mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
commit
e2b6845f8e
4
LCTT翻译规范.md
Normal file
4
LCTT翻译规范.md
Normal file
@ -0,0 +1,4 @@
|
||||
# Linux中国翻译规范
|
||||
1. 翻译中出现的专有名词,可参见Dict.md中的翻译。
|
||||
2. 英文人名,如无中文对应译名,一般不译。
|
||||
2. 缩写词,一般不须翻译,可考虑旁注中文全名。
|
||||
@ -7,7 +7,7 @@
|
||||
|
||||

|
||||
|
||||
使用这种方式的明显好处就是你可以通过使用他们各自的官方应用访问你的各种云存储。目前,提供官方Linux客户端的服务提供商有[SpiderOak](1), [Dropbox](2), [Ubuntu One](3),[Copy](5)。[Ubuntu One](3)虽不出名但的确是[一个不错的云存储竞争着](4)。[Copy][5]则提供比Dropbox更多的空间,是[Dropbox的替代选择之一](6)。使用这些官方Linux客户端可以保持你的电脑与他们的服务器之间的通信,还可以让你进行属性设置,如选择性同步。
|
||||
使用这种方式的明显好处就是你可以通过使用他们各自的官方应用访问你的各种云存储。目前,提供官方Linux客户端的服务提供商有[SpiderOak][1], [Dropbox][2], [Ubuntu One][3],[Copy][5]。[Ubuntu One][3]虽不出名但的确是[一个不错的云存储竞争着][4]。[Copy][5]则提供比Dropbox更多的空间,是[Dropbox的替代选择之一][6]。使用这些官方Linux客户端可以保持你的电脑与他们的服务器之间的通信,还可以让你进行属性设置,如选择性同步。
|
||||
|
||||
对于普通桌面用户,使用官方客户端是最好的选择,因为官方客户端可以提供最多的功能和最好的兼容性。使用它们也很简单,只需要下载他们对应你的发行版的软件包,然后安装安装完后在运行一下就Ok了。安装客户端时,它一般会指导你完成这些简单的过程。
|
||||
|
||||
@ -25,9 +25,9 @@
|
||||
|
||||
当你运行最后一条命令后,脚本会提醒你这是你第一次运行这个脚本。它将告诉你去浏览一个Dropbox的特定网页以便访问你的账户。它还会告诉你所有你需要放入网站的信息,这是为了让Dropbox给你App Key和App Secret以及赋予这个脚本你给予的访问权限。现在脚本就拥有了访问你账户的合法授权了。
|
||||
|
||||
这些一旦完成,你就可以这个脚本执行各种任务了,例如上传、下载、删除、移动、复制、创建文件夹、查看文件、共享文件、查看文件信息和取消共享。对于全部的语法解释,你可以查看一下[这个页面](9)。
|
||||
这些一旦完成,你就可以这个脚本执行各种任务了,例如上传、下载、删除、移动、复制、创建文件夹、查看文件、共享文件、查看文件信息和取消共享。对于全部的语法解释,你可以查看一下[这个页面][9]。
|
||||
|
||||
###通过[Storage Made Easy](7)将SkyDrive带到Linux上
|
||||
###通过[Storage Made Easy][7]将SkyDrive带到Linux上
|
||||
|
||||
微软并没有提供SkyDrive的官方Linux客户端,这一点也不令人惊讶。但是你并不意味着你不能在Linux上访问SkyDrive,记住:SkyDrive的web版本是可用的。
|
||||
|
||||
@ -41,7 +41,7 @@
|
||||
|
||||
第一次启动时。它会要求你登录,还有询问你要把云存储挂载到什么地方。在你做完了这些后,你就可以浏览你选择的文件夹,你还可以访问你的Storage Made Easy空间以及你的SkyDrive空间了!这种方法对于那些想在Linux上使用SkyDrive的人来说非常好,对于想把他们的多个云存储服务整合到一个地方的人来说也很不错。这种方法的缺点是你无法使用他们各自官方客户端中可以使用的特殊功能。
|
||||
|
||||
因为现在在你的Linux桌面上也可以使用SkyDrive,接下来你可能需要阅读一下我写的[SkyDrive与Google Drive的比较](8)以便于知道究竟哪种更适合于你。
|
||||
因为现在在你的Linux桌面上也可以使用SkyDrive,接下来你可能需要阅读一下我写的[SkyDrive与Google Drive的比较][8]以便于知道究竟哪种更适合于你。
|
||||
|
||||
###结论
|
||||
|
||||
|
||||
@ -2,8 +2,6 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
图片来源 : opensource.com
|
||||
|
||||
经过了一整天的Opensource.com[社区版主][1]年会,最后一项日程提了上来,内容只有“特邀嘉宾:待定”几个字。作为[Opensource.com][3]的项目负责人和社区管理员,[Jason Hibbets][2]起身解释道,“因为这个嘉宾有可能无法到场,因此我不想提前说是谁。在几个月前我问他何时有空过来,他给了我两个时间点,我选了其中一个。今天是这三周中Jim唯一能来的一天”。(译者注:Jim是指下文中提到的Jim Whitehurst,即红帽公司总裁兼首席执行官)
|
||||
|
||||
这句话在版主们(Moderators)中引起一阵轰动,他们从世界各地赶来参加此次的[拥抱开源大会(All Things Open Conference)][4]。版主们纷纷往前挪动椅子,仔细聆听。
|
||||
@ -14,7 +12,7 @@
|
||||
|
||||
“大家好!”,这个家伙开口了。他没穿正装,只是衬衫和休闲裤。
|
||||
|
||||
这时会场中第二高个子的人,红帽全球意识部门(Global Awareness)的高级主管[Jeff Mackanic][5],告诉他大部分社区版本今天都在场,然后让每个人开始作简单的自我介绍。
|
||||
这时会场中第二高个子的人,红帽全球意识部门(Global Awareness)的高级主管[Jeff Mackanic][5],告诉他大部分社区版主今天都在场,然后让每个人开始作简单的自我介绍。
|
||||
|
||||
“我叫[Jen Wike Huger][6],负责Opensource.com的内容管理,很高兴见到大家。”
|
||||
|
||||
@ -22,13 +20,13 @@
|
||||
|
||||
“我叫[Robin][9],从2013年开始参与版主项目。我在OSDC做了一些事情,工作是在[City of the Hague][10]维护[网站][11]。”
|
||||
|
||||
“我叫[Marcus Hanwell][12],来自英格兰,在[Kitware][13]工作。同时,我是FOSS科学软件的技术总监,和国家实验室在[Titan][14] Z和[Gpu programming][15]方面合作。我主要使用[Gentoo][16]和[KDE][17]。最后,我很激动能加入FOSS和开源科学。”
|
||||
“我叫[Marcus Hanwell][12],来自英格兰,在[Kitware][13]工作。同时,我是FOSS science software的技术总监,和国家实验室在[Titan][14] Z和[Gpu programming][15]方面合作。我主要使用[Gentoo][16]和[KDE][17]。最后,我很激动能参与到FOSS和开源科学。”
|
||||
|
||||
“我叫[Phil Shapiro][18],是华盛顿的一个小图书馆28个Linux工作站的管理员。我视各位为我的同事。非常高兴能一起交流分享,贡献力量。我主要关注FOSS和自豪感的关系,以及FOSS如何提升自豪感。”
|
||||
“我叫[Phil Shapiro][18],是华盛顿的一个小图书馆的28个Linux工作站的管理员。我视各位为我的同事。非常高兴能一起交流分享,贡献力量。我主要关注FOSS和自豪感的关系,以及FOSS如何提升自豪感。”
|
||||
|
||||
“我叫[Joshua Holm][19]。我大多数时间都在关注系统更新,以及帮助人们在网上找工作。”
|
||||
|
||||
“我叫[Mel Chernoff][20],在红帽工作,和[Jason Hibbets]和[Mark Bohannon]一起主要关注政府渠道方面。”
|
||||
“我叫[Mel Chernoff][20],在红帽工作,和[Jason Hibbets][22]和[Mark Bohannon][23]一起主要关注[政府][21]渠道方面。”
|
||||
|
||||
“我叫[Scott Nesbitt][24],写过很多东西,使用FOSS很久了。我是个普通人,不是系统管理员,也不是程序员,只希望能更加高效工作。我帮助人们在商业和生活中使用FOSS。”
|
||||
|
||||
@ -38,41 +36,41 @@
|
||||
|
||||
“你在[新FOSS Minor][30]教书?!”,Jim说道,“很酷!”
|
||||
|
||||
“我叫[Jason Baker][31]。我是红慢的一个云专家,主要做[OpenStack][32]方面的工作。”
|
||||
“我叫[Jason Baker][31]。我是红帽的一个云专家,主要做[OpenStack][32]方面的工作。”
|
||||
|
||||
“我叫[Mark Bohannan][33],是红帽全球开放协议的一员,在华盛顿外工作。和Mel一样,我花了相当多时间写作,也从法律和政府部门中找合作者。我做了一个很好的小册子来讨论正在发生在政府中的积极变化。”
|
||||
|
||||
“我叫[Jason Hibbets][34],我组织了这次会议。”
|
||||
“我叫[Jason Hibbets][34],我组织了这次讨论。”
|
||||
|
||||
会场中一片笑声。
|
||||
|
||||
“我也组织了这片讨论,可以这么说,”这个棕红色头发笑容灿烂的家伙说道。笑声持续一会逐渐平息。
|
||||
“我也组织了这个讨论,可以这么说,”这个棕红色头发笑容灿烂的家伙说道。笑声持续一会逐渐平息。
|
||||
|
||||
我当时在他左边,时不时从转录空隙中抬头看一眼,然后从眼神中注意到微笑背后暗示的那个自2008年1月起开始领导公司的人,红帽的CEO[Jim Whitehurst][35]。
|
||||
我当时在他左边,时不时从记录的间隙中抬头看一眼,我注意到淡淡微笑背后的那个令人瞩目的人,是自2008年1月起开始领导红帽公司的CEO [Jim Whitehurst][35]。
|
||||
|
||||
“我有世界上最好的工作,”稍稍向后靠、叉腿抱头,Whitehurst开始了演讲。“我开始领导红帽,在世界各地旅行到处看看情况。在这里的七年中,FOSS和广泛的开源创新所发生的美好的事情是开源已经脱离了条条框框。我现在认为,IT正处在FOSS之前所在的位置。我们可以预见FOSS从一个替代走向创新驱动力。”用户也看到了这一点。他们用FOSS并不是因为它便宜,而是因为它能提供和创新的解决方案。这也十一个全球现象。比如,我刚才还在印度,然后发现那里的用户拥抱开源的两个理由:一个是创新,另一个是那里的市场有些特殊,需要完全的控制。
|
||||
“我有世界上最好的工作,”稍稍向后靠、叉腿抱头,Whitehurst开始了演讲。“我开始领导红帽,在世界各地旅行到处看看情况。在这里的七年中,FOSS和广泛的开源创新所发生的最美好的事情是开源已经脱离了条条框框。我现在认为,信息技术正处在FOSS之前所在的位置。我们可以预见FOSS从一个替代品走向创新驱动力。我们的用户也看到了这一点。他们用FOSS并不是因为它便宜,而是因为它能带来可控和创新的解决方案。这也是个全球现象。比如,我刚才还在印度,然后发现那里的用户拥抱开源的两个理由:一个是创新,另一个是那里的市场有些特殊,需要完全的可控。”
|
||||
|
||||
“[孟买证券交易所][36]想得到源代码并加以控制,五年前这在证券交易领域闻所未闻。那时FOSS正在重复发明轮子。今天看来,FOSS正在做几乎所有的结合了大数据的事物。几乎所有的新框架,语言和方法论,包括流动(尽管不包括设备),都首先发生在开源世界。”
|
||||
“[孟买证券交易所][36]想得到源代码并加以控制,五年前这种事情在证券交易领域就没有听说过。那时FOSS正在重复发明轮子。今天看来,实际上大数据的每件事情都出现在FOSS领域。几乎所有的新框架,语言和方法论,包括移动通讯(尽管不包括设备),都首先发生在开源世界。”
|
||||
|
||||
“这是因为用户数量已经达到了相当的规模。这不只是红帽遇到的情况,[Google][37],[Amazon][38],[Facebook][39]等也出现这样的情况。他们想解决自己的问题,用开源的方式。忘掉协议吧,开源绝不仅如此。我们建立了一个交通工具,一套规则,例如[Hadoop][40],[Cassandra][41]和其他工具。事实上,开源驱动创新。例如,Hadoop在厂商们意识的规模带来的问题。他们实际上有足够的资和资源金来解决自己的问题。”开源是许多领域的默认技术方案。这在一个更加注重内容的世界中更是如此,例如[3D打印][42]和其他使用信息内容的物理产品。”
|
||||
“这是因为用户数量已经达到了相当的规模。这不只是红帽遇到的情况,[Google][37],[Amazon][38],[Facebook][39]等也出现这样的情况。他们想解决自己的问题,用开源的方式。忘掉许可协议吧,开源绝不仅如此。我们建立了一个交通工具,一套规则,例如[Hadoop][40],[Cassandra][41]和其他工具。事实上,开源驱动创新。例如,Hadoop是在厂商们意识到规模带来的问题时的一个解决方案。他们实际上有足够的资金和资源来解决自己的问题。开源是许多领域的默认技术方案。这在一个更加注重内容的世界中更是如此,例如[3D打印][42]和其他使用信息内容的实体产品。”
|
||||
|
||||
“源代码的开源确实很酷,但开源不应当仅限于此。在各行各业不同领域开源仍有可以用武之地。我们要问下自己:‘开源能够为教育,政府,法律带来什么?其它的呢?其它的领域如何能学习我们?’”
|
||||
|
||||
“还有内容的问题。内容在现在是免费的,当然我们可以投资更多的免费内容,不过我们也需要商业模式围绕的内容。这是我们更应该关注的。如果你相信开放的创新能带来更好,那么我们需要更多的商业模式。”
|
||||
“还有内容的问题。内容在现在是免费的,当然我们可以投资更多的免费内容,不过我们也需要商业模式围绕的内容。这是我们更应该关注的。如果你相信开放的创新更好,那么我们需要更多的商业模式。”
|
||||
|
||||
“教育让我担心其相比与‘社区’它更关注‘内容’。例如,无论我走到哪里,大学校长们都会说,‘等等,难道教育将会免费?!’对于下游来说FOSS免费很棒,但别忘了上游很强大。免费课程很棒,但我们同样需要社区来不断迭代和完善。这是很多人都在做的事情,Opensource.com是一个提供交流的社区。问题不是‘我们如何控制内容’,也不是‘如何建立和分发内容’,而是要确保它处在不断的完善当中,而且能给其他领域提供有价值的参考。”
|
||||
“教育让我担心,其相比与‘社区’它更关注‘内容’。例如,无论我走到哪里,大学的校长们都会说,‘等等,难道教育将会免费?!’对于下游来说FOSS免费很棒,但别忘了上游很强大。免费课程很棒,但我们同样需要社区来不断迭代和完善。这是很多人都在做的事情,Opensource.com是一个提供交流的社区。问题不是‘我们如何控制内容’,也不是‘如何建立和分发内容’,而是要确保它处在不断的完善当中,而且能给其他领域提供有价值的参考。”
|
||||
|
||||
“改变世界的潜力是无穷无尽的,我们已经取得了很棒的进步。”六年前我们痴迷于制定宣言,我们说‘我们是领导者’。我们用错词了,因为那潜在意味着控制。积极的参与者们同样也不能很好理解……[Máirín Duffy][43]提出了[催化剂][44]这个词。然后我们组成了红帽,不断地促进行动,指引方向。”
|
||||
|
||||
“Opensource.com也是其他领域的催化剂,而这正是它的本义所在,我希望你们也这样认为。当时的内容质量和现在比起来都令人难以置信。你可以看到每季度它都在进步。谢谢你们的时间!谢谢成为了催化剂!这是一个让世界变得更好的机会。我想听听你们的看法。”
|
||||
“Opensource.com也是其他领域的催化剂,而这正是它的本义所在,我希望你们也这样认为。当时的内容质量和现在比起来都令人难以置信。你可以看到每季度它都在进步。谢谢你们付出的时间!谢谢成为了催化剂!这是一个让世界变得更好的机会。我想听听你们的看法。”
|
||||
|
||||
我瞥了一下桌子,发现几个人眼中带泪。
|
||||
|
||||
然后Whitehurst又回顾了大会的开放教育议题。“极端一点看,如果你有一门[Ulysses][45]的公开课。在这里你能和一群人一起合作体验课堂。这样就和代码块一样的:大家一起努力,代码随着时间不断改进。”
|
||||
|
||||
在这一点上,我有发言权。当谈论其FOSS和学术团体之间的差异,向基础和可能的不调和这些词语都跳了出来。
|
||||
在这一点上,我有发言权。当谈论其FOSS和学术团体之间的差异,像“基础”和“可能不调和”这些词语都跳了出来。
|
||||
|
||||
**Remy**: “倒退带来死亡。如果你在论文或者发布的代码中烦了一个错误,有可能带来十分严重的后果。学校一直都是避免失败寻求正确答案的地方。复制意味着抄袭。轮子在一遍遍地教条地被发明。FOSS你能快速失败,但在学术界,你只能带来无效的结果。”
|
||||
**Remy**: “倒退带来死亡。如果你在论文或者发布的代码中犯了一个错误,有可能带来十分严重的后果。学校一直都是避免失败寻求正确答案的地方。复制意味着抄袭。轮子在一遍遍地教条地被发明。FOSS让你能快速失败,但在学术界,你只能带来无效的结果。”
|
||||
|
||||
**Nicole**: “学术界有太多自我的家伙,你们需要一个发布经理。”
|
||||
|
||||
@ -80,20 +78,21 @@
|
||||
|
||||
**Luis**: “团队和分享应该优先考虑,红帽可以多向它们强调这一点。”
|
||||
|
||||
**Jim**: “还有公司在其中扮演积极角色吗?”
|
||||
**Jim**: “还有公司在其中扮演积极角色了吗?”
|
||||
|
||||
[Phil Shapiro][46]: “我对FOSS的临界点感兴趣。联邦没有改用[LibreOffice][47]把我逼疯了。我们没有在软件上花税款,也不应当在字处理软件或者微软的Office上浪费税钱。”
|
||||
[Phil Shapiro][46]: “我对FOSS的临界点感兴趣。Fed没有改用[LibreOffice][47]把我逼疯了。我们没有在软件上花税款,也不应当在字处理软件或者微软的Office上浪费税钱。”
|
||||
|
||||
**Jim**: “我们经常提倡这一点。我们能做更多吗?这是个问题。首先,我们在我们的产品涉足的地方取得了进步。我们在政府中有坚实的专营权。我们比私有公司平均话费更多。银行和电信业都和政府挨着。我们在欧洲做的更好,我认为在那工作又更低的税。下一代计算就像‘终结者’,我们到处取得了进步,但仍然需要忧患意识。”
|
||||
**Jim**: “我们经常提倡这一点。我们能做更多吗?这是个问题。首先,我们在我们的产品涉足的地方取得了进步。我们在政府中有坚实的专营权。我们比私有公司平均花费更多。银行和电信业都和政府挨着。我们在欧洲做的更好,我认为在那工作有更低的税。下一代计算就像‘终结者’,我们到处取得了进步,但仍然需要忧患意识。”
|
||||
|
||||
突然,门开了。Jim转身向门口站着的执行助理点头。他要去参加下一场会了。他并拢双腿,站着向前微倾。然后,他再次向每个人的工作和奉献表示感谢,微笑着出了门……留给我们更多的激励。
|
||||
|
||||
突然,门开了。Jim转身向门口站着的执行助理点头。他要去参加下一场会了。他并拢双腿,站着向前微倾。然后,他再次向每个人的工作和奉献表示感谢,微笑着除了门……留给我们更多的激励。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/14/12/jim-whitehurst-inspiration-open-source
|
||||
|
||||
作者:[Remy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[fyh](https://github.com/fyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
7 个驱动开源发展的社区
|
||||
================================================================================
|
||||
不久前,开源模式还被成熟的工业级厂商以怀疑的态度认作是叛逆小孩的玩物。如今,开源的促进会和基金会在一长列的供应商提供者的支持下正蓬勃发展,而他们将开源模式视作创新的关键。
|
||||
|
||||

|
||||
|
||||
### 技术的开放发展驱动着创新 ###
|
||||
|
||||
在过去的 20 几年间,技术的开源推进已被视作驱动创新的关键因素。即使那些以前将开源视作威胁的公司也开始接受这个观点 — 例如微软,如今它在一系列的开源的促进会中表现活跃。到目前为止,大多数的开源推进都集中在软件方面,但甚至这个也正在改变,因为社区已经开始向开源硬件倡议方面聚拢。这里介绍 7 个成功地在硬件和软件方面同时促进和发展开源技术的组织。
|
||||
|
||||
### OpenPOWER 基金会 ###
|
||||
|
||||

|
||||
|
||||
[OpenPOWER 基金会][2] 由 IBM, Google, Mellanox, Tyan 和 NVIDIA 于 2013 年共同创建,在与开源软件发展相同的精神下,旨在驱动开放协作硬件的发展,在过去的 20 几年间,开源软件发展已经找到了肥沃的土壤。
|
||||
|
||||
IBM 通过开放其基于 Power 架构的硬件和软件技术,向使用 Power IP 的独立硬件产品提供许可证等方式为基金会的建立播下种子。如今超过 70 个成员共同协作来为基于 Linux 的数据中心提供自定义的开放服务器,组件和硬件。
|
||||
|
||||
去年四月,在比最新基于 x86 系统快 50 倍的数据分析能力的新的 POWER8 处理器的服务器的基础上, OpenPOWER 推出了一个技术路线图。七月, IBM 和 Google 发布了一个固件堆栈。去年十月见证了 NVIDIA GPU 带来加速 POWER8 系统的能力和来自 Tyan 的第一个 OpenPOWER 参考服务器。
|
||||
|
||||
### Linux 基金会 ###
|
||||
|
||||

|
||||
|
||||
于 2000 年建立的 [Linux 基金会][2] 如今成为掌控着历史上最大的开源协同开发成果,它有着超过 180 个合作成员和许多独立成员及学生成员。它赞助 Linux 核心开发者的工作并促进、保护和推进 Linux 操作系统,并协调软件的协作开发。
|
||||
|
||||
它最为成功的协作项目包括 Code Aurora Forum (一个拥有为移动无线产业服务的企业财团),MeeGo (一个为移动设备和 IVI [注:指的是车载消息娱乐设备,为 In-Vehicle Infotainment 的简称] 构建一个基于 Linux 内核的操作系统的项目) 和 Open Virtualization Alliance (开放虚拟化联盟,它促进自由和开源软件虚拟化解决方案的采用)。
|
||||
|
||||
### 开放虚拟化联盟 ###
|
||||
|
||||

|
||||
|
||||
[开放虚拟化联盟(OVA)][3] 的存在目的为:通过提供使用案例和对具有互操作性的通用接口和 API 的发展提供支持,来促进自由、开源软件的虚拟化解决方案,例如 KVM 的采用。KVM 将 Linux 内核转变为一个虚拟机管理程序。
|
||||
|
||||
如今, KVM 已成为和 OpenStack 共同使用的最为常见的虚拟机管理程序。
|
||||
|
||||
### OpenStack 基金会 ###
|
||||
|
||||

|
||||
|
||||
原本作为一个 IaaS(基础设施即服务) 产品由 NASA 和 Rackspace 于 2010 年启动,[OpenStack 基金会][4] 已成为最大的开源项目聚居地之一。它拥有超过 200 家公司成员,其中包括 AT&T, AMD, Avaya, Canonical, Cisco, Dell 和 HP。
|
||||
|
||||
大约以 6 个月为一个发行周期,基金会的 OpenStack 项目开发用于通过一个基于 Web 的仪表盘,命令行工具或一个 RESTful 风格的 API 来控制或调配流经一个数据中心的处理存储池和网络资源。至今为止,基金会支持的协同开发已经孕育出了一系列 OpenStack 组件,其中包括 OpenStack Compute(一个云计算网络控制器,它是一个 IaaS 系统的主要部分),OpenStack Networking(一个用以管理网络和 IP 地址的系统) 和 OpenStack Object Storage(一个可扩展的冗余存储系统)。
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||

|
||||
|
||||
作为来自 Linux 基金会的另一个协作项目, [OpenDaylight][5] 是一个由诸如 Dell, HP, Oracle 和 Avaya 等行业厂商于 2013 年 4 月建立的联合倡议。它的任务是建立一个由社区主导、开源、有工业支持的针对软件定义网络( SDN: Software-Defined Networking)的包含代码和蓝图的框架。其思路是提供一个可直接部署的全功能 SDN 平台,而不需要其他组件,供应商可提供附件组件和增强组件。
|
||||
|
||||
### Apache 软件基金会 ###
|
||||
|
||||

|
||||
|
||||
[Apache 软件基金会 (ASF)][7] 是将近 150 个顶级项目的聚居地,这些项目涵盖从开源的企业级自动化软件到与 Apache Hadoop 相关的分布式计算的整个生态系统。这些项目分发企业级、可免费获取的软件产品,而 Apache 协议则是为了让无论是商业用户还是个人用户更方便地部署 Apache 的产品。
|
||||
|
||||
ASF 是 1999 年成立的一个会员制,非盈利公司,以精英为其核心 — 要成为它的成员,你必须首先在基金会的一个或多个协作项目中做出积极贡献。
|
||||
|
||||
### 开放计算项目 ###
|
||||
|
||||

|
||||
|
||||
作为 Facebook 重新设计其 Oregon 数据中心的副产物, [开放计算项目][7] 旨在发展针对数据中心的开源硬件解决方案。 OCP 是一个由廉价无浪费的服务器、针对 Open Rack(为数据中心设计的机架标准,来让机架集成到数据中心的基础设施中) 的模块化 I/O 存储和一个相对 "绿色" 的数据中心设计方案等构成。
|
||||
|
||||
OCP 董事会成员包括来自 Facebook,Intel,Goldman Sachs,Rackspace 和 Microsoft 的代表。
|
||||
|
||||
OCP 最近宣布了有两种可选的许可证: 一个类似 Apache 2.0 的允许衍生工作的许可证,和一个更规范的鼓励将更改回馈到原有软件的许可证。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2866074/opensource-subnet/7-communities-driving-open-source-development.html
|
||||
|
||||
作者:[Thor Olavsrud][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Thor-Olavsrud/
|
||||
[1]:http://openpowerfoundation.org/
|
||||
[2]:http://www.linuxfoundation.org/
|
||||
[3]:https://openvirtualizationalliance.org/
|
||||
[4]:http://www.openstack.org/foundation/
|
||||
[5]:http://www.opendaylight.org/
|
||||
[6]:http://www.apache.org/
|
||||
[7]:http://www.opencompute.org/
|
||||
@ -0,0 +1,114 @@
|
||||
安装 Strongswan :Linux 上一个基于 IPsec 的 VPN 工具
|
||||
================================================================================
|
||||
|
||||
IPsec是一个提供网络层安全的标准。它包含认证头(AH)和安全负载封装(ESP)组件。AH提供包的完整性,ESP组件提供包的保密性。IPsec确保了在网络层的安全特性。
|
||||
|
||||
- 保密性
|
||||
- 数据包完整性
|
||||
- 来源不可抵赖性
|
||||
- 重放攻击防护
|
||||
|
||||
[Strongswan][1]是一个IPsec协议的开源代码实现,Strongswan的意思是强安全广域网(StrongS/WAN)。它支持IPsec的VPN中的两个版本的密钥自动交换(网络密钥交换(IKE)V1和V2)。
|
||||
|
||||
Strongswan基本上提供了在VPN的两个节点/网关之间自动交换密钥的共享,然后它使用了Linux内核的IPsec(AH和ESP)实现。密钥共享使用了之后用于ESP数据加密的IKE 机制。在IKE阶段,strongswan使用OpenSSL的加密算法(AES,SHA等等)和其他加密类库。无论如何,IPsec中的ESP组件使用的安全算法是由Linux内核实现的。Strongswan的主要特性如下:
|
||||
|
||||
- x.509证书或基于预共享密钥认证
|
||||
- 支持IKEv1和IKEv2密钥交换协议
|
||||
- 可选的,对于插件和库的内置完整性和加密测试
|
||||
- 支持椭圆曲线DH群和ECDSA证书
|
||||
- 在智能卡上存储RSA私钥和证书
|
||||
|
||||
它能被使用在客户端/服务器(road warrior模式)和网关到网关的情景。
|
||||
|
||||
### 如何安装 ###
|
||||
|
||||
几乎所有的Linux发行版都支持Strongswan的二进制包。在这个教程,我们会从二进制包安装strongswan,也会从源代码编译带有合适的特性的strongswan。
|
||||
|
||||
### 使用二进制包 ###
|
||||
|
||||
可以使用以下命令安装Strongswan到Ubuntu 14.04 LTS
|
||||
|
||||
$ sudo aptitude install strongswan
|
||||
|
||||

|
||||
|
||||
strongswan的全局配置(strongswan.conf)文件和ipsec配置(ipsec.conf/ipsec.secrets)文件都在/etc/目录下。
|
||||
|
||||
### strongswan源码编译安装的依赖包 ###
|
||||
|
||||
- GMP(strongswan使用的高精度数学库)
|
||||
- OpenSSL(加密算法来自这个库)
|
||||
- PKCS(1,7,8,11,12)(证书编码和智能卡集成)
|
||||
|
||||
#### 步骤 ####
|
||||
|
||||
**1)** 在终端使用下面命令到/usr/src/目录
|
||||
|
||||
$ cd /usr/src
|
||||
|
||||
**2)** 用下面命令从strongswan网站下载源代码
|
||||
|
||||
$ sudo wget http://download.strongswan.org/strongswan-5.2.1.tar.gz
|
||||
|
||||
(strongswan-5.2.1.tar.gz 是当前最新版。)
|
||||
|
||||

|
||||
|
||||
**3)** 用下面命令提取下载的软件,然后进入目录。
|
||||
|
||||
$ sudo tar –xvzf strongswan-5.2.1.tar.gz; cd strongswan-5.2.1
|
||||
|
||||
**4)** 使用configure命令配置strongswan每个想要的选项。
|
||||
|
||||
$ ./configure --prefix=/usr/local -–enable-pkcs11 -–enable-openssl
|
||||
|
||||

|
||||
|
||||
如果GMP库没有安装,配置脚本将会发生下面的错误。
|
||||
|
||||

|
||||
|
||||
因此,首先,使用下面命令安装GMP库然后执行配置脚本。
|
||||
|
||||

|
||||
|
||||
不过,如果GMP已经安装还报上述错误的话,在Ubuntu上使用如下命令,给在路径 /usr/lib,/lib/,/usr/lib/x86_64-linux-gnu/ 下的libgmp.so库创建软连接。
|
||||
|
||||
$ sudo ln -s /usr/lib/x86_64-linux-gnu/libgmp.so.10.1.3 /usr/lib/x86_64-linux-gnu/libgmp.so
|
||||
|
||||

|
||||
|
||||
创建libgmp.so软连接后,再执行./configure脚本也许就找到gmp库了。然而,如果gmp头文件发生其他错误,像下面这样。
|
||||
|
||||

|
||||
|
||||
为解决上面的错误,使用下面命令安装libgmp-dev包
|
||||
|
||||
$ sudo aptitude install libgmp-dev
|
||||
|
||||

|
||||
|
||||
安装gmp的开发库后,在运行一遍配置脚本,如果没有发生错误,则将看见下面的这些输出。
|
||||
|
||||

|
||||
|
||||
使用下面的命令编译安装strongswan。
|
||||
|
||||
$ sudo make ; sudo make install
|
||||
|
||||
安装strongswan后,全局配置(strongswan.conf)和ipsec策略/密码配置文件(ipsec.conf/ipsec.secretes)被放在**/usr/local/etc**目录。
|
||||
|
||||
根据我们的安全需要Strongswan可以用作隧道或者传输模式。它提供众所周知的site-2-site模式和road warrior模式的VPN。它很容易使用在Cisco,Juniper设备上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/install-strongswan/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:https://www.strongswan.org/
|
||||
@ -0,0 +1,150 @@
|
||||
在 Debian 中安装 OpenQRM 云计算平台
|
||||
================================================================================
|
||||
|
||||
### 简介 ###
|
||||
|
||||
**openQRM**是一个基于 Web 的开源云计算和数据中心管理平台,可灵活地与企业数据中心的现存组件集成。
|
||||
|
||||
它支持下列虚拟技术:
|
||||
|
||||
- KVM
|
||||
- XEN
|
||||
- Citrix XenServer
|
||||
- VMWare ESX
|
||||
- LXC
|
||||
- OpenVZ
|
||||
|
||||
openQRM 中的混合云连接器支持 **Amazon AWS**, **Eucalyptus** 或 **OpenStack** 等一系列的私有或公有云提供商,以此来按需扩展你的基础设施。它也可以自动地进行资源调配、 虚拟化、 存储和配置管理,且保证高可用性。集成的计费系统的自服务云门户可使终端用户按需请求新的服务器和应用堆栈。
|
||||
|
||||
openQRM 有两种不同风格的版本可获取:
|
||||
|
||||
- 企业版
|
||||
- 社区版
|
||||
|
||||
你可以在[这里][1]查看这两个版本间的区别。
|
||||
|
||||
### 特点 ###
|
||||
|
||||
- 私有/混合的云计算平台
|
||||
- 可管理物理或虚拟的服务器系统
|
||||
- 集成了所有主流的开源或商业的存储技术
|
||||
- 跨平台: Linux, Windows, OpenSolaris 和 BSD
|
||||
- 支持 KVM, XEN, Citrix XenServer, VMWare ESX(i), lxc, OpenVZ 和 VirtualBox
|
||||
- 支持使用额外的 Amazon AWS, Eucalyptus, Ubuntu UEC 等云资源来进行混合云设置
|
||||
- 支持 P2V, P2P, V2P, V2V 迁移和高可用性
|
||||
- 集成最好的开源管理工具 – 如 puppet, nagios/Icinga 或 collectd
|
||||
- 有超过 50 个插件来支持扩展功能并与你的基础设施集成
|
||||
- 针对终端用户的自服务门户
|
||||
- 集成了计费系统
|
||||
|
||||
### 安装 ###
|
||||
|
||||
在这里我们将在 Debian 7.5 上安装 openQRM。你的服务器必须至少满足以下要求:
|
||||
|
||||
- 1 GB RAM
|
||||
- 100 GB Hdd(硬盘驱动器)
|
||||
- 可选: Bios 支持虚拟化(Intel CPUs 的 VT 或 AMD CPUs AMD-V)
|
||||
|
||||
首先,安装 `make` 软件包来编译 openQRM 源码包:
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
sudo apt-get install make
|
||||
|
||||
然后,逐次运行下面的命令来安装 openQRM。
|
||||
|
||||
从[这里][2]下载最新的可用版本:
|
||||
|
||||
wget http://sourceforge.net/projects/openqrm/files/openQRM-Community-5.1/openqrm-community-5.1.tgz
|
||||
|
||||
tar -xvzf openqrm-community-5.1.tgz
|
||||
|
||||
cd openqrm-community-5.1/src/
|
||||
|
||||
sudo make
|
||||
|
||||
sudo make install
|
||||
|
||||
sudo make start
|
||||
|
||||
安装期间,会要求你更新文件 `php.ini`
|
||||
|
||||

|
||||
|
||||
输入 mysql root 用户密码。
|
||||
|
||||

|
||||
|
||||
再次输入密码:
|
||||
|
||||

|
||||
|
||||
选择邮件服务器配置类型:
|
||||
|
||||

|
||||
|
||||
假如你不确定该如何选择,可选择 `Local only`。在我们的这个示例中,我选择了 **Local only** 选项。
|
||||
|
||||

|
||||
|
||||
输入你的系统邮件名称,并最后输入 Nagios 管理员密码。
|
||||
|
||||

|
||||
|
||||
根据你的网络连接状态,上面的命令可能将花费很长的时间来下载所有运行 openQRM 所需的软件包,请耐心等待。
|
||||
|
||||
最后你将得到 openQRM 配置 URL 地址以及相关的用户名和密码。
|
||||
|
||||

|
||||
|
||||
### 配置 ###
|
||||
|
||||
在安装完 openQRM 后,打开你的 Web 浏览器并转到 URL: **http://ip-address/openqrm**
|
||||
|
||||
例如,在我的示例中为 http://192.168.1.100/openqrm 。
|
||||
|
||||
默认的用户名和密码是: **openqrm/openqrm** 。
|
||||
|
||||

|
||||
|
||||
选择一个网卡来给 openQRM 管理网络使用。
|
||||
|
||||

|
||||
|
||||
选择一个数据库类型,在我们的示例中,我选择了 mysql。
|
||||
|
||||

|
||||
|
||||
现在,配置数据库连接并初始化 openQRM, 在这里,我使用 **openQRM** 作为数据库名称, **root** 作为用户的身份,并将 debian 作为数据库的密码。 请小心,你应该输入先前在安装 openQRM 时创建的 mysql root 用户密码。
|
||||
|
||||

|
||||
|
||||
祝贺你! openQRM 已经安装并配置好了。
|
||||
|
||||

|
||||
|
||||
### 更新 openQRM ###
|
||||
|
||||
在任何时候可以使用下面的命令来更新 openQRM:
|
||||
|
||||
cd openqrm/src/
|
||||
make update
|
||||
|
||||
到现在为止,我们做的只是在我们的 Debian 服务器中安装和配置 openQRM, 至于 创建、运行虚拟,管理存储,额外的系统集成和运行你自己的私有云等内容,我建议你阅读 [openQRM 管理员指南][3]。
|
||||
|
||||
就是这些了,欢呼吧!周末快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-openqrm-cloud-computing-platform-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.openqrm-enterprise.com/products/edition-comparison.html
|
||||
[2]:http://sourceforge.net/projects/openqrm/files/?source=navbar
|
||||
[3]:http://www.openqrm-enterprise.com/fileadmin/Documents/Whitepaper/openQRM-Enterprise-Administrator-Guide-5.2.pdf
|
||||
@ -1,20 +1,20 @@
|
||||
如何在 Ubuntu 中管理和使用 LVM(Logical Volume Management,逻辑卷管理)
|
||||
如何在 Ubuntu 中管理和使用 逻辑卷管理 LVM
|
||||
================================================================================
|
||||

|
||||
|
||||
在我们之前的文章中,我们介绍了[什么是 LVM 以及能用 LVM 做什么][1],今天我们会给你介绍一些 LVM 的主要管理工具,使得你在设置和扩展安装时更游刃有余。
|
||||
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是,你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘驱动汇集而成或是一个软件磁盘阵列。
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘汇集而成的或是一个软件磁盘阵列。
|
||||
|
||||
要管理 LVM,这里有很多可用的 GUI 工具,但要真正理解 LVM 配置发生的事情,最好要知道一些命令行工具。这当你在一个服务器或不提供 GUI 工具的发行版上管理 LVM 时尤为有用。
|
||||
|
||||
LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以下其中之一开头:
|
||||
|
||||
- Physical Volume = pv
|
||||
- Volume Group = vg
|
||||
- Logical Volume = lv
|
||||
- Physical Volume (物理卷) = pv
|
||||
- Volume Group (卷组)= vg
|
||||
- Logical Volume (逻辑卷)= lv
|
||||
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组使得你的操作系统能使用指定的空间。
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组,使得你的操作系统能使用指定的空间。
|
||||
|
||||
### 可下载的 LVM 备忘单 ###
|
||||
|
||||
@ -26,7 +26,7 @@ LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以
|
||||
|
||||
### 如何查看当前 LVM 信息 ###
|
||||
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置好的开始点。
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令可以和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置的好起点。
|
||||
|
||||
display 命令会格式化输出信息,因此比 s 命令更易于理解。对每个命令你会看到名称和 pv/vg 的路径,它还会给出空闲和已使用空间的信息。
|
||||
|
||||
@ -40,17 +40,17 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||
#### 创建物理卷 ####
|
||||
|
||||
我们会从一个完全新的没有任何分区和信息的硬盘驱动开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
我们会从一个全新的没有任何分区和信息的硬盘开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
|
||||
> 注意:记住所有的命令都要以 root 身份运行或者在命令前面添加 'sudo' 。
|
||||
|
||||
fdisk -l
|
||||
|
||||
如果之前你的硬盘驱动从没有格式化或分区,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
如果之前你的硬盘从未格式化或分区过,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
|
||||

|
||||
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在驱动上创建一个新的分区。
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在磁盘上创建一个新的分区。
|
||||
|
||||
这里有大量能创建新分区的 GUI 工具,包括 [Gparted][2],但由于我们已经打开了终端,我们将使用 fdisk 命令创建需要的分区。
|
||||
|
||||
@ -62,9 +62,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
以指定的顺序输入命令创建一个使用新硬盘驱动 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或相应多个分区,我建议使用 GParted 或自己了解关于 fdisk 命令的使用。
|
||||
以指定的顺序输入命令创建一个使用新硬盘 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或想要多个分区,我建议使用 GParted 或自己了解一下关于 fdisk 命令的使用。
|
||||
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何信息。**
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何有用的信息。**
|
||||
|
||||
- n = 创建新分区
|
||||
- p = 创建主分区
|
||||
@ -79,9 +79,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
- t = 更改分区类型
|
||||
- 8e = 更改为 LVM 分区类型
|
||||
|
||||
核实并将信息写入硬盘驱动器。
|
||||
核实并将信息写入硬盘。
|
||||
|
||||
- p = 查看分区设置使得写入更改到磁盘之前可以回看
|
||||
- p = 查看分区设置使得在写入更改到磁盘之前可以回看
|
||||
- w = 写入更改到磁盘
|
||||
|
||||

|
||||
@ -102,7 +102,7 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
|
||||
#### 创建逻辑卷 ####
|
||||
|
||||
@ -112,7 +112,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 所以 lvcreate 命令知道从什么卷获取空间。
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 以便 lvcreate 命令知道从什么卷获取空间。
|
||||
|
||||
#### 格式化并挂载逻辑卷 ####
|
||||
|
||||
@ -131,7 +131,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
#### 重新设置逻辑卷大小 ####
|
||||
|
||||
逻辑卷的一个好处是你能使你的共享物理变大或变小而不需要移动所有东西到一个更大的硬盘驱动。另外,你可以添加新的硬盘驱动并同时扩展你的卷组。或者如果你有一个不使用的硬盘驱动,你可以从卷组中移除它使得逻辑卷变小。
|
||||
逻辑卷的一个好处是你能使你的存储物理地变大或变小,而不需要移动所有东西到一个更大的硬盘。另外,你可以添加新的硬盘并同时扩展你的卷组。或者如果你有一个不使用的硬盘,你可以从卷组中移除它使得逻辑卷变小。
|
||||
|
||||
这里有三个用于使物理卷、卷组和逻辑卷变大或变小的基础工具。
|
||||
|
||||
@ -147,9 +147,9 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
按照上面创建新分区并更改分区类型为 LVM(8e) 的步骤安装一个新硬盘驱动。然后用 pvcreate 命令创建一个 LVM 能识别的物理卷。
|
||||
|
||||
#### 添加新硬盘驱动到卷组 ####
|
||||
#### 添加新硬盘到卷组 ####
|
||||
|
||||
要添加新的硬盘驱动到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
要添加新的硬盘到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
|
||||
这会添加新物理卷到已存在的卷组中。
|
||||
|
||||
@ -189,7 +189,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
1. 调整文件系统大小 (调整之前确保已经移动文件到硬盘驱动安全的地方)
|
||||
1. 减小逻辑卷 (除了 + 可以扩展大小,你也可以用 - 压缩大小)
|
||||
1. 用 vgreduce 从卷组中移除硬盘驱动
|
||||
1. 用 vgreduce 从卷组中移除硬盘
|
||||
|
||||
#### 备份逻辑卷 ####
|
||||
|
||||
@ -197,7 +197,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该照片可以用于在不同的硬盘驱动上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的“照片”,该“照片”可以用于在不同的硬盘上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
|
||||
要创建一个快照,我们需要创建拥有足够空闲空间的逻辑卷,用于保存我们备份的时候会写入该逻辑卷的任何新信息。如果驱动并不是经常写入,你可以使用很小的一个存储空间。备份完成的时候我们只需要移除临时逻辑卷,原始逻辑卷会和往常一样。
|
||||
|
||||
@ -209,7 +209,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为驱动实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为该硬盘实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
|
||||
#### 挂载新快照 ####
|
||||
|
||||
@ -222,7 +222,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||
#### 复制快照和删除逻辑卷 ####
|
||||
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘驱动或者打包所有文件到一个文件。
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘或者打包所有文件到一个文件。
|
||||
|
||||
**注意:tar -c 会创建一个归档文件,-f 要指出归档文件的名称和路径。要获取 tar 命令的帮助信息,可以在终端中输入 man tar。**
|
||||
|
||||
@ -230,7 +230,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
记住备份发生的时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
记住备份时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
|
||||
备份完成后,卸载卷并移除临时快照。
|
||||
|
||||
@ -259,10 +259,10 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
[1]:https://linux.cn/article-5953-1.html
|
||||
[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
|
||||
[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
|
||||
@ -0,0 +1,67 @@
|
||||
Ubuntu 上使用 LVM 轻松调整分区并制作快照
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu的安装器提供了一个轻松“使用LVM”的复选框。它的描述中说,启用逻辑卷管理可以让你制作快照,并更容易地调整硬盘分区大小——这里将为大家讲述如何完成这些操作。
|
||||
|
||||
LVM是一种技术,某种程度上和[RAID阵列][1]或[Windows上的“存储空间”][2]类似。虽然该技术在服务器上更为有用,但是它也可以在桌面端PC上使用。
|
||||
|
||||
### 你应该在新安装Ubuntu时使用LVM吗? ###
|
||||
|
||||
第一个问题是,你是否想要在安装Ubuntu时使用LVM?如果是,那么Ubuntu让这一切变得很简单,只需要轻点鼠标就可以完成,但是该选项默认是不启用的。正如安装器所说的,它允许你调整分区、创建快照、将多个磁盘合并到一个逻辑卷等等——所有这一切都可以在系统运行时完成。不同于传统分区,你不需要关掉你的系统,从Live CD或USB驱动,然后[当这些分区不使用时才能调整][3]。
|
||||
|
||||
完全坦率地说,普通Ubuntu桌面用户可能不会意识到他们是否正在使用LVM。但是,如果你想要在今后做一些更高深的事情,那么LVM就会有所帮助了。LVM可能更复杂,可能会在你今后恢复数据时会导致问题——尤其是在你经验不足时。这里不会有显著的性能损失——LVM是彻底地在Linux内核中实现的。
|
||||
|
||||

|
||||
|
||||
### 逻辑卷管理说明 ###
|
||||
|
||||
前面,我们已经[说明了何谓LVM][4]。概括来讲,它在你的物理磁盘和呈现在你系统中的分区之间提供了一个抽象层。例如,你的计算机可能装有两个硬盘驱动器,它们的大小都是 1 TB。你必须得在这些磁盘上至少分两个区,每个区大小 1 TB。
|
||||
|
||||
LVM就在这些分区上提供了一个抽象层。用于取代磁盘上的传统分区,LVM将在你对这些磁盘初始化后,将它们当作独立的“物理卷”来对待。然后,你就可以基于这些物理卷创建“逻辑卷”。例如,你可以将这两个 1 TB 的磁盘组合成一个 2 TB 的分区,你的系统将只看到一个 2 TB 的卷,而LVM将会在后台处理这一切。一组物理卷以及一组逻辑卷被称之为“卷组”,一个典型的系统只会有一个卷组。
|
||||
|
||||
该抽象层使得调整分区、将多个磁盘组合成单个卷、甚至为一个运行着的分区的文件系统创建“快照”变得十分简单,而完成所有这一切都无需先卸载分区。
|
||||
|
||||
注意,如果你没有创建备份,那么将多个磁盘合并成一个卷将会是个糟糕的想法。它就像RAID 0——如果你将两个 1 TB 的卷组合成一个 2 TB 的卷,只要其中一个硬盘失败,你将丢失该卷上的重要数据。所以,如果你要走这条路,那么备份就及其重要。
|
||||
|
||||
### 管理LVM卷的图形化工具 ###
|
||||
|
||||
通常,[LVM通过Linux终端命令来管理][5]。这在Ubuntu上也行得通,但是有个更简单的图形化方法可供大家采用。如果你是一个Linux用户,对GParted或者与其类似的分区管理器熟悉,算了,别瞎掰了——GParted根本不支持LVM磁盘。
|
||||
|
||||
然而,你可以使用Ubuntu附带的磁盘工具。该工具也被称之为GNOME磁盘工具,或者叫Palimpsest。点击dash中的图标来开启它吧,搜索“磁盘”然后敲击回车。不像GParted,该磁盘工具将会在“其它设备”下显示LVM分区,因此你可以根据需要格式化这些分区,也可以调整其它选项。该工具在Live CD或USB 驱动下也可以使用。
|
||||
|
||||

|
||||
|
||||
不幸的是,该磁盘工具不支持LVM的大多数强大的特性,没有管理卷组、扩展分区,或者创建快照等选项。对于这些操作,你可以通过终端来实现,但是没有那个必要。相反,你可以打开Ubuntu软件中心,搜索关键字LVM,然后安装逻辑卷管理工具,你可以在终端窗口中运行**sudo apt-get install system-config-lvm**命令来安装它。安装完之后,你就可以从dash上打开逻辑卷管理工具了。
|
||||
|
||||
这个图形化配置工具是由红帽公司开发的,虽然有点陈旧了,但却是唯一的图形化方式,你可以通过它来完成上述操作,将那些终端命令抛诸脑后了。
|
||||
|
||||
比如说,你想要添加一个新的物理卷到卷组中。你可以打开该工具,选择未初始化条目下的新磁盘,然后点击“初始化条目”按钮。然后,你就可以在未分配卷下找到新的物理卷了,你可以使用“添加到现存卷组”按钮来将它添加到“ubuntu-vg”卷组,这是Ubuntu在安装过程中创建的卷组。
|
||||
|
||||

|
||||
|
||||
卷组视图会列出你所有的物理卷和逻辑卷的总览。这里,我们有两个横跨两个独立硬盘驱动器的物理分区,我们有一个交换分区和一个根分区,这是Ubuntu默认设置的分区图表。由于我们从另一个驱动器添加了第二个物理分区,现在那里有大量未使用空间。
|
||||
|
||||

|
||||
|
||||
要扩展逻辑分区到物理空间,你可以在逻辑视图下选择它,点击编辑属性,然后修改大小来扩大分区。你也可以在这里缩小分区。
|
||||
|
||||

|
||||
|
||||
system-config-lvm的其它选项允许你设置快照和镜像。对于传统桌面而言,你或许不需要这些特性,但是在这里也可以通过图形化处理。记住,你也可以[使用终端命令完成这一切][6]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/211937/how-to-use-lvm-on-ubuntu-for-easy-partition-resizing-and-snapshots/
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/162676/how-to-use-multiple-disks-intelligently-an-introduction-to-raid/
|
||||
[2]:http://www.howtogeek.com/109380/how-to-use-windows-8s-storage-spaces-to-mirror-combine-drives/
|
||||
[3]:http://www.howtogeek.com/114503/how-to-resize-your-ubuntu-partitions/
|
||||
[4]:http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
[5]:http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
[6]:http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
@ -0,0 +1,89 @@
|
||||
如何在树莓派 2 运行 ubuntu Snappy Core
|
||||
================================================================================
|
||||
物联网(Internet of Things, IoT) 时代即将来临。很快,过不了几年,我们就会问自己当初是怎么在没有物联网的情况下生存的,就像我们现在怀疑过去没有手机的年代。Canonical 就是一个物联网快速发展却还是开放市场下的竞争者。这家公司宣称自己把赌注压到了IoT 上,就像他们已经在“云”上做过的一样。在今年一月底,Canonical 启动了一个基于Ubuntu Core 的小型操作系统,名字叫做 [Ubuntu Snappy Core][1] 。
|
||||
|
||||
Snappy 代表了两种意思,它是一种用来替代 deb 的新的打包格式;也是一个用来更新系统的前端,从CoreOS、红帽子和其他系统借鉴了**原子更新**这个想法。自从树莓派 2 投入市场,Canonical 很快就发布了用于树莓派的Snappy Core 版本。而第一代树莓派因为是基于ARMv6 ,Ubuntu 的ARM 镜像是基于ARMv7 ,所以不能运行ubuntu 。不过这种状况现在改变了,Canonical 通过发布 Snappy Core 的RPI2 镜像,抓住机会证明了Snappy 就是一个用于云计算,特别是用于物联网的系统。
|
||||
|
||||
Snappy 同样可以运行在其它像Amazon EC2, Microsofts Azure, Google的 Compute Engine 这样的云端上,也可以虚拟化在 KVM、Virtuabox 和vagrant 上。Canonical Ubuntu 已经拥抱了微软、谷歌、Docker、OpenStack 这些重量级选手,同时也与一些小项目达成合作关系。除了一些创业公司,比如 Ninja Sphere、Erle Robotics,还有一些开发板生产商,比如 Odroid、Banana Pro, Udoo, PCDuino 和 Parallella 、全志,Snappy 也提供了支持。Snappy Core 同时也希望尽快运行到路由器上来帮助改进路由器生产商目前很少更新固件的策略。
|
||||
|
||||
接下来,让我们看看怎么样在树莓派 2 上运行 Ubuntu Snappy Core。
|
||||
|
||||
用于树莓派2 的Snappy 镜像可以从 [Raspberry Pi 网站][2] 上下载。解压缩出来的镜像必须[写到一个至少8GB 大小的SD 卡][3]。尽管原始系统很小,但是原子升级和回滚功能会占用不小的空间。使用 Snappy 启动树莓派 2 后你就可以使用默认用户名和密码(都是ubuntu)登录系统。
|
||||
|
||||
|
||||
|
||||
sudo 已经配置好了可以直接用,安全起见,你应该使用以下命令来修改你的用户名
|
||||
|
||||
$ sudo usermod -l <new name> <old name>
|
||||
|
||||
或者也可以使用`adduser` 为你添加一个新用户。
|
||||
|
||||
因为RPI缺少硬件时钟,而 Snappy Core 镜像并不知道这一点,所以系统会有一个小 bug:处理某些命令时会报很多错。不过这个很容易解决:
|
||||
|
||||
使用这个命令来确认这个bug 是否影响:
|
||||
|
||||
$ date
|
||||
|
||||
如果输出类似 "Thu Jan 1 01:56:44 UTC 1970", 你可以这样做来改正:
|
||||
|
||||
$ sudo date --set="Sun Apr 04 17:43:26 UTC 2015"
|
||||
|
||||
改成你的实际时间。
|
||||
|
||||

|
||||
|
||||
现在你可能打算检查一下,看看有没有可用的更新。注意通常使用的命令是不行的:
|
||||
|
||||
$ sudo apt-get update && sudo apt-get distupgrade
|
||||
|
||||
这时系统不会让你通过,因为 Snappy 使用它自己精简过的、基于dpkg 的包管理系统。这么做的原因是 Snappy 会运行很多嵌入式程序,而同时你也会试图所有事情尽可能的简化。
|
||||
|
||||
让我们来看看最关键的部分,理解一下程序是如何与 Snappy 工作的。运行 Snappy 的SD 卡上除了 boot 分区外还有3个分区。其中的两个构成了一个重复的文件系统。这两个平行文件系统被固定挂载为只读模式,并且任何时刻只有一个是激活的。第三个分区是一个部分可写的文件系统,用来让用户存储数据。通过更新系统,标记为'system-a' 的分区会保持一个完整的文件系统,被称作核心,而另一个平行的文件系统仍然会是空的。
|
||||
|
||||

|
||||
|
||||
如果我们运行以下命令:
|
||||
|
||||
$ sudo snappy update
|
||||
|
||||
系统将会在'system-b' 上作为一个整体进行更新,这有点像是更新一个镜像文件。接下来你将会被告知要重启系统来激活新核心。
|
||||
|
||||
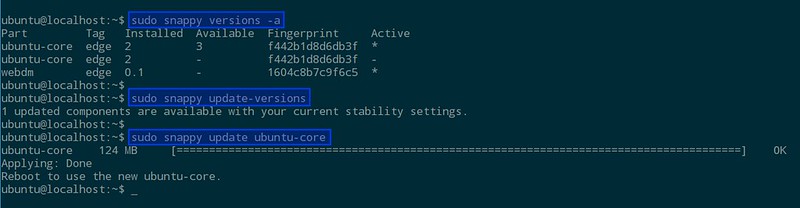
重启之后,运行下面的命令可以检查你的系统是否已经更新到最新版本,以及当前被激活的是哪个核心
|
||||
|
||||
$ sudo snappy versions -a
|
||||
|
||||
经过更新-重启两步操作,你应该可以看到被激活的核心已经被改变了。
|
||||
|
||||
因为到目前为止我们还没有安装任何软件,所以可以用下面的命令更新:
|
||||
|
||||
$ sudo snappy update ubuntu-core
|
||||
|
||||
如果你打算仅仅更新特定的OS 版本这就够了。如果出了问题,你可以使用下面的命令回滚:
|
||||
|
||||
$ sudo snappy rollback ubuntu-core
|
||||
|
||||
这将会把系统状态回滚到更新之前。
|
||||
|
||||
|
||||
|
||||
再来说说那些让 Snappy 变得有用的软件。这里不会讲的太多关于如何构建软件、向 Snappy 应用商店添加软件的基础知识,但是你可以通过 Freenode 上的IRC 频道 #snappy 了解更多信息,那个上面有很多人参与。你可以通过浏览器访问http://\<ip-address>:4200 来浏览应用商店,然后从商店安装软件,再在浏览器里访问 http://webdm.local 来启动程序。如何构建用于 Snappy 的软件并不难,而且也有了现成的[参考文档][4] 。你也可以很容易的把 DEB 安装包使用Snappy 格式移植到Snappy 上。
|
||||
|
||||
|
||||
|
||||
尽管 Ubuntu Snappy Core 吸引了我们去研究新型的 Snappy 安装包格式和 Canonical 式的原子更新操作,但是因为有限的可用应用,它现在在生产环境里还不是很有用。但是既然搭建一个 Snappy 环境如此简单,这看起来是一个学点新东西的好机会。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/ubuntu-snappy-core-raspberry-pi-2.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/ferdinand
|
||||
[1]:http://www.ubuntu.com/things
|
||||
[2]:http://www.raspberrypi.org/downloads/
|
||||
[3]:http://xmodulo.com/write-raspberry-pi-image-sd-card.html
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
@ -0,0 +1,131 @@
|
||||
如何通过反向 SSH 隧道访问 NAT 后面的 Linux 服务器
|
||||
================================================================================
|
||||
你在家里运行着一台 Linux 服务器,它放在一个 NAT 路由器或者限制性防火墙后面。现在你想在外出时用 SSH 登录到这台服务器。你如何才能做到呢?SSH 端口转发当然是一种选择。但是,如果你需要处理多级嵌套的 NAT 环境,端口转发可能会变得非常棘手。另外,在多种 ISP 特定条件下可能会受到干扰,例如阻塞转发端口的限制性 ISP 防火墙、或者在用户间共享 IPv4 地址的运营商级 NAT。
|
||||
|
||||
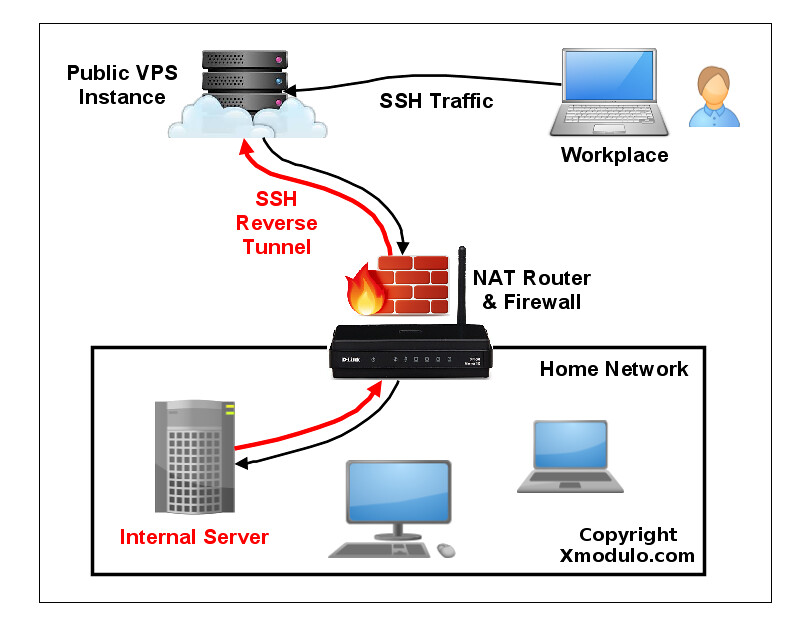
### 什么是反向 SSH 隧道? ###
|
||||
|
||||
SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧道的概念非常简单。使用这种方案,在你的受限的家庭网络之外你需要另一台主机(所谓的“中继主机”),你能从当前所在地通过 SSH 登录到它。你可以用有公网 IP 地址的 [VPS 实例][1] 配置一个中继主机。然后要做的就是从你的家庭网络服务器中建立一个到公网中继主机的永久 SSH 隧道。有了这个隧道,你就可以从中继主机中连接“回”家庭服务器(这就是为什么称之为 “反向” 隧道)。不管你在哪里、你的家庭网络中的 NAT 或 防火墙限制多么严格,只要你可以访问中继主机,你就可以连接到家庭服务器。
|
||||
|
||||
|
||||
|
||||
### 在 Linux 上设置反向 SSH 隧道 ###
|
||||
|
||||
让我们来看看怎样创建和使用反向 SSH 隧道。我们做如下假设:我们会设置一个从家庭服务器(homeserver)到中继服务器(relayserver)的反向 SSH 隧道,然后我们可以通过中继服务器从客户端计算机(clientcomputer) SSH 登录到家庭服务器。本例中的**中继服务器** 的公网 IP 地址是 1.1.1.1。
|
||||
|
||||
在家庭服务器上,按照以下方式打开一个到中继服务器的 SSH 连接。
|
||||
|
||||
homeserver~$ ssh -fN -R 10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
这里端口 10022 是任何你可以使用的端口数字。只需要确保中继服务器上不会有其它程序使用这个端口。
|
||||
|
||||
“-R 10022:localhost:22” 选项定义了一个反向隧道。它转发中继服务器 10022 端口的流量到家庭服务器的 22 号端口。
|
||||
|
||||
用 “-fN” 选项,当你成功通过 SSH 服务器验证时 SSH 会进入后台运行。当你不想在远程 SSH 服务器执行任何命令,就像我们的例子中只想转发端口的时候非常有用。
|
||||
|
||||
运行上面的命令之后,你就会回到家庭主机的命令行提示框中。
|
||||
|
||||
登录到中继服务器,确认其 127.0.0.1:10022 绑定到了 sshd。如果是的话就表示已经正确设置了反向隧道。
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 127.0.0.1:10022 0.0.0.0:* LISTEN 8493/sshd
|
||||
|
||||
现在就可以从任何其它计算机(客户端计算机)登录到中继服务器,然后按照下面的方法访问家庭服务器。
|
||||
|
||||
relayserver~$ ssh -p 10022 homeserver_user@localhost
|
||||
|
||||
需要注意的一点是你在上面为localhost输入的 SSH 登录/密码应该是家庭服务器的,而不是中继服务器的,因为你是通过隧道的本地端点登录到家庭服务器,因此不要错误输入中继服务器的登录/密码。成功登录后,你就在家庭服务器上了。
|
||||
|
||||
### 通过反向 SSH 隧道直接连接到网络地址变换后的服务器 ###
|
||||
|
||||
上面的方法允许你访问 NAT 后面的 **家庭服务器**,但你需要登录两次:首先登录到 **中继服务器**,然后再登录到**家庭服务器**。这是因为中继服务器上 SSH 隧道的端点绑定到了回环地址(127.0.0.1)。
|
||||
|
||||
事实上,有一种方法可以只需要登录到中继服务器就能直接访问NAT之后的家庭服务器。要做到这点,你需要让中继服务器上的 sshd 不仅转发回环地址上的端口,还要转发外部主机的端口。这通过指定中继服务器上运行的 sshd 的 **GatewayPorts** 实现。
|
||||
|
||||
打开**中继服务器**的 /etc/ssh/sshd_conf 并添加下面的行。
|
||||
|
||||
relayserver~$ vi /etc/ssh/sshd_conf
|
||||
|
||||
----------
|
||||
|
||||
GatewayPorts clientspecified
|
||||
|
||||
重启 sshd。
|
||||
|
||||
基于 Debian 的系统:
|
||||
|
||||
relayserver~$ sudo /etc/init.d/ssh restart
|
||||
|
||||
基于红帽的系统:
|
||||
|
||||
relayserver~$ sudo systemctl restart sshd
|
||||
|
||||
现在在家庭服务器中按照下面方式初始化一个反向 SSH 隧道。
|
||||
|
||||
homeserver~$ ssh -fN -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
登录到中继服务器然后用 netstat 命令确认成功建立的一个反向 SSH 隧道。
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 1.1.1.1:10022 0.0.0.0:* LISTEN 1538/sshd: dev
|
||||
|
||||
不像之前的情况,现在隧道的端点是 1.1.1.1:10022(中继服务器的公网 IP 地址),而不是 127.0.0.1:10022。这就意味着从外部主机可以访问隧道的另一端。
|
||||
|
||||
现在在任何其它计算机(客户端计算机),输入以下命令访问网络地址变换之后的家庭服务器。
|
||||
|
||||
clientcomputer~$ ssh -p 10022 homeserver_user@1.1.1.1
|
||||
|
||||
在上面的命令中,1.1.1.1 是中继服务器的公共 IP 地址,homeserver_user必须是家庭服务器上的用户账户。这是因为你真正登录到的主机是家庭服务器,而不是中继服务器。后者只是中继你的 SSH 流量到家庭服务器。
|
||||
|
||||
### 在 Linux 上设置一个永久反向 SSH 隧道 ###
|
||||
|
||||
现在你已经明白了怎样创建一个反向 SSH 隧道,然后把隧道设置为 “永久”,这样隧道启动后就会一直运行(不管临时的网络拥塞、SSH 超时、中继主机重启,等等)。毕竟,如果隧道不是一直有效,你就不能可靠的登录到你的家庭服务器。
|
||||
|
||||
对于永久隧道,我打算使用一个叫 autossh 的工具。正如名字暗示的,这个程序可以让你的 SSH 会话无论因为什么原因中断都会自动重连。因此对于保持一个反向 SSH 隧道非常有用。
|
||||
|
||||
第一步,我们要设置从家庭服务器到中继服务器的[无密码 SSH 登录][2]。这样的话,autossh 可以不需要用户干预就能重启一个损坏的反向 SSH 隧道。
|
||||
|
||||
下一步,在建立隧道的家庭服务器上[安装 autossh][3]。
|
||||
|
||||
在家庭服务器上,用下面的参数运行 autossh 来创建一个连接到中继服务器的永久 SSH 隧道。
|
||||
|
||||
homeserver~$ autossh -M 10900 -fN -o "PubkeyAuthentication=yes" -o "StrictHostKeyChecking=false" -o "PasswordAuthentication=no" -o "ServerAliveInterval 60" -o "ServerAliveCountMax 3" -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
“-M 10900” 选项指定中继服务器上的监视端口,用于交换监视 SSH 会话的测试数据。中继服务器上的其它程序不能使用这个端口。
|
||||
|
||||
“-fN” 选项传递给 ssh 命令,让 SSH 隧道在后台运行。
|
||||
|
||||
“-o XXXX” 选项让 ssh:
|
||||
|
||||
- 使用密钥验证,而不是密码验证。
|
||||
- 自动接受(未知)SSH 主机密钥。
|
||||
- 每 60 秒交换 keep-alive 消息。
|
||||
- 没有收到任何响应时最多发送 3 条 keep-alive 消息。
|
||||
|
||||
其余 SSH 隧道相关的选项和之前介绍的一样。
|
||||
|
||||
如果你想系统启动时自动运行 SSH 隧道,你可以将上面的 autossh 命令添加到 /etc/rc.local。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇博文中,我介绍了你如何能从外部通过反向 SSH 隧道访问限制性防火墙或 NAT 网关之后的 Linux 服务器。这里我介绍了家庭网络中的一个使用事例,但在企业网络中使用时你尤其要小心。这样的一个隧道可能被视为违反公司政策,因为它绕过了企业的防火墙并把企业网络暴露给外部攻击。这很可能被误用或者滥用。因此在使用之前一定要记住它的作用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:https://linux.cn/article-5444-1.html
|
||||
[3]:https://linux.cn/article-5459-1.html
|
||||
@ -0,0 +1,199 @@
|
||||
如何配置 MongoDB 副本集
|
||||
================================================================================
|
||||
|
||||
MongoDB 已经成为市面上最知名的 NoSQL 数据库。MongoDB 是面向文档的,它的无模式设计使得它在各种各样的WEB 应用当中广受欢迎。最让我喜欢的特性之一是它的副本集(Replica Set),副本集将同一数据的多份拷贝放在一组 mongod 节点上,从而实现数据的冗余以及高可用性。
|
||||
|
||||
这篇教程将向你介绍如何配置一个 MongoDB 副本集。
|
||||
|
||||
副本集的最常见配置需要一个主节点以及多个副节点。这之后启动的复制行为会从这个主节点到其他副节点。副本集不止可以针对意外的硬件故障和停机事件对数据库提供保护,同时也因为提供了更多的节点从而提高了数据库客户端数据读取的吞吐量。
|
||||
|
||||
### 配置环境 ###
|
||||
|
||||
这个教程里,我们会配置一个包括一个主节点以及两个副节点的副本集。
|
||||
|
||||

|
||||
|
||||
为了达到这个目的,我们使用了3个运行在 VirtualBox 上的虚拟机。我会在这些虚拟机上安装 Ubuntu 14.04,并且安装 MongoDB 官方包。
|
||||
|
||||
我会在一个虚拟机实例上配置好所需的环境,然后将它克隆到其他的虚拟机实例上。因此,选择一个名为 master 的虚拟机,执行以下安装过程。
|
||||
|
||||
首先,我们需要给 apt 增加一个 MongoDB 密钥:
|
||||
|
||||
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
|
||||
|
||||
然后,将官方的 MongoDB 仓库添加到 source.list 中:
|
||||
|
||||
$ sudo su
|
||||
# echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
|
||||
|
||||
接下来更新 apt 仓库并且安装 MongoDB。
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install -y mongodb-org
|
||||
|
||||
现在对 /etc/mongodb.conf 做一些更改
|
||||
|
||||
auth = true
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
replSet=myReplica
|
||||
|
||||
第一行的作用是表明我们的数据库需要验证才可以使用。keyfile 配置用于 MongoDB 节点间复制行为的密钥文件。replSet 为副本集设置一个名称。
|
||||
|
||||
接下来我们创建一个用于所有实例的密钥文件。
|
||||
|
||||
$ echo -n "MyRandomStringForReplicaSet" | md5sum > keyFile
|
||||
|
||||
这将会创建一个含有 MD5 字符串的密钥文件,但是由于其中包含了一些噪音,我们需要对他们清理后才能正式在 MongoDB 中使用。
|
||||
|
||||
$ echo -n "MyReplicaSetKey" | md5sum|grep -o "[0-9a-z]\+" > keyFile
|
||||
|
||||
grep 命令的作用的是把将空格等我们不想要的内容过滤掉之后的 MD5 字符串打印出来。
|
||||
|
||||
现在我们对密钥文件进行一些操作,让它真正可用。
|
||||
|
||||
$ sudo cp keyFile /var/lib/mongodb
|
||||
$ sudo chown mongodb:nogroup keyFile
|
||||
$ sudo chmod 400 keyFile
|
||||
|
||||
接下来,关闭此虚拟机。将其 Ubuntu 系统克隆到其他虚拟机上。
|
||||
|
||||

|
||||
|
||||
这是克隆后的副节点1和副节点2。确认你已经将它们的MAC地址重新初始化,并且克隆整个硬盘。
|
||||
|
||||

|
||||
|
||||
请注意,三个虚拟机示例需要在同一个网络中以便相互通讯。因此,我们需要它们弄到“互联网"上去。
|
||||
|
||||
这里推荐给每个虚拟机设置一个静态 IP 地址,而不是使用 DHCP。这样它们就不至于在 DHCP 分配IP地址给他们的时候失去连接。
|
||||
|
||||
像下面这样编辑每个虚拟机的 /etc/networks/interfaces 文件。
|
||||
|
||||
在主节点上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.2
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副节点1上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.3
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副节点2上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.4
|
||||
netmask 255.255.255.0
|
||||
|
||||
由于我们没有 DNS 服务,所以需要设置设置一下 /etc/hosts 这个文件,手工将主机名称放到此文件中。
|
||||
|
||||
在主节点上:
|
||||
|
||||
127.0.0.1 localhost primary
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副节点1上:
|
||||
|
||||
127.0.0.1 localhost secondary1
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副节点2上:
|
||||
|
||||
127.0.0.1 localhost secondary2
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
使用 ping 命令检查各个节点之间的连接。
|
||||
|
||||
$ ping primary
|
||||
$ ping secondary1
|
||||
$ ping secondary2
|
||||
|
||||
### 配置副本集 ###
|
||||
|
||||
验证各个节点可以正常连通后,我们就可以新建一个管理员用户,用于之后的副本集操作。
|
||||
|
||||
在主节点上,打开 /etc/mongodb.conf 文件,将 auth 和 replSet 两项注释掉。
|
||||
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
#auth = true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
#replSet=myReplica
|
||||
|
||||
在一个新安装的 MongoDB 上配置任何用户或副本集之前,你需要注释掉 auth 行。默认情况下,MongoDB 并没有创建任何用户。而如果在你创建用户前启用了 auth,你就不能够做任何事情。你可以在创建一个用户后再次启用 auth。
|
||||
|
||||
修改 /etc/mongodb.conf 之后,重启 mongod 进程。
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
现在连接到 MongoDB master:
|
||||
|
||||
$ mongo <master-ip-address>:27017
|
||||
|
||||
连接 MongoDB 后,新建管理员用户。
|
||||
|
||||
> use admin
|
||||
> db.createUser({
|
||||
user:"admin",
|
||||
pwd:"
|
||||
})
|
||||
|
||||
重启 MongoDB:
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
再次连接到 MongoDB,用以下命令将 副节点1 和副节点2节点添加到我们的副本集中。
|
||||
|
||||
> use admin
|
||||
> db.auth("admin","myreallyhardpassword")
|
||||
> rs.initiate()
|
||||
> rs.add ("secondary1:27017")
|
||||
> rs.add("secondary2:27017")
|
||||
|
||||
|
||||
现在副本集到手了,可以开始我们的项目了。参照 [官方驱动文档][1] 来了解如何连接到副本集。如果你想要用 Shell 来请求数据,那么你需要连接到主节点上来插入或者请求数据,副节点不行。如果你执意要尝试用副本集操作,那么以下错误信息就蹦出来招呼你了。
|
||||
|
||||
myReplica:SECONDARY>
|
||||
myReplica:SECONDARY> show databases
|
||||
2015-05-10T03:09:24.131+0000 E QUERY Error: listDatabases failed:{ "note" : "from execCommand", "ok" : 0, "errmsg" : "not master" }
|
||||
at Error ()
|
||||
at Mongo.getDBs (src/mongo/shell/mongo.js:47:15)
|
||||
at shellHelper.show (src/mongo/shell/utils.js:630:33)
|
||||
at shellHelper (src/mongo/shell/utils.js:524:36)
|
||||
at (shellhelp2):1:1 at src/mongo/shell/mongo.js:47
|
||||
|
||||
如果你要从 shell 连接到整个副本集,你可以安装如下命令。在副本集中的失败切换是自动的。
|
||||
|
||||
$ mongo primary,secondary1,secondary2:27017/?replicaSet=myReplica
|
||||
|
||||
如果你使用其它驱动语言(例如,JavaScript、Ruby 等等),格式也许不同。
|
||||
|
||||
希望这篇教程能对你有所帮助。你可以使用Vagrant来自动完成你的本地环境配置,并且加速你的代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-replica-set-mongodb.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
[1]:http://docs.mongodb.org/ecosystem/drivers/
|
||||
@ -0,0 +1,113 @@
|
||||
在 VirtualBox 中使用 Docker Machine 管理主机
|
||||
================================================================================
|
||||
大家好,今天我们学习在 VirtualBox 中使用 Docker Machine 来创建和管理 Docker 主机。Docker Machine 是一个可以帮助我们在电脑上、在云端、在数据中心内创建 Docker 主机的应用。它为根据用户的配置和需求创建服务器并在其上安装 Docker和客户端提供了一个轻松的解决方案。这个 API 可以用于在本地主机、或数据中心的虚拟机、或云端的实例提供 Docker 服务。Docker Machine 支持 Windows、OSX 和 Linux,并且是以一个独立的二进制文件包形式安装的。仍然使用(与现有 Docker 工具)相同的接口,我们就可以充分利用已经提供 Docker 基础框架的生态系统。只要一个命令,用户就能快速部署 Docker 容器。
|
||||
|
||||
本文列出一些简单的步骤用 Docker Machine 来部署 docker 容器。
|
||||
|
||||
### 1. 安装 Docker Machine ###
|
||||
|
||||
Docker Machine 完美支持所有 Linux 操作系统。首先我们需要从 [github][1] 下载最新版本的 Docker Machine,本文使用 curl 作为下载工具,Docker Machine 版本为 0.2.0。
|
||||
|
||||
**64 位操作系统**
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
**32 位操作系统**
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
下载完成后,找到 **/usr/local/bin** 目录下的 **docker-machine** 文件,让其可以执行:
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
确认是否成功安装了 docker-machine,可以运行下面的命令,它会打印 Docker Machine 的版本信息:
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
运行下面的命令,安装 Docker 客户端,以便于在我们自己的电脑止运行 Docker 命令:
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建 VirtualBox 虚拟机 ###
|
||||
|
||||
在 Linux 系统上安装完 Docker Machine 后,接下来我们可以安装 VirtualBox 虚拟机,运行下面的就可以了。`--driver virtualbox` 选项表示我们要在 VirtualBox 的虚拟机里面部署 docker,最后的参数“linux” 是虚拟机的名称。这个命令会下载 [boot2docker][2] iso,它是个基于 Tiny Core Linux 的轻量级发行版,自带 Docker 程序,然后 `docker-machine` 命令会创建一个 VirtualBox 虚拟机(LCTT译注:当然,我们也可以选择其他的虚拟机软件)来运行这个 boot2docker 系统。
|
||||
|
||||
# docker-machine create --driver virtualbox linux
|
||||
|
||||

|
||||
|
||||
测试下有没有成功运行 VirtualBox 和 Docker,运行命令:
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
如果执行成功,我们可以看到在 ACTIVE 那列下面会出现一个星号“*”。
|
||||
|
||||
### 3. 设置环境变量 ###
|
||||
|
||||
现在我们需要让 docker 与 docker-machine 通信,运行 `docker-machine env <虚拟机名称>` 来实现这个目的。
|
||||
|
||||
# eval "$(docker-machine env linux)"
|
||||
# docker ps
|
||||
|
||||
这个命令会设置 TLS 认证的环境变量,每次重启机器或者重新打开一个会话都需要执行一下这个命令,我们可以看到它的输出内容:
|
||||
|
||||
# docker-machine env linux
|
||||
|
||||
export DOCKER_TLS_VERIFY=1
|
||||
export DOCKER_CERT_PATH=/Users/<your username>/.docker/machine/machines/dev
|
||||
export DOCKER_HOST=tcp://192.168.99.100:2376
|
||||
|
||||
### 4. 运行 Docker 容器 ###
|
||||
|
||||
完成配置后我们就可以在 VirtualBox 上运行 docker 容器了。测试一下,我们可以运行虚拟机 `docker run busybox` ,并在里面里执行 `echo hello world` 命令,我们可以看到容器的输出信息。
|
||||
|
||||
# docker run busybox echo hello world
|
||||
|
||||

|
||||
|
||||
### 5. 拿到 Docker 主机的 IP ###
|
||||
|
||||
我们可以执行下面的命令获取运行 Docker 的主机的 IP 地址。我们可以看到在 Docker 主机的 IP 地址上的任何暴露出来的端口。
|
||||
|
||||
# docker-machine ip
|
||||
|
||||

|
||||
|
||||
### 6. 管理主机 ###
|
||||
|
||||
现在我们可以随心所欲地使用上述的 docker-machine 命令来不断创建主机了。
|
||||
|
||||
当你使用完 docker 时,可以运行 **docker-machine stop** 来停止所有主机,如果想开启所有主机,运行 **docker-machine start**。
|
||||
|
||||
# docker-machine stop
|
||||
# docker-machine start
|
||||
|
||||
你也可以只停止或开启一台主机:
|
||||
|
||||
$ docker-machine stop linux
|
||||
$ docker-machine start linux
|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,我们使用 Docker Machine 成功在 VirtualBox 上创建并管理一台 Docker 主机。Docker Machine 确实能让用户快速地在不同的平台上部署 Docker 主机,就像我们这里部署在 VirtualBox 上一样。这个 virtualbox 驱动可以在本地机器上使用,也可以在数据中心的虚拟机上使用。Docker Machine 驱动除了支持本地的 VirtualBox 之外,还支持远端的 Digital Ocean、AWS、Azure、VMware 以及其它基础设施。
|
||||
|
||||
如果你有任何疑问,或者建议,请在评论栏中写出来,我们会不断改进我们的内容。谢谢,祝愉快。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/host-virtualbox-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://github.com/docker/machine/releases
|
||||
[2]:https://github.com/boot2docker/boot2docker
|
||||
@ -0,0 +1,205 @@
|
||||
关于Linux防火墙'iptables'的面试问答
|
||||
================================================================================
|
||||
Nishita Agarwal是Tecmint的用户,她将分享关于她刚刚经历的一家公司(印度的一家私人公司Pune)的面试经验。在面试中她被问及许多不同的问题,但她是iptables方面的专家,因此她想分享这些关于iptables的问题和相应的答案给那些以后可能会进行相关面试的人。
|
||||
|
||||

|
||||
|
||||
所有的问题和相应的答案都基于Nishita Agarwal的记忆并经过了重写。
|
||||
|
||||
> “嗨,朋友!我叫**Nishita Agarwal**。我已经取得了理学学士学位,我的专业集中在UNIX和它的变种(BSD,Linux)。它们一直深深的吸引着我。我在存储方面有1年多的经验。我正在寻求职业上的变化,并将供职于印度的Pune公司。”
|
||||
|
||||
下面是我在面试中被问到的问题的集合。我已经把我记忆中有关iptables的问题和它们的答案记录了下来。希望这会对您未来的面试有所帮助。
|
||||
|
||||
### 1. 你听说过Linux下面的iptables和Firewalld么?知不知道它们是什么,是用来干什么的? ###
|
||||
|
||||
**答案** : iptables和Firewalld我都知道,并且我已经使用iptables好一段时间了。iptables主要由C语言写成,并且以GNU GPL许可证发布。它是从系统管理员的角度写的,最新的稳定版是iptables 1.4.21。iptables通常被用作类UNIX系统中的防火墙,更准确的说,可以称为iptables/netfilter。管理员通过终端/GUI工具与iptables打交道,来添加和定义防火墙规则到预定义的表中。Netfilter是内核中的一个模块,它执行包过滤的任务。
|
||||
|
||||
Firewalld是RHEL/CentOS 7(也许还有其他发行版,但我不太清楚)中最新的过滤规则的实现。它已经取代了iptables接口,并与netfilter相连接。
|
||||
|
||||
### 2. 你用过一些iptables的GUI或命令行工具么? ###
|
||||
|
||||
**答案** : 虽然我既用过GUI工具,比如与[Webmin][1]结合的Shorewall;以及直接通过终端访问iptables,但我必须承认通过Linux终端直接访问iptables能给予用户更高级的灵活性、以及对其背后工作更好的理解的能力。GUI适合初级管理员,而终端适合有经验的管理员。
|
||||
|
||||
### 3. 那么iptables和firewalld的基本区别是什么呢? ###
|
||||
|
||||
**答案** : iptables和firewalld都有着同样的目的(包过滤),但它们使用不同的方式。iptables与firewalld不同,在每次发生更改时都刷新整个规则集。通常iptables配置文件位于‘/etc/sysconfig/iptables‘,而firewalld的配置文件位于‘/etc/firewalld/‘。firewalld的配置文件是一组XML文件。以XML为基础进行配置的firewalld比iptables的配置更加容易,但是两者都可以完成同样的任务。例如,firewalld可以在自己的命令行界面以及基于XML的配置文件下使用iptables。
|
||||
|
||||
### 4. 如果有机会的话,你会在你所有的服务器上用firewalld替换iptables么? ###
|
||||
|
||||
**答案** : 我对iptables很熟悉,它也工作的很好。如果没有任何需求需要firewalld的动态特性,那么没有理由把所有的配置都从iptables移动到firewalld。通常情况下,目前为止,我还没有看到iptables造成什么麻烦。IT技术的通用准则也说道“为什么要修一件没有坏的东西呢?”。上面是我自己的想法,但如果组织愿意用firewalld替换iptables的话,我不介意。
|
||||
|
||||
### 5. 你看上去对iptables很有信心,巧的是,我们的服务器也在使用iptables。 ###
|
||||
|
||||
iptables使用的表有哪些?请简要的描述iptables使用的表以及它们所支持的链。
|
||||
|
||||
**答案** : 谢谢您的赞赏。至于您问的问题,iptables使用的表有四个,它们是:
|
||||
|
||||
- Nat 表
|
||||
- Mangle 表
|
||||
- Filter 表
|
||||
- Raw 表
|
||||
|
||||
Nat表 : Nat表主要用于网络地址转换。根据表中的每一条规则修改网络包的IP地址。流中的包仅遍历一遍Nat表。例如,如果一个通过某个接口的包被修饰(修改了IP地址),该流中其余的包将不再遍历这个表。通常不建议在这个表中进行过滤,由NAT表支持的链称为PREROUTING 链,POSTROUTING 链和OUTPUT 链。
|
||||
|
||||
Mangle表 : 正如它的名字一样,这个表用于校正网络包。它用来对特殊的包进行修改。它能够修改不同包的头部和内容。Mangle表不能用于地址伪装。支持的链包括PREROUTING 链,OUTPUT 链,Forward 链,Input 链和POSTROUTING 链。
|
||||
|
||||
Filter表 : Filter表是iptables中使用的默认表,它用来过滤网络包。如果没有定义任何规则,Filter表则被当作默认的表,并且基于它来过滤。支持的链有INPUT 链,OUTPUT 链,FORWARD 链。
|
||||
|
||||
Raw表 : Raw表在我们想要配置之前被豁免的包时被使用。它支持PREROUTING 链和OUTPUT 链。
|
||||
|
||||
### 6. 简要谈谈什么是iptables中的目标值(能被指定为目标),他们有什么用 ###
|
||||
|
||||
**答案** : 下面是在iptables中可以指定为目标的值:
|
||||
|
||||
- ACCEPT : 接受包
|
||||
- QUEUE : 将包传递到用户空间 (应用程序和驱动所在的地方)
|
||||
- DROP : 丢弃包
|
||||
- RETURN : 将控制权交回调用的链并且为当前链中的包停止执行下一调用规则
|
||||
|
||||
### 7. 让我们来谈谈iptables技术方面的东西,我的意思是说实际使用方面 ###
|
||||
|
||||
你怎么检测在CentOS中安装iptables时需要的iptables的rpm?
|
||||
|
||||
**答案** : iptables已经被默认安装在CentOS中,我们不需要单独安装它。但可以这样检测rpm:
|
||||
|
||||
# rpm -qa iptables
|
||||
|
||||
iptables-1.4.21-13.el7.x86_64
|
||||
|
||||
如果您需要安装它,您可以用yum来安装。
|
||||
|
||||
# yum install iptables-services
|
||||
|
||||
### 8. 怎样检测并且确保iptables服务正在运行? ###
|
||||
|
||||
**答案** : 您可以在终端中运行下面的命令来检测iptables的状态。
|
||||
|
||||
# service status iptables [On CentOS 6/5]
|
||||
# systemctl status iptables [On CentOS 7]
|
||||
|
||||
如果iptables没有在运行,可以使用下面的语句
|
||||
|
||||
---------------- 在CentOS 6/5下 ----------------
|
||||
# chkconfig --level 35 iptables on
|
||||
# service iptables start
|
||||
|
||||
---------------- 在CentOS 7下 ----------------
|
||||
# systemctl enable iptables
|
||||
# systemctl start iptables
|
||||
|
||||
我们还可以检测iptables的模块是否被加载:
|
||||
|
||||
# lsmod | grep ip_tables
|
||||
|
||||
### 9. 你怎么检查iptables中当前定义的规则呢? ###
|
||||
|
||||
**答案** : 当前的规则可以简单的用下面的命令查看:
|
||||
|
||||
# iptables -L
|
||||
|
||||
示例输出
|
||||
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
ACCEPT icmp -- anywhere anywhere
|
||||
ACCEPT all -- anywhere anywhere
|
||||
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
### 10. 你怎样刷新所有的iptables规则或者特定的链呢? ###
|
||||
|
||||
**答案** : 您可以使用下面的命令来刷新一个特定的链。
|
||||
|
||||
# iptables --flush OUTPUT
|
||||
|
||||
要刷新所有的规则,可以用:
|
||||
|
||||
# iptables --flush
|
||||
|
||||
### 11. 请在iptables中添加一条规则,接受所有从一个信任的IP地址(例如,192.168.0.7)过来的包。 ###
|
||||
|
||||
**答案** : 上面的场景可以通过运行下面的命令来完成。
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
|
||||
我们还可以在源IP中使用标准的斜线和子网掩码:
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
# iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
### 12. 怎样在iptables中添加规则以ACCEPT,REJECT,DENY和DROP ssh的服务? ###
|
||||
|
||||
**答案** : 但愿ssh运行在22端口,那也是ssh的默认端口,我们可以在iptables中添加规则来ACCEPT ssh的tcp包(在22号端口上)。
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
REJECT ssh服务(22号端口)的tcp包。
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j REJECT
|
||||
|
||||
DENY ssh服务(22号端口)的tcp包。
|
||||
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j DENY
|
||||
|
||||
DROP ssh服务(22号端口)的tcp包。
|
||||
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j DROP
|
||||
|
||||
### 13. 让我给你另一个场景,假如有一台电脑的本地IP地址是192.168.0.6。你需要封锁在21、22、23和80号端口上的连接,你会怎么做? ###
|
||||
|
||||
**答案** : 这时,我所需要的就是在iptables中使用‘multiport‘选项,并将要封锁的端口号跟在它后面。上面的场景可以用下面的一条语句搞定:
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
|
||||
|
||||
可以用下面的语句查看写入的规则。
|
||||
|
||||
# iptables -L
|
||||
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
ACCEPT icmp -- anywhere anywhere
|
||||
ACCEPT all -- anywhere anywhere
|
||||
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
**面试官** : 好了,我问的就是这些。你是一个很有价值的雇员,我们不会错过你的。我将会向HR推荐你的名字。如果你有什么问题,请问我。
|
||||
|
||||
作为一个候选人我不愿不断的问将来要做的项目的事以及公司里其他的事,这样会打断愉快的对话。更不用说HR轮会不会比较难,总之,我获得了机会。
|
||||
|
||||
同时我要感谢Avishek和Ravi(我的朋友)花时间帮我整理我的面试。
|
||||
|
||||
朋友!如果您有过类似的面试,并且愿意与数百万Tecmint读者一起分享您的面试经历,请将您的问题和答案发送到admin@tecmint.com。
|
||||
|
||||
谢谢!保持联系。如果我能更好的回答我上面的问题的话,请记得告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
@ -0,0 +1,95 @@
|
||||
Tickr:一个开源的 Linux 桌面 RSS 新闻速递应用
|
||||
================================================================================
|
||||

