||
Why? Well, you see, the same list is used each time. In Python, when we write the function like this, the list is instantiated as part of the function's definition. It is not instantiated each time the function is run. This means that the function keeps using the exact same list object again and again, unless of course we supply another one:
|
||||
|
||||
```
|
||||
fn(3, [4])
|
||||
```
|
||||
|
||||
**[4, 3]**
|
||||
|
||||
Just as expected. The correct way to achieve the desired result is:
|
||||
|
||||
```
|
||||
def fn(var1, var2=None):
|
||||
if not var2:
|
||||
var2 = []
|
||||
var2.append(var1)
|
||||
```
|
||||
|
||||
Or, in our first example:
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=None):
|
||||
if not add_to:
|
||||
add_to = []
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
This moves the instantiation from module load time so that it happens every time the function runs. Note that for immutable data types, like [**tuples**][7], [**strings**][8], or [**ints**][9], this is not necessary. That means it is perfectly fine to do something like:
|
||||
|
||||
```
|
||||
def func(message="my message"):
|
||||
print message
|
||||
```
|
||||
|
||||
### 2\. Mutable data types as class variables
|
||||
|
||||
Hot on the heels of the last error is one that is very similar. Consider the following:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
This code looks perfectly normal. We have an object with a storage of URLs. When we call the **add_url** method, it adds a given URL to the store. Perfect right? Let's see it in action:
|
||||
|
||||
```
|
||||
a = URLCatcher()
|
||||
a.add_url('http://www.google.')
|
||||
b = URLCatcher()
|
||||
b.add_url('http://www.bbc.co.')
|
||||
```
|
||||
|
||||
**b.urls
|
||||
['[http://www.google.com][2]', '[http://www.bbc.co.uk][3]']**
|
||||
|
||||
**a.urls
|
||||
['[http://www.google.com][4]', '[http://www.bbc.co.uk][5]']**
|
||||
|
||||
Wait, what?! We didn't expect that. We instantiated two separate objects, **a** and **b**. **A** was given one URL and **b** the other. How is it that both objects have both URLs?
|
||||
|
||||
Turns out it's kinda the same problem as in the first example. The URLs list is instantiated when the class definition is created. All instances of that class use the same list. Now, there are some cases where this is advantageous, but the majority of the time you don't want to do this. You want each object to have a separate store. To do that, we would modify the code like:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
def __init__(self):
|
||||
self.urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
Now the URLs list is instantiated when the object is created. When we instantiate two separate objects, they will be using two separate lists.
|
||||
|
||||
### 3\. Mutable assignment errors
|
||||
|
||||
This one confused me for a while. Let's change gears a little and use another mutable datatype, the [**dict**][10].
|
||||
|
||||
```
|
||||
a = {'1': "one", '2': 'two'}
|
||||
```
|
||||
|
||||
Now let's assume we want to take that **dict** and use it someplace else, leaving the original intact.
|
||||
|
||||
```
|
||||
b = a
|
||||
|
||||
b['3'] = 'three'
|
||||
```
|
||||
|
||||
Simple eh?
|
||||
|
||||
Now let's look at our original dict, **a**, the one we didn't want to modify:
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
Whoa, hold on a minute. What does **b** look like then?
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
Wait what? But… let's step back and see what happens with our other immutable types, a **tuple** for instance:
|
||||
|
||||
```
|
||||
c = (2, 3)
|
||||
d = c
|
||||
d = (4, 5)
|
||||
```
|
||||
|
||||
Now **c** is:
|
||||
**(2, 3)**
|
||||
|
||||
While **d** is:
|
||||
**(4, 5)**
|
||||
|
||||
That functions as expected. So what happened in our example? When using mutable types, we get something that behaves a little more like a pointer from C. When we said **b = a** in the code above, what we really meant was: **b** is now also a reference to **a**. They both point to the same object in Python's memory. Sound familiar? That's because it's similar to the previous problems. In fact, this post should really have been called, "The Trouble with Mutables."
|
||||
|
||||
Does the same thing happen with lists? Yes. So how do we get around it? Well, we have to be very careful. If we really need to copy a list for processing, we can do so like:
|
||||
|
||||
```
|
||||
b = a[:]
|
||||
```
|
||||
|
||||
This will go through and copy a reference to each item in the list and place it in a new list. But be warned: If any objects in the list are mutable, we will again get references to those, rather than complete copies.
|
||||
|
||||
Imagine having a list on a piece of paper. In the original example, Person A and Person B are looking at the same piece of paper. If someone changes that list, both people will see the same changes. When we copy the references, each person now has their own list. But let's suppose that this list contains places to search for food. If "fridge" is first on the list, even when it is copied, both entries in both lists point to the same fridge. So if the fridge is modified by Person A, by say eating a large gateaux, Person B will also see that the gateaux is missing. There is no easy way around this. It is just something that you need to remember and code in a way that will not cause an issue.
|
||||
|
||||
Dicts function in the same way, and you can create this expensive copy by doing:
|
||||
|
||||
```
|
||||
b = a.copy()
|
||||
```
|
||||
|
||||
Again, this will only create a new dictionary pointing to the same entries that were present in the original. Thus, if we have two lists that are identical and we modify a mutable object that is pointed to by a key from dict 'a', the dict object present in dict 'b' will also see those changes.
|
||||
|
||||
The trouble with mutable data types is that they are powerful. None of the above are real problems; they are things to keep in mind to prevent issues. The expensive copy operations presented as solutions in the third item are unnecessary 99% of the time. Your program can and probably should be modified so that those copies are not even required in the first place.
|
||||
|
||||
_Happy coding! And feel free to ask questions in the comments._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Pete Savage - Peter is a passionate Open Source enthusiast who has been promoting and using Open Source products for the last 10 years. He has volunteered in many different areas, starting in the Ubuntu community, before moving off into the realms of audio production and later into writing. Career wise he spent much of his early years managing and building datacenters as a sysadmin, before ending up working for Red Hat as a Principal Quailty Engineer for the CloudForms product. He occasionally pops out a
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python
|
||||
|
||||
作者:[Pete Savage ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psav
|
||||
[1]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python?rate=SfClhaQ6tQsJdKM8-YTNG00w53fsncvsNWafwuJbtqs
|
||||
[2]:http://www.google.com/
|
||||
[3]:http://www.bbc.co.uk/
|
||||
[4]:http://www.google.com/
|
||||
[5]:http://www.bbc.co.uk/
|
||||
[6]:https://opensource.com/user/36026/feed
|
||||
[7]:https://docs.python.org/2/library/functions.html?highlight=tuple#tuple
|
||||
[8]:https://docs.python.org/2/library/string.html
|
||||
[9]:https://docs.python.org/2/library/functions.html#int
|
||||
[10]:https://docs.python.org/2/library/stdtypes.html?highlight=dict#dict
|
||||
[11]:https://opensource.com/users/psav
|
||||
[12]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python#comments
|
||||
@ -1,173 +0,0 @@
|
||||
【Snaplee准备翻译】Build, test, and publish snap packages using snapcraft
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||
_This is a guest post by Ricardo Feliciano, Developer Evangelist at CircleCI. If you would like to contribute a guest post, please contact ubuntu-iot@canonical.com._
|
||||
|
||||
Snapcraft, the package management system fighting for its spot at the Linux table, re-imagines how you can deliver your software. A new set of cross-distro tools are available to help you build and publish “Snaps”. We’ll cover how to use CircleCI 2.0 to power this process and some potential gotchas along the way.
|
||||
|
||||
### What are snap packages? And Snapcraft?
|
||||
|
||||
**Snaps** are software packages for Linux distributions. They’re designed with lessons learned from delivering software on mobile platforms such as Android as well Internet of Things devices. **Snapcraft** is the name that encompasses Snaps and the command-line tool that builds them, [the website][9], and pretty much the entire ecosystem around the technologies that enables this.
|
||||
|
||||
Snap packages are designed to isolate and encapsulate an entire application. This concept enables Snapcraft’s goal of increasing security, stability, and portability of software allowing a single “snap” to be installed on not just multiple versions of Ubuntu, but Debian, Fedora, Arch, and more. Snapcraft’s description per their website:
|
||||
|
||||
“Package any app for every Linux desktop, server, cloud or device, and deliver updates directly.”
|
||||
|
||||
### Building a snap package on CircleCI 2.0
|
||||
|
||||
Building a snap on CircleCI is mostly the same as your local machine, wrapped with [CircleCI 2.0 syntax][10]. We’ll go through a sample config file in this post. If you’re not familiar with CircleCI or would like to know more about getting started with 2.0 specifically, you can start [here][11].
|
||||
|
||||
### Base Config
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
sudo snap install snapcraft --edge --classic
|
||||
/snap/bin/snapcraft
|
||||
|
||||
```
|
||||
|
||||
This example uses the `machine` executor to install `snapd`, the executable that allows you to manage snaps and enables the platform, as well as `snapcraft`, the tool for creating snaps.
|
||||
|
||||
The `machine` executor is used rather than the `docker` executor as we need a newer kernel for the build process. Linux 4.4 is available here, which is new enough for our purposes.
|
||||
|
||||
### Userspace dependencies
|
||||
|
||||
The example above uses the `machine` executor, which currently is [a VM with Ubuntu 14.04 (Trusty)][12] and the Linux v4.4 kernel. This is fine if your project/snap requires build dependencies available in the Trusty repositories. What if you need dependencies available in a different version, perhaps Ubuntu 16.04 (Xenial)? We can still use Docker within the `machine` executor to build our snap.
