diff --git a/translated/tech/20171102 Using User Namespaces on Docker.md b/published/20171102 Using User Namespaces on Docker.md
similarity index 53%
rename from translated/tech/20171102 Using User Namespaces on Docker.md
rename to published/20171102 Using User Namespaces on Docker.md
index 7d3282b85c..666beb1ae6 100644
--- a/translated/tech/20171102 Using User Namespaces on Docker.md
+++ b/published/20171102 Using User Namespaces on Docker.md
@@ -1,22 +1,24 @@
-使用 Docker 的 User Namespaces 功能
+使用 Docker 的用户名字空间功能
======
-User Namespaces 于 Docker1.10 版正式纳入其中,该功能允许主机系统将自身的 `uid` 和 `gid` 映射为容器进程中的另一个其他 `uid` 和 `gid`。这对 Docker 的安全性来说是一项巨大的改进。下面我会通过一个案例来展示一下 User Namespaces 能够解决的问题,以及如何启用该功能。
+
+用户名字空间 于 Docker 1.10 版本正式纳入其中,该功能允许主机系统将自身的 `uid` 和 `gid` 映射为容器进程中的另一个 `uid` 和 `gid`。这对 Docker 的安全性来说是一项巨大的改进。下面我会通过一个案例来展示一下用户名字空间能够解决的问题,以及如何启用该功能。
### 创建一个 Docker Machine
-如果你已经创建好了一台用来实验 User Namespaces 的 docker machine,那么可以跳过这一步。我在自己的 Macbook 上安装了 Docker Toolbox,因此我只需要使用 `docker-machine` 命令就很简单地创建一个基于 VirtualBox 的 Docker Machine( 这里假设主机名为 `host1`):
+如果你已经创建好了一台用来试验用户名字空间的 docker 机器,那么可以跳过这一步。我在自己的 Macbook 上安装了 Docker Toolbox,因此我只需用 `docker-machine` 命令就很简单地创建一个基于 VirtualBox 的 Docker 机器(这里假设主机名为 `host1`):
+
```
# Create host1
$ docker-machine create --driver virtualbox host1
# Login to host1
$ docker-machine ssh host1
-
```
-### 理解在 User Napespaces 未启用的情况下,非 root 用户能够做什么
+### 理解在用户名字空间未启用的情况下,非 root 用户能做什么
+
+在启用用户名字空间前,我们先来看一下会有什么问题。Docker 到底哪个地方做错了?首先,使用 Docker 的一大优势在于用户在容器中可以拥有 root 权限,因此用户可以很方便地安装软件包。但是在 Linux 容器技术中这也是一把双刃剑。只要经过少许操作,非 root 用户就能以 root 的权限访问主机系统中的内容,比如 `/etc`。下面是操作步骤。
-在启用 User Namespaces 前,我们先来看一下会有什么问题。Docker 到底哪个地方做错了?首先,使用 Docker 的一大优势在于用户在容器中可以拥有 root 权限,因此用户可以很方便地安装软件包。但是该项 Linux 容器技术是一把双刃剑。只要经过少许操作,非 root 用户就能以 root 的权限访问主机系统中的内容,比如 `/etc` . 下面是操作步骤。
```
# Run a container and mount host1's /etc onto /root/etc
$ docker run --rm -v /etc:/root/etc -it ubuntu
@@ -29,12 +31,12 @@ root@34ef23438542:/# exit
# Check /etc/hosts
$ cat /etc/hosts
-
```
-你可以看到,步骤简单到难以置信,很明显 Docker 并不适用于运行在多人共享的电脑上。但是现在,通过 User Namespaces,Docker 可以让你避免这个问题。
+你可以看到,步骤简单到难以置信,很明显 Docker 并不适用于运行在多人共享的电脑上。但是现在,通过用户名字空间,Docker 可以避免这个问题。
+
+### 启用用户名字空间
-### 启用 User Namespaces
```
# Create a user called "dockremap"
$ sudo adduser dockremap
@@ -42,42 +44,39 @@ $ sudo adduser dockremap
# Setup subuid and subgid
$ sudo sh -c 'echo dockremap:500000:65536 > /etc/subuid'
$ sudo sh -c 'echo dockremap:500000:65536 > /etc/subgid'
-
```
然后,打开 `/etc/init.d/docker`,并在 `/usr/local/bin/docker daemon` 后面加上 `--userns-remap=default`,像这样:
+
```
$ sudo vi /etc/init.d/docker
- :
- :
-/usr/local/bin/docker daemon --userns-remap=default -D -g "$DOCKER_DIR" -H unix:// $DOCKER_HOST $EXTRA_ARGS >> "$DOCKER_LOGFILE" 2>&1 &
- :
- :
+/usr/local/bin/docker daemon --userns-remap=default -D -g "$DOCKER_DIR" -H unix:// $DOCKER_HOST $EXTRA_ARGS >> "$DOCKER_LOGFILE" 2>&1 &
```
然后重启 Docker:
+
```
$ sudo /etc/init.d/docker restart
-
```
这就完成了!
-**注意:** 若你使用的是 CentOS 7,则你需要了解两件事。
+**注意**:若你使用的是 CentOS 7,则你需要了解两件事。
-**1。** 内核默认并没有启用 User Namespaces。运行下面命令并重启系统,可以启用该功能。
-```
-sudo grubby --args="user_namespace.enable=1" \
- --update-kernel=/boot/vmlinuz-3.10.0-XXX.XX.X.el7.x86_64
+1. 内核默认并没有启用用户名字空间。运行下面命令并重启系统,可以启用该功能。
-```
+ ```
+ sudo grubby --args="user_namespace.enable=1" \
+ --update-kernel=/boot/vmlinuz-3.10.0-XXX.XX.X.el7.x86_64
+ ```
-**2。** CentOS 7 使用 systemctl 来管理服务,因此你需要编辑的文件是 `/usr/lib/systemd/system/docker.service`。
+2. CentOS 7 使用 `systemctl` 来管理服务,因此你需要编辑的文件是 `/usr/lib/systemd/system/docker.service`。
-### 确认 User Namespaces 是否正常工作
+### 确认用户名字空间是否正常工作
若一切都配置妥当,则你应该无法再在容器中编辑 host1 上的 `/etc` 了。让我们来试一下。
+
```
# Create a container and mount host1's /etc to container's /root/etc
$ docker run --rm -v /etc:/root/etc -it ubuntu
@@ -90,8 +89,6 @@ drwx------ 3 root root 4096 Mar 21 23:50 ..
lrwxrwxrwx 1 nobody nogroup 19 Mar 21 23:07 acpi -> /usr/local/etc/acpi
-rw-r--r-- 1 nobody nogroup 48 Mar 10 22:09 boot2docker
drwxr-xr-x 2 nobody nogroup 60 Mar 21 23:07 default
- :
- :
# Try creating a file in /root/etc
root@d5802c5e670a:/# touch /root/etc/test
@@ -100,20 +97,19 @@ touch: cannot touch '/root/etc/test': Permission denied
# Try deleting a file
root@d5802c5e670a:/# rm /root/etc/hostname
rm: cannot remove '/root/etc/hostname': Permission denied
-
```
-好了,太棒了。这就是 User Namespaces 的工作方式。
+好了,太棒了。这就是用户名字空间的工作方式。
---------------------------------------------------------------------------------
+---
via: https://coderwall.com/p/s_ydlq/using-user-namespaces-on-docker
作者:[Koji Tanaka][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[pityonline](https://github.com/pityonline)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-[a]:https://coderwall.com/kjtanaka
+[a]: https://coderwall.com/kjtanaka
diff --git a/translated/talk/20180306 Try, learn, modify- The new IT leader-s code.md b/published/20180306 Try, learn, modify- The new IT leader-s code.md
similarity index 72%
rename from translated/talk/20180306 Try, learn, modify- The new IT leader-s code.md
rename to published/20180306 Try, learn, modify- The new IT leader-s code.md
index ce65693a2b..7ecf178a6f 100644
--- a/translated/talk/20180306 Try, learn, modify- The new IT leader-s code.md
+++ b/published/20180306 Try, learn, modify- The new IT leader-s code.md
@@ -1,11 +1,13 @@
-尝试,学习,修改:新 IT 领导者的代码
+尝试、学习、修改:新 IT 领导者的代码
=====
+> 随着创新步伐的增加, 长期规划变得越来越困难。让我们重新思考一下我们对变化的反应方式。
+

-几乎每一天,新的技术发展都在威胁破坏,甚至是那些最复杂,最完善的商业计划。组织经常发现自己正在努力适应新的环境,这导致了他们对未来规划的转变。
+几乎每一天,新的技术发展都可能会动摇那些甚至最复杂、最完善的商业计划。组织经常发现自己需要不断努力适应新的环境,这导致了他们对未来规划的转变。
-根据 CompTIA 2017 年的[研究][1],目前只有 34% 的公司正在制定超过 12 个月的 IT 架构计划。从长期计划转变的一个原因是:商业环境变化如此之快,以至于几乎不可能进一步规划未来。[CIO.com 说道][1]“如果你的公司正视图制定一项将持续五到十年的计划,那就忘了它。”
+根据 CompTIA 2017 年的[研究][1],目前只有 34% 的公司正在制定超过 12 个月的 IT 架构计划。从长期计划转变的一个原因是:商业环境变化如此之快,以至于几乎不可能进一步规划未来。[CIO.com 说道][1],“如果你的公司正视图制定一项将持续五到十年的计划,那就忘了它。”
我听过来自世界各地无数客户和合作伙伴的类似声明:技术创新正以一种前所未有的速度发生着。
@@ -13,21 +15,21 @@
### 计划是怎么死的
-正如我在 Open Organization(开源组织)中写的那样,传统经营组织针对工业经济进行了优化。他们采用等级结构和严格规定的流程,以实现地位竞争优势。要取得成功,他们必须确定他们想要实现的战略地位。然后,他们必须制定并规划实现目标的计划,并以最有效的方式执行这些计划,通过协调活动和推动合规性。
+正如我在《开放式组织》中写的那样,传统经营组织针对工业经济进行了优化。他们采用等级结构和严格规定的流程,以实现地位竞争优势。要取得成功,他们必须确定他们想要实现的战略地位。然后,他们必须制定并规划实现目标的计划,并以最有效的方式执行这些计划,通过协调活动和推动合规性。
-管理层的职责是优化这一过程:计划,规定,执行。包括:让我们想象一个有竞争力的优势地位;让我们来配置组织以最终到达那里;然后让我们通过确保组织的所有方面都遵守规定来推动执行。这就是我所说的“机械管理”,对于不同时期来说它都是一个出色的解决方案。
+管理层的职责是优化这一过程:计划、规定、执行。包括:让我们想象一个有竞争力的优势地位;让我们来配置组织以最终达成目标;然后让我们通过确保组织的所有方面都遵守规定来推动执行。这就是我所说的“机械管理”,对于不同时期来说它都是一个出色的解决方案。
-在当今动荡不定的世界中,我们预测和定义战略位置的能力正在下降,因为变化的速度,新变量的引入速度正在加速。传统的,长期的,战略性规划和执行不像以前那么有效。
+在当今动荡不定的世界中,我们预测和定义战略位置的能力正在下降,因为变化的速度,新变量的引入速度正在加速。传统的、长期的、战略性规划和执行不像以前那么有效。
如果长期规划变得如此困难,那么规定必要的行为就更具有挑战性。并且衡量对计划的合规性几乎是不可能的。
-这一切都极大地影响了人们的工作方式。与过去传统经营组织中的工人不同,他们为自己能够重复行动而感到自豪,几乎没有变化和舒适的确定性 -- 今天的工人在充满模糊性的环境中运作。他们的工作需要更大的创造力,直觉和批判性判断 -- 有更大的要求是背离过去的“正常”,适应当今的新情况。
+这一切都极大地影响了人们的工作方式。与过去传统经营组织中的工人不同,他们为自己能够重复行动而感到自豪,几乎没有变化和舒适的确定性 —— 今天的工人在充满模糊性的环境中运作。他们的工作需要更大的创造力、直觉和批判性判断 —— 更多的需要背离过去的“常规”,以适应当今的新情况。
以这种新方式工作对于价值创造变得更加重要。我们的管理系统必须专注于构建结构,系统和流程,以帮助创建积极主动的工人,他们能够以快速和敏捷的方式进行创新和行动。
-我们需要提出一个不同的解决方案来优化组织,以适应不同的经济时代,从自下而上而不是自上而下开始。我们需要替换过去的三步骤 -- 计划,规定,执行,以一种更适应当今动荡天气的方法来取得成功 -- 尝试,学习,修改。
+我们需要提出一个不同的解决方案来优化组织,以适应不同的经济时代,从自下而上而不是自上而下开始。我们需要替换过去的三步骤 —— 计划、规定、执行,以一种更适应当今动荡天气的方法来取得成功 —— 尝试、学习、修改。
-### 尝试,学习,修改
+### 尝试、学习、修改
因为环境变化如此之快,而且几乎没有任何预警,并且因为我们需要采取的步骤不再提前计划,我们需要培养鼓励创造性尝试和错误的环境,而不是坚持对五年计划的忠诚。以下是以这种方式开始工作的一些暗示:
@@ -46,7 +48,7 @@ via: https://opensource.com/open-organization/18/3/try-learn-modify
作者:[Jim Whitehurst][a]
译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180516 How to Read Outlook Emails by Python.md b/published/20180516 How to Read Outlook Emails by Python.md
similarity index 87%
rename from translated/tech/20180516 How to Read Outlook Emails by Python.md
rename to published/20180516 How to Read Outlook Emails by Python.md
index 944b00c0b5..d10a411b0e 100644
--- a/translated/tech/20180516 How to Read Outlook Emails by Python.md
+++ b/published/20180516 How to Read Outlook Emails by Python.md
@@ -1,31 +1,32 @@
如何用 Python 读取 Outlook 中的电子邮件
======
-
+
-从事电子邮件营销,准入邮箱列表是必不可少的。你可能已经有了准入列表,同时还使用电子邮件客户端软件。如果你能从电子邮件客户端中导出准入列表,那这份列表想必是极好的。
+从事电子邮件营销,准入邮箱列表是必不可少的。你可能已经有了准入列表,同时还使用电子邮件客户端软件。如果你能从电子邮件客户端中导出准入列表,那这份列表想必是极好的。
我使用一些代码来将 outlook 配置中的所有邮件写入一个临时文件中,现在让我来尝试解释一下这些代码。
-首先你需要倒入 win32com.client,为此你需要安装 pywin32
+首先你需要导入 win32com.client,为此你需要安装 pywin32:
+
```
pip install pywin32
-
```
-我们需要通过 MAPI 协议连接 Outlok
+我们需要通过 MAPI 协议连接 Outlok:
+
```
outlook = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI")
-
```
-然后从 outlook 配置中获取所有的账户。
+然后从 outlook 配置中获取所有的账户:
+
```
accounts= win32com.client.Dispatch("Outlook.Application").Session.Accounts;
-
```
-在然后需要从名为 emaileri_al 的收件箱中获取邮件。
+在然后需要从名为 emaileri_al 的收件箱中获取邮件:
+
```
def emailleri_al(folder):
messages = folder.Items
@@ -48,7 +49,8 @@ def emailleri_al(folder):
pass
```
-你需要进入所有账户的所有收件箱中获取电子邮件
+你需要进入所有账户的所有收件箱中获取电子邮件:
+
```
for account in accounts:
global inbox
@@ -77,7 +79,8 @@ for account in accounts:
print("*************************************************", file=
```
-下面是完整的代码
+下面是完整的代码:
+
```
import win32com.client
import win32com
@@ -148,7 +151,7 @@ via: https://www.codementor.io/aliacetrefli/how-to-read-outlook-emails-by-python
作者:[A.A. Cetrefli][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180609 Anatomy of a Linux DNS Lookup - Part I.md b/published/20180609 Anatomy of a Linux DNS Lookup - Part I.md
similarity index 71%
rename from translated/tech/20180609 Anatomy of a Linux DNS Lookup - Part I.md
rename to published/20180609 Anatomy of a Linux DNS Lookup - Part I.md
index b14bd66395..a72a088a31 100644
--- a/translated/tech/20180609 Anatomy of a Linux DNS Lookup - Part I.md
+++ b/published/20180609 Anatomy of a Linux DNS Lookup - Part I.md
@@ -1,49 +1,37 @@
-Linux DNS 查询剖析 – 第一部分
-============================================================
+Linux DNS 查询剖析(第一部分)
+======
-我经常与虚拟机集群打交道([文1][3], [文2][4], [文3][5], [文4][6], [文5][7], [文6][8]),期间花费了大量时间试图掌握 [DNS 查询][9]的工作原理。遇到问题时,我有时只是不求甚解的使用 StackOverflow 上的“解决方案”;甚至那些“解决方案”有时并不工作。
+我经常与虚拟机集群打交道([文1][3]、[文2][4]、[文3][5]、[文4][6]、[文5][7]、[文6][8]),因此最终花费了大量时间试图掌握 [DNS 查询][9]的工作原理。遇到问题时,我只是不求甚解的使用 StackOverflow 上的“解决方案”,而不知道它们为什么有时工作,有时不工作。
-最终我决定改变这种情况,决定一并找出所有问题的原因。我没有在网上找到完整手册或类似的其它东西,我问过一些同事,他们也是如此。
+最终我对此感到了厌倦,决定一并找出所有问题的原因。我没有在网上找到完整的指南,我问过一些同事,他们不知所以然(或许是问题太具体了)。
既然如此,我开始自己写这样的手册。
- _如果你在找第二部分, 点击 [这里][1]_
-
-结果发现,“Linux 执行一次 DNS 查询”的背后有相当多的工作。
-
-* * *
+结果发现,“Linux 执行一次 DNS 查询”这句话的背后有相当多的工作。

_“究竟有多难呢?”_
-* * *
+**本系列文章试图将 Linux 主机上程序获取(域名对应的) IP 地址的过程及期间涉及的组件进行分块剖析。**如果不理解这些块的协同工作方式,调试解决 `dnsmasq`、`vagrant landrush` 和 `resolvconf` 等相关的问题会让人感到眼花缭乱。
-本系列文章试图将 Linux 主机上程序获取(域名对应的) IP 地址的过程及期间涉及的组件进行分块剖析。如果不理解这些块的协同工作方式,调试并解决 `dnsmasq`,`vagrant landrush` 和 `resolvconf` 等相关的问题会让人感到眼花缭乱。
-
-同时这也是一份有价值的说明,指出原本很简单的东西可以如何随着时间的推移变得相当复杂。在弄清楚 DNS 查询的原理的过程中,我了解了大量不同的技术及其发展历程。
+同时这也是一份有价值的说明,指出原本很简单的东西是如何随着时间的推移变得相当复杂。在弄清楚 DNS 查询的原理的过程中,我了解了大量不同的技术及其发展历程。
我甚至编写了一些[自动化脚本][10],可以让我在虚拟机中进行实验。欢迎读者参与贡献或勘误。
-请注意,本系列主题并不是“DNS 工作原理”,而是与查询 Linux 主机配置的真实 DNS 服务器(这里假设查询了 DNS 服务器,但后面你会看到有时并不需要查询)相关的内容,以及如何确定使用哪个查询结果,或者何时使用其它方式确定 IP 地址。
-
-* * *
+**请注意,本系列主题并不是“DNS 工作原理”**,而是与查询 Linux 主机配置的真实 DNS 服务器(这里假设查询了一台 DNS 服务器,但后面你会看到有时并不需要)相关的内容,以及如何确定使用哪个查询结果,或者如何使用其它方式确定 IP 地址。
### 1) 其实并没有名为“DNS 查询”的系统调用
-* * *
-

- _工作方式并非如此_
+_工作方式并非如此_
-* * *
+**首先要了解的一点是,Linux 上并没有一个单独的方法可以完成 DNS 查询工作**;没有一个有这样的明确接口的核心系统调用。
-首先要了解的一点是,Linux 上并没有一个单独的方法可以完成 DNS 查询工作;至少没有如此明确接口的核心系统调用。
+不过,有一个标准 C 库函数调用 [`getaddrinfo`][2],不少程序使用了该调用;但不是所有程序或应用都使用该调用!