|
||||
|
||||
**最新的!最新的!阅读关于它的一切!**
|
||||
|
||||
好了,我们今天要推荐的应用程序可不是旧式报纸的二进制版本——它会以一种漂亮的方式将最新的新闻推送到你的桌面上。
|
||||
|
||||
Tickr 是一个基于 GTK 的 Linux 桌面新闻速递应用,能够以横条方式滚动显示最新头条新闻以及你最爱的RSS资讯文章标题,当然你可以放置在你桌面的任何地方。
|
||||
|
||||
请叫我 Joey Calamezzo;我把它放在底部,就像电视新闻台的滚动字幕一样。 (LCTT 译注: Joan Callamezzo 是 Pawnee Today 的主持人,一位 Pawnee 的本地新闻/脱口秀主持人。而本文作者是 Joey。)
|
||||
|
||||
“到你了,副标题”。
|
||||
|
||||
### RSS -还记得吗? ###
|
||||
|
||||
“谢谢,这段结束了。”
|
||||
|
||||
在一个充斥着推送通知、社交媒体、标题党,以及哄骗人们点击的清单体的时代,RSS看起来有一点过时了。
|
||||
|
||||
对我来说呢?恩,RSS是名副其实的真正简单的聚合(RSS : Really Simple Syndication)。这是将消息通知给我的最简单、最易于管理的方式。我可以在我愿意的时候,管理和阅读一些东西;没必要匆忙的去看,以防这条微博消失在信息流中,或者推送通知消失。
|
||||
|
||||
tickr的美在于它的实用性。你可以不断地有新闻滚动在屏幕的底部,然后不时地瞥一眼。
|
||||
|
||||

|
||||
|
||||
你不会有“阅读”或“标记所有为已读”的压力。当你看到一些你想读的东西,你只需点击它,将它在Web浏览器中打开。
|
||||
|
||||
### 开始设置 ###
|
||||
|
||||

|
||||
|
||||
尽管虽然tickr可以从Ubuntu软件中心安装,然而它已经很久没有更新了。当你打开笨拙的不直观的控制面板的时候,没有什么能够比这更让人感觉被遗弃的了。
|
||||
|
||||
要打开它:
|
||||
|
||||
1. 右键单击tickr条
|
||||
1. 转至编辑>首选项
|
||||
1. 调整各种设置
|
||||
|
||||
选项和设置行的后面,有些似乎是容易理解的。但是详细了解这些你才能够掌握一切,包括:
|
||||
|
||||
- 设置滚动速度
|
||||
- 选择鼠标经过时的行为
|
||||
- 资讯更新频率
|
||||
- 字体,包括字体大小和颜色
|
||||
- 消息分隔符(“delineator”)
|
||||
- tickr在屏幕上的位置
|
||||
- tickr条的颜色和不透明度
|
||||
- 选择每种资讯显示多少文章
|
||||
|
||||
有个值得一提的“怪癖”是,当你点击“应用”按钮,只会更新tickr的屏幕预览。当您退出“首选项”窗口时,请单击“确定”。
|
||||
|
||||
想要得到完美的显示效果, 你需要一点点调整,特别是在 Unity 上。
|
||||
|
||||
按下“全宽按钮”,能够让应用程序自动检测你的屏幕宽度。默认情况下,当放置在顶部或底部时,会留下25像素的间距(应用程序以前是在GNOME2.x桌面上创建的)。只需添加额外的25像素到输入框,来弥补这个问题。
|
||||
|
||||
其他可供选择的选项包括:选择文章在哪个浏览器打开;tickr是否以一个常规的窗口出现;是否显示一个时钟;以及应用程序多久检查一次文章资讯。
|
||||
|
||||
#### 添加资讯 ####
|
||||
|
||||
tickr自带的有超过30种不同的资讯列表,从技术博客到主流新闻服务。
|
||||
|
||||

|
||||
|
||||
你可以选择很多你想在屏幕上显示的新闻提要。如果你想添加自己的资讯,你可以:—
|
||||
|
||||
1. 右键单击tickr条
|
||||
1. 转至文件>打开资讯
|
||||
1. 输入资讯网址
|
||||
1. 点击“添加/更新”按钮
|
||||
1. 单击“确定”(选择)
|
||||
|
||||
如果想设置每个资讯在ticker中显示多少条文章,可以去另一个首选项窗口修改“每个资讯最大读取N条文章”
|
||||
|
||||
### 在Ubuntu 14.04 LTS或更高版本上安装Tickr ###
|
||||
|
||||
这就是 Tickr,它不会改变世界,但是它能让你知道世界上发生了什么。
|
||||
|
||||
在Ubuntu 14.04 LTS或更高版本中安装,点击下面的按钮转到Ubuntu软件中心。
|
||||
|
||||
- [点击此处进入Ubuntu软件中心安装tickr][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticker
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:apt://tickr
|
||||
@ -1,11 +1,14 @@
|
||||
如何使用Docker Machine部署Swarm集群
|
||||
================================================================================
|
||||
大家好,今天我们来研究一下如何使用Docker Machine部署Swarm集群。Docker Machine提供了独立的Docker API,所以任何与Docker守护进程进行交互的工具都可以使用Swarm来(透明地)扩增到多台主机上。Docker Machine可以用来在个人电脑、云端以及的数据中心里创建Docker主机。它为创建服务器,安装Docker以及根据用户设定配置Docker客户端提供了便捷化的解决方案。我们可以使用任何驱动来部署swarm集群,并且swarm集群将由于使用了TLS加密具有极好的安全性。
|
||||
|
||||
大家好,今天我们来研究一下如何使用Docker Machine部署Swarm集群。Docker Machine提供了标准的Docker API 支持,所以任何可以与Docker守护进程进行交互的工具都可以使用Swarm来(透明地)扩增到多台主机上。Docker Machine可以用来在个人电脑、云端以及的数据中心里创建Docker主机。它为创建服务器,安装Docker以及根据用户设定来配置Docker客户端提供了便捷化的解决方案。我们可以使用任何驱动来部署swarm集群,并且swarm集群将由于使用了TLS加密具有极好的安全性。
|
||||
|
||||
下面是我提供的简便方法。
|
||||
|
||||
### 1. 安装Docker Machine ###
|
||||
|
||||
Docker Machine 在任何Linux系统上都被支持。首先,我们需要从Github上下载最新版本的Docker Machine。我们使用curl命令来下载最先版本Docker Machine ie 0.2.0。
|
||||
Docker Machine 在各种Linux系统上都支持的很好。首先,我们需要从Github上下载最新版本的Docker Machine。我们使用curl命令来下载最先版本Docker Machine ie 0.2.0。
|
||||
|
||||
64位操作系统:
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
@ -18,7 +21,7 @@ Docker Machine 在任何Linux系统上都被支持。首先,我们需要从Git
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
在做完上面的事情以后,我们必须确保docker-machine已经安装好。怎么检查呢?运行docker-machine -v指令,指令将会给出我们系统上所安装的docker-machine版本。
|
||||
在做完上面的事情以后,我们要确保docker-machine已经安装正确。怎么检查呢?运行`docker-machine -v`指令,该指令将会给出我们系统上所安装的docker-machine版本。
|
||||
|
||||
# docker-machine -v
|
||||
|
||||
@ -31,14 +34,15 @@ Docker Machine 在任何Linux系统上都被支持。首先,我们需要从Git
|
||||
|
||||
### 2. 创建Machine ###
|
||||
|
||||
在将Docker Machine安装到我们的设备上之后,我们需要使用Docker Machine创建一个machine。在这片文章中,我们会将其部署在Digital Ocean Platform上。所以我们将使用“digitalocean”作为它的Driver API,然后将docker swarm运行在其中。这个Droplet会被设置为Swarm主节点,我们还要创建另外一个Droplet,并将其设定为Swarm节点代理。
|
||||
在将Docker Machine安装到我们的设备上之后,我们需要使用Docker Machine创建一个machine。在这篇文章中,我们会将其部署在Digital Ocean Platform上。所以我们将使用“digitalocean”作为它的Driver API,然后将docker swarm运行在其中。这个Droplet会被设置为Swarm主控节点,我们还要创建另外一个Droplet,并将其设定为Swarm节点代理。
|
||||
|
||||
创建machine的命令如下:
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
**Note**: 假设我们要创建一个名为“linux-dev”的machine。<API-Token>是用户在Digital Ocean Cloud Platform的Digital Ocean控制面板中生成的密钥。为了获取这个密钥,我们需要登录我们的Digital Ocean控制面板,然后点击API选项,之后点击Generate New Token,起个名字,然后在Read和Write两个选项上打钩。之后我们将得到一个很长的十六进制密钥,这个就是<API-Token>了。用其替换上面那条命令中的API-Token字段。
|
||||
**备注**: 假设我们要创建一个名为“linux-dev”的machine。<API-Token>是用户在Digital Ocean Cloud Platform的Digital Ocean控制面板中生成的密钥。为了获取这个密钥,我们需要登录我们的Digital Ocean控制面板,然后点击API选项,之后点击Generate New Token,起个名字,然后在Read和Write两个选项上打钩。之后我们将得到一个很长的十六进制密钥,这个就是<API-Token>了。用其替换上面那条命令中的API-Token字段。
|
||||
|
||||
现在,运行下面的指令,将Machine configuration装载进shell。
|
||||
现在,运行下面的指令,将Machine 的配置变量加载进shell里。
|
||||
|
||||
# eval "$(docker-machine env linux-dev)"
|
||||
|
||||
@ -48,7 +52,7 @@ Docker Machine 在任何Linux系统上都被支持。首先,我们需要从Git
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
现在,我们检查是否它(指machine)被标记为了 ACTIVE "*"。
|
||||
现在,我们检查它(指machine)是否被标记为了 ACTIVE "*"。
|
||||
|
||||
# docker-machine ls
|
||||
|
||||
@ -56,22 +60,21 @@ Docker Machine 在任何Linux系统上都被支持。首先,我们需要从Git
|
||||
|
||||
### 3. 运行Swarm Docker镜像 ###
|
||||
|
||||
现在,在我们创建完成了machine之后。我们需要将swarm docker镜像部署上去。这个machine将会运行这个docker镜像并且控制Swarm主节点和从节点。使用下面的指令运行镜像:
|
||||
现在,在我们创建完成了machine之后。我们需要将swarm docker镜像部署上去。这个machine将会运行这个docker镜像,并且控制Swarm主控节点和从节点。使用下面的指令运行镜像:
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
If you are trying to run swarm docker image using **32 bit Operating System** in the computer where Docker Machine is running, we'll need to SSH into the Droplet.
|
||||
如果你想要在**32位操作系统**上运行swarm docker镜像。你需要SSH登录到Droplet当中。
|
||||
|
||||
# docker-machine ssh
|
||||
#docker run swarm create
|
||||
#exit
|
||||
|
||||
### 4. 创建Swarm主节点 ###
|
||||
### 4. 创建Swarm主控节点 ###
|
||||
|
||||
在我们的swarm image已经运行在machine当中之后,我们将要创建一个Swarm主节点。使用下面的语句,添加一个主节点。(这里的感觉怪怪的,好像少翻译了很多东西,是我把Master翻译为主节点的原因吗?)
|
||||
在我们的swarm image已经运行在machine当中之后,我们将要创建一个Swarm主控节点。使用下面的语句,添加一个主控节点。
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
@ -83,9 +86,9 @@ If you are trying to run swarm docker image using **32 bit Operating System** in
|
||||
|
||||

|
||||
|
||||
### 5. 创建Swarm结点群 ###
|
||||
### 5. 创建Swarm从节点 ###
|
||||
|
||||
现在,我们将要创建一个swarm结点,此结点将与Swarm主节点相连接。下面的指令将创建一个新的名为swarm-node的droplet,其与Swarm主节点相连。到此,我们就拥有了一个两节点的swarm集群了。
|
||||
现在,我们将要创建一个swarm从节点,此节点将与Swarm主控节点相连接。下面的指令将创建一个新的名为swarm-node的droplet,其与Swarm主控节点相连。到此,我们就拥有了一个两节点的swarm集群了。
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
@ -96,21 +99,19 @@ If you are trying to run swarm docker image using **32 bit Operating System** in
|
||||
|
||||

|
||||
|
||||
### 6. Connecting to the Swarm Master ###
|
||||
### 6. 与Swarm主节点连接 ###
|
||||
### 6. 与Swarm主控节点连接 ###
|
||||
|
||||
现在,我们连接Swarm主节点以便我们可以依照需求和配置文件在节点间部署Docker容器。运行下列命令将Swarm主节点的Machine配置文件加载到环境当中。
|
||||
现在,我们连接Swarm主控节点以便我们可以依照需求和配置文件在节点间部署Docker容器。运行下列命令将Swarm主控节点的Machine配置文件加载到环境当中。
|
||||
|
||||
# eval "$(docker-machine env --swarm swarm-master)"
|
||||
|
||||
然后,我们就可以跨结点地运行我们所需的容器了。在这里,我们还要检查一下是否一切正常。所以,运行**docker info**命令来检查Swarm集群的信息。
|
||||
然后,我们就可以跨节点地运行我们所需的容器了。在这里,我们还要检查一下是否一切正常。所以,运行**docker info**命令来检查Swarm集群的信息。
|
||||
|
||||
# docker info
|
||||
|
||||
### Conclusion ###
|
||||
### 总结 ###
|
||||
|
||||
我们可以用Docker Machine轻而易举地创建Swarm集群。这种方法有非常高的效率,因为它极大地减少了系统管理员和用户的时间消耗。在这篇文章中,我们以Digital Ocean作为驱动,通过创建一个主节点和一个从节点成功地部署了集群。其他类似的应用还有VirtualBox,Google Cloud Computing,Amazon Web Service,Microsoft Azure等等。这些连接都是通过TLS进行加密的,具有很高的安全性。如果你有任何的疑问,建议,反馈,欢迎在下面的评论框中注明以便我们可以更好地提高文章的质量!
|
||||
我们可以用Docker Machine轻而易举地创建Swarm集群。这种方法有非常高的效率,因为它极大地减少了系统管理员和用户的时间消耗。在这篇文章中,我们以Digital Ocean作为驱动,通过创建一个主控节点和一个从节点成功地部署了集群。其他类似的驱动还有VirtualBox,Google Cloud Computing,Amazon Web Service,Microsoft Azure等等。这些连接都是通过TLS进行加密的,具有很高的安全性。如果你有任何的疑问,建议,反馈,欢迎在下面的评论框中注明以便我们可以更好地提高文章的质量!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -118,7 +119,7 @@ via: http://linoxide.com/linux-how-to/provision-swarm-clusters-using-docker-mach
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,53 +1,54 @@
|
||||
Autojump – 一个高级的‘cd’命令用以快速浏览 Linux 文件系统
|
||||
Autojump:一个可以在 Linux 文件系统快速导航的高级 cd 命令
|
||||
================================================================================
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行浏览有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行导航有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
现在,有一个用 Python 写的名为 `autojump` 的 Linux 命令行实用程序,它是 Linux ‘[cd][1]’命令的高级版本。
|
||||
|
||||

|
||||
|
||||
Autojump – 浏览 Linux 文件系统的最快方式
|
||||
*Autojump – Linux 文件系统导航的最快方式*
|
||||
|
||||
这个应用原本由 Joël Schaerer 编写,现在由 +William Ting 维护。
|
||||
|
||||
Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录浏览。与传统的 `cd` 命令相比,autojump 能够更加快速地浏览至目的目录。
|
||||
Autojump 应用可以从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录导航。与传统的 `cd` 命令相比,autojump 能够更加快速地导航至目的目录。
|
||||
|
||||
#### autojump 的特色 ####
|
||||
|
||||
- 免费且开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的浏览习惯中学习。
|
||||
- 更快速地浏览。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat and Fedora。
|
||||
- 自由开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的导航习惯中学习。
|
||||
- 更快速地导航。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat 和 Fedora。
|
||||
- 也能在其他平台中使用,例如 OS X(使用 Homebrew) 和 Windows (通过 Clink 来实现)
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以打开文件管理器来到达某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以用文件管理器打开某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
|
||||
#### 前提 ####
|
||||
|
||||
- 版本号不低于 2.6 的 Python
|
||||
|
||||
### 第 1 步: 做一次全局系统升级 ###
|
||||
### 第 1 步: 做一次完整的系统升级 ###
|
||||
|
||||
1. 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
1、 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [APT based systems]
|
||||
# yum update && yum upgrade [YUM based systems]
|
||||
# dnf update && dnf upgrade [DNF based systems]
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [基于 APT 的系统]
|
||||
# yum update && yum upgrade [基于 YUM 的系统]
|
||||
# dnf update && dnf upgrade [基于 DNF 的系统]
|
||||
|
||||
**注** : 这里特别提醒,在基于 YUM 或 DNF 的系统中,更新和升级执行相同的行动,大多数时间里它们是通用的,这点与基于 APT 的系统不同。
|
||||
|
||||
### 第 2 步: 下载和安装 Autojump ###
|
||||
|
||||
2. 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
2、 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
|
||||
#### 从源代码安装 ####
|
||||
|
||||
若没有安装 git,请安装它。我们需要使用它来克隆 git 仓库。
|
||||
|
||||
# apt-get install git [APT based systems]
|
||||
# yum install git [YUM based systems]
|
||||
# dnf install git [DNF based systems]
|
||||
# apt-get install git [基于 APT 的系统]
|
||||
# yum install git [基于 YUM 的系统]
|
||||
# dnf install git [基于 DNF 的系统]
|
||||
|
||||
一旦安装完 git,以常规用户身份登录,然后像下面那样来克隆 autojump:
|
||||
一旦安装完 git,以普通用户身份登录,然后像下面那样来克隆 autojump:
|
||||
|
||||
$ git clone git://github.com/joelthelion/autojump.git
|
||||
|
||||
@ -55,29 +56,29 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
$ cd autojump
|
||||
|
||||
下载,赋予脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
下载,赋予安装脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
|
||||
# chmod 755 install.py
|
||||
# ./install.py
|
||||
|
||||
#### 从软件仓库中安装 ####
|
||||
|
||||
3. 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
3、 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
|
||||
在 Debian, Ubuntu, Mint 及类似系统中安装 autojump :
|
||||
|
||||
# apt-get install autojump (注: 这里原文为 autojumo, 应该为 autojump)
|
||||
# apt-get install autojump
|
||||
|
||||
为了在 Fedora, CentOS, RedHat 及类似系统中安装 autojump, 你需要启用 [EPEL 软件仓库][2]。
|
||||
|
||||
# yum install epel-release
|
||||
# yum install autojump
|
||||
OR
|
||||
或
|
||||
# dnf install autojump
|
||||
|
||||
### 第 3 步: 安装后的配置 ###
|
||||
|
||||
4. 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
4、 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
|
||||
为了暂时激活 autojump 应用,即直到你关闭当前会话或打开一个新的会话之前让 autojump 均有效,你需要以常规用户身份运行下面的命令:
|
||||
|
||||
@ -89,7 +90,7 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
### 第 4 步: Autojump 的预测试和使用 ###
|
||||
|
||||
5. 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
5、 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
|
||||
$ cd
|
||||
$ cd
|
||||
@ -120,45 +121,45 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
现在,我们已经切换到过上面所列的目录,并为了测试创建了一些目录,一切准备就绪,让我们开始吧。
|
||||
|
||||
**需要记住的一点** : `j` 是 autojump 的一个包装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
**需要记住的一点** : `j` 是 autojump 的一个封装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
|
||||
6. 使用 -v 选项查看安装的 autojump 的版本。
|
||||
6、 使用 -v 选项查看安装的 autojump 的版本。
|
||||
|
||||
$ j -v
|
||||
or
|
||||
或
|
||||
$ autojump -v
|
||||
|
||||

|
||||
|
||||
查看 Autojump 的版本
|
||||
*查看 Autojump 的版本*
|
||||
|
||||
7. 跳到先前到过的目录 ‘/var/www‘。
|
||||
7、 跳到先前到过的目录 ‘/var/www‘。
|
||||
|
||||
$ j www
|
||||
|
||||
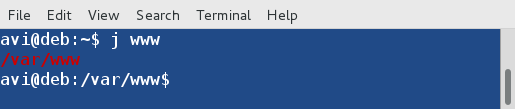
|
||||
|
||||
跳到目录
|
||||
*跳到目录*
|
||||
|
||||
8. 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
8、 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
|
||||
$ jc b
|
||||
|
||||

|
||||
|
||||
跳到子目录
|
||||
*跳到子目录*
|
||||
|
||||
9. 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
9、 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
|
||||
$ jo www
|
||||
|
||||
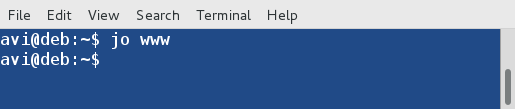
|
||||

|
||||
|
||||
跳到目录
|
||||
*打开目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开目录
|
||||
*在文件管理器中打开目录*
|
||||
|
||||
你也可以在一个文件管理器中打开一个子目录。
|
||||
|
||||
@ -166,19 +167,19 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||

|
||||
|
||||
打开子目录
|
||||
*打开子目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开子目录
|
||||
*在文件管理器中打开子目录*
|
||||
|
||||
10. 查看每个文件夹的关键权重和在所有目录权重中的总关键权重的相关统计数据。文件夹的关键权重代表在这个文件夹中所花的总时间。 目录权重是列表中目录的数目。(注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
10、 查看每个文件夹的权重和全部文件夹计算得出的总权重的统计数据。文件夹的权重代表在这个文件夹中所花的总时间。 文件夹权重是该列表中目录的数字。(LCTT 译注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
|
||||
$ j --stat
|
||||
|
||||

|
||||

|
||||
|
||||
查看目录统计数据
|
||||
*查看文件夹统计数据*
|
||||
|
||||
**提醒** : autojump 存储其运行日志和错误日志的地方是文件夹 `~/.local/share/autojump/`。千万不要重写这些文件,否则你将失去你所有的统计状态结果。
|
||||
|
||||
@ -186,15 +187,15 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
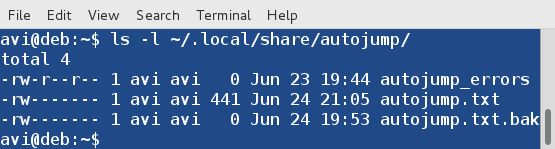
|
||||
|
||||
Autojump 的日志
|
||||
*Autojump 的日志*
|
||||
|
||||
11. 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
11、 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
|
||||
$ j --help
|
||||
|
||||

|
||||
|
||||
Autojump 的帮助和选项
|
||||
*Autojump 的帮助和选项*
|
||||
|
||||
### 功能需求和已知的冲突 ###
|
||||
|
||||
@ -204,18 +205,19 @@ Autojump 的帮助和选项
|
||||
|
||||
### 结论: ###
|
||||
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中浏览 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中导航 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
[3]:http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
@ -0,0 +1,56 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第一节 介绍)
|
||||
================================================================================
|
||||
|
||||
*作者声明: 如果你是因为某种神迹而在没看标题的情况下点开了这篇文章,那么我想再重申一些东西……这是一篇评论文章,文中的观点都是我自己的,不代表 Phoronix 网站和 Michael 的观点。它们完全是我自己的想法。*
|
||||
|
||||
另外,没错……这可能是一篇引战的文章。我希望 KDE 和 Gnome 社团变得更好一些,因为我想发起一个讨论并反馈给他们。为此,当我想指出(我所看到的)一个瑕疵时,我会尽量地做到具体而直接。这样,相关的讨论也能做到同样的具体和直接。再次声明:本文另一可选标题为“死于成千上万的[纸割][1]”(LCTT 译注:paper cuts——纸割,被纸片割伤——指易修复但烦人的缺陷。Ubuntu 从 9.10 开始,发起了 [One Hundred Papercuts][1] 项目,用于修复那些小而烦人的易用性问题)。
|
||||
|
||||
现在,重申完毕……文章开始。
|
||||
|
||||
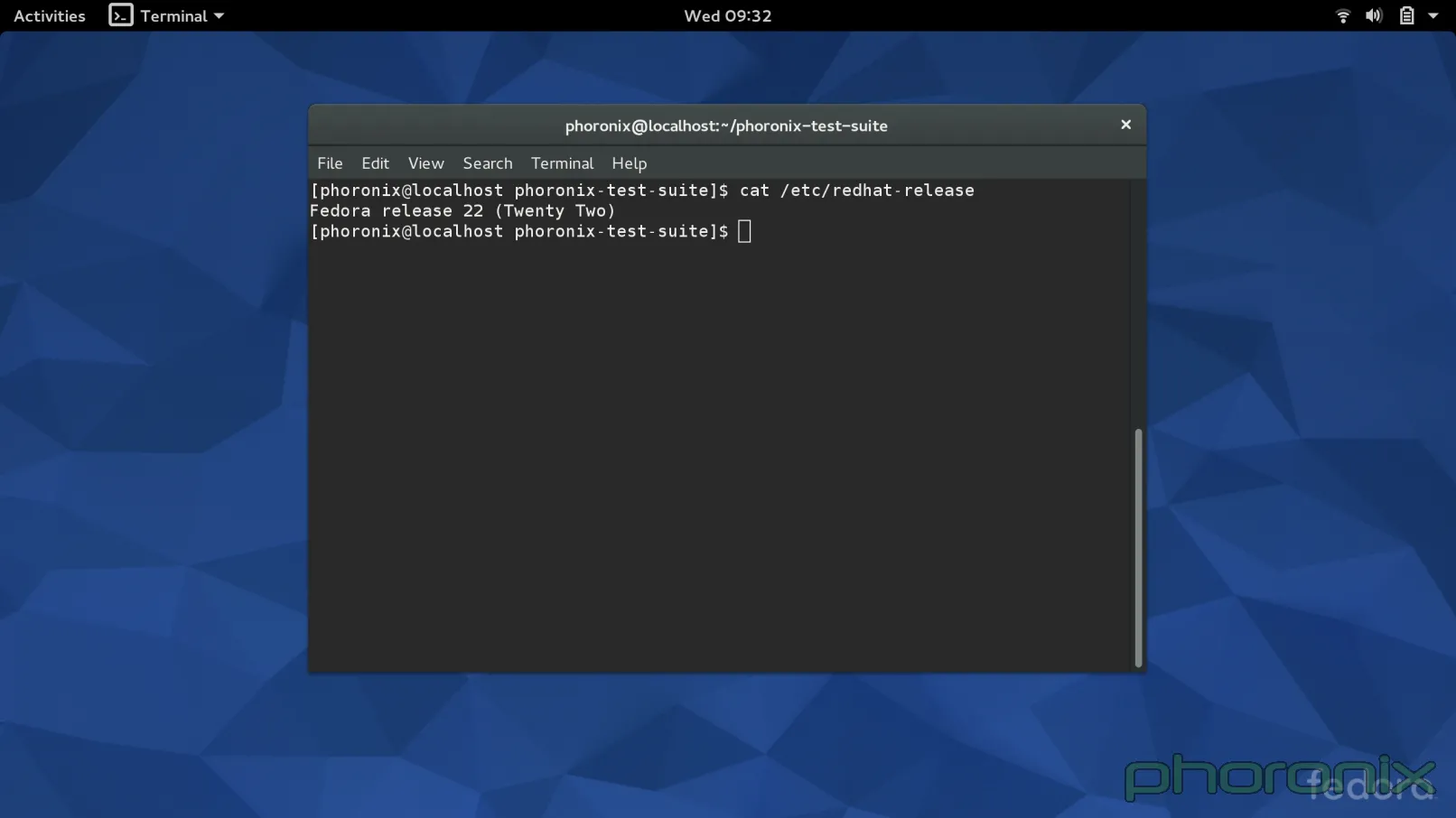
|
||||
|
||||
当我把[《评价 Fedora 22 KDE 》][2]一文发给 Michael 时,感觉很不是滋味。不是因为我不喜欢 KDE,或者不待见 Fedora,远非如此。事实上,我刚开始想把我的 T450s 的系统换为 Arch Linux 时,马上又决定放弃了,因为我很享受 fedora 在很多方面所带来的便捷性。
|
||||
|
||||
我感觉很不是滋味的原因是 Fedora 的开发者花费了大量的时间和精力在他们的“工作站”产品上,但是我却一点也没看到。在使用 Fedora 时,我并没用采用那些主要开发者希望用户采用的那种使用方式,因此我也就体验不到所谓的“ Fedora 体验”。它感觉就像一个人评价 Ubuntu 时用的却是 Kubuntu,评价 OS X 时用的却是 Hackintosh,或者评价 Gentoo 时用的却是 Sabayon。根据论坛里大量读者对 Michael 的说法,他们在评价各种发行版时都是使用的默认设置——我也不例外。但是我还是认为这些评价应该在“真实”配置下完成,当然我也知道在给定的情况下评论某些东西也的确是有价值的——无论是好是坏。
|
||||
|
||||
正是在怀着这种态度的情况下,我决定跳到 Gnome 这个水坑里来泡泡澡。
|
||||
|
||||
但是,我还要在此多加一个声明……我在这里所看到的 KDE 和 Gnome 都是打包在 Fedora 中的。OpenSUSE、 Kubuntu、 Arch等发行版的各个桌面可能有不同的实现方法,使得我这里所说的具体的“痛点”跟你所用的发行版有所不同。还有,虽然用了这个标题,但这篇文章将会是一篇“很 KDE”的重量级文章。之所以这样称呼,是因为我在“使用” Gnome 之后,才知道 KDE 的“纸割”到底有多么的多。
|
||||
|
||||
### 登录界面 ###
|
||||
|
||||
|
||||
|
||||
我一般情况下都不会介意发行版带着它们自己的特别主题,因为一般情况下桌面看起来会更好看。可我今天可算是找到了一个例外。
|
||||
|
||||
第一印象很重要,对吧?那么,GDM(LCTT 译注: Gnome Display Manage:Gnome 显示管理器。)绝对干得漂亮。它的登录界面看起来极度简洁,每一部分都应用了一致的设计风格。使用通用图标而不是文本框为它的简洁加了分。
|
||||
|
||||

|
||||
|
||||
这并不是说 Fedora 22 KDE ——现在已经是 SDDM 而不是 KDM 了——的登录界面不好看,但是看起来绝对没有它这样和谐。
|
||||
|
||||
问题到底出来在哪?顶部栏。看看 Gnome 的截图——你选择一个用户,然后用一个很小的齿轮简单地选择想登入哪个会话。设计很简洁,一点都不碍事,实话讲,如果你没注意的话可能完全会看不到它。现在看看那蓝色( LCTT 译注:blue,有忧郁之意,一语双关)的 KDE 截图,顶部栏看起来甚至不像是用同一个工具渲染出来的,它的整个位置的安排好像是某人想着:“哎哟妈呀,我们需要把这个选项扔在哪个地方……”之后决定下来的。
|
||||
|
||||
对于右上角的重启和关机选项也一样。为什么不单单用一个电源按钮,点击后会下拉出一个菜单,里面包括重启,关机,挂起的功能?按钮的颜色跟背景色不同肯定会让它更加突兀和显眼……但我可不觉得这样子有多好。同样,这看起来可真像“苦思”后的决定。
|
||||
|
||||
从实用观点来看,GDM 还要远远实用的多,再看看顶部一栏。时间被列了出来,还有一个音量控制按钮,如果你想保持周围安静,你甚至可以在登录前设置静音,还有一个可用性按钮来实现高对比度、缩放、语音转文字等功能,所有可用的功能通过简单的一个开关按钮就能得到。
|
||||
|
||||
|
||||
|
||||
切换到上游(KDE 自带)的 Breeve 主题……突然间,我抱怨的大部分问题都被解决了。通用图标,所有东西都放在了屏幕中央,但不是那么重要的被放到了一边。因为屏幕顶部和底部都是同样的空白,在中间也就酝酿出了一种美好的和谐。还是有一个文本框来切换会话,但既然电源按钮被做成了通用图标,那么这点还算可以原谅。当前时间以一种漂亮的感觉呈现,旁边还有电量指示器。当然 gnome 还是有一些很好的附加物,例如音量小程序和可用性按钮,但 Breeze 总归要比 Fedora 的 KDE 主题进步。
|
||||
|
||||
到 Windows(Windows 8和10之前)或者 OS X 中去,你会看到类似的东西——非常简洁的,“不碍事”的锁屏与登录界面,它们都没有文本框或者其它分散视觉的小工具。这是一种有效的不分散人注意力的设计。Fedora……默认带有 Breeze 主题。VDG 在 Breeze 主题设计上干得不错。可别糟蹋了它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=1
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://wiki.ubuntu.com/One%20Hundred%20Papercuts
|
||||
[2]:http://www.phoronix.com/scan.php?page=article&item=fedora-22-kde&num=1
|
||||
[3]:https://launchpad.net/hundredpapercuts
|
||||
@ -0,0 +1,32 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第二节 GNOME桌面)
|
||||
================================================================================
|
||||
|
||||
### 桌面 ###
|
||||
|
||||
|
||||
|
||||
在我这一周的前五天中,我都是直接手动登录进 Gnome 的——没有打开自动登录功能。在第五天的晚上,每一次都要手动登录让我觉得很厌烦,所以我就到用户管理器中打开了自动登录功能。下一次我登录的时候收到了一个提示:“你的密钥链(keychain)未解锁,请输入你的密码解锁”。在这时我才意识到了什么……Gnome 以前一直都在自动解锁我的密钥链(KDE 中叫做我的钱包),每当我通过 GDM 登录时 !当我绕开 GDM 的登录程序时,Gnome 才不得不介入让我手动解锁。
|
||||
|
||||
现在,鄙人的陋见是如果你打开了自动登录功能,那么你的密钥链也应当自动解锁——否则,这功能还有何用?无论如何,你还是需要输入你的密码,况且在 GDM 登录界面你还有机会选择要登录的会话,如果你想换的话。
|
||||
|
||||
但是,这点且不提,也就是在那一刻,我意识到要让这桌面感觉就像它在**和我**一起工作一样是多么简单的一件事。当我通过 SDDM 登录 KDE 时?甚至连启动界面都还没加载完成,就有一个窗口弹出来遮挡了启动动画(因此启动动画也就被破坏了),它提示我解锁我的 KDE 钱包或 GPG 钥匙环。
|
||||
|
||||
如果当前还没有钱包,你就会收到一个创建钱包的提醒——就不能在创建用户的时候同时为我创建一个吗?接着它又让你在两种加密模式中选择一种,甚至还暗示我们其中一种(Blowfish)是不安全的,既然是为了安全,为什么还要我选择一个不安全的东西?作者声明:如果你安装了真正的 KDE spin 版本而不是仅仅安装了被 KDE 搞过的版本,那么在创建用户时,它就会为你创建一个钱包。但很不幸的是,它不会帮你自动解锁,并且它似乎还使用了更老的 Blowfish 加密模式,而不是更新而且更安全的 GPG 模式。
|
||||
|
||||
|
||||
|
||||
如果你选择了那个安全的加密模式(GPG),那么它会尝试加载 GPG 密钥……我希望你已经创建过一个了,因为如果你没有,那么你可又要被指责一番了。怎么样才能创建一个?额……它不帮你创建一个……也不告诉你怎么创建……假如你真的搞明白了你应该使用 KGpg 来创建一个密钥,接着在你就会遇到一层层的菜单和一个个的提示,而这些菜单和提示只能让新手感到困惑。为什么你要问我 GPG 的二进制文件在哪?天知道在哪!如果不止一个,你就不能为我选择一个最新的吗?如果只有一个,我再问一次,为什么你还要问我?
|
||||
|
||||
为什么你要问我要使用多大的密钥大小和加密算法?你既然默认选择了 2048 和 RSA/RSA,为什么不直接使用?如果你想让这些选项能够被修改,那就把它们扔在下面的“Expert mode(专家模式)” 按钮里去。这里不仅仅是说让配置可被用户修改的问题,而是说根本不需要默认把多余的东西扔在了用户面前。这种问题将会成为这篇文章剩下的主要内容之一……KDE 需要更理智的默认配置。配置是好的,我很喜欢在使用 KDE 时的配置,但它还需要知道什么时候应该,什么时候不应该去提示用户。而且它还需要知道“嗯,它是可配置的”不能做为默认配置做得不好的借口。用户最先接触到的就是默认配置,不好的默认配置注定要失去用户。
|
||||
|
||||
让我们抛开密钥链的问题,因为我想我已经表达出了我的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=2
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,66 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第三节 GNOME应用)
|
||||
================================================================================
|
||||
|
||||
### 应用 ###
|
||||
|
||||
|
||||
|
||||
这是一个基本扯平的方面。每一个桌面环境都有一些非常好的应用,也有一些不怎么样的。再次强调,Gnome 把那些 KDE 完全错失的小细节给做对了。我不是想说 KDE 中有哪些应用不好。他们都能工作,但仅此而已。也就是说:它们合格了,但确实还没有达到甚至接近100分。
|
||||
|
||||
Gnome 在左,KDE 在右。Dragon 播放器运行得很好,清晰的标出了播放文件、URL或和光盘的按钮,正如你在 Gnome Videos 中能做到的一样……但是在便利的文件名和用户的友好度方面,Gnome 多走了一小步。它默认显示了在你的电脑上检测到的所有影像文件,不需要你做任何事情。KDE 有 [Baloo][](正如之前的 [Nepomuk][2],LCTT 译注:这是 KDE 中一种文件索引服务框架)为什么不使用它们?它们能列出可读取的影像文件……但却没被使用。
|
||||
|
||||
下一步……音乐播放器
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
这两个应用,左边的是 Rhythmbox ,右边的是 Amarok,都是打开后没有做任何修改直接截屏的。看到差别了吗?Rhythmbox 看起来像个音乐播放器,直接了当,排序文件的方法也很清晰,它知道它应该是什么样的,它的工作是什么:就是播放音乐。
|
||||
|
||||
Amarok 感觉就像是某个人为了展示而把所有的扩展和选项都尽可能地塞进一个应用程序中去,而做出来的一个技术演示产品(tech demos),或者一个库演示产品(library demos)——而这些是不应该做为产品装进去的,它只应该展示其中一点东西。而 Amarok 给人的感觉却是这样的:好像是某个人想把每一个感觉可能很酷的东西都塞进一个媒体播放器里,甚至都不停下来想“我想写啥来着?一个播放音乐的应用?”
|
||||
|
||||
看看默认布局就行了。前面和中心都呈现了什么?一个可视化工具和集成了维基百科——占了整个页面最大和最显眼的区域。第二大的呢?播放列表。第三大,同时也是最小的呢?真正的音乐列表。这种默认设置对于一个核心应用来说,怎么可能称得上理智?
|
||||
|
||||
软件管理器!它在最近几年当中有很大的进步,而且接下来的几个月中,很可能只能看到它更大的进步。不幸的是,这是另一个 KDE 做得差一点点就能……但还是在终点线前以脸戗地了。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
Gnome 软件中心可能是我的新的最爱的软件中心,先放下牢骚等下再发。Muon, 我想爱上你,真的。但你就是个设计上的梦魇。当 VDG 给你画设计草稿时(草图如下),你看起来真漂亮。白色空间用得很好,设计简洁,类别列表也很好,你的整个“不要分开做成两个应用程序”的设计都很不错。
|
||||
|
||||
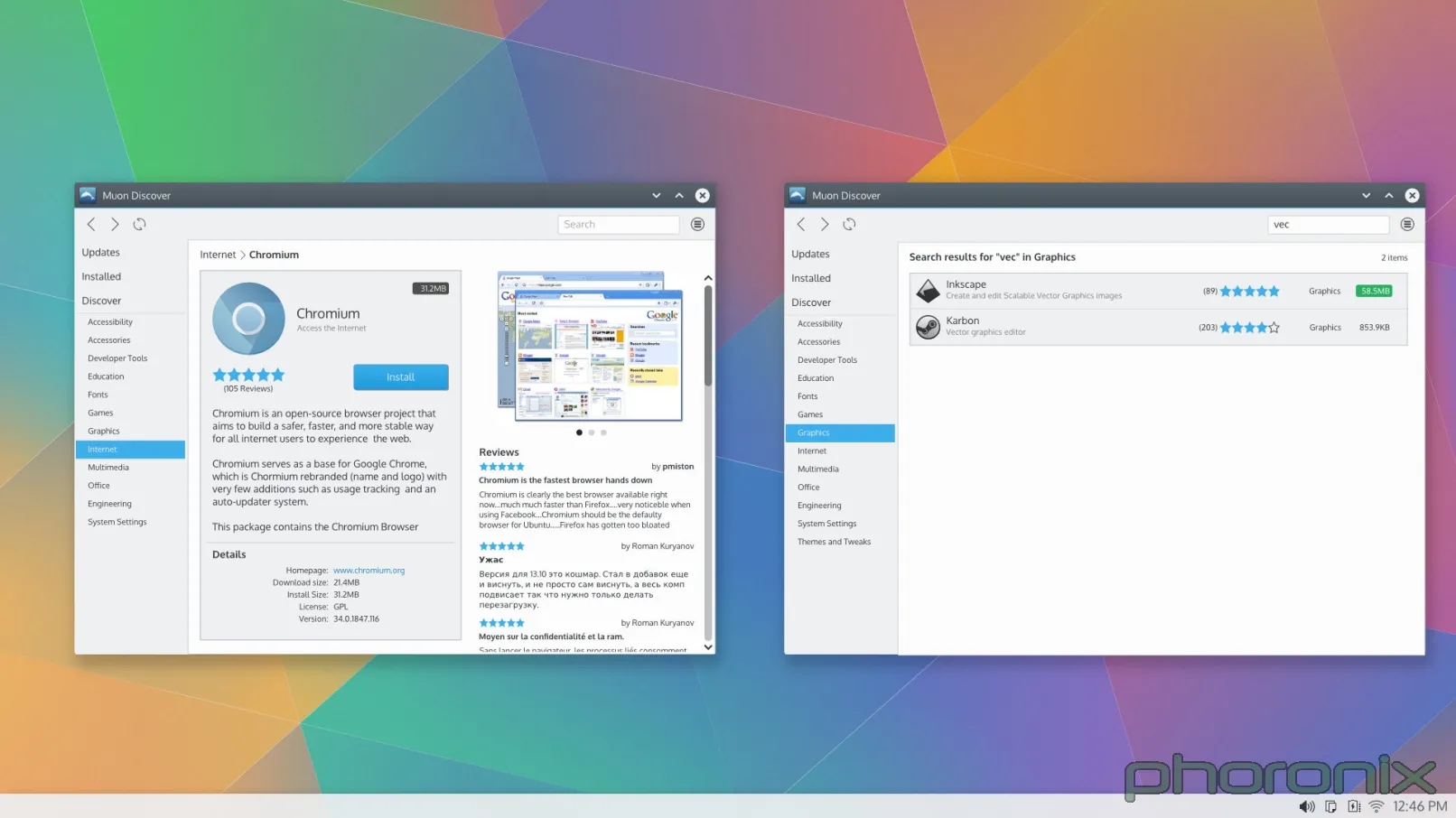
|
||||
|
||||
接着就有人为你写代码,实现真正的UI,但是,我猜这些家伙当时一定是喝醉了。
|
||||
|
||||
我们来看看 Gnome 软件中心。正中间是什么?软件,软件截图和软件描述等等。Muon 的正中心是什么?白白浪费的大块白色空间。Gnome 软件中心还有一个贴心便利特点,那就是放了一个“运行”的按钮在那儿,以防你已经安装了这个软件。便利性和易用性很重要啊,大哥。说实话,仅仅让 Muon 把东西都居中对齐了可能看起来的效果都要好得多。
|
||||
|
||||
Gnome 软件中心沿着顶部的东西是什么,像个标签列表?所有软件,已安装软件,软件升级。语言简洁,直接,直指要点。Muon,好吧,我们有个“发现”,这个语言表达上还算差强人意,然后我们又有一个“已安装软件”,然后,就没有然后了。软件升级哪去了?
|
||||
|
||||
好吧……开发者决定把升级独立分开成一个应用程序,这样你就得打开两个应用程序才能管理你的软件——一个用来安装,一个用来升级——自从有了新立得图形软件包管理器以来,首次有这种破天荒的设计,与任何已存的软件中心的设计范例相违背。
|
||||
|
||||
我不想贴上截图给你们看,因为我不想等下还得清理我的电脑,如果你进入 Muon 安装了什么,那么它就会在屏幕下方根据安装的应用名创建一个标签,所以如果你一次性安装很多软件的话,那么下面的标签数量就会慢慢的增长,然后你就不得不手动检查清除它们,因为如果你不这样做,当标签增长到超过屏幕显示时,你就不得不一个个找过去来才能找到最近正在安装的软件。想想:在火狐浏览器中打开50个标签是什么感受。太烦人,太不方便!
|
||||
|
||||
我说过我会给 Gnome 一点打击,我是认真的。Muon 有一点做得比 Gnome 软件中心做得好。在 Muon 的设置栏下面有个“显示技术包”,即:编辑器,软件库,非图形应用程序,无 AppData 的应用等等(LCTT 译注:AppData 是软件包中的一个特殊文件,用于专门存储软件的信息)。Gnome 则没有。如果你想安装其中任何一项你必须跑到终端操作。我想这是他们做得不对的一点。我完全理解他们推行 AppData 的心情,但我想他们太急了(LCTT 译注:推行所有软件包带有 AppData 是 Gnome 软件中心的目标之一)。我是在想安装 PowerTop,而 Gnome 不显示这个软件时我才发现这点的——因为它没有 AppData,也没有“显示技术包”设置。
|
||||
|
||||
更不幸的事实是,如果你在 KDE 下你不能说“用 [Apper][3] 就行了”,因为……
|
||||
|
||||
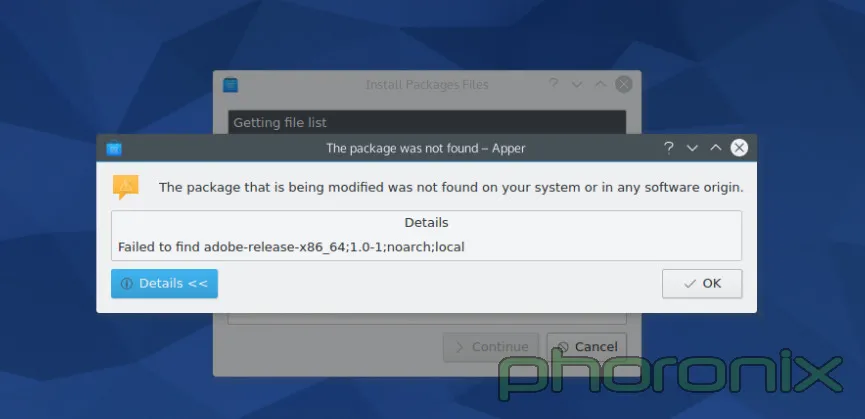
|
||||
|
||||
Apper 对安装本地软件包的支持大约在 Fedora 19 时就中止了,几乎两年了。我喜欢关注细节与质量。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=3
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://community.kde.org/Baloo
|
||||
[2]:http://www.ikde.org/tech/kde-tech-nepomuk/
|
||||
[3]:https://en.wikipedia.org/wiki/Apper
|
||||
@ -0,0 +1,52 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第四节 GNOME设置)
|
||||
================================================================================
|
||||
|
||||
### 设置 ###
|
||||
|
||||
在这我要挑一挑几个特定 KDE 控制模块的毛病,大部分原因是因为相比它们的对手GNOME来说,糟糕得太可笑,实话说,真是悲哀。
|
||||
|
||||
第一个接招的?打印机。
|
||||
|
||||
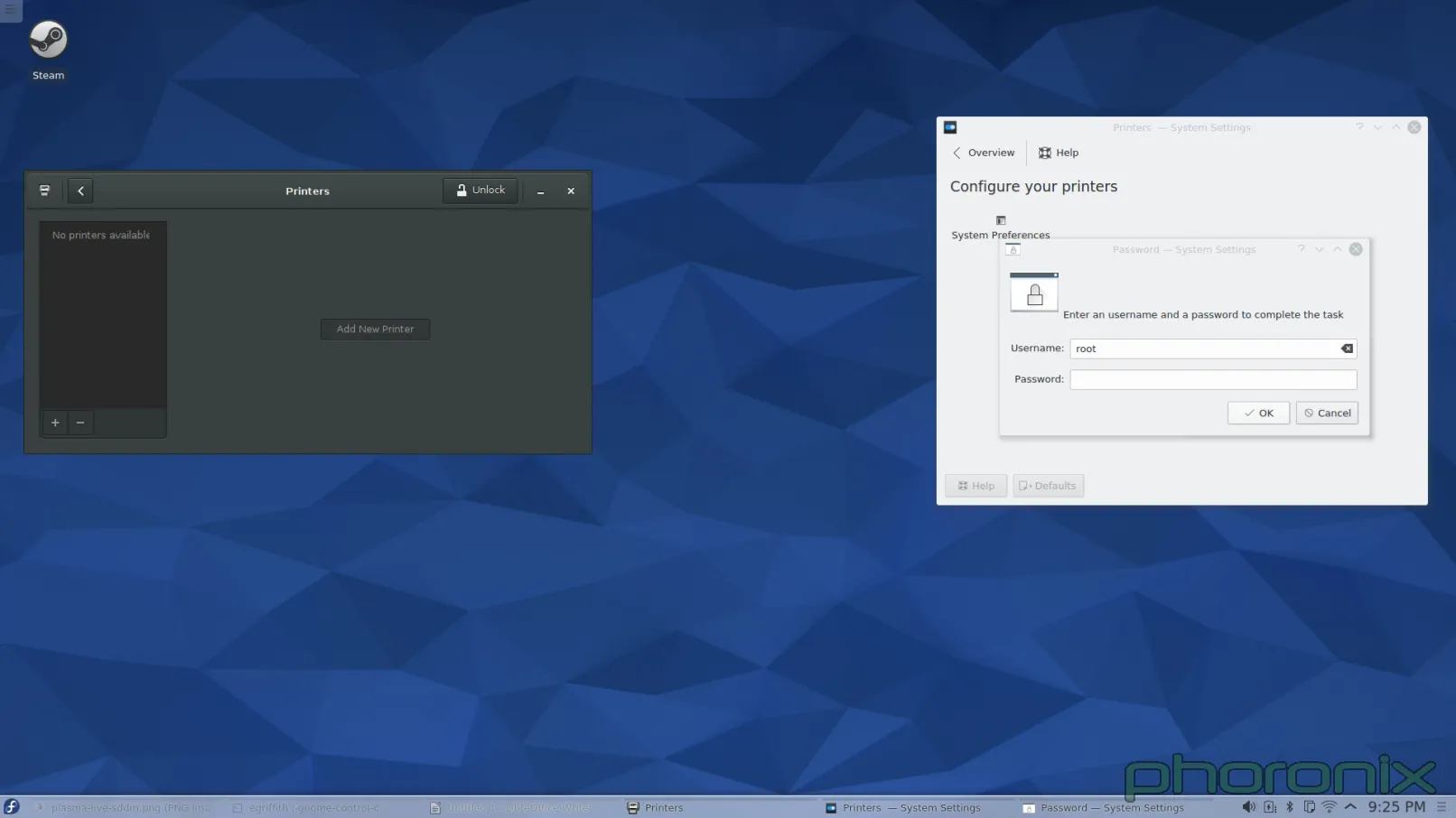
|
||||
|
||||
GNOME 在左,KDE 在右。你知道左边跟右边的打印程序有什么区别吗?当我在 GNOME 控制中心打开“打印机”时,程序窗口弹出来了,然后这样就可以使用了。而当我在 KDE 系统设置打开“打印机”时,我得到了一条密码提示。甚至我都没能看一眼打印机呢,我就必须先交出 ROOT 密码。
|
||||
|
||||
让我再重复一遍。在今天这个有了 PolicyKit 和 Logind 的日子里,对一个应该是 sudo 的操作,我依然被询问要求 ROOT 的密码。我安装系统的时候甚至都没设置 root 密码。所以我必须跑到 Konsole 去,接着运行 'sudo passwd root' 命令,这样我才能给 root 设一个密码,然后我才能回到系统设置中的打印程序,再交出 root 密码,然后仅仅是看一看哪些打印机可用。完成了这些工作后,当我点击“添加打印机”时,我再次得到请求 ROOT 密码的提示,当我解决了它后再选择一个打印机和驱动时,我再次得到请求 ROOT 密码的提示。仅仅是为了添加一个打印机到系统我就收到三次密码请求!
|
||||
|
||||
而在 GNOME 下添加打印机,在点击打印机程序中的“解锁”之前,我没有得到任何请求 SUDO 密码的提示。整个过程我只被请求过一次,仅此而已。KDE,求你了……采用 GNOME 的“解锁”模式吧。不到一定需要的时候不要发出提示。还有,不管是哪个库,只要它允许 KDE 应用程序绕过 PolicyKit/Logind(如果有的话)并直接请求 ROOT 权限……那就把它封进箱里吧。如果这是个多用户系统,那我要么必须交出 ROOT 密码,要么我必须时时刻刻待命,以免有一个用户需要升级、更改或添加一个新的打印机。而这两种情况都是完全无法接受的。
|
||||
|
||||
有还一件事……
|
||||
|
||||
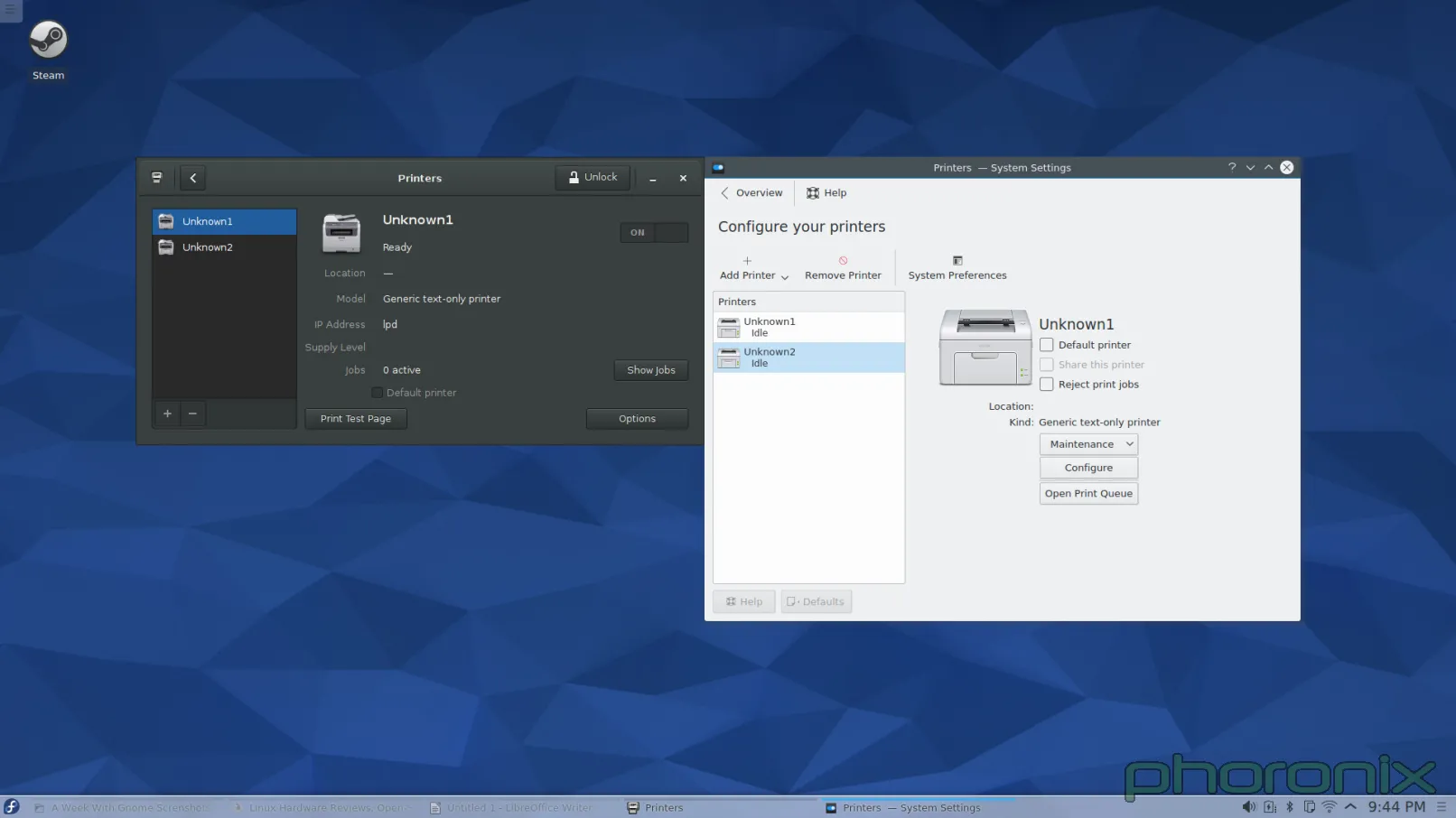
|
||||
|
||||
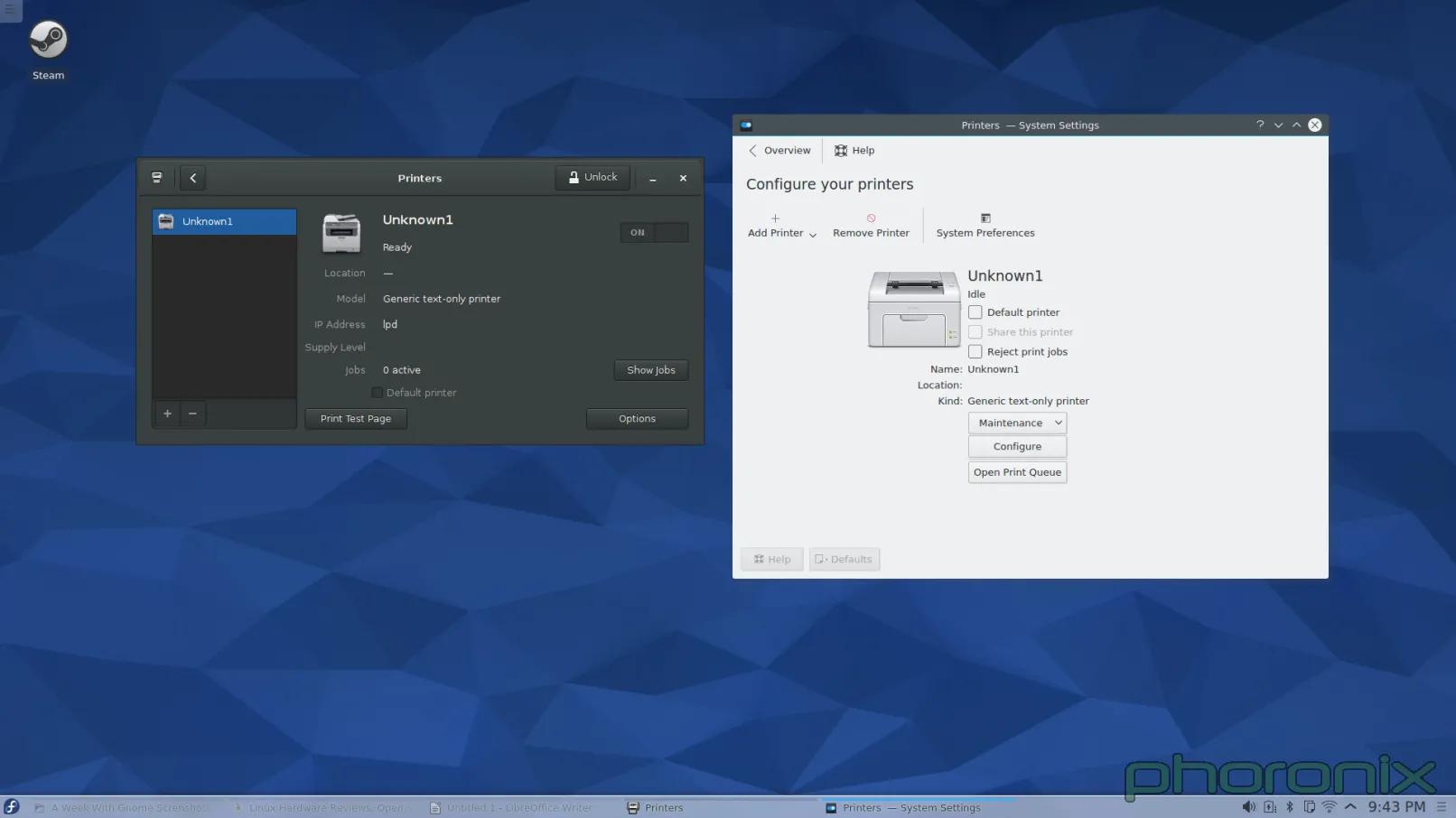
|
||||
|
||||
这个问题问大家:怎么样看起来更简洁?我在写这篇文章时意识到:当有任何附加的打印机准备好时,Gnome 打印机程序会把过程做得非常简洁,它们在左边上放了一个竖直栏来列出这些打印机。而我在 KDE 中添加第二台打印机时,它突然增加出一个左边栏来。而在添加之前,我脑海中已经有了一个恐怖的画面,它会像图片文件夹显示预览图一样直接在界面里插入另外一个图标。我很高兴也很惊讶的看到我是错的。但是事实是它直接“长出”另外一个从未存在的竖直栏,彻底改变了它的界面布局,而这样也称不上“好”。终究还是一种令人困惑,奇怪而又不直观的设计。
|
||||
|
||||
打印机说得够多了……下一个接受我公开石刑的 KDE 系统设置是?多媒体,即 Phonon。
|
||||
|
||||
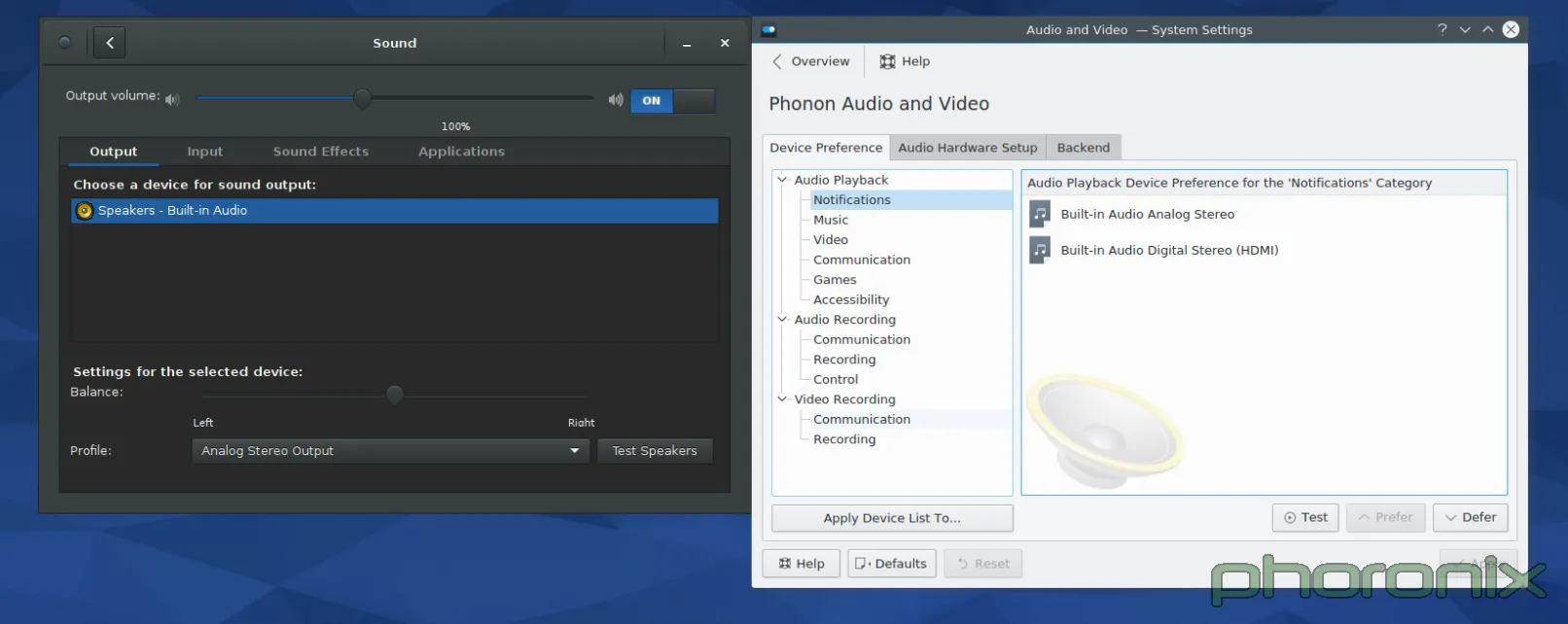
|
||||
|
||||
一如既往,GNOME 在左边,KDE 在右边。让我们先看看 GNOME 的系统设置先……眼睛移动是从左到右,从上到下,对吧?来吧,就这样做。首先:音量控制滑条。滑条中的蓝色条与空条百分百清晰地消除了哪边是“音量增加”的困惑。在音量控制条后马上就是一个 On/Off 开关,用来开关静音功能。Gnome 的再次得分在于静音后能记住当前设置的音量,而在点击音量增加按钮取消静音后能回到原来设置的音量中来。Kmixer,你个健忘的垃圾,我真的希望我能多讨论你一下。
|
||||
|
||||
继续!输入输出和应用程序的标签选项?每一个应用程序的音量随时可控?Gnome,每过一秒,我爱你越深。音量均衡选项、声音配置、和清晰地标上标志的“测试麦克风”选项。
|
||||
|
||||
我不清楚它能否以一种更干净更简洁的设计实现。是的,它只是一个 Gnome 化的 Pavucontrol,但我想这就是重要的地方。Pavucontrol 在这方面几乎完全做对了,Gnome 控制中心中的“声音”应用程序的改善使它向完美更进了一步。
|
||||
|
||||
Phonon,该你上了。但开始前我想说:我 TM 看到的是什么?!我知道我看到的是音频设备的优先级列表,但是它呈现的方式有点太坑。还有,那些用户可能关心的那些东西哪去了?拥有一个优先级列表当然很好,它也应该存在,但问题是优先级列表属于那种用户乱搞一两次之后就不会再碰的东西。它还不够重要,或者说不够常用到可以直接放在正中间位置的程度。音量控制滑块呢?对每个应用程序的音量控制功能呢?那些用户使用最频繁的东西呢?好吧,它们在 Kmix 中,一个分离的程序,拥有它自己的配置选项……而不是在系统设置下……这样真的让“系统设置”这个词变得有点用词不当。
|
||||
|
||||
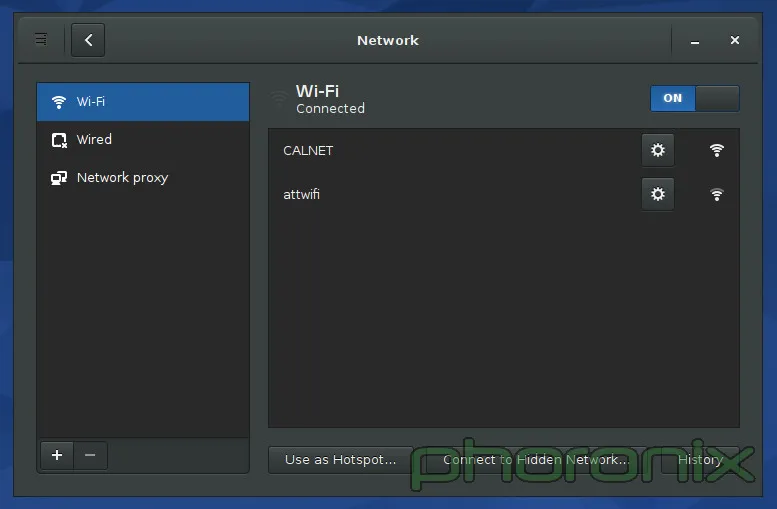
|
||||
|
||||
上面展示的 Gnome 的网络设置。KDE 的没有展示,原因就是我接下来要吐槽的内容了。如果你进入 KDE 的系统设置里,然后点击“网络”区域中三个选项中的任何一个,你会得到一大堆的选项:蓝牙设置、Samba 分享的默认用户名和密码(说真的,“连通性(Connectivity)”下面只有两个选项:SMB 的用户名和密码。TMD 怎么就配得上“连通性”这么大的词?),浏览器身份验证控制(只有 Konqueror 能用……一个已经倒闭的项目),代理设置,等等……我的 wifi 设置哪去了?它们没在这。哪去了?好吧,它们在网络应用程序的设置里面……而不是在网络设置里……
|
||||
|
||||
KDE,你这是要杀了我啊,你有“系统设置”当凶器,拿着它动手吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=4
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,40 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第三节 总结)
|
||||
================================================================================
|
||||
|
||||
### 用户体验和最后想法 ###
|
||||
|
||||
当 Gnome 2.x 和 KDE 4.x 要正面交锋时……我在它们之间左右逢源。我对它们爱恨交织,但总的来说它们使用起来还算是一种乐趣。然后 Gnome 3.x 来了,带着一场 Gnome Shell 的戏剧。那时我就放弃了 Gnome,我尽我所能的避开它。当时它对用户是不友好的,而且不直观,它打破了原有的设计典范,只为平板的统治世界做准备……而根据平板下跌的销量来看,这样的未来不可能实现。
|
||||
|
||||
在 Gnome 3 后续发布了八个版本后,奇迹发生了。Gnome 变得对对用户友好了,变得直观了。它完美吗?当然不。我还是很讨厌它想推动的那种设计范例,我讨厌它总想给我强加一种工作流(work flow),但是在付出时间和耐心后,这两都能被接受。只要你能够回头去看看 Gnome Shell 那外星人一样的界面,然后开始跟 Gnome 的其它部分(特别是控制中心)互动,你就能发现 Gnome 绝对做对了:细节,对细节的关注!
|
||||
|
||||
人们能适应新的界面设计范例,能适应新的工作流—— iPhone 和 iPad 都证明了这一点——但真正让他们操心的一直是“纸割”——那些不完美的细节。
|
||||
|
||||
它带出了 KDE 和 Gnome 之间最重要的一个区别。Gnome 感觉像一个产品,像一种非凡的体验。你用它的时候,觉得它是完整的,你要的东西都触手可及。它让人感觉就像是一个拥有 Windows 或者 OS X 那样桌面体验的 Linux 桌面版:你要的都在里面,而且它是被同一个目标一致的团队中的同一个人写出来的。天,即使是一个应用程序发出的 sudo 请求都感觉是 Gnome 下的一个特意设计的部分,就像在 Windows 下的一样。而在 KDE 下感觉就是随便一个应用程序都能创建的那种各种外观的弹窗。它不像是以系统本身这样的正式身份停下来说“嘿,有个东西要请求管理员权限!你要给它吗?”。
|
||||
|
||||
KDE 让人体验不到有凝聚力的体验。KDE 像是在没有方向地打转,感觉没有完整的体验。它就像是一堆东西往不同的的方向移动,只不过恰好它们都有一个共同享有的工具包而已。如果开发者对此很开心,那么好吧,他们开心就好,但是如果他们想提供最好体验的话,那么就需要多关注那些小地方了。用户体验跟直观应当做为每一个应用程序的设计中心,应当有一个视野,知道 KDE 要提供什么——并且——知道它看起来应该是什么样的。
|
||||
|
||||
是不是有什么原因阻止我在 KDE 下使用 Gnome 磁盘管理? Rhythmbox 呢? Evolution 呢? 没有,没有,没有。但是这样说又错过了关键。Gnome 和 KDE 都称它们自己为“桌面环境”。那么它们就应该是完整的环境,这意味着他们的各个部件应该汇集并紧密结合在一起,意味着你应该使用它们环境下的工具,因为它们说“您在一个完整的桌面中需要的任何东西,我们都支持。”说真的?只有 Gnome 看起来能符合完整的要求。KDE 在“汇集在一起”这一方面感觉就像个半成品,更不用说提供“完整体验”中你所需要的东西。Gnome 磁盘管理没有相应的对手—— kpartionmanage 要求 ROOT 权限。KDE 不运行“首次用户注册”的过程(原文:No 'First Time User' run through。可能是指系统安装过程中KDE没有创建新用户的过程,译注) ,现在也不过是在 Kubuntu 下引入了一个用户管理器。老天,Gnome 甚至提供了地图、笔记、日历和时钟应用。这些应用都是百分百要紧的吗?不,当然不了。但是正是这些应用帮助 Gnome 推动“Gnome 是一种完整丰富的体验”的想法。
|
||||
|
||||
我吐槽的 KDE 问题并非不可能解决,决对不是这样的!但是它需要人去关心它。它需要开发者为他们的作品感到自豪,而不仅仅是为它们实现的功能而感到自豪——组织的价值可大了去了。别夺走用户设置选项的能力—— GNOME 3.x 就是因为缺乏配置选项的能力而为我所诟病,但别把“好吧,你想怎么设置就怎么设置”作为借口而不提供任何理智的默认设置。默认设置是用户将看到的东西,它们是用户从打开软件的第一刻开始进行评判的关键。给用户留个好印象吧。
|
||||
|
||||
我知道 KDE 开发者们知道设计很重要,这也是为什么VDG(Visual Design Group 视觉设计组)存在的原因,但是感觉好像他们没有让 VDG 充分发挥,所以 KDE 里存在组织上的缺陷。不是 KDE 没办法完整,不是它没办法汇集整合在一起然后解决衰败问题,只是开发者们没做到。他们瞄准了靶心……但是偏了。
|
||||
|
||||
还有,在任何人说这句话之前……千万别说“欢迎给我们提交补丁啊"。因为当我开心的为某个人提交补丁时,只要开发者坚持以他们喜欢的却不直观的方式干事,更多这样的烦人事就会不断发生。这不关 Muon 有没有中心对齐。也不关 Amarok 的界面太丑。也不关每次我敲下快捷键后,弹出的音量和亮度调节窗口占用了我一大块的屏幕“地皮”(说真的,有人会把这些东西缩小)。
|
||||
|
||||
这跟心态的冷漠有关,跟开发者们在为他们的应用设计 UI 时根本就不多加思考有关。KDE 团队做的东西都工作得很好。Amarok 能播放音乐。Dragon 能播放视频。Kwin 或 Qt 和 kdelibs 似乎比 Mutter/gtk 更有力更效率(仅根据我的电池电量消耗计算。非科学性测试)。这些都很好,很重要……但是它们呈现的方式也很重要。甚至可以说,呈现方式是最重要的,因为它是用户看到的并与之交互的东西。
|
||||
|
||||
KDE 应用开发者们……让 VDG 参与进来吧。让 VDG 审查并核准每一个“核心”应用,让一个 VDG 的 UI/UX 专家来设计应用的使用模式和使用流程,以此保证其直观性。真见鬼,不管你们在开发的是啥应用,仅仅把它的模型发到 VDG 论坛寻求反馈甚至都可能都能得到一些非常好的指点跟反馈。你有这么好的资源在这,现在赶紧用吧。
|
||||
|
||||
我不想说得好像我一点都不懂感恩。我爱 KDE,我爱那些志愿者们为了给 Linux 用户一个可视化的桌面而付出的工作与努力,也爱可供选择的 Gnome。正是因为我关心我才写这篇文章。因为我想看到更好的 KDE,我想看到它走得比以前更加遥远。而这样做需要每个人继续努力,并且需要人们不再躲避批评。它需要人们对系统互动及系统崩溃的地方都保持诚实。如果我们不能直言批评,如果我们不说“这真垃圾!”,那么情况永远不会变好。
|
||||
|
||||
这周后我会继续使用 Gnome 吗?可能不。应该不。Gnome 还在试着强迫我接受其工作流,而我不想追随,也不想遵循,因为我在使用它的时候感觉变得不够高效,因为它并不遵循我的思维模式。可是对于我的朋友们,当他们问我“我该用哪种桌面环境?”我可能会推荐 Gnome,特别是那些不大懂技术,只要求“能工作”就行的朋友。根据目前 KDE 的形势来看,这可能是我能说出的最狠毒的评估了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=5
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,6 +1,6 @@
|
||||
如何在Ubuntu 14.04/15.04上配置Chef(服务端/客户端)
|
||||
如何在 Ubuntu 上安装配置管理系统 Chef (大厨)
|
||||
================================================================================
|
||||
Chef是对于信息技术专业人员的一款配置管理和自动化工具,它可以配置和管理你的设备无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,涉及到成百甚至上千的服务器和程序来支持大量的客户群。chef最有用的是让设备变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端设备或者终端用户。
|
||||
Chef是面对IT专业人员的一款配置管理和自动化工具,它可以配置和管理你的基础设施,无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,这涉及到可支持大量的客户群的成百上千的服务器和程序。chef最有用的是让基础设施变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端基础设施或者终端用户。
|
||||
|
||||
下面是我们将要在本篇中要设置和配置Chef的主要组件。
|
||||
|
||||
@ -10,34 +10,13 @@ Chef是对于信息技术专业人员的一款配置管理和自动化工具,
|
||||
|
||||
我们将在下面的基础环境下设置Chef配置管理系统。
|
||||
|
||||
注:表格
|
||||
<table width="701" style="height: 284px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="660" colspan="2"><strong>管理和配置工具:Chef</strong></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>基础操作系统</strong></td>
|
||||
<td width="492">Ubuntu 14.04.1 LTS (x86_64)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Server</strong></td>
|
||||
<td width="492">Version 12.1.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Manage</strong></td>
|
||||
<td width="492">Version 1.17.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Development Kit</strong></td>
|
||||
<td width="492">Version 0.6.2</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>内存和CPU</strong></td>
|
||||
<td width="492">4 GB , 2.0+2.0 GHZ</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|管理和配置工具:Chef||
|
||||
|-------------------------------|---|
|
||||
|基础操作系统|Ubuntu 14.04.1 LTS (x86_64)|
|
||||
|Chef Server|Version 12.1.0|
|
||||
|Chef Manage|Version 1.17.0|
|
||||
|Chef Development Kit|Version 0.6.2|
|
||||
|内存和CPU|4 GB , 2.0+2.0 GHz|
|
||||
|
||||
### Chef服务端的安装和配置 ###
|
||||
|
||||
@ -45,15 +24,15 @@ Chef服务端是核心组件,它存储配置以及其他和工作站交互的
|
||||
|
||||
我使用下面的命令来下载和安装它。
|
||||
|
||||
**1) 下载Chef服务端**
|
||||
####1) 下载Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**2) 安装Chef服务端**
|
||||
####2) 安装Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# dpkg -i chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**3) 重新配置Chef服务端**
|
||||
####3) 重新配置Chef服务端
|
||||
|
||||
现在运行下面的命令来启动所有的chef服务端服务,这步也许会花费一些时间,因为它有许多不同一起工作的服务组成来创建一个正常运作的系统。
|
||||
|
||||
@ -64,35 +43,35 @@ chef服务端启动命令'chef-server-ctl reconfigure'需要运行两次,这
|
||||
Chef Client finished, 342/350 resources updated in 113.71139964 seconds
|
||||
opscode Reconfigured!
|
||||
|
||||
**4) 重启系统 **
|
||||
####4) 重启系统
|
||||
|
||||
安装完成后重启系统使系统能最好的工作,不然我们或许会在创建用户的时候看到下面的SSL连接错误。
|
||||
|
||||
ERROR: Errno::ECONNRESET: Connection reset by peer - SSL_connect
|
||||
|
||||
**5) 创建心的管理员**
|
||||
####5) 创建新的管理员
|
||||
|
||||
运行下面的命令来创建一个新的用它自己的配置的管理员账户。创建过程中,用户的RSA私钥会自动生成并需要被保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
运行下面的命令来创建一个新的管理员账户及其配置。创建过程中,用户的RSA私钥会自动生成,它需要保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
|
||||
root@ubuntu-14-chef:/tmp# chef-server-ctl user-create kashi kashi kashi kashif.fareedi@gmail.com kashi123 --filename /root/kashi.pem
|
||||
|
||||
### Chef服务端的管理设置 ###
|
||||
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它启用了可视化的web用户界面并可以管理节点、数据包、规则、环境、配置和基于角色的访问控制(RBAC)
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它提供了可视化的web用户界面,可以管理节点、数据包、规则、环境、Cookbook 和基于角色的访问控制(RBAC)
|
||||
|
||||
**1) 下载Chef Manage**
|
||||
####1) 下载Chef Manage
|
||||
|
||||
从官网复制链接病下载chef manage的安装包。
|
||||
从官网复制链接并下载chef manage的安装包。
|
||||
|
||||
root@ubuntu-14-chef:~# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/opscode-manage_1.17.0-1_amd64.deb
|
||||
|
||||
**2) 安装Chef Manage**
|
||||
####2) 安装Chef Manage
|
||||
|
||||
使用下面的命令在root的家目录下安装它。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl install opscode-manage --path /root
|
||||
|
||||
**3) 重启Chef Manage和服务端**
|
||||
####3) 重启Chef Manage和服务端
|
||||
|
||||
安装完成后我们需要运行下面的命令来重启chef manage和服务端。
|
||||
|
||||
@ -101,28 +80,27 @@ Chef Manage是一个针对企业Chef用户的管理控制台,它启用了可
|
||||
|
||||
### Chef Manage网页控制台 ###
|
||||
|
||||
我们可以使用localhost访问网页控制台以及fqdn,并用已经创建的管理员登录
|
||||
我们可以使用localhost或它的全称域名来访问网页控制台,并用已经创建的管理员登录
|
||||
|
||||

|
||||
|
||||
**1) Chef Manage创建新的组织 **
|
||||
####1) Chef Manage创建新的组织
|
||||
|
||||
你或许被要求创建新的组织或者接受其他阻止的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
你或许被要求创建新的组织,或者也可以接受其他组织的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
|
||||

|
||||
|
||||
**2) 用命令行创建心的组织 **
|
||||
####2) 用命令行创建新的组织
|
||||
|
||||
We can also create new Organization from the command line by executing the following command.
|
||||
我们同样也可以运行下面的命令来创建新的组织。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create linux Linoxide Linux Org. --association_user kashi --filename linux.pem
|
||||
|
||||
### 设置工作站 ###
|
||||
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes、cookbooks、属性和其他任何的我们想要对Chef的修改。
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes([基础配置元素](https://docs.chef.io/recipes.html))、cookbooks([基础配置集](https://docs.chef.io/cookbooks.html))、attributes([节点属性](https://docs.chef.io/attributes.html))和其他任何的我们想要对Chef做的修改。
|
||||
|
||||
**1) 在Chef服务端上创建新的用户和组织 **
|
||||
####1) 在Chef服务端上创建新的用户和组织
|
||||
|
||||
为了设置工作站,我们用命令行创建一个新的用户和组织。
|
||||
|
||||
@ -130,25 +108,23 @@ We can also create new Organization from the command line by executing the follo
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create blogs Linoxide Blogs Inc. --association_user bloger --filename blogs.pem
|
||||
|
||||
**2) 下载工作站入门套件 **
|
||||
####2) 下载工作站入门套件
|
||||
|
||||
Now Download and Save starter-kit from the chef manage web console on a workstation and use it to work with Chef server.
|
||||
在工作站的网页控制台中下面并保存入门套件用于与服务端协同工作
|
||||
在工作站的网页控制台中下载保存入门套件,它用于与服务端协同工作
|
||||
|
||||

|
||||
|
||||
**3) 点击"Proceed"下载套件 **
|
||||
####3) 下载套件后,点击"Proceed"
|
||||
|
||||

|
||||
|
||||
### 对于工作站的Chef开发套件设置 ###
|
||||
### 用于工作站的Chef开发套件设置 ###
|
||||
|
||||
Chef开发套件是一款包含所有开发chef所需工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
Chef开发套件是一款包含开发chef所需的所有工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
|
||||
**1) 下载 Chef DK**
|
||||
####1) 下载 Chef DK
|
||||
|
||||
We can Download chef development kit from its official web link and choose the required operating system to get its chef development tool kit.
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来得到chef开发包。
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来下载chef开发包。
|
||||
|
||||

|
||||
|
||||
@ -156,13 +132,13 @@ We can Download chef development kit from its official web link and choose the r
|
||||
|
||||
root@ubuntu-15-WKS:~# wget https://opscode-omnibus-packages.s3.amazonaws.com/ubuntu/12.04/x86_64/chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**1) Chef开发套件安装**
|
||||
####2) Chef开发套件安装
|
||||
|
||||
使用dpkg命令安装开发套件
|
||||
|
||||
root@ubuntu-15-WKS:~# dpkg -i chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**3) Chef DK 验证**
|
||||
####3) Chef DK 验证
|
||||
|
||||
使用下面的命令验证客户端是否已经正确安装。
|
||||
|
||||
@ -195,7 +171,7 @@ We can Download chef development kit from its official web link and choose the r
|
||||
Verification of component 'chefspec' succeeded.
|
||||
Verification of component 'package installation' succeeded.
|
||||
|
||||
**连接Chef服务端**
|
||||
####4) 连接Chef服务端
|
||||
|
||||
我们将创建 ~/.chef并从chef服务端复制两个用户和组织的pem文件到chef的文件到这个目录下。
|
||||
|
||||
@ -209,7 +185,7 @@ We can Download chef development kit from its official web link and choose the r
|
||||
kashi.pem 100% 1678 1.6KB/s 00:00
|
||||
linux.pem 100% 1678 1.6KB/s 00:00
|
||||
|
||||
** 编辑配置来管理chef环境 **
|
||||
####5) 编辑配置来管理chef环境
|
||||
|
||||
现在使用下面的内容创建"~/.chef/knife.rb"。
|
||||
|
||||
@ -231,13 +207,13 @@ We can Download chef development kit from its official web link and choose the r
|
||||
|
||||
root@ubuntu-15-WKS:/# mkdir cookbooks
|
||||
|
||||
**测试Knife配置**
|
||||
####6) 测试Knife配置
|
||||
|
||||
运行“knife user list”和“knife client list”来验证knife是否在工作。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife user list
|
||||
|
||||
第一次运行的时候可能会得到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
第一次运行的时候可能会看到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
|
||||
ERROR: SSL Validation failure connecting to host: 172.25.10.173 - SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed
|
||||
ERROR: Could not establish a secure connection to the server.
|
||||
@ -245,7 +221,7 @@ We can Download chef development kit from its official web link and choose the r
|
||||
If your Chef Server uses a self-signed certificate, you can use
|
||||
`knife ssl fetch` to make knife trust the server's certificates.
|
||||
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl整数并重新运行knife user和client list,这时候应该就可以了。
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl证书,并重新运行knife user和client list,这时候应该就可以了。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife ssl fetch
|
||||
WARNING: Certificates from 172.25.10.173 will be fetched and placed in your trusted_cert
|
||||
@ -260,9 +236,9 @@ We can Download chef development kit from its official web link and choose the r
|
||||
root@ubuntu-15-WKS:/.chef#knife client list
|
||||
kashi-linux
|
||||
|
||||
### 与chef服务端交互的新的节点 ###
|
||||
### 配置与chef服务端交互的新节点 ###
|
||||
|
||||
节点是执行所有设备自动化的chef客户端。因此是时侯添加新的服务端到我们的chef环境下,在配置完chef-server和knife工作站后配置新的节点与chef-server交互。
|
||||
节点是执行所有基础设施自动化的chef客户端。因此,在配置完chef-server和knife工作站后,通过配置新的与chef-server交互的节点,来添加新的服务端到我们的chef环境下。
|
||||
|
||||
我们使用下面的命令来添加新的节点与chef服务端工作。
|
||||
|
||||
@ -291,16 +267,16 @@ We can Download chef development kit from its official web link and choose the r
|
||||
172.25.10.170 to file /tmp/install.sh.26024/metadata.txt
|
||||
172.25.10.170 trying wget...
|
||||
|
||||
之后我们可以在knife节点列表下看到新创建的节点,也会新节点列表下创建新的客户端。
|
||||
之后我们可以在knife节点列表下看到新创建的节点,它也会在新节点创建新的客户端。
|
||||
|
||||
root@ubuntu-15-WKS:~# knife node list
|
||||
mydns
|
||||
|
||||
相似地我们只要提供ssh证书通过上面的knife命令来创建多个节点到chef设备上。
|
||||
相似地我们只要提供ssh证书通过上面的knife命令,就可以在chef设施上创建多个节点。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置浏览了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置基本了解了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -308,7 +284,7 @@ via: http://linoxide.com/ubuntu-how-to/install-configure-chef-ubuntu-14-04-15-04
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,178 @@
|
||||
|
||||
如何收集 NGINX 指标(第二篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### 如何获取你所需要的 NGINX 指标 ###
|
||||
|
||||
如何获取需要的指标取决于你正在使用的 NGINX 版本以及你希望看到哪些指标。(参见 [如何监控 NGINX(第一篇)][1] 来深入了解NGINX指标。)自由开源的 NGINX 和商业版的 NGINX Plus 都有可以报告指标度量的状态模块,NGINX 也可以在其日志中配置输出特定指标:
|
||||
|
||||
**指标可用性**
|
||||
|
||||
| 指标 | [NGINX (开源)](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source) | [NGINX Plus](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus) | [NGINX 日志](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#logs)|
|
||||
|-----|------|-------|-----|
|
||||
|accepts(接受) / accepted(已接受)|x|x| |
|
||||
|handled(已处理)|x|x| |
|
||||
|dropped(已丢弃)|x|x| |
|
||||
|active(活跃)|x|x| |
|
||||
|requests (请求数)/ total(全部请求数)|x|x| |
|
||||
|4xx 代码||x|x|
|
||||
|5xx 代码||x|x|
|
||||
|request time(请求处理时间)|||x|
|
||||
|
||||
#### 指标收集:NGINX(开源版) ####
|
||||
|
||||
开源版的 NGINX 会在一个简单的状态页面上显示几个与服务器状态有关的基本指标,它们由你启用的 HTTP [stub status module][2] 所提供。要检查该模块是否已启用,运行以下命令:
|
||||
|
||||
nginx -V 2>&1 | grep -o with-http_stub_status_module
|
||||
|
||||
如果你看到终端输出了 **http_stub_status_module**,说明该状态模块已启用。
|
||||
|
||||
如果该命令没有输出,你需要启用该状态模块。你可以在[从源代码构建 NGINX ][3]时使用 `--with-http_stub_status_module` 配置参数:
|
||||
|
||||
./configure \
|
||||
… \
|
||||
--with-http_stub_status_module
|
||||
make
|
||||
sudo make install
|
||||
|
||||
在验证该模块已经启用或你自己启用它后,你还需要修改 NGINX 配置文件,来给状态页面设置一个本地可访问的 URL(例如: /nginx_status):
|
||||
|
||||
server {
|
||||
location /nginx_status {
|
||||
stub_status on;
|
||||
|
||||
access_log off;
|
||||
allow 127.0.0.1;
|
||||
deny all;
|
||||
}
|
||||
}
|
||||
|
||||
注:nginx 配置中的 server 块通常并不放在主配置文件中(例如:/etc/nginx/nginx.conf),而是放在主配置会加载的辅助配置文件中。要找到主配置文件,首先运行以下命令:
|
||||
|
||||
nginx -t
|
||||
|
||||
打开列出的主配置文件,在以 http 块结尾的附近查找以 include 开头的行,如:
|
||||
|
||||
include /etc/nginx/conf.d/*.conf;
|
||||
|
||||
在其中一个包含的配置文件中,你应该会找到主 **server** 块,你可以如上所示配置 NGINX 的指标输出。更改任何配置后,通过执行以下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
现在,你可以浏览状态页看到你的指标:
|
||||
|
||||
Active connections: 24
|
||||
server accepts handled requests
|
||||
1156958 1156958 4491319
|
||||
Reading: 0 Writing: 18 Waiting : 6
|
||||
|
||||
请注意,如果你希望从远程计算机访问该状态页面,则需要将远程计算机的 IP 地址添加到你的状态配置文件的白名单中,在上面的配置文件中的白名单仅有 127.0.0.1。
|
||||
|
||||
NGINX 的状态页面是一种快速查看指标状况的简单方法,但当连续监测时,你需要按照标准间隔自动记录该数据。监控工具箱 [Nagios][4] 或者 [Datadog][5],以及收集统计信息的服务 [collectD][6] 已经可以解析 NGINX 的状态信息了。
|
||||
|
||||
#### 指标收集: NGINX Plus ####
|
||||
|
||||
商业版的 NGINX Plus 通过它的 ngx_http_status_module 提供了比开源版 NGINX [更多的指标][7]。NGINX Plus 以字节流的方式提供这些额外的指标,提供了关于上游系统和高速缓存的信息。NGINX Plus 也会报告所有的 HTTP 状态码类型(1XX,2XX,3XX,4XX,5XX)的计数。一个 NGINX Plus 状态报告例子[可在此查看][8]:
|
||||
|
||||

