mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
e5e0b702c6
@ -1,51 +1,58 @@
|
||||
用户,组和其他 Linux 用户
|
||||
用户、组及其它 Linux 特性
|
||||
======
|
||||
|
||||
> Linux 和其他类 Unix 操作系统依赖于用户组,而不是逐个为用户分配权限和特权。一个组就是你想象的那样:一群在某种程度上相关的用户。
|
||||
|
||||

|
||||
|
||||
到这个阶段,[在看到如何操作目录或文件夹之后][1],但在让自己一头扎进文件之前,我们必须重新审视 _权限_, _users_ 和 _group_。幸运的是,[有一个网站上已经有了一个优秀而全面的教程,包括了权限][2],所以你应该去立刻阅读它。简而言之,你使用权限来确定谁可以对文件和目录执行操作,以及他们可以对每个文件和目录执行什么操作 -- 从中读取,写入,擦除等等。
|
||||
到这个阶段,[在看到如何操作目录或文件夹之后][1],但在让自己一头扎进文件之前,我们必须重新审视 _权限_、_用户_ 和 _组_。幸运的是,[有一个网站上已经有了一个优秀而全面的教程,讲到了权限][2],所以你应该去立刻阅读它。简而言之,你使用权限来确定谁可以对文件和目录执行操作,以及他们可以对每个文件和目录执行什么操作 —— 从中读取、写入、移动、擦除等等。
|
||||
|
||||
要尝试本教程涵盖的所有内容,你需要在系统上创建新用户。让我们实践起来,为每一个需要借用你电脑的人创建一个用户,我们称之为 _guest 账户_。
|
||||
要尝试本教程涵盖的所有内容,你需要在系统上创建新用户。让我们实践起来,为每一个需要借用你电脑的人创建一个用户,我们称之为 `guest` 账户。
|
||||
|
||||
**警告:** _例如,如果你错误地删除了自己的用户和目录,那么创建,特别是删除用户以及主目录会严重损坏系统。你可能不想在你日常的工作机中练习,那么请在另一台机器或者虚拟机上练习。无论你是否想要安全地练习,经常备份你的东西总是一个好主意。检查备份是否正常工作,为你自己以后避免很多咬牙切齿的事情。_
|
||||
**警告:** 例如,如果你错误地删除了自己的用户和目录,那么创建用户,特别是删除用户以及主目录会严重损坏系统。你可能不想在你日常的工作机中练习,那么请在另一台机器或者虚拟机上练习。无论你是否想要安全地练习,经常备份你的东西总是一个好主意。检查备份是否正常工作,为你自己以后避免很多咬牙切齿的事情。
|
||||
|
||||
### 一个新用户
|
||||
|
||||
你可以使用 `useradd` 命令来创建一个新用户。使用超级用户或 root 权限运行 `useradd`,即使用 `sudo` 或 `su`,这具体取决于你的系统,你可以:
|
||||
|
||||
```
|
||||
sudo useradd -m guest
|
||||
```
|
||||
|
||||
然后输入你的密码。或者也可以这样:
|
||||
|
||||
```
|
||||
su -c "useradd -m guest"
|
||||
```
|
||||
|
||||
然后输入 root 或超级用户的密码。
|
||||
|
||||
(_为了简洁起见,我们将从现在开始假设你使用 `sudo` 获得超级用户或 root 权限。_)
|
||||
( _为了简洁起见,我们将从现在开始假设你使用 `sudo` 获得超级用户或 root 权限。_ )
|
||||
|
||||
通过使用 `-m` 参数,`useradd` 将为新用户创建一个主目录。你可以通过列出 _/home/guest_ 来查看其内容。
|
||||
通过使用 `-m` 参数,`useradd` 将为新用户创建一个主目录。你可以通过列出 `/home/guest` 来查看其内容。
|
||||
|
||||
然后你可以使用以下命令来为新用户设置密码:
|
||||
|
||||
```
|
||||
sudo passwd guest
|
||||
```
|
||||
|
||||
或者你也可以使用 `adduser`,这是一个交互式的命令,它会询问你一些问题,包括你要为用户分配的 shell(是的,不止一个),你希望其主目录在哪里,你希望他们属于哪些组(有关这点稍后会讲到)等等。在运行 `adduser` 结束时,你可以设置密码。注意,默认情况下,在许多发行版中都没有安装 `adduser`,但安装了 `useradd`。
|
||||
或者你也可以使用 `adduser`,这是一个交互式的命令,它会询问你一些问题,包括你要为用户分配的 shell(是的,shell 有不止一种),你希望其主目录在哪里,你希望他们属于哪些组(有关这点稍后会讲到)等等。在运行 `adduser` 结束时,你可以设置密码。注意,默认情况下,在许多发行版中都没有安装 `adduser`,但安装了 `useradd`。
|
||||
|
||||
顺便说一下,你可以使用 `userdel` 来移除一个用户:
|
||||
|
||||
```
|
||||
sudo userdel -r guest
|
||||
```
|
||||
|
||||
使用 `-r` 选项,`userdel` 不仅删除了 _guest_ 用户,还删除了他们的主目录和邮件中的条目(如果有的话)。
|
||||
使用 `-r` 选项,`userdel` 不仅删除了 `guest` 用户,还删除了他们的主目录和邮件中的条目(如果有的话)。
|
||||
|
||||
### home 中的内容
|
||||
### 主目录中的内容
|
||||
|
||||
谈到用户的主目录,它依赖于你所使用的发行版。你可能已经注意到,当你使用 `-m` 选项时,`useradd` 使用子目录填充用户的目录,包括音乐,文档和诸如此类的内容以及各种各样的隐藏文件。要查看 guest 主目录中的所有内容,运行 `sudo ls -la /home/guest`。
|
||||
谈到用户的主目录,它依赖于你所使用的发行版。你可能已经注意到,当你使用 `-m` 选项时,`useradd` 使用子目录填充用户的目录,包括音乐、文档和诸如此类的内容以及各种各样的隐藏文件。要查看 `guest` 主目录中的所有内容,运行 `sudo ls -la /home/guest`。
|
||||
|
||||
进入新用户目录的内容通常是由 `/etc/skel` 架构目录确定的。有时它可能是一个不同的目录。要检查正在使用的目录,运行:
|
||||
|
||||
进入新用户目录的内容通常是由 _/etc/skel_ 架构目录确定的。有时它可能是一个不同的目录。要检查正在使用的目录,运行:
|
||||
```
|
||||
useradd -D
|
||||
GROUP=100
|
||||
@ -57,31 +64,36 @@ SKEL=/etc/skel
|
||||
CREATE_MAIL_SPOOL=no
|
||||
```
|
||||
|
||||
这给你一些额外的有趣信息,但你现在感兴趣的是 `SKEL=/etc/skel` 这一行,在这种情况下,按照惯例,它指向 _/etc/skel/_。
|
||||
这会给你一些额外的有趣信息,但你现在感兴趣的是 `SKEL=/etc/skel` 这一行,在这种情况下,按照惯例,它指向 `/etc/skel/`。
|
||||
|
||||
由于 Linux 中的所有东西都是可定制的,因此你可以更改那些放入新创建的用户目录的内容。试试这样做:在 `/etc/skel/` 中创建一个新目录:
|
||||
|
||||
由于 Linux 中的所有东西都是可定制的,因此你可以更改那些放入新创建的用户目录的内容。试试这样做:在 _/etc/skel/_ 中创建一个新目录:
|
||||
```
|
||||
sudo mkdir /etc/skel/Documents
|
||||
```
|
||||
|
||||
然后创建一个包含欢迎消息的文件,并将其复制过来:
|
||||
|
||||
```
|
||||
sudo cp welcome.txt /etc/skel/Documents
|
||||
```
|
||||
|
||||
现在删除 guest 账户:
|
||||
现在删除 `guest` 账户:
|
||||
|
||||
```
|
||||
sudo userdel -r guest
|
||||
```
|
||||
|
||||
再次创建:
|
||||
|
||||
```
|
||||
sudo useradd -m guest
|
||||
```
|
||||
|
||||
嘿 presto!(to 校正:这个 presto 是什么?)你的 _Documents/_ 目录和 _welcome.txt_ 文件神奇地出现在了 guest 的主目录中。
|
||||
嘿!你的 `Documents/` 目录和 `welcome.txt` 文件神奇地出现在了 `guest` 的主目录中。
|
||||
|
||||
你还可以在创建用户时通过编辑 `/etc/default/useradd` 来修改其他内容。我的看起来像这样:
|
||||
|
||||
你还可以在创建用户时通过编辑 _/etc/default/useradd_ 来修改其他内容。我的看起来像这样:
|
||||
```
|
||||
GROUP=users
|
||||
HOME=/home
|
||||
@ -96,11 +108,12 @@ CREATE_MAIL_SPOOL=no
|
||||
|
||||
### 群组心态
|
||||
|
||||
Linux 和其他类 Unix 操作系统依赖于 _groups_,而不是逐个为用户分配权限和特权。一个组就是你想象的那样:一群在某种程度上相关的用户。在你的系统上可能有一组允许使用打印机的用户,他们属于 _lp_(即 "_line printer_")组。传统上 _wheel_ 组的成员是唯一可以通过使用 _su_ 成为超级用户或 root 的成员。_network_ 用户组可以启动或关闭网络。还有许多诸如此类的。
|
||||
Linux 和其他类 Unix 操作系统依赖于用户组,而不是逐个为用户分配权限和特权。一个组就是你想象的那样:一群在某种程度上相关的用户。在你的系统上可能有一组允许使用打印机的用户,他们属于 `lp`(即 “_line printer_”)组。传统上 `wheel` 组的成员是唯一可以通过使用 `su` 成为超级用户或 root 的成员。`network` 用户组可以启动或关闭网络。还有许多诸如此类的。
|
||||
|
||||
不同的发行版有不同的组,具有相同或相似名称的组具有不同的权限,这也取决于你使用的发行版。因此,如果你在前一段中读到的内容与你系统中的内容不匹配,不要感到惊讶。
|
||||
|
||||
不管怎样g,要查看系统中有哪些组,你可以使用:
|
||||
不管怎样,要查看系统中有哪些组,你可以使用:
|
||||
|
||||
```
|
||||
getent group
|
||||
```
|
||||
@ -108,18 +121,20 @@ getent group
|
||||
`getent` 命令列出了某些系统数据库的内容。
|
||||
|
||||
要查找当前用户所属的组,尝试:
|
||||
|
||||
```
|
||||
groups
|
||||
```
|
||||
|
||||
当你使用 `useradd` 创建新用户时,除非你另行指定,否则用户讲只属于一个组:他们自己。一个 _guest_ 用户属于 _guest_ 组。组使用户有权管理自己的东西,仅此而已。
|
||||
当你使用 `useradd` 创建新用户时,除非你另行指定,否则用户将只属于一个组:他们自己。`guest` 用户属于 `guest` 组。组使用户有权管理自己的东西,仅此而已。
|
||||
|
||||
你可以使用 `groupadd` 命令创建新组,然后添加用户:
|
||||
|
||||
```
|
||||
sudo groupadd photos
|
||||
```
|
||||
|
||||
例如,这将创建 _photos_ 组。下一次,我们将使用它来构建一个共享目录,该组的所有成员都可以读取和写入,我们将更多地了解权限和特权。敬请关注!
|
||||
例如,这将创建 `photos` 组。下一次,我们将使用它来构建一个共享目录,该组的所有成员都可以读取和写入,我们将更多地了解权限和特权。敬请关注!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -129,11 +144,11 @@ via: https://www.linux.com/learn/intro-to-linux/2018/7/users-groups-and-other-li
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/2018/5/manipulating-directories-linux
|
||||
[1]:https://linux.cn/article-10066-1.html
|
||||
[2]:https://www.linux.com/learn/understanding-linux-file-permissions
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10375-1.html)
|
||||
[#]: subject: (11 Uses for a Raspberry Pi Around the Office)
|
||||
[#]: via: (https://blog.dxmtechsupport.com.au/11-uses-for-a-raspberry-pi-around-the-office/)
|
||||
[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
|
||||
@ -12,9 +12,9 @@
|
||||
|
||||
我知道你在想什么:树莓派只能用在修修补补、原型设计和个人爱好中。它实际不能用在业务中。
|
||||
|
||||
毫无疑问,这台电脑的处理能力相对较低、易损坏的 SD 卡、缺乏电池备份以及支持的 DIY 性质,这意味着它不会是一个能在任何时候执行最关键的操作的[专业的已安装和已配置的商业服务器][1]的可行替代,。
|
||||
毫无疑问,这台电脑的处理能力相对较低、易损坏的 SD 卡、缺乏电池备份以及支持的 DIY 性质,这意味着它不会是一个能在任何时候执行最关键的操作的[专业的、已安装好、配置好的商业服务器][1]的可行替代品。
|
||||
|
||||
但是它电路板便宜、功耗很小、很小几乎适合任何地方、无限灵活 - 这实际上是处理办公室一些基本任务的好方法。
|
||||
但是它电路板便宜、功耗很小、小到几乎适合任何地方、无限灵活 —— 这实际上是处理办公室一些基本任务的好方法。
|
||||
|
||||
而且,更好的是,已经有一些人完成了这些项目并很乐意分享他们是如何做到的。
|
||||
|
||||
@ -22,11 +22,11 @@
|
||||
|
||||
每次在浏览器中输入网站地址或者点击链接时,都需要将域名转换为数字 IP 地址,然后才能显示内容。
|
||||
|
||||
通常这意味着向互联网上某处 DNS 服务器发出请求 - 但你可以通过本地处理来加快浏览速度。
|
||||
通常这意味着向互联网上某处 DNS 服务器发出请求 —— 但你可以通过本地处理来加快浏览速度。
|
||||
|
||||
你还可以分配自己的子域,以便本地访问办公室中的计算机。
|
||||
|
||||
[这里是如何让这它工作。][2]
|
||||
[这里了解它是如何工作的。][2]
|
||||
|
||||
### 厕所占用标志
|
||||
|
||||
@ -34,37 +34,37 @@
|
||||
|
||||
这对于那些等待的人来说很烦人,花在处理它上面的时间会耗费你在办公室的工作效率。
|
||||
|
||||
我想你希望在办公室里也悬挂飞机上有的标志。
|
||||
我想你希望在办公室里也悬挂飞机上那个厕所有人的标志。
|
||||
|
||||
[Occu-pi][3] 是一个更简单的解决方案,使用磁性开关和树莓派来判断螺栓何时关闭并在 Slack 频道中更新厕所在使用中 - 这意味着整个办公室的人都可以看一眼电脑或者移动设备知道是否有空闲的隔间。
|
||||
[Occu-pi][3] 是一个非常简单的解决方案,使用磁性开关和树莓派来判断螺栓何时关闭,并在 Slack 频道中更新“厕所在使用中” —— 这意味着整个办公室的人都可以看一眼电脑或者移动设备知道是否有空闲的隔间。
|
||||
|
||||
### 针对黑客的蜜罐陷阱
|
||||
|
||||
黑客破坏了网络的第一个线索是一些事情变得糟糕,这应该会吓到大多数企业主。
|
||||
|
||||
这就是可以用到蜜罐的地方:一台没有任何服务的计算机位于你的网络,将特定端口打开伪装成黑客喜欢的目标。
|
||||
这就是可以用到蜜罐的地方:一台没有任何服务的计算机位于你的网络,将特定端口打开,伪装成黑客喜欢的目标。
|
||||
|
||||
安全研究人员经常在网络外部部署蜜罐,以收集攻击者正在做的事情的数据。
|
||||
|
||||
但对于普通的小型企业来说,这些作为一种绊脚石部署在内部更有用。因为普通用户没有真正的理由想要连接到蜜罐,所以任何发生的登录尝试都是正在进行捣乱的非常好的指示。
|
||||
|
||||
这可以提供对外部人员入侵的预警,并且可信赖的内部人员也没有任何好处。
|
||||
这可以提供对外部人员入侵的预警,并且也可以提供对值得信赖的内部人员的预警。
|
||||
|
||||
在较大的客户端/服务器网络中,将它作为虚拟机运行可能更为实际。但是在无线路由器上运行的点对点的小型办公室/家庭办公网络中,[HoneyPi][4] 之类的东西是一个很小的防盗报警器。
|
||||
在较大的客户端/服务器网络中,将它作为虚拟机运行可能更为实用。但是在无线路由器上运行的点对点的小型办公室/家庭办公网络中,[HoneyPi][4] 之类的东西是一个很小的防盗报警器。
|
||||
|
||||
### 打印服务器
|
||||
|
||||
网络连接的打印机更方便。
|
||||
联网打印机更方便。
|
||||
|
||||
但更换所有打印机可能会很昂贵 - 特别是如果你对它们感到满意的话。
|
||||
但更换所有打印机可能会很昂贵 —— 特别是如果你对现有的打印机感到满意的话。
|
||||
|
||||
[将树莓派设置为打印服务器][5]可能会更有意义。
|
||||
|
||||
### 网络附加存储 (NAS)
|
||||
### 网络附加存储(NAS)
|
||||
|
||||
将硬盘变为 NAS 是树莓派最早的实际应用之一,并且它仍然是最好的之一。
|
||||
|
||||
[这是如何使用树莓派创建NAS。][6]
|
||||
[这是如何使用树莓派创建 NAS。][6]
|
||||
|
||||
### 工单服务器
|
||||
|
||||
@ -74,13 +74,13 @@
|
||||
|
||||
### 数字标牌
|
||||
|
||||
无论是用于活动、广告、菜单还是其他任何东西,许多企业都需要一种显示数字标牌的方式 - 而树莓派的廉价和省电使其成为一个非常有吸引力的选择。
|
||||
无论是用于活动、广告、菜单还是其他任何东西,许多企业都需要一种显示数字标牌的方式 —— 而树莓派的廉价和省电使其成为一个非常有吸引力的选择。
|
||||
|
||||
[这有很多可供选择的选项。] [8]
|
||||
|
||||
### 目录和信息亭
|
||||
|
||||
[FullPageOS][9] 是一个基于 Raspbian 的 Linux 发行版,它直接引导到 Chromium 的全屏版本 - 这非常适合导购、图书馆目录等。
|
||||
[FullPageOS][9] 是一个基于 Raspbian 的 Linux 发行版,它直接引导到 Chromium 的全屏版本 —— 这非常适合导购、图书馆目录等。
|
||||
|
||||
### 基本的内联网 Web 服务器
|
||||
|
||||
@ -96,7 +96,7 @@ Kali Linux 是专为探测网络安全漏洞而构建的操作系统。通过将
|
||||
|
||||
[你可以在这里找到树莓派镜像的种子链接。][11]
|
||||
|
||||
绝对小心只在你自己的网络或你有权对它安全审计的网络中使用它 - 使用此方法来破解其他网络是严重的犯罪行为。
|
||||
绝对要小心只在你自己的网络或你有权对它安全审计的网络中使用它 —— 使用此方法来破解其他网络是严重的犯罪行为。
|
||||
|
||||
### VPN 服务器
|
||||
|
||||
@ -104,15 +104,15 @@ Kali Linux 是专为探测网络安全漏洞而构建的操作系统。通过将
|
||||
|
||||
你可以订阅任意数量的商业 VPN 服务,并且你可以在云中安装自己的服务,但是在办公室运行一个 VPN,这样你也可以从任何地方访问本地网络。
|
||||
|
||||
对于轻度使用 - 比如偶尔的商务旅行 - 树莓派是一种强大的,节约能源的设置 VPN 服务器的方式。(首先要检查一下你的路由器是不是不支持这个功能,许多路由器是支持的。)
|
||||
对于轻度使用 —— 比如偶尔的商务旅行 —— 树莓派是一种强大的,节约能源的设置 VPN 服务器的方式。(首先要检查一下你的路由器是不是不支持这个功能,许多路由器是支持的。)
|
||||
|
||||
[这是如何在树莓派上安装 OpenVPN。][12]
|
||||
|
||||
### 无线咖啡机
|
||||
|
||||
啊,美味:美味的饮料还是公司内工作效率的支柱。
|
||||
啊,美味:好喝的饮料是神赐之物,也是公司内工作效率的支柱。
|
||||
|
||||
那么, 为什么不[将办公室的咖啡机变成可以精确控制温度和无线连接的智能咖啡机呢?][13]
|
||||
那么,为什么不[将办公室的咖啡机变成可以精确控制温度和无线连接的智能咖啡机呢?][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -121,7 +121,7 @@ via: https://blog.dxmtechsupport.com.au/11-uses-for-a-raspberry-pi-around-the-of
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -139,4 +139,4 @@ via: https://blog.dxmtechsupport.com.au/11-uses-for-a-raspberry-pi-around-the-of
|
||||
[10]: https://maker.pro/raspberry-pi/projects/raspberry-pi-web-server
|
||||
[11]: https://www.offensive-security.com/kali-linux-arm-images/
|
||||
[12]: https://medium.freecodecamp.org/running-your-own-openvpn-server-on-a-raspberry-pi-8b78043ccdea
|
||||
[13]: https://www.techradar.com/au/how-to/how-to-build-your-own-smart-coffee-machine
|
||||
[13]: https://www.techradar.com/au/how-to/how-to-build-your-own-smart-coffee-machine
|
||||
@ -1,31 +1,33 @@
|
||||
持续集成与部署的3个最佳实践
|
||||
持续集成与部署的 3 个最佳实践
|
||||
======
|
||||
了解自动化,使用 Git 存储库以及参数化 Jenkins 管道。
|
||||
|
||||
> 了解自动化,使用 Git 存储库以及参数化 Jenkins 管道。
|
||||
|
||||

|
||||
|
||||
本文涵盖了三个关键主题:自动化 CI/CD 配置、使用 Git 存储库处理常见的 CI/CD 工件、参数化 Jenkins 管道。
|
||||
|
||||
### 术语
|
||||
|
||||
首先,我们定义一些术语。**CI/CD** 是允许团队快速自动化测试、打包、部署其应用程序的实践。它通常通过利用名为 **[Jenkins][1]** 的服务器来实现,该服务器充当 CI/CD 协调器。Jenkins 侦听特定输入(通常是代码签入后的 Git hook),并在触发时启动管道。
|
||||
首先,我们定义一些术语。**CI/CD** 是允许团队快速自动化测试、打包、部署其应用程序的实践。它通常通过利用名为 [Jenkins][1] 的服务器来实现,该服务器充当 CI/CD 协调器。Jenkins 侦听特定输入(通常是代码签入后的 Git 挂钩),并在触发时启动一个管道。
|
||||
|
||||
**pipeline** 由开发和/或运营团队编写的代码组成,这些代码指导 Jenkins 在 CI/CD 过程中采取哪些操作。这个流水线通常类似于“构建我的代码,然后测试我的代码,如果这些测试通过,则把我的应用程序部署到下一个最高环境(通常是开发、测试或生产环境)”。组织通常具有更复杂的流水线,并入了诸如工件存储库和代码分析器之类的工具,但是这提供了一个高级示例。
|
||||
<ruby>管道<rt>pipeline</rt></ruby> 由开发和/或运营团队编写的代码组成,这些代码指导 Jenkins 在 CI/CD 过程中采取哪些操作。这个流水线通常类似于“构建我的代码,然后测试我的代码,如果这些测试通过,则把我的应用程序部署到下一个最高环境(通常是开发、测试或生产环境)”。组织通常具有更复杂的管道,并入了诸如工件存储库和代码分析器之类的工具,这里提供了一个高级示例。
|
||||
|
||||
现在我们了解了关键术语,让我们深入研究一些最佳实践。
|
||||
|
||||
### 1\. 自动化是关键
|
||||
### 1、自动化是关键
|
||||
|
||||
要在 PaaS 上运行 CI/CD,需要在集群上配置适当的基础设施。在这个例子中,我将使用 [OpenShift][2]。
|
||||
|
||||
"Hello, World" 的实现很容易实现。简单地运行 **oc new-app jenkins- <persistent/ephemeral>** 和 voilà, 你已经准备好运行 Jenkins 服务器了。然而,在企业中的使用要复杂得多。除了 Jenkins 服务器之外,管理员通常还需要部署代码分析工具(如 SonarQube)和构件库(如 Nexus)。然后,它们必须创建管道来执行 CI/CD 和 Jenkins 从服务器,以减少主服务器的负载。这些实体中的大多数都由 OpenShift 资源支持,需要创建这些资源来部署所需的 CI/CD 基础设施。
|
||||
“Hello, World” 的实现很容易实现。简单地运行 `oc new-app jenkins-<persistent/ephemeral>`,然后,你就有了一个已经就绪的运行中的 Jenkins 服务器了。然而,在企业中的使用要复杂得多。除了 Jenkins 服务器之外,管理员通常还需要部署代码分析工具(如 SonarQube)和工件库(如 Nexus)。然后,它们必须创建管道来执行 CI/CD 和 Jenkins 从服务器,以减少主服务器的负载。这些实体中的大多数都由 OpenShift 资源支持,需要创建这些资源来部署所需的 CI/CD 基础设施。
|
||||
|
||||
最后,部署 CI/CD 组件所需要的手动步骤可能是需要被重复的,并且你可能不想成为执行那些重复步骤的人。为了确保结果能够像以前一样快速、无错误和准确地产生,应该在创建基础设施的方式中结合自动化方法。这可以是一个 Ansible 剧本、一个 Bash 脚本,或者任何您希望自动化 CI/CD 基础设施部署的其他方式。我已经使用 [Ansible][3] 和 [OpenShift-Applier][4] 角色来自动化我的实现。您可能会发现这些工具很有价值,或者您可能会发现其他一些对您和组织更有效的工具。无论哪种方式,您都将发现自动化显著地减少了重新创建 CI/CD 组件所需的工作量。
|
||||
最后,部署 CI/CD 组件所需要的手动步骤可能是需要重复进行的,而且你可能不想成为执行那些重复步骤的人。为了确保结果能够像以前一样快速、无错误和准确地产生,应该在创建基础设施的方式中结合自动化方法。这可以是一个 Ansible 剧本、一个 Bash 脚本,或者任何您希望自动化 CI/CD 基础设施部署的其它方式。我已经使用 [Ansible][3] 和 [OpenShift-Applier][4] 角色来自动化我的实现。您可能会发现这些工具很有价值,或者您可能会发现其他一些对您和组织更有效的工具。无论哪种方式,您都将发现自动化显著地减少了重新创建 CI/CD 组件所需的工作量。
|
||||
|
||||
#### 配置Jenkins主服务器
|
||||
#### 配置 Jenkins 主服务器
|
||||
|
||||
除了一般的“自动化”之外,我想单独介绍一下 Jenkins 主服务器,并讨论管理员如何利用 OpenShift 来自动化配置 Jenkins。来自 [Red Hat Container Catalog][5] 的 Jenkins 映像已经安装了 [OpenShift-Sync plugin][6]。在 [视频][7] 中,我们将讨论如何使用这个插件来创建 Jenkins 管道和从设备。
|
||||
除了一般的“自动化”之外,我想单独介绍一下 Jenkins 主服务器,并讨论管理员如何利用 OpenShift 来自动化配置 Jenkins。来自 [Red Hat Container Catalog][5] 的 Jenkins 镜像已经安装了 [OpenShift-Sync plugin][6]。在 [该视频][7] 中,我们将讨论如何使用这个插件来创建 Jenkins 管道和从设备。
|
||||
|
||||
要创建 Jenkins 流水线,请创建一个类似于下面的 OpenShift BuildConfig:
|
||||
要创建 Jenkins 管道,请创建一个类似于下面的 OpenShift BuildConfig:
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
@ -43,7 +45,7 @@ spec:
|
||||
type: JenkinsPipeline
|
||||
```
|
||||
|
||||
OpenShift-Sync 插件将注意到已经创建了带有 **jenkinsPipelineStrategy** 策略的 BuildConfig,并将其转换为 Jenkins 管道,从 Git 源指定的 Jenkins 文件中提取。也可以使用内联 Jenkinsfile,而不是从 Git 存储库中提取。有关更多信息,请参阅[文档][8]。
|
||||
OpenShift-Sync 插件将注意到已经创建了带有 `jenkinsPipelineStrategy` 策略的 BuildConfig,并将其转换为 Jenkins 管道,从 Git 源指定的 Jenkinsfile 中提取。也可以使用内联 Jenkinsfile,而不是从 Git 存储库中提取。有关更多信息,请参阅[文档][8]。
|
||||
|
||||
要创建 Jenkins 从站,请创建一个 OpenShift ImageStream,它从以下定义开始:
|
||||
|
||||
@ -55,12 +57,12 @@ metadata:
|
||||
slave-label: jenkins-slave
|
||||
labels:
|
||||
role: jenkins-slave
|
||||
…
|
||||
...
|
||||
```
|
||||
|
||||
注意在这个 ImageStream 中定义的元数据。OpenShift-Sync 插件将把带有标签 **role: jenkins-slave** 的任何ImageStream 转换为 Jenkins 从站。Jenkins 从站将以 **slave-label** 注释中的值命名。
|
||||
注意在这个 ImageStream 中定义的元数据。OpenShift-Sync 插件将把带有标签 `role: jenkins-slave` 的任何 ImageStream 转换为 Jenkins 从站。Jenkins 从站将以 `slave-label` 注释中的值命名。
|
||||
|
||||
ImageStreams 对于简单的 Jenkins 从属配置工作得很好,但是一些团队会发现有必要配置一些细节详情,比如资源限制、准备就绪和活动性探测,以及实例帽。这就是 ConfigMap 发挥作用的地方:
|
||||
ImageStreams 对于简单的 Jenkins 从属配置工作得很好,但是一些团队会发现有必要配置一些细节详情,比如资源限制、准备就绪和活动性探测,以及实例上限。这就是 ConfigMap 发挥作用的地方:
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
@ -74,21 +76,21 @@ data:
|
||||
<Kubernetes pod template>
|
||||
```
|
||||
|
||||
注意,仍然需要角色:jenkins-slave 标签来将 ConfigMap 转换为 Jenkins slave。Kubernetes pod 模板由一长段 XML 组成,它将根据组织的喜好配置每个细节。要查看此 XML,以及有关将 ImageStreams 和 ConfigMaps 转换为 Jenkins 从属的更多信息,请参阅[文档][9]。
|
||||
注意,仍然需要角色:`jenkins-slave` 标签来将 ConfigMap 转换为 Jenkins 从站。Kubernetes pod 模板由一长段 XML 组成,它将根据组织的喜好配置每个细节。要查看此 XML,以及有关将 ImageStreams 和 ConfigMaps 转换为 Jenkins 从站的更多信息,请参阅[文档][9]。
|
||||
|
||||
请注意上面所示的三个示例,其中没有一个操作需要管理员对 Jenkins 控制台进行手动更改。通过使用 OpenShift 资源,可以简单的自动化方式配置 Jenkins。
|
||||
|
||||
### 2\. 分享就是关心
|
||||
### 2、分享就是关爱
|
||||
|
||||
第二个最佳实践是维护一个公共 CI/CD 工件的 Git 存储库。主要思想是防止团队重新发明轮子。假设您的团队需要执行到 OpenShift 环境的蓝色/绿色部署,作为管道 CD 阶段的一部分。负责编写流水线的团队成员可能不是 OpenShift 专家,也不可能具有从头开始编写此功能的能力。幸运的是,有人已经编写了一个将此功能合并到一个公共 CI/CD 存储库中的函数,因此您的团队可以使用该函数而不是花时间编写一个函数。
|
||||
第二个最佳实践是维护一个公共 CI/CD 工件的 Git 存储库。主要思想是防止团队重新发明轮子。假设您的团队需要执行到 OpenShift 环境的蓝/绿部署,作为管道 CD 阶段的一部分。负责编写管道的团队成员可能不是 OpenShift 专家,也不可能具有从头开始编写此功能的能力。幸运的是,有人已经编写了一个将此功能合并到一个公共 CI/CD 存储库中的函数,因此您的团队可以使用该函数而不是花时间编写一个函数。
|
||||
|
||||
为了更进一步,您的组织可能决定维护整个管道。您可能会发现团队正在编写具有相似功能的流水线。对于那些团队来说,使用来自公共存储库的参数化管道要比从头开始编写自己的管道更有效。
|
||||
为了更进一步,您的组织可能决定维护整个管道。您可能会发现团队正在编写具有相似功能的管道。对于那些团队来说,使用来自公共存储库的参数化管道要比从头开始编写自己的管道更有效。
|
||||
|
||||
### 3\. 少即是多
|
||||
### 3、少即是多
|
||||
|
||||
正如我在前一节中提到的,第三个也是最后一个最佳实践是参数化您的 CI/CD 管道。参数化将防止过多的管道,使您的 CI/CD 系统更容易维护。假设我有多个区域可以部署应用程序。如果没有参数化,我需要为每个区域设置单独的管道。
|
||||
|
||||
要参数化作为 OpenShift 构建配置编写的管道,请将 **env** 节添加到配置:
|
||||
要参数化一个作为 OpenShift 构建配置编写的管道,请将 `env` 节添加到配置:
|
||||
|
||||
```
|
||||
...
|
||||
@ -103,9 +105,9 @@ spec:
|
||||
type: JenkinsPipeline
|
||||
```
|
||||
|
||||
使用此配置,我可以传递 **REGION** 参数管道以将我的应用程序部署到指定区域。
|
||||
使用此配置,我可以传递 `REGION` 参数给管道以将我的应用程序部署到指定区域。
|
||||
|
||||
这有一个[视频][7]提供了一个更实质性的情况,其中参数化是必须的。一些组织决定把他们的 CI/CD 管道分割成单独的 CI 和 CD 管道,通常是因为在部署之前有一些审批过程。假设我有四个映像和三个不同的环境要部署。如果没有参数化,我需要12个 CD 管道来允许所有部署可能性。这会很快失去控制。为了使 CD 流水线的维护更容易,组织会发现将映像和环境参数化以便允许一个流水线执行多个流水线的工作会更好。
|
||||
这有一个[视频][7]提供了一个更实质性的情况,其中参数化是必须的。一些组织决定把他们的 CI/CD 管道分割成单独的 CI 和 CD 管道,通常是因为在部署之前有一些审批过程。假设我有四个镜像和三个不同的环境要部署。如果没有参数化,我需要 12 个 CD 管道来允许所有部署可能性。这会很快失去控制。为了使 CD 流水线的维护更容易,组织会发现将镜像和环境参数化以便允许一个流水线执行多个流水线的工作会更好。
|
||||
|
||||
### 总结
|
||||
|
||||
@ -120,7 +122,7 @@ via: https://opensource.com/article/18/11/best-practices-cicd
|
||||
作者:[Austin Dewey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ChiZelin](https://github.com/ChiZelin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,28 +1,30 @@
|
||||
Bash 环境变量的那些事
|
||||
======
|
||||
> 初学者可以在此教程中了解环境变量。
|
||||
|
||||

