mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
e6592c4cdd
114
published/20180531 How to create shortcuts in vi.md
Normal file
114
published/20180531 How to create shortcuts in vi.md
Normal file
@ -0,0 +1,114 @@
|
||||
如何在 vi 中创建快捷键
|
||||
======
|
||||
|
||||
> 那些常见编辑任务的快捷键可以使 Vi 编辑器更容易使用,更有效率。
|
||||
|
||||

|
||||
|
||||
学习使用 [vi 文本编辑器][1] 确实得花点功夫,不过 vi 的老手们都知道,经过一小会儿的锻炼,就可以将基本的 vi 操作融汇贯通。我们都知道“肌肉记忆”,那么学习 vi 的过程可以称之为“手指记忆”。
|
||||
|
||||
当你抓住了基础的操作窍门之后,你就可以定制化地配置 vi 的快捷键,从而让其处理的功能更为强大、流畅。我希望下面描述的技术可以加速您的协作、编程和数据操作。
|
||||
|
||||
在开始之前,我想先感谢下 Chris Hermansen(是他雇佣我写了这篇文章)仔细地检查了我的另一篇关于使用 vi 增强版本 [Vim][2] 的文章。当然还有他那些我未采纳的建议。
|
||||
|
||||
首先,我们来说明下面几个惯例设定。我会使用符号 `<RET>` 来代表按下回车,`<SP>` 代表按下空格键,`CTRL-x` 表示一起按下 `Control` 键和 `x` 键(`x` 可以是需要的某个键)。
|
||||
|
||||
使用 `map` 命令来进行按键的映射。第一个例子是 `write` 命令,通常你之前保存使用这样的命令:
|
||||
|
||||
```
|
||||
:w<RET>
|
||||
```
|
||||
|
||||
虽然这里只有三个键,不过考虑到我用这个命令实在是太频繁了,我更想“一键”搞定它。在这里我选择逗号键,它不是标准的 vi 命令集的一部分。这样设置:
|
||||
|
||||
```
|
||||
:map , :wCTRL-v<RET>
|
||||
```
|
||||
|
||||
这里的 `CTRL-v` 事实上是对 `<RET>` 做了转义的操作,如果不加这个的话,默认 `<RET>` 会作为这条映射指令的结束信号,而非映射中的一个操作。 `CTRL-v` 后面所跟的操作会翻译为用户的实际操作,而非该按键平常的操作。
|
||||
|
||||
在上面的映射中,右边的部分会在屏幕中显示为 `:w^M`,其中 `^` 字符就是指代 `control`,完整的意思就是 `CTRL-m`,表示就是系统中一行的结尾。
|
||||
|
||||
目前来说,就很不错了。如果我编辑、创建了十二次文件,这个键位映射就可以省掉了 2*12 次按键。不过这里没有计算你建立这个键位映射所花费的 11 次按键(计算 `CTRL-v` 和 `:` 均为一次按键)。虽然这样已经省了很多次,但是每次打开 vi 都要重新建立这个映射也会觉得非常麻烦。
|
||||
|
||||
幸运的是,这里可以将这些键位映射放到 vi 的启动配置文件中,让其在每次启动的时候自动读取:文件为 `.exrc`,对于 vim 是 `.vimrc`。只需要将这些文件放在你的用户根目录中即可,并在文件中每行写入一个键位映射,之后就会在每次启动 vi 生效直到你删除对应的配置。
|
||||
|
||||
在继续说明 `map` 其他用法以及其他的缩写机制之前,这里在列举几个我常用提高文本处理效率的 map 设置:
|
||||
|
||||
| 映射 | 显示为 |
|
||||
|------|-------|
|
||||
| `:map X :xCTRL-v<RET>` | `:x^M` |
|
||||
| `:map X ,:qCTRL-v<RET>` | `,:q^M` |
|
||||
|
||||
上面的 `map` 指令的意思是写入并关闭当前的编辑文件。其中 `:x` 是 vi 原本的命令,而下面的版本说明之前的 `map` 配置可以继续用作第二个 `map` 键位映射。
|
||||
|
||||
| 映射 | 显示为 |
|
||||
|------|-------|
|
||||
| `:map v :e<SP>` | `:e` |
|
||||
|
||||
上面的指令意思是在 vi 编辑器内部切换文件,使用这个时候,只需要按 `v` 并跟着输入文件名,之后按 `<RET>` 键。
|
||||
|
||||
| 映射 | 显示为 |
|
||||
|------|-------|
|
||||
| `:map CTRL-vCTRL-e :e<SP>#CTRL-v<RET>` | `:e #^M` |
|
||||
|
||||
`#` 在这里是 vi 中标准的符号,意思是最后使用的文件名。所以切换当前与上一个文件的方法就使用上面的映射。
|
||||
|
||||
| 映射 | 显示为 |
|
||||
|------|-------|
|
||||
| `map CTRL-vCTRL-r :!spell %>err &CTRL-v<RET>` | `:!spell %>err&^M` |
|
||||
|
||||
(注意:在两个例子中出现的第一个 `CRTL-v` 在某些 vi 的版本中是不需要的)其中,`:!` 用来运行一个外部的(非 vi 内部的)命令。在这个拼写检查的例子中,`%` 是 vi 中的符号用来指代目前的文件, `>` 用来重定向拼写检查中的输出到 `err` 文件中,之后跟上 `&` 说明该命令是一个后台运行的任务,这样可以保证在拼写检查的同时还可以进行编辑文件的工作。这里我可以键入 `verr<RET>`(使用我之前定义的快捷键 `v` 跟上 `err`),进入 `spell` 输出结果的文件,之后再输入 `CTRL-e` 来回到刚才编辑的文件中。这样我就可以在拼写检查之后,使用 `CTRL-r` 来查看检查的错误,再通过 `CTRL-e` 返回刚才编辑的文件。
|
||||
|
||||
还用很多字符串输入的缩写,也使用了各种 `map` 命令,比如:
|
||||
|
||||
```
|
||||
:map! CTRL-o \fI
|
||||
:map! CTRL-k \fP
|
||||
```
|
||||
|
||||
这个映射允许你使用 `CTRL-o` 作为 `groff` 命令的缩写,从而让让接下来书写的单词有斜体的效果,并使用 `CTRL-k` 进行恢复。
|
||||
|
||||
还有两个类似的映射:
|
||||
|
||||
```
|
||||
:map! rh rhinoceros
|
||||
:map! hi hippopotamus
|
||||
```
|
||||
|
||||
上面的也可以使用 `ab` 命令来替换,就像下面这样(如果想这么用的话,需要首先按顺序运行: 1、 `unmap! rh`,2、`umap! hi`):
|
||||
|
||||
```
|
||||
:ab rh rhinoceros
|
||||
:ab hi hippopotamus
|
||||
```
|
||||
|
||||
在上面 `map!` 的命令中,缩写会马上的展开成原有的单词,而在 `ab` 命令中,单词展开的操作会在输入了空格和标点之后才展开(不过在 Vim 和我的 vi 中,展开的形式与 `map!` 类似)。
|
||||
|
||||
想要取消刚才设定的按键映射,可以对应的输入 `:unmap`、 `unmap!` 或 `:unab`。
|
||||
|
||||
在我使用的 vi 版本中,比较好用的候选映射按键包括 `g`、`K`、`q`、 `v`、 `V`、 `Z`,控制字符包括:`CTRL-a`、`CTRL-c`、 `CTRL-k`、`CTRL-n`、`CTRL-p`、`CTRL-x`;还有一些其他的字符如 `#`、 `*`,当然你也可以使用那些已经在 vi 中有过定义但不经常使用的字符,比如本文选择 `X` 和 `I`,其中 `X` 表示删除左边的字符,并立刻左移当前字符。
|
||||
|
||||
最后,下面的命令
|
||||
|
||||
```
|
||||
:map<RET>
|
||||
:map!<RET>
|
||||
:ab
|
||||
```
|
||||
|
||||
将会显示,目前所有的缩写和键位映射。
|
||||
|
||||
希望上面的技巧能够更好地更高效地帮助你使用 vi。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/shortcuts-vi-text-editor
|
||||
|
||||
作者:[Dan Sonnenschein][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[sd886393](https://github.com/sd886393)
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dannyman
|
||||
[1]:http://ex-vi.sourceforge.net/
|
||||
[2]:https://www.vim.org/
|
||||
@ -0,0 +1,170 @@
|
||||
Linux 防火墙:关于 iptables 和 firewalld 的那些事
|
||||
======
|
||||
|
||||
> 以下是如何使用 iptables 和 firewalld 工具来管理 Linux 防火墙规则。
|
||||
|
||||

|
||||
|
||||
这篇文章摘自我的书《[Linux in Action][1]》,尚未发布的第二个曼宁出版项目。
|
||||
|
||||
### 防火墙
|
||||
|
||||
防火墙是一组规则。当数据包进出受保护的网络区域时,进出内容(特别是关于其来源、目标和使用的协议等信息)会根据防火墙规则进行检测,以确定是否允许其通过。下面是一个简单的例子:
|
||||
|
||||
![防火墙过滤请求] [3]
|
||||
|
||||
*防火墙可以根据协议或基于目标的规则过滤请求。*
|
||||
|
||||
一方面, [iptables][4] 是 Linux 机器上管理防火墙规则的工具。
|
||||
|
||||
另一方面,[firewalld][5] 也是 Linux 机器上管理防火墙规则的工具。
|
||||
|
||||
你有什么问题吗?如果我告诉你还有另外一种工具,叫做 [nftables][6],这会不会糟蹋你的美好一天呢?