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
docker run -v $(pwd):$(pwd) -t ubuntu:xenial sh -c "apt update -qq && apt install snapcraft -y && cd $(pwd) && snapcraft"
|
||||
|
||||
```
|
||||
|
||||
In this example, we again install `snapd` in the `machine` executor’s VM, but we decide to install Snapcraft and build our snap within a Docker container built with the Ubuntu Xenial image. All `apt` packages available in Ubuntu 16.04 will be available to `snapcraft` during the build.
|
||||
|
||||
### Testing
|
||||
|
||||
Unit testing your software’s code has been covered extensively in [our blog][13], [our docs][14], and around the Internet. Searching for your language/framework and unit testing or CI will turn up tons of information. Building a snap on CircleCI means we end with a `.snap` file which we can test in addition to the code that created it.
|
||||
|
||||
### Workflows
|
||||
|
||||
Let’s say the snap we built was a webapp. We can build a testing suite to make sure this snap installs and runs correctly. We could try installing the snap. We could run [Selenium][15] to make sure the proper pages load, logins, work, etc. Here’s the catch, snaps are designed to run on multiple Linux distros. That means we need to be able to run this test suite in Ubuntu 16.04, Fedora 25, Debian 9, etc. CircleCI 2.0’s Workflows can efficiently solve this.
|
||||
|
||||
[A recent addition][16] to the CircleCI 2.0 beta is Workflows. This allows us to run discrete jobs in CircleCI with a certain flow logic. In this case, **after** our snap is built, which would be a single job, we could then kick off snap distro testing jobs, running in parallel. One for each distro we want to test. Each of these jobs would be a different [Docker image][17] for that distro (or in the future, additional `executors` will be available).
|
||||
|
||||
Here’s simple example of what this might look like:
|
||||
|
||||
```
|
||||
workflows:
|
||||
version: 2
|
||||
build-test-and-deploy:
|
||||
jobs:
|
||||
- build
|
||||
- acceptance_test_xenial:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_fedora_25:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_arch:
|
||||
requires:
|
||||
- build
|
||||
- publish:
|
||||
requires:
|
||||
- acceptance_test_xenial
|
||||
- acceptance_test_fedora_25
|
||||
- acceptance_test_arch
|
||||
|
||||
```
|
||||
|
||||
This setup builds the snap, and then runs acceptance tests on it with four different distros. If and when all distro builds pass, then we can run the publish `job` in order to finish up any remaining snap task before pushing it to the Snap Store.
|
||||
|
||||
### Persisting the .snap package
|
||||
|
||||
To test our `.snap` package in the workflows example, a way of persisting that file between builds is needed. I’ll mention two ways here.
|
||||
|
||||
1. **artifacts** – We could store the snap package as a CircleCI artifact during the `build`job. Then retrieve it within the following jobs. CircleCI Workflows has its own way of of handling sharing artifacts which can be found [here][1].
|
||||
|
||||
2. **snap store channels** – When publishing a snap to the Snap Store, there’s more than one `channel` to choose from. It’s becoming a common practice to publish the master branch of your snap to the `edge` channel for internal and/or user testing. This can be done in the `build` job, with the following jobs installing the snap from the edge channel.
|
||||
|
||||
The first method is faster to complete and has the advantage of being able to run acceptance tests on your snap before it hits the Snap Store and touches any user, even testing users. The second method has the advantage of install from the Snap Store being one of the test that is run during CI.
|
||||
|
||||
### Authenticating with the snap store
|
||||
|
||||
The script [snapcraft-config-generator.py][18] can generate the store credentials and save them to `.snapcraft/snapcraft.cfg` (note: always inspect public scripts before running them). You don’t want to store this file in plaintext in your repo (for security reasons). You can either base64 encode the file and store it as a [private environment variable][19] or you can [encrypt the file][20] and just store the key in a private environment variable.
|
||||
|
||||
Here’s an example of having the store credentials in an encrypted file, and using the creds in a `deploy` step to publish to the Snap Store:
|
||||
|
||||
```
|
||||
- deploy:
|
||||
name: Push to Snap Store
|
||||
command: |
|
||||
openssl aes-256-cbc -d -in .snapcraft/snapcraft.encrypted -out .snapcraft/snapcraft.cfg -k $KEY
|
||||
/snap/bin/snapcraft push *.snap
|
||||
|
||||
```
|
||||
|
||||
Instead of a deploy step, keeping with the Workflow examples from earlier, this could be a deploy job that only runs when and if the acceptance test jobs passed.
|
||||
|
||||
### More information
|
||||
|
||||
* Alan Pope’s [Forum Post][2]: “popey” is a Canonical employee and wrote the post in [Snapcraft’s Forum][3] that inspired this blog post
|
||||
|
||||
* [Snapcraft Website][4]: the official Snapcraft website
|
||||
|
||||
* [Snapcraft’s CircleCI Bug Report][5]: There is an open bug report on Launchpad to add support for CircleCI to Snapcraft. This will make this process a little easier and more “official”. Please add your support.
|
||||
|
||||
* How the [Nextcloud][6] snap is being built with CircleCI: a great blog post called [“Continuous acceptance tests for complex applications”][7]. Also influenced this blog post.
|
||||
|
||||
Original post [here][21]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/06/28/build-test-and-publish-snap-packages-using-snapcraft/
|
||||
|
||||
作者:[ Guest ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/guest/
|
||||
[1]:https://circleci.com/docs/2.0/workflows/#using-workspaces-to-share-artifacts-among-jobs
|
||||
[2]:https://forum.snapcraft.io/t/building-and-pushing-snaps-using-circleci/789
|
||||
[3]:https://forum.snapcraft.io/
|
||||
[4]:https://snapcraft.io/
|
||||
[5]:https://bugs.launchpad.net/snapcraft/+bug/1693451
|
||||
[6]:https://nextcloud.com/
|
||||
[7]:https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[8]:https://insights.ubuntu.com/author/guest/
|
||||
[9]:https://snapcraft.io/
|
||||
[10]:https://circleci.com/docs/2.0/
|
||||
[11]:https://circleci.com/docs/2.0/first-steps/
|
||||
[12]:https://circleci.com/docs/1.0/differences-between-trusty-and-precise/
|
||||
[13]:https://circleci.com/blog/
|
||||
[14]:https://circleci.com/docs/
|
||||
[15]:http://www.seleniumhq.org/
|
||||
[16]:https://circleci.com/blog/introducing-workflows-on-circleci-2-0/
|
||||
[17]:https://circleci.com/docs/2.0/building-docker-images/
|
||||
[18]:https://gist.github.com/3v1n0/479ad142eccdd17ad7d0445762dea755
|
||||
[19]:https://circleci.com/docs/1.0/environment-variables/#setting-environment-variables-for-all-commands-without-adding-them-to-git
|
||||
[20]:https://github.com/circleci/encrypted-files
|
||||
[21]:https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
@ -1,146 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
4 lightweight image viewers for the Linux desktop
|
||||
============================================================
|
||||
|
||||
### When you need more than a basic image viewer but less than a full image editor, check out these apps.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Internet Archive Book Images][17]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
Like most people, you probably have more than a few photos and other images on your computer. And, like most people, you probably like to take a peek at those images and photos every so often.
|
||||
|
||||
Firing up an editor like [GIMP][18] or [Pinta][19] is overkill for simply viewing images.
