mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
e5b39dc6a6
@ -0,0 +1,69 @@
|
||||
如何在家中使用 SSH 和 SFTP 协议
|
||||
======
|
||||
|
||||
> 通过 SSH 和 SFTP 协议,我们能够访问其他设备,有效而且安全的传输文件等等。
|
||||
|
||||

|
||||
|
||||
几年前,我决定配置另外一台电脑,以便我能在工作时访问它来传输我所需要的文件。要做到这一点,最基本的一步是要求你的网络提供商(ISP)提供一个固定的地址。
|
||||
|
||||
有一个不必要但很重要的步骤,就是保证你的这个可以访问的系统是安全的。在我的这种情况下,我计划只在工作场所访问它,所以我能够限定访问的 IP 地址。即使如此,你依然要尽多的采用安全措施。一旦你建立起来这个系统,全世界的人们马上就能尝试访问你的系统。这是非常令人惊奇及恐慌的。你能通过日志文件来发现这一点。我推测有探测机器人在尽其所能的搜索那些没有安全措施的系统。
|
||||
|
||||
在我设置好系统不久后,我觉得这种访问没什么大用,为此,我将它关闭了以便不再为它操心。尽管如此,只要架设了它,在家庭网络中使用 SSH 和 SFTP 还是有点用的。
|
||||
|
||||
当然,有一个必备条件,这个另外的电脑必须已经开机了,至于电脑是否登录与否无所谓的。你也需要知道其 IP 地址。有两个方法能够知道,一个是通过浏览器访问你的路由器,一般情况下你的地址格式类似于 192.168.1.254 这样。通过一些搜索,很容易找出当前是开机的并且接在 eth0 或者 wifi 上的系统。如何识别你所要找到的电脑可能是个挑战。
|
||||
|
||||
更容易找到这个电脑的方式是,打开 shell,输入 :
|
||||
|
||||
```
|
||||
ifconfig
|
||||
```
|
||||
|
||||
命令会输出一些信息,你所需要的信息在 `inet` 后面,看起来和 192.168.1.234 类似。当你发现这个后,回到你要访问这台主机的客户端电脑,在命令行中输入 :
|
||||
|
||||
```
|
||||
ssh gregp@192.168.1.234
|
||||
```
|
||||
|
||||
如果要让上面的命令能够正常执行,`gregp` 必须是该主机系统中正确的用户名。你会被询问其密码。如果你键入的密码和用户名都是正确的,你将通过 shell 环境连接上了这台电脑。我坦诚,对于 SSH 我并不是经常使用的。我偶尔使用它,我能够运行 `dnf` 来更新我所常使用电脑之外的其它电脑。通常,我用 SFTP :
|
||||
|
||||
```
|
||||
sftp grego@192.168.1.234
|
||||
```
|
||||
|
||||
我更需要用简单的方法来把一个文件传输到另一个电脑。相对于闪存棒和额外的设备,它更加方便,耗时更少。
|
||||
|
||||
一旦连接建立成功,SFTP 有两个基本的命令,`get`,从主机接收文件 ;`put`,向主机发送文件。在连接之前,我经常在客户端移动到我想接收或者传输的文件夹下。在连接之后,你将处于一个顶层目录里,比如 `home/gregp`。一旦连接成功,你可以像在客户端一样的使用 `cd`,改变你在主机上的工作路径。你也许需要用 `ls` 来确认你的位置。
|
||||
|
||||
如果你想改变你的客户端的工作目录。用 `lcd` 命令( 即 local change directory 的意思)。同样的,用 `lls` 来显示客户端工作目录的内容。
|
||||
|
||||
如果主机上没有你想要的目录名,你该怎么办?用 `mkdir` 在主机上创建一个新的目录。或者你可以将整个目录的文件全拷贝到主机 :
|
||||
|
||||
```
|
||||
put -r thisDir/
|
||||
```
|
||||
|
||||
这将在主机上创建该目录并复制它的全部文件和子目录到主机上。这种传输是非常快速的,能达到硬件的上限。不像在互联网传输一样遇到网络瓶颈。要查看你能在 SFTP 会话中能够使用的命令列表:
|
||||
|
||||
```
|
||||
man sftp
|
||||
```
|
||||
|
||||
我也能够在我的电脑上的 Windows 虚拟机内用 SFTP,这是配置一个虚拟机而不是一个双系统的另外一个优势。这让我能够在系统的 Linux 部分移入或者移出文件。而我只需要在 Windows 中使用一个客户端就行。
|
||||
|
||||
你能够使用 SSH 或 SFTP 访问通过网线或者 WIFI 连接到你路由器的任何设备。这里,我使用了一个叫做 [SSHDroid][1] 的应用,能够在被动模式下运行 SSH。换句话来说,你能够用你的电脑访问作为主机的 Android 设备。近来我还发现了另外一个应用,[Admin Hands][2],不管你的客户端是平板还是手机,都能使用 SSH 或者 SFTP 操作。这个应用对于备份和手机分享照片是极好的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/ssh-sftp-home-network
|
||||
|
||||
作者:[Geg Pittman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greg-p
|
||||
[1]: https://play.google.com/store/apps/details?id=berserker.android.apps.sshdroid
|
||||
[2]: https://play.google.com/store/apps/details?id=com.arpaplus.adminhands&hl=en_US
|
||||
@ -1,6 +1,7 @@
|
||||
使用 Python 为你的油箱加油
|
||||
======
|
||||
我来介绍一下我是如何使用 Python 来节省成本的。
|
||||
|
||||
> 我来介绍一下我是如何使用 Python 来节省成本的。
|
||||
|
||||

|
||||
|
||||
@ -82,7 +83,7 @@ while i < 21: # 20 次迭代 (加油次数)
|
||||
|
||||
如你所见,这个调整会令混合汽油号数始终略高于 91。当然,我的油量表并没有 1/12 的刻度,但是 7/12 略小于 5/8,我可以近似地计算。
|
||||
|
||||
一个更简单地方案是每次都首先加满 93 号汽油,然后在油箱半满时加入 89 号汽油直到耗尽,这可能会是我的常规方案。但就我个人而言,这种方法并不太好,有时甚至会产生一些麻烦。但对于长途旅行来说,这种方案会相对简便一些。有时我也会因为油价突然下跌而购买一些汽油,所以,这个方案是我可以考虑的一系列选项之一。
|
||||
一个更简单地方案是每次都首先加满 93 号汽油,然后在油箱半满时加入 89 号汽油直到耗尽,这可能会是我的常规方案。就我个人而言,这种方法并不太好,有时甚至会产生一些麻烦。但对于长途旅行来说,这种方案会相对简便一些。有时我也会因为油价突然下跌而购买一些汽油,所以,这个方案是我可以考虑的一系列选项之一。
|
||||
|
||||
当然最重要的是:开车不写码,写码不开车!
|
||||
|
||||
@ -93,7 +94,7 @@ via: https://opensource.com/article/18/10/python-gas-pump
|
||||
作者:[Greg Pittman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,25 @@
|
||||
如何创建和维护你的Man手册
|
||||
如何创建和维护你自己的 man 手册
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们已经讨论了一些[Man手册的替代方案] [1]。 这些替代方案主要用于学习简洁的Linux命令示例,而无需通过全面过于详细的手册页。 如果你正在寻找一种快速而简单的方法来轻松快速地学习Linux命令,那么这些替代方案值得尝试。 现在,你可能正在考虑 - 如何为Linux命令创建自己的man-like帮助页面? 这时**“Um”**就派上用场了。 Um是一个命令行实用程序,用于轻松创建和维护包含你到目前为止所了解的所有命令的Man页面。
|
||||
我们已经讨论了一些 [man 手册的替代方案][1]。 这些替代方案主要用于学习简洁的 Linux 命令示例,而无需通过全面而过于详细的手册页。 如果你正在寻找一种快速而简单的方法来轻松快速地学习 Linux 命令,那么这些替代方案值得尝试。 现在,你可能正在考虑 —— 如何为 Linux 命令创建自己的 man 式的帮助页面? 这时 “Um” 就派上用场了。 Um 是一个命令行实用程序,可以用于轻松创建和维护包含你到目前为止所了解的所有命令的 man 页面。
|
||||
|
||||
通过创建自己的手册页,你可以在手册页中避免大量不必要的细节,并且只包含你需要记住的内容。 如果你想创建自己的一套man-like页面,“Um”也能为你提供帮助。 在这个简短的教程中,我们将学习如何安装“Um”命令以及如何创建自己的man手册页。
|
||||
通过创建自己的手册页,你可以在手册页中避免大量不必要的细节,并且只包含你需要记住的内容。 如果你想创建自己的一套 man 式的页面,“Um” 也能为你提供帮助。 在这个简短的教程中,我们将学习如何安装 “Um” 命令以及如何创建自己的 man 手册页。
|
||||
|
||||
### 安装 Um
|
||||
|
||||
Um适用于Linux和Mac OS。 目前,它只能在Linux系统中使用** Linuxbrew **软件包管理器来进行安装。 如果你尚未安装Linuxbrew,请参考以下链接。
|
||||
Um 适用于 Linux 和Mac OS。 目前,它只能在 Linux 系统中使用 Linuxbrew 软件包管理器来进行安装。 如果你尚未安装 Linuxbrew,请参考以下链接:
|
||||
|
||||
安装Linuxbrew后,运行以下命令安装Um实用程序。
|
||||
- [Linuxbrew:一个用于 Linux 和 MacOS 的通用包管理器][3]
|
||||
|
||||
安装 Linuxbrew 后,运行以下命令安装 Um 实用程序。
|
||||
|
||||
```
|
||||
$ brew install sinclairtarget/wst/um
|
||||
|
||||
```
|
||||
|
||||
如果你会看到类似下面的输出,恭喜你! Um已经安装好并且可以使用了。
|
||||
如果你会看到类似下面的输出,恭喜你! Um 已经安装好并且可以使用了。
|
||||
|
||||
```
|
||||
[...]
|
||||
@ -49,88 +50,78 @@ Emacs Lisp files have been installed to:
|
||||
==> um
|
||||
Bash completion has been installed to:
|
||||
/home/linuxbrew/.linuxbrew/etc/bash_completion.d
|
||||
|
||||
```
|
||||
|
||||
在制作你的man手册页之前,你需要为Um启用bash补全。
|
||||
在制作你的 man 手册页之前,你需要为 Um 启用 bash 补全。
|
||||
|
||||
要开启bash'补全,首先你需要打开 **~/.bash_profile** 文件:
|
||||
要开启 bash 补全,首先你需要打开 `~/.bash_profile` 文件:
|
||||
|
||||
```
|
||||
$ nano ~/.bash_profile
|
||||
|
||||
```
|
||||
|
||||
并在其中添加以下内容:
|
||||
并在其中添加以下内容:
|
||||
|
||||
```
|
||||
if [ -f $(brew --prefix)/etc/bash_completion.d/um-completion.sh ]; then
|
||||
. $(brew --prefix)/etc/bash_completion.d/um-completion.sh
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
保存并关闭文件。运行以下命令以更新更改。
|
||||
|
||||
```
|
||||
$ source ~/.bash_profile
|
||||
|
||||
```
|
||||
|
||||
准备工作全部完成。让我们继续创建我们的第一个man手册页。
|
||||
准备工作全部完成。让我们继续创建我们的第一个 man 手册页。
|
||||
|
||||
### 创建并维护自己的man手册
|
||||
|
||||
### 创建并维护自己的Man手册
|
||||
|
||||
如果你想为“dpkg”命令创建自己的Man手册。请运行:
|
||||
如果你想为 `dpkg` 命令创建自己的 man 手册。请运行:
|
||||
|
||||
```
|
||||
$ um edit dpkg
|
||||
|
||||
```
|
||||
|
||||
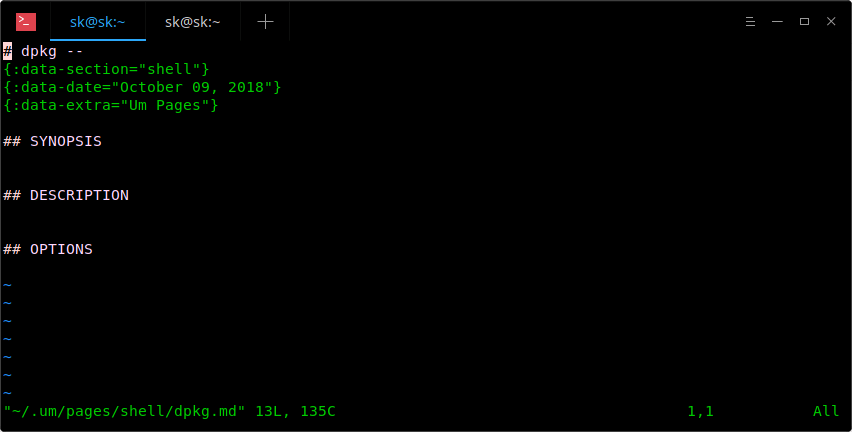
上面的命令将在默认编辑器中打开markdown模板:
|
||||
上面的命令将在默认编辑器中打开 markdown 模板:
|
||||
|
||||
|
||||
|
||||
我的默认编辑器是Vi,因此上面的命令会在Vi编辑器中打开它。现在,开始在此模板中添加有关“dpkg”命令的所有内容。
|
||||
我的默认编辑器是 Vi,因此上面的命令会在 Vi 编辑器中打开它。现在,开始在此模板中添加有关 `dpkg` 命令的所有内容。
|
||||
|
||||
下面是一个示例:
|
||||
下面是一个示例:
|
||||
|
||||

|
||||
|
||||
正如你在上图的输出中看到的,我为dpkg命令添加了概要,描述和两个参数选项。 你可以在Man手册中添加你所需要的所有部分。不过你也要确保为每个部分提供了适当且易于理解的标题。 完成后,保存并退出文件(如果使用Vi编辑器,请按ESC键并键入:wq)。
|
||||
正如你在上图的输出中看到的,我为 `dpkg` 命令添加了概要,描述和两个参数选项。 你可以在 man 手册中添加你所需要的所有部分。不过你也要确保为每个部分提供了适当且易于理解的标题。 完成后,保存并退出文件(如果使用 Vi 编辑器,请按 `ESC` 键并键入`:wq`)。
|
||||
|
||||
最后,使用以下命令查看新创建的Man手册页:
|
||||
最后,使用以下命令查看新创建的 man 手册页:
|
||||
|
||||
```
|
||||
$ um dpkg
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
如你所见,dpkg的Man手册页看起来与官方手册页完全相同。 如果要在手册页中编辑和/或添加更多详细信息,请再次运行相同的命令并添加更多详细信息。
|
||||
如你所见,`dpkg` 的 man 手册页看起来与官方手册页完全相同。 如果要在手册页中编辑和/或添加更多详细信息,请再次运行相同的命令并添加更多详细信息。
|
||||
|
||||
```
|
||||
$ um edit dpkg
|
||||
|
||||
```
|
||||
|
||||
要使用Um查看新创建的Man手册页列表,请运行:
|
||||
要使用 Um 查看新创建的 man 手册页列表,请运行:
|
||||
|
||||
```
|
||||
$ um list
|
||||
|
||||
```
|
||||
|
||||
所有手册页将保存在主目录中名为**`.um` **的目录下
|
||||
所有手册页将保存在主目录中名为 `.um` 的目录下
|
||||
|
||||
以防万一,如果你不想要某个特定页面,只需删除它,如下所示。
|
||||
|
||||
```
|
||||
$ um rm dpkg
|
||||
|
||||
```
|
||||
|
||||
要查看帮助部分和所有可用的常规选项,请运行:
|
||||
@ -151,7 +142,6 @@ Subcommands:
|
||||
um topics List all topics.
|
||||
um (c)onfig [config key] Display configuration environment.
|
||||
um (h)elp [sub-command] Display this help message, or the help message for a sub-command.
|
||||
|
||||
```
|
||||
|
||||
### 配置 Um
|
||||
@ -166,22 +156,18 @@ pager = less
|
||||
pages_directory = /home/sk/.um/pages
|
||||
default_topic = shell
|
||||
pages_ext = .md
|
||||
|
||||
```
|
||||
|
||||
在此文件中,你可以根据需要编辑和更改** pager **,** editor **,** default_topic **,** pages_directory **和** pages_ext **选项的值。 比如说,如果你想在** [Dropbox] [2] **文件夹中保存新创建的Um页面,只需更改/.um/umconfig**文件中** pages_directory **的值并将其更改为Dropbox文件夹即可。
|
||||
在此文件中,你可以根据需要编辑和更改 `pager`、`editor`、`default_topic`、`pages_directory` 和 `pages_ext` 选项的值。 比如说,如果你想在 [Dropbox][2] 文件夹中保存新创建的 Um 页面,只需更改 `~/.um/umconfig` 文件中 `pages_directory` 的值并将其更改为 Dropbox 文件夹即可。
|
||||
|
||||
```
|
||||
pages_directory = /Users/myusername/Dropbox/um
|
||||
|
||||
```
|
||||
|
||||
这就是全部内容,希望这些能对你有用,更多好的内容敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-create-and-maintain-your-own-man-pages/
|
||||
@ -189,7 +175,7 @@ via: https://www.ostechnix.com/how-to-create-and-maintain-your-own-man-pages/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -197,3 +183,4 @@ via: https://www.ostechnix.com/how-to-create-and-maintain-your-own-man-pages/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
|
||||
[3]: https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,3 +1,4 @@
|
||||
LuuMing translating
|
||||
Setting Up a Timer with systemd in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,299 +0,0 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
CLI: improved
|
||||
======
|
||||
I'm not sure many web developers can get away without visiting the command line. As for me, I've been using the command line since 1997, first at university when I felt both super cool l33t-hacker and simultaneously utterly out of my depth.
|
||||
|
||||
Over the years my command line habits have improved and I often search for smarter tools for the jobs I commonly do. With that said, here's my current list of improved CLI tools.
|
||||
|
||||
|
||||
### Ignoring my improvements
|
||||
|
||||
In a number of cases I've aliased the new and improved command line tool over the original (as with `cat` and `ping`).
|
||||
|
||||
If I want to run the original command, which is sometimes I do need to do, then there's two ways I can do this (I'm on a Mac so your mileage may vary):
|
||||
```
|
||||
$ \cat # ignore aliases named "cat" - explanation: https://stackoverflow.com/a/16506263/22617
|
||||
$ command cat # ignore functions and aliases
|
||||
|
||||
```
|
||||
|
||||
### bat > cat
|
||||
|
||||
`cat` is used to print the contents of a file, but given more time spent in the command line, features like syntax highlighting come in very handy. I found [ccat][3] which offers highlighting then I found [bat][4] which has highlighting, paging, line numbers and git integration.
|
||||
|
||||
The `bat` command also allows me to search during output (only if the output is longer than the screen height) using the `/` key binding (similarly to `less` searching).
|
||||
|
||||
![Simple bat output][5]
|
||||
|
||||
I've also aliased `bat` to the `cat` command:
|
||||
```
|
||||
alias cat='bat'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][4]
|
||||
|
||||
### prettyping > ping
|
||||
|
||||
`ping` is incredibly useful, and probably my goto tool for the "oh crap is X down/does my internet work!!!". But `prettyping` ("pretty ping" not "pre typing"!) gives ping a really nice output and just makes me feel like the command line is a bit more welcoming.
|
||||
|
||||
![/images/cli-improved/ping.gif][6]
|
||||
|
||||
I've also aliased `ping` to the `prettyping` command:
|
||||
```
|
||||
alias ping='prettyping --nolegend'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][7]
|
||||
|
||||
### fzf > ctrl+r
|
||||
|
||||
In the terminal, using `ctrl+r` will allow you to [search backwards][8] through your history. It's a nice trick, albeit a bit fiddly.
|
||||
|
||||
The `fzf` tool is a **huge** enhancement on `ctrl+r`. It's a fuzzy search against the terminal history, with a fully interactive preview of the possible matches.
|
||||
|
||||
In addition to searching through the history, `fzf` can also preview and open files, which is what I've done in the video below:
|
||||
|
||||
For this preview effect, I created an alias called `preview` which combines `fzf` with `bat` for the preview and a custom key binding to open VS Code:
|
||||
```
|
||||
alias preview="fzf --preview 'bat --color \"always\" {}'"
|
||||
# add support for ctrl+o to open selected file in VS Code
|
||||
export FZF_DEFAULT_OPTS="--bind='ctrl-o:execute(code {})+abort'"
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][9]
|
||||
|
||||
### htop > top
|
||||
|
||||
`top` is my goto tool for quickly diagnosing why the CPU on the machine is running hard or my fan is whirring. I also use these tools in production. Annoyingly (to me!) `top` on the Mac is vastly different (and inferior IMHO) to `top` on linux.
|
||||
|
||||
However, `htop` is an improvement on both regular `top` and crappy-mac `top`. Lots of colour coding, keyboard bindings and different views which have helped me in the past to understand which processes belong to which.
|
||||
|
||||
Handy key bindings include:
|
||||
|
||||
* P - sort by CPU
|
||||
* M - sort by memory usage
|
||||
* F4 - filter processes by string (to narrow to just "node" for instance)
|
||||
* space - mark a single process so I can watch if the process is spiking
|
||||
|
||||
|
||||
|
||||
![htop output][10]
|
||||
|
||||
There is a weird bug in Mac Sierra that can be overcome by running `htop` as root (I can't remember exactly what the bug is, but this alias fixes it - though annoying that I have to enter my password every now and again):
|
||||
```
|
||||
alias top="sudo htop" # alias top and fix high sierra bug
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][11]
|
||||
|
||||
### diff-so-fancy > diff
|
||||
|
||||
I'm pretty sure I picked this one up from Paul Irish some years ago. Although I rarely fire up `diff` manually, my git commands use diff all the time. `diff-so-fancy` gives me both colour coding but also character highlight of changes.
|
||||
|
||||
![diff so fancy][12]
|
||||
|
||||
Then in my `~/.gitconfig` I have included the following entry to enable `diff-so-fancy` on `git diff` and `git show`:
|
||||
```
|
||||
[pager]
|
||||
diff = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
show = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][13]
|
||||
|
||||
### fd > find
|
||||
|
||||
Although I use a Mac, I've never been a fan of Spotlight (I found it sluggish, hard to remember the keywords, the database update would hammer my CPU and generally useless!). I use [Alfred][14] a lot, but even the finder feature doesn't serve me well.
|
||||
|
||||
I tend to turn the command line to find files, but `find` is always a bit of a pain to remember the right expression to find what I want (and indeed the Mac flavour is slightly different non-mac find which adds to frustration).
|
||||
|
||||
`fd` is a great replacement (by the same individual who wrote `bat`). It is very fast and the common use cases I need to search with are simple to remember.
|
||||
|
||||
A few handy commands:
|
||||
```
|
||||
$ fd cli # all filenames containing "cli"
|
||||
$ fd -e md # all with .md extension
|
||||
$ fd cli -x wc -w # find "cli" and run `wc -w` on each file
|
||||
|
||||
```
|
||||
|
||||
![fd output][15]
|
||||
|
||||
💾 [Installation directions][16]
|
||||
|
||||
### ncdu > du
|
||||
|
||||
Knowing where disk space is being taking up is a fairly important task for me. I've used the Mac app [Disk Daisy][17] but I find that it can be a little slow to actually yield results.
|
||||
|
||||
The `du -sh` command is what I'll use in the terminal (`-sh` means summary and human readable), but often I'll want to dig into the directories taking up the space.
|
||||
|
||||
`ncdu` is a nice alternative. It offers an interactive interface and allows for quickly scanning which folders or files are responsible for taking up space and it's very quick to navigate. (Though any time I want to scan my entire home directory, it's going to take a long time, regardless of the tool - my directory is about 550gb).
|
||||
|
||||
Once I've found a directory I want to manage (to delete, move or compress files), I'll use the cmd + click the pathname at the top of the screen in [iTerm2][18] to launch finder to that directory.
