mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
commit
e3991b36a9
38
README.md
38
README.md
@ -30,6 +30,26 @@ LCTT的组成
|
||||
|
||||
请阅读[WIKI](https://github.com/LCTT/TranslateProject/wiki)。
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
|
||||
* 2013/09/10 倡议并得到了大家的积极响应,成立翻译组。
|
||||
* 2013/09/11 采用github进行翻译协作,并开始进行选题翻译。
|
||||
* 2013/09/16 公开发布了翻译组成立消息后,又有新的成员申请加入了。并从此建立见习成员制度。
|
||||
* 2013/09/24 鉴于大家使用Github的水平不一,容易导致主仓库的一些错误,因此换成了常规的fork+PR的模式来进行翻译流程。
|
||||
* 2013/10/11 根据对LCTT的贡献,划分了Core Translators组,最先的加入成员是vito-L和tinyeyeser。
|
||||
* 2013/10/12 取消对LINUX.CN注册用户的依赖,在QQ群内、文章内都采用github的注册ID。
|
||||
* 2013/10/18 正式启动man翻译计划。
|
||||
* 2013/11/10 举行第一次北京线下聚会。
|
||||
* 2014/01/02 增加了Core Translators 成员: geekpi。
|
||||
* 2014/05/04 更换了新的QQ群:198889102
|
||||
* 2014/05/16 增加了Core Translators 成员: will.qian、vizv。
|
||||
* 2014/06/18 由于GOLinux令人惊叹的翻译速度和不错的翻译质量,升级为Core Translators成员。
|
||||
* 2014/09/09 LCTT 一周年,做一年[总结](http://linux.cn/article-3784-1.html)。并将曾任 CORE 的成员分组为 Senior,以表彰他们的贡献。
|
||||
* 2014/10/08 提升bazz2为Core Translators成员。
|
||||
* 2014/11/04 提升zpl1025为Core Translators成员。
|
||||
* 2014/12/25 提升runningwater为Core Translators成员。
|
||||
|
||||
活跃成员
|
||||
-------------------------------
|
||||
|
||||
@ -119,21 +139,3 @@ LCTT的组成
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
|
||||
* 2013/09/10 倡议并得到了大家的积极响应,成立翻译组。
|
||||
* 2013/09/11 采用github进行翻译协作,并开始进行选题翻译。
|
||||
* 2013/09/16 公开发布了翻译组成立消息后,又有新的成员申请加入了。并从此建立见习成员制度。
|
||||
* 2013/09/24 鉴于大家使用Github的水平不一,容易导致主仓库的一些错误,因此换成了常规的fork+PR的模式来进行翻译流程。
|
||||
* 2013/10/11 根据对LCTT的贡献,划分了Core Translators组,最先的加入成员是vito-L和tinyeyeser。
|
||||
* 2013/10/12 取消对LINUX.CN注册用户的依赖,在QQ群内、文章内都采用github的注册ID。
|
||||
* 2013/10/18 正式启动man翻译计划。
|
||||
* 2013/11/10 举行第一次北京线下聚会。
|
||||
* 2014/01/02 增加了Core Translators 成员: geekpi。
|
||||
* 2014/05/04 更换了新的QQ群:198889102
|
||||
* 2014/05/16 增加了Core Translators 成员: will.qian、vizv。
|
||||
* 2014/06/18 由于GOLinux令人惊叹的翻译速度和不错的翻译质量,升级为Core Translators成员。
|
||||
* 2014/09/09 LCTT 一周年,做一年[总结](http://linux.cn/article-3784-1.html)。并将曾任 CORE 的成员分组为 Senior,以表彰他们的贡献。
|
||||
* 2014/10/08 提升bazz2为Core Translators成员。
|
||||
* 2014/11/04 提升zpl1025为Core Translators成员。
|
||||
@ -8,23 +8,23 @@ Linux能够提供消费者想要的东西吗?
|
||||
|
||||
Linux需要深深凝视自己的水晶球,仔细体会那场浏览器大战留下的尘埃,然后留意一下这点建议:
|
||||
|
||||
如果你不能提供他们想要的,他们就会离开。
|
||||
> 如果你不能提供他们想要的,他们就会离开。
|
||||
|
||||
而这种事与愿违的另一个例子是Windows 8。消费者不喜欢那套界面。而微软却坚持使用,因为这是把所有东西搬到Surface平板上所必须的。相同的情况也可能发生在Canonical和Ubuntu Unity身上 -- 尽管它们的目标并不是单一独特地针对平板电脑来设计(所以,整套界面在桌面系统上仍然很实用而且直观)。
|
||||
|
||||
一直以来,Linux开发者和设计者们看上去都按照他们自己的想法来做事情。他们过分在意“吃你自家的狗粮”这句话了。以至于他们忘记了一件非常重要的事情:
|
||||
|
||||
没有新用户,他们的“根基”也仅仅只属于他们自己。
|
||||
> 没有新用户,他们的“根基”也仅仅只属于他们自己。
|
||||
|
||||
换句话说,唱诗班不仅仅是被传道,他们也同时在宣传。让我给你看三个案例来完全掌握这一点。
|
||||
|
||||
- 多年以来,有在Linux系统中替代活动目录(Active Directory)的需求。我很想把这个名称换成LDAP,但是你真的用过LDAP吗?那就是个噩梦。开发者们也努力了想让LDAP能易用一点,但是没一个做到了。而让我很震惊的是这样一个从多用户环境下发展起来的平台居然没有一个能和AD正面较量的功能。这需要一组开发人员,从头开始建立一个AD的开源替代。这对那些寻求从微软产品迁移的中型企业来说是非常大的福利。但是在这个产品做好之前,他们还不能开始迁移。
|
||||
- 多年以来,一直有在Linux系统中替代活动目录(Active Directory)的需求。我很想把这个名称换成LDAP,但是你真的用过LDAP吗?那就是个噩梦。开发者们也努力了想让LDAP能易用一点,但是没一个做到了。而让我很震惊的是这样一个从多用户环境下发展起来的平台居然没有一个能和AD正面较量的功能。这需要一组开发人员,从头开始建立一个AD的开源替代。这对那些寻求从微软产品迁移的中型企业来说是非常大的福利。但是在这个产品做好之前,他们还不能开始迁移。
|
||||
- 另一个从微软激发的需求是Exchange/Outlook。是,我也知道许多人都开始用云。但是,事实上中等和大型规模生意仍然依赖于Exchange/Outlook组合,直到能有更好的产品出现。而这将非常有希望发生在开源社区。整个拼图的一小块已经摆好了(虽然还需要一些工作)- 群件客户端,Evolution。如果有人能够从Zimbra拉出一个分支,然后重新设计成可以配合Evolution(甚至Thunderbird)来提供服务实现Exchange的简单替代,那这个游戏就不是这么玩了,而消费者获得的利益将是巨大的。
|
||||
- 便宜,便宜,还是便宜。这是大多数人都得咽下去的苦药片 - 但是消费者(和生意)就是希望便宜。看看去年一年Chromebook的销量吧。现在,搜索一下Linux笔记本看能不能找到700美元以下的。而只用三分之一的价格,就可以买到一个让你够用的Chromebook(一个使用了Linux内核的平台)。但是因为Linux仍然是一个细分市场,很难降低成本。像红帽那种公司也许可以改变现状。他们也已经推出了服务器硬件。为什么不推出一些和Chromebook有类似定位但是却运行完整Linux环境的低价中档笔记本呢?(请看“[Cloudbook是Linux的未来吗?][1]”)其中的关键是这种设备要低成本并且符合普通消费者的要求。不要站在游戏玩家/开发者的角度去思考了,记住普通消费者真正的需求 - 一个网页浏览器,不会有更多了。这是Chromebook为什么可以这么轻松地成功。Google精确地知道消费者想要什么,然后推出相应的产品。而面对Linux,一些公司仍然认为他们吸引买家的唯一途径是高端昂贵的硬件。而有一点讽刺的是,口水战中最经常听到的却是Linux只能在更慢更旧的硬件上运行。
|
||||
|
||||
最后,Linux需要看一看乔布斯传(Book Of Jobs),搞清楚如何说服消费者们他们真正要的就是Linux。在生意上和在家里 -- 每个人都可以享受到Linux带来的好处。说真的,开源社区怎么可能做不到这点呢?Linux本身就已经带有很多漂亮的时髦术语标签:稳定性,可靠性,安全性,云,免费 -- 再加上Linux实际已经进入到绝大多数人手中了(只是他们自己还不清楚罢了)。现在是时候让他们知道这一点了。如果你是用Android或者Chromebooks,那么你就在用(某种形式上的)Linux。
|
||||
最后,Linux需要看一看乔布斯传(Book Of Jobs),搞清楚如何说服消费者们他们真正要的就是Linux。在公司里和在家里 -- 每个人都可以享受到Linux带来的好处。说真的,开源社区怎么可能做不到这点呢?Linux本身就已经带有很多漂亮的时髦术语标签:稳定性、可靠性、安全性、云、免费 -- 再加上Linux实际已经进入到绝大多数人手中了(只是他们自己还不清楚罢了)。现在是时候让他们知道这一点了。如果你是用Android或者Chromebooks,那么你就在用(某种形式上的)Linux。
|
||||
|
||||
搞清楚消费者需求一直以来都是Linux社区的绊脚石。而且我知道 -- 太多的Linux开发都基于某个开发者有个特殊的想法。这意味着这些开发都针对的“微型市场”。是时候,无论如何,让Linux开发社区能够进行全球性思考了。“一般用户有什么需求,我们怎么满足他们?”让我提几个最基本的点。
|
||||
搞清楚消费者需求一直以来都是Linux社区的绊脚石。而且我知道 -- 太多的Linux开发都基于某个开发者有个特殊的想法。这意味着这些开发都针对的“微型市场”。是时候了,无论如何,让Linux开发社区能够进行全球性思考了。“一般用户有什么需求,我们怎么满足他们?”让我提几个最基本的点。
|
||||
|
||||
一般用户想要:
|
||||
|
||||
@ -43,7 +43,7 @@ via: http://www.techrepublic.com/article/will-linux-ever-be-able-to-give-consume
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,27 +1,26 @@
|
||||
让下载更方便
|
||||
================================================================================
|
||||
下载管理器是一个电脑程序,专门处理下载文件,优化带宽占用,以及让下载更有条理等任务。有些网页浏览器,例如Firefox,也集成了一个下载管理器作为功能,但是它们的方式还是没有专门的下载管理器(或者浏览器插件)那么专业,没有最佳地使用带宽,也没有好用的文件管理功能。
|
||||
下载管理器是一个电脑程序,专门处理下载文件,优化带宽占用,以及让下载更有条理等任务。有些网页浏览器,例如Firefox,也集成了一个下载管理器作为功能,但是它们的使用方式还是没有专门的下载管理器(或者浏览器插件)那么专业,没有最佳地使用带宽,也没有好用的文件管理功能。
|
||||
|
||||
对于那些经常下载的人,使用一个好的下载管理器会更有帮助。它能够最大化下载速度(加速下载),断点续传以及制定下载计划,让下载更安全也更有价值。下载管理器已经没有之前流行了,但是最好的下载管理器还是很实用,包括和浏览器的紧密结合,支持类似YouTube的主流网站,以及更多。
|
||||
|
||||
有好几个能在Linux下工作都非常优秀的开源下载管理器,以至于让人无从选择。我整理了一个摘要,是我喜欢的下载管理器,以及Firefox里的一个非常好用的下载插件。这里列出的每一个程序都是开源许可发布的。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###uGet
|
||||
|
||||

|
||||
|
||||
uGet是一个轻量级,容易使用,功能完备的开源下载管理器。uGet允许用户从不同的源并行下载来加快速度,添加文件到下载序列,暂停或继续下载,提供高级分类管理,和浏览器集成,监控剪贴板,批量下载,支持26种语言,以及其他许多功能。
|
||||
|
||||
uGet是一个成熟的软件;保持开发超过11年。在这个时间里,它发展成一个非常多功能的下载管理器,拥有一套很高价值的功能集,还保持了易用性。
|
||||
uGet是一个成熟的软件;持续开发超过了11年。在这段时间里,它发展成一个非常多功能的下载管理器,拥有一套很高价值的功能集,还保持了易用性。
|
||||
|
||||
uGet是用C语言开发的,使用了cURL作为底层支持,以及应用库libcurl。uGet有非常好的平台兼容性。它一开始是Linux系统下的项目,但是被移植到在Mac OS X,FreeBSD,Android和Windows平台运行。
|
||||
|
||||
#### 功能点: ####
|
||||
|
||||
- 容易使用
|
||||
- 下载队列可以让下载任务按任意多或少或你希望的数量同时进行。
|
||||
- 下载队列可以让下载任务按任意数量或你希望的数量同时进行。
|
||||
- 断点续传
|
||||
- 默认分类
|
||||
- 完美实现的剪贴板监控功能
|
||||
@ -43,19 +42,19 @@ uGet是用C语言开发的,使用了cURL作为底层支持,以及应用库li
|
||||
- 支持GnuTLS
|
||||
- 支持26种语言,包括:阿拉伯语,白俄罗斯语,简体中文,繁体中文,捷克语,丹麦语,英语(默认),法语,格鲁吉亚语,德语,匈牙利语,印尼语,意大利语,波兰语,葡萄牙语(巴西),俄语,西班牙语,土耳其语,乌克兰语,以及越南语。
|
||||
|
||||
---
|
||||
|
||||
- 网站:[ugetdm.com][1]
|
||||
- 开发人员:C.H. Huang and contributors
|
||||
- 许可:GNU LGPL 2.1
|
||||
- 版本:1.10.5
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###DownThemAll!
|
||||
|
||||

|
||||
|
||||
DownThemAll!是一个小巧的,可靠的以及易用的,开源下载管理器/加速器,是Firefox的一个组件。它可以让用户下载一个页面上所有链接和图片以及更多功能。它可以让用户完全控制下载任务,随时分配下载速度以及同时下载的任务数量。通过使用Metalinks或者手动添加镜像的方式,可以同时从不同的服务器下载同一个文件。
|
||||
DownThemAll!是一个小巧可靠的、易用的开源下载管理器/加速器,是Firefox的一个组件。它可以让用户下载一个页面上所有链接和图片,还有更多功能。它可以让用户完全控制下载任务,随时分配下载速度以及同时下载的任务数量。通过使用Metalinks或者手动添加镜像的方式,可以同时从不同的服务器下载同一个文件。
|
||||
|
||||
DownThemAll会根据你要下载的文件大小,切割成不同的部分,然后并行下载。
|
||||
|
||||
@ -69,6 +68,7 @@ DownThemAll会根据你要下载的文件大小,切割成不同的部分,然
|
||||
- 高级重命名选项
|
||||
- 暂停和继续下载任务
|
||||
|
||||
---
|
||||
|
||||
- 网站:[addons.mozilla.org/en-US/firefox/addon/downthemall][2]
|
||||
- 开发人员:Federico Parodi, Stefano Verna, Nils Maier
|
||||
@ -77,13 +77,13 @@ DownThemAll会根据你要下载的文件大小,切割成不同的部分,然
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###JDownloader
|
||||
|
||||

|
||||
|
||||
JDownloader是一个免费,开源的下载管理工具,拥有一个大型社区的开发者支持,让下载更简单和快捷。用户可以开始,停止或暂停下载,设置带宽限制,自动解压缩包,以及更多功能。它提供了一个容易扩展的框架。
|
||||
|
||||
JDownloader简化了从一键下载网站下载文件。它还支持从不同并行资源下载,手势识别,自动文件解压缩以及更多功能。另外,还支持许多“加密链接”网站-所以你只需要复制粘贴“加密的”链接,然后JDownloader会处理剩下的事情。JDownloader还能导入CCF,RSDF和DLC文件。
|
||||
JDownloader简化了从一键下载网站下载文件。它还支持从不同并行资源下载、手势识别、自动文件解压缩以及更多功能。另外,还支持许多“加密链接”网站-所以你只需要复制粘贴“加密的”链接,然后JDownloader会处理剩下的事情。JDownloader还能导入CCF,RSDF和DLC文件。
|
||||
|
||||
#### 功能点: ####
|
||||
|
||||
@ -98,6 +98,7 @@ JDownloader简化了从一键下载网站下载文件。它还支持从不同并
|
||||
- 网页更新
|
||||
- 集成包管理器支持额外模块(例如,Webinterface,Shutdown)
|
||||
|
||||
---
|
||||
|
||||
- 网站:[jdownloader.org][3]
|
||||
- 开发人员:AppWork UG
|
||||
@ -106,11 +107,11 @@ JDownloader简化了从一键下载网站下载文件。它还支持从不同并
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###FreeRapid Downloader
|
||||
|
||||

|
||||
|
||||
FreeRapid Downloader是一个易用的开源下载程序,支持从Rapidshare,Youtube,Facebook,Picasa和其他文件分享网站下载。他的下载引擎基于一些插件,所以可以从特殊站点下载。
|
||||
FreeRapid Downloader是一个易用的开源下载程序,支持从Rapidshare,Youtube,Facebook,Picasa和其他文件分享网站下载。他的下载引擎基于一些插件,所以可以从那些特别的站点下载。
|
||||
|
||||
对于需要针对特定文件分享网站的下载管理器用户来说,FreeRapid Downloader是理想的选择。
|
||||
|
||||
@ -133,6 +134,7 @@ FreeRapid Downloader使用Java语言编写。需要至少Sun Java 7.0版本才
|
||||
- 支持多国语言:英语,保加利亚语,捷克语,芬兰语,葡萄牙语,斯洛伐克语,匈牙利语,简体中文,以及其他
|
||||
- 支持超过700个站点
|
||||
|
||||
---
|
||||
|
||||
- 网站:[wordrider.net/freerapid/][4]
|
||||
- 开发人员:Vity and contributors
|
||||
@ -141,7 +143,7 @@ FreeRapid Downloader使用Java语言编写。需要至少Sun Java 7.0版本才
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###FlashGot
|
||||
|
||||

|
||||
|
||||
@ -151,7 +153,7 @@ FlashGot把所支持的所有下载管理器统一成Firefox中的一个下载
|
||||
|
||||
#### 功能点: ####
|
||||
|
||||
- Linux下支持:Aria, Axel Download Accelerator, cURL, Downloader 4 X, FatRat, GNOME Gwget, FatRat, JDownloader, KDE KGet, pyLoad, SteadyFlow, uGet, wxDFast, 和wxDownload Fast
|
||||
- Linux下支持:Aria, Axel Download Accelerator, cURL, Downloader 4 X, FatRat, GNOME Gwget, FatRat, JDownloader, KDE KGet, pyLoad, SteadyFlow, uGet, wxDFast 和 wxDownload Fast
|
||||
- 支持图库功能,可以帮助把原来分散在不同页面的系列资源,整合到一个所有媒体库页面中,然后可以轻松迅速地“下载所有”
|
||||
- FlashGot Link会使用默认下载管理器下载当前鼠标选中的链接
|
||||
- FlashGot Selection
|
||||
@ -160,12 +162,13 @@ FlashGot把所支持的所有下载管理器统一成Firefox中的一个下载
|
||||
- FlashGot Media
|
||||
- 抓取页面里所有链接
|
||||
- 抓取所有标签栏的所有链接
|
||||
- 链接过滤(例如,只下载指定类型文件)
|
||||
- 链接过滤(例如只下载指定类型文件)
|
||||
- 在网页上抓取点击所产生的所有链接
|
||||
- 支持从大多数链接保护和文件托管服务器直接和批量下载
|
||||
- 隐私选项
|
||||
- 支持国际化
|
||||
|
||||
---
|
||||
|
||||
- 网站:[flashgot.net][5]
|
||||
- 开发人员:Giorgio Maone
|
||||
@ -178,7 +181,7 @@ via: http://www.linuxlinks.com/article/20140913062041384/DownloadManagers.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
如何在Ubuntu桌面上使用Steam Music音乐播放器
|
||||
================================================================================
|
||||
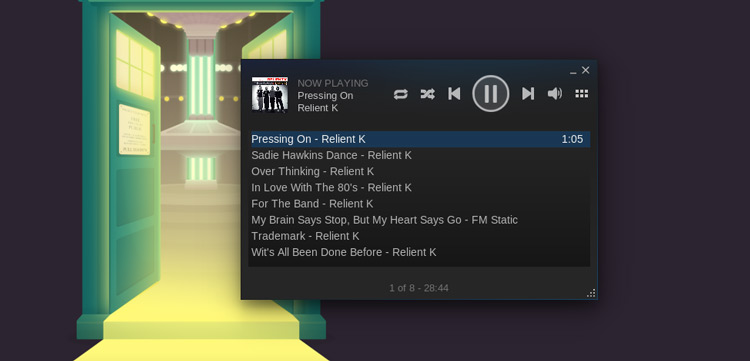
|
||||
|
||||
**‘音乐让人们走到一起’ 麦当娜曾这样唱道。但是Steam的新音乐播放器特性能否很好的混搭小资与叛逆?**
|
||||
|
||||
如果你曾与世隔绝,充耳不闻,你就会错过与Steam Music的相识。它的特性并不是全新的。从今年的早些时候开始,它就已经以这样或那样的形式进行了测试。
|
||||
|
||||
但Steam客户端最近一次在Windows、Mac和Linux上的定期更新中,所有的客户端都能使用它了。你会问为什么一个游戏客户端会添加一个音乐播放器呢?当然是为了让你能一边玩游戏一边一边听你最喜欢的音乐了。
|
||||
|
||||
别担心:在游戏的音乐声中再加上你自己的音乐,听起来并不会像你想象的那么糟(哈哈)。Steam会帮你减少或消除游戏的背景音乐,但在混音器中保持效果音的高音量,以便于你能和平时一样听到那些叮,嘭和各种爆炸声。
|
||||
|
||||
### 使用Steam Music音乐播放器 ###
|
||||
|
||||
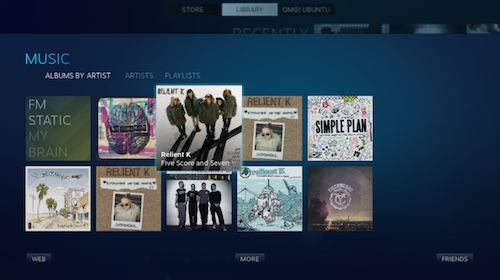
|
||||
|
||||
*大图模式*
|
||||
|
||||
任何使用最新版客户端的人都能使用Steam Music音乐播放器。它是个相当简单的附加程序:它让你能从你的电脑中添加、浏览并播放音乐。
|
||||
|
||||
播放器可以以两种方式进入:桌面和(超棒的)Steam大图模式。在两种方式下,控制播放都超级简单。
|
||||
|
||||
作为一个Rhythmbox的对手或是Spotify的继承者,把**为玩游戏时放音乐而设计**作为特点一点也不吸引人。事实上,他没有任何可购买音乐的商店,也没有整合Rdio,Grooveshark这类在线服务或是桌面服务。没错,你的多媒体键在Linux的播放器上完全不能用。
|
||||
|
||||
Valve说他们“*……计划增加更多的功能以便用户能以新的方式体验Steam Music。我们才刚刚开始。*”
|
||||
|
||||
#### Steam Music的重要特性:####
|
||||
|
||||
- 只能播放MP3文件
|
||||
- 与游戏中的音乐相融
|
||||
- 在游戏中可以控制音乐
|
||||
- 播放器可以在桌面上或在大图模式下运行
|
||||
- 基于播放列表的播放方式
|
||||
|
||||
**它没有整合到Ubuntu的声音菜单里,而且目前也不支持键盘上的多媒体键。**
|
||||
|
||||
### 在Ubuntu上使用Steam Music播放器 ###
|
||||
|
||||
显然,添加音乐是你播放音乐前的第一件事。在Ubuntu上,默认设置下,Steam会自动添加两个文件夹:Home下的标准Music目录和它自带的Steam Music文件夹。任何可下载的音轨都保存在其中。
|
||||
|
||||
注意:目前**Steam Music只能播放MP3文件**。如果你的大部分音乐都是其他文件格式(比如.acc、.m4a等等),这些文件不会被添加也不能被播放。
|
||||
|
||||
若想添加其他的文件夹或重新扫描:
|
||||
|
||||
- 到**View > Settings > Music**。
|
||||
- 点击‘**Add**‘将其他位置的文件夹添加到已列出两个文件夹的列表下。
|
||||
- 点击‘**Start Scanning**’
|
||||
|
||||
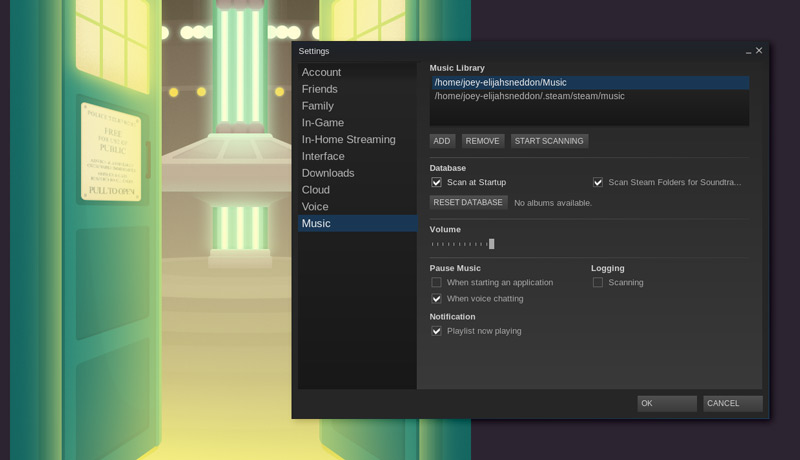
|
||||
|
||||
你还可以在这个对话框中调整其他设置,包括‘scan at start’。如果你经常添加新音乐而且很容易忘记手动启动扫描,请标记此项。你还可以选择当路径变化时是否显示提示,设置默认的音量,还能调整当你打开一个应用软件或语音聊天时的播放状态的改变。
|
||||
|
||||
一旦你的音乐源成功的被添加并扫描后,你就可以通过主客户端的**Library > Music**区域浏览你的音乐了。
|
||||
|
||||
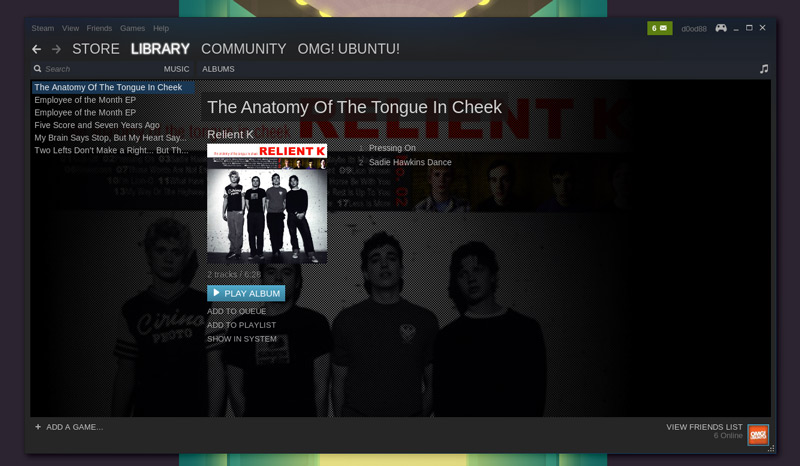
|
||||
|
||||
Steam Music会默认的将音乐按照专辑进行分组。若想按照乐队名进行浏览,你需要点击‘Albums’然后从下拉菜单中选择‘Artists’。
|
||||
|
||||
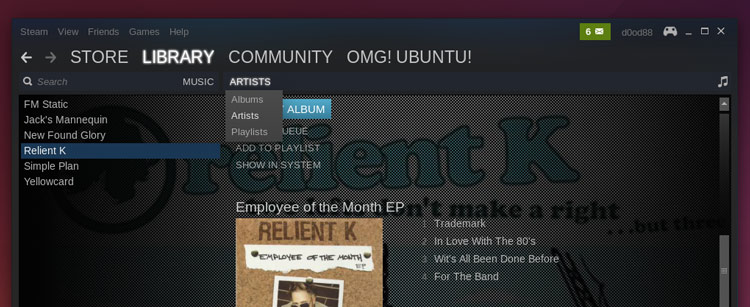
|
||||
|
||||
Steam Music是一个以‘队列’方式工作的系统。你可以通过双击浏览器里的音乐或右键单击并选择‘Add to Queue’来把音乐添加到播放队列里。
|
||||
|
||||
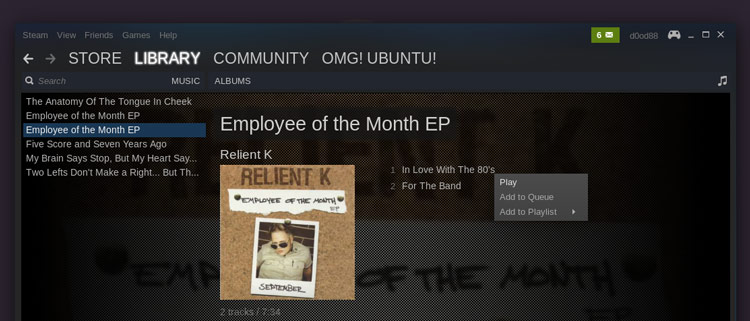
|
||||
|
||||
若想**启动桌面播放器**请点击右上角的音符图标或通过**View > Music Player**菜单。
|
||||
|
||||
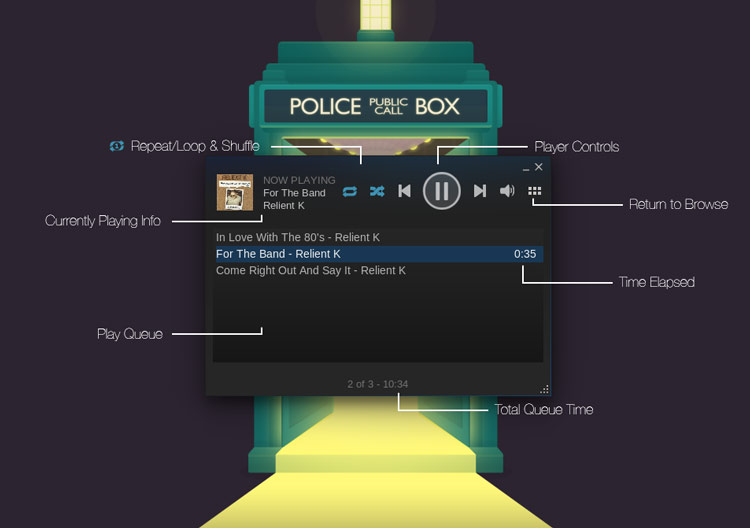
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/10/use-steam-music-player-linux
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
@ -1,4 +1,4 @@
|
||||
Linux问答时间--如何在CentOS上安装phpMyAdmin
|
||||
Linux有问必答:如何在CentOS上安装phpMyAdmin
|
||||
================================================================================
|
||||
> **问题**:我正在CentOS上运行一个MySQL/MariaDB服务,并且我想要通过网络接口来用phpMyAdmin来管理数据库。在CentOS上安装phpMyAdmin的最佳方法是什么?
|
||||
|
||||
@ -108,7 +108,7 @@ phpMyAdmin是一款以PHP为基础,基于Web的MySQL/MariaDB数据库管理工
|
||||
|
||||
### 测试phpMyAdmin ###
|
||||
|
||||
测试phpMyAdmin是否设置成功,访问这个页面:http://<web-server-ip-addresss>/phpmyadmin
|
||||
测试phpMyAdmin是否设置成功,访问这个页面:http://\<web-server-ip-addresss>/phpmyadmin
|
||||
|
||||