|
||||
|
||||
好吧,我承认整件事确实有点好笑,所以让我来解释一下。这一切都从 Netfilter 开始,它在 Linux 内核模块级别控制访问网络栈。几十年来,管理 Netfilter 钩子的主要命令行工具是 iptables 规则集。
|
||||
|
||||
因为调用这些规则所需的语法看起来有点晦涩难懂,所以各种用户友好的实现方式,如 [ufw][7] 和 firewalld 被引入,作为更高级别的 Netfilter 解释器。然而,ufw 和 firewalld 主要是为解决单独的计算机所面临的各种问题而设计的。构建全方面的网络解决方案通常需要 iptables,或者从 2014 年起,它的替代品 nftables (nft 命令行工具)。
|
||||
|
||||
iptables 没有消失,仍然被广泛使用着。事实上,在未来的许多年里,作为一名管理员,你应该会使用 iptables 来保护的网络。但是 nftables 通过操作经典的 Netfilter 工具集带来了一些重要的崭新的功能。
|
||||
|
||||
从现在开始,我将通过示例展示 firewalld 和 iptables 如何解决简单的连接问题。
|
||||
|
||||
### 使用 firewalld 配置 HTTP 访问
|
||||
|
||||
正如你能从它的名字中猜到的,firewalld 是 [systemd][8] 家族的一部分。firewalld 可以安装在 Debian/Ubuntu 机器上,不过,它默认安装在 RedHat 和 CentOS 上。如果您的计算机上运行着像 Apache 这样的 web 服务器,您可以通过浏览服务器的 web 根目录来确认防火墙是否正在工作。如果网站不可访问,那么 firewalld 正在工作。
|
||||
|
||||
你可以使用 `firewall-cmd` 工具从命令行管理 firewalld 设置。添加 `–state` 参数将返回当前防火墙的状态:
|
||||
|
||||
```
|
||||
# firewall-cmd --state
|
||||
running
|
||||
```
|
||||
|
||||
默认情况下,firewalld 处于运行状态,并拒绝所有传入流量,但有几个例外,如 SSH。这意味着你的网站不会有太多的访问者,这无疑会为你节省大量的数据传输成本。然而,这不是你对 web 服务器的要求,你希望打开 HTTP 和 HTTPS 端口,按照惯例,这两个端口分别被指定为 80 和 443。firewalld 提供了两种方法来实现这个功能。一个是通过 `–add-port` 参数,该参数直接引用端口号及其将使用的网络协议(在本例中为TCP)。 另外一个是通过 `–permanent` 参数,它告诉 firewalld 在每次服务器启动时加载此规则:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --add-port=80/tcp
|
||||
# firewall-cmd --permanent --add-port=443/tcp
|
||||
```
|
||||
|
||||
`–reload` 参数将这些规则应用于当前会话:
|
||||
|
||||
```
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
查看当前防火墙上的设置,运行 `–list-services`:
|
||||
|
||||
```
|
||||
# firewall-cmd --list-services
|
||||
dhcpv6-client http https ssh
|
||||
```
|
||||
|
||||
假设您已经如前所述添加了浏览器访问,那么 HTTP、HTTPS 和 SSH 端口现在都应该是和 `dhcpv6-client` 一样开放的 —— 它允许 Linux 从本地 DHCP 服务器请求 IPv6 IP 地址。
|
||||
|
||||
### 使用 iptables 配置锁定的客户信息亭
|
||||
|
||||
我相信你已经看到了信息亭——它们是放在机场、图书馆和商务场所的盒子里的平板电脑、触摸屏和 ATM 类电脑,邀请顾客和路人浏览内容。大多数信息亭的问题是,你通常不希望用户像在自己家一样,把他们当成自己的设备。它们通常不是用来浏览、观看 YouTube 视频或对五角大楼发起拒绝服务攻击的。因此,为了确保它们没有被滥用,你需要锁定它们。
|
||||
|
||||
一种方法是应用某种信息亭模式,无论是通过巧妙使用 Linux 显示管理器还是控制在浏览器级别。但是为了确保你已经堵塞了所有的漏洞,你可能还想通过防火墙添加一些硬性的网络控制。在下一节中,我将讲解如何使用iptables 来完成。
|
||||
|
||||
关于使用 iptables,有两件重要的事情需要记住:你给出的规则的顺序非常关键;iptables 规则本身在重新启动后将无法保持。我会一次一个地在解释这些。
|
||||
|
||||
### 信息亭项目
|
||||
|
||||
为了说明这一切,让我们想象一下,我们为一家名为 BigMart 的大型连锁商店工作。它们已经存在了几十年;事实上,我们想象中的祖父母可能是在那里购物并长大的。但是如今,BigMart 公司总部的人可能只是在数着亚马逊将他们永远赶下去的时间。
|
||||
|
||||
尽管如此,BigMart 的 IT 部门正在尽他们最大努力提供解决方案,他们向你发放了一些具有 WiFi 功能信息亭设备,你在整个商店的战略位置使用这些设备。其想法是,登录到 BigMart.com 产品页面,允许查找商品特征、过道位置和库存水平。信息亭还允许进入 bigmart-data.com,那里储存着许多图像和视频媒体信息。
|
||||
|
||||
除此之外,您还需要允许下载软件包更新。最后,您还希望只允许从本地工作站访问 SSH,并阻止其他人登录。下图说明了它将如何工作:
|
||||
|
||||
![信息亭流量IP表] [10]
|
||||
|
||||
*信息亭业务流由 iptables 控制。 *
|
||||
|
||||
### 脚本
|
||||
|
||||
以下是 Bash 脚本内容:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp --dport 80 -j DROP
|
||||
iptables -A OUTPUT -p tcp --dport 443 -j DROP
|
||||
iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
|
||||
```
|
||||
|
||||
我们从基本规则 `-A` 开始分析,它告诉 iptables 我们要添加规则。`OUTPUT` 意味着这条规则应该成为输出链的一部分。`-p` 表示该规则仅使用 TCP 协议的数据包,正如 `-d` 告诉我们的,目的地址是 [bigmart.com][11]。`-j` 参数的作用是当数据包符合规则时要采取的操作是 `ACCEPT`。第一条规则表示允许(或接受)请求。但,往下的规则你能看到丢弃(或拒绝)的请求。
|
||||
|
||||
规则顺序是很重要的。因为 iptables 会对一个请求遍历每个规则,直到遇到匹配的规则。一个向外发出的浏览器请求,比如访问 bigmart.com 是会通过的,因为这个请求匹配第一条规则,但是当它到达 `dport 80` 或 `dport 443` 规则时——取决于是 HTTP 还是 HTTPS 请求——它将被丢弃。当遇到匹配时,iptables 不再继续往下检查了。(LCTT 译注:此处原文有误,径改。)
|
||||
|
||||
另一方面,向 ubuntu.com 发出软件升级的系统请求,只要符合其适当的规则,就会通过。显然,我们在这里做的是,只允许向我们的 BigMart 或 Ubuntu 发送 HTTP 或 HTTPS 请求,而不允许向其他目的地发送。
|
||||
|
||||
最后两条规则将处理 SSH 请求。因为它不使用端口 80 或 443 端口,而是使用 22 端口,所以之前的两个丢弃规则不会拒绝它。在这种情况下,来自我的工作站的登录请求将被接受,但是对其他任何地方的请求将被拒绝。这一点很重要:确保用于端口 22 规则的 IP 地址与您用来登录的机器的地址相匹配——如果不这样做,将立即被锁定。当然,这没什么大不了的,因为按照目前的配置方式,只需重启服务器,iptables 规则就会全部丢失。如果使用 LXC 容器作为服务器并从 LXC 主机登录,则使用主机 IP 地址连接容器,而不是其公共地址。
|
||||
|
||||
如果机器的 IP 发生变化,请记住更新这个规则;否则,你会被拒绝访问。
|
||||
|
||||
在家玩(是在某种一次性虚拟机上)?太好了。创建自己的脚本。现在我可以保存脚本,使用 `chmod` 使其可执行,并以 `sudo` 的形式运行它。不要担心“igmart-data.com 没找到”之类的错误 —— 当然没找到;它不存在。
|
||||
|
||||
```
|
||||
chmod +X scriptname.sh
|
||||
sudo ./scriptname.sh
|
||||
```
|
||||
|
||||
你可以使用 `cURL` 命令行测试防火墙。请求 ubuntu.com 奏效,但请求 [manning.com][13] 是失败的 。
|
||||
|
||||
|
||||
```
|
||||
curl ubuntu.com
|
||||
curl manning.com
|
||||
```
|
||||
|
||||
### 配置 iptables 以在系统启动时加载
|
||||
|
||||
现在,我如何让这些规则在每次信息亭启动时自动加载?第一步是将当前规则保存。使用 `iptables-save` 工具保存规则文件。这将在根目录中创建一个包含规则列表的文件。管道后面跟着 `tee` 命令,是将我的`sudo` 权限应用于字符串的第二部分:将文件实际保存到否则受限的根目录。
|
||||
|
||||
然后我可以告诉系统每次启动时运行一个相关的工具,叫做 `iptables-restore` 。我们在上一章节(LCTT 译注:指作者的书)中看到的常规 cron 任务并不适用,因为它们在设定的时间运行,但是我们不知道什么时候我们的计算机可能会决定崩溃和重启。
|
||||
|
||||
有许多方法来处理这个问题。这里有一个:
|
||||
|
||||
在我的 Linux 机器上,我将安装一个名为 [anacron][14] 的程序,该程序将在 `/etc/` 目录中为我们提供一个名为 `anacrontab` 的文件。我将编辑该文件并添加这个 `iptables-restore` 命令,告诉它加载那个 .rule 文件的当前内容。当引导后,规则每天(必要时)01:01 时加载到 iptables 中(LCTT 译注:anacron 会补充执行由于机器没有运行而错过的 cron 任务,因此,即便 01:01 时机器没有启动,也会在机器启动会尽快执行该任务)。我会给该任务一个标识符(`iptables-restore`),然后添加命令本身。如果你在家和我一起这样,你应该通过重启系统来测试一下。
|
||||
|
||||
```
|
||||
sudo iptables-save | sudo tee /root/my.active.firewall.rules
|
||||
sudo apt install anacron
|
||||
sudo nano /etc/anacrontab
|
||||
1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
|
||||
```
|
||||
|
||||
我希望这些实际例子已经说明了如何使用 iptables 和 firewalld 来管理基于 Linux 的防火墙上的连接问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/linux-iptables-firewalld
|
||||
|
||||
作者:[David Clinton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/remyd
|
||||
[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
[2]: /file/409116
|
||||
[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
|
||||
[4]: https://en.wikipedia.org/wiki/Iptables
|
||||
[5]: https://firewalld.org/
|
||||
[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
|
||||
[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
|
||||
[8]: https://en.wikipedia.org/wiki/Systemd
|
||||
[9]: /file/409121
|
||||
[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
|
||||
[11]: http://bigmart.com/
|
||||
[12]: http://youtube.com/
|
||||
[13]: http://manning.com/
|
||||
[14]: https://sourceforge.net/projects/anacron/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating By houbaron
|
||||
|
||||
Five things that make Go fast
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Managing users on Linux systems
|
||||
translating by dianbanjiu Managing users on Linux systems
|
||||
======
|
||||
Your Linux users may not be raging bulls, but keeping them happy is always a challenge as it involves managing their accounts, monitoring their access rights, tracking down the solutions to problems they run into, and keeping them informed about important changes on the systems they use. Here are some of the tasks and tools that make the job a little easier.
