mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
20150518-1 选题
This commit is contained in:
parent
c402c307e3
commit
e49ed47aac
182
sources/tech/20150518 How to set up a Replica Set on MongoDB.md
Normal file
182
sources/tech/20150518 How to set up a Replica Set on MongoDB.md
Normal file
@ -0,0 +1,182 @@
|
||||
How to set up a Replica Set on MongoDB
|
||||
================================================================================
|
||||
MongoDB has become the most famous NoSQL database on the market. MongoDB is document-oriented, and its scheme-free design makes it a really attractive solution for all kinds of web applications. One of the features that I like the most is Replica Set, where multiple copies of the same data set are maintained by a group of mongod nodes for redundancy and high availability.
|
||||
|
||||
This tutorial describes how to configure a Replica Set on MonoDB.
|
||||
|
||||
The most common configuration for a Replica Set involves one primary and multiple secondary nodes. The replication will then be initiated from the primary toward the secondaries. Replica Sets can not only provide database protection against unexpected hardware failure and service downtime, but also improve read throughput of database clients as they can be configured to read from different nodes.
|
||||
|
||||
### Set up the Environment ###
|
||||
|
||||
In this tutorial, we are going to set up a Replica Set with one primary and two secondary nodes.
|
||||
|
||||

|
||||
|
||||
In order to implement this lab, we will use three virtual machines (VMs) running on VirtualBox. I am going to install Ubuntu 14.04 on the VMs, and install official packages for Mongodb.
|
||||
|
||||
I am going to set up a necessary environment on one VM instance, and then clone it to the other two VM instances. Thus pick one VM named master, and perform the following installations.
|
||||
|
||||
First, we need to add the MongoDB key for apt:
|
||||
|
||||
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
|
||||
|
||||
Then we need to add the official MongoDB repository to our source.list:
|
||||
|
||||
$ sudo su
|
||||
# echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
|
||||
|
||||
Let's update repositories and install MongoDB.
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install -y mongodb-org
|
||||
|
||||
Now let's make some changes in /etc/mongodb.conf.
|
||||
|
||||
auth = true
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
replSet=myReplica
|
||||
|
||||
The first line is to make sure that we are going to have authentication on our database. keyFile is to set up a keyfile that is going to be used by MongoDB to replicate between nodes. replSet sets up the name of our replica set.
|
||||
|
||||
Now we are going to create our keyfile, so that it can be in all our instances.
|
||||
|
||||
$ echo -n "MyRandomStringForReplicaSet" | md5sum > keyFile
|
||||
|
||||
This will create keyfile that contains a MD5 string, but it has some noise that we need to clean up before using it in MongoDB. Use the following command to clean it up:
|
||||
|
||||
$ echo -n "MyReplicaSetKey" | md5sum|grep -o "[0-9a-z]\+" > keyFile
|
||||
|
||||
What grep command does is to print MD5 string with no spaces or other characters that we don't want.
|
||||
|
||||
Now we are going to make the keyfile ready for use:
|
||||
|
||||
$ sudo cp keyFile /var/lib/mongodb
|
||||
$ sudo chown mongodb:nogroup keyFile
|
||||
$ sudo chmod 400 keyFile
|
||||
|
||||
Now we have our Ubuntu VM ready to be cloned. Power it off, and clone it to the other VMs.
|
||||
|
||||

|
||||
|
||||
I name the cloned VMs secondary1 and secondary2. Make sure to reinitialize the MAC address of cloned VMs and clone full disks.
|
||||
|
||||

|
||||
|
||||
All three VM instances should be on the same network to communicate with each other. For this, we are going to attach all three VMs to "Internet Network".
|
||||
|
||||
It is recommended that each VM instances be assigned a static IP address, as opposed to DHCP IP address, so that the VMs will not lose connectivity among themselves when a DHCP server assigns different IP addresses to them.
|
||||
|
||||
Let's edit /etc/networks/interfaces of each VM as follows.