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
On the other hand, the basic image viewer included with most Linux desktop environments might not be enough for your needs. If you want something with a few more features, but still want it to be lightweight, then take a closer look at these four image viewers for the Linux desktop, plus a handful of bonus options if they don't meet your needs.
|
||||
|
||||
### Feh
|
||||
|
||||
[Feh][20] is an old favorite from the days when I computed on older, slower hardware. It's simple, unadorned, and does what it's designed to do very well.
|
||||
|
||||
You drive Feh from the command line: just point it at an image or a folder containing images and away you go. Feh loads quickly, and you can scroll through a set of images with a mouse click or by using the left and right arrow keys on your keyboard. What could be simpler?
|
||||
|
||||
Feh might be light, but it offers some options. You can, for example, control whether Feh's window has a border, set the minimum and maximum sizes of the images you want to view, and tell Feh at which image in a folder you want to start viewing.
|
||||
|
||||
### [feh.png][6]
|
||||
|
||||

|
||||
|
||||
Feh in action
|
||||
|
||||
### Ristretto
|
||||
|
||||
If you've used Xfce as a desktop environment, you'll be familiar with [Ristretto][21]. It's small, simple, and very useful.
|
||||
|
||||
How simple? You open a folder containing images, click on one of the thumbnails on the left, and move through the images by clicking the navigation keys at the top of the window. Ristretto even has a slideshow feature.
|
||||
|
||||
Ristretto can do a bit more, too. You can use it to save a copy of an image you're viewing, set that image as your desktop wallpaper, and even open it in another application, for example, if you need to touch it up.
|
||||
|
||||
### [ristretto.png][7]
|
||||
|
||||

|
||||
|
||||
Viewing photos in Ristretto
|
||||
|
||||
### Mirage
|
||||
|
||||
On the surface, [Mirage][22] is kind of plain and nondescript. It does the same things just about every decent image viewer does: opens image files, scales them to the width of the window, and lets you scroll through a collection of images using your keyboard. It even runs slideshows.
|
||||
|
||||
Still, Mirage will surprise anyone who needs a little more from their image viewer. In addition to its core features, Mirage lets you resize and crop images, take screenshots, rename an image file, and even generate 150-pixel-wide thumbnails of the images in a folder.
|
||||
|
||||
If that wasn't enough, Mirage can display [SVG files][23]. You can even drive it [from the command line][24].
|
||||
|
||||
### [mirage.png][8]
|
||||
|
||||

|
||||
|
||||
Taking Mirage for a spin
|
||||
|
||||
### Nomacs
|
||||
|
||||
[Nomacs][25] is easily the heaviest of the image viewers described in this article. Its perceived bulk belies Nomacs' speed. It's quick and easy to use.
|
||||
|
||||
Nomacs does more than display images. You can also view and edit an image's [metadata][26], add notes to an image, and do some basic editing—including cropping, resizing, and converting the image to grayscale. Nomacs can even take screenshots.
|
||||
|
||||
One interesting feature is that you can run two instances of the application on your desktop and synchronize an image across those instances. The [Nomacs documentation][27]recommends this when you need to compare two images. You can even synchronize an image across a local area network. I haven't tried synchronizing across a network, but please share your experiences if you have.
|
||||
|
||||
### [nomacs.png][9]
|
||||
|
||||

|
||||
|
||||
A photo and its metadata in Nomacs
|
||||
|
||||
### A few other viewers worth looking at
|
||||
|
||||
If these four image viewers don't suit your needs, here are some others that might interest you.
|
||||
|
||||
**[Viewnior][11]** bills itself as a "fast and simple image viewer for GNU/Linux," and it fits that bill nicely. Its interface is clean and uncluttered, and Viewnior can even do some basic image manipulation.
|
||||
|
||||
If the command line is more your thing, then **display** might be the viewer for you. Both the **[ImageMagick][12]** and **[GraphicsMagick][13]** image manipulation packages have an application named display, and both versions have basic and advanced options for viewing images.
|
||||
|
||||
**[Geeqie][14]** is one of the lighter and faster image viewers out there. Don't let its simplicity fool you, though. It packs features, like metadata editing and viewing camera RAW image formats, that other viewers lack.
|
||||
|
||||
**[Shotwell][15]** is the photo manager for the GNOME desktop. While it does more than just view images, Shotwell is quite speedy and does a great job of displaying photos and other graphics.
|
||||
|
||||
_Do you have a favorite lightweight image viewer for the Linux desktop? Feel free to share your preferences by leaving a comment._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
cott Nesbitt - I'm a long-time user of free/open source software, and write various things for both fun and profit. I don't take myself too seriously. You can find me at these fine establishments on the web: Twitter, Mastodon, GitHub.
|
||||
|
||||
via: https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop
|
||||
|
||||
作者:[ Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/361216
|
||||
[7]:https://opensource.com/file/361231
|
||||
[8]:https://opensource.com/file/361221
|
||||
[9]:https://opensource.com/file/361226
|
||||
[10]:https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop?rate=UcKbaJQJAbLScWVu8qm9bqii7JMsIswjfcBHt3aRnEU
|
||||
[11]:http://siyanpanayotov.com/project/viewnior/
|
||||
[12]:https://www.imagemagick.org/script/display.php
|
||||
[13]:http://www.graphicsmagick.org/display.html
|
||||
[14]:http://geeqie.org/
|
||||
[15]:https://wiki.gnome.org/Apps/Shotwell
|
||||
[16]:https://opensource.com/user/14925/feed
|
||||
[17]:https://www.flickr.com/photos/internetarchivebookimages/14758810172/in/photolist-oubL5m-ocu2ck-odJwF4-oeq1na-odgZbe-odcugD-w7KHtd-owgcWd-oucGPe-oud585-rgBDNf-obLoQH-oePNvs-osVgEq-othPLM-obHcKo-wQR3KN-oumGqG-odnCyR-owgLg3-x2Zeyq-hMMxbq-oeRzu1-oeY49i-odumMM-xH4oJo-odrT31-oduJr8-odX8B3-obKG8S-of1hTN-ovhHWY-ow7Scj-ovfm7B-ouu1Hj-ods7Sg-qwgw5G-oeYz5D-oeXqFZ-orx8d5-hKPN4Q-ouNKch-our8E1-odvGSH-oweGTn-ouJNQQ-ormX8L-od9XZ1-roZJPJ-ot7Wf4
|
||||
[18]:https://www.gimp.org/
|
||||
[19]:https://pinta-project.com/pintaproject/pinta/
|
||||
[20]:https://feh.finalrewind.org/
|
||||
[21]:https://docs.xfce.org/apps/ristretto/start
|
||||
[22]:http://mirageiv.sourceforge.net/
|
||||
[23]:https://en.wikipedia.org/wiki/Scalable_Vector_Graphics
|
||||
[24]:http://mirageiv.sourceforge.net/docs-advanced.html#cli
|
||||
[25]:http://nomacs.org/
|
||||
[26]:https://iptc.org/standards/photo-metadata/photo-metadata/
|
||||
[27]:http://nomacs.org/synchronization/
|
||||
[28]:https://opensource.com/users/scottnesbitt
|
||||
[29]:https://opensource.com/users/scottnesbitt
|
||||
[30]:https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop#comments
|
||||
@ -1,427 +0,0 @@
|
||||
简洁的介绍TypeScript
|
||||
=============================================================
|
||||
|
||||
|
||||
**下文是James Henry([@MrJamesHenry][8])所编辑的内容。我是ESLint核心团队的一员,也是TypeScript的热衷者和发扬者。我和Todd合作在[UltimateAngular][9]平台上发布Angular和TypeScript的精品课程。**
|
||||
|
||||
> 本文的主旨是为了介绍我们对TypeScript的思考和在JavaScript开发当中的更好的使用。
|
||||
>
|
||||
> 我们将给出编译和关键字准确的定义
|
||||
|
||||
TypeScript强大之处远远不止这些,本篇文章无法涵盖,想要了解更多请阅读官方文档[official document][15],或者查阅[TypeScript courses over on UltimateAngular][16]UltimateAngular平台的TypeScript精品课程-从初学者到TypeScript高手
|
||||
|
||||
### [目录][17]
|
||||
|
||||
* [背景][10]
|
||||
* [关键知识的掌握][11]
|
||||
* [JavaScript解释型语言还是编译型语言][1]
|
||||
* [运行时间 VS 编译时间][2]
|
||||
* [TypeScript编译器][3]
|
||||
* [动态类型 VS 静态类型][4]
|
||||
* [TypeScript在我们JavaScript工作流程中的作用][12]
|
||||
* [我们的源文件是我们的文档,TypeScript是我们的拼写检查][5]
|
||||
* [TypeScript是一种可以启动其它工具的工具][13]
|
||||
* [什么是抽象语法树(AST)?][6]
|
||||
* [示例:在VS中重命名符号][7]
|
||||
* [总结][14]
|
||||
|
||||
### [背景][18]
|
||||
|
||||
TypeScript是很容易掌握的强大开发工具
|
||||
|
||||
然而,TypeScript可能比JavaScript要更为复杂,因为TypeScript可能同时向我们介绍以前没有考虑到的JavaScript程序相关的一些列技术概念。
|
||||
|
||||
每当我们谈论到类型、编译器等这些概念的时候。事情就会变的非常麻烦和不知所云起来。
|
||||
|
||||
这篇文章就是为了你在学习过程中你需要知道的许许多多不知所云的概念解答的,来帮助你TypeScript入门的,让你轻松自如的应对这些概念。
|
||||
|
||||
### [关键知识的掌握][19]
|
||||
|
||||
有时候运行我们的代码是在Web浏览器中运行,和我们平常运行代码有不同的感觉,它是怎样运行自己书写的代码的?“没有经过编译的,是正确的吗?”。“我敢肯定没有类型的...”