|
||||
|
||||
注:NGINX Plus 在状态仪表盘中的“Active”连接的定义和开源 NGINX 通过 stub_status_module 收集的“Active”连接指标略有不同。在 NGINX Plus 指标中,“Active”连接不包括Waiting状态的连接(即“Idle”连接)。
|
||||
|
||||
NGINX Plus 也可以输出 [JSON 格式的指标][9],可以用于集成到其他监控系统。在 NGINX Plus 中,你可以看到 [给定的上游服务器组][10]的指标和健康状况,或者简单地从上游服务器的[单个服务器][11]得到响应代码的计数:
|
||||
|
||||
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
|
||||
|
||||
要启动 NGINX Plus 指标仪表盘,你可以在 NGINX 配置文件的 http 块内添加状态 server 块。 (参见上一节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。)例如,要设置一个状态仪表盘 (http://your.ip.address:8080/status.html)和一个 JSON 接口(http://your.ip.address:8080/status),可以添加以下 server 块来设定:
|
||||
|
||||
server {
|
||||
listen 8080;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
location /status {
|
||||
status;
|
||||
}
|
||||
|
||||
location = /status.html {
|
||||
}
|
||||
}
|
||||
|
||||
当你重新加载 NGINX 配置后,状态页就可以用了:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
关于如何配置扩展状态模块,官方 NGINX Plus 文档有 [详细介绍][13] 。
|
||||
|
||||
#### 指标收集:NGINX 日志 ####
|
||||
|
||||
NGINX 的 [日志模块][14] 会把可自定义的访问日志写到你配置的指定位置。你可以通过[添加或移除变量][15]来自定义日志的格式和包含的数据。要存储详细的日志,最简单的方法是添加下面一行在你配置文件的 server 块中(参见上上节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。):
|
||||
|
||||
access_log logs/host.access.log combined;
|
||||
|
||||
更改 NGINX 配置文件后,执行如下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
默认包含的 “combined” 的日志格式,会包括[一系列关键的数据][17],如实际的 HTTP 请求和相应的响应代码。在下面的示例日志中,NGINX 记录了请求 /index.html 时的 200(成功)状态码和访问不存在的请求文件 /fail 的 404(未找到)错误。
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以通过在 NGINX 配置文件中的 http 块添加一个新的日志格式来记录请求处理时间:
|
||||
|
||||
log_format nginx '$remote_addr - $remote_user [$time_local] '
|
||||
'"$request" $status $body_bytes_sent $request_time '
|
||||
'"$http_referer" "$http_user_agent"';
|
||||
|
||||
并修改配置文件中 **server** 块的 access_log 行:
|
||||
|
||||
access_log logs/host.access.log nginx;
|
||||
|
||||
重新加载配置文件后(运行 `nginx -s reload`),你的访问日志将包括响应时间,如下所示。单位为秒,精度到毫秒。在这个例子中,服务器接收到一个对 /big.pdf 的请求时,发送 33973115 字节后返回 206(成功)状态码。处理请求用时 0.202 秒(202毫秒):
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以使用各种工具和服务来解析和分析 NGINX 日志。例如,[rsyslog][18] 可以监视你的日志,并将其传递给多个日志分析服务;你也可以使用自由开源工具,比如 [logstash][19] 来收集和分析日志;或者你可以使用一个统一日志记录层,如 [Fluentd][20] 来收集和解析你的 NGINX 日志。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
监视 NGINX 的哪一项指标将取决于你可用的工具,以及监控指标所提供的信息是否满足你们的需要。举例来说,错误率的收集是否足够重要到需要你们购买 NGINX Plus ,还是架设一个可以捕获和分析日志的系统就够了?
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。[在本文中][21]了解如何用 NGINX Datadog 来监控 ,并开始 [Datadog 的免费试用][22]吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
|
||||
[3]:http://wiki.nginx.org/InstallOptions
|
||||
[4]:https://exchange.nagios.org/directory/Plugins/Web-Servers/nginx
|
||||
[5]:http://docs.datadoghq.com/integrations/nginx/
|
||||
[6]:https://collectd.org/wiki/index.php/Plugin:nginx
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_status_module.html#data
|
||||
[8]:http://demo.nginx.com/status.html
|
||||
[9]:http://demo.nginx.com/status
|
||||
[10]:http://demo.nginx.com/status/upstreams/demoupstreams
|
||||
[11]:http://demo.nginx.com/status/upstreams/demoupstreams/0/responses
|
||||
[12]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[13]:http://nginx.org/en/docs/http/ngx_http_status_module.html#example
|
||||
[14]:http://nginx.org/en/docs/http/ngx_http_log_module.html
|
||||
[15]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[17]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[18]:http://www.rsyslog.com/
|
||||
[19]:https://www.elastic.co/products/logstash
|
||||
[20]:http://www.fluentd.org/
|
||||
[21]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[22]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#sign-up
|
||||
[23]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_collect_nginx_metrics.md
|
||||
[24]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -0,0 +1,146 @@
|
||||
如何使用 Datadog 监控 NGINX(第三篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
如果你已经阅读了前面的[如何监控 NGINX][1],你应该知道从你网络环境的几个指标中可以获取多少信息。而且你也看到了从 NGINX 特定的基础中收集指标是多么容易的。但要实现全面,持续的监控 NGINX,你需要一个强大的监控系统来存储并将指标可视化,当异常发生时能提醒你。在这篇文章中,我们将向你展示如何使用 Datadog 安装 NGINX 监控,以便你可以在定制的仪表盘中查看这些指标:
|
||||
|
||||

|
||||
|
||||
Datadog 允许你以单个主机、服务、流程和度量来构建图形和警告,或者使用它们的几乎任何组合构建。例如,你可以监控你的所有主机,或者某个特定可用区域的所有NGINX主机,或者您可以监视具有特定标签的所有主机的一个关键指标。本文将告诉您如何:
|
||||
|
||||
- 在 Datadog 仪表盘上监控 NGINX 指标,就像监控其他系统一样
|
||||
- 当一个关键指标急剧变化时设置自动警报来通知你
|
||||
|
||||
### 配置 NGINX ###
|
||||
|
||||
为了收集 NGINX 指标,首先需要确保 NGINX 已启用 status 模块和一个 报告 status 指标的 URL。一步步的[配置开源 NGINX][2] 和 [NGINX Plus][3] 请参见之前的相关文章。
|
||||
|
||||
### 整合 Datadog 和 NGINX ###
|
||||
|
||||
#### 安装 Datadog 代理 ####
|
||||
|
||||
Datadog 代理是[一个开源软件][4],它能收集和报告你主机的指标,这样就可以使用 Datadog 查看和监控他们。安装这个代理通常[仅需要一个命令][5]
|
||||
|
||||
只要你的代理启动并运行着,你会看到你主机的指标报告[在你 Datadog 账号下][6]。
|
||||
|
||||

|
||||
|
||||
#### 配置 Agent ####
|
||||
|
||||
接下来,你需要为代理创建一个简单的 NGINX 配置文件。在你系统中代理的配置目录应该[在这儿][7]找到。
|
||||
|
||||
在目录里面的 conf.d/nginx.yaml.example 中,你会发现[一个简单的配置文件][8],你可以编辑并提供 status URL 和可选的标签为每个NGINX 实例:
|
||||
|
||||
init_config:
|
||||
|
||||
instances:
|
||||
|
||||
- nginx_status_url: http://localhost/nginx_status/
|
||||
tags:
|
||||
- instance:foo
|
||||
|
||||
当你提供了 status URL 和任意 tag,将配置文件保存为 conf.d/nginx.yaml。
|
||||
|
||||
#### 重启代理 ####
|
||||
|
||||
你必须重新启动代理程序来加载新的配置文件。重新启动命令[在这里][9],根据平台的不同而不同。
|
||||
|
||||
#### 检查配置文件 ####
|
||||
|
||||
要检查 Datadog 和 NGINX 是否正确整合,运行 Datadog 的 info 命令。每个平台使用的命令[看这儿][10]。
|
||||
|
||||
如果配置是正确的,你会看到这样的输出:
|
||||
|
||||
Checks
|
||||
======
|
||||
|
||||
[...]
|
||||
|
||||
nginx
|
||||
-----
|
||||
- instance #0 [OK]
|
||||
- Collected 8 metrics & 0 events
|
||||
|
||||
#### 安装整合 ####
|
||||
|
||||
最后,在你的 Datadog 帐户打开“Nginx 整合”。这非常简单,你只要在 [NGINX 整合设置][11]中点击“Install Integration”按钮。
|
||||
|
||||

|
||||
|
||||
### 指标! ###
|
||||
|
||||
一旦代理开始报告 NGINX 指标,你会看到[一个 NGINX 仪表盘][12]出现在在你 Datadog 可用仪表盘的列表中。
|
||||
|
||||
基本的 NGINX 仪表盘显示有用的图表,囊括了几个[我们的 NGINX 监控介绍][13]中的关键指标。 (一些指标,特别是请求处理时间要求进行日志分析,Datadog 不支持。)
|
||||
|
||||
你可以通过增加 NGINX 之外的重要指标的图表来轻松创建一个全面的仪表盘,以监控你的整个网站设施。例如,你可能想监视你 NGINX 的主机级的指标,如系统负载。要构建一个自定义的仪表盘,只需点击靠近仪表盘的右上角的选项并选择“Clone Dash”来克隆一个默认的 NGINX 仪表盘。
|
||||
|
||||

|
||||
|
||||
你也可以使用 Datadog 的[主机地图][14]在更高层面监控你的 NGINX 实例,举个例子,用颜色标示你所有的 NGINX 主机的 CPU 使用率来辨别潜在热点。
|
||||
|
||||

|
||||
|
||||
### NGINX 指标警告 ###
|
||||
|
||||
一旦 Datadog 捕获并可视化你的指标,你可能会希望建立一些监控自动地密切关注你的指标,并当有问题提醒你。下面将介绍一个典型的例子:一个提醒你 NGINX 吞吐量突然下降时的指标监控器。
|
||||
|
||||
#### 监控 NGINX 吞吐量 ####
|
||||
|
||||
Datadog 指标警报可以是“基于吞吐量的”(当指标超过设定值会警报)或“基于变化幅度的”(当指标的变化超过一定范围会警报)。在这个例子里,我们会采取后一种方式,当每秒传入的请求急剧下降时会提醒我们。下降往往意味着有问题。
|
||||
|
||||
1. **创建一个新的指标监控**。从 Datadog 的“Monitors”下拉列表中选择“New Monitor”。选择“Metric”作为监视器类型。
|
||||
|
||||

|
||||
|
||||
2. **定义你的指标监视器**。我们想知道 NGINX 每秒总的请求量下降的数量,所以我们在基础设施中定义我们感兴趣的 nginx.net.request_per_s 之和。
|
||||
|
||||

|
||||
|
||||
3. **设置指标警报条件**。我们想要在变化时警报,而不是一个固定的值,所以我们选择“Change Alert”。我们设置监控为无论何时请求量下降了30%以上时警报。在这里,我们使用一个一分钟的数据窗口来表示 “now” 指标的值,对横跨该间隔内的平均变化和之前 10 分钟的指标值作比较。
|
||||
|
||||

|
||||
|
||||
4. **自定义通知**。如果 NGINX 的请求量下降,我们想要通知我们的团队。在这个例子中,我们将给 ops 团队的聊天室发送通知,并给值班工程师发送短信。在“Say what’s happening”中,我们会为监控器命名,并添加一个伴随该通知的短消息,建议首先开始调查的内容。我们会 @ ops 团队使用的 Slack,并 @pagerduty [将警告发给短信][15]。
|
||||
|
||||

|
||||
|
||||
5. **保存集成监控**。点击页面底部的“Save”按钮。你现在在监控一个关键的 NGINX [工作指标][16],而当它快速下跌时会给值班工程师发短信。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们谈到了通过整合 NGINX 与 Datadog 来可视化你的关键指标,并当你的网络基础架构有问题时会通知你的团队。
|
||||
|
||||
如果你一直使用你自己的 Datadog 账号,你现在应该可以极大的提升你的 web 环境的可视化,也有能力对你的环境、你所使用的模式、和对你的组织最有价值的指标创建自动监控。
|
||||
|
||||
如果你还没有 Datadog 帐户,你可以注册[免费试用][17],并开始监视你的基础架构,应用程序和现在的服务。
|
||||
|
||||
------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://linux.cn/article-5970-1.html
|
||||
[2]:https://linux.cn/article-5985-1.html#open-source
|
||||
[3]:https://linux.cn/article-5985-1.html#plus
|
||||
[4]:https://github.com/DataDog/dd-agent
|
||||
[5]:https://app.datadoghq.com/account/settings#agent
|
||||
[6]:https://app.datadoghq.com/infrastructure
|
||||
[7]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[8]:https://github.com/DataDog/dd-agent/blob/master/conf.d/nginx.yaml.example
|
||||
[9]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[10]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[11]:https://app.datadoghq.com/account/settings#integrations/nginx
|
||||
[12]:https://app.datadoghq.com/dash/integration/nginx
|
||||
[13]:https://linux.cn/article-5970-1.html
|
||||
[14]:https://www.datadoghq.com/blog/introducing-host-maps-know-thy-infrastructure/
|
||||
[15]:https://www.datadoghq.com/blog/pagerduty/
|
||||
[16]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/#metrics
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/#sign-up
|
||||
[18]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx_with_datadog.md
|
||||
[19]:https://github.com/DataDog/the-monitor/issues
|
||||
231
published/201508/20150717 How to monitor NGINX- Part 1.md
Normal file
231
published/201508/20150717 How to monitor NGINX- Part 1.md
Normal file
@ -0,0 +1,231 @@
|
||||
如何监控 NGINX(第一篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### NGINX 是什么? ###
|
||||
|
||||
[NGINX][1] (发音为 “engine X”) 是一种流行的 HTTP 和反向代理服务器。作为一个 HTTP 服务器,NGINX 可以使用较少的内存非常高效可靠地提供静态内容。作为[反向代理][2],它可以用作多个后端服务器或类似缓存和负载平衡这样的其它应用的单一访问控制点。NGINX 是一个自由开源的产品,并有一个具备更全的功能的叫做 NGINX Plus 的商业版。
|
||||
|
||||
NGINX 也可以用作邮件代理和通用的 TCP 代理,但本文并不直接讨论 NGINX 的那些用例的监控。
|
||||
|
||||
### NGINX 主要指标 ###
|
||||
|
||||
通过监控 NGINX 可以 捕获到两类问题:NGINX 本身的资源问题,和出现在你的基础网络设施的其它问题。大多数 NGINX 用户会用到以下指标的监控,包括**每秒请求数**,它提供了一个由所有最终用户活动组成的上层视图;**服务器错误率** ,这表明你的服务器已经多长没有处理看似有效的请求;还有**请求处理时间**,这说明你的服务器处理客户端请求的总共时长(并且可以看出性能降低或当前环境的其他问题)。
|
||||
|
||||
更一般地,至少有三个主要的指标类别来监视:
|
||||
|
||||
- 基本活动指标
|
||||
- 错误指标
|
||||
- 性能指标
|
||||
|
||||
下面我们将分析在每个类别中最重要的 NGINX 指标,以及用一个相当普遍但是值得特别提到的案例来说明:使用 NGINX Plus 作反向代理。我们还将介绍如何使用图形工具或可选择的监控工具来监控所有的指标。
|
||||
|
||||
本文引用指标术语[来自我们的“监控 101 系列”][3],,它提供了一个指标收集和警告框架。
|
||||
|
||||
#### 基本活跃指标 ####
|
||||
|
||||
无论你在怎样的情况下使用 NGINX,毫无疑问你要监视服务器接收多少客户端请求和如何处理这些请求。
|
||||
|
||||
NGINX Plus 上像开源 NGINX 一样可以报告基本活跃指标,但它也提供了略有不同的辅助模块。我们首先讨论开源的 NGINX,再来说明 NGINX Plus 提供的其他指标的功能。
|
||||
|
||||
**NGINX**
|
||||
|
||||
下图显示了一个客户端连接的过程,以及开源版本的 NGINX 如何在连接过程中收集指标。
|
||||
|
||||

|
||||
|
||||
Accepts(接受)、Handled(已处理)、Requests(请求)是一直在增加的计数器。Active(活跃)、Waiting(等待)、Reading(读)、Writing(写)随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepts | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Handled | 成功的客户端连接数 | 资源: 功能 |
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Dropped(已丢弃,计算得出)| 丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Requests | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
NGINX worker 进程接受 OS 的连接请求时 **Accepts** 计数器增加,而**Handled** 是当实际的请求得到连接时(通过建立一个新的连接或重新使用一个空闲的)。这两个计数器的值通常都是相同的,如果它们有差别则表明连接被**Dropped**,往往这是由于资源限制,比如已经达到 NGINX 的[worker_connections][4]的限制。
|
||||
|
||||
一旦 NGINX 成功处理一个连接时,连接会移动到**Active**状态,在这里对客户端请求进行处理:
|
||||
|
||||
Active状态
|
||||
|
||||
- **Waiting**: 活跃的连接也可以处于 Waiting 子状态,如果有在此刻没有活跃请求的话。新连接可以绕过这个状态并直接变为到 Reading 状态,最常见的是在使用“accept filter(接受过滤器)” 和 “deferred accept(延迟接受)”时,在这种情况下,NGINX 不会接收 worker 进程的通知,直到它具有足够的数据才开始响应。如果连接设置为 keep-alive ,那么它在发送响应后将处于等待状态。
|
||||
|
||||
- **Reading**: 当接收到请求时,连接离开 Waiting 状态,并且该请求本身使 Reading 状态计数增加。在这种状态下 NGINX 会读取客户端请求首部。请求首部是比较小的,因此这通常是一个快速的操作。
|
||||
|
||||
- **Writing**: 请求被读取之后,其使 Writing 状态计数增加,并保持在该状态,直到响应返回给客户端。这意味着,该请求在 Writing 状态时, 一方面 NGINX 等待来自上游系统的结果(系统放在 NGINX “后面”),另外一方面,NGINX 也在同时响应。请求往往会在 Writing 状态花费大量的时间。
|
||||
|
||||
通常,一个连接在同一时间只接受一个请求。在这种情况下,Active 连接的数目 == Waiting 的连接 + Reading 请求 + Writing 。然而,较新的 SPDY 和 HTTP/2 协议允许多个并发请求/响应复用一个连接,所以 Active 可小于 Waiting 的连接、 Reading 请求、Writing 请求的总和。 (在撰写本文时,NGINX 不支持 HTTP/2,但预计到2015年期间将会支持。)
|
||||
|
||||
**NGINX Plus**
|
||||
|
||||
正如上面提到的,所有开源 NGINX 的指标在 NGINX Plus 中是可用的,但另外也提供其他的指标。本节仅说明了 NGINX Plus 可用的指标。
|
||||
|
||||
|
||||

|
||||
|
||||
Accepted (已接受)、Dropped,总数是不断增加的计数器。Active、 Idle(空闲)和处于 Current(当前)处理阶段的各种状态下的连接或请求的当前数量随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepted | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Dropped |丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Idle | 没有当前请求的客户端连接| 资源: 功能 |
|
||||
| Total(全部) | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
当 NGINX Plus worker 进程接受 OS 的连接请求时 **Accepted** 计数器递增。如果 worker 进程为请求建立连接失败(通过建立一个新的连接或重新使用一个空闲),则该连接被丢弃, **Dropped** 计数增加。通常连接被丢弃是因为资源限制,如 NGINX Plus 的[worker_connections][4]的限制已经达到。
|
||||
|
||||
**Active** 和 **Idle** 和[如上所述][5]的开源 NGINX 的“active” 和 “waiting”状态是相同的,但是有一点关键的不同:在开源 NGINX 上,“waiting”状态包括在“active”中,而在 NGINX Plus 上“idle”的连接被排除在“active” 计数外。**Current** 和开源 NGINX 是一样的也是由“reading + writing” 状态组成。
|
||||
|
||||
**Total** 为客户端请求的累积计数。请注意,单个客户端连接可涉及多个请求,所以这个数字可能会比连接的累计次数明显大。事实上,(total / accepted)是每个连接的平均请求数量。
|
||||
|
||||
**开源 和 Plus 之间指标的不同**
|
||||
|
||||
|NGINX (开源) |NGINX Plus|
|
||||
|-----------------------|----------------|
|
||||
| accepts | accepted |
|
||||
| dropped 通过计算得来| dropped 直接得到 |
|
||||
| reading + writing| current|
|
||||
| waiting| idle|
|
||||
| active (包括 “waiting”状态) | active (排除 “idle” 状态)|
|
||||
| requests| total|
|
||||
|
||||
**提醒指标: 丢弃连接**
|
||||
|
||||
被丢弃的连接数目等于 Accepts 和 Handled 之差(NGINX 中),或是可直接得到标准指标(NGINX Plus 中)。在正常情况下,丢弃连接数应该是零。如果在每个单位时间内丢弃连接的速度开始上升,那么应该看看是否资源饱和了。
|
||||
|
||||

|
||||
|
||||
**提醒指标: 每秒请求数**
|
||||
|
||||
按固定时间间隔采样你的请求数据(开源 NGINX 的**requests**或者 NGINX Plus 中**total**) 会提供给你单位时间内(通常是分钟或秒)所接受的请求数量。监测这个指标可以查看进入的 Web 流量尖峰,无论是合法的还是恶意的,或者突然的下降,这通常都代表着出现了问题。每秒请求数若发生急剧变化可以提醒你的环境出现问题了,即使它不能告诉你确切问题的位置所在。请注意,所有的请求都同样计数,无论 URL 是什么。
|
||||
|
||||

|
||||
|
||||
**收集活跃指标**
|
||||
|
||||
开源的 NGINX 提供了一个简单状态页面来显示基本的服务器指标。该状态信息以标准格式显示,实际上任何图形或监控工具可以被配置去解析这些相关数据,以用于分析、可视化、或提醒。NGINX Plus 提供一个 JSON 接口来供给更多的数据。阅读相关文章“[NGINX 指标收集][6]”来启用指标收集的功能。
|
||||
|
||||
#### 错误指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 4xx 代码 | 客户端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
| 5xx 代码| 服务器端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
|
||||
NGINX 错误指标告诉你服务器是否经常返回错误而不是正常工作。客户端错误返回4XX状态码,服务器端错误返回5XX状态码。
|
||||
|
||||
**提醒指标: 服务器错误率**
|
||||
|
||||
服务器错误率等于在单位时间(通常为一到五分钟)内5xx错误状态代码的总数除以[状态码][7](1XX,2XX,3XX,4XX,5XX)的总数。如果你的错误率随着时间的推移开始攀升,调查可能的原因。如果突然增加,可能需要采取紧急行动,因为客户端可能收到错误信息。
|
||||
|
||||

|
||||
|
||||
关于客户端错误的注意事项:虽然监控4XX是很有用的,但从该指标中你仅可以捕捉有限的信息,因为它只是衡量客户的行为而不捕捉任何特殊的 URL。换句话说,4xx出现的变化可能是一个信号,例如网络扫描器正在寻找你的网站漏洞时。
|
||||
|
||||
**收集错误度量**
|
||||
|
||||
虽然开源 NGINX 不能马上得到用于监测的错误率,但至少有两种方法可以得到:
|
||||
|
||||
- 使用商业支持的 NGINX Plus 提供的扩展状态模块
|
||||
- 配置 NGINX 的日志模块将响应码写入访问日志
|
||||
|
||||
关于这两种方法,请阅读相关文章“[NGINX 指标收集][6]”。
|
||||
|
||||
#### 性能指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| request time (请求处理时间)| 处理每个请求的时间,单位为秒 | 工作:性能 | NGINX 日志|
|
||||
|
||||
**提醒指标: 请求处理时间**
|
||||
|
||||
请求处理时间指标记录了 NGINX 处理每个请求的时间,从读到客户端的第一个请求字节到完成请求。较长的响应时间说明问题在上游。
|
||||
|
||||
**收集处理时间指标**
|
||||
|
||||
NGINX 和 NGINX Plus 用户可以通过添加 $request_time 变量到访问日志格式中来捕捉处理时间数据。关于配置日志监控的更多细节在[NGINX指标收集][6]。
|
||||
|
||||
#### 反向代理指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 上游服务器的活跃链接 | 当前活跃的客户端连接 | 资源:功能 | NGINX Plus |
|
||||
| 上游服务器的 5xx 错误代码| 服务器错误 | 工作:错误 | NGINX Plus |
|
||||
| 每个上游组的可用服务器 | 服务器传递健康检查 | 资源:可用性| NGINX Plus
|
||||
|
||||
[反向代理][9]是 NGINX 最常见的使用方法之一。商业支持的 NGINX Plus 显示了大量有关后端(或“上游 upstream”)的服务器指标,这些与反向代理设置相关的。本节重点介绍了几个 NGINX Plus 用户可用的关键上游指标。
|
||||
|
||||
NGINX Plus 首先将它的上游指标按组分开,然后是针对单个服务器的。因此,例如,你的反向代理将请求分配到五个上游的 Web 服务器上,你可以一眼看出是否有单个服务器压力过大,也可以看出上游组中服务器的健康状况,以确保良好的响应时间。
|
||||
|
||||
**活跃指标**
|
||||
|
||||
**每上游服务器的活跃连接**的数量可以帮助你确认反向代理是否正确的分配工作到你的整个服务器组上。如果你正在使用 NGINX 作为负载均衡器,任何一台服务器处理的连接数的明显偏差都可能表明服务器正在努力消化请求,或者是你配置使用的负载均衡的方法(例如[round-robin 或 IP hashing][10])不是最适合你流量模式的。
|
||||
|
||||
**错误指标**
|
||||
|
||||
错误指标,上面所说的高于5XX(服务器错误)状态码,是监控指标中有价值的一个,尤其是响应码部分。 NGINX Plus 允许你轻松地提取**每个上游服务器的 5xx 错误代码**的数量,以及响应的总数量,以此来确定某个特定服务器的错误率。
|
||||
|
||||
**可用性指标**
|
||||
|
||||
对于 web 服务器的运行状况,还有另一种角度,NGINX 可以通过**每个组中当前可用服务器的总量**很方便监控你的上游组的健康。在一个大的反向代理上,你可能不会非常关心其中一个服务器的当前状态,就像你只要有可用的服务器组能够处理当前的负载就行了。但监视上游组内的所有工作的服务器总量可为判断 Web 服务器的健康状况提供一个更高层面的视角。
|
||||
|
||||
**收集上游指标**
|
||||
|
||||
NGINX Plus 上游指标显示在内部 NGINX Plus 的监控仪表盘上,并且也可通过一个JSON 接口来服务于各种外部监控平台。在我们的相关文章“[NGINX指标收集][6]”中有个例子。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经谈到了一些有用的指标,你可以使用表格来监控 NGINX 服务器。如果你是刚开始使用 NGINX,监控下面提供的大部分或全部指标,可以让你很好的了解你的网络基础设施的健康和活跃程度:
|
||||
|
||||
- [已丢弃的连接][12]
|
||||
- [每秒请求数][13]
|
||||
- [服务器错误率][14]
|
||||
- [请求处理数据][15]
|
||||
|
||||
最终,你会学到更多,更专业的衡量指标,尤其是关于你自己基础设施和使用情况的。当然,监控哪一项指标将取决于你可用的工具。参见相关的文章来[逐步指导你的指标收集][6],不管你使用 NGINX 还是 NGINX Plus。
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最少的设置来收集和监控所有 Web 服务器的指标。 [在本文中][17]了解如何用 NGINX Datadog来监控,并开始[免费试用 Datadog][18]吧。
|
||||
|
||||
### 诚谢 ###
|
||||
|
||||
在文章发表之前非常感谢 NGINX 团队审阅这篇,并提供重要的反馈和说明。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nginx.org/en/
|
||||
[2]:http://nginx.com/resources/glossary/reverse-proxy-server/
|
||||
[3]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
|
||||
[4]:http://nginx.org/en/docs/ngx_core_module.html#worker_connections
|
||||
[5]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#active-state
|
||||
[6]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[7]:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
[8]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[9]:https://en.wikipedia.org/wiki/Reverse_proxy
|
||||
[10]:http://nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[11]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[12]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#dropped-connections
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#requests-per-second
|
||||
[14]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#server-error-rate
|
||||
[15]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#request-processing-time
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[18]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#sign-up
|
||||
[19]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx.md
|
||||
[20]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,11 +1,13 @@
|
||||
如何在 Fedora 22 上配置 Proftpd 服务器
|
||||
================================================================================
|
||||
在本文中,我们将了解如何在运行 Fedora 22 的电脑或服务器上使用 Proftpd 架设 FTP 服务器。[ProFTPD][1] 是一款免费的基于 GPL 授权开源的 FTP 服务器软件,是 Linux 上的主流 FTP 服务器。它的主要设计目标是具备许多高级功能以及能为用户提供丰富的配置选项可以轻松实现定制。它的许多配置选项在其他一些 FTP 服务器软件里仍然没有集成。最初它是被开发作为 wu-ftpd 服务器的一个更安全更容易配置的替代。FTP 服务器是这样一个软件,用户可以通过 FTP 客户端从安装了它的远端服务器上传或下载文件和目录。下面是一些 ProFTPD 服务器的主要功能,更详细的资料可以访问 [http://www.proftpd.org/features.html][2]。
|
||||
在本文中,我们将了解如何在运行 Fedora 22 的电脑或服务器上使用 Proftpd 架设 FTP 服务器。[ProFTPD][1] 是一款基于 GPL 授权的自由开源 FTP 服务器软件,是 Linux 上的主流 FTP 服务器。它的主要设计目标是提供许多高级功能以及给用户提供丰富的配置选项以轻松实现定制。它具备许多在其他一些 FTP 服务器软件里仍然没有的配置选项。最初它是被开发作为 wu-ftpd 服务器的一个更安全更容易配置的替代。
|
||||
|
||||
- 每个目录都包含 ".ftpaccess" 文件用于访问控制,类似 Apache 的 ".htaccess"
|
||||
FTP 服务器是这样一个软件,用户可以通过 FTP 客户端从安装了它的远端服务器上传或下载文件和目录。下面是一些 ProFTPD 服务器的主要功能,更详细的资料可以访问 [http://www.proftpd.org/features.html][2]。
|
||||
|
||||
- 每个目录都可以包含 ".ftpaccess" 文件用于访问控制,类似 Apache 的 ".htaccess"
|
||||
- 支持多个虚拟 FTP 服务器以及多用户登录和匿名 FTP 服务。
|
||||
- 可以作为独立进程启动服务或者通过 inetd/xinetd 启动
|
||||
- 它的文件/目录属性、属主和权限采用类 UNIX 方式。
|
||||
- 它的文件/目录属性、属主和权限是基于 UNIX 方式的。
|
||||
- 它可以独立运行,保护系统避免 root 访问可能带来的损坏。
|
||||
- 模块化的设计让它可以轻松扩展其他模块,比如 LDAP 服务器,SSL/TLS 加密,RADIUS 支持,等等。
|
||||
- ProFTPD 服务器还支持 IPv6.
|
||||
@ -38,7 +40,7 @@
|
||||
|
||||
### 3. 添加 FTP 用户 ###
|
||||
|
||||
在设定好了基本的配置文件后,我们很自然地希望为指定目录添加 FTP 用户。目前用来登录的用户是 FTP 服务自动生成的,可以用来登录到 FTP 服务器。但是,在这篇教程里,我们将创建一个以 ftp 服务器上指定目录为主目录的新用户。
|
||||
在设定好了基本的配置文件后,我们很自然地希望添加一个以特定目录为根目录的 FTP 用户。目前登录的用户自动就可以使用 FTP 服务,可以用来登录到 FTP 服务器。但是,在这篇教程里,我们将创建一个以 ftp 服务器上指定目录为主目录的新用户。
|
||||
|
||||
下面,我们将建立一个名字是 ftpgroup 的新用户组。
|
||||
|
||||
@ -57,7 +59,7 @@
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
|
||||
现在,我们将通过下面命令为这个 ftp 用户设定主目录的读写权限。
|
||||
现在,我们将通过下面命令为这个 ftp 用户设定主目录的读写权限(LCTT 译注:这是SELinux 相关设置,如果未启用 SELinux,可以不用)。
|
||||
|
||||
$ sudo setsebool -P allow_ftpd_full_access=1
|
||||
$ sudo setsebool -P ftp_home_dir=1
|
||||
@ -158,7 +160,7 @@
|
||||
|
||||
### 7. 登录到 FTP 服务器 ###
|
||||
|
||||
现在,如果都是按照本教程设置好的,我们一定可以连接到 ftp 服务器并使用以上设置的信息登录上去。在这里,我们将配置一下 FTP 客户端 filezilla,使用 **服务器的 IP 或 URL **作为主机名,协议选择 **FTP**,用户名填入 **arunftp**,密码是在上面第 3 步中设定的密码。如果你按照第 4 步中的方式打开了 TLS 支持,还需要在加密类型中选择 **显式要求基于 TLS 的 FTP**,如果没有打开,也不想使用 TLS 加密,那么加密类型选择 **简单 FTP**。
|
||||
现在,如果都是按照本教程设置好的,我们一定可以连接到 ftp 服务器并使用以上设置的信息登录上去。在这里,我们将配置一下 FTP 客户端 filezilla,使用 **服务器的 IP 或名称 **作为主机名,协议选择 **FTP**,用户名填入 **arunftp**,密码是在上面第 3 步中设定的密码。如果你按照第 4 步中的方式打开了 TLS 支持,还需要在加密类型中选择 **要求显式的基于 TLS 的 FTP**,如果没有打开,也不想使用 TLS 加密,那么加密类型选择 **简单 FTP**。
|
||||
|
||||

|
||||
|
||||
@ -170,7 +172,7 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,我们成功地在 Fedora 22 机器上安装并配置好了 Proftpd FTP 服务器。Proftpd 是一个超级强大,能高度配置和扩展的 FTP 守护软件。上面的教程展示了如何配置一个采用 TLS 加密的安全 FTP 服务器。强烈建议设置 FTP 服务器支持 TLS 加密,因为它允许使用 SSL 凭证加密数据传输和登录。本文中,我们也没有配置 FTP 的匿名访问,因为一般受保护的 FTP 系统不建议这样做。 FTP 访问让人们的上传和下载变得非常简单也更高效。我们还可以改变用户端口增加安全性。好吧,如果你有任何疑问,建议,反馈,请在下面评论区留言,这样我们就能够改善并更新文章内容。谢谢!玩的开心 :-)
|
||||
最后,我们成功地在 Fedora 22 机器上安装并配置好了 Proftpd FTP 服务器。Proftpd 是一个超级强大,能高度定制和扩展的 FTP 守护软件。上面的教程展示了如何配置一个采用 TLS 加密的安全 FTP 服务器。强烈建议设置 FTP 服务器支持 TLS 加密,因为它允许使用 SSL 凭证加密数据传输和登录。本文中,我们也没有配置 FTP 的匿名访问,因为一般受保护的 FTP 系统不建议这样做。 FTP 访问让人们的上传和下载变得非常简单也更高效。我们还可以改变用户端口增加安全性。好吧,如果你有任何疑问,建议,反馈,请在下面评论区留言,这样我们就能够改善并更新文章内容。谢谢!玩的开心 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -178,7 +180,7 @@ via: http://linoxide.com/linux-how-to/configure-ftp-proftpd-fedora-22/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,7 +2,7 @@ Ubuntu 14.04中修复“update information is outdated”错误
|
||||
================================================================================
|
||||

|
||||
|
||||
看到Ubuntu 14.04的顶部面板上那个显示下面这个错误的红色三角形了吗?
|
||||
看到过Ubuntu 14.04的顶部面板上那个显示下面这个错误的红色三角形了吗?
|
||||
|
||||
> 更新信息过时。该错误可能是由网络问题,或者某个仓库不再可用而造成的。请通过从指示器菜单中选择‘显示更新’来手动更新,然后查看是否存在有失败的仓库。
|
||||
>
|
||||
@ -25,7 +25,7 @@ Ubuntu 14.04中修复“update information is outdated”错误
|
||||
|
||||
### 修复‘update information is outdated’错误 ###
|
||||
|
||||
这里讨论的‘解决方案’可能对Ubuntu的这些版本有用:Ubuntu 14.04,12.04或14.04。你所要做的仅仅是打开终端(Ctrl+Alt+T),然后使用下面的命令:
|
||||
这里讨论的‘解决方案’可能对Ubuntu的这些版本有用:Ubuntu 14.04,12.04。你所要做的仅仅是打开终端(Ctrl+Alt+T),然后使用下面的命令:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
@ -47,7 +47,7 @@ via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -56,4 +56,4 @@ via: http://itsfoss.com/fix-update-information-outdated-ubuntu/
|
||||
[2]:http://itsfoss.com/notification-terminal-command-completion-ubuntu/
|
||||
[3]:http://itsfoss.com/solve-gpg-error-signatures-verified-ubuntu/
|
||||
[4]:http://itsfoss.com/install-spotify-ubuntu-1504/
|
||||
[5]:http://itsfoss.com/fix-update-errors-ubuntu-1404/
|
||||
[5]:https://linux.cn/article-5603-1.html
|
||||
@ -6,17 +6,17 @@
|
||||
|
||||
每当你开机进入一个操作系统,一系列的应用将会自动启动。这些应用被称为‘开机启动应用’ 或‘开机启动程序’。随着时间的推移,当你在系统中安装了足够多的应用时,你将发现有太多的‘开机启动应用’在开机时自动地启动了,它们吃掉了很多的系统资源,并将你的系统拖慢。这可能会让你感觉卡顿,我想这种情况并不是你想要的。
|
||||
|
||||
让 Ubuntu 变得更快的方法之一是对这些开机启动应用进行控制。 Ubuntu 为你提供了一个 GUI 工具来让你发现这些开机启动应用,然后完全禁止或延迟它们的启动,这样就可以不让每个应用在开机时同时运行。
|
||||
让 Ubuntu 变得更快的方法之一是对这些开机启动应用进行控制。 Ubuntu 为你提供了一个 GUI 工具来让你找到这些开机启动应用,然后完全禁止或延迟它们的启动,这样就可以不让每个应用在开机时同时运行。
|
||||
|
||||
在这篇文章中,我们将看到 **在 Ubuntu 中,如何控制开机启动应用,如何让一个应用在开机时启动以及如何发现隐藏的开机启动应用。**这里提供的指导对所有的 Ubuntu 版本均适用,例如 Ubuntu 12.04, Ubuntu 14.04 和 Ubuntu 15.04。
|
||||
|
||||
### 在 Ubuntu 中管理开机启动应用 ###
|
||||
|
||||
默认情况下, Ubuntu 提供了一个`开机启动应用工具`来供你使用,你不必再进行安装。只需到 Unity 面板中就可以查找到该工具。
|
||||
默认情况下, Ubuntu 提供了一个`Startup Applications`工具来供你使用,你不必再进行安装。只需到 Unity 面板中就可以查找到该工具。
|
||||
|
||||

|
||||
|
||||
点击它来启动。下面是我的`开机启动应用`的样子:
|
||||
点击它来启动。下面是我的`Startup Applications`的样子:
|
||||
|
||||

|
||||
|
||||
@ -84,7 +84,7 @@
|
||||
|
||||
就这样,你将在下一次开机时看到这个程序会自动运行。这就是在 Ubuntu 中你能做的关于开机启动应用的所有事情。
|
||||
|
||||
到现在为止,我们已经讨论在开机时可见的应用,但仍有更多的服务,守护进程和程序并不在`开机启动应用工具`中可见。下一节中,我们将看到如何在 Ubuntu 中查看这些隐藏的开机启动程序。
|
||||
到现在为止,我们已经讨论在开机时可见到的应用,但仍有更多的服务,守护进程和程序并不在`开机启动应用工具`中可见。下一节中,我们将看到如何在 Ubuntu 中查看这些隐藏的开机启动程序。
|
||||
|
||||
### 在 Ubuntu 中查看隐藏的开机启动程序 ###
|
||||
|
||||
@ -97,13 +97,14 @@
|
||||

|
||||
|
||||
你可以像先前我们讨论的那样管理这些开机启动应用。我希望这篇教程可以帮助你在 Ubuntu 中控制开机启动程序。任何的问题或建议总是欢迎的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,32 +1,32 @@
|
||||
无忧之道:Docker中容器的备份、恢复和迁移
|
||||
================================================================================
|
||||
今天,我们将学习如何快速地对docker容器进行快捷备份、恢复和迁移。[Docker][1]是一个开源平台,用于自动化部署应用,以通过快捷的途径在称之为容器的轻量级软件层下打包、发布和运行这些应用。它使得应用平台独立,因为它扮演了Linux上一个额外的操作系统级虚拟化的自动化抽象层。它通过其组件cgroups和命名空间利用Linux内核的资源分离特性,达到避免虚拟机开销的目的。它使得用于部署和扩展web应用、数据库和后端服务的大规模构建块无需依赖于特定的堆栈或供应者。
|
||||
今天,我们将学习如何快速地对docker容器进行快捷备份、恢复和迁移。[Docker][1]是一个开源平台,用于自动化部署应用,以通过快捷的途径在称之为容器的轻量级软件层下打包、发布和运行这些应用。它使得应用平台独立,因为它扮演了Linux上一个额外的操作系统级虚拟化的自动化抽象层。它通过其组件cgroups和命名空间利用Linux内核的资源分离特性,达到避免虚拟机开销的目的。它使得用于部署和扩展web应用、数据库和后端服务的大规模构建组件无需依赖于特定的堆栈或供应者。
|
||||
|
||||
所谓的容器,就是那些创建自Docker镜像的软件层,它包含了独立的Linux文件系统和开箱即用的应用程序。如果我们有一个在盒子中运行着的Docker容器,并且想要备份这些容器以便今后使用,或者想要迁移这些容器,那么,本教程将帮助你掌握在Linux操作系统中备份、恢复和迁移Docker容器。
|
||||
所谓的容器,就是那些创建自Docker镜像的软件层,它包含了独立的Linux文件系统和开箱即用的应用程序。如果我们有一个在机器中运行着的Docker容器,并且想要备份这些容器以便今后使用,或者想要迁移这些容器,那么,本教程将帮助你掌握在Linux操作系统中备份、恢复和迁移Docker容器的方法。
|
||||
|
||||
我们怎样才能在Linux中备份、恢复和迁移Docker容器呢?这里为您提供了一些便捷的步骤。
|
||||
|
||||
### 1. 备份容器 ###
|
||||
|
||||
首先,为了备份Docker中的容器,我们会想看看我们想要备份的容器列表。要达成该目的,我们需要在我们运行这Docker引擎,并已创建了容器的Linux机器中运行 docker ps 命令。
|
||||
首先,为了备份Docker中的容器,我们会想看看我们想要备份的容器列表。要达成该目的,我们需要在我们运行着Docker引擎,并已创建了容器的Linux机器中运行 docker ps 命令。
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
在此之后,我们要选择我们想要备份的容器,然后我们会去创建该容器的快照。我们可以使用 docker commit 命令来创建快照。
|
||||
在此之后,我们要选择我们想要备份的容器,然后去创建该容器的快照。我们可以使用 docker commit 命令来创建快照。
|
||||
|
||||
# docker commit -p 30b8f18f20b4 container-backup
|
||||
|
||||

|
||||
|
||||
该命令会生成一个作为Docker镜像的容器快照,我们可以通过运行 docker images 命令来查看Docker镜像,如下。
|
||||
该命令会生成一个作为Docker镜像的容器快照,我们可以通过运行 `docker images` 命令来查看Docker镜像,如下。
|
||||
|
||||
# docker images
|
||||
|
||||

|
||||
|
||||
正如我们所看见的,上面做的快照已经作为Docker镜像保存了。现在,为了备份该快照,我们有两个选择,一个是我们可以登陆进Docker注册中心,并推送该镜像;另一个是我们可以将Docker镜像打包成tarball备份,以供今后使用。
|
||||
正如我们所看见的,上面做的快照已经作为Docker镜像保存了。现在,为了备份该快照,我们有两个选择,一个是我们可以登录进Docker注册中心,并推送该镜像;另一个是我们可以将Docker镜像打包成tar包备份,以供今后使用。
|
||||
|
||||
如果我们想要在[Docker注册中心][2]上传或备份镜像,我们只需要运行 docker login 命令来登录进Docker注册中心,然后推送所需的镜像即可。
|
||||
|
||||
@ -39,23 +39,23 @@
|
||||
|
||||

|
||||
|
||||
如果我们不想备份到docker注册中心,而是想要将此镜像保存在本地机器中,以供日后使用,那么我们可以将其作为tarball备份。要完成该操作,我们需要运行以下 docker save 命令。
|
||||
如果我们不想备份到docker注册中心,而是想要将此镜像保存在本地机器中,以供日后使用,那么我们可以将其作为tar包备份。要完成该操作,我们需要运行以下 `docker save` 命令。
|
||||
|
||||
# docker save -o ~/container-backup.tar container-backup
|
||||
|
||||

|
||||
|
||||
要验证tarball时候已经生成,我们只需要在保存tarball的目录中运行 ls 命令。
|
||||
要验证tar包是否已经生成,我们只需要在保存tar包的目录中运行 ls 命令即可。
|
||||
|
||||
### 2. 恢复容器 ###
|
||||
|
||||
接下来,在我们成功备份了我们的Docker容器后,我们现在来恢复这些被快照成Docker镜像的容器。如果我们已经在注册中心推送了这些Docker镜像,那么我们仅仅需要把那个Docker镜像拖回并直接运行即可。
|
||||
接下来,在我们成功备份了我们的Docker容器后,我们现在来恢复这些制作了Docker镜像快照的容器。如果我们已经在注册中心推送了这些Docker镜像,那么我们仅仅需要把那个Docker镜像拖回并直接运行即可。
|
||||
|
||||
# docker pull arunpyasi/container-backup:test
|
||||
|
||||

|
||||
|
||||
但是,如果我们将这些Docker镜像作为tarball文件备份到了本地,那么我们只要使用 docker load 命令,后面加上tarball的备份路径,就可以加载该Docker镜像了。
|
||||
但是,如果我们将这些Docker镜像作为tar包文件备份到了本地,那么我们只要使用 docker load 命令,后面加上tar包的备份路径,就可以加载该Docker镜像了。
|
||||
|
||||
# docker load -i ~/container-backup.tar
|
||||
|
||||
@ -63,7 +63,7 @@
|
||||
|
||||
# docker images
|
||||
|
||||
在镜像被加载后,我们将从加载的镜像去运行Docker容器。
|
||||
在镜像被加载后,我们将用加载的镜像去运行Docker容器。
|
||||
|
||||
# docker run -d -p 80:80 container-backup
|
||||
|
||||
@ -71,11 +71,11 @@
|
||||
|
||||
### 3. 迁移Docker容器 ###
|
||||
|
||||
迁移容器同时涉及到了上面两个操作,备份和恢复。我们可以将任何一个Docker容器从一台机器迁移到另一台机器。在迁移过程中,首先我们将容器的备份作为快照Docker镜像。然后,该Docker镜像或者是被推送到了Docker注册中心,或者被作为tarball文件保存到了本地。如果我们将镜像推送到了Docker注册中心,我们简单地从任何我们想要的机器上使用 docker run 命令来恢复并运行该容器。但是,如果我们将镜像打包成tarball备份到了本地,我们只需要拷贝或移动该镜像到我们想要的机器上,加载该镜像并运行需要的容器即可。
|
||||
迁移容器同时涉及到了上面两个操作,备份和恢复。我们可以将任何一个Docker容器从一台机器迁移到另一台机器。在迁移过程中,首先我们将把容器备份为Docker镜像快照。然后,该Docker镜像或者是被推送到了Docker注册中心,或者被作为tar包文件保存到了本地。如果我们将镜像推送到了Docker注册中心,我们简单地从任何我们想要的机器上使用 docker run 命令来恢复并运行该容器。但是,如果我们将镜像打包成tar包备份到了本地,我们只需要拷贝或移动该镜像到我们想要的机器上,加载该镜像并运行需要的容器即可。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
最后,我们已经学习了如何快速地备份、恢复和迁移Docker容器,本教程适用于各个成功运行Docker的操作系统平台。真的,Docker是一个相当简单易用,然而功能却十分强大的工具。它的命令相当易记,这些命令都非常短,带有许多简单而强大的标记和参数。上面的方法让我们备份容器时很是安逸,使得我们可以在日后很轻松地恢复它们。这会帮助我们恢复我们的容器和镜像,即便主机系统崩溃,甚至意外地被清除。如果你还有很多问题、建议、反馈,请在下面的评论框中写出来吧,可以帮助我们改进或更新我们的内容。谢谢大家!享受吧 :-)
|
||||
最后,我们已经学习了如何快速地备份、恢复和迁移Docker容器,本教程适用于各个可以成功运行Docker的操作系统平台。真的,Docker是一个相当简单易用,然而功能却十分强大的工具。它的命令相当易记,这些命令都非常短,带有许多简单而强大的标记和参数。上面的方法让我们备份容器时很是安逸,使得我们可以在日后很轻松地恢复它们。这会帮助我们恢复我们的容器和镜像,即便主机系统崩溃,甚至意外地被清除。如果你还有很多问题、建议、反馈,请在下面的评论框中写出来吧,可以帮助我们改进或更新我们的内容。谢谢大家!享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -83,7 +83,7 @@ via: http://linoxide.com/linux-how-to/backup-restore-migrate-containers-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -5,10 +5,12 @@
|
||||
我试着在Ubuntu中安装Emerald图标主题,而这个主题被打包成了.7z归档包。和以往一样,我试着通过在GUI中右击并选择“提取到这里”来将它解压缩。但是Ubuntu 15.04却并没有解压文件,取而代之的,却是丢给了我一个下面这样的错误信息:
|
||||
|
||||
> Could not open this file
|
||||
>
|
||||
> 无法打开该文件
|
||||
>
|
||||
> There is no command installed for 7-zip archive files. Do you want to search for a command to open this file?
|
||||
> 没有安装用于7-zip归档文件的命令。你是否想要搜索命令来打开该文件?
|
||||
>
|
||||
> 没有安装用于7-zip归档文件的命令。你是否想要搜索用于来打开该文件的命令?
|
||||
|
||||
错误信息看上去是这样的:
|
||||
|
||||
@ -42,7 +44,7 @@ via: http://itsfoss.com/fix-there-is-no-command-installed-for-7-zip-archive-file
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,120 @@
|
||||
如何更新 Linux 内核来提升系统性能
|
||||
================================================================================
|
||||

|
||||
|
||||
目前的 [Linux 内核][1]的开发速度是前所未有的,大概每2到3个月就会有一个主要的版本发布。每个发布都带来几个的新的功能和改进,可以让很多人的处理体验更快、更有效率、或者其它的方面更好。
|
||||
|
||||
问题是,你不能在这些内核发布的时候就用它们,你要等到你的发行版带来新内核的发布。我们先前讲到[定期更新内核的好处][2],所以你不必等到那时。让我们来告诉你该怎么做。
|
||||
|
||||
> 免责声明: 我们先前的一些文章已经提到过,升级内核有(很小)的风险可能会破坏你系统。如果发生这种情况,通常可以通过使用旧内核来使系统保持工作,但是有时还是不行。因此我们对系统的任何损坏都不负责,你得自己承担风险!
|
||||
|
||||
### 预备工作 ###
|
||||
|
||||
要更新你的内核,你首先要确定你使用的是32位还是64位的系统。打开终端并运行:
|
||||
|
||||
uname -a
|
||||
|
||||
检查一下输出的是 x86\_64 还是 i686。如果是 x86\_64,你就运行64位的版本,否则就运行32位的版本。千万记住这个,这很重要。
|
||||
|
||||

|
||||
|
||||
接下来,访问[官方的 Linux 内核网站][3],它会告诉你目前稳定内核的版本。愿意的话,你可以尝试下发布预选版(RC),但是这比稳定版少了很多测试。除非你确定想要需要发布预选版,否则就用稳定内核。
|
||||
|
||||

|
||||
|
||||
### Ubuntu 指导 ###
|
||||
|
||||
对 Ubuntu 及其衍生版的用户而言升级内核非常简单,这要感谢 Ubuntu 主线内核 PPA。虽然,官方把它叫做 PPA,但是你不能像其他 PPA 一样将它添加到你软件源列表中,并指望它自动升级你的内核。实际上,它只是一个简单的网页,你应该浏览并下载到你想要的内核。
|
||||
|
||||

|
||||
|
||||
现在,访问这个[内核 PPA 网页][4],并滚到底部。列表的最下面会含有最新发布的预选版本(你可以在名字中看到“rc”字样),但是这上面就可以看到最新的稳定版(说的更清楚些,本文写作时最新的稳定版是4.1.2。LCTT 译注:这里虽然 4.1.2 是当时的稳定版,但是由于尚未进入 Ubuntu 发行版中,所以文件夹名称为“-unstable”)。点击文件夹名称,你会看到几个选择。你需要下载 3 个文件并保存到它们自己的文件夹中(如果你喜欢的话可以放在下载文件夹中),以便它们与其它文件相隔离:
|
||||
|
||||
1. 针对架构的含“generic”(通用)的头文件(我这里是64位,即“amd64”)
|
||||
2. 放在列表中间,在文件名末尾有“all”的头文件
|
||||
3. 针对架构的含“generic”内核文件(再说一次,我会用“amd64”,但是你如果用32位的,你需要使用“i686”)
|
||||
|
||||
你还可以在下面看到含有“lowlatency”(低延时)的文件。但最好忽略它们。这些文件相对不稳定,并且只为那些通用文件不能满足像音频录制这类任务想要低延迟的人准备的。再说一次,首选通用版,除非你有特定的任务需求不能很好地满足。一般的游戏和网络浏览不是使用低延时版的借口。
|
||||
|
||||
你把它们放在各自的文件夹下,对么?现在打开终端,使用`cd`命令切换到新创建的文件夹下,如
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
接着运行:
|
||||
|
||||
sudo dpkg -i *.deb
|
||||
|
||||
这个命令会标记文件夹中所有的“.deb”文件为“待安装”,接着执行安装。这是推荐的安装方法,因为不可以很简单地选择一个文件安装,它总会报出依赖问题。这这样一起安装就可以避免这个问题。如果你不清楚`cd`和`sudo`是什么。快速地看一下 [Linux 基本命令][5]这篇文章。
|
||||
|
||||

|
||||
|
||||
安装完成后,**重启**你的系统,这时应该就会运行刚安装的内核了!你可以在命令行中使用`uname -a`来检查输出。
|
||||
|
||||
### Fedora 指导 ###
|
||||
|
||||
如果你使用的是 Fedora 或者它的衍生版,过程跟 Ubuntu 很类似。不同的是文件获取的位置不同,安装的命令也不同。
|
||||
|
||||

|
||||
|
||||
查看 [最新 Fedora 内核构建][6]列表。选取列表中最新的稳定版并翻页到下面选择 i686 或者 x86_64 版。这取决于你的系统架构。这时你需要下载下面这些文件并保存到它们对应的目录下(比如“Kernel”到下载目录下):
|
||||
|
||||
- kernel
|
||||
- kernel-core
|
||||
- kernel-headers
|
||||
- kernel-modules
|
||||
- kernel-modules-extra
|
||||
- kernel-tools
|
||||
- perf 和 python-perf (可选)
|
||||
|
||||
如果你的系统是 i686(32位)同时你有 4GB 或者更大的内存,你需要下载所有这些文件的 PAE 版本。PAE 是用于32位系统上的地址扩展技术,它允许你使用超过 3GB 的内存。
|
||||
|
||||
现在使用`cd`命令进入文件夹,像这样
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
接着运行下面的命令来安装所有的文件
|
||||
|
||||
yum --nogpgcheck localinstall *.rpm
|
||||
|
||||
最后**重启**你的系统,这样你就可以运行新的内核了!
|
||||
|
||||
#### 使用 Rawhide ####
|
||||
|
||||
另外一个方案是,Fedora 用户也可以[切换到 Rawhide][7],它会自动更新所有的包到最新版本,包括内核。然而,Rawhide 经常会破坏系统(尤其是在早期的开发阶段中),它**不应该**在你日常使用的系统中用。
|
||||
|
||||
### Arch 指导 ###
|
||||
|
||||
[Arch 用户][8]应该总是使用的是最新和最棒的稳定版(或者相当接近的版本)。如果你想要更接近最新发布的稳定版,你可以启用测试库提前2到3周获取到主要的更新。
|
||||
|
||||
要这么做,用[你喜欢的编辑器][9]以`sudo`权限打开下面的文件
|
||||
|
||||
/etc/pacman.conf
|
||||
|
||||
接着取消注释带有 testing 的三行(删除行前面的#号)。如果你启用了 multilib 仓库,就把 multilib-testing 也做相同的事情。如果想要了解更多参考[这个 Arch 的 wiki 界面][10]。
|
||||
|
||||
升级内核并不简单(有意这么做的),但是这会给你带来很多好处。只要你的新内核不会破坏任何东西,你可以享受它带来的性能提升,更好的效率,更多的硬件支持和潜在的新特性。尤其是你正在使用相对较新的硬件时,升级内核可以帮助到你。
|
||||
|
||||
|
||||
**怎么升级内核这篇文章帮助到你了么?你认为你所喜欢的发行版对内核的发布策略应该是怎样的?**。在评论栏让我们知道!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/update-linux-kernel-improved-system-performance/
|
||||
|
||||
作者:[Danny Stieben][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.makeuseof.com/tag/author/danny/
|
||||
[1]:http://www.makeuseof.com/tag/linux-kernel-explanation-laymans-terms/
|
||||
[2]:http://www.makeuseof.com/tag/5-reasons-update-kernel-linux/
|
||||
[3]:http://www.kernel.org/
|
||||
[4]:http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[5]:http://www.makeuseof.com/tag/an-a-z-of-linux-40-essential-commands-you-should-know/
|
||||
[6]:http://koji.fedoraproject.org/koji/packageinfo?packageID=8
|
||||
[7]:http://www.makeuseof.com/tag/bleeding-edge-linux-fedora-rawhide/
|
||||
[8]:http://www.makeuseof.com/tag/arch-linux-letting-you-build-your-linux-system-from-scratch/
|
||||
[9]:http://www.makeuseof.com/tag/nano-vs-vim-terminal-text-editors-compared/
|
||||
[10]:https://wiki.archlinux.org/index.php/Pacman#Repositories
|
||||
@ -1,47 +1,52 @@
|
||||
|
||||
用 CD 创建 ISO,观察用户活动和检查浏览器内存的技巧
|
||||
一些 Linux 小技巧
|
||||
================================================================================
|
||||
我已经写过 [Linux 提示和技巧][1] 系列的一篇文章。写这篇文章的目的是让你知道这些小技巧可以有效地管理你的系统/服务器。
|
||||
|
||||

|
||||
|
||||
在Linux中创建 Cdrom ISO 镜像和监控用户
|
||||
*在Linux中创建 Cdrom ISO 镜像和监控用户*
|
||||
|
||||
在这篇文章中,我们将看到如何使用 CD/DVD 驱动器中加载到的内容来创建 ISO 镜像,打开随机手册页学习,看到登录用户的详细情况和查看浏览器内存使用量,而所有这些完全使用本地工具/命令无任何第三方应用程序/组件。让我们开始吧...
|
||||
在这篇文章中,我们将看到如何使用 CD/DVD 驱动器中载入的碟片来创建 ISO 镜像;打开随机手册页学习;看到登录用户的详细情况和查看浏览器内存使用量,而所有这些完全使用本地工具/命令,无需任何第三方应用程序/组件。让我们开始吧……
|
||||
|
||||
### 用 CD 中创建 ISO 映像 ###
|
||||
### 用 CD 碟片创建 ISO 映像 ###
|
||||
|
||||
我们经常需要备份/复制 CD/DVD 的内容。如果你是在 Linux 平台上,不需要任何额外的软件。所有需要的是进入 Linux 终端。
|
||||
|
||||
要从 CD/DVD 上创建 ISO 镜像,你需要做两件事。第一件事就是需要找到CD/DVD 驱动器的名称。要找到 CD/DVD 驱动器的名称,可以使用以下三种方法。
|
||||
|
||||
**1. 从终端/控制台上运行 lsblk 命令(单个驱动器).**
|
||||
**1. 从终端/控制台上运行 lsblk 命令(列出块设备)**
|
||||
|
||||
$ lsblk
|
||||
|
||||

|
||||
|
||||
找驱动器
|
||||
*找块设备*
|
||||
|
||||
**2.要查看有关 CD-ROM 的信息,可以使用以下命令。**
|
||||
从上图可以看到,sr0 就是你的 cdrom (即 /dev/sr0 )。
|
||||
|
||||
**2. 要查看有关 CD-ROM 的信息,可以使用以下命令**
|
||||
|
||||
$ less /proc/sys/dev/cdrom/info
|
||||
|
||||

|
||||
|
||||
检查 Cdrom 信息
|
||||
*检查 Cdrom 信息*
|
||||
|
||||
从上图可以看到, 设备名称是 sr0 (即 /dev/sr0)。
|
||||
|
||||
**3. 使用 [dmesg 命令][2] 也会得到相同的信息,并使用 egrep 来自定义输出。**
|
||||
|
||||
命令 ‘dmesg‘ 命令的输出/控制内核缓冲区信息。‘egrep‘ 命令输出匹配到的行。选项 -i 和 -color 与 egrep 连用时会忽略大小写,并高亮显示匹配的字符串。
|
||||
命令 ‘dmesg‘ 命令的输出/控制内核缓冲区信息。‘egrep‘ 命令输出匹配到的行。egrep 使用选项 -i 和 -color 时会忽略大小写,并高亮显示匹配的字符串。
|
||||
|
||||
$ dmesg | egrep -i --color 'cdrom|dvd|cd/rw|writer'
|
||||
|
||||

|
||||
|
||||
查找设备信息
|
||||
*查找设备信息*
|
||||
|
||||
一旦知道 CD/DVD 的名称后,在 Linux 上你可以用下面的命令来创建 ISO 镜像。
|
||||
从上图可以看到,设备名称是 sr0 (即 /dev/sr0)。
|
||||
|
||||
一旦知道 CD/DVD 的名称后,在 Linux 上你可以用下面的命令来创建 ISO 镜像(你看,只需要 cat 即可!)。
|
||||
|
||||
$ cat /dev/sr0 > /path/to/output/folder/iso_name.iso
|
||||
|
||||
@ -49,11 +54,11 @@
|
||||
|
||||

|
||||
|
||||
创建 CDROM 的 ISO 映像
|
||||
*创建 CDROM 的 ISO 映像*
|
||||
|
||||
### 随机打开一个手册页 ###
|
||||
|
||||
如果你是 Linux 新人并想学习使用命令行开关,这个修改是为你做的。把下面的代码行添加在`〜/ .bashrc`文件的末尾。
|
||||
如果你是 Linux 新人并想学习使用命令行开关,这个技巧就是给你的。把下面的代码行添加在`〜/ .bashrc`文件的末尾。
|
||||
|
||||
/use/bin/man $(ls /bin | shuf | head -1)
|
||||
|
||||
@ -63,17 +68,19 @@
|
||||
|
||||

|
||||
|
||||
LoadKeys 手册页
|
||||
*LoadKeys 手册页*
|
||||
|
||||

|
||||
|
||||
Zgrep 手册页
|
||||
*Zgrep 手册页*
|
||||
|
||||
希望你知道如何退出手册页浏览——如果你已经厌烦了每次都看到手册页,你可以删除你添加到 `.bashrc`文件中的那几行。
|
||||
|
||||
### 查看登录用户的状态 ###
|
||||
|
||||
了解其他用户正在共享服务器上做什么。
|
||||
|
||||
一般情况下,你是共享的 Linux 服务器的用户或管理员的。如果你担心自己服务器的安全并想要查看哪些用户在做什么,你可以使用命令 'w'。
|
||||
一般情况下,你是共享的 Linux 服务器的用户或管理员的。如果你担心自己服务器的安全并想要查看哪些用户在做什么,你可以使用命令 `w`。
|
||||
|
||||
这个命令可以让你知道是否有人在执行恶意代码或篡改服务器,让他停下或使用其他方法。'w' 是查看登录用户状态的首选方式。
|
||||
|
||||
@ -83,33 +90,33 @@ Zgrep 手册页
|
||||
|
||||

|
||||
|
||||
检查 Linux 用户状态
|
||||
*检查 Linux 用户状态*
|
||||
|
||||
### 查看浏览器的内存使用状况 ###
|
||||
|
||||
最近有不少谈论关于 Google-chrome 内存使用量。如果你想知道一个浏览器的内存用量,你可以列出进程名,PID 和它的使用情况。要检查浏览器的内存使用情况,只需在地址栏输入 “about:memory” 不要带引号。
|
||||
最近有不少谈论关于 Google-chrome 的内存使用量。如要检查浏览器的内存使用情况,只需在地址栏输入 “about:memory”,不要带引号。
|
||||
|
||||
我已经在 Google-Chrome 和 Mozilla 的 Firefox 网页浏览器进行了测试。你可以查看任何浏览器,如果它工作得很好,你可能会承认我们在下面的评论。你也可以杀死浏览器进程在 Linux 终端的进程/服务中。
|
||||
|
||||
在 Google Chrome 中,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
在 Google Chrome 中,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
|
||||

|
||||
|
||||
查看 Chrome 内存使用状况
|
||||
*查看 Chrome 内存使用状况*
|
||||
|
||||
在Mozilla Firefox浏览器,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
|
||||

|
||||
|
||||
查看 Firefox 内存使用状况
|
||||
*查看 Firefox 内存使用状况*
|
||||
|
||||
如果你已经了解它是什么,除了这些选项。要检查内存用量,你也可以点击最左边的 ‘Measure‘ 选项。
|
||||
|
||||

|
||||
|
||||
Firefox 主进程
|
||||
*Firefox 主进程*
|
||||
|
||||
它将通过浏览器树形展示进程内存使用量
|
||||
它将通过浏览器树形展示进程内存使用量。
|
||||
|
||||
目前为止就这样了。希望上述所有的提示将会帮助你。如果你有一个(或多个)技巧,分享给我们,将帮助 Linux 用户更有效地管理他们的 Linux 系统/服务器。
|
||||
|
||||
@ -122,7 +129,7 @@ via: http://www.tecmint.com/creating-cdrom-iso-image-watch-user-activity-in-linu
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,118 @@
|
||||
轻松使用“Explain Shell”脚本来理解 Shell 命令
|
||||
================================================================================
|
||||
我们在Linux上工作时,每个人都会遇到需要查找shell命令的帮助信息的时候。 尽管内置的帮助像man pages、whatis命令有所助益, 但man pages的输出非常冗长, 除非是个有linux经验的人,不然从大量的man pages中获取帮助信息是非常困难的,而whatis命令的输出很少超过一行, 这对初学者来说是不够的。
|
||||
|
||||

|
||||
|
||||
*在Linux Shell中解释Shell命令*
|
||||
|
||||
有一些第三方应用程序, 像我们在[Linux 用户的命令行速查表][1]提及过的'cheat'命令。cheat是个优秀的应用程序,即使计算机没有联网也能提供shell命令的帮助, 但是它仅限于预先定义好的命令。
|
||||
|
||||
Jackson写了一小段代码,它能非常有效地在bash shell里面解释shell命令,可能最美之处就是你不需要安装第三方包了。他把包含这段代码的的文件命名为“explain.sh”。
|
||||
|
||||
#### explain.sh工具的特性 ####
|
||||
|
||||
- 易嵌入代码。
|
||||
- 不需要安装第三方工具。
|
||||
- 在解释过程中输出恰到好处的信息。
|
||||
- 需要网络连接才能工作。
|
||||
- 纯命令行工具。
|
||||
- 可以解释bash shell里面的大部分shell命令。
|
||||
- 无需使用root账户。
|
||||
|
||||
**先决条件**
|
||||
|
||||
唯一的条件就是'curl'包了。 在如今大多数Linux发行版里面已经预安装了curl包, 如果没有你可以按照下面的命令来安装。
|
||||
|
||||
# apt-get install curl [On Debian systems]
|
||||
# yum install curl [On CentOS systems]
|
||||
|
||||
### 在Linux上安装explain.sh工具 ###
|
||||
|
||||
我们要将下面这段代码插入'~/.bashrc'文件(LCTT译注: 若没有该文件可以自己新建一个)中。我们要为每个用户以及对应的'.bashrc'文件插入这段代码,但是建议你不要加在root用户下。
|
||||
|
||||
我们注意到.bashrc文件的第一行代码以(#)开始, 这个是可选的并且只是为了区分余下的代码。
|
||||
|
||||
\# explain.sh 标记代码的开始, 我们将代码插入.bashrc文件的底部。
|
||||
|
||||
# explain.sh begins
|
||||
explain () {
|
||||
if [ "$#" -eq 0 ]; then
|
||||
while read -p "Command: " cmd; do
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$cmd"
|
||||
done
|
||||
echo "Bye!"
|
||||
elif [ "$#" -eq 1 ]; then
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$1"
|
||||
else
|
||||
echo "Usage"
|
||||
echo "explain interactive mode."
|
||||
echo "explain 'cmd -o | ...' one quoted command to explain it."
|
||||
fi
|
||||
}
|
||||
|
||||
### explain.sh工具的使用 ###
|
||||
|
||||
在插入代码并保存之后,你必须退出当前的会话然后重新登录来使改变生效(LCTT译注:你也可以直接使用命令`source~/.bashrc` 来让改变生效)。每件事情都是交由‘curl’命令处理, 它负责将需要解释的命令以及命令选项传送给mankier服务,然后将必要的信息打印到Linux命令行。不必说的就是使用这个工具你总是需要连接网络。
|
||||
|
||||
让我们用explain.sh脚本测试几个笔者不懂的命令例子。
|
||||
|
||||
**1.我忘了‘du -h’是干嘛用的, 我只需要这样做:**
|
||||
|
||||
$ explain 'du -h'
|
||||
|
||||

|
||||
|
||||
*获得du命令的帮助*
|
||||
|
||||
**2.如果你忘了'tar -zxvf'的作用,你可以简单地如此做:**
|
||||
|
||||
$ explain 'tar -zxvf'
|
||||
|
||||

|
||||
|
||||
*Tar命令帮助*
|
||||
|
||||
**3.我的一个朋友经常对'whatis'以及'whereis'命令的使用感到困惑,所以我建议他:**
|
||||
|
||||
在终端简单的地敲下explain命令进入交互模式。
|
||||
|
||||
$ explain
|
||||
|
||||
然后一个接着一个地输入命令,就能在一个窗口看到他们各自的作用:
|
||||
|
||||
Command: whatis
|
||||
Command: whereis
|
||||
|
||||

|
||||
|
||||
*Whatis/Whereis命令的帮助*
|
||||
|
||||
你只需要使用“Ctrl+c”就能退出交互模式。
|
||||
|
||||
**4. 你可以通过管道来请求解释更多的命令。**
|
||||
|
||||
$ explain 'ls -l | grep -i Desktop'
|
||||
|
||||

|
||||
|
||||
*获取多条命令的帮助*
|
||||
|
||||
同样地,你可以请求你的shell来解释任何shell命令。 前提是你需要一个可用的网络。输出的信息是基于需要解释的命令,从服务器中生成的,因此输出的结果是不可定制的。
|
||||
|
||||
对于我来说这个工具真的很有用,并且它已经荣幸地添加在我的.bashrc文件中。你对这个项目有什么想法?它对你有用么?它的解释令你满意吗?请让我知道吧!
|
||||
|
||||
请在下面评论为我们提供宝贵意见,喜欢并分享我们以及帮助我们得到传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/explain-shell-commands-in-the-linux-shell/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cheat-command-line-cheat-sheet-for-linux-users/
|
||||
@ -1,26 +1,25 @@
|
||||
什么是逻辑分区管理工具,它怎么在Ubuntu启用?
|
||||
什么是逻辑分区管理 LVM ,如何在Ubuntu中使用?
|
||||
================================================================================
|
||||
> 逻辑分区管理(LVM)是每一个主流Linux发行版都含有的磁盘管理选项。无论你是否需要设置存储池或者只需要动态创建分区,LVM就是你正在寻找的。
|
||||
|
||||
> 逻辑分区管理(LVM)是每一个主流Linux发行版都含有的磁盘管理选项。无论是你需要设置存储池,还是只想动态创建分区,那么LVM就是你正在寻找的。
|
||||
|
||||
### 什么是 LVM? ###
|
||||
|
||||
逻辑分区管理是一个存在于磁盘/分区和操作系统之间的一个抽象层。在传统的磁盘管理中,你的操作系统寻找有哪些磁盘可用(/dev/sda、/dev/sdb等等)接着这些磁盘有哪些可用的分区(如/dev/sda1、/dev/sda2等等)。
|
||||
逻辑分区管理是一个存在于磁盘/分区和操作系统之间的一个抽象层。在传统的磁盘管理中,你的操作系统寻找有哪些磁盘可用(/dev/sda、/dev/sdb等等),并且这些磁盘有哪些可用的分区(如/dev/sda1、/dev/sda2等等)。
|
||||
|
||||
在LVM下,磁盘和分区可以抽象成一个设备中含有多个磁盘和分区。你的操作系统将不会知道这些区别,因为LVM只会给操作系统展示你设置的卷组(磁盘)和逻辑卷(分区)
|
||||
在LVM下,磁盘和分区可以抽象成一个含有多个磁盘和分区的设备。你的操作系统将不会知道这些区别,因为LVM只会给操作系统展示你设置的卷组(磁盘)和逻辑卷(分区)
|
||||
|
||||
,因此可以很容易地动态调整和创建新的磁盘和分区。除此之外,LVM带来你的文件系统不具备的功能。比如,ext3不支持实时快照,但是如果你正在使用LVM你可以不卸载磁盘的情况下做一个逻辑卷的快照。
|
||||
因为卷组和逻辑卷并不物理地对应到影片,因此可以很容易地动态调整和创建新的磁盘和分区。除此之外,LVM带来了你的文件系统所不具备的功能。比如,ext3不支持实时快照,但是如果你正在使用LVM你可以不卸载磁盘的情况下做一个逻辑卷的快照。
|
||||
|
||||
### 你什么时候该使用LVM? ###
|
||||
|
||||
在使用LVM之前首先得考虑的一件事是你要用你的磁盘和分区完成什么。一些发行版如Fedora已经默认安装了LVM。
|
||||
在使用LVM之前首先得考虑的一件事是你要用你的磁盘和分区来做什么。注意,一些发行版如Fedora已经默认安装了LVM。
|
||||
|
||||
如果你使用的是一台只有一块磁盘的Ubuntu笔记本电脑,并且你不需要像实时快照这样的扩展功能,那么你或许不需要LVM。如果I想要轻松地扩展或者想要将多块磁盘组成一个存储池,那么LVM或许正式你郑寻找的。
|
||||
如果你使用的是一台只有一块磁盘的Ubuntu笔记本电脑,并且你不需要像实时快照这样的扩展功能,那么你或许不需要LVM。如果你想要轻松地扩展或者想要将多块磁盘组成一个存储池,那么LVM或许正是你所寻找的。
|
||||
|
||||
### 在Ubuntu中设置LVM ###
|
||||
|
||||
使用LVM首先要了解的一件事是没有简单的方法将已经存在传统的分区转换成逻辑分区。可以将它移到一个使用LVM的新分区下,但是这并不会在本篇中提到;反之我们将全新安装一台Ubuntu 10.10来设置LVM
|
||||
|
||||

|
||||
使用LVM首先要了解的一件事是,没有一个简单的方法可以将已有的传统分区转换成逻辑卷。可以将数据移到一个使用LVM的新分区下,但是这并不会在本篇中提到;在这里,我们将全新安装一台Ubuntu 10.10来设置LVM。(LCTT 译注:本文针对的是较老的版本,新的版本已经不需如此麻烦了)
|
||||
|
||||
要使用LVM安装Ubuntu你需要使用另外的安装CD。从下面的链接中下载并烧录到CD中或者[使用unetbootin创建一个USB盘][1]。
|
||||
|
||||
@ -64,7 +63,7 @@ via: http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-
|
||||
|
||||
作者:[How-To Geek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
Ubuntu上比较PDF文件
|
||||
如何在 Ubuntu 上比较 PDF 文件
|
||||
================================================================================
|
||||
|
||||
如果你想要对PDF文件进行比较,你可以使用下面工具之一。
|
||||
|
||||
### Comparepdf ###
|
||||
|
||||
comparepdf是一个命令行应用,用于将两个PDF文件进行对比。默认对比模式文本模式,该模式会对各对相关页面进行文字对比。只要一检测到差异,该程序就会终止,并显示一条信息(除非设置了-v0)和一个指示性的返回码。
|
||||
comparepdf是一个命令行应用,用于将两个PDF文件进行对比。默认对比模式是文本模式,该模式会对各对相关页面进行文字对比。只要一检测到差异,该程序就会终止,并显示一条信息(除非设置了-v0)和一个指示性的返回码。
|
||||
|
||||
用于文本模式对比的选项有 -ct 或 --compare=text(默认),用于视觉对比(这对图标或其它图像发生改变时很有用)的选项有 -ca 或 --compare=appearance。而 -v=1 或 --verbose=1 选项则用于报告差异(或者对匹配文件不作任何回应):使用 -v=0 选项取消报告,或者 -v=2 来同时报告不同的和匹配的文件。
|
||||
用于文本模式对比的选项有 -ct 或 --compare=text(默认),用于视觉对比(这对图标或其它图像发生改变时很有用)的选项有 -ca 或 --compare=appearance。而 -v=1 或 --verbose=1 选项则用于报告差异(或者对匹配文件不作任何回应);使用 -v=0 选项取消报告,或者 -v=2 来同时报告不同的和匹配的文件。
|
||||
|
||||
### 安装comparepdf到Ubuntu ###
|
||||
#### 安装comparepdf到Ubuntu ####
|
||||
|
||||
打开终端,然后运行以下命令
|
||||
|
||||
@ -19,17 +19,17 @@ comparepdf是一个命令行应用,用于将两个PDF文件进行对比。默
|
||||
|
||||
comparepdf [OPTIONS] file1.pdf file2.pdf
|
||||
|
||||
**Diffpdf**
|
||||
###Diffpdf###
|
||||
|
||||
DiffPDF是一个图形化应用程序,用于对两个PDF文件进行对比。默认情况下,它只会对比两个相关页面的文字,但是也支持对图形化页面进行对比(例如,如果图表被修改过,或者段落被重新格式化过)。它也可以对特定的页面或者页面范围进行对比。例如,如果同一个PDF文件有两个版本,其中一个有页面1-12,而另一个则有页面1-13,因为这里添加了一个额外的页面4,它们可以通过指定两个页面范围来进行对比,第一个是1-12,而1-3,5-13则可以作为第二个页面范围。这将使得DiffPDF成对地对比这些页面(1,1),(2,2),(3,3),(4,5),(5,6),以此类推,直到(12,13)。
|
||||
|
||||
### 安装 diffpdf 到 ubuntu ###
|
||||
#### 安装 diffpdf 到 ubuntu ####
|
||||
|
||||
打开终端,然后运行以下命令
|
||||
|
||||
sudo apt-get install diffpdf
|
||||
|
||||
### 截图 ###
|
||||
#### 截图 ####
|
||||
|
||||

|
||||
|
||||
@ -41,7 +41,7 @@ via: http://www.ubuntugeek.com/compare-pdf-files-on-ubuntu.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,12 @@
|
||||
新手应知应会的Linux命令
|
||||
================================================================================
|
||||
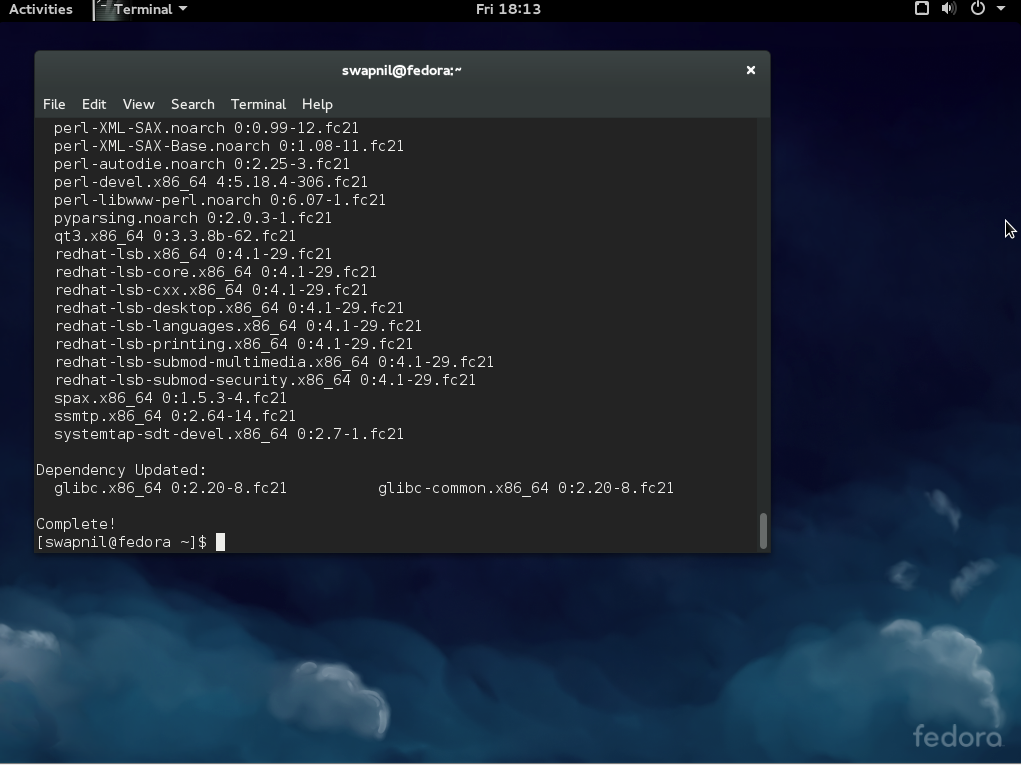
|
||||
在Fedora上通过命令行使用dnf来管理系统更新
|
||||
|
||||
基于Linux的系统的优点之一,就是你可以通过终端中使用命令该ing来管理整个系统。使用命令行的优势在于,你可以使用相同的知识和技能来管理随便哪个Linux发行版。
|
||||
*在Fedora上通过命令行使用dnf来管理系统更新*
|
||||
|
||||
对于各个发行版以及桌面环境(DE)而言,要一致地使用图形化用户界面(GUI)却几乎是不可能的,因为它们都提供了各自的用户界面。要明确的是,有那么些情况,你需要在不同的发行版上使用不同的命令来部署某些特定的任务,但是,或多或少它们的概念和意图却仍然是一致的。
|
||||
基于Linux的系统最美妙的一点,就是你可以在终端中使用命令行来管理整个系统。使用命令行的优势在于,你可以使用相同的知识和技能来管理随便哪个Linux发行版。
|
||||
|
||||
对于各个发行版以及桌面环境(DE)而言,要一致地使用图形化用户界面(GUI)却几乎是不可能的,因为它们都提供了各自的用户界面。要明确的是,有些情况下在不同的发行版上需要使用不同的命令来执行某些特定的任务,但是,基本来说它们的思路和目的是一致的。
|
||||
|
||||
在本文中,我们打算讨论Linux用户应当掌握的一些基本命令。我将给大家演示怎样使用命令行来更新系统、管理软件、操作文件以及切换到root,这些操作将在三个主要发行版上进行:Ubuntu(也包括其定制版和衍生版,还有Debian),openSUSE,以及Fedora。
|
||||
|
||||
@ -15,7 +16,7 @@
|
||||
|
||||
Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会导致安全漏洞。所以,保持你的系统更新到最新是十分重要的。这么想吧:运行过时的操作系统,就像是你坐在全副武装的坦克里头,而门却没有锁。武器会保护你吗?任何人都可以进入开放的大门,对你造成伤害。同样,在你的系统中也有没有打补丁的漏洞,这些漏洞会危害到你的系统。开源社区,不像专利世界,在漏洞补丁方面反应是相当快的,所以,如果你保持系统最新,你也获得了安全保证。
|
||||
|
||||
留意新闻站点,了解安全漏洞。如果发现了一个漏洞,请阅读之,然后在补丁出来的第一时间更新。不管怎样,在生产机器上,你每星期必须至少运行一次更新命令。如果你运行这一台复杂的服务器,那么就要额外当心了。仔细阅读变更日志,以确保更新不会搞坏你的自定义服务。
|
||||
留意新闻站点,了解安全漏洞。如果发现了一个漏洞,了解它,然后在补丁出来的第一时间更新。不管怎样,在生产环境上,你每星期必须至少运行一次更新命令。如果你运行着一台复杂的服务器,那么就要额外当心了。仔细阅读变更日志,以确保更新不会搞坏你的自定义服务。
|
||||
|
||||
**Ubuntu**:牢记一点:你在升级系统或安装不管什么软件之前,都必须要刷新仓库(也就是repos)。在Ubuntu上,你可以使用下面的命令来更新系统,第一个命令用于刷新仓库:
|
||||
|
||||
@ -29,7 +30,7 @@ Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会
|
||||
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
**openSUSE**:如果你是在openSUSE上,你可以使用以下命令来更新系统(照例,第一个命令的意思是更新仓库)
|
||||
**openSUSE**:如果你是在openSUSE上,你可以使用以下命令来更新系统(照例,第一个命令的意思是更新仓库):
|
||||
|
||||
sudo zypper refresh
|
||||
sudo zypper up
|
||||
@ -42,7 +43,7 @@ Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会
|
||||
### 软件安装与移除 ###
|
||||
|
||||
你只可以安装那些你系统上启用的仓库中可用的包,各个发行版默认都附带有并启用了一些官方或者第三方仓库。
|
||||
**Ubuntu**: To install any package on Ubuntu, first update the repo and then use this syntax:
|
||||
|
||||
**Ubuntu**:要在Ubuntu上安装包,首先更新仓库,然后使用下面的语句:
|
||||
|
||||
sudo apt-get install [package_name]
|
||||
@ -75,9 +76,9 @@ Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会
|
||||
|
||||
### 如何管理第三方软件? ###
|
||||
|
||||
在一个庞大的开发者社区中,这些开发者们为用户提供了许多的软件。不同的发行版有不同的机制来使用这些第三方软件,将它们提供给用户。同时也取决于开发者怎样将这些软件提供给用户,有些开发者会提供二进制包,而另外一些开发者则将软件发布到仓库中。
|
||||
在一个庞大的开发者社区中,这些开发者们为用户提供了许多的软件。不同的发行版有不同的机制来将这些第三方软件提供给用户。当然,同时也取决于开发者怎样将这些软件提供给用户,有些开发者会提供二进制包,而另外一些开发者则将软件发布到仓库中。
|
||||
|
||||
Ubuntu严重依赖于PPA(个人包归档),但是,不幸的是,它却没有提供一个内建工具来帮助用于搜索这些PPA仓库。在安装软件前,你将需要通过Google搜索PPA,然后手工添加该仓库。下面就是添加PPA到系统的方法:
|
||||
Ubuntu很多地方都用到PPA(个人包归档),但是,不幸的是,它却没有提供一个内建工具来帮助用于搜索这些PPA仓库。在安装软件前,你将需要通过Google搜索PPA,然后手工添加该仓库。下面就是添加PPA到系统的方法:
|
||||
|
||||
sudo add-apt-repository ppa:<repository-name>
|
||||
|
||||
@ -85,7 +86,7 @@ Ubuntu严重依赖于PPA(个人包归档),但是,不幸的是,它却
|
||||
|
||||
sudo add-apt-repository ppa:libreoffice/ppa
|
||||
|
||||
它会要你按下回车键来导入秘钥。完成后,使用'update'命令来刷新仓库,然后安装该包。
|
||||
它会要你按下回车键来导入密钥。完成后,使用'update'命令来刷新仓库,然后安装该包。
|
||||
|
||||
openSUSE拥有一个针对第三方应用的优雅的解决方案。你可以访问software.opensuse.org,一键点击搜索并安装相应包,它会自动将对应的仓库添加到你的系统中。如果你想要手工添加仓库,可以使用该命令:
|
||||
|
||||
@ -97,13 +98,13 @@ openSUSE拥有一个针对第三方应用的优雅的解决方案。你可以访
|
||||
sudo zypper refresh
|
||||
sudo zypper install libreoffice
|
||||
|
||||
Fedora用户只需要添加RPMFusion(free和non-free仓库一起),该仓库包含了大量的应用。如果你需要添加仓库,命令如下:
|
||||
Fedora用户只需要添加RPMFusion(包括自由软件和非自由软件仓库),该仓库包含了大量的应用。如果你需要添加该仓库,命令如下:
|
||||
|
||||
dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
### 一些基本命令 ###
|
||||
|
||||
我已经写了一些关于使用CLI来管理你系统上的文件的[文章][1],下面介绍一些基本米ing令,这些命令在所有发行版上都经常会用到。
|
||||
我已经写了一些关于使用CLI来管理你系统上的文件的[文章][1],下面介绍一些基本命令,这些命令在所有发行版上都经常会用到。
|
||||
|
||||
拷贝文件或目录到一个新的位置:
|
||||
|
||||
@ -113,13 +114,13 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
cp path_of_files/* path_of_the_directory_where_you_want_to_copy/
|
||||
|
||||
将一个文件从某个位置移动到另一个位置(尾斜杠是说在该目录中):
|
||||
将一个文件从某个位置移动到另一个位置(尾斜杠是说放在该目录中):
|
||||
|
||||
mv path_of_file_1 path_of_the_directory_where_you_want_to_move/
|
||||
mv path_of_file_1 path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
将所有文件从一个位置移动到另一个位置:
|
||||
|
||||
mv path_of_directory_where_files_are/* path_of_the_directory_where_you_want_to_move/
|
||||
mv path_of_directory_where_files_are/* path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
删除一个文件:
|
||||
|
||||
@ -135,11 +136,11 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
### 创建新目录 ###
|
||||
|
||||
要创建一个新目录,首先输入你要创建的目录的位置。比如说,你想要在你的Documents目录中创建一个名为'foundation'的文件夹。让我们使用 cd (即change directory,改变目录)命令来改变目录:
|
||||
要创建一个新目录,首先进入到你要创建该目录的位置。比如说,你想要在你的Documents目录中创建一个名为'foundation'的文件夹。让我们使用 cd (即change directory,改变目录)命令来改变目录:
|
||||
|
||||
cd /home/swapnil/Documents
|
||||
|
||||
(替换'swapnil'为你系统中的用户)
|
||||
(替换'swapnil'为你系统中的用户名)
|
||||
|
||||
然后,使用 mkdir 命令来创建该目录:
|
||||
|
||||
@ -149,13 +150,13 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
mdkir /home/swapnil/Documents/foundation
|
||||
|
||||
如果你想要创建父-子目录,那是指目录中的目录,那么可以使用 -p 选项。它会在指定路径中创建所有目录:
|
||||
如果你想要连父目录一起创建,那么可以使用 -p 选项。它会在指定路径中创建所有目录:
|
||||
|
||||
mdkir -p /home/swapnil/Documents/linux/foundation
|
||||
|
||||
### 成为root ###
|
||||
|
||||
你或许需要成为root,或者具有sudo权力的用户,来实施一些管理任务,如管理软件包或者对根目录或其下的文件进行一些修改。其中一个例子就是编辑'fstab'文件,该文件记录了挂载的硬件驱动器。它在'etc'目录中,而该目录又在根目录中,你只能作为超级用户来修改该文件。在大多数的发行版中,你可以通过'切换用户'来成为root。比如说,在openSUSE上,我想要成为root,因为我要在根目录中工作,你可以使用下面的命令之一:
|
||||
你或许需要成为root,或者具有sudo权力的用户,来实施一些管理任务,如管理软件包或者对根目录或其下的文件进行一些修改。其中一个例子就是编辑'fstab'文件,该文件记录了挂载的硬盘驱动器。它在'etc'目录中,而该目录又在根目录中,你只能作为超级用户来修改该文件。在大多数的发行版中,你可以通过'su'来成为root。比如说,在openSUSE上,我想要成为root,因为我要在根目录中工作,你可以使用下面的命令之一:
|
||||
|
||||
sudo su -
|
||||
|
||||
@ -165,7 +166,7 @@ dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
该命令会要求输入密码,然后你就具有root特权了。记住一点:千万不要以root用户来运行系统,除非你知道你正在做什么。另外重要的一点需要注意的是,你以root什么对目录或文件进行修改后,会将它们的拥有关系从该用户或特定的服务改变为root。你必须恢复这些文件的拥有关系,否则该服务或用户就不能访问或写入到那些文件。要改变用户,命令如下:
|
||||
|
||||
sudo chown -R user:user /path_of_file_or_directory
|
||||
sudo chown -R 用户:组 文件或目录名
|
||||
|
||||
当你将其它发行版上的分区挂载到系统中时,你可能经常需要该操作。当你试着访问这些分区上的文件时,你可能会碰到权限拒绝错误,你只需要改变这些分区的拥有关系就可以访问它们了。需要额外当心的是,不要改变根目录的权限或者拥有关系。
|
||||
|
||||
@ -177,7 +178,7 @@ via: http://www.linux.com/learn/tutorials/842251-must-know-linux-commands-for-ne
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,65 @@
|
||||
使用 Find 命令来帮你找到那些需要清理的文件
|
||||
================================================================================
|
||||