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
CLI: improved
|
||||
======
|
||||
I'm not sure many web developers can get away without visiting the command line. As for me, I've been using the command line since 1997, first at university when I felt both super cool l33t-hacker and simultaneously utterly out of my depth.
|
||||
|
||||
@ -1,89 +0,0 @@
|
||||
translating by lujun9972
|
||||
4 tips for better tmux sessions
|
||||
======
|
||||
|
||||

|
||||
|
||||
The tmux utility, a terminal multiplexer, lets you treat your terminal as a multi-paned window into your system. You can arrange the configuration, run different processes in each, and generally make better use of your screen. We introduced some readers to this powerful tool [in this earlier article][1]. Here are some tips that will help you get more out of tmux if you’re getting started.
|
||||
|
||||
This article assumes your current prefix key is Ctrl+b. If you’ve remapped that prefix, simply substitute your prefix in its place.
|
||||
|
||||
### Set your terminal to automatically use tmux
|
||||
|
||||
One of the biggest benefits of tmux is being able to disconnect and reconnect to sesions at wilI. This makes remote login sessions more powerful. Have you ever lost a connection and wished you could get back the work you were doing on the remote system? With tmux this problem is solved.
|
||||
|
||||
However, you may sometimes find yourself doing work on a remote system, and realize you didn’t start a session. One way to avoid this is to have tmux start or attach every time you login to a system with in interactive shell.
|
||||
|
||||
Add this to your remote system’s ~/.bash_profile file:
|
||||
|
||||
```
|
||||
if [ -z "$TMUX" ]; then
|
||||
tmux attach -t default || tmux new -s default
|
||||
fi
|
||||
```
|
||||
|
||||
Then logout of the remote system, and log back in with SSH. You’ll find you’re in a tmux session named default. This session will be regenerated at next login if you exit it. But more importantly, if you detach from it as normal, your work is waiting for you next time you login — especially useful if your connection is interrupted.
|
||||
|
||||
Of course you can add this to your local system as well. Note that terminals inside most GUIs won’t use the default session automatically, because they aren’t login shells. While you can change that behavior, it may result in nesting that makes the session less usable, so proceed with caution.
|
||||
|
||||
### Use zoom to focus on a single process
|
||||
|
||||
While the point of tmux is to offer multiple windows, panes, and processes in a single session, sometimes you need to focus. If you’re in a process and need more space, or to focus on a single task, the zoom command works well. It expands the current pane to take up the entire current window space.
|
||||
|
||||
Zoom can be useful in other situations too. For instance, imagine you’re using a terminal window in a graphical desktop. Panes can make it harder to copy and paste multiple lines from inside your tmux session. If you zoom the pane, you can do a clean copy/paste of multiple lines of data with ease.
|
||||
|
||||
To zoom into the current pane, hit Ctrl+b, z. When you’re finished with the zoom function, hit the same key combo to unzoom the pane.
|
||||
|
||||
### Bind some useful commands
|
||||
|
||||
By default tmux has numerous commands available. But it’s helpful to have some of the more common operations bound to keys you can easily remember. Here are some examples you can add to your ~/.tmux.conf file to make sessions more enjoyable:
|
||||
|
||||
```
|
||||
bind r source-file ~/.tmux.conf \; display "Reloaded config"
|
||||
```
|
||||
|
||||
This command rereads the commands and bindings in your config file. Once you add this binding, exit any tmux sessions and then restart one. Now after you make any other future changes, simply run Ctrl+b, r and the changes will be part of your existing session.
|
||||
|
||||
```
|
||||
bind V split-window -h
|
||||
bind H split-window
|
||||
```
|
||||
|
||||
These commands make it easier to split the current window across a vertical axis (note that’s Shift+V) or across a horizontal axis (Shift+H).
|
||||
|
||||
If you want to see how all keys are bound, use Ctrl+B, ? to see a list. You may see keys bound in copy-mode first, for when you’re working with copy and paste inside tmux. The prefix mode bindings are where you’ll see ones you’ve added above. Feel free to experiment with your own!
|
||||
|
||||
### Use powerline for great justice
|
||||
|
||||
[As reported in a previous Fedora Magazine article][2], the powerline utility is a fantastic addition to your shell. But it also has capabilities when used with tmux. Because tmux takes over the entire terminal space, the powerline window can provide more than just a better shell prompt.
|
||||
|
||||
[][3]
|
||||
|
||||
If you haven’t already, follow the instructions in the [Magazine’s powerline article][4] to install that utility. Then, install the addon [using sudo][5]:
|
||||
|
||||
```
|
||||
sudo dnf install tmux-powerline
|
||||
```
|
||||
|
||||
Now restart your session, and you’ll see a spiffy new status line at the bottom. Depending on the terminal width, the default status line now shows your current session ID, open windows, system information, date and time, and hostname. If you change directory into a git-controlled project, you’ll see the branch and color-coded status as well.
|
||||
|
||||
Of course, this status bar is highly configurable as well. Enjoy your new supercharged tmux session, and have fun experimenting with it.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-tips-better-tmux-sessions/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[2]:https://fedoramagazine.org/add-power-terminal-powerline/
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot-from-2018-08-25-19-36-53.png
|
||||
[4]:https://fedoramagazine.org/add-power-terminal-powerline/
|
||||
[5]:https://fedoramagazine.org/howto-use-sudo/
|
||||
@ -1,442 +0,0 @@
|
||||
Translating by pygmalion666
|
||||
How To Find And Delete Duplicate Files In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
I always backup the configuration files or any old files to somewhere in my hard disk before edit or modify them, so I can restore them from the backup if I accidentally did something wrong. But the problem is I forgot to clean up those files and my hard disk is filled with a lot of duplicate files after a certain period of time. I feel either too lazy to clean the old files or afraid that I may delete an important files. If you’re anything like me and overwhelming with multiple copies of same files in different backup directories, you can find and delete duplicate files using the tools given below in Unix-like operating systems.
|
||||
|
||||
**A word of caution:**
|
||||
|
||||
Please be careful while deleting duplicate files. If you’re not careful, it will lead you to [**accidental data loss**][1]. I advice you to pay extra attention while using these tools.
|
||||
|
||||
### Find And Delete Duplicate Files In Linux
|
||||
|
||||
For the purpose of this guide, I am going to discuss about three utilities namely,
|
||||
|
||||
1. Rdfind,
|
||||
2. Fdupes,
|
||||
3. FSlint.
|
||||
|
||||
|
||||
|
||||
These three utilities are free, open source and works on most Unix-like operating systems.
|
||||
|
||||
##### 1. Rdfind
|
||||
|
||||
**Rdfind** , stands for **r** edundant **d** ata **find** , is a free and open source utility to find duplicate files across and/or within directories and sub-directories. It compares files based on their content, not on their file names. Rdfind uses **ranking** algorithm to classify original and duplicate files. If you have two or more equal files, Rdfind is smart enough to find which is original file, and consider the rest of the files as duplicates. Once it found the duplicates, it will report them to you. You can decide to either delete them or replace them with [**hard links** or **symbolic (soft) links**][2].
|
||||
|
||||
**Installing Rdfind**
|
||||
|
||||
Rdfind is available in [**AUR**][3]. So, you can install it in Arch-based systems using any AUR helper program like [**Yay**][4] as shown below.
|
||||
|
||||
```
|
||||
$ yay -S rdfind
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install rdfind
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install rdfind
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
$ sudo yum install rdfind
|
||||
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
Once installed, simply run Rdfind command along with the directory path to scan for the duplicate files.
|
||||
|
||||
```
|
||||
$ rdfind ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
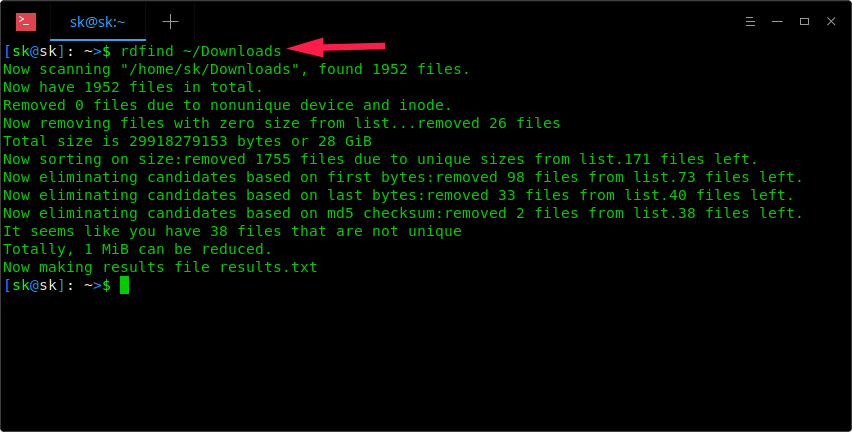
|
||||
|
||||
As you see in the above screenshot, Rdfind command will scan ~/Downloads directory and save the results in a file named **results.txt** in the current working directory. You can view the name of the possible duplicate files in results.txt file.
|
||||
|
||||
```
|
||||
$ cat results.txt
|
||||
# Automatically generated
|
||||
# duptype id depth size device inode priority name
|
||||
DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex
|
||||
DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex
|
||||
[...]
|
||||
DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf
|
||||
DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf
|
||||
# end of file
|
||||
|
||||
```
|
||||
|
||||
By reviewing the results.txt file, you can easily find the duplicates. You can remove the duplicates manually if you want to.
|
||||
|
||||
Also, you can **-dryrun** option to find all duplicates in a given directory without changing anything and output the summary in your Terminal:
|
||||
|
||||
```
|
||||
$ rdfind -dryrun true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Once you found the duplicates, you can replace them with either hardlinks or symlinks.
|
||||
|
||||
To replace all duplicates with hardlinks, run:
|
||||
|
||||
```
|
||||
$ rdfind -makehardlinks true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
To replace all duplicates with symlinks/soft links, run:
|
||||
|
||||
```
|
||||
$ rdfind -makesymlinks true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
You may have some empty files in a directory and want to ignore them. If so, use **-ignoreempty** option like below.