|
||||
|
||||
@ -153,14 +153,14 @@ phpMyAdmin是一款以PHP为基础,基于Web的MySQL/MariaDB数据库管理工
|
||||
via: http://ask.xmodulo.com/install-phpmyadmin-centos.html
|
||||
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/set-web-based-database-management-system-adminer.html
|
||||
[2]:http://xmodulo.com/install-lamp-stack-centos.html
|
||||
[3]:http://xmodulo.com/install-lemp-stack-centos.html
|
||||
[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[2]:http://linux.cn/article-1567-1.html
|
||||
[3]:http://linux.cn/article-4314-1.html
|
||||
[4]:http://linux.cn/article-2324-1.html
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
@ -1,6 +1,6 @@
|
||||
Linux的十条SCP传输命令
|
||||
十个 SCP 传输命令例子
|
||||
================================================================================
|
||||
Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是不安装**GUI**的。**SSH**可能是Linux系统管理员通过远程方式安全管理服务器的最流行协议。在**SSH**命令中内置了一种叫**SCP**的命令,用来在服务器之间安全传输文件。
|
||||
Linux系统管理员应该很熟悉**CLI**环境,因为通常在Linux服务器中是不安装**GUI**的。**SSH**可能是Linux系统管理员通过远程方式安全管理服务器的最流行协议。在**SSH**命令中内置了一种叫**SCP**的命令,用来在服务器之间安全传输文件。
|
||||
|
||||

|
||||
|
||||
@ -10,7 +10,7 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
scp source_file_name username@destination_host:destination_folder
|
||||
|
||||
**SCP**命令有很多参数供你使用,这里指的是每次都会用到的参数。
|
||||
**SCP**命令有很多可以使用的参数,这里指的是每次都会用到的参数。
|
||||
|
||||
### 用-v参数来提供SCP进程的详细信息 ###
|
||||
|
||||
@ -53,7 +53,7 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
### 用-C参数来让文件传输更快 ###
|
||||
|
||||
有一个参数能让传输文件更快,就是“**-C**”参数,它的作用是不停压缩所传输的文件。它特别之处在于压缩是在网络中进行,当文件传到目标服务器时,它会变回压缩之前的原始大小。
|
||||
有一个参数能让传输文件更快,就是“**-C**”参数,它的作用是不停压缩所传输的文件。它特别之处在于压缩是在网络传输中进行,当文件传到目标服务器时,它会变回压缩之前的原始大小。
|
||||
|
||||
来看看这些命令,我们使用一个**93 Mb**的单一文件来做例子。
|
||||
|
||||
@ -121,18 +121,18 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
看到了吧,压缩了文件之后,传输过程在**162.5**秒内就完成了,速度是不用“**-C**”参数的10倍。如果你要通过网络拷贝很多份文件,那么“**-C**”参数能帮你节省掉很多时间。
|
||||
|
||||
有一点我们需要注意,这个压缩的方法不是适用于所有文件。当源文件已经被压缩过了,那就没办法再压缩了。诸如那些像**.zip**,**.rar**,**pictures**和**.iso**的文件,用“**-C**”参数就无效。
|
||||
有一点我们需要注意,这个压缩的方法不是适用于所有文件。当源文件已经被压缩过了,那就没办法再压缩很多了。诸如那些像**.zip**,**.rar**,**pictures**和**.iso**的文件,用“**-C**”参数就没什么意义。
|
||||
|
||||
### 选择其它加密算法来加密文件 ###
|
||||
|
||||
**SCP**默认是用“**AES-128**”加密算法来加密文件的。如果你想要改用其它加密算法来加密文件,你可以用“**-c**”参数。我们来瞧瞧。
|
||||
**SCP**默认是用“**AES-128**”加密算法来加密传输的。如果你想要改用其它加密算法来加密传输,你可以用“**-c**”参数。我们来瞧瞧。
|
||||
|
||||
pungki@mint ~/Documents $ scp -c 3des Label.pdf mrarianto@202.x.x.x:.
|
||||
|
||||
mrarianto@202.x.x.x's password:
|
||||
Label.pdf 100% 3672KB 282.5KB/s 00:13
|
||||
|
||||
上述命令是告诉**SCP**用**3des algorithm**来加密文件。要注意这个参数是“**-c**”而不是“**-C**“。
|
||||
上述命令是告诉**SCP**用**3des algorithm**来加密文件。要注意这个参数是“**-c**”(小写)而不是“**-C**“(大写)。
|
||||
|
||||
### 限制带宽使用 ###
|
||||
|
||||
@ -143,24 +143,24 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
mrarianto@202.x.x.x's password:
|
||||
Label.pdf 100% 3672KB 50.3KB/s 01:13
|
||||
|
||||
在“**-l**”参数后面的这个**400**值意思是我们给**SCP**进程限制了带宽为**50 KB/秒**。有一点要记住,带宽是以**千比特/秒** (**kbps**)表示的,**8 比特**等于**1 字节**。
|
||||
在“**-l**”参数后面的这个**400**值意思是我们给**SCP**进程限制了带宽为**50 KB/秒**。有一点要记住,带宽是以**千比特/秒** (**kbps**)表示的,而**8 比特**等于**1 字节**。
|
||||
|
||||
因为**SCP**是用**千字节/秒** (**KB/s**)计算的,所以如果你想要限制**SCP**的最大带宽只有**50 KB/s**,你就需要设置成**50 x 8 = 400**。
|
||||
|
||||
### 指定端口 ###
|
||||
|
||||
通常**SCP**是把**22**作为默认端口。但是为了安全起见,你可以改成其它端口。比如说,我们想用**2249**端口,命令如下所示。
|
||||
通常**SCP**是把**22**作为默认端口。但是为了安全起见SSH 监听端口改成其它端口。比如说,我们想用**2249**端口,这种情况下就要指定端口。命令如下所示。
|
||||
|
||||
pungki@mint ~/Documents $ scp -P 2249 Label.pdf mrarianto@202.x.x.x:.
|
||||
|
||||
mrarianto@202.x.x.x's password:
|
||||
Label.pdf 100% 3672KB 262.3KB/s 00:14
|
||||
|
||||
确认一下写的是大写字母“**P**”而不是“**p**“,因为“**p**”已经被用来保留源文件的修改时间和模式。
|
||||
确认一下写的是大写字母“**P**”而不是“**p**“,因为“**p**”已经被用来保留源文件的修改时间和模式(LCTT 译注:和 ssh 命令不同了)。
|
||||
|
||||
### 递归拷贝文件和文件夹 ###
|
||||
|
||||
有时我们需要拷贝文件夹及其内部的所有**文件** / **文件夹**,我们如果能用一条命令解决问题那就更好了。**SCP**用“**-r**”参数就能做到。
|
||||
有时我们需要拷贝文件夹及其内部的所有**文件**/**子文件夹**,我们如果能用一条命令解决问题那就更好了。**SCP**用“**-r**”参数就能做到。
|
||||
|
||||
pungki@mint ~/Documents $ scp -r documents mrarianto@202.x.x.x:.
|
||||
|
||||
@ -172,7 +172,7 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
### 禁用进度条和警告/诊断信息 ###
|
||||
|
||||
如果你不想从SCP中看到进度条和警告/诊断信息,你可以用“**-q**”参数来禁用它们,举例如下。
|
||||
如果你不想从SCP中看到进度条和警告/诊断信息,你可以用“**-q**”参数来静默它们,举例如下。
|
||||
|
||||
pungki@mint ~/Documents $ scp -q Label.pdf mrarianto@202.x.x.x:.
|
||||
|
||||
@ -207,7 +207,7 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
### 选择不同的ssh_config文件 ###
|
||||
|
||||
对于经常在公司网络和公共网络之间切换的移动用户来说,一直改变SCP的设置显然是很痛苦的。如果我们能放一个不同的**ssh_config**文件来匹配我们的需求那就很好了。
|
||||
对于经常在公司网络和公共网络之间切换的移动用户来说,一直改变SCP的设置显然是很痛苦的。如果我们能放一个保存不同配置的**ssh_config**文件来匹配我们的需求那就很好了。
|
||||
|
||||
#### 以下是一个简单的场景 ####
|
||||
|
||||
@ -231,7 +231,7 @@ via: http://www.tecmint.com/scp-commands-examples/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,44 +1,46 @@
|
||||
2014年会是 "Linux桌面年"吗?
|
||||
================================================================================
|
||||
> 现在谈起Linux桌面终于能头头是道了
|
||||
> Linux桌面现在终于发出最强音!
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**看来Linux在2014年有很多改变,许多用户都表示今年Linux的确有进步,但是仅凭这个就能断定2014年就是"Linux桌面年"吗?**
|
||||
|
||||
"Linux桌面年"这句话,在过去几年就被传诵得像句颂歌一样,可以说是在试图用一种比较有意义的方式来标记它的发展进程。此类事情目前还没有发生过,在我们的见证下也从无先例,所以这就不难理解为什么Linux用户会用这个角度去看待这句话。
|
||||
|
||||
大多数软件和硬件领域不太会有这种快速的进步,都以较慢的速度发展,但是对于那些在工业领域有更好眼光的人来说,事情就会变得疯狂。即使有可能,针对某一时刻或某一事件还是比较困难的,但是Linux在几年的过程中还是以指数方式迅速发展成长。
|
||||
|
||||

|
||||
|
||||
|
||||
### Linux桌面年这句话不可轻言 ###
|
||||
|
||||
没有一个比较权威的人和机构能判定Linux桌面年已经到来或者已经过去,所以我们只能尝试根据迄今为止我们所看到的和用户所反映的去推断。有一些人比较保守,改变对他们影响不大,还有一些人则比较激进,永远不知满足。这真的要取决于你的见解了。
|
||||
|
||||
点燃这一切的火花似乎就是Linux上的Steam平台,尽管在这变成现实之前我们已经看到了一些Linux游戏已经开始有重要的动作了。在任何情况下,Valve都可能是我们今天所看到的一系列复苏事件的催化剂。
|
||||
|
||||
在过去的十年里,Linux桌面以一种缓慢的速度在发展,并没有什么真正的改变。创新肯定是有的,但是市场份额几乎还是保持不变。无论桌面变得多么酷或Linux相比之前的任何一版多出了多少特点,很大程度上还是在原地踏步,包括那些制作专有软件的公司,他们的参与度一直很小,基本上就忽略掉了Linux。
|
||||

|
||||
|
||||
在过去的十年里,Linux桌面以一种缓慢的速度在发展,并没有什么真正的改变。创新肯定是有的,但是市场份额几乎还是保持不变。无论桌面变得多么酷或Linux相比之前的任何一版多出了多少特点,很大程度上还是在原地踏步,包括那些开发商业软件的公司,他们的参与度一直很小,基本上就忽略掉了Linux。
|
||||
|
||||
|
||||

|
||||
|
||||
现在,相比过去的十年里,更多的公司表现出了对Linux平台的浓厚兴趣。或许这是一种自然地演变,Valve并没有做什么,但是Linux最终还是达到了一个能被普通用户接受并理解的水平,并不只是因为令人着迷的开源技术。
|
||||
|
||||
驱动程序能力强了,游戏工作室就会定期移植游戏,在Linux中我们前所未见的应用和中间件就会开始出现。Linux内核发展达到了难以置信的速度,大多数发行版的安装过程通常都不怎么难,所有这一切都只是冰山一角。
|
||||
|
||||

|
||||
|
||||
所以,当有人问你2014年是不是Linux桌面年时,你可以说“是的!”,因为Linux桌面完全统治了2014年。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Was-2014-The-Year-of-Linux-Desktop-467036.shtml
|
||||
|
||||
作者:[Silviu Stahie ][a]
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
Attic——重复数据删除备份程序
|
||||
Attic——删除重复数据的备份程序
|
||||
================================================================================
|
||||
Attic是一个Python写的重复数据删除备份程序,其主要目标是提供一种高效安全的数据备份方式。重复数据消除技术的使用使得Attic适用于日常备份,因为它可以只存储那些修改过的数据。
|
||||
Attic是一个Python写的删除重复数据的备份程序,其主要目标是提供一种高效安全的数据备份方式。重复数据消除技术的使用使得Attic适用于日常备份,因为它可以只存储那些修改过的数据。
|
||||
|
||||
### Attic特性 ###
|
||||
|
||||
#### 空间高效存储 ####
|
||||
|
||||
可变块大小重复数据消除技术用于减少检测到的冗余数据存储字节数量。每个文件被分割成若干可变长度组块,只有那些从没见过的组块会被压缩并添加到仓库中。
|
||||
可变块大小重复数据消除技术用于减少检测到的冗余数据存储字节数量。每个文件被分割成若干可变长度组块,只有那些从没见过的组合块会被压缩并添加到仓库中。
|
||||
|
||||
#### 可选数据加密 ####
|
||||
|
||||
@ -44,29 +44,29 @@ Attic可以通过SSH将数据存储到安装有Attic的远程主机上。
|
||||
|
||||
该备份将更快些,也更小些,因为只有之前从没见过的新数据会被存储。--stats选项会让Attic输出关于新创建的归档的统计数据,比如唯一数据(不和其它归档共享)的数量:
|
||||
|
||||
归档名:Tuesday
|
||||
归档指纹:387a5e3f9b0e792e91ce87134b0f4bfe17677d9248cb5337f3fbf3a8e157942a
|
||||
开始时间: Tue Mar 25 12:00:10 2014
|
||||
结束时间: Tue Mar 25 12:00:10 2014
|
||||
持续时间: 0.08 seconds
|
||||
文件数量: 358
|
||||
最初大小 压缩后大小 重复数据删除后大小
|
||||
本归档: 57.16 MB 46.78 MB 151.67 kB
|
||||
所有归档:114.02 MB 93.46 MB 44.81 MB
|
||||
归档名:Tuesday
|
||||
归档指纹:387a5e3f9b0e792e91ce87134b0f4bfe17677d9248cb5337f3fbf3a8e157942a
|
||||
开始时间: Tue Mar 25 12:00:10 2014
|
||||
结束时间: Tue Mar 25 12:00:10 2014
|
||||
持续时间: 0.08 seconds
|
||||
文件数量: 358
|
||||
最初大小 压缩后大小 重复数据删除后大小
|
||||
本归档: 57.16 MB 46.78 MB 151.67 kB
|
||||
所有归档:114.02 MB 93.46 MB 44.81 MB
|
||||
|
||||
列出仓库中所有归档:
|
||||
|
||||
$ attic list /somewhere/my-repository.attic
|
||||
|
||||
Monday Mon Mar 24 11:59:35 2014
|
||||
Tuesday Tue Mar 25 12:00:10 2014
|
||||
Monday Mon Mar 24 11:59:35 2014
|
||||
Tuesday Tue Mar 25 12:00:10 2014
|
||||
|
||||
列出Monday归档的内容:
|
||||
|
||||
$ attic list /somewhere/my-repository.attic::Monday
|
||||
|
||||
drwxr-xr-x user group 0 Jan 06 15:22 home/user/Documents
|
||||
-rw-r--r-- user group 7961 Nov 17 2012 home/user/Documents/Important.doc
|
||||
drwxr-xr-x user group 0 Jan 06 15:22 home/user/Documents
|
||||
-rw-r--r-- user group 7961 Nov 17 2012 home/user/Documents/Important.doc
|
||||
|
||||
恢复Monday归档:
|
||||
|
||||
@ -76,7 +76,7 @@ drwxr-xr-x user group 0 Jan 06 15:22 home/user/Documents
|
||||
|
||||
$ attic delete /somwhere/my-backup.attic::Monday
|
||||
|
||||
详情请查阅[Attic文档][1]
|
||||
详情请查阅[Attic文档][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -84,7 +84,7 @@ via: http://www.ubuntugeek.com/attic-deduplicating-backup-program.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
红帽反驳:“grinch”算不上Linux漏洞
|
||||
红帽反驳:“grinch(鬼精灵)”算不上Linux漏洞
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -14,7 +14,7 @@
|
||||
|
||||
Alert Logic 称攻击者可以使用第三方Linux 软件框架Policy Kit (Polkit)达到利用“鬼精灵”漏洞的目的。Polkit旨在帮助用户安装与运行软件包,此开源程序由红帽维护。Alert Logic 声称,允许用户安装软件程序的过程中往往需要超级用户权限,如此一来,Polkit也在不经意间或通过其它形式为恶意程序的运行洞开方便之门。
|
||||
|
||||
红帽对此不以为意,表示系统就是这么设计的,换句话说,“鬼精灵”不是臭虫而是一项特性。
|
||||
红帽对此不以为意,表示系统就是这么设计的,换句话说,**“鬼精灵”不是臭虫而是一项特性。**
|
||||
|
||||
安全监控公司Threat Stack联合创造人 Jen Andre [就此在一篇博客][4]中写道:“如果你任由用户通过使用那些利用了Policykit的软件,无需密码就可以在系统上安装任何软件,实际上也就绕过了Linux内在授权与访问控制。”
|
||||
|
||||
@ -52,7 +52,7 @@ via:http://www.computerworld.com/article/2861392/security0/the-grinch-isnt-a-lin
|
||||
|
||||
作者:[Joab Jackson][a]
|
||||
译者:[yupmoon](https://github.com/yupmoon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
Linux有问必答:如何在Debian下安装闭源软件包
|
||||
================================================================================
|
||||
> **提问**: 我需要在Debian下安装特定的闭源设备驱动。然而, 我无法在Debian中找到并安装软件包。如何在Debian下安装闭源软件包?
|
||||
|
||||
Debian是一个拥有[48,000][1]软件包的发行版. 这些软件包被分为三类: main, contrib 和 non-free, 主要是根据许可证要求, 参照[Debian开源软件指南][2] (DFSG)。
|
||||
|
||||
main软件仓库包括符合DFSG的开源软件。contrib也包括符合DFSG的开源软件,但是依赖闭源软件来编译或者执行。non-free包括不符合DFSG的、可再分发的闭源软件。main仓库被认为是Debian项目的一部分,但是contrib和non-free不是。后两者只是为了用户的方便而维护和提供。
|
||||
|
||||
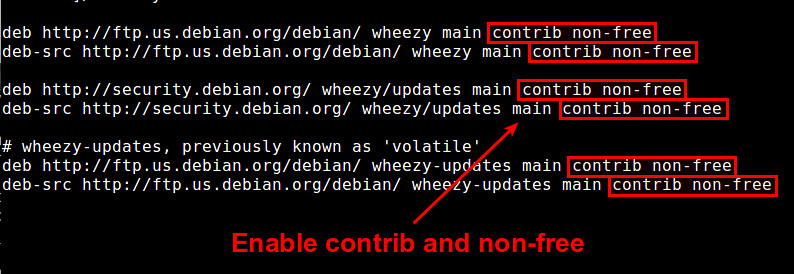
如果你想一直能够在Debian上安装闭源软件包,你需要添加contrib和non-free软件仓库。这样做,用文本编辑器打开 /etc/apt/sources.list 添加"contrib non-free""到每个源。
|
||||
|
||||
下面是适用于 Debian Wheezy的 /etc/apt/sources.list 例子。
|
||||
|
||||
deb http://ftp.us.debian.org/debian/ wheezy main contrib non-free
|
||||
deb-src http://ftp.us.debian.org/debian/ wheezy main contrib non-free
|
||||
|
||||
deb http://security.debian.org/ wheezy/updates main contrib non-free
|
||||
deb-src http://security.debian.org/ wheezy/updates main contrib non-free
|
||||
|
||||
# wheezy-updates, 之前叫做 'volatile'
|
||||
deb http://ftp.us.debian.org/debian/ wheezy-updates main contrib non-free
|
||||
deb-src http://ftp.us.debian.org/debian/ wheezy-updates main contrib non-free
|
||||
|
||||
|
||||
|
||||
修改完源后, 运行下面命令去下载contrib和non-free软件仓库的文件索引。
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
如果你用 aptitude, 运行下面命令。
|
||||
|
||||
$ sudo aptitude update
|
||||
|
||||
现在你在Debian上搜索和安装任何闭源软件包。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-nonfree-packages-debian.html
|
||||
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://packages.debian.org/stable/allpackages?format=txt.gz
|
||||
[2]:https://www.debian.org/social_contract.html#guidelines
|
||||
@ -1,44 +0,0 @@
|
||||
Linus Torvalds Launches Linux Kernel 3.19 RC1, One of the Biggest So Far
|
||||
================================================================================
|
||||
> new development cycle for Linux kernel has started
|
||||
|
||||

|
||||
|
||||
**The first Linux kernel Release Candidate has been made available in the 3.19 branch and it looks like it's one of the biggest ones so far. Linux Torvalds surprised everyone with an early launch, but it's easy to understand why.**
|
||||
|
||||
The Linux kernel development cycle has been refreshed with a new released, 3.19. Given the fact that the 3.18 branch reached stable status just a couple of weeks ago, today's release was not completely unexpected. The holidays are coming and many of the developers and maintainers will probably take a break. Usually, a new RC is launched on a weekly basis, but users might see a slight delay this time.
|
||||
|
||||
There is no mention of the regression problem that was identified in Linux kernel 3.18, but it's pretty certain that they are still working to fix it. On the other hand, Linux did say that this is a very large released, in fact it's one of the biggest ones made until now. It's likely that many devs wanted to push their patches before the holidays, so the next RC should be a smaller.
|
||||
|
||||
### Linux kernel 3.19 RC1 marks the start of a new cycle ###
|
||||
|
||||
The size of the releases has been increasing, along with the frequency. The development cycle for the kernel usually takes about 8 to 10 weeks and it seldom happens to be more than that, which brings a nice predictability for the project.
|
||||
|
||||
"That said, maybe there aren't any real stragglers - and judging by the size of rc1, there really can't have been much. Not only do I think there are more commits than there were in linux-next, this is one of the bigger rc1's (at least by commits) historically. We've had bigger ones (3.10 and 3.15 both had large merge windows leading up to them), but this was definitely not a small merge window."
|
||||
|
||||
"In the 'big picture', this looks like a fairly normal release. About two thirds driver updates, with about half of the rest being architecture updates (and no, the new nios2 patches are not at all dominant, it's about half ARM, with the new nios2 support being less than 10% of the arch updates by lines overall)," [reads][1] the announcement made by Linus Torvalds.
|
||||
|
||||
More details about this RC can be found on the official mailing list.
|
||||
|
||||
#### Download Linux kernel 3.19 RC1 source package: ####
|
||||
|
||||
- [tar.xz (3.18.1 Stable)][3]File size: 77.2 MB
|
||||
- [tar.xz (3.19 RC1 Unstable)][4]
|
||||
|
||||
It you want to test it, you will need to compile it yourself although it's advisable to not use a production machines.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Launches-Linux-kernel-3-19-RC1-One-of-the-Biggest-So-Far-468043.shtml
|
||||
|
||||
作者:[Silviu Stahie ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://lkml.iu.edu/hypermail/linux/kernel/1412.2/02480.html
|
||||
[2]:http://linux.softpedia.com/get/System/Operating-Systems/Kernels/Linux-Kernel-Development-8069.shtml
|
||||
[3]:https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.18.1.tar.xz
|
||||
[4]:https://www.kernel.org/pub/linux/kernel/v3.x/testing/linux-3.19-rc1.tar.xz
|
||||
@ -1,79 +0,0 @@
|
||||
How To Use Steam Music Player on Ubuntu Desktop
|
||||
================================================================================
|
||||

|
||||
|
||||
**‘Music makes the people come together’ Madonna once sang. But can Steam’s new music player feature mix the bourgeoisie and the rebel as well?**
|
||||
|
||||
If you’ve been living under a rock, ears pressed tight to a granite roof, word of Steam Music may have passed you by. The feature isn’t entirely new. It’s been in testing in some form or another since earlier this year.
|
||||
|
||||
But in the latest stable update of the Steam client on Windows, Mac and Linux it is now available to all. Why does a gaming client need to add a music player, you ask? To let you play your favourite music while gaming, of course.
|
||||
|
||||
Don’t worry: playing your music over in-game music is not as bad as it sounds (har har) on paper. Steam reduces/cancels out the game soundtrack in favour of your tunes, but keeps sound effects high in the mix so you can hear the plings, boops and blams all the same.
|
||||
|
||||
### Using Steam Music Player ###
|
||||
|
||||

|
||||
|
||||
Music in Big Picture Mode
|
||||
|
||||
Steam Music Player is available to anyone running the latest version of the client. It’s a pretty simple addition: it lets you add, browse and play music from your computer.
|
||||
|
||||
The player element itself is accessible on the desktop and when playing in Steam’s (awesome) Big Picture mode. In both instances, controlling playback is made dead simple.
|
||||
|
||||
As the feature is **designed for playing music while gaming** it is not pitching itself as a rival for Rhythmbox or successor to Spotify. In fact, there’s no store to purchase music from and no integration with online services like Rdio, Grooveshark, etc. or the desktop. Nope, your keyboard media keys won’t work with the player in Linux.
|
||||
|
||||
Valve say they “*…plan to add more features so you can experience Steam music in new ways. We’re just getting started.*”
|
||||
|
||||
#### Steam Music Key Features: ####
|
||||
|
||||
- Plays MP3s only
|
||||
- Mixes with in-game soundtrack
|
||||
- Music controls available in game
|
||||
- Player can run on the desktop or in Big Picture mode
|
||||
- Playlist/queue based playback
|
||||
|
||||
**It does not integrate with the Ubuntu Sound Menu and does not currently support keyboard media keys.**
|
||||
|
||||
### Using Steam Music on Ubuntu ###
|
||||
|
||||
The first thing to do before you can play music is to add some. On Ubuntu, by default, Steam automatically adds two folders: the standard Music directory in Home, and its own Steam Music folder, where any downloadable soundtracks are stored.
|
||||
|
||||
Note: at present **Steam Music only plays MP3s**. If the bulk of your music is in a different file format (e.g., .aac, .m4a, etc.) it won’t be added and cannot be played.
|
||||
|
||||
To add an additional source or scan files in those already listed:
|
||||
|
||||
- Head to **View > Settings > Music**.
|
||||
- Click ‘**Add**‘ to add a folder in a different location to the two listed entries
|
||||
- Hit ‘**Start Scanning**’
|
||||
|
||||

|
||||
|
||||
This dialog is also where you can adjust other preferences, including a ‘scan at start’. If you routinely add new music and are prone to forgetting to manually initiate a scan, tick this one on. You can also choose whether to see notifications on track change, set the default volume levels, and adjust playback behaviour when opening an app or taking a voice chat.
|
||||
|
||||
Once your music sources have been successfully added and scanned you are all set to browse through your entries from the **Library > Music** section of the main client.
|
||||
|
||||

|
||||
|
||||
The Steam Music section groups music by album title by default. To browse by band name you need to click the ‘Albums’ header and then select ‘Artists’ from the drop down menu.
|
||||
|
||||