|
||||
|
||||
![ncdu output][19]
|
||||
|
||||
There's another [alternative called nnn][20] which offers a slightly nicer interface and although it does file sizes and usage by default, it's actually a fully fledged file manager.
|
||||
|
||||
My `ncdu` is aliased to the following:
|
||||
```
|
||||
alias du="ncdu --color dark -rr -x --exclude .git --exclude node_modules"
|
||||
|
||||
```
|
||||
|
||||
The options are:
|
||||
|
||||
* `--color dark` \- use a colour scheme
|
||||
* `-rr` \- read-only mode (prevents delete and spawn shell)
|
||||
* `--exclude` ignore directories I won't do anything about
|
||||
|
||||
|
||||
|
||||
💾 [Installation directions][21]
|
||||
|
||||
### tldr > man
|
||||
|
||||
It's amazing that nearly every single command line tool comes with a manual via `man <command>`, but navigating the `man` output can be sometimes a little confusing, plus it can be daunting given all the technical information that's included in the manual output.
|
||||
|
||||
This is where the TL;DR project comes in. It's a community driven documentation system that's available from the command line. So far in my own usage, I've not come across a command that's not been documented, but you can [also contribute too][22].
|
||||
|
||||
![TLDR output for 'fd'][23]
|
||||
|
||||
As a nicety, I've also aliased `tldr` to `help` (since it's quicker to type!):
|
||||
```
|
||||
alias help='tldr'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][24]
|
||||
|
||||
### ack || ag > grep
|
||||
|
||||
`grep` is no doubt a powerful tool on the command line, but over the years it's been superseded by a number of tools. Two of which are `ack` and `ag`.
|
||||
|
||||
I personally flitter between `ack` and `ag` without really remembering which I prefer (that's to say they're both very good and very similar!). I tend to default to `ack` only because it rolls of my fingers a little easier. Plus, `ack` comes with the mega `ack --bar` argument (I'll let you experiment)!
|
||||
|
||||
Both `ack` and `ag` will (by default) use a regular expression to search, and extremely pertinent to my work, I can specify the file types to search within using flags like `--js` or `--html` (though here `ag` includes more files in the js filter than `ack`).
|
||||
|
||||
Both tools also support the usual `grep` options, like `-B` and `-A` for before and after context in the grep.
|
||||
|
||||
![ack in action][25]
|
||||
|
||||
Since `ack` doesn't come with markdown support (and I write a lot in markdown), I've got this customisation in my `~/.ackrc` file:
|
||||
```
|
||||
--type-set=md=.md,.mkd,.markdown
|
||||
--pager=less -FRX
|
||||
|
||||
```
|
||||
|
||||
💾 Installation directions: [ack][26], [ag][27]
|
||||
|
||||
[Futher reading on ack & ag][28]
|
||||
|
||||
### jq > grep et al
|
||||
|
||||
I'm a massive fanboy of [jq][29]. At first I struggled with the syntax, but I've since come around to the query language and use `jq` on a near daily basis (whereas before I'd either drop into node, use grep or use a tool called [json][30] which is very basic in comparison).
|
||||
|
||||
I've even started the process of writing a jq tutorial series (2,500 words and counting) and have published a [web tool][31] and a native mac app (yet to be released).
|
||||
|
||||
`jq` allows me to pass in JSON and transform the source very easily so that the JSON result fits my requirements. One such example allows me to update all my node dependencies in one command (broken into multiple lines for readability):
|
||||
```
|
||||
$ npm i $(echo $(\
|
||||
npm outdated --json | \
|
||||
jq -r 'to_entries | .[] | "\(.key)@\(.value.latest)"' \
|
||||
))
|
||||
|
||||
```
|
||||
|
||||
The above command will list all the node dependencies that are out of date, and use npm's JSON output format, then transform the source JSON from this:
|
||||
```
|
||||
{
|
||||
"node-jq": {
|
||||
"current": "0.7.0",
|
||||
"wanted": "0.7.0",
|
||||
"latest": "1.2.0",
|
||||
"location": "node_modules/node-jq"
|
||||
},
|
||||
"uuid": {
|
||||
"current": "3.1.0",
|
||||
"wanted": "3.2.1",
|
||||
"latest": "3.2.1",
|
||||
"location": "node_modules/uuid"
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
…to this:
|
||||
|
||||
That result is then fed into the `npm install` command and voilà, I'm all upgraded (using the sledgehammer approach).
|
||||
|
||||
### Honourable mentions
|
||||
|
||||
Some of the other tools that I've started poking around with, but haven't used too often (with the exception of ponysay, which appears when I start a new terminal session!):
|
||||
|
||||
* [ponysay][32] > cowsay
|
||||
* [csvkit][33] > awk et al
|
||||
* [noti][34] > `display notification`
|
||||
* [entr][35] > watch
|
||||
|
||||
|
||||
|
||||
### What about you?
|
||||
|
||||
So that's my list. How about you? What daily command line tools have you improved? I'd love to know.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://remysharp.com/2018/08/23/cli-improved
|
||||
|
||||
作者:[Remy Sharp][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://remysharp.com
|
||||
[1]: https://remysharp.com/images/terminal-600.jpg
|
||||
[2]: https://training.leftlogic.com/buy/terminal/cli2?coupon=READERS-DISCOUNT&utm_source=blog&utm_medium=banner&utm_campaign=remysharp-discount
|
||||
[3]: https://github.com/jingweno/ccat
|
||||
[4]: https://github.com/sharkdp/bat
|
||||
[5]: https://remysharp.com/images/cli-improved/bat.gif (Sample bat output)
|
||||
[6]: https://remysharp.com/images/cli-improved/ping.gif (Sample ping output)
|
||||
[7]: http://denilson.sa.nom.br/prettyping/
|
||||
[8]: https://lifehacker.com/278888/ctrl%252Br-to-search-and-other-terminal-history-tricks
|
||||
[9]: https://github.com/junegunn/fzf
|
||||
[10]: https://remysharp.com/images/cli-improved/htop.jpg (Sample htop output)
|
||||
[11]: http://hisham.hm/htop/
|
||||
[12]: https://remysharp.com/images/cli-improved/diff-so-fancy.jpg (Sample diff output)
|
||||
[13]: https://github.com/so-fancy/diff-so-fancy
|
||||
[14]: https://www.alfredapp.com/
|
||||
[15]: https://remysharp.com/images/cli-improved/fd.png (Sample fd output)
|
||||
[16]: https://github.com/sharkdp/fd/
|
||||
[17]: https://daisydiskapp.com/
|
||||
[18]: https://www.iterm2.com/
|
||||
[19]: https://remysharp.com/images/cli-improved/ncdu.png (Sample ncdu output)
|
||||
[20]: https://github.com/jarun/nnn
|
||||
[21]: https://dev.yorhel.nl/ncdu
|
||||
[22]: https://github.com/tldr-pages/tldr#contributing
|
||||
[23]: https://remysharp.com/images/cli-improved/tldr.png (Sample tldr output for 'fd')
|
||||
[24]: http://tldr-pages.github.io/
|
||||
[25]: https://remysharp.com/images/cli-improved/ack.png (Sample ack output with grep args)
|
||||
[26]: https://beyondgrep.com
|
||||
[27]: https://github.com/ggreer/the_silver_searcher
|
||||
[28]: http://conqueringthecommandline.com/book/ack_ag
|
||||
[29]: https://stedolan.github.io/jq
|
||||
[30]: http://trentm.com/json/
|
||||
[31]: https://jqterm.com
|
||||
[32]: https://github.com/erkin/ponysay
|
||||
[33]: https://csvkit.readthedocs.io/en/1.0.3/
|
||||
[34]: https://github.com/variadico/noti
|
||||
[35]: http://www.entrproject.org/
|
||||
@ -1,397 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to build rpm packages
|
||||
======
|
||||
|
||||
Save time and effort installing files and scripts across multiple hosts.
|
||||
|
||||

|
||||
|
||||
I have used rpm-based package managers to install software on Red Hat and Fedora Linux since I started using Linux more than 20 years ago. I have used the **rpm** program itself, **yum** , and **DNF** , which is a close descendant of yum, to install and update packages on my Linux hosts. The yum and DNF tools are wrappers around the rpm utility that provide additional functionality, such as the ability to find and install package dependencies.
|
||||
|
||||
Over the years I have created a number of Bash scripts, some of which have separate configuration files, that I like to install on most of my new computers and virtual machines. It reached the point that it took a great deal of time to install all of these packages, so I decided to automate that process by creating an rpm package that I could copy to the target hosts and install all of these files in their proper locations. Although the **rpm** tool was formerly used to build rpm packages, that function was removed and a new tool,was created to build new rpms.
|
||||
|
||||
When I started this project, I found very little information about creating rpm packages, but I managed to find a book, Maximum RPM, that helped me figure it out. That book is now somewhat out of date, as is the vast majority of information I have found. It is also out of print, and used copies go for hundreds of dollars. The online version of [Maximum RPM][1] is available at no charge and is kept up to date. The [RPM website][2] also has links to other websites that have a lot of documentation about rpm. What other information there is tends to be brief and apparently assumes that you already have a good deal of knowledge about the process.
|
||||
|
||||
In addition, every one of the documents I found assumes that the code needs to be compiled from sources as in a development environment. I am not a developer. I am a sysadmin, and we sysadmins have different needs because we don’t—or we shouldn’t—compile code to use for administrative tasks; we should use shell scripts. So we have no source code in the sense that it is something that needs to be compiled into binary executables. What we have is a source that is also the executable.
|
||||
|
||||
For the most part, this project should be performed as the non-root user student. Rpms should never be built by root, but only by non-privileged users. I will indicate which parts should be performed as root and which by a non-root, unprivileged user.
|
||||
|
||||
### Preparation
|
||||
|
||||
First, open one terminal session and `su` to root. Be sure to use the `-` option to ensure that the complete root environment is enabled. I do not believe that sysadmins should use `sudo` for any administrative tasks. Find out why in my personal blog post: [Real SysAdmins don’t sudo][3].
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ su -
|
||||
Password:
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
Create a student user that can be used for this project and set a password for that user.
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# useradd -c "Student User" student
|
||||
[root@testvm1 ~]# passwd student
|
||||
Changing password for user student.
|
||||
New password: <Enter the password>
|
||||
Retype new password: <Enter the password>
|
||||
passwd: all authentication tokens updated successfully.
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
Building rpm packages requires the `rpm-build` package, which is likely not already installed. Install it now as root. Note that this command will also install several dependencies. The number may vary, depending upon the packages already installed on your host; it installed a total of 17 packages on my test VM, which is pretty minimal.
|
||||
|
||||
```
|
||||
dnf install -y rpm-build
|
||||
```
|
||||
|
||||
The rest of this project should be performed as the user student unless otherwise explicitly directed. Open another terminal session and use `su` to switch to that user to perform the rest of these steps. Download a tarball that I have prepared of a development directory structure, utils.tar, from GitHub using the following command:
|
||||
|
||||
```
|
||||
wget https://github.com/opensourceway/how-to-rpm/raw/master/utils.tar
|
||||
```
|
||||
|
||||
This tarball includes all of the files and Bash scripts that will be installed by the final rpm. There is also a complete spec file, which you can use to build the rpm. We will go into detail about each section of the spec file.
|
||||
|
||||
As user student, using your home directory as your present working directory (pwd), untar the tarball.
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ cd ; tar -xvf utils.tar
|
||||
```
|
||||
|
||||
Use the `tree` command to verify that the directory structure of ~/development and the contained files looks like the following output:
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ tree development/
|
||||
development/
|
||||
├── license
|
||||
│ ├── Copyright.and.GPL.Notice.txt
|
||||
│ └── GPL_LICENSE.txt
|
||||
├── scripts
|
||||
│ ├── create_motd
|
||||
│ ├── die
|
||||
│ ├── mymotd
|
||||
│ └── sysdata
|
||||
└── spec
|
||||
└── utils.spec
|
||||
|
||||
3 directories, 7 files
|
||||
[student@testvm1 ~]$
|
||||
```
|
||||
|
||||
The `mymotd` script creates a “Message Of The Day” data stream that is sent to stdout. The `create_motd` script runs the `mymotd` scripts and redirects the output to the /etc/motd file. This file is used to display a daily message to users who log in remotely using SSH.
|
||||
|
||||
The `die` script is my own script that wraps the `kill` command in a bit of code that can find running programs that match a specified string and kill them. It uses `kill -9` to ensure that they cannot ignore the kill message.
|
||||
|
||||
The `sysdata` script can spew tens of thousands of lines of data about your computer hardware, the installed version of Linux, all installed packages, and the metadata of your hard drives. I use it to document the state of a host at a point in time. I can later use it for reference. I used to do this to maintain a record of hosts that I installed for customers.
|
||||
|
||||
You may need to change ownership of these files and directories to student.student. Do this, if necessary, using the following command:
|
||||
|
||||
```
|
||||
chown -R student.student development
|
||||
```
|
||||
|
||||
Most of the files and directories in this tree will be installed on Fedora systems by the rpm you create during this project.
|
||||
|
||||
### Creating the build directory structure
|
||||
|
||||
The `rpmbuild` command requires a very specific directory structure. You must create this directory structure yourself because no automated way is provided. Create the following directory structure in your home directory:
|
||||
|
||||
```
|
||||
~ ─ rpmbuild
|
||||
├── RPMS
|
||||
│ └── noarch
|
||||
├── SOURCES
|
||||
├── SPECS
|
||||
└── SRPMS
|
||||
```
|
||||
|
||||
We will not create the rpmbuild/RPMS/X86_64 directory because that would be architecture-specific for 64-bit compiled binaries. We have shell scripts that are not architecture-specific. In reality, we won’t be using the SRPMS directory either, which would contain source files for the compiler.
|
||||
|
||||
### Examining the spec file
|
||||
|
||||
Each spec file has a number of sections, some of which may be ignored or omitted, depending upon the specific circumstances of the rpm build. This particular spec file is not an example of a minimal file required to work, but it is a good example of a moderately complex spec file that packages files that do not need to be compiled. If a compile were required, it would be performed in the `%build` section, which is omitted from this spec file because it is not required.
|
||||
|
||||
#### Preamble
|
||||
|
||||
This is the only section of the spec file that does not have a label. It consists of much of the information you see when the command `rpm -qi [Package Name]` is run. Each datum is a single line which consists of a tag, which identifies it and text data for the value of the tag.
|
||||
|
||||
```
|
||||
###############################################################################
|
||||
# Spec file for utils
|
||||
################################################################################
|
||||
# Configured to be built by user student or other non-root user
|
||||
################################################################################
|
||||
#
|
||||
Summary: Utility scripts for testing RPM creation
|
||||
Name: utils
|
||||
Version: 1.0.0
|
||||
Release: 1
|
||||
License: GPL
|
||||
URL: http://www.both.org
|
||||
Group: System
|
||||
Packager: David Both
|
||||
Requires: bash
|
||||
Requires: screen
|
||||
Requires: mc
|
||||
Requires: dmidecode
|
||||
BuildRoot: ~/rpmbuild/
|
||||
|
||||
# Build with the following syntax:
|
||||
# rpmbuild --target noarch -bb utils.spec
|
||||
```
|
||||
|
||||
Comment lines are ignored by the `rpmbuild` program. I always like to add a comment to this section that contains the exact syntax of the `rpmbuild` command required to create the package. The Summary tag is a short description of the package. The Name, Version, and Release tags are used to create the name of the rpm file, as in utils-1.00-1.rpm. Incrementing the release and version numbers lets you create rpms that can be used to update older ones.
|
||||
|
||||
The License tag defines the license under which the package is released. I always use a variation of the GPL. Specifying the license is important to clarify the fact that the software contained in the package is open source. This is also why I included the license and GPL statement in the files that will be installed.
|
||||
|
||||
The URL is usually the web page of the project or project owner. In this case, it is my personal web page.
|
||||
|
||||
The Group tag is interesting and is usually used for GUI applications. The value of the Group tag determines which group of icons in the applications menu will contain the icon for the executable in this package. Used in conjunction with the Icon tag (which we are not using here), the Group tag allows adding the icon and the required information to launch a program into the applications menu structure.
|
||||
|
||||
The Packager tag is used to specify the person or organization responsible for maintaining and creating the package.
|
||||
|
||||
The Requires statements define the dependencies for this rpm. Each is a package name. If one of the specified packages is not present, the DNF installation utility will try to locate it in one of the defined repositories defined in /etc/yum.repos.d and install it if it exists. If DNF cannot find one or more of the required packages, it will throw an error indicating which packages are missing and terminate.
|
||||
|
||||
The BuildRoot line specifies the top-level directory in which the `rpmbuild` tool will find the spec file and in which it will create temporary directories while it builds the package. The finished package will be stored in the noarch subdirectory that we specified earlier. The comment showing the command syntax used to build this package includes the option `–target noarch`, which defines the target architecture. Because these are Bash scripts, they are not associated with a specific CPU architecture. If this option were omitted, the build would be targeted to the architecture of the CPU on which the build is being performed.
|
||||
|
||||
The `rpmbuild` program can target many different architectures, and using the `--target` option allows us to build architecture-specific packages on a host with a different architecture from the one on which the build is performed. So I could build a package intended for use on an i686 architecture on an x86_64 host, and vice versa.
|
||||
|
||||
Change the packager name to yours and the URL to your own website if you have one.
|
||||
|
||||
#### %description
|
||||
|
||||
The `%description` section of the spec file contains a description of the rpm package. It can be very short or can contain many lines of information. Our `%description` section is rather terse.
|
||||
|
||||
```
|
||||
%description
|
||||
A collection of utility scripts for testing RPM creation.
|
||||
```
|
||||
|
||||
#### %prep
|
||||
|
||||
The `%prep` section is the first script that is executed during the build process. This script is not executed during the installation of the package.
|
||||
|
||||
This script is just a Bash shell script. It prepares the build directory, creating directories used for the build as required and copying the appropriate files into their respective directories. This would include the sources required for a complete compile as part of the build.
|
||||
|
||||
The $RPM_BUILD_ROOT directory represents the root directory of an installed system. The directories created in the $RPM_BUILD_ROOT directory are fully qualified paths, such as /user/local/share/utils, /usr/local/bin, and so on, in a live filesystem.
|
||||
|
||||
In the case of our package, we have no pre-compile sources as all of our programs are Bash scripts. So we simply copy those scripts and other files into the directories where they belong in the installed system.
|
||||
|
||||
```
|
||||
%prep
|
||||
################################################################################
|
||||
# Create the build tree and copy the files from the development directories #
|
||||
# into the build tree. #
|
||||
################################################################################
|
||||
echo "BUILDROOT = $RPM_BUILD_ROOT"
|
||||
mkdir -p $RPM_BUILD_ROOT/usr/local/bin/
|
||||
mkdir -p $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
|
||||
cp /home/student/development/utils/scripts/* $RPM_BUILD_ROOT/usr/local/bin
|
||||
cp /home/student/development/utils/license/* $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
cp /home/student/development/utils/spec/* $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
|
||||
exit
|
||||
```
|
||||
|
||||
Note that the exit statement at the end of this section is required.
|
||||
|
||||
#### %files
|
||||
|
||||
This section of the spec file defines the files to be installed and their locations in the directory tree. It also specifies the file attributes and the owner and group owner for each file to be installed. The file permissions and ownerships are optional, but I recommend that they be explicitly set to eliminate any chance for those attributes to be incorrect or ambiguous when installed. Directories are created as required during the installation if they do not already exist.
|
||||
|
||||
```
|
||||
%files
|
||||
%attr(0744, root, root) /usr/local/bin/*
|
||||
%attr(0644, root, root) /usr/local/share/utils/*
|
||||
```
|
||||
|
||||
#### %pre
|
||||
|
||||
This section is empty in our lab project’s spec file. This would be the place to put any scripts that are required to run during installation of the rpm but prior to the installation of the files.
|
||||
|
||||
#### %post
|
||||
|
||||
This section of the spec file is another Bash script. This one runs after the installation of files. This section can be pretty much anything you need or want it to be, including creating files, running system commands, and restarting services to reinitialize them after making configuration changes. The `%post` script for our rpm package performs some of those tasks.
|
||||
|
||||
```
|
||||
%post
|
||||
################################################################################
|
||||
# Set up MOTD scripts #
|
||||
################################################################################
|
||||
cd /etc
|
||||
# Save the old MOTD if it exists
|
||||
if [ -e motd ]
|
||||
then
|
||||
cp motd motd.orig
|
||||
fi
|
||||
# If not there already, Add link to create_motd to cron.daily
|
||||
cd /etc/cron.daily
|
||||
if [ ! -e create_motd ]
|
||||
then
|
||||
ln -s /usr/local/bin/create_motd
|
||||
fi
|
||||
# create the MOTD for the first time
|
||||
/usr/local/bin/mymotd > /etc/motd
|
||||
```
|
||||
|
||||
The comments included in this script should make its purpose clear.
|
||||
|
||||
#### %postun
|
||||
|
||||
This section contains a script that would be run after the rpm package is uninstalled. Using rpm or DNF to remove a package removes all of the files listed in the `%files` section, but it does not remove files or links created by the `%post` section, so we need to handle that in this section.
|
||||
|
||||
This script usually consists of cleanup tasks that simply erasing the files previously installed by the rpm cannot accomplish. In the case of our package, it includes removing the link created by the `%post` script and restoring the saved original of the motd file.
|
||||
|
||||
```
|
||||
%postun
|
||||
# remove installed files and links
|
||||
rm /etc/cron.daily/create_motd
|
||||
|
||||
# Restore the original MOTD if it was backed up
|
||||
if [ -e /etc/motd.orig ]
|
||||
then
|
||||
mv -f /etc/motd.orig /etc/motd
|
||||
fi
|
||||
```
|
||||
|
||||
#### %clean
|
||||
|
||||
This Bash script performs cleanup after the rpm build process. The two lines in the `%clean` section below remove the build directories created by the `rpm-build` command. In many cases, additional cleanup may also be required.
|
||||
|
||||
```
|
||||
%clean
|
||||
rm -rf $RPM_BUILD_ROOT/usr/local/bin
|
||||
rm -rf $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
```
|
||||
|
||||
#### %changelog
|
||||
|
||||
This optional text section contains a list of changes to the rpm and files it contains. The newest changes are recorded at the top of this section.
|
||||
|
||||
```
|
||||
%changelog
|
||||
* Wed Aug 29 2018 Your Name <Youremail@yourdomain.com>
|
||||
- The original package includes several useful scripts. it is
|
||||
primarily intended to be used to illustrate the process of
|
||||
building an RPM.
|
||||
```
|
||||
|
||||
Replace the data in the header line with your own name and email address.
|
||||
|
||||
### Building the rpm
|
||||
|
||||
The spec file must be in the SPECS directory of the rpmbuild tree. I find it easiest to create a link to the actual spec file in that directory so that it can be edited in the development directory and there is no need to copy it to the SPECS directory. Make the SPECS directory your pwd, then create the link.
|
||||
|
||||
```
|
||||
cd ~/rpmbuild/SPECS/
|
||||
ln -s ~/development/spec/utils.spec
|
||||
```
|
||||
|
||||
Run the following command to build the rpm. It should only take a moment to create the rpm if no errors occur.
|
||||
|
||||
```
|
||||
rpmbuild --target noarch -bb utils.spec
|
||||
```
|
||||
|
||||
Check in the ~/rpmbuild/RPMS/noarch directory to verify that the new rpm exists there.
