mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
commit
e1fd6bdf4c
@ -1,22 +1,24 @@
|
||||
使用 Docker 的 User Namespaces 功能
|
||||
使用 Docker 的用户名字空间功能
|
||||
======
|
||||
User Namespaces 于 Docker1.10 版正式纳入其中,该功能允许主机系统将自身的 `uid` 和 `gid` 映射为容器进程中的另一个其他 `uid` 和 `gid`。这对 Docker 的安全性来说是一项巨大的改进。下面我会通过一个案例来展示一下 User Namespaces 能够解决的问题,以及如何启用该功能。
|
||||
|
||||
<ruby>用户名字空间<rt>User Namespaces</rt></ruby> 于 Docker 1.10 版本正式纳入其中,该功能允许主机系统将自身的 `uid` 和 `gid` 映射为容器进程中的另一个 `uid` 和 `gid`。这对 Docker 的安全性来说是一项巨大的改进。下面我会通过一个案例来展示一下用户名字空间能够解决的问题,以及如何启用该功能。
|
||||
|
||||
### 创建一个 Docker Machine
|
||||
|
||||
如果你已经创建好了一台用来实验 User Namespaces 的 docker machine,那么可以跳过这一步。我在自己的 Macbook 上安装了 Docker Toolbox,因此我只需要使用 `docker-machine` 命令就很简单地创建一个基于 VirtualBox 的 Docker Machine( 这里假设主机名为 `host1`):
|
||||
如果你已经创建好了一台用来试验用户名字空间的 docker <ruby>机器<rt>Machine</rt></ruby>,那么可以跳过这一步。我在自己的 Macbook 上安装了 Docker Toolbox,因此我只需用 `docker-machine` 命令就很简单地创建一个基于 VirtualBox 的 Docker 机器(这里假设主机名为 `host1`):
|
||||
|
||||
```
|
||||
# Create host1
|
||||
$ docker-machine create --driver virtualbox host1
|
||||
|
||||
# Login to host1
|
||||
$ docker-machine ssh host1
|
||||
|
||||
```
|
||||
|
||||
### 理解在 User Napespaces 未启用的情况下,非 root 用户能够做什么
|
||||
### 理解在用户名字空间未启用的情况下,非 root 用户能做什么
|
||||
|
||||
在启用用户名字空间前,我们先来看一下会有什么问题。Docker 到底哪个地方做错了?首先,使用 Docker 的一大优势在于用户在容器中可以拥有 root 权限,因此用户可以很方便地安装软件包。但是在 Linux 容器技术中这也是一把双刃剑。只要经过少许操作,非 root 用户就能以 root 的权限访问主机系统中的内容,比如 `/etc`。下面是操作步骤。
|
||||
|
||||
在启用 User Namespaces 前,我们先来看一下会有什么问题。Docker 到底哪个地方做错了?首先,使用 Docker 的一大优势在于用户在容器中可以拥有 root 权限,因此用户可以很方便地安装软件包。但是该项 Linux 容器技术是一把双刃剑。只要经过少许操作,非 root 用户就能以 root 的权限访问主机系统中的内容,比如 `/etc` . 下面是操作步骤。
|
||||
```
|
||||
# Run a container and mount host1's /etc onto /root/etc
|
||||
$ docker run --rm -v /etc:/root/etc -it ubuntu
|
||||
@ -29,12 +31,12 @@ root@34ef23438542:/# exit
|
||||
|
||||
# Check /etc/hosts
|
||||
$ cat /etc/hosts
|
||||
|
||||
```
|
||||
|
||||
你可以看到,步骤简单到难以置信,很明显 Docker 并不适用于运行在多人共享的电脑上。但是现在,通过 User Namespaces,Docker 可以让你避免这个问题。
|
||||
你可以看到,步骤简单到难以置信,很明显 Docker 并不适用于运行在多人共享的电脑上。但是现在,通过用户名字空间,Docker 可以避免这个问题。
|
||||
|
||||
### 启用用户名字空间
|
||||
|
||||
### 启用 User Namespaces
|
||||
```
|
||||
# Create a user called "dockremap"
|
||||
$ sudo adduser dockremap
|
||||
@ -42,42 +44,39 @@ $ sudo adduser dockremap
|
||||
# Setup subuid and subgid
|
||||
$ sudo sh -c 'echo dockremap:500000:65536 > /etc/subuid'
|
||||
$ sudo sh -c 'echo dockremap:500000:65536 > /etc/subgid'
|
||||
|
||||
```
|
||||
|
||||
然后,打开 `/etc/init.d/docker`,并在 `/usr/local/bin/docker daemon` 后面加上 `--userns-remap=default`,像这样:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/init.d/docker
|
||||
:
|
||||
:
|
||||
/usr/local/bin/docker daemon --userns-remap=default -D -g "$DOCKER_DIR" -H unix:// $DOCKER_HOST $EXTRA_ARGS >> "$DOCKER_LOGFILE" 2>&1 &
|
||||
:
|
||||
:
|
||||
|
||||
/usr/local/bin/docker daemon --userns-remap=default -D -g "$DOCKER_DIR" -H unix:// $DOCKER_HOST $EXTRA_ARGS >> "$DOCKER_LOGFILE" 2>&1 &
|
||||
```
|
||||
|
||||
然后重启 Docker:
|
||||
|
||||
```
|
||||
$ sudo /etc/init.d/docker restart
|
||||
|
||||
```
|
||||
|
||||
这就完成了!
|
||||
|
||||
**注意:** 若你使用的是 CentOS 7,则你需要了解两件事。
|
||||
**注意**:若你使用的是 CentOS 7,则你需要了解两件事。
|
||||
|
||||
**1。** 内核默认并没有启用 User Namespaces。运行下面命令并重启系统,可以启用该功能。
|
||||
```
|
||||
sudo grubby --args="user_namespace.enable=1" \
|
||||
--update-kernel=/boot/vmlinuz-3.10.0-XXX.XX.X.el7.x86_64
|
||||
1. 内核默认并没有启用用户名字空间。运行下面命令并重启系统,可以启用该功能。
|
||||
|
||||
```
|
||||
```
|
||||
sudo grubby --args="user_namespace.enable=1" \
|
||||
--update-kernel=/boot/vmlinuz-3.10.0-XXX.XX.X.el7.x86_64
|
||||
```
|
||||
|
||||
**2。** CentOS 7 使用 systemctl 来管理服务,因此你需要编辑的文件是 `/usr/lib/systemd/system/docker.service`。
|
||||
2. CentOS 7 使用 `systemctl` 来管理服务,因此你需要编辑的文件是 `/usr/lib/systemd/system/docker.service`。
|
||||
|
||||
### 确认 User Namespaces 是否正常工作
|
||||
### 确认用户名字空间是否正常工作
|
||||
|
||||
若一切都配置妥当,则你应该无法再在容器中编辑 host1 上的 `/etc` 了。让我们来试一下。
|
||||
|
||||
```
|
||||
# Create a container and mount host1's /etc to container's /root/etc
|
||||
$ docker run --rm -v /etc:/root/etc -it ubuntu
|
||||
@ -90,8 +89,6 @@ drwx------ 3 root root 4096 Mar 21 23:50 ..
|
||||
lrwxrwxrwx 1 nobody nogroup 19 Mar 21 23:07 acpi -> /usr/local/etc/acpi
|
||||
-rw-r--r-- 1 nobody nogroup 48 Mar 10 22:09 boot2docker
|
||||
drwxr-xr-x 2 nobody nogroup 60 Mar 21 23:07 default
|
||||
:
|
||||
:
|
||||
|
||||
# Try creating a file in /root/etc
|
||||
root@d5802c5e670a:/# touch /root/etc/test
|
||||
@ -100,20 +97,19 @@ touch: cannot touch '/root/etc/test': Permission denied
|
||||
# Try deleting a file
|
||||
root@d5802c5e670a:/# rm /root/etc/hostname
|
||||
rm: cannot remove '/root/etc/hostname': Permission denied
|
||||
|
||||
```
|
||||
|
||||
好了,太棒了。这就是 User Namespaces 的工作方式。
|
||||
好了,太棒了。这就是用户名字空间的工作方式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
---
|
||||
|
||||
via: https://coderwall.com/p/s_ydlq/using-user-namespaces-on-docker
|
||||
|
||||
作者:[Koji Tanaka][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://coderwall.com/kjtanaka
|
||||
[a]: https://coderwall.com/kjtanaka
|
||||
@ -1,11 +1,13 @@
|
||||
尝试,学习,修改:新 IT 领导者的代码
|
||||
尝试、学习、修改:新 IT 领导者的代码
|
||||
=====
|
||||
|
||||
> 随着创新步伐的增加, 长期规划变得越来越困难。让我们重新思考一下我们对变化的反应方式。
|
||||
|
||||

|
||||
|
||||
几乎每一天,新的技术发展都在威胁破坏,甚至是那些最复杂,最完善的商业计划。组织经常发现自己正在努力适应新的环境,这导致了他们对未来规划的转变。
|
||||
几乎每一天,新的技术发展都可能会动摇那些甚至最复杂、最完善的商业计划。组织经常发现自己需要不断努力适应新的环境,这导致了他们对未来规划的转变。
|
||||
|
||||
根据 CompTIA 2017 年的[研究][1],目前只有 34% 的公司正在制定超过 12 个月的 IT 架构计划。从长期计划转变的一个原因是:商业环境变化如此之快,以至于几乎不可能进一步规划未来。[CIO.com 说道][1]“如果你的公司正视图制定一项将持续五到十年的计划,那就忘了它。”
|
||||
根据 CompTIA 2017 年的[研究][1],目前只有 34% 的公司正在制定超过 12 个月的 IT 架构计划。从长期计划转变的一个原因是:商业环境变化如此之快,以至于几乎不可能进一步规划未来。[CIO.com 说道][1],“如果你的公司正视图制定一项将持续五到十年的计划,那就忘了它。”
|
||||
|
||||
我听过来自世界各地无数客户和合作伙伴的类似声明:技术创新正以一种前所未有的速度发生着。
|
||||
|
||||
@ -13,21 +15,21 @@
|
||||
|
||||
### 计划是怎么死的
|
||||
|
||||
正如我在 Open Organization(开源组织)中写的那样,传统经营组织针对工业经济进行了优化。他们采用等级结构和严格规定的流程,以实现地位竞争优势。要取得成功,他们必须确定他们想要实现的战略地位。然后,他们必须制定并规划实现目标的计划,并以最有效的方式执行这些计划,通过协调活动和推动合规性。
|
||||
正如我在《<ruby>开放式组织<rt>The Open Organization</rt></ruby>》中写的那样,传统经营组织针对工业经济进行了优化。他们采用等级结构和严格规定的流程,以实现地位竞争优势。要取得成功,他们必须确定他们想要实现的战略地位。然后,他们必须制定并规划实现目标的计划,并以最有效的方式执行这些计划,通过协调活动和推动合规性。
|
||||
|
||||
管理层的职责是优化这一过程:计划,规定,执行。包括:让我们想象一个有竞争力的优势地位;让我们来配置组织以最终到达那里;然后让我们通过确保组织的所有方面都遵守规定来推动执行。这就是我所说的“机械管理”,对于不同时期来说它都是一个出色的解决方案。
|
||||
管理层的职责是优化这一过程:计划、规定、执行。包括:让我们想象一个有竞争力的优势地位;让我们来配置组织以最终达成目标;然后让我们通过确保组织的所有方面都遵守规定来推动执行。这就是我所说的“机械管理”,对于不同时期来说它都是一个出色的解决方案。
|
||||
|
||||
在当今动荡不定的世界中,我们预测和定义战略位置的能力正在下降,因为变化的速度,新变量的引入速度正在加速。传统的,长期的,战略性规划和执行不像以前那么有效。
|
||||
在当今动荡不定的世界中,我们预测和定义战略位置的能力正在下降,因为变化的速度,新变量的引入速度正在加速。传统的、长期的、战略性规划和执行不像以前那么有效。
|
||||
|
||||
如果长期规划变得如此困难,那么规定必要的行为就更具有挑战性。并且衡量对计划的合规性几乎是不可能的。
|
||||
|
||||
这一切都极大地影响了人们的工作方式。与过去传统经营组织中的工人不同,他们为自己能够重复行动而感到自豪,几乎没有变化和舒适的确定性 -- 今天的工人在充满模糊性的环境中运作。他们的工作需要更大的创造力,直觉和批判性判断 -- 有更大的要求是背离过去的“正常”,适应当今的新情况。
|
||||
这一切都极大地影响了人们的工作方式。与过去传统经营组织中的工人不同,他们为自己能够重复行动而感到自豪,几乎没有变化和舒适的确定性 —— 今天的工人在充满模糊性的环境中运作。他们的工作需要更大的创造力、直觉和批判性判断 —— 更多的需要背离过去的“常规”,以适应当今的新情况。
|
||||
|
||||
以这种新方式工作对于价值创造变得更加重要。我们的管理系统必须专注于构建结构,系统和流程,以帮助创建积极主动的工人,他们能够以快速和敏捷的方式进行创新和行动。
|
||||
|
||||
我们需要提出一个不同的解决方案来优化组织,以适应不同的经济时代,从自下而上而不是自上而下开始。我们需要替换过去的三步骤 -- 计划,规定,执行,以一种更适应当今动荡天气的方法来取得成功 -- 尝试,学习,修改。
|
||||
我们需要提出一个不同的解决方案来优化组织,以适应不同的经济时代,从自下而上而不是自上而下开始。我们需要替换过去的三步骤 —— 计划、规定、执行,以一种更适应当今动荡天气的方法来取得成功 —— 尝试、学习、修改。
|
||||
|
||||
### 尝试,学习,修改
|
||||
### 尝试、学习、修改
|
||||
|
||||
因为环境变化如此之快,而且几乎没有任何预警,并且因为我们需要采取的步骤不再提前计划,我们需要培养鼓励创造性尝试和错误的环境,而不是坚持对五年计划的忠诚。以下是以这种方式开始工作的一些暗示:
|
||||
|
||||
@ -46,7 +48,7 @@ via: https://opensource.com/open-organization/18/3/try-learn-modify
|
||||
|
||||
作者:[Jim Whitehurst][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,31 +1,32 @@
|
||||
如何用 Python 读取 Outlook 中的电子邮件
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
从事电子邮件营销,准入邮箱列表是必不可少的。你可能已经有了准入列表,同时还使用电子邮件客户端软件。如果你能从电子邮件客户端中导出准入列表,那这份列表想必是极好的。
|
||||
从事电子邮件营销,<ruby>准入<rt>opt-in</rt></ruby>邮箱列表是必不可少的。你可能已经有了准入列表,同时还使用电子邮件客户端软件。如果你能从电子邮件客户端中导出准入列表,那这份列表想必是极好的。
|
||||
|
||||
我使用一些代码来将 outlook 配置中的所有邮件写入一个临时文件中,现在让我来尝试解释一下这些代码。
|
||||
|
||||
首先你需要倒入 win32com.client,为此你需要安装 pywin32
|
||||
首先你需要导入 win32com.client,为此你需要安装 pywin32:
|
||||
|
||||
```
|
||||
pip install pywin32
|
||||
|
||||
```
|
||||
|
||||
我们需要通过 MAPI 协议连接 Outlok
|
||||
我们需要通过 MAPI 协议连接 Outlok:
|
||||
|
||||
```
|
||||
outlook = win32com.client.Dispatch("Outlook.Application").GetNamespace("MAPI")
|
||||
|
||||
```
|
||||
|
||||
然后从 outlook 配置中获取所有的账户。
|
||||
然后从 outlook 配置中获取所有的账户:
|
||||
|
||||
```
|
||||
accounts= win32com.client.Dispatch("Outlook.Application").Session.Accounts;
|
||||
|
||||
```
|
||||
|
||||
在然后需要从名为 emaileri_al 的收件箱中获取邮件。
|
||||
在然后需要从名为 emaileri_al 的收件箱中获取邮件:
|
||||
|
||||
```
|
||||
def emailleri_al(folder):
|
||||
messages = folder.Items
|
||||
@ -48,7 +49,8 @@ def emailleri_al(folder):
|
||||
pass
|
||||
```
|
||||
|
||||
你需要进入所有账户的所有收件箱中获取电子邮件
|
||||
你需要进入所有账户的所有收件箱中获取电子邮件:
|
||||
|
||||
```
|
||||
for account in accounts:
|
||||
global inbox
|
||||
@ -77,7 +79,8 @@ for account in accounts:
|
||||
print("*************************************************", file=
|
||||
```
|
||||
|
||||
下面是完整的代码
|
||||
下面是完整的代码:
|
||||
|
||||
```
|
||||
import win32com.client
|
||||
import win32com
|
||||
@ -148,7 +151,7 @@ via: https://www.codementor.io/aliacetrefli/how-to-read-outlook-emails-by-python
|
||||
作者:[A.A. Cetrefli][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,49 +1,37 @@
|
||||
Linux DNS 查询剖析 – 第一部分
|
||||
============================================================
|
||||
Linux DNS 查询剖析(第一部分)
|
||||
======
|
||||
|
||||
我经常与虚拟机集群打交道([文1][3], [文2][4], [文3][5], [文4][6], [文5][7], [文6][8]),期间花费了大量时间试图掌握 [DNS 查询][9]的工作原理。遇到问题时,我有时只是不求甚解的使用 StackOverflow 上的“解决方案”;甚至那些“解决方案”有时并不工作。
|
||||
我经常与虚拟机集群打交道([文1][3]、[文2][4]、[文3][5]、[文4][6]、[文5][7]、[文6][8]),因此最终花费了大量时间试图掌握 [DNS 查询][9]的工作原理。遇到问题时,我只是不求甚解的使用 StackOverflow 上的“解决方案”,而不知道它们为什么有时工作,有时不工作。
|
||||
|
||||
最终我决定改变这种情况,决定一并找出所有问题的原因。我没有在网上找到完整手册或类似的其它东西,我问过一些同事,他们也是如此。
|
||||
最终我对此感到了厌倦,决定一并找出所有问题的原因。我没有在网上找到完整的指南,我问过一些同事,他们不知所以然(或许是问题太具体了)。
|
||||
|
||||
既然如此,我开始自己写这样的手册。
|
||||
|
||||
_如果你在找第二部分, 点击 [这里][1]_
|
||||
|
||||
结果发现,“Linux 执行一次 DNS 查询”的背后有相当多的工作。
|
||||
|
||||
* * *
|
||||
结果发现,“Linux 执行一次 DNS 查询”这句话的背后有相当多的工作。
|
||||
|
||||