|
||||
|
||||
Steam Music works off of a ‘queue’ system. You can add music to the queue by double-clicking on a track in the browser or by right-clicking and selecting ‘Add to Queue’.
|
||||
|
||||

|
||||
|
||||
To **launch the desktop player** click the musical note emblem in the upper-right hand corner or through the **View > Music Player** menu.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/10/use-steam-music-player-linux
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
@ -0,0 +1,47 @@
|
||||
How to Download Music from Grooveshark with a Linux OS
|
||||
================================================================================
|
||||
> The solution is actually much simpler than you think
|
||||
|
||||

|
||||
|
||||
**Grooveshark is a great online platform for people who want to listen to music, and there are a number of ways to download music from there. Groovesquid is just one of the applications that let users get music from Grooveshark, and it's multiplatform.**
|
||||
|
||||
If there is a service that streams something online, then there is a way to download the stuff that you are just watching or listening. As it turns out, it's not that difficult and there are a ton of solutions, no matter the platform. For example, there are dozens of YouTube downloaders and it stands to reason that it's not all that difficult to get stuff from Grooveshark either.
|
||||
|
||||
Now, there is the problem of legality. Like many other applications out there, Groovesquid is not actually illegal. It's the user's fault if they do something illegal with an application. The same reasoning can be applied to apps like utorrent or Bittorrent. As long as you don't touch copyrighted material, there are no problems in using Groovesquid.
|
||||
|
||||
### Groovesquid is fast and efficient ###
|
||||
|
||||
The only problem that you could find with Groovesquid is the fact that it's based on Java and that's never a good sign. This is a good way to ensure that an application runs on all the platforms, but it's an issue when it comes to the interface. It's not great, but it doesn't really matter all that much for users, especially since the app is doing a great job.
|
||||
|
||||
There is one caveat though. Groovesquid is a free application, but in order to remain free, it has to display an ad on the right side of the menu. This shouldn't be a problem for most people, but it's a good idea to mention that right from the start.
|
||||
|
||||
From a usability point of view, the application is pretty straightforward. Users can download a single song by entering the link in the top field, but the purpose of that field can be changed by accessing the small drop-down menu to its left. From there, it's possible to change to Song, Popular, Albums, Playlist, and Artist. Some of the options provide access to things like the most popular song on Grooveshark and other options allow you to download an entire playlist, for example.
|
||||
|
||||
You can download Groovesquid 0.7.0
|
||||
|
||||
- [jar][1] File size: 3.8 MB
|
||||
- [tar.gz][2] File size: 549 KB
|
||||
|
||||
You will get a Jar file and all you have to do is to make it executable and let Java do the rest.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/How-to-Download-Music-from-Grooveshark-with-a-Linux-OS-468268.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://github.com/groovesquid/groovesquid/releases/download/v0.7.0/Groovesquid.jar
|
||||
[2]:https://github.com/groovesquid/groovesquid/archive/v0.7.0.tar.gz
|
||||
@ -1,157 +0,0 @@
|
||||
disylee占个坑~
|
||||
Docker: Present and Future
|
||||
================================================================================
|
||||
### Docker - the story so far ###
|
||||
|
||||
Docker is a toolset for Linux containers designed to ‘build, ship and run’ distributed applications. It was first released as an open source project by DotCloud in March 2013. The project quickly became popular, leading to DotCloud rebranded as Docker Inc (and ultimately [selling off their original PaaS business][1]). [Docker 1.0][2] was released in June 2014, and the monthly release cadence that led up to the June release has been sustained since.
|
||||
|
||||
The 1.0 release marked the point where Docker Inc considered the platform sufficiently mature to be used in production (with the company and partners providing paid for support options). The monthly release of point updates shows that the project is still evolving quickly, adding new features, and addressing issues as they are found. The project has however successfully decoupled ‘ship’ from ‘run’, so images sourced from any version of Docker can be used with any other version (with both forward and backward compatibility), something that provides a stable foundation for Docker use despite rapid change.
|
||||
|
||||
The growth of Docker into one of the most popular open source projects could be perceived as hype, but there is a great deal of substance. Docker has attracted support from many brand names across the industry, including Amazon, Canonical, CenturyLink, Google, IBM, Microsoft, New Relic, Pivotal, Red Hat and VMware. This is making it almost ubiquitously available wherever Linux can be found. In addition to the big names many startups are growing up around Docker, or changing direction to be better aligned with Docker. Those partnerships (large and small) are helping to drive rapid evolution of the core project and its surrounding ecosystem.
|
||||
|
||||
### A brief technical overview of Docker ###
|
||||
|
||||
Docker makes use of Linux kernel facilities such as [cGroups][3], namespaces and [SElinux][4] to provide isolation between containers. At first Docker was a front end for the [LXC][5] container management subsystem, but release 0.9 introduced [libcontainer][6], which is a native Go language library that provides the interface between user space and the kernel.
|
||||
|
||||
Containers sit on top of a union file system, such as [AUFS][7], which allows for the sharing of components such as operating system images and installed libraries across multiple containers. The layering approach in the filesystem is also exploited by the [Dockerfile][8] DevOps tool, which is able to cache operations that have already completed successfully. This can greatly speed up test cycles by taking out the wait time usually taken to install operating systems and application dependencies. Shared libraries between containers can also reduce RAM footprint.
|
||||
|
||||
A container is started from an image, which may be locally created, cached locally, or downloaded from a registry. Docker Inc operates the [Docker Hub public registry][9], which hosts official repositories for a variety of operating systems, middleware and databases. Organisations and individuals can host public repositories for images at Docker Hub, and there are also subscription services for hosting private repositories. Since an uploaded image could contain almost anything Docker Hub provides an automated build facility (that was previously called ‘trusted build’) where images are constructed from a Dockerfile that serves as a manifest for the contents of the image.
|
||||
|
||||
### Containers versus VMs ###
|
||||
|
||||
Containers are potentially much more efficient than VMs because they’re able to share a single kernel and share application libraries. This can lead to substantially smaller RAM footprints even when compared to virtualisation systems that can make use of RAM overcommitment. Storage footprints can also be reduced where deployed containers share underlying image layers. IBM’s Boden Russel has done [benchmarking][10] that illustrates these differences.
|
||||
|
||||
Containers also present a lower systems overhead than VMs, so the performance of an application inside a container will generally be the same or better versus the same application running within a VM. A team of IBM researchers have published a [performance comparison of virtual machines and Linux containers][11].
|
||||
|
||||
One area where containers are weaker than VMs is isolation. VMs can take advantage of ring -1 [hardware isolation][12] such as that provided by Intel’s VT-d and VT-x technologies. Such isolation prevents VMs from ‘breaking out’ and interfering with each other. Containers don’t yet have any form of hardware isolation, which makes them susceptible to exploits. A proof of concept attack named [Shocker][13] showed that Docker versions prior to 1.0 were vulnerable. Although Docker 1.0 fixed the particular issue exploited by Shocker, Docker CTO Solomon Hykes [stated][14], “When we feel comfortable saying that Docker out-of-the-box can safely contain untrusted uid0 programs, we will say so clearly.”. Hykes’s statement acknowledges that other exploits and associated risks remain, and that more work will need to be done before containers can become trustworthy.
|
||||
|
||||
For many use cases the choice of containers or VMs is a false dichotomy. Docker works well within a VM, which allows it to be used on existing virtual infrastructure, private clouds and public clouds. It’s also possible to run VMs inside containers, which is something that Google uses as part of its cloud platform. Given the widespread availability of infrastructure as a service (IaaS) that provides VMs on demand it’s reasonable to expect that containers and VMs will be used together for years to come. It’s also possible that container management and virtualisation technologies might be brought together to provide a best of both worlds approach; so a hardware trust anchored micro virtualisation implementation behind libcontainer could integrate with the Docker tool chain and ecosystem at the front end, but use a different back end that provides better isolation. Micro virtualisation (such as Bromium’s [vSentry][15] and VMware’s [Project Fargo][16]) is already used in desktop environments to provide hardware based isolation between applications, so similar approaches could be used along with libcontainer as an alternative to the container mechanisms in the Linux kernel.
|
||||
|
||||
### ‘Dockerizing’ applications ###
|
||||
|
||||
Pretty much any Linux application can run inside a Docker container. There are no limitations on choice of languages or frameworks. The only practical limitation is what a container is allowed to do from an operating system perspective. Even that bar can be lowered by running containers in privileged mode, which substantially reduces controls (and correspondingly increases risk of the containerised application being able to cause damage to the host operating system).
|
||||
|
||||
Containers are started from images, and images can be made from running containers. There are essentially two ways to get applications into containers - manually and Dockerfile..
|
||||
|
||||
#### Manual builds ####
|
||||
|
||||
A manual build starts by launching a container with a base operating system image. An interactive terminal can then be used to install applications and dependencies using the package manager offered by the chosen flavour of Linux. Zef Hemel provides a walk through of the process in his article ‘[Using Linux Containers to Support Portable Application Deployment][17]’. Once the application is installed the container can be pushed to a registry (such as Docker Hub) or exported into a tar file.
|
||||
|
||||
#### Dockerfile ####
|
||||
|
||||
Dockerfile is a system for scripting the construction of Docker containers. Each Dockerfile specifies the base image to start from and then a series of commands that are run in the container and/or files that are added to the container. The Dockerfile can also specify ports to be exposed, the working directory when a container is started and the default command on startup. Containers built with Dockerfiles can be pushed or exported just like manual builds. Dockerfiles can also be used in Docker Hub’s automated build system so that images are built from scratch in a system under the control of Docker Inc with the source of that image visible to anybody that might use it.
|
||||
|
||||
#### One process? ####
|
||||
|
||||
Whether images are built manually or with Dockerfile a key consideration is that only a single process is invoked when the container is launched. For a container serving a single purpose, such as running an application server, running a single process isn’t an issue (and some argue that containers should only have a single process). For situations where it’s desirable to have multiple processes running inside a container a [supervisor][18] process must be launched that can then spawn the other desired processes. There is no init system within containers, so anything that relies on systemd, upstart or similar won’t work without modification.
|
||||
|
||||
### Containers and microservices ###
|
||||
|
||||
A full description of the philosophy and benefits of using a microservices architecture is beyond the scope of this article (and well covered in the [InfoQ eMag: Microservices][19]). Containers are however a convenient way to bundle and deploy instances of microservices.
|
||||
|
||||
Whilst most practical examples of large scale microservices deployments to date have been on top of (large numbers of) VMs, containers offer the opportunity to deploy at a smaller scale. The ability for containers to have a shared RAM and disk footprint for operating systems, libraries common application code also means that deploying multiple versions of services side by side can be made very efficient.
|
||||
|
||||
### Connecting containers ###
|
||||
|
||||
Small applications will fit inside a single container, but in many cases an application will be spread across multiple containers. Docker’s success has spawned a flurry of new application compositing tools, orchestration tools and platform as a service (PaaS) implementations. Behind most of these efforts is a desire to simplify the process of constructing an application from a set of interconnected containers. Many tools also help with scaling, fault tolerance, performance management and version control of deployed assets.
|
||||
|
||||
#### Connectivity ####
|
||||
|
||||
Docker’s networking capabilities are fairly primitive. Services within containers can be made accessible to other containers on the same host, and Docker can also map ports onto the host operating system to make services available across a network. The officially sponsored approach to connectivity is [libchan][20], which is a library that provides Go like [channels][21] over the network. Until libchan finds its way into applications there’s room for third parties to provide complementary network services. For example, [Flocker][22] has taken a proxy based approach to make services portable across hosts (along with their underlying storage).
|
||||
|
||||
#### Compositing ####
|
||||
|
||||
Docker has native mechanisms for linking containers together where metadata about a dependency can be passed into the dependent container and consumed within as environment variables and hosts entries. Application compositing tools like [Fig][23] and [geard][24] express the dependency graph inside a single file so that multiple containers can be brought together into a coherent system. CenturyLink’s [Panamax][25] compositing tool takes a similar underlying approach to Fig and geard, but adds a web based user interface, and integrates directly with GitHub so that applications can be shared.
|
||||
|
||||
#### Orchestration ####
|
||||
|
||||
Orchestration systems like [Decking][26], New Relic’s [Centurion][27] and Google’s [Kubernetes][28] all aim to help with the deployment and life cycle management of containers. There are also numerous examples (such as [Mesosphere][29]) of [Apache Mesos][30] (and particularly its [Marathon][31] framework for long running applications) being used along with Docker. By providing an abstraction between the application needs (e.g. expressed as a requirement for CPU cores and memory) and underlying infrastructure, the orchestration tools provide decoupling that’s designed to simplify both application development and data centre operations. There is such a variety of orchestration systems because many have emerged from internal systems previously developed to manage large scale deployments of containers; for example Kubernetes is based on Google’s [Omega][32] system that’s used to manage containers across the Google estate.
|
||||
|
||||
Whilst there is some degree of functional overlap between the compositing tools and the orchestration tools there are also ways that they can complement each other. For example Fig might be used to describe how containers interact functionally whilst Kubernetes pods might be used to provide monitoring and scaling.
|
||||
|
||||
#### Platforms (as a Service) ####
|
||||
|
||||
A number of Docker native PaaS implementations such as [Deis][33] and [Flynn][34] have emerged to take advantage of the fact that Linux containers provide a great degree of developer flexibility (rather than being ‘opinionated’ about a given set of languages and frameworks). Other platforms such as CloudFoundry, OpenShift and Apcera Continuum have taken the route of integrating Docker based functionality into their existing systems, so that applications based on Docker images (or the Dockerfiles that make them) can be deployed and managed alongside of apps using previously supported languages and frameworks.
|
||||
|
||||
### All the clouds ###
|
||||
|
||||
Since Docker can run in any Linux VM with a reasonably up to date kernel it can run in pretty much every cloud offering IaaS. Many of the major cloud providers have announced additional support for Docker and its ecosystem.
|
||||
|
||||
Amazon have introduced Docker into their Elastic Beanstalk system (which is an orchestration service over underlying IaaS). Google have Docker enabled ‘managed VMs’, which provide a halfway house between the PaaS of App Engine and the IaaS of Compute Engine. Microsoft and IBM have both announced services based on Kubernetes so that multi container applications can be deployed and managed on their clouds.
|
||||
|
||||
To provide a consistent interface to the wide variety of back ends now available the Docker team have introduced [libswarm][35], which will integrate with a multitude of clouds and resource management systems. One of the stated aims of libswarm is to ‘avoid vendor lock-in by swapping any service out with another’. This is accomplished by presenting a consistent set of services (with associated APIs) that attach to implementation specific back ends. For example the Docker server service presents the Docker remote API to a local Docker command line tool so that containers can be managed on an array of service providers.
|
||||
|
||||
New service types based on Docker are still in their infancy. London based Orchard labs offered a Docker hosting service, but Docker Inc said that the service wouldn’t be a priority after acquiring Orchard. Docker Inc has also sold its previous DotCloud PaaS business to cloudControl. Services based on older container management systems such as [OpenVZ][36] are already commonplace, so to a certain extent Docker needs to prove its worth to hosting providers.
|
||||
|
||||
### Docker and the distros ###
|
||||
|
||||
Docker has already become a standard feature of major Linux distributions like Ubuntu, Red Hat Enterprise Linux (RHEL) and CentOS. Unfortunately the distributions move at a different pace to the Docker project, so the versions found in a distribution can be well behind the latest available. For example Ubuntu 14.04 was released with Docker 0.9.1, and that didn’t change on the point release upgrade to Ubuntu 14.04.1 (by which time Docker was at 1.1.2). There are also namespace issues in official repositories since Docker was also the name of a KDE system tray; so with Ubuntu 14.04 the package name and command line tool are both ‘docker.io’.
|
||||
|
||||
Things aren’t much different in the Enterprise Linux world. CentOS 7 comes with Docker 0.11.1, a development release that precedes Docker Inc’s announcement of production readiness with Docker 1.0. Linux distribution users that want the latest version for promised stability, performance and security will be better off following the [installation instructions][37] and using repositories hosted by Docker Inc rather than taking the version included in their distribution.
|
||||
|
||||
The arrival of Docker has spawned new Linux distributions such as [CoreOS][38] and Red Hat’s [Project Atomic][39] that are designed to be a minimal environment for running containers. These distributions come with newer kernels and Docker versions than the traditional distributions. They also have lower memory and disk footprints. The new distributions also come with new tools for managing large scale deployments such as [fleet][40] ‘a distributed init system’ and [etcd][41] for metadata management. There are also new mechanisms for updating the distribution itself so that the latest versions of the kernel and Docker can be used. This acknowledges that one of the effects of using Docker is that it pushes attention away from the distribution and its package management solution, making the Linux kernel (and Docker subsystem using it) more important.
|
||||
|
||||
New distributions might be the best way of running Docker, but traditional distributions and their package managers remain very important within containers. Docker Hub hosts official images for Debian, Ubuntu, and CentOS. There’s also a ‘semi-official’ repository for Fedora images. RHEL images aren’t available in Docker Hub, as they’re distributed directly from Red Hat. This means that the automated build mechanism on Docker Hub is only available to those using pure open source distributions (and willing to trust the provenance of the base images curated by the Docker Inc team).
|
||||
|
||||
Whilst Docker Hub integrates with source control systems such as GitHub and Bitbucket for automated builds the package managers used during the build process create a complex relationship between a build specification (in a Dockerfile) and the image resulting from a build. Non deterministic results from the build process isn’t specifically a Docker problem - it’s a result of how package managers work. A build done one day will get a given version, and a build done another time may get a later version, which is why package managers have upgrade facilities. The container abstraction (caring less about the contents of a container) along with container proliferation (because of lightweight resource utilisation) is however likely to make this a pain point that gets associated with Docker.
|
||||
|
||||
### The future of Docker ###
|
||||
|
||||
Docker Inc has set a clear path on the development of core capabilities (libcontainer), cross service management (libswarm) and messaging between containers (libchan). Meanwhile the company has already shown a willingness to consume its own ecosystem with the Orchard Labs acquisition. There is however more to Docker than Docker Inc, with contributions to the project coming from big names like Google, IBM and Red Hat. With a benevolent dictator in the shape of CTO Solomon Hykes at the helm there is a clear nexus of technical leadership for both the company and the project. Over its first 18 months the project has shown an ability to move fast by using its own output, and there are no signs of that abating.
|
||||
|
||||
Many investors are looking at the features matrix for VMware’s ESX/vSphere platform from a decade ago and figuring out where the gaps (and opportunities) lie between enterprise expectations driven by the popularity of VMs and the existing Docker ecosystem. Areas like networking, storage and fine grained version management (for the contents of containers) are presently underserved by the existing Docker ecosystem, and provide opportunities for both startups and incumbents.
|
||||
|
||||
Over time it’s likely that the distinction between VMs and containers (the ‘run’ part of Docker) will become less important, which will push attention to the ‘build’ and ‘ship’ aspects. The changes here will make the question of ‘what happens to Docker?’ much less important than ‘what happens to the IT industry as a result of Docker?’.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoq.com/articles/docker-future
|
||||
|
||||
作者:[Chris Swan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoq.com/author/Chris-Swan
|
||||
[1]:http://blog.dotcloud.com/dotcloud-paas-joins-cloudcontrol
|
||||
[2]:http://www.infoq.com/news/2014/06/docker_1.0
|
||||
[3]:https://www.kernel.org/doc/Documentation/cgroups/cgroups.txt
|
||||
[4]:http://selinuxproject.org/page/Main_Page
|
||||
[5]:https://linuxcontainers.org/
|
||||
[6]:http://blog.docker.com/2014/03/docker-0-9-introducing-execution-drivers-and-libcontainer/
|
||||
[7]:http://aufs.sourceforge.net/aufs.html
|
||||
[8]:https://docs.docker.com/reference/builder/
|
||||
[9]:https://registry.hub.docker.com/
|
||||
[10]:http://bodenr.blogspot.co.uk/2014/05/kvm-and-docker-lxc-benchmarking-with.html?m=1
|
||||
[11]:http://domino.research.ibm.com/library/cyberdig.nsf/papers/0929052195DD819C85257D2300681E7B/$File/rc25482.pdf
|
||||
[12]:https://en.wikipedia.org/wiki/X86_virtualization#Hardware-assisted_virtualization
|
||||
[13]:http://stealth.openwall.net/xSports/shocker.c
|
||||
[14]:https://news.ycombinator.com/item?id=7910117
|
||||
[15]:http://www.bromium.com/products/vsentry.html
|
||||
[16]:http://cto.vmware.com/vmware-docker-better-together/
|
||||
[17]:http://www.infoq.com/articles/docker-containers
|
||||
[18]:http://docs.docker.com/articles/using_supervisord/
|
||||
[19]:http://www.infoq.com/minibooks/emag-microservices
|
||||
[20]:https://github.com/docker/libchan
|
||||
[21]:https://gobyexample.com/channels
|
||||
[22]:http://www.infoq.com/news/2014/08/clusterhq-launch-flocker
|
||||
[23]:http://www.fig.sh/
|
||||
[24]:http://openshift.github.io/geard/
|
||||
[25]:http://panamax.io/
|
||||
[26]:http://decking.io/
|
||||
[27]:https://github.com/newrelic/centurion
|
||||
[28]:https://github.com/GoogleCloudPlatform/kubernetes
|
||||
[29]:https://mesosphere.io/2013/09/26/docker-on-mesos/
|
||||
[30]:http://mesos.apache.org/
|
||||
[31]:https://github.com/mesosphere/marathon
|
||||
[32]:http://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/41684.pdf
|
||||
[33]:http://deis.io/
|
||||
[34]:https://flynn.io/
|
||||
[35]:https://github.com/docker/libswarm
|
||||
[36]:http://openvz.org/Main_Page
|
||||
[37]:https://docs.docker.com/installation/#installation
|
||||
[38]:https://coreos.com/
|
||||
[39]:http://www.projectatomic.io/
|
||||
[40]:https://github.com/coreos/fleet
|
||||
[41]:https://github.com/coreos/etcd
|
||||
@ -0,0 +1,100 @@
|
||||
The Good, The Bad And The Ugly Of Linux In 2014
|
||||
================================================================================
|
||||

|
||||
|
||||
Year 2014 is coming to an end and this is the time to summarize some of the **biggest Linux stories in year 2014**. All year round we have followed some good, some bad and some ugly stories related to Linux and Open Source. Let’ have a quick recap on how was the year 2014 for Linux.
|
||||
|
||||
### The Good ###
|
||||
|
||||
First and foremost, let’s see what were the positive stories for Linux lovers in 2014.
|
||||
|
||||
#### Netflix on Linux ####
|
||||
|
||||

|
||||
|
||||
Linux users have been trying several workaround to make Netflix work on Linux from using Wine to [using beta features in Chrome][1]. Good thing is that Netflix finally brought native support on Linux in year 2014 bringing smiles on the faces of Linux users where Netflix is available. People would still have to rely on workaround to [use Netflix outside US][2] (and other countries where Netflix is available officially).
|
||||
|
||||
#### Open Source/Linux adoption in European countries ####
|
||||
|
||||

|
||||
|
||||
Give the credit to economic meltdown, if you want, but Linux and Open Source adoption has been gripping European cities. I am not talking about Linux adoption by individuals but by government and authorities. All year round we heard stories of how [French][3] and [Italian cities saved millions of Euro by switching to Linux][4] and Open Office. And the trend was not limited just to Italy and France, the same could be seen in Spain, [Switzerland][5] and [Germany][6].
|
||||
|
||||
#### Windows 10 takes inspiration from Linux ####
|
||||
|
||||

|
||||
|
||||
The upcoming release of Microsoft’s flagship operating system, Windows will be called Windows 10 (no Windows 9). And Windows 10 boasts of a number of new features. But these ‘new features’ are new to Microsoft world only and most of those have been existing in Linux world for years. Have a look at such [Windows 10 features copied from Linux][7].
|
||||
|
||||
### The Bad ###
|
||||
|
||||
Everything was not rosy for Linux in year 2014. Some events happened that dented the image of Linux/Open Source.
|
||||
|
||||
#### Heartbleed ####
|
||||
|
||||

|
||||
|
||||
In April this year, a vulnerability was detected in [OpenSSL][8]. This bug, named [Heartbleed][9], impacted over half a million ‘secured’ websites including Facebook and Google. The bug actually allowed anyone to read memory of the system and hence giving the access to the key that is used to encrypt the traffic. A [comic at xkcd explains the Heartbleed][10] in easier way. Needless to say that this vulnerability was fixed in an update to OpenSSL.
|
||||
|
||||
#### Shellshock ####
|
||||
|
||||

|
||||
|
||||
As if Heartbleed was not enough, Linux world was further rocked in September with a vulnerability in Bash. The bug, named [Shellshock][11], further put Linux system at risk of remote attacks. The vulnerability was exploited by hackers to launch DDoS attacks. An update to Bash version supposedly fixed the issue.
|
||||
|
||||
#### Ubuntu Phone and Steam Console ####
|
||||
|
||||

|
||||
|
||||
Promises after promises, hopes after hopes. But even in year 2014 no one saw Ubuntu Phone or Steam gaming consoles. Lots of talks were around Ubuntu Phone tough. From February 2014 release to September to December, finally it is (hopefully slotted) for February 2015 release. No information on Steam consoles though. Read more for [Ubuntu Phone specification, price and release date][12].
|
||||
|
||||
### The Ugly ###
|
||||
|
||||
Things turned ugly with war over systemd adoption.
|
||||
|
||||
### systemd controversy ###
|
||||
|
||||

|
||||
|
||||
[init vs systemd][13] dispute is going on for some time. But it turned ugly in 2014 as systemd poised to replace init on several major Linux distribution including Debian, Ubuntu, OpenSUSE, Arch Linux and Fedora. It turned so ugly that it was not just limited to boycottsystemd.org like websites. Lennart Poettering (lead developer and author of systemd) claimed in a [Google Plus post][14] that anti systemd people were “collecting bitcoins to hire a hitman to kill him”. Lennart went on calling Open Source community “a sick place to be in”. People have taken this battle as far as forking Debian to a new OS named [Devuan][15].
|
||||
|
||||
### And the weird ###
|
||||
|
||||
Along with the good, the bad and the ugly comes the weird and that weird is none other than Microsoft.
|
||||
|
||||
#### Microsoft loves Linux ####
|
||||
|
||||

|
||||
|
||||
Yes! You read it right. [Microsoft loves Linux][16]. The same Microsoft whose CEO Steve Ballmer had once said that [Linux is cancer][17]. Change in Microsoft leadership saw some changes in its approach towards Linux and Open Source when the new CEO Satya Nadella announced that Microsoft loves Linux. This new found love for Linux is actually Microsoft’s attempt to make [Azure][18] as a better cloud platform. For this purpose it needs Hyper-V (core of Azure) virtualization to work with Linux. This desperation has made [Microsoft, fifth biggest contributor to Linux kernel][19].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/biggest-linux-stories-2014/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/watch-netflix-in-ubuntu-14-04/
|
||||
[2]:http://itsfoss.com/easiest-watch-netflix-hulu-usa/
|
||||
[3]:http://itsfoss.com/french-city-toulouse-saved-1-million-euro-libreoffice/
|
||||
[4]:http://itsfoss.com/italian-city-turin-open-source/
|
||||
[5]:http://itsfoss.com/170-primary-public-schools-geneva-switch-ubuntu/
|
||||
[6]:http://itsfoss.com/german-town-gummersbach-completes-switch-open-source/
|
||||
[7]:http://itsfoss.com/windows-10-inspired-linux/
|
||||
[8]:http://en.wikipedia.org/wiki/OpenSSL
|
||||
[9]:http://heartbleed.com/
|
||||
[10]:http://xkcd.com/1354/
|
||||
[11]:http://itsfoss.com/linux-shellshock-check-fix/
|
||||
[12]:http://itsfoss.com/ubuntu-phone-specification-release-date-pricing/
|
||||
[13]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[14]:https://plus.google.com/+LennartPoetteringTheOneAndOnly/posts/J2TZrTvu7vd
|
||||
[15]:http://debianfork.org/
|
||||
[16]:http://thenewstack.io/microsoft-professes-love-for-linux-adds-support-for-coreos-cloudera-and-host-of-new-features/
|
||||
[17]:http://www.theregister.co.uk/2001/06/02/ballmer_linux_is_a_cancer/
|
||||
[18]:http://azure.microsoft.com/en-us/
|
||||
[19]:http://www.zdnet.com/article/top-five-linux-contributor-microsoft/
|
||||
@ -1,146 +0,0 @@
|
||||
(translating by runningwater)
|
||||
How To Create A Bootable Ubuntu USB Drive For Mac In OS X
|
||||
================================================================================
|
||||