-有一个标准 C 库函数调用 `[getaddrinfo][2]`,不少程序使用了该调用;但不是所有程序或应用都使用该调用!
-
-我们只考虑两个简单的标准程序:`ping` 和 `host`:
+让我们看一下两个简单的标准程序:`ping` 和 `host`:
```
root@linuxdns1:~# ping -c1 bbc.co.uk | head -1
@@ -100,17 +88,15 @@ google.com has address 216.58.204.46
下面我们依次查看这两个 `.conf` 扩展名的文件。
-* * *
-
### 2) NSSwitch 与 `/etc/nsswitch.conf`
-我们已经确认应用可以自主决定选用哪个 DNS 服务器。很多应用(例如 `ping`)通过配置文件 `/etc/nsswitch.conf` (根据具体实现 (*))参考 NSSwitch 完成选择。
+我们已经确认应用可以自主决定选用哪个 DNS 服务器。很多应用(例如 `ping`)通过配置文件 `/etc/nsswitch.conf` (根据具体实现[^1] )参考 NSSwitch 完成选择。
-###### (*) ping 实现的变种之多令人惊叹。我 _不_ 希望在这里讨论过多。
+[^1]: `ping` 实现的变种之多令人惊叹。我 _不_ 希望在这里讨论过多。
NSSwitch 不仅用于 DNS 查询,例如,还用于密码与用户信息查询。
-NSSwitch 最初是 Solaris OS 的一部分,可以让应用无需将查询所需的文件或服务硬编码,而是在其它集中式的、无需应用开发人员管理的配置文件中找到。
+NSSwitch 最初是 Solaris OS 的一部分,可以让应用无需硬编码查询所需的文件或服务,而是在其它集中式的、无需应用开发人员管理的配置文件中找到。
下面是我的 `nsswitch.conf`:
@@ -130,12 +116,13 @@ netgroup: nis
我们需要关注的是 `hosts` 行。我们知道 `ping` 用到 `nsswitch.conf` 文件,那么我们修改这个文件(的 `hosts` 行),看看能够如何影响 `ping`。
-
-* ### 修改 `nsswitch.conf`, `hosts` 行仅保留 `files`
+#### 修改 `nsswitch.conf`, `hosts` 行仅保留 `files`
如果你修改 `nsswitch.conf`,将 `hosts` 行仅保留 `files`:
-`hosts: files`
+```
+hosts: files
+```
此时, `ping` 无法获取 google.com 对应的 IP 地址:
@@ -161,11 +148,13 @@ google.com has address 216.58.206.110
毕竟如我们之前看到的那样,`host` 不受 `nsswitch.conf` 影响。
-* ### 修改 `nsswitch.conf`, `hosts` 行仅保留 `dns`
+#### 修改 `nsswitch.conf`, `hosts` 行仅保留 `dns`
如果你修改 `nsswitch.conf`,将 `hosts` 行仅保留 `dns`:
-`hosts: dns`
+```
+hosts: dns
+```
此时,google.com 的解析恢复正常:
@@ -184,13 +173,9 @@ ping: unknown host localhost
下图给出默认 NSSwitch 中 `hosts` 行对应的查询逻辑:
-* * *
-

- _我的 `hosts:` 配置是 `nsswitch.conf` 给出的默认值_
-
-* * *
+_我的 `hosts:` 配置是 `nsswitch.conf` 给出的默认值_
### 3) `/etc/resolv.conf`
@@ -221,16 +206,16 @@ $ ping -c1 google.com
ping: unknown host google.com
```
-解析失败了,这是因为没有可用的 nameserver (*)。
+解析失败了,这是因为没有可用的名字服务器 [^2]。
-
-###### * 另一个需要注意的地方: `host` 在没有指定 nameserver 的情况下会尝试 127.0.0.1:53。
+[^2]: 另一个需要注意的地方: `host` 在没有指定 nameserver 的情况下会尝试 127.0.0.1:53。
该文件中还可以使用其它选项。例如,你可以在 `resolv.conf` 文件中增加如下行:
```
search com
```
+
然后执行 `ping google` (不写 `.com`)
```
@@ -248,10 +233,9 @@ PING google.com (216.58.204.14) 56(84) bytes of data.
* 操作系统中并不存在“DNS 查询”这个系统调用
* 不同程序可能采用不同的策略获取名字对应的 IP 地址
- * 例如, `ping` 使用 `nsswitch`,后者进而使用(或可以使用) `/etc/hosts`,`/etc/resolv.conf` 以及主机名得到解析结果
-
+ * 例如, `ping` 使用 `nsswitch`,后者进而使用(或可以使用) `/etc/hosts`、`/etc/resolv.conf` 以及主机名得到解析结果
* `/etc/resolv.conf` 用于决定:
- * 查询什么地址(LCTT 译注:这里可能指 search 带来的影响)
+ * 查询什么地址(LCTT 译注:这里可能指 `search` 带来的影响)
* 使用什么 DNS 服务器执行查询
如果你曾认为 DNS 查询很复杂,请跟随这个系列学习吧。
@@ -262,7 +246,7 @@ via: https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
作者:[dmatech][a]
译者:[pinewall](https://github.com/pinewall)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180618 Anatomy of a Linux DNS Lookup - Part II.md b/published/20180618 Anatomy of a Linux DNS Lookup - Part II.md
new file mode 100644
index 0000000000..9bd7f17347
--- /dev/null
+++ b/published/20180618 Anatomy of a Linux DNS Lookup - Part II.md
@@ -0,0 +1,223 @@
+Linux DNS 查询剖析(第二部分)
+==============================================
+
+在 [Linux DNS 查询剖析 - 第一部分][1] 中,我介绍了:
+
+* `nsswitch`
+* `/etc/hosts`
+* `/etc/resolv.conf`
+* `ping` 与 `host` 查询方式对比
+
+并且发现大多数程序选择要查询的 DNS 服务器时会参考 `/etc/resolv.conf` 配置文件。
+
+这种方式在 Linux 上比较普遍[^1]。虽然我使用了特定的发行版 Ubuntu,但背后的原理与 Debian 甚至是那些基于 CentOS 的发行版有相通的地方;当然,与更低或更高的 Ubuntu 版本相比,差异还是存在的。
+
+[^1]: 事实上,这是相对于 POSIX 标准的,故不限于 Linux (我从上一篇文章的一条极好的[回复][2]中了解到这一点)
+
+也就是说,接下来,你主机上的行为很可能与我描述的不一致。
+
+在第二部分中,我将介绍 `resolv.conf` 的更新机制、`systemctl restart networking` 命令的运行机制 ,以及 `dhclient` 是如何参与其中。
+
+### 1) 手动更新 /etc/resolv.conf
+
+我们知道 `/etc/resolv.conf` (有极大的可能性)被用到,故你自然可以通过该文件增加一个 `nameserver`,那么主机也将会(与已有的 `nameserver` 一起)使用新加入的 `nameserver` 吧?
+
+你可以尝试如下:
+
+```
+$ echo nameserver 10.10.10.10 >> /etc/resolv.conf
+```
+
+看上去新的 `nameserver` 已经加入:
+
+```
+# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
+# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
+nameserver 10.0.2.3
+search home
+nameserver 10.10.10.10
+```
+
+但主机网络服务重启后问题出现了:
+
+```
+$ systemctl restart networking
+$ cat /etc/resolv.conf
+# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
+# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
+nameserver 10.0.2.3
+search home
+```
+
+我们的 `10.10.10.10` 的 `nameserver` 不见了!
+
+在上一篇文章中我们忽略了这一点,本文进行补充说明。
+
+### 2) resolvconf
+
+你在 `/etc/resolv.conf` 文件中看到 `generated by resolvconf` 词组了吧?这就是我们的线索。
+
+如果深入研究 `systemctl restart networking` 命令,你会发现它做了很多事情,结束时调用了 `/etc/network/if-up.d/000resolvconf` 脚本。在该脚本中,可以发现一次对 `resolvconf` 命令的调用:
+
+```
+/sbin/resolvconf -a "${IFACE}.${ADDRFAM}"
+```
+
+稍微研究一下 man 手册,发现`-a` 参数允许我们:
+
+```
+Add or overwrite the record IFACE.PROG then run the update scripts
+if updating is enabled.
+```
+
+(增加或覆盖 IFACE.PROG 记录,如果开启更新选项,则运行更新脚本)
+
+故而也许我们可以直接调用该命令增加 `namserver`:
+
+```
+echo 'nameserver 10.10.10.10' | /sbin/resolvconf -a enp0s8.inet
+```
+
+测试表明确实可以!
+
+```
+$ cat /etc/resolv.conf | grep nameserver
+nameserver 10.0.2.3
+nameserver 10.10.10.10
+```
+
+是否已经找到答案,这就是 `/etc/resolv.conf` 更新的逻辑?调用 `resolvconf` 将 `nameserver` 添加到某个地方的数据库,然后(“如果配置了更新”,先不管具体什么含义)更新 `resolv.conf` 文件。
+
+并非如此。
+
+```
+$ systemctl restart networking
+root@linuxdns1:/etc# cat /etc/resolv.conf
+# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
+# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
+nameserver 10.0.2.3
+search home
+```
+
+呃!(网络服务重启后)新增的 `nameserver` 再次消失了。
+
+可见,`systemctl restart networking` 不仅仅运行了 `resolvconf`,还在其它地方获取 `nameserver` 信息。具体是哪里呢?
+
+### 3) ifup/ifdown
+
+继续深入研究 `systemctl restart networking`,发现它完成了一系列工作:
+
+```
+cat /lib/systemd/system/networking.service
+[...]
+[Service]
+Type=oneshot
+EnvironmentFile=-/etc/default/networking
+ExecStartPre=-/bin/sh -c '[ "$CONFIGURE_INTERFACES" != "no" ] && [ -n "$(ifquery --read-environment --list --exclude=lo)" ] && udevadm settle'
+ExecStart=/sbin/ifup -a --read-environment
+ExecStop=/sbin/ifdown -a --read-environment --exclude=lo
+[...]
+```
+
+首先,网络服务的重启实质是运行一个单触发的脚本,脚本包含如下命令:
+
+```
+/sbin/ifdown -a --read-environment --exclude=lo
+/bin/sh -c '[ "$CONFIGURE_INTERFACES" != "no" ] && [ -n "$(ifquery --read-environment --list --exclude=lo)" ] && udevadm settle'
+/sbin/ifup -a --read-environment
+```
+
+第一行使用 `ifdown` 关闭全部的网络接口,但本地回环接口除外。[^2]
+
+[^2]: 我不明白为何这没有导致我例子中的 vagrant 会话中断 (有谁明白吗?)。
+
+(LCTT 译注:其实这是因为很快就又启动了接口,间隔的时间没有超过 TCP 连接的超时时间,有人在评论中也做了类似回复)
+
+第二行用于确认系统已经完成关闭网络接口相关的全部工作,以便下一步使用 `ifup` 启动接口。这也让我们了解到,网络服务实质运行的就是 `ifdown` 和 `ifup`。
+
+文档中没有找到 `--read-environment` 参数的说明,该参数为 `systemctl` 正常工作所需。很多人以文档不完善为由不喜欢 `systemctl`。
+
+很好。那么 `ifup` (和其成对出现的 `ifdown`) 到底做了哪些工作呢?长话短说,它运行了 `/etc/network/if-pre-up.d/` 和 `/etc/network/if-up.d/` 目录下的全部脚本;期间,这些脚本也可能会调用另外的脚本,依此类推。
+
+其中一件工作就是运行了 `dhclient`,但我还不完全确定具体的机理,也许 `udev` 参与其中。
+
+### 4) dhclient
+
+`dhclient` 是一个程序,用于与 DHCP 服务器协商对应网络接口应该使用的 IP 地址的详细信息。同时,它也可以获取可用的 DNS 服务器并将其替换到 `/etc/resolv.conf` 中。
+
+让我们开始跟踪并模拟它的行为,但仅在我实验虚拟机的 `enp0s3` 接口上。事先已经删除 `/etc/resolv.conf` 文件中的 nameserver 配置:
+
+```
+$ sed -i '/nameserver.*/d' /run/resolvconf/resolv.conf
+$ cat /etc/resolv.conf | grep nameserver
+$ dhclient -r enp0s3 && dhclient -v enp0s3
+Killed old client process
+Internet Systems Consortium DHCP Client 4.3.3
+Copyright 2004-2015 Internet Systems Consortium.
+All rights reserved.
+For info, please visit https://www.isc.org/software/dhcp/
+Listening on LPF/enp0s8/08:00:27:1c:85:19
+Sending on LPF/enp0s8/08:00:27:1c:85:19
+Sending on Socket/fallback
+DHCPDISCOVER on enp0s8 to 255.255.255.255 port 67 interval 3 (xid=0xf2f2513e)
+DHCPREQUEST of 172.28.128.3 on enp0s8 to 255.255.255.255 port 67 (xid=0x3e51f2f2)
+DHCPOFFER of 172.28.128.3 from 172.28.128.2
+DHCPACK of 172.28.128.3 from 172.28.128.2
+bound to 172.28.128.3 -- renewal in 519 seconds.
+
+$ cat /etc/resolv.conf | grep nameserver
+nameserver 10.0.2.3
+```
+
+可见这就是 `nameserver` 的来源。
+
+但稍等一下,命令中的 `/run/resolvconf/resolv.conf` 是哪个文件,不应该是 `/etc/resolv.conf` 吗?