|
||||
|
||||
bash 变量,尤其是讨厌的环境变量,已经是一个老生常谈的话题了。我们也更应该对它有一个详细的了解,让它为我们所用。
|
||||
bash 变量,尤其是讨厌的*环境变量*,已经是一个老生常谈的话题了。我们也更应该对它有一个详细的了解,让它为我们所用。
|
||||
|
||||
下面就打开终端,开始吧。
|
||||
|
||||
### 环境变量
|
||||
|
||||
`HOME` 除了是你脱下帽子惬意休息的地方,同时也是 Linux 中的一个变量,它是当前用户主目录的路径:
|
||||
`HOME` (LCTT 译注:双关语)除了是你脱下帽子惬意休息的地方,同时也是 Linux 中的一个变量,它是当前用户主目录的路径:
|
||||
|
||||
```
|
||||
echo $HOME
|
||||
```
|
||||
|
||||
以上这个命令会显示当前用户的主目录路径,通常都在 `/home/` 下。
|
||||
以上这个命令会显示当前用户的主目录路径,通常都在 `/home/<your username>` 下。
|
||||
|
||||
顾名思义,一个变量的值并不是固定的。实际上,Linux 系统中每一个用户的 `HOME` 变量都是不一样的,当然你也可以这样自行更改 `HOME` 变量的值:
|
||||
顾名思义,变量的值是可以根据上下文变化的。实际上,Linux 系统中每一个用户的 `HOME` 变量都是不一样的,当然你也可以这样自行更改 `HOME` 变量的值:
|
||||
|
||||
```
|
||||
HOME=/home/<your username>/Documents
|
||||
```
|
||||
|
||||
以上这个命令将会把 `HOME` 变量设置为 `/home/<your username>/Documents` 目录。
|
||||
以上这个命令将会把 `HOME` 变量设置为你的 `Documents` 目录。
|
||||
|
||||
其中有三点需要留意:
|
||||
|
||||
@ -45,7 +47,7 @@ $ echo $PATH
|
||||
/usr/local/sbin:/usr/local/bin:/usr/bin:/usr/sbin:/bin:/sbin
|
||||
```
|
||||
|
||||
每两个目录之间使用冒号(`:`)分隔。如果某个应用程序的所在目录不在 `PATH` 变量中,那么运行的时候就需要声明应用程序的目录让 shell 能够找到。
|
||||
每两个目录之间使用冒号 `:` 分隔。如果某个应用程序的所在目录不在 `PATH` 变量中,那么运行的时候就需要声明应用程序的目录让 shell 能够找到。
|
||||
|
||||
```
|
||||
/home/<user name>/bin/my_program.sh
|
||||
@ -67,9 +69,9 @@ PATH=$PATH:$HOME/bin
|
||||
|
||||
然后 `/home/<user name>/bin/` 目录就会出现在 `PATH` 变量中了。但正如之前所说,这个变更只会在当前的 shell 生效,当前的 shell 一旦关闭,环境变量的值就又恢复原状了。
|
||||
|
||||
如果要让变更对当前用户持续生效,就不能在 shell 中直接执行对应的变更,而是应该将这些变更操作卸载每次启动 shell 时都会运行的文件当中。这个文件就是当前用户主目录中的 `.bashrc` 文件。文件名前面的点号表明这是一个隐藏文件,执行普通的 `ls` 命令是不会将这个文件显示出来的,但只要在 `ls` 命令中加入 `-a` 参数就可以看到这个文件了。
|
||||
如果要让变更对当前用户持续生效,就不能在 shell 中直接执行对应的变更,而是应该将这些变更操作写在每次启动 shell 时都会运行的文件当中。这个文件就是当前用户主目录中的 `.bashrc` 文件。文件名前面的点号表明这是一个隐藏文件,执行普通的 `ls` 命令是不会将这个文件显示出来的,但只要在 `ls` 命令中加入 `-a` 参数就可以看到这个文件了。
|
||||
|
||||
你可以使用诸如 [kate][1]、[gedit][2]、[nano][3] 或者 [vim][4] 这些文本编辑器来打开 `.bashrc` 文件(但不要用 LibreOffice Writer,它是一个文字处理软件,跟前面几个文字编辑器并不一个量级的东西)。打开 `.bashrc` 文件之后,你会看见里面放置了一些 shell 命令,是用于为当前用户设置环境的。
|
||||
你可以使用诸如 [kate][1]、[gedit][2]、[nano][3] 或者 [vim][4] 这些文本编辑器来打开 `.bashrc` 文件(但不要用 LibreOffice Writer,它是一个文字处理软件,跟前面几个文字编辑器完全不同)。打开 `.bashrc` 文件之后,你会看见里面放置了一些 shell 命令,是用于为当前用户设置环境的。
|
||||
|
||||
在文件的末尾添加新行并输入以下内容:
|
||||
|
||||
@ -97,13 +99,13 @@ source .bashrc
|
||||
new_variable="Hello"
|
||||
```
|
||||
|
||||
然后可以用一下的方式读取到已定义变量的值:
|
||||
然后可以用以下的方式读取到已定义变量的值:
|
||||
|
||||
```
|
||||
echo $new_variable
|
||||
```
|
||||
|
||||
程序的正常工作离不开各种变量,例如要将某个选项设置为 on,又或者让程序找到所需的代码库,都需要使用变量。在 bash 中运行程序的时候会生成一个子 shell,这个子 shell 和执行原程序的父 shell 并不是完全一样的,只是继承了父 shell 的部分内容,而且默认是不继承父 shell 中的变量的。因为变量默认情况下是局部变量,出于安全原因,一个 shell 中的局部变量不会被另一个 shell 读取到,即使是子 shell 也不可以。
|
||||
程序的正常工作离不开各种变量,例如要将某个选项设置为打开,又或者让程序找到所需的代码库,都需要使用变量。在 bash 中运行程序的时候会生成一个子 shell,这个子 shell 和执行原程序的父 shell 并不是完全一样的,只是继承了父 shell 的部分内容,而且默认是不继承父 shell 中的变量的。因为变量默认情况下是局部变量,出于安全原因,一个 shell 中的局部变量不会被另一个 shell 读取到,即使是子 shell 也不可以。
|
||||
|
||||
下面举一个例子。首先定义一个变量:
|
||||
|
||||
@ -198,7 +200,7 @@ via: https://www.linux.com/blog/learn/2018/12/bash-variables-environmental-and-o
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10373-1.html)
|
||||
[#]: subject: (How to Install Putty on Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/putty-linux/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -10,11 +10,11 @@
|
||||
如何在 Ubuntu 和其他 Linux 发行版上安装 Putty
|
||||
======
|
||||
|
||||
如果我没错,[Putty][1] 可能是 Windows 最受欢迎的 SSH 客户端。
|
||||
如果我没弄错,[Putty][1] 可能是 Windows 最受欢迎的 SSH 客户端。
|
||||
|
||||
I在 IT 公司中,开发环境通常在远程 Linux 系统上,而开发人员则使用 Windows 作为本地系统。Putty 用于从 Windows 机器连接到远程 Linux 系统。
|
||||
在 IT 公司中,开发环境通常在远程 Linux 系统上,而开发人员则使用 Windows 作为本地系统。Putty 用于从 Windows 机器连接到远程 Linux 系统。
|
||||
|
||||
Putty 不仅限于 Windows。你也可以在 Linux 和 macOS 上使用此开源软件。
|
||||
Putty 不是限定于 Windows 的。你也可以在 Linux 和 macOS 上使用此开源软件。
|
||||
|
||||
但是等等!当你已经拥有“真正的” Linux 终端时,为什么要在 Linux 上使用单独的 SSH 客户端?这有几个想在 Linux 上使用 Putty 的原因。
|
||||
|
||||
@ -22,8 +22,6 @@ Putty 不仅限于 Windows。你也可以在 Linux 和 macOS 上使用此开源
|
||||
* 你发现很难手动编辑 SSH 配置文件以保存各种 SSH 会话。你更喜欢 Putty 图形化保存 SSH 连接的方式。
|
||||
* 你想通过连接到原始套接字和串口进行调试。
|
||||
|
||||
|
||||
|
||||
无论是什么原因,如果你想在 Ubuntu 或任何其他 Linux 上使用 Putty,你当然可以这样做。让我告诉你如何做到。
|
||||
|
||||
### 在 Ubuntu Linux 上安装 Putty
|
||||
@ -38,7 +36,7 @@ Putty 不仅限于 Windows。你也可以在 Linux 和 macOS 上使用此开源
|
||||
sudo add-apt-repository universe
|
||||
```
|
||||
|
||||
启用 universe 存储库后,应使用以下命令更新 Ubuntu:
|
||||
启用 universe 仓库后,应使用以下命令更新 Ubuntu:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
@ -56,13 +54,13 @@ sudo apt install putty
|
||||
|
||||
![Putty in Linux][3]
|
||||
|
||||
当你输入远程系统的[主机名][4]或 IP 地址并连接到它时,Putty 将使用你主目录中已保存的 SSH 密钥。
|
||||
当你输入远程系统的[主机名][4]或 IP 地址并连接到它时,Putty 将使用你已保存在主目录中的 SSH 密钥。
|
||||
|
||||
![Using Putty in Ubuntu Linux][5]
|
||||
|
||||
### 在其他 Linux 发行版上安装 Putty
|
||||
|
||||
[Putty 可用于 Debian][6],所以你只需要使用 apt-get 或 aptitude 来安装它。
|
||||
[Putty 可用于 Debian][6],所以你只需要使用 `apt-get` 或 `aptitude` 来安装它。
|
||||
|
||||
```
|
||||
sudo apt-get install putty
|
||||
@ -82,7 +80,7 @@ sudo pacman -S putty
|
||||
|
||||
请记住,Putty 是一款开源软件。如果你真的想要,你也可以通过源代码安装它。你可以从下面的链接获取 Putty 的源代码。
|
||||
|
||||
[下载 Putty 源代码][8]
|
||||
- [下载 Putty 源代码][8]
|
||||
|
||||
我一直喜欢原生 Linux 终端而不是像 Putty 这样的 SSH 客户端。我觉得 GNOME 终端或 [Terminator][7] 更有家的感觉。但是,在 Linux 中使用默认终端或 Putty 是个人选择。
|
||||
|
||||
@ -95,7 +93,7 @@ via: https://itsfoss.com/putty-linux/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -108,4 +106,4 @@ via: https://itsfoss.com/putty-linux/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/12/putty-interface-ubuntu-1.jpeg?resize=800%2C430&ssl=1
|
||||
[6]: https://packages.debian.org/jessie/putty
|
||||
[7]: https://launchpad.net/terminator
|
||||
[8]: https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
|
||||
[8]: https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
|
||||
@ -1,3 +1,4 @@
|
||||
translated by lixinyuxx
|
||||
6 common questions about agile development practices for teams
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translated by lixinyuxx
|
||||
5 guiding principles you should know before you design a microservice
|
||||
======
|
||||
|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (alim0x)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (DevOps is for everyone)
|
||||
[#]: via: (https://opensource.com/article/18/11/how-non-engineer-got-devops)
|
||||
[#]: author: (Dawn Parych https://opensource.com/users/dawnparzych)
|
||||
[#]: url: ( )
|
||||
|
||||
DevOps is for everyone
|
||||
======
|
||||
|
||||
A non-engineer explains why you don't need to be a developer or an operations person to fall for DevOps.
|
||||
|
||||

|
||||
|
||||
I've never held a job as a developer nor in operations—so what am I doing writing an article about [DevOps][1]? I've always been interested in computers and technology. I also have a passion for people, psychology, and helping others. When I first heard about DevOps, the concept piqued my interest, as it seemed to merge many of the things I was interested in, even if I don't write code.
|
||||
|
||||
My first computer was a TRS-80, and I loved writing BASIC programs on it. I took the only two computer programming classes my high school offered. A few years later, I started a computer company. I made custom mailing labels, stationery, and built a database to store addresses.
|
||||
|
||||
The problem was I didn't enjoy writing code. I wanted to teach and to help people, and I didn't see writing code as an opportunity to do this. Yes, technology can help people and change lives, but writing code didn't spark my passion. I need to feel excited about my work and do something I love.
|
||||
|
||||
* The culture, not the code
|
||||
* The journey, not the result
|
||||
* Building an environment where everybody can continuously improve
|
||||
* Communicating and collaborating, not working independently
|
||||
|
||||
|
||||
|
||||
I found that I love DevOps. To me, DevOps is about:
|
||||
|
||||
Ultimately, DevOps is about being part of a community working towards the same goal. DevOps merges psychology, people, and technology. DevOps isn't a job title; it is a philosophy for life and work.
|
||||
|
||||
### Finding my people
|
||||
|
||||
Almost four years ago, I attended my first [DevOpsDays][2] conference in Seattle. I felt like I had found my people. I felt welcomed and accepted, even though I work in marketing and don't have a computer science degree. I could geek out over psychology and technology.
|
||||
|
||||
At DevOpsDays, I learned about the ["Three Ways" of DevOps][3]—flow, feedback, and continuous experimentation and learning—and new (to me) concepts such as Kaizen and Kaikaku. As I learned, I found myself saying things like, "I do this! I didn't know there was a name for this!"
|
||||
|
||||
[Kaizen][4] is the practice of continuous improvement and learning. Small, incremental changes over time can yield significant results. I found parallels between this and Carol Dweck's idea of a [growth mindset][5]. People aren't born experts. Becoming skilled at something takes time, practice, and often failure. Recognizing incremental improvement is necessary to make sure we don't give up.
|
||||
|
||||
[Kaikaku][6], on the other hand, is the notion that small changes over time sometimes won't work, and you need to make a radical or disruptive change. Quitting a job without having a new one lined up or moving to a new city can be pretty disruptive—yes, I've done both. But these radical changes can reap great rewards. I might not have learned about DevOps if I hadn't quit my job and taken some time off. Once I decided to return to work, I kept hearing about DevOps and started researching it. This led me to attend my first DevOpsDays, where I began to see all my passions come together. Since then, I have presented at five DevOpsDays and regularly write about DevOps topics.
|
||||
|
||||
### Putting the Three Ways to work
|
||||
|
||||
Change is hard and learning something new can be scary. The Three Ways of DevOps provide a framework for managing change. For example: How is information flowing? What is driving you to make a change? Once you know a change is needed, how do you get feedback about whether the changes you are making are the right changes? How do you know if you're making progress? Feedback is essential and should include both positive and constructive elements. The hard part is making sure the constructive elements don't outweigh the positive.
|
||||
|
||||
For me, the third Way—continuous experimentation and learning—is the most important part of DevOps. Having an environment where people are free to experiment and take risks can lead to unexpected outcomes. Sometimes those outcomes are good, sometimes not so good—and that's OK. Creating an environment where it is acceptable if things don't work out encourages people to take risks. We should all strive to continuously experiment and learn something new on a regular basis.
|
||||
|
||||
The Three Ways of DevOps provides a method of trying something, getting feedback, and learning from our mistakes. A few years ago, my son told me, "I don't ever want to be the best at something, because then I can't learn from my mistakes." We all make mistakes, and learning from them helps us grow and improve. We aren't willing to make mistakes if our culture doesn't support experimentation and learning.
|
||||
|
||||
### Being part of the community
|
||||
|
||||
I've worked in technology for over 20 years and often felt like an outsider until I found the DevOps community. If you're like me—passionate about technology but not the engineering or operations side of things—you can still be a part of DevOps, even if you work in sales, marketing, product marketing, technical writing, support, and more. DevOps is for everyone.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/how-non-engineer-got-devops
|
||||
|
||||
作者:[Dawn Parych][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dawnparzych
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/resources/devops
|
||||
[2]: https://www.devopsdays.org/
|
||||
[3]: https://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[4]: https://en.wikipedia.org/wiki/Kaizen
|
||||
[5]: https://en.wikipedia.org/wiki/Mindset#Fixed_and_growth
|
||||
[6]: https://en.wikipedia.org/wiki/Kaikaku
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 resolutions for open source project maintainers)
|
||||
[#]: via: (https://opensource.com/article/18/12/resolutions-open-source-project-maintainers)
|
||||
[#]: author: (Ben Cotton https://opensource.com/users/bcotton)
|
||||
|
||||
5 resolutions for open source project maintainers
|
||||
======
|
||||
No matter how you say it, good communication is essential to strong open source communities.
|
||||

|
||||
|
||||
I'm generally not big on New Year's resolutions. I have no problem with self-improvement, of course, but I tend to anchor around other parts of the calendar. Even so, there's something about taking down this year's free calendar and replacing it with next year's that inspires some introspection.
|
||||
|
||||
In 2017, I resolved to not share articles on social media until I'd read them. I've kept to that pretty well, and I'd like to think it has made me a better citizen of the internet. For 2019, I'm thinking about resolutions to make me a better open source software maintainer.
|
||||
|
||||
Here are some resolutions I'll try to stick to on the projects where I'm a maintainer or co-maintainer.
|
||||
|
||||
### 1\. Include a code of conduct
|
||||
|
||||
Jono Bacon included "not enforcing the code of conduct" in his article "[7 mistakes you're probably making][1]." Of course, to enforce a code of conduct, you must first have a code of conduct. I plan on defaulting to the [Contributor Covenant][2], but you can use whatever you like. As with licenses, it's probably best to use one that's already written instead of writing your own. But the important thing is to find something that defines how you want your community to behave, whatever that looks like. Once it's written down and enforced, people can decide for themselves if it looks like the kind of community they want to be a part of.
|
||||
|
||||
### 2\. Make the license clear and specific
|
||||
|
||||
You know what really stinks? Unclear licenses. "This software is licensed under the GPL" with no further text doesn't tell me much. Which version of the [GPL][3]? Do I get to pick? For non-code portions of a project, "licensed under a Creative Commons license" is even worse. I love the [Creative Commons licenses][4], but there are several different licenses with significantly different rights and obligations. So, I will make it very clear which variant and version of a license applies to my projects. I will include the full text of the license in the repo and a concise note in the other files.
|
||||
|
||||
Sort of related to this is using an [OSI][5]-approved license. It's tempting to come up with a new license that says exactly what you want it to say, but good luck if you ever need to enforce it. Will it hold up? Will the people using your project understand it?
|
||||
|
||||
### 3\. Triage bug reports and questions quickly
|
||||
|
||||
Few things in technology scale as poorly as open source maintainers. Even on small projects, it can be hard to find the time to answer every question and fix every bug. But that doesn't mean I can't at least acknowledge the person. It doesn't have to be a multi-paragraph reply. Even just labeling the GitHub issue shows that I saw it. Maybe I'll get to it right away. Maybe I'll get to it a year later. But it's important for the community to see that, yes, there is still someone here.
|
||||
|
||||
### 4\. Don't push features or bug fixes without accompanying documentation
|
||||
|
||||
For as much as my open source contributions over the years have revolved around documentation, my projects don't reflect the importance I put on it. There aren't many commits I can push that don't require some form of documentation. New features should obviously be documented at (or before!) the time they're committed. But even bug fixes should get an entry in the release notes. If nothing else, a push is a good opportunity to also make a commit to improving the docs.
|
||||
|
||||
### 5\. Make it clear when I'm abandoning a project
|
||||
|
||||
I'm really bad at saying "no" to things. I told the editors I'd write one or two articles for [Opensource.com][6] and here I am almost 60 articles later. Oops. But at some point, the things that once held my interests no longer do. Maybe the project is unnecessary because its functionality got absorbed into a larger project. Maybe I'm just tired of it. But it's unfair to the community (and potentially dangerous, as the recent [event-stream malware injection][7] showed) to leave a project in limbo. Maintainers have the right to walk away whenever and for whatever reason, but it should be clear that they have.
|
||||
|
||||
Whether you're an open source maintainer or contributor, if you know other resolutions project maintainers should make, please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/resolutions-open-source-project-maintainers
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/8/mistakes-open-source-avoid
|
||||
[2]: https://www.contributor-covenant.org/
|
||||
[3]: https://opensource.org/licenses/gpl-license
|
||||
[4]: https://creativecommons.org/share-your-work/licensing-types-examples/
|
||||
[5]: https://opensource.org/
|
||||
[6]: http://Opensource.com
|
||||
[7]: https://arstechnica.com/information-technology/2018/11/hacker-backdoors-widely-used-open-source-software-to-steal-bitcoin/
|
||||
@ -0,0 +1,111 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (8 tips to help non-techies move to Linux)
|
||||
[#]: via: (https://opensource.com/article/18/12/help-non-techies)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
8 tips to help non-techies move to Linux
|
||||
======
|
||||
Help your friends dump their proprietary operating systems and make the move to open source.
|
||||

|
||||
|
||||
Back in 2016, I took down the shingle for my technology coaching business. Permanently. Or so I thought.
|
||||
|
||||
Over the last 10 months, a handful of friends and acquaintances have pulled me back into that realm. How? With their desire to dump That Other Operating System™ and move to Linux.
|
||||
|
||||
This has been an interesting experience, in no small part because most of the people aren't at all technical. They know how to use a computer to do what they need to do. Beyond that, they're not interested in delving deeper. That said, they were (and are) attracted to Linux for a number of reasons—probably because I constantly prattle on about it.
|
||||
|
||||
While bringing them to the Linux side of the computing world, I learned a few things about helping non-techies move to Linux. If someone asks you to help them make the jump to Linux, these eight tips can help you.
|
||||
|
||||
### 1\. Be honest about Linux.
|
||||
|
||||
Linux is great. It's not perfect, though. It can be perplexing and sometimes frustrating for new users. It's best to prepare the person you're helping with a short pep talk.
|
||||
|
||||
What should you talk about? Briefly explain what Linux is and how it differs from other operating systems. Explain what you can and _can't_ do with it. Let them know some of the pain points they might encounter when using Linux daily.
|
||||
|
||||
If you take a bit of time to [ease them into][1] Linux and open source, the switch won't be as jarring.
|
||||
|
||||
### 2\. It's not about you.
|
||||
|
||||
It's easy to fall into what I call the _power user fallacy_ : the idea that everyone uses technology the same way you do. That's rarely, if ever, the case.
|
||||
|
||||
This isn't about you. It's not about your needs or how you use a computer. It's about the person you're helping's needs and intentions. Their needs, especially if they're not particularly technical, will be different from yours.
|
||||
|
||||
It doesn't matter if Ubuntu or Elementary or Manjaro aren't your distros of choice. It doesn't matter if you turn your nose up at window managers like GNOME, KDE, or Pantheon in favor of i3 or Ratpoison. The person you're helping might think otherwise.
|
||||
|
||||
Put your needs and prejudices aside and help them find the right Linux distribution for them. Find out what they use their computer for and tailor your recommendations for a distribution or three based on that.
|
||||
|
||||
### 3\. Not everyone's a techie.
|
||||
|
||||
And not everyone wants to be. Everyone I've helped move to Linux in the last 10 months has no interest in compiling kernels or code nor in editing and tweaking configuration files. Most of them will never crack open a terminal window. I don't expect them to be interested in doing any of that in the future, either.
|
||||
|
||||
Guess what? There's nothing wrong with that. Maybe they won't _get the most out of_ Linux (whatever that means) by not embracing their inner geeks. Not everyone will want to take on challenges of, say, installing and configuring Slackware or Arch. They need something that will work out of the box.
|
||||
|
||||
### 4\. Take stock of their hardware.
|
||||
|
||||
In an ideal world, we'd all have tricked-out, high-powered laptops or desktops with everything maxed out. Sadly, that world doesn't exist.
|
||||
|
||||
That probably includes the person you're helping move to Linux. They may have slightly (maybe more than slightly) older hardware that they're comfortable with and that works for them. Hardware that they might not be able to afford to upgrade or replace.
|
||||
|
||||
Also, remember that not everyone needs a system for heavy-duty development or gaming or audio and video production. They just need a computer for browsing the web, editing photos, running personal productivity software, and the like.
|
||||
|
||||
One person I recently helped adopt Linux had an Acer Aspire 1 laptop with 4GB of RAM and a 64GB SSD. That helped inform my recommendations, which revolved around a few lightweight Linux distributions.
|
||||
|
||||
### 5\. Help them test-drive some distros.
|
||||
|
||||
The [DistroWatch][2] database contains close to 900 Linux distributions. You should be able to find three to five Linux distributions to recommend. Make a short list of the distributions you think would be a good fit for them. Also, point them to reviews so they can get other perspectives on those distributions.
|
||||
|
||||
When it comes time to take those Linux distributions for a spin, don't just hand someone a bunch of flash drives and walk away. You might be surprised to learn that most people have never run a live Linux distribution or installed an operating system. Any operating system. Beyond plugging the flash drives in, they probably won't know what to do.
|
||||
|
||||
Instead, show them how to [create bootable flash drives][3] and set up their computer's BIOS to start from those drives. Then, let them spend some time running the distros off the flash drives. That will give them a rudimentary feel for the distros and their window managers' quirks.
|
||||
|
||||
### 6\. Walk them through an installation.
|
||||
|
||||
Running a live session with a flash drive tells someone only so much. They need to work with a Linux distribution for a couple or three weeks to really form an opinion of it and to understand its quirks and strengths.
|
||||
|
||||
There's a myth that Linux is difficult to install. That might have been true back in the mid-1990s, but today most Linux distributions are easy to install. You follow a few graphical prompts and let the software do the rest.
|
||||
|
||||
For someone who's never installed any operating system, installing Linux can be a bit daunting. They might not know what to choose when, say, they're asked which filesystem to use or whether or not to encrypt their hard disk.
|
||||
|
||||
Guide them through at least one installation. While you should let them do most of the work, be there to answer questions.
|
||||
|
||||
### 7\. Be prepared to do a couple of installs.
|
||||
|
||||
As I mentioned a paragraph or two ago, using a Linux distribution for two weeks gives someone ample time to regularly interact with it and see if it can be their daily driver. It often works out. Sometimes, though, it doesn't.
|
||||
|
||||
Remember the person with the Acer Aspire 1 laptop? She thought Xubuntu was the right distribution for her. After a few weeks of working with it, that wasn't the case. There wasn't a technical reason—Xubuntu ran smoothly on her laptop. It was just a matter of feel. Instead, she switched back to the first distro she test drove: [MX Linux][4]. She's been happily using MX ever since.
|
||||
|
||||
### 8\. Teach them to fish.
|
||||
|
||||
You can't always be there to be the guiding hand. Or to be the mechanic or plumber who can fix any problems the person encounters. You have a life, too.
|
||||
|
||||
Once they've settled on a Linux distribution, explain that you'll offer a helping hand for two or three weeks. After that, they're on their own. Don't completely abandon them. Be around to help with big problems, but let them know they'll have to learn to do things for themselves.
|
||||
|
||||
Introduce them to websites that can help them solve their problems. Point them to useful articles and books. Doing that will help make them more confident and competent users of Linux—and of computers and technology in general.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Helping someone move to Linux from another, more familiar operating system can be a challenge—a challenge for them and for you. If you take it slowly and follow the advice in this article, you can make the process smoother.
|
||||
|
||||
Do you have other tips for helping a non-techie switch to Linux? Feel free to share them by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/help-non-techies
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/business/15/2/ato2014-lightning-talks-scott-nesbitt
|
||||
[2]: https://distrowatch.com
|
||||
[3]: https://opensource.com/article/18/7/getting-started-etcherio
|
||||
[4]: https://opensource.com/article/18/2/mx-linux-17-distro-beginners
|
||||
146
sources/talk/20181218 The Rise and Demise of RSS.md
Normal file
146
sources/talk/20181218 The Rise and Demise of RSS.md
Normal file
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Rise and Demise of RSS)
|
||||
[#]: via: (https://twobithistory.org/2018/12/18/rss.html)
|
||||
[#]: author: (Two-Bit History https://twobithistory.org)
|
||||
|
||||
The Rise and Demise of RSS
|
||||
======
|
||||
|
||||
This post was originally published on [September 16th, 2018][1]. What follows is a revision that includes additional information gleaned from interviews with Ramanathan Guha, Ian Davis, Dan Libby, and Kevin Werbach.
|
||||
|
||||
About a decade ago, the average internet user might well have heard of RSS. Really Simple Syndication, or Rich Site Summary—what the acronym stands for depends on who you ask—is a standard that websites and podcasts can use to offer a feed of content to their users, one easily understood by lots of different computer programs. Today, though RSS continues to power many applications on the web, it has become, for most people, an obscure technology.
|
||||
|
||||
The story of how this happened is really two stories. The first is a story about a broad vision for the web’s future that never quite came to fruition. The second is a story about how a collaborative effort to improve a popular standard devolved into one of the most contentious forks in the history of open-source software development.
|
||||
|
||||
In the late 1990s, in the go-go years between Netscape’s IPO and the Dot-com crash, everyone could see that the web was going to be an even bigger deal than it already was, even if they didn’t know exactly how it was going to get there. One theory was that the web was about to be revolutionized by syndication. The web, originally built to enable a simple transaction between two parties—a client fetching a document from a single host server—would be broken open by new standards that could be used to repackage and redistribute entire websites through a variety of channels. Kevin Werbach, writing for Release 1.0, a newsletter influential among investors in the 1990s, predicted that syndication “would evolve into the core model for the Internet economy, allowing businesses and individuals to retain control over their online personae while enjoying the benefits of massive scale and scope.”
|
||||
|
||||
He invited his readers to imagine a future in which fencing aficionados, rather than going directly to an “online sporting goods site” or “fencing equipment retailer,” could buy a new épée directly through e-commerce widgets embedded into their favorite website about fencing. Just like in the television world, where big networks syndicate their shows to smaller local stations, syndication on the web would allow businesses and publications to reach consumers through a multitude of intermediary sites. This would mean, as a corollary, that consumers would gain significant control over where and how they interacted with any given business or publication on the web.
|
||||
|
||||
RSS was one of the standards that promised to deliver this syndicated future. To Werbach, RSS was “the leading example of a lightweight syndication protocol.” Another contemporaneous article called RSS the first protocol to realize the potential of XML. It was going to be a way for both users and content aggregators to create their own customized channels out of everything the web had to offer. And yet, two decades later, after the rise of social media and Google’s decision to shut down Google Reader, RSS appears to be [a slowly dying technology][2], now used chiefly by podcasters, programmers with tech blogs, and the occasional journalist. Though of course some people really do still rely on RSS readers, stubbornly adding an RSS feed to your blog, even in 2018, is a political statement. That little tangerine bubble has become a wistful symbol of defiance against a centralized web increasingly controlled by a handful of corporations, a web that hardly resembles the syndicated web of Werbach’s imagining.
|
||||
|
||||
The future once looked so bright for RSS. What happened? Was its downfall inevitable, or was it precipitated by the bitter infighting that thwarted the development of a single RSS standard?
|
||||
|
||||
### Muddied Water
|
||||
|
||||
RSS was invented twice. This meant it never had an obvious owner, a state of affairs that spawned endless debate and acrimony. But it also suggests that RSS was an important idea whose time had come.
|
||||
|
||||
In 1998, Netscape was struggling to envision a future for itself. Its flagship product, the Netscape Navigator web browser—once preferred by over 80 percent of web users—was quickly losing ground to Microsoft’s Internet Explorer. So Netscape decided to compete in a new arena. In May, a team was brought together to start work on what was known internally as “Project 60.” Two months later, Netscape announced “My Netscape,” a web portal that would fight it out with other portals like Yahoo, MSN, and Excite.
|
||||
|
||||
The following year, in March, Netscape announced an addition to the My Netscape portal called the “My Netscape Network.” My Netscape users could now customize their My Netscape page so that it contained “channels” featuring the most recent headlines from sites around the web. As long as your favorite website published a special file in a format dictated by Netscape, you could add that website to your My Netscape page, typically by clicking an “Add Channel” button that participating websites were supposed to add to their interfaces. A little box containing a list of linked headlines would then appear.
|
||||
|
||||
![A My Netscape Network Channel][3] A My Netscape Network channel for Mozilla.org, as it might look to users
|
||||
about to add it to their My Netscape page.
|
||||
|
||||
The special file that participating websites had to publish was an RSS file. In the My Netscape Network announcement, Netscape explained that RSS stood for “RDF Site Summary.” This was somewhat of a misnomer. RDF, or the Resource Description Framework, is basically a grammar for describing certain properties of arbitrary resources. (See [my article about the Semantic Web][4] if that sounds really exciting to you.) In 1999, a draft specification for RDF was being considered by the World Wide Web Consortium (W3C), the web’s main standards body. Though RSS was supposed to be based on RDF, the example RSS document Netscape actually released didn’t use any RDF tags at all. In a document that accompanied the Netscape RSS specification, Dan Libby, one of the specification’s authors, explained that “in this release of MNN, Netscape has intentionally limited the complexity of the RSS format.” The specification was given the 0.90 version number, the idea being that subsequent versions would bring RSS more in line with the W3C’s XML specification and the evolving draft of the RDF specification.
|
||||
|
||||
RSS had been created by Libby and two other Netscape employees, Eckart Walther and Ramanathan Guha. According to an email to me from Guha, he and Walther cooked up RSS in the beginning with some input from Libby; after AOL bought Netscape in 1998, he and Walther left and it became Libby’s responsibility. Before Netscape, Guha had worked for Apple, where he came up with something called the Meta Content Framework. MCF was a format for representing metadata about anything from web pages to local files. Guha demonstrated its power by developing an application called [HotSauce][5] that visualized relationships between files as a network of nodes suspended in 3D space. Immediately after leaving Apple for Netscape, Guha worked with a Netscape consultant named Tim Bray, who in a post on his blog said that he and Guha eventually produced an XML-based version of MCF that in turn became the foundation for the W3C’s RDF draft. It’s no surprise, then, that Guha, Walther, and Libby were keen to build on Guha’s prior work and incorporate RDF into RSS. But Libby later wrote that the original vision for an RDF-based RSS was pared back because of time constraints and the perception that RDF was “‘too complex’ for the ‘average user.’”
|
||||
|
||||
While Netscape was trying to win eyeballs in what became known as the “portal wars,” elsewhere on the web a new phenomenon known as “weblogging” was being pioneered. One of these pioneers was Dave Winer, CEO of a company called UserLand Software, which developed early content management systems that made blogging accessible to people without deep technical fluency. Winer ran his own blog, [Scripting News][6], which today is one of the oldest blogs on the internet. More than a year before Netscape announced My Netscape Network, on December 15, 1997, Winer published a post announcing that the blog would now be available in XML as well as HTML.
|
||||
|
||||
Dave Winer’s XML format became known as the Scripting News format. It was supposedly similar to Microsoft’s Channel Definition Format (a “push technology” standard submitted to the W3C in March, 1997), but I haven’t been able to find a file in the original format to verify that claim. Like Netscape’s RSS, it structured the content of Winer’s blog so that it could be understood by other software applications. When Netscape released RSS 0.90, Winer and UserLand Software began to support both formats. But Winer believed that Netscape’s format was “woefully inadequate” and “missing the key thing web writers and readers need.” It could only represent a list of links, whereas the Scripting News format could represent a series of paragraphs, each containing one or more links.
|
||||
|
||||
In June 1999, two months after Netscape’s My Netscape Network announcement, Winer introduced a new version of the Scripting News format, called ScriptingNews 2.0b1. Winer claimed that he decided to move ahead with his own format only after trying but failing to get anyone at Netscape to care about RSS 0.90’s deficiencies. The new version of the Scripting News format added several items to the `<header>` element that brought the Scripting News format to parity with RSS. But the two formats continued to differ in that the Scripting News format, which Winer nicknamed the “fat” syndication format, could include entire paragraphs and not just links.
|
||||
|
||||
Netscape got around to releasing RSS 0.91 the very next month. The updated specification was a major about-face. RSS no longer stood for “RDF Site Summary”; it now stood for “Rich Site Summary.” All the RDF—and there was almost none anyway—was stripped out. Many of the Scripting News tags were incorporated. In the text of the new specification, Libby explained:
|
||||
|
||||
> RDF references removed. RSS was originally conceived as a metadata format providing a summary of a website. Two things have become clear: the first is that providers want more of a syndication format than a metadata format. The structure of an RDF file is very precise and must conform to the RDF data model in order to be valid. This is not easily human-understandable and can make it difficult to create useful RDF files. The second is that few tools are available for RDF generation, validation and processing. For these reasons, we have decided to go with a standard XML approach.
|
||||
|
||||
Winer was enormously pleased with RSS 0.91, calling it “even better than I thought it would be.” UserLand Software adopted it as a replacement for the existing ScriptingNews 2.0b1 format. For a while, it seemed that RSS finally had a single authoritative specification.
|
||||
|
||||
### The Great Fork
|
||||
|
||||
A year later, the RSS 0.91 specification had become woefully inadequate. There were all sorts of things people were trying to do with RSS that the specification did not address. There were other parts of the specification that seemed unnecessarily constraining—each RSS channel could only contain a maximum of 15 items, for example.
|
||||
|
||||
By that point, RSS had been adopted by several more organizations. Other than Netscape, which seems to have lost interest after RSS 0.91, the big players were Dave Winer’s UserLand Software; O’Reilly Net, which ran an RSS aggregator called Meerkat; and Moreover.com, which also ran an RSS aggregator focused on news. Via mailing list, representatives from these organizations and others regularly discussed how to improve on RSS 0.91. But there were deep disagreements about what those improvements should look like.
|
||||
|
||||
The mailing list in which most of the discussion occurred was called the Syndication mailing list. [An archive of the Syndication mailing list][7] is still available. It is an amazing historical resource. It provides a moment-by-moment account of how those deep disagreements eventually led to a political rupture of the RSS community.
|
||||
|
||||
On one side of the coming rupture was Winer. Winer was impatient to evolve RSS, but he wanted to change it only in relatively conservative ways. In June, 2000, he published his own RSS 0.91 specification on the UserLand website, meant to be a starting point for further development of RSS. It made no significant changes to the 0.91 specification published by Netscape. Winer claimed in a blog post that accompanied his specification that it was only a “cleanup” documenting how RSS was actually being used in the wild, which was needed because the Netscape specification was no longer being maintained. In the same post, he argued that RSS had succeeded so far because it was simple, and that by adding namespaces (a way to explicitly distinguish between different RSS vocabularies) or RDF back to the format—some had suggested this be done in the Syndication mailing list—it “would become vastly more complex, and IMHO, at the content provider level, would buy us almost nothing for the added complexity.” In a message to the Syndication mailing list sent around the same time, Winer suggested that these issues were important enough that they might lead him to create a fork:
|
||||
|
||||
> I’m still pondering how to move RSS forward. I definitely want ICE-like stuff in RSS2, publish and subscribe is at the top of my list, but I am going to fight tooth and nail for simplicity. I love optional elements. I don’t want to go down the namespaces and schema road, or try to make it a dialect of RDF. I understand other people want to do this, and therefore I guess we’re going to get a fork. I have my own opinion about where the other fork will lead, but I’ll keep those to myself for the moment at least.
|
||||
|
||||
Arrayed against Winer were several other people, including Rael Dornfest of O’Reilly, Ian Davis (responsible for a search startup called Calaba), and a precocious, 14-year-old Aaron Swartz. This is the same Aaron Swartz that would later co-found Reddit and become famous for his hacktivism. (In 2000, according to an email to me from Davis, his dad often accompanied him to technology meetups.) Dornfest, Davis, and Swartz all thought that RSS needed namespaces in order to accommodate the many different things everyone wanted to do with it. On another mailing list hosted by O’Reilly, Davis proposed a namespace-based module system, writing that such a system would “make RSS as extensible as we like rather than packing in new features that over-complicate the spec.” The “namespace camp” believed that RSS would soon be used for much more than the syndication of blog posts, so namespaces, rather than being a complication, were the only way to keep RSS from becoming unmanageable as it supported more and more use cases.
|
||||
|
||||
At the root of this disagreement about namespaces was a deeper disagreement about what RSS was even for. Winer had invented his Scripting News format to syndicate the posts he wrote for his blog. Netscape had released RSS as “RDF Site Summary” because it was a way of recreating a site in miniature within the My Netscape online portal. Some people felt that Netscape’s original vision should be honored. Writing to the Syndication mailing list, Davis explained his view that RSS was “originally conceived as a way of building mini sitemaps,” and that now he and others wanted to expand RSS “to encompass more types of information than simple news headlines and to cater for the new uses of RSS that have emerged over the last 12 months.” This was a sensible point to make because the goal of the Netscape RSS project in the beginning was even loftier than Davis suggests: Guha told me that he wanted to create a technology that could support not just website channels but feeds about arbitrary entities such as, for example, Madonna. Further developing RSS so that it could do this would indeed be in keeping with that original motivation. But Davis’ argument also overstates the degree to which there was a unified vision at Netscape by the time the RSS specification was published. According to Libby, who I talked to via email, there was eventually contention between a “Let’s Build the Semantic Web” group and “Let’s Make This Simple for People to Author” group even within Netscape.
|
||||
|
||||
For his part, Winer argued that Netscape’s original goals were irrelevant because his Scripting News format was in fact the first RSS and it had been meant for a very different purpose. Given that the people most involved in the development of RSS disagreed about who had created RSS and why, a fork seems to have been inevitable.
|
||||
|
||||
The fork happened after Dornfest announced a proposed RSS 1.0 specification and formed the RSS-DEV Working Group—which would include Davis, Swartz, and several others but not Winer—to get it ready for publication. In the proposed specification, RSS once again stood for “RDF Site Summary,” because RDF had been added back in to represent metadata properties of certain RSS elements. The specification acknowledged Winer by name, giving him credit for popularizing RSS through his “evangelism.” But it also argued that RSS could not be improved in the way that Winer was advocating. Just adding more elements to RSS without providing for extensibility with a module system would “sacrifice scalability.” The specification went on to define a module system for RSS based on XML namespaces.
|
||||
|
||||
Winer felt that it was “unfair” that the RSS-DEV Working Group had arrogated the “RSS 1.0” name for themselves. In another mailing list about decentralization, he wrote that he had “recently had a standard stolen by a big name,” presumably meaning O’Reilly, which had convened the RSS-DEV Working Group. Other members of the Syndication mailing list also felt that the RSS-DEV Working Group should not have used the name “RSS” without unanimous agreement from the community on how to move RSS forward. But the Working Group stuck with the name. Dan Brickley, another member of the RSS-DEV Working Group, defended this decision by arguing that “RSS 1.0 as proposed is solidly grounded in the original RSS vision, which itself had a long heritage going back to MCF (an RDF precursor) and related specs (CDF etc).” He essentially felt that the RSS 1.0 effort had a better claim to the RSS name than Winer did, since RDF had originally been a part of RSS. The RSS-DEV Working Group published a final version of their specification in December. That same month, Winer published his own improvement to RSS 0.91, which he called RSS 0.92, on UserLand’s website. RSS 0.92 made several small optional improvements to RSS, among which was the addition of the `<enclosure>` tag soon used by podcasters everywhere. RSS had officially forked.
|
||||
|
||||
The fork might have been avoided if a better effort had been made to include Winer in the RSS-DEV Working Group. He obviously belonged there. He was a prominent contributor to the Syndication mailing list and responsible for much of RSS’ popularity, as the members of the Working Group themselves acknowledged. But, as Davis wrote in an email to me, Winer “wanted control and wanted RSS to be his legacy so was reluctant to work with us.” Tim O’Reilly, founder and CEO of O’Reilly, explained in a UserLand discussion group in September, 2000 that Winer basically refused to participate:
|
||||
|
||||
> A group of people involved in RSS got together to start thinking about its future evolution. Dave was part of the group. When the consensus of the group turned in a direction he didn’t like, Dave stopped participating, and characterized it as a plot by O’Reilly to take over RSS from him, despite the fact that Rael Dornfest of O’Reilly was only one of about a dozen authors of the proposed RSS 1.0 spec, and that many of those who were part of its development had at least as long a history with RSS as Dave had.
|
||||
|
||||
To this, Winer said:
|
||||
|
||||
> I met with Dale [Dougherty] two weeks before the announcement, and he didn’t say anything about it being called RSS 1.0. I spoke on the phone with Rael the Friday before it was announced, again he didn’t say that they were calling it RSS 1.0. The first I found out about it was when it was publicly announced.
|
||||
>
|
||||
> Let me ask you a straight question. If it turns out that the plan to call the new spec “RSS 1.0” was done in private, without any heads-up or consultation, or for a chance for the Syndication list members to agree or disagree, not just me, what are you going to do?
|
||||
>
|
||||
> UserLand did a lot of work to create and popularize and support RSS. We walked away from that, and let your guys have the name. That’s the top level. If I want to do any further work in Web syndication, I have to use a different name. Why and how did that happen Tim?
|
||||
|
||||
I have not been able to find a discussion in the Syndication mailing list about using the RSS 1.0 name prior to the announcement of the RSS 1.0 proposal. Winer, in a message to me, said that he was not trying to control RSS and just wanted to use it in his products.
|
||||
|
||||
RSS would fork again in 2003, when several developers frustrated with the bickering in the RSS community sought to create an entirely new format. These developers created Atom, a format that did away with RDF but embraced XML namespaces. Atom would eventually be specified by [a proposed IETF standard][8]. After the introduction of Atom, there were three competing versions of RSS: Winer’s RSS 0.92 (updated to RSS 2.0 in 2002 and renamed “Really Simple Syndication”), the RSS-DEV Working Group’s RSS 1.0, and Atom.
|
||||
|
||||
### Decline
|
||||
|
||||
The proliferation of competing RSS specifications may have hampered RSS in other ways that I’ll discuss shortly. But it did not stop RSS from becoming enormously popular during the 2000s. By 2004, the New York Times had started offering its headlines in RSS and had written an article explaining to the layperson what RSS was and how to use it. Google Reader, the RSS aggregator ultimately used by millions, was launched in 2005. By 2013, RSS seemed popular enough that the New York Times, in its obituary for Aaron Swartz, called the technology “ubiquitous.” For a while, before a third of the planet had signed up for Facebook, RSS was simply how many people stayed abreast of news on the internet.
|
||||
|
||||
The New York Times published Swartz’ obituary in January 2013. By that point, though, RSS had actually turned a corner and was well on its way to becoming an obscure technology. Google Reader was shut down in July 2013, ostensibly because user numbers had been falling “over the years.” This prompted several articles from various outlets declaring that RSS was dead. But people had been declaring that RSS was dead for years, even before Google Reader’s shuttering. Steve Gillmor, writing for TechCrunch in May 2009, advised that “it’s time to get completely off RSS and switch to Twitter” because “RSS just doesn’t cut it anymore.” He pointed out that Twitter was basically a better RSS feed, since it could show you what people thought about an article in addition to the article itself. It allowed you to follow people and not just channels. Gillmor told his readers that it was time to let RSS recede into the background. He ended his article with a verse from Bob Dylan’s “Forever Young.”
|
||||
|
||||
Today, RSS is not dead. But neither is it anywhere near as popular as it once was. Lots of people have offered explanations for why RSS lost its broad appeal. Perhaps the most persuasive explanation is exactly the one offered by Gillmor in 2009. Social networks, just like RSS, provide a feed featuring all the latest news on the internet. Social networks took over from RSS because they were simply better feeds. They also provide more benefits to the companies that own them. Some people have accused Google, for example, of shutting down Google Reader in order to encourage people to use Google+. Google might have been able to monetize Google+ in a way that it could never have monetized Google Reader. Marco Arment, the creator of Instapaper, wrote on his blog in 2013:
|
||||
|
||||
> Google Reader is just the latest casualty of the war that Facebook started, seemingly accidentally: the battle to own everything. While Google did technically “own” Reader and could make some use of the huge amount of news and attention data flowing through it, it conflicted with their far more important Google+ strategy: they need everyone reading and sharing everything through Google+ so they can compete with Facebook for ad-targeting data, ad dollars, growth, and relevance.
|
||||
|
||||
So both users and technology companies realized that they got more out of using social networks than they did out of RSS.
|
||||
|
||||
Another theory is that RSS was always too geeky for regular people. Even the New York Times, which seems to have been eager to adopt RSS and promote it to its audience, complained in 2006 that RSS is a “not particularly user friendly” acronym coined by “computer geeks.” Before the RSS icon was designed in 2004, websites like the New York Times linked to their RSS feeds using little orange boxes labeled “XML,” which can only have been intimidating. The label was perfectly accurate though, because back then clicking the link would take a hapless user to a page full of XML. [This great tweet][9] captures the essence of this explanation for RSS’ demise. Regular people never felt comfortable using RSS; it hadn’t really been designed as a consumer-facing technology and involved too many hurdles; people jumped ship as soon as something better came along.
|
||||
|
||||
RSS might have been able to overcome some of these limitations if it had been further developed. Maybe RSS could have been extended somehow so that friends subscribed to the same channel could syndicate their thoughts about an article to each other. Maybe browser support could have been improved. But whereas a company like Facebook was able to “move fast and break things,” the RSS developer community was stuck trying to achieve consensus. When they failed to agree on a single standard, effort that could have gone into improving RSS was instead squandered on duplicating work that had already been done. Davis told me, for example, that Atom would not have been necessary if the members of the Syndication mailing list had been able to compromise and collaborate, and “all that cleanup work could have been put into RSS to strengthen it.” So if we are asking ourselves why RSS is no longer popular, a good first-order explanation is that social networks supplanted it. If we ask ourselves why social networks were able to supplant it, then the answer may be that the people trying to make RSS succeed faced a problem much harder than, say, building Facebook. As Dornfest wrote to the Syndication mailing list at one point, “currently it’s the politics far more than the serialization that’s far from simple.”