|
||||
|
||||
I bought a Macbook Air yesterday after Dell lost my laptop from their service centre last month. And among the first few things I did was to dual boot Mac OS X with Ubuntu Linux. I’ll cover up Linux installation on Macbook in later articles as first we need to learn **how to create a bootable Ubuntu USB drive for Mac in OS X**.
|
||||
|
||||
While it is fairly easy to create a bootable USB in Ubuntu or in Windows, it is not the same story in Mac OS X. This is why the official Ubuntu guide suggest to use a disk rather than USB for live Ubuntu in Mac. Considering my Macbook Air neither has a CD drive nor do I possess a DVD, I preferred to create a live USB in Mac OS X.
|
||||
|
||||
### Create a Bootable Ubuntu USB Drive in Mac OS X ###
|
||||
|
||||
As I said earlier, creating a bootable USB in Mac OS X is a tricky procedure, be it for Ubuntu or any other bootable OS. But don’t worry, following all the steps carefully will have you going. Let’s see what you need to for a bootable USB:
|
||||
|
||||
#### Step 1: Format the USB drive ####
|
||||
|
||||
Apple is known for defining its own standards and no surprises that Mac OS X has its own file system type known as Mac OS Extended or [HFS Plus][1]. So the first thing you would need to do is to format your USB drive in Mac OS Extended format.
|
||||
|
||||
To format the USB drive, plug in the USB key. Go to **Disk Utility** program from Launchpad (A rocket symboled icon in the bottom plank).
|
||||
|
||||

|
||||
|
||||
- In Disk Utility, from the left hand pane, select the USB drive to format.
|
||||
- Click the **Partition** tab in the right side pane.
|
||||
- From the drop-down menu, select **1 Partition**.
|
||||
- Name this drive anything you desire.
|
||||
- Next, change the **Format to Mac OS Extended (Journaled)**
|
||||
|
||||
The screenshot below should help you.
|
||||
|
||||

|
||||
|
||||
There is one last thing to do before we go with formatting the USB. Click the Options button in the right side pane and make sure that the partition scheme is **GUID Partition Table**.
|
||||
|
||||

|
||||
|
||||
When all is set to go, just hit the **Apply** button. It will give you a warning message about formatting the USB drive. Of course hit the Partition button to format the USB drive.
|
||||
|
||||
#### Step 2: Download Ubuntu ####
|
||||
|
||||
Of course, you need to download ISO image of Ubuntu desktop. Jump to [Ubuntu website to download your favorite Ubuntu desktop OS][2]. Since you are using a Macbook Air, I suggest you to download the 64 Bit version of whichever version you want. Ubuntu 14.04 is the latest LTS version, and this is what I would recommend to you.
|
||||
|
||||
#### Step 3: Convert ISO to IMG ####
|
||||
|
||||
The file you downloaded is in ISO format but we need it to be in IMG format. This can be easily done using [hdiutil][3] command tool. Open a terminal, either from Launchpad or from the Spotlight, and then use the following command to convert the ISO to IMG format:
|
||||
|
||||
hdiutil convert -format UDRW -o ~/Path-to-IMG-file ~/Path-to-ISO-file
|
||||
|
||||
Normally the downloaded file should be in ~/Downloads directory. So for me, the command is like this:
|
||||
|
||||
hdiutil convert -format UDRW -o ~/Downloads/ubuntu-14.10-desktop-amd64 ~/Downloads/ubuntu-14.10-desktop-amd64.iso
|
||||
|
||||

|
||||
|
||||
You might notice that I did not put a IMG extension to the newly converted file. It is fine as the extension is symbolic and it is the file type that matters not the file name extension. Also, the converted file may have an additional .dmg extension added to it by Mac OS X. Don’t worry, it’s normal.
|
||||
|
||||
#### Step 4: Get the device number for USB drive ####
|
||||
|
||||
The next thing is to get the device number for the USB drive. Run the following command in terminal:
|
||||
|
||||
diskutil list
|
||||
|
||||
It will list all the ‘disks’ currently available in the system. You should be able to identify the USB disk by its size. To avoid confusion, I would suggest that you should have just one USB drive plugged in. In my case, the device number is 2 (for a USB of size 8 GB): /dev/disk2
|
||||
|
||||

|
||||
|
||||
When you got the disk number, run the following command:
|
||||
|
||||
diskutil unmountDisk /dev/diskN
|
||||
|
||||
Where N is the device number for the USB you got previously. So, in my case, the above command becomes:
|
||||
|
||||
diskutil unmountDisk /dev/disk2
|
||||
|
||||
The result should be: **Unmount of all volumes on disk2 was successful**.
|
||||
|
||||
#### Step 5: Creating the bootable USB drive of Ubuntu in Mac OS X ####
|
||||
|
||||
And finally we come to the final step of creating the bootable USB drive. We shall be using [dd command][4] which is a very powerful and must be used with caution. Therefore, do remember the correct device number of your USB drive or else you might end up corrupting Mac OS X. Use the following command in terminal:
|
||||
|
||||
sudo dd if=/Path-to-IMG-DMG-file of=/dev/rdiskN bs=1m
|
||||
|
||||
Here, we are using dd (copy and convert) to copy and convert input file (if) IMG to diskN. I hope you remember where you put the converted IMG file, in step 3. For me the command was like this:
|
||||
|
||||
sudo dd if=~/Downloads/ubuntu-14.10-desktop-amd64.dmg of=/dev/rdisk2 bs=1m
|
||||
|
||||
As we are running the above command with super user privileges (sudo), it will require you to enter the password. Similar to Linux, you won’t see any asterisks or something to indicate that you have entered some keyboard input, but that’s the way Unix terminal behaves.
|
||||
|
||||
Even after you enter the password, **you won’t see any immediate output and that’s norma**l. It will take a few minutes for the process to complete.
|
||||
|
||||
#### Step 6: Complete the bootable USB drive process ####
|
||||
|
||||
Once the dd command finishes its process, you may see a dialogue box saying: **The disk you inserted was not readable by this computer**.
|
||||
|
||||

|
||||
|
||||
Don’t panic. Everything is just fine. Just **don’t click either of Initialize, Ignore or Eject just now**. Go back to the terminal. You’ll see some information about the last completed process. For me it was:
|
||||
|
||||
> 1109+1 records in
|
||||
> 1109+1 records out
|
||||
> 1162936320 bytes transferred in 77.611025 secs (14984164 bytes/sec)
|
||||
|
||||

|
||||
|
||||
Now, in the terminal use the following command to eject our USB disk:
|
||||
|
||||
diskutil eject /dev/diskN
|
||||
|
||||
N is of course the device number we have used previously which is 2 in my case:
|
||||
|
||||
diskutil eject /dev/disk2
|
||||
|
||||
Once ejected, click on **Ignore** in the dialogue box that appeared previously. Now your bootable USB disk is ready. Remove it from the system.
|
||||
|
||||
#### Step 7: Checking your newly created bootable USB disk ####
|
||||
|
||||
Once you have completed the mammoth task of creating a live USB of USB in Mac OS X, it is time to test your efforts.
|
||||
|
||||
- Plugin the bootable USB and reboot the system.
|
||||
- At start up when the Apple tune starts up, press and hold option (or alt) key.
|
||||
- This should present you with the available disks to boot in to. I presume you know what to do next.
|
||||
|
||||
For me it showed tow EFI boot:
|
||||
|
||||

|
||||
|
||||
I selected the first one and it took me straight to Grub screen:
|
||||
|
||||

|
||||
|
||||
I hope this guide helped you to create a bootable USB disk of Ubuntu for Mac in OS X. We’ll see how to dual boot Ubuntu with OS X in next article. Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/create-bootable-ubuntu-usb-drive-mac-os/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://en.wikipedia.org/wiki/HFS_Plus
|
||||
[2]:http://www.ubuntu.com/download/desktop
|
||||
[3]:https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/hdiutil.1.html
|
||||
[4]:http://en.wikipedia.org/wiki/Dd_%28Unix%29
|
||||
@ -1,307 +0,0 @@
|
||||
Translating by GOLinux!
|
||||
Setting up a ‘PXE Network Boot Server’ for Multiple Linux Distribution Installations in RHEL/CentOS 7
|
||||
================================================================================
|
||||
**PXE Server** – Preboot eXecution Environment – instructs a client computer to boot, run or install an operating system directly form a network interface, eliminating the need to burn a CD/DVD or use a physical medium, or, can ease the job of installing Linux distributions on your network infrastructure on multiple machines the same time.
|
||||
|
||||

|
||||
Setting PXE Network Boot in RHEL/CentOS 7
|
||||
|
||||
#### Requirements ####
|
||||
|
||||
- [CentOS 7 Minimal Installation Procedure][1]
|
||||
- [RHEL 7 Minimal Installation Procedure][2]
|
||||
- [Configure Static IP Address in RHEL/CentOS 7][3]
|
||||
- [Remove Unwanted Services in RHEL/CentOS 7][4]
|
||||
- [Install NTP Server to Set Correct System Time in RHEL/CentOS 7][5]
|
||||
|
||||
This article will explain how you can install and configure a **PXE Server** on **RHEL/CentOS 7** x64-bit with mirrored local installation repositories, sources provided by CentOS 7 DVD ISO image, with the help of **DNSMASQ** Server.
|
||||
|
||||
Which provides **DNS** and **DHCP** services, **Syslinux** package which provides bootloaders for network booting, **TFTP-Server**, which makes bootable images available to be downloaded via network using **Trivial File Transfer Protocol** (TFTP) and **VSFTPD** Server which will host the local mounted mirrored DVD image – which will act as an official RHEL/CentOS 7 mirror installation repository from where the installer will extract its required packages.
|
||||
|
||||
### Step 1: Install and configure DNSMASQ Server ###
|
||||
|
||||
**1.** No need to remind you that is absolutely demanding that one of your network card interface, in case your server poses more NICs, must be configured with a static IP address from the same IP range that belongs to the network segment that will provide PXE services.
|
||||
|
||||
So, after you have configured your static IP Address, updated your system and performed other initial settings, use the following command to install **DNSMASQ** daemon.
|
||||
|
||||
# yum install dnsmasq
|
||||
|
||||

|
||||
Install dnsmasq Package
|
||||
|
||||
**2.** DNSMASQ main default configuration file located in **/etc** directory is self-explanatory but intends to be quite difficult to edit, do to its highly commented explanations.
|
||||
|
||||
First make sure you backup this file in case you need to review it later and, then, create a new blank configuration file using your favorite text editor by issuing the following commands.
|
||||
|
||||
# mv /etc/dnsmasq.conf /etc/dnsmasq.conf.backup
|
||||
# nano /etc/dnsmasq.conf
|
||||
|
||||
**3.** Now, copy and paste the following configurations on **dnsmasq.conf** file and assure that you change the below explained statements to match your network settings accordingly.
|
||||
|
||||
interface=eno16777736,lo
|
||||
#bind-interfaces
|
||||
domain=centos7.lan
|
||||
# DHCP range-leases
|
||||
dhcp-range= eno16777736,192.168.1.3,192.168.1.253,255.255.255.0,1h
|
||||
# PXE
|
||||
dhcp-boot=pxelinux.0,pxeserver,192.168.1.20
|
||||
# Gateway
|
||||
dhcp-option=3,192.168.1.1
|
||||
# DNS
|
||||
dhcp-option=6,92.168.1.1, 8.8.8.8
|
||||
server=8.8.4.4
|
||||
# Broadcast Address
|
||||
dhcp-option=28,10.0.0.255
|
||||
# NTP Server
|
||||
dhcp-option=42,0.0.0.0
|
||||
|
||||
pxe-prompt="Press F8 for menu.", 60
|
||||
pxe-service=x86PC, "Install CentOS 7 from network server 192.168.1.20", pxelinux
|
||||
enable-tftp
|
||||
tftp-root=/var/lib/tftpboot
|
||||
|
||||

|
||||
Dnsmasq Configuration
|
||||
|
||||
The statements that you need to change are follows:
|
||||
|
||||
- **interface** – Interfaces that the server should listen and provide services.
|
||||
- **bind-interfaces** – Uncomment to bind only on this interface.
|
||||
- **domain** – Replace it with your domain name.
|
||||
- **dhcp-range** – Replace it with IP range defined by your network mask on this segment.
|
||||
- **dhcp-boot** – Replace the IP statement with your interface IP Address.
|
||||
- **dhcp-option=3,192.168.1.1** – Replace the IP Address with your network segment Gateway.
|
||||
- **dhcp-option=6,92.168.1.1** – Replace the IP Address with your DNS Server IP – several DNS IPs can be defined.
|
||||
- **server=8.8.4.4** – Put your DNS forwarders IPs Addresses.
|
||||
- **dhcp-option=28,10.0.0.255** – Replace the IP Address with network broadcast address –optionally.
|
||||
- **dhcp-option=42,0.0.0.0** – Put your network time servers – optionally (0.0.0.0 Address is for self-reference).
|
||||
- **pxe-prompt** – Leave it as default – means to hit F8 key for entering menu 60 with seconds wait time..
|
||||
- **pxe=service** – Use x86PC for 32-bit/64-bit architectures and enter a menu description prompt under string quotes. Other values types can be: PC98, IA64_EFI, Alpha, Arc_x86, Intel_Lean_Client, IA32_EFI, BC_EFI, Xscale_EFI and X86-64_EFI.
|
||||
- **enable-tftp** – Enables the build-in TFTP server.
|
||||
- **tftp-root** – Use /var/lib/tftpboot – the location for all netbooting files.
|
||||
|
||||
For other advanced options concerning configuration file feel free to read [dnsmasq manual][6].
|
||||
|
||||
### Step 2: Install SYSLINUX Bootloaders ###
|
||||
|
||||
**4.** After you have edited and saved **DNSMASQ** main configuration file, go ahead and install **Syslinx** PXE bootloader package by issuing the following command.
|
||||
|
||||
# yum install syslinux
|
||||
|
||||

|
||||
Install Syslinux Bootloaders
|
||||
|
||||
**5.** The PXE bootloaders files reside in **/usr/share/syslinux** absolute system path, so you can check it by listing this path content. This step is optional, but you might need to be aware of this path because on the next step, we will copy of all its content to **TFTP Server** path.
|
||||
|
||||
# ls /usr/share/syslinux
|
||||
|
||||

|
||||
Syslinux Files
|
||||
|
||||
### Step 3: Install TFTP-Server and Populate it with SYSLINUX Bootloaders ###
|
||||
|
||||
**6.** Now, let’s move to next step and install **TFTP-Server** and, then, copy all bootloders files provided by Syslinux package from the above listed location to **/var/lib/tftpboot** path by issuing the following commands.
|
||||
|
||||
# yum install tftp-server
|
||||
# cp -r /usr/share/syslinux/* /var/lib/tftpboot
|
||||
|
||||

|
||||
Install TFTP Server
|
||||
|
||||
### Step 4: Setup PXE Server Configuration File ###
|
||||
|
||||
**7.** Typically the **PXE Server** reads its configuration from a group of specific files (**GUID** files – first, **MAC** files – next, **Default** file – last) hosted in a folder called **pxelinux.cfg**, which must be located in the directory specified in **tftp-root** statement from DNSMASQ main configuration file.
|
||||
|
||||
Create the required directory **pxelinux.cfg** and populate it with a **default** file by issuing the following commands.
|
||||
|
||||
# mkdir /var/lib/tftpboot/pxelinux.cfg
|
||||
# touch /var/lib/tftpboot/pxelinux.cfg/default
|
||||
|
||||
**8.** Now it’s time to edit **PXE Server** configuration file with valid Linux distributions installation options. Also note that all paths used in this file must be relative to the **/var/lib/tftpboot** directory.
|
||||
|
||||
Below you can see an example configuration file that you can use it, but modify the installation images (kernel and initrd files), protocols (FTP, HTTP, HTTPS, NFS) and IPs to reflect your network installation source repositories and paths accordingly.
|
||||
|
||||
# nano /var/lib/tftpboot/pxelinux.cfg/default
|
||||
|
||||
Add the following whole excerpt to the file.
|
||||
|
||||
default menu.c32
|
||||
prompt 0
|
||||
timeout 300
|
||||
ONTIMEOUT local
|
||||
|
||||
menu title ########## PXE Boot Menu ##########
|
||||
|
||||
label 1
|
||||
menu label ^1) Install CentOS 7 x64 with Local Repo
|
||||
kernel centos7/vmlinuz
|
||||
append initrd=centos7/initrd.img method=ftp://192.168.1.20/pub devfs=nomount
|
||||
|
||||
label 2
|
||||
menu label ^2) Install CentOS 7 x64 with http://mirror.centos.org Repo
|
||||
kernel centos7/vmlinuz
|
||||
append initrd=centos7/initrd.img method=http://mirror.centos.org/centos/7/os/x86_64/ devfs=nomount ip=dhcp
|
||||
|
||||
label 3
|
||||
menu label ^3) Install CentOS 7 x64 with Local Repo using VNC
|
||||
kernel centos7/vmlinuz
|
||||
append initrd=centos7/initrd.img method=ftp://192.168.1.20/pub devfs=nomount inst.vnc inst.vncpassword=password
|
||||
|
||||
label 4
|
||||
menu label ^4) Boot from local drive
|
||||
|
||||

|
||||
Configure PXE Server
|
||||
|
||||
As you can see CentOS 7 boot images (kernel and initrd) reside in a directory named **centos7** relative to **/var/lib/tftpboot** (on an absolute system path this would mean **/var/lib/tftpboot/centos7**) and the installer repositories can be reached by using FTP protocol on **192.168.1.20/pub** network location – in this case the repos are hosted locally because the IP address is the same as the PXE server address).
|
||||
|
||||
Also menu **label 3** specifies that the client installation should be done from a remote location via **VNC** (here replace VNC password with a strong password) in case you install on a headless client and the menu **label 2** specifies as installation sources a CentOS 7 official Internet mirror (this case requires an Internet connection available on client through DHCP and NAT).
|
||||
|
||||
**Important**: As you see in the above configuration, we’ve used CentOS 7 for demonstration purpose, but you can also define RHEL 7 images, and following whole instructions and configurations are based on CentOS 7 only, so be careful while choosing distribution.
|
||||
|
||||
### Step 5: Add CentOS 7 Boot Images to PXE Server ###
|
||||
|
||||
**9.** For this step CentOS kernel and initrd files are required. To get those files you need the **CentOS 7 DVD ISO** Image. So, go ahead and download CentOS DVD Image, put it in your DVD drive and mount the image to **/mnt** system path by issuing the below command.
|
||||
|
||||
The reason for using the DVD and not a Minimal CD Image is the fact that later this DVD content would be used to create the locally installer repositories for **FTP** sources.
|
||||
|
||||
# mount -o loop /dev/cdrom /mnt
|
||||
# ls /mnt
|
||||
|
||||

|
||||
Mount CentOS DVD
|
||||
|
||||
If your machine has no DVD drive you can also download **CentOS 7 DVD ISO** locally using **wget** or **curl** utilities from a [CentOS mirror][7] and mount it.
|
||||
|
||||
# wget http://mirrors.xservers.ro/centos/7.0.1406/isos/x86_64/CentOS-7.0-1406-x86_64-DVD.iso
|
||||
# mount -o loop /path/to/centos-dvd.iso /mnt
|
||||
|
||||
**10.** After the DVD content is made available, create the **centos7** directory and copy CentOS 7 bootable kernel and initrd images from the DVD mounted location to centos7 folder structure.
|
||||
|
||||
# mkdir /var/lib/tftpboot/centos7
|
||||
# cp /mnt/images/pxeboot/vmlinuz /var/lib/tftpboot/centos7
|
||||
# cp /mnt/images/pxeboot/initrd.img /var/lib/tftpboot/centos7
|
||||
|
||||

|
||||
Copy CentOS Bootable Files
|
||||
|
||||
The reason for using this approach is that, later you can create new separate directories in **/var/lib/tftpboot** path and add other Linux distributions to PXE menu without messing up the entire directory structure.
|
||||
|
||||
### Step 6: Create CentOS 7 Local Mirror Installation Source ###
|
||||
|
||||
**11.** Although you can setup **Installation Source Mirrors** via a variety of protocols such as HTTP, HTTPS or NFS, for this guide, I have chosen **FTP** protocol because is very reliable and easy to setup with the help of **vsftpd** server.
|
||||
|
||||
Further install vsftpd daemon, copy all DVD mounted content to **vsftpd** default server path (**/var/ftp/pub**) – this can take a while depending on your system resources and append readable permissions to this path by issuing the following commands.
|
||||
|
||||
# yum install vsftpd
|
||||
# cp -r /mnt/* /var/ftp/pub/
|
||||
# chmod -R 755 /var/ftp/pub
|
||||
|
||||

|
||||
Install Vsftpd Server
|
||||
|
||||

|
||||
Copy Files to FTP Path
|
||||
|
||||

|
||||
Set Permissions on FTP Path
|
||||
|
||||
### Step 7: Start and Enable Daemons System-Wide ###
|
||||
|
||||
**12.** Now that the PXE server configuration is finally finished, start **DNSMASQ** and **VSFTPD** servers, verify their status and enable it system-wide, to automatically start after every system reboot, by running the below commands.
|
||||
|
||||
# systemctl start dnsmasq
|
||||
# systemctl status dnsmasq
|
||||
# systemctl start vsftpd
|
||||
# systemctl status vsftpd
|
||||
# systemctl enable dnsmasq
|
||||
# systemctl enable vsftpd
|
||||
|
||||

|
||||
Start Dnsmasq Service
|
||||
|
||||

|
||||
Start Vsftpd Service
|
||||
|
||||
### Step 8: Open Firewall and Test FTP Installation Source ###
|
||||
|
||||
**13.** To get a list of all ports that needs to be open on your Firewall in order for client machines to reach and boot from PXE server, run **netstat** command and add CentOS 7 Firewalld rules accordingly to dnsmasq and vsftpd listening ports.
|
||||
|
||||
# netstat -tulpn
|
||||
# firewall-cmd --add-service=ftp --permanent ## Port 21
|
||||
# firewall-cmd --add-service=dns --permanent ## Port 53
|
||||
# firewall-cmd --add-service=dhcp --permanent ## Port 67
|
||||
# firewall-cmd --add-port=69/udp --permanent ## Port for TFTP
|
||||
# firewall-cmd --add-port=4011/udp --permanent ## Port for ProxyDHCP
|
||||
# firewall-cmd --reload ## Apply rules
|
||||
|
||||

|
||||
Check Listening Ports
|
||||
|
||||

|
||||
Open Ports in Firewall
|
||||
|
||||
**14.** To test FTP Installation Source network path open a browser locally ([**lynx**][8] should do it) or on a different computer and type the IP Address of your PXE server with FTP protocol followed by **/pub** network location on URL filed and the result should be as presented in the below screenshot.
|
||||
|
||||
ftp://192.168.1.20/pub
|
||||
|
||||

|
||||
Access FTP Files via Browser
|
||||
|
||||
**15.** To debug PXE server for eventual misconfigurations or other information and diagnostics in live mode run the following command.
|
||||
|
||||
# tailf /var/log/messages
|
||||
|
||||

|
||||
Check PXE Logs for Errors
|
||||
|
||||
**16.** Finally, the last required step that you need to do is to unmount CentOS 7 DVD and remove the physical medium.
|
||||
|
||||
# umount /mnt
|
||||
|
||||
### Step 9: Configure Clients to Boot from Network ###
|
||||
|
||||
**17.** Now your clients can boot and install CentOS 7 on their machines by configuring Network Boot as **primary boot device** from their systems BIOS or by hitting a specified key during **BIOS POST** operations as specified in motherboard manual.
|
||||
|
||||
In order to choose network booting. After first PXE prompt appears, press **F8** key to enter presentation and then hit **Enter** key to proceed forward to PXE menu.
|
||||
|
||||

|
||||
PXE Network Boot
|
||||
|
||||

|
||||
PXE Network OS Boot
|
||||
|
||||
**18.** Once you have reached PXE menu, choose your CentOS 7 installation type, hit **Enter** key and continue with the installation procedure the same way as you might install it from a local media boot device.
|
||||
|
||||
Please note down that using variant 2 from this menu requires an active Internet connection on the target client. Also, on below screenshots you can see an example of a client remote installation via VNC.
|
||||
|
||||
|
||||
PXE Menu
|
||||
|
||||

|
||||
Remote Linux Installation via VNC
|
||||
|
||||
|
||||
Remote Installation of CentOS
|
||||
|
||||
That’s all for setting up a minimal **PXE Server** on **CentOS 7**. On my next article from this series, I will discuss other issues concerning this PXE server configuration such as how to setup automated installations of **CentOS 7** using **Kickstart** files and adding other Linux distributions to PXE menu – **Ubuntu Server** and **Debian 7**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-pxe-network-boot-server-in-centos-7/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
[1]:http://www.tecmint.com/centos-7-installation/
|
||||
[2]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[3]:http://www.tecmint.com/configure-network-interface-in-rhel-centos-7-0/
|
||||
[4]:http://www.tecmint.com/remove-unwanted-services-in-centos-7/
|
||||
[5]:http://www.tecmint.com/install-ntp-server-in-centos/
|
||||
[6]:http://www.thekelleys.org.uk/dnsmasq/docs/dnsmasq-man.html
|
||||
[7]:http://isoredirect.centos.org/centos/7/isos/x86_64/
|
||||
[8]:http://www.tecmint.com/command-line-web-browsers/
|
||||
@ -1,75 +0,0 @@
|
||||
Linux FAQs with Answers--How to check SSH protocol version on Linux
|
||||
================================================================================
|
||||
> **Question**: I am aware that there exist SSH protocol version 1 and 2 (SSH1 and SSH2). What is the difference between SSH1 and SSH2, and how can I check which SSH protocol version is supported on a Linux server?
|
||||
|
||||
Secure Shell (SSH) is a network protocol that enables remote login or remote command execution between two hosts over a cryptographically secure communication channel. SSH was designed to replace insecure clear-text protocols such as telnet, rsh or rlogin. SSH provides a number of desirable features such as authentication, encryption, data integrity, authorization, and forwarding/tunneling.
|
||||
|
||||
### SSH1 vs. SSH2 ###
|
||||
|
||||
The SSH protocol specification has a number of minor version differences, but there are two major versions of the protocol: **SSH1** (SSH version 1.XX) and **SSH2** (SSH version 2.00).
|
||||
|
||||
In fact, SSH1 and SSH2 are two entirely different protocols with no compatibility in between. SSH2 is a significantly improved version of SSH1 in many respects. First of all, while SSH1 is a monolithic design where several different functions (e.g., authentication, transport, connection) are packed into a single protocol, SSH2 is a layered architecture designed with extensibility and flexibility in mind. In terms of security, SSH2 comes with a number of stronger security features than SSH1, such as MAC-based integrity check, flexible session re-keying, fully-negotiable cryptographic algorithms, public-key certificates, etc.
|
||||
|
||||
SSH2 is standardized by IETF, and as such its implementation is widely deployed and accepted in the industry. Due to SSH2's popularity and cryptographic superiority over SSH1, many products are dropping support for SSH1. As of this writing, OpenSSH still [supports][1] both SSH1 and SSH2, while on all modern Linux distributions, OpenSSH server comes with SSH1 disabled by default.
|
||||
|
||||
### Check Supported SSH Protocol Version ###
|
||||
|
||||
#### Method One ####
|
||||
|
||||
If you want to check what SSH protocol version(s) are supported by a local OpenSSH server, you can refer to **/etc/ssh/sshd_config** file. Open /etc/ssh/sshd_config with a text editor, and look for "Protocol" field.
|
||||
|
||||
If it shows the following, it means that OpenSSH server supports SSH2 only.
|
||||
|
||||
Protocol 2
|
||||
|
||||
If it displays the following instead, OpenSSH server supports both SSH1 and SSH2.
|
||||
|
||||
Protocol 1,2
|
||||
|
||||
#### Method Two ####
|
||||
|
||||
If you cannot access /etc/ssh/sshd_config because OpenSSH server is running on a remote server, you can test its SSH protocol support by using SSH client program called ssh. More specifically, we force ssh to use a specific SSH protocol, and see how the remote SSH server responds.
|
||||
|
||||
The following command will force ssh command to use SSH1:
|
||||
|
||||
$ ssh -1 user@remote_server
|
||||
|
||||
The following command will force ssh command to use SSH2:
|
||||
|
||||
$ ssh -2 user@remote_server
|
||||
|
||||
If the remote SSH server supports SSH2 only, the first command with "-1" option will fails with an error message like this:
|
||||
|
||||
Protocol major versions differ: 1 vs. 2
|
||||
|
||||
If the SSH server supports both SSH1 and SSH2, both commands should work successfully.
|
||||
|
||||
### Method Three ###
|
||||
|
||||
Another method to check supported SSH protocol version of a remote SSH server is to run an SSH scanning tool called [scanssh][2]. This command-line tool is useful when you want to check SSH protocol versions for a bulk of IP addresses or the entire local network to upgrade SSH1-capable SSH servers.
|
||||
|
||||
Here is the basic syntax of scanssh for SSH version scanning.
|
||||
|
||||
$ sudo scanssh -s ssh -n [ports] [IP addresses or CIDR prefix]
|
||||
|
||||
The "-n" option can specify the SSH port number(s) to scan. You can specify multiple port numbers separated by comma. Without this option, scanssh will scan port 22 by default.
|
||||
|
||||
Use the following command to discover SSH servers on 192.168.1.0/24 local nework, and detect their SSH protocol versions:
|
||||
|
||||
$ sudo scan -s ssh 192.168.1.0/24
|
||||
|
||||
|
||||
|
||||
If scanssh reports "SSH-1.XX-XXXX" for a particular IP address, it implies that the minimum SSH protocol version supported by the corresponding SSH server is SSH1. If the remote server supports SSH2 only, scanssh will show "SSH-2.0-XXXX".
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-ssh-protocol-version-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openssh.com/specs.html
|
||||
[2]:http://www.monkey.org/~provos/scanssh/
|
||||
@ -1,3 +1,4 @@
|
||||
(translating by runningwater)
|
||||
Linux FAQs with Answers--How to install 7zip on Linux
|
||||
================================================================================
|
||||
> **Question**: I need to extract files from an ISO image, and for that I want to use 7zip program. How can I install 7zip on [insert your Linux distro]?
|
||||
@ -66,7 +67,7 @@ To test the integrity of an archive:
|
||||
|
||||
via:http://ask.xmodulo.com/install-7zip-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Vic020
|
||||
|
||||
Linux FAQs with Answers--How to install Kingsoft Office on Linux
|
||||
================================================================================
|
||||
> **Question**: I heard good things about Kingsoft Office, so I would like to try it out on my Linux. How can I install Kingsoft Office on [insert your Linux distro]?
|
||||
@ -76,4 +78,4 @@ via: http://ask.xmodulo.com/install-kingsoft-office-linux.html
|
||||
|
||||
[1]:http://ksosoft.com/product/office-2013-linux.html
|
||||
[2]:http://ksosoft.com/product/office-2013-linux.html
|
||||
[3]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
[3]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
|
||||
@ -1,74 +0,0 @@
|
||||
Linux FAQs with Answers--How to install kernel headers on Linux
|
||||
================================================================================
|
||||
> **Question**: I need to install kernel headers to install a device driver for my kernel. What is a proper way to install matching kernel headers on [insert your Linux distro]?
|
||||
|
||||
When you compile a device driver a custom kernel module, you need to have kernel header files installed on your Linux system. Kernel headers are needed also when you build a userspace application which links directly against the kernel. When you install kernel headers in such cases, you must make sure to kernel headers are exactly matched with the kernel version of your system (e.g., 3.13.0-24-generic).
|
||||
|
||||
If your kernel is the default version that comes with the distribution, or you upgraded it using the default package manager (e.g., apt-get, aptitude or yum) from base repositories, you can install matching kernel headers using the package manager as well. On the other hand, if you downloaded the [kernel source][1] and compiled it manually, you can install matching kernel headers by using [make command][2].
|
||||
|
||||
Here we assume that your kernel comes from base repositories of your Linux distribution, and see how we can install matching kernel headers.
|
||||
|
||||
### Install Kernel Headers on Debian, Ubuntu or Linux Mint ###
|
||||
|
||||
Assuming that you did not manually compile the kernel, you can install matching kernel headers using apt-get command.
|
||||
|
||||
First, check if matching kernel headers are already available on your system using dpkg-query command.
|
||||
|
||||
$ dpkg-query -s linux-headers-$(uname -r)
|
||||
|
||||
----------
|
||||
|
||||
dpkg-query: package 'linux-headers-3.11.0-26-generic' is not installed and no information is available
|
||||
|
||||
Go ahead and install matching kernel headers as follows.
|
||||
|
||||
$ sudo apt-get install linux-headers-$(uname -r)
|
||||
|
||||