|
||||
|
||||
On primary:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.2
|
||||
netmask 255.255.255.0
|
||||
|
||||
On secondary1:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.3
|
||||
netmask 255.255.255.0
|
||||
|
||||
On secondary2:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.4
|
||||
netmask 255.255.255.0
|
||||
|
||||
Another file that needs to be set up is /etc/hosts, because we don't have DNS. We need to set the hostnames in /etc/hosts.
|
||||
|
||||
On primary:
|
||||
|
||||
127.0.0.1 localhost primary
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
On secondary1:
|
||||
|
||||
127.0.0.1 localhost secondary1
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
On secondary2:
|
||||
|
||||
127.0.0.1 localhost secondary2
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
Check connectivity among themselves by using ping command:
|
||||
|
||||
$ ping primary
|
||||
$ ping secondary1
|
||||
$ ping secondary2
|
||||
|
||||
### Set up a Replica Set ###
|
||||
|
||||
After verifying connectivity among VMs, we can go ahead and create the admin user so that we can start working on the Replica Set.
|
||||
|
||||
On primary node, open /etc/mongodb.conf, and comment out two lines that start with auth and replSet:
|
||||
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
#auth = true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
#replSet=myReplica
|
||||
|
||||
Restart mongod daemon.
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
Create an admin user after conencting to MongoDB:
|
||||
|
||||
> use admin
|
||||
> db.createUser({
|
||||
user:"admin",
|
||||
pwd:"
|
||||
})
|
||||
$ sudo service mongod restart
|
||||
|
||||
Connect to MongoDB and use these commands to add secondary1 and secondary2 to our Replicat Set.
|
||||
|
||||
> use admin
|
||||
> db.auth("admin","myreallyhardpassword")
|
||||
> rs.initiate()
|
||||
> rs.add ("secondary1:27017")
|
||||
> rs.add("secondary2:27017")
|
||||
|
||||
Now that we have our Replica Set, we can start working on our project. Consult the [official driver documentation][1] to see how to connect to a Replica Set. In case you want to query from shell, you have to connect to primary instance to insert or query the database. Secondary nodes will not let you do that. If you attempt to access the database on a secondary node, you will get this error message:
|
||||
|
||||
myReplica:SECONDARY>
|
||||
myReplica:SECONDARY> show databases
|
||||
2015-05-10T03:09:24.131+0000 E QUERY Error: listDatabases failed:{ "note" : "from execCommand", "ok" : 0, "errmsg" : "not master" }
|
||||
at Error ()
|
||||
at Mongo.getDBs (src/mongo/shell/mongo.js:47:15)
|
||||
at shellHelper.show (src/mongo/shell/utils.js:630:33)
|
||||
at shellHelper (src/mongo/shell/utils.js:524:36)
|
||||
at (shellhelp2):1:1 at src/mongo/shell/mongo.js:47
|
||||
|
||||
I hope you find this tutorial useful. You can use Vagrant to automate your local environments and help you code faster.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-replica-set-mongodb.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
[1]:http://docs.mongodb.org/ecosystem/drivers/
|
||||
@ -0,0 +1,114 @@
|
||||
Linux FAQs with Answers--How to block specific user agents on nginx web server
|
||||
================================================================================
|
||||
> **Question**: I notice that some robots often visit my nginx-powered website and scan it aggressively, ending up wasting a lot of my web server resources. I am trying to block those robots based on their user-agent string. How can I block specific user agent(s) on nginx web server?
|
||||
|
||||
The modern Internet is infested with various malicious robots and crawlers such as malware bots, spambots or content scrapers which are scanning your website in surreptitious ways, for example to detect potential website vulnerabilities, harvest email addresses, or just to steal content from your website. Many of these robots can be identified by their signature "user-agent" string.
|
||||
|
||||
As a first line of defense, you could try to block malicious bots from accessing your website by blacklisting their user-agents in robots.txt file. However, unfortunately this works only for "well-behaving" robots which are designed to obey robots.txt. Many malicious bots can simply ignore robots.txt and scan your website at will.
|
||||
|
||||
An alternative way to block particular robots is to configure your web server, such that it refuses to serve content to requests with certain user-agent strings. This post explains how to **block certain user-agent on nginx web server**.