+
+事实上,`/etc/resolv.conf` 并不一定只是一个普通文本文件。
+
+在我的虚拟机上,它是一个软链接,指向位于 `/run/resolvconf` 目录下的“真实文件”。这也暗示了我们,该文件是在系统启动时生成的;同时,这也是该文件注释告诉我们不要直接修改该文件的原因。
+
+(LCTT 译注:在 CentOS 7 中,没有 `resolvconf` 命令,`/etc/resolv.conf` 也不是软链接)
+
+假如上面命令中 `sed` 命令直接处理 `/etc/resolv.conf` 文件,效果是不同的,会有警告消息告知待操作的文件不能是软链接(`sed -i` 无法很好的处理软链接,它只会创建一个新文件)。
+
+(LCTT 译注:CentOS 7 测试时,`sed -i` 命令操作软链接并没有警告,但确实创建了新文件取代软链接)
+
+如果你继续深入查看配置文件 `/etc/dhcp/dhclient.conf` 的 `supersede` 部分,你会发现 `dhclient` 可以覆盖 DHCP 提供的 DNS 服务器。
+
+
+
+ _(大致)准确的关系图_
+
+* * *
+
+### 第二部分的结束语
+
+第二部分到此结束。信不信由你,这是一个某种程度上简化的流程版本,但我尽量保留重要和值得了解的部分,让你不会感到无趣。大部分内容都是围绕实际脚本的运行展开的。
+
+但我们的工作还没有结束,在第三部分,我们会介绍这些之上的更多层次。
+
+让我们简要列出我们已经介绍过的内容:
+
+* `nsswitch`
+* `/etc/hosts`
+* `/etc/resolv.conf`
+* `/run/resolvconf/resolv.conf`
+* `systemd` 和网络服务
+* `ifup` 和 `ifdown`
+* `dhclient`
+* `resolvconf`
+
+--------------------------------------------------------------------------------
+
+via: https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
+
+作者:[ZWISCHENZUGS][a]
+译者:[pinewall](https://github.com/pinewall)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://zwischenzugs.com/
+[1]:https://linux.cn/article-9943-1.html
+[2]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/#comment-2312
diff --git a/published/20180623 Intercepting and Emulating Linux System Calls with Ptrace - null program.md b/published/20180623 Intercepting and Emulating Linux System Calls with Ptrace - null program.md
new file mode 100644
index 0000000000..90b2310a32
--- /dev/null
+++ b/published/20180623 Intercepting and Emulating Linux System Calls with Ptrace - null program.md
@@ -0,0 +1,292 @@
+使用 Ptrace 去拦截和仿真 Linux 系统调用
+======
+
+`ptrace(2)`(“进程跟踪)系统调用通常都与调试有关。它是类 Unix 系统上通过原生调试器监测被调试进程的主要机制。它也是实现 [strace][1](系统调用跟踪)的常见方法。使用 Ptrace,跟踪器可以暂停被跟踪进程,[检查和设置寄存器和内存][2],监视系统调用,甚至可以拦截系统调用。
+
+通过拦截功能,意味着跟踪器可以篡改系统调用参数,篡改系统调用的返回值,甚至阻塞某些系统调用。言外之意就是,一个跟踪器本身完全可以提供系统调用服务。这是件非常有趣的事,因为这意味着**一个跟踪器可以仿真一个完整的外部操作系统**,而这些都是在没有得到内核任何帮助的情况下由 Ptrace 实现的。
+
+问题是,在同一时间一个进程只能被一个跟踪器附着,因此在那个进程的调试期间,不可能再使用诸如 GDB 这样的工具去仿真一个外部操作系统。另外的问题是,仿真系统调用的开销非常高。
+
+在本文中,我们将专注于 x86-64 [Linux 的 Ptrace][3],并将使用一些 Linux 专用的扩展。同时,在本文中,我们将忽略掉一些错误检查,但是完整的源代码仍然会包含这些错误检查。
+
+本文中的可直接运行的示例代码在这里:
+
+### strace
+
+在进入到最有趣的部分之前,我们先从回顾 strace 的基本实现来开始。它[不是 DTrace][4],但 strace 仍然非常有用。
+
+Ptrace 一直没有被标准化。它的接口在不同的操作系统上非常类似,尤其是在核心功能方面,但是在不同的系统之间仍然存在细微的差别。`ptrace(2)` 的原型基本上应该像下面这样,但特定的类型可能有些差别。
+
+```
+long ptrace(int request, pid_t pid, void *addr, void *data);
+```
+
+`pid` 是被跟踪进程的 ID。虽然**同一个时间**只有一个跟踪器可以附着到该进程上,但是一个跟踪器可以附着跟踪多个进程。
+
+`request` 字段选择一个具体的 Ptrace 函数,比如 `ioctl(2)` 接口。对于 strace,只需要两个:
+
+* `PTRACE_TRACEME`:这个进程被它的父进程跟踪。
+* `PTRACE_SYSCALL`:继续跟踪,但是在下一下系统调用入口或出口时停止。
+* `PTRACE_GETREGS`:取得被跟踪进程的寄存器内容副本。
+
+另外两个字段,`addr` 和 `data`,作为所选的 Ptrace 函数的一般参数。一般情况下,可以忽略一个或全部忽略,在那种情况下,传递零个参数。
+
+strace 接口实质上是前缀到另一个命令之前。
+
+```
+$ strace [strace options] program [arguments]
+```
+
+最小化的 strace 不需要任何选项,因此需要做的第一件事情是 —— 假设它至少有一个参数 —— 在 `argv` 尾部的 `fork(2)` 和 `exec(2)` 被跟踪进程。但是在加载目标程序之前,新的进程将告知内核,目标程序将被它的父进程继续跟踪。被跟踪进程将被这个 Ptrace 系统调用暂停。
+
+```
+pid_t pid = fork();
+switch (pid) {
+ case -1: /* error */
+ FATAL("%s", strerror(errno));
+ case 0: /* child */
+ ptrace(PTRACE_TRACEME, 0, 0, 0);
+ execvp(argv[1], argv + 1);
+ FATAL("%s", strerror(errno));
+}
+```
+
+父进程使用 `wait(2)` 等待子进程的 `PTRACE_TRACEME`,当 `wait(2)` 返回后,子进程将被暂停。
+
+```
+waitpid(pid, 0, 0);
+```
+
+在允许子进程继续运行之前,我们告诉操作系统,被跟踪进程和它的父进程应该一同被终止。一个真实的 strace 实现可能会设置其它的选择,比如: `PTRACE_O_TRACEFORK`。
+
+```
+ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
+```
+
+剩余部分就是一个简单的、无休止的循环了,每循环一次捕获一个系统调用。循环体总共有四步:
+
+1. 等待进程进入下一个系统调用。
+2. 输出系统调用的一个描述。
+3. 允许系统调用去运行并等待返回。
+4. 输出系统调用返回值。
+
+这个 `PTRACE_SYSCALL` 请求被用于等待下一个系统调用时开始,和等待那个系统调用退出。和前面一样,需要一个 `wait(2)` 去等待被跟踪进程进入期望的状态。
+
+```
+ptrace(PTRACE_SYSCALL, pid, 0, 0);
+waitpid(pid, 0, 0);
+```
+
+当 `wait(2)` 返回时,进行了系统调用的线程的寄存器中写入了该系统调用的系统调用号及其参数。尽管如此,*操作系统仍然没有为这个系统调用提供服务*。这个细节对后续操作很重要。
+
+接下来的一步是采集系统调用信息。这是各个系统架构不同的地方。在 x86-64 上,[系统调用号是在 `rax` 中传递的][5],而参数(最多 6 个)是在 `rdi`、`rsi`、`rdx`、`r10`、`r8` 和 `r9` 中传递的。这些寄存器是由另外的 Ptrace 调用读取的,不过这里再也不需要 `wait(2)` 了,因为被跟踪进程的状态再也不会发生变化了。
+
+```
+struct user_regs_struct regs;
+ptrace(PTRACE_GETREGS, pid, 0, ®s);
+long syscall = regs.orig_rax;
+
+fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
+ syscall,
+ (long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
+ (long)regs.r10, (long)regs.r8, (long)regs.r9);
+```
+
+这里有一个警告。由于 [内核的内部用途][6],系统调用号是保存在 `orig_rax` 中而不是 `rax` 中。而所有的其它系统调用参数都是非常简单明了的。
+
+接下来是它的另一个 `PTRACE_SYSCALL` 和 `wait(2)`,然后是另一个 `PTRACE_GETREGS` 去获取结果。结果保存在 `rax` 中。
+
+```
+ptrace(PTRACE_GETREGS, pid, 0, ®s);
+fprintf(stderr, " = %ld\n", (long)regs.rax);
+```
+
+这个简单程序的输出也是非常粗糙的。这里的系统调用都没有符号名,并且所有的参数都是以数字形式输出,甚至是一个指向缓冲区的指针也是如此。更完整的 strace 输出将能知道哪个参数是指针,并使用 `process_vm_readv(2)` 从被跟踪进程中读取哪些缓冲区,以便正确输出它们。
+
+然而,这些仅仅是系统调用拦截的基础工作。
+
+### 系统调用拦截
+
+假设我们想使用 Ptrace 去实现如 OpenBSD 的 [`pledge(2)`][7] 这样的功能,它是 [一个进程承诺只使用一套受限的系统调用][8]。初步想法是,许多程序一般都有一个初始化阶段,这个阶段它们都需要进行许多的系统访问(比如,打开文件、绑定套接字、等等)。初始化完成以后,它们进行一个主循环,在主循环中它们处理输入,并且仅使用所需的、很少的一套系统调用。
+
+在进入主循环之前,一个进程可以限制它自己只能运行所需要的几个操作。如果 [程序有缺陷][9],能够通过恶意的输入去利用该缺陷,这个**承诺**可以有效地限制漏洞利用的实现。
+
+使用与 strace 相同的模型,但不是输出所有的系统调用,我们既能够阻塞某些系统调用,也可以在它的行为异常时简单地终止被跟踪进程。终止它很容易:只需要在跟踪器中调用 `exit(2)`。因此,它也可以被设置为去终止被跟踪进程。阻塞系统调用和允许子进程继续运行都只是些雕虫小技而已。
+
+最棘手的部分是**当系统调用启动后没有办法去中断它**。当跟踪器在入口从 `wait(2)` 中返回到系统调用时,从一开始停止一个系统调用的仅有方式是,终止被跟踪进程。
+
+然而,我们不仅可以“搞乱”系统调用的参数,也可以改变系统调用号本身,将它修改为一个不存在的系统调用。返回时,在 `errno` 中 [通过正常的内部信号][10],我们就可以报告一个“友好的”错误信息。
+
+```
+for (;;) {
+ /* Enter next system call */
+ ptrace(PTRACE_SYSCALL, pid, 0, 0);
+ waitpid(pid, 0, 0);
+
+ struct user_regs_struct regs;
+ ptrace(PTRACE_GETREGS, pid, 0, ®s);
+
+ /* Is this system call permitted? */
+ int blocked = 0;
+ if (is_syscall_blocked(regs.orig_rax)) {
+ blocked = 1;
+ regs.orig_rax = -1; // set to invalid syscall
+ ptrace(PTRACE_SETREGS, pid, 0, ®s);
+ }
+
+ /* Run system call and stop on exit */
+ ptrace(PTRACE_SYSCALL, pid, 0, 0);
+ waitpid(pid, 0, 0);
+
+ if (blocked) {
+ /* errno = EPERM */
+ regs.rax = -EPERM; // Operation not permitted
+ ptrace(PTRACE_SETREGS, pid, 0, ®s);
+ }
+}
+```
+
+这个简单的示例只是检查了系统调用是否违反白名单或黑名单。而它们在这里并没有差别,比如,允许文件以只读而不是读写方式打开(`open(2)`),允许匿名内存映射但不允许非匿名映射等等。但是这里仍然没有办法去动态撤销被跟踪进程的权限。
+
+跟踪器与被跟踪进程如何沟通?使用人为的系统调用!
+
+### 创建一个人为的系统调用
+
+对于我的这个类似于 pledge 的系统调用 —— 我可以通过调用 `xpledge()` 将它与真实的系统调用区分开 —— 我设置 10000 作为它的系统调用号,这是一个非常大的数字,真实的系统调用中从来不会用到它。
+
+```
+#define SYS_xpledge 10000
+```
+
+为演示需要,我同时构建了一个非常小的接口,这在实践中并不是个好主意。它与 OpenBSD 的 `pledge(2)` 稍有一些相似之处,它使用了一个 [字符串接口][11]。*事实上*,设计一个健壮且安全的权限集是非常复杂的,正如在 `pledge(2)` 的手册页面上所显示的那样。下面是对被跟踪进程的系统调用的完整接口*和*实现:
+
+```
+#define _GNU_SOURCE
+#include
+
+#define XPLEDGE_RDWR (1 << 0)
+#define XPLEDGE_OPEN (1 << 1)
+
+#define xpledge(arg) syscall(SYS_xpledge, arg)
+```
+
+如果给它传递个参数 0 ,仅允许一些基本的系统调用,包括那些用于去分配内存的系统调用(比如 `brk(2)`)。 `PLEDGE_RDWR` 位允许 [各种][12] 读和写的系统调用(`read(2)`、`readv(2)`、`pread(2)`、`preadv(2)` 等等)。`PLEDGE_OPEN` 位允许 `open(2)`。
+
+为防止发生提升权限的行为,`pledge()` 会拦截它自己 —— 但这样也防止了权限撤销,以后再细说这方面内容。
+
+在 xpledge 跟踪器中,我需要去检查这个系统调用:
+
+```
+/* Handle entrance */
+switch (regs.orig_rax) {
+ case SYS_pledge:
+ register_pledge(regs.rdi);
+ break;
+}
+```
+
+操作系统将返回 `ENOSYS`(函数尚未实现),因为它不是一个*真实的*系统调用。为此在退出时我用一个 `success(0)` 去覆写它。
+
+```
+/* Handle exit */
+switch (regs.orig_rax) {
+ case SYS_pledge:
+ ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
+ break;
+}
+```
+
+我写了一小段测试程序去打开 `/dev/urandom`,做一个读操作,尝试去承诺后,然后试着第二次打开 `/dev/urandom`,然后确认它能够读取原始的 `/dev/urandom` 文件描述符。在没有承诺跟踪器的情况下运行,输出如下:
+
+```
+$ ./example
+fread("/dev/urandom")[1] = 0xcd2508c7
+XPledging...
+XPledge failed: Function not implemented
+fread("/dev/urandom")[2] = 0x0be4a986
+fread("/dev/urandom")[1] = 0x03147604
+```
+
+做一个无效的系统调用并不会让应用程序崩溃。它只是失败,这是一个很方便的返回方式。当它在跟踪器下运行时,它的输出如下:
+
+```
+$ ./xpledge ./example
+fread("/dev/urandom")[1] = 0xb2ac39c4
+XPledging...
+fopen("/dev/urandom")[2]: Operation not permitted
+fread("/dev/urandom")[1] = 0x2e1bd1c4
+```
+
+这个承诺很成功,第二次的 `fopen(3)` 并没有进行,因为跟踪器用一个 `EPERM` 阻塞了它。
+
+可以将这种思路进一步发扬光大,比如,改变文件路径或返回一个假的结果。一个跟踪器可以很高效地 chroot 它的被跟踪进程,通过一个系统调用将任意路径传递给 root 从而实现 chroot 路径。它甚至可以对用户进行欺骗,告诉用户它以 root 运行。事实上,这些就是 [Fakeroot NG][13] 程序所做的事情。
+
+### 仿真外部系统
+
+假设你不满足于仅拦截一些系统调用,而是想拦截*全部*系统调用。你就会有了 [一个打算在其它操作系统上运行的二进制程序][14],无需系统调用,这个二进制程序可以一直运行。