|
||||
|
||||
Verify that matching kernel headers are successfully installed.
|
||||
|
||||
$ dpkg-query -s linux-headers-$(uname -r)
|
||||
|
||||
----------
|
||||
|
||||
Package: linux-headers-3.11.0-26-generic
|
||||
Status: install ok installed
|
||||
|
||||
The default location of kernel headers on Debian, Ubuntu or Linux Mint is **/usr/src**.
|
||||
|
||||
### Install Kernel Headers on Fedora, CentOS or RHEL ###
|
||||
|
||||
If you did not manually upgrade the kernel, you can install matching kernel headers using yum command.
|
||||
|
||||
First, check if matching kernel headers are already installed on your system. If the following command does not produce any output, it means kernel headers are not available.
|
||||
|
||||
$ rpm -qa | grep kernel-headers-$(uname -r)
|
||||
|
||||
Go ahead and install kernel headers with yum command. This command will automatically find a package of matching kernel headers, and install it.
|
||||
|
||||
$ sudo yum install kernel-headers
|
||||
|
||||

|
||||
|
||||
Verify the status of the installed package.
|
||||
|
||||
$ rpm -qa | grep kernel-headers-$(uname -r)
|
||||
|
||||
----------
|
||||
|
||||
kernel-headers-3.10.0-123.9.3.el7.x86_64
|
||||
|
||||
The default location of kernel headers on Fedora, CentOS or RHEL is **/usr/include/linux**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-kernel-headers-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.kernel.org/pub/linux/kernel/
|
||||
[2]:https://www.kernel.org/doc/Documentation/kbuild/headers_install.txt
|
||||
@ -1,47 +0,0 @@
|
||||
Linux FAQs with Answers--How to install non-free packages on Debian
|
||||
================================================================================
|
||||
> **Question**: I need to install some proprietary device driver on Debian, which is part of a non-free package. However, I cannot find and install the package in my Debian box. How can I install non-free packages on Debian?
|
||||
|
||||
The Debian project is distributed as a collection of packages, [48,000][1] of them, as of Debian Wheezy. These packages are categorized into three areas: main, contrib and non-free, mainly based on licensing requirements, e.g., [Debian Free Software Guidelines][2] (DFSG).
|
||||
|
||||
The main area contains free software that complies with DFSG. The contrib area contains free software that complies with DFSG, but relies on non-free software for compilation or execution. Finally, the non-free area contains non-free packages that are not compliant with DFSG but redistributable. The main repository is considered a part of Debian, but neither contrib or non-free repository is. The latter two are maintained and provided only as a convenience to users.
|
||||
|
||||
If you want to install a non-free package maintained by Debian, you need to enable contrib and non-free repositories. To do so, open /etc/apt/sources.list with a text editor, and append "contrib non-free" to each source.
|
||||
|
||||
The following is an example of /etc/apt/sources.list for Debian Wheezy.
|
||||
|
||||
deb http://ftp.us.debian.org/debian/ wheezy main contrib non-free
|
||||
deb-src http://ftp.us.debian.org/debian/ wheezy main contrib non-free
|
||||
|
||||
deb http://security.debian.org/ wheezy/updates main contrib non-free
|
||||
deb-src http://security.debian.org/ wheezy/updates main contrib non-free
|
||||
|
||||
# wheezy-updates, previously known as 'volatile'
|
||||
deb http://ftp.us.debian.org/debian/ wheezy-updates main contrib non-free
|
||||
deb-src http://ftp.us.debian.org/debian/ wheezy-updates main contrib non-free
|
||||
|
||||

|
||||
|
||||
After modifying sources of packages, run the following command to download package index files for contrib and non-free repositories.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
If you are using aptitude, run the following instead.
|
||||
|
||||
$ sudo aptitude update
|
||||
|
||||
Now you are ready to search and install any non-free package on Debian.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-nonfree-packages-debian.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://packages.debian.org/stable/allpackages?format=txt.gz
|
||||
[2]:https://www.debian.org/social_contract.html#guidelines
|
||||
@ -1,82 +0,0 @@
|
||||
Linux FAQs with Answers--How to rename multiple files on Linux
|
||||
================================================================================
|
||||
> **Question**: I know I can rename a file using mv command. But what if I want to change the name of many files? It will be tedius to invoke mv command for every such file. Is there a more convenient way to rename multiple files at once?
|
||||
|
||||
In Linux, when you want to change a file name, mv command gets the job done. However, mv cannot rename multiple files using wildcard. There are ways to deal with multiple files by using a combination of sed, awk or find in conjunction with [xargs][1]. However, these CLIs are rather cumbersome and not user-friendly, and can be error-prone if you are not careful. You don't want to undo incorrect name change for 1,000 files.
|
||||
|
||||
When it comes to renaming multiple files, the rename utility is probably the easiest, the safest, and the most powerful command-line tool. The rename command is actually a Perl script, and comes pre-installed on all modern Linux distributions.
|
||||
|
||||
Here is the basic syntax of rename command.
|
||||
|
||||
rename [-v -n -f] <pcre> <files>
|
||||
|
||||
<pcre> is a Perl-compatible regular expression (PCRE) which represents file(s) to rename and how. This regular expression is in the form of 's/old-name/new-name/'.
|
||||
|
||||
The '-v' option shows the details of file name changes (e.g., XXX renamed as YYY).
|
||||
|
||||
The '-n' option tells rename to show how the files would be renamed without actually changing the names. This option is useful when you want to simulate filename change without touching files.
|
||||
|
||||
The '-f' option force overwriting existing files.
|
||||
|
||||
In the following, let's see several rename command examples.
|
||||
|
||||
### Change File Extensions ###
|
||||
|
||||
Suppose you have many image files with .jpeg extension. You want to change their file names to *.jpg. The following command converts *.jpeg files to *.jpg.
|
||||
|
||||
$ rename 's/\.jpeg$/\.jpg/' *.jpeg
|
||||
|
||||
### Convert Uppercase to Lowercase and Vice-Versa ###
|
||||
|
||||
In case you want to change text case in filenames, you can use the following commands.
|
||||
|
||||
To rename all files to lower-case:
|
||||
|
||||
# rename 'y/A-Z/a-z/' *
|
||||
|
||||
To rename all files to upper-case:
|
||||
|
||||
# rename 'y/a-z/A-Z/' *
|
||||
|
||||
|
||||
|
||||
### Change File Name Patterns ###
|
||||
|
||||
Now let's consider more complex regular expressions which involve subpatterns. In PCRE, a subpattern captured within round brackets can be referenced by a number preceded by a dollar sign (e.g., $1, $2).
|
||||
|
||||
For example, the following command will rename 'img_NNNN.jpeg' to 'dan_NNNN.jpg'.
|
||||
|
||||
# rename -v 's/img_(\d{4})\.jpeg$/dan_$1\.jpg/' *.jpeg
|
||||
|
||||
----------
|
||||
|
||||
img_5417.jpeg renamed as dan_5417.jpg
|
||||
img_5418.jpeg renamed as dan_5418.jpg
|
||||
img_5419.jpeg renamed as dan_5419.jpg
|
||||
img_5420.jpeg renamed as dan_5420.jpg
|
||||
img_5421.jpeg renamed as dan_5421.jpg
|
||||
|
||||
The next command will rename 'img_000NNNN.jpeg' to 'dan_NNNN.jpg'.
|
||||
|
||||
# rename -v 's/img_\d{3}(\d{4})\.jpeg$/dan_$1\.jpg/' *jpeg
|
||||
|
||||
----------
|
||||
|
||||
img_0005417.jpeg renamed as dan_5417.jpg
|
||||
img_0005418.jpeg renamed as dan_5418.jpg
|
||||
img_0005419.jpeg renamed as dan_5419.jpg
|
||||
img_0005420.jpeg renamed as dan_5420.jpg
|
||||
img_0005421.jpeg renamed as dan_5421.jpg
|
||||
|
||||
In both cases above, the subpattern '\d{4}' captures four consecutive digits. The captured four digits are then referred to as $1, and used as part of new filenames.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/rename-multiple-files-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/xargs-command-linux.html
|
||||
@ -0,0 +1,265 @@
|
||||
Real-World WordPress Benchmarks with PHP5.5 PHP5.6 PHP-NG and HHVM
|
||||
================================================================================
|
||||
**TL;DR In a local, Vagrant-based environment HHVM lost, probably due to a bug; it’s still investigated with the help of the HHVM guys! However on a DigitalOcean 4GB box it beat even the latest build of PHP-NG!**
|
||||
|
||||

|
||||
|
||||
**Update: Please take a look at the results at the end of the article! They reflect the power of HHVM better (after the JIT warmup), for some reason we cannot get these results with all setups though.
|
||||
|
||||
The tests below were done in a Vagrant/VVV environment, the results are still interesting, it might be a bug in HHVM or the Vagrant setup that’s preventing it from kicking into high speed, we’re investigating the issue with the HHVM guys.**
|
||||
|
||||
If you remember we [wrote an article a good couple of months ago][1] when WordPress 3.9 came out that HHVM was fully supported beginning with that release, and we were all happy about it. The initial benchmark results showed HHVM to be far more superior than the Zend engine that’s currently powering all PHP builds. Then the problems came:
|
||||
|
||||
- HHVM can only be run as one user, which means less security (in shared environments)
|
||||
- HHVM does not restart itself after it crashes, and unfortunately it still does that quite often
|
||||
- HHVM uses a lot of memory right from the start, and yes, it per-request memory usage will be lower once you scale compared to PHP-FPM
|
||||
|
||||
Obviously you have to compromise based on your (or rather your sites’) needs but is it worth it? How much of a performance gain can you expect by switching to HHVM?
|
||||
|
||||
At Kinsta we really like to test everything new and generally optimize everything to provide the best environment to our clients. Today I finally took the time to set up a test environment and do some tests to compare a couple of different builds with a fresh out of the box WordPress install and one that has a bunch of content added plus runs WooCommerce! To measure the script running time I simply added the
|
||||
|
||||
<?php timer_stop(1); ?>
|
||||
|
||||
line before the /body tag of the footer.php’s.
|
||||
|
||||
**Note:
|
||||
Previously this section contained benchmarks made with Vagrant/Virtualbox/Ubuntu14.04 however for some reason HHVM was really underperforming, probably due to a bug or a limitation of the virtualized environment. We feel that these test results do not reflect the reality so we re-run the tests on a cloud server and consider these valid.**
|
||||
|
||||
Here are the exact setup details of the environment:
|
||||
|
||||
- DigitalOcean 4GB droplet (2 CPU cores, 4GB RAM)
|
||||
- Ubuntu 14.04, MariaDB10
|
||||
- Test site: Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1
|
||||
- PHP 5.5.9, PHP 5.5.15, PHP 5.6.0 RC2, PHP-NG (20140718-git-6cc487d) and HHVM 3.2.0 (version says PHP 5.6.99-hhvm)
|
||||
|
||||
**Without further ado, these were my test results, the lower the better, values in seconds:**
|
||||
|
||||
### DigitalOcean 4GB droplet ###
|
||||
|
||||
Seconds, 10 runs, lower the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
It looks like that PHP-NG achieves its peak performance after the first run! HHVM needs a couple more reloads, but their performance seems to be almost equal! I can’t wait until PHP-NG is merged into the master! :)
|
||||
|
||||
Hits in a minute, higher the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
**PHP 5.5.15 OpCache Disabled**
|
||||
|
||||
- Transactions: **236 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.03 secs
|
||||
- Data transferred: 2.40 MB
|
||||
- Response time: 2.47 secs
|
||||
- Transaction rate: 4.00 trans/sec
|
||||
- Throughput: 0.04 MB/sec
|
||||
- Concurrency: 9.87
|
||||
- Successful transactions: 236
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 4.44
|
||||
- Shortest transaction: 0.48
|
||||
|
||||
**PHP 5.5.15 OpCache Enabled**
|
||||
|
||||
- Transactions: **441 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.55 secs
|
||||
- Data transferred: 4.48 MB
|
||||
- Response time: 1.34 secs
|
||||
- Transaction rate: 7.41 trans/sec
|
||||
- Throughput: 0.08 MB/sec
|
||||
- Concurrency: 9.91
|
||||
- Successful transactions: 441
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 2.19
|
||||
- Shortest transaction: 0.64
|
||||
|
||||
**PHP 5.6 RC2 OpCache Disabled**
|
||||
|
||||
- Transactions: **207 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.87 secs
|
||||
- Data transferred: 2.10 MB
|
||||
- Response time: 2.80 secs
|
||||
- Transaction rate: 3.46 trans/sec
|
||||
- Throughput: 0.04 MB/sec
|
||||
- Concurrency: 9.68
|
||||
- Successful transactions: 207
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 3.65
|
||||
- Shortest transaction: 0.54
|
||||
|
||||
**PHP 5.6 RC2 OpCache Enabled**
|
||||
|
||||
- Transactions: **412 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.03 secs
|
||||
- Data transferred: 4.18 MB
|
||||
- Response time: 1.42 secs
|
||||
- Transaction rate: 6.98 trans/sec
|
||||
- Throughput: 0.07 MB/sec
|
||||
- Concurrency: 9.88
|
||||
- Successful transactions: 412
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 1.93
|
||||
- Shortest transaction: 0.34
|
||||
|
||||
**HHVM 3.2.0 (version says PHP 5.6.99-hhvm)**
|
||||
|
||||
- Transactions: **955 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.69 secs
|
||||
- Data transferred: 9.18 MB
|
||||
- Response time: 0.62 secs
|
||||
- Transaction rate: 16.00 trans/sec
|
||||
- Throughput: 0.15 MB/sec
|
||||
- Concurrency: 9.94
|
||||
- Successful transactions: 955
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 0.85
|
||||
- Shortest transaction: 0.23
|
||||
|
||||
**PHP-NG OpCache Enabled (built: Jul 29 2014 )**
|
||||
|
||||
- Transactions: **849 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.88 secs
|
||||
- Data transferred: 8.63 MB
|
||||
- Response time: 0.70 secs
|
||||
- Transaction rate: 14.18 trans/sec
|
||||
- Throughput: 0.14 MB/sec
|
||||
- Concurrency: 9.94
|
||||
- Successful transactions: 849
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 1.06
|
||||
- Shortest transaction: 0.13
|
||||
|
||||
----------
|
||||
|
||||
**Note:
|
||||
These are the previous test results, they’re faulty. I left them here for future reference but please do NOT consider these values a truthful representation!**
|
||||
|
||||
Here are the exact setup details of the environment:
|
||||
|
||||
- Apple MacBook Pro mid-2011 (Intel Core i7 2 GHz 4 cores, 4GB RAM, 256GB Ocz Vertex 3 MI)
|
||||
- Current Varying Vagrant Vagrants build with Ubuntu 14.04, nginx 1.6.x, mysql 5.5.x, etc.
|
||||
- Test site 1: WordPress 3.9.1 bare minimum
|
||||
- Test site 2: Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1
|
||||
- PHP 5.5.9, PHP 5.5.15, PHP 5.6.0 RC2, PHP-NG (20140718-git-6cc487d) and HHVM 3.2.0 (version says PHP 5.6.99-hhvm)
|
||||
|
||||
**Default Theme, Default WordPress 3.9.1, PHP 5.5.9-1ubuntu4.3 (with OpCache 7.0.3)**
|
||||
|
||||
**Faulty results. Please read the note above!** Seconds, 10 runs, lower the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
### Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1 (OpCache Disabled) ###
|
||||
|
||||
**Faulty results. Please read the note above**! Seconds, 10 runs, lower the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
### Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1 (OpCache Enabled) ###
|
||||
|
||||
**Faulty results. Please read the note above!** Seconds, 10 runs, lower the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
**Siege
|
||||
parameters: 10 concurrent users for 1 minute: siege -c 10 -b -t 1M**
|
||||
|
||||
**Faulty results. Please read the note above!** Hits in a minute, higher the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
**PHP5.5 OpCache Disabled (PHP 5.5.15-1+deb.sury.org~trusty+1)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 35 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.04 secs
|
||||
- Data transferred: 2.03 MB
|
||||
- Response time: 14.56 secs
|
||||
- Transaction rate: 0.59 trans/sec
|
||||
- Throughput: 0.03 MB/sec
|
||||
- Concurrency: 8.63
|
||||
- Successful transactions: 35
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 18.73
|
||||
- Shortest transaction: 5.80
|
||||
|
||||
**HHVM 3.2.0 (version says PHP 5.6.99-hhvm)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 44 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.53 secs
|
||||
- Data transferred: 0.42 MB
|
||||
- Response time: 12.00 secs
|
||||
- Transaction rate: 0.74 trans/sec
|
||||
- Throughput: 0.01 MB/sec
|
||||
- Concurrency: 8.87
|
||||
- Successful transactions: 44
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 13.40
|
||||
- Shortest transaction: 2.65
|
||||
|
||||
**PHP5.5 OpCache Enabled (PHP 5.5.15-1+deb.sury.org~trusty+1 with OpCache 7.0.4-dev)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 100 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.30 secs
|
||||
- Data transferred: 5.81 MB
|
||||
- Response time: 5.69 secs
|
||||
- Transaction rate: 1.69 trans/sec
|
||||
- Throughput: 0.10 MB/sec
|
||||
- Concurrency: 9.60
|
||||
- Successful transactions: 100
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 7.25
|
||||
- Shortest transaction: 2.82
|
||||
|
||||
**PHP5.6 OpCache Enabled (PHP 5.6.0RC2 with OpCache 7.0.4-dev)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 103 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.99 secs
|
||||
- Data transferred: 5.98 MB
|
||||
- Response time: 5.51 secs
|
||||
- Transaction rate: 1.72 trans/sec
|
||||
- Throughput: 0.10 MB/sec
|
||||
- Concurrency: 9.45
|
||||
- Successful transactions: 103
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 6.87
|
||||
- Shortest transaction: 2.52
|
||||
|
||||
**PHP-NG OpCache Enabled (20140718-git-6cc487d)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 124 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.32 secs
|
||||
- Data transferred: 7.19 MB
|
||||
- Response time: 4.58 secs
|
||||
- Transaction rate: 2.09 trans/sec
|
||||
- Throughput: 0.12 MB/sec
|
||||
- Concurrency: 9.57
|
||||
- Successful transactions: 124
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 6.86
|
||||
- Shortest transaction: 2.24
|
||||
|
||||
**What do you think about this test? Did I miss something? What would you like to see in the next benchmarking article? Please leave your comment below!**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kinsta.com/blog/real-world-wordpress-benchmarks-with-php5-5-php5-6-php-ng-and-hhvm/
|
||||
|
||||
作者:[Mark Gavalda][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kinsta.com/blog/author/kinstadmin/
|
||||
[1]:https://kinsta.com/blog/hhvm-and-wordpress/
|
||||
@ -0,0 +1,125 @@
|
||||
4 Steps to Setup Local Repository in Ubuntu using APT-mirror
|
||||
================================================================================
|
||||
Today we will show you how to setup a local repository in your Ubuntu PC or Ubuntu Server straight from the official Ubuntu repository. There are a lot benefit of creating a local repository in your computer if you have a lot of computers to install software, security updates and fixes often in all systems, then having a local Ubuntu repository is an efficient way. Because all required packages are downloaded over the fast LAN connection from your local server, so that it will save your Internet bandwidth and reduces the annual cost of Internet..
|
||||
|
||||
You can setup a local repository of Ubuntu in your local PC or server using many tools, but we'll featuring about APT-Mirror in this tutorial. Here, we'll be mirroring packages from the default mirror to our Local Server or PC and we'll need at least **120 GB** or more free space in your local or external hard drive. It can be configured through a **HTTP** or **FTP** server to share its software packages with local system clients.
|
||||
|
||||
We'll need to install Apache Web Server and APT-Mirror to get our stuffs working out of the box. Here are the steps below to configure a working local repository:
|
||||
|
||||
### 1. Installing Required Packages ###
|
||||
|
||||
First of all, we are going to pull whole packages from the public repository of Ubuntu package server and save them in our local Ubuntu server hard disk.
|
||||
|
||||
We'll first install a web server to host our local repository. We'll install Apache web server but you can install any web server you wish, web server are necessary for the http protocol. You can additionally install FTP servers like proftpd, vsftpd,etc if you need to configure for ftp protocols and Rsync for rsync protocols.
|
||||
|
||||
$ sudo apt-get install apache2
|
||||
|
||||
And then we'll need to install apt-mirror:
|
||||
|
||||
$ sudo apt-get install apt-mirror
|
||||
|
||||

|
||||
|
||||
**Note: As I have already mentioned that we'll need at least 120 GBs free space to get all the packages mirrored or download.**
|
||||
|
||||
### 2. Configuring APT-Mirror ###
|
||||
|
||||
Now create a directory on your harddisk to save all packages. For example, let us create a directory called “/linoxide”. We are going to save all packages in this directory:
|
||||
|
||||
$ sudo mkdir /linoxide
|
||||
|
||||

|
||||
|
||||
Now, open the file **/etc/apt/mirror.list** file
|
||||
|
||||
$ sudo nano /etc/apt/mirror.list
|
||||
|
||||

|
||||
|
||||
Copy the below lines of configuration to mirror.list and edit as your requirements.
|
||||
|
||||
############# config ##################
|
||||
#
|
||||
set base_path /linoxide
|
||||
#
|
||||
# set mirror_path $base_path/mirror
|
||||
# set skel_path $base_path/skel
|
||||
# set var_path $base_path/var
|
||||
# set cleanscript $var_path/clean.sh
|
||||
# set defaultarch <running host architecture>
|
||||
# set postmirror_script $var_path/postmirror.sh
|
||||
# set run_postmirror 0
|
||||
set nthreads 20
|
||||
set _tilde 0
|
||||
#
|
||||
############# end config ##############
|
||||
|
||||
deb http://archive.ubuntu.com/ubuntu trusty main restricted universe multiverse
|
||||
deb http://archive.ubuntu.com/ubuntu trusty-security main restricted universe multiverse
|
||||
deb http://archive.ubuntu.com/ubuntu trusty-updates main restricted universe multiverse
|
||||
#deb http://archive.ubuntu.com/ubuntu trusty-proposed main restricted universe multiverse
|
||||
#deb http://archive.ubuntu.com/ubuntu trusty-backports main restricted universe multiverse
|
||||
|
||||
deb-src http://archive.ubuntu.com/ubuntu trusty main restricted universe multiverse
|
||||
deb-src http://archive.ubuntu.com/ubuntu trusty-security main restricted universe multiverse
|
||||
deb-src http://archive.ubuntu.com/ubuntu trusty-updates main restricted universe multiverse
|
||||
#deb-src http://archive.ubuntu.com/ubuntu trusty-proposed main restricted universe multiverse
|
||||
#deb-src http://archive.ubuntu.com/ubuntu trusty-backports main restricted universe multiverse
|
||||
|
||||
clean http://archive.ubuntu.com/ubuntu
|
||||
|
||||

|
||||
|
||||
**Note: You can replace the above official mirror server url by the nearest one, you can get your nearest server by visiting the page [Ubuntu Mirror Server][1]. If you are not in hurry and can wait for the mirroring, you can go with the default official one.**
|
||||
|
||||
Here, we are going to mirror package repository of the latest and greatest LTS release of Ubuntu ie. Ubuntu 14.04 LTS (Trusty Tahr) so, we have configured trusty. If you need to mirror of Saucy or other version of Ubuntu, please edit it as its codename.
|
||||
|
||||
Now, we'll have to run apt-mirror which will now get/mirror all the packages in the repository.
|
||||
|
||||
sudo apt-mirror
|
||||
|
||||
It will take time to download all the packages from the Ubuntu Server which depends upon the connection speed and performance with respect to you and the mirror server. I have interrupted the download as I have already done that...
|
||||
|
||||

|
||||
|
||||
### 3.Configuring Web Server ###
|
||||
|
||||
To be able to access the repo from other computers you need a webserver. You can also do it via ftp but I choose to use a webserver as I mentioned in above step 1. So, we are now gonna configure Apache Server:
|
||||
|
||||
We will create a symlink from our local repo's directory to a directory ubuntu in the hosting directory of Apache ie /var/www/ubuntu
|
||||
|
||||
$ sudo ln -s /linoxide /var/www/ubuntu
|
||||
$ sudo service apache2 start
|
||||
|
||||

|
||||
|
||||
The above command will allow us to browse our Mirrored Repo from our localhost ie http://127.0.0.1 by default.
|
||||
|
||||
### 4. Configuring Client Side ###
|
||||
|
||||
Finally, we need to add repository source in other computers which will fetch the packages and repository from our computer. To do that, we'll need to edit /etc/apt/sources.list and add the following lines.
|
||||
|
||||
$ sudo nano /etc/apt/sources.list
|
||||
|
||||
Add this line in /etc/apt/sources.list and save.
|
||||
|
||||
deb http://192.168.0.100/ubuntu/ trusty main restricted universe
|
||||
|
||||
**Note: here 192.168.0.100 is the LAN IP address of our server computer, you need to replace that with yours.**
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
Finally, we are done. Now you can install the required packages using sudo apt-get install packagename from your local Ubuntu repository with high speed download and with low bandwidth.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-local-repository-ubuntu/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://launchpad.net/ubuntu/+archivemirrors
|
||||
265
sources/tech/20141229 5 User Space Debugging Tools in Linux.md
Normal file
265
sources/tech/20141229 5 User Space Debugging Tools in Linux.md
Normal file
@ -0,0 +1,265 @@
|
||||
translating by mtunique
|
||||
5 User Space Debugging Tools in Linux
|
||||
================================================================================
|
||||
By definition, debugging tools are those programs which allow us to monitor ,control and correct errors in other programs while they execute. Why should we use debugging tools? To answer this, there are various situations where we get stuck while running some programs and will have the need to understand what exactly happened. For example, we might be running an application and it produces some error messages. To fix those errors, we should first figure out why and from where did the error messages come from. An application might suddenly hang and we will have to know what other processes were running at that time. We might also have to figure out what was process 'x' doing at the time of hang. In order to dissect such details, we will need the help of debugging tools. There are a few user space debugging tools and techniques in Linux which are quite useful in analysing user space problems. They are:
|
||||
|
||||
- **'print' statements**
|
||||
- **Querying (/proc, /sys etc)**
|
||||
- **Tracing (strace/ltrace)**
|
||||
- **Valgrind (memwatch)**
|
||||
- **GDB**
|
||||
|
||||
Let's go through each of them one by one.
|
||||
|
||||
### 1.'print' statements ###
|
||||
|
||||
This is a basic or primitive way of debugging a problem. We can insert print statements in the middle of a program to understand the control flow and get the value of key variables. Though it is a simple technique, it has some disadvantages to it. Programs need to be edited to add 'print 'statements which then will have to be recompiled and rerun to get the output. This is a time-consuming method if the program to be debugged is quite big.
|
||||
|
||||
### 2. Querying ###
|
||||
|
||||
In some situations, we might want to figure out in what state a running process is in the kernel or what is the memory map that it is occupying there etc. In order to obtain this type of information, we need not insert any code into the kernel. Instead, one can use the /proc filesystem.
|
||||
|
||||
/proc is a pseudo filesystem that gets populated with runtime system information (cpu information, amount of memory etc) once the system is up and running.
|
||||
|
||||