|
||||
|
||||
_“究竟有多难呢?”_
|
||||
|
||||
* * *
|
||||
**本系列文章试图将 Linux 主机上程序获取(域名对应的) IP 地址的过程及期间涉及的组件进行分块剖析。**如果不理解这些块的协同工作方式,调试解决 `dnsmasq`、`vagrant landrush` 和 `resolvconf` 等相关的问题会让人感到眼花缭乱。
|
||||
|
||||
本系列文章试图将 Linux 主机上程序获取(域名对应的) IP 地址的过程及期间涉及的组件进行分块剖析。如果不理解这些块的协同工作方式,调试并解决 `dnsmasq`,`vagrant landrush` 和 `resolvconf` 等相关的问题会让人感到眼花缭乱。
|
||||
|
||||
同时这也是一份有价值的说明,指出原本很简单的东西可以如何随着时间的推移变得相当复杂。在弄清楚 DNS 查询的原理的过程中,我了解了大量不同的技术及其发展历程。
|
||||
同时这也是一份有价值的说明,指出原本很简单的东西是如何随着时间的推移变得相当复杂。在弄清楚 DNS 查询的原理的过程中,我了解了大量不同的技术及其发展历程。
|
||||
|
||||
我甚至编写了一些[自动化脚本][10],可以让我在虚拟机中进行实验。欢迎读者参与贡献或勘误。
|
||||
|
||||
请注意,本系列主题并不是“DNS 工作原理”,而是与查询 Linux 主机配置的真实 DNS 服务器(这里假设查询了 DNS 服务器,但后面你会看到有时并不需要查询)相关的内容,以及如何确定使用哪个查询结果,或者何时使用其它方式确定 IP 地址。
|
||||
|
||||
* * *
|
||||
**请注意,本系列主题并不是“DNS 工作原理”**,而是与查询 Linux 主机配置的真实 DNS 服务器(这里假设查询了一台 DNS 服务器,但后面你会看到有时并不需要)相关的内容,以及如何确定使用哪个查询结果,或者如何使用其它方式确定 IP 地址。
|
||||
|
||||
### 1) 其实并没有名为“DNS 查询”的系统调用
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_工作方式并非如此_
|
||||
_工作方式并非如此_
|
||||
|
||||
* * *
|
||||
**首先要了解的一点是,Linux 上并没有一个单独的方法可以完成 DNS 查询工作**;没有一个有这样的明确接口的核心<ruby>系统调用<rt>system call</rt></ruby>。
|
||||
|
||||
首先要了解的一点是,Linux 上并没有一个单独的方法可以完成 DNS 查询工作;至少没有如此<ruby>明确接口<rt>clean interface</rt></ruby>的核心<ruby>系统调用<rt>system call</rt></ruby>。
|
||||
不过,有一个标准 C 库函数调用 [`getaddrinfo`][2],不少程序使用了该调用;但不是所有程序或应用都使用该调用!
|
||||
|
||||
有一个标准 C 库函数调用 `[getaddrinfo][2]`,不少程序使用了该调用;但不是所有程序或应用都使用该调用!
|
||||
|
||||
我们只考虑两个简单的标准程序:`ping` 和 `host`:
|
||||
让我们看一下两个简单的标准程序:`ping` 和 `host`:
|
||||
|
||||
```
|
||||
root@linuxdns1:~# ping -c1 bbc.co.uk | head -1
|
||||
@ -100,17 +88,15 @@ google.com has address 216.58.204.46
|
||||
|
||||
下面我们依次查看这两个 `.conf` 扩展名的文件。
|
||||
|
||||
* * *
|
||||
|
||||
### 2) NSSwitch 与 `/etc/nsswitch.conf`
|
||||
|
||||
我们已经确认应用可以自主决定选用哪个 DNS 服务器。很多应用(例如 `ping`)通过配置文件 `/etc/nsswitch.conf` (根据具体实现 (*))参考 NSSwitch 完成选择。
|
||||
我们已经确认应用可以自主决定选用哪个 DNS 服务器。很多应用(例如 `ping`)通过配置文件 `/etc/nsswitch.conf` (根据具体实现[^1] )参考 NSSwitch 完成选择。
|
||||
|
||||
###### (*) ping 实现的变种之多令人惊叹。我 _不_ 希望在这里讨论过多。
|
||||
[^1]: `ping` 实现的变种之多令人惊叹。我 _不_ 希望在这里讨论过多。
|
||||
|
||||
NSSwitch 不仅用于 DNS 查询,例如,还用于密码与用户信息查询。
|
||||
|
||||
NSSwitch 最初是 Solaris OS 的一部分,可以让应用无需将查询所需的文件或服务硬编码,而是在其它集中式的、无需应用开发人员管理的配置文件中找到。
|
||||
NSSwitch 最初是 Solaris OS 的一部分,可以让应用无需硬编码查询所需的文件或服务,而是在其它集中式的、无需应用开发人员管理的配置文件中找到。
|
||||
|
||||
下面是我的 `nsswitch.conf`:
|
||||
|
||||
@ -130,12 +116,13 @@ netgroup: nis
|
||||
|
||||
我们需要关注的是 `hosts` 行。我们知道 `ping` 用到 `nsswitch.conf` 文件,那么我们修改这个文件(的 `hosts` 行),看看能够如何影响 `ping`。
|
||||
|
||||
|
||||
* ### 修改 `nsswitch.conf`, `hosts` 行仅保留 `files`
|
||||
#### 修改 `nsswitch.conf`, `hosts` 行仅保留 `files`
|
||||
|
||||
如果你修改 `nsswitch.conf`,将 `hosts` 行仅保留 `files`:
|
||||
|
||||
`hosts: files`
|
||||
```
|
||||
hosts: files
|
||||
```
|
||||
|
||||
此时, `ping` 无法获取 google.com 对应的 IP 地址:
|
||||
|
||||
@ -161,11 +148,13 @@ google.com has address 216.58.206.110
|
||||
|
||||
毕竟如我们之前看到的那样,`host` 不受 `nsswitch.conf` 影响。
|
||||
|
||||
* ### 修改 `nsswitch.conf`, `hosts` 行仅保留 `dns`
|
||||
#### 修改 `nsswitch.conf`, `hosts` 行仅保留 `dns`
|
||||
|
||||
如果你修改 `nsswitch.conf`,将 `hosts` 行仅保留 `dns`:
|
||||
|
||||
`hosts: dns`
|
||||
```
|
||||
hosts: dns
|
||||
```
|
||||
|
||||
此时,google.com 的解析恢复正常:
|
||||
|
||||
@ -184,13 +173,9 @@ ping: unknown host localhost
|
||||
|
||||
下图给出默认 NSSwitch 中 `hosts` 行对应的查询逻辑:
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_我的 `hosts:` 配置是 `nsswitch.conf` 给出的默认值_
|
||||
|
||||
* * *
|
||||
_我的 `hosts:` 配置是 `nsswitch.conf` 给出的默认值_
|
||||
|
||||
### 3) `/etc/resolv.conf`
|
||||
|
||||
@ -221,16 +206,16 @@ $ ping -c1 google.com
|
||||
ping: unknown host google.com
|
||||
```
|
||||
|
||||
解析失败了,这是因为没有可用的 nameserver (*)。
|
||||
解析失败了,这是因为没有可用的名字服务器 [^2]。
|
||||
|
||||
|
||||
###### * 另一个需要注意的地方: `host` 在没有指定 nameserver 的情况下会尝试 127.0.0.1:53。
|
||||
[^2]: 另一个需要注意的地方: `host` 在没有指定 nameserver 的情况下会尝试 127.0.0.1:53。
|
||||
|
||||
该文件中还可以使用其它选项。例如,你可以在 `resolv.conf` 文件中增加如下行:
|
||||
|
||||
```
|
||||
search com
|
||||
```
|
||||
|
||||
然后执行 `ping google` (不写 `.com`)
|
||||
|
||||
```
|
||||
@ -248,10 +233,9 @@ PING google.com (216.58.204.14) 56(84) bytes of data.
|
||||
|
||||
* 操作系统中并不存在“DNS 查询”这个系统调用
|
||||
* 不同程序可能采用不同的策略获取名字对应的 IP 地址
|
||||
* 例如, `ping` 使用 `nsswitch`,后者进而使用(或可以使用) `/etc/hosts`,`/etc/resolv.conf` 以及主机名得到解析结果
|
||||
|
||||
* 例如, `ping` 使用 `nsswitch`,后者进而使用(或可以使用) `/etc/hosts`、`/etc/resolv.conf` 以及主机名得到解析结果
|
||||
* `/etc/resolv.conf` 用于决定:
|
||||
* 查询什么地址(LCTT 译注:这里可能指 search 带来的影响)
|
||||
* 查询什么地址(LCTT 译注:这里可能指 `search` 带来的影响)
|
||||
* 使用什么 DNS 服务器执行查询
|
||||
|
||||
如果你曾认为 DNS 查询很复杂,请跟随这个系列学习吧。
|
||||
@ -262,7 +246,7 @@ via: https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
|
||||
作者:[dmatech][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
223
published/20180618 Anatomy of a Linux DNS Lookup - Part II.md
Normal file
223
published/20180618 Anatomy of a Linux DNS Lookup - Part II.md
Normal file
@ -0,0 +1,223 @@
|
||||
Linux DNS 查询剖析(第二部分)
|
||||
==============================================
|
||||
|
||||
在 [Linux DNS 查询剖析 - 第一部分][1] 中,我介绍了:
|
||||
|
||||
* `nsswitch`
|
||||
* `/etc/hosts`
|
||||
* `/etc/resolv.conf`
|
||||
* `ping` 与 `host` 查询方式对比
|
||||
|
||||
并且发现大多数程序选择要查询的 DNS 服务器时会参考 `/etc/resolv.conf` 配置文件。
|
||||
|
||||
这种方式在 Linux 上比较普遍[^1]。虽然我使用了特定的发行版 Ubuntu,但背后的原理与 Debian 甚至是那些基于 CentOS 的发行版有相通的地方;当然,与更低或更高的 Ubuntu 版本相比,差异还是存在的。
|
||||
|
||||
[^1]: 事实上,这是相对于 POSIX 标准的,故不限于 Linux (我从上一篇文章的一条极好的[回复][2]中了解到这一点)
|
||||
|
||||
也就是说,接下来,你主机上的行为很可能与我描述的不一致。
|
||||
|
||||
在第二部分中,我将介绍 `resolv.conf` 的更新机制、`systemctl restart networking` 命令的运行机制 ,以及 `dhclient` 是如何参与其中。
|
||||
|
||||
### 1) 手动更新 /etc/resolv.conf
|
||||
|
||||
我们知道 `/etc/resolv.conf` (有极大的可能性)被用到,故你自然可以通过该文件增加一个 `nameserver`,那么主机也将会(与已有的 `nameserver` 一起)使用新加入的 `nameserver` 吧?
|
||||
|
||||
你可以尝试如下:
|
||||
|
||||
```
|
||||
$ echo nameserver 10.10.10.10 >> /etc/resolv.conf
|
||||
```
|
||||
|
||||
看上去新的 `nameserver` 已经加入:
|
||||
|
||||
```
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.3
|
||||
search home
|
||||
nameserver 10.10.10.10
|
||||
```
|
||||
|
||||
但主机网络服务重启后问题出现了:
|
||||
|
||||
```
|
||||
$ systemctl restart networking
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.3
|
||||
search home
|
||||
```
|
||||
|
||||
我们的 `10.10.10.10` 的 `nameserver` 不见了!
|
||||
|
||||
在上一篇文章中我们忽略了这一点,本文进行补充说明。
|
||||
|
||||
### 2) resolvconf
|
||||
|
||||
你在 `/etc/resolv.conf` 文件中看到 `generated by resolvconf` 词组了吧?这就是我们的线索。
|
||||
|
||||
如果深入研究 `systemctl restart networking` 命令,你会发现它做了很多事情,结束时调用了 `/etc/network/if-up.d/000resolvconf` 脚本。在该脚本中,可以发现一次对 `resolvconf` 命令的调用:
|
||||
|
||||
```
|
||||
/sbin/resolvconf -a "${IFACE}.${ADDRFAM}"
|
||||
```
|
||||
|
||||
稍微研究一下 man 手册,发现`-a` 参数允许我们:
|
||||
|
||||
```
|
||||
Add or overwrite the record IFACE.PROG then run the update scripts
|
||||
if updating is enabled.
|
||||
```
|
||||
|
||||
(增加或覆盖 IFACE.PROG 记录,如果开启更新选项,则运行更新脚本)
|
||||
|
||||
故而也许我们可以直接调用该命令增加 `namserver`:
|
||||
|
||||
```
|
||||
echo 'nameserver 10.10.10.10' | /sbin/resolvconf -a enp0s8.inet
|
||||
```
|
||||
|
||||
测试表明确实可以!
|
||||
|
||||
```
|
||||
$ cat /etc/resolv.conf | grep nameserver
|
||||
nameserver 10.0.2.3
|
||||
nameserver 10.10.10.10
|
||||
```
|
||||
|
||||
是否已经找到答案,这就是 `/etc/resolv.conf` 更新的逻辑?调用 `resolvconf` 将 `nameserver` 添加到某个地方的数据库,然后(“如果配置了更新”,先不管具体什么含义)更新 `resolv.conf` 文件。
|
||||
|
||||
并非如此。
|
||||
|
||||
```
|
||||
$ systemctl restart networking
|
||||
root@linuxdns1:/etc# cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.3
|
||||
search home
|
||||
```
|
||||
|
||||
呃!(网络服务重启后)新增的 `nameserver` 再次消失了。
|
||||
|
||||
可见,`systemctl restart networking` 不仅仅运行了 `resolvconf`,还在其它地方获取 `nameserver` 信息。具体是哪里呢?
|
||||
|
||||
### 3) ifup/ifdown
|
||||
|
||||
继续深入研究 `systemctl restart networking`,发现它完成了一系列工作:
|
||||
|
||||
```
|
||||
cat /lib/systemd/system/networking.service
|
||||
[...]
|
||||
[Service]
|
||||
Type=oneshot
|
||||
EnvironmentFile=-/etc/default/networking
|
||||
ExecStartPre=-/bin/sh -c '[ "$CONFIGURE_INTERFACES" != "no" ] && [ -n "$(ifquery --read-environment --list --exclude=lo)" ] && udevadm settle'
|
||||
ExecStart=/sbin/ifup -a --read-environment
|
||||
ExecStop=/sbin/ifdown -a --read-environment --exclude=lo
|
||||
[...]
|
||||
```
|
||||
|
||||
首先,网络服务的重启实质是运行一个<ruby>单触发<rt>oneshot</rt></ruby>的脚本,脚本包含如下命令:
|
||||
|
||||
```
|
||||
/sbin/ifdown -a --read-environment --exclude=lo
|
||||
/bin/sh -c '[ "$CONFIGURE_INTERFACES" != "no" ] && [ -n "$(ifquery --read-environment --list --exclude=lo)" ] && udevadm settle'
|
||||
/sbin/ifup -a --read-environment
|
||||
```
|
||||
|
||||
第一行使用 `ifdown` 关闭全部的网络接口,但<ruby>本地回环<rt>local, lo</rt></ruby>接口除外。[^2]
|
||||
|
||||
[^2]: 我不明白为何这没有导致我例子中的 vagrant 会话中断 (有谁明白吗?)。
|
||||
|
||||
(LCTT 译注:其实这是因为很快就又启动了接口,间隔的时间没有超过 TCP 连接的超时时间,有人在评论中也做了类似回复)
|
||||
|
||||
第二行用于确认系统已经完成关闭网络接口相关的全部工作,以便下一步使用 `ifup` 启动接口。这也让我们了解到,网络服务实质运行的就是 `ifdown` 和 `ifup`。
|
||||
|
||||
文档中没有找到 `--read-environment` 参数的说明,该参数为 `systemctl` 正常工作所需。很多人以文档不完善为由不喜欢 `systemctl`。
|
||||
|
||||
很好。那么 `ifup` (和其成对出现的 `ifdown`) 到底做了哪些工作呢?长话短说,它运行了 `/etc/network/if-pre-up.d/` 和 `/etc/network/if-up.d/` 目录下的全部脚本;期间,这些脚本也可能会调用另外的脚本,依此类推。
|
||||
|
||||
其中一件工作就是运行了 `dhclient`,但我还不完全确定具体的机理,也许 `udev` 参与其中。
|
||||
|
||||
### 4) dhclient
|
||||
|
||||
`dhclient` 是一个程序,用于与 DHCP 服务器协商对应网络接口应该使用的 IP 地址的详细信息。同时,它也可以获取可用的 DNS 服务器并将其替换到 `/etc/resolv.conf` 中。
|
||||
|
||||
让我们开始跟踪并模拟它的行为,但仅在我实验虚拟机的 `enp0s3` 接口上。事先已经删除 `/etc/resolv.conf` 文件中的 nameserver 配置:
|
||||
|
||||
```
|
||||
$ sed -i '/nameserver.*/d' /run/resolvconf/resolv.conf
|
||||
$ cat /etc/resolv.conf | grep nameserver
|
||||
$ dhclient -r enp0s3 && dhclient -v enp0s3
|
||||
Killed old client process
|
||||
Internet Systems Consortium DHCP Client 4.3.3
|
||||
Copyright 2004-2015 Internet Systems Consortium.
|
||||
All rights reserved.
|
||||
For info, please visit https://www.isc.org/software/dhcp/
|
||||
Listening on LPF/enp0s8/08:00:27:1c:85:19
|
||||
Sending on LPF/enp0s8/08:00:27:1c:85:19
|
||||
Sending on Socket/fallback
|
||||
DHCPDISCOVER on enp0s8 to 255.255.255.255 port 67 interval 3 (xid=0xf2f2513e)
|
||||
DHCPREQUEST of 172.28.128.3 on enp0s8 to 255.255.255.255 port 67 (xid=0x3e51f2f2)
|
||||
DHCPOFFER of 172.28.128.3 from 172.28.128.2
|
||||
DHCPACK of 172.28.128.3 from 172.28.128.2
|
||||
bound to 172.28.128.3 -- renewal in 519 seconds.
|
||||
|
||||
$ cat /etc/resolv.conf | grep nameserver
|
||||
nameserver 10.0.2.3
|
||||
```
|
||||
|
||||
可见这就是 `nameserver` 的来源。
|
||||
|
||||
但稍等一下,命令中的 `/run/resolvconf/resolv.conf` 是哪个文件,不应该是 `/etc/resolv.conf` 吗?
|
||||
|
||||
事实上,`/etc/resolv.conf` 并不一定只是一个普通文本文件。
|
||||
|
||||
在我的虚拟机上,它是一个软链接,指向位于 `/run/resolvconf` 目录下的“真实文件”。这也暗示了我们,该文件是在系统启动时生成的;同时,这也是该文件注释告诉我们不要直接修改该文件的原因。
|
||||
|
||||
(LCTT 译注:在 CentOS 7 中,没有 `resolvconf` 命令,`/etc/resolv.conf` 也不是软链接)
|
||||
|
||||
假如上面命令中 `sed` 命令直接处理 `/etc/resolv.conf` 文件,效果是不同的,会有警告消息告知待操作的文件不能是软链接(`sed -i` 无法很好的处理软链接,它只会创建一个新文件)。
|
||||
|
||||
(LCTT 译注:CentOS 7 测试时,`sed -i` 命令操作软链接并没有警告,但确实创建了新文件取代软链接)
|
||||
|
||||
如果你继续深入查看配置文件 `/etc/dhcp/dhclient.conf` 的 `supersede` 部分,你会发现 `dhclient` 可以覆盖 DHCP 提供的 DNS 服务器。
|
||||
|
||||

|
||||
|
||||
_(大致)准确的关系图_
|
||||
|
||||
* * *
|
||||
|
||||
### 第二部分的结束语
|
||||
|
||||
第二部分到此结束。信不信由你,这是一个某种程度上简化的流程版本,但我尽量保留重要和值得了解的部分,让你不会感到无趣。大部分内容都是围绕实际脚本的运行展开的。
|
||||
|
||||
但我们的工作还没有结束,在第三部分,我们会介绍这些之上的更多层次。
|
||||
|
||||
让我们简要列出我们已经介绍过的内容:
|
||||
|
||||
* `nsswitch`
|
||||
* `/etc/hosts`
|
||||
* `/etc/resolv.conf`
|
||||
* `/run/resolvconf/resolv.conf`
|
||||
* `systemd` 和网络服务
|
||||
* `ifup` 和 `ifdown`
|
||||
* `dhclient`
|
||||
* `resolvconf`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
|
||||
作者:[ZWISCHENZUGS][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://linux.cn/article-9943-1.html
|
||||
[2]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/#comment-2312
|
||||
@ -0,0 +1,292 @@
|
||||
使用 Ptrace 去拦截和仿真 Linux 系统调用
|
||||
======
|
||||
|
||||
`ptrace(2)`(“<ruby>进程跟踪<rt>process trace</rt></ruby>)系统调用通常都与调试有关。它是类 Unix 系统上通过原生调试器监测被调试进程的主要机制。它也是实现 [strace][1](<ruby>系统调用跟踪<rt>system call trace</rt></ruby>)的常见方法。使用 Ptrace,跟踪器可以暂停被跟踪进程,[检查和设置寄存器和内存][2],监视系统调用,甚至可以<ruby>拦截<rt>intercepting</rt></ruby>系统调用。
|
||||
|
||||
通过拦截功能,意味着跟踪器可以篡改系统调用参数,篡改系统调用的返回值,甚至阻塞某些系统调用。言外之意就是,一个跟踪器本身完全可以提供系统调用服务。这是件非常有趣的事,因为这意味着**一个跟踪器可以仿真一个完整的外部操作系统**,而这些都是在没有得到内核任何帮助的情况下由 Ptrace 实现的。
|
||||
|
||||
问题是,在同一时间一个进程只能被一个跟踪器附着,因此在那个进程的调试期间,不可能再使用诸如 GDB 这样的工具去仿真一个外部操作系统。另外的问题是,仿真系统调用的开销非常高。
|
||||
|
||||
在本文中,我们将专注于 x86-64 [Linux 的 Ptrace][3],并将使用一些 Linux 专用的扩展。同时,在本文中,我们将忽略掉一些错误检查,但是完整的源代码仍然会包含这些错误检查。
|
||||
|
||||
本文中的可直接运行的示例代码在这里:<https://github.com/skeeto/ptrace-examples>
|
||||
|
||||
### strace
|
||||
|
||||
在进入到最有趣的部分之前,我们先从回顾 strace 的基本实现来开始。它[不是 DTrace][4],但 strace 仍然非常有用。
|
||||
|
||||
Ptrace 一直没有被标准化。它的接口在不同的操作系统上非常类似,尤其是在核心功能方面,但是在不同的系统之间仍然存在细微的差别。`ptrace(2)` 的原型基本上应该像下面这样,但特定的类型可能有些差别。
|
||||
|
||||
```
|
||||
long ptrace(int request, pid_t pid, void *addr, void *data);
|
||||
```
|
||||
|
||||
`pid` 是被跟踪进程的 ID。虽然**同一个时间**只有一个跟踪器可以附着到该进程上,但是一个跟踪器可以附着跟踪多个进程。
|
||||
|
||||
`request` 字段选择一个具体的 Ptrace 函数,比如 `ioctl(2)` 接口。对于 strace,只需要两个:
|
||||
|
||||
* `PTRACE_TRACEME`:这个进程被它的父进程跟踪。
|
||||
* `PTRACE_SYSCALL`:继续跟踪,但是在下一下系统调用入口或出口时停止。
|
||||
* `PTRACE_GETREGS`:取得被跟踪进程的寄存器内容副本。
|
||||
|
||||
另外两个字段,`addr` 和 `data`,作为所选的 Ptrace 函数的一般参数。一般情况下,可以忽略一个或全部忽略,在那种情况下,传递零个参数。
|
||||
|
||||
strace 接口实质上是前缀到另一个命令之前。
|
||||
|
||||
```
|
||||
$ strace [strace options] program [arguments]
|
||||
```
|
||||
|
||||
最小化的 strace 不需要任何选项,因此需要做的第一件事情是 —— 假设它至少有一个参数 —— 在 `argv` 尾部的 `fork(2)` 和 `exec(2)` 被跟踪进程。但是在加载目标程序之前,新的进程将告知内核,目标程序将被它的父进程继续跟踪。被跟踪进程将被这个 Ptrace 系统调用暂停。
|
||||
|
||||
```
|
||||
pid_t pid = fork();
|
||||
switch (pid) {
|
||||
case -1: /* error */
|
||||
FATAL("%s", strerror(errno));
|
||||
case 0: /* child */
|
||||
ptrace(PTRACE_TRACEME, 0, 0, 0);
|
||||
execvp(argv[1], argv + 1);
|
||||
FATAL("%s", strerror(errno));
|
||||
}
|
||||
```
|
||||
|
||||
父进程使用 `wait(2)` 等待子进程的 `PTRACE_TRACEME`,当 `wait(2)` 返回后,子进程将被暂停。
|
||||
|
||||
```
|
||||
waitpid(pid, 0, 0);
|
||||
```
|
||||
|
||||
在允许子进程继续运行之前,我们告诉操作系统,被跟踪进程和它的父进程应该一同被终止。一个真实的 strace 实现可能会设置其它的选择,比如: `PTRACE_O_TRACEFORK`。
|
||||
|
||||
```
|
||||
ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
|
||||
```
|
||||
|
||||
剩余部分就是一个简单的、无休止的循环了,每循环一次捕获一个系统调用。循环体总共有四步:
|
||||
|
||||
1. 等待进程进入下一个系统调用。
|
||||
2. 输出系统调用的一个描述。
|
||||
3. 允许系统调用去运行并等待返回。
|
||||
4. 输出系统调用返回值。
|
||||
|
||||
这个 `PTRACE_SYSCALL` 请求被用于等待下一个系统调用时开始,和等待那个系统调用退出。和前面一样,需要一个 `wait(2)` 去等待被跟踪进程进入期望的状态。
|
||||
|
||||
```
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
```
|
||||
|
||||
当 `wait(2)` 返回时,进行了系统调用的线程的寄存器中写入了该系统调用的系统调用号及其参数。尽管如此,*操作系统仍然没有为这个系统调用提供服务*。这个细节对后续操作很重要。
|
||||
|
||||
接下来的一步是采集系统调用信息。这是各个系统架构不同的地方。在 x86-64 上,[系统调用号是在 `rax` 中传递的][5],而参数(最多 6 个)是在 `rdi`、`rsi`、`rdx`、`r10`、`r8` 和 `r9` 中传递的。这些寄存器是由另外的 Ptrace 调用读取的,不过这里再也不需要 `wait(2)` 了,因为被跟踪进程的状态再也不会发生变化了。
|
||||
|
||||
```
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
long syscall = regs.orig_rax;
|
||||
|
||||
fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
|
||||
syscall,
|
||||
(long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
|
||||
(long)regs.r10, (long)regs.r8, (long)regs.r9);
|
||||
```
|
||||
|
||||
这里有一个警告。由于 [内核的内部用途][6],系统调用号是保存在 `orig_rax` 中而不是 `rax` 中。而所有的其它系统调用参数都是非常简单明了的。
|
||||
|
||||
接下来是它的另一个 `PTRACE_SYSCALL` 和 `wait(2)`,然后是另一个 `PTRACE_GETREGS` 去获取结果。结果保存在 `rax` 中。
|
||||
|
||||
```
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
fprintf(stderr, " = %ld\n", (long)regs.rax);
|
||||
```
|
||||
|
||||
这个简单程序的输出也是非常粗糙的。这里的系统调用都没有符号名,并且所有的参数都是以数字形式输出,甚至是一个指向缓冲区的指针也是如此。更完整的 strace 输出将能知道哪个参数是指针,并使用 `process_vm_readv(2)` 从被跟踪进程中读取哪些缓冲区,以便正确输出它们。
|
||||
|
||||
然而,这些仅仅是系统调用拦截的基础工作。
|
||||
|
||||
### 系统调用拦截
|
||||
|
||||
假设我们想使用 Ptrace 去实现如 OpenBSD 的 [`pledge(2)`][7] 这样的功能,它是 [一个进程<ruby>承诺<rt>pledge</rt></ruby>只使用一套受限的系统调用][8]。初步想法是,许多程序一般都有一个初始化阶段,这个阶段它们都需要进行许多的系统访问(比如,打开文件、绑定套接字、等等)。初始化完成以后,它们进行一个主循环,在主循环中它们处理输入,并且仅使用所需的、很少的一套系统调用。
|
||||
|
||||
在进入主循环之前,一个进程可以限制它自己只能运行所需要的几个操作。如果 [程序有缺陷][9],能够通过恶意的输入去利用该缺陷,这个**承诺**可以有效地限制漏洞利用的实现。
|
||||
|
||||
使用与 strace 相同的模型,但不是输出所有的系统调用,我们既能够阻塞某些系统调用,也可以在它的行为异常时简单地终止被跟踪进程。终止它很容易:只需要在跟踪器中调用 `exit(2)`。因此,它也可以被设置为去终止被跟踪进程。阻塞系统调用和允许子进程继续运行都只是些雕虫小技而已。
|
||||
|
||||
最棘手的部分是**当系统调用启动后没有办法去中断它**。当跟踪器在入口从 `wait(2)` 中返回到系统调用时,从一开始停止一个系统调用的仅有方式是,终止被跟踪进程。
|
||||
|
||||
然而,我们不仅可以“搞乱”系统调用的参数,也可以改变系统调用号本身,将它修改为一个不存在的系统调用。返回时,在 `errno` 中 [通过正常的内部信号][10],我们就可以报告一个“友好的”错误信息。
|
||||
|
||||
```
|
||||
for (;;) {
|
||||
/* Enter next system call */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
/* Is this system call permitted? */
|
||||
int blocked = 0;
|
||||
if (is_syscall_blocked(regs.orig_rax)) {
|
||||
blocked = 1;
|
||||
regs.orig_rax = -1; // set to invalid syscall
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
|
||||
/* Run system call and stop on exit */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
if (blocked) {
|
||||
/* errno = EPERM */
|
||||
regs.rax = -EPERM; // Operation not permitted
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这个简单的示例只是检查了系统调用是否违反白名单或黑名单。而它们在这里并没有差别,比如,允许文件以只读而不是读写方式打开(`open(2)`),允许匿名内存映射但不允许非匿名映射等等。但是这里仍然没有办法去动态撤销被跟踪进程的权限。
|
||||
|
||||
跟踪器与被跟踪进程如何沟通?使用人为的系统调用!
|
||||
|
||||
### 创建一个人为的系统调用
|
||||
|
||||
对于我的这个类似于 pledge 的系统调用 —— 我可以通过调用 `xpledge()` 将它与真实的系统调用区分开 —— 我设置 10000 作为它的系统调用号,这是一个非常大的数字,真实的系统调用中从来不会用到它。
|
||||
|
||||
```
|
||||
#define SYS_xpledge 10000
|
||||
```
|
||||
|
||||
为演示需要,我同时构建了一个非常小的接口,这在实践中并不是个好主意。它与 OpenBSD 的 `pledge(2)` 稍有一些相似之处,它使用了一个 [字符串接口][11]。*事实上*,设计一个健壮且安全的权限集是非常复杂的,正如在 `pledge(2)` 的手册页面上所显示的那样。下面是对被跟踪进程的系统调用的完整接口*和*实现:
|
||||
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <unistd.h>
|
||||
|
||||
#define XPLEDGE_RDWR (1 << 0)
|
||||
#define XPLEDGE_OPEN (1 << 1)
|
||||
|
||||
#define xpledge(arg) syscall(SYS_xpledge, arg)
|
||||
```
|
||||
|
||||
如果给它传递个参数 0 ,仅允许一些基本的系统调用,包括那些用于去分配内存的系统调用(比如 `brk(2)`)。 `PLEDGE_RDWR` 位允许 [各种][12] 读和写的系统调用(`read(2)`、`readv(2)`、`pread(2)`、`preadv(2)` 等等)。`PLEDGE_OPEN` 位允许 `open(2)`。
|
||||
|
||||
为防止发生提升权限的行为,`pledge()` 会拦截它自己 —— 但这样也防止了权限撤销,以后再细说这方面内容。
|
||||
|
||||
在 xpledge 跟踪器中,我需要去检查这个系统调用:
|
||||
|
||||
```
|
||||
/* Handle entrance */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
register_pledge(regs.rdi);
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
操作系统将返回 `ENOSYS`(函数尚未实现),因为它不是一个*真实的*系统调用。为此在退出时我用一个 `success(0)` 去覆写它。
|
||||
|
||||
```
|
||||
/* Handle exit */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
|
||||
break;
|
||||
}
|
||||
```
|
||||
|
||||
我写了一小段测试程序去打开 `/dev/urandom`,做一个读操作,尝试去承诺后,然后试着第二次打开 `/dev/urandom`,然后确认它能够读取原始的 `/dev/urandom` 文件描述符。在没有承诺跟踪器的情况下运行,输出如下:
|
||||
|
||||
```
|
||||
$ ./example
|
||||
fread("/dev/urandom")[1] = 0xcd2508c7
|
||||
XPledging...
|
||||
XPledge failed: Function not implemented
|
||||
fread("/dev/urandom")[2] = 0x0be4a986
|
||||
fread("/dev/urandom")[1] = 0x03147604
|
||||
```
|
||||
|
||||
做一个无效的系统调用并不会让应用程序崩溃。它只是失败,这是一个很方便的返回方式。当它在跟踪器下运行时,它的输出如下:
|
||||
|
||||
```
|
||||
$ ./xpledge ./example
|
||||
fread("/dev/urandom")[1] = 0xb2ac39c4
|
||||
XPledging...
|
||||
fopen("/dev/urandom")[2]: Operation not permitted
|
||||
fread("/dev/urandom")[1] = 0x2e1bd1c4
|
||||
```
|
||||
|
||||
这个承诺很成功,第二次的 `fopen(3)` 并没有进行,因为跟踪器用一个 `EPERM` 阻塞了它。
|
||||
|
||||
可以将这种思路进一步发扬光大,比如,改变文件路径或返回一个假的结果。一个跟踪器可以很高效地 chroot 它的被跟踪进程,通过一个系统调用将任意路径传递给 root 从而实现 chroot 路径。它甚至可以对用户进行欺骗,告诉用户它以 root 运行。事实上,这些就是 [Fakeroot NG][13] 程序所做的事情。
|
||||
|
||||
### 仿真外部系统
|
||||
|
||||
假设你不满足于仅拦截一些系统调用,而是想拦截*全部*系统调用。你就会有了 [一个打算在其它操作系统上运行的二进制程序][14],无需系统调用,这个二进制程序可以一直运行。
|
||||
|
||||
使用我在前面所描述的这些内容你就可以管理这一切。跟踪器可以使用一个假冒的东西去代替系统调用号,允许它失败,以及为系统调用本身提供服务。但那样做的效率很低。其实质上是对每个系统调用做了三个上下文切换:一个是在入口上停止,一个是让系统调用总是以失败告终,还有一个是在系统调用退出时停止。
|
||||
|
||||
从 2005 年以后,对于这个技术,PTrace 的 Linux 版本有更高效的操作:`PTRACE_SYSEMU`。PTrace 仅在每个系统调用发出时停止*一次*,在允许被跟踪进程继续运行之前,由跟踪器为系统调用提供服务。
|
||||
|
||||
```
|
||||
for (;;) {
|
||||
ptrace(PTRACE_SYSEMU, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
switch (regs.orig_rax) {
|
||||
case OS_read:
|
||||
/* ... */
|
||||
|
||||
case OS_write:
|
||||
/* ... */
|
||||
|
||||
case OS_open:
|
||||
/* ... */
|
||||
|
||||
case OS_exit:
|
||||
/* ... */
|
||||
|
||||
/* ... and so on ... */
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
从任何具有(足够)稳定的系统调用 ABI(LCTT 译注:应用程序二进制接口),在相同架构的机器上运行一个二进制程序时,你只需要 `PTRACE_SYSEMU` 跟踪器、一个加载器(用于代替 `exec(2)`),和这个二进制程序所需要(或仅运行静态的二进制程序)的任何系统库即可。
|
||||
|
||||
事实上,这听起来有点像一个有趣的周末项目。
|
||||
|
||||
**参见**
|
||||
|
||||
- [给 Linux 内核克隆实现一个 OpenBSD 承诺][15]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nullprogram.com/blog/2018/06/23/
|
||||
|
||||
作者:[Chris Wellons][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://nullprogram.com
|
||||
[1]: https://blog.plover.com/Unix/strace-groff.html
|
||||
[2]: http://nullprogram.com/blog/2016/09/03/
|
||||
[3]: http://man7.org/linux/man-pages/man2/ptrace.2.html
|
||||
[4]: http://nullprogram.com/blog/2018/01/17/
|
||||
[5]: http://nullprogram.com/blog/2015/05/15/
|
||||
[6]: https://stackoverflow.com/a/6469069
|
||||
[7]: https://man.openbsd.org/pledge.2
|
||||
[8]: http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
|
||||
[9]: http://nullprogram.com/blog/2017/07/19/
|
||||
[10]: http://nullprogram.com/blog/2016/09/23/
|
||||
[11]: https://www.tedunangst.com/flak/post/string-interfaces
|
||||
[12]: http://nullprogram.com/blog/2017/03/01/
|
||||
[13]: https://fakeroot-ng.lingnu.com/index.php/Home_Page
|
||||
[14]: http://nullprogram.com/blog/2017/11/30/
|
||||
[15]: https://www.youtube.com/watch?v=uXgxMDglxVM
|
||||
@ -1,13 +1,15 @@
|
||||
重温 wallabag,Instapaper 的开源替代品
|
||||
重温 wallabag:Instapaper 的开源替代品
|
||||
======
|
||||
|
||||
> 这个稍后阅读应用增加了功能,使其成为诸如 Pocket、Paper 和 Instapaper 之类应用的可靠替代品。
|
||||
|
||||

|
||||
|
||||
早在 2014 年,我[写了篇关于 wallabag 的文章][1],它是稍后阅读应用如 Instapaper 和 Pocket 的开源替代品。如果你愿意,去看看那篇文章吧。别担心,我会等你的。
|
||||
早在 2014 年,我[写了篇关于 wallabag 的文章][1],它是诸如 Instapaper 和 Pocket 这样的稍后阅读应用的开源替代品。如果你愿意,去看看那篇文章吧。别担心,我会等你的。
|
||||
|
||||
好了么?很好
|
||||
好了么?很好。
|
||||
|
||||
自从我写这篇文章的四年来,[wallabag][2]的很多东西都发生了变化。现在是时候看看 wallabag 是如何成熟的。
|
||||
自从我写这篇文章的四年来,[wallabag][2] 的很多东西都发生了变化。现在是时候悄悄看一下 wallabag 是如何成熟的。
|
||||
|
||||
### 有什么新的
|
||||
|
||||
@ -15,11 +17,11 @@
|
||||
|
||||
那么这些变化有哪些呢?有[很多][3]。以下是我发现最有趣和最有用的内容。
|
||||
|
||||
除了使 wallabag 更加快速和稳定之外,程序的导入和导出内容的能力也得到了提高。你可以从 Pocket 和 Instapaper 导入文章,也可导入书签服务 [Pinboard][4] 中标记为 “To read” 的文章。你还可以导入 Firefox 和 Chrome 书签。
|
||||
除了使 wallabag 更加快速和稳定之外,该应用的导入和导出内容的能力也得到了提高。你可以从 Pocket 和 Instapaper 导入文章,也可导入书签服务 [Pinboard][4] 中标记为 “To read” 的文章。你还可以导入 Firefox 和 Chrome 书签。
|
||||
|
||||
你还可以以多种格式导出文章,包括 EPUB、MOBI、PDF 和纯文本。你可以为单篇文章、所有未读文章或所有已读和未读执行此操作。我四年前使用的 wallabag 版本可以导出到 EPUB 和 PDF,但有时导出很糟糕。现在,这些导出快速而顺利。
|
||||
|
||||
Web 界面中的注释和高亮显示现在可以更好,更一致地工作。不可否认,我并不经常使用它们 - 但它们不会像 wallabag v1 那样随机消失。
|
||||
Web 界面中的注释和高亮显示现在可以更好、更一致地工作。不可否认,我并不经常使用它们 —— 但它们不会像 wallabag v1 那样随机消失。
|
||||
|
||||

|
||||
|
||||
@ -27,7 +29,7 @@ wallabag 的外观和感觉也有所改善。这要归功于受 [Material Design
|
||||
|
||||
|
||||
|
||||
其中一个最大的变化是引入了 wallabag 的[托管版本][6]。不止一些人(包括你在内)没有服务器来运行网络程序,并且不太愿意这样做。当遇到任何技术问题时,我很窘迫。我不介意每年花 9 欧元(我写这篇文章的时候只要 10 美元),以获得一个我不需要关注的程序的完整工作版本。
|
||||
其中一个最大的变化是引入了 wallabag 的[托管版本][6]。不是只有少数人(包括你在内)没有服务器来运行网络程序,并且也不太愿意维护台服务器。当遇到任何技术问题时,我很窘迫。我不介意每年花 9 欧元(我写这篇文章的时候只要 10 美元),以获得一个我不需要关注的程序的完整工作版本。
|
||||
|
||||
### 没有改变什么
|
||||
|
||||
@ -37,11 +39,11 @@ Wallabag 的[浏览器扩展][7]以同样的方式完成同样的工作。我发
|
||||
|
||||
### 有什么令人失望的
|
||||
|
||||
移动应用良好,但没有很棒。它在渲染文章方面做得很好,并且有一些配置选项。但是你不能高亮或注释文章。也就是说,你可以使用该程序浏览你的存档文章。
|
||||
移动应用良好,但不算很棒。它在渲染文章方面做得很好,并且有一些配置选项。但是你不能高亮或注释文章。也就是说,你可以使用该程序浏览你的存档文章。
|
||||
|
||||
|
||||
|
||||
虽然 wallabag 在收藏文章方面做得很好,但有些网站的内容却无法保存。我没有碰到很多这样的网站,但已经遇到让人烦恼的情况。我不确定与 wallabag 有多大关系。相反,我怀疑它与网站的编码方式有关 - 我在使用几个专有的稍后阅读工具时遇到了同样的问题。
|
||||
虽然 wallabag 在收藏文章方面做得很好,但有些网站的内容却无法保存。我没有碰到很多这样的网站,但已经遇到让人烦恼的情况。我不确定与 wallabag 有多大关系。相反,我怀疑它与网站的编码方式有关 —— 我在使用几个专有的稍后阅读工具时遇到了同样的问题。
|
||||
|
||||
Wallabag 可能不是 Pocket 或 Instapaper 的等功能的替代品,但它做得很好。自从我第一次写这篇文章以来的四年里,它已经有了明显的改善。它仍然有改进的余地,但要做好它宣传的。
|
||||
|
||||
@ -56,7 +58,7 @@ via: https://opensource.com/article/18/7/wallabag
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,203 +1,158 @@
|
||||
Javascript 框架对比及案例(React、Vue 及 Hyperapp)
|
||||
============================================================
|
||||
在[我的上一片文章中][5],我试图解释为什么我认为[Hyperapp][6]是一个可用的 [React][7] 或 [Vue][8] 的替代品,我发现当我开始用它时,会容易的找到这个原因。许多人批评这篇文章,认为它自以为是,并没有给其他框架一个展示自己的机会。因此,在这篇文章中,我将尽可能客观的通过提供一些最小化的例子来比较这三个框架,以展示他们的能力。
|
||||
JavaScript 框架对比及案例(React、Vue 及 Hyperapp)
|
||||
=============================================
|
||||
|
||||
#### 臭名昭著计时器例子
|
||||
在[我的上一篇文章中][5],我试图解释为什么我认为 [Hyperapp][6] 是一个 [React][7] 或 [Vue][8] 的可用替代品,原因是,我发现它易于起步。许多人批评这篇文章,认为它自以为是,并没有给其它框架一个展示自己的机会。因此,在这篇文章中,我将尽可能客观的通过提供一些最小化的例子来比较这三个框架,以展示它们的能力。
|
||||
|
||||
计时器可能是响应式编程中最常用最容易理解的例子之一:
|
||||
### 耳熟能详的计时器例子
|
||||
|
||||
计时器可能是响应式编程中最常用的例子之一,极其易于理解:
|
||||
|
||||
* 你需要一个变量 `count` 保持对计数器的追踪。
|
||||
|
||||
* 你需要两个方法来增加或减少 `count` 变量的值。
|
||||
|
||||
* 你需要一种方法来渲染 `count` 变量,并将其呈现给用户。
|
||||
|
||||
* 你需要两个挂载到两个方法上的按钮,以便在用户和它们产生交互时变更 `count` 变量。
|
||||
* 你需要挂载到这两个方法上的两个按钮,以便在用户和它们产生交互时变更 `count` 变量。
|
||||
|
||||
下述代码是上述所有三个框架的实现:
|
||||
|
||||
|
||||
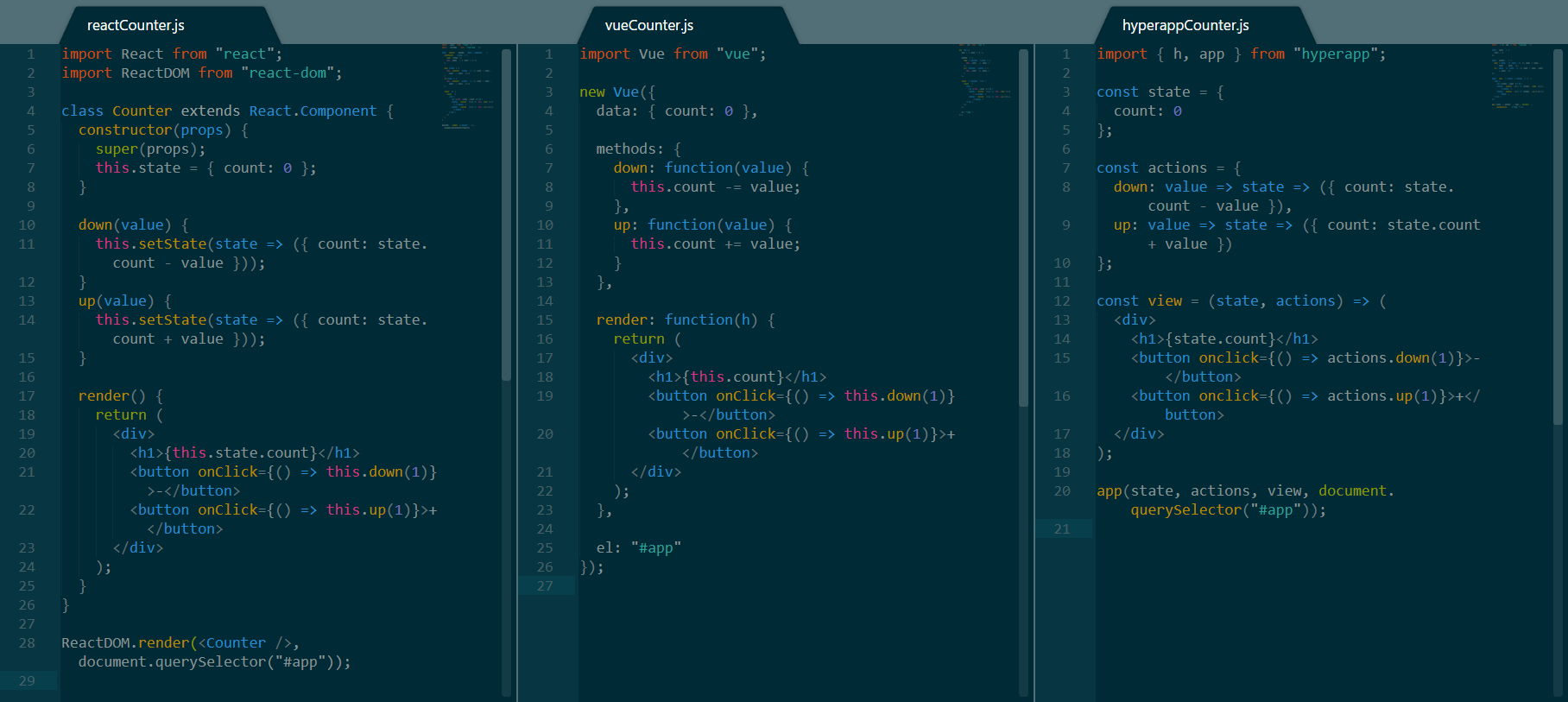
|
||||
使用 React、Vue 和 Hyperapp 实现的计数器
|
||||
|
||||
*使用 React、Vue 和 Hyperapp 实现的计数器*
|
||||
|
||||
这里或许会有很多要做的事情,特别是当你并不熟悉其中的一个或多个的时候,因此,我们来一步一步解构这些代码:
|
||||
这里或许会有很多要做的事情,特别是当你并不熟悉其中的一个或多个步骤的时候,因此,我们来一步一步解构这些代码:
|
||||
|
||||
* 这三个框架的顶部都有一些 `import` 语句
|
||||
|
||||
* React 更推崇面向对象的范式,就是创建一个 `Counter` 组件的 `class`,Vue 遵循类似的范式,并通过创建一个新的 `Vue` 类的实例并将信息传递给它来实现。 最后,Hyperapp 坚持函数范式,同时完全分离 `view`、`state`和`action` 。
|
||||
|
||||
* React 更推崇面向对象的范式,就是创建一个 `Counter` 组件的 `class`。Vue 遵循类似的范式,通过创建一个新的 `Vue` 类的实例并将信息传递给它来实现。最后,Hyperapp 坚持函数范式,同时完全彼此分离 `view`、`state`和`action`。
|
||||
* 就 `count` 变量而言, React 在组件的构造函数内对其进行实例化,而 Vue 和 Hyperapp 则分别是在它们的 `data` 和 `state` 中设置这些属性。
|
||||
|
||||
* 继续看,你可能注意到 React 和 Vue 有相同的方法来于 `count` 变量进行交互。 React 使用继承自 `React.Component` 的 `setState` 方法来修改它的状态,而 Vue 直接修改 `this.count`。 Hyperapp 使用 ES6 的双箭头语法来实现这个方法,并且,据我所知,这是唯一一个更推荐使用这种语法的框架,React 和 Vue 需要在它们的方法内使用 `this`。另一方面,Hyperapp 的方法需要将状态作为参数,这意味着可以在不同的上下文中重用它们。
|
||||
|
||||
* 这三个框架的渲染部分实际上是相同的。唯一的细微差别是 Vue 需要一个函数 `h` 作为参数传递给渲染器,事实上 Hyperapp 使用 `onclick` 替代 `onClick` 以及基于每个框架中实现状态的方式引用 `count` 变量的方式。
|
||||
|
||||
* 继续看,你可能注意到 React 和 Vue 有相同的方法来与 `count` 变量进行交互。 React 使用继承自 `React.Component` 的 `setState` 方法来修改它的状态,而 Vue 直接修改 `this.count`。 Hyperapp 使用 ES6 的双箭头语法来实现这个方法,而据我所知,这是唯一一个推荐使用这种语法的框架,React 和 Vue 需要在它们的方法内使用 `this`。另一方面,Hyperapp 的方法需要将状态作为参数,这意味着可以在不同的上下文中重用它们。
|
||||
* 这三个框架的渲染部分实际上是相同的。唯一的细微差别是 Vue 需要一个函数 `h` 作为参数传递给渲染器,事实上 Hyperapp 使用 `onclick` 替代 `onClick` ,以及基于每个框架中实现状态的方式引用 `count` 变量。
|
||||
* 最后,所有的三个框架都被挂载到了 `#app` 元素上。每个框架都有稍微不同的语法,Vue 则使用了最直接的语法,通过使用元素选择器而不是使用元素来提供最大的通用性。
|
||||
|
||||
#### 计数器案例对比意见
|
||||
|
||||
同时比较所有的三个框架,Hyperapp 需要最少的代码来实现计数器,并且它是唯一一个使用函数范式的框架。然而,Vue 的代码在绝对长度上似乎更短一些,元素选择器的挂载方式是一个很好的增强。React 的代码看起来最多,但是并不意味着代码不好理解。
|
||||
|
||||
同时比较所有的三个框架,Hyperapp 需要最少的代码来实现计数器,并且他是唯一一个使用函数范式的框架。然而,Vue 的代码在绝对长度上似乎更短一些,元素选择器的安装是一个很好的补充。React 的代码看起来最多,但是并不意味着代码不好理解。
|
||||
### 使用异步代码
|
||||
|
||||
* * *
|
||||
|
||||
#### 使用异步代码
|
||||
|
||||
偶尔你可能要不得不处理异步代码。最常见的异步操作之一是发送请求给一个 API。为了这个例子的目的,我将使用一个[占位 API]以及一些假数据来渲染一个文章的列表。必须做的事情如下:
|
||||
偶尔你可能需要处理异步代码。最常见的异步操作之一是发送请求给一个 API。为了这个例子的目的,我将使用一个[占位 API] 以及一些假数据来渲染一个文章列表。必须做的事情如下:
|
||||
|
||||
* 在状态里保存一个 `posts` 的数组
|
||||
|
||||
* 使用一个方法和正确的 URL 来调用 `fetch()` ,等待返回数据,转化为 JSON,最终使用接收到的数据更新 `posts` 变量。
|
||||
|
||||
* 使用一个方法和正确的 URL 来调用 `fetch()` ,等待返回数据,转化为 JSON,并最终使用接收到的数据更新 `posts` 变量。
|
||||
* 渲染一个按钮,这个按钮将调用抓取文章的方法。
|
||||
|
||||
* 渲染有主键的 `posts` 列表。
|
||||
|
||||
|
||||
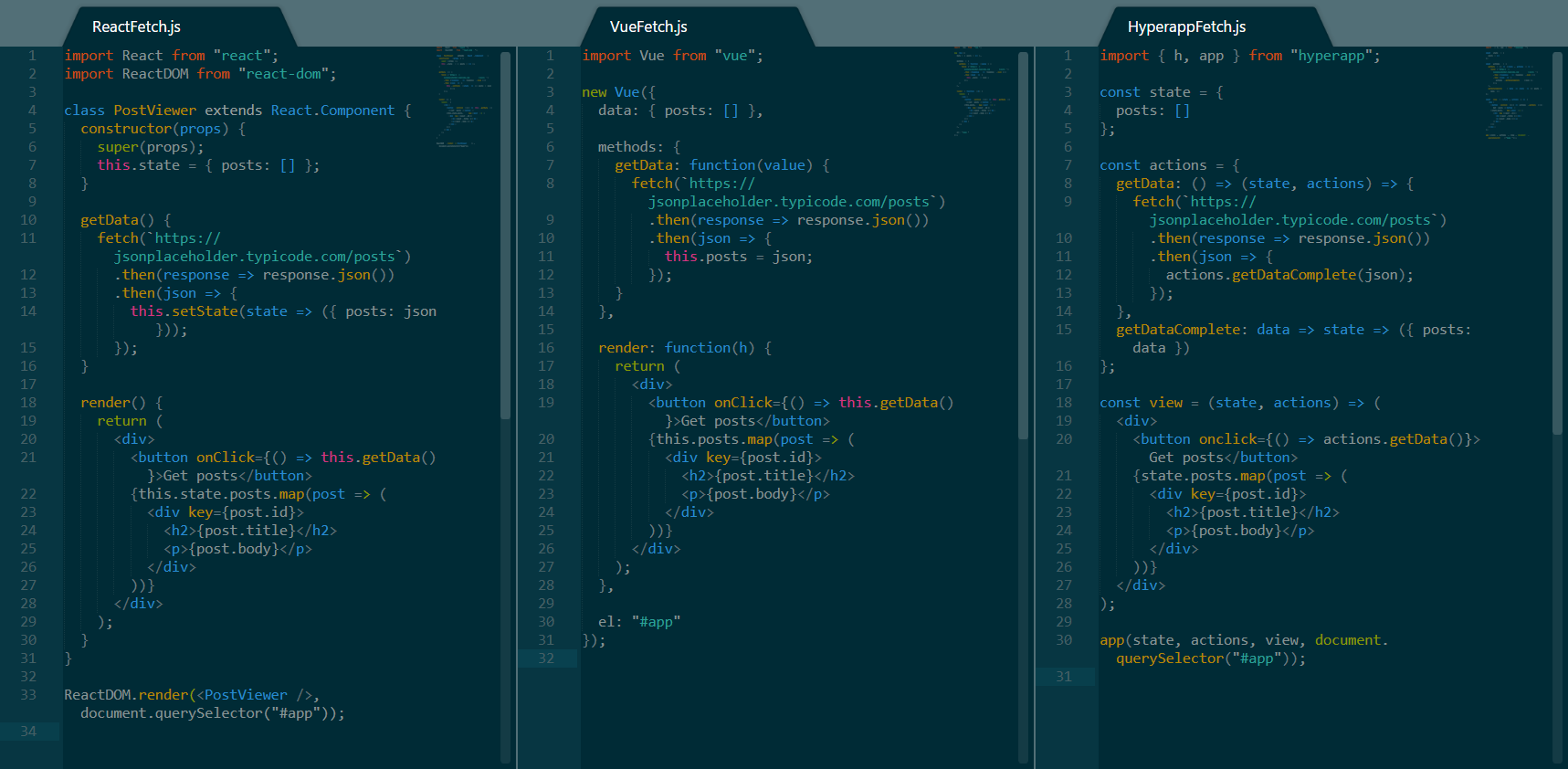
|
||||
从一个 RESTFul API 抓取数据
|
||||
|
||||
*从一个 RESTFul API 抓取数据*
|
||||
|
||||
让我们分解上面的代码,并比较三个框架:
|
||||
|
||||
* 与上面的技术里例子类似,这三个框架之间的存储状态、渲染试图和挂载非常相似。这些差异与上面的讨论相同。
|
||||
|
||||
* 在三个框架中使用 `fetch()` 抓取数据都非常简单并且可以像预期一样工作。然而其中的关键在于, Hyperapp 处理异步操作和其他两种框架有些不同。当数据被接收到并转换为JSON 时,该操作将调用不同的同步动作以取代直接在异步操作中修改状态。
|
||||
|
||||
* 就代码长度而言, Hyperapp 依然需要最少的代码行数来实现相同的结果,但是 Vue 的代码看起来不那么的冗长,同时拥有最少的绝对字符长度。
|
||||
* 与上面的技术里例子类似,这三个框架之间的存储状态、渲染视图和挂载非常相似。这些差异与上面的讨论相同。
|
||||
* 在三个框架中使用 `fetch()` 抓取数据都非常简单,并且可以像预期一样工作。然而其中的关键在于, Hyperapp 处理异步操作和其它两种框架有些不同。当数据被接收到并转换为 JSON 时,该操作将调用不同的同步动作以取代直接在异步操作中修改状态。
|
||||
* 就代码长度而言,Hyperapp 依然只用最少的代码行数实现了相同的结果,但是 Vue 的代码看起来不那么的冗长,同时拥有最少的绝对字符长度。
|
||||
|
||||
#### 异步代码对比意见
|
||||
|
||||
无论你选择哪种框架,异步操作都非常简单。在应用异步操作时, Hyperapp 可能会迫使你去遵循编写更加函数化和模块化的代码的路径。但是另外两个框架也确实可以做到这一点,并且在这一方面给你提供更多的选择。
|
||||
无论你选择哪种框架,异步操作都非常简单。在应用异步操作时, Hyperapp 可能会迫使你去遵循编写更加函数化和模块化的代码的方式。但是另外两个框架也确实可以做到这一点,并且在这一方面给你提供更多的选择。
|
||||
|
||||
* * *
|
||||
### To-Do 列表组件案例
|
||||
|
||||
#### To-Do List 组件案例
|
||||
|
||||
在响应式编程中,最出名的例子可能是使用每一个框架里来实现 To-Do List。我不打算在这里实现整个部分,我只实现一个无状态的组件,来展示三个框架如何帮助创建更小的可复用的块来协助构建应用程序。
|
||||
在响应式编程中,最出名的例子可能是使用每一个框架里来实现 To-Do 列表。我不打算在这里实现整个部分,我只实现一个无状态的组件,来展示三个框架如何创建更小的可复用的块来协助构建应用程序。
|
||||
|
||||
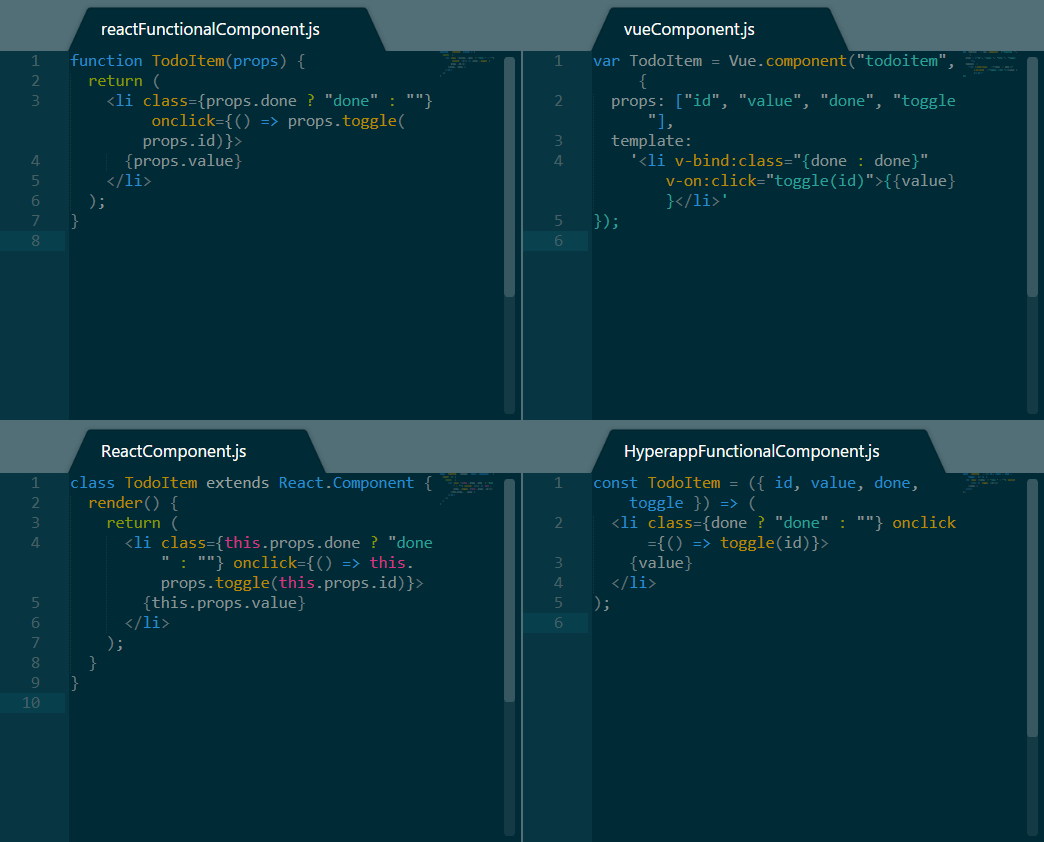
|
||||
演示 TodoItem 实现
|
||||
|
||||
*示例 TodoItem 实现*
|
||||
|
||||
上面的图片展示了每一个框架一个例子,并为 React 提供了一个额外的例子。接下来是我们从它们四个中看到的:
|
||||
|
||||
* React 在编程范式上最为灵活。它支持函数组件以及类组件。它还支持你在右下角看到的 Hyperapp 组件,无需任何修改。
|
||||
|
||||
* Hyperapp 还支持 React 的函数组件实现,这意味着两个框架之间还有实验的空间。
|
||||
|
||||
* 最后出现的 Vue 有着其合理而又奇怪的语法,即使是对另外两个很有经验的人,也不能马上理解其含义。
|
||||
|
||||
* React 在编程范式上最为灵活。它支持函数组件,也支持类组件。它还支持你在右下角看到的 Hyperapp 组件,无需任何修改。
|
||||
* Hyperapp 还支持 React 的函数组件实现,这意味着两个框架之间还有很多的实验空间。
|
||||
* 最后出现的 Vue 有着其合理而又奇怪的语法,即使是对另外两个框架很有经验的人,也不能马上理解其含义。
|
||||
* 在长度方面,所有的案例代码长度非常相似,在 React 的一些方法中稍微冗长一些。
|
||||
|
||||
#### To-Do List 项目对比意见
|
||||
#### To-Do 列表项目对比意见
|
||||
|
||||
Vue 需要花费一些时间来熟悉,因为它的模板和其他两个框架有一些不同。React 非常的灵活,支持多种不同的方法来创建组件,而 HyperApp 保持一切简单,并提供与 React 的兼容性,以免你希望在某些时刻进行切换。
|
||||
Vue 需要花费一些时间来熟悉,因为它的模板和其它两个框架有一些不同。React 非常的灵活,支持多种不同的方法来创建组件,而 HyperApp 保持一切简单,并提供与 React 的兼容性,以免你希望在某些时刻进行切换。
|
||||
|
||||
* * *
|
||||
### 生命周期方法比较
|
||||
|
||||
#### 生命周期方法比较
|
||||
|
||||
|
||||
另一个关键对比是组件的生命周期事件,每一个框架允许你根据你的需要来订阅和处理这些时间。下面是我根据各框架的 API 参考手册创建的表格:
|
||||
另一个关键对比是组件的生命周期事件,每一个框架允许你根据你的需要来订阅和处理事件。下面是我根据各框架的 API 参考手册创建的表格:
|
||||
|
||||

|
||||
Lifecycle method comparison
|
||||
|
||||
* Vue 提供了最多的生命周期钩子,提供了处理生命周期时间之前或之后发生任何时间的机会。这能有效帮助管理复杂的组件。
|
||||
|
||||
* React 和 Hyperapp 的生命周期钩子非常类似,React 将 `unmount` 和 `destory` 绑定在了一切,而 Hyperapp 则将 `create` 和 `mount` 绑定在了一起。两者在处理生命周期事件方面都提供了相当数量的控制。
|
||||
*生命周期方式比较*
|
||||
|
||||
* Vue 提供了最多的生命周期钩子,提供了处理生命周期事件之前或之后发生的任何事件的机会。这能有效帮助管理复杂的组件。
|
||||
* React 和 Hyperapp 的生命周期钩子非常类似,React 将 `unmount` 和 `destory` 绑定在了一起,而 Hyperapp 则将 `create` 和 `mount` 绑定在了一起。两者在处理生命周期事件方面都提供了相当多的控制。
|
||||
* Vue 根本没有处理 `unmount` (据我所理解),而是依赖于 `destroy` 事件在组件稍后的生命周期进行处理。 React 不处理 `destory` 事件,而是选择只处理 `unmount` 事件。最终,HyperApp 不处理 `create` 事件,取而代之的是只依赖 `mount` 事件。
|
||||
|
||||
#### 生命周期对比意见
|
||||
|
||||
总的来说,每个框架都提供了生命周期组件,它们帮助你处理组件生命周期中的许多事情。这三个框架都为它们的生命周期提供了钩子,其之间的细微差别,可能源自于实现和方案上的根本差异。通过提供更细粒度的时间处理,Vue 可以更进一步的允许你在开始或结束之后处理生命周期事件。
|
||||
|
||||
* * *
|
||||
|
||||
#### 性能比较
|
||||
|
||||
除了易用性和编码技术以外,性能也是大多数开发人员考虑的关键因素,尤其是在进行更复杂的应用程序时。[js-framework-benchmark][10]是一个很好的用于比较框架的工具,所以让我们看看每一组测评数据数组都说了些什么:
|
||||
### 性能比较
|
||||
|
||||
除了易用性和编码技术以外,性能也是大多数开发人员考虑的关键因素,尤其是在进行更复杂的应用程序时。[js-framework-benchmark][10] 是一个很好的用于比较框架的工具,所以让我们看看每一组测评数据数组都说了些什么:
|
||||
|
||||
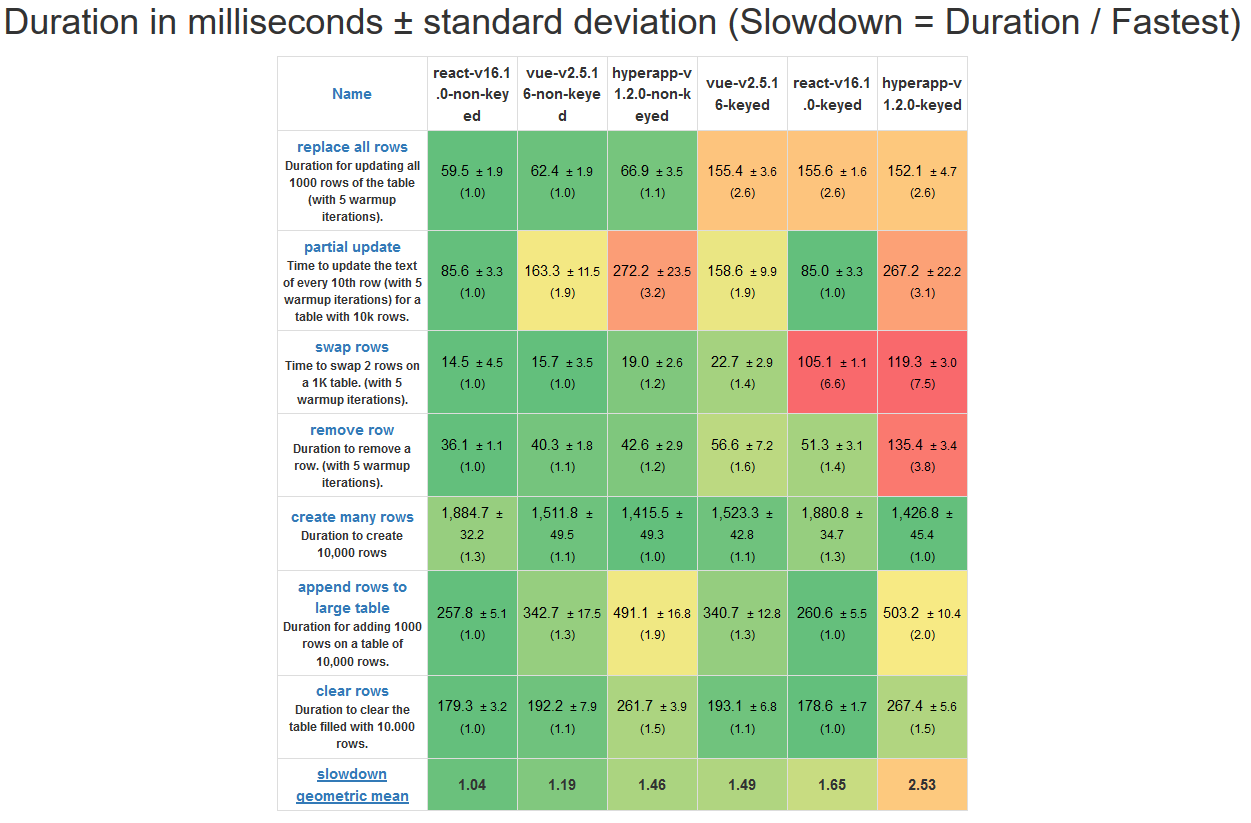
|
||||
测评操作表
|
||||
|
||||
*测评操作表*
|
||||
|
||||
* 与三个框架的有主键操作相比,无主键操作更快。
|
||||
|
||||
* 无主键的 React 在所有六种对比中拥有最强的性能,他在所有测试上都有令人深刻的表现。
|
||||
|
||||
* 有主键的 Vue 只比有主键的 React 性能稍强,而无主键的 Vue 要比无主键的 React 性能差。
|
||||
|
||||
* Vue 和 Hyperapp 在进行局部更新性能测试时遇见了一些问题,与此同时,React 似乎对该问题进行很好的优化。
|
||||
|
||||
* 无主键的 React 在所有六种对比中拥有最强的性能,它在所有测试上都有令人深刻的表现。
|
||||
* 有主键的 Vue 只比有主键的 React 性能稍强,而无主键的 Vue 要比无主键的 React 性能明显差。
|
||||
* Vue 和 Hyperapp 在进行局部更新的性能测试时遇见了一些问题,与此同时,React 似乎对该问题进行很好的优化。
|
||||
|
||||
|
||||
|
||||
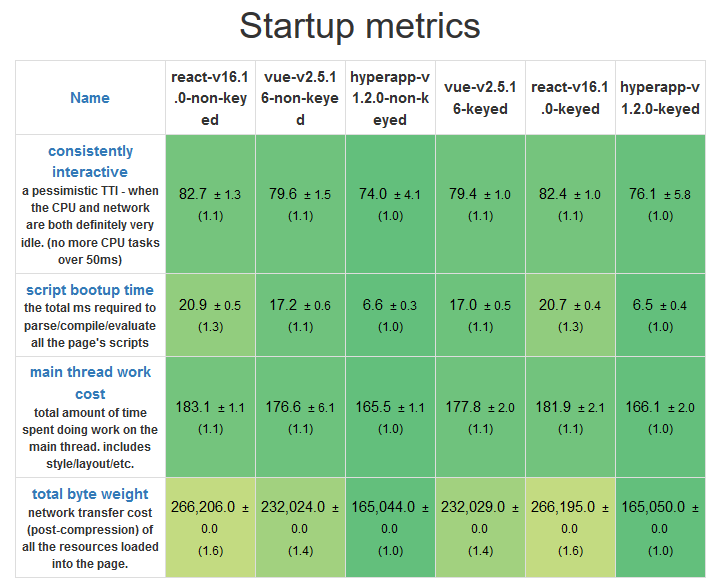
启动测试
|
||||
|
||||
* Hyperapp 是三个框架中最轻量的,而 React 和 Vue 有非常小尺度的差异。
|
||||
|
||||
* Hyperapp 具有最快的启动时间,这得益于他极小的大小和极简的API
|
||||
|
||||
* Vue 在启动上比 React 好一些,但是非常小。
|
||||
*启动测试*
|
||||
|
||||
* Hyperapp 是三个框架中最轻量的,而 React 和 Vue 有非常小的大小差异。
|
||||
* Hyperapp 具有最快的启动时间,这得益于它极小的大小和极简的 API
|
||||
* Vue 在启动上比 React 好一些,但是差异非常小。
|
||||
|
||||

|
||||
内存分配测试
|
||||
|
||||
* Hyperapp 是三者中对资源依赖最小的一个,与其他两者相比,任何一个操作都需要更少的内存。
|
||||
*内存分配测试*
|
||||
|
||||
* 资源消耗不是跟高,三者应该在现代硬件上进行类似的操作。
|
||||
* Hyperapp 是三者中对资源依赖最小的一个,与其它两者相比,任何一个操作都需要更少的内存。
|
||||
* 资源消耗不是非常高,三者都应该在现代硬件上进行类似的操作。
|
||||
|
||||
#### 性能对比意见
|
||||
|
||||
如果性能是一个问题,你应该考虑你正在使用什么样的应用程序以及你的需求是什么。看起来 Vue 和 React 用于更复杂的应用程序更好,而 Hyperapp 更适合于更小的应用程序、更少的数据处理和需要快速启动的应用程序,以及需要在低端硬件上工作的应用程序。
|
||||
|
||||
但是,要记住,这些测试远不能代表一般用例,所以在现实场景中可能会看到不同的结果。
|
||||
但是,要记住,这些测试远不能代表一般场景,所以在现实场景中可能会看到不同的结果。
|
||||
|
||||
* * *
|
||||
### 额外备注
|
||||
|
||||
#### 额外备注
|
||||
|
||||
Comparing React, Vue and Hyperapp might feel like comparing apples and oranges in many ways. There are some additional considerations concerning these frameworks that could very well help you decide on one over the other two:
|
||||
|
||||
比较 React、Vue 和 Hyperapp 可能像在许多方面比较苹果、橘子。关于这些框架还有一些其他的考虑,它们可以帮助你决定使用另一个框架。
|
||||
|
||||
* React 通过引入片段,避免了相邻的JSX元素必须封装在父元素中的问题,这些元素允许你将子元素列表分组,而无需向DOM添加额外的节点。
|
||||
|
||||
* Read还为你提供更高级别的组件,而VUE为你提供重用组件功能的MIXIN。
|
||||
比较 React、Vue 和 Hyperapp 可能像在许多方面比较苹果、橘子。关于这些框架还有一些其它的考虑,它们可以帮助你决定使用另一个框架。
|
||||
|
||||
* React 通过引入[片段][1],避免了相邻的 JSX 元素必须封装在父元素中的问题,这些元素允许你将子元素列表分组,而无需向 DOM 添加额外的节点。
|
||||
* React 还为你提供[更高级别的组件][2],而 VUE 为你提供重用组件功能的 [MIXIN][3]。
|
||||
* Vue 允许使用[模板][4]来分离结构和功能,从而更好的分离关注点。
|
||||
* 与其它两个相比,Hyperapp 感觉像是一个较低级别的 API,它的代码短得多,如果你愿意调整它并学习它的工作原理,那么它可以提供更多的通用性。
|
||||
|
||||
* 与其他两个相比,Hyperapp 感觉像是一个较低级别的API,它的代码短得多,如果你愿意调整它并学习它的工作原理,那么它可以提供更多的通用性。
|
||||
|
||||
* * *
|
||||
|
||||
#### 结论
|
||||
### 结论
|
||||
|
||||
我认为如果你已经阅读了这么多,你已经知道哪种工具更适合你的需求。毕竟,这不是讨论哪一个更好,而是讨论哪一个更适合每种情况。总而言之:
|
||||
|
||||
|
||||
* React 是一个非常强大的工具,他的周围有大量的开发者,可能会帮助你找到一个工作。入门并不难,但是掌握它肯定需要很多时间。然而,这是非常值得去花费你的时间全面掌握的。
|
||||
|
||||
* 如果你过去曾使用过另外一个 JavaScript 框架,Vue 可能看起来有点奇怪,但它也是一个非常有趣的工具。如果 React 不是你所喜欢的 ,那么它可能是一个可行的值得学习的选择。
|
||||
|
||||
* 最后,Hyperapp 是一个为小型项目而生的很酷的小框架,也是初学者入门的好地方。它提供比 React 或 Vue 更少的工具,但是它能帮助你快速构建原型并理解许多基本原理。你编写的许多代码都和其他两个框架兼容,或者是稍做更改,你可以在对它们中另外一个有信心时切换框架。
|
||||
* React 是一个非常强大的工具,围绕它有大规模的开发者社区,可能会帮助你找到一个工作。入门并不难,但是掌握它肯定需要很多时间。然而,这是非常值得去花费你的时间全面掌握的。
|
||||
* 如果你过去曾使用过另外的 JavaScript 框架,Vue 可能看起来有点奇怪,但它也是一个非常有趣的工具。如果 React 不是你所喜欢的,那么它可能是一个可行的、值得学习的选择。它有一些非常酷的内置功能,其社区也在增长中,甚至可能要比 React 增长还要快。
|
||||
* 最后,Hyperapp 是一个为小型项目而生的很酷的小框架,也是初学者入门的好地方。它提供比 React 或 Vue 更少的工具,但是它能帮助你快速构建原型并理解许多基本原理。你为它编写的许多代码和其它两个框架兼容,要么立即能用,或者是稍做更改就行,你可以在对它们中另外一个有信心时切换框架。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Web developer who loves to code, creator of 30 seconds of code (https://30secondsofcode.org/) and the mini.css framework (http://minicss.org).
|
||||
喜欢编码的 Web 开发者,“30 秒编码” ( https://30secondsofcode.org/ )和 mini.css 框架( http://minicss.org ) 的创建者。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/javascript-framework-comparison-with-examples-react-vue-hyperapp-97f064fb468d
|
||||
|
||||
作者:[Angelos Chalaris ][a]
|
||||
作者:[Angelos Chalaris][a]
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,48 @@
|
||||
开源网络方面的职位:创新与机遇的温床
|
||||
======
|
||||
|
||||
> 诸如容器、边缘计算这样的技术焦点领域大红大紫,对在这一领域能够整合、协作、创新的开发者和系统管理员们的需求在日益增进。
|
||||
|
||||

|
||||
|
||||
随着全球经济更加靠近数字化未来,每个垂直行业的公司和组织都在紧抓如何进一步在业务与运营上整合与部署技术。虽然 IT 企业在很大程度上遥遥领先,但是他们的经验与教训已经应用在了各行各业。尽管全国失业率为 4.1%,但整个科技专业人员的整体的失业率在 4 月份为 1.9%,开源工作的未来看起来尤其光明。我在开源网络领域工作,并且目睹着创新和机遇正在改变世界交流的方式。
|
||||
|
||||
它曾经是个发展缓慢的行业,现在由网络运营商、供应商、系统集成商和开发者所组成的网络生态系统正在采用开源软件,并且正在向商用硬件上运行的虚拟化和软件定义网络上转移。事实上,接近 70% 的全球移动用户由[低频网络][1]运营商成员所占据。该网络运营商成员致力于协调构成开放网络栈和相邻技术的项目。
|
||||
|
||||
### 技能需求
|
||||
|
||||
这一领域的开发者和系统管理员采用云原生和 DevOps 的方法开发新的使用案例,应对最紧迫的行业挑战。诸如容器、边缘计算等焦点领域大红大紫,并且在这一领域能够整合、协作、创新的开发者和系统管理员们的需求在日益增进。
|
||||
|
||||
开源软件与 Linux 使这一切成为可能,根据最近出版的 [2018开源软件工作报告][2],高达 80% 的招聘经理寻找会 Linux 技能的应聘者,**而 46% 希望在网络领域招聘人才,可以说“网络技术”在他们的招聘决策中起到了至关重要的作用。**
|
||||
|
||||
开发人员相当抢手,72% 的招聘经理都在找他们,其次是 DevOps 开发者(59%),工程师(57%)和系统管理员(49%)。报告同时指出,对容器技能需求的惊人的增长符合我们在网络领域所见到的,即云本地虚拟功能(CNF)的创建和持续集成/持续部署方式的激增,就如在 OPNFV 中的 [XCI 倡议][3] 一样。
|
||||
|
||||
### 开始吧
|
||||
|
||||
对于求职者来说,好消息是有着大量的关于开源软件的内容,包括免费的 [Linux 入门课程][4]。好的工作需要有多项证书,因此我鼓励你探索更多领域,去寻求培训的机会。计算机网络方面,在 [OPNFV][5] 上查看最新的培训课程或者是 [ONAP][6] 项目,也可以选择这门[开源网络技术简介][7]课程。
|
||||
|
||||
如果你还没有做好这些,下载 [2018 开源软件工作报告][2] 以获得更多见解,在广阔的开放源码技术世界中规划你的课程,去寻找另一边等待你的令人兴奋的职业!
|
||||
|
||||
点击这里[下载完整的开源软件工作报告][8]并且[了解更多关于 Linux 的认证][9]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/os-jobs-report/2018/7/open-source-networking-jobs-hotbed-innovation-and-opportunities
|
||||
|
||||
作者:[Brandon Wick][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/brandon-wick
|
||||
[1]:https://www.lfnetworking.org/
|
||||
[2]:https://www.linuxfoundation.org/publications/2018/06/open-source-jobs-report-2018/
|
||||
[3]:https://docs.opnfv.org/en/latest/submodules/releng-xci/docs/xci-overview.html
|
||||
[4]:https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-1
|
||||
[5]:https://training.linuxfoundation.org/training/opnfv-fundamentals/
|
||||
[6]:https://training.linuxfoundation.org/training/onap-fundamentals/
|
||||
[7]:https://www.edx.org/course/introduction-to-software-defined-networking-technologies
|
||||
[8]:https://www.linuxfoundation.org/publications/open-source-jobs-report-2018/
|
||||
[9]:https://training.linuxfoundation.org/certification
|
||||
@ -1,7 +1,7 @@
|
||||
6 个简单的方式来查看 Linux 中的用户名和其它信息
|
||||
======
|
||||
|
||||
这是一个非常基础的话题,在 Linux 中,每个人都知道如何使用 **id** 来查找用户信息。一些用户也从 **/etc/passwd** 文件中过滤用户信息。
|
||||
这是一个非常基础的话题,在 Linux 中,每个人都知道如何使用 `id` 来查找用户信息。一些用户也从 `/etc/passwd` 文件中过滤用户信息。
|
||||
|
||||
我们还使用其它命令来获取用户信息。
|
||||
|
||||
@ -11,45 +11,44 @@
|
||||
|
||||
这是帮助管理员在 Linux 中查找用户信息的基本命令之一。Linux 中的一切都是文件,甚至用户信息都存储在一个文件中。
|
||||
|
||||
**建议阅读:**
|
||||
建议阅读:
|
||||
|
||||
**(#)** [怎样在 Linux 上查看用户创建的日期][1]
|
||||
- [怎样在 Linux 上查看用户创建的日期][1]
|
||||
- [怎样在 Linux 上查看用户属于哪个组][2]
|
||||
- [怎样在 Linux 上查看强制用户在下次登录时改变密码][3]
|
||||
|
||||
**(#)** [怎样在 Linux 上查看用户属于哪个组][2]
|
||||
|
||||
**(#)** [怎样在 Linux 上查看强制用户在下次登录时改变密码][3]
|
||||
|
||||
所有用户都被添加在 `/etc/passwd` 文件中,这里保留了用户名和其它相关详细信息。在 Linux 中创建用户时,用户详细信息将存储在 /etc/passwd 文件中。passwd 文件将每个用户详细信息保存为一行,包含 7 字段。
|
||||
所有用户都被添加在 `/etc/passwd` 文件中,这里保留了用户名和其它相关详细信息。在 Linux 中创建用户时,用户详细信息将存储在 `/etc/passwd` 文件中。passwd 文件将每个用户详细信息保存为一行,包含 7 字段。
|
||||
|
||||
我们可以使用以下 6 种方法来查看用户信息。
|
||||
|
||||
* `id :`为指定的用户名打印用户和组信息。
|
||||
* `getent :`从 Name Service Switch 库中获取条目。
|
||||
* `/etc/passwd file :` /etc/passwd 文件包含每个用户的详细信息,每个用户详情是一行,包含 7 个字段。
|
||||
* `finger :`用户信息查询程序
|
||||
* `lslogins :`lslogins 显示系统中已有用户的信息
|
||||
* `compgen :`compgen 是 bash 内置命令,它将显示用户的所有可用命令。
|
||||
* `id`:为指定的用户名打印用户和组信息。
|
||||
* `getent`:从 Name Service Switch 库中获取条目。
|
||||
* `/etc/passwd`: 文件包含每个用户的详细信息,每个用户详情是一行,包含 7 个字段。
|
||||
* `finger`:用户信息查询程序
|
||||
* `lslogins`:显示系统中已有用户的信息
|
||||
* `compgen`:是 bash 内置命令,它将显示用户的所有可用命令。
|
||||
|
||||
### 1) 使用 id 命令
|
||||
|
||||
id 代表身份。它输出真实有效的用户和组 ID。也可以输出指定用户或当前用户的用户和组信息。
|
||||
`id` 代表<ruby>身份<rt>identity</rt></ruby>。它输出真实有效的用户和组 ID。也可以输出指定用户或当前用户的用户和组信息。
|
||||
|
||||
```
|
||||
# id daygeek
|
||||
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
|
||||
|
||||
```
|
||||
|
||||
下面是上述输出的详细信息:
|
||||
|
||||
* **`uid (1000/daygeek):`** 它显示用户 ID 和用户名
|
||||
* **`gid (1000/daygeek):`** 它显示用户的组 ID 和名称
|
||||
* **`groups:`** 它显示用户的附加组 ID 和名称
|
||||
* `uid (1000/daygeek)`: 它显示用户 ID 和用户名
|
||||
* `gid (1000/daygeek)`: 它显示用户的组 ID 和名称
|
||||
* `groups`: 它显示用户的附加组 ID 和名称
|
||||
|
||||
### 2) 使用 getent 命令
|
||||
|
||||
getent 命令显示 Name Service Switch 库支持的数据库中的条目,这些库在 /etc/nsswitch.conf 中配置。
|
||||
`getent` 命令显示 Name Service Switch 库支持的数据库中的条目,这些库在 `/etc/nsswitch.conf` 中配置。
|
||||
|
||||
`getent` 命令会显示类似于 `/etc/passwd` 文件的用户详情,它将每个用户的详细信息放在一行,包含 7 个字段。
|
||||
|
||||
getent 命令会显示类似于 /etc/passwd 文件的用户详情,它将每个用户的详细信息放在一行,包含 7 个字段。
|
||||
```
|
||||
# getent passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
@ -85,24 +84,24 @@ nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
|
||||
sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
下面是关于 7 个字段的详细信息。
|
||||
下面是关于 7 个字段的详细信息:
|
||||
|
||||
```
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
* **`Username (magesh):`** 已创建的用户名。字符长度应该在 1 到 32 之间。
|
||||
* **`Password (x):`** 它表明加密密码存储在 /etc/shadow 文件中。
|
||||
* **`User ID (UID-502):`** 它表示用户 ID(UID),每个用户应包含唯一的 UID。UID (0-Zero) 保留给 root,UID(1-99)是为系统用户保留的,UID(100-999)是为系统账户/组保留的。
|
||||
* **`Group ID (GID-503):`** 它表示组 ID(GID),每个组应该包含唯一的 GID,它存储在 /etc/group 文件中。
|
||||
* **`User ID Info (2g Admin - Magesh M):`** 它表示命令字段。这个字段可用于描述用户信息。
|
||||
* **`Home Directory (/home/magesh):`** 它表示用户家目录。
|
||||
* **`shell (/bin/bash):`** 它表示用户的 bash shell。
|
||||
* `Username (magesh)`: 已创建的用户名。字符长度应该在 1 到 32 之间。
|
||||
* `Password (x)`: 它表明加密密码存储在 `/etc/shadow` 文件中。
|
||||
* `User ID (UID-502)`: 它表示用户 ID(UID),每个用户应包含唯一的 UID。UID (0-Zero) 保留给 root,UID(1-99)是为系统用户保留的,UID(100-999)是为系统账户/组保留的。
|
||||
* `Group ID (GID-503)`: 它表示组 ID(GID),每个组应该包含唯一的 GID,它存储在 `/etc/group` 文件中。
|
||||
* `User ID Info (2g Admin - Magesh M)`: 它表示命令字段。这个字段可用于描述用户信息。
|
||||
* `Home Directory (/home/magesh)`: 它表示用户家目录。
|
||||
* `shell (/bin/bash)`: 它表示用户的 bash shell。
|
||||
|
||||
如果你只想在 `getent` 命令的输出中显示用户名,使用以下命令格式:
|
||||
|
||||
如果你只想在 getent 命令的输出中显示用户名,使用以下命令格式:
|
||||
```
|
||||
# getent passwd | cut -d: -f1
|
||||
root
|
||||
@ -138,10 +137,10 @@ nrpe
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
只显示用户的家目录,使用以下命令格式:
|
||||
|
||||
```
|
||||
# getent passwd | grep '/home' | cut -d: -f1
|
||||
centos
|
||||
@ -149,12 +148,12 @@ prakash
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
### 3) 使用 /etc/passwd 文件
|
||||
|
||||
`/etc/passwd` 是一个文本文件,它包含每个用户登录 Linux 系统所必需的的信息。它维护用户的有用信息,如用户名,密码,用户 ID,组 ID,用户 ID 信息,家目录和 shell。/etc/passwd 文件将每个用户详细信息放在一行中,包含 7 个字段,如下所示:
|
||||
`/etc/passwd` 是一个文本文件,它包含每个用户登录 Linux 系统所必需的的信息。它维护用户的有用信息,如用户名,密码,用户 ID,组 ID,用户 ID 信息,家目录和 shell。`/etc/passwd` 文件将每个用户详细信息放在一行中,包含 7 个字段,如下所示:
|
||||
|
||||
```
|
||||
# cat /etc/passwd
|
||||
root:x:0:0:root:/root:/bin/bash
|
||||
@ -190,24 +189,24 @@ nrpe:x:497:497:NRPE user for the NRPE service:/var/run/nrpe:/sbin/nologin
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
thanu:x:503:504:2g Editor - Thanisha M:/home/thanu:/bin/bash
|
||||
sudha:x:504:505:2g Editor - Sudha M:/home/sudha:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
以下是 7 个字段的详细信息。
|
||||
|
||||
```
|
||||
magesh:x:502:503:2g Admin - Magesh M:/home/magesh:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
* **`Username (magesh):`** 已创建的用户名。字符长度应该在 1 到 32 之间。
|
||||
* **`Password (x):`** 它表明加密密码存储在 /etc/shadow 文件中。
|
||||
* **`User ID (UID-502):`** 它表示用户 ID(UID),每个用户应包含唯一的 UID。UID (0-Zero) 保留给 root,UID(1-99)是为系统用户保留的,UID(100-999)是为系统账户/组保留的。
|
||||
* **`Group ID (GID-503):`** 它表示组 ID(GID),每个组应该包含唯一的 GID,它存储在 /etc/group 文件中。
|
||||
* **`User ID Info (2g Admin - Magesh M):`** 它表示命令字段。这个字段可用于描述用户信息。
|
||||
* **`Home Directory (/home/magesh):`** 它表示用户家目录。
|
||||
* **`shell (/bin/bash):`** 它表示用户的 bash shell。
|
||||
* `Username (magesh)`: 已创建的用户名。字符长度应该在 1 到 32 之间。
|
||||
* `Password (x)`: 它表明加密密码存储在 `/etc/shadow` 文件中。
|
||||
* `User ID (UID-502)`: 它表示用户 ID(UID),每个用户应包含唯一的 UID。UID (0-Zero) 保留给 root,UID(1-99)是为系统用户保留的,UID(100-999)是为系统账户/组保留的。
|
||||
* `Group ID (GID-503)`: 它表示组 ID(GID),每个组应该包含唯一的 GID,它存储在 `/etc/group` 文件中。
|
||||
* `User ID Info (2g Admin - Magesh M)`: 它表示命令字段。这个字段可用于描述用户信息。
|
||||
* `Home Directory (/home/magesh)`: 它表示用户家目录。
|
||||
* `shell (/bin/bash)`: 它表示用户的 bash shell。
|
||||
|
||||
如果你只想显示 `/etc/passwd` 文件中的用户名,使用以下格式:
|
||||
|
||||
如果你只想显示 /etc/passwd 文件中的用户名,使用以下格式:
|
||||
```
|
||||
# cut -d: -f1 /etc/passwd
|
||||
root
|
||||
@ -243,10 +242,10 @@ nrpe
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
只显示用户的家目录,使用以下格式:
|
||||
|
||||
```
|
||||
# cat /etc/passwd | grep '/home' | cut -d: -f1
|
||||
centos
|
||||
@ -254,12 +253,12 @@ prakash
|
||||
magesh
|
||||
thanu
|
||||
sudha
|
||||
|
||||
```
|
||||
|
||||
### 4) 使用 finger 命令
|
||||
|
||||
finger 命令显示有关系统用户的信息。它显示用户的真实姓名,终端名称和写入状态(如果没有写入权限,那么最为终端名称后面的 "*"),空闲时间和登录时间。
|
||||
`finger` 命令显示有关系统用户的信息。它显示用户的真实姓名,终端名称和写入状态(如果没有写入权限,那么最为终端名称后面的 `*`),空闲时间和登录时间。
|
||||
|
||||
```
|
||||
# finger magesh
|
||||
Login: magesh Name: 2g Admin - Magesh M
|
||||
@ -267,22 +266,22 @@ Directory: /home/magesh Shell: /bin/bash
|
||||
Last login Tue Jul 17 22:46 (EDT) on pts/2 from 103.5.134.167
|
||||
No mail.
|
||||
No Plan.
|
||||
|
||||
```
|
||||
|
||||
以下是上述输出的详细信息:
|
||||
|
||||
* **`Login:`** 用户名
|
||||
* **`Name:`** 附加/有关用户的其它信息
|
||||
* **`Directory:`** 用户家目录的信息
|
||||
* **`Shell:`** 用户的 shell 信息
|
||||
* **`LAST-LOGIN:`** 上次登录日期和其它信息
|
||||
* `Login`: 用户名
|
||||
* `Name`: 附加/有关用户的其它信息
|
||||
* `Directory`: 用户家目录的信息
|
||||
* `Shell`: 用户的 shell 信息
|
||||
* `LAST-LOGIN`: 上次登录日期和其它信息
|
||||
|
||||
### 5) 使用 lslogins 命令
|
||||
|
||||
它显示系统已知用户的信息。默认情况下,它将列出系统中所有用户的信息。
|
||||
|
||||
lslogins 使用程序的灵感来自于 logins 实用程序,该实用程序最初出现在 FreeBSD 4.10 中。
|
||||
`lslogins` 使用程序的灵感来自于 `logins` 实用程序,该实用程序最初出现在 FreeBSD 4.10 中。
|
||||
|
||||
```
|
||||
# lslogins -u
|
||||
UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
|
||||
@ -292,21 +291,21 @@ UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
|
||||
502 magesh 0 0 Jul17/22:46 2g Admin - Magesh M
|
||||
503 thanu 0 0 Jul18/00:40 2g Editor - Thanisha M
|
||||
504 sudha 0 0 Jul18/01:18 2g Editor - Sudha M
|
||||
|
||||
```
|
||||
|
||||
以下是上述输出的详细信息:
|
||||
|
||||
* **`UID:`** 用户 id
|
||||
* **`USER:`** 用户名
|
||||
* **`PWD-LOCK:`** 密码已设置,但是已锁定
|
||||
* **`PWD-DENY:`** 登录密码是否禁用
|
||||
* **`LAST-LOGIN:`** 上次登录日期
|
||||
* **`GECOS:`** 有关用户的其它信息
|
||||
* `UID`: 用户 id
|
||||
* `USER`: 用户名
|
||||
* `PWD-LOCK`: 密码已设置,但是已锁定
|
||||
* `PWD-DENY`: 登录密码是否禁用
|
||||
* `LAST-LOGIN`: 上次登录日期
|
||||
* `GECOS`: 有关用户的其它信息
|
||||
|
||||
### 6) 使用 compgen 命令
|
||||
|
||||
compgen 是 bash 内置命令,它将显示所有可用的命令,别名和函数。(to 校正:这个命令在 CentOS 中有,但是我没有搞懂它的输出)
|
||||
`compgen` 是 bash 内置命令,它将显示所有可用的命令,别名和函数。(LCTT 译注:它的 `-u` 参数可以列出系统中用户。)
|
||||
|
||||
```
|
||||
# compgen -u
|
||||
root
|
||||
@ -352,7 +351,7 @@ via: https://www.2daygeek.com/6-easy-ways-to-check-user-name-and-other-informati
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,104 +3,101 @@
|
||||
|
||||

|
||||
|
||||
有时,最新版本的安装包可能无法按预期工作。你的程序可能与更新的软件包不兼容,并且仅支持特定的旧版软件包。在这种情况下,你可以立即将有问题的软件包降级到其早期的工作版本。请参阅我们的旧指南,[**在这**][1]了解如何降级 Ubuntu 及其衍生版中的软件包以及[**在这**][1]了解如何降级 Arch Linux 及其衍生版中的软件包。但是,你无需降级某些软件包。我们可以同时使用多个版本。例如,假设你在测试部署在 Ubuntu 18.04 LTS 中的[**LAMP 栈**][3]的 PHP 程序。过了一段时间,你发现应用程序在 PHP5.6 中工作正常,但在 PHP 7.2 中不正常(Ubuntu 18.04 LTS 默认安装 PHP 7.x)。你打算重新安装 PHP 或整个 LAMP 栈吗?但是没有必要。你甚至不必将 PHP 降级到其早期版本。在这个简短的教程中,我将向你展示如何在 Ubuntu 18.04 LTS 中切换多个 PHP 版本。它没你想的那么难。请继续阅读。
|
||||
有时,最新版本的安装包可能无法按预期工作。你的程序可能与更新的软件包不兼容,并且仅支持特定的旧版软件包。在这种情况下,你可以立即将有问题的软件包降级到其早期的工作版本。请参阅我们的旧指南,[在这][1]了解如何降级 Ubuntu 及其衍生版中的软件包以及[在这][1]了解如何降级 Arch Linux 及其衍生版中的软件包。但是,你无需降级某些软件包。我们可以同时使用多个版本。例如,假设你在测试部署在 Ubuntu 18.04 LTS 中的[LAMP 栈][3]的 PHP 程序。过了一段时间,你发现应用程序在 PHP 5.6 中工作正常,但在 PHP 7.2 中不正常(Ubuntu 18.04 LTS 默认安装 PHP 7.x)。你打算重新安装 PHP 或整个 LAMP 栈吗?但是没有必要。你甚至不必将 PHP 降级到其早期版本。在这个简短的教程中,我将向你展示如何在 Ubuntu 18.04 LTS 中切换多个 PHP 版本。它没你想的那么难。请继续阅读。
|
||||
|
||||
### 在多个 PHP 版本之间切换
|
||||
|
||||
要查看 PHP 的默认安装版本,请运行:
|
||||
|
||||
```
|
||||
$ php -v
|
||||
PHP 7.2.7-0ubuntu0.18.04.2 (cli) (built: Jul 4 2018 16:55:24) ( NTS )
|
||||
Copyright (c) 1997-2018 The PHP Group
|
||||
Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies
|
||||
with Zend OPcache v7.2.7-0ubuntu0.18.04.2, Copyright (c) 1999-2018, by Zend Technologies
|
||||
|
||||
```
|
||||
|
||||
如你所见,已安装的 PHP 的版本为 7.2.7。在测试你的程序几天后,你会发现你的程序不支持 PHP7.2。在这种情况下,同时使用 PHP5.x 和 PHP7.x 是个不错的主意,这样你就可以随时轻松地在任何支持的版本之间切换。
|
||||
|
||||
你不必删除 PHP7.x 或重新安装 LAMP 栈。你可以同时使用 PHP5.x 和 7.x 版本。
|
||||
|
||||
我假设你还没有在你的系统中卸载 php5.6。万一你已将其删除,你可以使用下面的 PPA 再次安装它。
|
||||
我假设你还没有在你的系统中卸载 PHP 5.6。万一你已将其删除,你可以使用下面的 PPA 再次安装它。
|
||||
|
||||
你可以从 PPA 中安装 PHP 5.6:
|
||||
|
||||
你可以从 PPA 中安装 PHP5.6:
|
||||
```
|
||||
$ sudo add-apt-repository -y ppa:ondrej/php
|
||||
$ sudo apt update
|
||||
$ sudo apt install php5.6
|
||||
|
||||
```
|
||||
|
||||
#### 从 PHP7.x 切换到 PHP5.x.
|
||||
#### 从 PHP 7.x 切换到 PHP 5.x.
|
||||
|
||||
首先使用命令禁用 PHP 7.2 模块:
|
||||
|
||||
首先使用命令禁用 PHP7.2 模块:
|
||||
```
|
||||
$ sudo a2dismod php7.2
|
||||
Module php7.2 disabled.
|
||||
To activate the new configuration, you need to run:
|
||||
systemctl restart apache2
|
||||
|
||||
```
|
||||
|
||||
接下来,启用 PHP5.6 模块:
|
||||
接下来,启用 PHP 5.6 模块:
|
||||
|
||||
```
|
||||
$ sudo a2enmod php5.6
|
||||
|
||||
```
|
||||
|
||||
将 PHP5.6 设置为默认版本:
|
||||
将 PHP 5.6 设置为默认版本:
|
||||
|
||||
```
|
||||
$ sudo update-alternatives --set php /usr/bin/php5.6
|
||||
|
||||
```
|
||||
|
||||
或者,你可以运行以下命令来设置默认情况下要使用的全局 PHP 版本。
|
||||
|
||||
```
|
||||
$ sudo update-alternatives --config php
|
||||
|
||||
```
|
||||
|
||||
输入选择的号码将其设置为默认版本,或者只需按 ENTER 键保持当前选择。
|
||||
输入选择的号码将其设置为默认版本,或者只需按回车键保持当前选择。
|
||||
|
||||
如果你已安装其他 PHP 扩展,请将它们设置为默认值。
|
||||
|
||||
```
|
||||
$ sudo update-alternatives --set phar /usr/bin/phar5.6
|
||||
|
||||
```
|
||||
|
||||
最后,重启 Apache Web 服务器:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart apache2
|
||||
|
||||
```
|
||||
|
||||
现在,检查 PHP5.6 是否是默认版本:
|
||||
现在,检查 PHP 5.6 是否是默认版本:
|
||||
|
||||
```
|
||||
$ php -v
|
||||
PHP 5.6.37-1+ubuntu18.04.1+deb.sury.org+1 (cli)
|
||||
Copyright (c) 1997-2016 The PHP Group
|
||||
Zend Engine v2.6.0, Copyright (c) 1998-2016 Zend Technologies
|
||||
with Zend OPcache v7.0.6-dev, Copyright (c) 1999-2016, by Zend Technologies
|
||||
|
||||
```
|
||||
|
||||
#### 从 PHP5.x 切换到 PHP7.x.
|
||||
#### 从 PHP 5.x 切换到 PHP 7.x.
|
||||
|
||||
同样,你可以从 PHP 5.x 切换到 PHP 7.x 版本,如下所示。
|
||||
|
||||
同样,你可以从 PHP5.x 切换到 PHP7.x 版本,如下所示。
|
||||
```
|
||||
$ sudo a2enmod php7.2
|
||||
|
||||
$ sudo a2dismod php5.6
|
||||
|
||||
$ sudo update-alternatives --set php /usr/bin/php7.2
|
||||
|
||||
$ sudo systemctl restart apache2
|
||||
|
||||
```
|
||||
|
||||
**提醒一句:**
|
||||
|
||||
最终稳定版 PHP5.6 于 2017 年 1 月 19 日达到[**活跃支持截止**][4]。但是,直到 2018 年 12 月 31 日,PHP 5.6 将继续获得对关键安全问题的支持。所以,建议尽快升级所有 PHP 程序并与 PHP7.x 兼容。
|
||||
最终稳定版 PHP 5.6 于 2017 年 1 月 19 日达到[**活跃支持截止**][4]。但是,直到 2018 年 12 月 31 日,PHP 5.6 将继续获得对关键安全问题的支持。所以,建议尽快升级所有 PHP 程序并与 PHP 7.x 兼容。
|
||||
|
||||
如果你希望防止 PHP 将来自动升级,请参阅以下指南。
|
||||
|
||||
@ -109,7 +106,6 @@ $ sudo systemctl restart apache2
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-switch-between-multiple-php-versions-in-ubuntu/
|
||||
@ -117,7 +113,7 @@ via: https://www.ostechnix.com/how-to-switch-between-multiple-php-versions-in-ub
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,32 +3,32 @@ Fedora 下的图像创建程序
|
||||
|
||||

