mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-06 23:50:16 +08:00
commit
e60f0510e0
@ -1,17 +1,23 @@
|
||||
让我们使用 PC 键盘在终端演奏钢琴
|
||||
======
|
||||
厌倦了工作?那么来吧,让我们弹弹钢琴!是的,你没有看错。谁需要真的钢琴啊?我们可以用 PC 键盘在命令行下就能弹钢琴。向你们介绍一下 **Piano-rs** - 这是一款用 Rust 语言编写的,可以让你用 PC 键盘在终端弹钢琴的简单工具。它免费,开源,而且基于 MIT 协议。你可以在任何支持 Rust 的操作系统中使用它。
|
||||

|
||||
|
||||
### Piano-rs:使用 PC 键盘在终端弹钢琴
|
||||
厌倦了工作?那么来吧,让我们弹弹钢琴!是的,你没有看错,根本不需要真的钢琴。我们可以用 PC 键盘在命令行下就能弹钢琴。向你们介绍一下 `piano-rs` —— 这是一款用 Rust 语言编写的,可以让你用 PC 键盘在终端弹钢琴的简单工具。它自由开源,基于 MIT 协议。你可以在任何支持 Rust 的操作系统中使用它。
|
||||
|
||||
### piano-rs:使用 PC 键盘在终端弹钢琴
|
||||
|
||||
#### 安装
|
||||
|
||||
确保系统已经安装了 Rust 编程语言。若还未安装,运行下面命令来安装它。
|
||||
|
||||
```
|
||||
curl https://sh.rustup.rs -sSf | sh
|
||||
```
|
||||
|
||||
安装程序会问你是否默认安装还是自定义安装还是取消安装。我希望默认安装,因此输入 **1** (数字一)。
|
||||
(LCTT 译注:这种直接通过 curl 执行远程 shell 脚本是一种非常危险和不成熟的做法。)
|
||||
|
||||
安装程序会问你是否默认安装还是自定义安装还是取消安装。我希望默认安装,因此输入 `1` (数字一)。
|
||||
|
||||
```
|
||||
info: downloading installer
|
||||
|
||||
@ -43,7 +49,7 @@ default host triple: x86_64-unknown-linux-gnu
|
||||
1) Proceed with installation (default)
|
||||
2) Customize installation
|
||||
3) Cancel installation
|
||||
**1**
|
||||
1
|
||||
|
||||
info: syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
|
||||
223.6 KiB / 223.6 KiB (100 %) 215.1 KiB/s ETA: 0 s
|
||||
@ -72,9 +78,10 @@ environment variable. Next time you log in this will be done automatically.
|
||||
To configure your current shell run source $HOME/.cargo/env
|
||||
```
|
||||
|
||||
登出然后重启系统来将 cargo 的 bin 目录纳入 PATH 变量中。
|
||||
登出然后重启系统来将 cargo 的 bin 目录纳入 `PATH` 变量中。
|
||||
|
||||
校验 Rust 是否正确安装:
|
||||
|
||||
```
|
||||
$ rustc --version
|
||||
rustc 1.21.0 (3b72af97e 2017-10-09)
|
||||
@ -83,40 +90,44 @@ rustc 1.21.0 (3b72af97e 2017-10-09)
|
||||
太棒了!Rust 成功安装了。是时候构建 piano-rs 应用了。
|
||||
|
||||
使用下面命令克隆 Piano-rs 仓库:
|
||||
|
||||
```
|
||||
git clone https://github.com/ritiek/piano-rs
|
||||
```
|
||||
|
||||
上面命令会在当前工作目录创建一个名为 "piano-rs" 的目录并下载所有内容到其中。进入该目录:
|
||||
上面命令会在当前工作目录创建一个名为 `piano-rs` 的目录并下载所有内容到其中。进入该目录:
|
||||
|
||||
```
|
||||
cd piano-rs
|
||||
```
|
||||
|
||||
最后,运行下面命令来构建 Piano-rs:
|
||||
|
||||
```
|
||||
cargo build --release
|
||||
```
|
||||
|
||||
编译过程要花上一阵子。
|
||||
|
||||
#### Usage
|
||||
#### 用法
|
||||
|
||||
编译完成后,在 `piano-rs` 目录中运行下面命令:
|
||||
|
||||
编译完成后,在 **piano-rs** 目录中运行下面命令:
|
||||
```
|
||||
./target/release/piano-rs
|
||||
```
|
||||
|
||||
这就我们在终端上的钢琴键盘了!可以开始弹指一些音符了。按下按键可以弹奏相应音符。使用 **左/右** 方向键可以在弹奏时调整音频。而,使用 **上/下** 方向键可以在弹奏时调整音长。
|
||||
这就是我们在终端上的钢琴键盘了!可以开始弹指一些音符了。按下按键可以弹奏相应音符。使用 **左/右** 方向键可以在弹奏时调整音频。而,使用 **上/下** 方向键可以在弹奏时调整音长。
|
||||
|
||||
[![][1]][2]
|
||||
![][2]
|
||||
|
||||
Piano-rs 使用与 [**multiplayerpiano.com**][3] 一样的音符和按键。另外,你可以使用[**这些音符 **][4] 来学习弹指各种流行歌曲。
|
||||
Piano-rs 使用与 [multiplayerpiano.com][3] 一样的音符和按键。另外,你可以使用[这些音符][4] 来学习弹指各种流行歌曲。
|
||||
|
||||
要查看帮助。输入:
|
||||
|
||||
```
|
||||
$ ./target/release/piano-rs -h
|
||||
```
|
||||
```
|
||||
|
||||
piano-rs 0.1.0
|
||||
Ritiek Malhotra <ritiekmalhotra123@gmail.com>
|
||||
Play piano in the terminal using PC keyboard.
|
||||
@ -141,19 +152,18 @@ OPTIONS:
|
||||
此致敬礼!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/let-us-play-piano-terminal-using-pc-keyboard/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/10/Piano.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/10/Piano.png
|
||||
[3]:http://www.multiplayerpiano.com/
|
||||
[4]:https://pastebin.com/CX1ew0uB
|
||||
@ -0,0 +1,51 @@
|
||||
autorandr:自动调整屏幕布局
|
||||
======
|
||||
|
||||
像许多笔记本用户一样,我经常将笔记本插入到不同的显示器上(桌面上有多台显示器,演示时有投影机等)。运行 `xrandr` 命令或点击界面非常繁琐,编写脚本也不是很好。
|
||||
|
||||
最近,我遇到了 [autorandr][1],它使用 EDID(和其他设置)检测连接的显示器,保存 `xrandr` 配置并恢复它们。它也可以在加载特定配置时运行任意脚本。我已经打包了它,目前仍在 NEW 状态。如果你不能等待,[这是 deb][2],[这是 git 仓库][3]。
|
||||
|
||||
要使用它,只需安装软件包,并创建你的初始配置(我这里用的名字是 `undocked`):
|
||||
|
||||
```
|
||||
autorandr --save undocked
|
||||
```
|
||||
|
||||
然后,连接你的笔记本(或者插入你的外部显示器),使用 `xrandr`(或其他任何)更改配置,然后保存你的新配置(我这里用的名字是 workstation):
|
||||
|
||||
```
|
||||
autorandr --save workstation
|
||||
```
|
||||
|
||||
对你额外的配置(或当你有新的配置)进行重复操作。
|
||||
|
||||
`autorandr` 有 `udev`、`systemd` 和 `pm-utils` 钩子,当新的显示器出现时 `autorandr --change` 应该会立即运行。如果需要,也可以手动运行 `autorandr --change` 或 `autorandr - load workstation`。你也可以在加载配置后在 `~/.config/autorandr/$PROFILE/postswitch` 添加自己的脚本来运行。由于我运行 i3,我的工作站配置如下所示:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
xrandr --dpi 92
|
||||
xrandr --output DP2-2 --primary
|
||||
i3-msg '[workspace="^(1|4|6)"] move workspace to output DP2-2;'
|
||||
i3-msg '[workspace="^(2|5|9)"] move workspace to output DP2-3;'
|
||||
i3-msg '[workspace="^(3|8)"] move workspace to output DP2-1;'
|
||||
```
|
||||
|
||||
它适当地修正了 dpi,设置主屏幕(可能不需要?),并移动 i3 工作区。你可以通过在配置文件目录中添加一个 `block` 钩子来安排配置永远不会运行。
|
||||
|
||||
如果你定期更换显示器,请看一下!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.donarmstrong.com/posts/autorandr/
|
||||
|
||||
作者:[Don Armstrong][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.donarmstrong.com
|
||||
[1]:https://github.com/phillipberndt/autorandr
|
||||
[2]:https://www.donarmstrong.com/autorandr_1.2-1_all.deb
|
||||
[3]:https://git.donarmstrong.com/deb_pkgs/autorandr.git
|
||||
@ -1,82 +0,0 @@
|
||||
AI and machine learning bias has dangerous implications
|
||||
======
|
||||
translating
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
Algorithms are everywhere in our world, and so is bias. From social media news feeds to streaming service recommendations to online shopping, computer algorithms--specifically, machine learning algorithms--have permeated our day-to-day world. As for bias, we need only examine the 2016 American election to understand how deeply--both implicitly and explicitly--it permeates our society as well.
|
||||
|
||||
What's often overlooked, however, is the intersection between these two: bias in computer algorithms themselves.
|
||||
|
||||
Contrary to what many of us might think, technology is not objective. AI algorithms and their decision-making processes are directly shaped by those who build them--what code they write, what data they use to "[train][1]" the machine learning models, and how they [stress-test][2] the models after they're finished. This means that the programmers' values, biases, and human flaws are reflected in the software. If I fed an image-recognition algorithm the faces of only white researchers in my lab, for instance, it [wouldn't recognize non-white faces as human][3]. Such a conclusion isn't the result of a "stupid" or "unsophisticated" AI, but to a bias in training data: a lack of diverse faces. This has dangerous consequences.
|
||||
|
||||
There's no shortage of examples. [State court systems][4] across the country use "black box" algorithms to recommend prison sentences for convicts. [These algorithms are biased][5] against black individuals because of the data that trained them--so they recommend longer sentences as a result, thus perpetuating existing racial disparities in prisons. All this happens under the guise of objective, "scientific" decision-making.
|
||||
|
||||
The United States federal government uses machine-learning algorithms to calculate welfare payouts and other types of subsidies. But [information on these algorithms][6], such as their creators and their training data, is extremely difficult to find--which increases the risk of public officials operating under bias and meting out systematically unfair payments.
|
||||
|
||||
This list goes on. From Facebook news algorithms to medical care systems to police body cameras, we as a society are at great risk of inserting our biases--racism, sexism, xenophobia, socioeconomic discrimination, confirmation bias, and more--into machines that will be mass-produced and mass-distributed, operating under the veil of perceived technological objectivity.
|
||||
|
||||
This must stop.
|
||||
|
||||
While we should by no means halt research and development on artificial intelligence, we need to slow its development such that we tread carefully. The danger of algorithmic bias is already too great.
|
||||
|
||||
## How can we fight algorithmic bias?
|
||||
|
||||
One of the best ways to fight algorithmic bias is by vetting the training data fed into machine learning models themselves. As [researchers at Microsoft][2] point out, this can take many forms.
|
||||
|
||||
The data itself might have a skewed distribution--for instance, programmers may have more data about United States-born citizens than immigrants, and about rich men than poor women. Such imbalances will cause an AI to make improper conclusions about how our society is in fact represented--i.e., that most Americans are wealthy white businessmen--simply because of the way machine-learning models make statistical correlations.