|
||||
|
||||
情况变的更有趣了,当我们知道通过前后程序的定义来判断语法的正确与否
|
||||
|
||||
首先我们要作的是
|
||||
|
||||
#### [JavaScript 解释型语言还是编译型语言][20]
|
||||
|
||||
传统意义上,程序员经常将自己的程序编译之后运行出结果就认为这种语言是编译型语言。
|
||||
|
||||
> 从初学者的角度来说,编译的过程就是将我们自己编辑好的高级语言程序转换成机器实际运行过程中能够看懂的格式(一般是二进制文件格式)。
|
||||
|
||||
就像GO语言,可以使用go build的命令行工具编译.go的文件格式,将其编译成较低级的语言,可以直接运行的格式。(译者没有使用过GO语言,不清楚GO编译过程的机制,试着用C语言的方式说明)
|
||||
|
||||
```
|
||||
# We manually compile our .go file into something we can run
|
||||
# using the command line tool "go build"
|
||||
go build ultimate-angular.go
|
||||
# ...then we execute it!
|
||||
./ultimate-angular
|
||||
```
|
||||
|
||||
我们在日常使用JavaScript开发的时候并没有编译的这一步,这是JavaScript忽略了我们程序员对新一代构建工具和模块加载程序的热爱。
|
||||
|
||||
我们编写JavaScript代码在浏览器的<script>标签进行加载运行(或者在服务端环境运行,比如:node.js)
|
||||
|
||||
**是的,JavaScript没有进过编译,那他一定是解释型语言吗?
|
||||
|
||||
实际上,我们能够确定的一点是,JavaScript不是我们自己编译的,现在我们简单的回顾一个简单的解释型语言的例子,再来谈JavaScript的编译问题。
|
||||
|
||||
> 计算机的解释执行的过程就行人们看书一样,从上到下一行一行的阅读。
|
||||
|
||||
我们熟知的解释型语言是bash Script。我们终端中的bash解释器逐行读取我们的命令并且执行它。
|
||||
|
||||
现在我们回到JavaScript是解释执行还是编译执行的讨论中,解释执行要将逐行读取和执行程序分开理解,不要和在一起理解。
|
||||
|
||||
以此代码为例
|
||||
|
||||
```
|
||||
hello();
|
||||
function hello(){
|
||||
console.log("Hello")
|
||||
}
|
||||
```
|
||||
|
||||
这是正真意义上JavaScript输出Hello字符的程序代码,但是,在hello()在我们定义他之前就已经使用了这个函数,这是简单逐行执行办不到的,因为hello()在第一行没有任何意义,直到我们在之后声明了它。
|
||||
|
||||
像这样的在JavaScript是存在的,因为我们的代码实际上在执行之前就被所谓的”JavaScript引擎“或者是”特定的编译环境“编译过,这个编译的过程取决于具体的实现。(比如,使用v8引擎的node.js和Chome就和使用SpiderMonkey的FireFox就有所不一样)
|
||||
|
||||
我们不会在进一步的讲解编译型执行和解释型执行微妙之处。(这里的定义已经很好了)
|
||||
|
||||
> 请务必记住,我们编写的JavaScript代码已经不是普通用户(初学者)执行的代码了,即使<script>在HTML中只是个标签,也是不一样的。
|
||||
|
||||
#### [运行时间 VS 编译时间][21]
|
||||
|
||||
现在我们已经理解了编译和运行是二个不同的阶段,那运行时间和编译时间理解起来也就容易多了。
|
||||
|
||||
编译时间,就是我们在我们的编辑器或者IDE当中的代码转换成其它格式的代码
|
||||
|
||||
运行时间,就是我们程序实际执行的过程,例如:上面的hello()就是函数执行的具体时间
|
||||
|
||||
#### [TypeScript编译器][22]
|
||||
|
||||
现在我们了解了程序的生命周期中的关键阶段,接下来我们可以介绍TypeScript编译器了。
|
||||
|
||||
TypeScript编译器是帮助我们编写代码的核心。比如,我们不需将JavaScript代码包含到<script>标签当中,只需要通过TypeScript编译器传递它,以便在运行程序之前更好的修改程序
|
||||
|
||||
> 我们可以将这个新的步骤作为我们自己的个人“编译时间”,这将有助于我们的程序按照我们预期的方式编写,甚至达到了JavaScript引擎的作用。
|
||||
|
||||
它与上面Golang的实例类似,但是TypeScript编译器只是基于我们编写程序的方式提供提示信息,并不会将其转换成较低级的可执行文件,它只会生成纯JavaScript代码。
|
||||
|
||||
```
|
||||
# One option for passing our source .ts file through the TypeScript
|
||||
# compiler is to use the command line tool "tsc"
|
||||
tsc ultimate-angular.ts
|
||||
|
||||
# ...this will produce a .js file of the same name
|
||||
# i.e. ultimate-angular.js
|
||||
```
|
||||
|
||||
在[官方文档][23]中有许多关于将TypeScript编译器融入到你的现有工作流程中。这些已经超出本文范围。
|
||||
|
||||
#### [动态类型 VS 静态类型][24]
|
||||
|
||||
就像编译程序 VS 解释程序一样,动态类型 VS 静态类型在现有的资料中也是模棱两可的。
|
||||
|
||||
让我门先回顾一下,我们在JavaScript中对于类型的理解。
|
||||
|
||||
我门的代码如下:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
```
|
||||
|
||||
我门如何给别人描述这段代码。
|
||||
|
||||
我们声明了一个变量 name,它被分配了一个“James”的字符串,然后我们又申请了一个变量 sum,它被分配了一个数字1数字2的求和的数值结果值。
|
||||
|
||||
即使在这样一个简单的程序中,我们也使用了二个JavaScript的基本类型:String 和 Number
|
||||
|
||||
就像上面我们讲编译一样,我门不会陷入编程语言类型的细节当中,关键是要理解在JavaScript中类型的表示的是什么。以至于扩展到TypeScript的类型的理解上。
|
||||
|
||||
我们阅读官方最新的ECMAScript规范中的实例程序,它大量引入了JavaScript的类型和用法。
|
||||
|
||||
官方规定
|
||||
|
||||
> ECMAScript语言类型对应于使用ECMAScript语言的ECMAScript程序员直接操作的值。
|
||||
>
|
||||
> ECMAScript语言类型为Undefined,Null,Boolean,String,Symbol,Number和Object。
|
||||
|
||||
我们可以看到,JavaScript语言正式有7种类型,其中我们可能在我们现在程序中使用了6种(Symbol首次在ES2015中引入,也就是ES6)。
|
||||
|
||||
现在我们来深入一点的看上面的JavaScript代码中的“name 和 sum”
|
||||
|
||||
我们可以使用我们 name 当前被分配了字符串'James'的变量 ,并将其重新分配给我们的第二个当前值是数字3的变量 sum 。
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
该 name 变量开始“保持”一个字符串,但现在它保存一个数字。这突出了JavaScript中变量和类型的基本特性:
|
||||
|
||||
‘James’是一个字符串类型,而name变量可以分配任何类型的值。和sum赋值的情况相同,1 是一个数字类型,sum变量可以分配任何可能的值。
|
||||
|
||||
> 在JavaScript中,值是具有类型的,而变量是可以随时保存任何类型的值。
|
||||
|
||||
这也恰好是一个“动态类型语言”的定义。
|
||||
|
||||
相比之下,我们可以将“静态类型语言”视为我们可以(必须)将类型信息与特定变量相关联的语言:
|
||||
|
||||
```
|
||||
var name: string = ‘James’;
|
||||
```
|
||||
|
||||
在这段代码中,我们能够更好地显式声明我们对变量name的意图,我们希望它总是用作一个字符串。
|
||||
|
||||
你猜怎么着?我们刚刚看到我们的第一个TypeScript程序。
|
||||
|
||||