|
||||
|
||||
感觉有创意吗?Fedora 有很多程序可以帮助你的创造力。从数字绘图、矢量到像素艺术,每个人都可以在这个周末得到创意。本文重点介绍了 Fedora 下创建很棒图像的程序。
|
||||
有了创意吗?Fedora 有很多程序可以帮助你的创造力。从数字绘图、矢量到像素艺术,每个人都可以在这个周末发挥创意。本文重点介绍了 Fedora 下创建很棒图像的程序。
|
||||
|
||||
### 矢量图形:Inkscape
|
||||
|
||||
[Inkscape][1] 是一个众所周知受人喜爱的开源矢量图形编辑器。SVG 是 Inkscape 的主要文件格式,因此你所有的图形都可以伸缩!Inkscape 已存在多年,所以有一个坚实的社区和[大量的教程和其他资源][2]用于入门。
|
||||
[Inkscape][1] 是一个众所周知的、受人喜爱的开源矢量图形编辑器。SVG 是 Inkscape 的主要文件格式,因此你所有的图形都可以任意伸缩!Inkscape 已存在多年,所以有一个坚实的社区和用于入门的[大量教程和其他资源][2]。
|
||||
|
||||
作为矢量图形编辑器,Inkscape 更适合于简单的插图(例如简单的漫画风格)。然而,使用矢量模糊,一些艺术家创造了一些[令人惊奇的矢量图][3]。
|
||||
|
||||
![][4]
|
||||
|
||||
从 Fedora Workstation 中的软件应用安装 Inkscape,或在终端中使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf install inkscape
|
||||
|
||||
```
|
||||
|
||||
### 数字绘图:Krita 和 Mypaint
|
||||
|
||||
[Krita][5] 是一个流行的图像创建程序,用于数字绘图、光栅插图和纹理。此外,Krita 是一个活跃的项目,拥有一个充满活力的社区 - 所以[有很多教程用于入门] [6]。Krita 有多个画笔引擎,带弹出调色板的 UI,用于创建无缝图案的环绕模式、滤镜、图层等等。
|
||||
[Krita][5] 是一个流行的图像创建程序,用于数字绘图、光栅插图和纹理。此外,Krita 是一个活跃的项目,拥有一个充满活力的社区 —— 所以[有用于入门的很多教程][6]。Krita 有多个画笔引擎、带有弹出调色板的 UI、用于创建无缝图案的环绕模式、滤镜、图层等等。
|
||||
|
||||
![][7]
|
||||
|
||||
从 Fedora Workstation 中的软件应用安装 Krita,或在终端中使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf install krita
|
||||
|
||||
```
|
||||
|
||||
[Mypaint][8] 是另一款适用于 Fedora 令人惊奇的数字绘图程序。像 Krita 一样,它有多个画笔和使用图层的能力。
|
||||
@ -36,14 +36,14 @@ sudo dnf install krita
|
||||
![][9]
|
||||
|
||||
从 Fedora Workstation 中的软件应用安装 Mypaint,或在终端中使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf install mypaint
|
||||
|
||||
```
|
||||
|
||||
### 像素艺术:Libresprite
|
||||
|
||||
[Libresprite][10] 是一个专为创建像素艺术和像素动画而设计的程序。它支持一系列颜色模式并可导出为多种格式(包括动画 GIF)。此外,Libresprite 还有用于创建像素艺术的绘图工具:多边形工具、轮廓和着色工具。
|
||||
[Libresprite][10] 是一个专为创建像素艺术和像素动画而设计的程序。它支持一系列颜色模式,并可导出为多种格式(包括动画 GIF)。此外,Libresprite 还有用于创建像素艺术的绘图工具:多边形工具、轮廓和着色工具。
|
||||
|
||||
![][11]
|
||||
|
||||
@ -57,7 +57,7 @@ via: https://fedoramagazine.org/image-creation-applications-fedora/
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
108
published/20180812 Ubuntu 18.04 Vs. Fedora 28.md
Normal file
108
published/20180812 Ubuntu 18.04 Vs. Fedora 28.md
Normal file
@ -0,0 +1,108 @@
|
||||
对比 Ubuntu 18.04 和 Fedora 28
|
||||
======
|
||||
|
||||

|
||||
|
||||
大家好,我准备在今天突出说明一下两大主流 Linux 发行版,即 **Ubuntu 18.04** 和 **Fedora 28**,包括一些特性和差异。两者都有各自的包管理系统,其中 Ubuntu 使用 DEB,Fedora 使用 RPM;但二者使用同样的[<ruby>桌面环境<rt>Desktop Environment</rt></ruby>][3] (DE)[GNOME][4],并致力于为 Linux 用户提供高品质的<ruby>桌面体验<rt>desktop experience</rt></ruby>。
|
||||
|
||||
**Ubuntu 18.04** 是 Ubuntu 目前最新的 [<ruby>长期支持版本<rt>Long Term Support</rt></ruby>][1](LTS),为用户提供 GNOME 桌面系统。**Fedora 28** 也提供 GNOME 桌面系统,但落实到具体的软件包管理方面,二者的桌面体验存在差异;在<ruby>用户界面<rt>User Interfaces</rt></ruby>方面也显然存在差异。
|
||||
|
||||
### 基本概念
|
||||
|
||||
不知你是否了解,虽然 Ubuntu 基于 Debian,但 Ubuntu 比 Debian 更早提供最新版本的软件。举个例子,当 Ubuntu 提供流行网页浏览器 Firefox Quantum 时,Debian 仍在提供 Firefox 的<ruby>延期支持版<rt>Extended Support Release</rt></ruby>(ESR)。
|
||||
|
||||
(LCTT 译注:从 2012 年 1 月开始,Firefox 进入快速版本期,每 6 周发布新的主线版本,每隔 7 个主线版本发布新的 ESR 版本。Firefox 57 的桌面版发布时被命名为 Firefox Quantum,同期的 ESR 版本与 Firefox 52 一同发布并基于 Firefox 48。参考 [Wiki: History\_of\_Firefox][9])
|
||||
|
||||
同样的情况也适用于 Fedora,它为终端用户提供前沿的软件,也被用作下一个稳定版本的 RHEL (Red Hat Enterprise Linux) 的测试平台。
|
||||
|
||||
### 桌面预览
|
||||
|
||||
Fedora 提供<ruby>原汁原味的<rt>vanilla</rt></ruby> GNOME 桌面体验;相比之下,Ubuntu 18.04 对 GNOME 做了若干方面的微调,以便长期以来的 Unity 用户可以平滑的过渡到 GNOME 桌面环境。
|
||||
|
||||
_为节省开发时间,Canonical (从 Ubuntu [17.10][2] 开始)已经决定放弃 Unity 并转向 GNOME 桌面,以便可以将更多精力投入到 IoT 领域。_
|
||||
|
||||
因此,在 Fedora 的桌面预览中,我们可以看到一个简洁的无图标桌面和一个自动隐藏的侧边栏,整体外观采用 GNOME 默认的 Adwaita 主题。
|
||||
|
||||
[][5]
|
||||
|
||||
相比之下,Ubuntu 采用其经典的有图标桌面样式,左侧边栏用于模拟其传统的“<ruby>程序坞<rt>dock</rt></ruby>”,使用 Ubuntu Ambiance 主题定制化窗口,与其传统的(Unity 桌面)外观和体验基本一致。
|
||||
|
||||
[][6]
|
||||
|
||||
虽然存在一定差异,但习惯使用其中一种桌面环境后切换到另外一种并不困难。毕竟二者设计时都充分考虑了简洁性和用户友好性,即使是新用户也不会对这两种 Linux 发行版感到不适应。
|
||||
|
||||
但外观或 UI 并不是决定用户选择哪一种 Linux 发行版的唯一因素,还有其它因素也会影响用户的选择。下面主要介绍两种 Linux 发行版在软件包管理相关方面的内容。
|
||||
|
||||
### 软件中心
|
||||
|
||||
Ubuntu 使用 dpkg(即 Debian Package Management)将软件分发给终端用户;Fedora 则使用 rpm(全称为 Red Hat Package Management)。它们都是 Linux 社区中非常流行的包管理系统,对应的命令行工具也都简单易用。
|
||||
|
||||
[][7]
|
||||
|
||||
但在具体分发的软件方面,各个 Linux 发行版会有明显差异。Canonical 每 6 个月发布新版本的 Ubuntu,一般是在每年的 4 月和 10 月。对每个版本,开发者会维护一个开发计划;Ubuntu 新版本发布后,该版本就会进入<ruby>冻结<rt>freeze</rt></ruby>状态,即停止新软件的开发和测试。
|
||||
|
||||
相比之下,Fedora 也采用相似的 6 个月发布周期,看起来很像一种<ruby>滚动更新<rt>rolling release</rt></ruby>的 Linux 发行版(其实并不是这样)。与 Ubuntu 不同之处在于,(Fedora 中的)几乎所有软件包更新都很频繁,让用户有机会尝试最新版本的软件。但这样也导致软件 Bug 更频繁出现,给用户带来“不稳定性”,虽然还不至于导致系统不可用。
|
||||
|
||||
### 软件更新
|
||||
|
||||
我上面已经提到了 Ubuntu 版本的冻结状态。好吧,由于它对 Ubuntu 软件更新方式有着重要的影响,我再次提到这个状态:当 Ubuntu 新版本发布后,该版本的开发(这里是指测试新软件)就停止了。
|
||||
|
||||
_即将发布的下个版本的开发也随之开始,先后历经 “<ruby>每日构建<rt>daily build</rt></ruby>” 和 “<ruby>测试版<rt>beta release</rt></ruby>” 阶段,最后作为新版本发布给终端用户。_
|
||||
|
||||
在冻结状态下,Ubuntu 维护者不会在<ruby>软件源<rt>package repository</rt></ruby>中增加最新版软件,除非用于解决严重的安全问题。因此,Ubuntu 用户可用的软件更新更多涉及 Bug 修复而不是新特性,这样的好处在于系统可以保持稳定,不会扰乱用户的使用。
|
||||
|
||||
Fedora 试图为终端用户提供最新版本的软件,故用户的可用软件更新相比 Ubuntu 而言会更多涉及新特性。当然,开发者为了维持系统的稳定性,也采取了一系列措施。例如,在操作系统启动时,用户可以从最多三个<ruby>可用内核<rt>working kernel</rt></ruby>(最新内核处于最上方)中进行选择;当新内核无法启动时,用户可以回滚使用之前两个可用内核。
|
||||
|
||||
### Snaps 和 flatpak
|
||||
|
||||
它们都是新出现的酷炫工具,可以将软件发布到多个 Linux 发行版上。Ubuntu 提供 **snaps**,而 Fedora 则提供 **flatpak** 。二者之中 snaps 更加流行,更多流行软件或版权软件都在考虑上架 snap 商店。Flatpak 也在吸引关注,越来越多的软件上线该平台。
|
||||
|
||||
不幸的是,由于二者出现的时间都不久,很多人遇到“<ruby>窗口主题不一致<rt>window theme-breaking</rt></ruby>”问题并在网上表达不满。但由于二者都很易于使用,在二者之间切换并不是难事。
|
||||
|
||||
(LCTT 译注:按译者理解,由于二者都增加了一层安全隔离,读取系统主题方面会遇到问题;另外,似乎也有反馈 snap 专用主题无法及时应用于 snap 的问题)
|
||||
|
||||
### 应用对比
|
||||
|
||||
下面列出一些在 Ubuntu 和 Fedora 上共有的常见应用,然后在两个平台之间进行对比:
|
||||
|
||||
#### 计算器
|
||||
|
||||
Fedora 上的计算器程序启动速度更快。这是因为 Fedora 上的计算器程序是软件包形式安装的,而 Ubuntu 上的计算器程序则是 snap 版本。
|
||||
|
||||
#### 系统监视器
|
||||
|
||||
可能听上去比较书呆子气,但我认为观察计算机性能并杀掉令人讨厌的进程是必要且直观的。程序启动速度对比与计算器的结果一致,即 (软件包方式安装的)Fedora 版本快于(snap 形式提供的)Ubuntu 版本。
|
||||
|
||||
#### 帮助程序
|
||||
|
||||
我已经提到,(为便于长期以来的 Untiy 用户平滑切换到 GNOME),Ubuntu 提供的 GNOME 桌面环境是经过微调的版本。不幸的是,Ubuntu 开发者似乎忘记或忽略了对帮助程序的更新,用户阅读文档(入门视频)后会发现演示视频与真实环境有略微差异,这可能让人感到迷惑。
|
||||
|
||||
[][8]
|
||||
|
||||
### 结论
|
||||
|
||||
Ubuntu 和 Fedora 是两个主流的 Linux 发行版。两者都各自有一些华而不实的特性,因而新接触 Linux 的人很难抉择。我的建议是同时尝试二者,这样你在试用后可以发现哪个发行版提供的工具更适合你。
|
||||
|
||||
希望你阅读愉快,你可以在下方的评论区给出我漏掉的内容或你的建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/ubuntu-1804-vs-fedora-28
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/ubuntu-1804-codename-announced-bionic-beaver
|
||||
[2]:http://www.linuxandubuntu.com/home/what-new-is-going-to-be-in-ubuntu-1704-zesty-zapus
|
||||
[3]:http://www.linuxandubuntu.com/home/5-best-linux-desktop-environments-with-pros-cons
|
||||
[4]:http://www.linuxandubuntu.com/home/walkthrough-on-how-to-use-gnome-boxes
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-18-04-gnome_orig.jpg
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-gnome-18-04_orig.jpg
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-software-center_2_orig.jpg
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-18-04-help-manual_orig.jpg
|
||||
[9]:https://en.wikipedia.org/wiki/History_of_Firefox
|
||||
@ -3,32 +3,36 @@
|
||||
|
||||

|
||||
|
||||
几天前,我们曾经讨论如何[**如何在不同的 PHP 版本之间进行切换**][1]。在那篇文章中,我们使用 **update-alternatives** 命令实现从一个 PHP 版本切换到另一个 PHP 版本。也就是说,`update-alternatives` 命令可以将<ruby>系统范围<rt>system wide</rt></ruby>默认使用的 PHP 版本设置为我们希望的版本。通俗的来说,你可以通过 `update-alternatives` 命令从系统范围设置程序的版本。如果你希望可以在不同目录动态设置不同的程序版本,该如何完成呢?在这种情况下,**alt** 工具可以大显身手。`alt` 是一个命令行工具,可以让你在类 Unix 系统中切换相同程序的不同版本。该工具简单易用,是 **Rust** 语言编写的自由、开源软件。
|
||||
几天前,我们曾经讨论[如何在不同的 PHP 版本之间进行切换][1]。在那篇文章中,我们使用 `update-alternatives` 命令实现从一个 PHP 版本切换到另一个 PHP 版本。也就是说,`update-alternatives` 命令可以将<ruby>系统范围<rt>system wide</rt></ruby>默认使用的 PHP 版本设置为我们希望的版本。通俗的来说,你可以通过 `update-alternatives` 命令从系统范围设置程序的版本。如果你希望可以在不同目录动态设置不同的程序版本,该如何完成呢?在这种情况下,`alt` 工具可以大显身手。`alt` 是一个命令行工具,可以让你在类 Unix 系统中切换相同程序的不同版本。该工具简单易用,是 Rust 语言编写的自由、开源软件。
|
||||
|
||||
### 安装
|
||||
|
||||
安装 `alt` 工具十分简单。
|
||||
|
||||
运行如下命令,即可在 Linux 主机上安装 `alt`:
|
||||
|
||||
```
|
||||
$ curl -sL https://github.com/dotboris/alt/raw/master/install.sh | bash -s
|
||||
```
|
||||
|
||||
下一步,将 shims 目录添加到你的 PATH 环境变量中,具体操作取决于你使用的 Shell。
|
||||
下一步,将 `shims` 目录添加到你的 PATH 环境变量中,具体操作取决于你使用的 Shell。
|
||||
|
||||
对于 Bash:
|
||||
|
||||
```
|
||||
$ echo 'export PATH="$HOME/.local/alt/shims:$PATH"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
对于 Zsh:
|
||||
|
||||
```
|
||||
$ echo 'export PATH="$HOME/.local/alt/shims:$PATH"' >> ~/.zshrc
|
||||
$ source ~/.zshrc
|
||||
```
|
||||
|
||||
对于 Fish:
|
||||
|
||||
```
|
||||
$ echo 'set -x PATH "$HOME/.local/alt/shims" $PATH' >> ~/.config/fish/config.fish
|
||||
```
|
||||
@ -39,39 +43,41 @@ $ echo 'set -x PATH "$HOME/.local/alt/shims" $PATH' >> ~/.config/fish/config.fis
|
||||
|
||||
如我之前所述,alt 只影响当前目录。换句话说,当你进行版本切换时,只在当前目录生效,而不是整个系统范围。
|
||||
|
||||
下面举例说明。我在我的 Ubuntu 系统中安装了两个版本的 PHP,分别为 PHP 5.6 和 PHP 7.2;另外,在 **myproject** 目录中包含一些 PHP 应用。
|
||||
下面举例说明。我在我的 Ubuntu 系统中安装了两个版本的 PHP,分别为 PHP 5.6 和 PHP 7.2;另外,在 `myproject` 目录中包含一些 PHP 应用。
|
||||
|
||||
首先,通过命令查看系统范围默认的 PHP 版本:
|
||||
|
||||
```
|
||||
$ php -v
|
||||
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
示例输出:
|
||||
|
||||
![查找 PHP 版本][3]
|
||||
|
||||
如截图中所示,我系统中默认的 PHP 版本为 PHP7.2。
|
||||
如截图中所示,我系统中默认的 PHP 版本为 PHP 7.2。
|
||||
|
||||
然后,我将进入放置 PHP 应用的 `myproject` 目录。
|
||||
|
||||
然后,我将进入放置 PHP 应用的 "myproject" 目录。
|
||||
```
|
||||
$ cd myproject
|
||||
```
|
||||
|
||||
使用如下命令扫描可用的 PHP 版本:
|
||||
|
||||
```
|
||||
$ alt scan php
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
示例输出:
|
||||
|
||||
![扫描 PHP 版本][4]
|
||||
|
||||
可见,我有两个 PHP 版本,即 PHP5.6 和 PHP7.2。按下 **<空格>** 键选中当前可用的版本。选中全部可用版本后,你可以看到图中所示的<ruby>叉号<rt>cross mark</rt></ruby>。使用上下方向键在版本间移动,点击回车即可保存变更。
|
||||
可见,我有两个 PHP 版本,即 PHP 5.6 和 PHP 7.2。按下 `<空格>` 键选中当前可用的版本。选中全部可用版本后,你可以看到图中所示的<ruby>叉号<rt>cross mark</rt></ruby>。使用上下方向键在版本间移动,点击回车即可保存变更。
|
||||
|
||||
![选取 PHP 版本][5]
|
||||
|
||||
下面运行该命令并选取我们希望在 "myproject" 目录中使用的 PHP 版本:
|
||||
下面运行该命令并选取我们希望在 `myproject` 目录中使用的 PHP 版本:
|
||||
|
||||
```
|
||||
$ alt use php
|
||||
@ -81,22 +87,23 @@ $ alt use php
|
||||
|
||||
![设置 PHP 版本][6]
|
||||
|
||||
现在,你可以在 /home/sk/myproject 目录下使用 PHP5.6 版本啦。
|
||||
现在,你可以在 `/home/sk/myproject` 目录下使用 PHP 5.6 版本啦。
|
||||
|
||||
让我们检查一下,在 `myproject` 目录下是否默认使用 PHP 5.6 版本:
|
||||
|
||||
让我们检查一下,在 myproject 目录下是否默认使用 PHP5.6 版本:
|
||||
```
|
||||
$ php -v
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
示例输出:
|
||||
|
||||
![检查 PHP 版本][7]
|
||||
|
||||
只要你不设置成其它版本,(在该目录下)将一直使用 PHP5.6 版本。清楚了吗?很好!请注意,我们仅在这个目录下使用 PHP5.6 版本。在系统范围内(LCTT 译注:当然是没单独设置过其它版本的目录下),PHP7.2 仍是默认的版本。让我们检验一下,请看下图。
|
||||
只要你不设置成其它版本,(在该目录下)将一直使用 PHP 5.6 版本。清楚了吗?很好!请注意,我们仅在这个目录下使用 PHP 5.6 版本。在系统范围内(LCTT 译注:当然是没单独设置过其它版本的目录下),PHP 7.2 仍是默认的版本。让我们检验一下,请看下图。
|
||||
|
||||
![比对 PHP 版本][8]
|
||||
|
||||
从上面的截图中可以看出,我有两个版本的 PHP:在 "myproject" 目录下,使用的版本为 PHP5.6;在 myproject 外的其它目录,使用的版本为 PHP7.2。
|
||||
从上面的截图中可以看出,我有两个版本的 PHP:在 `myproject` 目录下,使用的版本为 PHP 5.6;在 `myproject` 外的其它目录,使用的版本为 PHP 7.2。
|
||||
|
||||
同理,你可以为每个目录设置你希望的程序版本。我这里使用 PHP 仅用于说明操作,但方法适用于任何你打算使用的软件,例如 NodeJS 等。
|
||||
|
||||
@ -117,7 +124,7 @@ via: https://www.ostechnix.com/how-to-switch-between-different-versions-of-comma
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,234 @@
|
||||
在 Linux 中如何以人性化的方式显示数据
|
||||
======
|
||||
|
||||
> 许多 Linux 命令现在都有使其输出更易于理解的选项。让我们了解一些可以让我们心爱的操作系统更友好的东西。
|
||||
|
||||

|
||||
|
||||
不是每个人都以二进制方式思考,他们不想在大脑中给大数字插入逗号来了解文件的大小。因此,Linux 命令在过去的几十年里不断发展,以更人性化的方式向用户显示信息,这一点也不奇怪。在今天的文章中,我们将看一看各种命令所提供的一些选项,它们使得数据变得更容易理解。
|
||||
|
||||
### 为什么默认显示不更友好一些?
|
||||
|
||||
如果你想知道为什么默认不显示得更人性化,毕竟,我们人类才是计算机的默认用户啊。你可能会问自己:“为什么我们不竭尽全力输出对每个人都有意义的命令的响应?”主要的答案是:改变命令的默认输出可能会干扰许多其它进程,这些进程是在期望默认响应之上构建的。其它的工具,以及过去几十年开发的脚本,如果突然以一种完全不同的格式输出,而不是它们过去所期望的那样,可能会被一种非常丑陋的方式破坏。
|
||||
|
||||
说真的,也许我们中的一些人可能更愿意看文件大小中的所有数字,即 1338277310 而不是 1.3G。在任何情况下,切换默认习惯都可能造成破坏,但是为更加人性化的响应提供一些简单的选项只需要让我们学习一些命令选项而已。
|
||||
|
||||
### 可以显示人性化数据的命令
|
||||
|
||||
有哪些简单的选项可以使 Unix 命令的输出更容易解析呢?让我们来看一些命令。
|
||||
|
||||
#### top
|
||||
|
||||
你可能没有注意到这个命令,但是在 top 命令中,你可以通过输入 `E`(大写字母 E)来更改显示全部内存使用的方式。连续按下将数字显示从 KiB 到 MiB,再到 GiB,接着是 TiB、PiB、EiB,最后回到 KiB。
|
||||
|
||||
认识这些单位吧?这里有一组定义:
|
||||
|
||||
```
|
||||
2`10 = 1,024 = 1 KiB (kibibyte)
|
||||
2`20 = 1,048,576 = 1 MiB (mebibyte)
|
||||
2`30 = 1,073,741,824 = 1 GiB (gibibyte)
|
||||
2`40 = 1,099,511,627,776 = 1 TiB (tebibyte)
|
||||
2`50 = 1,125,899,906,842,624 = PiB (pebibyte)
|
||||
2`60 = 1,152,921,504,606,846,976 = EiB (exbibyte)
|
||||
2`70 = 1,180,591,620,717,411,303,424 = 1 ZiB (zebibyte)
|
||||
2`80 = 1,208,925,819,614,629,174,706,176 = 1 YiB (yobibyte)
|
||||
```
|
||||
|
||||
这些单位与千字节(KB)、兆字节(MB)和千兆字节(GB)密切相关。虽然它们很接近,但是它们之间仍有很大的区别:一组是基于 10 的幂,另一组是基于 2 的幂。例如,比较千字节和千兆字节,我们可以看看它们不同点:
|
||||
|
||||
```
|
||||
KB = 1000 = 10`3
|
||||
KiB = 1024 = 2`10
|
||||
```
|
||||
|
||||
以下是 `top` 命令输出示例,使用 KiB 为单位默认显示:
|
||||
|
||||
```
|
||||
top - 10:49:06 up 5 days, 35 min, 1 user, load average: 0.05, 0.04, 0.01
|
||||
Tasks: 158 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
KiB Mem : 6102680 total, 4634980 free, 392244 used, 1075456 buff/cache
|
||||
KiB Swap: 2097148 total, 2097148 free, 0 used. 5407432 avail Mem
|
||||
```
|
||||
|
||||
在按下 `E` 之后,单位变成了 MiB:
|
||||
|
||||
```
|
||||
top - 10:49:31 up 5 days, 36 min, 1 user, load average: 0.03, 0.04, 0.01
|
||||
Tasks: 158 total, 2 running, 118 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.0 us, 0.6 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
MiB Mem : 5959.648 total, 4526.348 free, 383.055 used, 1050.246 buff/cache
|
||||
MiB Swap: 2047.996 total, 2047.996 free, 0.000 used. 5280.684 avail Mem
|
||||
```
|
||||
|
||||
再次按下 `E`,单位变为 GiB:
|
||||
|
||||
```
|
||||
top - 10:49:49 up 5 days, 36 min, 1 user, load average: 0.02, 0.03, 0.01
|
||||
Tasks: 158 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
GiB Mem : 5.820 total, 4.420 free, 0.374 used, 1.026 buff/cache
|
||||
GiB Swap: 2.000 total, 2.000 free, 0.000 used. 5.157 avail Mem
|
||||
```
|
||||
|
||||
你还可以通过按字母 `e` 来更改为显示每个进程使用内存的数字单位。它将从默认的 KiB 到 MiB,再到 GiB、TiB,接着到 PiB(估计你能看到小数点后的很多 0),然后返回 KiB。下面是按了一下 `e` 之后的 `top` 输出:
|
||||
|
||||
```
|
||||
top - 08:45:28 up 4 days, 22:32, 1 user, load average: 0.02, 0.03, 0.00
|
||||
Tasks: 167 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.2 us, 0.0 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
KiB Mem : 6102680 total, 4641836 free, 393348 used, 1067496 buff/cache
|
||||
KiB Swap: 2097148 total, 2097148 free, 0 used. 5406396 avail Mem
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
784 root 20 0 543.2m 26.8m 16.1m S 0.9 0.5 0:22.20 snapd
|
||||
733 root 20 0 107.8m 2.0m 1.8m S 0.4 0.0 0:18.49 irqbalance
|
||||
22574 shs 20 0 107.5m 5.5m 4.6m S 0.4 0.1 0:00.09 sshd
|
||||
1 root 20 0 156.4m 9.3m 6.7m S 0.0 0.2 0:05.59 systemd
|
||||
```
|
||||
|
||||
#### du
|
||||
|
||||
`du` 命令显示磁盘空间文件或目录使用了多少,如果使用 `-h` 选项,则将输出大小调整为最合适的单位。默认情况下,它以千字节(KB)为单位。
|
||||
|
||||
```
|
||||
$ du camper*
|
||||
360 camper_10.jpg
|
||||
5684 camper.jpg
|
||||
240 camper_small.jpg
|
||||
$ du -h camper*
|
||||
360K camper_10.jpg
|
||||
5.6M camper.jpg
|
||||
240K camper_small.jpg
|
||||
```
|
||||
|
||||
#### df
|
||||
|
||||
`df` 命令也提供了一个 `-h` 选项。请注意在下面的示例中是如何以千兆字节(GB)和兆字节(MB)输出的:
|
||||
|
||||
```
|
||||
$ df -h | grep -v loop
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
udev 2.9G 0 2.9G 0% /dev
|
||||
tmpfs 596M 1.7M 595M 1% /run
|
||||
/dev/sda1 110G 9.0G 95G 9% /
|
||||
tmpfs 3.0G 0 3.0G 0% /dev/shm
|
||||
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs 3.0G 0 3.0G 0% /sys/fs/cgroup
|
||||
tmpfs 596M 16K 596M 1% /run/user/121
|
||||
/dev/sdb2 457G 73M 434G 1% /apps
|
||||
tmpfs 596M 0 596M 0% /run/user/1000
|
||||
```
|
||||
|
||||
下面的命令使用了 `-h` 选项,同时使用 `-T` 选项来显示我们正在查看的文件系统的类型。
|
||||
|
||||
```
|
||||
$ df -hT /mnt2
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/sdb2 ext4 457G 73M 434G 1% /apps
|
||||
```
|
||||
|
||||
#### ls
|
||||
|
||||
即使是 `ls`,它也为我们提供了调整大小显示的选项,保证是最合理的单位。
|
||||
|
||||
```
|
||||
$ ls -l camper*
|
||||
-rw-rw-r-- 1 shs shs 365091 Jul 14 19:42 camper_10.jpg
|
||||
-rw-rw-r-- 1 shs shs 5818597 Jul 14 19:41 camper.jpg
|
||||
-rw-rw-r-- 1 shs shs 241844 Jul 14 19:45 camper_small.jpg
|
||||
$ ls -lh camper*
|
||||
-rw-rw-r-- 1 shs shs 357K Jul 14 19:42 camper_10.jpg
|
||||
-rw-rw-r-- 1 shs shs 5.6M Jul 14 19:41 camper.jpg
|
||||
-rw-rw-r-- 1 shs shs 237K Jul 14 19:45 camper_small.jpg
|
||||
```
|
||||
|
||||
#### free
|
||||
|
||||
`free` 命令允许你以字节(B),千字节(KB),兆字节(MB)和千兆字节(GB)为单位查看内存使用情况。
|
||||
|
||||
```
|
||||
$ free -b
|
||||
total used free shared buff/cache available
|
||||
Mem: 6249144320 393076736 4851625984 1654784 1004441600 5561253888
|
||||
Swap: 2147479552 0 2147479552
|
||||
$ free -k
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102680 383836 4737924 1616 980920 5430932
|
||||
Swap: 2097148 0 2097148
|
||||
$ free -m
|
||||
total used free shared buff/cache available
|
||||
Mem: 5959 374 4627 1 957 5303
|
||||
Swap: 2047 0 2047
|
||||
$ free -g
|
||||
total used free shared buff/cache available
|
||||
Mem: 5 0 4 0 0 5
|
||||
Swap: 1 0 1
|
||||
```
|
||||
|
||||
#### tree
|
||||
|
||||
虽然 `tree` 命令与文件或内存计算无关,但它也提供了非常人性化的文件视图,它分层显示文件以说明文件是如何组织的。当你试图了解如何安排目录内容时,这种显示方式非常有用。(LCTT 译注:也可以看看 `pstree`,它以树状结构显示进程树。)
|
||||
|
||||
```
|
||||
$ tree
|
||||
.g to
|
||||
├── 123
|
||||
├── appended.png
|
||||
├── appts
|
||||
├── arrow.jpg
|
||||
├── arrow.png
|
||||
├── bin
|
||||
│ ├── append
|
||||
│ ├── cpuhog1
|
||||
│ ├── cpuhog2
|
||||
│ ├── loop
|
||||
│ ├── mkhome
|
||||
│ ├── runme
|
||||
```
|
||||
|
||||
#### stat
|
||||
|
||||
`stat` 命令是另一个以非常人性化的格式显示信息的命令。它提供了更多关于文件的元数据,包括文件大小(以字节和块为单位)、文件类型、设备和 inode(索引节点)、文件所有者和组(名称和数字 ID)、以数字和 rwx 格式显示的文件权限以及文件的最后访问和修改日期。在某些情况下,它也可能显示最初创建文件的时间。
|
||||
|
||||
```
|
||||
$ stat camper*
|
||||
File: camper_10.jpg
|
||||
Size: 365091 Blocks: 720 IO Block: 4096 regular file
|
||||
Device: 801h/2049d Inode: 796059 Links: 1
|
||||
Access: (0664/-rw-rw-r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
|
||||
Access: 2018-07-19 18:56:31.841013385 -0400
|
||||
Modify: 2018-07-14 19:42:25.230519509 -0400
|
||||
Change: 2018-07-14 19:42:25.230519509 -0400
|
||||
Birth: -
|
||||
File: camper.jpg
|
||||
Size: 5818597 Blocks: 11368 IO Block: 4096 regular file
|
||||
Device: 801h/2049d Inode: 796058 Links: 1
|
||||
Access: (0664/-rw-rw-r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
|
||||
Access: 2018-07-19 18:56:31.845013872 -0400
|
||||
Modify: 2018-07-14 19:41:46.882024039 -0400
|
||||
Change: 2018-07-14 19:41:46.882024039 -0400
|
||||
Birth: -
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
Linux 命令提供了许多选项,可以让用户更容易理解或比较它们的输出。对于许多命令,`-h` 选项会显示更友好的输出格式。对于其它的,你可能必须通过使用某些特定选项或者按下某个键来查看你希望的输出。我希望这其中一些选项会让你的 Linux 系统看起来更友好一点。
|
||||
|
||||
加入[Facebook][1] 和 [LinkedIn][2] 上的网络世界社区,一起来评论重要的话题吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3296631/linux/displaying-data-in-a-human-friendly-way-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,135 @@
|
||||
将 Linux 终端会话录制成 SVG 动画
|
||||
======
|
||||
|
||||

|
||||
|
||||
录制终端会话可以满足我们不同类型的需求。通过录制终端会话,你可以完整记录你在终端中执行的操作,将其保存以供后续参考。通过录制终端会话,你还可以向青少年、学生或其它打算学习 Linux 的人展示各种 Linux 命令及其用例。值得庆幸的是,市面上已经有不少工具,可以帮助我们在类 Unix 操作系统下录制终端会话。我们已经介绍过一些可以帮助你录制终端会话的工具,可以在下面的链接中找到。
|
||||
|
||||
+ [如何录制你在终端中的所作所为][3]
|
||||
+ [Asciinema – 录制终端会话并在网上分享][4]
|
||||
|
||||
今天,我们要介绍另一款录制终端操作的工具,名字叫做 **Termtosvg**。从名字可以看出,Termtosvg 将你的终端会话录制成一个单独的 SVG 动画。它是一款简单的命令行工具,使用 **Python** 语言编写,可以生成轻量级、外观整洁的动画,可以嵌入到网页项目中。Termtosvg 支持自定义<ruby>色彩主题<rt>color themes</rt></ruby>、终端 UI,还可以通过 [SVG 模板][1]完成动画控制。它兼容 asciinema 录制格式,支持 GNU/Linux,Mac OS 和 BSD 等操作系统。
|
||||
|
||||
### 安装 Termtosvg
|
||||
|
||||
PIP 是一个面向 Python 语言编写的软件包的管理器,可以用于安装 Termtosvg。如果你没有安装 PIP,可以参考下面的指导:
|
||||
|
||||
[如何使用 PIP 管理 Python 软件包][5]
|
||||
|
||||
安装 PIP 后,运行如下命令安装 Termtosvg 工具:
|
||||
|
||||
```
|
||||
$ pip3 install --user termtosvg
|
||||
```
|
||||
|
||||
此外,还要安装渲染终端屏幕所需的依赖包:
|
||||
|
||||
```
|
||||
$ pip3 install pyte python-xlib svgwrite
|
||||
```
|
||||
|
||||
安装完毕,我们接下来生成 SVG 格式的终端会话。
|
||||
|
||||
### 将 Linux 终端会话录制成 SVG 动画
|
||||
|
||||
使用 `termtosvg` 录制终端会话十分容易。打开终端窗口,运行如下命令即可开始录制:
|
||||
|
||||
```
|
||||
$ termtosvg
|
||||
```
|
||||
|
||||
**注意:** 如果 `termtosvg` 命令不可用,重启操作系统一次即可。
|
||||
|
||||
运行 `termtosvg` 命令后,可以看到如下命令输出:
|
||||
|
||||
```
|
||||
Recording started, enter "exit" command or Control-D to end
|
||||
|
||||
```
|
||||
|
||||
你目前位于一个子 Shell 中,在这里可以像平常那样输入命令。你在终端中的所作所为都会被录制。
|
||||
|
||||
不妨随便输入一些命令:
|
||||
|
||||
```
|
||||
$ mkdir mydirectory
|
||||
$ cd mydirectory/
|
||||
$ touch file.txt
|
||||
$ cd ..
|
||||
$ uname -a
|
||||
|
||||
```
|
||||
|
||||
操作完成后,使用组合键 `CTRL+D` 或者输入 `exit` 停止录制。录制结果将会保存在 `/tmp` 目录,(由于做了唯一性处理)文件名并不会重复。
|
||||
|
||||

|
||||
|
||||
现在,你可以在命令行运行命令,使用你的浏览器打开 SVG 文件:
|
||||
|
||||
```
|
||||
$ firefox /tmp/termtosvg_ddkehjpu.svg
|
||||
```
|
||||
|
||||
你也可以在(图形界面的)浏览器中直接打开这个 SVG 文件( **File -> \<SVG 文件路径>** )。
|
||||
|
||||
我用 Firefox 浏览器打开的效果如下:
|
||||
|
||||

|
||||
|
||||
下面举例说明几种使用 Termtosvg 录制终端会话的方式。
|
||||
|
||||
我刚刚提到,Termtosvg 录制终端会话后默认保存成 `/tmp` 目录下的一个 SVG 动画文件。
|
||||
|
||||
但你可以指定 SVG 动画文件的文件名,例如 `animation.svg`;也可以指定一个存放路径,例如 `/home/sk/ostechnix/`。
|
||||
|
||||
```
|
||||
$ termtosvg /home/sk/ostechnix/animation.svg
|
||||
```
|
||||
|
||||
录制终端会话并使用特定模板进行渲染:
|
||||
|
||||
```
|
||||
$ termtosvg -t ~/templates/my_template.svg
|
||||
```
|
||||
|
||||
使用指定的<ruby>屏幕参数<rt>screen geometry</rt></ruby>录制终端会话:
|
||||
|
||||
```
|
||||
$ termtosvg -g 80x24 animation.svg
|
||||
```
|
||||
|
||||
使用 asciicast v2 格式录制终端会话:
|
||||
|
||||
```
|
||||
$ termtosvg record recording.cast
|
||||
```
|
||||
|
||||
将 asciicast 格式的录制结果渲染成 SVG 动画:
|
||||
|
||||
```
|
||||
$ termtosvg render recording.cast animation.svg
|
||||
```
|
||||
|
||||
欲了解更多细节,请参考 [**Termtosvg 手册**][2]。
|
||||
|
||||
好了,本次分享就到这里,希望对你有帮助。更多精彩内容,敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-record-terminal-sessions-as-svg-animations-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://nbedos.github.io/termtosvg/pages/templates.html
|
||||
[2]:https://github.com/nbedos/termtosvg/blob/develop/man/termtosvg.md
|
||||
[3]:https://www.ostechnix.com/record-everything-terminal/
|
||||
[4]:https://www.ostechnix.com/asciinema-record-terminal-sessions-share-web/
|
||||
[5]:https://www.ostechnix.com/manage-python-packages-using-pip/
|
||||
@ -0,0 +1,69 @@
|
||||
L1 终端错误漏洞(L1TF)如何影响 Linux 系统
|
||||
======
|
||||
|
||||
> L1 终端错误(L1TF)影响英特尔处理器和 Linux 操作系统。让我们了解一下这个漏洞是什么,以及 Linux 用户需要为它做点什么。
|
||||
|
||||

|
||||
|
||||
昨天(LCTT 译注:本文发表于 2018/8/15)在英特尔、微软和红帽的安全建议中宣布,一个新发现的漏洞英特尔处理器(还有 Linux)的漏洞称为 L1TF 或 “<ruby>L1 终端错误<rt>L1 Terminal Fault</rt></ruby>”,引起了 Linux 用户和管理员的注意。究竟什么是这个漏洞,谁应该担心它?
|
||||
|
||||
### L1TF、 L1 Terminal Fault 和 Foreshadow
|
||||
|
||||
处理器漏洞被称作 L1TF、L1 Terminal Fault 和 Foreshadow。研究人员在 1 月份发现了这个问题并向英特尔报告称其为 “Foreshadow”。它类似于过去发现的漏洞(例如 Spectre)。
|
||||
|
||||
此漏洞是特定于英特尔的。其他处理器不受影响。与其他一些漏洞一样,它之所以存在,是因为设计时为了优化内核处理速度,但允许其他进程访问数据。
|
||||
|
||||
**[另请阅读:[22 个必要的 Linux 安全命令][1]]**
|
||||
|
||||
已为此问题分配了三个 CVE:
|
||||
|
||||
* CVE-2018-3615:英特尔<ruby>软件保护扩展<rt>Software Guard Extension</rt></ruby>(英特尔 SGX)
|
||||
* CVE-2018-3620:操作系统和<ruby>系统管理模式<rt>ystem Management Mode</rt></ruby>(SMM)
|
||||
* CVE-2018-3646:虚拟化的影响
|
||||
|
||||
英特尔发言人就此问题发表了这一声明:
|
||||
|
||||
> “L1 Terminal Fault 通过今年早些时候发布的微代码更新得到解决,再加上从今天开始提供的操作系统和虚拟机管理程序软件的相应更新。我们在网上提供了更多信息,并继续鼓励每个人更新操作系统,因为这是得到保护的最佳方式之一。我们要感谢 imec-DistriNet、KU Leuven、以色列理工学院,密歇根大学,阿德莱德大学和 Data61 的研究人员以及我们的行业合作伙伴,他们帮助我们识别和解决了这个问题。“
|
||||
|
||||
### L1TF 会影响你的 Linux 系统吗?
|
||||
|
||||
简短的回答是“可能不会”。如果你因为在今年 1 月爆出的 [Spectre 和 Meltdown 漏洞][2]修补过系统,那你应该是安全的。与 Spectre 和 Meltdown 一样,英特尔声称真实世界中还没有系统受到影响的报告或者检测到。他们还表示,这些变化不太可能在单个系统上产生明显的性能影响,但它们可能对使用虚拟化操作系统的数据中心产生大的影响。
|
||||
|
||||
即使如此,仍然推荐频繁地打补丁。要检查你当前的内核版本,使用 `uname -r` 命令:
|
||||
|
||||
```
|
||||
$ uname -r
|
||||
4.18.0-041800-generic
|
||||
```
|
||||
|
||||
### 更多资源
|
||||
|
||||
请查看如下资源以了解 L1TF 的更多细节,以及为什么会出现这个漏洞:
|
||||
|
||||
- [L1TF explained in ~3 minutes (Red Hat)][5]
|
||||
- [L1TF explained in under 11 minutes (Red Hat)][6]
|
||||
- [Technical deep dive][7]
|
||||
- [Red Hat explanation of L1TF][8]
|
||||
- [Ubuntu updates for L1TF][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3298157/linux/linux-and-l1tf.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]: https://www.networkworld.com/article/3272286/open-source-tools/22-essential-security-commands-for-linux.html
|
||||
[2]: https://www.networkworld.com/article/3245813/security/meltdown-and-spectre-exploits-cutting-through-the-fud.html
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
[5]: https://www.youtube.com/watch?v=kBOsVt0iXE4&feature=youtu.be
|
||||
[6]: https://www.youtube.com/watch?v=kqg8_KH2OIQ
|
||||
[7]: https://www.redhat.com/en/blog/deeper-look-l1-terminal-fault-aka-foreshadow
|
||||
[8]: https://access.redhat.com/security/vulnerabilities/L1TF
|
||||
[9]: https://blog.ubuntu.com/2018/08/14/ubuntu-updates-for-l1-terminal-fault-vulnerabilities
|
||||
@ -0,0 +1,260 @@
|
||||
如何在 Linux Shell 编程中定义和使用函数
|
||||
======
|
||||
|
||||
函数是一段可复用的代码。我们通常把重复的代码放进函数中并且在不同的地方去调用它。库是函数的集合。我们可以在库中定义经常使用的函数,这样其它脚本便可以不再重复代码而使用这些函数。
|
||||
|
||||
![Functions-Linux-Shell-Script][1]
|
||||
|
||||
本文我们将讨论诸多关于函数的内容和一些使用技巧。为了方便演示,我将在 Ubuntu 系统上使用 **Bourne Again SHell (Bash)**。
|
||||
|
||||
### 调用函数
|
||||
|
||||
在 Shell 中调用函数和调用其它命令是一模一样的。例如,如果你的函数名称为 `my_func`,你可以在命令行中像下面这样执行它:
|
||||
|
||||
```
|
||||
$ my_func
|
||||
```
|
||||
|
||||
如果你的函数接收多个参数,那么可以像下面这样写(类似命令行参数的使用):
|
||||
|
||||
```
|
||||
$ my_func arg1 arg2 arg3
|
||||
```
|
||||
|
||||
### 定义函数
|
||||
|
||||
我们可以用下面的语法去定义一个函数:
|
||||
|
||||
```
|
||||
function function_name {
|
||||
Body of function
|
||||
}
|
||||
```
|
||||
|
||||
函数的主体可以包含任何有效的命令、循环语句和其它函数或脚本。现在让我们创建一个简单的函数,它向屏幕上显示一些消息(注:直接在命令行里写)。
|
||||
|
||||
```
|
||||
function print_msg {
|
||||
echo "Hello, World"
|
||||
}
|
||||
```
|
||||
|
||||
现在,让我们执行这个函数:
|
||||
|
||||
```
|
||||
$ print_msg
|
||||
Hello, World
|
||||
```
|
||||
|
||||
不出所料,这个函数在屏幕上显示了一些消息。
|
||||
|
||||
在上面的例子中,我们直接在终端里创建了一个函数。这个函数也可以保存到文件中。如下面的例子所示。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
function print_msg {
|
||||
echo "Hello, World"
|
||||
}
|
||||
print_msg
|
||||
```
|
||||
|
||||
我们已经在 `function.sh` 文件中定义了这个函数。现在让我们执行这个脚本:
|
||||
|
||||
```
|
||||
$ chmod +x function.sh
|
||||
$ ./function.sh
|
||||
Hello, World
|
||||
```
|
||||
|
||||
你可以看到,上面的输出和之前的是一模一样的。
|
||||
|
||||
### 更多函数用法
|
||||
|
||||
在上一小节中我们定义了一个非常简单的函数。然而在软件开发的过程中,我们需要更多高级的函数,它可以接收多个参数并且带有返回值。在这一小节中,我们将讨论这种函数。
|
||||
|
||||
#### 向函数传递参数
|
||||
|
||||
我们可以像调用其它命令那样给函数提供参数。我们可以在函数里使用美元 `$` 符号访问到这些参数。例如,`$1` 表示第一个参数,`$2` 代表第二个参数,以此类推。
|
||||
|
||||
让我们修改下之前的函数,让它以参数的形式接收信息。修改后的函数就像这样:
|
||||
|
||||
```
|
||||
function print_msg {
|
||||
echo "Hello $1"
|
||||
}
|
||||
```
|
||||
|
||||
在上面的函数中我们使用 `$1` 符号访问第一个参数。让我们执行这个函数:
|
||||
|
||||
```
|
||||
$ print_msg "LinuxTechi"
|
||||
```
|
||||
|
||||
执行完后,生成如下信息:
|
||||
|
||||
```
|
||||
Hello LinuxTechi
|
||||
```
|
||||
|
||||
#### 从函数中返回数值
|
||||
|
||||
跟其它编程语言一样,Bash 提供了返回语句让我们可以向调用者返回一些数值。让我们举例说明:
|
||||
|
||||
```
|
||||
function func_return_value {
|
||||
return 10
|
||||
}
|
||||
```
|
||||
|
||||
上面的函数向调用者返回 `10`。让我们执行这个函数:
|
||||
|
||||
```
|
||||
$ func_return_value
|
||||
$ echo "Value returned by function is: $?"
|
||||
```
|
||||
|
||||
当你执行完,将会产生如下的输出结果:
|
||||
|
||||
```
|
||||
Value returned by function is: 10
|
||||
```
|
||||
|
||||
**提示**:在 Bash 中使用 `$?` 去获取函数的返回值。
|
||||
|
||||
### 函数技巧
|
||||
|
||||
目前我们已经对 Bash 中的函数有了一些了解。现在让我们创建一些非常有用的 Bash 函数,它们可以让我们的生活变得更加轻松。
|
||||
|
||||
#### Logger
|
||||
|
||||
让我们创建一个 `logger` 函数,它可以输出带有日期和时间的 log 信息。
|
||||
|
||||
```
|
||||
function log_msg {
|
||||
echo "[`date '+ %F %T'` ]: $@"
|
||||
}
|
||||
```
|
||||
|
||||
执行这个函数:
|
||||
|
||||
```
|
||||
$ log_msg "This is sample log message"
|
||||
```
|
||||
|
||||
执行完,就会生成如下信息:
|
||||
|
||||
```
|
||||
[ 2018-08-16 19:56:34 ]: This is sample log message
|
||||
```
|
||||
|
||||
#### 显示系统信息
|
||||
|
||||
让我们创建一个显示 GNU/Linux 信息的函数
|
||||
|
||||
```
|
||||
function system_info {
|
||||
echo "### OS information ###"
|
||||
lsb_release -a
|
||||
|
||||
echo
|
||||
echo "### Processor information ###"
|
||||
processor=`grep -wc "processor" /proc/cpuinfo`
|
||||
model=`grep -w "model name" /proc/cpuinfo | awk -F: '{print $2}'`
|
||||
echo "Processor = $processor"
|
||||
echo "Model = $model"
|
||||
|
||||
echo
|
||||
echo "### Memory information ###"
|
||||
total=`grep -w "MemTotal" /proc/meminfo | awk '{print $2}'`
|
||||
free=`grep -w "MemFree" /proc/meminfo | awk '{print $2}'`
|
||||
echo "Total memory: $total kB"
|
||||
echo "Free memory : $free kB"
|
||||
}
|
||||
```
|
||||
|
||||
执行完后会生成以下信息:
|
||||
|
||||
```
|
||||
### OS information ###
|
||||
No LSB modules are available.
|
||||
Distributor ID: Ubuntu
|
||||
Description: Ubuntu 18.04.1 LTS
|
||||
Release: 18.04
|
||||
Codename: bionic
|
||||
|
||||
### Processor information ###
|
||||
Processor = 1
|
||||
Model = Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
|
||||
|
||||
### Memory information ###
|
||||
Total memory: 4015648 kB
|
||||
Free memory : 2915428 kB
|
||||
```
|
||||
|
||||
#### 在当前目录下查找文件或者目录
|
||||
|
||||
下面的函数从当前目录下查找文件或者目录:
|
||||
|
||||
```
|
||||
function search {
|
||||
find . -name $1
|
||||
}
|
||||
```
|
||||
|
||||
让我们使用下面的命令查找 `dir4` 这个目录:
|
||||
|
||||
```
|
||||
$ search dir4
|
||||
```
|
||||
|
||||
当你执行完命令后,将会产生如下输出:
|
||||
|
||||
```
|
||||
./dir1/dir2/dir3/dir4
|
||||
```
|
||||
|
||||
#### 数字时钟
|
||||
|
||||
下面的函数在终端里创建了一个简单的数字时钟:
|
||||
|
||||
```
|
||||
function digital_clock {
|
||||
clear
|
||||
while [ 1 ]
|
||||
do
|
||||
date +'%T'
|
||||
sleep 1
|
||||
clear
|
||||
done
|
||||
}
|
||||
```
|
||||
|
||||
### 函数库
|
||||
|
||||
库是函数的集合。将函数定义在文件里并在当前环境中导入那个文件,这样可以创建函数库。
|
||||
|
||||
假设我们已经在 `utils.sh` 中定义好了所有函数,接着在当前的环境下使用下面的命令导入函数:
|
||||
|
||||
```
|
||||
$ source utils.sh
|
||||
```
|
||||
|
||||
之后你就可以像调用其它 Bash 命令那样执行库中任何的函数了。
|
||||
|
||||
### 总结
|
||||
|
||||
本文我们讨论了诸多可以提升效率的实用技巧。我希望这篇文章能够启发你去创造自己的技巧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/define-use-functions-linux-shell-script/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linuxtechi.com/author/pradeep/
|
||||
[1]: https://www.linuxtechi.com/wp-content/uploads/2018/08/Functions-Linux-Shell-Script.jpg
|
||||
@ -1,46 +0,0 @@
|
||||
Open Source Networking Jobs: A Hotbed of Innovation and Opportunities
|
||||
======
|
||||
|
||||