+
+使用我在前面所描述的这些内容你就可以管理这一切。跟踪器可以使用一个假冒的东西去代替系统调用号,允许它失败,以及为系统调用本身提供服务。但那样做的效率很低。其实质上是对每个系统调用做了三个上下文切换:一个是在入口上停止,一个是让系统调用总是以失败告终,还有一个是在系统调用退出时停止。
+
+从 2005 年以后,对于这个技术,PTrace 的 Linux 版本有更高效的操作:`PTRACE_SYSEMU`。PTrace 仅在每个系统调用发出时停止*一次*,在允许被跟踪进程继续运行之前,由跟踪器为系统调用提供服务。
+
+```
+for (;;) {
+ ptrace(PTRACE_SYSEMU, pid, 0, 0);
+ waitpid(pid, 0, 0);
+
+ struct user_regs_struct regs;
+ ptrace(PTRACE_GETREGS, pid, 0, ®s);
+
+ switch (regs.orig_rax) {
+ case OS_read:
+ /* ... */
+
+ case OS_write:
+ /* ... */
+
+ case OS_open:
+ /* ... */
+
+ case OS_exit:
+ /* ... */
+
+ /* ... and so on ... */
+ }
+}
+```
+
+从任何具有(足够)稳定的系统调用 ABI(LCTT 译注:应用程序二进制接口),在相同架构的机器上运行一个二进制程序时,你只需要 `PTRACE_SYSEMU` 跟踪器、一个加载器(用于代替 `exec(2)`),和这个二进制程序所需要(或仅运行静态的二进制程序)的任何系统库即可。
+
+事实上,这听起来有点像一个有趣的周末项目。
+
+**参见**
+
+- [给 Linux 内核克隆实现一个 OpenBSD 承诺][15]
+
+--------------------------------------------------------------------------------
+
+via: http://nullprogram.com/blog/2018/06/23/
+
+作者:[Chris Wellons][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://nullprogram.com
+[1]: https://blog.plover.com/Unix/strace-groff.html
+[2]: http://nullprogram.com/blog/2016/09/03/
+[3]: http://man7.org/linux/man-pages/man2/ptrace.2.html
+[4]: http://nullprogram.com/blog/2018/01/17/
+[5]: http://nullprogram.com/blog/2015/05/15/
+[6]: https://stackoverflow.com/a/6469069
+[7]: https://man.openbsd.org/pledge.2
+[8]: http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
+[9]: http://nullprogram.com/blog/2017/07/19/
+[10]: http://nullprogram.com/blog/2016/09/23/
+[11]: https://www.tedunangst.com/flak/post/string-interfaces
+[12]: http://nullprogram.com/blog/2017/03/01/
+[13]: https://fakeroot-ng.lingnu.com/index.php/Home_Page
+[14]: http://nullprogram.com/blog/2017/11/30/
+[15]: https://www.youtube.com/watch?v=uXgxMDglxVM
diff --git a/translated/tech/20180706 Revisiting wallabag, an open source alternative to Instapaper.md b/published/20180706 Revisiting wallabag, an open source alternative to Instapaper.md
similarity index 69%
rename from translated/tech/20180706 Revisiting wallabag, an open source alternative to Instapaper.md
rename to published/20180706 Revisiting wallabag, an open source alternative to Instapaper.md
index 0f807d9e3e..ce46d44df2 100644
--- a/translated/tech/20180706 Revisiting wallabag, an open source alternative to Instapaper.md
+++ b/published/20180706 Revisiting wallabag, an open source alternative to Instapaper.md
@@ -1,13 +1,15 @@
-重温 wallabag,Instapaper 的开源替代品
+重温 wallabag:Instapaper 的开源替代品
======
+> 这个稍后阅读应用增加了功能,使其成为诸如 Pocket、Paper 和 Instapaper 之类应用的可靠替代品。
+

-早在 2014 年,我[写了篇关于 wallabag 的文章][1],它是稍后阅读应用如 Instapaper 和 Pocket 的开源替代品。如果你愿意,去看看那篇文章吧。别担心,我会等你的。
+早在 2014 年,我[写了篇关于 wallabag 的文章][1],它是诸如 Instapaper 和 Pocket 这样的稍后阅读应用的开源替代品。如果你愿意,去看看那篇文章吧。别担心,我会等你的。
-好了么?很好
+好了么?很好。
-自从我写这篇文章的四年来,[wallabag][2]的很多东西都发生了变化。现在是时候看看 wallabag 是如何成熟的。
+自从我写这篇文章的四年来,[wallabag][2] 的很多东西都发生了变化。现在是时候悄悄看一下 wallabag 是如何成熟的。
### 有什么新的
@@ -15,11 +17,11 @@
那么这些变化有哪些呢?有[很多][3]。以下是我发现最有趣和最有用的内容。
-除了使 wallabag 更加快速和稳定之外,程序的导入和导出内容的能力也得到了提高。你可以从 Pocket 和 Instapaper 导入文章,也可导入书签服务 [Pinboard][4] 中标记为 “To read” 的文章。你还可以导入 Firefox 和 Chrome 书签。
+除了使 wallabag 更加快速和稳定之外,该应用的导入和导出内容的能力也得到了提高。你可以从 Pocket 和 Instapaper 导入文章,也可导入书签服务 [Pinboard][4] 中标记为 “To read” 的文章。你还可以导入 Firefox 和 Chrome 书签。
你还可以以多种格式导出文章,包括 EPUB、MOBI、PDF 和纯文本。你可以为单篇文章、所有未读文章或所有已读和未读执行此操作。我四年前使用的 wallabag 版本可以导出到 EPUB 和 PDF,但有时导出很糟糕。现在,这些导出快速而顺利。
-Web 界面中的注释和高亮显示现在可以更好,更一致地工作。不可否认,我并不经常使用它们 - 但它们不会像 wallabag v1 那样随机消失。
+Web 界面中的注释和高亮显示现在可以更好、更一致地工作。不可否认,我并不经常使用它们 —— 但它们不会像 wallabag v1 那样随机消失。

@@ -27,7 +29,7 @@ wallabag 的外观和感觉也有所改善。这要归功于受 [Material Design
-其中一个最大的变化是引入了 wallabag 的[托管版本][6]。不止一些人(包括你在内)没有服务器来运行网络程序,并且不太愿意这样做。当遇到任何技术问题时,我很窘迫。我不介意每年花 9 欧元(我写这篇文章的时候只要 10 美元),以获得一个我不需要关注的程序的完整工作版本。
+其中一个最大的变化是引入了 wallabag 的[托管版本][6]。不是只有少数人(包括你在内)没有服务器来运行网络程序,并且也不太愿意维护台服务器。当遇到任何技术问题时,我很窘迫。我不介意每年花 9 欧元(我写这篇文章的时候只要 10 美元),以获得一个我不需要关注的程序的完整工作版本。
### 没有改变什么
@@ -37,11 +39,11 @@ Wallabag 的[浏览器扩展][7]以同样的方式完成同样的工作。我发
### 有什么令人失望的
-移动应用良好,但没有很棒。它在渲染文章方面做得很好,并且有一些配置选项。但是你不能高亮或注释文章。也就是说,你可以使用该程序浏览你的存档文章。
+移动应用良好,但不算很棒。它在渲染文章方面做得很好,并且有一些配置选项。但是你不能高亮或注释文章。也就是说,你可以使用该程序浏览你的存档文章。
-虽然 wallabag 在收藏文章方面做得很好,但有些网站的内容却无法保存。我没有碰到很多这样的网站,但已经遇到让人烦恼的情况。我不确定与 wallabag 有多大关系。相反,我怀疑它与网站的编码方式有关 - 我在使用几个专有的稍后阅读工具时遇到了同样的问题。
+虽然 wallabag 在收藏文章方面做得很好,但有些网站的内容却无法保存。我没有碰到很多这样的网站,但已经遇到让人烦恼的情况。我不确定与 wallabag 有多大关系。相反,我怀疑它与网站的编码方式有关 —— 我在使用几个专有的稍后阅读工具时遇到了同样的问题。
Wallabag 可能不是 Pocket 或 Instapaper 的等功能的替代品,但它做得很好。自从我第一次写这篇文章以来的四年里,它已经有了明显的改善。它仍然有改进的余地,但要做好它宣传的。
@@ -56,7 +58,7 @@ via: https://opensource.com/article/18/7/wallabag
作者:[Scott Nesbitt][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180711 Javascript Framework Comparison with Examples React Vue Hyperapp.md b/published/20180711 Javascript Framework Comparison with Examples React Vue Hyperapp.md
similarity index 51%
rename from translated/tech/20180711 Javascript Framework Comparison with Examples React Vue Hyperapp.md
rename to published/20180711 Javascript Framework Comparison with Examples React Vue Hyperapp.md
index c069ca1785..48c6187c94 100644
--- a/translated/tech/20180711 Javascript Framework Comparison with Examples React Vue Hyperapp.md
+++ b/published/20180711 Javascript Framework Comparison with Examples React Vue Hyperapp.md
@@ -1,203 +1,158 @@
-Javascript 框架对比及案例(React、Vue 及 Hyperapp)
-============================================================
-在[我的上一片文章中][5],我试图解释为什么我认为[Hyperapp][6]是一个可用的 [React][7] 或 [Vue][8] 的替代品,我发现当我开始用它时,会容易的找到这个原因。许多人批评这篇文章,认为它自以为是,并没有给其他框架一个展示自己的机会。因此,在这篇文章中,我将尽可能客观的通过提供一些最小化的例子来比较这三个框架,以展示他们的能力。
+JavaScript 框架对比及案例(React、Vue 及 Hyperapp)
+=============================================
-#### 臭名昭著计时器例子
+在[我的上一篇文章中][5],我试图解释为什么我认为 [Hyperapp][6] 是一个 [React][7] 或 [Vue][8] 的可用替代品,原因是,我发现它易于起步。许多人批评这篇文章,认为它自以为是,并没有给其它框架一个展示自己的机会。因此,在这篇文章中,我将尽可能客观的通过提供一些最小化的例子来比较这三个框架,以展示它们的能力。
-计时器可能是响应式编程中最常用最容易理解的例子之一:
+### 耳熟能详的计时器例子
+
+计时器可能是响应式编程中最常用的例子之一,极其易于理解:
* 你需要一个变量 `count` 保持对计数器的追踪。
-
* 你需要两个方法来增加或减少 `count` 变量的值。
-
* 你需要一种方法来渲染 `count` 变量,并将其呈现给用户。
-
-* 你需要两个挂载到两个方法上的按钮,以便在用户和它们产生交互时变更 `count` 变量。
+* 你需要挂载到这两个方法上的两个按钮,以便在用户和它们产生交互时变更 `count` 变量。
下述代码是上述所有三个框架的实现:
-
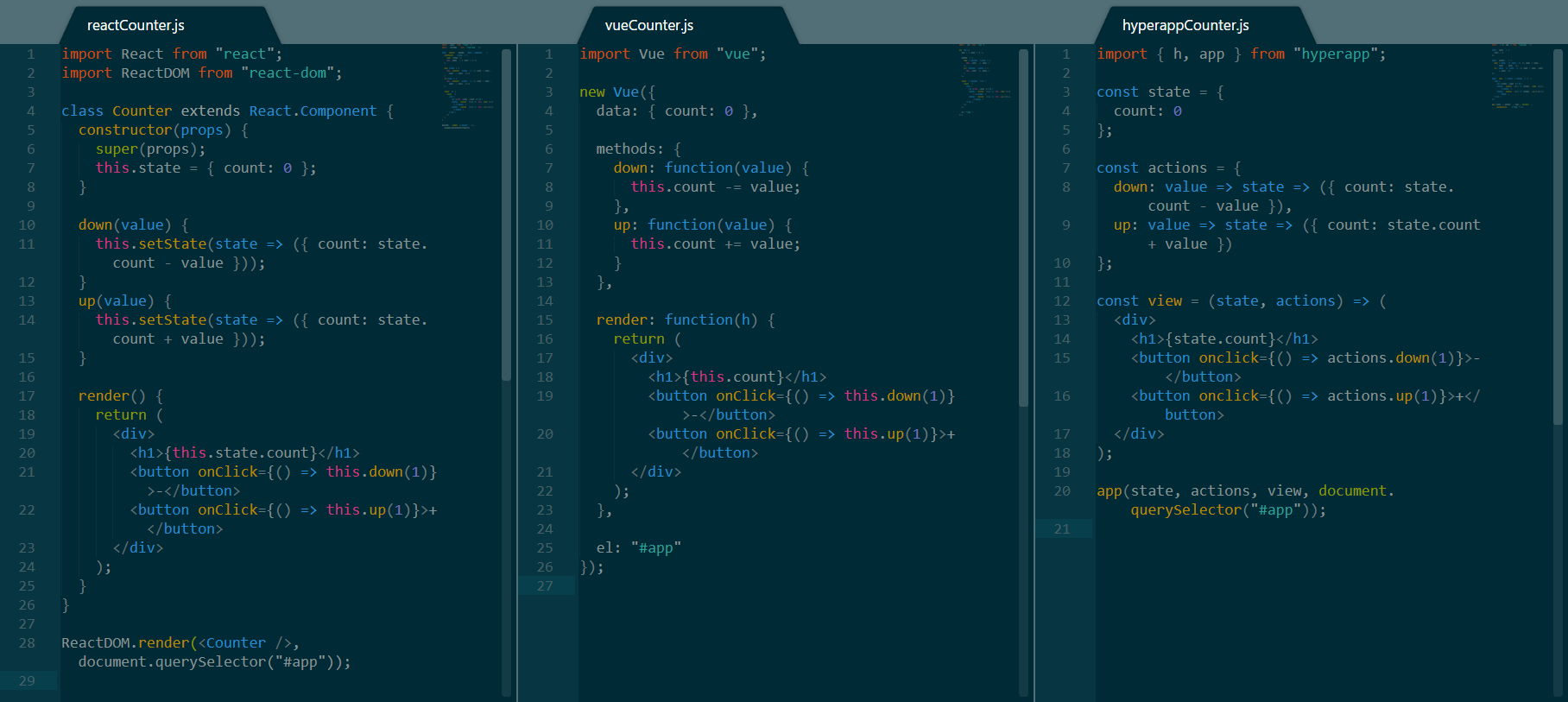
-使用 React、Vue 和 Hyperapp 实现的计数器
+*使用 React、Vue 和 Hyperapp 实现的计数器*
-这里或许会有很多要做的事情,特别是当你并不熟悉其中的一个或多个的时候,因此,我们来一步一步解构这些代码:
+这里或许会有很多要做的事情,特别是当你并不熟悉其中的一个或多个步骤的时候,因此,我们来一步一步解构这些代码:
* 这三个框架的顶部都有一些 `import` 语句
-
-* React 更推崇面向对象的范式,就是创建一个 `Counter` 组件的 `class`,Vue 遵循类似的范式,并通过创建一个新的 `Vue` 类的实例并将信息传递给它来实现。 最后,Hyperapp 坚持函数范式,同时完全分离 `view`、`state`和`action` 。
-
+* React 更推崇面向对象的范式,就是创建一个 `Counter` 组件的 `class`。Vue 遵循类似的范式,通过创建一个新的 `Vue` 类的实例并将信息传递给它来实现。最后,Hyperapp 坚持函数范式,同时完全彼此分离 `view`、`state`和`action`。
* 就 `count` 变量而言, React 在组件的构造函数内对其进行实例化,而 Vue 和 Hyperapp 则分别是在它们的 `data` 和 `state` 中设置这些属性。
-
-* 继续看,你可能注意到 React 和 Vue 有相同的方法来于 `count` 变量进行交互。 React 使用继承自 `React.Component` 的 `setState` 方法来修改它的状态,而 Vue 直接修改 `this.count`。 Hyperapp 使用 ES6 的双箭头语法来实现这个方法,并且,据我所知,这是唯一一个更推荐使用这种语法的框架,React 和 Vue 需要在它们的方法内使用 `this`。另一方面,Hyperapp 的方法需要将状态作为参数,这意味着可以在不同的上下文中重用它们。
-
-* 这三个框架的渲染部分实际上是相同的。唯一的细微差别是 Vue 需要一个函数 `h` 作为参数传递给渲染器,事实上 Hyperapp 使用 `onclick` 替代 `onClick` 以及基于每个框架中实现状态的方式引用 `count` 变量的方式。
-
+* 继续看,你可能注意到 React 和 Vue 有相同的方法来与 `count` 变量进行交互。 React 使用继承自 `React.Component` 的 `setState` 方法来修改它的状态,而 Vue 直接修改 `this.count`。 Hyperapp 使用 ES6 的双箭头语法来实现这个方法,而据我所知,这是唯一一个推荐使用这种语法的框架,React 和 Vue 需要在它们的方法内使用 `this`。另一方面,Hyperapp 的方法需要将状态作为参数,这意味着可以在不同的上下文中重用它们。
+* 这三个框架的渲染部分实际上是相同的。唯一的细微差别是 Vue 需要一个函数 `h` 作为参数传递给渲染器,事实上 Hyperapp 使用 `onclick` 替代 `onClick` ,以及基于每个框架中实现状态的方式引用 `count` 变量。
* 最后,所有的三个框架都被挂载到了 `#app` 元素上。每个框架都有稍微不同的语法,Vue 则使用了最直接的语法,通过使用元素选择器而不是使用元素来提供最大的通用性。
#### 计数器案例对比意见
+同时比较所有的三个框架,Hyperapp 需要最少的代码来实现计数器,并且它是唯一一个使用函数范式的框架。然而,Vue 的代码在绝对长度上似乎更短一些,元素选择器的挂载方式是一个很好的增强。React 的代码看起来最多,但是并不意味着代码不好理解。
-同时比较所有的三个框架,Hyperapp 需要最少的代码来实现计数器,并且他是唯一一个使用函数范式的框架。然而,Vue 的代码在绝对长度上似乎更短一些,元素选择器的安装是一个很好的补充。React 的代码看起来最多,但是并不意味着代码不好理解。
+### 使用异步代码
-* * *
-
-#### 使用异步代码
-
-偶尔你可能要不得不处理异步代码。最常见的异步操作之一是发送请求给一个 API。为了这个例子的目的,我将使用一个[占位 API]以及一些假数据来渲染一个文章的列表。必须做的事情如下:
+偶尔你可能需要处理异步代码。最常见的异步操作之一是发送请求给一个 API。为了这个例子的目的,我将使用一个[占位 API] 以及一些假数据来渲染一个文章列表。必须做的事情如下:
* 在状态里保存一个 `posts` 的数组
-