|
||||
|
||||
*Credit: Sandra H-S*
|
||||
|
||||
有一个问题几乎困扰着所有的文件系统 -- 包括 Unix 和其他的 -- 那就是文件的不断积累。几乎没有人愿意花时间清理掉他们不再使用的文件和整理文件系统,结果,文件变得很混乱,很难找到有用的东西,要使它们运行良好、维护备份、易于管理,这将是一种持久的挑战。
|
||||
|
||||
我见过的一种解决问题的方法是建议使用者将所有的数据碎屑创建一个文件集合的总结报告或"概况",来报告诸如所有的文件数量;最老的,最新的,最大的文件;并统计谁拥有这些文件等数据。如果有人看到五年前的一个包含五十万个文件的文件夹,他们可能会去删除哪些文件 -- 或者,至少会归档和压缩。主要问题是太大的文件夹会使人担心误删一些重要的东西。如果有一个描述文件夹的方法能帮助显示文件的性质,那么你就可以去清理它了。
|
||||
|
||||
当我准备做 Unix 文件系统的总结报告时,几个有用的 Unix 命令能提供一些非常有用的统计信息。要计算目录中的文件数,你可以使用这样一个 find 命令。
|
||||
|
||||
$ find . -type f | wc -l
|
||||
187534
|
||||
|
||||
虽然查找最老的和最新的文件是比较复杂,但还是相当方便的。在下面的命令,我们使用 find 命令再次查找文件,以文件时间排序并按年-月-日的格式显示,在列表顶部的显然是最老的。
|
||||
|
||||
在第二个命令,我们做同样的,但打印的是最后一行,这是最新的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | sort | head -n 1
|
||||
2006-02-03+02:40:33 ./skel/.xemacs/init.el
|
||||
$ find -type f -printf '%T+ %p\n' | sort | tail -n 1
|
||||
2015-07-19+14:20:16 ./.bash_history
|
||||
|
||||
printf 命令输出 %T(文件日期和时间)和 %P(带路径的文件名)参数。
|
||||
|
||||
如果我们在查找家目录时,无疑会发现,history 文件(如 .bash_history)是最新的,这并没有什么用。你可以通过 "un-grepping" 来忽略这些文件,也可以忽略以.开头的文件,如下图所示的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | grep -v "\./\." | sort | tail -n 1
|
||||
2015-07-19+13:02:12 ./isPrime
|
||||
|
||||
寻找最大的文件使用 %s(大小)参数,包括文件名(%f),因为这就是我们想要在报告中显示的。
|
||||
|
||||
$ find -type f -printf '%s %f \n' | sort -n | uniq | tail -1
|
||||
20183040 project.org.tar
|
||||
|
||||
统计文件的所有者,使用%u(所有者)
|
||||
|
||||
$ find -type f -printf '%u \n' | grep -v "\./\." | sort | uniq -c
|
||||
180034 shs
|
||||
7500 jdoe
|
||||
|
||||
如果文件系统能记录上次的访问日期,也将是非常有用的,可以用来看该文件有没有被访问过,比方说,两年之内没访问过。这将使你能明确分辨这些文件的价值。这个最后访问(%a)参数这样使用:
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | head -n 1
|
||||
Fri Dec 15 03:00:30 2006+ ./statreport
|
||||
|
||||
当然,如果大多数最近访问的文件也是在很久之前的,这看起来你需要处理更多文件了。
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | tail -n 1
|
||||
Wed Nov 26 03:00:27 2007+ ./my-notes
|
||||
|
||||
要想层次分明,可以为一个文件系统或大目录创建一个总结报告,显示这些文件的日期范围、最大的文件、文件所有者们、最老的文件和最新访问时间,可以帮助文件拥有者判断当前有哪些文件夹是重要的哪些该清理了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2949898/linux/profiling-your-file-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Sandra-Henry_Stocker/
|
||||
88
published/201508/20150803 Linux Logging Basics.md
Normal file
88
published/201508/20150803 Linux Logging Basics.md
Normal file
@ -0,0 +1,88 @@
|
||||
Linux 日志基础
|
||||
================================================================================
|
||||
首先,我们将描述有关 Linux 日志是什么,到哪儿去找它们,以及它们是如何创建的基础知识。如果你已经知道这些,请随意跳至下一节。
|
||||
|
||||
### Linux 系统日志 ###
|
||||
|
||||
许多有价值的日志文件都是由 Linux 自动地为你创建的。你可以在 `/var/log` 目录中找到它们。下面是在一个典型的 Ubuntu 系统中这个目录的样子:
|
||||
|
||||

|
||||
|
||||
一些最为重要的 Linux 系统日志包括:
|
||||
|
||||
- `/var/log/syslog` 或 `/var/log/messages` 存储所有的全局系统活动数据,包括开机信息。基于 Debian 的系统如 Ubuntu 在 `/var/log/syslog` 中存储它们,而基于 RedHat 的系统如 RHEL 或 CentOS 则在 `/var/log/messages` 中存储它们。
|
||||
- `/var/log/auth.log` 或 `/var/log/secure` 存储来自可插拔认证模块(PAM)的日志,包括成功的登录,失败的登录尝试和认证方式。Ubuntu 和 Debian 在 `/var/log/auth.log` 中存储认证信息,而 RedHat 和 CentOS 则在 `/var/log/secure` 中存储该信息。
|
||||
- `/var/log/kern` 存储内核的错误和警告数据,这对于排除与定制内核相关的故障尤为实用。
|
||||
- `/var/log/cron` 存储有关 cron 作业的信息。使用这个数据来确保你的 cron 作业正成功地运行着。
|
||||
|
||||
Digital Ocean 有一个关于这些文件的完整[教程][1],介绍了 rsyslog 如何在常见的发行版本如 RedHat 和 CentOS 中创建它们。
|
||||
|
||||
应用程序也会在这个目录中写入日志文件。例如像 Apache,Nginx,MySQL 等常见的服务器程序可以在这个目录中写入日志文件。其中一些日志文件由应用程序自己创建,其他的则通过 syslog (具体见下文)来创建。
|
||||
|
||||
### 什么是 Syslog? ###
|
||||
|
||||
Linux 系统日志文件是如何创建的呢?答案是通过 syslog 守护程序,它在 syslog 套接字 `/dev/log` 上监听日志信息,然后将它们写入适当的日志文件中。
|
||||
|
||||
单词“syslog” 代表几个意思,并经常被用来简称如下的几个名称之一:
|
||||
|
||||
1. **Syslog 守护进程** — 一个用来接收、处理和发送 syslog 信息的程序。它可以[远程发送 syslog][2] 到一个集中式的服务器或写入到一个本地文件。常见的例子包括 rsyslogd 和 syslog-ng。在这种使用方式中,人们常说“发送到 syslog”。
|
||||
1. **Syslog 协议** — 一个指定日志如何通过网络来传送的传输协议和一个针对 syslog 信息(具体见下文) 的数据格式的定义。它在 [RFC-5424][3] 中被正式定义。对于文本日志,标准的端口是 514,对于加密日志,端口是 6514。在这种使用方式中,人们常说“通过 syslog 传送”。
|
||||
1. **Syslog 信息** — syslog 格式的日志信息或事件,它包括一个带有几个标准字段的消息头。在这种使用方式中,人们常说“发送 syslog”。
|
||||
|
||||
Syslog 信息或事件包括一个带有几个标准字段的消息头,可以使分析和路由更方便。它们包括时间戳、应用程序的名称、在系统中信息来源的分类或位置、以及事件的优先级。
|
||||
|
||||
下面展示的是一个包含 syslog 消息头的日志信息,它来自于控制着到该系统的远程登录的 sshd 守护进程,这个信息描述的是一次失败的登录尝试:
|
||||
|
||||
<34>1 2003-10-11T22:14:15.003Z server1.com sshd - - pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
|
||||
|
||||
### Syslog 格式和字段 ###
|
||||
|
||||
每条 syslog 信息包含一个带有字段的信息头,这些字段是结构化的数据,使得分析和路由事件更加容易。下面是我们使用的用来产生上面的 syslog 例子的格式,你可以将每个值匹配到一个特定的字段的名称上。
|
||||
|
||||
<%pri%>%protocol-version% %timestamp:::date-rfc3339% %HOSTNAME% %app-name% %procid% %msgid% %msg%n
|
||||
|
||||
下面,你将看到一些在查找或排错时最常使用的 syslog 字段:
|
||||
|
||||
#### 时间戳 ####
|
||||
|
||||
[时间戳][4] (上面的例子为 2003-10-11T22:14:15.003Z) 暗示了在系统中发送该信息的时间和日期。这个时间在另一系统上接收该信息时可能会有所不同。上面例子中的时间戳可以分解为:
|
||||
|
||||
- **2003-10-11** 年,月,日。
|
||||
- **T** 为时间戳的必需元素,它将日期和时间分隔开。
|
||||
- **22:14:15.003** 是 24 小时制的时间,包括进入下一秒的毫秒数(**003**)。
|
||||
- **Z** 是一个可选元素,指的是 UTC 时间,除了 Z,这个例子还可以包括一个偏移量,例如 -08:00,这意味着时间从 UTC 偏移 8 小时,即 PST 时间。
|
||||
|
||||
#### 主机名 ####
|
||||
|
||||
[主机名][5] 字段(在上面的例子中对应 server1.com) 指的是主机的名称或发送信息的系统.
|
||||
|
||||
#### 应用名 ####
|
||||
|
||||
[应用名][6] 字段(在上面的例子中对应 sshd:auth) 指的是发送信息的程序的名称.
|
||||
|
||||
#### 优先级 ####
|
||||
|
||||
优先级字段或缩写为 [pri][7] (在上面的例子中对应 <34>) 告诉我们这个事件有多紧急或多严峻。它由两个数字字段组成:设备字段和紧急性字段。紧急性字段从代表 debug 类事件的数字 7 一直到代表紧急事件的数字 0 。设备字段描述了哪个进程创建了该事件。它从代表内核信息的数字 0 到代表本地应用使用的 23 。
|
||||
|
||||
Pri 有两种输出方式。第一种是以一个单独的数字表示,可以这样计算:先用设备字段的值乘以 8,再加上紧急性字段的值:(设备字段)(8) + (紧急性字段)。第二种是 pri 文本,将以“设备字段.紧急性字段” 的字符串格式输出。后一种格式更方便阅读和搜索,但占据更多的存储空间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/linux-logging-basics/
|
||||
|
||||
作者:[Jason Skowronski][a1],[Amy Echeverri][a2],[Sadequl Hussain][a3]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://www.digitalocean.com/community/tutorials/how-to-view-and-configure-linux-logs-on-ubuntu-and-centos
|
||||
[2]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.y2e9tdfk1cdb
|
||||
[3]:https://tools.ietf.org/html/rfc5424
|
||||
[4]:https://tools.ietf.org/html/rfc5424#section-6.2.3
|
||||
[5]:https://tools.ietf.org/html/rfc5424#section-6.2.4
|
||||
[6]:https://tools.ietf.org/html/rfc5424#section-6.2.5
|
||||
[7]:https://tools.ietf.org/html/rfc5424#section-6.2.1
|
||||
119
published/201508/20150803 Troubleshooting with Linux Logs.md
Normal file
119
published/201508/20150803 Troubleshooting with Linux Logs.md
Normal file
@ -0,0 +1,119 @@
|
||||
在 Linux 中使用日志来排错
|
||||
================================================================================
|
||||
|
||||
人们创建日志的主要原因是排错。通常你会诊断为什么问题发生在你的 Linux 系统或应用程序中。错误信息或一系列的事件可以给你提供找出根本原因的线索,说明问题是如何发生的,并指出如何解决它。这里有几个使用日志来解决的样例。
|
||||
|
||||
### 登录失败原因 ###
|
||||
|
||||
如果你想检查你的系统是否安全,你可以在验证日志中检查登录失败的和登录成功但可疑的用户。当有人通过不正当或无效的凭据来登录时会出现认证失败,这通常发生在使用 SSH 进行远程登录或 su 到本地其他用户来进行访问权时。这些是由[插入式验证模块(PAM)][1]来记录的。在你的日志中会看到像 Failed password 和 user unknown 这样的字符串。而成功认证记录则会包括像 Accepted password 和 session opened 这样的字符串。
|
||||
|
||||
失败的例子:
|
||||
|
||||
pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
|
||||
Failed password for invalid user hoover from 10.0.2.2 port 4791 ssh2
|
||||
pam_unix(sshd:auth): check pass; user unknown
|
||||
PAM service(sshd) ignoring max retries; 6 > 3
|
||||
|
||||
成功的例子:
|
||||
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
pam_unix(sshd:session): session opened for user hoover by (uid=0)
|
||||
pam_unix(sshd:session): session closed for user hoover
|
||||
|
||||
你可以使用 grep 来查找哪些用户失败登录的次数最多。这些都是潜在的攻击者正在尝试和访问失败的账户。这是一个在 ubuntu 系统上的例子。
|
||||
|
||||
$ grep "invalid user" /var/log/auth.log | cut -d ' ' -f 10 | sort | uniq -c | sort -nr
|
||||
23 oracle
|
||||
18 postgres
|
||||
17 nagios
|
||||
10 zabbix
|
||||
6 test
|
||||
|
||||
由于没有标准格式,所以你需要为每个应用程序的日志使用不同的命令。日志管理系统,可以自动分析日志,将它们有效的归类,帮助你提取关键字,如用户名。
|
||||
|
||||
日志管理系统可以使用自动解析功能从 Linux 日志中提取用户名。这使你可以看到用户的信息,并能通过点击过滤。在下面这个例子中,我们可以看到,root 用户登录了 2700 次之多,因为我们筛选的日志仅显示 root 用户的尝试登录记录。
|
||||
|
||||

|
||||
|
||||
日志管理系统也可以让你以时间为做坐标轴的图表来查看,使你更容易发现异常。如果有人在几分钟内登录失败一次或两次,它可能是一个真正的用户而忘记了密码。但是,如果有几百个失败的登录并且使用的都是不同的用户名,它更可能是在试图攻击系统。在这里,你可以看到在3月12日,有人试图登录 Nagios 几百次。这显然不是一个合法的系统用户。
|
||||
|
||||

|
||||
|
||||
### 重启的原因 ###
|
||||
|
||||
有时候,一台服务器由于系统崩溃或重启而宕机。你怎么知道它何时发生,是谁做的?
|
||||
|
||||
#### 关机命令 ####
|
||||
|
||||
如果有人手动运行 shutdown 命令,你可以在验证日志文件中看到它。在这里,你可以看到,有人从 IP 50.0.134.125 上作为 ubuntu 的用户远程登录了,然后关闭了系统。
|
||||
|
||||
Mar 19 18:36:41 ip-172-31-11-231 sshd[23437]: Accepted publickey for ubuntu from 50.0.134.125 port 52538 ssh
|
||||
Mar 19 18:36:41 ip-172-31-11-231 23437]:sshd[ pam_unix(sshd:session): session opened for user ubuntu by (uid=0)
|
||||
Mar 19 18:37:09 ip-172-31-11-231 sudo: ubuntu : TTY=pts/1 ; PWD=/home/ubuntu ; USER=root ; COMMAND=/sbin/shutdown -r now
|
||||
|
||||
#### 内核初始化 ####
|
||||
|
||||
如果你想看看服务器重新启动的所有原因(包括崩溃),你可以从内核初始化日志中寻找。你需要搜索内核类(kernel)和 cpu 初始化(Initializing)的信息。
|
||||
|
||||
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpuset
|
||||
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Initializing cgroup subsys cpu
|
||||
Mar 19 18:39:30 ip-172-31-11-231 kernel: [ 0.000000] Linux version 3.8.0-44-generic (buildd@tipua) (gcc version 4.6.3 (Ubuntu/Linaro 4.6.3-1ubuntu5) ) #66~precise1-Ubuntu SMP Tue Jul 15 04:01:04 UTC 2014 (Ubuntu 3.8.0-44.66~precise1-generic 3.8.13.25)
|
||||
|
||||
### 检测内存问题 ###
|
||||
|
||||
有很多原因可能导致服务器崩溃,但一个常见的原因是内存用尽。
|
||||
|
||||
当你系统的内存不足时,进程会被杀死,通常会杀死使用最多资源的进程。当系统使用了所有内存,而新的或现有的进程试图使用更多的内存时就会出现错误。在你的日志文件查找像 Out of Memory 这样的字符串或类似 kill 这样的内核警告信息。这些信息表明系统故意杀死进程或应用程序,而不是允许进程崩溃。
|
||||
|
||||
例如:
|
||||
|
||||
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child
|
||||
[29923450.995084] select 5230 (docker), adj 0, size 708, to kill
|
||||
|
||||
你可以使用像 grep 这样的工具找到这些日志。这个例子是在 ubuntu 中:
|
||||
|
||||
$ grep “Out of memory” /var/log/syslog
|
||||
[33238.178288] Out of memory: Kill process 6230 (firefox) score 53 or sacrifice child
|
||||
|
||||
请记住,grep 也要使用内存,所以只是运行 grep 也可能导致内存不足的错误。这是另一个你应该中央化存储日志的原因!
|
||||
|
||||
### 定时任务错误日志 ###
|
||||
|
||||
cron 守护程序是一个调度器,可以在指定的日期和时间运行进程。如果进程运行失败或无法完成,那么 cron 的错误出现在你的日志文件中。具体取决于你的发行版,你可以在 /var/log/cron,/var/log/messages,和 /var/log/syslog 几个位置找到这个日志。cron 任务失败原因有很多。通常情况下,问题出在进程中而不是 cron 守护进程本身。
|
||||
|
||||
默认情况下,cron 任务的输出会通过 postfix 发送电子邮件。这是一个显示了该邮件已经发送的日志。不幸的是,你不能在这里看到邮件的内容。
|
||||
|
||||
Mar 13 16:35:01 PSQ110 postfix/pickup[15158]: C3EDC5800B4: uid=1001 from=<hoover>
|
||||
Mar 13 16:35:01 PSQ110 postfix/cleanup[15727]: C3EDC5800B4: message-id=<20150310110501.C3EDC5800B4@PSQ110>
|
||||
Mar 13 16:35:01 PSQ110 postfix/qmgr[15159]: C3EDC5800B4: from=<hoover@loggly.com>, size=607, nrcpt=1 (queue active)
|
||||
Mar 13 16:35:05 PSQ110 postfix/smtp[15729]: C3EDC5800B4: to=<hoover@loggly.com>, relay=gmail-smtp-in.l.google.com[74.125.130.26]:25, delay=4.1, delays=0.26/0/2.2/1.7, dsn=2.0.0, status=sent (250 2.0.0 OK 1425985505 f16si501651pdj.5 - gsmtp)
|
||||
|
||||
你可以考虑将 cron 的标准输出记录到日志中,以帮助你定位问题。这是一个你怎样使用 logger 命令重定向 cron 标准输出到 syslog的例子。用你的脚本来代替 echo 命令,helloCron 可以设置为任何你想要的应用程序的名字。
|
||||
|
||||
*/5 * * * * echo ‘Hello World’ 2>&1 | /usr/bin/logger -t helloCron
|
||||
|
||||
它创建的日志条目:
|
||||
|
||||
Apr 28 22:20:01 ip-172-31-11-231 CRON[15296]: (ubuntu) CMD (echo 'Hello World!' 2>&1 | /usr/bin/logger -t helloCron)
|
||||
Apr 28 22:20:01 ip-172-31-11-231 helloCron: Hello World!
|
||||
|
||||
每个 cron 任务将根据任务的具体类型以及如何输出数据来记录不同的日志。
|
||||
|
||||
希望在日志中有问题根源的线索,也可以根据需要添加额外的日志记录。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/troubleshooting-with-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:http://linux.die.net/man/8/pam.d
|
||||
@ -0,0 +1,75 @@
|
||||
选择成为软件开发工程师的5个原因
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
这个星期我将给本地一所高中做一次有关于程序猿是怎样工作的演讲。我是志愿(由 [Transfer][1] 组织的)来到这所学校谈论我的工作的。这个学校本周将有一个技术主题日,并且他们很想听听科技行业是怎样工作的。因为我是从事软件开发的,这也是我将和学生们讲的内容。演讲的其中一部分是我为什么觉得软件开发是一个很酷的职业。主要原因如下:
|
||||
|
||||
### 5个原因 ###
|
||||
|
||||
**1、创造性**
|
||||
|
||||
如果你问别人创造性的工作有哪些,别人通常会说像作家,音乐家或者画家那样的(工作)。但是极少有人知道软件开发也是一项非常具有创造性的工作。它是最符合创造性定义的了,因为你创造了一个以前没有的新功能。这种解决方案可以在整体和细节上以很多形式来展现。我们经常会遇到一些需要做权衡的场景(比如说运行速度与内存消耗的权衡)。当然前提是这种解决方案必须是正确的。这些所有的行为都是需要强大的创造性的。
|
||||
|
||||
**2、协作性**
|
||||
|
||||
另外一个表象是程序猿们独自坐在他们的电脑前,然后撸一天的代码。但是软件开发事实上通常总是一个团队努力的结果。你会经常和你的同事讨论编程问题以及解决方案,并且和产品经理、测试人员、客户讨论需求以及其他问题。
|
||||
经常有人说,结对编程(2个开发人员一起在一个电脑上编程)是一种流行的最佳实践。
|
||||
|
||||
**3、高需性**
|
||||
|
||||
世界上越来越多的人在用软件,正如 [Marc Andreessen](https://en.wikipedia.org/wiki/Marc_Andreessen) 所说 " [软件正在吞噬世界][2] "。虽然程序猿现在的数量非常巨大(在斯德哥尔摩,程序猿现在是 [最普遍的职业][3] ),但是,需求量一直处于供不应求的局面。据软件公司说,他们最大的挑战之一就是 [找到优秀的程序猿][4] 。我也经常接到那些想让我跳槽的招聘人员打来的电话。我知道至少除软件行业之外的其他行业的雇主不会那么拼(的去招聘)。
|
||||
|
||||
**4、高酬性**
|
||||
|
||||
软件开发可以带来不菲的收入。卖一份你已经开发好的软件的额外副本是没有 [边际成本][5] 的。这个事实与对程序猿的高需求意味着收入相当可观。当然还有许多更捞金的职业,但是相比一般人群,我认为软件开发者确实“日进斗金”(知足吧!骚年~~)。
|
||||
|
||||
**5、前瞻性**
|
||||
|
||||
有许多工作岗位消失,往往是由于它们可以被计算机和软件代替。但是所有这些新的程序依然需要开发和维护,因此,程序猿的前景还是相当好的。
|
||||
|
||||
### 但是...###
|
||||
|
||||
**外包又是怎么一回事呢?**
|
||||
|
||||
难道所有外包到其他国家的软件开发的薪水都很低吗?这是一个理想丰满,现实骨感的例子(有点像 [瀑布开发模型][6] )。软件开发基本上跟设计的工作一样,是一个探索发现的工作。它受益于强有力的合作。更进一步说,特别当你的主打产品是软件的时候,你所掌握的开发知识是绝对的优势。知识在整个公司中分享的越容易,那么公司的发展也将越来越好。
|
||||
|
||||
换一种方式去看待这个问题。软件外包已经存在了相当一段时间了。但是对本土程序猿的需求量依旧非常高。因为许多软件公司看到了雇佣本土程序猿的带来的收益要远远超过了相对较高的成本(其实还是赚了)。
|
||||
|
||||
### 如何成为人生大赢家 ###
|
||||
|
||||
虽然我有许多我认为软件开发是一件非常有趣的事情的理由 (详情见: [为什么我热爱编程][7] )。但是这些理由,并不适用于所有人。幸运的是,尝试编程是一件非常容易的事情。在互联网上有数不尽的学习编程的资源。例如,[Coursera][8] 和 [Udacity][9] 都拥有很好的入门课程。如果你从来没有撸过码,可以尝试其中一个免费的课程,找找感觉。
|
||||
|
||||
寻找一个既热爱又能谋生的事情至少有2个好处。首先,由于你天天去做,工作将比你简单的只为谋生要有趣的多。其次,如果你真的非常喜欢,你将更好的擅长它。我非常喜欢下面一副关于伟大工作组成的韦恩图(作者 [@eskimon)][10]) 。因为编码的薪水确实相当不错,我认为如果你真的喜欢它,你将有一个很好的机会,成为人生的大赢家!
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://henrikwarne.com/2014/12/08/5-reasons-why-software-developer-is-a-great-career-choice/
|
||||
|
||||
作者:[Henrik Warne][a]
|
||||
译者:[mousycoder](https://github.com/mousycoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:http://henrikwarne.com/
|
||||
[1]:http://www.transfer.nu/omoss/transferinenglish.jspx?pageId=23
|
||||
[2]:http://www.wsj.com/articles/SB10001424053111903480904576512250915629460
|
||||
[3]:http://www.di.se/artiklar/2014/6/12/jobbet-som-tar-over-landet/
|
||||
[4]:http://computersweden.idg.se/2.2683/1.600324/examinationstakten-racker-inte-for-branschens-behov
|
||||
[5]:https://en.wikipedia.org/wiki/Marginal_cost
|
||||
[6]:https://en.wikipedia.org/wiki/Waterfall_model
|
||||
[7]:http://henrikwarne.com/2012/06/02/why-i-love-coding/
|
||||
[8]:https://www.coursera.org/
|
||||
[9]:https://www.udacity.com/
|
||||
[10]:https://eskimon.wordpress.com/about/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
Linux有问必答:如何修复“ImportError: No module named wxversion”错误
|
||||
================================================================================
|
||||
|
||||
> **问题** 我试着在[某某 Linux 发行版]上运行一个 Python 应用,但是我得到了这个错误“ImportError: No module named wxversion.”。我怎样才能解决 Python 程序中的这个错误呢?
|
||||
|
||||
Looking for python... 2.7.9 - Traceback (most recent call last):
|
||||
File "/home/dev/playonlinux/python/check_python.py", line 1, in
|
||||
import os, wxversion
|
||||
ImportError: No module named wxversion
|
||||
failed tests
|
||||
|
||||
该错误表明,你的Python应用是基于GUI的,依赖于一个名为wxPython的缺失模块。[wxPython][1]是一个用于wxWidgets GUI库的Python扩展模块,普遍被C++程序员用来设计GUI应用。该wxPython扩展允许Python开发者在任何Python应用中方便地设计和整合GUI。
|
||||
|
||||
摇解决这个 import 错误,你需要在你的 Linux 上安装 wxPython,如下:
|
||||
|
||||
### 安装wxPython到Debian,Ubuntu或Linux Mint ###
|
||||
|
||||
$ sudo apt-get install python-wxgtk2.8
|
||||
|
||||
### 安装wxPython到Fedora ###
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### 安装wxPython到CentOS/RHEL ###
|
||||
|
||||
wxPython可以在CentOS/RHEL的EPEL仓库中获取到,而基本仓库中则没有。因此,首先要在你的系统中[启用EPEL仓库][2],然后使用yum命令来安装。
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### 安装wxPython到Arch Linux ###
|
||||
|
||||
$ sudo pacman -S wxpython
|
||||
|
||||
### 安装wxPython到Gentoo ###
|
||||
|
||||
$ emerge wxPython
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/importerror-no-module-named-wxversion.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wxpython.org/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
@ -0,0 +1,75 @@
|
||||
Linux有问必答:如何在Linux上安装Git
|
||||
================================================================================
|
||||
|
||||
> **问题:** 我尝试从一个Git公共仓库克隆项目,但出现了这样的错误提示:“git: command not found”。 请问我该如何在某某发行版上安装Git?
|
||||
|
||||
Git是一个流行的开源版本控制系统(VCS),最初是为Linux环境开发的。跟CVS或者SVN这些版本控制系统不同的是,Git的版本控制被认为是“分布式的”,某种意义上,git的本地工作目录可以作为一个功能完善的仓库来使用,它具备完整的历史记录和版本追踪能力。在这种工作模型之下,各个协作者将内容提交到他们的本地仓库中(与之相对的会总是提交到核心仓库),如果有必要,再有选择性地推送到核心仓库。这就为Git这个版本管理系统带来了大型协作系统所必须的可扩展能力和冗余能力。
|
||||
|
||||
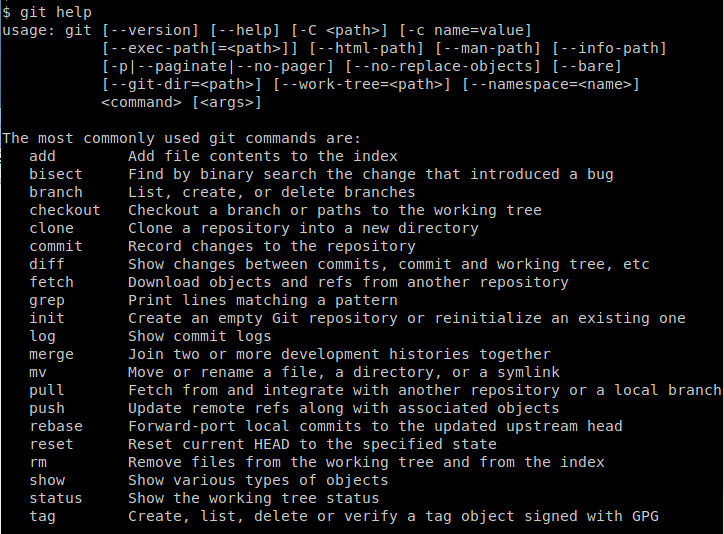
|
||||
|
||||
### 使用包管理器安装Git ###
|
||||
|
||||
Git已经被所有的主流Linux发行版所支持。所以安装它最简单的方法就是使用各个Linux发行版的包管理器。
|
||||
|
||||
**Debian, Ubuntu, 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||
**Fedora, CentOS 或 RHEL**
|
||||
|
||||
$ sudo yum install git
|
||||
或
|
||||
$ sudo dnf install git
|
||||
|
||||
**Arch Linux**
|
||||
|
||||
$ sudo pacman -S git
|
||||
|
||||
**OpenSUSE**
|
||||
|
||||
$ sudo zypper install git
|
||||
|
||||
**Gentoo**
|
||||
|
||||
$ emerge --ask --verbose dev-vcs/git
|
||||
|
||||
### 从源码安装Git ###
|
||||
|
||||
如果由于某些原因,你希望从源码安装Git,按照如下介绍操作。
|
||||
|
||||
**安装依赖包**
|
||||
|
||||
在构建Git之前,先安装它的依赖包。
|
||||
|
||||
**Debian, Ubuntu 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install libcurl4-gnutls-dev libexpat1-dev gettext libz-dev libssl-dev asciidoc xmlto docbook2x
|
||||
|
||||
**Fedora, CentOS 或 RHEL**
|
||||
|
||||
$ sudo yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel asciidoc xmlto docbook2x
|
||||
|
||||
#### 从源码编译Git ####
|
||||
|
||||
从 [https://github.com/git/git/releases][1] 下载最新版本的Git。然后在/usr下构建和安装。
|
||||
|
||||
注意,如果你打算安装到其他目录下(例如:/opt),那就把"--prefix=/usr"这个配置命令使用其他路径替换掉。
|
||||
|
||||
$ cd git-x.x.x
|
||||
$ make configure
|
||||
$ ./configure --prefix=/usr
|
||||
$ make all doc info
|
||||
$ sudo make install install-doc install-html install-info
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-git-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/git/git/releases
|
||||
@ -0,0 +1,98 @@
|
||||
如何在 Linux 上运行命令前临时清空 Bash 环境变量
|
||||
================================================================================
|
||||
我是个 bash shell 用户。我想临时清空 bash shell 环境变量。但我不想删除或者 unset 一个输出的环境变量。我怎样才能在 bash 或 ksh shell 的临时环境中运行程序呢?
|
||||
|
||||
你可以在 Linux 或类 Unix 系统中使用 env 命令设置并打印环境。env 命令可以按命令行指定的变量来修改环境,之后再执行程序。
|
||||
|
||||
### 如何显示当前环境? ###
|
||||
|
||||
打开终端应用程序并输入下面的其中一个命令:
|
||||
|
||||
printenv
|
||||
|
||||
或
|
||||
|
||||
env
|
||||
|
||||
输出样例:
|
||||
|
||||
|
||||
|
||||
*Fig.01: Unix/Linux: 列出所有环境变量*
|
||||
|
||||
### 统计环境变量数目 ###
|
||||
|
||||
输入下面的命令:
|
||||
|
||||
env | wc -l
|
||||
printenv | wc -l # 或者
|
||||
|
||||
输出样例:
|
||||
|
||||
20
|
||||
|
||||
### 在干净的 bash/ksh/zsh 环境中运行程序 ###
|
||||
|
||||
语法如下所示:
|
||||
|
||||
env -i your-program-name-here arg1 arg2 ...
|
||||
|
||||
例如,要在不使用 http_proxy 和/或任何其它环境变量的情况下运行 wget 程序。临时清除所有 bash/ksh/zsh 环境变量并运行 wget 程序:
|
||||
|
||||
env -i /usr/local/bin/wget www.cyberciti.biz
|
||||
env -i wget www.cyberciti.biz # 或者
|
||||
|
||||
这当你想忽视任何已经设置的环境变量来运行命令时非常有用。我每天都会多次使用这个命令,以便忽视 http_proxy 和其它我设置的环境变量。
|
||||
|
||||
#### 例子:使用 http_proxy ####
|
||||
|
||||
$ wget www.cyberciti.biz
|
||||
--2015-08-03 23:20:23-- http://www.cyberciti.biz/
|
||||
Connecting to 10.12.249.194:3128... connected.
|
||||
Proxy request sent, awaiting response... 200 OK
|
||||
Length: unspecified [text/html]
|
||||
Saving to: 'index.html'
|
||||
index.html [ <=> ] 36.17K 87.0KB/s in 0.4s
|
||||
2015-08-03 23:20:24 (87.0 KB/s) - 'index.html' saved [37041]
|
||||
|
||||
#### 例子:忽视 http_proxy ####
|
||||
|
||||
$ env -i /usr/local/bin/wget www.cyberciti.biz
|
||||
--2015-08-03 23:25:17-- http://www.cyberciti.biz/
|
||||
Resolving www.cyberciti.biz... 74.86.144.194
|
||||
Connecting to www.cyberciti.biz|74.86.144.194|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: unspecified [text/html]
|
||||
Saving to: 'index.html.1'
|
||||
index.html.1 [ <=> ] 36.17K 115KB/s in 0.3s
|
||||
2015-08-03 23:25:18 (115 KB/s) - 'index.html.1' saved [37041]
|
||||
|
||||
-i 选项使 env 命令完全忽视它继承的环境。但是,它并不会阻止你的命令(例如 wget 或 curl)设置新的变量。同时,也要注意运行 bash/ksh shell 的副作用:
|
||||
|
||||
env -i env | wc -l ## 空的 ##
|
||||
# 现在运行 bash ##
|
||||
env -i bash
|
||||
## bash 设置了新的环境变量 ##
|
||||
env | wc -l
|
||||
|
||||
#### 例子:设置一个环境变量 ####
|
||||
|
||||
语法如下:
|
||||
|
||||
env var=value /path/to/command arg1 arg2 ...
|
||||
## 或 ##
|
||||
var=value /path/to/command arg1 arg2 ...
|
||||
|
||||
例如设置 http_proxy:
|
||||
|
||||
env http_proxy="http://USER:PASSWORD@server1.cyberciti.biz:3128/" /usr/local/bin/wget www.cyberciti.biz
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/linux-unix-temporarily-clearing-environment-variables-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
61
published/201508/20150810 For Linux, Supercomputers R Us.md
Normal file
61
published/201508/20150810 For Linux, Supercomputers R Us.md
Normal file
@ -0,0 +1,61 @@
|
||||
有了 Linux,你就可以搭建自己的超级计算机
|
||||
================================================================================
|
||||
|
||||
> 几乎所有超级计算机上运行的系统都是 Linux,其中包括那些由树莓派(Raspberry Pi)板卡和 PlayStation 3游戏机组成的计算机。
|
||||
|
||||

|
||||
|
||||
*题图来源:By Michel Ngilen,[ CC BY 2.0 ], via Wikimedia Commons*
|
||||
|
||||
超级计算机是一种严肃的工具,做的都是高大上的计算。它们往往从事于严肃的用途,比如原子弹模拟、气候模拟和高等物理学。当然,它们的花费也很高大上。在最新的超级计算机 [Top500][1] 排名中,中国国防科技大学研制的天河 2 号位居第一,而天河 2 号的建造耗资约 3.9 亿美元!
|
||||
|
||||
但是,也有一个超级计算机,是由博伊西州立大学电气和计算机工程系的一名在读博士 Joshua Kiepert [用树莓派构建完成][2]的,其建造成本低于2000美元。
|
||||
|
||||
不,这不是我编造的。它一个真实的超级计算机,由超频到 1GHz 的 [B 型树莓派][3]的 ARM11 处理器与 VideoCore IV GPU 组成。每个都配备了 512MB 的内存、一对 USB 端口和 1 个 10/100 BaseT 以太网端口。
|
||||
|
||||
那么天河 2 号和博伊西州立大学的超级计算机有什么共同点吗?它们都运行 Linux 系统。世界最快的超级计算机[前 500 强中有 486][4] 个也同样运行的是 Linux 系统。这是从 20 多年前就开始的格局。而现在的趋势是超级计算机开始由廉价单元组成,因为 Kiepert 的机器并不是唯一一个无所谓预算的超级计算机。
|
||||
|
||||
麻省大学达特茅斯分校的物理学副教授 Gaurav Khanna 创建了一台超级计算机仅用了[不足 200 台的 PlayStation3 视频游戏机][5]。
|
||||
|
||||
PlayStation 游戏机由一个 3.2 GHz 的基于 PowerPC 的 Power 处理器所驱动。每个都配有 512M 的内存。你现在仍然可以花 200 美元买到一个,尽管索尼将在年底逐步淘汰它们。Khanna 仅用了 16 个 PlayStation 3 构建了他第一台超级计算机,所以你也可以花费不到 4000 美元就拥有你自己的超级计算机。
|
||||
|
||||
这些机器可能是用玩具建成的,但他们不是玩具。Khanna 已经用它做了严肃的天体物理学研究。一个白帽子黑客组织使用了类似的 [PlayStation 3 超级计算机在 2008 年破解了 SSL 的 MD5 哈希算法][6]。
|
||||
|
||||
两年后,美国空军研究实验室研制的 [Condor Cluster,使用了 1760 个索尼的 PlayStation 3 的处理器][7]和168 个通用的图形处理单元。这个低廉的超级计算机,每秒运行约 500 TFLOP ,即每秒可进行 500 万亿次浮点运算。
|
||||
|
||||
其他的一些便宜且适用于构建家庭超级计算机的构件包括,专业并行处理板卡,比如信用卡大小的 [99 美元的 Parallella 板卡][8],以及高端显卡,比如 [Nvidia 的 Titan Z][9] 和 [ AMD 的 FirePro W9100][10]。这些高端板卡的市场零售价约 3000 美元,一些想要一台梦幻般的机器的玩家为此参加了[英特尔极限大师赛:英雄联盟世界锦标赛][11],要是甚至有机会得到了第一名的话,能获得超过 10 万美元奖金。另一方面,一个能够自己提供超过 2.5TFLOPS 计算能力的计算机,对于科学家和研究人员来说,这为他们提供了一个可以拥有自己专属的超级计算机的经济的方法。
|
||||
|
||||
而超级计算机与 Linux 的连接,这一切都始于 1994 年戈达德航天中心的第一个名为 [Beowulf 超级计算机][13]。
|
||||
|
||||
按照我们的标准,Beowulf 不能算是最优越的。但在那个时期,作为第一台自制的超级计算机,它的 16 个英特尔486DX 处理器和 10Mbps 的以太网总线,是个伟大的创举。[Beowulf 是由美国航空航天局的承建商 Don Becker 和 Thomas Sterling 所设计的][14],是第一台“创客”超级计算机。它的“计算部件” 486DX PC,成本仅有几千美元。尽管它的速度只有个位数的 GFLOPS (吉拍,每秒10亿次)浮点运算,[Beowulf][15] 表明了你可以用商用现货(COTS)硬件和 Linux 创建超级计算机。
|
||||
|
||||
我真希望我参与创建了一部分,但是我 1994 年就离开了戈达德,开始了作为一名全职的科技记者的职业生涯。该死。
|
||||
|
||||
但是尽管我只是使用笔记本的记者,我依然能够体会到 COTS 和开源软件是如何永远的改变了超级计算机。我希望现在读这篇文章的你也能。因为,无论是 Raspberry Pi 集群,还是超过 300 万个英特尔的 Ivy Bridge 和 Xeon Phi 芯片的庞然大物,几乎所有当代的超级计算机都可以追溯到 Beowulf。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/2960701/linux/for-linux-supercomputers-r-us.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.top500.org/
|
||||
[2]:http://www.zdnet.com/article/build-your-own-supercomputer-out-of-raspberry-pi-boards/
|
||||
[3]:https://www.raspberrypi.org/products/model-b/
|
||||
[4]:http://www.zdnet.com/article/linux-still-rules-supercomputing/
|
||||
[5]:http://www.nytimes.com/2014/12/23/science/an-economical-way-to-save-progress.html?smid=fb-nytimes&smtyp=cur&bicmp=AD&bicmlukp=WT.mc_id&bicmst=1409232722000&bicmet=1419773522000&_r=4
|
||||
[6]:http://www.computerworld.com/article/2529932/cybercrime-hacking/researchers-hack-verisign-s-ssl-scheme-for-securing-web-sites.html
|
||||
[7]:http://phys.org/news/2010-12-air-playstation-3s-supercomputer.html
|
||||
[8]:http://www.zdnet.com/article/parallella-the-99-linux-supercomputer/
|
||||
[9]:http://blogs.nvidia.com/blog/2014/03/25/titan-z/
|
||||
[10]:http://www.amd.com/en-us/press-releases/Pages/amd-flagship-professional-2014apr7.aspx
|
||||
[11]:http://en.intelextrememasters.com/news/check-out-the-intel-extreme-masters-katowice-prize-money-distribution/
|
||||
|
||||
[13]:http://www.beowulf.org/overview/history.html
|
||||
[14]:http://yclept.ucdavis.edu/Beowulf/aboutbeowulf.html
|
||||
[15]:http://www.beowulf.org/
|
||||
@ -0,0 +1,64 @@
|
||||
在 Linux 中安装 Darkstat:基于网页的流量分析器
|
||||
================================================================================
|
||||
|
||||
Darkstat是一个简易的,基于网页的流量分析程序。它可以在主流的操作系统如Linux、Solaris、MAC、AIX上工作。它以守护进程的形式持续工作在后台,不断地嗅探网络数据,以简单易懂的形式展现在它的网页上。它可以为主机生成流量报告,识别特定的主机上哪些端口是打开的,它兼容IPv6。让我们看下如何在Linux中安装和配置它。
|
||||
|
||||
### 在Linux中安装配置Darkstat ###
|
||||
|
||||
** 在Fedora/CentOS/RHEL中安装Darkstat:**
|
||||
|
||||
要在Fedora/RHEL和CentOS中安装,运行下面的命令。
|
||||
|
||||
sudo yum install darkstat
|
||||
|
||||
**在Ubuntu/Debian中安装Darkstat:**
|
||||
|
||||
运行下面的命令在Ubuntu和Debian中安装。
|
||||
|
||||
sudo apt-get install darkstat
|
||||
|
||||
恭喜你,Darkstat已经在你的Linux中安装了。
|
||||
|
||||
### 配置 Darkstat ###
|
||||
|
||||
为了正确运行这个程序,我们需要执行一些基本的配置。运行下面的命令用gedit编辑器打开/etc/darkstat/init.cfg文件。
|
||||
|
||||
sudo gedit /etc/darkstat/init.cfg
|
||||
|
||||

|
||||
|
||||
*编辑 Darkstat*
|
||||
|
||||
修改START_DARKSTAT这个参数为yes,并在“INTERFACE”中提供你的网络接口。确保取消了DIR、PORT、BINDIP和LOCAL这些参数的注释。如果你希望绑定Darkstat到特定的IP,在BINDIP参数中提供它。
|
||||
|
||||
### 启动Darkstat守护进程 ###
|
||||
|
||||
安装并配置完Darkstat后,运行下面的命令启动它的守护进程。
|
||||
|
||||
sudo /etc/init.d/darkstat start
|
||||
|
||||

|
||||
|
||||
你可以用下面的命令来在开机时启动Darkstat:
|
||||
|
||||
chkconfig darkstat on
|
||||
|
||||
打开浏览器并打开**http://localhost:666**,它会显示Darkstat的网页界面。使用这个工具来分析你的网络流量。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
它是一个占用很少内存的轻量级工具。这个工具流行的原因是简易、易于配置使用。这是一个对系统管理员而言必须拥有的程序。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-darkstat-on-ubuntu-linux/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
@ -0,0 +1,100 @@
|
||||
如何在 Linux 上从 Google Play 商店里下载 apk 文件
|
||||
================================================================================
|
||||
|
||||
假设你想在你的 Android 设备中安装一个 Android 应用,然而由于某些原因,你不能在 Andord 设备上访问 Google Play 商店(LCTT 译注:显然这对于我们来说是常态)。接着你该怎么做呢?在不访问 Google Play 商店的前提下安装应用的一种可能的方法是,使用其他的手段下载该应用的 APK 文件,然后手动地在 Android 设备上 [安装 APK 文件][1]。
|
||||
|
||||
在非 Android 设备如常规的电脑和笔记本电脑上,有着几种方式来从 Google Play 商店下载到官方的 APK 文件。例如,使用浏览器插件(例如,针对 [Chrome][2] 或针对 [Firefox][3] 的插件) 或利用允许你使用浏览器下载 APK 文件的在线的 APK 存档等。假如你不信任这些闭源的插件或第三方的 APK 仓库,这里有另一种手动下载官方 APK 文件的方法,它使用一个名为 [GooglePlayDownloader][4] 的开源 Linux 应用。
|
||||
|
||||
GooglePlayDownloader 是一个基于 Python 的 GUI 应用,它可以让你从 Google Play 商店上搜索和下载 APK 文件。由于它是完全开源的,你可以放心地使用它。在本篇教程中,我将展示如何在 Linux 环境下,使用 GooglePlayDownloader 来从 Google Play 商店下载 APK 文件。
|
||||
|
||||
### Python 需求 ###
|
||||
|
||||
GooglePlayDownloader 需要使用带有 SNI(Server Name Indication 服务器名称指示)的 Python 来支持 SSL/TLS 通信,该功能由 Python 2.7.9 或更高版本引入。这使得一些旧的发行版本如 Debian 7 Wheezy 及早期版本,Ubuntu 14.04 及早期版本或 CentOS/RHEL 7 及早期版本均不能满足该要求。这里假设你已经有了一个带有 Python 2.7.9 或更高版本的发行版本,可以像下面这样接着安装 GooglePlayDownloader。
|
||||
|
||||
### 在 Ubuntu 上安装 GooglePlayDownloader ###
|
||||
|
||||
在 Ubuntu 上,你可以使用官方构建的 deb 包。有一个条件是你可能需要手动地安装一个必需的依赖。
|
||||
|
||||
#### 在 Ubuntu 14.10 上 ####
|
||||
|
||||
下载 [python-ndg-httpsclient][5] deb 软件包,这是一个较旧的 Ubuntu 发行版本中缺失的依赖。同时还要下载 GooglePlayDownloader 的官方 deb 软件包。
|
||||
|
||||
$ wget http://mirrors.kernel.org/ubuntu/pool/main/n/ndg-httpsclient/python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
如下所示,我们将使用 [gdebi 命令][6] 来安装这两个 deb 文件。 gedbi 命令将自动地处理任何其他的依赖。
|
||||
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
#### 在 Ubuntu 15.04 或更新的版本上 ####
|
||||
|
||||
最近的 Ubuntu 发行版本上已经配备了所有需要的依赖,所以安装过程可以如下面那样直接进行。
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
### 在 Debian 上安装 GooglePlayDownloader ###
|
||||
|
||||
由于其 Python 需求, Googleplaydownloader 不能被安装到 Debian 7 Wheezy 或早期版本上,除非你升级了它自备的 Python 版本。
|
||||
|
||||
#### 在 Debian 8 Jessie 及更高版本上: ####
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
### 在 Fedora 上安装 GooglePlayDownloader ###
|
||||
|
||||
由于 GooglePlayDownloader 原本是针对基于 Debian 的发行版本所开发的,假如你想在 Fedora 上使用它,你需要从它的源码开始安装。
|
||||
|
||||
首先安装必需的依赖。
|
||||
|
||||
$ sudo yum install python-pyasn1 wxPython python-ndg_httpsclient protobuf-python python-requests
|
||||
|
||||
然后像下面这样安装它。
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7.orig.tar.gz
|
||||
$ tar -xvf googleplaydownloader_1.7.orig.tar.gz
|
||||
$ cd googleplaydownloader-1.7
|
||||
$ chmod o+r -R .
|
||||
$ sudo python setup.py install
|
||||
$ sudo sh -c "echo 'python /usr/lib/python2.7/site-packages/googleplaydownloader-1.7-py2.7.egg/googleplaydownloader/googleplaydownloader.py' > /usr/bin/googleplaydownloader"
|
||||
|
||||
### 使用 GooglePlayDownloader 从 Google Play 商店下载 APK 文件 ###
|
||||
|
||||
一旦你安装好 GooglePlayDownloader 后,你就可以像下面那样从 Google Play 商店下载 APK 文件。(LCTT 译注:显然你需要让你的 Linux 能爬梯子)
|
||||
|
||||
首先通过输入下面的命令来启动该应用:
|
||||
|
||||
$ googleplaydownloader
|
||||
|
||||

|
||||
|
||||
在搜索栏中,输入你想从 Google Play 商店下载的应用的名称。
|
||||
|
||||
|
||||
|
||||
一旦你从搜索列表中找到了该应用,就选择该应用,接着点击 “下载选定的 APK 文件” 按钮。最后你将在你的家目录中找到下载的 APK 文件。现在,你就可以将下载到的 APK 文件转移到你所选择的 Android 设备上,然后手动安装它。
|
||||
|
||||
希望这篇教程对你有所帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/download-apk-files-google-play-store.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-install-apk-file-on-android-phone-or-tablet.html
|
||||
[2]:https://chrome.google.com/webstore/detail/apk-downloader/cgihflhdpokeobcfimliamffejfnmfii
|
||||
[3]:https://addons.mozilla.org/en-us/firefox/addon/apk-downloader/
|
||||
[4]:http://codingteam.net/project/googleplaydownloader
|
||||
[5]:http://packages.ubuntu.com/vivid/python-ndg-httpsclient
|
||||
[6]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
@ -0,0 +1,138 @@
|
||||
如何在 Ubuntu 15.04 系统中安装 Logwatch
|
||||
================================================================================
|
||||
|
||||
大家好,今天我们会讲述在 Ubuntu 15.04 操作系统上如何安装 Logwatch 软件,它也可以在各种 Linux 系统和类 Unix 系统上安装。Logwatch 是一款可定制的日志分析和日志监控报告生成系统,它可以根据一段时间的日志文件生成您所希望关注的详细报告。它具有易安装、易配置、可审查等特性,同时对其提供的数据的安全性上也有一些保障措施。Logwatch 会扫描重要的操作系统组件像 SSH、网站服务等的日志文件,然后生成用户所关心的有价值的条目汇总报告。
|
||||
|
||||
### 预安装设置 ###
|
||||
|
||||
我们会使用 Ubuntu 15.04 版本的操作系统来部署 Logwatch,所以安装 Logwatch 之前,要确保系统上邮件服务设置是正常可用的。因为它会每天把生成的报告通过日报的形式发送邮件给管理员。您的系统的源库也应该设置可用,以便可以从通用源库来安装 Logwatch。
|
||||
|
||||
然后打开您 ubuntu 系统的终端,用 root 账号登陆,在进入 Logwatch 的安装操作前,先更新您的系统软件包。
|
||||
|
||||
root@ubuntu-15:~# apt-get update
|
||||
|
||||
### 安装 Logwatch ###
|
||||
|
||||
只要你的系统已经更新和已经满足前面说的先决条件,那么就可以在您的机器上输入如下命令来安装 Logwatch。
|
||||
|
||||
root@ubuntu-15:~# apt-get install logwatch
|
||||
|
||||
在安装过程中,一旦您按提示按下“Y”键同意对系统修改的话,Logwatch 将会开始安装一些额外的必须软件包。
|
||||
|
||||
在安装过程中会根据您机器上的邮件服务器设置情况弹出提示对 Postfix 设置的配置界面。在这篇教程中我们使用最容易的 “仅本地(Local only)” 选项。根据您的基础设施情况也可以选择其它的可选项,然后点击“确定”继续。
|
||||
|
||||

|
||||
|
||||
随后您得选择邮件服务器名,这邮件服务器名也会被其它程序使用,所以它应该是一个完全合格域名/全称域名(FQDN)。
|
||||
|
||||

|
||||
|
||||
一旦按下在 postfix 配置提示底端的 “OK”,安装进程就会用 Postfix 的默认配置来安装,并且完成 Logwatch 的整个安装。
|
||||
|
||||

|
||||
|
||||
您可以在终端下发出如下命令来检查 Logwatch 状态,正常情况下它应该是激活状态。
|
||||
|
||||
root@ubuntu-15:~# service postfix status
|
||||
|
||||

|
||||
|
||||
要确认 Logwatch 在默认配置下的安装信息,可以如下示简单的发出“logwatch” 命令。
|
||||
|
||||
root@ubuntu-15:~# logwatch
|
||||
|
||||
上面执行命令的输出就是终端下编制出的报表展现格式。
|
||||
|
||||

|
||||
|
||||
### 配置 Logwatch ###
|
||||
|
||||
在成功安装好 Logwatch 后,我们需要在它的配置文件中做一些修改,配置文件位于如下所示的路径。那么,就让我们用文本编辑器打开它,然后按需要做些变动。
|
||||
|
||||
root@ubuntu-15:~# vim /usr/share/logwatch/default.conf/logwatch.conf
|
||||
|
||||
**输出/格式化选项**
|
||||
|
||||
默认情况下 Logwatch 会以无编码的文本打印到标准输出方式。要改为以邮件为默认方式,需设置“Output = mail”,要改为保存成文件方式,需设置“Output = file”。所以您可以根据您的要求设置其默认配置。
|
||||
|
||||
Output = stdout
|
||||
|
||||
如果使用的是因特网电子邮件配置,要用 Html 格式为默认出格式,需要修改成如下行所示的样子。
|
||||
|
||||
Format = text
|
||||
|
||||
现在增加默认的邮件报告接收人地址,可以是本地账号也可以是完整的邮件地址,需要的都可以在这行上写上
|
||||
|
||||
MailTo = root
|
||||
#MailTo = user@test.com
|
||||
|
||||
默认的邮件发送人可以是本地账号,也可以是您需要使用的其它名字。
|
||||
|
||||
# complete email address.
|
||||
MailFrom = Logwatch
|
||||
|
||||
对这个配置文件保存修改,至于其它的参数就让它保持默认,无需改动。
|
||||
|
||||
**调度任务配置**
|
||||
|
||||
现在编辑在 “daily crons” 目录下的 “00logwatch” 文件来配置从 logwatch 生成的报告需要发送的邮件地址。
|
||||
|
||||
root@ubuntu-15:~# vim /etc/cron.daily/00logwatch
|
||||
|
||||
在这儿您需要作用“--mailto user@test.com”来替换掉“--output mail”,然后保存文件。
|
||||
|
||||

|
||||
|
||||
### 生成报告 ###
|
||||
|
||||
现在我们在终端中执行“logwatch”命令来生成测试报告,生成的结果在终端中会以文本格式显示出来。
|
||||
|
||||
root@ubuntu-15:~#logwatch
|
||||
|
||||
生成的报告开始部分显示的是执行的时间和日期。它包含不同的部分,每个部分以开始标识开始而以结束标识结束,中间显示的是该部分的完整信息。
|
||||
|
||||
这儿显示的是开始的样子,它以显示系统上所有安装的软件包的部分开始,如下所示:
|
||||
|
||||

|
||||
|
||||
接下来的部分显示的日志信息是关于当前系统登录会话、rsyslogs 和当前及最近的 SSH 会话信息。
|
||||
|
||||

|
||||
|
||||
Logwatch 报告最后显示的是安全方面的 sudo 日志及根目录磁盘使用情况,如下示:
|
||||
|
||||

|
||||
|
||||
您也可以打开如下的文件来查看生成的 logwatch 报告电子邮件。
|
||||
|
||||
root@ubuntu-15:~# vim /var/mail/root
|
||||
|
||||
您会看到发送给你配置的用户的所有已生成的邮件及其邮件递交状态。
|
||||
|
||||
### 更多详情 ###
|
||||
|
||||
Logwatch 是一款很不错的工具,可以学习的很多很多,所以如果您对它的日志监控功能很感兴趣的话,也以通过如下所示的简短命令来获得更多帮助。
|
||||
|
||||
root@ubuntu-15:~# man logwatch
|
||||
|
||||
上面的命令包含所有关于 logwatch 的用户手册,所以仔细阅读,要退出手册的话可以简单的输入“q”。
|
||||
|
||||
关于 logwatch 命令的使用,您可以使用如下所示的帮助命令来获得更多的详细信息。
|
||||
|
||||
root@ubuntu-15:~# logwatch --help
|
||||
|
||||
### 结论 ###
|
||||
|
||||
教程结束,您也学会了如何在 Ubuntu 15.04 上对 Logwatch 的安装、配置等全部设置指导。现在您就可以自定义监控您的系统日志,不管是监控所有服务的运行情况还是对特定的服务在指定的时间发送报告都可以。所以,开始使用这工具吧,无论何时有问题或想知道更多关于 logwatch 的使用的都可以给我们留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-use-logwatch-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,70 @@
|
||||
如何在 Linux 终端中知道你的公有 IP
|
||||
================================================================================
|
||||

|
||||
|
||||
公有地址由 InterNIC 分配并由基于类的网络 ID 或基于 CIDR 的地址块构成(被称为 CIDR 块),并保证了在全球互联网中的唯一性。当公有地址被分配时,其路由将会被记录到互联网中的路由器中,这样访问公有地址的流量就能顺利到达。访问目标公有地址的流量可经由互联网抵达。比如,当一个 CIDR 块被以网络 ID 和子网掩码的形式分配给一个组织时,对应的 [网络 ID,子网掩码] 也会同时作为路由储存在互联网中的路由器中。目标是 CIDR 块中的地址的 IP 封包会被导向对应的位置。
|
||||
|
||||
在本文中我将会介绍在几种在 Linux 终端中查看你的公有 IP 地址的方法。这对普通用户来说并无意义,但 Linux 服务器(无GUI或者作为只能使用基本工具的用户登录时)会很有用。无论如何,从 Linux 终端中获取公有 IP 在各种方面都很意义,说不定某一天就能用得着。
|
||||
|
||||
以下是我们主要使用的两个命令,curl 和 wget。你可以换着用。
|
||||
|
||||
### Curl 纯文本格式输出: ###
|
||||
|
||||
curl icanhazip.com
|
||||
curl ifconfig.me
|
||||
curl curlmyip.com
|
||||
curl ip.appspot.com
|
||||
curl ipinfo.io/ip
|
||||
curl ipecho.net/plain
|
||||
curl www.trackip.net/i
|
||||
|
||||
### curl JSON格式输出: ###
|
||||
|
||||
curl ipinfo.io/json
|
||||
curl ifconfig.me/all.json
|
||||
curl www.trackip.net/ip?json (有点丑陋)
|
||||
|
||||
### curl XML格式输出: ###
|
||||
|
||||
curl ifconfig.me/all.xml
|
||||
|
||||
### curl 得到所有IP细节 (挖掘机)###
|
||||
|
||||
curl ifconfig.me/all
|
||||
|
||||
### 使用 DYDNS (当你使用 DYDNS 服务时有用)###
|
||||
|
||||
curl -s 'http://checkip.dyndns.org' | sed 's/.*Current IP Address: \([0-9\.]*\).*/\1/g'
|
||||
curl -s http://checkip.dyndns.org/ | grep -o "[[:digit:].]\+"
|
||||
|
||||
### 使用 Wget 代替 Curl ###
|
||||
|
||||
wget http://ipecho.net/plain -O - -q ; echo
|
||||
wget http://observebox.com/ip -O - -q ; echo
|
||||
|
||||
### 使用 host 和 dig 命令 ###
|
||||
|
||||
如果有的话,你也可以直接使用 host 和 dig 命令。
|
||||
|
||||
host -t a dartsclink.com | sed 's/.*has address //'
|
||||
dig +short myip.opendns.com @resolver1.opendns.com
|
||||
|
||||
### bash 脚本示例: ###
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
PUBLIC_IP=`wget http://ipecho.net/plain -O - -q ; echo`
|
||||
echo $PUBLIC_IP
|
||||
|
||||
简单易用。
|
||||
|
||||
我实际上是在写一个用于记录每日我的路由器中所有 IP 变化并保存到一个文件的脚本。我在搜索过程中找到了这些很好用的命令。希望某天它能帮到其他人。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/14/how-to-get-public-ip-from-linux-terminal/
|
||||
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,63 @@
|
||||
Ubuntu 有望让你安装最新 Nvidia Linux 驱动更简单
|
||||
================================================================================
|
||||

|
||||
|
||||
*Ubuntu 上的游戏玩家在增长——因而需要最新版驱动*
|
||||
|
||||
**在 Ubuntu 上安装上游的 NVIDIA 图形驱动即将变得更加容易。**
|
||||
|
||||
Ubuntu 开发者正在考虑构建一个全新的'官方' PPA,以便为桌面用户分发最新的闭源 NVIDIA 二进制驱动。
|
||||
|
||||
该项改变会让 Ubuntu 游戏玩家收益,并且*不会*给其它人造成 OS 稳定性方面的风险。
|
||||
|
||||
**仅**当用户明确选择它时,新的上游驱动将通过这个新 PPA 安装并更新。其他人将继续得到并使用更近的包含在 Ubuntu 归档中的稳定版 NVIDIA Linux 驱动快照。
|
||||
|
||||
### 为什么需要该项目? ###
|
||||
|
||||
|
||||
|
||||
*Ubuntu 提供了驱动——但是它们不是最新的*
|
||||
|
||||
可以从归档中(使用命令行、synaptic,或者通过额外驱动工具)安装到 Ubuntu 上的闭源 NVIDIA 图形驱动在大多数情况下都能工作得很好,并且可以轻松地处理 Unity 桌面外壳的混染。
|
||||
|
||||
但对于游戏需求而言,那完全是另外一码事儿。
|
||||
|
||||
如果你想要将最高帧率和 HD 纹理从最新流行的 Steam 游戏中压榨出来,你需要最新的二进制驱动文件。
|
||||
|
||||
驱动越新,越可能支持最新的特性和技术,或者带有预先打包的游戏专门的优化和漏洞修复。
|
||||
|
||||
问题在于,在 Ubuntu 上安装最新 Nvidia Linux 驱动不是件容易的事儿,而且也不具安全保证。
|
||||
|
||||
要填补这个空白,许多由热心人维护的第三方 PPA 就出现了。由于许多这些 PPA 也发布了其它实验性的或者前沿软件,它们的使用**并不是毫无风险的**。添加一个前沿的 PPA 通常是搞崩整个系统的最快的方式!
|
||||
|
||||
一个解决方法是,让 Ubuntu 用户安装最新的专有图形驱动以满足对第三方 PPA 的需要,**但是**提供一个安全机制,如果有需要,你可以回滚到稳定版本。
|
||||
|
||||
### ‘对全新驱动的需求难以忽视’ ###
|
||||
|
||||
> '一个让Ubuntu用户安全地获得最新硬件驱动的解决方案出现了。'
|
||||
|
||||
‘在快速发展的市场中,对全新驱动的需求正变得难以忽视,用户将想要最新的上游软件,’卡斯特罗在一封给 Ubuntu 桌面邮件列表的电子邮件中解释道。
|
||||
|
||||
‘[NVIDIA] 可以毫不费力为 [Windows 10] 用户带来了不起的体验。直到我们可以说服 NVIDIA 在 Ubuntu 中做了同样的工作,这样我们就可以搞定这一切了。’
|
||||
|
||||
卡斯特罗的“官方的” NVIDIA PPA 方案就是最实现这一目的的最容易的方式。
|
||||
|
||||
游戏玩家将可以在 Ubuntu 的默认专有软件驱动工具中选择接收来自该 PPA 的新驱动,再也不需要它们从网站或维基页面拷贝并粘贴终端命令了。
|
||||
|
||||
该 PPA 内的驱动将由一个选定的社区成员组成的团队打包并维护,并受惠于一个名为**自动化测试**的半官方方式。
|
||||
|
||||
就像卡斯特罗自己说的那样:'人们想要最新的闪光的东西,而不管他们想要做什么。我们也许也要在其周围放置一个框架,因此人们可以获得他们所想要的,而不必破坏他们的计算机。'
|
||||
|
||||
**你想要使用这个 PPA 吗?你怎样来评估 Ubuntu 上默认 Nvidia 驱动的性能呢?在评论中分享你的想法吧,伙计们!**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ubuntu-easy-install-latest-nvidia-linux-drivers
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
@ -0,0 +1,66 @@
|
||||
Ubuntu NVIDIA 显卡驱动 PPA 已经做好准备
|
||||
================================================================================
|
||||

|
||||
|
||||
加速你的帧率!
|
||||
|
||||
**嘿,各位,稍安勿躁,很快就好。**
|
||||
|
||||
就在提议开发一个[新的 PPA][1] 来给 Ubuntu 用户们提供最新的 NVIDIA 显卡驱动后不久,ubuntu 社区的人们又集结起来了,就是为了这件事。
|
||||
|
||||
顾名思义,‘**Graphics Drivers PPA**’ 包含了最新的 NVIDIA Linux 显卡驱动发布,已经打包好可供用户升级使用,没有让人头疼的二进制运行时文件!
|
||||
|
||||
这个 PPA 被设计用来让玩家们尽可能方便地在 Ubuntu 上运行最新款的游戏。
|
||||
|
||||
#### 万事俱备,只欠东风 ####
|
||||
|
||||
Jorge Castro 开发一个包含 NVIDIA 最新显卡驱动的 PPA 神器的想法得到了 Ubuntu 用户和广大游戏开发者的热烈响应。
|
||||
|
||||
就连那些致力于将“Steam平台”上的知名大作移植到 Linux 上的人们,也给了不少建议。
|
||||
|
||||
Edwin Smith,Feral Interactive 公司(‘Shadow of Mordor’) 的产品总监,对于“让用户更方便地更新驱动”的倡议表示非常欣慰。
|
||||
|
||||
### 如何使用最新的 Nvidia Drivers PPA###
|
||||
|
||||
虽然新的“显卡PPA”已经开发出来,但是现在还远远达不到成熟。开发者们提醒到:
|
||||
|
||||
> “这个 PPA 还处于测试阶段,在你使用它之前最好有一些打包的经验。请大家稍安勿躁,再等几天。”
|
||||
|
||||
将 PPA 试发布给 Ubuntu desktop 邮件列表的 Jorge,也强调说,使用现行的一些 PPA(比如 xorg-edgers)的玩家可能发现不了什么区别(因为现在的驱动只不过是把内容从其他那些现存驱动拷贝过来了)
|
||||
|
||||
“新驱动发布的时候,好戏才会上演呢,”他说。
|
||||
|
||||
截至写作本文时为止,这个 PPA 囊括了从 Ubuntu 12.04.1 到 15.10 各个版本的 Nvidia 驱动。注意这些驱动对所有的发行版都适用。
|
||||
|
||||
> **毫无疑问,除非你清楚自己在干些什么,并且知道如果出了问题应该怎么撤销,否则就不要进行下面的操作。**
|
||||
|
||||
新打开一个终端窗口,运行下面的命令加入 PPA:
|
||||
|
||||
sudo add-apt-repository ppa:graphics-drivers/ppa
|
||||
|
||||
安装或更新到最新的 Nvidia 显卡驱动:
|
||||
|
||||
sudo apt-get update && sudo apt-get install nvidia-355
|
||||
|
||||
记住:如果PPA把你的系统弄崩了,你可得自己去想办法,我们提醒过了哦。(译者注:切记!)
|
||||
|
||||
如果想要撤销对PPA的改变,使用 `ppa-purge` 命令。
|
||||
|
||||
有什么意见,想法,或者指正,就在下面的评论栏里写下来吧。(我没有 NVIDIA 的硬件来为我自己验证上面的这些东西,如果你可以验证的话,那就太感谢了。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ubuntu-nvidia-graphics-drivers-ppa-is-ready-for-action
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://linux.cn/article-6030-1.html
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,158 @@
|
||||
shellinabox:一款使用 AJAX 的基于 Web 的终端模拟器
|
||||
================================================================================
|
||||
|
||||
### shellinabox简介 ###
|
||||
|
||||
通常情况下,我们在访问任何远程服务器时,会使用常见的通信工具如OpenSSH和Putty等。但是,有可能我们在防火墙后面不能使用这些工具访问远程系统,或者防火墙只允许HTTPS流量才能通过。不用担心!即使你在这样的防火墙后面,我们依然有办法来访问你的远程系统。而且,你不需要安装任何类似于OpenSSH或Putty的通讯工具。你只需要有一个支持JavaScript和CSS的现代浏览器,并且你不用安装任何插件或第三方应用软件。
|
||||
|
||||
这个 **Shell In A Box**,发音是**shellinabox**,是由**Markus Gutschke**开发的一款自由开源的基于Web的Ajax的终端模拟器。它使用AJAX技术,通过Web浏览器提供了类似原生的 Shell 的外观和感受。
|
||||
|
||||
这个**shellinaboxd**守护进程实现了一个Web服务器,能够侦听指定的端口。其Web服务器可以发布一个或多个服务,这些服务显示在用 AJAX Web 应用实现的VT100模拟器中。默认情况下,端口为4200。你可以更改默认端口到任意选择的任意端口号。在你的远程服务器安装shellinabox以后,如果你想从本地系统接入,打开Web浏览器并导航到:**http://IP-Address:4200/**。输入你的用户名和密码,然后就可以开始使用你远程系统的Shell。看起来很有趣,不是吗?确实 有趣!
|
||||
|
||||
**免责声明**:
|
||||
|
||||
shellinabox不是SSH客户端或任何安全软件。它仅仅是一个应用程序,能够通过Web浏览器模拟一个远程系统的Shell。同时,它和SSH没有任何关系。这不是可靠的安全地远程控制您的系统的方式。这只是迄今为止最简单的方法之一。无论如何,你都不应该在任何公共网络上运行它。
|
||||
|
||||
### 安装shellinabox ###
|
||||
|
||||
#### 在Debian / Ubuntu系统上: ####
|
||||
|
||||
shellinabox在默认库是可用的。所以,你可以使用命令来安装它:
|
||||
|
||||
$ sudo apt-get install shellinabox
|
||||
|
||||
#### 在RHEL / CentOS系统上: ####
|
||||
|
||||
首先,使用命令安装EPEL仓库:
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
然后,使用命令安装shellinabox:
|
||||
|
||||
# yum install shellinabox
|
||||
|
||||
完成!
|
||||
|
||||
### 配置shellinabox ###
|
||||
|
||||
正如我之前提到的,shellinabox侦听端口默认为**4200**。你可以将此端口更改为任意数字,以防别人猜到。
|
||||
|
||||
在Debian/Ubuntu系统上shellinabox配置文件的默认位置是**/etc/default/shellinabox**。在RHEL/CentOS/Fedora上,默认位置在**/etc/sysconfig/shellinaboxd**。
|
||||
|
||||
如果要更改默认端口,
|
||||
|
||||
在Debian / Ubuntu:
|
||||
|
||||
$ sudo vi /etc/default/shellinabox
|
||||
|
||||
在RHEL / CentOS / Fedora:
|
||||
|
||||
# vi /etc/sysconfig/shellinaboxd
|
||||
|
||||
更改你的端口到任意数字。因为我在本地网络上测试它,所以我使用默认值。
|
||||
|
||||
# Shell in a box daemon configuration
|
||||
# For details see shellinaboxd man page
|
||||
|
||||
# Basic options
|
||||
USER=shellinabox
|
||||
GROUP=shellinabox
|
||||
CERTDIR=/var/lib/shellinabox
|
||||
PORT=4200
|
||||
OPTS="--disable-ssl-menu -s /:LOGIN"
|
||||
|
||||
# Additional examples with custom options:
|
||||
|
||||
# Fancy configuration with right-click menu choice for black-on-white:
|
||||
# OPTS="--user-css Normal:+black-on-white.css,Reverse:-white-on-black.css --disable-ssl-menu -s /:LOGIN"
|
||||
|
||||
# Simple configuration for running it as an SSH console with SSL disabled:
|
||||
# OPTS="-t -s /:SSH:host.example.com"
|
||||
|
||||
重启shelinabox服务。
|
||||
|
||||
**在Debian/Ubuntu:**
|
||||
|
||||
$ sudo systemctl restart shellinabox
|
||||
|
||||
或者
|
||||
|
||||
$ sudo service shellinabox restart
|
||||
|
||||
在RHEL/CentOS系统,运行下面的命令能在每次重启时自动启动shellinaboxd服务
|
||||
|
||||
# systemctl enable shellinaboxd
|
||||
|
||||
或者
|
||||
|
||||
# chkconfig shellinaboxd on
|
||||
|
||||
如果你正在运行一个防火墙,记得要打开端口**4200**或任何你指定的端口。
|
||||
|
||||
例如,在RHEL/CentOS系统,你可以如下图所示允许端口。
|
||||
|
||||
# firewall-cmd --permanent --add-port=4200/tcp
|
||||
|
||||
----------
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
### 使用 ###
|
||||
|
||||
现在,在你的客户端系统,打开Web浏览器并导航到:**https://ip-address-of-remote-servers:4200**。
|
||||
|
||||
**注意**:如果你改变了端口,请填写修改后的端口。
|
||||
|
||||
你会得到一个证书问题的警告信息。接受该证书并继续。
|
||||
|
||||

|
||||
|
||||
输入远程系统的用户名和密码。现在,您就能够从浏览器本身访问远程系统的外壳。
|
||||
|
||||

|
||||
|
||||
右键点击你浏览器的空白位置。你可以得到一些有很有用的额外菜单选项。
|
||||
|
||||

|
||||
|
||||
从现在开始,你可以通过本地系统的Web浏览器在你的远程服务器随意操作。
|
||||
|
||||
当你完成工作时,记得输入`exit`退出。
|
||||
|
||||
当再次连接到远程系统时,单击**连接**按钮,然后输入远程服务器的用户名和密码。
|
||||
|
||||

|
||||
|
||||
如果想了解shellinabox更多细节,在你的终端键入下面的命令:
|
||||
|
||||
# man shellinabox
|
||||
|
||||
或者
|
||||
|
||||
# shellinaboxd -help
|
||||
|
||||
同时,参考[shellinabox 在wiki页面的介绍][1],来了解shellinabox的综合使用细节。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
正如我之前提到的,如果你在服务器运行在防火墙后面,那么基于web的SSH工具是非常有用的。有许多基于web的SSH工具,但shellinabox是非常简单而有用的工具,可以从的网络上的任何地方,模拟一个远程系统的Shell。因为它是基于浏览器的,所以你可以从任何设备访问您的远程服务器,只要你有一个支持JavaScript和CSS的浏览器。
|
||||
|
||||
就这些啦。祝你今天有个好心情!
|
||||
|
||||
#### 参考链接: ####
|
||||
|
||||
- [shellinabox website][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/shellinabox-a-web-based-ajax-terminal-emulator/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://code.google.com/p/shellinabox/wiki/shellinaboxd_man
|
||||
[2]:https://code.google.com/p/shellinabox/
|
||||
@ -0,0 +1,115 @@
|
||||
Ubuntu 下五个最好的 BT 客户端
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
在寻找 **Ubuntu 中最好的 BT 客户端**吗?事实上,Linux 桌面平台中有许多 BT 客户端,但是它们中的哪些才是**最好的 Ubuntu 客户端**呢?
|
||||
|
||||
我将会列出 Linux 上最好的五个 BT 客户端,它们都拥有着体积轻盈,功能强大的特点,而且还有令人印象深刻的用户界面。自然,易于安装和使用也是特性之一。
|
||||
|
||||
### Ubuntu 下最好的 BT 客户端 ###
|
||||
|
||||
考虑到 Ubuntu 默认安装了 Transmission,所以我将会从这个列表中排除了 Transmission。但是这并不意味着 Transmission 没有资格出现在这个列表中,事实上,Transmission 是一个非常好的BT客户端,这也正是它被包括 Ubuntu 在内的多个发行版默认安装的原因。
|
||||
|
||||
### Deluge ###
|
||||
|
||||

|
||||
|
||||
[Deluge][1] 被 Lifehacker 评选为 Linux 下最好的 BT 客户端,这说明了 Deluge 是多么的有用。而且,并不仅仅只有 Lifehacker 是 Deluge 的粉丝,纵观多个论坛,你都会发现不少 Deluge 的忠实拥趸。
|
||||
|
||||
快速,时尚而直观的界面使得 Deluge 成为 Linux 用户的挚爱。
|
||||
|
||||
Deluge 可在 Ubuntu 的仓库中获取,你能够在 Ubuntu 软件中心中安装它,或者使用下面的命令:
|
||||
|
||||
sudo apt-get install deluge
|
||||
|
||||
### qBittorrent ###
|
||||
|
||||

|
||||
|
||||
正如它的名字所暗示的,[qBittorrent][2] 是著名的 [Bittorrent][3] 应用的 Qt 版本。如果曾经使用过它,你将会看到和 Windows 下的 Bittorrent 相似的界面。同样轻巧并且有着 BT 客户端的所有标准功能, qBittorrent 也可以在 Ubuntu 的默认仓库中找到。
|
||||
|
||||
它可以通过 Ubuntu 软件仓库安装,或者使用下面的命令:
|
||||
|
||||
sudo apt-get install qbittorrent
|
||||
|
||||
|
||||
### Tixati ###
|
||||
|
||||

|
||||
|
||||
[Tixati][4] 是另一个不错的 Ubuntu 下的 BT 客户端。它有着一个默认的黑暗主题,尽管很多人喜欢,但是我例外。它拥有着一切你能在 BT 客户端中找到的功能。
|
||||
|
||||
除此之外,它还有着数据分析的额外功能。你可以在美观的图表中分析流量以及其它数据。
|
||||
|
||||
- [下载 Tixati][5]
|
||||
|
||||
|
||||
|
||||
### Vuze ###
|
||||
|
||||

|
||||
|
||||
[Vuze][6] 是许多 Linux 以及 Windows 用户最喜欢的 BT 客户端。除了标准的功能,你可以直接在应用程序中搜索种子,也可以订阅系列片源,这样就无需再去寻找新的片源了,因为你可以在侧边栏中的订阅看到它们。
|
||||
|
||||
它还配备了一个视频播放器,可以播放带有字幕的高清视频等等。但是我不认为你会用它来代替那些更好的视频播放器,比如 VLC。
|
||||
|
||||
Vuze 可以通过 Ubuntu 软件中心安装或者使用下列命令:
|
||||
|
||||
sudo apt-get install vuze
|
||||
|
||||
|
||||
|
||||
### Frostwire ###
|
||||
|
||||

|
||||
|
||||
[Frostwire][7] 是一个你应该试一下的应用。它不仅仅是一个简单的 BT 客户端,它还可以应用于安卓,你可以用它通过 Wifi 来共享文件。
|
||||
|
||||
你可以在应用中搜索种子并且播放他们。除了下载文件,它还可以浏览本地的影音文件,并且将它们有条理的呈现在播放器中。这同样适用于安卓版本。
|
||||
|
||||
还有一个特点是:Frostwire 提供了独立音乐人的[合法音乐下载][13]。你可以下载并且欣赏它们,免费而且合法。
|
||||
|
||||
- [下载 Frostwire][8]
|
||||
|
||||
|
||||
|
||||
### 荣誉奖 ###
|
||||
|
||||
在 Windows 中,uTorrent(发音:mu torrent)是我最喜欢的 BT 应用。尽管 uTorrent 可以在 Linux 下运行,但是我还是特意忽略了它。因为在 Linux 下使用 uTorrent 不仅困难,而且无法获得完整的应用体验(运行在浏览器中)。
|
||||
|
||||
可以[在这里][9]阅读 Ubuntu下uTorrent 的安装教程。
|
||||
|
||||
#### 快速提示: ####
|
||||
|
||||
大多数情况下,BT 应用不会默认自动启动。如果想改变这一行为,请阅读[如何管理 Ubuntu 下的自启动程序][10]来学习。
|
||||
|
||||
### 你最喜欢的是什么? ###
|
||||
|
||||
这些是我对于 Ubuntu 下最好的 BT 客户端的意见。你最喜欢的是什么呢?请发表评论。也可以查看与本主题相关的[Ubuntu 最好的下载管理器][11]。如果使用 Popcorn Time,试试 [Popcorn Time 技巧][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-torrent-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Xuanwo](https://github.com/Xuanwo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://deluge-torrent.org/
|
||||
[2]:http://www.qbittorrent.org/
|
||||
[3]:http://www.bittorrent.com/
|
||||
[4]:http://www.tixati.com/
|
||||
[5]:http://www.tixati.com/download/
|
||||
[6]:http://www.vuze.com/
|
||||
[7]:http://www.frostwire.com/
|
||||
[8]:http://www.frostwire.com/downloads
|
||||
[9]:http://sysads.co.uk/2014/05/install-utorrent-3-3-ubuntu-14-04-13-10/
|
||||
[10]:http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
[11]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[12]:http://itsfoss.com/popcorn-time-tips/
|
||||
[13]:http://www.frostclick.com/wp/
|
||||
|
||||
@ -0,0 +1,100 @@
|
||||
Linux中通过命令行监控股票报价
|
||||
================================================================================
|
||||
|
||||
如果你是那些股票投资者或者交易者中的一员,那么监控证券市场将是你的日常工作之一。最有可能的是你会使用一个在线交易平台,这个平台有着一些漂亮的实时图表和全部种类的高级股票分析和交易工具。虽然这种复杂的市场研究工具是任何严肃的证券投资者了解市场的必备工具,但是监控最新的股票报价来构建有利可图的投资组合仍然有很长一段路要走。
|
||||
|
||||
如果你是一位长久坐在终端前的全职系统管理员,而证券交易又成了你日常生活中的业余兴趣,那么一个简单地显示实时股票报价的命令行工具会是给你的恩赐。
|
||||
|
||||
在本教程中,让我来介绍一个灵巧而简洁的命令行工具,它可以让你在Linux上从命令行监控股票报价。
|
||||
|
||||
这个工具叫做[Mop][1]。它是用GO编写的一个轻量级命令行工具,可以极其方便地跟踪来自美国市场的最新股票报价。你可以很轻松地自定义要监控的证券列表,它会在一个基于ncurses的便于阅读的界面显示最新的股票报价。
|
||||
|
||||
**注意**:Mop是通过雅虎金融API获取最新的股票报价的。你必须意识到,他们的的股票报价已知会有15分钟的延时。所以,如果你正在寻找0延时的“实时”股票报价,那么Mop就不是你的菜了。这种“现场”股票报价订阅通常可以通过向一些不开放的私有接口付费获取。了解这些之后,让我们来看看怎样在Linux环境下使用Mop吧。
|
||||
|
||||
### 安装 Mop 到 Linux ###
|
||||
|
||||
由于Mop是用Go实现的,你首先需要安装Go语言。如果你还没有安装Go,请参照[此指南][2]将Go安装到你的Linux平台中。请确保按指南中所讲的设置GOPATH环境变量。
|
||||
|
||||
安装完Go后,继续像下面这样安装Mop。
|
||||
|
||||
**Debian,Ubuntu 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
$ go get github.com/michaeldv/mop
|
||||
$ cd $GOPATH/src/github.com/michaeldv/mop
|
||||
$ make install
|
||||
|
||||
**Fedora,CentOS,RHEL**
|
||||
|
||||
$ sudo yum install git
|
||||
$ go get github.com/michaeldv/mop
|
||||
$ cd $GOPATH/src/github.com/michaeldv/mop
|
||||
$ make install
|
||||
|
||||
上述命令将安装Mop到$GOPATH/bin。
|
||||
|
||||
现在,编辑你的.bashrc,将$GOPATH/bin写到你的PATH变量中。
|
||||
|
||||
export PATH="$PATH:$GOPATH/bin"
|
||||
|
||||
----------
|
||||
|
||||
$ source ~/.bashrc
|
||||
|
||||
### 使用Mop来通过命令行监控股票报价 ###
|
||||
|
||||
要启动Mop,只需运行名为cmd的命令(LCTT 译注:这名字实在是……)。
|
||||
|
||||
$ cmd
|
||||
|
||||
首次启动,你将看到一些Mop预配置的证券行情自动收录器。
|
||||
|
||||

|
||||
|
||||
报价显示了像最新价格、交易百分比、每日低/高、52周低/高、股息以及年收益率等信息。Mop从[CNN][3]获取市场总览信息,从[雅虎金融][4]获得个股报价,股票报价信息它自己会在终端内周期性更新。
|
||||
|
||||
### 自定义Mop中的股票报价 ###
|
||||
|
||||
让我们来试试自定义证券列表吧。对此,Mop提供了易于记忆的快捷键:‘+’用于添加一只新股,而‘-’则用于移除一只股票。
|
||||
|
||||
要添加新股,请按‘+’,然后输入股票代码来添加(如MSFT)。你可以通过输入一个由逗号分隔的交易代码列表来一次添加多个股票(如”MSFT, AMZN, TSLA”)。
|
||||
|
||||

|
||||
|
||||
从列表中移除股票可以类似地按‘-’来完成。
|
||||
|
||||
### 对Mop中的股票报价排序 ###
|
||||
|
||||
你可以基于任何栏目对股票报价列表进行排序。要排序,请按‘o’,然后使用左/右键来选择排序的基准栏目。当选定了一个特定栏目后,你可以按回车来对列表进行升序排序,或者降序排序。
|
||||
|
||||
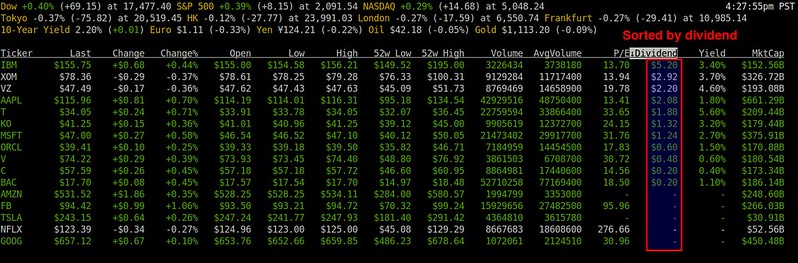
|
||||
|
||||
通过按‘g’,你可以根据股票当日的涨或跌来分组。涨的情况以绿色表示,跌的情况以白色表示。
|
||||
|
||||

|
||||
|
||||
如果你想要访问帮助页,只需要按‘?’。
|
||||
|
||||

|
||||
|
||||
### 尾声 ###
|
||||
|
||||
正如你所见,Mop是一个轻量级的,然而极其方便的证券监控工具。当然,你可以很轻松地从其它别的什么地方,从在线站点,你的智能手机等等访问到股票报价信息。然而,如果你在整天使用终端环境,Mop可以很容易地适应你的工作环境,希望没有让你过多地从你的工作流程中分心。只要让它在你其中一个终端中运行并保持市场日期持续更新,那就够了。
|
||||
|
||||
交易快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/monitor-stock-quotes-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://github.com/michaeldv/mop
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:http://money.cnn.com/data/markets/
|
||||
[4]:http://finance.yahoo.com/
|
||||
@ -0,0 +1,52 @@
|
||||
Linux无极限:IBM发布LinuxONE大型机
|
||||
================================================================================
|
||||

|
||||
|
||||
LinuxONE Emperor MainframeGood的Ubuntu服务器团队今天发布了一条消息关于[IBM发布了LinuxONE][1],一种只支持Linux的大型机,也可以运行Ubuntu。
|
||||
|
||||
IBM发布的最大的LinuxONE系统称作‘Emperor’,它可以扩展到8000台虚拟机或者上万台容器- 对任何一台Linux系统都可能的记录。
|
||||
|
||||
LinuxONE被IBM称作‘游戏改变者’,它‘释放了Linux的商业潜力’。
|
||||
|
||||
IBM和Canonical正在一起协作为LinuxONE和其他IBM z系统创建Ubuntu发行版。Ubuntu将会在IBM z加入RedHat和SUSE作为首屈一指的Linux发行版。
|
||||
|
||||
随着IBM ‘Emperor’发布的还有LinuxONE Rockhopper,一个为中等规模商业或者组织小一点的大型机。
|
||||
|
||||
IBM是大型机中的领导者,并且占有大型机市场中90%的份额。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/2ABfNrWs-ns?feature=oembed"></iframe>
|
||||
|
||||
### 大型机用于什么? ###
|
||||
|
||||
你阅读这篇文章所使用的电脑在一个‘大铁块’一样的大型机前会显得很矮小。它们是巨大的,笨重的机柜里面充满了高端的组件、自己设计的技术和眼花缭乱的大量存储(就是数据存储,没有空间放钢笔和尺子)。
|
||||
|
||||
大型机被大型机构和商业用来处理和存储大量数据,通过统计来处理数据和处理大规模的事务处理。
|
||||
|
||||
### ‘世界最快的处理器’ ###
|
||||
|
||||
IBM已经与Canonical Ltd组成了团队来在LinuxONE和其他IBM z系统中使用Ubuntu。
|
||||
|
||||
LinuxONE Emperor使用IBM z13处理器。发布于一月的芯片声称是时间上最快的微处理器。它可以在几毫秒内响应事务。
|
||||
|
||||
但是也可以很好地处理高容量的移动事务,z13中的LinuxONE系统也是一个理想的云系统。
|
||||
|
||||
每个核心可以处理超过50个虚拟服务器,总共可以超过8000台虚拟服务器么,这使它以更便宜,更环保、更高效的方式扩展到云。
|
||||
|
||||
**在阅读这篇文章时你不必是一个CIO或者大型机巡查员。LinuxONE提供的可能性足够清晰。**
|
||||
|
||||
来源: [Reuters (h/t @popey)][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www-03.ibm.com/systems/z/announcement.html
|
||||
[2]:http://www.reuters.com/article/2015/08/17/us-ibm-linuxone-idUSKCN0QM09P20150817
|
||||
@ -0,0 +1,53 @@
|
||||
Ubuntu Linux 来到 IBM 大型机
|
||||
================================================================================
|
||||
最终来到了。在 [LinuxCon][1] 上,IBM 和 [Canonical][2] 宣布 [Ubuntu Linux][3] 不久就会运行在 IBM 大型机 [LinuxONE][1] 上,这是一种只支持 Linux 的大型机,现在也可以运行 Ubuntu 了。
|
||||
|
||||
这个 IBM 发布的最大的 LinuxONE 系统称作‘Emperor’,它可以扩展到 8000 台虚拟机或者上万台容器,这可能是单独一台 Linux 系统的记录。
|
||||
|
||||
LinuxONE 被 IBM 称作‘游戏改变者’,它‘释放了 Linux 的商业潜力’。
|
||||
|
||||