|
||||
|
||||
As global economies move ever closer to a digital future, companies and organizations in every industry vertical are grappling with how to further integrate and deploy technology throughout their business and operations. While Enterprise IT largely led the way, the advantages and lessons learned are now starting to be applied across the board. While the national unemployment rate stands at 4.1%, the overall unemployment rate for tech professionals hit 1.9% in April and the future for open source jobs looks particularly bright. I work in the open source networking space and the innovations and opportunities I’m witnessing are transforming the way the world communicates.
|
||||
|
||||
Once a slower moving industry, the networking ecosystem of today -- made up of network operators, vendors, systems integrators, and developers -- is now embracing open source software and is shifting significantly towards virtualization and software defined networks running on commodity hardware. In fact, nearly 70% of global mobile subscribers are represented by network operator members of [LF Networking][1], an initiative working to harmonize projects that makes up the open networking stack and adjacent technologies.
|
||||
|
||||
### Demand for Skills
|
||||
|
||||
Developers and sysadmins working in this space are embracing cloud native and DevOps approaches and methods to develop new use cases and tackle the most pressing industry challenges. Focus areas like containers and edge computing are red hot and the demand for developers and sysadmins who can integrate, collaborate, and innovate in this space is exploding.
|
||||
|
||||
Open source and Linux makes this all possible, and per the recently published [2018 Open Source Jobs Report][2], fully 80% of hiring managers are looking for people with Linux skills **while 46% are looking to recruit in the networking area and a roughly equal equal percentage cite “Networking” as a technology most affecting their hiring decisions.**
|
||||
|
||||
Developers are the most sought-after position, with 72% of hiring managers looking for them, followed by DevOps skills (59%), engineers (57%) and sysadmins (49%). The report also measures the incredible growth in demand for containers skills which matches what we’re seeing in the networking space with the creation of cloud native virtual functions (CNFs) and the proliferation of Continuous Integration / Continuous Deployment approaches such as the [XCI initiative][3] in the OPNFV.
|
||||
|
||||
### Get Started
|
||||
|
||||
The good news for job seekers in that there are plenty of onramps into open source including the free [Introduction to Linux][4] course. Multiple certifications are mandatory for the top jobs so I encourage you to explore the range of training opportunities out there. Specific to networking, check out these new training courses in the [OPNFV][5] and [ONAP][6] projects, as well as this [introduction to open source networking technologies][7].
|
||||
|
||||
If you haven’t done so already, download the [2018 Open Source Jobs Report][2] now for more insights and plot your course through the wide world of open source technology to the exciting career that waits for you on the other side!
|
||||
|
||||
[Download the complete Open Source Jobs Report][8]now and[learn more about Linux certification here.][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/os-jobs-report/2018/7/open-source-networking-jobs-hotbed-innovation-and-opportunities
|
||||
|
||||
作者:[Brandon Wick][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/brandon-wick
|
||||
[1]:https://www.lfnetworking.org/
|
||||
[2]:https://www.linuxfoundation.org/publications/2018/06/open-source-jobs-report-2018/
|
||||
[3]:https://docs.opnfv.org/en/latest/submodules/releng-xci/docs/xci-overview.html
|
||||
[4]:https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-1
|
||||
[5]:https://training.linuxfoundation.org/training/opnfv-fundamentals/
|
||||
[6]:https://training.linuxfoundation.org/training/onap-fundamentals/
|
||||
[7]:https://www.edx.org/course/introduction-to-software-defined-networking-technologies
|
||||
[8]:https://www.linuxfoundation.org/publications/open-source-jobs-report-2018/
|
||||
[9]:https://training.linuxfoundation.org/certification
|
||||
@ -1,140 +0,0 @@
|
||||
What I Learned from Programming Interviews
|
||||
============================================================
|
||||
|
||||

|
||||
Whiteboard programming interviews
|
||||
|
||||
In 2017, I went to the [Grace Hopper Celebration][1] of women in computing. It’s the largest gathering of this kind, with 17,000 women attending last year.
|
||||
|
||||
This conference has a huge career fair where companies interview attendees. Some even get offers. Walking around the area, I noticed that some people looked stressed and worried. I overheard conversations, and some talked about how they didn’t do well in the interview.
|
||||
|
||||
I approached a group of people that I overheard and gave them advice. I considered some of the advice I gave to be basic, such as “it’s okay to think of the naive solution first.” But people were surprised by most of the advice I gave them.
|
||||
|
||||
I wanted to help more people with this. I gathered a list of tips that worked for me and published a [podcast episode][2] about them. They’re also the topic of this post.
|
||||
|
||||
I’ve had many programming interviews both for internships and full-time jobs. When I was in college studying Computer Science, there was a career fair every fall semester where the first round of interviews took place. I have failed at the first and final rounds of interviews. After each interview, I reflected on what I could’ve done better and had mock up interviews with friends who gave me feedback.
|
||||
|
||||
Whether we find a job through a job portal, networking, or university recruiting, part of the process involves doing a technical interview.
|
||||
|
||||
In recent years we’ve seen different interview formats emerge:
|
||||
|
||||
* Pair programming with an engineer
|
||||
|
||||
* Online quiz and online coding
|
||||
|
||||
* Whiteboard interviews
|
||||
|
||||
I’ll focus on the whiteboard interview because it’s the one that I have experienced. I’ve had many interviews. Some of them have gone well, while others haven’t.
|
||||
|
||||
### What I did wrong
|
||||
|
||||
First, I want to go over the things I did wrong in my interviews. This helps see the problems and what to improve.
|
||||
|
||||
When an interviewer gave me a technical problem, I immediately went to the whiteboard and started trying to solve it. _Without saying a word._
|
||||
|
||||
I made two mistakes here:
|
||||
|
||||
#### Not clarifying information that is crucial to solve a problem
|
||||
|
||||
For example, are we only working with numbers or also strings? Are we supporting multiple data types? If you don’t ask questions before you start working on a question, your interviewer can get the impression that you won’t ask questions before you start working on a project at their company. This is an important skill to have in the workplace. It is not like school anymore. You don’t get an assignment with all the steps detailed for you. You have to find out what those are and define them.
|
||||
|
||||
#### Thinking without writing or communicating
|
||||
|
||||
Often times I stood there thinking without writing. When I was doing a mock interview with a friend, he told me that he knew I was thinking because we had worked together. To a stranger, it can seem that I’m clueless, or that I’m thinking. It is also important not to rush on a solution right away. Take some time to brainstorm ideas. Sometimes the interviewer will gladly participate in this. After all, that’s how it is at work meetings.
|
||||
|
||||
### Coming up with a solution
|
||||
|
||||
Before you begin writing code, it helps if you come up with the algorithm first. Don’t start writing code and hope that you’ll solve the problem as you write.
|
||||
|
||||
This is what has worked for me:
|
||||
|
||||
1. Brainstorm
|
||||
|
||||
2. Coding
|
||||
|
||||
3. Error handling
|
||||
|
||||
4. Testing
|
||||
|
||||
#### 1\. Brainstorm
|
||||
|
||||
For me, it helps to visualize first what the problem is through a series of examples. If it’s a problem related to trees, I would start with the null case, one node, two nodes, three nodes. This can help you generalize a solution.
|
||||
|
||||
On the whiteboard, write down a list of the things the algorithm needs to do. This way, you can find bugs and issues before writing any code. Just keep track of the time. I made a mistake once where I spent too much time asking clarifying questions and brainstorming, and I barely had time to write the code. The downside of this is that your interviewer doesn’t get to see how you code. You can also come off as if you’re trying to avoid the coding portion. It helps to wear a wrist watch, or if there’s a clock in the room, look at it occasionally. Sometimes the interviewer will tell you, “I think we have the necessary information, let’s start coding it.”
|
||||
|
||||
#### 2\. Coding and code walkthrough
|
||||
|
||||
If you don’t have the solution right away, it always helps to point out the obvious naive solution. While you’re explaining this, you should be thinking of how to improve it. When you state the obvious, indicate why it is not the best solution. For this it helps to be familiar with big O notation. It is okay to go over 2–3 solutions first. The interviewer sometimes guides you by saying, “Can we do better?” This can sometimes mean they are looking for a more efficient solution.
|
||||
|
||||
#### 3\. Error handling
|
||||
|
||||
While you’re coding, point out that you’re leaving a code comment for error handling. Once an interviewer said, “That’s a good point. How would you handle it? Would you throw an exception? Or return a specific value?” This can make for a good short discussion about code quality. Mention a few error cases. Other times, the interviewer might say that you can assume that the parameters you’re getting already passed a validation. However, it is still important to bring this up to show that you are aware of error cases and quality.
|
||||
|
||||
#### 4\. Testing
|
||||
|
||||
After you have finished coding the solution, re-use the examples from brainstorming to walk through your code and make sure it works. For example you can say, “Let’s go over the example of a tree with one node, two nodes.”
|
||||
|
||||
After you finish this, the interviewer sometimes asks you how you would test your code, and what your test cases would be. I recommend that you organize your test cases in different categories.
|
||||
|
||||
Some examples are:
|
||||
|
||||
1. Performance
|
||||
|
||||
2. Error cases
|
||||
|
||||
3. Positive expected cases
|
||||
|
||||
For performance, think about extreme quantities. For example, if the problem is about lists, mention that you would have a case with a large list and a really small list. If it’s about numbers, you’ll test the maximum integer number and the smallest. I recommend reading about testing software to get more ideas. My favorite book on this is [How We Test Software at Microsoft][3].
|
||||
|
||||
For error cases, think about what is expected to fail and list those.
|
||||
|
||||
For positive expected cases, it helps to think of what the user requirements are. What are the cases that this solution is meant to solve? Those are the positive test cases.
|
||||
|
||||
### “Do you have any questions for me?”
|
||||
|
||||
Almost always there will be a few minutes dedicated at the end for you to ask questions. I recommend that you write down the questions you would ask your interviewer before the interview. Don’t say, “I don’t have any questions.” Even if you feel the interview didn’t go well, or you’re not super passionate about the company, there’s always something you can ask. It can be about what the person likes and hates most about his or her job. Or it can be something related to the person’s work, or technologies and practices used at the company. Don’t feel discouraged to ask something even if you feel you didn’t do well.
|
||||
|
||||
### Applying for a job
|
||||
|
||||
As for searching and applying for a job, I’ve been told that you should only apply to a place that you would be truly passionate to work for. They say pick a company that you love, or a product that you enjoy using, and see if you can work there.
|
||||
|
||||
I don’t recommend that you always do this. You can rule out many good options this way, especially if you’re looking for an internship or an entry-level job.
|
||||
|
||||
You can focus on other goals instead. What do I want to get more experience in? Is it cloud computing, web development, or artificial intelligence? When you talk to companies at the career fair, find out if their job openings are in this area. You might find a really good position at a company or a non-profit that wasn’t in your list.
|
||||
|
||||
#### Switching teams
|
||||
|
||||
After a year and a half at my first team, I decided that it was time to explore something different. I found a team I liked and had 4 rounds of interviews. I didn’t do well.
|
||||
|
||||
I didn’t practice anything, not even simply writing on a whiteboard. My logic had been, if I have been working at the company for almost 2 years, why would I need to practice? I was wrong about this. I struggled to write a solution on the whiteboard. Things like my writing being too small and running out of space by not starting at the top left all contributed to not passing.
|
||||
|
||||
I hadn’t brushed up on data structures and algorithms. If I had, I would’ve been more confident. Even if you’ve been working at a company as a Software Engineer, before you do a round of interviews with another team, I strongly recommend you go through practice problems on a whiteboard.
|
||||
|
||||
As for finding a team, if you are looking to switch teams at your company, it helps to talk informally with members of that team. For this, I found that almost everyone is willing to have lunch with you. People are mostly available at noon too, so there is low risk of lack of availability and meeting conflicts. This is an informal way to find out what the team is working on, and see what the personalities of your potential team members are like. You can learn many things from lunch meetings that can help you in the formal interviews.
|
||||
|
||||
It is important to know that at the end of the day, you are interviewing for a specific team. Even if you do really well, you might not get an offer because you are not a culture fit. That’s part of why I try to meet different people in the team first, but this is not always possible. Don’t get discouraged by a rejection, keep your options open, and practice.
|
||||
|
||||
This content is from the [“Programming interviews”][4] episode on [The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Software Engineer II at Microsoft Research, opinions are my own, host of www.thewomenintechshow.com
|
||||
|
||||
------------
|
||||
|
||||
via: https://medium.freecodecamp.org/what-i-learned-from-programming-interviews-29ba49c9b851
|
||||
|
||||
作者:[Edaena Salinas ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@edaenas
|
||||
[1]:https://anitab.org/event/2017-grace-hopper-celebration-women-computing/
|
||||
[2]:https://thewomenintechshow.com/2017/12/18/programming-interviews/
|
||||
[3]:https://www.amazon.com/How-We-Test-Software-Microsoft/dp/0735624259
|
||||
[4]:https://thewomenintechshow.com/2017/12/18/programming-interviews/
|
||||
[5]:https://thewomenintechshow.com/
|
||||
@ -1,112 +0,0 @@
|
||||
icecoobe translating
|
||||
|
||||
A gentle introduction to FreeDOS
|
||||
======
|
||||
|
||||

|
||||
|
||||
FreeDOS is an old operating system, but it is new to many people. In 1994, several developers and I came together to [create FreeDOS][1]—a complete, free, DOS-compatible operating system you can use to play classic DOS games, run legacy business software, or develop embedded systems. Any program that works on MS-DOS should also run on FreeDOS.
|
||||
|
||||
In 1994, FreeDOS was immediately familiar to anyone who had used Microsoft's proprietary MS-DOS. And that was by design; FreeDOS intended to mimic MS-DOS as much as possible. As a result, DOS users in the 1990s were able to jump right into FreeDOS. But times have changed. Today, open source developers are more familiar with the Linux command line or they may prefer a graphical desktop like [GNOME][2], making the FreeDOS command line seem alien at first.
|
||||
|
||||
New users often ask, "I [installed FreeDOS][3], but how do I use it?" If you haven't used DOS before, the blinking `C:\>` DOS prompt can seem a little unfriendly. And maybe scary. This gentle introduction to FreeDOS should get you started. It offers just the basics: how to get around and how to look at files. If you want to learn more than what's offered here, visit the [FreeDOS wiki][4].
|
||||
|
||||
### The DOS prompt
|
||||
|
||||
First, let's look at the empty prompt and what it means.
|
||||
|
||||

|
||||
|
||||
DOS is a "disk operating system" created when personal computers ran from floppy disks. Even when computers supported hard drives, it was common in the 1980s and 1990s to switch frequently between the different drives. For example, you might make a backup copy of your most important files to a floppy disk.
|
||||
|
||||
DOS referenced each drive by a letter. Early PCs could have only two floppy drives, which were assigned as the `A:` and `B:` drives. The first partition on the first hard drive was the `C:` drive, and so on for other drives. The `C:` in the prompt means you are using the first partition on the first hard drive.
|
||||
|
||||
Starting with PC-DOS 2.0 in 1983, DOS also supported directories and subdirectories, much like the directories and subdirectories on Linux filesystems. But unlike Linux, DOS directory names are delimited by `\` instead of `/`. Putting that together with the drive letter, the `C:\` in the prompt means you are in the top, or "root," directory of the `C:` drive.
|
||||
|
||||
The `>` is the literal prompt where you type your DOS commands, like the `$` prompt on many Linux shells. The part before the `>` tells you the current working directory, and you type commands at the `>` prompt.
|
||||
|
||||
### Finding your way around in DOS
|
||||
|
||||
The basics of navigating through directories in DOS are very similar to the steps you'd use on the Linux command line. You need to remember only a few commands.
|
||||
|
||||
#### Displaying a directory
|
||||
|
||||
When you want to see the contents of the current directory, use the `DIR` command. Since DOS commands are not case-sensitive, you could also type `dir`. By default, DOS displays the details of every file and subdirectory, including the name, extension, size, and last modified date and time.
|
||||
|
||||
|
||||
|
||||
If you don't want the extra details about individual file sizes, you can display a "wide" directory by using the `/w` option with the `DIR` command. Note that Linux uses the hyphen (`-`) or double-hyphen (`--`) to start command-line options, but DOS uses the slash character (`/`).
|
||||
|
||||
|
||||
|
||||
You can look inside a specific subdirectory by passing the pathname as a parameter to `DIR`. Again, another difference from Linux is that Linux files and directories are case-sensitive, but DOS names are case-insensitive. DOS will usually display files and directories in all uppercase, but you can equally reference them in lowercase.
|
||||
|
||||
|
||||
|
||||
|
||||
#### Changing the working directory
|
||||
|
||||
Once you can see the contents of a directory, you can "move into" any other directory. On DOS, you change your working directory with the `CHDIR` command, also abbreviated as `CD`. You can change into a subdirectory with a command like `CD CHOICE` or into a new path with `CD \FDOS\DOC\CHOICE`.
|
||||
|
||||
|
||||
|
||||
Just like on the Linux command line, DOS uses `.` to represent the current directory, and `..` for the parent directory (one level "up" from the current directory). You can combine these. For example, `CD ..` changes to the parent directory, and `CD ..\..` moves you two levels "up" from the current directory.
|
||||
|
||||
|
||||
|
||||
FreeDOS also borrows a feature from Linux: You can use `CD -` to jump back to your previous working directory. That is handy after you change into a new path to do one thing and want to go back to your previous work.
|
||||
|
||||
#### Changing the working drive
|
||||
|
||||
Under Linux, the concept of a "drive" is hidden. In Linux and other Unix systems, you "mount" a drive to a directory path, such as `/backup`, or the system does it for you automatically, such as `/var/run/media/user/flashdrive`. But DOS is a much simpler system. With DOS, you must change the working drive by yourself.
|
||||
|
||||
Remember that DOS assigns the first partition on the first hard drive as the `C:` drive, and so on for other drive letters. On modern systems, people rarely divide a hard drive with multiple DOS partitions; they simply use the whole disk—or as much of it as they can assign to DOS. Today, `C:` is usually the first hard drive, and `D:` is usually another hard drive or the CD-ROM drive. Other network drives can be mapped to other letters, such as `E:` or `Z:` or however you want to organize them.
|
||||
|
||||
Changing drives is easy under DOS. Just type the drive letter followed by a colon (`:`) on the command line, and DOS will change to that working drive. For example, on my [QEMU][5] system, I set my `D:` drive to a shared directory in my Linux home directory, where I keep installers for various DOS applications and games I want to test.
|
||||
|
||||
|
||||
|
||||
Be careful that you don't try to change to a drive that doesn't exist. DOS may set the working drive, but if you try to do anything there you'll get the somewhat infamous "Abort, Retry, Fail" DOS error message.
|
||||
|
||||
|
||||
|
||||
### Other things to try
|
||||
|
||||
With the `CD` and `DIR` commands, you have the basics of DOS navigation. These commands allow you to find your way around DOS directories and see what other subdirectories and files exist. Once you are comfortable with basic navigation, you might also try these other basic DOS commands:
|
||||
|
||||
* `MKDIR` or `MD` to create new directories
|
||||
* `RMDIR` or `RD` to remove directories
|
||||
* `TREE` to view a list of directories and subdirectories in a tree-like format
|
||||
* `TYPE` and `MORE` to display file contents
|
||||
* `RENAME` or `REN` to rename files
|
||||
* `DEL` or `ERASE` to delete files
|
||||
* `EDIT` to edit files
|
||||
* `CLS` to clear the screen
|
||||
|
||||
|
||||
|
||||
If those aren't enough, you can find a list of [all DOS commands][6] on the FreeDOS wiki.
|
||||
|
||||
In FreeDOS, you can use the `/?` parameter to get brief instructions to use each command. For example, `EDIT /?` will show you the usage and options for the editor. Or you can type `HELP` to use an interactive help system.
|
||||
|
||||
Like any DOS, FreeDOS is meant to be a simple operating system. The DOS filesystem is pretty simple to navigate with only a few basic commands. So fire up a QEMU session, install FreeDOS, and experiment with the DOS command line. Maybe now it won't seem so scary.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/gentle-introduction-freedos
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://opensource.com/article/17/10/freedos
|
||||
[2]:https://opensource.com/article/17/8/gnome-20-anniversary
|
||||
[3]:http://www.freedos.org/
|
||||
[4]:http://wiki.freedos.org/
|
||||
[5]:https://www.qemu.org/
|
||||
[6]:http://wiki.freedos.org/wiki/index.php/Dos_commands
|
||||
@ -1,240 +0,0 @@
|
||||
pinewall is translating
|
||||
|
||||
Anatomy of a Linux DNS Lookup – Part II
|
||||
============================================================
|
||||
|
||||
In [Anatomy of a Linux DNS Lookup – Part I][1] I covered:
|
||||
|
||||
* `nsswitch`
|
||||
|
||||
* `/etc/hosts`
|
||||
|
||||
* `/etc/resolv.conf`
|
||||
|
||||
* `ping` vs `host` style lookups
|
||||
|
||||
and determined that most programs reference `/etc/resolv.conf` along the way to figuring out which DNS server to look up.
|
||||
|
||||
That stuff was more general linux behaviour (*) but here we move firmly into distribution-specific territory. I use ubuntu, but a lot of this will overlap with Debian and even CentOS-based distributions, and also differ from earlier or later Ubuntu versions.
|
||||
|
||||
###### (*) in fact, it’s subject to a POSIX standard, so
|
||||
is not limited to Linux (I learned this from
|
||||
a fantastic [comment][2] on the previous post)
|
||||
|
||||
In other words: your host is more likely to differ in its behaviour in specifics from here.
|
||||
|
||||
In Part II I’ll cover how `resolv.conf` can get updated, what happens when `systemctl restart networking` is run, and how `dhclient` gets involved.
|
||||
|
||||
* * *
|
||||
|
||||
# 1) Updating /etc/resolv.conf by hand
|
||||
|
||||
We know that `/etc/resolv.conf` is (highly likely to be) referenced, so surely you can just add a nameserver to that file, and then your host will use that nameserver in addition to the others, right?
|
||||
|
||||
If you try that:
|
||||
|
||||
```
|
||||
$ echo nameserver 10.10.10.10 >> /etc/resolv.conf
|
||||
```
|
||||
|
||||
it all looks good:
|
||||
|
||||
```
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.3
|
||||
search home
|
||||
nameserver 10.10.10.10
|
||||
```
|
||||
|
||||
until the network is restarted:
|
||||
|
||||
```
|
||||
$ systemctl restart networking
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.3
|
||||
search home
|
||||
```
|
||||
|
||||
our `10.10.10.10` nameserver has gone!
|
||||
|
||||
This is where those comments we ignored in Part I come in…
|
||||
|
||||
* * *
|
||||
|
||||
# 2) resolvconf
|
||||
|
||||
You see the phrase `generated by resolvconf` in the `/etc/resolv.conf` file above? This is our clue.
|
||||
|
||||
If you dig into what `systemctl restart networking` does, among many other things, it ends up calling a script: `/etc/network/if-up.d/000resolvconf`. Within this script is a call to `resolvconf`:
|
||||
|
||||
```
|
||||
/sbin/resolvconf -a "${IFACE}.${ADDRFAM}"
|
||||
```
|
||||
|
||||
A little digging through the man pages reveals that the `-a` flag allows us to:
|
||||
|
||||
```
|
||||
Add or overwrite the record IFACE.PROG then run the update scripts
|
||||
if updating is enabled.
|
||||
```
|
||||
|
||||
So maybe we can call this directly to add a nameserver:
|
||||
|
||||
```
|
||||
echo 'nameserver 10.10.10.10' | /sbin/resolvconf -a enp0s8.inet
|
||||
```
|
||||
|
||||
Turns out we can!
|
||||
|
||||
```
|
||||
$ cat /etc/resolv.conf | grep nameserver
|
||||
nameserver 10.0.2.3
|
||||
nameserver 10.10.10.10
|
||||
```
|
||||
|
||||
So we’re done now, right? This is how `/etc/resolv.conf` gets updated? Calling `resolvconf` adds it to a database somewhere, and then updates (if configured, whatever that means) the `resolv.conf` file
|
||||
|
||||
No.
|
||||
|
||||
```
|
||||
$ systemctl restart networking
|
||||
root@linuxdns1:/etc# cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.3
|
||||
search home
|
||||
```
|
||||
|
||||
Argh! It’s gone again.
|
||||
|
||||
So `systemctl restart networking` does more than just run `resolvconf`. It must be getting the nameserver information from somewhere else. Where?
|
||||
|
||||
* * *
|
||||
|
||||
# 3) ifup/ifdown
|
||||
|
||||
Digging further into what `systemctl restart networking` does tells us a couple of things:
|
||||
|
||||
```
|
||||
cat /lib/systemd/system/networking.service
|
||||
[...]
|
||||
[Service]
|
||||
Type=oneshot
|
||||
EnvironmentFile=-/etc/default/networking
|
||||
ExecStartPre=-/bin/sh -c '[ "$CONFIGURE_INTERFACES" != "no" ] && [ -n "$(ifquery --read-environment --list --exclude=lo)" ] && udevadm settle'
|
||||
ExecStart=/sbin/ifup -a --read-environment
|
||||
ExecStop=/sbin/ifdown -a --read-environment --exclude=lo
|
||||
[...]
|
||||
```
|
||||
|
||||
First, the networking ‘service’ restart is actually a ‘oneshot’ script that runs these commands:
|
||||
|
||||
```
|
||||
/sbin/ifdown -a --read-environment --exclude=lo
|
||||
/bin/sh -c '[ "$CONFIGURE_INTERFACES" != "no" ] && [ -n "$(ifquery --read-environment --list --exclude=lo)" ] && udevadm settle'
|
||||
/sbin/ifup -a --read-environment
|
||||
```
|
||||
|
||||
The first line with `ifdown` brings down all the network interfaces (but excludes the local interface). (*)
|
||||
|
||||
###### (*) I’m unclear why this doesn’t boot me out of my
|
||||
vagrant session in my example code (anyone know?).
|
||||
|
||||
The second line makes sure the system has done all it needs to do regarding the bringing of network interfaces down before going ahead and bringing them all back up with `ifup` in the third line. So the second thing we learn is that `ifup` and `ifdown` are what the networking service ‘actually’ runs.
|
||||
|
||||
The `--read-environment` flag is undocumented, and is there so that `systemctl` can play nice with it. A lot of people hate `systemctl` for this kind of thing.
|
||||
|
||||
Great. So what does `ifup` (and its twin, `ifdown`) do? To cut another long story short, it runs all the scripts in `etc/network/if-pre-up.d/` and `/etc/network/if-up.d/`. These in turn might run other scripts, and so on.
|
||||
|
||||
One of the things it does (and I’m still not quite sure how – maybe `udev` is involved?) `dhclient` gets run.
|
||||
|
||||
* * *
|
||||
|
||||
# 4) dhclient
|
||||
|
||||
`dhclient` is a program that interacts with DHCP servers to negotiate the details of what IP address the network interface specified should use. It also can receive a DNS nameserver to use, which then gets placed in the `/etc/resolv.conf`.
|
||||
|
||||
Let’s cut to the chase and simulate what it does, but just on the `enp0s3` interface on my example VM, having first removed the nameserver from the `/etc/resolv.conf` file:
|
||||
|
||||
```
|
||||
$ sed -i '/nameserver.*/d' /run/resolvconf/resolv.conf
|
||||
$ cat /etc/resolv.conf | grep nameserver
|
||||
$ dhclient -r enp0s3 && dhclient -v enp0s3
|
||||
Killed old client process
|
||||
Internet Systems Consortium DHCP Client 4.3.3
|
||||
Copyright 2004-2015 Internet Systems Consortium.
|
||||
All rights reserved.
|
||||
For info, please visit https://www.isc.org/software/dhcp/
|
||||
Listening on LPF/enp0s8/08:00:27:1c:85:19
|
||||
Sending on LPF/enp0s8/08:00:27:1c:85:19
|
||||
Sending on Socket/fallback
|
||||
DHCPDISCOVER on enp0s8 to 255.255.255.255 port 67 interval 3 (xid=0xf2f2513e)
|
||||
DHCPREQUEST of 172.28.128.3 on enp0s8 to 255.255.255.255 port 67 (xid=0x3e51f2f2)
|
||||
DHCPOFFER of 172.28.128.3 from 172.28.128.2
|
||||
DHCPACK of 172.28.128.3 from 172.28.128.2
|
||||
bound to 172.28.128.3 -- renewal in 519 seconds.
|
||||
|
||||
$ cat /etc/resolv.conf | grep nameserver
|
||||
nameserver 10.0.2.3
|
||||
```
|
||||
|
||||
So that’s where the nameserver comes from…
|
||||
|
||||
But hang on a sec – what’s that `/run/resolvconf/resolv.conf` doing there, when it should be `/etc/resolv.conf`?
|
||||
|
||||
Well, it turns out that `/etc/resolv.conf` isn’t always ‘just’ a file.
|
||||
|
||||
On my VM, it’s a symlink to the ‘real’ file stored in `/run/resolvconf`. This is a clue that the file is constructed at run time, and one of the reasons we’re told not to edit the file directly.
|
||||
|
||||
If the `sed` command above were to be run on the `/etc/resolv.conf` file directly then the behaviour above would be different and a warning thrown about `/etc/resolv.conf` not being a symlink (`sed -i` doesn’t handle symlinks cleverly – it just creates a fresh file).
|
||||
|
||||
`dhclient` offers the capability to override the DNS server given to you by DHCP if you dig a bit deeper into the `supersede` setting in `/etc/dhcp/dhclient.conf`…
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_A (roughly) accurate map of what’s going on_
|
||||
|
||||
* * *
|
||||
|
||||
### End of Part II
|
||||
|
||||
That’s the end of Part II. Believe it or not that was a somewhat simplified version of what goes on, but I tried to keep it to the important and ‘useful to know’ stuff so you wouldn’t fall asleep. Most of that detail is around the twists and turns of the scripts that actually get run.
|
||||
|
||||
And we’re still not done yet. Part III will look at even more layers on top of these.
|
||||
|
||||
Let’s briefly list some of the things we’ve come across so far:
|
||||
|
||||
* `nsswitch`
|
||||
|
||||
* `/etc/hosts`
|
||||
|
||||
* `/etc/resolv.conf`
|
||||
|
||||
* `/run/resolvconf/resolv.conf`
|
||||
|
||||
* `systemd` and its `networking` service
|
||||
|
||||
* `ifup` and `ifdown`
|
||||
|
||||
* `dhclient`
|
||||
|
||||
* `resolvconf`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
|
||||
作者:[ZWISCHENZUGS][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[2]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/#comment-2312
|
||||
@ -0,0 +1,316 @@
|
||||
pinewall is translating
|
||||
|
||||
Anatomy of a Linux DNS Lookup – Part III
|
||||
============================================================
|
||||
|
||||
In [Anatomy of a Linux DNS Lookup – Part I][1] I covered:
|
||||
|
||||
* `nsswitch`
|
||||
|
||||
* `/etc/hosts`
|
||||
|
||||
* `/etc/resolv.conf`
|
||||
|
||||
* `ping` vs `host` style lookups
|
||||
|
||||
and in [Anatomy of a Linux DNS Lookup – Part II][2] I covered:
|
||||
|
||||
* `systemd` and its `networking` service
|
||||
|
||||
* `ifup` and `ifdown`
|
||||
|
||||
* `dhclient`
|
||||
|
||||
* `resolvconf`
|
||||
|
||||
and ended up here:
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_A (roughly) accurate map of what’s going on_
|
||||
|
||||
Unfortunately, that’s not the end of the story. There’s still more things that can get involved. In Part III, I’m going to cover NetworkManager and dnsmasq and briefly show how they play a part.
|
||||
|
||||
* * *
|
||||
|
||||
# 1) NetworkManager
|
||||
|
||||
As mentioned in Part II, we are now well away from POSIX standards and into Linux distribution-specific areas of DNS resolution management.
|
||||
|
||||
In my preferred distribution (Ubuntu), there is a service that’s available and often installed for me as a dependency of some other package I install called [NetworkManager][3]. It’s actually a service developed by RedHat in 2004 to help manage network interfaces for you.
|
||||
|
||||
What does this have to do with DNS? Install it to find out:
|
||||
|
||||
```
|
||||
$ apt-get install -y network-manager
|
||||
```
|
||||
|
||||
In my distribution, I get a config file.
|
||||
|
||||
```
|
||||
$ cat /etc/NetworkManager/NetworkManager.conf
|
||||
[main]
|
||||
plugins=ifupdown,keyfile,ofono
|
||||
dns=dnsmasq
|
||||
|
||||
[ifupdown]
|
||||
managed=false
|
||||
```
|
||||
|
||||
See that `dns=dnsmasq` there? That means that NetworkManager will use `dnsmasq` to manage DNS on the host.
|
||||
|
||||
* * *
|
||||
|
||||
# 2) dnsmasq
|
||||
|
||||
The dnsmasq program is that now-familiar thing: yet another level of indirection for `/etc/resolv.conf`.
|
||||
|
||||
Technically, dnsmasq can do a few things, but is primarily it acts as a DNS server that can cache requests to other DNS servers. It runs on port 53 (the standard DNS port), on all local network interfaces.
|
||||
|
||||
So where is `dnsmasq` running? NetworkManager is running:
|
||||
|
||||
```
|
||||
$ ps -ef | grep NetworkManager
|
||||
root 15048 1 0 16:39 ? 00:00:00 /usr/sbin/NetworkManager --no-daemon
|
||||
```
|
||||
|
||||
But no `dnsmasq` process exists:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
$
|
||||
```
|
||||
|
||||
Although it’s configured to be used, confusingly it’s not actually installed! So you’re going to install it.
|
||||
|
||||
Before you install it though, let’s check the state of `/etc/resolv.conf`.
|
||||
|
||||
```
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.2
|
||||
search home
|
||||
```
|
||||
|
||||
It’s not been changed by NetworkManager.
|
||||
|
||||
If `dnsmasq` is installed:
|
||||
|
||||
```
|
||||
$ apt-get install -y dnsmasq
|
||||
```
|
||||
|
||||
Then `dnsmasq` is up and running:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
dnsmasq 15286 1 0 16:54 ? 00:00:00 /usr/sbin/dnsmasq -x /var/run/dnsmasq/dnsmasq.pid -u dnsmasq -r /var/run/dnsmasq/resolv.conf -7 /etc/dnsmasq.d,.dpkg-dist,.dpkg-old,.dpkg-new --local-service --trust-anchor=.,19036,8,2,49AAC11D7B6F6446702E54A1607371607A1A41855200FD2CE1CDDE32F24E8FB5
|
||||
```
|
||||
|
||||
And `/etc/resolv.conf` has changed again!
|
||||
|
||||
```
|
||||
root@linuxdns1:~# cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
And `netstat` shows `dnsmasq` is serving on all interfaces at port 53:
|
||||
|
||||
```
|
||||
$ netstat -nlp4
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 10.0.2.15:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 172.28.128.11:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1237/sshd
|
||||
udp 0 0 127.0.0.1:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 10.0.2.15:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 172.28.128.11:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10758/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10530/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10185/dhclient
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
# 3) Unpicking dnsmasq
|
||||
|
||||
Now we are in a situation where all DNS queries are going to `127.0.0.1:53` and from there what happens?
|
||||
|
||||
We can get a clue from looking again at the `/var/run` folder. The `resolv.conf` in `resolvconf` has been changed to point to where `dnsmasq` is being served:
|
||||
|
||||
```
|
||||
$ cat /var/run/resolvconf/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
while there’s a new `dnsmasq` folder with its own `resolv.conf`.
|
||||
|
||||
```
|
||||
$ cat /run/dnsmasq/resolv.conf
|
||||
nameserver 10.0.2.2
|
||||
```
|
||||
|
||||
which has the nameserver given to us by `DHCP`.
|
||||
|
||||
We can reason about this without looking too deeply, but what if we really want to know what’s going on?
|
||||
|
||||
* * *
|
||||
|
||||
# 4) Debugging Dnsmasq
|
||||
|
||||
Frequently I’ve found myself wondering what dnsmasq’s state is. Fortunately, you can get a good amount of information out of it if you set change this line in `/etc/dnsmasq.conf`:
|
||||
|
||||
```
|
||||
#log-queries
|
||||
```
|
||||
|
||||
to:
|
||||
|
||||
```
|
||||
log-queries
|
||||
```
|
||||
|
||||
and restart `dnsmasq`
|
||||
|
||||
Now, if you do a simple:
|
||||
|
||||
```
|
||||
$ ping -c1 bbc.co.uk
|
||||
```
|
||||
|
||||
you will see something like this in `/var/log/syslog` (the `[...]` indicates that the line’s start is the same as the previous one):
|
||||
|
||||
```
|
||||
Jul 3 19:56:07 ubuntu-xenial dnsmasq[15372]: query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] forwarded bbc.co.uk to 10.0.2.2
|
||||
[...] reply bbc.co.uk is 151.101.192.81
|
||||
[...] reply bbc.co.uk is 151.101.0.81
|
||||
[...] reply bbc.co.uk is 151.101.64.81
|
||||
[...] reply bbc.co.uk is 151.101.128.81
|
||||
[...] query[PTR] 81.192.101.151.in-addr.arpa from 127.0.0.1
|
||||
[...] forwarded 81.192.101.151.in-addr.arpa to 10.0.2.2
|
||||
[...] reply 151.101.192.81 is NXDOMAIN
|
||||
```
|
||||
|
||||
which shows what `dnsmasq` received, where the query was forwarded to, and what reply was received.
|
||||
|
||||
If the query is returned from the cache (or, more exactly, the local ‘time-to-live’ for the query has not expired), then it looks like this in the logs:
|
||||
|
||||
```
|
||||
[...] query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] cached bbc.co.uk is 151.101.64.81
|
||||
[...] cached bbc.co.uk is 151.101.128.81
|
||||
[...] cached bbc.co.uk is 151.101.192.81
|
||||
[...] cached bbc.co.uk is 151.101.0.81
|
||||
[...] query[PTR] 81.64.101.151.in-addr.arpa from 127.0.0.1
|
||||
```
|
||||
|
||||
and if you ever want to know what’s in your cache, you can provoke dnsmasq into sending it to the same log file by sending the `USR1` signal to the dnsmasq process id:
|
||||
|
||||
```
|
||||
$ kill -SIGUSR1 <(cat /run/dnsmasq/dnsmasq.pid)
|
||||
```
|
||||
|
||||
and the output of the dump looks like this:
|
||||
|
||||
```
|
||||
Jul 3 15:08:08 ubuntu-xenial dnsmasq[15697]: time 1530630488
|
||||
[...] cache size 150, 0/5 cache insertions re-used unexpired cache entries.
|
||||
[...] queries forwarded 2, queries answered locally 0
|
||||
[...] queries for authoritative zones 0
|
||||
[...] server 10.0.2.2#53: queries sent 2, retried or failed 0
|
||||
[...] Host Address Flags Expires
|
||||
[...] linuxdns1 172.28.128.8 4FRI H
|
||||
[...] ip6-localhost ::1 6FRI H
|
||||
[...] ip6-allhosts ff02::3 6FRI H
|
||||
[...] ip6-localnet fe00:: 6FRI H
|
||||
[...] ip6-mcastprefix ff00:: 6FRI H
|
||||
[...] ip6-loopback : 6F I H
|
||||
[...] ip6-allnodes ff02: 6FRI H
|
||||
[...] bbc.co.uk 151.101.64.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.192.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.0.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.128.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] 151.101.64.81 4 R NX Tue Jul 3 15:34:17 2018
|
||||
[...] localhost 127.0.0.1 4FRI H
|
||||
[...] <Root> 19036 8 2 SF I
|
||||
[...] ip6-allrouters ff02::2 6FRI H
|
||||
```
|
||||
|
||||
In the above output, I believe (but don’t know, and ‘?’ indicates a relatively wild guess on my part) that:
|
||||
|
||||
* ‘4’ means IPv4
|
||||
|
||||
* ‘6’ means IPv6
|
||||
|
||||
* ‘H’ means address was read from an `/etc/hosts` file
|
||||
|
||||
* ‘I’ ? ‘Immortal’ DNS value? (ie no time-to-live value?)
|
||||
|
||||
* ‘F’ ?
|
||||
|
||||
* ‘R’ ?
|
||||
|
||||
* ‘S’?
|
||||
|
||||
* ‘N’?
|
||||
|
||||
* ‘X’
|
||||
|
||||
#### Alternatives to dnsmasq
|
||||
|
||||
`dnsmasq` is not the only option that can be passed to dns in NetworkManager. There’s `none` which does nothing to `/etc/resolv,conf`, `default`, which claims to ‘update `resolv.conf` to reflect currently active connections’, and `unbound`, which communicates with the `unbound` service and `dnssec-triggerd`, which is concerned with DNS security and is not covered here.
|
||||
|
||||
* * *
|
||||
|
||||
### End of Part III
|
||||
|
||||
That’s the end of Part III, where we covered the NetworkManager service, and its `dns=dnsmasq` setting.
|
||||
|
||||
Let’s briefly list some of the things we’ve come across so far:
|
||||
|
||||
* `nsswitch`
|
||||
|
||||
* `/etc/hosts`
|
||||
|
||||
* `/etc/resolv.conf`
|
||||
|
||||
* `/run/resolvconf/resolv.conf`
|
||||
|
||||
* `systemd` and its `networking` service
|
||||
|
||||
* `ifup` and `ifdown`
|
||||
|
||||
* `dhclient`
|
||||
|
||||
* `resolvconf`
|
||||
|
||||
* `NetworkManager`
|
||||
|
||||
* `dnsmasq`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
|
||||
作者:[ZWISCHENZUGS][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[2]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[3]:https://en.wikipedia.org/wiki/NetworkManager
|
||||
@ -1,72 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
3 cool productivity apps for Fedora 28
|
||||
======
|
||||
|
||||

|
||||
|
||||
Productivity apps are especially popular on mobile devices. But when you sit down to do work, you’re often at a laptop or desktop computer. Let’s say you use a Fedora system for your platform. Can you find apps that help you get your work done? Of course! Read on for tips on apps to help you focus on your goals.
|
||||
|
||||
All these apps are available for free on your Fedora system. And they also respect your freedom. (Many also let you use existing services where you may have an account.)
|
||||
|
||||
### FocusWriter
|
||||
|
||||
FocusWriter is simply a full screen word processor. The app makes you more productive because it covers everything else on your screen. When you use FocusWriter, you have nothing between you and your text. With this app at work, you can focus on your thoughts with fewer distractions.
|
||||
|
||||
[![Screenshot of FocusWriter][1]][2]
|
||||
|
||||
FocusWriter lets you adjust fonts, colors, and theme to best suit your preferences. It also remembers your last document and location. This feature lets you jump right back into focusing on writing without delay.
|
||||
|
||||
To install FocusWriter, use the Software app in your Fedora Workstation. Or run this command in a terminal [using sudo][3]:
|
||||
```
|
||||
sudo dnf install focuswriter
|
||||
|
||||
```
|
||||
|
||||
### GNOME ToDo
|
||||
|
||||
This unique app is designed, as you can guess, for the GNOME desktop environment. It’s a great fit for your Fedora Workstation for that reason. ToDo has a simple purpose: it lets you make lists of things you need to get done.
|
||||
|
||||
|
||||
|
||||
Using ToDo, you can prioritize and schedule deadlines for all your tasks. You can also build as many tasks lists as you want. ToDo has numerous extensions for useful functions to boost your productivity. These include GNOME Shell notifications, and list management with a todo.txt file. ToDo can even interface with a Todoist or Google account if you use one. It synchronizes tasks so you can share across your devices.
|
||||
|
||||
To install, search for ToDo in Software, or at the command line run:
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Zanshin
|
||||
|
||||
If you are a KDE using productivity fan, you may enjoy [Zanshin][4]. This organizer helps you plan your actions across multiple projects. It has a full featured interface, and lets you browse across your various tasks to see what’s most important to do next.
|
||||
|
||||
[![Screenshot of Zanshin on Fedora 28][5]][6]
|
||||
|
||||
Zanshin is extremely keyboard friendly, so you can be efficient during hacking sessions. It also integrates across numerous KDE applications as well as the Plasma Desktop. You can use it inline with KMail, KOrganizer, and KRunner.
|
||||
|
||||
To install, run this command:
|
||||
```
|
||||
sudo dnf install zanshin
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/3-cool-productivity-apps/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-15-18-10-18-1024x768.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-15-18-10-18.png
|
||||
[3]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]:https://zanshin.kde.org/
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot_20180715_192216-1024x653.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot_20180715_192216.png
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Getting started with Etcher.io
|
||||
======
|
||||
|
||||
|
||||
@ -1,92 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Install 2048 Game in Ubuntu and Other Linux Distributions
|
||||
======
|
||||
**Popular mobile puzzle game 2048 can also be played on Ubuntu and Linux distributions. Heck! You can even play 2048 in Linux terminal. Don’t blame me if your productivity goes down because of this addictive game.**
|
||||
|
||||
Back in 2014, 2048 was one of the most popular games on iOS and Android. This highly addictive game got so popular that it got a [browser version][1], desktop version as well as a terminal version on Linux.
|
||||
|
||||
<https://giphy.com/embed/wT8XEi5gckwJW>
|
||||
|
||||
This tiny game is played by moving the tiles up and down, left and right. The aim of this puzzle game is to reach 2048 by combining tiles with matching number. So 2+2 becomes 4, 4+4 becomes 16 and so on. It may sound simple and boring but trust me its hell of an addictive game.
|
||||
|
||||
### Play 2048 in Linux [GUI]
|
||||
|
||||
There are several implementations of 2048 game available in Ubuntu and other Linux. You can simply search for it in the Software Center and you’ll find a few of them there.
|
||||
|
||||
There is a [Qt-based][2] 2048 game that you can install on Ubuntu and other Debian and Ubuntu-based Linux distributions. You can install it using the command below:
|
||||
```
|
||||
sudo apt install 2048-qt
|
||||
|
||||
```
|
||||
|
||||
Once installed, you can find the game in the menu and start it. You can move the numbers using the arrow keys. Your highest score is saved as well.
|
||||
|
||||
![2048 Game in Ubuntu Linux][3]
|
||||
|
||||
### Play 2048 in Linux terminal
|
||||
|
||||
The popularity of 2048 brought it to the terminal. If this surprises you, you should know that there are plenty of [awesome terminal games in Linux][4] and 2048 is certainly one of them.
|
||||
|
||||
Now, there are a few ways you can play 2048 in Linux terminal. I’ll mention two of them here.
|
||||
|
||||
#### 1\. term2058 Snap application
|
||||
|
||||
There is a [snap application][5] called [term2048][6] that you can install in any [Snap supported Linux distribution][7].
|
||||
|
||||
If you have Snap enabled, just use this command to install term2048:
|
||||
```
|
||||
sudo snap install term2048
|
||||
|
||||
```
|
||||
|
||||
Ubuntu users can also find this game in the Software Center and install it from there.
|
||||
|
||||
![2048 Terminal Game in Linux][8]
|
||||
|
||||
Once installed, you can use the command term2048 to run the game. It looks something like this:
|
||||
|
||||
![2048 Terminal game][9]
|
||||
|
||||
You can move using the arrow keys.
|
||||
|
||||
#### 2\. Bash script for 2048 terminal game
|
||||
|
||||
This game is actually a shell script which you can run in any Linux terminal. Download the game/script from Github:
|
||||
|
||||
[Download Bash2048][10]
|
||||
|
||||
Extract the downloaded file. Go in the extracted directory and you’ll see a shell script named 2048.sh. Just run the shell script. The game will start immediately. You can move the tiles using the arrow keys.
|
||||
|
||||
![Linux Terminal game 2048][11]
|
||||
|
||||
#### What games do you play on Linux?
|
||||
|
||||
If you like playing games in Linux terminal, you should also try the [classic Snake game in Linux terminal][12].
|
||||
|
||||
Which games do you regularly play in Linux? Do you also play games in terminal? If yes, which is your favorite terminal game?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/2048-game/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:http://gabrielecirulli.github.io/2048/
|
||||
[2]:https://www.qt.io/
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/2048-qt-ubuntu.jpeg
|
||||
[4]:https://itsfoss.com/best-command-line-games-linux/
|
||||
[5]:https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[6]:https://snapcraft.io/term2048
|
||||
[7]:https://itsfoss.com/install-snap-linux/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/term2048-game.png
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/term2048.jpg
|
||||
[10]:https://github.com/mydzor/bash2048
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/2048-bash-terminal.png
|
||||
[12]:https://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/ (nSnake: Play The Classic Snake Game In Linux Terminal)
|
||||
@ -1,3 +1,5 @@
|
||||
pinewall translating
|
||||
|
||||
How do private keys work in PKI and cryptography?
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
idea2act translating
|
||||
|
||||
How to use VS Code for your Python projects
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating----geekpi
|
||||
|
||||
10 Popular Windows Apps That Are Also Available on Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Why I still love Alpine for email at the Linux terminal
|
||||
======
|
||||
|
||||
|
||||
182
sources/tech/20180806 Anatomy of a Linux DNS Lookup - Part IV.md
Normal file
182
sources/tech/20180806 Anatomy of a Linux DNS Lookup - Part IV.md
Normal file
@ -0,0 +1,182 @@
|
||||
pinewall is translating
|
||||
|
||||
[Anatomy of a Linux DNS Lookup – Part IV][2]
|
||||
============================================
|
||||
|
||||
In [Anatomy of a Linux DNS Lookup – Part I][3], [Part II][4], and [Part III][5] I covered:
|
||||
|
||||
* `nsswitch`
|
||||
|
||||
* `/etc/hosts`
|
||||
|
||||
* `/etc/resolv.conf`
|
||||
|
||||
* `ping` vs `host` style lookups
|
||||
|
||||
* `systemd` and its `networking` service
|
||||
|
||||
* `ifup` and `ifdown`
|
||||
|
||||
* `dhclient`
|
||||
|
||||
* `resolvconf`
|
||||
|
||||
* `NetworkManager`
|
||||
|
||||
* `dnsmasq`
|
||||
|
||||
In Part IV I’ll cover how containers do DNS. Yes, that’s not simple either…
|
||||
|
||||
* * *
|
||||
|
||||
1) Docker and DNS
|
||||
============================================================
|
||||
|
||||
In [part III][6] we looked at DNSMasq, and learned that it works by directing DNS queries to the localhost address `127.0.0.1`, and a process listening on port 53 there will accept the request.
|
||||
|
||||
So when you run up a Docker container, on a host set up like this, what do you expect to see in its `/etc/resolv.conf`?
|
||||
|
||||
Have a think, and try and guess what it will be.
|
||||
|
||||
Here’s the default output if you run a default Docker setup:
|
||||
|
||||
```
|
||||
$ docker run ubuntu cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
# 127.0.0.53 is the systemd-resolved stub resolver.
|
||||
# run "systemd-resolve --status" to see details about the actual nameservers.
|
||||
|
||||
search home
|
||||
nameserver 8.8.8.8
|
||||
nameserver 8.8.4.4
|
||||
```
|
||||
|
||||
Hmmm.
|
||||
|
||||
#### Where did the addresses `8.8.8.8` and `8.8.4.4` come from?
|
||||
|
||||
When I pondered this question, my first thought was that the container would inherit the `/etc/resolv.conf` settings from the host. But a little thought shows that that won’t always work.
|
||||
|
||||
If you have DNSmasq set up on the host, the `/etc/resolv.conf` file will be pointed at the `127.0.0.1` loopback address. If this were passed through to the container, the container would look up DNS addresses from within its own networking context, and there’s no DNS server available within the container context, so the DNS lookups would fail.
|
||||
|
||||
‘A-ha!’ you might think: we can always use the host’s DNS server by using the _host’s_ IP address, available from within the container as the default route:
|
||||
|
||||
```
|
||||
root@79a95170e679:/# ip route
|
||||
default via 172.17.0.1 dev eth0
|
||||
172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.2
|
||||
```
|
||||
|
||||
#### Use the host?
|
||||
|
||||
From that we can work out that the ‘host’ is on the ip address: `172.17.0.1`, so we could try manually pointing DNS at that using dig (you could also update the `/etc/resolv.conf` and then run `ping`, this just seems like a good time to introduce `dig` and its `@` flag, which points the request at the ip address you specify):
|
||||
|
||||
```
|
||||
root@79a95170e679:/# dig @172.17.0.1 google.com | grep -A1 ANSWER.SECTION
|
||||
;; ANSWER SECTION:
|
||||
google.com. 112 IN A 172.217.23.14
|
||||
```
|
||||
|
||||
However: that might work if you use DNSMasq, but if you don’t it won’t, as there’s no DNS server on the host to look up.
|
||||
|
||||
So Docker’s solution to this quandary is to bypass all that complexity and point your DNS lookups to Google’s DNS servers at `8.8.8.8` and `8.8.4.4`, ignoring whatever the host context is.
|
||||
|
||||
_Anecdote: This was the source of my first problem with Docker back in 2013\. Our corporate network blocked access to those IP addresses, so my containers couldn’t resolve URLs._
|
||||
|
||||
So that’s Docker containers, but container _orchestrators_ such as Kubernetes can do different things again…
|
||||
|
||||
# 2) Kubernetes and DNS
|
||||
|
||||
The unit of container deployment in Kubernetes is a Pod. A pod is a set of co-located containers that (among other things) share the same IP address.
|
||||
|
||||
An extra challenge with Kubernetes is to forward requests for Kubernetes services to the right resolver (eg `myservice.kubernetes.io`) to the private network allocated to those service addresses. These addresses are said to be on the ‘cluster domain’. This cluster domain is configurable by the administrator, so it might be `cluster.local` or `myorg.badger` depending on the configuration you set up.
|
||||
|
||||
In Kubernetes you have four options for configuring how DNS lookup works within your pod.
|
||||
|
||||
* Default
|
||||
|
||||
This (misleadingly-named) option takes the same DNS resolution path as the host the pod runs on, as in the ‘naive’ DNS lookup described earlier. It’s misleadingly named because it’s not the default! ClusterFirst is.
|
||||
|
||||
If you want to override the `/etc/resolv.conf` entries, you can in your config for the kubelet.
|
||||
|
||||
* ClusterFirst
|
||||
|
||||
ClusterFirst does selective forwarding on the DNS request. This is achieved in one of two ways based on the configuration.
|
||||
|
||||
In the first, older and simpler setup, a rule was followed where if the cluster domain was not found in the request, then it was forwarded to the host.
|
||||
|
||||
In the second, newer approach, you can configure selective forwarding on an internal DNS
|
||||
|
||||
Here’s what the config looks like and a diagram lifted from the [Kubernetes docs][7] which shows the flow:
|
||||
|
||||
```
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: kube-dns
|
||||
namespace: kube-system
|
||||
data:
|
||||
stubDomains: |
|
||||
{"acme.local": ["1.2.3.4"]}
|
||||
upstreamNameservers: |
|
||||
["8.8.8.8", "8.8.4.4"]
|
||||
```
|
||||
|
||||
The `stubDomains` entry defines specific DNS servers to use for specific domains. The upstream servers are the servers we defer to when nothing else has picked up the DNS request.
|
||||
|
||||
This is achieved with our old friend DNSMasq running in a pod.
|
||||
|
||||