|
||||
|
||||
### Blacklist Certain User-Agents in Nginx ###
|
||||
|
||||
To configure user-agent block list, open the nginx configuration file of your website, where the server section is defined. This file can be found in different places depending on your nginx setup or Linux distribution (e.g., /etc/nginx/nginx.conf, /etc/nginx/sites-enabled/<your-site>, /usr/local/nginx/conf/nginx.conf, /etc/nginx/conf.d/<your-site>).
|
||||
|
||||
server {
|
||||
listen 80 default_server;
|
||||
server_name xmodulo.com;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
Once you open the config file with the server section, add the following if statement(s) somewhere inside the section.
|
||||
|
||||
server {
|
||||
listen 80 default_server;
|
||||
server_name xmodulo.com;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
# case sensitive matching
|
||||
if ($http_user_agent ~ (Antivirx|Arian) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
# case insensitive matching
|
||||
if ($http_user_agent ~* (netcrawl|npbot|malicious)) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
As you can guess, these if statements match any bad user-string with regular expressions, and return 403 HTTP status code when a match is found. $http_user_agent is a variable that contains the user-agent string of an HTTP request. The '~' operator does case-sensitive matching against user-agent string, while the '~' operator does case-insensitive matching. The '|' operator is logical-OR, so you can put as many user-agent keywords in the if statements, and block them all.
|
||||
|
||||
After modifying the configuration file, you must reload nginx to activate the blocking:
|
||||
|
||||
$ sudo /path/to/nginx -s reload
|
||||
|
||||
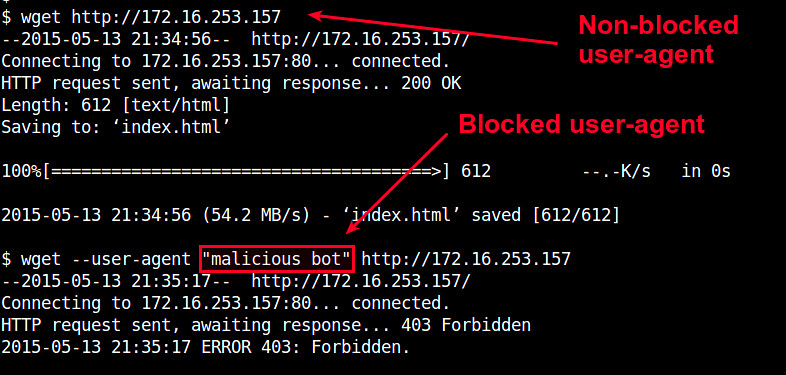
You can test user-agent blocking by using wget with "--user-agent" option.
|
||||
|
||||
$ wget --user-agent "malicious bot" http://<nginx-ip-address>
|
||||
|
||||
|
||||
|
||||
### Manage User-Agent Blacklist in Nginx ###
|
||||
|
||||
So far, I have shown how to block HTTP requests with a few user-agents in nginx. What if you have many different types of crawling bots to block?
|
||||
|
||||
Since the user-agent blacklist can grow very big, it is not a good idea to put them all inside your nginx's server section. Instead, you can create a separate file which lists all blocked user agents. For example, let's create /etc/nginx/useragent.rules, and define a map with all blocked user agents in the following format.
|
||||
|
||||
$ sudo vi /etc/nginx/useragent.rules
|
||||
|
||||
----------
|
||||
|
||||
map $http_user_agent $badagent {
|
||||
default 0;
|
||||
~*malicious 1;
|
||||
~*backdoor 1;
|
||||
~*netcrawler 1;
|
||||
~Antivirx 1;
|
||||
~Arian 1;
|
||||
~webbandit 1;
|
||||
}
|
||||
|
||||
Similar to the earlier setup, '~*' will match a keyword in case-insensitive manner, while '~' will match a keyword using a case-sensitive regular expression. The line that says "default 0" means that any other user-agent not listed in the file will be allowed.
|
||||
|
||||
Next, open an nginx configuration file of your website, which contains http section, and add the following line somewhere inside the http section.
|
||||
|
||||
http {
|
||||
.....