|
||||
|
||||
*很快你就可以在你的 IBM 大型机上安装 Ubuntu Linux orange 啦*
|
||||
|
||||
根据 IBM z 系统的总经理 Ross Mauri 以及 Canonical 和 Ubuntu 的创立者 Mark Shuttleworth 所言,这是因为客户需要。十多年来,IBM 大型机只支持 [红帽企业版 Linux (RHEL)][4] 和 [SUSE Linux 企业版 (SLES)][5] Linux 发行版。
|
||||
|
||||
随着 Ubuntu 越来越成熟,更多的企业把它作为企业级 Linux,也有更多的人希望它能运行在 IBM 大型机上。尤其是银行希望如此。不久,金融 CIO 们就可以满足他们的需求啦。
|
||||
|
||||
在一次采访中 Shuttleworth 说 Ubuntu Linux 在 2016 年 4 月下一次长期支持版 Ubuntu 16.04 中就可以用到大型机上。而在 2014 年底 Canonical 和 IBM 将 [Ubuntu 带到 IBM 的 POWER][6] 架构中就迈出了第一步。
|
||||
|
||||
在那之前,Canonical 和 IBM 差点签署了协议 [在 2011 年实现 Ubuntu 支持 IBM 大型机][7],但最终也没有实现。这次,真的发生了。
|
||||
|
||||
Canonical 的 CEO Jane Silber 解释说 “[把 Ubuntu 平台支持扩大][8]到 [IBM z 系统][9] 是因为认识到需要 z 系统运行其业务的客户数量以及混合云市场的成熟。”
|
||||
|
||||
**Silber 还说:**
|
||||
|
||||
> 由于 z 系统的支持,包括 [LinuxONE][10],Canonical 和 IBM 的关系进一步加深,构建了对 POWER 架构的支持和 OpenPOWER 生态系统。正如 Power 系统的客户受益于 Ubuntu 的可扩展能力,我们的敏捷开发过程也使得类似 POWER8 CAPI (Coherent Accelerator Processor Interface,一致性加速器接口)得到了市场支持,z 系统的客户也可以期望技术进步能快速部署,并从 [Juju][11] 和我们的其它云工具中获益,使得能快速向端用户提供新服务。另外,我们和 IBM 的合作包括实现扩展部署很多 IBM 和 Juju 的软件解决方案。大型机客户对于能通过 Juju 将丰富‘迷人的’ IBM 解决方案、其它软件供应商的产品、开源解决方案部署到大型机上感到高兴。
|
||||
|
||||
Shuttleworth 期望 z 系统上的 Ubuntu 能取得巨大成功。它发展很快,由于对 OpenStack 的支持,希望有卓越云性能的人会感到非常高兴。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/ubuntu-linux-is-coming-to-the-mainframe/
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a],[Joey-Elijah Sneddon][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh),[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[2]:http://www.canonical.com/
|
||||
[3]:http://www.ubuntu.comj/
|
||||
[4]:http://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[5]:https://www.suse.com/products/server/
|
||||
[6]:http://www.zdnet.com/article/ibm-doubles-down-on-linux/
|
||||
[7]:http://www.zdnet.com/article/mainframe-ubuntu-linux/
|
||||
[8]:https://insights.ubuntu.com/2015/08/17/ibm-and-canonical-plan-ubuntu-support-on-ibm-z-systems-mainframe/
|
||||
[9]:http://www-03.ibm.com/systems/uk/z/
|
||||
[10]:http://www.zdnet.com/article/linuxone-ibms-new-linux-mainframes/
|
||||
[11]:https://jujucharms.com/
|
||||
@ -0,0 +1,129 @@
|
||||
如何在 Linux 中安装 Visual Studio Code
|
||||
================================================================================
|
||||
大家好,今天我们一起来学习如何在 Linux 发行版中安装 Visual Studio Code。Visual Studio Code 是基于 Electron 优化代码后的编辑器,后者是基于 Chromium 的一款软件,用于为桌面系统发布 io.js 应用。Visual Studio Code 是微软开发的支持包括 Linux 在内的全平台代码编辑器和文本编辑器。它是免费软件但不开源,在专有软件许可条款下发布。它是可以用于我们日常使用的超级强大和快速的代码编辑器。Visual Studio Code 有很多很酷的功能,例如导航、智能感知支持、语法高亮、括号匹配、自动补全、代码片段、支持自定义键盘绑定、并且支持多种语言,例如 Python、C++、Jade、PHP、XML、Batch、F#、DockerFile、Coffee Script、Java、HandleBars、 R、 Objective-C、 PowerShell、 Luna、 Visual Basic、 .Net、 Asp.Net、 C#、 JSON、 Node.js、 Javascript、 HTML、 CSS、 Less、 Sass 和 Markdown。Visual Studio Code 集成了包管理器、库、构建,以及其它通用任务,以加速日常的工作流。Visual Studio Code 中最受欢迎的是它的调试功能,它包括流式支持 Node.js 的预览调试。
|
||||
|
||||
注意:请注意 Visual Studio Code 只支持 64 位的 Linux 发行版。
|
||||
|
||||
下面是在所有 Linux 发行版中安装 Visual Studio Code 的几个简单步骤。
|
||||
|
||||
### 1. 下载 Visual Studio Code 软件包 ###
|
||||
|
||||
首先,我们要从微软服务器中下载 64 位 Linux 操作系统的 Visual Studio Code 安装包,链接是 [http://go.microsoft.com/fwlink/?LinkID=534108][1]。这里我们使用 wget 下载并保存到 tmp/VSCODE 目录。
|
||||
|
||||
# mkdir /tmp/vscode; cd /tmp/vscode/
|
||||
# wget https://az764295.vo.msecnd.net/public/0.3.0/VSCode-linux-x64.zip
|
||||
|
||||
--2015-06-24 06:02:54-- https://az764295.vo.msecnd.net/public/0.3.0/VSCode-linux-x64.zip
|
||||
Resolving az764295.vo.msecnd.net (az764295.vo.msecnd.net)... 93.184.215.200, 2606:2800:11f:179a:1972:2405:35b:459
|
||||
Connecting to az764295.vo.msecnd.net (az764295.vo.msecnd.net)|93.184.215.200|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 64992671 (62M) [application/octet-stream]
|
||||
Saving to: ‘VSCode-linux-x64.zip’
|
||||
100%[================================================>] 64,992,671 14.9MB/s in 4.1s
|
||||
2015-06-24 06:02:58 (15.0 MB/s) - ‘VSCode-linux-x64.zip’ saved [64992671/64992671]
|
||||
|
||||
### 2. 提取软件包 ###
|
||||
|
||||
现在,下载好 Visual Studio Code 的 zip 压缩包之后,我们打算使用 unzip 命令解压它。我们要在终端或者控制台中运行以下命令。
|
||||
|
||||
# unzip /tmp/vscode/VSCode-linux-x64.zip -d /opt/
|
||||
|
||||
注意:如果我们还没有安装 unzip,我们首先需要通过软件包管理器安装它。如果你运行的是 Ubuntu,使用 apt-get,如果运行的是 Fedora、CentOS、可以用 dnf 或 yum 安装它。
|
||||
|
||||
### 3. 运行 Visual Studio Code ###
|
||||
|
||||
展开软件包之后,我们可以直接运行一个名为 Code 的文件启动 Visual Studio Code。
|
||||
|
||||
# sudo chmod +x /opt/VSCode-linux-x64/Code
|
||||
# sudo /opt/VSCode-linux-x64/Code
|
||||
|
||||
如果我们想通过终端在任何地方启动 Code,我们就需要创建 /opt/vscode/Code 的一个链接 /usr/local/bin/code。
|
||||
|
||||
# ln -s /opt/VSCode-linux-x64/Code /usr/local/bin/code
|
||||
|
||||
现在,我们就可以在终端中运行以下命令启动 Visual Studio Code 了。
|
||||
|
||||
# code .
|
||||
|
||||
### 4. 创建桌面启动 ###
|
||||
|
||||
下一步,成功展开 Visual Studio Code 软件包之后,我们打算创建桌面启动程序,使得根据不同桌面环境能够从启动器、菜单、桌面启动它。首先我们要复制一个图标文件到 /usr/share/icons/ 目录。
|
||||
|
||||
# cp /opt/VSCode-linux-x64/resources/app/vso.png /usr/share/icons/
|
||||
|
||||
然后,我们创建一个桌面启动程序,文件扩展名为 .desktop。这里我们使用喜欢的文本编辑器在 /tmp/VSCODE/ 目录中创建名为 visualstudiocode.desktop 的文件。
|
||||
|
||||
# vi /tmp/vscode/visualstudiocode.desktop
|
||||
|
||||
然后,粘贴下面的行到那个文件中。
|
||||
|
||||
[Desktop Entry]
|
||||
Name=Visual Studio Code
|
||||
Comment=Multi-platform code editor for Linux
|
||||
Exec=/opt/VSCode-linux-x64/Code
|
||||
Icon=/usr/share/icons/vso.png
|
||||
Type=Application
|
||||
StartupNotify=true
|
||||
Categories=TextEditor;Development;Utility;
|
||||
MimeType=text/plain;
|
||||
|
||||
创建完桌面文件之后,我们会复制这个桌面文件到 /usr/share/applications/ 目录,这样启动器和菜单中就可以单击启动 Visual Studio Code 了。
|
||||
|
||||
# cp /tmp/vscode/visualstudiocode.desktop /usr/share/applications/
|
||||
|
||||
完成之后,我们可以在启动器或者菜单中启动它。
|
||||
|
||||

|
||||
|
||||
### 在 Ubuntu 中 Visual Studio Code ###
|
||||
|
||||
要在 Ubuntu 14.04/14.10/15.04 Linux 发行版中安装 Visual Studio Code,我们可以使用 Ubuntu Make 0.7。这是在 ubuntu 中安装 code 最简单的方法,因为我们只需要执行几个命令。首先,我们要在我们的 ubuntu linux 发行版中安装 Ubuntu Make 0.7。要安装它,首先要为它添加 PPA。可以通过运行下面命令完成。
|
||||
|
||||
# add-apt-repository ppa:ubuntu-desktop/ubuntu-make
|
||||
|
||||
This ppa proposes package backport of Ubuntu make for supported releases.
|
||||
More info: https://launchpad.net/~ubuntu-desktop/+archive/ubuntu/ubuntu-make
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmpv0vf24us/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmpv0vf24us/pubring.gpg' created
|
||||
gpg: requesting key A1231595 from hkp server keyserver.ubuntu.com
|
||||
gpg: /tmp/tmpv0vf24us/trustdb.gpg: trustdb created
|
||||
gpg: key A1231595: public key "Launchpad PPA for Ubuntu Desktop" imported
|
||||
gpg: no ultimately trusted keys found
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
然后,更新本地库索引并安装 ubuntu-make。
|
||||
|
||||
# apt-get update
|
||||
# apt-get install ubuntu-make
|
||||
|
||||
在我们的 ubuntu 操作系统上安装完 Ubuntu Make 之后,我们可以在一个终端中运行以下命令来安装 Code。
|
||||
|
||||
# umake web visual-studio-code
|
||||
|
||||

|
||||
|
||||
运行完上面的命令之后,会要求我们输入想要的安装路径。然后,会请求我们允许在 ubuntu 系统中安装 Visual Studio Code。我们输入“a”(接受)。输入完后,它会在 ubuntu 机器上下载和安装 Code。最后,我们可以在启动器或者菜单中启动它。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们已经成功地在 Linux 发行版上安装了 Visual Studio Code。在所有 linux 发行版上安装 Visual Studio Code 都和上面介绍的相似,我们也可以使用 umake 在 Ubuntu 发行版中安装。Umake 是一个安装开发工具,IDEs 和语言的流行工具。我们可以用 Umake 轻松地安装 Android Studios、Eclipse 和很多其它流行 IDE。Visual Studio Code 是基于 Github 上一个叫 [Electron][2] 的项目,它是 [Atom.io][3] 编辑器的一部分。它有很多 Atom.io 编辑器没有的改进功能。当前 Visual Studio Code 只支持 64 位 linux 操作系统平台。
|
||||
|
||||
如果你有任何疑问、建议或者反馈,请在下面的评论框中留言以便我们改进和更新我们的内容。非常感谢!Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-visual-studio-code-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://go.microsoft.com/fwlink/?LinkID=534108
|
||||
[2]:https://github.com/atom/electron
|
||||
[3]:https://github.com/atom/atom
|
||||
@ -0,0 +1,49 @@
|
||||
Linux有问必答:如何检查MariaDB服务端版本
|
||||
================================================================================
|
||||
> **提问**: 我使用的是一台运行MariaDB的VPS。我该如何检查MariaDB服务端的版本?
|
||||
|
||||
有时候你需要知道你的数据库版本,比如当你升级你数据库或对已知缺陷打补丁时。这里有几种方法找出MariaDB版本的方法。
|
||||
|
||||
### 方法一 ###
|
||||
|
||||
第一种找出版本的方法是登录MariaDB服务器,登录之后,你会看到一些MariaDB的版本信息。
|
||||
|
||||

|
||||
|
||||
另一种方法是在登录MariaDB后出现的命令行中输入‘status’命令。输出会显示服务器的版本还有协议版本。
|
||||
|
||||
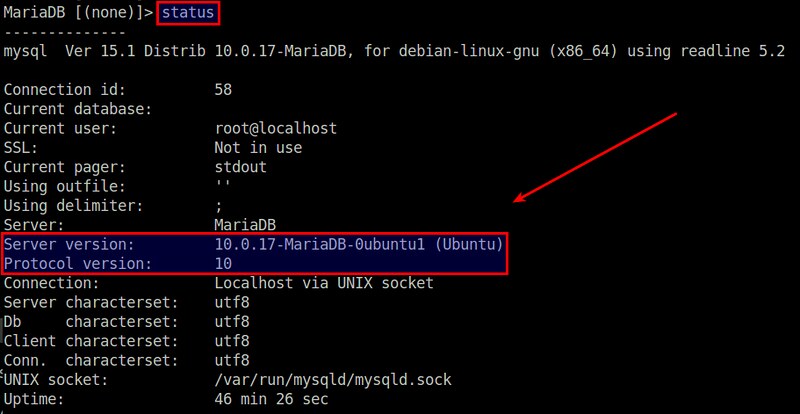
|
||||
|
||||
### 方法二 ###
|
||||
|
||||
如果你不能访问MariaDB服务器,那么你就不能用第一种方法。这种情况下你可以根据MariaDB的安装包的版本来推测。这种方法只有在MariaDB通过包管理器安装的才有用。
|
||||
|
||||
你可以用下面的方法检查MariaDB的安装包。
|
||||
|
||||
#### Debian、Ubuntu或者Linux Mint: ####
|
||||
|
||||
$ dpkg -l | grep mariadb
|
||||
|
||||
下面的输出说明MariaDB的版本是10.0.17。
|
||||
|
||||

|
||||
|
||||
#### Fedora、CentOS或者 RHEL: ####
|
||||
|
||||
$ rpm -qa | grep mariadb
|
||||
|
||||
下面的输出说明安装的版本是5.5.41。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-mariadb-server-version.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,74 @@
|
||||
如何在 Docker 容器中运行 Kali Linux 2.0
|
||||
================================================================================
|
||||
### 介绍 ###
|
||||
|
||||
Kali Linux 是一个对于安全测试人员和白帽的一个知名操作系统。它带有大量安全相关的程序,这让它很容易用于渗透测试。最近,[Kali Linux 2.0][1] 发布了,它被认为是这个操作系统最重要的一次发布。另一方面,Docker 技术由于它的可扩展性和易用性让它变得很流行。Dokcer 让你非常容易地将你的程序带给你的用户。好消息是你可以通过 Docker 运行Kali Linux 了,让我们看看该怎么做 :)
|
||||
|
||||
### 在 Docker 中运行 Kali Linux 2.0 ###
|
||||
|
||||
**相关提示**
|
||||
|
||||
> 如果你还没有在系统中安装docker,你可以运行下面的命令:
|
||||
|
||||
> **对于 Ubuntu/Linux Mint/Debian:**
|
||||
|
||||
> sudo apt-get install docker
|
||||
|
||||
> **对于 Fedora/RHEL/CentOS:**
|
||||
|
||||
> sudo yum install docker
|
||||
|
||||
> **对于 Fedora 22:**
|
||||
|
||||
> dnf install docker
|
||||
|
||||
> 你可以运行下面的命令来启动docker:
|
||||
|
||||
> sudo docker start
|
||||
|
||||
首先运行下面的命令确保 Docker 服务运行正常:
|
||||
|
||||
sudo docker status
|
||||
|
||||
Kali Linux 的开发团队已将 Kali Linux 的 docker 镜像上传了,只需要输入下面的命令来下载镜像。
|
||||
|
||||
docker pull kalilinux/kali-linux-docker
|
||||
|
||||

|
||||
|
||||
下载完成后,运行下面的命令来找出你下载的 docker 镜像的 ID。
|
||||
|
||||
docker images
|
||||
|
||||

|
||||
|
||||
现在运行下面的命令来从镜像文件启动 kali linux docker 容器(这里需用正确的镜像ID替换)。
|
||||
|
||||
docker run -i -t 198cd6df71ab3 /bin/bash
|
||||
|
||||
它会立刻启动容器并且让你登录到该操作系统,你现在可以在 Kaili Linux 中工作了。
|
||||
|
||||

|
||||
|
||||
你可以在容器外面通过下面的命令来验证容器已经启动/运行中了:
|
||||
|
||||
docker ps
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
Docker 是一种最聪明的用来部署和分发包的方式。Kali Linux docker 镜像非常容易上手,也不会消耗很大的硬盘空间,这样也可以很容易地在任何安装了 docker 的操作系统上测试这个很棒的发行版了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/run-kali-linux-2-0-in-docker-container/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
[1]:https://linux.cn/article-6005-1.html
|
||||
@ -0,0 +1,160 @@
|
||||
Alien 魔法:RPM 和 DEB 互转
|
||||
================================================================================
|
||||
|
||||
正如我确信,你们一定知道Linux下的多种软件安装方式:使用发行版所提供的包管理系统([aptitude,yum,或者zypper][1],还可以举很多例子),从源码编译(尽管现在很少用了,但在Linux发展早期却是唯一可用的方法),或者使用各自的低级工具dpkg用于.deb,以及rpm用于.rpm,预编译包,如此这般。
|
||||
|
||||

|
||||
|
||||
*使用Alien将RPM转换成DEB以及将DEB转换成RPM*
|
||||
|
||||
在本文中,我们将为你介绍alien,一个用于在各种不同的Linux包格式相互转换的工具,其最常见的用法是将.rpm转换成.deb(或者反过来)。
|
||||
|
||||
如果你需要某个特定类型的包,而你只能找到其它格式的包的时候,该工具迟早能派得上用场——即使是其作者不再维护,并且在其网站声明:alien将可能永远维持在实验状态。
|
||||
|
||||
例如,有一次,我正查找一个用于喷墨打印机的.deb驱动,但是却没有找到——生产厂家只提供.rpm包,这时候alien拯救了我。我安装了alien,将包进行转换,不久之后我就可以使用我的打印机了,没有任何问题。
|
||||
|
||||
即便如此,我们也必须澄清一下,这个工具不应当用来转换重要的系统文件和库,因为它们在不同的发行版中有不同的配置。只有在前面说的那种情况下所建议的安装方法根本不适合时,alien才能作为最后手段使用。
|
||||
|
||||
最后一项要点是,我们必须注意,虽然我们在本文中使用CentOS和Debian,除了前两个发行版及其各自的家族体系外,据我们所知,alien可以工作在Slackware中,甚至Solaris中。
|
||||
|
||||
### 步骤1:安装Alien及其依赖包 ###
|
||||
|
||||
要安装alien到CentOS/RHEL 7中,你需要启用EPEL和Nux Dextop(是的,是Dextop——不是Desktop)仓库,顺序如下:
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
启用Nux Dextop仓库的包的当前最新版本是0.5(2015年8月10日发布),在安装之前你可以查看[http://li.nux.ro/download/nux/dextop/el7/x86_64/][2]上是否有更新的版本。
|
||||
|
||||
# rpm --import http://li.nux.ro/download/nux/RPM-GPG-KEY-nux.ro
|
||||
# rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm
|
||||
|
||||
然后再做,
|
||||
|
||||
# yum update && yum install alien
|
||||
|
||||
在Fedora中,你只需要运行上面的命令即可。
|
||||
|
||||
在Debian及其衍生版中,只需要:
|
||||
|
||||
# aptitude install alien
|
||||
|
||||
### 步骤2:将.deb转换成.rpm包 ###
|
||||
|
||||
对于本次测试,我们选择了date工具,它提供了一系列日期和时间工具用于处理大量金融数据。我们将下载.deb包到我们的CentOS 7机器中,将它转换成.rpm并安装:
|
||||
|
||||
|
||||
|
||||
检查CentOS版本
|
||||
|
||||
# cat /etc/centos-release
|
||||
# wget http://ftp.us.debian.org/debian/pool/main/d/dateutils/dateutils_0.3.1-1.1_amd64.deb
|
||||
# alien --to-rpm --scripts dateutils_0.3.1-1.1_amd64.deb
|
||||
|
||||

|
||||
|
||||
*在Linux中将.deb转换成.rpm*
|
||||
|
||||
**重要**:(请注意alien是怎样来增加目标包的次版本号的。如果你想要无视该行为,请添加-keep-version标识)。
|
||||
|
||||
如果我们尝试马上安装该包,我们将碰到些许问题:
|
||||
|
||||
# rpm -Uvh dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||

|
||||
|
||||
*安装RPM包*
|
||||
|
||||
要解决该问题,我们需要启用epel-testing仓库,然后安装rpmbuild工具来编辑该包的配置以重建包:
|
||||
|
||||
# yum --enablerepo=epel-testing install rpmrebuild
|
||||
|
||||
然后运行,
|
||||
|
||||
# rpmrebuild -pe dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||
它会打开你的默认文本编辑器。请转到`%files`章节并删除涉及到错误信息中提到的目录的行,然后保存文件并退出:
|
||||
|
||||
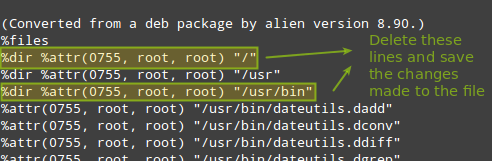
|
||||
|
||||
*转换.deb到Alien版*
|
||||
|
||||
但你退出该文件后,将提示你继续去重构。如果你选择“Y”,该文件会重构到指定的目录(与当前工作目录不同):
|
||||
|
||||
# rpmrebuild –pe dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||

|
||||
|
||||
*构建RPM包*
|
||||
|
||||
现在你可以像以往一样继续来安装包并验证:
|
||||
|
||||
# rpm -Uvh /root/rpmbuild/RPMS/x86_64/dateutils-0.3.1-2.1.x86_64.rpm
|
||||
# rpm -qa | grep dateutils
|
||||
|
||||

|
||||
|
||||
*安装构建RPM包*
|
||||
|
||||
最后,你可以列出date工具包含的各个工具,也可以查看各自的手册页:
|
||||
|
||||
# ls -l /usr/bin | grep dateutils
|
||||
|
||||
|
||||
|
||||
*验证安装的RPM包*
|
||||
|
||||
### 步骤3:将.rpm转换成.deb包 ###
|
||||
|
||||
在本节中,我们将演示如何将.rpm转换成.deb。在一台32位的Debian Wheezy机器中,让我们从CentOS 6操作系统仓库中下载用于zsh shell的.rpm包。注意,该shell在Debian及其衍生版的默认安装中是不可用的。
|
||||
|
||||
# cat /etc/shells
|
||||
# lsb_release -a | tail -n 4
|
||||
|
||||
|
||||
|
||||
*检查Shell和Debian操作系统版本*
|
||||
|
||||
# wget http://mirror.centos.org/centos/6/os/i386/Packages/zsh-4.3.11-4.el6.centos.i686.rpm
|
||||
# alien --to-deb --scripts zsh-4.3.11-4.el6.centos.i686.rpm
|
||||
|
||||
你可以安全地无视关于签名丢失的信息:
|
||||
|
||||

|
||||
|
||||
*将.rpm转换成.deb包*
|
||||
|
||||
过了一会儿后,.deb包应该已经生成,并可以安装了:
|
||||
|
||||
# dpkg -i zsh_4.3.11-5_i386.deb
|
||||
|
||||

|
||||
|
||||
*安装RPM转换来的Deb包*
|
||||
|
||||
安装完后,你看看可以zsh是否添加到了合法shell列表中:
|
||||
|
||||
# cat /etc/shells
|
||||
|
||||
|
||||
|
||||
*确认安装的Zsh包*
|
||||
|
||||
### 小结 ###
|
||||
|
||||
在本文中,我们已经解释了如何将.rpm转换成.deb及其反向转换,这可以作为这类程序不能从仓库中或者作为可分发源代码获得的最后安装手段。你一定想要将本文添加到书签中,因为我们都需要alien。
|
||||
|
||||
请自由分享你关于本文的想法,写到下面的表单中吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/convert-from-rpm-to-deb-and-deb-to-rpm-package-using-alien/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/linux-package-management/
|
||||
[2]:http://li.nux.ro/download/nux/dextop/el7/x86_64/
|
||||
@ -0,0 +1,169 @@
|
||||
Bash 下如何逐行读取一个文件
|
||||
================================================================================
|
||||
|
||||
在 Linux 或类 UNIX 系统下如何使用 KSH 或 BASH shell 逐行读取一个文件?
|
||||
|
||||
在 Linux、OSX、 *BSD 或者类 Unix 系统下你可以使用 while..do..done 的 bash 循环来逐行读取一个文件。
|
||||
|
||||
###在 Bash Unix 或者 Linux shell 中逐行读取一个文件的语法
|
||||
|
||||
对于 bash、ksh、 zsh 和其他的 shells 语法如下
|
||||
|
||||
while read -r line; do COMMAND; done < input.file
|
||||
|
||||
通过 -r 选项传递给 read 命令以防止阻止解释其中的反斜杠转义符。
|
||||
|
||||
在 read 命令之前添加 `IFS=` 选项,来防止首尾的空白字符被去掉。
|
||||
|
||||
while IFS= read -r line; do COMMAND_on $line; done < input.file
|
||||
|
||||
这是更适合人类阅读的语法:
|
||||
|
||||
#!/bin/bash
|
||||
input="/path/to/txt/file"
|
||||
while IFS= read -r var
|
||||
do
|
||||
echo "$var"
|
||||
done < "$input"
|
||||
|
||||
**示例**
|
||||
|
||||
下面是一些例子:
|
||||
|
||||
#!/bin/ksh
|
||||
file="/home/vivek/data.txt"
|
||||
while IFS= read line
|
||||
do
|
||||
# display $line or do somthing with $line
|
||||
echo "$line"
|
||||
done <"$file"
|
||||
|
||||
在 bash shell 中相同的例子:
|
||||
|
||||
#!/bin/bash
|
||||
file="/home/vivek/data.txt"
|
||||
while IFS= read -r line
|
||||
do
|
||||
# display $line or do somthing with $line
|
||||
printf '%s\n' "$line"
|
||||
done <"$file"
|
||||
|
||||
你还可以看看这个更好的:
|
||||
|
||||
#!/bin/bash
|
||||
file="/etc/passwd"
|
||||
while IFS=: read -r f1 f2 f3 f4 f5 f6 f7
|
||||
do
|
||||
# display fields using f1, f2,..,f7
|
||||
printf 'Username: %s, Shell: %s, Home Dir: %s\n' "$f1" "$f7" "$f6"
|
||||
done <"$file"
|
||||
|
||||
示例输出:
|
||||
|
||||
|
||||
|
||||
*图01:Bash 脚本:读取文件并逐行输出文件*
|
||||
|
||||
###Bash 脚本:逐行读取文本文件并创建为 pdf 文件
|
||||
|
||||
我的输入文件如下(faq.txt):
|
||||
|
||||
4|http://www.cyberciti.biz/faq/mysql-user-creation/|Mysql User Creation: Setting Up a New MySQL User Account
|
||||
4096|http://www.cyberciti.biz/faq/ksh-korn-shell/|What is UNIX / Linux Korn Shell?
|
||||
4101|http://www.cyberciti.biz/faq/what-is-posix-shell/|What Is POSIX Shell?
|
||||
17267|http://www.cyberciti.biz/faq/linux-check-battery-status/|Linux: Check Battery Status Command
|
||||
17245|http://www.cyberciti.biz/faq/restarting-ntp-service-on-linux/|Linux Restart NTPD Service Command
|
||||
17183|http://www.cyberciti.biz/faq/ubuntu-linux-determine-your-ip-address/|Ubuntu Linux: Determine Your IP Address
|
||||
17172|http://www.cyberciti.biz/faq/determine-ip-address-of-linux-server/|HowTo: Determine an IP Address My Linux Server
|
||||
16510|http://www.cyberciti.biz/faq/unix-linux-restart-php-service-command/|Linux / Unix: Restart PHP Service Command
|
||||
8292|http://www.cyberciti.biz/faq/mounting-harddisks-in-freebsd-with-mount-command/|FreeBSD: Mount Hard Drive / Disk Command
|
||||
8190|http://www.cyberciti.biz/faq/rebooting-solaris-unix-server/|Reboot a Solaris UNIX System
|
||||
|
||||
我的 bash 脚本:
|
||||
|
||||
#!/bin/bash
|
||||
# Usage: Create pdf files from input (wrapper script)
|
||||
# Author: Vivek Gite <Www.cyberciti.biz> under GPL v2.x+
|
||||
#---------------------------------------------------------
|
||||
|
||||
#Input file
|
||||
_db="/tmp/wordpress/faq.txt"
|
||||
|
||||
#Output location
|
||||
o="/var/www/prviate/pdf/faq"
|
||||
|
||||
_writer="~/bin/py/pdfwriter.py"
|
||||
|
||||
# If file exists
|
||||
if [[ -f "$_db" ]]
|
||||
then
|
||||
# read it
|
||||
while IFS='|' read -r pdfid pdfurl pdftitle
|
||||
do
|
||||
local pdf="$o/$pdfid.pdf"
|
||||
echo "Creating $pdf file ..."
|
||||
#Genrate pdf file
|
||||
$_writer --quiet --footer-spacing 2 \
|
||||
--footer-left "nixCraft is GIT UL++++ W+++ C++++ M+ e+++ d-" \
|
||||
--footer-right "Page [page] of [toPage]" --footer-line \
|
||||
--footer-font-size 7 --print-media-type "$pdfurl" "$pdf"
|
||||
done <"$_db"
|
||||
fi
|
||||
|
||||
###技巧:从 bash 变量中读取
|
||||
|
||||
让我们看看如何在 Debian 或者 Ubuntu Linux 下列出所有安装过的 php 包,请输入:
|
||||
|
||||
# 我将输出内容赋值到一个变量名为 $list中 #
|
||||
|
||||
list=$(dpkg --list php\* | awk '/ii/{print $2}')
|
||||
printf '%s\n' "$list"
|
||||
|
||||
示例输出:
|
||||
|
||||
php-pear
|
||||
php5-cli
|
||||
php5-common
|
||||
php5-fpm
|
||||
php5-gd
|
||||
php5-json
|
||||
php5-memcache
|
||||
php5-mysql
|
||||
php5-readline
|
||||
php5-suhosin-extension
|
||||
|
||||
你现在可以从 $list 中看到它们,并安装这些包:
|
||||
|
||||
#!/bin/bash
|
||||
# BASH can iterate over $list variable using a "here string" #
|
||||
while IFS= read -r pkg
|
||||
do
|
||||
printf 'Installing php package %s...\n' "$pkg"
|
||||
/usr/bin/apt-get -qq install $pkg
|
||||
done <<< "$list"
|
||||
printf '*** Do not forget to run php5enmod and restart the server (httpd or php5-fpm) ***\n'
|
||||
|
||||
示例输出:
|
||||
|
||||
Installing php package php-pear...
|
||||
Installing php package php5-cli...
|
||||
Installing php package php5-common...
|
||||
Installing php package php5-fpm...
|
||||
Installing php package php5-gd...
|
||||
Installing php package php5-json...
|
||||
Installing php package php5-memcache...
|
||||
Installing php package php5-mysql...
|
||||
Installing php package php5-readline...
|
||||
Installing php package php5-suhosin-extension...
|
||||
|
||||
*** Do not forget to run php5enmod and restart the server (httpd or php5-fpm) ***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/unix-howto-read-line-by-line-from-file/
|
||||
|
||||
作者: VIVEK GIT
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,174 @@
|
||||
使用 dd 命令进行硬盘 I/O 性能检测
|
||||
================================================================================
|
||||
|
||||
如何使用dd命令测试我的硬盘性能?如何在linux操作系统下检测硬盘的读写速度?
|
||||
|
||||
你可以使用以下命令在一个Linux或类Unix操作系统上进行简单的I/O性能测试。
|
||||
|
||||
- **dd命令** :它被用来在Linux和类Unix系统下对硬盘设备进行写性能的检测。
|
||||
- **hparm命令**:它用来在基于 Linux 的系统上获取或设置硬盘参数,包括测试读性能以及缓存性能等。
|
||||
|
||||
在这篇指南中,你将会学到如何使用dd命令来测试硬盘性能。
|
||||
|
||||
### 使用dd命令来监控硬盘的读写性能:###
|
||||
|
||||
- 打开shell终端。
|
||||
- 或者通过ssh登录到远程服务器。
|
||||
- 使用dd命令来测量服务器的吞吐率(写速度) `dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync`
|
||||
- 使用dd命令测量服务器延迟 `dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync`
|
||||
|
||||
####理解dd命令的选项###
|
||||
|
||||
在这个例子当中,我将使用搭载Ubuntu Linux 14.04 LTS系统的RAID-10(配有SAS SSD的Adaptec 5405Z)服务器阵列来运行。基本语法为:
|
||||
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
## GNU dd语法 ##
|
||||
dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync
|
||||
##另外一种GNU dd的语法 ##
|
||||
dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync
|
||||
|
||||
输出样例:
|
||||
|
||||

|
||||
|
||||
*图01: 使用dd命令获取的服务器吞吐率*
|
||||
|
||||
请各位注意在这个实验中,我们写入一个G的数据,可以发现,服务器的吞吐率是135 MB/s,这其中
|
||||
|
||||
- `if=/dev/zero` (if=/dev/input.file) :用来设置dd命令读取的输入文件名。
|
||||
- `of=/tmp/test1.img` (of=/path/to/output.file):dd命令将input.file写入的输出文件的名字。
|
||||
- `bs=1G` (bs=block-size) :设置dd命令读取的块的大小。例子中为1个G。
|
||||
- `count=1` (count=number-of-blocks):dd命令读取的块的个数。
|
||||
- `oflag=dsync` (oflag=dsync) :使用同步I/O。不要省略这个选项。这个选项能够帮助你去除caching的影响,以便呈现给你精准的结果。
|
||||
- `conv=fdatasyn`: 这个选项和`oflag=dsync`含义一样。
|
||||
|
||||
在下面这个例子中,一共写了1000次,每次写入512字节来获得RAID10服务器的延迟时间:
|
||||
|
||||
dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync
|
||||
|
||||
输出样例:
|
||||
|
||||
1000+0 records in
|
||||
1000+0 records out
|
||||
512000 bytes (512 kB) copied, 0.60362 s, 848 kB/s
|
||||
|
||||
请注意服务器的吞吐率以及延迟时间也取决于服务器/应用的负载。所以我推荐你在一个刚刚重启过并且处于峰值时间的服务器上来运行测试,以便得到更加准确的度量。现在你可以在你的所有设备上互相比较这些测试结果了。
|
||||
|
||||
###为什么服务器的吞吐率和延迟时间都这么差?###
|
||||
|
||||
低的数值并不意味着你在使用差劲的硬件。可能是硬件 RAID10的控制器缓存导致的。
|
||||
|
||||
使用hdparm命令来查看硬盘缓存的读速度。
|
||||
|
||||
我建议你运行下面的命令2-3次来对设备读性能进行检测,以作为参照和相互比较:
|
||||
|
||||
### 有缓存的硬盘读性能测试——/dev/sda ###
|
||||
hdparm -t /dev/sda1
|
||||
## 或者 ##
|
||||
hdparm -t /dev/sda
|
||||
|
||||
然后运行下面这个命令2-3次来对缓存的读性能进行对照性检测:
|
||||
|
||||
## Cache读基准——/dev/sda ###
|
||||
hdparm -T /dev/sda1
|
||||
## 或者 ##
|
||||
hdparm -T /dev/sda
|
||||
|
||||
或者干脆把两个测试结合起来:
|
||||
|
||||
hdparm -Tt /dev/sda
|
||||
|
||||
输出样例:
|
||||
|
||||
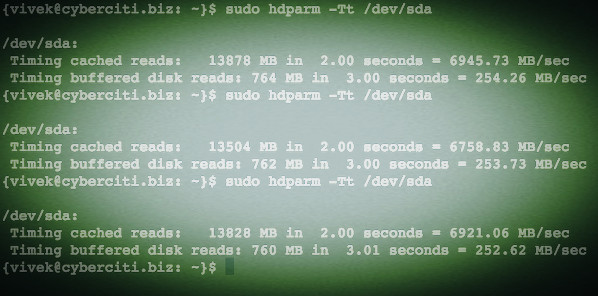
|
||||
|
||||
*图02: 检测硬盘读入以及缓存性能的Linux hdparm命令*
|
||||
|
||||
请再次注意,由于文件文件操作的缓存属性,你将总是会看到很高的读速度。
|
||||
|
||||
###使用dd命令来测试读取速度###
|
||||
|
||||
为了获得精确的读测试数据,首先在测试前运行下列命令,来将缓存设置为无效:
|
||||
|
||||
flush
|
||||
echo 3 | sudo tee /proc/sys/vm/drop_caches
|
||||
time time dd if=/path/to/bigfile of=/dev/null bs=8k
|
||||
|
||||
####笔记本上的示例####
|
||||
|
||||
运行下列命令:
|
||||
|
||||
### 带有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
###使cache失效###
|
||||
hdparm -W0 /dev/sda
|
||||
|
||||
###没有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
####苹果OS X Unix(Macbook pro)的例子####
|
||||
|
||||
GNU dd has many more options but OS X/BSD and Unix-like dd command need to run as follows to test real disk I/O and not memory add sync option as follows:
|
||||
|
||||
GNU dd命令有其他许多选项,但是在 OS X/BSD 以及类Unix中, dd命令需要像下面那样执行来检测去除掉内存地址同步的硬盘真实I/O性能:
|
||||
|
||||
## 运行这个命令2-3次来获得更好地结果 ###
|
||||
time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync"
|
||||
|
||||
输出样例:
|
||||
|
||||
1024+0 records in
|
||||
1024+0 records out
|
||||
104857600 bytes transferred in 0.165040 secs (635346520 bytes/sec)
|
||||
|
||||
real 0m0.241s
|
||||
user 0m0.004s
|
||||
sys 0m0.113s
|
||||
|
||||
本人Macbook Pro的写速度是635346520字节(635.347MB/s)。
|
||||
|
||||
###不喜欢用命令行?\^_^###
|
||||
|
||||
你可以在Linux或基于Unix的系统上使用disk utility(gnome-disk-utility)这款工具来得到同样的信息。下面的那个图就是在我的Fedora Linux v22 VM上截取的。
|
||||
|
||||
####图形化方法####
|
||||
|
||||
点击“Activites”或者“Super”按键来在桌面和Activites视图间切换。输入“Disks”
|
||||
|
||||
|
||||
|
||||
*图03: 打开Gnome硬盘工具*
|
||||
|
||||
在左边的面板上选择你的硬盘,点击configure按钮,然后点击“Benchmark partition”:
|
||||
|
||||
|
||||
|
||||
*图04: 评测硬盘/分区*
|
||||
|
||||
最后,点击“Start Benchmark...”按钮(你可能需要输入管理员用户名和密码):
|
||||
|
||||
|
||||
|
||||
*图05: 最终的评测结果*
|
||||
|
||||
如果你要问,我推荐使用哪种命令和方法?
|
||||
|
||||
- 我推荐在所有的类Unix系统上使用dd命令(`time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync`)
|
||||
- 如果你在使用GNU/Linux,使用dd命令 (`dd if=/dev/zero of=/tmp/testALT.img bs=1G count=1 conv=fdatasync`)
|
||||
- 确保你每次使用时,都调整了count以及bs参数以获得更好的结果。
|
||||
- GUI方法只适合桌面系统为Gnome2或Gnome3的Linux/Unix笔记本用户。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,156 @@
|
||||
在 Linux 下使用 RAID(一):介绍 RAID 的级别和概念
|
||||
================================================================================
|
||||
|
||||
RAID 的意思是廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks),但现在它被称为独立磁盘冗余阵列(Redundant Array of Independent Drives)。早先一个容量很小的磁盘都是非常昂贵的,但是现在我们可以很便宜的买到一个更大的磁盘。Raid 是一系列放在一起,成为一个逻辑卷的磁盘集合。
|
||||
|
||||

|
||||
|
||||
*在 Linux 中理解 RAID 设置*
|
||||
|
||||
RAID 包含一组或者一个集合甚至一个阵列。使用一组磁盘结合驱动器组成 RAID 阵列或 RAID 集。将至少两个磁盘连接到一个 RAID 控制器,而成为一个逻辑卷,也可以将多个驱动器放在一个组中。一组磁盘只能使用一个 RAID 级别。使用 RAID 可以提高服务器的性能。不同 RAID 的级别,性能会有所不同。它通过容错和高可用性来保存我们的数据。
|
||||
|
||||
这个系列被命名为“在 Linux 下使用 RAID”,分为9个部分,包括以下主题:
|
||||
|
||||
- 第1部分:介绍 RAID 的级别和概念
|
||||
- 第2部分:在Linux中如何设置 RAID0(条带化)
|
||||
- 第3部分:在Linux中如何设置 RAID1(镜像化)
|
||||
- 第4部分:在Linux中如何设置 RAID5(条带化与分布式奇偶校验)
|
||||
- 第5部分:在Linux中如何设置 RAID6(条带双分布式奇偶校验)
|
||||
- 第6部分:在Linux中设置 RAID 10 或1 + 0(嵌套)
|
||||
- 第7部分:增加现有的 RAID 阵列并删除损坏的磁盘
|
||||
- 第8部分:在 RAID 中恢复(重建)损坏的驱动器
|
||||
- 第9部分:在 Linux 中管理 RAID
|
||||
|
||||
这是9篇系列教程的第1部分,在这里我们将介绍 RAID 的概念和 RAID 级别,这是在 Linux 中构建 RAID 需要理解的。
|
||||
|
||||
### 软件 RAID 和硬件 RAID ###
|
||||
|
||||
软件 RAID 的性能较低,因为其使用主机的资源。 需要加载 RAID 软件以从软件 RAID 卷中读取数据。在加载 RAID 软件前,操作系统需要引导起来才能加载 RAID 软件。在软件 RAID 中无需物理硬件。零成本投资。
|
||||
|
||||
硬件 RAID 的性能较高。他们采用 PCI Express 卡物理地提供有专用的 RAID 控制器。它不会使用主机资源。他们有 NVRAM 用于缓存的读取和写入。缓存用于 RAID 重建时,即使出现电源故障,它会使用后备的电池电源保持缓存。对于大规模使用是非常昂贵的投资。
|
||||
|
||||
硬件 RAID 卡如下所示:
|
||||
|
||||

|
||||
|
||||
*硬件 RAID*
|
||||
|
||||
#### 重要的 RAID 概念 ####
|
||||
|
||||
- **校验**方式用在 RAID 重建中从校验所保存的信息中重新生成丢失的内容。 RAID 5,RAID 6 基于校验。
|
||||
- **条带化**是将切片数据随机存储到多个磁盘。它不会在单个磁盘中保存完整的数据。如果我们使用2个磁盘,则每个磁盘存储我们的一半数据。
|
||||
- **镜像**被用于 RAID 1 和 RAID 10。镜像会自动备份数据。在 RAID 1 中,它会保存相同的内容到其他盘上。
|
||||
- **热备份**只是我们的服务器上的一个备用驱动器,它可以自动更换发生故障的驱动器。在我们的阵列中,如果任何一个驱动器损坏,热备份驱动器会自动用于重建 RAID。
|
||||
- **块**是 RAID 控制器每次读写数据时的最小单位,最小 4KB。通过定义块大小,我们可以增加 I/O 性能。
|
||||
|
||||
RAID有不同的级别。在这里,我们仅列出在真实环境下的使用最多的 RAID 级别。
|
||||
|
||||
- RAID0 = 条带化
|
||||
- RAID1 = 镜像
|
||||
- RAID5 = 单磁盘分布式奇偶校验
|
||||
- RAID6 = 双磁盘分布式奇偶校验
|
||||
- RAID10 = 镜像 + 条带。(嵌套RAID)
|
||||
|
||||
RAID 在大多数 Linux 发行版上使用名为 mdadm 的软件包进行管理。让我们先对每个 RAID 级别认识一下。
|
||||
|
||||
#### RAID 0 / 条带化 ####
|
||||
|
||||
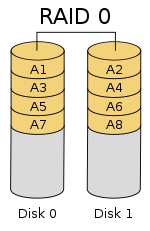
|
||||
|
||||
条带化有很好的性能。在 RAID 0(条带化)中数据将使用切片的方式被写入到磁盘。一半的内容放在一个磁盘上,另一半内容将被写入到另一个磁盘。
|
||||
|
||||
假设我们有2个磁盘驱动器,例如,如果我们将数据“TECMINT”写到逻辑卷中,“T”将被保存在第一盘中,“E”将保存在第二盘,'C'将被保存在第一盘,“M”将保存在第二盘,它会一直继续此循环过程。(LCTT 译注:实际上不可能按字节切片,是按数据块切片的。)
|
||||
|
||||
在这种情况下,如果驱动器中的任何一个发生故障,我们就会丢失数据,因为一个盘中只有一半的数据,不能用于重建 RAID。不过,当比较写入速度和性能时,RAID 0 是非常好的。创建 RAID 0(条带化)至少需要2个磁盘。如果你的数据是非常宝贵的,那么不要使用此 RAID 级别。
|
||||
|
||||
- 高性能。
|
||||
- RAID 0 中容量零损失。
|
||||
- 零容错。
|
||||
- 写和读有很高的性能。
|
||||
|
||||
#### RAID 1 / 镜像化 ####
|
||||
|
||||

|
||||
|
||||
镜像也有不错的性能。镜像可以对我们的数据做一份相同的副本。假设我们有两个2TB的硬盘驱动器,我们总共有4TB,但在镜像中,但是放在 RAID 控制器后面的驱动器形成了一个逻辑驱动器,我们只能看到这个逻辑驱动器有2TB。
|
||||
|
||||
当我们保存数据时,它将同时写入这两个2TB驱动器中。创建 RAID 1(镜像化)最少需要两个驱动器。如果发生磁盘故障,我们可以通过更换一个新的磁盘恢复 RAID 。如果在 RAID 1 中任何一个磁盘发生故障,我们可以从另一个磁盘中获取相同的数据,因为另外的磁盘中也有相同的数据。所以是零数据丢失。
|
||||
|
||||
- 良好的性能。
|
||||
- 总容量丢失一半可用空间。
|
||||
- 完全容错。
|
||||
- 重建会更快。
|
||||
- 写性能变慢。
|
||||
- 读性能变好。
|
||||
- 能用于操作系统和小规模的数据库。
|
||||
|
||||
#### RAID 5 / 分布式奇偶校验 ####
|
||||
|
||||
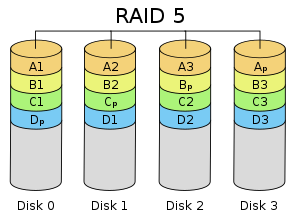
|
||||
|
||||
RAID 5 多用于企业级。 RAID 5 的以分布式奇偶校验的方式工作。奇偶校验信息将被用于重建数据。它从剩下的正常驱动器上的信息来重建。在驱动器发生故障时,这可以保护我们的数据。
|
||||
|
||||
假设我们有4个驱动器,如果一个驱动器发生故障而后我们更换发生故障的驱动器后,我们可以从奇偶校验中重建数据到更换的驱动器上。奇偶校验信息存储在所有的4个驱动器上,如果我们有4个 1TB 的驱动器。奇偶校验信息将被存储在每个驱动器的256G中,而其它768GB是用户自己使用的。单个驱动器故障后,RAID 5 依旧正常工作,如果驱动器损坏个数超过1个会导致数据的丢失。
|
||||
|
||||
- 性能卓越
|
||||
- 读速度将非常好。
|
||||
- 写速度处于平均水准,如果我们不使用硬件 RAID 控制器,写速度缓慢。
|
||||
- 从所有驱动器的奇偶校验信息中重建。
|
||||
- 完全容错。
|
||||
- 1个磁盘空间将用于奇偶校验。
|
||||
- 可以被用在文件服务器,Web服务器,非常重要的备份中。
|
||||
|
||||
#### RAID 6 双分布式奇偶校验磁盘 ####
|
||||
|
||||

|
||||
|
||||
RAID 6 和 RAID 5 相似但它有两个分布式奇偶校验。大多用在大数量的阵列中。我们最少需要4个驱动器,即使有2个驱动器发生故障,我们依然可以更换新的驱动器后重建数据。
|
||||
|
||||
它比 RAID 5 慢,因为它将数据同时写到4个驱动器上。当我们使用硬件 RAID 控制器时速度就处于平均水准。如果我们有6个的1TB驱动器,4个驱动器将用于数据保存,2个驱动器将用于校验。
|
||||
|
||||
- 性能不佳。
|
||||
- 读的性能很好。
|
||||
- 如果我们不使用硬件 RAID 控制器写的性能会很差。
|
||||
- 从两个奇偶校验驱动器上重建。
|
||||
- 完全容错。
|
||||
- 2个磁盘空间将用于奇偶校验。
|
||||
- 可用于大型阵列。
|
||||
- 用于备份和视频流中,用于大规模。
|
||||
|
||||
#### RAID 10 / 镜像+条带 ####
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
RAID 10 可以被称为1 + 0或0 +1。它将做镜像+条带两个工作。在 RAID 10 中首先做镜像然后做条带。在 RAID 01 上首先做条带,然后做镜像。RAID 10 比 01 好。
|
||||
|
||||
假设,我们有4个驱动器。当我逻辑卷上写数据时,它会使用镜像和条带的方式将数据保存到4个驱动器上。
|
||||
|
||||
如果我在 RAID 10 上写入数据“TECMINT”,数据将使用如下方式保存。首先将“T”同时写入两个磁盘,“E”也将同时写入另外两个磁盘,所有数据都写入两块磁盘。这样可以将每个数据复制到另外的磁盘。
|
||||
|
||||
同时它将使用 RAID 0 方式写入数据,遵循将“T”写入第一组盘,“E”写入第二组盘。再次将“C”写入第一组盘,“M”到第二组盘。
|
||||
|
||||
- 良好的读写性能。
|
||||
- 总容量丢失一半的可用空间。
|
||||
- 容错。
|
||||
- 从副本数据中快速重建。
|
||||
- 由于其高性能和高可用性,常被用于数据库的存储中。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经了解了什么是 RAID 和在实际环境大多采用哪个级别的 RAID。希望你已经学会了上面所写的。对于 RAID 的构建必须了解有关 RAID 的基本知识。以上内容可以基本满足你对 RAID 的了解。
|
||||
|
||||
在接下来的文章中,我将介绍如何设置和使用各种级别创建 RAID,增加 RAID 组(阵列)和驱动器故障排除等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
@ -0,0 +1,219 @@
|
||||
在 Linux 下使用 RAID(一):使用 mdadm 工具创建软件 RAID 0 (条带化)
|
||||
================================================================================
|
||||
|
||||
RAID 即廉价磁盘冗余阵列,其高可用性和可靠性适用于大规模环境中,相比正常使用,数据更需要被保护。RAID 是一些磁盘的集合,是包含一个阵列的逻辑卷。驱动器可以组合起来成为一个阵列或称为(组的)集合。
|
||||
|
||||
创建 RAID 最少应使用2个连接到 RAID 控制器的磁盘组成,来构成逻辑卷,可以根据定义的 RAID 级别将更多的驱动器添加到一个阵列中。不使用物理硬件创建的 RAID 被称为软件 RAID。软件 RAID 也叫做穷人 RAID。
|
||||
|
||||
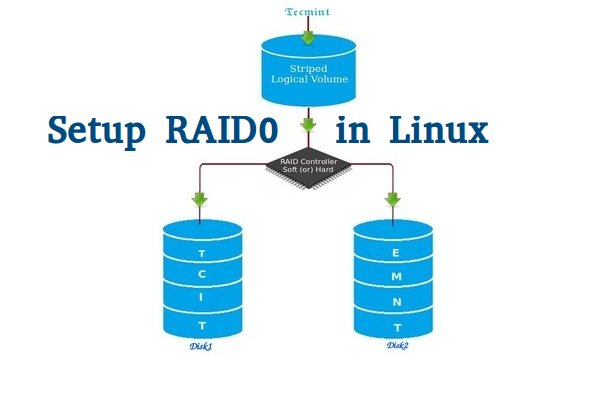
|
||||
|
||||
*在 Linux 中创建 RAID0*
|
||||
|
||||
使用 RAID 的主要目的是为了在发生单点故障时保存数据,如果我们使用单个磁盘来存储数据,如果它损坏了,那么就没有机会取回我们的数据了,为了防止数据丢失我们需要一个容错的方法。所以,我们可以使用多个磁盘组成 RAID 阵列。
|
||||
|
||||
#### 在 RAID 0 中条带是什么 ####
|
||||
|
||||
条带是通过将数据在同时分割到多个磁盘上。假设我们有两个磁盘,如果我们将数据保存到该逻辑卷上,它会将数据保存在两个磁盘上。使用 RAID 0 是为了获得更好的性能,但是如果驱动器中一个出现故障,我们将不能得到完整的数据。因此,使用 RAID 0 不是一种好的做法。唯一的解决办法就是安装有 RAID 0 逻辑卷的操作系统来提高重要文件的安全性。
|
||||
|
||||
- RAID 0 性能较高。
|
||||
- 在 RAID 0 上,空间零浪费。
|
||||
- 零容错(如果硬盘中的任何一个发生故障,无法取回数据)。
|
||||
- 写和读性能都很好。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
创建 RAID 0 允许的最小磁盘数目是2个,但你可以添加更多的磁盘,不过数目应该是2,4,6,8等的偶数。如果你有一个物理 RAID 卡并且有足够的端口,你可以添加更多磁盘。
|
||||
|
||||
在这里,我们没有使用硬件 RAID,此设置只需要软件 RAID。如果我们有一个物理硬件 RAID 卡,我们可以从它的功能界面访问它。有些主板默认内建 RAID 功能,还可以使用 Ctrl + I 键访问它的界面。
|
||||
|
||||
如果你是刚开始设置 RAID,请阅读我们前面的文章,我们已经介绍了一些关于 RAID 基本的概念。
|
||||
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
|
||||
**我的服务器设置**
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.225
|
||||
两块盘 : 20 GB each
|
||||
|
||||
这是9篇系列教程的第2部分,在这部分,我们将看看如何能够在 Linux 上创建和使用 RAID 0(条带化),以名为 sdb 和 sdc 两个 20GB 的硬盘为例。
|
||||
|
||||
### 第1步:更新系统和安装管理 RAID 的 mdadm 软件 ###
|
||||
|
||||
1、 在 Linux 上设置 RAID 0 前,我们先更新一下系统,然后安装`mdadm` 包。mdadm 是一个小程序,这将使我们能够在Linux下配置和管理 RAID 设备。
|
||||
|
||||
# yum clean all && yum update
|
||||
# yum install mdadm -y
|
||||
|
||||
|
||||
|
||||
*安装 mdadm 工具*
|
||||
|
||||
### 第2步:确认连接了两个 20GB 的硬盘 ###
|
||||
|
||||
2、 在创建 RAID 0 前,请务必确认两个硬盘能被检测到,使用下面的命令确认。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
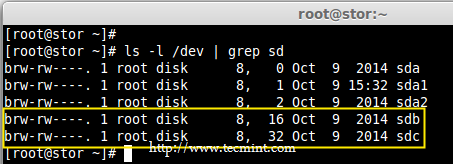
|
||||
|
||||
*检查硬盘*
|
||||
|
||||
3、 一旦检测到新的硬盘驱动器,同时检查是否连接的驱动器已经被现有的 RAID 使用,使用下面的`mdadm` 命令来查看。
|
||||
|
||||
# mdadm --examine /dev/sd[b-c]
|
||||
|
||||
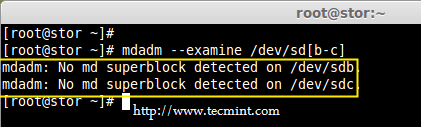
|
||||
|
||||
*检查 RAID 设备*
|
||||
|
||||
从上面的输出我们可以看到,没有任何 RAID 使用 sdb 和 sdc 这两个驱动器。
|
||||
|
||||
### 第3步:创建 RAID 分区 ###
|
||||
|
||||
4、 现在用 sdb 和 sdc 创建 RAID 的分区,使用 fdisk 命令来创建。在这里,我将展示如何创建 sdb 驱动器上的分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
请按照以下说明创建分区。
|
||||
|
||||
- 按`n` 创建新的分区。
|
||||
- 然后按`P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按`P` 来显示创建好的分区。
|
||||
|
||||

|
||||
|
||||
*创建分区*
|
||||
|
||||
请按照以下说明将分区创建为 Linux 的 RAID 类型。
|
||||
|
||||
- 按`L`,列出所有可用的类型。
|
||||
- 按`t` 去修改分区。
|
||||
- 键入`fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*在 Linux 上创建 RAID 分区*
|
||||
|
||||
**注**: 请使用上述步骤同样在 sdc 驱动器上创建分区。
|
||||
|
||||
5、 创建分区后,验证这两个驱动器是否正确定义 RAID,使用下面的命令。
|
||||
|
||||
# mdadm --examine /dev/sd[b-c]
|
||||
# mdadm --examine /dev/sd[b-c]1
|
||||
|
||||
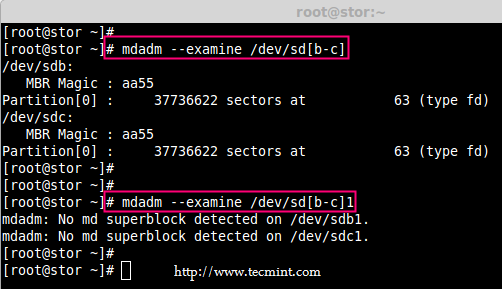
|
||||
|
||||
*验证 RAID 分区*
|
||||
|
||||
### 第4步:创建 RAID md 设备 ###
|
||||
|
||||
6、 现在使用以下命令创建 md 设备(即 /dev/md0),并选择 RAID 合适的级别。
|
||||
|
||||
# mdadm -C /dev/md0 -l raid0 -n 2 /dev/sd[b-c]1
|
||||
# mdadm --create /dev/md0 --level=stripe --raid-devices=2 /dev/sd[b-c]1
|
||||
|
||||
- -C – 创建
|
||||
- -l – 级别
|
||||
- -n – RAID 设备数
|
||||
|
||||
7、 一旦 md 设备已经建立,使用如下命令可以查看 RAID 级别,设备和阵列的使用状态。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||
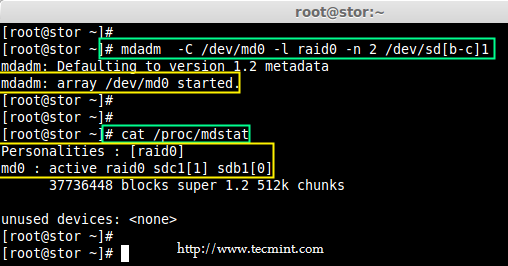
|
||||
|
||||
*查看 RAID 级别*
|
||||
|
||||
# mdadm -E /dev/sd[b-c]1
|
||||
|
||||

|
||||
|
||||
*查看 RAID 设备*
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*查看 RAID 阵列*
|
||||
|
||||
### 第5步:给 RAID 设备创建文件系统 ###
|
||||
|
||||
8、 将 RAID 设备 /dev/md0 创建为 ext4 文件系统,并挂载到 /mnt/raid0 下。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*创建 ext4 文件系统*
|
||||
|
||||
9、 在 RAID 设备上创建好 ext4 文件系统后,现在创建一个挂载点(即 /mnt/raid0),并将设备 /dev/md0 挂载在它下。
|
||||
|
||||
# mkdir /mnt/raid0
|
||||
# mount /dev/md0 /mnt/raid0/
|
||||
|
||||
10、下一步,使用 df 命令验证设备 /dev/md0 是否被挂载在 /mnt/raid0 下。
|
||||
|
||||
# df -h
|
||||
|
||||
11、 接下来,在挂载点 /mnt/raid0 下创建一个名为`tecmint.txt` 的文件,为创建的文件添加一些内容,并查看文件和目录的内容。
|
||||
|
||||
# touch /mnt/raid0/tecmint.txt
|
||||
# echo "Hi everyone how you doing ?" > /mnt/raid0/tecmint.txt
|
||||
# cat /mnt/raid0/tecmint.txt
|
||||
# ls -l /mnt/raid0/
|
||||
|
||||

|
||||
|
||||
*验证挂载的设备*
|
||||
|
||||
12、 当你验证挂载点后,就可以将它添加到 /etc/fstab 文件中。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
添加以下条目,根据你的安装位置和使用文件系统的不同,自行做修改。
|
||||
|
||||
/dev/md0 /mnt/raid0 ext4 deaults 0 0
|
||||
|
||||

|
||||
|
||||
*添加设备到 fstab 文件中*
|
||||
|
||||
13、 使用 mount 命令的 `-a` 来检查 fstab 的条目是否有误。
|
||||
|
||||
# mount -av
|
||||
|
||||
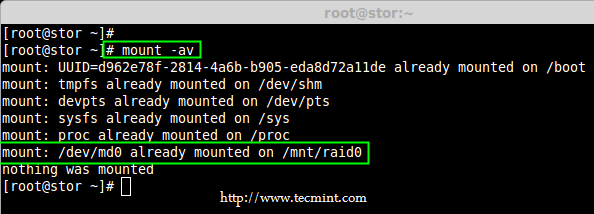
|
||||
|
||||
*检查 fstab 文件是否有误*
|
||||
|
||||
### 第6步:保存 RAID 配置 ###
|
||||
|
||||
14、 最后,保存 RAID 配置到一个文件中,以供将来使用。我们再次使用带有`-s` (scan) 和`-v` (verbose) 选项的 `mdadm` 命令,如图所示。
|
||||
|
||||
# mdadm -E -s -v >> /etc/mdadm.conf
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
# cat /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
*保存 RAID 配置*
|
||||
|
||||
就这样,我们在这里看到,如何通过使用两个硬盘配置具有条带化的 RAID 0 。在接下来的文章中,我们将看到如何设置 RAID 1。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid0-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
@ -0,0 +1,217 @@
|
||||
在 Linux 下使用 RAID(三):用两块磁盘创建 RAID 1(镜像)
|
||||
================================================================================
|
||||
|
||||
**RAID 镜像**意味着相同数据的完整克隆(或镜像),分别写入到两个磁盘中。创建 RAID 1 至少需要两个磁盘,而且仅用于读取性能或者可靠性要比数据存储容量更重要的场合。
|
||||
|
||||
|
||||
|
||||
|
||||
*在 Linux 中设置 RAID 1*
|
||||
|
||||
创建镜像是为了防止因硬盘故障导致数据丢失。镜像中的每个磁盘包含数据的完整副本。当一个磁盘发生故障时,相同的数据可以从其它正常磁盘中读取。而后,可以从正在运行的计算机中直接更换发生故障的磁盘,无需任何中断。
|
||||
|
||||
### RAID 1 的特点 ###
|
||||
|
||||
- 镜像具有良好的性能。
|
||||
|
||||
- 磁盘利用率为50%。也就是说,如果我们有两个磁盘每个500GB,总共是1TB,但在镜像中它只会显示500GB。
|
||||
|
||||
- 在镜像如果一个磁盘发生故障不会有数据丢失,因为两个磁盘中的内容相同。
|
||||
|
||||
- 读取性能会比写入性能更好。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
创建 RAID 1 至少要有两个磁盘,你也可以添加更多的磁盘,磁盘数需为2,4,6,8等偶数。要添加更多的磁盘,你的系统必须有 RAID 物理适配器(硬件卡)。
|
||||
|
||||
这里,我们使用软件 RAID 不是硬件 RAID,如果你的系统有一个内置的物理硬件 RAID 卡,你可以从它的功能界面或使用 Ctrl + I 键来访问它。
|
||||
|
||||
需要阅读: [介绍 RAID 的级别和概念][1]
|
||||
|
||||
#### 在我的服务器安装 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.226
|
||||
主机名 : rd1.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
|
||||
本文将指导你在 Linux 平台上使用 mdadm (用于创建和管理 RAID )一步步的建立一个软件 RAID 1 (镜像)。同样的做法也适用于如 RedHat,CentOS,Fedora 等 Linux 发行版。
|
||||
|
||||
### 第1步:安装所需软件并且检查磁盘 ###
|
||||
|
||||
1、 正如我前面所说,在 Linux 中我们需要使用 mdadm 软件来创建和管理 RAID。所以,让我们用 yum 或 apt-get 的软件包管理工具在 Linux 上安装 mdadm 软件包。
|
||||
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
2、 一旦安装好`mdadm`包,我们需要使用下面的命令来检查磁盘是否已经配置好。
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
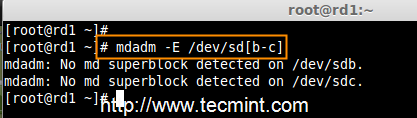
|
||||
|
||||
*检查 RAID 的磁盘*
|
||||
|
||||
正如你从上面图片看到的,没有检测到任何超级块,这意味着还没有创建RAID。
|
||||
|
||||
### 第2步:为 RAID 创建分区 ###
|
||||
|
||||
3、 正如我提到的,我们使用最少的两个分区 /dev/sdb 和 /dev/sdc 来创建 RAID 1。我们首先使用`fdisk`命令来创建这两个分区并更改其类型为 raid。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
按照下面的说明
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 按两次回车键默认将整个容量分配给它。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 修改分区类型。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*创建磁盘分区*
|
||||
|
||||
在创建“/dev/sdb”分区后,接下来按照同样的方法创建分区 /dev/sdc 。
|
||||
|
||||
# fdisk /dev/sdc
|
||||
|
||||

|
||||
|
||||
*创建第二个分区*
|
||||
|
||||
4、 一旦这两个分区创建成功后,使用相同的命令来检查 sdb 和 sdc 分区并确认 RAID 分区的类型如上图所示。
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
|
||||
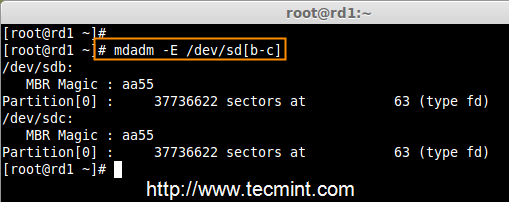
|
||||
|
||||
*验证分区变化*
|
||||
|
||||
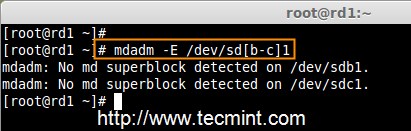
|
||||
|
||||
*检查 RAID 类型*
|
||||
|
||||
**注意**: 正如你在上图所看到的,在 sdb1 和 sdc1 中没有任何对 RAID 的定义,这就是我们没有检测到超级块的原因。
|
||||
|
||||
### 第3步:创建 RAID 1 设备 ###
|
||||
|
||||
5、 接下来使用以下命令来创建一个名为 /dev/md0 的“RAID 1”设备并验证它
|
||||
|
||||
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[b-c]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建RAID设备*
|
||||
|
||||
6、 接下来使用如下命令来检查 RAID 设备类型和 RAID 阵列
|
||||
|
||||
# mdadm -E /dev/sd[b-c]1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*检查 RAID 设备类型*
|
||||
|
||||

|
||||
|
||||
*检查 RAID 设备阵列*
|
||||
|
||||
从上图中,人们很容易理解,RAID 1 已经创建好了,使用了 /dev/sdb1 和 /dev/sdc1 分区,你也可以看到状态为 resyncing(重新同步中)。
|
||||
|
||||
### 第4步:在 RAID 设备上创建文件系统 ###
|
||||
|
||||
7、 给 md0 上创建 ext4 文件系统
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*创建 RAID 设备文件系统*
|
||||
|
||||
8、 接下来,挂载新创建的文件系统到“/mnt/raid1”,并创建一些文件,验证在挂载点的数据
|
||||
|
||||
# mkdir /mnt/raid1
|
||||
# mount /dev/md0 /mnt/raid1/
|
||||
# touch /mnt/raid1/tecmint.txt
|
||||
# echo "tecmint raid setups" > /mnt/raid1/tecmint.txt
|
||||
|
||||

|
||||
|
||||
*挂载 RAID 设备*
|
||||
|
||||
9、为了在系统重新启动自动挂载 RAID 1,需要在 fstab 文件中添加条目。打开`/etc/fstab`文件并添加以下行:
|
||||
|
||||
/dev/md0 /mnt/raid1 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
*自动挂载 Raid 设备*
|
||||
|
||||
10、 运行`mount -av`,检查 fstab 中的条目是否有错误
|
||||
|
||||
# mount -av
|
||||
|
||||
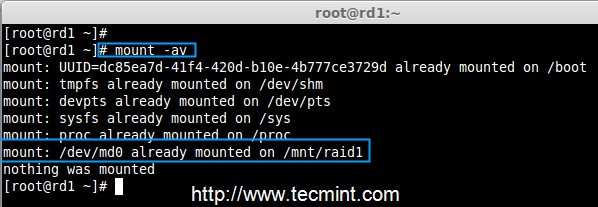
|
||||
|
||||
*检查 fstab 中的错误*
|
||||
|
||||
11、 接下来,使用下面的命令保存 RAID 的配置到文件“mdadm.conf”中。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
*保存 Raid 的配置*
|
||||
|
||||
上述配置文件在系统重启时会读取并加载 RAID 设备。
|
||||
|
||||
### 第5步:在磁盘故障后检查数据 ###
|
||||
|
||||
12、我们的主要目的是,即使在任何磁盘故障或死机时必须保证数据是可用的。让我们来看看,当任何一个磁盘不可用时会发生什么。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*验证 RAID 设备*
|
||||
|
||||
在上面的图片中,我们可以看到在 RAID 中有2个设备是可用的,并且 Active Devices 是2。现在让我们看看,当一个磁盘拔出(移除 sdc 磁盘)或损坏后会发生什么。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*测试 RAID 设备*
|
||||
|
||||
现在,在上面的图片中你可以看到,一个磁盘不见了。我从虚拟机上删除了一个磁盘。此时让我们来检查我们宝贵的数据。
|
||||
|
||||
# cd /mnt/raid1/
|
||||
# cat tecmint.txt
|
||||
|
||||
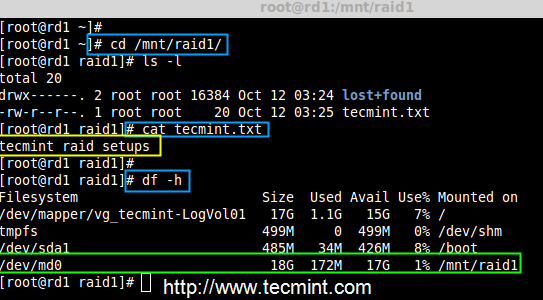
|
||||
|
||||
*验证 RAID 数据*
|
||||
|
||||
你可以看到我们的数据仍然可用。由此,我们可以了解 RAID 1(镜像)的优势。在接下来的文章中,我们将看到如何设置一个 RAID 5 条带化分布式奇偶校验。希望这可以帮助你了解 RAID 1(镜像)是如何工作的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid1-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
@ -0,0 +1,280 @@
|
||||
在 Linux 下使用 RAID(四):创建 RAID 5(条带化与分布式奇偶校验)
|
||||
================================================================================
|
||||
|
||||
在 RAID 5 中,数据条带化后存储在分布式奇偶校验的多个磁盘上。分布式奇偶校验的条带化意味着它将奇偶校验信息和条带化数据分布在多个磁盘上,这样会有很好的数据冗余。
|
||||
|
||||

|
||||
|
||||
*在 Linux 中配置 RAID 5*
|
||||
|
||||
对于此 RAID 级别它至少应该有三个或更多个磁盘。RAID 5 通常被用于大规模生产环境中,以花费更多的成本来提供更好的数据冗余性能。
|
||||
|
||||
#### 什么是奇偶校验? ####
|
||||
|
||||
奇偶校验是在数据存储中检测错误最简单的常见方式。奇偶校验信息存储在每个磁盘中,比如说,我们有4个磁盘,其中相当于一个磁盘大小的空间被分割去存储所有磁盘的奇偶校验信息。如果任何一个磁盘出现故障,我们可以通过更换故障磁盘后,从奇偶校验信息重建得到原来的数据。
|
||||
|
||||
#### RAID 5 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能。
|
||||
- 支持冗余和容错。
|
||||
- 支持热备份。
|
||||
- 将用掉一个磁盘的容量存储奇偶校验信息。
|
||||
- 单个磁盘发生故障后不会丢失数据。我们可以更换故障硬盘后从奇偶校验信息中重建数据。
|
||||
- 适合于面向事务处理的环境,读操作会更快。
|
||||
- 由于奇偶校验占用资源,写操作会慢一些。
|
||||
- 重建需要很长的时间。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
创建 RAID 5 最少需要3个磁盘,你也可以添加更多的磁盘,前提是你要有多端口的专用硬件 RAID 控制器。在这里,我们使用“mdadm”包来创建软件 RAID。
|
||||
|
||||
mdadm 是一个允许我们在 Linux 下配置和管理 RAID 设备的包。默认情况下没有 RAID 的配置文件,我们在创建和配置 RAID 后必须将配置文件保存在一个单独的文件 mdadm.conf 中。
|
||||
|
||||
在进一步学习之前,我建议你通过下面的文章去了解 Linux 中 RAID 的基础知识。
|
||||
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
- [用两块磁盘创建 RAID 1(镜像)][3]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.227
|
||||
主机名 : rd5.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
|
||||
这是9篇系列教程的第4部分,在这里我们要在 Linux 系统或服务器上使用三个20GB(名为/dev/sdb, /dev/sdc 和 /dev/sdd)的磁盘建立带有分布式奇偶校验的软件 RAID 5。
|
||||
|
||||
### 第1步:安装 mdadm 并检验磁盘 ###
|
||||
|
||||
1、 正如我们前面所说,我们使用 CentOS 6.5 Final 版本来创建 RAID 设置,但同样的做法也适用于其他 Linux 发行版。
|
||||
|
||||
# lsb_release -a
|
||||
# ifconfig | grep inet
|
||||
|
||||

|
||||
|
||||
*CentOS 6.5 摘要*
|
||||
|
||||
2、 如果你按照我们的 RAID 系列去配置的,我们假设你已经安装了“mdadm”包,如果没有,根据你的 Linux 发行版使用下面的命令安装。
|
||||
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
3、 “mdadm”包安装后,先使用`fdisk`命令列出我们在系统上增加的三个20GB的硬盘。
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
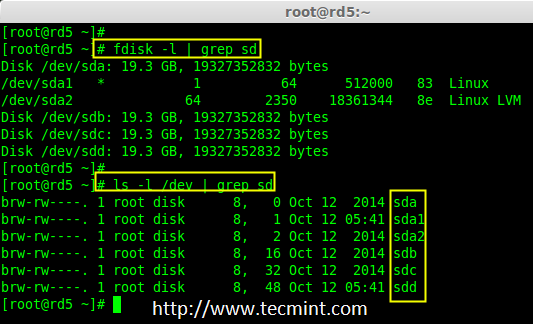
|
||||
|
||||
*安装 mdadm 工具*
|
||||
|
||||
4、 现在该检查这三个磁盘是否存在 RAID 块,使用下面的命令来检查。
|
||||
|
||||
# mdadm -E /dev/sd[b-d]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd # 或
|
||||
|
||||
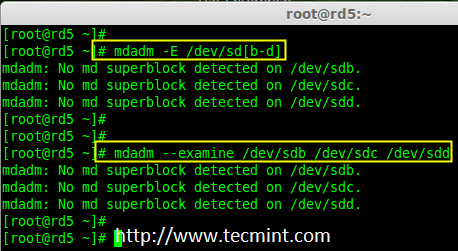
|
||||
|
||||
*检查 Raid 磁盘*
|
||||
|
||||
**注意**: 上面的图片说明,没有检测到任何超级块。所以,这三个磁盘中没有定义 RAID。让我们现在开始创建一个吧!
|
||||
|
||||
### 第2步:为磁盘创建 RAID 分区 ###
|
||||
|
||||
5、 首先,在创建 RAID 前磁盘(/dev/sdb, /dev/sdc 和 /dev/sdd)必须有分区,因此,在进行下一步之前,先使用`fdisk`命令进行分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
|
||||
#### 创建 /dev/sdb 分区 ####
|
||||
|
||||
请按照下面的说明在 /dev/sdb 硬盘上创建分区。
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。选择主分区是因为还没有定义过分区。
|
||||
- 接下来选择分区号为1。默认就是1。
|
||||
- 这里是选择柱面大小,我们没必要选择指定的大小,因为我们需要为 RAID 使用整个分区,所以只需按两次 Enter 键默认将整个容量分配给它。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 改变分区类型,按 `L`可以列出所有可用的类型。
|
||||
- 按 `t` 修改分区类型。
|
||||
- 这里使用`fd`设置为 RAID 的类型。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*创建 sdb 分区*
|
||||
|
||||
**注意**: 我们仍要按照上面的步骤来创建 sdc 和 sdd 的分区。
|
||||
|
||||
#### 创建 /dev/sdc 分区 ####
|
||||
|
||||
现在,通过下面的截图给出创建 sdc 和 sdd 磁盘分区的方法,或者你可以按照上面的步骤。
|
||||
|
||||
# fdisk /dev/sdc
|
||||
|
||||

|
||||
|
||||
*创建 sdc 分区*
|
||||
|
||||
#### 创建 /dev/sdd 分区 ####
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||

|
||||
|
||||
*创建 sdd 分区*
|
||||
|
||||
6、 创建分区后,检查三个磁盘 sdb, sdc, sdd 的变化。
|
||||
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
# mdadm -E /dev/sd[b-c] # 或
|
||||
|
||||
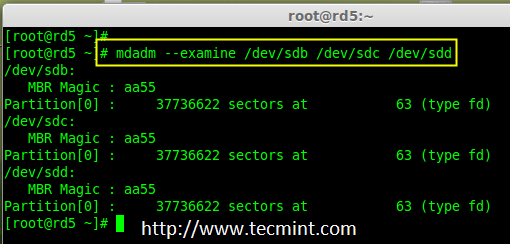
|
||||
|
||||
*检查磁盘变化*
|
||||
|
||||
**注意**: 在上面的图片中,磁盘的类型是 fd。
|
||||
|
||||
7、 现在在新创建的分区检查 RAID 块。如果没有检测到超级块,我们就能够继续下一步,在这些磁盘中创建一个新的 RAID 5 配置。
|
||||
|
||||
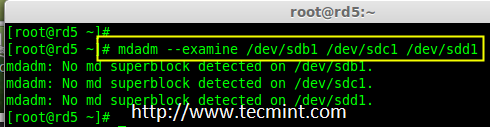
|
||||
|
||||
*在分区中检查 RAID *
|
||||
|
||||
### 第3步:创建 md 设备 md0 ###
|
||||
|
||||
8、 现在使用所有新创建的分区(sdb1, sdc1 和 sdd1)创建一个 RAID 设备“md0”(即 /dev/md0),使用以下命令。
|
||||
|
||||
# mdadm --create /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1
|
||||
# mdadm -C /dev/md0 -l=5 -n=3 /dev/sd[b-d]1 # 或
|
||||
|
||||
9、 创建 RAID 设备后,检查并确认 RAID,从 mdstat 中输出中可以看到包括的设备的 RAID 级别。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*验证 Raid 设备*
|
||||
|
||||
如果你想监视当前的创建过程,你可以使用`watch`命令,将 `cat /proc/mdstat` 传递给它,它会在屏幕上显示且每隔1秒刷新一次。
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||
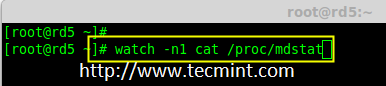
|
||||
|
||||
*监控 RAID 5 构建过程*
|
||||
|
||||

|
||||
|
||||
*Raid 5 过程概要*
|
||||
|
||||
10、 创建 RAID 后,使用以下命令验证 RAID 设备
|
||||
|
||||
# mdadm -E /dev/sd[b-d]1
|
||||
|
||||

|
||||
|
||||
*验证 Raid 级别*
|
||||
|
||||
**注意**: 因为它显示三个磁盘的信息,上述命令的输出会有点长。
|
||||
|
||||
11、 接下来,验证 RAID 阵列,假定包含 RAID 的设备正在运行并已经开始了重新同步。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*验证 RAID 阵列*
|
||||
|
||||
### 第4步:为 md0 创建文件系统###
|
||||
|
||||
12、 在挂载前为“md0”设备创建 ext4 文件系统。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*创建 md0 文件系统*
|
||||
|
||||
13、 现在,在`/mnt`下创建目录 raid5,然后挂载文件系统到 /mnt/raid5/ 下,并检查挂载点下的文件,你会看到 lost+found 目录。
|
||||
|
||||
# mkdir /mnt/raid5
|
||||
# mount /dev/md0 /mnt/raid5/
|
||||
# ls -l /mnt/raid5/
|
||||
|
||||
14、 在挂载点 /mnt/raid5 下创建几个文件,并在其中一个文件中添加一些内容然后去验证。
|
||||
|
||||
# touch /mnt/raid5/raid5_tecmint_{1..5}
|
||||
# ls -l /mnt/raid5/
|
||||
# echo "tecmint raid setups" > /mnt/raid5/raid5_tecmint_1
|
||||
# cat /mnt/raid5/raid5_tecmint_1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*挂载 RAID 设备*
|
||||
|
||||
15、 我们需要在 fstab 中添加条目,否则系统重启后将不会显示我们的挂载点。编辑 fstab 文件添加条目,在文件尾追加以下行。挂载点会根据你环境的不同而不同。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid5 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
*自动挂载 RAID 5*
|
||||
|
||||
16、 接下来,运行`mount -av`命令检查 fstab 条目中是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
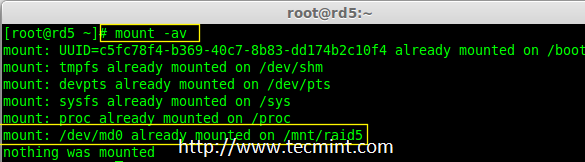
|
||||
|
||||
*检查 Fstab 错误*
|
||||
|
||||
### 第5步:保存 Raid 5 的配置 ###
|
||||
|
||||
17、 在前面章节已经说过,默认情况下 RAID 没有配置文件。我们必须手动保存。如果此步中没有跟随不属于 md0 的 RAID 设备,它会是一些其他随机数字。
|
||||
|
||||
所以,我们必须要在系统重新启动之前保存配置。如果配置保存它在系统重新启动时会被加载到内核中然后 RAID 也将被加载。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
*保存 RAID 5 配置*
|
||||
|
||||
注意:保存配置将保持 md0 设备的 RAID 级别稳定不变。
|
||||
|
||||
### 第6步:添加备用磁盘 ###
|
||||
|
||||
18、 备用磁盘有什么用?它是非常有用的,如果我们有一个备用磁盘,当我们阵列中的任何一个磁盘发生故障后,这个备用磁盘会进入激活重建过程,并从其他磁盘上同步数据,这样就有了冗余。
|
||||
|
||||
更多关于添加备用磁盘和检查 RAID 5 容错的指令,请阅读下面文章中的第6步和第7步。
|
||||
|
||||
- [在 RAID 5 中添加备用磁盘][4]
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经看到了如何使用三个磁盘配置一个 RAID 5 。在接下来的文章中,我们将看到如何故障排除并且当 RAID 5 中的一个磁盘损坏后如何恢复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-5-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
[3]:https://linux.cn/article-6093-1.html
|
||||
[4]:http://www.tecmint.com/create-raid-6-in-linux/
|
||||
@ -0,0 +1,320 @@
|
||||
在 Linux 下使用 RAID(五):安装 RAID 6(条带化双分布式奇偶校验)
|
||||
================================================================================
|
||||
|
||||
RAID 6 是 RAID 5 的升级版,它有两个分布式奇偶校验,即使两个磁盘发生故障后依然有容错能力。在两个磁盘同时发生故障时,系统的关键任务仍然能运行。它与 RAID 5 相似,但性能更健壮,因为它多用了一个磁盘来进行奇偶校验。
|
||||
|
||||
在之前的文章中,我们已经在 RAID 5 看了分布式奇偶校验,但在本文中,我们将看到的是 RAID 6 双分布式奇偶校验。不要期望比其他 RAID 有更好的性能,除非你也安装了一个专用的 RAID 控制器。在 RAID 6 中,即使我们失去了2个磁盘,我们仍可以通过更换磁盘,从校验中构建数据,然后取回数据。
|
||||
|
||||
|
||||
|
||||
*在 Linux 中安装 RAID 6*
|
||||
|
||||
要建立一个 RAID 6,一组最少需要4个磁盘。RAID 6 甚至在有些组中会有更多磁盘,这样将多个硬盘捆在一起,当读取数据时,它会同时从所有磁盘读取,所以读取速度会更快,当写数据时,因为它要将数据写在条带化的多个磁盘上,所以性能会较差。
|
||||
|
||||
现在,很多人都在讨论为什么我们需要使用 RAID 6,它的性能和其他 RAID 相比并不太好。提出这个问题首先需要知道的是,如果需要高容错性就选择 RAID 6。在每一个用于数据库的高可用性要求较高的环境中,他们需要 RAID 6 因为数据库是最重要,无论花费多少都需要保护其安全,它在视频流环境中也是非常有用的。
|
||||
|
||||
#### RAID 6 的的优点和缺点 ####
|
||||
|
||||
- 性能不错。
|
||||
- RAID 6 比较昂贵,因为它要求两个独立的磁盘用于奇偶校验功能。
|
||||
- 将失去两个磁盘的容量来保存奇偶校验信息(双奇偶校验)。
|
||||
- 即使两个磁盘损坏,数据也不会丢失。我们可以在更换损坏的磁盘后从校验中重建数据。
|
||||
- 读性能比 RAID 5 更好,因为它从多个磁盘读取,但对于没有专用的 RAID 控制器的设备写性能将非常差。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
要创建一个 RAID 6 最少需要4个磁盘。你也可以添加更多的磁盘,但你必须有专用的 RAID 控制器。使用软件 RAID 我们在 RAID 6 中不会得到更好的性能,所以我们需要一个物理 RAID 控制器。
|
||||
|
||||
如果你新接触 RAID 设置,我们建议先看完以下 RAID 文章。
|
||||
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
- [用两块磁盘创建 RAID 1(镜像)][3]
|
||||
- [创建 RAID 5(条带化与分布式奇偶校验)](4)
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.228
|
||||
主机名 : rd6.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
磁盘 4 [20GB] : /dev/sde
|
||||
|
||||
这是9篇系列教程的第5部分,在这里我们将看到如何在 Linux 系统或者服务器上使用四个 20GB 的磁盘(名为 /dev/sdb、 /dev/sdc、 /dev/sdd 和 /dev/sde)创建和设置软件 RAID 6 (条带化双分布式奇偶校验)。
|
||||
|
||||
### 第1步:安装 mdadm 工具,并检查磁盘 ###
|
||||
|
||||
1、 如果你按照我们最进的两篇 RAID 文章(第2篇和第3篇),我们已经展示了如何安装`mdadm`工具。如果你直接看的这篇文章,我们先来解释下在 Linux 系统中如何使用`mdadm`工具来创建和管理 RAID,首先根据你的 Linux 发行版使用以下命令来安装。
|
||||
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
2、 安装该工具后,然后来验证所需的四个磁盘,我们将会使用下面的`fdisk`命令来检查用于创建 RAID 的磁盘。
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
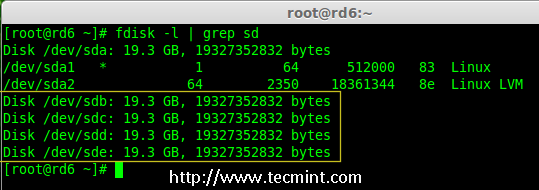
|
||||
|
||||
*在 Linux 中检查磁盘*
|
||||
|
||||
3、 在创建 RAID 磁盘前,先检查下我们的磁盘是否创建过 RAID 分区。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
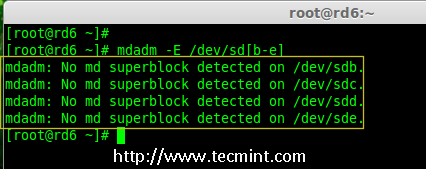
|
||||
|
||||
*在磁盘上检查 RAID 分区*
|
||||
|
||||
**注意**: 在上面的图片中,没有检测到任何 super-block 或者说在四个磁盘上没有 RAID 存在。现在我们开始创建 RAID 6。
|
||||
|
||||
### 第2步:为 RAID 6 创建磁盘分区 ###
|
||||
|
||||
4、 现在在 `/dev/sdb`, `/dev/sdc`, `/dev/sdd` 和 `/dev/sde`上为 RAID 创建分区,使用下面的 fdisk 命令。在这里,我们将展示如何在 sdb 磁盘创建分区,同样的步骤也适用于其他分区。
|
||||
|
||||
**创建 /dev/sdb 分区**
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
请按照说明进行操作,如下图所示创建分区。
|
||||
|
||||
- 按 `n`创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*创建 /dev/sdb 分区*
|
||||
|
||||
**创建 /dev/sdc 分区**
|
||||
|
||||
# fdisk /dev/sdc
|
||||
|
||||

|
||||
|
||||
*创建 /dev/sdc 分区*
|
||||
|
||||
**创建 /dev/sdd 分区**
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||

|
||||
|
||||
*创建 /dev/sdd 分区*
|
||||
|
||||
**创建 /dev/sde 分区**
|
||||
|
||||
# fdisk /dev/sde
|
||||
|
||||