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ cd rpmbuild/RPMS/noarch/
|
||||
[student@testvm1 noarch]$ ll
|
||||
total 24
|
||||
-rw-rw-r--. 1 student student 24364 Aug 30 10:00 utils-1.0.0-1.noarch.rpm
|
||||
[student@testvm1 noarch]$
|
||||
```
|
||||
|
||||
### Testing the rpm
|
||||
|
||||
As root, install the rpm to verify that it installs correctly and that the files are installed in the correct directories. The exact name of the rpm will depend upon the values you used for the tags in the Preamble section, but if you used the ones in the sample, the rpm name will be as shown in the sample command below:
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# cd /home/student/rpmbuild/RPMS/noarch/
|
||||
[root@testvm1 noarch]# ll
|
||||
total 24
|
||||
-rw-rw-r--. 1 student student 24364 Aug 30 10:00 utils-1.0.0-1.noarch.rpm
|
||||
[root@testvm1 noarch]# rpm -ivh utils-1.0.0-1.noarch.rpm
|
||||
Preparing... ################################# [100%]
|
||||
Updating / installing...
|
||||
1:utils-1.0.0-1 ################################# [100%]
|
||||
```
|
||||
|
||||
Check /usr/local/bin to ensure that the new files are there. You should also verify that the create_motd link in /etc/cron.daily has been created.
|
||||
|
||||
Use the `rpm -q --changelog utils` command to view the changelog. View the files installed by the package using the `rpm -ql utils` command (that is a lowercase L in `ql`.)
|
||||
|
||||
```
|
||||
[root@testvm1 noarch]# rpm -q --changelog utils
|
||||
* Wed Aug 29 2018 Your Name <Youremail@yourdomain.com>
|
||||
- The original package includes several useful scripts. it is
|
||||
primarily intended to be used to illustrate the process of
|
||||
building an RPM.
|
||||
|
||||
[root@testvm1 noarch]# rpm -ql utils
|
||||
/usr/local/bin/create_motd
|
||||
/usr/local/bin/die
|
||||
/usr/local/bin/mymotd
|
||||
/usr/local/bin/sysdata
|
||||
/usr/local/share/utils/Copyright.and.GPL.Notice.txt
|
||||
/usr/local/share/utils/GPL_LICENSE.txt
|
||||
/usr/local/share/utils/utils.spec
|
||||
[root@testvm1 noarch]#
|
||||
```
|
||||
|
||||
Remove the package.
|
||||
|
||||
```
|
||||
rpm -e utils
|
||||
```
|
||||
|
||||
### Experimenting
|
||||
|
||||
Now you will change the spec file to require a package that does not exist. This will simulate a dependency that cannot be met. Add the following line immediately under the existing Requires line:
|
||||
|
||||
```
|
||||
Requires: badrequire
|
||||
```
|
||||
|
||||
Build the package and attempt to install it. What message is displayed?
|
||||
|
||||
We used the `rpm` command to install and delete the `utils` package. Try installing the package with yum or DNF. You must be in the same directory as the package or specify the full path to the package for this to work.
|
||||
|
||||
### Conclusion
|
||||
|
||||
There are many tags and a couple sections that we did not cover in this look at the basics of creating an rpm package. The resources listed below can provide more information. Building rpm packages is not difficult; you just need the right information. I hope this helps you—it took me months to figure things out on my own.
|
||||
|
||||
We did not cover building from source code, but if you are a developer, that should be a simple step from this point.
|
||||
|
||||
Creating rpm packages is another good way to be a lazy sysadmin and save time and effort. It provides an easy method for distributing and installing the scripts and other files that we as sysadmins need to install on many hosts.
|
||||
|
||||
### Resources
|
||||
|
||||
* Edward C. Baily, Maximum RPM, Sams Publishing, 2000, ISBN 0-672-31105-4
|
||||
|
||||
* Edward C. Baily, [Maximum RPM][1], updated online version
|
||||
|
||||
* [RPM Documentation][4]: This web page lists most of the available online documentation for rpm. It includes many links to other websites and information about rpm.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/how-build-rpm-packages
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[1]: http://ftp.rpm.org/max-rpm/
|
||||
[2]: http://rpm.org/index.html
|
||||
[3]: http://www.both.org/?p=960
|
||||
[4]: http://rpm.org/documentation.html
|
||||
@ -1,110 +0,0 @@
|
||||
translating by ypingcn
|
||||
|
||||
Control your data with Syncthing: An open source synchronization tool
|
||||
======
|
||||
Decide how to store and share your personal information.
|
||||
|
||||

|
||||
|
||||
These days, some of our most important possessions—from pictures and videos of family and friends to financial and medical documents—are data. And even as cloud storage services are booming, so there are concerns about privacy and lack of control over our personal data. From the PRISM surveillance program to Google [letting app developers scan your personal emails][1], the news is full of reports that should give us all pause regarding the security of our personal information.
|
||||
|
||||
[Syncthing][2] can help put your mind at ease. An open source peer-to-peer file synchronization tool that runs on Linux, Windows, Mac, Android, and others (sorry, no iOS), Syncthing uses its own protocol, called [Block Exchange Protocol][3]. In brief, Syncthing lets you synchronize your data across many devices without owning a server.
|
||||
|
||||
### Linux
|
||||
|
||||
In this post, I will explain how to install and synchronize files between a Linux computer and an Android phone.
|
||||
|
||||
Syncthing is readily available for most popular distributions. Fedora 28 includes the latest version.
|
||||
|
||||
To install Syncthing in Fedora, you can either search for it in Software Center or execute the following command:
|
||||
|
||||
```
|
||||
sudo dnf install syncthing syncthing-gtk
|
||||
|
||||
```
|
||||
|
||||
Once it’s installed, open it. You’ll be welcomed by an assistant to help configure Syncthing. Click **Next** until it asks to configure the WebUI. The safest option is to keep the option **Listen on localhost**. That will disable the web interface and keep unauthorized users away.
|
||||
|
||||
![Syncthing in Setup WebUI dialog box][5]
|
||||
|
||||
Syncthing in Setup WebUI dialog box
|
||||
|
||||
Close the dialog. Now that Syncthing is installed, it’s time to share a folder, connect a device, and start syncing. But first, let’s continue with your other client.
|
||||
|
||||
### Android
|
||||
|
||||
Syncthing is available in Google Play and in F-Droid app stores.
|
||||
|
||||
|
||||
|
||||
Once the application is installed, you’ll be welcomed by a wizard. Grant Syncthing permissions to your storage. You might be asked to disable battery optimization for this application. It is safe to do so as we will optimize the app to synchronize only when plugged in and connected to a wireless network.
|
||||
|
||||
Click on the main menu icon and go to **Settings** , then **Run Conditions**. Tick **Always run in** **the background** , **Run only when charging** , and **Run only on wifi**. Now your Android client is ready to exchange files with your devices.
|
||||
|
||||
There are two important concepts to remember in Syncthing: folders and devices. Folders are what you want to share, but you must have a device to share with. Syncthing allows you to share individual folders with different devices. Devices are added by exchanging device IDs. A device ID is a unique, cryptographically secure identifier that is created when Syncthing starts for the first time.
|
||||
|
||||
### Connecting devices
|
||||
|
||||
Now let’s connect your Linux machine and your Android client.
|
||||
|
||||
In your Linux computer, open Syncthing, click on the **Settings** icon and click **Show ID**. A QR code will show up.
|
||||
|
||||
In your Android mobile, open Syncthing. In the main screen, click the **Devices** tab and press the **+** symbol. In the first field, press the QR code symbol to open the QR scanner.
|
||||
|
||||
Point your mobile camera to the computer QR code. The Device ID** **field will be populated with your desktop client Device ID. Give it a friendly name and save. Because adding a device goes two ways, you now need to confirm on the computer client that you want to add the Android mobile. It might take a couple of minutes for your computer client to ask for confirmation. When it does, click **Add**.
|
||||
|
||||

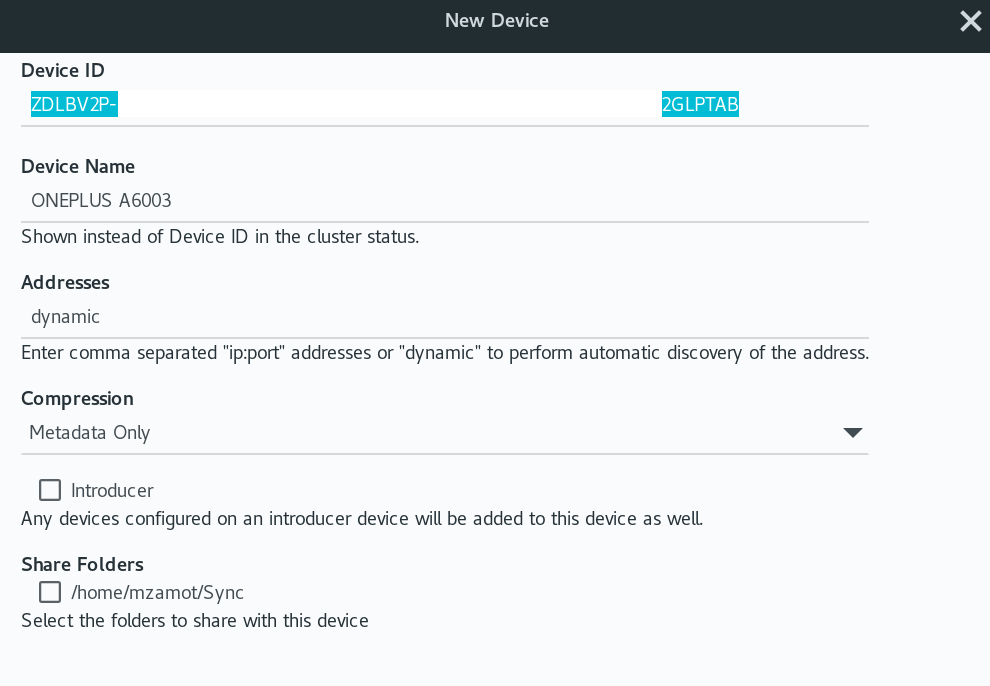
|
||||
|
||||
In the **New Device** window, you can verify and configure some options about your new device, like the **Device Name** and **Addresses**. If you keep dynamic, it will try to auto-discover the device IP, but if you want to force one, you can add it in this field. If you already created a folder (more on this later), you can also share it with this new device.
|
||||
|
||||
|
||||
|
||||
Your computer and Android are now paired and ready to exchange files. (If you have more than one computer or mobile phone, simply repeat these steps.)
|
||||
|
||||
### Sharing folders
|
||||
|
||||
Now that the devices you want to sync are already connected, it’s time to share a folder. You can share folders on your computer and the devices you add to that folder will get a copy.
|
||||
|
||||
To share a folder, go to **Settings** and click **Add Shared Folder** :
|
||||
|
||||
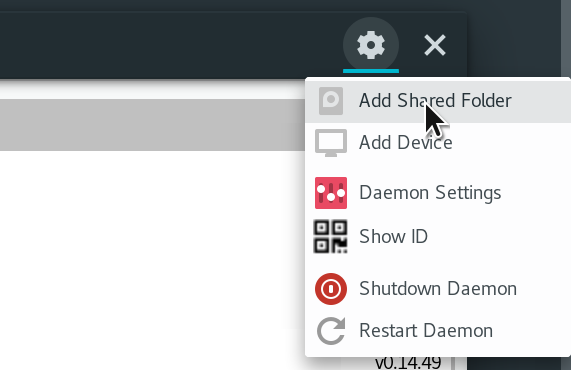
|
||||
|
||||
In the next window, enter the information of the folder you want to share:
|
||||
|
||||
|
||||
|
||||
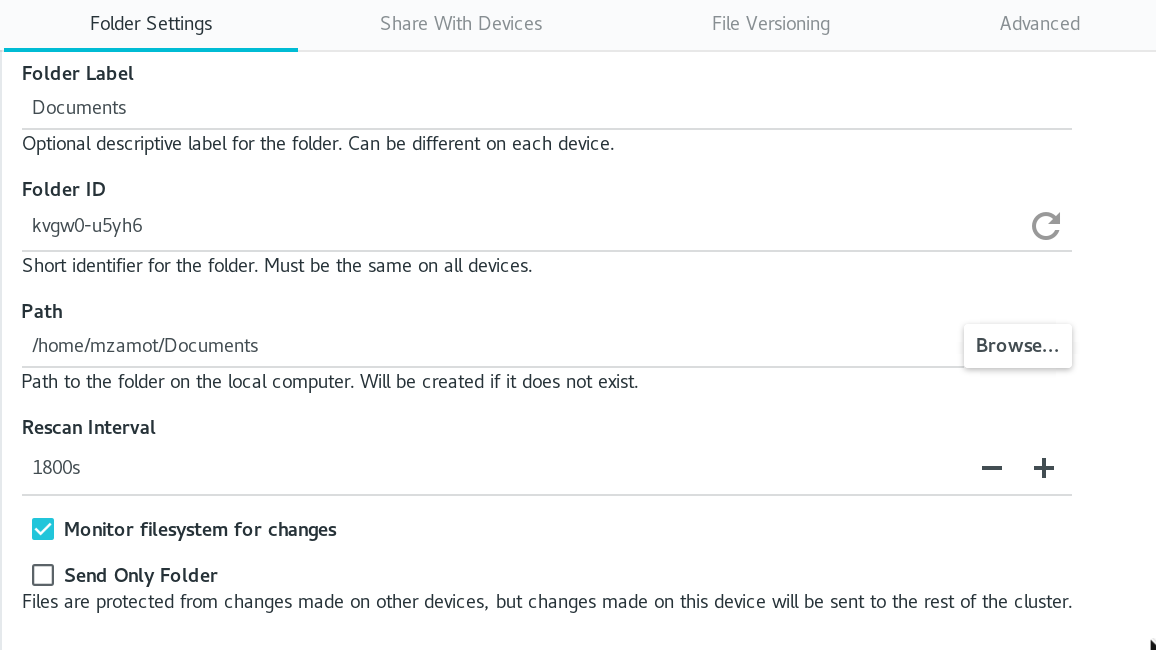
You can use any label you want. **Folder ID** will be generated randomly and will be used to identify the folder between the clients. In **Path** , click **Browse** and locate the folder you want to share. If you want Syncthing to monitor the folder for changes (such as deletes, new files, etc.), click **Monitor filesystem for changes**.
|
||||
|
||||
Remember, when you share a folder, any change that happens on the other clients will be reflected on every single device. That means that if you share a folder containing pictures with other computers or mobile devices, changes in these other clients will be reflected everywhere. If this is not what you want, you can make your folder “Send Only” so it will send files to the clients, but the other clients’ changes won’t be synced.
|
||||
|
||||
When this is done, go to **Share with Devices** and select the hosts you want to sync with your folder:
|
||||
|
||||
All the devices you select will need to accept the share request; you will get a notification from the devices:
|
||||
|
||||
Just as when you shared the folder, you must configure the new shared folder:
|
||||
|
||||
|
||||
|
||||
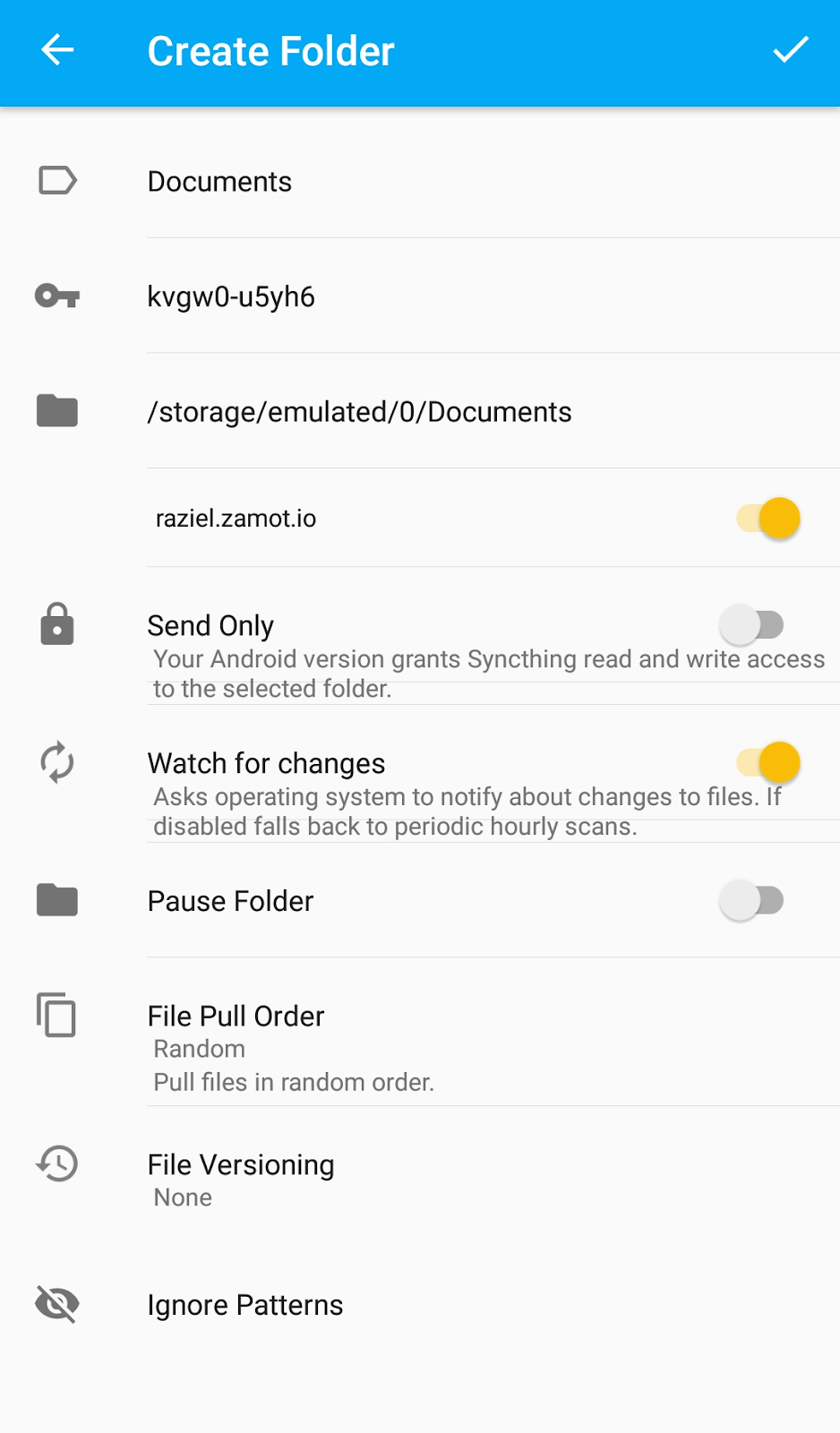
Again, here you can define any label, but the ID must match each client. In the folder option, select the destination for the folder and its files. Remember that any change done in this folder will be reflected with every device allowed in the folder.
|
||||
|
||||
These are the steps to connect devices and share folders with Syncthing. It might take a few minutes to start copying, depending on your network settings or if you are not on the same network.
|
||||
|
||||
Syncthing offers many more great features and options. Try it—and take control of your data.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/take-control-your-data-syncthing
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mzamot
|
||||
[1]: https://gizmodo.com/google-says-it-doesnt-go-through-your-inbox-anymore-bu-1827299695
|
||||
[2]: https://syncthing.net/
|
||||
[3]: https://docs.syncthing.net/specs/bep-v1.html
|
||||
[4]: /file/410191
|
||||
[5]: https://opensource.com/sites/default/files/uploads/syncthing1.png (Syncthing in Setup WebUI dialog box)
|
||||
@ -1,61 +1,59 @@
|
||||
translating by hopefully2333
|
||||
|
||||
Play Windows games on Fedora with Steam Play and Proton
|
||||
在 Fedora 上使用 Steam play 和 Proton 来玩 Windows 游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
Some weeks ago, Steam [announced][1] a new addition to Steam Play with Linux support for Windows games using Proton, a fork from WINE. This capability is still in beta, and not all games work. Here are some more details about Steam and Proton.
|
||||
几周前,Steam 宣布要给 Steam Play 增加一个新组件,用于支持在 Linux 平台上使用 Proton 来玩 Windows 的游戏,这个组件是 WINE 的一个分支。这个功能仍然处于测试阶段,且并非对所有游戏都有效。这里有一些关于 Steam 和 Proton 的细节。
|
||||
|
||||
According to the Steam website, there are new features in the beta release:
|
||||
据 Steam 网站称,测试版本中有以下这些新功能:
|
||||
|
||||
* Windows games with no Linux version currently available can now be installed and run directly from the Linux Steam client, complete with native Steamworks and OpenVR support.
|
||||
* DirectX 11 and 12 implementations are now based on Vulkan, which improves game compatibility and reduces performance impact.
|
||||
* Fullscreen support has been improved. Fullscreen games seamlessly stretch to the desired display without interfering with the native monitor resolution or requiring the use of a virtual desktop.
|
||||
* Improved game controller support. Games automatically recognize all controllers supported by Steam. Expect more out-of-the-box controller compatibility than even the original version of the game.
|
||||
* Performance for multi-threaded games has been greatly improved compared to vanilla WINE.
|
||||
* 现在没有 Linux 版本的 Windows 游戏可以直接从 Linux 上的 Steam 客户端进行安装和运行,并且有完整、原生的 Steamworks 和 OpenVR 的支持。
|
||||
* 现在 DirectX 11 和 12 的实现都基于 Vulkan,它可以提高游戏的兼容性并减小游戏性能收到的影响。
|
||||
* 全屏支持已经得到了改进,全屏游戏时可以无缝扩展到所需的显示程度,而不会干扰到显示屏本身的分辨率或者说需要使用虚拟桌面。
|
||||
* 改进了对游戏控制器的支持,游戏自动识别所有 Steam 支持的控制器,比起游戏的原始版本,能够获得更多开箱即用的控制器兼容性。
|
||||
* 和 vanilla WINE 比起来,游戏的多线程性能得到了极大的提高。
|
||||
|
||||
|
||||
|
||||
### Installation
|
||||
### 安装
|
||||
|
||||
If you’re interested in trying Steam with Proton out, just follow these easy steps. (Note that you can ignore the first steps to enable the Steam Beta if you have the [latest updated version of Steam installed][2]. In that case you no longer need Steam Beta to use Proton.)
|
||||
如果你有兴趣,想尝试一下 Steam 和 Proton。请按照下面这些简单的步骤进行操作。(请注意,如果你已经安装了最新版本的 Steam,可以忽略启用 Steam 测试版这个第一步。在这种情况下,你不再需要通过 Steam 测试版来使用 Proton。)
|
||||
|
||||
Open up Steam and log in to your account. This example screenshot shows support for only 22 games before enabling Proton.
|
||||
打开 Steam 并登陆到你的帐户,这个截屏示例显示的是在使用 Proton 之前仅支持22个游戏。
|
||||
|
||||
![][3]
|
||||
|
||||
Now click on Steam option on top of the client. This displays a drop down menu. Then select Settings.
|
||||
现在点击客户端顶部的 Steam 选项,这会显示一个下拉菜单。然后选择设置。
|
||||
|
||||
![][4]
|
||||
|
||||
Now the settings window pops up. Select the Account option and next to Beta participation, click on change.
|
||||
现在弹出了设置窗口,选择账户选项,并在 Beta participation 旁边,点击更改。
|
||||
|
||||
![][5]
|
||||
|
||||
Now change None to Steam Beta Update.
|
||||
现在将 None 更改为 Steam Beta Update。
|
||||
|
||||
![][6]
|
||||
|
||||
Click on OK and a prompt asks you to restart.
|
||||
点击确定,然后系统会提示你重新启动。
|
||||
|
||||
![][7]
|
||||
|
||||
Let Steam download the update. This can take a while depending on your internet speed and computer resources.
|
||||
让 Steam 下载更新,这会需要一段时间,具体需要多久这要取决于你的网络速度和电脑配置。
|
||||
|
||||
![][8]
|
||||
|
||||
After restarting, go back to the Settings window. This time you’ll see a new option. Make sure the check boxes for Enable Steam Play for supported titles, Enable Steam Play for all titles and Use this tool instead of game-specific selections from Steam are enabled. The compatibility tool should be Proton.