|
||||
|
||||
It's also possible, even if men and women are equally represented in training data, that the representations themselves result in prejudiced understandings of humanity. For instance, if all the pictures of "male occupation" are of CEOs and all those of "female occupation" are of secretaries (even if more CEOs are in fact male than female), the AI could conclude that women are inherently not meant to be CEOs.
|
||||
|
||||
We can imagine similar issues, for example, with law enforcement AIs that examine representations of criminality in the media, which dozens of studies have shown to be [egregiously slanted][7] towards black and Latino citizens.
|
||||
|
||||
Bias in training data can take many other forms as well--unfortunately, more than can be adequately covered here. Nonetheless, training data is just one form of vetting; it's also important that AI models are "stress-tested" after they're completed to seek out prejudice.
|
||||
|
||||
If we show an Indian face to our camera, is it appropriately recognized? Is our AI less likely to recommend a job candidate from an inner city than a candidate from the suburbs, even if they're equally qualified? How does our terrorism algorithm respond to intelligence on a white domestic terrorist compared to an Iraqi? Can our ER camera pull up medical records of children?
|
||||
|
||||
These are obviously difficult issues to resolve in the data itself, but we can begin to identify and address them through comprehensive testing.
|
||||
|
||||
## Why is open source well-suited for this task?
|
||||
|
||||
Both open source technology and open source methodologies have extreme potential to help in this fight against algorithmic bias.
|
||||
|
||||
Modern artificial intelligence is dominated by open source software, from TensorFlow to IBM Watson to packages like [scikit-learn][8]. The open source community has already proven extremely effective in developing robust and rigorously tested machine-learning tools, so it follows that the same community could effectively build anti-bias tests into that same software.
|
||||
|
||||
Debugging tools like [DeepXplore][9], out of Columbia and Lehigh Universities, for example, make the AI stress-testing process extensive yet also easy to navigate. This and other projects, such as work being done at [MIT's Computer Science and Artificial Intelligence Lab][10], develop the agile and rapid prototyping the open source community should adopt.
|
||||
|
||||
Open source technology has also proven to be extremely effective for vetting and sorting large sets of data. Nothing should make this more obvious than the domination of open source tools in the data analysis market (Weka, Rapid Miner, etc.). Tools for identifying data bias should be designed by the open source community, and those techniques should also be applied to the plethora of open training data sets already published on sites like [Kaggle][11].
|
||||
|
||||
The open source methodology itself is also well-suited for designing processes to fight bias. Making conversations about software open, democratized, and in tune with social good are pivotal to combating an issue that is partly caused by the very opposite--closed conversations, private software development, and undemocratized decision-making. If online communities, corporations, and academics can adopt these open source characteristics when approaching machine learning, fighting algorithmic bias should become easier.
|
||||
|
||||
## How can we all get involved?
|
||||
|
||||
Education is extremely important. We all know people who may be unaware of algorithmic bias but who care about its implications--for law, social justice, public policy, and more. It's critical to talk to those people and explain both how the bias is formed and why it matters because the only way to get these conversations started is to start them ourselves.
|
||||
|
||||
For those of us who work with artificial intelligence in some capacity--as developers, on the policy side, through academic research, or in other capacities--these conversations are even more important. Those who are designing the artificial intelligence of tomorrow need to understand the extreme dangers that bias presents today; clearly, integrating anti-bias processes into software design depends on this very awareness.
|
||||
|
||||
Finally, we should all build and strengthen open source community around ethical AI. Whether that means contributing to software tools, stress-testing machine learning models, or sifting through gigabytes of training data, it's time we leverage the power of open source methodology to combat one of the greatest threats of our digital age.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-bias
|
||||
|
||||
作者:[Justin Sherman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/justinsherman
|
||||
[1]:https://www.crowdflower.com/what-is-training-data/
|
||||
[2]:https://medium.com/microsoft-design/how-to-recognize-exclusion-in-ai-ec2d6d89f850
|
||||
[3]:https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms
|
||||
[4]:https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/
|
||||
[5]:https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
|
||||
[6]:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3012499
|
||||
[7]:https://www.hivlawandpolicy.org/sites/default/files/Race%20and%20Punishment-%20Racial%20Perceptions%20of%20Crime%20and%20Support%20for%20Punitive%20Policies%20%282014%29.pdf
|
||||
[8]:http://scikit-learn.org/stable/
|
||||
[9]:https://arxiv.org/pdf/1705.06640.pdf
|
||||
[10]:https://www.csail.mit.edu/research/understandable-deep-networks
|
||||
[11]:https://www.kaggle.com/datasets
|
||||
@ -1,113 +0,0 @@
|
||||
Translating by Torival Three steps to learning GDB
|
||||
============================================================
|
||||
|
||||
Debugging C programs used to scare me a lot. Then I was writing my [operating system][2] and I had so many bugs to debug! I was extremely fortunate to be using the emulator qemu, which lets me attach a debugger to my operating system. The debugger is called `gdb`.
|
||||
|
||||
I’m going to explain a couple of small things you can do with `gdb`, because I found it really confusing to get started. We’re going to set a breakpoint and examine some memory in a tiny program.
|
||||
|
||||
### 1\. Set breakpoints
|
||||
|
||||
If you’ve ever used a debugger before, you’ve probably set a breakpoint.
|
||||
|
||||
Here’s the program that we’re going to be “debugging” (though there aren’t any bugs):
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
void do_thing() {
|
||||
printf("Hi!\n");
|
||||
}
|
||||
int main() {
|
||||
do_thing();
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Save this as `hello.c`. We can debug it with gdb like this:
|
||||
|
||||
```
|
||||
bork@kiwi ~> gcc -g hello.c -o hello
|
||||
bork@kiwi ~> cat
|
||||
bork@kiwi ~> gdb ./hello
|
||||
```
|
||||
|
||||
This compiles `hello.c` with debugging symbols (so that gdb can do better work), and gives us kind of scary prompt that just says
|
||||
|
||||
`(gdb)`
|
||||
|
||||
We can then set a breakpoint using the `break` command, and then `run` the program.
|
||||
|
||||
```
|
||||
(gdb) break do_thing
|
||||
Breakpoint 1 at 0x4004f8
|
||||
(gdb) run
|
||||
Starting program: /home/bork/hello
|
||||
|
||||
Breakpoint 1, 0x00000000004004f8 in do_thing ()
|
||||
```
|
||||
|
||||
This stops the program at the beginning of `do_thing`.
|
||||
|
||||
We can find out where we are in the call stack with `where`: (thanks to [@mgedmin][3] for the tip)
|
||||
|
||||
```
|
||||
(gdb) where
|
||||
#0 do_thing () at hello.c:3
|
||||
#1 0x08050cdb in main () at hello.c:6
|
||||
(gdb)
|
||||
```
|
||||
|
||||
### 2\. Look at some assembly code
|
||||
|
||||
We can look at the assembly code for our function using the `disassemble`command! This is cool. This is x86 assembly. I don’t understand it very well, but the line that says `callq` is what does the `printf` function call.
|
||||
|
||||
```
|
||||
(gdb) disassemble do_thing
|
||||
Dump of assembler code for function do_thing:
|
||||
0x00000000004004f4 <+0>: push %rbp
|
||||
0x00000000004004f5 <+1>: mov %rsp,%rbp
|
||||
=> 0x00000000004004f8 <+4>: mov $0x40060c,%edi
|
||||
0x00000000004004fd <+9>: callq 0x4003f0
|
||||
0x0000000000400502 <+14>: pop %rbp
|
||||
0x0000000000400503 <+15>: retq
|
||||
```
|
||||
|
||||
You can also shorten `disassemble` to `disas`
|
||||
|
||||
### 3\. Examine some memory!
|
||||
|
||||
The main thing I used `gdb` for when I was debugging my kernel was to examine regions of memory to make sure they were what I thought they were. The command for examining memory is `examine`, or `x` for short. We’re going to use `x`.
|
||||
|
||||
From looking at that assembly above, it seems like `0x40060c` might be the address of the string we’re printing. Let’s check!
|
||||
|
||||
```
|
||||
(gdb) x/s 0x40060c
|
||||
0x40060c: "Hi!"
|
||||
```
|
||||
|
||||
It is! Neat! Look at that. The `/s` part of `x/s` means “show it to me like it’s a string”. I could also have said “show me 10 characters” like this:
|
||||
|
||||
```
|
||||
(gdb) x/10c 0x40060c
|
||||
0x40060c: 72 'H' 105 'i' 33 '!' 0 '\000' 1 '\001' 27 '\033' 3 '\003' 59 ';'
|
||||
0x400614: 52 '4' 0 '\000'
|
||||
```
|
||||
|
||||
You can see that the first four characters are ‘H’, ‘i’, and ‘!’, and ‘\0’ and then after that there’s more unrelated stuff.
|
||||
|
||||
I know that gdb does lots of other stuff, but I still don’t know it very well and `x`and `break` got me pretty far. You can read the [documentation for examining memory][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/spytools
|
||||
[2]:http://jvns.ca/blog/categories/kernel
|
||||
[3]:https://twitter.com/mgedmin
|
||||
[4]:https://ftp.gnu.org/old-gnu/Manuals/gdb-5.1.1/html_chapter/gdb_9.html#SEC56
|
||||
@ -1,246 +0,0 @@
|
||||
BriFuture is translating this article.
|
||||
|
||||
Let’s Build A Simple Interpreter. Part 2.
|
||||
======
|
||||
|
||||
In their amazing book "The 5 Elements of Effective Thinking" the authors Burger and Starbird share a story about how they observed Tony Plog, an internationally acclaimed trumpet virtuoso, conduct a master class for accomplished trumpet players. The students first played complex music phrases, which they played perfectly well. But then they were asked to play very basic, simple notes. When they played the notes, the notes sounded childish compared to the previously played complex phrases. After they finished playing, the master teacher also played the same notes, but when he played them, they did not sound childish. The difference was stunning. Tony explained that mastering the performance of simple notes allows one to play complex pieces with greater control. The lesson was clear - to build true virtuosity one must focus on mastering simple, basic ideas.
|
||||
|
||||
The lesson in the story clearly applies not only to music but also to software development. The story is a good reminder to all of us to not lose sight of the importance of deep work on simple, basic ideas even if it sometimes feels like a step back. While it is important to be proficient with a tool or framework you use, it is also extremely important to know the principles behind them. As Ralph Waldo Emerson said:
|
||||
|
||||
> "If you learn only methods, you'll be tied to your methods. But if you learn principles, you can devise your own methods."
|
||||
|
||||
On that note, let's dive into interpreters and compilers again.
|
||||
|
||||
Today I will show you a new version of the calculator from [Part 1][1] that will be able to:
|
||||
|
||||
1. Handle whitespace characters anywhere in the input string
|
||||
2. Consume multi-digit integers from the input
|
||||
3. Subtract two integers (currently it can only add integers)
|
||||
|
||||
|
||||
|
||||
Here is the source code for your new version of the calculator that can do all of the above:
|
||||
```
|
||||
# Token types
|
||||
# EOF (end-of-file) token is used to indicate that
|
||||
# there is no more input left for lexical analysis
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token type: INTEGER, PLUS, MINUS, or EOF
|
||||
self.type = type
|
||||
# token value: non-negative integer value, '+', '-', or None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
"""String representation of the class instance.