|
||||
|
||||
*创建 /dev/sde 分区*
|
||||
|
||||
5、 创建好分区后,检查磁盘的 super-blocks 是个好的习惯。如果 super-blocks 不存在我们可以按前面的创建一个新的 RAID。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 # 或
|
||||
|
||||
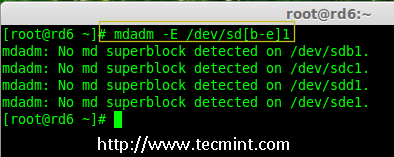
|
||||
|
||||
*在新分区中检查 RAID *
|
||||
|
||||
### 步骤3:创建 md 设备(RAID) ###
|
||||
|
||||
6、 现在可以使用以下命令创建 RAID 设备`md0` (即 /dev/md0),并在所有新创建的分区中应用 RAID 级别,然后确认 RAID 设置。
|
||||
|
||||
# mdadm --create /dev/md0 --level=6 --raid-devices=4 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 Raid 6 设备*
|
||||
|
||||
7、 你还可以使用 watch 命令来查看当前创建 RAID 的进程,如下图所示。
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*检查 RAID 6 创建过程*
|
||||
|
||||
8、 使用以下命令验证 RAID 设备。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
|
||||
**注意**::上述命令将显示四个磁盘的信息,这是相当长的,所以没有截取其完整的输出。
|
||||
|
||||
9、 接下来,验证 RAID 阵列,以确认重新同步过程已经开始。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*检查 Raid 6 阵列*
|
||||
|
||||
### 第4步:在 RAID 设备上创建文件系统 ###
|
||||
|
||||
10、 使用 ext4 为`/dev/md0`创建一个文件系统,并将它挂载在 /mnt/raid6 。这里我们使用的是 ext4,但你可以根据你的选择使用任意类型的文件系统。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 6 上创建文件系统*
|
||||
|
||||
11、 将创建的文件系统挂载到 /mnt/raid6,并验证挂载点下的文件,我们可以看到 lost+found 目录。
|
||||
|
||||
# mkdir /mnt/raid6
|
||||
# mount /dev/md0 /mnt/raid6/
|
||||
# ls -l /mnt/raid6/
|
||||
|
||||
12、 在挂载点下创建一些文件,在任意文件中添加一些文字并验证其内容。
|
||||
|
||||
# touch /mnt/raid6/raid6_test.txt
|
||||
# ls -l /mnt/raid6/
|
||||
# echo "tecmint raid setups" > /mnt/raid6/raid6_test.txt
|
||||
# cat /mnt/raid6/raid6_test.txt
|
||||
|
||||
|
||||
|
||||
*验证 RAID 内容*
|
||||
|
||||
13、 在 /etc/fstab 中添加以下条目使系统启动时自动挂载设备,操作系统环境不同挂载点可能会有所不同。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid6 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
*自动挂载 RAID 6 设备*
|
||||
|
||||
14、 接下来,执行`mount -a`命令来验证 fstab 中的条目是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
|
||||
|
||||
*验证 RAID 是否自动挂载*
|
||||
|
||||
### 第5步:保存 RAID 6 的配置 ###
|
||||
|
||||
15、 请注意,默认情况下 RAID 没有配置文件。我们需要使用以下命令手动保存它,然后检查设备`/dev/md0`的状态。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
# cat /etc/mdadm.conf
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*保存 RAID 6 配置*
|
||||
|
||||

|
||||
|
||||
*检查 RAID 6 状态*
|
||||
|
||||
### 第6步:添加备用磁盘 ###
|
||||
|
||||
16、 现在,已经使用了4个磁盘,并且其中两个作为奇偶校验信息来使用。在某些情况下,如果任意一个磁盘出现故障,我们仍可以得到数据,因为在 RAID 6 使用双奇偶校验。
|
||||
|
||||
如果第二个磁盘也出现故障,在第三块磁盘损坏前我们可以添加一个新的。可以在创建 RAID 集时加入一个备用磁盘,但我在创建 RAID 集合前没有定义备用的磁盘。不过,我们可以在磁盘损坏后或者创建 RAID 集合时添加一块备用磁盘。现在,我们已经创建好了 RAID,下面让我演示如何添加备用磁盘。
|
||||
|
||||
为了达到演示的目的,我已经热插入了一个新的 HDD 磁盘(即 /dev/sdf),让我们来验证接入的磁盘。
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||
|
||||
|
||||
*检查新磁盘*
|
||||
|
||||
17、 现在再次确认新连接的磁盘没有配置过 RAID ,使用 mdadm 来检查。
|
||||
|
||||
# mdadm --examine /dev/sdf
|
||||
|
||||
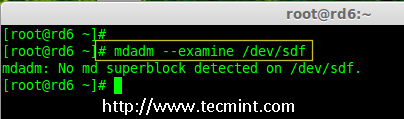
|
||||
|
||||
*在新磁盘中检查 RAID*
|
||||
|
||||
**注意**: 像往常一样,我们早前已经为四个磁盘创建了分区,同样,我们使用 fdisk 命令为新插入的磁盘创建新分区。
|
||||
|
||||
# fdisk /dev/sdf
|
||||
|
||||

|
||||
|
||||
*为 /dev/sdf 创建分区*
|
||||
|
||||
18、 在 /dev/sdf 创建新的分区后,在新分区上确认没有 RAID,然后将备用磁盘添加到 RAID 设备 /dev/md0 中,并验证添加的设备。
|
||||
|
||||
# mdadm --examine /dev/sdf
|
||||
# mdadm --examine /dev/sdf1
|
||||
# mdadm --add /dev/md0 /dev/sdf1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||
|
||||
|
||||
*在 sdf 分区上验证 Raid*
|
||||
|
||||
|
||||
|
||||
*添加 sdf 分区到 RAID *
|
||||
|
||||

|
||||
|
||||
*验证 sdf 分区信息*
|
||||
|
||||
### 第7步:检查 RAID 6 容错 ###
|
||||
|
||||
19、 现在,让我们检查备用驱动器是否能自动工作,当我们阵列中的任何一个磁盘出现故障时。为了测试,我将一个磁盘手工标记为故障设备。
|
||||
|
||||
在这里,我们标记 /dev/sdd1 为故障磁盘。
|
||||
|
||||
# mdadm --manage --fail /dev/md0 /dev/sdd1
|
||||
|
||||
|
||||
|
||||
*检查 RAID 6 容错*
|
||||
|
||||
20、 让我们查看 RAID 的详细信息,并检查备用磁盘是否开始同步。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*检查 RAID 自动同步*
|
||||
|
||||
**哇塞!** 这里,我们看到备用磁盘激活了,并开始重建进程。在底部,我们可以看到有故障的磁盘 /dev/sdd1 标记为 faulty。可以使用下面的命令查看进程重建。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*RAID 6 自动同步*
|
||||
|
||||
### 结论: ###
|
||||
|
||||
在这里,我们看到了如何使用四个磁盘设置 RAID 6。这种 RAID 级别是具有高冗余的昂贵设置之一。在接下来的文章中,我们将看到如何建立一个嵌套的 RAID 10 甚至更多。请继续关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-6-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
[3]:https://linux.cn/article-6093-1.html
|
||||
[4]:https://linux.cn/article-6102-1.html
|
||||
@ -0,0 +1,275 @@
|
||||
在 Linux 下使用 RAID(六):设置 RAID 10 或 1 + 0(嵌套)
|
||||
================================================================================
|
||||
|
||||
RAID 10 是组合 RAID 1 和 RAID 0 形成的。要设置 RAID 10,我们至少需要4个磁盘。在之前的文章中,我们已经看到了如何使用最少两个磁盘设置 RAID 1 和 RAID 0。
|
||||
|
||||
在这里,我们将使用最少4个磁盘组合 RAID 1 和 RAID 0 来设置 RAID 10。假设我们已经在用 RAID 10 创建的逻辑卷保存了一些数据。比如我们要保存数据 “TECMINT”,它将使用以下方法将其保存在4个磁盘中。
|
||||
|
||||
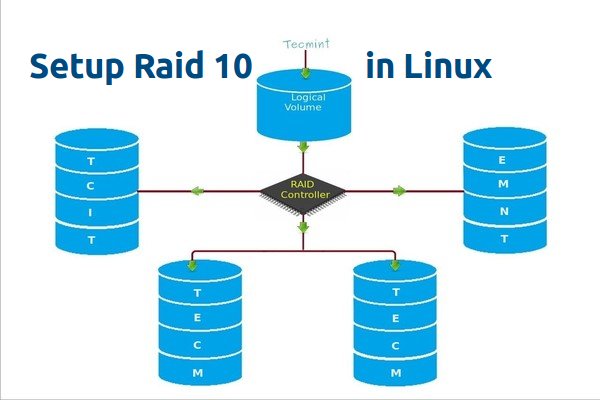
|
||||
|
||||
*在 Linux 中创建 Raid 10(LCTT 译注:此图有误,请参照文字说明和本系列第一篇文章)*
|
||||
|
||||
RAID 10 是先做镜像,再做条带。因此,在 RAID 1 中,相同的数据将被写入到两个磁盘中,“T”将同时被写入到第一和第二个磁盘中。接着的数据被条带化到另外两个磁盘,“E”将被同时写入到第三和第四个磁盘中。它将继续循环此过程,“C”将同时被写入到第一和第二个磁盘,以此类推。
|
||||
|
||||
(LCTT 译注:原文中此处描述混淆有误,已经根据实际情况进行修改。)
|
||||
|
||||
现在你已经了解 RAID 10 怎样组合 RAID 1 和 RAID 0 来工作的了。如果我们有4个20 GB 的磁盘,总共为 80 GB,但我们将只能得到40 GB 的容量,另一半的容量在构建 RAID 10 中丢失。
|
||||
|
||||
#### RAID 10 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能。
|
||||
- 在 RAID 10 中我们将失去一半的磁盘容量。
|
||||
- 读与写的性能都很好,因为它会同时进行写入和读取。
|
||||
- 它能解决数据库的高 I/O 磁盘写操作。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
在 RAID 10 中,我们至少需要4个磁盘,前2个磁盘为 RAID 1,其他2个磁盘为 RAID 0,就像我之前说的,RAID 10 仅仅是组合了 RAID 0和1。如果我们需要扩展 RAID 组,最少需要添加4个磁盘。
|
||||
|
||||
**我的服务器设置**
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.229
|
||||
主机名 : rd10.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdd
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
磁盘 4 [20GB] : /dev/sde
|
||||
|
||||
有两种方法来设置 RAID 10,在这里两种方法我都会演示,但我更喜欢第一种方法,使用它来设置 RAID 10 更简单。
|
||||
|
||||
### 方法1:设置 RAID 10 ###
|
||||
|
||||
1、 首先,使用以下命令确认所添加的4块磁盘没有被使用。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
2、 四个磁盘被检测后,然后来检查磁盘是否存在 RAID 分区。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
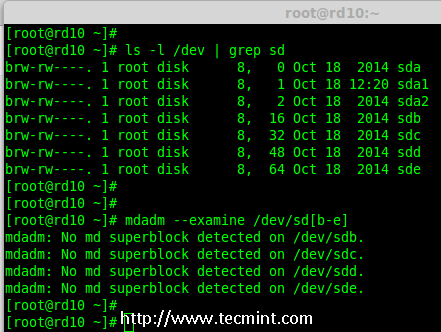
|
||||
|
||||
*验证添加的4块磁盘*
|
||||
|
||||
**注意**: 在上面的输出中,如果没有检测到 super-block 意味着在4块磁盘中没有定义过 RAID。
|
||||
|
||||
#### 第1步:为 RAID 分区 ####
|
||||
|
||||
3、 现在,使用`fdisk`,命令为4个磁盘(/dev/sdb, /dev/sdc, /dev/sdd 和 /dev/sde)创建新分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
#####为 /dev/sdb 创建分区#####
|
||||
|
||||
我来告诉你如何使用 fdisk 为磁盘(/dev/sdb)进行分区,此步也适用于其他磁盘。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
请使用以下步骤为 /dev/sdb 创建一个新的分区。
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*为磁盘 sdb 分区*
|
||||
|
||||
**注意**: 请使用上面相同的指令对其他磁盘(sdc, sdd sdd sde)进行分区。
|
||||
|
||||
4、 创建好4个分区后,需要使用下面的命令来检查磁盘是否存在 raid。
|
||||
|
||||
# mdadm -E /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd /dev/sde # 或
|
||||
|
||||
# mdadm -E /dev/sd[b-e]1
|
||||
# mdadm --examine /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 # 或
|
||||
|
||||
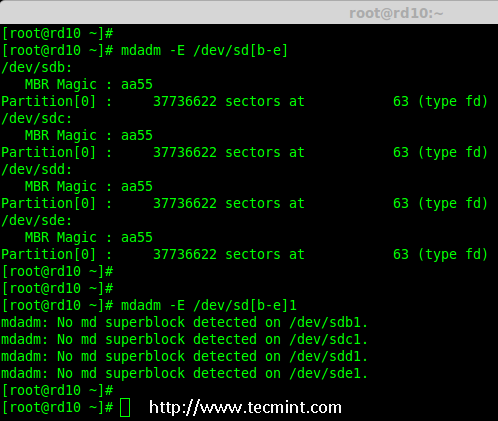
|
||||
|
||||
*检查磁盘*
|
||||
|
||||
**注意**: 以上输出显示,新创建的四个分区中没有检测到 super-block,这意味着我们可以继续在这些磁盘上创建 RAID 10。
|
||||
|
||||
#### 第2步: 创建 RAID 设备 `md` ####
|
||||
|
||||
5、 现在该创建一个`md`(即 /dev/md0)设备了,使用“mdadm” raid 管理工具。在创建设备之前,必须确保系统已经安装了`mdadm`工具,如果没有请使用下面的命令来安装。
|
||||
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
`mdadm`工具安装完成后,可以使用下面的命令创建一个`md` raid 设备。
|
||||
|
||||
# mdadm --create /dev/md0 --level=10 --raid-devices=4 /dev/sd[b-e]1
|
||||
|
||||
6、 接下来使用`cat`命令验证新创建的 raid 设备。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 md RAID 设备*
|
||||
|
||||
7、 接下来,使用下面的命令来检查4个磁盘。下面命令的输出会很长,因为它会显示4个磁盘的所有信息。
|
||||
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||
8、 接下来,使用以下命令来查看 RAID 阵列的详细信息。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*查看 RAID 阵列详细信息*
|
||||
|
||||
**注意**: 你在上面看到的结果,该 RAID 的状态是 active 和re-syncing。
|
||||
|
||||
#### 第3步:创建文件系统 ####
|
||||
|
||||
9、 使用 ext4 作为`md0′的文件系统,并将它挂载到`/mnt/raid10`下。在这里,我用的是 ext4,你可以使用你想要的文件系统类型。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
*创建 md 文件系统*
|
||||
|
||||
10、 在创建文件系统后,挂载文件系统到`/mnt/raid10`下,并使用`ls -l`命令列出挂载点下的内容。
|
||||
|
||||
# mkdir /mnt/raid10
|
||||
# mount /dev/md0 /mnt/raid10/
|
||||
# ls -l /mnt/raid10/
|
||||
|
||||
接下来,在挂载点下创建一些文件,并在文件中添加些内容,然后检查内容。
|
||||
|
||||
# touch /mnt/raid10/raid10_files.txt
|
||||
# ls -l /mnt/raid10/
|
||||
# echo "raid 10 setup with 4 disks" > /mnt/raid10/raid10_files.txt
|
||||
# cat /mnt/raid10/raid10_files.txt
|
||||
|
||||

|
||||
|
||||
*挂载 md 设备*
|
||||
|
||||
11、 要想自动挂载,打开`/etc/fstab`文件并添加下面的条目,挂载点根据你环境的不同来添加。使用 wq! 保存并退出。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
/dev/md0 /mnt/raid10 ext4 defaults 0 0
|
||||
|
||||

|
||||
|
||||
*挂载 md 设备*
|
||||
|
||||
12、 接下来,在重新启动系统前使用`mount -a`来确认`/etc/fstab`文件是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
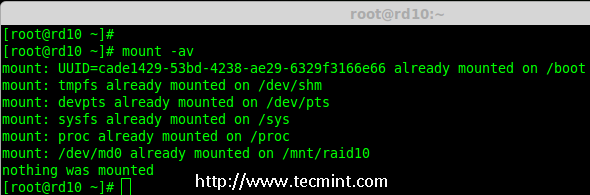
|
||||
|
||||
*检查 Fstab 中的错误*
|
||||
|
||||
#### 第四步:保存 RAID 配置 ####
|
||||
|
||||
13、 默认情况下 RAID 没有配置文件,所以我们需要在上述步骤完成后手动保存它。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||

|
||||
|
||||
*保存 RAID10 的配置*
|
||||
|
||||
就这样,我们使用方法1创建完了 RAID 10,这种方法是比较容易的。现在,让我们使用方法2来设置 RAID 10。
|
||||
|
||||
### 方法2:创建 RAID 10 ###
|
||||
|
||||
1、 在方法2中,我们必须定义2组 RAID 1,然后我们需要使用这些创建好的 RAID 1 的集合来定义一个 RAID 0。在这里,我们将要做的是先创建2个镜像(RAID1),然后创建 RAID0 (条带化)。
|
||||
|
||||
首先,列出所有的可用于创建 RAID 10 的磁盘。
|
||||
|
||||
# ls -l /dev | grep sd
|
||||
|
||||
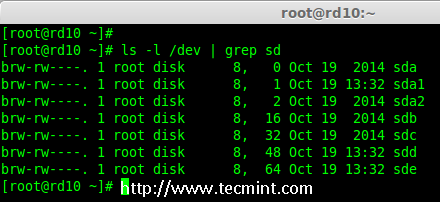
|
||||
|
||||
*列出了 4 个设备*
|
||||
|
||||
2、 将4个磁盘使用`fdisk`命令进行分区。对于如何分区,您可以按照上面的第1步。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
# fdisk /dev/sdd
|
||||
# fdisk /dev/sde
|
||||
|
||||
3、 在完成4个磁盘的分区后,现在检查磁盘是否存在 RAID块。
|
||||
|
||||
# mdadm --examine /dev/sd[b-e]
|
||||
# mdadm --examine /dev/sd[b-e]1
|
||||
|
||||
|
||||
|
||||
*检查 4 个磁盘*
|
||||
|
||||
#### 第1步:创建 RAID 1 ####
|
||||
|
||||
4、 首先,使用4块磁盘创建2组 RAID 1,一组为`sdb1′和 `sdc1′,另一组是`sdd1′ 和 `sde1′。
|
||||
|
||||
# mdadm --create /dev/md1 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[b-c]1
|
||||
# mdadm --create /dev/md2 --metadata=1.2 --level=1 --raid-devices=2 /dev/sd[d-e]1
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 RAID 1*
|
||||
|
||||

|
||||
|
||||
*查看 RAID 1 的详细信息*
|
||||
|
||||
#### 第2步:创建 RAID 0 ####
|
||||
|
||||
5、 接下来,使用 md1 和 md2 来创建 RAID 0。
|
||||
|
||||
# mdadm --create /dev/md0 --level=0 --raid-devices=2 /dev/md1 /dev/md2
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
*创建 RAID 0*
|
||||
|
||||
#### 第3步:保存 RAID 配置 ####
|
||||
|
||||
6、 我们需要将配置文件保存在`/etc/mdadm.conf`文件中,使其每次重新启动后都能加载所有的 RAID 设备。
|
||||
|
||||
# mdadm --detail --scan --verbose >> /etc/mdadm.conf
|
||||
|
||||
在此之后,我们需要按照方法1中的第3步来创建文件系统。
|
||||
|
||||
就是这样!我们采用的方法2创建完了 RAID 1+0。我们将会失去一半的磁盘空间,但相比其他 RAID ,它的性能将是非常好的。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这里,我们采用两种方法创建 RAID 10。RAID 10 具有良好的性能和冗余性。希望这篇文章可以帮助你了解 RAID 10 嵌套 RAID。在后面的文章中我们会看到如何扩展现有的 RAID 阵列以及更多精彩的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-raid-10-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
@ -0,0 +1,182 @@
|
||||
在 Linux 下使用 RAID(七):在 Raid 中扩展现有的 RAID 阵列和删除故障的磁盘
|
||||
================================================================================
|
||||
|
||||
每个新手都会对阵列(array)这个词所代表的意思产生疑惑。阵列只是磁盘的一个集合。换句话说,我们可以称阵列为一个集合(set)或一组(group)。就像一组鸡蛋中包含6个一样。同样 RAID 阵列中包含着多个磁盘,可能是2,4,6,8,12,16等,希望你现在知道了什么是阵列。
|
||||
|
||||
在这里,我们将看到如何扩展现有的阵列或 RAID 组。例如,如果我们在阵列中使用2个磁盘形成一个 raid 1 集合,在某些情况,如果该组中需要更多的空间,就可以使用 mdadm -grow 命令来扩展阵列大小,只需要将一个磁盘加入到现有的阵列中即可。在说完扩展(添加磁盘到现有的阵列中)后,我们将看看如何从阵列中删除故障的磁盘。
|
||||
|
||||
|
||||
|
||||
*扩展 RAID 阵列和删除故障的磁盘*
|
||||
|
||||
假设磁盘中的一个有问题了需要删除该磁盘,但我们需要在删除磁盘前添加一个备用磁盘来扩展该镜像,因为我们需要保存我们的数据。当磁盘发生故障时我们需要从阵列中删除它,这是这个主题中我们将要学习到的。
|
||||
|
||||
#### 扩展 RAID 的特性 ####
|
||||
|
||||
- 我们可以增加(扩展)任意 RAID 集合的大小。
|
||||
- 我们可以在使用新磁盘扩展 RAID 阵列后删除故障的磁盘。
|
||||
- 我们可以扩展 RAID 阵列而无需停机。
|
||||
|
||||
####要求 ####
|
||||
|
||||
- 为了扩展一个RAID阵列,我们需要一个已有的 RAID 组(阵列)。
|
||||
- 我们需要额外的磁盘来扩展阵列。
|
||||
- 在这里,我们使用一块磁盘来扩展现有的阵列。
|
||||
|
||||
在我们了解扩展和恢复阵列前,我们必须了解有关 RAID 级别和设置的基本知识。点击下面的链接了解这些。
|
||||
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP地址 : 192.168.0.230
|
||||
主机名 : grow.tecmintlocal.com
|
||||
2 块现有磁盘 : 1 GB
|
||||
1 块额外磁盘 : 1 GB
|
||||
|
||||
在这里,我们已有一个 RAID ,有2块磁盘,每个大小为1GB,我们现在再增加一个磁盘到我们现有的 RAID 阵列中,其大小为1GB。
|
||||
|
||||
### 扩展现有的 RAID 阵列 ###
|
||||
|
||||
1、 在扩展阵列前,首先使用下面的命令列出现有的 RAID 阵列。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*检查现有的 RAID 阵列*
|
||||
|
||||
**注意**: 以上输出显示,已经有了两个磁盘在 RAID 阵列中,级别为 RAID 1。现在我们增加一个磁盘到现有的阵列里。
|
||||
|
||||
2、 现在让我们添加新的磁盘“sdd”,并使用`fdisk`命令来创建分区。
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||
请使用以下步骤为 /dev/sdd 创建一个新的分区。
|
||||
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 按 `L`,列出所有可用的类型。
|
||||
- 按 `t` 去修改分区。
|
||||
- 键入 `fd` 设置为 Linux 的 RAID 类型,然后按回车确认。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
*为 sdd 创建新的分区*
|
||||
|
||||
3、 一旦新的 sdd 分区创建完成后,你可以使用下面的命令验证它。
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||
|
||||
|
||||
*确认 sdd 分区*
|
||||
|
||||
4、 接下来,在添加到阵列前先检查磁盘是否有 RAID 分区。
|
||||
|
||||
# mdadm --examine /dev/sdd1
|
||||
|
||||
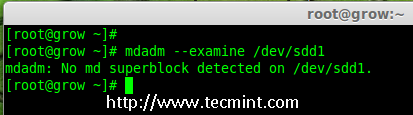
|
||||
|
||||
*在 sdd 分区中检查 RAID*
|
||||
|
||||
**注意**:以上输出显示,该盘有没有发现 super-blocks,意味着我们可以将新的磁盘添加到现有阵列。
|
||||
|
||||
5、 要添加新的分区 /dev/sdd1 到现有的阵列 md0,请使用以下命令。
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
|
||||
|
||||
*添加磁盘到 RAID 阵列*
|
||||
|
||||
6、 一旦新的磁盘被添加后,在我们的阵列中检查新添加的磁盘。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*确认将新磁盘添加到 RAID 中*
|
||||
|
||||
**注意**: 在上面的输出,你可以看到磁盘已经被添加作为备用的。在这里,我们的阵列中已经有了2个磁盘,但我们期待阵列中有3个磁盘,因此我们需要扩展阵列。
|
||||
|
||||
7、 要扩展阵列,我们需要使用下面的命令。
|
||||
|
||||
# mdadm --grow --raid-devices=3 /dev/md0
|
||||
|
||||
|
||||
|
||||
*扩展 Raid 阵列*
|
||||
|
||||
现在我们可以看到第三块磁盘(sdd1)已被添加到阵列中,在第三块磁盘被添加后,它将从另外两块磁盘上同步数据。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*确认 Raid 阵列*
|
||||
|
||||
**注意**: 对于大容量磁盘会需要几个小时来同步数据。在这里,我们使用的是1GB的虚拟磁盘,所以它非常快在几秒钟内便会完成。
|
||||
|
||||
### 从阵列中删除磁盘 ###
|
||||
|
||||
8、 在数据被从其他两个磁盘同步到新磁盘`sdd1`后,现在三个磁盘中的数据已经相同了(镜像)。
|
||||
|
||||
正如我前面所说的,假定一个磁盘出问题了需要被删除。所以,现在假设磁盘`sdc1`出问题了,需要从现有阵列中删除。
|
||||
|
||||
在删除磁盘前我们要将其标记为失效,然后我们才可以将其删除。
|
||||
|
||||
# mdadm --fail /dev/md0 /dev/sdc1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 阵列中模拟磁盘故障*
|
||||
|
||||
从上面的输出中,我们清楚地看到,磁盘在下面被标记为 faulty。即使它是 faulty 的,我们仍然可以看到 raid 设备有3个,1个损坏了,状态是 degraded。
|
||||
|
||||
现在我们要从阵列中删除 faulty 的磁盘,raid 设备将像之前一样继续有2个设备。
|
||||
|
||||
# mdadm --remove /dev/md0 /dev/sdc1
|
||||
|
||||
|
||||
|
||||
*在 Raid 阵列中删除磁盘*
|
||||
|
||||
9、 一旦故障的磁盘被删除,然后我们只能使用2个磁盘来扩展 raid 阵列了。
|
||||
|
||||
# mdadm --grow --raid-devices=2 /dev/md0
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
*在 RAID 阵列扩展磁盘*
|
||||
|
||||
从上面的输出中可以看到,我们的阵列中仅有2台设备。如果你需要再次扩展阵列,按照如上所述的同样步骤进行。如果你需要添加一个磁盘作为备用,将其标记为 spare,因此,如果磁盘出现故障时,它会自动顶上去并重建数据。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经看到了如何扩展现有的 RAID 集合,以及如何在重新同步已有磁盘的数据后从一个阵列中删除故障磁盘。所有这些步骤都可以不用停机来完成。在数据同步期间,系统用户,文件和应用程序不会受到任何影响。
|
||||
|
||||
在接下来的文章我将告诉你如何管理 RAID,敬请关注更新,不要忘了写评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/grow-raid-array-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
109
published/201508/kde-plasma-5.4.md
Normal file
109
published/201508/kde-plasma-5.4.md
Normal file
@ -0,0 +1,109 @@
|
||||
KDE Plasma 5.4.0 发布,八月特色版
|
||||
=============================
|
||||
|
||||

|
||||
|
||||
2015 年 8 月 25 ,星期二,KDE 发布了 Plasma 5 的一个特色新版本。
|
||||
|
||||
此版本为我们带来了许多非常棒的感受,如优化了对高分辨率的支持,KRunner 自动补全和一些新的 Breeze 漂亮图标。这还为不久以后的技术预览版的 Wayland 桌面奠定了基础。我们还带来了几个新组件,如声音音量部件,显示器校准工具和测试版的用户管理工具。
|
||||
|
||||
###新的音频音量程序
|
||||
|
||||

|
||||
|
||||
新的音频音量程序直接工作于 PulseAudio (Linux 上一个非常流行的音频服务) 之上 ,并且在一个漂亮的简约的界面提供一个完整的音量控制和输出设定。
|
||||
|
||||
###替代的应用控制面板起动器
|
||||
|
||||

|
||||
|
||||
Plasma 5.4 在 kdeplasma-addons 软件包中提供了一个全新的全屏的应用控制面板,它具有应用菜单的所有功能,还支持缩放和全空间键盘导航。新的起动器可以像你目前所用的“最近使用的”或“收藏的文档和联系人”一样简单和快速地查找应用。
|
||||
|
||||
###丰富的艺术图标
|
||||
|
||||

|
||||
|
||||
Plasma 5.4 提供了超过 1400 个的新图标,其中不仅包含 KDE 程序的,而且还为 Inkscape, Firefox 和 Libreoffice 提供 Breeze 主题的艺术图标,可以体验到更加一致和本地化的感觉。
|
||||
|
||||
###KRunner 历史记录
|
||||
|
||||

|
||||
|
||||
KRunner 现在可以记住之前的搜索历史并根据历史记录进行自动补全。
|
||||
|
||||
###Network 程序中实用的图形展示
|
||||
|
||||

|
||||
|
||||
Network 程序现在可以以图形形式显示网络流量了,同时也支持两个新的 VPN 插件:通过 SSH 连接或通过 SSTP 连接。
|
||||
|
||||
###Wayland 技术预览
|
||||
|
||||
随着 Plasma 5.4 ,Wayland 桌面发布了第一个技术预览版。在使用自由图形驱动(free graphics drivers)的系统上可以使用 KWin(Plasma 的 Wayland 合成器和 X11 窗口管理器)通过[内核模式设定][1]来运行 Plasma。现在已经支持的功能需求来自于[手机 Plasma 项目][2],更多的面向桌面的功能还未被完全实现。现在还不能作为替换那些基于 Xorg 的桌面,但可以轻松地对它测试和贡献,以及观看令人激动视频。有关如何在 Wayland 中使用 Plasma 的介绍请到:[KWin 维基页][3]。Wlayland 将随着我们构建的稳定版本而逐步得到改进。
|
||||
|
||||
###其他的改变和添加
|
||||
|
||||
- 优化对高 DPI 支持
|
||||
- 更少的内存占用
|
||||
- 桌面搜索使用了更快的新后端
|
||||
- 便笺增加拖拉支持和键盘导航
|
||||
- 回收站重新支持拖拉
|
||||
- 系统托盘获得更快的可配置性
|
||||
- 文档重新修订和更新
|
||||
- 优化了窄小面板上的数字时钟的布局
|
||||
- 数字时钟支持 ISO 日期
|
||||
- 切换数字时钟 12/24 格式更简单
|
||||
- 日历显示第几周
|
||||
- 任何项目都可以收藏进应用菜单(Kicker),支持收藏文档和 Telepathy 联系人
|
||||
- Telepathy 联系人收藏可以展示联系人的照片和实时状态
|
||||
- 优化程序与容器间的焦点和激活处理
|
||||
- 文件夹视图中各种小修复:更好的默认尺寸,鼠标交互问题以及文本标签换行
|
||||
- 任务管理器更好的呈现起动器默认的应用图标
|
||||
- 可再次通过将程序拖入任务管理器来添加启动器
|
||||
- 可配置中间键点击在任务管理器中的行为:无动作,关闭窗口,启动一个相同的程序的新实例
|
||||
- 任务管理器现在以列排序优先,无论用户是否更倾向于行优先;许多用户更喜欢这样排序是因为它会使更少的任务按钮像窗口一样移来移去
|
||||
- 优化任务管理器的图标和缩放边
|
||||
- 任务管理器中各种小修复:垂直下拉,触摸事件处理现在支持所有系统,组扩展箭头的视觉问题
|
||||
- 提供可用的目的框架技术预览版,可以使用 QuickShare Plasmoid,它可以让许多 web 服务分享文件更容易
|
||||
- 增加了显示器配置工具
|
||||
- 增加的 kwallet-pam 可以在登录时打开 wallet
|
||||
- 用户管理器现在会同步联系人到 KConfig 的设置中,用户账户模块被丢弃了
|
||||
- 应用程序菜单(Kicker)的性能得到改善
|
||||
- 应用程序菜单(Kicker)各种小修复:隐藏/显示程序更加可靠,顶部面板的对齐修复,文件夹视图中 “添加到桌面”更加可靠,在基于 KActivities 的最新模块中有更好的表现
|
||||
- 支持自定义菜单布局 (kmenuedit)和应用程序菜单(Kicker)支持菜单项目分隔
|
||||
- 当在面板中时,改进了文件夹视图,参见 [blog][4]
|
||||
- 将文件夹拖放到桌面容器现在会再次创建一个文件夹视图
|
||||
|
||||
[完整的 Plasma 5.4 变更日志在此](https://www.kde.org/announcements/plasma-5.3.2-5.4.0-changelog.php)
|
||||
|
||||
###Live 镜像
|
||||
|
||||
尝鲜的最简单的方式就是从 U 盘中启动,可以在 KDE 社区 Wiki 中找到 各种 [带有 Plasma 5 的 Live 镜像][5]。
|
||||
|
||||
###下载软件包
|
||||
|
||||
各发行版已经构建了软件包,或者正在构建,wiki 中的列出了各发行版的软件包名:[软件包下载维基页][6]。
|
||||
|
||||
###源码下载
|
||||
|
||||
可以直接从源码中安装 Plasma 5。KDE 社区 Wiki 已经介绍了[怎样编译][7]。
|
||||
|
||||
注意,Plasma 5 与 Plasma 4 不兼容,必须先卸载旧版本,或者安装到不同的前缀处。
|
||||
|
||||
|
||||
- [源代码信息页][8]
|
||||
|
||||
---
|
||||
|
||||
via: https://www.kde.org/announcements/plasma-5.4.0.php
|
||||
|
||||
译者:[Locez](http://locez.com) 校对:[wxy](http://github.com/wxy)
|
||||
|
||||
[1]:https://en.wikipedia.org/wiki/Direct_Rendering_Manager
|
||||
[2]:https://dot.kde.org/2015/07/25/plasma-mobile-free-mobile-platform
|
||||
[3]:https://community.kde.org/KWin/Wayland#Start_a_Plasma_session_on_Wayland
|
||||
[4]:https://blogs.kde.org/2015/06/04/folder-view-panel-popups-are-list-views-again
|
||||
[5]:https://community.kde.org/Plasma/LiveImages
|
||||
[6]:https://community.kde.org/Plasma/Packages
|
||||
[7]:http://community.kde.org/Frameworks/Building
|
||||
[8]:https://www.kde.org/info/plasma-5.4.0.php
|
||||
125
published/201509/20141223 Defending the Free Linux World.md
Normal file
125
published/201509/20141223 Defending the Free Linux World.md
Normal file
@ -0,0 +1,125 @@
|
||||
守卫自由的 Linux 世界
|
||||
================================================================================
|
||||

|
||||
|
||||
**合作是开源的一部分。OIN 的 CEO Keith Bergelt 解释说,开放创新网络(Open Invention Network)模式允许众多企业和公司决定它们该在哪较量,在哪合作。随着开源的演变,“我们需要为合作创造渠道,否则我们将会有几百个团体把数十亿美元花费到同样的技术上。”**
|
||||
|
||||
[开放创新网络(Open Invention Network)][1],即 OIN,正在全球范围内开展让 Linux 远离专利诉讼的伤害的活动。它的努力得到了一千多个公司的热烈回应,它们的加入让这股力量成为了历史上最大的反专利管理组织。
|
||||
|
||||
开放创新网络以白帽子组织的身份创建于2005年,目的是保护 Linux 免受来自许可证方面的困扰。包括 Google、 IBM、 NEC、 Novell、 Philips、 [Red Hat][2] 和 Sony 这些成员的董事会给予了它可观的经济支持。世界范围内的多个组织通过签署自由 OIN 协议加入了这个社区。
|
||||
|
||||
创立开放创新网络的组织成员把它当作利用知识产权保护 Linux 的大胆尝试。它的商业模式非常的难以理解。它要求它的成员采用免版权许可证,并永远放弃由于 Linux 相关知识产权起诉其他成员的机会。
|
||||
|
||||
然而,从 Linux 收购风波——想想服务器和云平台——那时起,保护 Linux 知识产权的策略就变得越加的迫切。
|
||||
|
||||
在过去的几年里,Linux 的版图曾经历了一场变革。OIN 不必再向人们解释这个组织的定义,也不必再解释为什么 Linux 需要保护。据 OIN 的 CEO Keith Bergelt 说,现在 Linux 的重要性得到了全世界的关注。
|
||||
|
||||
“我们已经见到了一场人们了解到 OIN 如何让合作受益的文化变革,”他对 LinuxInsider 说。
|
||||
|
||||
### 如何运作 ###
|
||||
|
||||
开放创新网络使用专利权的方式创建了一个协作环境。这种方法有助于确保创新的延续。这已经使很多软件厂商、顾客、新型市场和投资者受益。
|
||||
|
||||
开放创新网络的专利证可以让任何公司、公共机构或个人免版权使用。这些权利的获得建立在签署者同意不会专为了维护专利而攻击 Linux 系统的基础上。
|
||||
|
||||
OIN 确保 Linux 的源代码保持开放的状态。这让编程人员、设备厂商、独立软件开发者和公共机构在投资和使用 Linux 时不用过多的担心知识产权的问题。这让对 Linux 进行重新打包、嵌入和使用的公司省了不少钱。
|
||||
|
||||
“随着版权许可证越来越广泛的使用,对 OIN 许可证的需求也变得更加的迫切。现在,人们正在寻找更加简单或更实用的解决方法”,Bergelt 说。
|
||||
|
||||
OIN 法律防御援助对成员是免费的。成员必须承诺不对 OIN 名单上的软件发起专利诉讼。为了保护他们的软件,他们也同意提供他们自己的专利。最终,这些保证将让几十万的交叉许可通过该网络相互连接起来,Bergelt 如此解释道。
|
||||
|
||||
### 填补法律漏洞 ###
|
||||
|
||||
“OIN 正在做的事情是非常必要的。它提供另一层 IP (知识产权)保护,”[休斯顿法律中心大学][3]的副教授 Greg R. Vetter 这样说道。
|
||||
|
||||
他回答 LinuxInsider 说,第二版 GPL 许可证被某些人认为提供了隐含的专利许可,但是律师们更喜欢明确的许可。
|
||||
|
||||
OIN 所提供的许可填补了这个空白。它还明确的覆盖了 Linux 内核。据 Vetter 说,明确的专利许可并不是 GPLv2 中的必要部分,但是这个部分被加入到了 GPLv3 中。(LCTT 译注:Linux 内核采用的是 GPLv2 的许可)
|
||||
|
||||
拿一个在 GPLv3 中写了10000行代码的代码编写者来说。随着时间推移,其他的代码编写者会贡献更多行的代码,也加入到了知识产权中。GPLv3 中的软件专利许可条款将基于所有参与的贡献者的专利,保护全部代码的使用,Vetter 如此说道。
|
||||
|
||||
### 并不完全一样 ###
|
||||
|
||||
专利权和许可证在法律结构上层层叠叠互相覆盖。弄清两者对开源软件的作用就像是穿越雷区。
|
||||
|
||||
Vetter 说“通常,许可证是授予建立在专利和版权法律上的额外权利的法律结构。许可证被认为是给予了人们做一些的可能会侵犯到其他人的知识产权权利的事的许可。”
|
||||
|
||||
Vetter 指出,很多自由开源许可证(例如 Mozilla 公共许可、GNU GPLv3 以及 Apache 软件许可)融合了某些互惠专利权的形式。Vetter 指出,像 BSD 和 MIT 这样旧的许可证不会提到专利。
|
||||
|
||||
一个软件的许可证让其他人可以在某种程度上使用这个编程人员创造的代码。版权对所属权的建立是自动的,只要某个人写或者画了某个原创的东西。然而,版权只覆盖了个别的表达方式和衍生的作品。他并没有涵盖代码的功能性或可用的想法。
|
||||
|
||||
专利涵盖了功能性。专利权还可以被许可。版权可能无法保护某人如何独立地开发对另一个人的代码的实现,但是专利填补了这个小瑕疵,Vetter 解释道。
|
||||
|
||||
### 寻找安全通道 ###
|
||||
|
||||
许可证和专利混合的法律性质可能会对开源开发者产生威胁。据 [Chaotic Moon Studios][4] 的创办者之一、 [IEEE][5] 计算机协会成员 William Hurley 说,对于某些人来说,即使是 GPL 也会成为威胁。
|
||||
|
||||
“在很久以前,开源是个完全不同的世界。被彼此间的尊重和把代码视为艺术而非资产的观点所驱动,那时的程序和代码比现在更加的开放。我相信很多为最好的愿景所做的努力几乎最后总是背负着意外的结果,”Hurley 这样告诉 LinuxInsider。
|
||||
|
||||
他暗示说,成员人数超越了1000人(的组织)可能会在知识产权保护重要性方面意见不一。这可能会继续搅混开源生态系统这滩浑水。
|
||||
|
||||
“最终,这些显现出了围绕着知识产权的常见的一些错误概念。拥有几千个开发者并不会减少风险——而是增加。给出了专利许可的开发者越多,它们看起来就越值钱,”Hurley 说。“它们看起来越值钱,有着类似专利的或者其他知识产权的人就越可能试图利用并从中榨取他们自己的经济利益。”
|
||||
|
||||
### 共享与竞争共存 ###
|
||||
|
||||
竞合策略是开源的一部分。OIN 模型让各个公司能够决定他们将在哪竞争以及在哪合作,Bergelt 解释道。
|
||||
|
||||
“开源演化中的许多改变已经把我们移到了另一个方向上。我们必须为合作创造渠道。否则我们将会有几百个团体把数十亿美元花费到同样的技术上,”他说。
|
||||
|
||||
手机产业的革新就是个很好的例子。各个公司放出了不同的标准。没有共享,没有合作,Bergelt 解释道。
|
||||
|
||||
他说:“这让我们在美国接触技术的能力落后了七到十年。我们接触设备的经验远远落后于世界其他地方的人。在我们用不上 CDMA (Code Division Multiple Access 码分多址访问通信技术)时对 GSM (Global System for Mobile Communications 全球移动通信系统) 还沾沾自喜。”
|
||||
|
||||
### 改变格局 ###
|
||||
|
||||
OIN 在去年经历了激增400个新许可的增长。这意味着着开源有了新趋势。
|
||||
|
||||
Bergelt 说:“市场到达了一个临界点,组织内的人们终于意识到直白地合作和竞争的需要。结果是两件事同时进行。这可能会变得复杂、费力。”
|
||||
|
||||
然而,这个由人们开始考虑合作和竞争的文化革新所驱动的转换过程是可以接受的。他解释说,这也是一个人们怎样拥抱开源的转变——尤其是在 Linux 这个开源社区的领导者项目。
|
||||
|
||||
还有一个迹象是,最具意义的新项目都没有在 GPLv3 许可下开发。
|
||||
|
||||
### 二个总比一个好 ###
|
||||
|
||||
“GPL 极为重要,但是事实是有一堆的许可模型正被使用着。在 Eclipse、Apache 和 Berkeley 许可中,专利问题的相对可解决性通常远远低于在 GPLv3 中的。”Bergelt 说。
|
||||
|
||||
GPLv3 对于解决专利问题是个自然的补充——但是 GPL 自身不足以独自解决围绕专利使用的潜在冲突。所以 OIN 的设计是以能够补充版权许可为目的的,他补充道。
|
||||
|
||||
然而,层层叠叠的专利和许可也许并没有带来多少好处。到最后,专利在几乎所有的案例中都被用于攻击目的——而不是防御目的,Bergelt 暗示说。
|
||||
|
||||
“如果你不准备对其他人采取法律行动,那么对于你的知识产权来说专利可能并不是最佳的法律保护方式”,他说。“我们现在生活在一个对软件——开放的和专有的——误会重重的世界里。这些软件还被错误而过时的专利系统所捆绑。我们每天在工业化和被扼杀的创新中挣扎”,他说。
|
||||
|
||||
### 法院是最后的手段###
|
||||
|
||||
想到 OIN 的出现抑制了诉讼的泛滥就感到十分欣慰,Bergelt 说,或者至少可以说 OIN 的出现扼制了特定的某些威胁。
|
||||
|
||||
“可以说我们让人们放下他们的武器。同时我们正在创建一种新的文化规范。一旦你入股这个模型中的非侵略专利,所产生的相关影响就是对合作的鼓励”,他说。
|
||||
|
||||
如果你愿意承诺合作,你的第一反应就会趋向于不急着起诉。相反的,你会想如何让我们允许你使用我们所拥有的东西并让它为你赚钱,而同时我们也能使用你所拥有的东西,Bergelt 解释道。
|
||||
|
||||
“OIN 是个多面的解决方式。它鼓励签署者创造双赢协议”,他说,“这让起诉成为最逼不得已的行为。那才是它的位置。”
|
||||
|
||||
### 底线###
|
||||
|
||||
Bergelt 坚信,OIN 的运作是为了阻止 Linux 受到专利伤害。在这个需要 Linux 的世界里没有诉讼的地方。
|
||||
|
||||
唯一临近的是与微软的移动之争,这关系到行业的发展前景(原文: The only thing that comes close are the mobile wars with Microsoft, which focus on elements high in the stack. 不太理解,请指正。)。那些来自法律的挑战可能是为了提高包括使用 Linux 产品的所属权的成本,Bergelt 说。
|
||||
|
||||
尽管如此“这些并不是有关 Linux 诉讼”,他说。“他们的重点并不在于 Linux 的核心。他们关注的是 Linux 系统里都有些什么。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -1,5 +1,6 @@
|
||||
如何设置在 Quagga BGP 路由器中设置 IPv6 的 BGP 对等体和过滤
|
||||
================================================================================
|
||||
|
||||
在之前的教程中,我们演示了如何使用Quagga建立一个[完备的BGP路由器][1]和配置[前缀过滤][2]。在本教程中,我们会向你演示如何创建IPv6 BGP对等体并通过BGP通告IPv6前缀。同时我们也将演示如何使用前缀列表和路由映射特性来过滤通告的或者获取到的IPv6前缀。
|
||||
|
||||
### 拓扑 ###
|
||||
@ -47,7 +48,7 @@ Quagga内部提供一个叫作vtysh的shell,其界面与那些主流路由厂
|
||||
|
||||
# vtysh
|
||||
|
||||
提示将改为:
|
||||
提示符将改为:
|
||||
|
||||
router-a#
|
||||
|
||||
@ -65,7 +66,7 @@ Quagga内部提供一个叫作vtysh的shell,其界面与那些主流路由厂
|
||||
|
||||
router-a# configure terminal
|
||||
|
||||
提示将变更成:
|
||||
提示符将变更成:
|
||||
|
||||
router-a(config)#
|
||||
|
||||
@ -246,13 +247,13 @@ Quagga内部提供一个叫作vtysh的shell,其界面与那些主流路由厂
|
||||
via: http://xmodulo.com/ipv6-bgp-peering-filtering-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
[1]:https://linux.cn/article-4232-1.html
|
||||
[2]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
[3]:http://ask.xmodulo.com/open-port-firewall-centos-rhel.html
|
||||
[4]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
@ -0,0 +1,348 @@
|
||||
Shilpa Nair 分享的 RedHat Linux 包管理方面的面试经验
|
||||
========================================================================
|
||||
**Shilpa Nair 刚于2015年毕业。她之后去了一家位于 Noida,Delhi 的国家新闻电视台,应聘实习生的岗位。在她去年毕业季的时候,常逛 Tecmint 寻求作业上的帮助。从那时开始,她就常去 Tecmint。**
|
||||
|
||||

|
||||
|
||||
*有关 RPM 方面的 Linux 面试题*
|
||||
|
||||
所有的问题和回答都是 Shilpa Nair 根据回忆重写的。
|
||||
|
||||
> “大家好!我是来自 Delhi 的Shilpa Nair。我不久前才顺利毕业,正寻找一个实习的机会。在大学早期的时候,我就对 UNIX 十分喜爱,所以我也希望这个机会能适合我,满足我的兴趣。我被提问了很多问题,大部分都是关于 RedHat 包管理的基础问题。”
|
||||
|
||||
下面就是我被问到的问题,和对应的回答。我仅贴出了与 RedHat GNU/Linux 包管理相关的,也是主要被提问的。
|
||||
|
||||
### 1,Linux 里如何查找一个包安装与否?假设你需要确认 ‘nano’ 有没有安装,你怎么做? ###
|
||||
|
||||
**回答**:为了确认 nano 软件包有没有安装,我们可以使用 rpm 命令,配合 -q 和 -a 选项来查询所有已安装的包
|
||||
|
||||
# rpm -qa nano
|
||||
或
|
||||
# rpm -qa | grep -i nano
|
||||
|
||||
nano-2.3.1-10.el7.x86_64
|
||||
|
||||
同时包的名字必须是完整的,不完整的包名会返回到提示符,不打印任何东西,就是说这包(包名字不全)未安装。下面的例子会更好理解些:
|
||||
|
||||
我们通常使用 vim 替代 vi 命令。当时如果我们查找安装包 vi/vim 的时候,我们就会看到标准输出上没有任何结果。
|
||||
|
||||
# vi
|
||||
# vim
|
||||
|
||||
尽管如此,我们仍然可以像上面一样运行 vi/vim 命令来清楚地知道包有没有安装。只是因为我们不知道它的完整包名才不能找到的。如果我们不确切知道完整的文件名,我们可以使用通配符:
|
||||
|
||||
# rpm -qa vim*
|
||||
|
||||
vim-minimal-7.4.160-1.el7.x86_64
|
||||
|
||||
通过这种方式,我们可以获得任何软件包的信息,安装与否。
|
||||
|
||||
### 2. 你如何使用 rpm 命令安装 XYZ 软件包? ###
|
||||
|
||||
**回答**:我们可以使用 rpm 命令安装任何的软件包(*.rpm),像下面这样,选项 -i(安装),-v(冗余或者显示额外的信息)和 -h(在安装过程中,打印#号显示进度)。
|
||||
|
||||
# rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
|
||||
Preparing... ################################# [100%]
|
||||
Updating / installing...
|
||||
1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
|
||||
如果要升级一个早期版本的包,应加上 -U 选项,选项 -v 和 -h 可以确保我们得到用 # 号表示的冗余输出,这增加了可读性。
|
||||
|
||||
### 3. 你已经安装了一个软件包(假设是 httpd),现在你想看看软件包创建并安装的所有文件和目录,你会怎么做? ###
|
||||
|
||||
**回答**:使用选项 -l(列出所有文件)和 -q(查询)列出 httpd 软件包安装的所有文件(Linux 哲学:所有的都是文件,包括目录)。
|
||||
|
||||
# rpm -ql httpd
|
||||
|
||||
/etc/httpd
|
||||
/etc/httpd/conf
|
||||
/etc/httpd/conf.d
|
||||
...
|
||||
|
||||
### 4. 假如你要移除一个软件包,叫 postfix。你会怎么做? ###
|
||||
|
||||
**回答**:首先我们需要知道什么包安装了 postfix。查找安装 postfix 的包名后,使用 -e(擦除/卸载软件包)和 -v(冗余输出)两个选项来实现。
|
||||
|
||||
# rpm -qa postfix*
|
||||
|
||||
postfix-2.10.1-6.el7.x86_64
|
||||
|
||||
然后移除 postfix,如下:
|
||||
|
||||
# rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
|
||||
Preparing packages...
|
||||
postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. 获得一个已安装包的具体信息,如版本,发行号,安装日期,大小,总结和一个简短的描述。 ###
|
||||
|
||||
**回答**:我们通过使用 rpm 的选项 -qi,后面接包名,可以获得关于一个已安装包的具体信息。
|
||||
|
||||
举个例子,为了获得 openssh 包的具体信息,我需要做的就是:
|
||||
|
||||
# rpm -qi openssh
|
||||
|
||||
[root@tecmint tecmint]# rpm -qi openssh
|
||||
Name : openssh
|
||||
Version : 6.8p1
|
||||
Release : 5.fc22
|
||||
Architecture: x86_64
|
||||
Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
Group : Applications/Internet
|
||||
Size : 1542057
|
||||
License : BSD
|
||||
....
|
||||
|
||||
### 6. 假如你不确定一个指定包的配置文件在哪,比如 httpd。你如何找到所有 httpd 提供的配置文件列表和位置。 ###
|
||||
|
||||
**回答**: 我们需要用选项 -c 接包名,这会列出所有配置文件的名字和他们的位置。
|
||||
|
||||
# rpm -qc httpd
|
||||
|
||||
/etc/httpd/conf.d/autoindex.conf
|
||||
/etc/httpd/conf.d/userdir.conf
|
||||
/etc/httpd/conf.d/welcome.conf
|
||||
/etc/httpd/conf.modules.d/00-base.conf
|
||||
/etc/httpd/conf/httpd.conf
|
||||
/etc/sysconfig/httpd
|
||||
|
||||
相似地,我们可以列出所有相关的文档文件,如下:
|
||||
|
||||
# rpm -qd httpd
|
||||
|
||||
/usr/share/doc/httpd/ABOUT_APACHE
|
||||
/usr/share/doc/httpd/CHANGES
|
||||
/usr/share/doc/httpd/LICENSE
|
||||
...
|
||||
|
||||
我们也可以列出所有相关的证书文件,如下:
|
||||
|
||||
# rpm -qL openssh
|
||||
|
||||
/usr/share/licenses/openssh/LICENCE
|
||||
|
||||
忘了说明上面的选项 -d 和 -L 分别表示 “文档” 和 “证书”,抱歉。
|
||||
|
||||
### 7. 你找到了一个配置文件,位于‘/usr/share/alsa/cards/AACI.conf’,现在你不确定该文件属于哪个包。你如何查找出包的名字? ###
|
||||
|
||||
**回答**:当一个包被安装后,相关的信息就存储在了数据库里。所以使用选项 -qf(-f 查询包拥有的文件)很容易追踪谁提供了上述的包。
|
||||
|
||||
# rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
alsa-lib-1.0.28-2.el7.x86_64
|
||||
|
||||
类似地,我们可以查找(谁提供的)关于任何子包,文档和证书文件的信息。
|
||||
|
||||
### 8. 你如何使用 rpm 查找最近安装的软件列表? ###
|
||||
|
||||
**回答**:如刚刚说的,每一样被安装的文件都记录在了数据库里。所以这并不难,通过查询 rpm 的数据库,找到最近安装软件的列表。
|
||||
|
||||
我们通过运行下面的命令,使用选项 -last(打印出最近安装的软件)达到目的。
|
||||
|
||||
# rpm -qa --last
|
||||
|
||||
上面的命令会打印出所有安装的软件,最近安装的软件在列表的顶部。
|
||||
|
||||
如果我们关心的是找出特定的包,我们可以使用 grep 命令从列表中匹配包(假设是 sqlite ),简单如下:
|
||||
|
||||
# rpm -qa --last | grep -i sqlite
|
||||
|
||||
sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
|
||||
我们也可以获得10个最近安装的软件列表,简单如下:
|
||||
|
||||
# rpm -qa --last | head
|
||||
|
||||
我们可以重定义一下,输出想要的结果,简单如下:
|
||||
|
||||
# rpm -qa --last | head -n 2
|
||||
|
||||
上面的命令中,-n 代表数目,后面接一个常数值。该命令是打印2个最近安装的软件的列表。
|
||||
|
||||
### 9. 安装一个包之前,你如果要检查其依赖。你会怎么做? ###
|
||||
|
||||
**回答**:检查一个 rpm 包(XYZ.rpm)的依赖,我们可以使用选项 -q(查询包),-p(指定包名)和 -R(查询/列出该包依赖的包,嗯,就是依赖)。
|
||||
|
||||
# rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
|
||||
/bin/sh
|
||||
/usr/bin/env
|
||||
glib2(x86-32) >= 2.40.0
|
||||
gsettings-desktop-schemas
|
||||
gtk3(x86-32) >= 3.16
|
||||
gtksourceview3(x86-32) >= 3.16
|
||||
gvfs
|
||||
libX11.so.6
|
||||
...
|
||||
|
||||
### 10. rpm 是不是一个前端的包管理工具呢? ###
|
||||
|
||||
**回答**:**不是!**rpm 是一个后端管理工具,适用于基于 Linux 发行版的 RPM (此处指 Redhat Package Management)。
|
||||
|
||||
[YUM][1],全称 Yellowdog Updater Modified,是一个 RPM 的前端工具。YUM 命令自动完成所有工作,包括解决依赖和其他一切事务。
|
||||
|
||||
最近,[DNF][2](YUM命令升级版)在Fedora 22发行版中取代了 YUM。尽管 YUM 仍然可以在 RHEL 和 CentOS 平台使用,我们也可以安装 dnf,与 YUM 命令共存使用。据说 DNF 较于 YUM 有很多提高。
|
||||
|
||||
知道更多总是好的,保持自我更新。现在我们移步到前端部分来谈谈。
|
||||
|
||||
### 11. 你如何列出一个系统上面所有可用的仓库列表。 ###
|
||||
|
||||
**回答**:简单地使用下面的命令,我们就可以列出一个系统上所有可用的仓库列表。
|
||||
|
||||
# yum repolist
|
||||
或
|
||||
# dnf repolist
|
||||
|
||||
Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
repo id repo name status
|
||||
*fedora Fedora 22 - x86_64 44,762
|
||||
ozonos Repository for Ozon OS 61
|
||||
*updates Fedora 22 - x86_64 - Updates
|
||||
|
||||
上面的命令仅会列出可用的仓库。如果你需要列出所有的仓库,不管可用与否,可以这样做。
|
||||
|
||||
# yum repolist all
|
||||
或
|
||||
# dnf repolist all
|
||||
|
||||
Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
repo id repo name status
|
||||
*fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
fedora-source Fedora 22 - Source disabled
|
||||
ozonos Repository for Ozon OS enabled: 61
|
||||
*updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. 你如何列出一个系统上所有可用并且安装了的包? ###
|
||||
|
||||
**回答**:列出一个系统上所有可用的包,我们可以这样做:
|
||||
|
||||
# yum list available
|
||||
或
|
||||
# dnf list available
|
||||
|
||||
ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
Available Packages
|
||||
0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
0install.x86_64 2.6.1-2.fc21 fedora
|
||||
0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
....
|
||||
|
||||
而列出一个系统上所有已安装的包,我们可以这样做。
|
||||
|
||||
# yum list installed
|
||||
或
|
||||
# dnf list installed
|
||||
|
||||
Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
Installed Packages
|
||||
GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
....
|
||||
|
||||
而要同时满足两个要求的时候,我们可以这样做。
|
||||
|
||||
# yum list
|
||||
或
|
||||
# dnf list
|
||||
|
||||
Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
Installed Packages
|
||||
GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
acl.x86_64 2.2.52-7.fc22 @System
|
||||
....
|
||||
|
||||
### 13. 你会怎么在一个系统上面使用 YUM 或 DNF 分别安装和升级一个包与一组包? ###
|
||||
|
||||
**回答**:安装一个包(假设是 nano),我们可以这样做,
|
||||
|
||||
# yum install nano
|
||||
|
||||
而安装一组包(假设是 Haskell),我们可以这样做,
|
||||
|
||||
# yum groupinstall 'haskell'
|
||||
|
||||
升级一个包(还是 nano),我们可以这样做,
|
||||
|
||||
# yum update nano
|
||||
|
||||
而为了升级一组包(还是 haskell),我们可以这样做,
|
||||
|
||||
# yum groupupdate 'haskell'
|
||||
|
||||
### 14. 你会如何同步一个系统上面的所有安装软件到稳定发行版? ###
|
||||
|
||||
**回答**:我们可以一个系统上(假设是 CentOS 或者 Fedora)的所有包到稳定发行版,如下,
|
||||
|
||||
# yum distro-sync [在 CentOS/ RHEL]
|
||||
或
|
||||
# dnf distro-sync [在 Fedora 20之后版本]
|
||||
|
||||
似乎来面试之前你做了相当不多的功课,很好!在进一步交谈前,我还想问一两个问题。
|
||||
|
||||
### 15. 你对 YUM 本地仓库熟悉吗?你尝试过建立一个本地 YUM 仓库吗?让我们简单看看你会怎么建立一个本地 YUM 仓库。 ###
|
||||
|
||||
**回答**:首先,感谢你的夸奖。回到问题,我必须承认我对本地 YUM 仓库十分熟悉,并且在我的本地主机上也部署过,作为测试用。
|
||||
|
||||
1、 为了建立本地 YUM 仓库,我们需要安装下面三个包:
|
||||
|
||||
# yum install deltarpm python-deltarpm createrepo
|
||||
|
||||
2、 新建一个目录(假设 /home/$USER/rpm),然后复制 RedHat/CentOS DVD 上的 RPM 包到这个文件夹下
|
||||
|
||||
# mkdir /home/$USER/rpm
|
||||
# cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
|
||||
3、 新建基本的库头文件如下。
|
||||
|
||||
# createrepo -v /home/$USER/rpm
|
||||
|
||||
4、 在路径 /etc/yum.repo.d 下创建一个 .repo 文件(如 abc.repo):
|
||||
|
||||
cd /etc/yum.repos.d && cat << EOF abc.repo
|
||||
[local-installation]name=yum-local
|
||||
baseurl=file:///home/$USER/rpm
|
||||
enabled=1
|
||||
gpgcheck=0
|
||||
EOF
|
||||
|
||||
**重要**:用你的用户名替换掉 $USER。
|
||||
|
||||
以上就是创建一个本地 YUM 仓库所要做的全部工作。我们现在可以从这里安装软件了,相对快一些,安全一些,并且最重要的是不需要 Internet 连接。
|
||||
|
||||
好了!面试过程很愉快。我已经问完了。我会将你推荐给 HR。你是一个年轻且十分聪明的候选者,我们很愿意你加入进来。如果你有任何问题,你可以问我。
|
||||
|
||||
**我**:谢谢,这确实是一次愉快的面试,我感到今天非常幸运,可以搞定这次面试...
|
||||
|
||||
显然,不会在这里结束。我问了很多问题,比如他们正在做的项目。我会担任什么角色,负责什么,,,balabalabala
|
||||
|
||||
小伙伴们,这之后的 3 天会经过 HR 轮,到时候所有问题到时候也会被写成文档。希望我当时表现不错。感谢你们所有的祝福。
|
||||
|
||||
谢谢伙伴们和 Tecmint,花时间来编辑我的面试经历。我相信 Tecmint 好伙伴们做了很大的努力,必要要赞一个。当我们与他人分享我们的经历的时候,其他人从我们这里知道了更多,而我们自己则发现了自己的不足。
|
||||
|
||||
这增加了我们的信心。如果你最近也有任何类似的面试经历,别自己蔵着。分享出来!让我们所有人都知道。你可以使用如下的表单来与我们分享你的经历。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:https://linux.cn/article-5718-1.html
|
||||
@ -1,8 +1,9 @@
|
||||
如何在 Docker 中通过 Kitematic 交互式执行任务
|
||||
如何在 Windows 上通过 Kitematic 使用 Docker
|
||||
================================================================================
|
||||
在本篇文章中,我们会学习如何在 Windows 操作系统上安装 Kitematic 以及部署一个 Hello World Nginx Web 服务器。Kitematic 是一个自由开源软件,它有现代化的界面设计使得允许我们在 Docker 中交互式执行任务。Kitematic 设计非常漂亮、界面也很不错。我们可以简单快速地开箱搭建我们的容器而不需要输入命令,我们可以在图形用户界面中通过简单的点击从而在容器上部署我们的应用。Kitematic 集成了 Docker Hub,允许我们搜索、拉取任何需要的镜像,并在上面部署应用。它同时也能很好地切换到命令行用户接口模式。目前,它包括了自动映射端口、可视化更改环境变量、配置卷、精简日志以及其它功能。
|
||||
|
||||
下面是在 Windows 上安装 Kitematic 并部署 Hello World Nginx Web 服务器的 3 个简单步骤。
|
||||
在本篇文章中,我们会学习如何在 Windows 操作系统上安装 Kitematic 以及部署一个测试性的 Nginx Web 服务器。Kitematic 是一个具有现代化的界面设计的自由开源软件,它可以让我们在 Docker 中交互式执行任务。Kitematic 设计的非常漂亮、界面美观。使用它,我们可以简单快速地开箱搭建我们的容器而不需要输入命令,可以在图形用户界面中通过简单的点击从而在容器上部署我们的应用。Kitematic 集成了 Docker Hub,允许我们搜索、拉取任何需要的镜像,并在上面部署应用。它同时也能很好地切换到命令行用户接口模式。目前,它包括了自动映射端口、可视化更改环境变量、配置卷、流式日志以及其它功能。
|
||||
|
||||
下面是在 Windows 上安装 Kitematic 并部署测试性 Nginx Web 服务器的 3 个简单步骤。
|
||||
|
||||
### 1. 下载 Kitematic ###
|
||||
|
||||
@ -16,15 +17,15 @@
|
||||
|
||||
### 2. 安装 Kitematic ###
|
||||
|
||||
下载好可执行安装程序之后,我们现在打算在我们的 Windows 操作系统上安装 Kitematic。安装程序现在会开始下载并安装运行 Kitematic 需要的依赖,包括 Virtual Box 和 Docker。如果已经在系统上安装了 Virtual Box,它会把它升级到最新版本。安装程序会在几分钟内完成,但取决于你网络和系统的速度。如果你还没有安装 Virtual Box,它会问你是否安装 Virtual Box 网络驱动。建议安装它,因为它有助于 Virtual Box 的网络。
|
||||
下载好可执行安装程序之后,我们现在就可以在我们的 Windows 操作系统上安装 Kitematic了。安装程序现在会开始下载并安装运行 Kitematic 需要的依赖软件,包括 Virtual Box 和 Docker。如果已经在系统上安装了 Virtual Box,它会把它升级到最新版本。安装程序会在几分钟内完成,但取决于你网络和系统的速度。如果你还没有安装 Virtual Box,它会问你是否安装 Virtual Box 网络驱动。建议安装它,因为它用于 Virtual Box 的网络功能。
|
||||
|
||||

|
||||
|
||||
需要的依赖 Docker 和 Virtual Box 安装完成并运行后,会让我们登录到 Docker Hub。如果我们还没有账户或者还不想登录,可以点击 **SKIP FOR NOW** 继续后面的步骤。
|
||||
所需的依赖 Docker 和 Virtual Box 安装完成并运行后,会让我们登录到 Docker Hub。如果我们还没有账户或者还不想登录,可以点击 **SKIP FOR NOW** 继续后面的步骤。
|
||||
|
||||