|
||||
|
||||
So today we are left with centralized silos of information. Even so, the syndicated web that Werbach foresaw in 1999 has been realized, just not in the way he thought it would be. After all, The Onion is a publication that relies on syndication through Facebook and Twitter the same way that Seinfeld relied on syndication to rake in millions after the end of its original run. I asked Werbach what he thinks about this and he more or less agrees. He told me that RSS, on one level, was clearly a failure, because it isn’t now “a technology that is really the core of the whole blogging world or content world or world of assembling different elements of things into sites.” But, on another level, “the whole social media revolution is partly about the ability to aggregate different content and resources” in a manner reminiscent of RSS and his original vision for a syndicated web. To Werbach, “it’s the legacy of RSS, even if it’s not built on RSS.”
|
||||
|
||||
Unfortunately, syndication on the modern web still only happens through one of a very small number of channels, meaning that none of us “retain control over our online personae” the way that Werbach imagined we would. One reason this happened is garden-variety corporate rapaciousness—RSS, an open format, didn’t give technology companies the control over data and eyeballs that they needed to sell ads, so they did not support it. But the more mundane reason is that centralized silos are just easier to design than common standards. Consensus is difficult to achieve and it takes time, but without consensus spurned developers will go off and create competing standards. The lesson here may be that if we want to see a better, more open web, we have to get better at not screwing each other over.
|
||||
|
||||
If you enjoyed this post, more like it come out every four weeks! Follow [@TwoBitHistory][10] on Twitter or subscribe to the [RSS feed][11] to make sure you know when a new post is out.
|
||||
|
||||
Previously on TwoBitHistory…
|
||||
|
||||
> I've long wondered if the Unix commands on my Macbook are built from the same code that they were built from 20 or 30 years ago. The answer, it turns, out, is "kinda"!
|
||||
>
|
||||
> My latest post, on how the implementation of cat has changed over the years:<https://t.co/dHizjK50ES>
|
||||
>
|
||||
> — TwoBitHistory (@TwoBitHistory) [November 12, 2018][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/12/18/rss.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twobithistory.org/2018/09/16/the-rise-and-demise-of-rss.html
|
||||
[2]: https://trends.google.com/trends/explore?date=all&geo=US&q=rss
|
||||
[3]: https://twobithistory.org/images/mnn-channel.gif
|
||||
[4]: https://twobithistory.org/2018/05/27/semantic-web.html
|
||||
[5]: http://web.archive.org/web/19970703020212/http://mcf.research.apple.com:80/hs/screen_shot.html
|
||||
[6]: http://scripting.com
|
||||
[7]: https://groups.yahoo.com/neo/groups/syndication/info
|
||||
[8]: https://tools.ietf.org/html/rfc4287
|
||||
[9]: https://twitter.com/mgsiegler/status/311992206716203008
|
||||
[10]: https://twitter.com/TwoBitHistory
|
||||
[11]: https://twobithistory.org/feed.xml
|
||||
[12]: https://twitter.com/TwoBitHistory/status/1062114484209311746?ref_src=twsrc%5Etfw
|
||||
@ -1,180 +0,0 @@
|
||||
robsean translating
|
||||
Graphics and music tools for game development
|
||||
======
|
||||
|
||||

|
||||
|
||||
In early October, our club, [Geeks and Gadgets][1] from Marshall University, participated in the inaugural [Open Jam][2], a game jam that celebrated the best of open source tools. Game jams are events where participants work as teams to develop computer games for fun. Jams tend to be very short--only three days long--and very exhausting. Opensource.com [announced][3] Open Jam in late August, and more than [three dozen games][4] were entered into the competition.
|
||||
|
||||
Our club likes to create and use open source software in our projects, so Open Jam was naturally the jam we wanted to participate in. Our submission was an experimental game called [Mark My Words][5]. We used a variety of free and open source (FOSS) tools to develop it; in this article we'll discuss some of the tools we used and potential stumbling blocks to be aware of.
|
||||
|
||||
### Audio tools
|
||||
|
||||
#### MilkyTracker
|
||||
|
||||
[MilkyTracker][6] is one of the best software packages available for composing old-style video game music. It is an example of a [music tracker][7], a powerful MOD and XM file creator with a characteristic grid-based pattern editor. We used it to compose most of the musical pieces in our game. One of the great things about this program is that it consumed much less disk space and RAM than most of our other tools. Even so, MilkyTracker is still extremely powerful.
|
||||
|
||||
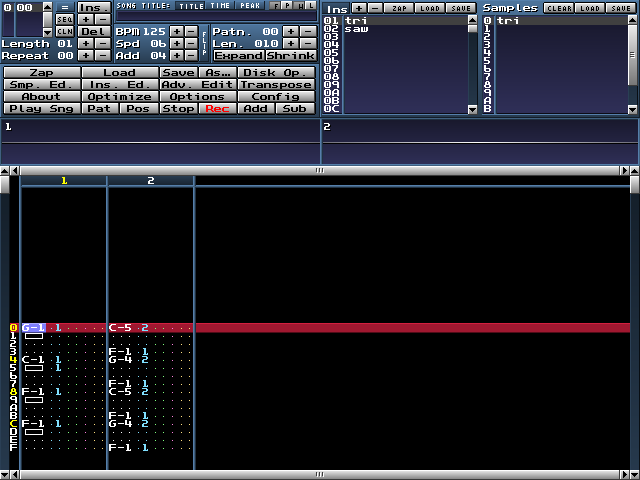
|
||||
|
||||
The user interface took a while to get used to, so here are some pointers for any musician who wants to try out MilkyTracker:
|
||||
|
||||
* Go to Config > Misc. and set the edit mode control style to "MilkyTracker." This will give you modern keyboard shortcuts for almost everything
|
||||
* Undo with Ctrl+Z
|
||||
* Redo with Ctrl+Y
|
||||
* Toggle pattern-edit mode with the Spacebar
|
||||
* Delete the previous note with the Backspace key
|
||||
* Insert a row with the Insert key
|
||||
* By default, a note will continue playing until it is replaced on that channel. You can end a note explicitly by inserting a KeyOff note with the backquote (`) key
|
||||
* You will have to create or find samples before you can start composing. We recommend finding [Creative Commons][8] licensed samples at websites such as [Freesound][9] or [ccMixter][10]
|
||||
|
||||
|
||||
|
||||
In addition, keep the [MilkyTracker documentation page][11] handy. It contains links to numerous tutorials and manuals. A good starting point is the [MilkyTracker Guide][12] on the project's wiki.
|
||||
|
||||
#### LMMS
|
||||
|
||||
Two of our musicians used the versatile and modern music creation tool [LMMS][13]. It comes with a library of cool samples and effects, plus a variety of flexible plugins for generating unique sounds. The learning curve for LMMS was surprisingly low, in part due to the nice beat/bassline editor.
|
||||
|
||||
|
||||
|
||||
We have one suggestion for musicians trying out LMMS: Use the plugins. For [chiptune][14]-style music, we recommend [sfxr][15], [BitInvader][16], and [FreeBoy][17]. For other styles, [ZynAddSubFX][18] is a good choice. It comes with a wide range of synthesized instruments that can be altered however you see fit.
|
||||
|
||||
### Graphics tools
|
||||
|
||||
#### Tiled
|
||||
|
||||
[Tiled][19] is a popular tilemap editor in open source game development. We used it to assemble consistent, retro-looking backgrounds for our in-game scenes.
|
||||
|
||||
|
||||
|
||||
Tiled can export maps as XML, JSON, or as flattened images. It is stable and cross-platform.
|
||||
|
||||
One of Tiled's features, which we did not use during the jam, allows you to define and place arbitrary game objects, such as coins and powerups, onto the map. All you have to do is load the object's graphics as a tileset, then place them using Insert Tile.
|
||||
|
||||
Overall, Tiled is a stellar piece of software that we recommend for any project that needs a map editor.
|
||||
|
||||
#### Piskel
|
||||
|
||||
[Piskel][20] is a pixel art editor whose source code is licensed under the [Apache License, Version 2.0][21]. We used Piskel for almost all our graphical assets during the jam, and we will certainly be using it in future projects as well.
|
||||
|
||||
Two features of Piskel that helped us immensely during the jam are onion skin and spritesheet exporting.
|
||||
|
||||
##### Onion skin
|
||||
|
||||
The onion skin feature will make Piskel show a ghostly overlay of the previous and next frames of your animation as you edit, like this:
|
||||
|
||||
|
||||
|
||||
Onion skin is handy because it serves as a drawing guide and helps you maintain consistent shapes and volumes on your characters throughout the animation process. To enable it, just click the onion-shaped icon underneath the preview window on the top-right of the screen.
|
||||
|
||||
|
||||
|
||||
##### Spritesheet exporting
|
||||
|
||||
Piskel's ability to export animations as a spritesheet was also very helpful. A spritesheet is a single raster image that contains all the frames of an animation. For example, here is a spritesheet we exported from Piskel:
|
||||
|
||||

|
||||
|
||||
The spritesheet consists of two frames. One frame is in the top half of the image and the other frame is in the bottom half of the image. Spritesheets greatly simplify a game's code by enabling an entire animation to be loaded from a single file. Here is an animated version of the above spritesheet:
|
||||
|
||||

|
||||
|
||||
##### Unpiskel.py
|
||||
|
||||
There were several times during the jam when we wanted to batch convert Piskel files into PNGs. Since the Piskel file format is based on JSON, we wrote a small GPLv3-licensed Python script called [unpiskel.py][22] to do the conversion.
|
||||
|
||||
It is invoked like this:
|
||||
```
|
||||
|
||||
|
||||
python unpiskel.py input.piskel
|
||||
```
|
||||
|
||||
The script will extract the PNG data frames and layers from a Piskel file (here `input.piskel`) and store them in their own files. The files follow the pattern `NAME_XX_YY.png` where `NAME` is the truncated name of the Piskel file, `XX` is the frame number, and `YY` is the layer number.
|
||||
|
||||
Because the script can be invoked from a shell, it can be used on a whole list of files.
|
||||
```
|
||||
for f in *.piskel; do python unpiskel.py "$f"; done
|
||||
```
|
||||
|
||||
### Python, Pygame, and cx_Freeze
|
||||
|
||||
#### Python and Pygame
|
||||
|
||||
We used the [Python][23] language to make our game. It is a scripting language that is commonly used for text processing and desktop app development. It can also be used for game development, as projects like [Angry Drunken Dwarves][24] and [Ren'Py][25] have shown. Both of these projects use a Python library called [Pygame][26] to display graphics and produce sound, so we decided to use this library in Open Jam, too.
|
||||
|
||||
Pygame turned out to be both stable and featureful, and it was great for the arcade-style game we were creating. The library's speed was fast enough at low resolutions, but its CPU-only rendering starts to slow down at higher resolutions. This is because Pygame does not use hardware-accelerated rendering. However, the infrastructure is there for developers to take full advantage of OpenGL.
|
||||
|
||||
If you're looking for a good 2D game programming library, Pygame is one to keep your eye on. Its website has [a good tutorial][27] to get started. Be sure to check it out!
|
||||
|
||||
#### cx_Freeze
|
||||
|
||||
Prepping our game for distribution was interesting. We knew that Windows users were unlikely to have a Python installation, and asking them to install it would have been too much. On top of that, they would have had to also install Pygame, which is not an intuitive task on Windows.
|
||||
|
||||
One thing was clear: We had to put our game into a more convenient form. Many of the other Open Jam participants used the proprietary game engine Unity, which enabled their games to be played in the web browser. This made them extremely convenient to play. Convenience was one thing our game didn't have even a sliver of. But, thanks to a vibrant Python ecosystem, we had options. Tools exist to help Python programmers prepare their programs for distribution on Windows. The two that we considered were [cx_Freeze][28] and [Pygame2exe][29] (which uses [py2exe][30]). We decided on cx_Freeze because it was cross-platform.
|
||||
|
||||
In cx_Freeze, you can pack a single-script game for distribution just by running a command like this in the shell:
|
||||
```
|
||||
cxfreeze main.py --target-dir dist
|
||||
```
|
||||
|
||||
This invocation of `cxfreeze` will take your script (here `main.py`) and the Python interpreter on your system and bundle them up into the `dist` directory. Once this is done, all you have to do is manually copy your game's data files into the `dist` directory. You will find that the `dist` directory contains an executable file that can be run to start your game.
|
||||
|
||||
There is a more involved way to use cx_Freeze that allows you to automate the copying of data files, but we found the straightforward invocation of `cxfreeze` to be good enough for our needs. Thanks to this tool, we made our game a little more convenient to play.
|
||||
|
||||
### Celebrating open source
|
||||
|
||||
Open Jam is important because it celebrates the open source model of software development. This is an opportunity to analyze the current state of open source tools and what we need to work on in the future. Game jams are perhaps the best time for game devs to try to push their tools to the limit, to learn what must be improved for the good of future game devs.
|
||||
|
||||
Open source tools enable people to explore their creativity without compromising their freedom and without investing money upfront. Although we might not become professional game developers, we were still able to get a small taste of it with our short, experimental game called [Mark My Words][5]. It is a linguistically themed game that depicts the evolution of a fictional writing system throughout its history. There were many other delightful submissions to Open Jam, and they are all worth checking out. Really, [go look][31]!
|
||||
|
||||
Before closing, we would like to thank all the [club members who participated][32] and made this experience truly worthwhile. We would also like to thank [Michael Clayton][33], [Jared Sprague][34], and [Opensource.com][35] for hosting Open Jam. It was a blast.
|
||||
|
||||
Now, we have some questions for readers. Are you a FOSS game developer? What are your tools of choice? Be sure to leave a comment below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/graphics-music-tools-game-dev
|
||||
|
||||
作者:[Charlie Murphy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rsg167
|
||||
[1]:http://mugeeks.org/
|
||||
[2]:https://itch.io/jam/open-jam-1
|
||||
[3]:https://opensource.com/article/17/8/open-jam-announcement
|
||||
[4]:https://opensource.com/article/17/11/open-jam
|
||||
[5]:https://mugeeksalpha.itch.io/mark-omy-words
|
||||
[6]:http://milkytracker.titandemo.org/
|
||||
[7]:https://en.wikipedia.org/wiki/Music_tracker
|
||||
[8]:https://creativecommons.org/
|
||||
[9]:https://freesound.org/
|
||||
[10]:http://ccmixter.org/view/media/home
|
||||
[11]:http://milkytracker.titandemo.org/documentation/
|
||||
[12]:https://github.com/milkytracker/MilkyTracker/wiki/MilkyTracker-Guide
|
||||
[13]:https://lmms.io/
|
||||
[14]:https://en.wikipedia.org/wiki/Chiptune
|
||||
[15]:https://github.com/grimfang4/sfxr
|
||||
[16]:https://lmms.io/wiki/index.php?title=BitInvader
|
||||
[17]:https://lmms.io/wiki/index.php?title=FreeBoy
|
||||
[18]:http://zynaddsubfx.sourceforge.net/
|
||||
[19]:http://www.mapeditor.org/
|
||||
[20]:https://www.piskelapp.com/
|
||||
[21]:https://github.com/piskelapp/piskel/blob/master/LICENSE
|
||||
[22]:https://raw.githubusercontent.com/MUGeeksandGadgets/MarkMyWords/master/tools/unpiskel.py
|
||||
[23]:https://www.python.org/
|
||||
[24]:https://www.sacredchao.net/~piman/angrydd/
|
||||
[25]:https://renpy.org/
|
||||
[26]:https://www.Pygame.org/
|
||||
[27]:http://Pygame.org/docs/tut/PygameIntro.html
|
||||
[28]:https://anthony-tuininga.github.io/cx_Freeze/
|
||||
[29]:https://Pygame.org/wiki/Pygame2exe
|
||||
[30]:http://www.py2exe.org/
|
||||
[31]:https://itch.io/jam/open-jam-1/entries
|
||||
[32]:https://github.com/MUGeeksandGadgets/MarkMyWords/blob/3e1e8aed12ebe13acccf0d87b06d4f3bd124b9db/README.md#credits
|
||||
[33]:https://twitter.com/mwcz
|
||||
[34]:https://twitter.com/caramelcode
|
||||
[35]:https://opensource.com/
|
||||
@ -1,167 +0,0 @@
|
||||
Protecting Code Integrity with PGP — Part 4: Moving Your Master Key to Offline Storage
|
||||
======
|
||||
|
||||

|
||||
In this tutorial series, we're providing practical guidelines for using PGP. You can catch up on previous articles here:
|
||||
|
||||
[Part 1: Basic Concepts and Tools][1]
|
||||
|
||||
[Part 2: Generating Your Master Key][2]
|
||||
|
||||
[Part 3: Generating PGP Subkeys][3]
|
||||
|
||||
Here in part 4, we continue the series with a look at how and why to move your master key from your home directory to offline storage. Let's get started.
|
||||
|
||||
### Checklist
|
||||
|
||||
* Prepare encrypted detachable storage (ESSENTIAL)
|
||||
|
||||
* Back up your GnuPG directory (ESSENTIAL)
|
||||
|
||||
* Remove the master key from your home directory (NICE)
|
||||
|
||||
* Remove the revocation certificate from your home directory (NICE)
|
||||
|
||||
|
||||
|
||||
|
||||
#### Considerations
|
||||
|
||||
Why would you want to remove your master [C] key from your home directory? This is generally done to prevent your master key from being stolen or accidentally leaked. Private keys are tasty targets for malicious actors -- we know this from several successful malware attacks that scanned users' home directories and uploaded any private key content found there.
|
||||
|
||||
It would be very damaging for any developer to have their PGP keys stolen -- in the Free Software world, this is often tantamount to identity theft. Removing private keys from your home directory helps protect you from such events.
|
||||
|
||||
##### Back up your GnuPG directory
|
||||
|
||||
**!!!Do not skip this step!!!**
|
||||
|
||||
It is important to have a readily available backup of your PGP keys should you need to recover them (this is different from the disaster-level preparedness we did with paperkey).
|
||||
|
||||
##### Prepare detachable encrypted storage
|
||||
|
||||
Start by getting a small USB "thumb" drive (preferably two!) that you will use for backup purposes. You will first need to encrypt them:
|
||||
|
||||
For the encryption passphrase, you can use the same one as on your master key.
|
||||
|
||||
##### Back up your GnuPG directory
|
||||
|
||||
Once the encryption process is over, re-insert the USB drive and make sure it gets properly mounted. Find out the full mount point of the device, for example by running the mount command (under Linux, external media usually gets mounted under /media/disk, under Mac it's /Volumes).
|
||||
|
||||
Once you know the full mount path, copy your entire GnuPG directory there:
|
||||
```
|
||||
$ cp -rp ~/.gnupg [/media/disk/name]/gnupg-backup
|
||||
|
||||
```
|
||||
|
||||
(Note: If you get any Operation not supported on socket errors, those are benign and you can ignore them.)
|
||||
|
||||
You should now test to make sure everything still works:
|
||||
```
|
||||
$ gpg --homedir=[/media/disk/name]/gnupg-backup --list-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
If you don't get any errors, then you should be good to go. Unmount the USB drive and distinctly label it, so you don't blow it away next time you need to use a random USB drive. Then, put in a safe place -- but not too far away, because you'll need to use it every now and again for things like editing identities, adding or revoking subkeys, or signing other people's keys.
|
||||
|
||||
##### Remove the master key
|
||||
|
||||
The files in our home directory are not as well protected as we like to think. They can be leaked or stolen via many different means:
|
||||
|
||||
* By accident when making quick homedir copies to set up a new workstation
|
||||
|
||||
* By systems administrator negligence or malice
|
||||
|
||||
* Via poorly secured backups
|
||||
|
||||
* Via malware in desktop apps (browsers, pdf viewers, etc)
|
||||
|
||||
* Via coercion when crossing international borders
|
||||
|
||||
|
||||
|
||||
|
||||
Protecting your key with a good passphrase greatly helps reduce the risk of any of the above, but passphrases can be discovered via keyloggers, shoulder-surfing, or any number of other means. For this reason, the recommended setup is to remove your master key from your home directory and store it on offline storage.
|
||||
|
||||
###### Removing your master key
|
||||
|
||||
Please see the previous section and make sure you have backed up your GnuPG directory in its entirety. What we are about to do will render your key useless if you do not have a usable backup!
|
||||
|
||||
First, identify the keygrip of your master key:
|
||||
```
|
||||
$ gpg --with-keygrip --list-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
The output will be something like this:
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
Keygrip = AAAA999988887777666655554444333322221111
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
sub rsa2048 2017-12-06 [E]
|
||||
Keygrip = BBBB999988887777666655554444333322221111
|
||||
sub rsa2048 2017-12-06 [S]
|
||||
Keygrip = CCCC999988887777666655554444333322221111
|
||||
|
||||
```
|
||||
|
||||
Find the keygrip entry that is beneath the pub line (right under the master key fingerprint). This will correspond directly to a file in your home .gnupg directory:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ ls
|
||||
AAAA999988887777666655554444333322221111.key
|
||||
BBBB999988887777666655554444333322221111.key
|
||||
CCCC999988887777666655554444333322221111.key
|
||||
|
||||
```
|
||||
|
||||
All you have to do is simply remove the .key file that corresponds to the master keygrip:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ rm AAAA999988887777666655554444333322221111.key
|
||||
|
||||
```
|
||||
|
||||
Now, if you issue the --list-secret-keys command, it will show that the master key is missing (the # indicates it is not available):
|
||||
```
|
||||
$ gpg --list-secret-keys
|
||||
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
ssb rsa2048 2017-12-06 [E]
|
||||
ssb rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
##### Remove the revocation certificate
|
||||
|
||||
Another file you should remove (but keep in backups) is the revocation certificate that was automatically created with your master key. A revocation certificate allows someone to permanently mark your key as revoked, meaning it can no longer be used or trusted for any purpose. You would normally use it to revoke a key that, for some reason, you can no longer control -- for example, if you had lost the key passphrase.
|
||||
|
||||
Just as with the master key, if a revocation certificate leaks into malicious hands, it can be used to destroy your developer digital identity, so it's better to remove it from your home directory.
|
||||
```
|
||||
cd ~/.gnupg/openpgp-revocs.d
|
||||
rm [fpr].rev
|
||||
|
||||
```
|
||||
|
||||
Next time, you'll learn how to secure your subkeys as well. Stay tuned.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,303 +0,0 @@
|
||||
Protecting Code Integrity with PGP — Part 5: Moving Subkeys to a Hardware Device
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this tutorial series, we're providing practical guidelines for using PGP. If you missed the previous article, you can catch up with the links below. But, in this article, we'll continue our discussion about securing your keys and look at some tips for moving your subkeys to a specialized hardware device.
|
||||
|
||||
[Part 1: Basic Concepts and Tools][1]
|
||||
|
||||
[Part 2: Generating Your Master Key][2]
|
||||
|
||||
[Part 3: Generating PGP Subkeys][3]
|
||||
|
||||
[Part 4: Moving Your Master Key to Offline Storage][4]
|
||||
|
||||
### Checklist
|
||||
|
||||
* Get a GnuPG-compatible hardware device (NICE)
|
||||
|
||||
* Configure the device to work with GnuPG (NICE)
|
||||
|
||||
* Set the user and admin PINs (NICE)
|
||||
|
||||
* Move your subkeys to the device (NICE)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
Even though the master key is now safe from being leaked or stolen, the subkeys are still in your home directory. Anyone who manages to get their hands on those will be able to decrypt your communication or fake your signatures (if they know the passphrase). Furthermore, each time a GnuPG operation is performed, the keys are loaded into system memory and can be stolen from there by sufficiently advanced malware (think Meltdown and Spectre).
|
||||
|
||||
The best way to completely protect your keys is to move them to a specialized hardware device that is capable of smartcard operations.
|
||||
|
||||
#### The benefits of smartcards
|
||||
|
||||
A smartcard contains a cryptographic chip that is capable of storing private keys and performing crypto operations directly on the card itself. Because the key contents never leave the smartcard, the operating system of the computer into which you plug in the hardware device is not able to retrieve the private keys themselves. This is very different from the encrypted USB storage device we used earlier for backup purposes -- while that USB device is plugged in and decrypted, the operating system is still able to access the private key contents. Using external encrypted USB media is not a substitute to having a smartcard-capable device.
|
||||
|
||||
Some other benefits of smartcards:
|
||||
|
||||
* They are relatively cheap and easy to obtain
|
||||
|
||||
* They are small and easy to carry with you
|
||||
|
||||
* They can be used with multiple devices
|
||||
|
||||
* Many of them are tamper-resistant (depends on manufacturer)
|
||||
|
||||
|
||||
|
||||
|
||||
#### Available smartcard devices
|
||||
|
||||
Smartcards started out embedded into actual wallet-sized cards, which earned them their name. You can still buy and use GnuPG-capable smartcards, and they remain one of the cheapest available devices you can get. However, actual smartcards have one important downside: they require a smartcard reader, and very few laptops come with one.
|
||||
|
||||
For this reason, manufacturers have started providing small USB devices, the size of a USB thumb drive or smaller, that either have the microsim-sized smartcard pre-inserted, or that simply implement the smartcard protocol features on the internal chip. Here are a few recommendations:
|
||||
|
||||
* [Nitrokey Start][5]: Open hardware and Free Software: one of the cheapest options for GnuPG use, but with fewest extra security features
|
||||
|
||||
* [Nitrokey Pro][6]: Similar to the Nitrokey Start, but is tamper-resistant and offers more security features (but not U2F, see the Fido U2F section of the guide)
|
||||
|
||||
* [Yubikey 4][7]: Proprietary hardware and software, but cheaper than Nitrokey Pro and comes available in the USB-C form that is more useful with newer laptops; also offers additional security features such as U2F
|
||||
|
||||
|
||||
|
||||
|
||||
Our recommendation is to pick a device that is capable of both smartcard functionality and U2F, which, at the time of writing, means a Yubikey 4.
|
||||
|
||||
#### Configuring your smartcard device
|
||||
|
||||
Your smartcard device should Just Work (TM) the moment you plug it into any modern Linux or Mac workstation. You can verify it by running:
|
||||
```
|
||||
$ gpg --card-status
|
||||
|
||||
```
|
||||
|
||||
If you didn't get an error, but a full listing of the card details, then you are good to go. Unfortunately, troubleshooting all possible reasons why things may not be working for you is way beyond the scope of this guide. If you are having trouble getting the card to work with GnuPG, please seek support via your operating system's usual support channels.
|
||||
|
||||
##### PINs don't have to be numbers
|
||||
|
||||
Note, that despite having the name "PIN" (and implying that it must be a "number"), neither the user PIN nor the admin PIN on the card need to be numbers.
|
||||
|
||||
Your device will probably have default user and admin PINs set up when it arrives. For Yubikeys, these are 123456 and 12345678, respectively. If those don't work for you, please check any accompanying documentation that came with your device.
|
||||
|
||||
##### Quick setup
|
||||
|
||||
To configure your smartcard, you will need to use the GnuPG menu system, as there are no convenient command-line switches:
|
||||
```
|
||||
$ gpg --card-edit
|
||||
[...omitted...]
|
||||
gpg/card> admin
|
||||
Admin commands are allowed
|
||||
gpg/card> passwd
|
||||
|
||||
```
|
||||
|
||||
You should set the user PIN (1), Admin PIN (3), and the Reset Code (4). Please make sure to record and store these in a safe place -- especially the Admin PIN and the Reset Code (which allows you to completely wipe the smartcard). You so rarely need to use the Admin PIN, that you will inevitably forget what it is if you do not record it.
|
||||
|
||||
Getting back to the main card menu, you can also set other values (such as name, sex, login data, etc), but it's not necessary and will additionally leak information about your smartcard should you lose it.
|
||||
|
||||
#### Moving the subkeys to your smartcard
|
||||
|
||||
Exit the card menu (using "q") and save all changes. Next, let's move your subkeys onto the smartcard. You will need both your PGP key passphrase and the admin PIN of the card for most operations. Remember, that [fpr] stands for the full 40-character fingerprint of your key.
|
||||
```
|
||||
$ gpg --edit-key [fpr]
|
||||
|
||||
Secret subkeys are available.
|
||||
|
||||
pub rsa4096/AAAABBBBCCCCDDDD
|
||||
created: 2017-12-07 expires: 2019-12-07 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
ssb rsa2048/1111222233334444
|
||||
created: 2017-12-07 expires: never usage: E
|
||||
ssb rsa2048/5555666677778888
|
||||
created: 2017-12-07 expires: never usage: S
|
||||
[ultimate] (1). Alice Engineer <alice@example.org>
|
||||
[ultimate] (2) Alice Engineer <allie@example.net>
|
||||
|
||||
gpg>
|
||||
|
||||
```
|
||||
|
||||
Using --edit-key puts us into the menu mode again, and you will notice that the key listing is a little different. From here on, all commands are done from inside this menu mode, as indicated by gpg>.
|
||||
|
||||
First, let's select the key we'll be putting onto the card -- you do this by typing key 1 (it's the first one in the listing, our [E] subkey):
|
||||
```
|
||||
gpg> key 1
|
||||
|
||||
```
|
||||
|
||||
The output should be subtly different:
|
||||
```
|
||||
pub rsa4096/AAAABBBBCCCCDDDD
|
||||
created: 2017-12-07 expires: 2019-12-07 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
ssb* rsa2048/1111222233334444
|
||||
created: 2017-12-07 expires: never usage: E
|
||||
ssb rsa2048/5555666677778888
|
||||
created: 2017-12-07 expires: never usage: S
|
||||
[ultimate] (1). Alice Engineer <alice@example.org>
|
||||
[ultimate] (2) Alice Engineer <allie@example.net>
|
||||
|
||||
```
|
||||
|
||||
Notice the * that is next to the ssb line corresponding to the key -- it indicates that the key is currently "selected." It works as a toggle, meaning that if you type key 1 again, the * will disappear and the key will not be selected any more.
|
||||
|
||||
Now, let's move that key onto the smartcard:
|
||||
```
|
||||
gpg> keytocard
|
||||
Please select where to store the key:
|
||||
(2) Encryption key
|
||||
Your selection? 2
|
||||
|
||||
```
|
||||
|
||||
Since it's our [E] key, it makes sense to put it into the Encryption slot. When you submit your selection, you will be prompted first for your PGP key passphrase, and then for the admin PIN. If the command returns without an error, your key has been moved.
|
||||
|
||||
**Important:** Now type key 1 again to unselect the first key, and key 2 to select the [S] key:
|
||||
```
|
||||
gpg> key 1
|
||||
gpg> key 2
|
||||
gpg> keytocard
|
||||
Please select where to store the key:
|
||||
(1) Signature key
|
||||
(3) Authentication key
|
||||
Your selection? 1
|
||||
|
||||
```
|
||||
|
||||
You can use the [S] key both for Signature and Authentication, but we want to make sure it's in the Signature slot, so choose (1). Once again, if your command returns without an error, then the operation was successful.
|
||||
|
||||
Finally, if you created an [A] key, you can move it to the card as well, making sure first to unselect key 2. Once you're done, choose "q":
|
||||
```
|
||||
gpg> q
|
||||
Save changes? (y/N) y
|
||||
|
||||
```
|
||||
|
||||
Saving the changes will delete the keys you moved to the card from your home directory (but it's okay, because we have them in our backups should we need to do this again for a replacement smartcard).
|
||||
|
||||
##### Verifying that the keys were moved
|
||||
|
||||
If you perform --list-secret-keys now, you will see a subtle difference in the output:
|
||||
```
|
||||
$ gpg --list-secret-keys
|
||||
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
ssb> rsa2048 2017-12-06 [E]
|
||||
ssb> rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
The > in the ssb> output indicates that the subkey is only available on the smartcard. If you go back into your secret keys directory and look at the contents there, you will notice that the .key files there have been replaced with stubs:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ strings *.key
|
||||
|
||||
```
|
||||
|
||||
The output should contain shadowed-private-key to indicate that these files are only stubs and the actual content is on the smartcard.
|
||||
|
||||
#### Verifying that the smartcard is functioning
|
||||
|
||||
To verify that the smartcard is working as intended, you can create a signature:
|
||||
```
|
||||
$ echo "Hello world" | gpg --clearsign > /tmp/test.asc
|
||||
$ gpg --verify /tmp/test.asc
|
||||
|
||||
```
|
||||
|
||||
This should ask for your smartcard PIN on your first command, and then show "Good signature" after you run gpg --verify.
|
||||
|
||||
Congratulations, you have successfully made it extremely difficult to steal your digital developer identity!
|
||||
|
||||
### Other common GnuPG operations
|
||||
|
||||
Here is a quick reference for some common operations you'll need to do with your PGP key.
|
||||
|
||||
In all of the below commands, the [fpr] is your key fingerprint.
|
||||
|
||||
#### Mounting your master key offline storage
|
||||
|
||||
You will need your master key for any of the operations below, so you will first need to mount your backup offline storage and tell GnuPG to use it. First, find out where the media got mounted, for example, by looking at the output of the mount command. Then, locate the directory with the backup of your GnuPG directory and tell GnuPG to use that as its home:
|
||||
```
|
||||
$ export GNUPGHOME=/media/disk/name/gnupg-backup
|
||||
$ gpg --list-secret-keys
|
||||
|
||||
```
|
||||
|
||||
You want to make sure that you see sec and not sec# in the output (the # means the key is not available and you're still using your regular home directory location).
|
||||
|
||||
##### Updating your regular GnuPG working directory
|
||||
|
||||
After you make any changes to your key using the offline storage, you will want to import these changes back into your regular working directory:
|
||||
```
|
||||
$ gpg --export | gpg --homedir ~/.gnupg --import
|
||||
$ unset GNUPGHOME
|
||||
|
||||
```
|
||||
|
||||
#### Extending key expiration date
|
||||
|
||||
The master key we created has the default expiration date of 2 years from the date of creation. This is done both for security reasons and to make obsolete keys eventually disappear from keyservers.
|
||||
|
||||
To extend the expiration on your key by a year from current date, just run:
|
||||
```
|
||||
$ gpg --quick-set-expire [fpr] 1y
|
||||
|
||||
```
|
||||
|
||||
You can also use a specific date if that is easier to remember (e.g. your birthday, January 1st, or Canada Day):
|
||||
```
|
||||
$ gpg --quick-set-expire [fpr] 2020-07-01
|
||||
|
||||
```
|
||||
|
||||
Remember to send the updated key back to keyservers:
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
#### Revoking identities
|
||||
|
||||
If you need to revoke an identity (e.g., you changed employers and your old email address is no longer valid), you can use a one-liner:
|
||||
```
|
||||
$ gpg --quick-revoke-uid [fpr] 'Alice Engineer <aengineer@example.net>'
|
||||
|
||||
```
|
||||
|
||||
You can also do the same with the menu mode using gpg --edit-key [fpr].
|
||||
|
||||
Once you are done, remember to send the updated key back to keyservers:
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
Next time, we'll look at how Git supports multiple levels of integration with PGP.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][8]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
[5]:https://shop.nitrokey.com/shop/product/nitrokey-start-6
|
||||
[6]:https://shop.nitrokey.com/shop/product/nitrokey-pro-3
|
||||
[7]:https://www.yubico.com/product/yubikey-4-series/
|
||||
[8]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,318 +0,0 @@
|
||||
Protecting Code Integrity with PGP — Part 6: Using PGP with Git
|
||||
======
|
||||
|
||||

|
||||
In this tutorial series, we're providing practical guidelines for using PGP, including basic concepts and generating and protecting your keys. If you missed the previous articles, you can catch up below. In this article, we look at Git's integration with PGP, starting with signed tags, then introducing signed commits, and finally adding support for signed pushes.
|
||||
|
||||
[Part 1: Basic Concepts and Tools][1]
|
||||
|
||||
[Part 2: Generating Your Master Key][2]
|
||||
|
||||
[Part 3: Generating PGP Subkeys][3]
|
||||
|
||||
[Part 4: Moving Your Master Key to Offline Storage][4]
|
||||
|
||||
[Part 5: Moving Subkeys to a Hardware Device][5]
|
||||
|
||||
One of the core features of Git is its decentralized nature -- once a repository is cloned to your system, you have full history of the project, including all of its tags, commits and branches. However, with hundreds of cloned repositories floating around, how does anyone verify that the repository you downloaded has not been tampered with by a malicious third party? You may have cloned it from GitHub or some other official-looking location, but what if someone had managed to trick you?
|
||||
|
||||
Or what happens if a backdoor is discovered in one of the projects you've worked on, and the "Author" line in the commit says it was done by you, while you're pretty sure you had [nothing to do with it][6]?
|
||||
|
||||
To address both of these issues, Git introduced PGP integration. Signed tags prove the repository integrity by assuring that its contents are exactly the same as on the workstation of the developer who created the tag, while signed commits make it nearly impossible for someone to impersonate you without having access to your PGP keys.
|
||||
|
||||
### Checklist
|
||||
|
||||
* Understand signed tags, commits, and pushes (ESSENTIAL)
|
||||
|
||||
* Configure git to use your key (ESSENTIAL)
|
||||
|
||||
* Learn how tag signing and verification works (ESSENTIAL)
|
||||
|
||||
* Configure git to always sign annotated tags (NICE)
|
||||
|
||||
* Learn how commit signing and verification works (ESSENTIAL)
|
||||
|
||||
* Configure git to always sign commits (NICE)
|
||||
|
||||
* Configure gpg-agent options (ESSENTIAL)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
Git implements multiple levels of integration with PGP, first starting with signed tags, then introducing signed commits, and finally adding support for signed pushes.
|
||||
|
||||
#### Understanding Git Hashes
|
||||
|
||||
Git is a complicated beast, but you need to know what a "hash" is in order to have a good grasp on how PGP integrates with it. We'll narrow it down to two kinds of hashes: tree hashes and commit hashes.
|
||||
|
||||
##### Tree hashes
|
||||
|
||||
Every time you commit a change to a repository, git records checksum hashes of all objects in it -- contents (blobs), directories (trees), file names and permissions, etc, for each subdirectory in the repository. It only does this for trees and blobs that have changed with each commit, so as not to re-checksum the entire tree unnecessarily if only a small part of it was touched.
|
||||
|
||||
Then it calculates and stores the checksum of the toplevel tree, which will inevitably be different if any part of the repository has changed.
|
||||
|
||||
##### Commit hashes
|
||||
|
||||
Once the tree hash has been created, git will calculate the commit hash, which will include the following information about the repository and the change being made:
|
||||
|
||||
* The checksum hash of the tree
|
||||
|
||||
* The checksum hash of the tree before the change (parent)
|
||||
|
||||
* Information about the author (name, email, time of authorship)
|
||||
|
||||
* Information about the committer (name, email, time of commit)
|
||||
|
||||
* The commit message
|
||||
|
||||
|
||||
|
||||
|
||||
##### Hashing function
|
||||
|
||||
At the time of writing, git still uses the SHA1 hashing mechanism to calculate checksums, though work is under way to transition to a stronger algorithm that is more resistant to collisions. Note, that git already includes collision avoidance routines, so it is believed that a successful collision attack against git remains impractical.
|
||||
|
||||
#### Annotated tags and tag signatures
|
||||
|
||||
Git tags allow developers to mark specific commits in the history of each git repository. Tags can be "lightweight" \-- more or less just a pointer at a specific commit, or they can be "annotated," which becomes its own object in the git tree. An annotated tag object contains all of the following information:
|
||||
|
||||
* The checksum hash of the commit being tagged
|
||||
|
||||
* The tag name
|
||||
|
||||
* Information about the tagger (name, email, time of tagging)
|
||||
|
||||
* The tag message
|
||||
|
||||
|
||||
|
||||
|
||||
A PGP-signed tag is simply an annotated tag with all these entries wrapped around in a PGP signature. When a developer signs their git tag, they effectively assure you of the following:
|
||||
|
||||
* Who they are (and why you should trust them)
|
||||
|
||||
* What the state of their repository was at the time of signing:
|
||||
|
||||
* The tag includes the hash of the commit
|
||||
|
||||
* The commit hash includes the hash of the toplevel tree
|
||||
|
||||
* Which includes hashes of all files, contents, and subtrees
|
||||
* It also includes all information about authorship
|
||||
|
||||
* Including exact times when changes were made
|
||||
|
||||
|
||||
|
||||
|
||||
When you clone a git repository and verify a signed tag, that gives you cryptographic assurance that all contents in the repository, including all of its history, are exactly the same as the contents of the repository on the developer's computer at the time of signing.
|
||||
|
||||
#### Signed commits
|
||||
|
||||
Signed commits are very similar to signed tags -- the contents of the commit object are PGP-signed instead of the contents of the tag object. A commit signature also gives you full verifiable information about the state of the developer's tree at the time the signature was made. Tag signatures and commit PGP signatures provide exact same security assurances about the repository and its entire history.
|
||||
|
||||
#### Signed pushes
|
||||
|
||||
This is included here for completeness' sake, since this functionality needs to be enabled on the server receiving the push before it does anything useful. As we saw above, PGP-signing a git object gives verifiable information about the developer's git tree, but not about their intent for that tree.
|
||||
|
||||
For example, you can be working on an experimental branch in your own git fork trying out a promising cool feature, but after you submit your work for review, someone finds a nasty bug in your code. Since your commits are properly signed, someone can take the branch containing your nasty bug and push it into master, introducing a vulnerability that was never intended to go into production. Since the commit is properly signed with your key, everything looks legitimate and your reputation is questioned when the bug is discovered.
|
||||
|
||||
Ability to require PGP-signatures during git push was added in order to certify the intent of the commit, and not merely verify its contents.
|
||||
|
||||
#### Configure git to use your PGP key
|
||||
|
||||
If you only have one secret key in your keyring, then you don't really need to do anything extra, as it becomes your default key.
|
||||
|
||||
However, if you happen to have multiple secret keys, you can tell git which key should be used ([fpr] is the fingerprint of your key):
|
||||
```
|
||||
$ git config --global user.signingKey [fpr]
|
||||
|
||||
```
|
||||
|
||||
NOTE: If you have a distinct gpg2 command, then you should tell git to always use it instead of the legacy gpg from version 1:
|
||||
```
|
||||
$ git config --global gpg.program gpg2
|
||||
|
||||
```
|
||||
|
||||
#### How to work with signed tags
|
||||
|
||||
To create a signed tag, simply pass the -s switch to the tag command:
|
||||
```
|
||||
$ git tag -s [tagname]
|
||||
|
||||
```
|
||||
|
||||
Our recommendation is to always sign git tags, as this allows other developers to ensure that the git repository they are working with has not been maliciously altered (e.g. in order to introduce backdoors).
|
||||
|
||||
##### How to verify signed tags
|
||||
|
||||
To verify a signed tag, simply use the verify-tag command:
|
||||
```
|
||||
$ git verify-tag [tagname]
|
||||
|
||||
```
|
||||
|
||||
If you are verifying someone else's git tag, then you will need to import their PGP key. Please refer to the "Trusted Team communication" document in the same repository for guidance on this topic.
|
||||
|
||||
##### Verifying at pull time
|
||||
|
||||
If you are pulling a tag from another fork of the project repository, git should automatically verify the signature at the tip you're pulling and show you the results during the merge operation:
|
||||
```
|
||||
$ git pull [url] tags/sometag
|
||||
|
||||
```
|
||||
|
||||
The merge message will contain something like this:
|
||||
```
|
||||
Merge tag 'sometag' of [url]
|
||||
|
||||
[Tag message]
|
||||
|
||||
# gpg: Signature made [...]
|
||||
# gpg: Good signature from [...]
|
||||
|
||||
```
|
||||
|
||||
#### Configure git to always sign annotated tags
|
||||
|
||||
Chances are, if you're creating an annotated tag, you'll want to sign it. To force git to always sign annotated tags, you can set a global configuration option:
|
||||
```
|
||||
$ git config --global tag.forceSignAnnotated true
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can just train your muscle memory to always pass the -s switch:
|
||||
```
|
||||
$ git tag -asm "Tag message" tagname
|
||||
|
||||
```
|
||||
|
||||
#### How to work with signed commits
|
||||
|
||||
It is easy to create signed commits, but it is much more difficult to incorporate them into your workflow. Many projects use signed commits as a sort of "Committed-by:" line equivalent that records code provenance -- the signatures are rarely verified by others except when tracking down project history. In a sense, signed commits are used for "tamper evidence," and not to "tamper-proof" the git workflow.
|
||||
|
||||
To create a signed commit, you just need to pass the -S flag to the git commit command (it's capital -S due to collision with another flag):
|
||||
```
|
||||
$ git commit -S
|
||||
|
||||
```
|
||||
|
||||
Our recommendation is to always sign commits and to require them of all project members, regardless of whether anyone is verifying them (that can always come at a later time).
|
||||
|
||||
##### How to verify signed commits
|
||||
|
||||
To verify a single commit you can use verify-commit:
|
||||
```
|
||||
$ git verify-commit [hash]
|
||||
|
||||
```
|
||||
|
||||
You can also look at repository logs and request that all commit signatures are verified and shown:
|
||||
```
|
||||
$ git log --pretty=short --show-signature
|
||||
|
||||
```
|
||||
|
||||
##### Verifying commits during git merge
|
||||
|
||||
If all members of your project sign their commits, you can enforce signature checking at merge time (and then sign the resulting merge commit itself using the -S flag):
|
||||
```
|
||||
$ git merge --verify-signatures -S merged-branch
|
||||
|
||||
```
|
||||
|
||||
Note, that the merge will fail if there is even one commit that is not signed or does not pass verification. As it is often the case, technology is the easy part -- the human side of the equation is what makes adopting strict commit signing for your project difficult.
|
||||
|
||||
##### If your project uses mailing lists for patch management
|
||||
|
||||
If your project uses a mailing list for submitting and processing patches, then there is little use in signing commits, because all signature information will be lost when sent through that medium. It is still useful to sign your commits, just so others can refer to your publicly hosted git trees for reference, but the upstream project receiving your patches will not be able to verify them directly with git.
|
||||
|
||||
You can still sign the emails containing the patches, though.
|
||||
|
||||
#### Configure git to always sign commits
|
||||
|
||||
You can tell git to always sign commits:
|
||||
```
|
||||
git config --global commit.gpgSign true
|
||||
|
||||
```
|
||||
|
||||
Or you can train your muscle memory to always pass the -S flag to all git commit operations (this includes --amend).
|
||||
|
||||
#### Configure gpg-agent options
|
||||
|
||||
The GnuPG agent is a helper tool that will start automatically whenever you use the gpg command and run in the background with the purpose of caching the private key passphrase. This way you only have to unlock your key once to use it repeatedly (very handy if you need to sign a bunch of git operations in an automated script without having to continuously retype your passphrase).
|
||||
|
||||
There are two options you should know in order to tweak when the passphrase should be expired from cache:
|
||||
|
||||
* default-cache-ttl (seconds): If you use the same key again before the time-to-live expires, the countdown will reset for another period. The default is 600 (10 minutes).
|
||||
|
||||
* max-cache-ttl (seconds): Regardless of how recently you've used the key since initial passphrase entry, if the maximum time-to-live countdown expires, you'll have to enter the passphrase again. The default is 30 minutes.
|
||||
|
||||
|
||||
|
||||
|
||||
If you find either of these defaults too short (or too long), you can edit your ~/.gnupg/gpg-agent.conf file to set your own values:
|
||||
```
|
||||
# set to 30 minutes for regular ttl, and 2 hours for max ttl
|
||||
default-cache-ttl 1800
|
||||
max-cache-ttl 7200
|
||||
|
||||
```
|
||||
|
||||
##### Bonus: Using gpg-agent with ssh
|
||||
|
||||
If you've created an [A] (Authentication) key and moved it to the smartcard, you can use it with ssh for adding 2-factor authentication for your ssh sessions. You just need to tell your environment to use the correct socket file for talking to the agent.
|
||||
|
||||
First, add the following to your ~/.gnupg/gpg-agent.conf:
|
||||
```
|
||||
enable-ssh-support
|
||||
|
||||
```
|
||||
|
||||
Then, add this to your .bashrc:
|
||||
```
|
||||
export SSH_AUTH_SOCK=$(gpgconf --list-dirs agent-ssh-socket)
|
||||
|
||||
```
|
||||
|
||||
You will need to kill the existing gpg-agent process and start a new login session for the changes to take effect:
|
||||
```
|
||||
$ killall gpg-agent
|
||||
$ bash
|
||||
$ ssh-add -L
|
||||
|
||||
```
|
||||
|
||||
The last command should list the SSH representation of your PGP Auth key (the comment should say cardno:XXXXXXXX at the end to indicate it's coming from the smartcard).
|
||||
|
||||
To enable key-based logins with ssh, just add the ssh-add -L output to ~/.ssh/authorized_keys on remote systems you log in to. Congratulations, you've just made your ssh credentials extremely difficult to steal.
|
||||
|
||||
As a bonus, you can get other people's PGP-based ssh keys from public keyservers, should you need to grant them ssh access to anything:
|
||||
```
|
||||
$ gpg --export-ssh-key [keyid]
|
||||
|
||||
```
|
||||
|
||||
This can come in super handy if you need to allow developers access to git repositories over ssh. Next time, we'll provide tips for protecting your email accounts as well as your PGP keys.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-6-using-pgp-git
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
[5]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device
|
||||
[6]:https://github.com/jayphelps/git-blame-someone-else
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Protecting Code Integrity with PGP — Part 7: Protecting Online Accounts
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translated by lixinyuxx
|
||||
4 Firefox extensions worth checking out
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translated by lixinyuxx
|
||||
The life cycle of a software bug
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by MjSeven
|
||||
Users, Groups and Other Linux Beasts: Part 2
|
||||
======
|
||||