|
||||
在重新启动之后,返回到上面的设置窗口。这次你会看到一个新选项。确定有为提供支持的游戏使用 Stream Play 这个复选框,让所有的游戏都使用 Steam Play 进行运行,而不是 steam 中游戏特定的选项。兼容性工具应该是 Proton。
|
||||
|
||||
![][9]
|
||||
|
||||
The Steam client asks you to restart. Do so, and once you log back into your Steam account, your game library for Linux should be extended.
|
||||
Steam 客户端会要求你重新启动,照做,然后重新登陆你的 Steam 账户,你的 Linux 的游戏库就能得到扩展了。
|
||||
|
||||
![][10]
|
||||
|
||||
### Installing a Windows game using Steam Play
|
||||
### 使用 Steam Play 来安装一个 Windows 游戏
|
||||
|
||||
Now that you have Proton enabled, install a game. Select the title you want and you’ll find the process is similar to installing a normal game on Steam, as shown in these screenshots.
|
||||
现在你已经启用 Proton,开始安装游戏,选择你想要安装的游戏,然后你会发现这个安装过程类似于在 Steam 上安装一个普通游戏,如下面这些截图所示。
|
||||
|
||||
![][11]
|
||||
|
||||
@ -65,13 +63,13 @@ Now that you have Proton enabled, install a game. Select the title you want and
|
||||
|
||||
![][14]
|
||||
|
||||
After the game is done downloading and installing, you can play it.
|
||||
在下载和安装完游戏后,你就可以开始玩了。
|
||||
|
||||
![][15]
|
||||
|
||||
![][16]
|
||||
|
||||
Some games may be affected by the beta nature of Proton. The game in this example, Chantelise, had no audio and a low frame rate. Keep in mind this capability is still in beta and Fedora is not responsible for results. If you’d like to read further, the community has created a [Google doc][17] with a list of games that have been tested.
|
||||
一些游戏可能会受到 Proton 测试性质的影响,在下面这个叫 Chantelise 游戏中,没有了声音并且帧率很低。请记住这个功能仍然在测试阶段,Fedora 不会对结果负责。如果你想要了解更多,社区已经创建了一个 Google 文档,这个文档里有已经测试过的游戏的列表。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -80,7 +78,7 @@ via: https://fedoramagazine.org/play-windows-games-steam-play-proton/
|
||||
|
||||
作者:[Francisco J. Vergara Torres][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
An introduction to Ansible Operators in Kubernetes
|
||||
======
|
||||
The new Operator SDK makes it easy to create a Kubernetes controller to deploy and manage a service or application in a cluster.
|
||||

|
||||
|
||||
For years, Ansible has been a go-to choice for infrastructure automation. As Kubernetes adoption has skyrocketed, Ansible has continued to shine in the emerging container orchestration ecosystem.
|
||||
|
||||
Ansible fits naturally into a Kubernetes workflow, using YAML to describe the desired state of the world. Multiple projects, including the [Automation Broker][1], are adapting Ansible for use behind specific APIs. This article will focus on a new technique, created through a joint effort by the Ansible core team and the developers of Automation Broker, that uses Ansible to create Operators with minimal effort.
|
||||
|
||||
### What is an Operator?
|
||||
|
||||
An [Operator][2] is a Kubernetes controller that deploys and manages a service or application in a cluster. It automates human operation knowledge and best practices to keep services running and healthy. Input is received in the form of a custom resource. Let's walk through that using a Memcached Operator as an example.
|
||||
|
||||
The [Memcached Operator][3] can be deployed as a service running in a cluster, and it includes a custom resource definition (CRD) for a resource called Memcached. The end user creates an instance of that custom resource to describe how the Memcached Deployment should look. The following example requests a Deployment with three Pods.
|
||||
|
||||
```
|
||||
apiVersion: "cache.example.com/v1alpha1"
|
||||
kind: "Memcached"
|
||||
metadata:
|
||||
name: "example-memcached"
|
||||
spec:
|
||||
size: 3
|
||||
```
|
||||
|
||||
The Operator's job is called reconciliation—continuously ensuring that what is specified in the "spec" matches the real state of the world. This sample Operator delegates Pod management to a Deployment controller. So while it does not directly create or delete Pods, if you change the size, the Operator's reconciliation loop ensures that the new value is applied to the Deployment resource it created.
|
||||
|
||||
A mature Operator can deploy, upgrade, back up, repair, scale, and reconfigure an application that it manages. As you can see, not only does an Operator provide a simple way to deploy arbitrary services using only native Kubernetes APIs; it enables full day-two (post-deployment, such as updates, backups, etc.) management, limited only by what you can code.
|
||||
|
||||
### Creating an Operator
|
||||
|
||||
The [Operator SDK][4] makes it easy to get started. It lays down the skeleton of a new Operator with many of the complex pieces already handled. You can focus on defining your custom resources and coding the reconciliation logic in Go. The SDK saves you a lot of time and ongoing maintenance burden, but you will still end up owning a substantial software project.
|
||||
|
||||
Ansible was recently introduced to the Operator SDK as an even simpler way to make an Operator, with no coding required. To create an Operator, you merely:
|
||||
|
||||
* Create a CRD in the form of YAML
|
||||
* Define what reconciliation should do by creating an Ansible role or playbook
|
||||
|
||||
|
||||
|
||||
It's YAML all the way down—a familiar experience for Kubernetes users.
|
||||
|
||||
### How does it work?
|
||||
|
||||
There is a preexisting Ansible Operator base container image that includes Ansible, [ansible-runner][5], and the Operator's executable service. The SDK helps to build a layer on top that adds one or more CRDs and associates each with an Ansible role or playbook.
|
||||
|
||||
When it's running, the Operator uses a Kubernetes feature to "watch" for changes to any resource of the type defined. Upon receiving such a notification, it reconciles the resource that changed. The Operator runs the corresponding role or playbook, and information about the resource is passed to Ansible as [extra-vars][6].
|
||||
|
||||
### Using Ansible with Kubernetes
|
||||
|
||||
Following several iterations, the Ansible community has produced a remarkably easy-to-use module for working with Kubernetes. Especially if you have any experience with a Kubernetes module prior to Ansible 2.6, you owe it to yourself to have a look at the [k8s module][7]. Creating, retrieving, and updating resources is a natural experience that will feel familiar to any Kubernetes user. It makes creating an Operator that much easier.
|
||||
|
||||
### Give it a try
|
||||
|
||||
If you need to build a Kubernetes Operator, doing so with Ansible could save time and complexity. To learn more, head over to the Operator SDK documentation and work through the [Getting Started Guide][8] for Ansible-based Operators. Then join us on the [Operator Framework mailing list][9] and let us know what you think.
|
||||
|
||||
Michael Hrivnak will present [Automating Multi-Service Deployments on Kubernetes][10] at [LISA18][11], October 29-31 in Nashville, Tennessee, USA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/ansible-operators-kubernetes
|
||||
|
||||
作者:[Michael Hrivnak][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhrivnak
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/2/automated-provisioning-kubernetes
|
||||
[2]: https://coreos.com/operators/
|
||||
[3]: https://github.com/operator-framework/operator-sdk-samples/tree/master/memcached-operator
|
||||
[4]: https://github.com/operator-framework/operator-sdk/
|
||||
[5]: https://github.com/ansible/ansible-runner
|
||||
[6]: https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#passing-variables-on-the-command-line
|
||||
[7]: https://docs.ansible.com/ansible/2.6/modules/k8s_module.html
|
||||
[8]: https://github.com/operator-framework/operator-sdk/blob/master/doc/ansible/user-guide.md
|
||||
[9]: https://groups.google.com/forum/#!forum/operator-framework
|
||||
[10]: https://www.usenix.org/conference/lisa18/presentation/hrivnak
|
||||
[11]: https://www.usenix.org/conference/lisa18
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Running Linux containers as a non-root with Podman
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,87 @@
|
||||
piwheels: Speedy Python package installation for the Raspberry Pi
|
||||
======
|
||||
https://opensource.com/article/18/10/piwheels-python-raspberrypi
|
||||
|
||||

|
||||
|
||||
One of the great things about the Python programming language is [PyPI][1], the Python Package Index, where third-party libraries are hosted, available for anyone to install and gain access to pre-existing functionality without starting from scratch. These libraries are handy utilities, written by members of the community, that aren't found within the Python standard library. But they work in much the same way—you import them into your code and have access to functions and classes you didn't write yourself.
|
||||
|
||||
### The cross-platform problem
|
||||
|
||||
Many of the 150,000+ libraries hosted on PyPI are written in Python, but that's not the only option—you can write Python libraries in C, C++, or anything with Python bindings. The usual benefit of writing a library in C or C++ is speed. The NumPy project is a good example: NumPy provides highly powerful mathematical functionality for dealing with matrix operations. It is highly optimized code that allows users to write in Python but have access to speedy mathematics operations.
|
||||
|
||||
The problem comes when trying to distribute libraries for others to use cross-platform. The standard is to create built distributions called Python wheels. While pure Python libraries are automatically compatible cross-platform, those implemented in C/C++ must be built separately for each operating system, Python version, and system architecture. So, if a library wanted to support Windows, MacOS, and Linux, for both 32-bit and 64-bit computers, and for Python 2.7, 3.4, 3.5, and 3.6, that would require 24 different versions! Some packages do this, but others rely on users building the package from the source code, which can take a long time and can often be complex.
|
||||
|
||||
### Raspberry Pi and Arm
|
||||
|
||||
While the Raspberry Pi runs Linux, it's not the same architecture as your regular PC—it's Arm, rather than Intel. That means the Linux wheels don't work, and Raspberry Pi users had to build from source—until the piwheels project came to fruition last year. [Piwheels][2] is an open source project that aims to build Raspberry Pi platform wheels for every package on PyPI.
|
||||
|
||||

|
||||
|
||||
Packages are natively compiled on Raspberry Pi 3 hardware and hosted in a data center provided by UK-based [Mythic Beasts][3], which provides cloud Pis as part of its hosting service. The piwheels website hosts the wheels in a [pip][4]-compatible web server configuration so Raspberry Pi users can use them easily. Raspbian Stretch even comes preconfigured to use piwheels.org as an additional index to PyPI by default.
|
||||
|
||||
### The piwheels stack
|
||||
|
||||
The piwheels project runs (almost) entirely on Raspberry Pi hardware:
|
||||
|
||||
* **Master**
|
||||
* A Raspberry Pi web server hosts the wheel files and distributes jobs to the builder Pis.
|
||||
* **Database server**
|
||||
* All package information is stored in a [Postgres database][5].
|
||||
* The master logs build attempts and downloads.
|
||||
* **Builders**
|
||||
* Builder Pis are given build jobs to attempt, and they communicate with the database.
|
||||
* The backlog of packages on PyPI was completed using around 20 Raspberry Pis.
|
||||
* A smaller number of Pis is required to keep up with new releases. Currently, there are three with Raspbian Jessie (Python 3.4) and two with Raspbian Stretch (Python 3.5).
|
||||
|
||||
|
||||
|
||||
The database server was originally a Raspberry Pi but was moved to another server when the database got too large.
|
||||
|
||||

|
||||
|
||||
### Time saved
|
||||
|
||||
Around 500,000 packages are downloaded from piwheels.org every month.
|
||||
|
||||
Every time a package is built by piwheels or downloaded by a user, its status information (including build duration) is recorded in a database. Therefore, it's possible to calculate how much time has been saved with pre-compiled packages.
|
||||
|
||||
In the 10 months that the service has been running, over 25 years of build time has been saved.
|
||||
|
||||
### Great for projects
|
||||
|
||||
Raspberry Pi project tutorials requiring Python libraries often include warnings like "this step takes a few hours"—but that's no longer true, thanks to piwheels. Piwheels makes it easy for makers and developers to dive straight into their project and not get bogged down waiting for software to install. Amazing libraries are just a **pip install** away; no need to wait for compilation.
|
||||
|
||||
Piwheels has wheels for NumPy, SciPy, OpenCV, Keras, and even [Tensorflow][6], Google's machine learning framework. These libraries are great for [home projects][7], including image and facial recognition with the [camera module][8]. For inspiration, take a look at the Raspberry Pi category on [PyImageSearch][9] (which is one of my [favorite Raspberry Pi blogs][10]) to follow.
|
||||
|
||||

|
||||
|
||||
Read more about piwheels on the project's [blog][11] and the [Raspberry Pi blog][12], see the [source code on GitHub][13], and check out the [piwheels website][2]. If you want to contribute to the project, check the [missing packages tag][14] and see if you can successfully build one of them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/piwheels-python-raspberrypi
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pypi.org/
|
||||
[2]: https://www.piwheels.org/
|
||||
[3]: https://www.mythic-beasts.com/order/rpi
|
||||
[4]: https://en.wikipedia.org/wiki/Pip_(package_manager)
|
||||
[5]: https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
|
||||
[6]: https://www.tensorflow.org/
|
||||
[7]: https://opensource.com/article/17/4/5-projects-raspberry-pi-home
|
||||
[8]: https://opensource.com/life/15/6/raspberry-pi-camera-projects
|
||||
[9]: https://www.pyimagesearch.com/category/raspberry-pi/
|
||||
[10]: https://opensource.com/article/18/8/top-10-raspberry-pi-blogs-follow
|
||||
[11]: https://blog.piwheels.org/
|
||||
[12]: https://www.raspberrypi.org/blog/piwheels/
|
||||
[13]: https://github.com/bennuttall/piwheels
|
||||
[14]: https://github.com/bennuttall/piwheels/issues?q=is%3Aissue+is%3Aopen+label%3A%22missing+package%22
|
||||
@ -0,0 +1,327 @@
|
||||
Automating upstream releases with release-bot
|
||||
======
|
||||
All you need to do is file an issue into your upstream repository and release-bot takes care of the rest.
|
||||

|
||||
|
||||
If you own or maintain a GitHub repo and have ever pushed a package from it into [PyPI][1] and/or [Fedora][2], you know it requires some additional work using the Fedora infrastructure.
|
||||
|
||||
Good news: We have developed a tool called [release-bot][3] that automates the process. All you need to do is file an issue into your upstream repository and release-bot takes care of the rest. But let’s not get ahead of ourselves. First, let’s look at what needs to be set up for this automation to happen. I’ve chosen the **meta-test-family** upstream repository as an example.
|
||||
|
||||
### Configuration files for release-bot
|
||||
|
||||
There are two configuration files for release-bot: **conf.yaml** and **release-conf.yaml**.
|
||||
|
||||
#### conf.yaml
|
||||
|
||||
**conf.yaml** must be accessible during bot initialization; it specifies how to access the GitHub repository. To show that, I have created a new git repository named **mtf-release-bot** , which contains **conf.yaml** and the other secret files.
|
||||
|
||||
```
|
||||
repository_name: name
|
||||
repository_owner: owner
|
||||
# https://help.github.com/articles/creating-a-personal-access-token-for-the-command-line/
|
||||
github_token: xxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
# time in seconds during checks for new releases
|
||||
refresh_interval: 180
|
||||
```
|
||||
|
||||
For the meta-test-family case, the configuration file looks like this:
|
||||
|
||||
```
|
||||
repository_name: meta-test-family
|
||||
repository_owner: fedora-modularity
|
||||
github_token: xxxxxxxxxxxxxxxxxxxxx
|
||||
refresh_interval: 180
|
||||
```
|
||||
|
||||
#### release-conf.yaml
|
||||
|
||||
**release-conf.yaml** must be stored [in the repository itself][4]; it specifies how to do GitHub/PyPI/Fedora releases.
|
||||
|
||||
```
|
||||
# list of major python versions that bot will build separate wheels for
|
||||
python_versions:
|
||||
- 2
|
||||
- 3
|
||||
# optional:
|
||||
changelog:
|
||||
- Example changelog entry
|
||||
- Another changelog entry
|
||||
# this is info for the authorship of the changelog
|
||||
# if this is not set, person who merged the release PR will be used as an author
|
||||
author_name: John Doe
|
||||
author_email: johndoe@example.com
|
||||
# whether to release on fedora. False by default
|
||||
fedora: false
|
||||
# list of fedora branches bot should release on. Master is always implied
|
||||
fedora_branches:
|
||||
- f27
|
||||
```
|
||||
|
||||
For the meta-test-family case, the configuration file looks like this:
|
||||
|
||||
```
|
||||
python_versions:
|
||||
- 2
|
||||
fedora: true
|
||||
fedora_branches:
|
||||
- f29
|
||||
- f28
|
||||
trigger_on_issue: true
|
||||
```
|
||||
|
||||
#### PyPI configuration file
|
||||
|
||||
The file **.pypirc** , stored in your **mtf-release-bot** private repository, is needed for uploading the new package version into PyPI:
|
||||
|
||||
```
|
||||
[pypi]
|
||||
username = phracek
|
||||
password = xxxxxxxx
|
||||
```
|
||||
|
||||
Private SSH key, **id_rsa** , that you configured in [FAS][5].
|
||||
|
||||
The final structure of the git repository, with **conf.yaml** and the others, looks like this:
|
||||
|
||||
```
|
||||
$ ls -la
|
||||
total 24
|
||||
drwxrwxr-x 3 phracek phracek 4096 Sep 24 12:38 .
|
||||
drwxrwxr-x. 20 phracek phracek 4096 Sep 24 12:37 ..
|
||||
-rw-rw-r-- 1 phracek phracek 199 Sep 24 12:26 conf.yaml
|
||||
drwxrwxr-x 8 phracek phracek 4096 Sep 24 12:38 .git
|
||||
-rw-rw-r-- 1 phracek phracek 3243 Sep 24 12:38 id_rsa
|
||||
-rw------- 1 phracek phracek 78 Sep 24 12:28 .pypirc
|
||||
```
|
||||
|
||||
### Requirements
|
||||
|
||||
**requirements.txt** with both versions of pip. You must also set up your PyPI login details in **$HOME/.pypirc** , as described in the `-k/–keytab`. Also, **fedpkg** requires that you have an SSH key in your keyring that you uploaded to FAS.
|
||||
|
||||
### How to deploy release-bot
|
||||
|
||||
Releasing to PyPI requires the [wheel package][6] for both Python 2 and Python 3, so installwith both versions of pip. You must also set up your PyPI login details in, as described in the [PyPI documentation][7] . If you are releasing to Fedora, you must have an active [Kerberos][8] ticket while the bot runs, or specify the path to the Kerberos keytab file with. Also,requires that you have an SSH key in your keyring that you uploaded to FAS.
|
||||
|
||||
There are two ways to use release-bot: as a Docker image or as an OpenShift template.
|
||||
|
||||
#### Docker image
|
||||
|
||||
Let’s build the image using the `s2i` command:
|
||||
|
||||
```
|
||||
$ s2i build $CONFIGURATION_REPOSITORY_URL usercont/release-bot app-name
|
||||
```
|
||||
|
||||
where `$CONFIGURATION_REPOSITORY_URL` is a reference to the GitHub repository, like _https:// <GIT_LAB_PATH>/mtf-release-conf._
|
||||
|
||||
Let’s look at Docker images:
|
||||
|
||||
```
|
||||
$ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
mtf-release-bot latest 08897871e65e 6 minutes ago 705 MB
|
||||
docker.io/usercont/release-bot latest 5b34aa670639 9 days ago 705 MB
|
||||
```
|
||||
|
||||
Now let’s try to run the **mtf-release-bot** image with this command:
|
||||
|
||||
```
|
||||
$ docker run mtf-release-bot
|
||||
---> Setting up ssh key...
|
||||
Agent pid 12
|
||||
Identity added: ./.ssh/id_rsa (./.ssh/id_rsa)
|
||||
12:21:18.982 configuration.py DEBUG Loaded configuration for fedora-modularity/meta-test-family
|
||||
12:21:18.982 releasebot.py INFO release-bot v0.4.1 reporting for duty!
|
||||
12:21:18.982 github.py DEBUG Fetching release-conf.yaml
|
||||
12:21:37.611 releasebot.py DEBUG No merged release PR found
|
||||
12:21:38.282 releasebot.py INFO Found new release issue with version: 0.8.5
|
||||
12:21:42.565 releasebot.py DEBUG No more open issues found
|
||||
12:21:43.190 releasebot.py INFO Making a new PR for release of version 0.8.5 based on an issue.
|
||||
12:21:46.709 utils.py DEBUG ['git', 'clone', 'https://github.com/fedora-modularity/meta-test-family.git', '.']
|
||||
|
||||
12:21:47.401 github.py DEBUG {"message":"Branch not found","documentation_url":"https://developer.github.com/v3/repos/branches/#get-branch"}
|
||||
12:21:47.994 utils.py DEBUG ['git', 'config', 'user.email', 'the.conu.bot@gmail.com']
|
||||
|
||||
12:21:47.996 utils.py DEBUG ['git', 'config', 'user.name', 'Release bot']
|
||||
|
||||
12:21:48.009 utils.py DEBUG ['git', 'checkout', '-b', '0.8.5-release']
|
||||
|
||||
12:21:48.014 utils.py ERROR No version files found. Aborting version update.
|
||||
12:21:48.014 utils.py WARNING No CHANGELOG.md present in repository
|
||||
[Errno 2] No such file or directory: '/tmp/tmpmbvb05jq/CHANGELOG.md'
|
||||
12:21:48.020 utils.py DEBUG ['git', 'commit', '--allow-empty', '-m', '0.8.5 release']
|
||||
[0.8.5-release 7ee62c6] 0.8.5 release
|
||||
|
||||
12:21:51.342 utils.py DEBUG ['git', 'push', 'origin', '0.8.5-release']
|
||||
|
||||
12:21:51.905 github.py DEBUG No open PR's found
|
||||
12:21:51.905 github.py DEBUG Attempting a PR for 0.8.5-release branch
|
||||
12:21:53.215 github.py INFO Created PR: https://github.com/fedora-modularity/meta-test-family/pull/243
|
||||
12:21:53.216 releasebot.py INFO I just made a PR request for a release version 0.8.5
|
||||
12:21:54.154 github.py DEBUG Comment added to PR: I just made a PR request for a release version 0.8.5
|
||||
Here's a [link to the PR](https://github.com/fedora-modularity/meta-test-family/pull/243)
|
||||
12:21:54.154 github.py DEBUG Attempting to close issue #242
|
||||
12:21:54.992 github.py DEBUG Closed issue #242
|
||||
```
|
||||
|
||||
As you can see, release-bot automatically closed the following issue, requesting a new upstream release of the meta-test-family: [https://github.com/fedora-modularity/meta-test-family/issues/243][9].
|
||||
|
||||
In addition, release-bot created a new PR with changelog. You can update the PR—for example, squash changelog—and once you merge it, it will automatically release to GitHub, and PyPI and Fedora will start.
|
||||
|
||||
You now have a working solution to easily release upstream versions of your package into PyPi and Fedora.
|
||||
|
||||
#### OpenShift template
|
||||
|
||||
Another option to deliver automated releases using release-bot is to deploy it in OpenShift.