当我们反思我们自己的代码(没有规划程序的双关语)时,我们可以得出的结论,即使我们使用动态语言(如JavaScript),在几乎所有的情况下,我们应该有非常明确的意图先定义我们的变量和函数参数然后再来使用他们。如果这些变量和参数被重新分配,将不同类型的值保存到我们首先分配给值的那些,那么有可能我们这样分配程序是不会工作的。
|
||||
|
||||
> 作为JavaScript开发者,TypeScript的静态类型注释给我们的一个巨大的帮助,够清楚地表达我们对变量的意图。
|
||||
|
||||
> 这种改进不仅有益于TypeScript编译器,还可以让我们的同事和将来的自己明白我们的代码。代码的阅读远远超过编写。
|
||||
|
||||
### [TypeScript在我们JavaScript工作流程中的作用][26]
|
||||
|
||||
我们已经开始看到为什么经常说TypeScript只是JavaScript + Static Types。: string 对于我们的 name 变量就是我们所谓的“类型注释”。 在编译时被使用 (换句话说,当我们通过TypeScript编译器传递代码时),以确保其余的代码符合我们原来的意图。
|
||||
|
||||
我们再来看看我们的程序,并添加显式注释,这次是我们的 sum 变量:
|
||||
|
||||
```
|
||||
var name: string = 'James';
|
||||
var sum: number = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
如果我们使用TypeScript编译器编译这个代码,我们现在就会收到一个在 name = sum 这行的错误,Type 'number' is not assignable to type 'string',我们被警告不能这样传递(运送),我们执行的代码可能有问题。
|
||||
|
||||
> 更厉害的是,如果我们想要继续执行,我们可以选择忽略来自TypeScript编译器的错误,因为它只是在将JavaScript代码发送给我们的用户之前给出了我们对JavaScript代码的反馈的工具。
|
||||
|
||||
TypeScript编译器为我们输出的最终JavaScript代码将与上述原始源代码完全相同:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
类型注释全部为我们自动删除,现在我们可以运行我们的代码。
|
||||
|
||||
> 注意:在此示例中,即使我们没有提供显式类型注释的 : string 和: number ,TypeScript编译器也可以为我们提供完全相同的错误 。
|
||||
>
|
||||
> TypeScript通常能够从我们使用它的方式推断变量的类型!
|
||||
|
||||
#### [我们的源文件是我们的文档,TypeScript是我们的拼写检查][27]
|
||||
|
||||
对于TypeScript与我们的源代码的关系来说,一个很好的类比,就是拼写检查与我们在Microsoft Word中写的文档的关系。
|
||||
|
||||
这两个例子有三个关键的共同点:
|
||||
|
||||
1. **我们写的东西是客观的,它可以告诉我们写的对不对:
|
||||
* _拼写检查:“我们已经写了字典中不存在的字”
|
||||
* _TypeScript:“我们引用了一个符号(例如一个变量),它没有在我们的程序中声明”
|
||||
|
||||
2. **它可以表明我们写的可能是错误的:
|
||||
* _拼写检查:“该工具无法完全推断特定条款的含义,并建议重写”
|
||||
* _TypeScript:“该工具不能完全推断特定变量的类型并警告不要使用它”
|
||||
|
||||
3. **我们的来源可以用于其原始目的,无论工具是否存在错误:
|
||||
* _拼写检查:“即使您的文档有很多拼写错误,您仍然可以打印出来,并将其用作文档”
|
||||
* _TypeScript:“即使您的源代码具有TypeScript错误,它仍然会生成JavaScript代码,您可以执行”
|
||||
|
||||
#### [TypeScript是一种可以启动其它工具的工具][28]
|
||||
|
||||
TypeScript编译器由几个不同的部分或阶段组成。我们将通过查看这些部分之一 -The Parser-(语法分析程序);为我们提供了构建其他开发人员工具的机会,除了TypeScript已经为我们做的以外。
|
||||
|
||||
编译过程的“解析器步骤”的结果是所谓的抽象语法树,简称为AST。
|
||||
|
||||
#### [什么是抽象语法树(AST)?}[29]
|
||||
|
||||
我们以自由的文本形式编写我们的程序,因为这是我们人类与计算机交互的最好方式,让他们能够做我们想要的东西。我们手工编写复杂的数据结构并不是很棒!
|
||||
|
||||
然而,在任何一种合理的方式下,自由文本实际上是一个非常棘手的事情。它可能包含程序不必要的东西,例如空格,或者可能存在不明确的部分。
|
||||
|
||||
因此,我们希望将我们的程序转换成数据结构,将数据结构映射出所有使用的所谓“令牌”,并将其插入到我们的程序中。
|
||||
|
||||
这个数据结构正是AST!
|
||||
|
||||
AST可以通过多种不同的方式表示,我使用JSON来看一看。
|
||||
|
||||
我们从这个令人难以置信的基本源代码来看:
|
||||
|
||||
```
|
||||
var a = 1;
|
||||
```
|
||||
|
||||
TypeScript编译器的Parser(语法分析程序)阶段的(简化的)输出将是以下AST:
|
||||
|
||||
```
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 256,
|
||||
"text": "var a = 1;",
|
||||
"statements": [
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 200,
|
||||
"declarationList": {
|
||||
"pos": 0,
|
||||
"end": 9,
|
||||
"kind": 219,
|
||||
"declarations": [
|
||||
{
|
||||
"pos": 3,
|
||||
"end": 9,
|
||||
"kind": 218,
|
||||
"name": {
|
||||
"pos": 3,
|
||||
"end": 5,
|
||||
"text": "a"
|
||||
},
|
||||
"initializer": {
|
||||
"pos": 7,
|
||||
"end": 9,
|
||||
"kind": 8,
|
||||
"text": "1"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
我们的AST中的对象称为节点。
|
||||
|
||||
#### [示例:在VS中重命名符号][30]
|
||||
|
||||
在内部,TypeScript编译器将使用Parser生成的AST来提供一些非常重要的事情,例如 编译程序时发生的类型检查。
|
||||
|
||||
但它不止于此!
|
||||
|
||||
> 我们可以使用AST在TypeScript之上开发自己的工具,如linters,formatter和分析工具。
|
||||
|
||||
建立在这个AST代码之上的工具的一个很好的例子是:语言服务器。
|
||||
|
||||
深入了解语言服务器的工作原理超出了本文的范围,但是当我们编写程序时,它能为我们提供一个重量级别功能,就是“重命名符号”。
|
||||
|
||||
假设我们有以下源代码:
|
||||
|
||||
```
|
||||
// The name of the author is James
|
||||
var first_name = 'James';
|
||||
console.log(first_name);
|
||||
```
|
||||
|
||||
经过代码审查和适当的 ,决定应该切换我们的变量命名;使用骆驼式命名方式,而不是我们当前正在使用这种方式。
|
||||
|
||||
在我们的代码编辑器中,我们一直以来可以选择多个相同的文本,并使用多个光标来一次更改它们。
|
||||
|
||||

|
||||
|
||||
当我们继续这样的操作的时候,我们已经陷入了一个典型的陷阱中。
|
||||
|
||||
的在我们手动匹配过程中,我们不想改变的“name”变量名在抽象语法书中的结构,可以这样的操作已经改变了。我们可以看到在现实世界的应用程序中更改这样的代码是有多高的风险?
|
||||
|
||||
正如我们在上面学到的那样,像TypeScript这样的东西在幕后生成一个AST的时候,它不再像我们的程序那样与自己的程序交互 ,每个标记在AST中都有自己的位置,而且它有很清晰的映射关系。
|
||||
|
||||
当我们右键单击我们的first_name变量(TypeScript语言服务器插件可用于其他编辑器)时,我们可以使用“代码符号”选项直接在VS中编辑。
|
||||
|
||||

|
||||
|
||||
好多了!现在我们的first_name变量是唯一需要改变的东西,如果合适,这个变化甚至会发生在我们项目中的多个文件中(与导出和导入的值一样)!