|
||||
|
||||
@ -1,185 +0,0 @@
|
||||
translating by hopefully2333
|
||||
|
||||
Improve login security with challenge-response authentication
|
||||
======
|
||||
|
||||

|
||||
|
||||
### Introduction
|
||||
|
||||
Today, Fedora offers multiple ways to improve the secure authentication of our user accounts. Of course it has the familiar user name and password to login. It also offers additional authentication options such as biometric, fingerprint, smart card, one-time password, and even challenge-response authentication.
|
||||
|
||||
Each authentication method has clear pros and cons. That, in itself, could be a topic for a rather lengthy article. Fedora Magazine has covered a few of these options previously:
|
||||
|
||||
|
||||
+ [Using the YubiKey4 with Fedora][1]
|
||||
+ [Fedora 28: Better smart card support in OpenSSH][2]
|
||||
|
||||
|
||||
One of the most secure methods in modern Fedora releases is offline hardware challenge-response. It’s also one of the easiest to deploy. Here’s how.
|
||||
|
||||
### Challenge-response authentication
|
||||
|
||||
Technically, when you provide a password, you’re responding to a user name challenge. The offline challenge response covered here requires your user name first. Next, Fedora challenges you to provide an encrypted physical hardware token. The token responds to the challenge with another encrypted key it stores via the Pluggable Authentication Modules (PAM) framework. Finally, Fedora prompts you for the password. This prevents someone from just using a found hardware token, or just using a user name and password without the correct encrypted key.
|
||||
|
||||
This means that in addition to your user name and password, you must have previously registered one or more encrypted hardware tokens with the OS. And you have to provide that physical hardware token to be able to authenticate with your user name.
|
||||
|
||||
Some challenge-response methods, like one time passwords (OTP), take an encrypted code key on the hardware token, and pass that key across the network to a remote authentication server. The server then tells Fedora’s PAM framework if it’s is a valid token for that user name. This is great if the authentication server(s) are on the local network. The downside is if the network connection is down or you’re working remote without a network connection, you can’t use this remote authentication method. You could be locked out of the system until you can connect through the network to the server.
|
||||
|
||||
Sometimes a workplace requires use of Yubikey One Time Passwords (OTP) configuration. However, on home or personal systems you may prefer a local challenge-response configuration. Everything is local, and the method requires no remote network calls. The following process works on Fedora 27, 28, and 29.
|
||||
|
||||
### Preparation
|
||||
|
||||
#### Hardware token keys
|
||||
|
||||
First you need a secure hardware token key. Specifically, this process requires a Yubikey 4, Yubikey NEO, or a recently released Yubikey 5 series device which also supports FIDO2. You should purchase two of them to provide a backup in case one becomes lost or damaged. You can use these keys on numerous workstations. The simpler FIDO or FIDO U2F only versions don’t work for this process, but are great for online services that use FIDO.
|
||||
|
||||
#### Backup, backup, and backup
|
||||
|
||||
Next, make a backup of all your important data. You may want to test the configuration in a Fedora 27/28/29 cloned VM to make sure you understand the process before setting up your personal workstation.
|
||||
|
||||
#### Updating and installing
|
||||
|
||||
Now make sure Fedora is up to date. Then install the required Fedora Yubikey packages via these dnf commands:
|
||||
|
||||
```
|
||||
$ sudo dnf upgrade
|
||||
$ sudo dnf install ykclient* ykpers* pam_yubico*
|
||||
$ cd
|
||||
```
|
||||
|
||||
If you’re in a VM environment, such as Virtual Box, make sure the Yubikey device is inserted in a USB port, and enable USB access to the Yubikey in the VM control.
|
||||
|
||||
### Configuring Yubikey
|
||||
|
||||
Verify that your user account has access to the USB Yubikey:
|
||||
|
||||
```
|
||||
$ ykinfo -v
|
||||
version: 3.5.0
|
||||
```
|
||||
|
||||
If the YubiKey is not detected, the following error message appears:
|
||||
|
||||
```
|
||||
Yubikey core error: no yubikey present
|
||||
```
|
||||
|
||||
Next, initialize each of your new Yubikeys with the following ykpersonalize command. This sets up the Yubikey configuration slot 2 with a Challenge Response using the HMAC-SHA1 algorithm, even with less than 64 characters. If you have already setup your Yubikeys for challenge-response, you don’t need to run ykpersonalize again.
|
||||
|
||||
```
|
||||
ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -oserial-api-visible
|
||||
```
|
||||
|
||||
Some users leave the YubiKey in their workstation while using it, and even use challenge-response for virtual machines. However, for more security you may prefer to manually trigger the Yubikey to respond to challenge.
|
||||
|
||||
To add that manual challenge button trigger, add the -ochal-btn-trig flag. This flag causes the Yubikey to flash the yubikey LED on a request. It waits for you to press the button on the hardware key area within 15 seconds to produce the response key.
|
||||
|
||||
```
|
||||
$ ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -ochal-btn-trig -oserial-api-visible
|
||||
```
|
||||
|
||||
Do this for each of your new hardware keys, only once per key. Once you have programmed your keys, store the Yubikey configuration to ~/.yubico with the following command:
|
||||
|
||||
```
|
||||
$ ykpamcfg -2 -v
|
||||
debug: util.c:222 (check_firmware_version): YubiKey Firmware version: 4.3.4
|
||||
|
||||
Sending 63 bytes HMAC challenge to slot 2
|
||||
Sending 63 bytes HMAC challenge to slot 2
|
||||
Stored initial challenge and expected response in '/home/chuckfinley/.yubico/challenge-9992567'.
|
||||
```
|
||||
|
||||
If you are setting up multiple keys for backup purposes, configure all the keys the same, and store each key’s challenge-response using the ykpamcfg utility. If you run the command ykpersonalize on an existing registered key, you must store the configuration again.
|
||||
|
||||
### Configuring /etc/pam.d/sudo
|
||||
|
||||
Now to verify this configuration worked, **in the same terminal window** you’ll setup sudo to require the use of the Yubikey challenge-response. Insert the following line into the /etc/pam.d/sudo file:
|
||||
|
||||
```
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
```
|
||||
|
||||
Insert the above auth line into the file above the auth include system-auth line. Then save the file and exit the editor. In a default Fedora 29 setup, /etc/pam.d/sudo should now look like this:
|
||||
|
||||
```
|
||||
#%PAM-1.0
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
auth include system-auth
|
||||
account include system-auth
|
||||
password include system-auth
|
||||
session optional pam_keyinit.so revoke
|
||||
session required pam_limits.so
|
||||
session include system-auth
|
||||
```
|
||||
|
||||
**Keep this original terminal window open** , and test by opening another new terminal window. In the new terminal window type:
|
||||
|
||||
```
|
||||
$ sudo echo testing
|
||||
```
|
||||
|
||||
You should notice the LED blinking on the key. Tap the Yubikey button and you should see a prompt for your sudo password. After you enter your password, you should see “testing” echoed in the terminal screen.
|
||||
|
||||
Now test to ensure a correct failure. Start another terminal window and remove the Yubikey from the USB port. Verify that sudo no longer works without the Yubikey with this command:
|
||||
|
||||
```
|
||||
$ sudo echo testing fail
|
||||
```
|
||||
|
||||
You should immediately be prompted for the sudo password. Even if you enter the password, it should fail.
|
||||
|
||||
### Configuring Gnome Desktop Manager
|
||||
|
||||
Once your testing is complete, now you can add challenge-response support for the graphical login. Re-insert your Yubikey into the USB port. Next you’ll add the following line to the /etc/pam.d/gdm-password file:
|
||||
|
||||
```
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
```
|
||||
|
||||
Open a terminal window, and issue the following command. You can use another editor if desired:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/pam.d/gdm-password
|
||||
```
|
||||
|
||||
You should see the yubikey LED blinking. Press the yubikey button, then enter the password at the prompt.
|
||||
|
||||
Modify the /etc/pam.d/gdm-password file to add the new auth line above the existing line auth substack password-auth. The top of the file should now look like this:
|
||||
|
||||
```
|
||||
auth [success=done ignore=ignore default=bad] pam_selinux_permit.so
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
auth substack password-auth
|
||||
auth optional pam_gnome_keyring.so
|
||||
auth include postlogin
|
||||
|
||||
account required pam_nologin.so
|
||||
```
|
||||
|
||||
Save the changes and exit the editor. If you use vi, the key sequence is to hit the **Esc** key, then type wq! at the prompt to save and exit.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Now log out of GNOME. With the Yubikey inserted into the USB port, click on your user name in the graphical login. The Yubikey LED begins to flash. Touch the button, and you will be prompted for your password.
|
||||
|
||||
If you lose the Yubikey, you can still use the secondary backup Yubikey in addition to your set password. You can also add additional Yubikey configurations to your user account.
|
||||
|
||||
If someone gains access to your password, they still can’t login without your physical hardware Yubikey. Congratulations! You’ve now dramatically increased the security of your workstation login.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/login-challenge-response-authentication/
|
||||
|
||||
作者:[nabooengineer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/nabooengineer/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/using-the-yubikey4-with-fedora/
|
||||
[2]: https://fedoramagazine.org/fedora-28-better-smart-card-support-openssh/
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: ( Auk7F7)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Arch-Audit : A Tool To Check Vulnerable Packages In Arch Linux)
|
||||
@ -7,6 +7,7 @@
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
[#]: url: ( )
|
||||
|
||||
|
||||
Arch-Audit : A Tool To Check Vulnerable Packages In Arch Linux
|
||||
======
|
||||
|
||||
|
||||
169
sources/tech/20181204 4 Unique Terminal Emulators for Linux.md
Normal file
169
sources/tech/20181204 4 Unique Terminal Emulators for Linux.md
Normal file
@ -0,0 +1,169 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 Unique Terminal Emulators for Linux)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2018/12/4-unique-terminals-linux)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
|
||||
4 Unique Terminal Emulators for Linux
|
||||
======
|
||||

|
||||
Let’s face it, if you’re a Linux administrator, you’re going to work with the command line. To do that, you’ll be using a terminal emulator. Most likely, your distribution of choice came pre-installed with a default terminal emulator that gets the job done. But this is Linux, so you have a wealth of choices to pick from, and that ideology holds true for terminal emulators as well. In fact, if you open up your distribution’s GUI package manager (or search from the command line), you’ll find a trove of possible options. Of those, many are pretty straightforward tools; however, some are truly unique.
|
||||
|
||||
In this article, I’ll highlight four such terminal emulators, that will not only get the job done, but do so while making the job a bit more interesting or fun. So, let’s take a look at these terminals.
|
||||
|
||||
### Tilda
|
||||
|
||||
[Tilda][1] is designed for Gtk and is a member of the cool drop-down family of terminals. That means the terminal is always running in the background, ready to drop down from the top of your monitor (such as Guake and Yakuake). What makes Tilda rise above many of the others is the number of configuration options available for the terminal (Figure 1).
|
||||

|
||||
|
||||
Tilda can be installed from the standard repositories. On a Ubuntu- (or Debian-) based distribution, the installation is as simple as:
|
||||
|
||||
```
|
||||
sudo apt-get install tilda -y
|
||||
```
|
||||
|
||||
Once installed, open Tilda from your desktop menu, which will also open the configuration window. Configure the app to suit your taste and then close the configuration window. You can then open and close Tilda by hitting the F1 hotkey. One caveat to using Tilda is that, after the first run, you won’t find any indication as to how to reach the configuration wizard. No worries. If you run the command tilda -C it will open the configuration window, while still retaining the options you’ve previously set.
|
||||
|
||||
Available options include:
|
||||
|
||||
* Terminal size and location
|
||||
|
||||
* Font and color configurations
|
||||
|
||||
* Auto Hide
|
||||
|
||||
* Title
|
||||
|
||||
* Custom commands
|
||||
|
||||
* URL Handling
|
||||
|
||||
* Transparency
|
||||
|
||||
* Animation
|
||||
|
||||
* Scrolling
|
||||
|
||||
* And more
|
||||
|
||||
|
||||
|
||||
|
||||
What I like about these types of terminals is that they easily get out of the way when you don’t need them and are just a button click away when you do. For those that hop in and out of the terminal, a tool like Tilda is ideal.
|
||||
|
||||
### Aterm
|
||||
|
||||
Aterm holds a special place in my heart, as it was one of the first terminals I used that made me realize how flexible Linux was. This was back when AfterStep was my window manager of choice (which dates me a bit) and I was new to the command line. What Aterm offered was a terminal emulator that was highly customizable, while helping me learn the ins and outs of using the terminal (how to add options and switches to a command). “How?” you ask. Because Aterm never had a GUI for customization. To run Aterm with any special options, it had to run as a command. For example, say you want to open Aterm with transparency enabled, green text, white highlights, and no scroll bar. To do this, issue the command:
|
||||
|
||||
```
|
||||
aterm -tr -fg green -bg white +xb
|
||||
```
|
||||
|
||||
The end result (with the top command running for illustration) would look like that shown in Figure 2.
|
||||
|
||||
![Aterm][3]
|
||||
|
||||
Figure 2: Aterm with a few custom options.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
Of course, you must first install Aterm. Fortunately, the application is still found in the standard repositories, so installing on the likes of Ubuntu is as simple as:
|
||||
|
||||
```
|
||||
sudo apt-get install aterm -y
|
||||
```
|
||||
|
||||
If you want to always open Aterm with those options, your best bet is to create an alias in your ~/.bashrc file like so:
|
||||
|
||||
```
|
||||
alias=”aterm -tr -fg green -bg white +sb”
|
||||
```
|
||||
|
||||
Save that file and, when you issue the command aterm, it will always open with those options. For more about creating aliases, check out [this tutorial][5].
|
||||
|
||||
### Eterm
|
||||
|
||||
Eterm is the second terminal that really showed me how much fun the Linux command line could be. Eterm is the default terminal emulator for the Enlightenment desktop. When I eventually migrated from AfterStep to Enlightenment (back in the early 2000s), I was afraid I’d lose out on all those cool aesthetic options. That turned out to not be the case. In fact, Eterm offered plenty of unique options, while making the task easier with a terminal toolbar. With Eterm, you can easily select from a large number of background images (should you want one - Figure 3) by selecting from the Background > Pixmap menu entry.
|
||||
|
||||
![Eterm][7]
|
||||
|
||||
Figure 3: Selecting from one of the many background images for Eterm.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
There are a number of other options to configure (such as font size, map alerts, toggle scrollbar, brightness, contrast, and gamma of background images, and more). The one thing you want to make sure is, after you’ve configured Eterm to suit your tastes, to click Eterm > Save User Settings (otherwise, all settings will be lost when you close the app).
|
||||
|
||||
Eterm can be installed from the standard repositories, with a command such as:
|
||||
|
||||
```
|
||||
sudo apt-get install eterm
|
||||
```
|
||||
|
||||
### Extraterm
|
||||
|
||||
[Extraterm][8] should probably win a few awards for coolest feature set of any terminal window project available today. The most unique feature of Extraterm is the ability to wrap commands in color-coded frames (blue for successful commands and red for failed commands - Figure 4).
|
||||
|
||||
![Extraterm][10]
|
||||
|
||||
Figure 4: Extraterm showing two failed command frames.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
When you run a command, Extraterm will wrap the command in an isolated frame. If the command succeeds, the frame will be outlined in blue. Should the command fail, the frame will be outlined in red.
|
||||
|
||||
Extraterm cannot be installed via the standard repositories. In fact, the only way to run Extraterm on Linux (at the moment) is to [download the precompiled binary][11] from the project’s GitHub page, extract the file, change into the newly created directory, and issue the command ./extraterm.
|
||||
|
||||
Once the app is running, to enable frames you must first enable bash integration. To do that, open Extraterm and then right-click anywhere in the window to reveal the popup menu. Scroll until you see the entry for Inject Bash shell Integration (Figure 5). Select that entry and you can then begin using the frames option.
|
||||
|
||||
![Extraterm][13]
|
||||
|
||||
Figure 5: Injecting Bash integration for Extraterm.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
If you run a command, and don’t see a frame appear, you probably have to create a new frame for the command (as Extraterm only ships with a few default frames). To do that, click on the Extraterm menu button (three horizontal lines in the top right corner of the window), select Settings, and then click the Frames tab. In this window, scroll down and click the New Rule button. You can then add a command you want to work with the frames option (Figure 6).
|
||||
|
||||
![frames][15]
|
||||
|
||||
Figure 6: Adding a new rule for frames.
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
If, after this, you still don’t see frames appearing, download the extraterm-commands file from the [Download page][11], extract the file, change into the newly created directory, and issue the command sh setup_extraterm_bash.sh. That should enable frames for Extraterm.
|
||||
There’s plenty more options available for Extraterm. I’m convinced, once you start playing around with this new take on the terminal window, you won’t want to go back to the standard terminal. Hopefully the developer will make this app available to the standard repositories soon (as it could easily become one of the most popular terminal windows in use).
|
||||
|
||||
### And Many More
|
||||
|
||||
As you probably expected, there are quite a lot of terminals available for Linux. These four represent (at least for me) four unique takes on the task, each of which do a great job of helping you run the commands every Linux admin needs to run. If you aren’t satisfied with one of these, give your package manager a look to see what’s available. You are sure to find something that works perfectly for you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/12/4-unique-terminals-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://tilda.sourceforge.net/tildadoc.php
|
||||
[2]: https://www.linux.com/files/images/terminals2jpg
|
||||
[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/terminals_2.jpg?itok=gBkRLwDI (Aterm)
|
||||
[4]: https://www.linux.com/licenses/category/used-permission
|
||||
[5]: https://www.linux.com/blog/learn/2018/12/aliases-diy-shell-commands
|
||||
[6]: https://www.linux.com/files/images/terminals3jpg
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/terminals_3.jpg?itok=RVPTJAtK (Eterm)
|
||||
[8]: http://extraterm.org
|
||||
[9]: https://www.linux.com/files/images/terminals4jpg
|
||||
[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/terminals_4.jpg?itok=2n01qdwO (Extraterm)
|
||||
[11]: https://github.com/sedwards2009/extraterm/releases
|
||||
[12]: https://www.linux.com/files/images/terminals5jpg
|
||||
[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/terminals_5.jpg?itok=FdaE1Mpf (Extraterm)
|
||||
[14]: https://www.linux.com/files/images/terminals6jpg
|
||||
[15]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/terminals_6.jpg?itok=lQ1Zv5wq (frames)
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,745 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (TLP – An Advanced Power Management Tool That Improve Battery Life On Linux Laptop)
|
||||
[#]: via: (https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
TLP – An Advanced Power Management Tool That Improve Battery Life On Linux Laptop
|
||||
======
|
||||
|
||||
Laptop battery is highly optimized for Windows OS, that i had realized when i was using Windows OS in my laptop but it’s not same for Linux.
|
||||
|
||||
Over the years Linux has improved a lot for battery optimization but still we need make some necessary things to improve laptop battery life in Linux.
|
||||
|
||||
When i think about battery life, i got few options for that but i felt TLP is a better solutions for me so, i’m going with it.
|
||||
|
||||
In this tutorial we are going to discuss about TLP in details to improve battery life.
|
||||
|
||||
We had written three articles previously in our site about **[laptop battery saving utilities][1]** for Linux **[PowerTOP][2]** and **[Battery Charging State][3]**.
|
||||
|
||||
### What is TLP?
|
||||
|
||||
[TLP][4] is a free opensource advanced power management tool that improve your battery life without making any configuration change.
|
||||
|
||||
Since it comes with a default configuration already optimized for battery life, so you may just install and forget it.
|
||||
|
||||
Also, it is highly customizable to fulfill your specific requirements. TLP is a pure command line tool with automated background tasks. It does not contain a GUI.
|
||||
|
||||
TLP runs on every laptop brand. Setting the battery charge thresholds is available for IBM/Lenovo ThinkPads only.
|
||||
|
||||
All TLP settings are stored in `/etc/default/tlp`. The default configuration provides optimized power saving out of the box.
|
||||
|
||||
The following TLP settings is available for customization and you need to make the necessary changes accordingly if you want it.
|
||||
|
||||
### TLP Features
|
||||
|
||||
* Kernel laptop mode and dirty buffer timeouts
|
||||
* Processor frequency scaling including “turbo boost” / “turbo core”
|
||||
* Limit max/min P-state to control power dissipation of the CPU
|
||||
* HWP energy performance hints
|
||||
* Power aware process scheduler for multi-core/hyper-threading
|
||||
* Processor performance versus energy savings policy (x86_energy_perf_policy)
|
||||
* Hard disk advanced power magement level (APM) and spin down timeout (per disk)
|
||||
* AHCI link power management (ALPM) with device blacklist
|
||||
* PCIe active state power management (PCIe ASPM)
|
||||
* Runtime power management for PCI(e) bus devices
|
||||
* Radeon graphics power management (KMS and DPM)
|
||||
* Wifi power saving mode
|
||||
* Power off optical drive in drive bay
|
||||
* Audio power saving mode
|
||||
* I/O scheduler (per disk)
|
||||
* USB autosuspend with device blacklist/whitelist (input devices excluded automatically)
|
||||
* Enable or disable integrated wifi, bluetooth or wwan devices upon system startup and shutdown
|
||||
* Restore radio device state on system startup (from previous shutdown).
|
||||
* Radio device wizard: switch radios upon network connect/disconnect and dock/undock
|
||||
* Disable Wake On LAN
|
||||
* Integrated WWAN and bluetooth state is restored after suspend/hibernate
|
||||
* Untervolting of Intel processors – requires kernel with PHC-Patch
|
||||
* Battery charge thresholds – ThinkPads only
|
||||
* Recalibrate battery – ThinkPads only
|
||||
|
||||
|
||||
|
||||
### How to Install TLP in Linux
|
||||
|
||||
TLP package is available in most of the distributions official repository so, use the distributions **[Package Manager][5]** to install it.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][6]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo dnf install tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPads require an additional packages.
|
||||
|
||||
```
|
||||
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
|
||||
$ sudo dnf install http://repo.linrunner.de/fedora/tlp/repos/releases/tlp-release.fc$(rpm -E %fedora).noarch.rpm
|
||||
$ sudo dnf install akmod-tp_smapi akmod-acpi_call kernel-devel
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo dnf install smartmontools
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][7]** or **[APT Command][8]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo apt install tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPads require an additional packages.
|
||||
|
||||
```
|
||||
$ sudo apt-get install tp-smapi-dkms acpi-call-dkms
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo apt-get install smartmontools
|
||||
```
|
||||
|
||||
When the official package becomes outdated for Ubuntu based systems then use the following PPA repository which provides an up-to-date version. Run the following commands to install TLP using the PPA.
|
||||
|
||||
```
|
||||
$ sudo apt-get install tlp tlp-rdw
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][9]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo pacman -S tlp tlp-rdw
|
||||
```
|
||||
|
||||
ThinkPads require an additional packages.
|
||||
|
||||
```
|
||||
$ pacman -S tp_smapi acpi_call
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo pacman -S smartmontools
|
||||
```
|
||||
|
||||
Enable TLP & TLP-Sleep service on boot for Arch Linux based systems.
|
||||
|
||||
```
|
||||
$ sudo systemctl enable tlp.service
|
||||
$ sudo systemctl enable tlp-sleep.service
|
||||
```
|
||||
|
||||
You should also mask the following services to avoid conflicts and assure proper operation of TLP’s radio device switching options for Arch Linux based systems.
|
||||
|
||||
```
|
||||
$ sudo systemctl mask systemd-rfkill.service
|
||||
$ sudo systemctl mask systemd-rfkill.socket
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][10]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo yum install tlp tlp-rdw
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo yum install smartmontools
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][11]** to install TLP.
|
||||
|
||||
```
|
||||
$ sudo zypper install TLP
|
||||
```
|
||||
|
||||
Install smartmontool to display S.M.A.R.T. data in tlp-stat.
|
||||
|
||||
```
|
||||
$ sudo zypper install smartmontools
|
||||
```
|
||||
|
||||
After successfully TLP installed, use the following command to start the service.
|
||||
|
||||
```
|
||||
$ systemctl start tlp.service
|
||||
```
|
||||
|
||||
To show battery information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -b
|
||||
or
|
||||
$ sudo tlp-stat --battery
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Battery Status
|
||||
/sys/class/power_supply/BAT0/manufacturer = SMP
|
||||
/sys/class/power_supply/BAT0/model_name = L14M4P23
|
||||
/sys/class/power_supply/BAT0/cycle_count = (not supported)
|
||||
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_full = 48850 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_now = 48850 [mWh]
|
||||
/sys/class/power_supply/BAT0/power_now = 0 [mW]
|
||||
/sys/class/power_supply/BAT0/status = Full
|
||||
|
||||
Charge = 100.0 [%]
|
||||
Capacity = 81.4 [%]
|
||||
```
|
||||
|
||||
To show disk information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -d
|
||||
or
|
||||
$ sudo tlp-stat --disk
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Storage Devices
|
||||
/dev/sda:
|
||||
Model = WDC WD10SPCX-24HWST1
|
||||
Firmware = 02.01A02
|
||||
APM Level = 128
|
||||
Status = active/idle
|
||||
Scheduler = mq-deadline
|
||||
|
||||
Runtime PM: control = on, autosuspend_delay = (not available)
|
||||
|
||||
SMART info:
|
||||
4 Start_Stop_Count = 18787
|
||||
5 Reallocated_Sector_Ct = 0
|
||||
9 Power_On_Hours = 606 [h]
|
||||
12 Power_Cycle_Count = 1792
|
||||
193 Load_Cycle_Count = 25775
|
||||
194 Temperature_Celsius = 31 [°C]
|
||||
|
||||
|
||||
+++ AHCI Link Power Management (ALPM)
|
||||
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
|
||||
|
||||
+++ AHCI Host Controller Runtime Power Management
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
|
||||
```
|
||||
|
||||
To show PCI device information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -e
|
||||
or
|
||||
$ sudo tlp-stat --pcie
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Runtime Power Management
|
||||
Device blacklist = (not configured)
|
||||
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
|
||||
|
||||
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
|
||||
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
|
||||
/sys/bus/pci/devices/0000:00:14.0/power/control = auto (0x0c0330, USB controller, xhci_hcd)
|
||||
/sys/bus/pci/devices/0000:00:16.0/power/control = auto (0x078000, Communication controller, mei_me)
|
||||
/sys/bus/pci/devices/0000:00:17.0/power/control = auto (0x010601, SATA controller, ahci)
|
||||
/sys/bus/pci/devices/0000:00:1c.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1c.2/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1c.3/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1d.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1f.0/power/control = auto (0x060100, ISA bridge, no driver)
|
||||
/sys/bus/pci/devices/0000:00:1f.2/power/control = auto (0x058000, Memory controller, no driver)
|
||||
/sys/bus/pci/devices/0000:00:1f.3/power/control = auto (0x040300, Audio device, snd_hda_intel)
|
||||
/sys/bus/pci/devices/0000:00:1f.4/power/control = auto (0x0c0500, SMBus, i801_smbus)
|
||||
/sys/bus/pci/devices/0000:01:00.0/power/control = auto (0x030200, 3D controller, nouveau)
|
||||
/sys/bus/pci/devices/0000:07:00.0/power/control = auto (0x080501, SD Host controller, sdhci-pci)
|
||||
/sys/bus/pci/devices/0000:08:00.0/power/control = auto (0x028000, Network controller, iwlwifi)
|
||||
/sys/bus/pci/devices/0000:09:00.0/power/control = auto (0x020000, Ethernet controller, r8168)
|
||||
/sys/bus/pci/devices/0000:0a:00.0/power/control = auto (0x010802, Non-Volatile memory controller, nvme)
|
||||
```
|
||||
|
||||
To show graphics card information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -g
|
||||
or
|
||||
$ sudo tlp-stat --graphics
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Intel Graphics
|
||||
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
|
||||
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
|
||||
/sys/module/i915/parameters/enable_psr = 0 (disabled)
|
||||
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
|
||||
```
|
||||
|
||||
To show Processor information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -p
|
||||
or
|
||||
$ sudo tlp-stat --processor
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Processor
|
||||
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
|
||||
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
|
||||
|
||||
x86_energy_perf_policy: program not installed.
|
||||
|
||||
/sys/module/workqueue/parameters/power_efficient = Y
|
||||
/proc/sys/kernel/nmi_watchdog = 0
|
||||
|
||||
+++ Undervolting
|
||||
PHC kernel not available.
|
||||
```
|
||||
|
||||
To show system data information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -s
|
||||
or
|
||||
$ sudo tlp-stat --system
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ System Info
|
||||
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
|
||||
BIOS = CDCN35WW
|
||||
Release = "Manjaro Linux"
|
||||
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
|
||||
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
|
||||
Init system = systemd
|
||||
Boot mode = BIOS (CSM, Legacy)
|
||||
|
||||
+++ TLP Status
|
||||
State = enabled
|
||||
Last run = 11:04:00 IST, 596 sec(s) ago
|
||||
Mode = battery
|
||||
Power source = battery
|
||||
```
|
||||
|
||||
To show temperatures and fan speed information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -t
|
||||
or
|
||||
$ sudo tlp-stat --temp
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Temperatures
|
||||
CPU temp = 36 [°C]
|
||||
Fan speed = (not available)
|
||||
```
|
||||
|
||||
To show USB device data information.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -u
|
||||
or
|
||||
$ sudo tlp-stat --usb
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ USB
|
||||
Autosuspend = disabled
|
||||
Device whitelist = (not configured)
|
||||
Device blacklist = (not configured)
|
||||
Bluetooth blacklist = disabled
|
||||
Phone blacklist = disabled
|
||||
WWAN blacklist = enabled
|
||||
|
||||
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
|
||||
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
|
||||
Bus 001 Device 002 ID 17ef:6053 control = on, autosuspend_delay_ms = 2000 -- Lenovo (usbhid)
|
||||
Bus 001 Device 004 ID 8087:0a2b control = auto, autosuspend_delay_ms = 2000 -- Intel Corp. (btusb)
|
||||
Bus 001 Device 001 ID 1d6b:0002 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 2.0 root hub (hub)
|
||||
```
|
||||
|
||||
To show warnings.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat -w
|
||||
or
|
||||
$ sudo tlp-stat --warn
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
No warnings detected.
|
||||
```
|
||||
|
||||
Status report with configuration and all active settings.
|
||||
|
||||
```
|
||||
$ sudo tlp-stat
|
||||
|
||||
--- TLP 1.1 --------------------------------------------
|
||||
|
||||
+++ Configured Settings: /etc/default/tlp
|
||||
TLP_ENABLE=1
|
||||
TLP_DEFAULT_MODE=AC
|
||||
TLP_PERSISTENT_DEFAULT=0
|
||||
DISK_IDLE_SECS_ON_AC=0
|
||||
DISK_IDLE_SECS_ON_BAT=2
|
||||
MAX_LOST_WORK_SECS_ON_AC=15
|
||||
MAX_LOST_WORK_SECS_ON_BAT=60
|
||||
CPU_HWP_ON_AC=balance_performance
|
||||
CPU_HWP_ON_BAT=balance_power
|
||||
SCHED_POWERSAVE_ON_AC=0
|
||||
SCHED_POWERSAVE_ON_BAT=1
|
||||
NMI_WATCHDOG=0
|
||||
ENERGY_PERF_POLICY_ON_AC=performance
|
||||
ENERGY_PERF_POLICY_ON_BAT=power
|
||||
DISK_DEVICES="sda sdb"
|
||||
DISK_APM_LEVEL_ON_AC="254 254"
|
||||
DISK_APM_LEVEL_ON_BAT="128 128"
|
||||
SATA_LINKPWR_ON_AC="med_power_with_dipm max_performance"
|
||||
SATA_LINKPWR_ON_BAT="med_power_with_dipm max_performance"
|
||||
AHCI_RUNTIME_PM_TIMEOUT=15
|
||||
PCIE_ASPM_ON_AC=performance
|
||||
PCIE_ASPM_ON_BAT=powersave
|
||||
RADEON_POWER_PROFILE_ON_AC=default
|
||||
RADEON_POWER_PROFILE_ON_BAT=low
|
||||
RADEON_DPM_STATE_ON_AC=performance
|
||||
RADEON_DPM_STATE_ON_BAT=battery
|
||||
RADEON_DPM_PERF_LEVEL_ON_AC=auto
|
||||
RADEON_DPM_PERF_LEVEL_ON_BAT=auto
|
||||
WIFI_PWR_ON_AC=off
|
||||
WIFI_PWR_ON_BAT=on
|
||||
WOL_DISABLE=Y
|
||||
SOUND_POWER_SAVE_ON_AC=0
|
||||
SOUND_POWER_SAVE_ON_BAT=1
|
||||
SOUND_POWER_SAVE_CONTROLLER=Y
|
||||
BAY_POWEROFF_ON_AC=0
|
||||
BAY_POWEROFF_ON_BAT=0
|
||||
BAY_DEVICE="sr0"
|
||||
RUNTIME_PM_ON_AC=on
|
||||
RUNTIME_PM_ON_BAT=auto
|
||||
RUNTIME_PM_DRIVER_BLACKLIST="amdgpu nouveau nvidia radeon pcieport"
|
||||
USB_AUTOSUSPEND=0
|
||||
USB_BLACKLIST_BTUSB=0
|
||||
USB_BLACKLIST_PHONE=0
|
||||
USB_BLACKLIST_PRINTER=1
|
||||
USB_BLACKLIST_WWAN=1
|
||||
RESTORE_DEVICE_STATE_ON_STARTUP=0
|
||||
|
||||
+++ System Info
|
||||
System = LENOVO Lenovo ideapad Y700-15ISK 80NV
|
||||
BIOS = CDCN35WW
|
||||
Release = "Manjaro Linux"
|
||||
Kernel = 4.19.6-1-MANJARO #1 SMP PREEMPT Sat Dec 1 12:21:26 UTC 2018 x86_64
|
||||
/proc/cmdline = BOOT_IMAGE=/boot/vmlinuz-4.19-x86_64 root=UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f rw quiet resume=UUID=a2092b92-af29-4760-8e68-7a201922573b
|
||||
Init system = systemd
|
||||
Boot mode = BIOS (CSM, Legacy)
|
||||
|
||||
+++ TLP Status
|
||||
State = enabled
|
||||
Last run = 11:04:00 IST, 684 sec(s) ago
|
||||
Mode = battery
|
||||
Power source = battery
|
||||
|
||||
+++ Processor
|
||||
CPU model = Intel(R) Core(TM) i7-6700HQ CPU @ 2.60GHz
|
||||
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu0/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu1/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu2/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu3/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu4/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu5/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu6/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_driver = intel_pstate
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_governor = powersave
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_available_governors = performance powersave
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_min_freq = 800000 [kHz]
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/scaling_max_freq = 3500000 [kHz]
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/energy_performance_preference = balance_power
|
||||
/sys/devices/system/cpu/cpu7/cpufreq/energy_performance_available_preferences = default performance balance_performance balance_power power
|
||||
|
||||
/sys/devices/system/cpu/intel_pstate/min_perf_pct = 22 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/max_perf_pct = 100 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/no_turbo = 0
|
||||
/sys/devices/system/cpu/intel_pstate/turbo_pct = 33 [%]
|
||||
/sys/devices/system/cpu/intel_pstate/num_pstates = 28
|
||||
|
||||
x86_energy_perf_policy: program not installed.
|
||||
|
||||
/sys/module/workqueue/parameters/power_efficient = Y
|
||||
/proc/sys/kernel/nmi_watchdog = 0
|
||||
|
||||
+++ Undervolting
|
||||
PHC kernel not available.
|
||||
|
||||
+++ Temperatures
|
||||
CPU temp = 42 [°C]
|
||||
Fan speed = (not available)
|
||||
|
||||
+++ File System
|
||||
/proc/sys/vm/laptop_mode = 2
|
||||
/proc/sys/vm/dirty_writeback_centisecs = 6000
|
||||
/proc/sys/vm/dirty_expire_centisecs = 6000
|
||||
/proc/sys/vm/dirty_ratio = 20
|
||||
/proc/sys/vm/dirty_background_ratio = 10
|
||||
|
||||
+++ Storage Devices
|
||||
/dev/sda:
|
||||
Model = WDC WD10SPCX-24HWST1
|
||||
Firmware = 02.01A02
|
||||
APM Level = 128
|
||||
Status = active/idle
|
||||
Scheduler = mq-deadline
|
||||
|
||||
Runtime PM: control = on, autosuspend_delay = (not available)
|
||||
|
||||
SMART info:
|
||||
4 Start_Stop_Count = 18787
|
||||
5 Reallocated_Sector_Ct = 0
|
||||
9 Power_On_Hours = 606 [h]
|
||||
12 Power_Cycle_Count = 1792
|
||||
193 Load_Cycle_Count = 25777
|
||||
194 Temperature_Celsius = 31 [°C]
|
||||
|
||||
|
||||
+++ AHCI Link Power Management (ALPM)
|
||||
/sys/class/scsi_host/host0/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host1/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host2/link_power_management_policy = med_power_with_dipm
|
||||
/sys/class/scsi_host/host3/link_power_management_policy = med_power_with_dipm
|
||||
|
||||
+++ AHCI Host Controller Runtime Power Management
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata1/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata2/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata3/power/control = on
|
||||
/sys/bus/pci/devices/0000:00:17.0/ata4/power/control = on
|
||||
|
||||
+++ PCIe Active State Power Management
|
||||
/sys/module/pcie_aspm/parameters/policy = powersave
|
||||
|
||||
+++ Intel Graphics
|
||||
/sys/module/i915/parameters/enable_dc = -1 (use per-chip default)
|
||||
/sys/module/i915/parameters/enable_fbc = 1 (enabled)
|
||||
/sys/module/i915/parameters/enable_psr = 0 (disabled)
|
||||
/sys/module/i915/parameters/modeset = -1 (use per-chip default)
|
||||
|
||||
+++ Wireless
|
||||
bluetooth = on
|
||||
wifi = on
|
||||
wwan = none (no device)
|
||||
|
||||
hci0(btusb) : bluetooth, not connected
|
||||
wlp8s0(iwlwifi) : wifi, connected, power management = on
|
||||
|
||||
+++ Audio
|
||||
/sys/module/snd_hda_intel/parameters/power_save = 1
|
||||
/sys/module/snd_hda_intel/parameters/power_save_controller = Y
|
||||
|
||||
+++ Runtime Power Management
|
||||
Device blacklist = (not configured)
|
||||
Driver blacklist = amdgpu nouveau nvidia radeon pcieport
|
||||
|
||||
/sys/bus/pci/devices/0000:00:00.0/power/control = auto (0x060000, Host bridge, skl_uncore)
|
||||
/sys/bus/pci/devices/0000:00:01.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:02.0/power/control = auto (0x030000, VGA compatible controller, i915)
|
||||
/sys/bus/pci/devices/0000:00:14.0/power/control = auto (0x0c0330, USB controller, xhci_hcd)
|
||||
/sys/bus/pci/devices/0000:00:16.0/power/control = auto (0x078000, Communication controller, mei_me)
|
||||
/sys/bus/pci/devices/0000:00:17.0/power/control = auto (0x010601, SATA controller, ahci)
|
||||
/sys/bus/pci/devices/0000:00:1c.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1c.2/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1c.3/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1d.0/power/control = auto (0x060400, PCI bridge, pcieport)
|
||||
/sys/bus/pci/devices/0000:00:1f.0/power/control = auto (0x060100, ISA bridge, no driver)
|
||||
/sys/bus/pci/devices/0000:00:1f.2/power/control = auto (0x058000, Memory controller, no driver)
|
||||
/sys/bus/pci/devices/0000:00:1f.3/power/control = auto (0x040300, Audio device, snd_hda_intel)
|
||||
/sys/bus/pci/devices/0000:00:1f.4/power/control = auto (0x0c0500, SMBus, i801_smbus)
|
||||
/sys/bus/pci/devices/0000:01:00.0/power/control = auto (0x030200, 3D controller, nouveau)
|
||||
/sys/bus/pci/devices/0000:07:00.0/power/control = auto (0x080501, SD Host controller, sdhci-pci)
|
||||
/sys/bus/pci/devices/0000:08:00.0/power/control = auto (0x028000, Network controller, iwlwifi)
|
||||
/sys/bus/pci/devices/0000:09:00.0/power/control = auto (0x020000, Ethernet controller, r8168)
|
||||
/sys/bus/pci/devices/0000:0a:00.0/power/control = auto (0x010802, Non-Volatile memory controller, nvme)
|
||||
|
||||
+++ USB
|
||||
Autosuspend = disabled
|
||||
Device whitelist = (not configured)
|
||||
Device blacklist = (not configured)
|
||||
Bluetooth blacklist = disabled
|
||||
Phone blacklist = disabled
|
||||
WWAN blacklist = enabled
|
||||
|
||||
Bus 002 Device 001 ID 1d6b:0003 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 3.0 root hub (hub)
|
||||
Bus 001 Device 003 ID 174f:14e8 control = auto, autosuspend_delay_ms = 2000 -- Syntek (uvcvideo)
|
||||
Bus 001 Device 002 ID 17ef:6053 control = on, autosuspend_delay_ms = 2000 -- Lenovo (usbhid)
|
||||
Bus 001 Device 004 ID 8087:0a2b control = auto, autosuspend_delay_ms = 2000 -- Intel Corp. (btusb)
|
||||
Bus 001 Device 001 ID 1d6b:0002 control = auto, autosuspend_delay_ms = 0 -- Linux Foundation 2.0 root hub (hub)
|
||||
|
||||
+++ Battery Status
|
||||
/sys/class/power_supply/BAT0/manufacturer = SMP
|
||||
/sys/class/power_supply/BAT0/model_name = L14M4P23
|
||||
/sys/class/power_supply/BAT0/cycle_count = (not supported)
|
||||
/sys/class/power_supply/BAT0/energy_full_design = 60000 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_full = 51690 [mWh]
|
||||
/sys/class/power_supply/BAT0/energy_now = 50140 [mWh]
|
||||
/sys/class/power_supply/BAT0/power_now = 12185 [mW]
|
||||
/sys/class/power_supply/BAT0/status = Discharging
|
||||
|
||||
Charge = 97.0 [%]
|
||||
Capacity = 86.2 [%]
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/tlp-increase-optimize-linux-laptop-battery-life/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/check-laptop-battery-status-and-charging-state-in-linux-terminal/
|
||||
[2]: https://www.2daygeek.com/powertop-monitors-laptop-battery-usage-linux/
|
||||
[3]: https://www.2daygeek.com/monitor-laptop-battery-charging-state-linux/
|
||||
[4]: https://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html
|
||||
[5]: https://www.2daygeek.com/category/package-management/
|
||||
[6]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
@ -0,0 +1,145 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Podman and user namespaces: A marriage made in heaven)
|
||||
[#]: via: (https://opensource.com/article/18/12/podman-and-user-namespaces)
|
||||
[#]: author: (Daniel J Walsh https://opensource.com/users/rhatdan)
|
||||
|
||||
Podman and user namespaces: A marriage made in heaven
|
||||
======
|
||||
Learn how to use Podman to run containers in separate user namespaces.
|
||||

|
||||
|
||||
[Podman][1], part of the [libpod][2] library, enables users to manage pods, containers, and container images. In my last article, I wrote about [Podman as a more secure way to run containers][3]. Here, I'll explain how to use Podman to run containers in separate user namespaces.
|
||||
|
||||
I have always thought of [user namespace][4], primarily developed by Red Hat's Eric Biederman, as a great feature for separating containers. User namespace allows you to specify a user identifier (UID) and group identifier (GID) mapping to run your containers. This means you can run as UID 0 inside the container and UID 100000 outside the container. If your container processes escape the container, the kernel will treat them as UID 100000. Not only that, but any file object owned by a UID that isn't mapped into the user namespace will be treated as owned by "nobody" (65534, kernel.overflowuid), and the container process will not be allowed access unless the object is accessible by "other" (world readable/writable).
|
||||
|
||||
If you have a file owned by "real" root with permissions [660][5], and the container processes in the user namespace attempt to read it, they will be prevented from accessing it and will see the file as owned by nobody.
|
||||
|
||||
### An example
|
||||
|
||||
Here's how that might work. First, I create a file in my system owned by root.
|
||||
|
||||
```
|
||||
$ sudo bash -c "echo Test > /tmp/test"
|
||||
$ sudo chmod 600 /tmp/test
|
||||
$ sudo ls -l /tmp/test
|
||||
-rw-------. 1 root root 5 Dec 17 16:40 /tmp/test
|
||||
```
|
||||
|
||||
Next, I volume-mount the file into a container running with a user namespace map 0:100000:5000.
|
||||
|
||||
```
|
||||
$ sudo podman run -ti -v /tmp/test:/tmp/test:Z --uidmap 0:100000:5000 fedora sh
|
||||
# id
|
||||
uid=0(root) gid=0(root) groups=0(root)
|
||||
# ls -l /tmp/test
|
||||
-rw-rw----. 1 nobody nobody 8 Nov 30 12:40 /tmp/test
|
||||
# cat /tmp/test
|
||||
cat: /tmp/test: Permission denied
|
||||
```
|
||||
|
||||
The **\--uidmap** setting above tells Podman to map a range of 5000 UIDs inside the container, starting with UID 100000 outside the container (so the range is 100000-104999) to a range starting at UID 0 inside the container (so the range is 0-4999). Inside the container, if my process is running as UID 1, it is 100001 on the host
|
||||
|
||||
Since the real UID=0 is not mapped into the container, any file owned by root will be treated as owned by nobody. Even if the process inside the container has **CAP_DAC_OVERRIDE** , it can't override this protection. **DAC_OVERRIDE** enables root processes to read/write any file on the system, even if the process was not owned by root or world readable or writable.
|
||||
|
||||
User namespace capabilities are not the same as capabilities on the host. They are namespaced capabilities. This means my container root has capabilities only within the container—really only across the range of UIDs that were mapped into the user namespace. If a container process escaped the container, it wouldn't have any capabilities over UIDs not mapped into the user namespace, including UID=0. Even if the processes could somehow enter another container, they would not have those capabilities if the container uses a different range of UIDs.
|
||||
|
||||
Note that SELinux and other technologies also limit what would happen if a container process broke out of the container.
|
||||
|
||||
### Using `podman top` to show user namespaces
|
||||
|
||||
We have added features to **podman top** to allow you to examine the usernames of processes running inside a container and identify their real UIDs on the host.
|
||||
|
||||
Let's start by running a sleep container using our UID mapping.
|
||||
|
||||
```
|
||||
$ sudo podman run --uidmap 0:100000:5000 -d fedora sleep 1000
|
||||
```
|
||||
|
||||
Now run **podman top** :
|
||||
|
||||
```
|
||||
$ sudo podman top --latest user huser
|
||||
USER HUSER
|
||||
root 100000
|
||||
|
||||
$ ps -ef | grep sleep
|
||||
100000 21821 21809 0 08:04 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 1000
|
||||
```
|
||||
|
||||
Notice **podman top** reports that the user process is running as root inside the container but as UID 100000 on the host (HUSER). Also the **ps** command confirms that the sleep process is running as UID 100000.
|
||||
|
||||
Now let's run a second container, but this time we will choose a separate UID map starting at 200000.
|
||||
|
||||
```
|
||||
$ sudo podman run --uidmap 0:200000:5000 -d fedora sleep 1000
|
||||
$ sudo podman top --latest user huser
|
||||
USER HUSER
|
||||
root 200000
|
||||
|
||||
$ ps -ef | grep sleep
|
||||
100000 21821 21809 0 08:04 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 1000
|
||||
200000 23644 23632 1 08:08 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 1000
|
||||
```
|
||||
|
||||
Notice that **podman top** reports the second container is running as root inside the container but as UID=200000 on the host.
|
||||
|
||||
Also look at the **ps** command—it shows both sleep processes running: one as 100000 and the other as 200000.
|
||||
|
||||
This means running the containers inside separate user namespaces gives you traditional UID separation between processes, which has been the standard security tool of Linux/Unix from the beginning.
|
||||
|
||||
### Problems with user namespaces
|
||||
|
||||
For several years, I've advocated user namespace as the security tool everyone wants but hardly anyone has used. The reason is there hasn't been any filesystem support or a shifting file system.
|
||||
|
||||
In containers, you want to share the **base** image between lots of containers. The examples above use the Fedora base image in each example. Most of the files in the Fedora image are owned by real UID=0. If I run a container on this image with the user namespace 0:100000:5000, by default it sees all of these files as owned by nobody, so we need to shift all of these UIDs to match the user namespace. For years, I've wanted a mount option to tell the kernel to remap these file UIDs to match the user namespace. Upstream kernel storage developers continue to investigate and make progress on this feature, but it is a difficult problem.
|
||||
|
||||
|
||||
Podman can use different user namespaces on the same image because of automatic [chowning][6] built into [containers/storage][7] by a team led by Nalin Dahyabhai. Podman uses containers/storage, and the first time Podman uses a container image in a new user namespace, container/storage "chowns" (i.e., changes ownership for) all files in the image to the UIDs mapped in the user namespace and creates a new image. Think of this as the **fedora:0:100000:5000** image.
|
||||
|
||||
When Podman runs another container on the image with the same UID mappings, it uses the "pre-chowned" image. When I run the second container on 0:200000:5000, containers/storage creates a second image, let's call it **fedora:0:200000:5000**.
|
||||
|
||||
Note if you are doing a **podman build** or **podman commit** and push the newly created image to a container registry, Podman will use container/storage to reverse the shift and push the image with all files chowned back to real UID=0.
|
||||
|
||||
This can cause a real slowdown in creating containers in new UID mappings since the **chown** can be slow depending on the number of files in the image. Also, on a normal [OverlayFS][8], every file in the image gets copied up. The normal Fedora image can take up to 30 seconds to finish the chown and start the container.
|
||||
|
||||
Luckily, the Red Hat kernel storage team, primarily Vivek Goyal and Miklos Szeredi, added a new feature to OverlayFS in kernel 4.19. The feature is called **metadata only copy-up**. If you mount an overlay filesystem with **metacopy=on** as a mount option, it will not copy up the contents of the lower layers when you change file attributes; the kernel creates new inodes that include the attributes with references pointing at the lower-level data. It will still copy up the contents if the content changes. This functionality is available in the Red Hat Enterprise Linux 8 Beta, if you want to try it out.
|
||||
|
||||
This means container chowning can happen in a couple of seconds, and you won't double the storage space for each container.
|
||||
|
||||
This makes running containers with tools like Podman in separate user namespaces viable, greatly increasing the security of the system.
|
||||
|
||||
### Going forward
|
||||
|
||||
I want to add a new flag, like **\--userns=auto** , to Podman that will tell it to automatically pick a unique user namespace for each container you run. This is similar to the way SELinux works with separate multi-category security (MCS) labels. If you set the environment variable **PODMAN_USERNS=auto** , you won't even need to set the flag.
|
||||
|
||||
Podman is finally allowing users to run containers in separate user namespaces. Tools like [Buildah][9] and [CRI-O][10] will also be able to take advantage of user namespaces. For CRI-O, however, Kubernetes needs to understand which user namespace will run the container engine, and the upstream is working on that.
|
||||
|
||||
In my next article, I will explain how to run Podman as non-root in a user namespace.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/podman-and-user-namespaces
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rhatdan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://podman.io/
|
||||
[2]: https://github.com/containers/libpod
|
||||
[3]: https://opensource.com/article/18/10/podman-more-secure-way-run-containers
|
||||
[4]: http://man7.org/linux/man-pages/man7/user_namespaces.7.html
|
||||
[5]: https://chmodcommand.com/chmod-660/
|
||||
[6]: https://en.wikipedia.org/wiki/Chown
|
||||
[7]: https://github.com/containers/storage
|
||||
[8]: https://en.wikipedia.org/wiki/OverlayFS
|
||||
[9]: https://buildah.io/
|
||||
[10]: http://cri-o.io/
|
||||
@ -0,0 +1,57 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Relax by the fire at your Linux terminal)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-aafire)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Relax by the fire at your Linux terminal
|
||||
======
|
||||
Chestnuts roasting on an open command prompt? Why not, with this fun Linux toy.
|
||||
|
||||
|
||||
|
||||
Welcome back. Here we are, just past the halfway mark at day 13 of our 24 days of Linux command-line toys. If this is your first visit to the series, see the link to the previous article at the bottom of this one, and take a look back to learn what it's all about. In short, our command-line toys are anything that's a fun diversion at the terminal.
|
||||
|
||||
Maybe some are familiar, and some aren't. Either way, we hope you have fun.
|
||||
|
||||
If you're in the northern hemisphere outside of the tropics, perhaps winter is starting to rear its frigid face outside. At least it is where I live. And some I'd love nothing more than to curl up by the fire with a cup of tea and my favorite book (or a digital equivalent).
|
||||
|
||||
The bad news is my house lacks a fireplace. The good news is that I can still pretend, thanks to the Linux terminal and today's command-line toy, **aafire**.
|
||||
|
||||
On my system, I found **aafire** packed with **aalib** , a delightful library for converting visual images into the style of ASCII art and making it available at your terminal (or elsewhere). **aalib** enables all sorts of fun graphics at the Linux terminal, so we may revisit a toy or two that make use of it before the end of our series. On Fedora, this meant installation was as simple as:
|
||||
|
||||
```
|
||||
$ sudo dnf install aalib
|
||||
```
|
||||
|
||||
Then, it was simple to launch with the **aafire** command. By default, **aalib** attempted to draw to my GUI, so I had to manually override it to keep my fire in the terminal (this is a command-line series, after all). Fortunately, it comes with a [curses][1] driver, so this meant I just had to run the following to get my fire going:
|
||||
|
||||
```
|
||||
$ aafire -driver curses
|
||||
```
|
||||

|
||||
You can find out more about the **aa-lib** library and download the source on [Sourceforge][2], under an LGPLv2 license.
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to include? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Check out yesterday's toy, [Patch into The Matrix at the Linux command line][3] , and check back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-aafire
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Curses_(programming_library)
|
||||
[2]: http://aa-project.sourceforge.net/aalib/
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-cmatrix
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (jlztan)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,179 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Install Rust Programming Language In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/how-to-install-rust-programming-language-in-linux/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
|
||||
How To Install Rust Programming Language In Linux
|
||||
======
|
||||
|
||||
Rust is often called rust-lang.
|
||||
|
||||
Rust is a general-purpose, multi-paradigm, modern, cross-platform, and open source systems programming language sponsored by Mozilla Research.
|
||||
|
||||
It was designed to be achieve a goals such as safety, speed, and concurrency.
|
||||
|
||||
Rust is syntactically similar to C++,[14] but its designers intend it to provide better memory safety while still maintaining performance.
|
||||
|
||||
Rust is currently used in many organization such as Firefox, Chef, Dropbox, Oracle, GNOME, etc,.
|
||||
|
||||
### How to Install Runs Language in Linux?
|
||||
|
||||
There are many ways we can install Rust but below is the officially recommended way to install it.
|
||||
|
||||
```
|
||||
$ curl https://sh.rustup.rs -sSf | sh
|
||||
info: downloading installer
|
||||
|
||||
Welcome to Rust!
|
||||
|
||||
This will download and install the official compiler for the Rust programming
|
||||
language, and its package manager, Cargo.
|
||||
|
||||
It will add the cargo, rustc, rustup and other commands to Cargo's bin
|
||||
directory, located at:
|
||||
|
||||
/home/daygeek/.cargo/bin
|
||||
|
||||
This path will then be added to your PATH environment variable by modifying the
|
||||
profile files located at:
|
||||
|
||||
/home/daygeek/.profile
|
||||
/home/daygeek/.bash_profile
|
||||
|
||||
You can uninstall at any time with rustup self uninstall and these changes will
|
||||
be reverted.
|
||||
|
||||
Current installation options:
|
||||
|
||||
default host triple: x86_64-unknown-linux-gnu
|
||||
default toolchain: stable
|
||||
modify PATH variable: yes
|
||||
|
||||
1) Proceed with installation (default)
|
||||
2) Customize installation
|
||||
3) Cancel installation
|
||||
>1
|
||||
|
||||
info: syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
|
||||
info: latest update on 2018-12-06, rust version 1.31.0 (abe02cefd 2018-12-04)
|
||||
info: downloading component 'rustc'
|
||||
77.7 MiB / 77.7 MiB (100 %) 1.2 MiB/s ETA: 0 s
|
||||
info: downloading component 'rust-std'
|
||||
54.2 MiB / 54.2 MiB (100 %) 1.2 MiB/s ETA: 0 s
|
||||
info: downloading component 'cargo'
|
||||
4.7 MiB / 4.7 MiB (100 %) 1.2 MiB/s ETA: 0 s
|
||||
info: downloading component 'rust-docs'
|
||||
8.5 MiB / 8.5 MiB (100 %) 1.2 MiB/s ETA: 0 s
|
||||
info: installing component 'rustc'
|
||||
info: installing component 'rust-std'
|
||||
info: installing component 'cargo'
|
||||
info: installing component 'rust-docs'
|
||||
info: default toolchain set to 'stable'
|
||||
|
||||
stable installed - rustc 1.31.0 (abe02cefd 2018-12-04)
|
||||
|
||||
|
||||
Rust is installed now. Great!
|
||||
|
||||
To get started you need Cargo's bin directory ($HOME/.cargo/bin) in your PATH
|
||||
environment variable. Next time you log in this will be done automatically.
|
||||
|
||||
To configure your current shell run source $HOME/.cargo/env
|
||||
```
|
||||
|
||||
Run the following command to configure your current shell.
|
||||
|
||||
```
|
||||
$ source $HOME/.cargo/env
|
||||
```
|
||||
|
||||
Run the following command to verify the installed Rust version.
|
||||
|
||||
```
|
||||
$ rustc --version
|
||||
rustc 1.31.0 (abe02cefd 2018-12-04)
|
||||
```
|
||||
|
||||
### How To Test Rust programming language?
|
||||
|
||||
Once you installed Rust follow the below steps to check whether Rust programe language is working fine or not.
|
||||
|
||||
```
|
||||
$ mkdir ~/projects
|
||||
$ cd ~/projects
|
||||
$ mkdir hello_world
|
||||
$ cd hello_world
|
||||
```
|
||||
|
||||
Create a file and add the below code and save the file. Make sure, Rust files always end in a .rs extension.
|
||||
|
||||
```
|
||||
$ vi 2g.rs
|
||||
|
||||
fn main() {
|
||||
println!("Hello, It's 2DayGeek.com - Best Linux Practical Blog!");
|
||||
}
|
||||
```
|
||||
|
||||
Run the following command to compile the rust code.
|
||||
|
||||
```
|
||||
$ rustc 2g.rs
|
||||
```
|
||||
|
||||
The above command will create a executable Rust program file in the same directory.
|
||||
|
||||
```
|
||||
$ ls -lh
|
||||
total 3.9M
|
||||
-rwxr-xr-x 1 daygeek daygeek 3.9M Dec 14 11:09 2g
|
||||
-rw-r--r-- 1 daygeek daygeek 86 Dec 14 11:09 2g.rs
|
||||
```
|
||||
|
||||
Run the Rust executable file to get the output.
|
||||
|
||||
```
|
||||
$ ./2g
|
||||
Hello, It's 2DayGeek.com - Best Linux Practical Blog!
|
||||
```
|
||||
|
||||
Yup! that’s working fine.
|
||||
|
||||
To update Rust to latest version.
|
||||
|
||||
```
|
||||
$ rustup update
|
||||
info: syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
|
||||
info: checking for self-updates
|
||||
|
||||
stable-x86_64-unknown-linux-gnu unchanged - rustc 1.31.0 (abe02cefd 2018-12-04)
|
||||
```
|
||||
|
||||
Run the following command to remove the Rust package from your system.
|
||||
|
||||
```
|
||||
$ rustup self uninstall
|
||||
```
|
||||
|
||||
Once you uninstalled the Rust package, remove the Rust project directory.
|
||||
|
||||
```
|
||||
$ rm -fr ~/projects
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-install-rust-programming-language-in-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,66 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Linux terminal is no one-trick pony)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-ponysay)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
The Linux terminal is no one-trick pony
|
||||
======
|
||||
Bring the magic of My Little Pony to your Linux command line.
|
||||

|
||||
|
||||
Welcome to another day of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
|
||||
|
||||
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
|
||||
|
||||
Reader [Lori][1] made the suggestion of today's toy in a comment on my previous article on [cowsay][2]:
|
||||
|
||||
"Hmmm, I've been playing with something called ponysay which seems to be a full-color variant on your cowsay."
|
||||
|
||||
Intrigued, I had to check it out, and I was not disappointed with what I found.
|
||||
|
||||
In a nutshell, **[ponysay][3]** is exactly that: a rewrite of **cowsay** that includes many full-color characters from [My Little Pony][4], that you can use to output phrases at the Linux command line. It's actually a really well-done project, that features over 400 characters and character combinations, and is incredibly well documented in a [78-page PDF][5] covering full usage.
|
||||
|
||||
To install **ponysay** , you'll want to check out the project [README][6] to select the installation method that works best for your distribution and situation. Since ponysay didn't appear to be packaged for my distribution, Fedora, I opted to try out the Docker container image, but do what works best for you; installation from source may also work for you.
|
||||
|
||||
I was curious to try out [**podman**][7] as a drop-in replacement for **docker** for a casual container users, and for me at least, it just worked!
|
||||
|
||||
```
|
||||
$ podman run -ti --rm mpepping/ponysay 'Ponytastic'
|
||||
```
|
||||
|
||||
The outputs are amazing, and I challenge you to try it out and let me know your favorite. Here was one of mine:
|
||||
|
||||

|
||||
|
||||
It's developers chose to write the code in [Pony][8]! (Update: Sadly, I was wrong about this. It's written in Python, though GitHub believes it to be Pony because of the file extensions.) Ponysay is licensed under the GPL version 3, and you can pick up its source code [on GitHub][3].
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Check out yesterday's toy, [Relax by the fire at your Linux terminal][9], and check back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-ponysay
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/users/n8chz
|
||||
[2]: https://opensource.com/article/18/12/linux-toy-cowsay
|
||||
[3]: https://github.com/erkin/ponysay
|
||||
[4]: https://en.wikipedia.org/wiki/My_Little_Pony
|
||||
[5]: https://github.com/erkin/ponysay/blob/master/ponysay.pdf?raw=true
|
||||
[6]: https://github.com/erkin/ponysay/blob/master/README.md
|
||||
[7]: https://opensource.com/article/18/10/podman-more-secure-way-run-containers
|
||||
[8]: https://opensource.com/article/18/5/pony
|
||||
[9]: https://opensource.com/article/18/12/linux-toy-aafire
|
||||
@ -0,0 +1,180 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Tips for using Flood Element for performance testing)
|
||||
[#]: via: (https://opensource.com/article/18/12/tips-flood-element-testing)
|
||||
[#]: author: (Nicole van der Hoeven https://opensource.com/users/nicolevanderhoeven)
|
||||
|
||||
Tips for using Flood Element for performance testing
|
||||
======
|
||||
Get started with this powerful, intuitive load testing tool.
|
||||

|
||||
|
||||
In case you missed it, there’s a new performance test tool on the block: [Flood Element][1]. It’s a scalable, browser-based tool that allows you to write scripts in JavaScript that interact with web pages like a real user would.
|
||||
|
||||
Browser Level Users is a [newer approach to load testing][2] that overcomes many of the common challenges we hear about traditional methods of testing. It offers:
|
||||
|
||||
* Scripting that is akin to common functional tools like Selenium and easier to learn
|
||||
* More realistic results that are based on true browser performance rather than API response
|
||||
* The ability to test against all components of your web app, including things like JavaScript that are rendered via the browser
|
||||
|
||||
|
||||
|
||||
Given the above benefits, it’s a no-brainer to check out Flood Element for your web load testing, especially if you have struggled with existing tools like JMeter or HP LoadRunner.
|
||||
|
||||
Pairing Element with [Flood][3] turns it into a pretty powerful load test tool. We have a [great guide here][4] that you can follow if you’d like to get started. I’ve been using and testing Element for several months now, and I’d like to share some tips I’ve learned along the way.
|
||||
|
||||
### Initializing your script
|
||||
|
||||
You can always start from scratch, but the quickest way to get started is to type `element init myfirstelementtest` from your terminal, filling in your preferred project name.
|
||||
|
||||
You’ll then be asked to type the title of your test as well as the URL you’d like to script against. After a minute, you’ll see that a new directory has been created:
|
||||
|
||||
|
||||
|
||||
Element will automatically create a file called **test.ts**. This file contains the skeleton of a script, along with some sample code to help you find a button and then click on it. But before you open it, let’s move on to…
|
||||
|
||||
### Choosing the right text editor
|
||||
|
||||
Scripting in Element is already pretty simple, but two things that help are syntax highlighting and code completion. Syntax highlighting will greatly improve the experience of learning a new test tool like Element, and code completion will make your scripting lightning-fast as you become more experienced. My text editor of choice is [Visual Studio Code][5], which has both of those features. It’s slick and clean, and it does the job.
|
||||
|
||||
Syntax highlighting is when the text editor intelligently changes the font color of your code according to its role in the programming language you’re using. Here’s a screenshot of the **test.ts** file we generated earlier in VS Code to show you what I mean:
|
||||
|
||||
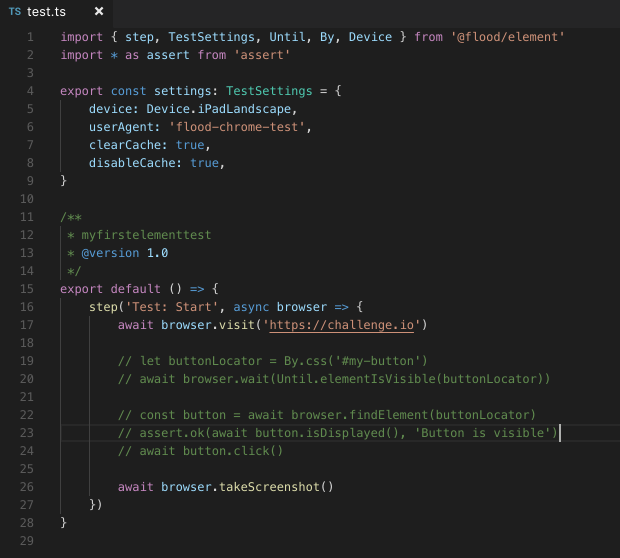
|
||||
|
||||
This makes it easier to make sense of the code at a glance: Comments are in green, values and labels are in orange, etc.
|
||||
|
||||
Code completion is when you start to type something, and VS Code helpfully opens a context menu with suggestions for methods you can use.
|
||||
|
||||
![][6]
|
||||
|
||||
I love this because it means I don’t need to remember the exact name of the method. It also suggests names of variables you’ve already defined and highlights code that doesn’t make sense. This will help to make your tests more maintainable and readable for others, which is a great benefit as you look to scale your testing out in the future.
|
||||
|
||||