|
||||
|
||||
The other two options are more niche:
|
||||
|
||||
* ClusterFirstWithHostNet
|
||||
|
||||
This applies if you use host network for your pods, ie you bypass the Docker networking setup to use the same network as you would directly on the host the pod is running on.
|
||||
|
||||
* None
|
||||
|
||||
None does nothing to DNS but forces you to specify the DNS settings in the `dnsConfig` field in the pod specification.
|
||||
|
||||
### CoreDNS Coming
|
||||
|
||||
And if that wasn’t enough, this is set to change again as CoreDNS comes to Kubernetes, replacing kube-dns. CoreDNS will offer a few benefits over kube-dns, being more configurabe and more efficient.
|
||||
|
||||
Find out more [here][8].
|
||||
|
||||
If you’re interested in OpenShift networking, I wrote a post on that [here][9]. But that was for 3.6 so is likely out of date now.
|
||||
|
||||
### End of Part IV
|
||||
|
||||
That’s part IV done. In it we covered.
|
||||
|
||||
* Docker DNS lookups
|
||||
|
||||
* Kubernetes DNS lookups
|
||||
|
||||
* Selective forwarding (stub domains)
|
||||
|
||||
* kube-dns
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
|
||||
|
||||
作者:[zwischenzugs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
|
||||
[2]:https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
|
||||
[3]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[4]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[5]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
[6]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
[7]:https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/#impacts-on-pods
|
||||
[8]:https://coredns.io/
|
||||
[9]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
|
||||
@ -0,0 +1,110 @@
|
||||
Recreate Famous Data Decryption Effect Seen On Sneakers Movie
|
||||
======
|
||||
|
||||

|
||||
|
||||
A while ago, we published a guide that described how to [**turn your Ubuntu Linux console into a veritable Hollywood technical melodrama hacker interface**][1] using **Hollywood** utility which is written by **Dustin Kirkland** from Canonical. Today, I have stumbled upon a similar CLI utility named “ **N** o **M** ore **S** ecrets”, shortly **nms**. Like Hollywood utility, the nms utility is also **USELESS** (Sorry!). You can use it just for fun. The nms will recreate the famous data decryption effect seen on Sneakers, released in 1992.
|
||||
|
||||
[**Sneakers**][2] is a comedy and crime-thriller genre movie, starred by **Robert Redford** among other famous actors named **Dan Aykroyd** , **David Strathairn** and **Ben Kingsley**. This movie is one of the popular hacker movie released in 1990s. If you haven’t watched it already, there is [**a scene**][3] in Sneakers movie where a group of experts who specialize in testing security systems will recover a top secret black box that has the ability to decrypt all existing encryption systems around the world. The nms utility simply simulates how exactly the data decryption effect scene looks like on Sneakers movie in your Terminal.
|
||||
|
||||
### Installing Nms
|
||||
|
||||
The nms project has no dependencies, but it relies on ANSI/VT100 terminal escape sequences to recreate the effect. Most modern terminal programs support these sequences by default. Just in case, if your Terminal doesn’t support these sequences, install **ncurses**. Ncurses is available in the default repositories of most Linux distributions. We are going to compile and install nms from source. So, just make sure you have installed the development tools in your Linux box. If you haven’t installed them already, refer the following links.
|
||||
|
||||
After installing, git, make, and gcc development tools, run the following commands one by one to compile and install nms utility.
|
||||
```
|
||||
$ git clone https://github.com/bartobri/no-more-secrets.git
|
||||
$ cd ./no-more-secrets
|
||||
$ make nms
|
||||
$ make sneakers
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
Finally, check if the installation was successful using command:
|
||||
```
|
||||
$ nms -v
|
||||
nms version 0.3.3
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can install nms using [**Linuxbrew**][4] package manager as shown below.
|
||||
```
|
||||
$ brew install no-more-secrets
|
||||
|
||||
```
|
||||
|
||||
Now it is time to run nms.
|
||||
|
||||
### Recreate Famous Data Decryption Effect Seen On Sneakers Movie Using Nms
|
||||
|
||||
The nms utility works on piped data. Pipe any Linux command’s output to nms tool like below and enjoy the effect right from your Terminal. Have a look at the following command:
|
||||
```
|
||||
$ ls -l | nms
|
||||
|
||||
```
|
||||
|
||||
By default, after the initial encrypted characters are displayed, the **nms** utility will wait for the user to press a key to start the decryption sequence. This is how the it is depicted in the Sneakers movie. Just press any key to start the decryption sequence to reveal the original plaintext characters.
|
||||
|
||||
If you don’t want to press any key, you can auto-initiate the decryption sequence using **-a** flag.
|
||||
```
|
||||
$ ls -l | nms -a
|
||||
|
||||
```
|
||||
|
||||
You can also set a foreground color, for example green, use **-f <color>** option as shown below.
|
||||
```
|
||||
$ ls -l | nms -f green
|
||||
|
||||
```
|
||||
|
||||
Remember If you don’t specify **-a** flag, you must press any key to initiate the decryption sequence.
|
||||
|
||||
To clear the screen before starting encryption and decryption processes, use **-c** flag.
|
||||
```
|
||||
$ ls -l | nms -c
|
||||
|
||||
```
|
||||
|
||||
To mask single blank space characters, use -s flag. Please note that other space characters such as tabs and newlines will not be masked.
|
||||
```
|
||||
$ ls -l | nms -s
|
||||
|
||||
```
|
||||
|
||||
You can also view the actual decryption effect scene in the Sneakers movie using the following command:
|
||||
```
|
||||
$ sneakers
|
||||
|
||||
```
|
||||
|
||||
Choose any option given to exit this utility.
|
||||
|
||||
Don’t like it? Sorry about that. Go to the nms project folder and simply run the following command to remove it.
|
||||
```
|
||||
$ sudo make uninstall
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/no-more-secrets-recreate-famous-data-decryption-effect-seen-on-sneakers-movie/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/turn-ubuntu-terminal-hollywood-technical-melodrama-hacker-interface/
|
||||
[2]:https://www.imdb.com/title/tt0105435/
|
||||
[3]:https://www.youtube.com/watch?v=F5bAa6gFvLs&t=35
|
||||
[4]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
@ -1,106 +0,0 @@
|
||||
translated by hopefully2333
|
||||
|
||||
5 open source role-playing games for Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games are often not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
|
||||
|
||||
So, can someone who only uses free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely ever to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download the game from the project's website in order to install and play it.
|
||||
|
||||
This article looks at role-playing games. I have already written about [arcade-style games][1], [board & card games][2], [puzzle games][3], and [racing & flying games][4]. In the final article in this series, I plan to cover strategy and simulation games.
|
||||
|
||||
### Endless Sky
|
||||
|
||||
|
||||
|
||||
[Endless Sky][5] is an open source clone of the [Escape Velocity][6] series from Ambrosia Software. Players captain a spaceship and travel between worlds delivering trade goods or passengers, taking on other missions along the way, or they can turn to piracy and steal from cargo ships. The game lets the player decide how they want to experience the game, and the extremely large map of solar systems is theirs to explore as they see fit. Endless Sky is one of those games that defies normal genre classifications, but this action, role-playing, space simulation, trading game is well worth checking out.
|
||||
|
||||
To install Endless Sky, run the following command:
|
||||
|
||||
On Fedora: `dnf install endless-sky`
|
||||
|
||||
On Debian/Ubuntu: `apt install endless-sky`
|
||||
|
||||
### FreeDink
|
||||
|
||||
|
||||
|
||||
[FreeDink][7] is the open source version of [Dink Smallwood][8], an action role-playing game released by RTSoft in 1997. Dink Smallwood became freeware in 1999, and the source code was released in 2003. In 2008 the game's data files, minus a few sound files, were also released under an open license. FreeDink replaces those sound files with alternatives to provide a complete game. Gameplay is similar to Nintendo's [The Legend of Zelda][9] series. The player's character, the eponymous Dink Smallwood, explores an over-world map filled with hidden items and caves as he moves from one quest to another. Due to its age, FreeDink is not going to stand up to modern commercial games, but it is still a fun game with an amusing story. The game can be expanded by using [D-Mods][10], which are add-on modules that provide additional quests, but the D-Mods do vary greatly in complexity, quality, and age-appropriateness; the main game is suitable for teenagers, but some of the add-ons are for adult audiences.
|
||||
|
||||
To install FreeDink, run the following command:
|
||||
|
||||
On Fedora: `dnf install freedink`
|
||||
|
||||
On Debian/Ubuntu: `apt install freedink`
|
||||
|
||||
### ManaPlus
|
||||
|
||||
|
||||
|
||||
Technically not a game in itself, [ManaPlus][11] is a client for accessing various massive multi-player online role-playing games. [The Mana World][12] and [Evol Online][13] are the two of the open source games available, but other servers are out there. The games feature 2D sprite graphics reminiscent of Super Nintendo games. While none of the games supported by ManaPlus are as popular as some of the commercial alternatives, they do have interesting worlds and at least a few players are online most of the time. Players are unlikely to run into massive groups of other players, but there are usually enough people around to make the games [MMORPG][14]s, not single-player games that require a connection to a server. The Mana World and Evol Online developers have joined together for future development, but for now, The Mana World's legacy server and Evol Online offer different experiences.
|
||||
|
||||
To install ManaPlus, run the following command:
|
||||
|
||||
On Fedora: `dnf install manaplus`
|
||||
|
||||
On Debian/Ubuntu: `apt install manaplus`
|
||||
|
||||
### Minetest
|
||||
|
||||
|
||||
|
||||
Explore and build in an open-ended world with [Minetest][15], a clone of Minecraft. Just like the game it is based on, Minetest provides an open-ended world where players can explore and build whatever they wish. Minetest provides a wide variety of block types and tools, making it a good alternative to Minecraft for anyone wanting a more open alternative. Beyond what comes with the basic game, Minetest can be extended with [add-on modules][16], which add even more options.
|
||||
|
||||
To install Minetest, run the following command:
|
||||
|
||||
On Fedora: `dnf install minetest`
|
||||
|
||||
On Debian/Ubuntu: `apt install minetest`
|
||||
|
||||
### NetHack
|
||||
|
||||
|
||||
|
||||
[NetHack][17] is a classic [Roguelike][18] role-playing game. Players explore a multi-level dungeon as one of several different character races, classes, and alignments. The object of the game is to retrieve the Amulet of Yendor. Players begin on the first level of the dungeon and try to work their way towards the bottom, with each level being randomly generated, which makes for a unique game experience each time. While this game features either ASCII graphics or basic tile graphics, the depth of game-play more than makes up for the primitive graphics. Players who want less primitive graphics might want to check out [Vulture for NetHack][19], which offers better graphics along with sound effects and background music.
|
||||
|
||||
To install NetHack, run the following command:
|
||||
|
||||
On Fedora: `dnf install nethack`
|
||||
|
||||
On Debian/Ubuntu: `apt install nethack-x11 or apt install nethack-console`
|
||||
|
||||
Did I miss one of your favorite open source role-playing games? Share it in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/role-playing-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://opensource.com/article/18/3/card-board-games-linux
|
||||
[3]:https://opensource.com/article/18/6/puzzle-games-linux
|
||||
[4]:https://opensource.com/article/18/7/racing-flying-games-linux
|
||||
[5]:https://endless-sky.github.io/
|
||||
[6]:https://en.wikipedia.org/wiki/Escape_Velocity_(video_game)
|
||||
[7]:http://www.gnu.org/software/freedink/
|
||||
[8]:http://www.rtsoft.com/pages/dink.php
|
||||
[9]:https://en.wikipedia.org/wiki/The_Legend_of_Zelda
|
||||
[10]:http://www.dinknetwork.com/files/category_dmod/
|
||||
[11]:http://manaplus.org/
|
||||
[12]:http://www.themanaworld.org/
|
||||
[13]:http://evolonline.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Massively_multiplayer_online_role-playing_game
|
||||
[15]:https://www.minetest.net/
|
||||
[16]:https://wiki.minetest.net/Mods
|
||||
[17]:https://www.nethack.org/
|
||||
[18]:https://en.wikipedia.org/wiki/Roguelike
|
||||
[19]:http://www.darkarts.co.za/vulture-for-nethack
|
||||
@ -1,3 +1,4 @@
|
||||
LuuMing translating
|
||||
6 Reasons Why Linux Users Switch to BSD
|
||||
======
|
||||
Thus far I have written several articles about [BSD][1] for It’s FOSS. There is always at least one person in the comments asking “Why bother with BSD?” I figure that the best way to respond was to write an article on the topic.
|
||||
|
||||
@ -1,129 +0,0 @@
|
||||
Ubuntu 18.04 Vs. Fedora 28
|
||||
======
|
||||

|
||||
|
||||
Hello folks. Today I'll highlight some of the features and differences between the two popular Linux distros; **Ubuntu 18.04** and **Fedora 28** . Each has their own package management; Ubuntu uses DEB while Fedora uses RPM, but both of them features the same [Desktop Environment][3] ([GNOME][4]) and aims to provide quality desktop experience for the Linux users.
|
||||
|
||||
**Ubuntu 18.04** is the latest Ubuntu [LTS][1] release and comes equipped with GNOME desktop. So is Fedora 28 that also features GNOME desktop, but both of them provides a unique desktop experience when it comes down to their software management and of course their User Interfaces too.
|
||||
|
||||
### Quick Facts
|
||||
|
||||
Did you know that Ubuntu which is based on Debian, provides the latest software earlier than the latter one? An example is the popular web browser Firefox Quantum found on Ubuntu while Debian follows behind on the ESR (Extended Support Release) version of the same web browser.
|
||||
|
||||
|
||||
|
||||
The same applies to Fedora which provides cutting-edge software to the end users and also acts as the testing platform for the next stable RHEL (Red Hat Enterprise Linux) release.
|
||||
|
||||
### Desktop overview
|
||||
|
||||
Fedora provides vanilla GNOME desktop experience while Ubuntu 18.04 have tweaked certain aspects of the desktop to enable long-time Unity users a smooth transition to GNOME Desktop Environment.
|
||||
|
||||
_Canonical decided to save development time by ditching Unity and switching to GNOME desktop (starting from Ubuntu [17.10][2]) so they can focus more on IoT.
|
||||
_
|
||||
|
||||
So on Fedora, we have a clean icon-less desktop, a hidden panel on the overview and its look featuring GNOME default theme: Adwaita.
|
||||
|
||||
[][5]
|
||||
|
||||
Whereas Ubuntu features its classic desktop style with icons, a panel on the left mimicking its traditional dock, and customized window looks (also traditional) with Ubuntu Ambiance theme set as its default look and feel.
|
||||
|
||||
[][6]
|
||||
|
||||
However, learning to use one of them and then switching to another won't cost you time. Instead, they are designed with simplicity and user-friendliness in mind so any newbie can feel right at home with either of the two Linux distros.
|
||||
|
||||
|
||||
|
||||
But it's not just the looks or UI that determines the user's decision to choose a Linux distro. Other factors come into the role too, and below are more sub-topics describing all about software management between the two Linux OS.
|
||||
|
||||
### Software center
|
||||
|
||||
Ubuntu uses dpkg; Debian Package Management, for distributing software to end users while Fedora uses Red Hat Package Management called rpm. Both are very popular package management among the Linux community and their command line tools are easy to use too.
|
||||
|
||||
[][7]
|
||||
|
||||
But each Linux distro quite varies when it comes to the software that's being distributed. Canonical releases new Ubuntu versions every six months; usually in the month of April and then on October. So for each release, the developers maintain a development schedule, after a new Ubuntu release, it enters into "freeze" state where its development on testing new software is halted.
|
||||
|
||||
|
||||
|
||||
Whereas, Fedora also following the same six months release cycle, pretty much mimics a rolling release Linux distro (though it is not one of those). Almost all software packages are updated regularly so users get the opportunity to try out the latest software, unlike Ubuntu. However, this invites "instability" on the user's side as software bugs are more commonly faced but not critical enough to render the system unusable.
|
||||
|
||||
### Software updates
|
||||
|
||||
I've mentioned above about Ubuntu "freeze" state. Well, I'll be exaggerating more about this state since it has some significant importance on the way Ubuntu software is updated... So, once a new version of Ubuntu is released, its development (testing new software) is halted.
|
||||
|
||||
_The development for the next upcoming Ubuntu release begins where it'll go through the phases of "daily builds" then "beta release" and finally shipping the new Ubuntu release to the end users._
|
||||
|
||||
In this "freeze" state Ubuntu maintainers no longer add the latest software (unless it fixes serious security issues) to its package repository. So Ubuntu users get more "bug fixes" updates than "feature" updates, which is great since the system would remain stable without disrupting user's productivity.
|
||||
|
||||
|
||||
|
||||
Fedora aims to provide cutting-edge software to the end users so users get more "feature" updates than on Ubuntu. Also, measures are taken by the developers to maintain its system stability. For instance, on computer start up the user will be given at most three working kernels (latest one on the top) choices so if one fails to start the user can revert to the other two previous working kernels.
|
||||
|
||||
### Snaps and flatpak
|
||||
|
||||
Both are new and cool sexy tools for distributing software across multiple Linux distributions. Ubuntu provides **snaps** out of the box while **flatpak** goes to Fedora. The most popular among the two is snaps where more popular and proprietary applications are finding their way on snap store. Flatpak too is gaining traction with more apps added onto its platform.
|
||||
|
||||
|
||||
|
||||
Unfortunately, both of them are still new and there are some "window theme-breaking" rants dispersed around the Internet. But still, switching between the two tools isn't nerve wrecking as they are easy to use.
|
||||
|
||||
### Apps showdown
|
||||
|
||||
Below are some of the common apps available on Ubuntu and Fedora, they are compared between the two platforms:
|
||||
|
||||
#### Calculator
|
||||
|
||||
The program launches faster on Fedora than on Ubuntu. The reason is on Fedora, calculator program is natively installed while on Ubuntu the snap version of the same program is installed.
|
||||
|
||||
#### System Monitor
|
||||
|
||||
This might sound nerdy but I find it necessary and intuitive to observe my computer performance and kill offending processes if any. The program's launch time is the same as above ie., faster on Fedora (natively installed) and slower on Ubuntu (snap version).
|
||||
|
||||
#### Help
|
||||
|
||||
I've mentioned above that Ubuntu provides a tweaked version of the GNOME Desktop Environment (for long time Unity users migration ease). Unfortunately, Ubuntu developers have either forgotten or ignored to update the Help program since it's somewhat confusing to look at the documentation (getting started videos) and finding out the demonstration videos and the actual environment varies a tad-bit slightly.
|
||||
|
||||
[][8]
|
||||
|
||||
### Conclusion
|
||||
|
||||
Ubuntu and Fedora are two popular Linux distros. Each has their own eye-candy features, so choosing between the two would be quite a challenge for newbies. I recommend trying both of them out so you can later find out which tools provided by the two Linux distro better suits you.
|
||||
|
||||
|
||||
|
||||
I hope you had a good read and let me know what I missed out/your opinions in the comment section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/ubuntu-1804-vs-fedora-28
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/ubuntu-1804-codename-announced-bionic-beaver
|
||||
[2]:http://www.linuxandubuntu.com/home/what-new-is-going-to-be-in-ubuntu-1704-zesty-zapus
|
||||
[3]:http://www.linuxandubuntu.com/home/5-best-linux-desktop-environments-with-pros-cons
|
||||
[4]:http://www.linuxandubuntu.com/home/walkthrough-on-how-to-use-gnome-boxes
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-18-04-gnome_orig.jpg
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-gnome-18-04_orig.jpg
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-software-center_2_orig.jpg
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-18-04-help-manual_orig.jpg
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/ubuntu-1804-vs-fedora-28
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
@ -1,67 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Convert file systems with Fstransform
|
||||
======
|
||||
|
||||

|
||||
|
||||
Few people know that they can convert their filesystems from one type to another without losing data, i.e. non-destructively. It may sound like magic, but [Fstransform][1] can convert an ext2, ext3, ext4, jfs, reiserfs or xfs partition to another type from the list in almost any combination. More importantly, it does so in-place, without formatting or copying data anywhere. Atop of all this goodness, there is a little bonus: Fstransform can also handle ntfs, btrfs, fat and exfat partitions as well.
|
||||
|
||||
### Before you run it
|
||||
|
||||
There are certain caveats and limitations in Fstransform, so it is strongly advised to back up before attempting a conversion. Additionally, there are some limitations to be aware of when using Fstransform:
|
||||
|
||||
* Both the source and target filesystems must be supported by your Linux kernel. Sounds like an obvious thing and exposes zero risk in case you want to use ext2, ext3, ext4, reiserfs, jfs and xfs partitions. Fedora supports all of that just fine.
|
||||
* Upgrading ext2 to ext3 or ext4 does not require Fstransform. Use the Tune2fs utility instead.
|
||||
* The device with source file system must have at least 5% of free space.
|
||||
* You need to be able to unmount the source filesystem before you begin.
|
||||
* The more data your source file system stores, the longer the conversion will last. The actual speed depends on your device, but expect it to be around one gigabyte per minute. The large amount of hard links can also slow down the conversion.
|
||||
* Although Fstransform is proved to be stable, please back up data on your source filesystem.
|
||||
|
||||
|
||||
|
||||
### Installation instructions
|
||||
|
||||
Fstransform is already a part of Fedora. Install with the command:
|
||||
```
|
||||
sudo dnf install fstransform
|
||||
|
||||
```
|
||||
|
||||
### Time to convert something
|
||||
|
||||
![][2]
|
||||
|
||||
The syntax of the fstransform command is very simple: fstransform <source device> <target file system>. Keep in mind that it needs root privileges to run, so don’t forget to add sudo in the beginning. Here goes an example:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ext4
|
||||
|
||||
```
|
||||
|
||||
Note that it is not possible to convert a root file system, which is a security measure. Use a test partition or an experimental thumb drive instead. In the meantime, Fstransform will through a lot of auxiliary output in the console. The most useful part is the estimated time of completion, which keep you informed about how long the process will take. Again, few small files on an almost empty drive will make Fstransform do its job in a minute or so, whereas more real-world tasks may involve hours of wait time.
|
||||
|
||||
### More file systems are supported
|
||||
|
||||
As mentioned above, it is possible to try Fstransform with ntfs, btrfs, fat and exfat partitions. These types are very experimental, and nobody can guarantee that the converion will flow perfect. Still, there are many success stories, and you can add your own by testing Fstransform with a sample data set on a test partition. Those additional file systems can be enabled by the use of the –force-untested-file-systems parameter:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ntfs --force-untested-file-systems
|
||||
|
||||
```
|
||||
|
||||
Sometimes the process may iterrupt with an error. Feel free to repeat the command again — it may eventually complete the conversion from second or third attempt.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/transform-file-systems-in-linux/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://github.com/cosmos72/fstransform
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot_20180805_230116.png
|
||||
@ -1,139 +0,0 @@
|
||||
How To Record Terminal Sessions As SVG Animations In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Recording Terminal sessions may help in several cases. You can use those recording sessions to document everything that you did in Terminal and save them for future reference. You can use them to demonstrate different Linux commands and its use cases to your juniors, students and anyone who are willing to Learn Linux. Luckily, we have many tools to record Terminal sessions in Unix-like operating systems. We already have featured some of the tools/commands which helps you to record the Terminal sessions in the past. You can go through them in the links given below.
|
||||
|
||||
|
||||
+ [How To Record Everything You Do In Terminal][3]
|
||||
+ [Asciinema – Record Terminal Sessions And Share Them On The Web][4]
|
||||
|
||||
|
||||
Today, we are going to see yet another tool to record the Terminal activities. Say hello to **“Termtosvg”**. As the name implies, Termtosvg records your Terminal sessions as standalone SVG animations. It is a simple command line utility written in **Python** programming language. It generates lightweight and clean looking animations embeddable on a project page. It supports custom color themes, terminal UI and animation controls via [SVG templates][1]. It is also compatible with asciinema recording format. Termtosvg supports GNU/Linux, Mac OS and BSD OSes.
|
||||
|
||||
|
||||
### Installing Termtosvg
|
||||
|
||||
Termtosvg can be installed using PIP, a python package manager to install applications written using Python language. If you haven’t installed PIP already, refer the following guide.
|
||||
|
||||
After installing PIP, run the following command to install Termtosvg tool:
|
||||
```
|
||||
$ pip3 install --user termtosvg
|
||||
|
||||
```
|
||||
|
||||
And, install the following prerequisites to render the Terminal screen.
|
||||
```
|
||||
$ pip3 install pyte python-xlib svgwrite
|
||||
|
||||
```
|
||||
|
||||
Done. Let us go ahead and generate Terminal sessions in SVG format.
|
||||
|
||||
### Record Terminal Sessions As SVG Animations In Linux
|
||||
|
||||
Recording Terminal sessions using Termtosvg is very simple. Just open your Terminal window and run the following command to start recording it.
|
||||
```
|
||||
$ termtosvg
|
||||
|
||||
```
|
||||
|
||||
**Note:** If you termtosvg command is not available, restart your system once.
|
||||
|
||||
You will see the following output after running ‘termtosvg’ command:
|
||||
```
|
||||
Recording started, enter "exit" command or Control-D to end
|
||||
|
||||
```
|
||||
|
||||
You will now be in a sub-shell where you can execute the Linux commands as usual. Everything you do in the Terminal will be recorded.
|
||||
|
||||
Let me run a random commands.
|
||||
```
|
||||
$ mkdir mydirectory
|
||||
|
||||
$ cd mydirectory/
|
||||
|
||||
$ touch file.txt
|
||||
|
||||
$ cd ..
|
||||
|
||||
$ uname -a
|
||||
|
||||
```
|
||||
|
||||
Once you’re done, press **CTRL+D** or type **exit** to stop recording. The resulting recording will be saved in **/tmp** folder with a unique name.
|
||||
|
||||

|
||||
|
||||
You can then open the SVG file in any web browser of your choice from Terminal like below.
|
||||
```
|
||||
$ firefox /tmp/termtosvg_ddkehjpu.svg
|
||||
|
||||
```
|
||||
|
||||
You can also directly open the SVG file from browser ( **File - > <path-to-svg>**).
|
||||
|
||||
Here is the output of the above recording in my Firefox browser.
|
||||
|
||||

|
||||
|
||||
Here is some more examples on how to use Termtosvg to record Terminal sessions.
|
||||
|
||||
Like I mentioned already, Termtosvg will record a terminal session and save it as an SVG animation file in **/tmp** directory by default.
|
||||
|
||||
However, you can generate an SVG animation with a custom name, for example **animation.svg** , and save it in a custom location, for example **/home/sk/ostechnix/**.
|
||||
```
|
||||
$ termtosvg /home/sk/ostechnix/animation.svg
|
||||
|
||||
```
|
||||
|
||||
Record a terminal session and render it using a specific template:
|
||||
```
|
||||
$ termtosvg -t ~/templates/my_template.svg
|
||||
|
||||
```
|
||||
|
||||
Record a terminal session with a specific screen geometry:
|
||||
```
|
||||
$ termtosvg -g 80x24 animation.svg
|
||||
|
||||
```
|
||||
|
||||
Record a terminal session in asciicast v2 format:
|
||||
```
|
||||
$ termtosvg record recording.cast
|
||||
|
||||
```
|
||||
|
||||
Render an SVG animation from a recording in asciicast format:
|
||||
```
|
||||
$ termtosvg render recording.cast animation.svg
|
||||
|
||||
```
|
||||
|
||||
For more details, refer [**Termtosvg manual**][2].
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-record-terminal-sessions-as-svg-animations-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://nbedos.github.io/termtosvg/pages/templates.html
|
||||
[2]:https://github.com/nbedos/termtosvg/blob/develop/man/termtosvg.md
|
||||
[3]: https://www.ostechnix.com/record-everything-terminal/
|
||||
[4]: https://www.ostechnix.com/asciinema-record-terminal-sessions-share-web/
|
||||
@ -1,3 +1,5 @@
|
||||
translated by stephenxs
|
||||
|
||||
Top Linux developers' recommended programming books
|
||||
======
|
||||
Without question, Linux was created by brilliant programmers who employed good computer science knowledge. Let the Linux programmers whose names you know share the books that got them started and the technology references they recommend for today's developers. How many of them have you read?
|
||||
|
||||
@ -1,55 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How the L1 Terminal Fault vulnerability affects Linux systems
|
||||
======
|
||||
|
||||

|
||||
|
||||
Announced just yesterday in security advisories from Intel, Microsoft and Red Hat, a newly discovered vulnerability affecting Intel processors (and, thus, Linux) called L1TF or “L1 Terminal Fault” is grabbing the attention of Linux users and admins. Exactly what is this vulnerability and who should be worrying about it?
|
||||
|
||||
### L1TF, L1 Terminal Fault, and Foreshadow
|
||||
|
||||
The processor vulnerability goes by L1TF, L1 Terminal Fault, and Foreshadow. Researchers who discovered the problem back in January and reported it to Intel called it "Foreshadow". It is similar to vulnerabilities discovered in the past (such as Spectre).
|
||||
|
||||
This vulnerability is Intel-specific. Other processors are not affected. And like some other vulnerabilities, it exists because of design choices that were implemented to optimize kernel processing speed but exposed data in ways that allowed access by other processes.
|
||||
|
||||
**[ Read also:[22 essential Linux security commands][1] ]**
|
||||
|
||||
Three CVEs have been assigned to this issue:
|
||||
|
||||
* CVE-2018-3615 for Intel Software Guard Extensions (Intel SGX)
|
||||
* CVE-2018-3620 for operating systems and System Management Mode (SMM)
|
||||
* CVE-2018-3646 for impacts to virtualization
|
||||
|
||||
|
||||
|
||||
An Intel spokesman made this statement regarding this issue: _" L1 Terminal Fault is addressed by microcode updates released earlier this year, coupled with corresponding updates to operating system and hypervisor software that are available starting today. We’ve provided more information on our web site and continue to encourage everyone to keep their systems up-to-date, as it's one of the best ways to stay protected. We’d like to extend our thanks to the researchers at imec-DistriNet, KU Leuven, Technion- Israel Institute of Technology, University of Michigan, University of Adelaide and Data61 and our industry partners for their collaboration in helping us identify and address this issue."_
|
||||
|
||||
### Does L1TF affect your Linux system?
|
||||
|
||||
The short answer is "probably not." You should be safe if you’ve patched your system since the earlier [Spectre and Meltdown vulnerabilities][2] were exposed back in January. As with Spectre and Meltdown, Intel claims that no real-world cases of systems being affected have been reported or detected. They also have said that the changes are unlikely to incur noticeable performance hits on individual systems, but they might represent significant performance hits for data centers using virtualized operating systems.
|
||||
|
||||
Even so, frequent patches are always recommended. To check your current kernel level, use the **uname -r** command:
|
||||
```
|
||||
$ uname -r
|
||||
4.18.0-041800-generic
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3298157/linux/linux-and-l1tf.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.networkworld.com/article/3272286/open-source-tools/22-essential-security-commands-for-linux.html
|
||||
[2]:https://www.networkworld.com/article/3245813/security/meltdown-and-spectre-exploits-cutting-through-the-fud.html
|
||||
[3]:https://www.facebook.com/NetworkWorld/
|
||||
[4]:https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,190 @@
|
||||
How To Lock The Keyboard And Mouse, But Not The Screen In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
My 4-years-old niece is a curious-kid. She loves “Avatar” movie very much. When the Avatar movie is on, she became so focused and her eyes are glued to the screen. But the problem is she often touches a key in the keyboard or move the mouse or click the mouse button while watching the movie. Sometimes, she accidentally close or pause the movie by pressing a key in the keyboard. So I was looking for a way to lock down both the keyboard and mouse, but not the screen. Luckily, I came across a perfect solution in Ubuntu forum. If you don’t want your cat or puppy walking on your keyboard or your kid messing up with the keyboard and mouse while you watching something important on the screen, I suggest you to try **“xtrlock”** utility. It is a simple, yet useful utility to lock the X display till the user enters their password at the keyboard. In this brief tutorial, I will show you how to lock the keyboard and mouse, but not the screen in Linux. This trick will work on all Linux operating systems.
|
||||
|
||||
### Install xtrlock
|
||||
|
||||
The xtrlock package is available in the default repositories of most Linux operating systems. So, you can install it using your distribution’s package manager.
|
||||
|
||||
On **Arch Linux** and derivatives, run the following command to install it.
|
||||
```
|
||||
$ sudo pacman -S xtrlock
|
||||
|
||||
```
|
||||
|
||||
On **Fedora** :
|
||||
```
|
||||
$ sudo dnf install xtrlock
|
||||
|
||||
```
|
||||
|
||||
On **RHEL, CentOS** :
|
||||
```
|
||||
$ sudo yum install xtrlock
|
||||
|
||||
```
|
||||
|
||||
On **SUSE/openSUSE** :
|
||||
```
|
||||
$ sudo zypper install xtrlock
|
||||
|
||||
```
|
||||
|
||||
On **Debian, Ubuntu, Linux Mint** :
|
||||
```
|
||||
$ sudo apt-get install xtrlock
|
||||
|
||||
```
|
||||
|
||||
### Lock the Keyboard and Mouse, but not the Screen using xtrlock
|
||||
|
||||
Once xtrlock installed, create a keyboard shortcut. You need this to lock the keyboard and mouse using the key combination of your choice.
|
||||
|
||||
Create a new file called **lockkbmouse** in **/usr/local/bin**.
|
||||
```
|
||||
$ sudo vi /usr/local/bin/lockkbmouse
|
||||
|
||||
```
|
||||
|
||||
Add the following lines into it.
|
||||
```
|
||||
#!/bin/bash
|
||||
sleep 1 && xtrlock
|
||||
|
||||
```
|
||||
|
||||
Save the file and close the file.
|
||||
|
||||
Make it as executable using the following command:
|
||||
```
|
||||
$ sudo chmod a+x /usr/local/bin/lockkbmouse
|
||||
|
||||
```
|
||||
|
||||
Next, we need to create keyboard a shortcut.
|
||||
|
||||
**In Arch Linux MATE desktop:**
|
||||
|
||||
Go to **System - > Preferences -> Hardware -> keyboard Shortcuts**.
|
||||
|
||||
Click **Add** to create a new shortcut.
|
||||
|
||||
![][2]
|
||||
|
||||
Enter the name for your shortcut and add the following line in the command box, and click **Apply** button.
|
||||
```
|
||||
bash -c "sleep 1 && xtrlock"
|
||||
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
To assign the shortcut key, just select or double click on it and type the key combination of your choice. For example, I use **Alt+k**.
|
||||
|
||||
![][4]
|
||||
|
||||
To clear the key combination, press BACKSPACE key. Once you finished, close the Keyboard Settings window.
|
||||
|
||||
**In Ubuntu GNOME DE:**
|
||||
|
||||
Go to **System Settings - > Devices -> Keyboard**. Click the **+** symbol at the end.
|
||||
|
||||
Enter the name for your shortcut and add the following line in the command box, and click **Add** button.
|
||||
```
|
||||
bash -c "sleep 1 && xtrlock"
|
||||
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
Next, assign the shortcut key to the newly created shortcut. To do so, just select or double click on it and click on **“Set shortcut”** button.
|
||||
|
||||
![][6]
|
||||
|
||||
You will now see the following screen.
|
||||
|
||||
![][7]
|
||||
|
||||
Type the key combination of your choice. For example, I use **Alt+k**.
|
||||
|
||||
![][8]
|
||||
|
||||
To clear the key combination, press BACKSPACE key. The shortcut key has been assigned. Once you finished, close the Keyboard Settings window.
|
||||
|
||||
From now on, whenever you press the keyboard shortcut key (ALT+k in our case), the mouse pointer will turn into a a padlock. Now, the keyboard and mouse have been locked, so you can freely watch the movies or whatever you want to. Even your kid or pet touches some keys on the keyboard or clicks a mouse button, they won’t work.
|
||||
|
||||
Here is xtrclock in action.
|
||||
|
||||
![][9]
|
||||
|
||||
Do you see the a small lock button? It means that the keyboard and mouse have been locked. Even if you move the lock button, nothing will happen. The task in the background will keep running until you unlock your screen and manually close the running task.
|
||||
|
||||
### Unlock keyboard and mouse
|
||||
|
||||
To unlock the keyboard and mouse, simply type your password and hit “Enter”. You will not see the password as you type it. Just type the password anyway and hit ENTER key. The mouse and keyboard will start to work after you entered the correct password. If you entered an incorrect password, you will hear a bell sound. Press **ESC** key to clear the incorrect password and re-enter the correct password again. To remove one character of a partially typed password, press either **BACKSPACE** or **DELETE** keys.
|
||||
|
||||
### What if I permanently get locked out of the screen?
|
||||
|
||||
The xtrclock tool may not work on some DEs, for example GDM. It may permanently lock you out of the screen. Please test it in a virtual machine and then try it in your personal or official desktop if it really works. I tested this on Arch Linux MATE desktop and Ubuntu 18.04 GNOME desktop. It worked just fine.
|
||||
|
||||
Just in case, you are locked out of the screen permanently, switch to the TTY (CTRL+ALT+F2) then run:
|
||||
```
|
||||
$ sudo killall xtrlock
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can use the **chvt** command to switch between TTY and X session.
|
||||
|
||||
For example, to switch to TTY1, run:
|
||||
```
|
||||
$ sudo chvt 1
|
||||
|
||||
```
|
||||
|
||||
To switch back to the X session again, type:
|
||||
```
|
||||
$ sudo chvt 7
|
||||
|
||||
```
|
||||
|
||||
Different distros uses different key combinations to switch between TTYs. Please refer your distribution’s official website for more details.
|
||||
|
||||
For more details about xtrlock, refer man pages.
|
||||
```
|
||||
$ man xtrlock
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this helps. If you find our guides useful, please spend a moment to share them on your social, professional networks and support OSTechNix.
|
||||
|
||||
**Resource:**
|
||||
|
||||
* [**Ubuntu forum**][10]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/lock-keyboard-mouse-not-screen-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/09/Keyboard-Shortcuts_001.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/09/Keyboard-Shortcuts_002.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/09/Keyboard-Shortcuts_003.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Add-xtrlock-shortcut.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/set-shortcut-key-1.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/set-shortcut-key-2.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/set-shortcut-key-3.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/01/xtrclock-1.png
|
||||
[10]:https://ubuntuforums.org/showthread.php?t=993800
|
||||
@ -0,0 +1,120 @@
|
||||
How To Disable Ads In Terminal Welcome Message In Ubuntu Server
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you’re using any latest Ubuntu server edition, you might have noticed some promotional links in welcome message which are not relevant to Ubuntu server platform. As you might already know **MOTD** , abbreviation of **M** essage **O** f **T** he **D** ay, displays a welcome message at every login in Linux systems. Usually, the welcome message contains the version of your OS, basic system information, official documentation link, and the links to read about the latest security updates etc. This is what we usually see at every time we login either via SSH or on the local machine. However, there some additional links started to appear in the terminal welcome message lately. I have already noticed this link few times, but I didn’t care about it and never clicked it though. Here is the Terminal welcome message shown in my Ubuntu 18.04 LTS server.
|
||||
|
||||
|
||||
|
||||
As you can see in the above screenshot, there is also a bit.ly link and Ubuntu wiki link in the welcome message. Some of you may surprise and wondering what this is. There is nothing to worry about the links in the welcome message. It may look sort of ad-like, but those are not really commercial ads. The links are actually pointing to [**Ubuntu official blog**][1] and [**Ubuntu wiki**][2]. As I said earlier, one of link is not relevant and doesn’t has any details related to Ubuntu server. That’s why I called them ads in the first place.
|
||||
|
||||
Even though most of us won’t visit bit.ly links, but some people may visit those links out of curiosity and ended up disappointed realizing that it simply points you to an external link. You can use any URL unshortners services, such as unshorten.it, to see where they lead before visiting the actual link. Alternatively, you can just type a plus sign ( **+** ) at the end of the bit.ly link to see where they lead and some statistics about the link.
|
||||
|
||||