|
||||
include /etc/nginx/useragent.rules
|
||||
}
|
||||
|
||||
Note that this include statement must appear before the server section (this is why we add it inside http section).
|
||||
|
||||
Now open an nginx configuration where your server section is defined, and add the following if statement:
|
||||
|
||||
server {
|
||||
....
|
||||
|
||||
if ($badagent) {
|
||||
return 403;
|
||||
}
|
||||
|
||||
....
|
||||
}
|
||||
|
||||
Finally, reload nginx.
|
||||
|
||||
$ sudo /path/to/nginx -s reload
|
||||
|
||||
Now any user-agent which contains a keyword listed in /etc/nginx/useragent.rules will be automatically banned by nginx.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/block-specific-user-agents-nginx-web-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,45 @@
|
||||
Linux FAQs with Answers--How to fix “404 Not Found” error with “apt-get update” on old Ubuntu
|
||||
================================================================================
|
||||
> **Question**: I have old Ubuntu 13.04 (Raring Ringtail) installation on my PC. When I run "sudo apt-get update" on it, it throws a bunch of "404 Not Found" errors, and I cannot install or update any package using apt-get or aptitude. Due to this error I cannot even upgrade it to a newer release. How can I fix this problem?
|
||||
|
||||
|
||||
|
||||
Every Ubuntu release has its end-of-life (EOL) time; regular Ubuntu releases are supported for 18 months, while LTS (Long Term Support) versions are supported up to 3 years (server edition) and 5 years (desktop edition). Once a Ubuntu release has reached EOL, its repositories will no longer be accessible, and you won't get any maintenance updates and security patches from Canonical. As of this writing, Ubuntu 13.04 (Raring Ringtail) has already reached EOL.
|
||||
|
||||
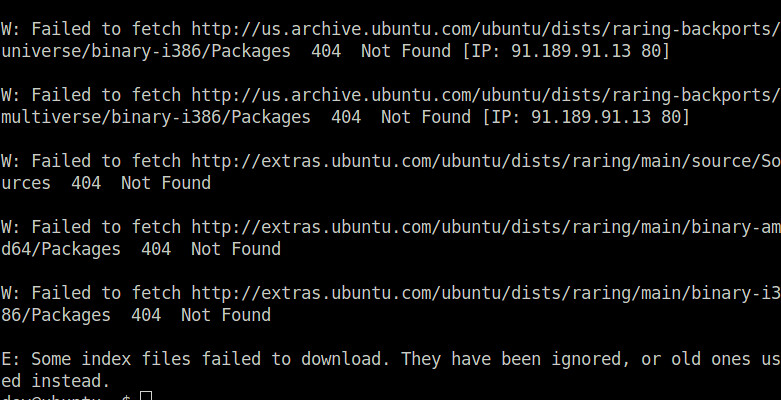
If the Ubuntu system you are using is EOL-ed, you will get the following 404 errors from apt-get or aptitude as its repositories have been deprecated.
|
||||
|
||||
W: Failed to fetch http://us.archive.ubuntu.com/ubuntu/dists/raring-backports/multiverse/binary-i386/Packages 404 Not Found [IP: 91.189.91.13 80]
|
||||
|
||||
W: Failed to fetch http://extras.ubuntu.com/ubuntu/dists/raring/main/binary-amd64/Packages 404 Not Found
|
||||
|
||||
W: Failed to fetch http://security.ubuntu.com/ubuntu/dists/raring-security/universe/binary-i386/Packages 404 Not Found [IP: 91.189.88.149 80]
|
||||
|
||||
E: Some index files failed to download. They have been ignored, or old ones used instead
|
||||
|
||||
For those users who are using old versions of Ubuntu, Canonical maintains old-releases.ubuntu.com, which is an archive of EOL-ed repositories. Thus, when Canonical's support for your Ubuntu installation ends, you need to switch to repositories at old-releases.ubuntu.com (unless you want to upgrade it before EOL).
|
||||
|
||||
Here is a quick way to fix "404 Not Found" errors on old Ubuntu by switching to old-releases repositories.