|
||||
|
||||
```
|
||||
$ rdfind -ignoreempty true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
If you don’t want the old files anymore, just delete duplicate files instead of replacing them with hard or soft links.
|
||||
|
||||
To delete all duplicates, simply run:
|
||||
|
||||
```
|
||||
$ rdfind -deleteduplicates true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
If you do not want to ignore empty files and delete them along with all duplicates, run:
|
||||
|
||||
```
|
||||
$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the help section:
|
||||
|
||||
```
|
||||
$ rdfind --help
|
||||
|
||||
```
|
||||
|
||||
And, the manual pages:
|
||||
|
||||
```
|
||||
$ man rdfind
|
||||
|
||||
```
|
||||
|
||||
##### 2. Fdupes
|
||||
|
||||
**Fdupes** is yet another command line utility to identify and remove the duplicate files within specified directories and the sub-directories. It is free, open source utility written in **C** programming language. Fdupes identifies the duplicates by comparing file sizes, partial MD5 signatures, full MD5 signatures, and finally performing a byte-by-byte comparison for verification.
|
||||
|
||||
Similar to Rdfind utility, Fdupes comes with quite handful of options to perform operations, such as:
|
||||
|
||||
* Recursively search duplicate files in directories and sub-directories
|
||||
* Exclude empty files and hidden files from consideration
|
||||
* Show the size of the duplicates
|
||||
* Delete duplicates immediately as they encountered
|
||||
* Exclude files with different owner/group or permission bits as duplicates
|
||||
* And a lot more.
|
||||
|
||||
|
||||
|
||||
**Installing Fdupes**
|
||||
|
||||
Fdupes is available in the default repositories of most Linux distributions.
|
||||
|
||||
On Arch Linux and its variants like Antergos, Manjaro Linux, install it using Pacman like below.
|
||||
|
||||
```
|
||||
$ sudo pacman -S fdupes
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install fdupes
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install fdupes
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
$ sudo yum install fdupes
|
||||
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
Fdupes usage is pretty simple. Just run the following command to find out the duplicate files in a directory, for example **~/Downloads**.
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Sample output from my system:
|
||||
|
||||
```
|
||||
/home/sk/Downloads/Hyperledger.pdf
|
||||
/home/sk/Downloads/Hyperledger(1).pdf
|
||||
|
||||
```
|
||||
|
||||
As you can see, I have a duplicate file in **/home/sk/Downloads/** directory. It shows the duplicates from the parent directory only. How to view the duplicates from sub-directories? Just use **-r** option like below.
|
||||
|
||||
```
|
||||
$ fdupes -r ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Now you will see the duplicates from **/home/sk/Downloads/** directory and its sub-directories as well.
|
||||
|
||||
Fdupes can also be able to find duplicates from multiple directories at once.
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads ~/Documents/ostechnix
|
||||
|
||||
```
|
||||
|
||||
You can even search multiple directories, one recursively like below:
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads -r ~/Documents/ostechnix
|
||||
|
||||
```
|
||||
|
||||
The above commands searches for duplicates in “~/Downloads” directory and “~/Documents/ostechnix” directory and its sub-directories.
|
||||
|
||||
Sometimes, you might want to know the size of the duplicates in a directory. If so, use **-S** option like below.
|
||||
|
||||
```
|
||||
$ fdupes -S ~/Downloads
|
||||
403635 bytes each:
|
||||
/home/sk/Downloads/Hyperledger.pdf
|
||||
/home/sk/Downloads/Hyperledger(1).pdf
|
||||
|
||||
```
|
||||
|
||||
Similarly, to view the size of the duplicates in parent and child directories, use **-Sr** option.
|
||||
|
||||
We can exclude empty and hidden files from consideration using **-n** and **-A** respectively.
|
||||
|
||||
```
|
||||
$ fdupes -n ~/Downloads
|
||||
|
||||
$ fdupes -A ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
The first command will exclude zero-length files from consideration and the latter will exclude hidden files from consideration while searching for duplicates in the specified directory.
|
||||
|
||||
To summarize duplicate files information, use **-m** option.
|
||||
|
||||
```
|
||||
$ fdupes -m ~/Downloads
|
||||
1 duplicate files (in 1 sets), occupying 403.6 kilobytes
|
||||
|
||||
```
|
||||
|
||||
To delete all duplicates, use **-d** option.
|
||||
|
||||
```
|
||||
$ fdupes -d ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf
|
||||
[2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf
|
||||
|
||||
Set 1 of 1, preserve files [1 - 2, all]:
|
||||
|
||||
```
|
||||
|
||||
This command will prompt you for files to preserve and delete all other duplicates. Just enter any number to preserve the corresponding file and delete the remaining files. Pay more attention while using this option. You might delete original files if you’re not be careful.
|
||||
|
||||
If you want to preserve the first file in each set of duplicates and delete the others without prompting each time, use **-dN** option (not recommended).
|
||||
|
||||
```
|
||||
$ fdupes -dN ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
To delete duplicates as they are encountered, use **-I** flag.
|
||||
|
||||
```
|
||||
$ fdupes -I ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
For more details about Fdupes, view the help section and man pages.
|
||||
|
||||
```
|
||||
$ fdupes --help
|
||||
|
||||
$ man fdupes
|
||||
|
||||
```
|
||||
|
||||
##### 3. FSlint
|
||||
|
||||
**FSlint** is yet another duplicate file finder utility that I use from time to time to get rid of the unnecessary duplicate files and free up the disk space in my Linux system. Unlike the other two utilities, FSlint has both GUI and CLI modes. So, it is more user-friendly tool for newbies. FSlint not just finds the duplicates, but also bad symlinks, bad names, temp files, bad IDS, empty directories, and non stripped binaries etc.
|
||||
|
||||
**Installing FSlint**
|
||||
|
||||
FSlint is available in [**AUR**][5], so you can install it using any AUR helpers.
|
||||
|
||||
```
|
||||
$ yay -S fslint
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install fslint
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install fslint
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
```
|
||||
|
||||
$ sudo yum install fslint
|
||||
|
||||
Once it is installed, launch it from menu or application launcher.
|
||||
|
||||
This is how FSlint GUI looks like.
|
||||
|
||||
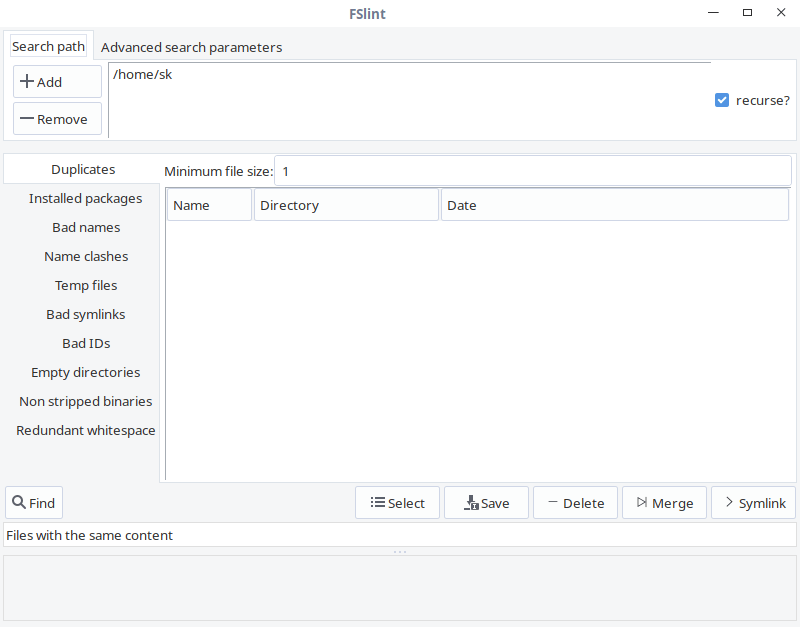
|
||||
|
||||
As you can see, the interface of FSlint is user-friendly and self-explanatory. In the **Search path** tab, add the path of the directory you want to scan and click **Find** button on the lower left corner to find the duplicates. Check the recurse option to recursively search for duplicates in directories and sub-directories. The FSlint will quickly scan the given directory and list out them.
|
||||
|
||||
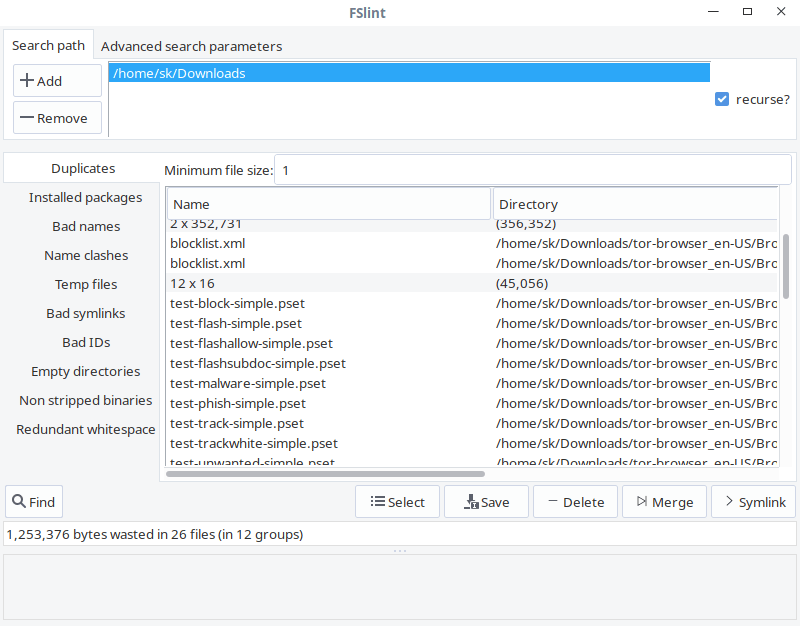
|
||||
|
||||
From the list, choose the duplicates you want to clean and select any one of them given actions like Save, Delete, Merge and Symlink.
|
||||
|
||||
In the **Advanced search parameters** tab, you can specify the paths to exclude while searching for duplicates.
|
||||
|
||||

|
||||
|
||||
**FSlint command line options**
|
||||
|
||||
FSlint provides a collection of the following CLI utilities to find duplicates in your filesystem:
|
||||
|
||||
* **findup** — find DUPlicate files
|
||||
* **findnl** — find Name Lint (problems with filenames)
|
||||
* **findu8** — find filenames with invalid utf8 encoding
|
||||
* **findbl** — find Bad Links (various problems with symlinks)
|
||||
* **findsn** — find Same Name (problems with clashing names)
|
||||
* **finded** — find Empty Directories
|
||||
* **findid** — find files with dead user IDs
|
||||
* **findns** — find Non Stripped executables
|
||||
* **findrs** — find Redundant Whitespace in files
|
||||
* **findtf** — find Temporary Files
|
||||
* **findul** — find possibly Unused Libraries
|
||||
* **zipdir** — Reclaim wasted space in ext2 directory entries
|
||||
|
||||
|
||||
|
||||
All of these utilities are available under **/usr/share/fslint/fslint/fslint** location.
|
||||
|
||||
For example, to find duplicates in a given directory, do:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/findup ~/Downloads/
|
||||
|
||||
```
|
||||
|
||||
Similarly, to find empty directories, the command would be:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/finded ~/Downloads/
|
||||
|
||||
```
|
||||
|
||||
To get more details on each utility, for example **findup** , run:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/findup --help
|
||||
|
||||
```
|
||||
|
||||
For more details about FSlint, refer the help section and man pages.