|
||||
|
||||
### Taking screenshots
|
||||
|
||||
One of the most powerful features of Element is its ability to take screenshots. I find it immensely useful when debugging because sometimes it’s just easier to see what’s going on visually. With protocol-based tools, debugging can be a much more involved and technical process.
|
||||
|
||||
There are two ways to take screenshots in Element:
|
||||
|
||||
1. Add a setting to automatically take a screenshot when an error is encountered. You can do this by setting `screenshotOnFailure` to "true" in `TestSettings`:
|
||||
|
||||
|
||||
|
||||
```
|
||||
export const settings: TestSettings = {
|
||||
device: Device.iPadLandscape,
|
||||
userAgent: 'flood-chrome-test',
|
||||
clearCache: true,
|
||||
disableCache: true,
|
||||
screenshotOnFailure: true,
|
||||
}
|
||||
```
|
||||
|
||||
2. Explicitly take a screenshot at a particular point in the script. You can do this by adding
|
||||
|
||||
|
||||
|
||||
```
|
||||
await browser.takeScreenshot()
|
||||
```
|
||||
|
||||
to your code.
|
||||
|
||||
### Viewing screenshots
|
||||
|
||||
Once you’ve taken screenshots within your tests, you will probably want to view them and know that they will be stored for future safekeeping. Whether you are running your test locally on have uploaded it to Flood to run with increased concurrency, Flood Element has you covered.
|
||||
|
||||
**Locally run tests**
|
||||
|
||||
Screenshots will be saved as .jpg files in a timestamped folder corresponding to your run. It should look something like this: **…myfirstelementtest/tmp/element-results/test/2018-11-20T135700.595Z/flood/screenshots/**. The screenshots will be uniquely named so that new screenshots, even for the same step, don’t overwrite older ones.
|
||||
|
||||
However, I rarely need to look up the screenshots in that folder because I prefer to see them in iTerm2 for MacOS. iTerm is an alternative to the terminal that works particularly well with Element. When you take a screenshot, iTerm actually shows it in-line:
|
||||
|
||||
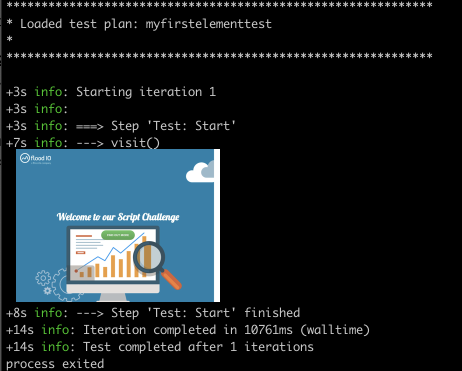
|
||||
|
||||
**Tests run in Flood**
|
||||
|
||||
Running an Element script on Flood is ideal when you need larger concurrency. Rather than accessing your screenshot locally, Flood will centralize the images into your account, so the images remain even after the cloud load injectors are destroyed. You can get to the screenshot files by downloading Archived Results:
|
||||
|
||||
|
||||
|
||||
You can also click on a step on the dashboard to see a filmstrip of your test:
|
||||
|
||||
|
||||
|
||||
### Using logs
|
||||
|
||||
You may need to check out the logs for more technical debugging, especially when the screenshots don’t tell the whole story. Again, whether you are running your test locally or have uploaded it to Flood to run with increased concurrency, Flood Element has you covered.
|
||||
|
||||
**Locally run tests**
|
||||
|
||||
You can print to the console by typing, for example: `console.log('orderValues = ’ + orderValues)`
|
||||
|
||||
This will print the value of the variable `orderValues` at that point in the script. You would see this in your terminal if you’re running Element locally.
|
||||
|
||||
**Tests run in Flood**
|
||||
|
||||
If you’re running the script on Flood, you can either download the log (in the same Archived Results zipped file mentioned earlier) or click on the Logs tab:
|
||||
|
||||
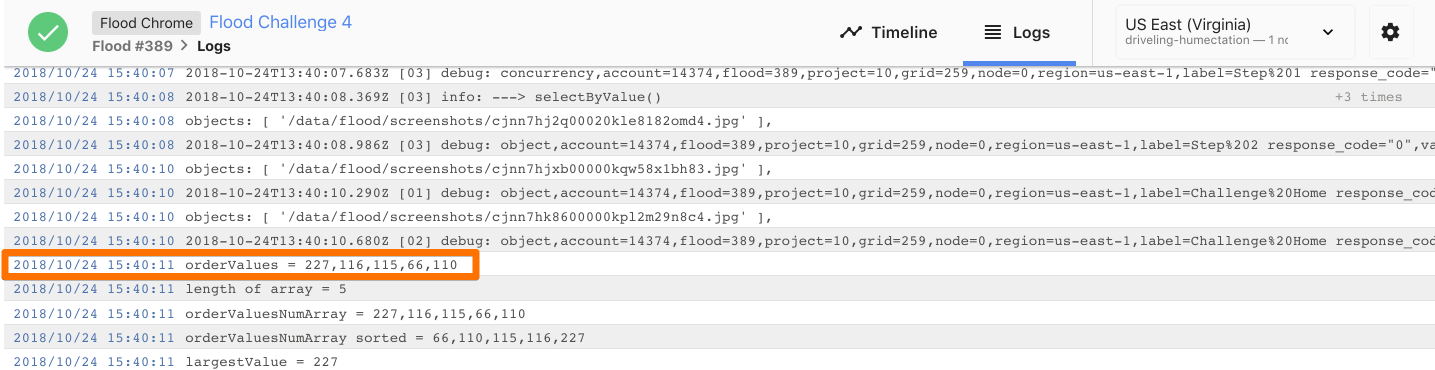
|
||||
|
||||
### Fun with flags
|
||||
|
||||
Element comes with a few flags that give you more control over how the script is run locally. Here are a few of my favorites:
|
||||
|
||||
**Headless flag**
|
||||
|
||||
When in doubt, run Element in non-headless mode to see the script actually opening the web app on Chrome and interacting with the page. This is only possible locally, but there’s nothing like actually seeing for yourself what’s happening in real time instead of relying on screenshots and logs after the fact. To enable this mode, add the flag when running your test:
|
||||
|
||||
```
|
||||
element run myfirstelementtest.ts --no-headless
|
||||
```
|
||||
|
||||
**Watch flag**
|
||||
|
||||
Element will automatically close the browser window when it encounters an error or finishes the iteration. Adding `--watch` will leave the browser window open and then monitor the script. As soon as the script is saved, it will automatically run it in the same window from the beginning. Simply add this flag like the above example:
|
||||
|
||||
```
|
||||
--watch
|
||||
```
|
||||
|
||||
**Dev tools flag**
|
||||
|
||||
This opens a browser instance and runs the script with the Chrome Dev Tools open, allowing you to find locators for the next action you want to script. Simply add this flag as in the first example:
|
||||
|
||||
```
|
||||
--dev-tools
|
||||
```
|
||||
|
||||
For more flags, use `element run --help`.
|
||||
|
||||
### Try Element
|
||||
|
||||
You’ve just gotten a crash course on Flood Element and are ready to get started. [Download Element][1] to start writing functional test scripts and reusing them as load test scripts on Flood. If you don’t have a Flood account, you can easily sign up for a free trial [on the Flood website][7].
|
||||
|
||||
We’re proud to contribute to the open source community and can’t wait to have you try this new addition to the Flood line.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/tips-flood-element-testing
|
||||
|
||||
作者:[Nicole van der Hoeven][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/nicolevanderhoeven
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://element.flood.io/
|
||||
[2]: https://flood.io/blog/why-you-should-load-test-with-browsers/
|
||||
[3]: https://flood.io/
|
||||
[4]: https://help.flood.io/getting-started-with-load-testing/step-by-step-guide-flood-element
|
||||
[5]: https://code.visualstudio.com/
|
||||
[6]: https://flood.io/wp-content/uploads/2018/11/vscode-codecompletion2.gif
|
||||
[7]: https://flood.io/load-performance-testing-tool/free-load-testing-trial/
|
||||
@ -0,0 +1,52 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Head to the arcade in your Linux terminal with this Pac-man clone)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-myman)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Head to the arcade in your Linux terminal with this Pac-man clone
|
||||
======
|
||||
Want to recreate the magic of your favorite arcade game? Today's command-line toy will transport you back in time.
|
||||
|
||||
|
||||
Welcome back to another day of the Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what command-line toys are all about. Basically, they're games and simple diversions that help you have fun at the terminal.
|
||||
|
||||
Some are new, and some are old classics. We hope you enjoy.
|
||||
|
||||
Today's toy, MyMan, is a fun clone of the classic arcade game [Pac-Man][1]. (You didn't think this was going to be about the [similarly-named][2] Linux package manager, did you?) If you're anything like me, you spent more than your fair share of quarters trying to hit a high score Pac-Man back in the day, and still give it a go whenever you get a chance.
|
||||
|
||||
MyMan isn't the only Pac-Man clone for the Linux terminal, but it's the one I chose to include because 1) I like its visual style, which rings true to the original and 2) it's conveniently packaged for my Linux distribution so it was an easy install. But you should check out your other options as well. Here's [another one][3] that looks like it may be promising, but I haven't tried it.
|
||||
|
||||
Since MyMan was packaged for Fedora, installation was as simple as:
|
||||
|
||||
```
|
||||
$ dnf install myman
|
||||
```
|
||||
|
||||
MyMan is made available under an MIT license and you can check out the source code on [SourceForge][4].
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Check out yesterday's toy, [The Linux terminal is no one-trick pony][5], and check back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-myman
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Pac-Man
|
||||
[2]: https://wiki.archlinux.org/index.php/pacman
|
||||
[3]: https://github.com/YoctoForBeaglebone/pacman4console
|
||||
[4]: https://myman.sourceforge.io/
|
||||
[5]: https://opensource.com/article/18/12/linux-toy-ponysay
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Schedule a visit with the Emacs psychiatrist)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-eliza)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Schedule a visit with the Emacs psychiatrist
|
||||
======
|
||||
Eliza is a natural language processing chatbot hidden inside of one of Linux's most popular text editors.
|
||||
|
||||
|
||||
Welcome to another day of the 24-day-long Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
|
||||
|
||||
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
|
||||
|
||||
Today's selection is a hidden gem inside of Emacs: Eliza, the Rogerian psychotherapist, a terminal toy ready to listen to everything you have to say.
|
||||
|
||||
A brief aside: While this toy is amusing, your health is no laughing matter. Please take care of yourself this holiday season, physically and mentally, and if stress and anxiety from the holidays are having a negative impact on your wellbeing, please consider seeing a professional for guidance. It really can help.
|
||||
|
||||
To launch [Eliza][1], first, you'll need to launch Emacs. There's a good chance Emacs is already installed on your system, but if it's not, it's almost certainly in your default repositories.
|
||||
|
||||
Since I've been pretty fastidious about keeping this series in the terminal, launch Emacs with the **-nw** flag to keep in within your terminal emulator.
|
||||
|
||||
```
|
||||
$ emacs -nw
|
||||
```
|
||||
|
||||
Inside of Emacs, type M-x doctor to launch Eliza. For those of you like me from a Vim background who have no idea what this means, just hit escape, type x and then type doctor. Then, share all of your holiday frustrations.
|
||||
|
||||
Eliza goes way back, all the way to the mid-1960s a the MIT Artificial Intelligence Lab. [Wikipedia][2] has a rather fascinating look at her history.
|
||||
|
||||
Eliza isn't the only amusement inside of Emacs. Check out the [manual][3] for a whole list of fun toys.
|
||||
|
||||
|
||||
![Linux toy: eliza animated][5]
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? We're running out of time, but I'd still love to hear your suggestions. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
|
||||
|
||||
Be sure to check out yesterday's toy, [Head to the arcade in your Linux terminal with this Pac-man clone][6], and come back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-eliza
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.emacswiki.org/emacs/EmacsDoctor
|
||||
[2]: https://en.wikipedia.org/wiki/ELIZA
|
||||
[3]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Amusements.html
|
||||
[4]: /file/417326
|
||||
[5]: https://opensource.com/sites/default/files/uploads/linux-toy-eliza-animated.gif (Linux toy: eliza animated)
|
||||
[6]: https://opensource.com/article/18/12/linux-toy-myman
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 cool new projects to try in COPR for December 2018)
|
||||
[#]: via: (https://fedoramagazine.org/4-try-copr-december-2018/)
|
||||
[#]: author: (Dominik Turecek https://fedoramagazine.org)
|
||||
|
||||
4 cool new projects to try in COPR for December 2018
|
||||
======
|
||||

|
||||
|
||||
COPR is a [collection][1] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
Here’s a set of new and interesting projects in COPR.
|
||||
|
||||
### MindForger
|
||||
|
||||
[MindForger][2] is a Markdown editor and a notebook. In addition to features you’d expect from a Markdown editor, MindForger lets you split a single file into multiple notes. It’s easy to organize the notes and move them around between files, as well as search through them. I’ve been using MindForger for some time for my study notes, so it’s nice that it’s available through COPR now.![][3]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides MindForger for Fedora 29 and Rawhide. To install MindForger, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable deadmozay/mindforger
|
||||
sudo dnf install mindforger
|
||||
```
|
||||
|
||||
### Clingo
|
||||
|
||||
[Clingo][4] is a program for solving logical problems using [answer set programming][5] (ASP) modeling language. With ASP, you can declaratively describe a problem as a logical program that Clingo then solves. As a result, Clingo produces solutions to the problem in the form of logical models, called answer sets.
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Clingo for Fedora 28 and 29. To install Clingo, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable timn/clingo
|
||||
sudo dnf install clingo
|
||||
```
|
||||
|
||||
### SGVrecord
|
||||
|
||||
[SGVrecord][6] is a simple tool for recording your screen. It allows you to either capture the whole screen or select just a part of it. Furthermore, it is possible to make the record with or without sound. Sgvrecord produces files in WebM format.![][7]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides SGVrecord for Fedora 28, 29, and Rawhide. To install SGVrecord, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable youssefmsourani/sgvrecord
|
||||
sudo dnf install sgvrecord
|
||||
```
|
||||
|
||||
### Watchman
|
||||
|
||||
[Watchman][8] is a service for monitoring and recording when changes are done to files.
|
||||
You can specify directory trees for Watchman to monitor, as well as define actions
|
||||
that are triggered when specified files are changed.
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Watchman for Fedora 29 and Rawhide. To install Watchman, use these commands:
|
||||
|
||||
```
|
||||
sudo dnf copr enable eklitzke/watchman
|
||||
sudo dnf install watchman
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-december-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://copr.fedorainfracloud.org/
|
||||
[2]: https://www.mindforger.com/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/12/mindforger.png
|
||||
[4]: https://potassco.org/clingo/
|
||||
[5]: https://en.wikipedia.org/wiki/Answer_set_programming
|
||||
[6]: https://github.com/yucefsourani/sgvrecord
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2018/12/SGVrecord.png
|
||||
[8]: https://facebook.github.io/watchman/
|
||||
@ -0,0 +1,78 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (6 tips and tricks for using KeePassX to secure your passwords)
|
||||
[#]: via: (https://opensource.com/article/18/12/keepassx-security-best-practices)
|
||||
[#]: author: (Michael McCune https://opensource.com/users/elmiko)
|
||||
|
||||
6 tips and tricks for using KeePassX to secure your passwords
|
||||
======
|
||||
Get more out of your password manager by following these best practices.
|
||||

|
||||
|
||||
Our increasingly interconnected digital world makes security an essential and common discussion topic. We hear about [data breaches][1] with alarming regularity and are often on our own to make informed decisions about how to use technology securely. Although security is a deep and nuanced topic, there are some easy daily habits you can keep to reduce your attack surface.
|
||||
|
||||
Securing passwords and account information is something that affects anyone today. Technologies like [OAuth][2] help make our lives simpler by reducing the number of accounts we need to create, but we are still left with a staggering number of places where we need new, unique information to keep our records secure. An easy way to deal with the increased mental load of organizing all this sensitive information is to use a password manager like [KeePassX][3].
|
||||
|
||||
In this article, I will explain the importance of keeping your password information secure and offer suggestions for getting the most out of KeePassX. For an introduction to KeePassX and its features, I highly recommend Ricardo Frydman's article "[Managing passwords in Linux with KeePassX][4]."
|
||||
|
||||
### Why are unique passwords important?
|
||||
|
||||
Using a different password for each account is the first step in ensuring that your accounts are not vulnerable to shared information leaks. Generating new credentials for every account is time-consuming, and it is extremely common for people to fall into the trap of using the same password on several accounts. The main problem with reusing passwords is that you increase the number of accounts an attacker could access if one of them experiences a credential breach.
|
||||
|
||||
It may seem like a burden to create new credentials for each account, but the few minutes you spend creating and recording this information will pay for itself many times over in the event of a data breach. This is where password management tools like KeePassX are invaluable for providing convenience and reliability in securing your logins.
|
||||
|
||||
### 3 tips for getting the most out of KeePassX
|
||||
|
||||
I have been using KeePassX to manage my password information for many years, and it has become a primary resource in my digital toolbox. Overall, it's fairly simple to use, but there are a few best practices I've learned that I think are worth highlighting.
|
||||
|
||||
1. Add the direct login URL for each account entry. KeePassX has a very convenient shortcut to open the URL listed with an entry. (It's Control+Shift+U on Linux.) When creating a new account entry for a website, I spend some time to locate the site's direct login URL. Although most websites have a login widget in their navigation toolbars, they also usually have direct pages for login forms. By putting this URL into the URL field on the account entry setup form, I can use the shortcut to directly open the login page in my browser.
|
||||
|
||||
|
||||
|
||||
2. Use the Notes field to record extra security information. In addition to passwords, most websites will ask several questions to create additional authentication factors for an account. I use the Notes sections in my account entries to record these additional factors.
|
||||
|
||||
|
||||
|
||||
3. Turn on automatic database locking. In the **Application Settings** under the **Tools** menu, there is an option to lock the database after a period of inactivity. Enabling this option is a good common-sense measure, similar to enabling a password-protected screen lock, that will help ensure your password database is not left open and unprotected if someone else gains access to your computer.
|
||||
|
||||
|
||||
|
||||
### Food for thought
|
||||
|
||||
Protecting your accounts with better password practices and daily habits is just the beginning. Once you start using a password manager, you need to consider issues like protecting the password database file and ensuring you don't forget or lose the master credentials.
|
||||
|
||||
The cloud-native world of disconnected devices and edge computing makes having a central password store essential. The practices and methodologies you adopt will help minimize your risk while you explore and work in the digital world.
|
||||
|
||||
1. Be aware of retention policies when storing your database in the cloud. KeePassX's database has an open format used by several tools on multiple platforms. Sooner or later, you will want to transfer your database to another device. As you do this, consider the medium you will use to transfer the file. The best option is to use some sort of direct transfer between devices, but this is not always convenient. Always think about where the database file might be stored as it winds its way through the information superhighway; an email may get cached on a server, an object store may move old files to a trash folder. Learn about these interactions for the platforms you are using before deciding where and how you will share your database file.
|
||||
|
||||
2. Consider the source of truth for your database while you're making edits. After you share your database file between devices, you might need to create accounts for new services or change information for existing services while using a device. To ensure your information is always correct across all your devices, you need to make sure any edits you make on one device end up in all copies of the database file. There is no easy solution to this problem, but you might think about making all edits from a single device or storing the master copy in a location where all your devices can make edits.
|
||||
|
||||
3. Do you really need to know your passwords? This is more of a philosophical question that touches on the nature of memorable passwords, convenience, and secrecy. I hardly look at passwords as I create them for new accounts; in most cases, I don't even click the "Show Password" checkbox. There is an idea that you can be more secure by not knowing your passwords, as it would be impossible to compel you to provide them. This may seem like a worrisome idea at first, but consider that you can recover or reset passwords for most accounts through alternate verification methods. When you consider that you might want to change your passwords on a semi-regular basis, it almost makes more sense to treat them as ephemeral information that can be regenerated or replaced.
|
||||
|
||||
|
||||
|
||||
|
||||
Here are a few more ideas to consider as you develop your best practices.
|
||||
|
||||
I hope these tips and tricks have helped expand your knowledge of password management and KeePassX. You can find tools that support the KeePass database format on nearly every platform. If you are not currently using a password manager or have never tried KeePassX, I highly recommend doing so now!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/keepassx-security-best-practices
|
||||
|
||||
作者:[Michael McCune][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/elmiko
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://vigilante.pw/
|
||||
[2]: https://en.wikipedia.org/wiki/OAuth
|
||||
[3]: https://www.keepassx.org/
|
||||
[4]: https://opensource.com/business/16/5/keepassx
|
||||
@ -0,0 +1,48 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( amwps290)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Take a swim at your Linux terminal with asciiquarium)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-asciiquarium)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Take a swim at your Linux terminal with asciiquarium
|
||||
======
|
||||
Darling it's better, when your command line is wetter, thanks to ASCII.
|
||||

|
||||
|
||||
We're now nearing the end of our 24-day-long Linux command-line toys advent calendar. Just one week left after today! If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
|
||||
|
||||
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
|
||||
|
||||
Today's selection is a fishy one. Say hello to **asciiquarium** , an undersea adventure for your terminal. I found **asciiquarium** in my Fedora repositories, so installing it was as simple as:
|
||||
|
||||
```
|
||||
$ sudo dnf install asciiquarium
|
||||
```
|
||||
|
||||
If you're running a different distribution, chances are it's packaged for you too. Just run **asciiquarium** at your terminal to feel happy as a clam. The project has been translated outside of the terminal as well, with screensavers of all of the aquatic pals being made for several non-Linux operating systems, and even an Android live wallpaper version is floating around out there.
|
||||
|
||||
Visit the **asciiquarium** [homepage][1] for more information or to download the Perl source code. The project is open source under a GPL version 2 license. And if you want to learn more about how open source, open data, and open science are making a difference in the actual oceans, take a moment to go learn about the [Ocean Health Index][2].
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? We're running out of time, but I'd still love to hear your suggestions. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
|
||||
|
||||
Be sure to check out yesterday's toy, [Schedule a visit with the Emacs psychiatrist][3], and come back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-asciiquarium
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://robobunny.com/projects/asciiquarium/html/
|
||||
[2]: https://opensource.com/article/18/12/protecting-world-oceans
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-eliza
|
||||
100
sources/tech/20181217 Working with tarballs on Linux.md
Normal file
100
sources/tech/20181217 Working with tarballs on Linux.md
Normal file
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Working with tarballs on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3328840/linux/working-with-tarballs-on-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Working with tarballs on Linux
|
||||
======
|
||||

|
||||
|
||||
The word “tarball” is often used to describe the type of file used to back up a select group of files and join them into a single file. The name comes from the **.tar** file extension and the **tar** command that is used to group together the files into a single file that is then sometimes compressed to make it smaller for its move to another system.
|
||||
|
||||
Tarballs are often used to back up personal or system files in place to create an archive, especially prior to making changes that might have to be reversed. Linux sysadmins, for example, will often create a tarball containing a series of configuration files before making changes to an application just in case they have to reverse those changes. Extracting the files from a tarball that’s sitting in place will generally be faster than having to retrieve the files from backups.
|
||||
|
||||
### How to create a tarball on Linux
|
||||
|
||||
You can create a tarball and compress it in a single step if you use a command like this one:
|
||||
|
||||
```
|
||||
$ tar -cvzf PDFs.tar.gz *.pdf
|
||||
```
|
||||
|
||||
The result in this case is a compressed (gzipped) file that contains all of the PDF files that are in the current directory. The compression is optional, of course. A slightly simpler command would just put all of the PDF files into an uncompressed tarball:
|
||||
|
||||
```
|
||||
$ tar -cvf PDFs.tar *.pdf
|
||||
```
|
||||
|
||||
Note that it’s the **z** in that list of options that causes the file to be compressed or “zipped”. The **c** specifies that you are creating the file and the **v** (verbose) indicates that you want some feedback while the command is running. Omit the **v** if you don't want to see the files listed.
|
||||
|
||||
Another common naming convention is to give zipped tarballs the extension **.tgz** instead of the double extension **.tar.gz** as shown in this command:
|
||||
|
||||
```
|
||||
$ tar cvzf MyPDFs.tgz *.pdf
|
||||
```
|
||||
|
||||
### How to extract files from a tarball
|
||||
|
||||
To extract all of the files from a gzipped tarball, you would use a command like this:
|
||||
|
||||
```
|
||||
$ tar -xvzf file.tar.gz
|
||||
```
|
||||
|
||||
If you use the .tgz naming convention, that command would look like this:
|
||||
|
||||
```
|
||||
$ tar -xvzf MyPDFs.tgz
|
||||
```
|
||||
|
||||
To extract an individual file from a gzipped tarball, you do almost the same thing but add the file name:
|
||||
|
||||
```
|
||||
$ tar -xvzf PDFs.tar.gz ShenTix.pdf
|
||||
ShenTix.pdf
|
||||
ls -l ShenTix.pdf
|
||||
-rw-rw-r-- 1 shs shs 122057 Dec 14 14:43 ShenTix.pdf
|
||||
```
|
||||
|
||||
You can even delete files from a tarball if the tarball is not compressed. For example, if we wanted to remove tile file that we extracted above from the PDFs.tar.gz file, we would do it like this:
|
||||
|
||||
```
|
||||
$ gunzip PDFs.tar.gz
|
||||
$ ls -l PDFs.tar
|
||||
-rw-rw-r-- 1 shs shs 10700800 Dec 15 11:51 PDFs.tar
|
||||
$ tar -vf PDFs.tar --delete ShenTix.pdf
|
||||
$ ls -l PDFs.tar
|
||||
-rw-rw-r-- 1 shs shs 10577920 Dec 15 11:45 PDFs.tar
|
||||
```
|
||||
|
||||
Notice that we shaved a little space off the tar file while deleting the ShenTix.pdf file. We can then compress the file again if we want:
|
||||
|
||||
```
|
||||
$ gzip -f PDFs.tar
|
||||
ls -l PDFs.tar.gz
|
||||
-rw-rw-r-- 1 shs shs 10134499 Dec 15 11:51 PDFs.tar.gzFlickr / James St. John
|
||||
```
|
||||
|
||||
The versatility of the command line options makes working with tarballs easy and very convenient.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3328840/linux/working-with-tarballs-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.facebook.com/NetworkWorld/
|
||||
[2]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,137 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Insync: The Hassleless Way of Using Google Drive on Linux)
|
||||
[#]: via: (https://itsfoss.com/insync-linux-review/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Insync: The Hassleless Way of Using Google Drive on Linux
|
||||
======
|
||||
|
||||
Using Google Drive on Linux is a pain and you probably already know that. There is no official desktop client of Google Drive for Linux. It’s been [more than six years since Google promised Google Drive on Linux][1] but it doesn’t seem to be happening.
|
||||
|
||||
In the absence of the official Google Drive client on Linux, you have no option other than trying the alternatives. I have already discussed a number of [tools that allow you to use Google Drive on Linux][2]. One of those to[ols is][3] Insync, and in my opinion, this is your best bet for a native Google Drive experience on desktop Linux.
|
||||
|
||||
Note that Insync is not an open source software. Heck, it is not even free to use.
|
||||
|
||||
But it has so many features that it becomes an essential tool for those Linux users who rely heavily on Google Drive.
|
||||
|
||||
I briefly discussed Insync in the old article about [Google Drive and Linux][2]. In this article, I’ll discuss Insync features in detail.
|
||||
|
||||
### Insync brings native Google Drive experience to Linux desktop
|
||||
|
||||
![Use insync to access Google Drive in Linux][4]
|
||||
|
||||
The core competency of Insync is syncing your Google Drive, but the app is much more than that. It has features to help you maximize and control your productivity, your Google Drive and your files such as:
|
||||
|
||||
* Cross-platform access (supports Linux, Windows and macOS)
|
||||
* Easy multiple Google Drive accounts access
|
||||
* Choose your syncing location. Sync files to your hard drive, external drives and NAS!
|
||||
* Support for features like file matching, symlink and ignore list
|
||||
|
||||
|
||||
|
||||
Let me show you some of the main features in action:
|
||||
|
||||
#### Cross-platform in true sense
|
||||
|
||||
Insync claims to run the same app across all operating systems i.e., Linux, Windows, and macOS. That means that you can access the same UI across different OSes, making it easy for you to manage your files across multiple machines.
|
||||
|
||||
![The UI of Insync and the default location of the Insync folder.][5]The UI of Insync and the default location of the Insync folder.
|
||||
|
||||
#### Multiple Google account management
|
||||
|
||||
Insync interface allows you to manage multiple Google Drive accounts seamlessly. You can easily switch between several accounts just by clicking your Google account.
|
||||
|
||||
![Switching between multiple Google accounts in Insync][6]Switching between multiple Google accounts
|
||||
|
||||
#### Custom sync folders
|
||||
|
||||
Customize the way you sync your files and folders. You can easily set your syncing destination anywhere on your machine including external drive and network drives.
|
||||
|
||||
![Customize sync location in Insync][7]Customize sync location
|
||||
|
||||
The selective syncing mode also allows you to easily select a number of files and folders you’d want to sync (or unsync) in your local machine. This includes selectively syncing files within folders.
|
||||
|
||||
![Selective synchronization in Insync][8]Selective synchronization
|
||||
|
||||
It has features like file matching and ‘ignore list’ to help you filter files you don’t want to sync or files that you already have on your machine.
|
||||
|
||||
![File matching feature in Insync][9]Avoids duplication of files
|
||||
|
||||
The ‘ignore list’ allows you to set rules to exclude certain type of files from synchronization.
|
||||
|
||||
![Selective syncing based on rules in Insync][10]Selective syncing based on rules
|
||||
|
||||
If you prefer to work out of the desktop, you have an “Add to Insync” feature that will allow you to add any local file to your Drive.
|
||||
|
||||
![Sync files right from your desktop][11]Sync files right from your desktop
|
||||
|
||||
Insync also supports symlinks for those with workflows that use symbolic links. To learn more about Insync and symlinks, you can refer to [this article.][12]
|
||||
|
||||
#### Exclusive features for Linux
|
||||
|
||||
Insync supports the most commonly used 64-bit Linux distributions like **Ubuntu, Debian and Fedora**. You can check out the full list of distribution support [here][13].
|
||||
|
||||
Insync also has [headless][14] support for those looking to sync through the command line interface. This is perfect if you use a distro that is not fully supported by the GUI app or if you are working with servers or if you simply prefer the CLI.
|
||||
|
||||
![Insync CLI][15]Command Line Interface
|
||||
|
||||
You can learn more about installing and running Insync headless [here][16].
|
||||
|
||||
### Insync pricing and special discount
|
||||
|
||||
Insync is a premium tool and it comes with a [price tag][17]. You have 2 licenses to choose from:
|
||||
|
||||
* **Prime** is priced at $29.99 per Google account. You’ll get access to: cross-platform syncing, multiple accounts access and **support**.
|
||||
* **Teams** is priced at $49.99 per Google account. You’ll be able to access all the Prime features + Team Drives syncing
|
||||
|
||||
|
||||
|
||||
It’s a one-time fee which means once you buy it, you don’t have to pay it again. In a world where everything is paid monthly, it’s refreshing to pay for software that is still one-time!
|
||||
|
||||
Each Google account has a 15-day free trial that will allow you to test the full suite of features, including [Team Drives][18] syncing.
|
||||
|
||||
If you think it’s a bit expensive for your budget, I have good news for you. As an It’s FOSS reader, you get Insync at 25% discount.
|
||||
|
||||
Just use the code ITSFOSS25 at checkout time and you will get 25% immediate discount on any license. Isn’t it cool?
|
||||
|
||||
If you are not certain yet, you can try Insync free for 15 days. And if you think it’s worth the money, purchase the license with **ITSFOSS25** coupon code.
|
||||
|
||||
You can download Insync from their website.
|
||||
|
||||
I have used Insync from the time when it was available for free and I have always liked it. They have added more features over the time and improved its UI and performance. Overall, it’s a nice-to-have application if you use Google Drive a lot and do not mind paying for the efforts of the developers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/insync-linux-review/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://abevoelker.github.io/how-long-since-google-said-a-google-drive-linux-client-is-coming/
|
||||
[2]: https://itsfoss.com/use-google-drive-linux/
|
||||
[3]: https://www.insynchq.com
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/12/google-drive-linux-insync.jpeg?resize=800%2C450&ssl=1
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_interface.jpeg?fit=800%2C501&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_multiple_google_account.jpeg?ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_folder_settings.png?ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_selective_sync.png?ssl=1
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_file_matching.jpeg?ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_ignore_list_1.png?ssl=1
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/add-to-insync-shortcut.jpeg?ssl=1
|
||||
[12]: https://help.insynchq.com/key-features-and-syncing-explained/syncing-superpowers/using-symlinks-on-google-drive-with-insync
|
||||
[13]: https://www.insynchq.com/downloads
|
||||
[14]: https://en.wikipedia.org/wiki/Headless_software
|
||||
[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/insync_cli.jpeg?fit=800%2C478&ssl=1
|
||||
[16]: https://help.insynchq.com/installation-on-windows-linux-and-macos/advanced/linux-controlling-insync-via-command-line-cli
|
||||
[17]: https://www.insynchq.com/pricing
|
||||
[18]: https://gsuite.google.com/learning-center/products/drive/get-started-team-drive/#!/
|
||||
@ -0,0 +1,170 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Termtosvg – Record Your Terminal Sessions As SVG Animations In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/termtosvg-record-your-terminal-sessions-as-svg-animations-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Termtosvg – Record Your Terminal Sessions As SVG Animations In Linux
|
||||
======
|
||||
|
||||
By default everyone prefer history command to review/recall the previously entered commands in terminal.
|
||||
|
||||
But unfortunately, that shows only the commands that we ran and doesn’t shows the commands output which was performed previously.
|
||||
|
||||
There are many utilities available in Linux to record the terminal session activity.
|
||||
|
||||
This tool will help us to record the users terminal activity, also will help us to identify other useful information from the output.
|
||||
|
||||
Also, we had written about few utilities in the past and today also we are going to discuss about the same kind of topic.
|
||||
|
||||
If you would like to check other utilities to record your Linux terminal session activity then you can give a try to **[Script Command][1]** and **[Terminalizer Tool][2]**.
|
||||
|
||||
But if you are looking for **[GIF Recorder][3]** then try **[Gifine][4]** , **[Kgif][5]** and **[Peek][6]** utilities.
|
||||
|
||||
Script is one of the best utility to record your terminal session on headless server.
|
||||
|
||||
Script is a Unix command line utility that records a terminal session (in other terms, It’s record everything displayed on your terminal).
|
||||
|
||||
It stores the output in the current directory as a text file and the default file name is typescript.
|
||||
|
||||
### What is Termtosvg
|
||||
|
||||
Termtosvg is a Unix terminal recorder written in Python that renders your command line sessions as standalone SVG animations.
|
||||
|
||||
### Termtosvg Features
|
||||
|
||||
* Produce lightweight and clean looking animations embeddable on a project page.
|
||||
* Custom color themes, terminal UI and animation controls via SVG templates.
|
||||
* Compatible with asciinema recording format.
|
||||
* It requires Python >= 3.5
|
||||
|
||||
|
||||
|
||||
### How to Install Termtosvg In Linux
|
||||
|
||||
It was written in Python and pip installation is a recommended method to install Termtosvg on Linux.
|
||||
|
||||
Make sure you should have installed python-pip package on your system. If no, use the following command to install it.
|
||||
|
||||
For Debian/Ubuntu users, use **[Apt Command][7]** or **[Apt-Get Command][8]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo apt install python-pip
|
||||
```
|
||||
|
||||
For Archlinux users, use **[Pacman Command][9]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo pacman -S python-pip
|
||||
```
|
||||
|
||||
For Fedora users, use **[DNF Command][10]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo dnf install python-pip
|
||||
```
|
||||
|
||||
For CentOS/RHEL users, use **[YUM Command][11]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo yum install python-pip
|
||||
```
|
||||
|
||||
For openSUSE users, use **[Zypper Command][12]** to install pip package.
|
||||
|
||||
```
|
||||
$ sudo zypper install python-pip
|
||||
```
|
||||
|
||||
Finally run the following **[pip command][13]** to install Termtosvg tool in Linux.
|
||||
|
||||
```
|
||||
$ sudo pip3 install termtosvg pyte python-xlib svgwrite
|
||||
```
|
||||
|
||||
### How to Record Your Terminal Session Using Termtosvg
|
||||
|
||||
Once you successfully installed Termtosvg. Just run the following command to start recording.
|
||||
|
||||
```
|
||||
$ termtosvg
|
||||
Recording started, enter "exit" command or Control-D to end
|
||||
```
|
||||
|
||||
For testing purpose run few commands and see whether it’s working fine or not.
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
Linux daygeek-Y700 4.19.8-2-MANJARO #1 SMP PREEMPT Sat Dec 8 14:45:36 UTC 2018 x86_64 GNU/Linux
|
||||
$ hostname
|
||||
daygeek-Y700
|
||||
$ cat /etc/*-release
|
||||
Manjaro Linux
|
||||
DISTRIB_ID=ManjaroLinux
|
||||
DISTRIB_RELEASE=18.0
|
||||
DISTRIB_CODENAME=Illyria
|
||||
DISTRIB_DESCRIPTION="Manjaro Linux"
|
||||
Manjaro Linux
|
||||
NAME="Manjaro Linux"
|
||||
ID=manjaro
|
||||
ID_LIKE=arch
|
||||
PRETTY_NAME="Manjaro Linux"
|
||||
ANSI_COLOR="1;32"
|
||||
HOME_URL="https://www.manjaro.org/"
|
||||
SUPPORT_URL="https://www.manjaro.org/"
|
||||
BUG_REPORT_URL="https://bugs.manjaro.org/"
|
||||
$ free -g
|
||||
free: Multiple unit options doesn't make sense.
|
||||
$ free -m
|
||||
free: Multiple unit options doesn't make sense.
|
||||
$ pip3 --version
|
||||
pip 18.1 from /usr/lib/python3.7/site-packages/pip (python 3.7)
|
||||
```
|
||||
|
||||
Once you have done, simple press `CTRL+D` or type `exit` to stop the recording. The result will be saved in `/tmp` folder with a unique name.
|
||||
|
||||
```
|
||||
$ exit
|
||||
exit
|
||||
Recording ended, SVG animation is /tmp/termtosvg_5waorper.svg
|
||||
```
|
||||
|
||||
We can open the SVG file output with help of any web browser.
|
||||
|
||||
```
|
||||
$ firefox /tmp/termtosvg_5waorper.svg
|
||||
```
|
||||
|
||||
![][15]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/termtosvg-record-your-terminal-sessions-as-svg-animations-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/script-command-record-save-your-terminal-session-activity-linux/
|
||||
[2]: https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/
|
||||
[3]: https://www.2daygeek.com/category/gif-recorder/
|
||||
[4]: https://www.2daygeek.com/gifine-create-animated-gif-vedio-recorder-linux-mint-debian-ubuntu/
|
||||
[5]: https://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
|
||||
[6]: https://www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
|
||||
[7]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[10]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[11]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[12]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[13]: https://www.2daygeek.com/install-pip-manage-python-packages-linux/
|
||||
[14]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2018/12/Termtosvg-Record-Your-Terminal-Sessions-As-SVG-Animations-In-Linux-1.gif
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use your Linux terminal to celebrate a banner year)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-figlet)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Use your Linux terminal to celebrate a banner year
|
||||
======
|
||||
Need make sure your command is heard? Pipe it to a banner and it won't be missed.
|
||||

|
||||
|
||||
|
||||
Hello again for another installment in our 24-day-long Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
|
||||
|
||||
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
|
||||
|
||||
Today's toy if **figlet** , a utility for printing text in banner form across your Linux terminal.
|
||||
|
||||
You'll likely find **figlet** packaged in your standard repositories. For me on Fedora, this meant installation was as simple as:
|
||||
|
||||
```
|
||||
$ sudo dnf install figlet
|
||||
```
|
||||
|
||||
After that, simply use the program's name to invoke it. You can either use it interactively, or, pipe some text to it, as below:
|
||||
|
||||
```
|
||||
echo "Hello world" | figlet
|
||||
_ _ _ _ _ _
|
||||
| | | | ___| | | ___ __ _____ _ __| | __| |
|
||||
| |_| |/ _ \ | |/ _ \ \ \ /\ / / _ \| '__| |/ _` |
|
||||
| _ | __/ | | (_) | \ V V / (_) | | | | (_| |
|
||||
|_| |_|\___|_|_|\___/ \_/\_/ \___/|_| |_|\__,_|
|
||||
```
|
||||
|
||||
There are a number of different font options available for **figlet**. To see the options available to you, try the command **showfigfonts**. For me, this displayed over a dozen. I've copied out a few of my favorites below.
|
||||
|
||||
```
|
||||
block :
|
||||
|
||||
_| _| _|
|
||||
_|_|_| _| _|_| _|_|_| _| _|
|
||||
_| _| _| _| _| _| _|_|
|
||||
_| _| _| _| _| _| _| _|
|
||||
_|_|_| _| _|_| _|_|_| _| _|
|
||||
|
||||
|
||||
bubble :
|
||||
_ _ _ _ _ _
|
||||
/ \ / \ / \ / \ / \ / \
|
||||
( b | u | b | b | l | e )
|
||||
\_/ \_/ \_/ \_/ \_/ \_/
|
||||
|
||||
|
||||
lean :
|
||||
|
||||
_/
|
||||
_/ _/_/ _/_/_/ _/_/_/
|
||||
_/ _/_/_/_/ _/ _/ _/ _/
|
||||
_/ _/ _/ _/ _/ _/
|
||||
_/ _/_/_/ _/_/_/ _/ _/
|
||||
|
||||
|
||||
script :
|
||||
|
||||
o
|
||||
, __ ,_ _ _|_
|
||||
/ \_/ / | | |/ \_|
|
||||
\/ \___/ |_/|_/|__/ |_/
|
||||
/|
|
||||
\|
|
||||
```
|
||||
|
||||
You can find out more about **figlet** on the project's [homepage][1]. The version I downloaded was made available as open source under an MIT license.
|
||||
|
||||
You'll find that **figlet** isn't the only banner-printer available for the Linux terminal. Another option that you may choose to check out is [toilet][2], which comes with its own set of ASCII-art style printing options.
|
||||
|
||||
Do you have a favorite command-line toy that you we should have included? Our calendar is basically set for the remainder of the series, but we'd still love to feature some cool command-line toys in the new year. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
|
||||
|
||||
Be sure to check out yesterday's toy, [Take a swim at your Linux terminal with asciiquarium][3], and come back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-figlet
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.figlet.org/
|
||||
[2]: http://caca.zoy.org/wiki/toilet
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-asciiquarium
|
||||
114
sources/tech/20181219 How to open source your Python library.md
Normal file
114
sources/tech/20181219 How to open source your Python library.md
Normal file
@ -0,0 +1,114 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to open source your Python library)
|
||||
[#]: via: (https://opensource.com/article/18/12/tips-open-sourcing-python-libraries)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
How to open source your Python library
|
||||
======
|
||||
This 12-step checklist will ensure a successful launch.
|
||||

|
||||
|
||||
You wrote a Python library. I'm sure it's amazing! Wouldn't it be neat if it was easy for people to use it? Here is a checklist of things to think about and concrete steps to take when open sourcing your Python library.
|
||||
|
||||
### 1\. Source
|
||||
|
||||
Put the code up on [GitHub][1], where most open source projects happen and where it is easiest for people to submit pull requests.
|
||||
|
||||
### 2\. License
|
||||
|
||||
Choose an open source license. A good, permissive default is the [MIT License][2]. If you have specific requirements, Creative Common's [Choose a License][3] can guide you through the alternatives. Most importantly, there are three rules to keep in mind when choosing a license:
|
||||
|
||||
* Don't create your own license.
|
||||
* Don't create your own license.
|
||||
* Don't create your own license.
|
||||
|
||||
|
||||
|
||||
### 3\. README
|
||||
|
||||
Put a file called README.rst, formatted with ReStructured Text, at the top of your tree.
|
||||
|
||||
GitHub will render ReStructured Text just as well as Markdown, and ReST plays better with Python's documentation ecosystem.
|
||||
|
||||
### 4\. Tests
|
||||
|
||||
Write tests. This is not useful just for you: it is useful for people who want to make patches that avoid breaking related functionality.
|
||||
|
||||
Tests help collaborators collaborate.
|
||||
|
||||
Usually, it is best if they are runnable with [**pytest**][4]. There are other test runners—but very little reason to use them.
|
||||
|
||||
### 5\. Style
|
||||
|
||||
Enforce style with a linter: PyLint, Flake8, or Black with **\--check**. Unless you use Black, make sure to specify configuration options in a file checked into source control.
|
||||
|
||||
### 6\. API documentation
|
||||
|
||||
Use docstrings to document modules, functions, classes, and methods.
|
||||
|
||||
There are a few styles you can use. I prefer the [Google-style docstrings][5], but [ReST docstrings][6] are an option.
|
||||
|
||||
Both Google-style and ReST docstrings can be processed by Sphinx to integrate API documentation with prose documentation.
|
||||
|
||||
### 7\. Prose documentation
|
||||
|
||||
Use [Sphinx][7]. (Read [our article on it][8].) A tutorial is useful, but it is also important to specify what this thing is, what it is good for, what it is bad for, and any special considerations.
|
||||
|
||||
### 8\. Building
|
||||
|
||||
Use **tox** or **nox** to automatically run your tests and linter and build the documentation. These tools support a "dependency matrix." These matrices tend to explode fast, but try to test against a reasonable sample, such as Python versions, versions of dependencies, and possibly optional dependencies you install.
|
||||
|
||||
### 9\. Packaging
|
||||
|
||||
Use [setuptools][9]. Write a **setup.py** and a **setup.cfg**. If you support both Python 2 and 3, specify universal wheels in the **setup.cfg**.
|
||||
|
||||
One thing **tox** or **nox** should do is build a wheel and run tests against the installed wheel.
|
||||
|
||||
Avoid C extensions. If you absolutely need them for performance or binding reasons, put them in a separate package. Properly packaging C extensions deserves its own post. There are a lot of gotchas!
|
||||
|
||||
### 10\. Continuous integration
|
||||
|
||||
### 11\. Versions
|
||||
|
||||
Use a public continuous integration runner. [TravisCI][10] and [CircleCI][11] offer free tiers for open source projects. Configure GitHub or other repo to require passing checks before merging pull requests, and you'll never have to worry about telling people to fix their tests or their style in code reviews.
|
||||
|
||||
Use either [SemVer][12] or [CalVer][13]. There are many tools to help manage versions: [incremental][14], [bumpversion][15], and [setuptools_scm][16] are all packages on PyPI that help manage versions for you.
|
||||
|
||||
### 12\. Release
|
||||
|
||||
Release by running **tox** or **nox** and using **twine** to upload the artifacts to PyPI. You can do a "test upload" by running [DevPI][17].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/tips-open-sourcing-python-libraries
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/
|
||||
[2]: https://en.wikipedia.org/wiki/MIT_License
|
||||
[3]: https://choosealicense.com/
|
||||
[4]: https://docs.pytest.org/en/latest/
|
||||
[5]: https://github.com/google/styleguide/blob/gh-pages/pyguide.md
|
||||
[6]: https://www.python.org/dev/peps/pep-0287/
|
||||
[7]: http://www.sphinx-doc.org/en/master/
|
||||
[8]: https://opensource.com/article/18/11/building-custom-workflows-sphinx
|
||||
[9]: https://pypi.org/project/setuptools/
|
||||
[10]: https://travis-ci.org/
|
||||
[11]: https://circleci.com/
|
||||
[12]: https://semver.org/
|
||||
[13]: https://calver.org/
|
||||
[14]: https://pypi.org/project/incremental/
|
||||
[15]: https://pypi.org/project/bumpversion/
|
||||
[16]: https://pypi.org/project/setuptools_scm/
|
||||
[17]: https://opensource.com/article/18/7/setting-devpi
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Solve a puzzle at the Linux command line with nudoku)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-nudoku)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Solve a puzzle at the Linux command line with nudoku
|
||||
======
|
||||
Sudokus are simple logic games that can be enjoyed just about anywhere, including in your Linux terminal.
|
||||
|
||||
|
||||
Welcome back to another installment in our 24-day-long Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
|
||||
|
||||
Some of you will have seen various selections from our calendar before, but we hope there’s at least one new thing for everyone.
|
||||
|
||||
Every year for Christmas, my mother-in-law gives my wife a Sudoku calendar. It sits on our coffee table for the year to follow. Each day is a separate sheet (except for Saturday and Sunday, that are combined onto one page), with the idea being that you have a new puzzle every day while also having a functioning calendar.
|
||||
|
||||
The problem, in practice, is that it's a great pad of puzzles but not a great calendar because it turns out some days are harder than others and we just don't get through them at the necessary rate of one a day. Then, we may have a week's worth that gets batched on a lazy Sunday.
|
||||
|
||||
Since I've already given you a [calendar][1] as a part of this series, I figure it's only fair to give you a Sudoku puzzle as well, except our command-line versions are decoupled so there's no pressure to complete exactly one a day.
|
||||
|
||||
I found **nudoku** in my default repositories on Fedora, so installing it was as simple as:
|
||||
|
||||
```
|
||||
$ sudo dnf install nudoku
|
||||
```
|
||||
|
||||
Once installed, just invoke **nudoku** by name to launch it, and it should be fairly self-explanatory from there. If you've never played Sudoku before, it's fairly simple: You need to make sure that each row, each column, and each of the nine 3x3 squares that make up the large square each have one of every digit, 1-9.
|
||||
|
||||
You can find **nudoku** 's c source code [on GitHub][2] under a GPLv3 license.
|
||||

|
||||
Do you have a favorite command-line toy that you we should have included? Our calendar is basically set for the remainder of the series, but we'd still love to feature some cool command-line toys in the new year. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
|
||||
|
||||
Be sure to check out yesterday's toy, [Use your Linux terminal to celebrate a banner][3] [year][3], and come back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-nudoku
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/12/linux-toy-cal
|
||||
[2]: https://github.com/jubalh/nudoku
|
||||
[3]: https://opensource.com/article/18/12/linux-toy-figlet
|
||||
166
sources/tech/20181220 Getting started with Prometheus.md
Normal file
166
sources/tech/20181220 Getting started with Prometheus.md
Normal file
@ -0,0 +1,166 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Prometheus)
|
||||
[#]: via: (https://opensource.com/article/18/12/introduction-prometheus)
|
||||
[#]: author: (Michael Zamot https://opensource.com/users/mzamot)
|
||||
|
||||
Getting started with Prometheus
|
||||
======
|
||||
Learn to install and write queries for the Prometheus monitoring and alerting system.
|
||||

|
||||
|
||||
[Prometheus][1] is an open source monitoring and alerting system that directly scrapes metrics from agents running on the target hosts and stores the collected samples centrally on its server. Metrics can also be pushed using plugins like **collectd_exporter** —although this is not Promethius' default behavior, it may be useful in some environments where hosts are behind a firewall or prohibited from opening ports by security policy.
|
||||
|
||||
Prometheus, a project of the [Cloud Native Computing Foundation][2], scales up using a federation model, which enables one Prometheus server to scrape another Prometheus server. This allows creation of a hierarchical topology, where a central system or higher-level Prometheus server can scrape aggregated data already collected from subordinate instances.
|
||||
|
||||
Besides the Prometheus server, its most common components are its [Alertmanager][3] and its exporters.
|
||||
|
||||
Alerting rules can be created within Prometheus and configured to send custom alerts to Alertmanager. Alertmanager then processes and handles these alerts, including sending notifications through different mechanisms like email or third-party services like [PagerDuty][4].
|
||||
|
||||
Prometheus' exporters can be libraries, processes, devices, or anything else that exposes the metrics that will be scraped by Prometheus. The metrics are available at the endpoint **/metrics** , which allows Prometheus to scrape them directly without needing an agent. The tutorial in this article uses **node_exporter** to expose the target hosts' hardware and operating system metrics. Exporters' outputs are plaintext and highly readable, which is one of Prometheus' strengths.
|
||||
|
||||
In addition, you can configure [Grafana][5] to use Prometheus as a backend to provide data visualization and dashboarding functions.
|
||||
|
||||
### Making sense of Prometheus' configuration file
|
||||
|
||||
The number of seconds between when **/metrics** is scraped controls the granularity of the time-series database. This is defined in the configuration file as the **scrape_interval** parameter, which by default is set to 60 seconds.
|
||||
|
||||
Targets are set for each scrape job in the **scrape_configs** section. Each job has its own name and a set of labels that can help filter, categorize, and make it easier to identify the target. One job can have many targets.
|
||||
|
||||
### Installing Prometheus
|
||||
|
||||
In this tutorial, for simplicity, we will install a Prometheus server and **node_exporter** with docker. Docker should already be installed and configured properly on your system. For a more in-depth, automated method, I recommend Steve Ovens' article [How to use Ansible to set up system monitoring with Prometheus][6].
|
||||
|
||||
Before starting, create the Prometheus configuration file **prometheus.yml** in your work directory as follows:
|
||||
|
||||
```
|
||||
global:
|
||||
scrape_interval: 15s
|
||||
evaluation_interval: 15s
|
||||
|
||||
scrape_configs:
|
||||
- job_name: 'prometheus'
|
||||
|
||||
static_configs:
|
||||
- targets: ['localhost:9090']
|
||||
|
||||
- job_name: 'webservers'
|
||||
|
||||
static_configs:
|
||||
- targets: ['<node exporter node IP>:9100']
|
||||
```
|
||||
|
||||
Start Prometheus with Docker by running the following command:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -p 9090:9090 -v
|
||||
/path/to/prometheus.yml:/etc/prometheus/prometheus.yml
|
||||
prom/prometheus
|
||||
```
|
||||
|
||||
By default, the Prometheus server will use port 9090. If this port is already in use, you can change it by adding the parameter **\--web.listen-address=" <IP of machine>:<port>"** at the end of the previous command.
|
||||
|
||||
In the machine you want to monitor, download and run the **node_exporter** container by using the following command:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -v "/proc:/host/proc" -v "/sys:/host/sys" -v
|
||||
"/:/rootfs" --net="host" prom/node-exporter --path.procfs
|
||||
/host/proc --path.sysfs /host/sys --collector.filesystem.ignored-
|
||||
mount-points "^/(sys|proc|dev|host|etc)($|/)"
|
||||
```
|
||||
|
||||
For the purposes of this learning exercise, you can install **node_exporter** and Prometheus on the same machine. Please note that it's not wise to run **node_exporter** under Docker in production—this is for testing purposes only.
|
||||
|
||||
To verify that **node_exporter** is running, open your browser and navigate to **http:// <IP of Node exporter host>:9100/metrics**. All the metrics collected will be displayed; these are the same metrics Prometheus will scrape.
|
||||
|
||||
|
||||
|
||||
To verify the Prometheus server installation, open your browser and navigate to <http://localhost:9090>.
|
||||
|
||||
You should see the Prometheus interface. Click on **Status** and then **Targets**. Under State, you should see your machines listed as **UP**.
|
||||
|
||||
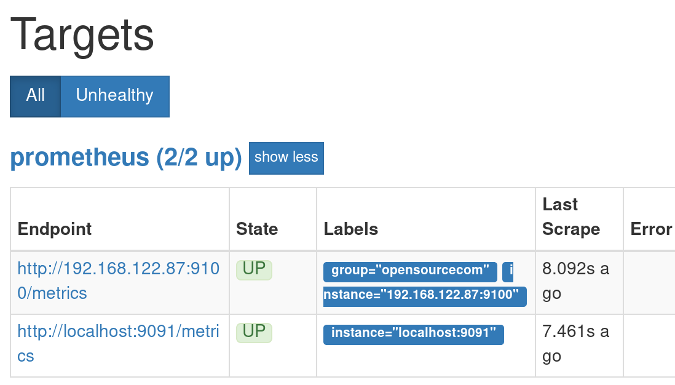
|
||||
|
||||
### Using Prometheus queries
|
||||
|
||||
It's time to get familiar with [PromQL][7], Prometheus' query syntax, and its graphing web interface. Go to **<http://localhost:9090/graph>** on your Prometheus server. You will see a query editor and two tabs: Graph and Console.
|
||||
|
||||
Prometheus stores all data as time series, identifying each one with a metric name. For example, the metric **node_filesystem_avail_bytes** shows the available filesystem space. The metric's name can be used in the expression box to select all of the time series with this name and produce an instant vector. If desired, these time series can be filtered using selectors and labels—a set of key-value pairs—for example:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype="ext4"}
|
||||
```
|
||||
|
||||
When filtering, you can match "exactly equal" ( **=** ), "not equal" ( **!=** ), "regex-match" ( **=~** ), and "do not regex-match" ( **!~** ). The following examples illustrate this:
|
||||
|
||||
To filter **node_filesystem_avail_bytes** to show both ext4 and XFS filesystems:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype=~"ext4|xfs"}
|
||||
```
|
||||
|
||||
To exclude a match:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype!="xfs"}
|
||||
```
|
||||
|
||||
You can also get a range of samples back from the current time by using square brackets. You can use **s** to represent seconds, **m** for minutes, **h** for hours, **d** for days, **w** for weeks, and **y** for years. When using time ranges, the vector returned will be a range vector.
|
||||
|
||||
For example, the following command produces the samples from five minutes to the present:
|
||||
|
||||
```
|
||||
node_memory_MemAvailable_bytes[5m]
|
||||
```
|
||||
|
||||
Prometheus also includes functions to allow advanced queries, such as this:
|
||||
|
||||
```
|
||||
100 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated (1 - avg by(instance)(irate(node_cpu_seconds_total{job='webservers',mode='idle'}[5m])))
|
||||
```
|
||||
|
||||
Notice how the labels are used to filter the job and the mode. The metric **node_cpu_seconds_total** returns a counter, and the **irate()** function calculates the per-second rate of change based on the last two data points of the range interval (meaning the range can be smaller than five minutes). To calculate the overall CPU usage, you can use the idle mode of the **node_cpu_seconds_total** metric. The idle percent of a processor is the opposite of a busy processor, so the **irate** value is subtracted from 1. To make it a percentage, multiply it by 100.
|
||||
|
||||
|
||||
|
||||
### Learn more
|
||||
|
||||
Prometheus is a powerful, scalable, lightweight, and easy to use and deploy monitoring tool that is indispensable for every system administrator and developer. For these and other reasons, many companies are implementing Prometheus as part of their infrastructure.
|
||||
|
||||
To learn more about Prometheus and its functions, I recommend the following resources:
|
||||
|
||||
+ About [PromQL][8]
|
||||
+ What [node_exporters collects][9]
|
||||
+ [Prometheus functions][10]
|
||||
+ [4 open source monitoring tools][11]
|
||||
+ [Now available: The open source guide to DevOps monitoring tools][12]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/introduction-prometheus
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mzamot
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://prometheus.io/
|
||||
[2]: https://www.cncf.io/
|
||||
[3]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[4]: https://en.wikipedia.org/wiki/PagerDuty
|
||||
[5]: https://grafana.com/
|
||||
[6]: https://opensource.com/article/18/3/how-use-ansible-set-system-monitoring-prometheus
|
||||
[7]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[8]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[9]: https://github.com/prometheus/node_exporter#collectors
|
||||
[10]: https://prometheus.io/docs/prometheus/latest/querying/functions/
|
||||
[11]: https://opensource.com/article/18/8/open-source-monitoring-tools
|
||||
[12]: https://opensource.com/article/18/8/now-available-open-source-guide-devops-monitoring-tools
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Let your Linux terminal speak its mind)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-espeak)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Let your Linux terminal speak its mind
|
||||
======
|
||||
eSpeak is an open source text-to-speech synthesizer that can be invoked from the Linux command line.
|
||||
|
||||
|
||||
Greetings from another day in our 24-day-long Linux command-line toys advent calendar. If this is your first visit to the series, you might be asking yourself what a command-line toy even is. We’re figuring that out as we go, but generally, it could be a game, or any simple diversion that helps you have fun at the terminal.
|
||||
|
||||
We hope that even if you've seen some of these before, there will be something new for everybody in our series.
|
||||
|
||||
Some of you may be too young to remember, but before there was Alexa, Siri, or the Google Assistant, computers still had voices.
|
||||
|
||||
Many of us will never forget HAL 9000 from [2001: A Space Odessey][1] helpfully conversing with the crew (sorry, Dave). But between 1960s science fiction and today, there was a whole generation of speaking computers. Some of them great, most of them, not so great.
|
||||
|
||||
One of my favorites is the open source project [eSpeak][2]. It's available in many forms, including a library version you can use to include speech technology in your own project, but it also coms as a command-line program that you can install and use easily. In my distribution, this was as simple as:
|
||||
|
||||
```
|
||||
$ sudo dnf install espeak
|
||||
```
|
||||
|
||||
Invoking eSpeak then can be invoked either interactively, or by piping text to it using the output of another program or a simple echo command. There are a number of [voice files][3] available for eSpeak, and if you're especially bored over the holidays, you could even create your own.
|
||||
|
||||
A fork of eSpeak called eSpeak NG ("Next Generation") was created in 2015 from some developers who wanted to continue development of the otherwise lightly-updated eSpeak. eSpeak is made available as open source under a GPL version 3 license, and you can find out more about the project and download the source code [on SourceForge][2].
|
||||
|
||||
I'll also throw in a bonus toy today, [cava][4]. Because I've been eager to give each of these articles a unique screenshot as the lead image, and today's toy outputs sound rather than something visual, I needed to find something to fill the space. Short for "console-based audio visualizer for ALSA" (although it supports more than just ALSA now), cava is a nice MIT-licensed terminal audio visualization tool that's fun to watch. Below, is a visualization of eSpeak's output of the following:
|
||||
|
||||
```
|
||||
$ echo "Rudolph, the red-nosed reindeer, had a very shiny nose." | espeak
|
||||
```
|
||||
|
||||
|
||||
|
||||
Do you have a favorite command-line toy that you we should have included? Our calendar is basically set for the remainder of the series, but we'd still love to feature some cool command-line toys in the new year. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
|
||||
|
||||
Be sure to check out yesterday's toy, [Solve a puzzle at the Linux command line with nudoku][5], and come back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-espeak
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey_(film)
|
||||
[2]: http://espeak.sourceforge.net/
|
||||
[3]: http://espeak.sourceforge.net/voices.html
|
||||
[4]: https://github.com/karlstav/cava
|
||||
[5]: https://opensource.com/article/18/12/linux-toy-nudoku
|
||||
74
translated/talk/20181121 DevOps is for everyone.md
Normal file
74
translated/talk/20181121 DevOps is for everyone.md
Normal file
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (alim0x)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (DevOps is for everyone)
|
||||
[#]: via: (https://opensource.com/article/18/11/how-non-engineer-got-devops)
|
||||
[#]: author: (Dawn Parych https://opensource.com/users/dawnparzych)
|
||||
[#]: url: ( )
|
||||
|
||||
所有人的 DevOps
|
||||
======
|
||||
|
||||
让一名非工程师来解释为什么你不必成为一位开发者或运维就能爱上 DevOps。
|
||||
|
||||