|
||||
|
||||
First, replace main/security repositories with old-releases versions as follows.
|
||||
|
||||
$ sudo sed -i -r 's/([a-z]{2}\.)?archive.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list
|
||||
$ sudo sed -i -r 's/security.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list
|
||||
|
||||
Then open /etc/apt/sources.list with a text editor, and look for extras.ubuntu.com. This repository is also no longer supported for 13.04. So you need to comment out extras.ubuntu.com by prepending '#' sign.
|
||||
|
||||
#deb http://extras.ubuntu.com/ubuntu raring main
|
||||
#deb-src http://extras.ubuntu.com/ubuntu raring main
|
||||
|
||||
Now you should be able to install or update packages on an old unsupported Ubuntu release.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/404-not-found-error-apt-get-update-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,31 @@
|
||||
Linux FAQs with Answers--How to fix “Encountered a section with no Package: header” error on Raspbian
|
||||
================================================================================
|
||||
> **Question**: I installed fresh Rasbian on Raspberry Pi. But when I tried to update APT package index by running sudo apt-get update, it throws the following error:
|
||||
|
||||
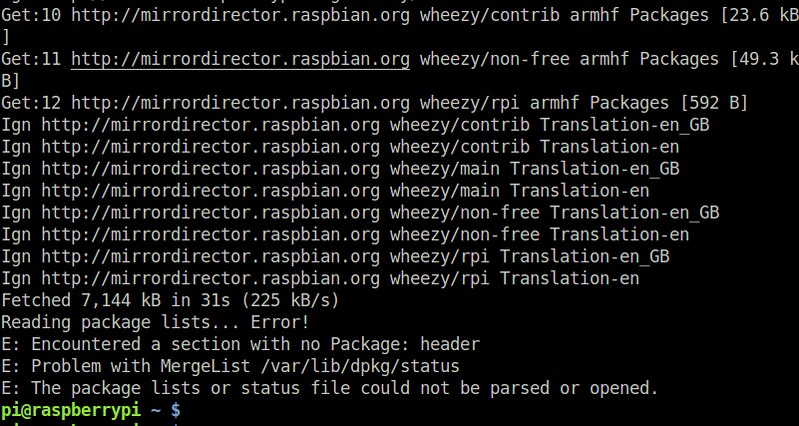
E: Encountered a section with no Package: header
|
||||
E: Problem with MergeList /var/lib/dpkg/status
|
||||
E: The package lists or status file could not be parsed or opened.
|
||||
|
||||
> I then cannot install any package on Raspbian. How can I solve this error?
|
||||
|
||||
|
||||
|
||||
The error saying "Problem with MergeList /var/lib/dpkg/status" indicates that the status file got corrupted for some reason, and so cannot be parsed. This status file contains information about installed deb packages, and thus needs to be carefully backed up.
|
||||
|
||||
In this case, since this is freshly installed Raspbian, you can safely remove the status file, and re-generate it as follows.
|
||||
|
||||
$ sudo rm /var/lib/dpkg/status
|
||||
$ sudo touch /var/lib/dpkg/status
|
||||
$ sudo apt-get update
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/encountered-section-with-no-package-header-error.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,33 @@
|
||||
Linux FAQs with Answers--How to fix “fatal error: security/pam_modules.h: No such file or directory”
|
||||
================================================================================
|
||||
> **Question**: I was trying to compile a program on [insert your Linux distro], but was getting the following compile error:
|
||||
>
|
||||
> "pam_otpw.c:27:34: fatal error: security/pam_modules.h: No such file or directory"
|
||||
>
|
||||
> How can I fix this error?
|
||||
|
||||
The missing header file 'security/pam_modules.h' is part of development files for libpam, a PAM (Pluggable Authentication Modules) library. Thus to fix this error, you need to install libpam development package, as described below.