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/fslint --help
|
||||
|
||||
$ man fslint
|
||||
|
||||
```
|
||||
|
||||
##### Conclusion
|
||||
|
||||
You know now about three tools to find and delete unwanted duplicate files in Linux. Among these three tools, I often use Rdfind. It doesn’t mean that the other two utilities are not efficient, but I am just happy with Rdfind so far. Well, it’s your turn. Which is your favorite tool and why? Let us know them in the comment section below.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
|
||||
[2]: https://www.ostechnix.com/explaining-soft-link-and-hard-link-in-linux-with-examples/
|
||||
[3]: https://aur.archlinux.org/packages/rdfind/
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]: https://aur.archlinux.org/packages/fslint/
|
||||
@ -1,134 +0,0 @@
|
||||
如何在 vi 中创建快捷键
|
||||
======
|
||||
|
||||

|
||||
|
||||
学习使用 [vi 文本编辑器][1] 确实得花点功夫,不过 vi 的老手们都知道,经过一小会的锻炼,就可以将基本的 vi 操作融汇贯通。我们都知道“肌肉记忆”,那么学习 vi 的过程可以称之为“手指记忆”。
|
||||
|
||||
当你抓住了基础的操作窍门之后,你就可以定制化地配置 vi 的快捷键,从而让其处理的功能更为强大、流畅。
|
||||
|
||||
在开始之前,我想先感谢下 Chris Hermansen(他雇佣我写了这篇文章)仔细地检查了我的另一篇关于使用 vi 增强版本[Vim][2]的文章。当然还有他那些我未采纳的建议。
|
||||
|
||||
首先,我们来说明下面几个惯例设定。我会使用符号<RET>来代表按下 RETURN 或者 ENTER 键,<SP> 代表按下空格键,CTRL-x 表示一起按下 Control 键和 x 键
|
||||
|
||||
使用 `map` 命令来进行按键的映射。第一个例子是 `write` 命令,通常你之前保存使用这样的命令:
|
||||
|
||||
```
|
||||
:w<RET>
|
||||
|
||||
```
|
||||
|
||||
虽然这里只有三个键,不过考虑到我用这个命令实在是太频繁了,我更想“一键”搞定它。在这里我选择逗号键,比如这样:
|
||||
```
|
||||
:map , :wCTRL-v<RET>
|
||||
|
||||
```
|
||||
|
||||
这里的 CTRL-v 事实上是对 <RET> 做了转义的操作,如果不加这个的话,默认 <RET> 会作为这条映射指令的结束信号,而非映射中的一个操作。 CTRL-v 后面所跟的操作会翻译为用户的实际操作,而非该按键平常的操作。
|
||||
|
||||
在上面的映射中,右边的部分会在屏幕中显示为 `:w^M`,其中 `^` 字符就是指代 `control`,完整的意思就是 CTRL-m,表示就是系统中一行的结尾
|
||||
|
||||
|
||||
目前来说,就很不错了。如果我编辑、创建了十二次文件,这个键位映射就可以省掉了 2*12 次按键。不过这里没有计算你建立这个键位映射所花费的 11次按键(计算CTRL-v 和 冒号均为一次按键)。虽然这样已经省了很多次,但是每次打开 vi 都要重新建立这个映射也会觉得非常麻烦。
|
||||
|
||||
幸运的是,这里可以将这些键位映射放到 vi 的启动配置文件中,让其在每次启动的时候自动读取:文件为 `.exrc`,对于 vim 是 `.vimrc`。只需要将这些文件放在你的用户根目录中即可,并在文件中每行写入一个键位映射,之后就会在每次启动 vi 生效直到你删除对应的配置。
|
||||
|
||||
在继续说明 `map` 其他用法以及其他的缩写机制之前,这里在列举几个我常用提高文本处理效率的 map 设置:
|
||||
```
|
||||
Displays as
|
||||
|
||||
|
||||
|
||||
:map X :xCTRL-v<RET> :x^M
|
||||
|
||||
|
||||
|
||||
or
|
||||
|
||||
|
||||
|
||||
:map X ,:qCTRL-v<RET> ,:q^M
|
||||
|
||||
```
|
||||
|
||||
上面的 map 指令的意思是写入并关闭当前的编辑文件。其中 `:x` 是 vi 原本的命令,而下面的版本说明之前的 map 配置可以继续用作第二个 map 键位映射。
|
||||
```
|
||||
:map v :e<SP> :e
|
||||
|
||||
```
|
||||
|
||||
上面的指令意思是在 vi 编辑器内部 切换文件,使用这个时候,只需要按 `v` 并跟着输入文件名,之后按 `<RET>` 键。
|
||||
```
|
||||
:map CTRL-vCTRL-e :e<SP>#CTRL-v<RET> :e #^M
|
||||
|
||||
```
|
||||
|
||||
`#` 在这里是 vi 中标准的符号,意思是最后使用的文件名。所以切换当前与上一个文件的方法就使用上面的映射。
|
||||
```
|
||||
map CTRL-vCTRL-r :!spell %>err &CTRL-v<RET> :!spell %>err&^M
|
||||
|
||||
```
|
||||
|
||||
(注意:在两个例子中出现的第一个 CRTL-v 在某些 vi 的版本中是不需要的)其中,`:!` 用来运行一个外部的(非 vi 内部的)命令。在这个拼写检查的例子中,`%` 是 vi 中的符号用来只带目前的文件, `>` 用来重定向拼写检查中的输出到 `err` 文件中,之后跟上 `&` 说明该命令是一个后台运行的任务,这样可以保证在拼写检查的同时还可以进行编辑文件的工作。这里我可以键入 `verr<RET>`(使用我之前定义的快捷键 `v` 跟上 `err`),进入 `spell` 输出结果的文件,之后再输入 `CTRL-e` 来回到刚才编辑的文件中。这样我就可以在拼写检查之后,使用 CTRL-r 来查看检查的错误,再通过 CTRL-e 返回刚才编辑的文件。
|
||||
|
||||
还用很多字符串输入的缩写,也使用了各种 map 命令,比如:
|
||||
```
|
||||
:map! CTRL-o \fI
|
||||
|
||||
:map! CTRL-k \fP
|
||||
|
||||
```
|
||||
|
||||
这个映射允许你使用 CTRL-o 作为 `groff` 命令的缩写,从而让让接下来书写的单词有斜体的效果,并使用 CTRL-k 进行恢复
|
||||
|
||||
还有两个类似的映射:
|
||||
```
|
||||
:map! rh rhinoceros
|
||||
|
||||
:map! hi hippopotamus
|
||||
|
||||
```
|
||||
|
||||
上面的也可以使用 `ab` 命令来替换,就像下面这样(如果想这么用的话,需要首先按顺序运行 1. `unmap! rh` 2. `umap! hi`):
|
||||
```
|
||||
:ab rh rhinoceros
|
||||
|
||||
:ab hi hippopotamus
|
||||
|
||||
```
|
||||
|
||||
在上面 `map!` 的命令中,缩写会马上的展开成原有的单词,而在 `ab` 命令中,单词展开的操作会在输入了空格和标点之后才展开(不过在Vim 和 本机使用的 vi中,展开的形式与 `map!` 类似)
|
||||
|
||||
想要取消刚才设定的按键映射,可以对应的输入 `:unmap`, `unmap!`, `:unab`
|
||||
|
||||
在我使用的 vi 版本中,比较好用的候选映射按键包括 `g, K, q, v, V, Z`,控制字符包括:`CTRL-a, CTRL-c, CTRL-k, CTRL-n, CTRL-p, CTRL-x`;还有一些其他的字符如`#, *`,当然你也可以使用那些已经在 vi 中有过定义但不经常使用的字符,比如本文选择`X`和`I`,其中`X`表示删除左边的字符,并立刻左移当前字符。
|
||||
|
||||
最后,下面的命令
|
||||
```
|
||||
:map<RET>
|
||||
|
||||
:map!<RET>
|
||||
|
||||
:ab
|
||||
|
||||
```
|
||||
|
||||
将会显示,目前所有的缩写和键位映射。
|
||||
will show all the currently defined mappings and abbreviations.