|
||||
|
||||
Examples:
|
||||
Token(INTEGER, 3)
|
||||
Token(PLUS '+')
|
||||
"""
|
||||
return 'Token({type}, {value})'.format(
|
||||
type=self.type,
|
||||
value=repr(self.value)
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
|
||||
class Interpreter(object):
|
||||
def __init__(self, text):
|
||||
# client string input, e.g. "3 + 5", "12 - 5", etc
|
||||
self.text = text
|
||||
# self.pos is an index into self.text
|
||||
self.pos = 0
|
||||
# current token instance
|
||||
self.current_token = None
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def error(self):
|
||||
raise Exception('Error parsing input')
|
||||
|
||||
def advance(self):
|
||||
"""Advance the 'pos' pointer and set the 'current_char' variable."""
|
||||
self.pos += 1
|
||||
if self.pos > len(self.text) - 1:
|
||||
self.current_char = None # Indicates end of input
|
||||
else:
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def skip_whitespace(self):
|
||||
while self.current_char is not None and self.current_char.isspace():
|
||||
self.advance()
|
||||
|
||||
def integer(self):
|
||||
"""Return a (multidigit) integer consumed from the input."""
|
||||
result = ''
|
||||
while self.current_char is not None and self.current_char.isdigit():
|
||||
result += self.current_char
|
||||
self.advance()
|
||||
return int(result)
|
||||
|
||||
def get_next_token(self):
|
||||
"""Lexical analyzer (also known as scanner or tokenizer)
|
||||
|
||||
This method is responsible for breaking a sentence
|
||||
apart into tokens.
|
||||
"""
|
||||
while self.current_char is not None:
|
||||
|
||||
if self.current_char.isspace():
|
||||
self.skip_whitespace()
|
||||
continue
|
||||
|
||||
if self.current_char.isdigit():
|
||||
return Token(INTEGER, self.integer())
|
||||
|
||||
if self.current_char == '+':
|
||||
self.advance()
|
||||
return Token(PLUS, '+')
|
||||
|
||||
if self.current_char == '-':
|
||||
self.advance()
|
||||
return Token(MINUS, '-')
|
||||
|
||||
self.error()
|
||||
|
||||
return Token(EOF, None)
|
||||
|
||||
def eat(self, token_type):
|
||||
# compare the current token type with the passed token
|
||||
# type and if they match then "eat" the current token
|
||||
# and assign the next token to the self.current_token,
|
||||
# otherwise raise an exception.
|
||||
if self.current_token.type == token_type:
|
||||
self.current_token = self.get_next_token()
|
||||
else:
|
||||
self.error()
|
||||
|
||||
def expr(self):
|
||||
"""Parser / Interpreter
|
||||
|
||||
expr -> INTEGER PLUS INTEGER
|
||||
expr -> INTEGER MINUS INTEGER
|
||||
"""
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
# we expect the current token to be an integer
|
||||
left = self.current_token
|
||||
self.eat(INTEGER)
|
||||
|
||||
# we expect the current token to be either a '+' or '-'
|
||||
op = self.current_token
|
||||
if op.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
else:
|
||||
self.eat(MINUS)
|
||||
|
||||
# we expect the current token to be an integer
|
||||
right = self.current_token
|
||||
self.eat(INTEGER)
|
||||
# after the above call the self.current_token is set to
|
||||
# EOF token
|
||||
|
||||
# at this point either the INTEGER PLUS INTEGER or
|
||||
# the INTEGER MINUS INTEGER sequence of tokens
|
||||
# has been successfully found and the method can just
|
||||
# return the result of adding or subtracting two integers,
|
||||
# thus effectively interpreting client input
|
||||
if op.type == PLUS:
|
||||
result = left.value + right.value
|
||||
else:
|
||||
result = left.value - right.value
|
||||
return result
|
||||
|
||||
|
||||
def main():
|
||||
while True:
|
||||
try:
|
||||
# To run under Python3 replace 'raw_input' call
|
||||
# with 'input'
|
||||
text = raw_input('calc> ')
|
||||
except EOFError:
|
||||
break
|
||||
if not text:
|
||||
continue
|
||||
interpreter = Interpreter(text)
|
||||
result = interpreter.expr()
|
||||
print(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
Save the above code into the calc2.py file or download it directly from [GitHub][2]. Try it out. See for yourself that it works as expected: it can handle whitespace characters anywhere in the input; it can accept multi-digit integers, and it can also subtract two integers as well as add two integers.
|
||||
|
||||
Here is a sample session that I ran on my laptop:
|
||||
```
|
||||
$ python calc2.py
|
||||
calc> 27 + 3
|
||||
30
|
||||
calc> 27 - 7
|
||||
20
|
||||
calc>
|
||||
```
|
||||
|
||||
The major code changes compared with the version from [Part 1][1] are:
|
||||
|
||||
1. The get_next_token method was refactored a bit. The logic to increment the pos pointer was factored into a separate method advance.
|
||||
2. Two more methods were added: skip_whitespace to ignore whitespace characters and integer to handle multi-digit integers in the input.
|
||||
3. The expr method was modified to recognize INTEGER -> MINUS -> INTEGER phrase in addition to INTEGER -> PLUS -> INTEGER phrase. The method now also interprets both addition and subtraction after having successfully recognized the corresponding phrase.
|
||||
|
||||
In [Part 1][1] you learned two important concepts, namely that of a **token** and a **lexical analyzer**. Today I would like to talk a little bit about **lexemes** , **parsing** , and **parsers**.
|
||||
|
||||
You already know about tokens. But in order for me to round out the discussion of tokens I need to mention lexemes. What is a lexeme? A **lexeme** is a sequence of characters that form a token. In the following picture you can see some examples of tokens and sample lexemes and hopefully it will make the relationship between them clear:
|
||||
|
||||
![][3]
|
||||
|
||||
Now, remember our friend, the expr method? I said before that that's where the interpretation of an arithmetic expression actually happens. But before you can interpret an expression you first need to recognize what kind of phrase it is, whether it is addition or subtraction, for example. That's what the expr method essentially does: it finds the structure in the stream of tokens it gets from the get_next_token method and then it interprets the phrase that is has recognized, generating the result of the arithmetic expression.
|
||||
|
||||
The process of finding the structure in the stream of tokens, or put differently, the process of recognizing a phrase in the stream of tokens is called **parsing**. The part of an interpreter or compiler that performs that job is called a **parser**.
|
||||
|
||||
So now you know that the expr method is the part of your interpreter where both **parsing** and **interpreting** happens - the expr method first tries to recognize ( **parse** ) the INTEGER -> PLUS -> INTEGER or the INTEGER -> MINUS -> INTEGER phrase in the stream of tokens and after it has successfully recognized ( **parsed** ) one of those phrases, the method interprets it and returns the result of either addition or subtraction of two integers to the caller.
|
||||
|
||||
And now it's time for exercises again.
|
||||
|
||||
![][4]
|
||||
|
||||
1. Extend the calculator to handle multiplication of two integers
|
||||
2. Extend the calculator to handle division of two integers
|
||||
3. Modify the code to interpret expressions containing an arbitrary number of additions and subtractions, for example "9 - 5 + 3 + 11"
|
||||
|
||||
|
||||
|
||||
**Check your understanding.**
|
||||
|
||||
1. What is a lexeme?
|
||||
2. What is the name of the process that finds the structure in the stream of tokens, or put differently, what is the name of the process that recognizes a certain phrase in that stream of tokens?
|
||||
3. What is the name of the part of the interpreter (compiler) that does parsing?
|
||||
|
||||
|
||||
|
||||
|
||||
I hope you liked today's material. In the next article of the series you will extend your calculator to handle more complex arithmetic expressions. Stay tuned.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part2/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[2]:https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py
|
||||
[3]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_lexemes.png
|
||||
[4]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_exercises.png
|
||||
@ -0,0 +1,96 @@
|
||||
How to resolve mount.nfs: Stale file handle error
|
||||
======
|
||||
Learn how to resolve mount.nfs: Stale file handle error on Linux platform. This is Network File System error can be resolved from client or server end.
|
||||
|
||||
_![][1]_
|
||||
|
||||
When you are using Network File System in your environment, you must have seen`mount.nfs: Stale file handle` error at times. This error denotes that NFS share is unable to mount since something has changed since last good known configuration.
|
||||
|
||||
Whenever you reboot NFS server or some of the NFS processes are not running on client or server or share is not properly exported at server; these can be reasons for this error. Moreover its irritating when this error comes to previously mounted NFS share. Because this means configuration part is correct since it was previously mounted. In such case once can try following commands:
|
||||
|
||||
Make sure NFS service are running good on client and server.
|
||||
|
||||
```
|
||||
# service nfs status
|
||||
rpc.svcgssd is stopped
|
||||
rpc.mountd (pid 11993) is running...
|
||||
nfsd (pid 12009 12008 12007 12006 12005 12004 12003 12002) is running...
|
||||
rpc.rquotad (pid 11988) is running...
|
||||
```
|
||||
|
||||
> Stay connected to your favorite windows applications from anywhere on any device with [ windows 7 cloud desktop ][2] from CloudDesktopOnline.com. Get Office 365 with expert support and free migration from [ Apps4Rent.com ][3].
|
||||
|
||||
If NFS share currently mounted on client, then un-mount it forcefully and try to remount it on NFS client. Check if its properly mounted by `df` command and changing directory inside it.
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
|
||||
# mount -t nfs server:/nfs_share /mydata_nfs
|
||||
|
||||
#df -k
|
||||
------ output clipped -----
|
||||
server:/nfs_share 41943040 892928 41050112 3% /mydata_nfs
|
||||
```
|
||||
|
||||
In above mount command, server can be IP or [hostname ][4]of NFS server.
|
||||
|
||||
If you are getting error while forcefully un-mounting like below :
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
umount2: Device or resource busy
|
||||
umount: /mydata_nfs: device is busy
|
||||
umount2: Device or resource busy
|
||||
umount: /mydata_nfs: device is busy
|
||||
```
|
||||
Then you can check which all processes or users are using that mount point with `lsof` command like below:
|
||||
|
||||
```
|
||||
# lsof |grep mydata_nfs
|
||||
lsof: WARNING: can't stat() nfs file system /mydata_nfs
|
||||
Output information may be incomplete.
|
||||
su 3327 root cwd unknown /mydata_nfs/dir (stat: Stale NFS file handle)
|
||||
bash 3484 grid cwd unknown /mydata_nfs/MYDB (stat: Stale NFS file handle)
|
||||
bash 20092 oracle11 cwd unknown /mydata_nfs/MPRP (stat: Stale NFS file handle)
|
||||
bash 25040 oracle11 cwd unknown /mydata_nfs/MUYR (stat: Stale NFS file handle)
|
||||
```
|
||||
|
||||
If you see in above example that 4 PID are using some files on said mount point. Try killing them off to free mount point. Once done you will be able to un-mount it properly.
|
||||
|
||||
Sometimes it still give same error for mount command. Then try mounting after restarting NFS service at client using below command.
|
||||
|
||||
```
|
||||
# service nfs restart
|
||||
Shutting down NFS daemon: [ OK ]
|
||||
Shutting down NFS mountd: [ OK ]
|
||||
Shutting down NFS quotas: [ OK ]
|
||||
Shutting down RPC idmapd: [ OK ]
|
||||
Starting NFS services: [ OK ]
|
||||
Starting NFS quotas: [ OK ]
|
||||
Starting NFS mountd: [ OK ]
|
||||
Starting NFS daemon: [ OK ]
|
||||
```
|
||||
|
||||
Also read : [How to restart NFS step by step in HPUX][5]
|
||||
|
||||
Even if this didnt solve your issue, final step is to restart services at NFS server. Caution! This will disconnect all NFS shares which are exported from NFS server. All clients will see mount point disconnect. This step is where 99% you will get your issue resolved. If not then [NFS configurations][6] must be checked, provided you have changed configuration and post that you started seeing this error.