|
||||
|
||||
我没有过开发或运维的工作——那怎么我在写一篇关于 [DevOps][1] 的文章?我一直都对计算机和技术有兴趣。我还对社群、心理学以及帮助他人充满热情。当我第一次听到 DevOps 时,这个概念激起了我的兴趣,因为它看起来融合了很多我感兴趣的东西,即便我是不写代码的。
|
||||
|
||||
我的第一台电脑是 TRS-80,我喜欢在上面编写 BASIC 程序。我只上过两门我的高中开设的计算机编程课程。若干年后,我创办了一家计算机公司。我定制邮件标签和信纸,并建立了一个数据库来存储地址。
|
||||
|
||||
问题是我并不能从写代码中获得享受。我想要教育和帮助人们,我没法将写代码看作这样的一个机会。是的,技术可以帮助人们并改变生活,但是写代码没有点燃我的热情。我需要对我的工作感到兴奋并做我喜欢的事情。
|
||||
|
||||
* 文化,而不是代码
|
||||
* 过程,而不是结果
|
||||
* 建立一个所有人可以持续提升的环境
|
||||
* 沟通与合作,而不是独立工作
|
||||
|
||||
|
||||
我发现我爱 DevOps。对我而言,DevOps 指的是:
|
||||
|
||||
归根结底,DevOps 是指成为社区工作的一部分,实现共同的目标。DevOps 融合了心理学、社群、技术。DevOps 不是一个职位名称,它是一种生活和工作的哲学。
|
||||
|
||||
### 找到我的社群
|
||||
|
||||
快四年前,我在西雅图参加了我的第一个 [DevOps 日][2] 会议。我感觉我找到了我的社群。我觉得受到了欢迎和接受,尽管我从事营销工作而且没有计算机科学文凭。我可以从心理学和技术中寻找乐趣。
|
||||
|
||||
在 DevOps 日,我学到了 [DevOps“三步工作法”][3]——流动,反馈,持续实验和学习——以及新(对我而言)的概念,如Kaizen(改善)和Kaikaku(改革)。随着我的学习深入,我发现我在说这样的话,“我是这样做的!我都不知道这样做还有个名字!”
|
||||
|
||||
[Kaizen(改善)][4]是持续改进和学习的实践。小的量变积累随着时间的推移可以引起质变。我发现它和卡罗尔.德韦克的[成长型思维][5]的想法很相似。人们不是生来就是专家。在某方面拥有经验需要花费时间,练习,以及常常还有失败。承认增量的改善对确保我们不会放弃是很有必要的。
|
||||
|
||||
另一方面,[Kaikaku(改革)][6]的概念是指,长时间的小的改变有时不能起作用,你需要做一些完全的或破坏性的改变。在没有找到下份工作前就辞职或移居新城市就足够有破坏性——是的,两者我都做过。但这些彻底的改变收获巨大。如果我没有辞职并休息一段时间,我也许不会接触到 DevOps。等我决定继续工作的时候,我一直听到 DevOps,我开始研究它。这引导我参加了我的第一个 DevOps 日,从那里我开始看到我的所有热情开始聚集。从那时起,我已经参加了五次 DevOps 日活动,并且定期撰写关于 DevOps 话题的文章。
|
||||
|
||||
### 将三步工作法用到工作中
|
||||
|
||||
改变是困难的,学习新事物可以听起来很吓人。DevOps 的三步工作法提供了一个管理改变的框架。比如:信息流动是怎样的?是什么驱动着你做出改变?一旦你认为一个改变是必需的,你如何获得这个改变是否正确的反馈?你如何知道你在取得进展?反馈是必要的,并且应该包含积极和有建设性的要素。困难的地方在于保证建设性的要素不要重于积极要素。
|
||||
|
||||
对我而言,第三步——持续实验和学习——是 DevOps 最重要的部分。有一个可以自由地实验和冒险的环境,人们可以获得意想不到的结果。有时这些结果是好的,有时不是太好——但这没事。创建一个可以接受失败结果的环境可以鼓励人们冒险。我们都应该力争定期的持续实验和学习。
|
||||
|
||||
DevOps 的三步工作法提供了一个尝试,获得反馈,以及从错误中获取经验的方法。几年前,我的儿子告诉我,“我从来就没想做到最好,因为那样我就没法从我的错误中学到东西了。”我们都会犯错,从中获得经验帮助我们成长和改善。如果我们的文化不支持尝试和学习,我们就不会愿意去犯错。
|
||||
|
||||
### 成为社区的一部分
|
||||
|
||||
我已经在技术领域工作了超过 20 年,直到我发现 DevOps 社区前,我还经常感觉自己是个外行。如果你像我一样——对技术充满热情,但不是工程和运维那方面——你仍然可以成为 DevOps 的一部分,即便你从事的是销售、营销、产品营销、技术写作、支持或其他工作。DevOps 是属于所有人的。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/how-non-engineer-got-devops
|
||||
|
||||
作者:[Dawn Parych][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dawnparzych
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/resources/devops
|
||||
[2]: https://www.devopsdays.org/
|
||||
[3]: https://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[4]: https://en.wikipedia.org/wiki/Kaizen
|
||||
[5]: https://en.wikipedia.org/wiki/Mindset#Fixed_and_growth
|
||||
[6]: https://en.wikipedia.org/wiki/Kaikaku
|
||||
@ -1,73 +1,75 @@
|
||||
一位 CEO 的 Emacs 指南
|
||||
============================================================
|
||||
===========
|
||||
|
||||
几年前,不,是几十年前,我就在用 Emacs。不论是码代码、编写文档,还是管理邮件和日程,我都用这个编辑器或者是说操作系统,而且我还乐此不疲。多年过去了,我也转向了其他更新,更好的工具。结果,我已经忘了如何在不用鼠标的情况下来浏览文件。大约三个月前,我意识到我在应用程序和计算机之间切换上耗费了大量的时间,于是就决定再试一次 Emacs。这是个很正确的决定,原因有以下几个。其中包括了 `.emacs` 和 Dropbox 的技巧,可以让你建立一个良好的,可移植的环境。
|
||||
几年前,不,是几十年前,我就在用 Emacs。不论是码代码、编写文档,还是管理邮件和日程,我都用这个编辑器或者是说操作系统,而且我还乐此不疲。许多年过去了,我也转向了其他更新、更好的工具。结果,我已经忘了如何在不用鼠标的情况下来浏览文件。大约三个月前,我意识到我在应用程序和计算机之间切换上耗费了大量的时间,于是就决定再试一次 Emacs。这是个很正确的决定,原因有以下几个。其中包括了 `.emacs` 和 Dropbox 的技巧,可以让你建立一个良好的、可移植的环境。
|
||||
|
||||
对于那先还没用过 Emacs 的人来说,你可能会讨厌它,但也可能喜欢上它。它有点像一个房子大小的 Rube Goldberg 机器,乍一看,它具备烤面包机的所有功能。这听起来不像是一种认可,但关键短语是“乍一看”。一旦你了解了Emacs,你就会意识到它其实是一种可以作为发动机的热核烤面包机。好吧,你想对文字做什么都可以。当考虑到计算寿命在很大程度上与文本有关时,这是一个相当大胆的声明,真的很大胆。
|
||||
对于那些还没用过 Emacs 的人来说,你可能会讨厌它,但也可能喜欢上它。它有点像一个房子大小的<ruby>鲁布·戈德堡机械<rt>Rube Goldberg machine</rt></ruby>,乍一看,它具备烤面包机的所有功能。这听起来不像是一种认可,但关键短语是“乍一看”。一旦你了解了 Emacs,你就会意识到它其实是一种可以作为发动机的热核烤面包机……好吧,你可以用来对文字做什么都可以。当考虑到你的计算生活在很大程度上与文本有关时,这是一个相当大胆的声明,真的很大胆。
|
||||
|
||||
也许对我来说更重要的是,它是我曾经使用过的一个应用程序,并让我觉得我真正的拥有它,而不是把我塑造成一个匿名的“用户”,就好像位于 [Soma][30] 或 Redmond 附近某个高档办公室的产品营销部门把钱作为明确的目标一样。现代生产力和创作应用程序(如文件或 `IDE`)就像碳纤维赛车,他们装备得很好,也很完整。而Emacs 就像一盒经典的 [Campagnolo][31] 零件和一个漂亮的拖钢框架,缺少曲柄臂和刹车杆,你必须在网上某个小众文化中找到它们。第二点就是它会给你带来无尽的快乐或烦恼,这取决于你自己,而且会一直持续到你生命的最后一天。我是那种在找到一堆老古董或用 `Emacs Lisp` 配置编辑器时同样感到高兴的人,具体情况因人而异。
|
||||
也许对我来说更重要的是,它是我曾经使用过的一个应用程序,并让我觉得我真正的拥有它,而不是把我塑造成一个匿名的“用户”,就好像位于 [Soma][30](LCTT 译注:旧金山的一个街区)或雷蒙德(LCTT 译注:微软总部所在地)附近某个高档办公室的产品营销部门把钱作为明确的目标一样。现代生产力和创作应用程序(如 Pages 或 IDE)就像碳纤维赛车,它们装备得很好,也很齐全。而 Emacs 就像一盒经典的 [Campagnolo][31] (LCTT 译注:世界上最好的三个公路自行车套件系统品牌之一)零件和一个漂亮的自行车牵引式钢框架,但缺少曲柄臂和刹车杆,你必须在网上某个小众文化中找到它们。第一点是它是更快更完整的。第二点就是它会给你带来无尽的快乐或烦恼,这取决于你自己,而且会一直持续到你生命的最后一天。我是那种在找到一堆老古董或用 `Emacs Lisp` 配置编辑器时同样感到高兴的人,具体情况因人而异。
|
||||
|
||||

|
||||
一辆我还在骑的1933年产的钢制自行车。你可以从查看框架管差别: [https://www.youtube.com/watch?v=khJQgRLKMU0][6].
|
||||

|
||||
|
||||
这可能给人一种 Emacs 已经过气或过时的印象。但它不是,它是强大和永恒的,只要你耐心地去理解它的一些规则。他的规则很另类,也很奇怪,但其中的逻辑却引人注目,且很有魅力。对于我来说, Emacs 更像是未来而不是过去。就像牵引式钢框架在未来几十年里将会变得好用和舒适,而神奇的碳纤维自行车将会被扔进垃圾场,在撞击中粉碎一样,Emacs 也将会作为一种在最新的流行应用早已被遗忘的时候的好用的工具继续存在这。
|
||||
*一辆我还在骑的1933年产的钢制自行车。你可以看看框架管差别: [https://www.youtube.com/watch?v=khJQgRLKMU0][6]*
|
||||
|
||||
如果通过编辑 `Lisp` 代码来构建自己的个人工作环境,并将这种非常适合自己的环境移植到任何计算机的想法吸引了你,那么你可能会爱上 Emacs。如果你喜欢很潮、很炫的,又不想投入太多时间和精力的情况下就能直接工作的话,那么它可能不适合你。我已经不再写代码了(除了 `Ludwig` 和 `Emacs Lisp`),但是 `Fugue` 的很多工程师都使用 Emacs 来提高码代码的效率。我公司有 30% 的工程师用 Emacs, 40% 用 `IDE` 和 30% 的用 vim。但这篇文章是关于 CEO 和其他[聪明的老板][32](PHB<sup>[1][7]</sup>)的 Emacs 指南,所以我将解释或者说辩解我为什么喜欢它以及我如何使用它。同时我也希望我能介绍清楚从而让你能有个良好的体验,而不是花上几个小时去 Google。
|
||||
这可能给人一种 Emacs 已经过气或过时的印象。但它不是,它是强大和永恒的,只要你耐心地去理解它的一些规则。它的规则很另类,也很奇怪,但其中的逻辑却引人注目,且很有魅力。对于我来说, Emacs 更像是未来而不是过去。就像牵引式钢框架在未来几十年里将会变得好用和舒适,而神奇的碳纤维自行车将会被扔进垃圾场,在撞击中粉碎一样,Emacs 也将会作为一种在最新的流行应用早已被遗忘的时候的好用的工具继续存在这里。
|
||||
|
||||
### 最后的优点
|
||||
如果通过编辑 Lisp 代码来构建自己的个人工作环境,并将这种非常适合自己的环境移植到任何计算机的想法吸引了你,那么你可能会爱上 Emacs。如果你喜欢很潮、很炫的,又不想投入太多时间和精力的情况下就能直接工作的话,那么它可能不适合你。我已经不再写代码了(除了 Ludwig 和 Emacs Lisp),但是 Fugue 公司的很多工程师都使用 Emacs 来提高码代码的效率。我公司有 30% 的工程师用 Emacs,40% 用 IDE 和 30% 的用 vim。但这篇文章是关于 CEO 和其他<ruby>[聪明的老板][32]<rt>Pointy-Haired Bosses</rt></ruby>(PHB[^1] )(以及,其它好奇的人)的 Emacs 指南,所以我将解释或者说辩解我为什么喜欢它以及我如何使用它。同时我也希望我能介绍清楚从而让你能有个良好的体验,而不是花上几个小时去 Google。
|
||||
|
||||
使用 Emacs 带来的长期优势是让生活更轻松。与最后的收获相比,最开始的付出完全值得。想想这些:
|
||||
### 恒久优势
|
||||
|
||||
### 无需上下文切换
|
||||
使用 Emacs 带来的长期优势是让生活更轻松。与最后的收获相比,最开始的付出完全值得。想想这些:
|
||||
|
||||
`Org` 模式本身就值得花时间,但如果你像我一样,你通常要处理十几份左右的文件 —— 从博客帖子到会议需要做什么的清单,再到员工评论。在现代计算世界中,这通常意味着要使用多个应用程序,所有这些应用程序都有不同的用户界面,保存方式、排序和搜索方式。结果就是你需要不断转换思维环境,记住细节。我讨厌上下文切换,因为它是一种强加到我身上的方式,原因是破坏了接口模型<sup>[2][8]</sup>,并且我讨厌记住计算机的命令,这本该是计算机要记住的东西。在单个环境下,Emacs 对 PHB 甚至比对于程序员更有用,因为程序员更多时候只需要专注于一个程序。转换思维环境的成本比通常看起来的要高。操作系统和应用程序供应商已经构建了各种接口,以分散我们对这一现实的注意力。如果你是技术人员,通过快捷键(`M-:`)来访问功能强大的[语言解释器][33]会方便的多<sup>[3][9]</sup>。
|
||||
#### 无需上下文切换
|
||||
|
||||
许多应用程序可以全天全屏并用于编辑文本。Emacs 是惟一的,因为它既是编辑器也是 `Emacs Lisp` 解释器。从本质上说,你工作时只要用电脑上的一两个键就能完成。如果你对编程略知一二,就能发现这一位置你可以在 Emacs 中做 _任何事情_。一旦你在内存中有了这些命令,你的电脑就可以在你工作时几乎实时地为你提供高效的运转。你不会想用 `Emacs Lisp` 来重建 Excel,只要用简单的一两行代码就能实现 Excel 中大多数的功能。如果我需要处理数字,我更有可能转到 scratch 缓冲区,编写一些代码,而不是打开电子表格。即便是我有一封多行的邮件要写,我通常也会先在 Emacs 中写完,然后再复制粘贴到邮件客户端中。当你可以流畅的书写时,为什么要去切换呢?你可以先从一两个简单的计算开始,随着时间的推移,你可以很容易的在 Emacs 中添加你所需要处理的计算。这在应用程序中可能是独一无二的,同时还提供了让为其他的人创造的丰富特性。还记得 Isaac Asimov 书中那些神奇的终端吗<sup>[4][10]</sup>? Emacs 是我所遇到的最接近他们的东西。我决定不再用什么应用程序来做这个或那个。相反,我只是工作。拥有一个伟大的工具并致力于此,这才是真正的动力和效率。
|
||||
Org 模式本身就值得花时间,但如果你像我一样,你通常要处理十几份左右的文件 —— 从博客帖子到会议需要做什么的清单,再到员工评估。在现代计算世界中,这通常意味着要使用多个应用程序,所有这些应用程序都有不同的用户界面、保存方式、排序和搜索方式。结果就是你需要不断转换思维环境,记住细节。我讨厌上下文切换,因为它是一种强加到我身上的方式,原因是破坏了界面模型[^2] ,并且我讨厌记住本该是计算机要为我记住的东西。在单个环境下,Emacs 对 PHB 甚至比对于程序员更有用,因为程序员更多时候只需要专注于一个程序。转换思维环境的成本比通常看起来的要高。操作系统和应用程序厂商已经构建了各种界面,以分散我们对这一现实的注意力。如果你是技术人员,通过快捷键(`M-:`)来访问功能强大的[语言解释器][33]会方便的多[^3] 。
|
||||
|
||||
### 在安静中创造事情
|
||||
许多应用程序可以全天全屏地用于编辑文本。Emacs 是惟一的,因为它既是编辑器也是 Emacs Lisp 解释器。从本质上说,你工作时只要用电脑上的一两个键就能完成。如果你对编程略知一二,就能发现这意味着你可以在 Emacs 中做 _任何事情_。一旦你在内存中有了这些命令,你的电脑就可以在你工作时几乎实时地为你提供高效的运转。你不会想用 Emacs Lisp 来重建 Excel,只要用简单的一两行代码就能实现 Excel 中大多数的功能。如果我需要处理数字,我更有可能转到 scratch 缓冲区,编写一些代码,而不是打开电子表格。即便是我有一封多行的邮件要写,我通常也会先在 Emacs 中写完,然后再复制粘贴到邮件客户端中。当你可以流畅的书写时,为什么要去切换呢?你可以先从一两个简单的算术开始,随着时间的推移,你可以很容易的在 Emacs 中添加你所需要处理的计算。这在应用程序中可能是独一无二的,同时还提供了让为其他的人创造的丰富特性。还记得艾萨克·阿西莫夫书中那些神奇的终端吗? Emacs 是我所遇到的最接近它们的东西[^4] 。我决定不再用什么应用程序来做这个或那个。相反,我只是工作。拥有一个伟大的工具并致力于此,这才是真正的动力和效率。
|
||||
|
||||
拥有我所发现的最好的文本编辑功能的最终结果是什么?有一群人在做各种各样有用的补充吗?拥有 `Lisp` 键盘的全部功能?这就是我用 Emacs 来完成所有的创作性工作,处理音乐和图片除外。
|
||||
#### 在安静中创造事情
|
||||
|
||||
我的办公桌上有两个显示器。其中一块竖屏是将 Emacs 全天全屏显示,另一个显示浏览器,用来搜索和阅读,通常也会打开一个终端。我将日历、邮件等保存在 OS X 的另一个桌面上,当我使用 Emacs 时,这个桌面是隐藏的,同时我也会关掉所有通知。这样就能让我专注于我手头上在做的事了。我发现,在更现代的 UI 应用程序中,消除干扰几乎是不可能的,因为这些应用程序努力提供帮助并使其易于使用。我不需要经常被提醒该如何操作,我已经做了成千上万次了,我真正需要的是一张干净整洁的白纸用来思考。也许因为年龄和自己的“恶习”,我不太喜欢处在嘈杂的环境中,但我认为这值得一试。看看在你电脑环境中有一些真正的宁静是怎样的。当然,现在很多应用程序都有隐藏界面的模式,谢天谢地,苹果和微软现在都有了真正意义上的全屏模式。但是,没有并没有应用程序可以强大到足以“处理”大多数事务。除非你整天写代码,或者像写一本书一样处理很长的文档,否则你仍然会面临其他应用程序的干扰。而且,大多数现代应用程序似乎同时显得自视甚高,缺乏功能和可用性<sup>[5][11]</sup>。比其 office 应用程序,我更讨厌在线版的应用程序。
|
||||
拥有我所发现的最好的文本编辑功能的最终结果是什么?有一群人在做各种各样有用的补充吗?发挥了 Lisp 键盘的全部威力了吗?我用 Emacs 来完成所有的创作性工作,处理音乐和图片除外。
|
||||
|
||||

|
||||
我的桌面布局, Emacs 在左边
|
||||
我的办公桌上有两个显示器。其中一块竖屏是将 Emacs 全天全屏显示,另一个显示浏览器,用来搜索和阅读,通常也会打开一个终端。我将日历、邮件等放在 OS X 的另一个桌面上,当我使用 Emacs 时,这个桌面是隐藏的,同时我也会关掉所有通知。这样就能让我专注于我手头上在做的事了。我发现,在更现代的 UI 应用程序中,消除干扰几乎是不可能的,因为这些应用程序致力于提供帮助和易用性。我不需要经常被提醒该如何操作,我已经做了成千上万次了,我真正需要的是一张干净整洁的白纸用来思考。也许因为年龄和自己的“恶习”,我不太喜欢处在嘈杂的环境中,但我认为这值得一试。看看在你电脑环境中有一些真正的宁静是怎样的。当然,现在很多应用程序都有隐藏界面的模式,谢天谢地,苹果和微软现在都有了真正意义上的全屏模式。但是,没有并没有应用程序可以强大到足以“处理”大多数事务。除非你整天写代码,或者像写一本书一样处理很长的文档,否则你仍然会面临其他应用程序的干扰。而且,大多数现代应用程序似乎同时显得自视甚高,缺乏功能和可用性[^5] 。比起 office 应用程序,我更讨厌其在线版。
|
||||
|
||||
但是交流呢?创造和交流之间的差别很大。当我为两者留出不同的时间时,我的效率会更高。在 `Fugue` 中使用了 `Slack`,痛并快乐着。我把它和我的日历、电子邮件放在一个即时通讯的桌面上,这样,当我正在做事时,我很高兴地能够忽略所有的聊天。仅仅是风投或董事会董事的一次懈怠,或一封电子邮件,就能让我立刻丢掉手头工作。但是,大多数事情通常可以等上一两个小时。
|
||||
|
||||
|
||||
### 带上一切,并保留着
|
||||
*我的桌面布局, Emacs 在左边*
|
||||
|
||||
第三个原因是,我发现 Emacs 比其它的环境更有优势的是你可以很容易的用它来处理事务。我的意思是,你所需要的只是通过 `Dropbox` 类似的网站同步一两个目录,而不是让大量的应用程序以它们自己的方式进行交互和同步。然后,你可以在任何地方,任何环境下工作了,因为你已经精心制作了适合目的套件了。我在 OS X,Windows,或有时在 Linux 都是这样做的。它非常简单可靠。这种功能很有用,以至于我害怕处理页面、Google Docs、Office 或其他类型的文件和应用程序,这些文件和应用程序会迫使我回到文件系统或云中的某个地方去寻找。
|
||||
但是交流呢?创造和交流之间的差别很大。当我为两者留出不同的时间段时,我的效率会更高。我们 Fugue 公司使用 Slack,痛并快乐着。我把它和我的日历、电子邮件放在一个即时通讯的桌面上,这样,当我正在做事时,我很高兴地能够忽略所有的聊天。只要一个 Slackstorm 或一封风投或董事会董事的电子邮件,就能让我立刻丢掉手头工作。但是,大多数事情通常可以等上一两个小时。
|
||||
|
||||
永久存储在计算机上的限制是文件格式。假设人类已经解决了存储<sup>[6][12]</sup>的问题,随着时间的推移,我们面临的问题是我们能否够继续访问我们创建的信息。文本文件是最持久的计算格式。你可以用 Emacs 轻松地打开 1970 年的文本文件。然而对于办公应用程序却并非如此。同时文本文件要比 Office 应用程序数据文件小得多,也要好的多。作为一个数码背包迷,作为一个在脑子里一闪而过就会做很多小笔记的人,拥有一个简单、轻便、永久、随时可用的东西对我来说很重要。
|
||||
#### 包罗万象,永久长青
|
||||
|
||||
第三个原因是,我发现 Emacs 比其它的环境更有优势的是你可以很容易的用它来处理事务。我的意思是,你所需要的只是通过 Dropbox 类似的网站同步一两个目录,而不是让大量的应用程序以它们自己的方式进行交互和同步。然后,你可以在任何你已经精心打造了适合你的目的的套件的环境中工作了。我在 OS X、Windows,或有时在 Linux 都是这样做的。它非常简单可靠。这种功能很有用,以至于我害怕处理 Pages、Google Docs、Office 或其他类型的文件和应用程序,这些文件和应用程序会迫使我回到文件系统或云中的某个地方去寻找。
|
||||
|
||||
限制在计算机上永久存储的因素是文件格式。假设人类已经解决了存储问题[^6] ,随着时间的推移,我们面临的问题是我们能否够继续访问我们创建的信息。文本文件是最长青的计算格式。你可以用 Emacs 轻松地打开 1970 年的文本文件。然而对于 Office 应用程序却并非如此。同时文本文件要比 Office 应用程序数据文件小得多,也要好的多。作为一个数码背包迷,作为一个在脑子里一闪而过就会做很多小笔记的人,拥有一个简单、轻便、永久、随时可用的东西对我来说很重要。
|
||||
|
||||
如果你准备尝试 Emacs,请继续阅读!下面的部分不会取代完整的教程,但是在完成阅读时,就可以操作了。
|
||||
|
||||
### 学会驾驭 Emacs —— 一个专业的配置
|
||||
|
||||
所有这些强大、精神上的平静和安宁的代价是,Emacs 有一个陡峭的学习曲线,它的一切都与你以前所习惯的不同。一开始,这会让你觉得你是在浪费时间在一个过时和奇怪的应用程序上,就好像现代世界已经过去了。这有点像你只开过车,却要你去学骑自行车<sup>[7][13]</sup>。
|
||||
所有这些强大、精神上的平静和安宁的代价是,Emacs 有一个陡峭的学习曲线,它的一切都与你以前所习惯的不同。一开始,这会让你觉得你是在浪费时间在一个过时和奇怪的应用程序上,就好像穿越到过去。这有点像你只开过车,却要你去学骑自行车[^7] 。
|
||||
|
||||
### 该选哪个 Emacs
|
||||
#### 该选哪个 Emacs
|
||||
|
||||
我用的是 GNU 中 OS X 和 Windows 的通用版本的 Emacs。你可以在 [][34][http://emacsformacos.com/][35] 获取 OS X 版本,在[][36][http://www.gnu.org/software/emacs/][37]获取 Windows 版本。市面上还有很多其他版本,尤其是 Mac 版本,但我发现,要做一些功能强大的东西(包括 `Lisp` 和许多模式),学习曲线要比实际操作低得多。下载,然后我们就可以开始了<sup>[8][14]</sup>!
|
||||
我用的是来自 GNU 的 OS X 和 Windows 的通用版本的 Emacs。你可以在 [http://emacsformacos.com/][35] 获取 OS X 版本,在 [http://www.gnu.org/software/emacs/][37] 获取 Windows 版本。市面上还有很多其他版本,尤其是 Mac 版本,但我发现,要做一些功能强大的东西(涉及到 Lisp 和许多模式),学习曲线要比实际操作低得多。下载,然后我们就可以开始了[^8] !
|
||||
|
||||
### 首先,学会浏览
|
||||
#### 首先,学会导航
|
||||
|
||||
在本文中,我将约定 Emacs 中的键和组合。`C` 表示 `Control` 键,`M` 表示 `meta`(通常是 `Alt` 或 `Option` 键),以及用于组合键的连字符。因此,`C-h t` 表示同时按下 `Control` 和 `h` 键,然后释放,再按下 `t`。这个组快捷键会指向一个教程,这是你首先要做的一件事。
|
||||
在本文中,我将使用 Emacs 的按键和组合键约定。`C` 表示 `Control` 键,`M` 表示 `meta`(通常是 `Alt` 或 `Option` 键),以及用于组合键的连字符。因此,`C-h t` 表示同时按下 `Control` 和 `h` 键,然后释放,再按下 `t`。这个组合快捷键会指向一个教程,这是你首先要做的一件事。
|
||||
|
||||
不要使用方向键或鼠标。它们可以工作,但是你应该给自己一周的时间来使用 Emacs 教程中的原生命令。一旦你这些命令变为了肌肉记忆,你可能就会乐在其中,无论到哪里,你都会非常想念它们。Emacs 教程在介绍它们方面做得很好,但是我将进行总结,所以您不需要阅读全部内容。最无聊的是,不用方向键,用 `C-b` 向前移动,用 `C-f` 向后移动,上一行用 `C-p`,下一行用 `C-n`。你可能会想:“我用方向键就很好,为什么还要这样做?” 有几个原因。首先,你不需要从主键盘区将你的手移开。第二,使用 `Alt`(或用 Emacs 的说法 `Meta`)键来向前或向后移动一个单词。显而易见这样更方便。第三,如果想重复某个命令,可以在命令前面加上一个数字。在编辑文档时,我经常使用这种方法,通过估计向前多少个单词或向上或线下移动多少行,然后按下 `C-9 C-p` 或 `M-5 M-b` 之类的快捷键。其他真正重要的浏览命令基于开头用 `a` 和结尾用 `e`。在行中使用 `C-a|e`,在句中使用 `M-a|e`。为了让句中的命令正常工作,需要在句号后增加两个空格,这同时提供了一个有用的特性,并消除了脑中的[希伯列][38]。如果需要将文档导出到单个空间[发布环境][39],可以编写一个宏来执行此操作。
|
||||
不要使用方向键或鼠标。它们可以工作,但是你应该给自己一周的时间来使用 Emacs 教程中的原生的导航命令。一旦你这些命令变为了肌肉记忆,你可能就会乐在其中,无论到哪里,你都会非常想念它们。这个 Emacs 教程在介绍它们方面做得很好,但是我将进行总结,所以您不需要阅读全部内容。最无聊的是,不用方向键,用 `C-b` 向前移动,用 `C-f` 向后移动,上一行用 `C-p`,下一行用 `C-n`。你可能会想:“我用方向键就很好,为什么还要这样做?” 有几个原因。首先,你不需要从主键盘区将你的手移开。第二,使用 `Alt`(或用 Emacs 的说法 `Meta`)键来向前或向后在单词间移动。显而易见这样更方便。第三,如果想重复某个命令,可以在命令前面加上一个数字。在编辑文档时,我经常使用这种方法,通过估计向后移动多少个单词或向上或向下移动多少行,然后按下 `C-9 C-p` 或 `M-5 M-b` 之类的快捷键。其它真正重要的导航命令基于开头用 `a` 和结尾用 `e`。在行中使用 `C-a|e`,在句中使用 `M-a|e`。为了让句中的命令正常工作,需要在句号后增加两个空格,这同时提供了一个有用的特性,并消除了脑中一个过时的[观点][38]。如果需要将文档导出到单个空间[发布环境][39],可以编写一个宏来执行此操作。
|
||||
|
||||
Emacs 附带的教程很值得去看。对于真正缺乏耐心的人,我将介绍一些重要的命令,但那个教程非常有用。记住:用 `C-h t` 进入教程。
|
||||
Emacs 所附带的教程很值得去看。对于真正缺乏耐心的人,我将介绍一些重要的命令,但那个教程非常有用。记住:用 `C-h t` 进入教程。
|
||||
|
||||
### 学会复制和粘贴
|
||||
#### 学会复制和粘贴
|
||||
|
||||
你可以叫 Emacs 设为 `CUA` 模式,这将会以熟悉的方式工作来操作复制粘贴,但是原生的 Emacs 方法更好,而且你一旦学会了它,就很容易。你可以使用 `Shift` 这样的浏览命令来标记区域(如选择)。所以 `C-F` 是选中管标前的一个字符,等等。亦可以用 `M-w` 来复制,用 `C-w` 剪切,然后用 `C-y` 粘贴。这些实际上叫做删除和召回,但它非常类似于剪切和粘贴。在删除的环中有些小技巧,但是现在,你只需要关注剪切、复制和粘贴。如果你在这开始摸索, `C-x u` 是撤销。
|
||||
你可以把 Emacs 设为 CUA 模式,这将会以熟悉的方式工作来操作复制粘贴,但是原生的 Emacs 方法更好,而且你一旦学会了它,就很容易。你可以使用 `Shift` 和导航命令来标记区域(如同选择)。所以 `C-F` 是选中光标前的一个字符,等等。亦可以用 `M-w` 来复制,用 `C-w` 剪切,然后用 `C-y` 粘贴。这些实际上叫做<ruby>删除<rt>killing</rt></ruby>和<ruby>召回<rt>yanking</rt></ruby>,但它非常类似于剪切和粘贴。在删除中有些小技巧,但是现在,你只需要关注剪切、复制和粘贴。如果你开始尝试了,那么 `C-x u` 是撤销。
|
||||
|
||||
### 下一步,学会用 `Ido` 模式
|
||||
#### 下一步,学会用 Ido 模式
|
||||
|
||||
相信我,`Ido` 会让文件的工作变得很简单。通常,你在 Emacs 中处理文件不需要使用一个单独分开的查找或文件资源管理器的窗口。相反的,你可以用编辑器的命令来创建、打开和保存文件。如果没有 `Ido` 的话,这将有点麻烦,所以我建议你在学习其他之前安装好它。 `Ido` 是 Emacs 的 22 版时开发出来的,但是需要对你的 `.emacs` 文件做一些调整,来确保它一直开启着。这是个配置环境的好理由。
|
||||
相信我,Ido 会让文件的工作变得很简单。通常,你在 Emacs 中处理文件不需要使用一个单独的访达或文件资源管理器的窗口。相反的,你可以用编辑器的命令来创建、打开和保存文件。如果没有 Ido 的话,这将有点麻烦,所以我建议你在学习其他之前安装好它。 Ido 是 Emacs 的 22 版时开始出现的,但是需要对你的 `.emacs` 文件做一些调整,来确保它一直开启着。这是个配置环境的好理由。
|
||||
|
||||
Emacs 中的大多数功能都表现在模式上。要安装制定的模式,需要做两件事。嗯,一开始你需要做一些额外的事情,但这些只需要做一次,然后再做这两件事。那么,额外的事情是你需要一个单独的位置来放置所有 `Emacs Lisp` 文件,并且你需要告诉 Emacs 这个位置在哪。我建议你在 Dropbox 上创建一个单独的目录,那是你 Emacs 主目录。在这里,你需要创建一个 `.emacs` 文件和 `.emacs.d` 目录。在 `.emacs.d` 目录下,创建一个 `lisp` 的目录。就像这样:
|
||||
Emacs 中的大多数功能都表现在模式上。要安装指定的模式,需要做两件事。嗯,一开始你需要做一些额外的事情,但这些只需要做一次,然后再做这两件事。那么,这件额外的事情是你需要一个单独的位置来放置所有 Emacs Lisp 文件,并且你需要告诉 Emacs 这个位置在哪。我建议你在 Dropbox 上创建一个单独的目录,那是你 Emacs 主目录。在这里,你需要创建一个 `.emacs` 文件和 `.emacs.d` 目录。在 `.emacs.d` 目录下,创建一个 `lisp` 的目录。就像这样:
|
||||
|
||||
```
|
||||
home
|
||||
@ -79,21 +81,23 @@ home
|
||||
-lisp
|
||||
```
|
||||
|
||||
你可以将那些像模式的 `.el` 文件放到 `home/.emacs.d/lis` 目录下,然后在你的 `.emacs` 文件中添加以下代码来指明该路径:
|
||||
你可以将那些比如模式的 `.el` 文件放到 `home/.emacs.d/lisp` 目录下,然后在你的 `.emacs` 文件中添加以下代码来指明该路径:
|
||||
|
||||
`(add-to-list 'load-path "~/.emacs.d/lisp/")`
|
||||
```
|
||||
(add-to-list 'load-path "~/.emacs.d/lisp/")
|
||||
```
|
||||
|
||||
`Ido` 模式是 Emacs 自带的,所以你不需要在你的 `lisp` 目录中放 `.el` 文件,但你仍然需要添加上面代码,因为下面的介绍会使用到它.
|
||||
Ido 模式是 Emacs 自带的,所以你不需要在你的 `lisp` 目录中放这个 `.el` 文件,但你仍然需要添加上面代码,因为下面的介绍会使用到它.
|
||||
|
||||
### 符号链接是你的好伙伴
|
||||
#### 符号链接是你的好伙伴
|
||||
|
||||
等等,这里写的 `.emacs` 和 `.emacs.d` 都是存放在你的主目录下,但我们把他们放到了 Dropbox 的某些愚蠢的文件夹!对,这就让你的环境在任何地方都很容易使用。把所有东西都保存在 Dropbox 上,并链接到 `.emacs` 和 `.emacs.d`,以及主目录 `~`。在 OS X 上,使用 `ln -s` 命令非常简单,但在 Windows 上却很麻烦。幸运的是,Emacs 提供了一种简单的方法来替代 Windows 上的符号链接,Windows 的 `HOME` 环境变量。转到 Windows 的环境变量(Windows 10,你可以按 Windows 键然后输入 “环境变量” 来搜索,这是 Windows 10 最好的一部分了),在你的帐户下创建一个指向你在 Dropbox 中 Emacs 的文件家的 `HOME` 环境变量。如果你想方便地浏览 Dropbox 之外的本地文件,你可能想在你的实际主目录下建立一个到 Dropbox 下 Emacs 主目录的符号链接。
|
||||
等等,这里写的 `.emacs` 和 `.emacs.d` 都是存放在你的主目录下,但我们把它们放到了 Dropbox 的某些愚蠢的文件夹!对,这就让你的环境在任何地方都很容易使用。把所有东西都保存在 Dropbox 上,并做符号链接到 `~` 下的 `.emacs` 、`.emacs.d` 和你的主要存放文档的目录。在 OS X 上,使用 `ln -s` 命令非常简单,但在 Windows 上却很麻烦。幸运的是,Emacs 提供了一种简单的方法来替代 Windows 上的符号链接,Windows 的 `HOME` 环境变量。转到 Windows 的环境变量(Windows 10,你可以按 Windows 键然后输入 “环境变量” 来搜索,这是 Windows 10 最好的地方了),在你的帐户下创建一个指向你在 Dropbox 中 Emacs 的文件夹的 `HOME` 环境变量。如果你想方便地浏览 Dropbox 之外的本地文件,你可能想在你的实际主目录下建立一个到 Dropbox 下 Emacs 主目录的符号链接。
|
||||
|
||||
至此,你已经完成了在任意机器上指向 Emacs 配置和配置文件所需的技巧。如果你买了一台新电脑,或者用别人的电脑一小时或一天,你就得到了你的整个工作环境。第一次做这个似乎有点困难,但是一旦你知道你在做什么,就只需要10分钟(最多)。
|
||||
至此,你已经完成了在任意机器上指向你的 Emacs 配置和文件所需的技巧。如果你买了一台新电脑,或者用别人的电脑一小时或一天,你就可以得到你的整个工作环境。第一次做这个似乎有点困难,但是一旦你知道你在做什么,就(最多)只需要 10 分钟。
|
||||
|
||||
但我们现在是在配置 `Ido`……
|
||||
但我们现在是在配置 Ido ……
|
||||
|
||||
按下 `C-x` `C-f` 然后输入 `~/.emacs RET RET` 来创建 `.emacs` 文件,将下面几行添加进去:
|
||||
按下 `C-x` `C-f` 然后输入 `~/.emacs` 和两次回车来创建 `.emacs` 文件,将下面几行添加进去:
|
||||
|
||||
```
|
||||
;; set up ido mode
|
||||
@ -103,19 +107,23 @@ home
|
||||
(ido-mode 1)
|
||||
```
|
||||
|
||||
在 `.emacs` 窗口开着的时候,执行 `M-x evaluate-buffer` 命令。如果某处弄错了的话,将得到一个错误,或者你将得到 `Ido`。`Ido` 改变了在 `minibuffer` 中操作文件操方式。有一篇比较好的文档,但是我也会指出一些技巧。有效地使用 `~/`;你可以在 `minibuffer` 的任何地方输入 `~/`,它就会跳转到主目录。这就意味着,你应该让你的大部分东西就近的放在主目录下。我用 `~/org` 目录来保存所有非代码的东西,用 `~/code` 保存代码。一旦你进入到正确的目录,通常会拥有一组具有不同扩展名的文件,特别是当你使用 `Org` 模式并从中发布的话。你可以输入 `period` 和想要的扩展名,无论你的在文件名的什么位置,`Ido` 都会将选择限制在具有该扩展名的文件中。例如,我在 `Org` 模式下写这篇博客,所以该文件是:
|
||||
在 `.emacs` 窗口开着的时候,执行 `M-x evaluate-buffer` 命令。如果某处弄错了的话,将得到一个错误,或者你将得到 Ido。Ido 改变了在 minibuffer 中操作文件操方式。关于这个有一篇比较好的文档,但是我也会指出一些技巧。有效地使用 `~/`;你可以在 minibuffer 的任何地方输入 `~/`,它就会跳转到主目录。这就意味着,你应该让你的大部分东西就近的放在主目录下。我用 `~/org` 目录来保存所有非代码的东西,用 `~/code` 保存代码。一旦你进入到正确的目录,通常会拥有一组具有不同扩展名的文件,特别是当你使用 Org 模式并从中发布的话。你可以输入 `.` 和想要的扩展名,无论你的在文件名的什么位置,Ido 都会将选择限制在具有该扩展名的文件中。例如,我在 Org 模式下写这篇博客,所以该文件是:
|
||||
|
||||
`~/org/blog/emacs.org`
|
||||
```
|
||||
~/org/blog/emacs.org
|
||||
```
|
||||
|
||||
我偶尔也会用 `Org` 模式发布成 HTML 格式,所以我将在同一目录下得到 `emacs.html` 文件。当我想打开 `Org` 文件时,我会输入:
|
||||
我偶尔也会用 Org 模式发布成 HTML 格式,所以我将在同一目录下得到 `emacs.html` 文件。当我想打开该 Org 文件时,我会输入:
|
||||
|
||||
`C-x C-f ~/o[RET]/bl[RET].or[RET]`
|
||||
```
|
||||
C-x C-f ~/o[RET]/bl[RET].or[RET]
|
||||
```
|
||||
|
||||
其中 `[RET]` 是我使用 `Ido` 模式的自动补全而按下的回车键。所以,这只需要按 12 个键,如果你习惯了的话, 这将比打开查找或文件资源管理器再用鼠标点要节省 _很_ 多时间。 `Ido` 模式很有用, 这真的是操作 Emacs 的一种实用的模式。下面让我们去探索一些其他对完成工作很有帮助的模式吧。
|
||||
其中 `[RET]` 是我使用 `Ido` 模式的自动补全而按下的回车键。所以,这只需要按 12 个键,如果你习惯了的话, 这将比打开访达或文件资源管理器再用鼠标点要节省 _很_ 多时间。 Ido 模式很有用,而这只是操作 Emacs 的一种实用模式而已。下面让我们去探索一些其它对完成工作很有帮助的模式吧。
|
||||
|
||||
### 字体及风格
|
||||
#### 字体及风格
|
||||
|
||||
我推荐在 Emacs 中使用很棒的字体系列。它们可以使用不同的括号、0和其他字符进行自定义。你可以在字体文件本身中构建额外的行间距。我推荐 1\.5 倍的行间距,并在代码和数据中使用它们适应比例的字体。写作中我用 `Serif` 字体,它有一种紧凑但时髦的感觉。你可以在 [http://input.fontbureau.com/][40] 上找到它们,在那里你可以根据自己的喜好进行定制。你可以使用 Emacs 中的菜单手动设置字体,但这会将代码保存到你的 `.emacs` 文件中,如果您使用多个设备,您可能需要一些不同的设置。我我将我的 `.emacs` 设置位根据使用的机器的名称,并配置适当的屏幕机字体。代码如下:
|
||||
我推荐在 Emacs 中使用漂亮的字体族。它们可以使用不同的括号、0 和其他字符进行自定义。你可以在字体文件本身中构建额外的行间距。我推荐 1.5 倍的行间距,并在代码和数据中使用不等宽字体。写作中我用 `Serif` 字体,它有一种紧凑但时髦的感觉。你可以在 [http://input.fontbureau.com/][40] 上找到它们,在那里你可以根据自己的喜好进行定制。你可以使用 Emacs 中的菜单手动设置字体,但这会将代码保存到你的 `.emacs` 文件中,如果您使用多个设备,您可能需要一些不同的设置。我将我的 `.emacs` 设置为根据使用的机器的名称来相应配置屏幕。代码如下:
|
||||
|
||||
```
|
||||
;; set up fonts for different OSes. OSX toggles to full screen.
|
||||
@ -132,9 +140,9 @@ home
|
||||
(set-face-attribute 'default nil :font myfont :height 104)))
|
||||
```
|
||||
|
||||
您应该将你的 Emacs 副本中 `system-name` 的值替换成你使用命令 `(system-name)` 得到的值。注意,在 Sampo (我的 MacBook)上,我还将 Emacs 设置为全屏。我也想在 Windows 实现这个,但是 Windows 和 Emacs 并不真正喜欢对方,当我尝试这个时,它总是不稳定。相反,我只是在启动后手动全屏。
|
||||
您应该将你的 Emacs 中的 `system-name` 的值替换成你通过 `(system-name)` 得到的值。注意,在 Sampo (我的 MacBook)上,我还将 Emacs 设置为全屏。我也想在 Windows 实现这个,但是 Windows 和 Emacs 并不真正喜欢对方,当我尝试这个时,它总是不稳定。相反,我只能在启动后手动全屏。
|
||||
|
||||
我还建议去掉 Emacs 中在 90 年代获得的难看的工具栏,当时最酷的事情是在应用程序中使用工具栏。我还去掉了一些其他的 `chrome`,这样我就有了一个简单、高效的界面。把这些加到你的 `.emacs` 的文件中,来去掉工具栏和滚动条,但要保留菜单 (在 OS X 上,它将被隐藏,除非你将鼠标到屏幕顶部):
|
||||
我还建议去掉 Emacs 中的上世纪 90 年代出现的难看工具栏,当时最酷的事情是在应用程序中使用工具栏。我还去掉了一些其它的“电镀层”,这样我就有了一个简单、高效的界面。把这些加到你的 `.emacs` 的文件中来去掉工具栏和滚动条,但要保留菜单(在 OS X 上,它将被隐藏,除非你将鼠标到屏幕顶部):
|
||||
|
||||
```
|
||||
(if (fboundp 'scroll-bar-mode) (scroll-bar-mode -1))
|
||||
@ -142,11 +150,11 @@ home
|
||||
(if (fboundp 'menu-bar-mode) (menu-bar-mode 1))
|
||||
```
|
||||
|
||||
### Org 模式
|
||||
#### Org 模式
|
||||
|
||||
我基本上 `Org` 模式下处理工作的。它是我创作文档、记笔记、列任务清单以及 90% 其他工作的首选环境。`Org` 最初是由一个在会议中使用笔记本电脑的家伙构想出来的,它是笔记和待办事项列表的组合工具。我反对在会议中使用笔记本电脑,自己也不使用,所以我的用法与他的有些不同。对我来说,`Org` 主要是一种处理结构中内容的方式。在 `Org` 模式中有标题和副标题等,它们的作用就像一个大纲。`Org` 允许你展开或隐藏文本内容,还可以重新排列文本。这非常很符合我的想法,而且我发现用这种方式使用它是一种乐趣。
|
||||
我基本上是在 Org 模式下处理工作的。它是我创作文档、记笔记、列任务清单以及 90% 其他工作的首选环境。Org 模式最初是由一个在会议中使用笔记本电脑的家伙构想出来的,它是笔记和待办事项列表的组合工具。我反对在会议中使用笔记本电脑,自己也不使用,所以我的用法与他的有些不同。对我来说,Org 模式主要是一种处理结构中内容的方式。在 Org 模式中有标题和副标题等,它们的作用就像一个大纲。Org 模式允许你展开或隐藏大纲树,还可以重新排列该树。这非常很符合我的想法,而且我发现用这种方式使用它是一种乐趣。
|
||||
|
||||
`Org` 模式也有很多让生活愉快的小功能。例如,脚注处理非常好,`LaTeX/PDF` 输出也很好。`Org` 能够根据所有文档中的待办事项生成议程,并能很好地将它们与日期/时间联系起来。我不把它用在任何形式的外部任务上,这些任务都是在一个共享的日历上处理的,但是在创建事物和跟踪我未来需要创建的东西时,它是无价的。安装它,你只要将 `org-mode.el` 放到你的 `lisp` 目录下,然后再在你的 `.emacs` 文件中添加如下代码,如果你想要它基于文档的结构进行缩进并在打开时全部展开的话:
|
||||
Org 模式也有很多让生活愉快的小功能。例如,脚注处理非常好,LaTeX/PDF 输出也很好。Org 模式能够根据所有文档中的待办事项生成议程,并能很好地将它们与日期/时间联系起来。我不把它用在任何形式的外部任务上,这些任务都是在一个共享的日历上处理的,但是在创建事物和跟踪我未来需要创建的东西时,它是无价的。安装它,你只要将 `org-mode.el` 放到你的 `lisp` 目录下,并且如果你想要它基于文档的结构进行缩进并在打开时全部展开的话,在你的 `.emacs` 文件中添加如下代码:
|
||||
|
||||
```
|
||||
;; set up org mode
|
||||
@ -155,15 +163,15 @@ home
|
||||
(setq org-directory "~/org")
|
||||
```
|
||||
|
||||
最后一行是让 `Org` 知道在哪里查找要包含在议程和其他事情中的文件。我把 `Org` 保存在我的主目录中,也就是说,像前面介绍的一样,它是 Dropbox 目录的一个符号链接。
|
||||
最后一行是让 Org 模式知道在哪里查找要包含在议程和其他事情中的文件。我把 Org 模式保存在我的主目录中,也就是说,像前面介绍的一样,它是 Dropbox 目录的一个符号链接。
|
||||
|
||||
我有一个总是在缓冲区中打开的 `stuff.org` 文件。我把它当作记事本。`Org` 使得提取待办事项和有期限的事情变得很容易。当你在内联 `Lisp` 代码并在需要计算它时,它特别有用。拥有包含内容的代码非常方便。同样,你可以使用 Emacs 访问实际的计算机,这是一种解放。
|
||||
我有一个总是在缓冲区中打开的 `stuff.org` 文件。我把它当作记事本。Org 模式使得提取待办事项和有期限的事情变得很容易。当你能够内联 Lisp 代码并在需要计算它时,它特别有用。拥有包含内容的代码非常方便。同样,你可以使用 Emacs 访问实际的计算机,这是一种解放。
|
||||
|
||||
#### 用 `Org` 模式进行发布
|
||||
##### 用 Org 模式进行发布
|
||||
|
||||
我关心的是文档的外观和格式。我我刚开始工作时是个设计师,而且我认为信息可以,也应该表现得清晰和美丽。`Org` 对将 `LaTeX` 生成 PDF 支持的很好, `LaTeX` 有自己的学习曲线,但是做简单的事情非常简单。
|
||||
我关心的是文档的外观和格式化。我刚开始工作时是个设计师,而且我认为信息可以,也应该表现得清晰和美丽。Org 模式对将 LaTeX 生成 PDF 支持的很好,LaTeX 虽然也有学习曲线,但是做简单的事情非常简单。
|
||||
|
||||
如果你想使用字体和样式,而不是典型的 `LaTeX` 字体和样式,你需要做些事。首先,你要用到 `XeLaTeX`,这样就可以使用普通的系统字体,而不是 `LaTeX` 的特殊字体。接下来,您需要将一下代码添加到 `.emacs` 中:
|
||||
如果你想使用字体和样式,而不是典型的 LaTeX 字体和样式,你需要做些事。首先,你要用到 XeLaTeX,这样就可以使用普通的系统字体,而不是 LaTeX 的特殊字体。接下来,您需要将以下代码添加到 `.emacs` 中:
|
||||
|
||||
```
|
||||
(setq org-latex-pdf-process
|
||||
@ -171,7 +179,7 @@ home
|
||||
"xelatex -interaction nonstopmode %f"))
|
||||
```
|
||||
|
||||
我把这个放在 `.emacs` 中 `Org` 配置部分的末尾来保持整洁。这让你在从 `Org` 发布时使用更多格式化选项。例如,我经常使用:
|
||||
我把这个放在 `.emacs` 中 Org 模式配置部分的末尾来保持整洁。这让你在从 Org 模式发布时可以使用更多格式化选项。例如,我经常使用:
|
||||
|
||||
```
|
||||
#+LaTeX_HEADER: \usepackage{fontspec}
|
||||
@ -185,11 +193,11 @@ home
|
||||
|
||||
这些都可以在你的 `.org` 文件中找到。我们的公司规定的正文字体是 `Maison Neue`,但你也可以在这写上任何适当的东西。我强烈反对使用 `Maison Neue`。它是一种糟糕的字体,任何人都不应该使用它。
|
||||
|
||||
这个文件是一个使用该配置输出为 PDF 的实例。这就是开箱即用的 `LaTeX` 一样。在我看来这还不错,但是字体很无聊,而且有点奇怪。此外,如果你使用标准格式,人们会认为他们正在阅读的东西是或假装是一篇学术论文。别怪我没提醒你。
|
||||
这个文件是一个使用该配置输出为 PDF 的实例。这就是开箱即用的 LaTeX 一样。在我看来这还不错,但是字体很平淡,而且有点奇怪。此外,如果你使用标准格式,人们会觉得他们正在阅读的东西是、或者假装是一篇学术论文。别怪我没提醒你。
|
||||
|
||||
### `Ace Jump` 模式
|
||||
#### Ace Jump 模式
|
||||
|
||||
如果你想使用的话,这是个辅助而不是主要功能。它的工作原理有点像 Jef Raskin 的 `Leap` 功能<sup>[9][15]</sup>。 按下 `C-c` `C-SPC`,然后输入要跳转到单词的第一个字母。它会高亮显示所有以该字母开头的单词,并将其替换为字母表中的字母。您只需键入所需位置的字母,光标就会跳转到该位置。我自己经常用这个作为导航键或搜索。将 `.el` 文件下到你的 `Lisp` 目录下,并在 `.emacs` 文件添加如下代码:
|
||||
这是个辅助而不是主要功能,但是或许你想使用。它的工作原理有点像之前的 Jef Raskin 的 Leap 功能[^9] 。 按下 `C-c C-SPC`,然后输入要跳转到单词的第一个字母。它会高亮显示所有以该字母开头的单词,并将其替换为字母表中的字母。您只需键入所需位置的字母,光标就会跳转到该位置。我自己经常用这个作为导航键或搜索。将 `.el` 文件下到你的 `lisp` 目录下,并在 `.emacs` 文件添加如下代码:
|
||||
|
||||
```
|
||||
;; set up ace-jump-mode
|
||||
@ -200,37 +208,26 @@ home
|
||||
|
||||
### 更多
|
||||
|
||||
这篇文章已经够详细了,你能在其中的到你所想要的。我很想了解除编程(或编程)之外你对 Emacs 的使用,以及这是否有用。在我使用 Emacs 的过程中,可能存在一些自作聪明的想法,如果你能指出它们,我将感激不尽。之后,我可能会写一些更新来引入其他特性或模式。我很确定我将会向你展示如何在 Emacs 和 `Ludwig` 模式下使用 `Fugue`,因为我会将它发展成比代码突出显示更有用的东西。把你的想法发到 [@fugueHQ][41] 上。
|
||||
这篇文章已经够详细了,你能在其中的到你所想要的。我很想了解除了编程之外(或用于编程)你对 Emacs 的使用情况,以及这是否有用。在我使用 Emacs 的过程中,可能存在一些自作聪明的老板式想法,如果你能指出它们,我将感激不尽。之后,我可能会写一些更新来介绍其它特性或模式。我很确定我将会向你展示如何在 Emacs 和 Ludwig 模式下使用 Fugue,因为我会将它发展成比代码高亮更有用的东西。请把你的想法发到 [@fugueHQ][41] 上。
|
||||
|
||||
* * *
|
||||
|
||||
#### 附注
|
||||
|
||||
1. [^][16] If you are now a PHB of some sort, but were never technical, Emacs likely isn’t for you. There may be a handful of folks for whom Emacs will form a path into the more technical aspects of computing, but this is probably a small population. It’s helpful to know how to use a Unix or Windows terminal, to have edited a dotfile or two, and to have written some code at some point in your life for Emacs to make much sense.
|
||||
|
||||
2. [^][17] [][18][http://archive.wired.com/wired/archive/2.08/tufte.html][19]
|
||||
|
||||
3. [^][20] I mainly use this to perform calculations while writing. For example, I was writing an offer letter to a new employee and wanted to calculate how many options to include in the offer. Since I have a variable defined in my `.emacs` for outstanding-shares, I can simply type `M-: (* .001 outstanding-shares)`and get a tenth of a point without opening a calculator or spreadsheet. I keep _lots_ of numbers in variables like this so I can avoid context switching.
|
||||
|
||||
4. [^][21] The missing piece of this is the web. There is an Emacs web browser called eww that will allow you to browse in Emacs. I actually use this, as it is both a great ad-blocker and removes most of the poor choices in readability from the web designer's hands. It's a bit like Reading Mode in Safari. Unfortunately, most websites have lots of annoying cruft and navigation that translates poorly into text.
|
||||
|
||||
5. [^][22] Usability is often confused with learnability. Learnability is how difficult it is to learn a tool. Usability is how useful the tool is. Often, these are at odds, such as with the mouse and menus. Menus are highly learnable, but have poor usability, so there have been keyboard shortcuts from the earliest days. Raskin was right on many points where he was ignored about GUIs in general. Now, OSes are putting things like decent search onto a keyboard shortcut. On OS X and Windows, my default method of navigation is search. Ubuntu's search is badly broken, as is the rest of its GUI.
|
||||
|
||||
6. [^][23] AWS S3 has effectively solved file storage for as long as we have the Internet. Trillions of objects are stored in S3 and they've never lost one of them. Most every service out there that offers cloud storage is built on S3 or imitates it. No one has the scale of S3, so I keep important stuff there, via Dropbox.
|
||||
|
||||
7. [^][24] By now, you might be thinking "what is it with this guy and bicycles?" ... I love them on every level. They are the most mechanically efficient form of transportation ever invented. They can be objects of real beauty. And, with some care, they can last a lifetime. I had Rivendell Bicycle Works build a frame for me back in 2001 and it still makes me happy every time I look at it. Bicycles and UNIX are the two best inventions I've interacted with. Well, they and Emacs.
|
||||
|
||||
8. [^][25] This is not a tutorial for Emacs. It comes with one and it's excellent. I do walk through some of the things that I find most important to getting a useful Emacs setup, but this is not a replacement in any way.
|
||||
|
||||
9. [^][26] Jef Raskin designed the Canon Cat computer in the 1980s after falling out with Steve Jobs on the Macintosh project, which he originally led. The Cat had a document-centric interface (as all computers should) and used the keyboard in innovative ways that you can now imitate with Emacs. If I could have a modern, powerful Cat with a giant high-res screen and Unix underneath, I'd trade my Mac for it right away. [][27][https://youtu.be/o_TlE_U_X3c?t=19s][28]
|
||||
[^1]: If you are now a PHB of some sort, but were never technical, Emacs likely isn’t for you. There may be a handful of folks for whom Emacs will form a path into the more technical aspects of computing, but this is probably a small population. It’s helpful to know how to use a Unix or Windows terminal, to have edited a dotfile or two, and to have written some code at some point in your life for Emacs to make much sense.
|
||||
[^2]: http://archive.wired.com/wired/archive/2.08/tufte.html
|
||||
[^3]: I mainly use this to perform calculations while writing. For example, I was writing an offer letter to a new employee and wanted to calculate how many options to include in the offer. Since I have a variable defined in my `.emacs` for outstanding-shares, I can simply type `M-: (* .001 outstanding-shares)`and get a tenth of a point without opening a calculator or spreadsheet. I keep _lots_ of numbers in variables like this so I can avoid context switching.
|
||||
[^4]: The missing piece of this is the web. There is an Emacs web browser called eww that will allow you to browse in Emacs. I actually use this, as it is both a great ad-blocker and removes most of the poor choices in readability from the web designer's hands. It's a bit like Reading Mode in Safari. Unfortunately, most websites have lots of annoying cruft and navigation that translates poorly into text.
|
||||
[^5]: Usability is often confused with learnability. Learnability is how difficult it is to learn a tool. Usability is how useful the tool is. Often, these are at odds, such as with the mouse and menus. Menus are highly learnable, but have poor usability, so there have been keyboard shortcuts from the earliest days. Raskin was right on many points where he was ignored about GUIs in general. Now, OSes are putting things like decent search onto a keyboard shortcut. On OS X and Windows, my default method of navigation is search. Ubuntu's search is badly broken, as is the rest of its GUI.
|
||||
[^6]: AWS S3 has effectively solved file storage for as long as we have the Internet. Trillions of objects are stored in S3 and they've never lost one of them. Most every service out there that offers cloud storage is built on S3 or imitates it. No one has the scale of S3, so I keep important stuff there, via Dropbox.
|
||||
[^7]: By now, you might be thinking "what is it with this guy and bicycles?" ... I love them on every level. They are the most mechanically efficient form of transportation ever invented. They can be objects of real beauty. And, with some care, they can last a lifetime. I had Rivendell Bicycle Works build a frame for me back in 2001 and it still makes me happy every time I look at it. Bicycles and UNIX are the two best inventions I've interacted with. Well, they and Emacs.
|
||||
[^8]: This is not a tutorial for Emacs. It comes with one and it's excellent. I do walk through some of the things that I find most important to getting a useful Emacs setup, but this is not a replacement in any way.
|
||||
[^9]: Jef Raskin designed the Canon Cat computer in the 1980s after falling out with Steve Jobs on the Macintosh project, which he originally led. The Cat had a document-centric interface (as all computers should) and used the keyboard in innovative ways that you can now imitate with Emacs. If I could have a modern, powerful Cat with a giant high-res screen and Unix underneath, I'd trade my Mac for it right away. [][27][https://youtu.be/o_TlE_U_X3c?t=19s][28]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.fugue.co/2015-11-11-guide-to-emacs.html
|
||||
|
||||
作者:[Josh Stella ][a]
|
||||
作者:[Josh Stella][a]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,177 @@
|
||||
用于游戏开发的图形和音乐工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
在十月初,我们的俱乐部,来自马歇尔大学的 [Geeks and Gadgets][1] , 参加就职 [Open Jam][2], 一个游戏 jam ,庆祝最好的开源工具。游戏 jams 是参与者为娱乐像团队协作的来开发计算机游戏的事件。Jams 倾向于非常简短--仅三天时间长--并非常让人精疲力尽。Opensource.com 在八月下旬 [宣布][3] Open Jam ,更多 [three dozen games][4] 进入到竞赛中。
|
||||
|
||||
我们的俱乐部希望在我们的工程中创建和使用开放源码软件,所以 Open Jam 自然是我们想要参与的 jam 。我们的提交的文件是一个实验性的名称为 [Mark My Words][5] 的游戏。我们使用多种自由和开放源码 (FOSS) 工具来开发它;在这篇文章中,我们将讨论一些我们使用和意识到有潜在的障碍物的工具。
|
||||
|
||||
### 音频工具
|
||||
|
||||
#### MilkyTracker
|
||||
|
||||
[MilkyTracker][6] 是最好的可用于构成旧样式电子游戏音乐的软件包中的一个。它是一个 [music tracker][7] 的一个示例,一个强大的带有特殊的基于网格的图形编辑器的 MOD 和 XM 文件创建器。在我们的游戏中,我们使用它来构成大多数的音乐片段。这个程序最好的特点是,它比我们其它的大多数工具消耗更少的硬盘空间和 RAM 。虽然如此,MilkyTracker 仍然非常强大。
|
||||
|
||||