|
||||
|
||||
希望上面的技巧能够更好地更高效地帮助你使用 vi。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/shortcuts-vi-text-editor
|
||||
|
||||
作者:[Dan Sonnenschein][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/sd886393)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dannyman
|
||||
[1]:http://ex-vi.sourceforge.net/
|
||||
[2]:https://www.vim.org/
|
||||
88
translated/tech/20180827 4 tips for better tmux sessions.md
Normal file
88
translated/tech/20180827 4 tips for better tmux sessions.md
Normal file
@ -0,0 +1,88 @@
|
||||
更好利用 tmux 会话的 4 个技巧
|
||||
======
|
||||
|
||||

|
||||
|
||||
tmux 是一个终端多路复用工具,它可以让你系统上的终端支持多面板。你可以安排好面板配置,在每个面板用运行不同进程,这通常可以更好的地用你的屏幕。我们在 [这篇早期的文章 ][1] 中向读者介绍过这一强力工具。如果你已经开始使用 tmux 了,那么这里有一些技巧可以帮你更好地使用它。
|
||||
|
||||
本文假设你当前的前缀键是 `Ctrl+b`。如果你已重新映射该前缀,只需在相应位置替换为你定义的前缀即可。。
|
||||
|
||||
### 设置终端为自动使用 tmux
|
||||
|
||||
使用 tmux 的一个最大好处就是可以随意的从会话中断开和重连。这使得远程登陆会话更加强力。你有没有遇到过丢失了与远程系统的连接,然后好希望能够恢复在远程系统上做过的那些工作的情况?tmux 能够解决这一问题。
|
||||
|
||||
然而,有时在远程系统上工作时,你可能会忘记开启一个会话。避免出现这一情况的一个方法就是每次通过交互式 shell 登陆系统时都让 tmux 启动或附加上一个会话。
|
||||
|
||||
在你远程系统上的 ~/.bash_profile 文件中加入下面内容:
|
||||
|
||||
```
|
||||
if [ -z "$TMUX" ]; then
|
||||
tmux attach -t default || tmux new -s default
|
||||
fi
|
||||
```
|
||||
|
||||
然后注销远程系统,并使用 SSH 重新登录。你会发现你处在一个名为 default 的 tmux 会话中了。如果退出该会话,则下次登录时还会重新生成此会话。但更重要的是,若您正常地从会话中分离,那么下次登录时你会发现之前工作并没有丢失 - 这在连接中断时非常有用。
|
||||
|
||||
你当然也可以将这段配置加入本地系统中。需要注意的是,大多数 GUI 界面的终端并不会自动使用这个 default 会话,因此它们并不是登陆 shell。虽然你可以修改这一行为,但它可能会导致终端嵌套执行附加到 tmux 会话这一动作从而导致会话不太可用,因此当进行此操作时请一定小心。
|
||||
|
||||
### 使用 zoom 使注意力专注于单个进程
|
||||
|
||||
然而 tmux 的目的就是在单个 session 中提供多窗口,多面板和多进程的能力,但有时候你需要专注。如果你正在与一个进程进行交互并且需要更多空间,或需要专注于某个任务,则可以使用 zoom 命令。该命令会将当前面板扩展,占据整个当前窗口的空间。
|
||||
|
||||
Zoom 在其他情况下也很有用。比如,想象你在图形桌面上运行一个终端窗口。面板会使得从 tmux 会话中拷贝和粘帖多行内容变得相对困难。但若你对面板进行用 zoom 进行了缩放,就可以很容易地对多行数据进行拷贝/粘帖。
|
||||
|
||||
要对当前面板进行缩放,按下 `Ctrl+b,z`。需要回复的话,按下相同按键组合来回复面板。
|
||||
|
||||
### 绑定一些有用的命令
|
||||
|
||||
tmux 默认有大量的命令可用。但将一些更常用的操作绑定到容易记忆的快捷键会很有有。下面一些例子可以让会话变得更好用,你可以添加到 ~/.tmux.conf 文件中:
|
||||
|
||||
```
|
||||
bind r source-file ~/.tmux.conf \; display "Reloaded config"
|
||||
```
|
||||
|
||||
该命令重新读取你配置文件中的命令和键绑定。添加该条绑定后,退出所有的 tmux 会话然后重启一个会话。现在你做了任何更改后,只需要简单的按下 `Ctrl+b,r` 就能将修改的内容应用到现有的会话中了。
|
||||
|
||||
```
|
||||
bind V split-window -h
|
||||
bind H split-window
|
||||
```
|
||||
|
||||
这些命令可以很方便地对窗口进行横向切分(按下 Shift+V) 和纵向切分 (Shift+H)。
|
||||
|
||||
若你想查看所有绑定的快捷键,按下 `Ctrl+B,?` 可以看到一个列表。你首先看到的应该是复制模式下的快捷键绑定,表示的是当你在 tmux 中进行复制粘帖时对应的快捷键。你添加的那两个键绑定会在前缀模式 (prefix mode) 中看到。请随意把玩吧!
|
||||
|
||||
### Use powerline for great justice
|
||||
|
||||
[如前文所示 ][2],powerline 工具是对 shell 的绝佳补充。而且它也兼容在 tmux 中使用。由于 tmux 接管了整个终端空间,powerline 窗口能理工的可不仅仅是更好的 shell 提示那么简单。
|
||||
|
||||
[][3]
|
||||
|
||||
如果你还没有这么做,按照 [本文 ][4] 中的指示来安装该工具。然后[使用 sudo][5] 来安装附件:
|
||||
|
||||
```
|
||||
sudo dnf install tmux-powerline
|
||||
```
|
||||
|
||||
然后重启会话,就会在底部看到一个漂亮的新状态栏。根据终端的宽度,默认的状态栏会显示你当前会话 ID,打开的窗口,系统信息,日期和时间,以及主机名。若你进入了使用 git 进行版本控制的项目目录中还能看到分支名和用色彩标注的版本库状态。
|
||||
|
||||
当然,这个状态栏具有很好的可配置性。享受你新增强的 tmux 会话吧,玩的开心点。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-tips-better-tmux-sessions/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[2]:https://fedoramagazine.org/add-power-terminal-powerline/
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot-from-2018-08-25-19-36-53.png
|
||||
[4]:https://fedoramagazine.org/add-power-terminal-powerline/
|
||||
[5]:https://fedoramagazine.org/howto-use-sudo/
|
||||
@ -1,178 +0,0 @@
|
||||
Linux 防火墙: 关于 iptables 和 firewalld,你需要知道些什么
|
||||
======
|
||||
|
||||
以下是如何使用 iptables 和 firewalld 工具来管理 Linux 防火墙规则。
|
||||
|
||||

|
||||
这篇文章摘自我的书[Linux in Action][1],第二 Manning project 尚未发布。
|
||||
|
||||
### 防火墙
|
||||
|
||||
|
||||
防火墙是一组规则。当数据包进出受保护的网络时,进出内容(特别是关于其来源、目标和使用的协议等信息)会根据防火墙规则进行检测,以确定是否允许其通过。下面是一个简单的例子:
|
||||
|
||||
|
||||
![防火墙过滤请求] [3]
|
||||
|
||||
防火墙可以根据协议或基于目标的规则过滤请求。
|
||||
|
||||
一方面, [iptables][4] 是 Linux 机器上管理防火墙规则的工具。
|
||||
|
||||
另一方面,[firewalld][5]也是 Linux 机器上管理防火墙规则的工具。
|
||||
|
||||
你有什么问题吗?如果我告诉你还有另外一种工具,叫做 [nftables][6],这会不会糟蹋你的一天呢?
|
||||
|
||||
好吧,我承认整件事确实有点好笑,所以让我解释一下了。这一切都从 Netfilter 开始,在 Linux 内核模块级别, Netfilter 控制访问网络栈。几十年来,管理 Netfilter 钩子的主要命令行工具是 iptables 规则集。
|
||||
|
||||
因为调用这些规则所需的语法看起来有点晦涩难懂,所以各种用户友好的实现方式,如[ufw][7] 和 firewalld 被引入作,并为更高级别的 Netfilter 解释器。然而,Ufw 和 firewalld 主要是为解决独立计算机面临的各种问题而设计的。构建全方面的网络解决方案通常需要 iptables,或者从2014年起,它的替代品 nftables (nft 命令行工具)。
|
||||
|
||||
|
||||
iptables 没有消失,仍然被广泛使用着。事实上,在未来的许多年里,作为一名管理员,你应该会使用 iptables 来保护的网络。但是nftables 通过操作经典的 Netfilter 工具集带来了一些重要的崭新的功能。
|
||||
|
||||
|
||||
从现在开始,我将通过示例展示 firewalld 和 iptables 如何解决简单的连接问题。
|
||||
|
||||
### 使用 firewalld 配置 HTTP 访问
|
||||
|
||||
正如你能从它的名字中猜到的,firewalld 是 [systemd][8] 家族的一部分。Firewalld 可以安装在 Debian/Ubuntu 机器上,不过, 它默认安装在 RedHat 和 CentOS 上。如果您的计算机上运行着像 Apache 这样的 web 服务器,您可以通过浏览服务器的 web 根目录来确认防火墙是否正在工作。如果网站不可访问,那么 firewalld 正在工作。
|
||||
|
||||
你可以使用 `firewall-cmd` 工具从命令行管理 firewalld 设置。添加 `–state` 参数将返回当前防火墙的状态:
|
||||
|
||||
```
|
||||
# firewall-cmd --state
|
||||
running
|
||||
```
|
||||
|
||||
默认情况下,firewalld 将处于运行状态,并将拒绝所有传入流量,但有几个例外,如 SSH。这意味着你的网站不会有太多的访问者,这无疑会为你节省大量的数据传输成本。然而,这不是你对 web 服务器的要求,你希望打开 HTTP 和 HTTPS 端口,按照惯例,这两个端口分别被指定为80和443。firewalld 提供了两种方法来实现这个功能。一个是通过 `–add-port` 参数,该参数直接引用端口号及其将使用的网络协议(在本例中为TCP )。 另外一个是通过`–permanent` 参数,它告诉 firewalld 在每次服务器启动时加载此规则:
|
||||
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --add-port=80/tcp
|
||||
# firewall-cmd --permanent --add-port=443/tcp
|
||||
```
|
||||
|
||||
`–reload` 参数将这些规则应用于当前会话:
|
||||
|
||||
```
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
查看当前防火墙上的设置, 运行 `–list-services` :
|
||||
|
||||
```
|
||||
# firewall-cmd --list-services
|
||||
dhcpv6-client http https ssh
|
||||
```
|
||||
|
||||
假设您已经如前所述添加了浏览器访问,那么 HTTP、HTTPS 和 SSH 端口现在都应该是开放的—— `dhcpv6-client` ,它允许 Linux 从本地 DHCP 服务器请求 IPv6 IP地址。
|
||||
|
||||
### 使用 iptables 配置锁定的客户信息亭
|
||||
|
||||