|
||||
|
||||
### What is MOTD and how it works?
|
||||
|
||||
Back in 2009, **Dustin Kirkland** from Canonical introduced the concept of MOTD in Ubuntu. It’s a flexible framework that enables the administrators or distro packages to add executable scripts in /etc/update-motd.d/* location to generate informative, interesting messages displayed at login. It was originally implemented for Landscape (a commercial service from Canonical), however other distribution maintainers found it useful and adopted this feature in their own distributions as well.
|
||||
|
||||
If you look in **/etc/update-motd.d/** location in your Ubuntu system, you’ll see a set of scripts. One prints the generic “welcome” banner. The next one prints 3 links showing where to find help for the OS. The other one counts and displays the number of package updates available for the local system. Another one tells you if a reboot is required and so on.
|
||||
|
||||
From Ubuntu 17.04 onwards, the developers have added **/etc/update-motd.d/50-motd-news** , a script to include some additional information in the welcome message. They additional information are;
|
||||
|
||||
1. Important critical information, such as
|
||||
|
||||
ShellShock, Heartbleed etc.
|
||||
|
||||
2. End-of-Life (EOL) messages, new feature availability, etc.
|
||||
|
||||
3. Some fun and informative posts published in Ubuntu official blog and other news about Ubuntu.
|
||||
|
||||
|
||||
|
||||
|
||||
Asynchronously, about 60 seconds after boot, a systemd timer runs “/etc/update-motd.d/50-motd-news –force” script. It sources 3 config variables defined in /etc/default/motd-news script. The default values are: ENABLED=1, URLS=”<https://motd.ubuntu.com”>, WAIT=”5″.
|
||||
|
||||
Here is the contents of /etc/default/motd-news file:
|
||||
```
|
||||
$ cat /etc/default/motd-news
|
||||
# Enable/disable the dynamic MOTD news service
|
||||
# This is a useful way to provide dynamic, informative
|
||||
# information pertinent to the users and administrators
|
||||
# of the local system
|
||||
ENABLED=1
|
||||
|
||||
# Configure the source of dynamic MOTD news
|
||||
# White space separated list of 0 to many news services
|
||||
# For security reasons, these must be https
|
||||
# and have a valid certificate
|
||||
# Canonical runs a service at motd.ubuntu.com, and you
|
||||
# can easily run one too
|
||||
URLS="https://motd.ubuntu.com"
|
||||
|
||||
# Specify the time in seconds, you're willing to wait for
|
||||
# dynamic MOTD news
|
||||
# Note that news messages are fetched in the background by
|
||||
# a systemd timer, so this should never block boot or login
|
||||
WAIT=5
|
||||
|
||||
```
|
||||
|
||||
Good thing is MOTD is fully customizable, so you can disable it entirely (ENABLED=0), change or add scripts as per your wish, and change the wait time in seconds
|
||||
|
||||
If MOTD is enabled, that systemd timer job will loop over each of the URLS, trim them to 80 characters per line, and a maximum of 10 lines, and concatenate them to a cache file in /var/cache/motd-news. This systemd timer job will re-run and update the /var/cache/motd-news every 12 hours. Upon user login, the contents of /var/cache/motd-news is just printed to screen. This is how MOTD works.
|
||||
|
||||
Also, a custom user-agent string is included in **/etc/update-motd.d/50-motd-news** file to report information about your computer. If you look into **/etc/update-motd.d/50-motd-news** file, you will see the following code.
|
||||
```
|
||||
# Piece together the user agent
|
||||
USER_AGENT="curl/$curl_ver $lsb $platform $cpu $uptime"
|
||||
|
||||
```
|
||||
|
||||
That means, the MOTD retriever reports your **operating system release** , **hardware platform** , **CPU type** and **uptime** to Canonical.
|
||||
|
||||
Hope you got the basic idea about MOTD.
|
||||
|
||||
Let us now get back to the topic. I don’t want this feature. How do I disable it? If the promotional links in the welcome message still bothers you and you wanted to disable them permanently, here is a quick way to disable it.
|
||||
|
||||
### Disable Ads In Terminal Welcome Message In Ubuntu Server
|
||||
|
||||
To disable these ads, edit file:
|
||||
```
|
||||
$ sudo vi /etc/default/motd-news
|
||||
|
||||
```
|
||||
|
||||
Find the following line and set its value as 0 (zero).
|
||||
```
|
||||
[...]
|
||||
ENABLED=0
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
Save and close the file. Now, reboot your system and see if the welcome message stills showing the links from Ubuntu blog.
|
||||
|
||||

|
||||
|
||||
See? There are no links from Ubuntu blog and Ubuntu wiki now.
|
||||
|
||||
And, that’s all for now. Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-disable-ads-in-terminal-welcome-message-in-ubuntu-server/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://blog.ubuntu.com/
|
||||
[2]:https://wiki.ubuntu.com/
|
||||
@ -0,0 +1,170 @@
|
||||
A checklist for submitting your first Linux kernel patch
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of the biggest—and the fastest moving—open source projects, the Linux kernel, is composed of about 53,600 files and nearly 20-million lines of code. With more than 15,600 programmers contributing to the project worldwide, the Linux kernel follows a maintainer model for collaboration.
|
||||
|
||||

|
||||
|
||||
In this article, I'll provide a quick checklist of steps involved with making your first kernel contribution, and look at what you should know before submitting a patch. For a more in-depth look at the submission process for contributing your first patch, read the [KernelNewbies First Kernel Patch tutorial][1].
|
||||
|
||||
### Contributing to the kernel
|
||||
|
||||
#### Step 1: Prepare your system.
|
||||
|
||||
Steps in this article assume you have the following tools on your system:
|
||||
|
||||
+ Text editor
|
||||
+ Email client
|
||||
+ Version control system (e.g., git)
|
||||
|
||||
#### Step 2: Download the Linux kernel code repository`:`
|
||||
```
|
||||
git clone -b staging-testing
|
||||
|
||||
git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/staging.git
|
||||
|
||||
```
|
||||
|
||||
### Copy your current config: ````
|
||||
```
|
||||
cp /boot/config-`uname -r`* .config
|
||||
|
||||
```
|
||||
|
||||
### Step 3: Build/install your kernel.
|
||||
```
|
||||
make -jX
|
||||
|
||||
sudo make modules_install install
|
||||
|
||||
```
|
||||
|
||||
### Step 4: Make a branch and switch to it.
|
||||
```
|
||||
git checkout -b first-patch
|
||||
|
||||
```
|
||||
|
||||
### Step 5: Update your kernel to point to the latest code base.
|
||||
```
|
||||
git fetch origin
|
||||
|
||||
git rebase origin/staging-testing
|
||||
|
||||
```
|
||||
|
||||
### Step 6: Make a change to the code base.
|
||||
|
||||
Recompile using `make` command to ensure that your change does not produce errors.
|
||||
|
||||
### Step 7: Commit your changes and create a patch.
|
||||
```
|
||||
git add <file>
|
||||
|
||||
git commit -s -v
|
||||
|
||||
git format-patch -o /tmp/ HEAD^
|
||||
|
||||
```
|
||||
|
||||
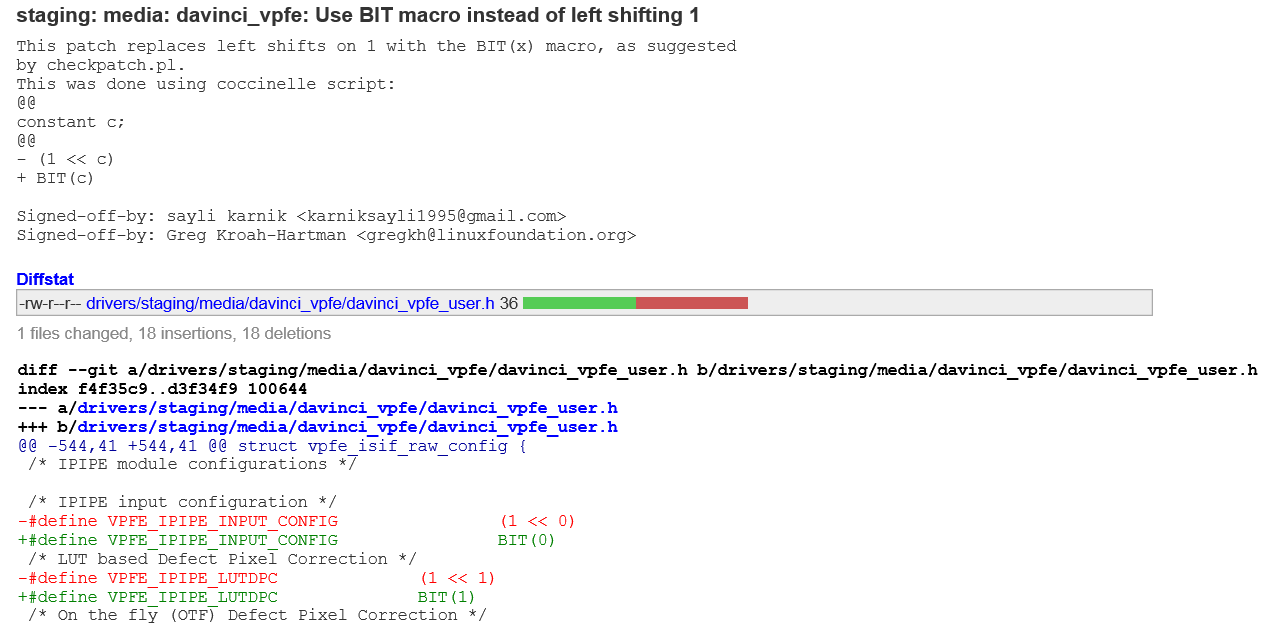
|
||||
|
||||
The subject consists of the path to the file name separated by colons, followed by what the patch does in the imperative tense. After a blank line comes the description of the patch and the mandatory signed off tag and, lastly, a diff of your patch.
|
||||
|
||||
Here is another example of a simple patch:
|
||||
|
||||
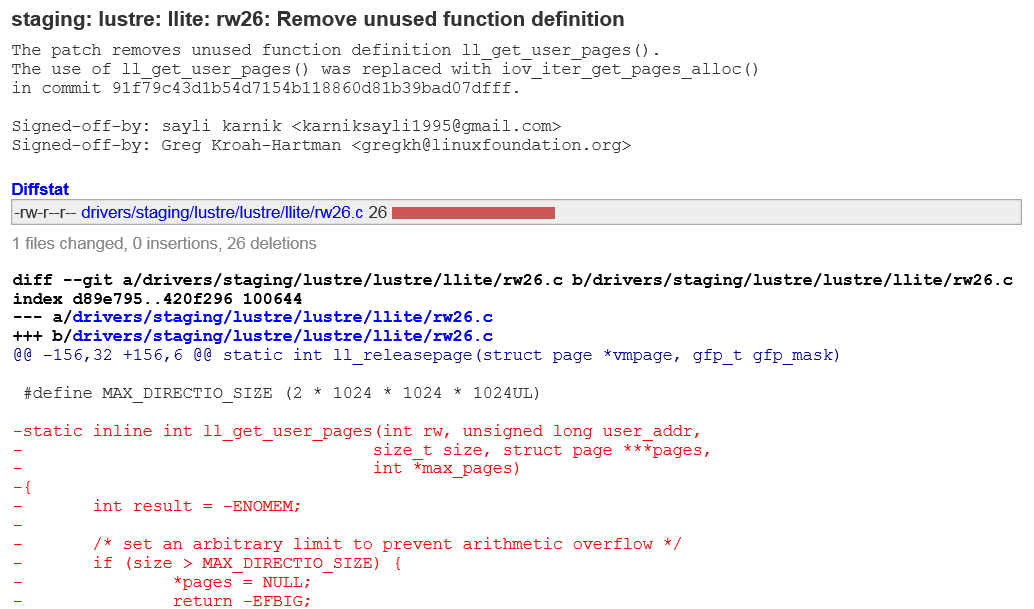
|
||||
|
||||
Next, send the patch [using email from the command line][2] (in this case, Mutt): ``
|
||||
```
|
||||
mutt -H /tmp/0001-<whatever your filename is>
|
||||
|
||||
```
|
||||
|
||||
To know the list of maintainers to whom to send the patch, use the [get_maintainer.pl script][11].
|
||||
|
||||
|
||||
### What to know before submitting your first patch
|
||||
|
||||
* [Greg Kroah-Hartman][3]'s [staging tree][4] is a good place to submit your [first patch][1] as he accepts easy patches from new contributors. When you get familiar with the patch-sending process, you could send subsystem-specific patches with increased complexity.
|
||||
|
||||
* You also could start with correcting coding style issues in the code. To learn more, read the [Linux kernel coding style documentation][5].
|
||||
|
||||
* The script [checkpatch.pl][6] detects coding style errors for you. For example, run:
|
||||
```
|
||||
perl scripts/checkpatch.pl -f drivers/staging/android/* | less
|
||||
|
||||
```
|
||||
|
||||
* You could complete TODOs left incomplete by developers:
|
||||
```
|
||||
find drivers/staging -name TODO
|
||||
```
|
||||
|
||||
* [Coccinelle][7] is a helpful tool for pattern matching.
|
||||
|
||||
* Read the [kernel mailing archives][8].
|
||||
|
||||
* Go through the [linux.git log][9] to see commits by previous authors for inspiration.
|
||||
|
||||
* Note: Do not top-post to communicate with the reviewer of your patch! Here's an example:
|
||||
|
||||
**Wrong way:**
|
||||
|
||||
Chris,
|
||||
_Yes let’s schedule the meeting tomorrow, on the second floor._
|
||||
> On Fri, Apr 26, 2013 at 9:25 AM, Chris wrote:
|
||||
> Hey John, I had some questions:
|
||||
> 1\. Do you want to schedule the meeting tomorrow?
|
||||
> 2\. On which floor in the office?
|
||||
> 3\. What time is suitable to you?
|
||||
|
||||
(Notice that the last question was unintentionally left unanswered in the reply.)
|
||||
|
||||
**Correct way:**
|
||||
|
||||
Chris,
|
||||
See my answers below...
|
||||
> On Fri, Apr 26, 2013 at 9:25 AM, Chris wrote:
|
||||
> Hey John, I had some questions:
|
||||
> 1\. Do you want to schedule the meeting tomorrow?
|
||||
_Yes tomorrow is fine._
|
||||
> 2\. On which floor in the office?
|
||||
_Let's keep it on the second floor._
|
||||
> 3\. What time is suitable to you?
|
||||
_09:00 am would be alright._
|
||||
|
||||
(All questions were answered, and this way saves reading time.)
|
||||
|
||||
* The [Eudyptula challenge][10] is a great way to learn kernel basics.
|
||||
|
||||
|
||||
To learn more, read the [KernelNewbies First Kernel Patch tutorial][1]. After that, if you still have any questions, ask on the [kernelnewbies mailing list][12] or in the [#kernelnewbies IRC channel][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/first-linux-kernel-patch
|
||||
|
||||
作者:[Sayli Karnik][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sayli
|
||||
[1]:https://kernelnewbies.org/FirstKernelPatch
|
||||
[2]:https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
|
||||
[3]:https://twitter.com/gregkh
|
||||
[4]:https://www.kernel.org/doc/html/v4.15/process/2.Process.html
|
||||
[5]:https://www.kernel.org/doc/html/v4.10/process/coding-style.html
|
||||
[6]:https://github.com/torvalds/linux/blob/master/scripts/checkpatch.pl
|
||||
[7]:http://coccinelle.lip6.fr/
|
||||
[8]:linux-kernel@vger.kernel.org
|
||||
[9]:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/log/
|
||||
[10]:http://eudyptula-challenge.org/
|
||||
[11]:https://github.com/torvalds/linux/blob/master/scripts/get_maintainer.pl
|
||||
[12]:https://kernelnewbies.org/MailingList
|
||||
[13]:https://kernelnewbies.org/IRC
|
||||
@ -0,0 +1,186 @@
|
||||
9 flowchart and diagramming tools for Linux
|
||||
======
|
||||
|
||||
|
||||
|
||||
Flowcharts are a great way to formalize the methodology for a new project. My team at work uses them as a tool in our brainstorming sessions and—once the ideation event wraps up—the flowchart becomes the project methodology (at least until someone changes it). My project methodology flowcharts are high-level and pretty straightforward—typically they contain just process, decision, and terminator objects—though they can be composed of many tens of these objects.
|
||||
|
||||
I work primarily in my Linux desktop environment, and most of my office colleagues use Windows. However, we're increasing our use of G Suite in part because it minimizes distractions related to our various desktop environments. Even so, I would prefer to find an open source tool—preferably a standalone app, rather than one that's part of another suite—that offers great support for flowcharts and is available on all the desktops our team uses.
|
||||
|
||||
It's been over four years since [Máirin Duffy reviewed Linux diagramming tools][1], so I decided to take a look at what's out there now for open source flowchart makers. I identified the following nine candidates:
|
||||
|
||||
| Candidate name | Linux desktop | Available for Windows? | Available for MacOS? |
|
||||
|-----------------------| --------------|------------------------|----------------------|
|
||||
| [Dia][2] | GNOME | Yes | Yes |
|
||||
| [LibreOffice Draw][3] | GNOME | Yes | Yes |
|
||||
| [Inkscape][4] | GNOME | Yes | Yes |
|
||||
| [Calligra Flow][5] | KDE | Preliminary | Preliminary |
|
||||
| [Diagramo][6] | Browser | Browser | Browser |
|
||||
| [Pencil][7] | ? | Yes | Yes |
|
||||
| [Graphviz][8] | CLI | Yes | Yes |
|
||||
| [Umbrello][9] | KDE | Yes | Yes |
|
||||
| [Draw.io][10] | Browser | Browser | Browser |
|
||||
|
||||
I'll share a bit of information about each below.
|
||||
|
||||
### Dia
|
||||
|
||||
|
||||
|
||||
I reviewed Dia 0.97.3 from the Ubuntu 18.04 repository; you can [download it here][2].
|
||||
|
||||
Dia is a standalone drawing tool. It offers some additional components, such as `dia-rib-network` for network diagrams and `dia2cod` for converting [UML][11] to code.
|
||||
|
||||
The installation process dragged in a few other packages, including: `dia-common`, `dia-shapes`, `gsfonts-x11`, `libpython-stdlib`, `python`, `python-cairo`, and `python-gobject2`.
|
||||
|
||||
[Dia's documentation][12] is quite thorough and available in English, German, French, Polish, and Basque. It includes information on related utilities; versions for Linux, Windows, and MacOS; a lot of stuff related to shapes; and much more. The bug tracker on the project's website is disabled, but bug reports are accepted on [GNOME Bugzilla][13].
|
||||
|
||||
Dia has complete support for making flowcharts—appropriate symbols, connectors, lots of connection points on objects, annotation for objects, etc. Even so, Dia's user experience (UX) feels unusual. For example, double-clicking on an object brings up properties and metadata, rather than the object's annotation; to edit annotation, you must select the object and click on Tools > Edit Text (or use the F2 key). The default text size, 22.68pt, or about 8mm, seems a bit weird. The text padding default is very large (0.50), and even when it's reduced by a factor of 10 (to 0.05), it still may leave a wide gap around the text (for example in the diamond decision object). You must also select the object before you can right-click on it. Cutting and pasting are somewhat limited—I couldn't copy text from my browser (with the standard Ctrl+C) and paste it into Dia. Dia launches ready to work with a multipage drawing, which is pretty handy if you need to make a 1x2 meter drawing and your printer accommodates only letter-size paper.
|
||||
|
||||
In general terms, performance is very snappy. Interaction can seem a bit odd (see above), but it doesn't require huge adjustments to get the hang of it. On the downside, the Help menu did not link properly to documentation, and I couldn't find a spell checker. Finally, from what I can tell, there is no active development on Dia.
|
||||
|
||||
### LibreOffice Draw
|
||||
|
||||
|
||||
|
||||
I reviewed [LibreOffice Draw][3] version 6.0.4.2, which was installed by default on my Ubuntu 18.04 desktop.
|
||||
|
||||
Since LibreOffice Draw is part of the LibreOffice suite, the UX will be familiar to anyone who uses LibreOffice Writer, Calc, or Impress. However, if you are looking for a standalone flowcharting tool and don't already use LibreOffice, this is likely to be a large [install][14].
|
||||
|
||||
The application includes an extensive help facility that is accessible from the Help menu, and you can find a great deal of information by searching online.
|
||||
|
||||
LibreOffice Draw has a set of predefined flowchart shapes that support annotation as well as connectors. Connection points are limited—all the shapes I use have just four points. Draw's UX will feel familiar to LibreOffice users; for example, double-clicking an object opens the object's annotation. Text wraps automatically when its length exceeds the width of a text box. However, annotation entered in a drawing object does not wrap; you must manually break the lines. Default text size, spacing, etc. are reasonable and easily changed. Draw permits multiple pages (which are called slides), but it doesn't support multipage drawings as easily as Dia does.
|
||||
|
||||
In general terms, LibreOffice Draw provides good, basic flowcharting capability with no UX surprises. It performs well, at least on smaller flowcharts, and standard LibreOffice writing tools, such as spell check, are available.
|
||||
|
||||
### Inkscape
|
||||
|
||||
|
||||
|
||||
I reviewed [Inkscape][4] version 0.92.3 from the Ubuntu 18.04 repositories; you can [download it here][15].
|
||||
|
||||
Inkscape is a standalone tool, and it is waaaaaay more than a flowchart drawing utility.
|
||||
|
||||
The installation process dragged in several other packages, including: `fig2dev`, `gawk`, `libgtkspell0`, `libimage-magick-perl`, `libimage-magick-q16-perl`, `libmagick+±6.q16-7`, `libpotrace0`, `libsigsegv2`, `libwmf-bin`, `python-scour`, `python3-scour`, `scour`, and `transfig`.
|
||||
|
||||
There is a great deal of Inkscape documentation available, including the Inkscape Manual available from the Help menu. This [tutorial][16] made it easier to get started with my first Inkscape flowchart.
|
||||
|
||||
Getting my first rectangle on the screen was pretty straightforward with the Create Rectangles and Squares toolbar item. I changed the shape's background color by using the color swatches across the bottom of the screen. However, it seems text is separate from other objects, i.e., there doesn't appear to be a concept of geometric objects with annotation, so I created the text first, then added the surrounding object, and finally put in connectors. Default text sizes were odd (30pt, if I recall correctly) but you can change the default. Bottom line: I could make the diagram, but—based on what I could learn in a few minutes—it was more of a diagram than a flowchart.
|
||||
|
||||
In general terms, Inkscape is an extremely full-featured vector drawing program with a learning curve. It's probably not the best tool for users who just want to draw a quick flowchart. There seems to be a spell checker available, although I didn't try it.
|
||||
|
||||
### Calligra Flow
|
||||
|
||||
From [the Calligra website][5]:
|
||||
|
||||
> Calligra Flow is an easy to use diagramming and flowcharting application with tight integration to the other Calligra applications. It enables you to create network diagrams, organisation charts, flowcharts, and more.
|
||||
|
||||
I could not find Calligra Flow in my repositories. Because of that and its tight integration with Calligra, which is oriented toward KDE users, I decided not to review it now. Based on its website, it looks like it's geared toward flowcharting, which could make it a good choice if you're using KDE.
|
||||
|
||||
### Diagramo
|
||||
|
||||
|
||||
|
||||
I reviewed [Diagramo][6] build number 2.4.0-3c215561787f-2014-07-01, accessed through [Try It Now!][17] on the Diagramo website using the Firefox browser.
|
||||
|
||||
Diagramo is standalone, web-based flowcharting software. It claims to be pure HTML5 and GPL, but the [source code repository][18] states the code is available under the Apache License 2.0.
|
||||
|
||||
The tool is accessible through a web browser, so no installation is required. (I didn't download the source code and try to install it locally.)
|
||||
|
||||
I couldn't find any documentation for Diagramo. The application's Help button allows bug filing and turning on the debugger, and the build number is available under About.
|
||||
|
||||
Diagramo offers several collections of drawing objects: Basic, Experimental, Network, Secondary, and UML State Machine. I limited my testing to the Basic set, which contained enough objects for me. To create a chart, you drag objects from the menu on the left and drop them on the canvas. You can set the canvas size in the options panel on the right. Sizes are in pixels, which is OK, although I prefer to work in points. The default text attributes were: 12px, Arial font, center alignment, with options to underline and change the text color. You can see the attributes in a popup menu above the text by double-clicking the default annotation, which is set to Text. You have to manually break lines of text, similar to in LibreOffice Draw. Objects have multiple connection points (I counted 12 on the rectangles and five on the diamonds). Connectors are separate from shapes and appear in the top toolbar. I couldn't save my test flowchart to my computer.
|
||||
|
||||
In general terms, Diagramo provides good basic flowcharting capability with no UX surprises. It performs well, at least on smaller flowcharts, but doesn't seem to take advantage of Firefox's spell checker.
|
||||
|
||||
### Pencil
|
||||
|
||||
|
||||
|
||||
I reviewed [Pencil][7] version 3.0.4, which I [downloaded][19] from the Pencil project website. I used `dpkg` to install the 64-bit .deb package file. It installed cleanly with no missing packages.
|
||||
|
||||
Pencil is a standalone drawing tool. Documentation and tutorials are available on [the project website][7].
|
||||
|
||||
To make my sample flowchart, I selected the flowchart shape set from the far-left menu panel. From there, I could drag Process, Decision, and Straight Connector shapes onto the page. I added annotation by double-clicking on the object and typing in the text. (Copy/paste also works.) You can drag the connector endpoints near the desired attachment point and they automatically attach. The default font setting (Arial, 12pt) is a good choice, but I couldn't find a spell check function.
|
||||
|
||||
In general, using Pencil is very simple and straightforward. It offers solid flowcharting capability with no UX surprises and performs well, at least on smaller flowcharts.
|
||||
|
||||
### Graphviz
|
||||
|
||||
According to the [Graphviz documentation][20]:
|
||||
|
||||
> The Graphviz layout programs take descriptions of graphs in a simple text language and make diagrams in useful formats, such as images and SVG for web pages; PDF or Postscript for inclusion in other documents; or display in an interactive graph browser. Graphviz has many useful features for concrete diagrams, such as options for colors, fonts, tabular node layouts, line styles, hyperlinks, and custom shapes.
|
||||
|
||||
I didn't do a full review of Graphviz. It looks like a very interesting package for converting text to graphical representations, and I might try it at some point. However, I don't see it as a good tool for people who are used to a more interactive UX. If you'd like to know more about it, [Stack Overflow][21] offers a quick overview of constructing a simple flowchart in Graphviz.
|
||||
|
||||
### Umbrello
|
||||
|
||||
I spotted [Umbrello][9] in my repositories, where I read:
|
||||
|
||||
> Umbrello UML Modeller is a Unified Modelling Language diagram editor for KDE. It can create diagrams of software and other systems in the industry-standard UML format, and can also generate code from UML diagrams in a variety of programming languages. This package is part of the KDE Software Development Kit module.
|
||||
|
||||
Because of its focus on UML rather than flowcharting and its KDE orientation, I decided to leave Umbrello to evaluate later.
|
||||
|
||||
### Draw.io
|
||||
|
||||
|
||||
|
||||
I reviewed [Draw.io][22] version 8.9.7, which I accessed through its website.
|
||||
|
||||
Draw.io is standalone, web-based drawing software, and a desktop version is available. Since it runs in the browser, there's no installation required.
|
||||
|
||||
[Documentation][23] is available on the Draw.io website.
|
||||
|
||||
Draw.io launches with a set of general flowchart drawing objects on the left and context-sensitive properties on the right. (It's reminiscent of the Properties window in LibreOffice.) Clicking on a shape makes it appear on the page. Text defaults to centered 12pt Helvetica. Double-clicking on the drawing object opens the annotation editor. Draw.io automatically splits long lines of text, but the splitting isn't perfect in the diamond object. Objects have a decent number of connection points (I count 12 on the rectangle and eight on the diamond). Similar to Google Draw, as objects are dragged around, alignment aids help square up the diagram. I saved my work to an .xml file on my computer, which is a cool option for a web-based service. Diagrams can also be shared.
|
||||
|
||||
In general terms, Draw.io provides solid flowcharting capability with no UX surprises, but no spell checker that I could find. It performs well, at least on smaller flowcharts, and the collaboration ability is nice.
|
||||
|
||||
### What's the verdict?
|
||||
|
||||
So, which of these flowcharting tools do I like best?
|
||||
|
||||
Bearing in mind that I was leaning toward a standalone tool that could operate on any desktop, Draw.io and Diagramo appealed to me for their simplicity and browser-based operation (which means no installation is necessary). I also really liked Pencil, although it must be installed.
|
||||
|
||||
Conversely, I felt Dia's UX was just a bit clunky and old-fashioned, although it certainly has great functionality.
|
||||
|
||||
LibreOffice Draw and Calligra Flow, due to their integration in their respective office suites, didn't achieve my goal for a standalone, lightweight tool.
|
||||
|
||||
Inkscape, Graphviz, and Umbrello seem like great tools in their own right, but trying to use them as simple, standalone flowchart creation tools seems like a real stretch.
|
||||
|
||||
Will any of these replace G Suite's drawing capability in our office? I think Draw.io, Diagramo and Pencil could. We shall see!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/flowchart-diagramming-linux
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clhermansen
|
||||
[1]:https://opensource.com/life/14/6/tools-diagramming-fedora
|
||||
[2]:http://dia-installer.de/
|
||||
[3]:https://www.libreoffice.org/discover/draw/
|
||||
[4]:https://inkscape.org/en/
|
||||
[5]:https://www.calligra.org/flow/
|
||||
[6]:http://diagramo.com/
|
||||
[7]:https://pencil.evolus.vn/
|
||||
[8]:http://graphviz.org/
|
||||
[9]:https://umbrello.kde.org/
|
||||
[10]:https://about.draw.io/about-us/
|
||||
[11]:https://en.wikipedia.org/wiki/Unified_Modeling_Language
|
||||
[12]:http://dia-installer.de/doc/index.html.en
|
||||
[13]:https://bugzilla.gnome.org/query.cgi?format=specific&product=dia&bug_status=__all__
|
||||
[14]:https://www.libreoffice.org/download/download/
|
||||
[15]:https://inkscape.org/en/release/0.92.3/
|
||||
[16]:http://goinkscape.com/create-beautiful-diagrams-in-inkscape/
|
||||
[17]:http://diagramo.com/editor/editor.php
|
||||
[18]:https://bitbucket.org/scriptoid/diagramo/src/33c88ca45ee942bf0b16f19879790c361fc9709d/LICENSE.txt?at=default&fileviewer=file-view-default
|
||||
[19]:https://pencil.evolus.vn/Downloads.html
|
||||
[20]:https://graphviz.gitlab.io/documentation/
|
||||
[21]:https://stackoverflow.com/questions/46365855/create-simple-flowchart-with-graphviz
|
||||
[22]:http://Draw.io
|
||||
[23]:https://about.draw.io/tag/user-documentation/
|
||||
@ -0,0 +1,106 @@
|
||||
How To Switch Between TTYs Without Using Function Keys In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
This brief guide describes how to switch between TTYs without function keys in Unix-like operating systems. Before going further, we will see what TTY is. As mentioned in an [**answer**][1] in AskUbuntu forum, the word **TTY** came from **T** ele **TY** pewriter. Back in the early days of Unix, the user terminals connected to computers were electromechanical teleprinters or teletypewriters( tty in short). Since then, the name TTY has continued to be used for text-only consoles. Nowadays, all text consoles represents virtual consoles, not physical consoles. The TTY command prints the file name of the terminal connected to standard input.
|
||||
|
||||
### Switch Between TTYs In Linux
|
||||
|
||||
By default, there are 7 ttys in Linux. They are known as tty1, tty2….. tty7. The 1 to 6 ttys are command line only. The 7th tty is GUI (your X desktop session). You can switch between different TTYs by using **CTRL+ALT+Fn** keys. For example to switch to tty1, we type CTRL+ALT+F1. This is how tty1 looks in Ubuntu 18.04 LTS server.
|
||||
|
||||
|
||||
|
||||
If your system has no X session,
|
||||
|
||||
In some Linux editions (Eg. from Ubuntu 17.10 onwards), the login screen now uses virtual console 1 . So, you need to press CTRL+ALT+F3 up to CTRL+ALT+F6 for accessing the virtual consoles. To go back to desktop environment, press CTRL+ALT+F2 or CTRL+ALT+F7 on Ubuntu 17.10 and later.
|
||||
|
||||
What we have seen so far is we can easily switch between TTYs using CTRL+ALT+Function_Key(F1-F7). However, if you don’t want to use the functions keys for any reason, there is a simple command named **“chvt”** in Linux.
|
||||
|
||||
The “chvt N” command allows you to switch to foreground terminal N, the same as pressing CTRL+ALT+Fn. The corresponding screen is created if it did not exist yet.
|
||||
|
||||
Let us see print the current tty:
|
||||
```
|
||||
$ tty
|
||||
|
||||
```
|
||||
|
||||
Sample output from my Ubuntu 18.04 LTS server.
|
||||
|
||||
Now let us switch to tty2. To do so, type:
|
||||
```
|
||||
$ sudo chvt 2
|
||||
|
||||
```
|
||||
|
||||
Remember you need to use “sudo” with chvt command.
|
||||
|
||||
Now, check the current tty using command:
|
||||
```
|
||||
$ tty
|
||||
|
||||
```
|
||||
|
||||
You will see that the tty has changed now.
|
||||
|
||||
Similarly, you can switch to tty3 using “sudo chvt 3”, tty4 using “sudo chvt 4” and so on.
|
||||
|
||||
Chvt command can be useful when any one of your function keys doesn’t work.
|
||||
|
||||
To view the total number of active virtual consoles, run:
|
||||
```
|
||||
$ fgconsole
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
As you can see, there are two active VTs in my system.
|
||||
|
||||
You can see the next unallocated virtual terminal using command:
|
||||
```
|
||||
$ fgconsole --next-available
|
||||
3
|
||||
|
||||
```
|
||||
|
||||
A virtual console is unused if it is not the foreground console, and no process has it open for reading or writing, and no text has been selected on its screen.
|
||||
|
||||
To get rid of unused VTs, just type:
|
||||
```
|
||||
$ deallocvt
|
||||
|
||||
```
|
||||
|
||||
The above command deallocates kernel memory and data structures for all unused virtual consoles. To put this simply, this command will free all resources connected to the unused virtual consoles.
|
||||
|
||||
For more details, refer the respective command’s man pages.
|
||||
```
|
||||
$ man tty
|
||||
|
||||
$ man chvt
|
||||
|
||||
$ man fgconsole
|
||||
|
||||
$ man deallocvt
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-switch-between-ttys-without-using-function-keys-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://askubuntu.com/questions/481906/what-does-tty-stand-for
|
||||
@ -1,65 +1,65 @@
|
||||
逃离 Google,重获自由(与君共勉)
|
||||
============================================================
|
||||
======
|
||||
|
||||
原名:How I Fully Quit Google (And You Can, Too)
|
||||
|
||||
>寻求挣脱科技巨头的一次开创性尝试
|
||||
> 寻求挣脱科技巨头的一次开创性尝试
|
||||
|
||||
在过去的六个月里,难以想象我到底经历了些什么。时间密集,启发性质的探索,最终换来的只是完全摒弃一家公司——Google(谷歌)——的产品。本该是件简简单单的任务,但真要去做,花费在研究和测试上的又何止几个小时。但我成功了。现在,我已经不需要 Google 了,作为西方世界中极其少数的群体中的一份子,不再使用世界上最有价值的两家科技公司的产品(是的,我也不用 [Facebook(脸书)][6])。
|
||||
在过去的六个月里,难以想象我到底经历了些什么。艰难的、时间密集的、启发性的探索,为的只是完全摒弃一家公司 —— Google(谷歌)—— 的产品。本该是件简简单单的任务,但真要去做,花费在研究和测试上的又何止几个小时。但我成功了。现在,我已经不需要 Google 了,作为西方世界中极其少数的群体中的一份子,不再使用世界上最有价值的两家科技公司的产品(是的,我也不用 [Facebook(脸书)][6])。
|
||||
|
||||
本篇指南将向你展示我逃离 Google 生态的始末。以及根据本人的研究和个人需求,选择的替代方案。我不是技术方面的专家,或者说程序员,但作为记者,我的工作要求我对安全和隐私的问题保持关注。
|
||||
本篇指南将向你展示我逃离 Google 生态的始末。以及根据本人的研究和个人需求,选择的替代方案。我不是技术方面的专家,或者说程序员,但作为记者,我的工作要求我对安全和隐私的问题保持警惕。
|
||||
|
||||
我选择替代方案时,主要考察其本身的长处、可用性、成本、以及是否具备我需要的功能。我的选择并不是那么大众,仅反映我自身的需求和期许,也不牵涉任何商业利益。下面列出的所有替代方案都没有给我赞助,也从未试图花钱诱使我使用他们的服务。
|
||||
|
||||
### 首先我们需要知道:为什么?
|
||||
|
||||
你们说这事情整的,我和 Google 可无冤无仇。事实上,不久前我还是个忠实的 Google 粉。还是记得是 90 年代末,当时我还在读高中,我和 Google 搜索引擎的第一次邂逅,那一瞬的美简直惊为天人。那时候的 Google 可比 Yahoo、Altavista、Ask Jeeves 等公司前卫了好几年。实打实的去帮用户找到他们想在网络上找的东西,但同样是那个时代,乌七八糟的网站和糟糕的索引遍地横生。
|
||||
你们说这事情整的,我和 Google 可无冤无仇。事实上,不久前我还是个忠实的 Google 粉。还是记得是 90 年代末,当时我还在读高中,我和 Google 搜索引擎的第一次邂逅,那一瞬的美简直惊为天人。那时候的 Google 可是领先了 Yahoo、Altavista、Ask Jeeves 这些公司好几年。Google 实打实地去帮用户找到他们想在网络上找的东西,但同样是那个时代,乌七八糟的网站和糟糕的索引遍地横生。
|
||||
|
||||
Google 很快就从仅提供检索服务转向提供其他服务,其中的许多都是我欣然拥抱的服务。早在 2005 年,当时你们可能还只能 [通过邀请][7] 加入 Gmail 的时候,我就已经是早期使用者了。Gmail 采用了线程对话、归档、标签,毫无疑问是我使用过的最好的电子邮件服务。 当 Google 在 2006 年推出其日历工具时,那种对操作的改进绝对是革命性的。针对不同日历使用不同的颜色进行编排、检索事件、以及发送可共享的邀请,操作极其简单。2007 年登陆的 Google Docs 同样令人惊叹。在我的第一份全职工作期间,我还促成我们团队使用支持多人同时编辑的 Google 电子表格、文档和演示文稿来完成我们的日常工作。
|
||||
Google 很快就从仅提供检索服务转向提供其它服务,其中许多都是我欣然拥抱的服务。早在 2005 年,当时你们可能还只能[通过邀请][7]加入 Gmail 的时候,我就已经是早期使用者了。Gmail 采用了线程对话、归档、标签,毫无疑问是我使用过的最好的电子邮件服务。当 Google 在 2006 年推出其日历工具时,那种对操作的改进绝对是革命性的。针对不同日历使用不同的颜色进行编排、检索事件、以及发送可共享的邀请,操作极其简单。2007 年推出的 Google Docs 同样令人惊叹。在我的第一份全职工作期间,我还促成我们团队使用支持多人同时编辑的 Google 电子表格、文档和演示文稿来完成日常工作。
|
||||
|
||||
和许多人样,我也是 Google 开疆拓土过程中的受害者。从搜索(引擎)到电子邮件、文档、分析、再到照片,许多其他服务都建立在彼此之上,相互勾连。Google 从一家发布实用产品的公司转变成诱困用户公司,于此同时将整个互联网,转变为牟利和数据采集的设备。Google 在我们的数字生活中几乎无处不在,这种程度的存在远非其他公司可以比拟。与之相比使用其他科技巨头的产品想要抽身就相对容易。对于 Apple(苹果),你要么身处 iWorld 之中,要么是局外人。亚马逊亦是如此,甚至连 Facebook 也不过是拥有少数的几个平台,不用(Facebook)更多的是 [心理挑战][8] 实际上并没有多么困难。
|
||||
和许多人样,我也是 Google 开疆拓土过程中的受害者。从搜索(引擎)到电子邮件、文档、分析、再到照片,许多其它服务都建立在彼此之上,相互勾连。Google 从一家发布实用产品的公司转变成诱困用户公司,与此同时将整个互联网转变为牟利和数据采集的机器。Google 在我们的数字生活中几乎无处不在,这种程度的存在远非其他公司可以比拟。与之相比使用其他科技巨头的产品想要抽身就相对容易。对于 Apple(苹果),你要么身处 iWorld 之中,要么是局外人。亚马逊亦是如此,甚至连 Facebook 也不过是拥有少数的几个平台,不用(Facebook)更多的是[心理挑战][8],实际上并没有多么困难。
|
||||
|
||||
然而,Google 无处不在。 无论是笔记本电脑、智能手机或者平板电脑,我猜之中至少会有那么一个 Google 的应用程序。在大多数智能手机上,Google 就是搜索(引擎)、地图、电子邮件、浏览器和操作系统的代名词。甚至还有些应用有赖于其提供的 “[服务][9]” 和分析,比方说 Uber 便需要采用 Google Maps 来运营其乘车服务。
|
||||
然而,Google 无处不在。无论是笔记本电脑、智能手机或者平板电脑,我猜其中至少会有那么一个 Google 的应用程序。Google 就是搜索(引擎)、地图、电子邮件、浏览器和大多数智能手机操作系统的代名词。甚至还有些应用有赖于其提供的“[服务][9]”和分析,比方说 Uber 便需要采用 Google Maps 来运营其乘车服务。
|
||||
|
||||
Google 现在俨然已是许多语言中的单词,但彰显其超然全球统治地位的方面显然不止于此。可以说只要你不是极其注重个人隐私,那其庞大而成套的工具几乎没有多少众所周知或广泛使用的替代品。这恰好也是大家选择 Google 的原因,在很多方面能更好的替代现有的产品。但现在,使我们的难以割舍的主要原因其实是 Google 已经成为了默认选择,或者说由于其主导地位导致替代品无法对我们构成足够的吸引。
|
||||
|
||||
事实上,替代方案是存在的,这些年自 Edward Snowden(爱德华·斯诺登)披露 Google 涉事 [Prism(棱镜)][10] 以来,又陆续涌现了许多替代品。我从去年年底开始着手这个项目。经过六个月的研究,测试以及大量的尝试和失败,我终于找到了所有我正在使用的 Google 产品对应的注重个人隐的私替代品。令我感到吃惊的是,其中的一些替代品比 Google 的做的还要好。
|
||||
事实上,替代方案是存在的,这些年自 Edward Snowden(爱德华·斯诺登)披露 Google 涉事 [Prism(棱镜)][10]以来,又陆续涌现了许多替代品。我从去年年底开始着手这个项目。经过六个月的研究、测评以及大量的尝试和失败,我终于找到了所有我正在使用的 Google 产品对应的注重个人隐私的替代品。令我感到吃惊的是,其中的一些替代品比 Google 的做的还要好。
|
||||
|
||||
### 一些注意事项
|
||||
|
||||
过程中需要面临的几个挑战的之一便是,大多数的替代方案,特别是那些隐私空间开源的替代方案,确实对用户不太友好。我不是技术人员,但是自己有一个网站,了解如何管理 Wordpress,可以排除一些基本的故障,但我用不来命令行,也做不来任何需要编码的事。
|
||||
过程中需要面临的几个挑战之一便是,大多数的替代方案,特别是那些注重隐私空间的开源替代方案,确实对用户不太友好。我不是技术人员,但是自己有一个网站,了解如何管理 Wordpress,可以排除一些基本的故障,但我用不来命令行,也做不来任何需要编码的事。
|
||||
|
||||
提供的这些替代方案中的大多数,即便不能完整替代 Google 产品的功能,但至少可以轻松上手。不过有些还有需要你有自己的 Web 主机或服务器的。
|
||||
提供的这些替代方案中的大多数,即便不能完整替代 Google 产品的功能,但至少可以轻松上手。不过有些还是需要你有自己的 Web 主机或服务器的。
|
||||
|
||||
此外,[Google Takeout][11] 是你的好棒手。我通过它下载了我所有的电子邮件历史记录,并将其上传到我的计算机上,再通过 Thunderbird 访问,这意味着我可以轻松访问这十年间的电子邮件。关于日历还有文档也同样如此,我将后者转换为 ODT 格式,存在我的替代云上,下面我将进一步介绍其中的细节。
|
||||
此外,[Google Takeout][11] 是你的好帮手。我通过它下载了我所有的电子邮件历史记录,并将其上传到我的计算机上,再通过 Thunderbird 访问,这意味着我可以轻松访问这十几年的电子邮件。关于日历和文档也同样如此,我将后者转换为 ODT 格式,存在我的替代云上,下面我将进一步介绍其中的细节。
|
||||
|
||||
### 初级
|
||||
|
||||
#### 搜索引擎
|
||||
|
||||
[DuckDuckGo][12] 和 [startpage][13] 都是以保护个人隐私为中心的搜索引擎,不收集任何搜索数据。我用这两个搜索引擎来负责之前用 Google 检索的所有内容。
|
||||
[DuckDuckGo][12] 和 [startpage][13] 都是以保护个人隐私为中心的搜索引擎,不收集任何搜索数据。我用这两个搜索引擎来负责之前用 Google 搜索的所有需求。
|
||||
|
||||
其他的替代方案:实际上并不多, Google 坐拥全球 74% 的市场份额时,剩下的那些主要是因为中国的封锁。不过还有 Ask.com,以及 Bing……
|
||||
其它的替代方案:实际上并不多,Google 坐拥全球 74% 的市场份额时,剩下的那些主要是因为中国的封锁。不过还有 Ask.com,以及 Bing……
|
||||
|
||||
#### Chrome
|
||||
|
||||
[Mozilla Firefox][14] — 近期的 [一次大升级][15],是对早期版本的巨大改进。是一个由积极致力于保护隐私的非营利基金会打造的浏览器。它的存在让你觉得没有必要死守 Chrome。
|
||||
[Mozilla Firefox][14] —— 近期的[一次大升级][15],是对早期版本的巨大改进。是一个由积极致力于保护隐私的非营利基金会打造的浏览器。它的存在让你觉得没有必要死守 Chrome。
|
||||
|
||||
其他的替代方案:考虑到 Opera 和 Vivaldi 都基于 Chrome。[Brave][16] 浏览器是我的第二选择。
|
||||
其它的替代方案:考虑到 Opera 和 Vivaldi 都基于 Chrome。[Brave][16] 浏览器是我的第二选择。
|
||||
|
||||
#### Hangouts(环聊) 和 Google Chat
|
||||
#### Hangouts(环聊)和 Google Chat
|
||||
|
||||
[Jitsi Meet][17] — 一款 Google Hangouts 的开源免费替代方案。你可以直接在浏览器上使用或下载应用程序。快速,安全,几乎适用于所有平台。
|
||||
[Jitsi Meet][17] —— 一款 Google Hangouts 的开源免费替代方案。你可以直接在浏览器上使用或下载应用程序。快速,安全,几乎适用于所有平台。
|
||||
|
||||
其他的替代方案:Zoom 在专业领域受到欢迎,但大部分的特性需要付费。[Signal][18],一个开源、安全的用于发消息的应用程序,可以用来打电话,不过仅限于移动设备。不推荐 Skype,既耗流量,界面还糟。
|
||||
其它的替代方案:Zoom 在专业领域渐受青睐,但大部分的特性需要付费。[Signal][18],一个开源、安全的消息通讯类应用程序,可以用来打电话,不过仅限于移动设备。不推荐 Skype,既耗流量,界面还糟。
|
||||
|
||||
#### Google Maps(地图)
|
||||
|
||||
桌面端:[HERE WeGo][19] — 加载速度更快,所有你能在 Google Maps 找到的你几乎都能找到。不过由于某些原因,还缺了一些国家,如日本。
|
||||
桌面端:[HERE WeGo][19] —— 加载速度更快,所有能在 Google Maps 找到的几乎都能找到。不过由于某些原因,还缺了一些国家,如日本。
|
||||
|
||||
移动端:[MAPS.ME][20] — 我一开始用的就是这款地图,但是这款 APP 的导航模式有点鸡肋。MAPS.ME 还是相当不错的,并且具有比 Google 更好的离线功能,这对像我这样的经常旅行的人来说非常好用。
|
||||
移动端:[MAPS.ME][20] —— 我一开始用的就是这款地图,但是自从他们专注于导航模式后地图功能就有点鸡肋了。MAPS.ME 还是相当不错的,并且具有比 Google 更好的离线功能,这对像我这样的经常旅行的人来说非常好用。
|
||||
|
||||
其他的替代方案:[OpenStreetMap][21] 是我全面支持的一个项目,不过功能严重缺乏。甚至无法找到我在奥克兰的家庭住址。
|
||||
其它的替代方案:[OpenStreetMap][21] 是我全心支持的一个项目,不过功能严重缺乏。甚至无法找到我在奥克兰的家庭住址。
|
||||
|
||||
### 初级(需付费)
|
||||
|
||||
@ -67,152 +67,150 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
请记住,虽说 Google 的许多服务都是免费的(更不必说包括 Facebook 在内的竞争对手的服务),那是因为他们正在积极地将我们的数据货币化。由于替代方案极力避免将数据货币化,这使他们不得不向我们收取费用。我愿意付钱来保护我的隐私,但也明白并非所有人都会做出这样的选择。
|
||||
|
||||
或许我们可以换一个方向来思考:可还曾记得以前寄信时也不得不支付邮票的费用吗?或者从商店购买周卡会员?从本质上讲,这就是使用以隐私为重的电子邮件或日历应用程序的成本。也没那么糟。
|
||||
或许我们可以换一个方向来思考:可还曾记得以前寄信时也不得不支付邮票的费用吗?或者从商店购买周卡会员?从本质上讲,这就是使用注重隐私的电子邮件或日历应用程序的成本。也没那么糟。
|
||||
|
||||
#### Gmail
|
||||
|
||||
[ProtonMail][22] — 由前 CERN(欧洲核子研究中心)的科学家创立,总部设在瑞士,一个拥有强大隐私保护的国家。 但 ProtonMail 真正吸引我的地方是,它与大多数其他注重隐私的电子邮件程序不同,用户体验友好。界面类似于 Gmail,带标签,有过滤器和文件夹,无需了解任何有关安全性或隐私的信息即可使用。
|
||||
[ProtonMail][22] —— 由前 CERN(欧洲核子研究中心)的科学家创立,总部设在瑞士,一个拥有强大隐私保护的国家。但 ProtonMail 真正吸引我的地方是,它与大多数其它注重隐私的电子邮件程序不同,用户体验友好。界面类似于 Gmail,带标签,有过滤器和文件夹,无需了解任何有关安全性或隐私的信息即可使用。
|
||||
|
||||
免费版只提供 500MB 的存储空间。而我选择的是付费 5GB 帐户及其 VPN 服务。
|
||||
|
||||
其他的替代方案:[Fastmail][23] 不仅面向注重隐私的用户,界面也很棒。还有 [Hushmail][24] 和 [Tutanota][25],两者都具有与 ProtonMail 相似的功能。
|
||||
其它的替代方案:[Fastmail][23] 不仅面向注重隐私的用户,界面也很棒。还有 [Hushmail][24] 和 [Tutanota][25],两者都具有与 ProtonMail 相似的功能。
|
||||
|
||||
#### Calendar(日历)
|
||||
|
||||
[Fastmail][26] 日历 — 这个决定异常艰难,也抛出了另一个问题。Google 的产品的存在在很多方面,可以用无处不在来形容,这导致初创公司甚至不再费心去创造替代品。在尝试了其他一些平庸的选项后,我最后还是推荐并选择 Fastmail 同时作为备用电子邮件和日历的选项。
|
||||
[Fastmail][26] 日历 —— 这个决定异常艰难,也抛出了另一个问题。Google 的产品存在于很多方面,可以用无处不在来形容,这导致初创公司甚至不再费心去创造替代品。在尝试了其它一些平庸的选项后,我最后还是推荐并选择 Fastmail 同时作为备用电子邮件和日历的选项。
|
||||
|
||||
### 进阶
|
||||
|
||||
这些需要一些技术知识,或者需要你自身具备 Web 主机。我尝试研究过更简单的替代方案,但最终都没能入围。
|
||||
这些需要一些技术知识,或者需要你自己有 Web 主机。我尝试研究过更简单的替代方案,但最终都没能入围。
|
||||
|
||||
#### Google Docs(文档)、Drive(云端硬盘)、Photos(照片)和 Contacts(联系人)
|
||||
|
||||
[Nextcloud][27] — 一个功能齐全、安全并且开源的云套件,具有直观、用户友好的界面。问题是你需要自己有主机才能使用 Nextcloud。我拥有一个用于部署自己网站的主机,并且能够使用 Softaculous 在我的主机的 C-Panel 上快速安装 Nextcloud。你需要一个 HTTPS 证书,我从 [Let's Encrypt][28] 上免费获得了一个。不似开通 Google Drive 帐户那般容易,但也不是很难。
|
||||
[Nextcloud][27] —— 一个功能齐全、安全并且开源的云套件,具有直观、友好的用户界面。问题是你需要自己有主机才能使用 Nextcloud。我有一个用于部署自己网站的主机,并且能够使用 Softaculous 在我主机的 C-Panel 上快速安装 Nextcloud。你需要一个 HTTPS 证书,我从 [Let's Encrypt][28] 上免费获得了一个。不似开通 Google Drive 帐户那般容易,但也不是很难。
|
||||
|
||||
我也同时在用 Nextcloud 作为 Google 的照片存储和联系人的替代方案,然后通过 CalDev 与手机同步。
|
||||
同时我也在用 Nextcloud 作为 Google 的照片存储和联系人的替代方案,然后通过 CalDev 与手机同步。
|
||||
|
||||
其他的替代方案:还有其他开源选项,如 [ownCloud][29] 或者 [Openstack][30]。一些营利的选项也很不错,因为作为首选的 Dropbox 和 Box 也没有采用从你的数据中牟利的运营模式。
|
||||
其它的替代方案:还有其它开源选项,如 [ownCloud][29] 或者 [Openstack][30]。一些营利的选项也很不错,因为作为首选的 Dropbox 和 Box 也没有采用从你的数据中牟利的运营模式。
|
||||
|
||||
#### Google Analytics(分析)
|
||||
|
||||
[Matomo][31] — 正式名为 Piwic,这是一个自托管的分析平台。虽然不像 Google 分析那样功能丰富,但可以很好地理解基本的网站流量,还有一个额外的好处,就是你无需为 Google 贡献流量数据了。
|
||||
[Matomo][31] —— 正式名为 Piwic,这是一个自托管的分析平台。虽然不像 Google 分析那样功能丰富,但可以很好地分析基本的网站流量,还有一个额外的好处,就是你无需为 Google 贡献流量数据了。
|
||||
|
||||
其他的替代方案:真的不多。[OpenWebAnalytics][32] 是另一个开源选项,还有一些营利性的选择,比如 GoStats 和 Clicky。
|
||||
其它的替代方案:真的不多。[OpenWebAnalytics][32] 是另一个开源选择,还有一些营利性的选择,比如 GoStats 和 Clicky。
|
||||
|
||||
#### Android(安卓)
|
||||
|
||||
[LineageOS][33] + [F-Droid App Store][34]。可悲的是,智能手机世界已成为一个字面上的双头垄断,Google 的 Android 和 Apple 的 iOS 控制着整个市场。几年前存在的几个可用的替代品,如 Blackberry OS 或 Mozilla 的 Firefox OS,也已不再维护。
|
||||
[LineageOS][33] + [F-Droid App Store][34]。可悲的是,智能手机世界已成为一个事实上的双头垄断,Google 的 Android 和 Apple 的 iOS 控制着整个市场。几年前存在的几个可用的替代品,如 Blackberry OS 或 Mozilla 的 Firefox OS,也已不再维护。
|
||||
|
||||
因此,只能选择次一级的 Lineage OS:一款注重隐私的、开源的 Android 版本,独立于 Google 服务及 APP,可单独安装。需要一些技术知识,因为安装的整个过程并不是那么一帆风顺,但运行状况良好,且不似大多数 Android 那般有大量预置软件。
|
||||
因此,只能选择次一级的 Lineage OS:一款注重隐私的、开源的 Android 版本,Google 服务及 APP 是选装的。这需要懂一些技术知识,因为安装的整个过程并不是那么一帆风顺,但运行状况良好,且不似大多数 Android 那般有大量预置软件。
|
||||
|
||||
其他的替代方案:emmm... Windows 10 Mobile? [PureOS][35] 看起来有那么点意思,[UbuntuTouch][36] 也差不多。
|
||||
其它的替代方案:呃…… Windows 10 Mobile?[PureOS][35] 看起来有那么点意思,[UbuntuTouch][36] 也差不多。
|
||||
|
||||
### 意想不到的挑战
|
||||
|
||||
首先,由于有关可用替代方案的优质资源匮乏,以及将数据从 Google 迁移到其他平台所面临的挑战,所以比我计划的时间要长许多。
|
||||
首先,由于有关可用替代方案的优质资源匮乏,以及将数据从 Google 迁移到其它平台所面临的挑战,所以比我计划的时间要长许多。
|
||||
|
||||
但最棘手的是电子邮件,这与 ProtonMail 或 Google 无关。
|
||||
|
||||
在我 2004 年加入 Gmail 之前,我可能每年都会切换一次电子邮件。我的第一个帐户是使用 Hotmail,然后我使用了 Mail.com,Yahoo Mail 以及像 Bigfoot 这样长期被遗忘的服务。当我在变更电子邮件提供商时,我未曾记得有这般麻烦。我会告诉所有朋友,更新他们的地址簿,并更改其他网络帐户的邮箱地址。以前定期更改邮箱地址非常必要——还记得曾几何时垃圾邮件是如何盘踞你旧收件箱的吗?
|
||||
在我 2004 年加入 Gmail 之前,我可能每年都会切换一次电子邮件。我的第一个帐户是使用 Hotmail,然后我使用了 Mail.com,Yahoo Mail 以及像 Bigfoot 这样被遗忘已久的服务。当我在变更电子邮件提供商时,我未曾记得有这般麻烦。我会告诉所有朋友,更新他们的地址簿,并更改其它网络帐户的邮箱地址。以前定期更改邮箱地址非常必要 —— 还记得曾几何时垃圾邮件是如何盘踞你旧收件箱的吗?
|
||||
|
||||
事实上,Gmail 最好的创新之一就是能够将垃圾邮件过滤掉。这意味着不需频繁更改邮箱地址。
|
||||
事实上,Gmail 最好的创新之一就是能够将垃圾邮件过滤掉。这意味着再也不用频繁更改邮箱地址了。
|
||||
|
||||
电子邮件是使用互联网的关键。你需要用它来开设 Facebook 帐户,使用网上银行,在留言板上发布等等。因此,当你决定切换帐户时,你就需要更新所有这些不同服务的邮箱地址。
|
||||
|
||||
令人惊讶的是,现在从 Gmail 迁出居然成为了最大的麻烦,因为遍地都需要通过邮箱地址来设置帐户。有几个站点不再允许你从后端执行此操作。有一些服务事实上就是让我注销现在的帐户,然后开通一个新的,只因他们无法更改我的邮箱地址,然后他们手动转移了我的帐户数据。另一些迫使我打电话给客户服务要求更改邮箱地址,无谓的浪费了很多时间。
|
||||
令人惊讶的是,现在从 Gmail 迁出居然成为了最大的麻烦,因为遍地都需要通过邮箱地址来设置帐户。有几个站点不再允许你从后台执行此操作。有个服务事实上就是让我注销现在的帐户,然后开通一个新的,只因他们无法更改我的邮箱地址,然后他们手动转移了我的帐户数据。另一些迫使我打电话给客服要求更改邮箱地址,无谓的浪费了很多时间。
|
||||
|
||||
更令人惊讶的是,另一些服务接受了我的更改,却仍继续向我原来的 Gmail 帐户发送邮件,就需要打一次电话了。另一些甚至更烦人,向我的新电子邮件发送了一些消息,但仍在使用我的旧帐户发送其他电子邮件。这事最后变得异常繁琐,迫使我不得不将我的 Gmail 帐户和我的新 ProtonMail 帐户一起开了几个月,以确保重要的电子邮件不会丢失。这是我花了六个月时间的主要元凶。
|
||||
更令人惊讶的是,另一些服务接受了我的更改,却仍继续向我原来的 Gmail 帐户发送邮件,就需要打一次电话了。另一些甚至更烦人,向我的新电子邮件发送了一些消息,但仍在使用我的旧帐户发送其它电子邮件。这事最后变得异常繁琐,迫使我不得不将我的 Gmail 帐户和我新的 ProtonMail 帐户同时开了几个月,以确保重要的电子邮件不会丢失。这是我花了六个月时间的主要元凶。
|
||||
|
||||
如今人们很少变更他们的邮箱地址,大多数公司的平台在设计时就没有考虑去处理这种可能性。这是表明当今网络糟糕状态的一个明显迹象,即便是在 2002 年更改邮箱地址都比 2018 年来的容易。技术也并不总是一成不变的向前发展。
|
||||
|
||||
### 那么,这些 Google 的替代方案都好用吗?
|
||||
|
||||
有些确实更好!Jitsi Meet 运行更顺畅,需要的带宽更少,并且比 Hangouts 更加平台友好。Firefox 比 Chrome 更稳定,占用的内存更少。Fastmail 的日历具有更好的时区集成。
|
||||
有些确实更好!Jitsi Meet 运行更顺畅,需要的带宽更少,并且比 Hangouts 跨平台支持好。Firefox 比 Chrome 更稳定,占用的内存更少。Fastmail 的日历具有更好的时区集成。
|
||||
|
||||
还有些旗鼓相当。ProtonMail 具有 Gmail 的大部分功能,但缺少一些好用的集成,例如我之前使用的 Boomerang 邮件调度程序。还缺少联系人界面,但我正在使用 Nextcloud。说到 Nextcloud,它非常适合托管文件,联系人,还包含了一个漂亮的笔记工具(以及诸多其他插件)。但它没有 Google Docs 丰富的多重编辑功能。在我的预算中,还没有找到可行的替代方案。虽然还有 Collabora Office,但这需要升级我的服务器,这对我来说不能算切实可行。
|
||||
还有些旗鼓相当。ProtonMail 具有 Gmail 的大部分功能,但缺少一些好用的集成,例如我之前使用的 Boomerang 邮件日程功能。还缺少联系人界面,但我正在使用 Nextcloud。说到 Nextcloud,它非常适合托管文件,联系人,还包含了一个漂亮的笔记工具(以及诸多其它插件)。但它没有 Google Docs 丰富的多人编辑功能。在我的预算中,还没有找到可行的替代方案。虽然还有 Collabora Office,但这需要升级我的服务器,这对我来说不能算切实可行。
|
||||
|
||||
一些取决于位置。在一些国家(如印度尼西亚),MAPS.ME 实际上比 Google 地图更好用,而在另一些国家(包括美国)就差了许多。
|
||||
|
||||
还有些人要求使用者牺牲一些特性或功能。Piwic 是一个穷人的 Google Analytics,缺乏前者的许多详细报告和搜索功能。DuckDuckGo 适用于一般搜索,但是在特定的搜索方面还存在问题,当我搜索非英文内容时,它和 startpage 时常都会检索失败。
|
||||
还有些要求用户牺牲一些特性或功能。Piwic 是一个穷人的 Google Analytics,缺乏前者的许多详细报告和搜索功能。DuckDuckGo 适用于一般搜索,但是在特定的搜索方面还存在问题,当我搜索非英文内容时,它和 startpage 时常都会检索失败。
|
||||
|
||||
### 最后,我不在心念 Google
|
||||
### 最后,我不再心念 Google
|
||||
|
||||
事实上,我感到自由。如此这般依赖单一公司的那么多产品是一种形式上奴役,特别是当你的数据经常为你买单的时候。而且,其中许多替代方案实际上更好。清楚自己正掌控自己数据的感觉真得很爽。
|
||||
事实上,我觉得我解放了。如此这般依赖单一公司的那么多产品是一种形式上奴役,特别是当你的数据经常为你买单的时候。而且,其中许多替代方案实际上更好。清楚自己正掌控自己数据的感觉真得很爽。
|
||||
|
||||
如果我们别无选择,只能使用 Google 的产品,那我们便失去了作为消费者的最后一丝力量。
|
||||
|
||||
我希望 Google,Facebook,Apple 和其他科技巨头在对待用户时不要这么理所当然,不要试图强迫我们进入其无所不包的生态系统。我也期待新选手能够出现并与之竞争,就像以前一样,Google 的新搜索工具可以与当时的行业巨头 Altavista 和 Yahoo 竞争,或者说 Facebook 的社交网络能够与 MySpace 和 Friendster 竞争。Google 给出了更好的搜索方案,使互联网变得更加美好。选择是个好东西。和便携性一样。
|
||||
我希望 Google,Facebook,Apple 和其他科技巨头在对待用户时不要这么理所当然,不要试图强迫我们进入其无所不包的生态系统。我也期待新选手能够出现并与之竞争,就像以前一样,Google 的新搜索工具可以与当时的行业巨头 Altavista 和 Yahoo 竞争,或者说 Facebook 的社交网络能够与 MySpace 和 Friendster 竞争。Google 给出了更好的搜索方案,使互联网变得更加美好。有选择是个好事,可移植也是。
|
||||
|
||||