-* 使用一个方法和正确的 URL 来调用 `fetch()` ,等待返回数据,转化为 JSON,最终使用接收到的数据更新 `posts` 变量。
-
+* 使用一个方法和正确的 URL 来调用 `fetch()` ,等待返回数据,转化为 JSON,并最终使用接收到的数据更新 `posts` 变量。
* 渲染一个按钮,这个按钮将调用抓取文章的方法。
-
* 渲染有主键的 `posts` 列表。
-
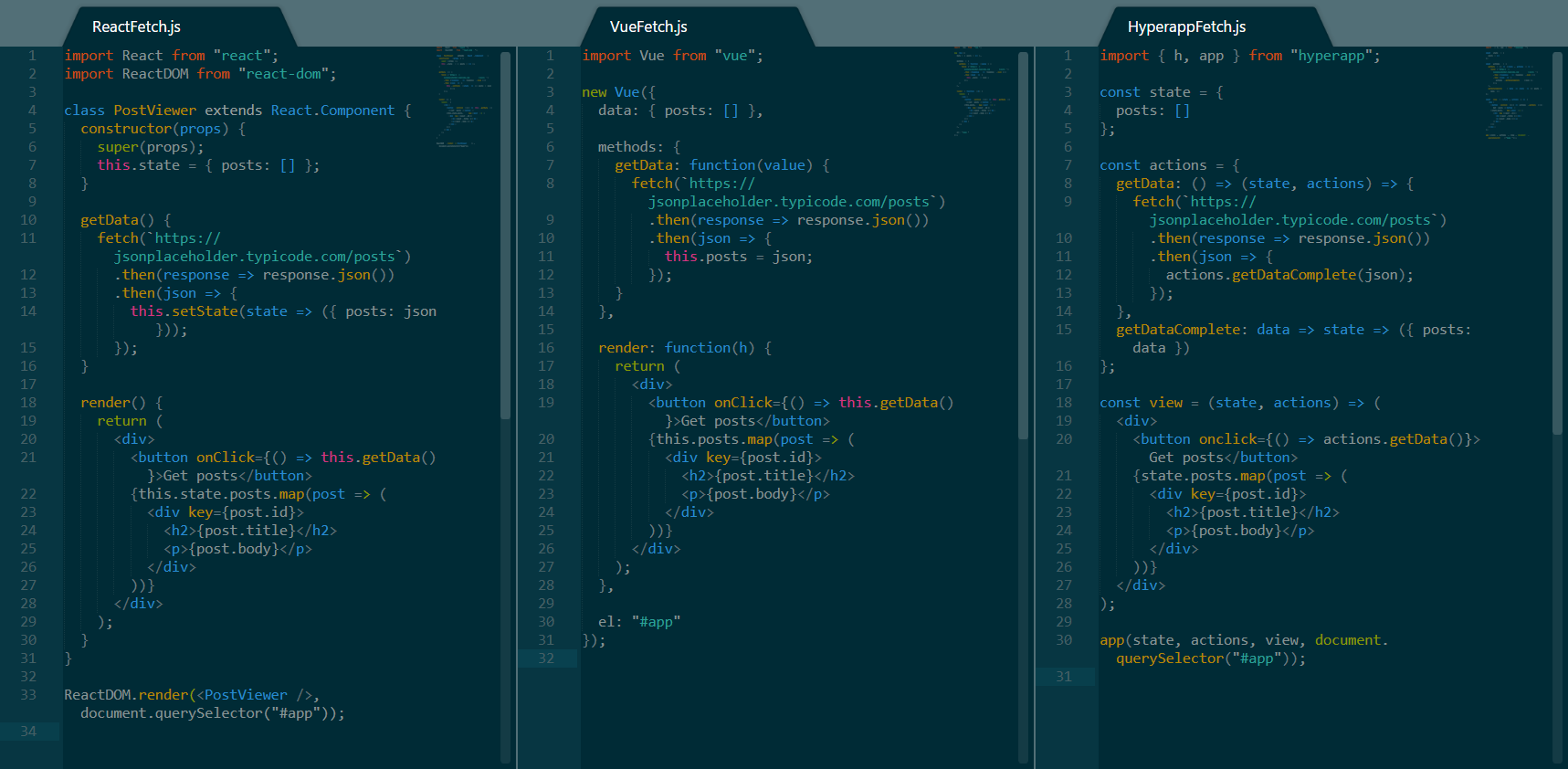
-从一个 RESTFul API 抓取数据
+
+*从一个 RESTFul API 抓取数据*
让我们分解上面的代码,并比较三个框架:
-* 与上面的技术里例子类似,这三个框架之间的存储状态、渲染试图和挂载非常相似。这些差异与上面的讨论相同。
-
-* 在三个框架中使用 `fetch()` 抓取数据都非常简单并且可以像预期一样工作。然而其中的关键在于, Hyperapp 处理异步操作和其他两种框架有些不同。当数据被接收到并转换为JSON 时,该操作将调用不同的同步动作以取代直接在异步操作中修改状态。
-
-* 就代码长度而言, Hyperapp 依然需要最少的代码行数来实现相同的结果,但是 Vue 的代码看起来不那么的冗长,同时拥有最少的绝对字符长度。
+* 与上面的技术里例子类似,这三个框架之间的存储状态、渲染视图和挂载非常相似。这些差异与上面的讨论相同。
+* 在三个框架中使用 `fetch()` 抓取数据都非常简单,并且可以像预期一样工作。然而其中的关键在于, Hyperapp 处理异步操作和其它两种框架有些不同。当数据被接收到并转换为 JSON 时,该操作将调用不同的同步动作以取代直接在异步操作中修改状态。
+* 就代码长度而言,Hyperapp 依然只用最少的代码行数实现了相同的结果,但是 Vue 的代码看起来不那么的冗长,同时拥有最少的绝对字符长度。
#### 异步代码对比意见
-无论你选择哪种框架,异步操作都非常简单。在应用异步操作时, Hyperapp 可能会迫使你去遵循编写更加函数化和模块化的代码的路径。但是另外两个框架也确实可以做到这一点,并且在这一方面给你提供更多的选择。
+无论你选择哪种框架,异步操作都非常简单。在应用异步操作时, Hyperapp 可能会迫使你去遵循编写更加函数化和模块化的代码的方式。但是另外两个框架也确实可以做到这一点,并且在这一方面给你提供更多的选择。
-* * *
+### To-Do 列表组件案例
-#### To-Do List 组件案例
-
-在响应式编程中,最出名的例子可能是使用每一个框架里来实现 To-Do List。我不打算在这里实现整个部分,我只实现一个无状态的组件,来展示三个框架如何帮助创建更小的可复用的块来协助构建应用程序。
+在响应式编程中,最出名的例子可能是使用每一个框架里来实现 To-Do 列表。我不打算在这里实现整个部分,我只实现一个无状态的组件,来展示三个框架如何创建更小的可复用的块来协助构建应用程序。
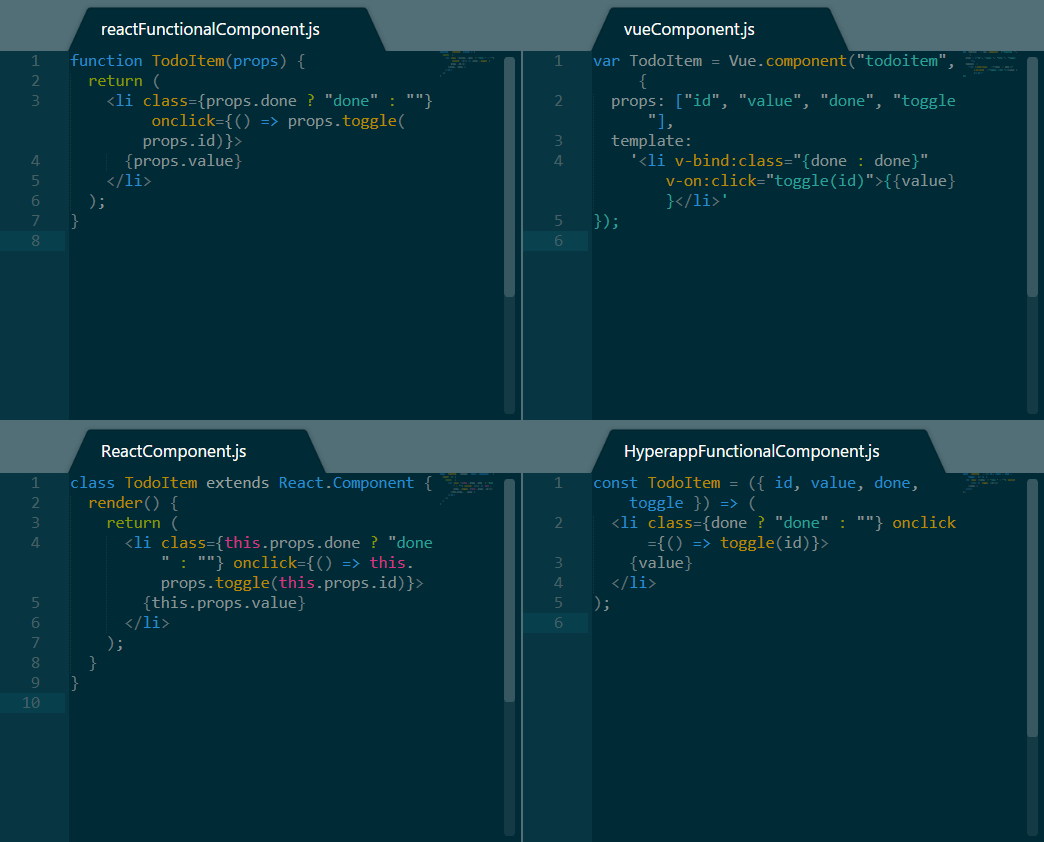
-演示 TodoItem 实现
+
+*示例 TodoItem 实现*
上面的图片展示了每一个框架一个例子,并为 React 提供了一个额外的例子。接下来是我们从它们四个中看到的:
-* React 在编程范式上最为灵活。它支持函数组件以及类组件。它还支持你在右下角看到的 Hyperapp 组件,无需任何修改。
-
-* Hyperapp 还支持 React 的函数组件实现,这意味着两个框架之间还有实验的空间。
-
-* 最后出现的 Vue 有着其合理而又奇怪的语法,即使是对另外两个很有经验的人,也不能马上理解其含义。
-
+* React 在编程范式上最为灵活。它支持函数组件,也支持类组件。它还支持你在右下角看到的 Hyperapp 组件,无需任何修改。
+* Hyperapp 还支持 React 的函数组件实现,这意味着两个框架之间还有很多的实验空间。
+* 最后出现的 Vue 有着其合理而又奇怪的语法,即使是对另外两个框架很有经验的人,也不能马上理解其含义。
* 在长度方面,所有的案例代码长度非常相似,在 React 的一些方法中稍微冗长一些。
-#### To-Do List 项目对比意见
+#### To-Do 列表项目对比意见
-Vue 需要花费一些时间来熟悉,因为它的模板和其他两个框架有一些不同。React 非常的灵活,支持多种不同的方法来创建组件,而 HyperApp 保持一切简单,并提供与 React 的兼容性,以免你希望在某些时刻进行切换。
+Vue 需要花费一些时间来熟悉,因为它的模板和其它两个框架有一些不同。React 非常的灵活,支持多种不同的方法来创建组件,而 HyperApp 保持一切简单,并提供与 React 的兼容性,以免你希望在某些时刻进行切换。
-* * *
+### 生命周期方法比较
-#### 生命周期方法比较
-
-
-另一个关键对比是组件的生命周期事件,每一个框架允许你根据你的需要来订阅和处理这些时间。下面是我根据各框架的 API 参考手册创建的表格:
+另一个关键对比是组件的生命周期事件,每一个框架允许你根据你的需要来订阅和处理事件。下面是我根据各框架的 API 参考手册创建的表格:

-Lifecycle method comparison
-* Vue 提供了最多的生命周期钩子,提供了处理生命周期时间之前或之后发生任何时间的机会。这能有效帮助管理复杂的组件。
-
-* React 和 Hyperapp 的生命周期钩子非常类似,React 将 `unmount` 和 `destory` 绑定在了一切,而 Hyperapp 则将 `create` 和 `mount` 绑定在了一起。两者在处理生命周期事件方面都提供了相当数量的控制。
+*生命周期方式比较*
+* Vue 提供了最多的生命周期钩子,提供了处理生命周期事件之前或之后发生的任何事件的机会。这能有效帮助管理复杂的组件。
+* React 和 Hyperapp 的生命周期钩子非常类似,React 将 `unmount` 和 `destory` 绑定在了一起,而 Hyperapp 则将 `create` 和 `mount` 绑定在了一起。两者在处理生命周期事件方面都提供了相当多的控制。
* Vue 根本没有处理 `unmount` (据我所理解),而是依赖于 `destroy` 事件在组件稍后的生命周期进行处理。 React 不处理 `destory` 事件,而是选择只处理 `unmount` 事件。最终,HyperApp 不处理 `create` 事件,取而代之的是只依赖 `mount` 事件。
#### 生命周期对比意见
总的来说,每个框架都提供了生命周期组件,它们帮助你处理组件生命周期中的许多事情。这三个框架都为它们的生命周期提供了钩子,其之间的细微差别,可能源自于实现和方案上的根本差异。通过提供更细粒度的时间处理,Vue 可以更进一步的允许你在开始或结束之后处理生命周期事件。
-* * *
-
-#### 性能比较
-
-除了易用性和编码技术以外,性能也是大多数开发人员考虑的关键因素,尤其是在进行更复杂的应用程序时。[js-framework-benchmark][10]是一个很好的用于比较框架的工具,所以让我们看看每一组测评数据数组都说了些什么:
+### 性能比较
+除了易用性和编码技术以外,性能也是大多数开发人员考虑的关键因素,尤其是在进行更复杂的应用程序时。[js-framework-benchmark][10] 是一个很好的用于比较框架的工具,所以让我们看看每一组测评数据数组都说了些什么:
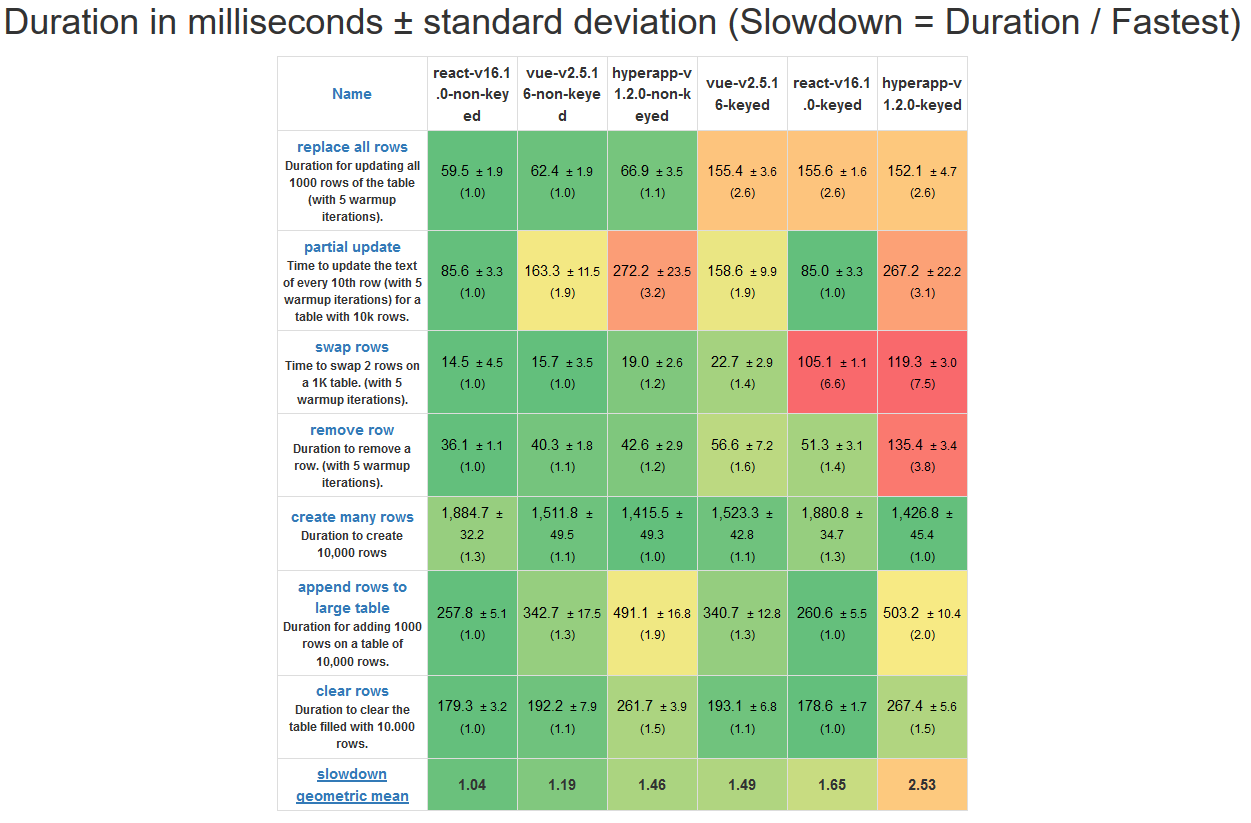
-测评操作表
+
+*测评操作表*
* 与三个框架的有主键操作相比,无主键操作更快。
-
-* 无主键的 React 在所有六种对比中拥有最强的性能,他在所有测试上都有令人深刻的表现。
-
-* 有主键的 Vue 只比有主键的 React 性能稍强,而无主键的 Vue 要比无主键的 React 性能差。
-
-* Vue 和 Hyperapp 在进行局部更新性能测试时遇见了一些问题,与此同时,React 似乎对该问题进行很好的优化。
-
+* 无主键的 React 在所有六种对比中拥有最强的性能,它在所有测试上都有令人深刻的表现。
+* 有主键的 Vue 只比有主键的 React 性能稍强,而无主键的 Vue 要比无主键的 React 性能明显差。
+* Vue 和 Hyperapp 在进行局部更新的性能测试时遇见了一些问题,与此同时,React 似乎对该问题进行很好的优化。
-启动测试
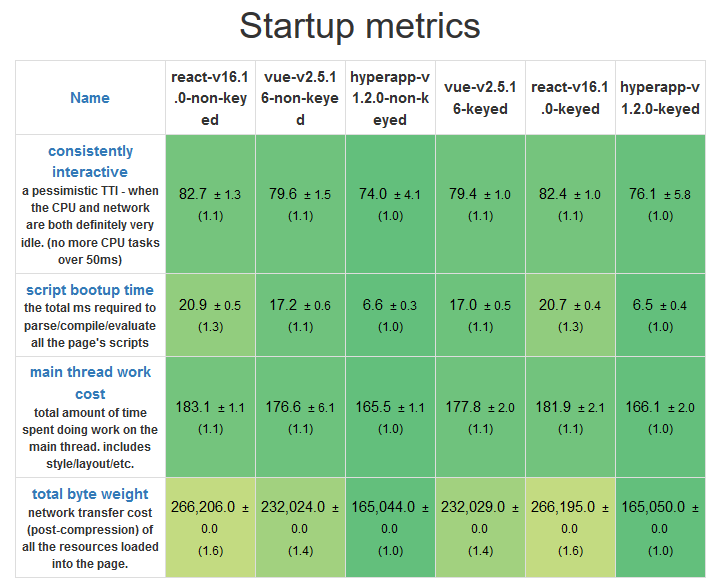
-
-* Hyperapp 是三个框架中最轻量的,而 React 和 Vue 有非常小尺度的差异。
-
-* Hyperapp 具有最快的启动时间,这得益于他极小的大小和极简的API
-
-* Vue 在启动上比 React 好一些,但是非常小。
+*启动测试*
+* Hyperapp 是三个框架中最轻量的,而 React 和 Vue 有非常小的大小差异。
+* Hyperapp 具有最快的启动时间,这得益于它极小的大小和极简的 API
+* Vue 在启动上比 React 好一些,但是差异非常小。

-内存分配测试
-* Hyperapp 是三者中对资源依赖最小的一个,与其他两者相比,任何一个操作都需要更少的内存。
+*内存分配测试*
-* 资源消耗不是跟高,三者应该在现代硬件上进行类似的操作。
+* Hyperapp 是三者中对资源依赖最小的一个,与其它两者相比,任何一个操作都需要更少的内存。
+* 资源消耗不是非常高,三者都应该在现代硬件上进行类似的操作。
#### 性能对比意见
如果性能是一个问题,你应该考虑你正在使用什么样的应用程序以及你的需求是什么。看起来 Vue 和 React 用于更复杂的应用程序更好,而 Hyperapp 更适合于更小的应用程序、更少的数据处理和需要快速启动的应用程序,以及需要在低端硬件上工作的应用程序。
-但是,要记住,这些测试远不能代表一般用例,所以在现实场景中可能会看到不同的结果。
+但是,要记住,这些测试远不能代表一般场景,所以在现实场景中可能会看到不同的结果。
-* * *
+### 额外备注
-#### 额外备注
-
-Comparing React, Vue and Hyperapp might feel like comparing apples and oranges in many ways. There are some additional considerations concerning these frameworks that could very well help you decide on one over the other two:
-
-比较 React、Vue 和 Hyperapp 可能像在许多方面比较苹果、橘子。关于这些框架还有一些其他的考虑,它们可以帮助你决定使用另一个框架。
-
-* React 通过引入片段,避免了相邻的JSX元素必须封装在父元素中的问题,这些元素允许你将子元素列表分组,而无需向DOM添加额外的节点。
-
-* Read还为你提供更高级别的组件,而VUE为你提供重用组件功能的MIXIN。
+比较 React、Vue 和 Hyperapp 可能像在许多方面比较苹果、橘子。关于这些框架还有一些其它的考虑,它们可以帮助你决定使用另一个框架。
+* React 通过引入[片段][1],避免了相邻的 JSX 元素必须封装在父元素中的问题,这些元素允许你将子元素列表分组,而无需向 DOM 添加额外的节点。
+* React 还为你提供[更高级别的组件][2],而 VUE 为你提供重用组件功能的 [MIXIN][3]。
* Vue 允许使用[模板][4]来分离结构和功能,从而更好的分离关注点。
+* 与其它两个相比,Hyperapp 感觉像是一个较低级别的 API,它的代码短得多,如果你愿意调整它并学习它的工作原理,那么它可以提供更多的通用性。
-* 与其他两个相比,Hyperapp 感觉像是一个较低级别的API,它的代码短得多,如果你愿意调整它并学习它的工作原理,那么它可以提供更多的通用性。
-
-* * *
-
-#### 结论
+### 结论
我认为如果你已经阅读了这么多,你已经知道哪种工具更适合你的需求。毕竟,这不是讨论哪一个更好,而是讨论哪一个更适合每种情况。总而言之:
-
-* React 是一个非常强大的工具,他的周围有大量的开发者,可能会帮助你找到一个工作。入门并不难,但是掌握它肯定需要很多时间。然而,这是非常值得去花费你的时间全面掌握的。
-
-* 如果你过去曾使用过另外一个 JavaScript 框架,Vue 可能看起来有点奇怪,但它也是一个非常有趣的工具。如果 React 不是你所喜欢的 ,那么它可能是一个可行的值得学习的选择。
-
-* 最后,Hyperapp 是一个为小型项目而生的很酷的小框架,也是初学者入门的好地方。它提供比 React 或 Vue 更少的工具,但是它能帮助你快速构建原型并理解许多基本原理。你编写的许多代码都和其他两个框架兼容,或者是稍做更改,你可以在对它们中另外一个有信心时切换框架。
+* React 是一个非常强大的工具,围绕它有大规模的开发者社区,可能会帮助你找到一个工作。入门并不难,但是掌握它肯定需要很多时间。然而,这是非常值得去花费你的时间全面掌握的。
+* 如果你过去曾使用过另外的 JavaScript 框架,Vue 可能看起来有点奇怪,但它也是一个非常有趣的工具。如果 React 不是你所喜欢的,那么它可能是一个可行的、值得学习的选择。它有一些非常酷的内置功能,其社区也在增长中,甚至可能要比 React 增长还要快。
+* 最后,Hyperapp 是一个为小型项目而生的很酷的小框架,也是初学者入门的好地方。它提供比 React 或 Vue 更少的工具,但是它能帮助你快速构建原型并理解许多基本原理。你为它编写的许多代码和其它两个框架兼容,要么立即能用,或者是稍做更改就行,你可以在对它们中另外一个有信心时切换框架。
--------------------------------------------------------------------------------
作者简介:
-Web developer who loves to code, creator of 30 seconds of code (https://30secondsofcode.org/) and the mini.css framework (http://minicss.org).
+喜欢编码的 Web 开发者,“30 秒编码” ( https://30secondsofcode.org/ )和 mini.css 框架( http://minicss.org ) 的创建者。
--------------------------------------------------------------------------------
via: https://hackernoon.com/javascript-framework-comparison-with-examples-react-vue-hyperapp-97f064fb468d
-作者:[Angelos Chalaris ][a]
+作者:[Angelos Chalaris][a]
译者:[Bestony](https://github.com/bestony)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180730 Open Source Networking Jobs- A Hotbed of Innovation and Opportunities.md b/published/20180730 Open Source Networking Jobs- A Hotbed of Innovation and Opportunities.md
new file mode 100644
index 0000000000..42f67043cd
--- /dev/null
+++ b/published/20180730 Open Source Networking Jobs- A Hotbed of Innovation and Opportunities.md
@@ -0,0 +1,48 @@
+开源网络方面的职位:创新与机遇的温床
+======
+
+> 诸如容器、边缘计算这样的技术焦点领域大红大紫,对在这一领域能够整合、协作、创新的开发者和系统管理员们的需求在日益增进。
+
+
+
+随着全球经济更加靠近数字化未来,每个垂直行业的公司和组织都在紧抓如何进一步在业务与运营上整合与部署技术。虽然 IT 企业在很大程度上遥遥领先,但是他们的经验与教训已经应用在了各行各业。尽管全国失业率为 4.1%,但整个科技专业人员的整体的失业率在 4 月份为 1.9%,开源工作的未来看起来尤其光明。我在开源网络领域工作,并且目睹着创新和机遇正在改变世界交流的方式。
+
+它曾经是个发展缓慢的行业,现在由网络运营商、供应商、系统集成商和开发者所组成的网络生态系统正在采用开源软件,并且正在向商用硬件上运行的虚拟化和软件定义网络上转移。事实上,接近 70% 的全球移动用户由[低频网络][1]运营商成员所占据。该网络运营商成员致力于协调构成开放网络栈和相邻技术的项目。
+
+### 技能需求
+
+这一领域的开发者和系统管理员采用云原生和 DevOps 的方法开发新的使用案例,应对最紧迫的行业挑战。诸如容器、边缘计算等焦点领域大红大紫,并且在这一领域能够整合、协作、创新的开发者和系统管理员们的需求在日益增进。
+
+开源软件与 Linux 使这一切成为可能,根据最近出版的 [2018开源软件工作报告][2],高达 80% 的招聘经理寻找会 Linux 技能的应聘者,**而 46% 希望在网络领域招聘人才,可以说“网络技术”在他们的招聘决策中起到了至关重要的作用。**
+
+开发人员相当抢手,72% 的招聘经理都在找他们,其次是 DevOps 开发者(59%),工程师(57%)和系统管理员(49%)。报告同时指出,对容器技能需求的惊人的增长符合我们在网络领域所见到的,即云本地虚拟功能(CNF)的创建和持续集成/持续部署方式的激增,就如在 OPNFV 中的 [XCI 倡议][3] 一样。
+
+### 开始吧
+
+对于求职者来说,好消息是有着大量的关于开源软件的内容,包括免费的 [Linux 入门课程][4]。好的工作需要有多项证书,因此我鼓励你探索更多领域,去寻求培训的机会。计算机网络方面,在 [OPNFV][5] 上查看最新的培训课程或者是 [ONAP][6] 项目,也可以选择这门[开源网络技术简介][7]课程。
+
+如果你还没有做好这些,下载 [2018 开源软件工作报告][2] 以获得更多见解,在广阔的开放源码技术世界中规划你的课程,去寻找另一边等待你的令人兴奋的职业!