|
||||
|
||||
用户界面需要一会来习惯,这里有对一些想试用MilkyTracker的音乐家的一些提示:
|
||||
|
||||
* 转到 Config > Misc. ,设置 edit 模式控制样式为 "MilkyTracker." 这将给你几乎所有的现代键盘快捷方式
|
||||
* 撤销 Ctrl+Z
|
||||
* 重做 Ctrl+Y
|
||||
* 切换 pattern-edit 模式 空格键
|
||||
* 删除先前的注释 退格键
|
||||
* 插入一行 Insert键
|
||||
* 默认情况下,一个注释将持续作用,直到它在这频道上被替换。你可以明确地结束一个注释,通过使用一个反引号 (`) 键插入一个 KeyOff 注释
|
||||
* 在你开始谱写乐曲前,你将不得不创建或查找示例。我们建议在网站上查找 [Creative Commons][8] 协议的示例,例如 [Freesound][9] 或 [ccMixter][10]
|
||||
|
||||
|
||||
|
||||
另外,保持 [MilkyTracker 文档页面][11] 在手边。它含有数不清的教程和手册的链接。一个好的开始点是在该项目 wiki 上的 [MilkyTracker 指南][12] 。
|
||||
|
||||
#### LMMS
|
||||
|
||||
我们中的两个音乐家使用多用途和现代音乐创建工具 [LMMS][13] 。它带来一个绝妙的示例和效果库,加一个灵活的多种多样的插件来生成独特的声音。 The learning curve for LMMS 的学习曲线令人吃惊的低,在某种程度上是因为友好的节拍/低音线编辑器。
|
||||
|
||||

|
||||
|
||||
我们对音乐家有一个建议,尝试 LMMS:使用插件。 对于 [chiptune][14]-样式音乐,我们推荐 [sfxr][15] ,[BitInvader][16] ,和 [FreeBoy][17] 。对于其它样式, [ZynAddSubFX][18] 是一个好的选择。它带来一个宽波段的可以被你任意更改的人工合成工具。
|
||||
|
||||
### 图形工具
|
||||
|
||||
#### Tiled
|
||||
|
||||
在开放源码游戏开发中,[Tiled][19] 是一个流行的组件地图类(tilemap)编辑器。我们使用它为来为我们在游戏场景中组合连续的,复古的背景。
|
||||
|
||||

|
||||
|
||||
Tiled 可以导出地图为 XM L,JSON ,或平坦的图像。它是稳定的和跨平台的。
|
||||
|
||||
Tiled 的特征一,在 jam 期间,我们不能使用, 允许你定义和随意的放置游戏对象,例如硬币和永久能力提升道具到地图上。你需要做的全部是加载对象的图像为一个平铺显示集,然后使用插入平铺显示放置它们。
|
||||
|
||||
一般来说,对于一些需要一个地图编辑器的工程,Tiled 是我们建议软件的一个主要的部分。
|
||||
|
||||
#### Piskel
|
||||
|
||||
[Piskel][20] 是一个像素艺术编辑器,它的源文件代码是在 [Apache 协议, 版本 2.0][21] 协议下。在 jam 期间,我们对我们的大多数的图像资源使用 Piskel ,我们当然也将在未来的工程中使用它。
|
||||
|
||||
Piskel 的特征二,在 jam 的 onion skin和Spritesheet导出期间极大地帮助我们。
|
||||
|
||||
##### Onion skin
|
||||
|
||||
onion skin 特征将使 Piskel 显示你编辑的动画的前一帧和后一帧的一个幽灵似的覆盖物,像这样:
|
||||
|
||||

|
||||
|
||||
Onion skin 是便于使用的,因为它适合作为一个绘制指南和在动画进程期间帮助你维护在你的角色上连续的图形和声音。为启用它,只需要在屏幕的右上方预览窗体的下面单击 onion-shaped 图标。
|
||||
|
||||

|
||||
|
||||
##### Spritesheet 导出
|
||||
|
||||
Piskel 的能力是导出动画为一个 spritesheet ,也是非常有用的。一个 spritesheet 是一个单个光栅图象,它包含一个动画的所有的帧。例如,这是一个我们从 Piskel 导出的 spritesheet :
|
||||
|
||||

|
||||
|
||||
spritesheet 包含两幅帧。一幅帧是图像的上半部分,另一帧是图像的下半部分。Spritesheets 通过启用一个完整的动画来从单个文件加载,大大地简化一个游戏的代码。这是上面的 spritesheet 的一个动画版本:
|
||||
|
||||

|
||||
|
||||
##### Unpiskel.py
|
||||
|
||||
在 jam 期间,我们很多次想批量转换 Piskel 文件到 PNG 文件。尽管 Piskel 文件格式基于 JSON ,我们写一个小的 GPLv3 协议的称为 [unpiskel.py][22] 的 Python 脚本来做转换。
|
||||
|
||||
它像这样被引用:
|
||||
```
|
||||
python unpiskel.py input.piskel
|
||||
```
|
||||
|
||||
这个脚本将从一个 Piskel 文件(这里 `input.piskel`)中提取 PNG 数据帧和层,并存储它们在它们拥有的文件中。这些文件采用模式 `NAME_XX_YY.png` ,在这里 `NAME` 是 Piskel 文件的缩减名称,`XX` 是帧的编号,`YY` 是层的编号。
|
||||
|
||||
因为脚本可以从一个 shell 中引用,它可以被使用在文件的整个列表中。
|
||||
```
|
||||
for f in *.piskel; do python unpiskel.py "$f"; done
|
||||
```
|
||||
|
||||
### Python, Pygame, 和 cx_Freeze
|
||||
|
||||
#### Python 和 Pygame
|
||||
|
||||
我们使用 [Python][23] 语言来自制作我们的游戏。它是一个脚本语言,通常被用于文本处理和桌面应用程序开发。它也可以用于游戏开发,例如工程,像 [Angry Drunken Dwarves][24] 和 [Ren'Py][25] 已经显示。这两个工程都使用一个称为 [Pygame][26] 的 Python 库来显示图形和产生声音,所以我们也决定在 Open Jam 中使用这个库。
|
||||
|
||||
Pygame 被证明是既稳定又富有特色,并且它对我们创建的街机游戏来说是优秀的。在低分辨率时,库的速度足够快的,但是在高分辨率时,它的仅 CPU 渲染开始变慢。这是因为 Pygame 不使用硬件加速渲染。然而,开发者可以充分利用 OpenGL 基础设施。
|
||||
|
||||
如果你正在寻找一个好的 2D 游戏编程库,Pygame 是值得密切注意的一个。它的网站有 [一个好的教程][27] 来开始。务必看看它!
|
||||
|
||||
#### cx_Freeze
|
||||
|
||||
准备发行我们的游戏是有趣的。我们知道,Windows 用户不喜欢有一个 Python 安装,并且要求他们来安装它可能很过分。除此之外,他们也可能不得不安装 Pygame ,在 Windows 上,这不是一个简单的工作。
|
||||
|
||||
有一件事很清楚:我们不得不放置我们的游戏到一个更方便的结构中。很多其他的 Open Jam 参与者使用专有的游戏引擎 Unity ,它能够使它们的游戏在网页浏览器中来玩。这使得它们非常方便地来玩。便利性是一个我们的游戏恰巧一丝的都没有的东西。但是,感谢生机勃勃的 Python 生态系统,我们有选择。在 Windows 上现有的工具帮助 Python 程序员准备发行他们的游戏。我们考虑的两个是 [cx_Freeze][28] 和 [Pygame2exe][29] (它使用 [py2exe][30])。我们下决心在 cx_Freeze 上,因为它是跨平台的。
|
||||
|
||||
在 cx_Freeze 中,你可以为发行版打包一个单个脚本游戏,只要在shell运行一个命令,像这样:
|
||||
```
|
||||
cxfreeze main.py --target-dir dist
|
||||
```
|
||||
|
||||
`cxfreeze` 的这个调用将拿你的脚本(这里 `main.py`) 和在你系统上的 Python 解释器,并捆绑定它们到 `dist` 目录。一旦完成它,你需要做的是手动复制你的游戏的数据文件到 `dist` 目录。你将发现,`dist` 目录包含一个可以运行来开始你的游戏的可执行文件。
|
||||
|
||||
这里有更复杂难解的方法来使用 cx_Freeze ,允许你自动地复制数据文件,但是我们发现简单的调用 `cxfreeze` 足够我们的需要。感谢这个工具,我们使我们的游戏稍微便利的运行。
|
||||
|
||||
### 庆祝开放源码
|
||||
|
||||
Open Jam 是重要的,因为它庆祝软件开发的开放源码模式。这是来分析开放源码工具的当前状态和我们在未来工作中需求的一个机会。,对于游戏开发者来设法推动它们的工具的使用范围,学习必需提高未来游戏开发者的益处,游戏 jams 或许是最好的时间。
|
||||
|
||||
开放源码工具使人们能够探索他们的创造性,而不妥协他们的自由和前期的投资。尽管我们可能不能成为专业的游戏开发者,我们仍然能获取它的一段小的体验,使用我们简短的,实验性的称为 [Mark My Words][5] 的游戏。它是一个语言学方面地的有特定主题的游戏,它描述一个小说写作系统在它历史期间的演化。Open Jam 有一些令人愉快的提交,并且它们是值得校核。真的, [去看看][31] !
|
||||
|
||||
在结束前,我们想要感谢所有的 [参加俱乐部的成员][32],使这次经历真正的有价值。我们也想要感谢 [Michael Clayton][33],[Jared Sprague][34] 和 [Opensource.com][35] 主办 open Jam。它是一次欢乐。
|
||||
|
||||
现在,我们对读者有一些问题。你是一个 FOSS 游戏开发者吗?你选择的工具是什么?务必在下面留下一个评论!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/graphics-music-tools-game-dev
|
||||
|
||||
作者:[Charlie Murphy][a]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rsg167
|
||||
[1]:http://mugeeks.org/
|
||||
[2]:https://itch.io/jam/open-jam-1
|
||||
[3]:https://opensource.com/article/17/8/open-jam-announcement
|
||||
[4]:https://opensource.com/article/17/11/open-jam
|
||||
[5]:https://mugeeksalpha.itch.io/mark-omy-words
|
||||
[6]:http://milkytracker.titandemo.org/
|
||||
[7]:https://en.wikipedia.org/wiki/Music_tracker
|
||||
[8]:https://creativecommons.org/
|
||||
[9]:https://freesound.org/
|
||||
[10]:http://ccmixter.org/view/media/home
|
||||
[11]:http://milkytracker.titandemo.org/documentation/
|
||||
[12]:https://github.com/milkytracker/MilkyTracker/wiki/MilkyTracker-Guide
|
||||
[13]:https://lmms.io/
|
||||
[14]:https://en.wikipedia.org/wiki/Chiptune
|
||||
[15]:https://github.com/grimfang4/sfxr
|
||||
[16]:https://lmms.io/wiki/index.php?title=BitInvader
|
||||
[17]:https://lmms.io/wiki/index.php?title=FreeBoy
|
||||
[18]:http://zynaddsubfx.sourceforge.net/
|
||||
[19]:http://www.mapeditor.org/
|
||||
[20]:https://www.piskelapp.com/
|
||||
[21]:https://github.com/piskelapp/piskel/blob/master/LICENSE
|
||||
[22]:https://raw.githubusercontent.com/MUGeeksandGadgets/MarkMyWords/master/tools/unpiskel.py
|
||||
[23]:https://www.python.org/
|
||||
[24]:https://www.sacredchao.net/~piman/angrydd/
|
||||
[25]:https://renpy.org/
|
||||
[26]:https://www.Pygame.org/
|
||||
[27]:http://Pygame.org/docs/tut/PygameIntro.html
|
||||
[28]:https://anthony-tuininga.github.io/cx_Freeze/
|
||||
[29]:https://Pygame.org/wiki/Pygame2exe
|
||||
[30]:http://www.py2exe.org/
|
||||
[31]:https://itch.io/jam/open-jam-1/entries
|
||||
[32]:https://github.com/MUGeeksandGadgets/MarkMyWords/blob/3e1e8aed12ebe13acccf0d87b06d4f3bd124b9db/README.md#credits
|
||||
[33]:https://twitter.com/mwcz
|
||||
[34]:https://twitter.com/caramelcode
|
||||
[35]:https://opensource.com/
|
||||
@ -0,0 +1,167 @@
|
||||
用 PGP 保护代码完整性(四):将主密钥移到离线存储中
|
||||
======
|
||||
|
||||

|
||||
在本系列教程中,我们为使用 PGP 提供了一个实用指南。你可以从下面的链接中查看前面的文章:
|
||||
|
||||
[第一部分:基本概念和工具][1]
|
||||
|
||||
[第二部分:生成你的主密钥][2]
|
||||
|
||||
[第三部分:生成 PGP 子密钥][3]
|
||||
|
||||
这是本系列教程的第四部分,我们继续本教程,我们将谈一谈如何及为什么要将主密钥从你的 Home 目录移到离线存储中。现在开始我们的教程。
|
||||
|
||||
### 清单
|
||||
|
||||
* 准备一个加密的可移除的存储(必要)
|
||||
|
||||
* 备份你的 GnuPG 目录(必要)
|
||||
|
||||
* 从你的 Home 目录中删除主密钥(推荐)
|
||||
|
||||
* 从你的 Home 目录中删除吊销证书(推荐)
|
||||
|
||||
|
||||
|
||||
|
||||
#### Considerations
|
||||
|
||||
为什么要从你的 Home 目录中删除你的主密钥 [C] ?这样做的主要原因是防止你的主密钥失窃或意外泄露。对于心怀不轨的人来说,私钥对他们具有很大的诱惑力 —— 我们知道有几个恶意软件成功地实现了扫描用户的 Home 目录并将发现的任何私钥内容上传。
|
||||
|
||||
对于任何开发者来说,私钥失窃是非常危险的事情 —— 在自由软件的世界中,这无疑是身份证明失窃。从你的 Home 目录中删除私钥将帮你防范这类事件的发生。
|
||||
|
||||
##### 备份你的 GnuPG 目录
|
||||
|
||||
**!!!绝对不要跳过这一步!!!**
|
||||
|
||||
备份你的 PGP 密钥将让你在需要的时候很容易地恢复它们,这很重要!(这与我们做的使用 paperkey 的灾难级备份是不一样的)。
|
||||
|
||||
##### 准备可移除的加密存储
|
||||
|
||||
我们从取得一个(最好是两个)小型的 USB “拇指“ 驱动器(可加密 U 盘)开始,我们将用它来做备份。你首先需要去加密它们:
|
||||
|
||||
加密密码可以使用与主密钥相同的密码。
|
||||
|
||||
##### 备份你的 GnuPG 目录
|
||||
|
||||
加密过程结束之后,重新插入 USB 驱动器并确保它能够正常挂载。你可以通过运行 `mount` 命令去找到设备挂载点的完全路径。(在 Linux 下,外置介质一般挂载在 /media/disk 下,Mac 一般在它的 /Volumes 下)
|
||||
|
||||
你知道了挂载点的全路径后,将你的整个 GnuPG 的目录复制进去:
|
||||
```
|
||||
$ cp -rp ~/.gnupg [/media/disk/name]/gnupg-backup
|
||||
|
||||
```
|
||||
|
||||
(注意:如果出现任何套接字不支持的错误,没有关系,直接忽略它们。)
|
||||
|
||||
现在,用如下的命令去测试一下,确保它们能够正常地工作:
|
||||
```
|
||||
$ gpg --homedir=[/media/disk/name]/gnupg-backup --list-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
如果没有出现任何错误,说明一切正常。弹出这个 USB 驱动器并给它粘上一个明确的标签,以便于你下次需要它时能够很快找到它。接着,将它放到一个安全的 —— 但不要太远 —— 的地方,因为从现在起,你需要偶尔使用它来做一些像编辑身份信息、添加或吊销子证书、或签署其它人的密钥这样的事情。
|
||||
|
||||
##### 删除主密钥
|
||||
|
||||
我们 Home 目录中的文件并没有像我们所想像的那样受到保护。它们可能会通过许多不同的方式被泄露或失窃:
|
||||
|
||||
* 通过快速复制来配置一个新工作站时的偶尔事故
|
||||
|
||||
* 通过系统管理员的疏忽或恶意操作
|
||||
|
||||
* 通过安全性欠佳的备份
|
||||
|
||||
* 通过桌面应用中的恶意软件(浏览器、pdf 查看器等等)
|
||||
|
||||
* 通过跨境胁迫
|
||||
|
||||
|
||||
|
||||
|
||||
使用一个很好的密码来保护你的密钥是降低上述风险的一个很好方法,但是密码能够通过键盘记录器、背后窥视、或其它方式被发现。基于以上原因,我们建议去配置一个从你的 Home 目录上可移除的主密钥,将它保存在一个离线存储中。
|
||||
|
||||
###### 删除主密钥
|
||||
|
||||
**请查看前面的节,确保你有完整的你的 GnuPG 目录的一个备份。如果你没有一个可用的备份,下面所做的操作将会使你的主密钥失效!!!**
|
||||
|
||||
首先,识别你的主密钥的 keygrip:
|
||||
```
|
||||
$ gpg --with-keygrip --list-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
它的输出应该像下面这样:
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
Keygrip = AAAA999988887777666655554444333322221111
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
sub rsa2048 2017-12-06 [E]
|
||||
Keygrip = BBBB999988887777666655554444333322221111
|
||||
sub rsa2048 2017-12-06 [S]
|
||||
Keygrip = CCCC999988887777666655554444333322221111
|
||||
|
||||
```
|
||||
|
||||
找到 pub 行下方的 keygrip 条目(就在主密钥指纹的下方)。它与你的 Home 目录下 `.gnupg` 目录下的一个文件是一致的:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ ls
|
||||
AAAA999988887777666655554444333322221111.key
|
||||
BBBB999988887777666655554444333322221111.key
|
||||
CCCC999988887777666655554444333322221111.key
|
||||
|
||||
```
|
||||
|
||||
现在你做的全部操作就是简单地删除与主密钥 keygrip 一致的 `.key` 文件:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ rm AAAA999988887777666655554444333322221111.key
|
||||
|
||||
```
|
||||
|
||||
现在,如果运行 --list-secret-keys 命令将出现问题,它将显示主密钥丢失(# 表示不可用):
|
||||
```
|
||||
$ gpg --list-secret-keys
|
||||
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
ssb rsa2048 2017-12-06 [E]
|
||||
ssb rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
##### 删除吊销证书
|
||||
|
||||
你应该去删除的另一个文件是吊销证书(**删除之前,确保你的备份中有它**),它是使用你的主密钥自动创建的。吊销证书允许一些人去永久标记你的证书为吊销状态,这意味着它无论在任何用途中将不再被使用或信任。一般是使用它来吊销由于某些原因不再受控的一个密钥 —— 比如,你丢失了密钥密码。
|
||||
|
||||
与使用主密钥一样,如果一个吊销证书泄露到恶意者手中,他们能够使用它去破坏你的开发者数字身份,因此,最好是从你的 Home 目录中删除它。
|
||||
```
|
||||
cd ~/.gnupg/openpgp-revocs.d
|
||||
rm [fpr].rev
|
||||
|
||||
```
|
||||
|
||||
在下一篇文章中,你将学习如何保护你的子密钥。敬请期待。
|
||||
|
||||
从来自 Linux 基金会和 edX 的免费课程 [“Linux 入门" ][4] 中学习更多 Linux 知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,304 @@
|
||||
用 PGP 保护代码完整性(五):将子密钥移到一个硬件设备中
|
||||
======
|
||||
|
||||

|
||||
|
||||
在本系列教程中,我们将提供一个使用 PGP 的实用指南。如果你没有看过前面的文章,你可以通过下面的链接去查看。在这篇文章中,我们将继续讨论如何保护你的密钥,谈一谈将你的子密钥移到一个专门的硬件设备中的一些技巧。
|
||||
|
||||
[第一部分:基本概念和工具][1]
|
||||
|
||||
[第二部分:生成你的主密钥][2]
|
||||
|
||||
[第三部分:生成 PGP 子密钥][3]
|
||||
|
||||
[第四部分:将主密钥移到离线存储中][4]
|
||||
|
||||
### 清单
|
||||
|
||||
* 取得一个 GnuPG 兼容的硬件设备(必要)
|
||||
|
||||
* 配置 GnuPG 在设备上工作(必要)
|
||||
|
||||
* 设置 user 和 admin 的 PIN(必要)
|
||||
|
||||
* 移动子密钥到设备中(必要)
|
||||
|
||||
|
||||
|
||||
|
||||
### 考虑事项
|
||||
|
||||
虽然现在主密钥已经不用担心泄露或失窃了,但子密钥仍然在你的 Home 目录中。任何得到它的人都能够解密你的通讯或假冒你的签名(如果他们知道密钥的密码)。并且,每次执行一个 GnuPG 操作都要将密钥加载到操作系统内存中,这将使一些更高级的恶意软件有机会得到你的密钥(想想 Meltdown 和 Spectre)。
|
||||
|
||||
完全保护密钥的最好方式就是,将它移到一个专门的硬件设备中,这种硬件设备是一个可操作的智能卡。
|
||||
|
||||
#### 智能卡的好处
|
||||
|
||||
一个智能卡包含一个加密芯片,它能够存储私钥,并且直接在智能卡内部执行秘密操作。因为密钥内容从来没有离开过智能卡,计算机操作系统并不能检索你插入的智能卡上的私钥。这与前面用于备份目的的加密 USB 存储是不同的 —— 虽然 USB 设备也是插入并解密的,但操作系统是能够去访问私钥内容的。使用外置的加密 USB 介质并不能代替智能卡设备的功能。
|
||||
|
||||
智能卡的一些其它好处:
|
||||
|
||||
* 它们很便宜且易于获得
|
||||
|
||||
* 它们小巧且易于携带
|
||||
|
||||
* 它们可以用于多种设备上
|
||||
|
||||
* 它们中的很多都具有防篡改功能(取决于制造商)
|
||||
|
||||
|
||||
|
||||
|
||||
#### 可用的智能卡设备
|
||||
|
||||
智能卡最初是嵌入到真实钱包大小的卡中,故而得名智能卡。你总是可以买到并使用 GnuPG 功能的智能卡,并且它们是你能得到的最便宜的可用设备之一。但是,事实上智能卡有一个很重要的缺点:它们需要一个智能卡读卡器,只有极小数的笔记本电脑上有这种读卡器。
|
||||
|
||||
由于这个原因,制造商开始推出小型 USB 设备,它的大小和 U 盘类似,内置有微型智能卡,并且在芯片上简单地实现了智能卡协议特性。下面推荐几个这样的设备:
|
||||
|
||||
* [Nitrokey Start][5]:开源硬件和自由软件,可用于 GnuPG 的最便宜的选择之一,但是额外的安全特性很少。
|
||||
|
||||
* [Nitrokey Pro][6]:类似于 Nitrokey Start,它提供防篡改及更多的安全特性(但没有 U2F,具体查看指南的 U2F 节)。
|
||||
|
||||
* [Yubikey 4][7]:专利硬件和软件,但比 Nitrokey Pro 便宜,并且可以用在最新的笔记本电脑上的 USB-C 接口;也提供像 U2F 这样的额外的安全特性。
|
||||
|
||||
|
||||
|
||||
|
||||
我们推荐选一个同时具备智能卡功能和 U2F 的设备,在写这篇文章时,只能选择 Yubikey 4。
|
||||
|
||||
#### 配置智能卡设备
|
||||
|
||||
你的智能卡设备插入任何一台现代的 Linux 或 Mac 工作站上都应该能正常工作。你可以通过运行如下的命令去验证它:
|
||||
```
|
||||
$ gpg --card-status
|
||||
|
||||
```
|
||||
|
||||
如果你没有收到错误,有一个完整的卡列表,就表示一切正常。不幸的是,排除为什么设备不能正常工作的所有可能原因,已经超出了本指南的范围。如果你的智能卡使用 GnuPG 时有问题,请通过你的操作系统的常见支持通道寻求支持。
|
||||
|
||||
##### PIN 不一定是数字
|
||||
|
||||
注意,尽管名为 “PIN”(暗示你它必须是一个“数字”),不论是 user PIN 还是 admin PIN 都不必非要是数字。
|
||||
|
||||
当你收到一个新设备时,它可能设置有一个默认的 user 和 admin PIN,对于 Yubikeys,它分别是 123456 和 12345678。如果它们的 PIN 不是默认的,请查看设备附带的说明书。
|
||||
|
||||
##### 快速设置
|
||||
|
||||
为配置你的智能卡,你需要使用 GnuPG 菜单系统,因此这里并没有更方便的命令行开关:
|
||||
```
|
||||
$ gpg --card-edit
|
||||
[...omitted...]
|
||||
gpg/card> admin
|
||||
Admin commands are allowed
|
||||
gpg/card> passwd
|
||||
|
||||
```
|
||||
|
||||
你应该去设置 user PIN (1)、admin PIN (3)、和 Reset Code (4)。请确保把它们记录并保存到一个安全的地方 —— 尤其是 Admin PIN 和 Reset Code(它允许你去擦除整个智能卡内容)。你很少使用到 Admin PIN,因此如果你不记录下来,很可能会忘掉它。
|
||||
|
||||
返回到智能卡主菜单,你也可以设置其它值(比如名字、性别、登入日期、等等),但是这些都不是必需的,一旦你的智能卡丢失了,将导致额外的信息泄露。
|
||||
|
||||
#### 将子密钥移到你的智能卡中
|
||||
|
||||
退出卡菜单(使用 “q” 命令)保存所有更改。接下来,我们将你的子密钥移到智能卡中。将需要用到你的 PGP 密钥的密码,在大多数的智能卡操作中都将用到 admin PIN。记住,那个 [fpr] 表示你的密钥的完整的 40 个字符的指纹。
|
||||
```
|
||||
$ gpg --edit-key [fpr]
|
||||
|
||||
Secret subkeys are available.
|
||||
|
||||
pub rsa4096/AAAABBBBCCCCDDDD
|
||||
created: 2017-12-07 expires: 2019-12-07 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
ssb rsa2048/1111222233334444
|
||||
created: 2017-12-07 expires: never usage: E
|
||||
ssb rsa2048/5555666677778888
|
||||
created: 2017-12-07 expires: never usage: S
|
||||
[ultimate] (1). Alice Engineer <alice@example.org>
|
||||
[ultimate] (2) Alice Engineer <allie@example.net>
|
||||
|
||||
gpg>
|
||||
|
||||
```
|
||||
|
||||
使用 --edit-key 再次进入到菜单模式,你将注意到那个密钥清单有一点小差别。从现在开始,所有的命令都是在这个菜单模式下运行,它用 gpg> 提示符来表示。
|
||||
|
||||
首先,我们来选择移到智能卡中的密钥 —— 你可以通过键入 `key 1`(它表示选择清单中的第一个密钥)来实现:
|
||||
```
|
||||
gpg> key 1
|
||||
|
||||
```
|
||||
|
||||
这个输出会有一点细微的差别:
|
||||
```
|
||||
pub rsa4096/AAAABBBBCCCCDDDD
|
||||
created: 2017-12-07 expires: 2019-12-07 usage: C
|
||||
trust: ultimate validity: ultimate
|
||||
ssb* rsa2048/1111222233334444
|
||||
created: 2017-12-07 expires: never usage: E
|
||||
ssb rsa2048/5555666677778888
|
||||
created: 2017-12-07 expires: never usage: S
|
||||
[ultimate] (1). Alice Engineer <alice@example.org>
|
||||
[ultimate] (2) Alice Engineer <allie@example.net>
|
||||
|
||||
```
|
||||
|
||||
注意与密钥对应的 ssb 行旁边的 `*` —— 它表示这是当前选定的密钥。它是可切换的,意味着如果你再次输入 `key 1`,这个 `*` 将消失,这个密钥将不再被选中。
|
||||
|
||||
现在,我们来将密钥移到智能卡中:
|
||||
```
|
||||
gpg> keytocard
|
||||
Please select where to store the key:
|
||||
(2) Encryption key
|
||||
Your selection? 2
|
||||
|
||||
```
|
||||
|
||||
由于它是我们的 [E] 密钥,把它移到加密区中是有很有意义的。当你提交了你的选择之后,将会被提示输入你的 PGP 密钥的保护密码,接下来输入智能卡的 admin PIN。如果命令没有返回错误,表示你的密钥已经被移到智能卡中了。
|
||||
|
||||
**重要:** 现在再次输入 `key 1` 去取消选中第一个密钥,并输入 `key 2` 去选择 [S] 密钥:
|
||||
|
||||
```
|
||||
gpg> key 1
|
||||
gpg> key 2
|
||||
gpg> keytocard
|
||||
Please select where to store the key:
|
||||
(1) Signature key
|
||||
(3) Authentication key
|
||||
Your selection? 1
|
||||
|
||||
```
|
||||
|
||||
你可以使用 [S] 密钥同时做签名和验证,但是我们希望确保它在签名区,因此,我们选择 (1)。完成后,如果你的命令没有返回错误,表示操作已成功。
|
||||
|
||||
最后,如果你创建了一个 [A] 密钥,你也可以将它移到智能卡中,但是你需要先取消选中 `key 2`。完成后,选择 “q":
|
||||
```
|
||||
gpg> q
|
||||
Save changes? (y/N) y
|
||||
|
||||
```
|
||||
|
||||
保存变更将把你的子密钥移到智能卡后,把你的 Home 目录中的相应子密钥删除(没有关系,因为我们的备份中还有,如果更换了智能卡,你需要再做一遍)。
|
||||
|
||||
##### 验证移动后的密钥
|
||||
|
||||
现在,如果你执行一个` --list-secret-keys` 操作,你将看到一个稍有不同的输出:
|
||||
```
|
||||
$ gpg --list-secret-keys
|
||||
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
ssb> rsa2048 2017-12-06 [E]
|
||||
ssb> rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
在 ssb> 的输出中的 `>` 表示子密钥仅在智能卡上有效。如果你进入到你的密钥目录中,查看目录的内容,你将会看到那个 `.key` 文件已经被存根替换:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ strings *.key
|
||||
|
||||
```
|
||||
|
||||
这个输出将包含一个影子私钥,它表示那个文件仅是个存根,真正的内容在智能卡中。
|
||||
|
||||
#### 验证智能卡的功能
|
||||
|
||||
验证智能卡能否如期正常运行,你可以通过创建一个签名来验证:
|
||||
```
|
||||
$ echo "Hello world" | gpg --clearsign > /tmp/test.asc
|
||||
$ gpg --verify /tmp/test.asc
|
||||
|
||||
```
|
||||
|
||||
首次运行这个命令时将询问你智能卡的 PIN,在你运行 `gpg —verify` 之后,它将显示 "Good signature”。
|
||||
|
||||
祝贺你,你已经成功将窃取你的开发者数字身份变得更加困难了!
|
||||
|
||||
### 其它常见 GnuPG 操作
|
||||
|
||||
下面是使用你的 PGP 密钥需要做的一些常见操作的快速指南。
|
||||
|
||||
在下面的所有命令中,[fpr] 表示你的密钥指纹。
|
||||
|
||||
#### 挂载主密钥离线存储
|
||||
|
||||
下面的一些操作将需要你的主密钥,因此首先需要去挂载你的主密钥离线存储,并告诉 GnuPG 去使用它。首先,找出介质挂载路径,可以通过查看 mount 命令的输出找到它。接着,设置你的 GnuPG 目录为你的介质上备份的目录,并告诉 GnuPG 将那个目录做为它的 Home:
|
||||
```
|
||||
$ export GNUPGHOME=/media/disk/name/gnupg-backup
|
||||
$ gpg --list-secret-keys
|
||||
|
||||
```
|
||||
|
||||
确保你在输出中看到的是 `sec` 而不是 `sec#`(这个 `#` 表示密钥不可用,仍然使用的是惯常的那个 Home 目录)。
|
||||
|
||||
##### 更新你惯常使用的那个 GnuPG 工作目录
|
||||
|
||||
在你的离线存储上做了任何更改之后,你应该将这些更改同步应用到你惯常使用的工作目录中:
|
||||
```
|
||||
$ gpg --export | gpg --homedir ~/.gnupg --import
|
||||
$ unset GNUPGHOME
|
||||
|
||||
```
|
||||
|
||||
#### 延长密钥过期日期
|
||||
|
||||
我们创建的主密钥的默认过期日期是自创建之日起两年后。这样做都是为安全考虑,这样将使淘汰密钥最终从密钥服务器上消失。
|
||||
|
||||
延长你的密钥过期日期,从当前日期延长一年,只需要运行如下命令:
|
||||
```
|
||||
$ gpg --quick-set-expire [fpr] 1y
|
||||
|
||||
```
|
||||
|
||||
如果为了好记住,你也可以使用一个特定日期(比如,你的生日、1 月 1 日、或加拿大国庆日):
|
||||
```
|
||||
$ gpg --quick-set-expire [fpr] 2020-07-01
|
||||
|
||||
```
|
||||
|
||||
记得将更新后的密钥发送到密钥服务器:
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
#### 吊销身份
|
||||
|
||||
如果你需要吊销一个身份(比如,你换了雇主并且旧的邮件地址不再有效了),你可以使用一行命令搞定:
|
||||
```
|
||||
$ gpg --quick-revoke-uid [fpr] 'Alice Engineer <aengineer@example.net>'
|
||||
|
||||
```
|
||||
|
||||
你也可以通过使用 `gpg --edit-key [fpr]` 在菜单模式下完成同样的事情。
|
||||
|
||||
完成后,记得将更新后的密钥发送到密钥服务器上:
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
下一篇文章中,我们将谈谈 Git 如何支持 PGP 的多级别集成。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门" ][8]学习更多 Linux 知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
[5]:https://shop.nitrokey.com/shop/product/nitrokey-start-6
|
||||
[6]:https://shop.nitrokey.com/shop/product/nitrokey-pro-3
|
||||
[7]:https://www.yubico.com/product/yubikey-4-series/
|
||||
[8]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,318 @@
|
||||
保护代码完整性(六):在 Git 上使用 PGP
|
||||
======
|
||||
|
||||