|
||||
|
||||
Outputs in above post are from RHEL6.3 server. Drop us your comments related to this post.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/troubleshooting/resolve-mount-nfs-stale-file-handle-error/
|
||||
|
||||
作者:[KernelTalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:http://kerneltalks.com/wp-content/uploads/2017/01/nfs_error-2-150x150.png
|
||||
[2]:https://www.clouddesktoponline.com/
|
||||
[3]:http://www.apps4rent.com
|
||||
[4]:https://kerneltalks.com/linux/all-you-need-to-know-about-hostname-in-linux/
|
||||
[5]:http://kerneltalks.com/hpux/restart-nfs-in-hpux/
|
||||
[6]:http://kerneltalks.com/linux/nfs-configuration-linux-hpux/
|
||||
@ -0,0 +1,156 @@
|
||||
Ansible Tutorial: Intorduction to simple Ansible commands
|
||||
======
|
||||
In our earlier Ansible tutorial, we discussed [**the installation & configuration of Ansible**][1]. Now in this ansible tutorial, we will learn some basic examples of ansible commands that we will use to manage our infrastructure. So let us start by looking at the syntax of a complete ansible command,
|
||||
|
||||
```
|
||||
$ ansible <group> -m <module> -a <arguments>
|
||||
```
|
||||
|
||||
Here, we can also use a single host or all in place of <group> & <arguments> are optional to provide. Now let's look at some basic commands to use with ansible,
|
||||
|
||||
### Check connectivity of hosts
|
||||
|
||||
We have used this command in our previous tutorial also. The command to check connectivity of hosts is
|
||||
|
||||
```
|
||||
$ ansible <group> -m ping
|
||||
```
|
||||
|
||||
### Rebooting hosts
|
||||
|
||||
```
|
||||
$ ansible <group> -a "/sbin/reboot"
|
||||
```
|
||||
|
||||
### Checking host 's system information
|
||||
|
||||
Ansible collects the system's information for all the hosts connected to it. To display the information of hosts, run
|
||||
|
||||
```
|
||||
$ ansible <group> -m setup | less
|
||||
```
|
||||
|
||||
Secondly, to check a particular info from the collected information by passing an argument,
|
||||
|
||||
```
|
||||
$ ansible <group> -m setup -a "filter=ansible_distribution"
|
||||
```
|
||||
|
||||
### Transfering files
|
||||
|
||||
For transferring files we use a module 'copy' & complete command that is used is
|
||||
|
||||
```
|
||||
$ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
```
|
||||
|
||||
### Manging users
|
||||
|
||||
So to manage the users on the connected hosts, we use a module named 'user' & comamnds to use it are as follows,
|
||||
|
||||
#### Creating a new user
|
||||
|
||||
```
|
||||
$ ansible <group> -m user -a "name=testuser password=<encrypted password>"
|
||||
```
|
||||
|
||||
#### Deleting a user
|
||||
|
||||
```
|
||||
$ ansible <group> -m user -a "name=testuser state=absent"
|
||||
```
|
||||
|
||||
**Note:-** To create an encrypted password, use the 'mkpasswd -method=sha-512' command.
|
||||
|
||||
### Changing permissions & ownership
|
||||
|
||||
So for changing ownership of files of connected hosts, we use module named 'file' & commands used are
|
||||
|
||||
### Changing permission of a file
|
||||
|
||||
```
|
||||
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777"
|
||||
```
|
||||
|
||||
### Changing ownership of a file
|
||||
|
||||
```
|
||||
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777 owner=dan group=dan"
|
||||
```
|
||||
|
||||
### Managing Packages
|
||||
|
||||
So, we can manage the packages installed on all the hosts connected to ansible by using 'yum' & 'apt' modules & the complete commands used are
|
||||
|
||||
#### Check if package is installed & update it
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=latest"
|
||||
```
|
||||
|
||||
#### Check if package is installed & don't update it
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=present"
|
||||
```
|
||||
|
||||
#### Check if package is at a specific version
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name= ntp-1.8 state=present"
|
||||
```
|
||||
|
||||
#### Check if package is not installed
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=absent"
|
||||
```
|
||||
|
||||
### Managing services
|
||||
|
||||
So to manage services with ansible, we use a modules 'service' & complete commands that are used are,
|
||||
|
||||
#### Starting a service
|
||||
|
||||
```
|
||||
$ansible <group> -m service -a "name=httpd state=started"
|
||||
```
|
||||
|
||||
#### Stopping a service
|
||||
|
||||
```
|
||||
$ ansible <group> -m service -a "name=httpd state=stopped"
|
||||
```
|
||||
|
||||
#### Restarting a service
|
||||
|
||||
```
|
||||
$ ansible <group> -m service -a "name=httpd state=restarted"
|
||||
```
|
||||
|
||||
So this completes our tutorial of some simple, one line commands that can be used with ansible. Also, for our future tutorials, we will learn to create plays & playbooks that help us manage our hosts more easliy & efficiently.
|
||||
|
||||
If you think we have helped you or just want to support us, please consider these :-
|
||||
|
||||
Connect to us: [Facebook][2] | [Twitter][3] | [Google Plus][4]
|
||||
|
||||
Become a Supporter - [Make a contribution via PayPal][5]
|
||||
|
||||
Linux TechLab is thankful for your continued support.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/ansible-tutorial-simple-commands/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/create-first-ansible-server-automation-setup/
|
||||
[2]:https://www.facebook.com/linuxtechlab/
|
||||
[3]:https://twitter.com/LinuxTechLab
|
||||
[4]:https://plus.google.com/+linuxtechlab
|
||||
[5]:http://linuxtechlab.com/contact-us-2/
|
||||
@ -1,68 +0,0 @@
|
||||
translating by lujun9972
|
||||
Run Linux On Android Devices, No Rooting Required!
|
||||
======
|
||||

|
||||
|
||||
The other day I was searching for a simple and easy way to run Linux on Android. My only intention was to just use Linux with some basic applications like SSH, Git, awk etc. Not much! I don't want to root the Android device. I have a Tablet PC that I mostly use for reading EBooks, news, and few Linux blogs. I don't use it much for other activities. So, I decided to use it for some Linux activities. After spending few minutes on Google Play Store, one app immediately caught my attention and I wanted to give it a try. If you're ever wondered how to run Linux on Android devices, this one might help.
|
||||
|
||||
### Termux - An Android terminal emulator to run Linux on Android and Chrome OS
|
||||
|
||||
**Termux** is an Android terminal emulator and Linux environment app. Unlike many other apps, you don 't need to root your device or no setup required. It just works out of the box! A minimal base Linux system will be installed automatically, and of course you can install other packages with APT package manager. In short, you can use your Android device like a pocket Linux computer. It's not just for Android, you can install it on your Chrome OS too.
|
||||
|
||||
Termux offers many significant features than you would think.
|
||||
|
||||
* It allows you to SSH to your remote server via openSSH.
|
||||
* You can also SSH into your Android devices from any remote system.
|
||||
* Sync your smart phone contacts to a remote system using rsync and curl.
|
||||
* You could choose any shells such as BASH, ZSH, and FISH etc.
|
||||
* You can choose different text editors such as Emacs, Nano, and Vim to edit/view files.
|
||||
* Install any packages of your choice in your Android devices using APT package manager. Up-to-date versions of Git, Perl, Python, Ruby and Node.js are all available.
|
||||
* Connect your Android device with a bluetooth Keyboard, mouse and external display and use it like a convergence device. Termux supports keyboard shortcuts .
|
||||
* Termux allows you to run almost all GNU/Linux commands.
|
||||
|
||||
|
||||
|
||||
It also has some extra features. You can enable them by installing the addons. For instance, **Termux:API** addon will allow you to Access Android and Chrome hardware features. The other useful addons are:
|
||||
|
||||
* Termux:Boot - Run script(s) when your device boots.
|
||||
* Termux:Float - Run Termux in a floating window.
|
||||
* Termux:Styling - Provides color schemes and powerline-ready fonts to customize the appearance of the Termux terminal.
|
||||
* Termux:Task - Provides an easy way to call Termux executables from Tasker and compatible apps.
|
||||
* Termux:Widget - Provides an easy way to start small scriptlets from the home screen.
|
||||
|
||||
|
||||
|
||||
To know more about termux, open the built-in help section by long-pressing anywhere on the terminal and selecting the Help menu option. The only drawback is it **requires Android 5.0 and higher versions**. It could be more useful for many users if it supports Android 4.x and older versions. Termux is available in **Google Play Store** and **F-Droid**.
|
||||
|
||||
To install Termux from Google Play Store, click the following button.
|
||||
|
||||
[![termux][1]][2]
|
||||
|
||||
To install it from F-Droid, click the following button.
|
||||
|
||||
[![][1]][3]
|
||||
|
||||
You know now how to try Linux on your android devices using Termux. Do you use any other better apps worth trying? Please mention them in the comment section below. I'd love to try them too!
|
||||
|
||||
Cheers!
|
||||
|
||||
Resource:
|
||||
|
||||
+[Termux website][4]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/termux-run-linux-android-devices-no-rooting-required/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:https://play.google.com/store/apps/details?id=com.termux
|
||||
[3]:https://f-droid.org/packages/com.termux/
|
||||
[4]:https://termux.com/
|
||||
@ -0,0 +1,261 @@
|
||||
How to install software applications on Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image by : Internet Archive Book Images. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
How do you install an application on Linux? As with many operating systems, there isn't just one answer to that question. Applications can come from so many sources--it's nearly impossible to count--and each development team may deliver their software whatever way they feel is best. Knowing how to install what you're given is part of being a true power user of your OS.
|
||||
|
||||
### Repositories
|
||||
|
||||
For well over a decade, Linux has used software repositories to distribute software. A "repository" in this context is a public server hosting installable software packages. A Linux distribution provides a command, and usually a graphical interface to that command, that pulls the software from the server and installs it onto your computer. It's such a simple concept that it has served as the model for all major cellphone operating systems and, more recently, the "app stores" of the two major closed source computer operating systems.
|
||||
|
||||
|
||||
![Linux repository][2]
|
||||
|
||||
Not an app store
|
||||
|
||||
Installing from a software repository is the primary method of installing apps on Linux. It should be the first place you look for any application you intend to install.
|
||||
|
||||
To install from a software repository, there's usually a command:
|
||||
```
|
||||
|
||||
|
||||
$ sudo dnf install inkscape
|
||||
```
|
||||
|
||||
The actual command you use depends on what distribution of Linux you use. Fedora uses `dnf`, OpenSUSE uses `zypper`, Debian and Ubuntu use `apt`, Slackware uses `sbopkg`, FreeBSD uses `pkg_add`, and Illumos-based OpenIndiana uses `pkg`. Whatever you use, the incantation usually involves searching for the proper name of what you want to install, because sometimes what you call software is not its official or solitary designation:
|
||||
```
|
||||
|
||||
|
||||
$ sudo dnf search pyqt
|
||||
|
||||
PyQt.x86_64 : Python bindings for Qt3
|
||||
|
||||
PyQt4.x86_64 : Python bindings for Qt4
|
||||
|
||||
python-qt5.x86_64 : PyQt5 is Python bindings for Qt5
|
||||
```
|
||||
|
||||
Once you have located the name of the package you want to install, use the `install` subcommand to perform the actual download and automated install:
|
||||
```
|
||||
|
||||
|
||||
$ sudo dnf install python-qt5
|
||||
```
|
||||
|
||||
For specifics on installing from a software repository, see your distribution's documentation.