|
||||
|
||||
The OpenShift template looks as follows:
|
||||
|
||||
```
|
||||
kind: Template
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: release-bot
|
||||
annotations:
|
||||
description: S2I Relase-bot image builder
|
||||
tags: release-bot s2i
|
||||
iconClass: icon-python
|
||||
labels:
|
||||
template: release-bot
|
||||
role: releasebot_application_builder
|
||||
objects:
|
||||
- kind : ImageStream
|
||||
apiVersion : v1
|
||||
metadata :
|
||||
name : ${APP_NAME}
|
||||
labels :
|
||||
appid : release-bot-${APP_NAME}
|
||||
- kind : ImageStream
|
||||
apiVersion : v1
|
||||
metadata :
|
||||
name : ${APP_NAME}-s2i
|
||||
labels :
|
||||
appid : release-bot-${APP_NAME}
|
||||
spec :
|
||||
tags :
|
||||
- name : latest
|
||||
from :
|
||||
kind : DockerImage
|
||||
name : usercont/release-bot:latest
|
||||
#importPolicy:
|
||||
# scheduled: true
|
||||
- kind : BuildConfig
|
||||
apiVersion : v1
|
||||
metadata :
|
||||
name : ${APP_NAME}
|
||||
labels :
|
||||
appid : release-bot-${APP_NAME}
|
||||
spec :
|
||||
triggers :
|
||||
- type : ConfigChange
|
||||
- type : ImageChange
|
||||
source :
|
||||
type : Git
|
||||
git :
|
||||
uri : ${CONFIGURATION_REPOSITORY}
|
||||
contextDir : ${CONFIGURATION_REPOSITORY}
|
||||
sourceSecret :
|
||||
name : release-bot-secret
|
||||
strategy :
|
||||
type : Source
|
||||
sourceStrategy :
|
||||
from :
|
||||
kind : ImageStreamTag
|
||||
name : ${APP_NAME}-s2i:latest
|
||||
output :
|
||||
to :
|
||||
kind : ImageStreamTag
|
||||
name : ${APP_NAME}:latest
|
||||
- kind : DeploymentConfig
|
||||
apiVersion : v1
|
||||
metadata :
|
||||
name: ${APP_NAME}
|
||||
labels :
|
||||
appid : release-bot-${APP_NAME}
|
||||
spec :
|
||||
strategy :
|
||||
type : Rolling
|
||||
triggers :
|
||||
- type : ConfigChange
|
||||
- type : ImageChange
|
||||
imageChangeParams :
|
||||
automatic : true
|
||||
containerNames :
|
||||
- ${APP_NAME}
|
||||
from :
|
||||
kind : ImageStreamTag
|
||||
name : ${APP_NAME}:latest
|
||||
replicas : 1
|
||||
selector :
|
||||
deploymentconfig : ${APP_NAME}
|
||||
template :
|
||||
metadata :
|
||||
labels :
|
||||
appid: release-bot-${APP_NAME}
|
||||
deploymentconfig : ${APP_NAME}
|
||||
spec :
|
||||
containers :
|
||||
- name : ${APP_NAME}
|
||||
image : ${APP_NAME}:latest
|
||||
resources:
|
||||
requests:
|
||||
memory: "64Mi"
|
||||
cpu: "50m"
|
||||
limits:
|
||||
memory: "128Mi"
|
||||
cpu: "100m"
|
||||
|
||||
parameters :
|
||||
- name : APP_NAME
|
||||
description : Name of application
|
||||
value :
|
||||
required : true
|
||||
- name : CONFIGURATION_REPOSITORY
|
||||
description : Git repository with configuration
|
||||
value :
|
||||
required : true
|
||||
```
|
||||
|
||||
The easiest way to deploy the **mtf-release-bot** repository with secret files into OpenShift is to use the following two commands:
|
||||
|
||||
```
|
||||
$ curl -sLO https://github.com/user-cont/release-bot/raw/master/openshift-template.yml
|
||||
```
|
||||
|
||||
In your OpenShift instance, deploy the template by running the following command:
|
||||
|
||||
```
|
||||
oc process -p APP_NAME="mtf-release-bot" -p CONFIGURATION_REPOSITORY="git@<git_lab_path>/mtf-release-conf.git" -f openshift-template.yml | oc apply
|
||||
```
|
||||
|
||||
### Summary
|
||||
|
||||
See the [example pull request][10] in the meta-test-family upstream repository, where you'll find information about what release-bot released. Once you get to this point, you can see that release-bot is able to push new upstream versions into GitHub, PyPI, and Fedora without heavy user intervention. It automates all the steps so you don’t need to manually upload and build new upstream versions of your package.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/upstream-releases-pypi-fedora-release-bot
|
||||
|
||||
作者:[Petr Stone Hracek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/phracek
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pypi.org/
|
||||
[2]: https://getfedora.org/
|
||||
[3]: https://github.com/user-cont/release-bot
|
||||
[4]: https://github.com/fedora-modularity/meta-test-family
|
||||
[5]: https://admin.fedoraproject.org/accounts/
|
||||
[6]: https://pypi.org/project/wheel/
|
||||
[7]: https://packaging.python.org/tutorials/distributing-packages/#create-an-account
|
||||
[8]: https://web.mit.edu/kerberos/
|
||||
[9]: https://github.com/fedora-modularity/meta-test-family/issues/238
|
||||
[10]: https://github.com/fedora-modularity/meta-test-family/pull/243
|
||||
@ -0,0 +1,80 @@
|
||||
Browsing the web with Min, a minimalist open source web browser
|
||||
======
|
||||
Not every web browser needs to carry every single feature. Min puts a minimalist spin on the everyday web browser.
|
||||

|
||||
|
||||
Does the world need another web browser? Even though the days of having a multiplicity of browsers to choose from are long gone, there still are folks out there developing new applications that help us use the web.
|
||||
|
||||
One of those new-fangled browsers is [Min][1]. As its name suggests (well, suggests to me, anyway), Min is a minimalist browser. That doesn't mean it's deficient in any significant way, and its open source, Apache 2.0 license piques my interest.
|
||||
|
||||
But is Min worth a look? Let's find out.
|
||||
|
||||
### Getting going
|
||||
|
||||
Min is one of many applications written using a development framework called [Electron][2]. (It's the same framework that brought us the [Atom text editor][3].) You can [get installers][4] for Linux, MacOS, and Windows. You can also grab the [source code from GitHub][5] and compile it if you're inclined.
|
||||
|
||||
I run Manjaro Linux, and there isn't an installer for that distro. Luckily, I was able to install Min from Manjaro's package manager.
|
||||
|
||||
Once that was done, I fired up Min by pressing Alt+F2, typing **min** in the run-application box, and pressing Enter, and I was ready to go.
|
||||
|
||||
|
||||
|
||||
Min is billed as a smarter, faster web browser. It definitely is fast—at the risk of drawing the ire of denizens of certain places on the web, I'll say that it starts faster than Firefox and Chrome on the laptops with which I tried it.
|
||||
|
||||
Browsing with Min is like browsing with Firefox or Chrome. Type a URL in the address bar, press Enter, and away you go.
|
||||
|
||||
### Min's features
|
||||
|
||||
While Min doesn't pack everything you'd find in browsers like Firefox or Chrome, it doesn't do too badly.
|
||||
|
||||
Like any other browser these days, Min supports multiple tabs. It also has a feature called Tasks, which lets you group your open tabs.
|
||||
|
||||
Min's default search engine is [DuckDuckGo][6]. I really like that touch because DuckDuckGo is one of my search engines of choice. If DuckDuckGo isn't your thing, you can set another search engine as the default in Min's preferences.
|
||||
|
||||
Instead of using tools like AdBlock to filter out content you don't want, Min has a built-in ad blocker. It uses the [EasyList filters][7], which were created for AdBlock. You can block scripts and images, and Min also has a built-in tracking blocker.
|
||||
|
||||
Like Firefox, Min has a reading mode called Reading List. Flipping the Reading List switch (well, clicking the icon in the address bar) removes most of the cruft from a page so you can focus on the words you're reading. Pages stay in the Reading List for 30 days.
|
||||
|
||||
|
||||
|
||||
Speaking of focus, Min also has a Focus Mode that hides and prevents you from opening other tabs. So, if you're working in a web application, you'll need to click a few times if you feel like procrastinating.
|
||||
|
||||
Of course, Min has a number of keyboard shortcuts that can make using it a lot faster. You can find a reference for those shortcuts [on GitHub][8]. You can also change a number of them in Min's preferences.
|
||||
|
||||
I was pleasantly surprised to find Min can play videos on YouTube, Vimeo, Dailymotion, and similar sites. I also played sample tracks at music retailer 7Digital. I didn't try playing music on popular sites like Spotify or Last.fm (because I don't have accounts with them).
|
||||
|
||||
|
||||
|
||||
### What's not there
|
||||
|
||||
The features that Min doesn't pack are as noticeable as the ones it does. There doesn't seem to be a way to bookmark sites. You either have to rely on Min's search history to find your favorite links, or you'll have to rely on a bookmarking service.
|
||||
|
||||
On top of that, Min doesn't support plugins. That's not a deal breaker for me—not having plugins is undoubtedly one of the reasons the browser starts and runs so quickly. I know a number of people who are … well, I wouldn't go so far to say junkies, but they really like their plugins. Min wouldn't cut it for them.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Min isn't a bad browser. It's light and fast enough to appeal to the minimalists out there. That said, it lacks features that hardcore web browser users clamor for.
|
||||
|
||||
If you want a zippy browser that isn't weighed down by all the features of so-called modern web browsers, I suggest giving Min a serious look.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/min-web-browser
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://minbrowser.github.io/min/
|
||||
[2]: http://electron.atom.io/apps/
|
||||
[3]: https://opensource.com/article/17/5/atom-text-editor-packages-writers
|
||||
[4]: https://github.com/minbrowser/min/releases/
|
||||
[5]: https://github.com/minbrowser/min
|
||||
[6]: http://duckduckgo.com
|
||||
[7]: https://easylist.to/
|
||||
[8]: https://github.com/minbrowser/min/wiki
|
||||
@ -0,0 +1,226 @@
|
||||
Chrony – An Alternative NTP Client And Server For Unix-like Systems
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this tutorial, we will be discussing how to install and configure **Chrony** , an alternative NTP client and server for Unix-like systems. Chrony can synchronise the system clock faster with better time accuracy and it can be particularly useful for the systems which are not online all the time. Chrony is free, open source and supports GNU/Linux and BSD variants such as FreeBSD, NetBSD, macOS, and Solaris.
|
||||
|
||||
### Installing Chrony
|
||||
|
||||
Chrony is available in the default repositories of most Linux distributions. If you’re on Arch Linux, run the following command to install it:
|
||||
|
||||
```
|
||||
$ sudo pacman -S chrony
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install chrony
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install chrony
|
||||
```
|
||||
|
||||
Once installed, start **chronyd.service** daemon if it is not started already:
|
||||
|
||||
```
|
||||
$ sudo systemctl start chronyd.service
|
||||
```
|
||||
|
||||
Make it to start automatically on every reboot using command:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable chronyd.service
|
||||
```
|
||||
|
||||
To verify if the Chronyd.service has been started, run:
|
||||
|
||||
```
|
||||
$ sudo systemctl status chronyd.service
|
||||
```
|
||||
|
||||
If everything is OK, you will see an output something like below.
|
||||
|
||||
```
|
||||
● chrony.service - chrony, an NTP client/server
|
||||
Loaded: loaded (/lib/systemd/system/chrony.service; enabled; vendor preset: ena
|
||||
Active: active (running) since Wed 2018-10-17 10:34:53 UTC; 3min 15s ago
|
||||
Docs: man:chronyd(8)
|
||||
man:chronyc(1)
|
||||
man:chrony.conf(5)
|
||||
Main PID: 2482 (chronyd)
|
||||
Tasks: 1 (limit: 2320)
|
||||
CGroup: /system.slice/chrony.service
|
||||
└─2482 /usr/sbin/chronyd
|
||||
|
||||
Oct 17 10:34:53 ubuntuserver systemd[1]: Starting chrony, an NTP client/server...
|
||||
Oct 17 10:34:53 ubuntuserver chronyd[2482]: chronyd version 3.2 starting (+CMDMON
|
||||
Oct 17 10:34:53 ubuntuserver chronyd[2482]: Initial frequency -268.088 ppm
|
||||
Oct 17 10:34:53 ubuntuserver systemd[1]: Started chrony, an NTP client/server.
|
||||
Oct 17 10:35:03 ubuntuserver chronyd[2482]: Selected source 85.25.84.166
|
||||
Oct 17 10:35:03 ubuntuserver chronyd[2482]: Source 85.25.84.166 replaced with 2403
|
||||
Oct 17 10:35:03 ubuntuserver chronyd[2482]: Selected source 91.189.89.199
|
||||
Oct 17 10:35:06 ubuntuserver chronyd[2482]: Selected source 106.10.186.200
|
||||
```
|
||||
|
||||
As you can see, Chrony service is started and working!
|
||||
|
||||
### Configure Chrony
|
||||
|
||||
The NTP clients needs to know which NTP servers it should contact to get the current time. We can specify the NTP servers in the **server** or **pool** directive in the NTP configuration file. Usually, the default configuration file is **/etc/chrony/chrony.conf** or **/etc/chrony.conf** depending upon the Linux distribution version. For better reliability, it is recommended to specify at least three servers.
|
||||
|
||||
The following lines are just an example taken from my Ubuntu 18.04 LTS server.
|
||||
|
||||
```
|
||||
[...]
|
||||
# About using servers from the NTP Pool Project in general see (LP: #104525).
|
||||
# Approved by Ubuntu Technical Board on 2011-02-08.
|
||||
# See http://www.pool.ntp.org/join.html for more information.
|
||||
pool ntp.ubuntu.com iburst maxsources 4
|
||||
pool 0.ubuntu.pool.ntp.org iburst maxsources 1
|
||||
pool 1.ubuntu.pool.ntp.org iburst maxsources 1
|
||||
pool 2.ubuntu.pool.ntp.org iburst maxsources 2
|
||||
[...]
|
||||
```
|
||||
|
||||
As you see in the above output, [**NTP Pool Project**][1] has been set as the default time server. For those wondering, NTP pool project is the cluster of time servers that provides NTP service for tens of millions clients across the world. It is the default time server for Ubuntu and most of the other major Linux distributions.
|
||||
|
||||
Here,
|
||||
|
||||
* the **iburst** option is used to speed up the initial synchronisation.
|
||||
* the **maxsources** refers the maximum number of NTP sources.
|
||||
|
||||
|
||||
|
||||
Please make sure that the NTP servers you have chosen are well synchronised, stable and close to your location to improve the accuracy of the time with NTP sources.
|
||||
|
||||
### Manage Chronyd from command line
|
||||
|
||||
Chrony has a command line utility named **chronyc** to control and monitor the **chrony** daemon (chronyd).
|
||||
|
||||
To check if **chrony** is synchronized, we can use the **tracking** command as shown below.
|
||||
|
||||
```
|
||||
$ chronyc tracking
|
||||
Reference ID : 6A0ABAC8 (t1.time.sg3.yahoo.com)
|
||||
Stratum : 3
|
||||
Ref time (UTC) : Wed Oct 17 11:48:51 2018
|
||||
System time : 0.000984587 seconds slow of NTP time
|
||||
Last offset : -0.000912981 seconds
|
||||
RMS offset : 0.007983995 seconds
|
||||
Frequency : 23.704 ppm slow
|
||||
Residual freq : +0.006 ppm
|
||||
Skew : 1.734 ppm
|
||||
Root delay : 0.089718960 seconds
|
||||
Root dispersion : 0.008760406 seconds
|
||||
Update interval : 515.1 seconds
|
||||
Leap status : Normal
|
||||
```
|
||||
|
||||
We can verify the current time sources that chrony uses with command:
|
||||
|
||||
```
|
||||
$ chronyc sources
|
||||
210 Number of sources = 8
|
||||
MS Name/IP address Stratum Poll Reach LastRx Last sample
|
||||
===============================================================================
|
||||
^- chilipepper.canonical.com 2 10 377 296 +102ms[ +104ms] +/- 279ms
|
||||
^- golem.canonical.com 2 10 377 302 +105ms[ +107ms] +/- 290ms
|
||||
^+ pugot.canonical.com 2 10 377 297 +36ms[ +38ms] +/- 238ms
|
||||
^- alphyn.canonical.com 2 10 377 279 -43ms[ -42ms] +/- 238ms
|
||||
^- dadns.cdnetworks.co.kr 2 10 377 1070 +40ms[ +42ms] +/- 314ms
|
||||
^* t1.time.sg3.yahoo.com 2 10 377 169 -13ms[ -11ms] +/- 80ms
|
||||
^+ sin1.m-d.net 2 10 275 567 -9633us[-7826us] +/- 115ms
|
||||
^- ns2.pulsation.fr 2 10 377 311 -75ms[ -73ms] +/- 250ms
|
||||
```
|
||||
|
||||
Chronyc utility can find the statistics of each sources, such as drift rate and offset estimation process, using **sourcestats** command.
|
||||
|
||||
```
|
||||
$ chronyc sourcestats
|
||||
210 Number of sources = 8
|
||||
Name/IP Address NP NR Span Frequency Freq Skew Offset Std Dev
|
||||
==============================================================================
|
||||
chilipepper.canonical.com 32 16 89m +6.293 14.345 +30ms 24ms
|
||||
golem.canonical.com 32 17 89m +0.312 18.887 +20ms 33ms
|
||||
pugot.canonical.com 32 18 89m +0.281 11.237 +3307us 23ms
|
||||
alphyn.canonical.com 31 20 88m -4.087 8.910 -58ms 17ms
|
||||
dadns.cdnetworks.co.kr 29 16 76m -1.094 9.895 -83ms 14ms
|
||||
t1.time.sg3.yahoo.com 32 16 91m +0.153 1.952 +2835us 4044us
|
||||
sin1.m-d.net 29 13 83m +0.049 6.060 -8466us 9940us
|
||||
ns2.pulsation.fr 32 17 88m +0.784 9.834 -62ms 22ms
|
||||
```
|
||||
|
||||
If your system is not connected to Internet, you need to notify Chrony that the system is not connected to the Internet. To do so, run:
|
||||
|
||||
```
|
||||
$ sudo chronyc offline
|
||||
[sudo] password for sk:
|
||||
200 OK
|
||||
```
|
||||
|
||||
To verify the status of your NTP sources, simply run:
|
||||
|
||||
```
|
||||
$ chronyc activity
|
||||
200 OK
|
||||
0 sources online
|
||||
8 sources offline
|
||||
0 sources doing burst (return to online)
|
||||
0 sources doing burst (return to offline)
|
||||
0 sources with unknown address
|
||||
```
|
||||
|
||||
As you see, all my NTP sources are down at the moment.
|
||||
|
||||
Once you’re connected to the Internet, just notify Chrony that your system is back online using command:
|
||||
|
||||
```
|
||||
$ sudo chronyc online
|
||||
200 OK
|
||||
```
|
||||
|
||||
To view the status of NTP source(s), run:
|
||||
|
||||
```
|
||||
$ chronyc activity
|
||||
200 OK
|
||||
8 sources online
|
||||
0 sources offline
|
||||
0 sources doing burst (return to online)
|
||||
0 sources doing burst (return to offline)
|
||||
0 sources with unknown address
|
||||
```
|
||||
|
||||
For more detailed explanation of all options and parameters, refer the man pages.
|
||||
|
||||
```
|
||||
$ man chronyc
|
||||
|
||||
$ man chronyd
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this was useful. In the subsequent tutorials, we will see how to setup a local NTP server using Chrony and configure the clients to use it to synchronise time.
|
||||
|
||||
Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/chrony-an-alternative-ntp-client-and-server-for-unix-like-systems/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ntppool.org/en/
|
||||
@ -1,131 +1,133 @@
|
||||
Linux vs Mac: Linux 比 Mac 好的七个原因
|
||||
======
|
||||
最近我们谈论了一些[为什么 Linux 比 Windows 好][1]的原因。毫无疑问, Linux 是个非常优秀的平台。但是它和其他的操作系统一样也会有缺点。对于某些专门的领域,像是游戏, Windows 当然更好。 而对于视频编辑等任务, Mac 系统可能更为方便。这一切都取决于你的爱好,以及你想用你的系统做些什么。在这篇文章中,我们将会介绍一些 Linux 相对于 Mac 更好的一些地方。
|
||||
|
||||
如果你已经在用 Mac 或者打算买一台 Mac 电脑,我们建议你仔细考虑一下,看看是改为使用 Linux 还是继续使用 Mac 。
|
||||
|
||||
### Linux 比 Mac 好的 7 个原因
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][2]
|
||||
|
||||
Linux 和 macOS 都是类 Unix 操作系统,并且都支持 Unix 命令行、 bash 和其他一些命令行工具,相比于 Windows ,他们所支持的应用和游戏比较少。但缺点也仅仅如此。
|
||||
|
||||
平面设计师和视频剪辑师更加倾向于使用 Mac 系统,而 Linux 更加适合做开发、系统管理、运维的工程师。
|
||||
|
||||
那要不要使用 Linux 呢,为什么要选择 Linux 呢?下面是根据实际经验和理性分析给出的一些建议。
|
||||
|
||||
#### 1\. 价格
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][3]
|
||||
|
||||
假设你只是需要浏览文件、看电影、下载图片、写文档、制作报表或者做一些类似的工作,并且你想要一个更加安全的系统。
|
||||
|
||||
那在这种情况下,你觉得花费几百块买个系统完成这项工作,或者花费更多直接买个 Macbook 划算吗?当然,最终的决定权还是在你。
|
||||
|
||||
买个装好 Mac 系统的电脑还是买个便宜的电脑,然后自己装上免费的 Linux 系统,这个要看你自己的偏好。就我个人而言,除了音视频剪辑创作之外,Linux 都非常好地用,而对于音视频方面,我更倾向于使用 Final Cut Pro (专业的视频编辑软件) 和 Logic Pro X (专业的音乐制作软件)(这两款软件都是苹果公司推出的)。
|
||||
|
||||
#### 2\. 硬件支持
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][4]
|
||||
|
||||
Linux 支持多种平台. 无论你的电脑配置如何,你都可以在上面安装 Linux,无论性能好或者差,Linux 都可以运行。[即使你的电脑已经使用很久了, 你仍然可以通过选择安装合适的发行版让 Linux 在你的电脑上流畅的运行][5].
|
||||
|
||||
而 Mac 不同,它是苹果机专用系统。如果你希望买个便宜的电脑,然后自己装上 Mac 系统,这几乎是不可能的。一般来说 Mac 都是和苹果设备连在一起的。
|
||||
|
||||
这是[在非苹果系统上安装 Mac OS 的教程][6]. 这里面需要用到的专业技术以及可能遇到的一些问题将会花费你许多时间,你需要想好这样做是否值得。
|
||||
|
||||
总之,Linux 所支持的硬件平台很广泛,而 MacOS 相对而言则非常少。
|
||||
|
||||
#### 3\. 安全性
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][7]
|
||||
|
||||
很多人都说 ios 和 Mac 是非常安全的平台。的确,相比于 Windows ,它确实比较安全,可并不一定有 Linux 安全。
|
||||
|
||||
我不是在危言耸听。 Mac 系统上也有不少恶意软件和广告,并且[数量与日俱增][8]。我认识一些不太懂技术的用户 使用着非常缓慢的 Mac 电脑并且为此苦苦挣扎。一项快速调查显示[浏览器恶意劫持软件][9]是罪魁祸首.
|
||||
|
||||
从来没有绝对安全的操作系统,Linux 也不例外。 Linux 也有漏洞,但是 Linux 发行版提供的及时更新弥补了这些漏洞。另外,到目前为止在 Linux 上还没有自动运行的病毒或浏览器劫持恶意软件的案例发生。
|
||||
|
||||
这可能也是一个你应该选择 Linux 而不是 Mac 的原因。
|
||||
|
||||
#### 4\. 可定制性与灵活性
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][10]
|
||||
|
||||
如果你有不喜欢的东西,自己定制或者修改它都行。
|
||||
|
||||
举个例子,如果你不喜欢 Ubuntu 18.04.1 的 [Gnome 桌面环境][11],你可以换成 [KDE Plasma][11]。 你也可以尝试一些 [Gnome 扩展][12]丰富你的桌面选择。这种灵活性和可定制性在 Mac OS 是不可能有的。
|
||||
|
||||
除此之外你还可以根据需要修改一些操作系统的代码(但是可能需要一些专业知识)以创造出适合你的系统。这个在 Mac OS 上可以做吗?