|
||||
output of 'ls /proc'
|
||||
|
||||
As you can see, each process that is running in the system has an entry in the /proc filesystem in the form of its process id . Details about each of these processes can be obtained by looking into the files present in its process id directory
|
||||
|
||||

|
||||
output of 'ls /proc/pid'
|
||||
|
||||
Explaining all the entries inside the /proc filesystem is beyond the scope of this document. Some of the useful ones are listed below:
|
||||
|
||||
- /proc/cmdline -> Kernel command line
|
||||
- /proc/cpuinfo -> information about the processor's make, model etc
|
||||
- /proc/filesystems -> filesystem information supported by the kernel
|
||||
- /proc//cmdline -> command line arguments passed to the current process
|
||||
- /proc//mem -> memory held by the process
|
||||
- /proc//status -> status of the process
|
||||
|
||||
### 3. Tracing ###
|
||||
|
||||
strace and ltrace are two of the tracing tools used in Linux to trace program execution details.
|
||||
|
||||
#### strace: ####
|
||||
|
||||
strace intercepts and records system calls within a process and the signals received by it. To the user, it displays the system calls, arguments passed to them and the return values. strace can be attached to a process that is already running or to a new process. It is useful as a diagnostic and debugging tools for developers and system administrators. It can also be used as a tool to understand how system calls work by tracing different programs. Advantage of this tool is that no source code is needed and programs need not be recompiled.
|
||||
|
||||
The basic syntax for using strace is:
|
||||
|
||||
**strace command**
|
||||
|
||||
There are various options that are available to be used with strace command. One can check out the man page for strace tool to get more details.
|
||||
|
||||
The output of strace can be quite lengthy and we may not be interested in going through each and every line that is displayed. We can use the '-e expr' option to filter the unwanted data.
|
||||
|
||||
Use '-p pid' option to attach it to a running process.
|
||||
|
||||
Output of the command can be redirected to a file using the '-o' option
|
||||
|
||||

|
||||
output of strace filtering only the open system call
|
||||
|
||||
#### ltrace: ####
|
||||
|
||||
ltrace tracks and records the dynamic (runtime) library calls made by a process and the signals received by it. It can also track the system calls made within a process. It's usage is similar to strace
|
||||
|
||||
**ltrace command**
|
||||
|
||||
'-i ' option prints the instruction pointer at the time of library call
|
||||
|
||||
'-S' option is used to display both system calls and library calls
|
||||
|
||||
Refer to the ltrace man page for all the available options.
|
||||
|
||||

|
||||
output of ltrace capturing 'strcmp' library call
|
||||
|
||||
### 4. Valgrind ###
|
||||
|
||||
Valgrind is a suite of debugging and profiling tools. One of the widely used and the default tool is a memory checking tool called 'Memcheck' which intercepts calls made to malloc(), new(), free() and delete(). In other words, it is useful in detecting problems like:
|
||||
|
||||
- memory leaks
|
||||
- double freeing
|
||||
- boundary overruns
|
||||
- using uninitialized memory
|
||||
- using a memory after it has been freed etc.
|
||||
|
||||
It works directly with the executable files.
|
||||
|
||||
Valgrind comes with a few drawbacks as well. It can slow down your program as it increases the memory footprint. It can sometimes produce false positives and false negatives. It cannot detect out-of-range access to statically allocated arrays
|
||||
|
||||
In order to use it, first download it and install it on your system. ([Valgrind's download page][1]). It can be installed using the package manager for the operating system that one is using.
|
||||
|
||||
Installation using command line involves decompressing and untarring the downloaded file.
|
||||
|
||||
tar -xjvf valgring-x.y.z.tar.bz2 (where x.y.z is the version number you are trying to install)
|
||||
|
||||
Get inside the newly created directory (valgrind-x.y.z)and run the following commands:
|
||||
|
||||
./configure
|
||||
make
|
||||
make install
|
||||
|
||||
Let's understand how valgrind works with a small program(test.c):
|
||||
|
||||
#include <stdio.h>
|
||||
|
||||
void f(void)
|
||||
|
||||
{
|
||||
int x = malloc(10 * sizeof(int));
|
||||
|
||||
x[10] = 0;
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
f();
|
||||
return 0;
|
||||
}
|
||||
|
||||
Compile the program:
|
||||
|
||||
gcc -o test -g test.c
|
||||
|
||||
Now we have an executable file called 'test'. We can now use valgrind to check for memory errors:
|
||||
|
||||
valgrind –tool=memcheck –leak-check=yes test
|
||||
|
||||
Here is the valgrind output showing the errors:
|
||||
|
||||

|
||||
output of valgrind showing heap block overrun and memory leak
|
||||
|
||||
As we can see in the above message, we are trying to access the area beyond what is allocated in function f and the allocated memory is not freed.
|
||||
|
||||
### 5. GDB ###
|
||||
|
||||
GDB is a debugger from Free Software Foundation. It is useful in locating and fixing problems in the code. It gives control to the user to perform various actions when the program to be debugged is running, like:
|
||||
|
||||
- starting the program
|
||||
- stop at specified locations
|
||||
- stop on specified conditions
|
||||
- examine required information
|
||||
- make changes to data in the program etc.
|
||||
|
||||
One can also attach a core dump of a crashed program to GDB and analyse the cause of crash.
|
||||
|
||||
GDB provides a lot of options to debug programs. However, we will cover some important options here so that one can get a feel of how to get started with GDB.
|
||||
|
||||
If you do not already have GDB installed, it can be downloaded from [GDB's official website][2].
|
||||
|
||||
#### Compiling programs: ####
|
||||
|
||||
In order to debug a program using GDB, it has to be compiled using gcc with the'-g' option. This produces debugging information in the operating system's native format and GDB works with this information.
|
||||
|
||||
Here is a simple program (example1.c)performing divide by zero to show the usage of GDB:
|
||||
|
||||
#include
|
||||
int divide()
|
||||
{
|
||||
int x=5, y=0;
|
||||
return x / y;
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
divide();
|
||||
}
|
||||
|
||||

|
||||
An example showing usage of gdb
|
||||
|
||||
#### Invoking GDB: ####
|
||||
|
||||
GDB can be started by executing 'gdb' in the command-line:
|
||||
|
||||

|
||||
invoking gdb
|
||||
|
||||
Once invoked, it remains there waiting for commands from the terminal and executing them until exited .
|
||||
|
||||
If a process is already running and you need to attach GDB to it, it can be done by specifying the process id Suppose a program has already crashed and one wants to analyse the cause of the problem, then attaching GDB to the core file helps.
|
||||
|
||||
#### Starting the program: ####
|
||||
|
||||
Once you are inside GDB, use the 'run' command to start the program to be debugged
|
||||
|
||||
#### Passing arguments to the program: ####
|
||||
|
||||
Use the 'set args' command to send the arguments to your program when it runs next time 'show args' will show the arguments passed to the program
|
||||
|
||||
#### Verifying the stack: ####
|
||||
|
||||
Whenever a program stops, first thing anyone wants to understand is why it stopped and how it stopped there. This information is called backtrace. Every function call generated by a program gets stored along with the local variables, arguments passed, call location etc in a block of data inside the stack and is called a frame. Using GDB we can examine all this data. GDB identifies these frames by giving them numbers starting from the innermost frame.
|
||||
|
||||
- **bt**: prints the backtrace of the entire stack
|
||||
- **bt <n>** prints the backtrace of n frames
|
||||
- **frame <frame number>**: switches to the specified frame and prints that frame
|
||||
- **up <n>**: move 'n' frames up
|
||||
- **down <n>**: move 'n' frames down. ( n is 1 by default)
|
||||
|
||||
#### Examining data: ####
|
||||
|
||||
Program's data can be examined inside GDB using the 'print' command. For example, if 'x' is a variable inside the debugging program, 'print x' prints the value of x.
|
||||
|
||||
#### Examining source: ####
|
||||
|
||||
Parts of source file can be printed within GDB. 'list' command by default prints 10 lines of code.
|
||||
|
||||
- **list <linenum>**: list the source file around 'linenum'
|
||||
- **list <function>**: list the source from the beginning of 'function'
|
||||
|
||||
- **disas <function>**: displays the machine code for the function
|
||||
|
||||
#### Stopping and resuming the program: ####
|
||||
|
||||
Using GDB, we can set breakpoints, watchpoint etc in order to stop the program wherever required.
|
||||
|
||||
- **break <location>**: Sets up a breakpoint at 'location'. When this is hit while the program is executing, control is given to the user.
|
||||
- **watch <expr>**: GDB stops when the 'expr' is written into by the program and it's value changes
|
||||
- **catch <event>**: GDB stops when the 'event' occurs.
|
||||
- **disable <breakpoint>**: disable the specified breakpoint
|
||||
- **enable <breakpoint>**: enable the specified breakpoint
|
||||
- **delete <breakpoint>**: delete the breakpoint / watchpoint / catch point passed. If no arguments are passed default action is to work on all the breakpoints
|
||||
|
||||
- **step**: execute the program step by step
|
||||
- **continue**: continue with program execution until execution is complete
|
||||
|
||||
#### Exiting GDB: ####
|
||||
|
||||
Use the 'quit' command to exit from GDB
|
||||
|
||||
There are many more options that are available with GDB. Use the help option once you are inside GDB for more details.
|
||||
|
||||

|
||||
getting help within gdb
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article, we have seen different types of user space debug tools available in Linux. To summarise all of them, here is a quick guideline on when to use what:
|
||||
Basic debugging, getting values of key variables – print statements
|
||||
|
||||
Get information about filesystems supported, available memory, cpus, status of a running program in the kernel etc - querying /proc filesystem
|
||||
|
||||
Initial problem diagnosis, system call or library call related issues , understanding program flow – strace / ltrace
|
||||
|
||||
Application space related memory problems – valgrind
|
||||
|
||||
To examine runtime behaviour of applications, analysing application crashes – gdb.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/user-space-debugging-tools-linux/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bnpoornima/
|
||||
[1]:http://valgrind.org/downloads.html
|
||||
[2]:http://www.gnu.org/software/gdb/download/
|
||||
@ -0,0 +1,202 @@
|
||||
How to Install Bugzilla 4.4 on Ubuntu / CentOS 6.x
|
||||
================================================================================
|
||||
Here, we are gonna show you how we can install Bugzilla in an Ubuntu 14.04 or CentOS 6.5/7. Bugzilla is a Free and Open Source Software(FOSS) which is web based bug tracking tool used to log and track defect database, its Bug-tracking systems allow individual or groups of developers effectively to keep track of outstanding problems with their product. Despite being "free", Bugzilla has many features its expensive counterparts lack. Consequently, Bugzilla has quickly become a favorite of thousands of organizations across the globe.
|
||||
|
||||
Bugzilla is very adaptable to various situations. They are used now a days in different IT support queues, Systems Administration deployment management, chip design and development problem tracking (both pre-and-post fabrication), and software and hardware bug tracking for luminaries such as Redhat, NASA, Linux-Mandrake, and VA Systems.
|
||||
|
||||
### 1. Installing dependencies ###
|
||||
|
||||
Setting up Bugzilla is fairly **easy**. This blog is specific to Ubuntu 14.04 and CentOS 6.5 ( though it might work with older versions too )
|
||||
|
||||
In order to get Bugzilla up and running in Ubuntu or CentOS, we are going to install Apache webserver ( SSL enabled ) , MySQL database server and also some tools that are required to install and configure Bugzilla.
|
||||
|
||||
To install Bugzilla in your server, you'll need to have the following components installed:
|
||||
|
||||
- Per l(5.8.1 or above)
|
||||
- MySQL
|
||||
- Apache2
|
||||
- Bugzilla
|
||||
- Perl modules
|
||||
- Bugzilla using apache
|
||||
|
||||
As we have mentioned that this article explains installation of both Ubuntu 14.04 and CentOS 6.5/7, we will have 2 different sections for them.
|
||||
|
||||
Here are the steps you need to follow to setup Bugzilla in your Ubuntu 14.04 LTS and CentOS 7:
|
||||
|
||||
**Preparing the required dependency packages:**
|
||||
|
||||
You need to install the essential packages by running the following command:
|
||||
|
||||
**For Ubuntu:**
|
||||
|
||||
$ sudo apt-get install apache2 mysql-server libapache2-mod-perl2
|
||||
libapache2-mod-perl2-dev libapache2-mod-perl2-doc perl postfix make gcc g++
|
||||
|
||||
**For CentOS:**
|
||||
|
||||
$ sudo yum install httpd mod_ssl mysql-server mysql php-mysql gcc perl* mod_perl-devel
|
||||
|
||||
**Note: Please run all the commands in a shell or terminal and make sure you have root access (sudo) on the machine.**
|
||||
|
||||
### 2. Running Apache server ###
|
||||
|
||||
As you have already installed the apache server from the above step, we need to now configure apache server and run it. We'll need to go for sudo or root mode to get all the commands working so, we'll gonna switch to root access.
|
||||
|
||||
$ sudo -s
|
||||
|
||||
Now, we need to open port 80 in the firewall and need to save the changes.
|
||||
|
||||
# iptables -I INPUT -p tcp --dport 80 -j ACCEPT
|
||||
# service iptables save
|
||||
|
||||
Now, we need to run the service:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# service httpd start
|
||||
|
||||
Lets make sure that Apache will restart every time you restart the machine:
|
||||
|
||||
# /sbin/chkconfig httpd on
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service apache2 start
|
||||
|
||||
Now, as we have started our apache http server, we will be able to open apache server at IP address of 127.0.0.1 by default.
|
||||
|
||||
### 3. Configuring MySQL Server ###
|
||||
|
||||
Now, we need to start our MySQL server:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# chkconfig mysqld on
|
||||
# service start mysqld
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service mysql-server start
|
||||
|
||||

|
||||
|
||||
Login with root access to MySQL and create a DB for Bugzilla. Change “mypassword” to anything you want for your mysql password. You will need it later when configuring Bugzilla too.
|
||||
|
||||
For Both CentOS 6.5 and Ubuntu 14.04 Trusty
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
# password: (You'll need to enter your password)
|
||||
|
||||
# mysql > create database bugs;
|
||||
|
||||
# mysql > grant all on bugs.* to root@localhost identified by "mypassword";
|
||||
|
||||
#mysql > quit
|
||||
|
||||
**Note: Please remember the DB name, passwords for mysql , we'll need it later.**
|
||||
|
||||
### 4. Installing and configuring Bugzilla ###
|
||||
|
||||
Now, as we have all the required packages set and running, we'll want to configure our Bugzilla.
|
||||
|
||||
So, first we'll want to download the latest Bugzilla package, here I am downloading version 4.5.2 .
|
||||
|
||||
To download using wget in a shell or terminal:
|
||||
|
||||
wget http://ftp.mozilla.org/pub/mozilla.org/webtools/bugzilla-4.5.2.tar.gz
|
||||
|
||||
You can also download from their official site ie. [http://www.bugzilla.org/download/][1]
|
||||
|
||||
**Extracting and renaming the downloaded bugzilla tarball:**
|
||||
|
||||
# tar zxvf bugzilla-4.5.2.tar.gz -C /var/www/html/
|
||||
|
||||
# cd /var/www/html/
|
||||
|
||||
# mv -v bugzilla-4.5.2 bugzilla
|
||||
|
||||
|
||||
|
||||
**Note**: Here, **/var/www/html/bugzilla/** is the directory where we're gonna **host Bugzilla**.
|
||||
|
||||
Now, we'll configure buzilla:
|
||||
|
||||
# cd /var/www/html/bugzilla/
|
||||
|
||||
# ./checksetup.pl --check-modules
|
||||
|
||||

|
||||
|
||||
After the check is done, we will see some missing modules that needs to be installed And that can be installed by the command below:
|
||||
|
||||
# cd /var/www/html/bugzilla
|
||||
# perl install-module.pl --all
|
||||
|
||||
This will take a bit time to download and install all dependencies. Run the **checksetup.pl –check-modules** command again to verify there are nothing left to install.
|
||||
|
||||
Now we'll need to run the below command which will automatically generate a file called “localconfig” in the /var/www/html/bugzilla directory.
|
||||
|
||||
# ./checksetup.pl
|
||||
|
||||
Make sure you input the correct database name, user, and password we created earlier in the localconfig file
|
||||
|
||||
# nano ./localconfig
|
||||
|
||||
# checksetup.pl
|
||||
|
||||

|
||||
|
||||
If all is well, checksetup.pl should now successfully configure Bugzilla.
|
||||
|
||||
Now we need to add Bugzilla to our Apache config file. so, we'll need to open /etc/httpd/conf/httpd.conf (For CentOS) or etc/apache2/apache2.conf (For Ubuntu) with a text editor:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# nano /etc/httpd/conf/httpd.conf
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# nano etc/apache2/apache2.conf
|
||||
|
||||
Now, we'll need to configure Apache server we'll need to add the below configuration in the config file:
|
||||
|
||||
<VirtualHost *:80>
|
||||
DocumentRoot /var/www/html/bugzilla/
|
||||
</VirtualHost>
|
||||
|
||||
<Directory /var/www/html/bugzilla>
|
||||
AddHandler cgi-script .cgi
|
||||
Options +Indexes +ExecCGI
|
||||
DirectoryIndex index.cgi
|
||||
AllowOverride Limit FileInfo Indexes
|
||||
</Directory>
|
||||
|
||||
Lastly, we need to edit .htaccess file and comment out “Options -Indexes” line at the top by adding “#”
|
||||
|
||||
Lets restart our apache server and test our installation.
|
||||
|
||||
For CentOS:
|
||||
|
||||
# service httpd restart
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||

|
||||
|
||||
Finally, our Bugzilla is ready to get bug reports now in our Ubuntu 14.04 LTS and CentOS 6.5 and you can browse to bugzilla by going to the localhost page ie 127.0.0.1 or to your IP address in your web browser .
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-bugzilla-ubuntu-centos/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.bugzilla.org/download/
|
||||
@ -0,0 +1,45 @@
|
||||
Linus Torvalds发布了Linux 3.19 RC1,目前为止最大的更新
|
||||
================================================================================
|
||||
> 新的内核开发周期开始了
|
||||
|
||||