|
||||
|
||||
The same generally holds true with the graphical tools. Search for what you think you want, and then install it.
|
||||
|
||||
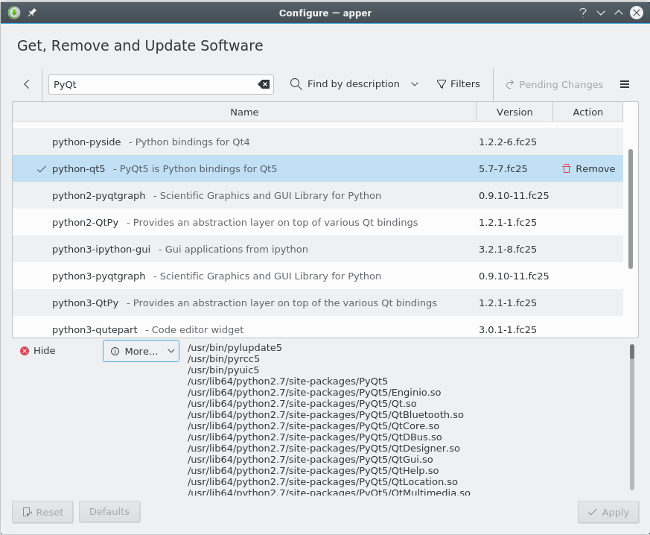
|
||||
|
||||
Like the underlying command, the name of the graphical installer depends on what distribution you are running. The relevant application is usually tagged with the software or package keywords, so search your launcher or menu for those terms, and you'll find what you need. Since open source is all about user choice, if you don't like the graphical user interface (GUI) that your distribution provides, there may be an alternative that you can install. And now you know how to do that.
|
||||
|
||||
#### Extra repositories
|
||||
|
||||
Your distribution has its standard repository for software that it packages for you, and there are usually extra repositories common to your distribution. For example, [EPEL][3] serves Red Hat Enterprise Linux and CentOS, [RPMFusion][4] serves Fedora, Ubuntu has various levels of support as well as a Personal Package Archive (PPA) network, [Packman][5] provides extra software for OpenSUSE, and [SlackBuilds.org][6] provides community build scripts for Slackware.
|
||||
|
||||
By default, your Linux OS is set to look at just its official repositories, so if you want to use additional software collections, you must add extra repositories yourself. You can usually install a repository as though it were a software package. In fact, when you install certain software, such as [GNU Ring][7] video chat, the [Vivaldi][8] web browser, Google Chrome, and many others, what you are actually installing is access to their private repositories, from which the latest version of their application is installed to your machine.
|
||||
|
||||
|
||||
![Installing a repo][10]
|
||||
|
||||
Installing a repo
|
||||
|
||||
You can also add the repository manually by editing a text file and adding it to your package manager's configuration directory, or by running a command to install the repository. As usual, the exact command you use depends on the distribution you are running; for example, here is a `dnf` command that adds a repository to the system:
|
||||
```
|
||||
|
||||
|
||||
$ sudo dnf config-manager --add-repo=http://example.com/pub/centos/7
|
||||
```
|
||||
|
||||
### Installing apps without repositories
|
||||
|
||||
The repository model is so popular because it provides a link between the user (you) and the developer. When important updates are released, your system kindly prompts you to accept the updates, and you can accept them all from one centralized location.
|
||||
|
||||
Sometimes, though, there are times when a package is made available with no repository attached. These installable packages come in several forms.
|
||||
|
||||
#### Linux packages
|
||||
|
||||
Sometimes, a developer distributes software in a common Linux packaging format, such as RPM, DEB, or the newer but very popular FlatPak or Snap formats. You make not get access to a repository with this download; you might just get the package.
|
||||
|
||||
The video editor [Lightworks][11], for example, provides a `.deb` file for APT users and an `.rpm` file for RPM users. When you want to update, you return to the website and download the latest appropriate file.
|
||||
|
||||
These one-off packages can be installed with all the same tools used when installing from a repository. If you double-click the package you download, a graphical installer launches and steps you through the install process.
|
||||
|
||||
Alternately, you can install from a terminal. The difference here is that a lone package file you've downloaded from the internet isn't coming from a repository. It's a "local" install, meaning your package management software doesn't need to download it to install it. Most package managers handle this transparently:
|
||||
```
|
||||
|
||||
|
||||
$ sudo dnf install ~/Downloads/lwks-14.0.0-amd64.rpm
|
||||
```
|
||||
|
||||
In some cases, you need to take additional steps to get the application to run, so carefully read the documentation about the software you're installing.
|
||||
|
||||
#### Generic install scripts
|
||||
|
||||
Some developers release their packages in one of several generic formats. Common extensions include `.run` and `.sh`. NVIDIA graphic card drivers, Foundry visual FX packages like Nuke and Mari, and many DRM-free games from [GOG][12] use this style of installer.
|
||||
|
||||
This model of installation relies on the developer to deliver an installation "wizard." Some of the installers are graphical, while others just run in a terminal.
|
||||
|
||||
There are two ways to run these types of installers.
|
||||
|
||||
1. You can run the installer directly from a terminal:
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
$ sh ./game/gog_warsow_x.y.z.sh
|
||||
```
|
||||
|
||||
2. Alternately, you can run it from your desktop by marking it as executable. To mark an installer executable, right-click on its icon and select **Properties**.
|
||||
|
||||
![Giving an installer executable permission][14]
|
||||
|
||||
|
||||
Giving an installer executable permission
|
||||
|
||||
Once you've given permission for it to run, double-click the icon to start the install.
|
||||
|
||||
![GOG installer][16]
|
||||
|
||||
GOG installer
|
||||
|
||||
For the rest of the install, just follow the instructions on the screen.
|
||||
|
||||
#### AppImage portable apps
|
||||
|
||||
The AppImage format is relatively new to Linux, although its concept is based on both NeXT and Rox. The idea is simple: everything required to run an application is placed into one directory, and then that directory is treated as an "app." To run the application, you just double-click the icon, and it runs. There's no need or expectation that the application is installed in the traditional sense; it just runs from wherever you have it lying around on your hard drive.
|
||||
|
||||
Despite its ability to run as a self-contained app, an AppImage usually offers to do some soft system integration.
|
||||
|
||||
![AppImage system integration][18]
|
||||
|
||||
AppImage system integration
|
||||
|
||||
If you accept this offer, a local `.desktop` file is installed to your home directory. A `.desktop` file is a small configuration file used by the Applications menu and mimetype system of a Linux desktop. Essentially, placing the desktop config file in your home directory's application list "installs" the application without actually installing it. You get all the benefits of having installed something, and the benefits of being able to run something locally, as a "portable app."
|
||||
|
||||
#### Application directory
|
||||
|
||||
Sometimes, a developer just compiles an application and posts the result as a download, with no install script and no packaging. Usually, this means that you download a TAR file, [extract it][19], and then double-click the executable file (it's usually the one with the name of the software you downloaded).
|
||||
|
||||
![Twine downloaded for Linux][21]
|
||||
|
||||
|
||||
Twine downloaded for Linux
|
||||
|
||||
When presented with this style of software delivery, you can either leave it where you downloaded it and launch it manually when you need it, or you can do a quick and dirty install yourself. This involves two simple steps:
|
||||
|
||||
1. Save the directory to a standard location and launch it manually when you need it.
|
||||
2. Save the directory to a standard location and create a `.desktop` file to integrate it into your system.
|
||||
|
||||
|
||||
|
||||
If you're just installing applications for yourself, it's traditional to keep a `bin` directory (short for "binary") in your home directory as a storage location for locally installed applications and scripts. If you have other users on your system who need access to the applications, it's traditional to place the binaries in `/opt`. Ultimately, it's up to you where you store the application.
|
||||
|
||||
Downloads often come in directories with versioned names, such as `twine_2.13` or `pcgen-v6.07.04`. Since it's reasonable to assume you'll update the application at some point, it's a good idea to either remove the version number or to create a symlink to the directory. This way, the launcher that you create for the application can remain the same, even though you update the application itself.
|
||||
|
||||
To create a `.desktop` launcher file, open a text editor and create a file called `twine.desktop`. The [Desktop Entry Specification][22] is defined by [FreeDesktop.org][23]. Here is a simple launcher for a game development IDE called Twine, installed to the system-wide `/opt` directory:
|
||||
```
|
||||
|
||||
|
||||
[Desktop Entry]
|
||||
|
||||
Encoding=UTF-8
|
||||
|
||||
Name=Twine
|
||||
|
||||
GenericName=Twine
|
||||
|
||||
Comment=Twine
|
||||
|
||||
Exec=/opt/twine/Twine
|
||||
|
||||
Icon=/usr/share/icons/oxygen/64x64/categories/applications-games.png
|
||||
|
||||
Terminal=false
|
||||
|
||||
Type=Application
|
||||
|
||||
Categories=Development;IDE;
|
||||
```
|
||||
|
||||
The tricky line is the `Exec` line. It must contain a valid command to start the application. Usually, it's just the full path to the thing you downloaded, but in some cases, it's something more complex. For example, a Java application might need to be launched as an argument to Java itself:
|
||||
```
|
||||
|
||||
|
||||
Exec=java -jar /path/to/foo.jar
|
||||
```
|
||||
|
||||
Sometimes, a project includes a wrapper script that you can run so you don't have to figure out the right command:
|
||||
```
|
||||
|
||||
|
||||
Exec=/opt/foo/foo-launcher.sh
|
||||
```
|
||||
|
||||
In the Twine example, there's no icon bundled with the download, so the example `.desktop` file assigns a generic gaming icon that shipped with the KDE desktop. You can use workarounds like that, but if you're more artistic, you can just create your own icon, or you can search the Internet for a good icon. As long as the `Icon` line points to a valid PNG or SVG file, your application will inherit the icon.
|
||||
|
||||
The example script also sets the application category primarily to Development, so in KDE, GNOME, and most other Application menus, Twine appears under the Development category.
|
||||
|
||||
To get this example to appear in an Application menu, place the `twine.desktop` file into one of two places:
|
||||
|
||||
* Place it in `~/.local/share/applications` if you're storing the application in your own home directory.
|
||||
* Place it in `/usr/share/applications` if you're storing the application in `/opt` or another system-wide location and want it to appear in all your users' Application menus.
|
||||
|
||||
|
||||
|
||||
And now the application is installed as it needs to be and integrated with the rest of your system.
|
||||
|
||||
### Compiling from source
|
||||
|
||||
Finally, there's the truly universal install format: source code. Compiling an application from source code is a great way to learn how applications are structured, how they interact with your system, and how they can be customized. It's by no means a push-button process, though. It requires a build environment, it usually involves installing dependency libraries and header files, and sometimes a little bit of debugging.
|
||||
|
||||
To learn more about compiling from source code, [read my article][24] on the topic.
|
||||
|
||||
### Now you know
|
||||
|
||||
Some people think installing software is a magical process that only developers understand, or they think it "activates" an application, as if the binary executable file isn't valid until it has been "installed." Hopefully, learning about the many different methods of installing has shown you that install is really just shorthand for "copying files from one place to the appropriate places on your system." There's nothing mysterious about it. As long as you approach each install without expectations of how it's supposed to happen, and instead look for what the developer has set up as the install process, it's generally easy, even if it is different from what you're used to.
|
||||
|
||||
The important thing is that an installer is honest with you. If you come across an installer that attempts to install additional software without your consent (or maybe it asks for consent, but in a confusing or misleading way), or that attempts to run checks on your system for no apparent reason, then don't continue an install.