|
||||
|
||||
另外你可以根据需要从一系列的 Linux 发行版进行选择。比如说,如果你想喜欢 Mac OS上的工作流, [Elementary OS][13] 可能是个不错的选择。你想在你的旧电脑上装上一个轻量级的 Linux 发行版系统吗?这里是一个[轻量级 Linux 发行版列表][5]。相比较而言, Mac OS 缺乏这种灵活性。
|
||||
|
||||
#### 5\. 使用 Linux 有助于你的职业生涯 [针对 IT 行业和科学领域的学生]
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][14]
|
||||
|
||||
对于 IT 领域的学生和求职者而言,这是有争议的但是也是有一定的帮助的。使用 Linux 并不会让你成为一个优秀的人,也不一定能让你得到任何与 IT 相关的工作。
|
||||
|
||||
但是当你开始使用 Linux 并且开始探索如何使用的时候,你将会获得非常多的经验。作为一名技术人员,你迟早会接触终端,学习通过命令行实现文件系统管理以及应用程序安装。你可能不会知道这些都是一些 IT 公司的新职员需要培训的内容。
|
||||
|
||||
除此之外,Linux 在就业市场上还有很大的发展空间。 Linux 相关的技术有很多( Cloud 、 Kubernetes 、Sysadmin 等),您可以学习,获得证书并获得一份相关的高薪的工作。要学习这些,你必须使用 Linux 。
|
||||
|
||||
#### 6\. 可靠
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][15]
|
||||
|
||||
想想为什么服务器上用的都是 Linux 系统,当然是因为它可靠。
|
||||
|
||||
但是它为什么可靠呢,相比于 Mac OS ,它的可靠体现在什么方面呢?
|
||||
|
||||
答案很简单——给用户更多的控制权,同时提供更好的安全性。在 Mac OS 上,你并不能完全控制它,这样做是为了让操作变得更容易,同时提高你的用户体验。使用 Linux ,你可以做任何你想做的事情——这可能会导致(对某些人来说)糟糕的用户体验——但它确实使其更可靠。
|
||||
|
||||
#### 7\. 开源
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][16]
|
||||
|
||||
开源并不是每个人都关心的。但对我来说,Linux 最重要的优势在于它的开源特性。下面讨论的大多数观点都是开源软件的直接优势。
|
||||
|
||||
简单解释一下,如果是开源软件,你可以自己查看或者修改它。但对 Mac 来说,苹果拥有独家控制权。即使你有足够的技术知识,也无法查看 Mac OS 的源代码。
|
||||
|
||||
形象点说,Mac 驱动的系统可以让你得到一辆车,但缺点是你不能打开引擎盖看里面是什么。那可能非常糟糕!
|
||||
|
||||
如果你想深入了解开源软件的优势,可以在 OpenSource.com 上浏览一下 [Ben Balter 的文章][17]。
|
||||
|
||||
### 总结
|
||||
|
||||
现在你应该知道为什么 Linux 比 Mac 好了吧,你觉得呢?上面的这些原因可以说服你选择 Linux 吗?如果不行的话那又是为什么呢?
|
||||
|
||||
在下方评论让我们知道你的想法。
|
||||
|
||||
Note: 这里的图片是以企鹅俱乐部为原型的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-vs-mac/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Ryze-Borgia](https://github.com/Ryze-Borgia)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://itsfoss.com/linux-better-than-windows/
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Linux-vs-mac-featured.png
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-1.jpeg
|
||||
[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-4.jpeg
|
||||
[5]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]: https://hackintosh.com/
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-2.jpeg
|
||||
[8]: https://www.computerworld.com/article/3262225/apple-mac/warning-as-mac-malware-exploits-climb-270.html
|
||||
[9]: https://www.imore.com/how-to-remove-browser-hijack
|
||||
[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-3.jpeg
|
||||
[11]: https://www.gnome.org/
|
||||
[12]: https://itsfoss.com/best-gnome-extensions/
|
||||
[13]: https://elementary.io/
|
||||
[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-5.jpeg
|
||||
[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-6.jpeg
|
||||
[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-7.jpeg
|
||||
[17]: https://opensource.com/life/15/12/why-open-source
|
||||
Linux vs Mac:Linux 比 Mac 好的 7 个原因
|
||||
======
|
||||
|
||||
最近我们谈论了一些[为什么 Linux 比 Windows 好][1]的原因。毫无疑问,Linux 是个非常优秀的平台。但是它和其它操作系统一样也会有缺点。对于某些专门的领域,像是游戏,Windows 当然更好。而对于视频编辑等任务,Mac 系统可能更为方便。这一切都取决于你的偏好,以及你想用你的系统做些什么。在这篇文章中,我们将会介绍一些 Linux 相对于 Mac 更好的一些地方。
|
||||
|
||||
如果你已经在用 Mac 或者打算买一台 Mac 电脑,我们建议你仔细考虑一下,看看是改为使用 Linux 还是继续使用 Mac。
|
||||
|
||||
### Linux 比 Mac 好的 7 个原因
|
||||
|
||||
![Linux vs Mac:为什么 Linux 更好][2]
|
||||
|
||||
Linux 和 macOS 都是类 Unix 操作系统,并且都支持 Unix 命令行、bash 和其它 shell,相比于 Windows,它们所支持的应用和游戏比较少。但也就是这点比较相似。
|
||||
|
||||
平面设计师和视频剪辑师更加倾向于使用 Mac 系统,而 Linux 更加适合做开发、系统管理、运维的工程师。
|
||||
|
||||
那要不要使用 Linux 呢,为什么要选择 Linux 呢?下面是根据实际经验和理性分析给出的一些建议。
|
||||
|
||||
#### 1、价格
|
||||
|
||||
![Linux vs Mac:为什么 Linux 更好][3]
|
||||
|
||||
假设你只是需要浏览文件、看电影、下载图片、写文档、制作报表或者做一些类似的工作,并且你想要一个更加安全的系统。
|
||||
|
||||
那在这种情况下,你觉得花费几百美金买个系统完成这项工作,或者花费更多直接买个 Macbook 更好?当然,最终的决定权还是在你。
|
||||
|
||||
买个装好 Mac 系统的电脑?还是买个便宜的电脑,然后自己装上免费的 Linux 系统?这个要看你自己的偏好。就我个人而言,除了音视频剪辑创作之外,Linux 都非常好地用,而对于音视频方面,我更倾向于使用 Final Cut Pro(专业的视频编辑软件)和 Logic Pro X(专业的音乐制作软件)(译注:这两款软件都是苹果公司推出的)。
|
||||
|
||||
#### 2、硬件支持
|
||||
|
||||
![Linux vs Mac:为什么 Linux 更好][4]
|
||||
|
||||
Linux 支持多种平台。无论你的电脑配置如何,你都可以在上面安装 Linux,无论性能好或者差,Linux 都可以运行。[即使你的电脑已经使用很久了,你仍然可以通过选择安装合适的发行版让 Linux 在你的电脑上流畅的运行][5]。
|
||||
|
||||
而 Mac 不同,它是苹果机专用系统。如果你希望买个便宜的电脑,然后自己装上 Mac 系统,这几乎是不可能的。一般来说 Mac 都是和苹果设备配套的。
|
||||
|
||||
这有一些[在非苹果系统上安装 Mac OS 的教程][6]。这里面需要用到的专业技术以及可能遇到的一些问题将会花费你许多时间,你需要想好这样做是否值得。
|
||||
|
||||
总之,Linux 所支持的硬件平台很广泛,而 MacOS 相对而言则非常少。
|
||||
|
||||
#### 3、安全性
|
||||
|
||||
![Linux vs Mac:为什么 Linux 更好][7]
|
||||
|
||||
很多人都说 iOS 和 Mac 是非常安全的平台。的确,或许相比于 Windows,它确实比较安全,可并不一定有 Linux 安全。
|
||||
|
||||
我不是在危言耸听。Mac 系统上也有不少恶意软件和广告,并且[数量与日俱增][8]。我认识一些不太懂技术的用户使用着很慢的 Mac 电脑并且为此深受折磨。一项快速调查显示[浏览器恶意劫持软件][9]是罪魁祸首。
|
||||
|
||||
从来没有绝对安全的操作系统,Linux 也不例外。Linux 也有漏洞,但是 Linux 发行版提供的及时更新弥补了这些漏洞。另外,到目前为止在 Linux 上还没有自动运行的病毒或浏览器劫持恶意软件的案例发生。
|
||||
|
||||
这可能也是一个你应该选择 Linux 而不是 Mac 的原因。
|
||||
|
||||
#### 4、可定制性与灵活性
|
||||
|
||||
![Linux vs Mac:为什么 Linux 更好][10]
|
||||
|
||||
如果你有不喜欢的东西,自己定制或者修改它都行。
|
||||
|
||||
举个例子,如果你不喜欢 Ubuntu 18.04.1 的 [Gnome 桌面环境][11],你可以换成 [KDE Plasma][18]。你也可以尝试一些 [Gnome 扩展][12]丰富你的桌面选择。这种灵活性和可定制性在 Mac OS 是不可能有的。
|
||||
|
||||
除此之外,你还可以根据需要修改一些操作系统的代码(但是可能需要一些专业知识)来打造适合你的系统。这个在 Mac OS 上可以做吗?
|
||||
|
||||
另外你可以根据需要从一系列的 Linux 发行版进行选择。比如说,如果你喜欢 Mac OS 上的工作流,[Elementary OS][13] 可能是个不错的选择。你想在你的旧电脑上装上一个轻量级的 Linux 发行版系统吗?这里是一个[轻量级 Linux 发行版列表][5]。相比较而言,Mac OS 缺乏这种灵活性。
|
||||
|
||||
#### 5、使用 Linux 有助于你的职业生涯(针对 IT 行业和科学领域的学生)
|
||||
|
||||
![Linux vs Mac:为什么 Linux 更好][14]
|
||||
|
||||
对于 IT 领域的学生和求职者而言,这是有争议的但是也是有一定的帮助的。使用 Linux 并不会让你成为一个优秀的人,也不一定能让你得到任何与 IT 相关的工作。
|
||||
|
||||
但是当你开始使用 Linux 并且探索如何使用的时候,你将会积累非常多的经验。作为一名技术人员,你迟早会接触终端,学习通过命令行操作文件系统以及安装应用程序。你可能不会知道这些都是一些 IT 公司的新员工需要培训的内容。
|
||||
|
||||
除此之外,Linux 在就业市场上还有很大的发展空间。Linux 相关的技术有很多(Cloud、Kubernetes、Sysadmin 等),你可以学习,考取专业技能证书并获得一份相关的高薪工作。要学习这些,你必须使用 Linux 。
|
||||
|
||||
#### 6、可靠
|
||||
|
||||
![Linux vs Mac:为什么 Linux 更好][15]
|
||||
|
||||
想想为什么服务器上用的都是 Linux 系统,当然是因为它可靠。
|
||||
|
||||
但是它为什么可靠呢,相比于 Mac OS,它的可靠体现在什么方面呢?
|
||||
|
||||
答案很简单 —— 给用户更多的控制权,同时提供更好的安全性。在 Mac OS 上,你并不能完全控制它,这样做是为了让操作变得更容易,同时提高你的用户体验。使用 Linux,你可以做任何你想做的事情 —— 这可能会导致(对某些人来说)糟糕的用户体验 —— 但它确实使其更可靠。
|
||||
|
||||
#### 7、开源
|
||||
|
||||
![Linux vs Mac:为什么 Linux 更好][16]
|
||||
|
||||
开源并不是每个人都关心的。但对我来说,Linux 最重要的优势在于它的开源特性。下面讨论的大多数观点都是开源软件的直接优势。
|
||||
|
||||
简单解释一下,如果是开源软件,你可以自己查看或者修改源代码。但对 Mac 来说,苹果拥有独家控制权。即使你有足够的技术知识,也无法查看 Mac OS 的源代码。
|
||||
|
||||
形象点说,Mac 驱动的系统可以让你得到一辆车,但缺点是你不能打开引擎盖看里面是什么。那可太差劲了!
|
||||
|
||||
如果你想深入了解开源软件的优势,可以在 OpenSource.com 上浏览一下 [Ben Balter 的文章][17]。
|
||||
|
||||
### 总结
|
||||
|
||||
现在你应该知道为什么 Linux 比 Mac 好了吧,你觉得呢?上面的这些原因可以说服你选择 Linux 吗?如果不行的话那又是为什么呢?
|
||||
|
||||
请在下方评论让我们知道你的想法。
|
||||
|
||||
提示:这里的图片是以企鹅俱乐部为原型的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-vs-mac/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Ryze-Borgia](https://github.com/Ryze-Borgia)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://itsfoss.com/linux-better-than-windows/
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Linux-vs-mac-featured.png
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-1.jpeg
|
||||
[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-4.jpeg
|
||||
[5]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]: https://hackintosh.com/
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-2.jpeg
|
||||
[8]: https://www.computerworld.com/article/3262225/apple-mac/warning-as-mac-malware-exploits-climb-270.html
|
||||
[9]: https://www.imore.com/how-to-remove-browser-hijack
|
||||
[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-3.jpeg
|
||||
[11]: https://www.gnome.org/
|
||||
[12]: https://itsfoss.com/best-gnome-extensions/
|
||||
[13]: https://elementary.io/
|
||||
[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-5.jpeg
|
||||
[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-6.jpeg
|
||||
[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-7.jpeg
|
||||
[17]: https://opensource.com/life/15/12/why-open-source
|
||||
[18]: https://www.kde.org/plasma-desktop
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
350
translated/tech/20180823 CLI- improved.md
Normal file
350
translated/tech/20180823 CLI- improved.md
Normal file
@ -0,0 +1,350 @@
|
||||
|
||||
命令行:增强版
|
||||
======
|
||||
|
||||
我不确定有多少Web 开发者能完全逃避使用命令行。就我来说,我从1997年上大学就开始使用命令行了,那时的l33t-hacker 让我着迷,同时我也觉得它很难掌握。
|
||||
|
||||
过去这些年我的命令行本领在逐步加强,我经常会去搜寻在我工作中能使用的更好的命令行工具。下面就是我现在使用的用于增强原有命令行工具的列表。
|
||||
|
||||
|
||||
### 怎么忽略我所做的命令行增强
|
||||
|
||||
通常情况下我会用别名将新的或者增强的命令行工具链接到原来的命令行(如`cat`和`ping`)。
|
||||
|
||||
|
||||
如果我需要运行原来的命令的话(有时我确实需要这么做),我会像下面这样来运行未加修改的原来的命令行。(我用的是Mac,你的输出可能不一样)
|
||||
|
||||
|
||||
```
|
||||
$ \cat # 忽略叫 "cat" 的别名 - 具体解释: https://stackoverflow.com/a/16506263/22617
|
||||
$ command cat # 忽略函数和别名
|
||||
|
||||
```
|
||||
|
||||
### bat > cat
|
||||
|
||||
`cat`用于打印文件的内容,如果你在命令行上要花很多时间的话,例如语法高亮之类的功能会非常有用。我首先发现了[ccat][3]这个有语法高亮功能的的工具,然后我发现了[bat][4],它的功能有语法高亮,分页,行号和git集成。
|
||||
|
||||
|
||||
`bat`命令也能让我在输出里(只要输出比屏幕的高度长)
|
||||
使用`/`关键字绑定来搜索(和用`less`搜索功能一样)。
|
||||
|
||||
|
||||
![Simple bat output][5]
|
||||
|
||||
我将别名`cat`链接到了`bat`命令:
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias cat='bat'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][4]
|
||||
|
||||
### prettyping > ping
|
||||
|
||||
`ping`非常有用,当我碰到“糟了,是不是什么服务挂了?/我的网不通了?”这种情况下我最先想到的工具就是它了。但是`prettyping`(“prettyping” 可不是指"pre typing")(译注:英文字面意思是'预打印')在`ping`上加上了友好的输出,这可让我感觉命令行友好了很多呢。
|
||||
|
||||
|
||||
![/images/cli-improved/ping.gif][6]
|
||||
|
||||
我也将`ping`用别名链接到了`prettyping`命令:
|
||||
|
||||
|
||||
```
|
||||
alias ping='prettyping --nolegend'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][7]
|
||||
|
||||
### fzf > ctrl+r
|
||||
|
||||
在命令行上使用`ctrl+r`将允许你在命令历史里[反向搜索][8]使用过的命令,这是个挺好的小技巧,但是它需要你给出非常精确的输入才能正常运行。
|
||||
|
||||
`fzf`这个工具相比于`ctrl+r`有了**巨大的**进步。它能针对命令行历史进行模糊查询,并且提供了对可能的合格结果进行全面交互式预览。
|
||||
|
||||
|
||||
除了搜索命令历史,`fzf`还能预览和打开文件,我在下面的视频里展示了这些功能。
|
||||
|
||||
|
||||
为了这个预览的效果,我创建了一个叫`preview`的别名,它将`fzf`和前文提到的`bat`组合起来完成预览功能,还给上面绑定了一个定制的热键Ctrl+o来打开 VS Code:
|
||||
|
||||
|
||||
```
|
||||
alias preview="fzf --preview 'bat --color \"always\" {}'"
|
||||
# 支持在 VS Code 里用ctrl+o 来打开选择的文件
|
||||
export FZF_DEFAULT_OPTS="--bind='ctrl-o:execute(code {})+abort'"
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][9]
|
||||
|
||||
### htop > top
|
||||
|
||||
`top`是当我想快速诊断为什么机器上的CPU跑的那么累或者风扇为什么突然呼呼大做的时候首先会想到的工具。我在产品环境也会使用这个工具。讨厌的是Mac上的`top`和 Linux 上的`top`有着极大的不同(恕我直言,应该是差的多)。
|
||||
|
||||
|
||||
不过,`htop`是对 Linux 上的`top`和 Mac 上蹩脚的`top`的极大改进。它增加了包括颜色输出编码,键盘热键绑定以及不同的视图输出,这极大的帮助了我来理解进程之间的父子关系。
|
||||
|
||||
|
||||
方便的热键绑定包括:
|
||||
|
||||
* P - CPU使用率排序
|
||||
* M - 内存使用排序
|
||||
* F4 - 用字符串过滤进程(例如只看包括"node"的进程)
|
||||
* space - 锚定一个单独进程,这样我能观察它是否有尖峰状态
|
||||
|
||||
|
||||
![htop output][10]
|
||||
|
||||
在Mac Sieera 上htop 有个奇怪的bug,不过这个bug可以通过以root运行来绕过(我实在记不清这个bug 是什么,但是这个别名能搞定它,有点讨厌的是我得每次都输入root密码。):
|
||||
|
||||
|
||||
```
|
||||
alias top="sudo htop" # 给top加上别名并且绕过 Sieera 上的bug
|
||||
```
|
||||
|
||||
💾 [Installation directions][11]
|
||||
|
||||
### diff-so-fancy > diff
|
||||
|
||||
我非常确定我是一些年前从 Paul Irish 那儿学来的这个技巧,尽管我很少直接使用`diff`,但我的git命令行会一直使用`diff`。`diff-so-fancy`给了我代码语法颜色和更改字符高亮的功能。
|
||||
|
||||
|
||||
![diff so fancy][12]
|
||||
|
||||
在我的`~/.gitconfig`文件里我有下面的选项来打开`git diff`和`git show`的`diff-so-fancy`功能。
|
||||
|
||||
|
||||
```
|
||||
[pager]
|
||||
diff = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
show = diff-so-fancy | less --tabs=1,5 -RFX
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][13]
|
||||
|
||||
### fd > find
|
||||
|
||||
尽管我使用 Mac, 但我从来不是一个Spotlight的拥趸,我觉得它的性能很差,关键字也难记,加上更新它自己的数据库时会拖慢CPU,简直一无是处。我经常使用[Alfred][14],但是它的搜索功能也工作的不是很好。
|
||||
|
||||
|
||||
我倾向于在命令行中搜索文件,但是`find`的难用在于很难去记住那些合适的表达式来描述我想要的文件。(而且 Mac 上的 find 命令和非Mac的find命令还有些许不同,这更加深了我的失望。)
|
||||
|
||||
`fd`是一个很好的替代品(它的作者和`bat`的作者是同一个人)。它非常快而且对于我经常要搜索的命令非常好记。
|
||||
|
||||
|
||||
|
||||
几个使用方便的例子:
|
||||
|
||||
```
|
||||
$ fd cli # 所有包含"cli"的文件名
|
||||
$ fd -e md # 所有以.md作为扩展名的文件
|
||||
$ fd cli -x wc -w # 搜索"cli"并且在每个搜索结果上运行`wc -w`
|
||||
|
||||
|
||||
```
|
||||
|
||||
![fd output][15]
|
||||
|
||||
💾 [Installation directions][16]
|
||||
|
||||
### ncdu > du
|
||||
|
||||
对我来说,知道当前的磁盘空间使用是非常重要的任务。我用过 Mac 上的[Dish Daisy][17],但是我觉得那个程序产生结果有点慢。
|
||||
|
||||
|
||||
`du -sh`命令是我经常会跑的命令(`-sh`是指结果以`总结`和`人类可读`的方式显示),我经常会想要深入挖掘那些占用了大量磁盘空间的目录,看看到底是什么在占用空间。
|
||||
|
||||
`ncdu`是一个非常棒的替代品。它提供了一个交互式的界面并且允许快速的扫描那些占用了大量磁盘空间的目录和文件,它又快又准。(尽管不管在哪个工具的情况下,扫描我的home目录都要很长时间,它有550G)
|
||||
|
||||
|
||||
一旦当我找到一个目录我想要“处理”一下(如删除,移动或压缩文件),我都会使用命令+点击屏幕[iTerm2][18]上部的目录名字来对那个目录执行搜索。
|
||||
|
||||
|
||||
![ncdu output][19]
|
||||
|
||||
还有另外一个选择[一个叫nnn的另外选择][20],它提供了一个更漂亮的界面,它也提供文件尺寸和使用情况,实际上它更像一个全功能的文件管理器。
|
||||
|
||||
|
||||
我的`ncdu`使用下面的别名链接:
|
||||
|
||||
```
|
||||
alias du="ncdu --color dark -rr -x --exclude .git --exclude node_modules"
|
||||
|
||||
```
|
||||
|
||||
|
||||
选项有:
|
||||
|
||||
* `--color dark` 使用颜色方案
|
||||
* `-rr` 只读模式(防止误删和运行新的登陆程序)
|
||||
* `--exclude` 忽略不想操作的目录
|
||||
|
||||
|
||||
|
||||
💾 [Installation directions][21]
|
||||
|
||||
### tldr > man
|
||||
|
||||
几乎所有的单独命令行工具都有一个相伴的手册,其可以被`man <命令名>`来调出,但是在`man`的输出里找到东西可有点让人困惑,而且在一个包含了所有的技术细节的输出里找东西也挺可怕的。
|
||||
|
||||
|
||||
这就是TL;DR(译注:英文里`文档太长,没空去读`的缩写)项目创建的初衷。这是一个由社区驱动的文档系统,而且针对的是命令行。就我现在用下来,我还没碰到过一个命令它没有相应的文档,你[也可以做贡献][22]。
|
||||
|
||||
|
||||
![TLDR output for 'fd'][23]
|
||||
|
||||
作为一个小技巧,我将`tldr`的别名链接到`help`(这样输入会快一点。。。)
|
||||
|
||||
```
|
||||
alias help='tldr'
|
||||
|
||||
```
|
||||
|
||||
💾 [Installation directions][24]
|
||||
|
||||
### ack || ag > grep
|
||||
|
||||
`grep`毫无疑问是一个命令行上的强力工具,但是这些年来它已经被一些工具超越了,其中两个叫`ack`和`ag`。
|
||||
|
||||
|
||||
我个人对`ack`和`ag`都尝试过,而且没有非常明显的个人偏好,(那也就是说他们都很棒,并且很相似)。我倾向于默认只使用`ack`,因为这三个字符就在指尖,很好打。并且,`ack`有大量的`ack --`参数可以使用,(你一定会体会到这一点。)
|
||||
|
||||
|
||||
`ack`和`ag`都将使用正则表达式来表达搜索,这非常契合我的工作,我能指定搜索的文件类型而不用使用类似于`--js`或`--html`的文件标识(尽管`ag`比`ack`在文件类型过滤器里包括了更多的文件类型。)
|
||||
|
||||
|
||||
两个工具都支持常见的`grep`选项,如`-B`和`-A`用于在搜索的上下文里指代`之前`和`之后`。
|
||||
|
||||
|
||||
![ack in action][25]
|
||||
|
||||
因为`ack`不支持markdown(而我又恰好写了很多markdown), 我在我的`~/.ackrc`文件里放了如下的定制语句:
|
||||
|
||||
|
||||
|
||||
```
|
||||
--type-set=md=.md,.mkd,.markdown
|
||||
--pager=less -FRX
|
||||
|
||||
```
|
||||
|
||||
💾 Installation directions: [ack][26], [ag][27]
|
||||
|
||||
[Futher reading on ack & ag][28]
|
||||
|
||||
### jq > grep et al
|
||||
|
||||
我是[jq][29]的粉丝之一。当然一开始我也在它的语法里苦苦挣扎,好在我对查询语言还算有些使用心得,现在我对`jq`可以说是每天都要用。(不过从前我要么使用grep 或者使用一个叫[json][30]的工具,相比而言后者的功能就非常基础了。)
|
||||
|
||||
|
||||
我甚至开始撰写一个`jq`的教程系列(有2500字并且还在增加),我还发布了一个[web tool][31]和一个Mac 上的应用(这个还没有发布。)
|
||||
|
||||
|
||||
`jq`允许我传入一个 JSON 并且能非常简单的将其转变为一个 使用JSON格式的结果,这正是我想要的。下面这个例子允许我用一个命令更新我的所有节点依赖(为了阅读方便,我将其分成为多行。)
|
||||
|
||||
|
||||
```
|
||||
$ npm i $(echo $(\
|
||||
npm outdated --json | \
|
||||
jq -r 'to_entries | .[] | "\(.key)@\(.value.latest)"' \
|
||||
))
|
||||
|
||||
```
|
||||
上面的命令将使用npm 的 JSON 输出格式来列出所有的过期节点依赖,然后将下面的源JSON转换为:
|
||||
|
||||
|
||||
```
|
||||
{
|
||||
"node-jq": {
|
||||
"current": "0.7.0",
|
||||
"wanted": "0.7.0",
|
||||
"latest": "1.2.0",
|
||||
"location": "node_modules/node-jq"
|
||||
},
|
||||
"uuid": {
|
||||
"current": "3.1.0",
|
||||
"wanted": "3.2.1",
|
||||
"latest": "3.2.1",
|
||||
"location": "node_modules/uuid"
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
转换结果为:(译注:原文此处并未给出结果)
|
||||
|
||||
上面的结果会被作为`npm install`的输入,你瞧,我的升级就这样全部搞定了。(当然,这里有点小题大做了。)
|
||||
|
||||
|
||||
### 很荣幸提及一些其他的工具
|
||||
|
||||
我也在开始尝试一些别的工具,但我还没有完全掌握他们。(除了`ponysay`,当我新启动一个命令行会话时,它就会出现。)