|
||||
|
||||
### [总结][31]
|
||||
|
||||
我们在这篇文章中已经讲了很多的内容。
|
||||
|
||||
我们把有关学术方面的规避开,围绕编译器和类型还有很多专业术语给出了通俗的定义。
|
||||
|
||||
我们查看了编译语言vs解释语言,运行时间与编译时间,动态类型vs静态类型,以及抽象语法树如何为我们的程序构建工具提供了更为优化的方法。
|
||||
|
||||
重要的是,我们提供了TypeScript思考方式作为我们JavaScript开发者的一种方式,它可以建立在如何提供更为惊人的实用程序,如重命名符号作为重构代码的一种方式。
|
||||
|
||||
快来UltimateAngular平台上学习从初学者到TypeScript高手的课程吧,开启你的学习之旅!
|
||||
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I‘m Todd, I teach the world Angular through @UltimateAngular. Conference speaker and Developer Expert at Google.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://toddmotto.com/typescript-the-missing-introduction
|
||||
|
||||
作者:[Todd][a]
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftoddmotto.com%2Ftypescript-the-missing-introduction%3Futm_source%3Djavascriptweekly%26utm_medium%3Demail&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=toddmotto&tw_p=followbutton
|
||||
[1]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[2]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[3]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[4]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[5]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[6]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[7]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[8]:https://twitter.com/MrJamesHenry
|
||||
[9]:https://ultimateangular.com/courses
|
||||
[10]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[11]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[12]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[13]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[14]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[15]:http://www.typescriptlang.org/docs
|
||||
[16]:https://ultimateangular.com/courses#typescript
|
||||
[17]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#table-of-contents
|
||||
[18]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[19]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[20]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[21]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[22]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[23]:http://www.typescriptlang.org/docs
|
||||
[24]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[25]:http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-262.pdf
|
||||
[26]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[27]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[28]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[29]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[30]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[31]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[32]:https://ultimateangular.com/courses#typescript
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,68 @@
|
||||
轻松应对 Linux 容器性能
|
||||
============================================================
|
||||
|
||||

|
||||
图片来源: CC0 Public Domain
|
||||
|
||||
应用程序的性能决定了软件能多快完成预期任务。这回答有关应用程序的几个问题,例如:
|
||||
|
||||
* 峰值负载下的响应时间
|
||||
* 与替代方案相比,它易于使用,受支持的功能和用例
|
||||
* 操作成本(CPU使用率、内存需求、数据吞吐量、带宽等)
|
||||
|
||||
该性能分析的价值超出了服务负载所需的计算资源的估计或满足峰值需求所需的应用实例数量。性能显然与成功企业的基本要素挂钩。它通知用户的总体体验,包括确定什么会拖慢客户预期的响应时间,通过设计满足带宽要求的内容交付来提高客户粘性,选择最佳设备,最终帮助企业发展业务。
|
||||
|
||||
### 问题
|
||||
|
||||
当然,这是对业务服务性能工程价值的过度简化。要了解完成我刚刚描述的挑战,让我们来做一个真正的,有点复杂的事情。
|
||||
|
||||

|
||||
|
||||
现实世界的应用程序可能托管在云端。应用程序可以利用非常大(或概念上无穷大)的计算资源。在硬件和软件方面的需求将通过云来满足。从事开发工作的开发人员将使用云提供的功能来实现更快的编码和部署。云托管不是免费的,但成本开销与应用程序的资源需求成正比。
|
||||
|
||||
搜索即服务(SaaS)、平台即服务(PaaS)、基础设施即服务(IaaS)以及负载平衡即服务(LBaaS),它是当云端管理托管程序的流量,开发人员可能还会使用这些快速增长的云服务中的一个或多个:
|
||||
|
||||
* 安全即服务 (SECaaS),可满足软件和用户的安全需求
|
||||
* 数据即服务 (DaaS),提供用户的应用需求数据
|
||||
* 登录即服务 (LaaS),DaaS 的近亲,提供有关日志传送和使用的分析指标
|
||||
* 搜索即服务 (SaaS),用于应用程序的分析和大数据需求
|
||||
* 网络即服务 (NaaS),用于通过公共网络发送和接收数据
|
||||
|
||||
云服务也呈指数级增长,因为它们使编写复杂应用程序的开发人员更容易。除了软件复杂性之外,所有这些分布式组件的相互作用变得越来越多。用户群变得更加多元化。该软件的要求列表变得更长。对其他服务的依赖性变大。由于这些因素,这个生态系统的缺陷会引发性能问题的多米诺效应。
|
||||
|
||||
例如,假设你有一个精心编写的应用程序,它遵循安全编码实践,旨在满足不同的负载要求,并经过彻底测试。另外假设你已经将基础架构和分析工作结合起来,以支持基本的性能要求。在系统的实现、设计和架构中建立性能标准需要做些什么?软件如何跟上不断变化的市场需求和新兴技术?如何测量关键参数以调整系统以获得最佳性能?如何使系统具有弹性和自我恢复能力?你如何更快地识别任何潜在的性能问题,并尽早解决?
|
||||
|
||||
### 进入容器
|
||||
|
||||
软件[容器][2]以[微服务][3]设计或面向服务的架构(SoA)的优点为基础,提高了性能,因为包含更小,自足的代码块的系统更容易编码,对其他系统组件有更清晰、定义良好的依赖。测试更容易,包括围绕资源利用和内存过度消耗的问题比在宏架构中更容易确定。
|
||||
|
||||
当伸缩系统以增加负载时,容器应用程序复制快速而简单。安全漏洞能更好地隔离。补丁可以独立版本化并快速部署。性能监控更有针对性,测量更可靠。你还可以重写和“改版”资源密集型代码,以满足不断变化的性能要求。
|
||||
|
||||
容器启动快速,停止也快速。它比虚拟机(VM)有更高效资源利用和更好的进程隔离。容器没有空闲内存和 CPU 开销。它们允许多个应用程序共享机器,而不会丢失数据或性能。容器使应用程序可移植,因此开发人员可以构建并将应用程序发送到任何支持容器技术 Linux 的服务器上,而不必担心性能损失。容器以它们的形式存在,并遵守其集群管理器(如 Cloud Foundry 的 Diego、[Kubernetes][4]、Apache Mesos 和 Docker Swarm)所规定的配额(比如包括存储、计算和对象计数配额)。