|
||||
|
||||
Good software is flexible, honest, and open. And now you know how to get good software onto your computer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-install-apps-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:/file/382591
|
||||
[2]:https://opensource.com/sites/default/files/u128651/repo.png (Linux repository)
|
||||
[3]:https://fedoraproject.org/wiki/EPEL
|
||||
[4]:http://rpmfusion.org
|
||||
[5]:http://packman.links2linux.org/
|
||||
[6]:http://slackbuilds.org
|
||||
[7]:https://ring.cx/en/download/gnu-linux
|
||||
[8]:http://vivaldi.com
|
||||
[9]:/file/382566
|
||||
[10]:https://opensource.com/sites/default/files/u128651/access.png (Installing a repo)
|
||||
[11]:https://www.lwks.com/
|
||||
[12]:http://gog.com
|
||||
[13]:/file/382581
|
||||
[14]:https://opensource.com/sites/default/files/u128651/exec.jpg (Giving an installer executable permission)
|
||||
[15]:/file/382586
|
||||
[16]:https://opensource.com/sites/default/files/u128651/gog.jpg (GOG installer)
|
||||
[17]:/file/382576
|
||||
[18]:https://opensource.com/sites/default/files/u128651/appimage.png (AppImage system integration)
|
||||
[19]:https://opensource.com/article/17/7/how-unzip-targz-file
|
||||
[20]:/file/382596
|
||||
[21]:https://opensource.com/sites/default/files/u128651/twine.jpg (Twine downloaded for Linux)
|
||||
[22]:https://specifications.freedesktop.org/desktop-entry-spec/desktop-entry-spec-latest.html
|
||||
[23]:http://freedesktop.org
|
||||
[24]:https://opensource.com/article/17/10/open-source-cats
|
||||
61
sources/tech/20180115 How To Boot Into Linux Command Line.md
Normal file
61
sources/tech/20180115 How To Boot Into Linux Command Line.md
Normal file
@ -0,0 +1,61 @@
|
||||
How To Boot Into Linux Command Line
|
||||
======
|
||||

|
||||
|
||||
There may be times where you need or want to boot up a [Linux][1] system without using a GUI, that is with no X, but rather opt for the command line. Whatever the reason, fortunately, booting straight into the Linux **command-line** is very simple. It requires a simple change to the boot parameter after the other kernel options. This change specifies the runlevel to boot the system into.
|
||||
|
||||
### Why Do This?
|
||||
|
||||
If your system does not run Xorg because the configuration is invalid, or if the display manager is broken, or whatever may prevent the GUI from starting properly, booting into the command-line will allow you to troubleshoot by logging into a terminal (assuming you know what you’re doing to start with) and do whatever you need to do. Booting into the command-line is also a great way to become more familiar with the terminal, otherwise, you can do it just for fun.
|
||||
|
||||
### Accessing GRUB Menu
|
||||
|
||||
On startup, you will need access to the GRUB boot menu. You may need to hold the SHIFT key down before the system boots if the menu isn’t set to display every time the computer is started. In the menu, the [Linux distribution][2] entry must be selected. Once highlighted, press ‘e’ to edit the boot parameters.
|
||||
|
||||
[][3]
|
||||
|
||||
Older GRUB versions follow a similar mechanism. The boot manager should provide instructions on how to edit the boot parameters.
|
||||
|
||||
### Specify the Runlevel
|
||||
|
||||
An editor will appear and you will see the options that GRUB parses to the kernel. Navigate to the line that starts with ‘linux’ (older GRUB versions may be ‘kernel’; select that and follow the instructions). This specifies parameters to parse into the kernel. At the end of that line (may appear to span multiple lines, depending on resolution), you simply specify the runlevel to boot into, which is 3 (multi-user mode, text-only).
|
||||
|
||||
[][4]
|
||||
|
||||
Pressing Ctrl-X or F10 will boot the system using those parameters. Boot-up will continue as normal. The only thing that has changed is the runlevel to boot into.
|
||||
|
||||
|
||||
|
||||
This is what was started up:
|
||||
|
||||
[][5]
|
||||
|
||||
### Runlevels
|
||||
|
||||
You can specify different runlevels to boot into with runlevel 5 being the default one. 1 boots into “single-user” mode, which boots into a root shell. 3 provides a multi-user, command-line only system.
|
||||
|
||||
### Switch From Command-Line
|
||||
|
||||
At some point, you may want to run the display manager again to use a GUI, and the quickest way to do that is running this:
|
||||
```
|
||||
$ sudo init 5
|
||||
```
|
||||
|
||||
And it is as simple as that. Personally, I find the command-line much more exciting and hands-on than using GUI tools; however, that’s just my preference.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/how-to-boot-into-linux-command-line
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/linux
|
||||
[2]:http://www.linuxandubuntu.com/home/category/distros
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnu-grub_orig.png
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_1_orig.png
|
||||
@ -0,0 +1,81 @@
|
||||
AI 和机器中暗含的算法偏见是怎样形成的,我们又能通过开源社区做些什么
|
||||
======
|
||||
|
||||

|
||||
|
||||
图片来源:opensource.com
|
||||
|
||||
在我们的世界里,算法无处不在,偏见也是一样。从社会媒体新闻的提供到流式媒体服务的推荐到线上购物,计算机算法,尤其是机器学习算法,已经渗透到我们日常生活的每一个角落。至于偏见,我们只需要参考 2016 年美国大选就可以知道,偏见是怎样在明处与暗处影响着我们的社会。
|
||||
|
||||
很难想像,我们经常忽略的一点是这二者的交集:计算机算法中存在的偏见。
|
||||
|
||||
与我们大多数人所认为的相反,科技并不是客观的。 AI 算法和它们的决策程序是由它们的研发者塑造的,他们写入的代码,使用的“[训练][1]”数据还有他们对算法进行[应力测试][2] 的过程,都会影响这些算法今后的选择。这意味着研发者的价值观,偏见和人类缺陷都会反映在软件上。如果我只给实验室中的人脸识别算法提供白人的照片,当遇到不是白人照片时,它[不会认为照片中的是人类][3] 。这结论并不意味着 AI 是“愚蠢的”或是“天真的”,它显示的是训练数据的分布偏差:缺乏多种的脸部照片。这会引来非常严重的后果。
|
||||
|
||||
这样的例子并不少。全美范围内的[州法院系统][4] 都使用“黑箱子”对罪犯进行宣判。由于训练数据的问题,[这些算法对黑人有偏见][5] ,他们对黑人罪犯会选择更长的服刑期,因此监狱中的种族差异会一直存在。而这些都发生在科技的客观性伪装下,这是“科学的”选择。
|
||||
|
||||
美国联邦政府使用机器学习算法来计算福利性支出和各类政府补贴。[但这些算法中的信息][6],例如它们的创造者和训练信息,都很难找到。这增加了政府工作人员进行不平等补助金分发操作的几率。
|
||||
|
||||
算法偏见情况还不止这些。从 Facebook 的新闻算法到医疗系统再到警方使用的相机,我们作为社会的一部分极有可能对这些算法输入各式各样的偏见,性别歧视,仇外思想,社会经济地位歧视,确认偏误等等。这些被输入了偏见的机器会大量生产分配,将种种社会偏见潜藏于科技客观性的面纱之下。
|
||||
|
||||
这种状况绝对不能再继续下去了。
|
||||
|
||||
在我们对人工智能进行不断开发研究的同时,需要降低它的开发速度,小心仔细地开发。算法偏见的危害已经足够大了。
|
||||
|
||||
## 我们能怎样减少算法偏见?
|
||||
|
||||
最好的方式是从算法训练的数据开始审查,根据 [Microsoft 的研究者][2] 所说,这方法很有效。
|
||||
|
||||
数据分布本身就带有一定的偏见性。编程者手中的美国公民数据分布并不均衡,本地居民的数据多于移民者,富人的数据多于穷人,这是极有可能出现的情况。这种数据的不平均会使 AI 对我们是社会组成得出错误的结论。例如机器学习算法仅仅通过统计分析,就得出“大多数美国人都是富有的白人”这个结论。
|
||||
|
||||
即使男性和女性的样本在训练数据中等量分布,也可能出现偏见的结果。如果训练数据中所有男性的职业都是 CEO,而所有女性的职业都是秘书(即使现实中男性 CEO 的数量要多于女性),AI 也可能得出女性天生不适合做 CEO 的结论。
|
||||
|
||||
同样的,大量研究表明,用于执法部门的 AI 在检测新闻中出现的罪犯照片时,结果会 [惊人地偏向][7] 黑人及拉丁美洲裔居民。
|
||||
|
||||
在训练数据中存在的偏见还有很多其他形式,不幸的是比这里提到的要多得多。但是训练数据只是审查方式的一种,通过“应力测验”找出人类存在的偏见也同样重要。
|
||||
|
||||
如果提供一张印度人的照片,我们自己的相机能够识别吗?在两名同样水平的应聘者中,我们的 AI 是否会倾向于推荐住在市区的应聘者呢?对于情报中本地白人恐怖分子和伊拉克籍恐怖分子,反恐算法会怎样选择呢?急诊室的相机可以调出儿童的病历吗?
|
||||
|
||||
这些对于 AI 来说是十分复杂的数据,但我们可以通过多项测试对它们进行定义和传达。
|
||||
|
||||
## 为什么开源很适合这项任务?
|
||||
|
||||
开源方法和开源技术都有着极大的潜力改变算法偏见。
|
||||
|
||||
现代人工智能已经被开源软件占领,TensorFlow、IBM Watson 还有 [scikit-learn][8] 这类的程序包都是开源软件。开源社区已经证明它能够开发出强健的,经得住严酷测试的机器学习工具。同样的,我相信,开源社区也能开发出消除偏见的测试程序,并将其应用于这些软件中。
|
||||
|
||||
调试工具如哥伦比亚大学和理海大学推出的 [DeepXplore][9],增强了 AI 应力测试的强度,同时提高了其操控性。还有 [麻省理工学院的计算机科学和人工智能实验室][10]完成的项目,它开发出敏捷快速的样机研究软件,这些应该会被开源社区采纳。
|
||||
|
||||
开源技术也已经证明了其在审查和分类大组数据方面的能力。最明显的体现在开源工具在数据分析市场的占有率上(Weka , Rapid Miner 等等)。应当由开源社区来设计识别数据偏见的工具,已经在网上发布的大量训练数据组比如 [Kaggle][11]也应当使用这种技术进行识别筛选。
|
||||
|
||||
开源方法本身十分适合消除偏见程序的设计。内部谈话,私人软件开发及非民主的决策制定引起了很多问题。开源社区能够进行软件公开的谈话,进行大众化,维持好与大众的关系,这对于处理以上问题是十分重要的。如果线上社团,组织和院校能够接受这些开源特质,那么由开源社区进行消除算法偏见的机器设计也会顺利很多。