|
||||
|
||||
On Debian, Ubuntu or Linux Mint:
|
||||
|
||||
$ sudo apt-get install libpam0g-dev
|
||||
|
||||
On CentOS, Fedora or RHEL:
|
||||
|
||||
$ sudo yum install gcc pam-devel
|
||||
|
||||
Now verify that the missing header file is installed under /usr/include/security.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fatal-error-security-pam-modules.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,57 @@
|
||||
Linux FAQs with Answers--How to view threads of a process on Linux
|
||||
================================================================================
|
||||
> **Question**: My program creates and executes multiple threads in it. How can I monitor individual threads of the program once they are created? I would like to see the details (e.g., CPU/memory usage) of individual threads with their names.
|
||||
|
||||
Threads are a popular programming abstraction for parallel execution on modern operating systems. When threads are forked inside a program for multiple flows of execution, these threads share certain resources (e.g., memory address space, open files) among themselves to minimize forking overhead and avoid expensive IPC (inter-process communication) channel. These properties make threads an efficient mechanism for concurrent execution.
|
||||
|
||||
In Linux, threads (also called Lightweight Processes (LWP)) created within a program will have the same "thread group ID" as the program's PID. Each thread will then have its own thread ID (TID). To the Linux kernel's scheduler, threads are nothing more than standard processes which happen to share certain resources. Classic command-line tools such as ps or top, which display process-level information by default, can be instructed to display thread-level information.
|
||||
|
||||
Here are several ways to **show threads for a process on Linux**.
|
||||
|
||||
### Method One: PS ###
|
||||
|
||||
In ps command, "-T" option enables thread views. The following command list all threads created by a process with <pid>.
|
||||
|
||||
$ ps -T -p <pid>
|
||||
|
||||

|
||||
|
||||
The "SID" column represents thread IDs, and "CMD" column shows thread names.
|
||||
|
||||
### Method Two: Top ###
|
||||
|
||||
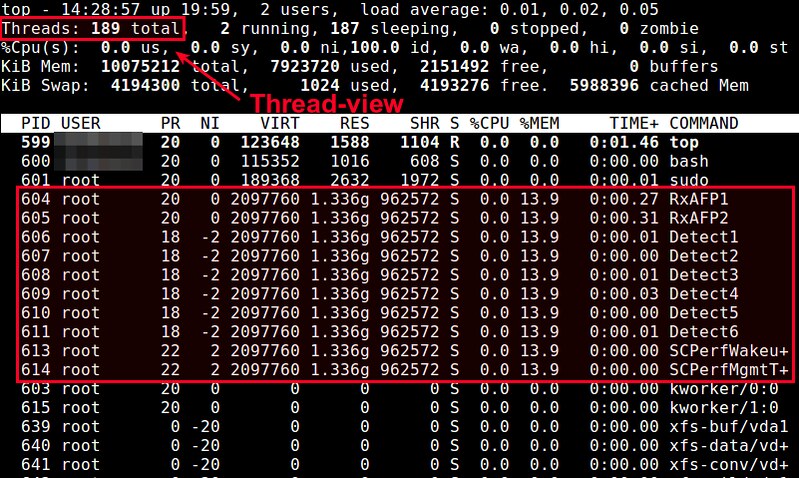
The top command can show a real-time view of individual threads. To enable thread views in the top output, invoke top with "-H" option. This will list all Linux threads. You can also toggle on or off thread view mode while top is running, by pressing 'H' key.