|
||||
在本系列教程中,我们提供了一个使用 PGP 的实用指南,包括基本概念和工具、生成和保护你的密钥。如果你错过了前面的文章,你可以查看下面的链接。在这篇文章中,我们谈一谈在 Git 中如何集成 PGP、使用签名的标签,然后介绍签名提交,最后添加签名推送的支持。
|
||||
|
||||
[第一部分:基本概念和工具][1]
|
||||
|
||||
[第二部分:生成你的主密钥][2]
|
||||
|
||||
[第三部分:生成 PGP 子密钥][3]
|
||||
|
||||
[第四部分:将主密钥移到离线存储中][4]
|
||||
|
||||
[第五部分:将子密钥移到硬件设备中][5]
|
||||
|
||||
Git 的核心特性之一就是它的去中心化本质 —— 一旦仓库克隆到你的本地系统,你就拥有了项目的完整历史,包括所有的标签、提交和分支。然而由于存在着成百上千的克隆仓库,如何才能验证你下载的仓库没有被恶意的第三方做过篡改?你可以从 GitHub 或一些貌似官方的位置来克隆它们,但是如果有些人故意欺骗了你怎么办?
|
||||
|
||||
或者在你参与的一些项目上发现了后门,而 "Author" 行显示是你干的,然而你很确定 [不是你干的][6],会发生什么情况?
|
||||
|
||||
为解决上述问题,Git 添加了 PGP 集成。签名的标签通过确认它的内容与创建这个标签的开发者的工作站上的内容完全一致来证明仓库的完整性,而签名的提交几乎是不可能在不访问你的 PGP 密钥的情况下能够假冒你。
|
||||
|
||||
### 清单
|
||||
|
||||
* 了解签名的标签、提交、和推送(必要)
|
||||
|
||||
* 配置 git 使用你的密钥(必要)
|
||||
|
||||
* 学习如何签名标签和验证工作(必要)
|
||||
|
||||
* 配置 git 总是签名注释的标签(推荐)
|
||||
|
||||
* 学习如何签名提交和验证工作(必要)
|
||||
|
||||
* 配置 git 总是签名提交(推荐)
|
||||
|
||||
* 配置 gpg-agent 选项(必要)
|
||||
|
||||
|
||||
|
||||
|
||||
### 考虑事项
|
||||
|
||||
Git 实现了 PGP 的多级集成,首先从签名标签开始,接着介绍签名提交,最后添加签名推送的支持。
|
||||
|
||||
#### 了解 Git 哈希
|
||||
|
||||
Git 是一个复杂的东西,为了你能够更好地掌握它如何集成 PGP,你需要了解什么是”哈希“。我们将它归纳为两种类型的哈希:树哈希和提交哈希。
|
||||
|
||||
##### 树哈希
|
||||
|
||||
每次你向仓库提交一个变更,对于仓库中的每个子目录,git 都会记录它里面所有对象的校验和哈希 —— 内容(blobs)、目录(trees)、文件名和许可等等。它只对每次提交中发生变更的树和内容做此操作,这样在只变更树的一小部分时就不必去重新计算整个树的校验和。
|
||||
|
||||
然后再计算和存储处于顶级的树的校验和,这样如果仓库的任何一部分发生变化,校验和将不可避免地发生变化。
|
||||
|
||||
##### 提交哈希
|
||||
|
||||
一旦创建了树哈希,git 将计算提交哈希,它将包含有关仓库和变更的下列信息:
|
||||
|
||||
* 树哈希的校验和
|
||||
|
||||
* 变更前树哈希的校验和(父级)
|
||||
|
||||
* 有关作者的信息(名字、email、创作时间)
|
||||
|
||||
* 有关提交者的信息(名字、email、提交时间)
|
||||
|
||||
* 提交信息
|
||||
|
||||
|
||||
|
||||
|
||||
##### 哈希函数
|
||||
|
||||
在写这篇文章时,虽然研究一种更强大的、抗碰撞的算法的工作正在进行,但 git 仍然使用的是 SHA1 哈希机制去计算校验和。注意,git 已经包含了碰撞防范程序,因此认为对 git 成功进行碰撞攻击仍然是不可行的。
|
||||
|
||||
#### 注释的标签和标签签名
|
||||
|
||||
在每个 Git 仓库中,标签允许开发者标记特定的提交。标签可以是 “轻量级的” —— 几乎只是一个特定提交上的指针,或者它们可以是 “注释的”,它成为 git 树中自己的项目。一个注释的标签对象包含所有下列的信息:
|
||||
|
||||
* 成为标签的提交哈希的校验和
|
||||
|
||||
* 标签名字
|
||||
|
||||
* 关于打标签的人的信息(名字、email、打标签时间)
|
||||
|
||||
* 标签信息
|
||||
|
||||
|
||||
|
||||
|
||||
一个 PGP 签名的标签是一个带有将所有这些条目封装进一个 PGP 签名的注释标签。当开发者签名他们的 git 标签时,他们实际上是向你保证了如下的信息:
|
||||
|
||||
* 他们是谁(以及他们为什么应该被信任)
|
||||
|
||||
* 他们在签名时的仓库状态是什么样:
|
||||
|
||||
* 标签包含提交的哈希
|
||||
|
||||
* 提交哈希包含了顶级树的哈希
|
||||
|
||||
* 顶级哈希包含了所有文件、内容和子树的哈希
|
||||
* 它也包含有关作者的所有信息
|
||||
|
||||
* 包含变更发生时的精确时间
|
||||
|
||||
|
||||
|
||||
|
||||
当你克隆一个仓库并验证一个签名标签时,就是向你以密码方式保证仓库中的所有内容、包括所有它的历史,与开发者签名时在它的计算机上的仓库完全一致。
|
||||
|
||||
#### 签名的提交
|
||||
|
||||
签名的提交与签名的标签非常类似 —— 提交对象的内容是 PGP 签名过的,而不是标签对象的内容。一个提交签名也给你提供了开发者签名时,开发者树上的全部可验证信息。标签签名和提交 PGP 签名提供了有关仓库和它的完整历史的完全一致的安全保证。
|
||||
|
||||
#### 签名的推送
|
||||
|
||||
为了完整起见,在这里包含了签名的推送这一功能,因为在你使用这个功能之前,需要在接收推送的服务器上先启用它。正如我们在上面所说过的,PGP 签名一个 git 对象就是提供了开发者的 git 树当时的可验证信息,但不提供开发者对那个树意图相关的信息。
|
||||
|
||||
比如,你可以在你自己 fork 的 git 仓库的一个实验分支上尝试一个很酷的特性,为了评估它,你提交了你的工作,但是有人在你的代码中发现了一个恶意的 bug。由于你的提交是经过正确签名的,因此有人可能将包含有恶意 bug 的分支推入到 master 分支中,从而在生产系统中引入一个漏洞。由于提交是经过你的密钥正确签名的,所以一切看起来都是合理合法的,而当 bug 被发现时,你的声誉就会因此而受到影响。
|
||||
|
||||
在 `git push` 时,为了验证提交的意图而不仅仅是验证它的内容,添加了要求 PGP 推送签名的功能。
|
||||
|
||||
#### 配置 git 使用你的 PGP 密钥
|
||||
|
||||
如果在你的钥匙环上只有一个密钥,那么你就不需要再做额外的事了,因为它是你的默认密钥。
|
||||
|
||||
然而,如果你有多个密钥,那么你必须要告诉 git 去使用哪一个密钥。([fpr] 是你的密钥的指纹):
|
||||
```
|
||||
$ git config --global user.signingKey [fpr]
|
||||
|
||||
```
|
||||
|
||||
注意:如果你有一个不同的 gpg2 命令,那么你应该告诉 git 总是去使用它,而不是传统的版本 1 的 gpg:
|
||||
```
|
||||
$ git config --global gpg.program gpg2
|
||||
|
||||
```
|
||||
|
||||
#### 如何使用签名标签
|
||||
|
||||
创建一个签名的标签,只要传递一个简单地 -s 开关给 tag 命令即可:
|
||||
```
|
||||
$ git tag -s [tagname]
|
||||
|
||||
```
|
||||
|
||||
我们建议始终对 git 标签签名,这样让其它的开发者确信他们使用的 git 仓库没有被恶意地修改过(比如,引入后门):
|
||||
|
||||
##### 如何验证签名的标签
|
||||
|
||||
验证一个签名的标签,只需要简单地使用 verify-tag 命令即可:
|
||||
```
|
||||
$ git verify-tag [tagname]
|
||||
|
||||
```
|
||||
|
||||
如果你要验证其他人的 git 标签,那么就需要你导入他的 PGP 公钥。请参考 “可信任的团队沟通” 一文中关于此主题的指导。
|
||||
|
||||
##### 在拉取时验证
|
||||
|
||||
如果你从项目仓库的其它 fork 中拉取一个标签,git 将自动验证签名,并在合并操作时显示结果:
|
||||
```
|
||||
$ git pull [url] tags/sometag
|
||||
|
||||
```
|
||||
|
||||
合并信息将包含类似下面的内容:
|
||||
```
|
||||
Merge tag 'sometag' of [url]
|
||||
|
||||
[Tag message]
|
||||
|
||||
# gpg: Signature made [...]
|
||||
# gpg: Good signature from [...]
|
||||
|
||||
```
|
||||
|
||||
#### 配置 git 始终签名注释的标签
|
||||
|
||||
很可能的是,你正在创建一个带注释的标签,你应该去签名它。强制 git 始终签名带注释的标签,你可以设置一个全局配置选项:
|
||||
```
|
||||
$ git config --global tag.forceSignAnnotated true
|
||||
|
||||
```
|
||||
|
||||
或者,你始终记得每次都传递一个 -s 开关:
|
||||
```
|
||||
$ git tag -asm "Tag message" tagname
|
||||
|
||||
```
|
||||
|
||||
#### 如何使用签名提交
|
||||
|
||||
创建一个签名提交很容易,但是将它纳入到你的工作流中却很困难。许多项目使用签名提交作为一种 "Committed-by:” 的等价行,它记录了代码来源 —— 除了跟踪项目历史外,签名很少有人去验证。在某种意义上,签名的提交用于 ”篡改证据“,而不是 git 工作流的 ”篡改证明“。
|
||||
|
||||
为创建一个签名的提交,你只需要 `git commit` 命令传递一个 -S 标志即可(由于它与另一个标志冲突,所以改为大写的 -S):
|
||||
```
|
||||
$ git commit -S
|
||||
|
||||
```
|
||||
|
||||
我们建议始终使用签名提交,并要求项目所有成员都这样做,这样其它人就可以验证它们(下面就讲到如何验证)。
|
||||
|
||||
##### 如何去验证签名的提交
|
||||
|
||||
验证签名的提交需要使用 verify-commit 命令:
|
||||
```
|
||||
$ git verify-commit [hash]
|
||||
|
||||
```
|
||||
|
||||
你也可以查看仓库日志,要求所有提交签名是被验证和显示的:
|
||||
```
|
||||
$ git log --pretty=short --show-signature
|
||||
|
||||
```
|
||||
|
||||
##### 在 git merge 时验证提交
|
||||
|
||||
如果项目的所有成员都签名了他们的提交,你可以在合并时强制进行签名检查(然后使用 -S 标志对合并操作本身进行签名):
|
||||
```
|
||||
$ git merge --verify-signatures -S merged-branch
|
||||
|
||||
```
|
||||
|
||||
注意,如果有一个提交没有签名或验证失败,将导致合并操作失败。通常情况下,技术是最容易的部分 —— 而人的因素使得项目中很难采用严格的提交验证。
|
||||
|
||||
##### 如果你的项目在补丁管理上采用邮件列表
|
||||
|
||||
如果你的项目在提交和处理补丁时使用一个邮件列表,那么一般很少使用签名提交,因为通过那种方式发送时,签名信息将会丢失。对提交进行签名仍然是非常有用的,这样引用你托管在公开 git 树的其他人就能以它作为参考,但是上游项目接收你的补丁时,仍然不能直接使用 git 去验证它们。
|
||||
|
||||
尽管,你仍然可以签名包含补丁的电子邮件。
|
||||
|
||||
#### 配置 git 始终签名提交
|
||||
|
||||
你可以告诉 git 总是签名提交:
|
||||
```
|
||||
git config --global commit.gpgSign true
|
||||
|
||||
```
|
||||
|
||||
或者你每次都记得给 `git commit` 操作传递一个 -S 标志(包括 —amend)。
|
||||
|
||||
#### 配置 gpg-agent 选项
|
||||
|
||||
GnuPG agent 是一个守护工具,它能在你使用 gpg 命令时随时自动启动,并运行在后台来缓存私钥的密码。这种方式让你只需要解锁一次密钥就可以重复地使用它(如果你需要在一个自动脚本中签署一组 git 操作,而不需要重复输入密钥,这种方式就很方便)。
|
||||
|
||||
为了调整缓存中的密钥过期时间,你应该知道这两个选项:
|
||||
|
||||
* default-cache-ttl(秒):如果在 time-to-live 过期之前再次使用同一个密钥,这个倒计时将重置成另一个倒计时周期。缺省值是 600(10 分钟)。
|
||||
|
||||
* max-cache-ttl(秒):自首次密钥输入以后,不论最近一次使用密钥是什么时间,只要最大值的 time-to-live 倒计时过期,你将被要求再次输入密码。它的缺省值是 30 分钟。
|
||||
|
||||
|
||||
|
||||
|
||||
如果你认为这些缺省值过短(或过长),你可以编辑 ~/.gnupg/gpg-agent.conf 文件去设置你自己的值:
|
||||
```
|
||||
# set to 30 minutes for regular ttl, and 2 hours for max ttl
|
||||
default-cache-ttl 1800
|
||||
max-cache-ttl 7200
|
||||
|
||||
```
|
||||
|
||||
##### 额外好处:与 ssh 一起使用 gpg-agent
|
||||
|
||||
如果你创建了一个 [A](验证)密钥,并将它移到了智能卡,你可以将它用到 ssh 上,为你的 ssh 会话添加一个双因子验证。为了与 agent 沟通你只需要告诉你的环境去使用正确的套接字文件即可。
|
||||
|
||||
首先,添加下列行到你的 ~/.gnupg/gpg-agent.conf 文件中:
|
||||
```
|
||||
enable-ssh-support
|
||||
|
||||
```
|
||||
|
||||
接着,添加下列行到你的 .bashrc 文件中:
|
||||
```
|
||||
export SSH_AUTH_SOCK=$(gpgconf --list-dirs agent-ssh-socket)
|
||||
|
||||
```
|
||||
|
||||
为了让改变生效,你需要 kill 掉正在运行的 gpg-agent 进程,并重新启动一个新的登入会话:
|
||||
```
|
||||
$ killall gpg-agent
|
||||
$ bash
|
||||
$ ssh-add -L
|
||||
|
||||
```
|
||||
|
||||
最后的命令将列出代表你的 PGP Auth 密钥的 SSH(注释应该会在结束的位置显示: cardno:XXXXXXXX,表示它来自智能卡)。
|
||||
|
||||
为了启用 ssh 的基于密钥的登入,只需要在你要登入的远程系统上添加 `ssh-add -L` 的输出到 ~/.ssh/authorized_keys 中。祝贺你,这将使你的 SSH 登入凭据更难以窃取。
|
||||
|
||||
作为一个福利,你可以从公共密钥服务器上下载其它人的基于 PGP 的 ssh 公钥,这样就可以赋予他登入 ssh 的权利:
|
||||
```
|
||||
$ gpg --export-ssh-key [keyid]
|
||||
|
||||
```
|
||||
|
||||
如果你有让开发人员通过 ssh 来访问 git 仓库的需要,这将让你非常方便。下一篇文章,我们将提供像保护你的密钥那样保护电子邮件帐户的小技巧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-6-using-pgp-git
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
[5]:https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-5-moving-subkeys-hardware-device
|
||||
[6]:https://github.com/jayphelps/git-blame-someone-else
|
||||
@ -0,0 +1,182 @@
|
||||
通过询问-响应身份认证提高登陆安全
|
||||
======
|
||||
|
||||

|
||||
|
||||
### 介绍
|
||||
|
||||
今天,Fedora 提供了多种方式来提高我们账户的身份认证的安全性。当然,它有我们熟悉的用户名密码登陆,它也同样提供了其他的身份认证选项,比如生物识别、指纹、智能卡、一次性密码,甚至是询问-响应身份认证。
|
||||
|
||||
每种认证方式都有明确的优缺点。这点本身就可以成为一篇相当冗长的文章的主题。Fedora 杂志之前就已经介绍过了这其中的一些选项:
|
||||
|
||||
|
||||
+ [Using the YubiKey4 with Fedora][1]
|
||||
+ [Fedora 28: Better smart card support in OpenSSH][2]
|
||||
|
||||
|
||||
在现在的 Fedora 版本中,最安全的方法之一就是离线硬件询问-响应。它也同样是最容易部署的方法之一。下面是具体方法:
|
||||
|
||||
### 询问-响应认证
|
||||
|
||||
从技术上来讲,当你输入密码的时候,你就正在响应用户名询问。离线的询问、响应包含了这些部分:首先是需要你的用户名,接下来,Fedora 会要你提供一个加密的物理硬件的令牌。令牌会将另一个通过可插入式身份认证模块(PAM)框架进行存储的加密密钥来响应询问。最后,Fedora 才会提示你输入密码。这可以防止其他人仅仅使用了找到的硬件令牌,或是只使用了账户名密码而没有正确的加密密钥。
|
||||
|
||||
这意味着除了你的账户名密码之外,你必须事先在你的操作系统中注册了一个或多个加密硬件令牌。你必须保证你的物理硬件令牌能够匹配你的用户名。
|
||||
|
||||
一些询问-响应的方法,比如一次性密码(OTP),在硬件令牌上获取加密代码密钥,然后将这个密钥通过网络传输到远程身份认证服务器。然后这个服务器会告诉 Fedora 的 PAM 框架,这是否是该用户的一个有效令牌。如果身份认证服务器在本地网络上,这个方法非常好。但它的缺点是如果网络连接断开或是你在没有网的远程端工作。你会被锁在系统之外,直到你能通过网络连接到身份认证服务器。
|
||||
|
||||
有时候,生产环境会需要通过 Yubikey 使用一次性密码(OTP)设置,然而,在家庭或个人的系统上,你可能更喜欢询问-响应设置。一切都是本地的,这种方法不需要通过远程网络呼叫。下面这些过程适用于 Fedora 27、28和29.
|
||||
|
||||
### 准备
|
||||
|
||||
#### 硬件令牌密钥
|
||||
|
||||
首先,你需要一个安全的硬件令牌密钥。具体来说,这个过程需要一个 Yubikey 4,Yubikey NEO,或者是最近发布的、同样支持 FIDO2 的 Yubikey 5 系列设备。你应该购买它们中的两个来有一个备份,以避免其中一个丢失或遭到损坏。你可以在不同的工作地点使用这些密钥。较为简单的 FIDO 和 FIDO U2F 版本不适用与这个过程,但是非常适合使用 FIDO 的在线服务。
|
||||
|
||||
#### 备份、备份,以及备份
|
||||
|
||||
接下来,为你所有的重要数据制作备份,你可能想在克隆在 VM 里的 Fedora 27/28/29 里测试配置,来确保你在设置你自己的个人工作环境之前理解这个过程。
|
||||
|
||||
#### 升级,然后安装
|
||||
|
||||
现在,确定你的 Fedora 是最新的,然后通过 dnf 命令安装所需要的 Fedora Yubikey 包。
|
||||
|
||||
```
|
||||
$ sudo dnf upgrade
|
||||
$ sudo dnf install ykclient* ykpers* pam_yubico*
|
||||
$ cd
|
||||
```
|
||||
|
||||
如果你使用的是 VM 环境,例如 Virtual Box,确保 Yubikey 设备已经插进了 USB 口,然后允许 VM 控制的 USB 访问 Yubikey。
|
||||
|
||||
### 配置 Yubikey
|
||||
|
||||
通过 USB Yubikey 验证你的账户:
|
||||
|
||||
```
|
||||
$ ykinfo -v
|
||||
version: 3.5.0
|
||||
```
|
||||
|
||||
如果 Yubikey 没有被检测到,会出现下面这些错误信息:
|
||||
|
||||
```
|
||||
Yubikey core error: no yubikey present
|
||||
```
|
||||
|
||||
接下来,通过下面这些 ykpersonalize 命令初始化你每个新的 Yubikeys。使用 HMAC-SHA1 算法进行询问响应,以此来设置 Yubikey 配置插槽 2。即使少于 64 个字符,如果你已经为询问响应设置好了你的 Yubikey。你就不需要再运行 ykpersonalize 了。
|
||||
|
||||
```
|
||||
ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -oserial-api-visible
|
||||
```
|
||||
|
||||
一些用户在使用的时候将 YubiKey 留在了工作环境里,甚至对虚拟机使用了询问响应。然而,为了更好的安全性,你可能会更愿意使用手动触发 YubiKey 来响应询问。
|
||||
|
||||
要添加手动询问按钮触发器,请添加 -ochal-btn-trig 标记,这个标记可以在请求中使得 Yubikey 闪烁 Yubikey LED。等待你在 15 秒内按下硬件密钥区域上的按钮来生成响应密钥。
|
||||
|
||||
```
|
||||
$ ykpersonalize -2 -ochal-resp -ochal-hmac -ohmac-lt64 -ochal-btn-trig -oserial-api-visible
|
||||
```
|
||||
|
||||
为你的每个新的硬件密钥执行此操作。每个密钥执行以此,使用下面的命令将 Yubikey 配置存储到 ~/.yubico:
|
||||
|
||||
```
|
||||
$ ykpamcfg -2 -v
|
||||
debug: util.c:222 (check_firmware_version): YubiKey Firmware version: 4.3.4
|
||||
|
||||
Sending 63 bytes HMAC challenge to slot 2
|
||||
Sending 63 bytes HMAC challenge to slot 2
|
||||
Stored initial challenge and expected response in '/home/chuckfinley/.yubico/challenge-9992567'.
|
||||
```
|
||||
|
||||
如果你要设置多个密钥用于备份。请将所有的密钥设置为相同,然后使用 ykpamcfg utility 存储每个密钥的询问-响应。如果你在一个已经存在的注册密钥上运行 ykpersonalize 命令,你就必须再次存储配置信息。
|
||||
|
||||
### 配置 /etc/pam.d/sudo
|
||||
|
||||
现在要去验证配置是否有效,在相同的终端窗口中,你需要设置 sudo 来要求使用 Yubikey 的询问-响应。将下面这几行插入到 /etc/pam.d/sudo 文件中。
|
||||
|
||||
```
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
```
|
||||
|
||||
将上面的 auth 行插入到 auth 文件中的 system-auth 行的上面,然后保存并退出编辑器。在默认的 Fedora 29 设置中,/etc/pam.d/sudo 应该像下面这样:
|
||||
|
||||
```
|
||||
#%PAM-1.0
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
auth include system-auth
|
||||
account include system-auth
|
||||
password include system-auth
|
||||
session optional pam_keyinit.so revoke
|
||||
session required pam_limits.so
|
||||
session include system-auth
|
||||
```
|
||||
|
||||
保持原始终端窗口打开,然后打开一个新的终端窗口进行测试,在新的终端窗口中输入:
|
||||
|
||||
```
|
||||
$ sudo echo testing
|
||||
```
|
||||
|
||||
你应该注意到了 key 上的 LED 在闪烁。点击 Yubikey 按钮,你应该会看见一个输入 sudo 密码的提示。在你输入你的密码之后,你应该会在终端屏幕上看见 ”testing“ 的字样。
|
||||
|
||||
现在去测试确保正常的失败,启动另一个终端窗口,并从 USB 插口中拔掉 Yubikey。使用下面这条命令验证,在没有 Yubikey 的情况下,sudo 是否会不再正常工作。
|
||||
|
||||
```
|
||||
$ sudo echo testing fail
|
||||
```
|
||||
你应该立刻被提示输入 sudo 密码,即使你输入了正确密码,登陆也应该失败。
|
||||
|
||||
### 设置 Gnome 桌面管理
|
||||
|
||||
一旦你的测试完成后,你就可以为图形登陆添加询问-响应支持了。将你的 Yubikey 再次插入进 USB 插口中。然后将下面这几行添加到 /etc/pam.d/gdm-password 文件中:
|
||||
|
||||
```
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
```
|
||||
|
||||
打开一个终端窗口,然后运行下面这些命令。如果需要,你可以使用其他的编辑器:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/pam.d/gdm-password
|
||||
```
|
||||
|
||||
你应该看到 yubikey 上的 LED 在闪烁,按下 yubikey 按钮,然后在提示符出输入密码。
|
||||
|
||||
修改 /etc/pam.d/gdm-password 文件,在已有的 password-auth 上添加新的 auth 行。这个文件的顶部应该像下面这样:
|
||||
|
||||
```
|
||||
auth [success=done ignore=ignore default=bad] pam_selinux_permit.so
|
||||
auth required pam_yubico.so mode=challenge-response
|
||||
auth substack password-auth
|
||||
auth optional pam_gnome_keyring.so
|
||||
auth include postlogin
|
||||
|
||||
account required pam_nologin.so
|
||||
```
|
||||
|
||||
保存更改并退出编辑器,如果你使用的是 vi,输入键是按 Esc 键,然后在提示符出输入 wq! 来保存并退出。
|
||||
|
||||
### 结论
|
||||
|
||||
现在注销 GNOME。将 Yubikey 插入到 USB 口,在图形登陆界面上点击你的用户名。Yubikey LED 会开始闪烁。触摸那个按钮,你会被提示输入你的密码。
|
||||
|
||||
如果你丢失了 Yubikey,除了重置密码之外,你还可以使用备份的 Yubikey。你还可以给你的账户增加额外的 Yubikey 配置。
|
||||
|
||||
如果有其他人获得了你的密码,他们在没有你的物理硬件 Yubikey 的情况下,仍然不能登陆。恭喜!你已经显著提高了你的工作环境登陆的安全性了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/login-challenge-response-authentication/
|
||||
|
||||
作者:[nabooengineer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/nabooengineer/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/using-the-yubikey4-with-fedora/
|
||||
[2]: https://fedoramagazine.org/fedora-28-better-smart-card-support-openssh/
|
||||
|
||||
@ -1,28 +1,28 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: ()
|
||||
[#]: publisher: ()
|
||||
[#]: url: ()
|
||||
[#]: subject: (How to Build a Netboot Server, Part 2)
|
||||
[#]: via: (https://fedoramagazine.org/how-to-build-a-netboot-server-part-2/)
|
||||
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||
|
||||
How to Build a Netboot Server, Part 2
|
||||
如何构建一台网络引导服务器(第二部分)
|
||||
======
|
||||
|
||||

|
||||
|
||||
The article [How to Build a Netboot Server, Part 1][1] showed you how to create a netboot image with a “liveuser” account whose home directory lives in volatile memory. Most users probably want to preserve files and settings across reboots, though. So this second part of the netboot series shows how to reconfigure the netboot image from part one so that [Active Directory][2] user accounts can log in and their home directories can be automatically mounted from a NFS server.
|
||||
在 [如何构建一台网络引导服务器(第一部分)][1] 的文章中,我们展示了如何创建一个网络引导镜像,在那个镜像中使用了一个名为 “liveuser” 帐户,它的 home 目录位于内存中,重启后 home 中的内容将全部消失。然而很多用户都希望机器重启后保存他们的文件和设置。因此,在本系列的第二部分,我们将向你展示如何在第一部分的基础上,重新配置网络引导镜像,使它能够使用 [活动目录][2] 中的用户帐户进行登陆,然后能够从一个 NFS 服务器上自动挂载他们的 home 目录。
|
||||
|
||||
Part 3 of this series will show how to make an interactive and centrally-configurable iPXE boot menu for the netboot clients.
|
||||
本系列的第三部分,我们将向你展示网络引导客户端如何与中心化配置的 iPXE 引导菜单进行交互。
|
||||
|
||||
### Setup NFS4 Home Directories with KRB5 Authentication
|
||||
### 设置使用 KRB5 认证的 NFS4 Home 目录
|
||||
|
||||
Follow the directions from the previous post “[Share NFS Home Directories Securely with Kerberos][3],” then return here.
|
||||
按以前的文章 “[使用 Kerberos 强化共享的 NFS Home 目录安全性][3]” 的指导来做这个设置。
|
||||
|
||||
### Remove the Liveuser Account
|
||||
### 删除 Liveuser 帐户
|
||||
|
||||
Remove the “liveuser” account created in part one of this series:
|
||||
删除本系列文章第一部分中创建的 “liveuser” 帐户:
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
@ -31,9 +31,9 @@ $ sudo -i
|
||||
# for i in passwd shadow group gshadow; do sed -i '/^liveuser:/d' /fc28/etc/$i; done
|
||||
```
|
||||
|
||||
### Configure NTP, KRB5 and SSSD
|
||||
### 配置 NTP、KRB5 和 SSSD
|
||||
|
||||
Next, we will need to duplicate the NTP, KRB5, and SSSD configuration that we set up on the server in the client image so that the same accounts will be available:
|
||||
接下来,我们需要将 NTP、KRB5、和 SSSD 的配置文件复制进客户端使用的镜像中,以便于它们能够使用同一个帐户:
|
||||
|
||||
```
|
||||
# MY_HOSTNAME=$(</etc/hostname)
|
||||
@ -45,27 +45,27 @@ Next, we will need to duplicate the NTP, KRB5, and SSSD configuration that we se
|
||||
# cp /etc/sssd/sssd.conf /fc28/etc/sssd
|
||||
```
|
||||
|
||||
Reconfigure sssd to provide authentication services, in addition to the identification service already configured:
|
||||
重新配置 sssd 在已配置的识别服务的基础上去提供认证服务:
|
||||
|
||||
```
|
||||
# sed -i '/services =/s/$/, pam/' /fc28/etc/sssd/sssd.conf
|
||||
```
|
||||
|
||||
Also, ensure none of the clients attempt to update the computer account password:
|
||||
另外,配置成确保客户端不能更改这个帐户密码:
|
||||
|
||||
```
|
||||
# sed -i '/id_provider/a \ \ ad_maximum_machine_account_password_age = 0' /fc28/etc/sssd/sssd.conf
|
||||
```
|
||||
|
||||
Also, copy the nfsnobody definitions:
|
||||
另外,复制 nfsnobody 的定义:
|
||||
|
||||
```
|
||||
# for i in passwd shadow group gshadow; do grep "^nfsnobody:" /etc/$i >> /fc28/etc/$i; done
|
||||
```
|
||||
|
||||
### Join Active Directory
|
||||
### 连接活动目录
|
||||
|
||||
Next, you’ll perform a chroot to join the client image to Active Directory. Begin by deleting any pre-existing computer account with the same name your netboot image will use:
|
||||
接下来,你将执行一个 chroot 将客户端镜像连接到活动目录。从删除预置在网络引导镜像中相同的计算机帐户开始:
|
||||
|
||||
```
|
||||
# MY_USERNAME=jsmith
|
||||
@ -73,20 +73,20 @@ Next, you’ll perform a chroot to join the client image to Active Directory. Be
|
||||
# adcli delete-computer "${MY_CLIENT_HOSTNAME%%.*}" -U "$MY_USERNAME"
|
||||
```
|
||||
|
||||
Also delete the krb5.keytab file from the netboot image if it exists:
|
||||
在网络引导镜像中如果有 krb5.keytab 文件,也删除它:
|
||||
|
||||
```
|
||||
# rm -f /fc28/etc/krb5.keytab
|
||||
```
|
||||
|
||||
Perform a chroot into the netboot image:
|
||||
在网络引导镜像中执行一个 chroot 操作:
|
||||
|
||||
```
|
||||
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done
|
||||
# chroot /fc28 /usr/bin/bash --login
|
||||
```
|
||||
|
||||
Perform the join:
|
||||
执行一个 join 操作:
|
||||
|
||||
```
|
||||
# MY_USERNAME=jsmith
|
||||
@ -97,7 +97,7 @@ Perform the join:
|
||||
# adcli join $MY_DOMAIN --login-user="$MY_USERNAME" --computer-name="${MY_HOSTNAME%%.*}" --host-fqdn="$MY_HOSTNAME" --user-principal="host/$MY_HOSTNAME@$MY_REALM" --domain-ou="$MY_OU"
|
||||
```
|
||||
|
||||
Now log out of the chroot and clear the root user’s command history:
|
||||
现在登出 chroot,并清除命令历史:
|
||||
|
||||
```
|
||||
# logout
|
||||
@ -105,9 +105,9 @@ Now log out of the chroot and clear the root user’s command history:
|
||||
# > /fc28/root/.bash_history
|
||||
```
|
||||
|
||||
### Install and Configure PAM Mount
|
||||
### 安装和配置 PAM Mount
|
||||
|
||||
We want our clients to automatically mount the user’s home directory when they log in. To accomplish this, we’ll use the “pam_mount” module. Install and configure pam_mount:
|
||||
我们希望客户端登入后自动挂载它的 home 目录。为实现这个目的,我们将要使用 “pam_mount” 模块。安装和配置 pam_mount:
|
||||
|
||||
```
|
||||
# dnf install -y --installroot=/fc28 pam_mount
|
||||
@ -123,7 +123,7 @@ We want our clients to automatically mount the user’s home directory when they
|
||||
END
|
||||
```
|
||||
|
||||
Reconfigure PAM to use pam_mount:
|
||||
重新配置 PAM 去使用 pam_mount:
|
||||
|
||||
```
|
||||
# dnf install -y patch
|
||||
@ -152,24 +152,24 @@ END
|
||||
# chroot /fc28 authselect select custom/sssd with-pammount --force
|
||||
```
|
||||
|
||||
Also ensure the NFS server’s hostname is always resolvable from the client:
|
||||
另外,要确保从客户端上总是可解析 NFS 服务器的主机名:
|
||||
|
||||
```
|
||||
# MY_IP=$(host -t A $MY_HOSTNAME | awk '{print $4}')
|
||||
# echo "$MY_IP $MY_HOSTNAME ${MY_HOSTNAME%%.*}" >> /fc28/etc/hosts
|
||||
```
|
||||
|
||||
Optionally, allow all users to run sudo:
|
||||
可选,允许所有用户去使用 sudo:
|
||||
|
||||
```
|
||||
# echo '%users ALL=(ALL) NOPASSWD: ALL' > /fc28/etc/sudoers.d/users
|
||||
```
|
||||
|
||||
### Convert the NFS Root to an iSCSI Backing-Store
|
||||
### 转换 NFS Root 到一个 iSCSI 背后的存储
|
||||
|
||||
Current versions of nfs-utils may have difficulty establishing a second connection from the client back to the NFS server for home directories when an nfsroot connection is already established. The client hangs when attempting to access the home directory. So, we will work around the problem by using a different protocol (iSCSI) for sharing our netboot image.
|
||||
在一个 nfsroot 连接建立之后,目前版本的 nfs-utils 可能很难为 home 目录维护一个从客户端到 NFS 服务器的二次连接。当尝试去访问 home 目录时,客户端将被挂住。因此,为了网络引导镜像可共享使用,我们将使用一个不同的协议(iSCSI)来解决这个问题。
|
||||
|
||||
First chroot into the image to reconfigure its initramfs for booting from an iSCSI root:
|
||||
首先 chroot 到镜像中,去重新配置它的 initramfs,让它从一个 iSCSI root 中去引导:
|
||||
|
||||
```
|
||||
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc28/$i; done
|
||||
@ -186,18 +186,18 @@ First chroot into the image to reconfigure its initramfs for booting from an iSC
|
||||
# > /fc28/root/.bash_history
|
||||
```
|
||||
|
||||
The qedi driver broke iscsi during testing, so it’s been disabled here.
|
||||
在测试时,qedi 驱动会破坏 iscsi,因此我们将它禁用。
|
||||
|
||||
Next, create a fc28.img [sparse file][4]. This file serves as the iSCSI target’s backing store:
|
||||
接着,创建一个 fc28.img 的 [稀疏文件][4]。这个稀疏文件代表 iSCSI 目标的背后存储:
|
||||
|
||||
```
|
||||
# FC28_SIZE=$(du -ms /fc28 | cut -f 1)
|
||||
# dd if=/dev/zero of=/fc28.img bs=1MiB count=0 seek=$(($FC28_SIZE*2))
|
||||
```
|
||||
|
||||
(If you have one available, a separate partition or disk drive can be used instead of creating a file.)
|
||||
(如果你有一个可使用的稀疏文件、一个单独的分区或磁盘驱动器,就可以代替它了,不用再去创建这个稀疏文件了。)
|
||||
|
||||
Next, format the image with a filesystem, mount it, and copy the netboot image into it:
|
||||
接着,使用一个文件系统去格式化镜像、挂载它、然后将网络引导镜像复制进去:
|
||||
|
||||
```
|
||||
# mkfs -t xfs -L NETROOT /fc28.img
|
||||
@ -207,19 +207,19 @@ Next, format the image with a filesystem, mount it, and copy the netboot image i
|
||||
# umount $TEMP_MNT
|
||||
```
|
||||
|
||||
During testing using SquashFS, the client would occasionally stutter. It seems that SquashFS does not perform well when doing random I/O from a multiprocessor client. (See also [The curious case of stalled squashfs reads][5].) If you want to improve throughput performance with filesystem compression, [ZFS][6] is probably a better option.
|
||||
在使用 SquashFS 测试时,客户端偶尔会出现小状况。似乎是因为 SquashFS 在多处理器客户端上没法执行一个随机 I/O。(更多内容见 [squashfs 读取卡顿的奇怪案例][5])。如果你希望使用一个压缩文件系统来提升吞吐性能,[ZFS][6] 或许是个很好的选择。
|
||||
|
||||
If you need extremely high throughput from the iSCSI server (say, for hundreds of clients), it might be possible to [load balance][7] a [Ceph][8] cluster. For more information, see [Load Balancing Ceph Object Gateway Servers with HAProxy and Keepalived][9].
|
||||
如果你对 iSCSI 服务器的吞吐性能要求非常高(比如,成百上千的客户端要连接它),可能需要使用带 [负载均衡][7] 的 [Ceph][8] 集群了。更多相关内容,请查看 [使用 HAProxy 和 Keepalived 负载均衡的 Ceph 对象网关][9]。
|
||||
|
||||
### Install and Configure iSCSI
|
||||
### 安装和配置 iSCSI
|
||||
|
||||
Install the scsi-target-utils package which will provide the iSCSI daemon for serving our image out to our clients:
|
||||
为了给我们的客户端提供网络引导镜像,安装 scsi-target-utils 包:
|
||||
|
||||
```
|
||||
# dnf install -y scsi-target-utils
|
||||
```
|
||||
|
||||
Configure the iSCSI daemon to serve the fc28.img file:
|
||||
配置 iSCSI 守护程序去提供 fc28.img 文件:
|
||||
|
||||
```
|
||||
# MY_REVERSE_HOSTNAME=$(echo $MY_HOSTNAME | tr '.' "\n" | tac | tr "\n" '.' | cut -b -${#MY_HOSTNAME})
|
||||
@ -231,9 +231,9 @@ Configure the iSCSI daemon to serve the fc28.img file:
|
||||
END
|
||||
```
|
||||
|
||||
The leading iqn. is expected by /usr/lib/dracut/modules.d/40network/net-lib.sh.
|
||||
通过 /usr/lib/dracut/modules.d/40network/net-lib.sh 来指示预期的 iqn。
|
||||
|
||||
Add an exception to the firewall and enable and start the service:
|
||||
添加一个防火墙例外,并启用和启动这个服务:
|
||||
|
||||
```
|
||||
# firewall-cmd --add-service=iscsi-target
|
||||
@ -242,13 +242,13 @@ Add an exception to the firewall and enable and start the service:
|
||||
# systemctl start tgtd.service
|
||||
```
|
||||
|
||||
You should now be able to see the image being shared with the tgtadm command:
|
||||
你现在应该能够使用 tatadm 命令看到这个共享后的镜像:
|
||||
|
||||
```
|
||||
# tgtadm --mode target --op show
|
||||
```
|
||||
|
||||
The above command should output something similar to the following:
|
||||
上述命令的输出应该类似如下的内容:
|
||||
|
||||
```
|
||||
Target 1: iqn.edu.example.server-01:fc28
|
||||
@ -290,7 +290,7 @@ Target 1: iqn.edu.example.server-01:fc28
|
||||
ALL
|
||||
```
|
||||
|
||||
We can now remove the NFS share that we created in part one of this series:
|
||||
现在,我们可以去删除本系列文章的第一部分中创建的 NFS 共享了:
|
||||
|
||||
```
|
||||
# rm -f /etc/exports.d/fc28.exports
|
||||
@ -300,11 +300,11 @@ We can now remove the NFS share that we created in part one of this series:
|
||||
# sed -i '/^\/fc28 /d' /etc/fstab
|
||||
```
|
||||
|
||||
You can also delete the /fc28 filesystem, but you may want to keep it for performing future updates.
|
||||
你也可以删除 /fc28 文件系统,但为了以后进一步更新,你可能需要保留它。
|
||||
|
||||
### Update the ESP to use the iSCSI Kernel
|
||||
### 更新 ESP 去使用 iSCSI 内核
|
||||
|
||||
Ipdate the ESP to contain the iSCSI-enabled initramfs:
|
||||
更新 ESP 去包含启用了 iSCSI 的 initramfs:
|
||||
|
||||
```
|
||||
$ rm -vf $HOME/esp/linux/*.fc28.*
|
||||
@ -313,7 +313,7 @@ $ cp $(find /fc28/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $MY_KRNL)
|
||||
$ cp $(find /fc28/boot -name 'init*' | grep -m 1 $MY_KRNL) $HOME/esp/linux/initramfs-$MY_KRNL.img
|
||||
```
|
||||
|
||||
Update the boot.cfg file to pass the new root and netroot parameters:
|
||||
更新 boot.cfg 文件去传递新的 root 和 netroot 参数:
|
||||
|
||||
```
|
||||
$ MY_NAME=server-01.example.edu
|
||||
@ -322,52 +322,52 @@ $ MY_ADDR=$(host -t A $MY_NAME | awk '{print $4}')
|
||||
$ sed -i "s! root=[^ ]*! root=/dev/disk/by-path/ip-$MY_ADDR:3260-iscsi-iqn.$MY_EMAN:fc28-lun-1 netroot=iscsi:$MY_ADDR::::iqn.$MY_EMAN:fc28!" $HOME/esp/linux/boot.cfg
|
||||
```
|
||||
|
||||
Now you just need to copy the updated files from your $HOME/esp/linux directory out to the ESPs of all your client systems. You should see results similar to what is shown in the below screenshot:
|
||||
现在,你只需要从 $HOME/esp/linux 目录中复制更新后的文件到所有客户端系统的 ESP 中。你应该会看到类似下面屏幕截图的结果:
|
||||
|
||||
![][10]
|
||||
|
||||
### Upgrading the Image
|
||||
### 更新镜像
|
||||
|
||||
First, make a copy of the current image:
|
||||
首先,复制出一个当前镜像的副本:
|
||||
|
||||
```
|
||||
# cp -a /fc28 /fc29
|
||||
```
|
||||
|
||||
Chroot into the new copy of the image:
|
||||
Chroot 进入到镜像的新副本:
|
||||
|
||||
```
|
||||
# for i in dev dev/pts dev/shm proc sys run; do mount -o bind /$i /fc29/$i; done
|
||||
# chroot /fc29 /usr/bin/bash --login
|
||||
```
|
||||
|
||||
Allow updating the kernel:
|
||||
允许更新内核:
|
||||
|
||||
```
|
||||
# sed -i 's/^exclude=kernel-\*$/#exclude=kernel-*/' /etc/dnf/dnf.conf
|
||||
```
|
||||
|
||||
Perform the upgrade:
|
||||
执行升级:
|
||||
|
||||
```
|
||||
# dnf distro-sync -y --releasever=29
|
||||
```
|
||||
|
||||
Prevent the kernel from being updated:
|
||||
阻止更新过的内核被再次更新:
|
||||
|
||||
```
|
||||
# sed -i 's/^#exclude=kernel-\*$/exclude=kernel-*/' /etc/dnf/dnf.conf
|
||||
```
|
||||
|
||||
The above command is optional, but saves you from having to copy a new kernel out to the clients if you add or update a few packages in the image at some future time.
|
||||
上述命令是可选的,但是在以后,如果在镜像中添加和更新了几个包,在你的客户端之外保存有一个最新内核的副本,会在关键时刻对你非常有帮助。
|
||||
|
||||
Clean up dnf’s package cache:
|
||||
清理 dnf 的包缓存:
|
||||
|
||||
```
|
||||
# dnf clean all
|
||||
```
|
||||
|
||||
Exit the chroot and clear root’s command history:
|
||||
退出 chroot 并清理 root 的命令历史:
|
||||
|
||||
```
|
||||
# logout
|
||||
@ -375,7 +375,7 @@ Exit the chroot and clear root’s command history:
|
||||
# > /fc29/root/.bash_history
|
||||
```
|
||||
|
||||
Create the iSCSI image:
|
||||
创建 iSCSI 镜像:
|
||||
|
||||
```
|
||||
# FC29_SIZE=$(du -ms /fc29 | cut -f 1)
|
||||
@ -387,7 +387,7 @@ Create the iSCSI image:
|
||||
# umount $TEMP_MNT
|
||||
```
|
||||
|
||||
Define a new iSCSI target that points to our new image and export it:
|
||||
定义一个新的 iSCSI 目标,指向到新的镜像并导出它:
|
||||
|
||||
```
|
||||
# MY_HOSTNAME=$(</etc/hostname)
|
||||
@ -401,7 +401,7 @@ END
|
||||
# tgt-admin --update ALL
|
||||
```
|
||||
|
||||
Add the new kernel and initramfs to the ESP:
|
||||
添加新内核并 initramfs 到 ESP:
|
||||
|
||||
```
|
||||
$ MY_KRNL=$(ls -c /fc29/lib/modules | head -n 1)
|
||||
@ -409,7 +409,7 @@ $ cp $(find /fc29/lib/modules -maxdepth 2 -name 'vmlinuz' | grep -m 1 $MY_KRNL)
|
||||
$ cp $(find /fc29/boot -name 'init*' | grep -m 1 $MY_KRNL) $HOME/esp/linux/initramfs-$MY_KRNL.img
|
||||
```
|
||||
|
||||
Update the boot.cfg in the ESP:
|
||||
更新 ESP 的 boot.cfg:
|
||||
|
||||
```
|
||||
$ MY_DNS1=192.0.2.91
|
||||
@ -426,8 +426,7 @@ boot || exit
|
||||
END
|
||||
```
|
||||
|
||||
Finally, copy the files from your $HOME/esp/linux directory out to the ESPs of all your client systems and enjoy!
|
||||
|
||||
最后,从我的 $HOME/esp/linux 目录中复制文件到所有客户端系统的 ESP 中去使用它吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -435,7 +434,7 @@ via: https://fedoramagazine.org/how-to-build-a-netboot-server-part-2/
|
||||
|
||||
作者:[Gregory Bartholomew][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user