|
||||
|
||||
|
||||
* [ponysay][32] > cowsay
|
||||
* [csvkit][33] > awk et al
|
||||
* [noti][34] > `display notification`
|
||||
* [entr][35] > watch
|
||||
|
||||
|
||||
|
||||
### 你有什么好点子吗?
|
||||
|
||||
|
||||
上面是我的命令行清单。能告诉我们你的吗?你有没有试着去增强一些你每天都会用到的命令呢?请告诉我,我非常乐意知道。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://remysharp.com/2018/08/23/cli-improved
|
||||
|
||||
作者:[Remy Sharp][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:DavidChenLiang(https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://remysharp.com
|
||||
[1]: https://remysharp.com/images/terminal-600.jpg
|
||||
[2]: https://training.leftlogic.com/buy/terminal/cli2?coupon=READERS-DISCOUNT&utm_source=blog&utm_medium=banner&utm_campaign=remysharp-discount
|
||||
[3]: https://github.com/jingweno/ccat
|
||||
[4]: https://github.com/sharkdp/bat
|
||||
[5]: https://remysharp.com/images/cli-improved/bat.gif (Sample bat output)
|
||||
[6]: https://remysharp.com/images/cli-improved/ping.gif (Sample ping output)
|
||||
[7]: http://denilson.sa.nom.br/prettyping/
|
||||
[8]: https://lifehacker.com/278888/ctrl%252Br-to-search-and-other-terminal-history-tricks
|
||||
[9]: https://github.com/junegunn/fzf
|
||||
[10]: https://remysharp.com/images/cli-improved/htop.jpg (Sample htop output)
|
||||
[11]: http://hisham.hm/htop/
|
||||
[12]: https://remysharp.com/images/cli-improved/diff-so-fancy.jpg (Sample diff output)
|
||||
[13]: https://github.com/so-fancy/diff-so-fancy
|
||||
[14]: https://www.alfredapp.com/
|
||||
[15]: https://remysharp.com/images/cli-improved/fd.png (Sample fd output)
|
||||
[16]: https://github.com/sharkdp/fd/
|
||||
[17]: https://daisydiskapp.com/
|
||||
[18]: https://www.iterm2.com/
|
||||
[19]: https://remysharp.com/images/cli-improved/ncdu.png (Sample ncdu output)
|
||||
[20]: https://github.com/jarun/nnn
|
||||
[21]: https://dev.yorhel.nl/ncdu
|
||||
[22]: https://github.com/tldr-pages/tldr#contributing
|
||||
[23]: https://remysharp.com/images/cli-improved/tldr.png (Sample tldr output for 'fd')
|
||||
[24]: http://tldr-pages.github.io/
|
||||
[25]: https://remysharp.com/images/cli-improved/ack.png (Sample ack output with grep args)
|
||||
[26]: https://beyondgrep.com
|
||||
[27]: https://github.com/ggreer/the_silver_searcher
|
||||
[28]: http://conqueringthecommandline.com/book/ack_ag
|
||||
[29]: https://stedolan.github.io/jq
|
||||
[30]: http://trentm.com/json/
|
||||
[31]: https://jqterm.com
|
||||
[32]: https://github.com/erkin/ponysay
|
||||
[33]: https://csvkit.readthedocs.io/en/1.0.3/
|
||||
[34]: https://github.com/variadico/noti
|
||||
[35]: http://www.entrproject.org/
|
||||
390
translated/tech/20180912 How to build rpm packages.md
Normal file
390
translated/tech/20180912 How to build rpm packages.md
Normal file
@ -0,0 +1,390 @@
|
||||
如何构建rpm包
|
||||
======
|
||||
|
||||
节省跨多个主机安装文件和脚本的时间和精力。
|
||||
|
||||

|
||||
|
||||
自20多年前我开始使用 Linux 以来,我已经使用过基于 rpm 的软件包管理器在 Red Hat 和 Fedora Linux系统上安装软件。我使用过 **rpm** 程序本身,还有 **yum** 和 **DNF** ,用于在我的 Linux 主机上安装和更新软件包,DNF 是 yum 的一个紧密后代。 yum 和 DNF 工具是 rpm 实用程序的包装器,它提供了其他功能,例如查找和安装包依赖项的功能。
|
||||
|
||||
多年来,我创建了许多 Bash 脚本,其中一些脚本具有单独的配置文件,我希望在大多数新计算机和虚拟机上安装这些脚本。这也能解决安装所有这些软件包需要花费大量时间的难题,因此我决定通过创建一个 rpm 软件包来自动执行该过程,我可以将其复制到目标主机并将所有这些文件安装在适当的位置。虽然 **rpm** 工具以前用于构建 rpm 包,但该功能已被删除,并且创建了一个新工具来构建新的 rpm。
|
||||
|
||||
当我开始这个项目时,我发现很少有关于创建 rpm 包的信息,但我找到了一本书,名为《Maximum RPM》,这本书才帮我弄明白了。这本书现在已经过时了,我发现的绝大多数信息都是如此。它也已经绝版,使用复印件需要花费数百美元。[Maximum RPM][1] 的在线版本是免费提供的,并保持最新。 [RPM 网站][2]还有其他网站的链接,这些网站上有很多关于 rpm 的文档。其他的信息往往是简短的,显然都是假设你已经对该过程有了很多了解。
|
||||
|
||||
此外,我发现的每个文档都假定代码需要在开发环境中从源代码编译。我不是开发人员。我是一个系统管理员,我们系统管理员有不同的需求,因为我们不需要或者我们不应该为了管理任务而去编译代码;我们应该使用 shell 脚本。所以我们没有源代码,因为它需要被编译成二进制可执行文件。我们拥有的是一个也是可执行的源代码。
|
||||
|
||||
在大多数情况下,此项目应作为非 root 用户执行。 Rpm 包永远不应该由 root 用户构建,而只能由非特权普通用户构建。我将指出哪些部分应该以 root 身份执行,哪些部分应由非 root,非特权用户执行。
|
||||
|
||||
### 准备
|
||||
|
||||
首先,打开一个终端会话,然后 `su` 到 root 用户。 请务必使用 `-` 选项以确保启用完整的 root 环境。 我不认为系统管理员应该使用 `sudo` 来执行任何管理任务。 在我的个人博客文章中可以找出为什么:[真正的系统管理员不要使用 sudo][3]。
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ su -
|
||||
Password:
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
创建可用于此项目的普通用户 student,并为该用户设置密码。
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# useradd -c "Student User" student
|
||||
[root@testvm1 ~]# passwd student
|
||||
Changing password for user student.
|
||||
New password: <Enter the password>
|
||||
Retype new password: <Enter the password>
|
||||
passwd: all authentication tokens updated successfully.
|
||||
[root@testvm1 ~]#
|
||||
```
|
||||
|
||||
构建 rpm 包需要 `rpm-build` 包,该包可能尚未安装。 现在以 root 身份安装它。 请注意,此命令还将安装多个依赖项。 数量可能会有所不同,具体取决于主机上已安装的软件包; 它在我的测试虚拟机上总共安装了17个软件包,这是非常小的。
|
||||
|
||||
```
|
||||
dnf install -y rpm-build
|
||||
```
|
||||
|
||||
除非另有明确指示,否则本项目的剩余部分应以普通用户用户 student 来执行。 打开另一个终端会话并使用 `su` 切换到该用户以执行其余步骤。 使用以下命令从 GitHub 下载我准备好的开发目录结构 utils.tar 这个<ruby>tar 包<rt>tarball</rt></ruby>(LCTT 译注:tarball 是以 tar 命令来打包和压缩的文件的统称):
|
||||
|
||||
```
|
||||
wget https://github.com/opensourceway/how-to-rpm/raw/master/utils.tar
|
||||
```
|
||||
|
||||
此 tar 包包含将由最终 rpm 程序安装的所有文件和 Bash 脚本。 还有一个完整的 spec 文件,你可以使用它来构建 rpm。 我们将详细介绍 spec 文件的每个部分。
|
||||
|
||||
作为普通学生 student,使用你的家目录作为当前工作目录(pwd),解压缩 tar 包。
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ cd ; tar -xvf utils.tar
|
||||
```
|
||||
|
||||
使用 `tree` 命令验证~/development 的目录结构和包含的文件,如下所示:
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ tree development/
|
||||
development/
|
||||
├── license
|
||||
│ ├── Copyright.and.GPL.Notice.txt
|
||||
│ └── GPL_LICENSE.txt
|
||||
├── scripts
|
||||
│ ├── create_motd
|
||||
│ ├── die
|
||||
│ ├── mymotd
|
||||
│ └── sysdata
|
||||
└── spec
|
||||
└── utils.spec
|
||||
|
||||
3 directories, 7 files
|
||||
[student@testvm1 ~]$
|
||||
```
|
||||
|
||||
`mymotd` 脚本创建一个发送到标准输出的“当日消息”数据流。 `create_motd` 脚本运行 `mymotd` 脚本并将输出重定向到 /etc/motd 文件。 此文件用于向使用SSH远程登录的用户显示每日消息。
|
||||
|
||||
`die` 脚本是我自己的脚本,它将 `kill` 命令包装在一些代码中,这些代码可以找到与指定字符串匹配的运行程序并将其终止。 它使用 `kill -9` 来确保kill命令一定会执行。
|
||||
|
||||
`sysdata` 脚本可以显示有关计算机硬件,还有已安装的 Linux 版本,所有已安装的软件包以及硬盘驱动器元数据的数万行数据。 我用它来记录某个时间点的主机状态。 我以后可以用它作为参考。 我曾经这样做是为了维护我为客户安装的主机记录。
|
||||
|
||||
你可能需要将这些文件和目录的所有权更改为 student:student 。 如有必要,使用以下命令执行此操作:
|
||||
|
||||
```
|
||||
chown -R student:student development
|
||||
```
|
||||
|
||||
此文件树中的大多数文件和目录将通过你在此项目期间创建的 rpm 包安装在 Fedora 系统上。
|
||||
|
||||
### 创建构建目录结构
|
||||
|
||||
`rpmbuild` 命令需要非常特定的目录结构。 你必须自己创建此目录结构,因为没有提供自动方式。 在家目录中创建以下目录结构:
|
||||
|
||||
```
|
||||
~ ─ rpmbuild
|
||||
├── RPMS
|
||||
│ └── noarch
|
||||
├── SOURCES
|
||||
├── SPECS
|
||||
└── SRPMS
|
||||
```
|
||||
|
||||
我们不会创建 rpmbuild/RPMS/X86_64 目录,因为对于64位编译的二进制文件这是特定于体系结构的。 我们有 shell 脚本,不是特定于体系结构的。 实际上,我们也不会使用 SRPMS 目录,它将包含编译器的源文件。
|
||||
|
||||
### 检查 spec 文件
|
||||
|
||||
每个 spec 文件都有许多部分,其中一些部分可能会被忽视或省略,取决于 rpm 构建的具体情况。 这个特定的 spec 文件不是工作所需的最小文件的示例,但它是一个很好的包含不需要编译的文件的中等复杂 spec 文件的例子。 如果需要编译,它将在`构建`部分中执行,该部分在此 spec 文件中省略掉了,因为它不是必需的。
|
||||
|
||||
#### 前言
|
||||
|
||||
这是 spec 文件中唯一没有标签的部分。 它包含运行命令 `rpm -qi [Package Name]` 时看到的大部分信息。 每个数据都是一行,由标签和标签值的文本数据组成。
|
||||
|
||||
```
|
||||
###############################################################################
|
||||
# Spec file for utils
|
||||
################################################################################
|
||||
# Configured to be built by user student or other non-root user
|
||||
################################################################################
|
||||
#
|
||||
Summary: Utility scripts for testing RPM creation
|
||||
Name: utils
|
||||
Version: 1.0.0
|
||||
Release: 1
|
||||
License: GPL
|
||||
URL: http://www.both.org
|
||||
Group: System
|
||||
Packager: David Both
|
||||
Requires: bash
|
||||
Requires: screen
|
||||
Requires: mc
|
||||
Requires: dmidecode
|
||||
BuildRoot: ~/rpmbuild/
|
||||
|
||||
# Build with the following syntax:
|
||||
# rpmbuild --target noarch -bb utils.spec
|
||||
```
|
||||
|
||||
`rpmbuild` 程序会忽略注释行。我总是喜欢在本节中添加注释,其中包含创建包所需的 `rpmbuild` 命令的确切语法。摘要标签是包的简短描述。 Name,Version 和 Release 标签用于创建 rpm 文件的名称,如utils-1.00-1.rpm 中所示。通过增加发行版号码和版本号,你可以创建 rpm 包去更新旧版本的。
|
||||
|
||||
许可证标签定义了发布包的许可证。我总是使用 GPL 的一个变体。指定许可证对于澄清包中包含的软件是开源的这一事实非常重要。这也是我将许可证和 GPL 语句包含在将要安装的文件中的原因。
|
||||
|
||||
URL 通常是项目或项目所有者的网页。在这种情况下,它是我的个人网页。
|
||||
|
||||
Group 标签很有趣,通常用于 GUI 应用程序。 Group 标签的值决定了应用程序菜单中的哪一组图标将包含此包中可执行文件的图标。与 Icon 标签(我们此处未使用)一起使用时,Group 标签允许添加图标和所需信息用于将程序启动到应用程序菜单结构中。
|
||||
|
||||
Packager 标签用于指定负责维护和创建包的人员或组织。
|
||||
|
||||
Requires 语句定义此 rpm 包的依赖项。每个都是包名。如果其中一个指定的软件包不存在,DNF 安装实用程序将尝试在 /etc/yum.repos.d 中定义的某个已定义的存储库中找到它,如果存在则安装它。如果 DNF 找不到一个或多个所需的包,它将抛出一个错误,指出哪些包丢失并终止。
|
||||
|
||||
BuildRoot 行指定顶级目录,`rpmbuild` 工具将在其中找到 spec 文件,并在构建包时在其中创建临时目录。完成的包将存储在我们之前指定的noarch子目录中。注释显示了构建此程序包的命令语法,包括定义了目标体系结构的 `–target noarch` 选项。因为这些是Bash脚本,所以它们与特定的CPU架构无关。如果省略此选项,则构建将选用正在执行构建的CPU的体系结构。
|
||||
|
||||
`rpmbuild` 程序可以针对许多不同的体系结构,并且使用 `--target` 选项允许我们在不同的体系结构主机上构建特定体系结构的包,其具有与执行构建的体系结构不同的体系结构。所以我可以在 x86_64 主机上构建一个用于 i686 架构的软件包,反之亦然。
|
||||
|
||||
如果你有自己的网站,请将打包者的名称更改为你自己的网站。
|
||||
|
||||
#### 描述
|
||||
|
||||
spec 文件的 `描述` 部分包含 rpm 包的描述。 它可以很短,也可以包含许多信息。 我们的 `描述` 部分相当简洁。
|
||||
|
||||
```
|
||||
%description
|
||||
A collection of utility scripts for testing RPM creation.
|
||||
```
|
||||
|
||||
#### 准备
|
||||
|
||||
`准备` 部分是在构建过程中执行的第一个脚本。 在安装程序包期间不会执行此脚本。
|
||||
|
||||
这个脚本只是一个 Bash shell 脚本。 它准备构建目录,根据需要创建用于构建的目录,并将相应的文件复制到各自的目录中。 这将包括完整编译作为构建的一部分所需的源。
|
||||
|
||||
$RPM_BUILD_ROOT 目录表示已安装系统的根目录。 在 $RPM_BUILD_ROOT 目录中创建的目录是实时文件系统中的绝对路径,例如 /user/local/share/utils,/usr/local/bin 等。
|
||||
|
||||
对于我们的包,我们没有预编译源,因为我们的所有程序都是 Bash 脚本。 因此,我们只需将这些脚本和其他文件复制到已安装系统的目录中。
|
||||
|
||||
```
|
||||
%prep
|
||||
################################################################################
|
||||
# Create the build tree and copy the files from the development directories #
|
||||
# into the build tree. #
|
||||
################################################################################
|
||||
echo "BUILDROOT = $RPM_BUILD_ROOT"
|
||||
mkdir -p $RPM_BUILD_ROOT/usr/local/bin/
|
||||
mkdir -p $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
|
||||
cp /home/student/development/utils/scripts/* $RPM_BUILD_ROOT/usr/local/bin
|
||||
cp /home/student/development/utils/license/* $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
cp /home/student/development/utils/spec/* $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
|
||||
exit
|
||||
```
|
||||
|
||||
请注意,本节末尾的 exit 语句是必需的。
|
||||
|
||||
#### 文件
|
||||
|
||||
spec 文件的这一部分定义了要安装的文件及其在目录树中的位置。 它还指定了要安装的每个文件的文件属性以及所有者和组所有者。 文件权限和所有权是可选的,但我建议明确设置它们以消除这些属性在安装时不正确或不明确的任何可能性。 如果目录尚不存在,则会在安装期间根据需要创建目录。
|
||||
|
||||
```
|
||||
%files
|
||||
%attr(0744, root, root) /usr/local/bin/*
|
||||
%attr(0644, root, root) /usr/local/share/utils/*
|
||||
```
|
||||
|
||||
#### 安装前
|
||||
|
||||
在我们的实验室项目的 spec 文件中,此部分为空。 这将放置那些需要 rpm 安装前执行的脚本。
|
||||
|
||||
#### 安装后
|
||||
|
||||
spec 文件的这一部分是另一个 Bash 脚本。 这个在安装文件后运行。 此部分几乎可以是你需要或想要的任何内容,包括创建文件,运行系统命令以及重新启动服务以在进行配置更改后重新初始化它们。 我们的 rpm 包的 `安装后` 脚本执行其中一些任务。
|
||||
|
||||
```
|
||||
%post
|
||||
################################################################################
|
||||
# Set up MOTD scripts #
|
||||
################################################################################
|
||||
cd /etc
|
||||
# Save the old MOTD if it exists
|
||||
if [ -e motd ]
|
||||
then
|
||||
cp motd motd.orig
|
||||
fi
|
||||
# If not there already, Add link to create_motd to cron.daily
|
||||
cd /etc/cron.daily
|
||||
if [ ! -e create_motd ]
|
||||
then
|
||||
ln -s /usr/local/bin/create_motd
|
||||
fi
|
||||
# create the MOTD for the first time
|
||||
/usr/local/bin/mymotd > /etc/motd
|
||||
```
|
||||
|
||||
此脚本中包含的注释应明确其用途。
|
||||
|
||||
#### 卸载后
|
||||
|
||||
此部分包含将在卸载 rpm 软件包后运行的脚本。 使用 rpm 或 DNF 删除包会删除文件部分中列出的所有文件,但它不会删除安装后部分创建的文件或链接,因此我们需要在本节中处理。
|
||||
|
||||
此脚本通常由清理任务组成,只是清除以前由rpm安装的文件,但rpm本身无法完成清除。 对于我们的包,它包括删除 `安装后` 脚本创建的链接并恢复 motd 文件的已保存原件。
|
||||
|
||||
```
|
||||
%postun
|
||||
# remove installed files and links
|
||||
rm /etc/cron.daily/create_motd
|
||||
|
||||
# Restore the original MOTD if it was backed up
|
||||
if [ -e /etc/motd.orig ]
|
||||
then
|
||||
mv -f /etc/motd.orig /etc/motd
|
||||
fi
|
||||
```
|
||||
|
||||
#### 清理
|
||||
|
||||
这个 Bash 脚本在 rpm 构建过程之后开始清理。 下面 `清理` 部分中的两行删除了 `rpm-build` 命令创建的构建目录。 在许多情况下,可能还需要额外的清理。
|
||||
|
||||
```
|
||||
%clean
|
||||
rm -rf $RPM_BUILD_ROOT/usr/local/bin
|
||||
rm -rf $RPM_BUILD_ROOT/usr/local/share/utils
|
||||
```
|
||||
|
||||
#### 更新日志
|
||||
|
||||
此可选的文本部分包含 rpm 及其包含的文件的更改列表。 最新的更改记录在本部分顶部。
|
||||
|
||||
```
|
||||
%changelog
|
||||
* Wed Aug 29 2018 Your Name <Youremail@yourdomain.com>
|
||||
- The original package includes several useful scripts. it is
|
||||
primarily intended to be used to illustrate the process of
|
||||
building an RPM.