|
||||
|
||||
如果你还没有账户,你可以在应用程序上点击注册链接并在 Docker Hub 上创建账户。
|
||||
如果你还没有账户,你可以在应用程序上点击注册(Sign Up)链接并在 Docker Hub 上创建账户。
|
||||
|
||||
完成之后,就会出现 Kitematic 应用程序的第一个界面。正如下面看到的这样。我们可以搜索可用的 docker 镜像。
|
||||
|
||||
@ -50,7 +51,11 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们终于成功在 Windows 操作系统上安装了 Kitematic 并部署了一个 Hello World Ngnix 服务器。总是推荐下载安装 Kitematic 最新的发行版,因为会增加很多新的高级功能。由于 Docker 运行在 64 位平台,当前 Kitematic 也是为 64 位操作系统构建。它只能在 Windows 7 以及更高版本上运行。在这篇教程中,我们部署了一个 Nginx Web 服务器,类似地我们可以在 Kitematic 中简单的点击就能通过镜像部署任何 docker 容器。Kitematic 已经有可用的 Mac OS X 和 Windows 版本,Linux 版本也在开发中很快就会发布。如果你有任何疑问、建议或者反馈,请在下面的评论框中写下来以便我们更改地改进或更新我们的内容。非常感谢!Enjoy :-)
|
||||
我们终于成功在 Windows 操作系统上安装了 Kitematic 并部署了一个 Hello World Ngnix 服务器。推荐下载安装 Kitematic 最新的发行版,因为会增加很多新的高级功能。由于 Docker 运行在 64 位平台,当前 Kitematic 也是为 64 位操作系统构建。它只能在 Windows 7 以及更高版本上运行。
|
||||
|
||||
在这篇教程中,我们部署了一个 Nginx Web 服务器,类似地我们可以在 Kitematic 中简单的点击就能通过镜像部署任何 docker 容器。Kitematic 已经有可用的 Mac OS X 和 Windows 版本,Linux 版本也在开发中很快就会发布。
|
||||
|
||||
如果你有任何疑问、建议或者反馈,请在下面的评论框中写下来以便我们更改地改进或更新我们的内容。非常感谢!Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -58,7 +63,7 @@ via: http://linoxide.com/linux-how-to/interactively-docker-kitematic/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,690 @@
|
||||
你知道 Linux 内核是如何构建的吗?
|
||||
================================================================================
|
||||
|
||||
###介绍
|
||||
|
||||
我不会告诉你怎么在自己的电脑上去构建、安装一个定制化的 Linux 内核,这样的[资料](https://encrypted.google.com/search?q=building+linux+kernel#q=building+linux+kernel+from+source+code)太多了,它们会对你有帮助。本文会告诉你当你在内核源码路径里敲下`make` 时会发生什么。
|
||||
|
||||
当我刚刚开始学习内核代码时,[Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 是我打开的第一个文件,这个文件看起来真令人害怕 :)。那时候这个 [Makefile](https://en.wikipedia.org/wiki/Make_%28software%29) 还只包含了`1591` 行代码,当我开始写本文时,内核已经是[4.2.0的第三个候选版本](https://github.com/torvalds/linux/commit/52721d9d3334c1cb1f76219a161084094ec634dc) 了。
|
||||
|
||||
这个 makefile 是 Linux 内核代码的根 makefile ,内核构建就始于此处。是的,它的内容很多,但是如果你已经读过内核源代码,你就会发现每个包含代码的目录都有一个自己的 makefile。当然了,我们不会去描述每个代码文件是怎么编译链接的,所以我们将只会挑选一些通用的例子来说明问题。而你不会在这里找到构建内核的文档、如何整洁内核代码、[tags](https://en.wikipedia.org/wiki/Ctags) 的生成和[交叉编译](https://en.wikipedia.org/wiki/Cross_compiler) 相关的说明,等等。我们将从`make` 开始,使用标准的内核配置文件,到生成了内核镜像 [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage) 结束。
|
||||
|
||||
如果你已经很了解 [make](https://en.wikipedia.org/wiki/Make_%28software%29) 工具那是最好,但是我也会描述本文出现的相关代码。
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
|
||||
###编译内核前的准备
|
||||
|
||||
在开始编译前要进行很多准备工作。最主要的就是找到并配置好配置文件,`make` 命令要使用到的参数都需要从这些配置文件获取。现在就让我们深入内核的根 `makefile` 吧
|
||||
|
||||
内核的根 `Makefile` 负责构建两个主要的文件:[vmlinux](https://en.wikipedia.org/wiki/Vmlinux) (内核镜像可执行文件)和模块文件。内核的 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 从定义如下变量开始:
|
||||
|
||||
```Makefile
|
||||
VERSION = 4
|
||||
PATCHLEVEL = 2
|
||||
SUBLEVEL = 0
|
||||
EXTRAVERSION = -rc3
|
||||
NAME = Hurr durr I'ma sheep
|
||||
```
|
||||
|
||||
这些变量决定了当前内核的版本,并且被使用在很多不同的地方,比如同一个 `Makefile` 中的 `KERNELVERSION` :
|
||||
|
||||
```Makefile
|
||||
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
|
||||
```
|
||||
|
||||
接下来我们会看到很多`ifeq` 条件判断语句,它们负责检查传递给 `make` 的参数。内核的 `Makefile` 提供了一个特殊的编译选项 `make help` ,这个选项可以生成所有的可用目标和一些能传给 `make` 的有效的命令行参数。举个例子,`make V=1` 会在构建过程中输出详细的编译信息,第一个 `ifeq` 就是检查传递给 make 的 `V=n` 选项。
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin V)", "command line")
|
||||
KBUILD_VERBOSE = $(V)
|
||||
endif
|
||||
ifndef KBUILD_VERBOSE
|
||||
KBUILD_VERBOSE = 0
|
||||
endif
|
||||
|
||||
ifeq ($(KBUILD_VERBOSE),1)
|
||||
quiet =
|
||||
Q =
|
||||
else
|
||||
quiet=quiet_
|
||||
Q = @
|
||||
endif
|
||||
|
||||
export quiet Q KBUILD_VERBOSE
|
||||
```
|
||||
如果 `V=n` 这个选项传给了 `make` ,系统就会给变量 `KBUILD_VERBOSE` 选项附上 `V` 的值,否则的话`KBUILD_VERBOSE` 就会为 `0`。然后系统会检查 `KBUILD_VERBOSE` 的值,以此来决定 `quiet` 和`Q` 的值。符号 `@` 控制命令的输出,如果它被放在一个命令之前,这条命令的输出将会是 `CC scripts/mod/empty.o`,而不是`Compiling .... scripts/mod/empty.o`(LCTT 译注:CC 在 makefile 中一般都是编译命令)。在这段最后,系统导出了所有的变量。
|
||||
|
||||
下一个 `ifeq` 语句检查的是传递给 `make` 的选项 `O=/dir`,这个选项允许在指定的目录 `dir` 输出所有的结果文件:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
|
||||
ifeq ("$(origin O)", "command line")
|
||||
KBUILD_OUTPUT := $(O)
|
||||
endif
|
||||
|
||||
ifneq ($(KBUILD_OUTPUT),)
|
||||
saved-output := $(KBUILD_OUTPUT)
|
||||
KBUILD_OUTPUT := $(shell mkdir -p $(KBUILD_OUTPUT) && cd $(KBUILD_OUTPUT) \
|
||||
&& /bin/pwd)
|
||||
$(if $(KBUILD_OUTPUT),, \
|
||||
$(error failed to create output directory "$(saved-output)"))
|
||||
|
||||
sub-make: FORCE
|
||||
$(Q)$(MAKE) -C $(KBUILD_OUTPUT) KBUILD_SRC=$(CURDIR) \
|
||||
-f $(CURDIR)/Makefile $(filter-out _all sub-make,$(MAKECMDGOALS))
|
||||
|
||||
skip-makefile := 1
|
||||
endif # ifneq ($(KBUILD_OUTPUT),)
|
||||
endif # ifeq ($(KBUILD_SRC),)
|
||||
```
|
||||
|
||||
系统会检查变量 `KBUILD_SRC`,它代表内核代码的顶层目录,如果它是空的(第一次执行 makefile 时总是空的),我们会设置变量 `KBUILD_OUTPUT` 为传递给选项 `O` 的值(如果这个选项被传进来了)。下一步会检查变量 `KBUILD_OUTPUT` ,如果已经设置好,那么接下来会做以下几件事:
|
||||
|
||||
* 将变量 `KBUILD_OUTPUT` 的值保存到临时变量 `saved-output`;
|
||||
* 尝试创建给定的输出目录;
|
||||
* 检查创建的输出目录,如果失败了就打印错误;
|
||||
* 如果成功创建了输出目录,那么就在新目录重新执行 `make` 命令(参见选项`-C`)。
|
||||
|
||||
下一个 `ifeq` 语句会检查传递给 make 的选项 `C` 和 `M`:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin C)", "command line")
|
||||
KBUILD_CHECKSRC = $(C)
|
||||
endif
|
||||
ifndef KBUILD_CHECKSRC
|
||||
KBUILD_CHECKSRC = 0
|
||||
endif
|
||||
|
||||
ifeq ("$(origin M)", "command line")
|
||||
KBUILD_EXTMOD := $(M)
|
||||
endif
|
||||
```
|
||||
|
||||
第一个选项 `C` 会告诉 `makefile` 需要使用环境变量 `$CHECK` 提供的工具来检查全部 `c` 代码,默认情况下会使用[sparse](https://en.wikipedia.org/wiki/Sparse)。第二个选项 `M` 会用来编译外部模块(本文不做讨论)。
|
||||
|
||||
系统还会检查变量 `KBUILD_SRC`,如果 `KBUILD_SRC` 没有被设置,系统会设置变量 `srctree` 为`.`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
srctree := .
|
||||
endif
|
||||
|
||||
objtree := .
|
||||
src := $(srctree)
|
||||
obj := $(objtree)
|
||||
|
||||
export srctree objtree VPATH
|
||||
```
|
||||
|
||||
这将会告诉 `Makefile` 内核的源码树就在执行 `make` 命令的目录,然后要设置 `objtree` 和其他变量为这个目录,并且将这些变量导出。接着就是要获取 `SUBARCH` 的值,这个变量代表了当前的系统架构(LCTT 译注:一般都指CPU 架构):
|
||||
|
||||
```Makefile
|
||||
SUBARCH := $(shell uname -m | sed -e s/i.86/x86/ -e s/x86_64/x86/ \
|
||||
-e s/sun4u/sparc64/ \
|
||||
-e s/arm.*/arm/ -e s/sa110/arm/ \
|
||||
-e s/s390x/s390/ -e s/parisc64/parisc/ \
|
||||
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
|
||||
-e s/sh[234].*/sh/ -e s/aarch64.*/arm64/ )
|
||||
```
|
||||
|
||||
如你所见,系统执行 [uname](https://en.wikipedia.org/wiki/Uname) 得到机器、操作系统和架构的信息。因为我们得到的是 `uname` 的输出,所以我们需要做一些处理再赋给变量 `SUBARCH` 。获得 `SUBARCH` 之后就要设置`SRCARCH` 和 `hfr-arch`,`SRCARCH` 提供了硬件架构相关代码的目录,`hfr-arch` 提供了相关头文件的目录:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(ARCH),i386)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
ifeq ($(ARCH),x86_64)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
|
||||
hdr-arch := $(SRCARCH)
|
||||
```
|
||||
|
||||
注意:`ARCH` 是 `SUBARCH` 的别名。如果没有设置过代表内核配置文件路径的变量 `KCONFIG_CONFIG`,下一步系统会设置它,默认情况下就是 `.config` :
|
||||
|
||||
```Makefile
|
||||
KCONFIG_CONFIG ?= .config
|
||||
export KCONFIG_CONFIG
|
||||
```
|
||||
|
||||
以及编译内核过程中要用到的 [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
|
||||
```Makefile
|
||||
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
|
||||
else if [ -x /bin/bash ]; then echo /bin/bash; \
|
||||
else echo sh; fi ; fi)
|
||||
```
|
||||
|
||||
接下来就要设置一组和编译内核的编译器相关的变量。我们会设置主机的 `C` 和 `C++` 的编译器及相关配置项:
|
||||
|
||||
```Makefile
|
||||
HOSTCC = gcc
|
||||
HOSTCXX = g++
|
||||
HOSTCFLAGS = -Wall -Wmissing-prototypes -Wstrict-prototypes -O2 -fomit-frame-pointer -std=gnu89
|
||||
HOSTCXXFLAGS = -O2
|
||||
```
|
||||
|
||||
接下来会去适配代表编译器的变量 `CC`,那为什么还要 `HOST*` 这些变量呢?这是因为 `CC` 是编译内核过程中要使用的目标架构的编译器,但是 `HOSTCC` 是要被用来编译一组 `host` 程序的(下面我们就会看到)。
|
||||
|
||||
然后我们就看到变量 `KBUILD_MODULES` 和 `KBUILD_BUILTIN` 的定义,这两个变量决定了我们要编译什么东西(内核、模块或者两者):
|
||||
|
||||
```Makefile
|
||||
KBUILD_MODULES :=
|
||||
KBUILD_BUILTIN := 1
|
||||
|
||||
ifeq ($(MAKECMDGOALS),modules)
|
||||
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
|
||||
endif
|
||||
```
|
||||
|
||||
在这我们可以看到这些变量的定义,并且,如果们仅仅传递了 `modules` 给 `make`,变量 `KBUILD_BUILTIN` 会依赖于内核配置选项 `CONFIG_MODVERSIONS`。
|
||||
|
||||
下一步操作是引入下面的文件:
|
||||
|
||||
```Makefile
|
||||
include scripts/Kbuild.include
|
||||
```
|
||||
|
||||
文件 [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt) 或者又叫做 `Kernel Build System` 是一个用来管理构建内核及其模块的特殊框架。`kbuild` 文件的语法与 makefile 一样。文件[scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) 为 `kbuild` 系统提供了一些常规的定义。因为我们包含了这个 `kbuild` 文件,我们可以看到和不同工具关联的这些变量的定义,这些工具会在内核和模块编译过程中被使用(比如链接器、编译器、来自 [binutils](http://www.gnu.org/software/binutils/) 的二进制工具包 ,等等):
|
||||
|
||||
```Makefile
|
||||
AS = $(CROSS_COMPILE)as
|
||||
LD = $(CROSS_COMPILE)ld
|
||||
CC = $(CROSS_COMPILE)gcc
|
||||
CPP = $(CC) -E
|
||||
AR = $(CROSS_COMPILE)ar
|
||||
NM = $(CROSS_COMPILE)nm
|
||||
STRIP = $(CROSS_COMPILE)strip
|
||||
OBJCOPY = $(CROSS_COMPILE)objcopy
|
||||
OBJDUMP = $(CROSS_COMPILE)objdump
|
||||
AWK = awk
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
在这些定义好的变量后面,我们又定义了两个变量:`USERINCLUDE` 和 `LINUXINCLUDE`。他们包含了头文件的路径(第一个是给用户用的,第二个是给内核用的):
|
||||
|
||||
```Makefile
|
||||
USERINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include/uapi \
|
||||
-Iarch/$(hdr-arch)/include/generated/uapi \
|
||||
-I$(srctree)/include/uapi \
|
||||
-Iinclude/generated/uapi \
|
||||
-include $(srctree)/include/linux/kconfig.h
|
||||
|
||||
LINUXINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include \
|
||||
...
|
||||
```
|
||||
|
||||
以及给 C 编译器的标准标志:
|
||||
|
||||
```Makefile
|
||||
KBUILD_CFLAGS := -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs \
|
||||
-fno-strict-aliasing -fno-common \
|
||||
-Werror-implicit-function-declaration \
|
||||
-Wno-format-security \
|
||||
-std=gnu89
|
||||
```
|
||||
|
||||
这并不是最终确定的编译器标志,它们还可以在其他 makefile 里面更新(比如 `arch/` 里面的 kbuild)。变量定义完之后,全部会被导出供其他 makefile 使用。
|
||||
|
||||
下面的两个变量 `RCS_FIND_IGNORE` 和 `RCS_TAR_IGNORE` 包含了被版本控制系统忽略的文件:
|
||||
|
||||
```Makefile
|
||||
export RCS_FIND_IGNORE := \( -name SCCS -o -name BitKeeper -o -name .svn -o \
|
||||
-name CVS -o -name .pc -o -name .hg -o -name .git \) \
|
||||
-prune -o
|
||||
export RCS_TAR_IGNORE := --exclude SCCS --exclude BitKeeper --exclude .svn \
|
||||
--exclude CVS --exclude .pc --exclude .hg --exclude .git
|
||||
```
|
||||
|
||||
这就是全部了,我们已经完成了所有的准备工作,下一个点就是如果构建`vmlinux`。
|
||||
|
||||
###直面内核构建
|
||||
|
||||
现在我们已经完成了所有的准备工作,根 makefile(注:内核根目录下的 makefile)的下一步工作就是和编译内核相关的了。在这之前,我们不会在终端看到 `make` 命令输出的任何东西。但是现在编译的第一步开始了,这里我们需要从内核根 makefile 的 [598](https://github.com/torvalds/linux/blob/master/Makefile#L598) 行开始,这里可以看到目标`vmlinux`:
|
||||
|
||||
```Makefile
|
||||
all: vmlinux
|
||||
include arch/$(SRCARCH)/Makefile
|
||||
```
|
||||
|
||||
不要操心我们略过的从 `export RCS_FIND_IGNORE.....` 到 `all: vmlinux.....` 这一部分 makefile 代码,他们只是负责根据各种配置文件(`make *.config`)生成不同目标内核的,因为之前我就说了这一部分我们只讨论构建内核的通用途径。
|
||||
|
||||
目标 `all:` 是在命令行如果不指定具体目标时默认使用的目标。你可以看到这里包含了架构相关的 makefile(在这里就指的是 [arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile))。从这一时刻起,我们会从这个 makefile 继续进行下去。如我们所见,目标 `all` 依赖于根 makefile 后面声明的 `vmlinux`:
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
```
|
||||
|
||||
`vmlinux` 是 linux 内核的静态链接可执行文件格式。脚本 [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 把不同的编译好的子模块链接到一起形成了 vmlinux。
|
||||
|
||||
第二个目标是 `vmlinux-deps`,它的定义如下:
|
||||
|
||||
```Makefile
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN)
|
||||
```
|
||||
|
||||
它是由内核代码下的每个顶级目录的 `built-in.o` 组成的。之后我们还会检查内核所有的目录,`kbuild` 会编译各个目录下所有的对应 `$(obj-y)` 的源文件。接着调用 `$(LD) -r` 把这些文件合并到一个 `build-in.o` 文件里。此时我们还没有`vmlinux-deps`,所以目标 `vmlinux` 现在还不会被构建。对我而言 `vmlinux-deps` 包含下面的文件:
|
||||
|
||||
```
|
||||
arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_64.o
|
||||
arch/x86/kernel/head64.o arch/x86/kernel/head.o
|
||||
init/built-in.o usr/built-in.o
|
||||
arch/x86/built-in.o kernel/built-in.o
|
||||
mm/built-in.o fs/built-in.o
|
||||
ipc/built-in.o security/built-in.o
|
||||
crypto/built-in.o block/built-in.o
|
||||
lib/lib.a arch/x86/lib/lib.a
|
||||
lib/built-in.o arch/x86/lib/built-in.o
|
||||
drivers/built-in.o sound/built-in.o
|
||||
firmware/built-in.o arch/x86/pci/built-in.o
|
||||
arch/x86/power/built-in.o arch/x86/video/built-in.o
|
||||
net/built-in.o
|
||||
```
|
||||
|
||||
下一个可以被执行的目标如下:
|
||||
|
||||
```Makefile
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
就像我们看到的,`vmlinux-dir` 依赖于两部分:`prepare` 和 `scripts`。第一个 `prepare` 定义在内核的根 `makefile` 中,准备工作分成三个阶段:
|
||||
|
||||
```Makefile
|
||||
prepare: prepare0
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
archprepare: archheaders archscripts prepare1 scripts_basic
|
||||
|
||||
prepare1: prepare2 $(version_h) include/generated/utsrelease.h \
|
||||
include/config/auto.conf
|
||||
$(cmd_crmodverdir)
|
||||
prepare2: prepare3 outputmakefile asm-generic
|
||||
```
|
||||
|
||||
第一个 `prepare0` 展开到 `archprepare` ,后者又展开到 `archheader` 和 `archscripts`,这两个变量定义在 `x86_64` 相关的 [Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)。让我们看看这个文件。`x86_64` 特定的 makefile 从变量定义开始,这些变量都是和特定架构的配置文件 ([defconfig](https://github.com/torvalds/linux/tree/master/arch/x86/configs),等等)有关联。在定义了编译 [16-bit](https://en.wikipedia.org/wiki/Real_mode) 代码的编译选项之后,根据变量 `BITS` 的值,如果是 `32`, 汇编代码、链接器、以及其它很多东西(全部的定义都可以在[arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)找到)对应的参数就是 `i386`,而 `64` 就对应的是 `x86_84`。
|
||||
|
||||
第一个目标是 makefile 生成的系统调用列表(syscall table)中的 `archheaders` :
|
||||
|
||||
```Makefile
|
||||
archheaders:
|
||||
$(Q)$(MAKE) $(build)=arch/x86/entry/syscalls all
|
||||
```
|
||||
|
||||
第二个目标是 makefile 里的 `archscripts`:
|
||||
|
||||
```Makefile
|
||||
archscripts: scripts_basic
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
我们可以看到 `archscripts` 是依赖于根 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile)里的`scripts_basic` 。首先我们可以看出 `scripts_basic` 是按照 [scripts/basic](https://github.com/torvalds/linux/blob/master/scripts/basic/Makefile) 的 makefile 执行 make 的:
|
||||
|
||||
```Maklefile
|
||||
scripts_basic:
|
||||
$(Q)$(MAKE) $(build)=scripts/basic
|
||||
```
|
||||
|
||||
`scripts/basic/Makefile` 包含了编译两个主机程序 `fixdep` 和 `bin2` 的目标:
|
||||
|
||||
```Makefile
|
||||
hostprogs-y := fixdep
|
||||
hostprogs-$(CONFIG_BUILD_BIN2C) += bin2c
|
||||
always := $(hostprogs-y)
|
||||
|
||||
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
|
||||
```
|
||||
|
||||
第一个工具是 `fixdep`:用来优化 [gcc](https://gcc.gnu.org/) 生成的依赖列表,然后在重新编译源文件的时候告诉make。第二个工具是 `bin2c`,它依赖于内核配置选项 `CONFIG_BUILD_BIN2C`,并且它是一个用来将标准输入接口(LCTT 译注:即 stdin)收到的二进制流通过标准输出接口(即:stdout)转换成 C 头文件的非常小的 C 程序。你可能注意到这里有些奇怪的标志,如 `hostprogs-y` 等。这个标志用于所有的 `kbuild` 文件,更多的信息你可以从[documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt) 获得。在我们这里, `hostprogs-y` 告诉 `kbuild` 这里有个名为 `fixed` 的程序,这个程序会通过和 `Makefile` 相同目录的 `fixdep.c` 编译而来。
|
||||
|
||||
执行 make 之后,终端的第一个输出就是 `kbuild` 的结果:
|
||||
|
||||
```
|
||||
$ make
|
||||
HOSTCC scripts/basic/fixdep
|
||||
```
|
||||
|
||||
当目标 `script_basic` 被执行,目标 `archscripts` 就会 make [arch/x86/tools](https://github.com/torvalds/linux/blob/master/arch/x86/tools/Makefile) 下的 makefile 和目标 `relocs`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
包含了[重定位](https://en.wikipedia.org/wiki/Relocation_%28computing%29) 的信息的代码 `relocs_32.c` 和 `relocs_64.c` 将会被编译,这可以在`make` 的输出中看到:
|
||||
|
||||
```Makefile
|
||||
HOSTCC arch/x86/tools/relocs_32.o
|
||||
HOSTCC arch/x86/tools/relocs_64.o
|
||||
HOSTCC arch/x86/tools/relocs_common.o
|
||||
HOSTLD arch/x86/tools/relocs
|
||||
```
|
||||
|
||||
在编译完 `relocs.c` 之后会检查 `version.h`:
|
||||
|
||||
```Makefile
|
||||
$(version_h): $(srctree)/Makefile FORCE
|
||||
$(call filechk,version.h)
|
||||
$(Q)rm -f $(old_version_h)
|
||||
```
|
||||
|
||||
我们可以在输出看到它:
|
||||
|
||||
```
|
||||
CHK include/config/kernel.release
|
||||
```
|
||||
|
||||
以及在内核的根 Makefiel 使用 `arch/x86/include/generated/asm` 的目标 `asm-generic` 来构建 `generic` 汇编头文件。在目标 `asm-generic` 之后,`archprepare` 就完成了,所以目标 `prepare0` 会接着被执行,如我上面所写:
|
||||
|
||||
```Makefile
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
```
|
||||
|
||||
注意 `build`,它是定义在文件 [scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include),内容是这样的:
|
||||
|
||||
```Makefile
|
||||
build := -f $(srctree)/scripts/Makefile.build obj
|
||||
```
|
||||
|
||||
或者在我们的例子中,它就是当前源码目录路径:`.`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.build obj=.
|
||||
```
|
||||
|
||||
脚本 [scripts/Makefile.build](https://github.com/torvalds/linux/blob/master/scripts/Makefile.build) 通过参数 `obj` 给定的目录找到 `Kbuild` 文件,然后引入 `kbuild` 文件:
|
||||
|
||||
```Makefile
|
||||
include $(kbuild-file)
|
||||
```
|
||||
|
||||
并根据这个构建目标。我们这里 `.` 包含了生成 `kernel/bounds.s` 和 `arch/x86/kernel/asm-offsets.s` 的 [Kbuild](https://github.com/torvalds/linux/blob/master/Kbuild) 文件。在此之后,目标 `prepare` 就完成了它的工作。 `vmlinux-dirs` 也依赖于第二个目标 `scripts` ,它会编译接下来的几个程序:`filealias`,`mk_elfconfig`,`modpost` 等等。之后,`scripts/host-programs` 就可以开始编译我们的目标 `vmlinux-dirs` 了。
|
||||
|
||||
首先,我们先来理解一下 `vmlinux-dirs` 都包含了那些东西。在我们的例子中它包含了下列内核目录的路径:
|
||||
|
||||
```
|
||||
init usr arch/x86 kernel mm fs ipc security crypto block
|
||||
drivers sound firmware arch/x86/pci arch/x86/power
|
||||
arch/x86/video net lib arch/x86/lib
|
||||
```
|
||||
|
||||
我们可以在内核的根 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 里找到 `vmlinux-dirs` 的定义:
|
||||
|
||||
```Makefile
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m)))
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
这里我们借助函数 `patsubst` 和 `filter`去掉了每个目录路径里的符号 `/`,并且把结果放到 `vmlinux-dirs` 里。所以我们就有了 `vmlinux-dirs` 里的目录列表,以及下面的代码:
|
||||
|
||||
```Makefile
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
符号 `$@` 在这里代表了 `vmlinux-dirs`,这就表明程序会递归遍历从 `vmlinux-dirs` 以及它内部的全部目录(依赖于配置),并且在对应的目录下执行 `make` 命令。我们可以在输出看到结果:
|
||||
|
||||
```
|
||||
CC init/main.o
|
||||
CHK include/generated/compile.h
|
||||
CC init/version.o
|
||||
CC init/do_mounts.o
|
||||
...
|
||||
CC arch/x86/crypto/glue_helper.o
|
||||
AS arch/x86/crypto/aes-x86_64-asm_64.o
|
||||
CC arch/x86/crypto/aes_glue.o
|
||||
...
|
||||
AS arch/x86/entry/entry_64.o
|
||||
AS arch/x86/entry/thunk_64.o
|
||||
CC arch/x86/entry/syscall_64.o
|
||||
```
|
||||
|
||||
每个目录下的源代码将会被编译并且链接到 `built-io.o` 里:
|
||||
|
||||
```
|
||||
$ find . -name built-in.o
|
||||
./arch/x86/crypto/built-in.o
|
||||
./arch/x86/crypto/sha-mb/built-in.o
|
||||
./arch/x86/net/built-in.o
|
||||
./init/built-in.o
|
||||
./usr/built-in.o
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
好了,所有的 `built-in.o` 都构建完了,现在我们回到目标 `vmlinux` 上。你应该还记得,目标 `vmlinux` 是在内核的根makefile 里。在链接 `vmlinux` 之前,系统会构建 [samples](https://github.com/torvalds/linux/tree/master/samples), [Documentation](https://github.com/torvalds/linux/tree/master/Documentation) 等等,但是如上文所述,我不会在本文描述这些。
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
...
|
||||
...
|
||||
+$(call if_changed,link-vmlinux)
|
||||
```
|
||||
|
||||
你可以看到,调用脚本 [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 的主要目的是把所有的 `built-in.o` 链接成一个静态可执行文件,和生成 [System.map](https://en.wikipedia.org/wiki/System.map)。 最后我们来看看下面的输出:
|
||||
|
||||
```
|
||||
LINK vmlinux
|
||||
LD vmlinux.o
|
||||
MODPOST vmlinux.o
|
||||
GEN .version
|
||||
CHK include/generated/compile.h
|
||||
UPD include/generated/compile.h
|
||||
CC init/version.o
|
||||
LD init/built-in.o
|
||||
KSYM .tmp_kallsyms1.o
|
||||
KSYM .tmp_kallsyms2.o
|
||||
LD vmlinux
|
||||
SORTEX vmlinux
|
||||
SYSMAP System.map
|
||||
```
|
||||
|
||||
`vmlinux` 和`System.map` 生成在内核源码树根目录下。
|
||||
|
||||
```
|
||||
$ ls vmlinux System.map
|
||||
System.map vmlinux
|
||||
```
|
||||
|
||||
这就是全部了,`vmlinux` 构建好了,下一步就是创建 [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
###制作bzImage
|
||||
|
||||
`bzImage` 就是压缩了的 linux 内核镜像。我们可以在构建了 `vmlinux` 之后通过执行 `make bzImage` 获得`bzImage`。同时我们可以仅仅执行 `make` 而不带任何参数也可以生成 `bzImage` ,因为它是在 [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile) 里预定义的、默认生成的镜像:
|
||||
|
||||
```Makefile
|
||||
all: bzImage
|
||||
```
|
||||
|
||||
让我们看看这个目标,它能帮助我们理解这个镜像是怎么构建的。我已经说过了 `bzImage` 是被定义在 [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile),定义如下:
|
||||
|
||||
```Makefile
|
||||
bzImage: vmlinux
|
||||
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
|
||||
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
|
||||
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
|
||||
```
|
||||
|
||||
在这里我们可以看到第一次为 boot 目录执行 `make`,在我们的例子里是这样的:
|
||||
|
||||
```Makefile
|
||||
boot := arch/x86/boot
|
||||
```
|
||||
|
||||
现在的主要目标是编译目录 `arch/x86/boot` 和 `arch/x86/boot/compressed` 的代码,构建 `setup.bin` 和 `vmlinux.bin`,最后用这两个文件生成 `bzImage`。第一个目标是定义在 [arch/x86/boot/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/Makefile) 的 `$(obj)/setup.elf`:
|
||||
|
||||
```Makefile
|
||||
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
|
||||
$(call if_changed,ld)
|
||||
```
|
||||
|
||||
我们已经在目录 `arch/x86/boot` 有了链接脚本 `setup.ld`,和扩展到 `boot` 目录下全部源代码的变量 `SETUP_OBJS` 。我们可以看看第一个输出:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/bioscall.o
|
||||
CC arch/x86/boot/cmdline.o
|
||||
AS arch/x86/boot/copy.o
|
||||
HOSTCC arch/x86/boot/mkcpustr
|
||||
CPUSTR arch/x86/boot/cpustr.h
|
||||
CC arch/x86/boot/cpu.o
|
||||
CC arch/x86/boot/cpuflags.o
|
||||
CC arch/x86/boot/cpucheck.o
|
||||
CC arch/x86/boot/early_serial_console.o
|
||||
CC arch/x86/boot/edd.o
|
||||
```
|
||||
|
||||
下一个源码文件是 [arch/x86/boot/header.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/header.S),但是我们不能现在就编译它,因为这个目标依赖于下面两个头文件:
|
||||
|
||||
```Makefile
|
||||
$(obj)/header.o: $(obj)/voffset.h $(obj)/zoffset.h
|
||||
```
|
||||
|
||||
第一个头文件 `voffset.h` 是使用 `sed` 脚本生成的,包含用 `nm` 工具从 `vmlinux` 获取的两个地址:
|
||||
|
||||
```C
|
||||
#define VO__end 0xffffffff82ab0000
|
||||
#define VO__text 0xffffffff81000000
|
||||
```
|
||||
|
||||
这两个地址是内核的起始和结束地址。第二个头文件 `zoffset.h` 在 [arch/x86/boot/compressed/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/Makefile) 可以看出是依赖于目标 `vmlinux`的:
|
||||
|
||||
```Makefile
|
||||
$(obj)/zoffset.h: $(obj)/compressed/vmlinux FORCE
|
||||
$(call if_changed,zoffset)
|
||||
```
|
||||
|
||||
目标 `$(obj)/compressed/vmlinux` 依赖于 `vmlinux-objs-y` —— 说明需要编译目录 [arch/x86/boot/compressed](https://github.com/torvalds/linux/tree/master/arch/x86/boot/compressed) 下的源代码,然后生成 `vmlinux.bin`、`vmlinux.bin.bz2`,和编译工具 `mkpiggy`。我们可以在下面的输出看出来:
|
||||
|
||||
```Makefile
|
||||
LDS arch/x86/boot/compressed/vmlinux.lds
|
||||
AS arch/x86/boot/compressed/head_64.o
|
||||
CC arch/x86/boot/compressed/misc.o
|
||||
CC arch/x86/boot/compressed/string.o
|
||||
CC arch/x86/boot/compressed/cmdline.o
|
||||
OBJCOPY arch/x86/boot/compressed/vmlinux.bin
|
||||
BZIP2 arch/x86/boot/compressed/vmlinux.bin.bz2
|
||||
HOSTCC arch/x86/boot/compressed/mkpiggy
|
||||
```
|
||||
|
||||
`vmlinux.bin` 是去掉了调试信息和注释的 `vmlinux` 二进制文件,加上了占用了 `u32` (LCTT 译注:即4-Byte)的长度信息的 `vmlinux.bin.all` 压缩后就是 `vmlinux.bin.bz2`。其中 `vmlinux.bin.all` 包含了 `vmlinux.bin` 和`vmlinux.relocs`(LCTT 译注:vmlinux 的重定位信息),其中 `vmlinux.relocs` 是 `vmlinux` 经过程序 `relocs` 处理之后的 `vmlinux` 镜像(见上文所述)。我们现在已经获取到了这些文件,汇编文件 `piggy.S` 将会被 `mkpiggy` 生成、然后编译:
|
||||
|
||||
```Makefile
|
||||
MKPIGGY arch/x86/boot/compressed/piggy.S
|
||||
AS arch/x86/boot/compressed/piggy.o
|
||||
```
|
||||
|
||||
这个汇编文件会包含经过计算得来的、压缩内核的偏移信息。处理完这个汇编文件,我们就可以看到 `zoffset` 生成了:
|
||||
|
||||
```Makefile
|
||||
ZOFFSET arch/x86/boot/zoffset.h
|
||||
```
|
||||
|
||||
现在 `zoffset.h` 和 `voffset.h` 已经生成了,[arch/x86/boot](https://github.com/torvalds/linux/tree/master/arch/x86/boot/) 里的源文件可以继续编译:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/header.o
|
||||
CC arch/x86/boot/main.o
|
||||
CC arch/x86/boot/mca.o
|
||||
CC arch/x86/boot/memory.o
|
||||
CC arch/x86/boot/pm.o
|
||||
AS arch/x86/boot/pmjump.o
|
||||
CC arch/x86/boot/printf.o
|
||||
CC arch/x86/boot/regs.o
|
||||
CC arch/x86/boot/string.o
|
||||
CC arch/x86/boot/tty.o
|
||||
CC arch/x86/boot/video.o
|
||||
CC arch/x86/boot/video-mode.o
|
||||
CC arch/x86/boot/video-vga.o
|
||||
CC arch/x86/boot/video-vesa.o
|
||||
CC arch/x86/boot/video-bios.o
|
||||
```
|
||||
|
||||
所有的源代码会被编译,他们最终会被链接到 `setup.elf` :
|
||||
|
||||
```Makefile
|
||||
LD arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
ld -m elf_x86_64 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpuflags.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
最后的两件事是创建包含目录 `arch/x86/boot/*` 下的编译过的代码的 `setup.bin`:
|
||||
|
||||
```
|
||||
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
|
||||
```
|
||||
|
||||
以及从 `vmlinux` 生成 `vmlinux.bin` :
|
||||
|
||||
```
|
||||
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
|
||||
```
|
||||
|
||||
最最后,我们编译主机程序 [arch/x86/boot/tools/build.c](https://github.com/torvalds/linux/blob/master/arch/x86/boot/tools/build.c),它将会用来把 `setup.bin` 和 `vmlinux.bin` 打包成 `bzImage`:
|
||||
|
||||
```
|
||||
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin arch/x86/boot/zoffset.h arch/x86/boot/bzImage
|
||||
```
|
||||
|
||||
实际上 `bzImage` 就是把 `setup.bin` 和 `vmlinux.bin` 连接到一起。最终我们会看到输出结果,就和那些用源码编译过内核的同行的结果一样:
|
||||
|
||||
```
|
||||
Setup is 16268 bytes (padded to 16384 bytes).
|
||||
System is 4704 kB
|
||||
CRC 94a88f9a
|
||||
Kernel: arch/x86/boot/bzImage is ready (#5)
|
||||
```
|
||||
|
||||
|
||||
全部结束。
|
||||
|
||||
###结论
|
||||
|
||||
这就是本文的结尾部分。本文我们了解了编译内核的全部步骤:从执行 `make` 命令开始,到最后生成 `bzImage`。我知道,linux 内核的 makefile 和构建 linux 的过程第一眼看起来可能比较迷惑,但是这并不是很难。希望本文可以帮助你理解构建 linux 内核的整个流程。
|
||||
|
||||
|
||||
###链接
|
||||
|
||||
* [GNU make util](https://en.wikipedia.org/wiki/Make_%28software%29)
|
||||
* [Linux kernel top Makefile](https://github.com/torvalds/linux/blob/master/Makefile)
|
||||
* [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler)
|
||||
* [Ctags](https://en.wikipedia.org/wiki/Ctags)
|
||||
* [sparse](https://en.wikipedia.org/wiki/Sparse)
|
||||
* [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage)
|
||||
* [uname](https://en.wikipedia.org/wiki/Uname)
|
||||
* [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
* [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt)
|
||||
* [binutils](http://www.gnu.org/software/binutils/)
|
||||
* [gcc](https://gcc.gnu.org/)
|
||||
* [Documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt)
|
||||
* [System.map](https://en.wikipedia.org/wiki/System.map)
|
||||
* [Relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.md
|
||||
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,175 @@
|
||||
如何在 CentOS 7 上安装开源 ITIL 门户 iTOP
|
||||
================================================================================
|
||||
|
||||
iTOP是一个简单的基于Web的开源IT服务管理工具。它有所有的ITIL功能,包括服务台、配置管理、事件管理、问题管理、变更管理和服务管理。iTOP依赖于Apache/IIS、MySQL和PHP,因此它可以运行在任何支持这些软件的操作系统中。因为iTOP是一个Web程序,因此你不必在用户的PC端任何客户端程序。一个简单的浏览器就足够每天的IT环境操作了。
|
||||
|
||||
我们要在一台有满足基本需求的LAMP环境的CentOS 7上安装和配置iTOP。
|
||||
|
||||
### 下载 iTOP ###
|
||||
|
||||
iTOP的下载包现在在SourceForge上,我们可以从这获取它的官方[链接][1]。
|
||||
|
||||

|
||||
|
||||
我们从这里的连接用wget命令获取压缩文件。
|
||||
|
||||
[root@centos-007 ~]# wget http://downloads.sourceforge.net/project/itop/itop/2.1.0/iTop-2.1.0-2127.zip
|
||||
|
||||
### iTop扩展和网络安装 ###
|
||||
|
||||
使用unzip命令解压到apache根目录下的itop文件夹下。
|
||||
|
||||
[root@centos-7 ~]# ls
|
||||
iTop-2.1.0-2127.zip
|
||||
[root@centos-7 ~]# unzip iTop-2.1.0-2127.zip -d /var/www/html/itop/
|
||||
|
||||
列出安装包中的内容。
|
||||
|
||||
[root@centos-7 ~]# ls -lh /var/www/html/itop/
|
||||
total 68K
|
||||
-rw-r--r--. 1 root root 1.4K Dec 17 2014 INSTALL
|
||||
-rw-r--r--. 1 root root 35K Dec 17 2014 LICENSE
|
||||
-rw-r--r--. 1 root root 23K Dec 17 2014 README
|
||||
drwxr-xr-x. 19 root root 4.0K Jul 14 13:10 web
|
||||
|
||||
这些是我们可以安装的扩展。
|
||||
|
||||
[root@centos-7 2.x]# ls
|
||||
authent-external itop-backup itop-config-mgmt itop-problem-mgmt itop-service-mgmt-provider itop-welcome-itil
|
||||
authent-ldap itop-bridge-virtualization-storage itop-datacenter-mgmt itop-profiles-itil itop-sla-computation version.xml
|
||||
authent-local itop-change-mgmt itop-endusers-devices itop-request-mgmt itop-storage-mgmt wizard-icons
|
||||
installation.xml itop-change-mgmt-itil itop-incident-mgmt-itil itop-request-mgmt-itil itop-tickets
|
||||
itop-attachments itop-config itop-knownerror-mgmt itop-service-mgmt itop-virtualization-mgmt
|
||||
|
||||
在解压的目录下,使用如下的 cp 命令将不同的数据模型从web 下的 datamodels 目录下复制到 extensions 目录,来迁移需要的扩展。
|
||||
|
||||
[root@centos-7 2.x]# pwd
|
||||
/var/www/html/itop/web/datamodels/2.x
|
||||
[root@centos-7 2.x]# cp -r itop-request-mgmt itop-service-mgmt itop-service-mgmt itop-config itop-change-mgmt /var/www/html/itop/web/extensions/
|
||||
|
||||
### 安装 iTop web界面 ###
|
||||
|
||||
大多数服务端设置和配置已经完成了。最后我们安装web界面来完成安装。
|
||||
|
||||
打开浏览器使用ip地址或者完整域名来访问iTop 的 web目录。
|
||||
|
||||
http://servers_ip_address/itop/web/
|
||||
|
||||
你会被重定向到iTOP的web安装页面。让我们按照要求配置,就像在这篇教程中做的那样。
|
||||
|
||||
#### 验证先决要求 ####
|
||||
|
||||
这一步你就会看到验证完成的欢迎界面。如果你看到了一些警告信息,你需要先安装这些软件来解决这些问题。
|
||||
|
||||

|
||||
|
||||
这一步有一个叫php mcrypt的可选包丢失了。下载下面的rpm包接着尝试安装php mcrypt包。
|
||||
|
||||
[root@centos-7 ~]#yum localinstall php-mcrypt-5.3.3-1.el6.x86_64.rpm libmcrypt-2.5.8-9.el6.x86_64.rpm.
|
||||
|
||||
成功安装完php-mcrypt后,我们需要重启apache服务,接着刷新页面,这时验证应该已经OK。
|
||||
|
||||
#### 安装或者升级 iTop ####
|
||||
|
||||
现在我们要在没有安装iTOP的服务器上选择全新安装。
|
||||
|
||||

|
||||
|
||||
#### iTop 许可协议 ####
|
||||
|
||||
勾选接受 iTOP所有组件的许可协议,并点击“NEXT”。
|
||||
|
||||

|
||||
|
||||
#### 数据库配置 ####
|
||||
|
||||
现在我们输入数据库凭据来配置数据库连接,接着选择如下选择创建新数据库。
|
||||
|
||||

|
||||
|
||||
#### 管理员账户 ####
|
||||
|
||||
这一步中我们会输入它的登录信息来配置管理员账户。
|
||||
|
||||

|
||||
|
||||
#### 杂项参数 ####
|
||||
|
||||
让我们选择额外的参数来选择你是否需要安装一个带有演示内容的数据库或者使用全新的数据库,接着下一步。
|
||||
|
||||

|
||||
|
||||
### iTop 配置管理 ###
|
||||
|
||||
下面的选项允许你配置在iTOP要管理的元素类型,像CMDB、数据中心设备、存储设备和虚拟化这些东西在iTOP中是必须的。
|
||||
|
||||

|
||||
|
||||
#### 服务管理 ####
|
||||
|
||||
选择一个最能描述你的IT设备和环境之间的关系的选项。因此我们这里选择为服务提供商的服务管理。
|
||||
|
||||

|
||||
|
||||
#### iTop Tickets 管理 ####
|
||||
|
||||
从不同的可用选项我们选择符合ITIL Tickets管理选项来管理不同类型的用户请求和事件。
|
||||
|
||||

|
||||
|
||||
#### 改变管理选项 ####
|
||||
|
||||
选择不同的ticket类型以便管理可用选项中的IT设备变更。我们选择ITTL变更管理选项。
|
||||
|
||||

|
||||
|
||||
#### iTop 扩展 ####
|
||||
|
||||
这一节我们选择额外的扩展来安装或者不选直接跳过。
|
||||
|
||||

|
||||
|
||||
### 准备开始web安装 ###
|
||||
|
||||
现在我们开始准备安装先前先前选择的组件。我们也可以下拉这些安装参数来浏览我们的配置。
|
||||
|
||||
确认安装参数后点击安装按钮。
|
||||
|
||||

|
||||
|
||||
让我们等待进度条来完成安装步骤。它也许会花费几分钟来完成安装步骤。
|
||||
|
||||

|
||||
|
||||
### iTop安装完成 ###
|
||||
|
||||
我们的iTOP安装已经完成了,只要如下一个简单的手动操作就可以进入到iTOP。
|
||||
|
||||

|
||||
|
||||
### 欢迎来到iTop (IT操作门户) ###
|
||||
|
||||

|
||||
|
||||
### iTop 面板 ###
|
||||
|
||||
你这里可以配置任何东西,服务、计算机、通讯录、位置、合同、网络设备等等。你可以创建你自己的。事实是刚安装的CMDB模块是每一个IT人员的必备模块。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
ITOP是一个最棒的开源桌面服务解决方案。我们已经在CentOS 7上成功地安装和配置了。因此,iTOP最强大的一方面是它可以很简单地通过扩展来自定义。如果你在安装中遇到任何问题欢迎评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/setup-itop-centos-7/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:http://www.combodo.com/spip.php?page=rubrique&id_rubrique=8
|
||||
@ -0,0 +1,129 @@
|
||||
如何使用 Weave 以及 Docker 搭建 Nginx 反向代理/负载均衡服务器
|
||||
================================================================================
|
||||
|
||||
Hi, 今天我们将会学习如何使用 Weave 和 Docker 搭建 Nginx 的反向代理/负载均衡服务器。Weave 可以创建一个虚拟网络将 Docker 容器彼此连接在一起,支持跨主机部署及自动发现。它可以让我们更加专注于应用的开发,而不是基础架构。Weave 提供了一个如此棒的环境,仿佛它的所有容器都属于同个网络,不需要端口/映射/连接等的配置。容器中的应用提供的服务在 weave 网络中可以轻易地被外部世界访问,不论你的容器运行在哪里。在这个教程里我们将会使用 weave 快速并且简单地将 nginx web 服务器部署为一个负载均衡器,反向代理一个运行在 Amazon Web Services 里面多个节点上的 docker 容器中的简单 php 应用。这里我们将会介绍 WeaveDNS,它提供一个不需要改变代码就可以让容器利用主机名找到的简单方式,并且能够让其他容器通过主机名连接彼此。
|
||||
|
||||
在这篇教程里,我们将使用 nginx 来将负载均衡分配到一个运行 Apache 的容器集合。最简单轻松的方法就是使用 Weave 来把运行在 ubuntu 上的 docker 容器中的 nginx 配置成负载均衡服务器。
|
||||
|
||||
### 1. 搭建 AWS 实例 ###
|
||||
|
||||
首先,我们需要搭建 Amzaon Web Service 实例,这样才能在 ubuntu 下用 weave 跑 docker 容器。我们将会使用[AWS 命令行][1] 来搭建和配置两个 AWS EC2 实例。在这里,我们使用最小的可用实例,t1.micro。我们需要一个有效的**Amazon Web Services 账户**使用 AWS 命令行界面来搭建和配置。我们先在 AWS 命令行界面下使用下面的命令将 github 上的 weave 仓库克隆下来。
|
||||
|
||||
$ git clone http://github.com/fintanr/weave-gs
|
||||
$ cd weave-gs/aws-nginx-ubuntu-simple
|
||||
|
||||
在克隆完仓库之后,我们执行下面的脚本,这个脚本将会部署两个 t1.micro 实例,每个实例中都是 ubuntu 作为操作系统并用 weave 跑着 docker 容器。
|
||||
|
||||
$ sudo ./demo-aws-setup.sh
|
||||
|
||||
在这里,我们将会在以后用到这些实例的 IP 地址。这些地址储存在一个 weavedemo.env 文件中,这个文件创建于执行 demo-aws-setup.sh 脚本期间。为了获取这些 IP 地址,我们需要执行下面的命令,命令输出类似下面的信息。
|
||||
|
||||
$ cat weavedemo.env
|
||||
|
||||
export WEAVE_AWS_DEMO_HOST1=52.26.175.175
|
||||
export WEAVE_AWS_DEMO_HOST2=52.26.83.141
|
||||
export WEAVE_AWS_DEMO_HOSTCOUNT=2
|
||||
export WEAVE_AWS_DEMO_HOSTS=(52.26.175.175 52.26.83.141)
|
||||
|
||||
请注意这些不是固定的 IP 地址,AWS 会为我们的实例动态地分配 IP 地址。
|
||||
|
||||
我们在 bash 下执行下面的命令使环境变量生效。
|
||||
|
||||
. ./weavedemo.env
|
||||
|
||||
### 2. 启动 Weave 和 WeaveDNS ###
|
||||
|
||||
在安装完实例之后,我们将会在每台主机上启动 weave 以及 weavedns。Weave 以及 weavedns 使得我们能够轻易地将容器部署到一个全新的基础架构以及配置中, 不需要改变代码,也不需要去理解像 Ambassador 容器以及 Link 机制之类的概念。下面是在第一台主机上启动 weave 以及 weavedns 的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch
|
||||
$ sudo weave launch-dns 10.2.1.1/24
|
||||
|
||||
下一步,我也准备在第二台主机上启动 weave 以及 weavedns。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave launch $WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave launch-dns 10.2.1.2/24
|
||||
|
||||
### 3. 启动应用容器 ###
|
||||
|
||||
现在,我们准备跨两台主机启动六个容器,这两台主机都用 Apache2 Web 服务实例跑着简单的 php 网站。为了在第一个 Apache2 Web 服务器实例跑三个容器, 我们将会使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.1/24 -h ws1.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.2/24 -h ws2.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.3/24 -h ws3.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
在那之后,我们将会在第二个实例上启动另外三个容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST2
|
||||
$ sudo weave run --with-dns 10.3.1.4/24 -h ws4.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.5/24 -h ws5.weave.local fintanr/weave-gs-nginx-apache
|
||||
$ sudo weave run --with-dns 10.3.1.6/24 -h ws6.weave.local fintanr/weave-gs-nginx-apache
|
||||
|
||||
注意: 在这里,--with-dns 选项告诉容器使用 weavedns 来解析主机名,-h x.weave.local 则使得 weavedns 能够解析该主机。
|
||||
|
||||
### 4. 启动 Nginx 容器 ###
|
||||
|
||||
在应用容器如预期的运行后,我们将会启动 nginx 容器,它将会在六个应用容器服务之间轮询并提供反向代理或者负载均衡。 为了启动 nginx 容器,请使用下面的命令。
|
||||
|
||||
ssh -i weavedemo-key.pem ubuntu@$WEAVE_AWS_DEMO_HOST1
|
||||
$ sudo weave run --with-dns 10.3.1.7/24 -ti -h nginx.weave.local -d -p 80:80 fintanr/weave-gs-nginx-simple
|
||||
|
||||
因此,我们的 nginx 容器在 $WEAVE_AWS_DEMO_HOST1 上公开地暴露成为一个 http 服务器。
|
||||
|
||||
### 5. 测试负载均衡服务器 ###
|
||||
|
||||
为了测试我们的负载均衡服务器是否可以工作,我们执行一段可以发送 http 请求给 nginx 容器的脚本。我们将会发送6个请求,这样我们就能看到 nginx 在一次的轮询中服务于每台 web 服务器之间。
|
||||
|
||||
$ ./access-aws-hosts.sh
|
||||
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws1.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws2.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws3.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws4.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws5.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
{
|
||||
"message" : "Hello Weave - nginx example",
|
||||
"hostname" : "ws6.weave.local",
|
||||
"date" : "2015-06-26 12:24:23"
|
||||
}
|
||||
|
||||
### 结束语 ###
|
||||
|
||||
我们最终成功地将 nginx 配置成一个反向代理/负载均衡服务器,通过使用 weave 以及运行在 AWS(Amazon Web Service)EC2 里面的 ubuntu 服务器中的 docker。从上面的步骤输出可以清楚的看到我们已经成功地配置了 nginx。我们可以看到请求在一次轮询中被发送到6个应用容器,这些容器在 Apache2 Web 服务器中跑着 PHP 应用。在这里,我们部署了一个容器化的 PHP 应用,使用 nginx 横跨多台在 AWS EC2 上的主机而不需要改变代码,利用 weavedns 使得每个容器连接在一起,只需要主机名就够了,眼前的这些便捷, 都要归功于 weave 以及 weavedns。
|
||||
|
||||
如果你有任何的问题、建议、反馈,请在评论中注明,这样我们才能够做得更好,谢谢:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/nginx-load-balancer-weave-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://console.aws.amazon.com/
|
||||
418
published/201509/20150803 Managing Linux Logs.md
Normal file
418
published/201509/20150803 Managing Linux Logs.md
Normal file
@ -0,0 +1,418 @@
|
||||
Linux 日志管理指南
|
||||
================================================================================
|
||||
|
||||
管理日志的一个最好做法是将你的日志集中或整合到一个地方,特别是在你有许多服务器或多层级架构时。我们将告诉你为什么这是一个好主意,然后给出如何更容易的做这件事的一些小技巧。
|
||||
|
||||
### 集中管理日志的好处 ###
|
||||
|
||||
如果你有很多服务器,查看某个日志文件可能会很麻烦。现代的网站和服务经常包括许多服务器层级、分布式的负载均衡器,等等。找到正确的日志将花费很长时间,甚至要花更长时间在登录服务器的相关问题上。没什么比发现你找的信息没有被保存下来更沮丧的了,或者本该保留的日志文件正好在重启后丢失了。
|
||||
|
||||
集中你的日志使它们查找更快速,可以帮助你更快速的解决产品问题。你不用猜测那个服务器存在问题,因为所有的日志在同一个地方。此外,你可以使用更强大的工具去分析它们,包括日志管理解决方案。一些解决方案能[转换纯文本日志][1]为一些字段,更容易查找和分析。
|
||||
|
||||
集中你的日志也可以使它们更易于管理:
|
||||
|
||||
- 它们更安全,当它们备份归档到一个单独区域时会有意无意地丢失。如果你的服务器宕机或者无响应,你可以使用集中的日志去调试问题。
|
||||
- 你不用担心ssh或者低效的grep命令在陷入困境的系统上需要更多的资源。
|
||||
- 你不用担心磁盘占满,这个能让你的服务器死机。
|
||||
- 你能保持你的产品服务器的安全性,只是为了查看日志无需给你所有团队登录权限。给你的团队从日志集中区域访问日志权限更安全。
|
||||
|
||||
随着集中日志管理,你仍需处理由于网络联通性不好或者耗尽大量网络带宽从而导致不能传输日志到中心区域的风险。在下面的章节我们将要讨论如何聪明的解决这些问题。
|
||||
|
||||
### 流行的日志归集工具 ###
|
||||
|
||||
在 Linux 上最常见的日志归集是通过使用 syslog 守护进程或者日志代理。syslog 守护进程支持本地日志的采集,然后通过syslog 协议传输日志到中心服务器。你可以使用很多流行的守护进程来归集你的日志文件:
|
||||
|
||||
- [rsyslog][2] 是一个轻量后台程序,在大多数 Linux 分支上已经安装。
|
||||
- [syslog-ng][3] 是第二流行的 Linux 系统日志后台程序。
|
||||
- [logstash][4] 是一个重量级的代理,它可以做更多高级加工和分析。
|
||||
- [fluentd][5] 是另一个具有高级处理能力的代理。
|
||||
|
||||
Rsyslog 是集中日志数据最流行的后台程序,因为它在大多数 Linux 分支上是被默认安装的。你不用下载或安装它,并且它是轻量的,所以不需要占用你太多的系统资源。
|
||||
|
||||
如果你需要更多先进的过滤或者自定义分析功能,如果你不在乎额外的系统负载,Logstash 是另一个最流行的选择。
|
||||
|
||||
### 配置 rsyslog.conf ###
|
||||
|
||||
既然 rsyslog 是最广泛使用的系统日志程序,我们将展示如何配置它为日志中心。它的全局配置文件位于 /etc/rsyslog.conf。它加载模块,设置全局指令,和包含位于目录 /etc/rsyslog.d 中的应用的特有的配置。目录中包含的 /etc/rsyslog.d/50-default.conf 指示 rsyslog 将系统日志写到文件。在 [rsyslog 文档][6]中你可以阅读更多相关配置。
|
||||
|
||||
rsyslog 配置语言是是[RainerScript][7]。你可以给日志指定输入,就像将它们输出到另外一个位置一样。rsyslog 已经配置标准输入默认是 syslog ,所以你通常只需增加一个输出到你的日志服务器。这里有一个 rsyslog 输出到一个外部服务器的配置例子。在本例中,**BEBOP** 是一个服务器的主机名,所以你应该替换为你的自己的服务器名。
|
||||
|
||||
action(type="omfwd" protocol="tcp" target="BEBOP" port="514")
|
||||
|
||||
你可以发送你的日志到一个有足够的存储容量的日志服务器来存储,提供查询,备份和分析。如果你存储日志到文件系统,那么你应该建立[日志轮转][8]来防止你的磁盘爆满。
|
||||
|
||||
作为一种选择,你可以发送这些日志到一个日志管理方案。如果你的解决方案是安装在本地你可以发送到系统文档中指定的本地主机和端口。如果你使用基于云提供商,你将发送它们到你的提供商特定的主机名和端口。
|
||||
|
||||
### 日志目录 ###
|
||||
|
||||
你可以归集一个目录或者匹配一个通配符模式的所有文件。nxlog 和 syslog-ng 程序支持目录和通配符(*)。
|
||||
|
||||
常见的 rsyslog 不能直接监控目录。作为一种解决办法,你可以设置一个定时任务去监控这个目录的新文件,然后配置 rsyslog 来发送这些文件到目的地,比如你的日志管理系统。举个例子,日志管理提供商 Loggly 有一个开源版本的[目录监控脚本][9]。
|
||||
|
||||
### 哪个协议: UDP、TCP 或 RELP? ###
|
||||
|
||||
当你使用网络传输数据时,有三个主流协议可以选择。UDP 在你自己的局域网是最常用的,TCP 用在互联网。如果你不能失去(任何)日志,就要使用更高级的 RELP 协议。
|
||||
|
||||
[UDP][10] 发送一个数据包,那只是一个单一的信息包。它是一个只外传的协议,所以它不会发送给你回执(ACK)。它只尝试发送包。当网络拥堵时,UDP 通常会巧妙的降级或者丢弃日志。它通常使用在类似局域网的可靠网络。
|
||||
|
||||
[TCP][11] 通过多个包和返回确认发送流式信息。TCP 会多次尝试发送数据包,但是受限于 [TCP 缓存][12]的大小。这是在互联网上发送送日志最常用的协议。
|
||||
|
||||
[RELP][13] 是这三个协议中最可靠的,但是它是为 rsyslog 创建的,而且很少有行业采用。它在应用层接收数据,如果有错误就会重发。请确认你的日志接受位置也支持这个协议。
|
||||
|
||||
### 用磁盘辅助队列可靠的传送 ###
|
||||
|
||||
如果 rsyslog 在存储日志时遭遇错误,例如一个不可用网络连接,它能将日志排队直到连接还原。队列日志默认被存储在内存里。无论如何,内存是有限的并且如果问题仍然存在,日志会超出内存容量。
|
||||
|
||||
**警告:如果你只存储日志到内存,你可能会失去数据。**
|
||||
|
||||
rsyslog 能在内存被占满时将日志队列放到磁盘。[磁盘辅助队列][14]使日志的传输更可靠。这里有一个例子如何配置rsyslog 的磁盘辅助队列:
|
||||
|
||||
$WorkDirectory /var/spool/rsyslog # 暂存文件(spool)放置位置
|
||||
$ActionQueueFileName fwdRule1 # 暂存文件的唯一名字前缀
|
||||
$ActionQueueMaxDiskSpace 1g # 1gb 空间限制(尽可能大)
|
||||
$ActionQueueSaveOnShutdown on # 关机时保存日志到磁盘
|
||||
$ActionQueueType LinkedList # 异步运行
|
||||
$ActionResumeRetryCount -1 # 如果主机宕机,不断重试
|
||||
|
||||
### 使用 TLS 加密日志 ###
|
||||
|
||||
如果你担心你的数据的安全性和隐私性,你应该考虑加密你的日志。如果你使用纯文本在互联网传输日志,嗅探器和中间人可以读到你的日志。如果日志包含私人信息、敏感的身份数据或者政府管制数据,你应该加密你的日志。rsyslog 程序能使用 TLS 协议加密你的日志保证你的数据更安全。
|
||||
|
||||
建立 TLS 加密,你应该做如下任务:
|
||||
|
||||
1. 生成一个[证书授权(CA)][15]。在 /contrib/gnutls 有一些证书例子,可以用来测试,但是你需要为产品环境创建自己的证书。如果你正在使用一个日志管理服务,它会给你一个证书。
|
||||
1. 为你的服务器生成一个[数字证书][16]使它能启用 SSL 操作,或者使用你自己的日志管理服务提供商的一个数字证书。
|
||||
1. 配置你的 rsyslog 程序来发送 TLS 加密数据到你的日志管理系统。
|
||||
|
||||
这有一个 rsyslog 配置 TLS 加密的例子。替换 CERT 和 DOMAIN_NAME 为你自己的服务器配置。
|
||||
|
||||
$DefaultNetstreamDriverCAFile /etc/rsyslog.d/keys/ca.d/CERT.crt
|
||||
$ActionSendStreamDriver gtls
|
||||
$ActionSendStreamDriverMode 1
|
||||
$ActionSendStreamDriverAuthMode x509/name
|
||||
$ActionSendStreamDriverPermittedPeer *.DOMAIN_NAME.com
|
||||
|
||||
### 应用日志的最佳管理方法 ###
|
||||
|
||||
除 Linux 默认创建的日志之外,归集重要的应用日志也是一个好主意。几乎所有基于 Linux 的服务器应用都把它们的状态信息写入到独立、专门的日志文件中。这包括数据库产品,像 PostgreSQL 或者 MySQL,网站服务器,像 Nginx 或者 Apache,防火墙,打印和文件共享服务,目录和 DNS 服务等等。
|
||||
|
||||
管理员安装一个应用后要做的第一件事是配置它。Linux 应用程序典型的有一个放在 /etc 目录里 .conf 文件。它也可能在其它地方,但是那是大家找配置文件首先会看的地方。
|
||||
|
||||
根据应用程序有多复杂多庞大,可配置参数的数量可能会很少或者上百行。如前所述,大多数应用程序可能会在某种日志文件写它们的状态:配置文件是定义日志设置和其它东西的地方。
|
||||
|
||||
如果你不确定它在哪,你可以使用locate命令去找到它:
|
||||
|
||||
[root@localhost ~]# locate postgresql.conf
|
||||
/usr/pgsql-9.4/share/postgresql.conf.sample
|
||||
/var/lib/pgsql/9.4/data/postgresql.conf
|
||||
|
||||
#### 设置一个日志文件的标准位置 ####
|
||||
|
||||
Linux 系统一般保存它们的日志文件在 /var/log 目录下。一般是这样,但是需要检查一下应用是否保存它们在 /var/log 下的特定目录。如果是,很好,如果不是,你也许想在 /var/log 下创建一个专用目录?为什么?因为其它程序也在 /var/log 下保存它们的日志文件,如果你的应用保存超过一个日志文件 - 也许每天一个或者每次重启一个 - 在这么大的目录也许有点难于搜索找到你想要的文件。
|
||||
|
||||
如果在你网络里你有运行多于一个的应用实例,这个方法依然便利。想想这样的情景,你也许有一打 web 服务器在你的网络运行。当排查任何一个机器的问题时,你就很容易知道确切的位置。
|
||||
|
||||
#### 使用一个标准的文件名 ####
|
||||
|
||||
给你的应用最新的日志使用一个标准的文件名。这使一些事变得容易,因为你可以监控和追踪一个单独的文件。很多应用程序在它们的日志文件上追加一种时间戳。它让 rsyslog 更难于找到最新的文件和设置文件监控。一个更好的方法是使用日志轮转给老的日志文件增加时间。这样更易去归档和历史查询。
|
||||
|
||||
#### 追加日志文件 ####
|
||||
|
||||
日志文件会在每个应用程序重启后被覆盖吗?如果这样,我们建议关掉它。每次重启 app 后应该去追加日志文件。这样,你就可以追溯重启前最后的日志。
|
||||
|
||||
#### 日志文件追加 vs. 轮转 ####
|
||||
|
||||
要是应用程序每次重启后写一个新日志文件,如何保存当前日志?追加到一个单独的、巨大的文件?Linux 系统并不以频繁重启或者崩溃而出名:应用程序可以运行很长时间甚至不间歇,但是也会使日志文件非常大。如果你查询分析上周发生连接错误的原因,你可能无疑的要在成千上万行里搜索。
|
||||
|
||||
我们建议你配置应用每天半晚轮转(rotate)它的日志文件。
|
||||
|
||||
为什么?首先它将变得可管理。找一个带有特定日期的文件名比遍历一个文件中指定日期的条目更容易。文件也小的多:你不用考虑当你打开一个日志文件时 vi 僵住。第二,如果你正发送日志到另一个位置 - 也许每晚备份任务拷贝到归集日志服务器 - 这样不会消耗你的网络带宽。最后第三点,这样帮助你做日志保留。如果你想剔除旧的日志记录,这样删除超过指定日期的文件比用一个应用解析一个大文件更容易。
|
||||
|
||||
#### 日志文件的保留 ####
|
||||
|
||||
你保留你的日志文件多长时间?这绝对可以归结为业务需求。你可能被要求保持一个星期的日志信息,或者管理要求保持一年的数据。无论如何,日志需要在一个时刻或其它情况下从服务器删除。
|
||||
|
||||
在我们看来,除非必要,只在线保持最近一个月的日志文件,并拷贝它们到第二个地方如日志服务器。任何比这更旧的日志可以被转到一个单独的介质上。例如,如果你在 AWS 上,你的旧日志可以被拷贝到 Glacier。
|
||||
|
||||
#### 给日志单独的磁盘分区 ####
|
||||
|
||||
更好的,Linux 通常建议挂载到 /var 目录到一个单独的文件系统。这是因为这个目录的高 I/O。我们推荐挂载 /var/log 目录到一个单独的磁盘系统下。这样可以节省与主要的应用数据的 I/O 竞争。另外,如果一些日志文件变的太多,或者一个文件变的太大,不会占满整个磁盘。
|
||||
|
||||
#### 日志条目 ####
|
||||
|
||||
每个日志条目中应该捕获什么信息?
|
||||
|
||||
这依赖于你想用日志来做什么。你只想用它来排除故障,或者你想捕获所有发生的事?这是一个捕获每个用户在运行什么或查看什么的规则条件吗?
|
||||
|
||||
如果你正用日志做错误排查的目的,那么只保存错误,报警或者致命信息。没有理由去捕获调试信息,例如,应用也许默认记录了调试信息或者另一个管理员也许为了故障排查而打开了调试信息,但是你应该关闭它,因为它肯定会很快的填满空间。在最低限度上,捕获日期、时间、客户端应用名、来源 ip 或者客户端主机名、执行的动作和信息本身。
|
||||
|
||||
#### 一个 PostgreSQL 的实例 ####
|
||||
|
||||
作为一个例子,让我们看看 vanilla PostgreSQL 9.4 安装的主配置文件。它叫做 postgresql.conf,与其它Linux 系统中的配置文件不同,它不保存在 /etc 目录下。下列的代码段,我们可以在我们的 Centos 7 服务器的 /var/lib/pgsql 目录下找到它:
|
||||
|
||||
root@localhost ~]# vi /var/lib/pgsql/9.4/data/postgresql.conf
|
||||
...
|
||||
#------------------------------------------------------------------------------
|
||||
# ERROR REPORTING AND LOGGING
|
||||
#------------------------------------------------------------------------------
|
||||
# - Where to Log -
|
||||
log_destination = 'stderr'
|
||||
# Valid values are combinations of
|
||||
# stderr, csvlog, syslog, and eventlog,
|
||||
# depending on platform. csvlog
|
||||
# requires logging_collector to be on.
|
||||
# This is used when logging to stderr:
|
||||
logging_collector = on
|
||||
# Enable capturing of stderr and csvlog
|
||||
# into log files. Required to be on for
|
||||
# csvlogs.
|
||||
# (change requires restart)
|
||||
# These are only used if logging_collector is on:
|
||||
log_directory = 'pg_log'
|
||||
# directory where log files are written,
|
||||
# can be absolute or relative to PGDATA
|
||||
log_filename = 'postgresql-%a.log' # log file name pattern,
|
||||
# can include strftime() escapes
|
||||
# log_file_mode = 0600 .
|
||||
# creation mode for log files,
|
||||
# begin with 0 to use octal notation
|
||||
log_truncate_on_rotation = on # If on, an existing log file with the
|
||||
# same name as the new log file will be
|
||||
# truncated rather than appended to.
|
||||
# But such truncation only occurs on
|
||||
# time-driven rotation, not on restarts
|
||||
# or size-driven rotation. Default is
|
||||
# off, meaning append to existing files
|
||||
# in all cases.
|
||||
log_rotation_age = 1d
|
||||
# Automatic rotation of logfiles will happen after that time. 0 disables.
|
||||
log_rotation_size = 0 # Automatic rotation of logfiles will happen after that much log output. 0 disables.
|
||||
# These are relevant when logging to syslog:
|
||||
#syslog_facility = 'LOCAL0'
|
||||
#syslog_ident = 'postgres'
|
||||
# This is only relevant when logging to eventlog (win32):
|
||||
#event_source = 'PostgreSQL'
|
||||
# - When to Log -
|
||||
#client_min_messages = notice # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# log
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
#log_min_messages = warning # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic
|
||||
#log_min_error_statement = error # values in order of decreasing detail:
|
||||
# debug5
|
||||
# debug4
|
||||
# debug3
|
||||
# debug2
|
||||
# debug1
|
||||
# info
|
||||
# notice
|
||||
# warning
|
||||
# error
|
||||
# log
|
||||
# fatal
|
||||
# panic (effectively off)
|
||||
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
|
||||
# and their durations, > 0 logs only
|
||||
# statements running at least this number
|
||||
# of milliseconds
|
||||
# - What to Log
|
||||
#debug_print_parse = off
|
||||
#debug_print_rewritten = off
|
||||
#debug_print_plan = off
|
||||
#debug_pretty_print = on
|
||||
#log_checkpoints = off
|
||||
#log_connections = off
|
||||
#log_disconnections = off
|
||||
#log_duration = off
|
||||
#log_error_verbosity = default
|
||||
# terse, default, or verbose messages
|
||||
#log_hostname = off
|
||||
log_line_prefix = '< %m >' # special values:
|
||||
# %a = application name
|
||||
# %u = user name
|
||||
# %d = database name
|
||||
# %r = remote host and port
|
||||
# %h = remote host
|
||||
# %p = process ID
|
||||
# %t = timestamp without milliseconds
|
||||
# %m = timestamp with milliseconds
|
||||
# %i = command tag
|
||||
# %e = SQL state
|
||||
# %c = session ID
|
||||
# %l = session line number
|
||||
# %s = session start timestamp
|
||||
# %v = virtual transaction ID
|
||||
# %x = transaction ID (0 if none)
|
||||
# %q = stop here in non-session
|
||||
# processes
|
||||
# %% = '%'
|
||||
# e.g. '<%u%%%d> '
|
||||
#log_lock_waits = off # log lock waits >= deadlock_timeout
|
||||
#log_statement = 'none' # none, ddl, mod, all
|
||||
#log_temp_files = -1 # log temporary files equal or larger
|
||||
# than the specified size in kilobytes;5# -1 disables, 0 logs all temp files5
|
||||
log_timezone = 'Australia/ACT'
|
||||
|
||||
虽然大多数参数被加上了注释,它们使用了默认值。我们可以看见日志文件目录是 pg_log(log_directory 参数,在 /var/lib/pgsql/9.4/data/ 下的子目录),文件名应该以 postgresql 开头(log_filename参数),文件每天轮转一次(log_rotation_age 参数)然后每行日志记录以时间戳开头(log_line_prefix参数)。特别值得说明的是 log_line_prefix 参数:全部的信息你都可以包含在这。
|
||||
|
||||
看 /var/lib/pgsql/9.4/data/pg_log 目录下展现给我们这些文件:
|
||||
|
||||
[root@localhost ~]# ls -l /var/lib/pgsql/9.4/data/pg_log
|
||||
total 20
|
||||
-rw-------. 1 postgres postgres 1212 May 1 20:11 postgresql-Fri.log
|
||||
-rw-------. 1 postgres postgres 243 Feb 9 21:49 postgresql-Mon.log
|
||||
-rw-------. 1 postgres postgres 1138 Feb 7 11:08 postgresql-Sat.log
|
||||
-rw-------. 1 postgres postgres 1203 Feb 26 21:32 postgresql-Thu.log
|
||||
-rw-------. 1 postgres postgres 326 Feb 10 01:20 postgresql-Tue.log
|
||||
|
||||
所以日志文件名只有星期命名的标签。我们可以改变它。如何做?在 postgresql.conf 配置 log_filename 参数。
|
||||
|
||||
查看一个日志内容,它的条目仅以日期时间开头:
|
||||
|
||||
[root@localhost ~]# cat /var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.log
|
||||
...
|
||||
< 2015-02-27 01:21:27.020 EST >LOG: received fast shutdown request
|
||||
< 2015-02-27 01:21:27.025 EST >LOG: aborting any active transactions
|
||||
< 2015-02-27 01:21:27.026 EST >LOG: autovacuum launcher shutting down
|
||||
< 2015-02-27 01:21:27.036 EST >LOG: shutting down
|
||||
< 2015-02-27 01:21:27.211 EST >LOG: database system is shut down
|
||||
|
||||
### 归集应用的日志 ###
|
||||
|
||||
#### 使用 imfile 监控日志 ####
|
||||
|
||||
习惯上,应用通常记录它们数据在文件里。文件容易在一个机器上寻找,但是多台服务器上就不是很恰当了。你可以设置日志文件监控,然后当新的日志被添加到文件尾部后就发送事件到一个集中服务器。在 /etc/rsyslog.d/ 里创建一个新的配置文件然后增加一个配置文件,然后输入如下:
|
||||
|
||||
$ModLoad imfile
|
||||
$InputFilePollInterval 10
|
||||
$PrivDropToGroup adm
|
||||
|
||||
-----
|
||||
# Input for FILE1
|
||||
$InputFileName /FILE1
|
||||
$InputFileTag APPNAME1
|
||||
$InputFileStateFile stat-APPNAME1 #this must be unique for each file being polled
|
||||
$InputFileSeverity info
|
||||
$InputFilePersistStateInterval 20000
|
||||
$InputRunFileMonitor
|
||||
|
||||
替换 FILE1 和 APPNAME1 为你自己的文件名和应用名称。rsyslog 将发送它到你配置的输出目标中。
|
||||
|
||||
#### 本地套接字日志与 imuxsock ####
|
||||
|
||||
套接字类似 UNIX 文件句柄,所不同的是套接字内容是由 syslog 守护进程读取到内存中,然后发送到目的地。不需要写入文件。作为一个例子,logger 命令发送它的日志到这个 UNIX 套接字。
|
||||
|
||||
如果你的服务器 I/O 有限或者你不需要本地文件日志,这个方法可以使系统资源有效利用。这个方法缺点是套接字有队列大小的限制。如果你的 syslog 守护进程宕掉或者不能保持运行,然后你可能会丢失日志数据。
|
||||
|
||||
rsyslog 程序将默认从 /dev/log 套接字中读取,但是你需要使用如下命令来让 [imuxsock 输入模块][17] 启用它:
|
||||
|
||||
$ModLoad imuxsock
|
||||
|
||||
#### UDP 日志与 imupd ####
|
||||
|
||||
一些应用程序使用 UDP 格式输出日志数据,这是在网络上或者本地传输日志文件的标准 syslog 协议。你的 syslog 守护进程接受这些日志,然后处理它们或者用不同的格式传输它们。备选的,你可以发送日志到你的日志服务器或者到一个日志管理方案中。
|
||||
|
||||
使用如下命令配置 rsyslog 通过 UDP 来接收标准端口 514 的 syslog 数据:
|
||||
|
||||
$ModLoad imudp
|
||||
|
||||
----------
|
||||
|
||||
$UDPServerRun 514
|
||||
|
||||
### 用 logrotate 管理日志 ###
|
||||
|
||||
日志轮转是当日志到达指定的时期时自动归档日志文件的方法。如果不介入,日志文件一直增长,会用尽磁盘空间。最后它们将破坏你的机器。
|
||||
|
||||
logrotate 工具能随着日志的日期截取你的日志,腾出空间。你的新日志文件保持该文件名。你的旧日志文件被重命名加上后缀数字。每次 logrotate 工具运行,就会创建一个新文件,然后现存的文件被逐一重命名。你来决定何时旧文件被删除或归档的阈值。
|
||||
|
||||
当 logrotate 拷贝一个文件,新的文件会有一个新的 inode,这会妨碍 rsyslog 监控新文件。你可以通过增加copytruncate 参数到你的 logrotate 定时任务来缓解这个问题。这个参数会拷贝现有的日志文件内容到新文件然后从现有文件截短这些内容。因为日志文件还是同一个,所以 inode 不会改变;但它的内容是一个新文件。
|
||||
|
||||
logrotate 工具使用的主配置文件是 /etc/logrotate.conf,应用特有设置在 /etc/logrotate.d/ 目录下。DigitalOcean 有一个详细的 [logrotate 教程][18]
|
||||
|
||||
### 管理很多服务器的配置 ###
|
||||
|
||||
当你只有很少的服务器,你可以登录上去手动配置。一旦你有几打或者更多服务器,你可以利用工具的优势使这变得更容易和更可扩展。基本上,所有的事情就是拷贝你的 rsyslog 配置到每个服务器,然后重启 rsyslog 使更改生效。
|
||||
|
||||
#### pssh ####
|
||||
|
||||
这个工具可以让你在很多服务器上并行的运行一个 ssh 命令。使用 pssh 部署仅用于少量服务器。如果你其中一个服务器失败,然后你必须 ssh 到失败的服务器,然后手动部署。如果你有很多服务器失败,那么手动部署它们会话费很长时间。
|
||||
|
||||
#### Puppet/Chef ####
|
||||
|
||||
Puppet 和 Chef 是两个不同的工具,它们能在你的网络按你规定的标准自动的配置所有服务器。它们的报表工具可以使你了解错误情况,然后定期重新同步。Puppet 和 Chef 都有一些狂热的支持者。如果你不确定那个更适合你的部署配置管理,你可以拜读一下 [InfoWorld 上这两个工具的对比][19]
|
||||
|
||||
一些厂商也提供一些配置 rsyslog 的模块或者方法。这有一个 Loggly 上 Puppet 模块的例子。它提供给 rsyslog 一个类,你可以添加一个标识令牌:
|
||||
|
||||
node 'my_server_node.example.net' {
|
||||
# Send syslog events to Loggly
|
||||
class { 'loggly::rsyslog':
|
||||
customer_token => 'de7b5ccd-04de-4dc4-fbc9-501393600000',
|
||||
}
|
||||
}
|
||||
|
||||
#### Docker ####
|
||||
|
||||
Docker 使用容器去运行应用,不依赖于底层服务。所有东西都运行在内部的容器,你可以把它想象为一个功能单元。ZDNet 有一篇关于在你的数据中心[使用 Docker][20] 的深入文章。
|
||||
|
||||
这里有很多方式从 Docker 容器记录日志,包括链接到一个日志容器,记录到一个共享卷,或者直接在容器里添加一个 sysllog 代理。其中最流行的日志容器叫做 [logspout][21]。
|
||||
|
||||
#### 供应商的脚本或代理 ####
|
||||
|
||||
大多数日志管理方案提供一些脚本或者代理,可以从一个或更多服务器相对容易地发送数据。重量级代理会耗尽额外的系统资源。一些供应商像 Loggly 提供配置脚本,来使用现存的 syslog 守护进程更轻松。这有一个 Loggly 上的例子[脚本][22],它能运行在任意数量的服务器上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/managing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a1]
|
||||
作者:[Amy Echeverri][a2]
|
||||
作者:[Sadequl Hussain][a3]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.esrreycnpnbl
|
||||
[2]:http://www.rsyslog.com/
|
||||
[3]:http://www.balabit.com/network-security/syslog-ng/opensource-logging-system
|
||||
[4]:http://logstash.net/
|
||||
[5]:http://www.fluentd.org/
|
||||
[6]:http://www.rsyslog.com/doc/rsyslog_conf.html
|
||||
[7]:http://www.rsyslog.com/doc/master/rainerscript/index.html
|
||||
[8]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.eck7acdxin87
|
||||
[9]:https://www.loggly.com/docs/file-monitoring/
|
||||
[10]:http://www.networksorcery.com/enp/protocol/udp.htm
|
||||
[11]:http://www.networksorcery.com/enp/protocol/tcp.htm
|
||||
[12]:http://blog.gerhards.net/2008/04/on-unreliability-of-plain-tcp-syslog.html
|
||||
[13]:http://www.rsyslog.com/doc/relp.html
|
||||
[14]:http://www.rsyslog.com/doc/queues.html
|
||||
[15]:http://www.rsyslog.com/doc/tls_cert_ca.html
|
||||
[16]:http://www.rsyslog.com/doc/tls_cert_machine.html
|
||||
[17]:http://www.rsyslog.com/doc/v8-stable/configuration/modules/imuxsock.html
|
||||
[18]:https://www.digitalocean.com/community/tutorials/how-to-manage-log-files-with-logrotate-on-ubuntu-12-10
|
||||
[19]:http://www.infoworld.com/article/2614204/data-center/puppet-or-chef--the-configuration-management-dilemma.html
|
||||
[20]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[21]:https://github.com/progrium/logspout
|
||||
[22]:https://www.loggly.com/docs/sending-logs-unixlinux-system-setup/
|
||||
@ -0,0 +1,69 @@
|
||||
Linux有问必答:如何启用Open vSwitch的日志功能以便调试和排障
|
||||
================================================================================
|
||||
> **问题** 我试着为我的Open vSwitch部署排障,鉴于此,我想要检查它的由内建日志机制生成的调试信息。我怎样才能启用Open vSwitch的日志功能,并且修改它的日志等级(如,修改成INFO/DEBUG级别)以便于检查更多详细的调试信息呢?
|
||||
|
||||
Open vSwitch(OVS)是Linux平台上最流行的开源的虚拟交换机。由于当今的数据中心日益依赖于软件定义网络(SDN)架构,OVS被作为数据中心的SDN部署中的事实标准上的网络元素而得到飞速应用。
|
||||
|
||||
Open vSwitch具有一个内建的日志机制,它称之为VLOG。VLOG工具允许你在各种网络交换组件中启用并自定义日志,由VLOG生成的日志信息可以被发送到一个控制台、syslog以及一个便于查看的单独日志文件。你可以通过一个名为`ovs-appctl`的命令行工具在运行时动态配置OVS日志。
|
||||
|
||||
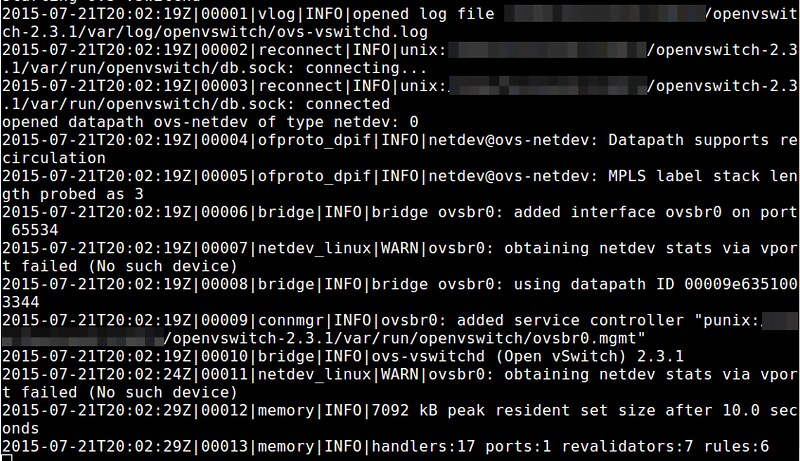
|
||||
|
||||
这里为你演示如何使用`ovs-appctl`启用Open vSwitch中的日志功能,并进行自定义。
|
||||
|
||||
下面是`ovs-appctl`自定义VLOG的语法。
|
||||
|
||||
$ sudo ovs-appctl vlog/set module[:facility[:level]]
|
||||
|
||||
- **Module**:OVS中的任何合法组件的名称(如netdev,ofproto,dpif,vswitchd等等)
|
||||
- **Facility**:日志信息的目的地(必须是:console,syslog,或者file)
|
||||
- **Level**:日志的详细程度(必须是:emer,err,warn,info,或者dbg)
|
||||
|
||||
在OVS源代码中,模块名称在源文件中是以以下格式定义的:
|
||||
|
||||
VLOG_DEFINE_THIS_MODULE(<module-name>);
|
||||
|
||||
例如,在lib/netdev.c中,你可以看到:
|
||||
|
||||
VLOG_DEFINE_THIS_MODULE(netdev);
|
||||
|
||||
这个表明,lib/netdev.c是netdev模块的一部分,任何在lib/netdev.c中生成的日志信息将属于netdev模块。
|
||||
|
||||
在OVS源代码中,有多个严重度等级用于定义几个不同类型的日志信息:VLOG_INFO()用于报告,VLOG_WARN()用于警告,VLOG_ERR()用于错误提示,VLOG_DBG()用于调试信息,VLOG_EMERG用于紧急情况。日志等级和工具确定哪个日志信息发送到哪里。
|
||||
|
||||
要查看可用模块、工具和各自日志级别的完整列表,请运行以下命令。该命令必须在你启动OVS后调用。
|
||||
|
||||
$ sudo ovs-appctl vlog/list
|
||||
|
||||
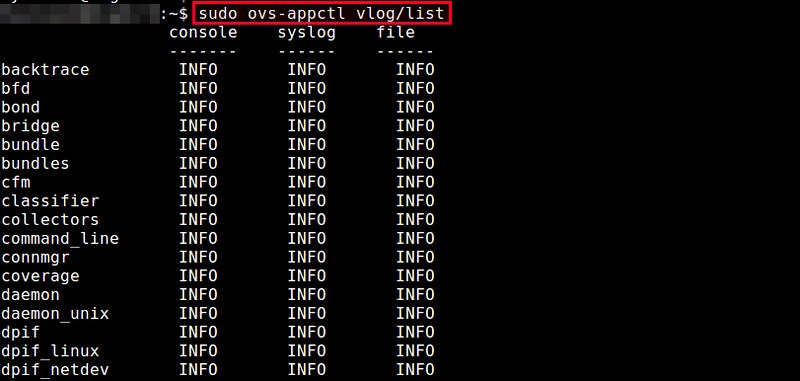
|
||||
|
||||
输出结果显示了用于三个场合(facility:console,syslog,file)的各个模块的调试级别。默认情况下,所有模块的日志等级都被设置为INFO。
|
||||
|
||||
指定任何一个OVS模块,你可以选择性地修改任何特定场合的调试级别。例如,如果你想要在控制台屏幕中查看dpif更为详细的调试信息,可以运行以下命令。
|
||||
|
||||
$ sudo ovs-appctl vlog/set dpif:console:dbg
|
||||
|
||||
你将看到dpif模块的console工具已经将其日志等级修改为DBG,而其它两个场合syslog和file的日志级别仍然没有改变。
|
||||
|
||||
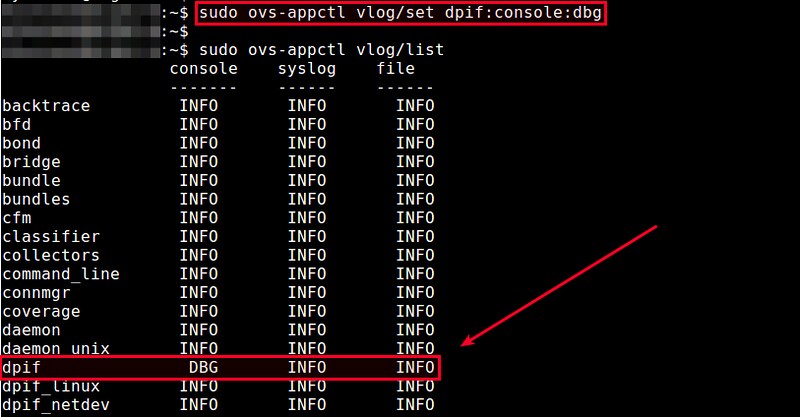
|
||||
|
||||
如果你想要修改所有模块的日志等级,你可以指定“ANY”作为模块名。例如,下面命令将修改每个模块的console的日志级别为DBG。
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:console:dbg
|
||||
|
||||
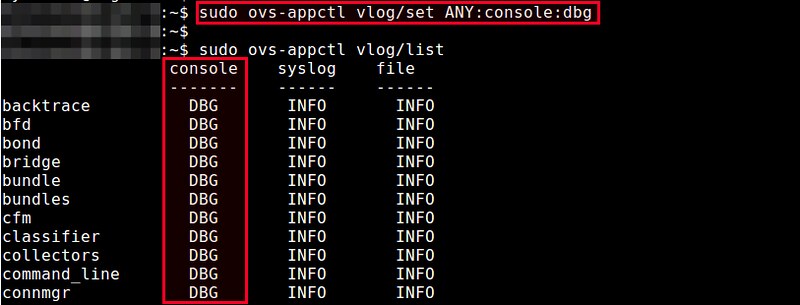
|
||||
|
||||
同时,如果你想要一次性修改所有三个场合的日志级别,你可以指定“ANY”作为场合名。例如,下面的命令将修改每个模块的所有场合的日志级别为DBG。
|
||||
|
||||
$ sudo ovs-appctl vlog/set ANY:ANY:dbg
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/enable-logging-open-vswitch.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,207 @@
|
||||
在 Ubuntu 15.04 中如何安装和使用 Snort
|
||||
================================================================================
|
||||
|
||||
对于网络安全而言入侵检测是一件非常重要的事。入侵检测系统(IDS)用于检测网络中非法与恶意的请求。Snort是一款知名的开源的入侵检测系统。其 Web界面(Snorby)可以用于更好地分析警告。Snort使用iptables/pf防火墙来作为入侵检测系统。本篇中,我们会安装并配置一个开源的入侵检测系统snort。
|
||||
|
||||
### Snort 安装 ###
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
snort所使用的数据采集库(DAQ)用于一个调用包捕获库的抽象层。这个在snort上就有。下载过程如下截图所示。
|
||||
|
||||

|
||||
|
||||
解压并运行./configure、make、make install来安装DAQ。然而,DAQ要求其他的工具,因此,./configure脚本会生成下面的错误。
|
||||
|
||||
flex和bison错误
|
||||
|
||||

|
||||
|
||||
libpcap错误
|
||||
|
||||

|
||||
|
||||
因此在安装DAQ之前先安装flex/bison和libcap。
|
||||
|
||||

|
||||
|
||||
如下所示安装libpcap开发库
|
||||
|
||||

|
||||
|
||||
安装完必要的工具后,再次运行./configure脚本,将会显示下面的输出。
|
||||
|
||||

|
||||
|
||||
make和make install 命令的结果如下所示。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
成功安装DAQ之后,我们现在安装snort。如下图使用wget下载它。
|
||||
|
||||

|
||||
|
||||
使用下面的命令解压安装包。
|
||||
|
||||
#tar -xvzf snort-2.9.7.3.tar.gz
|
||||
|
||||

|
||||
|
||||
创建安装目录并在脚本中设置prefix参数。同样也建议启用包性能监控(PPM)的sourcefire标志。
|
||||
|
||||
#mkdir /usr/local/snort
|
||||
|
||||
#./configure --prefix=/usr/local/snort/ --enable-sourcefire
|
||||
|
||||

|
||||
|
||||
配置脚本会由于缺少libpcre-dev、libdumbnet-dev 和zlib开发库而报错。
|
||||
|
||||
配置脚本由于缺少libpcre库报错。
|
||||
|
||||

|
||||
|
||||
配置脚本由于缺少dnet(libdumbnet)库而报错。
|
||||
|
||||

|
||||
|
||||
配置脚本由于缺少zlib库而报错
|
||||
|
||||

|
||||
|
||||
如下所示,安装所有需要的开发库。
|
||||
|
||||
# aptitude install libpcre3-dev
|
||||
|
||||

|
||||
|
||||
# aptitude install libdumbnet-dev
|
||||
|
||||

|
||||
|
||||
# aptitude install zlib1g-dev
|
||||
|
||||

|
||||
|
||||
安装完snort需要的库之后,再次运行配置脚本就不会报错了。
|
||||
|
||||
运行make和make install命令在/usr/local/snort目录下完成安装。
|
||||
|
||||
#make
|
||||
|
||||

|
||||
|
||||
#make install
|
||||
|
||||

|
||||
|
||||
最后,从/usr/local/snort/bin中运行snort。现在它对eth0的所有流量都处在promisc模式(包转储模式)。
|
||||
|
||||

|
||||
|
||||
如下图所示snort转储流量。
|
||||
|
||||

|
||||
|
||||
#### Snort的规则和配置 ####
|
||||
|
||||
从源码安装的snort还需要设置规则和配置,因此我们需要复制规则和配置到/etc/snort下面。我们已经创建了单独的bash脚本来用于设置规则和配置。它会设置下面这些snort设置。
|
||||
|
||||
- 在linux中创建用于snort IDS服务的snort用户。
|
||||
- 在/etc下面创建snort的配置文件和文件夹。
|
||||
- 权限设置并从源代码的etc目录中复制数据。
|
||||
- 从snort文件中移除规则中的#(注释符号)。
|
||||
|
||||
-
|
||||
|
||||
#!/bin/bash#
|
||||
# snort源代码的路径
|
||||
snort_src="/home/test/Downloads/snort-2.9.7.3"
|
||||
echo "adding group and user for snort..."
|
||||
groupadd snort &> /dev/null
|
||||
useradd snort -r -s /sbin/nologin -d /var/log/snort -c snort_idps -g snort &> /dev/null#snort configuration
|
||||
echo "Configuring snort..."mkdir -p /etc/snort
|
||||
mkdir -p /etc/snort/rules
|
||||
touch /etc/snort/rules/black_list.rules
|
||||
touch /etc/snort/rules/white_list.rules
|
||||
touch /etc/snort/rules/local.rules
|
||||
mkdir /etc/snort/preproc_rules
|
||||
mkdir /var/log/snort
|
||||
mkdir -p /usr/local/lib/snort_dynamicrules
|
||||
chmod -R 775 /etc/snort
|
||||
chmod -R 775 /var/log/snort
|
||||
chmod -R 775 /usr/local/lib/snort_dynamicrules
|
||||
chown -R snort:snort /etc/snort
|
||||
chown -R snort:snort /var/log/snort
|
||||
chown -R snort:snort /usr/local/lib/snort_dynamicrules
|
||||
###copy configuration and rules from etc directory under source code of snort
|
||||
echo "copying from snort source to /etc/snort ....."
|
||||
echo $snort_src
|
||||
echo "-------------"
|
||||
cp $snort_src/etc/*.conf* /etc/snort
|
||||
cp $snort_src/etc/*.map /etc/snort##enable rules
|
||||
sed -i 's/include \$RULE\_PATH/#include \$RULE\_PATH/' /etc/snort/snort.conf
|
||||
echo "---DONE---"
|
||||
|
||||
改变脚本中的snort源目录路径并运行。下面是成功的输出。
|
||||
|
||||

|
||||
|
||||
上面的脚本从snort源中复制下面的文件和文件夹到/etc/snort配置文件中
|
||||
|
||||

|
||||
|
||||
snort的配置非常复杂,要让IDS能正常工作需要进行下面必要的修改。
|
||||
|
||||
ipvar HOME_NET 192.168.1.0/24 # LAN side
|
||||
|
||||
----------
|
||||
|
||||
ipvar EXTERNAL_NET !$HOME_NET # WAN side
|
||||
|
||||

|
||||
|
||||
var RULE_PATH /etc/snort/rules # snort signature path
|
||||
var SO_RULE_PATH /etc/snort/so_rules #rules in shared libraries
|
||||
var PREPROC_RULE_PATH /etc/snort/preproc_rules # Preproces path
|
||||
var WHITE_LIST_PATH /etc/snort/rules # dont scan
|
||||
var BLACK_LIST_PATH /etc/snort/rules # Must scan
|
||||
|
||||

|
||||
|
||||
include $RULE_PATH/local.rules # file for custom rules
|
||||
|
||||
移除ftp.rules、exploit.rules前面的注释符号(#)。
|
||||
|
||||

|
||||
|
||||
现在[下载社区规则][1]并解压到/etc/snort/rules。启用snort.conf中的社区及紧急威胁规则。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
进行了上面的更改后,运行下面的命令来检验配置文件。
|
||||
|
||||
#snort -T -c /etc/snort/snort.conf
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇中,我们关注了开源IDPS系统snort在Ubuntu上的安装和配置。通常它用于监控事件,然而它可以被配置成用于网络保护的在线模式。snort规则可以在离线模式中可以使用pcap捕获文件进行测试和分析
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/install-snort-usage-ubuntu-15-04/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:https://www.snort.org/downloads/community/community-rules.tar.gz
|
||||
@ -0,0 +1,264 @@
|
||||
fdupes:Linux中查找并删除重复文件的命令行工具
|
||||
================================================================================
|
||||
对于大多数计算机用户而言,查找并替换重复的文件是一个常见的需求。查找并移除重复文件真是一项令人不胜其烦的工作,它耗时又耗力。但如果你的机器上跑着GNU/Linux,那么查找重复文件会变得十分简单,这多亏了`fdupes`工具。
|
||||
|
||||

|
||||
|
||||
*fdupes——在Linux中查找并删除重复文件*
|
||||
|
||||
### fdupes是啥东东? ###
|
||||
|
||||
**fdupes**是Linux下的一个工具,它由**Adrian Lopez**用C编程语言编写并基于MIT许可证发行,该应用程序可以在指定的目录及子目录中查找重复的文件。fdupes通过对比文件的MD5签名,以及逐字节比较文件来识别重复内容,fdupes有各种选项,可以实现对文件的列出、删除、替换为文件副本的硬链接等操作。
|
||||
|
||||
文件对比以下列顺序开始:
|
||||
|
||||
**大小对比 > 部分 MD5 签名对比 > 完整 MD5 签名对比 > 逐字节对比**
|
||||
|
||||
### 安装 fdupes 到 Linux ###
|
||||
|
||||
在基于**Debian**的系统上,如**Ubuntu**和**Linux Mint**,安装最新版fdupes,用下面的命令手到擒来。
|
||||
|
||||
$ sudo apt-get install fdupes
|
||||
|
||||
在基于CentOS/RHEL和Fedora的系统上,你需要开启[epel仓库][1]来安装fdupes包。
|
||||
|
||||
# yum install fdupes
|
||||
# dnf install fdupes [On Fedora 22 onwards]
|
||||
|
||||
**注意**:自Fedora 22之后,默认的包管理器yum被dnf取代了。
|
||||
|
||||
### fdupes命令如何使用 ###
|
||||
|
||||
1、 作为演示的目的,让我们来在某个目录(比如 tecmint)下创建一些重复文件,命令如下:
|
||||
|
||||
$ mkdir /home/"$USER"/Desktop/tecmint && cd /home/"$USER"/Desktop/tecmint && for i in {1..15}; do echo "I Love Tecmint. Tecmint is a very nice community of Linux Users." > tecmint${i}.txt ; done
|
||||
|
||||
在执行以上命令后,让我们使用ls[命令][2]验证重复文件是否创建。
|
||||
|
||||
$ ls -l
|
||||
|
||||
total 60
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint10.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint11.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint12.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint13.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint14.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint15.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint1.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint2.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint3.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint4.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint5.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint6.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint7.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint8.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9.txt
|
||||
|
||||
上面的脚本创建了**15**个文件,名称分别为tecmint1.txt,tecmint2.txt……tecmint15.txt,并且每个文件的数据相同,如
|
||||
|
||||
"I Love Tecmint. Tecmint is a very nice community of Linux Users."
|
||||
|
||||
2、 现在在**tecmint**文件夹内搜索重复的文件。
|
||||
|
||||
$ fdupes /home/$USER/Desktop/tecmint
|
||||
|
||||
/home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
3、 使用**-r**选项在每个目录包括其子目录中递归搜索重复文件。
|
||||
|
||||
它会递归搜索所有文件和文件夹,花一点时间来扫描重复文件,时间的长短取决于文件和文件夹的数量。在此其间,终端中会显示全部过程,像下面这样。
|
||||
|
||||
$ fdupes -r /home
|
||||
|
||||
Progress [37780/54747] 69%
|
||||
|
||||
4、 使用**-S**选项来查看某个文件夹内找到的重复文件的大小。
|
||||
|
||||
$ fdupes -S /home/$USER/Desktop/tecmint
|
||||
|
||||
65 bytes each:
|
||||
/home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
5、 你可以同时使用**-S**和**-r**选项来查看所有涉及到的目录和子目录中的重复文件的大小,如下:
|
||||
|
||||
$ fdupes -Sr /home/avi/Desktop/
|
||||
|
||||
65 bytes each:
|
||||
/home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