如今,我们很少有人哪怕只是尝试其他产品,因为我们已经习惯了 Google。我们不再更改邮箱地址,因为这太难了。我们甚至不尝试使用 Facebook 以外的替代品,因为我们所有的朋友都在 Facebook 上。这些我明白。
|
||||
如今,我们很少有人哪怕只是尝试其它产品,因为我们已经习惯了 Google。我们不再更改邮箱地址,因为这太难了。我们甚至不尝试使用 Facebook 以外的替代品,因为我们所有的朋友都在 Facebook 上。这些我明白。
|
||||
|
||||
你不必完全脱离 Google。但最好给其他选择一个机会。到时候时你可能会感到惊讶,并想起那些年上网的初衷。
|
||||
你不必完全脱离 Google。但最好给其它选择一个机会。到时候时你可能会感到惊讶,并想起那些年上网的初衷。
|
||||
|
||||
* * *
|
||||
---
|
||||
|
||||
#### 其他资源
|
||||
### 其它资源
|
||||
|
||||
我并未打算让这篇文章成为包罗万象的指南,这只不过是一个关于我如何脱离 Google 的故事。以下的那些资源会向你展示其他替代方案。其中有一些对我来说过于专业,还有一些我还没有时间去探索。
|
||||
我并未打算让这篇文章成为包罗万象的指南,这只不过是一个关于我如何脱离 Google 的故事。以下的那些资源会向你展示其它替代方案。其中有一些对我来说过于专业,还有一些我还没有时间去探索。
|
||||
|
||||
* [Localization Lab][2] 一份开源或隐私技术的项目的详细清单 — 有些技术含量高,有些比较用户友好。
|
||||
* [Localization Lab][2] 一份开源或注重隐私技术的项目的详细清单 —— 有些技术含量高,有些用户友好度比较好。
|
||||
* [Framasoft][3] 有一整套针对 Google 的替代方案,大部分是开源的,虽然大部分是法语。
|
||||
* Restore Privacy 也[整理了一份替代方案的清单][4]。
|
||||
|
||||
* [Framasoft][3] 有一整套针对 Google 的替代方案,大部分是开源的,虽然大部分是法语。
|
||||
到你了。你可以直接回复或者通过 Twitter 来分享你喜欢的 Google 产品的替代方案。我确信我遗漏了许多,也非常乐意尝试。我并不打算一直固守我列出的这些方案。
|
||||
|
||||
* Restore Privacy 也 [整理了一份替代方案的清单][4].
|
||||
|
||||
到你了。你可以直接回复或者通过 Twitter 来分享你喜欢的 Google 制品的替代方案。我确信我遗漏了许多,也非常乐意尝试。我并不打算一直固守我列出的这些方案。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
---
|
||||
|
||||
作者简介:
|
||||
|
||||
Nithin Coca
|
||||
|
||||
自由撰稿人,涵盖政治,环境和人权以及全球科技的社会影响。 更多参考 http://www.nithincoca.com
|
||||
自由撰稿人,涵盖政治,环境和人权以及全球科技的社会影响。更多参考 http://www.nithincoca.com
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
---
|
||||
|
||||
via: https://medium.com/s/story/how-i-fully-quit-google-and-you-can-too-4c2f3f85793a
|
||||
|
||||
作者:[Nithin Coca][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@excinit
|
||||
[1]:https://medium.com/@excinit
|
||||
[2]:https://www.localizationlab.org/projects/
|
||||
[3]:https://framasoft.org/?l=en
|
||||
[4]:https://restoreprivacy.com/google-alternatives/
|
||||
[5]:https://medium.com/@excinit
|
||||
[6]:https://www.nithincoca.com/2011/11/20/7-months-no-facebook/
|
||||
[7]:https://www.quora.com/How-long-was-Gmail-in-private-%28invitation-only%29-beta
|
||||
[8]:https://www.theverge.com/2018/4/28/17293056/facebook-deletefacebook-social-network-monopoly
|
||||
[9]:https://en.wikipedia.org/wiki/Google_Play_Services
|
||||
[10]:https://www.theguardian.com/world/2013/jun/06/us-tech-giants-nsa-data
|
||||
[11]:https://takeout.google.com/settings/takeout
|
||||
[12]:https://duckduckgo.com/
|
||||
[13]:https://www.startpage.com/
|
||||
[14]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[15]:https://www.seattletimes.com/business/firefox-is-back-and-its-time-to-give-it-a-try/
|
||||
[16]:https://brave.com/
|
||||
[17]:https://jitsi.org/jitsi-meet/
|
||||
[18]:https://signal.org/
|
||||
[19]:https://wego.here.com/
|
||||
[20]:https://maps.me/
|
||||
[21]:https://www.openstreetmap.org/
|
||||
[22]:https://protonmail.com/
|
||||
[23]:https://www.fastmail.com/
|
||||
[24]:https://www.hushmail.com/
|
||||
[25]:https://tutanota.com/
|
||||
[26]:https://www.fastmail.com/
|
||||
[27]:https://nextcloud.com/
|
||||
[28]:https://letsencrypt.org/
|
||||
[29]:https://owncloud.org/
|
||||
[30]:https://www.openstack.org/
|
||||
[31]:https://matomo.org/
|
||||
[32]:http://www.openwebanalytics.com/
|
||||
[33]:https://lineageos.org/
|
||||
[34]:https://f-droid.org/en/
|
||||
[35]:https://puri.sm/posts/tag/pureos/
|
||||
[36]:https://ubports.com/
|
||||
[a]: https://medium.com/@excinit
|
||||
[1]: https://medium.com/@excinit
|
||||
[2]: https://www.localizationlab.org/projects/
|
||||
[3]: https://framasoft.org/?l=en
|
||||
[4]: https://restoreprivacy.com/google-alternatives/
|
||||
[5]: https://medium.com/@excinit
|
||||
[6]: https://www.nithincoca.com/2011/11/20/7-months-no-facebook/
|
||||
[7]: https://www.quora.com/How-long-was-Gmail-in-private-%28invitation-only%29-beta
|
||||
[8]: https://www.theverge.com/2018/4/28/17293056/facebook-deletefacebook-social-network-monopoly
|
||||
[9]: https://en.wikipedia.org/wiki/Google_Play_Services
|
||||
[10]: https://www.theguardian.com/world/2013/jun/06/us-tech-giants-nsa-data
|
||||
[11]: https://takeout.google.com/settings/takeout
|
||||
[12]: https://duckduckgo.com/
|
||||
[13]: https://www.startpage.com/
|
||||
[14]: https://www.mozilla.org/en-US/firefox/new/
|
||||
[15]: https://www.seattletimes.com/business/firefox-is-back-and-its-time-to-give-it-a-try/
|
||||
[16]: https://brave.com/
|
||||
[17]: https://jitsi.org/jitsi-meet/
|
||||
[18]: https://signal.org/
|
||||
[19]: https://wego.here.com/
|
||||
[20]: https://maps.me/
|
||||
[21]: https://www.openstreetmap.org/
|
||||
[22]: https://protonmail.com/
|
||||
[23]: https://www.fastmail.com/
|
||||
[24]: https://www.hushmail.com/
|
||||
[25]: https://tutanota.com/
|
||||
[26]: https://www.fastmail.com/
|
||||
[27]: https://nextcloud.com/
|
||||
[28]: https://letsencrypt.org/
|
||||
[29]: https://owncloud.org/
|
||||
[30]: https://www.openstack.org/
|
||||
[31]: https://matomo.org/
|
||||
[32]: http://www.openwebanalytics.com/
|
||||
[33]: https://lineageos.org/
|
||||
[34]: https://f-droid.org/en/
|
||||
[35]: https://puri.sm/posts/tag/pureos/
|
||||
[36]: https://ubports.com/
|
||||
|
||||
@ -0,0 +1,146 @@
|
||||
|
||||
我从编程面试中学到的
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
聊聊白板编程面试
|
||||
|
||||
在2017年,我参加了[Grace Hopper Celebration][1]‘计算机行业中的女性’这一活动。这个活动是这类科技活动中最大的一个。共有17,000名女性IT工作者参加。
|
||||
|
||||
这个会议有个大型的配套招聘会,会上有招聘公司来面试会议参加者。有些人甚至现场拿到offer。我在现场晃荡了一下,注意到一些应聘者看上去非常紧张忧虑。我还隐隐听到应聘者之间的谈话,其中一些人谈到在面试中做的并不好。
|
||||
|
||||
我走近我听到谈话的那群人并和她们聊了起来并给了一些面试上的小建议。我想我的建议还是比较偏基本的,如“(在面试时)一开始给出个能工作的解决方案也还说的过去”之类的,但是当她们听到我的一些其他的建议时还是颇为吃惊。
|
||||
|
||||
为了能更多的帮到像她们一样的白面面试者,我收集了一些过去对我有用的小点子,这些小点子我已经发表在了[prodcast episode][2]上。它们也是这篇文章的主题。
|
||||
|
||||
为了实习生职位和全职工作,我做过很多次的面试。当我还在大学主修计算机科学时,学校每个秋季学期都有招聘会,第一轮招聘会在校园里举行。(我在第一和最后一轮都搞砸过。)不过,每次面试后,我都会反思哪些方面我能做的更好,我还会和朋友们做模拟面试,这样我就能从他们那儿得到更多的面试反馈。
|
||||
|
||||
不管我们怎么样找工作: 工作中介,网络,或者学校招聘,他们的招聘流程中都会涉及到技术面试:
|
||||
|
||||
近年来,我注意到了一些新的不同的面试形式出现了:
|
||||
|
||||
* 与招聘方的一位工程师结对编程
|
||||
* 网络在线测试及在线编码
|
||||
* 白板编程(LCTT译者注: 这种形式应该不新了)
|
||||
|
||||
|
||||
我将重点谈谈白板面试,这种形式我经历的最多。我有过很多次面试,有些挺不错的,有些被我搞砸了。
|
||||
|
||||
#### 我做错的地方
|
||||
|
||||
首先,我想回顾一下我做的不好的地方。知错能改,善莫大焉。
|
||||
|
||||
当面试者提出一个要我解决的问题时, 我立即马上立刻开始在白板上写代码,_什么都不问。_
|
||||
|
||||
这里我犯了两个错误:
|
||||
|
||||
#### 没有澄清对解决问题有关键作用的信息
|
||||
|
||||
比如,我们是否只用处理数字或者字符串?我们要支持多种数据类型吗?如果你在开始解题前不去问这些问题的话,你的面试官会有一种不好的印象:这个人在我们公司的话,他不会在开始项目工作之前不问清楚到底要做什么。而这恰恰是在工作场合很重要的一个工作习惯。公司可不像学校,你在开始工作前可不会得到写有所有详细步骤的作业说明。你得靠自己找到这些步骤并自己定义他们。
|
||||
|
||||
#### 只会默默思考,不去记录想法或和面试官沟通
|
||||
|
||||
在面试中,很多时候我也会傻傻站在那思考,什么都不写。我和一个朋友模拟面试的时候,他告诉我因为他曾经和我一起工作过所以他知道我在思考,但是如果他是个陌生的面试官的话,他会觉得要么我正站在那冥思苦想,毫无头绪。不要急匆匆的直奔解题而去是很重要的。花点时间多想想各种解题的可能性。有时候面试官会乐意和你一起探索解题的步骤。不管怎样,这就是在一家公司开工作会议的的普遍方式,大家各抒己见,一起讨论如何解决问题。
|
||||
|
||||
### 想到一个解题方法
|
||||
|
||||
在你开始写代码之前,如果你能总结一下要使用到的算法就太棒了。不要上来就写代码并认为你的代码肯定能解决问题。
|
||||
|
||||
这是对我管用的步骤:
|
||||
|
||||
1. 头脑风暴
|
||||
|
||||
2. 写代码
|
||||
|
||||
3. 处理错误路径
|
||||
|
||||
4. 测试
|
||||
|
||||
#### 1\. 头脑风暴
|
||||
|
||||
对我来说,我会首先通过一些例子来视觉化我要解决的问题。比如说如果这个问题和数据结构中的树有关,我就会从树底层的空节点开始思考,如何处理一个节点的情况呢?两个节点呢?三个节点呢?这能帮助你从具体例子里抽象出你的解决方案。
|
||||
|
||||
在白板上先写下你的算法要做的事情列表。这样做,你往往能在开始写代码前就发现bug和缺陷(不过你可得掌握好时间)。我犯过的一个错误是我花了过多的时间在澄清问题和头脑风暴上,最后几乎没有留下时间给我写代码。你的面试官可能没有机会看你在白板上写下代码,这可太糟了。你可以带块手表,或者房间有钟的话,你也可以抬头看看时间。有些时候面试者会提醒你你已经得到了所有的信息(这时你就不要再问别的了),'我想我们已经把所有需要的信息都澄清了,让我们写代码实现吧'
|
||||
|
||||
#### 2\. 开始写代码,一气呵成
|
||||
|
||||
如果你还没有得到问题的完美解决方法,从最原始的解法开始总的可以的。当你在向面试官解释最显而易见的解法时,你要想想怎么去完善它,并指明这种做法是最原始,未加优化的。(请熟悉算法中的O()的概念,这对面试非常有用。)在向面试者提交前请仔细检查你的解决方案两三遍。面试者有时会给你些提示, ‘还有更好的方法吗?’,这句话的意思是面试官提示你有更优化的解决方案。
|
||||
|
||||
#### 3\. 错误处理
|
||||
|
||||
当你在编码时,对你想做错误处理的代码行做个注释。当面试者说,'很好,这里你想到了错误处理。你想怎么处理呢?抛出异常还是返回错误码?',这将给你个机会去引出关于代码质量的一番讨论。当然,这种地方提出几个就够了。有时,面试者为了节省编码的时间,会告诉你可以假设外界输入的参数都已经通过了校验。不管怎样,你都要展现你对错误处理和编码质量的重要性的认识。
|
||||
|
||||
#### 4\. 测试
|
||||
|
||||
在编码完成后,用你在前面头脑风暴中写的用例来在你脑子里“跑”一下你的代码,确定万无一失。例如你可以说,‘让我用前面写下的树的例子来跑一下我的代码,如果是一个节点是什么结果,如果是两个节点是什么结果。。。’
|
||||
|
||||
在你结束之后,面试者有时会问你你将会怎么测试你的代码,你会涉及什么样的测试用例。我建议你用下面不同的分类来组织你的错误用例:
|
||||
|
||||
一些分类可以为:
|
||||
|
||||
1. 性能
|
||||
2. 错误用例
|
||||
3. 期望的正常用例
|
||||
|
||||
对于性能测试,要考虑极端数量下的情况。例如,如果问题是关于列表的,你可以说你将会使用一个非常大的列表以及的非常小的列表来测试。如果和数字有关,你将会测试系统中的最大整数和最小整数。我建议读一些有关软件测试的书来得到更多的知识。在这个领域我最喜欢的书是[How We Test Software at Microsoft][3]。
|
||||
|
||||
对于错误用例,想一下什么是期望的错误情况并一一写下。
|
||||
|
||||
对于正向期望用例,想想用户需求是什么?你的解决方案要解决什么问题?这些都可以成为正向期望用例。
|
||||
|
||||
### “你还有什么要问我的吗?”
|
||||
|
||||
面试最后总是会留几分钟给你问问题。我建议你在面试前写下你想问的问题。千万别说,‘我没什么问题了’,就算你觉得面试砸了或者你对这间公司不怎么感兴趣,你总有些东西可以问问。你甚至可以问面试者他最喜欢自己的工作什么,最讨厌自己的工作什么。或者你可以问问面试官的工作具体是什么,在用什么技术和实践。不要因为觉得自己在面试中做的不好而心灰意冷,不想问什么问题。
|
||||
|
||||
### 申请一份工作
|
||||
|
||||
|
||||
关于找工作申请工作,有人曾经告诉我,你应该去找你真正有激情工作的地方。去找一家你喜欢的公司,或者你喜欢使用的产品,看看你能不能去那儿工作。
|
||||
|
||||
我个人并不推荐你用上述的方法去找工作。你会排除很多很好的公司,特别是你是在找实习工作或者入门级的职位时。
|
||||
|
||||
你也可以集中在其他的一些目标上。如:我想从这个工作里得到哪方面的更多经验?这个工作是关于云计算?Web开发?或是人工智能?当在招聘会上与招聘公司沟通是,看看他们的工作单位有没有在这些领域的。你可能会在一家并非在你的想去公司列表上的公司(或非盈利机构)里找到你想找的职位。
|
||||
|
||||
#### 换组
|
||||
|
||||
在这家公司里的第一个组里呆了一年半以后,我觉得是时候去探索一下不同的东西了。我找到了一个我喜欢的组并进行了4轮面试。结果我搞砸了。
|
||||
|
||||
|
||||
我什么都没有准备,甚至都没在白板上练练手。我当时的逻辑是,如果我都已经在一家公司干了快2年了,我还需要练什么?我完全错了,我在接下去的白板面试中跌跌撞撞。我的板书写得太小,而且因为没有从最左上角开始写代码,我的代码大大超出了一个白板的空间,这些都导致了白板面试失败。
|
||||
|
||||
|
||||
我在面试前也没有刷过数据结构和算法题。如果我做了的话,我将会在面试中更有信心。就算你已经在一家公司担任了软件工程师,在你去另外一个组面试前,我强烈建议你在一块白板上演练一下如何写代码。
|
||||
|
||||
|
||||
对于换项目组这件事,如果你是在公司内部换组的话,事先能同那个组的人非正式聊聊会很有帮助。对于这一点,我发现几乎每个人都很乐于和你一起吃个午饭。人一般都会在中午有空,约不到人或者别人正好有会议冲突的风险会很低。这是一种非正式的途径来了解你想去的组正在干什么,以及这个组成员个性是怎么样的。相信我, 你能从一次午餐中得到很多信息,这可会对你的正式面试帮助不小。
|
||||
|
||||
|
||||
非常重要的一点是,你在面试一个特定的组时,就算你在面试中做的很好,因为文化不契合的原因,你也很可能拿不到offer。这也是为什么我一开始就想去见见组里不同的人的原因(有时这也不太可能),我希望你不要被一次拒绝所击倒,请保持开放的心态,选择新的机会,并多多练习。
|
||||
|
||||
|
||||
以上内容来自["Programming interviews"][4] 章节,选自 [The Women in Tech Show: Technical Interviews with Prominent Women in Tech][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
微软研究院Software Engineer II, www.thewomenintechshow.com站长,所有观点都只代表本人意见。
|
||||
|
||||
------------
|
||||
|
||||
via: https://medium.freecodecamp.org/what-i-learned-from-programming-interviews-29ba49c9b851
|
||||
|
||||
作者:[Edaena Salinas ][a]
|
||||
译者:DavidChenLiang (https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@edaenas
|
||||
[1]:https://anitab.org/event/2017-grace-hopper-celebration-women-computing/
|
||||
[2]:https://thewomenintechshow.com/2017/12/18/programming-interviews/
|
||||
[3]:https://www.amazon.com/How-We-Test-Software-Microsoft/dp/0735624259
|
||||
[4]:https://thewomenintechshow.com/2017/12/18/programming-interviews/
|
||||
[5]:https://thewomenintechshow.com/
|
||||
109
translated/tech/20180424 A gentle introduction to FreeDOS.md
Normal file
109
translated/tech/20180424 A gentle introduction to FreeDOS.md
Normal file
@ -0,0 +1,109 @@
|
||||
Free DOS 的简单介绍
|
||||
======
|
||||
|
||||

|
||||
|
||||
FreeDOS 是一个古老的操作系统,但是对于多数人而言它又是陌生的。在 1994 年,我和几个开发者一起 [开发 FreeDOS][1]--一个完整、自由、DOS 兼容的操作系统,你可以用它来玩经典的 DOS 游戏、运行遗留的商业软件或者开发嵌入式系统。任何在 MS-DOS 下工作的程序在 FreeDOS 下也可以运行。
|
||||
|
||||
在 1994 年,任何一个曾经使用过微软专利的 MS-DOS 的人都会迅速地熟悉 FreeDOS。这是设计而为之的;FreeDOS 尽可能地去模仿 MS-DOS。结果,1990 年代的 DOS 用户能够直接转换到 FreeDOS。但是,时代变了。今天,开源的开发者们对于 Linux 命令行更熟悉或者他们可能倾向于像 [GNOME][2] 一样的图形桌面环境,这导致 FreeDOS 命令行界面最初看起来像个异类。
|
||||
|
||||
新的用户通常会问,“我已经安装了 [FreeDOS][3],但是如何使用呢?”。如果你之前并没有使用过 DOS,那么闪烁的 `C:\>` DOS 提示符看起来会有点不太友好,而且可能有点吓人。这份 FreeDOS 的简单介绍将带你起步。它只提供了基础:如何浏览以及如何查看文件。如果你想了解比这里提及的更多的知识,访问 [FreeDOS 维基][4]。
|
||||
|
||||
### DOS 提示符
|
||||
|
||||
首先,让我们看一下空的提示符以及它的含义。
|
||||
|
||||

|
||||
|
||||
DOS 是在个人电脑从软盘运行时期创建的一个“磁盘操作系统”。甚至当电脑支持硬盘了,在 1980 年代和 1990 年代,频繁地在不同的驱动器之间切换也是很普遍的。举例来说,你可能想将最重要的文件都备份一份拷贝到软盘中。
|
||||
|
||||
DOS 使用一个字母来指代每个驱动器。早期的电脑仅拥有两个软盘驱动器,他们被分配了 `A:` 和 `B:` 盘符。硬盘上的第一个分区盘符是 `C:` ,然后其它的盘符依次这样分配下去。提示符中的 `C:` 表示你正在使用第一个硬盘的第一个分区。
|
||||
|
||||
从 1983 年的 PC-DOS 2.0 开始,DOS 也支持目录和子目录,非常类似 Linux 文件系统中的目录和子目录。但是跟 Linux 不一样的是,DOS 目录名由 `\` 分隔而不是 `/`。将这个与驱动器字母合起来看,提示符中的 `C:\` 表示你正在 `C:` 盘的顶端或者“根”目录。
|
||||
|
||||
`>` 修饰符提示你输入 DOS 命令的地方,就像众多 Linux shell 的 `$`。`>` 前面的部分告诉你当前的工作目录,然后你在 `>` 提示符这输入命令。
|
||||
|
||||
### 在 DOS 中找到你的使用方式
|
||||
|
||||
在 DOS 中浏览目录的基本方式和你在 Linux 命令行下的步骤非常相似。你仅需要记住少数的命令。
|
||||
|
||||
#### 显示一个目录
|
||||
|
||||
当你想要查看当前目录的内容时,使用 `DIR` 命令。因为 DOS 命令是大小写不敏感的,你也可以输入 `dir`。默认地,DOS 会显示每个文件和子目录的细节,包括了名字、扩展类型、大小以及最后一次更改的日期和时间。
|
||||
|
||||

|
||||
|
||||
如果你不想显示单个文件大小的额外细节,你可以在 `DIR` 命令中使用 `/w` 选项来显示一个“宽泛”文件夹。注意,Linux 用户使用连字号(`-`)或者双连字号(`--`)来开启命令行选项,而 DOS 使用斜线字符(`/`)。
|
||||
|
||||

|
||||
|
||||
你可以将特定子目录的路径名作为参数传递给 `DIR` 命令来查看它。此外,另一个与 Linux 系统的区别是 Linux 文件和目录是大小写敏感的,而 DOS 下的名称是大小写不敏感的。DOS 通常将文件和目录使用全部大写的方式显示,不过你可以等同地用小写格式来使用它们。
|
||||
|
||||

|
||||
|
||||
|
||||
#### 切换当前工作目录
|
||||
|
||||
一旦你能够查看一个目录的内容,你就能够“移动到”任何其它的目录。在 DOS 上,使用 `CHDIR` 命令来切换工作目录,也可以简写为 `CD`。你可以使用类似 `CD CHOICE` 的命令进入到一个子目录或者使用 `CD \FDOS\DOC\CHOICE` 进入到一个新的路径。
|
||||
|
||||

|
||||
|
||||
就像在 Linux 命令行,DOS 使用 `.` 来表示当前目录,而 `..` 表示父目录(当前目录的上一级)。你可以将这些组合起来使用。比如,`CD ..` 进入到父目录,然后 `CD ..\..` 由当前目录做两个“向上”目录级别的操作。
|
||||
|
||||

|
||||
|
||||
FreeDOS 也从 Linux 那借鉴了一些特性:你可以使用 `CD -` 跳转回之前的工作目录。在你进入一个新的路径做完一件事之后,想要回退到之前工作状态的情况下,这会很方便。
|
||||
|
||||
#### 切换当前工作盘符
|
||||
|
||||
在 Linux 下,“磁盘”的概念是隐藏的。在 Linux 和其它 Unix 系统中,你“挂载”磁盘到一个目录,例如 `/backup`,或者系统自动帮你完成,比如 `/var/run/media/user/flashdrive`。但是 DOS 是一个相对简单的系统。使用 DOS,你必须自行更改工作磁盘。
|
||||
|
||||
记住 DOS 分配第一块硬盘的第一个分区为 `C:` 盘,然后这样依次分配其它盘符。在现代系统中,人们很少将硬盘分割成多个 DOS 分区;他们简单地使用整个磁盘或者尽可能多地分配给 DOS。如今 `C:` 通常是第一块硬盘,而 `D:` 通常是另一块硬盘或者 CD-ROM 驱动器。其它的网络磁盘驱动器也可以被映射到别的盘符,比如 `E:` 或者 `Z:` 或者任何你想要的组织方式。
|
||||
|
||||
在 DOS 下切换磁盘很容易。只要在命令行输入盘符后附加一个冒号(`:`),然后 DOS 就会切换到该工作磁盘。举例来说,在我的 [QEMU][5] 系统上,我将 `D:` 设置到我的 Linux 主目录下的一个共享目录,那里存放了各种我想测试的 DOS 应用程序和游戏的安装文件。
|
||||
|
||||

|
||||
|
||||
小心不要尝试切换到一个不存在的磁盘。DOS 可能会将它设置为工作磁盘,但是如果你尝试在那做任何事,你将会遇到略微臭名昭著的“退出、重试、失败” DOS 错误信息。
|
||||
|
||||

|
||||
|
||||
### 其它可以尝试的事情
|
||||
|
||||
使用 `CD` 和 `DIR` 命令,你就拥有了基础的浏览 DOS 能力。这些命令允许你查找 DOS 目录并查看其他子目录和文件的存在。一旦你熟悉基础浏览操作,你还可以尝试其它的这些基础 DOS 命令:
|
||||
|
||||
* `MKDIR` 或 `MD` 创建新的目录
|
||||
* `RMDIR` 或 `RD` 删除目录
|
||||
* `TREE` 以树状格式显示目录和子目录列表
|
||||
* `TYPE` 和 `MORE` 显示文件内容
|
||||
* `RENAME` 或 `REN` 重命名文件
|
||||
* `DEL` 或 `ERASE` 删除文件
|
||||
* `EDIT` 编辑文件
|
||||
* `CLS` 清除屏幕
|
||||
|
||||
|
||||
如果这些还不够,你可以在 FreeDOS 维基上面找到[所有 DOS 命令][6]的清单。
|
||||
|
||||
在 FreeDOS 下,针对每个命令你都能够使用 `/?` 参数来获取简要的说明。举例来说,`EDIT /?` 会告诉你编辑器的用法和选项。或者你可以输入 `HELP` 来使用交互式帮助系统。
|
||||
|
||||
像任何一个 DOS 一样,FreeDOS 被认为是一个简单的操作系统。仅使用一些基本命令就可以轻松浏览 DOS 文件系统。那么启动一个 QEMU 会话,安装 FreeDOS,然后尝试一下 DOS 命令行界面。也许它现在看起来就没那么吓人了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/gentle-introduction-freedos
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[icecoobe](https://github.com/icecoobe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://opensource.com/article/17/10/freedos
|
||||
[2]:https://opensource.com/article/17/8/gnome-20-anniversary
|
||||
[3]:http://www.freedos.org/
|
||||
[4]:http://wiki.freedos.org/
|
||||
[5]:https://www.qemu.org/
|
||||
[6]:http://wiki.freedos.org/wiki/index.php/Dos_commands
|
||||
@ -1,82 +1,81 @@
|
||||
Go 编译器介绍
|
||||
======
|
||||
|
||||
// Copyright 2018 The Go Authors. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
## Go编译器介绍
|
||||
> Copyright 2018 The Go Authors. All rights reserved.
|
||||
> Use of this source code is governed by a BSD-style
|
||||
> license that can be found in the LICENSE file.
|
||||
|
||||
`cmd/compile` 包含构成 Go 编译器主要的包。编译器在逻辑上可以被分为四个阶段,我们将简要介绍这几个阶段以及包含相应代码的包的列表。
|
||||
|
||||
在谈到编译器时,有时可能会听到“前端”和“后端”这两个术语。粗略地说,这些对应于我们将在此列出的前两个和后两个阶段。第三个术语“中间端”通常指的是第二阶段执行的大部分工作。
|
||||
在谈到编译器时,有时可能会听到<ruby>前端<rt>front-end</rt></ruby>和<ruby>后端<rt>back-end</rt></ruby>这两个术语。粗略地说,这些对应于我们将在此列出的前两个和后两个阶段。第三个术语<ruby>中间端<rt>middle-end</rt></ruby>通常指的是第二阶段执行的大部分工作。
|
||||
|
||||
请注意,`go/parser` 和 `go/types` 等 `go/*` 系列包与编译器无关。由于编译器最初是用C编写的,所以这些 `go/*` 包被开发出来以便于能够写出和 `Go` 代码一起工作的工具,例如 `gofmt` 和 `vet`。
|
||||
请注意,`go/parser` 和 `go/types` 等 `go/*` 系列的包与编译器无关。由于编译器最初是用 C 编写的,所以这些 `go/*` 包被开发出来以便于能够写出和 `Go` 代码一起工作的工具,例如 `gofmt` 和 `vet`。
|
||||
|
||||
需要澄清的是,名称“gc”代表“Go 编译器”,与大写 GC 无关,后者代表垃圾收集。
|
||||
需要澄清的是,名称 “gc” 代表 “Go 编译器”,与大写 GC 无关,后者代表<ruby>垃圾收集<rt>garbage collection</rt></ruby>。
|
||||
|
||||
### 1. 解析
|
||||
|
||||
* `cmd/compile/internal/syntax` (词法分析器、解析器、语法树)
|
||||
* `cmd/compile/internal/syntax`(<ruby>词法分析器<rt>lexer</rt></ruby>、<ruby>解析器<rt>parser</rt></ruby>、<ruby>语法树<rt>syntax tree</rt></ruby>)
|
||||
|
||||
在编译的第一阶段,源代码被标记化(词法分析),解析(语法分析),并为每个源文件构造语法树(译注:这里标记指token,它是一组预定义、能够识别的字符串,通常由名字和值构成,其中名字一般是词法的类别,如标识符、关键字、分隔符、操作符、文字和注释等;语法树,以及下文提到的AST,Abstract Syntax Tree,抽象语法树,是指用树来表达程序设计语言的语法结构,通常叶子节点是操作数,其它节点是操作码)。
|
||||
在编译的第一阶段,源代码被标记化(词法分析),解析(语法分析),并为每个源文件构造语法树(译注:这里标记指 token,它是一组预定义的、能够识别的字符串,通常由名字和值构成,其中名字一般是词法的类别,如标识符、关键字、分隔符、操作符、文字和注释等;语法树,以及下文提到的<ruby>抽象语法树<rt>Abstract Syntax Tree</rt></ruby>(AST),是指用树来表达程序设计语言的语法结构,通常叶子节点是操作数,其它节点是操作码)。
|
||||
|
||||
每棵语法树都是相应源文件的确切表示,其中节点对应于源文件的各种元素,例如表达式,声明和语句。语法树还包括位置信息,用于错误报告和创建调试信息。
|
||||
每个语法树都是相应源文件的确切表示,其中节点对应于源文件的各种元素,例如表达式、声明和语句。语法树还包括位置信息,用于错误报告和创建调试信息。
|
||||
|
||||
### 2. 类型检查和AST变形
|
||||
### 2. 类型检查和 AST 变形
|
||||
|
||||
* `cmd/compile/internal/gc` (创建编译器AST,类型检查,AST变形)
|
||||
* `cmd/compile/internal/gc`(创建编译器 AST,<ruby>类型检查<rt>type-checking</rt></ruby>,<ruby>AST 变形<rt>AST transformation</rt></ruby>)
|
||||
|
||||
gc 包中包含一个继承自(早期)C 语言实现的版本的 AST 定义。所有代码都是基于该 AST 编写的,所以 gc 包必须做的第一件事就是将 syntax 包(定义)的语法树转换为编译器的 AST 表示法。这个额外步骤可能会在将来重构。
|
||||
gc 包中包含一个继承自(早期)C 语言实现的版本的 AST 定义。所有代码都是基于它编写的,所以 gc 包必须做的第一件事就是将 syntax 包(定义)的语法树转换为编译器的 AST 表示法。这个额外步骤可能会在将来重构。
|
||||
|
||||
然后对 AST 进行类型检查。第一步是名字解析和类型推断,它们确定哪个对象属于哪个标识符,以及每个表达式具有的类型。类型检查包括特定的额外检查,例如“声明但未使用”以及确定函数是否会终止。
|
||||
|
||||
特定转换也基于 AST 上完成。一些节点被基于类型信息而细化,例如把字符串加法从算术加法的节点类型中拆分出来。其他一些例子是死代码消除,函数调用内联和逃逸分析(译注:逃逸分析是一种分析指针有效范围的方法)。
|
||||
特定转换也基于 AST 完成。一些节点被基于类型信息而细化,例如把字符串加法从算术加法的节点类型中拆分出来。其它一些例子是<ruby>死代码消除<rt>dead code elimination</rt></ruby>,<ruby>函数调用内联<rt>function call inlining</rt></ruby>和<ruby>逃逸分析<rt>escape analysis</rt></ruby>(译注:逃逸分析是一种分析指针有效范围的方法)。
|
||||
|
||||
### 3. 通用SSA
|
||||
### 3. 通用 SSA
|
||||
|
||||
* `cmd/compile/internal/gc` (转换成 SSA)
|
||||
* `cmd/compile/internal/gc`(转换成 SSA)
|
||||
* `cmd/compile/internal/ssa`(SSA 相关的 pass 和规则)
|
||||
|
||||
* `cmd/compile/internal/ssa` (SSA 相关的 pass 和规则)
|
||||
(译注:许多常见高级语言的编译器无法通过一次扫描源代码或 AST 就完成所有编译工作,取而代之的做法是多次扫描,每次完成一部分工作,并将输出结果作为下次扫描的输入,直到最终产生目标代码。这里每次扫描称作一遍 pass;最后一遍 pass 之前所有的 pass 得到的结果都可称作中间表示法,本文中 AST、SSA 等都属于中间表示法。SSA,静态单赋值形式,是中间表示法的一种性质,它要求每个变量只被赋值一次且在使用前被定义)。
|
||||
|
||||
(译注:许多常见高级语言的编译器无法通过一次扫描源代码或 AST 就完成所有编译工作,取而代之的做法是多次扫描,每次完成一部分工作,并将输出结果作为下次扫描的输入,直到最终产生目标代码。这里每次扫描称作一遍,即 pass;最后一遍之前所有的 pass 得到的结果都可称作中间表示法,本文中 AST、SSA 等都属于中间表示法。SSA,静态单赋值形式,是中间表示法的一种性质,它要求每个变量只被赋值一次且在使用前被定义)。
|
||||
在此阶段,AST 将被转换为<ruby>静态单赋值<rt>Static Single Assignment</rt></ruby>(SSA)形式,这是一种具有特定属性的低级<ruby>中间表示法<rt>intermediate representation</rt></ruby>,可以更轻松地实现优化并最终从它生成机器码。
|
||||
|
||||
在此阶段,AST 将被转换为静态单赋值形式(SSA)形式,这是一种具有特定属性的低级中间表示法,可以更轻松地实现优化并最终从它生成机器代码。
|
||||
在这个转换过程中,将完成<ruby>内置函数<rt>function intrinsics</rt></ruby>的处理。这些是特殊的函数,编译器被告知逐个分析这些函数并决定是否用深度优化的代码替换它们(译注:内置函数指由语言本身定义的函数,通常编译器的处理方式是使用相应实现函数的指令序列代替对函数的调用指令,有点类似内联函数)。
|
||||
|
||||
在这个转换过程中,将完成内置函数的处理。 这些是特殊的函数,编译器被告知逐个分析这些函数并决定是否用深度优化的代码替换它们(译注:内置函数指由语言本身定义的函数,通常编译器的处理方式是使用相应实现函数的指令序列代替对函数的调用指令,有点类似内联函数)。
|
||||
在 AST 转化成 SSA 的过程中,特定节点也被低级化为更简单的组件,以便于剩余的编译阶段可以基于它们工作。例如,内建的拷贝被替换为内存移动,range 循环被改写为 for 循环。由于历史原因,目前这里面有些在转化到 SSA 之前发生,但长期计划则是把它们都移到这里(转化 SSA)。
|
||||
|
||||
在 AST 转化成 SSA 的过程中,特定节点也被低级化为更简单的组件,以便于剩余的编译阶段可以基于它们工作。例如,内建的拷贝被替换为内存移动,range循环被改写为for循环。由于历史原因,目前这里面有些在转化到 SSA 之前发生,但长期计划则是把它们都移到这里(转化 SSA)。
|
||||
然后,一系列机器无关的规则和 pass 会被执行。这些并不考虑特定计算机体系结构,因此对所有 `GOARCH` 变量的值都会运行。
|
||||
|
||||
然后,一系列机器无关的规则和pass会被执行。这些并不考虑特定计算机体系结构,因此对所有 `GOARCH` 变量的值都会运行。
|
||||
|
||||
这类通用的 pass 的一些例子包括,死代码消除,移除不必要的空指针检查,以及移除无用的分支等。通用改写规则主要考虑表达式,例如将一些表达式替换为常量,优化乘法和浮点操作。
|
||||
这类通用 pass 的一些例子包括,死代码消除,移除不必要的空值检查,以及移除无用的分支等。通用改写规则主要考虑表达式,例如将一些表达式替换为常量,优化乘法和浮点操作。
|
||||
|
||||
### 4. 生成机器码
|
||||
|
||||
* `cmd/compile/internal/ssa` (SSA 低级化和体系结构特定的pass)
|
||||
* `cmd/compile/internal/ssa`(SSA 低级化和架构特定的 pass)
|
||||
* `cmd/internal/obj`(机器码生成)
|
||||
|
||||
* `cmd/internal/obj` (机器代码生成)
|
||||
编译器中机器相关的阶段开始于“低级”的 pass,该阶段将通用变量改写为它们的特定的机器码形式。例如,在 amd64 架构中操作数可以在内存中操作,这样许多<ruby>加载-存储<rt>load-store</rt></ruby>操作就可以被合并。
|
||||
|
||||
编译器中机器相关的阶段开始于“低级”的 pass,该阶段将通用变量改写为它们的机器相关变形形式。例如,在 amd64 体系结构中操作数可以在内存中,这样许多装载-存储操作就可以被合并。
|
||||
注意低级的 pass 运行所有机器特定的重写规则,因此当前它也应用了大量优化。
|
||||
|
||||
注意低级的 pass 运行所有机器特定的重写规则,因此它也应用了很多优化。
|
||||
一旦 SSA 被“低级化”并且更具体地针对目标体系结构,就要运行最终代码优化的 pass 了。这包含了另外一个死代码消除的 pass,它将变量移动到更靠近它们使用的地方,移除从来没有被读过的局部变量,以及<ruby>寄存器<rt>register</rt></ruby>分配。
|
||||
|
||||
一旦 SSA 被“低级化”并且更具体地针对目标体系结构,就要运行最终代码优化的 pass 了。这包含了另外一个死代码消除的 pass,它将变量移动到更靠近它们使用的地方,移除从来没有被读过的局部变量,以及寄存器分配。
|
||||
本步骤中完成的其它重要工作包括<ruby>堆栈布局<rt>stack frame layout</rt></ruby>,它将堆栈偏移位置分配给局部变量,以及<ruby>指针活性分析<rt>pointer liveness analysis</rt></ruby>,后者计算每个垃圾收集安全点上的哪些堆栈上的指针仍然是活动的。
|
||||
|
||||
本步骤中完成的其它重要工作包括堆栈布局,它将指定局部变量在堆栈中的偏移位置,以及指针活性分析,后者计算每个垃圾收集安全点上的哪些堆栈上的指针仍然是活动的。
|
||||
在 SSA 生成阶段结束时,Go 函数已被转换为一系列 `obj.Prog` 指令。它们被传递给汇编程序(`cmd/internal/obj`),后者将它们转换为机器码并输出最终的目标文件。目标文件还将包含反射数据,导出数据和调试信息。
|
||||
|
||||
在 SSA 生成阶段结束时,Go 函数已被转换为一系列 obj.Prog 指令。它们被传递给汇编程序(`cmd/internal/obj`),后者将它们转换为机器代码并输出最终的目标文件。目标文件还将包含反射数据,导出数据和调试信息。
|
||||
### 扩展阅读
|
||||
|
||||
### 后续读物
|
||||
|
||||
要深入了解 SSA 包的工作方式,包括它的 pass 和规则,请转到 cmd/compile/internal/ssa/README.md。
|
||||
要深入了解 SSA 包的工作方式,包括它的 pass 和规则,请转到 [cmd/compile/internal/ssa/README.md][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/golang/go/blob/master/src/cmd/compile/README.md
|
||||
|
||||
作者:[mvdan ][a]
|
||||
作者:[mvdan][a]
|
||||
译者:[stephenxs](https://github.com/stephenxs)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/mvdan
|
||||
[1]: https://github.com/golang/go/blob/master/src/cmd/compile/internal/ssa/README.md
|
||||
|
||||
@ -1,33 +1,35 @@
|
||||
逐层拼接云原生栈
|
||||
======
|
||||
在 Packet,我们的价值(自动化的基础设施)是非常基础的。因此,我们花费大量的时间来研究我们之上所有生态系统中的参与者和趋势 —— 以及之下的极少数!
|
||||
|
||||
> 看着我们在纽约的办公大楼,我们发现了一种观察不断变化的云原生领域的完美方式。
|
||||
|
||||
在 Packet,我们的工作价值(基础设施自动化)是非常基础的。因此,我们花费大量的时间来研究我们之上所有生态系统中的参与者和趋势 —— 以及之下的极少数!
|
||||
|
||||
当你在任何生态系统的汪洋大海中徜徉时,很容易困惑或迷失方向。我知道这是事实,因为当我去年进入 Packet 工作时,从 Bryn Mawr 获得的英语学位,并没有让我完全得到一个 Kubernetes 的认证。 :)
|
||||
|
||||
由于它超快的演进和巨大的影响,云原生生态系统打破了先例。似乎每眨一次眼睛,之前全新的技术(更不用说所有相关的理念了)就变得有意义 ... 或至少有趣了。和其他许多人一样,我依据无处不在的 CNCF 的 “[云原生蓝图][1]” 作为我去了解这个空间的参考标准。尽管如此,如果有一个定义这个生态系统的元素,那它一定是贡献和控制他们的人。
|
||||
由于它超快的演进和巨大的影响,云原生生态系统打破了先例。似乎每眨一次眼睛,之前全新的技术(更不用说所有相关的理念了)就变得有意义 ... 或至少有趣了。和其他许多人一样,我依据无处不在的 CNCF 的 “[云原生蓝图][1]” 作为我去了解这个空间的参考标准。尽管如此,如果有一个定义这个生态系统的元素,那它一定是贡献和控制它们的人。
|
||||
|
||||
所以,在 12 月份一个很冷的下午,当我们走回办公室时,我们偶然发现了一个给投资人解释“云原生”的创新方式,当我们谈到从 Aporeto 中区分 Cilium 的细微差别时,他的眼睛中充满了兴趣,以及为什么从 CoreDNS 和 Spiffe 到 Digital Rebar 和 Fission 的所有这些都这么有趣。
|
||||
所以,在 12 月份一个很冷的下午,当我们走回办公室时,我们偶然发现了一个给投资人解释“云原生”的创新方式,当我们谈到从 Aporeto 中区分 Cilium 的细微差别时,以及为什么从 CoreDNS 和 Spiffe 到 Digital Rebar 和 Fission 的所有这些都这么有趣时,他的眼睛中充满了兴趣。
|
||||
|
||||
在新世贸中心的阴影下,看到我们位于 13 层的狭窄办公室,我突然想到一个好主意,把我们带到《兔子洞》的艺术世界中:为什么不把它画出来呢?
|
||||
在新世贸中心的阴影下,看到我们位于 13 层的狭窄办公室,我突然想到一个把我们带到那个神奇世界的好主意:为什么不把它画出来呢?(LCTT 译注:“rabbit hole” 有多种含义,此处采用“爱丽丝梦游仙境”中的“兔子洞”含义。)
|
||||
|
||||
![][2]
|
||||
|
||||
于是,我们开始了把云原生栈逐层拼接起来的旅程。让我们一起探索它,并且我们可以给你一个“仅限今日”的低价。
|
||||
于是,我们开始了把云原生栈逐层拼接起来的旅程。让我们一起探索它,给你一个“仅限今日有效”的福利。(LCTT 译注:意即云原生领域变化很快,可能本文/本图中所述很快过时。)
|
||||
|
||||
[[查看高清大图][3]] 或给我们发邮件索取副本。
|
||||
[[查看高清大图][3]] (25Mb)或给我们发邮件索取副本。
|
||||
|
||||
### 从最底层开始
|
||||
|
||||
当我们开始下笔的时候,我们知道,我们希望首先亮出的是每天都与之交互的栈的那一部分,但它对用户却是不可见的:硬件。就像任何投资于下一个伟大的(通常是私有的)东西的秘密实验室一样,我们认为地下室是最好的地点。
|
||||
当我们开始下笔的时候,我们知道,我们希望首先亮出的是我们每天都与之交互的而对用户却是基本上不可见的那一部分:硬件。就像任何投资于下一个伟大的(通常是私有的)东西的秘密实验室一样,我们认为地下室是其最好的地点。
|
||||
|
||||
从大家公认的像 Intel、AMD 和华为(传言他们雇佣的工程师接近 80000 名)这样的巨头,到像 Mellanox 这样的细分市场参与者,硬件生态系统现在非常火。事实上,随着数十亿美元投入去攻克新的 offloads、GPU、定制协处理器,我们可能正在进入硬件的黄金时代。
|
||||
从大家公认的像 Intel、AMD 和华为(传言他们雇佣的工程师接近 80000 名)这样的巨头,到像 Mellanox 这样的细分市场参与者,硬件生态系统现在非常火。事实上,随着数十亿美元投入去攻克新的 offload(LCTT 译注:网卡的 offload 特性是将本来该操作系统进行的一些诸如数据包分片、重组等处理任务放到网卡硬件中去做,降低系统 CPU 消耗的同时,提高处理的性能)、GPU、定制协处理器,我们可能正在进入硬件的黄金时代。
|
||||
|
||||
著名的软件先驱 Alan Kay 在 25 年前说过:“对软件非常认真的人都应该去制造他自己的硬件” ,为 Alan 打 call!
|
||||
著名的软件先驱<ruby>阿伦凯<rt>Alan Kay</rt></ruby> 在 25 年前说过:“对软件非常认真的人都应该去制造他自己的硬件” ,为阿伦凯打 call!
|
||||
|
||||
### 云即资本
|
||||
|
||||
就像我们的 CEO Zac Smith 多次告诉我:所有都是钱的问题。不仅要制造它,还要消费它!在云中,数十亿美元的投入才能让数据中心出现计算机,这样才能让开发者使用软件去消费它。换句话说:
|
||||
|
||||
就像我们的 CEO Zac Smith 多次告诉我:所有都是钱的问题。不仅要制造它,还要消费它!在云中,数十亿美元的投入才能让数据中心出现计算机,这样才能让开发者使用软件去消费它。换句话说(根本没云,它只是别人的电脑而已):
|
||||
|
||||
![][4]
|
||||
|
||||
@ -51,7 +53,7 @@
|
||||
|
||||
居于“连接”和“动力”之上的这一层,我们爱称为“处理器们”。这是奇迹发生的地方 —— 我们将来自下层的创新和实物投资转变成一个 API 尽头的某些东西。
|
||||
|
||||
由于这是纽约的一个大楼,我们让在这里的云供应商处于纽约的中心。这就是为什么你会看到(Digital Ocean 系的)鲨鱼 Sammy 和在 Google 之上的 “meet me” 的房间中和我打招呼的原因了。
|
||||
由于这是纽约的一个大楼,我们让在这里的云供应商处于纽约的中心。这就是为什么你会看到(Digital Ocean 系的)鲨鱼 Sammy,以及 Google 出现在会客室中的原因了。
|
||||
|
||||
正如你所见,这个场景是非常写实的。它就是一垛一垛堆起来的。尽管我们爱 EWR1 的设备经理(Michael Pedrazzini),我们努力去尽可能减少这种体力劳动。毕竟布线专业的博士学位是很难拿到的。
|
||||
|
||||
@ -59,31 +61,31 @@
|
||||
|
||||
### 供给
|
||||
|
||||
再上一层,在基础设施层之上是供给层。这是我们最喜欢的地方之一,它以前被我们称为“配置管理”。但是现在到处都是一开始就是不可改变的基础设施和自动化:Terraform、Ansible、Quay.io 等等类似的东西。你可以看出软件是按它的方式来工作的,对吗?
|
||||
再上一层,在基础设施层之上是供给层。这是我们最喜欢的地方之一,它以前被我们称为“配置管理”。但是现在到处都是一开始就是<ruby>不可变基础设施<rt>immutable infrastructure</rt></ruby>和自动化:Terraform、Ansible、Quay.io 等等类似的东西。你可以看出软件是按它的方式来工作的,对吗?
|
||||
|
||||
Kelsey Hightower 最近写道“呆在无聊的基础设施中是一个让人兴奋的时刻”,我不认为它说的是物理部分(虽然我们认为它非常让人兴奋),但是由于软件持续侵入到栈的所有层,可以保证你有一个疯狂的旅程。
|
||||
Kelsey Hightower 最近写道“呆在无聊的基础设施中是一个让人兴奋的时刻”,我不认为它说的是物理部分(虽然我们认为它非常让人兴奋),但是由于软件持续侵入到栈的所有层,那必将是一个疯狂的旅程。
|
||||
|
||||
![][8]
|
||||
|
||||
### 操作系统
|
||||
|
||||
供应就绪后,我们来到操作系统层。这就是我们开始取笑我们最喜欢的一个人的地方:注意上面 Brian Redbeard 的瑜珈姿势。:)
|
||||
供应就绪后,我们来到操作系统层。在这里你可以看到我们打趣一些我们最喜欢的同事:注意上面 Brian Redbeard 的瑜珈姿势。:)
|
||||
|
||||
Packet 为我们的客户提供了 11 种主要的操作系统去选择,包括一些你在图中看到的:Ubuntu、CoreOS、FreeBSD、Suse、和各种 Red Hat 的作品。我们看到越来越多的人们在这一层上有了他们自己的看法:从定制的内核和为了不可改变的部署而使用的他们最喜欢的发行版,到像 NixOS 和 LinuxKit 这样的项目。
|
||||
Packet 为我们的客户提供了 11 种主要的操作系统可供选择,包括一些你在图中看到的:Ubuntu、CoreOS、FreeBSD、Suse、和各种 Red Hat 的作品。我们看到越来越多的人们在这一层上有了他们自己的看法:从定制的内核和用于不可变部署中的惯用发行版光盘,到像 NixOS 和 LinuxKit 这样的项目。
|
||||
|
||||
![][9]
|
||||
|
||||
### 运行时
|
||||
|
||||
我们玩的很开心,因此我们将运行时放在了体育馆内,并在 CoreOS 赞助的 rkt 和 Docker 的容器化之间进行了一场锦标赛。无论哪种方式赢家都是 CNCF!
|
||||
为了有趣些,我们将运行时放在了体育馆内,并为 CoreOS 赞助的 rkt 和 Docker 的容器化举行了一次比赛。而无论如何赢家都是 CNCF!
|
||||
|
||||
我们认为快速演进的存储生态系统应该得到一些可上锁的储物柜。关于存储部分有趣的地方在于许多的新玩家尝试去解决持久性的挑战问题,以及性能和灵活性问题。就像他们说的:存储很简单。
|
||||
我们认为快速演进的存储生态系统应该是一些可上锁的储物柜。关于存储部分有趣的地方在于许多的新玩家尝试去解决持久性的挑战问题,以及性能和灵活性问题。就像他们说的:存储很简单。
|
||||
|
||||
![][10]
|
||||
|
||||
### 编排
|
||||
|
||||
在过去的这些年里,编排层所有都是关于 Kubernetes 的,因此我们选取了其中一位著名的布道者(Kelsey Hightower),并在这个古怪的会议场景中给他一个特写。在我们的团队中有一些主要的 Nomad 粉丝,并且如果没有 Docker 和它的工具集的影响,根本就没有办法去考虑云原生空间。
|
||||
在过去的这些年里,编排层全是 Kubernetes 了,因此我们选取了其中一位著名的布道者(Kelsey Hightower),并在这个古怪的会议场景中给他一个特写。在我们的团队中有一些 Nomad (LCTT 译注:一个管理机器集群并在集群上运行应用程序的工具)的忠实粉丝,并且如果抛开 Docker 和它的工具集的影响,就无从谈起云原生。
|
||||
|
||||
虽然负载编排应用程序在我们栈中的地位非常高,我们看到的各种各样的证据表明,这些强大的工具开始去深入到栈中,以帮助用户利用 GPU 和其它特定硬件的优势。请继续关注 —— 我们正处于容器化革命的早期阶段!
|
||||
|
||||
@ -91,23 +93,23 @@ Packet 为我们的客户提供了 11 种主要的操作系统去选择,包括
|
||||
|
||||
### 平台
|
||||
|
||||
这是栈中我们喜欢的层之一,因为每个平台都有很多技能帮助用户去完成他们想要做的事情(顺便说一下,不是去运行容器,而是运行应用程序)。从 Rancher 和 Kontena,到 Tectonic 和 Redshift 都是像 Cycle.io 和 Flynn.io 一样是完全不同的方法 —— 我们看到这些项目如何以不同的方式为用户提供服务,总是激动不已。
|
||||
这是栈中我们喜欢的层之一,因为每个平台都有如此多的工具帮助用户去完成他们想要做的事情(顺便说一下,不是去运行容器,而是运行应用程序)。从 Rancher 和 Kontena,到 Tectonic 和 Redshift 都是像 Cycle.io 和 Flynn.io 一样是完全不同的方法 —— 我们看到这些项目如何以不同的方式为用户提供服务,总是激动不已。
|
||||
|
||||
关键点:这些平台是帮助去转化各种各样的云原生生态系统的快速变化部分给用户。很高兴能看到他们每个人带来的东西!
|
||||
关键点:这些平台是帮助去转化各种各样的快速变化的云原生生态系统给用户。很高兴能看到他们每个人带来的东西!
|
||||
|
||||
![][12]
|
||||
|
||||
### 安全
|
||||
|
||||
当说到安全时,今年是很忙的一年!我们尝试去展示一些很著名的攻击,并说明随着工作负载变得更加分散和更加便携(当然,同时攻击也变得更加智能),这些各式各样的工具是如何去帮助保护我们的。
|
||||
当说到安全时,今年真是很忙的一年!我们尝试去展示一些很著名的攻击,并说明随着工作负载变得更加分散和更加可迁移(当然,同时攻击者也变得更加智能),这些各式各样的工具是如何去帮助保护我们的。
|
||||
|
||||
我们看到一个用于不可信环境(Aporeto)和低级安全(Cilium)的强大动作,以及尝试在网络级别上的像 Tigera 这样的可信方法。不管你的方法如何,记住这一点:关于安全这肯定不够。:0
|
||||
我们看到一个用于不可信环境(如 Aporeto)和低级安全(Cilium)的强大动作,以及尝试在网络级别上的像 Tigera 这样的可信方法。不管你的方法如何,记住这一点:安全无止境。:0
|
||||
|
||||
![][13]
|
||||
|
||||
### 应用程序
|
||||
|
||||
如何去表示海量的、无限的应用程序生态系统?在这个案例中,很容易:我们在纽约,选我们最喜欢的。;) 从 Postgres “房间里的大象” 和 Timescale 时钟,到鬼鬼崇崇的 ScyllaDB 垃圾桶和 chillin 的《特拉维斯兄弟》—— 我们把这个片子拼到一起很有趣。
|
||||
如何去表示海量的、无限的应用程序生态系统?在这个案例中,很容易:我们在纽约,选我们最喜欢的。;) 从 Postgres “房间里的大象” 和 Timescale 时钟,到暗藏的 ScyllaDB 垃圾桶和无所事事的《特拉维斯兄弟》—— 我们把这个片子拼到一起很有趣。
|
||||
|
||||
让我们感到很惊奇的一件事情是:很少有人注意到那个复印他的屁股的家伙。我想现在复印机已经不常见了吧?
|
||||
|
||||
@ -115,7 +117,7 @@ Packet 为我们的客户提供了 11 种主要的操作系统去选择,包括
|
||||
|
||||
### 可观测性
|
||||
|
||||
由于我们的工作负载开始到处移动,规模也越来越大,这里没有一件事情能够像一个非常好用的 Grafana 仪表盘、或方便的 Datadog 代理让人更加欣慰了。由于复杂度的提升,“SRE” 的产生开始越来越多地依赖警报和其它情报事件去帮我们感知发生的事件,以及获得越来越多的自我修复的基础设施和应用程序。
|
||||
由于我们的工作负载开始到处移动,规模也越来越大,这里没有一件事情能够像一个非常好用的 Grafana 仪表盘、或方便的 Datadog 代理让人更加欣慰了。由于复杂度的提升,“SRE” 一代开始越来越多地依赖警报和其它智能事件去帮我们感知发生的事件,出现越来越多的自我修复的基础设施和应用程序。
|
||||
|
||||
在未来的几个月或几年中,我们将看到什么样的公司进入这一领域 … 或许是一些人工智能、区块链、机器学习支撑的仪表盘?:-)
|
||||
|
||||
@ -123,25 +125,25 @@ Packet 为我们的客户提供了 11 种主要的操作系统去选择,包括
|
||||
|
||||
### 流量管理
|
||||
|
||||
人们倾向于认为互联网“只是工作而已”,但事实上,我们很惊讶于它的工作方式。我的意思是,大规模的独立的网络的一个松散连接 —— 你不是在开玩笑吧?
|
||||
人们往往认为互联网“就该这样工作”,但事实上,我们很惊讶于它能工作。我的意思是,这是大规模的、不同的网络间的松散连接 —— 你不是在开玩笑吧?
|
||||
|
||||
能够把所有的这些独立的网络拼接到一起的一个原因是流量管理、DNS 和类似的东西。随着规模越来越大,这些参与者帮助让互联网变得更快、更安全、同时更具弹性。我们尤其高兴的是看到像 Fly.io 和 NS1 这样的新贵与优秀的老牌参与者进行竞争,最后的结果是整个生态系统都得以提升。让竞争来的更激烈吧!
|
||||
能够把所有的这些独立的网络拼接到一起的一个原因是流量管理、DNS 和类似的东西。随着规模越来越大,这些让互联网变得更快、更安全、同时更具弹性。我们尤其高兴的是看到像 Fly.io 和 NS1 这样的新贵与优秀的老牌玩家进行竞争,最后的结果是整个生态系统都得以提升。让竞争来的更激烈吧!
|
||||
|
||||
![][16]
|
||||
|
||||
### 用户
|
||||
|
||||
如果没有非常棒的用户,技术栈还有什么用呢?确实,它们位于大量的创新之上,但在云原生的世界里,他们所做的远不止消费这么简单:他们设计和贡献。从像 Kubernetes 这样的大量的贡献者到越来越多的(但同样重要)更多方面,我们都是其中的非常棒的一份子。
|
||||
如果没有非常棒的用户,技术栈还有什么用呢?确实,他们享受了大量的创新,但在云原生的世界里,他们所做的远不止消费这么简单:他们创立并贡献了很多。从像 Kubernetes 这样的大量的贡献者到越来越多的(但同样重要)更多方面,而我们都是其中的非常棒的一份子。
|
||||
|
||||
在我们屋顶的客厅上的许多用户,比如 Ticketmaster 和《纽约时报》,而不仅仅是新贵:这些组织采用了一种新的方式去部署和管理他们的应用程序,并且他们自己的用户正在收获回报。
|
||||
|
||||
![][17]
|
||||
|
||||
### 最后的但并非是不重要的,成熟的监管!
|
||||
### 同样重要的,成熟的监管!
|
||||
|
||||
在以前的生态系统中,基金会扮演了一个“在场景背后”的非常被动的角色。而 CNCF 不是!他们的目标(构建一个健壮的云原生生态系统),被美妙的流行动向所推动 —— 他们不仅已迎头赶上还一路领先。
|
||||
在以前的生态系统中,基金会扮演了一个非常被动的“幕后”角色。而 CNCF 不是!他们的目标(构建一个健壮的云原生生态系统),勇立潮流之先 —— 他们不仅已迎头赶上还一路领先。
|
||||
|
||||
从坚实的管理和一个经过深思熟虑的项目组,到提出像 CNCF 这样的蓝图,CNCF 横跨云 CI、Kubernetes 认证、和演讲者委员会 —— CNCF 已不再是 “仅仅” 受欢迎的 KubeCon + CloudNativeCon 了。
|
||||
从坚实的治理和经过深思熟虑的项目组,到提出像 CNCF 这样的蓝图,CNCF 横跨云 CI、Kubernetes 认证、和演讲者委员会 —— CNCF 已不再是 “仅仅” 受欢迎的 KubeCon + CloudNativeCon 了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -150,7 +152,7 @@ via: https://www.packet.net/blog/splicing-the-cloud-native-stack/
|
||||
作者:[Zoe Allen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,293 +0,0 @@
|
||||
使用 Ptrace 去监听和仿真 Linux 系统调用 « null program
|
||||
======
|
||||
|
||||
`ptrace(2)`(”进程跟踪“)系统调用通常都与调试有关。它是类 Unix 系统上通过原生调试器监测调试进程的主要机制。它也是实现 [strace][1](系统调用跟踪)的常见方法。使用 Ptrace,跟踪器可以暂停跟踪过程,[检查和设置寄存器和内存][2],监视系统调用,甚至可以监听系统调用。
|
||||
|
||||
通过监听功能,意味着跟踪器可以修改系统调用参数,修改系统调用的返回值,甚至监听某些系统调用。言外之意就是,一个跟踪器可以完全服务于系统调用本身。这是件非常有趣的事,因为这意味着**一个跟踪器可以仿真一个完整的外部操作系统**,而这些都是在没有得到内核任何帮助的情况下由 Ptrace 实现的。
|
||||
|
||||
问题是,在同一时间一个进程只能被一个跟踪器附着,因此在那个进程的调试期间,不可能再使用诸如 GDB 这样的工具去仿真一个外部操作系统。另外的问题是,仿真系统调用的开销非常高。
|
||||
|
||||
在本文中,我们将专注于 x86-64 [Linux 的 Ptrace][3],并将使用一些 Linux 专用的扩展。同时,在本文中,我们将忽略掉一些错误检查,但是完整的源代码仍然会包含这些错误检查。
|
||||
|
||||
本文中的可直接运行的示例代码在这里:
|
||||
|
||||
**<https://github.com/skeeto/ptrace-examples>**
|
||||
|
||||
### strace
|
||||
|
||||
在进入到最有趣的部分之前,我们先从回顾 strace 的基本实现来开始。它不是 [DTrace][4],但 strace 仍然非常有用。
|
||||
|
||||
Ptrace 还没有被标准化。它的界面在不同的操作系统上非常类似,尤其是在核心功能方面,但是在不同的系统之间仍然存在细微的差别。`ptrace(2)` 的样子看起来应该像下面这样,但特定的类型可能有些差别。
|
||||
```
|
||||
long ptrace(int request, pid_t pid, void *addr, void *data);
|
||||
|
||||
```
|
||||
|
||||
`pid` 是跟踪的进程 ID。虽然**同一个时间**只有一个跟踪器可以附着到进程上,但是一个跟踪器可以附着跟踪多个进程。
|
||||
|
||||
`request` 字段选择一个具体的 Ptrace 函数,比如 `ioctl(2)` 接口。对于 strace,只需要两个:
|
||||
|
||||
* `PTRACE_TRACEME`:这个进程被它的父进程跟踪。
|
||||
* `PTRACE_SYSCALL`:继续跟踪,但是在下一下系统调用入口或出口时停止。
|
||||
* `PTRACE_GETREGS`:取得被跟踪进程的寄存器内容副本。
|
||||
|
||||
|
||||
|
||||
另外两个字段,`addr` 和 `data`,作为所选的 Ptrace 函数的一般参数。一般情况下,可以忽略一个或全部忽略,在那种情况下,传递零个参数。
|
||||
|
||||
strace 接口实质上是另一个命令的前缀。
|
||||
```
|
||||
$ strace [strace options] program [arguments]
|
||||
|
||||
```
|
||||
|
||||
最小化的 strace 不需要任何选项,因此需要做的第一件事情是 — 假设它至少有一个参数 — 在 `argv` 尾部的 `fork(2)` 和 `exec(2)` 被跟踪进程。但是在加载目标程序之前,新的进程将告知内核,目标程序将被它的父进程继续跟踪。被跟踪进程将被这个 Ptrace 系统调用暂停。
|
||||
```
|
||||
pid_t pid = fork();
|
||||
switch (pid) {
|
||||
case -1: /* error */
|
||||
FATAL("%s", strerror(errno));
|
||||
case 0: /* child */
|
||||
ptrace(PTRACE_TRACEME, 0, 0, 0);
|
||||
execvp(argv[1], argv + 1);
|
||||
FATAL("%s", strerror(errno));
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
父进程使用 `wait(2)` 等待子进程的 `PTRACE_TRACEME`,当 `wait(2)` 返回后,子进程将被暂停。
|
||||
```
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
在允许子进程继续运行之前,我们告诉操作系统,被跟踪进程被它的父进程的跟踪应该被终止。一个真实的 strace 实现可能会设置其它的选择,比如: `PTRACE_O_TRACEFORK`。
|
||||
```
|
||||
ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_EXITKILL);
|
||||
|
||||
```
|
||||
|
||||
剩余部分就是一个简单的、无休止的循环了,每循环一次捕获一个系统调用。循环体总共有四步:
|
||||
|
||||
1. 等待进程进入下一个系统调用。
|
||||
2. 输出一个系统调用的描述。
|
||||
3. 允许系统调用去运行和等待返回。
|
||||
4. 输出系统调用返回值。
|
||||
|
||||
|
||||
|
||||
`PTRACE_SYSCALL` 要求用于等待下一个系统调用时开始,和等待那个系统调用去退出。和前面一样,需要一个 `wait(2)` 去等待跟踪进入期望的状态。
|
||||
```
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
```
|
||||
|
||||
当 `wait(2)` 返回时,线程寄存器中写入了被系统调用所产生的系统调用号和它的参数。尽管如此,操作系统将不再为这个系统调用提供服务。线程寄存器中的详细内容对后续操作很重要。
|
||||
|
||||
接下来的一步是采集系统调用信息。这是得到特定系统架构的地方。在 x86-64 上,[系统调用号是在 `rax` 中传递的][5],而参数(最多 6 个)是在 `rdi`、`rsi`、`rdx`、`r10`、`r8`、和 `r9` 中传递的。另外的 Ptrace 调用将读取这些寄存器,不过这里再也不需要 `wait(2)` 了,因为跟踪状态再也不会发生变化了。
|
||||
```
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
long syscall = regs.orig_rax;
|
||||
|
||||
fprintf(stderr, "%ld(%ld, %ld, %ld, %ld, %ld, %ld)",
|
||||
syscall,
|
||||
(long)regs.rdi, (long)regs.rsi, (long)regs.rdx,
|
||||
(long)regs.r10, (long)regs.r8, (long)regs.r9);
|
||||
|
||||
```
|
||||
|
||||
这里有一个敬告。由于 [内核的内部用途][6],系统调用号是保存在 `orig_rax` 中而不是 `rax` 中。而所有的其它系统调用参数都是非常简单明了的。
|
||||
|
||||
接下来是它的另一个 `PTRACE_SYSCALL` 和 `wait(2)`,然后是另一个 `PTRACE_GETREGS` 去获取结果。结果保存在 `rax` 中。
|
||||
```
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
fprintf(stderr, " = %ld\n", (long)regs.rax);
|
||||
|
||||
```
|
||||
|
||||
这个简单程序的输出也是非常粗糙的。这里的系统调用都没有符号名,并且所有的参数都是以数字形式输出,甚至是一个指向缓冲区的指针。更完整的 strace 输出将能知道哪个参数是指针,以及 `process_vm_readv(2)` 为了从跟踪中正确输出内容而读取了哪些缓冲区。
|
||||
|
||||
然后,这些仅仅是系统调用监听的基础工作。
|
||||
|
||||
### 系统调用监听
|
||||
|
||||
假设我们想使用 Ptrace 去实现如 OpenBSD 的 [`pledge(2)`][7] 这样的功能,它是 [一个进程承诺只使用一套受限的系统调用][8]。初步想法是,许多程序一般都有一个初始化阶段,这个阶段它们都需要进行许多的系统访问(比如,打开文件、绑定套接字、等等)。初始化完成以后,它们进行一个主循环,在主循环中它们处理输入,并且仅使用所需的、很少的一套系统调用。
|
||||
|
||||
在进入主循环之前,可以限制一个进程只能运行它自己所需要的几个操作。如果 [程序有 Bug][9],允许通过恶意的输入去利用这个 Bug,这个承诺可以有效地限制漏洞利用的实现。
|
||||
|
||||
使用与 strace 相同的模型,但不是输出所有的系统调用,我们既能够拦截某些系统调用,也可以在它的行为异常时简单地终止被跟踪进程。终止它很容易:只需要在跟踪器中调用 `exit(2)`。因此,它也可以被设置为去终止被跟踪进程。拦截系统调用和允许子进程继续运行都只是些雕虫小技而已。
|
||||
|
||||
最棘手的部分是**当系统调用启动后没有办法去中断它**。进入系统调用之后,当跟踪器从 `wait(2)` 中返回,停止一个系统调用的仅有方式是,发生被跟踪进程终止的情况。
|
||||
|
||||
然而,我们不仅可以“搞乱”系统调用的参数,也可以改变系统调用号本身,将它修改为一个不存在的系统调用。返回时,在 `errno` 中 [通过正常的内部信号][10],我们就可以报告一个“友好的”错误信息。
|
||||
```
|
||||
for (;;) {
|
||||
/* Enter next system call */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
/* Is this system call permitted? */
|
||||
int blocked = 0;
|
||||
if (is_syscall_blocked(regs.orig_rax)) {
|
||||
blocked = 1;
|
||||
regs.orig_rax = -1; // set to invalid syscall
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
|
||||
/* Run system call and stop on exit */
|
||||
ptrace(PTRACE_SYSCALL, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
if (blocked) {
|
||||
/* errno = EPERM */
|
||||
regs.rax = -EPERM; // Operation not permitted
|
||||
ptrace(PTRACE_SETREGS, pid, 0, ®s);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个简单的示例只是检查了系统调用是否违反白名单或黑名单。而它们在这里并没有差别,比如,允许文件以只读而不是读写方式打开(`open(2)`),允许匿名内存映射但不允许非匿名映射等等。但是这里仍然没有办法去动态撤销被跟踪进程的权限。
|
||||
|
||||
跟踪器与被跟踪进程如何沟通?使用人为的系统调用!
|
||||
|
||||
### 创建一个人为的系统调用
|
||||
|
||||
对于我的这个类似于 pledge 的系统调用 — 我可以通过调用 `xpledge()` 将它与真实的系统调用区分开 — 我设置 10000 作为它的系统调用号,这是一个非常大的数字,真实的系统调用中从来不会用到它。
|
||||
```
|
||||
#define SYS_xpledge 10000
|
||||
|
||||
```
|
||||
|
||||
为演示需要,我同时构建了一个非常小的界面,这在实践中并不是个好主意。它与 OpenBSD 的 `pledge(2)` 稍有一些相似之处,它使用了一个 [字符串界面][11]。事实上,设计一个健壮且安全的权限集是非常复杂的,正如在 `pledge(2)` 的手册页面上所显示的那样。下面是对被跟踪进程的完整界面和系统调用的实现:
|
||||
```
|
||||
#define _GNU_SOURCE
|
||||
#include <unistd.h>
|
||||
|
||||
#define XPLEDGE_RDWR (1 << 0)
|
||||
#define XPLEDGE_OPEN (1 << 1)
|
||||
|
||||
#define xpledge(arg) syscall(SYS_xpledge, arg)
|
||||
|
||||
```
|
||||
|
||||
如果给它传递零个参数,仅允许一些基本的系统调用,包括那些用于去分配内存的系统调用(比如 `brk(2)`)。 `PLEDGE_RDWR` 位允许 [各种][12] 读和写的系统调用(`read(2)`、`readv(2)`、`pread(2)`、`preadv(2)` 等等)。`PLEDGE_OPEN` 位允许 `open(2)`。
|
||||
|
||||
为防止发生提升权限的行为,`pledge()` 会拦截它自己 — 但这样也防止了权限撤销,以后再细说这方面内容。
|
||||
|
||||
在 xpledge 跟踪器中,我需要去检查这个系统调用:
|
||||
```
|
||||
/* Handle entrance */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
register_pledge(regs.rdi);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
操作系统将返回 `ENOSYS`(因为函数还没有实现),因此它不是一个真实的系统调用。为此在退出时我用一个 `success (0)` 去覆写它。
|
||||
```
|
||||
/* Handle exit */
|
||||
switch (regs.orig_rax) {
|
||||
case SYS_pledge:
|
||||
ptrace(PTRACE_POKEUSER, pid, RAX * 8, 0);
|
||||
break;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我写了一小段测试程序去打开 `/dev/urandom`,做一个读操作,尝试去承诺后,我第二次打开 `/dev/urandom`,然后确认它能够读取原始的 `/dev/urandom` 文件描述符。在没有承诺跟踪器的情况下运行,输出如下:
|
||||
```
|
||||
$ ./example
|
||||
fread("/dev/urandom")[1] = 0xcd2508c7
|
||||
XPledging...
|
||||
XPledge failed: Function not implemented
|
||||
fread("/dev/urandom")[2] = 0x0be4a986
|
||||
fread("/dev/urandom")[1] = 0x03147604
|
||||
|
||||
```
|
||||
|
||||
做一个无效的系统调用并不会让应用程序崩溃。它只是失败,这是一个很方便的返回方式。当它在跟踪器下运行时,它的输出如下:
|
||||
```
|
||||
$ ./xpledge ./example
|
||||
fread("/dev/urandom")[1] = 0xb2ac39c4
|
||||
XPledging...
|
||||
fopen("/dev/urandom")[2]: Operation not permitted
|
||||
fread("/dev/urandom")[1] = 0x2e1bd1c4
|
||||
|
||||
```
|
||||
|
||||
这个承诺很成功,第二次的 `fopen(3)` 并没有实现,因为跟踪器用一个 `EPERM` 拦截了它。
|
||||
|
||||
可以将这种思路进一步发扬光大,比如,改变文件路径或返回一个假的结果。一个跟踪器可以很高效地 chroot 它的被跟踪进程,通过一个系统调用将任意路径传递给 root 从而实现 chroot 路径。它甚至可以对用户进行欺骗,告诉用户它以 root 运行。事实上,这些就是 [Fakeroot NG][13] 程序所做的事情。
|
||||
|
||||
### 仿真外部系统
|
||||
|
||||
假设你不满足于仅监听一些系统调用,而是想监听全部系统调用。你收到 [一个打算在其它操作系统上运行的二进制程序][14],因为没有系统调用,这个二进制程序将无法正常运行。
|
||||
|
||||
使用我在前面所描述的这些内容你就可以管理这一切。跟踪器可以使用一个假冒的东西去代替系统调用号,允许它去失败,以及为系统调用本身提供服务。但那样做的效率很低。其实质上是对每个系统调用做了三个上下文切换:一个是在入口上停止,一个是让系统调用总是以失败告终,还有一个是在系统调用退出时停止。
|
||||
|
||||
从 2005 年以后,对于这个技术,PTrace 的 Linux 版本有更高效的操作:`PTRACE_SYSEMU`。PTrace 仅在每个系统调用发出时停止一次,在允许被跟踪进程继续运行之前,由跟踪器为系统调用提供服务。
|
||||
```
|
||||
for (;;) {
|
||||
ptrace(PTRACE_SYSEMU, pid, 0, 0);
|
||||
waitpid(pid, 0, 0);
|
||||
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, pid, 0, ®s);
|
||||
|
||||
switch (regs.orig_rax) {
|
||||
case OS_read:
|
||||
/* ... */
|
||||
|
||||
case OS_write:
|
||||
/* ... */
|
||||
|
||||
case OS_open:
|
||||
/* ... */
|
||||
|
||||
case OS_exit:
|
||||
/* ... */
|
||||
|
||||
/* ... and so on ... */
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
从任何使用(足够)稳定的系统调用 ABI(译注:应用程序二进制接口),在相同架构的机器上运行一个二进制程序时,你只需要 `PTRACE_SYSEMU` 跟踪器,一个加载器(用于代替 `exec(2)`),和这个二进制程序所需要(或仅运行静态的二进制程序)的任何系统库即可。
|
||||
|
||||
事实上,这听起来有点像一个有趣的周末项目。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nullprogram.com/blog/2018/06/23/
|
||||
|
||||
作者:[Chris Wellons][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nullprogram.com
|
||||
[1]:https://blog.plover.com/Unix/strace-groff.html
|
||||
[2]:http://nullprogram.com/blog/2016/09/03/
|
||||
[3]:http://man7.org/linux/man-pages/man2/ptrace.2.html
|
||||
[4]:http://nullprogram.com/blog/2018/01/17/
|
||||
[5]:http://nullprogram.com/blog/2015/05/15/
|
||||
[6]:https://stackoverflow.com/a/6469069
|
||||
[7]:https://man.openbsd.org/pledge.2
|
||||
[8]:http://www.openbsd.org/papers/hackfest2015-pledge/mgp00001.html
|
||||
[9]:http://nullprogram.com/blog/2017/07/19/
|
||||
[10]:http://nullprogram.com/blog/2016/09/23/
|
||||
[11]:https://www.tedunangst.com/flak/post/string-interfaces
|
||||
[12]:http://nullprogram.com/blog/2017/03/01/
|
||||
[13]:https://fakeroot-ng.lingnu.com/index.php/Home_Page
|
||||
[14]:http://nullprogram.com/blog/2017/11/30/
|
||||
@ -0,0 +1,70 @@
|
||||
适用于 Fedora 28 的 3 款酷炫生产力应用
|
||||
======
|
||||
|
||||

|
||||
|
||||
生产力应用在移动设备上特别受欢迎。但是当你坐下来做工作时,你经常在笔记本电脑或台式电脑上工作。假设你使用 Fedora 系统。你能找到帮助你完成工作的程序吗?当然!请继续阅读了解帮助你专注目标的程序。
|
||||
|
||||
所有这些程序都可以在 Fedora 系统上免费使用。他们也尊重你的自由。 (许多还允许你使用你可能拥有帐户的现有服务。)
|
||||
|
||||
### FocusWriter
|
||||
|
||||
FocusWriter 只是一个全屏文字处理器。该程序可以提高你的工作效率,因为它覆盖了屏幕其他地方。当你使用 FocusWriter 时,你和文本之间没有任何内容。有了这个程序,你可以专注于你的想法,减少分心。
|
||||
|
||||
[![Screenshot of FocusWriter][1]][2]
|
||||
|
||||
FocusWriter 允许你调整字体、颜色和主题以最适合你的喜好。它还会记住你上一个文档和位置。此功能可让你快速重新专注于书写。
|
||||
|
||||
要安装 FocusWriter,请使用 Fedora Workstation 中的软件中心。或者在终端中[使用 sudo ][3]运行此命令:
|
||||
```
|
||||
sudo dnf install focuswriter
|
||||
|
||||
```
|
||||
|
||||
### GNOME ToDo
|
||||
|
||||
你可以猜到这个独特的程序是为 GNOME 桌面环境设计的。因此,它非常适合你的 Fedora Workstation。ToDo 有一个简单的目的:它可以让你列出你需要完成的事情。
|
||||
|
||||

|
||||
|
||||
使用 ToDo,你可以为所有任务确定优先级并安排截止日期。你还可以根据需要构建任意数量的任务列表。ToDo 为有用的功能提供了大量扩展,以提高你的工作效率。这些包括 GNOME Shell 通知,以及带有 todo.txt 的列表管理。如果你有 Todoist 或者 Google 帐户,ToDo 甚至可以与它们交互。它可以同步任务,因此你可以跨设备共享。
|
||||
|
||||
要安装它,在软件中心搜索 ToDo,或在命令行运行:
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Zanshin
|
||||
|
||||
如果你是使用 KDE 的生产力粉丝,你可能会喜欢 [Zanshin][4]。该组织者可帮助你规划跨多个项目的操作。它有完整的功能界面,可让你浏览各种任务,以了解下一步要做的最重要的事情。
|
||||
|
||||
[![Screenshot of Zanshin on Fedora 28][5]][6]
|
||||
|
||||
Zanshin 非常适合键盘操作,因此你可在 hacking 期间提高效率。它还集成了众多 KDE 程序以及 Plasma 桌面。你可以将其与 KMail、KOrganizer 和 KRunner 一起使用。
|
||||
|
||||
要安装它,请运行以下命令:
|
||||
```
|
||||
sudo dnf install zanshin
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/3-cool-productivity-apps/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-15-18-10-18-1024x768.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-15-18-10-18.png
|
||||
[3]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[4]:https://zanshin.kde.org/
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot_20180715_192216-1024x653.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot_20180715_192216.png
|
||||
@ -0,0 +1,90 @@
|
||||
如何在 Ubuntu 和其他 Linux 发行版中安装 2048 游戏
|
||||
======
|
||||
**流行的移动益智游戏 2048 也可以在 Ubuntu 和 Linux 发行版上玩。啊!你甚至可以在 Linux 终端上玩 2048。如果你的生产率因为这个让人上瘾的游戏下降,请不要怪我。**
|
||||
|
||||
早在 2014 年,2048 就是 iOS 和 Android 上最受欢迎的游戏之一。这款令人上瘾的游戏非常受欢迎,它在 Linux 上有[浏览器版][1]、桌面版和终端版。
|
||||
|
||||
<https://giphy.com/embed/wT8XEi5gckwJW>
|
||||
|
||||
通过向上和向下,向左和向右移动滑块来玩这个小游戏。这个益智游戏的目的是通过组合匹配的滑块到数字 2048。因此 2+2 变成 4,4+4 变成 16,依此类推。这可能听起来简单而无聊,但相信我是一个令人上瘾的游戏。
|
||||
|
||||
### 在 Linux 中玩 2048 [GUI]
|
||||
|
||||
在 Ubuntu 和其他 Linux 中有些 2048 游戏。你可以在软件中心中搜索它,你可以在那里找到一些。
|
||||
|
||||
有一个[基于 Qt ][2]的 2048 游戏,你可以在 Ubuntu 和其他基于 Debian 和 Ubuntu 的 Linux 发行版上安装。你可以使用以下命令安装它:
|
||||
```
|
||||
sudo apt install 2048-qt
|
||||
|
||||
```
|
||||
|
||||
安装完成后,你可以在菜单中找到该游戏并启动它。你可以使用箭头键移动数字。你的最高分也会保存。
|
||||
|
||||
![2048 Game in Ubuntu Linux][3]
|
||||
|
||||
### 在 Linux 终端玩 2048
|
||||
|
||||
2048 的流行将它带到了终端。如果这让你感到惊讶,你应该知道 Linux 中有很多[很棒的终端游戏][4],而 2048 肯定就是其中之一。
|
||||
|
||||
现在,有几种方法可以在 Linux 终端中玩 2048。我在这里提其中两个。
|
||||
|
||||
#### 1\. term2048 Snap 程序
|
||||
|
||||
有一个名为 [term2048][6] 的[ snap 程序][5]可以安装在任何[支持 Snap 的 Linux 发行版][7]中。
|
||||
|
||||
如果你启用了 Snap,只需使用此命令安装 term2048:
|
||||
```
|
||||
sudo snap install term2048
|
||||
|
||||
```
|
||||
|
||||
Ubuntu 用户也可以在软件中心找到这个游戏并从那里安装它。
|
||||
|
||||
![2048 Terminal Game in Linux][8]
|
||||
|
||||
安装后,你可以使用命令 term2048 来运行游戏。它看起来像这样:
|
||||
|
||||
![2048 Terminal game][9]
|
||||
|
||||
你可以使用箭头键移动。
|
||||
|
||||
#### 2\. 2048 游戏的 Bash 脚本
|
||||
|
||||
这个游戏实际上是一个 shell 脚本,你可以在任何 Linux 终端上运行。从 Github 下载游戏/脚本:
|
||||
|
||||
[下载 Bash2048][10]
|
||||
|
||||
解压下载的文件。进入解压后的目录,你将看到名为 2048.sh 的 shell 脚本。只需运行 shell 脚本。游戏将立即开始。你可以使用箭头键移动滑块。
|
||||
|
||||
![Linux Terminal game 2048][11]
|
||||
|
||||
#### 你在Linux上玩什么游戏?
|
||||
|
||||
如果你喜欢在 Linux 终端上玩游戏,你也应该尝试 [Linux 终端中的经典 Snake 游戏][12]。
|
||||
|
||||
你经常在 Linux 中玩哪些游戏?你也在终端中玩游戏吗?如果是的话,哪个是你最喜欢的终端游戏?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/2048-game/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:http://gabrielecirulli.github.io/2048/
|
||||
[2]:https://www.qt.io/
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/2048-qt-ubuntu.jpeg
|
||||
[4]:https://itsfoss.com/best-command-line-games-linux/
|
||||
[5]:https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[6]:https://snapcraft.io/term2048
|
||||
[7]:https://itsfoss.com/install-snap-linux/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/term2048-game.png
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/term2048.jpg
|
||||
[10]:https://github.com/mydzor/bash2048
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/2048-bash-terminal.png
|
||||
[12]:https://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/ (nSnake: Play The Classic Snake Game In Linux Terminal)
|
||||
@ -0,0 +1,107 @@
|
||||
|
||||
五个 Linux 上的开源角色扮演游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
游戏是 Linux 的传统弱点之一,感谢 Stean、GOG 和其他的游戏开发商将商业游戏移植到了多个操作系统,Linux 的这个弱点在近几年有所改观,但是这些游戏通常都不是开源的。当然,这些游戏可以在开源系统上运行,但是对于开源的纯粹主义者来说这还不够好。
|
||||
|
||||
那么,有没有一款能让只使用免费和开源软件的人在不影响他们开源理念的情况下也能享受到可靠游戏体验的精致游戏呢?
|
||||
|
||||
当然有啦!虽然开源游戏不太可能和拥有大量开发预算的 3A 级大作相媲美,但有许多类型的开源游戏也很有趣,而且他们可以直接从大多数主要的 Linux 发行版的仓库中进行安装。即使某个游戏没有被某些仓库打包,你也可以很简单地从这个游戏的官网下载它,并进行安装和运行。
|
||||
|
||||
这篇文章着眼于角色扮演游戏,我已经写过关于街机游戏,棋牌游戏,益智游戏,以及赛车和飞行游戏。在本系列的最后一篇文章中,我打算覆盖战略游戏和模拟游戏这两方面。
|
||||
|
||||
### Endless Sky
|
||||
|
||||