|
||||
```
|
||||
|
||||
使用你自己的姓名和电子邮件地址替换标题行中的数据。
|
||||
|
||||
### 构建 rpm
|
||||
|
||||
spec 文件必须位于 rpmbuild 目录树的 SPECS 目录中。 我发现最简单的方法是创建一个指向该目录中实际 spec 文件的链接,以便可以在开发目录中对其进行编辑,而无需将其复制到 SPECS 目录。 将 SPECS 目录设为当前工作目录,然后创建链接。
|
||||
|
||||
```
|
||||
cd ~/rpmbuild/SPECS/
|
||||
ln -s ~/development/spec/utils.spec
|
||||
```
|
||||
|
||||
运行以下命令以构建 rpm 。 如果没有错误发生,只需要花一点时间来创建 rpm 。
|
||||
|
||||
```
|
||||
rpmbuild --target noarch -bb utils.spec
|
||||
```
|
||||
|
||||
检查 ~/rpmbuild/RPMS/noarch 目录以验证新的 rpm 是否存在。
|
||||
|
||||
```
|
||||
[student@testvm1 ~]$ cd rpmbuild/RPMS/noarch/
|
||||
[student@testvm1 noarch]$ ll
|
||||
total 24
|
||||
-rw-rw-r--. 1 student student 24364 Aug 30 10:00 utils-1.0.0-1.noarch.rpm
|
||||
[student@testvm1 noarch]$
|
||||
```
|
||||
|
||||
### 测试 rpm
|
||||
|
||||
以 root 用户身份安装 rpm 以验证它是否正确安装并且文件是否安装在正确的目录中。 rpm 的确切名称将取决于你在 Preamble 部分中标签的值,但如果你使用了示例中的值,则 rpm 名称将如下面的示例命令所示:
|
||||
|
||||
```
|
||||
[root@testvm1 ~]# cd /home/student/rpmbuild/RPMS/noarch/
|
||||
[root@testvm1 noarch]# ll
|
||||
total 24
|
||||
-rw-rw-r--. 1 student student 24364 Aug 30 10:00 utils-1.0.0-1.noarch.rpm
|
||||
[root@testvm1 noarch]# rpm -ivh utils-1.0.0-1.noarch.rpm
|
||||
Preparing... ################################# [100%]
|
||||
Updating / installing...
|
||||
1:utils-1.0.0-1 ################################# [100%]
|
||||
```
|
||||
|
||||
检查 /usr/local/bin 以确保新文件存在。 你还应验证是否已创建 /etc/cron.daily 中的 create_motd 链接。
|
||||
|
||||
使用 `rpm -q --changelog utils` 命令查看更改日志。 使用 `rpm -ql utils` 命令(在 `ql`中为小写 L )查看程序包安装的文件。
|
||||
|
||||
```
|
||||
[root@testvm1 noarch]# rpm -q --changelog utils
|
||||
* Wed Aug 29 2018 Your Name <Youremail@yourdomain.com>
|
||||
- The original package includes several useful scripts. it is
|
||||
primarily intended to be used to illustrate the process of
|
||||
building an RPM.
|
||||
|
||||
[root@testvm1 noarch]# rpm -ql utils
|
||||
/usr/local/bin/create_motd
|
||||
/usr/local/bin/die
|
||||
/usr/local/bin/mymotd
|
||||
/usr/local/bin/sysdata
|
||||
/usr/local/share/utils/Copyright.and.GPL.Notice.txt
|
||||
/usr/local/share/utils/GPL_LICENSE.txt
|
||||
/usr/local/share/utils/utils.spec
|
||||
[root@testvm1 noarch]#
|
||||
```
|
||||
|
||||
删除包。
|
||||
|
||||
```
|
||||
rpm -e utils
|
||||
```
|
||||
|
||||
### 试验
|
||||
|
||||
现在,你将更改 spec 文件以要求一个不存在的包。 这将模拟无法满足的依赖关系。 在现有依赖行下立即添加以下行:
|
||||
|
||||
```
|
||||
Requires: badrequire
|
||||
```
|
||||
|
||||
构建包并尝试安装它。 显示什么消息?
|
||||
|
||||
我们使用 `rpm` 命令来安装和删除 `utils` 包。 尝试使用 yum 或 DNF 安装软件包。 你必须与程序包位于同一目录中,或指定程序包的完整路径才能使其正常工作。
|
||||
|
||||
### 总结
|
||||
|
||||
在这里看一下创建 rpm 包的基础知识,我们没有涉及很多标签和很多部分。 下面列出的资源可以提供更多信息。 构建 rpm 包并不困难;你只需要正确的信息。 我希望这对你有所帮助——我花了几个月的时间来自己解决问题。
|
||||
|
||||
我们没有涵盖源代码构建,但如果你是开发人员,那么从这一点开始应该是一个简单的步骤。
|
||||
|
||||
创建 rpm 包是另一种成为懒惰系统管理员的好方法,可以节省时间和精力。 它提供了一种简单的方法来分发和安装那些我们作为系统管理员需要在许多主机上安装的脚本和其他文件。
|
||||
|
||||
### 资料
|
||||
|
||||
- Edward C. Baily,Maximum RPM,Sams著,于2000年,ISBN 0-672-31105-4
|
||||
- Edward C. Baily,[Maximum RPM][1],更新在线版本
|
||||
- [RPM文档][4]:此网页列出了 rpm 的大多数可用在线文档。 它包括许多其他网站的链接和有关 rpm 的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/how-build-rpm-packages
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dboth
|
||||
[1]: http://ftp.rpm.org/max-rpm/
|
||||
[2]: http://rpm.org/index.html
|
||||
[3]: http://www.both.org/?p=960
|
||||
[4]: http://rpm.org/documentation.html
|
||||
@ -0,0 +1,111 @@
|
||||
使用 Syncthing —— 一个开源同步工具来把握你数据的控制权
|
||||
|
||||
决定如何存储和共享您的个人信息。
|
||||
|
||||
======
|
||||
|
||||

|
||||
|
||||
如今,我们的一些最重要的财产——从家人和朋友的照片和视频到财务和医疗文件——都是数据。
|
||||
即便是云存储服务的迅猛发展,我们仍有对隐私和个人数据缺乏控制的担忧。从 PRISM 的监控计划到谷歌[让 APP 开发者扫描你的个人邮件][1],这些新闻的报道应该会让我们对我们个人信息的安全性有所顾虑。
|
||||
|
||||
[Syncthing][2] 可以让你放下心来。它是一款开源点对点的文件同步工具,可以运行在Linux、Windows、Mac、Android和其他 (抱歉,没有iOS)。Syncthing 使用自定的协议,叫[块交换协议](3)。简而言之,Syncting 能让你无需拥有服务器来跨设备同步数据,。
|
||||
|
||||
### Linux
|
||||
|
||||
在这篇文章中,我将解释如何在 Linux 电脑和安卓手机之间安装和同步文件。
|
||||
|
||||
Syncting 在大多数流行的发行版都能下载。Fedora 28 包含其最新版本。
|
||||
|
||||
要在 Fedora 上安装 Syncthing,你能在软件中心搜索,或者执行以下命令:
|
||||
|
||||
```
|
||||
sudo dnf install syncthing syncthing-gtk
|
||||
```
|
||||
|
||||
一旦安装好后,打开它。你将会看到一个助手帮你配置 Syncthing。点击 **下一步** 直到它要求配置 WebUI。最安全的选项是选择**监听本地地址**。那将会禁止 Web 接口并且阻止未经授权的用户。
|
||||
|
||||
![Syncthing in Setup WebUI dialog box][5]
|
||||
|
||||
Syncthing 安装时的 WebUI 对话框
|
||||
|
||||
关闭对话框。现在 Syncthing 安装好了。是时间分享一个文件夹,连接一台设备开始同步了。但是,让我们用你其他的客户端继续。
|
||||
|
||||
### Android
|
||||
|
||||
Syncthing 在 Google Play 和 F-Droid 应用商店都能下载
|
||||
|
||||

|
||||
|
||||
安装应用程序后,会显示欢迎界面。给 Syncthing 授予你设备存储的权限。
|
||||
你可能会被要求为了此应用程序而禁用电池优化。这样做是安全的,因为我们将优化应用程序,使其仅在插入并连接到无线网络时同步。
|
||||
|
||||
点击主菜单图标来到**设置**,然后是**运行条件**。点击**总是在后台运行**, **仅在充电时运行**和**仅在 WIFI 下运行**。现在你的安卓客户端已经准备好与你的设备交换文件。
|
||||
|
||||
Syncting 中有两个重要的概念需要记住:文件夹和设备。文件夹是你想要分享的,但是你必须有一台设备来分享。 Syncthing 允许你用不同的设备分享独立的文件夹。设备是通过交换设备 ID 来添加的。设备ID是在 Syncting 首次启动时创建的一个唯一的密码安全标识符。
|
||||
|
||||
### 连接设备
|
||||
|
||||
现在让我们连接你的Linux机器和你的Android客户端。
|
||||
|
||||
在您的Linux计算机中,打开 Syncting,单击 **设置** 图标,然后单击 **显示ID** ,就会显示一个二维码。
|
||||
|
||||
在你的安卓手机上,打开 Syncthing。在主界面上,点击 **设备** 页后点击 **+** 。在第一个区域内点击二维码符号来启动二维码扫描。
|
||||
|
||||
将你手机的摄像头对准电脑上的二维码。设备ID字段将由您的桌面客户端设备 ID 填充。起一个适合的名字并保存。因为添加设备有两种方式,现在你需要在电脑客户端上确认你想要添加安卓手机。你的电脑客户端可能会花上好几分钟来请求确认。当提示确认时,点击**添加**。
|
||||
|
||||

|
||||
|
||||
在 **新设备** 窗口,你能确认并配置一些关于你设备的选项,像是**设备名** 和 **地址**。如果你在地址那一栏选择 dynamic (动态),客户端将会自动探测设备的 IP 地址,但是你想要保持住某一个 IP 地址,你能将该地址填进这一栏里。如果你已经创建了文件夹(或者在这之后),你也能与新设备分享这个文件夹。
|
||||
|
||||

|
||||
|
||||
你的电脑和安卓设备已经配对,可以交换文件了。(如果你有多台电脑或手机,只需重复这些步骤。)
|
||||
|
||||
### 分享文件夹
|
||||
|
||||
既然您想要同步的设备之间已经连接,现在是时候共享一个文件夹了。您可以在电脑上共享文件夹,添加了该文件夹中的设备将获得一份副本。
|
||||
|
||||
若要共享文件夹,请转至**设置**并单击**添加共享文件夹**:
|
||||
|
||||

|
||||
|
||||
在下一个窗口中,输入要共享的文件夹的信息:
|
||||
|
||||

|
||||
|
||||
你可以使用任何你想要的标签。**文件夹ID **将随机生成,用于识别客户端之间的文件夹。在**路径**里,点击**浏览**就能定位到你想要分享的文件夹。如果你想 Syncthing 监控文件夹的变化(例如删除,新建文件等),点击** 监控文件系统变化**
|
||||
|
||||
记住,当你分享一个文件夹,在其他客户端的任何改动都将会反映到每一台设备上。这意味着如果你在其他电脑和手机设备之间分享了一个包含图片的文件夹,在这些客户端上的改动都会同步到每一台设备。如果这不是你想要的,你能让你的文件夹“只是发送"给其他客户端,但是其他客户端的改动都不会被同步。
|
||||
|
||||
完成后,转至**与设备共享**页并选择要与之同步文件夹的主机:
|
||||
|
||||
您选择的所有设备都需要接受共享请求;您将在设备上收到通知。
|
||||
|
||||
正如共享文件夹时一样,您必须配置新的共享文件夹:
|
||||
|
||||

|
||||
|
||||
同样,在这里您可以定义任何标签,但是 ID 必须匹配每个客户端。在文件夹选项中,选择文件夹及其文件的位置。请记住,此文件夹中所做的任何更改都将反映到文件夹所允许同步的每个设备上。
|
||||
|
||||
这些是连接设备和与 Syncting 共享文件夹的步骤。开始复制可能需要几分钟时间,这取决于您的网络设置或您是否不在同一网络上。
|
||||
|
||||
Syncting 提供了更多出色的功能和选项。试试看,并把握你数据的控制权。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/take-control-your-data-syncthing
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ypingcn](https://github.com/ypingcn)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mzamot
|
||||
[1]: https://gizmodo.com/google-says-it-doesnt-go-through-your-inbox-anymore-bu-1827299695
|
||||
[2]: https://syncthing.net/
|
||||
[3]: https://docs.syncthing.net/specs/bep-v1.html
|
||||
[4]: /file/410191
|
||||
[5]: https://opensource.com/sites/default/files/uploads/syncthing1.png "Syncthing in Setup WebUI dialog box"
|
||||
@ -1,74 +0,0 @@
|
||||
如何在家中使用 SSH 和 SFTP 协议
|
||||
======
|
||||
|
||||
通过 SSH 和 SFTP 协议 ,我们能够访问其他设备 ,有效而且安全的传输文件及更多 。
|
||||
|
||||

|
||||
|
||||
多年前 ,我决定配置一个额外的电脑 ,以便我能在工作时能够访问它来传输我所需要的文件 。最基本的一步是要求你的网络提供商 ( ISP )提供一个固定的地址 ( IP Address )。
|
||||
|
||||
保证你系统的访问是安全的 ,这是一个不必要但很重要的步骤 。在此种特殊情况下 ,我计划只在工作的时候能够访问它 。所以我能够约束访问的 IP 地址 。即使如此 ,你依然要尽多的采用安全措施 。一旦你建立起来这个 ,全世界的人们都能立即访问你的系统 。这是非常令人惊奇及恐慌的 。你能通过日志文件来发现这一点 。我推测有探测机器人在尽它们所能的搜索那些没有安全措施的系统 。
|
||||
|
||||
在我建立系统不久后 ,我觉得我的访问是一个简单的玩具而不是我想要的 ,为此 ,我将它关闭了好让我不在为它而担心 。尽管如此 ,这个系统在家庭网络中对于 SSH 和 SFTP 还有其他的用途 ,它至少已经为你而创建了 。
|
||||
|
||||
一个必备条件 ,你家的另一台电脑必须已经开机了 ,至于电脑是否已经非常老旧是没有影响的 。你也需要知道另一台电脑的 IP 地址 。有两个方法能够知道做到 ,一个是通过网页进入你的路由器 ,一般情况下你的地址格式类似于 **192.168.1.254** 。通过一些搜索 ,找出当前是开机的并且和系统 eth0 或者 wifi 挂钩的系统是足够简单的 。如何组织你所敢兴趣的电脑是一个挑战 。
|
||||
|
||||
询问电脑问题是简单的 ,打开 shell ,输入 :
|
||||
|
||||
```
|
||||
ifconfig
|
||||
|
||||
```
|
||||
|
||||
命令会输出一些信息 ,你所需要的信息在 `inet` 后面 ,看起来和 **192.168.1.234** 类似 。当你发现这个后 ,回到你的客户端电脑 ,在命令行中输入 :
|
||||
|
||||
```
|
||||
ssh gregp@192.168.1.234
|
||||
|
||||
```
|
||||
|
||||
上面的命令能够正常执行 ,**gregp** 必须在主机系统中是中确的用户名 。用户的密码也会被需要 。如果你键入的密码和用户名都是正确的 ,你将通过 shell 环境连接上了其他电脑 。我坦诚 ,对于 SSH 我并不是经常使用的 。我偶尔使用它 ,所以我能够运行 `dnf` 来更新我就坐的其他电脑 。通常 ,我用 SFTP :
|
||||
|
||||
```
|
||||
sftp grego@192.168.1.234
|
||||
|
||||
```
|
||||
|
||||
对于用更简单的方法来把一个文件传输到另一个文件 ,我有很强烈的需求 。相对于闪存棒和额外的设备 ,它更加方便 ,耗时更少 。
|
||||
|
||||
一旦连接建立成功 ,SFTP 有两个基本的命令 ,`get` ,从主机接收文件 ;`put` ,向主机发送文件 。在客户端 ,我经常移动到我想接收或者传输的文件夹下 ,在开始连接之前 。在连接之后 ,你将在顶层目录 **home/gregp** 。一旦连接成功 ,你将和在客户端一样的使用 `cd` ,除非在主机上你改变了你的工作路径 。你会需要用 `ls` 来确认你的位置 。
|
||||
|
||||
在客户端 ,如果你想改变工作路劲 。用 `lcd` 命令 ( **local change directory**)。相同的 ,用 `lls` 来显示客户端工作目录的内容 。
|
||||
|
||||
如果你不喜欢主机工作目录的名字时 ,你该怎么办 ?用 `mkdir` 在主机上创建一个新的文件夹 。或者将整个文件全拷贝到主机 :
|
||||
|
||||
```
|
||||
put -r thisDir/
|
||||
|
||||
```
|
||||
|
||||
在主机上创建文件夹和传输文件以及子文件夹是非常快速的 ,能达到硬件的上限 。在网络传输的过程中不会遇到瓶颈 。查看 SFTP 能够使用的功能 ,查看 :
|
||||
|
||||
```
|
||||
man sftp
|
||||
|
||||
```
|
||||
|
||||
在我的电脑上我也可以在 windows 虚拟机上用 SFTP ,另一个优势是配置一个虚拟机而不是一个双系统 。这让我能够在系统的 Linux 部分移入或者移出文件 。到目前为止 ,我只用了 windows 的客户端 。
|
||||
|
||||
你能够进入到任何通过无线或者 WIFI 连接到你路由器的设备 。暂时 ,我使用一个叫做 [SSHDroid][1] 的应用 ,能够在被动模式下运行 SSH 。换句话来说 ,你能够用你的电脑访问作为主机的 Android 设备 。近来我还发现了另外一个应用 ,[Admin Hands][2] ,不管你的客户端是桌面还是手机 ,都能使用 SSH 或者 SFTP 操作 。这个应用对于备份和手机分享照片是极好的 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/ssh-sftp-home-network
|
||||
|
||||
作者:[Geg Pittman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greg-p
|
||||
[1]: https://play.google.com/store/apps/details?id=berserker.android.apps.sshdroid
|
||||
[2]: https://play.google.com/store/apps/details?id=com.arpaplus.adminhands&hl=en_US
|
||||
@ -1,24 +1,25 @@
|
||||
在 Linux 命令行中使用 ls 列出文件的提示
|
||||
======
|
||||
学习一些 Linux "ls" 命令最有用的变化。
|
||||
|
||||
学习一些 Linux `ls` 命令最有用的变化。
|
||||
|
||||

|
||||
|
||||
我在 Linux 中最先学到的命令之一就是 `ls`。了解系统中文件所在目录中的内容非常重要。能够查看和修改不仅仅是一些文件还要所有文件也很重要。
|
||||
我在 Linux 中最先学到的命令之一就是 `ls`。了解系统中文件所在目录中的内容非常重要。能够查看和修改不仅仅是一些文件还有所有文件也很重要。
|
||||
|
||||
我的第一个 Linux 备忘录是[单页 Linux 手册][1],它于 1999 年发布,它成为我的首选参考资料。当我开始探索 Linux 时,我把它贴在桌子上并经常参考它。它的第一页第一列的底部有使用 `ls -l` 列出文件的命令。
|
||||
我的第一个 Linux 备忘录是[单页 Linux 手册][1],它于 1999 年发布,成了我的首选参考资料。当我开始探索 Linux 时,我把它贴在桌子上并经常参考它。它在第一页第一列的底部介绍了 `ls -l` 列出文件的命令。
|
||||
|
||||
之后,我将学习这个最基本命令的其他迭代。通过 `ls` 命令,我开始了解 Linux 文件权限的复杂性以及哪些是我的文件,哪些需要 root 或者 root 权限来修改。随着时间的推移,我习惯使用命令行,虽然我仍然使用 `ls -l` 来查找目录中的文件,但我经常使用 `ls -al`,这样我就可以看到可能需要更改的隐藏文件,比如那些配置文件。
|
||||
之后,我将学习这个最基本命令的其它迭代。通过 `ls` 命令,我开始了解 Linux 文件权限的复杂性,以及哪些是我的文件,哪些需要 root 或者 sudo 权限来修改。随着时间的推移,我习惯了使用命令行,虽然我仍然使用 `ls -l` 来查找目录中的文件,但我经常使用 `ls -al`,这样我就可以看到可能需要更改的隐藏文件,比如那些配置文件。
|
||||
|
||||
根据 Eric Fischer 在[Linux 文档项目][2]中关于 `ls` 命令的文章,该命令的根源可以追溯到 1961年 MIT 的相容分时系统 (CTSS
|
||||
) 上的 `listf` 命令。当 CTSS 被 [Multics][3] 代替时,命令变为 `list`,并有像 `list -all` 的开关。根据[维基百科][4],“ls” 出现在 AT&T Unix 的原始版本中。我们今天在 Linux 系统上使用的 `ls` 命令来自 [GNU Core Utilities][5]。
|
||||
根据 Eric Fischer 在 [Linux 文档项目][2]中关于 `ls` 命令的文章,该命令的起源可以追溯到 1961 年 MIT 的<ruby>相容分时系统<rt>Compatible Time-Sharing System</rt></ruby>(CTSS)上的 `listf` 命令。当 CTSS 被 [Multics][3] 代替时,命令变为 `list`,并有像 `list -all` 的开关。根据[维基百科][4],`ls` 出现在 AT&T Unix 的原始版本中。我们今天在 Linux 系统上使用的 `ls` 命令来自 [GNU Core Utilities][5]。
|
||||
|
||||
大多数时候,我只使用几个迭代的命令。使用 `ls` 或 `ls -al` 查看目录内部是我通常使用该命令的方法,但是你还应该熟悉许多其他选项。
|
||||
大多数时候,我只使用几个迭代的命令。我通常用 `ls` 或 `ls -al` 查看目录内容,但是你还应该熟悉许多其它选项。
|
||||
|
||||
`$ ls -l` 提供了一个简单的目录列表:
|
||||
`ls -l` 提供了一个简单的目录列表:
|
||||
|
||||
|
||||
|
||||
使用我的 Fedora 28 系统中的手册页,我发现 `ls` 还有许多其他选项,所有这些选项都提供了有关 Linux 文件系统的有趣且有用的信息。通过在命令提示符下输入 `man ls`,我们可以开始探索其他一些选项:
|
||||
在我的 Fedora 28 系统的手册页中,我发现 `ls` 还有许多其它选项,所有这些选项都提供了有关 Linux 文件系统的有趣且有用的信息。通过在命令提示符下输入 `man ls`,我们可以开始探索其它一些选项:
|
||||
|
||||
|
||||
|
||||
@ -38,18 +39,16 @@
|
||||
|
||||
|
||||
|
||||
以下是我认为有用且有趣的一些其他选项:
|
||||
以下是我认为有用且有趣的一些其它选项:
|
||||
|
||||
* 仅列出目录中的 .txt 文件:`ls * .txt`
|
||||
* 按文件大小列出:`ls -s`
|
||||
* 按时间和日期排序:`ls -d`
|
||||
* 按扩展名排序:`ls -X`
|
||||
* 按文件大小排序:`ls -S`
|
||||
* 带有文件大小的长格式:`ls -ls`
|
||||
* 仅列出目录中的 .txt 文件:`ls *.txt`
|
||||
* 按文件大小列出:`ls -s`
|
||||
* 按时间和日期排序:`ls -t`
|
||||
* 按扩展名排序:`ls -X`
|
||||
* 按文件大小排序:`ls -S`
|
||||
* 带有文件大小的长格式:`ls -ls`
|
||||
|
||||
|
||||
|
||||
要生成指定格式的目录列表并将其定向到文件供以后查看,请输入 `ls -al> mydirectorylist`。最后,我找到的一个更奇特的命令是 `ls -R`,它提供了计算机上所有目录及其内容的递归列表。
|
||||
要生成指定格式的目录列表并将其定向到文件供以后查看,请输入 `ls -al > mydirectorylist`。最后,我找到的一个更奇特的命令是 `ls -R`,它提供了计算机上所有目录及其内容的递归列表。
|
||||
|
||||
有关 `ls` 命令的所有迭代的完整列表,请参阅 [GNU Core Utilities][6]。
|
||||
|
||||
@ -60,7 +59,7 @@ via: https://opensource.com/article/18/10/ls-command
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user