|
||||
|
||||
$ top -H
|
||||
|
||||
|
||||
|
||||
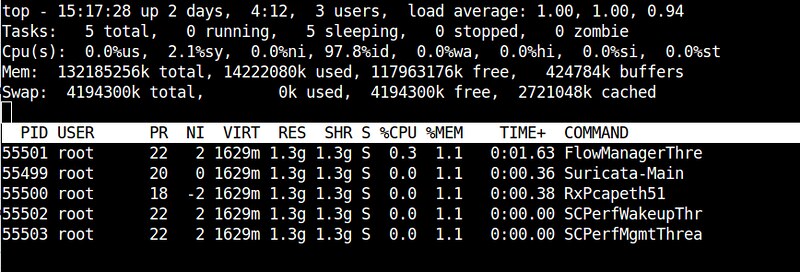
To restrict the top output to a particular process <pid> and check all threads running inside the process:
|
||||
|
||||
$ top -H -p <pid>
|
||||
|
||||
|
||||
|
||||
### Method Three: Htop ###
|
||||
|
||||
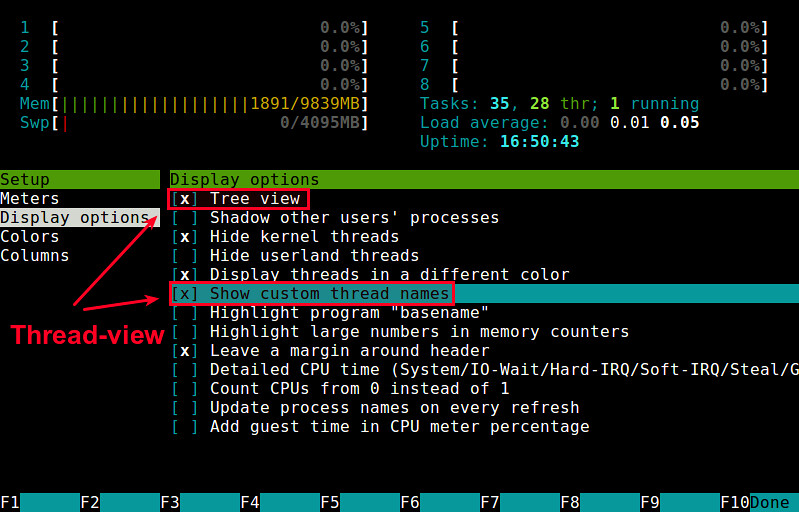
A more user-friendly way to view threads per process is via htop, an ncurses-based interactive process viewer. This program allows you to monitor individual threads in tree views.
|
||||
|
||||
To enable thread views in htop, launch htop, and press <F2> to enter htop setup menu. Choose "Display option" under "Setup" column, and toggle on "Three view" and "Show custom thread names" options. Presss <F10> to exit the setup.
|
||||
|
||||
|
||||
|
||||
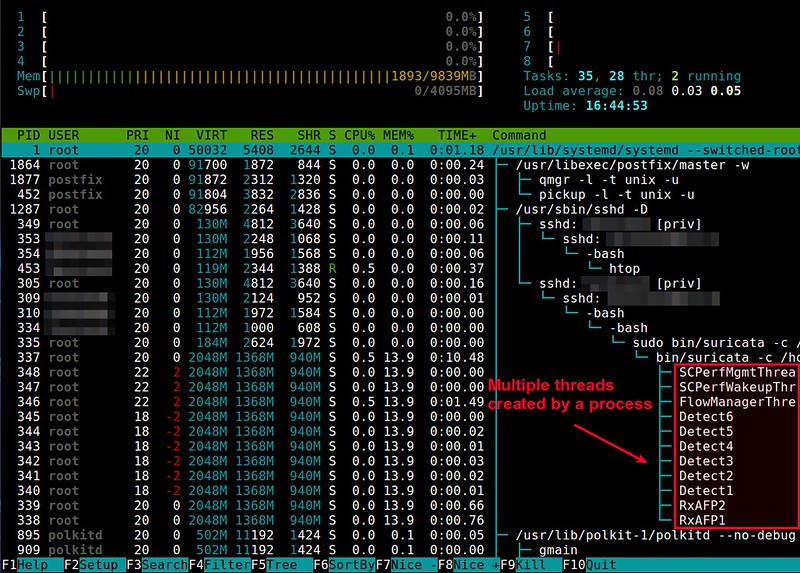
Now you will see the follow threaded view of individual processes.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/view-threads-process-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,81 @@
|
||||
Linux FAQs with Answers--What is the Apache error log location on Linux
|
||||
================================================================================
|
||||
> **Question**: I am trying to troubleshoot Apache web server errors on my Linux system. Where is the Apache error log file located on [insert your Linux distro]?
|
||||
|
||||
Error log and access log files are a useful piece of information for system admins, for example to troubleshoot their web server, [protect][1] it from various malicious activities, or just to run [various][2] [analytics][3] for HTTP server monitoring. Depending on your web server setup, its error/access logs may be found in different places on your system.