|
||||
|
||||
Endless Sky 是 Ambrosia Software 的 Escape Velocity 系列的开源克隆。玩家乘坐一艘宇宙飞船,在不同的世界之间旅行来运送货物和乘客,并在沿途中承接其他任务,或者玩家也可以变成海盗,并从其他货船中偷取货物。这个游戏让玩家自己决定要如何去体验这个游戏,以太阳系为背景的超大地图是非常具有探索性的。Endless Sky 是那些违背正常游戏类别分类的游戏之一。但这个兼具动作、角色扮演、太空模拟和交易这四种类型的游戏非常值得一试。
|
||||
|
||||
如果要安装 Endless Sky ,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install endless-sky`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install endless-sky`
|
||||
|
||||
### FreeDink
|
||||
|
||||

|
||||
|
||||
FreeDink 是 Dink Smallwood 的开源版本,Dink Smallwood 是一个由 RTSoft 在1997 年发售的动作角色扮演游戏。Dink Smallwood 在 1999 年时变为了免费游戏,并在 2003 年时公布了源代码。在 2008 年时,游戏的数据除了少部分的声音文件,都在开源协议下进行了开源。FreeDink 用一些替代的声音文件替换了缺少的那部分文件,来提供了一个完整的游戏。游戏的玩法类似于任天堂的塞尔达传说系列。玩家控制的角色和 Dink Smallwood 同名,他在从一个任务地点移动到下一个任务地点的时候,探索这个充满隐藏物品和隐藏洞穴的世界地图。由于这个游戏的年龄,FreeDink 不能和现代的商业游戏相抗衡,但它仍然是一个拥有着有趣故事的有趣的游戏。游戏可以通过 D-Mods 进行扩展,D-Mods 是提供额外任务的附加模块,但是 D-Mods 在复杂性,质量,和年龄适应性上确实有很大的差异。游戏主要适合青少年,但也有部分额外组件适用于成年玩家。
|
||||
|
||||
要安装 FreeDink ,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install freedink`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install freedink`
|
||||
|
||||
### ManaPlus
|
||||
|
||||

|
||||
|
||||
从技术上讲,ManaPlus 本身并不是一个游戏,它是一个访问各种大型多人在线角色扮演游戏的客户端。The Mana World 和 Evol Online 是两款可以通过 ManaPlus 访问的开源游戏,但是游戏的服务器不在那里。这个游戏的 2D 精灵图像让人想起超级任天堂游戏,虽然 ManaPlus 支持的游戏没有一款能像商业游戏那样受欢迎的,但他们都有一个有趣的世界,并且在绝大部分时间里都有至少一小部分玩家在线。一个玩家不太可能遇到很多的其他玩家,但通常都能有足够的人一起在这个 MMORPG 游戏里进行冒险,而不是一个需要连接到服务器的单机游戏。Mana World 和 Evol Online 的开发者联合起来进行未来的开发,但是对于目前而言,Mana World 的历史服务器和 Evol Online 提供了不同的游戏体验。
|
||||
|
||||
要安装 ManaPlus,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install manaplus`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install manaplus`
|
||||
|
||||
### Minetest
|
||||
|
||||

|
||||
|
||||
使用 Minetest 来在一个开放式世界里进行探索和创造,Minetest 是 Minecraft 的克隆,就像它所基于的游戏一样,Minetest 提供了一个开放的世界,玩家可以在这个世界里探索和创造他们想要的一切。Minetest 提供了各种各样的方块和工具,对于想要一个比 Minecraft 更加开放的游戏的人来说,Minetest 是一个很好的替代品。除了基本的游戏之外,Minetest 还可以通过额外的模块进行可扩展,增加更多的选项。
|
||||
|
||||
如果要安装 Minetest ,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install minetest`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install minetest`
|
||||
|
||||
### NetHack
|
||||
|
||||

|
||||
|
||||
NetHack 是一款经典的 Roguelike 类型的角色扮演游戏,玩家可以从不同的角色种族、层次和路线中进行选择,来探索这个多层次的地下层。这个游戏的目的就是找回 Yendor 的护身符,玩家从地下层的第一层开始探索,并尝试向下一层移动,每一层都是随机生成的,这样每次都能获得不同的游戏体验。虽然这个游戏只具有 ASCII 图形和基本图形,但是游戏玩法的深度能够弥补画面的不足。玩家如果想要更好一些的画面的话,可能就需要去查看 NetHack 中的 Vulture 了,这个选项可以提供更好的图像、声音和背景音乐。
|
||||
|
||||
如果要安装 NetHack ,请运行下面的命令:
|
||||
|
||||
在 Fedora 上: `dnf install nethack`
|
||||
|
||||
在 Debian/Ubuntu 上: `apt install nethack-x11 or apt install nethack-console`
|
||||
|
||||
我有错过了你最喜欢的角色扮演游戏吗?请在下面的评论区分享出来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/role-playing-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://opensource.com/article/18/3/card-board-games-linux
|
||||
[3]:https://opensource.com/article/18/6/puzzle-games-linux
|
||||
[4]:https://opensource.com/article/18/7/racing-flying-games-linux
|
||||
[5]:https://endless-sky.github.io/
|
||||
[6]:https://en.wikipedia.org/wiki/Escape_Velocity_(video_game)
|
||||
[7]:http://www.gnu.org/software/freedink/
|
||||
[8]:http://www.rtsoft.com/pages/dink.php
|
||||
[9]:https://en.wikipedia.org/wiki/The_Legend_of_Zelda
|
||||
[10]:http://www.dinknetwork.com/files/category_dmod/
|
||||
[11]:http://manaplus.org/
|
||||
[12]:http://www.themanaworld.org/
|
||||
[13]:http://evolonline.org/
|
||||
[14]:https://en.wikipedia.org/wiki/Massively_multiplayer_online_role-playing_game
|
||||
[15]:https://www.minetest.net/
|
||||
[16]:https://wiki.minetest.net/Mods
|
||||
[17]:https://www.nethack.org/
|
||||
[18]:https://en.wikipedia.org/wiki/Roguelike
|
||||
[19]:http://www.darkarts.co.za/vulture-for-nethack
|
||||
@ -0,0 +1,65 @@
|
||||
使用 Fstransform 转换文件系统
|
||||
======
|
||||
|
||||

|
||||
|
||||
很少有人知道他们可以将文件系统从一种类型转换为另一种类型而不会丢失数据,即非破坏性的。这可能听起来像魔术,但 [Fstransform][1] 可以几乎以任意组合将 ext2、ext3、ext4、jfs、reiserfs 或 xfs 分区转换成另一类型。更重要的是,它可以直接执行,而无需格式化或复制数据。除此之外,还有一点好处:Fstransform 也可以处理 ntfs、btrfs、fat 和 exfat 分区。
|
||||
|
||||
### 在运行之前
|
||||
|
||||
Fstransform 中存在一些警告和限制,因此强烈建议在尝试转换之前进行备份。此外,使用 Fstransform 时需要注意一些限制:
|
||||
|
||||
* Linux 内核必须支持源文件系统和目标文件系统。听起来很明显,如果你想使用 ext2、ext3、ext4、reiserfs、jfs 和 xfs 分区,这样不会出现风险。Fedora 支持所有分区,所以没问题。
|
||||
* 将 ext2 升级到 ext3 或 ext4 不需要 Fstransform。请使用 Tune2fs。
|
||||
* 源文件系统的设备必须至少有 5% 的可用空间。
|
||||
* 你需要在开始之前卸载源文件系统。
|
||||
* 源文件系统存储的数据越多,转换的时间就越长。实际速度取决于你的设备,但预计它大约为每分钟 1GB。大量的硬链接也会降低转换速度。
|
||||
* 虽然 Fstransform 被证明是稳定的,但请备份源文件系统上的数据。
|
||||
|
||||
|
||||
|
||||
### 安装说明
|
||||
|
||||
Fstransform 已经是 Fedora 的一部分。使用以下命令安装:
|
||||
```
|
||||
sudo dnf install fstransform
|
||||
|
||||
```
|
||||
|
||||
### 转换时间
|
||||
|
||||
![][2]
|
||||
|
||||
fstransform 命令的语法非常简单:fstransform <源设备> <目标文件系统>。请记住,它需要 root 权限才能运行,所以不要忘记在开头添加 sudo。这是一个例子:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ext4
|
||||
|
||||
```
|
||||
|
||||
请注意,无法转换根文件系统,这是一种安全措施。请改用测试分区或实验性 USB。与此同时,Fstransform 会在控制台中有许多辅助输出。最有用的部分是预计完成时间,让你随时了解该过程需要多长时间。同样,几乎空的驱动器上的几个小文件将使 Fstransform 在一分钟左右完成其工作,而更多真实世界的任务可能需要数小时的等待时间。
|
||||
|
||||
### 更多支持的文件系统
|
||||
|
||||
如上所述,可以尝试在 ntfs、btrfs、fat 和 exfat 分区使用 Fstransform。这些类型是非常实验性的,没有人能保证完美转换。尽管如此,还是有许多成功案例,你可以通过在测试分区上使用示例数据集测试 Fstransform 来添加自己的成功案例。可以使用 -force-untested-file-systems 参数启用这些额外的文件系统:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ntfs --force-untested-file-systems
|
||||
|
||||
```
|
||||
|
||||
有时,该过程可能会因错误而中断。请放心再次执行命令 - 它可能最终会在 2,3 次尝试后完成转换。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/transform-file-systems-in-linux/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://github.com/cosmos72/fstransform
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot_20180805_230116.png
|
||||
@ -1,232 +0,0 @@
|
||||
在 Linux 中如何以人性化的方式显示数据
|
||||
======
|
||||
|
||||

|
||||
|
||||
不是每个人都以二进制方式思考,他们不想在大脑中插入逗号来处理大量数字并获得文件的大小。因此,Linux 命令在过去的几十年里不断发展,以更人性化的方式向用户显示信息,这一点也不奇怪。在今天的文章中,我们将看一看各种命令所提供的一些选项,它们使得数据变得更容易理解。
|
||||
|
||||
### 为什么默认显示不更友好一些?
|
||||
|
||||
如果你想知道为什么默认不显示得更人性化,原因是:我们人类毕竟是计算机的默认用户(to 校正:这里分很不理解,感觉不对,既然人类是默认用户,那么为什么不人性化呢)。你可能会问自己:“为什么我们不竭尽全力去获得对每个人都有意义的命令的响应?”答案是:改变命令的默认输出可能会干扰许多其它进程,这些进程是在期望默认响应之上构建的。其它的工具,以及过去几十年开发的脚本,如果突然以一种完全不同的格式输出,而不是它们过去所期望的那样,可能会被一种非常丑陋的方式破坏。
|
||||
|
||||
说真的,也许我们中的一些人可能更愿意看文件大小中的所有数字,即 1338277310 而不是 1.3G。在任何情况下,切换默认值都可能造成破坏,但是为更加人性化的响应提供一些简单的选项只会让我们学习一些命令选项。
|
||||
|
||||
### 可以显示人性化数据的命令
|
||||
|
||||
有哪些简单的选项可以使 Unix 命令的输出更容易解析呢?让我们来看一些命令。
|
||||
|
||||
#### top
|
||||
|
||||
你可能没有注意到这个命令,但是在 top 命令中,你可以通过输入 “**E**”(大写字母 E)来更改显示全部内存使用的方式。连续按下将数字显示从 KiB 到 MiB, 再到 GiB, 接着是 TiB, PiB, EiB,最后回到 KiB。
|
||||
|
||||
认识这些单位吧?这里有一组定义:
|
||||
```
|
||||
2**10 = 1,024 = 1 KiB (kibibyte)
|
||||
2**20 = 1,048,576 = 1 MiB (mebibyte)
|
||||
2**30 = 1,073,741,824 = 1 GiB (gibibyte)
|
||||
2**40 = 1,099,511,627,776 = 1 TiB (tebibyte)
|
||||
2**50 = 1,125,899,906,842,624 = PiB (pebibyte)
|
||||
2**60 = 1,152,921,504,606,846,976 = EiB (exbibyte)
|
||||
2**70 = 1,180,591,620,717,411,303,424 = 1 ZiB (zebibyte)
|
||||
2**80 = 1,208,925,819,614,629,174,706,176 = 1 YiB (yobibyte)
|
||||
|
||||
```
|
||||
|
||||
这些单位与千字节,兆字节和千兆字节密切相关。虽然它们很接近,但是它们之间仍有很大的区别:一组是基于 10 的幂,另一组是基于 2 的幂。例如,比较千字节和千比字节,我们可以看看它们不同点:
|
||||
```
|
||||
KB = 1000 = 10**3
|
||||
KiB = 1024 = 2**10
|
||||
|
||||
```
|
||||
|
||||
以下是 top 命令输出示例,使用 KiB 为单位默认显示:
|
||||
```
|
||||
top - 10:49:06 up 5 days, 35 min, 1 user, load average: 0.05, 0.04, 0.01
|
||||
Tasks: 158 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
KiB Mem : 6102680 total, 4634980 free, 392244 used, 1075456 buff/cache
|
||||
KiB Swap: 2097148 total, 2097148 free, 0 used. 5407432 avail Mem
|
||||
|
||||
```
|
||||
|
||||
在按下 E 之后,单位变成了 MiB:
|
||||
```
|
||||
top - 10:49:31 up 5 days, 36 min, 1 user, load average: 0.03, 0.04, 0.01
|
||||
Tasks: 158 total, 2 running, 118 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.0 us, 0.6 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
MiB Mem : 5959.648 total, 4526.348 free, 383.055 used, 1050.246 buff/cache
|
||||
MiB Swap: 2047.996 total, 2047.996 free, 0.000 used. 5280.684 avail Mem
|
||||
|
||||
```
|
||||
|
||||
再次按下 E,单位变为 GiB:
|
||||
```
|
||||
top - 10:49:49 up 5 days, 36 min, 1 user, load average: 0.02, 0.03, 0.01
|
||||
Tasks: 158 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
GiB Mem : 5.820 total, 4.420 free, 0.374 used, 1.026 buff/cache
|
||||
GiB Swap: 2.000 total, 2.000 free, 0.000 used. 5.157 avail Mem
|
||||
|
||||
```
|
||||
|
||||
你还可以通过按字母 “**e**” 来更改为显示每个进程使用内存的数字单位。它将从默认的 KiB 到 MiB,再到 GiB, TiB,接着到 PiB(期望看到很多0 (to 校正者:意思是以 PB 为单位前面很多 0)),然后返回 KiB。下面是按了一下 “**e**” 之后的 top 输出:
|
||||
```
|
||||
top - 08:45:28 up 4 days, 22:32, 1 user, load average: 0.02, 0.03, 0.00
|
||||
Tasks: 167 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 0.2 us, 0.0 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
KiB Mem : 6102680 total, 4641836 free, 393348 used, 1067496 buff/cache
|
||||
KiB Swap: 2097148 total, 2097148 free, 0 used. 5406396 avail Mem
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
784 root 20 0 543.2m 26.8m 16.1m S 0.9 0.5 0:22.20 snapd
|
||||
733 root 20 0 107.8m 2.0m 1.8m S 0.4 0.0 0:18.49 irqbalance
|
||||
22574 shs 20 0 107.5m 5.5m 4.6m S 0.4 0.1 0:00.09 sshd
|
||||
1 root 20 0 156.4m 9.3m 6.7m S 0.0 0.2 0:05.59 systemd
|
||||
|
||||
```
|
||||
|
||||
#### du
|
||||
|
||||
du 命令显示磁盘空间文件或目录使用了多少,如果使用 **-h** 选项,则将输出大小调整为最合适的单位。默认情况下,它以千字节(KB)为单位。
|
||||
```
|
||||
$ du camper*
|
||||
360 camper_10.jpg
|
||||
5684 camper.jpg
|
||||
240 camper_small.jpg
|
||||
$ du -h camper*
|
||||
360K camper_10.jpg
|
||||
5.6M camper.jpg
|
||||
240K camper_small.jpg
|
||||
|
||||
```
|
||||
|
||||
#### df
|
||||
|
||||
df 命令也提供了一个 -h 选项。请注意在下面的示例中是如何以千兆字节(GB)和兆字节(MB)输出的:
|
||||
```
|
||||
$ df -h | grep -v loop
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
udev 2.9G 0 2.9G 0% /dev
|
||||
tmpfs 596M 1.7M 595M 1% /run
|
||||
/dev/sda1 110G 9.0G 95G 9% /
|
||||
tmpfs 3.0G 0 3.0G 0% /dev/shm
|
||||
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs 3.0G 0 3.0G 0% /sys/fs/cgroup
|
||||
tmpfs 596M 16K 596M 1% /run/user/121
|
||||
/dev/sdb2 457G 73M 434G 1% /apps
|
||||
tmpfs 596M 0 596M 0% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
下面的命令使用了 **-h** 选项,同时使用 **-T** 选项来显示我们正在查看的文件系统的类型。
|
||||
```
|
||||
$ df -hT /mnt2
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/sdb2 ext4 457G 73M 434G 1% /apps
|
||||
|
||||
```
|
||||
|
||||
#### ls
|
||||
|
||||
即使是 ls,它也为我们提供了调整大小显示的选项,保证是最合理的。
|
||||
```
|
||||
$ ls -l camper*
|
||||
-rw-rw-r-- 1 shs shs 365091 Jul 14 19:42 camper_10.jpg
|
||||
-rw-rw-r-- 1 shs shs 5818597 Jul 14 19:41 camper.jpg
|
||||
-rw-rw-r-- 1 shs shs 241844 Jul 14 19:45 camper_small.jpg
|
||||
$ ls -lh camper*
|
||||
-rw-rw-r-- 1 shs shs 357K Jul 14 19:42 camper_10.jpg
|
||||
-rw-rw-r-- 1 shs shs 5.6M Jul 14 19:41 camper.jpg
|
||||
-rw-rw-r-- 1 shs shs 237K Jul 14 19:45 camper_small.jpg
|
||||
|
||||
```
|
||||
|
||||
#### free
|
||||
|
||||
free 命令允许你以字节(B),千字节(KB),兆字节(MB)和千兆字节(GB)为单位查看内存使用情况。
|
||||
```
|
||||
$ free -b
|
||||
total used free shared buff/cache available
|
||||
Mem: 6249144320 393076736 4851625984 1654784 1004441600 5561253888
|
||||
Swap: 2147479552 0 2147479552
|
||||
$ free -k
|
||||
total used free shared buff/cache available
|
||||
Mem: 6102680 383836 4737924 1616 980920 5430932
|
||||
Swap: 2097148 0 2097148
|
||||
$ free -m
|
||||
total used free shared buff/cache available
|
||||
Mem: 5959 374 4627 1 957 5303
|
||||
Swap: 2047 0 2047
|
||||
$ free -g
|
||||
total used free shared buff/cache available
|
||||
Mem: 5 0 4 0 0 5
|
||||
Swap: 1 0 1
|
||||
|
||||
```
|
||||
|
||||
#### tree
|
||||
|
||||
虽然 tree 命令与文件或内存计算无关,但它也提供了非常人性化的文件视图,它分层显示文件以说明文件是如何组织的。当你试图了解如何安排目录内容时,这种显示方式非常有用。
|
||||
```
|
||||
$ tree
|
||||
.g to
|
||||
├── 123
|
||||
├── appended.png
|
||||
├── appts
|
||||
├── arrow.jpg
|
||||
├── arrow.png
|
||||
├── bin
|
||||
│ ├── append
|
||||
│ ├── cpuhog1
|
||||
│ ├── cpuhog2
|
||||
│ ├── loop
|
||||
│ ├── mkhome
|
||||
│ ├── runme
|
||||
|
||||
```
|
||||
|
||||
#### stat
|
||||
|
||||
stat 命令是另一个以非常人性化的格式显示信息的命令。它提供了更多关于文件的元数据,包括文件大小(以字节和块为单位),文件类型,设备和 inode(索引节点),文件所有者和组(名称和数字 ID),以数字和 rwx 格式显示的文件权限以及文件的最后访问和修改日期。在某些情况下,它也可能显示最初创建文件的时间。
|
||||
```
|
||||
$ stat camper*
|
||||
File: camper_10.jpg
|
||||
Size: 365091 Blocks: 720 IO Block: 4096 regular file
|
||||
Device: 801h/2049d Inode: 796059 Links: 1
|
||||
Access: (0664/-rw-rw-r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
|
||||
Access: 2018-07-19 18:56:31.841013385 -0400
|
||||
Modify: 2018-07-14 19:42:25.230519509 -0400
|
||||
Change: 2018-07-14 19:42:25.230519509 -0400
|
||||
Birth: -
|
||||
File: camper.jpg
|
||||
Size: 5818597 Blocks: 11368 IO Block: 4096 regular file
|
||||
Device: 801h/2049d Inode: 796058 Links: 1
|
||||
Access: (0664/-rw-rw-r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
|
||||
Access: 2018-07-19 18:56:31.845013872 -0400
|
||||
Modify: 2018-07-14 19:41:46.882024039 -0400
|
||||
Change: 2018-07-14 19:41:46.882024039 -0400
|
||||
Birth: -
|
||||
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
Linux 命令提供了许多选项,可以让用户更容易理解或比较它们的输出。对于许多命令,**-h** 选项会显示更友好的输出格式。对于其它的,你可能必须通过使用某些特定选项或者按下某个键来查看你希望的输出。我希望这其中一些选项会让你的 Linux 系统看起来更友好一点。
|
||||
|
||||
加入[Facebook][1] 和 [LinkedIn][2] 上的网络世界社区,一起来评论重要的话题吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3296631/linux/displaying-data-in-a-human-friendly-way-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,313 @@
|
||||
打包更多有用的 Unix 实用程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们都了解 **<ruby>GNU 核心实用程序<rt>GNU Core Utilities</rt></ruby>**,所有类 Unix 操作系统都预装了它们。它们是 GNU 操作系统中与文件、Shell 和 文本处理相关的基础实用工具。GNU 核心实用程序包括很多日常操作命令,例如 `cat`,`ls`, `rm`,`mkdir`,`rmdir`,`touch`,`tail` 和 `wc` 等。除了这些实用程序,还有更多有用的实用程序没有预装在类 Unix 操作系统中,它们汇集起来构成了 `moreutilis` 这个日益增长的集合。`moreutils` 可以在 GNU/Linux 和包括 FreeBSD,openBSD 及 Mac OS 在内的多种 Unix 类型操作系统上安装。
|
||||
|
||||
截至到编写这份指南时, `moreutils` 提供如下实用程序:
|
||||
|
||||
* `chronic` – 运行程序并忽略正常运行的输出
|
||||
* `combine` – 使用布尔操作合并文件
|
||||
* `errno` – 查询 errno 名称及描述
|
||||
* `ifdata` – 获取网络接口信息,无需解析 `ifconfig` 的结果
|
||||
* `ifne` – 在标准输入非空的情况下运行程序
|
||||
* `isutf8` – 检查文件或标准输入是否采用 UTF-8 编码
|
||||
* `lckdo` – 运行程序时考虑文件锁
|
||||
* `mispipe` – 使用管道连接两个命令,返回第一个命令的退出状态
|
||||
* `parallel` – 同时运行多个任务
|
||||
* `pee` – 将标准输入传递给多个管道
|
||||
* `sponge` – 整合标准输入并写入文件
|
||||
* `ts` – 为标准输入增加时间戳信息
|
||||
* `vidir` – 使用你默认的文本编辑器操作目录文件
|
||||
* `vipe` – 在管道中插入信息编辑
|
||||
* `zrun` – 自动解压并将其作为参数传递给命令
|
||||
|
||||
### 在 Linux 上安装 moreutils
|
||||
|
||||
由于 `moreutils` 已经被打包到多种 Linux 发行版中,你可以使用发行版对应的软件包管理器安装 `moreutils`。
|
||||
|
||||
在 **Arch Linux** 或衍生的 **Antergos** 和 **Manjaro Linux** 上,运行如下命令安装 `moreutils`:
|
||||
|
||||
```
|
||||
$ sudo pacman -S moreutils
|
||||
```
|
||||
|
||||
在 **Fedora** 上,运行:
|
||||
|
||||
```
|
||||
$ sudo dnf install moreutils
|
||||
```
|
||||
|
||||
在 **RHEL**,**CentOS** 和 **Scientific Linux** 上,运行:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum install moreutils
|
||||
```
|
||||
|
||||
在 **Debian**,**Ubuntu** 和 **Linux Mint** 上,运行:
|
||||
|
||||
```
|
||||
$ sudo apt-get install moreutils
|
||||
```
|
||||
|
||||
### Moreutils – 打包更多有用的 Unix 实用程序
|
||||
|
||||
让我们看一下几个 `moreutils` 工具的用法细节。
|
||||
|
||||
##### combine 实用程序
|
||||
|
||||
正如 `combine` 名称所示,moreutils 中的这个实用程序可以使用包括 `and`,`not`,`or` 和 `xor` 在内的布尔操作,合并两个文件中的行。
|
||||
|
||||
* `and` – 输出 `file1` 和 `file2` 都包含的行。
|
||||
* `not` – 输出 `file1` 包含但 `file2` 不包含的行。
|
||||
* `or` – 输出 `file1` 或 `file2` 包含的行。
|
||||
* `xor` – 输出仅被 `file1` 或 `file2` 包含的行
|
||||
|
||||
下面举例说明,方便你理解该实用程序的功能。这里有两个文件,文件名分别为 `file1` 和 `file2`,其内容如下:
|
||||
|
||||
```
|
||||
$ cat file1
|
||||
is
|
||||
was
|
||||
were
|
||||
where
|
||||
there
|
||||
|
||||
$ cat file2
|
||||
is
|
||||
were
|
||||
there
|
||||
```
|
||||
|
||||
下面,我使用 `and` 布尔操作合并这两个文件。
|
||||
|
||||
```
|
||||
$ combine file1 and file2
|
||||
is
|
||||
were
|
||||
there
|
||||
```
|
||||
|
||||
从上例的输出中可以看出,`and` 布尔操作只输出那些 `file1` 和 `file2` 都包含的行;更具体的来说,命令输出为两个文件共有的行,即 is,were 和 there。
|
||||
|
||||
下面我们换成 `not` 操作,观察一下输出。
|
||||
|
||||
```
|
||||
$ combine file1 not file2
|
||||
was
|
||||
where
|
||||
```
|
||||
|
||||
从上面的输出中可以看出,`not` 操作输出 `file1` 包含但 `file2` 不包含的行。
|
||||
|
||||
##### ifdata 实用程序
|
||||
|
||||
`ifdata` 实用程序可用于检查网络接口是否存在,也可用于获取网络接口的信息,例如 IP 地址等。与预装的 `ifconfig` 和 `ip` 命令不同,`ifdata` 的输出更容易解析,这种设计的初衷是便于在 Shell 脚本中使用。
|
||||
|
||||
如果希望查看某个接口的 IP 地址,不妨以 `wlp9s0` 为例,运行如下命令:
|
||||
|
||||
```
|
||||
$ ifdata -p wlp9s0
|
||||
192.168.43.192 255.255.255.0 192.168.43.255 1500
|
||||
```
|
||||
|
||||
如果只查看掩码信息,运行如下命令:
|
||||
|
||||
```
|
||||
$ ifdata -pn wlp9s0
|
||||
255.255.255.0
|
||||
```
|
||||
|
||||
如果查看网络接口的物理地址,运行如下命令:
|
||||
|
||||
```
|
||||
$ ifdata -ph wlp9s0
|
||||
A0:15:46:90:12:3E
|
||||
```
|
||||
|
||||
如果判断接口是否存在,可以使用 `-pe` 参数:
|
||||
|
||||
```
|
||||
$ ifdata -pe wlp9s0
|
||||
yes
|
||||
```
|
||||
|
||||
##### pee 命令
|
||||
|
||||
该命令某种程度上类似于 `tee` 命令。
|
||||
|
||||
我们先用一个例子看一下 `tee` 的用法。
|
||||
|
||||
```
|
||||
$ echo "Welcome to OSTechNIx" | tee file1 file2
|
||||
Welcome to OSTechNIx
|
||||
```
|
||||
|
||||
上述命令首先创建两个文件,名为 `file1` 和 `file2`;接着,将 “Welcome to OSTechNix” 行分别附加到两个文件中;最后,在终端中打印输出 “Welcome to OSTechNix”。
|
||||
|
||||
`pee` 命令提供类似的功能,但与 `tee` 又稍微有些差异。查看下面的例子:
|
||||
|
||||
```
|
||||
$ echo "Welcome to OSTechNIx" | pee cat cat
|
||||
Welcome to OSTechNIx
|
||||
Welcome to OSTechNIx
|
||||
```
|
||||
|
||||
从上面的命令输出中可以看出,有两个 `cat` 命令实例获取 `echo` 命令的输出并执行,因而终端中出现两个同样的输出。
|
||||
|
||||
##### sponge 实用程序
|
||||
|
||||
这是 `moreutils` 软件包中的另一个有用的实用程序。`sponge` 读取标准输入并写入到指定的文件中。与 Shell 中的重定向不同,`sponge` 接收到完整输入后再写入输出文件。
|
||||
|
||||
查看下面这个文本文件的内容:
|
||||
|
||||
```
|
||||
$ cat file1
|
||||
I
|
||||
You
|
||||
Me
|
||||
We
|
||||
Us
|
||||
```
|
||||
|
||||
可见,文件包含了一些无序的行;更具体的说,这些行“没有”按照字母顺序排序。如果希望将其内容安装字母顺序排序,你会怎么做呢?
|
||||
|
||||
```
|
||||
$ sort file1 > file1_sorted
|
||||
```
|
||||
|
||||
这样做没错,对吧?当然没错!在上面的命令中,我将 `file1` 文件内容按照字母顺序排序,将排序后的内容保存在 `file1_sorted` 文件中。但如果使用 `sponge` 命令,你可以在不创建新文件(即 `file1_sorted`)的情况下完成同样的任务,命令如下:
|
||||
|
||||
```
|
||||
$ sort file1 | sponge file1
|
||||
```
|
||||
|
||||
那么,让我们检查一下文件内容是否已经按照字母顺序排序:
|
||||
|
||||
```
|
||||
$ cat file1
|
||||
I
|
||||
Me
|
||||
Us
|
||||
We
|
||||
You
|
||||
```
|
||||
|
||||
看到了吧?并不需要创建新文件。在脚本编程中,这非常有用。另一个好消息是,如果待写入的文件已经存在,`sponge` 会保持其<ruby>权限信息<rt>permissions</rt></ruby>不变。
|
||||
|
||||
##### ts 实用程序
|
||||
|
||||
正如名称所示,`ts` 命令在每一行输出的行首增加<ruby>时间戳<rt>timestamp</rt></ruby>。
|
||||
|
||||
查看如下命令的输出:
|
||||
|
||||
```
|
||||
$ ping -c 2 localhost
|
||||
PING localhost(localhost.localdomain (::1)) 56 data bytes
|
||||
64 bytes from localhost.localdomain (::1): icmp_seq=1 ttl=64 time=0.055 ms
|
||||
64 bytes from localhost.localdomain (::1): icmp_seq=2 ttl=64 time=0.079 ms
|
||||
|
||||
--- localhost ping statistics ---
|
||||
2 packets transmitted, 2 received, 0% packet loss, time 1018ms
|
||||
rtt min/avg/max/mdev = 0.055/0.067/0.079/0.012 ms
|
||||
```
|
||||
|
||||
下面,结合 `ts` 实用程序运行同样地命令:
|
||||
|
||||
```
|
||||
$ ping -c 2 localhost | ts
|
||||
Aug 21 13:32:28 PING localhost(localhost (::1)) 56 data bytes
|
||||
Aug 21 13:32:28 64 bytes from localhost (::1): icmp_seq=1 ttl=64 time=0.063 ms
|
||||
Aug 21 13:32:28 64 bytes from localhost (::1): icmp_seq=2 ttl=64 time=0.113 ms
|
||||
Aug 21 13:32:28
|
||||
Aug 21 13:32:28 --- localhost ping statistics ---
|
||||
Aug 21 13:32:28 2 packets transmitted, 2 received, 0% packet loss, time 4ms
|
||||
Aug 21 13:32:28 rtt min/avg/max/mdev = 0.063/0.088/0.113/0.025 ms
|
||||
```
|
||||
|
||||
对比输出可以看出,`ts` 在每一行行首增加了时间戳。下面给出另一个例子:
|
||||
|
||||
```
|
||||
$ ls -l | ts
|
||||
Aug 21 13:34:25 total 120
|
||||
Aug 21 13:34:25 drwxr-xr-x 2 sk users 12288 Aug 20 20:05 Desktop
|
||||
Aug 21 13:34:25 drwxr-xr-x 2 sk users 4096 Aug 10 18:44 Documents
|
||||
Aug 21 13:34:25 drwxr-xr-x 24 sk users 12288 Aug 21 13:06 Downloads
|
||||
[...]
|
||||
```
|
||||
|
||||
##### vidir 实用程序
|
||||
|
||||
`vidir` 实用程序可以让你使用 `vi` 编辑器(或其它 `$EDITOR` 环境变量指定的编辑器)编辑指定目录的内容。如果没有指定目录,`vidir` 会默认编辑你当前的目录。
|
||||
|
||||
下面的命令编辑 `Desktop` 目录的内容:
|
||||
|
||||
```
|
||||
$ vidir Desktop/
|
||||
```
|
||||
|
||||
![vidir][2]
|
||||
|
||||
上述命令使用 `vi` 编辑器打开了指定的目录,其中目录内的文件都会对应一个数字。下面你可以按照 `vi` 的操作方式来编辑目录中的这些文件:例如,删除行意味着删除目录中对应的文件,修改行中字符串意味着对文件进行重命名。
|
||||
|
||||
你也可以编辑子目录。下面的命令会编辑当前目录及所有子目录:
|
||||
|
||||
```
|
||||
$ find | vidir -
|
||||
```
|
||||
|
||||
请注意命令结尾的 `-`。如果 `-` 被指定为待编辑的目录,`vidir` 会从标准输入读取一系列文件名,列出它们让你进行编辑。
|
||||
|
||||
如果你只想编辑当前目录下的文件,可以使用如下命令:
|
||||
|
||||
```
|
||||
$ find -type f | vidir -
|
||||
```
|
||||
|
||||
只想编辑特定类型的文件,例如 `.PNG` 文件?你可以使用如下命令:
|
||||
|
||||
```
|
||||
$ vidir *.png
|
||||
```
|
||||
|
||||
这时命令只会编辑当前目录下以 `.PNG` 为后缀的文件。
|
||||
|
||||
##### vipe 实用程序
|
||||
|
||||
`vipe` 命令可以让你使用默认编辑器接收 Unix 管道输入,编辑之后使用管道输出供下一个程序使用。
|
||||
|
||||
执行下面的命令会打开 `vi` 编辑器(当然是我默认使用的编辑器),你可以编辑 `echo` 命令的管道输入(即 “Welcome to OSTechNix”),最后将编辑过的内容输出到终端中。
|
||||
|
||||
```
|
||||
$ echo "Welcome to OSTechNIx" | vipe
|
||||
Hello World
|
||||
```
|
||||
|
||||
从上面的输出可以看出,我通过管道将“Welcome to OSTechNix”输入到 `vi` 编辑器中,将内容编辑为“Hello World”,最后显示该内容。
|
||||
|
||||
好了,就介绍这么多吧。我只介绍了一小部分实用程序,而 `moreutils` 包含更多有用的实用程序。我在文章开始的时候已经列出目前 `moreutils` 软件包内包含的实用程序,你可以通过 `man` 帮助页面获取更多相关命令的细节信息。举个例子,如果你想了解 `vidir` 命令,请运行:
|
||||
|
||||
```
|
||||
$ man vidir
|
||||
```
|
||||
|
||||
希望这些内容对你有所帮助。我还将继续分享其它有趣且实用的指南,如果你认为这些内容对你有所帮助,请分享到社交网络或专业圈子,也欢迎你支持 OSTechNix 项目。
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/moreutils-collection-useful-unix-utilities/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/08/sk@sk_001-1.png
|
||||
Loading…
Reference in New Issue
Block a user