|
||||
|
||||
## 我们怎样才能够参与其中?
|
||||
|
||||
教育是一个很重要的环节。我们身边有很多还没意识到算法偏见的人,但算法偏见在立法,社会公正,政策及更多领域产生的影响与他们息息相关。让这些人知道算法偏见是怎样形成的和它们带来的重要影响是很重要的,因为想要改变目前是局面,从我们自身做起是唯一的方法。
|
||||
|
||||
对于我们中间那些与人工智能一起工作的人来说,这种沟通尤其重要。不论是人工智能的研发者,警方或是科研人员,当他们为今后设计人工智能时,应当格外意识到现今这种偏见存在的危险性,很明显,想要消除人工智能中存在的偏见,就要从意识到偏见的存在开始。
|
||||
|
||||
最后,我们需要围绕 AI 伦理化建立并加强开源社区。不论是需要建立应力实验训练模型,软件工具,或是从千兆字节的训练数据中筛选,现在已经到了我们利用开源方法来应对数字化时代最大的威胁的时间了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-bias
|
||||
|
||||
作者:[Justin Sherman][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/justinsherman
|
||||
[1]:https://www.crowdflower.com/what-is-training-data/
|
||||
[2]:https://medium.com/microsoft-design/how-to-recognize-exclusion-in-ai-ec2d6d89f850
|
||||
[3]:https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms
|
||||
[4]:https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/
|
||||
[5]:https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
|
||||
[6]:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3012499
|
||||
[7]:https://www.hivlawandpolicy.org/sites/default/files/Race%20and%20Punishment-%20Racial%20Perceptions%20of%20Crime%20and%20Support%20for%20Punitive%20Policies%20%282014%29.pdf
|
||||
[8]:http://scikit-learn.org/stable/
|
||||
[9]:https://arxiv.org/pdf/1705.06640.pdf
|
||||
[10]:https://www.csail.mit.edu/research/understandable-deep-networks
|
||||
[11]:https://www.kaggle.com/datasets
|
||||
108
translated/tech/20140210 Three steps to learning GDB.md
Normal file
108
translated/tech/20140210 Three steps to learning GDB.md
Normal file
@ -0,0 +1,108 @@
|
||||
# 三步上手GDB
|
||||
|
||||
调试C程序,曾让我很困扰。然而当我之前在写我的[操作系统][2]时,我有很多的BUG需要调试。我很幸运的使用上了qemu模拟器,它允许我将调试器附加到我的操作系统。这个调试器就是`gdb`。
|
||||
|
||||
我得解释一下,你可以使用`gdb`先做一些小事情,因为我发现初学它的时候真的很混乱。我们接下来会在一个小程序中,设置断点,查看内存。.
|
||||
|
||||
### 1. 设断点
|
||||
|
||||
如果你曾经使用过调试器,那你可能已经会设置断点了。
|
||||
|
||||
下面是一个我们要调试的程序(虽然没有任何Bug):
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
void do_thing() {
|
||||
printf("Hi!\n");
|
||||
}
|
||||
int main() {
|
||||
do_thing();
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
另存为 `hello.c`. 我们可以使用dbg调试它,像这样:
|
||||
|
||||
```
|
||||
bork@kiwi ~> gcc -g hello.c -o hello
|
||||
bork@kiwi ~> gdb ./hello
|
||||
```
|
||||
|
||||
以上是带调试信息编译 `hello.c`(为了gdb可以更好工作),并且它会给我们醒目的提示符,就像这样:
|
||||
`(gdb)`
|
||||
|
||||
我们可以使用`break`命令设置断点,然后使用`run`开始调试程序。
|
||||
|
||||
```
|
||||
(gdb) break do_thing
|
||||
Breakpoint 1 at 0x4004f8
|
||||
(gdb) run
|
||||
Starting program: /home/bork/hello
|
||||
|
||||
Breakpoint 1, 0x00000000004004f8 in do_thing ()
|
||||
```
|
||||
程序暂停在了`do_thing`开始的地方。
|
||||
|
||||
我们可以通过`where`查看我们所在的调用栈。
|
||||
```
|
||||
(gdb) where
|
||||
#0 do_thing () at hello.c:3
|
||||
#1 0x08050cdb in main () at hello.c:6
|
||||
(gdb)
|
||||
```
|
||||
|
||||
### 2. 阅读汇编代码
|
||||
|
||||
使用`disassemble`命令,我们可以看到这个函数的汇编代码。棒级了。这是x86汇编代码。虽然我不是很懂它,但是`callq`这一行是`printf`函数调用。
|
||||
|
||||
```
|
||||
(gdb) disassemble do_thing
|
||||
Dump of assembler code for function do_thing:
|
||||
0x00000000004004f4 <+0>: push %rbp
|
||||
0x00000000004004f5 <+1>: mov %rsp,%rbp
|
||||
=> 0x00000000004004f8 <+4>: mov $0x40060c,%edi
|
||||
0x00000000004004fd <+9>: callq 0x4003f0
|
||||
0x0000000000400502 <+14>: pop %rbp
|
||||
0x0000000000400503 <+15>: retq
|
||||
```
|
||||
|
||||
你也可以使用`disassemble`的缩写`disas`。`
|
||||
|
||||
### 3. 查看内存
|
||||
|
||||
当调试我的内核时,我使用`gdb`的主要原因是,以确保内存布局是如我所想的那样。检查内存的命令是`examine`,或者使用缩写`x`。我们将使用`x`。
|
||||
|
||||
通过阅读上面的汇编代码,似乎`0x40060c`可能是我们所要打印的字符串地址。我们来试一下。
|
||||
|
||||
```
|
||||
(gdb) x/s 0x40060c
|
||||
0x40060c: "Hi!"
|
||||
```
|
||||
|
||||
的确是这样。`x/s`中`/s`部分,意思是“把它作为字符串展示”。我也可以“展示10个字符”,像这样:
|
||||
|
||||
```
|
||||
(gdb) x/10c 0x40060c
|
||||
0x40060c: 72 'H' 105 'i' 33 '!' 0 '\000' 1 '\001' 27 '\033' 3 '\003' 59 ';'
|
||||
0x400614: 52 '4' 0 '\000'
|
||||
```
|
||||
|
||||
你可以看到前四个字符是'H','i','!',和'\0',并且它们之后的是一些不相关的东西。
|
||||
|
||||
我知道gdb很多其他的东西,但是我任然不是很了解它,其中`x`和`break`让我获得很多。你还可以阅读 [do umentation for examining memory][4]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[Torival](https://github.com/Torival)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/spytools
|
||||
[2]:http://jvns.ca/blog/categories/kernel
|
||||
[3]:https://twitter.com/mgedmin
|
||||
[4]:https://ftp.gnu.org/old-gnu/Manuals/gdb-5.1.1/html_chapter/gdb_9.html#SEC56
|
||||
@ -0,0 +1,234 @@
|
||||
让我们做个简单的解释器(2)
|
||||
======
|
||||
|
||||
在一本叫做 《高效思考的 5 要素》 的书中,作者 Burger 和 Starbird 讲述了一个关于他们如何研究 Tony Plog 的故事,一个举世闻名的交响曲名家,为一些有才华的演奏者开创了一个大师班。这些学生一开始演奏复杂的乐曲,他们演奏的非常好。然后他们被要求演奏非常基础简单的乐曲。当他们演奏这些乐曲时,与之前所演奏的相比,听起来非常幼稚。在他们结束演奏后,老师也演奏了同样的乐曲,但是听上去非常娴熟。差别令人震惊。Tony 解释道,精通简单符号可以让人更好的掌握复杂的部分。这个例子很清晰 - 要成为真正的名家,必须要掌握简单基础的思想。
|
||||
|
||||
故事中的例子明显不仅仅适用于音乐,而且适用于软件开发。这个故事告诉我们不要忽视繁琐工作中简单基础的概念的重要性,哪怕有时候这让人感觉是一种倒退。尽管熟练掌握一门工具或者框架非常重要,了解他们背后的原理也是极其重要的。正如 Palph Waldo Emerson 所说:
|
||||
|
||||
> “如果你只学习方法,你就会被方法束缚。但如果你知道原理,就可以发明自己的方法。”
|
||||
|
||||
有鉴于此,让我们再次深入了解解释器和编译器。
|
||||
|
||||
今天我会向你们展示一个全新的计算器,与 [第一部分][1] 相比,它可以做到:
|
||||
|
||||
1. 处理输入字符串任意位置的空白符
|
||||
2. 识别输入字符串中的多位整数
|
||||
3. 做两个整数之间的减法(目前它仅能加减整数)
|
||||
|
||||
|
||||
新版本计算器的源代码在这里,它可以做到上述的所有事情:
|
||||
```
|
||||
# 标记类型
|
||||
# EOF (end-of-file 文件末尾) 标记是用来表示所有输入都解析完成
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token 类型: INTEGER, PLUS, MINUS, or EOF
|
||||
self.type = type
|
||||
# token 值: 非负整数值, '+', '-', 或无
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
"""String representation of the class instance.
|
||||
|
||||
Examples:
|
||||
Token(INTEGER, 3)
|
||||
Token(PLUS '+')
|
||||
"""
|
||||
return 'Token({type}, {value})'.format(
|
||||
type=self.type,
|
||||
value=repr(self.value)
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
|
||||
class Interpreter(object):
|
||||
def __init__(self, text):
|
||||
# 客户端字符输入, 例如. "3 + 5", "12 - 5",
|
||||
self.text = text
|
||||
# self.pos 是 self.text 的索引
|
||||
self.pos = 0
|
||||
# 当前标记实例
|
||||
self.current_token = None
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def error(self):
|
||||
raise Exception('Error parsing input')
|
||||
|
||||
def advance(self):
|
||||
"""Advance the 'pos' pointer and set the 'current_char' variable."""
|
||||
self.pos += 1
|
||||
if self.pos > len(self.text) - 1:
|
||||
self.current_char = None # Indicates end of input
|
||||
else:
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def skip_whitespace(self):
|
||||
while self.current_char is not None and self.current_char.isspace():
|
||||
self.advance()
|
||||
|
||||
def integer(self):
|
||||
"""Return a (multidigit) integer consumed from the input."""
|
||||
result = ''
|
||||
while self.current_char is not None and self.current_char.isdigit():
|
||||
result += self.current_char
|
||||
self.advance()
|
||||
return int(result)
|
||||
|
||||
def get_next_token(self):
|
||||
"""Lexical analyzer (also known as scanner or tokenizer)
|
||||
|
||||
This method is responsible for breaking a sentence
|
||||
apart into tokens.