+
+点击这里[下载完整的开源软件工作报告][8]并且[了解更多关于 Linux 的认证][9]。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/os-jobs-report/2018/7/open-source-networking-jobs-hotbed-innovation-and-opportunities
+
+作者:[Brandon Wick][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[LuuMing](https://github.com/LuuMing)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/brandon-wick
+[1]:https://www.lfnetworking.org/
+[2]:https://www.linuxfoundation.org/publications/2018/06/open-source-jobs-report-2018/
+[3]:https://docs.opnfv.org/en/latest/submodules/releng-xci/docs/xci-overview.html
+[4]:https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-1
+[5]:https://training.linuxfoundation.org/training/opnfv-fundamentals/
+[6]:https://training.linuxfoundation.org/training/onap-fundamentals/
+[7]:https://www.edx.org/course/introduction-to-software-defined-networking-technologies
+[8]:https://www.linuxfoundation.org/publications/open-source-jobs-report-2018/
+[9]:https://training.linuxfoundation.org/certification
diff --git a/translated/tech/20180802 6 Easy Ways to Check User Name And Other Information in Linux.md b/published/20180802 6 Easy Ways to Check User Name And Other Information in Linux.md
similarity index 62%
rename from translated/tech/20180802 6 Easy Ways to Check User Name And Other Information in Linux.md
rename to published/20180802 6 Easy Ways to Check User Name And Other Information in Linux.md
index 0582c84019..32fe8a11c0 100644
--- a/translated/tech/20180802 6 Easy Ways to Check User Name And Other Information in Linux.md
+++ b/published/20180802 6 Easy Ways to Check User Name And Other Information in Linux.md
@@ -1,7 +1,7 @@
6 个简单的方式来查看 Linux 中的用户名和其它信息
======
-这是一个非常基础的话题,在 Linux 中,每个人都知道如何使用 **id** 来查找用户信息。一些用户也从 **/etc/passwd** 文件中过滤用户信息。
+这是一个非常基础的话题,在 Linux 中,每个人都知道如何使用 `id` 来查找用户信息。一些用户也从 `/etc/passwd` 文件中过滤用户信息。
我们还使用其它命令来获取用户信息。
@@ -11,45 +11,44 @@
这是帮助管理员在 Linux 中查找用户信息的基本命令之一。Linux 中的一切都是文件,甚至用户信息都存储在一个文件中。
-**建议阅读:**
+建议阅读:
-**(#)** [怎样在 Linux 上查看用户创建的日期][1]
+- [怎样在 Linux 上查看用户创建的日期][1]
+- [怎样在 Linux 上查看用户属于哪个组][2]
+- [怎样在 Linux 上查看强制用户在下次登录时改变密码][3]
-**(#)** [怎样在 Linux 上查看用户属于哪个组][2]
-
-**(#)** [怎样在 Linux 上查看强制用户在下次登录时改变密码][3]
-
-所有用户都被添加在 `/etc/passwd` 文件中,这里保留了用户名和其它相关详细信息。在 Linux 中创建用户时,用户详细信息将存储在 /etc/passwd 文件中。passwd 文件将每个用户详细信息保存为一行,包含 7 字段。
+所有用户都被添加在 `/etc/passwd` 文件中,这里保留了用户名和其它相关详细信息。在 Linux 中创建用户时,用户详细信息将存储在 `/etc/passwd` 文件中。passwd 文件将每个用户详细信息保存为一行,包含 7 字段。
我们可以使用以下 6 种方法来查看用户信息。
- * `id :`为指定的用户名打印用户和组信息。
- * `getent :`从 Name Service Switch 库中获取条目。
- * `/etc/passwd file :` /etc/passwd 文件包含每个用户的详细信息,每个用户详情是一行,包含 7 个字段。
- * `finger :`用户信息查询程序
- * `lslogins :`lslogins 显示系统中已有用户的信息
- * `compgen :`compgen 是 bash 内置命令,它将显示用户的所有可用命令。
+ * `id`:为指定的用户名打印用户和组信息。
+ * `getent`:从 Name Service Switch 库中获取条目。
+ * `/etc/passwd`: 文件包含每个用户的详细信息,每个用户详情是一行,包含 7 个字段。
+ * `finger`:用户信息查询程序
+ * `lslogins`:显示系统中已有用户的信息
+ * `compgen`:是 bash 内置命令,它将显示用户的所有可用命令。
### 1) 使用 id 命令
-id 代表身份。它输出真实有效的用户和组 ID。也可以输出指定用户或当前用户的用户和组信息。
+`id` 代表身份。它输出真实有效的用户和组 ID。也可以输出指定用户或当前用户的用户和组信息。
+
```
# id daygeek
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
-
```
下面是上述输出的详细信息:
- * **`uid (1000/daygeek):`** 它显示用户 ID 和用户名
- * **`gid (1000/daygeek):`** 它显示用户的组 ID 和名称
- * **`groups:`** 它显示用户的附加组 ID 和名称
+ * `uid (1000/daygeek)`: 它显示用户 ID 和用户名
+ * `gid (1000/daygeek)`: 它显示用户的组 ID 和名称
+ * `groups`: 它显示用户的附加组 ID 和名称
### 2) 使用 getent 命令
-getent 命令显示 Name Service Switch 库支持的数据库中的条目,这些库在 /etc/nsswitch.conf 中配置。
+`getent` 命令显示 Name Service Switch 库支持的数据库中的条目,这些库在 `/etc/nsswitch.conf` 中配置。
+
+`getent` 命令会显示类似于 `/etc/passwd` 文件的用户详情,它将每个用户的详细信息放在一行,包含 7 个字段。
-getent 命令会显示类似于 /etc/passwd 文件的用户详情,它将每个用户的详细信息放在一行,包含 7 个字段。
```
# getent passwd
root:x:0:0:root:/root:/bin/bash
@@ -85,24 +84,24 @@ nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
-
```
-下面是关于 7 个字段的详细信息。
+下面是关于 7 个字段的详细信息:
+
```
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
-
```
- * **`Username (magesh):`** 已创建的用户名。字符长度应该在 1 到 32 之间。
- * **`Password (x):`** 它表明加密密码存储在 /etc/shadow 文件中。
- * **`User ID (UID-502):`** 它表示用户 ID(UID),每个用户应包含唯一的 UID。UID (0-Zero) 保留给 root,UID(1-99)是为系统用户保留的,UID(100-999)是为系统账户/组保留的。
- * **`Group ID (GID-503):`** 它表示组 ID(GID),每个组应该包含唯一的 GID,它存储在 /etc/group 文件中。
- * **`User ID Info (2g Admin - Magesh M):`** 它表示命令字段。这个字段可用于描述用户信息。
- * **`Home Directory (/home/magesh):`** 它表示用户家目录。
- * **`shell (/bin/bash):`** 它表示用户的 bash shell。
+ * `Username (magesh)`: 已创建的用户名。字符长度应该在 1 到 32 之间。
+ * `Password (x)`: 它表明加密密码存储在 `/etc/shadow` 文件中。
+ * `User ID (UID-502)`: 它表示用户 ID(UID),每个用户应包含唯一的 UID。UID (0-Zero) 保留给 root,UID(1-99)是为系统用户保留的,UID(100-999)是为系统账户/组保留的。
+ * `Group ID (GID-503)`: 它表示组 ID(GID),每个组应该包含唯一的 GID,它存储在 `/etc/group` 文件中。
+ * `User ID Info (2g Admin - Magesh M)`: 它表示命令字段。这个字段可用于描述用户信息。
+ * `Home Directory (/home/magesh)`: 它表示用户家目录。
+ * `shell (/bin/bash)`: 它表示用户的 bash shell。
+
+如果你只想在 `getent` 命令的输出中显示用户名,使用以下命令格式:
-如果你只想在 getent 命令的输出中显示用户名,使用以下命令格式:
```
# getent passwd | cut -d: -f1
root
@@ -138,10 +137,10 @@ nrpe
magesh
thanu
sudha
-
```
只显示用户的家目录,使用以下命令格式:
+
```
# getent passwd | grep '/home' | cut -d: -f1
centos
@@ -149,12 +148,12 @@ prakash
magesh
thanu
sudha
-
```
### 3) 使用 /etc/passwd 文件
-`/etc/passwd` 是一个文本文件,它包含每个用户登录 Linux 系统所必需的的信息。它维护用户的有用信息,如用户名,密码,用户 ID,组 ID,用户 ID 信息,家目录和 shell。/etc/passwd 文件将每个用户详细信息放在一行中,包含 7 个字段,如下所示:
+`/etc/passwd` 是一个文本文件,它包含每个用户登录 Linux 系统所必需的的信息。它维护用户的有用信息,如用户名,密码,用户 ID,组 ID,用户 ID 信息,家目录和 shell。`/etc/passwd` 文件将每个用户详细信息放在一行中,包含 7 个字段,如下所示:
+
```
# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
@@ -190,24 +189,24 @@ nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
-
```
以下是 7 个字段的详细信息。
+
```
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
-
```
- * **`Username (magesh):`** 已创建的用户名。字符长度应该在 1 到 32 之间。
- * **`Password (x):`** 它表明加密密码存储在 /etc/shadow 文件中。
- * **`User ID (UID-502):`** 它表示用户 ID(UID),每个用户应包含唯一的 UID。UID (0-Zero) 保留给 root,UID(1-99)是为系统用户保留的,UID(100-999)是为系统账户/组保留的。
- * **`Group ID (GID-503):`** 它表示组 ID(GID),每个组应该包含唯一的 GID,它存储在 /etc/group 文件中。
- * **`User ID Info (2g Admin - Magesh M):`** 它表示命令字段。这个字段可用于描述用户信息。
- * **`Home Directory (/home/magesh):`** 它表示用户家目录。
- * **`shell (/bin/bash):`** 它表示用户的 bash shell。
+ * `Username (magesh)`: 已创建的用户名。字符长度应该在 1 到 32 之间。
+ * `Password (x)`: 它表明加密密码存储在 `/etc/shadow` 文件中。
+ * `User ID (UID-502)`: 它表示用户 ID(UID),每个用户应包含唯一的 UID。UID (0-Zero) 保留给 root,UID(1-99)是为系统用户保留的,UID(100-999)是为系统账户/组保留的。
+ * `Group ID (GID-503)`: 它表示组 ID(GID),每个组应该包含唯一的 GID,它存储在 `/etc/group` 文件中。
+ * `User ID Info (2g Admin - Magesh M)`: 它表示命令字段。这个字段可用于描述用户信息。
+ * `Home Directory (/home/magesh)`: 它表示用户家目录。
+ * `shell (/bin/bash)`: 它表示用户的 bash shell。
+
+如果你只想显示 `/etc/passwd` 文件中的用户名,使用以下格式:
-如果你只想显示 /etc/passwd 文件中的用户名,使用以下格式:
```
# cut -d: -f1 /etc/passwd
root
@@ -243,10 +242,10 @@ nrpe
magesh
thanu
sudha
-
```
只显示用户的家目录,使用以下格式:
+
```
# cat /etc/passwd | grep '/home' | cut -d: -f1
centos
@@ -254,12 +253,12 @@ prakash
magesh
thanu
sudha
-
```
### 4) 使用 finger 命令
-finger 命令显示有关系统用户的信息。它显示用户的真实姓名,终端名称和写入状态(如果没有写入权限,那么最为终端名称后面的 "*"),空闲时间和登录时间。
+`finger` 命令显示有关系统用户的信息。它显示用户的真实姓名,终端名称和写入状态(如果没有写入权限,那么最为终端名称后面的 `*`),空闲时间和登录时间。
+
```
# finger magesh
Login: magesh Name: 2g Admin - Magesh M
@@ -267,22 +266,22 @@ Directory: /home/magesh Shell: /bin/bash
Last login Tue Jul 17 22:46 (EDT) on pts/2 from 103.5.134.167
No mail.
No Plan.
-
```
以下是上述输出的详细信息:
- * **`Login:`** 用户名
- * **`Name:`** 附加/有关用户的其它信息
- * **`Directory:`** 用户家目录的信息
- * **`Shell:`** 用户的 shell 信息
- * **`LAST-LOGIN:`** 上次登录日期和其它信息
+ * `Login`: 用户名
+ * `Name`: 附加/有关用户的其它信息
+ * `Directory`: 用户家目录的信息
+ * `Shell`: 用户的 shell 信息
+ * `LAST-LOGIN`: 上次登录日期和其它信息
### 5) 使用 lslogins 命令
它显示系统已知用户的信息。默认情况下,它将列出系统中所有用户的信息。
-lslogins 使用程序的灵感来自于 logins 实用程序,该实用程序最初出现在 FreeBSD 4.10 中。
+`lslogins` 使用程序的灵感来自于 `logins` 实用程序,该实用程序最初出现在 FreeBSD 4.10 中。
+
```
# lslogins -u
UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
@@ -292,21 +291,21 @@ UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
502 magesh 0 0 Jul17/22:46 2g Admin - Magesh M
503 thanu 0 0 Jul18/00:40 2g Editor - Thanisha M
504 sudha 0 0 Jul18/01:18 2g Editor - Sudha M
-
```
以下是上述输出的详细信息:
- * **`UID:`** 用户 id
- * **`USER:`** 用户名
- * **`PWD-LOCK:`** 密码已设置,但是已锁定
- * **`PWD-DENY:`** 登录密码是否禁用
- * **`LAST-LOGIN:`** 上次登录日期
- * **`GECOS:`** 有关用户的其它信息
+ * `UID`: 用户 id
+ * `USER`: 用户名
+ * `PWD-LOCK`: 密码已设置,但是已锁定
+ * `PWD-DENY`: 登录密码是否禁用
+ * `LAST-LOGIN`: 上次登录日期
+ * `GECOS`: 有关用户的其它信息
### 6) 使用 compgen 命令
-compgen 是 bash 内置命令,它将显示所有可用的命令,别名和函数。(to 校正:这个命令在 CentOS 中有,但是我没有搞懂它的输出)
+`compgen` 是 bash 内置命令,它将显示所有可用的命令,别名和函数。(LCTT 译注:它的 `-u` 参数可以列出系统中用户。)
+
```
# compgen -u
root
@@ -352,7 +351,7 @@ via: https://www.2daygeek.com/6-easy-ways-to-check-user-name-and-other-informati
作者:[Prakash Subramanian][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md b/published/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md
similarity index 66%
rename from translated/tech/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md
rename to published/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md
index bf743b5d5b..acf5b328ce 100644
--- a/translated/tech/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md
+++ b/published/20180809 How To Switch Between Multiple PHP Versions In Ubuntu.md
@@ -3,104 +3,101 @@

-有时,最新版本的安装包可能无法按预期工作。你的程序可能与更新的软件包不兼容,并且仅支持特定的旧版软件包。在这种情况下,你可以立即将有问题的软件包降级到其早期的工作版本。请参阅我们的旧指南,[**在这**][1]了解如何降级 Ubuntu 及其衍生版中的软件包以及[**在这**][1]了解如何降级 Arch Linux 及其衍生版中的软件包。但是,你无需降级某些软件包。我们可以同时使用多个版本。例如,假设你在测试部署在 Ubuntu 18.04 LTS 中的[**LAMP 栈**][3]的 PHP 程序。过了一段时间,你发现应用程序在 PHP5.6 中工作正常,但在 PHP 7.2 中不正常(Ubuntu 18.04 LTS 默认安装 PHP 7.x)。你打算重新安装 PHP 或整个 LAMP 栈吗?但是没有必要。你甚至不必将 PHP 降级到其早期版本。在这个简短的教程中,我将向你展示如何在 Ubuntu 18.04 LTS 中切换多个 PHP 版本。它没你想的那么难。请继续阅读。
+有时,最新版本的安装包可能无法按预期工作。你的程序可能与更新的软件包不兼容,并且仅支持特定的旧版软件包。在这种情况下,你可以立即将有问题的软件包降级到其早期的工作版本。请参阅我们的旧指南,[在这][1]了解如何降级 Ubuntu 及其衍生版中的软件包以及[在这][1]了解如何降级 Arch Linux 及其衍生版中的软件包。但是,你无需降级某些软件包。我们可以同时使用多个版本。例如,假设你在测试部署在 Ubuntu 18.04 LTS 中的[LAMP 栈][3]的 PHP 程序。过了一段时间,你发现应用程序在 PHP 5.6 中工作正常,但在 PHP 7.2 中不正常(Ubuntu 18.04 LTS 默认安装 PHP 7.x)。你打算重新安装 PHP 或整个 LAMP 栈吗?但是没有必要。你甚至不必将 PHP 降级到其早期版本。在这个简短的教程中,我将向你展示如何在 Ubuntu 18.04 LTS 中切换多个 PHP 版本。它没你想的那么难。请继续阅读。
### 在多个 PHP 版本之间切换
要查看 PHP 的默认安装版本,请运行:
+
```
$ php -v
PHP 7.2.7-0ubuntu0.18.04.2 (cli) (built: Jul 4 2018 16:55:24) ( NTS )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies
with Zend OPcache v7.2.7-0ubuntu0.18.04.2, Copyright (c) 1999-2018, by Zend Technologies
-
```
如你所见,已安装的 PHP 的版本为 7.2.7。在测试你的程序几天后,你会发现你的程序不支持 PHP7.2。在这种情况下,同时使用 PHP5.x 和 PHP7.x 是个不错的主意,这样你就可以随时轻松地在任何支持的版本之间切换。
你不必删除 PHP7.x 或重新安装 LAMP 栈。你可以同时使用 PHP5.x 和 7.x 版本。
-我假设你还没有在你的系统中卸载 php5.6。万一你已将其删除,你可以使用下面的 PPA 再次安装它。
+我假设你还没有在你的系统中卸载 PHP 5.6。万一你已将其删除,你可以使用下面的 PPA 再次安装它。
+
+你可以从 PPA 中安装 PHP 5.6:
-你可以从 PPA 中安装 PHP5.6:
```
$ sudo add-apt-repository -y ppa:ondrej/php
$ sudo apt update
$ sudo apt install php5.6
-
```
-#### 从 PHP7.x 切换到 PHP5.x.