我相信你已经看到了信息亭——它们是放在机场、图书馆和商务场所的盒子里的平板电脑、触摸屏和ATM类电脑,邀请顾客和路人浏览内容。大多数信息亭的问题是,你通常不希望用户像在自己家一样,把他们当成自己的设备。它们通常不是用来浏览、观看 YouTube 视频或对五角大楼发起拒绝服务攻击的。因此,为了确保它们没有被滥用,你需要锁定它们。
|
||||
|
||||
|
||||
一种方法是应用某种信息亭模式,无论是通过巧妙使用Linux显示管理器还是在浏览器级别。但是为了确保你已经堵塞了所有的漏洞,你可能还想通过防火墙添加一些硬网络控制。在下一节中,我将讲解如何使用iptables 来完成。
|
||||
|
||||
|
||||
关于使用iptables,有两件重要的事情需要记住:你给规则的顺序非常关键,iptables 规则本身在重新启动后将无法存活。我会一次一个地在解释这些。
|
||||
|
||||
### 信息亭项目
|
||||
|
||||
为了说明这一切,让我们想象一下,我们为一家名为 BigMart 的大型连锁商店工作。它们已经存在了几十年;事实上,我们想象中的祖父母可能是在那里购物并长大的。但是这些天,BigMart 公司总部的人可能只是在数着亚马逊将他们永远赶下去的时间。
|
||||
|
||||
尽管如此,BigMart 的IT部门正在尽他们最大努力提供解决方案,他们向你发放了一些具有 WiFi 功能信息亭设备,你在整个商店的战略位置使用这些设备。其想法是,登录到 BigMart.com 产品页面,允许查找商品特征、过道位置和库存水平。信息亭还允许进入 bigmart-data.com,那里储存着许多图像和视频媒体信息。
|
||||
|
||||
除此之外,您还需要允许下载软件包更新。最后,您还希望只允许从本地工作站访问SSH,并阻止其他人登录。下图说明了它将如何工作:
|
||||
|
||||
![信息亭流量IP表] [10]
|
||||
|
||||
信息亭业务流由 iptables 控制。
|
||||
|
||||
### 脚本
|
||||
|
||||
以下是 Bash 脚本内容:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp --dport 80 -j DROP
|
||||
iptables -A OUTPUT -p tcp --dport 443 -j DROP
|
||||
iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
|
||||
```
|
||||
|
||||
我们从基本规则 `-A` 开始分析,它告诉iptables 我们要添加规则。`OUTPUT` 意味着这条规则应该成为输出的一部分。`-p` 表示该规则仅使用TCP协议的数据包,正如`-d` 告诉我们的,目的地址是 [bigmart.com][11]。`-j` 参数作用为数据包符合规则时要采取的操作是 `ACCEPT`。第一条规则表示允许或接受请求。但,最后一条规则表示删除或拒绝的请求。
|
||||
|
||||
规则顺序是很重要的。iptables 仅仅允许匹配规则的内容请求通过。一个向外发出的浏览器请求,比如访问[youtube.com][12] 是会通过的,因为这个请求匹配第四条规则,但是当它到达“dport 80”或“dport 443”规则时——取决于是HTTP还是HTTPS请求——它将被删除。iptables不再麻烦检查了,因为那是一场比赛。
|
||||
|
||||
另一方面,向ubuntu.com 发出软件升级的系统请求,只要符合其适当的规则,就会通过。显然,我们在这里做的是,只允许向我们的 BigMart 或 Ubuntu 发送 HTTP 或 HTTPS 请求,而不允许向其他目的地发送。
|
||||
|
||||
最后两条规则将处理 SSH 请求。因为它不使用端口80或443端口,而是使用22端口,所以之前的两个丢弃规则不会拒绝它。在这种情况下,来自我的工作站的登录请求将被接受,但是对其他任何地方的请求将被拒绝。这一点很重要:确保用于端口22规则的IP地址与您用来登录的机器的地址相匹配——如果不这样做,将立即被锁定。当然,这没什么大不了的,因为按照目前的配置方式,只需重启服务器,iptables 规则就会全部丢失。如果使用 LXC 容器作为服务器并从 LXC 主机登录,则使用主机 IP 地址连接容器,而不是其公共地址。
|
||||
|
||||
如果机器的IP发生变化,请记住更新这个规则;否则,你会被拒绝访问。
|
||||
|
||||
在家玩(是在某种性虚拟机上)?太好了。创建自己的脚本。现在我可以保存脚本,使用`chmod` 使其可执行,并以`sudo` 的形式运行它。不要担心 `igmart-data.com没找到`错误——当然没找到;它不存在。
|
||||
|
||||
```
|
||||
chmod +X scriptname.sh
|
||||
sudo ./scriptname.sh
|
||||
```
|
||||
|
||||
你可以使用`cURL` 命令行测试防火墙。请求 ubuntu.com 奏效,但请求 [manning.com][13]是失败的 。
|
||||
|
||||
|
||||
```
|
||||
curl ubuntu.com
|
||||
curl manning.com
|
||||
```
|
||||
|
||||
### 配置 iptables 以在系统启动时加载
|
||||
|
||||
现在,我如何让这些规则在每次 kiosk 启动时自动加载?第一步是将当前规则保存。使用`iptables-save` 工具保存规则文件。将在根目录中创建一个包含规则列表的文件。管道后面跟着 tee 命令,是将我的`sudo` 权限应用于字符串的第二部分:将文件实际保存到否则受限的根目录。
|
||||
|
||||
然后我可以告诉系统每次启动时运行一个相关的工具,叫做`iptables-restore` 。我们在上一模块中看到的常规cron 作业,因为它们在设定的时间运行,但是我们不知道什么时候我们的计算机可能会决定崩溃和重启。
|
||||
|
||||
有许多方法来处理这个问题。这里有一个:
|
||||
|
||||
|
||||
在我的 Linux 机器上,我将安装一个名为 [anacron][14] 的程序,该程序将在 /etc/ 目录中为我们提供一个名为anacrondab 的文件。我将编辑该文件并添加这个 `iptables-restore` 命令,告诉它加载该文件的当前值。引导后一分钟,规则每天(必要时)加载到 iptables 中。我会给作业一个标识符( `iptables-restore` ),然后添加命令本身。如果你在家和我一起这样,你应该通过重启系统来测试一下。
|
||||
|
||||
```
|
||||
sudo iptables-save | sudo tee /root/my.active.firewall.rules
|
||||
sudo apt install anacron
|
||||
sudo nano /etc/anacrontab
|
||||
1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
|
||||
|
||||
```
|
||||
|
||||
我希望这些实际例子已经说明了如何使用 iptables 和 firewalld 来管理基于Linux的防火墙上的连接问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/linux-iptables-firewalld
|
||||
|
||||
作者:[David Clinton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/remyd
|
||||
[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
[2]: /file/409116
|
||||
[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
|
||||
[4]: https://en.wikipedia.org/wiki/Iptables
|
||||
[5]: https://firewalld.org/
|
||||
[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
|
||||
[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
|
||||
[8]: https://en.wikipedia.org/wiki/Systemd
|
||||
[9]: /file/409121
|
||||
[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
|
||||
[11]: http://bigmart.com/
|
||||
[12]: http://youtube.com/
|
||||
[13]: http://manning.com/
|
||||
[14]: https://sourceforge.net/projects/anacron/
|
||||
@ -0,0 +1,439 @@
|
||||
如何在 Linux 中找到并删除重复文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
在编辑或修改配置文件或旧文件前,我经常会把它们备份到硬盘的某个地方,因此我如果意外地改错了这些文件,我可以从备份中恢复它们。但问题是如果我忘记清理备份文件,一段时间之后,我的磁盘会被这些大量重复文件填满。我觉得要么是懒得清理这些旧文件,要么是担心可能会删掉重要文件。如果你们像我一样,在类 Unix 操作系统中,大量多版本的相同文件放在不同的备份目录,你可以使用下面的工具找到并删除重复文件。
|
||||
|
||||
**提醒一句:**
|
||||
|
||||
在删除重复文件的时请尽量小心。如果你不小心,也许会导致[**意外丢失数据**][1]。我建议你在使用这些工具的时候要特别注意。
|
||||
|
||||
### 在 Linux 中找到并删除重复文件
|
||||
|
||||
|
||||
出于本指南的目的,我将讨论下面的三个工具:
|
||||
|
||||
1. Rdfind
|
||||
2. Fdupes
|
||||
3. FSlint
|
||||
|
||||
|
||||
|
||||
这三个工具是免费的、开源的,且运行在大多数类 Unix 系统中。
|
||||
|
||||
##### 1. Rdfind
|
||||
|
||||
**Rdfind** 代表找到找到冗余数据,是一个通过访问目录和子目录来找出重复文件的免费、开源的工具。它是基于文件内容而不是文件名来比较。Rdfind 使用**排序**算法来区分原始文件和重复文件。如果你有两个或者更多的相同文件,Rdfind 会很智能的找到原始文件并认定剩下的文件为重复文件。一旦找到副本文件,它会向你报告。你可以决定是删除还是使用[**硬链接**或者**符号(软)链接**][2]代替它们。
|
||||
|
||||
**安装 Rdfind**
|
||||
|
||||
Rdfind 存在于 [**AUR**][3] 中。因此,在基于 Arch 的系统中,你可以像下面一样使用任一如 [**Yay**][4] AUR 程序助手安装它。
|
||||
|
||||
```
|
||||
$ yay -S rdfind
|
||||
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install rdfind
|
||||
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install rdfind
|
||||
|
||||
```
|
||||
|
||||
在 RHEL、CentOS 上:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
$ sudo yum install rdfind
|
||||
|
||||
```
|
||||
|
||||
**用法**
|
||||
|
||||
一旦安装完成,仅带上目录路径运行 Rdfind 命令就可以扫描重复文件。
|
||||
|
||||
```
|
||||
$ rdfind ~/Downloads
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
正如你看到上面的截屏,Rdfind 命令将扫描 ~/Downloads 目录,并将结果存储到当前工作目录下一个名为 **results.txt** 的文件中。你可以在 results.txt 文件中看到可能是重复文件的名字。
|
||||
|
||||
```
|
||||
$ cat results.txt
|
||||
# Automatically generated
|
||||
# duptype id depth size device inode priority name
|
||||
DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex
|
||||
DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex
|
||||
[...]