|
||||
|
||||
**首个内核候选版本在3.19分支上发布了,它看上去像目前最大的更新。这个早先发布让众人惊喜,但是很容易理解为什么。**
|
||||
|
||||
内核开发周期被新的3.19的发布而刷新了。事实是3.18分支才几周前才发布,今天的发布并不是完全在预期中。假期要来了,很多开发者和维护任何可能会休息。一般来说RC版本每周发布一次,但是用户可能会看到轻微的延误。
|
||||
|
||||
这个版本没有提到在Linux 3.18中确认的回归问题,但是可以确定的是,开发人员仍在努力修复中。另一方面,Linus说这是一个很大的更新,事实上这是目前为止最大的更新。很有可能是许多开发者想要在节日之前推送他们的补丁,因此,下一个RC版本会小一些。
|
||||
|
||||
### Linux 3.19 RC1 标志着新的一个周期的开始 ###
|
||||
|
||||
发布版本的大小随着更新的频率正在增加。内核的开发周期通常大约8到10周,并且很少多于这个,这给项目一个很好的预测。
|
||||
|
||||
[阅读][1] Linus Torvalds的发布声明中说:“也就是说,也许没有真正的落后者,并且从rc1的大小来看,真的已经不多了。我不仅觉得下一个版本有更多的提交,并且比历史上的rc1更多(知道在提交数量上)。我们已经有比较大的版本(3.10和3.15的都有很大的很并窗口导致的),但是这明显不是一个小的合并窗口。”
|
||||
|
||||
“在这个在蓝图下,这看上去只是一个常规发布。大约三分之二的驱动更新,这剩下的一半是架构的更新(新的nios2补丁还没有优势,它只有ARM一半的性能,新的niso2支持小于整体架构更新的10%)。”
|
||||
|
||||
|
||||
具体关于这个RC的细节可以在官方邮件列表中找到。
|
||||
|
||||
#### 下载 Linux 3.19 RC1 源码包: ####
|
||||
|
||||
- [tar.xz (3.18.1 Stable)][3]文件大小 77.2 MB
|
||||
- [tar.xz (3.19 RC1 Unstable)][4]
|
||||
|
||||
如果你想要测试,需要自己编译。并不建议在生产机器上测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Launches-Linux-kernel-3-19-RC1-One-of-the-Biggest-So-Far-468043.shtml
|
||||
|
||||
作者:[Silviu Stahie ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://lkml.iu.edu/hypermail/linux/kernel/1412.2/02480.html
|
||||
[2]:http://linux.softpedia.com/get/System/Operating-Systems/Kernels/Linux-Kernel-Development-8069.shtml
|
||||
[3]:https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.18.1.tar.xz
|
||||
[4]:https://www.kernel.org/pub/linux/kernel/v3.x/testing/linux-3.19-rc1.tar.xz
|
||||
168
translated/talk/20141203 Docker--Present and Future.md
Normal file
168
translated/talk/20141203 Docker--Present and Future.md
Normal file
@ -0,0 +1,168 @@
|
||||
Docker的现状与未来
|
||||
================================================================================
|
||||
|
||||
### Docker - 故事渊源流长 ###
|
||||
|
||||
Docker是一个专为Linux容器而设计的工具集,用于‘构建,交付和运行’分布式应用。它最初是通过DotCloud作为一个开源项目在2013年3月的时候发布的。这个项目越来越受欢迎,这使得DotCloud更名为Docker公司(并最终 [出售了原有的PaaS业务][1]).[Docker 1.0][2]是在2014年6月发布的,而且延续了之前每月更新一个版本的习惯。
|
||||
|
||||
|
||||
1.0版本的发布标志着Docker公司认为这个平台的充分成熟已经足以用于生产环境中(由本公司与合作伙伴提供付费支持选项).每个月发布的更新显示,该项目正在迅速发展,增添一些新特性、解决一些他们发现的问题。然而该项目已经成功地从‘运行’和‘交付’实现分离,所以任何版本的Docker镜像源都可以与其它版本共同使用(具备向前和向后兼容的特性),这为Docker使用的快速变化提供了稳定的保障。
|
||||
|
||||
Docker之所以能够成为最受欢迎的开源项目之一除了很多人会认为是的炒作成分,也是由坚实的物质基础奠定的。Docker的影响力已经得到整个行业许多品牌的支持,包括亚马逊, Canonical公司, 世纪互联, 谷歌, IBM, 微软, New Relic, Pivotal, 红帽和VMware. 这使只要Linux可使用的地方,Docker的使用便无处不在。除了这些鼎鼎有名的大公司以外,许多初创公司也在围绕着Docker在成长,或者改变他们的发展方向来与Docker更好地结合起来。这些合作关系(无论大于小)都将帮助推动Docker核心项目及其周边生态环境的快速发展。
|
||||
|
||||
|
||||
### Docker技术的简要综述 ###
|
||||
|
||||
Docker利用Linux的一些内核工具例如[cGroups][3],命名空间和[SElinux][4]来实现容器之间的隔离。起初Docker只是[LXC][5]容器管理器子系统的前端,但是在0.9版本中引入了[libcontainer][6],这是原生go语言库用于提供用户空间和内核之间的接口。
|
||||
|
||||
容器位于联合文件系统的顶部,例如[AUFS][7],它允许跨多个容器共享例如操作系统镜和安装相关库的组件。在文件系统中的分层方法也利用[ Dockerfile ] [8]中的DevOps工具,这些工具能够成功地完成高速缓存的操作。利用等待时间来安装操作系统和相关应用程序依赖包将会极大地加速测试周期。容器之间的共享库也能够减少内存的占用。
|
||||
|
||||
一个容器是从一个镜像开始运行的,它可以本地创建,本地缓存,或者通过注册表来下载。Docker公司经营的 [Docker 公有注册库][9],这为各种操作系统、中间件和数据库提供了主机官方仓库。组织和个人可以在docker公司的为镜像创建公有库,并且也有举办私人仓库的订阅服务。由于上传的镜像会包含几乎所有Docker提供的自动化构建工具(以往称为“受信任的构建”),它的镜像是从Dockerfile创建的,而Dockerfile是镜像内容的清单。
|
||||
|
||||
### 容器 vs 虚拟机 ###
|
||||
|
||||
容器会比虚拟机更高效,因为它们能够分享一个内核和分享共享应用程序库。相比虚拟机系统,这也将使得Docker使用的内存空间很小,即使虚拟机利用了内存超量使用的技术。部署容器时共享底层的镜像层也可以减少内存的占用。IBM的Boden Russel已经做了一些[基准测试][10]说明两者的不同。
|
||||
|
||||
相比虚拟机系统,容器呈现出较低系统开销的优势,所以在容器中,应用程序的运行效率将会等效于在同样的应用程序在虚拟机中运行甚至效果更佳。IBM的一个研究团队已经发表了一本名为[虚拟机与Linux容器的性能比较]的文章[11].
|
||||
|
||||
|
||||
容器在隔离特性上要比虚拟机逊色。虚拟机可以利用ring-1[硬件隔离][12]例如Intel的VT-d和VT-x技术。这种隔离可以防止虚拟机爆发和彼此交互。而容器至今还没有任何形式的硬件隔离,这使它容易受到攻击。一个命名为[Shocker][13]的概念攻击验证表明,在之前的1.0版本中Docker是存在这种脆弱性的。尽管Docker1.0修复了许多由于Shocker漏洞引发较为的严重问题,Docker的CTO Solomon Hykes仍然[表态][14],“当我们自然而然地说Docker的开箱即用是安全的,即便包含了不收信任的uid0程序,我们将会很明确地这样表述。”Hykes的声明承认,其它的漏洞及相关的风险依旧存在,所以在容器成为受信任的工具之前将有更多的工作需要被完成。
|
||||
|
||||
对于许多用户案例而言,在容器和虚拟机两者之间选择一种是一种错误的二分法。Docker同样可以在虚拟机中很好工作,它可以被用于现有的虚拟基础措施、私有云或者公有云。同样也可以在容器里跑虚拟机,这也是谷歌使用云平台的一部分。给予一个广泛可利用的基础设施例如IaaS服务,可以为虚拟机提供合理的预期需求,这个合理的预期即容器与虚拟机一起使用的情景将会在数年后出现。容器管理和虚拟机技术有可能被集成到一起提供一个两全其美的方案;所以,位于libcontainer 容器后面的硬件信任锚微虚拟化实施例,可与前端 Docker 工具链和生态系统整合,而不同于后端使用的是能够提供更好绝缘性。微虚拟化(例如Bromium的[vSentry][15]和VMware的 [Project Fargo][16])已经在桌面环境中使用以提供应用程序之间基于硬件的隔离,所以类似的方法可以用于连接libcontainer代替Linux内核中的容器机制。
|
||||
|
||||
### ‘Dockerizing’ 应用程序 ###
|
||||
|
||||
几乎所有Linux应用程序都可以在Docker容器中运行。它们不受任何语言的选择或框架的限制。唯一在实践中受限的是从操作系统的角度来允许容器做什么。即使如此,bar可以在特权模式下通过运行容器,从而大大减少了控制(并相应地增加了容器中的应用程序,这将会导致损坏主机操作系统存在的风险)。
|
||||
|
||||
|
||||
容器都是从镜像开始运行的,而镜像也可以从运行中的容器获取。通常使用2中方法从容器中获取应用程序,分别是手动获取和Dockerfile..
|
||||
|
||||
#### 手动构建 ####
|
||||
|
||||
手动构建首先通过基础操作系统镜像启动一个基本操作。交互式的终端可以安装应用程序和用于包管理的依赖项来选择所需要的Linux风格。Zef Hemel在‘[使用Linux容器来支持便携式应用程序部署][17]’的文章中讲述了他部署的过程。一旦应用程序被安装之后,容器可以被推送至注册中心(例如Docker Hub)或者导出一个tar文件。
|
||||
|
||||
#### Dockerfile ####
|
||||
|
||||
Dockerfile是一个用于构建Docker容器的脚本化系统。每一个Dockerfile定义了开始的基础镜像,从一系列的命令在容器中运行或者一些列的文件被添加到容器中。当容器启动时默认命令会在启动时被执行,Dockerfile也可以指定对外的端口和当前工作目录。容器类似手工构建一样可以通过可推送或导出的Dockerfiles来构建。Dockerfiles也可以被用于Docker Hub的自动构建系统,使用的镜像受Docker公司的控制并且该镜像源代码是任何人可视的。
|
||||
|
||||
|
||||
####仅仅一个进程? ####
|
||||
|
||||
无论镜像是手动构建还是通过Dockerfile构建,有一个关键的考虑因素是当容器启动时,只有一个进程进程被启动。对于一个容器一对一服务的目的,例如运行一个应用服务器,运行一个单一的进程不是一个问题(有些关于容器应该只有一个单独的进程的争议)。对于一些容器需要启动多个进程的情况,必须先启动 [supervisor][18]进程,才能生成其它内部所需的进程。
|
||||
|
||||
### 容器和微服务 ###
|
||||
|
||||
一个完整的关于使用微服务结构体系的原理和好处已经远远超出了这篇文章(并已经覆盖了[InfoQ eMag: Microservices][19])的范围).然而容器是微服务捆绑和部署实例的捷径。
|
||||
|
||||
尽管大多数实际案例表明大量的微服务目前还是大多数部署在虚拟机,容器相对拥有较小的部署机会。容器具备位操作系统共享内存和硬盘占用量的能力,库常见的应用程序代码也意味着并排部署多个办法的服务是非常高效的。
|
||||
|
||||
### 连接容器 ###
|
||||
|
||||
一些小的应用程序适合放在单独的容器中,但在许多案例中应用程序将遍布多个容器。Docker的成功包括催生了一连串的新应用程序组合工具、业务流程工具和实现平台作为服务(PaaS)过程。许多工具还帮助实现缩放、容错、业务管理以及对已部署资产进行版本控制。
|
||||
|
||||
|
||||
#### 连接 ####
|
||||
|
||||
Docker的网络功能是相当原始的。在同一主机,容器内的服务和一互相访问,而且Docker也可以通过端口映射到主机操作系统使服务可以通过网络服务被调用。官方的赞助方式是连接到[libchan][20],这是一个提供给Go语言的网络服务库,类似于[channels][21]。直至libcan找到方法进入应用程序,第三方应用仍然有很大空间可提供配套的网络服务。例如,[Flocker][22]已经采取了基于代理的方法使服务实现跨主机(以及底层存储)移植。
|
||||
|
||||
#### 合成 ####
|
||||
|
||||
Docker本身拥有把容器连接在一起的机制,与元数据相关的依赖项可以被传递到相依赖的容器并用于环境变量和主机入口的消耗。应用合成工具例如[Fig][23]和[geard][24]展示出其依赖关系图在一个独立的文件中,于是多个容器可以汇聚成一个连贯的系统。世纪互联公司的[Panamax][25]合成工具类似底层Fig和 geard的方法,但新增了一些基于web的用户接口,并直接与GitHub相结合,以便于应用程序可以直接被共享。
|
||||
|
||||
#### 业务流程 ####
|
||||
|
||||
业务流程系统例如[Decking][26],New Relic公司的[Centurion][27]和谷歌公司的[Kubernetes][28]都是旨在帮助部署容器和管理其生命周期系统。也有无数的例子(例如[Apache Mesos][30](特别是[Marathon(马拉松式)持续运行很久的框架] 的 [Mesosphere][29]正在与Docker一起使用。通过为应用程序(例如传递CPU核数和内存的需求)与底层基础架构之间提供一个抽象的模型,业务流程工具提供了解耦,旨在简化应用程序开发和数据中心操作。还有各种各样的业务流程系统,因为人们已经淘汰了以前开发的内部系统,取而代之的是大量容器部署的管理系统;例如Kubernetes是基于谷歌的[Omega][32]系统,这个系统用于管理谷歌区域内的容器。
|
||||
|
||||
虽然从某种程度上来说合成工具和业务流程工具的功能存在重叠,另外这也是它们之间互补的一种方式。例如Fig可以被用于描述容器间如何实现功能交互,而Kubernetes pods可能用于提供监控和缩放。
|
||||
|
||||
|
||||
#### 平台 (类似一个服务) ####
|
||||
|
||||
大量的Docker已经实现本地PaaS安装部署,例如[Deis][33] 和 [Flynn][34]的出现并在现实中得到利用,Linux容器在很大程度上为开发人员提供了灵活性(而不是“固执己见”地给出一组语言和框架)。其它平台例如CloudFoundry, OpenShift 和 Apcera Continuum都已经采取Docker基础功能融入其现有的系统,这样基于Docker镜像(或者基于Dockerfile)的应用程序也可以用之前支持的语言和框架一起部署和管理。
|
||||
|
||||
### 支持所有的云 ###
|
||||
|
||||
由于Docker能够在任何的Linux虚拟机中运行并合理地更新内核,它几乎可以为所有云提供IaaS服务。大多数的云厂商已经宣布对码头及其生态系统提供附加支持。
|
||||
|
||||
亚马逊已经把Docker引入它们的Elastic Beanstalk系统(这是在底层IaaS的一个业务流程系统)。谷歌已经启用‘managed VMs'’,这是提供
|
||||
程序引擎PaaS和计算引擎IaaS之间的中转站。微软和IBM都已经宣布基于Kubernetes的服务,所以多容器应用程序可以在它们的云上被部署和管理。
|
||||
|
||||
为了给现有种类繁多的后端提供可用的一致接口,Docker团队已经引进[libswarm][35], 它能用于集成众多云和资源管理系统。Libswarm所阐明的目标之一是‘避免供应商通过交换任何服务锁定另一个’。这是通过呈现一组一致服务(与API相关联的)来完成的,该服务会附加执行特定的后端服务。例如装有Docker服务的服务器将对Docker命令行工具展示Docker远程API,这样容器就可以被托管在一些列的服务供应商。
|
||||
|
||||
基于Docker的新服务类型仍在起步阶段。总部位于伦敦的Orchard实验室提供了Docker的托管服务,但是Docker公司表示,收购后,Orchard的服务将不会是一个有优先事项。Docker公司也出售之前DotCloud的PaaS业务给cloudControl。基于就更早前的容器管理系统的服务例如[OpenVZ][36]已经司空见惯了,所以在一定程度上Docker需要向托管供应商证明其价值。
|
||||
|
||||
### Docker 及其发行版 ###
|
||||
|
||||
Docker已经成为大多数Linux发行版例如Ubuntu,Red Hat企业版(RHEL)和CentOS的一个标准功能。遗憾的是发布是以不同的移动速度到Docker项目,所以在发布版中找到的版本总是远远落后于可用版本。例如Ubuntu 14.04版本是对应Docker 0.9.1版本发布的,但是并没有相应的版本更改点当Ubuntu升级至14.04.1(这个时候Docker已经升至1.1.2版本)。由于Docker也是一个KDE系统托盘,所以在官方库同样存在命名问题;所以在Ubuntu14.04版本中相关安装包的名字和命令行工具都是使用‘Docker.io’命名。
|
||||
|
||||
在企业版的Linux世界中,情况也并没有因此而不同。CentOS7伴随着Docker 0.11.1的到来,该发行版本即是之前Docker公司宣布准备发行Docker 1.0版本的准备版。Linux发行版用户希望最新版本可以承诺其稳定性,性能和安全性能够更完善,并且更好地结合[安装说明][37]和使用Docker公司的库托管而不是采取包括其分布的版本库。
|
||||
|
||||
Docker的到来催生了新的Linux发行版本例如[CoreOS][38]和红帽被用于设计为运行容器最小环境的[Project Atomic][39]。这些发布版相比传统的发布版伴随着更多新内核和Docker版本的特性。它们对内存的使用和硬盘占用率更小。新的发行也配备了新的工具用于大型部署例如[fleet][40],这是‘一个分布式init系统’和[etcd][41]是用于元数据管理。也有新机制用于更新发布版本身来使得内核和Docker可以被使用。这也意味着使用Docker的影响之一是它抛开分布版和相关的包管理解决方案的关注,使Linux内核(即Docker子系统正在使用)更加重要。
|
||||
|
||||
新的发布版将是运行Docker的最好方式,但是传统的发布版本和它们的包管理对容器来说仍然是非常重要的。Docker Hub托管的官方镜像有Debian,Ubuntu和CentOS。当然也有一个‘半官方’的库用于Fedora镜像。RHEL镜像在Docker Hub中不可用,因为是从Red Hat直接发布的。这意味着在Docker Hub的自动构建机制仅仅用于那些纯粹的开源发布版不(并愿意信任基于Docker公司团队所策划镜像的出处)。
|
||||
|
||||
|
||||
虽然Docker Hub与源代码控制系统相结合,例如Git Hub和Bitbucket在构建过程中用于自动创建包管理及生成规范之间的复杂关系(在Dockerfile中),并在构建过程中建立镜像。在构建过程中的非确定性结果并非是Docker具体的问题——这个是由于软件包如何管理工作的结果。在构建完成的当天将会给出一个版本,这个构建完成的另外一次将会得到最新版本,这就是为什么软件包管理需要升级措施。容器的抽象(较少关注一个容器的内容)以及容器的分散(因为轻量级资源利用率)是更有可能与Docker获取关联的痛点。
|
||||
|
||||
### Docker的未来 ###
|
||||
|
||||
Docker公司对核心功能(libcontainer),跨服务管理(libswarm) 和容器间的信息传递(libchan)的发展提出了明确的路线。与此同时公司已经表明愿意利用自身生态系统和收购Orchard实验室。然而Docker相比Docker公司意味着更多,随着项目的壮大,越来越多对这个项目的
|
||||
大牌贡献者,其中不乏像谷歌、IBM和Red Hat这样的大公司。在仁慈独裁者CTO Solomon Hykes 掌舵的形势下,为公司和项目明确了技术领导的关系。在前18个月的项目中通过成果输出展现了快速行动的能力,而且这种趋势并没有减弱的迹象。
|
||||
|
||||
许多投资者正在寻找10年前VMware公司的ESX/vSphere平台的特征矩阵,并找出虚拟机的普及而驱动的企业预期和当前Docker生态系统两者的距离(和机会)。目前Docker生态系统正缺乏类似网络、存储和版本细粒度的管理(对容器的内容),这些都为初创企业和在职人员提供机会。
|
||||
|
||||
随着时间的推移,在虚拟机和容器(Docker的运行部分)之间的区别将变得不重要了,而关注点将会转移到‘构建’和‘交付’缓解。这些变化将会使‘Docker发生什么?’这个问题变得比‘Docker将会给IT产业带来什么?’更不重要了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoq.com/articles/docker-future
|
||||
|
||||
作者:[Chris Swan][a]
|
||||
译者:[disylee](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoq.com/author/Chris-Swan
|
||||
[1]:http://blog.dotcloud.com/dotcloud-paas-joins-cloudcontrol
|
||||
[2]:http://www.infoq.com/news/2014/06/docker_1.0
|
||||
[3]:https://www.kernel.org/doc/Documentation/cgroups/cgroups.txt
|
||||
[4]:http://selinuxproject.org/page/Main_Page
|
||||
[5]:https://linuxcontainers.org/
|
||||
[6]:http://blog.docker.com/2014/03/docker-0-9-introducing-execution-drivers-and-libcontainer/
|
||||
[7]:http://aufs.sourceforge.net/aufs.html
|
||||
[8]:https://docs.docker.com/reference/builder/
|
||||
[9]:https://registry.hub.docker.com/
|
||||
[10]:http://bodenr.blogspot.co.uk/2014/05/kvm-and-docker-lxc-benchmarking-with.html?m=1
|
||||
[11]:http://domino.research.ibm.com/library/cyberdig.nsf/papers/0929052195DD819C85257D2300681E7B/$File/rc25482.pdf
|
||||
[12]:https://en.wikipedia.org/wiki/X86_virtualization#Hardware-assisted_virtualization
|
||||
[13]:http://stealth.openwall.net/xSports/shocker.c
|
||||
[14]:https://news.ycombinator.com/item?id=7910117
|
||||
[15]:http://www.bromium.com/products/vsentry.html
|
||||
[16]:http://cto.vmware.com/vmware-docker-better-together/
|
||||
[17]:http://www.infoq.com/articles/docker-containers
|
||||
[18]:http://docs.docker.com/articles/using_supervisord/
|
||||
[19]:http://www.infoq.com/minibooks/emag-microservices
|
||||
[20]:https://github.com/docker/libchan
|
||||
[21]:https://gobyexample.com/channels
|
||||
[22]:http://www.infoq.com/news/2014/08/clusterhq-launch-flocker
|
||||
[23]:http://www.fig.sh/
|
||||
[24]:http://openshift.github.io/geard/
|
||||
[25]:http://panamax.io/
|
||||
[26]:http://decking.io/
|
||||
[27]:https://github.com/newrelic/centurion
|
||||
[28]:https://github.com/GoogleCloudPlatform/kubernetes
|
||||
[29]:https://mesosphere.io/2013/09/26/docker-on-mesos/
|
||||
[30]:http://mesos.apache.org/
|
||||
[31]:https://github.com/mesosphere/marathon
|
||||
[32]:http://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/41684.pdf
|
||||
[33]:http://deis.io/
|
||||
[34]:https://flynn.io/
|
||||
[35]:https://github.com/docker/libswarm
|
||||
[36]:http://openvz.org/Main_Page
|
||||
[37]:https://docs.docker.com/installation/#installation
|
||||
[38]:https://coreos.com/
|
||||
[39]:http://www.projectatomic.io/
|
||||
[40]:https://github.com/coreos/fleet
|
||||
[41]:https://github.com/coreos/etcd
|
||||
@ -0,0 +1,147 @@
|
||||
在 Mac OS X 系统中创建可启动的 Ubuntu USB 驱动盘
|
||||
================================================================================
|
||||

|
||||
|
||||
上个月,在戴尔的服务中心丢失我的笔记本后,我买了一台 Macbook Air 笔记本。买回来后我首先做的一些事就是给机器装上双系统,使 Ubuntu Linux 和 Mac OS X 都可用。随后的文章我会介绍如何在 Macbook 上安装 Linux ,刚开始我们需要学习 **如何在 Mac 的 OS X 系统中创建可启动的 Ubuntu USB 驱动盘**。
|
||||
|
||||
在 Ubuntu 系统或 Windows 系统中创建可启动的 USB 是非常容易的,但在 Mac OS X 系统中就没这么简单了。这就是为什么 Ubuntu 的官方指南上,在 Mac 中安装 live Ubuntu 推荐使用磁盘安装而不是 USB 的原因。考虑到我的 Macbook Air 既没有 CD 驱动也没有 DVD 驱动,所以我更愿意在 Mac OS X 下创建一个 live USB.
|
||||
|
||||
### 在 Mac OS X 下创建可启动 USB 驱动盘###
|
||||
|
||||
如前所述,在 Mac OS X 上创建对于像 Ubuntu 或任何其它可引导的操作系统这样的可启动 USB 盘是个极其麻烦的过程。但请别担心,按照下面的步骤一步一步操作就行。让我们就开始创建一个可启动的 USB 盘的操作吧:
|
||||
|
||||
#### 步骤 1: 格式化 USB 驱动盘 ####
|
||||
|
||||
苹果是以它自定义的标准而闻名的,所以 Mac OS X 系统有自己的文件系统类型就好不奇怪了,它的文件系统叫做 Mac OS 扩展或 [HFS 插件][1]。因此,您需要做的第一件事就是用 Mac OS 扩展文件系统来格式化您的 USB 驱动盘。
|
||||
|
||||
要格式化 USB 盘,插入 USB 钥匙链。从 Launchpad(在底部面板上的一个火箭形状的图标)上前往**磁盘工具**应用程序。
|
||||
|
||||

|
||||
|
||||
- 在磁盘工具中,从左手边的面板上选择 USB 驱动盘来格式化。
|
||||
- 点击右边面板的**分区**标签。
|
||||
- 从下拉菜单中,选择 **1 分区**。
|
||||
- 给这驱动盘起个您想要的名字。
|
||||
- 接下来,切换来**格式化成 Mac OS 扩展 (日志型)**
|
||||
|
||||
下面的截屏将会对您有所帮助。
|
||||
|
||||

|
||||
|
||||
在我们开始真正格式化 USB 盘之前这是唯一一件要做的操作。点击在右边面板的选项按纽,要确保分区的模式是 **GUID 分区表**形式的。
|
||||
|
||||

|
||||
|
||||
当所有的都已经设置完了后,仅仅只需点击**应用**按纽。它会弹出一个要格式化 USB 驱动盘的警告消息,当然是要点击分区按纽来格式化 USB 驱动盘拉。
|
||||
|
||||
#### 步骤 2: 下载 Ubuntu ####
|
||||
|
||||
当然,您需要下载 Ubuntu 桌面版本的 ISO 镜像文件。链接到[ Ubuntu 官网去下载您喜欢的 Ubuntu 桌面版本系统][2]。因为您使用的是 Macbook Air,我建议您下载 64 位版本中的一款。Ubuntu 14.04 是最新的 LTS 版本,我建议您们使用它。
|
||||
|
||||
#### 步骤 3: 把 ISO 格式转成 IMG 格式 ####
|
||||
|
||||
您下载的文件是 ISO 格式的,但我们需要它是 IMG 格式的,使用 [hdiutil][3] 命令工具就可以很容易的转换。打开终端,也可以从 Launchpad 或 Spotlight 中打开,然后使用如下的命令就可以把 ISO 格式的转换成 IMG 格式的了:
|
||||
|
||||
hdiutil convert -format UDRW -o ~/Path-to-IMG-file ~/Path-to-ISO-file
|
||||
|
||||
通常下载的文件会在 ~/Downloads 目录下。所以在我的系统来,输入的命令是:
|
||||
|
||||
hdiutil convert -format UDRW -o ~/Downloads/ubuntu-14.10-desktop-amd64 ~/Downloads/ubuntu-14.10-desktop-amd64.iso
|
||||
|
||||

|
||||
|
||||
您可能已经注意到我并没有新转换出的文件加上 IMG 后缀。这是没问题的,因为后缀只是个标志,它代表的是文件类型并不是文件的扩展名。转换出来的文件可能会被 Mac OS X 系统自动加上个 .dmg 后缀。别担心,这是正常的。
|
||||
|
||||
#### 步骤 4: 获得 USB 驱动盘的设备号 ####
|
||||
|
||||
接下来的事情就是获得 USB 驱动盘的设备号。在终端中运行如下命令:
|
||||
|
||||
diskutil list
|
||||
|
||||
它会列出系统中当前可用的所有‘磁盘’信息。从它的大小上您应该能识别出此 USB 驱动盘。为了避免混淆,我建议您只插入一个 USB 盘。我的示例中,设置号是 2 (一个大小为 8G 的 USB): /dev/disk2
|
||||
|
||||

|
||||
|
||||
当得到设备号后,运行如下命令:
|
||||
|
||||
diskutil unmountDisk /dev/diskN
|
||||
|
||||
这儿的 N 就是前面您得到的 USB 的设备号。所以,我的示例中,上面的命令就变成:
|
||||
|
||||
diskutil unmountDisk /dev/disk2
|
||||
|
||||
执行结果应该是:**成功的卸载 disk2 上的所有卷**。
|
||||
|
||||
#### 步骤 5: 在 Mac OS X 中创建可启动的 USB 驱动盘####
|
||||
|
||||
终于我们只有创建可启动的 USB 盘这最后一步了。我们会使用 [dd 命令][4],它非常的强大,必须得小心使用。因此,一定要记得您 USB 驱动盘的正确设备号,要不然会使 Mac OS X 系统崩溃。在终端中使用如下命令:
|
||||
|
||||
sudo dd if=/Path-to-IMG-DMG-file of=/dev/rdiskN bs=1m
|
||||
|
||||
这儿我们使用 dd (拷贝和转换) 来把 IMG 输入文件 (if) 拷贝和转换到 磁盘 N 中。我希望您还记得在步骤 3 中已经生成的 IMG 文件的存放位置。对我的机器来说,命令如下所示:
|
||||
|
||||
sudo dd if=~/Downloads/ubuntu-14.10-desktop-amd64.dmg of=/dev/rdisk2 bs=1m
|
||||
|
||||
我们用超级用户权限(sudo)来运行上面的命令,还需要您输入密码。跟 Linux 中类似,您从键盘中输入密码时,将看不到任何星号或显示的提示,不用担心,这是 Unix 终端的习惯。
|
||||
|
||||
甚至在您输入完密码后,**您都不会看到立即的输出,这是正常的**。需要一小会儿时间才会处理完成。
|
||||
|
||||
#### 步骤 6: 完成可启动 USB 驱动盘的整个处理过程 ####
|
||||
|
||||
一旦 DD 命令处理完成,会弹出一个对话框:**您插入的磁盘在这机器上不可读**。
|
||||
|
||||

|
||||
|
||||
别惊慌,一切正常。只是**现在不要点击初始化、忽略或弹出按纽**。回到终端,您会看到最新处理完成的一些信息。我的机器中显示如下:
|
||||
|
||||
> 1109+1 records in
|
||||
>
|
||||
> 1109+1 records out
|
||||
>
|
||||
> 1162936320 bytes transferred in 77.611025 secs (14984164 bytes/sec)
|
||||
|
||||

|
||||
|
||||
现在,在终端中使用如下命令来弹出我们的 USB 驱动盘:
|
||||
|
||||
diskutil eject /dev/diskN
|
||||
|
||||
N 当然指的是我们前面使用过的设备号,在我的示例中是 2 :
|
||||
|
||||
diskutil eject /dev/disk2
|
||||
|
||||
一旦弹出,点击前面出现那对话框上的**忽略**按纽。现在您的可启动 USB 磁盘已经创建好了,把它从系统中移除。
|
||||
|
||||
#### 步骤 7: 检查您新创建的可启动 USB 盘 ####
|
||||
|
||||
一旦您在 Mac OS X 中完成了创建一个 live USB 这么重大的任务,是时候测试您的幸成果了。
|
||||
|
||||
- 插入可启动 USB 盘,重启系统。
|
||||
- 在苹果启动的时候,一直按着 option (或 alt)键。
|
||||
- 这会引导您进入启动时需要访问的可使用磁盘界面。我假设您知道接下来的操作步骤。
|
||||
|
||||
对我机器来说它显示了两个 EFI 启动盘:
|
||||
|
||||

|
||||
|
||||
我选择第一个,然后它就会直接进入 Grub 界面:
|
||||
|
||||

|
||||
|
||||
我希望这篇教程对您想要在 Mac OS X 下创建可启动的 Ubuntu 系统 USB 驱动盘。在接下来的一篇文章中您会学到怎么样安装 OS X 和 Ubuntu 双系统。请继续关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/create-bootable-ubuntu-usb-drive-mac-os/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://en.wikipedia.org/wiki/HFS_Plus
|
||||
[2]:http://www.ubuntu.com/download/desktop
|
||||
[3]:https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/hdiutil.1.html
|
||||
[4]:http://en.wikipedia.org/wiki/Dd_%28Unix%29
|
||||
@ -0,0 +1,307 @@
|
||||
|
||||
RHEL/CentOS 7中配置用于多版本Linux安装的“PXE网络启动服务器”
|
||||
================================================================================
|
||||
**PXE服务器**——预启动执行环境——指示客户端计算机直接从网络接口启动、运行或安装操作系统,而不需要烧录CD/DVD或使用某个物理介质,它也可以减轻你网络中多台机器同时安装Linux发行版的工作。
|
||||
|
||||

|
||||
在RHEL/CentOS 7中设置PXE网络启动
|
||||
|
||||
#### 需求 ####
|
||||
|
||||
- [CentOS 7最小化安装步骤][1]
|
||||
- [RHEL 7最小化安装步骤][2]
|
||||
- [在RHEL/CentOS 7中配置静态IP地址][3]
|
||||
- [移除RHEL/CentOS 7中不要的服务][4]
|
||||
- [安装NTP服务器以设置RHEL/CentOS 7的正确时间][5]
|
||||
|
||||
本文将介绍如何在配置有本地镜像安装仓库的**RHEL/CentOS 7** 64位上安装并配置一台**PXE服务器**,仓库源由CentOS 7 DVD ISO镜像提供,并由**DNSMASQ**服务器提供解析。
|
||||
|
||||
该机器提供了**DNS**和**DHCP**服务,用于网络启动引导的**Syslinux**包,**TFTP-Server**——提供了可通过网络使用**小文件传输协议**下载的可启动镜像,以及提供本地挂载DVD镜像的**VSFTPD**服务器——它将扮演官方RHEL/CentOS 7镜像安装仓库的角色,安装器将从这里提取所需的包。
|
||||
|
||||
### 步骤1: 安装并配置DNSMASQ服务器 ###
|
||||
|
||||
**1.** 不需要提醒你来确定你的网络接口卡吧,除非你的服务器上有多个网络接口卡,该网卡必须配置有静态IP地址,该IP地址必须处于你要提供PXE服务的网段中。
|
||||
|
||||
那么,在你配置好静态IP地址后,更新你的系统并进行其它初始设置。请使用以下命令来安装**DNSMASQ**进程。
|
||||
|
||||
# yum install dnsmasq
|
||||
|
||||

|
||||
安装dnsmasq包
|
||||
|
||||
**2.** DNSMASQ的默认主配置文件位于**/etc**目录中,虽然不需要任何说明就能看懂,但编辑起来确实相当困难的,即使有很详细的说明性注释。
|
||||
|
||||
首先,确保你备份了该文件,以便你需要在以后对它进行恢复。然后使用你喜爱的文本编辑器创建一个新的空配置文件,命令如下。
|
||||
|
||||
# mv /etc/dnsmasq.conf /etc/dnsmasq.conf.backup
|
||||
# nano /etc/dnsmasq.conf
|
||||
|
||||
**3.** 现在,复制并粘贴以下配置到**dnsmasq.conf**文件中,并确保根据如下说明进行相应修改,以适应你的网络设置。
|
||||
|
||||
interface=eno16777736,lo
|
||||
#bind-interfaces
|
||||
domain=centos7.lan
|
||||
# DHCP range-leases
|
||||
dhcp-range= eno16777736,192.168.1.3,192.168.1.253,255.255.255.0,1h
|
||||
# PXE
|
||||
dhcp-boot=pxelinux.0,pxeserver,192.168.1.20
|
||||
# Gateway
|
||||
dhcp-option=3,192.168.1.1
|
||||
# DNS
|
||||
dhcp-option=6,92.168.1.1, 8.8.8.8
|
||||
server=8.8.4.4
|
||||
# Broadcast Address
|
||||
dhcp-option=28,10.0.0.255
|
||||
# NTP Server
|
||||
dhcp-option=42,0.0.0.0
|
||||
|
||||
pxe-prompt="Press F8 for menu.", 60
|
||||
pxe-service=x86PC, "Install CentOS 7 from network server 192.168.1.20", pxelinux
|
||||
enable-tftp
|
||||
tftp-root=/var/lib/tftpboot
|
||||
|
||||

|
||||
Dnsmasq配置
|
||||
|
||||
你需要修改的声明有以下这些:
|
||||
|
||||
- **interface** – 服务器需要监听并提供服务的网络接口。
|
||||
- **bind-interfaces** – 取消注释来绑定到该网络接口
|
||||
- **domain** – 替换为你的域名。
|
||||
- **dhcp-range** – 替换为你的网络掩码定义的网段。
|
||||
- **dhcp-boot** – 替换该IP地址为你的网络接口IP地址。
|
||||
- **dhcp-option=3,192.168.1.1** – 替换该IP地址为你的网段的网关。
|
||||
- **dhcp-option=6,92.168.1.1** – 替换该IP地址为你的DNS服务器IP——可以定义多个IP地址。
|
||||
- **server=8.8.4.4** – 这里放置DNS转发服务器IP地址。
|
||||
- **dhcp-option=28,10.0.0.255** – 替换该IP地址为网络广播地址——可选项。
|
||||
- **dhcp-option=42,0.0.0.0** – 这里放置网络时钟服务器——可选项(0.0.0.0地址表示参考自身)。
|
||||
- **pxe-prompt** – 保持默认——按F8进入菜单,60秒等待时间。
|
||||
- **pxe=service** – 使用x86PC作为32为/64位架构,并在字符串引述中输入菜单描述提示。其它类型值可以是:PC98,IA_EFI,Alpha,Arc_x86,Intel_Lean_Client,IA32_EFI,BC_EFI,Xscale_EFI和X86-64_EFI。
|
||||
- **enable-tftp** – 启用内建TFTP服务器。
|
||||
- **tftp-root** – 使用/var/lib/tftpboot——所有网络启动文件所在位置。
|
||||
|
||||
其它和配置文件相关的高级选项,请参阅[dnsmasq手册][6]。
|
||||
|
||||
### 步骤2: 安装SYSLINUX启动加载器 ###
|
||||
|
||||
**4.** 在编辑并保存**DNSMASQ**主配置文件后,我们将继续安装**Syslinux** PXE启动加载器,命令如下。
|
||||
|
||||
# yum install syslinux
|
||||
|
||||

|
||||
安装Syslinux启动加载器
|
||||
|
||||
**5.** PXE启动加载器文件位于**/usr/share/syslinux**系统绝对路径下,你可以通过列出该路径下的内容来查看。该步骤不是必须的,但你可能需要知道该路径,因为在下一步中,我们将拷贝该路径下的所有内容到**TFTP服务器**路径下。
|
||||
|
||||
# ls /usr/share/syslinux
|
||||
|
||||