|
||||
|
||||
This post may help you **find Apache error log location on Linux**.
|
||||
|
||||
|
||||
|
||||
### Apache Error Log Location on Debian, Ubuntu or Linux Mint ###
|
||||
|
||||
#### Default Error Log ####
|
||||
|
||||
On Debian-based Linux, the system-wide default location of Apache error log is **/var/log/apache2/error.log**. The default location can be customized by editing Apache configuration file.
|
||||
|
||||
#### Custom Error Log ####
|
||||
|
||||
To find a custom error log location, open /etc/apache2/apache2.conf with a text editor, and look for a line that starts with ErrorLog. This line specifies a custom location of Apache error log file. For example, the unmodified Apache configuration file has the following line:
|
||||
|
||||
ErrorLog ${APACHE_LOG_DIR}/error.log
|
||||
|
||||
In this case, the location is configured using APACHE_LOG_DIR environment variable, which is defined in /etc/apache2/envvars.
|
||||
|
||||
export APACHE_LOG_DIR=/var/log/apache2$SUFFIX
|
||||
|
||||
In reality, ErrorLog may point to any arbitrary path on your Linux system.
|
||||
|
||||
#### Custom Error Log with VirtualHost ####
|
||||
|
||||
If VirtualHost is used in Apache web server, ErrorLog directive can be specified within VirtualHost container, in which case the system-wide error log location described above will be ignored.
|
||||
|
||||
With VirtualHost enabled, each VirtualHost can define its own custom error log location. To find out the error log location of a particular VirtualHost, you can open /etc/apache2/sites-enabled/<your-site>.conf, and look for ErrorLog directive, which will show a site-specific error log file.
|
||||
|
||||
### Apache Error Log Location on CentOS, Fedora or RHEL ###
|
||||
|
||||
#### Default Error Log ####
|
||||
|
||||
On Red Hat based Linux, a system-wide Apache error log file is by default placed in **/var/log/httpd/error_log**. This default location can be customized by editing Apache configuration file.
|
||||
|
||||
#### Custom Error Log ####
|
||||
|
||||
To find out the custom location of Apache error log, open /etc/httpd/conf/httpd.conf with a text editor, and look for ServerRoot, which shows the top of the Apache server directory tree, under which log files and configurations are located. For example:
|
||||
|
||||
ServerRoot "/etc/httpd"
|
||||
|
||||
Now look for a line that starts with ErrorLog, which indicates where Apache web server is writing its error logs. Note that the specified location is relative to the ServerRoot value. For example:
|
||||
|
||||
ErrorLog "log/error_log"
|
||||
|
||||
Combine the above two directives to obtain the full path of an error log, which is by default /etc/httpd/logs/error_log. This is a symlink to /var/log/httpd/error_log with freshly installed Apache.
|
||||
|
||||
In reality, ErrorLog may point to any arbitrary location on your Linux system.
|
||||
|
||||
#### Custom Error Log with VirtualHost ####
|
||||
|
||||
If you enabled VirtualHost, you can find the error log location of individual VirtualHosts by checking /etc/httpd/conf/httpd.conf (or any file where VirtualHost is defined). Look for ErrorLog inside individual VirtualHost sections. For example, in the following VirtualHost section, an error log is found in /var/www/xmodulo.com/logs/error_log.
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerAdmin webmaster@xmodulo.com
|
||||
DocumentRoot /var/www/xmodulo.com/public_html
|
||||
ServerName www.xmodulo.com
|
||||
ServerAlias xmodulo.com
|
||||
ErrorLog /var/www/xmodulo.com/logs/error_log
|
||||
CustomLog /var/www/xmodulo.com/logs/access_log
|
||||
<VirtualHost>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/apache-error-log-location-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/configure-fail2ban-apache-http-server.html
|
||||
[2]:http://xmodulo.com/interactive-apache-web-server-log-analyzer-linux.html
|
||||
[3]:http://xmodulo.com/sql-queries-apache-log-files-linux.html
|
||||
Loading…
Reference in New Issue
Block a user