|
||||
|
||||
虽然容器在性能方面表现出色,但即将到来的 “serverless” 计算(也称为功能即服务(FaaS))的浪潮将扩大容器的优势。在 FaaS 时代,这些临时性或短期的容器将带来超越应用程序性能的优势,直接转化为在云中托管的间接成本的节省。如果容器的工作更快,那么它的寿命就会更短,而且计算量负载纯粹是按需的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Garima 是 Red Hat 的工程经理,专注于 OpenShift 容器平台。在加入 Red Hat 之前,Garima 帮助 Akamai Technologies&MathWorks Inc. 开创了创新。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/performance-container-world
|
||||
|
||||
作者:[Garima][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/garimavsharma
|
||||
[1]:https://opensource.com/article/17/2/performance-container-world?rate=RozKaIY39AZNxbayqFkUmtkkhoGdctOVuGOAJqVJII8
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers
|
||||
[3]:https://opensource.com/resources/what-are-microservices
|
||||
[4]:https://opensource.com/resources/what-is-kubernetes
|
||||
[5]:https://opensource.com/user/109286/feed
|
||||
[6]:https://opensource.com/article/17/2/performance-container-world#comments
|
||||
[7]:https://opensource.com/users/garimavsharma
|
||||
@ -0,0 +1,73 @@
|
||||
# 在 Kali Linux 的 Wireshark 中过滤数据包
|
||||
|
||||
内容
|
||||
|
||||
* * [1. 介绍][1]
|
||||
|
||||
* [2. 布尔表达式和比较运算符][2]
|
||||
|
||||
* [3. 过滤抓包][3]
|
||||
|
||||
* [4. 过滤结果][4]
|
||||
|
||||
* [5. 总结思考][5]
|
||||
|
||||
### 介绍
|
||||
|
||||
过滤可让你专注于你有兴趣查看的精确数据集。如你所见,Wireshark 默认会抓取_所有_数据包。这可能会妨碍你寻找具体的数据。 Wireshark 提供了两个功能强大的过滤工具,让你简单并且无痛苦地获得精确的数据。
|
||||
|
||||
Wireshark 可以通过两种方式过滤数据包。它可以过滤只收集某些数据包,或者在抓取数据包后进行过滤。当然,这些可以彼此结合使用,并且它们各自的用处取决于收集的数据和信息的多少。
|
||||
|
||||
### 布尔表达式和比较运算符
|
||||
|
||||
Wireshark 有很多很棒的内置过滤器。输入任何一个过滤器字段,你将看到它们会自动完成。大多数对应于用户在数据包之间会出现的更常见的区别。仅过滤 HTTP 请求将是一个很好的例子。
|
||||
|
||||
对于其他的,Wireshark 使用布尔表达式和/或比较运算符。如果你曾经做过任何编程,你应该熟悉布尔表达式。他们是使用 “and”、“or”、“not” 来验证声明或表达的真假。比较运算符要简单得多他们只是确定两件或更多件事情是否相等、大于或小于彼此。
|
||||
|
||||
### 过滤抓包
|
||||
|
||||
在深入自定义抓包过滤器之前,请先查看 Wireshark 已经内置的内容。单击顶部菜单上的 “Capture” 选项卡,然后点击 “Options”。可用接口下面是可以编写抓包过滤器的行。直接移到左边一个标有 “Capture Filter” 的按钮上。点击它,你将看到一个新的对话框,其中包含内置的抓包过滤器列表。看看里面有些什么。
|
||||
|
||||

|
||||
|
||||
|
||||
在对话框的底部,有一个小的表单来创建并保存抓包过滤器。按左边的 “New” 按钮。它将创建一个有默认数据的新的抓包过滤器。要保存新的过滤器,只需将实际需要的名称和表达式替换原来的默认值,然后单击“Ok”。过滤器将被保存并应用。使用此工具,你可以编写并保存多个不同的过滤器,并让它们将来可以再次使用。
|
||||
|
||||
抓包有自己的过滤语法。对于比较,它不使用等于号,并使用 `>` 来用于大于或小于。对于布尔值来说,它使用 “and”、“or” 和 “not”。
|
||||
|
||||
例如,如果你只想监听 80 端口的流量,你可以使用这样的表达式:`port 80`。如果你只想从特定的 IP 监听端口 80,你可以 `port 80 and host 192.168.1.20`。如你所见,抓包过滤器有特定的关键字。这些关键字用于告诉 Wireshark 如何监控数据包以及哪些数据。例如,`host` 用于查看来自 IP 的所有流量。`src`用于查看源自该 IP 的流量。与之相反,`net` 只监听目标到这个 IP 的流量。要查看一组 IP 或网络上的流量,请使用 `net`。
|
||||
|
||||
### 过滤结果
|
||||
|
||||
界面的底部菜单栏是专门用于过滤结果的菜单栏。此过滤器不会更改 Wireshark 收集的数据,它只允许你更轻松地对其进行排序。有一个文本字段用于输入新的过滤器表达式,并带有一个下拉箭头以查看以前输入的过滤器。旁边是一个标为 “Expression” 的按钮,另外还有一些用于清除和保存当前表达式的按钮。
|
||||
|
||||
点击 “Expression” 按钮。你将看到一个小窗口,其中包含多个选项。左边一栏有大量的条目,每个都有额外的折叠子列表。这些都是你可以过滤的所有不同的协议、字段和信息。你不可能看完所有,所以最好是大概看下。你应该注意到了一些熟悉的选项,如 HTTP、SSL 和 TCP。
|
||||
|
||||

|
||||
|
||||
子列表包含可以过滤的不同部分和请求方法。你可以看到通过 GET 和 POST 请求过滤 HTTP 请求。
|
||||
|
||||
你还可以在中间看到运算符列表。通过从每列中选择条目,你可以使用此窗口创建过滤器,而不用记住 Wireshark 可以过滤的每个条目。对于过滤结果,比较运算符使用一组特定的符号。 `==` 用于确定是否相等。`>`确定一件东西是否大于另一个东西,`<` 找出是否小一些。 `>=` 和 `<=` 分别用于大于等于和小于等于。它们可用于确定数据包是否包含正确的值或按大小过滤。使用 `==` 仅过滤 HTTP GET 请求的示例如下:`http.request.method == "GET"`。
|
||||
|
||||
布尔运算符基于多个条件将小的表达式串到一起。不像是抓包所使用的单词,它使用三个基本的符号来做到这一点。`&&` 代表 “and”。当使用时,`&&` 两边的两个语句都必须为 true,以便 Wireshark 来过滤这些包。`||` 表示 “或”。只要两个表达式任何一个为 true,它就会被过滤。如果你正在查找所有的 GET 和 POST 请求,你可以这样使用 `||`:`(http.request.method == "GET") || (http.request.method == "POST")`。`!`是 “not” 运算符。它会寻找除了指定的东西之外的所有东西。例如,`!http` 将展示除了 HTTP 请求之外的所有东西。
|
||||
|
||||
### 总结思考
|
||||
|
||||
过滤 Wireshark 可以让你有效监控网络流量。熟悉可以使用的选项并习惯你可以创建过滤器的强大表达式需要一些时间。然而一旦你做了,你将能够快速收集和查找你要的网络数据,而无需梳理长长的数据包或进行大量的工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
|
||||
作者:[Nick Congleton ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
[1]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h1-introduction
|
||||
[2]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h2-boolean-expressions-and-comparison-operators
|
||||
[3]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h3-filtering-capture
|
||||
[4]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h4-filtering-results
|
||||
[5]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h5-closing-thoughts
|
||||
@ -0,0 +1,172 @@
|
||||
# 使用 Snapcraft 构建、测试并发布 Snaps
|
||||
|
||||
---
|
||||
|
||||
这篇客座文章的作者是 Ricardo Feliciano —— CircleCi 的开发者传道士。如果您也有兴趣投稿,请联系 ubuntu-iot@canonical.com。
|
||||
|
||||
`Snapcraft` 是一个正在为其在 Linux 中的位置而奋斗的包管理系统,它为你重新想象了分发软件的方式。你可以使用一系列新的跨版本工具来构建和发布 `Snaps`。接下来我们将会讲述怎么使用 `CircleCI 2.0` 来加速这个过程