/home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
107 bytes each:
|
||||
/home/tecmint/Desktop/resume_files/r-csc.html
|
||||
/home/tecmint/Desktop/resume_files/fc.html
|
||||
|
||||
6、 不同于在一个或所有文件夹内递归搜索,你可以选择按要求有选择性地在两个或三个文件夹内进行搜索。不必再提醒你了吧,如有需要,你可以使用**-S**和/或**-r**选项。
|
||||
|
||||
$ fdupes /home/avi/Desktop/ /home/avi/Templates/
|
||||
|
||||
7、 要删除重复文件,同时保留一个副本,你可以使用`-d`选项。使用该选项,你必须额外小心,否则最终结果可能会是文件/数据的丢失。郑重提醒,此操作不可恢复。
|
||||
|
||||
$ fdupes -d /home/$USER/Desktop/tecmint
|
||||
|
||||
[1] /home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
[2] /home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
[3] /home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
[4] /home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
[5] /home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
[6] /home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
[7] /home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
[8] /home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
[9] /home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
[10] /home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
[11] /home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
[12] /home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
[13] /home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
[14] /home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
[15] /home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
Set 1 of 1, preserve files [1 - 15, all]:
|
||||
|
||||
你可能注意到了,所有重复的文件被列了出来,并给出删除提示,一个一个来,或者指定范围,或者一次性全部删除。你可以选择一个范围,就像下面这样,来删除指定范围内的文件。
|
||||
|
||||
Set 1 of 1, preserve files [1 - 15, all]: 2-15
|
||||
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint13.txt
|
||||
[+] /home/tecmint/Desktop/tecmint/tecmint8.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint11.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint3.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint4.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint6.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint7.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint9.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint10.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint2.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint5.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint14.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint1.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint15.txt
|
||||
[-] /home/tecmint/Desktop/tecmint/tecmint12.txt
|
||||
|
||||
8、 从安全角度出发,你可能想要打印`fdupes`的输出结果到文件中,然后检查文本文件来决定要删除什么文件。这可以降低意外删除文件的风险。你可以这么做:
|
||||
|
||||
$ fdupes -Sr /home > /home/fdupes.txt
|
||||
|
||||
**注意**:你应该替换`/home`为你想要的文件夹。同时,如果你想要递归搜索并打印大小,可以使用`-r`和`-S`选项。
|
||||
|
||||
9、 你可以使用`-f`选项来忽略每个匹配集中的首个文件。
|
||||
|
||||
首先列出该目录中的文件。
|
||||
|
||||
$ ls -l /home/$USER/Desktop/tecmint
|
||||
|
||||
total 20
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9 (3rd copy).txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9 (4th copy).txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9 (another copy).txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9 (copy).txt
|
||||
-rw-r--r-- 1 tecmint tecmint 65 Aug 8 11:22 tecmint9.txt
|
||||
|
||||
然后,忽略掉每个匹配集中的首个文件。
|
||||
|
||||
$ fdupes -f /home/$USER/Desktop/tecmint
|
||||
|
||||
/home/tecmint/Desktop/tecmint9 (copy).txt
|
||||
/home/tecmint/Desktop/tecmint9 (3rd copy).txt
|
||||
/home/tecmint/Desktop/tecmint9 (another copy).txt
|
||||
/home/tecmint/Desktop/tecmint9 (4th copy).txt
|
||||
|
||||
10、 检查已安装的fdupes版本。
|
||||
|
||||
$ fdupes --version
|
||||
|
||||
fdupes 1.51
|
||||
|
||||
11、 如果你需要关于fdupes的帮助,可以使用`-h`开关。
|
||||
|
||||
$ fdupes -h
|
||||
|
||||
Usage: fdupes [options] DIRECTORY...
|
||||
|
||||
-r --recurse for every directory given follow subdirectories
|
||||
encountered within
|
||||
-R --recurse: for each directory given after this option follow
|
||||
subdirectories encountered within (note the ':' at
|
||||
the end of the option, manpage for more details)
|
||||
-s --symlinks follow symlinks
|
||||
-H --hardlinks normally, when two or more files point to the same
|
||||
disk area they are treated as non-duplicates; this
|
||||
option will change this behavior
|
||||
-n --noempty exclude zero-length files from consideration
|
||||
-A --nohidden exclude hidden files from consideration
|
||||
-f --omitfirst omit the first file in each set of matches
|
||||
-1 --sameline list each set of matches on a single line
|
||||
-S --size show size of duplicate files
|
||||
-m --summarize summarize dupe information
|
||||
-q --quiet hide progress indicator
|
||||
-d --delete prompt user for files to preserve and delete all
|
||||
others; important: under particular circumstances,
|
||||
data may be lost when using this option together
|
||||
with -s or --symlinks, or when specifying a
|
||||
particular directory more than once; refer to the
|
||||
fdupes documentation for additional information
|
||||
-N --noprompt together with --delete, preserve the first file in
|
||||
each set of duplicates and delete the rest without
|
||||
prompting the user
|
||||
-v --version display fdupes version
|
||||
-h --help display this help message
|
||||
|
||||
到此为止了。让我知道你以前怎么在Linux中查找并删除重复文件的吧?同时,也让我知道你关于这个工具的看法。在下面的评论部分中提供你有价值的反馈吧,别忘了为我们点赞并分享,帮助我们扩散哦。
|
||||
|
||||
我正在使用另外一个移除重复文件的工具,它叫**fslint**。很快就会把使用心得分享给大家哦,你们一定会喜欢看的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/fdupes-find-and-delete-duplicate-files-in-linux/
|
||||
|
||||
作者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://linux.cn/article-2324-1.html
|
||||
[2]:https://linux.cn/article-5109-1.html
|
||||
@ -0,0 +1,145 @@
|
||||
Linux 小技巧:Chrome 小游戏,让文字说话,计划作业,重复执行命令
|
||||
================================================================================
|
||||
|
||||
重要的事情说两遍,我完成了一个[Linux提示与彩蛋][1]系列,让你的Linux获得更多创造和娱乐。
|
||||
|
||||

|
||||
|
||||
*Linux提示与彩蛋系列*
|
||||
|
||||
本文,我将会讲解Google-chrome内建小游戏,在终端中如何让文字说话,使用‘at’命令设置作业和使用watch命令重复执行命令。
|
||||
|
||||
### 1. Google Chrome 浏览器小游戏彩蛋 ###
|
||||
|
||||
网线脱掉或者其他什么原因连不上网时,Google Chrome就会出现一个小游戏。声明,我并不是游戏玩家,因此我的电脑上并没有安装任何第三方的恶意游戏。安全是第一位。
|
||||
|
||||
所以当Internet发生出错,会出现一个这样的界面:
|
||||
|
||||

|
||||
|
||||
*不能连接到互联网*
|
||||
|
||||
按下空格键来激活Google-chrome彩蛋游戏。游戏没有时间限制。并且还不需要浪费时间安装使用。
|
||||
|
||||
不需要第三方软件的支持。同样支持Windows和Mac平台,但是我的平台是Linux,我也只谈论Linux。当然在Linux,这个游戏运行很好。游戏简单,但也很花费时间。
|
||||
|
||||
使用空格/向上方向键来跳跃。请看下列截图:
|
||||
|
||||

|
||||
|
||||
*Google Chrome中玩游戏*
|
||||
|
||||
### 2. Linux 终端中朗读文字 ###
|
||||
|
||||
对于那些不能文字朗读的设备,有个小工具可以实现文字说话的转换器。用各种语言写一些东西,espeak就可以朗读给你。
|
||||
|
||||
系统应该默认安装了Espeak,如果你的系统没有安装,你可以使用下列命令来安装:
|
||||
|
||||
# apt-get install espeak (Debian)
|
||||
# yum install espeak (CentOS)
|
||||
# dnf install espeak (Fedora 22 及其以后)
|
||||
|
||||
你可以让espeak接受标准输入的交互输入并及时转换成语音朗读出来。如下:
|
||||
|
||||
$ espeak [按回车键]
|
||||
|
||||
更详细的输出你可以这样做:
|
||||
|
||||
$ espeak --stdout | aplay [按回车键][再次回车]
|
||||
|
||||
espeak设置灵活,也可以朗读文本文件。你可以这样设置:
|
||||
|
||||
$ espeak --stdout /path/to/text/file/file_name.txt | aplay [Hit Enter]
|
||||
|
||||
espeak可以设置朗读速度。默认速度是160词每分钟。使用-s参数来设置。
|
||||
|
||||
设置每分钟30词的语速:
|
||||
|
||||
$ espeak -s 30 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
设置每分钟200词的语速:
|
||||
|
||||
$ espeak -s 200 -f /path/to/text/file/file_name.txt | aplay
|
||||
|
||||
说其他语言,比如北印度语(作者母语),这样设置:
|
||||
|
||||
$ espeak -v hindi --stdout 'टेकमिंट विश्व की एक बेहतरीन लाइंक्स आधारित वेबसाइट है|' | aplay
|
||||
|
||||
你可以使用各种语言,让espeak如上面说的以你选择的语言朗读。使用下列命令来获得语言列表:
|
||||
|
||||
$ espeak --voices
|
||||
|
||||
### 3. 快速调度任务 ###
|
||||
|
||||
我们已经非常熟悉使用[cron][2]守护进程执行一个计划命令。
|
||||
|
||||
Cron是一个Linux系统管理的高级命令,用于计划定时任务如备份或者指定时间或间隔的任何事情。
|
||||
|
||||
但是,你是否知道at命令可以让你在指定时间调度一个任务或者命令?at命令可以指定时间执行指定内容。
|
||||
|
||||
例如,你打算在早上11点2分执行uptime命令,你只需要这样做:
|
||||
|
||||
$ at 11:02
|
||||
uptime >> /home/$USER/uptime.txt
|
||||
Ctrl+D
|
||||
|
||||

|
||||
|
||||
*Linux中计划任务*
|
||||
|
||||
检查at命令是否成功设置,使用:
|
||||
|
||||
$ at -l
|
||||
|
||||

|
||||
|
||||
*浏览计划任务*
|
||||
|
||||
at支持计划多个命令,例如:
|
||||
|
||||
$ at 12:30
|
||||
Command – 1
|
||||
Command – 2
|
||||
…
|
||||
command – 50
|
||||
…
|
||||
Ctrl + D
|
||||
|
||||
### 4. 特定时间重复执行命令 ###
|
||||
|
||||
有时,我们可以需要在指定时间间隔执行特定命令。例如,每3秒,想打印一次时间。
|
||||
|
||||
查看现在时间,使用下列命令。
|
||||
|
||||
$ date +"%H:%M:%S
|
||||
|
||||

|
||||
|
||||
*Linux中查看日期和时间*
|
||||
|
||||
为了每三秒查看一下这个命令的输出,我需要运行下列命令:
|
||||
|
||||
$ watch -n 3 'date +"%H:%M:%S"'
|
||||
|
||||

|
||||
|
||||
*Linux中watch命令*
|
||||
|
||||
watch命令的‘-n’开关设定时间间隔。在上述命令中,我们定义了时间间隔为3秒。你可以按你的需求定义。同样watch
|
||||
也支持其他命令或者脚本。
|
||||
|
||||
至此。希望你喜欢这个系列的文章,让你的linux更有创造性,获得更多快乐。所有的建议欢迎评论。欢迎你也看看其他文章,谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/text-to-speech-in-terminal-schedule-a-job-and-watch-commands-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[VicYu/Vic020](http://vicyu.net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
@ -0,0 +1,104 @@
|
||||
如何在 Docker 容器中运行支持 OData 的 JBoss 数据虚拟化 GA
|
||||
================================================================================
|
||||
|
||||
大家好,我们今天来学习如何在一个 Docker 容器中运行支持 OData(译者注:Open Data Protocol,开放数据协议) 的 JBoss 数据虚拟化 6.0.0 GA(译者注:GA,General Availability,具体定义可以查看[WIKI][4])。JBoss 数据虚拟化是数据提供和集成解决方案平台,将多种分散的数据源转换为一种数据源统一对待,在正确的时间将所需数据传递给任意的应用或者用户。JBoss 数据虚拟化可以帮助我们将数据快速组合和转换为可重用的商业友好的数据模型,通过开放标准接口简单可用。它提供全面的数据抽取、联合、集成、转换,以及传输功能,将来自一个或多个源的数据组合为可重复使用和共享的灵活数据。要了解更多关于 JBoss 数据虚拟化的信息,可以查看它的[官方文档][1]。Docker 是一个提供开放平台用于打包,装载和以轻量级容器运行任何应用的开源平台。使用 Docker 容器我们可以轻松处理和启用支持 OData 的 JBoss 数据虚拟化。
|
||||
|
||||
下面是该指南中在 Docker 容器中运行支持 OData 的 JBoss 数据虚拟化的简单步骤。
|
||||
|
||||
### 1. 克隆仓库 ###
|
||||
|
||||
首先,我们要用 git 命令从 [https://github.com/jbossdemocentral/dv-odata-docker-integration-demo][2] 克隆带数据虚拟化的 OData 仓库。假设我们的机器上运行着 Ubuntu 15.04 linux 发行版。我们要使用 apt-get 命令安装 git。
|
||||
|
||||
# apt-get install git
|
||||
|
||||
安装完 git 之后,我们运行下面的命令克隆仓库。
|
||||
|
||||
# git clone https://github.com/jbossdemocentral/dv-odata-docker-integration-demo
|
||||
|
||||
Cloning into 'dv-odata-docker-integration-demo'...
|
||||
remote: Counting objects: 96, done.
|
||||
remote: Total 96 (delta 0), reused 0 (delta 0), pack-reused 96
|
||||
Unpacking objects: 100% (96/96), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
### 2. 下载 JBoss 数据虚拟化安装器 ###
|
||||
|
||||
现在,我们需要从下载页 [http://www.jboss.org/products/datavirt/download/][3] 下载 JBoss 数据虚拟化安装器。下载了 **jboss-dv-installer-6.0.0.GA-redhat-4.jar** 后,我们把它保存在名为 **software** 的目录下。
|
||||
|
||||
### 3. 创建 Docker 镜像 ###
|
||||
|
||||
下一步,下载了 JBoss 数据虚拟化安装器之后,我们打算使用 Dockerfile 和刚从仓库中克隆的资源创建 docker 镜像。
|
||||
|
||||
# cd dv-odata-docker-integration-demo/
|
||||
# docker build -t jbossdv600 .
|
||||
|
||||
...
|
||||
Step 22 : USER jboss
|
||||
---> Running in 129f701febd0
|
||||
---> 342941381e37
|
||||
Removing intermediate container 129f701febd0
|
||||
Step 23 : EXPOSE 8080 9990 31000
|
||||
---> Running in 61e6d2c26081
|
||||
---> 351159bb6280
|
||||
Removing intermediate container 61e6d2c26081
|
||||
Step 24 : CMD $JBOSS_HOME/bin/standalone.sh -c standalone.xml -b 0.0.0.0 -bmanagement 0.0.0.0
|
||||
---> Running in a9fed69b3000
|
||||
---> 407053dc470e
|
||||
Removing intermediate container a9fed69b3000
|
||||
Successfully built 407053dc470e
|
||||
|
||||
注意:在这里我们假设你已经安装了 docker 并正在运行。
|
||||
|
||||
### 4. 启动 Docker 容器 ###
|
||||
|
||||
创建了支持 oData 的 JBoss 数据虚拟化 Docker 镜像之后,我们打算运行 docker 容器并用 -P 标签指定端口。我们运行下面的命令来实现。
|
||||
|
||||
# docker run -p 8080:8080 -d -t jbossdv600
|
||||
|
||||
7765dee9cd59c49ca26850e88f97c21f46859d2dc1d74166353d898773214c9c
|
||||
|
||||
### 5. 获取容器 IP ###
|
||||
|
||||
启动了 Docker 容器之后,我们想要获取正在运行的 docker 容器的 IP 地址。要做到这点,我们运行后面添加了正在运行容器 id 号的 docker inspect 命令。
|
||||
|
||||
# docker inspect <$containerID>
|
||||
|
||||
...
|
||||
"NetworkSettings": {
|
||||
"Bridge": "",
|
||||
"EndpointID": "3e94c5900ac5954354a89591a8740ce2c653efde9232876bc94878e891564b39",
|
||||
"Gateway": "172.17.42.1",
|
||||
"GlobalIPv6Address": "",
|
||||
"GlobalIPv6PrefixLen": 0,
|
||||
"HairpinMode": false,
|
||||
"IPAddress": "172.17.0.8",
|
||||
"IPPrefixLen": 16,
|
||||
"IPv6Gateway": "",
|
||||
"LinkLocalIPv6Address": "",
|
||||
"LinkLocalIPv6PrefixLen": 0,
|
||||
|
||||
### 6. Web 界面 ###
|
||||
|
||||
现在,如果一切如期望的那样进行,当我们用浏览器打开 http://container-ip:8080/ 和 http://container-ip:9990 时会看到支持 oData 的 JBoss 数据虚拟化登录界面和 JBoss 管理界面。管理验证的用户名和密码分别是 admin 和 redhat1!数据虚拟化验证的用户名和密码都是 user。之后,我们可以通过 web 界面在内容间导航。
|
||||
|
||||
**注意**: 强烈建议在第一次登录后尽快修改密码。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
终于我们成功地运行了跑着支持 OData 多源虚拟数据库的 JBoss 数据虚拟化 的 Docker 容器。JBoss 数据虚拟化真的是一个很棒的平台,它为多种不同来源的数据进行虚拟化,并将它们转换为商业友好的数据模型,产生通过开放标准接口简单可用的数据。使用 Docker 技术可以简单、安全、快速地部署支持 OData 多源虚拟数据库的 JBoss 数据虚拟化。如果你有任何疑问、建议或者反馈,请在下面的评论框中写下来,以便我们可以改进和更新内容。非常感谢!Enjoy:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/run-jboss-data-virtualization-ga-odata-docker-container/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.redhat.com/en/technologies/jboss-middleware/data-virtualization
|
||||
[2]:https://github.com/jbossdemocentral/dv-odata-docker-integration-demo
|
||||
[3]:http://www.jboss.org/products/datavirt/download/
|
||||
[4]:https://en.wikipedia.org/wiki/Software_release_life_cycle#General_availability_.28GA.29
|
||||
440
published/201509/20150813 Linux file system hierarchy v2.0.md
Normal file
440
published/201509/20150813 Linux file system hierarchy v2.0.md
Normal file
@ -0,0 +1,440 @@
|
||||
Linux 文件系统结构介绍
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
Linux中的文件是什么?它的文件系统又是什么?那些配置文件又在哪里?我下载好的程序保存在哪里了?在 Linux 中文件系统是标准结构的吗?好了,上图简明地阐释了Linux的文件系统的层次关系。当你苦于寻找配置文件或者二进制文件的时候,这便显得十分有用了。我在下方添加了一些解释以及例子,不过“篇幅较长,可以有空再看”。
|
||||
|
||||
另外一种情况便是当你在系统中获取配置以及二进制文件时,出现了不一致性问题,如果你是在一个大型组织中,或者只是一个终端用户,这也有可能会破坏你的系统(比如,二进制文件运行在旧的库文件上了)。若然你在[你的Linux系统上做安全审计][1]的话,你将会发现它很容易遭到各种攻击。所以,保持一个清洁的操作系统(无论是Windows还是Linux)都显得十分重要。
|
||||
|
||||
### Linux的文件是什么? ###
|
||||
|
||||
对于UNIX系统来说(同样适用于Linux),以下便是对文件简单的描述:
|
||||
|
||||
> 在UNIX系统中,一切皆为文件;若非文件,则为进程
|
||||
|
||||
这种定义是比较正确的,因为有些特殊的文件不仅仅是普通文件(比如命名管道和套接字),不过为了让事情变的简单,“一切皆为文件”也是一个可以让人接受的说法。Linux系统也像UNIX系统一样,将文件和目录视如同物,因为目录只是一个包含了其他文件名的文件而已。程序、服务、文本、图片等等,都是文件。对于系统来说,输入和输出设备,基本上所有的设备,都被当做是文件。
|
||||
|
||||
题图版本历史:
|
||||
|
||||
- Version 2.0 – 17-06-2015
|
||||
- – Improved: 添加标题以及版本历史
|
||||
- – Improved: 添加/srv,/meida和/proc
|
||||
- – Improved: 更新了反映当前的Linux文件系统的描述
|
||||
- – Fixed: 多处的打印错误
|
||||
- – Fixed: 外观和颜色
|
||||
- Version 1.0 – 14-02-2015
|
||||
- – Created: 基本的图表
|
||||
- – Note: 摒弃更低的版本
|
||||
|
||||
### 下载链接 ###
|
||||
|
||||
以下是大图的下载地址。如果你需要其他格式,请跟原作者联系,他会尝试制作并且上传到某个地方以供下载
|
||||
|
||||
- [大图 (PNG 格式) – 2480×1755 px – 184KB][2]
|
||||
- [最大图 (PDF 格式) – 9919x7019 px – 1686KB][3]
|
||||
|
||||
**注意**: PDF格式文件是打印的最好选择,因为它画质很高。
|
||||
|
||||
### Linux 文件系统描述 ###
|
||||
|
||||
为了有序地管理那些文件,人们习惯把这些文件当做是硬盘上的有序的树状结构,正如我们熟悉的'MS-DOS'(磁盘操作系统)就是一个例子。大的分枝包括更多的分枝,分枝的末梢是树的叶子或者普通的文件。现在我们将会以这树形图为例,但晚点我们会发现为什么这不是一个完全准确的一幅图。
|
||||
|
||||
<table cellspacing="2" border="4" style="border-collapse: collapse; width: 731px; height: 2617px;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th scope="col">目录</th>
|
||||
<th scope="col">描述</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/</code>
|
||||
</td>
|
||||
<td><i>主层次</i> 的根,也是整个文件系统层次结构的根目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/bin</code>
|
||||
</td>
|
||||
<td>存放在单用户模式可用的必要命令二进制文件,所有用户都可用,如 cat、ls、cp等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/boot</code>
|
||||
</td>
|
||||
<td>存放引导加载程序文件,例如kernels、initrd等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/dev</code>
|
||||
</td>
|
||||
<td>存放必要的设备文件,例如<code>/dev/null</code> </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/etc</code>
|
||||
</td>
|
||||
<td>存放主机特定的系统级配置文件。其实这里有个关于它名字本身意义上的的争议。在贝尔实验室的UNIX实施文档的早期版本中,/etc表示是“其他(etcetera)目录”,因为从历史上看,这个目录是存放各种不属于其他目录的文件(然而,文件系统目录标准 FSH 限定 /etc 用于存放静态配置文件,这里不该存有二进制文件)。早期文档出版后,这个目录名又重新定义成不同的形式。近期的解释中包含着诸如“可编辑文本配置”或者“额外的工具箱”这样的重定义</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/opt</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存储着新增包的配置文件 <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/sgml</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存放配置文件,比如 catalogs,用于那些处理SGML(译者注:标准通用标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/X11</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>X Window 系统11版本的的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/etc/xml</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>配置文件,比如catalogs,用于那些处理XML(译者注:可扩展标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/home</code>
|
||||
</td>
|
||||
<td>用户的主目录,包括保存的文件,个人配置,等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/lib</code>
|
||||
</td>
|
||||
<td><code>/bin/</code> 和 <code>/sbin/</code>中的二进制文件的必需的库文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/lib<架构位数></code>
|
||||
</td>
|
||||
<td>备用格式的必要的库文件。 这样的目录是可选的,但如果他们存在的话肯定是有需要用到它们的程序</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/media</code>
|
||||
</td>
|
||||
<td>可移动的多媒体(如CD-ROMs)的挂载点。(出现于 FHS-2.3)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/mnt</code>
|
||||
</td>
|
||||
<td>临时挂载的文件系统</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/opt</code>
|
||||
</td>
|
||||
<td>可选的应用程序软件包</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/proc</code>
|
||||
</td>
|
||||
<td>以文件形式提供进程以及内核信息的虚拟文件系统,在Linux中,对应进程文件系统(procfs )的挂载点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/root</code>
|
||||
</td>
|
||||
<td>根用户的主目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/sbin</code>
|
||||
</td>
|
||||
<td>必要的系统级二进制文件,比如, init, ip, mount</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/srv</code>
|
||||
</td>
|
||||
<td>系统提供的站点特定数据</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/tmp</code>
|
||||
</td>
|
||||
<td>临时文件 (另见 <code>/var/tmp</code>). 通常在系统重启后删除</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/usr</code>
|
||||
</td>
|
||||
<td><i>二级层级</i>存储用户的只读数据; 包含(多)用户主要的公共文件以及应用程序</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/bin</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>非必要的命令二进制文件 (在单用户模式中不需要用到的);用于所有用户</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/include</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>标准的包含文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/lib</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>库文件,用于<code>/usr/bin/</code> 和 <code>/usr/sbin/</code>中的二进制文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/lib<架构位数></code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>备用格式库(可选的)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/local</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td><i>三级层次</i> 用于本地数据,具体到该主机上的。通常会有下一个子目录, <i>比如</i>, <code>bin/</code>, <code>lib/</code>, <code>share/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/local/sbin</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>非必要系统的二进制文件,比如用于不同网络服务的守护进程</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/share</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>架构无关的 (共享) 数据.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/src</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>源代码,比如内核源文件以及与它相关的头文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/usr/X11R6</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>X Window系统,版本号:11,发行版本:6</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
<code>/var</code>
|
||||
</td>
|
||||
<td>各式各样的(Variable)文件,一些随着系统常规操作而持续改变的文件就放在这里,比如日志文件,脱机文件,还有临时的电子邮件文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/cache</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>应用程序缓存数据. 这些数据是由耗时的I/O(输入/输出)的或者是运算本地生成的结果。这些应用程序是可以重新生成或者恢复数据的。当没有数据丢失的时候,可以删除缓存文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/lib</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>状态信息。这些信息随着程序的运行而不停地改变,比如,数据库,软件包系统的元数据等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/lock</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>锁文件。这些文件用于跟踪正在使用的资源</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/log</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>日志文件。包含各种日志。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/mail</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>内含用户邮箱的相关文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/opt</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>来自附加包的各种数据都会存储在 <code>/var/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/run</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存放当前系统上次启动以来的相关信息,例如当前登入的用户以及当前运行的<a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons(守护进程)</a>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/spool</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>该spool主要用于存放将要被处理的任务,比如打印队列以及邮件外发队列</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
|
||||
|
||||
<code>/var/mail</code>
|
||||
|
||||
|
||||
|
||||
|
||||
</td>
|
||||
<td>过时的位置,用于放置用户邮箱文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>
|
||||
|
||||
|
||||
<code>/var/tmp</code>
|
||||
|
||||
|
||||
</td>
|
||||
<td>存放重启后保留的临时文件</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Linux的文件类型 ###
|
||||
|
||||
大多数文件仅仅是普通文件,他们被称为`regular`文件;他们包含普通数据,比如,文本、可执行文件、或者程序、程序的输入或输出等等
|
||||
|
||||
虽然你可以认为“在Linux中,一切你看到的皆为文件”这个观点相当保险,但这里仍有着一些例外。
|
||||
|
||||
- `目录`:由其他文件组成的文件
|
||||
- `特殊文件`:用于输入和输出的途径。大多数特殊文件都储存在`/dev`中,我们将会在后面讨论这个问题。
|
||||
- `链接文件`:让文件或者目录出现在系统文件树结构上多个地方的机制。我们将详细地讨论这个链接文件。
|
||||
- `(域)套接字`:特殊的文件类型,和TCP/IP协议中的套接字有点像,提供进程间网络通讯,并受文件系统的访问控制机制保护。
|
||||
- `命名管道` : 或多或少有点像sockets(套接字),提供一个进程间的通信机制,而不用网络套接字协议。
|
||||
|
||||
### 现实中的文件系统 ###
|
||||
|
||||
对于大多数用户和常规系统管理任务而言,“文件和目录是一个有序的类树结构”是可以接受的。然而,对于电脑而言,它是不会理解什么是树,或者什么是树结构。
|
||||
|
||||
每个分区都有它自己的文件系统。想象一下,如果把那些文件系统想成一个整体,我们可以构思一个关于整个系统的树结构,不过这并没有这么简单。在文件系统中,一个文件代表着一个`inode`(索引节点),这是一种包含着构建文件的实际数据信息的序列号:这些数据表示文件是属于谁的,还有它在硬盘中的位置。
|
||||
|
||||
每个分区都有一套属于他们自己的inode,在一个系统的不同分区中,可以存在有相同inode的文件。
|
||||
|
||||
每个inode都表示着一种在硬盘上的数据结构,保存着文件的属性,包括文件数据的物理地址。当硬盘被格式化并用来存储数据时(通常发生在初始系统安装过程,或者是在一个已经存在的系统中添加额外的硬盘),每个分区都会创建固定数量的inode。这个值表示这个分区能够同时存储各类文件的最大数量。我们通常用一个inode去映射2-8k的数据块。当一个新的文件生成后,它就会获得一个空闲的inode。在这个inode里面存储着以下信息:
|
||||
|
||||
- 文件属主和组属主
|
||||
- 文件类型(常规文件,目录文件......)
|
||||
- 文件权限
|
||||
- 创建、最近一次读文件和修改文件的时间
|
||||
- inode里该信息被修改的时间
|
||||
- 文件的链接数(详见下一章)
|
||||
- 文件大小
|
||||
- 文件数据的实际地址
|
||||
|
||||
唯一不在inode的信息是文件名和目录。它们存储在特殊的目录文件。通过比较文件名和inode的数目,系统能够构造出一个便于用户理解的树结构。用户可以通过ls -i查看inode的数目。在硬盘上,inodes有他们独立的空间。
|
||||
|
||||
------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/18/linux-file-system-hierarchy-v2-0/
|
||||
|
||||
译者:[tnuoccalanosrep](https://github.com/tnuoccalanosrep)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.blackmoreops.com/2015/02/15/in-light-of-recent-linux-exploits-linux-security-audit-is-a-must/
|
||||
[2]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-file-system-hierarchy-v2.0-2480px-blackMORE-Ops.png
|
||||
[3]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-File-System-Hierarchy-blackMORE-Ops.pdf
|
||||
@ -0,0 +1,187 @@
|
||||
在 Linux 中怎样将 MySQL 迁移到 MariaDB 上
|
||||
================================================================================
|
||||
|
||||
自从甲骨文收购 MySQL 后,由于甲骨文对 MySQL 的开发和维护更多倾向于闭门的立场,很多 MySQL 的开发者和用户放弃了 MySQL。在社区驱动下,促使更多人移到 MySQL 的另一个叫 MariaDB 的分支。在原有 MySQL 开发人员的带领下,MariaDB 的开发遵循开源的理念,并确保[它的二进制格式与 MySQL 兼容][1]。Linux 发行版如 Red Hat 家族(Fedora,CentOS,RHEL),Ubuntu 和 Mint,openSUSE 和 Debian 已经开始使用,并支持 MariaDB 作为 MySQL 的直接替换品。
|
||||
|
||||
如果你想要将 MySQL 中的数据库迁移到 MariaDB 中,这篇文章就是你所期待的。幸运的是,由于他们的二进制兼容性,MySQL-to-MariaDB 迁移过程是非常简单的。如果你按照下面的步骤,将 MySQL 迁移到 MariaDB 会是无痛的。
|
||||
|
||||
### 准备 MySQL 数据库和表 ###
|
||||
|
||||
出于演示的目的,我们在做迁移之前在数据库中创建一个测试的 MySQL 数据库和表。如果你在 MySQL 中已经有了要迁移到 MariaDB 的数据库,跳过此步骤。否则,按以下步骤操作。
|
||||
|
||||
在终端输入 root 密码登录到 MySQL 。
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||
创建一个数据库和表。
|
||||
|
||||
mysql> create database test01;
|
||||
mysql> use test01;
|
||||
mysql> create table pet(name varchar(30), owner varchar(30), species varchar(20), sex char(1));
|
||||
|
||||
在表中添加一些数据。
|
||||
|
||||
mysql> insert into pet values('brandon','Jack','puddle','m'),('dixie','Danny','chihuahua','f');
|
||||
|
||||
退出 MySQL 数据库.
|
||||
|
||||
### 备份 MySQL 数据库 ###
|
||||
|
||||
下一步是备份现有的 MySQL 数据库。使用下面的 mysqldump 命令导出现有的数据库到文件中。运行此命令之前,请确保你的 MySQL 服务器上启用了二进制日志。如果你不知道如何启用二进制日志,请参阅结尾的教程说明。
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdb.sql
|
||||
|
||||
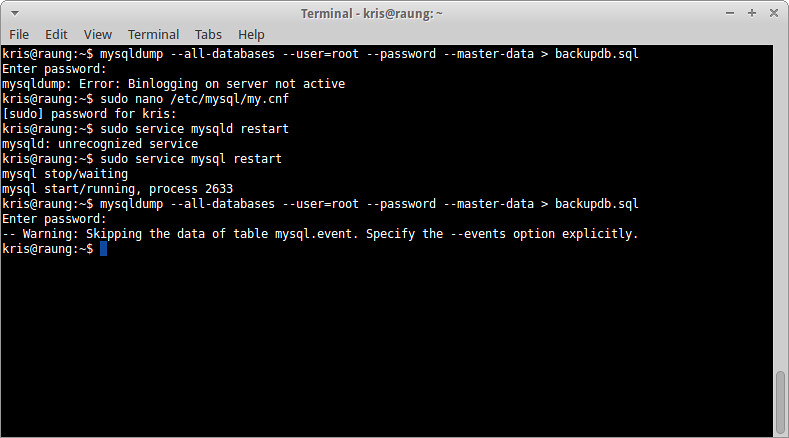
|
||||
|
||||
现在,在卸载 MySQL 之前先在系统上备份 my.cnf 文件。此步是可选的。
|
||||
|
||||
$ sudo cp /etc/mysql/my.cnf /opt/my.cnf.bak
|
||||
|
||||
### 卸载 MySQL ###
|
||||
|
||||
首先,停止 MySQL 服务。
|
||||
|
||||
$ sudo service mysql stop
|
||||
|
||||
或者:
|
||||
|
||||
$ sudo systemctl stop mysql
|
||||
|
||||
或:
|
||||
|
||||
$ sudo /etc/init.d/mysql stop
|
||||
|
||||
然后继续下一步,使用以下命令移除 MySQL 和配置文件。
|
||||
|
||||
在基于 RPM 的系统上 (例如, CentOS, Fedora 或 RHEL):
|
||||
|
||||
$ sudo yum remove mysql* mysql-server mysql-devel mysql-libs
|
||||
$ sudo rm -rf /var/lib/mysql
|
||||
|
||||
在基于 Debian 的系统上(例如, Debian, Ubuntu 或 Mint):
|
||||
|
||||
$ sudo apt-get remove mysql-server mysql-client mysql-common
|
||||
$ sudo apt-get autoremove
|
||||
$ sudo apt-get autoclean
|
||||
$ sudo deluser mysql
|
||||
$ sudo rm -rf /var/lib/mysql
|
||||
|
||||
### 安装 MariaDB ###
|
||||
|
||||
在 CentOS/RHEL 7和Ubuntu(14.04或更高版本)上,最新的 MariaDB 已经包含在其官方源。在 Fedora 上,自19 版本后 MariaDB 已经替代了 MySQL。如果你使用的是旧版本或 LTS 类型如 Ubuntu 13.10 或更早的,你仍然可以通过添加其官方仓库来安装 MariaDB。
|
||||
|
||||
[MariaDB 网站][2] 提供了一个在线工具帮助你依据你的 Linux 发行版中来添加 MariaDB 的官方仓库。此工具为 openSUSE, Arch Linux, Mageia, Fedora, CentOS, RedHat, Mint, Ubuntu, 和 Debian 提供了 MariaDB 的官方仓库.
|
||||
|
||||

|
||||
|
||||
下面例子中,我们使用 Ubuntu 14.04 发行版和 CentOS 7 配置 MariaDB 库。
|
||||
|
||||
**Ubuntu 14.04**
|
||||
|
||||
$ sudo apt-get install software-properties-common
|
||||
$ sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
|
||||
$ sudo add-apt-repository 'deb http://mirror.mephi.ru/mariadb/repo/5.5/ubuntu trusty main'
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install mariadb-server
|
||||
|
||||
**CentOS 7**
|
||||
|
||||
以下为 MariaDB 创建一个自定义的 yum 仓库文件。
|
||||
|
||||
$ sudo vi /etc/yum.repos.d/MariaDB.repo
|
||||
|
||||
----------
|
||||
|
||||
[mariadb]
|
||||
name = MariaDB
|
||||
baseurl = http://yum.mariadb.org/5.5/centos7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
|
||||
----------
|
||||
|
||||
$ sudo yum install MariaDB-server MariaDB-client
|
||||
|
||||
安装了所有必要的软件包后,你可能会被要求为 MariaDB 的 root 用户创建一个新密码。设置 root 的密码后,别忘了恢复备份的 my.cnf 文件。
|
||||
|
||||
$ sudo cp /opt/my.cnf /etc/mysql/
|
||||
|
||||
现在启动 MariaDB 服务。
|
||||
|
||||
$ sudo service mariadb start
|
||||
|
||||
或:
|
||||
|
||||
$ sudo systemctl start mariadb
|
||||
|
||||
或:
|
||||
|
||||
$ sudo /etc/init.d/mariadb start
|
||||
|
||||
### 导入 MySQL 的数据库 ###
|
||||
|
||||
最后,我们将以前导出的数据库导入到 MariaDB 服务器中。
|
||||
|
||||
$ mysql -u root -p < backupdb.sql
|
||||
|
||||
输入你 MariaDB 的 root 密码,数据库导入过程将开始。导入过程完成后,将返回到命令提示符下。
|
||||
|
||||
要检查导入过程是否完全成功,请登录到 MariaDB 服务器,并查看一些样本来检查。
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||
----------
|
||||
|
||||
MariaDB [(none)]> show databases;
|
||||
MariaDB [(none)]> use test01;
|
||||
MariaDB [test01]> select * from pet;
|
||||
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
如你在本教程中看到的,MySQL-to-MariaDB 的迁移并不难。你应该知道,MariaDB 相比 MySQL 有很多新的功能。至于配置方面,在我的测试情况下,我只是将我旧的 MySQL 配置文件(my.cnf)作为 MariaDB 的配置文件,导入过程完全没有出现任何问题。对于配置文件,我建议你在迁移之前请仔细阅读 MariaDB 配置选项的文件,特别是如果你正在使用 MySQL 的特定配置。
|
||||
|
||||
如果你正在运行有海量的表、包括群集或主从复制的数据库的复杂配置,看一看 Mozilla IT 和 Operations 团队的 [更详细的指南][3] ,或者 [官方的 MariaDB 文档][4]。
|
||||
|
||||
### 故障排除 ###
|
||||
|
||||
1、 在运行 mysqldump 命令备份数据库时出现以下错误。
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdb.sql
|
||||
|
||||
----------
|
||||
|
||||
mysqldump: Error: Binlogging on server not active
|
||||
|
||||
通过使用 "--master-data",你可以在导出的输出中包含二进制日志信息,这对于数据库的复制和恢复是有用的。但是,二进制日志未在 MySQL 服务器启用。要解决这个错误,修改 my.cnf 文件,并在 [mysqld] 部分添加下面的选项。
|
||||
|
||||
log-bin=mysql-bin
|
||||
|
||||
保存 my.cnf 文件,并重新启动 MySQL 服务:
|
||||
|
||||
$ sudo service mysql restart
|
||||
|
||||
或者:
|
||||
|
||||
$ sudo systemctl restart mysql
|
||||
|
||||
或:
|
||||
|
||||
$ sudo /etc/init.d/mysql restart
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/migrate-mysql-to-mariadb-linux.html
|
||||
|
||||
作者:[Kristophorus Hadiono][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/kristophorus
|
||||
[1]:https://mariadb.com/kb/en/mariadb/mariadb-vs-mysql-compatibility/
|
||||
[2]:https://downloads.mariadb.org/mariadb/repositories/#mirror=aasaam
|
||||
[3]:https://blog.mozilla.org/it/2013/12/16/upgrading-from-mysql-5-1-to-mariadb-5-5/
|
||||
[4]:https://mariadb.com/kb/en/mariadb/documentation/
|
||||
@ -0,0 +1,50 @@
|
||||
Linux 有问必答:如何在 Linux 中统计一个进程的线程数
|
||||
================================================================================
|
||||
> **问题**: 我正在运行一个程序,它在运行时会派生出多个线程。我想知道程序在运行时会有多少线程。在 Linux 中检查进程的线程数最简单的方法是什么?
|
||||
|
||||
如果你想看到 Linux 中每个进程的线程数,有以下几种方法可以做到这一点。
|
||||
|
||||
### 方法一: /proc ###
|
||||
|
||||
proc 伪文件系统,它驻留在 /proc 目录,这是最简单的方法来查看任何活动进程的线程数。 /proc 目录以可读文本文件形式输出,提供现有进程和系统硬件相关的信息如 CPU、中断、内存、磁盘等等.
|
||||
|
||||
$ cat /proc/<pid>/status
|
||||
|
||||
上面的命令将显示进程 \<pid> 的详细信息,包括过程状态(例如, sleeping, running),父进程 PID,UID,GID,使用的文件描述符的数量,以及上下文切换的数量。输出也包括**进程创建的总线程数**如下所示。
|
||||
|
||||
Threads: <N>
|
||||
|
||||
例如,检查 PID 20571进程的线程数:
|
||||
|
||||
$ cat /proc/20571/status
|
||||
|
||||
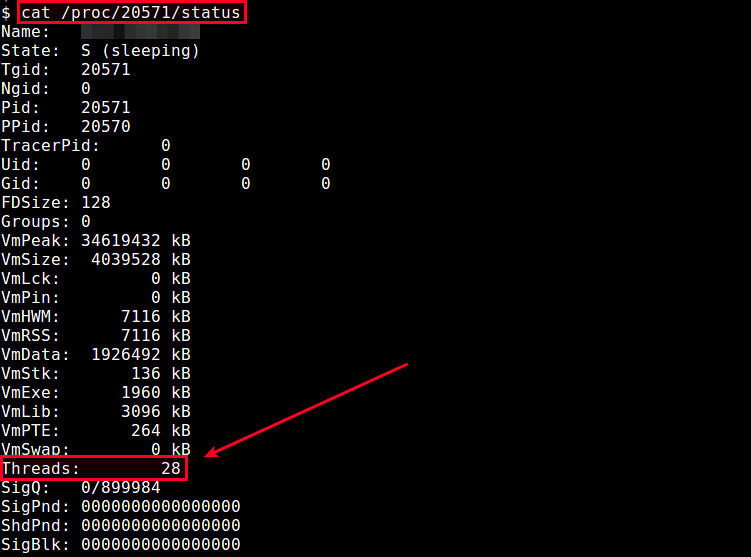
|
||||
|
||||
输出表明该进程有28个线程。
|
||||
|
||||
或者,你可以在 /proc/<pid>/task 中简单的统计子目录的数量,如下所示。
|
||||
|
||||
$ ls /proc/<pid>/task | wc
|
||||
|
||||
这是因为,对于一个进程中创建的每个线程,在 `/proc/<pid>/task` 中会创建一个相应的目录,命名为其线程 ID。由此在 `/proc/<pid>/task` 中目录的总数表示在进程中线程的数目。
|
||||
|
||||
### 方法二: ps ###
|
||||
|
||||
如果你是功能强大的 ps 命令的忠实用户,这个命令也可以告诉你一个进程(用“H”选项)的线程数。下面的命令将输出进程的线程数。“h”选项需要放在前面。
|
||||
|
||||
$ ps hH p <pid> | wc -l
|
||||
|
||||
如果你想监视一个进程的不同线程消耗的硬件资源(CPU & memory),请参阅[此教程][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/number-of-threads-process-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://linux.cn/article-5633-1.html
|
||||
@ -0,0 +1,65 @@
|
||||
Linux 有问必答:如何解决 Linux 上的 Wireshark 界面僵死
|
||||
================================================================================
|
||||
> **问题**: 当我试图在 Ubuntu 上的 Wireshark 中打开一个 pre-recorded 数据包转储时,它的界面突然死机,在我运行 Wireshark 的终端出现了下面的错误和警告。我该如何解决这个问题?
|
||||
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GObject'
|
||||
(wireshark:3480): GLib-GObject-CRITICAL **: g_object_set_qdata_full: assertion 'G_IS_OBJECT (object)' failed
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GtkRange'
|
||||
(wireshark:3480): Gtk-CRITICAL **: gtk_range_get_adjustment: assertion 'GTK_IS_RANGE (range)' failed
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GtkOrientable'
|
||||
(wireshark:3480): Gtk-CRITICAL **: gtk_orientable_get_orientation: assertion 'GTK_IS_ORIENTABLE (orientable)' failed
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GtkScrollbar'
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GtkWidget'
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GObject'
|
||||
(wireshark:3480): GLib-GObject-CRITICAL **: g_object_get_qdata: assertion 'G_IS_OBJECT (object)' failed
|
||||
(wireshark:3480): Gtk-CRITICAL **: gtk_widget_set_name: assertion 'GTK_IS_WIDGET (widget)' failed
|
||||
|
||||
|
||||
Wireshark 是一个基于 GUI 的数据包捕获和嗅探工具。该工具被网络管理员普遍使用,网络安全工程师或开发人员对于各种任务的数据包级的网络分析是必需的,例如在网络故障,漏洞测试,应用程序调试,或逆向协议工程是必需的。 Wireshark 允许实时记录数据包,并通过便捷的图形用户界面浏览他们的协议首部和有效负荷。
|
||||
|
||||

|
||||
|
||||
这是 Wireshark 的 UI,尤其是在 Ubuntu 桌面下运行时,当你向上或向下滚动分组列表视图时,或开始加载一个 pre-recorded 包转储文件时,有时会挂起或冻结,并出现以下错误。
|
||||
|
||||

|
||||
|
||||
显然,这个错误是由 Wireshark 和叠加滚动条之间的一些不兼容造成的,在最新的 Ubuntu 桌面还没有被解决(例如,Ubuntu 15.04 的桌面)。
|
||||
|
||||
一种避免 Wireshark 的 UI 卡死的办法就是 **暂时禁用叠加滚动条**。在 Wireshark 上有两种方法来禁用叠加滚动条,这取决于你在桌面上如何启动 Wireshark 的。
|
||||
|
||||
### 命令行解决方法 ###
|
||||
|
||||
叠加滚动条可以通过设置"**LIBOVERLAY_SCROLLBAR**"环境变量为“0”来被禁止。
|
||||
|
||||
所以,如果你是在终端使用命令行启动 Wireshark 的,你可以在 Wireshark 中禁用叠加滚动条,如下所示。
|
||||
|
||||
打开你的 .bashrc 文件,并定义以下 alias。
|
||||
|
||||
alias wireshark="LIBOVERLAY_SCROLLBAR=0 /usr/bin/wireshark"
|
||||
|
||||
### 桌面启动解决方法 ###
|
||||
|
||||
如果你是使用桌面启动器启动的 Wireshark,你可以编辑它的桌面启动器文件。
|
||||
|
||||
$ sudo vi /usr/share/applications/wireshark.desktop
|
||||
|
||||
查找以"Exec"开头的行,并如下更改。
|
||||
|
||||
Exec=env LIBOVERLAY_SCROLLBAR=0 wireshark %f
|
||||
|
||||
虽然这种解决方法可以在系统级帮助到所有桌面用户,但升级 Wireshark 就没用了。如果你想保留修改的 .desktop 文件,如下所示将它复制到你的主目录。
|
||||
|
||||
$ cp /usr/share/applications/wireshark.desktop ~/.local/share/applications/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fix-wireshark-gui-freeze-linux-desktop.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
Debian GNU/Linux,22 年未完的美妙旅程
|
||||
================================================================================
|
||||
|
||||
在2015年8月16日, Debian项目组庆祝了 Debian 的22周年纪念日;这也是开源世界历史最悠久、热门的发行版之一。 Debian项目于1993年由Ian Murdock创立。彼时,Slackware 作为最早的 Linux 发行版已经名声在外。
|
||||
|
||||

|
||||
|
||||
*22岁生日快乐! Debian Linux!*
|
||||
|
||||
Ian Ashly Murdock, 一个美国职业软件工程师, 在他还是普渡大学的学生时构想出了 Debian 项目的计划。他把这个项目命名为 Debian 是由于这个名字组合了他彼时女友的名字 Debra Lynn 和他自己的名字 Ian。 他之后和 Lynn 结婚并在2008年1月离婚。
|
||||
|
||||

|
||||
|
||||
*Debian 创始人:Ian Murdock*
|
||||
|
||||
Ian 目前是 ExactTarget 的平台与开发社区的副总裁。
|
||||
|
||||
Debian (如同Slackware一样) 都是由于当时缺乏满足合乎标准的发行版才应运而生的。 Ian 在一次采访中说:“免费提供一流的产品会是 Debian 项目的唯一使命。 尽管过去的 Linux 发行版均不尽然可靠抑或是优秀。 我印象里...比如在不同的文件系统间移动文件, 处理大型文件经常会导致内核出错。 但是 Linux 其实是很可靠的, 自由的源代码让这个项目本质上很有前途。”
|
||||
|
||||
"我记得过去我像其他想解决问题的人一样, 想在家里运行一个像 UNIX 的东西。 但那是不可能的, 无论是经济上还是法律上或是别的什么角度。 然后我就听闻了 GNU 内核开发项目, 以及这个项目是如何没有任何法律纷争", Ian 补充到。 他早年在开发 Debian 时曾被自由软件基金会(FSF)资助, 这份资助帮助 Debian 取得了长足的发展; 尽管一年后由于学业原因 Ian 退出了 FSF 转而去完成他的学位。
|
||||
|
||||
### Debian开发历史 ###
|
||||
|
||||
- **Debian 0.01 – 0.09** : 发布于 1993 年八月 – 1993 年十二月。
|
||||
- **Debian 0.91** : 发布于 1994 年一月。 有了原始的包管理系统, 没有依赖管理机制。
|
||||
- **Debian 0.93 rc5** : 发布于 1995 年三月。 “现代”意义的 Debian 的第一次发布, 在基础系统安装后会使用dpkg 安装以及管理其他软件包。
|
||||
- **Debian 0.93 rc6**: 发布于 1995 年十一月。 最后一次 a.out 发布, deselect 机制第一次出现, 有60位开发者在彼时维护着软件包。
|
||||
- **Debian 1.1**: 发布于 1996 年六月。 项目代号 – Buzz, 软件包数量 – 474, 包管理器 dpkg, 内核版本 2.0, ELF 二进制。
|
||||
- **Debian 1.2**: 发布于 1996 年十二月。 项目代号 – Rex, 软件包数量 – 848, 开发者数量 – 120。
|
||||
- **Debian 1.3**: 发布于 1997 年七月。 项目代号 – Bo, 软件包数量 974, 开发者数量 – 200。
|
||||
- **Debian 2.0**: 发布于 1998 年七月。 项目代号 - Hamm, 支持构架 – Intel i386 以及 Motorola 68000 系列, 软件包数量: 1500+, 开发者数量: 400+, 内置了 glibc。
|
||||
- **Debian 2.1**: 发布于1999 年三月九日。 项目代号 – slink, 支持构架 - Alpha 和 Sparc, apt 包管理器开始成型, 软件包数量 – 2250。
|
||||
- **Debian 2.2**: 发布于 2000 年八月十五日。 项目代号 – Potato, 支持构架 – Intel i386, Motorola 68000 系列, Alpha, SUN Sparc, PowerPC 以及 ARM 构架。 软件包数量: 3900+ (二进制) 以及 2600+ (源代码), 开发者数量 – 450。 有一群人在那时研究并发表了一篇论文, 论文展示了自由软件是如何在被各种问题包围的情况下依然逐步成长为优秀的现代操作系统的。
|
||||
- **Debian 3.0**: 发布于 2002 年七月十九日。 项目代号 – woody, 支持构架新增 – HP, PA_RISC, IA-64, MIPS 以及 IBM, 首次以DVD的形式发布, 软件包数量 – 8500+, 开发者数量 – 900+, 支持加密。
|
||||
- **Debian 3.1**: 发布于 2005 年六月六日。 项目代号 – sarge, 支持构架 – 新增 AMD64(非官方渠道发布), 内核 – 2.4 以及 2.6 系列, 软件包数量: 15000+, 开发者数量 : 1500+, 增加了诸如 OpenOffice 套件, Firefox 浏览器, Thunderbird, Gnome 2.8, 支持: RAID, XFS, LVM, Modular Installer。
|
||||
- **Debian 4.0**: 发布于 2007 年四月八日。 项目代号 – etch, 支持构架 – 如前,包括 AMD64。 软件包数量: 18,200+ 开发者数量 : 1030+, 图形化安装器。
|
||||
- **Debian 5.0**: 发布于 2009 年二月十四日。 项目代号 – lenny, 支持构架 – 新增 ARM。 软件包数量: 23000+, 开发者数量: 1010+。
|
||||
- **Debian 6.0**: 发布于 2009 年七月二十九日。 项目代号 – squeeze, 包含的软件包: 内核 2.6.32, Gnome 2.3. Xorg 7.5, 同时包含了 DKMS, 基于依赖包支持。 支持构架 : 新增 kfreebsd-i386 以及 kfreebsd-amd64, 基于依赖管理的启动过程。
|
||||
- **Debian 7.0**: 发布于 2013 年五月四日。 项目代号: wheezy, 支持 Multiarch, 私有云工具, 升级了安装器, 移除了第三方软件依赖, 全功能多媒体套件-codec, 内核版本 3.2, Xen Hypervisor 4.1.4 ,软件包数量: 37400+。
|
||||
- **Debian 8.0**: 发布于 2015 年五月二十五日。 项目代号: Jessie, 将 Systemd 作为默认的初始化系统, 内核版本 3.16, 增加了快速启动(fast booting), service进程所依赖的 cgroups 使隔离部分 service 进程成为可能, 43000+ 软件包。 Sysvinit 初始化工具在 Jessie 中可用。
|
||||
|
||||
**注意**: Linux的内核第一次是在1991 年十月五日被发布, 而 Debian 的首次发布则在1993 年九月十三日。 所以 Debian 已经在只有24岁的 Linux 内核上运行了整整22年了。
|
||||
|
||||
### Debian 的那些事 ###
|
||||
|
||||
1994年管理和重整了 Debian 项目以使得其他开发者能更好地加入,所以在那一年并没有发布面向用户的更新, 当然, 内部版本肯定是有的。
|
||||
|
||||
Debian 1.0 从来就没有被发布过。 一家 CD-ROM 的生产商错误地把某个未发布的版本标注为了 1.0, 为了避免产生混乱, 原本的 Debian 1.0 以1.1的面貌发布了。 从那以后才有了所谓的官方CD-ROM的概念。
|
||||
|
||||
每个 Debian 新版本的代号都是玩具总动员里某个角色的名字哦。
|
||||
|
||||
Debian 有四种可用版本: 旧稳定版(old stable), 稳定版(stable), 测试版(testing) 以及 试验版(experimental)。 始终如此。
|
||||
|
||||
Debian 项目组一直工作在不稳定发行版上, 这个不稳定版本始终被叫做Sid(玩具总动员里那个邪恶的臭小孩)。 Sid是unstable版本的永久名称, 同时Sid也取自'Still In Development"(译者:还在开发中)的首字母。 Sid 将会成为下一个稳定版, 当前的稳定版本代号为 jessie。
|
||||
|
||||
Debian 的官方发行版只包含开源并且自由的软件, 绝无其他东西. 不过 contrib 和非自由软件包使得安装那些本身自由但是其依赖的软件包不自由(contrib)的软件和非自由软件成为了可能。
|
||||
|
||||
Debian 是一堆Linux 发行版之母。 举几个例子:
|
||||
|
||||
- Damn Small Linux
|
||||
- KNOPPIX
|
||||
- Linux Advanced
|
||||
- MEPIS
|
||||
- Ubuntu
|
||||
- 64studio (不再活跃开发)
|
||||
- LMDE
|
||||
|
||||
Debian 是世界上最大的非商业 Linux 发行版。它主要是由C编写的(32.1%), 一并的还有其他70多种语言。
|
||||
|
||||

|
||||
|
||||
*Debian 开发语言贡献表,图片来源: [Xmodulo][1]*
|
||||
|
||||
Debian 项目包含6,850万行代码, 以及 450万行空格和注释。
|
||||
|
||||
国际空间站放弃了 Windows 和红帽子, 进而换成了 Debian - 在上面的宇航员使用落后一个版本的稳定发行版, 目前是 squeeze; 这么做是为了稳定程度以及来自 Debian 社区的雄厚帮助支持。
|
||||
|
||||
感谢上帝! 我们差点就听到来自国际空间宇航员面对 Windows Metro 界面的尖叫了 :P
|
||||
|
||||
#### 黑色星期三 ####
|
||||
|
||||
2002 年十一月二十日, Twente 大学的网络运营中心(NOC)着火。 当地消防部门放弃了服务器区域。 NOC维护着satie.debian.org 的网站服务器, 这个网站包含了安全、非美国相关的存档、新维护者资料、数量报告、数据库等等;这一切都化为了灰烬。 之后这些服务由 Debian 重建了。
|
||||
|
||||
#### 未来版本 ####
|
||||
|
||||
下一个待发布版本是 Debian 9, 项目代号 – Stretch, 它会带来什么还是个未知数。 满心期待吧!
|
||||
|
||||
有很多发行版在 Linux 发行版的历史上出现过一瞬间然后很快消失了。 在多数情况下, 维护一个日渐庞大的项目是开发者们面临的挑战。 但这对 Debian 来说不是问题。 Debian 项目有全世界成百上千的开发者、维护者。 它在 Linux 诞生的之初起便一直存在。
|
||||
|
||||
Debian 在 Linux 生态环境中的贡献是难以用语言描述的。 如果 Debian 没有出现过, 那么 Linux 世界将不会像现在这样丰富和用户友好。 Debian 是为数不多可以被认为安全可靠又稳定的发行版,是作为网络服务器完美选择。
|
||||
|
||||
这仅仅是 Debian 的一个开始。 它走过了这么长的征程, 并将一直走下去。 未来即是现在! 世界近在眼前! 如果你到现在还从来没有使用过 Debian, 我只想问, 你还再等什么? 快去下载一份镜像试试吧, 我们会在此守候遇到任何问题的你。
|
||||
|
||||
- [Debian 主页][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/happy-birthday-to-debian-gnu-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[jerryling315](http://moelf.xyz)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://xmodulo.com/2013/08/interesting-facts-about-debian-linux.html
|
||||
[2]:https://www.debian.org/
|
||||
@ -0,0 +1,53 @@
|
||||
Docker 在安全组件、实时容器迁移方面的进展
|
||||
================================================================================
|
||||

|
||||
|
||||
**这是 Docker 开发者在 Containercon 上的演讲,谈论将来的容器在安全和实时迁移方面的创新**
|
||||
|
||||
来自西雅图的消息。当前 IT 界最热的词汇是“容器”,美国有两大研讨会:Linuxcon USA 和 Containercon,后者就是为容器而生的。
|
||||
|
||||
Docker 公司是开源 Docker 项目的商业赞助商,本次研讨会这家公司有 3 位高管带来主题演讲,但公司创始人 Solomon Hykes 没上场演讲。
|
||||
|
||||
Hykes 曾在 2014 年的 Linuxcon 上进行过一次主题演讲,但今年的 Containeron 他只坐在观众席上。而工程部高级副总裁 Marianna Tessel、Docker 首席安全官 Diogo Monica 和核心维护员 Michael Crosby 为我们演讲 Docker 新增的功能和将来会有的功能。
|
||||
|
||||
Tessel 强调 Docker 现在已经被很多世界上大型组织用在生产环境中,包括美国政府。Docker 也被用在小环境中,比如树莓派,一块树莓派上可以跑 2300 个容器。
|
||||
|
||||
“Docker 的功能正在变得越来越强大,而部署方法变得越来越简单。”Tessel 在会上说道。
|
||||
|
||||
Tessel 把 Docker 形容成一艘游轮,内部由强大而复杂的机器驱动,外部为乘客提供平稳航行的体验。
|
||||
|
||||
Docker 试图解决的领域是简化安全配置。Tessel 认为对于大多数用户和组织来说,避免网络漏洞所涉及的安全问题是一个乏味而且复杂的过程。
|
||||
|
||||
于是 Docker Content Trust 就出现在 Docker 1.8 release 版本中了。安全项目领导 Diogo Mónica 中加入了 Tessel 的台上讨论,说安全是一个难题,而 Docker Content Trust 就是为解决这个难道而存在的。
|
||||
|
||||
Docker Content Trust 提供一种方法来验证一个 Docker 应用是否可信,以及多种方法来限制欺骗和病毒注入。
|
||||
|
||||
为了证明他的观点,Monica 做了个现场示范,演示 Content Trust 的效果。在一个实验中,一个网站在更新过程中其 Web App 被人为攻破,而当 Content Trust 启动后,这个黑客行为再也无法得逞。
|
||||
|
||||
“不要被这个表面上简单的演示欺骗了,”Tessel 说道,“你们看的是最安全的可行方案。”
|
||||
|
||||
Docker 以前没有实现的领域是实时迁移,这个技术在 VMware 虚拟机中叫做 vMotion,而现在,Docker 也实现了这个功能。
|
||||
|
||||
Docker 首席维护员 Micheal Crosby 在台上做了个实时迁移的演示,Crosby 把这个过程称为快照和恢复:首先从运行中的容器拿到一个快照,之后将这个快照移到另一个地方恢复。
|
||||
|
||||
一个容器也可以克隆到另一个地方,Crosby 将他的克隆容器称为“多利”,就是世界上第一只被克隆出来的羊的名字。
|
||||
|
||||
Tessel 也花了点时间聊了下 RunC 组件,这是个正在被 Open Container Initiative 作为多方开发的项目,目的是让它可以从 Linux 扩展到包括 Windows 和 Solaris 在内的多种操作系统。
|
||||
|
||||
Tessel 总结说她不知道 Docker 的未来是什么样,但对此抱非常乐观的态度。
|
||||
|
||||
“我不确定未来是什么样的,但我很确定 Docker 会在这个世界中脱颖而出”,Tessel 说的。
|
||||
|
||||
Sean Michael Kerner 是 eWEEK 和 InternetNews.com 网站的高级编辑,可通过推特 @TechJournalist 关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.eweek.com/virtualization/docker-working-on-security-components-live-container-migration.html
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.eweek.com/cp/bio/Sean-Michael-Kerner/
|
||||
@ -0,0 +1,49 @@
|
||||
LinuxCon: 服务器操作系统的转型
|
||||
================================================================================
|
||||
西雅图报道。容器迟早要改变世界,以及改变操作系统的角色。这是 Wim Coekaerts 带来的 LinuxCon 演讲主题,Coekaerts 是 Oracle 公司 Linux 与虚拟化工程的高级副总裁。
|
||||
|
||||

|
||||
|
||||
Coekaerts 在开始演讲的时候拿出一张关于“桌面之年”的幻灯片,引发了现场观众的一片笑声。之后他说 2015 年很明显是容器之年,更是应用之年,应用才是容器的关键。
|
||||
|
||||
“你需要操作系统做什么事情?”,Coekaerts 回答现场观众:“只需一件事:运行一个应用。操作系统负责管理硬件和资源,来让你的应用运行起来。”
|
||||
|
||||
Coakaerts 补充说,在 Docker 容器的帮助下,我们的注意力再次集中在应用上,而在 Oracle,我们将注意力放在如何让应用更好地运行在操作系统上。
|
||||
|
||||
“许多人过去常常需要繁琐地安装应用,而现在的年轻人只需要按一个按钮就能让应用在他们的移动设备上运行起来”。
|
||||
|
||||
人们对安装企业版的软件需要这么复杂的步骤而感到惊讶,而 Docker 帮助他们脱离了这片苦海。
|
||||
|
||||
“操作系统的角色已经变了。” Coekaerts 说。
|
||||
|
||||
Docker 的出现不代表虚拟机的淘汰,容器化过程需要经过很长时间才能变得成熟,然后才能在世界范围内得到应用。
|
||||
|
||||
在这段时间内,容器会与虚拟机共存,并且我们需要一些工具,将应用在容器和虚拟机之间进行转换迁移。Coekaerts 举例说 Oracle 的 VirtualBox 就可以用来帮助用户运行 Docker,而它原来是被广泛用在桌面系统上的一项开源技术。现在 Docker 的 Kitematic 项目将在 Mac 上使用 VirtualBox 运行 Docker。
|
||||
|
||||
### 容器的开放计算计划和一次写随处部署 ###
|
||||
|
||||
一个能让容器成功的关键是“一次写,随处部署”的概念。而在容器之间的互操作领域,Linux 基金会的开放计算计划(OCI)扮演一个非常关键的角色。
|
||||
|
||||
“使用 OCI,应用编译一次后就可以很方便地在多地运行,所以你可以将你的应用部署在任何地方”。
|
||||
|
||||
Coekaerts 总结说虽然在迁移到容器模型过程中会发生很多好玩的事情,但容器还没真正做好准备,他强调 Oracle 现在正在验证将产品运行在容器内的可行性,但这是一个非常艰难的过程。
|
||||
|
||||
“运行数据库很简单,难的是要搞定数据库所需的环境”,Coekaerts 说:“容器与虚拟机不一样,一些需要依赖底层系统配置的应用无法从主机迁移到容器中。”
|
||||
|
||||
另外,Coekaerts 指出在容器内调试问题与在虚拟机内调试问题也是不一样的,现在还没有成熟的工具来进行容器应用的调试。
|
||||
|
||||
Coekaerts 强调当容器足够成熟时,有一点很重要:不要抛弃现有的技术。组织和企业不能抛弃现有的部署好的应用,而完全投入新技术的怀抱。
|
||||
|
||||
“部署新技术是很困难的事情,你需要缓慢地迁移过去,能让你顺利迁移的技术才是成功的技术。”Coekaerts 说。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.serverwatch.com/server-news/linuxcon-the-changing-role-of-the-server-os.html
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.serverwatch.com/author/Sean-Michael-Kerner-101580.htm
|
||||
@ -0,0 +1,49 @@
|
||||
对 Linux 内核的发展方向的展望
|
||||
================================================================================
|
||||

|
||||
|
||||
** Linux 4.2 内核涉及到史上最多的贡献者数量,内核开发者 Jonathan Corbet 如是说。**
|
||||
|
||||
西雅图报道。Linux 内核持续增长:代码量在增加,代码贡献者数量也在增加。而随之而来的一些挑战需要处理一下。以上是 Jonathan Corbet 在今年的 LinuxCon 的内核年度报告上提出的主要观点。以下是他的主要演讲内容:
|
||||
|
||||
Linux 4.2 内核已经于上月底释出。Corbet 强调有 1569 名开发者为这个版本贡献了代码,其中 277 名是第一次提交代码。
|
||||
|
||||
越来越多的开发者的加入,内核更新非常快,Corbet 估计现在大概 63 天就能产生一个新的内核里程碑。
|
||||
|
||||
Linux 4.2 涉及多方面的更新。其中一个就是引进了 OverLayFS,这是一种只读型文件系统,它可以实现在一个容器之上再放一个容器。
|
||||
|
||||
网络系统对小包传输性能也有了提升,这对于高频金融交易而言非常重要。提升的方面主要集中在减小处理数据包的时间的能耗。
|
||||
|
||||
依然有新的驱动中加入内核。在每个内核发布周期,平均会有 60 到 80 个新增或升级驱动中加入。
|
||||
|
||||
另一个主要更新是实时内核补丁,这个特性在 4.0 版首次引进,好处是系统管理员可以在生产环境中打上内核补丁而不需要重启系统。当补丁所需要的元素都已准备就绪,打补丁的过程会在后台持续而稳定地进行。
|
||||
|
||||
**Linux 安全, IoT 和其他关注点**
|
||||
|
||||
过去一年中,安全问题在开源社区是一个很热的话题,这都归因于那些引发高度关注的事件,比如 Heartbleed 和 Shellshock。
|
||||
|
||||
“我毫不怀疑 Linux 代码对这些方面的忽视会产生一些令人不悦的问题”,Corbet 原话。
|
||||
|
||||
他强调说过去 10 年间有超过 3 百万行代码不再被开发者修改,而产生 Shellshock 漏洞的代码的年龄已经是 20 岁了,近年来更是无人问津。
|
||||
|
||||
另一个关注点是 2038 问题,Linux 界的“千年虫”,如果不解决,2000 年出现过的问题还会重现。2038 问题说的是在 2038 年一些 Linux 和 Unix 机器会死机(LCTT译注:32 位系统记录的时间,在2038年1月19日星期二晚上03:14:07之后的下一秒,会变成负数)。Corbet 说现在离 2038 年还有 23 年时间,现在部署的系统都会考虑 2038 问题。
|
||||
|
||||
Linux 已经启动一些初步的方案来修复 2038 问题了,但做的还远远不够。“现在就要修复这个问题,而不是等 20 年后把这个头疼的问题留给下一代解决,我们却享受着退休的美好时光”。
|
||||
|
||||
物联网(IoT)也是 Linux 关注的领域,Linux 是物联网嵌入式操作系统的主要占有者,然而这并没有什么卵用。Corget 认为日渐臃肿的内核对于未来的物联网设备来说肯定过于庞大。
|
||||
|
||||
现在有一个项目就是做内核最小化的,获取足够的支持对于这个项目来说非常重要。
|
||||
|
||||
“除了 Linux 之外,也有其他项目可以做物联网,但那些项目不会像 Linux 一样开放”,Corbet 说,“我们不能指望 Linux 在物联网领域一直保持优势,我们需要靠自己的努力去做到这点,我们需要注意不能让内核变得越来越臃肿。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.eweek.com/enterprise-apps/a-look-at-whats-next-for-the-linux-kernel.html
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.eweek.com/cp/bio/Sean-Michael-Kerner/
|
||||
@ -0,0 +1,79 @@
|
||||
4 个开源的命令行邮件客户端
|
||||
================================================================================
|
||||

|
||||
|
||||
无论你承认与否,email并没有消亡。对那些对命令行至死不渝的 Linux 高级用户而言,离开 shell 转而使用传统的桌面或网页版邮件客户端并不适应。归根结底,命令行最善于处理文件,特别是文本文件,能使效率倍增。
|
||||
|
||||
幸运的是,也有不少的命令行邮件客户端,而它们的用户大都乐于帮助你入门并回答你使用中遇到的问题。但别说我没警告过你:一旦你完全掌握了其中一个客户端,你会发现很难回到基于图形界面的客户端!
|
||||
|
||||
要安装下述四个客户端中的任何一个是非常容易的;主要的 Linux 发行版的软件仓库中都提供此类软件,并可通过包管理器进行安装。你也可以在其它的操作系统中寻找并安装这类客户端,但我并未尝试过也没有相关的经验。
|
||||
|
||||
### Mutt ###
|
||||
|
||||
- [项目主页][1]
|
||||
- [源代码][2]
|
||||
- 授权协议: [GPLv2][3]
|
||||
|
||||
许多终端爱好者都听说过甚至熟悉 Mutt 和 Alpine, 他们已经存在多年。让我们先看看 Mutt。
|
||||
|
||||
Mutt 支持许多你所期望 email 系统支持的功能:会话,颜色区分,支持多语言,同时还有很多设置选项。它支持 POP3 和 IMAP 这两个主要的邮件传输协议,以及许多邮箱格式。自从1995年诞生以来, Mutt 就拥有了一个活跃的开发社区,但最近几年,新版本更多的关注于修复问题和安全更新而非提供新功能。这对大多数 Mutt 用户而言并无大碍,他们钟爱这样的界面,并支持此项目的口号:“所有邮件客户端都很烂,只是这个烂的没那么彻底。”
|
||||
|
||||
### Alpine ###
|
||||
|
||||
- [项目主页][4]
|
||||
- [源代码][5]
|
||||
- 授权协议: [Apache 2.0][6]
|
||||
|
||||
Alpine 是另一款知名的终端邮件客户端,它由华盛顿大学开发,设计初衷是作为一个开源的、支持 unicode 的 Pine (也来自华盛顿大学)的替代版本。
|
||||
|
||||
Alpine 不仅容易上手,还为高级用户提供了很多特性,它支持很多协议 —— IMAP, LDAP, NNTP, POP, SMTP 等,同时也支持不同的邮箱格式。Alpine 内置了一款名为 Pico 的可独立使用的简易文本编辑工具,但你也可以使用你常用的文本编辑器: vi, Emacs等。
|
||||
|
||||
尽管 Alpine 的升级并不频繁,不过有个名为 re-alpine 的分支为不同的开发者提供了开发此项目的机会。
|
||||
|
||||
Alpine 支持在屏幕上显示上下文帮助,但一些用户会喜欢 Mutt 式的独立说明手册,不过它们两个的文档都很完善。用户可以同时尝试 Mutt 和 Alpine,并由个人喜好作出决定,也可以尝试以下的几个新选择。
|
||||
|
||||
### Sup ###
|
||||
|
||||
- [项目主页][7]
|
||||
- [源代码][8]
|
||||
- 授权协议: [GPLv2][9]
|
||||
|
||||
Sup 是我们列表中能被称为“大容量邮件客户端”的二者之一。自称“为邮件较多的人设计的命令行客户端”,Sup 的目标是提供一个支持层次化设计并允许为会话添加标签进行简单整理的界面。
|
||||
|
||||
由于采用 Ruby 编写,Sup 能提供十分快速的搜索并能自动管理联系人列表,同时还允许自定义插件。对于使用 Gmail 作为网页邮件客户端的人们,这些功能都是耳熟能详的,这就使得 Sup 成为一种比较现代的命令行邮件管理方式。
|
||||
|
||||
### Notmuch ###
|
||||
|
||||
- [项目主页][10]
|
||||
- [源代码][11]
|
||||
- 授权协议: [GPLv3][12]
|
||||
|
||||
"Sup? Notmuch." Notmuch 作为 Sup 的回应,最初只是重写了 Sup 的一小部分来提高性能。最终,这个项目逐渐变大并成为了一个独立的邮件客户端。
|
||||
|
||||
Notmuch 是一款相当精简的软件。它并不能独立的收发邮件,启用 Notmuch 的快速搜索功能的代码实际上是设计成一个程序可以调用的独立库。但这样的模块化设计也使得你能使用你最爱的工具进行写信,发信和收信,集中精力做好一件事情并有效浏览和管理你的邮件。
|
||||
|
||||
这个列表并不完整,还有很多 email 客户端,它们或许才是你的最佳选择。你喜欢什么客户端呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[KevinSJ](https://github.com/KevinSj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/jason-baker
|
||||
[1]:http://www.mutt.org/
|
||||
[2]:http://dev.mutt.org/trac/
|
||||
[3]:https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[4]:http://www.washington.edu/alpine/
|
||||
[5]:http://www.washington.edu/alpine/acquire/
|
||||
[6]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[7]:http://supmua.org/
|
||||
[8]:https://github.com/sup-heliotrope/sup
|
||||
[9]:https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
|
||||
[10]:http://notmuchmail.org/
|
||||
[11]:http://notmuchmail.org/releases/
|
||||
[12]:http://www.gnu.org/licenses/gpl.html
|
||||
@ -0,0 +1,154 @@
|
||||
Nmcli 网络管理命令行工具基础
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
### 介绍 ###
|
||||
|
||||
在本教程中,我们会在CentOS / RHEL 7中讨论网络管理工具(NetworkManager command line tool),也叫**nmcli**。那些使用**ifconfig**的用户应该在CentOS 7中避免使用**ifconfig** 了。
|
||||
|
||||
让我们用nmcli工具配置一些网络设置。
|
||||
|
||||
#### 要得到系统中所有接口的地址信息 ####
|
||||
|
||||
[root@localhost ~]# ip addr show
|
||||
|
||||
**示例输出:**
|
||||
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
inet 127.0.0.1/8 scope host lo
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 ::1/128 scope host
|
||||
valid_lft forever preferred_lft forever
|
||||
2: eno16777736: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
|
||||
link/ether 00:0c:29:67:2f:4c brd ff:ff:ff:ff:ff:ff
|
||||
inet 192.168.1.51/24 brd 192.168.1.255 scope global eno16777736
|
||||
valid_lft forever preferred_lft forever
|
||||
inet6 fe80::20c:29ff:fe67:2f4c/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
#### 检索与已连接的接口相关的数据包统计 ####
|
||||
|
||||
[root@localhost ~]# ip -s link show eno16777736
|
||||
|
||||
**示例输出:**
|
||||
|
||||

|
||||
|
||||
#### 得到路由配置 ####
|
||||
|
||||
[root@localhost ~]# ip route
|
||||
|
||||
示例输出:
|
||||
|
||||
default via 192.168.1.1 dev eno16777736 proto static metric 100
|
||||
192.168.1.0/24 dev eno16777736 proto kernel scope link src 192.168.1.51 metric 100
|
||||
|
||||
#### 分析主机/网站路径 ####
|
||||
|
||||
[root@localhost ~]# tracepath unixmen.com
|
||||
|
||||
输出像traceroute,但是更加完整。
|
||||
|
||||

|
||||
|
||||
### nmcli 工具 ###
|
||||
|
||||
**nmcli** 是一个非常丰富和灵活的命令行工具。nmcli使用的情况有:
|
||||
|
||||
- **设备** – 正在使用的网络接口
|
||||
- **连接** – 一组配置设置,对于一个单一的设备可以有多个连接,可以在连接之间切换。
|
||||
|
||||
#### 找出有多少连接服务于多少设备 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection show
|
||||
|
||||

|
||||
|
||||
#### 得到特定连接的详情 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection show eno1
|
||||
|
||||
**示例输出:**
|
||||
|
||||

|
||||
|
||||
#### 得到网络设备状态 ####
|
||||
|
||||
[root@localhost ~]# nmcli device status
|
||||
|
||||
----------
|
||||
|
||||
DEVICE TYPE STATE CONNECTION
|
||||
eno16777736 ethernet connected eno1
|
||||
lo loopback unmanaged --
|
||||
|
||||
#### 使用“dhcp”创建新的连接 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection add con-name "dhcp" type ethernet ifname eno16777736
|
||||
|
||||
这里,
|
||||
|
||||
- **connection add** – 添加新的连接
|
||||
- **con-name** – 连接名
|
||||
- **type** – 设备类型
|
||||
- **ifname** – 接口名
|
||||
|
||||
这个命令会使用dhcp协议添加连接
|
||||
|
||||
**示例输出:**
|
||||
|
||||
Connection 'dhcp' (163a6822-cd50-4d23-bb42-8b774aeab9cb) successfully added.
|
||||
|
||||
#### 不通过dhcp分配IP,使用“static”添加地址 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection add con-name "static" ifname eno16777736 autoconnect no type ethernet ip4 192.168.1.240 gw4 192.168.1.1
|
||||
|
||||
**示例输出:**
|
||||
|
||||
Connection 'static' (8e69d847-03d7-47c7-8623-bb112f5cc842) successfully added.
|
||||
|
||||
**更新连接:**
|
||||
|
||||
[root@localhost ~]# nmcli connection up eno1
|
||||
|
||||
再检查一遍,ip地址是否已经改变
|
||||
|
||||
[root@localhost ~]# ip addr show
|
||||
|
||||

|
||||
|
||||
#### 添加DNS设置到静态连接中 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" ipv4.dns 202.131.124.4
|
||||
|
||||
#### 添加更多的DNS ####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.dns 8.8.8.8
|
||||
|
||||
**注意**:要使用额外的**+**符号,并且要是**+ipv4.dns**,而不是**ip4.dns**。
|
||||
|
||||
####添加一个额外的ip地址####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.addresses 192.168.200.1/24
|
||||
|
||||
使用命令刷新设置:
|
||||
|
||||
[root@localhost ~]# nmcli connection up eno1
|
||||
|
||||

|
||||
|
||||
你会看见,设置生效了。
|
||||
|
||||
完结。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/basics-networkmanager-command-line-tool-nmcli/
|
||||
|
||||
作者:Rajneesh Upadhyay
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,98 @@
|
||||
修复安装完 Ubuntu 后无可引导设备的错误
|
||||
================================================================================
|
||||
|
||||
通常情况下,我会安装启动 Ubuntu 和 Windows 的双系统,但是这次我决定完全消除 Windows 纯净安装 Ubuntu。纯净安装 Ubuntu 完成后,结束时屏幕输出 **无可引导设备(no bootable device found)** 而不是进入 GRUB 界面。显然,安装搞砸了 UEFI 引导设置。
|
||||
|
||||

|
||||
|
||||
我会告诉你我是如何修复**在宏碁笔记本上安装 Ubuntu 后出现无可引导设备错误**的。我声明了我使用的是宏碁灵越 R13,这很重要,因为我们需要更改固件设置,而这些设置可能因制造商和设备有所不同。
|
||||
|
||||
因此在你开始这里介绍的步骤之前,先看一下发生这个错误时我计算机的状态:
|
||||
|
||||
- 我的宏碁灵越 R13 预装了 Windows 8.1 和 UEFI 引导管理器
|
||||
- 安全引导( Secure boot)没有关闭,(我的笔记本刚维修过,维修人员又启用了它,直到出现了问题我才发现)。你可以阅读这篇博文了解[如何在宏碁笔记本中关闭安全引导(secure boot)][1]
|
||||
- 我选择了清除所有东西安装 Ubuntu,例如现有的 Windows 8.1,各种分区等
|
||||
- 安装完 Ubuntu 之后,从硬盘启动时我看到无可引导设备错误。但能从 USB 设备正常启动
|
||||
|
||||
在我看来,没有禁用安全引导(secure boot)可能是这个错误的原因。但是,我没有数据支撑我的观点。这仅仅是预感。有趣的是,双系统启动 Windows 和 Linux 经常会出现这两个 Grub 问题:
|
||||
|
||||
- [错误:没有 grub 救援分区][2]
|
||||
- [支持最小化 BASH 式的行编辑][3]
|
||||
|
||||
如果你遇到类似的情况,你可以试试我的修复方法。
|
||||
|
||||
### 修复安装完 Ubuntu 后无可引导设备错误 ###
|
||||
|
||||
请原谅我的图片质量很差。我的一加相机不能很好地拍摄笔记本屏幕。
|
||||
|
||||
#### 第一步 ####
|
||||
|
||||
关闭电源并进入引导设置。我需要在宏碁灵越 R13 上快速地按下 Fn+F2。如果你使用固态硬盘的话要按的非常快,因为固态硬盘启动速度很快。这取决于你的制造商,你可能要用 Del 或 F10 或者 F12。
|
||||
|
||||
#### 第二步 ####
|
||||
|
||||
在引导设置中,确保启用了 Secure Boot。它在 Boot 标签里。
|
||||
|
||||
#### 第三步 ####
|
||||
|
||||
进入到 Security 标签,找到 “选择一个用于执行的可信任 UEFI 文件(Select an UEFI file as trusted for executing)” 并敲击回车。
|
||||
|
||||

|
||||
|
||||
特意说明,我们这一步是要在你的设备中添加 UEFI 设置文件(安装 Ubuntu 的时候生成)到可信 UEFI 启动中。如果你记得的话,UEFI 启动的主要目的是提供安全性,由于(可能)没有禁用安全引导(Secure Boot),设备不会试图从新安装的操作系统中启动。添加它到类似白名单的可信列表,会使设备从 Ubuntu UEFI 文件启动。
|
||||
|
||||
#### 第四步 ####
|
||||
|
||||
在这里你可以看到你的硬盘,例如 HDD0。如果你有多块硬盘,我希望你记住你安装 Ubuntu 的那块。同样敲击回车。
|
||||
|
||||

|
||||
|
||||
#### 第五步 ####
|
||||
|
||||
你应该可以看到 \<EFI> 了,敲击回车。
|
||||
|
||||

|
||||
|
||||
#### 第六步 ####
|
||||
|
||||
在下一个屏幕中你会看到 \<Ubuntu>。耐心点,马上就好了。
|
||||
|
||||

|
||||
|
||||
#### 第七步 ####
|
||||
|
||||
你可以看到 shimx64.efi,grubx64.efi 和 MokManager.efi 文件。重要的是 shimx64.efi。选中它并敲击回车。
|
||||
|
||||
|
||||

|
||||
|
||||
在下一个屏幕中,输入 Yes 并敲击回车。
|
||||
|
||||

|
||||
|
||||
#### 第八步 ####
|
||||
|
||||
当我们添加它到可信 EFI 文件并执行后,按 F10 保存并退出。
|
||||
|
||||

|
||||
|
||||
重启你的系统,这时你就可以看到熟悉的 GRUB 界面了。就算你没有看到 Grub 界面,起码也再也不会看到“无可引导设备”。你应该可以进入 Ubuntu 了。
|
||||
|
||||
如果修复后搞乱了你的 Grub 界面,但你确实能登录系统,你可以重装 Grub 并进入到 Ubuntu 熟悉的紫色 Grub 界面。
|
||||
|
||||
我希望这篇指南能帮助你修复无可引导设备错误。欢迎提出任何疑问、建议或者感谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/no-bootable-device-found-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/disable-secure-boot-in-acer/
|
||||
[2]:http://itsfoss.com/solve-error-partition-grub-rescue-ubuntu-linux/
|
||||
[3]:http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux/
|
||||
@ -0,0 +1,48 @@
|
||||
也许你需要在 Antergos 与 Arch Linux 中查看印度语和梵文?
|
||||
================================================================================
|
||||

|
||||
|
||||
你们到目前或许知道,我最近一直在尝试体验 [Antergos Linux][1]。在安装完[Antergos][2]后我所首先注意到的一些事情是在默认的 Chromium 浏览器中**没法正确显示印度语脚本**。
|
||||
|
||||
这是一件奇怪的事情,在我之前桌面Linux的体验中是从未遇到过的。起初,我认为是浏览器的问题,所以我安装了Firefox,然而问题依旧,Firefox也不能正确显示印度语。和Chromium不显示任何东西不同的是,Firefox确实显示了一些东西,但是毫无可读性。
|
||||
|
||||

|
||||
|
||||
*Chromium中的印度语显示*
|
||||
|
||||
|
||||

|
||||
|
||||
*Firefox中的印度语显示*
|
||||
|
||||
奇怪吧?那么,默认情况下基于Arch的Antergos Linux中没有印度语的支持吗?我没有去验证,但是我假设其它基于梵语脚本的印地语之类会产生同样的问题。
|
||||
|
||||
在这个快速指南中,我打算为大家演示如何来添加梵语支持,以便让印度语和其它印地语都能正确显示。
|
||||
|
||||
### 在Antergos和Arch Linux中添加印地语支持 ###
|
||||
|
||||
打开终端,使用以下命令:
|
||||
|
||||
sudo yaourt -S ttf-indic-otf
|
||||
|
||||
键入密码,它会提供给你对于印地语的译文支持。
|
||||
|
||||
重启Firefox,会马上正确显示印度语了,但是它需要一次重启来显示印度语。因此,我建议你在安装了印地语字体后**重启你的系统**。
|
||||
|
||||

|
||||
|
||||
我希望这篇快速指南能够帮助你,让你可以在Antergos和其它基于Arch的Linux发行版中,如Manjaro Linux,阅读印度语、梵文、泰米尔语、泰卢固语、马拉雅拉姆语、孟加拉语,以及其它印地语。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/display-hindi-arch-antergos/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://antergos.com/
|
||||
[2]:http://itsfoss.com/tag/antergos/
|
||||
@ -0,0 +1,77 @@
|
||||
如何在 Ubuntu 15.04 下创建一个可供 Android/iOS 连接的 AP
|
||||
================================================================================
|
||||
我成功地在 Ubuntu 15.04 下用 Gnome Network Manager 创建了一个无线AP热点。接下来我要分享一下我的步骤。请注意:你必须要有一个可以用来创建AP热点的无线网卡。如果你不知道如何确认它的话,在终端(Terminal)里输入`iw list`。
|
||||
|
||||
如果你没有安装`iw`的话, 在Ubuntu下你可以使用`sudo apt-get install iw`进行安装.
|
||||
|
||||
在你键入`iw list`之后, 查看“支持的接口模式”, 你应该会看到类似下面的条目中看到 AP:
|
||||
|
||||
Supported interface modes:
|
||||
|
||||
* IBSS
|
||||
* managed
|
||||
* AP
|
||||
* AP/VLAN
|
||||
* monitor
|
||||
* mesh point
|
||||
|
||||
让我们一步步看:
|
||||
|
||||
1、 断开WIFI连接。使用有线网络接入你的笔记本。
|
||||
|
||||
2、 在顶栏面板里点击网络的图标 -> Edit Connections(编辑连接) -> 在弹出窗口里点击Add(新增)按钮。
|
||||
|
||||
3、 在下拉菜单内选择Wi-Fi。
|
||||
|
||||
4、 接下来:
|
||||
|
||||
a、 输入一个链接名 比如: Hotspot 1
|
||||
|
||||
b、 输入一个 SSID 比如: Hotspot 1
|
||||
|
||||
c、 选择模式(mode): Infrastructure (基础设施)
|
||||
|
||||
d、 设备 MAC 地址: 在下拉菜单里选择你的无线设备
|
||||
|
||||

|
||||
|
||||
5、 进入Wi-Fi安全选项卡,选择 WPA & WPA2 Personal 并且输入密码。
|
||||
6、 进入IPv4设置选项卡,在Method(方法)下拉菜单里,选择Shared to other computers(共享至其他电脑)。
|
||||
|
||||

|
||||
|
||||
7、 进入IPv6选项卡,在Method(方法)里设置为忽略ignore (只有在你不使用IPv6的情况下这么做)
|
||||
8、 点击 Save(保存) 按钮以保存配置。
|
||||
9、 从 menu/dash 里打开Terminal。
|
||||
10、 修改你刚刚使用 network settings 创建的连接。
|
||||
|
||||
使用 VIM 编辑器:
|
||||
|
||||
sudo vim /etc/NetworkManager/system-connections/Hotspot
|
||||
|
||||
或使用Gedit 编辑器:
|
||||
|
||||
gksu gedit /etc/NetworkManager/system-connections/Hotspot
|
||||
|
||||
把名字 Hotspot 用你在第4步里起的连接名替换掉。
|
||||
|
||||

|
||||
|
||||
a、 把 `mode=infrastructure` 改成 `mode=ap` 并且保存文件。
|
||||
b、 一旦你保存了这个文件,你应该能在 Wifi 菜单里看到你刚刚建立的AP了。(如果没有的话请再顶栏里 关闭/打开 Wifi 选项一次)
|
||||
|
||||

|
||||
|
||||
11、你现在可以把你的设备连上Wifi了。已经过 Android 5.0的小米4测试。(下载了1GB的文件以测试速度与稳定性)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxveda.com/2015/08/23/how-to-create-an-ap-in-ubuntu-15-04-to-connect-to-androidiphone/
|
||||
|
||||
作者:[Sayantan Das][a]
|
||||
译者:[jerryling315](https://github.com/jerryling315)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxveda.com/author/sayantan_das/
|
||||
@ -0,0 +1,26 @@
|
||||
Linux 上将出现一个新的文件系统:bcachefs
|
||||
================================================================================
|
||||
|
||||
这个有 5 年历史,由 Kent Oberstreet 创建,过去属于谷歌的文件系统,最近完成了全部关键组件。Bcachefs 文件系统自称其性能和稳定性与 ext4 和 xfs 相同,而其他方面的功能又可以与 btrfs 和 zfs 相媲美。主要特性包括校验、压缩、多设备支持、缓存、快照与其他“漂亮”的特性。
|
||||
|
||||
Bcachefs 来自 **bcache**,这是一个块级缓存层。从 bcaceh 到一个功能完整的[写时复制][1]文件系统,堪称是一项质的转变。
|
||||
|
||||
对自己的问题“为什么要出一个新的文件系统”中,Kent Oberstreet 自问自答道:当我还在谷歌的时候,我与其他在 bcache 上工作的同事在偶然的情况下意识到我们正在使用的东西可以成为一个成熟文件系统的功能块,我们可以用 bcache 创建一个拥有干净而优雅设计的文件系统,而最重要的一点是,bcachefs 的主要目的就是在性能和稳定性上能与 ext4 和 xfs 匹敌,同时拥有 btrfs 和 zfs 的特性。
|
||||
|
||||
Overstreet 邀请人们在自己的系统上测试 bcachefs,可以通过邮件列表[通告]获取 bcachefs 的操作指南。
|
||||
|
||||
Linux 生态系统中文件系统几乎处于一家独大状态,Fedora 在第 16 版的时候就想用 btrfs 换掉 ext4 作为其默认文件系统,但是到现在(LCTT:都出到 Fedora 22 了)还在使用 ext4。而几乎所有 Debian 系的发行版(Ubuntu、Mint、elementary OS 等)也使用 ext4 作为默认文件系统,并且这些主流的发行版都没有替换默认文件系统的意思。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxveda.com/2015/08/22/linux-gain-new-file-system-bcachefs/
|
||||
|
||||
作者:[Paul Hill][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxveda.com/author/paul_hill/
|
||||
[1]:https://en.wikipedia.org/wiki/Copy-on-write
|
||||
[2]:https://lkml.org/lkml/2015/8/21/22
|
||||
@ -0,0 +1,157 @@
|
||||
Mhddfs:将多个小分区合并成一个大的虚拟存储
|
||||
================================================================================
|
||||
|
||||
让我们假定你有30GB的电影,并且你有3个驱动器,每个的大小为20GB。那么,你会怎么来存放东西呢?
|
||||
|
||||
很明显,你可以将你的视频分割成2个或者3个不同的卷,并将它们手工存储到驱动器上。这当然不是一个好主意,它成了一项费力的工作,它需要你手工干预,而且花费你大量时间。
|
||||
|
||||
另外一个解决方案是创建一个 [RAID磁盘阵列][1]。然而,RAID在存储可靠性,磁盘空间可用性差等方面声名狼藉。另外一个解决方案,就是mhddfs。
|
||||
|
||||

|
||||
|
||||
*Mhddfs——在Linux中合并多个分区*
|
||||
|
||||
mhddfs是一个用于Linux的设备驱动,它可以将多个挂载点合并到一个虚拟磁盘中。它是一个基于FUSE的驱动,提供了一个用于大数据存储的简单解决方案。它可以将所有小文件系统合并,创建一个单一的大虚拟文件系统,该文件系统包含其成员文件系统的所有内容,包括文件和空闲空间。
|
||||
|
||||
#### 你为什么需要Mhddfs? ####
|
||||
|
||||
你的所有存储设备会创建为一个单一的虚拟池,它可以在启动时被挂载。这个小工具可以智能地照看并处理哪个存储满了,哪个存储空着,以及将数据写到哪个存储中。当你成功创建虚拟驱动器后,你可以使用[SAMBA][2]来共享你的虚拟文件系统。你的客户端将在任何时候都看到一个巨大的驱动器和大量的空闲空间。
|
||||
|
||||
#### Mhddfs特性 ####
|
||||
|
||||
- 获取文件系统属性和系统信息。
|
||||
- 设置文件系统属性。
|
||||
- 创建、读取、移除和写入目录和文件。
|
||||
- 在单一设备上支持文件锁和硬链接。
|
||||
|
||||
|mhddfs的优点|mhddfs的缺点|
|
||||
|-----------|-----------|
|
||||
|适合家庭用户|mhddfs驱动没有内建在Linux内核中 |
|
||||
|运行简单|运行时需要大量处理能力|
|
||||
|没有明显的数据丢失|没有冗余解决方案|
|
||||
|不需要分割文件|不支持移动硬链接|
|
||||
|可以添加新文件到组成的虚拟文件系统||
|
||||
|可以管理文件保存的位置||
|
||||
|支持扩展文件属性||
|
||||
|
||||
### Linux中安装Mhddfs ###
|
||||
|
||||
在Debian及其类似的移植系统中,你可以使用下面的命令来安装mhddfs包。
|
||||
|
||||
# apt-get update && apt-get install mhddfs
|
||||
|
||||

|
||||
|
||||
*安装Mhddfs到基于Debian的系统中*
|
||||
|
||||
在RHEL/CentOS Linux系统中,你需要开启[epel仓库][3],然后执行下面的命令来安装mhddfs包。
|
||||
|
||||
# yum install mhddfs
|
||||
|
||||
在Fedora 22及以上系统中,你可以通过dnf包管理来获得它,就像下面这样。
|
||||
|
||||
# dnf install mhddfs
|
||||
|
||||

|
||||
|
||||
*安装Mhddfs到Fedora*
|
||||
|
||||
如果万一mhddfs包不能从epel仓库获取到,那么你需要解决下面的依赖,然后像下面这样来编译源码并安装。
|
||||
|
||||
- FUSE头文件
|
||||
- GCC
|
||||
- libc6头文件
|
||||
- uthash头文件
|
||||
- libattr1头文件(可选)
|
||||
|
||||
接下来,只需从下面建议的地址下载最新的源码包,然后编译。
|
||||
|
||||
# wget http://mhddfs.uvw.ru/downloads/mhddfs_0.1.39.tar.gz
|
||||
# tar -zxvf mhddfs*.tar.gz
|
||||
# cd mhddfs-0.1.39/
|
||||
# make
|
||||
|
||||
你应该可以在当前目录中看到mhddfs的二进制文件,以root身份将它移动到/usr/bin/和/usr/local/bin/中。
|
||||
|
||||
# cp mhddfs /usr/bin/
|
||||
# cp mhddfs /usr/local/bin/
|
||||
|
||||
一切搞定,mhddfs已经可以用了。
|
||||
|
||||
### 我怎么使用Mhddfs? ###
|
||||
|
||||
1、 让我们看看当前所有挂载到我们系统中的硬盘。
|
||||
|
||||
$ df -h
|
||||
|
||||
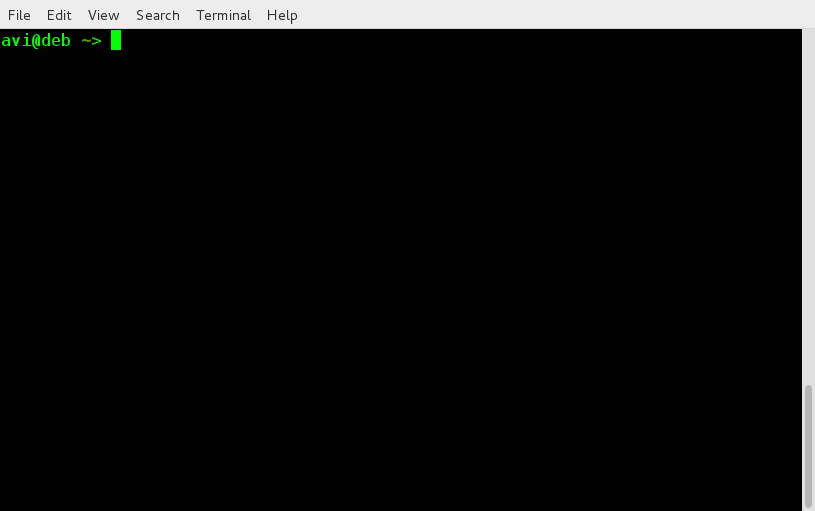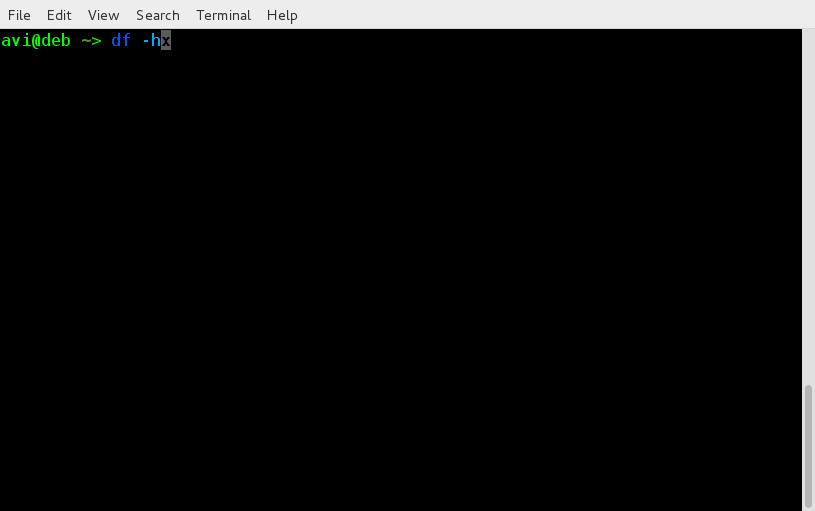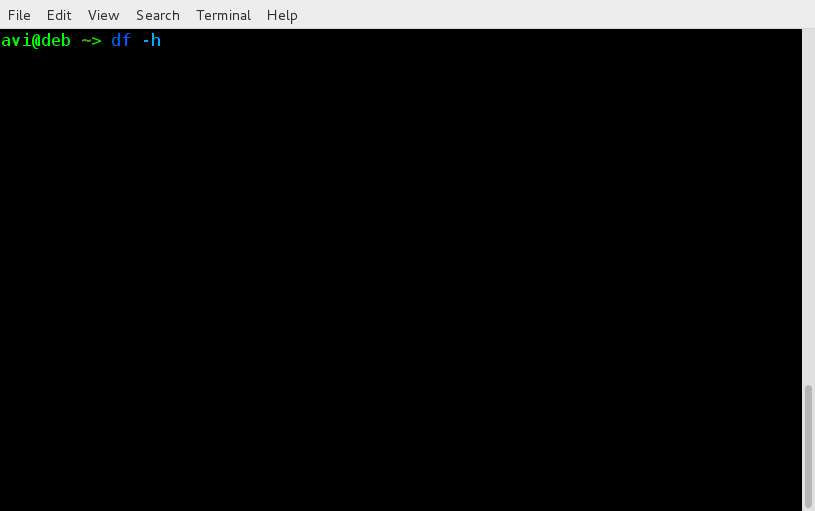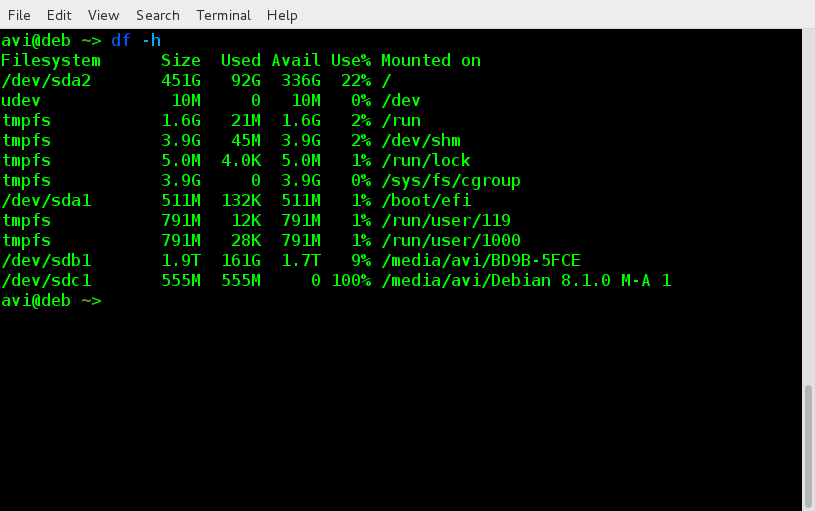
|
||||
|
||||
**样例输出**
|
||||
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
|
||||
/dev/sda1 511M 132K 511M 1% /boot/efi
|
||||
/dev/sda2 451G 92G 336G 22% /
|
||||
/dev/sdb1 1.9T 161G 1.7T 9% /media/avi/BD9B-5FCE
|
||||
/dev/sdc1 555M 555M 0 100% /media/avi/Debian 8.1.0 M-A 1
|
||||
|
||||
注意这里的‘挂载点’名称,我们后面会使用到它们。
|
||||
|
||||
2、 创建目录‘/mnt/virtual_hdd’,所有这些文件系统将会在这里组织到一起。
|
||||
|
||||
# mkdir /mnt/virtual_hdd
|
||||
|
||||
3、 然后,挂载所有文件系统。你可以通过root或者FUSE组中的某个用户来完成。
|
||||
|
||||
# mhddfs /boot/efi, /, /media/avi/BD9B-5FCE/, /media/avi/Debian\ 8.1.0\ M-A\ 1/ /mnt/virtual_hdd -o allow_other
|
||||
|
||||

|
||||
|
||||
*在Linux中挂载所有文件系统*
|
||||
|
||||
**注意**:这里我们使用了所有硬盘的挂载点名称,很明显,你的挂载点名称会有所不同。也请注意“-o allow_other”选项可以让这个虚拟文件系统让其它所有人可见,而不仅仅是创建它的人。
|
||||
|
||||
4、 现在,运行“df -h”来看看所有文件系统。它应该包含了你刚才创建的那个。
|
||||
|
||||
$ df -h
|
||||
|
||||

|
||||
|
||||
*验证虚拟文件系统挂载*
|
||||
|
||||
你可以像对已挂在的驱动器那样给虚拟文件系统应用所有的选项。
|
||||
|
||||
5、 要在每次系统启动创建这个虚拟文件系统,你应该以root身份添加下面的这行代码(在你那里会有点不同,取决于你的挂载点)到/etc/fstab文件的末尾。
|
||||
|
||||
mhddfs# /boot/efi, /, /media/avi/BD9B-5FCE/, /media/avi/Debian\ 8.1.0\ M-A\ 1/ /mnt/virtual_hdd fuse defaults,allow_other 0 0
|
||||
|
||||
6、 如果在任何时候你想要添加/移除一个新的驱动器到/从虚拟硬盘,你可以挂载一个新的驱动器,拷贝/mnt/vritual_hdd的内容,卸载卷,弹出你要移除的的驱动器并/或挂载你要包含的新驱动器。使用mhddfs命令挂载全部文件系统到Virtual_hdd下,这样就全部搞定了。
|
||||
|
||||
#### 我怎么卸载Virtual_hdd? ####
|
||||
|
||||
卸载virtual_hdd相当简单,就像下面这样
|
||||
|
||||
# umount /mnt/virtual_hdd
|
||||
|
||||
|
||||
|
||||
*卸载虚拟文件系统*
|
||||
|
||||
注意,是umount,而不是unmount,很多用户都输错了。
|
||||
|
||||
到现在为止全部结束了。我正在写另外一篇文章,你们一定喜欢读的。到那时,请保持连线。请在下面的评论中给我们提供有用的反馈吧。请为我们点赞并分享,帮助我们扩散。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/combine-partitions-into-one-in-linux-using-mhddfs/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/mount-filesystem-in-linux/
|
||||
[3]:https://linux.cn/article-2324-1.html
|
||||
@ -0,0 +1,34 @@
|
||||
看这些孩子在 Ubuntu 的 Linux 终端下玩耍
|
||||
================================================================================
|
||||
我发现了一个孩子们在他们的计算机教室里玩得很开心的视频。我不知道他们在哪里,但我猜测是在印度尼西亚或者马来西亚。视频请自行搭梯子: http://www.youtube.com/z8taQPomp0Y
|
||||
|
||||
### 在Linux终端下面跑火车 ###
|
||||
|
||||
这里没有魔术。只是一个叫做“sl”的命令行工具。我想它是在把ls打错的情况下为了好玩而开发的。如果你曾经在Linux的命令行下工作,你会知道ls是一个最常使用的一个命令,也许也是一个最经常打错的命令。
|
||||
|
||||
如果你想从这个终端下的火车获得一些乐趣,你可以使用下面的命令安装它。
|
||||
|
||||
sudo apt-get install sl
|
||||
|
||||
要运行终端火车,只需要在终端中输入**sl**。它有以下几个选项:
|
||||
|
||||
- -a : 意外模式。你会看见哭救的群众
|
||||
- -l : 显示一个更小的火车但有更多的车厢
|
||||
- -F : 一个飞行的火车
|
||||
- -e : 允许通过Ctrl+C。使用其他模式你不能使用Ctrl+C中断火车。但是,它不能长时间运行。
|
||||
|
||||
正常情况下,你应该会听到汽笛声但是在大多数Linux系统下都不管用,Ubuntu是其中一个。这就是一个意外的终端火车。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/ubuntu-terminal-train/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user