|
||||
Syslinux文件
|
||||
|
||||
### 步骤3: 安装TFTP-Server并加入SYSLINUX加载启动器 ###
|
||||
|
||||
**6.** 现在,让我们进入下一步,安装**TFTP-Server**。然后,拷贝上述位置中Syslinux包提供所有启动加载器文件到**/var/lib/tftpboot**路径中,命令如下。
|
||||
|
||||
# yum install tftp-server
|
||||
# cp -r /usr/share/syslinux/* /var/lib/tftpboot
|
||||
|
||||

|
||||
安装TFTP服务器
|
||||
|
||||
### 步骤4: 设置PXE服务器配置文件 ###
|
||||
|
||||
**7.** 通常,**PXE服务器**从位于**pxelinux.cfg**文件夹中一组指定的文件中读取配置(首先是**GUID**文件,接下来是**MAC**文件,最后是**Default**文件),该文件夹必须位于DNSMASQ主配置文件中**tftp-root**声明指定的目录中。
|
||||
|
||||
创建需要的目录**pxelinux.cfg**,然后添加**default**文件到该目录中,命令如下。
|
||||
|
||||
# mkdir /var/lib/tftpboot/pxelinux.cfg
|
||||
# touch /var/lib/tftpboot/pxelinux.cfg/default
|
||||
|
||||
**8.** 现在,该来编辑**PXE服务器**配置文件了,为它添加合法的Linux发行版安装选项。请注意,该文件中使用的所有路径必须是相对于**/var/lib/tftpboot**目录的。
|
||||
|
||||
下面,你可以看到配置文件的样例,你可以使用该模板,但请修改安装镜像(kernel和initrd文件)、协议(FTP、HTTP、HTTPS、NFS)以及映射你网络安装源仓库和路径的IP地址。
|
||||
|
||||
# nano /var/lib/tftpboot/pxelinux.cfg/default
|
||||
|
||||
添加一下整个节录到文件中。
|
||||
|
||||
default menu.c32
|
||||
prompt 0
|
||||
timeout 300
|
||||
ONTIMEOUT local
|
||||
|
||||
menu title ########## PXE Boot Menu ##########
|
||||
|
||||
label 1
|
||||
menu label ^1) Install CentOS 7 x64 with Local Repo
|
||||
kernel centos7/vmlinuz
|
||||
append initrd=centos7/initrd.img method=ftp://192.168.1.20/pub devfs=nomount
|
||||
|
||||
label 2
|
||||
menu label ^2) Install CentOS 7 x64 with http://mirror.centos.org Repo
|
||||
kernel centos7/vmlinuz
|
||||
append initrd=centos7/initrd.img method=http://mirror.centos.org/centos/7/os/x86_64/ devfs=nomount ip=dhcp
|
||||
|
||||
label 3
|
||||
menu label ^3) Install CentOS 7 x64 with Local Repo using VNC
|
||||
kernel centos7/vmlinuz
|
||||
append initrd=centos7/initrd.img method=ftp://192.168.1.20/pub devfs=nomount inst.vnc inst.vncpassword=password
|
||||
|
||||
label 4
|
||||
menu label ^4) Boot from local drive
|
||||
|
||||

|
||||
配置PXE服务器
|
||||
|
||||
正如你所见,CentOS 7启动镜像(kernel和initrd)位于名为**centos7**的目录,该目录是**/var/lib/tftpboot**目录的相对路径(其系统绝对路径为**/var/lib/tftpboot/centos7**),而安装器仓库位于可通过FTP协议访问的**192.168.1.20/pub**网络位置中——在本例中,这些仓库位于本地,因为IP地址和PXE服务器地址相同。
|
||||
|
||||
同时,菜单**label 3**指定客户端安装应该通过**VNC**从一个远程位置实现(这里替换VNC密码为一个健壮的密码),如果你在一台没有输入输出的客户端上安装,菜单**label 2**指定了作为安装源的一个CentOS 7官方互联网镜像(这种情况要求客户端通过DHCP和NAT连接到互联网)。
|
||||
|
||||
**重要**:正如你在上述配置中说看到的,我们使用了CentOS 7进行演示,但是你也可以定义RHEL 7镜像。而下面的完整说明和配置都只是基于CentOS 7的,所以在选在发行版时要当心。
|
||||
|
||||
### 步骤5: 添加CentOS 7启动镜像到PXE服务器 ###
|
||||
|
||||
**9.** 对于此步骤,需要用到CentOS的kernel和initrd文件。要获取这些文件,你需要**CentOS 7 DVD ISO**镜像。所以,去下载CentOS DVD镜像吧,然后把它放入你的DVD驱动器并挂载镜像到**/mnt**路径,命令见下面。
|
||||
|
||||
使用DVD,而不是最小化CD镜像的原因在于,在后面我们将使用该DVD的内容为**FTP**源创建本地安装器仓库。
|
||||
|
||||
# mount -o loop /dev/cdrom /mnt
|
||||
# ls /mnt
|
||||
|
||||

|
||||
挂载CentOS DVD
|
||||
|
||||
如果你的机器没有DVD驱动器,你也可以使用**wget**或**curl**工具从[CentOS镜像站][7]下载**CentOS 7 DVD ISO**到本地并挂载。
|
||||
|
||||
# wget http://mirrors.xservers.ro/centos/7.0.1406/isos/x86_64/CentOS-7.0-1406-x86_64-DVD.iso
|
||||
# mount -o loop /path/to/centos-dvd.iso /mnt
|
||||
|
||||
**10.** 在DVD内容可供使用后,创建**centos7**目录并将CentOS 7可启动kernel和initrd映像文件从DVD挂载位置拷贝到centos7文件夹。
|
||||
|
||||
# mkdir /var/lib/tftpboot/centos7
|
||||
# cp /mnt/images/pxeboot/vmlinuz /var/lib/tftpboot/centos7
|
||||
# cp /mnt/images/pxeboot/initrd.img /var/lib/tftpboot/centos7
|
||||
|
||||

|
||||
拷贝CentOS可启动文件
|
||||
|
||||
使用该方法的原因在于,今后你可能会在**/var/lib/tftpboot**路径中创建新的独立的目录,并添加其它Linux发行版到PXE菜单中,你就不会将整个目录结构弄得一团糟了。
|
||||
|
||||
### 步骤6: 创建CentOS 7本地镜像安装源 ###
|
||||
|
||||
**11.** 虽然你可以通过多种协议设置**安装源镜像**,如HTTP、HTTPS或NFS,但对于本指南,我选择使用**FTP**协议。因为通过**vsftpd**,你可以很便捷地配置,而且它也很稳定。
|
||||
|
||||
接下里,安装vsftpd进程,然后复制所有DVD挂载目录中的内容到**vsftpd**默认服务器路径下(**/var/ftp/pub**)——这会花费一些时间,这取决于你的系统资源。然后为该路径设置可读权限,命令如下。
|
||||
|
||||
# yum install vsftpd
|
||||
# cp -r /mnt/* /var/ftp/pub/
|
||||
# chmod -R 755 /var/ftp/pub
|
||||
|
||||

|
||||
安装Vsftpd服务器
|
||||
|
||||

|
||||
拷贝Files到FTP路径
|
||||
|
||||

|
||||
设置FTP路径的权限
|
||||
|
||||
### 步骤7: 在系统范围内启动并启用进程 ###
|
||||
|
||||
**12.** 既然PXE服务器配置已经完成,那么就来启动**DNSMASQ**和**VSFTPD**服务器吧。验证它们的状况并在系统范围内启用,以便让这些服务在每次系统重启后都能随系统启动,命令如下。
|
||||
|
||||
# systemctl start dnsmasq
|
||||
# systemctl status dnsmasq
|
||||
# systemctl start vsftpd
|
||||
# systemctl status vsftpd
|
||||
# systemctl enable dnsmasq
|
||||
# systemctl enable vsftpd
|
||||
|
||||

|
||||
启动Dnsmasq服务
|
||||
|
||||

|
||||
启动Vsftpd服务
|
||||
|
||||
### 步骤8: 打开防火墙并测试FTP安装源 ###
|
||||
|
||||
**13.** 要获取需要在防火墙打开的端口列表,以便让客户机可访问并从PXE服务器启动,请运行**netstat**命令并根据dnsmasq和vsftpd监听列表添加CentOS 7防火墙规则。
|
||||
|
||||
# netstat -tulpn
|
||||
# firewall-cmd --add-service=ftp --permanent ## Port 21
|
||||
# firewall-cmd --add-service=dns --permanent ## Port 53
|
||||
# firewall-cmd --add-service=dhcp --permanent ## Port 67
|
||||
# firewall-cmd --add-port=69/udp --permanent ## Port for TFTP
|
||||
# firewall-cmd --add-port=4011/udp --permanent ## Port for ProxyDHCP
|
||||
# firewall-cmd --reload ## Apply rules
|
||||
|
||||

|
||||
检查监听端口
|
||||
|
||||

|
||||
在防火墙上开启端口
|
||||
|
||||
**14.** 要测试FTP安装源网络路径,请在本地或另外一台计算机上打开浏览器([**lynx**][8]就可以做此事),然后输入你架设有FTP服务的PXE服务器的IP地址,并在填入的URL后面加上**/pub**网络位置,结果应该和截图中看到的一样。
|
||||
|
||||
ftp://192.168.1.20/pub
|
||||
|
||||

|
||||
通过浏览器访问FTP文件
|
||||
|
||||
**15.** 要解决PXE服务器最终的配置或其它信息产生的问题,请在live模式下诊断,命令如下:
|
||||
|
||||
# tailf /var/log/messages
|
||||
|
||||

|
||||
检查PXE日志错误
|
||||
|
||||
**16.** 最后,最后所需的步骤就是卸载CentOS 7 DVD,并移除物理介质。
|
||||
|
||||
# umount /mnt
|
||||
|
||||
### 步骤9: 配置客户端从网络启动 ###
|
||||
|
||||
**17.** 现在,你的客户端可以通过它们的系统BIOS或在**BIOS开机自检**时按指定键来配置网络启动作为**首要启动设备**,具体方法见主板说明手册。
|
||||
|
||||
为了选择网络启动,在第一次PXE提示符出现时,请按下**F8**键进入到PXE安装界面,然后敲**回车**键继续进入PXE菜单。
|
||||
|
||||

|
||||
PXE网络启动
|
||||
|
||||

|
||||
PXE网络OS启动
|
||||
|
||||
**18.** 一旦你进入PXE菜单,请选择你的CentOS 7安装类型,敲**回车**键继续安装过程,就像你使用本地启动介质安装一样。
|
||||
|
||||
请记下这一点,使用菜单中的变体2需要激活目标客户端上的互联网连接。在下面的屏幕截图中,你可以通过VNC看到远程安装的实例。
|
||||
|
||||

|
||||
PXE菜单
|
||||
|
||||

|
||||
通过VNC远程安装Linux
|
||||
|
||||

|
||||
远程安装CentOS
|
||||
|
||||
以上是**CentOS 7**上配置最小化**PXE服务器**的所有内容。在我的本系列下一篇文章中,我将讨论其它PXE服务器配置过程中的其它问题,如怎样使用**Kickstart**文件来配置自动化安装**CentOS 7**,以及添加其它Linux发行版到PXE菜单——**Ubuntu Server**和**Debian 7**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-pxe-network-boot-server-in-centos-7/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
[1]:http://www.tecmint.com/centos-7-installation/
|
||||
[2]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[3]:http://www.tecmint.com/configure-network-interface-in-rhel-centos-7-0/
|
||||
[4]:http://www.tecmint.com/remove-unwanted-services-in-centos-7/
|
||||
[5]:http://www.tecmint.com/install-ntp-server-in-centos/
|
||||
[6]:http://www.thekelleys.org.uk/dnsmasq/docs/dnsmasq-man.html
|
||||
[7]:http://isoredirect.centos.org/centos/7/isos/x86_64/
|
||||
[8]:http://www.tecmint.com/command-line-web-browsers/
|
||||
@ -0,0 +1,77 @@
|
||||
Linux有问必答-- 如何在Linux上检查SSH的版本
|
||||
================================================================================
|
||||
> **Question**:我想到SSH存在1和2两个版本(SSH1和SSH2)。这两者之间有什么不同?还有我该怎么在Linux上检查SSH协议的版本?
|
||||
|
||||
Secure Shell (SSH) is a network protocol that enables remote login or remote command execution between two hosts over a cryptographically secure communication channel. SSH was designed to replace insecure clear-text protocols such as telnet, rsh or rlogin. SSH provides a number of desirable features such as authentication, encryption, data integrity, authorization, and forwarding/tunneling.
|
||||
安全Shell(SSH)通过加密的安全通信通道来远程登录或者远程执行命令。SSH被设计来替代不安全的明文协议,如telnet、rsh和rlogin。SSH提供了大量需要的特性,如认证、加密、数据完整性、授权和转发/通道。
|
||||
|
||||
### SSH1 vs. SSH2 ###
|
||||
|
||||
SSH协议规范存在一些小版本的差异,但是有两个主要的大版本:**SSH1** (版本号 1.XX) 和 **SSH2** (版本号 2.00)。
|
||||
|
||||
事实上,SSH1和SSH2是两个完全不同互不兼容的协议。SSH2明显地提升了SSH1中的很多方面。首先,SSH是宏设计,几个不同的功能(如:认证、传输、连接)被打包进一个单一的协议,SSH2带来了比SSH1更强大的安全特性,如基于MAC的完整性检查,灵活的会话密钥更新、充分协商的加密算法、公钥证书等等。
|
||||
|
||||
SSH2 is standardized by IETF, and as such its implementation is widely deployed and accepted in the industry. Due to SSH2's popularity and cryptographic superiority over SSH1, many products are dropping support for SSH1. As of this writing, OpenSSH still [supports][1] both SSH1 and SSH2, while on all modern Linux distributions, OpenSSH server comes with SSH1 disabled by default.
|
||||
SSH2由IETF标准化,且它的实现在业界被广泛部署和接受。由于SSH2对于SSH1的流行和加密优势,许多产品对SSH1放弃了支持。在写这篇文章的时候,OpenSSH仍旧[支持][1]SSH1和SSH2,然而在所有的现代Linux发行版中,OpenSSH服务器默认禁用了SSH1。
|
||||
|
||||
### 检查支持的SSH协议版本 ###
|
||||
|
||||
#### 方法一 ####
|
||||
|
||||
如果你想检查本地OpenSSH服务器支持的SSH协议版本,你可以参考**/etc/ssh/sshd_config**这个文件。用文本编辑器打开/etc/ssh/sshd_config,并且查看"Protocol"字段。
|
||||
|
||||
如果如下显示,就代表服务器只支持SSH2。
|
||||
|
||||
Protocol 2
|
||||
|
||||
如果如下显示,就代表服务器同时支持SSH1和SSH2。
|
||||
|
||||
Protocol 1,2
|
||||
|
||||
#### 方法二 ####
|
||||
|
||||
如果因为OpenSSH服务其运行在远端服务器上而你不能访问/etc/ssh/sshd_config。你可以使用叫ssh的SSH客户端来检查支持的协议。具体说来,就是强制ssh使用特定的SSH协议,接着我么查看SSH服务器的响应。
|
||||
|
||||
下面的命令强制ssh使用SSH1:
|
||||
|
||||
$ ssh -1 user@remote_server
|
||||
|
||||
下面的命令强制ssh使用SSH2:
|
||||
|
||||
$ ssh -2 user@remote_server
|
||||
|
||||
如果远程SSH服务器只支持SSH2,那么第一个带“-1”的选项就会出现像下面的错误信息:
|
||||
|
||||
Protocol major versions differ: 1 vs. 2
|
||||
|
||||
如果SSH服务器同时支持SSH1和SSH2,那么两个命令都有效。
|
||||
|
||||
### 方法三 ###
|
||||
|
||||
另一个检查版本的方法是运行SSH扫描工具,叫做[scanssh][2]。这个命令行工具在你想要检查一组IP地址或者整个本地网络来升级SSH1兼容的SSH服务器时很有用。
|
||||
|
||||
下面是基本的SSH版本扫描语法。
|
||||
|
||||
$ sudo scanssh -s ssh -n [ports] [IP addresses or CIDR prefix]
|
||||
|
||||
"-n"选项可以指定扫描的SSH端口。你可以用都好分隔来扫描多个端口,不带这个选项,scanssh会默认扫描22端口。
|
||||
|
||||
使用下面的命令来发现192.168.1.0/24本地网络中的SSH服务器,并检查SSH协议v版本:
|
||||
|
||||
$ sudo scan -s ssh 192.168.1.0/24
|
||||
|
||||

|
||||
|
||||
如果scanssh为特定IP地址报告“SSH-1.XX-XXXX”,这暗示着相关的SSH服务器支持的最低版本是SSH1.如果远程服务器只支持SSH2,scanssh会显示“SSH-2.0-XXXX”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-ssh-protocol-version-linux.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openssh.com/specs.html
|
||||
[2]:http://www.monkey.org/~provos/scanssh/
|
||||
@ -0,0 +1,74 @@
|
||||
Linux有问必答-- 如何在Linux上安装内核头文件
|
||||
================================================================================
|
||||
> **提问**:我在安装一个设备驱动前先要安装内核头文件。怎样安装合适的内核头文件?
|
||||
|
||||
当你在编译一个设备驱动模块时,你需要在系统中安装内核头文件。内核头文件同样在你编译与内核直接链接的用户空间程序时需要。当你在这些情况下安装内核头文件时,你必须确保内核头文件精确地与你当前内核版本匹配(比如:3.13.0-24-generic)。
|
||||
|
||||
如果你的内核发行版自带的内核版本,或者使用默认的包管理器的基础仓库升级的(比如:apt-ger、aptitude或者yum),你也可以使用包管理器来安装内核头文件。另一方面,如果下载的是[kernel源码][1]并且手动编译的,你可以使用[make命令][2]来安装匹配的内核头文件。
|
||||
|
||||
现在我们假设你的内核是发行版自带的,让我们看下该如何安装匹配的头文件。
|
||||
|
||||
### 在 Debian、Ubuntu 或者 Linux Mint 上安装内核头文件 ###
|
||||
|
||||
假设你没有手动编译内核,你可以使用apt-get命令来安装匹配的内核头文件。
|
||||
|
||||
首先,使用dpkg-query命令检查是否有可用的内核头文件。
|
||||
|
||||
$ dpkg-query -s linux-headers-$(uname -r)
|
||||
|
||||
----------
|
||||
|
||||
dpkg-query: package 'linux-headers-3.11.0-26-generic' is not installed and no information is available
|
||||
|
||||
接着使用下面的命令安装匹配的内核头文件。
|
||||
|
||||
$ sudo apt-get install linux-headers-$(uname -r)
|
||||
|
||||

|
||||
|
||||
验证头文件是否成功安装。
|
||||
|
||||
$ dpkg-query -s linux-headers-$(uname -r)
|
||||
|
||||
----------
|
||||
|
||||
Package: linux-headers-3.11.0-26-generic
|
||||
Status: install ok installed
|
||||
|
||||
Debian、Ubuntu、Linux Mint默认头文件在**/usr/src**下。
|
||||
|
||||
### 在 Fedora、CentOS 或者 RHEL 上安装内核头文件 ###
|
||||
|
||||
假设你没有手动编译内核,你可以使用yum命令来安装匹配的内核头文件。
|
||||
|
||||
首先,用下面的命令检查系统是否已经按炸ung了头文件。如果下面的命令没有任何输出,这就意味着还没有头文件。
|
||||
|
||||
$ rpm -qa | grep kernel-headers-$(uname -r)
|
||||
|
||||
接着用yum命令安装头文件。这个命令会自动找出合适的头文件并安装。
|
||||
|
||||
$ sudo yum install kernel-headers
|
||||
|
||||

|
||||
|
||||
验证包安装的状态。
|
||||
|
||||
$ rpm -qa | grep kernel-headers-$(uname -r)
|
||||
|
||||
----------
|
||||
|
||||
kernel-headers-3.10.0-123.9.3.el7.x86_64
|
||||
|
||||
Fedora、CentOS 或者 RHEL上默认内核头文件的位置是**/usr/include/linux**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-kernel-headers-linux.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.kernel.org/pub/linux/kernel/
|
||||
[2]:https://www.kernel.org/doc/Documentation/kbuild/headers_install.txt
|
||||
@ -0,0 +1,83 @@
|
||||
Linux有问必答-- 如何在Linux重命名多个文件
|
||||
================================================================================
|
||||
> **提问**:我知道我可以用mv命令重命名文件。但是当我想重命名很多文件怎么办?如果为每个文件都这么做将会是很乏味的。有没有办法一次性重命名多个文件?
|
||||
|
||||
在Linux中,当你想要改变一个文件名,使用mv命令就好了。然而mv不能使用通配符重命名多个文件。可以用sed、awk或者与[xargs][1]结合使用来处理多个文件的情况。然而,这些命令行即繁琐u又不友好,并且如果不小心的话还很容易出错。你不会想要撤销1000个文件的错误名的。
|
||||
|
||||
When it comes to renaming multiple files, the rename utility is probably the easiest, the safest, and the most powerful command-line tool. The rename command is actually a Perl script, and comes pre-installed on all modern Linux distributions.
|
||||
当你想要重命名多个文件的时候,重命名的工具或许是最简单、最安全和最强大的命令行工具。重命名命令实际上是一个Perl脚本,它预安装在所有的现在Linux发行班上
|
||||
|
||||
下面是重命名命令的基本语法。
|
||||
|
||||
rename [-v -n -f] <pcre> <files>
|
||||
|
||||
<pcre> 是Perl兼容正则表达式,它表示的是要重命名的文件和该怎么做。正则表达式的形式是‘s/old-name/new-name/’。
|
||||
|
||||
‘-v’选项会显示文件名改变的细节(比如:XXX重命名成YYY)。
|
||||
|
||||
‘-n’选项告诉rename会在不实际改变名称的情况下显示文件将会重命名的情况。这个选项在你想要在不改变文件名的情况下模拟改变文件名的情况下很有用。
|
||||
|
||||
‘-f’选项强制覆盖存在的文件。
|
||||
|
||||
下面,就让我们看下rename命令的几个实际例子。
|
||||
|
||||
### 改变文件扩展名 ###
|
||||
|
||||
假设你有许多.jpeg的图片文件。你想要把它们的名字改成*.jpg。下面的命令就会将*.jpeg 文件改成 *.jpg。
|
||||
|
||||
$ rename 's/\.jpeg$/\.jpg/' *.jpeg
|
||||
|
||||
### 大写改成小写,反之亦然 ###
|
||||
|
||||
有时你想要改变文件名的大小写,你可以使用下面的命令。
|
||||
|
||||
把所有的文件改成小写:
|
||||
|
||||
# rename 'y/A-Z/a-z/' *
|
||||
|
||||
把所有的文件改成大写:
|
||||
|
||||
# rename 'y/a-z/A-Z/' *
|
||||
|
||||

|
||||
|
||||
### 更改文件名模式 ###
|
||||
|
||||
现在让我们考虑包含子模式的更复杂的正则表达式。在PCRE中,子模式包含在圆括号中,$符后接上数字(比如$1,$2)。
|
||||
|
||||
比如,下面的命令会将‘img_NNNN.jpeg’变成‘dan_NNNN.jpg’。
|
||||
|
||||
# rename -v 's/img_(\d{4})\.jpeg$/dan_$1\.jpg/' *.jpeg
|
||||
|
||||
----------
|
||||
|
||||
img_5417.jpeg renamed as dan_5417.jpg
|
||||
img_5418.jpeg renamed as dan_5418.jpg
|
||||
img_5419.jpeg renamed as dan_5419.jpg
|
||||
img_5420.jpeg renamed as dan_5420.jpg
|
||||
img_5421.jpeg renamed as dan_5421.jpg
|
||||
|
||||
比如,下面的命令会将‘img_000NNNN.jpeg’变成‘dan_NNNN.jpg’。
|
||||
|
||||
# rename -v 's/img_\d{3}(\d{4})\.jpeg$/dan_$1\.jpg/' *jpeg
|
||||
|
||||
----------
|
||||
|
||||
img_0005417.jpeg renamed as dan_5417.jpg
|
||||
img_0005418.jpeg renamed as dan_5418.jpg
|
||||
img_0005419.jpeg renamed as dan_5419.jpg
|
||||
img_0005420.jpeg renamed as dan_5420.jpg
|
||||
img_0005421.jpeg renamed as dan_5421.jpg
|
||||
|
||||
上面的例子中,子模式‘\d{4}’会捕捉4个连续的数字,捕捉的四个数字就是$1, 将会用于新的文件名。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/rename-multiple-files-linux.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/xargs-command-linux.html
|
||||
@ -0,0 +1,84 @@
|
||||
Btrfs文件系统在Linux中的创建及其特性
|
||||
================================================================================
|
||||
|
||||
**Btrfs**(B-tree file system,B-tree文件系统)是针对Linux开发的一个新的CoW(copy-on-write,写时复制)文件系统。它最初是由[甲骨文公司][1]在2007年着手开始开发的,并在2014年8月正式发布其稳定版。开发Btrfs的目的在于解决Linux文件系统中缺少池、快照、校验和以及集成的跨多设备访问等问题,目标在于实现Linux的规模化存储。规模化不仅仅是指解决存储问题,也意味着通过简洁的界面提供对存储的管控和管理能力,让大家能看到已使用的内容并使它更可靠。
|
||||
|
||||
你应该注意到,Btrfs才刚刚发布稳定版,所以强烈推荐你使用最新版的内核以避免可能出现的问题和漏洞。
|
||||
|
||||
### Btrfs特性 ###
|
||||
|
||||
新文件系统的最重要的特性有:
|
||||
|
||||
- 基于扩展的文件存储
|
||||
- 文件大小上限16EiB
|
||||
- 小文件和索引目录的高效空间利用
|
||||
- 动态索引节点分配
|
||||
- 支持快照可写和快照只读
|
||||
- 子卷(分离内部文件系统的根)
|
||||
- 支持数据和元数据的校验和
|
||||
- 压缩 (gzip和LZO)
|
||||
- 整合的多设备支持
|
||||
- 支持文件条块化、文件镜像和文件条块化+镜像三种部署方案
|
||||
- 高效的增量备份
|
||||
- 后台消除进程支持查找和修复冗余副本上的文件错误
|
||||
- 支持在线文件系统碎片整理和离线文件系统检查
|
||||
- Btrfs文件系统对RAID 5/RAID 6加强支持,[在linux 3.19中添加了许多漏洞修补][2]
|
||||
|
||||
你可以在此关于本主题的维基文章中[阅读关于新特性的内容][3]。
|
||||
|
||||
### 转换到Btrfs ###
|
||||
|
||||
**警告:在尝试转换文件系统前,请务必备份数据。虽然此操作很稳定,也很安全,但它仍然可能导致数据丢失,而防止此情况发生的唯一途径就是进行数据备份。**
|
||||
|
||||
将现存的ext4文件系统转换到btrfs是相当简单而易懂的。你首先需要使用fsck来检查你现存分区上是否存在错误,然后使用btrfs-convert命令进行转换。如果你想要对/dev/sda3分区进行转换,你可以进行以下操作:
|
||||
|
||||
# fsck.ext4 /dev/sda4
|
||||
# btrfs-convert /dev/sda4
|
||||
|
||||
然后,你就可以使用mount命令将它挂载到你想要的任何位置。
|
||||
|
||||

|
||||
|
||||
### 转换根分区 ###
|
||||
|
||||
如果你想要对你系统上的根分区进行转换,你首先需要使用Live CD启动。对于Ubuntu,你可以使用Ubuntu安装CD来完成此操作,在启动后第一个屏幕选择“尝试Ubuntu”。对于其它系统,你同样可以使用Live CD镜像,操作类似。
|
||||
|
||||
在启动后,打开终端,使用下面的命令来转换文件系统。
|
||||
|
||||
# fsck.ext4 /dev/sda1
|
||||
# btrfs-convert /dev/sda1
|
||||
|
||||
接下来,chroot到文件系统,这样你就可以修改fstab并重新安装grub了。
|
||||
|
||||
# mount /dev/sda1 /mnt
|
||||
# for i in dev dev/pts proc sys ; do mount --bind /$i /mnt/$i ; done
|
||||
# chroot /mnt
|
||||
# blkid | grep sda1
|
||||
|
||||

|
||||
|
||||
现在来编辑fstab,并根据blkid输出的结果来修改当前/文件系统的UUID,并将它的文件系统类型修改为btrfs,修改后的行如下:
|
||||
|
||||
UUID=8e7e80aa-337e-4179-966d-d60128bd3714 / btrfs defaults 0 1
|
||||
|
||||
然后,重新安装Grub:
|
||||
|
||||
# grub-install /dev/sda
|
||||
# update-grub
|
||||
|
||||
现在,你可以把启动光盘丢到一边了,重启机器后,你就可以使用新的文件系统了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/file-system/create-btrfs-features/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:http://www.oracle.com/index.html
|
||||
[2]:http://lkml.iu.edu/hypermail/linux/kernel/1412.1/03583.html
|
||||
[3]:https://btrfs.wiki.kernel.org/index.php/Main_Page#Features
|
||||
Loading…
Reference in New Issue
Block a user