|
||||
"""
|
||||
while self.current_char is not None:
|
||||
|
||||
if self.current_char.isspace():
|
||||
self.skip_whitespace()
|
||||
continue
|
||||
|
||||
if self.current_char.isdigit():
|
||||
return Token(INTEGER, self.integer())
|
||||
|
||||
if self.current_char == '+':
|
||||
self.advance()
|
||||
return Token(PLUS, '+')
|
||||
|
||||
if self.current_char == '-':
|
||||
self.advance()
|
||||
return Token(MINUS, '-')
|
||||
|
||||
self.error()
|
||||
|
||||
return Token(EOF, None)
|
||||
|
||||
def eat(self, token_type):
|
||||
# 将当前的标记类型与传入的标记类型作比较,如果他们相匹配,就
|
||||
# “eat” 掉当前的标记并将下一个标记赋给 self.current_token,
|
||||
# 否则抛出一个异常
|
||||
if self.current_token.type == token_type:
|
||||
self.current_token = self.get_next_token()
|
||||
else:
|
||||
self.error()
|
||||
|
||||
def expr(self):
|
||||
"""Parser / Interpreter
|
||||
|
||||
expr -> INTEGER PLUS INTEGER
|
||||
expr -> INTEGER MINUS INTEGER
|
||||
"""
|
||||
# 将输入中的第一个标记设置成当前标记
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
# 当前标记应该是一个整数
|
||||
left = self.current_token
|
||||
self.eat(INTEGER)
|
||||
|
||||
# 当前标记应该是 ‘+’ 或 ‘-’
|
||||
op = self.current_token
|
||||
if op.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
else:
|
||||
self.eat(MINUS)
|
||||
|
||||
# 当前标记应该是一个整数
|
||||
right = self.current_token
|
||||
self.eat(INTEGER)
|
||||
# 在上述函数调用后,self.current_token 就被设为 EOF 标记
|
||||
|
||||
# 这时要么是成功地找到 INTEGER PLUS INTEGER,要么是 INTEGER MINUS INTEGER
|
||||
# 序列的标记,并且这个方法可以仅仅返回两个整数的加或减的结果,就能高效解释客户端的输入
|
||||
if op.type == PLUS:
|
||||
result = left.value + right.value
|
||||
else:
|
||||
result = left.value - right.value
|
||||
return result
|
||||
|
||||
|
||||
def main():
|
||||
while True:
|
||||
try:
|
||||
# To run under Python3 replace 'raw_input' call
|
||||
# with 'input'
|
||||
text = raw_input('calc> ')
|
||||
except EOFError:
|
||||
break
|
||||
if not text:
|
||||
continue
|
||||
interpreter = Interpreter(text)
|
||||
result = interpreter.expr()
|
||||
print(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
把上面的代码保存到 calc2.py 文件中,或者直接从 [GitHub][2] 上下载。试着运行它。看看它是不是正常工作:它应该能够处理输入中任意位置的空白符;能够接受多位的整数,并且能够对两个整数做减法和加法。
|
||||
|
||||
这是我在自己的笔记本上运行的示例:
|
||||
```
|
||||
$ python calc2.py
|
||||
calc> 27 + 3
|
||||
30
|
||||
calc> 27 - 7
|
||||
20
|
||||
calc>
|
||||
```
|
||||
|
||||
与 [第一部分][1] 的版本相比,主要的代码改动有:
|
||||
|
||||
1. get_next_token 方法重写了很多。增加指针位置的逻辑之前是放在一个单独的方法中。
|
||||
2. 增加了一些方法:skip_whitespace 用于忽略空白字符,integer 用于处理输入字符的多位整数。
|
||||
3. expr 方法修改成了可以识别 “整数 -> 减号 -> 整数” 词组和 “整数 -> 加号 -> 整数” 词组。在成功识别相应的词组后,这个方法现在可以解释加法和减法。
|
||||
|
||||
[第一部分][1] 中你学到了两个重要的概念,叫做 **标记** 和 **词法分析**。现在我想谈一谈 **词法**, **解析**,和**解析器**。
|
||||
|
||||
你已经知道标记。但是为了让我详细的讨论标记,我需要谈一谈词法。词法是什么?**词法** 是一个标记中的字符序列。在下图中你可以看到一些关于标记的例子,还好这可以让它们之间的关系变得清晰:
|
||||
|
||||
![][3]
|
||||
|
||||
现在还记得我们的朋友,expr 方法吗?我之前说过,这是数学表达式实际被解释的地方。但是你要先识别这个表达式有哪些词组才能解释它,比如它是加法还是减法。expr 方法最重要的工作是:它从 get_next_token 方法中得到流,并找出标记流的结构然后解释已经识别出的词组,产生数学表达式的结果。
|
||||
|
||||
在标记流中找出结构的过程,或者换种说法,识别标记流中的词组的过程就叫 **解析**。解释器或者编译器中执行这个任务的部分就叫做 **解析器**。
|
||||
|
||||
现在你知道 expr 方法就是你的解释器的部分,**解析** 和 **解释** 都在这里发生 - expr 方法首先尝试识别(**解析**)标记流里的 “整数 -> 加法 -> 整数” 或者 “整数 -> 减法 -> 整数” 词组,成功识别后 (**解析**) 其中一个词组,这个方法就开始解释它,返回两个整数的和或差。
|
||||
|
||||
又到了练习的时间。
|
||||
|
||||
![][4]
|
||||
|
||||
1. 扩展这个计算器,让它能够计算两个整数的乘法
|
||||
2. 扩展这个计算器,让它能够计算两个整数的除法
|
||||
3. 修改代码,让它能够解释包含了任意数量的加法和减法的表达式,比如 “9 - 5 + 3 + 11”
|
||||
|
||||
|
||||
|
||||
**检验你的理解:**
|
||||
|
||||
1. 词法是什么?
|
||||
2. 找出标记流结构的过程叫什么,或者换种说法,识别标记流中一个词组的过程叫什么?
|
||||
3. 解释器(编译器)执行解析的部分叫什么?
|
||||
|
||||
|
||||
希望你喜欢今天的内容。在该系列的下一篇文章里你就能扩展计算器从而处理更多复杂的算术表达式。敬请期待。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part2/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[2]:https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py
|
||||
[3]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_lexemes.png
|
||||
[4]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_exercises.png
|
||||
@ -0,0 +1,65 @@
|
||||
无需 Root 实现在 Android 设备上运行 Linux
|
||||
======
|
||||

|
||||
|
||||
曾今,我尝试过搜索一种简单的可以在 Android 上运行 Linux 的方法。我当时唯一的意图只是想使用 Linux 以及一些基本的用用程序,比如 SSH,Git,awk 等。要求的并不多!我不不想 root Android 设备。我有一台平板电脑,主要用于阅读电子书,新闻和少数 Linux 博客。除此之外也不怎么用它了。因此我决定用它来实现一些 Linux 的功能。在 Google Play 商店上浏览了几分钟后,一个应用程序瞬间引起了我的注意,勾起了我实验的欲望。如果你也想在 Android 设备上运行 Linux,这个应用可能会有所帮助。
|
||||
|
||||
### Termux - 在 Android 和 Chrome OS 上运行的 Android 终端模拟器
|
||||
|
||||
**Termux** 是一个 Android 终端模拟器以及提供 Linux 环境的应用程序。跟许多其他应用程序不同,你无需 root 设备也无需进行设置。它是开箱即用的!它会自动安装好一个最基本的 Linux 系统,当然你也可以使用 APT 软件包管理器来安装其他软件包。总之,你可以让你的 Android 设备变成一台袖珍的 Linux 电脑。它不仅适用于 Android,你还能在 Chrome OS 上安装它。
|
||||
|
||||
|
||||
|
||||
Termux 提供了许多重要的功能,比您想象的要多。
|
||||
|
||||
* 它允许你通过 openSSH 登陆远程服务器
|
||||
* 你还能够从远程系统 SSH 到 Android 设备中。
|
||||
* 使用 rsync 和 curl 将您的智能手机通讯录同步到远程系统。
|
||||
* 支持不同的 shell,比如 BASH,ZSH,以及 FISH 等等。
|
||||
* 可以选择不同的文本编辑器来编辑/查看文件,支持 Emacs,Nano 和 Vim。
|
||||
* 使用 APT 软件包管理器在 Android 设备上安装你想要的软件包。支持 Git,Perl,Python,Ruby 和 Node.js 的最新版本。
|
||||
* 可以将 Android 设备与蓝牙键盘,鼠标和外置显示器连接起来,就像是整合在一起的设备一样。Termux 支持键盘快捷键。
|
||||
* Termux 支持几乎所有 GNU/Linux 命令。
|
||||
|
||||
此外通过安装插件可以启用其他一些功能。例如,**Termux:API** 插件允许你访问 Android 和 Chrome 的硬件功能。其他有用的插件包括:
|
||||
|
||||
* Termux:Boot - 设备启动时运行脚本
|
||||
* Termux:Float - 在浮动窗口中运行 Termux
|
||||
* Termux:Styling - 提供配色方案和支持 powerline 的字体来定制 Termux 终端的外观。
|
||||
* Termux:Task - 提供一种从任务栏类的应用中调用 Termux 可执行文件的简易方法。
|
||||
* Termux:Widget - 提供一种从主屏幕启动小脚本的建议方法。
|
||||
|
||||
要了解更多有关 termux 的信息,请长按终端上的任意位置并选择“帮助”菜单选项来打开内置的帮助部分。它唯一的缺点就是**需要 Android 5.0 及更高版本**。如果它支持 Android 4.x 和旧版本的话,将会更有用的多。你可以在** Google Play 商店 **和** F-Droid **中找到并安装 Termux。
|
||||
|
||||
要在 Google Play 商店中安装 Termux,点击下面按钮。
|
||||
|
||||
[![termux][1]][2]
|
||||
|
||||
若要在 F-Droid 中安装,则点击下面按钮。
|
||||
|
||||
[![][1]][3]
|
||||
|
||||
你现在知道如何使用 Termux 在 Android 设备上使用 Linux 了。你有用过其他更好的应用吗?请在下面留言框中留言。我很乐意也去尝试他们!
|
||||
|
||||
此致敬礼!
|
||||
|
||||
相关资源:
|
||||
|
||||
+[Termux 官网 ][4]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/termux-run-linux-android-devices-no-rooting-required/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:https://play.google.com/store/apps/details?id=com.termux
|
||||
[3]:https://f-droid.org/packages/com.termux/
|
||||
[4]:https://termux.com/
|
||||
@ -1,50 +0,0 @@
|
||||
Autorandr:自动调整屏幕布局
|
||||
======
|
||||
像许多笔记本用户一样,我经常将笔记本插入到不同的显示器上(桌面上有多台显示器,演示时有投影机等)。运行 xrandr 命令或点击界面非常繁琐,编写脚本也不是很好。
|
||||
|
||||
最近,我遇到了 [autorandr][1],它使用 EDID(和其他设置)检测连接的显示器,保存 xrandr 配置并恢复它们。它也可以在加载特定配置时运行任意脚本。我已经打包了它,目前仍在 NEW 状态。如果你不能等待,[这是 deb][2],[这是 git 仓库][3]。
|
||||
|
||||
要使用它,只需安装软件包,并创建你的初始配置(我这里是 undocked):
|
||||
```
|
||||
autorandr --save undocked
|
||||
|
||||
```
|
||||
|
||||
然后,连接你的笔记本(或者插入你的外部显示器),使用 xrandr(或其他任何)更改配置,然后保存你的新配置(我这里是 workstation):
|
||||
```
|
||||
autorandr --save workstation
|
||||
|
||||
```
|
||||
|
||||
对你额外的配置(或当你有新的配置)进行重复操作。
|
||||
|
||||
Autorandr 有 `udev`、`systemd` 和 `pm-utils` 钩子,当新的显示器出现时 `autorandr --change` 应该会立即运行。如果需要,也可以手动运行 `autorandr --change` 或 `autorandr - load workstation`。你也可以在加载配置后在 `~/.config/autorandr/$PROFILE/postswitch` 添加自己的脚本来运行。由于我运行 i3,我的工作站配置如下所示:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
xrandr --dpi 92
|
||||
xrandr --output DP2-2 --primary
|
||||
i3-msg '[workspace="^(1|4|6)"] move workspace to output DP2-2;'
|
||||
i3-msg '[workspace="^(2|5|9)"] move workspace to output DP2-3;'
|
||||
i3-msg '[workspace="^(3|8)"] move workspace to output DP2-1;'
|
||||
|
||||
```
|
||||
|
||||
它适当地修正了 dpi,设置主屏幕(可能不需要?),并移动 i3 工作区。你可以通过在配置文件目录中添加一个 `block` 钩子来安排配置永远不会运行。
|
||||
|
||||
如果你定期更换显示器,请看一下!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.donarmstrong.com/posts/autorandr/
|
||||
|
||||
作者:[Don Armstrong][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.donarmstrong.com
|
||||
[1]:https://github.com/phillipberndt/autorandr
|
||||
[2]:https://www.donarmstrong.com/autorandr_1.2-1_all.deb
|
||||
[3]:https://git.donarmstrong.com/deb_pkgs/autorandr.git
|
||||
Loading…
Reference in New Issue
Block a user