+#### 从 PHP 7.x 切换到 PHP 5.x.
+
+首先使用命令禁用 PHP 7.2 模块:
-首先使用命令禁用 PHP7.2 模块:
```
$ sudo a2dismod php7.2
Module php7.2 disabled.
To activate the new configuration, you need to run:
systemctl restart apache2
-
```
-接下来,启用 PHP5.6 模块:
+接下来,启用 PHP 5.6 模块:
+
```
$ sudo a2enmod php5.6
-
```
-将 PHP5.6 设置为默认版本:
+将 PHP 5.6 设置为默认版本:
+
```
$ sudo update-alternatives --set php /usr/bin/php5.6
-
```
或者,你可以运行以下命令来设置默认情况下要使用的全局 PHP 版本。
+
```
$ sudo update-alternatives --config php
-
```
-输入选择的号码将其设置为默认版本,或者只需按 ENTER 键保持当前选择。
+输入选择的号码将其设置为默认版本,或者只需按回车键保持当前选择。
如果你已安装其他 PHP 扩展,请将它们设置为默认值。
+
```
$ sudo update-alternatives --set phar /usr/bin/phar5.6
-
```
最后,重启 Apache Web 服务器:
+
```
$ sudo systemctl restart apache2
-
```
-现在,检查 PHP5.6 是否是默认版本:
+现在,检查 PHP 5.6 是否是默认版本:
+
```
$ php -v
PHP 5.6.37-1+ubuntu18.04.1+deb.sury.org+1 (cli)
Copyright (c) 1997-2016 The PHP Group
Zend Engine v2.6.0, Copyright (c) 1998-2016 Zend Technologies
with Zend OPcache v7.0.6-dev, Copyright (c) 1999-2016, by Zend Technologies
-
```
-#### 从 PHP5.x 切换到 PHP7.x.
+#### 从 PHP 5.x 切换到 PHP 7.x.
+
+同样,你可以从 PHP 5.x 切换到 PHP 7.x 版本,如下所示。
-同样,你可以从 PHP5.x 切换到 PHP7.x 版本,如下所示。
```
$ sudo a2enmod php7.2
-
$ sudo a2dismod php5.6
-
$ sudo update-alternatives --set php /usr/bin/php7.2
-
$ sudo systemctl restart apache2
-
```
**提醒一句:**
-最终稳定版 PHP5.6 于 2017 年 1 月 19 日达到[**活跃支持截止**][4]。但是,直到 2018 年 12 月 31 日,PHP 5.6 将继续获得对关键安全问题的支持。所以,建议尽快升级所有 PHP 程序并与 PHP7.x 兼容。
+最终稳定版 PHP 5.6 于 2017 年 1 月 19 日达到[**活跃支持截止**][4]。但是,直到 2018 年 12 月 31 日,PHP 5.6 将继续获得对关键安全问题的支持。所以,建议尽快升级所有 PHP 程序并与 PHP 7.x 兼容。
如果你希望防止 PHP 将来自动升级,请参阅以下指南。
@@ -109,7 +106,6 @@ $ sudo systemctl restart apache2
干杯!
-
--------------------------------------------------------------------------------
via: https://www.ostechnix.com/how-to-switch-between-multiple-php-versions-in-ubuntu/
@@ -117,7 +113,7 @@ via: https://www.ostechnix.com/how-to-switch-between-multiple-php-versions-in-ub
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180810 Image creation applications for Fedora.md b/published/20180810 Image creation applications for Fedora.md
similarity index 70%
rename from translated/tech/20180810 Image creation applications for Fedora.md
rename to published/20180810 Image creation applications for Fedora.md
index 967e2eef01..113c367ba9 100644
--- a/translated/tech/20180810 Image creation applications for Fedora.md
+++ b/published/20180810 Image creation applications for Fedora.md
@@ -3,32 +3,32 @@ Fedora 下的图像创建程序

-感觉有创意吗?Fedora 有很多程序可以帮助你的创造力。从数字绘图、矢量到像素艺术,每个人都可以在这个周末得到创意。本文重点介绍了 Fedora 下创建很棒图像的程序。
+有了创意吗?Fedora 有很多程序可以帮助你的创造力。从数字绘图、矢量到像素艺术,每个人都可以在这个周末发挥创意。本文重点介绍了 Fedora 下创建很棒图像的程序。
### 矢量图形:Inkscape
-[Inkscape][1] 是一个众所周知受人喜爱的开源矢量图形编辑器。SVG 是 Inkscape 的主要文件格式,因此你所有的图形都可以伸缩!Inkscape 已存在多年,所以有一个坚实的社区和[大量的教程和其他资源][2]用于入门。
+[Inkscape][1] 是一个众所周知的、受人喜爱的开源矢量图形编辑器。SVG 是 Inkscape 的主要文件格式,因此你所有的图形都可以任意伸缩!Inkscape 已存在多年,所以有一个坚实的社区和用于入门的[大量教程和其他资源][2]。
作为矢量图形编辑器,Inkscape 更适合于简单的插图(例如简单的漫画风格)。然而,使用矢量模糊,一些艺术家创造了一些[令人惊奇的矢量图][3]。
![][4]
从 Fedora Workstation 中的软件应用安装 Inkscape,或在终端中使用以下命令:
+
```
sudo dnf install inkscape
-
```
### 数字绘图:Krita 和 Mypaint
-[Krita][5] 是一个流行的图像创建程序,用于数字绘图、光栅插图和纹理。此外,Krita 是一个活跃的项目,拥有一个充满活力的社区 - 所以[有很多教程用于入门] [6]。Krita 有多个画笔引擎,带弹出调色板的 UI,用于创建无缝图案的环绕模式、滤镜、图层等等。
+[Krita][5] 是一个流行的图像创建程序,用于数字绘图、光栅插图和纹理。此外,Krita 是一个活跃的项目,拥有一个充满活力的社区 —— 所以[有用于入门的很多教程][6]。Krita 有多个画笔引擎、带有弹出调色板的 UI、用于创建无缝图案的环绕模式、滤镜、图层等等。
![][7]
从 Fedora Workstation 中的软件应用安装 Krita,或在终端中使用以下命令:
+
```
sudo dnf install krita
-
```
[Mypaint][8] 是另一款适用于 Fedora 令人惊奇的数字绘图程序。像 Krita 一样,它有多个画笔和使用图层的能力。
@@ -36,14 +36,14 @@ sudo dnf install krita
![][9]
从 Fedora Workstation 中的软件应用安装 Mypaint,或在终端中使用以下命令:
+
```
sudo dnf install mypaint
-
```
### 像素艺术:Libresprite
-[Libresprite][10] 是一个专为创建像素艺术和像素动画而设计的程序。它支持一系列颜色模式并可导出为多种格式(包括动画 GIF)。此外,Libresprite 还有用于创建像素艺术的绘图工具:多边形工具、轮廓和着色工具。
+[Libresprite][10] 是一个专为创建像素艺术和像素动画而设计的程序。它支持一系列颜色模式,并可导出为多种格式(包括动画 GIF)。此外,Libresprite 还有用于创建像素艺术的绘图工具:多边形工具、轮廓和着色工具。
![][11]
@@ -57,7 +57,7 @@ via: https://fedoramagazine.org/image-creation-applications-fedora/
作者:[Ryan Lerch][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180812 Ubuntu 18.04 Vs. Fedora 28.md b/published/20180812 Ubuntu 18.04 Vs. Fedora 28.md
new file mode 100644
index 0000000000..37b1a6620a
--- /dev/null
+++ b/published/20180812 Ubuntu 18.04 Vs. Fedora 28.md
@@ -0,0 +1,108 @@
+对比 Ubuntu 18.04 和 Fedora 28
+======
+
+
+
+大家好,我准备在今天突出说明一下两大主流 Linux 发行版,即 **Ubuntu 18.04** 和 **Fedora 28**,包括一些特性和差异。两者都有各自的包管理系统,其中 Ubuntu 使用 DEB,Fedora 使用 RPM;但二者使用同样的[桌面环境][3] (DE)[GNOME][4],并致力于为 Linux 用户提供高品质的桌面体验。
+
+**Ubuntu 18.04** 是 Ubuntu 目前最新的 [长期支持版本][1](LTS),为用户提供 GNOME 桌面系统。**Fedora 28** 也提供 GNOME 桌面系统,但落实到具体的软件包管理方面,二者的桌面体验存在差异;在用户界面方面也显然存在差异。
+
+### 基本概念
+
+不知你是否了解,虽然 Ubuntu 基于 Debian,但 Ubuntu 比 Debian 更早提供最新版本的软件。举个例子,当 Ubuntu 提供流行网页浏览器 Firefox Quantum 时,Debian 仍在提供 Firefox 的延期支持版(ESR)。
+
+(LCTT 译注:从 2012 年 1 月开始,Firefox 进入快速版本期,每 6 周发布新的主线版本,每隔 7 个主线版本发布新的 ESR 版本。Firefox 57 的桌面版发布时被命名为 Firefox Quantum,同期的 ESR 版本与 Firefox 52 一同发布并基于 Firefox 48。参考 [Wiki: History\_of\_Firefox][9])
+
+同样的情况也适用于 Fedora,它为终端用户提供前沿的软件,也被用作下一个稳定版本的 RHEL (Red Hat Enterprise Linux) 的测试平台。
+
+### 桌面预览
+
+Fedora 提供原汁原味的 GNOME 桌面体验;相比之下,Ubuntu 18.04 对 GNOME 做了若干方面的微调,以便长期以来的 Unity 用户可以平滑的过渡到 GNOME 桌面环境。
+
+_为节省开发时间,Canonical (从 Ubuntu [17.10][2] 开始)已经决定放弃 Unity 并转向 GNOME 桌面,以便可以将更多精力投入到 IoT 领域。_
+
+因此,在 Fedora 的桌面预览中,我们可以看到一个简洁的无图标桌面和一个自动隐藏的侧边栏,整体外观采用 GNOME 默认的 Adwaita 主题。
+
+ [][5]
+
+相比之下,Ubuntu 采用其经典的有图标桌面样式,左侧边栏用于模拟其传统的“程序坞”,使用 Ubuntu Ambiance 主题定制化窗口,与其传统的(Unity 桌面)外观和体验基本一致。
+
+ [][6]
+
+虽然存在一定差异,但习惯使用其中一种桌面环境后切换到另外一种并不困难。毕竟二者设计时都充分考虑了简洁性和用户友好性,即使是新用户也不会对这两种 Linux 发行版感到不适应。
+
+但外观或 UI 并不是决定用户选择哪一种 Linux 发行版的唯一因素,还有其它因素也会影响用户的选择。下面主要介绍两种 Linux 发行版在软件包管理相关方面的内容。
+
+### 软件中心
+
+Ubuntu 使用 dpkg(即 Debian Package Management)将软件分发给终端用户;Fedora 则使用 rpm(全称为 Red Hat Package Management)。它们都是 Linux 社区中非常流行的包管理系统,对应的命令行工具也都简单易用。
+
+ [][7]
+
+但在具体分发的软件方面,各个 Linux 发行版会有明显差异。Canonical 每 6 个月发布新版本的 Ubuntu,一般是在每年的 4 月和 10 月。对每个版本,开发者会维护一个开发计划;Ubuntu 新版本发布后,该版本就会进入冻结状态,即停止新软件的开发和测试。
+
+相比之下,Fedora 也采用相似的 6 个月发布周期,看起来很像一种滚动更新的 Linux 发行版(其实并不是这样)。与 Ubuntu 不同之处在于,(Fedora 中的)几乎所有软件包更新都很频繁,让用户有机会尝试最新版本的软件。但这样也导致软件 Bug 更频繁出现,给用户带来“不稳定性”,虽然还不至于导致系统不可用。
+
+### 软件更新
+
+我上面已经提到了 Ubuntu 版本的冻结状态。好吧,由于它对 Ubuntu 软件更新方式有着重要的影响,我再次提到这个状态:当 Ubuntu 新版本发布后,该版本的开发(这里是指测试新软件)就停止了。
+
+_即将发布的下个版本的开发也随之开始,先后历经 “每日构建” 和 “测试版” 阶段,最后作为新版本发布给终端用户。_
+
+在冻结状态下,Ubuntu 维护者不会在软件源中增加最新版软件,除非用于解决严重的安全问题。因此,Ubuntu 用户可用的软件更新更多涉及 Bug 修复而不是新特性,这样的好处在于系统可以保持稳定,不会扰乱用户的使用。
+
+Fedora 试图为终端用户提供最新版本的软件,故用户的可用软件更新相比 Ubuntu 而言会更多涉及新特性。当然,开发者为了维持系统的稳定性,也采取了一系列措施。例如,在操作系统启动时,用户可以从最多三个可用内核(最新内核处于最上方)中进行选择;当新内核无法启动时,用户可以回滚使用之前两个可用内核。
+
+### Snaps 和 flatpak
+
+它们都是新出现的酷炫工具,可以将软件发布到多个 Linux 发行版上。Ubuntu 提供 **snaps**,而 Fedora 则提供 **flatpak** 。二者之中 snaps 更加流行,更多流行软件或版权软件都在考虑上架 snap 商店。Flatpak 也在吸引关注,越来越多的软件上线该平台。
+
+不幸的是,由于二者出现的时间都不久,很多人遇到“窗口主题不一致”问题并在网上表达不满。但由于二者都很易于使用,在二者之间切换并不是难事。
+
+(LCTT 译注:按译者理解,由于二者都增加了一层安全隔离,读取系统主题方面会遇到问题;另外,似乎也有反馈 snap 专用主题无法及时应用于 snap 的问题)
+
+### 应用对比
+
+下面列出一些在 Ubuntu 和 Fedora 上共有的常见应用,然后在两个平台之间进行对比:
+
+#### 计算器
+
+Fedora 上的计算器程序启动速度更快。这是因为 Fedora 上的计算器程序是软件包形式安装的,而 Ubuntu 上的计算器程序则是 snap 版本。
+
+#### 系统监视器
+
+可能听上去比较书呆子气,但我认为观察计算机性能并杀掉令人讨厌的进程是必要且直观的。程序启动速度对比与计算器的结果一致,即 (软件包方式安装的)Fedora 版本快于(snap 形式提供的)Ubuntu 版本。
+
+#### 帮助程序
+
+我已经提到,(为便于长期以来的 Untiy 用户平滑切换到 GNOME),Ubuntu 提供的 GNOME 桌面环境是经过微调的版本。不幸的是,Ubuntu 开发者似乎忘记或忽略了对帮助程序的更新,用户阅读文档(入门视频)后会发现演示视频与真实环境有略微差异,这可能让人感到迷惑。
+
+ [][8]
+
+### 结论
+
+Ubuntu 和 Fedora 是两个主流的 Linux 发行版。两者都各自有一些华而不实的特性,因而新接触 Linux 的人很难抉择。我的建议是同时尝试二者,这样你在试用后可以发现哪个发行版提供的工具更适合你。
+
+希望你阅读愉快,你可以在下方的评论区给出我漏掉的内容或你的建议。
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxandubuntu.com/home/ubuntu-1804-vs-fedora-28
+
+作者:[LinuxAndUbuntu][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[pinewall](https://github.com/pinewall)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxandubuntu.com
+[1]:http://www.linuxandubuntu.com/home/ubuntu-1804-codename-announced-bionic-beaver
+[2]:http://www.linuxandubuntu.com/home/what-new-is-going-to-be-in-ubuntu-1704-zesty-zapus
+[3]:http://www.linuxandubuntu.com/home/5-best-linux-desktop-environments-with-pros-cons
+[4]:http://www.linuxandubuntu.com/home/walkthrough-on-how-to-use-gnome-boxes
+[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-18-04-gnome_orig.jpg
+[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-gnome-18-04_orig.jpg
+[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-software-center_2_orig.jpg
+[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-18-04-help-manual_orig.jpg
+[9]:https://en.wikipedia.org/wiki/History_of_Firefox
diff --git a/translated/tech/20180813 How To Switch Between Different Versions Of Commands In Linux.md b/published/20180813 How To Switch Between Different Versions Of Commands In Linux.md
similarity index 62%
rename from translated/tech/20180813 How To Switch Between Different Versions Of Commands In Linux.md
rename to published/20180813 How To Switch Between Different Versions Of Commands In Linux.md
index 1095920c78..6a393bfb92 100644
--- a/translated/tech/20180813 How To Switch Between Different Versions Of Commands In Linux.md
+++ b/published/20180813 How To Switch Between Different Versions Of Commands In Linux.md
@@ -3,32 +3,36 @@

-几天前,我们曾经讨论如何[**如何在不同的 PHP 版本之间进行切换**][1]。在那篇文章中,我们使用 **update-alternatives** 命令实现从一个 PHP 版本切换到另一个 PHP 版本。也就是说,`update-alternatives` 命令可以将系统范围默认使用的 PHP 版本设置为我们希望的版本。通俗的来说,你可以通过 `update-alternatives` 命令从系统范围设置程序的版本。如果你希望可以在不同目录动态设置不同的程序版本,该如何完成呢?在这种情况下,**alt** 工具可以大显身手。`alt` 是一个命令行工具,可以让你在类 Unix 系统中切换相同程序的不同版本。该工具简单易用,是 **Rust** 语言编写的自由、开源软件。
+几天前,我们曾经讨论[如何在不同的 PHP 版本之间进行切换][1]。在那篇文章中,我们使用 `update-alternatives` 命令实现从一个 PHP 版本切换到另一个 PHP 版本。也就是说,`update-alternatives` 命令可以将系统范围默认使用的 PHP 版本设置为我们希望的版本。通俗的来说,你可以通过 `update-alternatives` 命令从系统范围设置程序的版本。如果你希望可以在不同目录动态设置不同的程序版本,该如何完成呢?在这种情况下,`alt` 工具可以大显身手。`alt` 是一个命令行工具,可以让你在类 Unix 系统中切换相同程序的不同版本。该工具简单易用,是 Rust 语言编写的自由、开源软件。
### 安装
安装 `alt` 工具十分简单。
运行如下命令,即可在 Linux 主机上安装 `alt`:
+
```
$ curl -sL https://github.com/dotboris/alt/raw/master/install.sh | bash -s
```
-下一步,将 shims 目录添加到你的 PATH 环境变量中,具体操作取决于你使用的 Shell。
+下一步,将 `shims` 目录添加到你的 PATH 环境变量中,具体操作取决于你使用的 Shell。
对于 Bash:
+
```
$ echo 'export PATH="$HOME/.local/alt/shims:$PATH"' >> ~/.bashrc
$ source ~/.bashrc
```
对于 Zsh:
+
```
$ echo 'export PATH="$HOME/.local/alt/shims:$PATH"' >> ~/.zshrc
$ source ~/.zshrc
```
对于 Fish:
+
```
$ echo 'set -x PATH "$HOME/.local/alt/shims" $PATH' >> ~/.config/fish/config.fish
```
@@ -39,39 +43,41 @@ $ echo 'set -x PATH "$HOME/.local/alt/shims" $PATH' >> ~/.config/fish/config.fis
如我之前所述,alt 只影响当前目录。换句话说,当你进行版本切换时,只在当前目录生效,而不是整个系统范围。
-下面举例说明。我在我的 Ubuntu 系统中安装了两个版本的 PHP,分别为 PHP 5.6 和 PHP 7.2;另外,在 **myproject** 目录中包含一些 PHP 应用。
+下面举例说明。我在我的 Ubuntu 系统中安装了两个版本的 PHP,分别为 PHP 5.6 和 PHP 7.2;另外,在 `myproject` 目录中包含一些 PHP 应用。
首先,通过命令查看系统范围默认的 PHP 版本:
+
```
$ php -v
-
```
-**示例输出:**
+示例输出:
![查找 PHP 版本][3]
-如截图中所示,我系统中默认的 PHP 版本为 PHP7.2。
+如截图中所示,我系统中默认的 PHP 版本为 PHP 7.2。
+
+然后,我将进入放置 PHP 应用的 `myproject` 目录。
-然后,我将进入放置 PHP 应用的 "myproject" 目录。
```
$ cd myproject
```
使用如下命令扫描可用的 PHP 版本:
+
```
$ alt scan php
```
-**示例输出:**
+示例输出:
![扫描 PHP 版本][4]
-可见,我有两个 PHP 版本,即 PHP5.6 和 PHP7.2。按下 **<空格>** 键选中当前可用的版本。选中全部可用版本后,你可以看到图中所示的叉号。使用上下方向键在版本间移动,点击回车即可保存变更。
+可见,我有两个 PHP 版本,即 PHP 5.6 和 PHP 7.2。按下 `<空格>` 键选中当前可用的版本。选中全部可用版本后,你可以看到图中所示的叉号。使用上下方向键在版本间移动,点击回车即可保存变更。
![选取 PHP 版本][5]
-下面运行该命令并选取我们希望在 "myproject" 目录中使用的 PHP 版本:
+下面运行该命令并选取我们希望在 `myproject` 目录中使用的 PHP 版本:
```
$ alt use php
@@ -81,22 +87,23 @@ $ alt use php
![设置 PHP 版本][6]
-现在,你可以在 /home/sk/myproject 目录下使用 PHP5.6 版本啦。
+现在,你可以在 `/home/sk/myproject` 目录下使用 PHP 5.6 版本啦。
+
+让我们检查一下,在 `myproject` 目录下是否默认使用 PHP 5.6 版本:
-让我们检查一下,在 myproject 目录下是否默认使用 PHP5.6 版本:
```
$ php -v
```
-**示例输出:**
+示例输出:
![检查 PHP 版本][7]
-只要你不设置成其它版本,(在该目录下)将一直使用 PHP5.6 版本。清楚了吗?很好!请注意,我们仅在这个目录下使用 PHP5.6 版本。在系统范围内(LCTT 译注:当然是没单独设置过其它版本的目录下),PHP7.2 仍是默认的版本。让我们检验一下,请看下图。
+只要你不设置成其它版本,(在该目录下)将一直使用 PHP 5.6 版本。清楚了吗?很好!请注意,我们仅在这个目录下使用 PHP 5.6 版本。在系统范围内(LCTT 译注:当然是没单独设置过其它版本的目录下),PHP 7.2 仍是默认的版本。让我们检验一下,请看下图。
![比对 PHP 版本][8]
-从上面的截图中可以看出,我有两个版本的 PHP:在 "myproject" 目录下,使用的版本为 PHP5.6;在 myproject 外的其它目录,使用的版本为 PHP7.2。
+从上面的截图中可以看出,我有两个版本的 PHP:在 `myproject` 目录下,使用的版本为 PHP 5.6;在 `myproject` 外的其它目录,使用的版本为 PHP 7.2。
同理,你可以为每个目录设置你希望的程序版本。我这里使用 PHP 仅用于说明操作,但方法适用于任何你打算使用的软件,例如 NodeJS 等。
@@ -117,7 +124,7 @@ via: https://www.ostechnix.com/how-to-switch-between-different-versions-of-comma
作者:[SK][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[pinewall](https://github.com/pinewall)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180813 How to display data in a human-friendly way on Linux.md b/published/20180813 How to display data in a human-friendly way on Linux.md
new file mode 100644
index 0000000000..95c2da43bd
--- /dev/null
+++ b/published/20180813 How to display data in a human-friendly way on Linux.md
@@ -0,0 +1,234 @@
+在 Linux 中如何以人性化的方式显示数据
+======
+
+> 许多 Linux 命令现在都有使其输出更易于理解的选项。让我们了解一些可以让我们心爱的操作系统更友好的东西。
+
+
+
+不是每个人都以二进制方式思考,他们不想在大脑中给大数字插入逗号来了解文件的大小。因此,Linux 命令在过去的几十年里不断发展,以更人性化的方式向用户显示信息,这一点也不奇怪。在今天的文章中,我们将看一看各种命令所提供的一些选项,它们使得数据变得更容易理解。
+
+### 为什么默认显示不更友好一些?