|
||||
DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf
|
||||
DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf
|
||||
# end of file
|
||||
|
||||
```
|
||||
|
||||
通过检查 results.txt 文件,你可以很容易的找到那些重复文件。如果愿意你可以手动的删除它们。
|
||||
|
||||
此外,你可在不修改其他事情情况下使用 **-dryrun** 选项找出所有重复文件,并在终端上输出汇总信息。
|
||||
|
||||
```
|
||||
$ rdfind -dryrun true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
一旦找到重复文件,你可以使用硬链接或符号链接代替他们。
|
||||
|
||||
使用硬链接代替所有重复文件,运行:
|
||||
|
||||
```
|
||||
$ rdfind -makehardlinks true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
使用符号链接/软链接代替所有重复文件,运行:
|
||||
|
||||
```
|
||||
$ rdfind -makesymlinks true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
目录中有一些空文件,也许你想忽略他们,你可以像下面一样使用 **-ignoreempty** 选项:
|
||||
|
||||
```
|
||||
$ rdfind -ignoreempty true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
如果你不再想要这些旧文件,删除重复文件,而不是使用硬链接或软链接代替它们。
|
||||
|
||||
删除重复文件,就运行:
|
||||
|
||||
```
|
||||
$ rdfind -deleteduplicates true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
如果你不想忽略空文件,并且和所哟重复文件一起删除。运行:
|
||||
|
||||
```
|
||||
$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
更多细节,参照帮助部分:
|
||||
|
||||
```
|
||||
$ rdfind --help
|
||||
|
||||
```
|
||||
|
||||
手册页:
|
||||
|
||||
```
|
||||
$ man rdfind
|
||||
|
||||
```
|
||||
|
||||
##### 2. Fdupes
|
||||
|
||||
**Fdupes** 是另一个在指定目录以及子目录中识别和移除重复文件的命令行工具。这是一个使用 **C** 语言编写的免费、开源工具。Fdupes 通过对比文件大小、部分 MD5 签名、全部 MD5 签名,最后执行逐个字节对比校验来识别重复文件。
|
||||
|
||||
与 Rdfind 工具类似,Fdupes 附带非常少的选项来执行操作,如:
|
||||
|
||||
* 在目录和子目录中递归的搜索重复文件
|
||||
* 从计算中排除空文件和隐藏文件
|
||||
* 显示重复文件大小
|
||||
* 出现重复文件时立即删除
|
||||
* 使用不同的拥有者/组或权限位来排除重复文件
|
||||
* 更多
|
||||
|
||||
|
||||
|
||||
**安装 Fdupes**
|
||||
|
||||
Fdupes 存在于大多数 Linux 发行版的默认仓库中。
|
||||
|
||||
在 Arch Linux 和它的变种如 Antergos、Manjaro Linux 上,如下使用 Pacman 安装它。
|
||||
|
||||
```
|
||||
$ sudo pacman -S fdupes
|
||||
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install fdupes
|
||||
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install fdupes
|
||||
|
||||
```
|
||||
|
||||
在 RHEL、CentOS 上:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
$ sudo yum install fdupes
|
||||
|
||||
```
|
||||
|
||||
**用法**
|
||||
|
||||
Fdupes 用法非常简单。仅运行下面的命令就可以在目录中找到重复文件,如:**~/Downloads**.
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
我系统中的样例输出:
|
||||
|
||||
```
|
||||
/home/sk/Downloads/Hyperledger.pdf
|
||||
/home/sk/Downloads/Hyperledger(1).pdf
|
||||
|
||||
```
|
||||
你可以看到,在 **/home/sk/Downloads/** 目录下有一个重复文件。它仅显示了父级目录中的重复文件。如何显示子目录中的重复文件?像下面一样,使用 **-r** 选项。
|
||||
|
||||
```
|
||||
$ fdupes -r ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
现在你将看到 **/home/sk/Downloads/** 目录以及子目录中的重复文件。
|
||||
|
||||
Fdupes 也可用来从多个目录中迅速查找重复文件。
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads ~/Documents/ostechnix
|
||||
|
||||
```
|
||||
|
||||
你甚至可以搜索多个目录,递归搜索其中一个目录,如下:
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads -r ~/Documents/ostechnix
|
||||
|
||||
```
|
||||
|
||||
上面的命令将搜索 “~/Downloads” 目录,“~/Documents/ostechnix” 目录和它的子目录中的重复文件。
|
||||
|
||||
有时,你可能想要知道一个目录中重复文件的大小。你可以使用 **-S** 选项,如下:
|
||||
|
||||
```
|
||||
$ fdupes -S ~/Downloads
|
||||
403635 bytes each:
|
||||
/home/sk/Downloads/Hyperledger.pdf
|
||||
/home/sk/Downloads/Hyperledger(1).pdf
|
||||
|
||||
```
|
||||
|
||||
类似的,为了显示父目录和子目录中重复文件的大小,使用 **-Sr** 选项。
|
||||
|
||||
我们可以在计算时分别使用 **-n** 和 **-A** 选项排除空白文件以及排除隐藏文件。
|
||||
|
||||
```
|
||||
$ fdupes -n ~/Downloads
|
||||
|
||||
$ fdupes -A ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
在搜索指定目录的重复文件时,第一个命令将排除零长度文件,后面的命令将排除隐藏文件。
|
||||
|
||||
汇总重复文件信息,使用 **-m** 选项。
|
||||
|
||||
```
|
||||
$ fdupes -m ~/Downloads
|
||||
1 duplicate files (in 1 sets), occupying 403.6 kilobytes
|
||||
|
||||
```
|
||||
|
||||
删除所有重复文件,使用 **-d** 选项。
|
||||
|
||||
```
|
||||
$ fdupes -d ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
样例输出:
|
||||
|
||||
```
|
||||
[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf
|
||||
[2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf
|
||||
|
||||
Set 1 of 1, preserve files [1 - 2, all]:
|
||||
|
||||
```
|
||||
|
||||
这个命令将提示你保留还是删除所有其他重复文件。输入任一号码保留相应的文件,并删除剩下的文件。当使用这个选项的时候需要更加注意。如果不小心,你可能会删除原文件。
|
||||
|
||||
如果你想要每次保留每个重复文件集合的第一个文件,且无提示的删除其他文件,使用 **-dN** 选项(不推荐)。
|
||||
|
||||
```
|
||||
$ fdupes -dN ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
当遇到重复文件时删除它们,使用 **-I** 标志。
|
||||
|
||||
```
|
||||
$ fdupes -I ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
关于 Fdupes 的更多细节,查看帮助部分和 man 页面。
|
||||
|
||||
```
|
||||
$ fdupes --help
|
||||
|
||||
$ man fdupes
|
||||
|
||||
```
|
||||
|
||||
##### 3. FSlint
|
||||
|
||||
**FSlint** 是另外一个查找重复文件的工具,有时我用它去掉 Linux 系统中不需要的重复文件并释放磁盘空间。不像另外两个工具,FSlint 有 GUI 和 CLI 两种模式。因此对于新手来说它更友好。FSlint 不仅仅找出重复文件,也找出坏符号链接、坏名字文件、临时文件、坏 IDS、空目录和非剥离二进制文件等等。
|
||||
|
||||
**安装 FSlint**
|
||||
|
||||
FSlint 存在于 [**AUR**][5],因此你可以使用任一 AUR 助手安装它。
|
||||
|
||||
```
|
||||
$ yay -S fslint
|
||||
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install fslint
|
||||
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install fslint
|
||||
|
||||
```
|
||||
|
||||
在 RHEL,CentOS 上:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum install fslint
|
||||
|
||||
```
|
||||
|
||||
一旦安装完成,从菜单或者应用程序启动器启动它。
|
||||
|
||||
FSlint GUI 展示如下:
|
||||
|
||||

|
||||
|
||||
如你所见,FSlint 接口友好、一目了然。在 **Search path** 栏,添加你要扫描的目录路径,点击左下角 **Find** 按钮查找重复文件。验证递归选项可以在目录和子目录中递归的搜索重复文件。FSlint 将快速的扫描给定的目录并列出重复文件。
|
||||
|
||||

|
||||
|
||||
从列表中选择那些要清理的重复文件,也可以选择 Save、Delete、Merge 和 Symlink 操作他们。
|
||||
|
||||
在 **Advanced search parameters** 栏,你可以在搜索重复文件的时候指定排除的路径。
|
||||
|
||||

|
||||
|
||||
**FSlint 命令行选项**
|
||||
|
||||
FSlint 提供下面的 CLI 工具集在你的文件系统中查找重复文件。
|
||||
|
||||
* **findup** — 查找重复文件
|
||||
* **findnl** — 查找 Lint 名称文件(有问题的文件名)
|
||||
* **findu8** — 查找非法的 utf8 编码文件
|
||||
* **findbl** — 查找坏链接(有问题的符号链接)
|
||||
* **findsn** — 查找同名文件(可能有冲突的文件名)
|
||||
* **finded** — 查找空目录
|
||||
* **findid** — 查找死用户的文件
|
||||
* **findns** — 查找非剥离的可执行文件
|
||||
* **findrs** — 查找文件中多于的空白
|
||||
* **findtf** — 查找临时文件
|
||||
* **findul** — 查找可能未使用的库
|
||||
* **zipdir** — 回收 ext2 目录实体下浪费的空间
|
||||
|
||||
|
||||
|
||||
所有这些工具位于 **/usr/share/fslint/fslint/fslint** 下面。
|
||||
|
||||
|
||||
例如,在给定的目录中查找重复文件,运行:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/findup ~/Downloads/
|
||||
|
||||
```
|
||||
|
||||
类似的,找出空目录命令是:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/finded ~/Downloads/
|
||||
|
||||
```
|
||||
|
||||
获取每个工具更多细节,例如:**findup**,运行:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/findup --help
|
||||
|
||||
```
|
||||
|
||||
关于 FSlint 的更多细节,参照帮助部分和 man 页。
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/fslint --help
|
||||
|
||||
$ man fslint
|
||||
|
||||
```
|
||||
|
||||
##### 总结
|
||||
|
||||
现在你知道在 Linux 中,使用三个工具来查找和删除不需要的重复文件。这三个工具中,我经常使用 Rdfind。这并不意味着其他的两个工具效率低下,因为到目前为止我更喜欢 Rdfind。好了,到你了。你的最喜欢哪一个工具呢?为什么?在下面的评论区留言让我们知道吧。
|
||||
|
||||
就到这里吧。希望这篇文章对你有帮助。更多的好东西就要来了,敬请期待。
|
||||
|
||||
谢谢!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pygmalion666](https://github.com/pygmalion666)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
|
||||
[2]: https://www.ostechnix.com/explaining-soft-link-and-hard-link-in-linux-with-examples/
|
||||
[3]: https://aur.archlinux.org/packages/rdfind/
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]: https://aur.archlinux.org/packages/fslint/
|
||||
Loading…
Reference in New Issue
Block a user