|
||||
以及一些在这个过程中的可能遇到的问题。
|
||||
|
||||
### Snaps 是什么?Snapcraft 又是什么?
|
||||
|
||||
`Snaps` 是用于 Linux 发行版的软件包,它们在设计的时候吸取了在移动平台,比如 Android 以及物联网设备,分发软件的经验教训。`Snapcraft` 这个名字涵盖了 Snaps 和用来构建它们的命令行工具,[snapcraft.io][1],以及在这些技术的支撑下构建的几乎整个生态系统。
|
||||
|
||||
Snaps 被设计成用来隔离并封装整个应用程序。这些概念使得 Snapcraft 提高软件安全性、稳定性和可移植性的目标得以实现,其中可移植性允许单个 `snap` 包不仅可以在 Ubuntu 的多个版本中安装,而且也可以在 Debian、Fedora 和 Arch 等发行版中安装。Snapcraft 网站对其的描述如下:
|
||||
> 为每个 Linux 桌面、服务器、云或设备打包任何应用程序,并且直接交付更新。
|
||||
|
||||
### 在 CircleCI 2.0 上构建 Snaps
|
||||
|
||||
在 CircleCI 上使用 [CircleCI 2.0 语法][2] 来构建 Snaps 和在本地机器上基本相同。在本文中,我们将会讲解一个示例配置文件。如果您对 CircleCI 还不熟悉,或者想了解更多有关 2.0 的入门知识,您可以从 [这里][3] 开始。
|
||||
|
||||
### 基础配置
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
sudo snap install snapcraft --edge --classic
|
||||
/snap/bin/snapcraft
|
||||
```
|
||||
|
||||
这个例子使用了 `machine` 执行器来安装用于管理运行 Snaps 的 `snapd` 和制作 Snaps 的 `Snapcraft`。
|
||||
|
||||
由于构建过程需要使用比较新的内核,所以我们使用了 `machine` 执行器而没有用 `docker` 执行器。在这里,Linux v4.4 已经足够满足我们的需求了。
|
||||
|
||||
### 用户空间的依赖关系
|
||||
|
||||
上面的例子使用了 `machine` 执行器,它实际上是一个内核为 Linux v4.4 的 [Ubuntu 14.04 (Trusty) 虚拟机][4]。你的 project/snap 可以很方便的使用 Trusty 仓库来构建依赖关系。如果需要构建其他版本的依赖关系,比如 Ubuntu 16.04 (Xenial),我们仍然可以在 `machine` 执行器中使用 `Docker` 来构建我们的 Snaps 。
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
docker run -v $(pwd):$(pwd) -t ubuntu:xenial sh -c "apt update -qq && apt install snapcraft -y && cd $(pwd) && snapcraft"
|
||||
|
||||
```
|
||||
这个例子中,我们同样在 `machine` 执行器的虚拟机中安装了 `snapd`,但是我们决定将 Snapcraft 安装在 Ubuntu Xenial 镜像构建的 Docker 容器中,并使用它来构建我们的 Snaps。这样,在 `Snapcraft` 运行的过程中就可以使用所有在 Ubuntu 16.04 中可用的 `apt` 包。
|
||||
|
||||
### 测试
|
||||
|
||||
在我们的博客、文档以及互联网上已经有很多讲述如何对软件代码进行单元测试的内容。如果你用语言或者框架外加单元测试或者 CI 为关键词进行搜索的话将会出现大量相关的信息。在 CircleCI 上构建 Snaps 我们最终会得到一个 `.snap` 的文件,这意味着除了创造它的代码外我们还可以对它进行测试。
|
||||
|
||||
### 工作流
|
||||
|
||||
假设我们构建的 Snaps 是一个 `webapp`,我们可以通过测试套件来确保构建的 Snaps 可以正确的安装和运行,我们也可以试着安装它或者使用 [Selenium][5] 来测试页面加载、登录等功能。但是这里有一个问题,由于 Snaps 是被设计成可以在多个 Linux 发行版上运行,这就需要我们的测试套件可以在 Ubuntu 16.04、Fedora 25 和 Debian 9 等发行版中可以正常运行。这个问题我们可以通过 CircleCI 2.0 的工作流来有效地解决。
|
||||
|
||||
工作流是在最近的 CircleCI 2.0 测试版中加入的,它允许我们通过特定的逻辑流程来运行离散的任务。这样,使用单个任务构建完 Snaps 后,我们就可以开始并行的运行所有的 snap 发行版测试任务,每个任务对应一个不同的发行版的 [Docker 镜像][6] (或者在将来,还会有其他可用的执行器)。
|
||||
|
||||
这里有一个简单的例子:
|
||||
|
||||
```
|
||||
workflows:
|
||||
version: 2
|
||||
build-test-and-deploy:
|
||||
jobs:
|
||||
- build
|
||||
- acceptance_test_xenial:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_fedora_25:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_arch:
|
||||
requires:
|
||||
- build
|
||||
- publish:
|
||||
requires:
|
||||
- acceptance_test_xenial
|
||||
- acceptance_test_fedora_25
|
||||
- acceptance_test_arch
|
||||
|
||||
```
|
||||
在这个例子中首先构建了 Snaps,然后在四个不同的发行版上运行验收测试。如果所有的发行版都通过测试了,那么我们就可以运行发布 `job`,以便在将其推送到 snap 商店之前完成剩余的 snap 任务。
|
||||
|
||||
### 保存 .snap 包
|
||||
|
||||
为了测试我们在工作流示例中使用的 Snaps,我们需要一种在构建的时候保存 Snaps 的方法。在这里我将提供两种方法:
|
||||
|
||||
1. **artifacts** —— 在运行 `build` 任务的时候我们可以将 Snaps 保存为一个 CircleCI artifact(artifact 也是 snapcraft.yaml 中的一个 `Plugin-specific keywords` 暂时可以不翻译 ),然后在接下来的任务中检索它。CircleCI 工作流有自己处理共享 artifacts 的方式,相关信息可以在 [这里][7] 找到。
|
||||
|
||||
2. **snap 商店通道** —— 当发布 Snaps 到 snap 商店时,有多种通道可供我们选择。将 Snaps 的主分支发布到边缘通道以供内部或者用户测试已经成为一种常见做法。我们可以在构建任务的时候完成这些工作,然后接下来的的任务就可以从边缘通道来安装构建好的 Snaps。
|
||||
|
||||
第一种方法速度更快,并且它还可以在 Snaps 上传到 snap 商店供用户甚至是测试用户使用之前对 Snaps 进行验收测试。第二种方法的好处是我们可以从 snap 商店安装 Snaps,这也是 CI 运行期间的一个测试项。
|
||||
|
||||
### Snap 商店的身份验证
|
||||
|
||||
[snapcraft-config-generator.py][8] 脚本可以生成商店证书并将其保存到 `.snapcraft/snapcraft.cfg` 中(注意:在运行公共脚本之前一定要对其进行检查)。如果觉得使用明文来保存这个文件不安全,你可以用 `base64` 编码文件,并将其存储为 [私有环境变量][9],或者你也可以对文件 [进行加密][10],并将密钥存储在一个私有环境变量中。
|
||||
|
||||
下面是一个示例,将商店证书放在一个加密的文件中,并在 `deploy` 中使用它将 Snaps 发布到 snap 商店中。
|
||||
|
||||
```
|
||||
- deploy:
|
||||
name: Push to Snap Store
|
||||
command: |
|
||||
openssl aes-256-cbc -d -in .snapcraft/snapcraft.encrypted -out .snapcraft/snapcraft.cfg -k $KEY
|
||||
/snap/bin/snapcraft push *.snap
|
||||
|
||||
```
|
||||
|
||||
和前面的工作流示例一样,替代部署步骤的 `deploy` 任务也只有当验收测试任务通过时才会运行。
|
||||
|
||||
### 更多的信息
|
||||
|
||||
* Alan Pope 在 [论坛中发的帖子][11]:“popey” 是 Canonical 的员工,他在 Snapcraft 的论坛上写了这篇文章,并启发作者写了这篇博文。
|
||||
|
||||
* [Snapcraft 网站][12]: Snapcraft 官方网站。
|
||||
|
||||
* [Snapcraft 的 CircleCI Bug 报告][13]:在 Launchpad 上有一个开放的 bug 报告页面,用来改善 CircleCI 对 Snapcraft 的支持。同时这将使这个过程变得更简单并且更“正式”。期待您的支持。
|
||||
|
||||
* 怎么使用 CircleCI 构建 [Nextcloud][14] 的 Snaps:这里有一篇题为 [“复杂应用的持续验收测试”][15] 的博文,它同时也影响了这篇博文。
|
||||
|
||||
|
||||
|
||||
原始文章可以从 [这里][18] 找到。
|
||||
|
||||
---
|
||||
|
||||
via: https://insights.ubuntu.com/2017/06/28/build-test-and-publish-snap-packages-using-snapcraft/
|
||||
|
||||
译者简介:
|
||||
> 常年混迹于 snapcraft.io,对 Ubuntu Core、Snaps 和 Snapcraft 有浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人的公众号: `Snapcraft`
|
||||
|
||||
作者:[Guest ][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/guest/
|
||||
|
||||
|
||||
[1]: https://snapcraft.io/
|
||||
[2]:https://circleci.com/docs/2.0/
|
||||
[3]: https://circleci.com/docs/2.0/first-steps/
|
||||
[4]: https://circleci.com/docs/1.0/differences-between-trusty-and-precise/
|
||||
[5]:http://www.seleniumhq.org/
|
||||
[6]:https://circleci.com/docs/2.0/building-docker-images/
|
||||
[7]: https://circleci.com/docs/2.0/workflows/#using-workspaces-to-share-artifacts-among-jobs
|
||||
[8]:https://gist.github.com/3v1n0/479ad142eccdd17ad7d0445762dea755
|
||||
[9]: https://circleci.com/docs/1.0/environment-variables/#setting-environment-variables-for-all-commands-without-adding-them-to-git
|
||||
[10]: https://github.com/circleci/encrypted-files
|
||||
[11]:https://forum.snapcraft.io/t/building-and-pushing-snaps-using-circleci/789
|
||||
[12]:https://snapcraft.io/
|
||||
[13]:https://bugs.launchpad.net/snapcraft/+bug/1693451
|
||||
[14]:https://nextcloud.com/
|
||||
[15]: https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[16]:https://nextcloud.com/
|
||||
[17]:https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[18]: https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
[19]:https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
Loading…
Reference in New Issue
Block a user