+
+如果你想知道为什么默认不显示得更人性化,毕竟,我们人类才是计算机的默认用户啊。你可能会问自己:“为什么我们不竭尽全力输出对每个人都有意义的命令的响应?”主要的答案是:改变命令的默认输出可能会干扰许多其它进程,这些进程是在期望默认响应之上构建的。其它的工具,以及过去几十年开发的脚本,如果突然以一种完全不同的格式输出,而不是它们过去所期望的那样,可能会被一种非常丑陋的方式破坏。
+
+说真的,也许我们中的一些人可能更愿意看文件大小中的所有数字,即 1338277310 而不是 1.3G。在任何情况下,切换默认习惯都可能造成破坏,但是为更加人性化的响应提供一些简单的选项只需要让我们学习一些命令选项而已。
+
+### 可以显示人性化数据的命令
+
+有哪些简单的选项可以使 Unix 命令的输出更容易解析呢?让我们来看一些命令。
+
+#### top
+
+你可能没有注意到这个命令,但是在 top 命令中,你可以通过输入 `E`(大写字母 E)来更改显示全部内存使用的方式。连续按下将数字显示从 KiB 到 MiB,再到 GiB,接着是 TiB、PiB、EiB,最后回到 KiB。
+
+认识这些单位吧?这里有一组定义:
+
+```
+2`10 = 1,024 = 1 KiB (kibibyte)
+2`20 = 1,048,576 = 1 MiB (mebibyte)
+2`30 = 1,073,741,824 = 1 GiB (gibibyte)
+2`40 = 1,099,511,627,776 = 1 TiB (tebibyte)
+2`50 = 1,125,899,906,842,624 = PiB (pebibyte)
+2`60 = 1,152,921,504,606,846,976 = EiB (exbibyte)
+2`70 = 1,180,591,620,717,411,303,424 = 1 ZiB (zebibyte)
+2`80 = 1,208,925,819,614,629,174,706,176 = 1 YiB (yobibyte)
+```
+
+这些单位与千字节(KB)、兆字节(MB)和千兆字节(GB)密切相关。虽然它们很接近,但是它们之间仍有很大的区别:一组是基于 10 的幂,另一组是基于 2 的幂。例如,比较千字节和千兆字节,我们可以看看它们不同点:
+
+```
+KB = 1000 = 10`3
+KiB = 1024 = 2`10
+```
+
+以下是 `top` 命令输出示例,使用 KiB 为单位默认显示:
+
+```
+top - 10:49:06 up 5 days, 35 min, 1 user, load average: 0.05, 0.04, 0.01
+Tasks: 158 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
+%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
+KiB Mem : 6102680 total, 4634980 free, 392244 used, 1075456 buff/cache
+KiB Swap: 2097148 total, 2097148 free, 0 used. 5407432 avail Mem
+```
+
+在按下 `E` 之后,单位变成了 MiB:
+
+```
+top - 10:49:31 up 5 days, 36 min, 1 user, load average: 0.03, 0.04, 0.01
+Tasks: 158 total, 2 running, 118 sleeping, 0 stopped, 0 zombie
+%Cpu(s): 0.0 us, 0.6 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
+MiB Mem : 5959.648 total, 4526.348 free, 383.055 used, 1050.246 buff/cache
+MiB Swap: 2047.996 total, 2047.996 free, 0.000 used. 5280.684 avail Mem
+```
+
+再次按下 `E`,单位变为 GiB:
+
+```
+top - 10:49:49 up 5 days, 36 min, 1 user, load average: 0.02, 0.03, 0.01
+Tasks: 158 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
+%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
+GiB Mem : 5.820 total, 4.420 free, 0.374 used, 1.026 buff/cache
+GiB Swap: 2.000 total, 2.000 free, 0.000 used. 5.157 avail Mem
+```
+
+你还可以通过按字母 `e` 来更改为显示每个进程使用内存的数字单位。它将从默认的 KiB 到 MiB,再到 GiB、TiB,接着到 PiB(估计你能看到小数点后的很多 0),然后返回 KiB。下面是按了一下 `e` 之后的 `top` 输出:
+
+```
+top - 08:45:28 up 4 days, 22:32, 1 user, load average: 0.02, 0.03, 0.00
+Tasks: 167 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
+%Cpu(s): 0.2 us, 0.0 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
+KiB Mem : 6102680 total, 4641836 free, 393348 used, 1067496 buff/cache
+KiB Swap: 2097148 total, 2097148 free, 0 used. 5406396 avail Mem
+
+ PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
+ 784 root 20 0 543.2m 26.8m 16.1m S 0.9 0.5 0:22.20 snapd
+ 733 root 20 0 107.8m 2.0m 1.8m S 0.4 0.0 0:18.49 irqbalance
+22574 shs 20 0 107.5m 5.5m 4.6m S 0.4 0.1 0:00.09 sshd
+ 1 root 20 0 156.4m 9.3m 6.7m S 0.0 0.2 0:05.59 systemd
+```
+
+#### du
+
+`du` 命令显示磁盘空间文件或目录使用了多少,如果使用 `-h` 选项,则将输出大小调整为最合适的单位。默认情况下,它以千字节(KB)为单位。
+
+```
+$ du camper*
+360 camper_10.jpg
+5684 camper.jpg
+240 camper_small.jpg
+$ du -h camper*
+360K camper_10.jpg
+5.6M camper.jpg
+240K camper_small.jpg
+```
+
+#### df
+
+`df` 命令也提供了一个 `-h` 选项。请注意在下面的示例中是如何以千兆字节(GB)和兆字节(MB)输出的:
+
+```
+$ df -h | grep -v loop
+Filesystem Size Used Avail Use% Mounted on
+udev 2.9G 0 2.9G 0% /dev
+tmpfs 596M 1.7M 595M 1% /run
+/dev/sda1 110G 9.0G 95G 9% /
+tmpfs 3.0G 0 3.0G 0% /dev/shm
+tmpfs 5.0M 4.0K 5.0M 1% /run/lock
+tmpfs 3.0G 0 3.0G 0% /sys/fs/cgroup
+tmpfs 596M 16K 596M 1% /run/user/121
+/dev/sdb2 457G 73M 434G 1% /apps
+tmpfs 596M 0 596M 0% /run/user/1000
+```
+
+下面的命令使用了 `-h` 选项,同时使用 `-T` 选项来显示我们正在查看的文件系统的类型。
+
+```
+$ df -hT /mnt2
+Filesystem Type Size Used Avail Use% Mounted on
+/dev/sdb2 ext4 457G 73M 434G 1% /apps
+```
+
+#### ls
+
+即使是 `ls`,它也为我们提供了调整大小显示的选项,保证是最合理的单位。
+
+```
+$ ls -l camper*
+-rw-rw-r-- 1 shs shs 365091 Jul 14 19:42 camper_10.jpg
+-rw-rw-r-- 1 shs shs 5818597 Jul 14 19:41 camper.jpg
+-rw-rw-r-- 1 shs shs 241844 Jul 14 19:45 camper_small.jpg
+$ ls -lh camper*
+-rw-rw-r-- 1 shs shs 357K Jul 14 19:42 camper_10.jpg
+-rw-rw-r-- 1 shs shs 5.6M Jul 14 19:41 camper.jpg
+-rw-rw-r-- 1 shs shs 237K Jul 14 19:45 camper_small.jpg
+```
+
+#### free
+
+`free` 命令允许你以字节(B),千字节(KB),兆字节(MB)和千兆字节(GB)为单位查看内存使用情况。
+
+```
+$ free -b
+ total used free shared buff/cache available
+Mem: 6249144320 393076736 4851625984 1654784 1004441600 5561253888
+Swap: 2147479552 0 2147479552
+$ free -k
+ total used free shared buff/cache available
+Mem: 6102680 383836 4737924 1616 980920 5430932
+Swap: 2097148 0 2097148
+$ free -m
+ total used free shared buff/cache available
+Mem: 5959 374 4627 1 957 5303
+Swap: 2047 0 2047
+$ free -g
+ total used free shared buff/cache available
+Mem: 5 0 4 0 0 5
+Swap: 1 0 1
+```
+
+#### tree
+
+虽然 `tree` 命令与文件或内存计算无关,但它也提供了非常人性化的文件视图,它分层显示文件以说明文件是如何组织的。当你试图了解如何安排目录内容时,这种显示方式非常有用。(LCTT 译注:也可以看看 `pstree`,它以树状结构显示进程树。)
+
+```
+$ tree
+.g to
+├── 123
+├── appended.png
+├── appts
+├── arrow.jpg
+├── arrow.png
+├── bin
+│ ├── append
+│ ├── cpuhog1
+│ ├── cpuhog2
+│ ├── loop
+│ ├── mkhome
+│ ├── runme
+```
+
+#### stat
+
+`stat` 命令是另一个以非常人性化的格式显示信息的命令。它提供了更多关于文件的元数据,包括文件大小(以字节和块为单位)、文件类型、设备和 inode(索引节点)、文件所有者和组(名称和数字 ID)、以数字和 rwx 格式显示的文件权限以及文件的最后访问和修改日期。在某些情况下,它也可能显示最初创建文件的时间。
+
+```
+$ stat camper*
+ File: camper_10.jpg
+ Size: 365091 Blocks: 720 IO Block: 4096 regular file
+Device: 801h/2049d Inode: 796059 Links: 1
+Access: (0664/-rw-rw-r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
+Access: 2018-07-19 18:56:31.841013385 -0400
+Modify: 2018-07-14 19:42:25.230519509 -0400
+Change: 2018-07-14 19:42:25.230519509 -0400
+ Birth: -
+ File: camper.jpg
+ Size: 5818597 Blocks: 11368 IO Block: 4096 regular file
+Device: 801h/2049d Inode: 796058 Links: 1
+Access: (0664/-rw-rw-r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
+Access: 2018-07-19 18:56:31.845013872 -0400
+Modify: 2018-07-14 19:41:46.882024039 -0400
+Change: 2018-07-14 19:41:46.882024039 -0400
+ Birth: -
+```
+
+### 总结
+
+Linux 命令提供了许多选项,可以让用户更容易理解或比较它们的输出。对于许多命令,`-h` 选项会显示更友好的输出格式。对于其它的,你可能必须通过使用某些特定选项或者按下某个键来查看你希望的输出。我希望这其中一些选项会让你的 Linux 系统看起来更友好一点。
+
+加入[Facebook][1] 和 [LinkedIn][2] 上的网络世界社区,一起来评论重要的话题吧。
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3296631/linux/displaying-data-in-a-human-friendly-way-on-linux.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[1]:https://www.facebook.com/NetworkWorld/
+[2]:https://www.linkedin.com/company/network-world
diff --git a/published/20180814 How To Record Terminal Sessions As SVG Animations In Linux.md b/published/20180814 How To Record Terminal Sessions As SVG Animations In Linux.md
new file mode 100644
index 0000000000..b9df74963d
--- /dev/null
+++ b/published/20180814 How To Record Terminal Sessions As SVG Animations In Linux.md
@@ -0,0 +1,135 @@
+将 Linux 终端会话录制成 SVG 动画
+======
+
+
+
+录制终端会话可以满足我们不同类型的需求。通过录制终端会话,你可以完整记录你在终端中执行的操作,将其保存以供后续参考。通过录制终端会话,你还可以向青少年、学生或其它打算学习 Linux 的人展示各种 Linux 命令及其用例。值得庆幸的是,市面上已经有不少工具,可以帮助我们在类 Unix 操作系统下录制终端会话。我们已经介绍过一些可以帮助你录制终端会话的工具,可以在下面的链接中找到。
+
++ [如何录制你在终端中的所作所为][3]
++ [Asciinema – 录制终端会话并在网上分享][4]
+
+今天,我们要介绍另一款录制终端操作的工具,名字叫做 **Termtosvg**。从名字可以看出,Termtosvg 将你的终端会话录制成一个单独的 SVG 动画。它是一款简单的命令行工具,使用 **Python** 语言编写,可以生成轻量级、外观整洁的动画,可以嵌入到网页项目中。Termtosvg 支持自定义色彩主题、终端 UI,还可以通过 [SVG 模板][1]完成动画控制。它兼容 asciinema 录制格式,支持 GNU/Linux,Mac OS 和 BSD 等操作系统。
+
+### 安装 Termtosvg
+
+PIP 是一个面向 Python 语言编写的软件包的管理器,可以用于安装 Termtosvg。如果你没有安装 PIP,可以参考下面的指导:
+
+[如何使用 PIP 管理 Python 软件包][5]
+
+安装 PIP 后,运行如下命令安装 Termtosvg 工具:
+
+```
+$ pip3 install --user termtosvg
+```
+
+此外,还要安装渲染终端屏幕所需的依赖包:
+
+```
+$ pip3 install pyte python-xlib svgwrite
+```
+
+安装完毕,我们接下来生成 SVG 格式的终端会话。
+
+### 将 Linux 终端会话录制成 SVG 动画
+
+使用 `termtosvg` 录制终端会话十分容易。打开终端窗口,运行如下命令即可开始录制:
+
+```
+$ termtosvg
+```
+
+**注意:** 如果 `termtosvg` 命令不可用,重启操作系统一次即可。
+
+运行 `termtosvg` 命令后,可以看到如下命令输出:
+
+```
+Recording started, enter "exit" command or Control-D to end
+
+```
+
+你目前位于一个子 Shell 中,在这里可以像平常那样输入命令。你在终端中的所作所为都会被录制。
+
+不妨随便输入一些命令:
+
+```
+$ mkdir mydirectory
+$ cd mydirectory/
+$ touch file.txt
+$ cd ..
+$ uname -a
+
+```
+
+操作完成后,使用组合键 `CTRL+D` 或者输入 `exit` 停止录制。录制结果将会保存在 `/tmp` 目录,(由于做了唯一性处理)文件名并不会重复。
+
+
+
+现在,你可以在命令行运行命令,使用你的浏览器打开 SVG 文件:
+
+```
+$ firefox /tmp/termtosvg_ddkehjpu.svg
+```
+
+你也可以在(图形界面的)浏览器中直接打开这个 SVG 文件( **File -> \